├── .all-contributorsrc
├── .gitignore
├── LICENSE
├── MANIFEST.in
├── README.md
├── examples
├── comparison_example.ipynb
└── usage_example.ipynb
├── self_paced_ensemble
├── __init__.py
├── __version__.py
├── canonical_ensemble
│ ├── __init__.py
│ └── canonical_ensemble.py
├── canonical_resampling
│ ├── __init__.py
│ └── canonical_resampling.py
├── self_paced_ensemble
│ ├── __init__.py
│ ├── _base_sampler.py
│ ├── _self_paced_ensemble.py
│ ├── _self_paced_under_sampler.py
│ └── base.py
└── utils
│ ├── __init__.py
│ ├── _plot.py
│ ├── _utils.py
│ ├── _validation.py
│ ├── _validation_data.py
│ └── _validation_param.py
└── setup.py
/.all-contributorsrc:
--------------------------------------------------------------------------------
1 | {
2 | "files": [
3 | "README.md"
4 | ],
5 | "imageSize": 100,
6 | "commit": false,
7 | "badgeTemplate": " -orange.svg\">",
8 | "contributors": [
9 | {
10 | "login": "ZhiningLiu1998",
11 | "name": "Zhining Liu",
12 | "avatar_url": "https://avatars.githubusercontent.com/u/26108487?v=4",
13 | "profile": "http://zhiningliu.com",
14 | "contributions": [
15 | "code",
16 | "doc",
17 | "example"
18 | ]
19 | },
20 | {
21 | "login": "rudolffu",
22 | "name": "Yuming Fu",
23 | "avatar_url": "https://avatars.githubusercontent.com/u/23732534?v=4",
24 | "profile": "https://yumingfu.space/",
25 | "contributions": [
26 | "code",
27 | "bug"
28 | ]
29 | },
30 | {
31 | "login": "thulio",
32 | "name": "Thúlio Costa",
33 | "avatar_url": "https://avatars.githubusercontent.com/u/95307?v=4",
34 | "profile": "https://thul.io",
35 | "contributions": [
36 | "code",
37 | "bug"
38 | ]
39 | },
40 | {
41 | "login": "jerrylususu",
42 | "name": "Neko Null",
43 | "avatar_url": "https://avatars.githubusercontent.com/u/17522475?v=4",
44 | "profile": "https://github.com/jerrylususu",
45 | "contributions": [
46 | "maintenance"
47 | ]
48 | },
49 | {
50 | "login": "lirenjieArthur",
51 | "name": "lirenjieArthur",
52 | "avatar_url": "https://avatars.githubusercontent.com/u/31763604?v=4",
53 | "profile": "https://github.com/lirenjieArthur",
54 | "contributions": [
55 | "bug"
56 | ]
57 | },
58 | {
59 | "login": "mokeeqian",
60 | "name": "AC手动机",
61 | "avatar_url": "https://avatars.githubusercontent.com/u/45727636?v=4",
62 | "profile": "https://github.com/mokeeqian",
63 | "contributions": [
64 | "bug"
65 | ]
66 | },
67 | {
68 | "login": "cnmoro",
69 | "name": "Carlo Moro",
70 | "avatar_url": "https://avatars.githubusercontent.com/u/21183273?v=4",
71 | "profile": "https://www.linkedin.com/in/carlo-moro-4a20a7132",
72 | "contributions": [
73 | "ideas"
74 | ]
75 | }
76 | ],
77 | "contributorsPerLine": 7,
78 | "projectName": "self-paced-ensemble",
79 | "projectOwner": "ZhiningLiu1998",
80 | "repoType": "github",
81 | "repoHost": "https://github.com",
82 | "skipCi": true
83 | }
84 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | .vscode/
7 |
8 | # C extensions
9 | *.so
10 |
11 | # Distribution / packaging
12 | .Python
13 | build/
14 | develop-eggs/
15 | dist/
16 | downloads/
17 | eggs/
18 | .eggs/
19 | lib/
20 | lib64/
21 | parts/
22 | sdist/
23 | var/
24 | wheels/
25 | pip-wheel-metadata/
26 | share/python-wheels/
27 | *.egg-info/
28 | .installed.cfg
29 | *.egg
30 | MANIFEST
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .nox/
46 | .coverage
47 | .coverage.*
48 | .cache
49 | nosetests.xml
50 | coverage.xml
51 | *.cover
52 | *.py,cover
53 | .hypothesis/
54 | .pytest_cache/
55 |
56 | # Translations
57 | *.mo
58 | *.pot
59 |
60 | # Django stuff:
61 | *.log
62 | local_settings.py
63 | db.sqlite3
64 | db.sqlite3-journal
65 |
66 | # Flask stuff:
67 | instance/
68 | .webassets-cache
69 |
70 | # Scrapy stuff:
71 | .scrapy
72 |
73 | # Sphinx documentation
74 | docs/_build/
75 |
76 | # PyBuilder
77 | target/
78 |
79 | # Jupyter Notebook
80 | .ipynb_checkpoints
81 |
82 | # IPython
83 | profile_default/
84 | ipython_config.py
85 |
86 | # pyenv
87 | .python-version
88 |
89 | # pipenv
90 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
91 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
92 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
93 | # install all needed dependencies.
94 | #Pipfile.lock
95 |
96 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
97 | __pypackages__/
98 |
99 | # Celery stuff
100 | celerybeat-schedule
101 | celerybeat.pid
102 |
103 | # SageMath parsed files
104 | *.sage.py
105 |
106 | # Environments
107 | .env
108 | .venv
109 | env/
110 | venv/
111 | ENV/
112 | env.bak/
113 | venv.bak/
114 |
115 | # Spyder project settings
116 | .spyderproject
117 | .spyproject
118 |
119 | # Rope project settings
120 | .ropeproject
121 |
122 | # mkdocs documentation
123 | /site
124 |
125 | # mypy
126 | .mypy_cache/
127 | .dmypy.json
128 | dmypy.json
129 |
130 | # Pyre type checker
131 | .pyre/
132 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2021 Zhining Liu
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include README.md
2 | include LICENSE
3 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | 
4 |
5 |
-orange.svg\">",
8 | "contributors": [
9 | {
10 | "login": "ZhiningLiu1998",
11 | "name": "Zhining Liu",
12 | "avatar_url": "https://avatars.githubusercontent.com/u/26108487?v=4",
13 | "profile": "http://zhiningliu.com",
14 | "contributions": [
15 | "code",
16 | "doc",
17 | "example"
18 | ]
19 | },
20 | {
21 | "login": "rudolffu",
22 | "name": "Yuming Fu",
23 | "avatar_url": "https://avatars.githubusercontent.com/u/23732534?v=4",
24 | "profile": "https://yumingfu.space/",
25 | "contributions": [
26 | "code",
27 | "bug"
28 | ]
29 | },
30 | {
31 | "login": "thulio",
32 | "name": "Thúlio Costa",
33 | "avatar_url": "https://avatars.githubusercontent.com/u/95307?v=4",
34 | "profile": "https://thul.io",
35 | "contributions": [
36 | "code",
37 | "bug"
38 | ]
39 | },
40 | {
41 | "login": "jerrylususu",
42 | "name": "Neko Null",
43 | "avatar_url": "https://avatars.githubusercontent.com/u/17522475?v=4",
44 | "profile": "https://github.com/jerrylususu",
45 | "contributions": [
46 | "maintenance"
47 | ]
48 | },
49 | {
50 | "login": "lirenjieArthur",
51 | "name": "lirenjieArthur",
52 | "avatar_url": "https://avatars.githubusercontent.com/u/31763604?v=4",
53 | "profile": "https://github.com/lirenjieArthur",
54 | "contributions": [
55 | "bug"
56 | ]
57 | },
58 | {
59 | "login": "mokeeqian",
60 | "name": "AC手动机",
61 | "avatar_url": "https://avatars.githubusercontent.com/u/45727636?v=4",
62 | "profile": "https://github.com/mokeeqian",
63 | "contributions": [
64 | "bug"
65 | ]
66 | },
67 | {
68 | "login": "cnmoro",
69 | "name": "Carlo Moro",
70 | "avatar_url": "https://avatars.githubusercontent.com/u/21183273?v=4",
71 | "profile": "https://www.linkedin.com/in/carlo-moro-4a20a7132",
72 | "contributions": [
73 | "ideas"
74 | ]
75 | }
76 | ],
77 | "contributorsPerLine": 7,
78 | "projectName": "self-paced-ensemble",
79 | "projectOwner": "ZhiningLiu1998",
80 | "repoType": "github",
81 | "repoHost": "https://github.com",
82 | "skipCi": true
83 | }
84 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | .vscode/
7 |
8 | # C extensions
9 | *.so
10 |
11 | # Distribution / packaging
12 | .Python
13 | build/
14 | develop-eggs/
15 | dist/
16 | downloads/
17 | eggs/
18 | .eggs/
19 | lib/
20 | lib64/
21 | parts/
22 | sdist/
23 | var/
24 | wheels/
25 | pip-wheel-metadata/
26 | share/python-wheels/
27 | *.egg-info/
28 | .installed.cfg
29 | *.egg
30 | MANIFEST
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .nox/
46 | .coverage
47 | .coverage.*
48 | .cache
49 | nosetests.xml
50 | coverage.xml
51 | *.cover
52 | *.py,cover
53 | .hypothesis/
54 | .pytest_cache/
55 |
56 | # Translations
57 | *.mo
58 | *.pot
59 |
60 | # Django stuff:
61 | *.log
62 | local_settings.py
63 | db.sqlite3
64 | db.sqlite3-journal
65 |
66 | # Flask stuff:
67 | instance/
68 | .webassets-cache
69 |
70 | # Scrapy stuff:
71 | .scrapy
72 |
73 | # Sphinx documentation
74 | docs/_build/
75 |
76 | # PyBuilder
77 | target/
78 |
79 | # Jupyter Notebook
80 | .ipynb_checkpoints
81 |
82 | # IPython
83 | profile_default/
84 | ipython_config.py
85 |
86 | # pyenv
87 | .python-version
88 |
89 | # pipenv
90 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
91 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
92 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
93 | # install all needed dependencies.
94 | #Pipfile.lock
95 |
96 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
97 | __pypackages__/
98 |
99 | # Celery stuff
100 | celerybeat-schedule
101 | celerybeat.pid
102 |
103 | # SageMath parsed files
104 | *.sage.py
105 |
106 | # Environments
107 | .env
108 | .venv
109 | env/
110 | venv/
111 | ENV/
112 | env.bak/
113 | venv.bak/
114 |
115 | # Spyder project settings
116 | .spyderproject
117 | .spyproject
118 |
119 | # Rope project settings
120 | .ropeproject
121 |
122 | # mkdocs documentation
123 | /site
124 |
125 | # mypy
126 | .mypy_cache/
127 | .dmypy.json
128 | dmypy.json
129 |
130 | # Pyre type checker
131 | .pyre/
132 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2021 Zhining Liu
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include README.md
2 | include LICENSE
3 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | 
4 |
5 |
6 |
7 |  8 |
9 |
10 |
8 |
9 |
10 |  11 |
12 |
13 |
11 |
12 |
13 |  14 |
15 |
16 |
14 |
15 |
16 |  17 |
18 |
19 |
17 |
18 |
19 |  20 |
21 |
22 |
20 |
21 |
22 |  23 |
24 |
25 |
23 |
24 |
25 |  26 |
27 |
28 |
26 |
27 |
28 |  29 |
30 |
31 |
29 |
30 |
31 |  32 |
33 |
34 |
32 |
33 |
34 |  35 |
36 |
37 |
35 |
36 |
37 |  38 |
39 |
38 |
39 |
40 |
41 |
42 | Self-paced Ensemble for Highly Imbalanced Massive Data Classification
43 | (ICDE 2020)
44 |
45 |
46 |
57 |
58 |
59 | **Self-paced Ensemble (SPE) is an ensemble learning framework for massive highly imbalanced classification. It is an easy-to-use solution to class-imbalanced problems, features outstanding computing efficiency, good performance, and wide compatibility with different learning models. This SPE implementation supports multi-class classification.**
60 |
61 | |
62 | Note:
63 |
64 | SPE is now a part of imbalanced-ensemble [Doc, PyPI]. Try it for more methods and advanced features!
65 |
66 | |
67 |
68 | ## Cite Us
69 |
70 | **If you find this repository helpful in your work or research, we would greatly appreciate citations to the following [paper](https://arxiv.org/pdf/1909.03500v3.pdf):**
71 |
72 | ```bib
73 | @inproceedings{liu2020self-paced-ensemble,
74 | title={Self-paced Ensemble for Highly Imbalanced Massive Data Classification},
75 | author={Liu, Zhining and Cao, Wei and Gao, Zhifeng and Bian, Jiang and Chen, Hechang and Chang, Yi and Liu, Tie-Yan},
76 | booktitle={2020 IEEE 36th International Conference on Data Engineering (ICDE)},
77 | pages={841--852},
78 | year={2020},
79 | organization={IEEE}
80 | }
81 | ```
82 |
83 | ## Installation
84 |
85 | It is recommended to use **pip** for installation.
86 | Please make sure the **latest version** is installed to avoid potential problems:
87 | ```shell
88 | $ pip install self-paced-ensemble # normal install
89 | $ pip install --upgrade self-paced-ensemble # update if needed
90 | ```
91 |
92 | Or you can install SPE by clone this repository:
93 | ```shell
94 | $ git clone https://github.com/ZhiningLiu1998/self-paced-ensemble.git
95 | $ cd self-paced-ensemble
96 | $ python setup.py install
97 | ```
98 |
99 | Following dependencies are required:
100 | - [python](https://www.python.org/) (>=3.6)
101 | - [numpy](https://numpy.org/) (>=1.13.3)
102 | - [scipy](https://www.scipy.org/) (>=0.19.1)
103 | - [joblib](https://pypi.org/project/joblib/) (>=0.11)
104 | - [scikit-learn](https://scikit-learn.org/stable/) (>=0.24)
105 | - [imblearn](https://pypi.org/project/imblearn/) (>=0.7.0)
106 | - [imbalanced-ensemble](https://pypi.org/project/imbalanced-ensemble/) (>=0.1.3)
107 |
108 | ## Table of Contents
109 |
110 | - [Cite Us](#cite-us)
111 | - [Installation](#installation)
112 | - [Table of Contents](#table-of-contents)
113 | - [Background](#background)
114 | - [Documentation](#documentation)
115 | - [Examples](#examples)
116 | - [**API demo**](#api-demo)
117 | - [**Advanced usage example**](#advanced-usage-example)
118 | - [Save \& Load model](#save--load-model)
119 | - [**Compare SPE with other methods**](#compare-spe-with-other-methods)
120 | - [Results](#results)
121 | - [Miscellaneous](#miscellaneous)
122 | - [References](#references)
123 | - [Related Projects](#related-projects)
124 | - [Contributors ✨](#contributors-)
125 |
126 | ## Background
127 |
128 | SPE performs strictly balanced under-sampling in each iteration and is therefore very *computationally efficient*. In addition, SPE does not rely on calculating the distance between samples to perform resampling. It can be easily applied to datasets that lack well-defined distance metrics (e.g. with categorical features / missing values) without any modification. Moreover, as a *generic ensemble framework*, our methods can be easily adapted to most of the existing learning methods (e.g., C4.5, SVM, GBDT, and Neural Network) to boost their performance on imbalanced data. Compared to existing imbalance learning methods, *SPE works particularly well on datasets that are large-scale, noisy, and highly imbalanced (e.g. with imbalance ratio greater than 100:1).* Such kind of data widely exists in real-world industrial applications. The figure below gives an overview of the SPE framework.
129 |
130 | 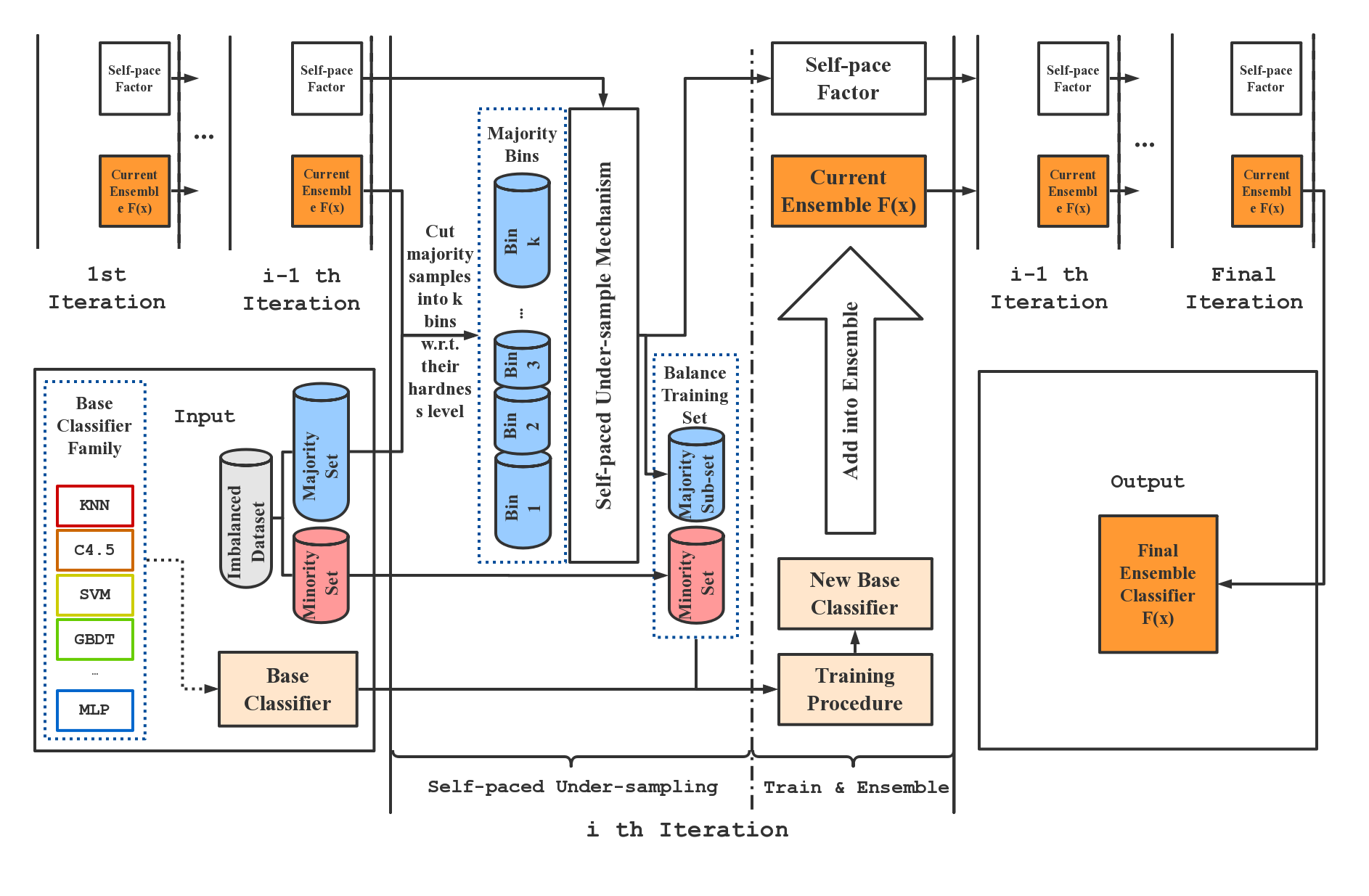
131 |
132 | ## Documentation
133 |
134 | **Our SPE implementation can be used much in the same way as the [`sklearn.ensemble`](https://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble) classifiers. Detailed documentation of ``SelfPacedEnsembleClassifier`` can be found [HERE](https://imbalanced-ensemble.readthedocs.io/en/latest/api/ensemble/_autosummary/imbens.ensemble.SelfPacedEnsembleClassifier.html).**
135 |
136 | ## Examples
137 |
138 | You can check out [**examples using SPE**](https://imbalanced-ensemble.readthedocs.io/en/latest/api/ensemble/_autosummary/imbens.ensemble.SelfPacedEnsembleClassifier.html#examples-using-imbalanced-ensemble-ensemble-selfpacedensembleclassifier) for more comprehensive usage examples.
139 |
140 |
141 | 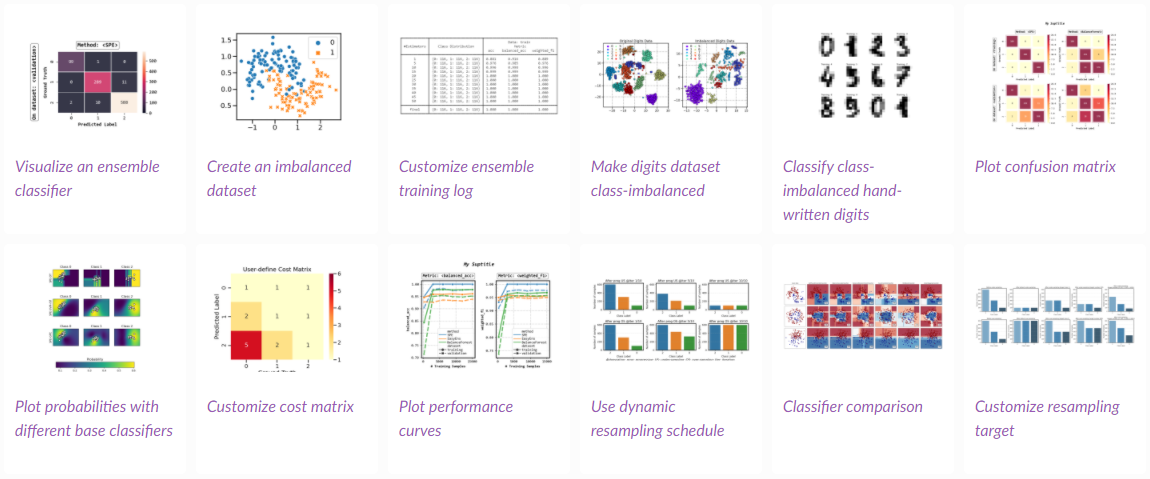
142 |
143 |
144 | ### **API demo**
145 | ```python
146 | from self_paced_ensemble import SelfPacedEnsembleClassifier
147 | from sklearn.tree import DecisionTreeClassifier
148 | from sklearn.datasets import make_classification
149 | from sklearn.model_selection import train_test_split
150 |
151 | # Prepare class-imbalanced train & test data
152 | X, y = make_classification(n_classes=2, random_state=42, weights=[0.1, 0.9])
153 | X_train, X_test, y_train, y_test = train_test_split(
154 | X, y, test_size=0.5, random_state=42)
155 |
156 | # Train an SPE classifier
157 | clf = SelfPacedEnsembleClassifier(
158 | base_estimator=DecisionTreeClassifier(),
159 | n_estimators=10,
160 | ).fit(X_train, y_train)
161 |
162 | # Predict with an SPE classifier
163 | clf.predict(X_test)
164 | ```
165 |
166 | ### **Advanced usage example**
167 |
168 | Please see [usage_example.ipynb](https://github.com/ZhiningLiu1998/self-paced-ensemble/blob/master/examples/usage_example.ipynb).
169 |
170 | ### Save & Load model
171 |
172 | We recommend to use joblib or pickle for saving and loading SPE models, e.g.,
173 | ```python
174 | from joblib import dump, load
175 |
176 | # save the model
177 | dump(clf, filename='clf.joblib')
178 | # load the model
179 | clf = load('clf.joblib')
180 | ```
181 | You can also use the alternative APIs provided in SPE:
182 | ```python
183 | from self_paced_ensemble.utils import save_model, load_model
184 |
185 | # save the model
186 | clf.save('clf.joblib') # option 1
187 | save_model(clf, 'clf.joblib') # option 2
188 | # load the model
189 | clf = load_model('clf.joblib')
190 | ```
191 |
192 | ### **Compare SPE with other methods**
193 |
194 | Please see [comparison_example.ipynb](https://github.com/ZhiningLiu1998/self-paced-ensemble/blob/master/examples/comparison_example.ipynb).
195 |
196 | ## Results
197 |
198 | Dataset links:
199 | [Credit Fraud](https://www.kaggle.com/mlg-ulb/creditcardfraud),
200 | [KDDCUP](https://archive.ics.uci.edu/ml/datasets/kdd+cup+1999+data),
201 | [Record Linkage](https://archive.ics.uci.edu/ml/datasets/Record+Linkage+Comparison+Patterns),
202 | [Payment Simulation](https://www.kaggle.com/ealaxi/paysim1).
203 |
204 | 
205 |
206 | Comparisons of SPE with traditional resampling/ensemble methods in terms of performance & computational efficiency.
207 |
208 |
209 |
210 | 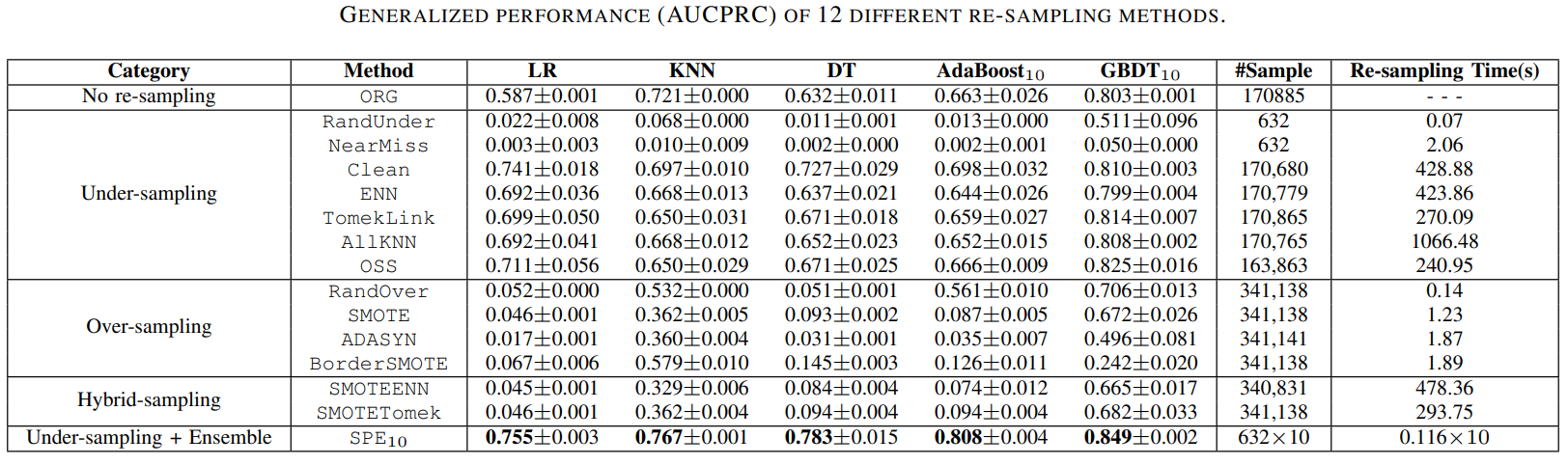
211 |
212 | 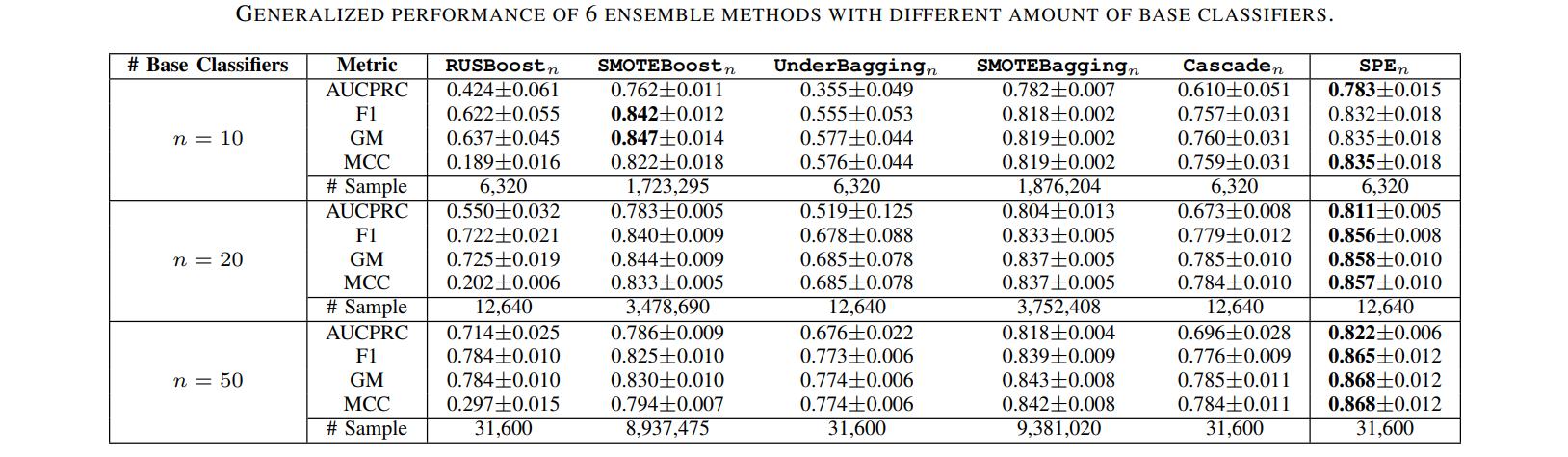
213 |
214 | 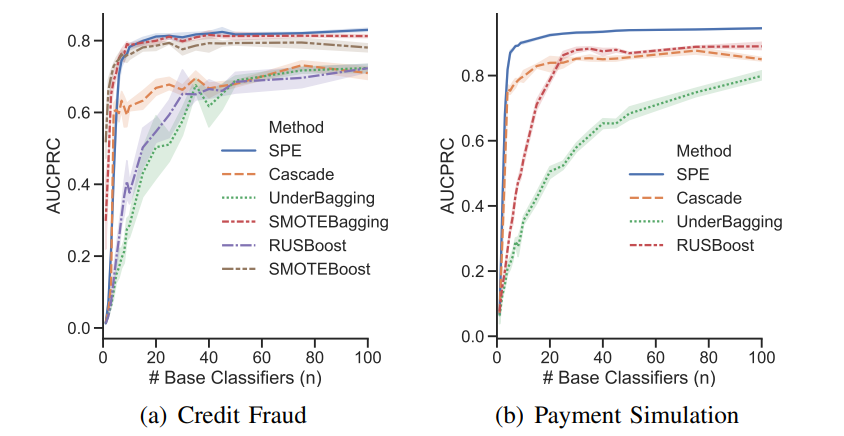
215 |
216 | ## Miscellaneous
217 |
218 | **This repository contains:**
219 | - Implementation of Self-paced Ensemble
220 | - Implementation of 5 ensemble-based imbalance learning baselines
221 | - `SMOTEBoost` [1]
222 | - `SMOTEBagging` [2]
223 | - `RUSBoost` [3]
224 | - `UnderBagging` [4]
225 | - `BalanceCascade` [5]
226 | - Implementation of resampling based imbalance learning baselines [6]
227 | - Additional experimental results
228 |
229 | **NOTE:** The implementations of other ensemble and resampling methods are based on [imbalanced-ensemble](https://github.com/ZhiningLiu1998/imbalanced-ensemble) and [imbalanced-learn](https://github.com/scikit-learn-contrib/imbalanced-learn).
230 |
231 | ## References
232 |
233 | | # | Reference |
234 | | --- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
235 | | [1] | N. V. Chawla, A. Lazarevic, L. O. Hall, and K. W. Bowyer, Smoteboost: Improving prediction of the minority class in boosting. in European conference on principles of data mining and knowledge discovery. Springer, 2003, pp. 107–119 |
236 | | [2] | S. Wang and X. Yao, Diversity analysis on imbalanced data sets by using ensemble models. in 2009 IEEE Symposium on Computational Intelligence and Data Mining. IEEE, 2009, pp. 324–331. |
237 | | [3] | C. Seiffert, T. M. Khoshgoftaar, J. Van Hulse, and A. Napolitano, “Rusboost: A hybrid approach to alleviating class imbalance,” IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, vol. 40, no. 1, pp. 185–197, 2010. |
238 | | [4] | R. Barandela, R. M. Valdovinos, and J. S. Sanchez, “New applications´ of ensembles of classifiers,” Pattern Analysis & Applications, vol. 6, no. 3, pp. 245–256, 2003. |
239 | | [5] | X.-Y. Liu, J. Wu, and Z.-H. Zhou, “Exploratory undersampling for class-imbalance learning,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 39, no. 2, pp. 539–550, 2009. |
240 | | [6] | Guillaume Lemaître, Fernando Nogueira, and Christos K. Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. Journal of Machine Learning Research, 18(17):1–5, 2017. |
241 |
242 | ## Related Projects
243 |
244 | **Check out [Zhining](https://zhiningliu.com/)'s other open-source projects!**
245 |
269 |
270 | ## Contributors ✨
271 |
272 | Thanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):
273 |
274 |
275 |
276 |
277 |
288 |
289 |
290 |
291 |
292 |
293 |
294 | This project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!
295 |
--------------------------------------------------------------------------------
/examples/comparison_example.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## This example compares the ``SelfPacedEnsembleClassifier`` with other methods"
8 | ]
9 | },
10 | {
11 | "cell_type": "code",
12 | "execution_count": 1,
13 | "metadata": {},
14 | "outputs": [],
15 | "source": [
16 | "RANDOM_STATE = 42"
17 | ]
18 | },
19 | {
20 | "cell_type": "markdown",
21 | "metadata": {},
22 | "source": [
23 | "## Preparation\n",
24 | "First, we will import necessary packages and load the **covtype** dataset."
25 | ]
26 | },
27 | {
28 | "cell_type": "code",
29 | "execution_count": 2,
30 | "metadata": {},
31 | "outputs": [],
32 | "source": [
33 | "from self_paced_ensemble import SelfPacedEnsembleClassifier\n",
34 | "from self_paced_ensemble.canonical_ensemble import *\n",
35 | "from self_paced_ensemble.utils import load_covtype_dataset\n",
36 | "from self_paced_ensemble.self_paced_ensemble.base import sort_dict_by_key\n",
37 | "\n",
38 | "from time import time\n",
39 | "from collections import Counter\n",
40 | "import matplotlib.pyplot as plt\n",
41 | "\n",
42 | "from sklearn.decomposition import KernelPCA\n",
43 | "from sklearn.datasets import make_classification\n",
44 | "from sklearn.model_selection import train_test_split\n",
45 | "from sklearn.metrics import average_precision_score"
46 | ]
47 | },
48 | {
49 | "cell_type": "code",
50 | "execution_count": 3,
51 | "metadata": {},
52 | "outputs": [
53 | {
54 | "name": "stdout",
55 | "output_type": "stream",
56 | "text": [
57 | "\n",
58 | "Dataset used: \t\tForest covertypes from UCI (10.0% random subset)\n",
59 | "Positive target:\t7\n",
60 | "Imbalance ratio:\t27.328\n",
61 | "Original training dataset shape {0: 44840, 1: 1640}\n",
62 | "Original test dataset shape {0: 11211, 1: 411}\n"
63 | ]
64 | }
65 | ],
66 | "source": [
67 | "X_train, X_test, y_train, y_test = load_covtype_dataset(subset=0.1, random_state=RANDOM_STATE)\n",
68 | "\n",
69 | "origin_distr = sort_dict_by_key(Counter(y_train))\n",
70 | "test_distr = sort_dict_by_key(Counter(y_test))\n",
71 | "print('Original training dataset shape %s' % origin_distr)\n",
72 | "print('Original test dataset shape %s' % test_distr)"
73 | ]
74 | },
75 | {
76 | "cell_type": "markdown",
77 | "metadata": {},
78 | "source": [
79 | "## Train all ensemble classifiers"
80 | ]
81 | },
82 | {
83 | "cell_type": "code",
84 | "execution_count": 4,
85 | "metadata": {},
86 | "outputs": [
87 | {
88 | "name": "stdout",
89 | "output_type": "stream",
90 | "text": [
91 | "Training SelfPacedEnsemble | AUPRC 0.907 | Time 0.482s\n",
92 | "Training SMOTEBagging | AUPRC 0.895 | Time 14.080s\n",
93 | "Training SMOTEBoost | AUPRC 0.479 | Time 3.110s\n",
94 | "Training UnderBagging | AUPRC 0.769 | Time 0.583s\n",
95 | "Training RUSBoost | AUPRC 0.531 | Time 0.196s\n",
96 | "Training BalanceCascade | AUPRC 0.871 | Time 0.464s\n"
97 | ]
98 | }
99 | ],
100 | "source": [
101 | "init_kwargs = {\n",
102 | " 'n_estimators': 10,\n",
103 | " 'random_state': RANDOM_STATE,\n",
104 | "}\n",
105 | "fit_kwargs = {\n",
106 | " 'X': X_train,\n",
107 | " 'y': y_train,\n",
108 | "}\n",
109 | "\n",
110 | "ensembles = {\n",
111 | " 'SelfPacedEnsemble': SelfPacedEnsembleClassifier,\n",
112 | " 'SMOTEBagging': SMOTEBaggingClassifier,\n",
113 | " 'SMOTEBoost': SMOTEBoostClassifier,\n",
114 | " 'UnderBagging': UnderBaggingClassifier,\n",
115 | " 'RUSBoost': RUSBoostClassifier,\n",
116 | " 'BalanceCascade': BalanceCascadeClassifier,\n",
117 | "}\n",
118 | "\n",
119 | "fit_ensembles = {}\n",
120 | "for ensemble_name, ensemble_class in ensembles.items():\n",
121 | " ensemble_clf = ensemble_class(**init_kwargs)\n",
122 | " print ('Training {:^20s} '.format(ensemble_name), end='')\n",
123 | " start_time = time()\n",
124 | " ensemble_clf.fit(X_train, y_train)\n",
125 | " fit_time = time() - start_time\n",
126 | " y_pred = ensemble_clf.predict_proba(X_test)[:, 1]\n",
127 | " score = average_precision_score(y_test, y_pred)\n",
128 | " print ('| AUPRC {:.3f} | Time {:.3f}s'.format(score, fit_time))"
129 | ]
130 | }
131 | ],
132 | "metadata": {
133 | "kernelspec": {
134 | "display_name": "Python 3",
135 | "language": "python",
136 | "name": "python3"
137 | },
138 | "language_info": {
139 | "codemirror_mode": {
140 | "name": "ipython",
141 | "version": 3
142 | },
143 | "file_extension": ".py",
144 | "mimetype": "text/x-python",
145 | "name": "python",
146 | "nbconvert_exporter": "python",
147 | "pygments_lexer": "ipython3",
148 | "version": "3.11.5"
149 | }
150 | },
151 | "nbformat": 4,
152 | "nbformat_minor": 4
153 | }
154 |
--------------------------------------------------------------------------------
/self_paced_ensemble/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ``self-paced ensemble`` is a python-based ensemble learning framework for
3 | dealing with binary class-imbalanced classification problems in machine learning.
4 |
5 | Subpackages
6 | -----------
7 | self_paced_ensemble
8 | Module which provides our SelfPacedEnsembleClassifier implementation.
9 | canonical_ensemble
10 | Module which provides baseline methods based on ensemble learning.
11 | canonical_resampling
12 | Module which provides baseline methods based on data resampling.
13 | utils
14 | Module including various utilities.
15 | """
16 |
17 | from . import self_paced_ensemble
18 | from . import canonical_ensemble
19 | from . import canonical_resampling
20 | from . import utils
21 |
22 | from .self_paced_ensemble import SelfPacedEnsembleClassifier
23 |
24 | from .__version__ import __version__
25 |
26 | __all__ = [
27 | "SelfPacedEnsembleClassifier",
28 | "self_paced_ensemble",
29 | "canonical_ensemble",
30 | "canonical_resampling",
31 | "utils",
32 | "__version__",
33 | ]
--------------------------------------------------------------------------------
/self_paced_ensemble/__version__.py:
--------------------------------------------------------------------------------
1 | """
2 | ``self-paced ensemble`` is a python-based ensemble learning framework for
3 | dealing with binary class-imbalanced classification problems in machine learning.
4 | """
5 | # License: MIT
6 |
7 | __version__ = '0.1.7'
--------------------------------------------------------------------------------
/self_paced_ensemble/canonical_ensemble/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ------------------------------------------------------------------------------
3 | The `self_paced_ensemble.canonical_ensemble` module implement 5 ensemble
4 | learning algorithms for imbalanced classification, including:
5 | 'SMOTEBaggingClassifier', 'SMOTEBoostClassifier', 'RUSBoostClassifier',
6 | 'UnderBaggingClassifier', and 'BalanceCascadeClassifier'.
7 |
8 | Note: methods in this module are now included in the `imbalanced-ensemble`.
9 | Please refer to https://imbalanced-ensemble.readthedocs.io/ for more details.
10 | ------------------------------------------------------------------------------
11 | """
12 |
13 | from .canonical_ensemble import (
14 | SMOTEBaggingClassifier,
15 | SMOTEBoostClassifier,
16 | RUSBoostClassifier,
17 | UnderBaggingClassifier,
18 | BalanceCascadeClassifier,
19 | )
20 |
21 | __all__ = [
22 | "SMOTEBaggingClassifier",
23 | "SMOTEBoostClassifier",
24 | "RUSBoostClassifier",
25 | "UnderBaggingClassifier",
26 | "BalanceCascadeClassifier",
27 | ]
28 |
--------------------------------------------------------------------------------
/self_paced_ensemble/canonical_ensemble/canonical_ensemble.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | Five ensemble learning algorithms for imbalanced classification, including:
4 | 'SMOTEBaggingClassifier', 'SMOTEBoostClassifier', 'RUSBoostClassifier',
5 | 'UnderBaggingClassifier', and 'BalanceCascadeClassifier'.
6 |
7 | Note: methods in this module are now included in the `imbalanced-ensemble`.
8 | Please refer to https://imbalanced-ensemble.readthedocs.io/ for more details.
9 | """
10 |
11 | # Created on Sun Jan 13 14:32:27 2019
12 | # Authors: Zhining Liu
13 | # License: MIT
14 |
15 | # %%
16 |
17 | from imbens.ensemble import SMOTEBoostClassifier
18 | from imbens.ensemble import SMOTEBaggingClassifier
19 | from imbens.ensemble import RUSBoostClassifier
20 | from imbens.ensemble import UnderBaggingClassifier
21 | from imbens.ensemble import BalanceCascadeClassifier
--------------------------------------------------------------------------------
/self_paced_ensemble/canonical_resampling/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | --------------------------------------------------------------------------
3 | The `self_paced_ensemble.canonical_resampling` module implement a
4 | resampling-based classifier for imbalanced classification.
5 | 15 resampling algorithms are included:
6 | 'RUS', 'CNN', 'ENN', 'NCR', 'Tomek', 'ALLKNN', 'OSS',
7 | 'NM', 'CC', 'SMOTE', 'ADASYN', 'BorderSMOTE', 'SMOTEENN',
8 | 'SMOTETomek', 'ORG'.
9 |
10 | Note: the implementation of these resampling algorithms is based on
11 | imblearn python package.
12 | See https://github.com/scikit-learn-contrib/imbalanced-learn.
13 | --------------------------------------------------------------------------
14 | """
15 |
16 |
17 | from .canonical_resampling import ResampleClassifier
18 |
19 | __all__ = [
20 | "ResampleClassifier",
21 | ]
22 |
--------------------------------------------------------------------------------
/self_paced_ensemble/canonical_resampling/canonical_resampling.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | A resampling-based classifier for imbalanced classification.
4 | 15 resampling algorithms are included:
5 | 'RUS', 'CNN', 'ENN', 'NCR', 'Tomek', 'ALLKNN', 'OSS',
6 | 'NM', 'CC', 'SMOTE', 'ADASYN', 'BorderSMOTE', 'SMOTEENN',
7 | 'SMOTETomek', 'ORG'.
8 |
9 | The implementation of these resampling algorithms is based on `imblearn`.
10 | Please refer to https://github.com/scikit-learn-contrib/imbalanced-learn.
11 | """
12 |
13 | # Created on Sun Jan 13 14:32:27 2019
14 | # Authors: Zhining Liu
15 | # License: MIT
16 |
17 | from imblearn.under_sampling import (
18 | ClusterCentroids,
19 | NearMiss,
20 | RandomUnderSampler,
21 | EditedNearestNeighbours,
22 | AllKNN,
23 | TomekLinks,
24 | OneSidedSelection,
25 | CondensedNearestNeighbour,
26 | NeighbourhoodCleaningRule,
27 | )
28 | from imblearn.over_sampling import (
29 | SMOTE, ADASYN, BorderlineSMOTE,
30 | )
31 | from imblearn.combine import (
32 | SMOTEENN, SMOTETomek,
33 | )
34 |
35 | from sklearn.tree import DecisionTreeClassifier as DT
36 |
37 |
38 | SUPPORT_RESAMPLING = ['RUS', 'CNN', 'ENN', 'NCR', 'Tomek', 'ALLKNN', 'OSS',
39 | 'NM', 'CC', 'SMOTE', 'ADASYN', 'BorderSMOTE', 'SMOTEENN',
40 | 'SMOTETomek', 'ORG']
41 |
42 |
43 | class Error(Exception):
44 | pass
45 |
46 | class ResampleClassifier(object):
47 | '''
48 | Re-sampling methods for imbalance classification, based on imblearn python package.
49 | imblearn url: https://github.com/scikit-learn-contrib/imbalanced-learn
50 | Hyper-parameters:
51 | base_estimator : scikit-learn classifier object
52 | optional (default=DecisionTreeClassifier)
53 | The base estimator used for training after re-sampling
54 | '''
55 | def __init__(self, base_estimator=DT()):
56 | self.base_estimator = base_estimator
57 |
58 | def predict(self, X):
59 | return self.base_estimator.predict(X)
60 |
61 | def fit(self, X, y, by, random_state=None, visualize=False):
62 | '''
63 | by: String
64 | The method used to perform re-sampling
65 | support: ['RUS', 'CNN', 'ENN', 'NCR', 'Tomek', 'ALLKNN', 'OSS',
66 | 'NM', 'CC', 'SMOTE', 'ADASYN', 'BorderSMOTE', 'SMOTEENN',
67 | 'SMOTETomek', 'ORG']
68 | '''
69 | if by == 'RUS':
70 | sampler = RandomUnderSampler(random_state=random_state)
71 | elif by == 'CNN':
72 | sampler = CondensedNearestNeighbour(random_state=random_state)
73 | elif by == 'ENN':
74 | sampler = EditedNearestNeighbours()
75 | elif by == 'NCR':
76 | sampler = NeighbourhoodCleaningRule()
77 | elif by == 'Tomek':
78 | sampler = TomekLinks()
79 | elif by == 'ALLKNN':
80 | sampler = AllKNN()
81 | elif by == 'OSS':
82 | sampler = OneSidedSelection(random_state=random_state)
83 | elif by == 'NM':
84 | sampler = NearMiss()
85 | elif by == 'CC':
86 | sampler = ClusterCentroids(random_state=random_state)
87 | elif by == 'SMOTE':
88 | sampler = SMOTE(random_state=random_state)
89 | elif by == 'ADASYN':
90 | sampler = ADASYN(random_state=random_state)
91 | elif by == 'BorderSMOTE':
92 | sampler = BorderlineSMOTE(random_state=random_state)
93 | elif by == 'SMOTEENN':
94 | sampler = SMOTEENN(random_state=random_state)
95 | elif by == 'SMOTETomek':
96 | sampler = SMOTETomek(random_state=random_state)
97 | elif by == 'ORG':
98 | sampler = None
99 | else:
100 | raise Error('Unexpected \'by\' type {}'.format(by))
101 |
102 | if by != 'ORG':
103 | X_train, y_train = sampler.fit_resample(X, y)
104 | else:
105 | X_train, y_train = X, y
106 | self.base_estimator.fit(X_train, y_train)
--------------------------------------------------------------------------------
/self_paced_ensemble/self_paced_ensemble/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | --------------------------------------------------------------------------
3 | The `self_paced_ensemble.self_paced_ensemble` module implement a
4 | self-paced Ensemble (SPE) Classifier for binary class-imbalanced learning.
5 |
6 | Self-paced Ensemble (SPE) is an ensemble learning framework for massive highly
7 | imbalanced classification. It is an easy-to-use solution to class-imbalanced
8 | problems, features outstanding computing efficiency, good performance, and wide
9 | compatibility with different learning models.
10 |
11 | See https://github.com/ZhiningLiu1998/self-paced-ensemble.
12 |
13 | Reference:
14 | Liu Z, Cao W, Gao Z, et al. Self-paced ensemble for highly imbalanced
15 | massive data classification[C]//2020 IEEE 36th International Conference
16 | on Data Engineering (ICDE). IEEE, 2020: 841-852.
17 | --------------------------------------------------------------------------
18 | """
19 |
20 | from ._self_paced_ensemble import SelfPacedEnsembleClassifier
21 |
22 | __all__ = [
23 | "SelfPacedEnsembleClassifier",
24 | ]
25 |
--------------------------------------------------------------------------------
/self_paced_ensemble/self_paced_ensemble/_base_sampler.py:
--------------------------------------------------------------------------------
1 | """Base class for sampling."""
2 |
3 | # Authors: Zhining Liu
4 | # License: MIT
5 |
6 | # %%
7 |
8 | from abc import ABCMeta, abstractmethod
9 |
10 | import numpy as np
11 |
12 | from sklearn.base import BaseEstimator
13 | from sklearn.utils.validation import _check_sample_weight
14 | from sklearn.preprocessing import label_binarize
15 | from sklearn.utils.multiclass import check_classification_targets
16 |
17 |
18 | from ..utils._validation import (ArraysTransformer,
19 | _deprecate_positional_args,
20 | check_sampling_strategy,
21 | check_target_type)
22 |
23 | # # For local test
24 | # import sys
25 | # sys.path.append("..")
26 | # from utils._validation import (ArraysTransformer,
27 | # _deprecate_positional_args,
28 | # check_sampling_strategy,
29 | # check_target_type)
30 |
31 |
32 | class SamplerMixin(BaseEstimator, metaclass=ABCMeta):
33 | """Mixin class for samplers with abstract method.
34 |
35 | Warning: This class should not be used directly. Use the derive classes
36 | instead.
37 | """
38 |
39 | _estimator_type = "sampler"
40 |
41 | def fit(self, X, y):
42 | """Check inputs and statistics of the sampler.
43 |
44 | You should use ``fit_resample`` in all cases.
45 |
46 | Parameters
47 | ----------
48 | X : {array-like, dataframe, sparse matrix} of shape \
49 | (n_samples, n_features)
50 | Data array.
51 |
52 | y : array-like of shape (n_samples,)
53 | Target array.
54 |
55 | Returns
56 | -------
57 | self : object
58 | Return the instance itself.
59 | """
60 | X, y, _ = self._check_X_y(X, y)
61 | self.sampling_strategy_ = check_sampling_strategy(
62 | self.sampling_strategy, y, self._sampling_type
63 | )
64 | return self
65 |
66 | @_deprecate_positional_args
67 | def fit_resample(self, X, y, *, sample_weight=None, **kwargs):
68 | """Resample the dataset.
69 |
70 | Parameters
71 | ----------
72 | X : {array-like, dataframe, sparse matrix} of shape \
73 | (n_samples, n_features)
74 | Matrix containing the data which have to be sampled.
75 |
76 | y : array-like of shape (n_samples,)
77 | Corresponding label for each sample in X.
78 |
79 | sample_weight : array-like of shape (n_samples,), default=None
80 | Corresponding weight for each sample in X.
81 |
82 | - If ``None``, perform normal resampling and return
83 | ``(X_resampled, y_resampled)``.
84 | - If array-like, the given ``sample_weight`` will be resampled
85 | along with ``X`` and ``y``, and the *resampled* sample weights
86 | will be added to returns. The function will return
87 | ``(X_resampled, y_resampled, sample_weight_resampled)``.
88 |
89 | Returns
90 | -------
91 | X_resampled : {array-like, dataframe, sparse matrix} of shape \
92 | (n_samples_new, n_features)
93 | The array containing the resampled data.
94 |
95 | y_resampled : array-like of shape (n_samples_new,)
96 | The corresponding label of `X_resampled`.
97 |
98 | sample_weight_resampled : array-like of shape (n_samples_new,), default=None
99 | The corresponding weight of `X_resampled`.
100 | *Only will be returned if input sample_weight is not* ``None``.
101 | """
102 | check_classification_targets(y)
103 | arrays_transformer = ArraysTransformer(X, y)
104 | X, y, binarize_y = self._check_X_y(X, y)
105 |
106 | self.sampling_strategy_ = check_sampling_strategy(
107 | self.sampling_strategy, y, self._sampling_type
108 | )
109 |
110 | if sample_weight is None:
111 | output = self._fit_resample(X, y, **kwargs)
112 | else:
113 | try:
114 | sample_weight = _check_sample_weight(sample_weight, X, dtype=np.float64)
115 | except Exception as e:
116 | e_args = list(e.args)
117 | e_args[0] += \
118 | f"\n'sample_weight' should be an array-like of shape (n_samples,)," + \
119 | f" got {type(sample_weight)}, please check your usage."
120 | e.args = tuple(e_args)
121 | raise e
122 | else:
123 | output = self._fit_resample(X, y, sample_weight=sample_weight, **kwargs)
124 |
125 | y_ = label_binarize(output[1], classes=np.unique(y)) if binarize_y else output[1]
126 |
127 | X_, y_ = arrays_transformer.transform(output[0], y_)
128 | return (X_, y_) if len(output) == 2 else output
129 |
130 | @abstractmethod
131 | def _fit_resample(self, X, y, sample_weight=None):
132 | """Base method defined in each sampler to defined the sampling
133 | strategy.
134 |
135 | Parameters
136 | ----------
137 | X : {array-like, sparse matrix} of shape (n_samples, n_features)
138 | Matrix containing the data which have to be sampled.
139 |
140 | y : array-like of shape (n_samples,)
141 | Corresponding label for each sample in X.
142 |
143 | Returns
144 | -------
145 | X_resampled : {ndarray, sparse matrix} of shape \
146 | (n_samples_new, n_features)
147 | The array containing the resampled data.
148 |
149 | y_resampled : ndarray of shape (n_samples_new,)
150 | The corresponding label of `X_resampled`.
151 |
152 | """
153 | pass
154 |
155 |
156 | class BaseSampler(SamplerMixin):
157 | """Base class for sampling algorithms.
158 |
159 | Warning: This class should not be used directly. Use the derive classes
160 | instead.
161 | """
162 |
163 | def __init__(self, sampling_strategy="auto"):
164 | self.sampling_strategy = sampling_strategy
165 |
166 | def _check_X_y(self, X, y, accept_sparse=None):
167 | if accept_sparse is None:
168 | accept_sparse = ["csr", "csc"]
169 | y, binarize_y = check_target_type(y, indicate_one_vs_all=True)
170 | X, y = self._validate_data(X, y, reset=True, accept_sparse=accept_sparse)
171 | return X, y, binarize_y
172 |
173 | def _more_tags(self):
174 | return {"X_types": ["2darray", "sparse", "dataframe"]}
175 |
176 |
177 | def _identity(X, y):
178 | return X, y
179 |
180 |
181 | class FunctionSampler(BaseSampler):
182 | """Construct a sampler from calling an arbitrary callable.
183 |
184 | Parameters
185 | ----------
186 | func : callable, default=None
187 | The callable to use for the transformation. This will be passed the
188 | same arguments as transform, with args and kwargs forwarded. If func is
189 | None, then func will be the identity function.
190 |
191 | accept_sparse : bool, default=True
192 | Whether sparse input are supported. By default, sparse inputs are
193 | supported.
194 |
195 | kw_args : dict, default=None
196 | The keyword argument expected by ``func``.
197 |
198 | validate : bool, default=True
199 | Whether or not to bypass the validation of ``X`` and ``y``. Turning-off
200 | validation allows to use the ``FunctionSampler`` with any type of
201 | data.
202 |
203 | See Also
204 | --------
205 |
206 | sklearn.preprocessing.FunctionTransfomer : Stateless transformer.
207 | """
208 |
209 | _sampling_type = "bypass"
210 |
211 | @_deprecate_positional_args
212 | def __init__(self, *, func=None, accept_sparse=True, kw_args=None, validate=True):
213 | super().__init__()
214 | self.func = func
215 | self.accept_sparse = accept_sparse
216 | self.kw_args = kw_args
217 | self.validate = validate
218 |
219 | def fit(self, X, y):
220 | """Check inputs and statistics of the sampler.
221 |
222 | You should use ``fit_resample`` in all cases.
223 |
224 | Parameters
225 | ----------
226 | X : {array-like, dataframe, sparse matrix} of shape \
227 | (n_samples, n_features)
228 | Data array.
229 |
230 | y : array-like of shape (n_samples,)
231 | Target array.
232 |
233 | Returns
234 | -------
235 | self : object
236 | Return the instance itself.
237 | """
238 | # we need to overwrite SamplerMixin.fit to bypass the validation
239 | if self.validate:
240 | check_classification_targets(y)
241 | X, y, _ = self._check_X_y(X, y, accept_sparse=self.accept_sparse)
242 |
243 | self.sampling_strategy_ = check_sampling_strategy(
244 | self.sampling_strategy, y, self._sampling_type
245 | )
246 |
247 | return self
248 |
249 | def fit_resample(self, X, y):
250 | """Resample the dataset.
251 |
252 | Parameters
253 | ----------
254 | X : {array-like, sparse matrix} of shape (n_samples, n_features)
255 | Matrix containing the data which have to be sampled.
256 |
257 | y : array-like of shape (n_samples,)
258 | Corresponding label for each sample in X.
259 |
260 | Returns
261 | -------
262 | X_resampled : {array-like, sparse matrix} of shape \
263 | (n_samples_new, n_features)
264 | The array containing the resampled data.
265 |
266 | y_resampled : array-like of shape (n_samples_new,)
267 | The corresponding label of `X_resampled`.
268 | """
269 | arrays_transformer = ArraysTransformer(X, y)
270 |
271 | if self.validate:
272 | check_classification_targets(y)
273 | X, y, binarize_y = self._check_X_y(X, y, accept_sparse=self.accept_sparse)
274 |
275 | self.sampling_strategy_ = check_sampling_strategy(
276 | self.sampling_strategy, y, self._sampling_type
277 | )
278 |
279 | output = self._fit_resample(X, y)
280 |
281 | if self.validate:
282 |
283 | y_ = label_binarize(output[1], classes=np.unique(y)) if binarize_y else output[1]
284 | X_, y_ = arrays_transformer.transform(output[0], y_)
285 | return (X_, y_) if len(output) == 2 else (X_, y_, output[2])
286 |
287 | return output
288 |
289 | def _fit_resample(self, X, y):
290 | func = _identity if self.func is None else self.func
291 | output = func(X, y, **(self.kw_args if self.kw_args else {}))
292 | return output
293 |
294 | # %%
295 |
--------------------------------------------------------------------------------
/self_paced_ensemble/self_paced_ensemble/_self_paced_ensemble.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """
3 | A self-paced Ensemble (SPE) Classifier for binary class-imbalanced learning.
4 |
5 | Self-paced Ensemble (SPE) is an ensemble learning framework for massive highly
6 | imbalanced classification. It is an easy-to-use solution to class-imbalanced
7 | problems, features outstanding computing efficiency, good performance, and wide
8 | compatibility with different learning models.
9 | """
10 |
11 | # Created on Tue May 14 14:32:27 2019
12 | # @author: ZhiningLiu1998
13 | # mailto: zhining.liu@outlook.com
14 |
15 | # %%
16 |
17 | from collections import Counter
18 | import numpy as np
19 | from joblib import dump
20 |
21 |
22 | from .base import BaseImbalancedEnsemble, MAX_INT
23 | from ._self_paced_under_sampler import SelfPacedUnderSampler
24 | from ..utils._validation import _deprecate_positional_args
25 | from ..utils._validation_data import check_eval_datasets
26 | from ..utils._validation_param import (check_target_label_and_n_target_samples,
27 | check_balancing_schedule,
28 | check_train_verbose,
29 | check_eval_metrics,)
30 |
31 | # # For local test
32 | # import sys
33 | # sys.path.append("..")
34 | # from self_paced_ensemble.base import BaseImbalancedEnsemble, MAX_INT
35 | # from self_paced_ensemble._self_paced_under_sampler import SelfPacedUnderSampler
36 | # from utils._validation import _deprecate_positional_args
37 | # from utils._validation_data import check_eval_datasets
38 | # from utils._validation_param import (check_target_label_and_n_target_samples,
39 | # check_balancing_schedule,
40 | # check_train_verbose,
41 | # check_eval_metrics,)
42 |
43 | # %%
44 |
45 | # Properties
46 | _method_name = 'SelfPacedEnsembleClassifier'
47 | _sampler_class = SelfPacedUnderSampler
48 |
49 | _solution_type = 'resampling'
50 | _sampling_type = 'under-sampling'
51 | _ensemble_type = 'general'
52 | _training_type = 'iterative'
53 |
54 | _properties = {
55 | 'solution_type': _solution_type,
56 | 'sampling_type': _sampling_type,
57 | 'ensemble_type': _ensemble_type,
58 | 'training_type': _training_type,
59 | }
60 |
61 | class SelfPacedEnsembleClassifier(BaseImbalancedEnsemble):
62 | """A self-paced ensemble (SPE) Classifier for class-imbalanced learning.
63 |
64 | Self-paced Ensemble (SPE) [1]_ is an ensemble learning framework for massive highly
65 | imbalanced classification. It is an easy-to-use solution to class-imbalanced
66 | problems, features outstanding computing efficiency, good performance, and wide
67 | compatibility with different learning models.
68 |
69 | This implementation extends SPE to support multi-class classification.
70 |
71 | Parameters
72 | ----------
73 | base_estimator : estimator object, default=None
74 | The base estimator to fit on self-paced under-sampled subsets
75 | of the dataset. Support for sample weighting is NOT required,
76 | but need proper ``classes_`` and ``n_classes_`` attributes.
77 | If ``None``, then the base estimator is ``DecisionTreeClassifier()``.
78 |
79 | n_estimators : int, default=50
80 | The number of base estimators in the ensemble.
81 |
82 | k_bins : int, default=5
83 | The number of hardness bins that were used to approximate
84 | hardness distribution. It is recommended to set it to 5.
85 | One can try a larger value when the smallest class in the
86 | data set has a sufficient number (say, > 1000) of samples.
87 |
88 | soft_resample_flag : bool, default=False
89 | Whether to use weighted sampling to perform soft self-paced
90 | under-sampling, rather than explicitly cut samples into
91 | ``k``-bins and perform hard sampling.
92 |
93 | replacement : bool, default=True
94 | Whether samples are drawn with replacement. If ``False``
95 | and ``soft_resample_flag = False``, may raise an error when
96 | a bin has insufficient number of data samples for resampling.
97 |
98 | estimator_params : list of str, default=tuple()
99 | The list of attributes to use as parameters when instantiating a
100 | new base estimator. If none are given, default parameters are used.
101 |
102 | {n_jobs}
103 |
104 | {random_state}
105 |
106 | verbose : int, default=0
107 | Controls the verbosity when predicting.
108 |
109 | Attributes
110 | ----------
111 | base_estimator : estimator
112 | The base estimator from which the ensemble is grown.
113 |
114 | base_sampler_ : SelfPacedUnderSampler
115 | The base sampler.
116 |
117 | estimators_ : list of estimator
118 | The collection of fitted base estimators.
119 |
120 | samplers_ : list of SelfPacedUnderSampler
121 | The collection of fitted samplers.
122 |
123 | classes_ : ndarray of shape (n_classes,)
124 | The classes labels.
125 |
126 | n_classes_ : int
127 | The number of classes.
128 |
129 | feature_importances_ : ndarray of shape (n_features,)
130 | The feature importances if supported by the ``base_estimator``.
131 |
132 | estimators_n_training_samples_ : list of ints
133 | The number of training samples for each fitted
134 | base estimators.
135 |
136 | See Also
137 | --------
138 | BalanceCascadeClassifier : Ensemble with cascade dynamic under-sampling.
139 |
140 | EasyEnsembleClassifier : Bag of balanced boosted learners.
141 |
142 | RUSBoostClassifier : Random under-sampling integrated in AdaBoost.
143 |
144 | Notes
145 | -----
146 | See :ref:`sphx_glr_auto_examples_basic_plot_basic_example.py` for an example.
147 |
148 | References
149 | ----------
150 | .. [1] Liu, Z., Cao, W., Gao, Z., Bian, J., Chen, H., Chang, Y., & Liu, T. Y.
151 | "Self-paced ensemble for highly imbalanced massive data classification."
152 | 2020 IEEE 36th International Conference on Data Engineering (ICDE).
153 | IEEE, 2010: 841-852.
154 |
155 | Examples
156 | --------
157 | {example}
158 | """
159 |
160 | def __init__(self,
161 | base_estimator=None,
162 | n_estimators:int=50,
163 | k_bins:int=5,
164 | soft_resample_flag:bool=False,
165 | replacement:bool=True,
166 | estimator_params=tuple(),
167 | n_jobs=None,
168 | random_state=None,
169 | verbose=0,):
170 |
171 | super(SelfPacedEnsembleClassifier, self).__init__(
172 | base_estimator=base_estimator,
173 | n_estimators=n_estimators,
174 | estimator_params=estimator_params,
175 | random_state=random_state,
176 | n_jobs=n_jobs,
177 | verbose=verbose)
178 |
179 | self.__name__ = _method_name
180 | self.base_sampler = _sampler_class()
181 | self._sampling_type = _sampling_type
182 | self._sampler_class = _sampler_class
183 | self._properties = _properties
184 |
185 | self.k_bins = k_bins
186 | self.soft_resample_flag = soft_resample_flag
187 | self.replacement = replacement
188 |
189 |
190 | def fit(self, X, y, *, sample_weight=None, **kwargs):
191 | """Build a SPE classifier from the training set (X, y).
192 |
193 | Parameters
194 | ----------
195 | X : {array-like, sparse matrix} of shape (n_samples, n_features)
196 | The training input samples. Sparse matrix can be CSC, CSR, COO,
197 | DOK, or LIL. DOK and LIL are converted to CSR.
198 |
199 | y : array-like of shape (n_samples,)
200 | The target values (class labels).
201 |
202 | sample_weight : array-like of shape (n_samples,), default=None
203 | Sample weights. If None, the sample weights are initialized to
204 | ``1 / n_samples``.
205 |
206 | target_label : int, default=None
207 | Specify the class targeted by the under-sampling.
208 | All other classes that have more samples than the target class will
209 | be considered as majority classes. They will be under-sampled until
210 | the number of samples is equalized. The remaining minority classes
211 | (if any) will stay unchanged.
212 |
213 | n_target_samples : int or dict, default=None
214 | Specify the desired number of samples (of each class) after the
215 | under-sampling.
216 |
217 | - If ``int``, all classes that have more than the ``n_target_samples``
218 | samples will be under-sampled until the number of samples is equalized.
219 | - If ``dict``, the keys correspond to the targeted classes. The values
220 | correspond to the desired number of samples for each targeted class.
221 |
222 | balancing_schedule : str, or callable, default='uniform'
223 | Scheduler that controls how to sample the data set during the ensemble
224 | training process.
225 |
226 | - If ``str``, using the predefined balancing schedule.
227 | Possible choices are:
228 |
229 | - ``'uniform'``: resample to target distribution for all base estimators;
230 | - ``'progressive'``: The resample class distributions are progressive
231 | interpolation between the original and the target class distribution.
232 | Example: For a class :math:`c`, say the number of samples is :math:`N_{c}`
233 | and the target number of samples is :math:`N'_{c}`. Suppose that we are
234 | training the :math:`t`-th base estimator of a :math:`T`-estimator ensemble, then
235 | we expect to get :math:`(1-\frac{t}{T}) \cdot N_{c} + \frac{t}{T} \cdot N'_{c}`
236 | samples after resampling;
237 |
238 | - If callable, function takes 4 positional arguments with order (``'origin_distr'``:
239 | ``dict``, ``'target_distr'``: ``dict``, ``'i_estimator'``: ``int``, ``'total_estimator'``:
240 | ``int``), and returns a ``'result_distr'``: ``dict``. For all parameters of type ``dict``,
241 | the keys of type ``int`` correspond to the targeted classes, and the values of type ``str``
242 | correspond to the (desired) number of samples for each class.
243 |
244 | eval_datasets : dict, default=None
245 | Dataset(s) used for evaluation during the ensemble training process.
246 | The keys should be strings corresponding to evaluation datasets' names.
247 | The values should be tuples corresponding to the input samples and target
248 | values.
249 |
250 | Example: ``eval_datasets = {'valid' : (X_valid, y_valid)}``
251 |
252 | eval_metrics : dict, default=None
253 | Metric(s) used for evaluation during the ensemble training process.
254 |
255 | - If ``None``, use 3 default metrics:
256 |
257 | - ``'acc'``:
258 | ``sklearn.metrics.accuracy_score()``
259 | - ``'balanced_acc'``:
260 | ``sklearn.metrics.balanced_accuracy_score()``
261 | - ``'weighted_f1'``:
262 | ``sklearn.metrics.f1_score(average='weighted')``
263 |
264 | - If ``dict``, the keys should be strings corresponding to evaluation
265 | metrics' names. The values should be tuples corresponding to the metric
266 | function (``callable``) and additional kwargs (``dict``).
267 |
268 | - The metric function should at least take 2 named/keyword arguments,
269 | ``y_true`` and one of [``y_pred``, ``y_score``], and returns a float
270 | as the evaluation score. Keyword arguments:
271 |
272 | - ``y_true``, 1d-array of shape (n_samples,), true labels or binary
273 | label indicators corresponds to ground truth (correct) labels.
274 | - When using ``y_pred``, input will be 1d-array of shape (n_samples,)
275 | corresponds to predicted labels, as returned by a classifier.
276 | - When using ``y_score``, input will be 2d-array of shape (n_samples,
277 | n_classes,) corresponds to probability estimates provided by the
278 | predict_proba method. In addition, the order of the class scores
279 | must correspond to the order of ``labels``, if provided in the metric
280 | function, or else to the numerical or lexicographical order of the
281 | labels in ``y_true``.
282 |
283 | - The metric additional kwargs should be a dictionary that specifies
284 | the additional arguments that need to be passed into the metric function.
285 |
286 | Example: ``{'weighted_f1': (sklearn.metrics.f1_score, {'average': 'weighted'})}``
287 |
288 | train_verbose : bool, int or dict, default=False
289 | Controls the verbosity during ensemble training/fitting.
290 |
291 | - If ``bool``: ``False`` means disable training verbose. ``True`` means
292 | print training information to sys.stdout use default setting:
293 |
294 | - ``'granularity'`` : ``int(n_estimators/10)``
295 | - ``'print_distribution'`` : ``True``
296 | - ``'print_metrics'`` : ``True``
297 |
298 | - If ``int``, print information per ``train_verbose`` rounds.
299 |
300 | - If ``dict``, control the detailed training verbose settings. They are:
301 |
302 | - ``'granularity'``: corresponding value should be ``int``, the training
303 | information will be printed per ``granularity`` rounds.
304 | - ``'print_distribution'``: corresponding value should be ``bool``,
305 | whether to print the data class distribution
306 | after resampling. Will be ignored if the
307 | ensemble training does not perform resampling.
308 | - ``'print_metrics'``: corresponding value should be ``bool``,
309 | whether to print the latest performance score.
310 | The performance will be evaluated on the training
311 | data and all given evaluation datasets with the
312 | specified metrics.
313 |
314 | .. warning::
315 | Setting a small ``'granularity'`` value with ``'print_metrics'`` enabled
316 | can be costly when the training/evaluation data is large or the metric
317 | scores are hard to compute. Normally, one can set ``'granularity'`` to
318 | ``n_estimators/10`` (this is used by default).
319 |
320 | Returns
321 | -------
322 | self : object
323 | """
324 | return super().fit(
325 | X, y, sample_weight=sample_weight, **kwargs
326 | )
327 |
328 |
329 | @_deprecate_positional_args
330 | def _fit(self, X, y,
331 | *,
332 | sample_weight=None,
333 | target_label:int=None,
334 | n_target_samples:int or dict=None,
335 | balancing_schedule:str or function='uniform',
336 | eval_datasets:dict=None,
337 | eval_metrics:dict=None,
338 | train_verbose:bool or int or dict=False,
339 | ):
340 |
341 | # X, y, sample_weight, base_estimators_ (default=DecisionTreeClassifier),
342 | # n_estimators, random_state, sample_weight are already validated in super.fit()
343 | random_state, n_estimators, replacement, k_bins, soft_resample_flag, classes_ = \
344 | self.random_state, self.n_estimators, self.replacement, self.k_bins, \
345 | self.soft_resample_flag, self.classes_
346 |
347 | # Check evaluation data
348 | check_x_y_args = self.check_x_y_args
349 | self.eval_datasets_ = check_eval_datasets(eval_datasets, X, y, **check_x_y_args)
350 |
351 | # Check target sample strategy
352 | origin_distr_ = dict(Counter(y))
353 | target_label_, target_distr_ = \
354 | check_target_label_and_n_target_samples(
355 | y, target_label, n_target_samples, self._sampling_type)
356 | self.origin_distr_, self.target_label_, self.target_distr_ = \
357 | origin_distr_, target_label_, target_distr_
358 |
359 | # Check balancing schedule
360 | balancing_schedule_ = check_balancing_schedule(balancing_schedule)
361 | self.balancing_schedule_ = balancing_schedule_
362 |
363 | # Check evaluation metrics
364 | self.eval_metrics_ = check_eval_metrics(eval_metrics)
365 |
366 | # Check training train_verbose format
367 | self.train_verbose_ = check_train_verbose(
368 | train_verbose, self.n_estimators, **self._properties)
369 |
370 | # Set training verbose format
371 | self._init_training_log_format()
372 |
373 | # Clear any previous fit results.
374 | self.estimators_ = []
375 | self.estimators_features_ = []
376 | self.estimators_n_training_samples_ = np.zeros(n_estimators, dtype=int)
377 | self.samplers_ = []
378 |
379 | # Genrate random seeds array
380 | seeds = random_state.randint(MAX_INT, size=n_estimators)
381 | self._seeds = seeds
382 |
383 | # Check if sample_weight is specified
384 | specified_sample_weight = (sample_weight is not None)
385 |
386 | for i_iter in range(n_estimators):
387 |
388 | current_iter_distr = balancing_schedule_(
389 | origin_distr=origin_distr_,
390 | target_distr=target_distr_,
391 | i_estimator=i_iter,
392 | total_estimator=n_estimators,
393 | )
394 |
395 | sampler = self._make_sampler(
396 | append=True,
397 | random_state=seeds[i_iter],
398 | sampling_strategy=current_iter_distr,
399 | k_bins=k_bins,
400 | soft_resample_flag=soft_resample_flag,
401 | replacement=replacement,
402 | )
403 |
404 | # update self.y_pred_proba_latest
405 | self._update_cached_prediction_probabilities(i_iter, X)
406 |
407 | # compute alpha
408 | alpha = np.tan(np.pi*0.5*(i_iter/(max(n_estimators-1, 1))))
409 |
410 | # Perform self-paced under-sampling
411 | resample_out = sampler.fit_resample(X, y,
412 | y_pred_proba=self.y_pred_proba_latest,
413 | alpha=alpha,
414 | classes_=classes_,
415 | sample_weight=sample_weight)
416 |
417 | # Train a new base estimator on resampled data
418 | # and add it into self.estimators_
419 | estimator = self._make_estimator(append=True, random_state=seeds[i_iter])
420 | if specified_sample_weight:
421 | (X_resampled, y_resampled, sample_weight_resampled) = resample_out
422 | estimator.fit(X_resampled, y_resampled, sample_weight=sample_weight_resampled)
423 | else:
424 | (X_resampled, y_resampled) = resample_out
425 | estimator.fit(X_resampled, y_resampled)
426 |
427 | self.estimators_features_.append(self.features_)
428 | self.estimators_n_training_samples_[i_iter] = y_resampled.shape[0]
429 |
430 | # Print training infomation to console.
431 | self._training_log_to_console(i_iter, y_resampled)
432 |
433 | return self
434 |
435 |
436 | def _update_cached_prediction_probabilities(self, i_iter, X):
437 | """Private function that maintains a latest prediction probabilities of the training
438 | data during ensemble training. Must be called in each iteration before fit the
439 | base_estimator."""
440 |
441 | if i_iter == 0:
442 | self.y_pred_proba_latest = np.zeros((self._n_samples, self.n_classes_),
443 | dtype=np.float64)
444 | else:
445 | y_pred_proba_latest = self.y_pred_proba_latest
446 | y_pred_proba_new = self.estimators_[-1].predict_proba(X)
447 | self.y_pred_proba_latest = (y_pred_proba_latest * i_iter + y_pred_proba_new) / (i_iter+1)
448 | return
449 |
450 | def save(self, filename:str):
451 | """Save the model to a file."""
452 | dump(self, filename=filename)
453 |
454 | # %%
455 |
456 | if __name__ == '__main__':
457 | from collections import Counter
458 | from copy import copy
459 | from sklearn.tree import DecisionTreeClassifier
460 | from sklearn.datasets import make_classification
461 | from sklearn.model_selection import train_test_split
462 | from sklearn.metrics import accuracy_score, balanced_accuracy_score, f1_score
463 |
464 | # X, y = make_classification(n_classes=2, class_sep=2, # 2-class
465 | # weights=[0.1, 0.9], n_informative=3, n_redundant=1, flip_y=0,
466 | # n_features=20, n_clusters_per_class=1, n_samples=1000, random_state=10)
467 | X, y = make_classification(n_classes=3, class_sep=2, # 3-class
468 | weights=[0.1, 0.3, 0.6], n_informative=3, n_redundant=1, flip_y=0,
469 | n_features=20, n_clusters_per_class=1, n_samples=2000, random_state=10)
470 |
471 | X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.5, random_state=42)
472 |
473 | origin_distr = dict(Counter(y_train)) # {2: 600, 1: 300, 0: 100}
474 | print('Original training dataset shape %s' % origin_distr)
475 |
476 | target_distr = {2: 200, 1: 100, 0: 100}
477 |
478 | init_kwargs_default = {
479 | 'base_estimator': None,
480 | # 'base_estimator': DecisionTreeClassifier(max_depth=10),
481 | 'n_estimators': 100,
482 | 'k_bins': 5,
483 | 'soft_resample_flag': False,
484 | 'replacement': True,
485 | 'estimator_params': tuple(),
486 | 'n_jobs': None,
487 | 'random_state': 42,
488 | # 'random_state': None,
489 | 'verbose': 0,
490 | }
491 |
492 | fit_kwargs_default = {
493 | 'X': X_train,
494 | 'y': y_train,
495 | 'sample_weight': None,
496 | 'target_label': None,
497 | 'n_target_samples': None,
498 | # 'n_target_samples': target_distr,
499 | 'balancing_schedule': 'uniform',
500 | 'eval_datasets': {'valid': (X_valid, y_valid)},
501 | 'eval_metrics': {
502 | 'acc': (accuracy_score, {}),
503 | 'balanced_acc': (balanced_accuracy_score, {}),
504 | 'weighted_f1': (f1_score, {'average':'weighted'}),},
505 | 'train_verbose': {
506 | 'granularity': 10,
507 | 'print_distribution': True,
508 | 'print_metrics': True,},
509 | }
510 |
511 | ensembles = {}
512 |
513 | init_kwargs, fit_kwargs = copy(init_kwargs_default), copy(fit_kwargs_default)
514 | spe = SelfPacedEnsembleClassifier(**init_kwargs).fit(**fit_kwargs)
515 | ensembles['spe'] = spe
516 |
517 | init_kwargs, fit_kwargs = copy(init_kwargs_default), copy(fit_kwargs_default)
518 | fit_kwargs.update({
519 | 'balancing_schedule': 'progressive'
520 | })
521 | spe_prog = SelfPacedEnsembleClassifier(**init_kwargs).fit(**fit_kwargs)
522 | ensembles['spe_prog'] = spe_prog
523 |
524 | init_kwargs, fit_kwargs = copy(init_kwargs_default), copy(fit_kwargs_default)
525 | init_kwargs.update({
526 | 'soft_resample_flag': True,
527 | 'replacement': False,
528 | })
529 | spe_soft = SelfPacedEnsembleClassifier(**init_kwargs).fit(**fit_kwargs)
530 | ensembles['spe_soft'] = spe_soft
531 |
532 |
533 | # %%
534 | from imbens.visualizer import ImbalancedEnsembleVisualizer
535 |
536 | visualizer = ImbalancedEnsembleVisualizer(
537 | eval_datasets = None,
538 | eval_metrics = None,
539 | ).fit(
540 | ensembles = ensembles,
541 | granularity = 5,
542 | )
543 | fig, axes = visualizer.performance_lineplot(
544 | on_ensembles=None,
545 | on_datasets=None,
546 | split_by=[],
547 | n_samples_as_x_axis=False,
548 | sub_figsize=(4, 3.3),
549 | sup_title=True,
550 | alpha=0.8,
551 | )
552 | fig, axes = visualizer.confusion_matrix_heatmap(
553 | on_ensembles=None,
554 | on_datasets=None,
555 | sub_figsize=(4, 3.3),
556 | )
557 |
558 | # %%
559 |
--------------------------------------------------------------------------------
/self_paced_ensemble/self_paced_ensemble/_self_paced_under_sampler.py:
--------------------------------------------------------------------------------
1 | """Class to perform self-paced under-sampling."""
2 |
3 | # Authors: Zhining Liu
4 | # License: MIT
5 |
6 | # %%
7 |
8 | import numbers
9 | import numpy as np
10 |
11 | from sklearn.utils import check_random_state
12 | from sklearn.utils import _safe_indexing
13 |
14 | from ._base_sampler import BaseSampler
15 | from ..utils._validation_param import check_pred_proba, check_type
16 | from ..utils._validation import _deprecate_positional_args, check_target_type
17 |
18 | # # For local test
19 | # import sys
20 | # sys.path.append("..")
21 | # from self_paced_ensemble._base_sampler import BaseSampler
22 | # from utils._validation_param import check_pred_proba, check_type
23 | # from utils._validation import _deprecate_positional_args, check_target_type
24 |
25 | # %%
26 |
27 | class SelfPacedUnderSampler(BaseSampler):
28 | """Class to perform self-paced under-sampling in [1]_.
29 |
30 | Parameters
31 | ----------
32 | sampling_strategy : float, str, dict, callable, default='auto'
33 | Sampling information to sample the data set.
34 |
35 | - When ``float``, it corresponds to the desired ratio of the number of
36 | samples in the minority class over the number of samples in the
37 | majority class after resampling. Therefore, the ratio is expressed as
38 | :math:`\alpha_{us} = N_{m} / N_{rM}` where :math:`N_{m}` is the
39 | number of samples in the minority class and
40 | :math:`N_{rM}` is the number of samples in the majority class
41 | after resampling.
42 |
43 | .. warning::
44 | ``float`` is only available for **binary** classification. An
45 | error is raised for multi-class classification.
46 |
47 | - When ``str``, specify the class targeted by the resampling. The
48 | number of samples in the different classes will be equalized.
49 | Possible choices are:
50 |
51 | ``'majority'``: resample only the majority class;
52 |
53 | ``'not minority'``: resample all classes but the minority class;
54 |
55 | ``'not majority'``: resample all classes but the majority class;
56 |
57 | ``'all'``: resample all classes;
58 |
59 | ``'auto'``: equivalent to ``'not minority'``.
60 |
61 | - When ``dict``, the keys correspond to the targeted classes. The
62 | values correspond to the desired number of samples for each targeted
63 | class.
64 |
65 | - When callable, function taking ``y`` and returns a ``dict``. The keys
66 | correspond to the targeted classes. The values correspond to the
67 | desired number of samples for each class.
68 |
69 | k_bins : int, default=5
70 | The number of hardness bins that were used to approximate
71 | hardness distribution. It is recommended to set it to 5.
72 | One can try a larger value when the smallest class in the
73 | data set has a sufficient number (say, > 1000) of samples.
74 |
75 | soft_resample_flag : bool, default=False
76 | Whether to use weighted sampling to perform soft self-paced
77 | under-sampling, rather than explicitly cut samples into
78 | ``k``-bins and perform hard sampling.
79 |
80 | replacement : bool, default=True
81 | Whether samples are drawn with replacement. If ``False``
82 | and ``soft_resample_flag = False``, may raise an error when
83 | a bin has insufficient number of data samples for resampling.
84 |
85 | random_state : int, RandomState instance, default=None
86 | Control the randomization of the algorithm.
87 |
88 | - If ``int``, ``random_state`` is the seed used by the random number
89 | generator;
90 | - If ``RandomState`` instance, random_state is the random number
91 | generator;
92 | - If ``None``, the random number generator is the ``RandomState``
93 | instance used by ``np.random``.
94 |
95 | Attributes
96 | ----------
97 | sample_indices_ : ndarray of shape (n_new_samples,)
98 | Indices of the samples selected.
99 |
100 | See Also
101 | --------
102 | BalanceCascadeUnderSampler : Dynamic under-sampling for BalanceCascade.
103 |
104 | Notes
105 | -----
106 | Supports multi-class resampling by sampling each class independently.
107 | Supports heterogeneous data as object array containing string and numeric
108 | data.
109 |
110 | References
111 | ----------
112 | .. [1] Liu, Z., Cao, W., Gao, Z., Bian, J., Chen, H., Chang, Y., & Liu, T. Y.
113 | "Self-paced ensemble for highly imbalanced massive data classification."
114 | 2020 IEEE 36th International Conference on Data Engineering (ICDE).
115 | IEEE, 2010: 841-852.
116 | """
117 |
118 | _sampling_type = 'under-sampling'
119 |
120 | @_deprecate_positional_args
121 | def __init__(
122 | self, *,
123 | sampling_strategy="auto",
124 | k_bins=5,
125 | soft_resample_flag=True,
126 | replacement=False,
127 | random_state=None,
128 | ):
129 | super().__init__(sampling_strategy=sampling_strategy)
130 |
131 | self.k_bins = k_bins
132 | self.soft_resample_flag = soft_resample_flag
133 | self.replacement = replacement
134 | self.random_state = random_state
135 |
136 | # Check parameters
137 | self.k_bins_ = check_type(k_bins, 'k_bins', numbers.Integral)
138 | self.replacement_ = check_type(replacement, 'replacement', bool)
139 | self.soft_resample_flag_ = check_type(soft_resample_flag,
140 | 'soft_resample_flag', bool)
141 |
142 |
143 | def _check_X_y(self, X, y):
144 | y, binarize_y = check_target_type(y, indicate_one_vs_all=True)
145 | X, y = self._validate_data(
146 | X,
147 | y,
148 | reset=True,
149 | accept_sparse=["csr", "csc"],
150 | dtype=None,
151 | force_all_finite=False,
152 | )
153 | return X, y, binarize_y
154 |
155 |
156 | def fit_resample(self, X, y, *, sample_weight, **kwargs):
157 | """Resample the dataset.
158 |
159 | Parameters
160 | ----------
161 | X : {array-like, dataframe, sparse matrix} of shape \
162 | (n_samples, n_features)
163 | Matrix containing the data which have to be sampled.
164 |
165 | y : array-like of shape (n_samples,)
166 | Corresponding label for each sample in X.
167 |
168 | y_pred_proba : array-like of shape (n_samples, n_classes)
169 | The predicted class probabilities of the input samples
170 | by the current SPE ensemble classifier. The order of the
171 | classes corresponds to that in the parameter `classes_`.
172 |
173 | alpha : float
174 | The self-paced factor that controls SPE under-sampling.
175 |
176 | classes_ : ndarray of shape (n_classes,)
177 | The classes labels.
178 |
179 | sample_weight : array-like of shape (n_samples,), default=None
180 | Corresponding weight for each sample in X.
181 |
182 | Returns
183 | -------
184 | X_resampled : {array-like, dataframe, sparse matrix} of shape \
185 | (n_samples_new, n_features)
186 | The array containing the resampled data.
187 |
188 | y_resampled : array-like of shape (n_samples_new,)
189 | The corresponding label of `X_resampled`.
190 |
191 | sample_weight : array-like of shape (n_samples_new,), default=None
192 | The corresponding weight of `X_resampled`.
193 | Only will be returned if input sample_weight is not None.
194 | """
195 | return super().fit_resample(X, y, sample_weight=sample_weight, **kwargs)
196 |
197 |
198 | @_deprecate_positional_args
199 | def _fit_resample(self, X, y, *,
200 | y_pred_proba, alpha:float,
201 | classes_, sample_weight=None):
202 |
203 | n_samples, n_classes = X.shape[0], classes_.shape[0]
204 |
205 | # Check random_state and predict probabilities
206 | random_state = check_random_state(self.random_state)
207 | y_pred_proba = check_pred_proba(y_pred_proba, n_samples, n_classes, dtype=np.float64)
208 |
209 | # Check the self-paced factor alpha
210 | alpha = check_type(alpha, 'alpha', numbers.Number)
211 | if alpha < 0:
212 | raise ValueError("'alpha' must not be negative.")
213 |
214 | indexes = np.arange(n_samples)
215 | index_list = []
216 |
217 | # For each class C
218 | for target_class in classes_:
219 | if target_class in self.sampling_strategy_.keys():
220 |
221 | # Get the desired & actual number of samples of class C
222 | # and the index mask of class C
223 | n_target_samples_c = self.sampling_strategy_[target_class]
224 | class_index_mask = y == target_class
225 | n_samples_c = np.count_nonzero(class_index_mask)
226 |
227 | # Compute the hardness array
228 | hardness_c=np.abs(
229 | np.ones(n_samples_c) - \
230 | y_pred_proba[class_index_mask, target_class])
231 |
232 | # index_c: absolute indexes of class C samples
233 | index_c = indexes[class_index_mask]
234 |
235 | if n_target_samples_c <= n_samples_c:
236 |
237 | # Get the absolute indexes of resampled class C samples
238 | index_c_result = self._undersample_single_class(
239 | hardness_c=hardness_c,
240 | n_target_samples_c=n_target_samples_c,
241 | index_c=index_c,
242 | alpha=alpha,
243 | random_state=random_state)
244 |
245 | # If no sufficient samples in class C, raise an RuntimeError
246 | else: raise RuntimeError(
247 | f"Got n_target_samples_c ({n_target_samples_c})"
248 | f" > n_samples_c ({n_samples_c} for class {target_class}.)"
249 | )
250 | index_list.append(index_c_result)
251 |
252 | # Concatenate the result
253 | index_spu = np.hstack(index_list)
254 |
255 | # Store the final undersample indexes
256 | self.sample_indices_ = index_spu
257 |
258 | # Return the resampled X, y
259 | # also return resampled sample_weight (if sample_weight is not None)
260 | if sample_weight is not None:
261 | # sample_weight is already validated in super().fit_resample()
262 | weights_under = _safe_indexing(sample_weight, index_spu)
263 | return _safe_indexing(X, index_spu), _safe_indexing(y, index_spu), weights_under
264 | else: return _safe_indexing(X, index_spu), _safe_indexing(y, index_spu)
265 |
266 |
267 | def _undersample_single_class(self, hardness_c, n_target_samples_c,
268 | index_c, alpha, random_state):
269 | """Perform self-paced under-sampling in a single class"""
270 | k_bins = self.k_bins_
271 | soft_resample_flag = self.soft_resample_flag_
272 | replacement = self.replacement_
273 | n_samples_c = hardness_c.shape[0]
274 |
275 | # if hardness is not distinguishable or no sample will be dropped
276 | if hardness_c.max() == hardness_c.min() or n_target_samples_c == n_samples_c:
277 | # perform random under-sampling
278 | return random_state.choice(
279 | index_c,
280 | size=n_target_samples_c,
281 | replace=replacement)
282 |
283 | with np.errstate(divide='ignore', invalid='ignore'):
284 | # compute population & hardness contribution of each bin
285 | populations, edges = np.histogram(hardness_c, bins=k_bins)
286 | contributions = np.zeros(k_bins)
287 | index_bins = []
288 | for i_bin in range(k_bins):
289 | index_bin = ((hardness_c >= edges[i_bin]) & (hardness_c < edges[i_bin+1]))
290 | if i_bin == (k_bins-1):
291 | index_bin = index_bin | (hardness_c==edges[i_bin+1])
292 | index_bins.append(index_bin)
293 | if populations[i_bin] > 0:
294 | contributions[i_bin] = hardness_c[index_bin].mean()
295 |
296 | # compute the expected number of samples to be sampled from each bin
297 | bin_weights = 1. / (contributions + alpha)
298 | bin_weights[np.isnan(bin_weights)|np.isinf(bin_weights)] = 0
299 | n_target_samples_bins = n_target_samples_c * bin_weights / bin_weights.sum()
300 | # check whether exists empty bins
301 | n_invalid_samples = sum(n_target_samples_bins[populations==0])
302 | if n_invalid_samples > 0:
303 | n_valid_samples = n_target_samples_c-n_invalid_samples
304 | n_target_samples_bins *= n_target_samples_c / n_valid_samples
305 | n_target_samples_bins[populations==0] = 0
306 | n_target_samples_bins = n_target_samples_bins.astype(int)+1
307 |
308 | if soft_resample_flag:
309 | with np.errstate(divide='ignore', invalid='ignore'):
310 | # perform soft (weighted) self-paced under-sampling
311 | soft_spu_bin_weights = n_target_samples_bins / populations
312 | soft_spu_bin_weights[~np.isfinite(soft_spu_bin_weights)] = 0
313 | # compute sampling probabilities
314 | soft_spu_sample_proba = np.zeros_like(hardness_c)
315 | for i_bin in range(k_bins):
316 | soft_spu_sample_proba[index_bins[i_bin]] = soft_spu_bin_weights[i_bin]
317 | soft_spu_sample_proba /= soft_spu_sample_proba.sum()
318 | # sample with respect to the sampling probabilities
319 | return random_state.choice(
320 | index_c,
321 | size=n_target_samples_c,
322 | replace=replacement,
323 | p=soft_spu_sample_proba,)
324 | else:
325 | # perform hard self-paced under-sampling
326 | index_c_results = []
327 | for i_bin in range(k_bins):
328 | # if no sufficient data in bin for resampling, raise an RuntimeError
329 | if populations[i_bin] < n_target_samples_bins[i_bin] and not replacement:
330 | raise RuntimeError(
331 | f"Met {i_bin}-th bin with insufficient number of data samples"
332 | f" ({populations[i_bin]}, expected"
333 | f" >= {n_target_samples_bins[i_bin]})."
334 | f" Set 'soft_resample_flag' or 'replacement' to `True` to."
335 | f" avoid this issue."
336 | )
337 | index_c_bin = index_c[index_bins[i_bin]]
338 | # random sample from each bin
339 | if len(index_c_bin) > 0:
340 | index_c_results.append(
341 | random_state.choice(
342 | index_c_bin,
343 | size=n_target_samples_bins[i_bin],
344 | replace=replacement,)
345 | )
346 | # concatenate and return the result
347 | index_c_result = np.hstack(index_c_results)
348 | return index_c_result
349 |
350 |
351 | def _more_tags(self):
352 | return {
353 | "X_types": ["2darray", "string", "sparse", "dataframe"],
354 | "sample_indices": True,
355 | "allow_nan": True,
356 | }
357 |
358 | # %%
359 |
360 | if __name__ == "__main__":
361 |
362 | from collections import Counter
363 | import numpy as np
364 |
365 | from sklearn.utils import check_random_state
366 | from sklearn.utils import _safe_indexing
367 | from sklearn.datasets import make_classification
368 | from sklearn.ensemble import BaggingClassifier
369 |
370 | X, y = make_classification(n_classes=3, class_sep=2,
371 | weights=[0.1, 0.3, 0.6], n_informative=3, n_redundant=1, flip_y=0,
372 | n_features=20, n_clusters_per_class=1, n_samples=1000, random_state=10)
373 | print('Original dataset shape %s' % Counter(y))
374 |
375 | sampling_strategy_ = {2: 200, 1: 100, 0: 90}
376 | print('Target dataset shape %s' % sampling_strategy_)
377 |
378 | sample_weight = np.full_like(y, fill_value=1/y.shape[0], dtype=float)
379 | clf = BaggingClassifier(
380 | n_estimators=50,
381 | ).fit(X, y)
382 |
383 | y_pred_proba = clf.predict_proba(X)
384 |
385 | alpha = 0
386 |
387 | spu = SelfPacedUnderSampler(
388 | sampling_strategy=sampling_strategy_,
389 | k_bins=5,
390 | soft_resample_flag=True,
391 | replacement=False,
392 | random_state=0,
393 | )
394 | X_res, y_res, weights_res = spu.fit_resample(X, y,
395 | y_pred_proba=y_pred_proba, alpha=0, sample_weight=sample_weight,
396 | classes_=clf.classes_)
397 | print('Resampled dataset shape %s' % Counter(y_res))
398 |
399 | # %%
400 |
--------------------------------------------------------------------------------
/self_paced_ensemble/self_paced_ensemble/base.py:
--------------------------------------------------------------------------------
1 | """Mixin and base class for ensemble classifiers.
2 | """
3 |
4 | # Authors: Zhining Liu
5 | # License: MIT
6 |
7 |
8 | # %%
9 |
10 | from abc import ABCMeta, abstractmethod
11 |
12 | import numpy as np
13 | from collections import Counter
14 | from joblib import Parallel
15 | import numpy as np
16 | from inspect import signature
17 |
18 | from sklearn.base import ClassifierMixin, clone
19 | from sklearn.ensemble import BaseEnsemble
20 | from sklearn.ensemble._base import _set_random_states
21 | from sklearn.ensemble._base import _partition_estimators
22 | from sklearn.ensemble._bagging import _parallel_predict_proba
23 | from sklearn.tree import DecisionTreeClassifier
24 | from sklearn.utils import check_random_state
25 | from sklearn.utils import check_array
26 | from sklearn.utils.fixes import delayed
27 | from sklearn.utils.multiclass import check_classification_targets
28 | from sklearn.utils.validation import (_check_sample_weight,
29 | check_random_state,
30 | check_is_fitted,
31 | column_or_1d,
32 | check_array,
33 | has_fit_parameter,)
34 |
35 |
36 | from ..utils._validation import _deprecate_positional_args
37 |
38 | # # For local test
39 | # import sys
40 | # sys.path.append("..")
41 | # from utils._validation import _deprecate_positional_args
42 |
43 | TRAINING_LOG_HEAD_TITLES = {
44 | 'iter': '#Estimators',
45 | 'class_distr': 'Class Distribution',
46 | 'datasets': 'Datasets',
47 | 'metrics': 'Metrics',
48 | }
49 |
50 | TRAINING_TYPES = ('iterative', 'parallel')
51 |
52 | MAX_INT = np.iinfo(np.int32).max
53 |
54 | # %%
55 |
56 | def sort_dict_by_key(d):
57 | """Sort a dict by key, return sorted dict."""
58 | return dict(sorted(d.items(), key=lambda k: k[0]))
59 |
60 |
61 | class ImbalancedEnsembleClassifierMixin(ClassifierMixin):
62 | """Mixin class for all ensemble classifiers in imbalanced-ensemble.
63 |
64 | This class is essential for a derived class to be identified by the
65 | sklearn and imbalanced-ensemble package. Additionally, it provides
66 | several utilities for formatting training logs of imbalanced-ensemble
67 | classifiers.
68 |
69 | Attributes
70 | ----------
71 | _estimator_type : ``'classifier'``
72 | scikit-learn use this attribute to identify a classifier.
73 |
74 | _estimator_ensemble_type : ``'imbalanced_ensemble_classifier'``
75 | imbalanced-ensemble use this attribute to identify a classifier.
76 | """
77 |
78 | _estimator_type = "classifier"
79 |
80 | _estimator_ensemble_type = "imbalanced_ensemble_classifier"
81 |
82 |
83 | def _evaluate(self,
84 | dataset_name:str,
85 | eval_metrics:dict=None,
86 | return_header:bool=False,
87 | return_value_dict:bool=False,) -> str or dict:
88 | """Private function for performance evaluation during the
89 | ensemble training process.
90 | """
91 |
92 | eval_datasets_ = self.eval_datasets_
93 | classes_ = self.classes_
94 | verbose_format_ = self.train_verbose_format_
95 |
96 | # Temporarily disable verbose
97 | support_verbose = hasattr(self, 'verbose')
98 | if support_verbose:
99 | verbose, self.verbose = self.verbose, 0
100 |
101 | # If no eval_metrics is given, use self.eval_metrics_
102 | if eval_metrics == None:
103 | eval_metrics = self.eval_metrics_
104 |
105 | # If return numerical results
106 | if return_value_dict == True:
107 | value_dict = {}
108 | for data_name, (X_eval, y_eval) in eval_datasets_.items():
109 | y_predict_proba = self.predict_proba(X_eval)
110 | data_value_dict = {}
111 | for metric_name, (metric_func, kwargs, ac_proba, ac_labels) \
112 | in eval_metrics.items():
113 | if ac_labels: kwargs['labels'] = classes_
114 | if ac_proba: # If the metric take predict probabilities
115 | score = metric_func(y_eval, y_predict_proba, **kwargs)
116 | else: # If the metric do not take predict probabilities
117 | y_predict = classes_.take(np.argmax(
118 | y_predict_proba, axis=1), axis=0)
119 | score = metric_func(y_eval, y_predict, **kwargs)
120 | data_value_dict[metric_name] = score
121 | value_dict[data_name] = data_value_dict
122 | out = value_dict
123 |
124 | # If return string
125 | else:
126 | eval_info = ""
127 | if return_header == True:
128 | for metric_name in eval_metrics.keys():
129 | eval_info = self._training_log_add_block(
130 | eval_info, metric_name, "", "", " ",
131 | verbose_format_['len_metrics'][metric_name], strip=False)
132 | else:
133 | (X_eval, y_eval) = eval_datasets_[dataset_name]
134 | y_predict_proba = self.predict_proba(X_eval)
135 | for metric_name, (metric_func, kwargs, ac_proba, ac_labels) \
136 | in eval_metrics.items():
137 | if ac_labels: kwargs['labels'] = classes_
138 | if ac_proba: # If the metric take predict probabilities
139 | score = metric_func(y_eval, y_predict_proba, **kwargs)
140 | else: # If the metric do not take predict probabilities
141 | y_predict = classes_.take(np.argmax(
142 | y_predict_proba, axis=1), axis=0)
143 | score = metric_func(y_eval, y_predict, **kwargs)
144 | eval_info = self._training_log_add_block(
145 | eval_info, "{:.3f}".format(score), "", "", " ",
146 | verbose_format_['len_metrics'][metric_name], strip=False)
147 | out = eval_info[:-1]
148 |
149 | # Recover verbose state
150 | if support_verbose:
151 | self.verbose = verbose
152 |
153 | return out
154 |
155 |
156 | def _init_training_log_format(self):
157 | """Private function for initialization of the training verbose format"""
158 |
159 | if self.train_verbose_:
160 | len_iter = max(
161 | len(str(self.n_estimators)),
162 | len(TRAINING_LOG_HEAD_TITLES['iter'])) + 2
163 | if self.train_verbose_['print_distribution']:
164 | len_class_distr = max(
165 | len(str(self.target_distr_)),
166 | len(str(self.origin_distr_)),
167 | len(TRAINING_LOG_HEAD_TITLES['class_distr'])) + 2
168 | else: len_class_distr = 0
169 | len_metrics = {
170 | metric_name: max(len(metric_name), 5) + 2
171 | for metric_name in self.eval_metrics_.keys()
172 | }
173 | metrics_total_length = sum(len_metrics.values()) + len(len_metrics) - 1
174 | len_datasets = {
175 | dataset_name: max(metrics_total_length, len("Data: "+dataset_name)+2)
176 | for dataset_name in self.eval_datasets_.keys()
177 | }
178 | self.train_verbose_format_ = {
179 | 'len_iter': len_iter,
180 | 'len_class_distr': len_class_distr,
181 | 'len_metrics': len_metrics,
182 | 'len_datasets': len_datasets,}
183 |
184 | return
185 |
186 |
187 | def _training_log_add_block(self, info, text, sta_char, fill_char,
188 | end_char, width, strip=True):
189 | """Private function for adding a block to training log."""
190 |
191 | info = info.rstrip(end_char) if strip else info
192 | info += "{}{:{fill}^{width}s}{}".format(
193 | sta_char, text, end_char,
194 | fill=fill_char, width=width)
195 |
196 | return info
197 |
198 |
199 | def _training_log_add_line(self, info="", texts=None, tabs=None,
200 | widths=None, flags=None):
201 | """Private function for adding a line to training log."""
202 |
203 | if texts == None:
204 | texts = ("", "", tuple("" for _ in self.eval_datasets_.keys()))
205 | if tabs == None:
206 | tabs = ("┃", "┃", "┃", " ")
207 | if widths == None:
208 | widths = (
209 | self.train_verbose_format_['len_iter'],
210 | self.train_verbose_format_['len_class_distr'],
211 | tuple(self.train_verbose_format_['len_datasets'].values())
212 | )
213 | if flags == None:
214 | flags = (True, self.train_verbose_['print_distribution'], self.train_verbose_['print_metrics'])
215 | (sta_char, mid_char, end_char, fill_char) = tabs
216 | (flag_iter, flag_distr, flag_metric) = flags
217 | (text_iter, text_distr, text_metrics) = texts
218 | (width_iter, width_distr, width_metrics) = widths
219 | if flag_iter:
220 | info = self._training_log_add_block(
221 | info, text_iter, sta_char, fill_char, end_char, width_iter)
222 | if flag_distr:
223 | info = self._training_log_add_block(
224 | info, text_distr, mid_char, fill_char, end_char, width_distr)
225 | if flag_metric:
226 | for text_metric, width_metric in zip(text_metrics, width_metrics):
227 | info = self._training_log_add_block(
228 | info, text_metric, mid_char, fill_char, end_char, width_metric)
229 |
230 | return info
231 |
232 |
233 | def _training_log_to_console_head(self):
234 | """Private function for printing a table header."""
235 |
236 | # line 1
237 | info = self._training_log_add_line(
238 | tabs=("┏", "┳", "┓", "━"),
239 | )+"\n"
240 | # line 2
241 | info = self._training_log_add_line(info,
242 | texts=("", "", tuple("Data: "+data_name
243 | for data_name in self.eval_datasets_.keys()))
244 | )+"\n"
245 | # line 3
246 | info = self._training_log_add_line(info,
247 | texts=(
248 | TRAINING_LOG_HEAD_TITLES['iter'],
249 | TRAINING_LOG_HEAD_TITLES['class_distr'],
250 | tuple("Metric" for data_name in self.eval_datasets_.keys())
251 | )
252 | )+"\n"
253 | # line 4
254 | info = self._training_log_add_line(info,
255 | texts=("", "", tuple(
256 | self._evaluate('', return_header=True)
257 | for data_name in self.eval_datasets_.keys()))
258 | )+"\n"
259 | # line 5
260 | info = self._training_log_add_line(info,
261 | tabs=("┣", "╋", "┫", "━"))
262 |
263 | return info
264 |
265 |
266 | def _training_log_to_console(self, i_iter=None, y=None):
267 | """Private function for printing training log to sys.stdout."""
268 |
269 | if self.train_verbose_:
270 |
271 | if not hasattr(self, '_properties'):
272 | raise AttributeError(
273 | f"All imbalanced-ensemble estimators should" + \
274 | f" have a `_properties` attribute to specify" + \
275 | f" the method family they belong to."
276 | )
277 |
278 | try:
279 | training_type = self._properties['training_type']
280 | except Exception as e:
281 | e_args = list(e.args)
282 | e_args[0] += \
283 | f" The key 'training_type' does not exist in" + \
284 | f" the `_properties` attribute, please check" + \
285 | f" your usage."
286 | e.args = tuple(e_args)
287 | raise e
288 |
289 | if training_type not in TRAINING_TYPES:
290 | raise ValueError(f"'training_type' should be in {TRAINING_TYPES}")
291 | if training_type == 'iterative':
292 | self._training_log_to_console_iterative(i_iter, y)
293 | elif training_type == 'parallel':
294 | self._training_log_to_console_parallel()
295 | else: raise NotImplementedError(
296 | f"'_training_log_to_console' for 'training_type' = {training_type}"
297 | f" needs to be implemented."
298 | )
299 |
300 |
301 | def _training_log_to_console_iterative(self, i_iter, y_resampled):
302 | """Private function for printing training log to sys.stdout.
303 | (for ensemble classifiers that train in an iterative manner)"""
304 |
305 | if i_iter == 0:
306 | print(self._training_log_to_console_head())
307 |
308 | eval_data_names = self.eval_datasets_.keys()
309 |
310 | if (i_iter+1) % self.train_verbose_['granularity'] == 0 or i_iter == 0:
311 | print(self._training_log_add_line(texts=(
312 | f"{i_iter+1}", f"{sort_dict_by_key(Counter(y_resampled))}",
313 | tuple(self._evaluate(data_name) for data_name in eval_data_names)
314 | )))
315 |
316 | if (i_iter+1) == self.n_estimators:
317 | print(self._training_log_add_line(tabs=("┣", "╋", "┫", "━")))
318 | print(self._training_log_add_line(texts=(
319 | "final", f"{dict(Counter(y_resampled))}",
320 | tuple(self._evaluate(data_name) for data_name in eval_data_names)
321 | )))
322 | print(self._training_log_add_line(tabs=("┗", "┻", "┛", "━")))
323 |
324 |
325 | def _training_log_to_console_parallel(self):
326 | """Private function for printing training log to sys.stdout.
327 | (for ensemble classifiers that train in a parallel manner)"""
328 |
329 | eval_data_names = self.eval_datasets_.keys()
330 | print(self._training_log_to_console_head())
331 | print(self._training_log_add_line(texts=(
332 | str(self.n_estimators), "",
333 | tuple(self._evaluate(data_name) for data_name in eval_data_names)
334 | )))
335 | print(self._training_log_add_line(tabs=("┗", "┻", "┛", "━")))
336 |
337 |
338 | _properties = {
339 | 'ensemble_type': 'general',
340 | }
341 |
342 |
343 | class BaseImbalancedEnsemble(ImbalancedEnsembleClassifierMixin,
344 | BaseEnsemble, metaclass=ABCMeta):
345 | """Base class for DupleBalanceClassifier.
346 |
347 | Warning: This class should not be used directly. Use derived classes
348 | instead.
349 |
350 | Parameters
351 | ----------
352 | base_estimator : object
353 | The base estimator from which the ensemble is built.
354 |
355 | n_estimators : int, default=10
356 | The number of estimators in the ensemble.
357 |
358 | estimator_params : list of str, default=tuple()
359 | The list of attributes to use as parameters when instantiating a
360 | new base estimator. If none are given, default parameters are used.
361 |
362 | n_jobs : int, default=None
363 | The number of jobs to run in parallel for :meth:`predict`.
364 | ``None`` means 1 unless in a :obj:`joblib.parallel_backend`
365 | context. ``-1`` means using all processors. See `Glossary `_
366 | for more details.
367 |
368 | random_state : int, RandomState instance or None, default=None
369 | Control the randomization of the algorithm.
370 | If the base estimator accepts a `random_state` attribute, a different
371 | seed is generated for each instance in the ensemble.
372 | Pass an ``int`` for reproducible output across multiple function calls.
373 |
374 | - If ``int``, ``random_state`` is the seed used by the random number
375 | generator;
376 | - If ``RandomState`` instance, random_state is the random number
377 | generator;
378 | - If ``None``, the random number generator is the ``RandomState``
379 | instance used by ``np.random``.
380 |
381 | verbose : int, default=0
382 | Controls the verbosity when predicting.
383 |
384 | Attributes
385 | ----------
386 | base_estimator_ : estimator
387 | The base estimator from which the ensemble is grown.
388 |
389 | estimators_ : list of estimators
390 | The collection of fitted base estimators.
391 | """
392 |
393 | def __init__(self,
394 | base_estimator,
395 | n_estimators=10,
396 | estimator_params=tuple(),
397 | random_state=None,
398 | n_jobs=None,
399 | verbose=0,):
400 |
401 | self.random_state = random_state
402 | self.n_jobs = n_jobs
403 | self.verbose = verbose
404 | self.check_x_y_args = {
405 | 'accept_sparse': ['csr', 'csc'],
406 | 'force_all_finite': False,
407 | 'dtype': None,
408 | }
409 |
410 | super(BaseImbalancedEnsemble, self).__init__(
411 | base_estimator=base_estimator,
412 | n_estimators=n_estimators,
413 | estimator_params=estimator_params,
414 | )
415 |
416 | self._properties = _properties
417 |
418 |
419 | def _validate_y(self, y):
420 | """Validate the label vector."""
421 | y = column_or_1d(y, warn=True)
422 | check_classification_targets(y)
423 | self.classes_, y = np.unique(y, return_inverse=True)
424 | self.n_classes_ = len(self.classes_)
425 | return y
426 |
427 |
428 | def _validate_estimator(self, default):
429 | """Check the estimator, sampler and the n_estimator attribute.
430 |
431 | Sets the base_estimator_` and base_sampler_` attributes.
432 | """
433 |
434 | # validate estimator using
435 | # sklearn.ensemble.BaseEnsemble._validate_estimator
436 | super()._validate_estimator(default=default)
437 |
438 | if hasattr(self, 'base_sampler'):
439 | # validate sampler and sampler_kwargs
440 | # validated sampler stored in self.base_sampler_
441 | try:
442 | self.base_sampler_ = clone(self.base_sampler)
443 | except Exception as e:
444 | e_args = list(e.args)
445 | e_args[0] = "Exception occurs when trying to validate" + \
446 | " base_sampler: " + e_args[0]
447 | e.args = tuple(e_args)
448 | raise e
449 |
450 |
451 | def _make_sampler(self, append=True, random_state=None, **overwrite_kwargs):
452 | """Make and configure a copy of the `base_sampler_` attribute.
453 |
454 | Warning: This method should be used to properly instantiate new
455 | sub-samplers.
456 | """
457 |
458 | sampler = clone(self.base_sampler_)
459 | if hasattr(self, 'sampler_kwargs_'):
460 | sampler.set_params(**self.sampler_kwargs_)
461 |
462 | # Arguments passed to _make_sampler function have higher priority,
463 | # they will overwrite the self.sampler_kwargs_
464 | sampler.set_params(**overwrite_kwargs)
465 |
466 | if random_state is not None:
467 | _set_random_states(sampler, random_state)
468 |
469 | if append:
470 | self.samplers_.append(sampler)
471 |
472 | return sampler
473 |
474 |
475 | @_deprecate_positional_args
476 | def fit(self, X, y, *, sample_weight=None, **kwargs):
477 | """Build the ensemble classifier from the training set (X, y)."""
478 |
479 | # Check random state
480 | self.random_state = check_random_state(self.random_state)
481 |
482 | # Convert data (X is required to be 2d and indexable)
483 | X, y = self._validate_data(X, y, **self.check_x_y_args)
484 | if sample_weight is not None:
485 | sample_weight = _check_sample_weight(sample_weight, X, dtype=np.float64)
486 | sample_weight /= sample_weight.sum()
487 | if np.any(sample_weight < 0):
488 | raise ValueError("sample_weight cannot contain negative weights")
489 |
490 | # Remap output
491 | n_samples, self.n_features_ = X.shape
492 | self.features_ = np.arange(self.n_features_)
493 | self._n_samples = n_samples
494 | y = self._validate_y(y)
495 |
496 | # Check parameters
497 | self._validate_estimator(default=DecisionTreeClassifier())
498 |
499 | # If the base estimator do not support sample weight and sample weight
500 | # is not None, raise an ValueError
501 | support_sample_weight = has_fit_parameter(self.base_estimator_,
502 | "sample_weight")
503 | if not support_sample_weight and sample_weight is not None:
504 | raise ValueError("The base estimator doesn't support sample weight")
505 |
506 | self.estimators_, self.estimators_features_ = [], []
507 |
508 | return self._fit(X, y, sample_weight=sample_weight, **kwargs)
509 |
510 |
511 | @abstractmethod
512 | def _fit(self, X, y, sample_weight, **kwargs):
513 | """Needs to be implemented in the derived class"""
514 | return self
515 |
516 |
517 | def predict_proba(self, X):
518 | """Predict class probabilities for X.
519 |
520 | The predicted class probabilities of an input sample is computed as
521 | the mean predicted class probabilities of the base estimators in the
522 | ensemble. If base estimators do not implement a ``predict_proba``
523 | method, then it resorts to voting and the predicted class probabilities
524 | of an input sample represents the proportion of estimators predicting
525 | each class.
526 |
527 | Parameters
528 | ----------
529 | X : {array-like, sparse matrix} of shape = [n_samples, n_features]
530 | The training input samples. Sparse matrices are accepted only if
531 | they are supported by the base estimator.
532 |
533 | Returns
534 | -------
535 | p : array of shape = [n_samples, n_classes]
536 | The class probabilities of the input samples.
537 | """
538 |
539 | check_is_fitted(self)
540 | # Check data
541 | X = check_array(
542 | X, accept_sparse=['csr', 'csc'], dtype=None,
543 | force_all_finite=False
544 | )
545 | if self.n_features_ != X.shape[1]:
546 | raise ValueError("Number of features of the model must "
547 | "match the input. Model n_features is {0} and "
548 | "input n_features is {1}."
549 | "".format(self.n_features_, X.shape[1]))
550 |
551 | # Parallel loop
552 | n_jobs, _, starts = _partition_estimators(self.n_estimators,
553 | self.n_jobs)
554 |
555 | all_proba = Parallel(n_jobs=n_jobs, verbose=self.verbose,
556 | **self._parallel_args())(
557 | delayed(_parallel_predict_proba)(
558 | self.estimators_[starts[i]:starts[i + 1]],
559 | self.estimators_features_[starts[i]:starts[i + 1]],
560 | X,
561 | self.n_classes_)
562 | for i in range(n_jobs))
563 |
564 | # Reduce
565 | proba = sum(all_proba) / len(self.estimators_)
566 |
567 | return proba
568 |
569 |
570 | def predict(self, X):
571 | """Predict class for X.
572 |
573 | The predicted class of an input sample is computed as the class with
574 | the highest mean predicted probability. If base estimators do not
575 | implement a ``predict_proba`` method, then it resorts to voting.
576 |
577 | Parameters
578 | ----------
579 | X : {array-like, sparse matrix} of shape (n_samples, n_features)
580 | The training input samples. Sparse matrices are accepted only if
581 | they are supported by the base estimator.
582 |
583 | Returns
584 | -------
585 | y : ndarray of shape (n_samples,)
586 | The predicted classes.
587 | """
588 |
589 | predicted_probabilitiy = self.predict_proba(X)
590 | return self.classes_.take((np.argmax(predicted_probabilitiy, axis=1)),
591 | axis=0)
592 |
593 |
594 | @property
595 | def feature_importances_(self):
596 | """The impurity-based feature importances.
597 | The higher, the more important the feature.
598 | The importance of a feature is computed as the (normalized)
599 | total reduction of the criterion brought by that feature. It is also
600 | known as the Gini importance.
601 | Warning: impurity-based feature importances can be misleading for
602 | high cardinality features (many unique values). See
603 | :func:`sklearn.inspection.permutation_importance` as an alternative.
604 | Returns
605 | -------
606 | feature_importances_ : ndarray of shape (n_features,)
607 | The feature importances.
608 | """
609 | if self.estimators_ is None or len(self.estimators_) == 0:
610 | raise ValueError(
611 | "Estimator not fitted, call `fit` before `feature_importances_`."
612 | )
613 |
614 | try:
615 | if hasattr(self, 'estimator_weights_'):
616 | norm = self.estimator_weights_.sum()
617 | return (
618 | sum(
619 | weight * clf.feature_importances_
620 | for weight, clf in zip(self.estimator_weights_, self.estimators_)
621 | )
622 | / norm
623 | )
624 | else:
625 | return (
626 | sum(
627 | clf.feature_importances_ for clf in self.estimators_
628 | )
629 | / len(self.estimators_)
630 | )
631 |
632 | except AttributeError as e:
633 | raise AttributeError(
634 | "Unable to compute feature importances "
635 | "since base_estimator does not have a "
636 | "feature_importances_ attribute"
637 | ) from e
638 |
639 |
640 | def _parallel_args(self):
641 | return {}
642 |
643 | # %%
644 |
--------------------------------------------------------------------------------
/self_paced_ensemble/utils/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | --------------------------------------------------------------------------
3 | The `self-paced-ensemble.utils` module implement various utilities.
4 | --------------------------------------------------------------------------
5 | """
6 |
7 | from ._utils import (
8 | load_covtype_dataset,
9 | make_binary_classification_target,
10 | imbalance_train_test_split,
11 | imbalance_random_subset,
12 | auc_prc,
13 | f1_optim,
14 | gm_optim,
15 | mcc_optim,
16 | save_model,
17 | load_model,
18 | )
19 |
20 | __all__ = [
21 | "load_covtype_dataset",
22 | "make_binary_classification_target",
23 | "imbalance_train_test_split",
24 | "imbalance_random_subset",
25 | "auc_prc",
26 | "f1_optim",
27 | "gm_optim",
28 | "mcc_optim",
29 | "save_model",
30 | "load_model",
31 | ]
32 |
--------------------------------------------------------------------------------
/self_paced_ensemble/utils/_plot.py:
--------------------------------------------------------------------------------
1 | """Utilities for data visualization."""
2 |
3 | # Authors: Zhining Liu
4 | # License: MIT
5 |
6 | import pandas as pd
7 | import numpy as np
8 |
9 | from copy import copy
10 | from collections import Counter
11 | import matplotlib.pyplot as plt
12 | import seaborn as sns
13 |
14 | from sklearn.decomposition import KernelPCA
15 |
16 | DEFAULT_VIS_KWARGS = {
17 | 'cmap': plt.cm.rainbow,
18 | 'edgecolor': 'black',
19 | 'alpha': 0.6,
20 | }
21 |
22 | def set_ax_border(ax, border_color='black', border_width=2):
23 | for _, spine in ax.spines.items():
24 | spine.set_color(border_color)
25 | spine.set_linewidth(border_width)
26 |
27 | return ax
28 |
29 | def plot_scatter(X, y, ax=None, weights=None, title='',
30 | projection=None, vis_params=None):
31 | if ax is None:
32 | ax = plt.axes()
33 | X_vis = projection.transform(X) if X.shape[1] > 2 else X
34 | title += ' (2D projection by {})'.format(
35 | str(projection.__class__).split('.')[-1][:-2]
36 | )
37 | size = 50 if weights is None else weights
38 | if np.unique(y).shape[0] > 2:
39 | vis_params['palette'] = plt.cm.rainbow
40 | sns.scatterplot(x=X_vis[:, 0], y=X_vis[:, 1],
41 | hue=y, style=y, s=size, **vis_params, legend='full', ax=ax)
42 |
43 | ax.set_title(title)
44 | ax = set_ax_border(ax, border_color='black', border_width=2)
45 | ax.grid(color='black', linestyle='-.', alpha=0.5)
46 |
47 | return ax
48 |
49 | def plot_class_distribution(y, ax=None, title='',
50 | sort_values=False, plot_average=True):
51 | count = pd.DataFrame(list(Counter(y).items()),
52 | columns=['Class', 'Frequency'])
53 | if sort_values:
54 | count = count.sort_values(by='Frequency', ascending=False)
55 | if ax is None:
56 | ax = plt.axes()
57 | count.plot.bar(x='Class', y='Frequency', title=title, ax=ax)
58 |
59 | ax.set_title(title)
60 | ax = set_ax_border(ax, border_color='black', border_width=2)
61 | ax.grid(color='black', linestyle='-.', alpha=0.5, axis='y')
62 |
63 | if plot_average:
64 | ax.axhline(y=count['Frequency'].mean(),ls="dashdot",c="red")
65 | xlim_min, xlim_max, ylim_min, ylim_max = ax.axis()
66 | ax.text(
67 | x=xlim_min+(xlim_max-xlim_min)*0.82,
68 | y=count['Frequency'].mean()+(ylim_max-ylim_min)*0.03,
69 | c="red",s='Average')
70 |
71 | return ax
72 |
73 | def plot_2Dprojection_and_cardinality(X, y, figsize=(10, 4), vis_params=None,
74 | projection=None, weights=None, plot_average=True,
75 | title1='Dataset', title2='Class Distribution'):
76 |
77 | if vis_params is None:
78 | vis_params = copy(DEFAULT_VIS_KWARGS)
79 |
80 | fig, (ax1, ax2) = plt.subplots(1, 2, figsize=figsize)
81 | if projection == None:
82 | projection = KernelPCA(n_components=2).fit(X, y)
83 | ax1 = plot_scatter(X, y, ax=ax1, weights=weights, title=title1,
84 | projection=projection, vis_params=vis_params)
85 | ax2 = plot_class_distribution(y, ax=ax2, title=title2,
86 | sort_values=True, plot_average=plot_average)
87 | plt.tight_layout()
88 | return fig
--------------------------------------------------------------------------------
/self_paced_ensemble/utils/_utils.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | """Utilities."""
3 |
4 | # Authors: Zhining Liu
5 | # License: MIT
6 |
7 | from joblib import dump, load
8 | from sklearn.metrics import (
9 | precision_recall_curve,
10 | average_precision_score,
11 | matthews_corrcoef,
12 | )
13 | from sklearn import datasets
14 | from sklearn.model_selection import train_test_split
15 | import numpy as np
16 |
17 | def load_covtype_dataset(subset=0.1, test_size=0.2, random_state=None):
18 | '''Load & Split training/test covtype dataset.'''
19 | print ('\nDataset used: \t\tForest covertypes from UCI ({:.1%} random subset)'.format(subset))
20 | X, y = datasets.fetch_covtype(return_X_y=True)
21 | y = make_binary_classification_target(y, 7, verbose=True)
22 | X, y = imbalance_random_subset(
23 | X, y, size=subset, random_state=random_state)
24 | X_train, X_test, y_train, y_test = imbalance_train_test_split(
25 | X, y, test_size=test_size, random_state=random_state)
26 | return X_train, X_test, y_train, y_test
27 |
28 | def make_binary_classification_target(y, pos_label, verbose=False):
29 | '''Turn multi-class targets into binary classification targets.'''
30 | pos_idx = (y==pos_label)
31 | y[pos_idx] = 1
32 | y[~pos_idx] = 0
33 | if verbose:
34 | print ('Positive target:\t{}'.format(pos_label))
35 | print ('Imbalance ratio:\t{:.3f}'.format((y==0).sum()/(y==1).sum()))
36 | return y
37 |
38 | def imbalance_train_test_split(X, y, test_size, random_state=None):
39 | '''Train/Test split that guarantee same class distribution between split datasets.'''
40 | X_maj = X[y==0]; y_maj = y[y==0]
41 | X_min = X[y==1]; y_min = y[y==1]
42 | X_train_maj, X_test_maj, y_train_maj, y_test_maj = train_test_split(
43 | X_maj, y_maj, test_size=test_size, random_state=random_state)
44 | X_train_min, X_test_min, y_train_min, y_test_min = train_test_split(
45 | X_min, y_min, test_size=test_size, random_state=random_state)
46 | X_train = np.concatenate([X_train_maj, X_train_min])
47 | X_test = np.concatenate([X_test_maj, X_test_min])
48 | y_train = np.concatenate([y_train_maj, y_train_min])
49 | y_test = np.concatenate([y_test_maj, y_test_min])
50 | return X_train, X_test, y_train, y_test
51 |
52 | def imbalance_random_subset(X, y, size, random_state=None):
53 | '''Get random subset while guarantee same class distribution.'''
54 | _, X, _, y = imbalance_train_test_split(X, y,
55 | test_size=size, random_state=random_state)
56 | return X, y
57 |
58 | def auc_prc(label, y_pred):
59 | '''Compute AUCPRC score.'''
60 | return average_precision_score(label, y_pred)
61 |
62 | def f1_optim(label, y_pred):
63 | '''Compute optimal F1 score.'''
64 | y_pred = y_pred.copy()
65 | prec, reca, _ = precision_recall_curve(label, y_pred)
66 | f1s = 2 * (prec * reca) / (prec + reca)
67 | return max(f1s)
68 |
69 | def gm_optim(label, y_pred):
70 | '''Compute optimal G-mean score.'''
71 | y_pred = y_pred.copy()
72 | prec, reca, _ = precision_recall_curve(label, y_pred)
73 | gms = np.power((prec*reca), 0.5)
74 | return max(gms)
75 |
76 | def mcc_optim(label, y_pred):
77 | '''Compute optimal MCC score.'''
78 | mccs = []
79 | for t in range(100):
80 | y_pred_b = y_pred.copy()
81 | y_pred_b[y_pred_b < 0+t*0.01] = 0
82 | y_pred_b[y_pred_b >= 0+t*0.01] = 1
83 | mcc = matthews_corrcoef(label, y_pred_b)
84 | mccs.append(mcc)
85 | return max(mccs)
86 |
87 | def save_model(model, filename:str):
88 | """Save model to file."""
89 | dump(model, filename=filename)
90 |
91 | def load_model(filename:str):
92 | """Load model from file."""
93 | return load(filename)
--------------------------------------------------------------------------------
/self_paced_ensemble/utils/_validation.py:
--------------------------------------------------------------------------------
1 | """Utilities for input validation."""
2 |
3 | # Adapted from imbalanced-learn
4 |
5 | # Authors: Guillaume Lemaitre
6 | # License: MIT
7 |
8 | import warnings
9 | from collections import OrderedDict
10 | from functools import wraps
11 | from inspect import signature, Parameter
12 | from numbers import Integral, Real
13 |
14 | import numpy as np
15 |
16 | from sklearn.utils import column_or_1d
17 | from sklearn.utils.multiclass import type_of_target
18 |
19 |
20 | SAMPLING_KIND = (
21 | "over-sampling",
22 | "under-sampling",
23 | "clean-sampling",
24 | "hybrid-sampling",
25 | "ensemble",
26 | "bypass",
27 | )
28 | TARGET_KIND = ("binary", "multiclass", "multilabel-indicator")
29 |
30 |
31 | class ArraysTransformer:
32 | """A class to convert sampler output arrays to their original types."""
33 |
34 | def __init__(self, X, y):
35 | self.x_props = self._gets_props(X)
36 | self.y_props = self._gets_props(y)
37 |
38 | def transform(self, X, y):
39 | X = self._transfrom_one(X, self.x_props)
40 | y = self._transfrom_one(y, self.y_props)
41 | return X, y
42 |
43 | def _gets_props(self, array):
44 | props = {}
45 | props["type"] = array.__class__.__name__
46 | props["columns"] = getattr(array, "columns", None)
47 | props["name"] = getattr(array, "name", None)
48 | props["dtypes"] = getattr(array, "dtypes", None)
49 | return props
50 |
51 | def _transfrom_one(self, array, props):
52 | type_ = props["type"].lower()
53 | if type_ == "list":
54 | ret = array.tolist()
55 | elif type_ == "dataframe":
56 | import pandas as pd
57 |
58 | ret = pd.DataFrame(array, columns=props["columns"])
59 | ret = ret.astype(props["dtypes"])
60 | elif type_ == "series":
61 | import pandas as pd
62 |
63 | ret = pd.Series(array, dtype=props["dtypes"], name=props["name"])
64 | else:
65 | ret = array
66 | return ret
67 |
68 |
69 | def _count_class_sample(y):
70 | unique, counts = np.unique(y, return_counts=True)
71 | return dict(zip(unique, counts))
72 |
73 |
74 | def check_target_type(y, indicate_one_vs_all=False):
75 | """Check the target types to be conform to the current samplers.
76 |
77 | The current samplers should be compatible with ``'binary'``,
78 | ``'multilabel-indicator'`` and ``'multiclass'`` targets only.
79 |
80 | Parameters
81 | ----------
82 | y : ndarray
83 | The array containing the target.
84 |
85 | indicate_one_vs_all : bool, default=False
86 | Either to indicate if the targets are encoded in a one-vs-all fashion.
87 |
88 | Returns
89 | -------
90 | y : ndarray
91 | The returned target.
92 |
93 | is_one_vs_all : bool, optional
94 | Indicate if the target was originally encoded in a one-vs-all fashion.
95 | Only returned if ``indicate_multilabel=True``.
96 | """
97 | type_y = type_of_target(y)
98 | if type_y == "multilabel-indicator":
99 | if np.any(y.sum(axis=1) > 1):
100 | raise ValueError(
101 | "Imbalanced-learn currently supports binary, multiclass and "
102 | "binarized encoded multiclasss targets. Multilabel and "
103 | "multioutput targets are not supported."
104 | )
105 | y = y.argmax(axis=1)
106 | else:
107 | y = column_or_1d(y)
108 |
109 | return (y, type_y == "multilabel-indicator") if indicate_one_vs_all else y
110 |
111 |
112 | def _sampling_strategy_all(y, sampling_type):
113 | """Returns sampling target by targeting all classes."""
114 | target_stats = _count_class_sample(y)
115 | if sampling_type == "over-sampling":
116 | n_sample_majority = max(target_stats.values())
117 | sampling_strategy = {
118 | key: n_sample_majority - value for (key, value) in target_stats.items()
119 | }
120 | elif sampling_type == "under-sampling" or sampling_type == "clean-sampling":
121 | n_sample_minority = min(target_stats.values())
122 | sampling_strategy = {key: n_sample_minority for key in target_stats.keys()}
123 | else:
124 | raise NotImplementedError
125 |
126 | return sampling_strategy
127 |
128 |
129 | def _sampling_strategy_majority(y, sampling_type):
130 | """Returns sampling target by targeting the majority class only."""
131 | if sampling_type == "over-sampling":
132 | raise ValueError(
133 | "'sampling_strategy'='majority' cannot be used with over-sampler."
134 | )
135 | elif sampling_type == "under-sampling" or sampling_type == "clean-sampling":
136 | target_stats = _count_class_sample(y)
137 | class_majority = max(target_stats, key=target_stats.get)
138 | n_sample_minority = min(target_stats.values())
139 | sampling_strategy = {
140 | key: n_sample_minority
141 | for key in target_stats.keys()
142 | if key == class_majority
143 | }
144 | else:
145 | raise NotImplementedError
146 |
147 | return sampling_strategy
148 |
149 |
150 | def _sampling_strategy_not_majority(y, sampling_type):
151 | """Returns sampling target by targeting all classes but not the
152 | majority."""
153 | target_stats = _count_class_sample(y)
154 | if sampling_type == "over-sampling":
155 | n_sample_majority = max(target_stats.values())
156 | class_majority = max(target_stats, key=target_stats.get)
157 | sampling_strategy = {
158 | key: n_sample_majority - value
159 | for (key, value) in target_stats.items()
160 | if key != class_majority
161 | }
162 | elif sampling_type == "under-sampling" or sampling_type == "clean-sampling":
163 | n_sample_minority = min(target_stats.values())
164 | class_majority = max(target_stats, key=target_stats.get)
165 | sampling_strategy = {
166 | key: n_sample_minority
167 | for key in target_stats.keys()
168 | if key != class_majority
169 | }
170 | else:
171 | raise NotImplementedError
172 |
173 | return sampling_strategy
174 |
175 |
176 | def _sampling_strategy_not_minority(y, sampling_type):
177 | """Returns sampling target by targeting all classes but not the
178 | minority."""
179 | target_stats = _count_class_sample(y)
180 | if sampling_type == "over-sampling":
181 | n_sample_majority = max(target_stats.values())
182 | class_minority = min(target_stats, key=target_stats.get)
183 | sampling_strategy = {
184 | key: n_sample_majority - value
185 | for (key, value) in target_stats.items()
186 | if key != class_minority
187 | }
188 | elif sampling_type == "under-sampling" or sampling_type == "clean-sampling":
189 | n_sample_minority = min(target_stats.values())
190 | class_minority = min(target_stats, key=target_stats.get)
191 | sampling_strategy = {
192 | key: n_sample_minority
193 | for key in target_stats.keys()
194 | if key != class_minority
195 | }
196 | else:
197 | raise NotImplementedError
198 |
199 | return sampling_strategy
200 |
201 |
202 | def _sampling_strategy_minority(y, sampling_type):
203 | """Returns sampling target by targeting the minority class only."""
204 | target_stats = _count_class_sample(y)
205 | if sampling_type == "over-sampling":
206 | n_sample_majority = max(target_stats.values())
207 | class_minority = min(target_stats, key=target_stats.get)
208 | sampling_strategy = {
209 | key: n_sample_majority - value
210 | for (key, value) in target_stats.items()
211 | if key == class_minority
212 | }
213 | elif sampling_type == "under-sampling" or sampling_type == "clean-sampling":
214 | raise ValueError(
215 | "'sampling_strategy'='minority' cannot be used with"
216 | " under-sampler and clean-sampler."
217 | )
218 | else:
219 | raise NotImplementedError
220 |
221 | return sampling_strategy
222 |
223 |
224 | def _sampling_strategy_auto(y, sampling_type):
225 | """Returns sampling target auto for over-sampling and not-minority for
226 | under-sampling."""
227 | if sampling_type == "over-sampling":
228 | return _sampling_strategy_not_majority(y, sampling_type)
229 | elif sampling_type == "under-sampling" or sampling_type == "clean-sampling":
230 | return _sampling_strategy_not_minority(y, sampling_type)
231 |
232 |
233 | def _sampling_strategy_dict(sampling_strategy, y, sampling_type):
234 | """Returns sampling target by converting the dictionary depending of the
235 | sampling."""
236 | target_stats = _count_class_sample(y)
237 | # check that all keys in sampling_strategy are also in y
238 | set_diff_sampling_strategy_target = set(sampling_strategy.keys()) - set(
239 | target_stats.keys()
240 | )
241 | if len(set_diff_sampling_strategy_target) > 0:
242 | raise ValueError(
243 | f"The {set_diff_sampling_strategy_target} target class is/are not "
244 | f"present in the data."
245 | )
246 | # check that there is no negative number
247 | if any(n_samples < 0 for n_samples in sampling_strategy.values()):
248 | raise ValueError(
249 | f"The number of samples in a class cannot be negative."
250 | f"'sampling_strategy' contains some negative value: {sampling_strategy}"
251 | )
252 | sampling_strategy_ = {}
253 | if sampling_type == "over-sampling":
254 | n_samples_majority = max(target_stats.values())
255 | class_majority = max(target_stats, key=target_stats.get)
256 | for class_sample, n_samples in sampling_strategy.items():
257 | if n_samples < target_stats[class_sample]:
258 | raise ValueError(
259 | f"With over-sampling methods, the number"
260 | f" of samples in a class should be greater"
261 | f" or equal to the original number of samples."
262 | f" Originally, there is {target_stats[class_sample]} "
263 | f"samples and {n_samples} samples are asked."
264 | )
265 | if n_samples > n_samples_majority:
266 | warnings.warn(
267 | f"After over-sampling, the number of samples ({n_samples})"
268 | f" in class {class_sample} will be larger than the number of"
269 | f" samples in the majority class (class #{class_majority} ->"
270 | f" {n_samples_majority})"
271 | )
272 | sampling_strategy_[class_sample] = n_samples - target_stats[class_sample]
273 | elif sampling_type == "under-sampling":
274 | for class_sample, n_samples in sampling_strategy.items():
275 | if n_samples > target_stats[class_sample]:
276 | raise ValueError(
277 | f"With under-sampling methods, the number of"
278 | f" samples in a class should be less or equal"
279 | f" to the original number of samples."
280 | f" Originally, there is {target_stats[class_sample]} "
281 | f"samples and {n_samples} samples are asked."
282 | )
283 | sampling_strategy_[class_sample] = n_samples
284 | elif sampling_type == "clean-sampling":
285 | raise ValueError(
286 | "'sampling_strategy' as a dict for cleaning methods is "
287 | "not supported. Please give a list of the classes to be "
288 | "targeted by the sampling."
289 | )
290 | elif sampling_type == "hybrid-sampling":
291 | for class_sample, n_samples in sampling_strategy.items():
292 | sampling_strategy_[class_sample] = n_samples
293 | else:
294 | raise NotImplementedError
295 |
296 | return sampling_strategy_
297 |
298 |
299 | def _sampling_strategy_list(sampling_strategy, y, sampling_type):
300 | """With cleaning methods, sampling_strategy can be a list to target the
301 | class of interest."""
302 | if sampling_type != "clean-sampling":
303 | raise ValueError(
304 | "'sampling_strategy' cannot be a list for samplers "
305 | "which are not cleaning methods."
306 | )
307 |
308 | target_stats = _count_class_sample(y)
309 | # check that all keys in sampling_strategy are also in y
310 | set_diff_sampling_strategy_target = set(sampling_strategy) - set(
311 | target_stats.keys()
312 | )
313 | if len(set_diff_sampling_strategy_target) > 0:
314 | raise ValueError(
315 | f"The {set_diff_sampling_strategy_target} target class is/are not "
316 | f"present in the data."
317 | )
318 |
319 | return {
320 | class_sample: min(target_stats.values()) for class_sample in sampling_strategy
321 | }
322 |
323 |
324 | def _sampling_strategy_float(sampling_strategy, y, sampling_type):
325 | """Take a proportion of the majority (over-sampling) or minority
326 | (under-sampling) class in binary classification."""
327 | type_y = type_of_target(y)
328 | if type_y != "binary":
329 | raise ValueError(
330 | '"sampling_strategy" can be a float only when the type '
331 | "of target is binary. For multi-class, use a dict."
332 | )
333 | target_stats = _count_class_sample(y)
334 | if sampling_type == "over-sampling":
335 | n_sample_majority = max(target_stats.values())
336 | class_majority = max(target_stats, key=target_stats.get)
337 | sampling_strategy_ = {
338 | key: int(n_sample_majority * sampling_strategy - value)
339 | for (key, value) in target_stats.items()
340 | if key != class_majority
341 | }
342 | if any([n_samples <= 0 for n_samples in sampling_strategy_.values()]):
343 | raise ValueError(
344 | "The specified ratio required to remove samples "
345 | "from the minority class while trying to "
346 | "generate new samples. Please increase the "
347 | "ratio."
348 | )
349 | elif sampling_type == "under-sampling":
350 | n_sample_minority = min(target_stats.values())
351 | class_minority = min(target_stats, key=target_stats.get)
352 | sampling_strategy_ = {
353 | key: int(n_sample_minority / sampling_strategy)
354 | for (key, value) in target_stats.items()
355 | if key != class_minority
356 | }
357 | if any(
358 | [
359 | n_samples > target_stats[target]
360 | for target, n_samples in sampling_strategy_.items()
361 | ]
362 | ):
363 | raise ValueError(
364 | "The specified ratio required to generate new "
365 | "sample in the majority class while trying to "
366 | "remove samples. Please increase the ratio."
367 | )
368 | else:
369 | raise ValueError(
370 | "'clean-sampling' methods do let the user specify the sampling ratio."
371 | )
372 | return sampling_strategy_
373 |
374 |
375 | def check_sampling_strategy(sampling_strategy, y, sampling_type, **kwargs):
376 | """Sampling target validation for samplers.
377 |
378 | Checks that ``sampling_strategy`` is of consistent type and return a
379 | dictionary containing each targeted class with its corresponding
380 | number of sample. It is used in :class:`~imblearn.base.BaseSampler`.
381 |
382 | Parameters
383 | ----------
384 | sampling_strategy : float, str, dict, list or callable,
385 | Sampling information to sample the data set.
386 |
387 | - When ``float``:
388 |
389 | For **under-sampling methods**, it corresponds to the ratio
390 | :math:`\\alpha_{us}` defined by :math:`N_{rM} = \\alpha_{us}
391 | \\times N_{m}` where :math:`N_{rM}` and :math:`N_{m}` are the
392 | number of samples in the majority class after resampling and the
393 | number of samples in the minority class, respectively;
394 |
395 | For **over-sampling methods**, it correspond to the ratio
396 | :math:`\\alpha_{os}` defined by :math:`N_{rm} = \\alpha_{os}
397 | \\times N_{m}` where :math:`N_{rm}` and :math:`N_{M}` are the
398 | number of samples in the minority class after resampling and the
399 | number of samples in the majority class, respectively.
400 |
401 | .. warning::
402 | ``float`` is only available for **binary** classification. An
403 | error is raised for multi-class classification and with cleaning
404 | samplers.
405 |
406 | - When ``str``, specify the class targeted by the resampling. For
407 | **under- and over-sampling methods**, the number of samples in the
408 | different classes will be equalized. For **cleaning methods**, the
409 | number of samples will not be equal. Possible choices are:
410 |
411 | ``'minority'``: resample only the minority class;
412 |
413 | ``'majority'``: resample only the majority class;
414 |
415 | ``'not minority'``: resample all classes but the minority class;
416 |
417 | ``'not majority'``: resample all classes but the majority class;
418 |
419 | ``'all'``: resample all classes;
420 |
421 | ``'auto'``: for under-sampling methods, equivalent to ``'not
422 | minority'`` and for over-sampling methods, equivalent to ``'not
423 | majority'``.
424 |
425 | - When ``dict``, the keys correspond to the targeted classes. The
426 | values correspond to the desired number of samples for each targeted
427 | class.
428 |
429 | .. warning::
430 | ``dict`` is available for both **under- and over-sampling
431 | methods**. An error is raised with **cleaning methods**. Use a
432 | ``list`` instead.
433 |
434 | - When ``list``, the list contains the targeted classes. It used only
435 | for **cleaning methods**.
436 |
437 | .. warning::
438 | ``list`` is available for **cleaning methods**. An error is raised
439 | with **under- and over-sampling methods**.
440 |
441 | - When callable, function taking ``y`` and returns a ``dict``. The keys
442 | correspond to the targeted classes. The values correspond to the
443 | desired number of samples for each class.
444 |
445 | y : ndarray of shape (n_samples,)
446 | The target array.
447 |
448 | sampling_type : {{'over-sampling', 'under-sampling', 'clean-sampling'}}
449 | The type of sampling. Can be either ``'over-sampling'``,
450 | ``'under-sampling'``, or ``'clean-sampling'``.
451 |
452 | kwargs : dict
453 | Dictionary of additional keyword arguments to pass to
454 | ``sampling_strategy`` when this is a callable.
455 |
456 | Returns
457 | -------
458 | sampling_strategy_converted : dict
459 | The converted and validated sampling target. Returns a dictionary with
460 | the key being the class target and the value being the desired
461 | number of samples.
462 |
463 | """
464 | if sampling_type not in SAMPLING_KIND:
465 | raise ValueError(
466 | f"'sampling_type' should be one of {SAMPLING_KIND}. "
467 | f"Got '{sampling_type} instead."
468 | )
469 |
470 | if np.unique(y).size <= 1:
471 | raise ValueError(
472 | f"The target 'y' needs to have more than 1 class. "
473 | f"Got {np.unique(y).size} class instead"
474 | )
475 |
476 | if sampling_type in ("ensemble", "bypass"):
477 | return sampling_strategy
478 |
479 | if isinstance(sampling_strategy, str):
480 | if sampling_strategy not in SAMPLING_TARGET_KIND.keys():
481 | raise ValueError(
482 | f"When 'sampling_strategy' is a string, it needs"
483 | f" to be one of {SAMPLING_TARGET_KIND}. Got '{sampling_strategy}' "
484 | f"instead."
485 | )
486 | return OrderedDict(
487 | sorted(SAMPLING_TARGET_KIND[sampling_strategy](y, sampling_type).items())
488 | )
489 | elif isinstance(sampling_strategy, dict):
490 | return OrderedDict(
491 | sorted(_sampling_strategy_dict(sampling_strategy, y, sampling_type).items())
492 | )
493 | elif isinstance(sampling_strategy, list):
494 | return OrderedDict(
495 | sorted(_sampling_strategy_list(sampling_strategy, y, sampling_type).items())
496 | )
497 | elif isinstance(sampling_strategy, Real):
498 | if sampling_strategy <= 0 or sampling_strategy > 1:
499 | raise ValueError(
500 | f"When 'sampling_strategy' is a float, it should be "
501 | f"in the range (0, 1]. Got {sampling_strategy} instead."
502 | )
503 | return OrderedDict(
504 | sorted(
505 | _sampling_strategy_float(sampling_strategy, y, sampling_type).items()
506 | )
507 | )
508 | elif callable(sampling_strategy):
509 | sampling_strategy_ = sampling_strategy(y, **kwargs)
510 | return OrderedDict(
511 | sorted(
512 | _sampling_strategy_dict(sampling_strategy_, y, sampling_type).items()
513 | )
514 | )
515 |
516 |
517 | SAMPLING_TARGET_KIND = {
518 | "minority": _sampling_strategy_minority,
519 | "majority": _sampling_strategy_majority,
520 | "not minority": _sampling_strategy_not_minority,
521 | "not majority": _sampling_strategy_not_majority,
522 | "all": _sampling_strategy_all,
523 | "auto": _sampling_strategy_auto,
524 | }
525 |
526 |
527 | def _deprecate_positional_args(f):
528 | """Decorator for methods that issues warnings for positional arguments
529 |
530 | Using the keyword-only argument syntax in pep 3102, arguments after the
531 | * will issue a warning when passed as a positional argument.
532 |
533 | Parameters
534 | ----------
535 | f : function
536 | function to check arguments on.
537 | """
538 | sig = signature(f)
539 | kwonly_args = []
540 | all_args = []
541 |
542 | for name, param in sig.parameters.items():
543 | if param.kind == Parameter.POSITIONAL_OR_KEYWORD:
544 | all_args.append(name)
545 | elif param.kind == Parameter.KEYWORD_ONLY:
546 | kwonly_args.append(name)
547 |
548 | @wraps(f)
549 | def inner_f(*args, **kwargs):
550 | extra_args = len(args) - len(all_args)
551 | if extra_args > 0:
552 | # ignore first 'self' argument for instance methods
553 | args_msg = [
554 | f"{name}={arg}"
555 | for name, arg in zip(kwonly_args[:extra_args], args[-extra_args:])
556 | ]
557 | warnings.warn(
558 | f"Pass {', '.join(args_msg)} as keyword args. From version 0.9 "
559 | f"passing these as positional arguments will "
560 | f"result in an error",
561 | FutureWarning,
562 | )
563 | kwargs.update({k: arg for k, arg in zip(sig.parameters, args)})
564 | return f(**kwargs)
565 |
566 | return inner_f
567 |
--------------------------------------------------------------------------------
/self_paced_ensemble/utils/_validation_data.py:
--------------------------------------------------------------------------------
1 | """Utilities for data validation."""
2 |
3 | # Authors: Zhining Liu
4 | # License: MIT
5 |
6 |
7 | from collections import OrderedDict
8 | from sklearn.utils import check_X_y
9 |
10 |
11 | VALID_DATA_INFO = "'eval_datasets' should be a `dict` of validation data," + \
12 | " e.g., {..., dataset_name : (X_valid, y_valid), ...}."
13 |
14 | TRAIN_DATA_NAME = "train"
15 |
16 |
17 | def _check_eval_datasets_name(data_name):
18 | if not isinstance(data_name, str):
19 | raise TypeError(
20 | VALID_DATA_INFO + \
21 | f" The keys must be `string`, got {type(data_name)}, " + \
22 | f" please check your usage."
23 | )
24 | if data_name == TRAIN_DATA_NAME:
25 | raise ValueError(
26 | f"The name {TRAIN_DATA_NAME} is reserved for the training"
27 | f" data (it will automatically add into the 'eval_datasets_'"
28 | f" attribute after calling `fit`), please use another name"
29 | f" for your evaluation dataset."
30 | )
31 | return data_name
32 |
33 |
34 | def _check_eval_datasets_tuple(data_tuple, data_name, **check_x_y_kwargs):
35 | if not isinstance(data_tuple, tuple):
36 | raise TypeError(
37 | VALID_DATA_INFO + \
38 | f" The value of '{data_name}' is {type(data_tuple)} (should be tuple)," + \
39 | f" please check your usage."
40 | )
41 | elif len(data_tuple) != 2:
42 | raise ValueError(
43 | VALID_DATA_INFO + \
44 | f" The data tuple of '{data_name}' has {len(data_tuple)} element(s)" + \
45 | f" (should be 2), please check your usage."
46 | )
47 | else:
48 | X, y = check_X_y(data_tuple[0], data_tuple[1], **check_x_y_kwargs)
49 | return (X, y)
50 |
51 |
52 | def _check_eval_datasets_dict(eval_datasets_dict, **check_x_y_kwargs):
53 |
54 | if TRAIN_DATA_NAME in eval_datasets_dict.keys():
55 | raise ValueError(
56 | f"The name '{TRAIN_DATA_NAME}' could not be used"
57 | f" for the validation datasets. Please use another name."
58 | )
59 |
60 | eval_datasets_dict_ = {}
61 | for data_name, data_tuple in eval_datasets_dict.items():
62 | data_name_ = _check_eval_datasets_name(data_name)
63 | data_tuple_ = _check_eval_datasets_tuple(data_tuple, data_name_, **check_x_y_kwargs)
64 | eval_datasets_dict_[data_name_] = data_tuple_
65 |
66 | return eval_datasets_dict_
67 |
68 |
69 | def _all_elements_equal(list_to_check:list) -> bool:
70 | if len(list_to_check) == 1:
71 | return True
72 | return all([
73 | (list_to_check[i] == list_to_check[i+1])
74 | for i in range(len(list_to_check)-1)
75 | ])
76 |
77 |
78 | def check_eval_datasets(eval_datasets, X_train_=None, y_train_=None, **check_x_y_kwargs):
79 | """Check `eval_datasets` parameter."""
80 | # Whether to add training data in to returned data dictionary
81 | if X_train_ is None and y_train_ is None:
82 | result_datasets = OrderedDict({})
83 | else:
84 | result_datasets = OrderedDict({TRAIN_DATA_NAME: (X_train_, y_train_)})
85 |
86 | # If eval_datasets is None
87 | # return data dictionary
88 | if eval_datasets == None:
89 | return result_datasets
90 |
91 | # If eval_datasets is dict
92 | elif isinstance(eval_datasets, dict):
93 |
94 | # Check dict and validate all names (keys) and data tuples (values)
95 | eval_datasets_ = _check_eval_datasets_dict(eval_datasets, **check_x_y_kwargs)
96 |
97 | # Combine train_datasets and eval_datasets_
98 | result_datasets.update(eval_datasets_)
99 |
100 | # Ensure all datasets have the same number of features
101 | if not _all_elements_equal([data_tuple[0].shape[1]
102 | for data_tuple in result_datasets.values()]):
103 | raise ValueError(
104 | f"The train + evaluation datasets have inconsistent number of"
105 | f" features. Make sure that the data given in 'eval_datasets'"
106 | f" and the training data ('X', 'y') are sampled from the same"
107 | f" task/distribution."
108 | )
109 | return result_datasets
110 |
111 | # Else raise TypeError
112 | else:
113 | raise TypeError(
114 | VALID_DATA_INFO + \
115 | f" Got {type(eval_datasets)}, please check your usage."
116 | )
--------------------------------------------------------------------------------
/self_paced_ensemble/utils/_validation_param.py:
--------------------------------------------------------------------------------
1 | """Utilities for parameter validation."""
2 |
3 | # Authors: Zhining Liu
4 | # License: MIT
5 |
6 |
7 | from copy import copy
8 | from warnings import warn
9 | from collections import Counter
10 | from inspect import signature
11 |
12 | import numbers
13 | import numpy as np
14 | from math import ceil
15 | from sklearn.ensemble import BaseEnsemble
16 | from sklearn.utils import check_array, check_X_y
17 | from sklearn.utils.validation import check_is_fitted
18 | from sklearn.metrics import accuracy_score, balanced_accuracy_score, f1_score
19 |
20 |
21 | SAMPLING_KIND = (
22 | "over-sampling",
23 | "under-sampling",
24 | "multi-class-hybrid-sampling",
25 | )
26 | SamplingKindError = NotImplementedError(
27 | f"'sampling_type' must be one of {SAMPLING_KIND}."
28 | )
29 |
30 |
31 | def _target_samples_int(y, n_target_samples, sampling_type):
32 | target_stats = dict(Counter(y))
33 | max_class_ = max(target_stats, key=target_stats.get)
34 | min_class_ = min(target_stats, key=target_stats.get)
35 | n_max_class_samples_ = target_stats[max_class_]
36 | n_min_class_samples_ = target_stats[min_class_]
37 | if sampling_type == 'under-sampling':
38 | if n_target_samples >= n_max_class_samples_:
39 | raise ValueError(
40 | f"'n_target_samples' >= the number of samples"
41 | f" of the largest class ({n_max_class_samples_})."
42 | f" Set 'n_target_samples' < {n_max_class_samples_}"
43 | f" to perform under-sampling properly."
44 | )
45 | target_distr = dict([
46 | (label, min(n_target_samples, target_stats[label]))
47 | for label in target_stats.keys()
48 | ])
49 | return target_distr
50 | elif sampling_type == 'over-sampling':
51 | if n_target_samples <= n_min_class_samples_:
52 | raise ValueError(
53 | f"'n_target_samples' <= the number of samples"
54 | f" of the largest class ({n_min_class_samples_})."
55 | f" Set 'n_target_samples' > {n_min_class_samples_}"
56 | f" to perform over-sampling properly."
57 | )
58 | target_distr = dict([
59 | (label, max(n_target_samples, target_stats[label]))
60 | for label in target_stats.keys()
61 | ])
62 | return target_distr
63 | elif sampling_type == "multi-class-hybrid-sampling":
64 | warning_info = f" Set 'n_target_samples' between [{n_min_class_samples_}" + \
65 | f" , {n_max_class_samples_}] if you want to perform" + \
66 | f" multi-class hybrid-sampling (under-sample the minority" + \
67 | f" classes, over-sample the majority classes) properly."
68 | if n_target_samples >= n_max_class_samples_:
69 | raise Warning(
70 | f"'n_target_samples' >= the number of samples" + \
71 | f" of the largest class ({n_max_class_samples_})." + \
72 | f" ONLY over-sampling will be applied to all classes." + warning_info
73 | )
74 | elif n_target_samples <= n_min_class_samples_:
75 | raise Warning(
76 | f"'n_target_samples' <= the number of samples" + \
77 | f" of the largest class ({n_min_class_samples_})." + \
78 | f" ONLY under-sampling will be applied to all classes." + warning_info
79 | )
80 | target_distr = dict([
81 | (label, n_target_samples)
82 | for label in target_stats.keys()
83 | ])
84 | return target_distr
85 | else: raise SamplingKindError
86 |
87 |
88 | def _target_samples_dict(y, n_target_samples, sampling_type):
89 | target_stats = dict(Counter(y))
90 | # check that all keys in n_target_samples are also in y
91 | set_diff_sampling_strategy_target = set(n_target_samples.keys()) - set(
92 | target_stats.keys()
93 | )
94 | if len(set_diff_sampling_strategy_target) > 0:
95 | raise ValueError(
96 | f"The {set_diff_sampling_strategy_target} target class is/are not "
97 | f"present in the data."
98 | )
99 | # check that there is no negative number
100 | if any(n_samples < 0 for n_samples in n_target_samples.values()):
101 | raise ValueError(
102 | f"The number of samples in a class cannot be negative."
103 | f"'n_target_samples' contains some negative value: {n_target_samples}"
104 | )
105 |
106 | if sampling_type == 'under-sampling':
107 | target_distr = copy(target_stats)
108 | for class_label, n_target_sample in n_target_samples.items():
109 | n_origin_sample = target_stats[class_label]
110 | if n_target_sample > n_origin_sample:
111 | raise ValueError(
112 | f" The target number of samples of class {class_label}"
113 | f" should be < {n_origin_sample} (number of samples"
114 | f" in class {class_label}) to perform under-sampling,"
115 | f" got {n_target_sample}."
116 | )
117 | else:
118 | target_distr[class_label] = n_target_sample
119 | return target_distr
120 |
121 | elif sampling_type == 'over-sampling':
122 | target_distr = copy(target_stats)
123 | for class_label, n_target_sample in n_target_samples.items():
124 | n_origin_sample = target_stats[class_label]
125 | if n_target_sample < n_origin_sample:
126 | raise ValueError(
127 | f" The target number of samples of class {class_label}"
128 | f" should be > {n_origin_sample} (number of samples"
129 | f" in class {class_label}) to perform over-sampling,"
130 | f" got {n_target_sample}."
131 | )
132 | else:
133 | target_distr[class_label] = n_target_sample
134 | return target_distr
135 |
136 | elif sampling_type == "multi-class-hybrid-sampling":
137 | target_distr = copy(target_stats)
138 | if all(n_target_samples[label] <= target_stats[label] for label in n_target_samples.keys()):
139 | raise Warning(
140 | f"The target number of samples is smaller than the number"
141 | f" of original samples for all classes. ONLY under-sampling"
142 | f" will be carried out."
143 | )
144 | elif all(n_target_samples[label] >= target_stats[label] for label in n_target_samples.keys()):
145 | raise Warning(
146 | f"The target number of samples is greater than the number"
147 | f" of original samples for all classes. ONLY over-sampling"
148 | f" will be carried out."
149 | )
150 | target_distr.update(n_target_samples)
151 | return target_distr
152 |
153 | else: raise SamplingKindError
154 |
155 |
156 | def check_n_target_samples(y, n_target_samples, sampling_type):
157 | if isinstance(n_target_samples, numbers.Integral):
158 | return _target_samples_int(y, n_target_samples, sampling_type)
159 | elif isinstance(n_target_samples, dict):
160 | return _target_samples_dict(y, n_target_samples, sampling_type)
161 | else: raise ValueError(
162 | f"'n_target_samples' should be of type `int` or `dict`,"
163 | f" got {type(n_target_samples)}."
164 | )
165 |
166 |
167 | def check_target_label(y, target_label, sampling_type):
168 | """check parameter `target_label`."""
169 |
170 | target_stats = dict(Counter(y))
171 | if isinstance(target_label, numbers.Integral):
172 | if target_label in target_stats.keys():
173 | return target_label
174 | else: raise ValueError(
175 | f"The target class {target_label} is not present in the data."
176 | )
177 | else: raise TypeError(
178 | f"'target_label' should be of type `int`,"
179 | f" got {type(target_label)}."
180 | )
181 |
182 |
183 | def check_target_label_and_n_target_samples(y, target_label, n_target_samples, sampling_type):
184 | """Jointly check `target_label` and `n_target_samples` parameters."""
185 |
186 | # Store the original target class distribution
187 | target_stats = dict(Counter(y))
188 | min_class = min(target_stats, key=target_stats.get)
189 | maj_class = max(target_stats, key=target_stats.get)
190 |
191 | # if n_target_samples is NOT specified
192 | if n_target_samples == None:
193 | # Set target_label if NOT specified
194 | if target_label == None:
195 | if sampling_type == "under-sampling":
196 | target_label_ = min_class
197 | elif sampling_type == "over-sampling":
198 | target_label_ = maj_class
199 | elif sampling_type == "multi-class-hybrid-sampling":
200 | raise ValueError(
201 | f"For \"multi-class-hybrid-sampling\", must specify"
202 | f" 'n_target_samples' or 'target_label'."
203 | )
204 | else: raise SamplingKindError
205 | # Check target_label
206 | else: target_label_ = check_target_label(y, target_label, sampling_type)
207 | # Set n_target_samples
208 | n_target_samples = target_stats[target_label_]
209 |
210 | # if n_target_samples is specified
211 | else:
212 | if target_label == None:
213 | target_label_ = target_label
214 | # n_target_samples and target_label CANNOT both be both specified
215 | else:
216 | raise ValueError(
217 | f"'n_target_samples' and 'target_label' cannot"
218 | f" be specified at the same time."
219 | )
220 |
221 | # Check n_target_samples
222 | target_distr_ = check_n_target_samples(y, n_target_samples, sampling_type)
223 |
224 | return target_label_, target_distr_
225 |
226 |
227 | BALANCING_SCHEDULE_PARAMS_TYPE = {
228 | 'origin_distr': dict,
229 | 'target_distr': dict,
230 | 'i_estimator': numbers.Integral,
231 | 'total_estimator': numbers.Integral,
232 | }
233 |
234 |
235 | def _uniform_schedule(origin_distr, target_distr, i_estimator, total_estimator):
236 | """Return target distribution"""
237 | for param, (param_name, param_type) in zip(
238 | [origin_distr, target_distr, i_estimator, total_estimator],
239 | list(BALANCING_SCHEDULE_PARAMS_TYPE.items())):
240 | if not isinstance(param, param_type):
241 | raise TypeError(
242 | f"'{param_name}' must be `{param_type}`, got {type(param)}."
243 | )
244 | if i_estimator >= total_estimator:
245 | raise ValueError(
246 | f"'i_estimator' should < 'total_estimator',"
247 | f" got 'i_estimator' = {i_estimator} >= 'total_estimator' = {total_estimator}."
248 | )
249 | return target_distr
250 |
251 |
252 | def _progressive_schedule(origin_distr, target_distr, i_estimator, total_estimator):
253 | """Progressively interpolate between original and target distribution"""
254 | for param, (param_name, param_type) in zip(
255 | [origin_distr, target_distr, i_estimator, total_estimator],
256 | list(BALANCING_SCHEDULE_PARAMS_TYPE.items())):
257 | if not isinstance(param, param_type):
258 | raise TypeError(
259 | f"'{param_name}' must be `{param_type}`, got {type(param)}."
260 | )
261 | if i_estimator >= total_estimator:
262 | raise ValueError(
263 | f"'i_estimator' should < 'total_estimator',"
264 | f" got 'i_estimator' = {i_estimator} >= 'total_estimator' = {total_estimator}."
265 | )
266 | result_distr = {}
267 | if total_estimator == 1:
268 | progress_ = 1
269 | else: progress_ = i_estimator / (total_estimator-1)
270 | for label in origin_distr.keys():
271 | result_distr[label] = ceil(
272 | origin_distr[label]*(1.-progress_) + \
273 | target_distr[label]*progress_ - 1e-10
274 | )
275 | return result_distr
276 |
277 |
278 | BALANCING_KIND_MAPPING = {
279 | "uniform": _uniform_schedule,
280 | "progressive": _progressive_schedule,
281 | }
282 | BALANCING_KIND = list(BALANCING_KIND_MAPPING.keys())
283 | BALANCING_SCHEDULE_INFO = \
284 | "\nNote: self-defined `balancing_schedule` should take 4 positional" + \
285 | " arguments with order ('origin_distr': `dict`, 'target_distr':" + \
286 | " `dict`, 'i_estimator': `int`, 'total_estimator': `int`), and" + \
287 | " return a 'result_distr': `dict`. For all `dict`, the keys" + \
288 | " correspond to the targeted classes, and the values correspond to the" + \
289 | " (desired) number of samples for each class."
290 |
291 |
292 | def check_balancing_schedule(balancing_schedule):
293 | """Check the `balancing_schedule` parameter."""
294 | if callable(balancing_schedule):
295 | try:
296 | return_value = balancing_schedule({}, {}, 0, 0)
297 | except Exception as e:
298 | e_args = list(e.args)
299 | e_args[0] += BALANCING_SCHEDULE_INFO
300 | e.args = tuple(e_args)
301 | raise e
302 | else:
303 | if not isinstance(return_value, dict):
304 | raise TypeError(
305 | f" The self-defined `balancing_schedule` must return a `dict`," + \
306 | f" got {type(return_value)}" + \
307 | BALANCING_SCHEDULE_INFO
308 | )
309 | return balancing_schedule
310 |
311 | if balancing_schedule in BALANCING_KIND:
312 | return BALANCING_KIND_MAPPING[balancing_schedule]
313 | else:
314 | balancing_schedule_info = balancing_schedule if isinstance(balancing_schedule, str) \
315 | else type(balancing_schedule)
316 | raise TypeError(
317 | f"'balancing_schedule' should be one of {BALANCING_KIND} or `callable`,"
318 | f" got {balancing_schedule_info}."
319 | )
320 |
321 |
322 | EVAL_METRICS_DEFAULT = {
323 | 'acc': (accuracy_score, {}),
324 | 'balanced_acc': (balanced_accuracy_score, {}),
325 | 'weighted_f1': (f1_score, {'average':'weighted'}),
326 | }
327 | EVAL_METRICS_INFO = \
328 | " Example 'eval_metrics': {..., 'metric_name': ('metric_func', 'metric_kwargs'), ...}."
329 | # " where `metric_name` is string, `metric_func` is `callable`," + \
330 | # " and `metric_arguments` is a dict of arguments" + \
331 | # " that needs to be passed to the metric function," + \
332 | # " e.g., {..., `argument_name`: `value`}."
333 | EVAL_METRICS_TUPLE_TYPE = {
334 | 'metric_func': callable,
335 | 'metric_kwargs': dict,
336 | }
337 | EVAL_METRICS_TUPLE_LEN = len(EVAL_METRICS_TUPLE_TYPE)
338 |
339 |
340 | def _check_eval_metric_func(metric_func):
341 | if not callable(metric_func):
342 | raise TypeError(
343 | f" The 'metric_func' should be `callable`, got {type(metric_func)},"
344 | f" please check your usage."
345 | + EVAL_METRICS_INFO
346 | )
347 | if 'y_true' not in signature(metric_func).parameters:
348 | raise RuntimeError(
349 | f"The metric function must have the keyword argument 'y_true'"
350 | f" (true labels or binary label indicators, 1d-array of shape (n_samples,))."
351 | )
352 | if 'y_pred' not in signature(metric_func).parameters and \
353 | 'y_score' not in signature(metric_func).parameters:
354 | raise RuntimeError(
355 | f"The metric function must have the keyword argument 'y_pred' or 'y_score'."
356 | f" When use 'y_pred': it corresponds to predicted labels, 1d-array of shape (n_samples,)."
357 | f" When use 'y_score': it corresponds to predicted labels, or an array of shape"
358 | f" (n_samples, n_classes) of probability estimates provided by the predict_proba method.)"
359 | )
360 | accept_proba = 'y_score' in signature(metric_func).parameters
361 | accept_labels = 'labels' in signature(metric_func).parameters
362 | return metric_func, accept_proba, accept_labels
363 |
364 |
365 | def _check_eval_metric_args(metric_kwargs):
366 | if not isinstance(metric_kwargs, dict):
367 | raise TypeError(
368 | f" The 'metric_kwargs' should be a `dict` of arguments"
369 | f" that needs to be passed to the metric function,"
370 | f" got {type(metric_kwargs)}, "
371 | f" please check your usage."
372 | + EVAL_METRICS_INFO
373 | )
374 | return metric_kwargs
375 |
376 |
377 | def _check_eval_metric_name(metric_name):
378 | if not isinstance(metric_name, str):
379 | raise TypeError(
380 | f" The keys must be `string`, got {type(metric_name)}, "
381 | f" please check your usage."
382 | + EVAL_METRICS_INFO
383 | )
384 | return metric_name
385 |
386 |
387 | def _check_eval_metric_tuple(metric_tuple, metric_name):
388 | if not isinstance(metric_tuple, tuple):
389 | raise TypeError(
390 | f" The value of '{metric_name}' is {type(metric_tuple)} (should be tuple)," + \
391 | f" please check your usage."
392 | + EVAL_METRICS_INFO
393 | )
394 | elif len(metric_tuple) != EVAL_METRICS_TUPLE_LEN:
395 | raise ValueError(
396 | f" The data tuple of '{metric_name}' has {len(metric_tuple)} element(s)" + \
397 | f" (should be {EVAL_METRICS_TUPLE_LEN}), please check your usage."
398 | + EVAL_METRICS_INFO
399 | )
400 | else:
401 | metric_func_, accept_proba, accept_labels = _check_eval_metric_func(metric_tuple[0])
402 | metric_kwargs_ = _check_eval_metric_args(metric_tuple[1])
403 | return (
404 | metric_func_,
405 | metric_kwargs_,
406 | accept_proba,
407 | accept_labels,
408 | )
409 |
410 |
411 | def _check_eval_metrics_dict(eval_metrics_dict):
412 | """check 'eval_metrics' dict."""
413 | eval_metrics_dict_ = {}
414 | for metric_name, metric_tuple in eval_metrics_dict.items():
415 |
416 | metric_name_ = _check_eval_metric_name(metric_name)
417 | metric_tuple_ = _check_eval_metric_tuple(metric_tuple, metric_name_)
418 | eval_metrics_dict_[metric_name_] = metric_tuple_
419 |
420 | return eval_metrics_dict_
421 |
422 | def check_eval_metrics(eval_metrics):
423 | """Check parameter `eval_metrics`."""
424 | if eval_metrics is None:
425 | return _check_eval_metrics_dict(EVAL_METRICS_DEFAULT)
426 | elif isinstance(eval_metrics, dict):
427 | return _check_eval_metrics_dict(eval_metrics)
428 | else:
429 | raise TypeError(
430 | f"'eval_metrics' must be of type `dict`, got {type(eval_metrics)}, please check your usage."
431 | + EVAL_METRICS_INFO
432 | )
433 |
434 |
435 | TRAIN_VERBOSE_TYPE = {
436 | 'granularity': numbers.Integral,
437 | 'print_distribution': bool,
438 | 'print_metrics': bool,
439 | }
440 |
441 | TRAIN_VERBOSE_DEFAULT = {
442 | # 'granularity' will be set to int(n_estimators_ensemble/10)
443 | # when check_train_verbose() is called
444 | 'print_distribution': True,
445 | 'print_metrics': True,
446 | }
447 |
448 | TRAIN_VERBOSE_DICT_INFO = \
449 | " When 'train_verbose' is `dict`, at least one of the following" + \
450 | " terms should be specified: " + \
451 | " {'granularity': `int` (default=1)," + \
452 | " 'print_distribution': `bool` (default=True)," + \
453 | " 'print_metrics': `bool` (default=True)}."
454 |
455 |
456 | def check_train_verbose(train_verbose:bool or numbers.Integral or dict,
457 | n_estimators_ensemble:int, training_type:str,
458 | **ignored_properties):
459 | # n_estimators_ensemble:int,):
460 |
461 | train_verbose_ = copy(TRAIN_VERBOSE_DEFAULT)
462 | train_verbose_.update({
463 | 'granularity': max(1, int(n_estimators_ensemble/10))
464 | })
465 |
466 | if training_type == 'parallel':
467 | # For ensemble classifiers trained in parallel
468 | # train_verbose can only be of type bool
469 | if isinstance(train_verbose, bool):
470 | if train_verbose == True:
471 | train_verbose_['print_distribution'] = False
472 | return train_verbose_
473 | if train_verbose == False:
474 | return False
475 | else: raise TypeError(
476 | f"'train_verbose' can only be of type `bool`"
477 | f" for ensemble classifiers trained in parallel,"
478 | f" gor {type(train_verbose)}."
479 | )
480 |
481 | elif training_type == 'iterative':
482 | # For ensemble classifiers trained in iterative manner
483 | # train_verbose can be of type bool / int / dict
484 | if isinstance(train_verbose, bool):
485 | if train_verbose == True:
486 | return train_verbose_
487 | if train_verbose == False:
488 | return False
489 |
490 | if isinstance(train_verbose, numbers.Integral):
491 | train_verbose_.update({'granularity': train_verbose})
492 | return train_verbose_
493 |
494 | if isinstance(train_verbose, dict):
495 | # check key value type
496 | set_diff_verbose_keys = set(train_verbose.keys()) - set(TRAIN_VERBOSE_TYPE.keys())
497 | if len(set_diff_verbose_keys) > 0:
498 | raise ValueError(
499 | f"'train_verbose' keys {set_diff_verbose_keys} are not supported." + \
500 | TRAIN_VERBOSE_DICT_INFO
501 | )
502 | for key, value in train_verbose.items():
503 | if not isinstance(value, TRAIN_VERBOSE_TYPE[key]):
504 | raise TypeError(
505 | f"train_verbose['{key}'] has wrong data type, should be {TRAIN_VERBOSE_TYPE[key]}." + \
506 | TRAIN_VERBOSE_DICT_INFO
507 | )
508 | train_verbose_.update(train_verbose)
509 | return train_verbose_
510 |
511 | else: raise TypeError(
512 | f"'train_verbose' should be of type `bool`, `int`, or `dict`, got {type(train_verbose)} instead." + \
513 | TRAIN_VERBOSE_DICT_INFO
514 | )
515 |
516 | else: raise NotImplementedError(
517 | f"'check_train_verbose' for 'training_type' = {training_type}"
518 | f" needs to be implemented."
519 | )
520 |
521 |
522 | VISUALIZER_ENSEMBLES_EXAMPLE_INFO = " Example: {..., ensemble_name: ensemble, ...}"
523 |
524 | VISUALIZER_ENSEMBLES_USAGE_INFO = \
525 | f" All imbalanced ensemble estimators should use the same training & validation" + \
526 | f" datasets and dataset names for comparable visualizations." + \
527 | f" Call `fit` with same 'X', 'y', 'eval_datasets'."
528 |
529 |
530 | def _check_visualizer_ensemble_item(name, estimator) -> bool:
531 | if not isinstance(name, str):
532 | raise TypeError(
533 | f"Ensemble name must be `string`, got {type(name)}."
534 | )
535 |
536 | # Ensure estimator is an fitted sklearn/imbalanced-ensemble estimator
537 | # and is already fitted.
538 | check_is_fitted(estimator)
539 |
540 | if not isinstance(estimator, BaseEnsemble):
541 | raise TypeError(
542 | f"Value with name '{name}' is not an ensemble classifier instance."
543 | )
544 |
545 | if getattr(estimator, "_estimator_ensemble_type", None) == \
546 | "imbalanced_ensemble_classifier":
547 | is_imbalanced_ensemble_clf = True
548 | else: is_imbalanced_ensemble_clf = False
549 |
550 | return is_imbalanced_ensemble_clf
551 |
552 |
553 | def get_dict_subset_by_key(dictionary:dict, subset_keys:list, exclude:bool=False):
554 | if exclude:
555 | return {k: v for k, v in dictionary.items() if k not in subset_keys}
556 | else: return {k: v for k, v in dictionary.items() if k in subset_keys}
557 |
558 |
559 | def check_visualizer_ensembles(ensembles:dict, eval_datasets_:dict, eval_metrics_:dict) -> dict:
560 |
561 | # Check 'ensembles' parameter
562 | if not isinstance(ensembles, dict):
563 | raise TypeError(
564 | f"'ensembles' must be a `dict`, got {type(ensembles)}." + \
565 | VISUALIZER_ENSEMBLES_EXAMPLE_INFO
566 | )
567 | if len(ensembles) == 0:
568 | raise ValueError(
569 | f"'ensembles' must not be empty." + VISUALIZER_ENSEMBLES_EXAMPLE_INFO
570 | )
571 |
572 | # Check all key-value pairs of 'ensembles' and
573 | # record names of those are not imbalanced ensemble classifier
574 | names_imbalanced_ensemble = []
575 | for name, estimator in ensembles.items():
576 | if _check_visualizer_ensemble_item(name, estimator):
577 | names_imbalanced_ensemble.append(name)
578 | names_sklearn_ensemble = list(set(ensembles.keys()) - set(names_imbalanced_ensemble))
579 |
580 | # Raise error if not all ensembles have the same n_features_
581 | n_features_fitted = _check_all_estimators_have_same_attribute(ensembles,
582 | attr_alias = ('n_features_', 'n_features_in_'))
583 |
584 | sklearn_ensembles = get_dict_subset_by_key(ensembles, names_sklearn_ensemble)
585 | imb_ensembles = get_dict_subset_by_key(ensembles, names_sklearn_ensemble, exclude=True)
586 |
587 | # Raise error if not all imbalanced ensembles have the same eval_datasets names
588 | if not _all_elements_equal([list(estimator.eval_datasets_.keys())
589 | for estimator in imb_ensembles.values()]):
590 | raise ValueError(
591 | f"Got ensemble estimators that used inconsistent dataset names." + \
592 | VISUALIZER_ENSEMBLES_USAGE_INFO
593 | )
594 |
595 | # If eval_datasets_ is not given
596 | if len(eval_datasets_) == 0:
597 | # If all are sklearn ensemble classifier
598 | if len(imb_ensembles) == 0:
599 | raise ValueError(
600 | f"The 'eval_datasets' must not be empty when all "
601 | f" input 'ensembles' are sklearn.ensemble classifiers."
602 | )
603 | else:
604 | # Use imbalanced-ensemble estimators' evaluation datasets by default
605 | return_eval_datasets_ = copy(list(imb_ensembles.values())[0].eval_datasets_)
606 |
607 | # If got mixed types of ensemble classifier and eval_datasets_ is not given
608 | if len(sklearn_ensembles) > 0:
609 | warn(
610 | f"the 'eval_datasets' is not specified and the input 'ensembles'"
611 | f" contains sklearn.ensemble classifier, using evaluation datasets"
612 | f" of other imbalanced-ensemble classifiers by default."
613 | )
614 | # If eval_datasets_ is given
615 | else:
616 | # eval_datasets_ is already validated,
617 | # all data should have the same number of features
618 | n_features_given = list(eval_datasets_.values())[0][0].shape[1]
619 |
620 | # If the given data is inconsistent with the training data
621 | if n_features_given != n_features_fitted:
622 | raise ValueError(
623 | f"Given data in 'eval_datasets' has {n_features_given} features,"
624 | f" but the ensemble estimators are trained on data with"
625 | f" {n_features_fitted} features."
626 | )
627 |
628 | # Use the given evaluation datasets
629 | return_eval_datasets_ = copy(eval_datasets_)
630 |
631 | ensemble_names = list(ensembles.keys())
632 | dataset_names = list(return_eval_datasets_.keys())
633 | metric_names = list(eval_metrics_.keys())
634 | vis_format = {
635 | 'n_ensembles': len(ensemble_names),
636 | 'ensemble_names': tuple(ensemble_names),
637 | 'n_datasets': len(dataset_names),
638 | 'dataset_names': tuple(dataset_names),
639 | 'n_metrics': len(metric_names),
640 | 'metric_names': tuple(metric_names),
641 | }
642 |
643 | return ensembles, return_eval_datasets_, vis_format
644 |
645 |
646 | def _check_all_estimators_have_same_attribute(
647 | ensembles:dict, attr_alias:tuple):
648 |
649 | has_attrs, values, not_has_attr_names = [], [], []
650 | for name, estimator in ensembles.items():
651 | recorded_flag = False
652 | for alias in attr_alias:
653 | if hasattr(estimator, alias):
654 | recorded_flag = True
655 | has_attrs.append(True)
656 | values.append(getattr(estimator, alias))
657 | break
658 | if not recorded_flag:
659 | has_attrs.append(False)
660 | values.append(None)
661 | not_has_attr_names.append(name)
662 |
663 | if not all(has_attrs):
664 | raise ValueError(
665 | f"Estimators with name {not_has_attr_names} has no"
666 | f" attribute {attr_alias}, check your usage."
667 | )
668 |
669 | if not _all_elements_equal(values):
670 | raise ValueError(
671 | f"Got ensemble estimators that has inconsistent {attr_alias}."
672 | f" Make sure that the training data for all estimators"
673 | f" (also the evaluation data for imbalanced-ensemble estimators)"
674 | f" are sampled from the same task/distribution."
675 | )
676 |
677 | return values[0]
678 |
679 |
680 | def _all_elements_equal(list_to_check:list) -> bool:
681 | """Private function to check whether all elements of
682 | list_to_check are equal."""
683 |
684 | # set() is not used here as some times the list
685 | # elements are not hashable, e.g., strings.
686 | if len(list_to_check) == 1:
687 | return True
688 | return all([
689 | (list_to_check[i] == list_to_check[i+1])
690 | for i in range(len(list_to_check)-1)
691 | ])
692 |
693 |
694 | PLOT_FIGSIZE_INFO = " Example: (width, height)."
695 |
696 | def check_plot_figsize(figsize):
697 | if not isinstance(figsize, tuple):
698 | raise TypeError(
699 | f"'figsize' must be a tuple with 2 elements,"
700 | f" got {type(figsize)}." + PLOT_FIGSIZE_INFO
701 | )
702 | if len(figsize) != 2:
703 | raise ValueError(
704 | f"'figsize' must be a tuple with 2 elements,"
705 | f" got {len(figsize)} elements." + PLOT_FIGSIZE_INFO
706 | )
707 | for value in figsize:
708 | if not isinstance(value, numbers.Number):
709 | raise ValueError(
710 | f"Elements of 'figsize' must be a `int` or `float`,"
711 | f" got {type(value)}." + PLOT_FIGSIZE_INFO
712 | )
713 | return figsize
714 |
715 |
716 | def check_has_diff_elements(given_set:list or set,
717 | universal_set:list or set,
718 | msg:str=""):
719 | diff_set = set(given_set) - set(universal_set)
720 | if len(diff_set) > 0:
721 | raise ValueError(
722 | msg % {"diff_set": diff_set}
723 | )
724 |
725 |
726 | def check_type(param, param_name:str, typ, typ_name:str=None):
727 | if not isinstance(param, typ):
728 | typ_name = str(typ) if typ_name is None else typ_name
729 | raise ValueError(
730 | f"'{param_name}' should be of type `{typ_name}`,"
731 | f" got {type(param)}."
732 | )
733 | return param
734 |
735 |
736 | def check_pred_proba(y_pred_proba, n_samples, n_classes, dtype=None):
737 | """Private function for validating y_pred_proba"""
738 | if dtype is not None and dtype not in [np.float32, np.float64]:
739 | dtype = np.float64
740 |
741 | if dtype is None:
742 | dtype = [np.float64, np.float32]
743 | y_pred_proba = check_array(
744 | y_pred_proba, accept_sparse=False, ensure_2d=False, dtype=dtype,
745 | order="C"
746 | )
747 | if y_pred_proba.ndim != 2:
748 | raise ValueError("Predicted probabilites must be 2D array")
749 |
750 | if y_pred_proba.shape != (n_samples, n_classes):
751 | raise ValueError("y_pred_proba.shape == {}, expected {}!"
752 | .format(y_pred_proba.shape, (n_samples, n_classes)))
753 | return y_pred_proba
754 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | # Note: To use the 'upload' functionality of this file, you must:
5 | # $ pipenv install twine --dev
6 |
7 | # %%
8 | import io
9 | import os
10 | import sys
11 | from shutil import rmtree
12 |
13 | from setuptools import find_packages, setup, Command
14 |
15 | # %%
16 |
17 | # get __version__ from _version.py
18 | ver_file = os.path.join("self_paced_ensemble", "__version__.py")
19 | with open(ver_file) as f:
20 | exec(f.read())
21 |
22 | # Package meta-data.
23 | NAME = 'self-paced-ensemble'
24 | DESCRIPTION = 'Self-paced Ensemble for classification on class-imbalanced data.'
25 | URL = 'https://github.com/ZhiningLiu1998/self-paced-ensemble'
26 | PROJECT_URLS = {
27 | 'Documentation': 'https://imbalanced-ensemble.readthedocs.io/en/latest/api/ensemble/_autosummary/imbens.ensemble.under_sampling.SelfPacedEnsembleClassifier.html',
28 | 'Source': 'https://github.com/ZhiningLiu1998/self-paced-ensemble',
29 | 'Tracker': 'https://github.com/ZhiningLiu1998/self-paced-ensemble/issues',
30 | 'Download': 'https://pypi.org/project/self-paced-ensemble/#files',
31 | }
32 | EMAIL = 'zhining.liu@outlook.com'
33 | AUTHOR = 'Zhining Liu'
34 | REQUIRES_PYTHON = '>=3.6.0'
35 | VERSION = __version__
36 | LICENSE = "MIT"
37 | REQUIRED = [
38 | "numpy>=1.13.3",
39 | "pandas>=1.1.3",
40 | "scipy>=0.19.1",
41 | "scikit-learn>=0.24",
42 | "joblib>=0.11",
43 | "imbalanced-learn>=0.12.0",
44 | "imbalanced-ensemble>=0.2.1",
45 | ]
46 | EXTRAS = {
47 | }
48 | CLASSIFIERS = [
49 | "Intended Audience :: Science/Research",
50 | "Intended Audience :: Developers",
51 | "License :: OSI Approved",
52 | "Programming Language :: C",
53 | "Programming Language :: Python",
54 | "Topic :: Software Development",
55 | "Topic :: Scientific/Engineering",
56 | "Operating System :: Microsoft :: Windows",
57 | "Operating System :: POSIX",
58 | "Operating System :: Unix",
59 | "Operating System :: MacOS",
60 | "Programming Language :: Python :: 3.6",
61 | "Programming Language :: Python :: 3.7",
62 | "Programming Language :: Python :: 3.8",
63 | "Programming Language :: Python :: 3.9",
64 | ]
65 |
66 | # %%
67 |
68 | # The rest you shouldn't have to touch too much :)
69 | # ------------------------------------------------
70 | # Except, perhaps the License and Trove Classifiers!
71 | # If you do change the License, remember to change the Trove Classifier for that!
72 |
73 | here = os.path.abspath(os.path.dirname(__file__))
74 |
75 | # Import the README and use it as the long-description.
76 | # Note: this will only work if 'README.md' is present in your MANIFEST.in file!
77 | try:
78 | with io.open(os.path.join(here, 'README.md'), encoding='utf-8') as f:
79 | long_description = '\n' + f.read()
80 | except FileNotFoundError:
81 | long_description = DESCRIPTION
82 |
83 | # Load the package's __version__.py module as a dictionary.
84 | about = {}
85 | if not VERSION:
86 | project_slug = NAME.lower().replace("-", "_").replace(" ", "_")
87 | with open(os.path.join(here, project_slug, '__version__.py')) as f:
88 | exec(f.read(), about)
89 | else:
90 | about['__version__'] = VERSION
91 |
92 |
93 | class UploadCommand(Command):
94 | """Support setup.py upload."""
95 |
96 | description = 'Build and publish the package.'
97 | user_options = []
98 |
99 | @staticmethod
100 | def status(s):
101 | """Prints things in bold."""
102 | print('\033[1m{0}\033[0m'.format(s))
103 |
104 | def initialize_options(self):
105 | pass
106 |
107 | def finalize_options(self):
108 | pass
109 |
110 | def run(self):
111 | try:
112 | self.status('Removing previous builds…')
113 | rmtree(os.path.join(here, 'dist'))
114 | except OSError:
115 | pass
116 |
117 | self.status('Building Source and Wheel (universal) distribution…')
118 | os.system('{0} setup.py sdist bdist_wheel --universal'.format(sys.executable))
119 |
120 | self.status('Uploading the package to PyPI via Twine…')
121 | os.system('twine upload dist/*')
122 |
123 | self.status('Pushing git tags…')
124 | os.system('git tag v{0}'.format(about['__version__']))
125 | os.system('git push --tags')
126 |
127 | sys.exit()
128 |
129 |
130 | # Where the magic happens:
131 | setup(
132 | name=NAME,
133 | version=about['__version__'],
134 | description=DESCRIPTION,
135 | long_description=long_description,
136 | long_description_content_type='text/markdown',
137 | author=AUTHOR,
138 | author_email=EMAIL,
139 | python_requires=REQUIRES_PYTHON,
140 | url=URL,
141 | project_urls=PROJECT_URLS,
142 | packages=find_packages(exclude=["tests", "*.tests", "*.tests.*", "tests.*"]),
143 | # If your package is a single module, use this instead of 'packages':
144 | # py_modules=['mypackage'],
145 |
146 | # entry_points={
147 | # 'console_scripts': ['mycli=mymodule:cli'],
148 | # },
149 | install_requires=REQUIRED,
150 | extras_require=EXTRAS,
151 | include_package_data=True,
152 | license=LICENSE,
153 | classifiers=CLASSIFIERS,
154 | # $ setup.py publish support.
155 | cmdclass={
156 | 'upload': UploadCommand,
157 | },
158 | )
159 |
160 | # %%
161 |
--------------------------------------------------------------------------------

 250 |
251 |
250 |
251 | 
 255 |
256 |
255 |
256 | 
 260 |
261 |
260 |
261 | 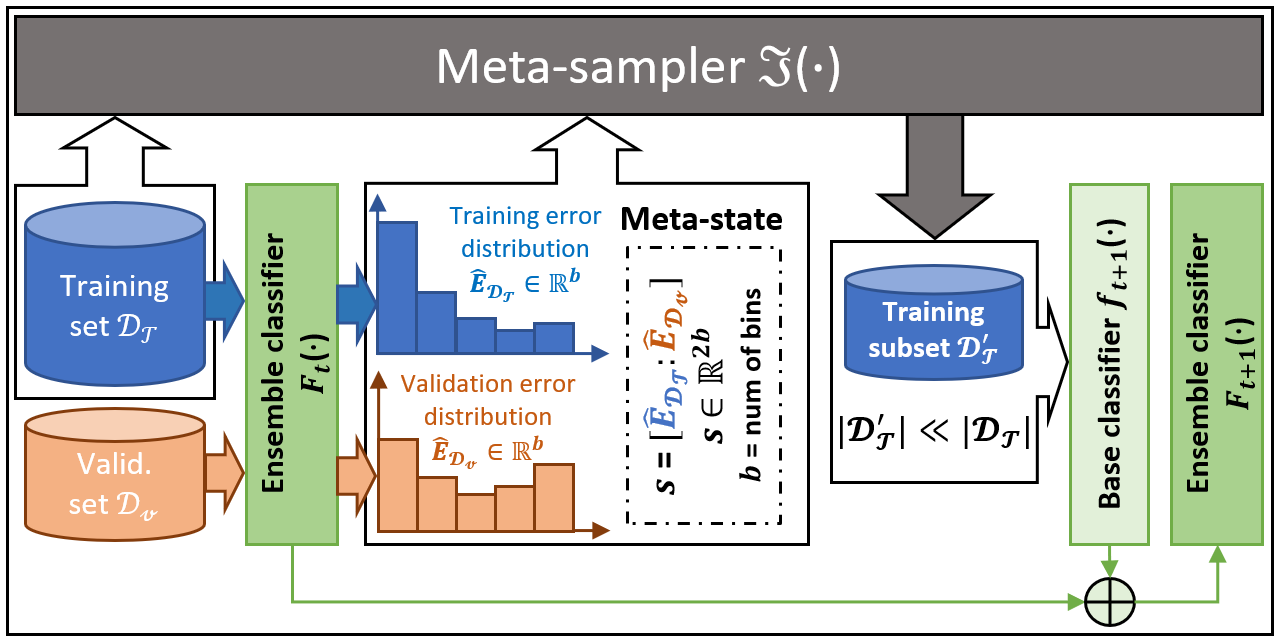
 265 |
266 |
265 |
266 | 





