├── Linux内核知识体系.png
├── Linux学习笔记.pdf
├── README.md
├── 文章
├── Linux IO 之 IO与网络模型.md
├── Linux操作系统学习——内核初始化.md
├── Linux操作系统学习——内核运行.md
├── Linux操作系统学习——启动.md
├── 任务空间管理.md
├── 你真的理解Linux中断机制嘛.md
├── 内存管理
│ ├── 1.txt
│ ├── Linux中的内存管理机制.md
│ ├── 一文了解,Linux内存管理,malloc、free 实现原理.md
│ ├── 其他工程问题以及调优.md
│ ├── 内存与IO的交换.md
│ ├── 内存的动态申请和释放.md
│ ├── 内存管理之内存映射.md
│ ├── 内存管理之分页.md
│ ├── 多核心Linux内核路径优化的不二法门之-slab与伙伴系统.md
│ ├── 尽情阅读,技术进阶,详解mmap原理.md
│ ├── 浅谈Linux内存管理机制.md
│ ├── 熟读精思,熟读玩味,Linux虚拟内存管理,MMU机制,原来如此也.md
│ ├── 硬件原理 和 分页管理.md
│ └── 进程的内存消耗和泄漏.md
├── 文件系统
│ ├── 1.txt
│ ├── Linux IO 之 块IO流程与IO调度器.md
│ ├── Linux IO 之 文件系统的实现.md
│ ├── Linux IO 之 文件系统的架构.md
│ ├── Linux 操作系统原理-文件系统(1).md
│ ├── Linux 操作系统原理-文件系统(2).md
│ ├── Linux操作系统学习之文件系统.md
│ ├── Linux文件系统详解.md
│ ├── 磁盘IO那些事.md
│ └── 虚拟文件系统.md
├── 浅谈Linux内核之CPU缓存.md
├── 系统调用.md
├── 网络协议栈
│ ├── 1.txt
│ ├── Linux 中的五种IO模型.md
│ ├── Linux内核之epoll模型.md
│ ├── Linux内核网络UDP数据包发送(三)—IP协议层分析.md
│ ├── Linux内核网络udp数据包发送(一).md
│ ├── Linux内核网络udp数据包发送(二)-UDP协议层分析.md
│ ├── Linux操作系统原理—内核网络协议栈.md
│ ├── Linux网络栈解剖.md
│ ├── Linux网络源代码学习——整体介绍.md
│ ├── 深入分析Linux操作系统对于TCP IP栈的实现原理与具体过程.md
│ ├── 透过现象看本质,从linux源码角度看epoll.md
│ └── 驾驭Linux内部网络实现——关键数据结构 sk_buff.md
├── 设备驱动
│ ├── 1.txt
│ ├── Linux 总线、设备、驱动模型的探究.md
│ ├── Linux 设备和驱动的相遇.md
│ └── Linux操作系统学习之字符设备.md
└── 进程管理
│ ├── 1.txt
│ ├── Linux进程、线程、调度(一).md
│ ├── Linux进程、线程、调度(三).md
│ ├── Linux进程、线程、调度(二).md
│ ├── Linux进程、线程、调度(四).md
│ ├── Linux进程状态总结.md
│ ├── 一文带你,彻底了解,零拷贝Zero-Copy技术.md
│ ├── 任务调度.md
│ ├── 进程、线程的创建和派生.md
│ ├── 进程的核心——task_truct.md
│ ├── 进程间通信之信号.md
│ ├── 进程间通信之共享内存和信号量.md
│ ├── 进程间通信之管道.md
│ └── 进程间通信,管道,socket,XSI(System V).md
├── 源码组织结构.png
├── 电子书籍
├── 1.txt
├── Linux内核完全注释V3.0书签版.pdf
├── Linux命令行大全 - 绍茨 (william E.shotts).pdf
├── Linux命令速查手册.mobi
├── Linux就该这么学.epub
├── Linux性能优化大师.epub
├── Linux环境编程:从应用到内核 (Linux Unix技术丛书).pdf
├── Linux集群和自动化运维 余洪春.pdf
├── Linux驱动程序开发实例(第2版).pdf
├── Linux高级程序设计(第3版).epub
├── 构建高可用Linux服务器(第4版).epub
└── 深入了解Linux内核.pdf
├── 论文
├── 1.txt
├── 《A Novel DDoS Floods Detection and Testing Approaches for Network Traffic based on Linux Techniques》.pdf
├── 《A Permission Check Analysis Framework for Linux Kernel》.pdf
├── 《A dataset of feature additions and feature removals from the Linux kernel》.pdf
├── 《An Evaluation of Adaptive Partitioning of Real-Time Workloads on Linux》.pdf
├── 《Analysis and Study of Security Mechanisms inside Linux Kernel 》.pdf
├── 《Architecture of the Linux kernel》.pdf
├── 《Automated Patch Backporting in Linux》.pdf
├── 《Automated Voxel Placement A Linux-based Suite of Tools for Accurate and Reliable Single Voxel Coregistration》.pdf
├── 《Automatic Rebootless Kernel Updates》.pdf
├── 《Communication on Linux using Socket Programming in ‘C’》.pdf
├── 《Compatibility of Linux Architecture for Diskless Technology System》.pdf
├── 《Concurrency in the Linux kernel》.pdf
├── 《Container-based real-time scheduling in the Linux kernel》.pdf
├── 《Crash Consistency Test Generation for the Linux Kernel》.pdf
├── 《Designing of a Virtual File System》.pdf
├── 《Efficient Formal Verification for the Linux Kernel》.pdf
├── 《Exploiting Uses of Uninitialized Stack Variables in Linux Kernels to Leak Kernel Pointers》.pdf
├── 《Hybrid Fuzzing on the Linux Kernel》.pdf
├── 《In-Process Memory Isolation for Modern Linux Systems》.pdf
├── 《Introduction to the Linux kernel challenges and case studies》.pdf
├── 《Kernel Mode Linux Toward an Operating System Protected by a Type Theory》.pdf
├── 《Linux Kernel Transport Layer Security》.pdf
├── 《Linux Kernel Workshop Hacking the Kernel for Fun and Profit》.pdf
├── 《Linux Kernel development》.pdf
├── 《Linux Network Device Drivers an Overview》.pdf
├── 《Linux Physical Memory Page Allocation》.pdf
├── 《Linux Random Number Generator – A New Approach》.pdf
├── 《Linux kernel vulnerabilities State-of-the-art defenses and open problems》.pdf
├── 《Machine Learning for Load Balancing in the Linux Kernel》.pdf
├── 《Performance of IPv6 Segment Routing in Linux Kernel》.pdf
├── 《Professional Linux® Kernel Architecture》.pdf
├── 《Research of Performance Linux Kernel File Systems》.pdf
├── 《Resource Management for Hardware Accelerated Linux Kernel Network Functions》.pdf
├── 《Rethinking Compiler Optimizations for the Linux Kernel An Explorative Study》.pdf
├── 《Securing the Linux Boot Process From Start to Finish》.pdf
├── 《Security Applications of Extended BPF Under the Linux Kernel》.pdf
├── 《Simple and precise static analysis of untrusted Linux kernel extensions》.pdf
├── 《Speeding Up Linux Disk Encryption》.pdf
├── 《Stateless model checking of the Linux kernel's hierarchical read-copy-update (tree RCU)》.pdf
├── 《Survey Paper on Adding System Call in Linux Kernel 3.2+ & 3.16》.pdf
├── 《TRACING THE WAY OF DATA IN A TCP CONNECTION THROUGH THE LINUX KERNEL》.pdf
├── 《The benefits and costs of writing a POSIX kernel in a high-level language》.pdf
├── 《The real-time Linux kernel a Survey on PREEMPT_RT》.pdf
├── 《Trace-Based Analysis of Locking in the Linux Kernel》.pdf
├── 《Tracing Network Packets in the Linux Kernel using eBPF》.pdf
├── 《Understanding Linux Kernel》.pdf
├── 《Understanding Linux Malware》.pdf
├── 《Using kAFS on Linux for Network Home Directories》.pdf
├── 《Verification of tree-based hierarchical read-copy update in the Linux kernel》.pdf
└── 《XDP test suite for Linux kernel》.pdf
└── 面试题
├── 1.txt
├── 面试题一.md
└── 面试题二.md
/Linux内核知识体系.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/Linux内核知识体系.png
--------------------------------------------------------------------------------
/Linux学习笔记.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/Linux学习笔记.pdf
--------------------------------------------------------------------------------
/文章/Linux IO 之 IO与网络模型.md:
--------------------------------------------------------------------------------
1 | ## Linux内核针对不同并发场景的工具实现
2 |
3 | 
4 |
5 | ### atomic 原子变量
6 |
7 | x86在多核环境下,多核竞争数据总线时,提供Lock指令进行锁总线操作。保证“读-修改-写”的操作在芯片级的原子性。
8 |
9 | ### spinlock 自旋锁
10 |
11 | 自旋锁将当前线程不停地执行循环体,而不改变线程的运行状态,在CPU上实现忙等,以此保证响应速度更快。这种类型的线程数不断增加时,性能明显下降。所以自旋锁保护的临界区必须小,操作过程必须短。
12 |
13 | ### semaphore 信号量
14 |
15 | 信号量用于保护有限数量的临界资源,信号量在获取和释放时,通过自旋锁保护,当有中断会把中断保存到eflags寄存器,最后再恢复中断。
16 |
17 | ### mutex 互斥锁
18 |
19 | 为了控制同一时刻只有一个线程进入临界区,让无法进入临界区的线程休眠。
20 |
21 | ### rw-lock 读写锁
22 |
23 | 读写锁,把读操作和写操作分别进行加锁处理,减小了加锁粒度,优化了读大于写的场景。
24 |
25 | ### preempt 抢占
26 |
27 | * 时间片用完后调用schedule函数。
28 | * 由于IO等原因自己主动调用schedule。
29 | * 其他情况,当前进程被其他进程替换的时候。
30 |
31 | ### per-cpu 变量
32 |
33 | linux为解决cpu 各自使用的L2 cache 数据与内存中的不一致的问题。
34 |
35 | ### RCU机制 (Read, Copy, Update)
36 |
37 | 用于解决多个CPU同时读写共享数据的场景。它允许多个CPU同时进行写操作,不使用锁,并且实现垃圾回收来处理旧数据。
38 |
39 | 
40 |
41 | ### 内存屏障 memory-barrier
42 |
43 | 程序运行过程中,对内存访问不一定按照代码编写的顺序来进行。
44 |
45 | * 编译器对代码进行优化。
46 | * 多cpu架构存在指令乱序访问内存的可能。
47 |
48 | ## I/O 与网络模型
49 |
50 | 介绍各种各样的I/O模型,包括以下场景:
51 |
52 | * 阻塞 & 非阻塞
53 | * 多路复用
54 | * Signal IO
55 | * 异步 IO
56 | * libevent
57 |
58 | 现实生活中的场景复杂,Linux CPU和IO行为,他们之间互相等待。例如,阻塞的IO可能会让CPU暂停。
59 |
60 | I/O模型很难说好与坏,只能说在某些场景下,更适合某些IO模型。其中,1、4 更适合块设备,2、3 更适用于字符设备。
61 |
62 | 为什么硬盘没有所谓的 多路复用,libevent,signal IO?
63 |
64 | > 因为select(串口), epoll(socket) 这些都是在监听事件,所以各种各样的IO模型,更多是描述字符设备和网络socket的问题。但硬盘的文件,只有读写,没有 epoll这些。
65 | > 这些IO模型更多是在字符设备,网络socket的场景。
66 |
67 | ### 为什么程序要选择正确的IO模型?
68 |
69 | 蓝色代表:cpu,红色代表:io
70 |
71 | 
72 |
73 | 如上图,某个应用打开一个图片文件,先需要100ms初始化,接下来100ms读这个图片。那打开这个图片就需要200ms。
74 |
75 | 但是 是否可以开两个线程,同时做这两件事?
76 |
77 | 
78 |
79 | 如上图,网络收发程序,如果串行执行,CPU和IO会需要互相等待。
80 | 为什么CPU和IO可以并行?因为一般硬件,IO通过DMA,cpu消耗比较小,在硬件上操作的时间更长。CPU和硬盘是两个不同的硬件。
81 |
82 | 再比如开机加速中systemd使用的readahead功能:
83 | 第一次启动过程,读的文件,会通过Linux inotify监控linux内核文件被操作的情况,记录下来。第二次启动,后台有进程直接读这些文件,而不是等到需要的时候再读。
84 |
85 | 
86 |
87 | I/O模型会深刻影响应用的最终性能,阻塞 & 非阻塞 、异步 IO 是针对硬盘, 多路复用、signal io、libevent 是针对字符设备和 socket。
88 |
89 | ### 简单的IO模型
90 |
91 | 
92 |
93 | 当一个进程需要读 键盘、触屏、鼠标时,进程会阻塞。但对于大量并发的场景,阻塞IO无法搞定,也可能会被信号打断。
94 |
95 | 内核程序等待IO,gobal fifo read不到
96 |
97 | 一般情况select返回,会调用 if signal_pending,进程会返回 ERESTARTSYS;此时,进程的read 返回由singal决定。有可能返回(EINTR),也有可能不返回。
98 |
99 | #### demo:
100 |
101 | ```c
102 | #include
103 | #include
104 | #include
105 | #include
106 | #include
107 | #include
108 | #include
109 |
110 | static void sig_handler(int signum)
111 | {
112 | printf("int handler %d\n", signum);
113 | }
114 |
115 | int main(int argc, char **argv)
116 | {
117 | char buf[100];
118 | ssize_t ret;
119 | struct sigaction oldact;
120 | struct sigaction act;
121 |
122 | act.sa_handler = sig_handler;
123 | act.sa_flags = 0;
124 | // act.sa_flags |= SA_RESTART;
125 | sigemptyset(&act.sa_mask);
126 | if (-1 == sigaction(SIGUSR1, &act, &oldact)) {
127 | printf("sigaction failed!/n");
128 | return -1;
129 | }
130 |
131 | bzero(buf, 100);
132 | do {
133 | ret = read(STDIN_FILENO, buf, 10);
134 | if ((ret == -1) && (errno == EINTR))
135 | printf("retry after eintr\n");
136 | } while((ret == -1) && (errno == EINTR));
137 |
138 | if (ret > 0)
139 | printf("read %d bytes, content is %s\n", ret, buf);
140 | return 0;
141 | }
142 | ```
143 |
144 | 
145 |
146 | 一个阻塞的IO,在睡眠等IO时Ready,但中途被信号打断,linux响应信号,read/write请求阻塞。
147 | 配置信号时,在SA_FLAG是不是加“自动”,SA_RESTART指定 被阻塞的IO请求是否重发,并且应用中可以捕捉。加了SA_RESTART重发,就不会返回出错码EINTR。
148 | 没有加SA_RESTART重发,就会返回出错码(EINTR),这样可以检测read被信号打断时的返回。
149 |
150 | 但Linux中有一些系统调用,即便你加了自动重发,也不能自动重发。man signal.
151 |
152 | 
153 |
154 | 当使用阻塞IO时,要小心这部分。
155 |
156 | 
157 |
158 | ### 多进程、多线程模型
159 |
160 | 当有多个socket消息需要处理,阻塞IO搞不定,有一种可能是多个进程/线程,每当有一个连接建立(accept socket),都会启动一个线程去处理新建立的连接。但是,这种模型性能不太好,创建多进程、多线程时会有开销。
161 |
162 | 经典的C10K问题,意思是 在一台服务器上维护1w个连接,需要建立1w个进程或者线程。那么如果维护1亿用户在线,则需要1w台服务器。
163 |
164 | IO多路复用,则是解决以上问题的场景。
165 |
166 | 总结:多进程、多线程模型企图把每一个fd放到不同的线程/进程处理,避免阻塞的问题,从而引入了进程创建\撤销,调度的开销。能否在一个线程内搞定所有IO? -- 这就是多路复用的作用。
167 |
168 | ### 多路复用
169 |
170 | 
171 |
172 | #### select
173 |
174 | select:效率低,性能不太好。不能解决大量并发请求的问题。
175 |
176 | 它把1000个fd加入到fd_set(文件描述符集合),通过select监控fd_set里的fd是否有变化。如果有一个fd满足读写事件,就会依次查看每个文件描述符,那些发生变化的描述符在fd_set对应位设为1,表示socket可读或者可写。
177 |
178 | Select通过轮询的方式监听,对监听的FD数量 t通过FD_SETSIZE限制。
179 |
180 | 两个问题:
181 |
182 | 1、select初始化时,要告诉内核,关注1000个fd, 每次初始化都需要重新关注1000个fd。前期准备阶段长。
183 | 2、select返回之后,要扫描1000个fd。 后期扫描维护成本大,CPU开销大。
184 |
185 | #### epoll
186 |
187 | epoll :在内核中的实现不是通过轮询的方式,而是通过注册callback函数的方式。当某个文件描述符发现变化,就主动通知。成功解决了select的两个问题,“epoll 被称为解决 C10K 问题的利器。”
188 |
189 | 1、select的“健忘症”,一返回就不记得关注了多少fd。api 把告诉内核等哪些文件,和最终监听哪些文件,都是同一个api。而epoll,告诉内核等哪些文件 和具体等哪些文件分开成两个api,epoll的“等”返回后,还是知道关注了哪些fd。
190 | 2、select在返回后的维护开销很大,而epoll就可以直接知道需要等fd。
191 |
192 | 
193 |
194 | 
195 |
196 | epoll获取事件的时候,无须遍历整个被侦听的描述符集,只要遍历那些被内核I/O事件异步唤醒而加入就绪队列的描述符集合。
197 |
198 | epoll_create: 创建epoll池子。
199 | epoll_ctl:向epoll注册事件。告诉内核epoll关心哪些文件,让内核没有健忘症。
200 | epoll_wait:等待就绪事件的到来。专门等哪些文件,第2个参数 是输出参数,包含满足的fd,不需要再遍历所有的fd文件。
201 |
202 | 
203 |
204 | 如上图,epoll在CPU的消耗上,远低于select,这样就可以在一个线程内监控更多的IO。
205 |
206 | ```c
207 | #include
208 | #include
209 | #include
210 | #include
211 | #include
212 | #include
213 |
214 | static void call_epoll(void)
215 | {
216 | int epfd, fifofd, pipefd;
217 | struct epoll_event ev, events[2];
218 | int ret;
219 |
220 | epfd = epoll_create(2);
221 | if (epfd < 0) {
222 | perror("epoll_create()");
223 | return;
224 | }
225 |
226 | ev.events = EPOLLIN|EPOLLET;
227 |
228 | fifofd = open("/dev/globalfifo", O_RDONLY, S_IRUSR);
229 | printf("fifo fd:%d\n", fifofd);
230 | ev.data.fd = fifofd;
231 | ret = epoll_ctl(epfd, EPOLL_CTL_ADD, fifofd, &ev);
232 |
233 | pipefd = open("pipe", O_RDONLY|O_NONBLOCK, S_IRUSR);
234 | printf("pipe fd:%d\n", pipefd);
235 | ev.data.fd = pipefd;
236 | ret = epoll_ctl(epfd, EPOLL_CTL_ADD, pipefd, &ev);
237 |
238 | while(1) {
239 | ret = epoll_wait(epfd, events, 2, 50000);
240 | if (ret < 0) {
241 | perror("epoll_wait()");
242 | } else if (ret == 0) {
243 | printf("No data within 50 seconds.\n");
244 | } else {
245 | int i;
246 | for(i=0;i
36 | 2、收回刚刚结束使用寿命的程序所占内存空间。
37 | 3、让内核代码占据内存物理地址最开始的、天然的、有利的位置。
38 |
39 | 此时,重要角色要登场了,他们就是中断描述符表IDT和全局描述符表GDT。
40 |
41 | * GDT(Global Descriptor Table,全局描述符表),在系统中唯一的存放段寄存器内容(段描述符)的数组,配合程序进行保护模式下的段寻址。它在操作系统的进程切换中具有重要意义,可理解为所有进程的总目录表,其中存放每一个任务(task)局部描述符表(LDT, Local Descriptor Table)地址和任务状态段(TSS, Task Structure Segment)地址,完成进程中各段的寻址、现场保护与现场恢复。GDTR是GDT基地址寄存器,当程序通过段寄存器引用一个段描述符时,需要取得GDT的入口,GDTR标识的即为此入口。在操作系统对GDT的初始化完成后,可以用LGDT(Load GDT)指令将GDT基地址加载至GDTR。
42 | * IDT(Interrupt Descriptor Table,中断描述符表),保存保护模式下所有中断服务程序的入口地址,类似于实模式下的中断向量表。IDTR(IDT基地址寄存器),保存IDT的起始地址。
43 |
44 | 32位的中断机制和16位的中断机制,在原理上有比较大的差别。最明显的是16位的中断机制用的是中断向量表,中断向量表的起始位置在0x00000处,这个位置是固定的;32位的中断机制用的是中断描述符表(IDT),位置是不固定的,可以由操作系统的设计者根据设计要求灵活安排,由IDTR来锁定其位置。GDT是保护模式下管理段描述符的数据结构,对操作系统自身的运行以及管理、调度进程有重大意义。
45 |
46 | 此时此刻内核尚未真正运行起来,还没有进程,所以现在创建的GDT第一项为空,第二项为内核代码段描述符,第三项为内核数据段描述符,其余项皆为空。IDT虽然已经设置,实为一张空表,原因是目前已关中断,无需调用中断服务程序。此处反映的是数据“够用即得”的思想。
47 |
48 | 创建这两个表的过程可理解为是分两步进行的:
49 |
50 | 1、在设计内核代码时,已经将两个表写好,并且把需要的数据也写好。此处的数据区域是在内核源代码中设定、编译并直接加载至内存形成的一块数据区域。专用寄存器的指向由程序中的lidt和lgdt指令完成
51 | 2、将专用寄存器(IDTR、GDTR)指向表。
52 |
53 | ## 三. A20
54 |
55 | A20启用是一个标志性的动作,由上文提到的lzma_decompress.img 调用 real_to_prot启动。打开A20,意味着CPU可以进行32位寻址,最大寻址空间为4 GB。注意图1-19中内存条范围的变化:从5个F扩展到8个F,即0xFFFFFFFF(4 GB)。
56 |
57 | 实模式下,当程序寻址超过0xFFFFF时,CPU将“回滚”至内存地址起始处寻址(注意,在只有20根地址线的条件下,0xFFFFF+1=0x00000,最高位溢出)。例如,系统的段寄存器(如CS)的最大允许地址为0xFFFF,指令指针(IP)的最大允许段内偏移也为0xFFFF,两者确定的最大绝对地址为0x10FFEF,这将意味着程序中可产生的实模式下的寻址范围比1 MB多出将近64 KB(一些特殊寻址要求的程序就利用了这个特点)。这样,此处对A20地址线的启用相当于关闭CPU在实模式下寻址的“回滚”机制。如下所示为利用此特点来验证A20地址线是否确实已经打开。注意此处代码并不在此时运行,而是在后续head运行过程中为了检测是否处于保护模式中使用。
58 |
59 | #boot/head.s
60 | ……
61 | xorl %eax,%eax
62 | 1:incl%eax#check that A20 really IS enabled
63 | movl %eax,0x000000#loop forever if it isn't
64 | cmpl %eax,0x100000
65 | je 1b
66 | ……
67 |
68 | A20如果没打开,则计算机处于20位的寻址模式,超过0xFFFFF寻址必然“回滚”。一个特例是0x100000会回滚到0x000000,也就是说,地址0x100000处存储的值必然和地址0x000000处存储的值完全相同。通过在内存0x000000位置写入一个数据,然后比较此处和1 MB(0x100000,注意,已超过实模式寻址范围)处数据是否一致,就可以检验A20地址线是否已打开。
69 |
70 | ## 四. 进入main函数
71 |
72 | 这里涉及到一个硬件知识:在X86体系中,采用的终端控制芯片名为8259A,此芯片,是可以用程序控制的中断控制器。单个的8259A能管理8级向量优先级中断,在不增加其他电路的情况下,最多可以级联成64级的向量优先级中断系统。CPU在保护模式下,int 0x00~int 0x1F被Intel保留作为内部(不可屏蔽)中断和异常中断。如果不对8259A进行重新编程,int 0x00~int 0x1F中断将被覆盖。例如,IRQ0(时钟中断)为8号(int 0x08)中断,但在保护模式下此中断号是Intel保留的“Double Fault”(双重故障)。因此,必须通过8259A编程将原来的IRQ0x00~IRQ0x0F对应的中断号重新分布,即在保护模式下,IRQ0x00~IRQ0x0F的中断号是int 0x20~int 0x2F。
73 |
74 | setup程序通过下面代码将CPU工作方式设为保护模式。这里涉及到一个CR0寄存器:0号32位控制寄存器,放系统控制标志。第0位为PE(Protected Mode Enable,保护模式使能)标志,置1时CPU工作在保护模式下,置0时为实模式。将CR0寄存器第0位(PE)置1,即设定处理器工作方式为保护模式。CPU工作方式转变为保护模式,一个重要的特征就是要根据GDT决定后续执行哪里的程序。前文提到GDT初始时已写好了数据,这些将用来完成从setup程序到head程序的跳转。
75 |
76 | #boot/setup.s
77 | mov ax,#0x0001!protected mode(PE)bit
78 | lmsw ax!This is it!
79 | jmpi 0,8!jmp offset 0 of segment 8(cs)
80 |
81 | head程序是进入main之前的最后一步了。head在空间创建了内核分页机制,即在0x000000的位置创建了页目录表、页表、缓冲区、GDT、IDT,并将head程序已经执行过的代码所占内存空间覆盖。这意味着head程序自己将自己废弃,main函数即将开始执行。具体的分页机制因为较为复杂,所以打算放在后续介绍内存管理的部分再单独介绍。
82 |
83 | head构造IDT,使中断机制的整体架构先搭建起来(实际的中断服务程序挂接则在main函数中完成),并使所有中断服务程序指向同一段只显示一行提示信息就返回的服务程序。从编程技术上讲,这种初始化操作,既可以防止无意中覆盖代码或数据而引起的逻辑混乱,也可以对开发过程中的误操作给出及时的提示。IDT有256个表项,实际只使用了几十个,对于误用未使用的中断描述符,这样的提示信息可以提醒开发人员注意错误。
84 |
85 | 除此之外,head程序要废除已有的GDT,并在内核中的新位置重新创建GDT。原来GDT所在的位置是设计代码时在setup.s里面设置的数据,将来这个setup模块所在的内存位置会在设计缓冲区时被覆盖。如果不改变位置,将来GDT的内容肯定会被缓冲区覆盖掉,从而影响系统的运行。这样一来,将来整个内存中唯一安全的地方就是现在head.s所在的位置了。
86 |
87 | 下来步骤主要包括
88 |
89 | 1、初始化段寄存器和堆栈
90 |
91 | 2、主要包括将DS和ES寄存器指向相同的地址,并将DS和CS设置为相同的值。
92 |
93 | 3、清零eflag寄存器以及内核未初始化数据区
94 |
95 | 4、调用decompress_kernel()解压内核映像并跳转至0X00100000处。
96 |
97 | 5、段寄存器初始化为最终值并填充BSS字段为0
98 |
99 | 初始化临时内核页表
100 |
101 | 最终完成了分页机制初始化后,PG(Paging) 标志位将会置1,表示地址映射模式采取分页机制,最终跳转至main函数,内核开始初始化工作。
102 |
103 | ## 五. 内核初始化
104 |
105 | 注意,至此为止,我们尚未打开中断,而必须通过main函数完成一系列的初始化后才会打开新的中断,从而使内核正式运行起来。该部分主要包括:
106 |
107 | 1、为进程0建立内核态堆栈
108 |
109 | 2、清零eflags寄存器
110 |
111 | 3、调用setup_idt()用空的中断处理程序填充IDT
112 |
113 | 4、把BIOS中获得的参数传递给第一个页框
114 |
115 | 5、用GDT和IDT表填充寄存器
116 |
117 | 完成这些之后,内核就正式运行,开始创建0号进程了。
118 |
119 | ## 六. 总结
120 |
121 | 本文介绍了实模式到保护模式的整个切换过程,完成了内核的加载并开始正式准备创建0号进程。后续将继续分析启动内核创建0号、1号、2号进程的整个过程。本文介绍过程中忽略了很多汇编代码以及一些虽然很重要但是不属于基本流程的知识,有兴趣了解的可以根据文中链接、文末的源码和参考资料进行更深入的学习研究。
122 |
--------------------------------------------------------------------------------
/文章/Linux操作系统学习——启动.md:
--------------------------------------------------------------------------------
1 | ## 一. 前言
2 |
3 | Linux操作系统内核是服务端学习的根基,也是提高编程能力、源码阅读能力和进阶知识学习能力的重要部分,本文开始将记录Linux操作系统中的各个部分源码学习历程。
4 |
5 | 关于如何学习源码,个人觉得可以从以下角度入手,有效地提高阅读和学习的效率。(学习语言就不说了,这是基本功。学习IDE推荐Source Insight或者Visual Studio,网站源码阅读推荐woboq)
6 |
7 | * 理解代码的组织结构。 以Linux源码举例,首先你得知道操作系统分为哪几个部分,他们单独做了什么功能,如何进行配合完成更为具体的功能。建立整体的印象有助于后续深入学习的时候方便理解,毕竟代码是用的不是看的,理解他的作用有利于理解为什么要这么做。
8 |
9 | * 深入各个模块学习
10 | * 模块接口: 这里推荐微软的画图工具visio或者思维导图xmind,用其画图可以将各个模块的接口列出,并绘制各个模块之间的关系,通过了解接口可以清楚各个模块之间的关系,即绘制模块组织图
11 | * 工作流程:通过上面一步得到各模块间的关系,然后实际用断点或log等方式看一看整体的工作流程,在模块组织图的基础上绘制程序流程图
12 | * 模块粘合层:我们的代码有很多都是用来粘合代码的,比如中间件(middleware)、Promises 模式、回调(Callback)、代理委托、依赖注入等。这些代码模块间的粘合技术是非常重要的,因为它们会把本来平铺直述的代码给分裂开来,让你不容易看明白它们的关系。这些可以作为程序流程图的补充,让其中本来无法顺畅衔接的地方变得通畅无阻。
13 | * 模块具体实现 :这是最难得地方,涉及到大量具体源码的学习。深入细节容易迷失在细节的海洋里,因此需要有一些重点去关注,将非重点的内容省略。通过学习绘制模块具体架构图和模块的算法时序图,可以帮助你更好的掌握源码的精髓。
14 |
15 | * 需要关注的包括
16 | * 代码逻辑。代码有两种逻辑,一种是业务逻辑,这种逻辑是真正的业务处理逻辑;另一种是控制逻辑,这种逻辑只是用控制程序流转的,不是业务逻辑。比如:flag 之类的控制变量,多线程处理的代码,异步控制的代码,远程通讯的代码,对象序列化反序列化的代码等。这两种逻辑你要分开,很多代码之所以混乱就是把这两种逻辑混在一起了。
17 | * 重要的算法。一般来说,我们的代码里会有很多重要的算法,我说的并不一定是什么排序或是搜索算法,可能会是一些其它的核心算法,比如一些索引表的算法,全局唯一 ID 的算法、信息推荐的算法、统计算法、通读算法(如 Gossip)等。这些比较核心的算法可能会非常难读,但它们往往是最有技术含量的部分。
18 | * 底层交互。有一些代码是和底层系统的交互,一般来说是和操作系统或是 JVM 的交互。因此,读这些代码通常需要一定的底层技术知识,不然,很难读懂。
19 |
20 | * 可以忽略的包括
21 | * 出错处理。根据二八原则,20% 的代码是正常的逻辑,80% 的代码是在处理各种错误,所以,你在读代码的时候,完全可以把处理错误的代码全部删除掉,这样就会留下比较干净和简单的正常逻辑的代码。排除干扰因素,可以更高效地读代码。
22 | * 数据处理。只要你认真观察,就会发现,我们好多代码就是在那里倒腾数据。比如 DAO、DTO,比如 JSON、XML,这些代码冗长无聊,不是主要逻辑,可以不理。
23 |
24 | * 忽略过多的实现细节。在第一遍阅读源码时,已弄懂整体流程为主,至于具体的实现细节先简单的理清处过一遍,不用过于纠结。当梳理清楚全部的框架逻辑后,第二遍再深入的学习研究各个模块的实现,此时应该解决第一遍中的疑惑。第三遍可以跳出代码的实现,来看Linux的设计思路、编程艺术和演进之路。
25 |
26 | * 重在实践。Linux的代码都是可以调试的,看很多遍也许不如跟着调试走一遍,然后再自己修改修改做一些小测试。
27 |
28 | * 传授知识。当你能将知识讲述给别人听,并让别人听懂时,你已经可以自豪的说洞悉了这些知识。所以不妨从一个小的例子开始自说自话,看能不能自圆其说,甚至写成博客、做成PPT给大家讲解。
29 |
30 | 说了一大堆的废话,下面就正式开始操作系统的深入学习记录之旅了。
31 |
32 | ## 二. 混沌初开
33 |
34 | 本文分析从按下电源键到加载BIOS以及后续bootloader的整个过程。犹如盘古开天辟地一般,该过程将混沌的操作系统世界分为清晰的内核态和用户态,并经历从实模式到保护模式的变化。这里先简单介绍一下名词,便于后续理解。
35 |
36 | * 实模式(Real Mode):又名 Real Address Mode,在此模式下地址访问的是真实地内存地址所在位置。在此模式下,可以使用20位(1MB)的地址空间,软件可以不受限制的操作所有地址的空间和IO设备。
37 | * 保护模式(Protected Mode):又名 Protected Virtual Address Mode,采用虚拟内存、页等机制对内存进行了保护,比起实模式更为安全可靠,同时也增加了灵活性和扩展性。
38 |
39 | ### 2.1 从启动电源到BIOS
40 |
41 | 当我们按下电源键,主板会发向电源组发出信号,接收到信号后,电源会提供合适的电压给计算机。当主板收到电源正常启动的信号后,主板会启动CPU。CPU重置所有寄存器数据,并设置初始化数据,这个初始化数据在X86架构里如下所示:
42 |
43 | IP 0xfff0
44 | CS selector 0xf000
45 | CS base 0xffff0000
46 | IP/EIP (Instruction Pointer) : 指令指针寄存器,记录将要执行的指令在代码段内的偏移地址
47 | CS(Code Segment Register):代码段寄存器,指向CPU当前执行代码在内存中的区域(定义了存放代码的存储器的起始地址)
48 |
49 | 实模式采取内存段来管理 0 - 0xFFFFF的这1M内存空间,但是由于只有16位寄存器,所以最大地址只能表示为0xFFFFF(64KB),因此不得不采取将内存按段划分为64KB的方式来充分利用1M空间。也就是上所示的,采取段选择子 + 偏移量的表示法。这种方法在保护模式中对于页的设计上也沿用了下来,可谓祖传的智慧了。具体的计算公式如下所示:
50 |
51 | PhysicalAddress = Segment Selector * 16 + Offset
52 |
53 | 该部分由硬件完成,通过计算访问0XFFFF0,如果该位置没有可执行代码则计算机无法启动。如果有,则执行该部分代码,这里也就是我们故事的开始,BIOS程序了。
54 |
55 | ### 2.2 BIOS到BootLoader
56 |
57 | BIOS执行程序存储在ROM中,起始位置为0XFFFF0,当CS:IP指向该位置时,BIOS开始执行。BIOS主要包括以下内存映射:
58 |
59 | 0x00000000 - 0x000003FF - Real Mode Interrupt Vector Table
60 | 0x00000400 - 0x000004FF - BIOS Data Area
61 | 0x00000500 - 0x00007BFF - Unused
62 | 0x00007C00 - 0x00007DFF - Our Bootloader
63 | 0x00007E00 - 0x0009FFFF - Unused
64 | 0x000A0000 - 0x000BFFFF - Video RAM (VRAM) Memory
65 | 0x000B0000 - 0x000B7777 - Monochrome Video Memory
66 | 0x000B8000 - 0x000BFFFF - Color Video Memory
67 | 0x000C0000 - 0x000C7FFF - Video ROM BIOS
68 | 0x000C8000 - 0x000EFFFF - BIOS Shadow Area
69 | 0x000F0000 - 0x000FFFFF - System BIOS
70 |
71 | 其中最重要的莫过于中断向量表和中断服务程序。BIOS程序在内存最开始的位置(0x00000)用1 KB的内存空间(0x00000~0x003FF)构建中断向量表,在紧挨着它的位置用256字节的内存空间构建BIOS数据区(0x00400~0x004FF),并在大约57 KB以后的位置(0x0E05B)加载了8 KB左右的与中断向量表相应的若干中断服务程序。中断向量表中有256个中断向量,每个中断向量占4字节,其中两个字节是CS的值,两个字节是IP的值。每个中断向量都指向一个具体的中断服务程序。
72 |
73 | BIOS程序会选择一个启动设备,并将控制权转交给启动扇区中的代码。主要工作即使用中断向量和中断服务程序完成BootLoader的加载,最终将boot.img加载至0X7C00的位置启动。Linux内核通过Boot Protocol定义如何实现该引导程序,有如GRUB 2和syslinux等具体实现方式,这里仅介绍GRUB2。
74 |
75 | ### 2.3 BootLoader的工作
76 |
77 | boot.img由boot.S编译而成,512字节,安装在启动盘的第一个扇区,即MBR。由于空间有限,其代码十分简单,仅仅是起到一个引导的作用,指向后续的核心镜像文件,即core.img。core.img包括很多重要的部分,如lzma_decompress.img、diskboot.img、kernel.img等,结构如下图。
78 |
79 | 
80 |
81 | 整个加载流程如下:
82 |
83 | 1、boot.img加载core.img的第一个扇区,即diskboot.img,对应代码为diskboot.S
84 | 2、diskboot.img加载core.img的其他部分模块,先是解压缩程序 lzma_decompress.img,再往下是 kernel.img,最后是各个模块 module 对应的映像。这里需要注意,它不是 Linux 的内核,而是 grub 的内核。注意,lzma_decompress.img 对应的代码是 startup_raw.S,本来 kernel.img 是压缩过的,现在执行的时候,需要解压缩。
85 | 3、加载完core之后,启动grub_main函数。
86 | 4、grub_main函数初始化控制台,计算模块基地址,设置 root 设备,读取 grub 配置文件,加载模块。最后,将 GRUB 置于 normal 模式,在这个模式中,grub_normal_execute (from grub-core/normal/main.c) 将被调用以完成最后的准备工作,然后显示一个菜单列出所用可用的操作系统。当某个操作系统被选择之后,grub_menu_execute_entry 开始执行,它将调用 GRUB 的 boot 命令,来引导被选中的操作系统。
87 |
88 | 在这之前,我们所有遇到过的程序都非常非常小,完全可以在实模式下运行,但是随着我们加载的东西越来越大,实模式这 1M 的地址空间实在放不下了,所以在真正的解压缩之前,lzma_decompress.img 做了一个重要的决定,就是调用 real_to_prot,切换到保护模式,这样就能在更大的寻址空间里面,加载更多的东西。
89 |
90 | 开机时的16位实模式与内核启动的main函数执行需要的32位保护模式之间有很大的差距,这个差距谁来填补?head.S做的就是这项工作。就像 kernel boot protocol 所描述的,引导程序必须填充 kernel setup header (位于 kernel setup code 偏移 0x01f1 处) 的必要字段,这些均在head.S中定义。在这期间,head程序打开A20,打开pe、pg,废弃旧的、16位的中断响应机制,建立新的32位的IDT……这些工作都做完了,计算机已经处在32位的保护模式状态了,调用32位内核的一切条件已经准备完毕,这时顺理成章地调用main函数。后面的操作就可以用32位编译的main函数完成,从而正式启动内核,进入波澜壮阔的Linux内核操作系统之中。
91 |
92 | ## 三. 总结
93 |
94 | 本文介绍了从按下电源开关至加载完毕BootLoader的整个过程,后续将继续分析从实模式进入保护模式,从而启动内核创建0号、1号、2号进程的整个过程。本文介绍过程中忽略了很多汇编代码以及一些虽然很重要但是不属于基本流程的知识,有兴趣了解的可以根据文中链接、文末的源码和参考资料进行更深入的学习研究。
95 |
96 |
97 |
98 |
99 |
100 |
101 |
102 |
103 |
104 |
105 |
106 |
107 |
108 |
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 |
117 |
118 |
119 |
--------------------------------------------------------------------------------
/文章/你真的理解Linux中断机制嘛.md:
--------------------------------------------------------------------------------
1 | Linux中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
2 |
3 | 进程的不可中断状态是系统的一种保护机制,可以保证硬件的交互过程不被意外打断。所以,短时间的不可中断状态是很正常的。但是,当进程长时间都处于不可中断状态时,你就需要提起注意力确认下是不是磁盘I/O存在问题,相关的进程和磁盘设备是否工作正常。
4 |
5 | 今天我们详细了解一下中断的机制,进而对其中的软中断进行一个剖析。
6 |
7 | ## 概念解释
8 |
9 | (1)中断:是一种异步的事件处理机制,可以提高系统的并发处理能力。
10 |
11 | (2)如何解决中断处理程序执行过长和中断丢失的问题:
12 | Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部。
13 | 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。也就是我们常说的硬中断,特点是快速执行。
14 | 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行。也就是我们常说的软中断,特点是延迟执行。
15 |
16 | (3)proc 文件系统:是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。
17 | /proc/softirqs 提供了软中断的运行情况;
18 | /proc/interrupts 提供了硬中断的运行情况。
19 |
20 | (4)硬中断:硬中断是由硬件产生的,比如,像磁盘,网卡,键盘,时钟等。每个设备或设备集都有它自己的IRQ(中断请求)。基于IRQ,CPU可以将相应的请求分发到对应的硬件驱动上。硬中断可以直接中断CPU,引起内核中相关的代码被触发。
21 |
22 | (5)软中断:软中断仅与内核相关,由当前正在运行的进程所产生。 通常,软中断是一些对I/O的请求,这些请求会调用内核中可以调度I/O发生的程序。 软中断并不会直接中断CPU,也只有当前正在运行的代码(或进程)才会产生软中断。这种中断是一种需要内核为正在运行的进程去做一些事情(通常为I/O)的请求。
23 | 除了iowait(等待I/O的CPU使用率)升高,软中断(softirq)CPU使用率升高也是最常见的一种性能问题。
24 |
25 | ## 查看软中断和内核线程
26 |
27 | 小伙伴们肯定好奇该怎么查看系统里有哪些软中断?接下来将教给大家方法。
28 | 前面有提到过proc文件系统,它是一种内核空间和用户空间进行通信的机制, 可以用来查看内核的数据结构,或者用来动态修改内核的配置。
29 |
30 | * /proc/softirqs 提供了软中断的运行情况;
31 | * /proc/interrupts 提供了硬中断的运行情况。
32 |
33 | (1)如何查看各种类型软中断在不同 CPU上的累积运行次数:
34 |
35 | ```
36 | $ cat /proc/softirqs
37 | CPU0 CPU1 CPU2 CPU3
38 | HI: 276180 286764 2509097 254357
39 | TIMER: 1550133 1285854 1440533 1812909
40 | NET_TX: 102895 16 15 57
41 | NET_RX: 155 178 115 1619192
42 | BLOCK: 1713 15048 251826 1082
43 | IRQ_POLL: 0 0 0 0
44 | TASKLET: 9 63 6 2830
45 | SCHED: 1484942 1207449 1310735 1724911
46 | HRTIMER: 0 0 0 0
47 | RCU: 690954 685825 787447 878963
48 |
49 | ```
50 |
51 | 软中断的类型:对应第1列,包含了10个类别,分别对应不同的工作类型。比如说NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中 断。
52 |
53 | 同一种软中断类型在不同CPU上的分布情况:对应每一行,正常情况下,同一种中断类型在不同CPU上的累计次数基本在同一个数量级。但是也有例外,比如TASKLET
54 |
55 | 拓展:什么是TASKLET?
56 | * TASKLET是最常用的软中断实现机制,每个TASKLET只会运行一次就会结束,并且只在调用它的函数所在的CPU上运行,不能并行而只能串行执行。
57 | * 多个不同类型的TASKLET可以并行在多个CPU上。
58 | * 软中断是静态,只能支持有限的几种软中断类型,一旦内核编译好之后就不能改变;而TASKLET灵活很多,可以通过添加内核模块的方式在运行时修改。
59 |
60 |
61 | (2)如何查看软中断内核线程的运行状况?
62 | 软中断是以内核线程的方式运行的,每个CPU都会对应一个软中断内核线程,查看的方式如下:
63 |
64 | ```
65 | $ ps -ef|grep softirq
66 | root 7 2 0 Nov04 ? 00:00:53 [ksoftirqd/0]
67 | root 16 2 0 Nov04 ? 00:00:51 [ksoftirqd/1]
68 | root 22 2 0 Nov04 ? 00:00:53 [ksoftirqd/2]
69 | root 28 2 0 Nov04 ? 00:00:53 [ksoftirqd/3]
70 | ```
71 |
72 | 这些线程的名字外面都有中括号,这说明 ps 无法获取它们的命令行参数 (cmline)。
73 |
74 | 一般来说,ps 的输出中,名字括在中括号里的,一般都是内核线程。
75 |
76 | (3)如何查看硬中断运行情况
77 |
78 | ```
79 | $ cat /proc/interrupts
80 | CPU0 CPU1 CPU2 CPU3
81 | 0: 33 0 0 0 IO-APIC-edge timer
82 | 1: 10 0 0 0 IO-APIC-edge i8042
83 | 4: 325 0 0 0 IO-APIC-edge serial
84 | 8: 1 0 0 0 IO-APIC-edge rtc0
85 | 9: 0 0 0 0 IO-APIC-fasteoi acpi
86 | 10: 0 0 0 0 IO-APIC-fasteoi virtio3
87 | 40: 0 0 0 0 PCI-MSI-edge virtio1-config
88 | 41: 16669006 0 0 0 PCI-MSI-edge virtio1-requests
89 | 42: 0 0 0 0 PCI-MSI-edge virtio2-config
90 | 43: 59166530 0 0 0 PCI-MSI-edge virtio2-requests
91 | 44: 0 0 0 0 PCI-MSI-edge virtio0-config
92 | 45: 6689988 0 0 0 PCI-MSI-edge virtio0-input.0
93 | 46: 0 0 0 0 PCI-MSI-edge virtio0-output.0
94 | 47: 2093616484 0 0 0 PCI-MSI-edge peth1-TxRx-0
95 | 48: 5 2045859720 0 0 PCI-MSI-edge peth1-TxRx-1
96 | 49: 81 0 0 0 PCI-MSI-edge peth1
97 | NMI: 0 0 0 0 Non-maskable interrupts
98 | LOC: 2936184495 965056330 1641503935 1442909354 Local timer interrupts
99 | SPU: 0 0 0 0 Spurious interrupts
100 | PMI: 0 0 0 0 Performance monitoring interrupts
101 | IWI: 53775871 47387196 47737572 44243915 IRQ work interrupts
102 | RTR: 0 0 0 0 APIC ICR read retries
103 | RES: 1198594562 964481221 966552350 902484234 Rescheduling interrupts
104 | CAL: 4294967071 4438 430547422 419910155 Function call interrupts
105 | TLB: 1206563963 65932469 1378887038 1028081848 TLB shootdowns
106 | TRM: 0 0 0 0 Thermal event interrupts
107 | THR: 0 0 0 0 Threshold APIC interrupts
108 | MCE: 0 0 0 0 Machine check exceptions
109 | MCP: 65623 65623 65623 65623 Machine check polls
110 | ERR: 0
111 | ```
112 |
113 | ## 工具与技巧
114 |
115 | 
116 |
117 |
118 | (1)sar 是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告历史统计数据。
119 | 命令:sar -n DEV 1
120 | 含义:-n DEV 1 表示显示网络收发的报告,间隔1秒输出一组数据
121 |
122 | ```
123 | $ sar -n DEV 1
124 | 16:01:21 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
125 | 16:01:22 eth0 12605.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01
126 | 16:01:22 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00
127 | 16:01:22 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
128 | 16:01:22 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05
129 | ```
130 |
131 | 第1列:表示报告的时间
132 |
133 | 第2列:IFACE 表示网卡
134 |
135 | 第3,4列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是 PPS
136 |
137 | 第5,6列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS。
138 |
139 | (2)tcpdump 是一个常用的网络抓包工具,常用来分析各种网络问题。
140 |
141 | 命令:tcpdump -i eth0 -n tcp port 80
142 | 含义:-i eth0 只抓取eth0网卡,-n不解析协议名和主机名
143 | tcp port 80表示只抓取tcp协议并且端口号为80的网络帧
144 |
145 |
--------------------------------------------------------------------------------
/文章/内存管理/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/文章/内存管理/Linux中的内存管理机制.md:
--------------------------------------------------------------------------------
1 | 程序在运行时所有的数据结构的分配都是在堆和栈上进行的,而堆和栈都是建立在内存之上。内存作为现代计算机运行的核心,CPU可以直接访问的通用存储只有内存和处理器内置的寄存器,所有的代码都需要装载到内存之后才能让CPU通过指令寄存器找到相应的地址进行访问。
2 |
3 | ## 地址空间和MMU
4 |
5 | 内存管理单元(MMU)是硬件提供的最底层的内存管理机制,是CPU的一部分,用来管理内存的控制线路,提供把虚拟地址映射为物理地址的能力。
6 |
7 | 在x86体系结构下,CPU对内存的寻址都是通过分段方式进行的。其工作流程为:CPU生成逻辑地址并交给分段单元。分段单元为每个逻辑地址生成一个线性地址。然后线性地址交给分页单元,以生成内存的物理地址。因此也就是分段和分页单元组成了内存管理单元(MMU)。
8 |
9 | 
10 |
11 | 其中: + 虚拟地址:在段中的偏移地址 + 线性地址:在某个段中“基地址+偏移地址”得出的地址 + 物理地址:在x86中,MMU还提供了分页机制,假如没有开启分页机制,那么线性地址就等于物理地址;否则还需要经过分页机制换算后线性地址才能转换成物理地址。 一个段是由“基地址+段界限(该段长度)+类型”组成,主要确定了段的起始地址,段的界限长度和确定段的属性如是否可读、可写、段的基本粒度单位、表述该段是数据段还是代码段等。 分段允许进程的物理地址空间是非连续的,分页则是提供这一优势的另外一种内存管理方案,并且**分页避免了外部碎片和紧缩,分段却不可以**。在x86体系中MMU支持多级的分页模型,主要分为以下三种情况: 1. 32为系统分为2级分页模型 2. 32位系统开启了物理地址扩展模式(PAE),则分为3级分页模型 3. 64位系统分为4级分页模型 80x86的分页机制由CR0中的PG位开启,若PG=0则禁用分页机制,也就是直接将线性地址作为物理地址。32位的线性地址主要分为三个部分:
12 |
13 | 
14 |
15 | * 22-31位指向页目录表中的某一项,页目录表中的每一项存有4子节地址指向页表。所以页表目录大小为4 * 210 = 4K
16 | * 12-21位指向页表中的某一项,页表大小与页目录表相同为4K
17 | * 一个物理页为4K,刚好0-11位指向页表中的偏移,一个页表刚好4K(212)
18 |
19 | 页表和页目录表可以存放在内存的任何地方,当分页机制开启后,需要让CR3寄存器指向页目录表的起始地址。
20 |
21 | > CR0-CR4这五个寄存器为系统内的控制寄存器,与分页机制密切相关。
22 | > CR0控制寄存器是一些特殊的寄存器,可以控制CPU的一些重要特性;
23 | > CR1是未定义的控制寄存器,供将来使用;
24 | > CR2是页故障线性地址寄存器,保存最后一次出现页故障的全32位线性地址;
25 | > CR3是页目录基址寄存器,保存页目录表的物理地址(页目录表总是放在4k为单位的存储器边界上,因此其低12位总为0不起作用,即使写上内容也不会被理会)
26 | > CR4在Pentium系列(包括486后期版本)处理器中才出现,处理事务包括何时启用虚拟8086模式等。
27 |
28 | ### Linux中的分段与分页
29 |
30 | MMU在保护模式下分段数据主要定义在GDT中。
31 |
32 | ```c
33 | //arch/x86/kernel/cpu/common.c
34 |
35 | DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
36 | ...
37 | [GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff), //代码段
38 | [GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff), //数据段
39 | [GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
40 | [GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
41 | ...
42 | } };
43 | EXPORT_PER_CPU_SYMBOL_GPL(gdt_page);
44 | ```
45 |
46 | 通过代码可知道这些段的基地址都是0,界限为4G。说明Linux只定义了一个段,并没有真正利用分段机制。
47 |
48 | Linux中只用了一个段,而且基地址从0开始,那么在程序中使用的虚地址就是线性地址了。Linux为了兼容64位、32位及其PAE扩展情况,在代码中通过4级分页机制来做兼容。
49 |
50 | ## Linux的内存分配与管理
51 |
52 | 在32位的x86设备中,Linux为每个进程分配的虚拟地址空间都是0-4GB,其中
53 |
54 | * 0-3GB用于用户态使用
55 | * 3GB-3GB+896MB映射到物理地址的0-896MB处,作为内核态地址空间
56 | * 3GB+896MB-4GB之间的128MB空间用于vmalloc保留区域,该区域用于kmalloc、kmap固定地址映射等功能,可以让内核访问高端物理地址空间
57 |
58 | 
59 |
60 | Linux中进程的地址空间由mm_struct来描述,一个进程只会有一个mm_struct。系统中的内核态是共享的,不会发生缺页中断或者访问用户进程空间,所以内核线程的task_struct->mm为NULL。
61 |
62 | 页表的分配分为两个部分:
63 |
64 | 1、内核页表,也就是在系统启动中,最后会在paging_init函数中,把ZONE_DMA和ZONE_NORMAL区域的物理页面与虚拟地址空间的3GB-3GB+896MB进行直接映射
65 | 2、内核高端地址和用户态地址,都是通过MMU机制修改线性地址(虚拟地址)和物理地址的映射关系,然后刷新页表缓存来达到的
66 |
67 | > 物理内存中ZONE_DMA的范围是0-16MB,该区域的物理页面专门供IO设备的DMA使用,之所以要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存不经过MMU,并且需要连续的缓冲区。为了能够提供物理上的连续缓冲区,必须从物理地址专门划分出一段区域用于DMA。 ZONE_NORMAL的范围是16MB-896MB,该区域的物理页面是内核能够直接使用的。 ZONE_HIGHMEM的范围是896MB-结束,该区域即高端内存,内核不能直接使用。
68 |
69 | ### 伙伴系统
70 | 对于物理内存经过频繁地申请和释放后会产生外部碎片,Linux通过伙伴系统来解决外部碎片的问题。
71 |
72 | 满足:
73 | 1.具有相同的大小;
74 | 2.物理地址连续条件的两个块为伙伴。主要实现思路位伙伴系统在申请内存的时候让最小的块满足申请的需求,在归还的时候,尽量让连续的小块内存伙伴合并成大块,降低外部碎片出现的可能性。
75 |
76 | 在Linux系统中伙伴系统维护了11个块链表,每个块链表分别包含了大小为20-211个连续的物理页。对1024个页的最大请求对应着4MB大小的连续RAM块。每个快的第一个页框的物理地址就是该块大小的整数倍。如大小为16个页框的块,其起始地址为16×212(212=4KB这是一个页的大小)的倍数。
77 |
78 | 系统在初始化的时候把内各节点各区域都释放到伙伴系统中,每个区域还维护了per-cpu高速缓存来处理单页的分配,各个区域都通过伙伴算法进行物理内存的分配。
79 |
80 | ### slab分配器
81 |
82 | Linux系统通过伙伴算法解决了外部碎片的问题,此外还提供了slab分配器来处理内部碎片的问题。slab分配器也是一种内存预分配机制,是一种空间换时间的做法,并且其假定从slab分配器中获得的内存都是比页还小的小内存块。
83 |
84 | 
85 |
86 | slab的设计思想就是把若干的页框合在一起形成一大存储块——slab,并在这个slab中只存储同一类数据,这样就可以在这个slab内部打破页的界限,以该类型数据的大小来定义分配粒度,存放多个数据,这样就可以尽可能地减少页内碎片了。在Linux中,多个存储同类数据的slab的集合叫做一类对象的缓冲区——cache。注意,这不是硬件的那个cache,只是借用这个名词而已。
87 |
88 | Linux中slab的可分为以下三种状态:
89 |
90 | 1、slabs_full:该链表中slab已经完全分配出去
91 | 2、slabs_free:该链表中的slab都是空闲可分配状态
92 | 3、labs_partial:该链表中的slab部分已经被分配出去了
93 |
94 | 其中slab代表物理地址连续的内存块,由1-N个物理页面组成,在一个slab中可以分配多个object对象。
95 |
96 | slab的优点:
97 |
98 | * 内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题;
99 | * slab 分配器还支持通用对象的初始化,从而避免了为同一目的而对一个对象重复进行初始化;
100 | * slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
101 |
102 | slab的缺点:
103 |
104 | * 较多复杂的队列管理。在slab分配器中存在众多的队列,例如针对处理器的本地缓存队列,slab中空闲队列,每个slab处于一个特定状态的队列之中。
105 | * slab管理数据和队列的存储开销比较大。每个slab需要一个struct slab数据结构和一个管理者kmem_bufctl_t型的数组。当对象体积较小时,该数组将造成较大的开销(比如对象大小为32字节时,将浪费1/8空间)。同时,缓冲区针对节点和处理器的队列也会浪费不少内存。
106 | * 缓冲区回收、性能调试调优比较复杂。
107 |
108 |
109 | ### 内核态内存管理
110 |
111 | 根据之前的的Linux的内存管理机制,即伙伴系统和slab分配器。对于内核态的内存分配主要通过函数kmalloc和vmalloc完成。
112 |
113 | 
114 |
115 | 其中kmalloc函数可以为内核申请连续物理地址的内存空间,由于kmalloc是基于slab分配器实现的,所以比较适合较小块的内存申请。kmalloc函数的调用过程为:`kmalloc->__kmalloc->__do_kmalloc`,其中`__do_kmalloc`的实现主要分为两步:
116 |
117 | 1、通过`kmalloc_slab`找到一个合适的`kmem_cache`缓存
118 | 2、通过`slab_alloc`向slab分配器申请对象内存空间
119 |
120 | Linux提供的vmalloc函数可以获得连续的虚拟空间,但是其物理内存不一定连续。vmalloc函数的调用过程为:`vmalloc->__vmalloc_node_flags->__vmalloc_node->__vmalloc_node_range`。其中`__vmalloc_node_range`函数也分为两步:
121 |
122 | 1、通过`__get_vm_area_node`分配一个可用的虚拟地址空间
123 | 2、`__vmalloc_node_range`通过`alloc_pages`一页一页申请物理内存,再为刚才申请的虚拟地址空间分配物理页表映射
124 |
125 |
126 |
--------------------------------------------------------------------------------
/文章/内存管理/一文了解,Linux内存管理,malloc、free 实现原理.md:
--------------------------------------------------------------------------------
1 | ## malloc / free 简介
2 |
3 | ```c
4 | void *malloc(size_t size)
5 | void free(void *ptr)
6 | ```
7 | `malloc` 分配指定大小的内存空间,返回一个指向该空间的指针。大小以字节为单位。返回 `void*` 指针,需要强制类型转换后才能引用其中的值。
8 | `free` 释放一个由 `malloc` 所分配的内存空间。`ptr` 指向一个要释放内存的内存块,该指针应当是之前调用 `malloc` 的返回值。
9 |
10 | 使用示例:
11 |
12 | ```c
13 | int* ptr;
14 | ptr = (int*)malloc(10 * sizeof(int)); /* 进行强制类型转换 */
15 | free(ptr);
16 | ```
17 |
18 | ## 动态内存分配的系统调用:`brk / sbrk`
19 |
20 | 动态分配的内存都在堆中,堆从低地址向高地址增长:
21 |
22 | 
23 |
24 | Linux 提供了两个系统调用 `brk` 和 `sbrk`:
25 |
26 | ```c
27 | int brk(void *addr);
28 | void *sbrk(intptr_t increment);
29 | ```
30 |
31 | `brk` 用于返回堆的顶部地址;`sbrk` 用于扩展堆,通过参数 `increment` 指定要增加的大小,如果扩展成功,返回 `brk` 的旧值。如果 `increment` 为零,返回 `brk` 的当前值。
32 |
33 | 我们不会直接通过 `brk` 或 `sbrk` 来分配堆内存,而是先通过 `sbrk` 扩展堆,将这部分空闲内存空间作为缓冲池,然后通过 `malloc / free` 管理缓冲池中的内存。这是一种池化思想,能够避免频繁的系统调用,提高程序性能。
34 |
35 | ## malloc / free 实现思路
36 |
37 | `malloc` 使用空闲链表组织堆中的空闲区块,空闲链表有时也用双向链表实现。每个空闲区块都有一个相同的首部,称为“内存控制块” `mem_control_block`,其中记录了空闲区块的元信息,比如指向下一个分配块的指针、当前分配块的长度、或者当前区块是否已经被分配出去。这个首部对于程序是不可见的,`malloc `返回的是紧跟在首部后面的地址,即可用空间的起始地址。
38 |
39 | `malloc` 分配时会搜索空闲链表,根据匹配原则,找到一个大于等于所需空间的空闲区块,然后将其分配出去,返回这部分空间的指针。如果没有这样的内存块,则向操作系统申请扩展堆内存。注意,返回的指针是从可用空间开始的,而不是从首部开始的:
40 |
41 | 
42 |
43 | malloc 所实际使用的内存匹配算法有很多,执行时间和内存消耗各有不同。到底使用哪个匹配算法,取决于实现。常见的内存匹配算法有:
44 |
45 | * 最佳适应法
46 | * 最差适应法
47 | * 首次适应法
48 | * 下一个适应法
49 |
50 | free 会将区块重新插入到空闲链表中。free 只接受一个指针,却可以释放恰当大小的内存,这是因为在分配的区域的首部保存了该区域的大小。
51 |
52 | ## malloc 的实现方式一:显式空闲链表 + 整块分配
53 |
54 | malloc 的实现方式有很多种。最简单的方法是使用一个链表来管理所有已分配和未分配的内存块,在每个内存块的首部记录当前块的大小、当前区块是否已经被分配出去。首部对应这样的结构体:
55 |
56 | ```c
57 | struct mem_control_block {
58 | int is_available; // 是否可用(如果还没被分配出去,就是 1)
59 | int size; // 实际空间的大小
60 | };
61 | ```
62 |
63 | 使用首次适应法进行分配:遍历整个链表,找到第一个未被分配、大小合适的内存块;如果没有这样的内存块,则向操作系统申请扩展堆内存。
64 |
65 | 下面是这种实现方式的代码:
66 |
67 | ```c
68 | int has_initialized = 0; // 初始化标志
69 | void *managed_memory_start; // 指向堆底(内存块起始位置)
70 | void *last_valid_address; // 指向堆顶
71 |
72 | void malloc_init() {
73 | // 这里不向操作系统申请堆空间,只是为了获取堆的起始地址
74 | last_valid_address = sbrk(0);
75 | managed_memory_start = last_valid_address;
76 | has_initialized = 1;
77 | }
78 |
79 | void *malloc(long numbytes) {
80 | void *current_location; // 当前访问的内存位置
81 | struct mem_control_block *current_location_mcb; // 只是作了一个强制类型转换
82 | void *memory_location; // 这是要返回的内存位置。初始时设为
83 | // 0,表示没有找到合适的位置
84 | if (!has_initialized) {
85 | malloc_init();
86 | }
87 | // 要查找的内存必须包含内存控制块,所以需要调整 numbytes 的大小
88 | numbytes = numbytes + sizeof(struct mem_control_block);
89 | // 初始时设为 0,表示没有找到合适的位置
90 | memory_location = 0;
91 | /* Begin searching at the start of managed memory */
92 | // 从被管理内存的起始位置开始搜索
93 | // managed_memory_start 是在 malloc_init 中通过 sbrk() 函数设置的
94 | current_location = managed_memory_start;
95 | while (current_location != last_valid_address) {
96 | // current_location 是一个 void 指针,用来计算地址;
97 | // current_location_mcb 是一个具体的结构体类型
98 | // 这两个实际上是一个含义
99 | current_location_mcb = (struct mem_control_block *)current_location;
100 | if (current_location_mcb->is_available) {
101 | if (current_location_mcb->size >= numbytes) {
102 | // 找到一个可用、大小适合的内存块
103 | current_location_mcb->is_available = 0; // 设为不可用
104 | memory_location = current_location; // 设置内存地址
105 | break;
106 | }
107 | }
108 | // 否则,当前内存块不可用或过小,移动到下一个内存块
109 | current_location = current_location + current_location_mcb->size;
110 | }
111 | // 循环结束,没有找到合适的位置,需要向操作系统申请更多内存
112 | if (!memory_location) {
113 | // 扩展堆
114 | sbrk(numbytes);
115 | // 新的内存的起始位置就是 last_valid_address 的旧值
116 | memory_location = last_valid_address;
117 | // 将 last_valid_address 后移 numbytes,移动到整个内存的最右边界
118 | last_valid_address = last_valid_address + numbytes;
119 | // 初始化内存控制块 mem_control_block
120 | current_location_mcb = memory_location;
121 | current_location_mcb->is_available = 0;
122 | current_location_mcb->size = numbytes;
123 | }
124 | // 最终,memory_location 保存了大小为 numbyte的内存空间,
125 | // 并且在空间的开始处包含了一个内存控制块,记录了元信息
126 | // 内存控制块对于用户而言应该是透明的,因此返回指针前,跳过内存分配块
127 | memory_location = memory_location + sizeof(struct mem_control_block);
128 | // 返回内存块的指针
129 | return memory_location;
130 | }
131 | ```
132 |
133 | 对应的free实现:
134 |
135 | ```c
136 | void free(void *ptr) { // ptr 是要回收的空间
137 | struct mem_control_block *free;
138 | free = ptr - sizeof(struct mem_control_block); // 找到该内存块的控制信息的地址
139 | free->is_available = 1; // 该空间置为可用
140 | return;
141 | }
142 | ```
143 |
144 | 这种方法的缺点是:
145 |
146 | 1、已分配和未分配的内存块位于同一个链表中,每次分配都需要从头到尾遍历
147 | 2、采用首次适应法,内存块会被整体分配,容易产生较多内部碎片
148 |
149 | ## malloc 的实现方式二:显式空闲链表 + 按需分配
150 |
151 | 这种实现方式维护一个空闲块链表,只包含未分配的内存块。malloc 分配时会搜索空闲链表,找到第一个大于等于所需空间的空闲区块,然后从该区块的尾部取出所需要的空间,剩余空间还是存在空闲链表中;如果该区块的剩余部分不足以放下首部信息,则直接将其从空闲链表摘除。最后返回这部分空间的指针。
152 | 下面是这种实现方式的几个示例:
153 |
154 | 
155 |
156 | 
157 |
158 | 
159 |
160 | 通过 free 释放内存时,会将内存块加入到空闲链表中,并将前后相邻的空闲内存合并,这时使用双向链表管理空闲链表就很有用了。
161 |
162 | 和第一种方式相比,这种方式的优点主要是:
163 | * 空闲链表中只包含未被分配的内存块,节省遍历开销
164 | * 只分配必须大小的空间,避免内存浪费
165 |
166 | 这种方式的缺点是:多次调用 malloc 后,空闲内存被切成很多的小内存片段,产生较多外部碎片,会导致用户在申请内存使用时,找不到足够大的内存空间。这时需要进行内存整理,将连续的空闲内存合并,但是这会降低函数性能。
167 |
168 | 注意:内存紧凑在这里一般是不可用的,因为这会改变之前 malloc 返回的空间的地址。
169 |
170 | ## malloc 的实现方式三:分离的空闲链表
171 |
172 | 上面的两种分配方法,分配时间都和空闲块的数量成线性关系。
173 |
174 | 另一种实现方式是分离存储,即维护多个空闲链表,其中每个链表中的块有大致相等或者相同的大小。一般常见的是根据 2 的幂来划分块大小。分配时,可以直接在某个空闲链表里搜索合适的块。如果没有找到合适的块与之匹配,就搜索下一个链表,以此类推。
175 |
176 | ### 简单分离存储
177 |
178 | 每个大小类的空闲链表包含大小相等的块。分配时,从某个空闲链表取下一块,或者向操作系统请求内存片并分割成大小相等的块,形成新的链表。释放时,只需要简单的将块插入到相应空闲链表的前面。
179 |
180 | 优点一是分配和释放只需要在链表头进行操作,都是常数时间,二是因为每个块大小都是固定的,所以只需要一个 next 指针,不需要额外的控制信息,节省空间。缺点是容易造成内部碎片和外部碎片。内部碎片显而易见,因为每个块都是整体分配的,不会被分割。外部碎片在这样的模式下很容易产生:应用频繁地申请和释放较小大小的内存块,由于这些内存块不会合并,所以系统维护了大量小内存块形成的空闲链表,而没有多余空间来分配大内存块,导致产生外部碎片。
181 |
182 | ### 分离适配
183 | 这种方法同样维护了多个空闲链表,只不过每个链表中的块是大致相等的大小,比如每个链表中的块大小范围可能是:
184 |
185 | * 1
186 | * 2
187 | * 3~4
188 | * 5~8
189 | * …
190 | * 1025~2048
191 | * 2049~4096
192 | * 4097~∞
193 |
194 | 在分配的时候,需要先根据申请内存的大小选择适当的空闲链表,然后遍历该链表,根据匹配算法(如首次适应)寻找合适的块。如果找到一个块,将其分割(可选),并将剩余部分插入到适当的空闲链表中。如果找不到合适的块,则查找下一个更大的大小类的空闲链表,以此类推,直到找到或者向操作系统申请额外的堆内存。在释放一个块时,合并前后相邻的空闲块,并将结果放到相应的空闲链表中。
195 |
196 | 分离适配方法是一种常见的选择,C 标准库中提供的 GNU malloc 包就是采用的这种方法。这种方法既快速,对内存的使用也很有效率。由于搜索被限制在堆的某个部分而不是整个堆,所以搜索时间减少了。内存利用率也得到了改善,避免大量内部碎片和外部碎片。
197 |
198 | ### 伙伴系统
199 |
200 | 伙伴系统是分离适配的一种特例。它的每个大小类的空闲链表包含大小相等的块,并且大小都是 2 的幂。最开始时,全局只有一个大小为 2m2m 字的空闲块,2m2m 是堆的大小。
201 |
202 | 假设分配的块的大小都是 2 的幂,为了分配一个大小为 2k2k 的块,需要找到大小恰好是 2k2k 的空闲块。如果找到,则整体分配。如果没有找到,则将刚好比它大的块分割成两块,每个剩下的半块(也叫做伙伴)被放置在相应的空闲链表中,以此类推,直到得到大小恰好是 2k2k 的空闲块。释放一个大小为 2k2k 的块时,将其与空闲的伙伴合并,得到新的更大的块,以此类推,直到伙伴已分配时停止合并。
203 |
204 | 伙伴系统分配器的主要优点是它的快速搜索和快速合并。主要缺点是要求块大小为 2 的幂可能导致显著的内部碎片。因此,伙伴系统分配器不适合通用目的的工作负载。然而,对于某些特定应用的工作负载,其中块大小预先知道是 2 的幂,伙伴系统分配器就很有吸引力了。
205 |
206 | ### tcmalloc
207 |
208 | tcmalloc 是 Google 开发的内存分配器,全称 Thread-Caching Malloc,即线程缓存的 malloc,实现了高效的多线程内存管理。
209 |
210 | tcmalloc 主要利用了池化思想来管理内存分配。对于每个线程,都有自己的私有缓存池,内部包含若干个不同大小的内存块。对于一些小容量的内存申请,可以使用线程的私有缓存;私有缓存不足或大容量内存申请时再从全局缓存中进行申请。在线程内分配时不需要加锁,因此在多线程的情况下可以大大提高分配效率。
211 |
212 | ## 总结
213 | malloc 使用链表管理内存块。malloc 有多种实现方式,在不同场景下可能会使用不同的匹配算法。
214 |
215 | malloc 分配的空间中包含一个首部来记录控制信息,因此它分配的空间要比实际需要的空间大一些。这个首部对用户而言是透明的,malloc 返回的是紧跟在首部后面的地址,即可用空间的起始地址。
216 |
217 | malloc 分配的函数应该是字对齐的。在 32 位模式中,malloc 返回的块总是 8 的倍数。在 64 位模式中,该地址总是 16 的倍数。最简单的方式是先让堆的起始位置字对齐,然后始终分配字大小倍数的内存。
218 |
219 | malloc 只分配几种固定大小的内存块,可以减少外部碎片,简化对齐实现,降低管理成本。
220 |
221 | free 只需要传递一个指针就可以释放内存,空间大小可以从首部读取。
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
--------------------------------------------------------------------------------
/文章/内存管理/其他工程问题以及调优.md:
--------------------------------------------------------------------------------
1 | ## 其他工程问题以及调优
2 | * DMA和cache一致性
3 | * 内存的cgroup
4 | * memcg子系统分析
5 | * 性能方面的调优: page in/out, swap in/out
6 | * Dirty ratio的一些设置
7 | * swappiness
8 |
9 | ### DMA和cache一致性
10 |
11 | 
12 |
13 | 工程中,DMA可以直接在内存和外设进行数据搬移,而CPU访问内存时要经过MMU。DMA访问不到CPU内部的cache,所以会出现cache不一致的问题。因为CPU读写内存时,如果在cache中命中,就不会再访问内存。
14 |
15 | 当CPU 写memory时,cache有两种算法:write_back ,write_through。一般都采用write_back。cache的硬件,使用LRU算法,把cache中的数据替换到磁盘。
16 |
17 | 
18 |
19 | cache一致性问题,主要靠以上两类api来解决这个问题。一致性DMA缓冲区api,和流式DMA映射api。CPU通过MMU访问DMA区域,在页表项中可以配置这片区域是否带cache。
20 |
21 | 现代的SoC,DMA引擎可以自动维护cache的同步。
22 |
23 | ### 内存的cgroup
24 | 进程分group,内存也分group。
25 |
26 | 进程调度时,把一组进程加到一个cgroup,控制这一组进程的CPU权重和最大CPU占用率。在/sys/fs/cgroup/memory创建一个目录,把进程放到这个group。可以限制某个group下的进程不用swap,每个group的swapiness都可以配置。
27 |
28 | 比如,当你把某个group下的swapiness设置为0,那么这个group下进程的匿名页就不允许交换了。
29 | /proc/sys/vm/swapiness是控制全局的swap特性,不影响加到group中的进程。
30 |
31 | 也可以控制每个group的最大内存消耗为200M,当这个group下进程使用的内存达到200M,就oom。
32 |
33 | demo: 演示用memory cgroup来限制进程group内存资源消耗的方法
34 |
35 | ```
36 | swapoff -a
37 | echo 1 > /proc/sys/vm/overcommit_memory # 进程申请多少资源,内核都允许
38 |
39 | root@whale:/sys/fs/cgroup/memory# mkdir A
40 | root@whale:/sys/fs/cgroup/memory# cd A
41 | root@whale:/sys/fs/cgroup/memory/A# echo $((200*1024*1024)) > memory.limit_in_bytes
42 |
43 | cgexec -g memory:A ./a.out
44 |
45 |
46 | [ 560.618666] Memory cgroup out of memory: Kill process 5062 (a.out) score 977 or sacrifice child
47 | [ 560.618817] Killed process 5062 (a.out) total-vm:2052084kB, anon-rss:204636kB, file-rss:1240kB
48 | ```
49 |
50 | ### memory cgroup子系统分析
51 | memcg v1的参数有25个, 通过数据结构 res_counter 来计算。
52 |
53 | ```
54 | ~~~
55 | /* * The core object. the cgroup that wishes to account for some
56 | * resource may include this counter into its structures and use
57 | * the helpers described beyond */
58 |
59 | struct res_counter {
60 | unsigned long long usage; /* * 目前资源消费的级别 */
61 | unsigned long long max_usage; /* *从counter创建的最大使用值 */
62 | unsigned long long limit; /* * 不能超过的使用限制 */
63 | unsigned long long soft_limit; /* * 可以超过使用的限制 */
64 | unsigned long long failcnt; /* * 尝试消费资源的失败数 */
65 | spinlock_t lock; /* * the lock to protect all of the above.
66 | * the routines below consider this to be IRQ-safe */
67 | struct res_counter *parent; /* * Parent counter, used for hierarchial resource accounting */
68 | };
69 | ```
70 | 内存的使用量 mem_cgroup_usage 通过递归RSS和page cache之和来计算。
71 |
72 | struct mem_cgroup是负责内存 cgroup 的结构
73 |
74 | ```c
75 | struct mem_cgroup {
76 | struct cgroup_subsys_state css; // 通过css关联cgroup.
77 | struct res_counter res; // mem统计变量
78 | res_counter memsw; // mem+sw的和
79 | struct res_counter kmem; // 内核内存统计量 ...
80 | }
81 | ```
82 | 这些参数的入口都在mm/memcontrol.c下,比如说memory.usage_in_bytes的读取调用的是mem_cgroup_read函数, 统计的入口是mem_cgroup_charge_common(),如果统计值超过限制就会在cgroup内进行回收。调用者分别是缺页时调用的mem_cgroup_newpage_charge和 page cache相关的mem_cgroup_cache_charge。
83 |
84 | 当进程进入缺页异常的时候就会分配具体的物理内存,当物理内存使用超过高水平线以后,换页daemon(kswapd)就会被唤醒用于把内存交换到交换空间以腾出内存,当内存恢复至高水平线以后换页daemon进入睡眠。
85 |
86 | 缺页异常的入口是 __do_fault,
87 |
88 | RSS在page_fault的时候记录,page cache是插入到inode的radix-tree中才记录的。
89 | RSS在完全unmap的时候减少计数,page cache的page在离开inode的radix-tree才减少计数。
90 | 即使RSS完全unmap,也就是被kswapd给换出,可能作为SwapCache存留在系统中,除非不作为SwapCache,不然还是会被计数。
91 | 一个换入的page不会马上计数,只有被map的时候才会,当进行换页的时候,会预读一些不属于当前进程的page,而不是通过page fault,所以不在换入的时候计数。
92 |
93 | ### 脏页写回的“时空”控制
94 |
95 | 
96 |
97 | “脏页”:当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的。
98 |
99 | 通过时间(dirty_expire_centisecs)和比例,控制Linux脏页返回。
100 |
101 | dirty_expire_centisecs:当Linux中脏页的时间到达dirty_expire_centisecs,无论脏页的数量多少,必须立即写回。通过在后台启动进程,进行脏页写回。
102 | 默认时间设置为30s。
103 |
104 | dirty_ratio,dirty_background_ratio 基于空间的脏页写回控制。
105 | 不能让内存中存在太多空间的脏页。如果一个进程在循环调用write,当达到dirty_background_ratio后,后台进程就开始写回脏页。默认值5%。当达到第2个阈值dirty_ratio时,应用进程被阻塞。当内存中的脏页在两个阈值之间时,应用程序是不会阻塞。
106 |
107 | ### 内存何时回收:水位控制
108 | 脏页写回不是 内存回收。
109 |
110 | 脏页写回:是保证在内存不在磁盘的数据不要太多。
111 | 水位控制:是指内存何时开始回收。
112 |
113 | 
114 |
115 | 由/pro/sys/vm/min_free_kbytes 控制,根据内存大小算出来的平方根。
116 | pf_mem_alloc,允许内存达到低水位以下,还可以继续申请。内存的回收,在最低水位以上就开始回收。
117 |
118 | 
119 |
120 | 每个Zone都有自己的三个水位,最小的水位是根据min_free_kbytes控制。5/4min_free_kbytes =low 3/2min_free_kbytes =high ,
121 | Zone的最小内存达到5/4的low 水位,Linux开始后台回收内存。直到达到6/4的high水位,开始不回收。
122 | 当Zone的最小内存达到min水位,应用程序的写会直接阻塞。
123 |
124 | 实时操作系统,
125 |
126 | 
127 |
128 | 当你要开始回收内存时,回收比例通过swappiness越大,越倾向于回收匿名页;swappiness越小,越倾向于回收file-backed的页面。
129 | 当把cgroup中的swapiness设置为0,就不回收匿名页了。
130 | 当你的应用会经常去访问数据malloc的内存,需要把swapiness设置小。dirty的设置,水位的设置都没有一个标准,要看应用使用内存的情况而定。
131 |
132 | getdelays工具:用来评估应用等待CPU,内存,IO,的时间。
133 | linux/Documents/accounting
134 |
135 | 
136 |
137 | CONFIG_TASK_DELAY_ACCT=y
138 | CONFIG_TASKSTATS=y
139 |
140 | vmstat 可以展现给定时间间隔的服务器的状态值,包括Linux的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
141 | ```
142 | vmstat 1
143 | ```
144 | Documents/sysctl/vm.txt 中有所有参数最细节的描述。
145 |
146 |
--------------------------------------------------------------------------------
/文章/内存管理/内存与IO的交换.md:
--------------------------------------------------------------------------------
1 | ## 内存与I/O的交换
2 | 堆、栈、代码段是否常驻内存?本文主要介绍两类不同的页面,以及这两类页面如何在内存和磁盘间进行交换?以及内存和磁盘的颠簸行为- swaping,和硬盘的swap分区。
3 |
4 | ### page cache
5 |
6 | **file-backed的页面**:(有文件背景的页面,比如代码段、比如read/write方法读写的文件、比如mmap读写的文件;他们有对应的硬盘文件,因此如果要交换,可以直接和硬盘对应的文件进行交换),此部分页面进page cache。
7 |
8 | **匿名页**:匿名页,如stack,heap,CoW后的数据段等;他们没有对应的硬盘文件,因此如果要交换,只能交换到虚拟内存-swapfile或者Linux的swap硬盘分区),此部分页面,如果系统内存不充分,可以被swap到swapfile或者硬盘的swap分区。
9 |
10 | 
11 |
12 | 内核通过两种方式打开硬盘的文件,**任何时候打开文件,Linux会申请一个page cache,然后把文件读到page cache里。**page cache 是内存针对硬盘的缓存。
13 |
14 | Linux读写文件有两种方式:read/write 和 mmap
15 |
16 | 1)read/write: read会把内核空间的page cache,往用户空间的buffer拷贝。
17 | 参数 fd, buffer, size ,write只是把用户空间的buffer拷贝到内核空间的page cache。
18 |
19 | 2)mmap:可以避免内核空间到用户空间拷贝的过程,直接把文件映射成一个虚拟地址指针,指向linux内核申请的page cache。也就知道page cache和硬盘里文件的对应关系。
20 |
21 | 参数 fd,
22 |
23 | 文件对于应用程序,只是一部分内存。Linux使用write写文件,只是把文件写进内存,并没有sync。而内存的数据和硬盘交换的功能去完成。
24 |
25 | ELF可执行程序的头部会记录,从xxx到xxx是代码段。把代码段映射到虚拟地址,0~3 G, 权限是RX。这段地址映射到内核空间的page cache, 这段page cache又映射到可执行程序。
26 |
27 | page cache,会根据LRU算法(最近最少使用)进行替换。
28 |
29 | demo演示 page cache会多大程度影响程序执行时间。
30 |
31 | ```
32 | echo 3 > /proc/sys/vm/drop_caches
33 | time python hello.py
34 | \time -v python hello.py
35 |
36 | root@whale:/home/gzzhangyi2015# \time -v python hello.py
37 | Hello World! Love, Python
38 | Command being timed: "python hello.py"
39 | User time (seconds): 0.01
40 | System time (seconds): 0.00
41 | Percent of CPU this job got: 40%
42 | Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.03
43 | Average shared text size (kbytes): 0
44 | Average unshared data size (kbytes): 0
45 | Average stack size (kbytes): 0
46 | Average total size (kbytes): 0
47 | Maximum resident set size (kbytes): 6544
48 | Average resident set size (kbytes): 0
49 | Major (requiring I/O) page faults: 10
50 | Minor (reclaiming a frame) page faults: 778
51 | Voluntary context switches: 54
52 | Involuntary context switches: 9
53 | Swaps: 0
54 | File system inputs: 6528
55 | File system outputs: 0
56 | Socket messages sent: 0
57 | Socket messages received: 0
58 | Signals delivered: 0
59 | Page size (bytes): 4096
60 | Exit status: 0
61 |
62 | root@whale:/home/gzzhangyi2015# \time -v python hello.py
63 | Hello World! Love, Python
64 | Command being timed: "python hello.py"
65 | User time (seconds): 0.01
66 | System time (seconds): 0.00
67 | Percent of CPU this job got: 84%
68 | Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.01
69 | Average shared text size (kbytes): 0
70 | Average unshared data size (kbytes): 0
71 | Average stack size (kbytes): 0
72 | Average total size (kbytes): 0
73 | Maximum resident set size (kbytes): 6624
74 | Average resident set size (kbytes): 0
75 | Major (requiring I/O) page faults: 0
76 | Minor (reclaiming a frame) page faults: 770
77 | Voluntary context switches: 1
78 | Involuntary context switches: 4
79 | Swaps: 0
80 | File system inputs: 0
81 | File system outputs: 0
82 | Socket messages sent: 0
83 | Socket messages received: 0
84 | Signals delivered: 0
85 | Page size (bytes): 4096
86 | Exit status: 0
87 | ```
88 |
89 | 总结:Linux有两种方式读取文件,不管以何种方式读文件,都会产生page cache 。
90 |
91 | ### free命令的详细解释
92 |
93 | ```
94 | total used free shared buffers cached
95 | Mem: 49537244 1667532 47869712 146808 21652 421268
96 | -/+ buffers/cache: 1224612 48312632
97 | Swap: 4194300 0 4194300
98 | ```
99 |
100 | 
101 |
102 | buffers/cache都是文件系统的缓存,当访问ext3/ext4,fat等文件系统中的文件,产生cache。当直接访问裸分区(/dev/sdax)时,产生buffer。
103 |
104 | 访问裸分区的用户,主要是应用程序直接打开 or 文件系统本身。dd命令 or 硬盘备份 or sd卡,会访问裸分区,产生的缓存就是buffer。而ext4文件系统把硬盘当作裸分区。
105 |
106 | buffer和cache没有本质的区别,只是背景的区别。
107 |
108 | -/+ buffer/cache 的公式
109 | used buffers/cache = used - buffers - cached
110 | free buffers/cache = free + buffers + cached
111 |
112 | 新版free
113 | available参数:评估出有多少空闲内存给应用程序使用,free + 可回收的。
114 |
115 | 
116 |
117 | ### File-backed和Anonymous page
118 |
119 | * File-backed映射把进程的虚拟地址空间映射到files
120 | * 比如 代码段
121 | * 比如 mmap一个字体文件
122 |
123 | * Anonymous映射是进程的虚拟地址空间没有映射到任何file
124 | * Stack
125 | * Heap
126 | * CoW pages
127 |
128 | anonymous pages(没有任何文件背景)分配一个swapfile文件或者一个swap分区,来进行交换到磁盘的动作。
129 |
130 | read/write和 mmap 本质上都是有文件背景的映射,把进程的虚拟地址空间映射到files。在内存中的副本,只是一个page cache。是page cache就有可能被踢出内存。CPU 内部的cache,当访问新的内存时,也会被踢出cache。
131 |
132 | demo:演示进程的代码段是如何被踢出去的?
133 |
134 | ```
135 | pidof firefox
136 | cat /proc//smaps
137 |
138 | 运行 oom.c
139 |
140 | ```
141 | ### swap以及zRAM
142 |
143 | 数据段,在未写过时,有文件背景。在写过之后,变成没有文件背景,就被当作匿名页。linux把swap分区,当作匿名页的文件背景。
144 | ```
145 | swap(v.),内存和硬盘之间的颠簸行为。
146 | swap(n.),swap分区和swap文件,当作内存中匿名页的交换背景。在windows内,被称作虚拟内存。pagefile.sys
147 | ```
148 | ### 页面回收和LRU
149 |
150 | 
151 |
152 | 回收匿名页和 回收有文件背景的页面。
153 | 后台慢慢回收:通过kswapd进程,回收到高水位(high)时,才停止回收。从low -> high
154 | 直接回收:当水位达到min水位,会在两种页面同时进行回收,回收比例通过swappiness越大,越倾向于回收匿名页;swappiness越小,越倾向于回收file-backed的页面。当然,它们的回收方法都是一样的LRU算法。
155 |
156 | ### Linux Page Replacement
157 |
158 | 用LRU算法来进行swap和page cache的页面替换。
159 |
160 | 
161 |
162 | ```
163 | 现在cache的大小是4页,前四次,1,2,3,4文件被一次使用,注意第七次,5文件被使用,系统评估最近最少被使用的文件是3,那么不好意思,3被swap出去,5加载进来,依次类推。
164 |
165 | 所以LRU可能会触发page cache或者anonymous页与对应文件的数据交换。
166 | ```
167 |
168 | ### 嵌入式系统的zRAM
169 |
170 | 
171 |
172 | zRAM: 用内存来做swap分区。从内存中开辟一小段出来,模拟成硬盘分区,做交换分区,交换匿名页,自带透明压缩功能。当应用程序往zRAM写数据时,会自动把匿名页进行压缩。当应用程序访问匿名页时,内存页表里不命中,发生page fault(major)。从zRAM中把匿名页透明解压出来,还到内存。
173 |
174 |
175 |
176 |
177 |
178 |
179 |
180 |
181 |
182 |
183 |
184 |
185 |
186 |
--------------------------------------------------------------------------------
/文章/内存管理/内存的动态申请和释放.md:
--------------------------------------------------------------------------------
1 | ## 内存的动态申请和释放
2 |
3 | 内核空间 和用户空间申请的内存最终和buddy怎么交互?以及在页表映射上的区别?虚拟地址到物理地址,什么时候开始映射?
4 |
5 | ### Buddy的问题
6 | 分配的粒度太大
7 | buddy算法把空闲页面分成1,2,4页,buddy算法会明确知道哪一页内存空闲还是被占用?
8 |
9 | 4k,8k,16k
10 |
11 | 无论是在应用还是内核,都需要申请很小的内存。
12 |
13 | 从buddy要到的内存,会进行slab切割。
14 |
15 | ### slab原理:
16 | 比如在内核中申请8字节的内存,buddy分配4K,分成很多个小的8个字节,每个都是一个object。
17 |
18 | slab,slub,slob 是slab机制的三种不同实现算法。
19 |
20 | Linux 会针对一些常规的小的内存申请,数据结构,会做slab申请。
21 |
22 | cat /proc/slabinfo 可以看到内核空间小块内存的申请情况,也是slab分配的情况。
23 |
24 | :每个slab一共可以分出多少个obj,
25 | :还可以分配多少个obj,
26 | < pagesperslab>:每个slab对应多少个pages,
27 | < objperslab>:每个slab可以分出多少个object,
28 | < objsize>:每个obj多大,
29 |
30 | slab主要分为两类:
31 |
32 | 一、常用数据结构像 nfsd_drc, UDPv6,TCPv6 ,这些经常申请和释放的数据结构。比如,存在TCPv6的slab,之后申请 TCPv6 数据结构时,会通过这个slab来申请。
33 |
34 | 
35 |
36 | 二、常规的小内存申请,做的slab。例如 kmalloc-32,kmalloc-64, kmalloc-96, kmalloc-128
37 |
38 | 
39 |
40 | 
41 |
42 | 注意,slab申请和分配的都是只针对内核空间,与用户空间申请分配内存无关。用户空间的malloc和free调用的是libc。
43 |
44 | slab和buddy的关系?
45 | 1、slab的内存来自于buddy。slab相当于二级管理器。
46 | 2、slab和buddy在算法上,级别是对等的。
47 |
48 | 两者都是内存分配器,buddy是把内存条分成多个Zone来管理分配,slab是把从buddy拿到的内存,进行管理分配。
49 |
50 | 同理,malloc 和free也不找buddy拿内存。 malloc 和free不是系统调用,只是c库中的函数。
51 |
52 | ### mallopt
53 | 在C库中有一个api是mallopt,可以控制一系列的选项。
54 |
55 | 
56 |
57 | M_TRIM_THRESHOLD:控制c库把内存还给内核的阈值。
58 | -1UL 代表最大的正整数。
59 |
60 | 此处代表应用程序把内存还给c库后,c库并不把内存还给内核。
61 |
62 | <\do your RT-thing>
63 | 程序在此处申请内存,都不需要再和内核交互了,此时程序的实时性比较高。
64 |
65 | ### kmalloc vs. vmalloc/ioremap
66 |
67 | 内存空间: 内存+寄存器
68 |
69 | register --> LDR/STR
70 |
71 | 所有内存空间的东西,CPU去访问,都要通过虚拟地址。
72 | CPU --> virt --> mmu --> phys
73 |
74 | cpu请求虚拟地址,mmu根据cpu请求的虚拟地址,查页表得物理地址。
75 |
76 | buddy算法,管理这一页的使用情况。
77 |
78 | 两个虚拟地址可以映射到同一个物理地址。
79 |
80 | 
81 |
82 | 页表 -> 数组,
83 |
84 | 任何一个虚拟地址,都可以用地址的高20位,作为页表的行号去读对应的页表项。而低12位,是指页内偏移。(由于一页是4K,2^12 足够描述)
85 |
86 | kmalloc 和 vmalloc 申请的内存,有什么区别?
87 | 答:申请之后,是否还要去改页表。一般情况,kmalloc申请内存,不需要再去改页表。同一张页表,几个虚拟地址可以同时映射到同一个物理地址。
88 |
89 | 寄存器,通过ioremap往vmalloc区域,进行映射。然后改进程的虚拟地址页表。
90 |
91 | 总结:所有的页,最底层都是用buddy算法进行管理,用虚拟地址找物理地址。理解内存分配和映射的区别,无论是lowmem还是highmem 都可以被vmalloc拿走,也可能被用户拿走,只不过拿走之后,还要把虚拟地址往物理地址再映射一遍。但如果是被kmalloc拿走,一般指低端内存,就不需要再改进程的页表。因为这部分低端内存,已经做好了虚实映射。
92 | ```
93 | cat /proc/vmallocinfo |grep ioremap
94 | ```
95 | 可以看到寄存器中的哪个区域,被映射到哪个虚拟地址。
96 |
97 | vmalloc区域主要用来,vmalloc申请的内存从这里找虚拟地址 和 寄存器的ioremap映射。
98 |
99 | ### Linux内存分配的lazy行为
100 |
101 | Linux总是以最lazy的方式,给应用程序分配内存。
102 |
103 | 
104 |
105 | malloc 100M内存成功时,其实并没有真实拿到。只有当100M内存中的任何一页,被写一次的时候,才成功。
106 |
107 | vss:虚拟地址空间。 rss:常驻内存空间
108 |
109 | malloc 100M内存成功时,Linux把100M内存全部以只读的形式,映射到一个全部清0的页面。
110 |
111 | 当应用程序写100M中每一页任意字节时,会发出page fault。 linux 内核收到缺页中断后,从硬件寄存器中读取到,包括缺页中断发生的原因和虚拟地址。Linux从内存条申请一页内存,执行cow,把页面重新拷贝到新申请的页表,再把进程页表中的虚拟地址,指向一个新的物理地址,权限也被改成R+W。
112 |
113 | 调用brk 把8k变成 16k。
114 |
115 | 针对应用程序的堆、代码、栈、等,会使用lazy分配机制,只有当写内存页时,才会真实请求内存分配页表。但,当内核使用kmalloc申请内存时,就真实的分配相应的内存,不使用lazy机制。
116 |
117 | ### 内存OOM
118 |
119 | 当真实去写内存时,应用程序并不能拿到真实的内存时。Linux启动OOM,linux在运行时,会对每一个进程进行out-of-memory打分。打分主要基于,耗费的内存。耗费的内存越多,打分越高。
120 |
121 | ```
122 | cat /proc//oom_score
123 | ```
124 |
125 | demo:
126 |
127 | ```c
128 | #include
129 | #include
130 | #include
131 | int main(int argc, char **argv)
132 | {
133 | int max = -1;
134 | int mb = 0;
135 | char *buffer;
136 | int i;
137 | #define SIZE 2000
138 | unsigned int *p = malloc(1024 * 1024 * SIZE);
139 | printf("malloc buffer: %p\n", p);
140 | for (i = 0; i < 1024 * 1024 * (SIZE/sizeof(int)); i++) {
141 | p[i] = 123;
142 | if ((i & 0xFFFFF) == 0) {
143 | printf("%dMB written\n", i >> 18);
144 | usleep(100000);
145 | }
146 | }
147 | pause();
148 | return 0;
149 | }
150 | ```
151 |
152 | 设定条件:
153 |
154 | 总内存1G
155 | 1、swapoff -a 关掉swap交换
156 | 2、echo 1 > /proc/sys/vm/overcommit_memory
157 | 3、内核不去评估系统还有多少空闲内存
158 |
159 | Linux进行OOM打分,主要是看耗费内存情况,此外还会参考用户权限,比如root权限,打分会减少30分。
160 |
161 | 还有OOM打分因子:/proc/pid/oom_score_adj (加减)和 /proc/pid/oom_adj (乘除)。
162 |
163 | 
164 |
165 | ### 总结:
166 | 1、slab的作用,针对在内核空间小内存分配,和常用数据结构的申请。
167 | 2、同样的二次分配器,在用户空间是C库。malloc和free的时候,内存不一定从buddy分配和还给buddy。
168 | 3、kmalloc,vmalloc 和malloc的区别
169 |
170 | * kmalloc:申请内存,一般在低端内存区。申请到时,内存已经映射过了,不需要再去改进程的页表。所以,申请到的物理页是连续的。
171 | * vmalloc:申请内存,申请到就拿到内存,并且已经修改了进程页表的虚拟地址到物理地址的映射。vmalloc()申请的内存并不保证物理地址的连续。
172 | * 用户空间的malloc:申请内存,申请到并没有拿到,写的时候才去拿到。拿到之后,才去改页表。申请成功,页表只读,只有到写时,发生page fault,才去buddy拿内存。
173 | * kmalloc和vmalloc针对内核空间,malloc针对用户空间。这些内存,可以来自任何一个Zone。
174 | * 无论是kmalloc,vmalloc还是用户空间的malloc,都可以使用内存条的不同Zone,无论是highmem zone、lowmem zone 和 DMA zone。
175 |
176 | 4、如果在从buddy拿不到内存时,会触发Linux对所有进程进行OOM打分。当Linux出现内存耗尽,就kill一个oom score 最高的那个进程。oom_score,可以根据 oom_adj (-17~25)。
177 |
178 | 安卓的程序,不停的调整前台和后台进程oom_score,当被切换到后台时,oom_score会被调整的比较大。以保证前台的进程不容易因为oom而kill掉。
179 |
180 |
--------------------------------------------------------------------------------
/文章/内存管理/多核心Linux内核路径优化的不二法门之-slab与伙伴系统.md:
--------------------------------------------------------------------------------
1 | Linux内核的slab来自一种很简单的思想,即事先准备好一些会频繁分配,释放的数据结构。然而标准的slab实现太复杂且维护开销巨大,因此便分化 出了更加小巧的slub,因此本文讨论的就是slub,后面所有提到slab的地方,指的都是slub。另外又由于本文主要描述内核优化方面的内容,并不 是基本原理介绍,因此想了解slab细节以及代码实现的请自行百度或者看源码。
2 |
3 | ## 单CPU上单纯的slab
4 |
5 | 下图给出了单CPU上slab在分配和释放对象时的情景序列:
6 |
7 | 
8 |
9 | 可以看出,非常之简单,而且完全达到了slab设计之初的目标。
10 |
11 | ## 扩展到多核心CPU
12 |
13 | 现在我们简单的将上面的模型扩展到多核心CPU,同样差不多的分配序列如下图所示:
14 |
15 | 
16 |
17 | 我们看到,在只有单一slab的时候,如果多个CPU同时分配对象,冲突是不可避免的,解决冲突的几乎是唯一的办法就是加锁排队,然而这将大大增加延迟,我们看到,申请单一对象的整个时延从T0开始,到T4结束,这太久了。
18 |
19 | 多CPU无锁化并行化操作的直接思路-复制给每个CPU一套相同的数据结构。
20 |
21 | 不二法门就是增加“每CPU变量”。对于slab而言,可以扩展成下面的样子:
22 |
23 | 
24 |
25 | 如果以为这么简单就结束了,那这就太没有意义了。
26 |
27 | ## 问题
28 |
29 | 首先,我们来看一个简单的问题,如果单独的某个CPU的slab缓存没有对象可分配了,但是其它CPU的slab缓存仍有大量空闲对象的情况,如下图所示:
30 |
31 | 
32 |
33 | 这 是可能的,因为对单独一种slab的需求是和该CPU上执行的进程/线程紧密相关的,比如如果CPU0只处理网络,那么它就会对skb等数据结构有大量的 需求,对于上图最后引出的问题,如果我们选择从伙伴系统中分配一个新的page(或者pages,取决于对象大小以及slab cache的order),那么久而久之就会造成slab在CPU间分布的不均衡,更可能会因此吃掉大量的物理内存,这都是不希望看到的。
34 |
35 | 在继续之前,首先要明确的是,我们需要在CPU间均衡slab,并且这些必须靠slab内部的机制自行完成,这个和进程在CPU间负载均衡是完全不同的, 对进程而言,拥有一个核心调度机制,比如基于时间片,或者虚拟时钟的步进速率等,但是对于slab,完全取决于使用者自身,只要对象仍然在使用,就不能剥 夺使用者继续使用的权利,除非使用者自己释放。因此slab的负载均衡必须设计成合作型的,而不是抢占式的。
36 |
37 | 好了。现在我们知道,从伙伴系统重新分配一个page(s)并不是一个好主意,它应该是最终的决定,在执行它之前,首先要试一下别的路线。
38 |
39 | 现在,我们引出第二个问题,如下图所示:
40 |
41 | 
42 |
43 | 谁也不能保证分配slab对象的CPU和释放slab对象的CPU是同一个CPU,谁也不能保证一个CPU在一个slab对象的生命周期内没有分配新的 page(s),这期间的复杂操作谁也没有规定。这些问题该怎么解决呢?事实上,理解了这些问题是怎么解决的,一个slab框架就彻底理解了。
44 |
45 | ## 问题的解决-分层slab cache
46 |
47 | 无级变速总是让人向往。
48 |
49 | 如果一个CPU的slab缓存满了,直接去抢同级别的别的CPU的slab缓存被认为是一种鲁莽且不道义的做法。那么为何不设置另外一个slab缓存,获 取它里面的对象不像直接获取CPU的slab缓存那么简单且直接,但是难度却又不大,只是稍微增加一点消耗,这不是很好吗?事实上,CPU的 L1,L2,L3 cache不就是这个方案设计的吗?这事实上已经成为cache设计的不二法门。这个设计思想同样作用于slab,就是Linux内核的slub实现。
50 | 现在可以给出概念和解释了。
51 |
52 | * Linux kernel slab cache:一个分为3层的对象cache模型。
53 | * Level 1 slab cache:一个空闲对象链表,每个CPU一个的独享cache,分配释放对象无需加锁。
54 | * Level 2 slab cache:一个空闲对象链表,每个CPU一个的共享page(s) cache,分配释放对象时仅需要锁住该page(s),与Level 1 slab cache互斥,不互相包容。
55 | * Level 3 slab cache:一个page(s)链表,每个NUMA NODE的所有CPU共享的cache,单位为page(s),获取后被提升到对应CPU的Level 1 slab cache,同时该page(s)作为Level 2的共享page(s)存在。
56 | * 共享page(s):该page(s)被一个或者多个CPU占 有,每一个CPU在该page(s)上都可以拥有互相不充图的空闲对象链表,该page(s)拥有一个唯一的Level 2 slab cache空闲链表,该链表与上述一个或多个Level 1 slab cache空闲链表亦不冲突,多个CPU获取该Level 2 slab cache时必须争抢,获取后可以将该链表提升成自己的Level 1 slab cache。
57 |
58 | 该slab cache的图示如下:
59 |
60 | 
61 |
62 | 其行为如下图所示:
63 |
64 | 
65 |
66 | ## 2个场景
67 |
68 | 对于常规的对象分配过程,下图展示了其细节:
69 |
70 | 
71 |
72 | 事实上,对于多个CPU共享一个page(s)的情况,还可以有另一种玩法,如下图所示:
73 |
74 | 
75 |
76 | ## 伙伴系统
77 |
78 | 前面我们简短的体会了Linux内核的slab设计,不宜过长,太长了不易理解.但是最后,如果Level 3也没有获取page(s),那么最终会落到终极的伙伴系统。
79 |
80 | 伙伴系统是为了防内存分配碎片化的,所以它尽可能地做两件事:
81 |
82 | **1).尽量分配尽可能大的内存**
83 | **2).尽量合并连续的小块内存成一块大内存**
84 |
85 | 我们可以通过下面的图解来理解上面的原则:
86 |
87 | 
88 |
89 | 注意,本文是关于优化的,不是伙伴系统的科普,所以我假设大家已经理解了伙伴系统。
90 |
91 | 鉴于slab缓存对象大多数都是不超过1个页面的小结构(不仅仅slab系统,超过1个页面的内存需求相比1个页面的内存需求,很少),因此会有大量的针 对1个页面的内存分配需求。从伙伴系统的分配原理可知,如果持续大量分配单一页面,会有大量的order大于0的页面分裂成单一页面,在单核心CPU上, 这不是问题,但是在多核心CPU上,由于每一个CPU都会进行此类分配,而伙伴系统的分裂,合并操作会涉及大量的链表操作,这个锁开销是巨大的,因此需要 优化!
92 |
93 | Linux内核对伙伴系统针对单一页面的分配需求采取的批量分配“每CPU单一页面缓存”的方式!
94 |
95 | 每一个CPU拥有一个单一页面缓存池,需要单一页面的时候,可以无需加锁从当前CPU对应的页面池中获取页面。而当池中页面不足时,系统会批量从伙伴系统中拉取一堆页面到池中,反过来,在单一页面释放的时候,会择优将其释放到每CPU的单一页面缓存中。
96 |
97 | 为了维持“每CPU单一页面缓存”中页面的数量不会太多或太少(太多会影响伙伴系统,太少会影响CPU的需求),系统保持了两个值,当缓存页面数量低于 low值的时候,便从伙伴系统中批量获取页面到池中,而当缓存页面数量大于high的时候,便会释放一些页面到伙伴系统中。
98 |
99 | ## 小结
100 |
101 | 多 CPU操作系统内核中,关键的开销就是锁的开销。我认为这是一开始的设计导致的,因为一开始,多核CPU并没有出现,单核CPU上的共享保护几乎都是可以 用“禁中断”,“禁抢占”来简单实现的,到了多核时代,操作系统同样简单平移到了新的平台,因此同步操作是在单核的基础上后来添加的。简单来讲,目前的主 流操作系统都是在单核年代创造出来的,因此它们都是顺应单核环境的,对于多核环境,可能它们一开始的设计就有问题。
102 |
103 | 不管怎么说,优化操作的不二法门就是禁止或者尽量减少锁的操作。随之而来的思路就是为共享的关键数据结构创建"每CPU的缓存“,而这类缓存分为两种类型:
104 |
105 | 1).数据通路缓存。
106 | 比如路由表之类的数据结构,你可以用RCU锁来保护,当然如果为每一个CPU都创建一个本地路由表缓存,也是不错的,现在的问题是何时更新它们,因为所有的缓存都是平级的,因此一种批量同步的机制是必须的。
107 | 2).管理机制缓存。
108 | 比 如slab对象缓存这类,其生命周期完全取决于使用者,因此不存在同步问题,然而却存在管理问题。采用分级cache的思想是好的,这个非常类似于CPU 的L1/L2/L3缓存,采用这种平滑的开销逐渐增大,容量逐渐增大的机制,并配合以设计良好的换入/换出等算法,效果是非常明显的。
109 |
--------------------------------------------------------------------------------
/文章/内存管理/尽情阅读,技术进阶,详解mmap原理.md:
--------------------------------------------------------------------------------
1 | ## 1. 一句话概括mmap
2 |
3 | mmap的作用,在应用这一层,是让你把文件的某一段,当作内存一样来访问。将文件映射到物理内存,将进程虚拟空间映射到那块内存。
4 |
5 | 这样,进程不仅能像访问内存一样读写文件,多个进程映射同一文件,还能保证虚拟空间映射到同一块物理内存,达到内存共享的作用。
6 |
7 | ## 2. 虚拟内存?虚拟空间?
8 |
9 | 其实是一个概念,前一篇对于这个词没有确切的定义,现在定义一下:
10 |
11 | 虚拟空间就是进程看到的所有地址组成的空间,虚拟空间是某个进程对分配给它的所有物理地址(已经分配的和将会分配的)的重新映射。
12 |
13 | 而虚拟内存,为啥叫虚拟内存,是因为它就不是真正的内存,是假的,因为它是由地址组成的空间,所以在这里,使用虚拟空间这个词更加确切和易懂。(不过虚拟内存这个词也不算错)
14 |
15 | ### 2.1 虚拟空间原理
16 |
17 | #### 2.1.1物理内存
18 |
19 | 首先,物理地址实际上也不是连续的,通常是包含作为主存的DRAM和IO寄存器
20 |
21 | 
22 |
23 | 以前的CPU(如X86)是为IO划分单独的地址空间,所以不能用直接访问内存的方式(如指针)IO,只能用专门的方法(in/read/out/write)诸如此类。
24 |
25 | 现在的CPU利用PCI总线将IO寄存器映射到物理内存,所以出现了基于内存访问的IO。
26 |
27 | 还有一点补充的,就如同进程空间有一块内核空间一样,物理内存也会有极小一部分是不能访问的,为内核所用。
28 |
29 | ### 2.1.2三个总线
30 |
31 | 这里再补充下三个总线的知识,即:地址总线、数据总线、控制总线
32 | * 地址总线,用来传输地址
33 | * 数据总线,用来传输数据
34 | * 控制总线,用来传输命令
35 |
36 | 比如CPU通过控制总线发送读取命令,同时用地址总线发送要读取的数据虚地址,经过MMU后到内存
37 |
38 | 内存通过数据总线将数据传输给CPU。
39 |
40 | 虚拟地址的空间和指令集的地址长度有关,不一定和物理地址长度一致,比如现在的64位处理器,从VA角度看来,可以访问64位的地址,但地址总线长度只有48位,所以你可以访问一个位于2^52这个位置的地址。
41 |
42 | #### 2.1.3虚拟内存地址转换(虚地址转实地址)
43 |
44 | 上面已经明确了虚拟内存是虚拟空间,即地址的集合这一概念。基于此,来说说原理。
45 |
46 | 如果还记得操作系统课程里面提到的虚地址,那么这个虚地址就是虚拟空间的地址了,虚地址通过转换得到实地址,转换方式课程内也讲得很清楚,虚地址头部包含了页号(段地址和段大小,看存储模式:页存储、段存储,段页式),剩下部分是偏移量,经过MMU转换成实地址。
47 |
48 | 
49 |
50 | 存储方式
51 |
52 | 
53 |
54 | 如图则是页式存储动态地址变换的方式
55 |
56 | 虚拟地址头部为页号通过查询页表得到物理页号,假设一页时1K,那么页号*偏移量就得到物理地址
57 |
58 | 
59 |
60 | 如图所示,段式存储
61 |
62 | 虚拟地址头部为段号,段表中找到段基地址加上偏移量得到实地址
63 |
64 | 
65 |
66 | 段页式结合两者,如图所示。
67 |
68 | ## 3. mmap映射
69 |
70 | 至此,如果对虚拟空间已经了解了,那么接下来,作为coder,应该自动把虚拟空间无视掉,因为Linux的目的也是要让更多额进程能享用内存,又不让进程做麻烦的事情,是将虚拟空间和MMU都透明化,让进程(和coder)只需要管对内存怎样使用。
71 |
72 | 所以现在开始不再强调虚拟空间了。
73 |
74 | mmap就是将文件映射到内存上,进程直接对内存进行读写,然后就会反映到磁盘上。
75 |
76 | 
77 |
78 | * 虚拟空间获取到一段连续的地址
79 | * 在没有读写的时候,这个地址指向不存在的地方(所以,上图中起始地址和终止地址是还没分配给进程的)
80 | * 好了,根据偏移量,进程要读文件数据了,数据占在两个页当中(物理内存着色部分)
81 | * 这时,进程开始使用内存了,所以OS给这两个页分配了内存(即缺页异常)(其余部分还是没有分配)
82 | * 然后刚分配的页内是空的,所以再将相同偏移量的文件数据拷贝到物理内存对应页上。
83 |
--------------------------------------------------------------------------------
/文章/内存管理/浅谈Linux内存管理机制.md:
--------------------------------------------------------------------------------
1 | ## 活学活用
2 |
3 | OOM Killer 在 Linux 系统里如果内存不足时,会杀死一个正在运行的进程来释放一些内存。
4 |
5 | Linux 里的程序都是调用 malloc() 来申请内存,如果内存不足,直接 malloc() 返回失败就可以,为什么还要去杀死正在运行的进程呢?Linux允许进程申请超过实际物理内存上限的内存。因为 malloc() 申请的是内存的虚拟地址,系统只是给了程序一个地址范围,由于没有写入数据,所以程序并没有得到真正的物理内存。物理内存只有程序真的往这个地址写入数据的时候,才会分配给程序。
6 |
7 | 
8 |
9 | ## 内存管理
10 |
11 | 对于内存的访问,用户态的进程使用虚拟地址,内核的也基本都是使用虚拟地址
12 |
13 | ## 物理内存空间布局
14 |
15 | 
16 |
17 | ## 虚拟内存与物理内存的映射
18 |
19 | 
20 |
21 | ## 进程“独占”虚拟内存及虚拟内存划分
22 |
23 | 为了保证操作系统的稳定性和安全性。用户程序不可以直接访问硬件资源,如果用户程序需要访问硬件资源,必须调用操作系统提供的接口,这个调用接口的过程也就是系统调用。每一次系统调用都会存在两个内存空间之间的相互切换,通常的网络传输也是一次系统调用,通过网络传输的数据先是从内核空间接收到远程主机的数据,然后再从内核空间复制到用户空间,供用户程序使用。这种从内核空间到用户空间的数据复制很费时,虽然保住了程序运行的安全性和稳定性,但是牺牲了一部分的效率。
24 |
25 | 如何分配用户空间和内核空间的比例也是一个问题,是更多地分配给用户空间供用户程序使用,还是首先保住内核有足够的空间来运行。在当前的Windows 32位操作系统中,默认用户空间:内核空间的比例是1:1,而在32位Linux系统中的默认比例是3:1(3GB用户空间、1GB内核空间)(这里只是地址空间,映射到物理地址,可没有某个物理地址的内存只能存储内核态数据或用户态数据的说法)。
26 |
27 | 
28 |
29 | 
30 |
31 | 左右两侧均表示虚拟地址空间,左侧以描述内核空间为主,右侧以描述用户空间为主。
32 |
33 | 
34 |
35 | 在内核里面也会有内核的代码,同样有 Text Segment、Data Segment 和 BSS Segment,别忘了内核代码也是 ELF 格式的。
36 |
37 | **在代码上的体现**
38 |
39 | ```c
40 | // 持有task_struct 便可以访问进程在内存中的所有数据
41 | struct task_struct {
42 | ...
43 | struct mm_struct *mm;
44 | struct mm_struct *active_mm;
45 | ...
46 | void *stack; // 指向内核栈的指针
47 | }
48 | ```
49 |
50 | 内核使用内存描述符mm_struct来表示进程的地址空间,该描述符表示着进程所有地址空间的信息
51 |
52 | 
53 |
54 | 在用户态,进程觉着整个空间是它独占的,没有其他进程存在。但是到了内核里面,无论是从哪个进程进来的,看到的都是同一个内核空间,看到的都是同一个进程列表。虽然内核栈是各用个的,但是如果想知道的话,还是能够知道每个进程的内核栈在哪里的。所以,如果要访问一些公共的数据结构,需要进行锁保护。
55 |
56 | 
57 |
58 | ## 地址空间内的栈
59 |
60 | 栈是主要用途就是支持函数调用。
61 |
62 | 大多数的处理器架构,都有实现硬件栈。有专门的栈指针寄存器,以及特定的硬件指令来完成 入栈/出栈 的操作。
63 |
64 | ### 用户栈和内核栈的切换
65 |
66 | 内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
67 |
68 | 当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。
69 |
70 | 如何相互切换呢?
71 |
72 | 进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态执行时,在内核态执行的最后,将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
73 |
74 | 那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
75 |
76 | 关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,一旦进程从内核态返回到用户态后,内核栈中保存的信息无效,会全部恢复。因此,每次进程从用户态陷入内核的时候得到的内核栈都是空的,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
77 |
78 | ### 为什么需要单独的进程内核栈?
79 |
80 | 内核地址空间所有进程空闲,但内核栈却不共享。为什么需要单独的进程内核栈?因为同时可能会有多个进程在内核运行。
81 |
82 | 所有进程运行的时候,都可能通过系统调用陷入内核态继续执行。假设第一个进程 A 陷入内核态执行的时候,需要等待读取网卡的数据,主动调用 schedule() 让出 CPU;此时调度器唤醒了另一个进程 B,碰巧进程 B 也需要系统调用进入内核态。那问题就来了,如果内核栈只有一个,那进程 B 进入内核态的时候产生的压栈操作,必然会破坏掉进程 A 已有的内核栈数据;一但进程 A 的内核栈数据被破坏,很可能导致进程 A 的内核态无法正确返回到对应的用户态了。
83 |
84 | 进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
85 |
86 | ### 进程切换带来的用户栈切换和内核栈切换
87 |
88 | ```c
89 | // 持有task_struct 便可以访问进程在内存中的所有数据
90 | struct task_struct {
91 | ...
92 | struct mm_struct *mm;
93 | struct mm_struct *active_mm;
94 | ...
95 | void *stack; // 指向内核栈的指针
96 | }
97 | ```
98 |
99 | 从进程 A 切换到进程 B,用户栈要不要切换呢?当然要,在切换内存空间的时候就切换了,每个进程的用户栈都是独立的,都在内存空间里面。
100 |
101 | 那内核栈呢?已经在 __switch_to 里面切换了,也就是将 current_task 指向当前的 task_struct。里面的 void *stack 指针,指向的就是当前的内核栈。
102 |
103 | 内核栈的栈顶指针呢?在 __switch_to_asm 里面已经切换了栈顶指针,并且将栈顶指针在 __switch_to加载到了 TSS 里面。
104 |
105 | 用户栈的栈顶指针呢?如果当前在内核里面的话,它当然是在内核栈顶部的 pt_regs 结构里面呀。当从内核返回用户态运行的时候,pt_regs 里面有所有当时在用户态的时候运行的上下文信息,就可以开始运行了。
106 |
107 | 主线程的用户栈和一般现成的线程栈
108 |
109 | 
110 |
111 | 对应着jvm 一个线程一个栈
112 |
113 | ### 中断栈
114 |
115 | 中断有点类似于我们经常说的事件驱动编程,而这个事件通知机制是怎么实现的呢,硬件中断的实现通过一个导线和 CPU 相连来传输中断信号,软件上会有特定的指令,例如执行系统调用创建线程的指令,而 CPU 每执行完一个指令,就会检查中断寄存器中是否有中断,如果有就取出然后执行该中断对应的处理程序。
116 |
117 | 当系统收到中断事件后,进行中断处理的时候,也需要中断栈来支持函数调用。由于系统中断的时候,系统当然是处于内核态的,所以中断栈是可以和内核栈共享的。但是具体是否共享,这和具体处理架构密切相关。ARM 架构就没有独立的中断栈。
118 |
119 | ## 内存管理的进程和硬件背景
120 |
121 | ### 页表的位置
122 |
123 | 每个进程都有独立的地址空间,为了这个进程独立完成映射,每个进程都有独立的进程页表,这个页表的最顶级的 pgd 存放在 task_struct 中的 mm_struct 的 pgd 变量里面。
124 |
125 | 在一个进程新创建的时候,会调用 fork,对于内存的部分会调用 copy_mm,里面调用 dup_mm。
126 |
127 | ```c
128 | // Allocate a new mm structure and copy contents from the mm structure of the passed in task structure.
129 | static struct mm_struct *dup_mm(struct task_struct *tsk){
130 | struct mm_struct *mm, *oldmm = current->mm;
131 | mm = allocate_mm();
132 | memcpy(mm, oldmm, sizeof(*mm));
133 | if (!mm_init(mm, tsk, mm->user_ns))
134 | goto fail_nomem;
135 | err = dup_mmap(mm, oldmm);
136 | return mm;
137 | }
138 | ```
139 |
140 | 除了创建一个新的 mm_struct,并且通过memcpy将它和父进程的弄成一模一样之外,我们还需要调用 mm_init 进行初始化。接下来,mm_init 调用 mm_alloc_pgd,分配全局页目录项,赋值给mm_struct 的 pdg 成员变量。
141 |
142 | ```c
143 | static inline int mm_alloc_pgd(struct mm_struct *mm){
144 | mm->pgd = pgd_alloc(mm);
145 | return 0;
146 | }
147 | ```
148 |
149 | 一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表。在内核里面,映射靠内核页表,这里内核页表会拷贝一份到进程的页表
150 |
151 | 如果是用户态进程页表,会有 mm_struct 指向进程顶级目录 pgd,对于内核来讲,也定义了一个 mm_struct,指向 swapper_pg_dir(指向内核最顶级的目录 pgd)。
152 |
153 | ```c
154 | struct mm_struct init_mm = {
155 | .mm_rb = RB_ROOT,
156 | // pgd 页表最顶级目录
157 | .pgd = swapper_pg_dir,
158 | .mm_users = ATOMIC_INIT(2),
159 | .mm_count = ATOMIC_INIT(1),
160 | .mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
161 | .page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
162 | .mmlist = LIST_HEAD_INIT(init_mm.mmlist),
163 | .user_ns = &init_user_ns,
164 | INIT_MM_CONTEXT(init_mm)
165 | };
166 |
167 | ```
168 |
169 | ### 页表的应用
170 |
171 | 一个进程 fork 完毕之后,有了内核页表(内核初始化时即弄好了内核页表, 所有进程共享),有了自己顶级的 pgd,但是对于用户地址空间来讲,还完全没有映射过(用户空间页表一开始是不完整的,只有最顶级目录pgd这个“光杆司令”)。这需要等到这个进程在某个 CPU 上运行,并且对内存访问的那一刻了
172 |
173 | 当这个进程被调度到某个 CPU 上运行的时候,要调用 context_switch 进行上下文切换。对于内存方面的切换会调用 switch_mm_irqs_off,这里面会调用 load_new_mm_cr3。
174 |
175 | cr3 是 CPU 的一个寄存器,它会指向当前进程的顶级 pgd。如果 CPU 的指令要访问进程的虚拟内存,它就会自动从cr3 里面得到 pgd 在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。
176 |
177 | 这里需要注意两点。第一点,cr3 里面存放当前进程的顶级 pgd,这个是硬件的要求。cr3 里面需要存放 pgd 在物理内存的地址,不能是虚拟地址。第二点,用户进程在运行的过程中,访问虚拟内存中的数据,会被 cr3 里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态。
178 |
179 | 
180 |
181 | 这就可以解释,为什么页表数据在 task_struct 的mm_struct里却又 可以融入硬件地址翻译机制了。
182 |
183 | ### 通过缺页中断来“填充”页表
184 |
185 | 内存管理并不直接分配物理内存,只有等你真正用的那一刻才会开始分配。只有访问虚拟内存的时候,发现没有映射多物理内存,页表也没有创建过,才触发缺页异常。进入内核调用 do_page_fault,一直调用到 __handle_mm_fault,__handle_mm_fault 调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项。
186 |
187 | ```c
188 | static noinline void
189 | __do_page_fault(struct pt_regs *regs, unsigned long error_code,
190 | unsigned long address){
191 | struct vm_area_struct *vma;
192 | struct task_struct *tsk;
193 | struct mm_struct *mm;
194 | tsk = current;
195 | mm = tsk->mm;
196 | // 判断缺页是否发生在内核
197 | if (unlikely(fault_in_kernel_space(address))) {
198 | if (vmalloc_fault(address) >= 0)
199 | return;
200 | }
201 | ......
202 | // 找到待访问地址所在的区域 vm_area_struct
203 | vma = find_vma(mm, address);
204 | ......
205 | fault = handle_mm_fault(vma, address, flags);
206 | ......
207 |
208 | static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
209 | unsigned int flags){
210 | struct vm_fault vmf = {
211 | .vma = vma,
212 | .address = address & PAGE_MASK,
213 | .flags = flags,
214 | .pgoff = linear_page_index(vma, address),
215 | .gfp_mask = __get_fault_gfp_mask(vma),
216 | };
217 | struct mm_struct *mm = vma->vm_mm;
218 | pgd_t *pgd;
219 | p4d_t *p4d;
220 | int ret;
221 | pgd = pgd_offset(mm, address);
222 | p4d = p4d_alloc(mm, pgd, address);
223 | ......
224 | vmf.pud = pud_alloc(mm, p4d, address);
225 | ......
226 | vmf.pmd = pmd_alloc(mm, vmf.pud, address);
227 | ......
228 | return handle_pte_fault(&vmf);
229 | }
230 | ```
231 |
232 | 以handle_pte_fault 的一种场景 do_anonymous_page为例:先通过 pte_alloc 分配一个页表项,然后通过 alloc_zeroed_user_highpage_movable 分配一个页,接下来要调用 mk_pte,将页表项指向新分配的物理页,set_pte_at 会将页表项塞到页表里面。
233 |
234 | ```c
235 | static int do_anonymous_page(struct vm_fault *vmf){
236 | struct vm_area_struct *vma = vmf->vma;
237 | struct mem_cgroup *memcg;
238 | struct page *page;
239 | int ret = 0;
240 | pte_t entry;
241 | ......
242 | if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
243 | return VM_FAULT_OOM;
244 | ......
245 | page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
246 | ......
247 | entry = mk_pte(page, vma->vm_page_prot);
248 | if (vma->vm_flags & VM_WRITE)
249 | entry = pte_mkwrite(pte_mkdirty(entry));
250 | vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
251 | &vmf->ptl);
252 | ......
253 | set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
254 | ......
255 | }
256 |
257 | ```
258 |
--------------------------------------------------------------------------------
/文章/内存管理/熟读精思,熟读玩味,Linux虚拟内存管理,MMU机制,原来如此也.md:
--------------------------------------------------------------------------------
1 | ## MMU
2 |
3 | 现代操作系统普遍采用虚拟内存管理(Virtual Memory Management)机制,这需要处理器中的MMU(Memory Management Unit,内存管理单元)提供支持。
4 |
5 | 首先引入 PA 和 VA 两个概念。
6 |
7 | ## PA
8 |
9 | 如果处理器没有MMU,或者有MMU但没有启用,CPU执行单元发出的内存地址将直接传到芯片引脚上,被内存芯片(以下称为物理内存,以便与虚拟内存区分)接收,这称为PA(Physical Address,以下简称PA),如下图所示。
10 |
11 | 
12 |
13 |
14 | ## VA
15 | 如果处理器启用了MMU,CPU执行单元发出的内存地址将被MMU截获,从CPU到MMU的地址称为虚拟地址(Virtual Address,以下简称VA),而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将VA映射成PA,如下图所示。
16 |
17 | 
18 |
19 | 如果是32位处理器,则内地址总线是32位的,与CPU执行单元相连(图中只是示意性地画了4条地址线),而经过MMU转换之后的外地址总线则不一定是32位的。也就是说,虚拟地址空间和物理地址空间是独立的,32位处理器的虚拟地址空间是4GB,而物理地址空间既可以大于也可以小于4GB。
20 |
21 | MMU将VA映射到PA是以页(Page)为单位的,32位处理器的页尺寸通常是4KB。例如,MMU可以通过一个映射项将VA的一页0xb7001000~0xb7001fff映射到PA的一页0x2000~0x2fff,如果CPU执行单元要访问虚拟地址0xb7001008,则实际访问到的物理地址是0x2008。物理内存中的页称为物理页面或者页帧(Page Frame)。虚拟内存的哪个页面映射到物理内存的哪个页帧是通过页表(Page Table)来描述的,页表保存在物理内存中,MMU会查找页表来确定一个VA应该映射到什么PA。
22 |
23 | ## 进程地址空间
24 |
25 | 
26 |
27 | x86平台的虚拟地址空间是0x0000 0000~0xffff ffff,大致上前3GB(0x0000 0000~0xbfff ffff)是用户空间,后1GB(0xc000 0000~0xffff ffff)是内核空间。
28 |
29 | Text Segmest 和 Data Segment
30 |
31 | * Text Segment,包含.text段、.rodata段、.plt段等。是从/bin/bash加载到内存的,访问权限为r-x。
32 | * Data Segment,包含.data段、.bss段等。也是从/bin/bash加载到内存的,访问权限为rw-。
33 |
34 | ## 堆和栈
35 |
36 | * 堆(heap):堆说白了就是电脑内存中的剩余空间,malloc函数动态分配内存是在这里分配的。在动态分配内存时堆空间是可以向高地址增长的。堆空间的地址上限称为Break,堆空间要向高地址增长就要抬高Break,映射新的虚拟内存页面到物理内存,这是通过系统调用brk实现的,malloc函数也是调用brk向内核请求分配内存的。
37 | * 栈(stack):栈是一个特定的内存区域,其中高地址的部分保存着进程的环境变量和命令行参数,低地址的部分保存函数栈帧,栈空间是向低地址增长的,但显然没有堆空间那么大的可供增长的余地,因为实际的应用程序动态分配大量内存的并不少见,但是有几十层深的函数调用并且每层调用都有很多局部变量的非常少见。
38 |
39 | 如果写程序的时候没有注意好内存的分配问题,在堆和栈这两个地方可能产生以下几种问题:
40 |
41 | 1、内存泄露:如果你在一个函数里通过 malloc 在堆里申请了一块空间,并在栈里声明一个指针变量保存它,那么当该函数结束时,该函数的成员变量将会被释放,包括这个指针变量,那么这块空间也就找不回来了,也就无法得到释放。久而久之,可能造成下面的内存泄露问题。
42 | 2、栈溢出:如果你放太多数据到栈中(例如大型的结构体和数组),那么就可能会造成“栈溢出”(Stack Overflow)问题,程序也将会终止。为了避免这个问题,在声明这类变量时应使用 malloc 申请堆的空间。
43 | 3、野指针 和 段错误:如果一个指针所指向的空间已经被释放,此时再试图用该指针访问已经被释放了的空间将会造成“段错误”(Segment Fault)问题。此时指针已经变成野指针,应该及时手动将野指针置空。
44 |
45 | ## 虚拟内存管理的作用
46 |
47 | 1、虚拟内存管理可以控制物理内存的访问权限。物理内存本身是不限制访问的,任何地址都可以读写,而操作系统要求不同的页面具有不同的访问权限,这是利用CPU模式和MMU的内存保护机制实现的。
48 | 2、虚拟内存管理最主要的作用是让每个进程有独立的地址空间。所谓独立的地址空间是指,不同进程中的同一个VA被MMU映射到不同的PA,并且在某一个进程中访问任何地址都不可能访问到另外一个进程的数据,这样使得任何一个进程由于执行错误指令或恶意代码导致的非法内存访问都不会意外改写其它进程的数据,不会影响其它进程的运行,从而保证整个系统的稳定性。另一方面,每个进程都认为自己独占整个虚拟地址空间,这样链接器和加载器的实现会比较容易,不必考虑各进程的地址范围是否冲突。
49 |
50 | 
51 |
52 | 3、VA到PA的映射会给分配和释放内存带来方便,物理地址不连续的几块内存可以映射成虚拟地址连续的一块内存。比如要用malloc分配一块很大的内存空间,虽然有足够多的空闲物理内存,却没有足够大的连续空闲内存,这时就可以分配多个不连续的物理页面而映射到连续的虚拟地址范围。
53 |
54 | 
55 |
56 | 4、一个系统如果同时运行着很多进程,为各进程分配的内存之和可能会大于实际可用的物理内存,虚拟内存管理使得这种情况下各进程仍然能够正常运行。因为各进程分配的只不过是虚拟内存的页面,这些页面的数据可以映射到物理页面,也可以临时保存到磁盘上而不占用物理页面,在磁盘上临时保存虚拟内存页面的可能是一个磁盘分区,也可能是一个磁盘文件,称为交换设备(Swap Device)。当物理内存不够用时,将一些不常用的物理页面中的数据临时保存到交换设备,然后这个物理页面就认为是空闲的了,可以重新分配给进程使用,这个过程称为换出(Page out)。如果进程要用到被换出的页面,就从交换设备再加载回物理内存,这称为换入(Page in)。换出和换入操作统称为换页(Paging),因此:\[\mbox{系统中可分配的内存总量} = \mbox{物理内存的大小} + \mbox{交换设备的大小}\]
57 |
58 | 如下图所示。第一张图是换出,将物理页面中的数据保存到磁盘,并解除地址映射,释放物理页面。第二张图是换入,从空闲的物理页面中分配一个,将磁盘暂存的页面加载回内存,并建立地址映射。
59 |
60 | 
61 |
62 | ## malloc 和 free
63 |
64 | C标准库函数malloc可以在堆空间动态分配内存,它的底层通过brk系统调用向操作系统申请内存。动态分配的内存用完之后可以用free释放,更准确地说是归还给malloc,这样下次调用malloc时这块内存可以再次被分配。
65 |
66 | ```c
67 | #include
68 |
69 | void *malloc(size_t size);
70 | 返回值:成功返回所分配内存空间的首地址,出错返回NULL
71 |
72 | void free(void *ptr);
73 | ```
74 |
75 | malloc的参数size表示要分配的字节数,如果分配失败(可能是由于系统内存耗尽)则返回NULL。由于malloc函数不知道用户拿到这块内存要存放什么类型的数据,所以返回通用指针void *,用户程序可以转换成其它类型的指针再访问这块内存。malloc函数保证它返回的指针所指向的地址满足系统的对齐要求,例如在32位平台上返回的指针一定对齐到4字节边界,以保证用户程序把它转换成任何类型的指针都能用。
76 | 动态分配的内存用完之后可以用free释放掉,传给free的参数正是先前malloc返回的内存块首地址。
77 |
78 | **示例**
79 |
80 | ```c
81 | #include
82 | #include
83 | #include
84 |
85 | typedef struct {
86 | int number;
87 | char *msg;
88 | } unit_t;
89 |
90 | int main(void)
91 | {
92 | unit_t *p = malloc(sizeof(unit_t));
93 |
94 | if (p == NULL) {
95 | printf("out of memory\n");
96 | exit(1);
97 | }
98 | p->number = 3;
99 | p->msg = malloc(20);
100 | strcpy(p->msg, "Hello world!");
101 | printf("number: %d\nmsg: %s\n", p->number, p->msg);
102 | free(p->msg);
103 | free(p);
104 | p = NULL;
105 |
106 | return 0;
107 | }
108 | ```
109 |
110 | **说明**
111 |
112 | * `unit_t *p = malloc(sizeof(unit_t))`;这一句,等号右边是`void *`类型,等号左边是`unit_t *`类型,编译器会做隐式类型转换,我们讲过`void *`类型和任何指针类型之间可以相互隐式转换。
113 | * 虽然内存耗尽是很不常见的错误,但写程序要规范,malloc之后应该判断是否成功。以后要学习的大部分系统函数都有成功的返回值和失败的返回值,每次调用系统函数都应该判断是否成功。
114 | * `free(p)`;之后,p所指的内存空间是归还了,但是p的值并没有变,因为从free的函数接口来看根本就没法改变p的值,p现在指向的内存空间已经不属于用户,换句话说,p成了野指针,为避免出现野指针,我们应该在`free(p)`;之后手动置`p = NULL`;。
115 | * 应该先`free(p->msg)`,再`free(p)`。如果先`free(p)`,p成了野指针,就不能再通过`p->msg`访问内存了。
116 |
117 | ## 内存泄漏
118 |
119 | 如果一个程序长年累月运行(例如网络服务器程序),并且在循环或递归中调用malloc分配内存,则必须有free与之配对,分配一次就要释放一次,否则每次循环都分配内存,分配完了又不释放,就会慢慢耗尽系统内存,这种错误称为内存泄漏(Memory Leak)。另外,malloc返回的指针一定要保存好,只有把它传给free才能释放这块内存,如果这个指针丢失了,就没有办法free这块内存了,也会造成内存泄漏。例如:
120 |
121 | ```c
122 | void foo(void)
123 | {
124 | char *p = malloc(10);
125 | ...
126 | }
127 | ```
128 |
129 | foo函数返回时要释放局部变量p的内存空间,它所指向的内存地址就丢失了,这10个字节也就没法释放了。内存泄漏的Bug很难找到,因为它不会像访问越界一样导致程序运行错误,少量内存泄漏并不影响程序的正确运行,大量的内存泄漏会使系统内存紧缺,导致频繁换页,不仅影响当前进程,而且把整个系统都拖得很慢。
130 |
131 | 关于malloc和free还有一些特殊情况。malloc(0)这种调用也是合法的,也会返回一个非NULL的指针,这个指针也可以传给free释放,但是不能通过这个指针访问内存。free(NULL)也是合法的,不做任何事情,但是free一个野指针是不合法的,例如先调用malloc返回一个指针p,然后连着调用两次free§;,则后一次调用会产生运行时错误。
132 |
--------------------------------------------------------------------------------
/文章/内存管理/硬件原理 和 分页管理.md:
--------------------------------------------------------------------------------
1 | ### 前言
2 | 内存管理相对复杂,涉及到硬件和软件,从微机原理到应用程序到内核。比如,硬件上的cache,CPU如何去寻址内存,页表, DMA,IOMMU。 软件上,要知道底层怎么分配内存,怎么管理内存,应用程序怎么申请内存。
3 |
4 | 常见的误解包括:
5 |
6 | 对free命令 cache和buffer的理解。
7 | 1、应用程序申请10M内存,申请成功其实并没有分配。内存其实是边写边拿。代码段有10M,并不是真的内存里占了10M。
8 | 2、内存管理学习难,一是网上的资料不准确,二是学习时执行代码,具有欺骗性。看到的东西不一定真实,要想理解必须陷入Linux本身。
9 |
10 | 学习时,不要过快陷入太多细节,而要先对整个流程整个框架理解。
11 |
12 | 先理清楚脉络和主干,从硬件到最底层内存的分配算法,-->到内核的内存分配算法,-->应用程序与内核的交互,-->到内存如何做磁盘的缓存, --> 内存如何和磁盘替换。
13 |
14 | 再动手实践demo。
15 |
16 | ### 硬件原理 和 分页管理
17 | 本文主要让大家理解内存管理最底层的buddy算法,内存为什么要分成多个Zone?
18 |
19 | * CPU寻址内存,虚拟地址、物理地址
20 | * MMU 以及RWX权限、kernel和user模式权限
21 | * 内存的zone: DMA、Normal和HIGHMEM
22 | * Linux内存管理Buddy算法
23 | * 连续内存分配器(CMA)
24 |
25 | 内存分页
26 |
27 | 
28 |
29 | CPU 一旦开启MMU,MMU是个硬件。CPU就只知道虚拟地址了。如果地址是32位,0x12345670 。
30 |
31 | 假设MMU的管理是把每一页的内存分成4K,那么其中的670是页内偏移,作为d;0x12345 是页号,作为p。通过虚拟地址去查对应的物理地址,用0x12345去查一张页表,页表(Page table)本身在内存。
32 |
33 | 硬件里有寄存器,记录页表的基地址,每次进程切换时,寄存器就会更新一次,因为每个进程的页表不同。
34 |
35 | CPU一旦访问虚拟地址,通过页表查到页表项,页表项记录对应的物理地址。
36 |
37 | 总结:一旦开启MMU,CPU只能看到虚拟地址,MMU才能看到物理地址。
38 | 虚拟地址是指针,物理地址是个整数。内存中的一切均通过虚拟地址来访问。
39 | ```
40 | typedef u64 phys_addr_t;
41 | ```
42 | 去内存里读取页表会比较慢,CPU里有个高速单元tlb,它是页表的高速缓存。CPU就不需要在内存里读页表,直接在tlb中读取,从虚拟地址到物理地址的映射。如果tlb中读取不到,才回到内存里读取页表映射,并且在tlb中命中。
43 |
44 | 虚拟地址:0x12345 670 --> 1M
45 |
46 | 物理地址:1M+670 MMU去访问这个物理地址。
47 |
48 | 内存的映射以页为单位。
49 | ### 页表(Page table)记录的页权限
50 | cpu虚拟地址,mmu根据cpu请求的虚拟地址,访问页表,查得物理地址。
51 |
52 | 每个MMU中的页表项,除了有虚拟地址到物理地址的映射之外,还可以标注这个页的 RWX权限和 kernel和user模式权限(用户空间,内核空间读取地址的权限),它们是内存管理两个的非常重要的权限。
53 |
54 | 一是,这一页地址的RWX权限 ,标记这4k地址的权限。一般用来做保护。
55 |
56 | Pagefault,是CPU提供的功能。两种情况会出现Pagefault,一是,CPU通过虚拟地址没有查到对应的物理地址。二是,MMU没有访问物理地址的权限。
57 |
58 | MPU,memory protection unit.
59 |
60 | 二是,MMU的页表项中,还可以标注这一页的地址:可以在内核态访问,还是只能在用户态访问。用户一般映射到0~3G,只有当CPU陷入到内核模式,才可以访问3G以上地址。
61 |
62 | 程序在用户态运行,处于CPU非特权模式,不能访问特权模式才能访问的内存。内核运行在CPU的特权模式,从用户态陷入到内核态,发送 软中断指令,CPU进行切环,x86从3环切到0环,到一个固定的地址去执行。软件就从非特权模式,跳到特权模式去执行。
63 |
64 | MMU,能把某一段地址指定为只有特权模式才能够访问,会把内核空间3G以上的页表项里的每一行,指定为只有CPU 0环才能访问。应用程序没有陷入到内核态,是无法访问内核态的东西。
65 |
66 | intel的漏洞meltdown,就是让用户可以在用户态读到内核态的东西。
67 |
68 | meltdown 攻击原理: 基于时间的 旁路攻击 side-channel
69 |
70 | 李小璐买汉堡的故事 --> 安全的基于时间的旁路攻击技巧。
71 |
72 | 比如试探用户名,密码。比如一个软件比较傻,每次第一个字母就不对,就不对比第2个字母了。那我每次26个字母实验换一次,看哪个字母反弹地最慢,就证明是这个字母的密码。
73 |
74 | 密码是abc, 我敲了d,那么第一个字母就不对,软件这个时候如果快速的返回出错,我知道首字母不是d,我可以实验出来首字母是a,然后接着一个个字母实,就可以把密码试探出来了。类似地原理。。
75 |
76 | 下面的这个例子,演示 page table记录的RWX权限的作用
77 |
78 | 
79 |
80 | 页表的权限,RWX权限,和 用户空间,内核空间读取的权限。
81 |
82 | ### 内存分Zone
83 | 下面解释内存为什么分Zone? DMA zone.
84 |
85 | 
86 |
87 | 内存的分Zone,全都是物理地址的概念。内存条,被分为三个Zone。
88 |
89 | 分DMA Zone的原因,是DMA引擎的缺陷。DMA引擎 可以直接访问内存空间的地址,但不一定能够访问到所有的内存,访问内存时会存在一定的限制。
90 |
91 | 当CPU 和DMA同时访问内存时,硬件上会有仲裁器,选择优先级高的去访问内存。
92 |
93 | 为什么要切DMA zone?
94 | DMA Zone的大小,是由硬件决定的。访问不到更高的内存。
95 |
96 | 什么叫做 normal zone? highmem zone?
97 |
98 | highmem和lowmem 都是指的内存条,在虚拟地址空间,只能称为highmem,lowmem映射区。
99 |
100 | 如上图,内存虚拟地址空间0~4G,3~4G是内核空间的虚拟地址,0-3G 是用户空间的虚拟地址。
101 |
102 | 内核空间,访问任何一片内存都要虚拟地址。Linux为了简化内存访问,开机就把lowmem的物理地址一一映射到虚拟地址。highmem 地址包括了 normal + DMA。
103 |
104 | 
105 |
106 | lowmem是开机就直接映射好的内存,CPU访问这片内存,也是通过3G以上的虚拟地址。这段地址的虚拟地址和物理地址是直接线性映射,通过linux的两个api (phys_to_virt / virt_to_phys)在虚拟和物理之间进行映射, highmem 不能直接用。
107 |
108 | 内核空间一般不使用highmem,内核一般使用kmalloc在lowmem申请内存,使用 kmmap在highmem 申请内存。lowmem 映射了,并不代表被内核使用掉了,只是不需要重建页表。内核使用lowmem内存,同样是要申请。 应用程序一样可以申请 lowmem 和highmem。
109 |
110 | 总结:
111 | 内存分highmem zone的原因,地址空间整体不够。
112 | DMA zone产生的原因,硬件DMA引擎的访问缺陷。
113 |
114 | 
115 |
116 | ### 硬件层的内存管理- buddy算法
117 |
118 | 每个zone都会使用buddy算法,把所有的空闲页面变成2的n次方进行管理。
119 |
120 | /proc/buddyinfo
121 |
122 | 通过/proc/buddyinfo,可以看出空闲内存的情况
123 |
124 | 
125 |
126 | CPU寻址内存的方法:通过MMU提供的虚拟地址到物理地址的映射访问。
127 |
128 | 如何处理内存碎片
129 |
130 | 
131 |
132 | X86 linux 内核有一个线程 compaction, 会进行内存碎片整理,会尽量移出大内存。
133 |
134 | CMA:continuous memory allocation
135 |
136 | 内核把虚拟地址 指向新的物理地址,让应用程序毫无知觉情况,把64M内存腾出来给DMA。当用DMA的api申请内存,会走到CMA。在dts中指定哪块区域做CMA。
137 |
138 | Documentation/devicetree/bindings
139 |
140 | reserved-memory/reserved-memory.txt
141 |
142 | dma_alloc_coherent
143 |
144 | **CMA, iommu,**
145 |
146 | CMA主要是给需要连续内存的DMA用的。但是为了避免DMA不用的时候浪费,才在DMA不用的时候给可移动的页面用。不能移动的页面,不能从CMA里面拿。所以主要是APP和文件的page cache的内存,才可以在CMA区域拿。
147 |
148 | 这样当DMA想拿CMA区域的时候,要么移走,要么抛弃。总之,必须保证DMA需要这片CMA区域的时候,之前占着CMA的统统滚蛋。
149 |
150 | 不具备滚蛋能力的内存,不能从CMA区域申请。你申请也滚蛋不了,待会DMA上来用的时候,DMA就完蛋了。
151 |
152 | 要搞清楚CMA的真正房东是那些需要连续内存的DMA,其他的人都只是租客。DMA要住的时候,租客必须走。哪个房东会把房子租给一辈子都不准备走的人?内核绝大多数情况下的内存申请,都是无法走的。应用走起来很容易,改下页面就行了。
153 |
154 | CMA和不可移动之间,没有任何交集。CMA唯一的好处是,房东不住的时候,免得房子空置。
155 |
156 |
157 |
158 |
159 |
160 |
161 |
162 |
163 |
--------------------------------------------------------------------------------
/文章/内存管理/进程的内存消耗和泄漏.md:
--------------------------------------------------------------------------------
1 | ## 进程的内存消耗和泄漏
2 | * 进程的VMA
3 | * 进程内存消耗的4个概念: vss、rss、pss和uss
4 | * page fault的几种可能性, major 和 minor
5 | * 应用内存泄漏的界定方法
6 | * 应用内存泄漏的检测方法:valgrind 和 addresssanitizer
7 |
8 | 本节重点阐述 Linux的应用程序究竟消耗了多少内存?
9 |
10 | 一是,看到的内存消耗,并不是一定是真的消耗。
11 |
12 | 二是,Linux存在大量的内存共享的情况。
13 | 动态链接库的特点:代码段共享内存,数据段写时拷贝。
14 | 把一个应用程序跑两个进程,这两个进程的代码段也是共享的。
15 |
16 | 当我们评估进程消耗多少内存时,就是指在用户空间消耗的内存,即虚拟地址在0~3G的部分,对应的物理地址内存。内核空间的内存消耗属于内核,系统调用申请了很多内存,这些内存是不属于进程消耗的。
17 |
18 | ### 进程的虚拟地址空间VMA
19 |
20 | 
21 |
22 | task_struct里面有个mm_struct指针, 它代表进程的内存资源。pgd,代表 页表的地址; mmap 指向vm_area_struct 链表。 vm_area_struct 的每一段代表进程的一个虚拟地址空间。vma的每一段,都可能是可执行程序的某个数据段、某个代码段,堆、或栈。一个进程的虚拟地址,是在0~3G之间任意分布的。
23 |
24 | 
25 |
26 | 上图 提供三种方式,看到进程的VMA空间。
27 |
28 | pmap 3474
29 |
30 | 基地址,size, 权限,
31 |
32 | 通过以上的方式,可以看到进程的虚拟地址空间,分布在0~3G,任意一小段一小段分布的。
33 |
34 | 应用程序运行起来,就是一堆各种各样的VMA。VMA对应着 堆、栈、代码段、数据段、等,不在任何段里的虚拟地址空间,被认为是非法的。
35 |
36 | 
37 |
38 | 当指针访问地址时,落在一个非法的地址,即不在任何一个VMA区域。相当于访问一个非法的地址,这些虚拟地址没有对应的物理地址。应用程序收到page fault,查看原因,访问非法位置,返回segv。
39 |
40 | 在VMA的东西,不等于在内存。调malloc申请了100M内存,立马会多出一个100M的 VMA,代表这段vma区域有r+w权限。
41 |
42 | **应用程序访问内存,必须落在一个VMA里。其次,落在一个VMA里也不一定对。把100M的堆申请出来,100M内存页全部映射为0页。页表里每一页写的只读,页表和硬件对应,MMU只查页表。而在页表项中指向物理地址的权限是只读,所以在任何时候,去写其中任何一页,硬件都会发生缺页中断。**
43 |
44 | **Linux 内核在缺页中断的处理程序,通过MMU寄存器读出发生page fault的地址和原因。发现此时page fault的原因是写一个页表里记录只读的物理地址,而vma记录的虚拟地址又是r+w,此时,linux会申请一页内存。同时把页表中的权限改为r+w。**
45 |
46 | 总结:
47 | Linux 内核通过VMA管理进程每一段虚拟地址空间和权限。一旦发生page fault,如果没有落在任何一个vma区域,会干掉。
48 |
49 | VMA的起始地址+size,用来限定程序访问的地址是否合法。VMA中每一段的权限,是来界定访问这段地址是否使用正确的方式访问。
50 |
51 | 把所有的vma加起来,构成进程的虚拟地址空间,但这并不代表进程真实耗费的内存。拿到之后才是真实耗费的内存,RSS。耗费的虚拟内存,是VSS。
52 |
53 | ### page fault的几种可能性
54 |
55 | 
56 |
57 | 1、申请堆内存vma,第一次写,页表里的权限是R ,发生page fault,linux会去申请一页内存,此时把页表权限设置为 R+W。
58 | 2、内存访问落在空白非法区域,程序收到segv段错误。
59 | 3、代码段在VMA记录是R+X,此时如果对代码段执行写,程序会收到segv段错误。
60 |
61 | #### minor 和major 缺页
62 |
63 | 缺页,分为两种情况:主缺页 和次缺页。
64 |
65 | 主缺页 和次缺页,区别就是 申请内存时,是否需要读硬盘。前者需要。
66 |
67 | 如上图第4种情况,在代码段里执行时,出现缺页。linux申请一页内存,而且要从硬盘中读取代码段的内容,此时产生了IO,称为 major缺页。
68 |
69 | 无论是代码段还是堆,都是边执行边产生缺页中断,申请实际的内存给代码段,且从硬盘中读取代码段的内容到内存。这个过程时间比较长。
70 |
71 | minor: malloc的内存,产生缺页中断。去申请一页内存,没有产生IO的行为。major缺页处理时间,远大于minor。
72 |
73 | 
74 |
75 | ### vss、rss、pss和uss的区别
76 |
77 | 
78 |
79 | ```
80 | VSS - Virtual Set Size
81 | RSS - Resident Set Size
82 | PSS - Proportional Set Size
83 | USS - Unique Set Size
84 | ASAN - AddressSanitizer
85 | LSAN - LeakSanitizer
86 | ```
87 |
88 | 如上图,中间是一根内存条。三个进程分别是1044,1045,1054, 每一个进程对应一个page table,页表项记录虚拟地址如何往物理地址转换。硬件里的寄存器,记录页表的物理地址。当linux做进程上下文切换时,页表也跟着一起切换。
89 |
90 | 
91 |
92 | 三个进程都需要使用libc的代码段。
93 | VSS = 1 +2 +3
94 | RSS = 4 +5 +6
95 | PSS= 4/3 + 5/2 + 6 比例化的
96 | USS= 6 独占且驻留的
97 |
98 | 工具:smem ,查看进程使用内存的情况。
99 | 一般来讲,进程使用的内存量,还是看PSS,强调公平性。看内存泄漏看USS 就好了。
100 |
101 | ### 内存泄漏 界定和检测方法
102 | 界定:连续多点采样法,随着时间越久,进程耗费内存越多。
103 |
104 | 主要由内存申请和释放不是成对引起。RSS/USS曲线,
105 |
106 | 观察方法:使用smem工具查看多次进程使用内存,USS使用量。
107 |
108 | 检查工具:
109 | 1、valgrind ,会跑一个虚拟机,运行时检查进程的内存行为。会放慢程序的速度。不需要重新编译程序。
110 | 2、addressanitizer,需要重新编译程序。编译时加参数,-fsanitize
111 | gcc 4.9才支持,只会放慢程序速度2~3倍。
112 |
113 |
114 |
115 |
116 |
--------------------------------------------------------------------------------
/文章/文件系统/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/文章/文件系统/Linux IO 之 文件系统的实现.md:
--------------------------------------------------------------------------------
1 | * Ext2/3/4 的layout
2 | * 文件系统的一致性: append一个文件的全流程
3 | * 掉电与文件系统的一致性
4 | * fsck
5 | * 文件系统的日志
6 | * ext4 mount选项
7 | * 文件系统的debug和dump
8 | * Copy On Write 文件系统: btrfs
9 |
10 | 预备知识:数据库里的transaction(事务)有什么特性?
11 |
12 | * 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
13 | * 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。
14 | * 持久性(Durability):一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
15 |
16 | ## Ext2/3/4 的layout
17 |
18 | 
19 |
20 | 如上图,任何一个文件,在硬盘上有inode、 datablocks,和一些元数据信息(- 描述数据的数据)。其中,inode的信息包括,inode bitmap 和 inode table。通过inode bitmap和block bitmap来描述具体的inode table 和data blocks是否被占用。inode table包括文件的 读写权限和 指针表。
21 |
22 | 
23 |
24 | Linux对硬盘上一个文件,是分不同角度描述。创建一个文件,包括修改inode bitmap 和 block bitmap的描述。包括修改datablock和 inode bitmap的信息等等。所以“修改文件”这个操作,并不是原子的。所以存在文件系统的执行一致性的问题。
25 |
26 | 
27 |
28 | 分Group的好处,在同一个目录下的东西,尽量放在同一个group,用来减少硬盘的来回寻道。
29 |
30 | 文件系统的一致性: append一个文件的全流程
31 |
32 | 
33 |
--------------------------------------------------------------------------------
/文章/文件系统/Linux IO 之 文件系统的架构.md:
--------------------------------------------------------------------------------
1 | ## 本文概述:
2 | 应用程序 ->read ->文件系统的代码 如何实现?
3 | 当目录里面 A/B/C ,是如何找到C的全过程?
4 | 文件系统如何描述文件在磁盘的哪些位置?
5 | 硬链接和 符号链接的详细区别?
6 | userspace的文件系统的实现?
7 |
8 | ## 一切都是文件: VFS
9 |
10 | 
11 |
12 | 文件系统的设计,类似 抽象基类,面向对象的思想。
13 |
14 | 虚函数都必须由底层派生出的实例实现,使用成员函数 file_operations。在linux里面的文件操作,底层都要实现file_operations,抽象出owner,write,open,release。所以,无论是字符块,还是文件系统的文件,最终操作就必须是file_operations。
15 |
16 | 例如,实现一个字符设备驱动,就是去实现file_operations。VFS_read时就会调用字符设备的file_operations。
17 |
18 |
19 | ## 字符设备文件、块设备文件
20 |
21 | 块设备的两种访问方法,一是访问裸分区,二是访问文件系统。
22 |
23 | 当直接访问裸分区,是通过fs/block_dev.c 中的 file_operations def_blk_fops,也有read,write,open,一切继承到file_operations。如果是访问文件系统,就会通过实现 {ext4}_file_operations 来对接VFS对文件的操作。
24 |
25 | 块设备驱动就不需要知道file_operations,无论是裸设备,还是文件系统的file。他们实现的file_operations是把linux中的各种设备,hook进 VFS的方法。
26 |
27 | ### 文件最终如何转化成对磁盘的访问?
28 |
29 | file_operation 跟pagecache 以及硬盘的关系?
30 |
31 | 
32 |
33 | 整个文件系统里,除了放文件本身的数据,还包括文件的管理数据,包括
34 |
35 | * super block,保存在全局的 superblock结构中。
36 | * inode,是文件的唯一特定标识,文件系统使用bitmap来标识,inode是否使用。
37 | * block bitmap,来表示这些block是否占用,它在改变文件大小,创建删除等操作时,都会改变。
38 | * inode table/diagram : bitmap 只是表示inode和block是否被占用。
39 |
40 | 
41 |
42 | ## 超级块、目录、inode
43 |
44 | * file_system_type 数据结构: 指的是 文件系统的类型,mount/umount 的时候会用。
45 | * superblock数据结构:包含super_operations,其中包含如何分配/销毁一个inode。
46 | * inode 数据结构:包含 inode_operations 和 file_operations。
47 |
48 | > file_operations里面记录这种类型的文件,包含哪些操作。
49 | > inode_operations里面包含如何生成新的inode,根据文件名字找到inode,如何mkdir,unlink.
50 |
51 | * dentry 数据结构: 对应路径,目录在文件系统里面是一个特殊的文件,文件的内容是一个inode和文件的表格。
52 | * file 数据结构:
53 |
54 | 
55 |
56 | * inode表:包含文件的一些基本信息,大小,创建日期,属性。还有一些成员指向硬盘所在的位置。
57 | 申请slab区域,比如 ext4_inode_cache , ext3_inode_cache. 这些cache会创建单独的slab,这些slab和内存里的page一一对应。
58 |
59 | ext2/ext4文件系统中存在间接映射表。
60 |
61 | 
62 |
63 | 
64 |
65 | 
66 |
67 | 硬盘里的inode diagram里的数据结构,在内存中会通过slab分配器,组织成 xxx_inode_cache,出现在meminfo的可回收的内存。 inode表也会记录每一个inode 在硬盘中摆放的位置。
68 |
69 | ## 目录的组织
70 |
71 | 
72 |
73 | 目录在硬盘里是一个特殊的文件,和之前的file结构体不同。目录在硬盘中对应一个inode,记录文件的名字和inode号。查找一个文件时,文件系统的 根inode和目录,根据根目录和根inode,找到根目录所在硬盘的位置。再去做字符串匹配,能够找到 /A/B/ 。inode表也会记录每一个inode 在硬盘中摆放的位置。
74 |
75 | ## icache和dcache,slab shrink
76 |
77 | 
78 |
79 | 文件系统在实现时,在vfs这一层的 inode cache 和 dentry cache,不管硬盘的系统,跨所有文件系统的通用信息。
80 |
81 | 针对这些cache,这些可以回收的slab,linux提供了专门的slab shrink- 收缩函数。
82 | 最后所有可回收的内存,都必须通过LRU算法去回收。
83 | 有些自己申请的 reclaim的内存,由于没有写 shrink函数,所以就无法进行内存的回收。
84 |
85 | ## 文件读写如何通过file_operation 和pagecache的关系
86 |
87 | 
88 |
89 | 
90 |
91 | 
92 |
93 |
94 | ## 发现并读取/usr/bin/xxx的全流程
95 |
96 | 
97 |
98 | 如上图,当你在硬盘查找 /usr/bin/emacs文件时,从根的inode和dentry,根据/的inode表,找到/ 目录文件所在的硬盘中的位置,读硬盘/目录文件的内容,发现 usr 对应inode 2, bin 对应inode 3, share 对应inode4。再去查inode表,inode 2所在硬盘的位置,即/usr 目录文件所在硬盘的位置。读出内容包括 var 对应 inode 10, bin 对应inode 11, opt对应inode 12,。
99 |
100 | 这个过程会查找很多inode和 dentry,这些都会通过 icache 和dcache缓存。
101 |
102 | ## 符号链接 与 硬链接
103 |
104 | 
105 |
106 | 文件名是特殊目录文件的内容,比如 A目录下有b\c\d,其实就是 A这个目录文件,里面对应目录b,c,d和对应inode的表。
107 |
108 | 硬链接:在硬盘中是同一个inode存在,在目录文件中多了一个目录和inode对应。
109 |
110 | 符号链接:是linux中是真实存在的实体文件,文件内容指向 其他文件。符号链接和文件是不同的inode。
111 |
112 | 1、硬链接不能跨本地文件系统
113 | 2、硬链接不能针对目录
114 | 3、针对目录的软链接,用rm -fr 删除不了目录里的内容
115 | 4、针对目录的软链接,"cd .."进的是软链接所在目录的上级目录
116 | 5、可以对文件执行unlink或rm,但是不能对目录执行unlink
117 |
118 | ## 用户空间的文件系统: FUSE
119 |
120 | 用户空间文件系统 是操作系统中的概念,指完全在用户态实现的文件系统。
121 |
122 | 目前Linux通过内核模块对此进行支持。一些文件系统如ZFS,glusterfs使用FUSE实现。
123 |
124 | 
125 |
126 | FUSE的工作原理如上图所示。假设基于FUSE的用户态文件系统hello挂载在/tmp/fuse目录下。当应用层程序要访问/tmp/fuse下的文件时,通过glibc中的函数进行系统调用,处理这些系统调用的VFS中的函数会调用FUSE在内核中的文件系统;内核中的FUSE文件系统将用户的请求,发送给用户态文件系统hello;用户态文件系统收到请求后,进行处理,将结果返回给内核中的FUSE文件系统;最后,内核中的FUSE文件系统将数据返回给用户态程序。
127 |
128 |
--------------------------------------------------------------------------------
/文章/文件系统/Linux操作系统学习之文件系统.md:
--------------------------------------------------------------------------------
1 | ## 一. 前言
2 |
3 | 本节开始将分析Linux的文件系统。Linux一切皆文件的思想可谓众所周知,而其文件系统又是字符设备、块设备、管道、进程间通信、网络等等的必备知识,因此其重要性可想而知。本文将先介绍文件系统基础知识,然后介绍最重要的结构体inode以及构建于其上的一层层的文件系统。
4 |
5 | ## 二. 文件系统基础知识
6 |
7 | 一切设计均是为了实现需求,因此我们从文件系统需要的基本功能来看看其该如何设计。首先,一个文件系统需要有以下基本要求
8 |
9 | * 文件需要让人易于读写,并避免名字冲突等
10 | * 文件需要易于查找、整理归类
11 | * 操作系统需要有文档记录功能以便管理
12 |
13 | 由此,文件系统设计了如下特性
14 |
15 | * 采取树形结构、文件夹设计
16 | * 对热点文件进行缓存,便于读写
17 | * 采用索引结构,便于查找分类
18 | * 维护一套数据结构用于记录哪些文档正在被哪些任务使用
19 |
20 | 依此基本设计,我们可以开始慢慢展开看看Linux博大而精神的文件系统。
21 |
22 | ## 三. inode结构体和文件系统
23 |
24 | ### 3.1 块存储的表示
25 |
26 | 硬盘中我们以块为存储单元,而在文件系统中,我们需要有一个存储块信息的基本结构体,这就是文件系统的基石inode,其源码如下。inode意为index node,即索引节点。从这个数据结构中我们可以看出,inode 里面有文件的读写权限 i_mode,属于哪个用户 i_uid,哪个组 i_gid,大小是多少 i_size_lo,占用多少个块 i_blocks_lo。另外,这里面还有几个与文件相关的时间。i_atime 即 access time,是最近一次访问文件的时间;i_ctime 即 change time,是最近一次更改 inode 的时间;i_mtime 即 modify time,是最近一次更改文件的时间。
27 | ```c
28 | /*
29 | * Structure of an inode on the disk
30 | */
31 | struct ext4_inode {
32 | __le16 i_mode; /* File mode */
33 | __le16 i_uid; /* Low 16 bits of Owner Uid */
34 | __le32 i_size_lo; /* Size in bytes */
35 | __le32 i_atime; /* Access time */
36 | __le32 i_ctime; /* Inode Change time */
37 | __le32 i_mtime; /* Modification time */
38 | __le32 i_dtime; /* Deletion Time */
39 | __le16 i_gid; /* Low 16 bits of Group Id */
40 | __le16 i_links_count; /* Links count */
41 | __le32 i_blocks_lo; /* Blocks count */
42 | __le32 i_flags; /* File flags */
43 | ......
44 | __le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
45 | ......
46 | };
47 |
48 | #define EXT4_NDIR_BLOCKS 12
49 | #define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
50 | #define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
51 | #define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
52 | #define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)
53 | ```
54 | 这里我们需要重点关注以下i_block,该成员变量实际存储了文件内容的每一个块。在ext2和ext3格式的文件系统中,我们用前12个块存放对应的文件数据,每个块4KB,如果文件较大放不下,则需要使用后面几个间接存储块来保存数据,下图很形象的表示了其存储原理。
55 |
56 | 
57 |
58 | 该存储结构带来的问题是对于大型文件,我们需要多次调用才可以访问对应块的内容,因此访问速度较慢。为此,ext4提出了新的解决方案:Extents。简单的说,Extents以一个树形结构来连续存储文件块,从而提高访问速度,大致结构如下图所示。
59 |
60 | 
61 |
62 | 主要结构体为节点ext4_extent_header,eh_entries 表示这个节点里面有多少项。这里的项分两种:
63 |
64 | * 如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点 ext4_extent;
65 | * 如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点 ext4_extent_idx。这两种类型的项的大小都是 12 个 byte。
66 |
67 | 如果文件不大,inode 里面的 i_block 中,可以放得下一个 ext4_extent_header 和 4 项 ext4_extent。所以这个时候,eh_depth 为 0,也即 inode 里面的就是叶子节点,树高度为 0。如果文件比较大,4 个 extent 放不下,就要分裂成为一棵树,eh_depth>0 的节点就是索引节点,其中根节点深度最大,在 inode 中。最底层 eh_depth=0 的是叶子节点。除了根节点,其他的节点都保存在一个块 4k 里面,4k 扣除 ext4_extent_header 的 12 个 byte,剩下的能够放 340 项,每个 extent 最大能表示 128MB 的数据,340 个 extent 会使你表示的文件达到 42.5GB。这已经非常大了,如果再大,我们可以增加树的深度。
68 | ```c
69 | /*
70 | * Each block (leaves and indexes), even inode-stored has header.
71 | */
72 | struct ext4_extent_header {
73 | __le16 eh_magic; /* probably will support different formats */
74 | __le16 eh_entries; /* number of valid entries */
75 | __le16 eh_max; /* capacity of store in entries */
76 | __le16 eh_depth; /* has tree real underlying blocks? */
77 | __le32 eh_generation; /* generation of the tree */
78 | };
79 |
80 | /*
81 | * This is the extent on-disk structure.
82 | * It's used at the bottom of the tree.
83 | */
84 | struct ext4_extent {
85 | __le32 ee_block; /* first logical block extent covers */
86 | __le16 ee_len; /* number of blocks covered by extent */
87 | __le16 ee_start_hi; /* high 16 bits of physical block */
88 | __le32 ee_start_lo; /* low 32 bits of physical block */
89 | };
90 |
91 | /*
92 | * This is index on-disk structure.
93 | * It's used at all the levels except the bottom.
94 | */
95 | struct ext4_extent_idx {
96 | __le32 ei_block; /* index covers logical blocks from 'block' */
97 | __le32 ei_leaf_lo; /* pointer to the physical block of the next *
98 | * level. leaf or next index could be there */
99 | __le16 ei_leaf_hi; /* high 16 bits of physical block */
100 | __u16 ei_unused;
101 | };
102 | ```
103 | 由此,我们可以通过inode来表示一系列的块,从而构成了一个文件。在硬盘上,通过一系列的inode,我们可以存储大量的文件。但是我们尚需要一种方式去存储和管理inode,这就是位图。同样的,我们会用块位图去管理块的信息。如下所示为创建inode的过程中对位图的访问,我们需要找出下一个0位所在,即空闲inode的位置。
104 | ```c
105 | struct inode *__ext4_new_inode(handle_t *handle, struct inode *dir,
106 | umode_t mode, const struct qstr *qstr,
107 | __u32 goal, uid_t *owner, __u32 i_flags,
108 | int handle_type, unsigned int line_no,
109 | int nblocks)
110 | {
111 | ......
112 | inode_bitmap_bh = ext4_read_inode_bitmap(sb, group);
113 | ......
114 | ino = ext4_find_next_zero_bit((unsigned long *)
115 | inode_bitmap_bh->b_data,
116 | EXT4_INODES_PER_GROUP(sb), ino);
117 | ......
118 | }
119 | ```
120 | ### 3.2 文件系统的格式
121 |
122 | inode和块是文件系统的最小组成单元,在此之上还有多级系统,大致有如下这些:
123 |
124 | * 块组:存储一块数据的组成单元,数据结构为ext4_group_desc。这里面对于一个块组里的 inode 位图 bg_inode_bitmap_lo、块位图 bg_block_bitmap_lo、inode 列表 bg_inode_table_lo均有相应的定义。一个个块组,就基本构成了我们整个文件系统的结构。
125 | * 块组描述符表:多个块组的描述符构成的表
126 | * 超级块:对整个文件系统的情况进行描述,即ext4_super_block,存储全局信息,如整个文件系统一共有多少 inode:s_inodes_count;一共有多少块:s_blocks_count_lo,每个块组有多少 inode:s_inodes_per_group,每个块组有多少块:s_blocks_per_group 等。
127 | * 引导块:对于整个文件系统,我们需要预留一块区域作为引导区用于操作系统的启动,所以第一个块组的前面要留 1K,用于启动引导区。
128 |
129 | 
130 |
131 | 超级块和块组描述符表都是全局信息,而且这些数据很重要。如果这些数据丢失了,整个文件系统都打不开了,这比一个文件的一个块损坏更严重。所以,这两部分我们都需要备份,但是采取不同的策略。
132 |
133 | * 默认策略:在每个块中均保存一份超级块和块组描述表的备份
134 | * sparse_super策略:采取稀疏存储的方式,仅在块组索引为 0、3、5、7 的整数幂里存储。
135 | * Meta Block Groups策略:我们将块组分为多个元块组(Meta Block Groups),每个元块组里面的块组描述符表仅仅包括自己的内容,一个元块组包含 64 个块组,这样一个元块组中的块组描述符表最多 64 项。这种做法类似于merkle tree,可以在很大程度上优化空间。
136 |
137 | 
138 |
139 | ### 3.3 目录的存储格式
140 |
141 | 为了便于文件的查找,我们必须要有索引,即文件目录。其实目录本身也是个文件,也有 inode。inode 里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。这些信息我们称为 ext4_dir_entry。这里有两个版本,第二个版本 ext4_dir_entry_2 是将一个 16 位的 name_len,变成了一个 8 位的 name_len 和 8 位的 file_type。
142 |
143 | ```c
144 | struct ext4_dir_entry {
145 | __le32 inode; /* Inode number */
146 | __le16 rec_len; /* Directory entry length */
147 | __le16 name_len; /* Name length */
148 | char name[EXT4_NAME_LEN]; /* File name */
149 | };
150 | struct ext4_dir_entry_2 {
151 | __le32 inode; /* Inode number */
152 | __le16 rec_len; /* Directory entry length */
153 | __u8 name_len; /* Name length */
154 | __u8 file_type;
155 | char name[EXT4_NAME_LEN]; /* File name */
156 | };
157 | ```
158 | 在目录文件的块中,最简单的保存格式是列表,就是一项一项地将 ext4_dir_entry_2 列在哪里。每一项都会保存这个目录的下一级的文件的文件名和对应的 inode,通过这个 inode,就能找到真正的文件。第一项是“.”,表示当前目录,第二项是“…”,表示上一级目录,接下来就是一项一项的文件名和 inode。有时候,如果一个目录下面的文件太多的时候,我们想在这个目录下找一个文件,按照列表一个个去找太慢了,于是我们就添加了索引的模式。如果在 inode 中设置 EXT4_INDEX_FL 标志,则目录文件的块的组织形式将发生变化,变成了下面定义的这个样子:
159 | ```c
160 | struct dx_root
161 | {
162 | struct fake_dirent dot;
163 | char dot_name[4];
164 | struct fake_dirent dotdot;
165 | char dotdot_name[4];
166 | struct dx_root_info
167 | {
168 | __le32 reserved_zero;
169 | u8 hash_version;
170 | u8 info_length; /* 8 */
171 | u8 indirect_levels;
172 | u8 unused_flags;
173 | }
174 | info;
175 | struct dx_entry entries[0];
176 | };
177 | ```
178 | 当前目录和上级目录不变,文件列表改用dx_root_info结构体,其中最重要的成员变量是 indirect_levels,表示间接索引的层数。索引项由结构体 dx_entry表示,本质上是文件名的哈希值和数据块的一个映射关系。
179 | ```c
180 | struct dx_entry
181 | {
182 | __le32 hash;
183 | __le32 block;
184 | };
185 | ```
186 | 如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是 ext4_dir_entry_2 的列表,我们只要一项一项找文件名就行。通过索引树,我们可以将一个目录下面的 N 多的文件分散到很多的块里面,可以很快地进行查找。
187 |
188 | 
189 |
190 | ### 3.4 软链接和硬链接的存储格式
191 |
192 | 软链接和硬链接也是文件的一种,可以通过如下命令创建。ln -s 创建的是软链接,不带 -s 创建的是硬链接。
193 |
194 | ln [参数][源文件或目录][目标文件或目录]
195 |
196 | 硬链接与原始文件共用一个 inode ,但是 inode 是不跨文件系统的,每个文件系统都有自己的 inode 列表,因而硬链接是没有办法跨文件系统的。而软链接不同,软链接相当于重新创建了一个文件。这个文件也有独立的 inode,只不过打开这个文件看里面内容的时候,内容指向另外的一个文件。这就很灵活了。我们可以跨文件系统,甚至目标文件被删除了链接文件也依然存在,只不过指向的文件找不到了而已。
197 |
198 | 
199 |
200 | ## 四. 总结
201 |
202 | 本文主要从文件系统的设计角度出发,逐步分析了inode和基于inode的ext4文件系统结构和主要组成部分,下面引用极客时间中的一张图作为总结。
203 |
204 | 
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
219 |
220 |
221 |
222 |
223 |
224 |
225 |
226 |
227 |
228 |
229 |
230 |
231 |
232 |
233 |
234 |
235 |
236 |
--------------------------------------------------------------------------------
/文章/文件系统/Linux文件系统详解.md:
--------------------------------------------------------------------------------
1 | ## Linux的一切皆文件
2 | Linux 中的各种事物比如像文档、目录(Mac OS X 和 Windows 系统下称之为文件夹)、键盘、监视器、硬盘、可移动媒体设备、打印机、调制解调器、虚拟终端,还有进程间通信(IPC)和网络通信等输入/输出资源都是定义在文件系统空间下的字节流。
3 | 一切都可看作是文件,其最显著的好处是对于上面所列出的输入/输出资源,只需要相同的一套 Linux 工具、实用程序和 API。你可以使用同一套api(read, write)和工具(cat , 重定向, 管道)来处理unix中大多数的资源.
4 | 设计一个系统的终极目标往往就是要找到原子操作,一旦锁定了原子操作,设计工作就会变得简单而有序。“文件”作为一个抽象概念,其原子操作非常简单,只有读和写,这无疑是一个非常好的模型。通过这个模型,API的设计可以化繁为简,用户可以使用通用的方式去访问任何资源,自有相应的中间件做好对底层的适配。
5 | 现代操作系统为解决信息能独立于进程之外被长期存储引入了文件,文件作为进程创建信息的逻辑单元可被多个进程并发使用。在 UNIX 系统中,操作系统为磁盘上的文本与图像、鼠标与键盘等输入设备及网络交互等 I/O 操作设计了一组通用 API,使他们被处理时均可统一使用字节流方式。换言之,UNIX 系统中除进程之外的一切皆是文件,而 Linux 保持了这一特性。为了便于文件的管理,Linux 还引入了目录(有时亦被称为文件夹)这一概念。目录使文件可被分类管理,且目录的引入使 Linux 的文件系统形成一个层级结构的目录树
6 |
7 | > 在Linux系统中,一切都是文件,理解文件系统,对于学习Linux来说,是一个非常有必要的前提
8 |
9 | Linux上的文件系统一般来说就是EXT2或EXT3,但这篇文章并不准备一上来就直接讲它们,而希望结合Linux操作系统并从文件系统建立的基础——硬盘开始,一步步认识Linux的文件系统。
10 |
11 | ## 1. 机械硬盘的物理存储机制
12 |
13 | > * 现代计算机大部分文件存储功能都是由机械硬盘这种设备提供的。(现在的SSD和闪存从概念和逻辑上都部分继承自机械硬盘,所以使用机械硬盘来进行理解也是没有问题的)
14 | > * 机械硬盘能实现信息存储的功能基于:磁性存储介质能够被磁化,且磁化后会长久保留被磁化的状态,这种被磁化状态能够被读取出来,同时这种磁化状态还能够不断被修改,磁化正好有两个方向,所以可以表示0和1。于是硬盘就是把这种磁性存储介质做成一个个盘片,每一个盘片上都分布着数量巨大的磁性存储单位,使用磁性读写头对盘片进行写入和读取(从原理上类似黑胶唱片的播放)。
15 | > * 一个硬盘中的磁性存储单位数以亿计(1T硬盘就有约80亿个),所以需要一套规则来规划信息如何存取(比如一本存储信息的书我们还会分为页,每一页从上到下从左到右读取,同时还有章节目录)于是就有了这些物理、逻辑概念:
16 | > 1、一个硬盘有多张盘片叠成,不同盘片有编号
17 | 2、每张盘片上的存储颗粒成环形一圈圈地排布,每一圈称为磁道,有编号
18 | 3、每条磁道上都有一圈存储颗粒,每512*8(512字节,0.5KB)个存储颗粒作为一个扇区,扇区是硬盘上存储的最小物理单位
19 | 4、N个扇区可以组成簇,N取决于不同的文件系统或是文件系统的配置,簇是此文件系统中的最小存储单位
20 | 5、所有盘面上的同一磁道构成一个圆柱,称为柱面,柱面是系统分区的最小单位
21 | > 磁头读写文件的时候,首先是分区读写的,由inode编号(区内唯一的编号后面介绍)找到对应的磁道和扇区,然后一个柱面一个柱面地进行读写。机械硬盘的读写控制系统是一个令人叹为观止的精密工程(一个盘面上有几亿个存储单位,每个磁道宽度不到几十纳米,磁盘每分钟上万转),同时关于读写的逻辑也是有诸多细节(比如扇区的编号并不是连续的),非常有意思,可以自行搜索文章拓展阅读。
22 | > 有了硬盘并不意味着LInux可以立刻把它用来存储,还需要组合进Linux的文件体系才能被Linux使用。
23 |
24 | 
25 |
26 |
27 | ## 2.Linux文件体系
28 | Linux以文件的形式对计算机中的数据和硬件资源进行管理,也就是彻底的一切皆文件,反映在Linux的文件类型上就是:普通文件、目录文件(也就是文件夹)、设备文件、链接文件、管道文件、套接字文件(数据通信的接口)等等。而这些种类繁多的文件被Linux使用目录树进行管理, 所谓的目录树就是以根目录(/)为主,向下呈现分支状的一种文件结构。不同于纯粹的ext2之类的文件系统,我把它称为文件体系,一切皆文件和文件目录树的资源管理方式一起构成了Linux的文件体系,让Linux操作系统可以方便使用系统资源。所以文件系统比文件体系涵盖的内容少很多,Linux文件体系主要在于把操作系统相关的东西用文件这个载体实现:文件系统挂载在操作系统上,操作系统整个系统又放在文件系统里。但本文中文件体系的相关内容不是很多,大部分地方都可以用文件系统代替文件体系。
29 | ### 1. Linux中的文件类型:
30 | #### 1.1. 普通文件(-)
31 | 从Linux的角度来说,类似mp4、pdf、html这样应用层面上的文件类型都属于普通文件Linux用户可以根据访问权限对普通文件进行查看、更改和删除
32 | #### 1.2. 目录文件(d,directory file)
33 | 目录文件对于用惯Windows的用户来说不太容易理解,目录也是文件的一种目录文件包含了各自目录下的文件名和指向这些文件的指针,打开目录事实上就是打开目录文件,只要有访问权限,你就可以随意访问这些目录下的文件(普通文件的执行权限就是目录文件的访问权限),但是只有内核的进程能够修改它们虽然不能修改,但是我们能够通过vim去查看目录文件的内容
34 | #### 1.3. 符号链接(l,symbolic link)
35 | 这种类型的文件类似Windows中的快捷方式,是指向另一个文件的间接指针,也就是我们常说的软链接
36 | #### 1.4. 块设备文件(b,block)和字符设备文件(c,char)
37 | 这些文件一般隐藏在/dev目录下,在进行设备读取和外设交互时会被使用到比如磁盘光驱就是块设备文件,串口设备则属于字符设备文件系统中的所有设备要么是块设备文件,要么是字符设备文件,无一例外
38 | #### 1.5. FIFO(p,pipe)
39 | 管道文件主要用于进程间通讯。比如使用mkfifo命令可以创建一个FIFO文件,启用一个进程A从FIFO文件里读数据,启动进程B往FIFO里写数据,先进先出,随写随读。
40 | #### 1.6. 套接字(s,socket)
41 | 用于进程间的网络通信,也可以用于本机之间的非网络通信这些文件一般隐藏在/var/run目录下,证明着相关进程的存在
42 | Linux 的文件是没有所谓的扩展名的,一个 Linux文件能不能被执行与它是否可执行的属性有关,只要你的权限中有 x ,比如[ -rwx-r-xr-x ] 就代表这个文件可以被执行,与文件名没有关系。跟在 Windows下能被执行的文件扩展名通常是 .com .exe .bat 等不同。不过,可以被执行跟可以执行成功不一样。比如在 root 主目彔下的 install.log 是一个文本文件,修改权限成为 -rwxrwxrwx 后这个文件能够真的执行成功吗? 当然不行,因为它的内容根本就没有可以执行的数据。所以说,这个 x 代表这个文件具有可执行的能力, 但是能不能执行成功,当然就得要看该文件的内容了。
43 | 虽然如此,不过我们仍然希望能从扩展名来了解该文件是什么东西,所以一般我们还是会以适当的扩展名来表示该文件是什么种类的。所以Linux 系统上的文件名真的只是让你了解该文件可能的用途而已, 真正的执行与否仍然需要权限的规范才行。比如常见的/bin/ls 这个显示文件属性的指令要是权限被修改为无法执行,那么ls 就变成不能执行了。这种问题最常发生在文件传送的过程中。例如你在网络上下载一个可执行文件,但是偏偏在你的 Linux 系统中就是无法执行,那就可能是档案的属性被改变了。而且从网络上传送到你 的 Linux 系统中,文件的属性权限确实是会被改变的
44 |
45 | ### 2. Linux目录树
46 | 对Linux系统和用户来说,所有可操作的计算机资源都存在于目录树这个逻辑结构中,对计算机资源的访问都可以认为是目录树的访问。就硬盘来说,所有对硬盘的访问都变成了对目录树中某个节点也就是文件夹的访问,访问时不需要知道它是硬盘还是硬盘中的文件夹。目录树的逻辑结构也非常简单,就是从根目录(/)开始,不断向下展开各级子目录。
47 |
48 | ## 3.硬盘分区
49 | 硬盘分区是硬盘结合到文件体系的第一步,本质是「硬盘」这个物理概念转换成「区」这个逻辑概念,为下一步格式化做准备。所以分本身并不是必须的,你完全可以把一整块硬盘作为一个区。但从数据的安全性以及系统性能角度来看,分区还是有很多用处的,所以一般都会对硬盘进行分区。
50 |
51 | 讲分区就不得不先提每块硬盘上最重要的第一扇区,这个扇区中有硬盘主引导记录(Master boot record, MBR) 及分区表(partition table), 其中 MBR 占有 446 bytes,而分区表占有 64 bytes。硬盘主引导记录放有最基本的引导加载程序,是系统开机启动的关键环节,在附录中有更详细的说明。而分区表则跟分区有关,它记录了硬盘分区的相关信息,但因分区表仅有 64bytes , 所以最多只能记彔四块分区(分区本身其实就是对分区表进行设置)。
52 |
53 | 只能分四个区实在太少了,于是就有了扩展分区的概念,既然第一个扇区所在的分区表只能记录四条数据, 那我可否利用额外的扇区来记录更多的分区信息。
54 | 把普通可以访问的分区称为主分区,扩展分区不同于主分区,它本身并没有内容,它是为进一步逻辑分区提供空间的。在某块分区指定为扩展分区后,就可以对这块扩展分区进一步分成多个逻辑分区。操作系统规定:
55 |
56 | 1、四块分区每块都可以是主分区或扩展分区
57 | 2、扩展分区最多只能有一个(也没必要有多个)
58 | 3、扩展分区可以进一步分割为多个逻辑分区
59 | 4、扩展分区只是逻辑概念,本身不能被访问,也就是不能被格式化后作为数据访问的分区,能够作为数据访问的分区只有主分区和逻辑分区
60 | 5、逻辑分区的数量依操作系统而不同,在 Linux 系统中,IDE 硬盘最多有 59 个逻辑分区(5 号到 63 号), SATA 硬盘则有 11 个逻辑分区(5 号到 15 号)
61 |
62 | 一般给硬盘进行分区时,一个主分区一个扩展分区,然后把扩展分区划分为N个逻辑分区是最好的
63 |
64 | 是否可以不要主分区呢?不知道,但好像不用管,你创建分区的时候会自动给你配置类型特殊的,你最好单独分一个swap区(内存置换空间),它独为一类,功能是:当有数据被存放在物理内存里面,但是这些数据又不是常被 CPU 所取用时,那么这些不常被使用的程序将会被丢到硬盘的 swap 置换空间当中, 而将速度较快的物理内存空间释放出来给真正需要的程序使用
65 |
66 | ## 4.格式化
67 | 我们知道Linux操作系统支持很多不同的文件系统,比如ext2、ext3、XFS、FAT等等,而Linux把对不同文件系统的访问交给了VFS(虚拟文件系统),VFS能访问和管理各种不同的文件系统。所以有了区之后就需要把它格式化成具体的文件系统以便VFS访问。
68 |
69 | 标准的Linux文件系统Ext2是使用「基于inode的文件系统」
70 |
71 | 1、我们知道一般操作系统的文件数据除了文件实际内容外, 还带有很多属性,例如 Linux 操作系统的文件权限(rwx)与文件属性(拥有者、群组、 时间参数等),文件系统通常会将属性和实际内容这两部分数据分别存放在不同的区块
72 | 2、在基于inode的文件系统中,权限与属性放置到 inode 中,实际数据放到 data block 区块中,而且inode和data block都有编号
73 |
74 | Ext2 文件系统在此基础上
75 |
76 | 1、文件系统最前面有一个启动扇区(boot sector)
77 | * 这个启动扇区可以安装开机管理程序, 这个设计让我们能将不同的引导装载程序安装到个别的文件系统前端,而不用覆盖整个硬盘唯一的MBR, 也就是这样才能实现多重引导的功能
78 |
79 | 2、把每个区进一步分为多个块组 (block group),每个块组有独立的inode/block体系
80 | * 如果文件系统高达数百 GB 时,把所有的 inode 和block 通通放在一起会因为 inode 和 block的数量太庞大,不容易管理
81 | * 这其实很好理解,因为分区是用户的分区,实际计算机管理时还有个最适合的大小,于是计算机会进一步的在分区中分块
82 | * (但这样岂不是可能出现大文件放不了的问题?有什么机制善后吗?)
83 |
84 | 3、每个块组实际还会分为分为6个部分,除了inode table 和 data block外还有4个附属模块,起到优化和完善系统性能的作用
85 |
86 | 所以整个分区大概会这样划分:
87 |
88 | 
89 |
90 | ### inode table
91 |
92 | 1.主要记录文件的属性以及该文件实际数据是放置在哪些block中,它记录的信息至少有这些:
93 | * 大小、真正内容的block号码(一个或多个)
94 | * 访问模式(read/write/excute)
95 | * 拥有者与群组(owner/group)
96 | * 各种时间:建立或状态改变的时间、最近一次的读取时间、最近修改的时间
97 | * 没有文件名!文件名在目录的block中!
98 |
99 | 2、一个文件占用一个 inode,每个inode有编号
100 | 3、Linux 系统存在 inode 号被用完但磁盘空间还有剩余的情况
101 | 4、注意,这里的文件不单单是普通文件,目录文件也就是文件夹其实也是一个文件,还有其他的也是
102 | 5、inode 的数量与大小在格式化时就已经固定了,每个inode 大小均固定为128 bytes (新的ext4 与xfs 可设定到256 bytes)
103 | 6、文件系统能够建立的文件数量与inode 的数量有关,存在空间还够但inode不够的情况
104 | 7、系统读取文件时需要先找到inode,并分析inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容
105 | 8、inode 要记录的资料非常多,但偏偏又只有128bytes , 而inode 记录一个block 号码要花掉4byte ,假设我一个文件有400MB 且每个block 为4K 时, 那么至少也要十万条block 号码的记录!inode 哪有这么多空间来存储?为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区(详细见附录)
106 |
107 | ### data block
108 |
109 | 1、放置文件内容数据的地方
110 | 2、在格式化时block的大小就固定了,且每个block都有编号,以方便inode的记录
111 |
112 | * 原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化)
113 |
114 | 3、在Ext2文件系统中所支持的block大小有1K, 2K及4K三种,由于block大小的区别,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量各不相同:
115 | * Block 大小 1KB 2KB 4KB
116 | * 最大单一档案限制 16GB 256GB 2TB
117 | * 最大档案系统总容量 2TB 8TB 16TB
118 |
119 | 4、每个block 内最多只能够放置一个文件的资料,但一个文件可以放在多个block中(大的话)
120 | 5、若文件小于block ,则该block 的剩余容量就不能够再被使用了(磁盘空间会浪费)
121 |
122 | * 所以如果你的档案都非常小,但是你的block 在格式化时却选用最大的4K 时,可能会产生容量的浪费
123 | * 既然大的block 可能会产生较严重的磁碟容量浪费,那么我们是否就将block 大小定为1K ?这也不妥,因为如果block 较小的话,那么大型档案将会占用数量更多的block ,而inode 也要记录更多的block 号码,此时将可能导致档案系统不良的读写效能
124 | * 事实上现在的磁盘容量都太大了,所以一般都会选择4K 的block 大小
125 |
126 | ### superblock
127 | 1、记录整个文件系统相关信息的地方,一般大小为1024bytes,记录的信息主要有:
128 |
129 | * block 与inode 的总量
130 | * 未使用与已使用的inode / block 数量
131 | * 一个valid bit 数值,若此文件系统已被挂载,则valid bit 为0 ,若未被挂载,则valid bit 为1
132 | * block 与inode 的大小 (block 为1, 2, 4K,inode 为128bytes 或256bytes);
133 | * 其他各种文件系统相关信息:filesystem 的挂载时间、最近一次写入资料的时间、最近一次检验磁碟(fsck) 的时间
134 |
135 | 2、Superblock是非常重要的, 没有Superblock ,就没有这个文件系统了,因此如果superblock死掉了,你的文件系统可能就需要花费很多时间去挽救
136 | 3、每个块都可能含有superblock,但是我们也说一个文件系统应该仅有一个superblock 而已,那是怎么回事?事实上除了第一个块内会含有superblock 之外,后续的块不一定含有superblock,而若含有superblock则该superblock主要是做为第一个块内superblock的备份,这样可以进行superblock的救援
137 |
138 | ### Filesystem Description
139 | 1、文件系统描述
140 | 2、这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, data block)分别介于哪一个block号码之间
141 |
142 | ### block bitmap
143 | 1、块对照表
144 | 2、如果你想要新增文件时要使用哪个block 来记录呢?当然是选择「空的block」来记录。那你怎么知道哪个block 是空的?这就得要通过block bitmap了,它会记录哪些block是空的,因此我们的系统就能够很快速的找到可使用的空间来记录
145 | 3、同样在你删除某些文件时,那些文件原本占用的block号码就得要释放出来, 此时在block bitmap 中对应该block号码的标志位就得要修改成为「未使用中」
146 |
147 | ### inode bitmap
148 | 1、与block bitmap 是类似的功能,只是block bitmap 记录的是使用与未使用的block 号码, 至于inode bitmap 则是记录使用与未使用的inode 号码
149 |
150 | ## 5.挂载
151 | 在一个区被格式化为一个文件系统之后,它就可以被Linux操作系统使用了,只是这个时候Linux操作系统还找不到它,所以我们还需要把这个文件系统「注册」进Linux操作系统的文件体系里,这个操作就叫「挂载」 (mount)。挂载是利用一个目录当成进入点(类似选一个现成的目录作为代理),将文件系统放置在该目录下,也就是说,进入该目录就可以读取该文件系统的内容,类似整个文件系统只是目录树的一个文件夹(目录)。这个进入点的目录我们称为「挂载点」。
152 |
153 | 由于整个 Linux 系统最重要的是根目录,因此根目录一定需要挂载到某个分区。 而其他的目录则可依用户自己的需求来给予挂载到不同的分去。
154 |
155 | 到这里Linux的文件体系的构建过程其实已经大体讲完了,总结一下就是:硬盘经过分区和格式化,每个区都成为了一个文件系统,挂载这个文件系统后就可以让Linux操作系统通过VFS访问硬盘时跟访问一个普通文件夹一样。这里通过一个在目录树中读取文件的实际例子来细讲一下目录文件和普通文件。
156 |
157 | ## 6.目录树的读取过程
158 |
159 | 首先我们要知道
160 |
161 | 1、每个文件(不管是一般文件还是目录文件)都会占用一个inode
162 | 2、依据文件内容的大小来分配一个或多个block给该文件使用
163 | 3、创建一个文件后,文件完整信息分布在3处地方,生成2个新文件:
164 |
165 | * 文件名记录在该文件所在目录的目录文件的block中,没有新文件生成
166 | * 文件属性、权限信息、记录具体内容的block编号记录在inode中,inode是新生成文件
167 | * 文件具体内存记录在block中,block是新生成文件
168 |
169 | 4、因为文件名的记录是在目录的block当中,「新增/删除/更名文件名」与目录的w权限有关所以在Linux/Unix中,文件名称只是文件的一个属性,叫别名也好,叫绰号也罢,仅为了方便用户记忆和使用,但系统内部并不需要用文件名来定为文件位置,这样处理最直观的好处就是,你可以对正在使用的文件改名,换目录,甚至放到废纸篓,都不会影响当前文件的使用,这在Windows里是无法想象的。比如你打开个Word文件,然后对其进行重命名操作,Windows会告诉你门儿都没有,关闭文件先!但在Mac里就毫无压力,因为Mac的操作系统同样采用了inode的设计。
170 |
171 | ### 创建文件过程
172 | 当在ext2下建立一个一般文件时, ext2 会分配一个inode 与相对于该文件大小的block 数量给该文件
173 |
174 | * 例如:假设我的一个block 为4 Kbytes ,而我要建立一个100 KBytes 的文件,那么linux 将分配一个inode 与25 个block 来储存该文件
175 | * 但同时请注意,由于inode 仅有12 个直接指向,因此还要多一个block 来作为区块号码的记录
176 |
177 | ### 创建目录过程
178 | 当在ext2文件系统建立一个目录时(就是新建了一个目录文件),文件系统会分配一个inode与至少一块block给该目录
179 |
180 | * inode记录该目录的相关权限与属性,并记录分配到的那块block号码
181 | * 而block则是记录在这个目录下的文件名与该文件对应的inode号
182 | * block中还会自动生成两条记录,一条是.文件夹记录,inode指向自身,另一条是..文件夹记录,inode指向父文件夹
183 |
184 | ### 从目录树中读取某个文件过程
185 |
186 | * 因为文件名是记录在目录的block当中,因此当我们要读取某个文件时,就一定会经过目录的inode与block ,然后才能够找到那个待读取文件的inode号码,最终才会读到正确的文件的block内的资料。
187 | * 由于目录树是由根目录开始,因此操作系统先通过挂载信息找到挂载点的inode号,由此得到根目录的inode内容,并依据该inode读取根目录的block信息,再一层一层的往下读到正确的文件。举例来说,如果我想要读取/etc/passwd 这个文件时,系统是如何读取的呢?先看一下这个文件以及有关路径文件夹的信息:
188 |
189 | ```
190 | 1$ ll -di / /etc /etc/passwd
191 | 2 128 dr-xr-x r-x . 17 root root 4096 May 4 17:56 /
192 | 333595521 drwxr-x r-x . 131 root root 8192 Jun 17 00:20 /et
193 | c436628004 -rw-r-- r-- . 1 root root 2092 Jun 17 00:20 /etc/passwd
194 | ```
195 |
196 | 于是该文件的读取流程为:
197 |
198 | 1、/的inode:
199 | 通过挂载点的信息找到inode号码为128的根目录inode,且inode规定的权限让我们可以读取该block的内容(有r与x)
200 | 2、/的block:
201 | 经过上个步骤取得block的号码,并找到该内容有etc/目录的inode号码(33595521)
202 | 3、etc/的inode:
203 | 读取33595521号inode得知具有r与x的权限,因此可以读取etc/的block内容
204 | 4、etc/的block:
205 | 经过上个步骤取得block号码,并找到该内容有passwd文件的inode号码(36628004)
206 | 5、passwd的inode:
207 | 读取36628004号inode得知具有r的权限,因此可以读取passwd的block内容
208 | 6、passwd的block:
209 | 最后将该block内容的资料读出来
210 |
--------------------------------------------------------------------------------
/文章/浅谈Linux内核之CPU缓存.md:
--------------------------------------------------------------------------------
1 | ## 一、什么是CPU缓存
2 |
3 | ### 1. CPU缓存的来历
4 |
5 | 众所周知,CPU是计算机的大脑,它负责执行程序的指令,而内存负责存数据, 包括程序自身的数据。在很多年前,CPU的频率与内存总线的频率在同一层面上。内存的访问速度仅比寄存器慢一些。但是,这一局面在上世纪90年代被打破了。CPU的频率大大提升,但内存总线的频率与内存芯片的性能却没有得到成比例的提升。并不是因为造不出更快的内存,只是因为太贵了。内存如果要达到目前CPU那样的速度,那么它的造价恐怕要贵上好几个数量级。所以,CPU的运算速度要比内存读写速度快很多,这样会使CPU花费很长的时间等待数据的到来或把数据写入到内存中。所以,为了解决CPU运算速度与内存读写速度不匹配的矛盾,就出现了CPU缓存。
6 |
7 | ### 2. CPU缓存的概念
8 |
9 | CPU缓存是位于CPU与内存之间的临时数据交换器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU缓存一般直接跟CPU芯片集成或位于主板总线互连的独立芯片上。
10 |
11 | 为了简化与内存之间的通信,高速缓存控制器是针对数据块,而不是字节进行操作的。高速缓存其实就是一组称之为缓存行(Cache Line)的固定大小的数据块组成的,典型的一行是64字节。
12 |
13 | ### 3. CPU缓存的意义
14 |
15 | CPU往往需要重复处理相同的数据、重复执行相同的指令,如果这部分数据、指令CPU能在CPU缓存中找到,CPU就不需要从内存或硬盘中再读取数据、指令,从而减少了整机的响应时间。所以,缓存的意义满足以下两种局部性原理:
16 |
17 | * 时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
18 | * 空间局部性(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
19 |
20 | ## 二、CPU的三级缓存
21 |
22 | ### 1. CPU的三级缓存
23 |
24 | 随着多核CPU的发展,CPU缓存通常分成了三个级别:L1,L2,L3。级别越小越接近CPU,所以速度也更快,同时也代表着容量越小。L1 是最接近CPU的, 它容量最小(例如:32K),速度最快,每个核上都有一个 L1 缓存,L1 缓存每个核上其实有两个 L1 缓存, 一个用于存数据的 L1d Cache(Data Cache),一个用于存指令的 L1i Cache(Instruction Cache)。L2 缓存 更大一些(例如:256K),速度要慢一些, 一般情况下每个核上都有一个独立的L2 缓存; L3 缓存是三级缓存中最大的一级(例如3MB),同时也是最慢的一级, 在同一个CPU插槽之间的核共享一个 L3 缓存。
25 | 下面是三级缓存的处理速度参考表:
26 |
27 | 
28 |
29 | 下图是Intel Core i5-4285U的CPU三级缓存示意图:
30 |
31 | 
32 |
33 | 就像数据库缓存一样,获取数据时首先会在最快的缓存中找数据,如果缓存没有命中(Cache miss) 则往下一级找, 直到三级缓存都找不到时,那只有向内存要数据了。一次次地未命中,代表取数据消耗的时间越长。
34 |
35 | ### 2. 带有高速缓存CPU执行计算的流程
36 |
37 | 1、程序以及数据被加载到主内存
38 | 2、指令和数据被加载到CPU的高速缓存
39 | 3、CPU执行指令,把结果写到高速缓存
40 | 4、高速缓存中的数据写回主内存
41 |
42 | 目前流行的多级缓存结构如下图:
43 |
44 | 
45 |
46 | ## 三、CPU缓存一致性协议(MESI)
47 |
48 | MESI(Modified Exclusive Shared Or Invalid)(也称为伊利诺斯协议,是因为该协议由伊利诺斯州立大学提出的)是一种广泛使用的支持写回策略的缓存一致性协议。为了保证多个CPU缓存中共享数据的一致性,定义了缓存行(Cache Line)的四种状态,而CPU对缓存行的四种操作可能会产生不一致的状态,因此缓存控制器监听到本地操作和远程操作的时候,需要对地址一致的缓存行的状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。
49 |
50 | ### 1. MESI协议中的状态
51 | CPU中每个缓存行(Cache line)使用4种状态进行标记,使用2bit来表示:
52 |
53 | 
54 |
55 | > 注意:对于M和E状态而言总是精确的,他们在和该缓存行的真正状态是一致的,而S状态可能是非一致的。如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
56 |
57 | 从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务。
58 |
59 | MESI状态转换图:
60 |
61 | 
62 |
63 | 下图表示了当一个缓存行(Cache line)的调整的状态的时候,另外一个缓存行(Cache line)需要调整的状态。
64 |
65 | 
66 |
67 | 举个示例:
68 | > 假设cache 1 中有一个变量x = 0的 Cache line 处于S状态(共享)。
69 | > 那么其他拥有x变量的 cache 2、cache 3 等x的 Cache line调整为S状态(共享)或者调整为I状态(无效)。
70 |
71 | ### 2. 多核缓存协同操作
72 |
73 | #### (1) 内存变量
74 | 假设有三个CPU A、B、C,对应三个缓存分别是cache a、b、c。在主内存中定义了x的引用值为0。
75 |
76 | 
77 |
78 | #### (2) 单核读取
79 |
80 | 执行流程是:
81 |
82 | * CPU A发出了一条指令,从主内存中读取x。
83 | * 从主内存通过 bus 读取到 CPU A 的缓存中(远端读取 Remote read),这时该 Cache line 修改为 E 状态(独享)。
84 |
85 | 
86 |
87 | #### (3) 双核读取
88 |
89 | 执行流程是:
90 |
91 | * CPU A发出了一条指令,从主内存中读取x。
92 | * CPU A从主内存通过bus读取到 cache a 中并将该 Cache line 设置为E状态。
93 | * CPU B发出了一条指令,从主内存中读取x。
94 | * CPU B试图从主内存中读取x时,CPU A检测到了地址冲突。这时CPU A对相关数据做出响应。此时x存储于 cache a 和 cache b 中,x在 chche a 和 cache b 中都被设置为S状态(共享)。
95 |
96 | 
97 |
98 | #### (4) 修改数据
99 |
100 | 执行流程是:
101 |
102 | * CPU A 计算完成后发指令需要修改x.
103 | * CPU A 将x设置为M状态(修改)并通知缓存了x的 CPU B, CPU B 将本地 cache b 中的x设置为I状态(无效)
104 | * CPU A 对x进行赋值。
105 |
106 | 
107 |
108 | #### (5) 同步数据
109 |
110 | 那么执行流程是:
111 |
112 | * CPU B 发出了要读取x的指令。
113 | * CPU B 通知CPU A,CPU A将修改后的数据同步到主内存时cache a 修改为E(独享)
114 | * CPU A同步CPU B的x,将cache a和同步后cache b中的x设置为S状态(共享)。
115 |
116 | ### 3. CPU 存储模型简介
117 |
118 | MESI协议为了保证多个 CPU cache 中共享数据的一致性,定义了 Cache line 的四种状态,而 CPU 对 cache 的4种操作可能会产生不一致状态,因此 cache 控制器监听到本地操作和远程操作的时候,需要对地址一致的 Cache line 状态做出一定的修改,从而保证数据在多个cache之间流转的一致性。
119 |
120 | 但是,缓存的一致性消息传递是要时间的,这就使得状态切换会有更多的延迟。某些状态的切换需要特殊的处理,可能会阻塞处理器。这些都将会导致各种各样的稳定性和性能问题。比如你需要修改本地缓存中的一条信息,那么你必须将I(无效)状态通知到其他拥有该缓存数据的CPU缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。因为这个等待远远比一个指令的执行时间长的多。所以,为了为了避免这种阻塞导致时间的浪费,引入了存储缓存(Store Buffer)和无效队列(Invalidate Queue)。
121 |
122 | #### (1) 存储缓存
123 |
124 | 在没有存储缓存时,CPU 要写入一个量,有以下情况:
125 |
126 | * 量不在该 CPU 缓存中,则需要发送 Read Invalidate 信号,再等待此信号返回,之后再写入量到缓存中。
127 | * 量在该 CPU 缓存中,如果该量的状态是 Exclusive 则直接更改。而如果是 Shared 则需要发送 Invalidate 消息让其它 CPU 感知到这一更改后再更改。
128 |
129 | 这些情况中,很有可能会触发该 CPU 与其它 CPU 进行通讯,接着需要等待它们回复。这会浪费大量的时钟周期!为了提高效率,可以使用异步的方式去处理:先将值写入到一个 Buffer 中,再发送通讯的信号,等到信号被响应,再应用到 cache 中。并且此 Buffer 能够接受该 CPU 读值。这个 Buffer 就是 Store Buffer。而不须要等待对某个量的赋值指令的完成才继续执行下一条指令,直接去 Store Buffer 中读该量的值,这种优化叫Store Forwarding。
130 |
131 | #### (2) 无效队列
132 |
133 | 同理,解决了主动发送信号端的效率问题,那么,接受端 CPU 接受到 Invalidate 信号后如果立即采取相应行动(去其它 CPU 同步值),再返回响应信号,则时钟周期也太长了,此处也可优化。接受端 CPU 接受到信号后不是立即采取行动,而是将 Invalidate 信号插入到一个队列 Queue 中,立即作出响应。等到合适的时机,再去处理这个 Queue 中的 Invalidate 信号,并作相应处理。这个 Queue 就是Invalidate Queue。
134 |
135 | ## 四、乱序执行
136 |
137 | 乱序执行(out-of-orderexecution):是指CPU允许将多条指令不按程序规定的顺序分开发送给各相应电路单元处理的技术。这样将根据各电路单元的状态和各指令能否提前执行的具体情况分析后,将能提前执行的指令立即发送给相应电路。
138 |
139 | 这好比请A、B、C三个名人为晚会题写横幅“春节联欢晚会”六个大字,每人各写两个字。如果这时在一张大纸上按顺序由A写好”春节”后再交给B写”联欢”,然后再由C写”晚会”,那么这样在A写的时候,B和C必须等待,而在B写的时候C仍然要等待而A已经没事了。
140 |
141 | 但如果采用三个人分别用三张纸同时写的做法, 那么B和C都不必须等待就可以同时各写各的了,甚至C和B还可以比A先写好也没关系(就象乱序执行),但当他们都写完后就必须重新在横幅上(自然可以由别人做,就象CPU中乱序执行后的重新排列单元)按”春节联欢晚会”的顺序排好才能挂出去。
142 |
143 | 所以,CPU 为什么会有乱序执行优化?本质原因是CPU为了效率,将长费时的操作“异步”执行,排在后面的指令不等前面的指令执行完毕就开始执行后面的指令。而且允许排在前面的长费时指令后于排在后面的指令执行完。
144 |
145 | CPU 执行乱序主要有以下几种:
146 |
147 | * **写写乱序(store store)**:a=1;b=2; -> b=2;a=1;
148 | * **写读乱序(store load)**:a=1;load(b); -> load(b);a=1;
149 | * **读读乱序(load load)**:load(a);load(b); -> load(b);load(a);
150 | * **读写乱序(load store)**:load(a);b=2; -> b=2;load(a);
151 |
152 | 总而言之,CPU的乱序执行优化指的是处理器为提高运算速度而做出违背代码原有顺序的优化。
153 |
--------------------------------------------------------------------------------
/文章/网络协议栈/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/文章/网络协议栈/Linux内核网络udp数据包发送(一).md:
--------------------------------------------------------------------------------
1 | ## 1.前言
2 |
3 | 本文首先从宏观上概述了数据包发送的流程,然后分析了协议层注册进内核以及被套接字的过程,最后介绍了通过套接字发送网络数据的过程。
4 |
5 | ## 2.数据包发送宏观视角
6 |
7 | 从宏观上看,一个数据包从用户程序到达硬件网卡的整个过程如下:
8 |
9 | 1、使用系统调用(如 sendto,sendmsg 等)写数据
10 | 2、数据分段socket顶部,进入socket协议族(protocol family)系统
11 | 3、协议族处理:数据跨越协议层,这一过程(在许多情况下)转变数据(数据)转换成数据包(packet)
12 | 4、数据传输路由层,这会涉及路由缓存和ARP缓存的更新;如果目的MAC不在ARP缓存表中,将触发一次ARP广播来查找MAC地址
13 | 5、穿过协议层,packet到达设备无关层(设备不可知层)
14 | 6、使用XPS(如果启用)或散列函数选择发送坐标
15 | 7、调用网卡驱动的发送函数
16 | 8、数据传送到网卡的 qdisc(queue纪律,排队规则)
17 | 9、qdisc会直接发送数据(如果可以),或者将其放到串行,然后触发NET_TX类型软中断(softirq)的时候再发送
18 | 10、数据从qdisc传送给驱动程序
19 | 11、驱动程序创建所需的DMA映射,刹车网卡从RAM读取数据
20 | 12、驱动向网卡发送信号,通知数据可以发送了
21 | 13、网卡从RAM中获取数据并发送
22 | 14、发送完成后,设备触发一个硬中断(IRQ),表示发送完成
23 | 15、中断硬处理函数被唤醒执行。对许多设备来说,会这触发NET_RX类型的软中断,然后NAPI投票循环开始收包
24 | 16、poll函数会调用驱动程序的相应函数,解除DMA映射,释放数据
25 |
26 | ## 3.协议层注册
27 |
28 | 协议层分析我们将关注IP和UDP层,其他协议层可参考这个过程。
29 | 当用户程序像下面这样创建UDP套接字时会发生什么?
30 |
31 | ```
32 | sock = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP)
33 | ```
34 |
35 | 简单来说,内核会去查找由UDP协议栈创建的一个单独的函数(其中包括用于发送和接收网络数据的函数),并赋予给套接字相应的分区 AF_INET 。
36 | 内核初始化的很早阶段就执行了 inet_init 函数,这个函数会注册 AF_INET 协议族,以及该协议族内部的各协议栈(TCP,UDP,ICMP和RAW),并初始化函数使协议栈准备好处理网络数据。inet_init 定义在net / ipv4 / af_inet.c。
37 | AF_INET 协议族源自一个包含 create 方法的 struct net_proto_family 类型实例。当从用户程序创建socket时,内核会调用此方法:
38 |
39 | ```c
40 | static const struct net_proto_family inet_family_ops = {
41 | .family = PF_INET,
42 | .create = inet_create,
43 | .owner = THIS_MODULE,
44 | };
45 | ```
46 |
47 | inet_create 根据传递的套接字参数,在已注册的协议中查找对应的协议:
48 |
49 | ```c
50 | /* Look for the requested type/protocol pair. */
51 | lookup_protocol:
52 | err = -ESOCKTNOSUPPORT;
53 | rcu_read_lock();
54 | list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
55 |
56 | err = 0;
57 | /* Check the non-wild match. */
58 | if (protocol == answer->protocol) {
59 | if (protocol != IPPROTO_IP)
60 | break;
61 | } else {
62 | /* Check for the two wild cases. */
63 | if (IPPROTO_IP == protocol) {
64 | protocol = answer->protocol;
65 | break;
66 | }
67 | if (IPPROTO_IP == answer->protocol)
68 | break;
69 | }
70 | err = -EPROTONOSUPPORT;
71 | }
72 | ```
73 |
74 | 然后,引入协议的某些方法(集合)赋给这个新创建的socket:
75 |
76 | ```c
77 | sock->ops = answer->ops;
78 | ```
79 |
80 | 可以在 af_inet.c 中看到所有协议的初始化参数。下面是TCP和UDP的初始化参数:
81 |
82 | ```c
83 | /* Upon startup we insert all the elements in inetsw_array[] into
84 | * the linked list inetsw.
85 | */
86 | static struct inet_protosw inetsw_array[] =
87 | {
88 | {
89 | .type = SOCK_STREAM,
90 | .protocol = IPPROTO_TCP,
91 | .prot = &tcp_prot,
92 | .ops = &inet_stream_ops,
93 | .no_check = 0,
94 | .flags = INET_PROTOSW_PERMANENT |
95 | INET_PROTOSW_ICSK,
96 | },
97 |
98 | {
99 | .type = SOCK_DGRAM,
100 | .protocol = IPPROTO_UDP,
101 | .prot = &udp_prot,
102 | .ops = &inet_dgram_ops,
103 | .no_check = UDP_CSUM_DEFAULT,
104 | .flags = INET_PROTOSW_PERMANENT,
105 | },
106 |
107 | /* .... more protocols ... */
108 | ```
109 |
110 | IPPROTO_UDP 协议类型有一个 ops 变量,包含很多信息,包括用于发送和接收数据的替代函数:
111 |
112 | ```c
113 | const struct proto_ops inet_dgram_ops = {
114 | .family = PF_INET,
115 | .owner = THIS_MODULE,
116 |
117 | /* ... */
118 |
119 | .sendmsg = inet_sendmsg,
120 | .recvmsg = inet_recvmsg,
121 |
122 | /* ... */
123 | };
124 | EXPORT_SYMBOL(inet_dgram_ops);
125 | ```
126 |
127 | prot UDP协议对应的 prot 变量为 udp_prot,定义在net / ipv4 / udp.c:
128 | ```c
129 | struct proto udp_prot = {
130 | .name = "UDP",
131 | .owner = THIS_MODULE,
132 |
133 | /* ... */
134 |
135 | .sendmsg = udp_sendmsg,
136 | .recvmsg = udp_recvmsg,
137 |
138 | /* ... */
139 | };
140 | EXPORT_SYMBOL(udp_prot);
141 | ```
142 |
143 | 现在,让我们转向发送UDP数据的用户程序,看看 udp_sendmsg 是如何在内核中被调用的。
144 |
145 | ## 4.通过套接字发送网络数据
146 |
147 | 用户程序想发送UDP网络数据,因此它使用 sendto 系统调用:
148 |
149 | ```
150 | ret = sendto(socket, buffer, buflen, 0, &dest, sizeof(dest));
151 | ```
152 |
153 | 该系统调用串联Linux系统调用(系统调用)层,最后到达net / socket.c中的这个函数:
154 |
155 | ```c
156 | /*
157 | * Send a datagram to a given address. We move the address into kernel
158 | * space and check the user space data area is readable before invoking
159 | * the protocol.
160 | */
161 |
162 | SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len,
163 | unsigned int, flags, struct sockaddr __user *, addr,
164 | int, addr_len)
165 | {
166 | /* ... code ... */
167 |
168 | err = sock_sendmsg(sock, &msg, len);
169 |
170 | /* ... code ... */
171 | }
172 | ```
173 | SYSCALL_DEFINE6 宏会展开成一堆宏,并通过一波复杂操作创建出一个带。6个参数的系统调用(因此叫 DEFINE6)。作为结果之一,会看到内核中的所有系统调用都带 sys_相连。
174 | sendto 代码会先将数据整理成一体的可能可以处理的格式,然后调用 sock_sendmsg。特别地,依次传递给 sendto 的地址放到另一个变量(msg)中:
175 |
176 | ```c
177 | iov.iov_base = buff;
178 | iov.iov_len = len;
179 | msg.msg_name = NULL;
180 | msg.msg_iov = &iov;
181 | msg.msg_iovlen = 1;
182 | msg.msg_control = NULL;
183 | msg.msg_controllen = 0;
184 | msg.msg_namelen = 0;
185 | if (addr) {
186 | err = move_addr_to_kernel(addr, addr_len, &address);
187 | if (err < 0)
188 | goto out_put;
189 | msg.msg_name = (struct sockaddr *)&address;
190 | msg.msg_namelen = addr_len;
191 | }
192 | ```
193 |
194 | 这段代码将用户程序传入到内核的(存放待发送数据的)地址,作为 msg_name 字段嵌入到 struct msghdr 类型变量中。状语从句:这用户程序直接调用 sendmsg 而不是 sendto 发送数据差不多,这之所以可行,因为的英文 sendto 状语从句: sendmsg 底层都会调用 sock_sendmsg。
195 |
196 | ### 4.1 `sock_sendmsg`, `__sock_sendmsg`, `__sock_sendmsg_nosec`
197 | `sock_sendmsg` 做一些错误检查,然后调用`__sock_sendmsg`;后者做一些自己的错误检查,然后调用`__sock_sendmsg_nosec`。
198 |
199 | `__sock_sendmsg_nosec `将数据传递到插座子系统的更深处:
200 | ```c
201 | static inline int __sock_sendmsg_nosec(struct kiocb *iocb, struct socket *sock,
202 | struct msghdr *msg, size_t size)
203 | {
204 | struct sock_iocb *si = ....
205 |
206 | /* other code ... */
207 |
208 | return sock->ops->sendmsg(iocb, sock, msg, size);
209 | }
210 | ```
211 |
212 | 通过前面介绍的socket创建过程,可以知道注册到这里的 sendmsg 方法就是 inet_sendmsg。
213 |
214 | ### 4.2 inet_sendmsg
215 | 从名字可以猜到,的英文这 AF_INET 协议族提供的通用函数此函数首先调用。 sock_rps_record_flow 来记录最后一个处理该(数据所属的)流的CPU; 接下来,调用套接字的协议类型(本例是UDP)对应的 sendmsg 方法:
216 |
217 | ```c
218 | int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
219 | size_t size)
220 | {
221 | struct sock *sk = sock->sk;
222 |
223 | sock_rps_record_flow(sk);
224 |
225 | /* We may need to bind the socket. */
226 | if (!inet_sk(sk)->inet_num && !sk->sk_prot->no_autobind && inet_autobind(sk))
227 | return -EAGAIN;
228 |
229 | return sk->sk_prot->sendmsg(iocb, sk, msg, size);
230 | }
231 | EXPORT_SYMBOL(inet_sendmsg);
232 | ```
233 |
234 | 本例是UDP协议,因此上面的 sk->sk_prot->sendmsg 指向的是之前udp_prot 看到的(通过 导出的)udp_sendmsg 函数。
235 | sendmsg()函数作为分界点,处理逻辑从AF_INET协议族通用处理转移到特定的UDP协议的处理。
236 |
--------------------------------------------------------------------------------
/文章/网络协议栈/Linux操作系统原理—内核网络协议栈.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 本文主要记录 Linux 内核网络协议栈的运行原理
3 |
4 | ### 数据报文的封装与分用
5 |
6 | 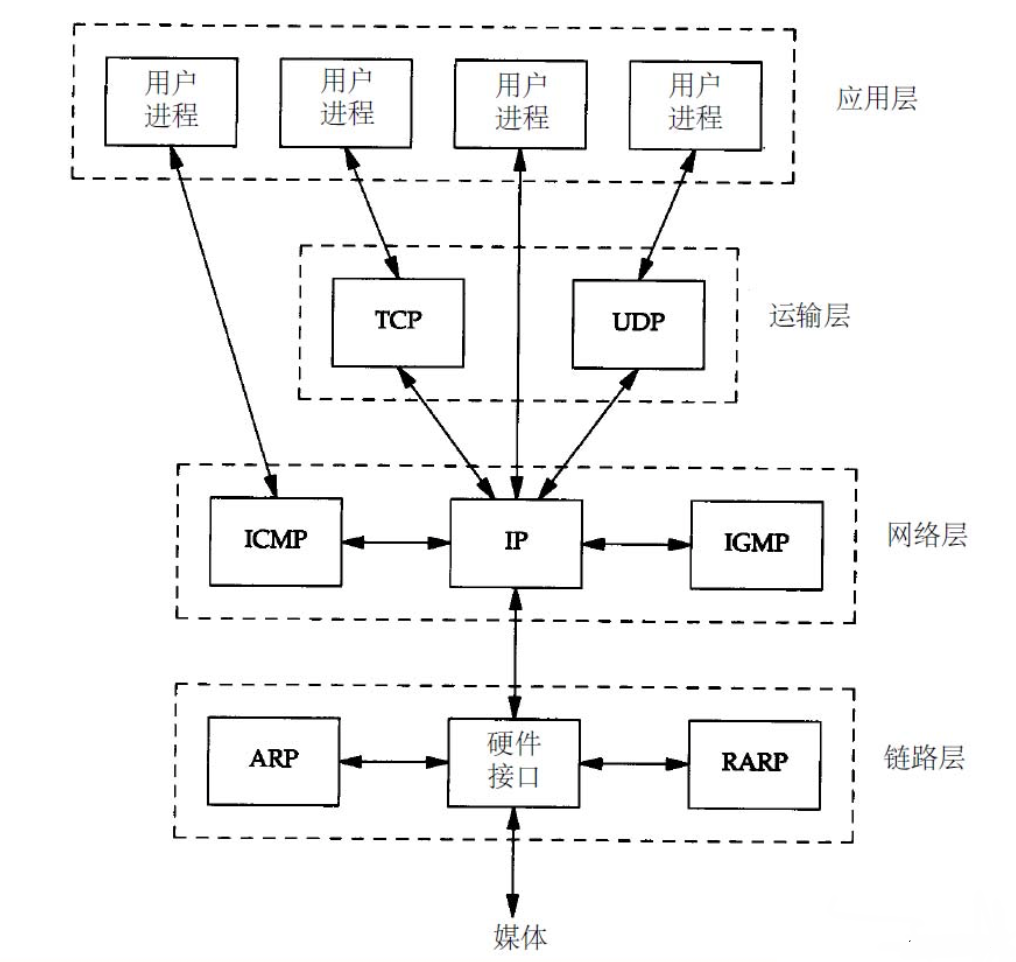
7 |
8 | 封装:当应用程序用 TCP 协议传送数据时,数据首先进入内核网络协议栈中,然后逐一通过 TCP/IP 协议族的每层直到被当作一串比特流送入网络。对于每一层而言,对收到的数据都会封装相应的协议首部信息(有时还会增加尾部信息)。TCP 协议传给 IP 协议的数据单元称作 TCP 报文段,或简称 TCP 段(TCP segment)。IP 传给数据链路层的数据单元称作 IP 数据报(IP datagram),最后通过以太网传输的比特流称作帧(Frame)
9 |
10 | 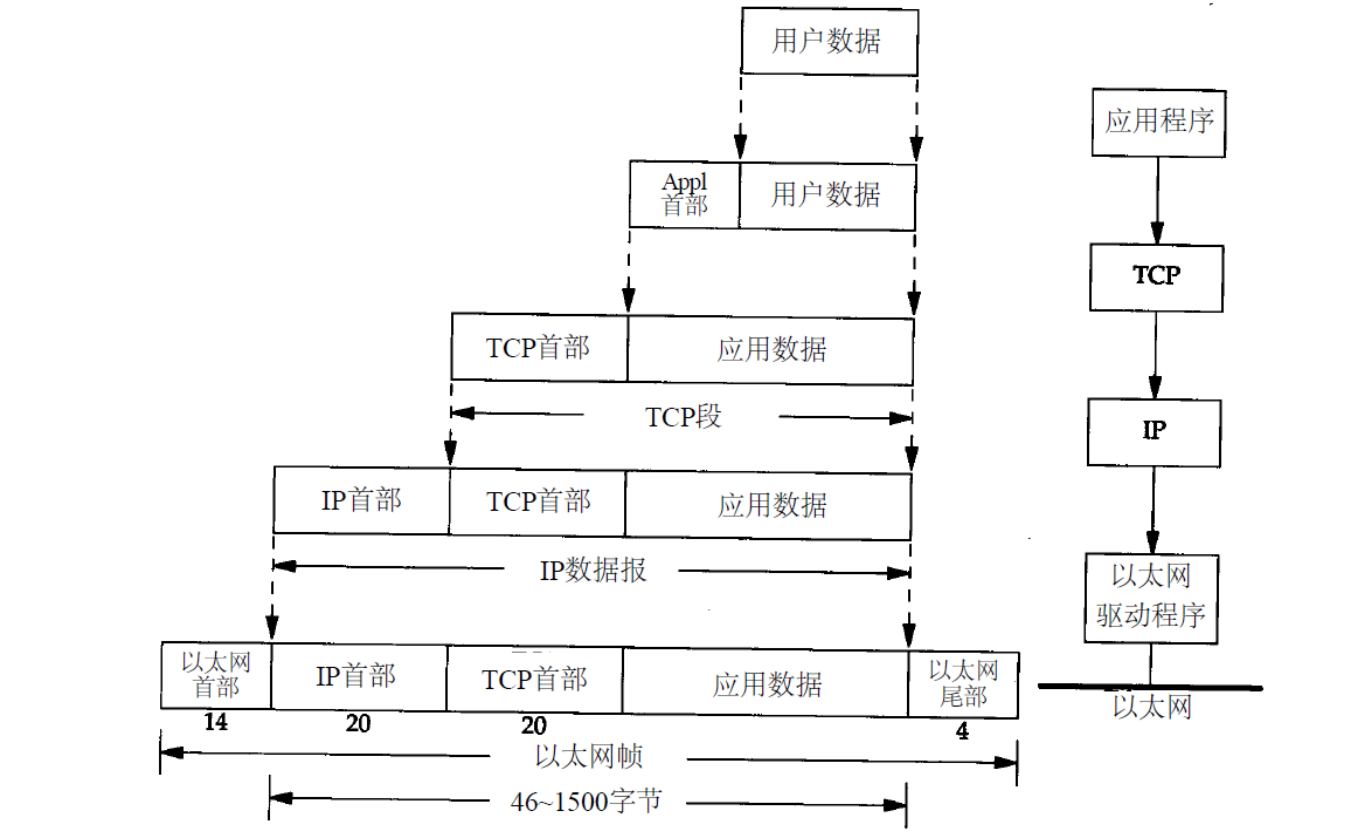
11 |
12 | 分用:当目的主机收到一个以太网数据帧时,数据就开始从内核网络协议栈中由底向上升,同时去掉各层协议加上的报文首部。每层协议都会检查报文首部中的协议标识,以确定接收数据的上层协议。这个过程称作分用。
13 |
14 | 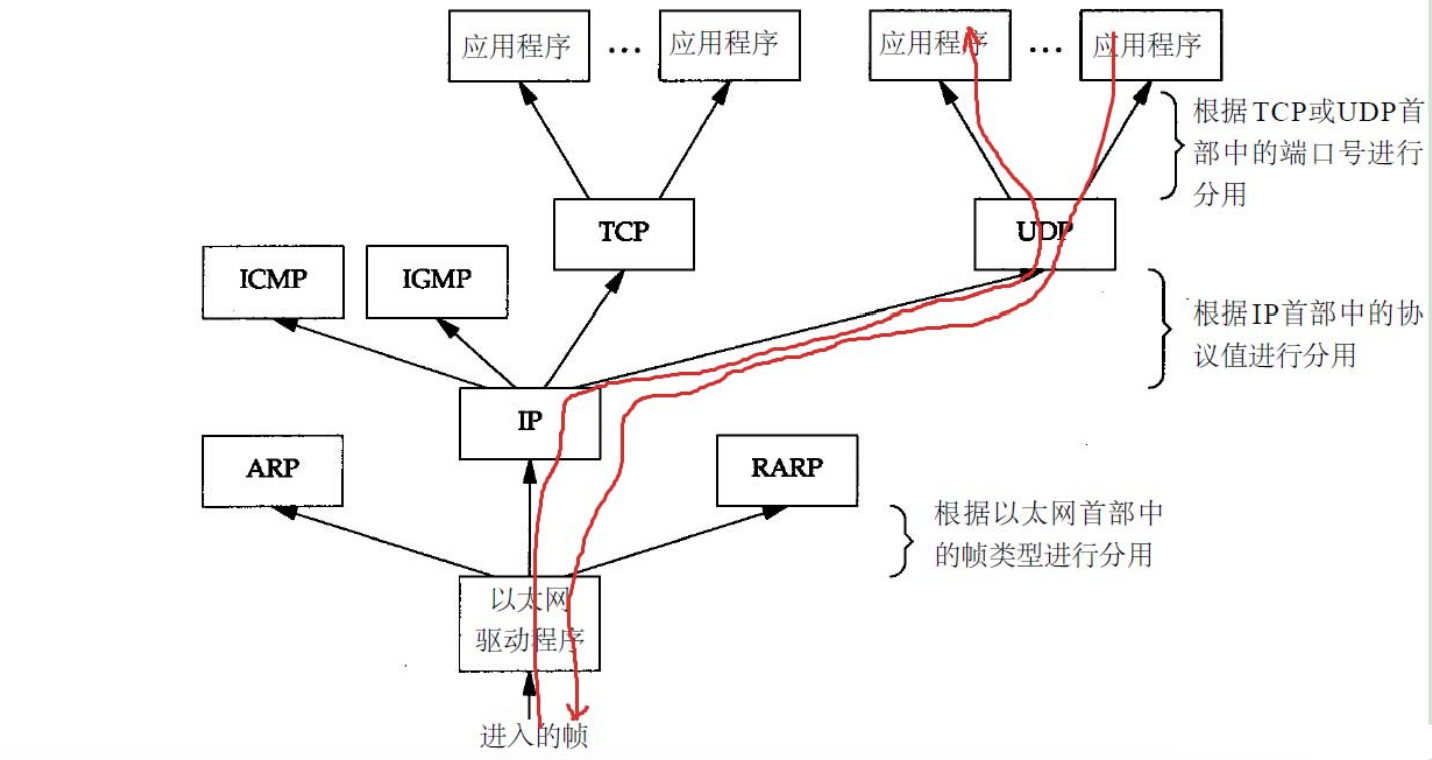
15 |
16 | ## Linux 内核网络协议栈
17 |
18 | ### 协议栈的全景图
19 |
20 | 
21 |
22 | ### 协议栈的分层结构
23 |
24 | 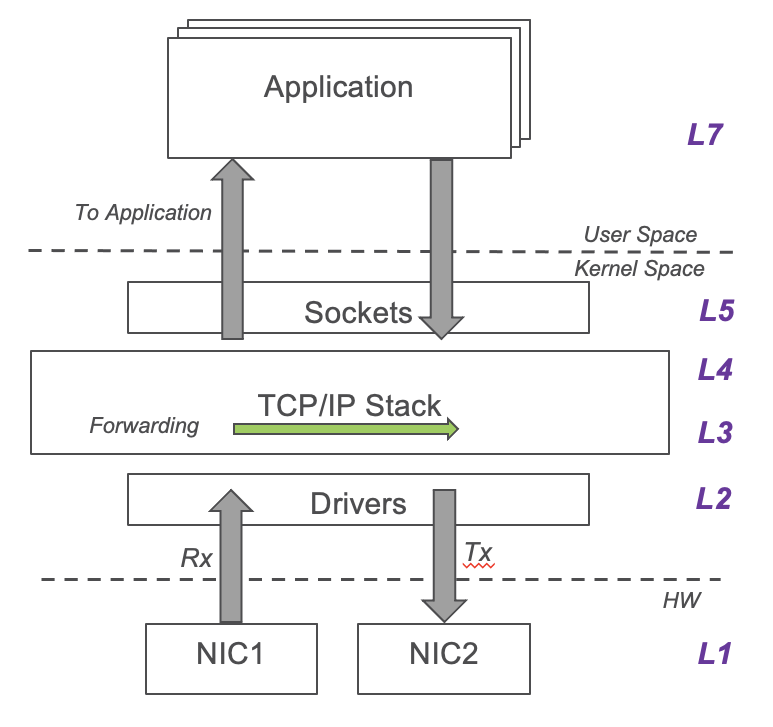
25 |
26 | 
27 |
28 | **逻辑抽象层级:**
29 |
30 | 物理层:主要提供各种连接的物理设备,如各种网卡,串口卡等。
31 |
32 | 链路层:主要提供对物理层进行访问的各种接口卡的驱动程序,如网卡驱动等。
33 |
34 | 网路层:是负责将网络数据包传输到正确的位置,最重要的网络层协议是 IP 协议,此外还有如 ICMP,ARP,RARP 等协议。
35 |
36 | 传输层:为应用程序之间提供端到端连接,主要为 TCP 和 UDP 协议。
37 |
38 | 应用层:顾名思义,主要由应用程序提供,用来对传输数据进行语义解释的 “人机交互界面层”,比如 HTTP,SMTP,FTP 等协议。
39 |
40 | **协议栈实现层级:**
41 |
42 | 硬件层(Physical device hardware):又称驱动程序层,提供连接硬件设备的接口。
43 |
44 | 设备无关层(Device agnostic interface):又称设备接口层,提供与具体设备无关的驱动程序抽象接口。这一层的目的主要是为了统一不同的接口卡的驱动程序与网络协议层的接口,它将各种不同的驱动程序的功能统一抽象为几个特殊的动作,如 open,close,init 等,这一层可以屏蔽底层不同的驱动程序。
45 |
46 | 网络协议层(Network protocols):对应 IP layer 和 Transport layer。毫无疑问,这是整个内核网络协议栈的核心。这一层主要实现了各种网络协议,最主要的当然是 IP,ICMP,ARP,RARP,TCP,UDP 等。
47 |
48 | 协议无关层(Protocol agnostic interface),又称协议接口层,本质就是 SOCKET 层。这一层的目的是屏蔽网络协议层中诸多类型的网络协议(主要是 TCP 与 UDP 协议,当然也包括 RAW IP, SCTP 等等),以便提供简单而同一的接口给上面的系统调用层调用。简单的说,不管我们应用层使用什么协议,都要通过系统调用接口来建立一个 SOCKET,这个 SOCKET 其实是一个巨大的 sock 结构体,它和下面的网络协议层联系起来,屏蔽了不同的网络协议,通过系统调用接口只把数据部分呈献给应用层。
49 |
50 | BSD(Berkeley Software Distribution)socket:BSD Socket 层,提供统一的 SOCKET 操作接口,与 socket 结构体关系紧密。
51 |
52 | INET(指一切支持 IP 协议的网络) socket:INET socket 层,调用 IP 层协议的统一接口,与 sock 结构体关系紧密。
53 |
54 | 系统调用接口层(System call interface),实质是一个面向用户空间(User Space)应用程序的接口调用库,向用户空间应用程序提供使用网络服务的接口。
55 |
56 | 
57 |
58 | ### 协议栈的数据结构
59 |
60 | 
61 |
62 | msghdr:描述了从应用层传递下来的消息格式,包含有用户空间地址,消息标记等重要信息。
63 |
64 | iovec:描述了用户空间地址的起始位置。
65 |
66 | file:描述文件属性的结构体,与文件描述符一一对应。
67 |
68 | file_operations:文件操作相关结构体,包括 read()、write()、open()、ioctl() 等。
69 |
70 | socket:向应用层提供的 BSD socket 操作结构体,协议无关,主要作用为应用层提供统一的 Socket 操作。
71 |
72 | sock:网络层 sock,定义与协议无关操作,是网络层的统一的结构,传输层在此基础上实现了 inet_sock。
73 |
74 | sock_common:最小网络层表示结构体。
75 |
76 | inet_sock:表示层结构体,在 sock 上做的扩展,用于在网络层之上表示 inet 协议族的的传输层公共结构体。
77 |
78 | udp_sock:传输层 UDP 协议专用 sock 结构,在传输层 inet_sock 上扩展。
79 |
80 | proto_ops:BSD socket 层到 inet_sock 层接口,主要用于操作 socket 结构。
81 |
82 | proto:inet_sock 层到传输层操作的统一接口,主要用于操作 sock 结构。
83 |
84 | net_proto_family:用于标识和注册协议族,常见的协议族有 IPv4、IPv6。
85 |
86 | softnet_data:内核为每个 CPU 都分配一个这样的 softnet_data 数据空间。每个 CPU 都有一个这样的队列,用于接收数据包。
87 |
88 | sk_buff:描述一个帧结构的属性,包含 socket、到达时间、到达设备、各层首部大小、下一站路由入口、帧长度、校验和等等。
89 |
90 | sk_buff_head:数据包队列结构。
91 |
92 | net_device:这个巨大的结构体描述一个网络设备的所有属性,数据等信息。
93 |
94 | inet_protosw:向 IP 层注册 socket 层的调用操作接口。
95 |
96 | inetsw_array:socket 层调用 IP 层操作接口都在这个数组中注册。
97 |
98 | sock_type:socket 类型。
99 |
100 | IPPROTO:传输层协议类型 ID。
101 |
102 | net_protocol:用于传输层协议向 IP 层注册收包的接口。
103 |
104 | packet_type:以太网数据帧的结构,包括了以太网帧类型、处理方法等。
105 |
106 | rtable:路由表结构,描述一个路由表的完整形态。
107 |
108 | rt_hash_bucket:路由表缓存。
109 |
110 | dst_entry:包的去向接口,描述了包的去留,下一跳等路由关键信息。
111 |
112 | napi_struct:NAPI 调度的结构。NAPI 是 Linux 上采用的一种提高网络处理效率的技术,它的核心概念就是不采用中断的方式读取数据,而代之以首先采用中断唤醒数据接收服务,然后采用 poll 的方法来轮询数据。NAPI 技术适用于高速率的短长度数据包的处理。
113 |
114 | ### 网络协议栈初始化流程
115 |
116 | 这需要从内核启动流程说起。当内核完成自解压过程后进入内核启动流程,这一过程先在 arch/mips/kernel/head.S 程序中,这个程序负责数据区(BBS)、中断描述表(IDT)、段描述表(GDT)、页表和寄存器的初始化,程序中定义了内核的入口函数 kernel_entry()、kernel_entry() 函数是体系结构相关的汇编代码,它首先初始化内核堆栈段为创建系统中的第一过程进行准备,接着用一段循环将内核映像的未初始化的数据段清零,最后跳到 start_kernel() 函数中初始化硬件相关的代码,完成 Linux Kernel 环境的建立。
117 |
118 | start_kenrel() 定义在 init/main.c 中,真正的内核初始化过程就是从这里才开始。函数 start_kerenl() 将会调用一系列的初始化函数,如:平台初始化,内存初始化,陷阱初始化,中断初始化,进程调度初始化,缓冲区初始化,完成内核本身的各方面设置,目的是最终建立起基本完整的 Linux 内核环境。
119 |
120 | start_kernel() 中主要函数及调用关系如下:
121 |
122 | 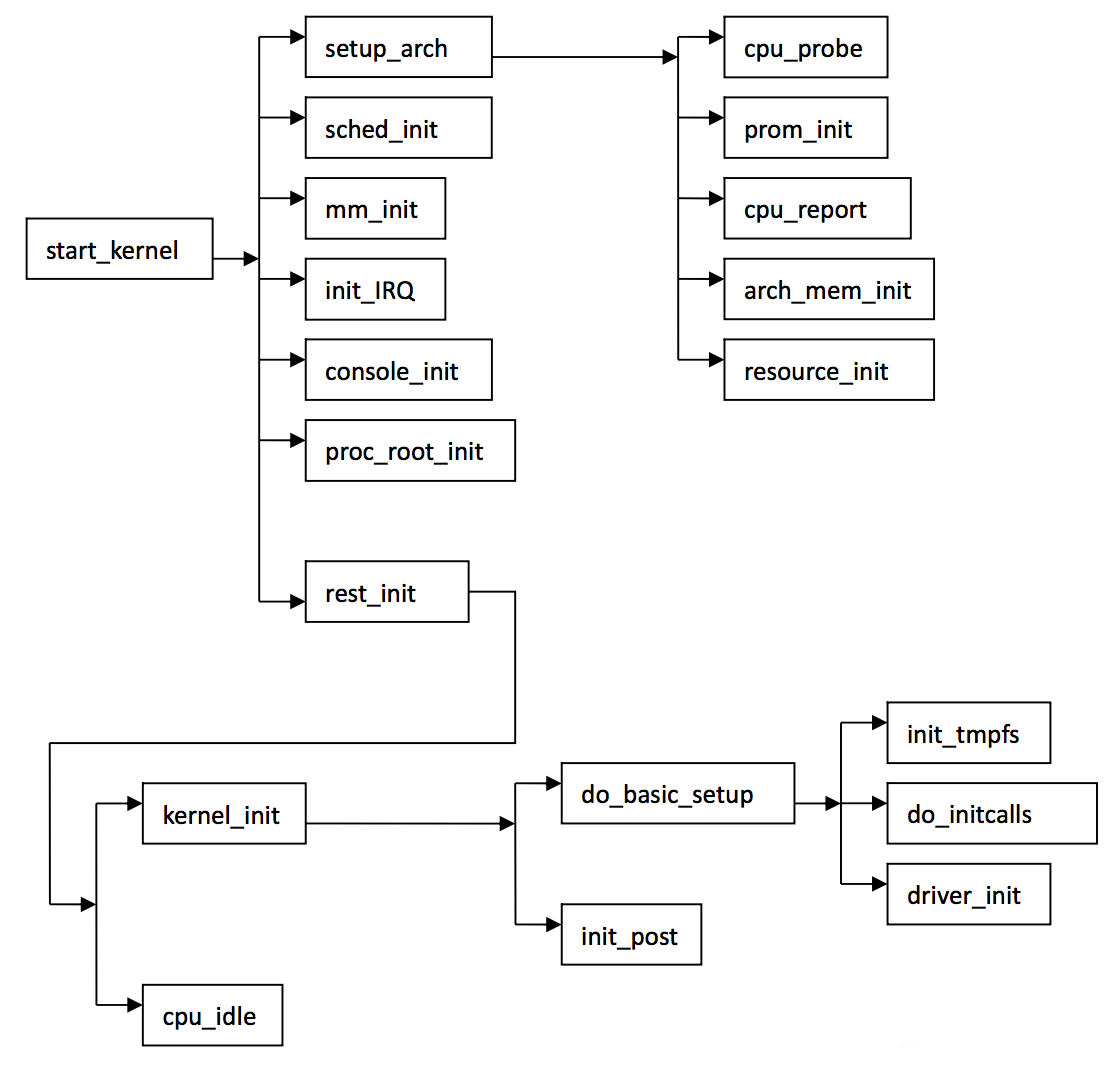
123 |
124 | start_kernel() 的过程中会执行 socket_init() 来完成协议栈的初始化,实现如下:
125 |
126 | ```c
127 | void sock_init(void)//网络栈初始化
128 | {
129 | int i;
130 |
131 | printk("Swansea University Computer Society NET3.019\n");
132 |
133 | /*
134 | * Initialize all address (protocol) families.
135 | */
136 |
137 | for (i = 0; i < NPROTO; ++i) pops[i] = NULL;
138 |
139 | /*
140 | * Initialize the protocols module.
141 | */
142 |
143 | proto_init();
144 |
145 | #ifdef CONFIG_NET
146 | /*
147 | * Initialize the DEV module.
148 | */
149 |
150 | dev_init();
151 |
152 | /*
153 | * And the bottom half handler
154 | */
155 |
156 | bh_base[NET_BH].routine= net_bh;
157 | enable_bh(NET_BH);
158 | #endif
159 | }
160 | ```
161 |
162 | 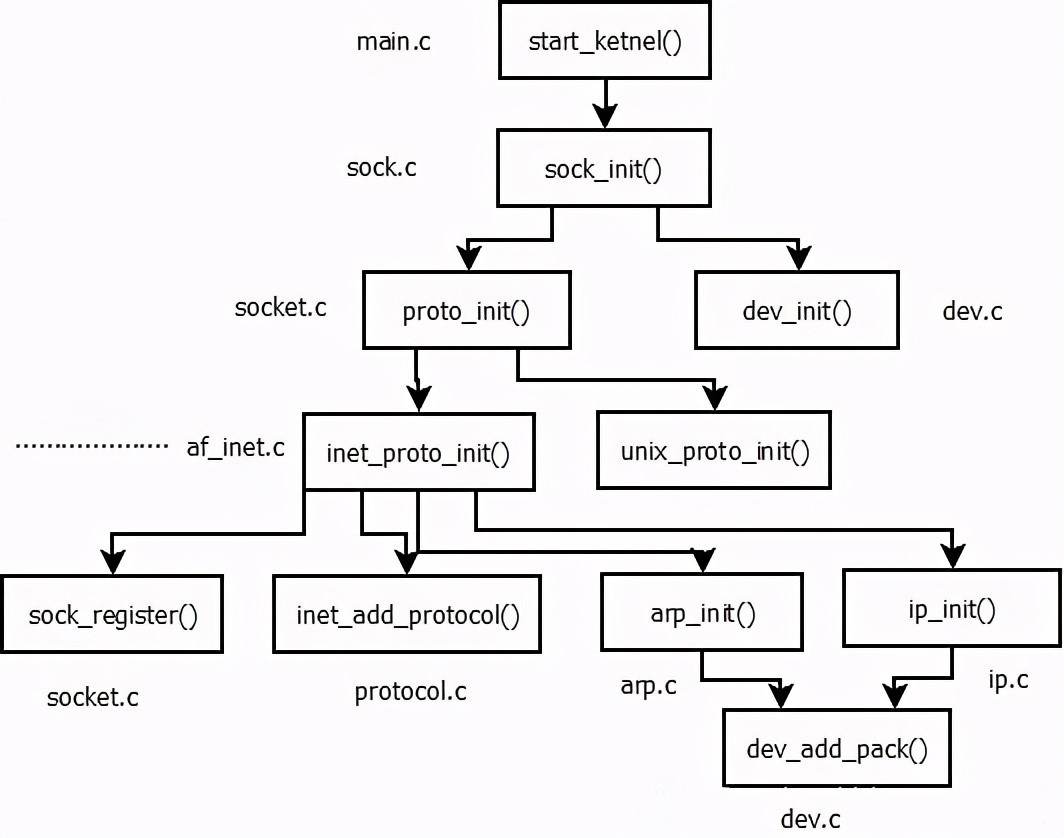
163 |
164 | sock_init() 包含了内核协议栈的初始化工作:
165 |
166 | sock_init:Initialize sk_buff SLAB cache,注册 SOCKET 文件系统。
167 |
168 | net_inuse_init:为每个 CPU 分配缓存。
169 |
170 | proto_init:在 /proc/net 域下建立 protocols 文件,注册相关文件操作函数。
171 |
172 | net_dev_init:建立 netdevice 在 /proc/sys 相关的数据结构,并且开启网卡收发中断;为每个 CPU 初始化一个数据包接收队列(softnet_data),包接收的回调;注册本地回环操作,注册默认网络设备操作。
173 |
174 | inet_init:注册 INET 协议族的 SOCKET 创建方法,注册 TCP、UDP、ICMP、IGMP 接口基本的收包方法。为 IPv4 协议族创建 proc 文件。此函数为协议栈主要的注册函数:
175 |
176 | rc = proto_register(&udp_prot, 1);:注册 INET 层 UDP 协议,为其分配快速缓存。
177 |
178 | (void)sock_register(&inet_family_ops);:向 static const struct net_proto_family *net_families[NPROTO] 结构体注册 INET 协议族的操作集合(主要是 INET socket 的创建操作)。
179 |
180 | inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0;:向 externconst struct net_protocol *inet_protos[MAX_INET_PROTOS] 结构体注册传输层 UDP 的操作集合。
181 |
182 | static struct list_head inetsw[SOCK_MAX]; for (r = &inetsw[0]; r < &inetsw[SOCK_MAX];++r) INIT_LIST_HEAD(r);:初始化 SOCKET 类型数组,其中保存了这是个链表数组,每个元素是一个链表,连接使用同种 SOCKET 类型的协议和操作集合。
183 |
184 | for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q):
185 |
186 | inet_register_protosw(q);:向 sock 注册协议的的调用操作集合。
187 |
188 | arp_init();:启动 ARP 协议支持。
189 |
190 | ip_init();:启动 IP 协议支持。
191 |
192 | udp_init();:启动 UDP 协议支持。
193 |
194 | dev_add_pack(&ip_packet_type);:向 ptype_base[PTYPE_HASH_SIZE]; 注册 IP 协议的操作集合。
195 |
196 | socket.c 提供的系统调用接口。
197 |
198 | 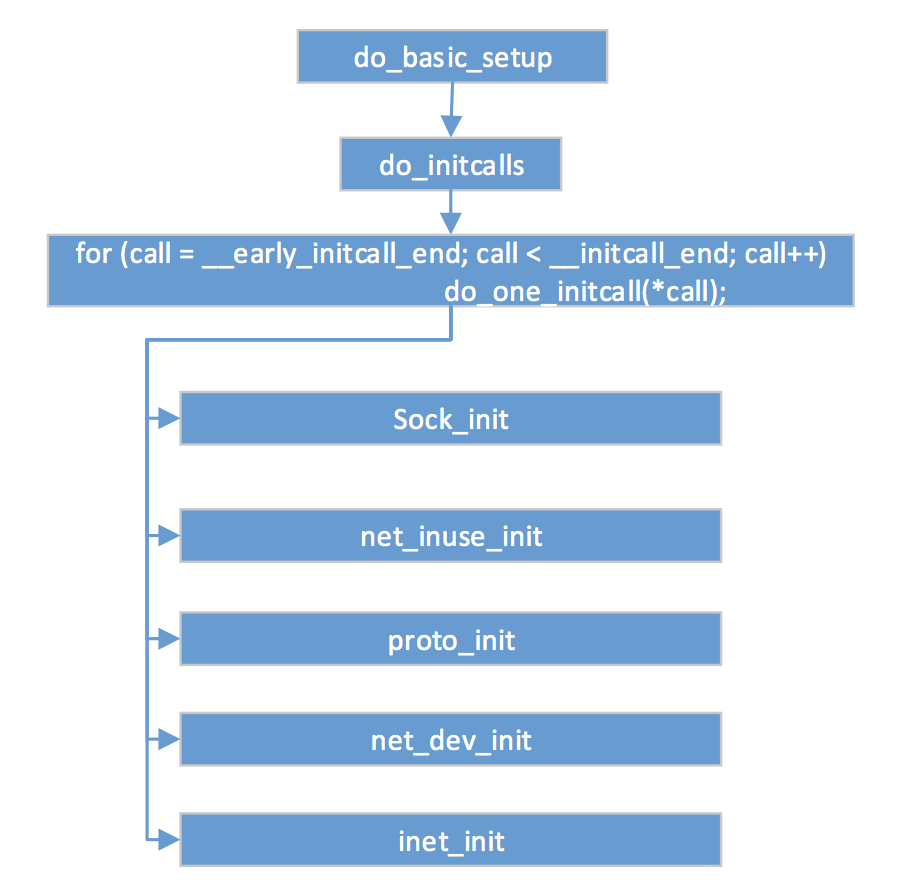
199 |
200 | [](https://imgtu.com/i/WTgxRx)
201 |
202 | 协议栈初始化完成后再执行 dev_init(),继续设备的初始化。
203 |
204 | ## Socket 创建流程
205 |
206 | 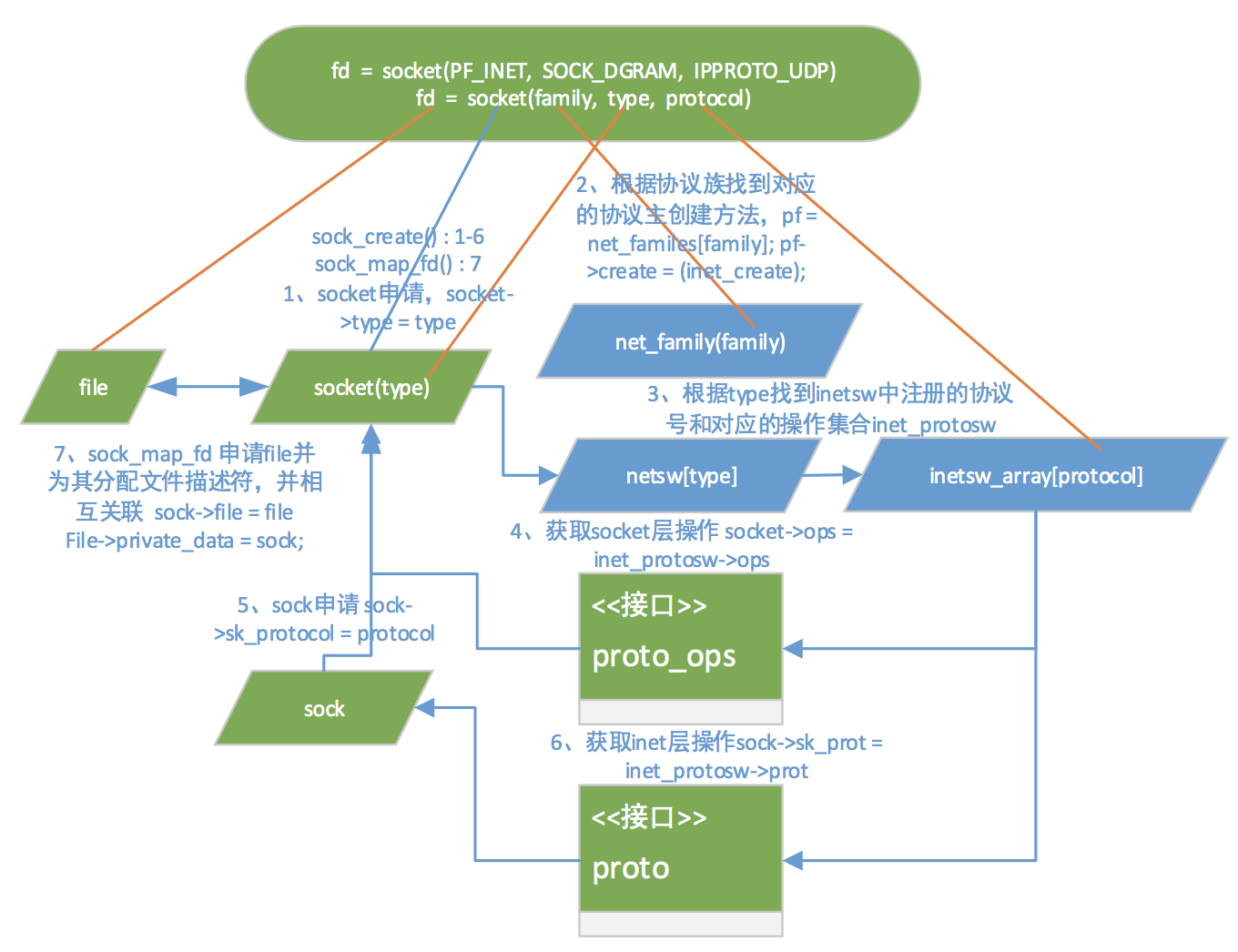
207 |
208 | ## 协议栈收包流程概述
209 |
210 | 硬件层与设备无关层:硬件监听物理介质,进行数据的接收,当接收的数据填满了缓冲区,硬件就会产生中断,中断产生后,系统会转向中断服务子程序。在中断服务子程序中,数据会从硬件的缓冲区复制到内核的空间缓冲区,并包装成一个数据结构(sk_buff),然后调用对驱动层的接口函数 netif_rx() 将数据包发送给设备无关层。该函数的实现在 net/inet/dev.c 中,采用了 bootom half 技术,该技术的原理是将中断处理程序人为的分为两部分,上半部分是实时性要求较高的任务,后半部分可以稍后完成,这样就可以节省中断程序的处理时间,整体提高了系统的性能。
211 |
212 | NOTE:在整个协议栈实现中 dev.c 文件的作用重大,它衔接了其下的硬件层和其上的网络协议层,可以称它为链路层模块,或者设备无关层的实现。
213 |
214 | 网络协议层:就以 IP 数据报为例,从设备无关层向网络协议层传递时会调用 ip_rcv()。该函数会根据 IP 首部中使用的传输层协议来调用相应协议的处理函数。UDP 对应 udp_rcv()、TCP 对应 tcp_rcv()、ICMP 对应 icmp_rcv()、IGMP 对应 igmp_rcv()。以 tcp_rcv() 为例,所有使用 TCP 协议的套接字对应的 sock 结构体都被挂入 tcp_prot 全局变量表示的 proto 结构之 sock_array 数组中,采用以本地端口号为索引的插入方式。所以,当 tcp_rcv() 接收到一个数据包,在完成必要的检查和处理后,其将以 TCP 协议首部中目的端口号为索引,在 tcp_prot 对应的 sock 结构体之 sock_array 数组中得到正确的 sock 结构体队列,再辅之以其他条件遍历该队列进行对应 sock 结构体的查询,在得到匹配的 sock 结构体后,将数据包挂入该 sock 结构体中的缓存队列中(由 sock 结构体中的 receive_queue 字段指向),从而完成数据包的最终接收。
215 |
216 | NOTE:虽然这里的 ICMP、IGMP 通常被划分为网络层协议,但是实际上他们都封装在 IP 协议里面,作为传输层对待。
217 |
218 | 协议无关层和系统调用接口层:当用户需要接收数据时,首先根据文件描述符 inode 得到 socket 结构体和 sock 结构体,然后从 sock 结构体中指向的队列 recieve_queue 中读取数据包,将数据包 copy 到用户空间缓冲区。数据就完整的从硬件中传输到用户空间。这样也完成了一次完整的从下到上的传输。
219 |
220 | ## 协议栈发包流程概述
221 |
222 | 1、应用层可以通过系统调用接口层或文件操作来调用内核函数,BSD socket 层的 sock_write() 会调用 INET socket 层的 inet_wirte()。INET socket 层会调用具体传输层协议的 write 函数,该函数是通过调用本层的 inet_send() 来实现的,inet_send() 的 UDP 协议对应的函数为 udp_write()。
223 |
224 | 2、在传输层 udp_write() 调用本层的 udp_sendto() 完成功能。udp_sendto() 完成 sk_buff 结构体相应的设置和报头的填写后会调用 udp_send() 来发送数据。而在 udp_send() 中,最后会调用 ip_queue_xmit() 将数据包下放的网络层。
225 |
226 | 3、在网络层,函数 ip_queue_xmit() 的功能是将数据包进行一系列复杂的操作,比如是检查数据包是否需要分片,是否是多播等一系列检查,最后调用 dev_queue_xmit() 发送数据。
227 |
228 | 4、在链路层中,函数调用会调用具体设备提供的发送函数来发送数据包,e.g. dev->hard_start_xmit(skb, dev);。具体设备的发送函数在协议栈初始化的时候已经设置了。这里以 8390 网卡为例来说明驱动层的工作原理,在 net/drivers/8390.c 中函数 ethdev_init() 的设置如下:
229 |
230 | ```c
231 | /* Initialize the rest of the 8390 device structure. */
232 | int ethdev_init(struct device *dev)
233 | {
234 | if (ei_debug > 1)
235 | printk(version);
236 |
237 | if (dev->priv == NULL) { //申请私有空间
238 | struct ei_device *ei_local; //8390 网卡设备的结构体
239 |
240 | dev->priv = kmalloc(sizeof(struct ei_device), GFP_KERNEL); //申请内核内存空间
241 | memset(dev->priv, 0, sizeof(struct ei_device));
242 | ei_local = (struct ei_device *)dev->priv;
243 | #ifndef NO_PINGPONG
244 | ei_local->pingpong = 1;
245 | #endif
246 | }
247 |
248 | /* The open call may be overridden by the card-specific code. */
249 | if (dev->open == NULL)
250 | dev->open = &ei_open; // 设备的打开函数
251 | /* We should have a dev->stop entry also. */
252 | dev->hard_start_xmit = &ei_start_xmit; // 设备的发送函数,定义在 8390.c 中
253 | dev->get_stats = get_stats;
254 | #ifdef HAVE_MULTICAST
255 | dev->set_multicast_list = &set_multicast_list;
256 | #endif
257 |
258 | ether_setup(dev);
259 |
260 | return 0;
261 | }
262 | ```
263 | ## UDP 的收发包流程总览
264 |
265 | 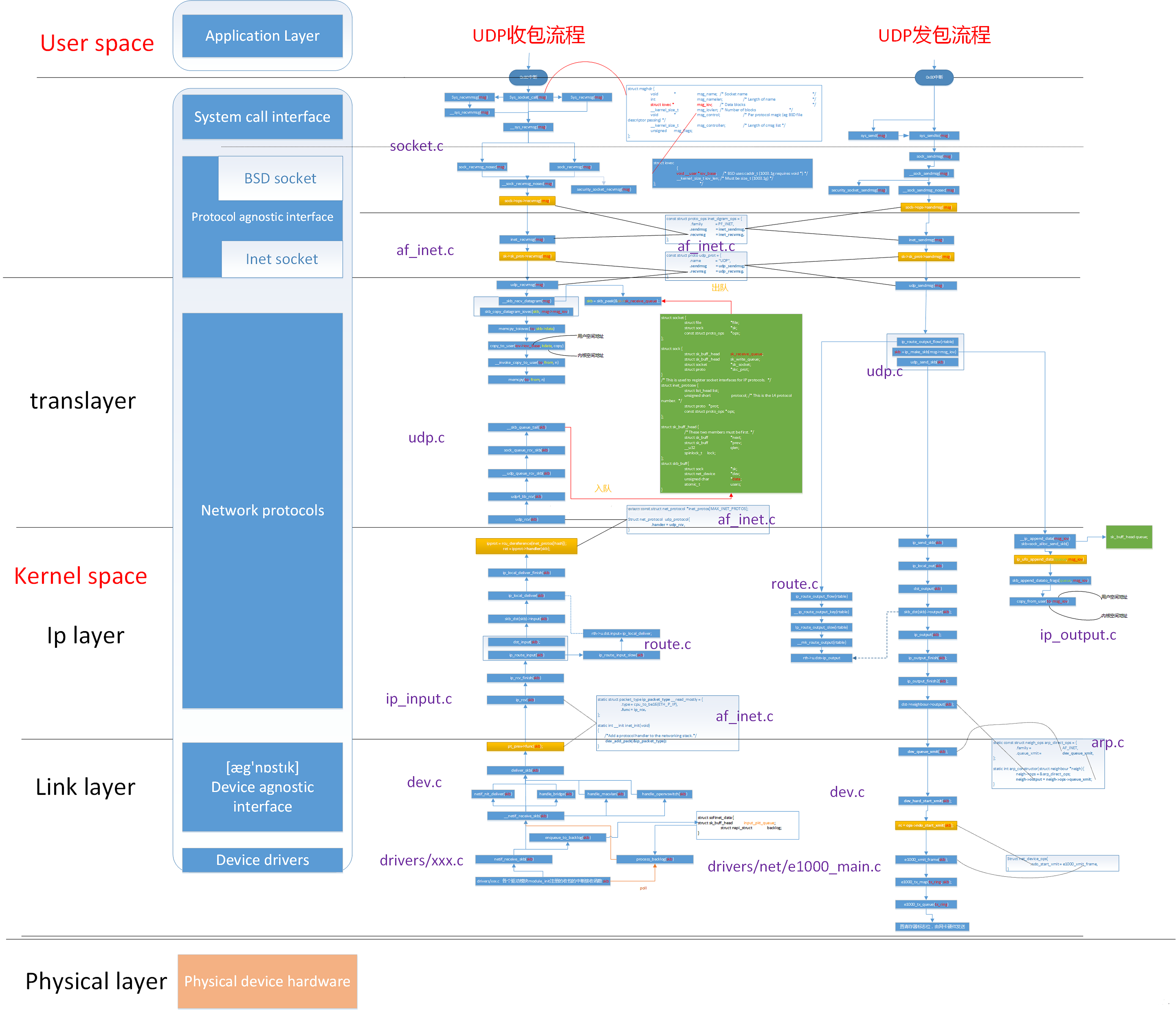
266 |
267 | ## 内核中断收包流程
268 |
269 | 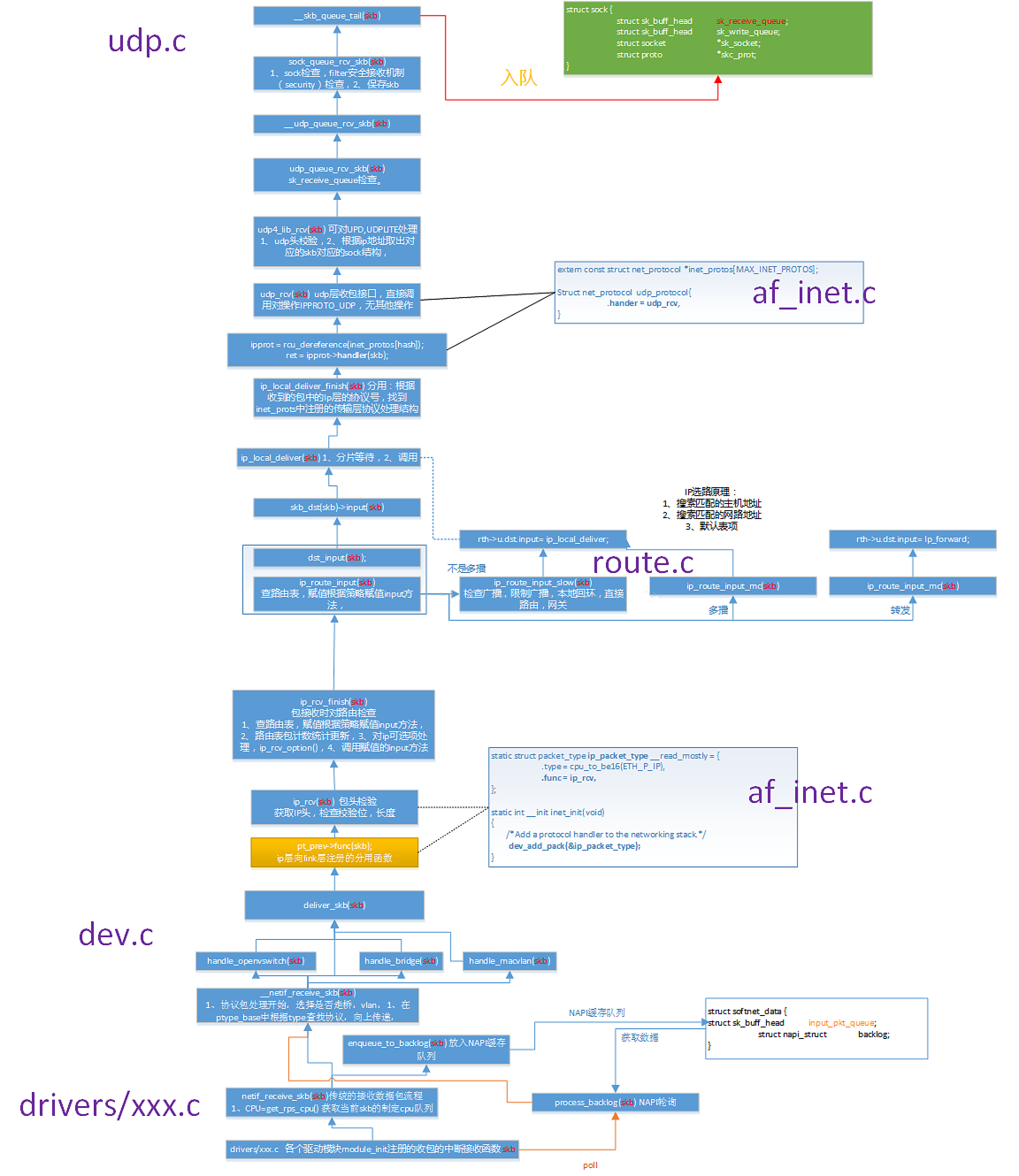
270 |
271 | ## UDP 收包流程
272 |
273 | [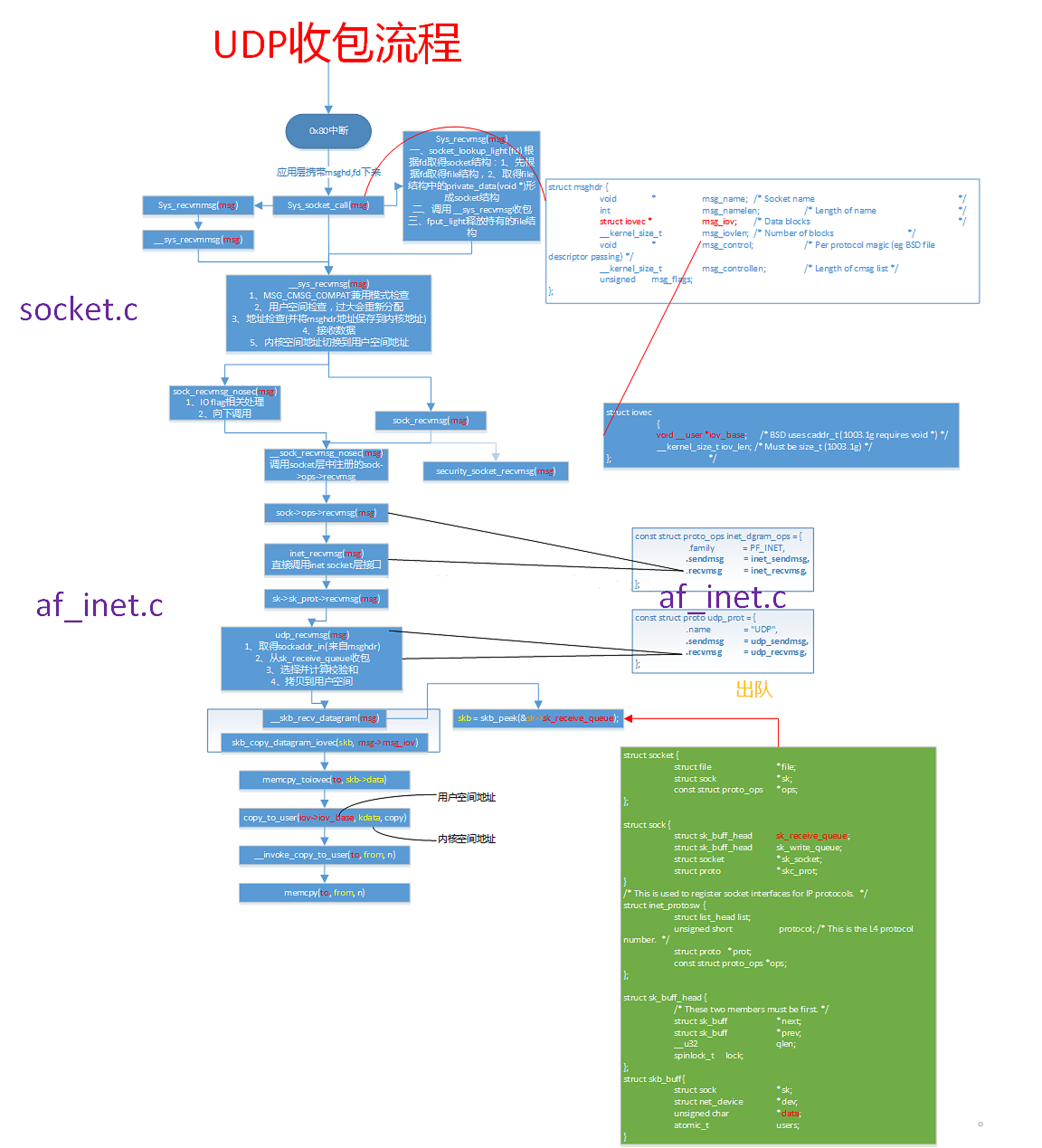](https://imgtu.com/i/WTgrxf)
274 |
275 | ## UDP 发包流程
276 |
277 | [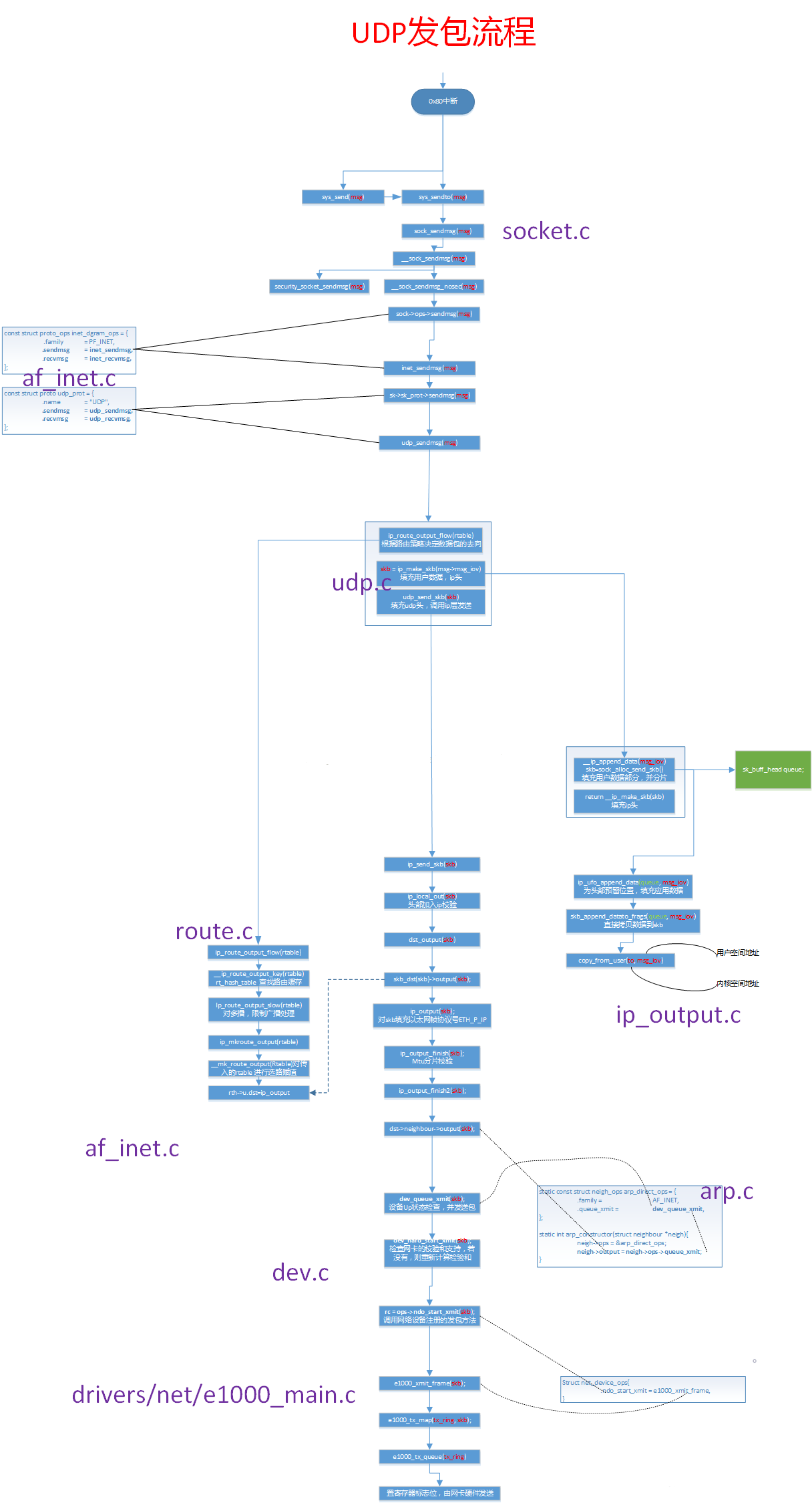](https://imgtu.com/i/WTgDRP)
278 |
279 |
--------------------------------------------------------------------------------
/文章/网络协议栈/Linux网络栈解剖.md:
--------------------------------------------------------------------------------
1 | Linux®操作系统的最大功能之一是其网络栈。它最初是BSD协议栈的衍生物,并且组织良好,具有一组干净的接口。其接口范围从协议无关接口(如通用socket层接口或设备层)到各个网络协议的特定接口。本文从网络栈各层的角度探讨了Linux网络栈的结构,并探讨了其一些主要结构体。
2 |
3 | ## 协议介绍
4 | 虽然网络的正式介绍通常是指七层开放系统互连(OSI)模型,但是Linux中基本网络栈的介绍使用互联网模型的四层模型(参见图1)。
5 |
6 | 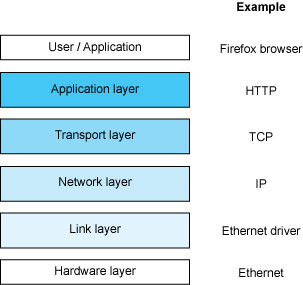
7 |
8 | 网络栈的底部是链路层。链路层是指提供访问物理层的设备驱动程序(物理层可以是各种各样的介质,诸如串行链路或以太网设备)。链路层上面是网络层,负责将数据包引导到目的地。再上一层是传输层,它负责点对点通信(例如,在主机内,像ssh 127.0.0.1)。网络层管理主机之间的通信,传输层管理这些主机之上的端点(Endpoint)之间的通信。最后是应用层,即可以理解所传输的数据的语义层。
9 |
10 | 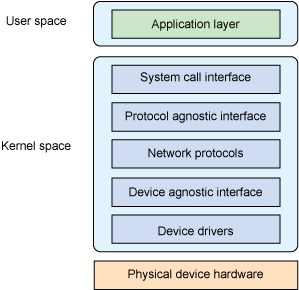
11 |
12 | ## 核心网络架构
13 |
14 | 现在讨论Linux网络栈的架构以及它如何实现Internet模型。图2提供了Linux网络栈的高级视图。顶部是定义网络栈用户的用户空间层或应用层。底部是提供与网络(串行或高速网络(如以太网))连接的物理设备。在中间的内核空间,是本文重点要讨论的网络子系统。通过网络栈的内部流量socket缓冲区(sk_buffs),它们在源和目的之间移动数据包数据。你很快会看到sk_buff结构。
15 |
16 | 首先简要介绍Linux网络子系统的核心元素,当然后面还会有更详细的介绍。在顶部(见图2)是系统调用接口。这只是为用户空间应用程序提供访问内核网络子系统的一种方式。接下来是一个协议无关的层,提供了一种常用的方法来处理底层的传输层协议。接下来是实际的协议,在Linux中包括TCP,UDP和IP的内置协议。接下来是另一个设备无关的层,它允许使用通用接口与单个设备驱动程序交互,之后是各个设备驱动程序本身。
17 |
18 | ### 系统调用接口
19 |
20 | 系统调用接口可以从两个角度进行描述。当用户进行网络调用时,通过系统调用接口多路复用到内核中。这最终作为 `sys_socketcall(./net/socket.c)`中的调用,然后进一步解复用到其预期目标的调用。
21 |
22 | ```c
23 | SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
24 | SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
25 | SYSCALL_DEFINE2(listen, int, fd, int, backlog)
26 | SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
27 | int __user *, upeer_addrlen)
28 | SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
29 | int, addrlen)
30 | ...
31 | ```
32 |
33 | 系统调用接口的另一个角度是使用正常的文件操作进行网络I/O。例如,典型的读写操作可以在网络socket(由文件描述符表示,就像普通文件)一样执行。因此,虽然存在一些特定于网络的操作(调用socket创建socket,调用connect将socket连接到目的地等等),但还是有一些适用于网络对象的标准文件操作,就像常规文件一样。
34 |
35 | ```c
36 | static const struct file_operations socket_file_ops = {
37 | .owner = THIS_MODULE,
38 | .llseek = no_llseek,
39 | .read_iter = sock_read_iter,
40 | .write_iter = sock_write_iter,
41 | struct file *sock_alloc_file(struct socket *sock, int flags, const char *dname)
42 | {
43 | file = alloc_file(&path, FMODE_READ | FMODE_WRITE,
44 | &socket_file_ops);
45 | ```
46 |
47 | 最后,系统调用接口提供了在用户空间应用程序和内核之间传输控制的手段。
48 |
49 |
50 | ### 协议无关接口
51 |
52 | socket层是协议无关接口,其提供一组通用功能,以支持各种不同的协议。socket层不仅支持典型的TCP和UDP协议,还支持IP,原始以太网和其他传输协议,如流控制传输协议(SCTP)。
53 |
54 | 网络栈使用socket通信。Linux中的socket结构struct sock是在linux/include/net/sock.h中定义的。该大型结构包含特定socket的所有必需状态,包括socket使用的特定协议以及可能在其上执行的操作。
55 |
56 | ```c
57 | struct sock {
58 | /*
59 | * Now struct inet_timewait_sock also uses sock_common, so please just
60 | * don't add nothing before this first member (__sk_common) --acme
61 | */
62 | struct sock_common __sk_common;
63 | #define sk_prot __sk_common.skc_prot
64 | struct proto *sk_prot_creator;
65 | ```
66 |
67 | 网络子系统通过定义了其功能的特殊结构(即proto)来了解各个可用协议。每个协议维护一个名为proto(在linux/include/net/sock.h中找到)的结构。该结构定义了可以从socket层到传输层执行的特定socket操作(例如,如何创建socket,如何与socket建立连接,如何关闭socket等)。
68 |
69 | ```c
70 | struct proto tcp_prot = {
71 | .name = "TCP",
72 | .owner = THIS_MODULE,
73 | .close = tcp_close,
74 | .connect = tcp_v4_connect,
75 | .disconnect = tcp_disconnect,
76 | .accept = inet_csk_accept,
77 | ...
78 | ```
79 |
80 | ### 网络协议
81 |
82 | 网络协议部分定义了可用的特定网络协议(如TCP,UDP等)。这些是在linux/net/ipv4/af_inet.c中的inet_init函数的开头进行初始化的(因为TCP和UDP是协议inet族的一部分)。inet_init函数调用proto_register注册每个内置协议。proto_register在linux/net/core/sock.c中定义,除了将协议添加到活动协议列表之外,还可以根据需要分配一个或多个slab缓存。
83 |
84 | ```c
85 | int proto_register(struct proto *prot, int alloc_slab)
86 | {
87 | if (alloc_slab) {
88 | }
89 |
90 | mutex_lock(&proto_list_mutex);
91 | list_add(&prot->node, &proto_list);
92 | assign_proto_idx(prot);
93 | mutex_unlock(&proto_list_mutex);
94 | static int __init inet_init(void)
95 | {
96 | struct inet_protosw *q;
97 | struct list_head *r;
98 | int rc = -EINVAL;
99 |
100 | sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
101 |
102 | rc = proto_register(&tcp_prot, 1);
103 | if (rc)
104 | goto out;
105 |
106 | rc = proto_register(&udp_prot, 1);
107 | if (rc)
108 | goto out_unregister_tcp_proto;
109 | ..
110 | for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
111 | inet_register_protosw(q);
112 |
113 | arp_init();
114 | ip_init();
115 | tcp_init();
116 | udp_init();
117 | ...
118 | static struct inet_protosw inetsw_array[] =
119 | {
120 | {
121 | .type = SOCK_STREAM,
122 | .protocol = IPPROTO_TCP,
123 | .prot = &tcp_prot,
124 | .ops = &inet_stream_ops,
125 | .flags = INET_PROTOSW_PERMANENT |
126 | INET_PROTOSW_ICSK,
127 | },
128 | ```
129 |
130 | 您可以通过linux/net/ipv4/中的文件tcp_ipv4.c,udp.c和raw.c中的proto结构来了解各自的协议。这些协议的proto结构体都按照类型和协议映射到inetsw_array,将内部协议映射到对应的操作(which maps the built-in protocols to their operations.)。结构体inetsw_array及其关系如图3所示。该数组中的每个协议都在初始化inetsw时,通过在inet_init调用inet_register_protosw来初始化。函数inet_init还初始化各种inet模块,如ARP,ICMP,IP模块,TCP和UDP模块。
131 |
132 | 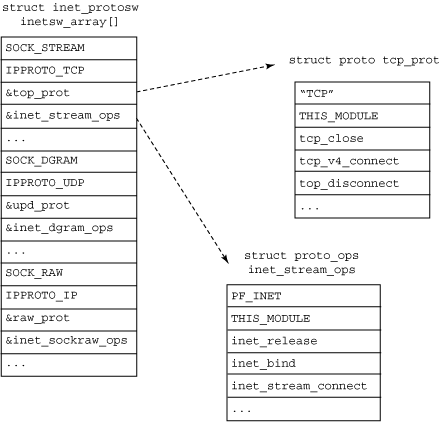
133 |
134 | #### Socket协议关联
135 |
136 | 回想下,当创建一个socket时,它定义了类型和协议,如 my_sock = socket( AF_INET, SOCK_STREAM, 0 )。其中AF_INET表示基于Internet地址族,SOCK_STREAM表示其为流式socket(如上所示inetsw_array)。
137 |
138 | 从图3可以看出, proto结构定义了特定传输协议的方法,而proto_ops结构定义了一般的socket方法。其他额外的协议可以通过调用inet_register_protosw将自己加入到inetsw协议开关机(protocol switch) 。例如,SCTP通过在linux/net/sctp/protocol.c中调用sctp_init来添加自己。
139 |
140 | > 补充:prot/prot_ops二者有点相似,这里特意说明下:kernel的调用顺序是先inet(即prot_ops),后protocal(即prot),inet层处于socket和具体protocol之间。下面以connect为例,ops即为prot_ops,它调用的bind是inet_listen,然后才是具体protocol的tcp_v4_connect。这一关系主要记录在inetsw_array中。
141 |
142 | ```c
143 | SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
144 | int, addrlen)
145 | {
146 | struct socket *sock;
147 | ...
148 | err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
149 | sock->file->f_flags);
150 | int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
151 | int addr_len, int flags, int is_sendmsg)
152 | {
153 | struct sock *sk = sock->sk;
154 | switch (sock->state) {
155 | case SS_UNCONNECTED:
156 | err = -EISCONN;
157 | if (sk->sk_state != TCP_CLOSE)
158 | goto out;
159 |
160 | err = sk->sk_prot->connect(sk, uaddr, addr_len);
161 | if (err < 0)
162 | goto out;
163 | ```
164 |
165 | socket的数据移动使用核心结构socket缓冲区(sk_buff)来进行。一个sk_buff 包含包数据(package data),和状态数据(state data, 覆盖协议栈的多个层)。每个发送或接收的数据包都用一个sk_buff来表示。该sk_buff 结构是在linux/include/linux/skbuff.h中定义的,并在图4中示出。
166 |
167 | 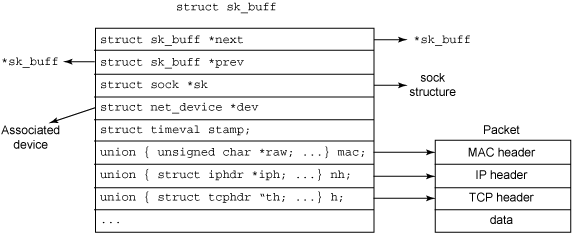
168 |
169 |
170 | 如图所示,一个给定连接的多个sk_buff可以串联在一起。每个sk_buff标识了要发送数据包或从其接收数据包的设备结构`(net_device *dev)`。由于每个包都表示为一个sk_buff,数据包报头可方便地通过一组指针来寻址(th,iph以及mac(MAC报头)),内核会保证这块内存是连续的。由于sk_buff 是socket数据管理的核心,因此kernel已经创建了许多支撑函数来管理它们,包括sk_buff的创建和销毁,克隆和队列管理等函数。
171 |
172 | 总的来说,内核socket缓冲器设计思路是,某一的socket的sk_buff串链接在一起,并且sk_buff包括许多信息,包括到协议头的指针,时间戳(发送或接收数据包的时间)以及与数据包相关的网络设备。
173 |
174 | ### 设备无关接口
175 |
176 | 协议层下面是另一个无关的接口层,将协议连接到具有不同功能的各种硬件设备的驱动程序。该层提供了一组通用的功能,由较低级别的网络设备驱动程序使用,以允许它们使用较高级协议栈进行操作。
177 |
178 | 首先,设备驱动程序可以通过调用register_netdevice/unregister_netdevice将自己注册/去注册到内核。调用者首先填写net_device结构,然后将其传入register_netdevice进行注册。内核调用其init功能(如果有定义),执行许多健全检查,创建一个 sysfs条目,然后将新设备添加到设备列表(在内核中Active设备的链表)。你可以 在linux/include/linux/netdevice.h中找到net_device结构。各个函数在linux/net/core/dev.c中实现。
179 |
180 | 使用dev_queue_xmit函数将sk_buff从协议层发送到网络设备。dev_queue_xmit函数会将sk_buff添加到底层网络设备驱动程序最终要传输的队列中(网络设备在net_device或者sk_buff->dev中定义)。dev结构包含函数hard_start_xmit,保存用于启动sk_buff传输的驱动程序功能的方法。
181 |
182 | 通常使用netif_rx接收报文数据。当下级设备驱动程序接收到一个包(包含在新分配的sk_buff)时,内核通过调用netif_rx将sk_buff传递给网络层。然后,netif_rx通过调用netif_rx_schedule将sk_buff排队到上层协议的队列以进行进一步处理。您可以在linux/net/core/dev.c 中找到dev_queue_xmit和netif_rx函数。
183 |
184 | 最近,在内核中引入了一个新的应用程序接口(NAPI),以允许驱动程序与设备无关层(dev)进行交互。一些驱动程序使用NAPI,但绝大多数仍然使用较旧的帧接收接口(by a rough factor of six to one)。NAPI可以通过避免每个传入帧的中断,在高负载下得到更好的性能。
185 |
186 | ### 设备驱动程序
187 |
188 | 网络栈的底部是管理物理网络设备的设备驱动程序。该层的设备示例包括串行接口上的SLIP驱动程序或以太网设备上的以太网驱动程序。
189 |
190 | 在初始化时,设备驱动程序分配一个net_device结构,然后用其必需的例程进行初始化。dev->hard_start_xmit就是其中一个例程,它定义了上层如何排队sk_buff用以传输。这个程序需要一个sk_buff。此功能的操作取决于底层硬件,但通常将sk_buff中的数据包移动到硬件环或队列。如设备无关层所述,帧接收使用该netif_rx接口或符合NAPI的网络驱动程序的netif_receive_skb。NAPI驱动程序对底层硬件的功能提出了约束。
191 |
192 | 在设备驱动程序配置其结构中的dev接口后,调用register_netdevice以后驱动就可以使用了。您可以在linux/drivers/net中找到网络设备专用的驱动程序。
193 |
--------------------------------------------------------------------------------
/文章/网络协议栈/Linux网络源代码学习——整体介绍.md:
--------------------------------------------------------------------------------
1 | * 简介
2 | * 源码目录
3 | * 网络分层
4 | * 网络与文件操作
5 | * 数据结构
6 | * sk_buff结构
7 | * 网络协议栈实现——数据struct 和 协议struct
8 | * 面向过程/对象/ioc
9 | * 其它
10 |
11 | 以下来自linux1.2.13源码。
12 | linux的网络部分由网卡的驱动程序和kernel的网络协议栈部分组成,它们相互交互,完成数据的接收和发送。
13 |
14 | ## 源码目录
15 |
16 | ```
17 | linux-1.2.13
18 | |
19 | |---net
20 | |
21 | |---protocols.c
22 | |---socket.c
23 | |---unix
24 | | |
25 | | |---proc.c
26 | | |---sock.c
27 | | |---unix.h
28 | |---inet
29 | |
30 | |---af_inet.c
31 | |---arp.h,arp.c
32 | |---...
33 | |---udp.c,utils.c
34 | ```
35 |
36 | 其中 unix 子文件夹中三个文件是有关 UNIX 域代码, UNIX 域是模拟网络传输方式在本机范围内用于进程间数据传输的一种机制。
37 |
38 | 系统调用通过 INT $0x80 进入内核执行函数,该函数根据 AX 寄存器中的系统调用号,进一步调用内核网络栈相应的实现函数。
39 |
40 | ## 网络分层
41 |
42 | 
43 |
44 | 从这个图中,可以看到,到传输层时,横生枝节,代码不再针对任何数据包都通用。从下到上,收到的数据包由哪个传输层协议处理,根据从数据包传输层header中解析的数据确定。从上到下,数据包的发送使用什么传输层协议,由socket初始化时确定。
45 |
46 | 1、vfs层
47 | 2、socket 是用于负责对上给用户提供接口,并且和文件系统关联。
48 | 3、sock,负责向下对接内核网络协议栈
49 | 4、tcp层 和 ip 层, linux 1.2.13相关方法都在 tcp_prot中。在高版本linux 中,sock 负责tcp 层, ip层另由struct inet_connection_sock 和 icsk_af_ops 负责。分层之后,诸如拥塞控制和滑动窗口的 字段和方法就只体现在struct sock和tcp_prot中,代码实现与tcp规范设计是一致的
50 | 5、ip层 负责路由等逻辑,并执行nf_hook,也就是netfilter。netfilter是工作于内核空间当中的一系列网络(TCP/IP)协议栈的钩子(hook),为内核模块在网络协议栈中的不同位置注册回调函数(callback)。也就是说,在数据包经过网络协议栈的不同位置时做相应的由iptables配置好的处理逻辑。
51 | 6、link 层,先寻找下一跳(ip ==> mac),有了 MAC 地址,就可以调用 dev_queue_xmit发送二层网络包了,它会调用 `__dev_xmit_skb` 会将请求放入块设备的队列。同时还会处理一些vlan 的逻辑
52 | 7、设备层:网卡是发送和接收网络包的基本设备。在系统启动过程中,网卡通过内核中的网卡驱动程序注册到系统中。而在网络收发过程中,内核通过中断跟网卡进行交互。网络包的发送会触发一个软中断 NET_TX_SOFTIRQ 来处理队列中的数据。这个软中断的处理函数是 net_tx_action。在软中断处理函数中,会将网络包从队列上拿下来,调用网络设备的传输函数 ixgb_xmit_frame,将网络包发的设备的队列上去。
53 |
54 | 
55 |
56 | 网卡中断处理程序为网络帧分配的,内核数据结构 sk_buff 缓冲区;是一个维护网络帧结构的双向链表,链表中的每一个元素都是一个网络帧(Packet)。**虽然 TCP/IP 协议栈分了好几层,但上下不同层之间的传递,实际上只需要操作这个数据结构中的指针,而无需进行数据复制。**
57 |
58 | ## 网络与文件操作
59 |
60 | 
61 |
62 | VFS为文件系统抽象了一套API,实现了该系列API就可以把对应的资源当作文件使用,当调用socket函数的时候,我们拿到的不是socket本身,而是一个文件描述符fd。
63 |
64 | 
65 |
66 | 从linux5.9看网络层的设计整个网络层的实际中,主要分为socket层、af_inet层和具体协议层(TCP、UDP等)。当使用网络编程的时候,首先会创建一个socket结构体(socket层),socket结构体是最上层的抽象,然后通过协议簇类型创建一个对应的sock结构体,sock是协议簇抽象(af_inet层),同一个协议簇下又分为不同的协议类型,比如TCP、UDP(具体协议层),然后根据socket的类型(流式、数据包)找到对应的操作函数集并赋值到socket和sock结构体中,后续的操作就调用对应的函数就行,调用某个网络函数的时候,会从socket层到af_inet层,af_inet做了一些封装,必要的时候调用底层协议(TCP、UDP)对应的函数。而不同的协议只需要实现自己的逻辑就能加入到网络协议中。
67 |
68 | file_operations 结构定义了普通文件操作函数集。系统中每个文件对应一个 file 结构, file 结构中有一个 file_operations 变量,当使用 write,read 函数对某个文件描述符进行读写操作时,系统首先根据文件描述符索引到其对应的 file 结构,然后调用其成员变量 file_operations 中对应函数完成请求。
69 |
70 | ```c
71 | // 参见socket.c
72 | static struct file_operations socket_file_ops = {
73 | sock_lseek, // δʵÏÖ
74 | sock_read,
75 | sock_write,
76 | sock_readdir, // δʵÏÖ
77 | sock_select,
78 | sock_ioctl,
79 | NULL, /* mmap */
80 | NULL, /* no special open code... */
81 | sock_close,
82 | NULL, /* no fsync */
83 | sock_fasync
84 | };
85 | ```
86 |
87 | 以上 socket_file_ops 变量中声明的函数即是网络协议对应的普通文件操作函数集合。从而使得read, write, ioctl 等这些常见普通文件操作函数也可以被使用在网络接口的处理上。kernel维护一个struct file list,通过fd ==> struct file ==> file->ops ==> socket_file_ops,便可以以文件接口的方式进行网络操作。同时,每个 file 结构都需要有一个 inode 结构对应。用于存储struct file的元信息
88 |
89 | ```c
90 | struct inode{
91 | ...
92 | union {
93 | ...
94 | struct ext_inode_info ext_i;
95 | struct nfs_inode_info nfs_i;
96 | struct socket socket_i;
97 | }u
98 | }
99 | ```
100 |
101 | 也就是说,对linux系统,一切皆文件,由struct file描述,通过file->ops指向具体操作,由file->inode 存储一些元信息。对于ext文件系统,是载入内存的超级块、磁盘块等数据。对于网络通信,则是待发送和接收的数据块、网络设备等信息。从这个角度看,struct socket和struct ext_inode_info 等是类似的。
102 |
103 | ## 数据结构
104 |
105 | ### sk_buff结构
106 |
107 | sk_buff部分字段如下,
108 |
109 | ```c
110 | struct sk_buff {
111 | /* These two members must be first. */
112 | struct sk_buff *next;
113 | struct sk_buff *prev;
114 |
115 | struct sk_buff_head *list;
116 | struct sock *sk;
117 | struct timeval stamp;
118 | struct net_device *dev;
119 | struct net_device *real_dev;
120 |
121 | union {
122 | struct tcphdr *th;
123 | struct udphdr *uh;
124 | struct icmphdr *icmph;
125 | struct igmphdr *igmph;
126 | struct iphdr *ipiph;
127 | unsigned char *raw;
128 | } h; // Transport layer header
129 |
130 | union {
131 | struct iphdr *iph;
132 | struct ipv6hdr *ipv6h;
133 | struct arphdr *arph;
134 | unsigned char *raw;
135 | } nh; // Network layer header
136 |
137 | union {
138 | struct ethhdr *ethernet;
139 | unsigned char *raw;
140 | } mac; // Link layer header
141 |
142 | struct dst_entry *dst;
143 | struct sec_path *sp;
144 |
145 | void (*destructor)(struct sk_buff *skb);
146 |
147 | /* These elements must be at the end, see alloc_skb() for details. */
148 | unsigned int truesize;
149 | atomic_t users;
150 | unsigned char *head,
151 | *data,
152 | *tail,
153 | *end;
154 | };
155 | ```
156 |
157 | head和end字段指向了buf的起始位置和终止位置。然后使用header指针指像各种协议填值。然后data就是实际数据。tail记录了数据的偏移值。
158 |
159 | sk_buff 是各层通用的,在应用层数据包叫 data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为 frame。下层协议将上层协议数据作为data部分,并加上自己的header。这也是为什么代码注释中说,哪些字段必须在最前,哪些必须在最后, 这个其中的妙处可以自己体会。
160 |
161 | sk_buff由sk_buff_head组织
162 |
163 | ```c
164 | struct sk_buff_head {
165 | struct sk_buff * volatile next;
166 | struct sk_buff * volatile prev;
167 | #if CONFIG_SKB_CHECK
168 | int magic_debug_cookie;
169 | #endif
170 | };
171 | ```
172 |
173 | 
174 |
175 | ### 网络协议栈实现——数据struct 和 协议struct
176 |
177 | socket分为多种,除了inet还有unix。反应在代码结构上,就是net包下只有net/unix,net/inet两个文件夹。之所以叫unix域,可能跟描述其地址时,使用unix://xxx有关
178 |
179 | The difference is that an INET socket is bound to an IP address-port tuple, while a UNIX socket is “bound” to a special file on your filesystem. Generally, only processes running on the same machine can communicate through the latter.
180 |
181 | 本文重点是inet,net/inet下有以下几个比较重要的文件,这跟网络书上的知识就对上了。
182 |
183 | ```
184 | arp.c
185 | eth.c
186 | ip.c
187 | route.c
188 | tcp.c
189 | udp.c
190 | datalink.h // 应该是数据链路层
191 | ```
192 |
193 | 
194 |
195 | 怎么理解整个表格呢?协议struct和数据struct有何异同?
196 |
197 | 1、struct一般由一个数组或链表组织,数组用index,链表用header(比如packet_type_base、inet_protocol_base)指针查找数据。
198 | 2、协议struct是怎么回事呢?通常是一个函数操作集,类似于controller-server-dao之间的interface定义,类似于本文开头的file_operations,有open、close、read等方法,但对ext是一回事,对socket操作是另一回事。
199 | 3、数据struct实例可以有很多,比如一个主机有多少个连接就有多少个struct sock,而协议struct个数由协议类型个数决定,具体的协议struct比如tcp_prot就只有一个。比较特别的是,通过tcp_prot就可以找到所有的struct sock实例。
200 | 4、socket、sock、device等数据struct经常被作为分析的重点,其实各种协议struct 才是流程的关键,并且契合了网络协议分层的理念。
201 |
202 | 以ip.c为例,在该文件中定义了ip_rcv(读数据)、ip_queue_xmit(用于写数据),链路层收到数据后,通过ptype_base找到ip_packet_type,进而执行ip_rcv。tcp发送数据时,通过tcp_proto找到ip_queue_xmit并执行。
203 |
204 | tcp_protocol是为了从下到上的数据接收,其函数集主要是handler、frag_handler和err_handler,对应数据接收后的处理。tcp_prot是为了从上到下的数据发送(所以struct proto没有icmp对应的结构),其函数集connect、read等主要对应上层接口方法。
205 |
206 | 到bsd socket层,相关的结构在/include/linux下定义,而不是在net包下。这就对上了,bsd socket是一层接口规范,而net包下的相关struct则是linux自己的抽象了。
207 |
208 | 主要要搞清楚三个问题,具体可以参见相关的书籍,此处不详述。参见Linux1.0中的Linux1.2.13内核网络栈源码分析的第四章节。
209 |
210 | 1、这些结构如何初始化。有的结构直接就是定义好的,比如tcp_protocol等
211 | 2、如何接收数据。由中断程序触发。接收数据的时候,可以得到device,从数据中可以取得协议数据,进而从ptype_base及inet_protocol_base执行相应的rcv
212 | 3、如何发送数据。通常不直接发送,先发到queue里。可以从socket初始化时拿到protocol类型(比如tcp)、目的ip,通过route等决定device,于是一路向下执行xx_write方法
213 |
214 | ## 面向过程/对象/ioc
215 |
216 | 
217 |
218 | 
219 |
220 | 重要的不是细节,这个过程让我想到了web编程中的controller,service,dao。都是分层,区别是web请求要立即返回,网络通信则不用。
221 |
222 | mac ==> device ==> ip_rcv ==> tcp_rcv ==> 上层
223 | url ==> controller ==> service ==> dao ==> 数据库
224 | 想一想,整个网络协议栈,其实就是一群loopbackController、eth0Controller、ipService、TcpDao组成,该是一件多么有意思的事。
225 |
226 | 
227 |
228 | ## 其它
229 | 无论 TCP 还是 UDP,端口号都只占 16 位,也就说其最大值也只有 65535。那是不是说,如果使用 TCP 协议,在单台机器、单个 IP 地址时,并发连接数最大也只有 65535 呢?对于这个问题,首先你要知道,Linux 协议栈,通过五元组来标志一个连接(即协议,源 IP、源端口、目的 IP、目的端口)。对客户端来说,每次发起 TCP 连接请求时,都需要分配一个空闲的本地端口,去连接远端的服务器。由于这个本地端口是独占的,所以客户端最多只能发起 65535 个连接。对服务器端来说,其通常监听在固定端口上(比如 80 端口),等待客户端的连接。根据五元组结构,我们知道,客户端的 IP 和端口都是可变的。如果不考虑 IP 地址分类以及资源限制,服务器端的理论最大连接数,可以达到 2 的 48 次方(IP 为 32 位,端口号为 16 位),远大于 65535。服务器端可支持的连接数是海量的,当然,由于 Linux 协议栈本身的性能,以及各种物理和软件的资源限制等,这么大的连接数,还是远远达不到的(实际上,C10M 就已经很难了)。
230 |
231 | 软中断有专门的内核线程 ksoftirqd处理。每个 CPU 都会绑定一个 ksoftirqd 内核线程,比如, 2 个 CPU 时,就会有 ksoftirqd/0 和 ksoftirqd/1 这两个内核线程。
232 |
233 |
--------------------------------------------------------------------------------
/文章/设备驱动/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/文章/设备驱动/Linux 总线、设备、驱动模型的探究.md:
--------------------------------------------------------------------------------
1 | ## 设备驱动模型的需求
2 |
3 | 总线、设备和驱动模型,如果把它们之间的关系比喻成生活中的例子是比较容易理解的。举个例子,充电墙壁插座安静的嵌入在墙面上,无论设备是电脑还是手机,插座都能依然不动的完成它的使命——充电,没有说为了满足各种设备充电而去更换插座的。其实这就是软件工程强调的高内聚、低耦合概念。
4 |
5 | 所谓高内聚低耦合是模块内各元素联系越紧密就代表内聚性就越高,模块间联系越不紧密就代表耦合性低。所以高内聚、低耦合强调的就是内部要紧紧抱团。设备和驱动就是基于这种模型去实现彼此隔离不相干的。这里,有的读者就要问了,高内聚、低耦合的软件模型理解,可设备和驱动为什么要采用这种模型呢?没错,好问题。下面进入今天的话题——总线、设备和驱动模型的探究。
6 |
7 | 设想一个叫 GITCHAT 的网卡,它需要接在 CPU 的内部总线上,需要地址总线、数据总线和控制总线,以及中断 pin 脚等。
8 |
9 | 
10 |
11 | 那么在 GITCHAT 的驱动里需要定义 GITCHAT 的基地址、中断号等信息。假设 GITCHAT 的地址为0x0001,中断号是 2,那么:
12 |
13 | ```c
14 | #define GITCHAT_BASE 0x0001
15 | #define GITCHAT_INTERRUPT 2
16 |
17 | int gitchat_send()
18 | {
19 | writel(GITCHAT_BASE + REG, 1);
20 | ...
21 | }
22 |
23 | int gitchat_init()
24 | {
25 | request_init(GITCHAT_INTERRUPT, ...);
26 | ...
27 | }
28 | ```
29 |
30 | 但是世界上的板子千千万,有三星、华为、飞思卡尔……每个板子的信息也都不一样,站在驱动的角度看,当每次重新换板子的时候,`GITCHAT_BASE` 和 `GITCHAT_INTERRUPT` 就不再一样,那驱动代码也要随之改变。这样的话一万个开发板要写一万个驱动了,这就是文章刚开始提到的高内聚、低耦合的应用场景。
31 |
32 | 驱动想以不变应万变的姿态适配各种设备连接的话就要实现设备驱动模型。基本上我们可以认为驱动不会因为 CPU 的改变而改变,所以它应该是跨平台的。自然像 `“#define GITCHAT_BASE 0x0001,#define GITCHAT_INTERRUPT 2”` 这样描述和 CPU 相关信息的代码不应该出现在驱动里。
33 |
34 | ## 设备驱动模型的实现
35 |
36 | 现在 CPU 板级信息和驱动分开的需求已经刻不容缓。但是基地址、中断号等板级信息始终和驱动是有一定联系的,因为驱动毕竟要取出基地址、中断号等。怎么取?有一种方法是 GITCHAT 驱动满世界去询问各个板子:请问你的基地址是多少?中断号是几?细心的读者会发现这仍然是一个耦合的情况。
37 |
38 | 
39 |
40 | 对软件工程熟悉的读者肯定立刻想到能不能设计一个类似接口适配器的类(adapter)去适配不同的板级信息,这样板子上的基地址、中断号等信息都在一个 adapter 里去维护,然后驱动通过这个 adapter 不同的 API 去获取对应的硬件信息。没错,Linux 内核里就是运用了这种设计思想去对设备和驱动进行适配隔离的,只不过在内核里我们不叫做适配层,而取名为总线,意为通过这个总线去把驱动和对应的设备绑定一起,如图:
41 |
42 | 
43 |
44 | 基于这种设计思想,Linux 把设备驱动分为了总线、设备和驱动三个实体,这三个实体在内核里的职责分别如下:
45 |
46 | 
47 |
48 | 模型设计好后,下面来看一下具体驱动的实践,首先把板子的硬件信息填入设备端,然后让设备向总线注册,这样总线就间接的知道了设备的硬件信息。比如一个板子上有一个 GITCHAT,首先向总线注册:
49 |
50 | ```c
51 | static struct resource gitchat_resource[] = {
52 | {
53 | .start = ...,
54 | .end = ...,
55 | .flags = IORESOURCE_MEM
56 | }...
57 | };
58 |
59 | static struct platform_device gitchat_device = {
60 | .name = "gitchat";
61 | .id = 0;
62 | .num_resources = ARRAY_SIZE(gitchat_resource);
63 | .resource = gitchat_resource,
64 | };
65 |
66 | static struct platform_device *ip0x_device __initdata = {
67 | &gitchat_device,
68 | ...
69 | };
70 |
71 | static ini __init ip0x_init(void)
72 | {
73 | platform_add_devices(ip0x_device, ARRAY_SIZE(ip0x_device));
74 | }
75 | ```
76 | 现在 platform 总线上自然知道了板子上关于 GITCHAT 设备的硬件信息,一旦 GITCHAT 的驱动也被注册的话,总线就会把驱动和设备绑定起来,从而驱动就获得了基地址、中断号等板级信息。总线存在的目的就是把设备和对应的驱动绑定起来,让内核成为该是谁的就是谁的和谐世界,有点像我们生活中红娘的角色,把有缘人通过红线牵在一起。设备注册总线的代码例子看完了,下面看下驱动注册总线的代码示例:
77 |
78 | ```c
79 | static struct resource gitchat_resource[] = {
80 | {
81 | .start = ...,
82 | .end = ...,
83 | .flags = IORESOURCE_MEM
84 | }...
85 | };
86 |
87 | static struct platform_device gitchat_device = {
88 | .name = "gitchat";
89 | .id = 0;
90 | .num_resources = ARRAY_SIZE(gitchat_resource);
91 | .resource = gitchat_resource,
92 | };
93 |
94 | static struct platform_device *ip0x_device __initdata = {
95 | &gitchat_device,
96 | ...
97 | };
98 |
99 | static ini __init ip0x_init(void)
100 | {
101 | platform_add_devices(ip0x_device, ARRAY_SIZE(ip0x_device));
102 | }
103 | ```
104 |
105 | 现在 platform 总线上自然知道了板子上关于 GITCHAT 设备的硬件信息,一旦 GITCHAT 的驱动也被注册的话,总线就会把驱动和设备绑定起来,从而驱动就获得了基地址、中断号等板级信息。总线存在的目的就是把设备和对应的驱动绑定起来,让内核成为该是谁的就是谁的和谐世界,有点像我们生活中红娘的角色,把有缘人通过红线牵在一起。设备注册总线的代码例子看完了,下面看下驱动注册总线的代码示例:
106 |
107 | ```c
108 | static int gitchat_probe(struct platform_device *pdev)
109 | {
110 | ...
111 | db->addr_res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
112 | db->data_res = platform_get_resource(pdev, IORESOURCE_MEM, 1);
113 | db->irq_res = platform_get_resource(pdev, IORESOURCE_IRQ, 2);
114 | ...
115 | }
116 | ```
117 | 从代码中看到驱动是通过总线 API 接口 platform_get_resource 取得板级信息,这样驱动和设备之间就实现了高内聚、低耦合的设计,无论你设备怎么换,我驱动就可以岿然不动。
118 |
119 | 看到这里,可能有些喜欢探究本质的读者又要问了,设备向总线注册了板级信息,驱动也向总线注册了驱动模块,但总线是怎么做到驱动和设备匹配的呢?接下来就讲下设备和驱动是怎么通过总线进行“联姻”的。
120 |
121 | 总线里有很多匹配方式,比如:
122 |
123 | ```c
124 | static int platform_match(struct device *dev, struct device_driver *drv)
125 | {
126 | struct platform_device *pdev = to_platform_device(dev);
127 | struct platform_driver *pdrv = to_platform_driver(drv);
128 |
129 | /* When driver_override is set, only bind to the matching driver */
130 | if (pdev->driver_override)
131 | return !strcmp(pdev->driver_override, drv->name);
132 |
133 | /* Attempt an OF style match first */
134 | if (of_driver_match_device(dev, drv))
135 | return 1;
136 |
137 | /* Then try ACPI style match */
138 | if (acpi_driver_match_device(dev, drv))
139 | return 1;
140 |
141 | /* Then try to match against the id table */
142 | if (pdrv->id_table)
143 | return platform_match_id(pdrv->id_table, pdev) != NULL;
144 |
145 | /* fall-back to driver name match */
146 | return (strcmp(pdev->name, drv->name) == 0);
147 | }
148 | ```
149 | 从上面可知 platform 总线下的设备和驱动是通过名字进行匹配的,先去匹配 platform_driver 中的 id_table 表中的各个名字与 platform_device->name 名字是否相同,如果相同则匹配。
150 |
151 | ## 设备驱动模型的改善
152 |
153 | 
154 |
155 | 最底层是不同板子的板级文件代码,中间层是内核的总线,最上层是对应的驱动,现在描述板级的代码已经和驱动解耦了,这也是 Linux 设备驱动模型最早的实现机制,但随着时代的发展,就像是人类的贪婪促进了社会的进步一样,开发人员对这种模型有了更高的要求,虽然驱动和设备解耦了,但是天下设备千千万,每次设备的需求改动都要去修改 board-xxx.c 设备文件的话,这样下去,有太多的板级文件需要维护。完美的 Linux 怎么会允许这样的事情存在,于是乎,设备树(DTS)就登向了历史舞台
156 |
157 |
158 |
159 |
160 |
--------------------------------------------------------------------------------
/文章/设备驱动/Linux 设备和驱动的相遇.md:
--------------------------------------------------------------------------------
1 | 本文结合设备信息集合的详细讲解来认识一下设备和驱动是如何绑定的。所谓设备信息集合,就是根据不同的外设寻找各自的外设信息,我们知道一个完整的开发板有 CPU 和各种控制器(如 I2C 控制器、SPI 控制器、DMA 控制器等),CPU 和控制器可以统称为 SOC,除此之外还有各种外设 IP,如 LCD、HDMI、SD、CAMERA 等,如下图:
2 |
3 | 
4 |
5 | 我们看到一个开发板有很多的设备,这些设备是如何一层一层展开的呢?设备和驱动又是如何绑定的呢?我们带着这些疑问进入本节的主题。
6 |
7 | ## 各级设备的展开
8 |
9 | 内核启动的时候是一层一层展开地去寻找设备,设备树之所以叫设备树也是因为设备在内核中的结构就像树一样,从根部一层一层的向外展开,为了更形象的理解来看一张图:
10 |
11 | 
12 |
13 |
14 | 大的圆圈中就是我们常说的 soc,里面包括 CPU 和各种控制器 A、B、I2C、SPI,soc 外面接了外设 E 和 F。IP 外设有具体的总线,如 I2C 总线、SPI 总线,对应的 I2C 设备和 SPI 设备就挂在各自的总线上,但是在 soc 内部只有系统总线,是没有具体总线的。
15 |
16 | 第一节中讲了总线、设备和驱动模型的原理,即任何驱动都是通过对应的总线和设备发生联系的,故虽然 soc 内部没有具体的总线,但是内核通过 platform 这条虚拟总线,把控制器一个一个找到,一样遵循了内核高内聚、低耦合的设计理念。下面我们按照 platform 设备、i2c 设备、spi 设备的顺序探究设备是如何一层一层展开的。
17 |
18 | ### 1.展开 platform 设备
19 |
20 | 上图中可以看到红色字体标注的 simple-bus,这些就是连接各类控制器的总线,在内核里即为 platform 总线,挂载的设备为 platform 设备。下面看下 platform 设备是如何展开的。
21 |
22 | 还记得上一节讲到在内核初始化的时候有一个叫做 `init_machine()` 的回调函数吗?如果你在板级文件里注册了这个函数,那么在系统启动的时候这个函数会被调用,如果没有定义,则会通过调用 of_platform_populate() 来展开挂在“simple-bus”下的设备,如图(分别位于 kernel/arch/arm/kernel/setup.c,kernel/drivers/of/platform.c):
23 |
24 | 
25 |
26 | 这样就把 simple-bus 下面的节点一个一个的展开为 platform 设备。
27 |
28 | ### 2.展开 i2c 设备
29 |
30 | 有经验的小伙伴知道在写 i2c 控制器的时候肯定会调用 `i2c_register_adapter()` 函数,该函数的实现如下(kernel/drivers/i2c/i2c-core.c):
31 |
32 | 
33 |
34 |
35 | 注册函数的最后有一个函数 `of_i2c_register_devices(adap)`,实现如下:
36 |
37 | 
38 |
39 | `of_i2c_register_devices()`函数中会遍历控制器下的节点,然后通过`of_i2c_register_device()`函数把 i2c 控制器下的设备注册进去。
40 |
41 | ### 3.展开 spi 设备
42 |
43 | spi 设备的注册和 i2c 设备一样,在 spi 控制器下遍历 spi 节点下的设备,然后通过相应的注册函数进行注册,只是和 i2c 注册的 api 接口不一样,下面看一下具体的代码(kernel/drivers/spi/spi.c):
44 |
45 | 
46 |
47 |
48 | 当通过 spi_register_master 注册 spi 控制器的时候会通过 of_register_spi_devices 来遍历 spi 总线下的设备,从而注册。这样就完成了 spi 设备的注册。
49 |
50 | ## 各级设备的展开
51 |
52 | 学到这里相信应该了解设备的硬件信息是从设备树里获取的,如寄存器地址、中断号、时钟等等。接下来我们一起看下这些信息在设备树里是怎么记录的,为下一节动手定制开发板做好准备。
53 |
54 | ### 1.reg 寄存器
55 |
56 | 
57 |
58 | 我们先看设备树里的 soc 描述信息,红色标注的代表着寄存器地址用几个数据量来表述,绿色标注的代表着寄存器空间大小用几个数据量来表述。图中的含义是中断控制器的基地址是 0xfec00000,空间大小是 0x1000。如果 address-cells 的值是 2 的话表示需要两个数量级来表示基地址,比如寄存器是 64 位的话就需要两个数量级来表示,每个代表着 32 位的数。
59 |
60 | ## 2.ranges 取值范围
61 |
62 | 
63 |
64 | ranges 代表了 local 地址向 parent 地址的转换,如果 ranges 为空的话代表着与 cpu 是 1:1 的映射关系,如果没有 range 的话表示不是内存区域。
65 |
66 |
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 |
75 |
76 |
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 |
85 |
86 |
87 |
--------------------------------------------------------------------------------
/文章/进程管理/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/文章/进程管理/Linux进程、线程、调度(一).md:
--------------------------------------------------------------------------------
1 | 希望可以通过本小结 彻底地搞清楚进程生命周期,进程生命周期创建、退出、停止,以及僵尸进程的本质;
2 |
3 | 进程 是处于执行期的程序以及相关的资源的总称,是操作系统资源分配的单位。
4 |
5 | ```
6 | 进程的资源到底包括什么?
7 | 1.打开的文件
8 | 2.挂起的信号
9 | 3.内核的内部数据
10 | 4.处理器的状态
11 | 5.内存映射的内存地址空间 等等
12 | ```
13 |
14 | Linux系统 对线程和进程并不特别区分。线程仅仅被视为一个与其他线程共享某些资源的进程。每个线程都拥有唯一自己的task_struct。
15 |
16 | 内核调度的对象是根据task_struct结构体。可以说是线程,而不是进程。
17 |
18 | 不仅仅要有资源,还需要有进程的描述,例如:pid
19 |
20 | ### 进程描述符及task_struct
21 | linux通过task_struct结构体描述一个进程。
22 |
23 | mm 成员:描述内存资源
24 | fs 成员:描述文件系统资源
25 | files 成员:进程运行时打开了多少文件,fd的数组
26 | signal 成员:进程接收的信号资源
27 |
28 | 
29 |
30 | Linux通过slab分配器分配task_struct结构,只需在栈底创建新的结构,struct thread_info。
31 | 每个任务的thread_info结构在它的内核栈的尾端分配。
32 |
33 | pid的数量是有限的
34 |
35 | $ cat /proc/sys/kernel/pid_max
36 | 32768
37 |
38 | task_struct被管理
39 | 形成链表 --> 形成树 -->形成哈希: pid --> task_struct
40 |
41 | 根据哈希来进行pid检索
42 |
43 | ### Linux进程生命周期(就绪、运行、睡眠、停止、僵死)
44 |
45 | 
46 |
47 | ### 进程、线程、协程
48 | 在linux系统里,进程和线程都是通过task_struct结构体来描述。
49 | 进程之间不共享地址空间,而线程与创建它的进程是共享地址空间的。
50 |
51 | 线程又分为:内核线程、用户级线程和 协程。
52 |
53 | 对于I/O密集型场景,就算开多个线程来处理,也未必能提升CPU的利用率,反而会增加线程切换的开销。
54 |
55 | 此外,多线程之间如果存在临界区或者共享数据,那么同步的开销也不容忽视。
56 |
57 | 而协程就是用来解决这个问题的,一个用户线程上可以跑多个协程,以此提升单核的利用率。
58 |
59 | tips: Linux中对进程和线程创建的几个系统调用发现, 创建时最终都会调用do_fork()函数,不同之处是传入的参数不同(clone_flags),最终结果就是进程有独立的地址空间和栈 ,而用户线程 可以自己制定用户栈,地址空间和父进程共享,内核线程则 只有和内核共享的一个栈,同一个地址空间。 不管是进程还是线程,do_fork最终会创建一个task_struct结构。
60 |
61 | ### 什么是僵尸进程?
62 | 僵尸是子进程死了,资源已经释放。所以不可能有内存泄漏等。但是父进程还没有来得及去wait回收它。task_struct 还在,父进程可以查到子进程的死因。
63 |
64 | kill -9 僵尸进程,无效。 [a.out]< defunct> Z+
65 |
66 | 僵尸进程是一个特别短暂的状态。
67 |
68 | ### 停止状态与作业控制,cpulimit
69 |
70 | Linux在早期使用cpulimit 进行 cpu利用率控制。
71 | cpulimit 限制进程 CPU利用率的原理如上,利用进程的停止态。但是不是精确的。
72 | ```
73 | cpulimit -l 10 -p 12296 把进程12296CPU使用率控制在 10%以内
74 | cpulimit -l 40 -p 12296
75 | ```
76 | ctrl+z ,fg/bg
77 |
78 | ### 进程的睡眠
79 |
80 | 
81 |
82 | 深睡眠 和 浅睡眠,都是自发的。停止态是被动的。
83 |
84 | 深:必须等到资源才能wake_up.
85 | 浅:除了被资源wake_up,还可以被信号唤醒。
86 |
87 | 睡眠是主动的,暂停是人为的信号控制,属于作业控制。深度睡眠,只能在内核中进入。
88 |
89 | 睡眠态等到资源后,为什么不能直接进入运行态?
90 | 进程醒来后,优先级不一定是最高的。醒来后,先就绪。
91 |
92 | 执行应用程序代码段发生page fault,代码段还没有进内存。接下来,要从硬盘中读到内存,此时,会把进程设置到深度睡眠。
93 | 为什么?
94 | 发生两次pagefault,非常难控制。
95 |
96 | 进程的睡眠实现,依赖内核数据结构wait queue。类似设计模式的,发布者和订阅者。
97 |
98 | 进程P1,P2,P3,P4 把自己放在等待队列,资源来了只需要唤醒等待队列。等待队列类似订阅消息的中间媒介
99 |
100 | ### 初见fork
101 |
102 | ```c
103 | main()
104 | {
105 | fork();
106 | printf("hello\n");
107 | fork();
108 | printf("hello\n");
109 | while(1);
110 | }
111 | ```
112 | ### 内存泄漏的真实含义
113 | 内存泄漏,不是(进程死了,内存没释放),而是,进程活着,运行越久,耗费内存越多。
114 |
115 | 如何观察 内存泄漏?
116 |
117 | 连续多点观察法。
118 |
119 |
120 |
121 |
122 |
123 |
124 |
125 |
--------------------------------------------------------------------------------
/文章/进程管理/Linux进程、线程、调度(三).md:
--------------------------------------------------------------------------------
1 | 本节主要介绍进程的调度器,设计的目标:吞吐和响应,轮流让其他进程获取CPU资源。
2 |
3 | ### 进程调度机制的架构
4 | 操作系统通过中断机制,来周期性地触发调度算法进行进程的切换。
5 |
6 | * rq: 可运行队列,每个CPU对应一个,包含自旋锁,进程数量,用于公平调度的CFS结构体,当前正在运行的进程描述符。
7 | * cfs_rq: cfs调度的运行队列信息,包含红黑色的根节点,正在运行的进程指针,用于负载均衡的叶子队列等。
8 | * sched_entity: 调度实体,包含负载权重值,对应红黑树节点,虚拟运行时vruntime等。
9 | * sched_class: 调度算法抽象成的调度类,包含一组通用的调度操作接口,将接口和实现分离。
10 |
11 | 
12 |
13 | schedule函数的流程包括:
14 |
15 | 1、关闭内核抢占,标识cpu状态。通知RCU更新状态,关闭本地终端,获取所要保护的运行队列的自旋锁,为查找可运行进程做准备。
16 | 2、检查prev状态,决定是否将进程插入到运行队列,或者从运行队列中删除。
17 | 3、task_on_rq_queued(prev) : 将pre进程插入到运行队列的队尾。
18 | 4、pick_next_task : 选取下一个将要执行的进程。
19 | 5、context_switch(rq, prev, next) 进行进程上下文切换。
20 |
21 | ### CPU/IO消耗型进程
22 |
23 | 吞吐 vs. 响应
24 |
25 | * 响应:最小化某个任务的响应时间,哪怕牺牲其他的任务为代价。
26 | * 吞吐:全局视野,整个系统的workload被最大化处理。
27 | *
28 | 任何操作系统的调度器设计只追求2个目标:吞吐率大和延迟低。这2个目标有点类似零和游戏,因为吞吐率要大,势必要把更多的时间放在做真实的有用功,而不是把时间浪费在频繁的进程上下文切换;而延迟要低,势必要求优先级高的进程可以随时抢占进来,打断别人,强行插队。但是,抢占会引起上下文切换,上下文切换的时间本身对吞吐率来讲,是一个消耗,这个消耗可以低到2us或者更低(这看起来没什么?),但是上下文切换更大的消耗不是切换本身,而是切换会引起大量的cache miss。你明明weibo跑的很爽,现在切过去微信,那么CPU的cache是不太容易命中微信的。
29 |
30 | 操作系统中估算"上下文切换"对吞吐能力影响时,不是计算上下文切换本身,而是在CPU 高速cache中的miss。一旦从一个进程切到另一个进程,会造成比较多的cache miss,从而影响吞吐能力。
31 |
32 | 在内核编译的时候,Kernel Features ---> Preemption Model选项实际上可以让我们编译内核的时候,是倾向于支持吞吐,还是支持响应
33 |
34 | preemption model:选择内核的抢占模型,影响调度算法
35 | 1、No Forced Preemption (Server): 不强制抢占,更在意吞吐,支撑比较大的连接等。
36 | 2、Voluntary kernel preemption (Desktop): 内核不能抢占。
37 | 3、Preemtible Kernel(low-latency desktop): 内核都可以抢占,更在意响应,滑动触摸屏等操作需要立刻响应。
38 |
39 | I/O消耗型 vs. CPU消耗型
40 |
41 | * IO bound: CPU利用率低,进程的运行效率主要受限于I/O速度;
42 | * tips: IO 消耗型对拿到CPU(延迟)比较敏感,应该被优先调度。一般需要CPU的响应速度快,即优先级要求比较高。
43 | * CPU bound: 多数时间花在CPU上面(做运算);
44 |
45 | ### 调度算法: 策略 + 优先级
46 | 早期2.6调度器:优先级数组 和 Bitmaps
47 |
48 | * 0~ 139: 在内核空间, 把整个Linux优先级划分为0~139,数字越小,优先级越高。用户空间设置时,是反过来的。
49 | * 某个优先级有TASK_RUNNING进程,响应bit设置1。
50 | * 调度第一个bitmap设置为1的进程
51 |
52 | 
53 |
54 | #### SCHED_FIFO、SCHED_RR
55 |
56 | 实时(RT)进程调度策略: 0~99采用的RT,100~139是非RT的。
57 |
58 | * SCHED_FIFO: 不同优先级按照优先级高的先跑到睡眠,优先级低的再跑;同等优先级先进先出。
59 | * SCHED_RR:不同优先级按照优先级高的先跑到睡眠,优先级低的再跑;同等优先级轮转。
60 |
61 | 
62 |
63 | 当所有的SCHED_FIFO和SCHED_RR都运行至睡眠态,就开始运行 100~139之间的 普通task_struct。这些进程讲究 nice,
64 |
65 | #### SCHED_NORMAL
66 |
67 | **非实时进程的调度和动态优先级:**
68 |
69 | 早期内核2.6的调度器,100对应nice值为 -20,139对应nice值为19。对于普通进程,优先级高不会形成对优先级低的绝对优势,并不会阻塞优先级低的进程拿到时间片。
70 | 普通进程在不同优先级之间进行轮转,nice值越高,优先级越低。此时优先级的具体作用是:
71 |
72 | 1、时间片。优先级高的进程可以得到更多时间片。
73 | 2、抢占。从睡眠状态到醒来,可以优先去抢占优先级低的进程。
74 | **Linux根据睡眠情况,动态奖励和惩罚。** 越睡,优先级越高。想让CPU消耗型进程和IO消耗型进程竞争时,IO消耗型的进程可以竞争过CPU消耗型。
75 |
76 | #### rt的门限
77 | Linux内核在period的时间里RT最多只能跑runtime的时间。
78 | 在参数 /proc/sys/kernel/sched_rt_period_us 和 /proc/sys/kernel/sched_rt_runtime_us 中设置。单位:微秒。
79 |
80 | #### CFS 完全公平调度
81 | 后期,Linux对普通进程调度,提供了 完全公平调度算法,每次都会调vruntime最小的进程调度。
82 |
83 | 红黑树,左边节点小于右边节点的值,运行到目前为止 (vruntime最小)的进程,同时考虑了CPU/IO和nice。
84 |
85 | 
86 |
87 | 
88 |
89 | vruntime: virtual runtime,= pruntime/weight 权重* 系数。
90 |
91 | 随着时间运行,分子pruntime变大,vruntime也就变大,优先级变低。喜欢睡眠、IO消耗型的进程,分子小。nice值低的,分母大。但是RT的进程,优先级高于所有普通的进程。
92 |
93 | 红黑树实现的CFS,用分子pruntime来照顾 睡眠情况,用分母来照顾nice值。
94 |
95 | 当进程里fork了多个线程,每个线程的 调度策略都可以不同,优先级可以不同。原因显然。
96 |
97 | #### 工具 chrt 和 renice
98 |
99 | ```c
100 | #include
101 | #include
102 | #include
103 | #include
104 |
105 | void *thread_fun(void *param)
106 | {
107 | printf("thread pid:%d, tid:%lu\n", getpid(), pthread_self());
108 | while (1) ;
109 | return NULL;
110 | }
111 |
112 | int main(void)
113 | {
114 | pthread_t tid1, tid2;
115 | int ret;
116 | printf("main pid:%d, tid:%lu\n", getpid(), pthread_self());
117 | ret = pthread_create(&tid1, NULL, thread_fun, NULL);
118 | if (ret == -1) {
119 | perror("cannot create new thread");
120 | return 1;
121 | }
122 | ret = pthread_create(&tid2, NULL, thread_fun, NULL);
123 | if (ret == -1) {
124 | perror("cannot create new thread");
125 | return 1;
126 | }
127 | if (pthread_join(tid1, NULL) != 0) {
128 | perror("call pthread_join function fail");
129 | return 1;
130 | }
131 | if (pthread_join(tid2, NULL) != 0) {
132 | perror("call pthread_join function fail");
133 | return 1;
134 | }
135 | return 0;
136 | }
137 |
138 | 1.编译two-loops.c, gcc two-loops.c -pthread,运行两份
139 | root@whale:~/develop$ gcc two-loops.c -pthread
140 | root@whale:~/develop$ ./a.out &
141 | [1] 13682
142 | root@whale:~/develop$ main pid:13682, tid:3075434240
143 | thread pid:13682, tid:3067038528
144 | thread pid:13682, tid:3075431232
145 |
146 | root@whale:~/develop$ ./a.out &
147 | [2] 13685
148 | root@whale:~/develop$
149 | main pid:13685, tid:3075925760
150 | thread pid:13685, tid:3067530048
151 | thread pid:13685, tid:3075922752
152 |
153 | ### top命令观察CPU利用率:
154 | 13682 root 20 0 18684 616 552 S 98.4 0.0 1:12.09 a.out
155 | 13685 root 20 0 18684 644 580 S 98.1 0.0 1:07.32 a.out
156 |
157 | ### renice其中之一,再观察CPU利用率
158 |
159 | sudo renice -n -5 -g 13682
160 |
161 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
162 | 13682 root 15 -5 18684 616 552 S 147.4 0.0 4:52.73 a.out
163 | 13685 root 20 0 18684 644 580 S 48.6 0.0 4:12.77 a.out
164 |
165 | killall a.out
166 |
167 | 2.编译two-loops.c, gcc two-loops.c -pthread,运行一份
168 | top发现其CPU利用率接近200%
169 | -f:把它的所有线程设置为SCHED_FIFO
170 | -a : 所有线程
171 |
172 | chrt -f -a -p 50 进程PID
173 |
174 | 再观察它的CPU利用率
175 |
176 | 答:CPU利用率会下降,rt的限制,1s中只能占0.95。
177 | 此时虽然CPU使用率下降,但是服务器的响应更慢了。因为鼠标等应用的优先级没有a.out 这个进程的优先级高。
178 |
179 | ```
180 |
181 |
182 |
--------------------------------------------------------------------------------
/文章/进程管理/Linux进程、线程、调度(二).md:
--------------------------------------------------------------------------------
1 | ### fork 、vfork、clone
2 |
3 | 
4 |
5 | Linux 内核的调度算法,是根据task_struct结构体来进行调度的。
6 |
7 | ### 写时拷贝技术
8 |
9 | 当p1把p2创建出来时,会把task_struct里描述的资源结构体对拷给p2。
10 | 区分进程的标志,就是 p2的资源不是p1的资源。两个task_struct 的资源都相同,那就不叫两个进程了。
11 |
12 | 执行一个copy,但是任何修改都造成分裂,如:chroot,open,写memory,
13 | 最难copy的是 mm 这个部分,因为要做写时拷贝。
14 |
15 | Linux通过MMU进行虚拟地址到物理地址的转换,当进程执行fork()后,会把页表中的权限设置为RD-ONLY,当P1,P2去写该页时,CPU会收到page fault,申请新的内存。Linux再将页表中的virt1指向新的物理地址。
16 |
17 | 
18 |
19 | ```c
20 | #include
21 | #include
22 | #include
23 | #include
24 | int data = 10;
25 | int child_process()
26 | {
27 | printf("Child process %d, data %d\n",getpid(),data);
28 | data = 20;
29 | printf("Child process %d, data %d\n",getpid(),data);
30 | _exit(0);
31 | }
32 |
33 | int main(int argc, char* argv[])
34 | {
35 | int pid;
36 | pid = fork();
37 | if(pid==0) {
38 | child_process();
39 | }
40 | else{
41 | sleep(1);
42 | printf("Parent process %d, data %d\n",getpid(), data);
43 | exit(0);
44 | }
45 | }
46 | ```
47 |
48 | CoW,严重依赖CPU的MMU。Mmu-less Linux 无copy-on-write, 没有fork,而使用vfork。
49 |
50 | 使用vfork:父进程p1 vfork出子进程p2之后阻塞,直到子进程发生以下两种情况。
51 | 1) exit
52 | 2) exec
53 |
54 | 
55 |
56 | 进程执行vfork时,P2的task_struct中的*mm 与 P1共享,P1的内存资源就是P2的内存资源。
57 |
58 | pthread_create -> clone
59 |
60 | 
61 |
62 | Linux创建线程的API,本质上去调 clone。要求把P2的所有资源的指针,都指向P1。线程,也被称为 Light weight process。
63 |
64 | 而Linux在clone线程时也十分灵活,可以选择共享/不共享部分资源。
65 |
66 | 
67 |
68 | POSIX标准要求,进程里面如果有多个线程,在用户空间 getpid() 看到的都是同一个id,这个id其实是TGID。
69 |
70 | 一个进程里面创建了多个线程,在/proc 下 的是 tgid,/proc/tgid/task/{pidx,y,z}
71 |
72 | pthread_self() 看到的是用户空间pthread线程库里获得的id 。
73 |
74 | ```c
75 | #include
76 | #include
77 | #include
78 | #include
79 | #include
80 |
81 | static pid_t gettid( void )
82 | {
83 | return syscall(__NR_gettid);
84 | }
85 |
86 | static void *thread_fun(void *param)
87 | {
88 | printf("thread pid:%d, tid:%d pthread_self:%lu\n", getpid(), gettid(),pthread_self());
89 | while(1);
90 | return NULL;
91 | }
92 |
93 | int main(void)
94 | {
95 | pthread_t tid1, tid2;
96 | int ret;
97 | printf("thread pid:%d, tid:%d pthread_self:%lu\n", getpid(), gettid(),pthread_self());
98 | ret = pthread_create(&tid1, NULL, thread_fun, NULL);
99 |
100 | if (ret == -1) {
101 | perror("cannot create new thread");
102 | return -1;
103 | }
104 | ret = pthread_create(&tid2, NULL, thread_fun, NULL);
105 |
106 | if (ret == -1) {
107 | perror("cannot create new thread");
108 | return -1;
109 | }
110 | if (pthread_join(tid1, NULL) != 0) {
111 | perror("call pthread_join function fail");
112 | return -1;
113 | }
114 | if (pthread_join(tid2, NULL) != 0) {
115 | perror("call pthread_join function fail");
116 | return -1;
117 | }
118 | return 0;
119 | }
120 | ```
121 |
122 | ```
123 | gcc thread.c -pthread
124 | ```
125 | ### 总结 fork , vfork, clone
126 |
127 | 由于执行fork()引入了 写时拷贝并且明确了子进程先执行,所以 vfork()的好处就仅限于不拷贝父进程的页表项mm_struct。vfork()系统调用的实现是通过向clone()系统调用传递一个特殊标志来进行。
128 |
129 | vfork场景下父进程会先休眠,等唤醒子进程后,再唤醒父进程。
130 |
131 | 这么做的好处是:由于子进程被创建出来,与父进程共享地址空间,且只读。只有在执行exec的创建新的内存映射时才会拷贝父进程的数据,来创建新的地址空间。如果此时,父进程还在执行,就有可能产生脏数据,或发生死锁。
132 |
133 | ### 进程0和进程1
134 | init进程是被Linux 0进程创建,0进程把init进程fork出来后,就退化成IDLE进程。这个进程,是特殊调度类,所有进程都停止或睡眠后,就会调度进程0运行,此时处于CPU低功耗状态。
135 |
136 | ### 孤儿进程与托孤,subreaper
137 |
138 | 
139 |
140 | 当父进程退出后,子进程会寻找subreaper 或 init进程。
141 |
142 |
--------------------------------------------------------------------------------
/文章/进程管理/Linux进程、线程、调度(四).md:
--------------------------------------------------------------------------------
1 | 延续(三)中,调度器的其他内容:关于多核、分群、硬实时
2 |
3 | ### 多核下的负载均衡
4 | Linux 每个CPU可能有多个操作线程,每个核均运行的调度算法是 SCHED_FIFO, SCHED_RR,SCHED_NORMAL(CFS)等,每个核都“以劳动为乐”。
5 |
6 | tips: 旧的调度算法是通过+/- 5 nice值,来照顾IO型,惩罚CPU型。新的进程调度算法CFS,会根据ptime/nice值进行红黑树匹配。
7 |
8 | ```c
9 | #include
10 | #include
11 | #include
12 |
13 | void *thread_fun(void *param)
14 | {
15 | printf("thread pid:%d, tid:%lu\n", getpid(), pthread_self());
16 | while (1) ;
17 | return NULL;
18 | }
19 |
20 | int main(void)
21 | {
22 | pthread_t tid1, tid2;
23 | int ret;
24 | printf("main pid:%d, tid:%lu\n", getpid(), pthread_self());
25 | ret = pthread_create(&tid1, NULL, thread_fun, NULL);
26 | if (ret == -1) {
27 | perror("cannot create new thread");
28 | return 1;
29 | }
30 | ret = pthread_create(&tid2, NULL, thread_fun, NULL);
31 | if (ret == -1) {
32 | perror("cannot create new thread");
33 | return 1;
34 | }
35 | if (pthread_join(tid1, NULL) != 0) {
36 | perror("call pthread_join function fail");
37 | return 1;
38 | }
39 | if (pthread_join(tid2, NULL) != 0) {
40 | perror("call pthread_join function fail");
41 | return 1;
42 | }
43 | return 0;
44 | }
45 |
46 | 1.编译two-loops.c, gcc two-loops.c -pthread,运行:
47 | $ time ./a.out
48 | main pid:14958, tid:3075917568
49 | thread pid:14958, tid:3067521856
50 | thread pid:14958, tid:3075914560
51 | ^C
52 |
53 | real 1m10.050s
54 | user 2m20.016s
55 | sys 0m0.004s
56 |
57 | * 我们得到时间分布比例,理解2个死循环被均分到2个core。
58 | * (user+sys)/2=real ,原因:两个线程被Linux自动分配到两个核上,但是两个线程可能随机分配到任意CPU上运行。
59 | ```
60 | * RT进程(task_struct): 保证N个优先级最高的RT分布到N个核
61 | pull_rt_task()
62 | push_rt_task()
63 |
64 | RT的进程,更多强调的是实时性,因为优先级大于Normal 进程。例如,4核CPU,有8个RT的进程,会优先找其中4个优先级最高的让他们运行到4个核上。
65 |
66 | * 普通进程:
67 | 周期性负载均衡: 当操作系统的时钟节拍来临,会查这个核是否空闲,旁边一个核是否忙,当旁边的核忙到一定程度,会自动从旁边较忙的CPU核上,pull task过来。
68 | IDLE时负载均衡: 当CPU IDLE为0,会从旁边的CPU核上pull task。
69 | fork和exec时负载均衡:fork时会创建一个新的task_struct,会把这个task_struct放在最空闲的核上运行。
70 | 总结:每个核通过push/pull task来实现任务的负载均衡。所以,Linux上运行的多线程,可能会“动态”的出现在各个不同的CPU核上。
71 |
72 | ### 设置 CPU task affinity
73 | 程序员通过设置 affinity,即设置某个线程跟哪个CPU更亲和。
74 | 内核API提供了两个系统调用,让用户可以修改位掩码或查看当前的位掩码。
75 | 而该位掩码 , 正是对应 进程task_struct数据结构中的cpus_allowed属性,与cpu的每个逻辑核心一一对应。
76 |
77 | 
78 |
79 | 上图 np代表 none posix,比如电脑有7个核,但线程只想在第1、2个核上运行。就把cpu_set_t设置为 0x6,代表 110。如果线程只想在第2个核上,就设置为 0x4。
80 |
81 | 还可以通过 taskset工具 设置进程的线程在哪个CPU上跑。
82 |
83 | ```
84 | 2. 编译two-loops.c, gcc two-loops.c -pthread,运行一份
85 | top发现其CPU利用率接近200%
86 |
87 | 把它的所有线程affinity设置为01, 02, 03后分辨来看看CPU利用率
88 |
89 | taskset -a -p 02 进程PID
90 | taskset -a -p 01 进程PID
91 | taskset -a -p 03 进程PID
92 |
93 | 前两次设置后,a.out CPU利用率应该接近100%,最后一次接近200%
94 |
95 | 03代表,第1个或第2个CPU核上运行。
96 | -a 代表 进程下的所有线程。
97 |
98 | 运行结果:前两次,a.out程序CPU的使用率均为100%,第3次,a.out程序CPU的使用率为200%。
99 | ```
100 |
101 | ### 中断负载均衡、RPS软中断负载均衡
102 | IRQ affinity
103 |
104 | 中断也可以负载均衡,Linux每个中断号下面smp_affinity。
105 |
106 | * 分配IRQ到某个CPU
107 | [root@boss ~]# echo 01 > /proc/irq/145/smp_affinity
108 | [root@boss ~]# cat /proc/irq/145/smp_affinity
109 | 00000001
110 |
111 | 
112 |
113 | 比如上图,有个网卡有4个收发队列,分别是 74,75,76,77。把4个网卡收发队列的中断分别设置为01,02,04,08,那么这个网卡4个队列的中断就被均分到4个核上。
114 |
115 | 但是有些中断不能被负载均衡。比如,一张网卡只有1个队列,8个核。队列上的中断就发到1个核上。网卡中断里,CPU0收到一个中断irq之后,如果在这个irq中调用了soft irq,那么这个soft irq也会运行在CPU0。因为CPU0上中断中调度的软中断,也是会运行在CPU0上。那么这个核上 ,中断的负载和 软中断的负载 均很重,因为TCP/IP协议栈的处理,都丢到软中断中,此时网卡的吞吐率肯定上不来。
116 |
117 | 此时,出现了RPS补丁,实现 多核间的softIRQ 负载均衡
118 |
119 | * RPS将包处理负载均衡到多个CPU
120 |
121 | [root@whale~]# echo fffe > /sys/class/net/eth1/queues/rx-0/rps_cpus
122 | fffe
123 | [root@whale~]# watch -d "cat /proc/softirqs |grep NET_RX"
124 |
125 | 每个网卡的队列下面,均有一个文件 rps_cpus, 如果echo fffe到这个文件,就会让某个核上的软中断,负载均衡到0~15个核上。一般来说,CPU0上收到的中断,软中断都会在CPU0。但是CPU0会把收到中断的软中断派发到其他核上,这样其他核也可以处理TCP/IP收到的包处理的工作。
126 |
127 | ### cgroups和CPU资源分群分配
128 | 比如,有两个用户在OS上执行编译程序,用户A创建1000个线程,用户B创建32个线程。如果这1010个线程nice值均为0,那么按照CFS的调度算法,用户A可以拿到1000/1032的cpu时间片,用户B只能拿到 32/1032的cpu时间片。
129 |
130 | 此时,Linux通过分层调度,把某些task_struct 加到cgroup A,另外的task_struct加到cgroup B , cgroup A和B 先按照某个权重进行CPU的分配,再到不同cgroup里面,按照调度算法进行调度。
131 |
132 | * 定义不同cgroup CPU分享的share --> cpu.shares
133 | * 定义某个cgroup在某个周期里面最多跑多久 --> cpu.cfs_quota_us 和 cpu.cfs_period_us
134 |
135 | cpu.cfs_period_us:默认100000 us= 100ms
136 | cpu.cfs_quota_us:
137 |
138 | demo
139 |
140 | ```
141 | 3.编译two-loops.c, gcc two-loops.c -pthread,运行三份
142 | 用top观察CPU利用率,大概各自66%。
143 | 创建A,B两个cgroup
144 |
145 | root@whale:/sys/fs/cgroup/cpu$ sudo mkdir A
146 | root@whale:/sys/fs/cgroup/cpu$ sudo mkdir B
147 |
148 | 把3个a.out中的2个加到A,1个加到B。
149 |
150 | 此时,发现两个cgroup下的cpu.shares 相同,均为1024.
151 |
152 | 然后把两个进程下的所有线程都加入到cgroupA,如果只想加某个线程,则echo pid到tasks文件。
153 |
154 | root@whale:/sys/fs/cgroup/cpu/A$ sudo sh -c 'echo 14995 > cgroup.procs'
155 | root@whale:/sys/fs/cgroup/cpu/A$ sudo sh -c 'echo 14998 > cgroup.procs'
156 | root@whale:/sys/fs/cgroup/cpu/A$ cd ..
157 | root@whale:/sys/fs/cgroup/cpu$ cd B/
158 | root@whale:/sys/fs/cgroup/cpu/B$ sudo sh -c 'echo 15001 > cgroup.procs'
159 |
160 | 这次发现3个a.out的CPU利用率大概是50%, 50%, 100%。
161 |
162 | 杀掉第2个和第3个a.out,然后调整cgroup A的quota,观察14995的CPU利用率变化
163 |
164 | root@whale:/sys/fs/cgroup/cpu/B$ kill 14998
165 | root@whale:/sys/fs/cgroup/cpu/B$ kill 15001
166 |
167 |
168 | 设置A group的quota为20ms:
169 |
170 | root@whale:/sys/fs/cgroup/cpu/A$ sudo sh -c 'echo 20000 > cpu.cfs_quota_us'
171 |
172 | 设置A group的quota为40ms:
173 |
174 | root@whale:/sys/fs/cgroup/cpu/A$ sudo sh -c 'echo 40000 > cpu.cfs_quota_us'
175 |
176 |
177 | 以上各自情况,用top观察a.out CPU利用率。
178 |
179 | 当设置为 20000 us = 20ms , CPU利用率立即变为20%; 当设置为 40000 us = 40ms ,CPU利用率立即变为40%
180 | 当设置为 120000 us 时, CPU利用率立即变为120%。quota可以大于period,因为此时 CPU为多核,100ms里面可以运行200ms,该值最大为CPU核数* period。
181 | ```
182 |
183 | ### Android和Docker对cgroup的采用
184 | * apps, bg_non_interactive
185 | 安卓把应用分为app group ,和 bg_non_interactive 背景非交互的group,
186 | 并且bg_non_interactive的group权重非常低,这样做的好处是,让桌面运行的程序可以更大程度的抢到CPU。
187 |
188 | ```
189 | Shares:
190 | apps: cpu.shares = 1024
191 | bg_non_interactive: cpu.shares = 52
192 |
193 | Quota:
194 | apps:
195 | cpu.rt_period_us: 1000000 cpu.rt_runtime_us: 800000
196 | bg_non_interactive:
197 | cpu.rt_period_us: 1000000 cpu.rt_runtime_us: 700000
198 | ```
199 |
200 | * docker run时也可以指定 --cpu-quota 、--cpu-period、 --cpu-shares参数
201 |
202 | Linux 通过Cgroup控制多个容器在运行时,如何分享CPU。这些会在之后的Cgroups详解中详细阐述。
203 |
204 | 比如说A容器配置的--cpu-period=100000 --cpu-quota=50000,那么A容器就可以最多使用50%个CPU资源,如果配置的--cpu-quota=200000,那就可以使用200%个CPU资源。所有对采集到的CPU used的绝对值没有意义,还需要参考上限。还是这个例子--cpu-period=100000 --cpu-quota=50000,如果容器试图在0.1秒内使用超过0.05秒,则throttled就会触发,所有throttled的count和time是衡量CPU是否达到瓶颈的最直观指标。
205 |
206 | ### Linux为什么不是硬实时的
207 | 如何理解硬实时?并不代表越快越好,硬实时最主要的意思是:可预期。
208 |
209 | 
210 |
211 | 如上图,在一个硬实时操作系统中,当唤醒一个高优先级的RT任务,从“你唤醒它”到“它可以被调度”的这段时间,是不会超过截止期限的。
212 | ```
213 | 4.cyclictest -p 99 -t1 -n
214 | 观察min, max, act, avg时间,分析hard realtime问题
215 | 加到系统负载,运行一些硬盘访问,狂收发包的程序,观察cyclictest的max变化
216 | 延迟具有不确定性,最大值可能随着load改变而改变。
217 | ```
218 |
219 | Kernel 越发支持抢占
220 |
221 | 
222 |
223 | Linux为什么不是硬实时?
224 |
225 | Linux运行时,CPU时间主要花在“四类区间”上,包括中断、软中断、进程上下文(spin_lock),进程上下文(可调度)。
226 | 其中 进程上下文陷入内核拿到spin_lock,此时拿到spin_lock的CPU核上的调度器就会被关掉,该核就无法进行调度。
227 |
228 | 程序运行在只有 进程上下文(可调度)这个区间可以调度,其他区间都不能被调度。
229 |
230 | 中断是指 进程收到硬件的中断信号,就算在中断里唤醒一个高优先级的RT,也无法调度。
231 | 软中断和中断的唯一区别是,软中断中可以再中断,但中断中不能再中断。Linux 2.6.32之后完全不允许中断嵌套。软中断里唤醒一个高优先级的RT,也无法调度。
232 |
233 | 如下图,一个绿色的普通进程在T1时刻持有spin_lock进入一个critical section(该核调度被关),绿色进程T2时刻被中断打断,而后T3时刻IRQ1里面唤醒了红色的RT进程(如果是硬实时RTOS,这个时候RT进程应该能抢入),之后IRQ1后又执行了IRQ2,到T4时刻IRQ1和IRQ2都结束了,红色RT进程仍然不能执行(因为绿色进程还在spin_lock里面),直到T5时刻,普通进程释放spin_lock后,红色RT进程才抢入。从T3到T5要多久,鬼都不知道,这样就无法满足硬实时系统的“可预期”延迟性,因此Linux不是硬实时操作系统。
234 |
235 | 
236 |
237 | ### preempt-rt对Linux实时性的改造
238 |
239 | 
240 |
241 | Linux的preempt-rt补丁试图把中断、软中断线程化,变成可以被抢占的区间,而把会关本核调度器的spin_lock替换为可以调度的mutex,它实现了在T3时刻唤醒RT进程的时刻,RT进程可以立即抢占调度进入的目标,避免了T3-T5之间延迟的非确定性。
242 |
243 |
244 |
--------------------------------------------------------------------------------
/文章/进程管理/一文带你,彻底了解,零拷贝Zero-Copy技术.md:
--------------------------------------------------------------------------------
1 | ## 1、数据拷贝基础过程
2 |
3 | 在Linux系统内部缓存和内存容量都是有限的,更多的数据都是存储在磁盘中。对于Web服务器来说,经常需要从磁盘中读取数据到内存,然后再通过网卡传输给用户:
4 |
5 | 
6 |
7 | ### 1.1 仅CPU方式
8 |
9 | * 当应用程序需要读取磁盘数据时,调用read()从用户态陷入内核态,read()这个系统调用最终由CPU来完成;
10 | * CPU向磁盘发起I/O请求,磁盘收到之后开始准备数据;
11 | * 磁盘将数据放到磁盘缓冲区之后,向CPU发起I/O中断,报告CPU数据已经Ready了;
12 | * CPU收到磁盘控制器的I/O中断之后,开始拷贝数据,完成之后read()返回,再从内核态切换到用户态;
13 |
14 | 
15 |
16 | ### 1.2 CPU&DMA方式
17 |
18 | CPU的时间宝贵,让它做杂活就是浪费资源。
19 |
20 | 直接内存访问(Direct Memory Access),是一种硬件设备绕开CPU独立直接访问内存的机制。所以DMA在一定程度上解放了CPU,把之前CPU的杂活让硬件直接自己做了,提高了CPU效率。
21 |
22 | 目前支持DMA的硬件包括:网卡、声卡、显卡、磁盘控制器等。
23 |
24 | 
25 |
26 | 有了DMA的参与之后的流程发生了一些变化:
27 |
28 | 
29 |
30 | 最主要的变化是,CPU不再和磁盘直接交互,而是DMA和磁盘交互并且将数据从磁盘缓冲区拷贝到内核缓冲区,之后的过程类似。
31 |
32 | > 无论从仅CPU方式和DMA&CPU方式,都存在多次冗余数据拷贝和内核态&用户态的切换。
33 |
34 | 继续思考Web服务器读取本地磁盘文件数据再通过网络传输给用户的详细过程。
35 |
36 | ## 2、普通模式数据交互
37 |
38 | 一次完成的数据交互包括几个部分:系统调用syscall、CPU、DMA、网卡、磁盘等。
39 |
40 | 
41 |
42 | 系统调用syscall是应用程序和内核交互的桥梁,每次进行调用/返回就会产生两次切换:
43 |
44 | * 调用syscall 从用户态切换到内核态
45 | * syscall返回 从内核态切换到用户态
46 |
47 | 
48 |
49 | 来看下完整的数据拷贝过程简图:
50 |
51 | 
52 |
53 | #### 读数据过程:
54 |
55 | * 应用程序要读取磁盘数据,调用read()函数从而实现用户态切换内核态,这是第1次状态切换;
56 | * DMA控制器将数据从磁盘拷贝到内核缓冲区,这是第1次DMA拷贝;
57 | * CPU将数据从内核缓冲区复制到用户缓冲区,这是第1次CPU拷贝;
58 | * CPU完成拷贝之后,read()函数返回实现用户态切换用户态,这是第2次状态切换;
59 |
60 | #### 写数据过程:
61 |
62 | * 应用程序要向网卡写数据,调用write()函数实现用户态切换内核态,这是第1次切换;
63 | * CPU将用户缓冲区数据拷贝到内核缓冲区,这是第1次CPU拷贝;
64 | * DMA控制器将数据从内核缓冲区复制到socket缓冲区,这是第1次DMA拷贝;
65 | * 完成拷贝之后,write()函数返回实现内核态切换用户态,这是第2次切换;
66 |
67 | #### 综上所述:
68 |
69 | * 读过程涉及2次空间切换、1次DMA拷贝、1次CPU拷贝;
70 | * 写过程涉及2次空间切换、1次DMA拷贝、1次CPU拷贝;
71 |
72 | 可见传统模式下,涉及多次空间切换和数据冗余拷贝,效率并不高,接下来就该零拷贝技术出场了。
73 |
74 | ## 3、零拷贝技术
75 |
76 | ### 3.1 出现原因
77 |
78 | 可以看到,如果应用程序不对数据做修改,从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区。两次数据拷贝都需要CPU的参与,并且涉及用户态与内核态的多次切换,加重了CPU负担。
79 | 需要降低冗余数据拷贝、解放CPU,这也就是零拷贝Zero-Copy技术。
80 |
81 | ### 3.2 解决思路
82 |
83 | 目前来看,零拷贝技术的几个实现手段包括:mmap+write、sendfile、sendfile+DMA收集、splice等。
84 |
85 | 
86 |
87 | #### 3.2.1 mmap方式
88 |
89 | mmap是Linux提供的一种内存映射文件的机制,它实现了将内核中读缓冲区地址与用户空间缓冲区地址进行映射,从而实现内核缓冲区与用户缓冲区的共享。
90 |
91 | 这样就减少了一次用户态和内核态的CPU拷贝,但是在内核空间内仍然有一次CPU拷贝。
92 |
93 | 
94 |
95 | mmap对大文件传输有一定优势,但是小文件可能出现碎片,并且在多个进程同时操作文件时可能产生引发coredump的signal。
96 |
97 | #### 3.2.2 sendfile方式
98 |
99 | mmap+write方式有一定改进,但是由系统调用引起的状态切换并没有减少。
100 |
101 | sendfile系统调用是在 Linux 内核2.1版本中被引入,它建立了两个文件之间的传输通道。
102 |
103 | sendfile方式只使用一个函数就可以完成之前的read+write 和 mmap+write的功能,这样就少了2次状态切换,由于数据不经过用户缓冲区,因此该数据无法被修改。
104 |
105 | 
106 |
107 | 
108 |
109 | 从图中可以看到,应用程序只需要调用sendfile函数即可完成,只有2次状态切换、1次CPU拷贝、2次DMA拷贝。
110 |
111 | 但是sendfile在内核缓冲区和socket缓冲区仍然存在一次CPU拷贝,或许这个还可以优化。
112 |
113 | #### 3.2.3 sendfile+DMA收集
114 |
115 | Linux 2.4 内核对 sendfile 系统调用进行优化,但是需要硬件DMA控制器的配合。
116 |
117 | 升级后的sendfile将内核空间缓冲区中对应的数据描述信息(文件描述符、地址偏移量等信息)记录到socket缓冲区中。
118 |
119 | DMA控制器根据socket缓冲区中的地址和偏移量将数据从内核缓冲区拷贝到网卡中,从而省去了内核空间中仅剩1次CPU拷贝。
120 |
121 | 
122 |
123 | 这种方式有2次状态切换、0次CPU拷贝、2次DMA拷贝,但是仍然无法对数据进行修改,并且需要硬件层面DMA的支持,并且sendfile只能将文件数据拷贝到socket描述符上,有一定的局限性。
124 |
125 | #### 3.2.4 splice方式
126 |
127 | splice系统调用是Linux 在 2.6 版本引入的,其不需要硬件支持,并且不再限定于socket上,实现两个普通文件之间的数据零拷贝。
128 |
129 | 
130 |
131 | splice 系统调用可以在内核缓冲区和socket缓冲区之间建立管道来传输数据,避免了两者之间的 CPU 拷贝操作。
132 |
133 | 
134 |
135 | splice也有一些局限,它的两个文件描述符参数中有一个必须是管道设备。
136 |
137 |
--------------------------------------------------------------------------------
/源码组织结构.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/源码组织结构.png
--------------------------------------------------------------------------------
/电子书籍/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/电子书籍/Linux内核完全注释V3.0书签版.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux内核完全注释V3.0书签版.pdf
--------------------------------------------------------------------------------
/电子书籍/Linux命令行大全 - 绍茨 (william E.shotts).pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux命令行大全 - 绍茨 (william E.shotts).pdf
--------------------------------------------------------------------------------
/电子书籍/Linux命令速查手册.mobi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux命令速查手册.mobi
--------------------------------------------------------------------------------
/电子书籍/Linux就该这么学.epub:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux就该这么学.epub
--------------------------------------------------------------------------------
/电子书籍/Linux性能优化大师.epub:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux性能优化大师.epub
--------------------------------------------------------------------------------
/电子书籍/Linux环境编程:从应用到内核 (Linux Unix技术丛书).pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux环境编程:从应用到内核 (Linux Unix技术丛书).pdf
--------------------------------------------------------------------------------
/电子书籍/Linux集群和自动化运维 余洪春.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux集群和自动化运维 余洪春.pdf
--------------------------------------------------------------------------------
/电子书籍/Linux驱动程序开发实例(第2版).pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux驱动程序开发实例(第2版).pdf
--------------------------------------------------------------------------------
/电子书籍/Linux高级程序设计(第3版).epub:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/Linux高级程序设计(第3版).epub
--------------------------------------------------------------------------------
/电子书籍/构建高可用Linux服务器(第4版).epub:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/构建高可用Linux服务器(第4版).epub
--------------------------------------------------------------------------------
/电子书籍/深入了解Linux内核.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/电子书籍/深入了解Linux内核.pdf
--------------------------------------------------------------------------------
/论文/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/论文/《A Novel DDoS Floods Detection and Testing Approaches for Network Traffic based on Linux Techniques》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《A Novel DDoS Floods Detection and Testing Approaches for Network Traffic based on Linux Techniques》.pdf
--------------------------------------------------------------------------------
/论文/《A Permission Check Analysis Framework for Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《A Permission Check Analysis Framework for Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《A dataset of feature additions and feature removals from the Linux kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《A dataset of feature additions and feature removals from the Linux kernel》.pdf
--------------------------------------------------------------------------------
/论文/《An Evaluation of Adaptive Partitioning of Real-Time Workloads on Linux》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《An Evaluation of Adaptive Partitioning of Real-Time Workloads on Linux》.pdf
--------------------------------------------------------------------------------
/论文/《Analysis and Study of Security Mechanisms inside Linux Kernel 》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Analysis and Study of Security Mechanisms inside Linux Kernel 》.pdf
--------------------------------------------------------------------------------
/论文/《Architecture of the Linux kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Architecture of the Linux kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Automated Patch Backporting in Linux》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Automated Patch Backporting in Linux》.pdf
--------------------------------------------------------------------------------
/论文/《Automated Voxel Placement A Linux-based Suite of Tools for Accurate and Reliable Single Voxel Coregistration》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Automated Voxel Placement A Linux-based Suite of Tools for Accurate and Reliable Single Voxel Coregistration》.pdf
--------------------------------------------------------------------------------
/论文/《Automatic Rebootless Kernel Updates》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Automatic Rebootless Kernel Updates》.pdf
--------------------------------------------------------------------------------
/论文/《Communication on Linux using Socket Programming in ‘C’》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Communication on Linux using Socket Programming in ‘C’》.pdf
--------------------------------------------------------------------------------
/论文/《Compatibility of Linux Architecture for Diskless Technology System》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Compatibility of Linux Architecture for Diskless Technology System》.pdf
--------------------------------------------------------------------------------
/论文/《Concurrency in the Linux kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Concurrency in the Linux kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Container-based real-time scheduling in the Linux kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Container-based real-time scheduling in the Linux kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Crash Consistency Test Generation for the Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Crash Consistency Test Generation for the Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Designing of a Virtual File System》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Designing of a Virtual File System》.pdf
--------------------------------------------------------------------------------
/论文/《Efficient Formal Verification for the Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Efficient Formal Verification for the Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Exploiting Uses of Uninitialized Stack Variables in Linux Kernels to Leak Kernel Pointers》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Exploiting Uses of Uninitialized Stack Variables in Linux Kernels to Leak Kernel Pointers》.pdf
--------------------------------------------------------------------------------
/论文/《Hybrid Fuzzing on the Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Hybrid Fuzzing on the Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《In-Process Memory Isolation for Modern Linux Systems》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《In-Process Memory Isolation for Modern Linux Systems》.pdf
--------------------------------------------------------------------------------
/论文/《Introduction to the Linux kernel challenges and case studies》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Introduction to the Linux kernel challenges and case studies》.pdf
--------------------------------------------------------------------------------
/论文/《Kernel Mode Linux Toward an Operating System Protected by a Type Theory》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Kernel Mode Linux Toward an Operating System Protected by a Type Theory》.pdf
--------------------------------------------------------------------------------
/论文/《Linux Kernel Transport Layer Security》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Linux Kernel Transport Layer Security》.pdf
--------------------------------------------------------------------------------
/论文/《Linux Kernel Workshop Hacking the Kernel for Fun and Profit》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Linux Kernel Workshop Hacking the Kernel for Fun and Profit》.pdf
--------------------------------------------------------------------------------
/论文/《Linux Kernel development》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Linux Kernel development》.pdf
--------------------------------------------------------------------------------
/论文/《Linux Network Device Drivers an Overview》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Linux Network Device Drivers an Overview》.pdf
--------------------------------------------------------------------------------
/论文/《Linux Physical Memory Page Allocation》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Linux Physical Memory Page Allocation》.pdf
--------------------------------------------------------------------------------
/论文/《Linux Random Number Generator – A New Approach》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Linux Random Number Generator – A New Approach》.pdf
--------------------------------------------------------------------------------
/论文/《Linux kernel vulnerabilities State-of-the-art defenses and open problems》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Linux kernel vulnerabilities State-of-the-art defenses and open problems》.pdf
--------------------------------------------------------------------------------
/论文/《Machine Learning for Load Balancing in the Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Machine Learning for Load Balancing in the Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Performance of IPv6 Segment Routing in Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Performance of IPv6 Segment Routing in Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Professional Linux® Kernel Architecture》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Professional Linux® Kernel Architecture》.pdf
--------------------------------------------------------------------------------
/论文/《Research of Performance Linux Kernel File Systems》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Research of Performance Linux Kernel File Systems》.pdf
--------------------------------------------------------------------------------
/论文/《Resource Management for Hardware Accelerated Linux Kernel Network Functions》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Resource Management for Hardware Accelerated Linux Kernel Network Functions》.pdf
--------------------------------------------------------------------------------
/论文/《Rethinking Compiler Optimizations for the Linux Kernel An Explorative Study》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Rethinking Compiler Optimizations for the Linux Kernel An Explorative Study》.pdf
--------------------------------------------------------------------------------
/论文/《Securing the Linux Boot Process From Start to Finish》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Securing the Linux Boot Process From Start to Finish》.pdf
--------------------------------------------------------------------------------
/论文/《Security Applications of Extended BPF Under the Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Security Applications of Extended BPF Under the Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Simple and precise static analysis of untrusted Linux kernel extensions》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Simple and precise static analysis of untrusted Linux kernel extensions》.pdf
--------------------------------------------------------------------------------
/论文/《Speeding Up Linux Disk Encryption》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Speeding Up Linux Disk Encryption》.pdf
--------------------------------------------------------------------------------
/论文/《Stateless model checking of the Linux kernel's hierarchical read-copy-update (tree RCU)》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Stateless model checking of the Linux kernel's hierarchical read-copy-update (tree RCU)》.pdf
--------------------------------------------------------------------------------
/论文/《Survey Paper on Adding System Call in Linux Kernel 3.2+ & 3.16》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Survey Paper on Adding System Call in Linux Kernel 3.2+ & 3.16》.pdf
--------------------------------------------------------------------------------
/论文/《TRACING THE WAY OF DATA IN A TCP CONNECTION THROUGH THE LINUX KERNEL》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《TRACING THE WAY OF DATA IN A TCP CONNECTION THROUGH THE LINUX KERNEL》.pdf
--------------------------------------------------------------------------------
/论文/《The benefits and costs of writing a POSIX kernel in a high-level language》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《The benefits and costs of writing a POSIX kernel in a high-level language》.pdf
--------------------------------------------------------------------------------
/论文/《The real-time Linux kernel a Survey on PREEMPT_RT》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《The real-time Linux kernel a Survey on PREEMPT_RT》.pdf
--------------------------------------------------------------------------------
/论文/《Trace-Based Analysis of Locking in the Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Trace-Based Analysis of Locking in the Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Tracing Network Packets in the Linux Kernel using eBPF》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Tracing Network Packets in the Linux Kernel using eBPF》.pdf
--------------------------------------------------------------------------------
/论文/《Understanding Linux Kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Understanding Linux Kernel》.pdf
--------------------------------------------------------------------------------
/论文/《Understanding Linux Malware》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Understanding Linux Malware》.pdf
--------------------------------------------------------------------------------
/论文/《Using kAFS on Linux for Network Home Directories》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Using kAFS on Linux for Network Home Directories》.pdf
--------------------------------------------------------------------------------
/论文/《Verification of tree-based hierarchical read-copy update in the Linux kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《Verification of tree-based hierarchical read-copy update in the Linux kernel》.pdf
--------------------------------------------------------------------------------
/论文/《XDP test suite for Linux kernel》.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ZhongYi-LinuxDriverDev/linux_kernel_wiki/3f6c0f20abec5b11af937f1cbcdd9ca2809befef/论文/《XDP test suite for Linux kernel》.pdf
--------------------------------------------------------------------------------
/面试题/1.txt:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/面试题/面试题二.md:
--------------------------------------------------------------------------------
1 | ## 问题一:
2 |
3 | 绝对路径用什么符号表示?当前目录、上层目录用什么表示?主目录用什么表示? 切换目录用什么命令?
4 |
5 | ### 答案:
6 | 绝对路径: 如/etc/init.d
7 | 当前目录和上层目录: ./ ../
8 | 主目录: ~/
9 | 切换目录: cd
10 |
11 | ## 问题二:
12 |
13 | 怎么查看当前进程?怎么执行退出?怎么查看当前路径?
14 |
15 | ### 答案:
16 | 查看当前进程: ps
17 | 执行退出: exit
18 | 查看当前路径: pwd
19 |
20 | ## 问题三:
21 |
22 | 怎么清屏?怎么退出当前命令?怎么执行睡眠?怎么查看当前用户 id?查看指定帮助用什么命令?
23 |
24 | ### 答案:
25 | 清屏: clear
26 | 退出当前命令: ctrl+c 彻底退出
27 | 执行睡眠 : ctrl+z 挂起当前进程fg 恢复后台
28 | 查看当前用户 id: ”id“:查看显示目前登陆账户的 uid 和 gid 及所属分组及用户名
29 | 查看指定帮助: 如 man adduser 这个很全 而且有例子; adduser --help 这个告诉你一些常用参数; info adduesr;
30 |
31 | ## 问题四:
32 |
33 | Ls 命令执行什么功能? 可以带哪些参数,有什么区别?
34 |
35 | ### 答案:
36 | ls 执行的功能: 列出指定目录中的目录,以及文件
37 | 哪些参数以及区别: a 所有文件l 详细信息,包括大小字节数,可读可写可执行的权限等
38 |
39 | ## 问题五:
40 |
41 | 建立软链接(快捷方式),以及硬链接的命令。
42 |
43 | ### 答案:
44 | 软链接: ln -s slink source
45 | 硬链接: ln link source
46 |
47 | ## 问题六:
48 |
49 | 目录创建用什么命令?创建文件用什么命令?复制文件用什么命令?
50 |
51 | ### 答案:
52 | 创建目录: mkdir
53 | 创建文件:典型的如 touch,vi 也可以创建文件,其实只要向一个不存在的文件输出,都会创建文件
54 | 复制文件: cp 7. 文件权限修改用什么命令?格式是怎么样的?
55 | 文件权限修改: chmod
56 | 格式如下:
57 | ```
58 | chmodu+xfile给file的属主增加执行权限 chmod 751 file 给 file 的属主分配读、写、执行(7)的权限,给 file 的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限
59 | chmodu=rwx,g=rx,o=xfile上例的另一种形式 chmod =r file 为所有用户分配读权限
60 | chmod444file同上例 chmod a-wx,a+r file同上例
61 | $ chmod -R u+r directory 递归地给 directory 目录下所有文件和子目录的属主分配读的权限
62 | ```
63 |
64 | ## 问题七:
65 |
66 | 使用哪一个命令可以查看自己文件系统的磁盘空间配额呢?
67 |
68 |
69 | ### 答案:
70 |
71 | 使用命令repquota 能够显示出一个文件系统的配额信息
72 |
73 |
74 | ## 问题八:
75 |
76 | 查看文件内容有哪些命令可以使用?
77 |
78 | ### 答案:
79 | vi 文件名 #编辑方式查看,可修改
80 | cat 文件名 #显示全部文件内容
81 | more 文件名 #分页显示文件内容
82 | less 文件名 #与 more 相似,更好的是可以往前翻页
83 | tail 文件名 #仅查看尾部,还可以指定行数
84 | head 文件名 #仅查看头部,还可以指定行数
85 |
86 | ## 问题九:
87 |
88 | 随意写文件命令?怎么向屏幕输出带空格的字符串,比如”hello world”?
89 |
90 | ### 答案:
91 |
92 | 写文件命令:vi
93 |
94 | 向屏幕输出带空格的字符串:`echo hello world`
95 |
96 |
97 |
98 | ## 问题十:
99 |
100 | 终端是哪个文件夹下的哪个文件?黑洞文件是哪个文件夹下的哪个命令?
101 |
102 | ### 答案:
103 | 终端 /dev/tty
104 | 黑洞文件 /dev/null
105 |
106 | ## 问题十一:
107 |
108 | 移动文件用哪个命令?改名用哪个命令?
109 |
110 | ### 答案:
111 | ```
112 | mv mv
113 | ```
114 |
115 | ## 问题十二:
116 |
117 | 复制文件用哪个命令?如果需要连同文件夹一块复制呢?如果需要有提示功能呢?
118 |
119 | ### 答案:
120 | ```
121 | cp cp -r ????
122 | ```
123 |
124 | ## 问题十三:
125 |
126 | 删除文件用哪个命令?如果需要连目录及目录下文件一块删除呢?删除空文件夹用什么命令?
127 |
128 | ### 答案:
129 | rm rm -r rmdir
130 |
131 | ## 问题十四:
132 |
133 | Linux 下命令有哪几种可使用的通配符?分别代表什么含义?
134 |
135 | ### 答案:
136 |
137 | “?”可替代单个字符。
138 | “*”可替代任意多个字符。
139 | 方括号“[charset]”可替代 charset 集中的任何单个字符,如[a-z],[abABC]
140 |
141 |
142 |
143 | ## 问题十五:
144 |
145 | 用什么命令对一个文件的内容进行统计?(行号、单词数、字节数)
146 |
147 | ### 答案:
148 |
149 | wc 命令 - c 统计字节数 - l 统计行数 - w 统计字数。
150 |
151 | ## 问题十六:
152 |
153 | Grep 命令有什么用? 如何忽略大小写? 如何查找不含该串的行?
154 |
155 | ### 答案:
156 | 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。
157 | grep [stringSTRING] filename grep [^string] filename
158 |
159 | ## 问题十七:
160 |
161 | Linux 中进程有哪几种状态?在 ps 显示出来的信息中,分别用什么符号表示的?
162 |
163 | ### 答案:
164 | (1)、不可中断状态:进程处于睡眠状态,但是此刻进程是不可中断的。不可中断, 指进程不响应异步信号。
165 | (2)、暂停状态/跟踪状态:向进程发送一个 SIGSTOP 信号,它就会因响应该信号 而进入 TASK_STOPPED 状态;当进程正在被跟踪时,它处于 TASK_TRACED 这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。
166 | (3)、就绪状态:在 run_queue 队列里的状态
167 | (4)、运行状态:在 run_queue 队列里的状态
168 | (5)、可中断睡眠状态:处于这个状态的进程因为等待某某事件的发生(比如等待 socket 连接、等待信号量),而被挂起
169 | (6)、zombie 状态(僵尸):父亲没有通过 wait 系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉
170 | (7)、退出状态
171 |
172 | D 不可中断 Uninterruptible(usually IO)
173 | R 正在运行,或在队列中的进程
174 | S 处于休眠状态
175 | T 停止或被追踪
176 | Z 僵尸进程
177 | W 进入内存交换(从内核 2.6 开始无效)
178 | X 死掉的进程
179 |
180 |
181 |
182 | ## 问题十八:
183 |
184 | 怎么使一个命令在后台运行?
185 |
186 | ### 答案:
187 | 一般都是使用 & 在命令结尾来让程序自动运行。(命令后可以不追加空格)
188 |
189 |
190 | ## 问题十九:
191 |
192 | 利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息?
193 |
194 | ### 答案:
195 | ps -ef (system v 输出)
196 |
197 | ps -aux bsd 格式输出
198 |
199 | ps -ef | grep pid
200 |
201 | ## 问题二十:
202 |
203 | 哪个命令专门用来查看后台任务?
204 |
205 |
206 | ### 答案:
207 |
208 | `job -l`
209 |
210 |
211 | ## 问题二十一:
212 |
213 | 把后台任务调到前台执行使用什么命令?把停下的后台任务在后台执行起来用什么命令?
214 |
215 | ### 答案:
216 | 把后台任务调到前台执行 fg
217 |
218 | 把停下的后台任务在后台执行起来 bg
219 |
220 |
221 |
222 | ## 问题二十二:
223 |
224 | 终止进程用什么命令? 带什么参数?
225 |
226 |
227 | ### 答案:
228 |
229 | kill [-s <信息名称或编号>][程序] 或 kill [-l <信息编号>]
230 |
231 | kill-9 pid
232 |
233 |
234 |
235 | ## 问题二十三:
236 |
237 | 怎么查看系统支持的所有信号?
238 |
239 |
240 | ### 答案:
241 |
242 | `kill -l`
243 |
244 | ## 问题二十四:
245 |
246 | 搜索文件用什么命令? 格式是怎么样的?
247 |
248 |
249 | ### 答案:
250 |
251 | find <指定目录> <指定条件> <指定动作>
252 |
253 | whereis 加参数与文件名
254 |
255 | locate 只加文件名
256 |
257 | find 直接搜索磁盘,较慢。
258 |
259 | find / -name "string*"
260 |
261 |
262 |
263 | ## 问题二十五:
264 |
265 | 查看当前谁在使用该主机用什么命令? 查找自己所在的终端信息用什么命令?
266 |
267 | ### 答案:
268 | 查找自己所在的终端信息:who am i
269 | 查看当前谁在使用该主机:who
270 |
271 |
272 |
273 | ## 问题二十六:
274 |
275 | 使用什么命令查看用过的命令列表?
276 |
277 |
278 | ### 答案:
279 |
280 | `history`
281 |
282 |
283 | ## 问题二十七:
284 |
285 | 使用什么命令查看磁盘使用空间? 空闲空间呢?
286 |
287 |
288 | ### 答案:
289 |
290 | df -hl
291 | 文件系统 容量 已用 可用 已用% 挂载点
292 | Filesystem Size Used Avail Use% Mounted on /dev/hda2 45G 19G 24G 44% /
293 | /dev/hda1 494M 19M 450M 4% /boot
294 |
295 | ## 问题二十八:
296 |
297 | 使用什么命令查看网络是否连通?
298 |
299 | ### 答案:
300 |
301 | `netstat`
302 |
303 | ## 问题二十九:
304 |
305 | 使用什么命令查看 ip 地址及接口信息?
306 |
307 |
308 | ### 答案:
309 |
310 | ifconfig
311 |
312 | ## 问题三十:
313 |
314 | 查看各类环境变量用什么命令?
315 |
316 |
317 | ### 答案:
318 |
319 | 查看所有 env
320 | 查看某个,如 home: env $HOME
321 |
322 | ## 问题三十一:
323 |
324 | 通过什么命令指定命令提示符?
325 |
326 |
327 | ### 答案:
328 |
329 | \u:显示当前用户账号
330 |
331 | \h:显示当前主机名
332 |
333 | \W:只显示当前路径最后一个目录
334 |
335 | \w:显示当前绝对路径(当前用户目录会以~代替)
336 |
337 | $PWD:显示当前全路径
338 |
339 | $:显示命令行’$'或者’#'符号
340 |
341 | \#:下达的第几个命令
342 |
343 | \d:代表日期,格式为week day month date,例如:"MonAug1"
344 |
345 | \t:显示时间为24小时格式,如:HH:MM:SS
346 |
347 | \T:显示时间为12小时格式
348 |
349 | \A:显示时间为24小时格式:HH:MM
350 |
351 | \v:BASH的版本信息 如export PS1=’[\u@\h\w\#]$‘
352 |
353 |
354 |
355 | ## 问题三十二:
356 |
357 | 查找命令的可执行文件是去哪查找的? 怎么对其进行设置及添加?
358 |
359 |
360 | ### 答案:
361 |
362 | whereis [-bfmsu][-B <目录>...][-M <目录>...][-S <目录>...][文件...]
363 |
364 | 补充说明:whereis 指令会在特定目录中查找符合条件的文件。这些文件的烈性应属于原始代码,二进制文件,或是帮助文件。
365 |
366 | -b 只查找二进制文件。
367 | -B<目录> 只在设置的目录下查找二进制文件。 -f 不显示文件名前的路径名称。
368 | -m 只查找说明文件。
369 | -M<目录> 只在设置的目录下查找说明文件。 -s 只查找原始代码文件。
370 | -S<目录> 只在设置的目录下查找原始代码文件。 -u 查找不包含指定类型的文件。
371 | which 指令会在 PATH 变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
372 | -n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。
373 | -p 与-n 参数相同,但此处的包括了文件的路径。 -w 指定输出时栏位的宽度。
374 | -V 显示版本信息
375 |
376 |
377 |
378 | ## 问题三十三:
379 |
380 | 通过什么命令查找执行命令?
381 |
382 | ### 答案:
383 | which 只能查可执行文件
384 |
385 | whereis 只能查二进制文件、说明文档,源文件等
386 |
387 |
388 | ## 问题三十四:
389 |
390 | 怎么对命令进行取别名?
391 |
392 | ### 答案:
393 | alias la='ls -a'
394 |
395 | ## 问题三十五:
396 |
397 | du 和 df 的定义,以及区别?
398 |
399 | ### 答案:
400 |
401 | du 显示目录或文件的大小
402 | df 显示每个<文件>所在的文件系统的信息,默认是显示所有文件系统。
403 | (文件系统分配其中的一些磁盘块用来记录它自身的一些数据,如 i 节点,磁盘分布图,间接块,超级块等。这些数据对大多数用户级的程序来说是不可见的,通常称为 Meta Data。) du 命令是用户级的程序,它不考虑 Meta Data,而 df 命令则查看文件系统的磁盘分配图并考虑 Meta Data。
404 | df 命令获得真正的文件系统数据,而 du 命令只查看文件系统的部分情况。
405 |
406 | ## 问题三十六:
407 |
408 | awk 详解。
409 |
410 | ### 答案:
411 |
412 | awk '{pattern + action}' {filenames}
413 | #cat /etc/passwd |awk -F ':' '{print 1"\t"7}' //-F 的意思是以':'分隔 root /bin/bash
414 | daemon /bin/sh 搜索/etc/passwd 有 root 关键字的所有行
415 |
416 | #awk -F: '/root/' /etc/passwd root:x:0:0:root:/root:/bin/bash
417 |
418 |
419 |
420 | ## 问题三十七:
421 |
422 | 当你需要给命令绑定一个宏或者按键的时候,应该怎么做呢?
423 |
424 |
425 | ### 答案:
426 |
427 | 可以使用bind命令,bind可以很方便地在shell中实现宏或按键的绑定。
428 |
429 | 在进行按键绑定的时候,我们需要先获取到绑定按键对应的字符序列。
430 |
431 | 比如获取F12的字符序列获取方法如下:先按下Ctrl+V,然后按下F12 .我们就可以得到F12的字符序列 ^[[24~。
432 |
433 | 接着使用bind进行绑定。
434 |
435 | [root@localhost ~]# bind ‘”\e[24~":"date"'
436 |
437 | 注意:相同的按键在不同的终端或终端模拟器下可能会产生不同的字符序列。
438 |
439 | 【附】也可以使用showkey -a命令查看按键对应的字符序列。
440 |
441 |
442 |
443 | ## 问题三十八:
444 |
445 | 如果一个linux新手想要知道当前系统支持的所有命令的列表,他需要怎么做?
446 |
447 |
448 | ###
449 | ### 答案:
450 |
451 | 使用命令compgen -c,可以打印出所有支持的命令列表。
452 |
453 | [root@localhost ~]$ compgen -c
454 |
455 | l.
456 |
457 | ll
458 |
459 | ls
460 |
461 | which
462 |
463 | if
464 |
465 | then
466 |
467 | else
468 |
469 | elif
470 |
471 | fi
472 |
473 | case
474 |
475 | esac
476 |
477 | for
478 |
479 | select
480 |
481 | while
482 |
483 | until
484 |
485 | do
486 |
487 | done
488 |
489 | …
490 |
491 |
492 |
493 | ## 问题三十九:
494 |
495 | 如果你的助手想要打印出当前的目录栈,你会建议他怎么做?
496 |
497 |
498 | ### 答案:
499 |
500 | 使用Linux 命令dirs可以将当前的目录栈打印出来。
501 |
502 | [root@localhost ~]# dirs
503 |
504 | /usr/share/X11
505 |
506 | 【附】:目录栈通过pushd popd 来操作。
507 |
508 |
509 |
510 | ## 问题四十:
511 |
512 | 你的系统目前有许多正在运行的任务,在不重启机器的条件下,有什么方法可以把所有正在运行的进程移除呢?
513 |
514 |
515 | ### 答案:
516 |
517 | 使用linux命令 ’disown -r ’可以将所有正在运行的进程移除。
518 |
519 |
520 |
521 | ## 问题四十一:
522 |
523 | bash shell 中的hash 命令有什么作用?
524 |
525 |
526 | ### 答案:
527 |
528 | linux命令’hash’管理着一个内置的哈希表,记录了已执行过的命令的完整路径, 用该命令可以打印出你所使用过的命令以及执行的次数。
529 |
530 | [root@localhost ~]# hash
531 |
532 | hits command
533 |
534 | 2 /bin/ls
535 |
536 | 2 /bin/su
537 |
538 |
539 |
540 | ## 问题四十二:
541 |
542 | 哪一个bash内置命令能够进行数学运算。
543 |
544 |
545 | ### 答案:
546 |
547 | bash shell 的内置命令let 可以进行整型数的数学运算。
548 |
549 | #! /bin/bash
550 | …
551 | …
552 | let c=a+b
553 | …
554 | …
555 |
556 |
557 |
558 | ## 问题四十三:
559 |
560 | 怎样一页一页地查看一个大文件的内容呢?
561 |
562 |
563 | ### 答案:
564 |
565 | 通过管道将命令”cat file_name.txt” 和 ’more’ 连接在一起可以实现这个需要.
566 |
567 | [root@localhost ~]# cat file_name.txt | more
568 |
569 |
570 |
571 | ## 问题四十四:
572 |
573 | 数据字典属于哪一个用户的?
574 |
575 |
576 | ### 答案:
577 |
578 | 数据字典是属于’SYS’用户的,用户‘SYS’ 和 ’SYSEM’是由系统默认自动创建的
579 |
580 |
581 |
582 | ## 问题四十五:
583 |
584 | 怎样查看一个linux命令的概要与用法?假设你在/bin目录中偶然看到一个你从没见过的的命令,怎样才能知道它的作用和用法呢?
585 |
586 |
587 | ### 答案:
588 |
589 | 使用命令whatis 可以先出显示出这个命令的用法简要,比如,你可以使用whatis zcat 去查看‘zcat’的介绍以及使用简要。
590 |
591 | [root@localhost ~]# whatis zcat
592 |
593 | zcat [gzip] (1) – compress or expand files
594 |
--------------------------------------------------------------------------------