The demo python introduces several python courses.
4 |Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: 5 | Basic Python and Advanced Python.
6 | -------------------------------------------------------------------------------- /python123demo/python123demo/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/python123demo/python123demo/__init__.py -------------------------------------------------------------------------------- /python123demo/python123demo/__pycache__/__init__.cpython-36.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/python123demo/python123demo/__pycache__/__init__.cpython-36.pyc -------------------------------------------------------------------------------- /python123demo/python123demo/__pycache__/settings.cpython-36.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/python123demo/python123demo/__pycache__/settings.cpython-36.pyc -------------------------------------------------------------------------------- /python123demo/python123demo/items.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your scraped items 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/items.html 7 | 8 | import scrapy 9 | 10 | 11 | class Python123DemoItem(scrapy.Item): 12 | # define the fields for your item here like: 13 | # name = scrapy.Field() 14 | pass 15 | -------------------------------------------------------------------------------- /python123demo/python123demo/middlewares.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your spider middleware 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 7 | 8 | from scrapy import signals 9 | 10 | 11 | class Python123DemoSpiderMiddleware(object): 12 | # Not all methods need to be defined. If a method is not defined, 13 | # scrapy acts as if the spider middleware does not modify the 14 | # passed objects. 15 | 16 | @classmethod 17 | def from_crawler(cls, crawler): 18 | # This method is used by Scrapy to create your spiders. 19 | s = cls() 20 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 21 | return s 22 | 23 | def process_spider_input(self, response, spider): 24 | # Called for each response that goes through the spider 25 | # middleware and into the spider. 26 | 27 | # Should return None or raise an exception. 28 | return None 29 | 30 | def process_spider_output(self, response, result, spider): 31 | # Called with the results returned from the Spider, after 32 | # it has processed the response. 33 | 34 | # Must return an iterable of Request, dict or Item objects. 35 | for i in result: 36 | yield i 37 | 38 | def process_spider_exception(self, response, exception, spider): 39 | # Called when a spider or process_spider_input() method 40 | # (from other spider middleware) raises an exception. 41 | 42 | # Should return either None or an iterable of Response, dict 43 | # or Item objects. 44 | pass 45 | 46 | def process_start_requests(self, start_requests, spider): 47 | # Called with the start requests of the spider, and works 48 | # similarly to the process_spider_output() method, except 49 | # that it doesn’t have a response associated. 50 | 51 | # Must return only requests (not items). 52 | for r in start_requests: 53 | yield r 54 | 55 | def spider_opened(self, spider): 56 | spider.logger.info('Spider opened: %s' % spider.name) 57 | 58 | 59 | class Python123DemoDownloaderMiddleware(object): 60 | # Not all methods need to be defined. If a method is not defined, 61 | # scrapy acts as if the downloader middleware does not modify the 62 | # passed objects. 63 | 64 | @classmethod 65 | def from_crawler(cls, crawler): 66 | # This method is used by Scrapy to create your spiders. 67 | s = cls() 68 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 69 | return s 70 | 71 | def process_request(self, request, spider): 72 | # Called for each request that goes through the downloader 73 | # middleware. 74 | 75 | # Must either: 76 | # - return None: continue processing this request 77 | # - or return a Response object 78 | # - or return a Request object 79 | # - or raise IgnoreRequest: process_exception() methods of 80 | # installed downloader middleware will be called 81 | return None 82 | 83 | def process_response(self, request, response, spider): 84 | # Called with the response returned from the downloader. 85 | 86 | # Must either; 87 | # - return a Response object 88 | # - return a Request object 89 | # - or raise IgnoreRequest 90 | return response 91 | 92 | def process_exception(self, request, exception, spider): 93 | # Called when a download handler or a process_request() 94 | # (from other downloader middleware) raises an exception. 95 | 96 | # Must either: 97 | # - return None: continue processing this exception 98 | # - return a Response object: stops process_exception() chain 99 | # - return a Request object: stops process_exception() chain 100 | pass 101 | 102 | def spider_opened(self, spider): 103 | spider.logger.info('Spider opened: %s' % spider.name) 104 | -------------------------------------------------------------------------------- /python123demo/python123demo/pipelines.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define your item pipelines here 4 | # 5 | # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 | # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 | 8 | 9 | class Python123DemoPipeline(object): 10 | def process_item(self, item, spider): 11 | return item 12 | -------------------------------------------------------------------------------- /python123demo/python123demo/settings.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Scrapy settings for python123demo project 4 | # 5 | # For simplicity, this file contains only settings considered important or 6 | # commonly used. You can find more settings consulting the documentation: 7 | # 8 | # https://doc.scrapy.org/en/latest/topics/settings.html 9 | # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 10 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 11 | 12 | BOT_NAME = 'python123demo' 13 | 14 | SPIDER_MODULES = ['python123demo.spiders'] 15 | NEWSPIDER_MODULE = 'python123demo.spiders' 16 | 17 | 18 | # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 | #USER_AGENT = 'python123demo (+http://www.yourdomain.com)' 20 | 21 | # Obey robots.txt rules 22 | ROBOTSTXT_OBEY = True 23 | 24 | # Configure maximum concurrent requests performed by Scrapy (default: 16) 25 | #CONCURRENT_REQUESTS = 32 26 | 27 | # Configure a delay for requests for the same website (default: 0) 28 | # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay 29 | # See also autothrottle settings and docs 30 | #DOWNLOAD_DELAY = 3 31 | # The download delay setting will honor only one of: 32 | #CONCURRENT_REQUESTS_PER_DOMAIN = 16 33 | #CONCURRENT_REQUESTS_PER_IP = 16 34 | 35 | # Disable cookies (enabled by default) 36 | #COOKIES_ENABLED = False 37 | 38 | # Disable Telnet Console (enabled by default) 39 | #TELNETCONSOLE_ENABLED = False 40 | 41 | # Override the default request headers: 42 | #DEFAULT_REQUEST_HEADERS = { 43 | # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 44 | # 'Accept-Language': 'en', 45 | #} 46 | 47 | # Enable or disable spider middlewares 48 | # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html 49 | #SPIDER_MIDDLEWARES = { 50 | # 'python123demo.middlewares.Python123DemoSpiderMiddleware': 543, 51 | #} 52 | 53 | # Enable or disable downloader middlewares 54 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 55 | #DOWNLOADER_MIDDLEWARES = { 56 | # 'python123demo.middlewares.Python123DemoDownloaderMiddleware': 543, 57 | #} 58 | 59 | # Enable or disable extensions 60 | # See https://doc.scrapy.org/en/latest/topics/extensions.html 61 | #EXTENSIONS = { 62 | # 'scrapy.extensions.telnet.TelnetConsole': None, 63 | #} 64 | 65 | # Configure item pipelines 66 | # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 67 | #ITEM_PIPELINES = { 68 | # 'python123demo.pipelines.Python123DemoPipeline': 300, 69 | #} 70 | 71 | # Enable and configure the AutoThrottle extension (disabled by default) 72 | # See https://doc.scrapy.org/en/latest/topics/autothrottle.html 73 | #AUTOTHROTTLE_ENABLED = True 74 | # The initial download delay 75 | #AUTOTHROTTLE_START_DELAY = 5 76 | # The maximum download delay to be set in case of high latencies 77 | #AUTOTHROTTLE_MAX_DELAY = 60 78 | # The average number of requests Scrapy should be sending in parallel to 79 | # each remote server 80 | #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 81 | # Enable showing throttling stats for every response received: 82 | #AUTOTHROTTLE_DEBUG = False 83 | 84 | # Enable and configure HTTP caching (disabled by default) 85 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 86 | #HTTPCACHE_ENABLED = True 87 | #HTTPCACHE_EXPIRATION_SECS = 0 88 | #HTTPCACHE_DIR = 'httpcache' 89 | #HTTPCACHE_IGNORE_HTTP_CODES = [] 90 | #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' 91 | -------------------------------------------------------------------------------- /python123demo/python123demo/spiders/__init__.py: -------------------------------------------------------------------------------- 1 | # This package will contain the spiders of your Scrapy project 2 | # 3 | # Please refer to the documentation for information on how to create and manage 4 | # your spiders. 5 | -------------------------------------------------------------------------------- /python123demo/python123demo/spiders/__pycache__/__init__.cpython-36.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/python123demo/python123demo/spiders/__pycache__/__init__.cpython-36.pyc -------------------------------------------------------------------------------- /python123demo/python123demo/spiders/__pycache__/demo.cpython-36.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/python123demo/python123demo/spiders/__pycache__/demo.cpython-36.pyc -------------------------------------------------------------------------------- /python123demo/python123demo/spiders/demo.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | import scrapy 3 | 4 | 5 | class DemoSpider(scrapy.Spider): 6 | name = 'demo' 7 | #allowed_domains = ['python123.io'] 8 | start_urls = ['http://python123.io/ws/demo.html'] 9 | 10 | def parse(self, response): 11 | fname=response.url.split('/')[-1] 12 | with open(fname,'wb') as f: 13 | f.write(response.body) 14 | self.log('Saved file %s.' % fname) 15 | -------------------------------------------------------------------------------- /python123demo/scrapy.cfg: -------------------------------------------------------------------------------- 1 | # Automatically created by: scrapy startproject 2 | # 3 | # For more information about the [deploy] section see: 4 | # https://scrapyd.readthedocs.io/en/latest/deploy.html 5 | 6 | [settings] 7 | default = python123demo.settings 8 | 9 | [deploy] 10 | #url = http://localhost:6800/ 11 | project = python123demo 12 | -------------------------------------------------------------------------------- /story/English_story.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Sat May 4 19:02:32 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | import requests 9 | from bs4 import BeautifulSoup 10 | import smtplib 11 | from email.mime.text import MIMEText 12 | import datetime 13 | import time 14 | 15 | def getDays(): 16 | 17 | inlove_date=datetime.datetime(2017,8,31) 18 | today_date=datetime.datetime.today() 19 | inlove_days=(today_date-inlove_date).days 20 | return str(inlove_days) 21 | 22 | def getHTMLText(url,headers): 23 | try: 24 | r=requests.get(url,headers=headers,timeout=30) 25 | r.raise_for_status() 26 | r.encoding=r.apparent_encoding 27 | #print(r.text) 28 | return r.text 29 | 30 | except: 31 | return "爬取失败" 32 | 33 | def parsehtml(namelist,urllist,html): 34 | url='http://www.en8848.com.cn/' 35 | soup=BeautifulSoup(html,'html.parser') 36 | t=soup.find(attrs={'class':'ch_content'}) 37 | #print(t) 38 | i=t.find_all('a') 39 | #print(i) 40 | for link in i[1:59:2]: 41 | urllist.append(url+link.get('href')) 42 | namelist.append(link.get('title')) 43 | 44 | 45 | def parsehtml2(html): 46 | text=[] 47 | soup=BeautifulSoup(html,'html.parser') 48 | t=soup.find(attrs={'class':'jxa_content','id':'articlebody'}) 49 | for i in t.findAll('p'): 50 | text.append(i.text) 51 | #print(text) 52 | return "\n".join(text) 53 | 54 | def sendemail(url,headers,title): 55 | date_today=time.strftime("%Y-%m-%d", time.localtime()) 56 | msg_from='870407139@qq.com' #发送方邮箱 57 | passwd='' #填入发送方邮箱的授权码 58 | receivers=['870407139@qq.com'] #收件人邮箱 59 | 60 | subject="Today's story from Laofei " +str(date_today) #主题 61 | html=getHTMLText(url,headers) 62 | content='Dear Xiaofei:\n We have been in love for '+getDays()+' Days !\n\n⭐⭐⭐⭐⭐❤❤💗❤❤⭐⭐⭐⭐⭐'+parsehtml2(html) #正文 63 | msg = MIMEText(content) 64 | msg['Subject'] = subject 65 | msg['From'] = msg_from 66 | msg['To'] = ','.join(receivers) 67 | try: 68 | s=smtplib.SMTP_SSL("smtp.qq.com",465) #邮件服务器及端口号 69 | s.login(msg_from, passwd) 70 | s.sendmail(msg_from, msg['To'].split(','), msg.as_string()) 71 | print("发送成功") 72 | except: 73 | print("发送失败") 74 | finally: 75 | s.quit() 76 | 77 | def main(): 78 | 79 | 80 | headers = {'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 81 | } 82 | 83 | urllist=[] 84 | namelist=[] 85 | for i in range(1,21): 86 | if i==1: 87 | url='http://www.en8848.com.cn/article/love/dating/index.html' 88 | else: 89 | url='http://www.en8848.com.cn/article/love/dating/index_'+str(i)+'.html' 90 | print ("正在爬取第%s页的英语短文链接:" % (i)) 91 | print (url+'\n') 92 | html=getHTMLText(url,headers) 93 | parsehtml(namelist,urllist,html) 94 | print("爬取链接完成") 95 | date=int(getDays())-611 96 | sendemail(urllist[date],headers,namelist[date]) 97 | 98 | 99 | if __name__=='__main__': 100 | main() 101 | -------------------------------------------------------------------------------- /story/README.md: -------------------------------------------------------------------------------- 1 | # 睡前小故事 2 | ## [Link1](http://www.tom61.com/ertongwenxue/shuiqiangushi/) 3 | ## [Link2](http://www.en8848.com.cn/article/love/dating/index.html) 4 |  5 | ## Target 6 | * 爬取睡前小故事,并在每天晚上9点定时发送到邮箱 7 |  8 | ## Code 9 | * story.py 10 | ## Todo 11 | * 爬取的故事是随机选取一则发送,可能会出现重复发送的现象 12 | * 发送的小故事未带上响应的标题一起发送 13 | 14 | ## Tips 15 | * 之前的问题在我找到一个英文故事网站之后全部解决 16 | * 按照日期顺序每天发送一则,并且带上了相应的标题 17 | 18 |  19 | ## Code 20 | * English_story.py 21 | 22 | -------------------------------------------------------------------------------- /story/story.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Thu Mar 14 21:25:45 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | import requests 9 | from bs4 import BeautifulSoup 10 | import smtplib 11 | from email.mime.text import MIMEText 12 | import random 13 | 14 | 15 | def getHTMLText(url,headers): 16 | try: 17 | r=requests.get(url,headers=headers,timeout=30) 18 | r.raise_for_status() 19 | r.encoding=r.apparent_encoding 20 | #print(r.text) 21 | return r.text 22 | 23 | except: 24 | return "爬取失败" 25 | 26 | def parsehtml(namelist,urllist,html): 27 | url='http://www.tom61.com/' 28 | soup=BeautifulSoup(html,'html.parser') 29 | t=soup.find('dl',attrs={'class':'txt_box'}) 30 | #print(t) 31 | i=t.find_all('a') 32 | #print(i) 33 | for link in i: 34 | urllist.append(url+link.get('href')) 35 | namelist.append(link.get('title')) 36 | 37 | 38 | def parsehtml2(html): 39 | text=[] 40 | soup=BeautifulSoup(html,'html.parser') 41 | t=soup.find('div',class_='t_news_txt') 42 | for i in t.findAll('p'): 43 | text.append(i.text) 44 | #print(text) 45 | return "\n".join(text) 46 | 47 | def sendemail(url,headers): 48 | 49 | msg_from='' #发送方邮箱 50 | passwd='' #填入发送方邮箱的授权码 51 | receivers=[','] #收件人邮箱 52 | 53 | subject='今日份的睡前小故事' #主题 54 | html=getHTMLText(url,headers) 55 | content=parsehtml2(html) #正文 56 | msg = MIMEText(content) 57 | msg['Subject'] = subject 58 | msg['From'] = msg_from 59 | msg['To'] = ','.join(receivers) 60 | try: 61 | s=smtplib.SMTP_SSL("smtp.qq.com",465) #邮件服务器及端口号 62 | s.login(msg_from, passwd) 63 | s.sendmail(msg_from, msg['To'].split(','), msg.as_string()) 64 | print("发送成功") 65 | except: 66 | print("发送失败") 67 | finally: 68 | s.quit() 69 | 70 | def main(): 71 | 72 | 73 | headers = {'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50', 74 | } 75 | 76 | urllist=[] 77 | namelist=[] 78 | for i in range(1,11): 79 | if i==1: 80 | url='http://www.tom61.com/ertongwenxue/shuiqiangushi/index.html' 81 | else: 82 | url='http://www.tom61.com/ertongwenxue/shuiqiangushi/index_'+str(i)+'.html' 83 | print ("正在爬取第%s页的故事链接:" % (i)) 84 | print (url+'\n') 85 | html=getHTMLText(url,headers) 86 | parsehtml(namelist,urllist,html) 87 | print("爬取链接完成") 88 | ''' 89 | for i in urllist: 90 | html=getHTMLText(i,headers) 91 | parsehtml2(html) 92 | ''' 93 | sendemail(random.choice(urllist),headers) 94 | if __name__=='__main__': 95 | main() 96 | -------------------------------------------------------------------------------- /story/story1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/story/story1.png -------------------------------------------------------------------------------- /story/story2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/story/story2.png -------------------------------------------------------------------------------- /story/weather.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Tue Aug 6 13:11:58 2019 4 | 5 | @author: Lee 6 | """ 7 | 8 | 9 | # import itchat 10 | import time 11 | import requests 12 | from lxml import etree 13 | import wxpy 14 | 15 | def getWeather(): 16 | # 使用BeautifulSoup获取天气信息 17 | r=requests.get('https://tianqi.sogou.com/?tid=101280601') 18 | tree=etree.HTML(r.text) 19 | today=tree.xpath('//div[@class="row2 row2-1"]/a/text()')[0] 20 | weather=tree.xpath('//p[@class="des"]/text()')[1] 21 | wind=tree.xpath('//p[@class="wind"]/text()')[1] 22 | quality=tree.xpath('//span[@class="liv-text"]/a/em/text()')[0] 23 | rank=tree.xpath('//span[@class="liv-img liv-img-cor1"]/text()')[0] 24 | high=tree.xpath('//div[@class="r-temp"]/@data-high')[0].split(',')[1] 25 | low=tree.xpath('//div[@class="r-temp"]/@data-low')[0].split(',')[1] 26 | content='早上好,亲爱的!\n今日份的天气请注意查看喔~\n今天是:'+today+'\n天气:'+weather+'\n风级:'+wind+'\n最高温度:'+high+'\n最低温度:'+low+'\n空气质量指数:'+quality+' 等级:'+rank 27 | print(content) 28 | return content 29 | 30 | 31 | def main(): 32 | 33 | message = getWeather() 34 | print('成功获取天气信息') 35 | 36 | # # 参数hotReload=True实现保持微信网页版登陆状态,下次发送无需再次扫码 37 | # itchat.auto_login() 38 | # users=itchat.search_friends('') 39 | # print(users) 40 | # userName=users[0]['UserName'] 41 | # ret=itchat.send(msg = message, toUserName = userName) 42 | # if ret: 43 | # print("成功发送") 44 | # else: 45 | # print("发送失败") 46 | # time.sleep(3) 47 | # itchat.logout() 48 | 49 | bot=wxpy.Bot() 50 | my_friend=bot.friends().search('Snall')[0] 51 | my_friend.send(message[0]) 52 | 53 | 54 | 55 | 56 | if __name__ == '__main__': 57 | main() 58 | -------------------------------------------------------------------------------- /story/web1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/story/web1.png -------------------------------------------------------------------------------- /unsplash/README.md: -------------------------------------------------------------------------------- 1 | # Unsplash海量图片 2 | ## 爬取方法一:Requests 3 | * 进入[图片网站](https://unsplash.com/),先按F12打开开发者工具,观察Network,滚动页面,向下翻页,可以发现下图photos?page=3&per_page=12 4 | 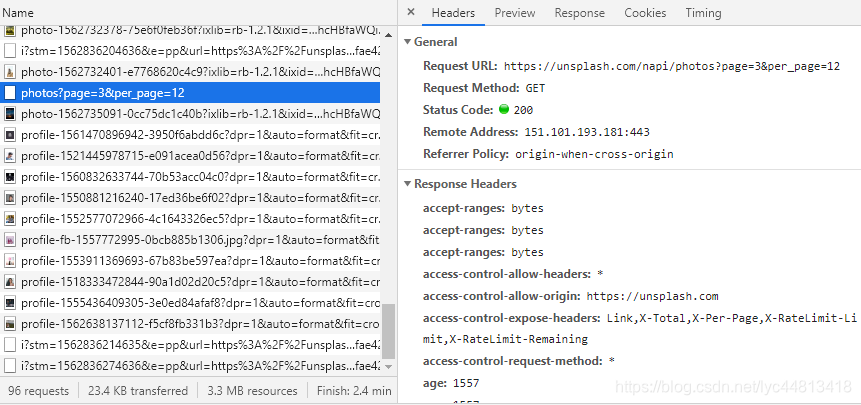 5 | * 观察其request URL,从其构造不难看出每页12张图片,当前是第三页,继续下滑网页,发现出现photos?page=4&per_page=12,观察得到参数仅有page不同,也验证了猜想,接下来继续观察这个链接,不难发现,图片的下载链接就藏在其中。 6 | 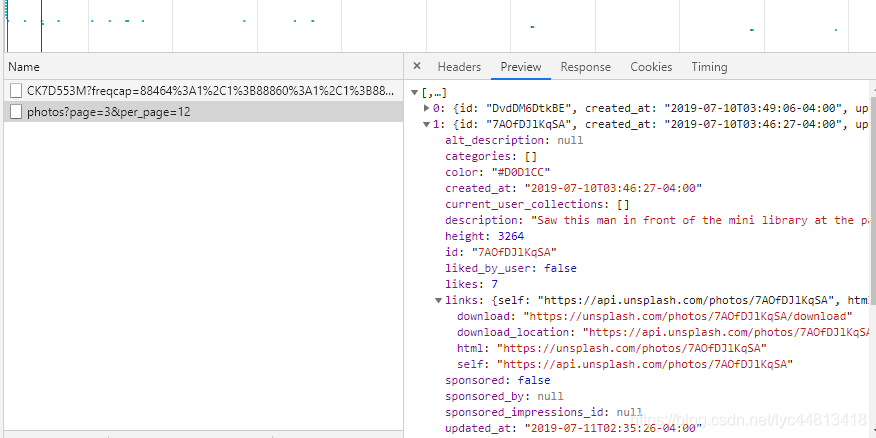 7 | * 这个网页对新人爬虫还是非常友好的嘛!立马动手展开代码书写,只要在循环之中改变page的值就可以爬取整个网页的所有图片! 8 | 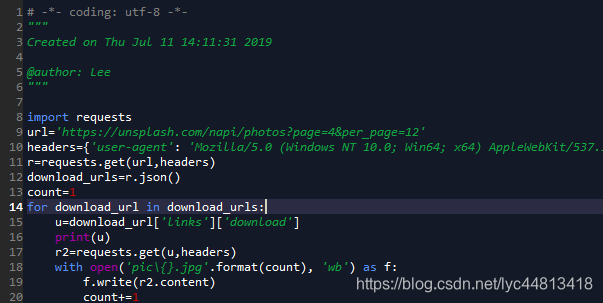 9 | * 程序成功地运行!但是它的速度真是让人不敢恭维,一页12张图片都需要不少的时间代价,这10多万张图不得爬到猴年马月?于是我选择Scrapy框架来爬取图片。 10 | # 11 | 12 | # 爬取方法二:Scrapy 13 | * 首先,与昨天相同输入命令建立工程,若不记得可以参看[Scrapy实战](https://mp.weixin.qq.com/s?__biz=MzkyMTAwMjQ4NA==&tempkey=MTAxN19kSjFFYUtwSEVrSGZpODd1YlZQT0tDYVB0aEtSS0FzTDJ6V3duMDd0bnJjanhaM3NoSG41empwYmtFa1J0a2tjaU5UUnJiTndOVVgySnJ6dDFXaVdBWENHbG42ZW80MmZjS3Nua0tDZW5nTTRQdHh0MHJ4M0dPM3lfT0hQZllSc21POHJBUUYycVVIcno1V3VEakFJQWdjVnVIa0E5bG5sdi00NWp3fn4%3D&chksm=418b099e76fc808807861b5ad71c926cafca187b09530709f256f6790430fb65d490cbc2d382#rd)。然后来编写各组件的代码: 14 | ### spider 15 | * 这部分是爬虫的主要部分,start_urls设置了请求的网页链接,然后用到了json库将网页返回的内容变成json格式,提取出其中的图片下载链接。并且利用了**scrapy.Request**对unsplash网返回的内容进行二次解析,并将图片交给pipelines进行输出。 16 | 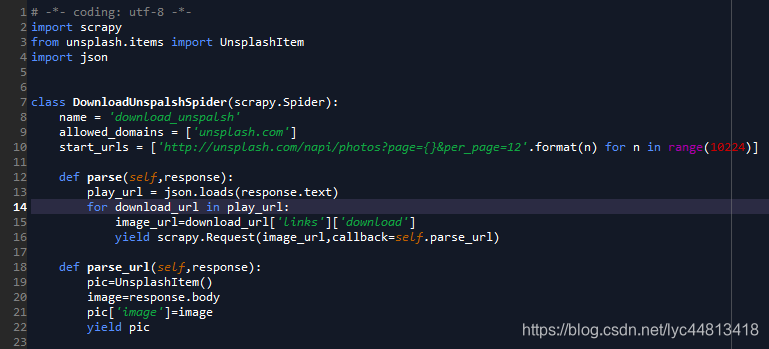 17 | ### pipelines 18 | * 这部分是进行图片的输出存储,利用了MD5生成摘要来给图片命名,这样可以完成去重存储。 19 | 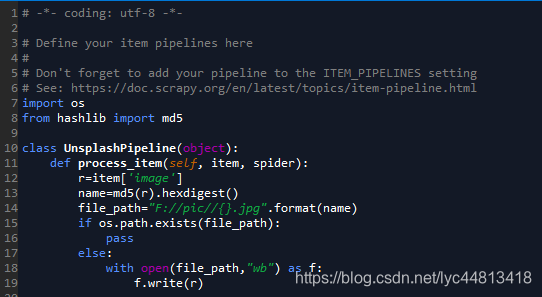 20 | ### settings 21 | * 既然对pipelines函数进行了编写,需要在settings.py中取消其注释,并且加上随机的代理头,加上一定的时延,来增强其假装浏览器的能力,当然也不要忘了在items.py中设置fields。 22 | 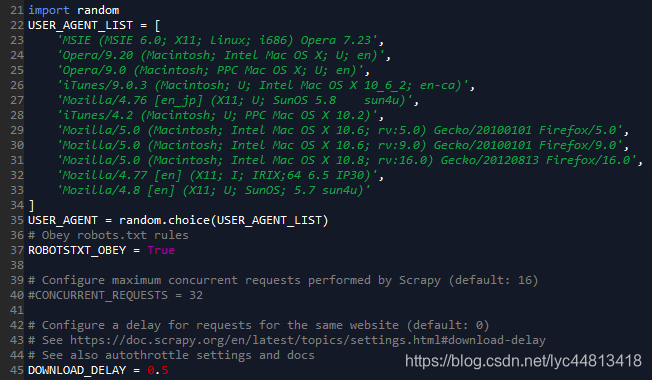 23 | ## 爬取结果 24 | * 完成程序的编写之后,启动项目来看看成果,嗯,一大堆高清图片已收入囊中。 25 |  -------------------------------------------------------------------------------- /unsplash/scrapy.cfg: -------------------------------------------------------------------------------- 1 | # Automatically created by: scrapy startproject 2 | # 3 | # For more information about the [deploy] section see: 4 | # https://scrapyd.readthedocs.io/en/latest/deploy.html 5 | 6 | [settings] 7 | default = unsplash.settings 8 | 9 | [deploy] 10 | #url = http://localhost:6800/ 11 | project = unsplash 12 | -------------------------------------------------------------------------------- /unsplash/unsplash/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/unsplash/unsplash/__init__.py -------------------------------------------------------------------------------- /unsplash/unsplash/__pycache__/__init__.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/unsplash/unsplash/__pycache__/__init__.cpython-37.pyc -------------------------------------------------------------------------------- /unsplash/unsplash/__pycache__/items.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/unsplash/unsplash/__pycache__/items.cpython-37.pyc -------------------------------------------------------------------------------- /unsplash/unsplash/__pycache__/pipelines.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/unsplash/unsplash/__pycache__/pipelines.cpython-37.pyc -------------------------------------------------------------------------------- /unsplash/unsplash/__pycache__/settings.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/unsplash/unsplash/__pycache__/settings.cpython-37.pyc -------------------------------------------------------------------------------- /unsplash/unsplash/items.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your scraped items 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/items.html 7 | 8 | import scrapy 9 | 10 | 11 | class UnsplashItem(scrapy.Item): 12 | # define the fields for your item here like: 13 | # name = scrapy.Field() 14 | image=scrapy.Field() 15 | -------------------------------------------------------------------------------- /unsplash/unsplash/middlewares.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your spider middleware 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 7 | 8 | from scrapy import signals 9 | 10 | 11 | class UnsplashSpiderMiddleware(object): 12 | # Not all methods need to be defined. If a method is not defined, 13 | # scrapy acts as if the spider middleware does not modify the 14 | # passed objects. 15 | 16 | @classmethod 17 | def from_crawler(cls, crawler): 18 | # This method is used by Scrapy to create your spiders. 19 | s = cls() 20 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 21 | return s 22 | 23 | def process_spider_input(self, response, spider): 24 | # Called for each response that goes through the spider 25 | # middleware and into the spider. 26 | 27 | # Should return None or raise an exception. 28 | return None 29 | 30 | def process_spider_output(self, response, result, spider): 31 | # Called with the results returned from the Spider, after 32 | # it has processed the response. 33 | 34 | # Must return an iterable of Request, dict or Item objects. 35 | for i in result: 36 | yield i 37 | 38 | def process_spider_exception(self, response, exception, spider): 39 | # Called when a spider or process_spider_input() method 40 | # (from other spider middleware) raises an exception. 41 | 42 | # Should return either None or an iterable of Response, dict 43 | # or Item objects. 44 | pass 45 | 46 | def process_start_requests(self, start_requests, spider): 47 | # Called with the start requests of the spider, and works 48 | # similarly to the process_spider_output() method, except 49 | # that it doesn’t have a response associated. 50 | 51 | # Must return only requests (not items). 52 | for r in start_requests: 53 | yield r 54 | 55 | def spider_opened(self, spider): 56 | spider.logger.info('Spider opened: %s' % spider.name) 57 | 58 | 59 | class UnsplashDownloaderMiddleware(object): 60 | # Not all methods need to be defined. If a method is not defined, 61 | # scrapy acts as if the downloader middleware does not modify the 62 | # passed objects. 63 | 64 | @classmethod 65 | def from_crawler(cls, crawler): 66 | # This method is used by Scrapy to create your spiders. 67 | s = cls() 68 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 69 | return s 70 | 71 | def process_request(self, request, spider): 72 | # Called for each request that goes through the downloader 73 | # middleware. 74 | 75 | # Must either: 76 | # - return None: continue processing this request 77 | # - or return a Response object 78 | # - or return a Request object 79 | # - or raise IgnoreRequest: process_exception() methods of 80 | # installed downloader middleware will be called 81 | return None 82 | 83 | def process_response(self, request, response, spider): 84 | # Called with the response returned from the downloader. 85 | 86 | # Must either; 87 | # - return a Response object 88 | # - return a Request object 89 | # - or raise IgnoreRequest 90 | return response 91 | 92 | def process_exception(self, request, exception, spider): 93 | # Called when a download handler or a process_request() 94 | # (from other downloader middleware) raises an exception. 95 | 96 | # Must either: 97 | # - return None: continue processing this exception 98 | # - return a Response object: stops process_exception() chain 99 | # - return a Request object: stops process_exception() chain 100 | pass 101 | 102 | def spider_opened(self, spider): 103 | spider.logger.info('Spider opened: %s' % spider.name) 104 | -------------------------------------------------------------------------------- /unsplash/unsplash/pipelines.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define your item pipelines here 4 | # 5 | # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 | # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 | import os 8 | from hashlib import md5 9 | 10 | class UnsplashPipeline(object): 11 | def process_item(self, item, spider): 12 | r=item['image'] 13 | name=md5(r).hexdigest() 14 | file_path="F://pic//{}.jpg".format(name) 15 | if os.path.exists(file_path): 16 | pass 17 | else: 18 | with open(file_path,"wb") as f: 19 | f.write(r) 20 | 21 | 22 | 23 | -------------------------------------------------------------------------------- /unsplash/unsplash/settings.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Scrapy settings for unsplash project 4 | # 5 | # For simplicity, this file contains only settings considered important or 6 | # commonly used. You can find more settings consulting the documentation: 7 | # 8 | # https://doc.scrapy.org/en/latest/topics/settings.html 9 | # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 10 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 11 | 12 | BOT_NAME = 'unsplash' 13 | 14 | SPIDER_MODULES = ['unsplash.spiders'] 15 | NEWSPIDER_MODULE = 'unsplash.spiders' 16 | 17 | 18 | # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 | #USER_AGENT = 'unsplash (+http://www.yourdomain.com)' 20 | # ÉèÖÃUA 21 | import random 22 | USER_AGENT_LIST = [ 23 | 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23', 24 | 'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)', 25 | 'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)', 26 | 'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)', 27 | 'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)', 28 | 'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)', 29 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0', 30 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0', 31 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0', 32 | 'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)', 33 | 'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)' 34 | ] 35 | USER_AGENT = random.choice(USER_AGENT_LIST) 36 | # Obey robots.txt rules 37 | ROBOTSTXT_OBEY = True 38 | 39 | # Configure maximum concurrent requests performed by Scrapy (default: 16) 40 | #CONCURRENT_REQUESTS = 32 41 | 42 | # Configure a delay for requests for the same website (default: 0) 43 | # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay 44 | # See also autothrottle settings and docs 45 | # DOWNLOAD_DELAY = 0.5 46 | # The download delay setting will honor only one of: 47 | #CONCURRENT_REQUESTS_PER_DOMAIN = 16 48 | #CONCURRENT_REQUESTS_PER_IP = 16 49 | 50 | # Disable cookies (enabled by default) 51 | #COOKIES_ENABLED = False 52 | 53 | # Disable Telnet Console (enabled by default) 54 | #TELNETCONSOLE_ENABLED = False 55 | 56 | # Override the default request headers: 57 | #DEFAULT_REQUEST_HEADERS = { 58 | # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 59 | # 'Accept-Language': 'en', 60 | #} 61 | 62 | # Enable or disable spider middlewares 63 | # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html 64 | #SPIDER_MIDDLEWARES = { 65 | # 'unsplash.middlewares.UnsplashSpiderMiddleware': 543, 66 | #} 67 | 68 | # Enable or disable downloader middlewares 69 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 70 | #DOWNLOADER_MIDDLEWARES = { 71 | # 'unsplash.middlewares.UnsplashDownloaderMiddleware': 543, 72 | #} 73 | 74 | # Enable or disable extensions 75 | # See https://doc.scrapy.org/en/latest/topics/extensions.html 76 | #EXTENSIONS = { 77 | # 'scrapy.extensions.telnet.TelnetConsole': None, 78 | #} 79 | 80 | # Configure item pipelines 81 | # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 82 | ITEM_PIPELINES = { 83 | 'unsplash.pipelines.UnsplashPipeline': 300, 84 | } 85 | 86 | # Enable and configure the AutoThrottle extension (disabled by default) 87 | # See https://doc.scrapy.org/en/latest/topics/autothrottle.html 88 | #AUTOTHROTTLE_ENABLED = True 89 | # The initial download delay 90 | #AUTOTHROTTLE_START_DELAY = 5 91 | # The maximum download delay to be set in case of high latencies 92 | #AUTOTHROTTLE_MAX_DELAY = 60 93 | # The average number of requests Scrapy should be sending in parallel to 94 | # each remote server 95 | #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 96 | # Enable showing throttling stats for every response received: 97 | #AUTOTHROTTLE_DEBUG = False 98 | 99 | # Enable and configure HTTP caching (disabled by default) 100 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 101 | #HTTPCACHE_ENABLED = True 102 | #HTTPCACHE_EXPIRATION_SECS = 0 103 | #HTTPCACHE_DIR = 'httpcache' 104 | #HTTPCACHE_IGNORE_HTTP_CODES = [] 105 | #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' 106 | -------------------------------------------------------------------------------- /unsplash/unsplash/spiders/__init__.py: -------------------------------------------------------------------------------- 1 | # This package will contain the spiders of your Scrapy project 2 | # 3 | # Please refer to the documentation for information on how to create and manage 4 | # your spiders. 5 | -------------------------------------------------------------------------------- /unsplash/unsplash/spiders/__pycache__/__init__.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/unsplash/unsplash/spiders/__pycache__/__init__.cpython-37.pyc -------------------------------------------------------------------------------- /unsplash/unsplash/spiders/__pycache__/download_unspalsh.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/unsplash/unsplash/spiders/__pycache__/download_unspalsh.cpython-37.pyc -------------------------------------------------------------------------------- /unsplash/unsplash/spiders/download_unsplash.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | import scrapy 3 | from unsplash.items import UnsplashItem 4 | import json 5 | 6 | 7 | class DownloadUnspalshSpider(scrapy.Spider): 8 | name = 'download_unsplash' 9 | allowed_domains = ['unsplash.com'] 10 | start_urls = ['http://unsplash.com/napi/photos?page={}&per_page=12'.format(n) for n in range(10224)] 11 | 12 | def parse(self,response): 13 | play_url = json.loads(response.text) 14 | for download_url in play_url: 15 | image_url=download_url['links']['download'] 16 | yield scrapy.Request(image_url,callback=self.parse_url) 17 | 18 | def parse_url(self,response): 19 | pic=UnsplashItem() 20 | image=response.body 21 | pic['image']=image 22 | yield pic 23 | 24 | 25 | -------------------------------------------------------------------------------- /wyy/README.md: -------------------------------------------------------------------------------- 1 | # 网易云音乐歌手粉丝 2 | 3 | ## Target 4 | * 解决之前评论接口限制数目的问题 5 | * 破解网易云js加密,主要是两个参数,一个是params,一个是encSecKey 6 | 7 |  8 | 9 | ## Tips 10 | 11 | * 具体详解请看[JS逆向之网易云音乐](https://mp.weixin.qq.com/s/prahlIq527XkirDE51jMjg) 12 | 13 | ## TODO 14 | * 该接口只能抓取50页,即1000个粉丝信息 15 | * 网易云音乐app可以显示所有粉丝信息 16 | 17 | -------------------------------------------------------------------------------- /wyy/fans.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/fans.png -------------------------------------------------------------------------------- /wyy/scrapy.cfg: -------------------------------------------------------------------------------- 1 | # Automatically created by: scrapy startproject 2 | # 3 | # For more information about the [deploy] section see: 4 | # https://scrapyd.readthedocs.io/en/latest/deploy.html 5 | 6 | [settings] 7 | default = wyy.settings 8 | 9 | [deploy] 10 | #url = http://localhost:6800/ 11 | project = wyy 12 | -------------------------------------------------------------------------------- /wyy/wyy/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/__init__.py -------------------------------------------------------------------------------- /wyy/wyy/__pycache__/__init__.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/__pycache__/__init__.cpython-37.pyc -------------------------------------------------------------------------------- /wyy/wyy/__pycache__/items.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/__pycache__/items.cpython-37.pyc -------------------------------------------------------------------------------- /wyy/wyy/__pycache__/pipelines.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/__pycache__/pipelines.cpython-37.pyc -------------------------------------------------------------------------------- /wyy/wyy/__pycache__/settings.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/__pycache__/settings.cpython-37.pyc -------------------------------------------------------------------------------- /wyy/wyy/items.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your scraped items 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/items.html 7 | 8 | import scrapy 9 | 10 | 11 | class WyyItem(scrapy.Item): 12 | # define the fields for your item here like: 13 | # name = scrapy.Field() 14 | avatar = scrapy.Field() 15 | userId = scrapy.Field() 16 | # vipRights = scrapy.Field() 17 | vipType =scrapy.Field() 18 | gender = scrapy.Field() 19 | eventCount = scrapy.Field() 20 | fan_followeds = scrapy.Field() 21 | fan_follows = scrapy.Field() 22 | signature = scrapy.Field() 23 | time = scrapy.Field() 24 | nickname = scrapy.Field() 25 | playlistCount = scrapy.Field() 26 | total_record_count = scrapy.Field() 27 | week_record_count = scrapy.Field() -------------------------------------------------------------------------------- /wyy/wyy/middlewares.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your spider middleware 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 7 | 8 | from scrapy import signals 9 | 10 | 11 | class WyySpiderMiddleware(object): 12 | # Not all methods need to be defined. If a method is not defined, 13 | # scrapy acts as if the spider middleware does not modify the 14 | # passed objects. 15 | 16 | @classmethod 17 | def from_crawler(cls, crawler): 18 | # This method is used by Scrapy to create your spiders. 19 | s = cls() 20 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 21 | return s 22 | 23 | def process_spider_input(self, response, spider): 24 | # Called for each response that goes through the spider 25 | # middleware and into the spider. 26 | 27 | # Should return None or raise an exception. 28 | return None 29 | 30 | def process_spider_output(self, response, result, spider): 31 | # Called with the results returned from the Spider, after 32 | # it has processed the response. 33 | 34 | # Must return an iterable of Request, dict or Item objects. 35 | for i in result: 36 | yield i 37 | 38 | def process_spider_exception(self, response, exception, spider): 39 | # Called when a spider or process_spider_input() method 40 | # (from other spider middleware) raises an exception. 41 | 42 | # Should return either None or an iterable of Response, dict 43 | # or Item objects. 44 | pass 45 | 46 | def process_start_requests(self, start_requests, spider): 47 | # Called with the start requests of the spider, and works 48 | # similarly to the process_spider_output() method, except 49 | # that it doesn’t have a response associated. 50 | 51 | # Must return only requests (not items). 52 | for r in start_requests: 53 | yield r 54 | 55 | def spider_opened(self, spider): 56 | spider.logger.info('Spider opened: %s' % spider.name) 57 | 58 | 59 | class WyyDownloaderMiddleware(object): 60 | # Not all methods need to be defined. If a method is not defined, 61 | # scrapy acts as if the downloader middleware does not modify the 62 | # passed objects. 63 | 64 | @classmethod 65 | def from_crawler(cls, crawler): 66 | # This method is used by Scrapy to create your spiders. 67 | s = cls() 68 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 69 | return s 70 | 71 | def process_request(self, request, spider): 72 | # Called for each request that goes through the downloader 73 | # middleware. 74 | 75 | # Must either: 76 | # - return None: continue processing this request 77 | # - or return a Response object 78 | # - or return a Request object 79 | # - or raise IgnoreRequest: process_exception() methods of 80 | # installed downloader middleware will be called 81 | return None 82 | 83 | def process_response(self, request, response, spider): 84 | # Called with the response returned from the downloader. 85 | 86 | # Must either; 87 | # - return a Response object 88 | # - return a Request object 89 | # - or raise IgnoreRequest 90 | return response 91 | 92 | def process_exception(self, request, exception, spider): 93 | # Called when a download handler or a process_request() 94 | # (from other downloader middleware) raises an exception. 95 | 96 | # Must either: 97 | # - return None: continue processing this exception 98 | # - return a Response object: stops process_exception() chain 99 | # - return a Request object: stops process_exception() chain 100 | pass 101 | 102 | def spider_opened(self, spider): 103 | spider.logger.info('Spider opened: %s' % spider.name) 104 | -------------------------------------------------------------------------------- /wyy/wyy/pipelines.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define your item pipelines here 4 | # 5 | # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 | # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 | from pymongo import MongoClient 8 | 9 | class WyyPipeline(object): 10 | 11 | def __init__(self) -> None: 12 | # 连接 13 | self.client = MongoClient(host='localhost', port=27017) 14 | # 如果设置有权限, 则需要先登录 15 | # db_auth = self.client.admin 16 | # db_auth.authenticate('root', 'root') 17 | # 需要保存到的collection 18 | self.col = self.client['wyy'] 19 | self.fans = self.col.fans2 20 | 21 | 22 | def process_item(self, item, spider): 23 | res = dict(item) 24 | self.fans.update_one({"userId":res['userId']}, {"$set": res}, upsert = True) 25 | return item 26 | 27 | def open_spider(self, spider): 28 | pass 29 | 30 | def close_spider(self, spider): 31 | self.client.close() 32 | 33 | -------------------------------------------------------------------------------- /wyy/wyy/settings.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Scrapy settings for wyy project 4 | # 5 | # For simplicity, this file contains only settings considered important or 6 | # commonly used. You can find more settings consulting the documentation: 7 | # 8 | # https://doc.scrapy.org/en/latest/topics/settings.html 9 | # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 10 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 11 | 12 | BOT_NAME = 'wyy' 13 | 14 | SPIDER_MODULES = ['wyy.spiders'] 15 | NEWSPIDER_MODULE = 'wyy.spiders' 16 | 17 | # 设置UA 18 | import random 19 | USER_AGENT_LIST = [ 20 | 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23', 21 | 'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)', 22 | 'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)', 23 | 'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)', 24 | 'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)', 25 | 'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)', 26 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0', 27 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0', 28 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0', 29 | 'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)', 30 | 'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)' 31 | ] 32 | USER_AGENT = random.choice(USER_AGENT_LIST) 33 | # Crawl responsibly by identifying yourself (and your website) on the user-agent 34 | #USER_AGENT = 'wyy (+http://www.yourdomain.com)' 35 | 36 | # Obey robots.txt rules 37 | ROBOTSTXT_OBEY = True 38 | 39 | # Configure maximum concurrent requests performed by Scrapy (default: 16) 40 | #CONCURRENT_REQUESTS = 32 41 | 42 | # Configure a delay for requests for the same website (default: 0) 43 | # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay 44 | # See also autothrottle settings and docs 45 | #DOWNLOAD_DELAY = 3 46 | # The download delay setting will honor only one of: 47 | #CONCURRENT_REQUESTS_PER_DOMAIN = 16 48 | #CONCURRENT_REQUESTS_PER_IP = 16 49 | 50 | # Disable cookies (enabled by default) 51 | #COOKIES_ENABLED = False 52 | 53 | # Disable Telnet Console (enabled by default) 54 | #TELNETCONSOLE_ENABLED = False 55 | 56 | # Override the default request headers: 57 | #DEFAULT_REQUEST_HEADERS = { 58 | # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 59 | # 'Accept-Language': 'en', 60 | #} 61 | 62 | # Enable or disable spider middlewares 63 | # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html 64 | #SPIDER_MIDDLEWARES = { 65 | # 'wyy.middlewares.WyySpiderMiddleware': 543, 66 | #} 67 | 68 | # Enable or disable downloader middlewares 69 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 70 | #DOWNLOADER_MIDDLEWARES = { 71 | # 'wyy.middlewares.WyyDownloaderMiddleware': 543, 72 | #} 73 | 74 | # Enable or disable extensions 75 | # See https://doc.scrapy.org/en/latest/topics/extensions.html 76 | #EXTENSIONS = { 77 | # 'scrapy.extensions.telnet.TelnetConsole': None, 78 | #} 79 | 80 | # Configure item pipelines 81 | # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 82 | ITEM_PIPELINES = { 83 | 'wyy.pipelines.WyyPipeline': 300, 84 | } 85 | 86 | # Enable and configure the AutoThrottle extension (disabled by default) 87 | # See https://doc.scrapy.org/en/latest/topics/autothrottle.html 88 | #AUTOTHROTTLE_ENABLED = True 89 | # The initial download delay 90 | #AUTOTHROTTLE_START_DELAY = 5 91 | # The maximum download delay to be set in case of high latencies 92 | #AUTOTHROTTLE_MAX_DELAY = 60 93 | # The average number of requests Scrapy should be sending in parallel to 94 | # each remote server 95 | #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 96 | # Enable showing throttling stats for every response received: 97 | #AUTOTHROTTLE_DEBUG = False 98 | 99 | # Enable and configure HTTP caching (disabled by default) 100 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 101 | #HTTPCACHE_ENABLED = True 102 | #HTTPCACHE_EXPIRATION_SECS = 0 103 | #HTTPCACHE_DIR = 'httpcache' 104 | #HTTPCACHE_IGNORE_HTTP_CODES = [] 105 | #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' 106 | -------------------------------------------------------------------------------- /wyy/wyy/spiders/__init__.py: -------------------------------------------------------------------------------- 1 | # This package will contain the spiders of your Scrapy project 2 | # 3 | # Please refer to the documentation for information on how to create and manage 4 | # your spiders. 5 | -------------------------------------------------------------------------------- /wyy/wyy/spiders/__pycache__/__init__.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/spiders/__pycache__/__init__.cpython-37.pyc -------------------------------------------------------------------------------- /wyy/wyy/spiders/__pycache__/wwy_fans1.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/spiders/__pycache__/wwy_fans1.cpython-37.pyc -------------------------------------------------------------------------------- /wyy/wyy/spiders/__pycache__/wyy_fans.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/spiders/__pycache__/wyy_fans.cpython-37.pyc -------------------------------------------------------------------------------- /wyy/wyy/spiders/__pycache__/wyy_fans2.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/wyy/wyy/spiders/__pycache__/wyy_fans2.cpython-37.pyc -------------------------------------------------------------------------------- /xueqiu/readme.md: -------------------------------------------------------------------------------- 1 | ### 雪球 实时股票信息统计 2 | 3 | 4 | [港股股票行情](https://xueqiu.com/hq#exchange=HK&firstName=2&secondName=2_0) 5 | 6 | tips: 雪球封的比较快,如果要实时抓的话建议上代理池。 -------------------------------------------------------------------------------- /xueqiu/xueqiu.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | import requests 4 | import time 5 | 6 | _type_ = "US" #香港就填Hk 7 | 8 | headers={ 9 | "user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36", 10 | "Cookie": "", #上雪球把自己的cookie复制下来 11 | } 12 | 13 | f = open("xueqiu.csv", "w") 14 | f.write("symbol, name, current, percent, market_capital, pe_ttm\n") 15 | 16 | 17 | def get_json(page): #带上cookie get请求 18 | return requests.get("https://xueqiu.com/service/v5/stock/screener/quote/list?page={}" 19 | "&size=30&order=desc&orderby=percent&order_by=percent&market={}" 20 | "&type={}&_={}".format(page, _type_, _type_, int(time.time()*1000)), 21 | headers=headers).json() 22 | 23 | 24 | def parse_json(data, _all): #解析数据 25 | _list = data["data"]["list"] 26 | for _each in _list: 27 | symbol = _each.get("symbol") #股票代码 28 | name = _each.get("name") #股票名称 29 | current = _each.get("current") #当前价格 30 | percent = _each.get("percent") #涨跌幅 31 | market_capital = _each.get("market_capital") #市值 32 | pe_ttm = _each.get("pe_ttm") #市盈率 33 | f.write(','.join(map(str, [symbol,name,current,percent,market_capital,pe_ttm]))) 34 | f.write("\n") 35 | _all += 1 36 | if _all == 100: 37 | break 38 | return _all 39 | 40 | 41 | def main(): 42 | _all = 0 43 | for i in range(1,5): 44 | data = get_json(i) 45 | _all = parse_json(data, _all) 46 | 47 | time.sleep(5) #sleep 5s, 48 | 49 | 50 | def test(): 51 | print(requests.get("https://xueqiu.com/service/v5/stock/screener/quote/list?page=3&size=30&order=desc&orderby=percent&order_by=percent&market=US&type=us&_=1555485032232", 52 | headers=headers).json()) 53 | 54 | if __name__ == "__main__": 55 | 56 | main() 57 | # test() 58 | -------------------------------------------------------------------------------- /今日头条/README.md: -------------------------------------------------------------------------------- 1 | # 今日头条街拍图片 2 | ## [Link](https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D) 3 |  4 | ## Target 5 | * 获取街拍图片,并下载到本地存储 6 |  7 | ## Tips 8 | * urlencode用来拼接url链接 9 | * 利用了多线程或者多进程来处理 10 | * 图片的名称使用其内容的MD5值,这样可以去除重复 11 | * 构造一个生成器,将图片链接和图片所属的标题一并返回 12 | ```python 13 | for image in images: 14 | yield { 15 | 'image': image.get('url'), 16 | 'title': title 17 | } 18 | ``` 19 | * 利用正则表达式将不符合命名规范的title去除 20 | 21 | -------------------------------------------------------------------------------- /今日头条/download.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/今日头条/download.png -------------------------------------------------------------------------------- /今日头条/jiepai.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Sun Jun 30 17:07:29 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | import requests 9 | from urllib.parse import urlencode 10 | import os 11 | from hashlib import md5 12 | from multiprocessing.pool import Pool 13 | import re 14 | import threading 15 | 16 | 17 | def get_page(offset): 18 | headers = { 19 | 'cookie': 'tt_webid=6667396596445660679; csrftoken=3a212e0c06e7821650315a4fecf47ac9; tt_webid=6667396596445660679; WEATHER_CITY=%E5%8C%97%E4%BA%AC; UM_distinctid=16b846003e03d7-0dd00a2eb5ea11-353166-1fa400-16b846003e1566; CNZZDATA1259612802=2077267981-1561291030-https%253A%252F%252Fwww.baidu.com%252F%7C1561361230; __tasessionId=4vm71cznd1561363013083; sso_uid_tt=47d6f9788277e4e071f3825a3c36a294; toutiao_sso_user=e02fd616c83dff880adda691cd201aaa; login_flag=6859a0b8ffdb01687b00fe96bbeeba6e; sessionid=21f852358a845d783bdbe1236c9b385b; uid_tt=d40499ec45187c2d411cb7bf656330730d8c15a783bb6284da0f73104cd300a2; sid_tt=21f852358a845d783bdbe1236c9b385b; sid_guard="21f852358a845d783bdbe1236c9b385b|1561363028|15552000|Sat\054 21-Dec-2019 07:57:08 GMT"; s_v_web_id=6f40e192e0bdeb62ff50fca2bcdf2944', 20 | 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36', 21 | 'x-requested-with': 'XMLHttpRequest', 22 | 'referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D', 23 | } 24 | params = { 25 | 'aid': '24', 26 | 'app_name': 'web_search', 27 | 'offset': offset, 28 | 'format': 'json', 29 | 'keyword': '街拍', 30 | 'autoload': 'true', 31 | 'count': '20', 32 | 'en_qc': '1', 33 | 'cur_tab': '1', 34 | 'from': 'search_tab', 35 | 'pd': 'synthesis', 36 | } 37 | base_url = 'https://www.toutiao.com/api/search/content/?' 38 | url = base_url + urlencode(params) 39 | try: 40 | r = requests.get(url, headers=headers) 41 | if 200 == r.status_code: 42 | return r.json() 43 | except: 44 | return None 45 | 46 | 47 | def get_images(json): 48 | if json.get('data'): 49 | data = json.get('data') 50 | for item in data: 51 | if item.get('title') is None: 52 | continue 53 | title = re.sub('[\t\\\|]', '', item.get('title')) 54 | images = item.get('image_list') 55 | for image in images: 56 | origin_image = re.sub("list.*?pgc-image", "large/pgc-image", image.get('url')) 57 | yield { 58 | 'image': origin_image, 59 | 'title': title 60 | } 61 | 62 | 63 | def save_image(item): 64 | img_path = 'img' + os.path.sep + item.get('title') 65 | if not os.path.exists(img_path): 66 | os.makedirs(img_path) 67 | r = requests.get(item.get('image')) 68 | file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format( 69 | file_name=md5(r.content).hexdigest(), 70 | file_suffix='jpg') 71 | if not os.path.exists(file_path): 72 | with open(file_path, 'wb') as f: 73 | f.write(r.content) 74 | print("Downloaded image path is {}".format(file_path)) 75 | else: 76 | print("Already Downloaded") 77 | 78 | 79 | 80 | 81 | def main(offset): 82 | json = get_page(offset) 83 | for item in get_images(json): 84 | try: 85 | save_image(item) 86 | except: 87 | print("下载图片失败!") 88 | 89 | 90 | if __name__ == '__main__': 91 | 92 | #pool = Pool() # 进程池 93 | groups = ([x * 20 for x in range(10)]) 94 | ''' 95 | pool.map(main, groups) 96 | pool.close() 97 | pool.join() 98 | ''' 99 | tasks = [] # 线程池 100 | 101 | for group in groups: 102 | task = threading.Thread(target=main, args=(group,)) 103 | tasks.append(task) 104 | task.start() 105 | 106 | # 等待所有线程完成 107 | for _ in tasks: 108 | _.join() 109 | print("完成图片爬取并存储到本地!") 110 | -------------------------------------------------------------------------------- /今日头条/web.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/今日头条/web.png -------------------------------------------------------------------------------- /代理IP/README.md: -------------------------------------------------------------------------------- 1 | # 高可用代理IP 2 | 3 | ## Source 4 |  5 | * [仓库链接](https://github.com/dxxzst/free-proxy-list) 6 | * 该仓库提供了免费的ip代理,可用性和实时性都可以接受 7 | 8 | 9 | ## Target 10 | * 爬取该repo上的代理IP列表,进行筛选并验证IP的可用性 11 | * getgoodip.py 12 |  13 | 14 | ## Tips 15 | * http://ip.tool.chinaz.com/ 是校验IP的网站 16 | * 如何使用: 17 | 18 | ```python 19 | 20 | conn=MongoClient('127.0.0.1', 27017) 21 | db=conn.proxy 22 | mongo_proxy=db.good_proxy 23 | proxy_data=mongo_proxy.find() 24 | proxies=json_normalize([ip for ip in proxy_data]) 25 | proxy_list=list(proxies['ip']) 26 | proxy=random.choice(proxy_list) 27 | r=requests.get(url,headers=headers,proxies={'https': 'https://{}'.format(proxy),'http':'http://{}'.format(proxy)}) 28 | 29 | ``` 30 | 31 | -------------------------------------------------------------------------------- /代理IP/download.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/代理IP/download.png -------------------------------------------------------------------------------- /代理IP/getgoodip.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Tue Jul 30 12:27:42 2019 4 | 5 | @author: Lee 6 | """ 7 | 8 | import requests 9 | from bs4 import BeautifulSoup 10 | import threading 11 | from pymongo import MongoClient 12 | from lxml import etree 13 | 14 | 15 | def checkip(proxy): 16 | try: 17 | url='http://ip.tool.chinaz.com/' 18 | headers={'User-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'} 19 | r1=requests.get(url,headers=headers,proxies={'https': 'https://{}'.format(proxy),'http': 'http://{}'.format(proxy)},timeout=30) 20 | tree=etree.HTML(r1.text) 21 | ipaddress=tree.xpath('//dd[@class="fz24"]/text()') 22 | # print(ipaddress) 23 | 24 | if ipaddress[0]==proxy[:-5]: 25 | return True 26 | elif ipaddress[0]==proxy[:-6]: 27 | return True 28 | else: 29 | return False 30 | except: 31 | return False 32 | 33 | 34 | 35 | 36 | def getgoodproxy(ip,ip_type): 37 | 38 | if checkip(ip): 39 | print('{}可用,类型为{}'.format(ip,ip_type)) 40 | goodip.append(ip) 41 | handler.insert_one({'ip':ip}) 42 | 43 | 44 | if __name__ == '__main__': 45 | 46 | url='https://github.com/dxxzst/free-proxy-list' 47 | headers={ 'User-Agent': "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50"} 48 | r=requests.get(url,headers=headers) 49 | soup=BeautifulSoup(r.text,"html.parser") 50 | table=soup.find_all('table')[1] 51 | ulist1=[] 52 | ulist2=[] 53 | for tr in table.find_all('tr')[1:]: 54 | a=tr.text.split("\n") 55 | if a[4]=='high': 56 | # 'https': 'https://{}'.format(proxy) 57 | if a[3]=='http': 58 | ulist1.append("{}:{}".format(a[1],a[2])) 59 | else: 60 | ulist2.append("{}:{}".format(a[1],a[2])) 61 | 62 | goodip=[] 63 | client=MongoClient() 64 | db=client.proxy 65 | handler=db.good_proxy 66 | handler.delete_many({}) 67 | tasks=[] # 线程池 68 | 69 | for ip1 in ulist1: 70 | task=threading.Thread(target=getgoodproxy, args=(ip1,'http',)) 71 | tasks.append(task) 72 | task.start() 73 | 74 | for ip2 in ulist2: 75 | task=threading.Thread(target=getgoodproxy, args=(ip2,'https',)) 76 | tasks.append(task) 77 | task.start() 78 | 79 | 80 | # 等待所有线程完成 81 | for _ in tasks: 82 | _.join() 83 | print("完成代理ip验证并存储到本地!") 84 | -------------------------------------------------------------------------------- /代理IP/ip.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/代理IP/ip.png -------------------------------------------------------------------------------- /代理IP/proxy.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Tue Feb 12 21:57:49 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | from bs4 import BeautifulSoup 9 | import requests 10 | import json 11 | import time 12 | from pymongo import MongoClient as Client 13 | 14 | 15 | def dict2proxy(dic): 16 | s=dic['类型']+'://'+dic['ip']+':'+str(dic['端口']) 17 | print(s) 18 | return {'http':s,'https':s} 19 | 20 | 21 | def getHTMLText(url,headers,code='utf-8'): 22 | try: 23 | r=requests.get(url,headers=headers,timeout=30) 24 | r.raise_for_status() 25 | r.encoding=code 26 | return r.text 27 | except: 28 | return "url异常" 29 | 30 | def getIP(html,ulist): 31 | 32 | soup=BeautifulSoup(html,'html.parser') 33 | items=soup.find_all('tr')[1:] 34 | #第一个不是ip 35 | 36 | for item in items: 37 | tds=item.find_all('td') 38 | ulist.append({'ip':tds[0].text,'端口':tds[1].text,'类型':tds[3].text,'位置':tds[4].text,'响应速度':tds[5].text,'最后验证时间':tds[6].text}) 39 | #print(ulist) 40 | return ulist 41 | 42 | 43 | 44 | def saveAsJson(ulist): 45 | with open('proxy.json','w',encoding='utf-8') as f: 46 | json.dump(ulist,f,indent=7,ensure_ascii=False)#ensure_ascii参数使显示为中文 47 | 48 | def saveAsJson1(ulist): 49 | with open('goodproxy.json','w',encoding='utf-8') as f: 50 | json.dump(ulist,f,indent=7,ensure_ascii=False) 51 | 52 | 53 | ''' 54 | def write_to_mongo(ip): 55 | client=Client(host='localhost',port=27017) 56 | db=client['proxies_db'] 57 | coll=db['proxies'] 58 | for i in ip: 59 | if coll.find({'ip':i['ip']}).count==0: 60 | coll.insert_one(i) 61 | client.close() 62 | ''' 63 | 64 | def checkip(ip): 65 | try: 66 | proxies=dict2proxy(ip) 67 | url='http://www.ipip.net/' 68 | headers={'User-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE'} 69 | r=requests.get(url,headers=headers,proxies=proxies,timeout=5) 70 | r.raise_for_status() 71 | except: 72 | return False 73 | else: 74 | return True 75 | 76 | def getgoodip(ip): 77 | goodip=[] 78 | for i in ip: 79 | if checkip(i): 80 | goodip.append(i) 81 | return goodip 82 | 83 | 84 | def main(): 85 | ulist=[] 86 | headers={'Accept':'image/webp,image/apng,image/*,*/*;q=0.8', 87 | 'Accept-encoding':'gzip, deflate, br', 88 | 'Accept-language':'zh-CN,zh;q=0.9', 89 | 'User-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 QIHU 360SE' 90 | } 91 | for num in range(1,11): 92 | url='https://www.kuaidaili.com/free/inha/%s' % num 93 | print("正在爬取第{}页".format(num)) 94 | html=getHTMLText(url,headers) 95 | # time.sleep(5) #增加间隔 96 | #print(html) 97 | iplist=getIP(html,ulist) 98 | saveAsJson(iplist) 99 | print("爬取完成!") 100 | print("开始检验ip") 101 | goodip=getgoodip(ulist) 102 | print("打印可以使用的ip:{}".format(goodip)) 103 | print("开始存储可以使用的ip") 104 | saveAsJson1(goodip) 105 | print("完成存储") 106 | 107 | 108 | 109 | if __name__ == '__main__': 110 | main() -------------------------------------------------------------------------------- /全国历史天气/README.md: -------------------------------------------------------------------------------- 1 | # 全国历史天气 2 | 3 | ## Target 4 | * 获取2012年-2018年全国各地历史天气信息 5 |  6 | 7 | * 包含各个地区每天的天气情况 8 |  -------------------------------------------------------------------------------- /全国历史天气/download.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/download.png -------------------------------------------------------------------------------- /全国历史天气/weather.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Sat Aug 31 20:08:11 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | import requests 9 | import threading 10 | from pymongo import MongoClient 11 | from lxml import etree 12 | import time 13 | 14 | 15 | class weather(object): 16 | 17 | def __init__(self): 18 | 19 | self.origin_url='https://m.tianqi.com' 20 | self.url='https://m.tianqi.com/lishi/{}/{}{}.html' 21 | self.headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36"} 22 | self.conn=MongoClient('127.0.0.1',27017) 23 | self.db=self.conn.weather 24 | 25 | def get_province(self): 26 | 27 | r=requests.get('https://m.tianqi.com/lishi.html',headers=self.headers) 28 | tree=etree.HTML(r.text) 29 | province_link=tree.xpath('//ul[@class="clear"]/li/a/@href')[:34] 30 | province=tree.xpath('//li/a/text()')[:34] 31 | return province_link,province 32 | 33 | def get_direct(self,directs,name): 34 | 35 | province_link,province=self.get_province() 36 | print(province) 37 | for pro in province_link: 38 | r=requests.get(self.origin_url+pro,headers=self.headers) 39 | tree=etree.HTML(r.text) 40 | direct_per_pro=tree.xpath('//ul[@class="clear"]/li/a/@href') 41 | name_per_pro=tree.xpath('//ul[@class="clear"]/li/a/text()') 42 | directs.append(direct_per_pro) 43 | name.append(name_per_pro) 44 | 45 | return province 46 | 47 | def get_weather(self,directs,name,province): 48 | 49 | # direct_name=[] 50 | # for i in range(len(province)): 51 | # for direct in directs[i]: 52 | # direct_name.append(direct[7:-11]) 53 | # print(direct_name) 54 | for i in range(len(province)): 55 | for j in range(len(directs[i])): 56 | 57 | for year in range(2012,2019): 58 | tasks=[] 59 | for month in range(1,13): 60 | task=threading.Thread(target=self.run, args=(i,j,year,month,directs[i][j][7:-11],province[i])) 61 | tasks.append(task) 62 | task.start() 63 | # 等待所有线程完成 64 | for _ in tasks: 65 | _.join() 66 | 67 | 68 | def run(self,i,j,year,month,direct_name,province_name): 69 | 70 | try: 71 | if month<10: 72 | r=requests.get(self.url.format(direct_name,year,'0'+str(month)),headers=self.headers) 73 | else: 74 | r=requests.get(self.url.format(direct_name,year,month),headers=self.headers) 75 | tree=etree.HTML(r.text) 76 | average_high_tem=tree.xpath('//h5[@class="red"]/text()')[0] 77 | max_high_tem=tree.xpath('//h5[@class="red"]/text()')[1] 78 | average_low_tem=tree.xpath('//tr/td[2]/h5/text()')[0] 79 | min_low_tem=tree.xpath('//tr/td[2]/h5/text()')[1] 80 | best_quality=tree.xpath('//td[@colspan="2"]/h5/text()')[0] 81 | worst_quality=tree.xpath('//td[@colspan="2"]/h5/text()')[1] 82 | date=tree.xpath('//dd[@class="date"]/text()') 83 | weather=tree.xpath('//dd[@class="txt1"]/text()') 84 | date=[d[:5] for d in date] 85 | dic=dict(zip(date,weather)) 86 | item1={ 87 | 'average_high_tem':average_high_tem, 88 | 'max_high_tem':max_high_tem, 89 | 'average_low_tem':average_low_tem, 90 | 'min_low_tem':min_low_tem, 91 | 'best_quality':best_quality, 92 | 'worst_quality':worst_quality, 93 | 'city':name[i][j], 94 | 'year':year, 95 | 'month':month, 96 | 'weather':dic, 97 | 'province':province_name 98 | } 99 | self.db['info'].insert_one(item1) 100 | except Exception as e: 101 | print(e) 102 | #time.sleep(2) 103 | #self.run(i,j,year,month,direct_name,province_name) 104 | 105 | 106 | if __name__=='__main__': 107 | 108 | All_weather=weather() 109 | directs=[] 110 | name=[] 111 | province=All_weather.get_direct(directs,name) 112 | print(directs) 113 | All_weather.get_weather(directs,name,province) 114 | 115 | -------------------------------------------------------------------------------- /全国历史天气/weather/scrapy.cfg: -------------------------------------------------------------------------------- 1 | # Automatically created by: scrapy startproject 2 | # 3 | # For more information about the [deploy] section see: 4 | # https://scrapyd.readthedocs.io/en/latest/deploy.html 5 | 6 | [settings] 7 | default = weather.settings 8 | 9 | [deploy] 10 | #url = http://localhost:6800/ 11 | project = weather 12 | -------------------------------------------------------------------------------- /全国历史天气/weather/weather/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/weather/weather/__init__.py -------------------------------------------------------------------------------- /全国历史天气/weather/weather/__pycache__/__init__.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/weather/weather/__pycache__/__init__.cpython-37.pyc -------------------------------------------------------------------------------- /全国历史天气/weather/weather/__pycache__/pipelines.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/weather/weather/__pycache__/pipelines.cpython-37.pyc -------------------------------------------------------------------------------- /全国历史天气/weather/weather/__pycache__/settings.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/weather/weather/__pycache__/settings.cpython-37.pyc -------------------------------------------------------------------------------- /全国历史天气/weather/weather/items.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your scraped items 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/items.html 7 | 8 | import scrapy 9 | 10 | 11 | class WeatherItem(scrapy.Item): 12 | # define the fields for your item here like: 13 | # name = scrapy.Field() 14 | pass 15 | -------------------------------------------------------------------------------- /全国历史天气/weather/weather/middlewares.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define here the models for your spider middleware 4 | # 5 | # See documentation in: 6 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 7 | 8 | from scrapy import signals 9 | 10 | 11 | class WeatherSpiderMiddleware(object): 12 | # Not all methods need to be defined. If a method is not defined, 13 | # scrapy acts as if the spider middleware does not modify the 14 | # passed objects. 15 | 16 | @classmethod 17 | def from_crawler(cls, crawler): 18 | # This method is used by Scrapy to create your spiders. 19 | s = cls() 20 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 21 | return s 22 | 23 | def process_spider_input(self, response, spider): 24 | # Called for each response that goes through the spider 25 | # middleware and into the spider. 26 | 27 | # Should return None or raise an exception. 28 | return None 29 | 30 | def process_spider_output(self, response, result, spider): 31 | # Called with the results returned from the Spider, after 32 | # it has processed the response. 33 | 34 | # Must return an iterable of Request, dict or Item objects. 35 | for i in result: 36 | yield i 37 | 38 | def process_spider_exception(self, response, exception, spider): 39 | # Called when a spider or process_spider_input() method 40 | # (from other spider middleware) raises an exception. 41 | 42 | # Should return either None or an iterable of Response, dict 43 | # or Item objects. 44 | pass 45 | 46 | def process_start_requests(self, start_requests, spider): 47 | # Called with the start requests of the spider, and works 48 | # similarly to the process_spider_output() method, except 49 | # that it doesn’t have a response associated. 50 | 51 | # Must return only requests (not items). 52 | for r in start_requests: 53 | yield r 54 | 55 | def spider_opened(self, spider): 56 | spider.logger.info('Spider opened: %s' % spider.name) 57 | 58 | 59 | class WeatherDownloaderMiddleware(object): 60 | # Not all methods need to be defined. If a method is not defined, 61 | # scrapy acts as if the downloader middleware does not modify the 62 | # passed objects. 63 | 64 | @classmethod 65 | def from_crawler(cls, crawler): 66 | # This method is used by Scrapy to create your spiders. 67 | s = cls() 68 | crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 69 | return s 70 | 71 | def process_request(self, request, spider): 72 | # Called for each request that goes through the downloader 73 | # middleware. 74 | 75 | # Must either: 76 | # - return None: continue processing this request 77 | # - or return a Response object 78 | # - or return a Request object 79 | # - or raise IgnoreRequest: process_exception() methods of 80 | # installed downloader middleware will be called 81 | return None 82 | 83 | def process_response(self, request, response, spider): 84 | # Called with the response returned from the downloader. 85 | 86 | # Must either; 87 | # - return a Response object 88 | # - return a Request object 89 | # - or raise IgnoreRequest 90 | return response 91 | 92 | def process_exception(self, request, exception, spider): 93 | # Called when a download handler or a process_request() 94 | # (from other downloader middleware) raises an exception. 95 | 96 | # Must either: 97 | # - return None: continue processing this exception 98 | # - return a Response object: stops process_exception() chain 99 | # - return a Request object: stops process_exception() chain 100 | pass 101 | 102 | def spider_opened(self, spider): 103 | spider.logger.info('Spider opened: %s' % spider.name) 104 | -------------------------------------------------------------------------------- /全国历史天气/weather/weather/pipelines.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Define your item pipelines here 4 | # 5 | # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 | # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 | 8 | 9 | from pymongo import MongoClient 10 | 11 | # 将爬取的内容保存到mongoDB中 12 | class WeatherPipeline(object): 13 | 14 | def __init__(self): 15 | # 连接 16 | self.client = MongoClient() 17 | 18 | self.col = self.client['weather'] 19 | self.info = self.col.info 20 | # 先清除之前保存的数据 21 | # self.ershoufang.delete_many({}) 22 | 23 | def process_item(self, item, spider): 24 | self.info.insert_one(item) 25 | return item 26 | 27 | def open_spider(self, spider): 28 | pass 29 | 30 | def close_spider(self, spider): 31 | self.client.close() -------------------------------------------------------------------------------- /全国历史天气/weather/weather/settings.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | 3 | # Scrapy settings for weather project 4 | # 5 | # For simplicity, this file contains only settings considered important or 6 | # commonly used. You can find more settings consulting the documentation: 7 | # 8 | # https://doc.scrapy.org/en/latest/topics/settings.html 9 | # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 10 | # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 11 | 12 | BOT_NAME = 'weather' 13 | 14 | SPIDER_MODULES = ['weather.spiders'] 15 | NEWSPIDER_MODULE = 'weather.spiders' 16 | 17 | 18 | # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 | #USER_AGENT = 'weather (+http://www.yourdomain.com)' 20 | 21 | import random 22 | USER_AGENT_LIST = [ 23 | 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23', 24 | 'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)', 25 | 'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)', 26 | 'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)', 27 | 'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)', 28 | 'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)', 29 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0', 30 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0', 31 | 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0', 32 | 'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)', 33 | 'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)' 34 | ] 35 | USER_AGENT = random.choice(USER_AGENT_LIST) 36 | 37 | # Obey robots.txt rules 38 | # ROBOTSTXT_OBEY = True 39 | 40 | # Configure maximum concurrent requests performed by Scrapy (default: 16) 41 | #CONCURRENT_REQUESTS = 32 42 | 43 | # Configure a delay for requests for the same website (default: 0) 44 | # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay 45 | # See also autothrottle settings and docs 46 | DOWNLOAD_DELAY = random.random() 47 | # The download delay setting will honor only one of: 48 | #CONCURRENT_REQUESTS_PER_DOMAIN = 16 49 | #CONCURRENT_REQUESTS_PER_IP = 16 50 | 51 | # Disable cookies (enabled by default) 52 | #COOKIES_ENABLED = False 53 | 54 | # Disable Telnet Console (enabled by default) 55 | #TELNETCONSOLE_ENABLED = False 56 | 57 | # Override the default request headers: 58 | #DEFAULT_REQUEST_HEADERS = { 59 | # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 60 | # 'Accept-Language': 'en', 61 | #} 62 | 63 | # Enable or disable spider middlewares 64 | # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html 65 | #SPIDER_MIDDLEWARES = { 66 | # 'weather.middlewares.WeatherSpiderMiddleware': 543, 67 | #} 68 | 69 | # Enable or disable downloader middlewares 70 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 71 | #DOWNLOADER_MIDDLEWARES = { 72 | # 'weather.middlewares.WeatherDownloaderMiddleware': 543, 73 | #} 74 | 75 | # Enable or disable extensions 76 | # See https://doc.scrapy.org/en/latest/topics/extensions.html 77 | #EXTENSIONS = { 78 | # 'scrapy.extensions.telnet.TelnetConsole': None, 79 | #} 80 | 81 | # Configure item pipelines 82 | # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 83 | ITEM_PIPELINES = { 84 | 'weather.pipelines.WeatherPipeline': 300, 85 | } 86 | 87 | # Enable and configure the AutoThrottle extension (disabled by default) 88 | # See https://doc.scrapy.org/en/latest/topics/autothrottle.html 89 | #AUTOTHROTTLE_ENABLED = True 90 | # The initial download delay 91 | #AUTOTHROTTLE_START_DELAY = 5 92 | # The maximum download delay to be set in case of high latencies 93 | #AUTOTHROTTLE_MAX_DELAY = 60 94 | # The average number of requests Scrapy should be sending in parallel to 95 | # each remote server 96 | #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 97 | # Enable showing throttling stats for every response received: 98 | #AUTOTHROTTLE_DEBUG = False 99 | 100 | # Enable and configure HTTP caching (disabled by default) 101 | # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 102 | #HTTPCACHE_ENABLED = True 103 | #HTTPCACHE_EXPIRATION_SECS = 0 104 | #HTTPCACHE_DIR = 'httpcache' 105 | #HTTPCACHE_IGNORE_HTTP_CODES = [] 106 | #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' 107 | -------------------------------------------------------------------------------- /全国历史天气/weather/weather/spiders/__init__.py: -------------------------------------------------------------------------------- 1 | # This package will contain the spiders of your Scrapy project 2 | # 3 | # Please refer to the documentation for information on how to create and manage 4 | # your spiders. 5 | -------------------------------------------------------------------------------- /全国历史天气/weather/weather/spiders/__pycache__/__init__.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/weather/weather/spiders/__pycache__/__init__.cpython-37.pyc -------------------------------------------------------------------------------- /全国历史天气/weather/weather/spiders/__pycache__/getweather.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/weather/weather/spiders/__pycache__/getweather.cpython-37.pyc -------------------------------------------------------------------------------- /全国历史天气/weather/weather/spiders/__pycache__/untitled3.cpython-37.pyc: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/weather/weather/spiders/__pycache__/untitled3.cpython-37.pyc -------------------------------------------------------------------------------- /全国历史天气/weather/weather/spiders/getweather.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | import scrapy 3 | 4 | 5 | class GetweatherSpider(scrapy.Spider): 6 | name = 'getweather' 7 | start_urls = ['https://lishi.tianqi.com/'] 8 | 9 | def parse(self, response): 10 | city_url=[] 11 | city_name=[] 12 | for alpha in [chr(i) for i in range(65,91)]: 13 | city_url.extend(response.xpath('//ul[@id="city_{}"]/li/a/@href'.format(alpha)).extract()[1:]) 14 | city_name.extend(response.xpath('//ul[@id="city_{}"]/li/a/text()'.format(alpha)).extract()[1:]) 15 | for j in range(len(city_url)): 16 | yield scrapy.Request(city_url[j],callback=self.parse_info1,meta={'city':city_name[j]}) 17 | 18 | def parse_info1(self,response): 19 | 20 | detail_href=response.xpath('//div[@class="tqtongji1"]/ul/li/a/@href').extract()[:-24] 21 | print(detail_href) 22 | for href in detail_href: 23 | yield scrapy.Request(href,callback=self.parse_info2,meta=response.meta) 24 | 25 | 26 | 27 | def parse_info2(self,response): 28 | 29 | date=response.xpath('//div[@class="tqtongji2"]/ul/li[1]/a/text()').extract() 30 | high_temp=response.xpath('//div[@class="tqtongji2"]/ul/li[2]/text()').extract()[1:] 31 | low_temp=response.xpath('//div[@class="tqtongji2"]/ul/li[3]/text()').extract()[1:] 32 | weather=response.xpath('//div[@class="tqtongji2"]/ul/li[4]/text()').extract()[1:] 33 | wind_direct=response.xpath('//div[@class="tqtongji2"]/ul/li[5]/text()').extract()[1:] 34 | wind_power=response.xpath('//div[@class="tqtongji2"]/ul/li[6]/text()').extract()[1:] 35 | 36 | for i in range(len(date)): 37 | yield { 38 | '城市': response.meta['city'], 39 | '日期': date[i], 40 | '最高气温': high_temp[i], 41 | '最低气温': low_temp[i], 42 | '天气情况': weather[i], 43 | '风向': wind_direct[i], 44 | '风力': wind_power[i], 45 | } -------------------------------------------------------------------------------- /全国历史天气/web.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/全国历史天气/web.png -------------------------------------------------------------------------------- /公交/hangzhou_bus_info.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Wed May 22 13:24:46 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | import requests 9 | import re 10 | from lxml import etree 11 | 12 | 13 | class Spyder_bus(object): 14 | 15 | def __init__(self): 16 | self.headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; \ 17 | x64) AppleWebKit/537.36 (KHTML, like Gecko) \ 18 | Chrome/70.0.3538.102 Safari/537.36'} 19 | self.items=[] 20 | self.url='https://hangzhou.8684.cn/' 21 | 22 | def parse_navigation(self): 23 | r = requests.get(self.url, headers=self.headers) 24 | # 解析内容,获取所有导航链接 25 | tree = etree.HTML(r.text) 26 | number_href_list = tree.xpath('//div[@class="bus_kt_r1"]/a/@href') 27 | letter_href_list = tree.xpath('//div[@class="bus_kt_r2"]/a/@href') 28 | all_navigation=number_href_list + letter_href_list 29 | return all_navigation 30 | 31 | def parse_third_url(self,content): 32 | tree = etree.HTML(content) 33 | # 依次获取公交详细内容 34 | # 获取公交线路信息 35 | bus_number = tree.xpath('//div[@class="bus_i_t1"]/h1/text()')[0] 36 | bus_number = bus_number.replace(' ', '') 37 | # 获取运行时间 38 | run_time = tree.xpath('//p[@class="bus_i_t4"][1]/text()')[0] 39 | run_time = re.sub(r'(.*?:)', '', run_time) 40 | # 获取票价信息 41 | ticket_info = tree.xpath('//p[@class="bus_i_t4"][2]/text()')[0] 42 | ticket_info = re.sub(r'(.*?:)', '', ticket_info) 43 | # 该公交线路公司名称 44 | company_info = tree.xpath('//p[@class="bus_i_t4"]/a/text()')[0] 45 | # 获取更新时间 46 | update_time = tree.xpath('//p[@class="bus_i_t4"][4]/text()')[0] 47 | update_time = re.sub(r'(.*?:)', '', update_time) 48 | 49 | total_list = tree.xpath('//span[@class="bus_line_no"]/text()') 50 | # 获取上行总站数 51 | up_total = total_list[0] 52 | # 将里面空格去掉 53 | up_total = up_total.replace('\xa0', '') 54 | # 获取上行所有站名 55 | up_site_list = tree.xpath('//div[@class="bus_line_site "][1]/div/div/a/text()') 56 | 57 | #有些线路只有单线,内环外环线路 58 | try: 59 | # 获取下行总站数 60 | down_total = total_list[1] 61 | down_total = down_total.replace('\xa0','') 62 | # 获取下行所有站名 63 | down_site_list = tree.xpath('//div[@class="bus_line_site "][2]/div/div/a/text()') 64 | # 将每一条公交线路存放到字典中 65 | except Exception as e: 66 | down_total = '' 67 | down_site_list = [] 68 | 69 | item = { 70 | '线路名': bus_number, 71 | '运行时间': run_time, 72 | '票价信息': ticket_info, 73 | '公司名称': company_info, 74 | '更新时间': update_time, 75 | '上行站数': up_total, 76 | '上行站点': up_site_list, 77 | '下行站数': down_total, 78 | '下行站点': down_site_list 79 | } 80 | self.items.append(item) 81 | 82 | 83 | def parse_second_url(self,content): 84 | tree = etree.HTML(content) 85 | route_list = tree.xpath('//div[@id="con_site_1"]/a/@href') 86 | route_name = tree.xpath('//div[@id="con_site_1"]/a/text()') 87 | # 遍历上面的列表 88 | i = 0 89 | for route in route_list: 90 | print('开始爬取%s线路' % route_name[i]) 91 | route = self.url + route 92 | r = requests.get(url=route, headers=self.headers) 93 | print('结束爬取%s线路' % route_name[i]) 94 | # 解析内容,获取每一路公交的详细信息 95 | self.parse_third_url(r.text) 96 | i += 1 97 | 98 | 99 | def parse_first_url(self,navi_list): 100 | # 遍历列表,依次发送请求,解析内容,获取每个页面的所有公交线的url 101 | for url in navi_list: 102 | first_url =self.url + url 103 | print('开始爬取%s所有的公交信息' % first_url) 104 | r = requests.get(url=first_url, headers=self.headers) 105 | # 解析内容,获取每一路公交的详细的url 106 | self.parse_second_url(r.text) 107 | print('结束爬取%s所有的公交信息' % first_url) 108 | 109 | def save_to_txt(self): 110 | 111 | with open('hangzhou_bus_info.txt', 'w', encoding='utf-8') as f: 112 | for item in self.items: 113 | f.write(str(item)+'\n') 114 | 115 | 116 | 117 | if __name__ == '__main__': 118 | 119 | bus_info=Spyder_bus() 120 | navigation=bus_info.parse_navigation() 121 | #print(navigation) 122 | bus_info.parse_first_url(navigation) 123 | bus_info.save_to_txt() 124 | 125 | 126 | 127 | 128 | 129 | 130 | -------------------------------------------------------------------------------- /大众点评/README.md: -------------------------------------------------------------------------------- 1 | # 大众点评 2 | 3 | ## Target 4 | * 破解字体反爬,获得餐厅的评论信息 5 |  6 | 7 | ## Tips 8 | 9 | * 具体详解请看[字体反爬之大众点评](https://mp.weixin.qq.com/s/q-lIhCcaCZR9L1m9r_Jmyw) 10 | 11 | -------------------------------------------------------------------------------- /大众点评/a.woff: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/大众点评/a.woff -------------------------------------------------------------------------------- /大众点评/comment.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/大众点评/comment.png -------------------------------------------------------------------------------- /实习僧/README.md: -------------------------------------------------------------------------------- 1 | # 实习僧 2 | 3 | ## Target 4 | * 破解字体反爬,获得相关招聘岗位信息并存入数据库 5 |  6 | 7 | ## Tips 8 | 9 | * 具体详解请看[字体反爬之实习僧](https://mp.weixin.qq.com/s/3tyPmarn_gcsn78cSKgnAQ) 10 | 11 | -------------------------------------------------------------------------------- /实习僧/download.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/实习僧/download.png -------------------------------------------------------------------------------- /实习僧/new_font.woff: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/实习僧/new_font.woff -------------------------------------------------------------------------------- /微信公众号/README.md: -------------------------------------------------------------------------------- 1 | # 微信公众号文章 2 | ## [Link](https://mp.weixin.qq.com/s/Fqp9h27uwycbs_PJ3Tqggw) 3 |  4 | ## Target 5 | * 获取某微信公众号的全部内容,文章URL存入数据库,并以PDF的形式下载到本地存储 6 |  7 |  8 | ## Tips 9 | * 常见方法一:通过搜狗微信去获取,但是只能获取最新的十篇文章 10 | * 常见方法二:通过微信公众号的素材管理,获取公众号文章。但是需要有一个自己的公众号 11 | * 通过Fiddler抓包发现链接的一些必要参数,在访问链接的时候带上这些参数,参数从抓包工具中获取 12 | * 通过pdfkit这个模块导出pdf文件 13 | * 上述模块需要安装[Wkhtmltopdf](https://wkhtmltopdf.org/downloads.html)才能使用 14 | 15 | ## TODO 16 | * 有比较大的局限性,每爬取一个公众号的所有文章,就需要通过抓包更新这些必要的参数 17 | 18 | -------------------------------------------------------------------------------- /微信公众号/article2pdf.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Sat Jul 6 12:51:10 2019 4 | 5 | @author: Lee 6 | """ 7 | from pymongo import MongoClient 8 | from pandas.io.json import json_normalize 9 | import pdfkit 10 | import re 11 | 12 | 13 | 14 | # Mongo配置 15 | conn=MongoClient('127.0.0.1', 27017) 16 | db=conn.wx #连接wx数据库,没有则自动创建 17 | mongo_wx=db.article #使用article集合,没有则自动创建 18 | 19 | # 配置wkhtmltopdf 20 | config=pdfkit.configuration(wkhtmltopdf=r"F:\wkhtmltopdf\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe") 21 | wx_url_data=mongo_wx.find() 22 | data=json_normalize([comment for comment in wx_url_data]) 23 | url_list=list(data['content_url']) 24 | title_list=list(data['title']) 25 | # 修改title名,使之能够成为文件名 26 | for i in range(len(title_list)): 27 | if title_list[i]: 28 | title_list[i]=re.sub('[\t\\\|\?\*\:\<\>\"\/]', '', title_list[i]) 29 | count=0 30 | # url 转换成pdf存储 31 | for url in url_list: 32 | if url: 33 | pdfkit.from_url(url, '{}.pdf'.format(title_list[count]),configuration=config) 34 | count+=1 35 | print("已经将所有文章转换为PDF文件!") 36 | 37 | 38 | 39 | -------------------------------------------------------------------------------- /微信公众号/download1.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/微信公众号/download1.png -------------------------------------------------------------------------------- /微信公众号/download2.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/微信公众号/download2.png -------------------------------------------------------------------------------- /微信公众号/web.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/微信公众号/web.png -------------------------------------------------------------------------------- /微信公众号/wechatarticle.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Fri Jul 5 21:51:21 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | import requests 9 | import json 10 | import time 11 | from pymongo import MongoClient 12 | 13 | url='http://mp.weixin.qq.com/mp/profile_ext' 14 | 15 | # Mongo配置 16 | conn=MongoClient('127.0.0.1', 27017) 17 | db=conn.wx #连接wx数据库,没有则自动创建 18 | mongo_wx=db.article #使用article集合,没有则自动创建 19 | 20 | def get_wx_article(biz,uin,key,pass_ticket,appmsg_token,count=10): 21 | offset=1+(index+1)*11 22 | params={ 23 | '__biz':biz, 24 | 'uin':uin, 25 | 'key':key, 26 | 'offset':offset, 27 | 'count':count, 28 | 'action':'getmsg', 29 | 'f':'json', 30 | 'pass_ticket':pass_ticket, 31 | 'scene':124, 32 | 'is_ok':1, 33 | 'appmsg_token':appmsg_token, 34 | 'x5':0, 35 | } 36 | 37 | headers={ 38 | 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' 39 | } 40 | 41 | r=requests.get(url=url, params=params, headers=headers) 42 | resp_json=r.json() 43 | #print(resp_json) 44 | if resp_json.get('errmsg') == 'ok': 45 | # 是否还有分页数据,若没有更多数据则返回 46 | can_msg_continue=resp_json['can_msg_continue'] 47 | # 当前分页文章数 48 | msg_count=resp_json['msg_count'] 49 | print("当前分页共有{}篇文章".format(msg_count)) 50 | general_msg_list=json.loads(resp_json['general_msg_list']) 51 | infolist=general_msg_list.get('list') 52 | print(infolist, "\n**************") 53 | for info in infolist: 54 | app_msg_ext_info=info['app_msg_ext_info'] 55 | # 标题 56 | title=app_msg_ext_info['title'] 57 | # 文章链接 58 | content_url=app_msg_ext_info['content_url'] 59 | # 封面图 60 | cover=app_msg_ext_info['cover'] 61 | # 发布时间 62 | datetime=info['comm_msg_info']['datetime'] 63 | datetime=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(datetime)) 64 | 65 | mongo_wx.insert({ 66 | 'title': title, 67 | 'content_url': content_url, 68 | 'cover': cover, 69 | 'datetime': datetime 70 | }) 71 | if can_msg_continue==1: 72 | return True 73 | return False 74 | else: 75 | print('获取文章异常...') 76 | return False 77 | 78 | 79 | if __name__ == '__main__': 80 | # 参数通过抓包获得 81 | biz='' 82 | uin='' 83 | key='' 84 | pass_ticket='' 85 | appmsg_token='' 86 | index=-1 87 | while 1: 88 | print(f'开始抓取公众号第{index + 1} 页文章.') 89 | flag=get_wx_article(biz,uin,key,pass_ticket,appmsg_token,index=index) 90 | # 防止和谐,暂停8秒 91 | time.sleep(8) 92 | index+=1 93 | if not flag: 94 | print('该公众号文章已全部抓取并且存入本地数据库') 95 | break 96 | 97 | print('..........准备抓取公众号第 {} 页文章.'.format(index+2)) 98 | 99 | 100 | 101 | 102 | 103 | 104 | 105 | 106 | 107 | 108 | 109 | 110 | 111 | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | 120 | 121 | 122 | 123 | -------------------------------------------------------------------------------- /拉钩/README.md: -------------------------------------------------------------------------------- 1 | # 拉钩职位信息 2 | ## [Link](https://www.lagou.com/) 3 |  4 | ## Target 5 | * 获取Python相关的职位信息,并下载到本地存储 6 |  7 | ## Tips 8 | * headers中需写入**Referer**,不然会报错,在同一次session中访问,提取cookies 9 | ```python 10 | 'status': False, 'msg': '您操作太频繁,请稍后再访问', 'clientIp': '117.136.41.41', 'state': 2402 11 | ``` 12 | * 在请求中去掉timeout,不然容易提取未加载的新页面 13 | ``` 14 | 页面加载中... 15 | ``` 16 | * 调用csv模块,可以将数据写入csv文件 17 | ```python 18 | import csv 19 | with open('lagou_data.csv','w',encoding='gbk',newline='') as f: 20 | csv_write = csv.writer(f) 21 | title = ['id','职位','城市','学历','工作年限','薪资','第一标签','第二标签','第三标签','技能库','公司名称','融资阶段','公司规模'] 22 | csv_write.writerow(title) 23 | ``` 24 | 25 | ## TODO 26 | * 依然会出现 “页面加载中”的情况,难以获得所有的具体招聘要求和职位描述 27 | 28 | -------------------------------------------------------------------------------- /拉钩/download.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/拉钩/download.png -------------------------------------------------------------------------------- /拉钩/web.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/拉钩/web.png -------------------------------------------------------------------------------- /有道翻译/README.md: -------------------------------------------------------------------------------- 1 | # 有道翻译 2 | ## [Link](http://fanyi.youdao.com/) 3 | ## Target 4 | * 破解有道翻译网页版的参数加密 5 | ## Tips 6 | * JS调试 7 | * 具体详解请看[JS逆向初探之有道翻译](https://mp.weixin.qq.com/s/a-ORkG5XGSAP_-6GNilBbQ) 8 | 9 | -------------------------------------------------------------------------------- /有道翻译/youdao.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Wed Jul 3 13:16:37 2019 4 | 5 | @author: Lee 6 | """ 7 | import requests 8 | import time 9 | import hashlib 10 | import random 11 | 12 | class youdao_crawl(): 13 | def __init__(self): 14 | self.headers = { 15 | 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36', 16 | 'Referer': 'http://fanyi.youdao.com/', 17 | 'Cookie': 'OUTFOX_SEARCH_USER_ID=850665018@10.169.0.83; OUTFOX_SEARCH_USER_ID_NCOO=71221285.04687975; _ntes_nnid=6f09e5c54e440a52f10b177100aa9d1d,1561431366198; JSESSIONID=aaavC3vS98F0m-IjbuAVw; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc32dNbypRD-5CwnJAVw; user-from=http://www.youdao.com/w/eng/%E8%8B%B9%E6%9E%9C/; from-page=http://www.youdao.com/w/eng/%E8%8B%B9%E6%9E%9C/; ___rl__test__cookies=1562740161910' 18 | } 19 | self.data = { 20 | 'i': None, 21 | 'from': 'AUTO', 22 | 'to': 'AUTO', 23 | 'smartresult': 'dict', 24 | 'client': 'fanyideskweb', 25 | 'salt': None, 26 | 'sign': None, 27 | 'ts': None, 28 | 'bv': None, 29 | 'doctype': 'json', 30 | 'version': '2.1', 31 | 'keyfrom': 'fanyi.web', 32 | 'action': 'FY_BY_REALTlME' 33 | } 34 | self.url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' 35 | 36 | def translate(self, word): 37 | ts = str(int(time.time()*10000)) 38 | salt = str(int(time.time()*10000) + random.random()*10 + 10) 39 | sign = 'fanyideskweb' + word + salt + '97_3(jkMYg@T[KZQmqjTK' 40 | sign = hashlib.md5(sign.encode('utf-8')).hexdigest() 41 | bv = '5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' 42 | bv = hashlib.md5(bv.encode('utf-8')).hexdigest() 43 | self.data['i'] = word 44 | self.data['salt'] = salt 45 | self.data['sign'] = sign 46 | self.data['ts'] = ts 47 | self.data['bv'] = bv 48 | re = requests.post(self.url, headers=self.headers, data=self.data) 49 | return re.json()['translateResult'][0][0].get('tgt') 50 | 51 | 52 | if __name__ == '__main__': 53 | youdao = youdao_crawl() 54 | while True: 55 | content = input("请输入您需要翻译的内容:") 56 | if content == "q": 57 | break 58 | trans = youdao.translate(content) 59 | print(trans) -------------------------------------------------------------------------------- /梦幻西游/CBG.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Tue Aug 27 11:20:53 2019 4 | 5 | @author: Administrator 6 | """ 7 | 8 | import requests 9 | import re 10 | import json 11 | import execjs 12 | from pymongo import MongoClient 13 | import time 14 | 15 | class CBG(object): 16 | 17 | def __init__(self): 18 | 19 | self.url='https://xyq.cbg.163.com/cgi-bin/equipquery.py?act=overall_rank&rank_type=31&page={}' 20 | self.headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'} 21 | self.conn=MongoClient('127.0.0.1', 27017) 22 | self.db=self.conn.MHXY 23 | 24 | def get_json(self,i): 25 | r=requests.get(self.url.format(i),headers=self.headers) 26 | js=re.findall(r"var data = (.*);",r.text)[0] 27 | js=json.loads(js) 28 | return js 29 | 30 | def decode(self,data): 31 | with open('test.js','r') as f: 32 | javascript=f.read() 33 | ctx=execjs.compile(javascript) 34 | real_content=ctx.call('get_g',data) 35 | return real_content 36 | 37 | def get_highlights(self,data): 38 | highlights=data.encode().decode("unicode_escape") 39 | return highlights 40 | 41 | def get_equip_info(self,i): 42 | js=self.get_json(i) 43 | equip_list=js["equip_list"] 44 | for equip in equip_list: 45 | gem_level=equip['gem_level'] 46 | large_equip_desc=self.decode(equip['large_equip_desc']) 47 | sum_dex=equip['sum_dex'] 48 | create_time=equip['create_time'] 49 | collect_num=equip['collect_num'] 50 | highlights=self.get_highlights(equip['highlights']) 51 | price=equip['price'] 52 | rank=equip['rank'] 53 | expire_time=equip['expire_time'] 54 | server_name=equip['server_name'] 55 | item={ 56 | 'gem_level':gem_level, 57 | 'large_equip_desc':large_equip_desc, 58 | 'sum_dex':sum_dex, 59 | 'create_time':create_time, 60 | 'collect_num':collect_num, 61 | 'highlights':highlights, 62 | 'price':price, 63 | 'rank':rank, 64 | 'expire_time':expire_time, 65 | 'server_name':server_name 66 | } 67 | self.db['cbg'].insert_one(item) 68 | 69 | 70 | 71 | 72 | if __name__=='__main__': 73 | 74 | mhxycbg=CBG() 75 | for i in range(1,11): 76 | mhxycbg.get_equip_info(i) 77 | time.sleep(1) 78 | print("第{}页装备信息已存入数据库!".format(i)) -------------------------------------------------------------------------------- /汽车之家/README.md: -------------------------------------------------------------------------------- 1 | # 汽车之家论坛 2 | 3 | ## Target 4 | * 破解字体反爬,获得字体解密后的页面源代码 5 |  6 | 7 | ## Tips 8 | * FontCreator观察ttf文件 9 | * 坐标近似视为同一个字 10 | * 具体详解请看[字体反爬之汽车之家](https://mp.weixin.qq.com/s/zIDHQ1iRSElfV5PBAokFJw) 11 | 12 | -------------------------------------------------------------------------------- /汽车之家/base.ttf: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/汽车之家/base.ttf -------------------------------------------------------------------------------- /汽车之家/luntan.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Sun Jul 21 08:28:59 2019 4 | 5 | @author: Lee 6 | """ 7 | import requests 8 | import re 9 | from fontTools.ttLib import TTFont 10 | 11 | 12 | 13 | 14 | def get_new_ttf(url): 15 | """ 16 | 输入:网页链接 17 | 输出:新字体以及网页源代码 18 | """ 19 | r1=requests.get(url,headers=headers) 20 | ttf=re.findall(r",url\('(//.*\.ttf)'\)",r1.text)[0] 21 | r=requests.get('https:'+ttf) 22 | with open('new.ttf','wb') as f: 23 | f.write(r.content) 24 | font2=TTFont('new.ttf') 25 | # font2.saveXML('font_2.xml') 26 | return font2,r1.text 27 | 28 | 29 | def compare(c1,c2): 30 | """ 31 | 输入:某俩个对象字体的坐标列表 32 | 输出:bool类型,True则可视为是同一个字 33 | """ 34 | if len(c1)!=len(c2): 35 | return False 36 | else: 37 | for i in range(len(c1)): 38 | if abs(c1[i][0]-c2[i][0])<50 and abs(c1[i][1]-c2[i][1])<50: 39 | pass 40 | else: 41 | return False 42 | return True 43 | 44 | def decrypt_font(font1,font2,response): 45 | """ 46 | 输入:base字体,新字体以及网页源代码 47 | 输出:字体解密后的网页源代码 48 | """ 49 | word_list=['九','呢','着','地','得','的','五','六','低','右','一','二','远','更','了','好','三','多','小','长','是','坏','十','近','少','八','很','四','短','上','七','下','不','和','高','左','矮','大'] 50 | uniname_list1=['uniEC1F', 'uniEC21', 'uniEC39', 'uniEC3B', 'uniEC55', 'uniEC67', 'uniEC71', 'uniEC81', 'uniEC82', 'uniEC8B', 'uniEC9D', 'uniECAE', 'uniECB7', 'uniECB8', 'uniECD3', 'uniECE4', 'uniECED', 'uniECFE', 'uniED00', 'uniED09', 'uniED18', 'uniED1A', 'uniED34', 'uniED36', 'uniED46', 'uniED50', 'uniED61', 'uniED6A', 'uniED7C', 'uniED96', 'uniED97', 'uniEDB2', 'uniEDC3', 'uniEDCC', 'uniEDCD', 'uniEDDD', 'uniEDE8', 'uniEDF9'] 51 | uniname_list2=font2.getGlyphNames()[1:] 52 | base_dict=dict(zip(uniname_list1,word_list)) 53 | 54 | # 保存每个字符的坐标信息,分别存入coordinate_list1和coordinate_list2 55 | coordinate_list1=[] 56 | for uniname in uniname_list1: 57 | # 获取字体对象的横纵坐标信息 58 | coordinate=font1['glyf'][uniname].coordinates 59 | coordinate_list1.append(list(coordinate)) 60 | 61 | coordinate_list2=[] 62 | for i in uniname_list2: 63 | coordinate=font2['glyf'][i].coordinates 64 | coordinate_list2.append(list(coordinate)) 65 | 66 | index2=-1 67 | new_dict={} 68 | for name2 in coordinate_list2: 69 | index2+=1 70 | index1=-1 71 | for name1 in coordinate_list1: 72 | index1+=1 73 | if compare(name1,name2): 74 | new_dict[uniname_list2[index2]]=base_dict[uniname_list1[index1]] 75 | 76 | for uniname in uniname_list2: 77 | pattern='&#x'+uniname[3:].lower()+';' 78 | response=re.sub(pattern,new_dict[uniname],response) 79 | return response 80 | 81 | 82 | 83 | 84 | 85 | if __name__ == '__main__': 86 | 87 | font1=TTFont('base.ttf') 88 | # font.saveXML('font_1.xml') 89 | headers={ 90 | "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36", 91 | "Cookie": "fvlid=1563667948613fkOHKfG2zR; sessionip=114.213.210.86; sessionid=BDFE3D02-CE41-4D60-8D53-5277BD287ECF%7C%7C2019-07-21+08%3A12%3A27.462%7C%7Cwww.baidu.com; autoid=c3a5376fa8c6cf9ca92ff9ceb0176be2; sessionvid=CBD6AA01-530C-475E-AC39-EF6C90CE57DF; area=340111; ahpau=1; sessionuid=BDFE3D02-CE41-4D60-8D53-5277BD287ECF%7C%7C2019-07-21+08%3A12%3A27.462%7C%7Cwww.baidu.com; __ah_uuid_ng=c_BDFE3D02-CE41-4D60-8D53-5277BD287ECF; cookieCityId=110100; ahpvno=9; pvidchain=3311277,3454442,3311253,6826817,6826819; ref=www.baidu.com%7C0%7C0%7C0%7C2019-07-21+08%3A44%3A19.829%7C2019-07-21+08%3A12%3A27.462; ahrlid=1563669858351rrF6xJuLHZ-1563669896292", 92 | "Host": "club.autohome.com.cn"} 93 | url='https://club.autohome.com.cn/bbs/thread/e27f0f48dcb56de8/81875131-1.html' 94 | font2,response=get_new_ttf(url) 95 | after_decrypt_response=decrypt_font(font1,font2,response) 96 | print(after_decrypt_response) 97 | 98 | 99 | 100 | 101 | 102 | 103 | -------------------------------------------------------------------------------- /汽车之家/new.ttf: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/汽车之家/new.ttf -------------------------------------------------------------------------------- /汽车之家/sourcecode.png: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/Zevs6/Reptile/4bb3847bd4a722edd081ce2c4d24828d1bd251ca/汽车之家/sourcecode.png -------------------------------------------------------------------------------- /牛客网/niuke.py: -------------------------------------------------------------------------------- 1 | # -*- coding: utf-8 -*- 2 | """ 3 | Created on Wed Sep 11 13:35:56 2019 4 | 5 | @author: Lee 6 | """ 7 | 8 | import requests 9 | from lxml import etree 10 | import re 11 | from bs4 import BeautifulSoup 12 | import random 13 | import time 14 | import os 15 | import threading 16 | from retry import retry 17 | 18 | 19 | 20 | class niuke(object): 21 | 22 | def __init__(self): 23 | 24 | self.url='https://www.nowcoder.com/discuss/tag/{}?type=2&page={}' 25 | self.headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36"} 26 | self.prefix='https://www.nowcoder.com' 27 | self.origin_url='https://www.nowcoder.com/discuss/tags?type=2' 28 | 29 | def get_enterprise(self): 30 | 31 | r=requests.get(self.origin_url,headers=self.headers) 32 | tree=etree.HTML(r.text) 33 | enterprise=tree.xpath('//div[@data-nav="企业"]/ul[@class="discuss-tags-mod"]/li/a/@data-href') 34 | enterprise_name=tree.xpath('//div[@data-nav="企业"]/ul[@class="discuss-tags-mod"]/li/a/span[@class="discuss-tag-item"]/text()') 35 | num=tree.xpath('//div[@data-nav="企业"]/ul[@class="discuss-tags-mod"]/li/span[@class="discuss-tag-num"]/text()') 36 | enterprise=[i[13:-7] for i in enterprise] 37 | num=[int(i[:-1]) for i in num] 38 | 39 | return enterprise,enterprise_name,num 40 | 41 | 42 | def get_href(self,enterprise,page): 43 | 44 | titles_new=[] 45 | r=requests.get(self.url.format(enterprise,page),headers=self.headers) 46 | tree=etree.HTML(r.text) 47 | hrefs=tree.xpath('//div[@class="discuss-main clearfix"]/a[1]/@href') 48 | titles=tree.xpath('//div[@class="discuss-main clearfix"]/a[1]/text()') 49 | hrefs=[self.prefix+href for href in hrefs] 50 | for title in titles: 51 | if title!='\n': 52 | titles_new.append(title.replace("\n","").replace("[","").replace("]","").replace("/","").replace("|"," ").replace("*","").replace("?","").replace("\\",",").replace(":",",").replace("<","").replace(">","")) 53 | 54 | # print(hrefs) 55 | # print(titles_new) 56 | return hrefs,titles_new 57 | 58 | def get_article(self,enterprise_name,hrefs,titles): 59 | 60 | for i in range(len(hrefs)): 61 | if os.path.exists('{}/{}.txt'.format(enterprise_name,titles[i])): 62 | pass 63 | else: 64 | r=requests.get(hrefs[i],headers=self.headers) 65 | # soup=BeautifulSoup(r.text,'html.parser') 66 | # text=soup.find(attrs={"class":"post-topic-des nc-post-content"}) 67 | # text=str(text).replace("