├── sample_docs
├── new_added.txt
├── Can LLMs Generate Novel Research Ideas.pdf
└── healthcare_records.json
├── assets
├── chat_snapshot.png
└── nexusync_logo.png
├── MANIFEST.in
├── src
└── nexusync
│ ├── core
│ ├── __init__.py
│ ├── querier.py
│ ├── indexing_functions.py
│ ├── chat_engine.py
│ └── indexer.py
│ ├── models
│ ├── __init__.py
│ ├── embedding_models.py
│ └── language_models.py
│ ├── utils
│ ├── __init__.py
│ ├── logging_config.py
│ └── file_operations.py
│ ├── __init__.py
│ └── nexusync.py
├── requirements.txt
├── dummy_dataset.json
├── LICENSE.txt
├── setup.py
├── .gitignore
├── back_end_api.py
├── README.md
├── index.html
└── notebooks
├── data_structure_generator.ipynb
└── NHS_Application_Test.ipynb
/sample_docs/new_added.txt:
--------------------------------------------------------------------------------
1 | Breaking News: Trump and Harris had a fight!!!!
--------------------------------------------------------------------------------
/assets/chat_snapshot.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Zakk-Yang/nexusync/HEAD/assets/chat_snapshot.png
--------------------------------------------------------------------------------
/assets/nexusync_logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Zakk-Yang/nexusync/HEAD/assets/nexusync_logo.png
--------------------------------------------------------------------------------
/sample_docs/Can LLMs Generate Novel Research Ideas.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/Zakk-Yang/nexusync/HEAD/sample_docs/Can LLMs Generate Novel Research Ideas.pdf
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include LICENSE
2 | include README.md
3 | include requirements.txt
4 | recursive-include src *.py
5 | recursive-include docs *.md
6 | recursive-include tests *.py
--------------------------------------------------------------------------------
/src/nexusync/core/__init__.py:
--------------------------------------------------------------------------------
1 | # src/core/__init__.py
2 | from .indexer import Indexer
3 | from .querier import Querier
4 | from .chat_engine import ChatEngine
5 |
6 | __all__ = ["Indexer", "Querier", "ChatEngine"]
7 |
--------------------------------------------------------------------------------
/src/nexusync/models/__init__.py:
--------------------------------------------------------------------------------
1 | # src/models/__init__.py
2 |
3 | from .embedding_models import set_embedding_model
4 | from .language_models import set_language_model
5 |
6 | __all__ = ["set_embedding_model", "set_language_model"]
7 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | llama_index
2 | llama-index-llms-ollama
3 | llama-index-embeddings-huggingface
4 | chromadb
5 | llama-index-vector-stores-chroma
6 | transformers>=4.45.2
7 | python-pptx
8 | Pillow
9 | docx2txt
10 | openpyxl
11 | python-dotenv
12 | spacy
13 | flask
--------------------------------------------------------------------------------
/src/nexusync/utils/__init__.py:
--------------------------------------------------------------------------------
1 | # src/utils/__init__.py
2 |
3 | from .logging_config import get_logger
4 | from .file_operations import get_all_files, get_file_hash, get_changed_files
5 |
6 | __all__ = [
7 | "get_logger",
8 | "get_all_files",
9 | "get_file_hash",
10 | "get_changed_files",
11 | ]
12 |
--------------------------------------------------------------------------------
/src/nexusync/__init__.py:
--------------------------------------------------------------------------------
1 | # src/__init__.py
2 |
3 | from .core.indexer import Indexer
4 | from .core.querier import Querier
5 | from .core.chat_engine import ChatEngine
6 | from .core.indexing_functions import rebuild_index
7 | from .nexusync import NexuSync
8 |
9 | __all__ = [
10 | "NexuSync",
11 | "Indexer",
12 | "Querier",
13 | "ChatEngine",
14 | "rebuild_index",
15 | ]
16 |
--------------------------------------------------------------------------------
/dummy_dataset.json:
--------------------------------------------------------------------------------
1 | {
2 | "demographics": {
3 | "patient_id": "P123456789",
4 | "first_name": "Jane",
5 | "last_name": "Doe",
6 | "date_of_birth": "1985-07-24",
7 | "gender": "Female",
8 | "contact_information": {
9 | "address": "123 Elm Street, Springfield, IL, 62704",
10 | "phone": "+44 7911 123456",
11 | "email": "jane.doe@example.com"
12 | }
13 | },
14 | "emergency_contact": {
15 | "name": "John Doe",
16 | "relationship": "Spouse",
17 | "phone": "+44 7911 654321"
18 | }
19 | }
--------------------------------------------------------------------------------
/src/nexusync/utils/logging_config.py:
--------------------------------------------------------------------------------
1 | # src/utils/logging_config.py
2 |
3 |
4 | import logging
5 | import warnings
6 |
7 |
8 | def silence_all_warnings():
9 | # Ignore all warnings
10 | warnings.filterwarnings("ignore")
11 |
12 |
13 | def get_logger(name):
14 | # Silence all warnings
15 | silence_all_warnings()
16 |
17 | logger = logging.getLogger(name)
18 |
19 | if not logger.handlers:
20 | logger.setLevel(logging.INFO)
21 | handler = logging.StreamHandler()
22 | formatter = logging.Formatter(
23 | "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
24 | )
25 | handler.setFormatter(formatter)
26 | logger.addHandler(handler)
27 | logger.propagate = False # Prevent propagation to ancestor loggers
28 |
29 | return logger
30 |
--------------------------------------------------------------------------------
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 Zakk-Yang
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | # setup.py
2 |
3 | from setuptools import setup, find_packages
4 |
5 | with open("README.md", "r", encoding="utf-8") as fh:
6 | long_description = fh.read()
7 |
8 | setup(
9 | packages=find_packages(where="src"),
10 | package_dir={"": "src"},
11 | name="nexusync",
12 | version="0.3.6",
13 | author="Zakk Yang",
14 | author_email="zakkyang@protonmail.com",
15 | description="A powerful document indexing and querying tool built on top of LlamaIndex",
16 | long_description=long_description,
17 | long_description_content_type="text/markdown",
18 | url="https://github.com/Zakk-Yang/nexusync.git",
19 | classifiers=[
20 | "Programming Language :: Python :: 3",
21 | "License :: OSI Approved :: MIT License",
22 | "Operating System :: OS Independent",
23 | ],
24 | python_requires=">=3.10",
25 | install_requires=[
26 | "llama_index",
27 | "llama-index-llms-ollama",
28 | "llama-index-embeddings-huggingface",
29 | "chromadb",
30 | "llama-index-vector-stores-chroma",
31 | "transformers>=4.45.2",
32 | "python-pptx",
33 | "Pillow",
34 | "docx2txt",
35 | "openpyxl",
36 | "python-dotenv",
37 | "spacy",
38 | "flask",
39 | ],
40 | include_package_data=True, # Ensures files specified in MANIFEST.in are included
41 | )
42 |
--------------------------------------------------------------------------------
/src/nexusync/models/embedding_models.py:
--------------------------------------------------------------------------------
1 | # src/utils/embedding_models.py
2 |
3 | from typing import Optional
4 | from llama_index.embeddings.huggingface import HuggingFaceEmbedding
5 | from llama_index.embeddings.openai import OpenAIEmbedding
6 | from llama_index.core import Settings
7 | import os
8 | from dotenv import load_dotenv
9 | from nexusync.utils.logging_config import get_logger
10 |
11 |
12 | def set_embedding_model(
13 | openai_model: Optional[str] = None, huggingface_model: Optional[str] = None
14 | ) -> None:
15 | """
16 | Set up the embedding model for the index.
17 |
18 | Args:
19 | openai_model (Optional[str]): Name of the OpenAI embedding model.
20 | huggingface_model (Optional[str]): Name of the HuggingFace embedding model.
21 |
22 | Raises:
23 | ValueError: If both or neither embedding model is specified.
24 | """
25 | logger = get_logger("nexusync.utils.embedding_models.set_embedding_model")
26 | load_dotenv()
27 |
28 | if (openai_model and huggingface_model) or (
29 | not openai_model and not huggingface_model
30 | ):
31 | raise ValueError(
32 | "Specify either OpenAI or HuggingFace embedding model, not both or neither."
33 | )
34 |
35 | if openai_model:
36 | openai_api_key = os.getenv("OPENAI_API_KEY")
37 | if not openai_api_key:
38 | raise ValueError("OpenAI API key not found in environment variables.")
39 | Settings.embed_model = OpenAIEmbedding(
40 | model=openai_model, api_key=openai_api_key
41 | )
42 | logger.info(f"Using OpenAI embedding model: {openai_model}")
43 | else:
44 | Settings.embed_model = HuggingFaceEmbedding(model_name=huggingface_model)
45 | logger.info(f"Using HuggingFace embedding model: {huggingface_model}")
46 |
--------------------------------------------------------------------------------
/src/nexusync/models/language_models.py:
--------------------------------------------------------------------------------
1 | # src/utils/language_models.py
2 |
3 | from typing import Optional
4 | from llama_index.llms.ollama import Ollama
5 | from llama_index.llms.openai import OpenAI
6 | from llama_index.core import Settings
7 | import os
8 | from dotenv import load_dotenv
9 | from nexusync.utils.logging_config import get_logger
10 |
11 |
12 | def set_language_model(
13 | openai_model: Optional[str] = None,
14 | ollama_model: Optional[str] = None,
15 | temperature: Optional[float] = 0.7,
16 | base_url: Optional[str] = None,
17 | ) -> None:
18 | """
19 | Set up the language model for the index.
20 |
21 | Args:
22 | openai_model (Optional[str]): Name of the OpenAI model.
23 | ollama_model (Optional[str]): Name of the Ollama model.
24 | temperature (Optional[float]): Temperature for the language model.
25 | base_url (Optional[str]): Ollama base url
26 |
27 | Raises:
28 | ValueError: If both or neither model is specified, or if OpenAI API key is missing.
29 | """
30 | logger = get_logger("nexusync.utils.embedding_models.set_language_model")
31 | load_dotenv()
32 |
33 | if (openai_model and ollama_model) or (not openai_model and not ollama_model):
34 | raise ValueError("Specify either OpenAI or Ollama model, not both or neither.")
35 |
36 | if openai_model:
37 | openai_api_key = os.getenv("OPENAI_API_KEY")
38 | if not openai_api_key:
39 | raise ValueError("OpenAI API key not found in environment variables.")
40 | Settings.llm = OpenAI(
41 | model=openai_model, temperature=temperature, api_key=openai_api_key
42 | )
43 | logger.info(f"Using OpenAI LLM model: {openai_model}")
44 | else:
45 | Settings.llm = Ollama(
46 | model=ollama_model, temperature=temperature, base_url=base_url
47 | )
48 | logger.info(
49 | f"Ollama LLM initialized with model: {ollama_model} and base_url: {base_url}"
50 | )
51 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # Distribution / packaging
7 | .Python
8 | build/
9 | develop-eggs/
10 | dist/
11 | downloads/
12 | eggs/
13 | .eggs/
14 | lib/
15 | lib64/
16 | parts/
17 | sdist/
18 | var/
19 | *.egg-info/
20 | .installed.cfg
21 | *.egg
22 |
23 | # PyInstaller
24 | # Usually these files are written by a python script from a template
25 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
26 | *.manifest
27 | *.spec
28 |
29 | # Installer logs
30 | pip-log.txt
31 | pip-delete-this-directory.txt
32 |
33 | # Unit test / coverage reports
34 | htmlcov/
35 | .tox/
36 | .coverage
37 | .coverage.*
38 | .cache
39 | nosetests.xml
40 | coverage.xml
41 | *.cover
42 | *.py,cover
43 | .hypothesis/
44 | .pytest_cache/
45 |
46 | # Translations
47 | *.mo
48 | *.pot
49 |
50 | # Django stuff:
51 | *.log
52 | local_settings.py
53 | db.sqlite3
54 | db.sqlite3-journal
55 |
56 | # Flask stuff:
57 | instance/
58 | .webassets-cache
59 |
60 | # Scrapy stuff:
61 | .scrapy
62 |
63 | # Sphinx documentation
64 | docs/_build/
65 |
66 | # PyBuilder
67 | target/
68 |
69 | # IPython Notebook
70 | .ipynb_checkpoints
71 |
72 | # pyenv
73 | .python-version
74 |
75 | # celery beat schedule file
76 | celerybeat-schedule
77 |
78 | # dotenv
79 | .env
80 |
81 | # virtualenv
82 | venv/
83 | ENV/
84 | env/
85 |
86 | # Spyder project settings
87 | .spyderproject
88 | .spyproject
89 |
90 | # Rope project settings
91 | .ropeproject
92 |
93 |
94 | # Ignore .DS_Store files
95 | .DS_Store
96 |
97 |
98 | # Ignore Python cache files
99 | __pycache__/
100 | *.pyc
101 |
102 | # Ignore environment files
103 | .env
104 |
105 | # Ignore user documents and data directories
106 | documents/
107 | storage/
108 | chroma_db/
109 | indexed_files.json
110 |
111 | # Ignore logs and temporary files
112 | *.log
113 | *.tmp
114 |
115 | # Ignore OS-specific files
116 | .DS_Store
117 | Thumbs.db
118 |
119 | # Ignore virtual environment directories (if any)
120 | venv/
121 | env/
122 | test.ipynb
123 | storage/
124 | index_storage/
125 |
126 | # Python Bytecode
127 | __pycache__/
128 | *.py[cod]
129 |
130 | test.py
--------------------------------------------------------------------------------
/src/nexusync/utils/file_operations.py:
--------------------------------------------------------------------------------
1 | # src/utils/file_operations.py
2 |
3 | import os
4 | from typing import List, Tuple
5 | import hashlib
6 |
7 |
8 | def get_all_files(directory: str, recursive: bool = True) -> List[str]:
9 | """
10 | Get all file paths in the given directory.
11 |
12 | Args:
13 | directory (str): The directory to search for files.
14 | recursive (bool): If True, search subdirectories as well. Defaults to True.
15 |
16 | Returns:
17 | List[str]: A list of file paths.
18 | """
19 | file_paths = []
20 | if recursive:
21 | for root, _, files in os.walk(directory):
22 | for file in files:
23 | file_paths.append(os.path.join(root, file))
24 | else:
25 | file_paths = [
26 | os.path.join(directory, f)
27 | for f in os.listdir(directory)
28 | if os.path.isfile(os.path.join(directory, f))
29 | ]
30 | return file_paths
31 |
32 |
33 | def get_file_hash(file_path: str) -> str:
34 | """
35 | Compute the MD5 hash of a file.
36 |
37 | Args:
38 | file_path (str): The path to the file.
39 |
40 | Returns:
41 | str: The MD5 hash of the file.
42 | """
43 | hasher = hashlib.md5()
44 | with open(file_path, "rb") as file:
45 | buf = file.read()
46 | hasher.update(buf)
47 | return hasher.hexdigest()
48 |
49 |
50 | def get_changed_files(
51 | directory: str, old_hashes: dict
52 | ) -> Tuple[List[str], List[str], List[str]]:
53 | """
54 | Determine which files in the directory have been added, modified, or deleted.
55 |
56 | Args:
57 | directory (str): The directory to check for changes.
58 | old_hashes (dict): A dictionary of file paths and their previous hashes.
59 |
60 | Returns:
61 | Tuple[List[str], List[str], List[str]]: Lists of added, modified, and deleted file paths.
62 | """
63 | current_files = get_all_files(directory)
64 | current_hashes = {file: get_file_hash(file) for file in current_files}
65 |
66 | added = [file for file in current_files if file not in old_hashes]
67 | modified = [
68 | file
69 | for file in current_files
70 | if file in old_hashes and current_hashes[file] != old_hashes[file]
71 | ]
72 | deleted = [file for file in old_hashes if file not in current_files]
73 |
74 | return added, modified, deleted
75 |
--------------------------------------------------------------------------------
/src/nexusync/core/querier.py:
--------------------------------------------------------------------------------
1 | # src/core/querier.py
2 |
3 | from typing import List, Optional, Dict, Any
4 | from llama_index.core import (
5 | VectorStoreIndex,
6 | PromptTemplate,
7 | )
8 | import logging
9 | from llama_index.core.postprocessor import SentenceEmbeddingOptimizer
10 | from llama_index.core.postprocessor import KeywordNodePostprocessor
11 | from nexusync.utils.logging_config import get_logger
12 |
13 |
14 | class Querier:
15 | def __init__(self, index: VectorStoreIndex):
16 | """
17 | Initialize the Querier with a VectorStoreIndex.
18 |
19 | Args:
20 | index (VectorStoreIndex): The index to be used for querying.
21 | """
22 | self.index = index
23 | self.logger = get_logger("nexusync.core.querier")
24 |
25 | def query(
26 | self, text_qa_template: str, query: str, similarity_top_k: int = 3
27 | ) -> Dict[str, Any]:
28 | """
29 | Query the index using a query engine.
30 |
31 | Args:
32 | text_qa_template (str): The template for the QA prompt.
33 | query (str): The query string.
34 | similarity_top_k (int, optional): Number of top similar documents to consider. Defaults to 3.
35 |
36 | Returns:
37 | Dict[str, Any]: A dictionary containing the response and metadata.
38 | """
39 | try:
40 | qa_template = PromptTemplate(text_qa_template)
41 | query_engine = self.index.as_query_engine(
42 | text_qa_template=qa_template,
43 | similarity_top_k=similarity_top_k,
44 | node_postprocessors=[
45 | SentenceEmbeddingOptimizer(percentile_cutoff=0.5),
46 | KeywordNodePostprocessor(required_keywords=[]),
47 | ],
48 | )
49 |
50 | response = query_engine.query(query)
51 |
52 | answer = str(response)
53 | metadata = {"sources": []}
54 |
55 | if hasattr(response, "source_nodes"):
56 | for node in response.source_nodes:
57 | source_info = {
58 | "source_text": node.node.get_text(),
59 | "metadata": node.node.metadata,
60 | }
61 | metadata["sources"].append(source_info)
62 |
63 | return {"response": answer, "metadata": metadata}
64 |
65 | except Exception as e:
66 | self.logger.error(f"An error occurred during query: {e}", exc_info=True)
67 | return {
68 | "response": f"An error occurred while processing your request: {str(e)}",
69 | "metadata": {},
70 | }
71 |
72 | def get_relevant_documents(
73 | self, query: str, num_docs: int = 3
74 | ) -> List[Dict[str, Any]]:
75 | """
76 | Retrieve the most relevant documents for a given query.
77 |
78 | Args:
79 | query (str): The query string.
80 | num_docs (int): The number of documents to retrieve. Defaults to 3.
81 |
82 | Returns:
83 | List[Dict[str, Any]]: A list of dictionaries containing document info and relevance scores.
84 | """
85 | try:
86 | retriever = self.index.as_retriever(similarity_top_k=num_docs)
87 | nodes = retriever.retrieve(query)
88 |
89 | relevant_docs = []
90 | for node in nodes:
91 | doc_info = {
92 | "content": node.node.get_text(),
93 | "metadata": node.node.metadata,
94 | "score": node.score,
95 | }
96 | relevant_docs.append(doc_info)
97 |
98 | return relevant_docs
99 |
100 | except Exception as e:
101 | self.logger.error(
102 | f"An error occurred while retrieving relevant documents: {e}",
103 | exc_info=True,
104 | )
105 | return []
106 |
--------------------------------------------------------------------------------
/src/nexusync/core/indexing_functions.py:
--------------------------------------------------------------------------------
1 | # src/core/indexing_functions.py
2 |
3 | import shutil
4 | import os
5 | from nexusync.core.indexer import Indexer
6 | from nexusync.utils.logging_config import get_logger
7 | from llama_index.core import Settings
8 | from typing import List
9 | import os
10 | from typing import List, Optional, Dict, Any
11 | from llama_index.core import (
12 | VectorStoreIndex,
13 | SimpleDirectoryReader,
14 | StorageContext,
15 | load_index_from_storage,
16 | )
17 |
18 | from llama_index.vector_stores.chroma import ChromaVectorStore
19 | import chromadb
20 | from nexusync.utils.logging_config import get_logger
21 | import shutil
22 | from llama_index.core import Settings
23 | from nexusync.models.embedding_models import set_embedding_model
24 | from nexusync.models.language_models import set_language_model
25 |
26 | logger = get_logger("nexusync.core.indexing_functions")
27 |
28 |
29 | def rebuild_index(
30 | input_dirs: List[str],
31 | openai_model_yn: bool,
32 | embedding_model: str,
33 | language_model: str,
34 | temperature: float,
35 | chroma_db_dir: str,
36 | index_persist_dir: str,
37 | chroma_collection_name: str,
38 | chunk_overlap: int,
39 | chunk_size: int,
40 | recursive: bool,
41 | base_url: Optional[str] = None,
42 | ):
43 | """
44 | Standalone function to rebuild the index.
45 |
46 | This function can be called independently of NexuSync initialization.
47 | """
48 | logger.info("Starting index rebuild process...")
49 |
50 | Settings.chunk_overlap = chunk_overlap
51 | Settings.chunk_size = chunk_size
52 | # Initialize the embedding and language model
53 | if openai_model_yn:
54 | set_embedding_model(openai_model=embedding_model)
55 | set_language_model(openai_model=language_model)
56 |
57 | else:
58 | set_embedding_model(huggingface_model=embedding_model)
59 | set_language_model(
60 | ollama_model=language_model, temperature=temperature, base_url=base_url
61 | )
62 |
63 | # Step 1: Delete the existing index directory
64 | if os.path.exists(index_persist_dir):
65 | logger.info(f"Deleting existing index directory: {index_persist_dir}")
66 | shutil.rmtree(index_persist_dir)
67 | else:
68 | logger.warning(
69 | f"Index directory {index_persist_dir} does not exist. Skipping deletion."
70 | )
71 |
72 | # Step 2: Delete the Chroma database directory
73 | if os.path.exists(chroma_db_dir):
74 | logger.info(f"Deleting existing Chroma DB directory: {chroma_db_dir}")
75 | shutil.rmtree(chroma_db_dir)
76 | else:
77 | logger.warning(
78 | f"Chroma DB directory {chroma_db_dir} does not exist. Skipping deletion."
79 | )
80 |
81 | try:
82 | storage_context = StorageContext.from_defaults(persist_dir=index_persist_dir)
83 | index = load_index_from_storage(storage_context)
84 | logger.info("Index already built. Loading from disk.")
85 | except FileNotFoundError:
86 | logger.warning("Index not found. Building a new index.")
87 | document_list = []
88 | total_files = 0
89 | for file_path in input_dirs:
90 | if not os.path.isdir(file_path):
91 | logger.error(f"Directory {file_path} does not exist.")
92 | raise ValueError(f"Directory {file_path} does not exist.")
93 | # Count files before loading
94 | file_count = sum(
95 | len(files)
96 | for _, _, files in os.walk(file_path)
97 | if recursive or _ == file_path
98 | )
99 | total_files += file_count
100 | documents = SimpleDirectoryReader(
101 | file_path, filename_as_id=True, recursive=recursive
102 | ).load_data()
103 | logger.info(f"Loaded {file_count} files from all directories.")
104 | document_list.extend(documents)
105 | index = VectorStoreIndex.from_documents(document_list)
106 | index.storage_context.persist(persist_dir=index_persist_dir)
107 | chroma_client = chromadb.PersistentClient(path=chroma_db_dir)
108 | chroma_collection = chroma_client.get_or_create_collection(
109 | chroma_collection_name
110 | )
111 | vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
112 | storage_context = StorageContext.from_defaults(
113 | persist_dir=index_persist_dir, vector_store=vector_store
114 | )
115 |
116 | if not document_list:
117 | logger.error("No documents found to build the index.")
118 | raise ValueError("No documents found to build the index.")
119 |
120 | logger.info("Index Built.")
121 | except Exception as e:
122 | logger.error(f"An unexpected error occurred during initiation: {e}")
123 | raise
124 |
--------------------------------------------------------------------------------
/src/nexusync/nexusync.py:
--------------------------------------------------------------------------------
1 | # src/nexusync/nexusync.py
2 |
3 | from .core.indexer import Indexer
4 | from .core.querier import Querier
5 | from .core.chat_engine import ChatEngine
6 | from .models.embedding_models import set_embedding_model
7 | from .models.language_models import set_language_model
8 | from nexusync.utils.logging_config import get_logger
9 | from typing import List, Dict, Any
10 | from dotenv import load_dotenv
11 |
12 |
13 | class NexuSync:
14 | def __init__(
15 | self,
16 | input_dirs: List[str],
17 | openai_model_yn: bool = None,
18 | language_model: str = None,
19 | base_url: str = None,
20 | embedding_model: str = None,
21 | temperature: float = 0.4,
22 | chroma_db_dir: str = "chroma_db",
23 | index_persist_dir: str = "index_storage",
24 | chroma_collection_name: str = "my_collection",
25 | chunk_size: int = 1024,
26 | chunk_overlap: int = 20,
27 | recursive: bool = True,
28 | ):
29 | load_dotenv()
30 | self.logger = get_logger("nexusync.NexuSync")
31 | self.input_dirs = input_dirs
32 | self.embedding_model = embedding_model
33 | self.language_model = language_model
34 | self.base_url = str(base_url) if base_url else None
35 | self.temperature = temperature
36 | self.chroma_db_dir = chroma_db_dir
37 | self.index_persist_dir = index_persist_dir
38 | self.chroma_collection_name = chroma_collection_name
39 | self.chunk_size = chunk_size
40 | self.chunk_overlap = chunk_overlap
41 | self.recursive = recursive
42 | self.openai_model_yn = openai_model_yn
43 | self._initialize_models()
44 | self.indexer = Indexer(
45 | input_dirs=self.input_dirs,
46 | recursive=self.recursive,
47 | chroma_db_dir=self.chroma_db_dir,
48 | index_persist_dir=self.index_persist_dir,
49 | chroma_collection_name=self.chroma_collection_name,
50 | chunk_size=self.chunk_size,
51 | chunk_overlap=self.chunk_overlap,
52 | )
53 | self.logger.info("Vectors and Querier initialized successfully.")
54 | self.index_vector_store = self.indexer.initialize_index()
55 |
56 | # Initialize querier with the indexer
57 | self.querier = Querier(index=self.index_vector_store)
58 |
59 | # Initialize chat engine with the indexer
60 | self.chat_engine = ChatEngine(index=self.index_vector_store)
61 |
62 | def _initialize_models(self):
63 | # Initialize the embedding and language model
64 | if self.openai_model_yn:
65 | set_embedding_model(openai_model=self.embedding_model)
66 | set_language_model(
67 | openai_model=self.language_model, temperature=self.temperature
68 | )
69 |
70 | else:
71 | set_embedding_model(huggingface_model=self.embedding_model)
72 | set_language_model(
73 | ollama_model=self.language_model,
74 | temperature=self.temperature,
75 | base_url=self.base_url,
76 | )
77 |
78 | def initialize_stream_chat(
79 | self,
80 | text_qa_template: str,
81 | chat_mode: str = "context",
82 | similarity_top_k: int = 3,
83 | ):
84 | self.chat_engine.initialize_chat_engine(
85 | text_qa_template=text_qa_template,
86 | chat_mode=chat_mode,
87 | similarity_top_k=similarity_top_k,
88 | )
89 |
90 | def start_chat_stream(self, query: str):
91 | if not self.chat_engine:
92 | raise ValueError(
93 | "Chat engine not initialized. Call initialize_stream_chat first."
94 | )
95 | return self.chat_engine.chat_stream(query)
96 |
97 | def start_query(
98 | self, text_qa_template: str, query: str, similarity_top_k: int = 3
99 | ) -> Dict[str, Any]:
100 | """
101 | Start a query using the initialized Querier.
102 |
103 | Args:
104 | text_qa_template (str): The template for the QA prompt.
105 | query (str): The query string.
106 | similarity_top_k (int, optional): Number of top similar documents to consider. Defaults to 3.
107 |
108 | Returns:
109 | Dict[str, Any]: A dictionary containing the response and metadata.
110 |
111 | Raises:
112 | ValueError: If the Querier is not initialized.
113 | """
114 | if not self.querier:
115 | self.logger.error("Querier not initialized. Call initialize_vectors first.")
116 | raise ValueError("Querier not initialized. Call initialize_vectors first.")
117 |
118 | try:
119 | self.logger.info(f"Starting query: {query}")
120 | response = self.querier.query(text_qa_template, query, similarity_top_k)
121 | self.logger.info("Query completed successfully.")
122 | return response
123 | except Exception as e:
124 | self.logger.error(
125 | f"An error occurred during query: {str(e)}", exc_info=True
126 | )
127 | return {
128 | "response": f"An error occurred while processing your request: {str(e)}",
129 | "metadata": {},
130 | }
131 |
132 | def refresh_index(self):
133 | self.indexer.refresh()
134 |
135 | def get_index_stats(self):
136 | return self.indexer.get_index_stats()
137 |
--------------------------------------------------------------------------------
/src/nexusync/core/chat_engine.py:
--------------------------------------------------------------------------------
1 | from typing import Dict, Any, List, Generator
2 | from llama_index.core import VectorStoreIndex, PromptTemplate
3 | from llama_index.core.memory import ChatMemoryBuffer
4 | from llama_index.core.postprocessor import (
5 | SentenceEmbeddingOptimizer,
6 | KeywordNodePostprocessor,
7 | )
8 | from nexusync.utils.logging_config import get_logger
9 |
10 |
11 | class ChatEngine:
12 | def __init__(self, index: VectorStoreIndex):
13 | """
14 | Initialize the ChatEngine with a VectorStoreIndex.
15 |
16 | Args:
17 | index (VectorStoreIndex): The index to be used for querying in chat.
18 | """
19 | self.logger = get_logger("nexusync.core.chat_engine")
20 | self.chat_engine = None
21 | self.chat_history = []
22 | self.index = index
23 |
24 | def initialize_chat_engine(
25 | self,
26 | text_qa_template: str,
27 | chat_mode: str = "context",
28 | similarity_top_k: int = 3,
29 | ):
30 | """
31 | Initialize the chat engine.
32 |
33 | Args:
34 | text_qa_template (str): The template for the QA prompt.
35 | chat_mode (str, optional): The mode for the chat engine. Defaults to 'context'.
36 | similarity_top_k (int, optional): Number of top similar documents to consider. Defaults to 3.
37 | """
38 | qa_template = PromptTemplate(text_qa_template)
39 | memory = ChatMemoryBuffer.from_defaults(token_limit=3000)
40 | if not isinstance(self.index, VectorStoreIndex):
41 | raise ValueError("The index does not contain a valid VectorStoreIndex")
42 |
43 | self.chat_engine = self.index.as_chat_engine(
44 | memory=memory,
45 | chat_mode=chat_mode,
46 | text_qa_template=qa_template,
47 | similarity_top_k=similarity_top_k,
48 | node_postprocessors=[
49 | SentenceEmbeddingOptimizer(percentile_cutoff=0.7),
50 | KeywordNodePostprocessor(required_keywords=[]),
51 | ],
52 | )
53 | self.logger.info("Chat engine initialized")
54 |
55 | def chat(self, query: str) -> Dict[str, Any]:
56 | """
57 | Process a query using the chat engine.
58 |
59 | Args:
60 | query (str): The user's query string.
61 |
62 | Returns:
63 | Dict[str, Any]: A dictionary containing the response and metadata.
64 |
65 | Raises:
66 | ValueError: If the chat engine is not initialized.
67 | """
68 | if self.chat_engine is None:
69 | raise ValueError(
70 | "Chat engine not initialized. Call initialize_chat_engine first."
71 | )
72 |
73 | try:
74 | response = self.chat_engine.chat(query)
75 |
76 | answer = str(response)
77 | metadata: Dict[str, List[Dict[str, Any]]] = {"sources": []}
78 |
79 | if hasattr(response, "source_nodes"):
80 | for node in response.source_nodes:
81 | source_info = {
82 | "source_text": node.node.get_text(),
83 | "metadata": node.node.metadata,
84 | }
85 | metadata["sources"].append(source_info)
86 |
87 | self.chat_history.append({"query": query, "response": answer})
88 |
89 | return {"response": answer, "metadata": metadata}
90 |
91 | except Exception as e:
92 | self.logger.error(f"An error occurred during chat: {e}", exc_info=True)
93 | return {
94 | "response": f"An error occurred while processing your request: {str(e)}",
95 | "metadata": {},
96 | }
97 |
98 | def chat_stream(self, query: str) -> Generator[str | Dict[str, Any], None, None]:
99 | if self.chat_engine is None:
100 | raise ValueError(
101 | "Chat engine not initialized. Call initialize_chat_engine first."
102 | )
103 |
104 | try:
105 | response_stream = self.chat_engine.stream_chat(query)
106 |
107 | full_response = ""
108 | for token in response_stream.response_gen:
109 | full_response += token
110 | yield token # Yield each token as it's generated
111 |
112 | # After all tokens have been yielded, prepare and yield the final response with metadata
113 | metadata = {"sources": []}
114 | if hasattr(response_stream, "source_nodes"):
115 | for node in response_stream.source_nodes:
116 | source_info = {
117 | "source_text": node.node.get_text(),
118 | "metadata": node.node.metadata,
119 | }
120 | metadata["sources"].append(source_info)
121 |
122 | # Append to chat history
123 | self.chat_history.append({"query": query, "response": full_response})
124 |
125 | # Yield the final response with metadata
126 | yield {
127 | "response": full_response,
128 | "metadata": metadata,
129 | }
130 |
131 | except Exception as e:
132 | self.logger.error(
133 | f"An error occurred during chat streaming: {e}", exc_info=True
134 | )
135 | yield {
136 | "response": f"An error occurred while processing your request: {str(e)}",
137 | "metadata": {},
138 | }
139 |
140 | def clear_chat_history(self):
141 | self.chat_history = []
142 | self.logger.info("Chat history cleared")
143 |
144 | if hasattr(self.chat_engine, "memory") and self.chat_engine.memory is not None:
145 | self.chat_engine.memory.clear()
146 | self.logger.info("Chat engine memory cleared")
147 |
148 | def get_chat_history(self) -> List[Dict[str, str]]:
149 | """
150 | Get the current chat history.
151 |
152 | Returns:
153 | List[Dict[str, str]]: A list of dictionaries containing queries and responses.
154 | """
155 | return self.chat_history
156 |
--------------------------------------------------------------------------------
/src/nexusync/core/indexer.py:
--------------------------------------------------------------------------------
1 | # src/core/indexer.py
2 |
3 | import os
4 | from typing import List, Optional, Dict, Any
5 | from llama_index.core import (
6 | VectorStoreIndex,
7 | SimpleDirectoryReader,
8 | StorageContext,
9 | load_index_from_storage,
10 | )
11 |
12 | from llama_index.vector_stores.chroma import ChromaVectorStore
13 | import chromadb
14 | from nexusync.utils.logging_config import get_logger
15 | from llama_index.core import Settings
16 |
17 |
18 | class Indexer:
19 | """
20 | Indexer is responsible for managing the indexing operations, including creating, refreshing,
21 | and deleting documents from the index. It supports integration with Chroma for efficient similarity search.
22 |
23 | Attributes:
24 | input_dirs (List[str]): A list of directory paths containing documents to be indexed.
25 | recursive (bool): Indicates if subdirectories within input_dirs should be scanned for documents.
26 | chroma_db_dir (str): The directory where the Chroma database is stored.
27 | index_persist_dir (str): The directory where the index is persisted to disk for future use.
28 | chroma_collection_name (str): The name of the collection within the Chroma database.
29 | index (VectorStoreIndex): The current index instance, loaded or created during initialization.
30 | logger (logging.Logger): A logger instance for logging operations and errors.
31 | storage_context (StorageContext): The context for managing the storage and loading of the index.
32 | """
33 |
34 | def __init__(
35 | self,
36 | input_dirs: List[str],
37 | recursive: bool = True,
38 | chroma_db_dir: str = "chroma_db",
39 | index_persist_dir: str = "index_storage",
40 | chroma_collection_name: str = "my_collection",
41 | chunk_size: int = 1024, # Default from llamaindex
42 | chunk_overlap: int = 20, # Default from llamaindex
43 | ):
44 | """
45 | Initialize the Indexer with the given parameters.
46 |
47 | Args:
48 | input_dirs (List[str]): Directories containing documents to be indexed.
49 | recursive (bool, optional): Scan subdirectories if True. Defaults to True.
50 | chroma_db_dir (str, optional): Directory for Chroma database. Defaults to "chroma_db".
51 | index_persist_dir (str, optional): Directory to persist the index. Defaults to "index_storage".
52 | chroma_collection_name (str, optional): Name of the Chroma collection. Defaults to "my_collection".
53 | chunk_size (int, optional): Size of each text chunk. Defaults to 1024.
54 | chunk_overlap (int, optional): Overlap between chunks. Defaults to 20.
55 |
56 | Note:
57 | The __init__ method doesn't create the index immediately. Instead, it calls the _initiate method,
58 | which either loads an existing index or builds a new one.
59 | """
60 | self.logger = get_logger("nexusync.core.indexer") # Use full logger name
61 | self.input_dirs = input_dirs
62 | self.recursive = recursive
63 | self.chroma_db_dir = chroma_db_dir
64 | self.index_persist_dir = index_persist_dir
65 | self.chroma_collection_name = chroma_collection_name
66 | self.chunk_size = chunk_size
67 | self.chunk_overlap = chunk_overlap
68 | self.index = None
69 | Settings.chunk_overlap = chunk_overlap
70 | Settings.chunk_size = chunk_size
71 |
72 | def initialize_index(self):
73 | """
74 | Load an existing index from storage or create a new one if not found.
75 |
76 | Raises:
77 | ValueError: If no documents are found in the specified directories.
78 | """
79 |
80 | try:
81 | self.storage_context = StorageContext.from_defaults(
82 | persist_dir=self.index_persist_dir
83 | )
84 | self.index = load_index_from_storage(self.storage_context)
85 | self.logger.info("Index already built. Loading from disk.")
86 | except FileNotFoundError:
87 | self.logger.warning("Index not found. Building a new index.")
88 | self.document_list = []
89 | total_files = 0
90 | for file_path in self.input_dirs:
91 | if not os.path.isdir(file_path):
92 | self.logger.error(f"Directory {file_path} does not exist.")
93 | raise ValueError(f"Directory {file_path} does not exist.")
94 | file_count = sum(len(files) for _, _, files in os.walk(file_path))
95 | total_files += file_count
96 | documents = SimpleDirectoryReader(
97 | file_path, filename_as_id=True
98 | ).load_data()
99 | self.logger.info(f"Loaded {total_files} files from all directories.")
100 | self.document_list.extend(documents)
101 |
102 | self.index = VectorStoreIndex.from_documents(self.document_list)
103 | self.index.storage_context.persist(persist_dir=self.index_persist_dir)
104 | chroma_client = chromadb.PersistentClient(path=self.chroma_db_dir)
105 | chroma_collection = chroma_client.get_or_create_collection(
106 | self.chroma_collection_name
107 | )
108 | vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
109 | self.storage_context = StorageContext.from_defaults(
110 | persist_dir=self.index_persist_dir, vector_store=vector_store
111 | )
112 |
113 | if not self.document_list:
114 | self.logger.error("No documents found to build the index.")
115 | raise ValueError("No documents found to build the index.")
116 |
117 | self.logger.info("Index Built.")
118 | except Exception as e:
119 | self.logger.error(f"An unexpected error occurred during initiation: {e}")
120 | raise
121 | return self.index
122 |
123 | def refresh(self):
124 | """
125 | Refresh the index by performing incremental updates and deletions based on the current
126 | state of the files.
127 |
128 | Raises:
129 | RuntimeError: If an error occurs during the refresh process.
130 | """
131 | self.logger.info("Starting index refresh process...")
132 | try:
133 | # Step 1: Collect current files
134 | current_files = set()
135 | for input_dir in self.input_dirs:
136 | for root, _, files in os.walk(input_dir):
137 | for file in files:
138 | current_files.add(os.path.abspath(os.path.join(root, file)))
139 |
140 | # Step 2: Perform upinsert (this will add new and update existing documents)
141 | self.upinsert()
142 |
143 | # Step 3: Perform delete (this will remove documents that no longer exist)
144 | self.delete(current_files)
145 |
146 | # Step 4: Verify and log the results
147 | updated_stats = self.get_index_stats()
148 |
149 | if updated_stats["num_documents"] != len(current_files):
150 | self.logger.warning(
151 | f"Mismatch between indexed documents ({updated_stats['num_documents']}) and files in directories ({len(current_files)})"
152 | )
153 |
154 | except Exception as e:
155 | self.logger.error(
156 | f"An error occurred during index refresh: {e}", exc_info=True
157 | )
158 | raise
159 |
160 | def upinsert(self):
161 | """
162 | Upsert (update or insert) documents into the index based on changes or new additions.
163 |
164 | Raises:
165 | RuntimeError: If an error occurs while performing the upinsert operation.
166 | """
167 | total_documents = 0
168 | total_refreshed = 0
169 |
170 | for input_dir in self.input_dirs:
171 | self.logger.info(f"Processing directory: {input_dir}")
172 | documents = SimpleDirectoryReader(
173 | input_dir, recursive=self.recursive, filename_as_id=True
174 | ).load_data()
175 | total_documents += len(documents)
176 | loaded_file_count = self.get_index_stats()["num_documents"]
177 | self.logger.info(f"Loaded {loaded_file_count} files from {input_dir}")
178 |
179 | refreshed_docs = self.index.refresh_ref_docs(documents)
180 | num_refreshed = sum(1 for r in refreshed_docs if r)
181 | total_refreshed += num_refreshed
182 |
183 | if num_refreshed == 0:
184 | self.logger.info(f"No files were modified or added in {input_dir}")
185 | else:
186 | for doc, is_refreshed in zip(documents, refreshed_docs):
187 | if is_refreshed:
188 | doc_path = doc.metadata.get("file_path", "Unknown path")
189 | self.logger.info(f"Updated file: {doc_path}")
190 |
191 | if total_refreshed == 0:
192 | self.logger.info("No files were modified or added in any directory")
193 | else:
194 | self.logger.info(f"Total files modified or added: {total_refreshed}")
195 |
196 | def delete(self, current_files: set):
197 | """Delete documents from the index if their corresponding files have been deleted from the filesystem."""
198 | ref_doc_info = self.index.ref_doc_info
199 | deleted_docs = []
200 |
201 | for doc_id, info in ref_doc_info.items():
202 | file_path = info.metadata.get("file_path")
203 | if file_path and os.path.abspath(file_path) not in current_files:
204 | self.logger.info(f"Deleted file: {file_path}")
205 | deleted_docs.append(doc_id)
206 |
207 | if deleted_docs:
208 | self.logger.info(f"Deleting {len(deleted_docs)} chunks from the index.")
209 | for doc_id in deleted_docs:
210 | self.index.delete_ref_doc(doc_id, delete_from_docstore=True)
211 | self.logger.info("Deletion process completed.")
212 | else:
213 | self.logger.info("No deleted files found.")
214 |
215 | def get_index_stats(self) -> Dict[str, Any]:
216 | """Get statistics about the current index."""
217 | # Count unique file paths in the index
218 | unique_files = set()
219 | for doc_id, info in self.index.ref_doc_info.items():
220 | file_path = info.metadata.get("file_path")
221 | if file_path:
222 | unique_files.add(file_path)
223 |
224 | return {
225 | "num_documents": len(unique_files), # Count of unique documents
226 | "num_nodes": len(self.index.ref_doc_info), # Total number of nodes
227 | "index_persist_dir": self.index_persist_dir,
228 | "chroma_db_dir": self.chroma_db_dir,
229 | "chroma_collection_name": self.chroma_collection_name,
230 | }
231 |
--------------------------------------------------------------------------------
/back_end_api.py:
--------------------------------------------------------------------------------
1 | # back_end_api.py
2 | from flask import Flask, request, jsonify, Response, send_from_directory
3 | import json
4 | import logging
5 | from nexusync import NexuSync, rebuild_index
6 |
7 | app = Flask(__name__)
8 |
9 | # Configure logging
10 | logging.basicConfig(level=logging.DEBUG)
11 |
12 | # Configuration Parameters
13 | # For non-openai model:
14 | # OPENAI_MODEL_YN = False
15 | # EMBEDDING_MODEL = "BAAI/bge-base-en-v1.5"
16 | # LANGUAGE_MODEL = "llama3.2"
17 |
18 | # For openai model: need to create .env in the src folder to include OPENAI_API_KEY = 'sk-xxx'
19 | OPENAI_MODEL_YN = True
20 | EMBEDDING_MODEL = "text-embedding-3-large"
21 | LANGUAGE_MODEL = "gpt-4o-mini"
22 | TEMPERATURE = 0.4
23 | INPUT_DIRS = ["sample_docs/"] # Can include multiple paths
24 | CHROMA_DB_DIR = "chroma_db"
25 | INDEX_PERSIST_DIR = "index_storage"
26 | CHROMA_COLLECTION_NAME = "my_collection"
27 | CHUNK_SIZE = 1024
28 | CHUNK_OVERLAP = 20
29 | RECURSIVE = True
30 |
31 |
32 | # Define the QA Prompt Template
33 | text_qa_template = """
34 | Context Information:
35 | {context_str}
36 | Query: {query_str}
37 | Instructions:
38 | You are helping NHS doctors to review patients' medical records and give interperetations on the results.
39 | Carefully read the context information and the query.
40 | If the query is in the format [patient_id, summary_report], generate a summary report using the template below.
41 | Use the available information from the context to fill in each section.
42 | Include relevant dates and timeline information in each section.
43 | If information for a section is not available, state "No information available" for that section.
44 | Provide concise and accurate information based on the given context.
45 | Adapt the template as needed to fit the patient's specific medical history and conditions.
46 |
47 | Summary Report Template:
48 |
49 | Patient Summary Report for {patient_id}
50 | 1. Demographics
51 |
52 | Name: [First Name] [Last Name]
53 | Date of Birth: [DOB]
54 | Gender: [Gender]
55 | Contact Information:
56 |
57 | Address: [Address]
58 | Phone: [Phone Number]
59 | Email: [Email Address]
60 |
61 |
62 |
63 | 2. Past Medical History & Procedures
64 |
65 | Chronic Conditions: [List of chronic conditions with diagnosis dates]
66 | Major Illnesses: [List of major illnesses with dates]
67 | Surgical Procedures: [List of surgical procedures with dates]
68 | Other Significant Medical Events: [List with dates]
69 | Your interpretation: [Your interpretation of the medical records]
70 |
71 | 3. Medication History
72 | [List each current medication with the following information]
73 |
74 | Name: [Medication Name]
75 | Dosage: [Dosage]
76 | Frequency: [Frequency]
77 | Start Date: [Start Date]
78 | Prescriber: [Prescriber Name]
79 | Purpose: [Brief description of why the medication is prescribed]
80 |
81 | [Include a brief list of significant past medications, if available]
82 | 4. Allergies and Adverse Reactions
83 |
84 | Medication Allergies: [List or "No known medication allergies"]
85 | Other Allergies: [List or "No known other allergies"]
86 | Adverse Reactions: [List any significant adverse reactions to treatments or medications]
87 |
88 | 5. Social History & Occupation
89 |
90 | Occupation: [Current or most recent occupation]
91 | Smoking Status: [Current smoker, former smoker, never smoker]
92 | Alcohol Use: [Description of alcohol use]
93 | Recreational Drug Use: [If applicable]
94 | Exercise Habits: [Brief description]
95 | Diet: [Any significant dietary information]
96 | Other Relevant Social Factors: [e.g., living situation, support system]
97 | Your interpretation: [Your interpretation of the social history]
98 |
99 | 6. Physical Examination & Vital Signs
100 | Most Recent Vital Signs (Date: [Date of most recent vital signs])
101 |
102 | Blood Pressure: [BP]
103 | Heart Rate: [HR]
104 | Respiratory Rate: [RR]
105 | Temperature: [Temp]
106 | Oxygen Saturation: [O2 Sat]
107 | Weight: [Weight]
108 | Height: [Height]
109 | BMI: [BMI]
110 | Your interpretation: [Your interpretation of the vital signs]
111 | [Include any significant physical examination findings]
112 |
113 | 7. Laboratory Results
114 | [List most recent significant laboratory tests with dates, results, and normal ranges]
115 |
116 | 8. Imaging and Diagnostic Results
117 | [List recent imaging studies and other diagnostic tests with dates and summary of results]
118 |
119 | 9. Treatment Plan and Interventions
120 |
121 | Current Treatment Plans: [List current treatments or interventions]
122 | Ongoing Therapies: [e.g., physical therapy, chemotherapy, dialysis]
123 | Recent Changes in Management: [Any recent significant changes in treatment]
124 | Your interpretation: [Your interpretation of the treatment plan]
125 |
126 | 10. Immunizations
127 | [List relevant immunizations with dates]
128 |
129 | 11. Upcoming Appointments and Follow-ups
130 | [List any scheduled appointments with dates, types, and locations]
131 |
132 |
133 | Answer: [Generate the report based on the template above, filling in the available information from the context]
134 |
135 | Answer: """
136 |
137 | ns = NexuSync(
138 | input_dirs=INPUT_DIRS,
139 | openai_model_yn=OPENAI_MODEL_YN,
140 | embedding_model=EMBEDDING_MODEL,
141 | language_model=LANGUAGE_MODEL,
142 | temperature=TEMPERATURE,
143 | chroma_db_dir=CHROMA_DB_DIR,
144 | index_persist_dir=INDEX_PERSIST_DIR,
145 | chroma_collection_name=CHROMA_COLLECTION_NAME,
146 | chunk_overlap=CHUNK_OVERLAP,
147 | chunk_size=CHUNK_SIZE,
148 | recursive=RECURSIVE,
149 | )
150 |
151 |
152 | # Initialize the Chat Engine Once
153 | ns.initialize_stream_chat(
154 | text_qa_template=text_qa_template, chat_mode="context", similarity_top_k=3
155 | )
156 |
157 |
158 | # Root Route - Serve the index.html file
159 | @app.route("/")
160 | def index():
161 | return send_from_directory(".", "index.html")
162 |
163 |
164 | @app.route("/chat", methods=["POST"])
165 | def chat():
166 | data = request.get_json()
167 | if not data or "message" not in data:
168 | return jsonify({"error": "Invalid request. 'message' field is required."}), 400
169 |
170 | user_input = data["message"]
171 |
172 | def generate_response():
173 | try:
174 | source_file_paths = []
175 | response_generator = ns.chat_engine.chat_stream(user_input)
176 |
177 | for item in response_generator:
178 | if isinstance(item, str):
179 | # Stream individual tokens
180 | yield json.dumps({"response": item}) + "\n"
181 | elif isinstance(item, dict):
182 | # Final response with metadata
183 | metadata = item.get("metadata", {})
184 | sources = metadata.get("sources", [])
185 |
186 | # Extract source file paths
187 | for source in sources:
188 | metadata_info = source.get("metadata", {})
189 | file_path = metadata_info.get("file_path", "Unknown source")
190 | source_file_paths.append(file_path)
191 |
192 | # Remove duplicates while preserving order
193 | source_file_paths = list(dict.fromkeys(source_file_paths))
194 |
195 | # Format the source file paths
196 | if source_file_paths:
197 | sources_formatted = "\n".join(
198 | f"- {path}" for path in source_file_paths
199 | )
200 | yield json.dumps(
201 | {"sources": sources_formatted, "final": True}
202 | ) + "\n"
203 | else:
204 | yield json.dumps(
205 | {"sources": "No sources found", "final": True}
206 | ) + "\n"
207 |
208 | except Exception as e:
209 | logging.error(f"Error in chat endpoint: {e}", exc_info=True)
210 | yield json.dumps(
211 | {"error": f"An error occurred while processing your request: {str(e)}"}
212 | ) + "\n"
213 |
214 | return Response(generate_response(), mimetype="application/json")
215 |
216 |
217 | @app.route("/rebuild_index", methods=["POST"])
218 | def rebuild_index_route():
219 | global ns, EMBEDDING_MODEL, LANGUAGE_MODEL, TEMPERATURE, INPUT_DIRS
220 |
221 | data = request.get_json()
222 | if not data:
223 | return jsonify({"error": "No data provided"}), 400
224 |
225 | try:
226 | # Update global variables
227 | EMBEDDING_MODEL = data.get("embedding_model", EMBEDDING_MODEL)
228 | LANGUAGE_MODEL = data.get("llm_model", LANGUAGE_MODEL)
229 | TEMPERATURE = data.get("temperature", TEMPERATURE)
230 | INPUT_DIRS = data.get("input_dirs", INPUT_DIRS)
231 |
232 | # Rebuild index
233 | rebuild_index(
234 | input_dirs=INPUT_DIRS,
235 | openai_model_yn=OPENAI_MODEL_YN,
236 | embedding_model=EMBEDDING_MODEL,
237 | language_model=LANGUAGE_MODEL,
238 | temperature=TEMPERATURE,
239 | chroma_db_dir=CHROMA_DB_DIR,
240 | index_persist_dir=INDEX_PERSIST_DIR,
241 | chroma_collection_name=CHROMA_COLLECTION_NAME,
242 | chunk_overlap=CHUNK_OVERLAP,
243 | chunk_size=CHUNK_SIZE,
244 | recursive=RECURSIVE,
245 | )
246 |
247 | # Reinitialize NexuSync
248 | ns = NexuSync(
249 | input_dirs=INPUT_DIRS,
250 | openai_model_yn=OPENAI_MODEL_YN,
251 | embedding_model=EMBEDDING_MODEL,
252 | language_model=LANGUAGE_MODEL,
253 | temperature=TEMPERATURE,
254 | chroma_db_dir=CHROMA_DB_DIR,
255 | index_persist_dir=INDEX_PERSIST_DIR,
256 | chroma_collection_name=CHROMA_COLLECTION_NAME,
257 | chunk_overlap=CHUNK_OVERLAP,
258 | chunk_size=CHUNK_SIZE,
259 | recursive=RECURSIVE,
260 | )
261 |
262 | # Reinitialize the chat engine
263 | ns.initialize_stream_chat(
264 | text_qa_template=text_qa_template, chat_mode="context", similarity_top_k=3
265 | )
266 |
267 | return jsonify({"status": "Index rebuilt successfully"}), 200
268 | except Exception as e:
269 | app.logger.error(f"Error rebuilding index: {e}", exc_info=True)
270 | return jsonify({"error": str(e)}), 500
271 |
272 |
273 | @app.route("/reset_chat", methods=["POST"])
274 | def reset_chat():
275 | try:
276 | ns.chat_engine.clear_chat_history()
277 | return jsonify({"status": "Chat history cleared successfully."}), 200
278 | except Exception as e:
279 | logging.error(f"Error resetting chat history: {e}", exc_info=True)
280 | return jsonify({"error": f"An error occurred: {str(e)}"}), 500
281 |
282 |
283 | @app.route("/refresh_index", methods=["POST"])
284 | def refresh_index():
285 | try:
286 | ns.indexer.refresh()
287 | return jsonify({"status": "Index refreshed successfully."}), 200
288 | except Exception as e:
289 | logging.error(f"Error refreshing index: {e}", exc_info=True)
290 | return jsonify({"error": f"An error occurred: {str(e)}"}), 500
291 |
292 |
293 | if __name__ == "__main__":
294 | # Run the Flask app
295 | app.run(host="0.0.0.0", port=2024, debug=True)
296 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [pypi](https://pypi.org/project/nexusync/)
2 | [GitHub](https://github.com/Zakk-Yang/nexusync)
3 | [](https://pepy.tech/project/nexusync)
4 |
5 |
6 |
7 |
8 |
9 |
10 | Newest version = 0.3.6: torch package needs to be installed seperately to make sure your system env matches;
11 |
12 | Development Plan for the next version:
13 | - Adding PDF OCF using ollama llama3.2 vision
14 |
15 |
16 | # NexuSync
17 |
18 | *NexuSync* is a lightweight yet powerful library for building Retrieval-Augmented Generation (RAG) systems, built on top of **LlamaIndex**. It offers a simple and user-friendly interface for developers to configure and deploy RAG systems efficiently. Choose between using the **Ollama LLM** model for offline, privacy-focused applications or the **OpenAI API** for a hosted solution.
19 |
20 | ---
21 |
22 | ## 🚀 Features
23 |
24 | - **Lightweight Design**: Simplify the integration and configuration of RAG systems without unnecessary complexity.
25 | - **User-Friendly Interface**: Intuitive APIs and clear documentation make setup a breeze.
26 | - **Flexible Document Indexing**: Automatically index documents from specified directories, keeping your knowledge base up-to-date.
27 | - **Efficient Querying**: Use natural language to query your document collection and get relevant answers quickly.
28 | - **Conversational Interface**: Engage in chat-like interactions for more intuitive information retrieval.
29 | - **Customizable Embedding Options**: Choose between HuggingFace Embedding models or OpenAI's offerings.
30 | - **Incremental Updates**: Easily update and insert new documents into the index or delete the index for removed documents.
31 | - **Automatic Deletion Handling**: Documents removed from the filesystem are automatically removed from the index.
32 | - **Extensive File Format Support**: Supports multiple file formats including `.csv`, `.docx`, `.epub`, `.hwp`, `.ipynb`, `.mbox`, `.md`, `.pdf`, `.png`, `.ppt`, `.pptm`, `.pptx`, `.json`, and more.
33 |
34 |
35 | ---
36 |
37 |
38 | ## 🛠 Prerequisites
39 | - Python 3.10 or higher
40 | - Install Pytorch, please visit https://pytorch.org/get-started/locally/
41 | - Install Ollama: https://ollama.com/download or OpenAI API (need to create .env file to include OPENAI_API_KEY = 'sk-xxx')
42 | - Suggested to use conda for your env control to avoid enviroment conflicts:
43 |
44 | **Install `conda` for WSL2 (Windows Subsystem for Linux 2)**:
45 | 1. Open your WSL2 terminal
46 | 2. Download the Miniconda installer:
47 | `wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh`
48 | 3. Run the installer:
49 | `bash Miniconda3-latest-Linux-x86_64.sh`
50 | 4. Follow the prompts to complete the installation
51 | 5. Restart your terminal or run source ~/.bashrc
52 |
53 | **Install `conda` for Windows**:
54 | 1. Download the Miniconda installer for Windows from https://docs.conda.io/en/latest/miniconda.html
55 | 2. Run the .exe file and follow the installation prompts
56 | 3. Choose whether to add Conda to your PATH environment variable during installation
57 |
58 | **Install `conda` for Linux**:
59 | 1. Open a terminal
60 | 2. Download the Miniconda installer
61 | `wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh`
62 | 3. Run the installer:
63 | `bash Miniconda3-latest-Linux-x86_64.sh`
64 | 4.Follow the prompts to complete the installation
65 | 5. Restart your terminal or run `source ~/.bashrc`
66 |
67 | **Install `conda` for macOS**:
68 | 1. Open a terminal
69 | 2. Download the Miniconda installer
70 | `curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-MacOSX-x86_64.sh`
71 | 3. Run the installer:
72 | `bash Miniconda3-latest-MacOSX-x86_64.sh`
73 | 4.Follow the prompts to complete the installation
74 | 5. Restart your terminal or run `source ~/.bash_profile`
75 |
76 | **After installation on any platform, verify the installation by running**:
77 | `conda --version`
78 |
79 | ---
80 |
81 |
82 | ## 📦Installation
83 | 1. Use conda to create env in your project folder:
84 | ```bash
85 | conda create env --name python=3.10
86 | conda activate
87 | ```
88 |
89 | 2. Then, install NexuSync under your conda env, run the following command:
90 |
91 | ```bash
92 | pip install nexusync
93 | ```
94 | Or `git clone https://github.com/Zakk-Yang/nexusync.git`
95 |
96 |
97 | 3. Install pytorch (https://pytorch.org/get-started/locally/):
98 | - If you are using cuda, make sure your cuda version matches:
99 | - For CUDA 11.8 (example, for windows and wsl2/linux)
100 | `pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118`
101 | - For CUDA 12.1 (example, for windows and wsl2/linux)
102 | `pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121`
103 | - For macOS
104 | `pip3 install torch torchvision torchaudio`
105 |
106 | ---
107 |
108 |
109 | ## 🌟 Quick Start
110 |
111 | Here's how you can get started with NexuSync:
112 |
113 | 1. ### Import NexuSync
114 | ```python
115 | from nexusync import NexuSync
116 | ```
117 | 2. ### Choose Your Model
118 | ##### **Option A: Using OpenAI Model**
119 | ```python
120 | #------- Use OpenAI Model -------
121 | # Customize your parameters for openai model, create .env file in the project folder to include OPENAI_API_KEY = 'sk-xxx'
122 | OPENAI_MODEL_YN = True
123 | EMBEDDING_MODEL = "text-embedding-3-large"
124 | LANGUAGE_MODEL = "gpt-4o-mini"
125 | TEMPERATURE = 0.4 # range from 0 to 1, higher means higher creativitiy level
126 | CHROMA_DB_DIR = 'chroma_db' # Your path to the chroma db
127 | INDEX_PERSIST_DIR = 'index_storage' # Your path to the index storage
128 | CHROMA_COLLECTION_NAME = 'my_collection'
129 | INPUT_DIRS = ["../sample_docs"] # can specify multiple document paths
130 | CHUNK_SIZE = 1024 # Size of text chunks for creating embeddings
131 | CHUNK_OVERLAP = 20 # Overlap between text chunks to maintain context
132 | RECURSIVE = True # Recursive or not under one folder
133 | ```
134 |
135 | ##### **Option B: Using Ollama Model**
136 | ```python
137 | #------- Use Ollama Model -------
138 | # Customize your parameters for ollama model
139 | OPENAI_MODEL_YN = False # if False, you will use ollama model
140 | EMBEDDING_MODEL = "BAAI/bge-base-en-v1.5" # suggested embedding model, you can replace with any HuggingFace embedding models
141 | LANGUAGE_MODEL = 'llama3.2' # you need to download ollama model first, please check https://ollama.com/download
142 | BASE_URL = "http://localhost:11434" # you can swith to different base_url for Ollama model
143 | TEMPERATURE = 0.4 # range from 0 to 1, higher means higher creativitiy level
144 | CHROMA_DB_DIR = 'chroma_db' # Your path to the chroma db
145 | INDEX_PERSIST_DIR = 'index_storage' # Your path to the index storage
146 | CHROMA_COLLECTION_NAME = 'my_collection'
147 | INPUT_DIRS = ["../sample_docs"] # can specify multiple document paths
148 | CHUNK_SIZE = 1024 # Size of text chunks for creating embeddings
149 | CHUNK_OVERLAP = 20 # Overlap between text chunks to maintain context
150 | RECURSIVE = True # Recursive or not under one folder
151 | ```
152 |
153 | ### 3. Initialize Vector DB
154 | ```python
155 | # example for Ollama Model
156 | ns = NexuSync(input_dirs=INPUT_DIRS,
157 | openai_model_yn=False,
158 | embedding_model=EMBEDDING_MODEL,
159 | language_model=LANGUAGE_MODEL,
160 | base_url = BASE_URL, # OpenAI model does not need base_url, here we use Ollama Model as an example
161 | temperature=TEMPERATURE,
162 | chroma_db_dir = CHROMA_DB_DIR,
163 | index_persist_dir = INDEX_PERSIST_DIR,
164 | chroma_collection_name=CHROMA_COLLECTION_NAME,
165 | chunk_overlap=CHUNK_OVERLAP,
166 | chunk_size=CHUNK_SIZE,
167 | recursive=RECURSIVE
168 | )
169 | ```
170 |
171 | ### 4. Start Quering (quick quering with no memory)
172 | ```python
173 | #------- Start Quering (one-time, no memory and without stream chat) -----
174 | query = "main result of the paper can llm generate novltive ideas"
175 |
176 | text_qa_template = """
177 | Context Information:
178 | --------------------
179 | {context_str}
180 | --------------------
181 |
182 | Query: {query_str}
183 |
184 | Instructions:
185 | 1. Carefully read the context information and the query.
186 | 2. Think through the problem step by step.
187 | 3. Provide a concise and accurate answer based on the given context.
188 | 4. If the answer cannot be determined from the context, state "Based on the given information, I cannot provide a definitive answer."
189 | 5. If you need to make any assumptions, clearly state them.
190 | 6. If relevant, provide a brief explanation of your reasoning.
191 |
192 | Answer: """
193 |
194 | response = ns.start_query(text_qa_template = text_qa_template, query = query )
195 |
196 | print(f"Query: {query}")
197 | print(f"Response: {response['response']}")
198 | print(f"Response: {response['metadata']}")
199 | ```
200 |
201 | ### 5. Engage in Stream Chat (token by token output, with Memory)
202 | ```python
203 | # First, initalize the stream chat engine
204 | ns.initialize_stream_chat(
205 | text_qa_template=text_qa_template,
206 | chat_mode="context",
207 | similarity_top_k=3
208 | )
209 |
210 | query = "main result of the paper can llm generate novltive ideas"
211 |
212 | for item in ns.start_chat_stream(query):
213 | if isinstance(item, str):
214 | # This is a token, print or process as needed
215 | print(item, end='', flush=True)
216 | else:
217 | # This is the final response with metadata
218 | print("\n\nFull response:", item['response'])
219 | print("Metadata:", item['metadata'])
220 | break
221 | ```
222 |
223 | ### 6. Access Chat History (for stream chat)
224 | ```python
225 | chat_history = ns.chat_engine.get_chat_history()
226 | print("Chat History:")
227 | for entry in chat_history:
228 | print(f"Human: {entry['query']}")
229 | print(f"AI: {entry['response']}\n")
230 | ```
231 |
232 | ### 7. Incrementally Refresh Index
233 | ```python
234 | #------- Incrementaly Refresh Index without Rebuilding it -----
235 | # If you have files modified, inserted or deleted, you don't need to rebuild all the index
236 | ns.refresh_index()
237 | ```
238 | ### 8. Rebuild Index From Scratch
239 | ```python
240 | #------- Rebuild Index -----
241 | # Rebuild the index when either of the following is changed:
242 | # - openai_model_yn
243 | # - embedding_model
244 | # - language_model
245 | # - base_url
246 | # - chroma_db_dir
247 | # - index_persist_dir
248 | # - chroma_collection_name
249 | # - chunk_overlap
250 | # - chunk_size
251 | # - recursive
252 |
253 | from nexusync import rebuild_index
254 | from nexusync import NexuSync
255 |
256 | OPENAI_MODEL_YN = True # if False, you will use ollama model
257 | EMBEDDING_MODEL = "text-embedding-3-large" # suggested embedding model
258 | LANGUAGE_MODEL = 'gpt-4o-mini' # you need to download ollama model first, please check https://ollama.com/download
259 | TEMPERATURE = 0.4 # range from 0 to 1, higher means higher creativitiy level
260 | CHROMA_DB_DIR = 'chroma_db'
261 | INDEX_PERSIST_DIR = 'index_storage'
262 | CHROMA_COLLECTION_NAME = 'my_collection'
263 | INPUT_DIRS = ["../sample_docs"] # can specify multiple document paths
264 | CHUNK_SIZE = 1024
265 | CHUNK_OVERLAP = 20
266 | RECURSIVE = True
267 |
268 | # Assume we changed the model from Ollama to OPENAI
269 | rebuild_index(input_dirs=INPUT_DIRS,
270 | openai_model_yn=OPENAI_MODEL_YN,
271 | embedding_model=EMBEDDING_MODEL,
272 | language_model=LANGUAGE_MODEL,
273 | temperature=TEMPERATURE,
274 | chroma_db_dir = CHROMA_DB_DIR,
275 | index_persist_dir = INDEX_PERSIST_DIR,
276 | chroma_collection_name=CHROMA_COLLECTION_NAME,
277 | chunk_overlap=CHUNK_OVERLAP,
278 | chunk_size=CHUNK_SIZE,
279 | recursive=RECURSIVE
280 | )
281 |
282 | # Reinitiate the ns after rebuilding the index
283 | ns = NexuSync(input_dirs=INPUT_DIRS,
284 | openai_model_yn=OPENAI_MODEL_YN,
285 | embedding_model=EMBEDDING_MODEL,
286 | language_model=LANGUAGE_MODEL,
287 | temperature=TEMPERATURE,
288 | chroma_db_dir = CHROMA_DB_DIR,
289 | index_persist_dir = INDEX_PERSIST_DIR,
290 | chroma_collection_name=CHROMA_COLLECTION_NAME,
291 | chunk_overlap=CHUNK_OVERLAP,
292 | chunk_size=CHUNK_SIZE,
293 | recursive=RECURSIVE
294 | )
295 |
296 | # Test the new built index
297 | query = "main result of the paper can llm generate novltive ideas"
298 |
299 | text_qa_template = """
300 | Context Information:
301 | --------------------
302 | {context_str}
303 | --------------------
304 |
305 | Query: {query_str}
306 |
307 | Instructions:
308 | 1. Carefully read the context information and the query.
309 | 2. Think through the problem step by step.
310 | 3. Provide a concise and accurate answer based on the given context.
311 | 4. If the answer cannot be determined from the context, state "Based on the given information, I cannot provide a definitive answer."
312 | 5. If you need to make any assumptions, clearly state them.
313 | 6. If relevant, provide a brief explanation of your reasoning.
314 |
315 | Answer: """
316 |
317 |
318 | response = ns.start_query(text_qa_template = text_qa_template, query = query )
319 |
320 | print(f"Query: {query}")
321 | print(f"Response: {response['response']}")
322 | print(f"Response: {response['metadata']}")
323 | ```
324 | ---
325 |
326 | ## 🎯 User Interface
327 | 1. git clone or download this project:
328 | ```bash
329 | git clone https://github.com/Zakk-Yang/nexusync.git
330 | ```
331 | 2. Configure Backend
332 | - Open back_end_api.py in your IDE.
333 | - Adjust the parameters according to your requirements.
334 |
335 | 3. Open the terminal and run
336 | ```
337 | python back_end_api.py
338 | ```
339 | Ensure that the parameters in `back_end_api.py` align with the settings in the side panel of the interface. If not, copy and paste your desired Embedding Model and Language Model in the side panel and click "Apply Settings".
340 |
341 | 4. Start interacting with your data!
342 |
343 |
344 |
345 |
346 |
347 | ---
348 |
349 | ## 📚 Documentation & Examples
350 | For more detailed usage examples, check out the demo notebooks.
351 |
352 | ---
353 |
354 | ## 📝 License
355 | This project is licensed under the MIT License - see the LICENSE file for details.
356 |
357 | ---
358 |
359 | ## 📫 Contact
360 | For questions or suggestions, feel free to open an issue or contact the maintainer:
361 |
362 | Name: Zakk Yang
363 | Email: zakkyang@hotmail.com
364 | GitHub: Zakk-Yang
365 |
366 | ---
367 |
368 | ## 🌟 Support
369 | If you find this project helpful, please give it a ⭐ on [GitHub](https://github.com/Zakk-Yang/nexusync)! Your support is appreciated.
370 |
--------------------------------------------------------------------------------
/index.html:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 | NexuSync Chat Interface
9 |
217 |
218 |
219 |
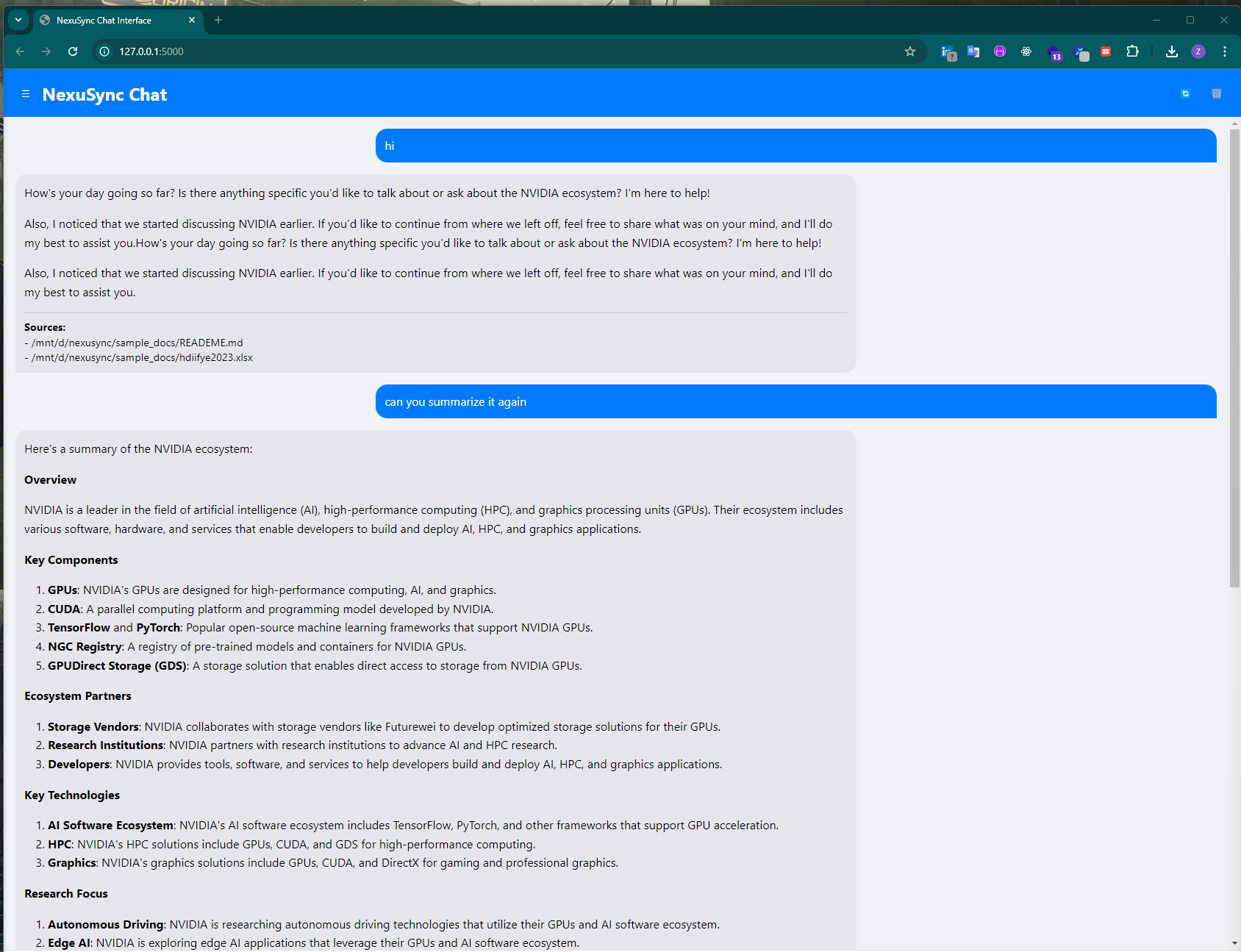 345 |
345 |