├── pywick
├── models
│ ├── localization
│ │ └── __init__.py
│ ├── segmentation
│ │ ├── testnets
│ │ │ ├── hrnetv2
│ │ │ │ ├── __init__.py
│ │ │ │ └── bn_helper.py
│ │ │ ├── drnet
│ │ │ │ ├── __init__.py
│ │ │ │ └── utils.py
│ │ │ ├── tkcnet
│ │ │ │ └── __init__.py
│ │ │ ├── gscnn
│ │ │ │ ├── utils
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── AttrDict.py
│ │ │ │ ├── my_functionals
│ │ │ │ │ └── __init__.py
│ │ │ │ ├── mynn.py
│ │ │ │ ├── __init__.py
│ │ │ │ └── config.py
│ │ │ ├── axial_deeplab
│ │ │ │ └── __init__.py
│ │ │ ├── lg_kernel_exfuse
│ │ │ │ └── __init__.py
│ │ │ ├── mixnet
│ │ │ │ ├── __init__.py
│ │ │ │ ├── layers.py
│ │ │ │ └── mdconv.py
│ │ │ ├── exfuse
│ │ │ │ ├── __init__.py
│ │ │ │ └── unet_layer.py
│ │ │ ├── flatten.py
│ │ │ ├── __init__.py
│ │ │ └── msc.py
│ │ ├── da_basenets
│ │ │ ├── __init__.py
│ │ │ ├── segbase.py
│ │ │ ├── model_store.py
│ │ │ └── jpu.py
│ │ ├── emanet
│ │ │ ├── __init__.py
│ │ │ └── settings.py
│ │ ├── galdnet
│ │ │ └── __init__.py
│ │ ├── refinenet
│ │ │ └── __init__.py
│ │ ├── mnas_linknets
│ │ │ └── __init__.py
│ │ ├── gcnnets
│ │ │ └── __init__.py
│ │ ├── config.py
│ │ ├── LICENSE-BSD3-Clause.txt
│ │ ├── __init__.py
│ │ ├── fcn32s.py
│ │ ├── drn_seg.py
│ │ ├── fcn16s.py
│ │ ├── seg_net.py
│ │ └── lexpsp.py
│ ├── classification
│ │ ├── dpn
│ │ │ └── __init__.py
│ │ ├── testnets
│ │ │ ├── __init__.py
│ │ │ └── se_module.py
│ │ ├── resnext_features
│ │ │ └── __init__.py
│ │ ├── pretrained_notes.txt
│ │ └── __init__.py
│ ├── LICENSE-MIT.txt
│ ├── __init__.py
│ ├── LICENSE-BSD 2-Clause.txt
│ ├── LICENSE-BSD.txt
│ ├── LICENSE_LIP6.txt
│ └── model_locations.py
├── modules
│ ├── __init__.py
│ └── stn.py
├── dictmodels
│ ├── __init__.py
│ ├── model_spec.py
│ └── dict_config.py
├── meters
│ ├── meter.py
│ ├── averagemeter.py
│ ├── __init__.py
│ ├── msemeter.py
│ ├── timemeter.py
│ ├── movingaveragevaluemeter.py
│ ├── mapmeter.py
│ ├── averagevaluemeter.py
│ └── classerrormeter.py
├── README_loss_functions.md
├── functions
│ ├── __init__.py
│ ├── mish.py
│ ├── LICENSE-MIT.txt
│ ├── swish.py
│ └── activations_autofn.py
├── datasets
│ ├── tnt
│ │ ├── __init__.py
│ │ ├── table.py
│ │ ├── dataset.py
│ │ ├── concatdataset.py
│ │ ├── transform.py
│ │ ├── resampledataset.py
│ │ ├── transformdataset.py
│ │ ├── listdataset.py
│ │ └── shuffledataset.py
│ ├── UsefulDataset.py
│ ├── __init__.py
│ ├── ClonedFolderDataset.py
│ ├── PredictFolderDataset.py
│ └── TensorDataset.py
├── transforms
│ ├── README.md
│ ├── __init__.py
│ └── utils.py
├── gridsearch
│ ├── __init__.py
│ ├── grid_test.py
│ └── pipeline.py
├── __init__.py
├── optimizers
│ ├── rangerlars.py
│ ├── lookaheadsgd.py
│ ├── __init__.py
│ ├── addsign.py
│ ├── powersign.py
│ └── lookahead.py
├── callbacks
│ ├── __init__.py
│ ├── LambdaCallback.py
│ ├── EarlyStopping.py
│ ├── History.py
│ ├── TQDM.py
│ ├── LRScheduler.py
│ ├── Callback.py
│ ├── CSVLogger.py
│ └── CallbackContainer.py
├── configs
│ ├── eval_classifier.yaml
│ └── train_classifier.json
├── LICENSE-MIT.txt
├── custom_regularizers.py
└── cust_random.py
├── setup.cfg
├── examples
├── imgs
│ ├── orig1.png
│ ├── orig2.png
│ ├── orig3.png
│ ├── tform1.png
│ ├── tform2.png
│ └── tform3.png
├── 17flowers_split.py
├── mnist_example.py
└── mnist_loader_example.py
├── docs
└── source
│ ├── help.rst
│ ├── api
│ ├── losses.rst
│ ├── samplers.rst
│ ├── initializers.rst
│ ├── regularizers.rst
│ ├── constraints.rst
│ ├── conditions.rst
│ ├── pywick.gridsearch.rst
│ ├── pywick.models.localization.rst
│ ├── pywick.models.rst
│ ├── pywick.functions.rst
│ ├── pywick.transforms.rst
│ ├── pywick.models.torchvision.rst
│ ├── pywick.datasets.rst
│ ├── pywick.meters.rst
│ ├── pywick.datasets.tnt.rst
│ └── pywick.rst.old
│ ├── requirements.txt
│ ├── segmentation_guide.md
│ ├── description.rst
│ ├── classification_guide.md
│ └── index.rst
├── .deepsource.toml
├── requirements.txt
├── tests
├── run_test.sh
└── integration
│ ├── fit_simple
│ ├── single_input_no_target.py
│ ├── simple_multi_input_no_target.py
│ ├── simple_multi_input_single_target.py
│ ├── single_input_single_target.py
│ ├── single_input_multi_target.py
│ └── simple_multi_input_multi_target.py
│ └── fit_loader_simple
│ ├── single_input_single_target.py
│ └── single_input_multi_target.py
├── .gitignore
├── entrypoint.sh
├── readthedocs.yml
├── LICENSE.txt
├── setup.py
└── Dockerfile
/pywick/models/localization/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | description-file = README.md
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/hrnetv2/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/pywick/models/classification/dpn/__init__.py:
--------------------------------------------------------------------------------
1 | from .dualpath import *
--------------------------------------------------------------------------------
/pywick/models/segmentation/da_basenets/__init__.py:
--------------------------------------------------------------------------------
1 | from . import *
--------------------------------------------------------------------------------
/pywick/models/segmentation/emanet/__init__.py:
--------------------------------------------------------------------------------
1 | from .emanet import *
--------------------------------------------------------------------------------
/pywick/models/segmentation/galdnet/__init__.py:
--------------------------------------------------------------------------------
1 | from .GALDNet import *
2 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/refinenet/__init__.py:
--------------------------------------------------------------------------------
1 | from .refinenet import *
--------------------------------------------------------------------------------
/pywick/modules/__init__.py:
--------------------------------------------------------------------------------
1 | from .module_trainer import ModuleTrainer
2 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/mnas_linknets/__init__.py:
--------------------------------------------------------------------------------
1 | from .linknet import *
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/drnet/__init__.py:
--------------------------------------------------------------------------------
1 | from .drnet import DRNet
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/tkcnet/__init__.py:
--------------------------------------------------------------------------------
1 | from .tkcnet import *
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/gscnn/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from .AttrDict import *
2 |
--------------------------------------------------------------------------------
/pywick/dictmodels/__init__.py:
--------------------------------------------------------------------------------
1 | from .dict_config import *
2 | from .model_spec import *
3 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/axial_deeplab/__init__.py:
--------------------------------------------------------------------------------
1 | from .axial_deeplab import *
--------------------------------------------------------------------------------
/examples/imgs/orig1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/achaiah/pywick/HEAD/examples/imgs/orig1.png
--------------------------------------------------------------------------------
/examples/imgs/orig2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/achaiah/pywick/HEAD/examples/imgs/orig2.png
--------------------------------------------------------------------------------
/examples/imgs/orig3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/achaiah/pywick/HEAD/examples/imgs/orig3.png
--------------------------------------------------------------------------------
/examples/imgs/tform1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/achaiah/pywick/HEAD/examples/imgs/tform1.png
--------------------------------------------------------------------------------
/examples/imgs/tform2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/achaiah/pywick/HEAD/examples/imgs/tform2.png
--------------------------------------------------------------------------------
/examples/imgs/tform3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/achaiah/pywick/HEAD/examples/imgs/tform3.png
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/lg_kernel_exfuse/__init__.py:
--------------------------------------------------------------------------------
1 | from .large_kernel_exfuse import *
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/mixnet/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Source: https://github.com/zsef123/MixNet-PyTorch
3 | """
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/exfuse/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Source: https://github.com/rplab-snu/nucleus_segmentation
3 | """
--------------------------------------------------------------------------------
/docs/source/help.rst:
--------------------------------------------------------------------------------
1 | Help
2 | ======
3 | Please visit our `github page`_.
4 |
5 | .. _github page: https://github.com/achaiah/pywick
--------------------------------------------------------------------------------
/pywick/models/classification/testnets/__init__.py:
--------------------------------------------------------------------------------
1 | from .se_densenet_full import se_densenet121, se_densenet161, se_densenet169, se_densenet201
--------------------------------------------------------------------------------
/.deepsource.toml:
--------------------------------------------------------------------------------
1 | version = 1
2 |
3 | [[analyzers]]
4 | name = "python"
5 | enabled = true
6 |
7 | [analyzers.meta]
8 | runtime_version = "3.x.x"
--------------------------------------------------------------------------------
/docs/source/api/losses.rst:
--------------------------------------------------------------------------------
1 | Losses
2 | ========
3 |
4 | .. automodule:: pywick.losses
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
--------------------------------------------------------------------------------
/docs/source/api/samplers.rst:
--------------------------------------------------------------------------------
1 | Samplers
2 | ==========
3 |
4 | .. automodule:: pywick.samplers
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
--------------------------------------------------------------------------------
/docs/source/api/initializers.rst:
--------------------------------------------------------------------------------
1 | Initializers
2 | ============
3 |
4 | .. automodule:: pywick.initializers
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
--------------------------------------------------------------------------------
/docs/source/api/regularizers.rst:
--------------------------------------------------------------------------------
1 | Regularizers
2 | ============
3 |
4 | .. automodule:: pywick.regularizers
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
--------------------------------------------------------------------------------
/docs/source/api/constraints.rst:
--------------------------------------------------------------------------------
1 | Constraints
2 | ============
3 |
4 | .. automodule:: pywick.constraints
5 | :members: Constraint, MaxNorm, NonNeg, UnitNorm
6 | :undoc-members:
--------------------------------------------------------------------------------
/pywick/models/segmentation/gcnnets/__init__.py:
--------------------------------------------------------------------------------
1 | from .gcn import *
2 | from .gcn_nasnet import *
3 | from .gcn_densenet import *
4 | from .gcn_psp import *
5 | from .gcn_resnext import *
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/flatten.py:
--------------------------------------------------------------------------------
1 | from torch.nn import Module
2 |
3 |
4 | class Flatten(Module):
5 | @staticmethod
6 | def forward(x):
7 | return x.view(x.size(0), -1)
8 |
--------------------------------------------------------------------------------
/docs/source/api/conditions.rst:
--------------------------------------------------------------------------------
1 | Conditions
2 | ============
3 |
4 | .. automodule:: pywick.conditions
5 | :members: Condition, SegmentationInputAsserts, SegmentationOutputAsserts
6 | :undoc-members:
--------------------------------------------------------------------------------
/pywick/models/classification/resnext_features/__init__.py:
--------------------------------------------------------------------------------
1 | from .resnext101_32x4d_features import resnext101_32x4d_features
2 | from .resnext101_64x4d_features import resnext101_64x4d_features
3 | from .resnext50_32x4d_features import resnext50_32x4d_features
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/gscnn/my_functionals/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
3 | Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
4 | """
5 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | albumentations
2 | dill
3 | #hickle
4 | h5py
5 | # inplace_abn
6 | numpy
7 | opencv-python-headless
8 | pandas
9 | pillow
10 | prodict
11 | pycm
12 | pyyaml
13 | scipy
14 | requests
15 | scikit-image
16 | six
17 | tabulate
18 | tini
19 | tqdm
20 | yacs
--------------------------------------------------------------------------------
/pywick/meters/meter.py:
--------------------------------------------------------------------------------
1 |
2 | class Meter:
3 | """
4 | Abstract meter class from which all other meters inherit
5 | """
6 | def reset(self):
7 | pass
8 |
9 | def add(self):
10 | pass
11 |
12 | def value(self):
13 | pass
14 |
--------------------------------------------------------------------------------
/docs/source/requirements.txt:
--------------------------------------------------------------------------------
1 | albumentations
2 | dill
3 | #hickle
4 | h5py
5 | # inplace_abn
6 | numpy
7 | opencv-python-headless
8 | pandas
9 | pillow
10 | prodict
11 | pycm
12 | pyyaml
13 | scipy
14 | requests
15 | scikit-image
16 | six
17 | tabulate
18 | tini
19 | tqdm
20 | yacs
--------------------------------------------------------------------------------
/pywick/README_loss_functions.md:
--------------------------------------------------------------------------------
1 | ## Summarized Loss functions and their use-cases
2 | 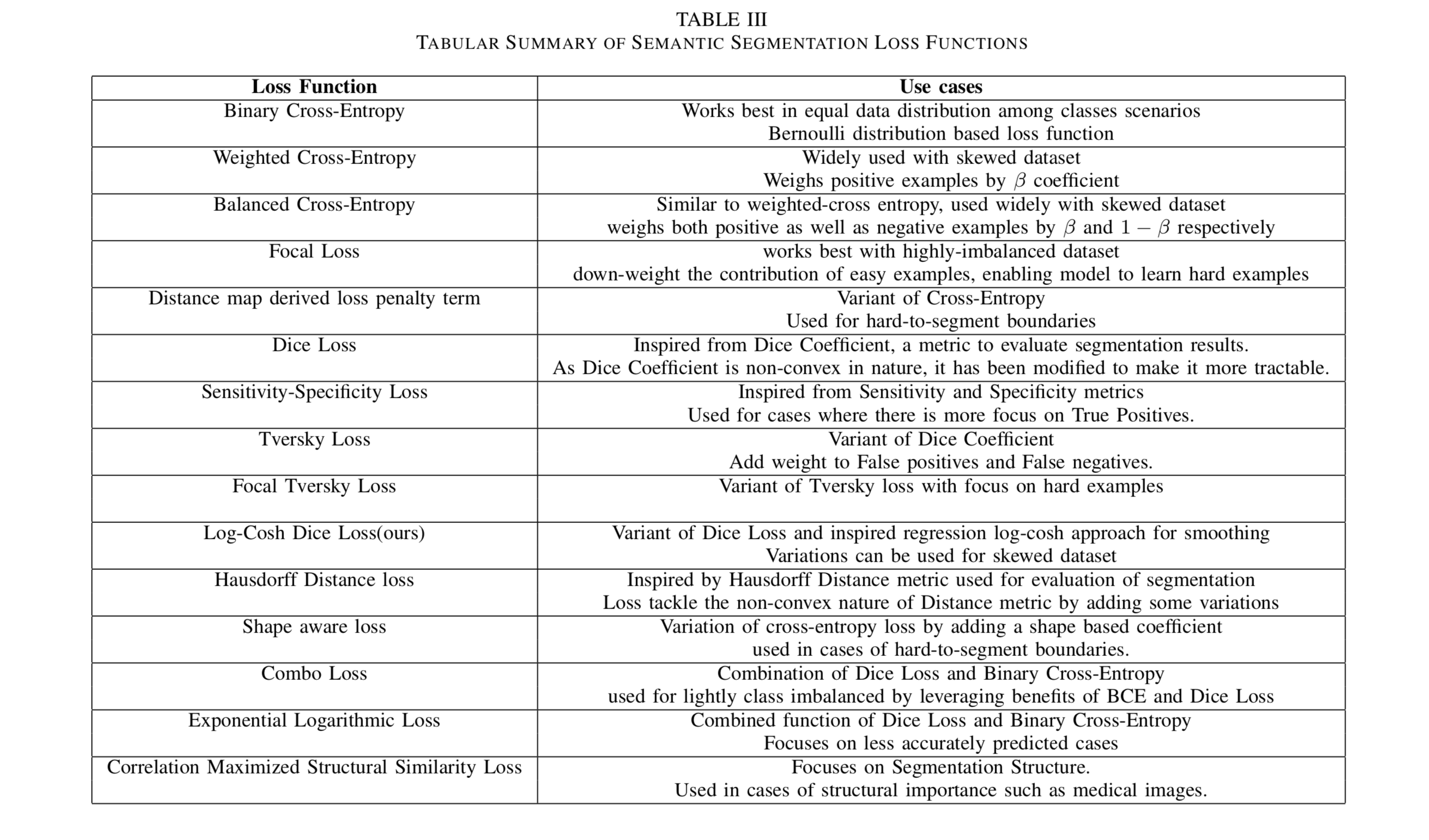
3 |
4 | 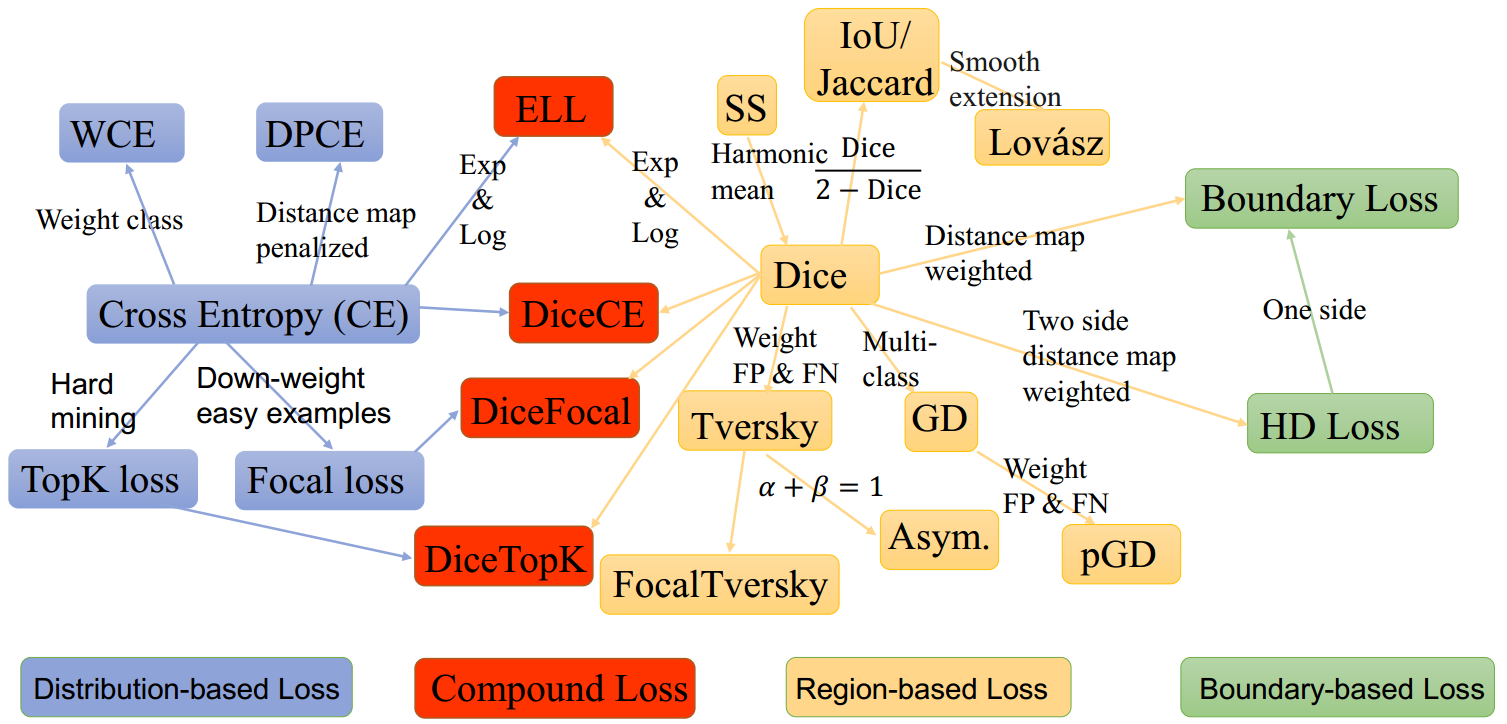
5 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/hrnetv2/bn_helper.py:
--------------------------------------------------------------------------------
1 |
2 | import torch
3 | import functools
4 |
5 | if torch.__version__.startswith('0'):
6 | from inplace_abn import InPlaceABNSync
7 | BatchNorm2d = functools.partial(InPlaceABNSync, activation='none')
8 | BatchNorm2d_class = InPlaceABNSync
9 | relu_inplace = False
10 | else:
11 | BatchNorm2d_class = BatchNorm2d = torch.nn.SyncBatchNorm
12 | relu_inplace = True
--------------------------------------------------------------------------------
/pywick/functions/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Here you can find a collection of functions that are used in neural networks. One of the most important aspects of a neural
3 | network is a good activation function. Pytorch already has a solid `collection `_
4 | of activation functions but here are a few more experimental ones to play around with.
5 | """
6 |
7 | from . import *
8 |
--------------------------------------------------------------------------------
/docs/source/api/pywick.gridsearch.rst:
--------------------------------------------------------------------------------
1 | Gridsearch
2 | =========================
3 |
4 | .. automodule:: pywick.gridsearch
5 | :members:
6 | :undoc-members:
7 |
8 | Gridsearch
9 | -------------
10 |
11 | .. automodule:: pywick.gridsearch.gridsearch
12 | :members:
13 | :undoc-members:
14 |
15 | Pipeline
16 | ---------------------------------
17 |
18 | .. automodule:: pywick.gridsearch.pipeline
19 | :members: Pipeline
20 | :undoc-members:
21 |
--------------------------------------------------------------------------------
/pywick/meters/averagemeter.py:
--------------------------------------------------------------------------------
1 | class AverageMeter:
2 | """Computes and stores the average and current value"""
3 | def __init__(self):
4 | self.reset()
5 |
6 | def reset(self):
7 | self.val = 0
8 | self.avg = 0
9 | self.sum = 0
10 | self.count = 0
11 |
12 | def update(self, val, n=1):
13 | self.val = val
14 | self.sum += val * n
15 | self.count += n
16 | self.avg = self.sum / self.count
--------------------------------------------------------------------------------
/pywick/datasets/tnt/__init__.py:
--------------------------------------------------------------------------------
1 | from .batchdataset import BatchDataset
2 | from .concatdataset import ConcatDataset
3 | from .dataset import Dataset
4 | from .listdataset import ListDataset
5 | from .multipartitiondataset import MultiPartitionDataset
6 | from .resampledataset import ResampleDataset
7 | from .shuffledataset import ShuffleDataset
8 | from .splitdataset import SplitDataset
9 | from .table import *
10 | from .transform import *
11 | from .transformdataset import TransformDataset
12 |
--------------------------------------------------------------------------------
/pywick/transforms/README.md:
--------------------------------------------------------------------------------
1 | ### Transforms
2 | Various transform functions have been collected here over the years to make augmentations easier to use. However, most transforms involving images
3 | (rather than numpy arrays or tensors) will be deprecated in favor of the [albumentations](https://github.com/albu/albumentations) package
4 | that you can install separately.
5 |
6 | ### Removed Transforms
7 | * CV2_transforms have been removed in favor of the [albumentations](https://github.com/albu/albumentations) package
--------------------------------------------------------------------------------
/tests/run_test.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | set -e
3 |
4 | PYCMD=${PYCMD:="python"}
5 | if [ "$1" == "coverage" ];
6 | then
7 | coverage erase
8 | PYCMD="coverage run --parallel-mode --source torch "
9 | echo "coverage flag found. Setting python command to: \"$PYCMD\""
10 | fi
11 |
12 | pushd "$(dirname "$0")"
13 |
14 | $PYCMD test_meters.py
15 | $PYCMD unit/transforms/test_affine_transforms.py
16 | $PYCMD unit/transforms/test_image_transforms.py
17 | $PYCMD unit/transforms/test_tensor_transforms.py
18 |
--------------------------------------------------------------------------------
/pywick/gridsearch/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | When trying to find the right hyperparameters for your neural network, sometimes you just have to do a lot of trial and error.
3 | Currently, our Gridsearch implementation is pretty basic, but it allows you to supply ranges of input values for various
4 | metaparameters and then executes training runs in either random or sequential fashion.\n
5 | Warning: this class is a bit underdeveloped. Tread with care.
6 | """
7 |
8 | from .gridsearch import GridSearch
9 | from .pipeline import Pipeline
--------------------------------------------------------------------------------
/docs/source/api/pywick.models.localization.rst:
--------------------------------------------------------------------------------
1 | Localization
2 | ==================================
3 |
4 | FPN
5 | -------------------------------------
6 |
7 | .. automodule:: pywick.models.localization.fpn
8 | :members: FPN, FPN101
9 | :undoc-members:
10 | :show-inheritance:
11 |
12 | Retina\_FPN
13 | ---------------------------------------------
14 |
15 | .. automodule:: pywick.models.localization.retina_fpn
16 | :members: RetinaFPN, RetinaFPN101
17 | :undoc-members:
18 | :show-inheritance:
19 |
--------------------------------------------------------------------------------
/pywick/transforms/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Along with custom transforms provided by Pywick, we fully support integration of Albumentations `_ which contains a great number of useful transform functions. See train_classifier.py for an example of how to incorporate albumentations into training.
3 | """
4 |
5 | from .affine_transforms import *
6 | from .distortion_transforms import *
7 | from .image_transforms import *
8 | from .tensor_transforms import *
9 | from .utils import *
10 |
--------------------------------------------------------------------------------
/pywick/__init__.py:
--------------------------------------------------------------------------------
1 | __version__ = '0.6.5'
2 | __author__ = 'Achaiah'
3 | __description__ = 'High-level batteries-included neural network training library for Pytorch'
4 |
5 | from pywick import (
6 | callbacks,
7 | conditions,
8 | constraints,
9 | datasets,
10 | dictmodels,
11 | functions,
12 | gridsearch,
13 | losses,
14 | meters,
15 | metrics,
16 | misc,
17 | models,
18 | modules,
19 | optimizers,
20 | regularizers,
21 | samplers,
22 | transforms,
23 | utils
24 | )
25 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .git/
2 | sandbox/
3 |
4 | *.DS_Store
5 | *__pycache__*
6 | __pycache__
7 | *.pyc
8 | .ipynb_checkpoints/
9 | *.ipynb_checkpoints/
10 | *.bkbn
11 | .spyderworkspace
12 | .spyderproject
13 |
14 | # setup.py working directory
15 | build
16 | # sphinx build directory
17 | doc/_build
18 | docs/build
19 | docs/Makefile
20 | docs/make.bat
21 | docs/source/_build
22 | # setup.py dist directory
23 | dist
24 | # Egg metadata
25 | *.egg-info
26 | .eggs
27 |
28 | .idea
29 | /pywick.egg-info/
30 |
31 | pywick/configs/train_classifier_local.yaml
32 |
--------------------------------------------------------------------------------
/pywick/datasets/tnt/table.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def canmergetensor(tbl):
5 | if not isinstance(tbl, list):
6 | return False
7 |
8 | if torch.is_tensor(tbl[0]):
9 | sz = tbl[0].numel()
10 | for v in tbl:
11 | if v.numel() != sz:
12 | return False
13 | return True
14 | return False
15 |
16 |
17 | def mergetensor(tbl):
18 | sz = [len(tbl)] + list(tbl[0].size())
19 | res = tbl[0].new(torch.Size(sz))
20 | for i,v in enumerate(tbl):
21 | res[i].copy_(v)
22 | return res
23 |
--------------------------------------------------------------------------------
/pywick/optimizers/rangerlars.py:
--------------------------------------------------------------------------------
1 | from .lookahead import *
2 | from .ralamb import *
3 |
4 | # RAdam + LARS + LookAHead
5 |
6 | class RangerLars(Lookahead):
7 |
8 | def __init__(self, params, alpha=0.5, k=6, *args, **kwargs):
9 | """
10 | Combination of RAdam + LARS + LookAhead
11 |
12 | :param params:
13 | :param alpha:
14 | :param k:
15 | :param args:
16 | :param kwargs:
17 | :return:
18 | """
19 | ralamb = Ralamb(params, *args, **kwargs)
20 | super().__init__(ralamb, alpha, k)
21 |
--------------------------------------------------------------------------------
/docs/source/api/pywick.models.rst:
--------------------------------------------------------------------------------
1 | Models
2 | =====================
3 |
4 | .. automodule:: pywick.models
5 | :members:
6 | :undoc-members:
7 |
8 | .. toctree::
9 |
10 | pywick.models.torchvision
11 | pywick.models.rwightman
12 | pywick.models.classification
13 | pywick.models.localization
14 | pywick.models.segmentation
15 |
16 |
17 | utility functions
18 | ---------------------------------
19 |
20 | .. automodule:: pywick.models.model_utils
21 | :members: load_checkpoint, get_model, get_fc_names, get_supported_models
22 | :show-inheritance:
23 |
--------------------------------------------------------------------------------
/docs/source/segmentation_guide.md:
--------------------------------------------------------------------------------
1 | ## Segmentation
2 |
3 | In a short while we will publish a walk-through that will go into detail
4 | on how to do segmentation with Pywick. In the meantime, if you feel
5 | adventurous feel free to look at our [README](https://pywick.readthedocs.io/en/latest/README.html).
6 |
7 | You can also take a look at our [Classification guide](https://pywick.readthedocs.io/en/latest/classification_guide.html) to get a good idea of how to get started on your own. The segmentation training process is very similar but involves more complicated directory structure for data.
8 |
--------------------------------------------------------------------------------
/pywick/dictmodels/model_spec.py:
--------------------------------------------------------------------------------
1 | from typing import Dict
2 |
3 | from prodict import Prodict
4 |
5 |
6 | class ModelSpec(Prodict):
7 | """
8 | Model specification to instantiate. Most models will have pre-configured and pre-trained variants but this gives you more fine-grained control
9 | """
10 |
11 | model_name : int # Size of the batch to use when training (per GPU)
12 | model_params : Dict # where to find the training data
13 |
14 | def init(self):
15 | # nothing initialized yet but will be expanded in the future
16 | pass
17 |
--------------------------------------------------------------------------------
/pywick/models/classification/pretrained_notes.txt:
--------------------------------------------------------------------------------
1 | last_linear
2 | ----------
3 | NOTE: Some pretrained models contain '.fc' as the name of the last layer. Simply rename it to 'last_linear' before loading the weights.
4 |
5 | inceptionresnetv2
6 | inceptionv4
7 | nasnetalarge
8 | nasnetamobile
9 | pnasnet
10 | polynet
11 | resnet_swish
12 | resnext101_x
13 | SENet / se_resnet50, se_resnet101, se_resnet152 etc
14 | WideResNet
15 |
16 |
17 | Conv2D (1x1 kernel)
18 | -----------
19 | DPN (dpn68, dpn68b, dpn92, dpn98, dpn107, dpn131)
20 |
21 |
22 | Multiple FC
23 | -----------
24 | inception (torchvision) (fc)
25 | pyramid_resnet (fc2, fc3, fc4)
26 | resnet (torchvision) (fc)
27 | se_resnet (relies on resnet) (fc)
--------------------------------------------------------------------------------
/docs/source/api/pywick.functions.rst:
--------------------------------------------------------------------------------
1 | Functions
2 | ========================
3 |
4 | .. automodule:: pywick.functions
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
9 | CyclicLR
10 | --------------------------------
11 |
12 | .. automodule:: pywick.functions.cyclicLR
13 | :members:
14 | :undoc-members:
15 | :show-inheritance:
16 |
17 | Mish
18 | --------------------------------
19 |
20 | .. automodule:: pywick.functions.mish
21 | :members:
22 | :undoc-members:
23 | :show-inheritance:
24 |
25 | Swish + Aria
26 | -----------------------------
27 |
28 | .. automodule:: pywick.functions.swish
29 | :members:
30 | :undoc-members:
31 | :show-inheritance:
32 |
--------------------------------------------------------------------------------
/pywick/meters/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Meters are used to accumulate values over time or batch and generally provide some statistical measure of your process.
3 | """
4 |
5 | from pywick.meters.apmeter import APMeter
6 | from pywick.meters.aucmeter import AUCMeter
7 | from pywick.meters.averagemeter import AverageMeter
8 | from pywick.meters.averagevaluemeter import AverageValueMeter
9 | from pywick.meters.classerrormeter import ClassErrorMeter
10 | from pywick.meters.confusionmeter import ConfusionMeter
11 | from pywick.meters.mapmeter import mAPMeter
12 | from pywick.meters.movingaveragevaluemeter import MovingAverageValueMeter
13 | from pywick.meters.msemeter import MSEMeter
14 | from pywick.meters.timemeter import TimeMeter
15 |
--------------------------------------------------------------------------------
/pywick/modules/stn.py:
--------------------------------------------------------------------------------
1 |
2 | import torch.nn as nn
3 |
4 | from ..functions import F_affine2d, F_affine3d
5 |
6 |
7 | class STN2d(nn.Module):
8 |
9 | def __init__(self, local_net):
10 | super(STN2d, self).__init__()
11 | self.local_net = local_net
12 |
13 | def forward(self, x):
14 | params = self.local_net(x)
15 | x_transformed = F_affine2d(x[0], params.view(2,3))
16 | return x_transformed
17 |
18 |
19 | class STN3d(nn.Module):
20 |
21 | def __init__(self, local_net):
22 | self.local_net = local_net
23 |
24 | def forward(self, x):
25 | params = self.local_net(x)
26 | x_transformed = F_affine3d(x, params.view(3,4))
27 | return x_transformed
28 |
29 |
--------------------------------------------------------------------------------
/pywick/optimizers/lookaheadsgd.py:
--------------------------------------------------------------------------------
1 | from pywick.optimizers.lookahead import *
2 | from torch.optim import SGD
3 |
4 |
5 | class LookaheadSGD(Lookahead):
6 |
7 | def __init__(self, params, lr, alpha=0.5, k=6, momentum=0.9, dampening=0, weight_decay=0.0001, nesterov=False):
8 | """
9 | Combination of SGD + LookAhead
10 |
11 | :param params:
12 | :param lr:
13 | :param alpha:
14 | :param k:
15 | :param momentum:
16 | :param dampening:
17 | :param weight_decay:
18 | :param nesterov:
19 | """
20 | sgd = SGD(params, lr=lr, momentum=momentum, dampening=dampening, weight_decay=weight_decay, nesterov=nesterov)
21 | super().__init__(sgd, alpha, k)
22 |
--------------------------------------------------------------------------------
/docs/source/description.rst:
--------------------------------------------------------------------------------
1 | Welcome to Pywick!
2 | ========================
3 |
4 | About
5 | ^^^^^
6 | Pywick is a high-level Pytorch training framework that aims to get you up and running quickly with state of the art neural networks.
7 | Does the world need another Pytorch framework? Probably not. But we started this project when no good frameworks were available and
8 | it just kept growing. So here we are.
9 |
10 | Pywick tries to stay on the bleeding edge of research into neural networks. If you just wish to run a vanilla CNN, this is probably
11 | going to be overkill. However, if you want to get lost in the world of neural networks, fine-tuning and hyperparameter optimization
12 | for months on end then this is probably the right place for you :)
--------------------------------------------------------------------------------
/entrypoint.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | # run demo if "demo" env variable is set
4 | if [ -n "$demo" ]; then
5 | # prepare directories
6 | mkdir -p /data /jobs && cd /data && \
7 | # get the dataset
8 | wget https://www.robots.ox.ac.uk/~vgg/data/flowers/17/17flowers.tgz && \
9 | tar xzf 17flowers.tgz && rm 17flowers.tgz && \
10 | # refactor images into correct structure
11 | python /home/pywick/examples/17flowers_split.py && \
12 | rm -rf jpg && \
13 | # train on the dataset
14 | cd /home/pywick/pywick && python train_classifier.py configs/train_classifier.yaml
15 | echo "keeping container alive ..."
16 | tail -f /dev/null
17 |
18 | # otherwise keep the container alive
19 | else
20 | echo "running a blank container..."
21 | tail -f /dev/null
22 | fi
--------------------------------------------------------------------------------
/readthedocs.yml:
--------------------------------------------------------------------------------
1 | # .readthedocs.yml
2 | # Read the Docs configuration file
3 | # See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
4 |
5 | # Required
6 | version: 2
7 |
8 | # Build documentation in the docs/ directory with Sphinx
9 | sphinx:
10 | configuration: docs/source/conf.py
11 |
12 | # Build documentation with MkDocs
13 | #mkdocs:
14 | # configuration: mkdocs.yml
15 |
16 | # Optionally build your docs in additional formats such as PDF and ePub
17 | formats: all
18 |
19 | # Configuration for the documentation build process
20 | build:
21 | image: latest
22 |
23 | # Optionally set the version of Python and requirements required to build your docs
24 | python:
25 | version: 3.6
26 | install:
27 | - requirements: docs/source/requirements.txt
--------------------------------------------------------------------------------
/docs/source/api/pywick.transforms.rst:
--------------------------------------------------------------------------------
1 | Transforms
2 | =========================
3 |
4 | Affine
5 | -------------------------------------------
6 |
7 | .. automodule:: pywick.transforms.affine_transforms
8 | :members:
9 | :undoc-members:
10 |
11 |
12 | Distortion
13 | -----------------------------------------------
14 |
15 | .. automodule:: pywick.transforms.distortion_transforms
16 | :members:
17 | :undoc-members:
18 |
19 |
20 | Image
21 | ------------------------------------------
22 |
23 | .. automodule:: pywick.transforms.image_transforms
24 | :members:
25 | :undoc-members:
26 |
27 |
28 | Tensor
29 | -------------------------------------------
30 |
31 | .. automodule:: pywick.transforms.tensor_transforms
32 | :members:
33 | :undoc-members:
34 |
35 |
--------------------------------------------------------------------------------
/pywick/meters/msemeter.py:
--------------------------------------------------------------------------------
1 | import math
2 | from . import meter
3 | import torch
4 |
5 |
6 | class MSEMeter(meter.Meter):
7 | def __init__(self, root=False):
8 | super(MSEMeter, self).__init__()
9 | self.reset()
10 | self.root = root
11 |
12 | def reset(self):
13 | self.n = 0
14 | self.sesum = 0.0
15 |
16 | def add(self, output, target):
17 | if not torch.is_tensor(output) and not torch.is_tensor(target):
18 | output = torch.from_numpy(output)
19 | target = torch.from_numpy(target)
20 | self.n += output.numel()
21 | self.sesum += torch.sum((output - target) ** 2)
22 |
23 | def value(self):
24 | mse = self.sesum / max(1, self.n)
25 | return math.sqrt(mse) if self.root else mse
26 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/mixnet/layers.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 |
5 | class Swish(nn.Module):
6 | @staticmethod
7 | def forward(x):
8 | return x * torch.sigmoid(x)
9 |
10 |
11 | class Flatten(nn.Module):
12 | @staticmethod
13 | def forward(x):
14 | return x.view(x.shape[0], -1)
15 |
16 |
17 | class SEModule(nn.Module):
18 | def __init__(self, ch, squeeze_ch):
19 | super().__init__()
20 | self.se = nn.Sequential(
21 | nn.AdaptiveAvgPool2d(1),
22 | nn.Conv2d(ch, squeeze_ch, 1, 1, 0, bias=True),
23 | Swish(),
24 | nn.Conv2d(squeeze_ch, ch, 1, 1, 0, bias=True),
25 | )
26 |
27 | def forward(self, x):
28 | return x * torch.sigmoid(self.se(x))
29 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/config.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | # here (https://github.com/pytorch/vision/tree/master/torchvision/models) to find the download link of pretrained models
4 |
5 | root = '/models/pytorch'
6 | res50_path = os.path.join(root, 'resnet50-19c8e357.pth')
7 | res101_path = os.path.join(root, 'resnet101-5d3b4d8f.pth')
8 | res152_path = os.path.join(root, 'resnet152-b121ed2d.pth')
9 | inception_v3_path = os.path.join(root, 'inception_v3_google-1a9a5a14.pth')
10 | vgg19_bn_path = os.path.join(root, 'vgg19_bn-c79401a0.pth')
11 | vgg16_path = os.path.join(root, 'vgg16-397923af.pth')
12 | dense201_path = os.path.join(root, 'densenet201-4c113574.pth')
13 |
14 | '''
15 | vgg16 trained using caffe
16 | visit this (https://github.com/jcjohnson/pytorch-vgg) to download the converted vgg16
17 | '''
18 | vgg16_caffe_path = os.path.join(root, 'vgg16-caffe.pth')
19 |
--------------------------------------------------------------------------------
/pywick/callbacks/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Callbacks are the primary mechanism by which one can embed event hooks into the training process. Many useful callbacks are provided
3 | out of the box but in all likelihood you will want to implement your own to execute actions based on training events. To do so,
4 | simply extend the pywick.callbacks.Callback class and overwrite functions that you are interested in acting upon.
5 |
6 | """
7 | from .Callback import *
8 | from .CallbackContainer import *
9 | from .CSVLogger import *
10 | from .CyclicLRScheduler import *
11 | from .EarlyStopping import *
12 | from .ExperimentLogger import *
13 | from .History import *
14 | from .LambdaCallback import *
15 | from .LRScheduler import *
16 | from .ModelCheckpoint import *
17 | from .OneCycleLRScheduler import *
18 | from .ReduceLROnPlateau import *
19 | from .SimpleModelCheckpoint import *
20 | from .TQDM import *
21 |
--------------------------------------------------------------------------------
/pywick/meters/timemeter.py:
--------------------------------------------------------------------------------
1 | import time
2 | from . import meter
3 |
4 | class TimeMeter(meter.Meter):
5 | """
6 | This meter is designed to measure the time between events and can be
7 | used to measure, for instance, the average processing time per batch of data.
8 | It is different from most other meters in terms of the methods it provides:
9 |
10 | Mmethods:
11 |
12 | * `reset()` resets the timer, setting the timer and unit counter to zero.
13 | * `value()` returns the time passed since the last `reset()`; divided by the counter value when `unit=true`.
14 | """
15 | def __init__(self, unit):
16 | super(TimeMeter, self).__init__()
17 | self.unit = unit
18 | self.reset()
19 |
20 | def reset(self):
21 | self.n = 0
22 | self.time = time.time()
23 |
24 | def value(self):
25 | return time.time() - self.time
26 |
--------------------------------------------------------------------------------
/pywick/models/classification/testnets/se_module.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/zhouyuangan/SE_DenseNet/blob/master/se_module.py (License: MIT)
2 |
3 | from torch import nn
4 |
5 |
6 | class SELayer(nn.Module):
7 | def __init__(self, channel, reduction=16):
8 | if channel <= reduction:
9 | raise AssertionError("Make sure your input channel bigger than reduction which equals to {}".format(reduction))
10 | super(SELayer, self).__init__()
11 | self.avg_pool = nn.AdaptiveAvgPool2d(1)
12 | self.fc = nn.Sequential(
13 | nn.Linear(channel, channel // reduction),
14 | nn.ReLU(inplace=True),
15 | nn.Linear(channel // reduction, channel),
16 | nn.Sigmoid()
17 | )
18 |
19 | def forward(self, x):
20 | b, c, _, _ = x.size()
21 | y = self.avg_pool(x).view(b, c)
22 | y = self.fc(y).view(b, c, 1, 1)
23 | return x * y
--------------------------------------------------------------------------------
/pywick/configs/eval_classifier.yaml:
--------------------------------------------------------------------------------
1 | # This specification extends / overrides default.yaml where necessary
2 | __include__: default.yaml
3 |
4 | eval:
5 | batch_size: 1 # size of batch to run through eval
6 | dataroots: '/data/eval' # directory containing evaluation data
7 | eval_chkpt: '/data/models/best.pth' # saved checkpoint to use for evaluation
8 | gpu_id: 0
9 | has_grnd_truth: True # whether ground truth is provided (as directory names under which images reside)
10 | # input_size: 224 # should be saved with the model but could be overridden here
11 | jobroot: '/jobs/eval_output' # where to output predictions
12 | topK: 5 # number of results to return
13 | use_gpu: False # toggle gpu use for inference
14 | workers: 1 # keep at 1 otherwise statistics may not be accurate
--------------------------------------------------------------------------------
/examples/17flowers_split.py:
--------------------------------------------------------------------------------
1 | import shutil
2 | import os
3 |
4 | directory = "jpg"
5 | target_train = "17flowers"
6 |
7 | if not os.path.isdir(target_train):
8 | os.makedirs(target_train)
9 |
10 | classes = [
11 | "daffodil",
12 | "snowdrop",
13 | "lilyvalley",
14 | "bluebell",
15 | "crocus",
16 | "iris",
17 | "tigerlily",
18 | "tulip",
19 | "fritillary",
20 | "sunflower",
21 | "daisy",
22 | "coltsfoot",
23 | "dandelion",
24 | "cowslip",
25 | "buttercup",
26 | "windflower",
27 | "pansy",
28 | ]
29 |
30 | j = 0
31 | for i in range(1, 1361):
32 | label_dir = os.path.join(target_train, classes[j])
33 |
34 | if not os.path.isdir(label_dir):
35 | os.makedirs(label_dir)
36 |
37 | filename = "image_" + str(i).zfill(4) + ".jpg"
38 | shutil.copy(
39 | os.path.join(directory, filename), os.path.join(label_dir, filename)
40 | )
41 |
42 | if i % 80 == 0:
43 | j += 1
--------------------------------------------------------------------------------
/docs/source/api/pywick.models.torchvision.rst:
--------------------------------------------------------------------------------
1 | Torchvision Models
2 | ====================================
3 |
4 | All standard `torchvision models `_
5 | are supported out of the box.
6 |
7 | * AlexNet
8 | * Densenet (121, 161, 169, 201)
9 | * GoogLeNet
10 | * Inception V3
11 | * Mobilenet V2
12 | * ResNet (18, 34, 50, 101, 152)
13 | * ShuffleNet V2
14 | * SqueezeNet (1.0, 1.1)
15 | * VGG (11, 13, 16, 19)
16 |
17 | Keep in mind that if you use torvision loading methods (e.g. ``torchvision.models.alexnet(...)``) you
18 | will get a vanilla pretrained model based on Imagenet with 1000 classes. However, more typically,
19 | you'll want to use a pretrained model with your own dataset (and your own number of classes). In that
20 | case you should instead use Pywick's ``models.model_utils.get_model(...)`` utility function
21 | which will do all the dirty work for you and give you a pretrained model but with your custom
22 | number of classes!
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/gscnn/mynn.py:
--------------------------------------------------------------------------------
1 | """
2 | Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
3 | Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
4 | """
5 |
6 | import torch.nn as nn
7 | from .config import cfg
8 |
9 |
10 | def Norm2d(in_channels):
11 | """
12 | Custom Norm Function to allow flexible switching
13 | """
14 | layer = cfg.MODEL.BNFUNC
15 | normalizationLayer = layer(in_channels)
16 | return normalizationLayer
17 |
18 |
19 | def initialize_weights(*models):
20 | for model in models:
21 | for module in model.modules():
22 | if isinstance(module(nn.Conv2d, nn.Linear)):
23 | nn.init.kaiming_normal(module.weight)
24 | if module.bias is not None:
25 | module.bias.data.zero_()
26 | elif isinstance(module, nn.BatchNorm2d):
27 | module.weight.data.fill_(1)
28 | module.bias.data.zero_()
29 |
--------------------------------------------------------------------------------
/pywick/functions/mish.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/rwightman/gen-efficientnet-pytorch/blob/master/geffnet/activations/activations.py (Apache 2.0)
2 | # Note. Cuda-compiled source can be found here: https://github.com/thomasbrandon/mish-cuda (MIT)
3 |
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 | def mish(x, inplace: bool = False):
8 | """Mish: A Self Regularized Non-Monotonic Neural Activation Function - https://arxiv.org/abs/1908.08681
9 | """
10 | return x.mul(F.softplus(x).tanh())
11 |
12 | class Mish(nn.Module):
13 | """
14 | Mish - "Mish: A Self Regularized Non-Monotonic Neural Activation Function"
15 | https://arxiv.org/abs/1908.08681v1
16 | implemented for PyTorch / FastAI by lessw2020
17 | github: https://github.com/lessw2020/mish
18 | """
19 | def __init__(self, inplace: bool = False):
20 | super(Mish, self).__init__()
21 | self.inplace = inplace
22 |
23 | def forward(self, x):
24 | return mish(x, self.inplace)
25 |
--------------------------------------------------------------------------------
/pywick/models/LICENSE-MIT.txt:
--------------------------------------------------------------------------------
1 | The MIT License
2 |
3 | Copyright 2019
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
6 |
7 | The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
8 |
9 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/__init__.py:
--------------------------------------------------------------------------------
1 | from .autofocusNN import *
2 | from .axial_deeplab import *
3 | from .dabnet import *
4 | from .deeplabv3 import DeepLabV3 as TEST_DLV3
5 | from .deeplabv2 import DeepLabV2 as TEST_DLV2
6 | from .deeplabv3_xception import DeepLabv3_plus as TEST_DLV3_Xception
7 | from .deeplabv3_xception import create_DLX_V3_pretrained as TEST_DLX_V3
8 | from .deeplabv3_resnet import create_DLR_V3_pretrained as TEST_DLR_V3
9 | from .difnet import DifNet101, DifNet152
10 | from .drnet import DRNet
11 | from .encnet import EncNet as TEST_EncNet, encnet_resnet50 as TEST_EncNet_Res50, encnet_resnet101 as TEST_EncNet_Res101, encnet_resnet152 as TEST_EncNet_Res152
12 | from .exfuse import UnetExFuse
13 | from .gscnn import GSCNN
14 | from .lg_kernel_exfuse import GCNFuse
15 | from .psanet import *
16 | from .psp_saeed import PSPNet as TEST_PSPNet2
17 | from .tkcnet import TKCNet_Resnet101
18 | from .tiramisu_test import FCDenseNet57 as TEST_Tiramisu57
19 | from .Unet_nested import UNet_Nested_dilated as TEST_Unet_nested_dilated
20 | from .unet_plus_plus import NestNet as Unet_Plus_Plus
--------------------------------------------------------------------------------
/pywick/transforms/utils.py:
--------------------------------------------------------------------------------
1 | import cv2
2 |
3 |
4 | def read_cv2_as_rgba(path):
5 | """
6 | Reads files from the provided path and returns them as a dictionary of: {'image': rgba, 'mask': rgba[:, :, 3]}
7 | :param path: Absolute file path
8 |
9 | :return: {'image': rgba, 'mask': rgba[:, :, 3]}
10 | """
11 | image = cv2.imread(path, -1)
12 | # By default OpenCV uses BGR color space for color images, so we need to convert the image to RGB color space.
13 | rgba = cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA)
14 | return {'image': rgba, 'mask': rgba[:, :, 3]}
15 |
16 |
17 | def read_cv2_as_rgb(path):
18 | """
19 | Reads files from the provided path and returns them as a dictionary of: {'image': rgb} in RGB format
20 | :param path: Absolute file path
21 |
22 | :return: CV2 / numpy array in RGB format
23 | """
24 | image = cv2.imread(path, -1)
25 | # By default OpenCV uses BGR color space for color images, so we need to convert the image to RGB color space.
26 | return {'image': cv2.cvtColor(image, cv2.COLOR_BGR2RGB)}
27 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/emanet/settings.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import numpy as np
3 | from torch import Tensor
4 |
5 |
6 | # Data settings
7 | DATA_ROOT = '/path/to/VOC'
8 | MEAN = Tensor(np.array([0.485, 0.456, 0.406]))
9 | STD = Tensor(np.array([0.229, 0.224, 0.225]))
10 | SCALES = (0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0)
11 | CROP_SIZE = 513
12 | IGNORE_LABEL = 255
13 |
14 | # Model definition
15 | N_CLASSES = 21
16 | N_LAYERS = 101
17 | STRIDE = 8
18 | BN_MOM = 3e-4
19 | EM_MOM = 0.9
20 | STAGE_NUM = 3
21 |
22 | # Training settings
23 | BATCH_SIZE = 16
24 | ITER_MAX = 30000
25 | ITER_SAVE = 2000
26 |
27 | LR_DECAY = 10
28 | LR = 9e-3
29 | LR_MOM = 0.9
30 | POLY_POWER = 0.9
31 | WEIGHT_DECAY = 1e-4
32 |
33 | DEVICE = 0
34 | DEVICES = list(range(0, 4))
35 |
36 | LOG_DIR = './logdir'
37 | MODEL_DIR = './models'
38 | NUM_WORKERS = 16
39 |
40 | logger = logging.getLogger('train')
41 | logger.setLevel(logging.INFO)
42 | ch = logging.StreamHandler()
43 | ch.setLevel(logging.INFO)
44 | formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
45 | ch.setFormatter(formatter)
46 | logger.addHandler(ch)
47 |
--------------------------------------------------------------------------------
/pywick/datasets/tnt/dataset.py:
--------------------------------------------------------------------------------
1 | from torch.utils.data import DataLoader
2 |
3 |
4 | class Dataset:
5 | def __init__(self):
6 | pass
7 |
8 | def __len__(self):
9 | pass
10 |
11 | def __getitem__(self, idx):
12 | if idx >= len(self):
13 | raise IndexError("CustomRange index out of range")
14 | pass
15 |
16 | def batch(self, *args, **kwargs):
17 | from .batchdataset import BatchDataset
18 | return BatchDataset(self, *args, **kwargs)
19 |
20 | def transform(self, *args, **kwargs):
21 | from .transformdataset import TransformDataset
22 | return TransformDataset(self, *args, **kwargs)
23 |
24 | def shuffle(self, *args, **kwargs):
25 | from .shuffledataset import ShuffleDataset
26 | return ShuffleDataset(self, *args, **kwargs)
27 |
28 | def parallel(self, *args, **kwargs):
29 | return DataLoader(self, *args, **kwargs)
30 |
31 | def partition(self, *args, **kwargs):
32 | from .multipartitiondataset import MultiPartitionDataset
33 | return MultiPartitionDataset(self, *args, **kwargs)
34 |
35 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/gscnn/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
3 | Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
4 | """
5 |
6 | import importlib
7 | import torch
8 | import logging
9 |
10 | from .gscnn import GSCNN
11 |
12 | def get_net(args, criterion):
13 | net = get_model(network=args.arch, num_classes=args.dataset_cls.num_classes,
14 | criterion=criterion, trunk=args.trunk)
15 | num_params = sum([param.nelement() for param in net.parameters()])
16 | logging.info('Model params = {:2.1f}M'.format(num_params / 1000000))
17 |
18 | net = net.cuda()
19 | net = torch.nn.DataParallel(net)
20 | return net
21 |
22 |
23 | def get_model(network, num_classes, criterion, trunk):
24 |
25 | module = network[:network.rfind('.')]
26 | model = network[network.rfind('.')+1:]
27 | mod = importlib.import_module(module)
28 | net_func = getattr(mod, model)
29 | net = net_func(num_classes=num_classes, trunk=trunk, criterion=criterion)
30 | return net
31 |
32 |
33 |
--------------------------------------------------------------------------------
/pywick/LICENSE-MIT.txt:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017 Elad Hoffer
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/pywick/meters/movingaveragevaluemeter.py:
--------------------------------------------------------------------------------
1 | import math
2 | from . import meter
3 | import torch
4 |
5 |
6 | class MovingAverageValueMeter(meter.Meter):
7 | """
8 | Keeps track of mean and standard deviation of some value for a given window.
9 | """
10 | def __init__(self, windowsize):
11 | super(MovingAverageValueMeter, self).__init__()
12 | self.windowsize = windowsize
13 | self.valuequeue = torch.Tensor(windowsize)
14 | self.reset()
15 |
16 | def reset(self):
17 | self.sum = 0.0
18 | self.n = 0
19 | self.var = 0.0
20 | self.valuequeue.fill_(0)
21 |
22 | def add(self, value):
23 | queueid = (self.n % self.windowsize)
24 | oldvalue = self.valuequeue[queueid]
25 | self.sum += value - oldvalue
26 | self.var += value * value - oldvalue * oldvalue
27 | self.valuequeue[queueid] = value
28 | self.n += 1
29 |
30 | def value(self):
31 | n = min(self.n, self.windowsize)
32 | mean = self.sum / max(1, n)
33 | std = math.sqrt(max((self.var - n * mean * mean) / max(1, n-1), 0))
34 | return mean, std
35 |
36 |
--------------------------------------------------------------------------------
/pywick/functions/LICENSE-MIT.txt:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017 Elad Hoffer
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/pywick/datasets/UsefulDataset.py:
--------------------------------------------------------------------------------
1 | import torch.utils.data.dataset as ds
2 |
3 | class UsefulDataset(ds.Dataset):
4 | '''
5 | A ``torch.utils.data.Dataset`` class with additional useful functions.
6 | '''
7 |
8 | def __init__(self):
9 | self.num_inputs = 1 # these are hardcoded for the fit module to work
10 | self.num_targets = 1 # these are hardcoded for the fit module to work
11 |
12 | def getdata(self):
13 | """
14 | Data that the Dataset class operates on. Typically iterable/list of tuple(label,target).
15 | Note: This is different than simply calling myDataset.data because some datasets are comprised of multiple other datasets!
16 | The dataset returned should be the `combined` dataset!
17 |
18 | :return: iterable - Representation of the entire dataset (combined if necessary from multiple other datasets)
19 | """
20 | raise NotImplementedError
21 |
22 | def getmeta_data(self):
23 | """
24 | Additional data to return that might be useful to consumer. Typically a dict.
25 |
26 | :return: dict(any)
27 | """
28 | raise NotImplementedError
--------------------------------------------------------------------------------
/pywick/datasets/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Datasets are the primary mechanism by which Pytorch assembles training and testing data
3 | to be used while training neural networks. While `pytorch` already provides a number of
4 | handy `datasets `_ and
5 | `torchvision` further extends them to common
6 | `academic sets `_,
7 | the implementations below provide some very powerful options for loading all kinds of data.
8 | We had to extend the default Pytorch implementation as by default it does not keep track
9 | of some useful metadata. That said, you can use our datasets in the normal fashion you're used to
10 | with Pytorch.
11 | """
12 |
13 | from .BaseDataset import BaseDataset
14 | from .ClonedFolderDataset import ClonedFolderDataset
15 | from .CSVDataset import CSVDataset
16 | from .FolderDataset import FolderDataset
17 | from .MultiFolderDataset import MultiFolderDataset
18 | from .PredictFolderDataset import PredictFolderDataset
19 | from .TensorDataset import TensorDataset
20 | from .UsefulDataset import UsefulDataset
21 | from . import data_utils
22 | from .tnt import *
23 |
--------------------------------------------------------------------------------
/pywick/meters/mapmeter.py:
--------------------------------------------------------------------------------
1 | from . import meter, APMeter
2 |
3 | class mAPMeter(meter.Meter):
4 | """
5 | The mAPMeter measures the mean average precision over all classes.
6 |
7 | The mAPMeter is designed to operate on `NxK` Tensors `output` and
8 | `target`, and optionally a `Nx1` Tensor weight where (1) the `output`
9 | contains model output scores for `N` examples and `K` classes that ought to
10 | be higher when the model is more convinced that the example should be
11 | positively labeled, and smaller when the model believes the example should
12 | be negatively labeled (for instance, the output of a sigmoid function); (2)
13 | the `target` contains only values 0 (for negative examples) and 1
14 | (for positive examples); and (3) the `weight` ( > 0) represents weight for
15 | each sample.
16 | """
17 | def __init__(self):
18 | super(mAPMeter, self).__init__()
19 | self.apmeter = APMeter()
20 |
21 | def reset(self):
22 | self.apmeter.reset()
23 |
24 | def add(self, output, target, weight=None):
25 | self.apmeter.add(output, target, weight)
26 |
27 | def value(self):
28 | return self.apmeter.value().mean()
29 |
--------------------------------------------------------------------------------
/pywick/optimizers/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Optimizers govern the path that your neural network takes as it tries to minimize error.
3 | Picking the right optimizer and initializing it with the right parameters will either make your network learn successfully
4 | or will cause it not to learn at all! Pytorch already implements the most widely used flavors such as SGD, Adam, RMSProp etc.
5 | Here we strive to include optimizers that Pytorch has missed (and any cutting edge ones that have not yet been added).
6 | """
7 |
8 | from .a2grad import A2GradInc, A2GradExp, A2GradUni
9 | from .adabelief import AdaBelief
10 | from .adahessian import Adahessian
11 | from .adamp import AdamP
12 | from .adamw import AdamW
13 | from .addsign import AddSign
14 | from .apollo import Apollo
15 | from .eve import Eve
16 | from .lars import Lars
17 | from .lookahead import Lookahead
18 | from .lookaheadsgd import LookaheadSGD
19 | from .madgrad import MADGRAD
20 | from .nadam import Nadam
21 | from .powersign import PowerSign
22 | from .qhadam import QHAdam
23 | from .radam import RAdam
24 | from .ralamb import Ralamb
25 | from .rangerlars import RangerLars
26 | from .sgdw import SGDW
27 | from .swa import SWA
28 | from torch.optim import *
29 |
--------------------------------------------------------------------------------
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | COPYRIGHT
2 |
3 | Copyright (c) 2019, Achaiah.
4 | All rights reserved.
5 |
6 | LICENSE
7 |
8 | The MIT License (MIT)
9 |
10 | Permission is hereby granted, free of charge, to any person obtaining a copy
11 | of this software and associated documentation files (the "Software"), to deal
12 | in the Software without restriction, including without limitation the rights
13 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
14 | copies of the Software, and to permit persons to whom the Software is
15 | furnished to do so, subject to the following conditions:
16 |
17 | The above copyright notice and this permission notice shall be included in all
18 | copies or substantial portions of the Software.
19 |
20 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
21 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
22 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
23 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
24 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
25 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
26 | SOFTWARE.
27 |
--------------------------------------------------------------------------------
/pywick/datasets/tnt/concatdataset.py:
--------------------------------------------------------------------------------
1 | from .dataset import Dataset
2 | import numpy as np
3 |
4 |
5 | class ConcatDataset(Dataset):
6 | """
7 | Dataset to concatenate multiple datasets.
8 |
9 | Purpose: useful to assemble different existing datasets, possibly
10 | large-scale datasets as the concatenation operation is done in an
11 | on-the-fly manner.
12 |
13 | Args:
14 | datasets (iterable): List of datasets to be concatenated
15 | """
16 |
17 | def __init__(self, datasets):
18 | super(ConcatDataset, self).__init__()
19 |
20 | self.datasets = list(datasets)
21 | if len(datasets) <= 0:
22 | raise AssertionError('datasets should not be an empty iterable')
23 | self.cum_sizes = np.cumsum([len(x) for x in self.datasets])
24 |
25 | def __len__(self):
26 | return self.cum_sizes[-1]
27 |
28 | def __getitem__(self, idx):
29 | super(ConcatDataset, self).__getitem__(idx)
30 | dataset_index = self.cum_sizes.searchsorted(idx, 'right')
31 |
32 | if dataset_index == 0:
33 | dataset_idx = idx
34 | else:
35 | dataset_idx = idx - self.cum_sizes[dataset_index - 1]
36 |
37 | return self.datasets[dataset_index][dataset_idx]
38 |
--------------------------------------------------------------------------------
/pywick/gridsearch/grid_test.py:
--------------------------------------------------------------------------------
1 | import json
2 | from .gridsearch import GridSearch
3 |
4 | my_args = {
5 | 'shape': '+plus+',
6 | 'animal':['cat', 'mouse', 'dog'],
7 | 'number':[4, 5, 6],
8 | 'device':['CUP', 'MUG', 'TPOT'],
9 | 'flower' : '=Rose='
10 | }
11 |
12 | def tryme(args_dict):
13 | print(json.dumps(args_dict, indent=4))
14 |
15 | def tryme_vars(animal='', number=0, device='', shape='', flower=''):
16 | print(animal + " : " + str(number) + " : " + device + " : " + shape + " : " + flower)
17 |
18 | def main():
19 | grids = GridSearch(tryme, grid_params=my_args, search_behavior='exhaustive', args_as_dict=True)
20 |
21 | print('-------- INITIAL SETTINGS ---------')
22 | tryme(my_args)
23 | print('-------------- END ----------------')
24 | print('-------------- --- ----------------')
25 | print()
26 | print('+++++++++++ Dict Result ++++++++++')
27 | grids.run()
28 | print('+++++++++++++ End Dict Result +++++++++++\n\n')
29 |
30 | grids = GridSearch(tryme_vars, grid_params=my_args, search_behavior='sampled_0.5', args_as_dict=False)
31 | print('========== Vars Result ==========')
32 | grids.run()
33 | print('========== End Vars Result ==========')
34 | # exit()
35 |
36 | if __name__ == '__main__':
37 | main()
38 |
--------------------------------------------------------------------------------
/pywick/models/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Neural network models is what deep learning is all about! While you can download some standard models from
3 | `torchvision `_, we strive to create a library of models
4 | that are on the cutting edge of AI. Whenever possible, `we provide pretrained solutions as well!`\n
5 | That said, we didn't come up with any of these on our own so we owe a huge debt of gratitude to the many researchers who have shared
6 | their models and weights on github.\n
7 | **Caution:** While we strive to ensure that all models can be used out of the box, sometimes things become broken due to Pytorch updates
8 | or misalignment of the planets. Please don't yell at us. Gently point out what's broken, or even better, submit a pull request to fix it!\n
9 | **Here Be Dragons:** Aaand one more thing - we constantly plumb the depths of github for new models or tweaks to existing ones. While we don't
10 | list this in the docs, there is a special `testnets` directory with tons of probably broken, semi-working, and at times crazy awesome
11 | models and model-variations. If you're interested in the bleeding edge, that's where you'd look (see ``models.__init__.py`` for what's available)
12 | """
13 |
14 | from . import model_locations
15 | from .classification import *
16 | from .segmentation import *
17 | from .model_utils import *
18 |
--------------------------------------------------------------------------------
/pywick/models/LICENSE-BSD 2-Clause.txt:
--------------------------------------------------------------------------------
1 | BSD 2-Clause License
2 |
3 | Copyright (c) 2018, ericsun99
4 | All rights reserved.
5 |
6 | Redistribution and use in source and binary forms, with or without
7 | modification, are permitted provided that the following conditions are met:
8 |
9 | * Redistributions of source code must retain the above copyright notice, this
10 | list of conditions and the following disclaimer.
11 |
12 | * Redistributions in binary form must reproduce the above copyright notice,
13 | this list of conditions and the following disclaimer in the documentation
14 | and/or other materials provided with the distribution.
15 |
16 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
17 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
18 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
19 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
20 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
21 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
22 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
23 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
24 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
25 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
26 |
--------------------------------------------------------------------------------
/pywick/meters/averagevaluemeter.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 | from . import meter
4 |
5 |
6 | class AverageValueMeter(meter.Meter):
7 | """
8 | Keeps track of mean and standard deviation for some value.
9 | """
10 | def __init__(self):
11 | super(AverageValueMeter, self).__init__()
12 | self.reset()
13 | self.val = 0
14 |
15 | def add(self, value, n=1):
16 | self.val = value
17 | self.sum += value
18 | self.var += value * value
19 | self.n += n
20 |
21 | if self.n == 0:
22 | self.mean, self.std = np.nan, np.nan
23 | elif self.n == 1:
24 | self.mean = 0.0 + self.sum # This is to force a copy in torch/numpy
25 | self.std = np.inf
26 | self.mean_old = self.mean
27 | self.m_s = 0.0
28 | else:
29 | self.mean = self.mean_old + (value - n * self.mean_old) / float(self.n)
30 | self.m_s += (value - self.mean_old) * (value - self.mean)
31 | self.mean_old = self.mean
32 | self.std = np.sqrt(self.m_s / (self.n - 1.0))
33 |
34 | def value(self):
35 | return self.mean, self.std
36 |
37 | def reset(self):
38 | self.n = 0
39 | self.sum = 0.0
40 | self.var = 0.0
41 | self.val = 0.0
42 | self.mean = np.nan
43 | self.mean_old = 0.0
44 | self.m_s = 0.0
45 | self.std = np.nan
46 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/msc.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # coding: utf-8
3 | #
4 | # Author: Kazuto Nakashima
5 | # URL: http://kazuto1011.github.io
6 | # Created: 2018-03-26
7 |
8 | # Source: https://raw.githubusercontent.com/kazuto1011/deeplab-pytorch/master/libs/models/msc.py
9 |
10 | import torch
11 | import torch.nn as nn
12 | import torch.nn.functional as F
13 |
14 |
15 | class MSC(nn.Module):
16 | """Multi-scale inputs"""
17 |
18 | def __init__(self, scale, pyramids=None):
19 | if pyramids is None:
20 | pyramids = [0.5, 0.75]
21 | super(MSC, self).__init__()
22 | self.scale = scale
23 | self.pyramids = pyramids
24 |
25 | def forward(self, x):
26 | # Original
27 | logits = self.scale(x)
28 | interp = lambda l: F.interpolate(l, size=logits.shape[2:], mode="bilinear", align_corners=True)
29 |
30 | # Scaled
31 | logits_pyramid = []
32 | for p in self.pyramids:
33 | size = [int(s * p) for s in x.shape[2:]]
34 | h = F.interpolate(x, size=size, mode="bilinear", align_corners=True)
35 | logits_pyramid.append(self.scale(h))
36 |
37 | # Pixel-wise max
38 | logits_all = [logits] + [interp(l) for l in logits_pyramid]
39 | logits_max = torch.max(torch.stack(logits_all), dim=0)[0]
40 |
41 | if self.training:
42 | return [logits] + logits_pyramid + [logits_max]
43 | else:
44 | return logits_max
45 |
--------------------------------------------------------------------------------
/pywick/callbacks/LambdaCallback.py:
--------------------------------------------------------------------------------
1 | from . import Callback
2 |
3 | class LambdaCallback(Callback):
4 | """
5 | Callback for creating simple, custom callbacks on-the-fly.
6 | """
7 |
8 | def __init__(self,
9 | on_epoch_begin=None,
10 | on_epoch_end=None,
11 | on_batch_begin=None,
12 | on_batch_end=None,
13 | on_train_begin=None,
14 | on_train_end=None,
15 | **kwargs):
16 | super(LambdaCallback, self).__init__()
17 | self.__dict__.update(kwargs)
18 | if on_epoch_begin is not None:
19 | self.on_epoch_begin = on_epoch_begin
20 | else:
21 | self.on_epoch_begin = lambda epoch, logs: None
22 | if on_epoch_end is not None:
23 | self.on_epoch_end = on_epoch_end
24 | else:
25 | self.on_epoch_end = lambda epoch, logs: None
26 | if on_batch_begin is not None:
27 | self.on_batch_begin = on_batch_begin
28 | else:
29 | self.on_batch_begin = lambda batch, logs: None
30 | if on_batch_end is not None:
31 | self.on_batch_end = on_batch_end
32 | else:
33 | self.on_batch_end = lambda batch, logs: None
34 | if on_train_begin is not None:
35 | self.on_train_begin = on_train_begin
36 | else:
37 | self.on_train_begin = lambda logs: None
38 | if on_train_end is not None:
39 | self.on_train_end = on_train_end
40 | else:
41 | self.on_train_end = lambda logs: None
42 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/drnet/utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 |
4 | def upsample_filt(size):
5 | factor = (size + 1) // 2
6 | if size % 2 == 1:
7 | center = factor - 1
8 | else:
9 | center = factor - 0.5
10 | og = np.ogrid[:size, :size]
11 | return (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
12 |
13 | def bilinear_upsample_weights(factor, number_of_classes):
14 | filter_size = 2 * factor - factor % 2
15 | weights = np.zeros((number_of_classes,
16 | number_of_classes,
17 | filter_size,
18 | filter_size,), dtype=np.float32)
19 |
20 | upsample_kernel = upsample_filt(filter_size)
21 |
22 | for i in range(number_of_classes):
23 | weights[i, i, :, :] = upsample_kernel
24 | return torch.Tensor(weights)
25 |
26 | def get_padding(output_size, input_size, factor):
27 | TH = output_size[2] - ((input_size[2]-1)*factor) - (factor*2)
28 | TW = output_size[3] - ((input_size[3]-1)*factor) - (factor*2)
29 | padding_H = int(np.ceil(TH / (-2)))
30 | out_padding_H = TH - padding_H*(-2)
31 |
32 | padding_W = int(np.ceil(TW / (-2)))
33 | out_padding_W = TW - padding_W*(-2)
34 | return (padding_H, padding_W), (out_padding_H, out_padding_W)
35 |
36 | def cfgs2name(cfgs):
37 | name = '%s_%s_%s(%s,%s,%s)' % \
38 | (cfgs['dataset'], cfgs['backbone'], cfgs['loss'], cfgs['a'], cfgs['b'],cfgs['c'])
39 | if 'MultiCue' in cfgs['dataset']:
40 | name = name + '_' + str(cfgs['multicue_seq'])
41 | return name
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/mixnet/mdconv.py:
--------------------------------------------------------------------------------
1 | # https://github.com/tensorflow/tpu/blob/master/models/official/mnasnet/mixnet/custom_layers.py
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 |
7 | def _split_channels(total_filters, num_groups):
8 | """
9 | https://github.com/tensorflow/tpu/blob/master/models/official/mnasnet/mixnet/custom_layers.py#L33
10 | """
11 | split = [total_filters // num_groups for _ in range(num_groups)]
12 | split[0] += total_filters - sum(split)
13 | return split
14 |
15 |
16 | class MDConv(nn.Module):
17 | def __init__(self, in_channels, kernel_sizes, stride, dilatied=False, bias=False):
18 | super().__init__()
19 |
20 | if not isinstance(kernel_sizes, list):
21 | kernel_sizes = [kernel_sizes]
22 |
23 | self.in_channels = _split_channels(in_channels, len(kernel_sizes))
24 |
25 | self.convs = nn.ModuleList()
26 | for ch, k in zip(self.in_channels, kernel_sizes):
27 | dilation = 1
28 | if stride[0] == 1 and dilatied:
29 | dilation, stride = (k - 1) // 2, 3
30 | print("Use dilated conv with dilation rate = {}".format(dilation))
31 | pad = ((stride[0] - 1) + dilation * (k - 1)) // 2
32 |
33 | conv = nn.Conv2d(ch, ch, k, stride, pad, dilation,
34 | groups=ch, bias=bias)
35 | self.convs.append(conv)
36 |
37 | def forward(self, x):
38 | xs = torch.split(x, self.in_channels, 1)
39 | return torch.cat([conv(x) for conv, x in zip(self.convs, xs)], 1)
--------------------------------------------------------------------------------
/pywick/models/LICENSE-BSD.txt:
--------------------------------------------------------------------------------
1 | BSD License
2 |
3 | For fb.resnet.torch software
4 |
5 | Copyright (c) 2016, Facebook, Inc. All rights reserved.
6 |
7 | Redistribution and use in source and binary forms, with or without modification,
8 | are permitted provided that the following conditions are met:
9 |
10 | * Redistributions of source code must retain the above copyright notice, this
11 | list of conditions and the following disclaimer.
12 |
13 | * Redistributions in binary form must reproduce the above copyright notice,
14 | this list of conditions and the following disclaimer in the documentation
15 | and/or other materials provided with the distribution.
16 |
17 | * Neither the name Facebook nor the names of its contributors may be used to
18 | endorse or promote products derived from this software without specific
19 | prior written permission.
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
22 | ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
23 | WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR
25 | ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
26 | (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
27 | LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON
28 | ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
29 | (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
30 | SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
31 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/LICENSE-BSD3-Clause.txt:
--------------------------------------------------------------------------------
1 | BSD 3-Clause License
2 |
3 | Copyright (c) 2017, Fisher Yu
4 | All rights reserved.
5 |
6 | Redistribution and use in source and binary forms, with or without
7 | modification, are permitted provided that the following conditions are met:
8 |
9 | * Redistributions of source code must retain the above copyright notice, this
10 | list of conditions and the following disclaimer.
11 |
12 | * Redistributions in binary form must reproduce the above copyright notice,
13 | this list of conditions and the following disclaimer in the documentation
14 | and/or other materials provided with the distribution.
15 |
16 | * Neither the name of the copyright holder nor the names of its
17 | contributors may be used to endorse or promote products derived from
18 | this software without specific prior written permission.
19 |
20 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30 |
--------------------------------------------------------------------------------
/docs/source/api/pywick.datasets.rst:
--------------------------------------------------------------------------------
1 | Datasets
2 | =======================
3 |
4 | .. automodule:: pywick.datasets
5 | :members:
6 | :undoc-members:
7 | :show-inheritance:
8 |
9 | BaseDataset
10 | ----------------------------------
11 |
12 | .. automodule:: pywick.datasets.BaseDataset
13 | :members:
14 | :show-inheritance:
15 |
16 | CSVDataset
17 | ---------------------------------
18 |
19 | .. automodule:: pywick.datasets.CSVDataset
20 | :members:
21 | :show-inheritance:
22 |
23 | ClonedFolderDataset
24 | ------------------------------------
25 |
26 | .. automodule:: pywick.datasets.ClonedFolderDataset
27 | :members:
28 | :show-inheritance:
29 |
30 | FolderDataset
31 | ------------------------------------
32 |
33 | .. automodule:: pywick.datasets.FolderDataset
34 | :members:
35 | :show-inheritance:
36 |
37 | MultiFolderDataset
38 | -----------------------------------------
39 |
40 | .. automodule:: pywick.datasets.MultiFolderDataset
41 | :members:
42 | :show-inheritance:
43 |
44 | PredictFolderDataset
45 | -------------------------------------------
46 |
47 | .. automodule:: pywick.datasets.PredictFolderDataset
48 | :members:
49 | :show-inheritance:
50 |
51 | TensorDataset
52 | ------------------------------------
53 |
54 | .. automodule:: pywick.datasets.TensorDataset
55 | :members:
56 | :show-inheritance:
57 |
58 | UsefulDataset
59 | ------------------------------------
60 |
61 | .. automodule:: pywick.datasets.UsefulDataset
62 | :members:
63 | :show-inheritance:
64 |
65 | data utilities
66 | ----------------------------------
67 |
68 | .. automodule:: pywick.datasets.data_utils
69 | :members:
70 |
--------------------------------------------------------------------------------
/docs/source/classification_guide.md:
--------------------------------------------------------------------------------
1 | ## Classification
2 |
3 | With Pywick it is incredibly easy to perform classification training on your dataset. In a typical scenario you will not need to write any code but rather provide a configuration yaml file. See [configs/train_classifier.yaml](https://github.com/achaiah/pywick/blob/master/pywick/configs/train_classifier.yaml) for configuration options. Most of them are well-documented inside the configuration file.
4 |
5 | Your dataset should be arranged such that each directory under your root dir is named after the corresponding class of images that it contains (e.g. 17flowers/colt, 17flowers/daisy etc). You can include multiple `dataroots` directories as a list. As an easy starting point, download [17 flowers](https://www.robots.ox.ac.uk/~vgg/data/flowers/17/) dataset and run [examples/17flowers_split.py](https://github.com/achaiah/pywick/blob/master/examples/17flowers_split.py) to convert it into appropriate directory structure.
6 |
7 | Some options you may want to tweak:
8 | - `dataroots` - where to find the training data
9 | - `model_spec` - model to use
10 | - `num_epochs` - number of epochs to train for
11 | - `output_root` - where to save outputs (e.g. trained NNs)
12 | - `use_gpu` - whether to use the GPU(s) for training
13 |
14 | Once you are happy with your configuration, simply invoke the pywick training code:
15 | ```bash
16 | # change to pywick
17 | cd pywick/pywick
18 | python3 train_classifier.py configs/train_classifier.yaml
19 | ```
20 |
21 | To see how the training code is structured under the hood and to customize it to your liking, see [train_classifier.py](https://github.com/achaiah/pywick/blob/master/pywick/train_classifier.py).
--------------------------------------------------------------------------------
/pywick/datasets/tnt/transform.py:
--------------------------------------------------------------------------------
1 | from six import iteritems
2 | from .table import canmergetensor as canmerge
3 | from .table import mergetensor
4 |
5 |
6 | def compose(transforms):
7 | if not isinstance(transforms, list):
8 | raise AssertionError
9 | for tr in transforms:
10 | if not callable(tr):
11 | raise AssertionError('list of functions expected')
12 |
13 | def composition(z):
14 | for tr in transforms:
15 | z = tr(z)
16 | return z
17 | return composition
18 |
19 |
20 | def tablemergekeys():
21 | def mergekeys(tbl):
22 | mergetbl = {}
23 | if isinstance(tbl, dict):
24 | for idx, elem in tbl.items():
25 | for key, value in elem.items():
26 | if key not in mergetbl:
27 | mergetbl[key] = {}
28 | mergetbl[key][idx] = value
29 | elif isinstance(tbl, list):
30 | for elem in tbl:
31 | for key, value in elem.items():
32 | if key not in mergetbl:
33 | mergetbl[key] = []
34 | mergetbl[key].append(value)
35 | return mergetbl
36 | return mergekeys
37 |
38 | tableapply = lambda f: lambda d: dict(
39 | map(lambda kv: (kv[0], f(kv[1])), iteritems(d)))
40 |
41 |
42 | def makebatch(merge=None):
43 | if merge:
44 | makebatch = compose([tablemergekeys(), merge])
45 | else:
46 | makebatch = compose([
47 | tablemergekeys(),
48 | tableapply(lambda field: mergetensor(field)
49 | if canmerge(field) else field)
50 | ])
51 |
52 | return makebatch
53 |
--------------------------------------------------------------------------------
/pywick/configs/train_classifier.json:
--------------------------------------------------------------------------------
1 | {
2 | "train": {
3 | "lr": 0.001,
4 | "momentum": 0.9,
5 | "weight_decay": 0.0001,
6 | "auto_balance_dataset": false,
7 | "batch_size": 32,
8 | "dataroots": [
9 | "/data/17flowers"
10 | ],
11 | "gpu_ids": [
12 | 0
13 | ],
14 | "input_size": 224,
15 | "mean_std": [
16 | [
17 | 0.485,
18 | 0.456,
19 | 0.406
20 | ],
21 | [
22 | 0.229,
23 | 0.224,
24 | 0.225
25 | ]
26 | ],
27 | "model_spec": "resnet50",
28 | "num_epochs": 15,
29 | "optimizer": {
30 | "name": "SGD",
31 | "params": {
32 | "lr": 0.001,
33 | "momentum": 0.9,
34 | "weight_decay": 0.0001
35 | }
36 | },
37 | "output_root": "/jobs/17flowers",
38 | "random_seed": 1337,
39 | "save_callback": {
40 | "name": "ModelCheckpoint",
41 | "params": {
42 | "do_minimize": true,
43 | "max_saves": 5,
44 | "monitored_log_key": "val_loss",
45 | "save_best_only": false,
46 | "save_interval": 1,
47 | "save_dir": "/jobs/17flowers",
48 | "custom_func": null,
49 | "verbose": false
50 | }
51 | },
52 | "scheduler": {
53 | "name": "OnceCycleLRScheduler",
54 | "params": {
55 | "epochs": 15,
56 | "max_lr": 0.05,
57 | "pct_start": 0.2
58 | }
59 | },
60 | "train_val_ratio": 0.9,
61 | "use_apex": false,
62 | "use_gpu": true,
63 | "val_root": null,
64 | "workers": 6
65 | },
66 | "eval": {
67 | "batch_size": 1,
68 | "CUDA_VISIBLE_DEVICES": "0",
69 | "dataroots": "/data/eval",
70 | "eval_chkpt": "/data/models/best.pth",
71 | "gpu_id": [
72 | 0
73 | ],
74 | "has_grnd_truth": true,
75 | "jobroot": "/jobs/eval_output",
76 | "topK": 5,
77 | "use_gpu": false,
78 | "workers": 1
79 | }
80 | }
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | from setuptools import setup, find_packages
4 | from pywick import __version__ as version, __author__ as author, __description__ as descr
5 |
6 | # read the contents of your README file per https://packaging.python.org/guides/making-a-pypi-friendly-readme/
7 | from os import path
8 | this_directory = path.abspath(path.dirname(__file__))
9 | with open(path.join(this_directory, 'README.md'), encoding='utf-8') as f:
10 | long_description = f.read()
11 |
12 | setup(name='pywick',
13 | version=version,
14 | description=descr,
15 | long_description=long_description,
16 | long_description_content_type='text/markdown',
17 | author=author,
18 | install_requires=[
19 | 'albumentations',
20 | 'dill',
21 | 'h5py',
22 | 'numpy',
23 | 'opencv-python-headless',
24 | 'pandas',
25 | 'pillow',
26 | 'prodict',
27 | 'pycm',
28 | 'pyyaml',
29 | 'scipy',
30 | 'requests',
31 | 'scikit-image',
32 | 'setuptools',
33 | 'six',
34 | 'tabulate',
35 | 'torch >= 1.6.0',
36 | 'torchvision',
37 | 'tqdm',
38 | 'yacs',
39 | 'wheel'
40 | ],
41 | packages=find_packages(),
42 | url='https://github.com/achaiah/pywick',
43 | download_url=f'https://github.com/achaiah/pywick/archive/v{version}.tar.gz',
44 | keywords=['ai', 'artificial intelligence', 'pytorch', 'classification', 'deep learning', 'neural networks', 'semantic-segmentation', 'framework'],
45 | classifiers=['Development Status :: 4 - Beta',
46 | 'Intended Audience :: Developers',
47 | 'License :: OSI Approved :: MIT License',
48 | 'Programming Language :: Python :: 3.8',
49 | ],
50 | )
51 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Below you will find all the latest image segmentation models. To get a list of specific model names that are available programmatically, call the ``pywick.models.model_utils.get_supported_models(...)`` method.
3 | To load one of these models with your own number of classes you have two options:
4 | 1. You can always load the model directly from the API. Most models allow you to customize *number of classes* as well as *pretrained* options.
5 | 2. You can use the ``pywick.models.model_utils.get_model(...)`` method and pass the name of the model
6 | that you want as a string. Note: Some models allow you to customize additional parameters. You can take a look at the ``pywick.models.model_utils.get_model(...)`` method
7 | or at the definition of the model to see what's possible. ``pywick.models.model_utils.get_model(...)`` takes in a ``**kwargs`` argument that you can populate with whatever parameters you'd like
8 | to pass to the model you are creating.
9 | """
10 |
11 | from .bisenet import *
12 | from .carvana_unet import *
13 | from ..classification import resnext101_64x4d
14 | from .danet import *
15 | from .deeplab_v2_res import *
16 | from .deeplab_v3 import *
17 | from .deeplab_v3_plus import *
18 | from .denseaspp import *
19 | from .drn_seg import *
20 | from .duc_hdc import *
21 | from .dunet import *
22 | from .emanet import EMANet, EmaNet152
23 | from .enet import *
24 | from .fcn8s import *
25 | from .fcn16s import *
26 | from .fcn32s import *
27 | from .frrn1 import *
28 | from .fusionnet import *
29 | from .galdnet import *
30 | from .gcnnets import *
31 | from .lexpsp import *
32 | from .mnas_linknets import *
33 | from .ocnet import *
34 | from .refinenet import *
35 | from .resnet_gcn import *
36 | from .seg_net import *
37 | from .testnets import *
38 | from .tiramisu import *
39 | from .u_net import *
40 | from .unet_dilated import *
41 | from .unet_res import *
42 | from .unet_stack import *
43 | from .upernet import *
44 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/da_basenets/segbase.py:
--------------------------------------------------------------------------------
1 | """Base Model for Semantic Segmentation"""
2 | import torch.nn as nn
3 | from pywick.models.segmentation.da_basenets.resnetv1b import resnet50_v1s, resnet101_v1s, resnet152_v1s
4 |
5 | __all__ = ['SegBaseModel']
6 |
7 |
8 | class SegBaseModel(nn.Module):
9 | r"""Base Model for Semantic Segmentation
10 |
11 | Parameters
12 | ----------
13 | backbone : string
14 | Pre-trained dilated backbone network type (default:'resnet50'; 'resnet50',
15 | 'resnet101' or 'resnet152').
16 | """
17 |
18 | def __init__(self, num_classes, pretrained=True, aux=False, backbone='resnet101', **kwargs):
19 | super(SegBaseModel, self).__init__()
20 | self.aux = aux
21 | self.nclass = num_classes
22 | if backbone == 'resnet50':
23 | self.pretrained = resnet50_v1s(pretrained=pretrained, **kwargs)
24 | elif backbone == 'resnet101':
25 | self.pretrained = resnet101_v1s(pretrained=pretrained, **kwargs)
26 | elif backbone == 'resnet152':
27 | self.pretrained = resnet152_v1s(pretrained=pretrained, **kwargs)
28 | else:
29 | raise RuntimeError('unknown backbone: {}'.format(backbone))
30 |
31 | def base_forward(self, x):
32 | """forwarding pre-trained network"""
33 | x = self.pretrained.conv1(x)
34 | x = self.pretrained.bn1(x)
35 | x = self.pretrained.relu(x)
36 | x = self.pretrained.maxpool(x)
37 | c1 = self.pretrained.layer1(x)
38 | c2 = self.pretrained.layer2(c1)
39 | c3 = self.pretrained.layer3(c2)
40 | c4 = self.pretrained.layer4(c3)
41 | return c1, c2, c3, c4
42 |
43 | def evaluate(self, x):
44 | """evaluating network with inputs and targets"""
45 | return self.forward(x)[0]
46 |
47 | def demo(self, x):
48 | pred = self.forward(x)
49 | if self.aux:
50 | pred = pred[0]
51 | return pred
52 |
--------------------------------------------------------------------------------
/tests/integration/fit_simple/single_input_no_target.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from pywick.modules import ModuleTrainer
7 |
8 | import os
9 | from torchvision import datasets
10 | ROOT = '/data/mnist'
11 | dataset = datasets.MNIST(ROOT, train=True, download=True)
12 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
13 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
14 |
15 | x_train = x_train.float()
16 | y_train = y_train.long()
17 | x_test = x_test.float()
18 | y_test = y_test.long()
19 |
20 | x_train = x_train / 255.
21 | x_test = x_test / 255.
22 | x_train = x_train.unsqueeze(1)
23 | x_test = x_test.unsqueeze(1)
24 |
25 | # only train on a subset
26 | x_train = x_train[:1000]
27 | y_train = y_train[:1000]
28 | x_test = x_test[:1000]
29 | y_test = y_test[:1000]
30 |
31 |
32 | # Define your model EXACTLY as if you were using nn.Module
33 | class Network(nn.Module):
34 | def __init__(self):
35 | super(Network, self).__init__()
36 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
37 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
38 | self.fc1 = nn.Linear(1600, 128)
39 | self.fc2 = nn.Linear(128, 1)
40 |
41 | def forward(self, x):
42 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
43 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
44 | x = x.view(-1, 1600)
45 | x = F.relu(self.fc1(x))
46 | x = F.dropout(x, training=self.training)
47 | x = self.fc2(x)
48 | return th.abs(10 - x)
49 |
50 |
51 | model = Network()
52 | trainer = ModuleTrainer(model)
53 |
54 | trainer.compile(criterion='unconstrained_sum',
55 | optimizer='adadelta')
56 |
57 | trainer.fit(x_train,
58 | num_epoch=3,
59 | batch_size=128,
60 | verbose=1)
61 |
62 | ypred = trainer.predict(x_train)
63 | print(ypred.size())
64 |
65 | eval_loss = trainer.evaluate(x_train, None)
66 | print(eval_loss)
--------------------------------------------------------------------------------
/pywick/callbacks/EarlyStopping.py:
--------------------------------------------------------------------------------
1 | from . import Callback
2 |
3 | __all__ = ['EarlyStopping']
4 |
5 | class EarlyStopping(Callback):
6 | """
7 | Early Stopping to terminate training early under certain conditions
8 |
9 | EarlyStopping callback to exit the training loop if training or
10 | validation loss does not improve by a certain amount for a certain
11 | number of epochs
12 |
13 | :param monitor: (string in {'val_loss', 'loss'}):
14 | whether to monitor train or val loss
15 | :param min_delta: (float):
16 | minimum change in monitored value to qualify as improvement.
17 | This number should be positive.
18 | :param patience: (int):
19 | number of epochs to wait for improvment before terminating.
20 | the counter be reset after each improvment
21 | """
22 |
23 | def __init__(self, monitor='val_loss', min_delta=0, patience=5):
24 | self.monitor = monitor
25 | self.min_delta = min_delta
26 | self.patience = patience
27 | self.wait = 0
28 | self.best_loss = 1e-15
29 | self.stopped_epoch = 0
30 | super(EarlyStopping, self).__init__()
31 |
32 | def on_train_begin(self, logs=None):
33 | self.wait = 0
34 | self.best_loss = 1e15
35 |
36 | def on_epoch_end(self, epoch, logs=None):
37 | current_loss = logs.get(self.monitor)
38 | if current_loss is None:
39 | pass
40 | else:
41 | if (current_loss - self.best_loss) < -self.min_delta:
42 | self.best_loss = current_loss
43 | self.wait = 1
44 | else:
45 | if self.wait >= self.patience:
46 | self.stopped_epoch = epoch + 1
47 | self.trainer._stop_training = True
48 | self.wait += 1
49 |
50 | def on_train_end(self, logs=None):
51 | if self.stopped_epoch > 0:
52 | print(f'\nTerminated Training for Early Stopping at Epoch: {self.stopped_epoch}')
53 |
--------------------------------------------------------------------------------
/pywick/datasets/tnt/resampledataset.py:
--------------------------------------------------------------------------------
1 | from .dataset import Dataset
2 |
3 |
4 | class ResampleDataset(Dataset):
5 | """
6 | Dataset which resamples a given dataset.
7 |
8 | Given a `dataset`, creates a new dataset which will (re-)sample from this
9 | underlying dataset using the provided `sampler(dataset, idx)` function.
10 |
11 | If `size` is provided, then the newly created dataset will have the
12 | specified `size`, which might be different than the underlying dataset
13 | size. If `size` is not provided, then the new dataset will have the same
14 | size as the underlying one.
15 |
16 | Purpose: shuffling data, re-weighting samples, getting a subset of the
17 | data. Note that an important sub-class `ShuffleDataset` is provided for
18 | convenience.
19 |
20 | Args:
21 | dataset (Dataset): Dataset to be resampled.
22 | sampler (function, optional): Function used for sampling. `idx`th
23 | sample is returned by `dataset[sampler(dataset, idx)]`. By default
24 | `sampler(dataset, idx)` is the identity, simply returning `idx`.
25 | `sampler(dataset, idx)` must return an index in the range
26 | acceptable for the underlying `dataset`.
27 | size (int, optional): Desired size of the dataset after resampling. By
28 | default, the new dataset will have the same size as the underlying
29 | one.
30 | """
31 |
32 | def __init__(self, dataset, sampler=lambda ds, idx: idx, size=None):
33 | super(ResampleDataset, self).__init__()
34 | self.dataset = dataset
35 | self.sampler = sampler
36 | self.size = size
37 |
38 | def __len__(self):
39 | return self.size if (self.size and self.size > 0) else len(self.dataset)
40 |
41 | def __getitem__(self, idx):
42 | super(ResampleDataset, self).__getitem__(idx)
43 | idx = self.sampler(self.dataset, idx)
44 |
45 | if idx < 0 or idx >= len(self.dataset):
46 | raise IndexError('out of range')
47 |
48 | return self.dataset[idx]
49 |
--------------------------------------------------------------------------------
/tests/integration/fit_simple/simple_multi_input_no_target.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from pywick.modules import ModuleTrainer
7 |
8 | import os
9 | from torchvision import datasets
10 | ROOT = '/data/mnist'
11 | dataset = datasets.MNIST(ROOT, train=True, download=True)
12 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
13 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
14 |
15 | x_train = x_train.float()
16 | y_train = y_train.long()
17 | x_test = x_test.float()
18 | y_test = y_test.long()
19 |
20 | x_train = x_train / 255.
21 | x_test = x_test / 255.
22 | x_train = x_train.unsqueeze(1)
23 | x_test = x_test.unsqueeze(1)
24 |
25 | # only train on a subset
26 | x_train = x_train[:1000]
27 | y_train = y_train[:1000]
28 | x_test = x_test[:1000]
29 | y_test = y_test[:1000]
30 |
31 |
32 | # Define your model EXACTLY as if you were using nn.Module
33 | class Network(nn.Module):
34 | def __init__(self):
35 | super(Network, self).__init__()
36 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
37 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
38 | self.fc1 = nn.Linear(1600, 128)
39 | self.fc2 = nn.Linear(128, 1)
40 |
41 | def forward(self, x, y, z):
42 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
43 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
44 | x = x.view(-1, 1600)
45 | x = F.relu(self.fc1(x))
46 | x = F.dropout(x, training=self.training)
47 | x = self.fc2(x)
48 | return th.abs(10 - x)
49 |
50 |
51 | model = Network()
52 | trainer = ModuleTrainer(model)
53 |
54 | trainer.compile(criterion='unconstrained_sum',
55 | optimizer='adadelta')
56 |
57 | trainer.fit([x_train, x_train, x_train],
58 | num_epoch=3,
59 | batch_size=128,
60 | verbose=1)
61 |
62 | ypred = trainer.predict([x_train, x_train, x_train])
63 | print(ypred.size())
64 |
65 | eval_loss = trainer.evaluate([x_train, x_train, x_train])
66 | print(eval_loss)
67 |
68 |
--------------------------------------------------------------------------------
/pywick/models/LICENSE_LIP6.txt:
--------------------------------------------------------------------------------
1 | Copyright (c) 2017 LIP6 Lab
2 |
3 | Permission is hereby granted, free of charge, to any person obtaining
4 | a copy of this software and associated documentation files (the
5 | "Software"), to deal in the Software without restriction, including
6 | without limitation the rights to use, copy, modify, merge, publish,
7 | distribute, sublicense, and/or sell copies of the Software, and to
8 | permit persons to whom the Software is furnished to do so, subject to
9 | the following conditions:
10 |
11 | The above copyright notice and this permission notice shall be
12 | included in all copies or substantial portions of the Software.
13 |
14 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
15 | EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
16 | MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
17 | NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
18 | LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
19 | OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
20 | WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
21 |
22 | -------------------------------------------------
23 |
24 | This product contains portions of third party software provided under this license:
25 |
26 | dump_filters.py (x)
27 | ===============
28 |
29 | Copyright 2015 Google Inc. All Rights Reserved.
30 |
31 | Licensed under the Apache License, Version 2.0 (the "License");
32 | you may not use this file except in compliance with the License.
33 | You may obtain a copy of the License at
34 |
35 | http://www.apache.org/licenses/LICENSE-2.0
36 |
37 | Unless required by applicable law or agreed to in writing, software
38 | distributed under the License is distributed on an "AS IS" BASIS,
39 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
40 | See the License for the specific language governing permissions and
41 | limitations under the License.
42 |
43 |
44 | (x) adapted from https://github.com/tensorflow/tensorflow/blob/411f57e/tensorflow/models/image/imagenet/classify_image.py
--------------------------------------------------------------------------------
/docs/source/api/pywick.meters.rst:
--------------------------------------------------------------------------------
1 | Meters
2 | =====================
3 |
4 | .. automodule:: pywick.meters
5 | :members:
6 |
7 | APMeter
8 | ----------------------------
9 |
10 | .. automodule:: pywick.meters.apmeter
11 | :members:
12 | :undoc-members:
13 | :show-inheritance:
14 |
15 | AUCMeter
16 | -----------------------------
17 |
18 | .. automodule:: pywick.meters.aucmeter
19 | :members:
20 | :undoc-members:
21 | :show-inheritance:
22 |
23 | AverageMeter
24 | ---------------------------------
25 |
26 | .. automodule:: pywick.meters.averagemeter
27 | :members:
28 | :undoc-members:
29 | :show-inheritance:
30 |
31 | AverageValueMeter
32 | --------------------------------------
33 |
34 | .. automodule:: pywick.meters.averagevaluemeter
35 | :members:
36 | :undoc-members:
37 | :show-inheritance:
38 |
39 | ClassErrorMeter
40 | ------------------------------------
41 |
42 | .. automodule:: pywick.meters.classerrormeter
43 | :members:
44 | :undoc-members:
45 | :show-inheritance:
46 |
47 | ConfusionMeter
48 | -----------------------------------
49 |
50 | .. automodule:: pywick.meters.confusionmeter
51 | :members:
52 | :undoc-members:
53 | :show-inheritance:
54 |
55 | MAPMeter
56 | -----------------------------
57 |
58 | .. automodule:: pywick.meters.mapmeter
59 | :members:
60 | :undoc-members:
61 | :show-inheritance:
62 |
63 | Meter
64 | --------------------------
65 |
66 | .. automodule:: pywick.meters.meter
67 | :members:
68 | :undoc-members:
69 | :show-inheritance:
70 |
71 | MovingAverageValueMeter
72 | --------------------------------------------
73 |
74 | .. automodule:: pywick.meters.movingaveragevaluemeter
75 | :members:
76 | :undoc-members:
77 | :show-inheritance:
78 |
79 | MSEMeter
80 | -----------------------------
81 |
82 | .. automodule:: pywick.meters.msemeter
83 | :members:
84 | :undoc-members:
85 | :show-inheritance:
86 |
87 | TimeMeter
88 | ------------------------------
89 |
90 | .. automodule:: pywick.meters.timemeter
91 | :members:
92 | :undoc-members:
93 | :show-inheritance:
94 |
--------------------------------------------------------------------------------
/tests/integration/fit_simple/simple_multi_input_single_target.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from pywick.modules import ModuleTrainer
7 |
8 | import os
9 | from torchvision import datasets
10 | ROOT = '/data/mnist'
11 | dataset = datasets.MNIST(ROOT, train=True, download=True)
12 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
13 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
14 |
15 | x_train = x_train.float()
16 | y_train = y_train.long()
17 | x_test = x_test.float()
18 | y_test = y_test.long()
19 |
20 | x_train = x_train / 255.
21 | x_test = x_test / 255.
22 | x_train = x_train.unsqueeze(1)
23 | x_test = x_test.unsqueeze(1)
24 |
25 | # only train on a subset
26 | x_train = x_train[:1000]
27 | y_train = y_train[:1000]
28 | x_test = x_test[:100]
29 | y_test = y_test[:100]
30 |
31 |
32 | # Define your model EXACTLY as if you were using nn.Module
33 | class Network(nn.Module):
34 | def __init__(self):
35 | super(Network, self).__init__()
36 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
37 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
38 | self.fc1 = nn.Linear(1600, 128)
39 | self.fc2 = nn.Linear(128, 10)
40 |
41 | def forward(self, x, y, z):
42 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
43 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
44 | x = x.view(-1, 1600)
45 | x = F.relu(self.fc1(x))
46 | x = F.dropout(x, training=self.training)
47 | x = self.fc2(x)
48 | return F.log_softmax(x)
49 |
50 |
51 | model = Network()
52 | trainer = ModuleTrainer(model)
53 |
54 | trainer.compile(criterion='nll_loss',
55 | optimizer='adadelta')
56 |
57 | trainer.fit([x_train, x_train, x_train], y_train,
58 | val_data=([x_test, x_test, x_test], y_test),
59 | num_epoch=3,
60 | batch_size=128,
61 | verbose=1)
62 |
63 | ypred = trainer.predict([x_train, x_train, x_train])
64 | print(ypred.size())
65 |
66 | eval_loss = trainer.evaluate([x_train, x_train, x_train], y_train)
67 | print(eval_loss)
--------------------------------------------------------------------------------
/pywick/datasets/tnt/transformdataset.py:
--------------------------------------------------------------------------------
1 | from .dataset import Dataset
2 |
3 |
4 | class TransformDataset(Dataset):
5 | """
6 | Dataset which transforms a given dataset with a given function.
7 |
8 | Given a function `transform`, and a `dataset`, `TransformDataset` applies
9 | the function in an on-the-fly manner when querying a sample with
10 | `__getitem__(idx)` and therefore returning `transform[dataset[idx]]`.
11 |
12 | `transform` can also be a dict with functions as values. In this case, it
13 | is assumed that `dataset[idx]` is a dict which has all the keys in
14 | `transform`. Then, `transform[key]` is applied to dataset[idx][key] for
15 | each key in `transform`
16 |
17 | The size of the new dataset is equal to the size of the underlying
18 | `dataset`.
19 |
20 | Purpose: when performing pre-processing operations, it is convenient to be
21 | able to perform on-the-fly transformations to a dataset.
22 |
23 | Args:
24 | dataset (Dataset): Dataset which has to be transformed.
25 | transforms (function/dict): Function or dict with function as values.
26 | These functions will be applied to data.
27 | """
28 |
29 | def __init__(self, dataset, transforms):
30 | super(TransformDataset, self).__init__()
31 |
32 | if not (isinstance(transforms, dict) or callable(transforms)):
33 | raise AssertionError('expected a dict of transforms or a function')
34 | if isinstance(transforms, dict):
35 | for k, v in transforms.items():
36 | if not callable(v):
37 | raise AssertionError(str(k) + ' is not a function')
38 |
39 | self.dataset = dataset
40 | self.transforms = transforms
41 |
42 | def __len__(self):
43 | return len(self.dataset)
44 |
45 | def __getitem__(self, idx):
46 | super(TransformDataset, self).__getitem__(idx)
47 | z = self.dataset[idx]
48 |
49 | if isinstance(self.transforms, dict):
50 | for k, transform in self.transforms.items():
51 | z[k] = transform(z[k])
52 | else:
53 | z = self.transforms(z)
54 |
55 | return z
56 |
--------------------------------------------------------------------------------
/pywick/meters/classerrormeter.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | import numbers
4 | from . import meter
5 |
6 |
7 | class ClassErrorMeter(meter.Meter):
8 | def __init__(self, topk=None, accuracy=False):
9 | if topk is None:
10 | topk = [1]
11 | super(ClassErrorMeter, self).__init__()
12 | self.topk = np.sort(topk)
13 | self.accuracy = accuracy
14 | self.reset()
15 |
16 | def reset(self):
17 | self.sum = {v: 0 for v in self.topk}
18 | self.n = 0
19 |
20 | def add(self, output, target):
21 | if torch.is_tensor(output):
22 | output = output.cpu().squeeze().numpy()
23 | if torch.is_tensor(target):
24 | target = np.atleast_1d(target.cpu().squeeze().numpy())
25 | elif isinstance(target, numbers.Number):
26 | target = np.asarray([target])
27 | if np.ndim(output) == 1:
28 | output = output[np.newaxis]
29 | else:
30 | if np.ndim(output) != 2:
31 | raise AssertionError('wrong output size (1D or 2D expected)')
32 | if np.ndim(target) != 1:
33 | raise AssertionError('target and output do not match')
34 | if target.shape[0] != output.shape[0]:
35 | raise AssertionError('target and output do not match')
36 | topk = self.topk
37 | maxk = int(topk[-1]) # seems like Python3 wants int and not np.int64
38 | no = output.shape[0]
39 |
40 | pred = torch.from_numpy(output).topk(maxk, 1, True, True)[1].numpy()
41 | correct = pred == target[:, np.newaxis].repeat(pred.shape[1], 1)
42 |
43 | for k in topk:
44 | self.sum[k] += no - correct[:, 0:k].sum()
45 | self.n += no
46 |
47 | def value(self, k=-1):
48 | if k != -1:
49 | if k not in self.sum.keys():
50 | raise AssertionError('invalid k (this k was not provided at construction time)')
51 | if self.accuracy:
52 | return (1. - float(self.sum[k]) / self.n) * 100.0
53 | else:
54 | return float(self.sum[k]) / self.n * 100.0
55 | else:
56 | return [self.value(k_) for k_ in self.topk]
57 |
--------------------------------------------------------------------------------
/pywick/datasets/ClonedFolderDataset.py:
--------------------------------------------------------------------------------
1 | import random
2 | from .FolderDataset import FolderDataset
3 |
4 |
5 | class ClonedFolderDataset(FolderDataset):
6 | """
7 | Dataset that can be initialized with a dictionary of internal parameters (useful when trying to clone a FolderDataset)
8 |
9 | :param data: (list):
10 | list of data on which the dataset operates
11 |
12 | :param meta_data: (dict):
13 | parameters that correspond to the target dataset's attributes
14 |
15 | :param kwargs: (args):
16 | variable set of key-value pairs to set as attributes for the dataset
17 | """
18 | def __init__(self, data, meta_data, **kwargs):
19 |
20 | if len(data) == 0:
21 | raise (RuntimeError('No data provided'))
22 | print('Initializing with %i data items' % len(data))
23 |
24 | self.data = data
25 |
26 | # Source: https://stackoverflow.com/questions/2466191/set-attributes-from-dictionary-in-python
27 | # generic way of initializing the object
28 | for key in meta_data:
29 | setattr(self, key, meta_data[key])
30 | for key in kwargs:
31 | setattr(self, key, kwargs[key])
32 |
33 |
34 | def random_split_dataset(orig_dataset, splitRatio=0.8, random_seed=None):
35 | '''
36 | Randomly split the given dataset into two datasets based on the provided ratio
37 |
38 | :param orig_dataset: (UsefulDataset):
39 | dataset to split (of type pywick.datasets.UsefulDataset)
40 |
41 | :param splitRatio: (float):
42 | ratio to use when splitting the data
43 |
44 | :param random_seed: (int):
45 | random seed for replicability of results
46 |
47 | :return: tuple of split ClonedFolderDatasets
48 | '''
49 | random.seed(a=random_seed)
50 |
51 | # not cloning the dictionary at this point... maybe it should be?
52 | orig_dict = orig_dataset.getmeta_data()
53 | part1 = []
54 | part2 = []
55 |
56 | for i, item in enumerate(orig_dataset.getdata()):
57 | if random.random() < splitRatio:
58 | part1.append(item)
59 | else:
60 | part2.append(item)
61 |
62 | return ClonedFolderDataset(part1, orig_dict), ClonedFolderDataset(part2, orig_dict)
--------------------------------------------------------------------------------
/pywick/datasets/tnt/listdataset.py:
--------------------------------------------------------------------------------
1 | from .dataset import Dataset
2 |
3 |
4 | class ListDataset(Dataset):
5 | """
6 | Dataset which loads data from a list using given function.
7 |
8 | Considering a `elem_list` (can be an iterable or a `string` ) i-th sample
9 | of a dataset will be returned by `load(elem_list[i])`, where `load()`
10 | is a function provided by the user.
11 |
12 | If `path` is provided, `elem_list` is assumed to be a list of strings, and
13 | each element `elem_list[i]` will prefixed by `path/` when fed to `load()`.
14 |
15 | Purpose: many low or medium-scale datasets can be seen as a list of files
16 | (for example representing input samples). For this list of file, a target
17 | can be often inferred in a simple manner.
18 |
19 | Args:
20 | elem_list (iterable/str): List of arguments which will be passed to
21 | `load` function. It can also be a path to file with each line
22 | containing the arguments to `load`
23 | load (function, optional): Function which loads the data.
24 | i-th sample is returned by `load(elem_list[i])`. By default `load`
25 | is identity i.e, `lambda x: x`
26 | path (str, optional): Defaults to None. If a string is provided,
27 | `elem_list` is assumed to be a list of strings, and each element
28 | `elem_list[i]` will prefixed by this string when fed to `load()`.
29 |
30 | """
31 |
32 | def __init__(self, elem_list, load=lambda x: x, path=None):
33 | super(ListDataset, self).__init__()
34 |
35 | if isinstance(elem_list, str):
36 | with open(elem_list) as f:
37 | self.list = [line.replace('\n', '') for line in f]
38 | else:
39 | # just assume iterable
40 | self.list = elem_list
41 |
42 | self.path = path
43 | self.load = load
44 |
45 | def __len__(self):
46 | return len(self.list)
47 |
48 | def __getitem__(self, idx):
49 | super(ListDataset, self).__getitem__(idx)
50 |
51 | if self.path is not None:
52 | return self.load("%s/%s" % (self.path, self.list[idx]))
53 | else:
54 | return self.load(self.list[idx])
55 |
--------------------------------------------------------------------------------
/tests/integration/fit_simple/single_input_single_target.py:
--------------------------------------------------------------------------------
1 |
2 | import os
3 |
4 | import torch as th
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 | from torchvision import datasets
8 | from pywick import regularizers as reg
9 | from pywick.modules import ModuleTrainer
10 |
11 | ROOT = '/data/mnist'
12 | dataset = datasets.MNIST(ROOT, train=True, download=True)
13 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
14 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
15 |
16 | x_train = x_train.float()
17 | y_train = y_train.long()
18 | x_test = x_test.float()
19 | y_test = y_test.long()
20 |
21 | x_train = x_train / 255.
22 | x_test = x_test / 255.
23 | x_train = x_train.unsqueeze(1)
24 | x_test = x_test.unsqueeze(1)
25 |
26 | # only train on a subset
27 | x_train = x_train[:1000]
28 | y_train = y_train[:1000]
29 | x_test = x_test[:1000]
30 | y_test = y_test[:1000]
31 |
32 |
33 | # Define your model EXACTLY as if you were using nn.Module
34 | class Network(nn.Module):
35 | def __init__(self):
36 | super(Network, self).__init__()
37 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
38 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
39 | self.fc1 = nn.Linear(1600, 128)
40 | self.fc2 = nn.Linear(128, 10)
41 |
42 | def forward(self, x):
43 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
44 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
45 | x = x.view(-1, 1600)
46 | x = F.relu(self.fc1(x))
47 | #x = F.dropout(x, training=self.training)
48 | x = self.fc2(x)
49 | return F.log_softmax(x)
50 |
51 |
52 | model = Network()
53 | trainer = ModuleTrainer(model)
54 |
55 | trainer.compile(criterion='nll_loss',
56 | optimizer='adadelta',
57 | regularizers=[reg.L1Regularizer(1e-4)])
58 |
59 | trainer.fit(x_train, y_train,
60 | val_data=(x_test, y_test),
61 | num_epoch=3,
62 | batch_size=128,
63 | verbose=1)
64 |
65 | ypred = trainer.predict(x_train)
66 | print(ypred.size())
67 |
68 | eval_loss = trainer.evaluate(x_train, y_train)
69 | print(eval_loss)
70 |
71 | print(trainer.history)
72 | #print(trainer.history['loss'])
73 |
74 |
--------------------------------------------------------------------------------
/pywick/callbacks/History.py:
--------------------------------------------------------------------------------
1 | from . import Callback
2 |
3 | __all__ = ['History']
4 |
5 |
6 | class History(Callback):
7 | """
8 | Callback that records events into a `History` object.
9 |
10 | This callback is automatically applied to
11 | every SuperModule.
12 | """
13 |
14 | def __init__(self, trainer):
15 | super(History, self).__init__()
16 | self.samples_seen = 0.
17 | self.trainer = trainer
18 |
19 | def on_train_begin(self, logs=None):
20 | self.epoch_metrics = {
21 | 'loss': []
22 | }
23 | self.batch_size = logs['batch_size']
24 | self.has_val_data = logs['has_val_data']
25 | self.has_regularizers = logs['has_regularizers']
26 | if self.has_val_data:
27 | self.epoch_metrics['val_loss'] = []
28 | if self.has_regularizers:
29 | self.epoch_metrics['reg_loss'] = []
30 |
31 | def on_epoch_begin(self, epoch, logs=None):
32 | if hasattr(self.trainer._optimizer, '_optimizer'): # accounts for meta-optimizers like YellowFin
33 | self.lrs = [p['lr'] for p in self.trainer._optimizer._optimizer.param_groups]
34 | else:
35 | self.lrs = [p['lr'] for p in self.trainer._optimizer.param_groups]
36 | self.batch_metrics = {
37 | 'loss': 0.
38 | }
39 | if self.has_regularizers:
40 | self.batch_metrics['reg_loss'] = 0.
41 | self.samples_seen = 0.
42 |
43 | def on_epoch_end(self, epoch, logs=None):
44 | if logs:
45 | self.epoch_metrics['loss'].append(logs['loss'])
46 | if logs.get('val_loss'): # if it exists
47 | self.epoch_metrics['val_loss'].append(logs['val_loss'])
48 |
49 | def on_batch_end(self, batch, logs=None):
50 | for k in self.batch_metrics:
51 | self.batch_metrics[k] = (self.samples_seen * self.batch_metrics[k] + logs[k] * self.batch_size) / (self.samples_seen + self.batch_size)
52 | self.samples_seen += self.batch_size
53 |
54 | def __getitem__(self, name):
55 | return self.epoch_metrics[name]
56 |
57 | def __repr__(self):
58 | return str(self.epoch_metrics)
59 |
60 | def __str__(self):
61 | return str(self.epoch_metrics)
--------------------------------------------------------------------------------
/pywick/datasets/PredictFolderDataset.py:
--------------------------------------------------------------------------------
1 | from .FolderDataset import FolderDataset, identity_x
2 |
3 | class PredictFolderDataset(FolderDataset):
4 | """
5 | Convenience class for loading out-of-memory data that is more geared toward prediction data loading (where ground truth is not available). \n
6 | If not transformed in any way (either via one of the loaders or transforms) the inputs and targets will be identical (paths to the discovered files)\n
7 | Instead, the intended use is that the input path is loaded into some kind of binary representation (usually an image), while the target is either
8 | left as a path or is post-processed to accommodate some special need.
9 |
10 | Arguments
11 | ---------
12 | :param root: (string):
13 | path to main directory
14 |
15 | :param input_regex: (string `(default is any valid image file)`):
16 | regular expression to find inputs.
17 | e.g. if all your inputs have the word 'input',
18 | you'd enter something like input_regex='*input*'
19 |
20 | :param input_transform: (torch transform):
21 | transform to apply to each input before returning
22 |
23 | :param input_loader: (callable `(default: identity)`):
24 | defines how to load input samples from file.
25 | If a function is provided, it should take in a file path as input and return the loaded sample. Identity simply returns the input.
26 |
27 | :param target_loader: (callable `(default: None)`):
28 | defines how to load target samples from file (which, in our case, are the same as inputs)
29 | If a function is provided, it should take in a file path as input and return the loaded sample.
30 |
31 | :param exclusion_file: (string):
32 | list of files to exclude when enumerating all files.
33 | The list must be a full path relative to the root parameter
34 | """
35 | def __init__(self, root, input_regex='*', input_transform=None, input_loader=identity_x, target_loader=None, exclusion_file=None):
36 |
37 | super().__init__(root=root, class_mode='path', input_regex=input_regex, target_extension=None, transform=input_transform,
38 | default_loader=input_loader, target_loader=target_loader, exclusion_file=exclusion_file, target_index_map=None)
39 |
40 |
--------------------------------------------------------------------------------
/tests/integration/fit_loader_simple/single_input_single_target.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | from torch.utils.data import DataLoader
6 |
7 | from pywick.modules import ModuleTrainer
8 | from pywick.datasets.TensorDataset import TensorDataset
9 |
10 | import os
11 | from torchvision import datasets
12 | ROOT = '/data/mnist'
13 | dataset = datasets.MNIST(ROOT, train=True, download=True)
14 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
15 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
16 |
17 | x_train = x_train.float()
18 | y_train = y_train.long()
19 | x_test = x_test.float()
20 | y_test = y_test.long()
21 |
22 | x_train = x_train / 255.
23 | x_test = x_test / 255.
24 | x_train = x_train.unsqueeze(1)
25 | x_test = x_test.unsqueeze(1)
26 |
27 | # only train on a subset
28 | x_train = x_train[:1000]
29 | y_train = y_train[:1000]
30 | x_test = x_test[:1000]
31 | y_test = y_test[:1000]
32 |
33 | train_data = TensorDataset(x_train, y_train)
34 | train_loader = DataLoader(train_data, batch_size=128)
35 |
36 | # Define your model EXACTLY as if you were using nn.Module
37 | class Network(nn.Module):
38 | def __init__(self):
39 | super(Network, self).__init__()
40 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
41 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
42 | self.fc1 = nn.Linear(1600, 128)
43 | self.fc2 = nn.Linear(128, 10)
44 |
45 | def forward(self, x):
46 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
47 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
48 | x = x.view(-1, 1600)
49 | x = F.relu(self.fc1(x))
50 | #x = F.dropout(x, training=self.training)
51 | x = self.fc2(x)
52 | return F.log_softmax(x)
53 |
54 |
55 | model = Network()
56 | trainer = ModuleTrainer(model)
57 |
58 | trainer.compile(criterion='nll_loss',
59 | optimizer='adadelta')
60 |
61 | trainer.fit_loader(train_loader,
62 | num_epoch=3,
63 | verbose=1)
64 |
65 | ypred = trainer.predict(x_train)
66 | print(ypred.size())
67 |
68 | eval_loss = trainer.evaluate(x_train, y_train)
69 | print(eval_loss)
70 |
71 | print(trainer.history)
72 | #print(trainer.history['loss'])
73 |
74 |
--------------------------------------------------------------------------------
/pywick/callbacks/TQDM.py:
--------------------------------------------------------------------------------
1 | from tqdm import tqdm
2 | from . import Callback
3 |
4 | __all__ = ['TQDM']
5 |
6 |
7 | class TQDM(Callback):
8 | """
9 | Callback that displays progress bar and useful statistics in terminal
10 | """
11 |
12 | def __init__(self):
13 | """
14 | TQDM Progress Bar callback
15 |
16 | This callback is automatically applied to
17 | every SuperModule if verbose > 0
18 | """
19 | self.progbar = None
20 | self.train_logs = None
21 | super(TQDM, self).__init__()
22 |
23 | def __enter__(self):
24 | return self
25 |
26 | def __exit__(self, exc_type, exc_val, exc_tb):
27 | # make sure the dbconnection gets closed
28 | if self.progbar is not None:
29 | self.progbar.close()
30 |
31 | def on_train_begin(self, logs=None):
32 | self.train_logs = logs
33 |
34 | def on_epoch_begin(self, epoch, logs=None):
35 | try:
36 | self.progbar = tqdm(total=self.train_logs['num_batches'],
37 | unit=' batches')
38 | self.progbar.set_description('Epoch %i/%i' %
39 | (epoch + 1, self.train_logs['num_epoch']))
40 | except:
41 | pass
42 |
43 | def on_epoch_end(self, epoch, logs=None):
44 | log_data = {key: '%.04f' % value for key, value in self.trainer.history.batch_metrics.items()}
45 | for k, v in logs.items():
46 | if k.endswith('metric'):
47 | log_data[k.split('_metric')[0]] = '%.02f' % v
48 | else:
49 | log_data[k] = v
50 | log_data['learn_rates'] = self.trainer.history.lrs
51 | self.progbar.set_postfix(log_data)
52 | self.progbar.update()
53 | self.progbar.close()
54 |
55 | def on_batch_begin(self, batch, logs=None):
56 | self.progbar.update(1)
57 |
58 | def on_batch_end(self, batch, logs=None):
59 | log_data = {key: '%.04f' % value for key, value in self.trainer.history.batch_metrics.items()}
60 | for k, v in logs.items():
61 | if k.endswith('metric'):
62 | log_data[k.split('_metric')[0]] = '%.02f' % v
63 | log_data['learn_rates'] = self.trainer.history.lrs
64 | self.progbar.set_postfix(log_data)
--------------------------------------------------------------------------------
/pywick/callbacks/LRScheduler.py:
--------------------------------------------------------------------------------
1 | import warnings
2 |
3 | from . import Callback
4 |
5 | __all__ = ['LRScheduler']
6 |
7 |
8 | class LRScheduler(Callback):
9 | """
10 | Schedule the learning rate according to some function of the
11 | current epoch index, current learning rate, and current train/val loss.
12 |
13 | :param schedule: (callable):
14 | should return a number of learning rates equal to the number
15 | of optimizer.param_groups. It should take the epoch index and
16 | **kwargs (or logs) as argument. **kwargs (or logs) will return
17 | the epoch logs such as mean training and validation loss from
18 | the epoch
19 | """
20 |
21 | def __init__(self, schedule):
22 | if isinstance(schedule, dict):
23 | schedule = self.schedule_from_dict
24 | self.schedule_dict = schedule
25 | if any(k < 1.0 for k in schedule.keys()):
26 | self.fractional_bounds = False
27 | else:
28 | self.fractional_bounds = True
29 | self.schedule = schedule
30 | super(LRScheduler, self).__init__()
31 |
32 | def schedule_from_dict(self, epoch, logs=None):
33 | learn_rate = None
34 | for epoch_bound, learn_rate in self.schedule_dict.items():
35 | # epoch_bound is in units of "epochs"
36 | if not self.fractional_bounds:
37 | if epoch_bound < epoch:
38 | return learn_rate
39 | # epoch_bound is in units of "cumulative percent of epochs"
40 | else:
41 | if epoch <= epoch_bound * logs['num_epoch']:
42 | return learn_rate
43 | warnings.warn('Check the keys in the schedule dict.. Returning last value')
44 | return learn_rate
45 |
46 | def on_epoch_begin(self, epoch, logs=None):
47 | """
48 | WARNING: Do NOT use this callback with self-adjusting learners like Yellowfin
49 | """
50 | current_lrs = [p['lr'] for p in self.trainer._optimizer.param_groups]
51 | lr_list = self.schedule(epoch, current_lrs, **logs)
52 | if not isinstance(lr_list, list):
53 | lr_list = [lr_list]
54 |
55 | for param_group, lr_change in zip(self.trainer._optimizer.param_groups, lr_list):
56 | param_group['lr'] = lr_change
--------------------------------------------------------------------------------
/docs/source/index.rst:
--------------------------------------------------------------------------------
1 | Welcome to Pywick!
2 | ========================
3 |
4 | About
5 | ^^^^^
6 | Pywick is a high-level Pytorch training framework that aims to get you up and running quickly with state of the art neural networks.
7 | Does the world need another Pytorch framework? Probably not. But we started this project when no good frameworks were available and
8 | it just kept growing. So here we are.
9 |
10 | Pywick tries to stay on the bleeding edge of research into neural networks. If you just wish to run a vanilla CNN, this is probably
11 | going to be overkill. However, if you want to get lost in the world of neural networks, fine-tuning and hyperparameter optimization
12 | for months on end then this is probably the right place for you :)
13 |
14 | Guide
15 | ^^^^^^
16 | We started this project because of the work we were doing on image classification and segmentation so this is where most of
17 | the updates are happening. However, along the way we've added many powerful tools for fine-tuning your results, from specifying
18 | custom *Constraints* on your network layers, to awesomely flexible *Dataloaders* for your data needs, to a variety of standard
19 | and not-so-standard *loss functions* to *Optimizers*, *Regularizers* and *Transforms*. You'll find a pretty decent description of
20 | each one of them in the navigation pane.
21 |
22 | And of course, if you have any questions, feel free to drop by our `github page `_
23 |
24 | .. toctree::
25 | :maxdepth: 1
26 | :hidden:
27 |
28 | README.md
29 |
30 | .. toctree::
31 | :caption: Getting Started
32 |
33 | classification_guide
34 | segmentation_guide
35 |
36 | .. toctree::
37 | :caption: Lego Blocks (aka API)
38 | :maxdepth: 6
39 |
40 | api/pywick.callbacks
41 | api/conditions
42 | api/constraints
43 | api/pywick.datasets
44 | api/pywick.functions
45 | api/pywick.gridsearch
46 | api/initializers
47 | api/losses
48 | api/pywick.meters
49 | api/pywick.models
50 | api/pywick.optimizers
51 | api/regularizers
52 | api/samplers
53 | api/pywick.transforms
54 |
55 | .. toctree::
56 | :caption: Misc
57 | :maxdepth: 2
58 |
59 | license
60 | help
61 |
62 |
63 | Indices and tables
64 | ==================
65 |
66 | * :ref:`genindex`
67 | * :ref:`modindex`
68 | * :ref:`search`
69 |
--------------------------------------------------------------------------------
/pywick/functions/swish.py:
--------------------------------------------------------------------------------
1 | # Source: https://forums.fast.ai/t/implementing-new-activation-functions-in-fastai-library/17697
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 |
7 |
8 | class Swish(nn.Module):
9 | """
10 | Swish activation function, a special case of ARiA,
11 | for ARiA = f(x, 1, 0, 1, 1, b, 1)
12 | """
13 |
14 | def __init__(self, b = 1.):
15 | super(Swish, self).__init__()
16 | self.b = b
17 |
18 | def forward(self, x):
19 | sigmoid = F.sigmoid(x) ** self.b
20 | return x * sigmoid
21 |
22 |
23 | class Aria(nn.Module):
24 | """
25 | Aria activation function described in `this paper `_.
26 | """
27 |
28 | def __init__(self, A=0, K=1., B = 1., v=1., C=1., Q=1.):
29 | super(Aria, self).__init__()
30 | # ARiA parameters
31 | self.A = A # lower asymptote, values tested were A = -1, 0, 1
32 | self.k = K # upper asymptote, values tested were K = 1, 2
33 | self.B = B # exponential rate, values tested were B = [0.5, 2]
34 | self.v = v # v > 0 the direction of growth, values tested were v = [0.5, 2]
35 | self.C = C # constant set to 1
36 | self.Q = Q # related to initial value, values tested were Q = [0.5, 2]
37 |
38 | def forward(self, x):
39 | aria = self.A + (self.k - self.A) / ((self.C + self.Q * F.exp(-x) ** self.B) ** (1/self.v))
40 | return x * aria
41 |
42 |
43 | class Aria2(nn.Module):
44 | """
45 | ARiA2 activation function, a special case of ARiA, for ARiA = f(x, 1, 0, 1, 1, b, 1/a)
46 | """
47 |
48 | def __init__(self, a=1.5, b = 2.):
49 | super(Aria2, self).__init__()
50 | self.alpha = a
51 | self.beta = b
52 |
53 | def forward(self, x):
54 | return x * torch.sigmoid(self.beta*x) ** self.alpha
55 |
56 |
57 | # Source: https://github.com/rwightman/gen-efficientnet-pytorch/blob/master/geffnet/activations/activations.py (Apache 2.0)
58 | def hard_swish(x, inplace: bool = False):
59 | inner = F.relu6(x + 3.).div_(6.)
60 | return x.mul_(inner) if inplace else x.mul(inner)
61 |
62 |
63 | class HardSwish(nn.Module):
64 | def __init__(self, inplace: bool = False):
65 | super(HardSwish, self).__init__()
66 | self.inplace = inplace
67 |
68 | def forward(self, x):
69 | return hard_swish(x, self.inplace)
70 |
--------------------------------------------------------------------------------
/pywick/callbacks/Callback.py:
--------------------------------------------------------------------------------
1 | from typing import Collection
2 |
3 |
4 | class Callback:
5 | """
6 | Abstract base class used to build new callbacks. Extend this class to build your own callbacks and overwrite functions
7 | that you want to monitor. Functions will be called automatically from the trainer once per relevant training event
8 | (e.g. at the beginning of epoch, end of epoch, beginning of batch, end of batch etc.)
9 | """
10 |
11 | def __init__(self):
12 | self.params = None
13 | self.trainer = None
14 |
15 | def set_params(self, params):
16 | self.params = params
17 |
18 | def set_trainer(self, trainer):
19 | self.trainer = trainer
20 |
21 | def on_epoch_begin(self, epoch: int, logs: Collection = None):
22 | """
23 | Called at the beginning of a new epoch
24 | :param epoch: epoch number
25 | :param logs: collection of logs to process / parse / add to
26 | :return:
27 | """
28 | pass
29 |
30 | def on_epoch_end(self, epoch: int, logs: Collection = None):
31 | """
32 | Called at the end of an epoch
33 | :param epoch: epoch number
34 | :param logs: collection of logs to process / parse / add to
35 | :return:
36 | """
37 | pass
38 |
39 | def on_batch_begin(self, batch: int, logs: Collection = None):
40 | """
41 | Called at the beginning of a new batch
42 | :param batch: batch number
43 | :param logs: collection of logs to process / parse / add to
44 | :return:
45 | """
46 | pass
47 |
48 | def on_batch_end(self, batch: int, logs: Collection = None):
49 | """
50 | Called at the end of an epoch
51 | :param batch: batch number
52 | :param logs: collection of logs to process / parse / add to
53 | :return:
54 | """
55 | pass
56 |
57 | def on_train_begin(self, logs: Collection = None):
58 | """
59 | Called at the beginning of a new training run
60 | :param logs: collection of logs to process / parse / add to
61 | :return:
62 | """
63 | pass
64 |
65 | def on_train_end(self, logs: Collection = None):
66 | """
67 | Called at the end of a training run
68 | :param logs: collection of logs to process / parse / add to
69 | :return:
70 | """
71 | pass
72 |
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM nvidia/cuda:11.3.1-cudnn8-devel-centos8
2 |
3 | ENV HOME /home/pywick
4 |
5 | RUN yum install -y epel-release && yum install -y dnf-plugins-core && yum config-manager --set-enabled powertools
6 | RUN yum update -y && yum -y install atop bzip2-devel ca-certificates cmake curl git grep htop less libffi-devel hdf5-devel libjpeg-devel xz-devel libuuid-devel libXext libSM libXrender make nano openssl-devel sed screen tini vim wget unzip
7 |
8 | RUN yum groupinstall -y "Development Tools"
9 |
10 | RUN wget https://www.python.org/ftp/python/3.9.5/Python-3.9.5.tgz
11 | RUN tar xvf Python-3.9.5.tgz && cd Python-3.9*/ && ./configure --enable-optimizations && make altinstall && cd .. && rm -rf Python*
12 |
13 | RUN cd /usr/bin && rm python3 pip3 && ln -s /usr/local/bin/python3.9 python && ln -s /usr/local/bin/python3.9 python3 && ln -s /usr/local/bin/pip3.9 pip3 && ln -s /usr/local/bin/pip3.9 pip
14 | RUN pip install --upgrade pip setuptools wheel
15 |
16 | ### Pytorch V1.8.2 + CUDA (py3.9_cuda11.1_cudnn7.6.3_0)
17 | RUN pip install torch==1.8.2+cu111 torchvision==0.9.2+cu111 torchaudio==0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
18 |
19 | ## MacOS currently not supported for CUDA or LTS
20 | #RUN pip install torch torchvision torchaudio
21 |
22 | RUN mkdir -p /home && rm -rf $HOME
23 | RUN cd /home && git clone https://github.com/achaiah/pywick
24 | # To build from a different branch or tag specify per example below
25 | #RUN cd $HOME && git checkout WIP2
26 |
27 | # install requirements
28 | RUN pip install versioned-hdf5
29 | RUN pip install --upgrade -r $HOME/requirements.txt
30 |
31 | ENV PYTHONPATH=/home:$HOME:$HOME/configs
32 | WORKDIR $HOME
33 |
34 | RUN chmod -R +x $HOME/*.sh
35 |
36 | CMD ["/bin/bash", "/home/pywick/entrypoint.sh"]
37 |
38 | ###########
39 | # Build with:
40 | # git clone https://github.com/achaiah/pywick
41 | # cd pywick
42 | # docker build -t "achaiah/pywick:latest" .
43 | #
44 | # Run 17flowers demo with:
45 | # docker run --rm -it --ipc=host --init -e demo=true achaiah/pywick:latest
46 | # Optionally specify local dir where you want to save output: docker run --rm -it --ipc=host -v your_local_out_dir:/jobs/17flowers --init -e demo=true achaiah/pywick:latest
47 | # Run container that just stays up (for your own processes):
48 | # docker run --rm -it --ipc=host -v : -v : --init achaiah/pywick:latest
49 | ###########
--------------------------------------------------------------------------------
/pywick/functions/activations_autofn.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/rwightman/gen-efficientnet-pytorch/blob/master/geffnet/activations/activations_autofn.py (Apache 2.0)
2 |
3 | import torch
4 | from torch import nn
5 | from torch.nn import functional as F
6 |
7 |
8 | __all__ = ['swish_auto', 'SwishAuto', 'mish_auto', 'MishAuto']
9 |
10 |
11 | class SwishAutoFn(torch.autograd.Function):
12 | """Swish - Described in: https://arxiv.org/abs/1710.05941
13 | Memory efficient variant from:
14 | https://medium.com/the-artificial-impostor/more-memory-efficient-swish-activation-function-e07c22c12a76
15 | """
16 | @staticmethod
17 | def forward(ctx, x):
18 | result = x.mul(torch.sigmoid(x))
19 | ctx.save_for_backward(x)
20 | return result
21 |
22 | @staticmethod
23 | def backward(ctx, grad_output):
24 | x = ctx.saved_tensors[0]
25 | x_sigmoid = torch.sigmoid(x)
26 | return grad_output.mul(x_sigmoid * (1 + x * (1 - x_sigmoid)))
27 |
28 |
29 | def swish_auto(x, inplace=False):
30 | # inplace ignored
31 | return SwishAutoFn.apply(x)
32 |
33 |
34 | class SwishAuto(nn.Module):
35 | def __init__(self, inplace: bool = False):
36 | super(SwishAuto, self).__init__()
37 | self.inplace = inplace
38 |
39 | @staticmethod
40 | def forward(x):
41 | return SwishAutoFn.apply(x)
42 |
43 |
44 | class MishAutoFn(torch.autograd.Function):
45 | """Mish: A Self Regularized Non-Monotonic Neural Activation Function - https://arxiv.org/abs/1908.08681
46 | Experimental memory-efficient variant
47 | """
48 |
49 | @staticmethod
50 | def forward(ctx, x):
51 | ctx.save_for_backward(x)
52 | y = x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
53 | return y
54 |
55 | @staticmethod
56 | def backward(ctx, grad_output):
57 | x = ctx.saved_tensors[0]
58 | x_sigmoid = torch.sigmoid(x)
59 | x_tanh_sp = F.softplus(x).tanh()
60 | return grad_output.mul(x_tanh_sp + x * x_sigmoid * (1 - x_tanh_sp * x_tanh_sp))
61 |
62 |
63 | def mish_auto(x, inplace=False):
64 | # inplace ignored
65 | return MishAutoFn.apply(x)
66 |
67 |
68 | class MishAuto(nn.Module):
69 | def __init__(self, inplace: bool = False):
70 | super(MishAuto, self).__init__()
71 | self.inplace = inplace
72 |
73 | @staticmethod
74 | def forward(x):
75 | return MishAutoFn.apply(x)
76 |
77 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/fcn32s.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/zijundeng/pytorch-semantic-segmentation/tree/master/models (MIT)
2 |
3 | """
4 | Implementation of `Fully Convolutional Networks for Semantic Segmentation `_
5 | """
6 |
7 | import torch
8 | from torch import nn
9 | from torchvision import models
10 |
11 | from .fcn_utils import get_upsampling_weight
12 | from .config import vgg16_caffe_path
13 |
14 | __all__ = ['FCN32VGG']
15 |
16 |
17 | class FCN32VGG(nn.Module):
18 | def __init__(self, num_classes, pretrained=True, **kwargs):
19 | super(FCN32VGG, self).__init__()
20 | vgg = models.vgg16()
21 | if pretrained:
22 | vgg.load_state_dict(torch.load(vgg16_caffe_path))
23 | features, classifier = list(vgg.features.children()), list(vgg.classifier.children())
24 |
25 | features[0].padding = (100, 100)
26 |
27 | for f in features:
28 | if 'MaxPool' in f.__class__.__name__:
29 | f.ceil_mode = True
30 | elif 'ReLU' in f.__class__.__name__:
31 | f.inplace = True
32 |
33 | self.features5 = nn.Sequential(*features)
34 |
35 | fc6 = nn.Conv2d(512, 4096, kernel_size=7)
36 | fc6.weight.data.copy_(classifier[0].weight.data.view(4096, 512, 7, 7))
37 | fc6.bias.data.copy_(classifier[0].bias.data)
38 | fc7 = nn.Conv2d(4096, 4096, kernel_size=1)
39 | fc7.weight.data.copy_(classifier[3].weight.data.view(4096, 4096, 1, 1))
40 | fc7.bias.data.copy_(classifier[3].bias.data)
41 | score_fr = nn.Conv2d(4096, num_classes, kernel_size=1)
42 | score_fr.weight.data.zero_()
43 | score_fr.bias.data.zero_()
44 | self.score_fr = nn.Sequential(
45 | fc6, nn.ReLU(inplace=True), nn.Dropout(), fc7, nn.ReLU(inplace=True), nn.Dropout(), score_fr
46 | )
47 |
48 | self.upscore = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=64, stride=32, bias=False)
49 | self.upscore.weight.data.copy_(get_upsampling_weight(num_classes, num_classes, 64))
50 |
51 | def forward(self, x):
52 | x_size = x.size()
53 | pool5 = self.features5(x)
54 | score_fr = self.score_fr(pool5)
55 | upscore = self.upscore(score_fr)
56 | return upscore[:, :, 19: (19 + x_size[2]), 19: (19 + x_size[3])].contiguous()
57 |
--------------------------------------------------------------------------------
/pywick/callbacks/CSVLogger.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import os
3 | from collections.abc import Iterable
4 | from collections import OrderedDict
5 |
6 | import torch
7 |
8 | from . import Callback
9 |
10 | __all__ = ['CSVLogger']
11 |
12 |
13 | class CSVLogger(Callback):
14 | """
15 | Logs epoch-level metrics to a CSV file
16 |
17 | :param file: (string) path to csv file
18 | :param separator: (string) delimiter for file
19 | :param append: (bool) whether to append result to existing file or make new file
20 | """
21 |
22 | def __init__(self, file, separator=',', append=False):
23 |
24 | self.file = file
25 | self.sep = separator
26 | self.append = append
27 | self.writer = None
28 | self.keys = None
29 | self.append_header = True
30 | super(CSVLogger, self).__init__()
31 |
32 | def on_train_begin(self, logs=None):
33 | if self.append:
34 | if os.path.exists(self.file):
35 | with open(self.file) as f:
36 | self.append_header = not bool(len(f.readline()))
37 | self.csv_file = open(self.file, 'a')
38 | else:
39 | self.csv_file = open(self.file, 'w')
40 |
41 | def on_epoch_end(self, epoch, logs=None):
42 | logs = logs or {}
43 | RK = {'num_batches', 'num_epoch'}
44 |
45 | def handle_value(k):
46 | is_zero_dim_tensor = isinstance(k, torch.Tensor) and k.dim() == 0
47 | if isinstance(k, Iterable) and not is_zero_dim_tensor:
48 | return '"[%s]"' % (', '.join(map(str, k)))
49 | else:
50 | return k
51 |
52 | if not self.writer:
53 | self.keys = sorted(logs.keys())
54 |
55 | class CustomDialect(csv.excel):
56 | delimiter = self.sep
57 |
58 | self.writer = csv.DictWriter(self.csv_file,
59 | fieldnames=['epoch'] + [k for k in self.keys if k not in RK],
60 | dialect=CustomDialect)
61 | if self.append_header:
62 | self.writer.writeheader()
63 |
64 | row_dict = OrderedDict({'epoch': epoch})
65 | row_dict.update((key, handle_value(logs[key])) for key in self.keys if key not in RK)
66 | self.writer.writerow(row_dict)
67 | self.csv_file.flush()
68 |
69 | def on_train_end(self, logs=None):
70 | self.csv_file.close()
71 | self.writer = None
--------------------------------------------------------------------------------
/tests/integration/fit_simple/single_input_multi_target.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from pywick.modules import ModuleTrainer
7 |
8 | import os
9 | from torchvision import datasets
10 | ROOT = '/data/mnist'
11 | dataset = datasets.MNIST(ROOT, train=True, download=True)
12 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
13 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
14 |
15 | x_train = x_train.float()
16 | y_train = y_train.long()
17 | x_test = x_test.float()
18 | y_test = y_test.long()
19 |
20 | x_train = x_train / 255.
21 | x_test = x_test / 255.
22 | x_train = x_train.unsqueeze(1)
23 | x_test = x_test.unsqueeze(1)
24 |
25 | # only train on a subset
26 | x_train = x_train[:1000]
27 | y_train = y_train[:1000]
28 | x_test = x_test[:1000]
29 | y_test = y_test[:1000]
30 |
31 |
32 | # Define your model EXACTLY as if you were using nn.Module
33 | class Network(nn.Module):
34 | def __init__(self):
35 | super(Network, self).__init__()
36 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
37 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
38 | self.fc1 = nn.Linear(1600, 128)
39 | self.fc2 = nn.Linear(128, 10)
40 |
41 | def forward(self, x):
42 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
43 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
44 | x = x.view(-1, 1600)
45 | x = F.relu(self.fc1(x))
46 | x = F.dropout(x, training=self.training)
47 | x = self.fc2(x)
48 | return F.log_softmax(x), F.log_softmax(x)
49 |
50 |
51 | # one loss function for multiple targets
52 | model = Network()
53 | trainer = ModuleTrainer(model)
54 | trainer.compile(criterion='nll_loss',
55 | optimizer='adadelta')
56 |
57 | trainer.fit(x_train,
58 | [y_train, y_train],
59 | num_epoch=3,
60 | batch_size=128,
61 | verbose=1)
62 | ypred1, ypred2 = trainer.predict(x_train)
63 | print(ypred1.size(), ypred2.size())
64 |
65 | eval_loss = trainer.evaluate(x_train, [y_train, y_train])
66 | print(eval_loss)
67 | # multiple loss functions
68 | model = Network()
69 | trainer = ModuleTrainer(model)
70 | trainer.compile(criterion=['nll_loss', 'nll_loss'],
71 | optimizer='adadelta')
72 | trainer.fit(x_train,
73 | [y_train, y_train],
74 | num_epoch=3,
75 | batch_size=128,
76 | verbose=1)
77 |
78 |
79 |
80 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/da_basenets/model_store.py:
--------------------------------------------------------------------------------
1 | """Model store which provides pretrained models."""
2 | import os
3 | import zipfile
4 |
5 | from .download import download, check_sha1
6 |
7 | __all__ = ['get_model_file', 'get_resnet_file']
8 |
9 | _model_sha1 = {name: checksum for checksum, name in [
10 | ('25c4b50959ef024fcc050213a06b614899f94b3d', 'resnet50'),
11 | ('2a57e44de9c853fa015b172309a1ee7e2d0e4e2a', 'resnet101'),
12 | ('0d43d698c66aceaa2bc0309f55efdd7ff4b143af', 'resnet152'),
13 | ]}
14 |
15 | encoding_repo_url = 'https://hangzh.s3.amazonaws.com/'
16 | _url_format = '{repo_url}encoding/models/{file_name}.zip'
17 |
18 |
19 | def short_hash(name):
20 | if name not in _model_sha1:
21 | raise ValueError('Pretrained model for {name} is not available.'.format(name=name))
22 | return _model_sha1[name][:8]
23 |
24 |
25 | def get_resnet_file(name, root='~/.torch/models'):
26 | file_name = '{name}-{short_hash}'.format(name=name, short_hash=short_hash(name))
27 | root = os.path.expanduser(root)
28 |
29 | file_path = os.path.join(root, file_name + '.pth')
30 | sha1_hash = _model_sha1[name]
31 | if os.path.exists(file_path):
32 | if check_sha1(file_path, sha1_hash):
33 | return file_path
34 | else:
35 | print('Mismatch in the content of model file {} detected. Downloading again.'.format(file_path))
36 | else:
37 | print('Model file {} is not found. Downloading.'.format(file_path))
38 |
39 | if not os.path.exists(root):
40 | os.makedirs(root)
41 |
42 | zip_file_path = os.path.join(root, file_name + '.zip')
43 | repo_url = os.environ.get('ENCODING_REPO', encoding_repo_url)
44 | if repo_url[-1] != '/':
45 | repo_url = repo_url + '/'
46 | download(_url_format.format(repo_url=repo_url, file_name=file_name),
47 | path=zip_file_path,
48 | overwrite=True)
49 | with zipfile.ZipFile(zip_file_path) as zf:
50 | zf.extractall(root)
51 | os.remove(zip_file_path)
52 |
53 | if check_sha1(file_path, sha1_hash):
54 | return file_path
55 | else:
56 | raise ValueError('Downloaded file has different hash. Please try again.')
57 |
58 |
59 | def get_model_file(name, root='~/.torch/models'):
60 | root = os.path.expanduser(root)
61 | file_path = os.path.join(root, name + '.pth')
62 | if os.path.exists(file_path):
63 | return file_path
64 | else:
65 | raise ValueError('Model file is not found. Downloading or trainning.')
66 |
--------------------------------------------------------------------------------
/pywick/datasets/tnt/shuffledataset.py:
--------------------------------------------------------------------------------
1 | from .resampledataset import ResampleDataset
2 | import torch
3 |
4 |
5 | class ShuffleDataset(ResampleDataset):
6 | """
7 | Dataset which shuffles a given dataset.
8 |
9 | `ShuffleDataset` is a sub-class of `ResampleDataset` provided for
10 | convenience. It samples uniformly from the given `dataset` with, or without
11 | `replacement`. The chosen partition can be redrawn by calling `resample()`
12 |
13 | If `replacement` is `true`, then the specified `size` may be larger than
14 | the underlying `dataset`.
15 | If `size` is not provided, then the new dataset size will be equal to the
16 | underlying `dataset` size.
17 |
18 | Purpose: the easiest way to shuffle a dataset!
19 |
20 | Args:
21 | dataset (Dataset): Dataset to be shuffled.
22 | size (int, optional): Desired size of the shuffled dataset. If
23 | `replacement` is `true`, then can be larger than the `len(dataset)`.
24 | By default, the new dataset will have the same size as `dataset`.
25 | replacement (bool, optional): True if uniform sampling is to be done
26 | with replacement. False otherwise. Defaults to false.
27 |
28 | Raises:
29 | ValueError: If `size` is larger than the size of the underlying dataset
30 | and `replacement` is False.
31 | """
32 |
33 | def __init__(self, dataset, size=None, replacement=False):
34 | if size and not replacement and size > len(dataset):
35 | raise ValueError('size cannot be larger than underlying dataset \
36 | size when sampling without replacement')
37 |
38 | super(ShuffleDataset, self).__init__(dataset,
39 | lambda dataset, idx: self.perm[idx],
40 | size)
41 | self.replacement = replacement
42 | self.resample()
43 |
44 | def resample(self, seed=None):
45 | """Resample the dataset.
46 |
47 | Args:
48 | seed (int, optional): Seed for resampling. By default no seed is
49 | used.
50 | """
51 | if seed is not None:
52 | gen = torch.manual_seed(seed)
53 | else:
54 | gen = torch.default_generator
55 |
56 | if self.replacement:
57 | self.perm = torch.LongTensor(len(self)).random_(len(self.dataset), generator=gen)
58 | else:
59 | self.perm = torch.randperm(len(self.dataset), generator=gen).narrow(0, 0, len(self))
60 |
--------------------------------------------------------------------------------
/docs/source/api/pywick.datasets.tnt.rst:
--------------------------------------------------------------------------------
1 | datasets.tnt
2 | ===========================
3 |
4 |
5 | tnt.batchdataset
6 | ---------------------------------------
7 |
8 | .. automodule:: pywick.datasets.tnt.batchdataset
9 | :members:
10 | :undoc-members:
11 | :show-inheritance:
12 |
13 | tnt.concatdataset
14 | ----------------------------------------
15 |
16 | .. automodule:: pywick.datasets.tnt.concatdataset
17 | :members:
18 | :undoc-members:
19 | :show-inheritance:
20 |
21 | tnt.dataset
22 | ----------------------------------
23 |
24 | .. automodule:: pywick.datasets.tnt.dataset
25 | :members:
26 | :undoc-members:
27 | :show-inheritance:
28 |
29 | tnt.listdataset
30 | --------------------------------------
31 |
32 | .. automodule:: pywick.datasets.tnt.listdataset
33 | :members:
34 | :undoc-members:
35 | :show-inheritance:
36 |
37 | tnt.multipartitiondataset
38 | ------------------------------------------------
39 |
40 | .. automodule:: pywick.datasets.tnt.multipartitiondataset
41 | :members:
42 | :undoc-members:
43 | :show-inheritance:
44 |
45 | tnt.resampledataset
46 | ------------------------------------------
47 |
48 | .. automodule:: pywick.datasets.tnt.resampledataset
49 | :members:
50 | :undoc-members:
51 | :show-inheritance:
52 |
53 | tnt.shuffledataset
54 | -----------------------------------------
55 |
56 | .. automodule:: pywick.datasets.tnt.shuffledataset
57 | :members:
58 | :undoc-members:
59 | :show-inheritance:
60 |
61 | tnt.splitdataset
62 | ---------------------------------------
63 |
64 | .. automodule:: pywick.datasets.tnt.splitdataset
65 | :members:
66 | :undoc-members:
67 | :show-inheritance:
68 |
69 | tnt.table
70 | --------------------------------
71 |
72 | .. automodule:: pywick.datasets.tnt.table
73 | :members:
74 | :undoc-members:
75 | :show-inheritance:
76 |
77 | tnt.tensordataset
78 | ----------------------------------------
79 |
80 | .. automodule:: pywick.datasets.tnt.tensordataset
81 | :members:
82 | :undoc-members:
83 | :show-inheritance:
84 |
85 | tnt.transform
86 | ------------------------------------
87 |
88 | .. automodule:: pywick.datasets.tnt.transform
89 | :members:
90 | :undoc-members:
91 | :show-inheritance:
92 |
93 | tnt.transformdataset
94 | -------------------------------------------
95 |
96 | .. automodule:: pywick.datasets.tnt.transformdataset
97 | :members:
98 | :undoc-members:
99 | :show-inheritance:
100 |
--------------------------------------------------------------------------------
/tests/integration/fit_loader_simple/single_input_multi_target.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 | from torch.utils.data import DataLoader
6 |
7 | from pywick.modules import ModuleTrainer
8 | from pywick.datasets.TensorDataset import TensorDataset
9 |
10 | import os
11 | from torchvision import datasets
12 | ROOT = '/data/mnist'
13 | dataset = datasets.MNIST(ROOT, train=True, download=True)
14 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
15 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
16 |
17 | x_train = x_train.float()
18 | y_train = y_train.long()
19 | x_test = x_test.float()
20 | y_test = y_test.long()
21 |
22 | x_train = x_train / 255.
23 | x_test = x_test / 255.
24 | x_train = x_train.unsqueeze(1)
25 | x_test = x_test.unsqueeze(1)
26 |
27 | # only train on a subset
28 | x_train = x_train[:1000]
29 | y_train = y_train[:1000]
30 | x_test = x_test[:1000]
31 | y_test = y_test[:1000]
32 |
33 | train_data = TensorDataset(x_train, [y_train, y_train])
34 | train_loader = DataLoader(train_data, batch_size=128)
35 |
36 | # Define your model EXACTLY as if you were using nn.Module
37 | class Network(nn.Module):
38 | def __init__(self):
39 | super(Network, self).__init__()
40 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
41 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
42 | self.fc1 = nn.Linear(1600, 128)
43 | self.fc2 = nn.Linear(128, 10)
44 |
45 | def forward(self, x):
46 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
47 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
48 | x = x.view(-1, 1600)
49 | x = F.relu(self.fc1(x))
50 | x = F.dropout(x, training=self.training)
51 | x = self.fc2(x)
52 | return F.log_softmax(x), F.log_softmax(x)
53 |
54 |
55 | # one loss function for multiple targets
56 | model = Network()
57 | trainer = ModuleTrainer(model)
58 | trainer.compile(criterion='nll_loss',
59 | optimizer='adadelta')
60 |
61 | trainer.fit_loader(train_loader,
62 | num_epoch=3,
63 | verbose=1)
64 | ypred1, ypred2 = trainer.predict(x_train)
65 | print(ypred1.size(), ypred2.size())
66 |
67 | eval_loss = trainer.evaluate(x_train, [y_train, y_train])
68 | print(eval_loss)
69 | # multiple loss functions
70 | model = Network()
71 | trainer = ModuleTrainer(model)
72 | trainer.compile(criterion=['nll_loss', 'nll_loss'],
73 | optimizer='adadelta')
74 | trainer.fit_loader(train_loader,
75 | num_epoch=3,
76 | verbose=1)
77 |
78 |
79 |
80 |
--------------------------------------------------------------------------------
/pywick/gridsearch/pipeline.py:
--------------------------------------------------------------------------------
1 | def merge_dicts(*dict_args):
2 | """
3 | Given any number of dicts, shallow copy and merge into a new dict,
4 | precedence goes to key value pairs in latter dicts.
5 | """
6 | result = {}
7 | for dictionary in dict_args:
8 | result.update(dictionary)
9 | return result
10 |
11 | class Pipeline:
12 | """
13 | Defines a pipeline for operating on data. Output of first function will be passed to the second and so forth.
14 |
15 | :param ordered_func_list: (list):
16 | list of functions to call
17 | :param func_args: (dict):
18 | optional dictionary of params to pass to functions in addition to last output
19 | the dictionary should be in the form of:
20 | func_name: list(params)
21 | """
22 |
23 | def __init__(self, ordered_func_list, func_args=None):
24 | self.pipes = ordered_func_list
25 | self.func_args = func_args
26 | self.output = None
27 |
28 | def call(self, input_):
29 | """Apply the functions in current Pipeline to an input.
30 |
31 | :param input_: The input to process with the Pipeline.
32 | """
33 | out = input_
34 | for pipe in self.pipes:
35 | if pipe.__name__ in self.func_args: # if additional arguments present
36 | all_args = self.func_args[pipe.__name__]
37 | all_args.insert(0, out)
38 | else:
39 | all_args = list(out)
40 | out = pipe(*all_args) # pass list to the function to be executed
41 | return out
42 |
43 | def add_before(self, func, args_dict=None):
44 | """
45 | Add a function to be applied before the rest in the pipeline
46 |
47 | :param func: The function to apply
48 | """
49 | if args_dict: # update args dictionary if necessary
50 | self.func_args = merge_dicts(self.func_args, args_dict)
51 |
52 | self.pipes.insert(0, func)
53 | return self
54 |
55 | def add_after(self, func, args_dict=None):
56 | """
57 | Add a function to be applied at the end of the pipeline
58 |
59 | :param func: The function to apply
60 | """
61 | if args_dict: # update args dictionary if necessary
62 | self.func_args = merge_dicts(self.func_args, args_dict)
63 |
64 | self.pipes.append(func)
65 | return self
66 |
67 | @staticmethod
68 | def identity(x):
69 | """Return a copy of the input.
70 |
71 | This is here for serialization compatibility with pickle.
72 | """
73 | return x
74 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/drn_seg.py:
--------------------------------------------------------------------------------
1 | from .drn import *
2 | import torch.nn as nn
3 | import math
4 | import torch.nn.functional as F
5 |
6 | __all__ = ['DRNSeg']
7 |
8 | class DRNSeg(nn.Module):
9 | def __init__(self, num_classes, pretrained=True, model_name=None, use_torch_up=False, **kwargs):
10 | super(DRNSeg, self).__init__()
11 |
12 | if model_name == 'DRN_C_42':
13 | model = drn_c_42(pretrained=pretrained, num_classes=1000)
14 | elif model_name == 'DRN_C_58':
15 | model = drn_c_58(pretrained=pretrained, num_classes=1000)
16 | elif model_name == 'DRN_D_38':
17 | model = drn_d_38(pretrained=pretrained, num_classes=1000)
18 | elif model_name == 'DRN_D_54':
19 | model = drn_d_54(pretrained=pretrained, num_classes=1000)
20 | elif model_name == 'DRN_D_105':
21 | model = drn_d_105(pretrained=pretrained, num_classes=1000)
22 | else:
23 | raise Exception('model_name must be supplied to DRNSeg constructor.')
24 |
25 | self.base = nn.Sequential(*list(model.children())[:-2])
26 |
27 | self.seg = nn.Conv2d(model.out_dim, num_classes, kernel_size=1, bias=True)
28 | self.softmax = nn.LogSoftmax()
29 | m = self.seg
30 | n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
31 | m.weight.data.normal_(0, math.sqrt(2. / n))
32 | m.bias.data.zero_()
33 | self.use_torch_up = use_torch_up
34 |
35 | up = nn.ConvTranspose2d(num_classes, num_classes, 16, stride=8, padding=4,
36 | output_padding=0, groups=num_classes,
37 | bias=False)
38 | fill_up_weights(up)
39 | up.weight.requires_grad = False
40 | self.up = up
41 |
42 | def forward(self, x):
43 | base = self.base(x)
44 | final = self.seg(base)
45 | if self.use_torch_up:
46 | return F.interpolate(final, x.size()[2:], mode='bilinear')
47 | else:
48 | return self.up(final)
49 |
50 | def optim_parameters(self, memo=None):
51 | for param in self.base.parameters():
52 | yield param
53 | for param in self.seg.parameters():
54 | yield param
55 |
56 | def fill_up_weights(up):
57 | w = up.weight.data
58 | f = math.ceil(w.size(2) / 2)
59 | c = (2 * f - 1 - f % 2) / (2. * f)
60 | for i in range(w.size(2)):
61 | for j in range(w.size(3)):
62 | w[0, 0, i, j] = \
63 | (1 - math.fabs(i / f - c)) * (1 - math.fabs(j / f - c))
64 | for c in range(1, w.size(0)):
65 | w[c, 0, :, :] = w[0, 0, :, :]
--------------------------------------------------------------------------------
/pywick/custom_regularizers.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import numpy as np
3 | import torch
4 |
5 | # ==== Laplace === #
6 | # Source: https://raw.githubusercontent.com/atlab/attorch/master/attorch/regularizers.py
7 | # License: MIT
8 | def laplace():
9 | return np.array([[0.25, 0.5, 0.25], [0.5, -3.0, 0.5], [0.25, 0.5, 0.25]]).astype(np.float32)[None, None, ...]
10 |
11 |
12 | def laplace3d():
13 | l = np.zeros((3, 3, 3))
14 | l[1, 1, 1] = -6.
15 | l[1, 1, 2] = 1.
16 | l[1, 1, 0] = 1.
17 | l[1, 0, 1] = 1.
18 | l[1, 2, 1] = 1.
19 | l[0, 1, 1] = 1.
20 | l[2, 1, 1] = 1.
21 | return l.astype(np.float32)[None, None, ...]
22 |
23 |
24 | class Laplace(nn.Module):
25 | """
26 | Laplace filter for a stack of data.
27 | """
28 |
29 | def __init__(self):
30 | super().__init__()
31 | self.conv = nn.Conv2d(1, 1, 3, bias=False, padding=1)
32 | self.conv.weight.data.copy_(torch.from_numpy(laplace()))
33 | self.conv.weight.requires_grad = False
34 |
35 | def forward(self, x):
36 | return self.conv(x)
37 |
38 |
39 | class Laplace3D(nn.Module):
40 | """
41 | Laplace filter for a stack of data.
42 | """
43 |
44 | def __init__(self):
45 | super().__init__()
46 | self.conv = nn.Conv3d(1, 1, 3, bias=False, padding=1)
47 | self.conv.weight.data.copy_(torch.from_numpy(laplace3d()))
48 | self.conv.weight.requires_grad = False
49 |
50 | def forward(self, x):
51 | return self.conv(x)
52 |
53 |
54 | class LaplaceL2(nn.Module):
55 | """
56 | Laplace regularizer for a 2D convolutional layer.
57 | """
58 |
59 | def __init__(self):
60 | super().__init__()
61 | self.laplace = Laplace()
62 |
63 | def forward(self, x):
64 | ic, oc, k1, k2 = x.size()
65 | return self.laplace(x.view(ic * oc, 1, k1, k2)).pow(2).mean() / 2
66 |
67 |
68 | class LaplaceL23D(nn.Module):
69 | """
70 | Laplace regularizer for a 2D convolutional layer.
71 | """
72 |
73 | def __init__(self):
74 | super().__init__()
75 | self.laplace = Laplace3D()
76 |
77 | def forward(self, x):
78 | ic, oc, k1, k2, k3 = x.size()
79 | return self.laplace(x.view(ic * oc, 1, k1, k2, k3)).pow(2).mean() / 2
80 |
81 |
82 | class LaplaceL1(nn.Module):
83 | """
84 | Laplace regularizer for a 2D convolutional layer.
85 | """
86 |
87 | def __init__(self):
88 | super().__init__()
89 | self.laplace = Laplace()
90 |
91 | def forward(self, x):
92 | ic, oc, k1, k2 = x.size()
93 | return self.laplace(x.view(ic * oc, 1, k1, k2)).abs().mean()
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/exfuse/unet_layer.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 | def weights_init_kaiming(m):
6 | classname = m.__class__.__name__
7 | #print(classname)
8 | if classname.find('Conv') != -1:
9 | nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
10 | elif classname.find('Linear') != -1:
11 | nn.init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
12 | elif classname.find('BatchNorm') != -1:
13 | nn.init.normal_(m.weight.data, 1.0, 0.02)
14 | nn.init.constant_(m.bias.data, 0.0)
15 |
16 | class ConvBNReLU(nn.Module):
17 | def __init__(self, in_size, out_size, norm, kernel_size=3, stride=1, padding=1, act=nn.ReLU):
18 | super(ConvBNReLU, self).__init__()
19 | self.conv1 = nn.Sequential(nn.Conv2d(in_size, out_size, kernel_size, stride, padding),
20 | norm(out_size),
21 | act(inplace=True),)
22 | # initialise the blocks
23 | for m in self.children():
24 | m.apply(weights_init_kaiming)
25 |
26 | def forward(self, inputs):
27 | return self.conv1(inputs)
28 |
29 | class UnetConv2D(nn.Module):
30 | def __init__(self, in_size, out_size, norm, kernel_size=3, stride=1, padding=1, act=nn.ReLU):
31 | super(UnetConv2D, self).__init__()
32 | self.conv1 = ConvBNReLU(in_size, out_size, norm, kernel_size, stride, padding, act)
33 | self.conv2 = ConvBNReLU(out_size, out_size, norm, kernel_size, 1, padding, act)
34 |
35 |
36 | def forward(self, inputs):
37 | x = self.conv1(inputs)
38 | return self.conv2(x)
39 |
40 | class UnetUpConv2D(nn.Module):
41 | def __init__(self, in_size, out_size, norm, is_deconv=True, act=nn.ReLU):
42 | super(UnetUpConv2D, self).__init__()
43 |
44 | self.conv = UnetConv2D(in_size, out_size, norm, act=act)
45 | if is_deconv:
46 | self.up = nn.ConvTranspose2d(in_size, out_size, kernel_size=4, stride=2, padding=1)
47 | else:
48 | self.up = nn.UpsamplingBilinear2d(scale_factor=2)
49 |
50 | # initialise the blocks
51 | for m in self.children():
52 | if m.__class__.__name__.find('UnetConv2D') != -1:
53 | continue
54 | m.apply(weights_init_kaiming)
55 |
56 | def forward(self, input1, input2):
57 | output2 = self.up(input2)
58 | offset = output2.size()[2] - input1.size()[2]
59 | padding = [offset // 2] * 4
60 | output1 = F.pad(input1, padding)
61 | output = torch.cat([output1, output2], 1)
62 | return self.conv(output)
63 |
--------------------------------------------------------------------------------
/pywick/datasets/TensorDataset.py:
--------------------------------------------------------------------------------
1 | from .BaseDataset import BaseDataset
2 | from .data_utils import _process_array_argument, _return_first_element_of_list, _process_transform_argument, _process_co_transform_argument, _pass_through
3 |
4 | class TensorDataset(BaseDataset):
5 |
6 | """
7 | Dataset class for loading in-memory data.
8 |
9 | :param inputs: (numpy array)
10 |
11 | :param targets: (numpy array)
12 |
13 | :param input_transform: (transform):
14 | transform to apply to input sample individually
15 |
16 | :param target_transform: (transform):
17 | transform to apply to target sample individually
18 |
19 | :param co_transform: (transform):
20 | transform to apply to both input and target sample simultaneously
21 |
22 | """
23 | def __init__(self,
24 | inputs,
25 | targets=None,
26 | input_transform=None,
27 | target_transform=None,
28 | co_transform=None):
29 | self.inputs = _process_array_argument(inputs)
30 | self.num_inputs = len(self.inputs)
31 | self.input_return_processor = _return_first_element_of_list if self.num_inputs==1 else _pass_through
32 |
33 | if targets is None:
34 | self.has_target = False
35 | else:
36 | self.targets = _process_array_argument(targets)
37 | self.num_targets = len(self.targets)
38 | self.target_return_processor = _return_first_element_of_list if self.num_targets==1 else _pass_through
39 | self.min_inputs_or_targets = min(self.num_inputs, self.num_targets)
40 | self.has_target = True
41 |
42 | self.input_transform = _process_transform_argument(input_transform, self.num_inputs)
43 | if self.has_target:
44 | self.target_transform = _process_transform_argument(target_transform, self.num_targets)
45 | self.co_transform = _process_co_transform_argument(co_transform, self.num_inputs, self.num_targets)
46 |
47 | def __getitem__(self, index):
48 | """
49 | Index the dataset and return the input + target
50 | """
51 | input_sample = [self.input_transform[i](self.inputs[i][index]) for i in range(self.num_inputs)]
52 |
53 | if self.has_target:
54 | target_sample = [self.target_transform[i](self.targets[i][index]) for i in range(self.num_targets)]
55 | #for i in range(self.min_inputs_or_targets):
56 | # input_sample[i], target_sample[i] = self.co_transform[i](input_sample[i], target_sample[i])
57 |
58 | return self.input_return_processor(input_sample), self.target_return_processor(target_sample)
59 | else:
60 | return self.input_return_processor(input_sample)
--------------------------------------------------------------------------------
/pywick/models/classification/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Below you will find all the latest image classification models.
3 | By convention, model names starting with lowercase are pretrained on imagenet while uppercase are not (vanilla). To load one of the pretrained
4 | models with your own number of classes use the ``models.model_utils.get_model(...)`` function and specify the name of the model
5 | exactly like the pretrained model method name (e.g. if the method name reads ``pywick.models.classification.dpn.dualpath.dpn68`` then use
6 | `dpn68` as the model name for ``models.model_utils.get_model(...)``.
7 |
8 | Note: Since Pywick v0.6.5 we include 200+ models from `rwightman's repo `_ which can be used by simply specifying the appropriate model name (all lowercase) in the yaml configuration file!
9 | """
10 |
11 | from .dpn.dualpath import * # dpnXX = pretrained on imagenet, DPN = not pretrained
12 | from .bn_inception import * # bninception = pretrained on imagenet, BNInception not pretrained
13 | from .fbresnet import * # only fbresnet152 pretrained
14 | from .inception_resv2_wide import InceptionResV2 # InceptionResV2 not pretrained
15 | from .inceptionresnet_v2 import * # inceptionresnetv2 = pretrained on imagenet, InceptionResNetV2 not pretrained
16 | from .inception_v4 import * # inceptionv4 = pretrained on imagenet, InceptionV4 not pretrained
17 | from .nasnet import * # nasnetalarge = pretrained on NASNetALarge, InceptionV4 not pretrained
18 | from .nasnet_mobile import * # nasnetamobile = pretrained on imagenet, NASNetAMobile not pretrained
19 | from .pnasnet import * # pnasnet5large = pretrained on imagenet, PNASNet5Large not pretrained
20 | from .poly_net import * # polynet = pretrained on imagenet, PolyNet not pretrained
21 | from .pyramid_resnet import * # pyresnetxx = pretrained on imagenet, PyResNet not pretrained
22 | from .resnet_preact import * # not pretrained
23 | from .resnet_swish import * # not pretrained
24 | from .resnext import * # resnextxxx = pretrained on imagenet, ResNeXt not pretrained
25 | from .senet import * # SENet not pretrained, all others pretrained
26 | from .wideresnet import * # models have not been vetted
27 | from .xception1 import * # xception = pretrained on imagenet, Xception not pretrained
28 |
29 | from .testnets import *
30 |
--------------------------------------------------------------------------------
/examples/mnist_example.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from pywick.modules import ModuleTrainer
7 | from pywick.callbacks import EarlyStopping, ReduceLROnPlateau
8 | from pywick.regularizers import L1Regularizer, L2Regularizer
9 | from pywick.constraints import UnitNorm
10 | from pywick.initializers import XavierUniform
11 | from pywick.metrics import CategoricalAccuracy
12 |
13 | import os
14 | from torchvision import datasets
15 | ROOT = '/data/mnist'
16 | dataset = datasets.MNIST(ROOT, train=True, download=True)
17 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
18 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
19 |
20 | x_train = x_train.float()
21 | y_train = y_train.long()
22 | x_test = x_test.float()
23 | y_test = y_test.long()
24 |
25 | x_train = x_train / 255.
26 | x_test = x_test / 255.
27 | x_train = x_train.unsqueeze(1)
28 | x_test = x_test.unsqueeze(1)
29 |
30 | # only train on a subset
31 | x_train = x_train[:10000]
32 | y_train = y_train[:10000]
33 | x_test = x_test[:1000]
34 | y_test = y_test[:1000]
35 |
36 |
37 | # Define your model EXACTLY as if you were using nn.Module
38 | class Network(nn.Module):
39 | def __init__(self):
40 | super(Network, self).__init__()
41 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
42 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
43 | self.fc1 = nn.Linear(1600, 128)
44 | self.fc2 = nn.Linear(128, 10)
45 |
46 | def forward(self, x):
47 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
48 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
49 | x = x.view(-1, 1600)
50 | x = F.relu(self.fc1(x))
51 | x = F.dropout(x, training=self.training)
52 | x = self.fc2(x)
53 | return F.log_softmax(x)
54 |
55 |
56 | model = Network()
57 | trainer = ModuleTrainer(model)
58 |
59 |
60 | callbacks = [EarlyStopping(patience=10),
61 | ReduceLROnPlateau(factor=0.5, patience=5)]
62 | regularizers = [L1Regularizer(scale=1e-3, module_filter='conv*'),
63 | L2Regularizer(scale=1e-5, module_filter='fc*')]
64 | constraints = [UnitNorm(frequency=3, unit='batch', module_filter='fc*')]
65 | initializers = [XavierUniform(bias=False, module_filter='fc*')]
66 | metrics = [CategoricalAccuracy(top_k=3)]
67 |
68 | trainer.compile(criterion='nll_loss',
69 | optimizer='adadelta',
70 | regularizers=regularizers,
71 | constraints=constraints,
72 | initializers=initializers,
73 | metrics=metrics)
74 |
75 | #summary = trainer.summary([1,28,28])
76 | #print(summary)
77 |
78 | trainer.fit(x_train, y_train,
79 | val_data=(x_test, y_test),
80 | num_epoch=20,
81 | batch_size=128,
82 | verbose=1)
83 |
84 |
85 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/gscnn/config.py:
--------------------------------------------------------------------------------
1 | """
2 | Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
3 | Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
4 |
5 | # Code adapted from:
6 | # https://github.com/facebookresearch/Detectron/blob/master/detectron/core/config.py
7 |
8 | Source License
9 | # Copyright (c) 2017-present, Facebook, Inc.
10 | #
11 | # Licensed under the Apache License, Version 2.0 (the "License");
12 | # you may not use this file except in compliance with the License.
13 | # You may obtain a copy of the License at
14 | #
15 | # http://www.apache.org/licenses/LICENSE-2.0
16 | #
17 | # Unless required by applicable law or agreed to in writing, software
18 | # distributed under the License is distributed on an "AS IS" BASIS,
19 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
20 | # See the License for the specific language governing permissions and
21 | # limitations under the License.
22 | ##############################################################################
23 | #
24 | # Based on:
25 | # --------------------------------------------------------
26 | # Fast R-CNN
27 | # Copyright (c) 2015 Microsoft
28 | # Licensed under The MIT License [see LICENSE for details]
29 | # Written by Ross Girshick
30 | # --------------------------------------------------------
31 | """
32 |
33 | import torch
34 |
35 | from .utils.AttrDict import AttrDict
36 |
37 | __C = AttrDict()
38 | # Consumers can get config by:
39 | # from fast_rcnn_config import cfg
40 | cfg = __C
41 | __C.EPOCH = 0
42 | __C.CLASS_UNIFORM_PCT=0.0
43 | __C.BATCH_WEIGHTING=False
44 | __C.BORDER_WINDOW=1
45 | __C.REDUCE_BORDER_EPOCH= -1
46 | __C.STRICTBORDERCLASS= None
47 |
48 | __C.DATASET =AttrDict()
49 | __C.DATASET.CITYSCAPES_DIR='/home/username/data/cityscapes'
50 | __C.DATASET.CV_SPLITS=3
51 |
52 | __C.MODEL = AttrDict()
53 | __C.MODEL.BN = 'regularnorm'
54 | __C.MODEL.BNFUNC = torch.nn.BatchNorm2d
55 | __C.MODEL.BIGMEMORY = False
56 |
57 |
58 | def assert_and_infer_cfg(args, make_immutable=True):
59 | """Call this function in your script after you have finished setting all cfg
60 | values that are necessary (e.g., merging a config from a file, merging
61 | command line config options, etc.). By default, this function will also
62 | mark the global cfg as immutable to prevent changing the global cfg settings
63 | during script execution (which can lead to hard to debug errors or code
64 | that's harder to understand than is necessary).
65 | """
66 |
67 | if args.batch_weighting:
68 | __C.BATCH_WEIGHTING=True
69 |
70 | if args.syncbn:
71 | import encoding
72 | __C.MODEL.BN = 'syncnorm'
73 | __C.MODEL.BNFUNC = encoding.nn.BatchNorm2d
74 | else:
75 | __C.MODEL.BNFUNC = torch.nn.BatchNorm2d
76 | print('Using regular batch norm')
77 |
78 | if make_immutable:
79 | cfg.immutable(True)
80 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/testnets/gscnn/utils/AttrDict.py:
--------------------------------------------------------------------------------
1 | """
2 | Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
3 | Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
4 |
5 | # Code adapted from:
6 | # https://github.com/facebookresearch/Detectron/blob/master/detectron/utils/collections.py
7 |
8 | Source License
9 | # Copyright (c) 2017-present, Facebook, Inc.
10 | #
11 | # Licensed under the Apache License, Version 2.0 (the "License");
12 | # you may not use this file except in compliance with the License.
13 | # You may obtain a copy of the License at
14 | #
15 | # http://www.apache.org/licenses/LICENSE-2.0
16 | #
17 | # Unless required by applicable law or agreed to in writing, software
18 | # distributed under the License is distributed on an "AS IS" BASIS,
19 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
20 | # See the License for the specific language governing permissions and
21 | # limitations under the License.
22 | ##############################################################################
23 | #
24 | # Based on:
25 | # --------------------------------------------------------
26 | # Fast R-CNN
27 | # Copyright (c) 2015 Microsoft
28 | # Licensed under The MIT License [see LICENSE for details]
29 | # Written by Ross Girshick
30 | # --------------------------------------------------------
31 | """
32 |
33 |
34 | class AttrDict(dict):
35 |
36 | IMMUTABLE = '__immutable__'
37 |
38 | def __init__(self, *args, **kwargs):
39 | super(AttrDict, self).__init__(*args, **kwargs)
40 | self.__dict__[AttrDict.IMMUTABLE] = False
41 |
42 | def __getattr__(self, name):
43 | if name in self.__dict__:
44 | return self.__dict__[name]
45 | elif name in self:
46 | return self[name]
47 | else:
48 | raise AttributeError(name)
49 |
50 | def __setattr__(self, name, value):
51 | if not self.__dict__[AttrDict.IMMUTABLE]:
52 | if name in self.__dict__:
53 | self.__dict__[name] = value
54 | else:
55 | self[name] = value
56 | else:
57 | raise AttributeError(
58 | 'Attempted to set "{}" to "{}", but AttrDict is immutable'.
59 | format(name, value)
60 | )
61 |
62 | def immutable(self, is_immutable):
63 | """Set immutability to is_immutable and recursively apply the setting
64 | to all nested AttrDicts.
65 | """
66 | self.__dict__[AttrDict.IMMUTABLE] = is_immutable
67 | # Recursively set immutable state
68 | for v in self.__dict__.values():
69 | if isinstance(v, AttrDict):
70 | v.immutable(is_immutable)
71 | for v in self.values():
72 | if isinstance(v, AttrDict):
73 | v.immutable(is_immutable)
74 |
75 | def is_immutable(self):
76 | return self.__dict__[AttrDict.IMMUTABLE]
77 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/da_basenets/jpu.py:
--------------------------------------------------------------------------------
1 | """Joint Pyramid Upsampling"""
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | __all__ = ['JPU']
7 |
8 |
9 | class SeparableConv2d(nn.Module):
10 | def __init__(self, inplanes, planes, kernel_size=3, stride=1, padding=1,
11 | dilation=1, bias=False, norm_layer=nn.BatchNorm2d):
12 | super(SeparableConv2d, self).__init__()
13 | self.conv = nn.Conv2d(inplanes, inplanes, kernel_size, stride, padding, dilation, groups=inplanes, bias=bias)
14 | self.bn = norm_layer(inplanes)
15 | self.pointwise = nn.Conv2d(inplanes, planes, 1, bias=bias)
16 |
17 | def forward(self, x):
18 | x = self.conv(x)
19 | x = self.bn(x)
20 | x = self.pointwise(x)
21 | return x
22 |
23 |
24 | # copy from: https://github.com/wuhuikai/FastFCN/blob/master/encoding/nn/customize.py
25 | class JPU(nn.Module):
26 | def __init__(self, in_channels, width=512, norm_layer=nn.BatchNorm2d, **kwargs):
27 | super(JPU, self).__init__()
28 |
29 | self.conv5 = nn.Sequential(
30 | nn.Conv2d(in_channels[-1], width, 3, padding=1, bias=False),
31 | norm_layer(width),
32 | nn.ReLU(True))
33 | self.conv4 = nn.Sequential(
34 | nn.Conv2d(in_channels[-2], width, 3, padding=1, bias=False),
35 | norm_layer(width),
36 | nn.ReLU(True))
37 | self.conv3 = nn.Sequential(
38 | nn.Conv2d(in_channels[-3], width, 3, padding=1, bias=False),
39 | norm_layer(width),
40 | nn.ReLU(True))
41 |
42 | self.dilation1 = nn.Sequential(
43 | SeparableConv2d(3 * width, width, 3, padding=1, dilation=1, bias=False),
44 | norm_layer(width),
45 | nn.ReLU(True))
46 | self.dilation2 = nn.Sequential(
47 | SeparableConv2d(3 * width, width, 3, padding=2, dilation=2, bias=False),
48 | norm_layer(width),
49 | nn.ReLU(True))
50 | self.dilation3 = nn.Sequential(
51 | SeparableConv2d(3 * width, width, 3, padding=4, dilation=4, bias=False),
52 | norm_layer(width),
53 | nn.ReLU(True))
54 | self.dilation4 = nn.Sequential(
55 | SeparableConv2d(3 * width, width, 3, padding=8, dilation=8, bias=False),
56 | norm_layer(width),
57 | nn.ReLU(True))
58 |
59 | def forward(self, *inputs):
60 | feats = [self.conv5(inputs[-1]), self.conv4(inputs[-2]), self.conv3(inputs[-3])]
61 | size = feats[-1].size()[2:]
62 | feats[-2] = F.interpolate(feats[-2], size, mode='bilinear', align_corners=True)
63 | feats[-3] = F.interpolate(feats[-3], size, mode='bilinear', align_corners=True)
64 | feat = torch.cat(feats, dim=1)
65 | feat = torch.cat([self.dilation1(feat), self.dilation2(feat), self.dilation3(feat), self.dilation4(feat)],
66 | dim=1)
67 |
68 | return inputs[0], inputs[1], inputs[2], feat
69 |
--------------------------------------------------------------------------------
/examples/mnist_loader_example.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from torch.utils.data import DataLoader
7 |
8 | from pywick.modules import ModuleTrainer
9 | from pywick.callbacks import EarlyStopping, ReduceLROnPlateau
10 | from pywick.regularizers import L1Regularizer, L2Regularizer
11 | from pywick.constraints import UnitNorm
12 | from pywick.initializers import XavierUniform
13 | from pywick.metrics import CategoricalAccuracy
14 | from pywick import TensorDataset
15 |
16 | import os
17 | from torchvision import datasets
18 | ROOT = '/data/mnist'
19 | dataset = datasets.MNIST(ROOT, train=True, download=True)
20 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
21 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
22 |
23 | x_train = x_train.float()
24 | y_train = y_train.long()
25 | x_test = x_test.float()
26 | y_test = y_test.long()
27 |
28 | x_train = x_train / 255.
29 | x_test = x_test / 255.
30 | x_train = x_train.unsqueeze(1)
31 | x_test = x_test.unsqueeze(1)
32 |
33 | # only train on a subset
34 | x_train = x_train[:10000]
35 | y_train = y_train[:10000]
36 | x_test = x_test[:1000]
37 | y_test = y_test[:1000]
38 |
39 | train_dataset = TensorDataset(x_train, y_train)
40 | train_loader = DataLoader(train_dataset, batch_size=32)
41 | val_dataset = TensorDataset(x_test, y_test)
42 | val_loader = DataLoader(val_dataset, batch_size=32)
43 |
44 | # Define your model EXACTLY as if you were using nn.Module
45 | class Network(nn.Module):
46 | def __init__(self):
47 | super(Network, self).__init__()
48 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
49 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
50 | self.fc1 = nn.Linear(1600, 128)
51 | self.fc2 = nn.Linear(128, 10)
52 |
53 | def forward(self, x):
54 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
55 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
56 | x = x.view(-1, 1600)
57 | x = F.relu(self.fc1(x))
58 | x = F.dropout(x, training=self.training)
59 | x = self.fc2(x)
60 | return F.log_softmax(x)
61 |
62 |
63 | model = Network()
64 | trainer = ModuleTrainer(model)
65 |
66 | callbacks = [EarlyStopping(patience=10),
67 | ReduceLROnPlateau(factor=0.5, patience=5)]
68 | regularizers = [L1Regularizer(scale=1e-3, module_filter='conv*'),
69 | L2Regularizer(scale=1e-5, module_filter='fc*')]
70 | constraints = [UnitNorm(frequency=3, unit='batch', module_filter='fc*')]
71 | initializers = [XavierUniform(bias=False, module_filter='fc*')]
72 | metrics = [CategoricalAccuracy(top_k=3)]
73 |
74 | trainer.compile(criterion='nll_loss',
75 | optimizer='adadelta',
76 | regularizers=regularizers,
77 | constraints=constraints,
78 | initializers=initializers,
79 | metrics=metrics,
80 | callbacks=callbacks)
81 |
82 | trainer.fit_loader(train_loader, val_loader, num_epoch=20, verbose=1)
83 |
84 |
85 |
86 |
--------------------------------------------------------------------------------
/docs/source/api/pywick.rst.old:
--------------------------------------------------------------------------------
1 | pywick package
2 | ==============
3 |
4 | Subpackages
5 | -----------
6 |
7 | .. toctree::
8 |
9 | pywick.callbacks
10 | pywick.datasets
11 | pywick.functions
12 | pywick.gridsearch
13 | pywick.meters
14 | pywick.models
15 | pywick.modules
16 | pywick.optimizers
17 | pywick.transforms
18 |
19 | Submodules
20 | ----------
21 |
22 | pywick.conditions module
23 | ------------------------
24 |
25 | .. automodule:: pywick.conditions
26 | :members:
27 | :undoc-members:
28 | :show-inheritance:
29 |
30 | pywick.constraints module
31 | -------------------------
32 |
33 | .. automodule:: pywick.constraints
34 | :members:
35 | :undoc-members:
36 | :show-inheritance:
37 |
38 | pywick.custom\_regularizers module
39 | ----------------------------------
40 |
41 | .. automodule:: pywick.custom_regularizers
42 | :members:
43 | :undoc-members:
44 | :show-inheritance:
45 |
46 | pywick.data\_stats module
47 | -------------------------
48 |
49 | .. automodule:: pywick.data_stats
50 | :members:
51 | :undoc-members:
52 | :show-inheritance:
53 |
54 | pywick.image\_utils module
55 | --------------------------
56 |
57 | .. automodule:: pywick.image_utils
58 | :members:
59 | :undoc-members:
60 | :show-inheritance:
61 |
62 | pywick.initializers module
63 | --------------------------
64 |
65 | .. automodule:: pywick.initializers
66 | :members:
67 | :undoc-members:
68 | :show-inheritance:
69 |
70 | pywick.losses module
71 | --------------------
72 |
73 | .. automodule:: pywick.losses
74 | :members:
75 | :undoc-members:
76 | :show-inheritance:
77 |
78 | pywick.lovasz\_losses module
79 | ----------------------------
80 |
81 | .. automodule:: pywick.lovasz_losses
82 | :members:
83 | :undoc-members:
84 | :show-inheritance:
85 |
86 | pywick.meanstd module
87 | ---------------------
88 |
89 | .. automodule:: pywick.meanstd
90 | :members:
91 | :undoc-members:
92 | :show-inheritance:
93 |
94 | pywick.metrics module
95 | ---------------------
96 |
97 | .. automodule:: pywick.metrics
98 | :members:
99 | :undoc-members:
100 | :show-inheritance:
101 |
102 | pywick.misc module
103 | ------------------
104 |
105 | .. automodule:: pywick.misc
106 | :members:
107 | :undoc-members:
108 | :show-inheritance:
109 |
110 | pywick.regularizers module
111 | --------------------------
112 |
113 | .. automodule:: pywick.regularizers
114 | :members:
115 | :undoc-members:
116 | :show-inheritance:
117 |
118 | pywick.samplers module
119 | ----------------------
120 |
121 | .. automodule:: pywick.samplers
122 | :members:
123 | :undoc-members:
124 | :show-inheritance:
125 |
126 | pywick.utils module
127 | -------------------
128 |
129 | .. automodule:: pywick.utils
130 | :members:
131 | :undoc-members:
132 | :show-inheritance:
133 |
134 |
135 | Module contents
136 | ---------------
137 |
138 | .. automodule:: pywick
139 | :members:
140 | :undoc-members:
141 | :show-inheritance:
142 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/fcn16s.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/zijundeng/pytorch-semantic-segmentation/tree/master/models (MIT)
2 |
3 | """
4 | Implementation of `Fully Convolutional Networks for Semantic Segmentation `_
5 | """
6 |
7 | import torch
8 | from torch import nn
9 | from torchvision import models
10 |
11 | from .fcn_utils import get_upsampling_weight
12 | from .config import vgg16_caffe_path
13 |
14 | __all__ = ['FCN16VGG']
15 |
16 | class FCN16VGG(nn.Module):
17 | def __init__(self, num_classes, pretrained=True, **kwargs):
18 | super(FCN16VGG, self).__init__()
19 | vgg = models.vgg16()
20 | if pretrained:
21 | vgg.load_state_dict(torch.load(vgg16_caffe_path))
22 | features, classifier = list(vgg.features.children()), list(vgg.classifier.children())
23 |
24 | features[0].padding = (100, 100)
25 |
26 | for f in features:
27 | if 'MaxPool' in f.__class__.__name__:
28 | f.ceil_mode = True
29 | elif 'ReLU' in f.__class__.__name__:
30 | f.inplace = True
31 |
32 | self.features4 = nn.Sequential(*features[: 24])
33 | self.features5 = nn.Sequential(*features[24:])
34 |
35 | self.score_pool4 = nn.Conv2d(512, num_classes, kernel_size=1)
36 | self.score_pool4.weight.data.zero_()
37 | self.score_pool4.bias.data.zero_()
38 |
39 | fc6 = nn.Conv2d(512, 4096, kernel_size=7)
40 | fc6.weight.data.copy_(classifier[0].weight.data.view(4096, 512, 7, 7))
41 | fc6.bias.data.copy_(classifier[0].bias.data)
42 | fc7 = nn.Conv2d(4096, 4096, kernel_size=1)
43 | fc7.weight.data.copy_(classifier[3].weight.data.view(4096, 4096, 1, 1))
44 | fc7.bias.data.copy_(classifier[3].bias.data)
45 | score_fr = nn.Conv2d(4096, num_classes, kernel_size=1)
46 | score_fr.weight.data.zero_()
47 | score_fr.bias.data.zero_()
48 | self.score_fr = nn.Sequential(
49 | fc6, nn.ReLU(inplace=True), nn.Dropout(), fc7, nn.ReLU(inplace=True), nn.Dropout(), score_fr
50 | )
51 |
52 | self.upscore2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, bias=False)
53 | self.upscore16 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=32, stride=16, bias=False)
54 | self.upscore2.weight.data.copy_(get_upsampling_weight(num_classes, num_classes, 4))
55 | self.upscore16.weight.data.copy_(get_upsampling_weight(num_classes, num_classes, 32))
56 |
57 | def forward(self, x):
58 | x_size = x.size()
59 | pool4 = self.features4(x)
60 | pool5 = self.features5(pool4)
61 |
62 | score_fr = self.score_fr(pool5)
63 | upscore2 = self.upscore2(score_fr)
64 |
65 | score_pool4 = self.score_pool4(0.01 * pool4)
66 | upscore16 = self.upscore16(score_pool4[:, :, 5: (5 + upscore2.size()[2]), 5: (5 + upscore2.size()[3])]
67 | + upscore2)
68 | return upscore16[:, :, 27: (27 + x_size[2]), 27: (27 + x_size[3])].contiguous()
69 |
--------------------------------------------------------------------------------
/pywick/optimizers/addsign.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/cydonia999/AddSign_PowerSign_in_PyTorch/tree/master/torch/optim
2 |
3 | import torch
4 | from torch.optim.optimizer import Optimizer
5 |
6 |
7 | class AddSign(Optimizer):
8 | """Implements AddSign algorithm.
9 |
10 | It has been proposed in `Neural Optimizer Search with Reinforcement Learning`_.
11 |
12 | :param params: (iterable): iterable of parameters to optimize or dicts defining
13 | parameter groups
14 | :param lr: (float, optional): learning rate (default: 1e-3)
15 | :param beta: (float, optional): coefficients used for computing
16 | running averages of gradient (default: 0.9)
17 | :param alpha: (float, optional): term added to
18 | the internal_decay * sign(g) * sign(m) (default: 1)
19 | :param sign_internal_decay: (callable, optional): a function that returns
20 | an internal decay calculated based on the current training step and
21 | the total number of training steps.
22 | If None, the internal decay is assumed to be 1.
23 |
24 | .. _Neural Optimizer Search with Reinforcement Learning:
25 | https://arxiv.org/abs/1709.07417
26 | """
27 |
28 | def __init__(self, params, lr=1e-3, beta=0.9, alpha=1, sign_internal_decay=None):
29 | if sign_internal_decay is not None and not callable(sign_internal_decay):
30 | raise TypeError('{} is not a callable'.format(
31 | type(sign_internal_decay).__name__))
32 | defaults = dict(lr=lr, beta=beta, alpha=alpha,
33 | sign_internal_decay=sign_internal_decay if sign_internal_decay is not None else lambda _: 1)
34 | super(AddSign, self).__init__(params, defaults)
35 |
36 | def step(self, closure=None):
37 | """Performs a single optimization step.
38 |
39 | :param closure: (callable, optional): A closure that reevaluates the model
40 | and returns the loss.
41 | """
42 | loss = None
43 | if closure is not None:
44 | loss = closure()
45 |
46 | for group in self.param_groups:
47 | for p in group['params']:
48 | if p.grad is None:
49 | continue
50 | grad = p.grad.data
51 |
52 |
53 | state = self.state[p]
54 |
55 | # State initialization
56 | if len(state) == 0:
57 | state['step'] = 0
58 | # Exponential moving average of gradient values
59 | state['exp_avg'] = torch.zeros_like(p.data)
60 |
61 | exp_avg = state['exp_avg']
62 | beta = group['beta']
63 | alpha = group['alpha']
64 |
65 | state['step'] += 1
66 | internal_decay = group['sign_internal_decay'](state['step'] - 1)
67 |
68 | # Decay the first moment running average coefficient
69 | exp_avg.mul_(beta).add_(1 - beta, grad)
70 | add_sign = grad.mul(alpha + internal_decay * grad.sign() * exp_avg.sign())
71 | p.data.add_(-group['lr'], add_sign)
72 |
73 | return loss
74 |
--------------------------------------------------------------------------------
/pywick/callbacks/CallbackContainer.py:
--------------------------------------------------------------------------------
1 | import time
2 | import datetime
3 |
4 | def _get_current_time():
5 | time_s = time.time()
6 | return time_s, datetime.datetime.fromtimestamp(time_s).strftime("%B %d, %Y - %I:%M%p")
7 |
8 |
9 | class CallbackContainer:
10 | """
11 | Container holding a list of callbacks.
12 | """
13 |
14 | def __init__(self, callbacks=None, queue_length=10):
15 | self.initial_epoch = -1
16 | self.final_epoch = -1
17 | self.has_val_data = False
18 | self.callbacks = callbacks or []
19 | self.queue_length = queue_length
20 |
21 | def append(self, callback):
22 | self.callbacks.append(callback)
23 |
24 | def set_params(self, params):
25 | for callback in self.callbacks:
26 | callback.set_params(params)
27 |
28 | def set_trainer(self, trainer):
29 | self.trainer = trainer
30 | for callback in self.callbacks:
31 | callback.set_trainer(trainer)
32 |
33 | def on_epoch_begin(self, epoch, logs=None):
34 | if self.initial_epoch == -1:
35 | self.initial_epoch = epoch
36 | logs = logs or {}
37 | for callback in self.callbacks:
38 | callback.on_epoch_begin(epoch, logs)
39 |
40 | def on_epoch_end(self, epoch, logs=None):
41 | if self.final_epoch < epoch:
42 | self.final_epoch = epoch
43 |
44 | logs = logs or {}
45 | for callback in self.callbacks:
46 | callback.on_epoch_end(epoch, logs)
47 |
48 | def on_batch_begin(self, batch, logs=None):
49 | logs = logs or {}
50 | for callback in self.callbacks:
51 | callback.on_batch_begin(batch, logs)
52 |
53 | def on_batch_end(self, batch, logs=None):
54 | logs = logs or {}
55 | for callback in self.callbacks:
56 | callback.on_batch_end(batch, logs)
57 |
58 | def on_train_begin(self, logs=None):
59 | self.has_val_data = logs['has_val_data']
60 | logs = logs or {}
61 | self.start_time_s, self.start_time_date = _get_current_time()
62 | logs['start_time'] = self.start_time_date
63 | logs['start_time_s'] = self.start_time_s
64 | for callback in self.callbacks:
65 | callback.on_train_begin(logs)
66 |
67 | def on_train_end(self, logs=None):
68 | logs = logs or {}
69 | logs['initial_epoch'] = self.initial_epoch
70 | logs['final_epoch'] = self.final_epoch
71 |
72 | logs['final_loss'] = self.trainer.history.epoch_metrics['loss'][-1]
73 | logs['best_loss'] = min(self.trainer.history.epoch_metrics['loss'])
74 | if self.has_val_data:
75 | logs['final_val_loss'] = self.trainer.history.epoch_metrics['val_loss'][-1]
76 | logs['best_val_loss'] = min(self.trainer.history.epoch_metrics['val_loss'])
77 |
78 | logs['start_time'] = self.start_time_date
79 | logs['start_time_s'] = self.start_time_s
80 |
81 | time_s, time_date = _get_current_time()
82 | logs['stop_time'] = time_date
83 | logs['stop_time_s'] = time_s
84 | for callback in self.callbacks:
85 | callback.on_train_end(logs)
--------------------------------------------------------------------------------
/pywick/dictmodels/dict_config.py:
--------------------------------------------------------------------------------
1 | import time
2 | from typing import List
3 |
4 | from prodict import Prodict
5 |
6 |
7 | class ExpConfig(Prodict):
8 | """
9 | Default configuration class to define some static types (based on configs/train_classifier.yaml)
10 | """
11 |
12 | auto_balance_dataset: bool # whether to attempt to fix imbalances in class representation within the dataset (default: False)
13 | batch_size : int # Size of the batch to use when training (per GPU)
14 | dataroots : List # where to find the training data
15 | exp_id : str # id of the experiment (default: generated from datetime)
16 | gpu_ids : List # list of GPUs to use
17 | input_size : int # size of the input image. Networks with atrous convolutions (densenet, fbresnet, inceptionv4) allow flexible image sizes while others do not
18 | # see table: https://github.com/rwightman/pytorch-image-models/blob/master/results/results-imagenet-a.csv
19 | mean_std : List # mean, std to use for image transforms
20 | model_spec : str # model to use (over 200 models available! see: https://github.com/rwightman/pytorch-image-models/blob/master/results/results-imagenet-a.csv)
21 | num_epochs : int # number of epochs to train for (use small number if starting from pretrained NN)
22 | optimizer : dict # optimizer configuration
23 | output_root : str # where to save outputs (e.g. trained NNs)
24 | random_seed : int # random seed to use (default: 1377)
25 | save_callback : dict # callback to use for saving the model (if any)
26 | scheduler : dict # scheduler configuration
27 | train_val_ratio : float # ratio of train to val data (if splitting a single dataset)
28 | use_apex : bool # whether to use APEX optimization (only valid if use_gpu = True)
29 | use_gpu : bool # whether to use the GPU for training (default: False)
30 | val_root : str # root dir to use for validation data (if different from dataroots)
31 | workers : int # number of workers to read training data from disk and feed it to the GPU (default: 8)
32 |
33 | keys_to_verify : List # Minimum set of keys that must be set to ensure proper configuration
34 |
35 | def init(self):
36 | self.auto_balance_dataset = False
37 | self.exp_id = str(int(time.time() * 1000))
38 | self.mean_std = [[0.485, 0.456, 0.406], [0.229, 0.224, 0.225]] # imagenet default
39 | self.random_seed = 1337
40 | self.train_val_ratio = 0.8
41 | self.use_gpu = False
42 |
43 | self.keys_to_verify = ['batch_size', 'dataroots', 'input_size', 'model_spec', 'num_epochs', 'optimizer', 'output_root', 'scheduler', 'use_gpu', 'workers']
44 |
45 | def verify_properties(self):
46 | mapped_keys = [i in self.keys() for i in self.keys_to_verify]
47 | if not all(mapped_keys):
48 | raise Exception(f'Property verification failed. Not all required properties have been set: {[i for (i, v) in zip(self.keys_to_verify, mapped_keys) if not v]}')
--------------------------------------------------------------------------------
/pywick/models/segmentation/seg_net.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/zijundeng/pytorch-semantic-segmentation/tree/master/models (MIT)
2 |
3 | """
4 | Implementation of `Segnet: A deep convolutional encoder-decoder architecture for image segmentation `_
5 | """
6 |
7 | import torch
8 | from torch import nn
9 | from torchvision import models
10 |
11 | from .fcn_utils import initialize_weights
12 | from .config import vgg19_bn_path
13 |
14 | __all__ = ['SegNet']
15 |
16 | class _DecoderBlock(nn.Module):
17 | def __init__(self, in_channels, out_channels, num_conv_layers):
18 | super(_DecoderBlock, self).__init__()
19 | middle_channels = in_channels / 2
20 | layers = [
21 | nn.ConvTranspose2d(in_channels, in_channels, kernel_size=2, stride=2),
22 | nn.Conv2d(in_channels, middle_channels, kernel_size=3, padding=1),
23 | nn.BatchNorm2d(middle_channels),
24 | nn.ReLU(inplace=True)
25 | ]
26 | layers += [
27 | nn.Conv2d(middle_channels, middle_channels, kernel_size=3, padding=1),
28 | nn.BatchNorm2d(middle_channels),
29 | nn.ReLU(inplace=True),
30 | ] * (num_conv_layers - 2)
31 | layers += [
32 | nn.Conv2d(middle_channels, out_channels, kernel_size=3, padding=1),
33 | nn.BatchNorm2d(out_channels),
34 | nn.ReLU(inplace=True),
35 | ]
36 | self.decode = nn.Sequential(*layers)
37 |
38 | def forward(self, x):
39 | return self.decode(x)
40 |
41 |
42 | class SegNet(nn.Module):
43 | def __init__(self, num_classes, pretrained=True, **kwargs):
44 | super(SegNet, self).__init__()
45 | vgg = models.vgg19_bn()
46 | if pretrained:
47 | vgg.load_state_dict(torch.load(vgg19_bn_path))
48 | features = list(vgg.features.children())
49 | self.enc1 = nn.Sequential(*features[0:7])
50 | self.enc2 = nn.Sequential(*features[7:14])
51 | self.enc3 = nn.Sequential(*features[14:27])
52 | self.enc4 = nn.Sequential(*features[27:40])
53 | self.enc5 = nn.Sequential(*features[40:])
54 |
55 | self.dec5 = nn.Sequential(
56 | *([nn.ConvTranspose2d(512, 512, kernel_size=2, stride=2)] +
57 | [nn.Conv2d(512, 512, kernel_size=3, padding=1),
58 | nn.BatchNorm2d(512),
59 | nn.ReLU(inplace=True)] * 4)
60 | )
61 | self.dec4 = _DecoderBlock(1024, 256, 4)
62 | self.dec3 = _DecoderBlock(512, 128, 4)
63 | self.dec2 = _DecoderBlock(256, 64, 2)
64 | self.dec1 = _DecoderBlock(128, num_classes, 2)
65 | initialize_weights(self.dec5, self.dec4, self.dec3, self.dec2, self.dec1)
66 |
67 | def forward(self, x):
68 | enc1 = self.enc1(x)
69 | enc2 = self.enc2(enc1)
70 | enc3 = self.enc3(enc2)
71 | enc4 = self.enc4(enc3)
72 | enc5 = self.enc5(enc4)
73 |
74 | dec5 = self.dec5(enc5)
75 | dec4 = self.dec4(torch.cat([enc4, dec5], 1))
76 | dec3 = self.dec3(torch.cat([enc3, dec4], 1))
77 | dec2 = self.dec2(torch.cat([enc2, dec3], 1))
78 | dec1 = self.dec1(torch.cat([enc1, dec2], 1))
79 | return dec1
80 |
--------------------------------------------------------------------------------
/pywick/models/model_locations.py:
--------------------------------------------------------------------------------
1 | cadeneroot = 'http://data.lip6.fr/cadene/pretrainedmodels/'
2 | dpnroot = 'https://s3.amazonaws.com/dpn-pytorch-weights/'
3 | drnroot = 'https://tigress-web.princeton.edu/~fy/drn/models/'
4 | torchroot = 'https://download.pytorch.org/models/'
5 |
6 |
7 | model_urls = {
8 | 'alexnet': torchroot + 'alexnet-owt-4df8aa71.pth',
9 | 'bninception': cadeneroot + 'bn_inception-52deb4733.pth',
10 | 'densenet121': cadeneroot + 'densenet121-fbdb23505.pth',
11 | 'densenet169': cadeneroot + 'densenet169-f470b90a4.pth',
12 | 'densenet201': cadeneroot + 'densenet201-5750cbb1e.pth',
13 | 'densenet161': cadeneroot + 'densenet161-347e6b360.pth',
14 | 'dpn68': dpnroot + 'dpn68-4af7d88d2.pth',
15 | 'dpn68b-extra': dpnroot + 'dpn68b_extra-363ab9c19.pth',
16 | 'dpn92-extra': dpnroot + 'dpn92_extra-fda993c95.pth',
17 | 'dpn98': dpnroot + 'dpn98-722954780.pth',
18 | 'dpn107-extra': dpnroot + 'dpn107_extra-b7f9f4cc9.pth',
19 | 'dpn131': dpnroot + 'dpn131-7af84be88.pth',
20 | 'drn-c-26': drnroot + 'drn_c_26-ddedf421.pth',
21 | 'drn-c-42': drnroot + 'drn_c_42-9d336e8c.pth',
22 | 'drn-c-58': drnroot + 'drn_c_58-0a53a92c.pth',
23 | 'drn-d-22': drnroot + 'drn_d_22-4bd2f8ea.pth',
24 | 'drn-d-38': drnroot + 'drn_d_38-eebb45f0.pth',
25 | 'drn-d-54': drnroot + 'drn_d_54-0e0534ff.pth',
26 | 'drn-d-105': drnroot + 'drn_d_105-12b40979.pth',
27 | 'fbresnet152': cadeneroot + 'fbresnet152-2e20f6b4.pth',
28 | 'inception_v3': torchroot + 'inception_v3_google-1a9a5a14.pth',
29 | 'inceptionv4': cadeneroot + 'inceptionv4-8e4777a0.pth',
30 | 'inceptionresnetv2': cadeneroot + 'inceptionresnetv2-520b38e4.pth',
31 | 'nasnetalarge': cadeneroot + 'nasnetalarge-a1897284.pth',
32 | 'nasnetamobile': cadeneroot + 'nasnetamobile-7e03cead.pth',
33 | 'pnasnet5large': cadeneroot + 'pnasnet5large-bf079911.pth',
34 | 'resnet18': torchroot + 'resnet18-5c106cde.pth',
35 | 'resnet34': torchroot + 'resnet34-333f7ec4.pth',
36 | 'resnet50': torchroot + 'resnet50-19c8e357.pth',
37 | 'resnet101': torchroot + 'resnet101-5d3b4d8f.pth',
38 | 'resnet152': torchroot + 'resnet152-b121ed2d.pth',
39 | 'resnext101_32x4d': cadeneroot + 'resnext101_32x4d-29e315fa.pth',
40 | 'resnext101_64x4d': cadeneroot + 'resnext101_64x4d-e77a0586.pth',
41 | 'senet_res50': 'http://ideaflux.net/files/models/senet_res50.pkl',
42 | 'se_resnet50': cadeneroot + 'se_resnet50-ce0d4300.pth',
43 | 'se_resnet101': cadeneroot + 'se_resnet101-7e38fcc6.pth',
44 | 'se_resnet152': cadeneroot + 'se_resnet152-d17c99b7.pth',
45 | 'se_resnext50_32x4d': cadeneroot + 'se_resnext50_32x4d-a260b3a4.pth',
46 | 'se_resnext101_32x4d': cadeneroot + 'se_resnext101_32x4d-3b2fe3d8.pth',
47 | 'senet154': cadeneroot + 'senet154-c7b49a05.pth',
48 | 'squeezenet1_0': torchroot + 'squeezenet1_0-a815701f.pth',
49 | 'squeezenet1_1': torchroot + 'squeezenet1_1-f364aa15.pth',
50 | 'vgg11': torchroot + 'vgg11-bbd30ac9.pth',
51 | 'vgg13': torchroot + 'vgg13-c768596a.pth',
52 | 'vgg16': torchroot + 'vgg16-397923af.pth',
53 | 'vgg19': torchroot + 'vgg19-dcbb9e9d.pth',
54 | 'wideresnet50': 'https://s3.amazonaws.com/pytorch/h5models/wide-resnet-50-2-export.hkl',
55 | 'xception': cadeneroot + 'xception-43020ad28.pth'
56 | }
--------------------------------------------------------------------------------
/pywick/optimizers/powersign.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/cydonia999/AddSign_PowerSign_in_PyTorch/tree/master/torch/optim
2 |
3 | import torch
4 | from torch.optim.optimizer import Optimizer
5 | import math
6 |
7 |
8 | class PowerSign(Optimizer):
9 | """Implements PowerSign algorithm.
10 |
11 | It has been proposed in `Neural Optimizer Search with Reinforcement Learning`_.
12 |
13 | :param params: (iterable): iterable of parameters to optimize or dicts defining
14 | parameter groups
15 | :param lr: (float, optional): learning rate (default: 1e-3)
16 | :param beta: (float, optional): coefficients used for computing
17 | running averages of gradient (default: 0.9)
18 | :param alpha: (float, optional): term powered to
19 | the internal_decay * sign(g) * sign(m) (default: math.e)
20 | :param sign_internal_decay: (callable, optional): a function that returns
21 | an internal decay calculated based on the current training step and
22 | the total number of training steps.
23 | If None, the internal decay is assumed to be 1.
24 |
25 | .. _Neural Optimizer Search with Reinforcement Learning:
26 | https://arxiv.org/abs/1709.07417
27 |
28 | """
29 |
30 | def __init__(self, params, lr=1e-3, beta=0.9, alpha=math.e, sign_internal_decay=None):
31 | if sign_internal_decay is not None and not callable(sign_internal_decay):
32 | raise TypeError('{} is not a callable'.format(
33 | type(sign_internal_decay).__name__))
34 | if alpha <= 0:
35 | raise ValueError("alpha should be > 0.")
36 | defaults = dict(lr=lr, beta=beta, alpha=alpha,
37 | sign_internal_decay=sign_internal_decay if sign_internal_decay is not None else lambda _: 1)
38 | super(PowerSign, self).__init__(params, defaults)
39 |
40 | def step(self, closure=None):
41 | """Performs a single optimization step.
42 |
43 | :param closure: (callable, optional): A closure that reevaluates the model
44 | and returns the loss.
45 | """
46 | loss = None
47 | if closure is not None:
48 | loss = closure()
49 |
50 | for group in self.param_groups:
51 | for p in group['params']:
52 | if p.grad is None:
53 | continue
54 | grad = p.grad.data
55 |
56 |
57 | state = self.state[p]
58 |
59 | # State initialization
60 | if len(state) == 0:
61 | state['step'] = 0
62 | # Exponential moving average of gradient values
63 | state['exp_avg'] = torch.zeros_like(p.data)
64 |
65 | exp_avg = state['exp_avg']
66 | beta = group['beta']
67 | alpha = group['alpha']
68 |
69 | state['step'] += 1
70 | internal_decay = group['sign_internal_decay'](state['step'] - 1)
71 |
72 | # Decay the first moment running average coefficient
73 | exp_avg.mul_(beta).add_(1 - beta, grad)
74 |
75 | power_sign = grad.mul(torch.pow(alpha, internal_decay * grad.sign() * exp_avg.sign()))
76 | p.data.add_(-group['lr'], power_sign)
77 |
78 | return loss
79 |
--------------------------------------------------------------------------------
/tests/integration/fit_simple/simple_multi_input_multi_target.py:
--------------------------------------------------------------------------------
1 |
2 | import torch as th
3 | import torch.nn as nn
4 | import torch.nn.functional as F
5 |
6 | from pywick.modules import ModuleTrainer
7 |
8 | import os
9 | from torchvision import datasets
10 | ROOT = '/data/mnist'
11 | dataset = datasets.MNIST(ROOT, train=True, download=True)
12 | x_train, y_train = th.load(os.path.join(dataset.root, 'processed/training.pt'))
13 | x_test, y_test = th.load(os.path.join(dataset.root, 'processed/test.pt'))
14 |
15 | x_train = x_train.float()
16 | y_train = y_train.long()
17 | x_test = x_test.float()
18 | y_test = y_test.long()
19 |
20 | x_train = x_train / 255.
21 | x_test = x_test / 255.
22 | x_train = x_train.unsqueeze(1)
23 | x_test = x_test.unsqueeze(1)
24 |
25 | # only train on a subset
26 | x_train = x_train[:1000]
27 | y_train = y_train[:1000]
28 | x_test = x_test[:100]
29 | y_test = y_test[:100]
30 |
31 |
32 | # Define your model EXACTLY as if you were using nn.Module
33 | class Network(nn.Module):
34 | def __init__(self):
35 | super(Network, self).__init__()
36 | self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
37 | self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
38 | self.fc1 = nn.Linear(1600, 128)
39 | self.fc2 = nn.Linear(128, 10)
40 |
41 | def forward(self, x, y, z):
42 | x = F.relu(F.max_pool2d(self.conv1(x), 2))
43 | x = F.relu(F.max_pool2d(self.conv2(x), 2))
44 | x = x.view(-1, 1600)
45 | x = F.relu(self.fc1(x))
46 | x = F.dropout(x, training=self.training)
47 | x = self.fc2(x)
48 | return F.log_softmax(x), F.log_softmax(x), F.log_softmax(x)
49 |
50 | # with one loss function given
51 | model = Network()
52 | trainer = ModuleTrainer(model)
53 |
54 | trainer.compile(criterion='nll_loss',
55 | optimizer='adadelta')
56 |
57 | trainer.fit([x_train, x_train, x_train],
58 | [y_train, y_train, y_train],
59 | num_epoch=3,
60 | batch_size=128,
61 | verbose=1)
62 |
63 | yp1, yp2, yp3 = trainer.predict([x_train, x_train, x_train])
64 | print(yp1.size(), yp2.size(), yp3.size())
65 |
66 | eval_loss = trainer.evaluate([x_train, x_train, x_train],
67 | [y_train, y_train, y_train])
68 | print(eval_loss)
69 |
70 | # With multiple loss functions given
71 | model = Network()
72 | trainer = ModuleTrainer(model)
73 |
74 | trainer.compile(criterion=['nll_loss', 'nll_loss', 'nll_loss'],
75 | optimizer='adadelta')
76 |
77 | trainer.fit([x_train, x_train, x_train],
78 | [y_train, y_train, y_train],
79 | num_epoch=3,
80 | batch_size=128,
81 | verbose=1)
82 |
83 | # should raise exception for giving multiple loss functions
84 | # but not giving a loss function for every input
85 | try:
86 | model = Network()
87 | trainer = ModuleTrainer(model)
88 |
89 | trainer.compile(criterion=['nll_loss', 'nll_loss'],
90 | optimizer='adadelta')
91 |
92 | trainer.fit([x_train, x_train, x_train],
93 | [y_train, y_train, y_train],
94 | num_epoch=3,
95 | batch_size=128,
96 | verbose=1)
97 | except:
98 | print('Exception correctly caught')
99 |
100 |
--------------------------------------------------------------------------------
/pywick/optimizers/lookahead.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/alphadl/lookahead.pytorch/blob/master/lookahead.py (MIT)
2 |
3 | from collections import defaultdict
4 | from torch.optim.optimizer import Optimizer
5 | import torch
6 |
7 |
8 | class Lookahead(Optimizer):
9 | r"""
10 | Implementation of `Lookahead Optimizer: k steps forward, 1 step back `_
11 |
12 | Args:
13 | :param optimizer: - the optimizer to work with (sgd, adam etc)
14 | :param k: (int) - number of steps to look ahead (default=5)
15 | :param alpha: (float) - slow weights step size
16 | """
17 |
18 | def __init__(self, optimizer, k=5, alpha=0.5):
19 | """
20 | :param optimizer: - the optimizer to work with (sgd, adam etc)
21 | :param k: (int) - number of steps to look ahead (default=5)
22 | :param alpha: (float) - slow weights step size
23 | """
24 | self.optimizer = optimizer
25 | self.k = k
26 | self.alpha = alpha
27 | self.param_groups = self.optimizer.param_groups
28 | self.state = defaultdict(dict)
29 | self.fast_state = self.optimizer.state
30 | for group in self.param_groups:
31 | group["counter"] = 0
32 |
33 | def update(self, group):
34 | for fast in group["params"]:
35 | param_state = self.state[fast]
36 | if "slow_param" not in param_state:
37 | param_state["slow_param"] = torch.zeros_like(fast.data)
38 | param_state["slow_param"].copy_(fast.data)
39 | slow = param_state["slow_param"]
40 | slow += (fast.data - slow) * self.alpha
41 | fast.data.copy_(slow)
42 |
43 | def update_lookahead(self):
44 | for group in self.param_groups:
45 | self.update(group)
46 |
47 | def step(self, closure=None):
48 | loss = self.optimizer.step(closure)
49 | for group in self.param_groups:
50 | if group["counter"] == 0:
51 | self.update(group)
52 | group["counter"] += 1
53 | if group["counter"] >= self.k:
54 | group["counter"] = 0
55 | return loss
56 |
57 | def state_dict(self):
58 | fast_state_dict = self.optimizer.state_dict()
59 | slow_state = {
60 | (id(k) if isinstance(k, torch.Tensor) else k): v
61 | for k, v in self.state.items()
62 | }
63 | fast_state = fast_state_dict["state"]
64 | param_groups = fast_state_dict["param_groups"]
65 | return {
66 | "fast_state": fast_state,
67 | "slow_state": slow_state,
68 | "param_groups": param_groups,
69 | }
70 |
71 | def load_state_dict(self, state_dict):
72 | slow_state_dict = {
73 | "state": state_dict["slow_state"],
74 | "param_groups": state_dict["param_groups"],
75 | }
76 | fast_state_dict = {
77 | "state": state_dict["fast_state"],
78 | "param_groups": state_dict["param_groups"],
79 | }
80 | super(Lookahead, self).load_state_dict(slow_state_dict)
81 | self.optimizer.load_state_dict(fast_state_dict)
82 | self.fast_state = self.optimizer.state
83 |
84 | def add_param_group(self, param_group):
85 | param_group["counter"] = 0
86 | self.optimizer.add_param_group(param_group)
87 |
--------------------------------------------------------------------------------
/pywick/models/segmentation/lexpsp.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/Lextal/pspnet-pytorch
2 |
3 | """
4 | Implementation of `Pyramid Scene Parsing Network `_
5 | """
6 |
7 | from .lex_extractors import *
8 |
9 | __all__ = ['PSPNet']
10 |
11 | extractor_models = {
12 | 'resnet18': resnet18,
13 | 'resnet34': resnet34,
14 | 'resnet50': resnet50,
15 | 'resnet101': resnet101,
16 | 'resnet152': resnet152,
17 | 'densenet121': densenet
18 | }
19 |
20 | class PSPModule(nn.Module):
21 | def __init__(self, features, out_features=1024, sizes=(1, 2, 3, 6)):
22 | super().__init__()
23 | self.stages = []
24 | self.stages = nn.ModuleList([self._make_stage(features, size) for size in sizes])
25 | self.bottleneck = nn.Conv2d(features * (len(sizes) + 1), out_features, kernel_size=1)
26 | self.relu = nn.ReLU()
27 |
28 | @staticmethod
29 | def _make_stage(features, size):
30 | prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
31 | conv = nn.Conv2d(features, features, kernel_size=1, bias=False)
32 | return nn.Sequential(prior, conv)
33 |
34 | def forward(self, feats):
35 | h, w = feats.size(2), feats.size(3)
36 | priors = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear') for stage in self.stages] + [feats]
37 | bottle = self.bottleneck(torch.cat(priors, 1))
38 | return self.relu(bottle)
39 |
40 |
41 | class PSPUpsample(nn.Module):
42 | def __init__(self, in_channels, out_channels):
43 | super().__init__()
44 | self.conv = nn.Sequential(
45 | nn.Conv2d(in_channels, out_channels, 3, padding=1),
46 | nn.BatchNorm2d(out_channels),
47 | nn.PReLU()
48 | )
49 |
50 | def forward(self, x):
51 | h, w = 2 * x.size(2), 2 * x.size(3)
52 | p = F.upsample(input=x, size=(h, w), mode='bilinear')
53 | return self.conv(p)
54 |
55 |
56 | class PSPNet(nn.Module):
57 | def __init__(self, num_classes=18, pretrained=True, backend='densenet121', sizes=(1, 2, 3, 6), psp_size=2048, deep_features_size=1024, **kwargs):
58 | super().__init__()
59 | self.feats = extractor_models[backend](pretrained=pretrained)
60 | self.psp = PSPModule(psp_size, 1024, sizes)
61 | self.drop_1 = nn.Dropout2d(p=0.3)
62 |
63 | self.up_1 = PSPUpsample(1024, 256)
64 | self.up_2 = PSPUpsample(256, 64)
65 | self.up_3 = PSPUpsample(64, 64)
66 |
67 | self.drop_2 = nn.Dropout2d(p=0.15)
68 | self.final = nn.Conv2d(64, num_classes, kernel_size=1)
69 | # self.final = nn.Sequential(
70 | # nn.Conv2d(64, num_classes, kernel_size=1),
71 | # nn.LogSoftmax()
72 | # )
73 |
74 | self.classifier = nn.Sequential(
75 | nn.Linear(deep_features_size, 256),
76 | nn.ReLU(),
77 | nn.Linear(256, num_classes)
78 | )
79 |
80 | def forward(self, x):
81 | f, class_f = self.feats(x)
82 | p = self.psp(f)
83 | p = self.drop_1(p)
84 |
85 | p = self.up_1(p)
86 | p = self.drop_2(p)
87 |
88 | p = self.up_2(p)
89 | p = self.drop_2(p)
90 |
91 | p = self.up_3(p)
92 | p = self.drop_2(p)
93 |
94 | # auxiliary = F.adaptive_max_pool2d(input=class_f, output_size=(1, 1)).view(-1, class_f.size(1))
95 |
96 | return self.final(p) #, self.classifier(auxiliary)
97 |
--------------------------------------------------------------------------------
/pywick/cust_random.py:
--------------------------------------------------------------------------------
1 | # Source: https://github.com/PetrochukM/PyTorch-NLP/blob/master/torchnlp/random.py (BSD 3)
2 |
3 | from collections import namedtuple
4 | from contextlib import contextmanager
5 |
6 | import functools
7 | import random
8 |
9 | import numpy as np
10 | import torch
11 |
12 | RandomGeneratorState = namedtuple('RandomGeneratorState', ['random', 'torch', 'numpy', 'torch_cuda'])
13 |
14 |
15 | def get_random_generator_state(cuda=torch.cuda.is_available()):
16 | """ Get the `torch`, `numpy` and `random` random generator state.
17 |
18 | Args:
19 | cuda (bool, optional): If `True` saves the `cuda` seed also. Note that getting and setting
20 | the random generator state for CUDA can be quite slow if you have a lot of GPUs.
21 |
22 | Returns:
23 | RandomGeneratorState
24 | """
25 | return RandomGeneratorState(random.getstate(), torch.random.get_rng_state(), np.random.get_state(), torch.cuda.get_rng_state_all() if cuda else None)
26 |
27 |
28 | def set_random_generator_state(state):
29 | """ Set the `torch`, `numpy` and `random` random generator state.
30 |
31 | Args:
32 | state (RandomGeneratorState)
33 | """
34 | random.setstate(state.random)
35 | torch.random.set_rng_state(state.torch)
36 | np.random.set_state(state.numpy)
37 | if state.torch_cuda is not None and torch.cuda.is_available() and len(state.torch_cuda) == torch.cuda.device_count(): # pragma: no cover
38 | torch.cuda.set_rng_state_all(state.torch_cuda)
39 |
40 |
41 | @contextmanager
42 | def fork_rng(seed=None, cuda=torch.cuda.is_available()):
43 | """ Forks the `torch`, `numpy` and `random` random generators, so that when you return, the
44 | random generators are reset to the state that they were previously in.
45 |
46 | Example:
47 | with fork_rng(seed=123): # Ensure determinism
48 | print('Random:', random.randint(1, 2**31))
49 | print('Numpy:', numpy.random.randint(1, 2**31))
50 | print('Torch:', int(torch.randint(1, 2**31, (1,))))
51 |
52 | Args:
53 | seed (int or None, optional): If defined this sets the seed values for the random
54 | generator fork. This is a convenience parameter.
55 | cuda (bool, optional): If `True` saves the `cuda` seed also. Getting and setting the random
56 | generator state can be quite slow if you have a lot of GPUs.
57 | """
58 | state = get_random_generator_state(cuda)
59 | if seed is not None:
60 | set_seed(seed, cuda)
61 | try:
62 | yield
63 | finally:
64 | set_random_generator_state(state)
65 |
66 |
67 | def fork_rng_wrap(function=None, **kwargs):
68 | """ Decorator alias for `fork_rng`.
69 | """
70 | if not function:
71 | return functools.partial(fork_rng_wrap, **kwargs)
72 |
73 | @functools.wraps(function)
74 | def wrapper():
75 | with fork_rng(**kwargs):
76 | return function()
77 |
78 | return wrapper
79 |
80 |
81 | def set_seed(seed, cuda=torch.cuda.is_available()):
82 | """ Set seed values for random generators.
83 |
84 | Args:
85 | seed (int): Value used as a seed.
86 | cuda (bool, optional): If `True` sets the `cuda` seed also.
87 | """
88 | random.seed(seed)
89 | torch.manual_seed(seed)
90 | np.random.seed(seed)
91 | if cuda: # pragma: no cover
92 | torch.cuda.manual_seed(seed)
93 | torch.cuda.manual_seed_all(seed)
94 |
--------------------------------------------------------------------------------