├── utils
├── bremm.png
├── saveload.py
├── basic.py
├── data.py
├── samp.py
├── loss.py
├── misc.py
└── py.py
├── .gitignore
├── demo_video
└── download_video.sh
├── download_reference_model.sh
├── requirements.txt
├── LICENSE
├── datasets
├── davisdataset.py
├── rgbstackingdataset.py
├── kineticsdataset.py
├── robotapdataset.py
├── egopointsdataset.py
├── crohddataset.py
├── badjadataset.py
├── horsedataset.py
├── drivetrackdataset.py
├── kubric_movif_dataset.py
├── exportdataset.py
├── pointdataset.py
└── dynrep_dataset.py
├── README.md
├── demo.py
├── test_dense_on_sparse.py
└── train_stage1.py
/utils/bremm.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aharley/alltracker/HEAD/utils/bremm.png
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *~
2 | *#*
3 | *pyc
4 | #.*
5 | .DS_Store
6 | *.out
7 | *.gif
8 | stock_videos/
9 | logs*
10 | *.mp4
11 | temp_*
12 |
--------------------------------------------------------------------------------
/demo_video/download_video.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | FILE="monkey.mp4"
3 | echo "downloading ${FILE} from dropbox"
4 | wget --max-redirect=20 -O ${FILE} https://www.dropbox.com/scl/fi/fm2m3ylhzmqae05bzwm8q/monkey.mp4?rlkey=ibf81gaqpxkh334rccu7zrioe&st=mli9bqb6&dl=1
5 |
--------------------------------------------------------------------------------
/download_reference_model.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | FILE="alltracker_reference.tar.gz"
3 | echo "downloading ${FILE} from dropbox"
4 | wget --max-redirect=20 -O ${FILE} https://www.dropbox.com/scl/fi/ng66ceortfy07bgie3r54/alltracker_reference.tar.gz?rlkey=o781im2v0sl7035hy8fcuv1d5&st=u5mcttcx&dl=1
5 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | torchaudio
3 | torchvision
4 | pytorch_lightning==2.4.0
5 | opencv-python==4.10.0.84
6 | einops==0.8.0
7 | moviepy==1.0.3
8 | h5py==3.12.1
9 | matplotlib==3.9.2
10 | scikit-learn==1.5.2
11 | scikit-image==0.24.0
12 | tensorboardX==2.6.2.2
13 | prettytable==3.12.0
14 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2025 Adam W. Harley
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/datasets/davisdataset.py:
--------------------------------------------------------------------------------
1 | from numpy import random
2 | import torch
3 | import numpy as np
4 | import pickle
5 | from datasets.pointdataset import PointDataset
6 | import utils.data
7 | import cv2
8 |
9 | class DavisDataset(PointDataset):
10 | def __init__(
11 | self,
12 | data_root='../datasets/tapvid_davis',
13 | crop_size=(384,512),
14 | seq_len=None,
15 | only_first=False,
16 | ):
17 | super(DavisDataset, self).__init__(
18 | data_root=data_root,
19 | crop_size=crop_size,
20 | seq_len=seq_len,
21 | )
22 |
23 | print('loading TAPVID-DAVIS dataset...')
24 |
25 | self.dname = 'davis'
26 | self.only_first = only_first
27 |
28 | input_path = '%s/tapvid_davis.pkl' % data_root
29 | with open(input_path, 'rb') as f:
30 | data = pickle.load(f)
31 | if isinstance(data, dict):
32 | data = list(data.values())
33 | self.data = data
34 | print('found %d videos in %s' % (len(self.data), data_root))
35 |
36 | def __getitem__(self, index):
37 | dat = self.data[index]
38 | rgbs = dat['video'] # list of H,W,C uint8 images
39 | trajs = dat['points'] # N,S,2 array
40 | visibs = 1-dat['occluded'] # N,S array
41 | # note the annotations are only valid when not occluded
42 |
43 | trajs = trajs.transpose(1,0,2) # S,N,2
44 | visibs = visibs.transpose(1,0) # S,N
45 | valids = visibs.copy()
46 |
47 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
48 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
49 |
50 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
51 | # in this data, 1.0,1.0 should lie at the bottom-right corner pixel
52 | H, W = rgbs[0].shape[:2]
53 | trajs[:,:,0] *= W
54 | trajs[:,:,1] *= H
55 |
56 | rgbs = torch.from_numpy(np.stack(rgbs,0)).permute(0,3,1,2).contiguous().float() # S,C,H,W
57 | trajs = torch.from_numpy(trajs).float() # S,N,2
58 | valids = torch.from_numpy(valids).float() # S,N
59 | visibs = torch.from_numpy(visibs).float() # S,N
60 |
61 | sample = utils.data.VideoData(
62 | video=rgbs,
63 | trajs=trajs,
64 | visibs=visibs,
65 | valids=valids,
66 | dname=self.dname,
67 | )
68 | return sample, True
69 |
70 | def __len__(self):
71 | return len(self.data)
72 |
73 |
74 |
--------------------------------------------------------------------------------
/datasets/rgbstackingdataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import pickle
4 | from datasets.pointdataset import PointDataset
5 | import utils.data
6 | import cv2
7 |
8 | class RGBStackingDataset(PointDataset):
9 | def __init__(
10 | self,
11 | data_root='../datasets/tapvid_rgbstacking',
12 | crop_size=(384,512),
13 | seq_len=None,
14 | only_first=False,
15 | ):
16 | super(RGBStackingDataset, self).__init__(
17 | data_root=data_root,
18 | crop_size=crop_size,
19 | seq_len=seq_len,
20 | )
21 |
22 | print('loading TAPVID-RGB-Stacking dataset...')
23 |
24 | self.dname = 'rgbstacking'
25 | self.only_first = only_first
26 |
27 | input_path = '%s/tapvid_rgb_stacking.pkl' % data_root
28 | with open(input_path, 'rb') as f:
29 | data = pickle.load(f)
30 | if isinstance(data, dict):
31 | data = list(data.values())
32 | self.data = data
33 | print('found %d videos in %s' % (len(self.data), data_root))
34 |
35 | def __getitem__(self, index):
36 | dat = self.data[index]
37 | rgbs = dat['video'] # list of H,W,C uint8 images
38 | trajs = dat['points'] # N,S,2 array
39 | visibs = 1-dat['occluded'] # N,S array
40 | # note the annotations are only valid when visib
41 | valids = visibs.copy()
42 |
43 | trajs = trajs.transpose(1,0,2) # S,N,2
44 | visibs = visibs.transpose(1,0) # S,N
45 | valids = valids.transpose(1,0) # S,N
46 |
47 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
48 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
49 |
50 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
51 | # 1.0,1.0 should lie at the bottom-right corner pixel
52 | H, W = rgbs[0].shape[:2]
53 | trajs[:,:,0] *= W-1
54 | trajs[:,:,1] *= H-1
55 |
56 | rgbs = torch.from_numpy(np.stack(rgbs,0)).permute(0,3,1,2).contiguous().float() # S,C,H,W
57 | trajs = torch.from_numpy(trajs).float() # S,N,2
58 | visibs = torch.from_numpy(visibs).float() # S,N
59 | valids = torch.from_numpy(valids).float() # S,N
60 |
61 | sample = utils.data.VideoData(
62 | video=rgbs,
63 | trajs=trajs,
64 | visibs=visibs,
65 | valids=valids,
66 | dname=self.dname,
67 | )
68 | return sample, True
69 |
70 | def __len__(self):
71 | return len(self.data)
72 |
73 |
74 |
--------------------------------------------------------------------------------
/datasets/kineticsdataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import pickle
4 | from datasets.pointdataset import PointDataset
5 | import utils.data
6 | import cv2
7 | from pathlib import Path
8 | import io
9 | from PIL import Image
10 |
11 | def decode(frame):
12 | byteio = io.BytesIO(frame)
13 | img = Image.open(byteio)
14 | return np.array(img)
15 |
16 | class KineticsDataset(PointDataset):
17 | def __init__(
18 | self,
19 | data_root='../datasets/tapvid_kinetics',
20 | crop_size=(384,512),
21 | seq_len=None,
22 | only_first=False,
23 | ):
24 | super(KineticsDataset, self).__init__(
25 | data_root=data_root,
26 | crop_size=crop_size,
27 | seq_len=seq_len,
28 | )
29 |
30 | print('loading TAPVID-Kinetics dataset...')
31 |
32 | self.dname = 'kinetics'
33 | self.only_first = only_first
34 |
35 | self.data = []
36 | for vid_pkl in sorted(list(Path(data_root).glob('*.pkl')))[:]:
37 | vid_pkl = vid_pkl.name
38 | print(vid_pkl)
39 | input_path = "%s/%s" % (data_root, vid_pkl)
40 | with open(input_path, "rb") as f:
41 | data = pickle.load(f)
42 | self.data += data
43 | print("found %d videos in %s" % (len(self.data), data_root))
44 |
45 | def __getitem__(self, index):
46 | dat = self.data[index]
47 | rgbs = dat['video'] # list of H,W,C uint8 images
48 | if isinstance(rgbs[0], bytes): # decode if needed
49 | rgbs = [decode(frame) for frame in rgbs]
50 | trajs = dat['points'] # N,S,2 array
51 | visibs = 1-dat['occluded'] # N,S array
52 | # note the annotations are only valid when visib
53 |
54 | trajs = trajs.transpose(1,0,2) # S,N,2
55 | visibs = visibs.transpose(1,0) # S,N
56 | valids = visibs.copy()
57 |
58 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
59 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
60 |
61 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
62 | H, W = rgbs[0].shape[:2]
63 | trajs[:,:,0] *= W-1
64 | trajs[:,:,1] *= H-1
65 |
66 | rgbs = torch.from_numpy(np.stack(rgbs,0)).permute(0,3,1,2).contiguous().float() # S,C,H,W
67 | trajs = torch.from_numpy(trajs).float() # S,N,2
68 | visibs = torch.from_numpy(visibs).float() # S,N
69 | valids = torch.from_numpy(valids).float() # S,N
70 |
71 | sample = utils.data.VideoData(
72 | video=rgbs,
73 | trajs=trajs,
74 | visibs=visibs,
75 | valids=valids,
76 | dname=self.dname,
77 | )
78 | return sample, True
79 |
80 | def __len__(self):
81 | return len(self.data)
82 |
83 |
84 |
--------------------------------------------------------------------------------
/datasets/robotapdataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import pickle
4 | from datasets.pointdataset import PointDataset
5 | import utils.data
6 | import cv2
7 |
8 | class RobotapDataset(PointDataset):
9 | def __init__(
10 | self,
11 | data_root='../datasets/robotap',
12 | crop_size=(384,512),
13 | seq_len=None,
14 | only_first=False,
15 | ):
16 | super(RobotapDataset, self).__init__(
17 | data_root=data_root,
18 | crop_size=crop_size,
19 | seq_len=seq_len,
20 | )
21 |
22 | self.dname = 'robo'
23 | self.only_first = only_first
24 |
25 | # self.train_pkls = ['robotap_split0.pkl', 'robotap_split1.pkl', 'robotap_split2.pkl']
26 | self.val_pkls = ['robotap_split3.pkl', 'robotap_split4.pkl']
27 |
28 | print("loading robotap dataset...")
29 | # self.vid_pkls = self.train_pkls if is_training else self.val_pkls
30 | self.data = []
31 | for vid_pkl in self.val_pkls:
32 | print(vid_pkl)
33 | input_path = "%s/%s" % (data_root, vid_pkl)
34 | with open(input_path, "rb") as f:
35 | data = pickle.load(f)
36 | keys = list(data.keys())
37 | self.data += [data[key] for key in keys]
38 | print("found %d videos in %s" % (len(self.data), data_root))
39 |
40 | def __len__(self):
41 | return len(self.data)
42 |
43 | def getitem_helper(self, index):
44 | dat = self.data[index]
45 | rgbs = dat["video"] # list of H,W,C uint8 images
46 | trajs = dat["points"] # N,S,2 array
47 | visibs = 1 - dat["occluded"] # N,S array
48 |
49 | # note the annotations are only valid when not occluded
50 | trajs = trajs.transpose(1,0,2) # S,N,2
51 | visibs = visibs.transpose(1,0) # S,N
52 | valids = visibs.copy()
53 |
54 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
55 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
56 |
57 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
58 | # 1.0,1.0 should lie at the bottom-right corner pixel
59 | H, W = rgbs[0].shape[:2]
60 | trajs[:,:,0] *= W-1
61 | trajs[:,:,1] *= H-1
62 |
63 | rgbs = torch.from_numpy(np.stack(rgbs,0)).permute(0,3,1,2).contiguous().float() # S,C,H,W
64 | trajs = torch.from_numpy(trajs).float() # S,N,2
65 | visibs = torch.from_numpy(visibs).float() # S,N
66 | valids = torch.from_numpy(valids).float() # S,N
67 |
68 | if self.seq_len is not None:
69 | rgbs = rgbs[:self.seq_len]
70 | trajs = trajs[:self.seq_len]
71 | valids = valids[:self.seq_len]
72 | visibs = visibs[:self.seq_len]
73 |
74 | sample = utils.data.VideoData(
75 | video=rgbs,
76 | trajs=trajs,
77 | visibs=visibs,
78 | valids=valids,
79 | dname=self.dname,
80 | )
81 | return sample, True
82 |
--------------------------------------------------------------------------------
/utils/saveload.py:
--------------------------------------------------------------------------------
1 | import pathlib
2 | import os
3 | import torch
4 |
5 | def save(ckpt_dir, module, optimizer, scheduler, global_step, keep_latest=2, model_name='model'):
6 | pathlib.Path(ckpt_dir).mkdir(exist_ok=True, parents=True)
7 | prev_ckpts = list(pathlib.Path(ckpt_dir).glob('%s-*pth' % model_name))
8 | prev_ckpts.sort(key=lambda p: p.stat().st_mtime,reverse=True)
9 | if len(prev_ckpts) > keep_latest-1:
10 | for f in prev_ckpts[keep_latest-1:]:
11 | f.unlink()
12 | save_path = '%s/%s-%09d.pth' % (ckpt_dir, model_name, global_step)
13 | save_dict = {
14 | "model": module.state_dict(),
15 | "optimizer": optimizer.state_dict(),
16 | "global_step": global_step,
17 | }
18 | if scheduler is not None:
19 | save_dict['scheduler'] = scheduler.state_dict()
20 | print(f"saving {save_path}")
21 | torch.save(save_dict, save_path)
22 | return False
23 |
24 | def load(fabric, ckpt_path, model, optimizer=None, scheduler=None, model_ema=None, step=0, model_name='model', ignore_load=None, strict=True, verbose=True, weights_only=False):
25 | if verbose:
26 | print('reading ckpt from %s' % ckpt_path)
27 | if not os.path.exists(ckpt_path):
28 | print('...there is no full checkpoint in %s' % ckpt_path)
29 | print('-- note this function no longer appends "saved_checkpoints/" before the ckpt_path --')
30 | assert(False)
31 | else:
32 | if os.path.isfile(ckpt_path):
33 | path = ckpt_path
34 | print('...found checkpoint %s' % (path))
35 | else:
36 | prev_ckpts = list(pathlib.Path(ckpt_path).glob('%s-*pth' % model_name))
37 | prev_ckpts.sort(key=lambda p: p.stat().st_mtime,reverse=True)
38 | if len(prev_ckpts):
39 | path = prev_ckpts[0]
40 | # e.g., './checkpoints/2Ai4_5e-4_base18_1539/model-000050000.pth'
41 | # OR ./whatever.pth
42 | step = int(str(path).split('-')[-1].split('.')[0])
43 | if verbose:
44 | print('...found checkpoint %s; (parsed step %d from path)' % (path, step))
45 | else:
46 | print('...there is no full checkpoint here!')
47 | return 0
48 | if fabric is not None:
49 | checkpoint = fabric.load(path)
50 | else:
51 | checkpoint = torch.load(path, weights_only=weights_only)
52 | if optimizer is not None:
53 | optimizer.load_state_dict(checkpoint['optimizer'])
54 | if scheduler is not None:
55 | scheduler.load_state_dict(checkpoint['scheduler'])
56 | assert ignore_load is None # not ready yet
57 | if 'model' in checkpoint:
58 | state_dict = checkpoint['model']
59 | else:
60 | state_dict = checkpoint
61 | model.load_state_dict(state_dict, strict=strict)
62 | return step
63 |
64 |
65 |
66 |
--------------------------------------------------------------------------------
/datasets/egopointsdataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | from datasets.pointdataset import PointDataset
4 | import utils.data
5 | import cv2
6 | from pathlib import Path
7 |
8 | class EgoPointsDataset(PointDataset):
9 | def __init__(
10 | self,
11 | data_root='../datasets/ego_points',
12 | crop_size=(384,512),
13 | seq_len=None,
14 | only_first=False,
15 | ):
16 | super(EgoPointsDataset, self).__init__(
17 | data_root=data_root,
18 | crop_size=crop_size,
19 | seq_len=seq_len,
20 | )
21 |
22 | print('loading egopoints dataset...')
23 |
24 | self.dname = 'egopoints'
25 | self.only_first = only_first
26 |
27 | self.data = []
28 | for subfolder in Path(data_root).iterdir():
29 | if subfolder.is_dir():
30 | annot_fn = subfolder / 'annot.npz'
31 | if not annot_fn.exists():
32 | continue
33 | data = np.load(annot_fn)
34 | trajs_2d, valids, visibs, vis_valids = data['trajs_2d'], data['valids'], data['visibs'], data['vis_valids']
35 |
36 | self.data.append({
37 | 'rgb_paths': sorted(subfolder.glob('rgbs/*.jpg')),
38 | 'trajs_2d': trajs_2d,
39 | 'valids': valids,
40 | 'visibs': visibs,
41 | 'vis_valids': vis_valids,
42 | })
43 |
44 | print('found %d videos in %s' % (len(self.data), data_root))
45 |
46 | def __getitem__(self, index):
47 | dat = self.data[index]
48 | rgb_paths = dat['rgb_paths']
49 | trajs = dat['trajs_2d'] # S,N,2
50 | valids = dat['valids'] # S,N
51 | visibs = valids.copy() # we don't use this
52 |
53 | rgbs = [cv2.imread(str(rgb_path))[..., ::-1] for rgb_path in rgb_paths]
54 |
55 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
56 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
57 |
58 | # resize
59 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
60 | rgb0_raw = cv2.imread(str(rgb_paths[0]))[..., ::-1]
61 | trajs = trajs / (np.array([rgb0_raw.shape[1], rgb0_raw.shape[0]]) - 1)
62 | trajs = np.maximum(np.minimum(trajs, 1.), 0.)
63 | # 1.0,1.0 should map to the bottom-right corner pixel
64 | H, W = rgbs[0].shape[:2]
65 | trajs[:,:,0] *= W-1
66 | trajs[:,:,1] *= H-1
67 |
68 | rgbs = torch.from_numpy(np.stack(rgbs,0)).permute(0,3,1,2).contiguous().float() # S,C,H,W
69 | trajs = torch.from_numpy(trajs).float() # S,N,2
70 | valids = torch.from_numpy(valids).float() # S,N
71 | visibs = torch.from_numpy(visibs).float()
72 |
73 | if self.seq_len is not None:
74 | rgbs = rgbs[:self.seq_len]
75 | trajs = trajs[:self.seq_len]
76 | valids = valids[:self.seq_len]
77 | visibs = visibs[:self.seq_len]
78 |
79 | # req at least one timestep valid (after cutting)
80 | val_ok = torch.sum(valids, axis=0) > 0
81 | trajs = trajs[:,val_ok]
82 | valids = valids[:,val_ok]
83 | visibs = visibs[:,val_ok]
84 |
85 | sample = utils.data.VideoData(
86 | video=rgbs,
87 | trajs=trajs,
88 | valids=valids,
89 | visibs=visibs,
90 | dname=self.dname,
91 | )
92 | return sample, True
93 |
94 | def __len__(self):
95 | return len(self.data)
96 |
97 |
98 |
--------------------------------------------------------------------------------
/datasets/crohddataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import os
4 | from PIL import Image
5 | import cv2
6 | from datasets.pointdataset import PointDataset
7 | import utils.data
8 |
9 | class CrohdDataset(PointDataset):
10 | def __init__(
11 | self,
12 | data_root='../datasets/crohd',
13 | crop_size=(384, 512),
14 | seq_len=None,
15 | only_first=False,
16 | ):
17 | super(CrohdDataset, self).__init__(
18 | data_root=data_root,
19 | crop_size=crop_size,
20 | seq_len=seq_len,
21 | )
22 |
23 | self.dname = 'crohd'
24 | self.seq_len = seq_len
25 | self.only_first = only_first
26 |
27 | dataset_dir = "%s/HT21/train" % self.data_root
28 | label_location = "%s/HT21Labels/train" % self.data_root
29 | subfolders = ["HT21-01", "HT21-02", "HT21-03", "HT21-04"]
30 |
31 | print("loading data from {0}".format(dataset_dir))
32 | self.dataset_dir = dataset_dir
33 | self.subfolders = subfolders
34 | print("found %d samples" % len(self.subfolders))
35 |
36 | def getitem_helper(self, index):
37 | subfolder = self.subfolders[index]
38 |
39 | label_path = os.path.join(self.dataset_dir, subfolder, "gt/gt.txt")
40 | labels = np.loadtxt(label_path, delimiter=",")
41 |
42 | n_frames = int(labels[-1, 0])
43 | n_heads = int(labels[:, 1].max())
44 |
45 | bboxes = np.zeros((n_frames, n_heads, 4))
46 | visibs = np.zeros((n_frames, n_heads))
47 |
48 | for i in range(labels.shape[0]):
49 | (
50 | frame_id,
51 | head_id,
52 | bb_left,
53 | bb_top,
54 | bb_width,
55 | bb_height,
56 | conf,
57 | cid,
58 | vis,
59 | ) = labels[i]
60 | frame_id = int(frame_id) - 1 # convert 1-indexing to 0-indexing
61 | head_id = int(head_id) - 1 # convert 1-indexing to 0-indexing
62 |
63 | visibs[frame_id, head_id] = vis
64 | box_cur = np.array(
65 | [bb_left, bb_top, bb_left + bb_width, bb_top + bb_height]
66 | ) # convert xywh to x1, y1, x2, y2
67 | bboxes[frame_id, head_id] = box_cur
68 |
69 | prescale = 0.75 # to save memory
70 |
71 | # take the center of each head box as a coordinate
72 | trajs = np.stack([bboxes[:, :, [0, 2]].mean(2), bboxes[:, :, [1, 3]].mean(2)], axis=2) # S,N,2
73 | trajs = trajs * prescale
74 | valids = visibs.copy()
75 |
76 | S, N = valids.shape
77 |
78 | rgbs = []
79 | for ii in range(S):
80 | rgb_path = os.path.join(self.dataset_dir, subfolder, "img1", str(ii + 1).zfill(6) + ".jpg")
81 | rgb = Image.open(rgb_path) # 1920x1080
82 | rgb = rgb.resize((int(rgb.size[0] * prescale), int(rgb.size[1] * prescale)), Image.BILINEAR) # save memory by downsampling here
83 | rgbs.append(rgb)
84 | rgbs = np.stack(rgbs) # S,H,W,3
85 |
86 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
87 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
88 |
89 | H, W = rgbs[0].shape[:2]
90 | S, N = trajs.shape[:2]
91 | sx = W / self.crop_size[1]
92 | sy = H / self.crop_size[0]
93 | trajs[:,:,0] /= sx
94 | trajs[:,:,1] /= sy
95 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
96 | rgbs = np.stack(rgbs)
97 | H,W = rgbs[0].shape[:2]
98 |
99 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
100 | trajs = torch.from_numpy(trajs).float()
101 | visibs = torch.from_numpy(visibs).float()
102 | valids = torch.from_numpy(valids).float()
103 |
104 | sample = utils.data.VideoData(
105 | video=rgbs,
106 | trajs=trajs,
107 | visibs=visibs,
108 | valids=valids,
109 | dname=self.dname,
110 | )
111 | return sample, True
112 |
113 | def __len__(self):
114 | return len(self.subfolders)
115 |
116 |
117 |
--------------------------------------------------------------------------------
/datasets/badjadataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | from datasets.pointdataset import PointDataset
4 | import utils.data
5 | import cv2
6 | import glob
7 | import imageio
8 | import pandas as pd
9 |
10 | # this is badja with annotations hand-cleaned by adam in 2022
11 |
12 | class BadjaDataset(PointDataset):
13 | def __init__(
14 | self,
15 | data_root='../datasets/badja',
16 | crop_size=(384,512),
17 | seq_len=None,
18 | only_first=False,
19 | ):
20 | super(BadjaDataset, self).__init__(
21 | data_root=data_root,
22 | crop_size=crop_size,
23 | seq_len=seq_len,
24 | )
25 |
26 | self.dname = 'badja'
27 | self.seq_len = seq_len
28 | self.only_first = only_first
29 |
30 | npzs = glob.glob('%s/complete_aa/*.npz' % self.data_root)
31 | npzs = sorted(npzs)
32 | df = pd.read_csv('%s/picks_and_coords.txt' % self.data_root, sep=' ', header=None)
33 | track_names = df[0].tolist()
34 | pick_frames = np.array(df[1])
35 |
36 | self.animal_names = []
37 | self.animal_trajs = []
38 | self.animal_visibs = []
39 | self.animal_valids = []
40 | self.animal_picks = []
41 |
42 | for ind in range(len(npzs)):
43 | o = np.load(npzs[ind])
44 |
45 | animal_name = o['animal_name']
46 | trajs = o['trajs_g']
47 | valids = o['valids_g']
48 |
49 | S, N, D = trajs.shape
50 |
51 | assert(D==2)
52 |
53 | N = trajs.shape[1]
54 |
55 | # hand-picked frame where it's fair to start tracking this kp
56 | pick_g = np.zeros((N), dtype=np.int32)
57 |
58 | for n in range(N):
59 | short_name = '%s_%02d' % (animal_name, n)
60 | txt_id = track_names.index(short_name)
61 | pick_id = pick_frames[txt_id]
62 | pick_g[n] = pick_id
63 |
64 | # discard annotations before the pick
65 | valids[:pick_id,n] = 0
66 | valids[pick_id,n] = 2
67 |
68 | self.animal_names.append(animal_name)
69 | self.animal_trajs.append(trajs)
70 | self.animal_valids.append(valids)
71 |
72 | def __getitem__(self, index):
73 | animal_name = self.animal_names[index]
74 | trajs = self.animal_trajs[index].copy()
75 | valids = self.animal_valids[index]
76 | valids = (valids==2) * 1.0
77 | visibs = valids.copy()
78 |
79 | S,N,D = trajs.shape
80 |
81 | filenames = glob.glob('%s/videos/%s/*.png' % (self.data_root, animal_name)) + glob.glob('%s/videos/%s/*.jpg' % (self.data_root, animal_name))
82 | filenames = sorted(filenames)
83 | S = len(filenames)
84 | filenames_short = [fn.split('/')[-1] for fn in filenames]
85 |
86 | rgbs = []
87 | for s in range(S):
88 | filename_actual = filenames[s]
89 | rgb = imageio.imread(filename_actual)
90 | rgbs.append(rgb)
91 |
92 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
93 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
94 |
95 | S = len(rgbs)
96 | H, W, C = rgbs[0].shape
97 | N = trajs.shape[1]
98 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
99 | sx = W / self.crop_size[1]
100 | sy = H / self.crop_size[0]
101 | trajs[:,:,0] /= sx
102 | trajs[:,:,1] /= sy
103 | rgbs = np.stack(rgbs, 0)
104 | H, W, C = rgbs[0].shape
105 |
106 | rgbs = torch.from_numpy(rgbs).reshape(S, H, W, 3).permute(0,3,1,2).float()
107 | trajs = torch.from_numpy(trajs).reshape(S, N, 2).float()
108 | visibs = torch.from_numpy(visibs).reshape(S, N).float()
109 | valids = torch.from_numpy(valids).reshape(S, N).float()
110 |
111 | sample = utils.data.VideoData(
112 | video=rgbs,
113 | trajs=trajs,
114 | visibs=visibs,
115 | valids=valids,
116 | dname=self.dname,
117 | )
118 | return sample, True
119 |
120 | def __len__(self):
121 | return len(self.animal_names)
122 |
123 |
--------------------------------------------------------------------------------
/utils/basic.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import os
4 | EPS = 1e-6
5 |
6 | def sub2ind(height, width, y, x):
7 | return y*width + x
8 |
9 | def ind2sub(height, width, ind):
10 | y = ind // width
11 | x = ind % width
12 | return y, x
13 |
14 | def get_lr_str(lr):
15 | lrn = "%.1e" % lr # e.g., 5.0e-04
16 | lrn = lrn[0] + lrn[3:5] + lrn[-1] # e.g., 5e-4
17 | return lrn
18 |
19 | def strnum(x):
20 | s = '%g' % x
21 | if '.' in s:
22 | if x < 1.0:
23 | s = s[s.index('.'):]
24 | s = s[:min(len(s),4)]
25 | return s
26 |
27 | def assert_same_shape(t1, t2):
28 | for (x, y) in zip(list(t1.shape), list(t2.shape)):
29 | assert(x==y)
30 |
31 | def mkdir(path):
32 | if not os.path.exists(path):
33 | os.makedirs(path)
34 |
35 | def print_stats(name, tensor):
36 | shape = tensor.shape
37 | tensor = tensor.detach().cpu().numpy()
38 | print('%s (%s) min = %.2f, mean = %.2f, max = %.2f' % (name, tensor.dtype, np.min(tensor), np.mean(tensor), np.max(tensor)), shape)
39 |
40 | def normalize_single(d):
41 | # d is a whatever shape torch tensor
42 | dmin = torch.min(d)
43 | dmax = torch.max(d)
44 | d = (d-dmin)/(EPS+(dmax-dmin))
45 | return d
46 |
47 | def normalize(d):
48 | # d is B x whatever. normalize within each element of the batch
49 | out = torch.zeros(d.size(), dtype=d.dtype, device=d.device)
50 | B = list(d.size())[0]
51 | for b in list(range(B)):
52 | out[b] = normalize_single(d[b])
53 | return out
54 |
55 | def meshgrid2d(B, Y, X, stack=False, norm=False, device='cuda', on_chans=False):
56 | # returns a meshgrid sized B x Y x X
57 |
58 | grid_y = torch.linspace(0.0, Y-1, Y, device=torch.device(device))
59 | grid_y = torch.reshape(grid_y, [1, Y, 1])
60 | grid_y = grid_y.repeat(B, 1, X)
61 |
62 | grid_x = torch.linspace(0.0, X-1, X, device=torch.device(device))
63 | grid_x = torch.reshape(grid_x, [1, 1, X])
64 | grid_x = grid_x.repeat(B, Y, 1)
65 |
66 | if norm:
67 | grid_y, grid_x = normalize_grid2d(
68 | grid_y, grid_x, Y, X)
69 |
70 | if stack:
71 | # note we stack in xy order
72 | # (see https://pytorch.org/docs/stable/nn.functional.html#torch.nn.functional.grid_sample)
73 | if on_chans:
74 | grid = torch.stack([grid_x, grid_y], dim=1)
75 | else:
76 | grid = torch.stack([grid_x, grid_y], dim=-1)
77 | return grid
78 | else:
79 | return grid_y, grid_x
80 |
81 | def gridcloud2d(B, Y, X, norm=False, device='cuda'):
82 | # we want to sample for each location in the grid
83 | grid_y, grid_x = meshgrid2d(B, Y, X, norm=norm, device=device)
84 | x = torch.reshape(grid_x, [B, -1])
85 | y = torch.reshape(grid_y, [B, -1])
86 | # these are B x N
87 | xy = torch.stack([x, y], dim=2)
88 | # this is B x N x 2
89 | return xy
90 |
91 | def reduce_masked_mean(x, mask, dim=None, keepdim=False, broadcast=False):
92 | # x and mask are the same shape, or at least broadcastably so < actually it's safer if you disallow broadcasting
93 | # returns shape-1
94 | # axis can be a list of axes
95 | if not broadcast:
96 | for (a,b) in zip(x.size(), mask.size()):
97 | if not a==b:
98 | print('some shape mismatch:', x.shape, mask.shape)
99 | assert(a==b) # some shape mismatch!
100 | # assert(x.size() == mask.size())
101 | prod = x*mask
102 | if dim is None:
103 | numer = torch.sum(prod)
104 | denom = EPS+torch.sum(mask)
105 | else:
106 | numer = torch.sum(prod, dim=dim, keepdim=keepdim)
107 | denom = EPS+torch.sum(mask, dim=dim, keepdim=keepdim)
108 | mean = numer/denom
109 | return mean
110 |
111 | def reduce_masked_median(x, mask, keep_batch=False):
112 | # x and mask are the same shape
113 | assert(x.size() == mask.size())
114 | device = x.device
115 |
116 | B = list(x.shape)[0]
117 | x = x.detach().cpu().numpy()
118 | mask = mask.detach().cpu().numpy()
119 |
120 | if keep_batch:
121 | x = np.reshape(x, [B, -1])
122 | mask = np.reshape(mask, [B, -1])
123 | meds = np.zeros([B], np.float32)
124 | for b in list(range(B)):
125 | xb = x[b]
126 | mb = mask[b]
127 | if np.sum(mb) > 0:
128 | xb = xb[mb > 0]
129 | meds[b] = np.median(xb)
130 | else:
131 | meds[b] = np.nan
132 | meds = torch.from_numpy(meds).to(device)
133 | return meds.float()
134 | else:
135 | x = np.reshape(x, [-1])
136 | mask = np.reshape(mask, [-1])
137 | if np.sum(mask) > 0:
138 | x = x[mask > 0]
139 | med = np.median(x)
140 | else:
141 | med = np.nan
142 | med = np.array([med], np.float32)
143 | med = torch.from_numpy(med).to(device)
144 | return med.float()
145 |
--------------------------------------------------------------------------------
/datasets/horsedataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import os
4 | from PIL import Image
5 | import cv2
6 | from datasets.pointdataset import PointDataset
7 | import pickle
8 | import utils.data
9 |
10 | class HorseDataset(PointDataset):
11 | def __init__(
12 | self,
13 | data_root='../datasets/horse10',
14 | crop_size=(384, 512),
15 | seq_len=None,
16 | only_first=False,
17 | ):
18 | super(HorseDataset, self).__init__(
19 | data_root=data_root,
20 | crop_size=crop_size,
21 | seq_len=seq_len,
22 | )
23 | print("loading horse dataset...")
24 |
25 | self.seq_len = seq_len
26 | self.only_first = only_first
27 | self.dname = 'hor'
28 |
29 | self.dataset_location = data_root
30 | self.anno_path = os.path.join(self.dataset_location, "seq_annotation.pkl")
31 | with open(self.anno_path, "rb") as f:
32 | self.annotation = pickle.load(f)
33 |
34 | self.video_names = []
35 |
36 | for video_name in list(self.annotation.keys()):
37 | video = self.annotation[video_name]
38 |
39 | rgbs = []
40 | trajs = []
41 | visibs = []
42 | for sample in video:
43 | img_path = sample["img_path"]
44 | img_path = self.dataset_location + '/' + img_path
45 | rgb = Image.open(img_path)
46 | rgbs.append(rgb)
47 | trajs.append(np.squeeze(sample["keypoints"], 0))
48 | visibs.append(np.squeeze(sample["keypoints_visible"], 0))
49 |
50 | rgbs = np.stack(rgbs, axis=0)
51 | trajs = np.stack(trajs, axis=0)
52 | visibs = np.stack(visibs, axis=0)
53 | valids = visibs.copy()
54 |
55 | S, H, W, C = rgbs.shape
56 | _, N, D = trajs.shape
57 |
58 | for si in range(S):
59 | # avoid 2px edge, since these are not really visible (according to adam)
60 | oob_inds = np.logical_or(
61 | np.logical_or(trajs[si, :, 0] < 2, trajs[si, :, 0] >= W-2),
62 | np.logical_or(trajs[si, :, 1] < 2, trajs[si, :, 1] >= H-2),
63 | )
64 | visibs[si, oob_inds] = 0
65 |
66 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
67 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
68 |
69 | N = trajs.shape[1]
70 | if N > 0:
71 | self.video_names.append(video_name)
72 |
73 | print(f"found {len(self.annotation)} unique videos in {self.dataset_location}")
74 |
75 | def getitem_helper(self, index):
76 | video_name = self.video_names[index]
77 | video = self.annotation[video_name]
78 |
79 | rgbs = []
80 | trajs = []
81 | visibs = []
82 | for sample in video:
83 | img_path = sample["img_path"]
84 | img_path = self.dataset_location + '/' + img_path
85 | rgb = Image.open(img_path)
86 | rgbs.append(rgb)
87 | trajs.append(np.squeeze(sample["keypoints"], 0))
88 | visibs.append(np.squeeze(sample["keypoints_visible"], 0))
89 |
90 | rgbs = np.stack(rgbs, axis=0)
91 | trajs = np.stack(trajs, axis=0)
92 | visibs = np.stack(visibs, axis=0)
93 | valids = visibs.copy()
94 |
95 | S, H, W, C = rgbs.shape
96 | _, N, D = trajs.shape
97 |
98 | for si in range(S):
99 | # avoid 2px edge, since these are not really visible (according to adam)
100 | oob_inds = np.logical_or(
101 | np.logical_or(trajs[si, :, 0] < 2, trajs[si, :, 0] >= W-2),
102 | np.logical_or(trajs[si, :, 1] < 2, trajs[si, :, 1] >= H-2),
103 | )
104 | visibs[si, oob_inds] = 0
105 |
106 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
107 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
108 |
109 | H, W = rgbs[0].shape[:2]
110 | trajs[:,:,0] /= W-1
111 | trajs[:,:,1] /= H-1
112 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
113 | rgbs = np.stack(rgbs)
114 | H,W = rgbs[0].shape[:2]
115 | trajs[:,:,0] *= W-1
116 | trajs[:,:,1] *= H-1
117 |
118 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
119 | trajs = torch.from_numpy(trajs)
120 | visibs = torch.from_numpy(visibs)
121 | valids = torch.from_numpy(valids)
122 |
123 | sample = utils.data.VideoData(
124 | video=rgbs,
125 | trajs=trajs,
126 | visibs=visibs,
127 | valids=valids,
128 | dname=self.dname,
129 | )
130 | return sample, True
131 |
132 | def __len__(self):
133 | return len(self.video_names)
134 |
--------------------------------------------------------------------------------
/utils/data.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import dataclasses
3 | import torch.nn.functional as F
4 | from dataclasses import dataclass
5 | from typing import Any, Optional, Dict
6 | import utils.misc
7 | import numpy as np
8 |
9 | def replace_invalid_xys_with_nearest(xys, valids):
10 | # replace invalid xys with nearby ones
11 | invalid_idx = np.where(valids==0)[0]
12 | valid_idx = np.where(valids==1)[0]
13 | for idx in invalid_idx:
14 | nearest = valid_idx[np.argmin(np.abs(valid_idx - idx))]
15 | xys[idx] = xys[nearest]
16 | return xys
17 |
18 | def standardize_test_data(rgbs, trajs, visibs, valids, S_cap=600, only_first=False, seq_len=None):
19 | trajs = trajs.astype(np.float32) # S,N,2
20 | visibs = visibs.astype(np.float32) # S,N
21 | valids = valids.astype(np.float32) # S,N
22 |
23 | # only take tracks that make sense
24 | visval_ok = np.sum(valids*visibs, axis=0) > 1
25 | trajs = trajs[:,visval_ok]
26 | visibs = visibs[:,visval_ok]
27 | valids = valids[:,visval_ok]
28 |
29 | # fill in missing data (for visualization)
30 | N = trajs.shape[1]
31 | for ni in range(N):
32 | trajs[:,ni] = replace_invalid_xys_with_nearest(trajs[:,ni], valids[:,ni])
33 |
34 | # use S_cap or seq_len (legacy)
35 | if seq_len is not None:
36 | S = min(len(rgbs), seq_len)
37 | else:
38 | S = len(rgbs)
39 | S = min(S, S_cap)
40 |
41 | if only_first:
42 | # we'll find the best frame to start on
43 | best_count = 0
44 | best_ind = 0
45 |
46 | for si in range(0,len(rgbs)-64):
47 | # try this slice
48 | visibs_ = visibs[si:min(si+S,len(rgbs)+1)] # S,N
49 | valids_ = valids[si:min(si+S,len(rgbs)+1)] # S,N
50 | visval_ok0 = (visibs_[0]*valids_[0]) > 0 # N
51 | visval_okA = np.sum(visibs_*valids_, axis=0) > 1 # N
52 | all_ok = visval_ok0 & visval_okA
53 | # print('- slicing %d to %d; sum(ok) %d' % (si, min(si+S,len(rgbs)+1), np.sum(all_ok)))
54 | if np.sum(all_ok) > best_count:
55 | best_count = np.sum(all_ok)
56 | best_ind = si
57 | si = best_ind
58 | rgbs = rgbs[si:si+S]
59 | trajs = trajs[si:si+S]
60 | visibs = visibs[si:si+S]
61 | valids = valids[si:si+S]
62 | vis_ok0 = visibs[0] > 0 # N
63 | trajs = trajs[:,vis_ok0]
64 | visibs = visibs[:,vis_ok0]
65 | valids = valids[:,vis_ok0]
66 | # print('- best_count', best_count, 'best_ind', best_ind)
67 |
68 | if seq_len is not None:
69 | rgbs = rgbs[:seq_len]
70 | trajs = trajs[:seq_len]
71 | valids = valids[:seq_len]
72 |
73 | # req two timesteps valid (after seqlen trim)
74 | visval_ok = np.sum(visibs*valids, axis=0) > 1
75 | trajs = trajs[:,visval_ok]
76 | valids = valids[:,visval_ok]
77 | visibs = visibs[:,visval_ok]
78 |
79 | return rgbs, trajs, visibs, valids
80 |
81 |
82 | @dataclass(eq=False)
83 | class VideoData:
84 | """
85 | Dataclass for storing video tracks data.
86 | """
87 |
88 | video: torch.Tensor # B,S,C,H,W
89 | trajs: torch.Tensor # B,S,N,2
90 | visibs: torch.Tensor # B,S,N
91 | valids: Optional[torch.Tensor] = None # B,S,N
92 | dname: Optional[str] = None
93 |
94 |
95 | def collate_fn(batch):
96 | """
97 | Collate function for video tracks data.
98 | """
99 | video = torch.stack([b.video for b in batch], dim=0)
100 | trajs = torch.stack([b.trajs for b in batch], dim=0)
101 | visibs = torch.stack([b.visibs for b in batch], dim=0)
102 | dname = [b.dname for b in batch]
103 |
104 | return VideoData(
105 | video=video,
106 | trajs=trajs,
107 | visibs=visibs,
108 | dname=dname,
109 | )
110 |
111 |
112 | def collate_fn_train(batch):
113 | """
114 | Collate function for video tracks data during training.
115 | """
116 | gotit = [gotit for _, gotit in batch]
117 | video = torch.stack([b.video for b, _ in batch], dim=0)
118 | trajs = torch.stack([b.trajs for b, _ in batch], dim=0)
119 | visibs = torch.stack([b.visibs for b, _ in batch], dim=0)
120 | valids = torch.stack([b.valids for b, _ in batch], dim=0)
121 | dname = [b.dname for b, _ in batch]
122 |
123 | return (
124 | VideoData(
125 | video=video,
126 | trajs=trajs,
127 | visibs=visibs,
128 | valids=valids,
129 | dname=dname,
130 | ),
131 | gotit,
132 | )
133 |
134 |
135 | def try_to_cuda(t: Any) -> Any:
136 | """
137 | Try to move the input variable `t` to a cuda device.
138 |
139 | Args:
140 | t: Input.
141 |
142 | Returns:
143 | t_cuda: `t` moved to a cuda device, if supported.
144 | """
145 | try:
146 | t = t.float().cuda()
147 | except AttributeError:
148 | pass
149 | return t
150 |
151 |
152 | def dataclass_to_cuda_(obj):
153 | """
154 | Move all contents of a dataclass to cuda inplace if supported.
155 |
156 | Args:
157 | batch: Input dataclass.
158 |
159 | Returns:
160 | batch_cuda: `batch` moved to a cuda device, if supported.
161 | """
162 | for f in dataclasses.fields(obj):
163 | setattr(obj, f.name, try_to_cuda(getattr(obj, f.name)))
164 | return obj
165 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # AllTracker: Efficient Dense Point Tracking at High Resolution
2 |
3 | **[[Paper](https://arxiv.org/abs/2506.07310)] [[Project Page](https://alltracker.github.io/)] [[Gradio Demo](https://huggingface.co/spaces/aharley/alltracker)]**
4 |
5 | 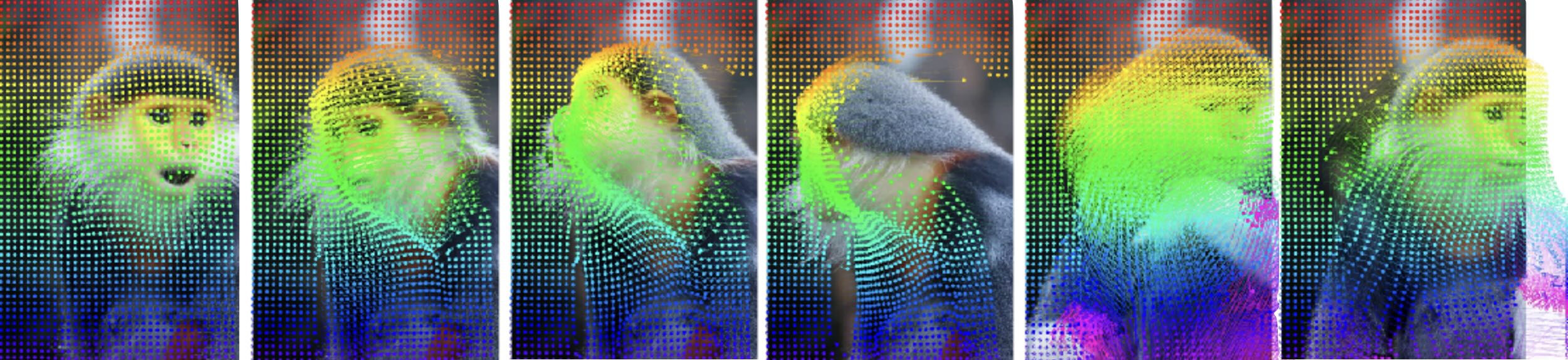 6 |
7 | **AllTracker is a point tracking model which is faster and more accurate than other similar models, while also producing dense output at high resolution.**
8 |
9 | AllTracker estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame.
10 |
11 | We are actively adding to this repo, but please ping or open an issue if you notice something missing or broken. The demo (at least) should work for everyone!
12 |
13 |
14 | ## Env setup
15 |
16 | Install miniconda:
17 | ```
18 | mkdir -p ~/miniconda3
19 | wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
20 | bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
21 | rm ~/miniconda3/miniconda.sh
22 | source ~/miniconda3/bin/activate
23 | conda init
24 | ```
25 |
26 | Set up a fresh conda environment for AllTracker:
27 |
28 | ```
29 | conda create -n alltracker python=3.12.8
30 | conda activate alltracker
31 | pip install -r requirements.txt
32 | ```
33 |
34 | ## Running the demo
35 |
36 | Download the sample video:
37 | ```
38 | cd demo_video
39 | sh download_video.sh
40 | cd ..
41 | ```
42 |
43 | Run the demo:
44 | ```
45 | python demo.py --mp4_path ./demo_video/monkey.mp4
46 | ```
47 | The demo script will automatically download the model weights from [huggingface](https://huggingface.co/aharley/alltracker/tree/main) if needed.
48 |
49 | For a fancier visualization, giving a side-by-side view of the input and output, try this:
50 | ```
51 | python demo.py --mp4_path ./demo_video/monkey.mp4 --query_frame 32 --conf_thr 0.01 --bkg_opacity 0.0 --rate 2 --hstack --query_frame 16
52 | ```
53 |
54 |
55 |
56 |
57 | ## Training
58 |
59 | AllTracker is trained in two stages: Stage 1 is kubric alone; Stage 2 is a mix of datasets. This 2-stage regime enables fair comparisons with models that train only on Kubric.
60 |
61 | ### Data prep
62 |
63 | Start by downloding Kubric.
64 |
65 | - 24-frame data: [kubric_au.tar.gz](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/kubric_au.tar.gz?download=true)
66 |
67 | - 64-frame data: [part1](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/ce64_kub_aa?download=true), [part2](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/ce64_kub_ab?download=true), [part3](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/ce64_kub_ac?download=true)
68 |
69 | Merge the parts by concatenating:
70 | ```
71 | cat ce64_kub_aa ce64_kub_ab ce64_kub_ac > ce64_kub.tar.gz
72 | ```
73 |
74 | The 24-frame Kubric data is a torch export of the official `kubric-public/tfds/movi_f/512x512` data.
75 |
76 | With Kubric, you can skip the other datasets and start training Stage 1.
77 |
78 | Download the rest of the point tracking datasets from [here](https://huggingface.co/datasets/aharley/alltracker_data/tree/main). There you will find 24-frame datasets, `ce24*.tar.gz`, and 64-frame datasets, `ce64*.tar.gz`. Some of the datasets are large, and they are split into parts, so you need to create the full files by concatenating.
79 |
80 | On disk, the point tracking datasets should look like this:
81 | ```
82 | data/
83 | ├── ce24/
84 | │ ├── drivingpt/
85 | │ ├── fltpt/
86 | │ ├── monkapt/
87 | │ ├── springpt/
88 | ├── ce64/
89 | │ ├── drivingpt/
90 | │ ├── kublong/
91 | │ ├── monkapt/
92 | │ ├── podlong/
93 | │ ├── springpt/
94 | ├── dynamicreplica/
95 | ├── kubric_au/
96 | ```
97 |
98 | Download the optical flow datasets from the official websites: [FlyingChairs, FlyingThings3D, Monkaa, Driving](https://lmb.informatik.uni-freiburg.de/resources/datasets) [AutoFlow](https://autoflow-google.github.io/), [SPRING](https://spring-benchmark.org/), [VIPER](https://playing-for-benchmarks.org/download/), [HD1K](http://hci-benchmark.iwr.uni-heidelberg.de/), [KITTI](https://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=flow), [TARTANAIR](https://theairlab.org/tartanair-dataset/).
99 |
100 |
101 | ### Stage 1
102 |
103 | Stage 1 is to train the model for 200k steps on Kubric.
104 |
105 | ```
106 | export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7; python train_stage1.py --mixed_precision --lr 5e-4 --max_steps 200000 --data_dir /data --exp "stage1abc"
107 | ```
108 |
109 | This should produce a tensorboard log in `./logs_train/`, and checkpoints in `./checkpoints/`, in folder names similar to "64Ai4i3_5e-4m_stage1abc_1318". (The 4-digit string at the end is a timecode indicating when the run began, to help make the filepaths unique.)
110 |
111 | ### Stage 2
112 |
113 | Stage 2 is to train the model for 400k steps on a mix of point tracking datasets and optical flow datasets. This stage initializes from the output of Stage 1.
114 |
115 | ```
116 | export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7; python train_stage2.py --mixed_precision --init_dir '64Ai4i3_5e-4m_stage1abc_1318' --lr 1e-5 --max_steps 400000 --exp 'stage2abc'
117 | ```
118 |
119 | ## Evaluation
120 |
121 | Test the model on point tracking datasets with a command like:
122 |
123 | ```
124 | python test_dense_on_sparse.py --dname 'dav'
125 | ```
126 |
127 | At the end, you should see:
128 | ```
129 | da: 76.3,
130 | aj: 63.3,
131 | oa: 90.0,
132 | ```
133 | which represent `d_avg` (accuracy), Average Jaccard, and Occlusion Accuracy. We find that small numerical issues (even across GPUs) may cause +- 0.1 fluctuation on these metrics.
134 |
135 | Test it at higher resolution with the `image_size` arg, like: `--image_size 448 768`, which should produce `da: 78.8, aj: 65.9, oa: 90.2` or `--image_size 768 1024`, which should produce `da: 80.6, aj: 67.2, oa: 89.7`.
136 |
137 | Note that AJ and OA are not reliable metrics in all datasets, because not all datasets follow the same rules about visibility annotation.
138 |
139 | Dataloaders for all test datasets are in the repo, and can be run in sequence with a command like:
140 | ```
141 | python test_dense_on_sparse.py --dname 'bad,cro,dav,dri,ego,hor,kin,rgb,rob'
142 | ```
143 | but if you have multiple GPUs, we recomend running the tests in parallel.
144 |
145 |
146 | ## Citation
147 |
148 | If you use this code for your research, please cite:
149 |
150 | ```
151 | Adam W. Harley, Yang You, Xinglong Sun, Yang Zheng, Nikhil Raghuraman, Yunqi Gu, Sheldon Liang, Wen-Hsuan Chu, Achal Dave, Pavel Tokmakov, Suya You, Rares Ambrus, Katerina Fragkiadaki, Leonidas J. Guibas. AllTracker: Efficient Dense Point Tracking at High Resolution. ICCV 2025.
152 | ```
153 |
154 | Bibtex:
155 | ```
156 | @inproceedings{harley2025alltracker,
157 | author = {Adam W. Harley and Yang You and Xinglong Sun and Yang Zheng and Nikhil Raghuraman and Yunqi Gu and Sheldon Liang and Wen-Hsuan Chu and Achal Dave and Pavel Tokmakov and Suya You and Rares Ambrus and Katerina Fragkiadaki and Leonidas J. Guibas},
158 | title = {All{T}racker: {E}fficient Dense Point Tracking at High Resolution}
159 | booktitle = {ICCV},
160 | year = {2025}
161 | }
162 | ```
163 |
--------------------------------------------------------------------------------
/utils/samp.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import utils.basic
3 | import torch.nn.functional as F
4 |
5 | def bilinear_sampler(input, coords, align_corners=True, padding_mode="border"):
6 | r"""Sample a tensor using bilinear interpolation
7 |
8 | `bilinear_sampler(input, coords)` samples a tensor :attr:`input` at
9 | coordinates :attr:`coords` using bilinear interpolation. It is the same
10 | as `torch.nn.functional.grid_sample()` but with a different coordinate
11 | convention.
12 |
13 | The input tensor is assumed to be of shape :math:`(B, C, H, W)`, where
14 | :math:`B` is the batch size, :math:`C` is the number of channels,
15 | :math:`H` is the height of the image, and :math:`W` is the width of the
16 | image. The tensor :attr:`coords` of shape :math:`(B, H_o, W_o, 2)` is
17 | interpreted as an array of 2D point coordinates :math:`(x_i,y_i)`.
18 |
19 | Alternatively, the input tensor can be of size :math:`(B, C, T, H, W)`,
20 | in which case sample points are triplets :math:`(t_i,x_i,y_i)`. Note
21 | that in this case the order of the components is slightly different
22 | from `grid_sample()`, which would expect :math:`(x_i,y_i,t_i)`.
23 |
24 | If `align_corners` is `True`, the coordinate :math:`x` is assumed to be
25 | in the range :math:`[0,W-1]`, with 0 corresponding to the center of the
26 | left-most image pixel :math:`W-1` to the center of the right-most
27 | pixel.
28 |
29 | If `align_corners` is `False`, the coordinate :math:`x` is assumed to
30 | be in the range :math:`[0,W]`, with 0 corresponding to the left edge of
31 | the left-most pixel :math:`W` to the right edge of the right-most
32 | pixel.
33 |
34 | Similar conventions apply to the :math:`y` for the range
35 | :math:`[0,H-1]` and :math:`[0,H]` and to :math:`t` for the range
36 | :math:`[0,T-1]` and :math:`[0,T]`.
37 |
38 | Args:
39 | input (Tensor): batch of input images.
40 | coords (Tensor): batch of coordinates.
41 | align_corners (bool, optional): Coordinate convention. Defaults to `True`.
42 | padding_mode (str, optional): Padding mode. Defaults to `"border"`.
43 |
44 | Returns:
45 | Tensor: sampled points.
46 | """
47 |
48 | sizes = input.shape[2:]
49 |
50 | assert len(sizes) in [2, 3]
51 |
52 | if len(sizes) == 3:
53 | # t x y -> x y t to match dimensions T H W in grid_sample
54 | coords = coords[..., [1, 2, 0]]
55 |
56 | if align_corners:
57 | coords = coords * torch.tensor(
58 | [2 / max(size - 1, 1) for size in reversed(sizes)], device=coords.device
59 | )
60 | else:
61 | coords = coords * torch.tensor(
62 | [2 / size for size in reversed(sizes)], device=coords.device
63 | )
64 |
65 | coords -= 1
66 |
67 | return F.grid_sample(
68 | input, coords, align_corners=align_corners, padding_mode=padding_mode
69 | )
70 |
71 |
72 | def sample_features4d(input, coords):
73 | r"""Sample spatial features
74 |
75 | `sample_features4d(input, coords)` samples the spatial features
76 | :attr:`input` represented by a 4D tensor :math:`(B, C, H, W)`.
77 |
78 | The field is sampled at coordinates :attr:`coords` using bilinear
79 | interpolation. :attr:`coords` is assumed to be of shape :math:`(B, R,
80 | 3)`, where each sample has the format :math:`(x_i, y_i)`. This uses the
81 | same convention as :func:`bilinear_sampler` with `align_corners=True`.
82 |
83 | The output tensor has one feature per point, and has shape :math:`(B,
84 | R, C)`.
85 |
86 | Args:
87 | input (Tensor): spatial features.
88 | coords (Tensor): points.
89 |
90 | Returns:
91 | Tensor: sampled features.
92 | """
93 |
94 | B, _, _, _ = input.shape
95 |
96 | # B R 2 -> B R 1 2
97 | coords = coords.unsqueeze(2)
98 |
99 | # B C R 1
100 | feats = bilinear_sampler(input, coords)
101 |
102 | return feats.permute(0, 2, 1, 3).view(
103 | B, -1, feats.shape[1] * feats.shape[3]
104 | ) # B C R 1 -> B R C
105 |
106 |
107 | def sample_features5d(input, coords):
108 | r"""Sample spatio-temporal features
109 |
110 | `sample_features5d(input, coords)` works in the same way as
111 | :func:`sample_features4d` but for spatio-temporal features and points:
112 | :attr:`input` is a 5D tensor :math:`(B, T, C, H, W)`, :attr:`coords` is
113 | a :math:`(B, R1, R2, 3)` tensor of spatio-temporal point :math:`(t_i,
114 | x_i, y_i)`. The output tensor has shape :math:`(B, R1, R2, C)`.
115 |
116 | Args:
117 | input (Tensor): spatio-temporal features.
118 | coords (Tensor): spatio-temporal points.
119 |
120 | Returns:
121 | Tensor: sampled features.
122 | """
123 |
124 | B, T, _, _, _ = input.shape
125 |
126 | # B T C H W -> B C T H W
127 | input = input.permute(0, 2, 1, 3, 4)
128 |
129 | # B R1 R2 3 -> B R1 R2 1 3
130 | coords = coords.unsqueeze(3)
131 |
132 | # B C R1 R2 1
133 | feats = bilinear_sampler(input, coords)
134 |
135 | return feats.permute(0, 2, 3, 1, 4).view(
136 | B, feats.shape[2], feats.shape[3], feats.shape[1]
137 | ) # B C R1 R2 1 -> B R1 R2 C
138 |
139 |
140 | def bilinear_sample2d(im, x, y, return_inbounds=False):
141 | # x and y are each B, N
142 | # output is B, C, N
143 | B, C, H, W = list(im.shape)
144 | N = list(x.shape)[1]
145 |
146 | x = x.float()
147 | y = y.float()
148 | H_f = torch.tensor(H, dtype=torch.float32)
149 | W_f = torch.tensor(W, dtype=torch.float32)
150 |
151 | # inbound_mask = (x>-0.5).float()*(y>-0.5).float()*(x -0.5).byte() & (x < float(W_f - 0.5)).byte()
208 | y_valid = (y > -0.5).byte() & (y < float(H_f - 0.5)).byte()
209 | inbounds = (x_valid & y_valid).float()
210 | inbounds = inbounds.reshape(B, N) # something seems wrong here for B>1; i'm getting an error here (or downstream if i put -1)
211 | return output, inbounds
212 |
213 | return output # B, C, N
214 |
--------------------------------------------------------------------------------
/datasets/drivetrackdataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import os
4 | import glob
5 | import cv2
6 | from datasets.pointdataset import PointDataset
7 | import pickle
8 | import utils.data
9 | from pathlib import Path
10 |
11 | class DrivetrackDataset(PointDataset):
12 | def __init__(
13 | self,
14 | data_root='../datasets/drivetrack',
15 | crop_size=(384, 512),
16 | seq_len=None,
17 | traj_per_sample=512,
18 | only_first=False,
19 | ):
20 | super(DrivetrackDataset, self).__init__(
21 | data_root=data_root,
22 | crop_size=crop_size,
23 | seq_len=seq_len,
24 | traj_per_sample=traj_per_sample,
25 | )
26 | print("loading drivetrack dataset...")
27 |
28 | self.dname = 'drivetrack'
29 | self.only_first = only_first
30 | S = seq_len
31 |
32 | self.dataset_location = Path(data_root)
33 | self.S = S
34 | video_fns = sorted(list(self.dataset_location.glob('*.npz')))
35 |
36 | self.video_fns = []
37 | for video_fn in video_fns[:100]: # drivetrack is huge and self-similar, so we trim to 100
38 | ds = np.load(video_fn, allow_pickle=True)
39 | rgbs, trajs, visibs = ds['video'], ds['tracks'], ds['visibles']
40 | # rgbs is T,1280,1920,3
41 | # trajs is N,T,2
42 | # visibs is N,T
43 |
44 | trajs = np.transpose(trajs, (1,0,2)).astype(np.float32) # S,N,2
45 | visibs = np.transpose(visibs, (1,0)).astype(np.float32) # S,N
46 | valids = visibs.copy()
47 | # print('N0', trajs.shape[1])
48 |
49 | # discard tracks with any inf/nan
50 | idx = np.nonzero(np.isfinite(trajs.sum(0).sum(1)))[0] # N
51 | trajs = trajs[:,idx]
52 | visibs = visibs[:,idx]
53 | valids = valids[:,idx]
54 | # print('N1', trajs.shape[1])
55 |
56 | if trajs.shape[1] < self.traj_per_sample:
57 | continue
58 |
59 | # shuffle and trim
60 | inds = np.random.permutation(trajs.shape[1])
61 | inds = inds[:10000]
62 | trajs = trajs[:,inds]
63 | visibs = visibs[:,inds]
64 | valids = valids[:,inds]
65 | # print('N2', trajs.shape[1])
66 |
67 | S,H,W,C = rgbs.shape
68 |
69 | # set OOB to invisible
70 | visibs[trajs[:, :, 0] > W-1] = False
71 | visibs[trajs[:, :, 0] < 0] = False
72 | visibs[trajs[:, :, 1] > H-1] = False
73 | visibs[trajs[:, :, 1] < 0] = False
74 |
75 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
76 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
77 | # print('N3', trajs.shape[1])
78 |
79 | if trajs.shape[1] < self.traj_per_sample:
80 | continue
81 |
82 | trajs = torch.from_numpy(trajs)
83 | visibs = torch.from_numpy(visibs)
84 | valids = torch.from_numpy(valids)
85 | # discard tracks that go far OOB
86 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
87 | close_pts_inds = torch.all(
88 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
89 | dim=0,
90 | )
91 | trajs = trajs[:, close_pts_inds]
92 | visibs = visibs[:, close_pts_inds]
93 | valids = valids[:, close_pts_inds]
94 | # print('N4', trajs.shape[1])
95 |
96 | if trajs.shape[1] < self.traj_per_sample:
97 | continue
98 |
99 | visible_inds = (valids[0]*visibs[0]).nonzero(as_tuple=False)[:, 0]
100 | trajs = trajs[:, visible_inds].float()
101 | visibs = visibs[:, visible_inds].float()
102 | valids = valids[:, visible_inds].float()
103 | # print('N5', trajs.shape[1])
104 |
105 | if trajs.shape[1] >= self.traj_per_sample:
106 | self.video_fns.append(video_fn)
107 |
108 | print(f"found {len(self.video_fns)} unique videos in {self.dataset_location}")
109 |
110 | def getitem_helper(self, index):
111 | video_fn = self.video_fns[index]
112 | ds = np.load(video_fn, allow_pickle=True)
113 | rgbs, trajs, visibs = ds['video'], ds['tracks'], ds['visibles']
114 | # rgbs is T,1280,1920,3
115 | # trajs is N,T,2
116 | # visibs is N,T
117 |
118 | trajs = np.transpose(trajs, (1,0,2)).astype(np.float32) # S,N,2
119 | visibs = np.transpose(visibs, (1,0)).astype(np.float32) # S,N
120 | valids = visibs.copy()
121 |
122 | # discard inf/nan
123 | idx = np.nonzero(np.isfinite(trajs.sum(0).sum(1)))[0] # N
124 | trajs = trajs[:,idx]
125 | visibs = visibs[:,idx]
126 | valids = valids[:,idx]
127 |
128 | # shuffle and trim
129 | inds = np.random.permutation(trajs.shape[1])
130 | inds = inds[:10000]
131 | trajs = trajs[:,inds]
132 | visibs = visibs[:,inds]
133 | valids = valids[:,inds]
134 | N = trajs.shape[1]
135 | # print('N2', trajs.shape[1])
136 |
137 | S,H,W,C = rgbs.shape
138 | # set OOB to invisible
139 | visibs[trajs[:, :, 0] > W-1] = False
140 | visibs[trajs[:, :, 0] < 0] = False
141 | visibs[trajs[:, :, 1] > H-1] = False
142 | visibs[trajs[:, :, 1] < 0] = False
143 |
144 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
145 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
146 |
147 | H, W = rgbs[0].shape[:2]
148 | trajs[:,:,0] /= W-1
149 | trajs[:,:,1] /= H-1
150 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
151 | rgbs = np.stack(rgbs)
152 | H,W = rgbs[0].shape[:2]
153 | trajs[:,:,0] *= W-1
154 | trajs[:,:,1] *= H-1
155 |
156 | trajs = torch.from_numpy(trajs)
157 | visibs = torch.from_numpy(visibs)
158 | valids = torch.from_numpy(valids)
159 |
160 | # discard tracks that go far OOB
161 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
162 | close_pts_inds = torch.all(
163 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
164 | dim=0,
165 | )
166 | trajs = trajs[:, close_pts_inds]
167 | visibs = visibs[:, close_pts_inds]
168 | valids = valids[:, close_pts_inds]
169 | # print('N3', trajs.shape[1])
170 |
171 | visible_pts_inds = (valids[0]*visibs[0]).nonzero(as_tuple=False)[:, 0]
172 | point_inds = torch.randperm(len(visible_pts_inds))[: self.traj_per_sample]
173 | if len(point_inds) < self.traj_per_sample:
174 | return None, False
175 | visible_inds_sampled = visible_pts_inds[point_inds]
176 | trajs = trajs[:, visible_inds_sampled].float()
177 | visibs = visibs[:, visible_inds_sampled].float()
178 | valids = valids[:, visible_inds_sampled].float()
179 | # print('N4', trajs.shape[1])
180 |
181 | trajs = trajs[:, :self.traj_per_sample]
182 | visibs = visibs[:, :self.traj_per_sample]
183 | valids = valids[:, :self.traj_per_sample]
184 | # print('N5', trajs.shape[1])
185 |
186 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
187 |
188 | sample = utils.data.VideoData(
189 | video=rgbs,
190 | trajs=trajs,
191 | visibs=visibs,
192 | valids=valids,
193 | dname=self.dname,
194 | )
195 | return sample, True
196 |
197 | def __len__(self):
198 | return len(self.video_fns)
199 |
--------------------------------------------------------------------------------
/utils/loss.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import torch.nn as nn
4 | from typing import List
5 | import utils.basic
6 |
7 |
8 | def sequence_loss(
9 | flow_preds,
10 | flow_gt,
11 | valids,
12 | vis=None,
13 | gamma=0.8,
14 | use_huber_loss=False,
15 | loss_only_for_visible=False,
16 | ):
17 | """Loss function defined over sequence of flow predictions"""
18 | total_flow_loss = 0.0
19 | for j in range(len(flow_gt)):
20 | B, S, N, D = flow_gt[j].shape
21 | B, S2, N = valids[j].shape
22 | assert S == S2
23 | n_predictions = len(flow_preds[j])
24 | flow_loss = 0.0
25 | for i in range(n_predictions):
26 | i_weight = gamma ** (n_predictions - i - 1)
27 | flow_pred = flow_preds[j][i]
28 | if use_huber_loss:
29 | i_loss = huber_loss(flow_pred, flow_gt[j], delta=6.0)
30 | else:
31 | i_loss = (flow_pred - flow_gt[j]).abs() # B, S, N, 2
32 | i_loss = torch.mean(i_loss, dim=3) # B, S, N
33 | valid_ = valids[j].clone()
34 | if loss_only_for_visible:
35 | valid_ = valid_ * vis[j]
36 | flow_loss += i_weight * utils.basic.reduce_masked_mean(i_loss, valid_)
37 | flow_loss = flow_loss / n_predictions
38 | total_flow_loss += flow_loss
39 | return total_flow_loss / len(flow_gt)
40 |
41 | def sequence_loss_dense(
42 | flow_preds,
43 | flow_gt,
44 | valids,
45 | vis=None,
46 | gamma=0.8,
47 | use_huber_loss=False,
48 | loss_only_for_visible=False,
49 | ):
50 | """Loss function defined over sequence of flow predictions"""
51 | total_flow_loss = 0.0
52 | for j in range(len(flow_gt)):
53 | # print('flow_gt[j]', flow_gt[j].shape)
54 | B, S, D, H, W = flow_gt[j].shape
55 | B, S2, _, H, W = valids[j].shape
56 | assert S == S2
57 | n_predictions = len(flow_preds[j])
58 | flow_loss = 0.0
59 | # import ipdb; ipdb.set_trace()
60 | for i in range(n_predictions):
61 | # print('flow_e[j][i]', flow_preds[j][i].shape)
62 | i_weight = gamma ** (n_predictions - i - 1)
63 | flow_pred = flow_preds[j][i] # B,S,2,H,W
64 | if use_huber_loss:
65 | i_loss = huber_loss(flow_pred, flow_gt[j], delta=6.0) # B,S,2,H,W
66 | else:
67 | i_loss = (flow_pred - flow_gt[j]).abs() # B,S,2,H,W
68 | i_loss_ = torch.mean(i_loss, dim=2) # B,S,H,W
69 | valid_ = valids[j].reshape(B,S,H,W)
70 | # print(' (%d,%d) i_loss_' % (i,j), i_loss_.shape)
71 | # print(' (%d,%d) valid_' % (i,j), valid_.shape)
72 | if loss_only_for_visible:
73 | valid_ = valid_ * vis[j].reshape(B,-1,H,W) # usually B,S,H,W, but maybe B,1,H,W
74 | flow_loss += i_weight * utils.basic.reduce_masked_mean(i_loss_, valid_, broadcast=True)
75 | # import ipdb; ipdb.set_trace()
76 | flow_loss = flow_loss / n_predictions
77 | total_flow_loss += flow_loss
78 | return total_flow_loss / len(flow_gt)
79 |
80 |
81 | def huber_loss(x, y, delta=1.0):
82 | """Calculate element-wise Huber loss between x and y"""
83 | diff = x - y
84 | abs_diff = diff.abs()
85 | flag = (abs_diff <= delta).float()
86 | return flag * 0.5 * diff**2 + (1 - flag) * delta * (abs_diff - 0.5 * delta)
87 |
88 |
89 | def sequence_BCE_loss(vis_preds, vis_gts, valids=None, use_logits=False):
90 | total_bce_loss = 0.0
91 | # all_vis_preds = [torch.stack(vp) for vp in vis_preds]
92 | # all_vis_preds = torch.stack(all_vis_preds)
93 | # utils.basic.print_stats('all_vis_preds', all_vis_preds)
94 | for j in range(len(vis_preds)):
95 | n_predictions = len(vis_preds[j])
96 | bce_loss = 0.0
97 | for i in range(n_predictions):
98 | # utils.basic.print_stats('vis_preds[%d][%d]' % (j,i), vis_preds[j][i])
99 | # utils.basic.print_stats('vis_gts[%d]' % (i), vis_gts[i])
100 | if use_logits:
101 | loss = F.binary_cross_entropy_with_logits(vis_preds[j][i], vis_gts[j], reduction='none')
102 | else:
103 | loss = F.binary_cross_entropy(vis_preds[j][i], vis_gts[j], reduction='none')
104 | if valids is None:
105 | bce_loss += loss.mean()
106 | else:
107 | bce_loss += (loss * valids[j]).mean()
108 | bce_loss = bce_loss / n_predictions
109 | total_bce_loss += bce_loss
110 | return total_bce_loss / len(vis_preds)
111 |
112 |
113 | # def sequence_BCE_loss_dense(vis_preds, vis_gts):
114 | # total_bce_loss = 0.0
115 | # for j in range(len(vis_preds)):
116 | # n_predictions = len(vis_preds[j])
117 | # bce_loss = 0.0
118 | # for i in range(n_predictions):
119 | # vis_e = vis_preds[j][i]
120 | # vis_g = vis_gts[j]
121 | # print('vis_e', vis_e.shape, 'vis_g', vis_g.shape)
122 | # vis_loss = F.binary_cross_entropy(vis_e, vis_g)
123 | # bce_loss += vis_loss
124 | # bce_loss = bce_loss / n_predictions
125 | # total_bce_loss += bce_loss
126 | # return total_bce_loss / len(vis_preds)
127 |
128 |
129 | def sequence_prob_loss(
130 | tracks: torch.Tensor,
131 | confidence: torch.Tensor,
132 | target_points: torch.Tensor,
133 | visibility: torch.Tensor,
134 | expected_dist_thresh: float = 12.0,
135 | use_logits=False,
136 | ):
137 | """Loss for classifying if a point is within pixel threshold of its target."""
138 | # Points with an error larger than 12 pixels are likely to be useless; marking
139 | # them as occluded will actually improve Jaccard metrics and give
140 | # qualitatively better results.
141 | total_logprob_loss = 0.0
142 | for j in range(len(tracks)):
143 | n_predictions = len(tracks[j])
144 | logprob_loss = 0.0
145 | for i in range(n_predictions):
146 | err = torch.sum((tracks[j][i].detach() - target_points[j]) ** 2, dim=-1)
147 | valid = (err <= expected_dist_thresh**2).float()
148 | if use_logits:
149 | loss = F.binary_cross_entropy_with_logits(confidence[j][i], valid, reduction="none")
150 | else:
151 | loss = F.binary_cross_entropy(confidence[j][i], valid, reduction="none")
152 | loss *= visibility[j]
153 | loss = torch.mean(loss, dim=[1, 2])
154 | logprob_loss += loss
155 | logprob_loss = logprob_loss / n_predictions
156 | total_logprob_loss += logprob_loss
157 | return total_logprob_loss / len(tracks)
158 |
159 | def sequence_prob_loss_dense(
160 | tracks: torch.Tensor,
161 | confidence: torch.Tensor,
162 | target_points: torch.Tensor,
163 | visibility: torch.Tensor,
164 | expected_dist_thresh: float = 12.0,
165 | use_logits=False,
166 | ):
167 | """Loss for classifying if a point is within pixel threshold of its target."""
168 | # Points with an error larger than 12 pixels are likely to be useless; marking
169 | # them as occluded will actually improve Jaccard metrics and give
170 | # qualitatively better results.
171 |
172 | # all_confidence = [torch.stack(vp) for vp in confidence]
173 | # all_confidence = torch.stack(all_confidence)
174 | # utils.basic.print_stats('all_confidence', all_confidence)
175 |
176 | total_logprob_loss = 0.0
177 | for j in range(len(tracks)):
178 | n_predictions = len(tracks[j])
179 | logprob_loss = 0.0
180 | for i in range(n_predictions):
181 | # print('trajs_e', tracks[j][i].shape)
182 | # print('trajs_g', target_points[j].shape)
183 | err = torch.sum((tracks[j][i].detach() - target_points[j]) ** 2, dim=2)
184 | positive = (err <= expected_dist_thresh**2).float()
185 | # print('conf', confidence[j][i].shape, 'positive', positive.shape)
186 | if use_logits:
187 | loss = F.binary_cross_entropy_with_logits(confidence[j][i].squeeze(2), positive, reduction="none")
188 | else:
189 | loss = F.binary_cross_entropy(confidence[j][i].squeeze(2), positive, reduction="none")
190 | loss *= visibility[j].squeeze(2) # B,S,H,W
191 | loss = torch.mean(loss, dim=[1,2,3])
192 | logprob_loss += loss
193 | logprob_loss = logprob_loss / n_predictions
194 | total_logprob_loss += logprob_loss
195 | return total_logprob_loss / len(tracks)
196 |
197 |
198 | def masked_mean(data, mask, dim):
199 | if mask is None:
200 | return data.mean(dim=dim, keepdim=True)
201 | mask = mask.float()
202 | mask_sum = torch.sum(mask, dim=dim, keepdim=True)
203 | mask_mean = torch.sum(data * mask, dim=dim, keepdim=True) / torch.clamp(
204 | mask_sum, min=1.0
205 | )
206 | return mask_mean
207 |
208 |
209 | def masked_mean_var(data: torch.Tensor, mask: torch.Tensor, dim: List[int]):
210 | if mask is None:
211 | return data.mean(dim=dim, keepdim=True), data.var(dim=dim, keepdim=True)
212 | mask = mask.float()
213 | mask_sum = torch.sum(mask, dim=dim, keepdim=True)
214 | mask_mean = torch.sum(data * mask, dim=dim, keepdim=True) / torch.clamp(
215 | mask_sum, min=1.0
216 | )
217 | mask_var = torch.sum(
218 | mask * (data - mask_mean) ** 2, dim=dim, keepdim=True
219 | ) / torch.clamp(mask_sum, min=1.0)
220 | return mask_mean.squeeze(dim), mask_var.squeeze(dim)
221 |
--------------------------------------------------------------------------------
/datasets/kubric_movif_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import cv2
4 | import imageio
5 | import numpy as np
6 | import glob
7 | from pathlib import Path
8 | import utils.data
9 | from datasets.pointdataset import PointDataset
10 | import random
11 |
12 | class KubricMovifDataset(PointDataset):
13 | def __init__(
14 | self,
15 | data_root,
16 | crop_size=(384, 512),
17 | seq_len=24,
18 | traj_per_sample=768,
19 | traj_max_factor=24, # multiplier on traj_per_sample
20 | use_augs=False,
21 | random_seq_len=False,
22 | random_first_frame=False,
23 | random_frame_rate=False,
24 | random_number_traj=False,
25 | shuffle_frames=False,
26 | shuffle=True,
27 | only_first=False,
28 | ):
29 | super(KubricMovifDataset, self).__init__(
30 | data_root=data_root,
31 | crop_size=crop_size,
32 | seq_len=seq_len,
33 | traj_per_sample=traj_per_sample,
34 | use_augs=use_augs,
35 | )
36 | print('loading kubric S%d dataset...' % seq_len)
37 |
38 | self.dname = 'kubric%d' % seq_len
39 |
40 | self.only_first = only_first
41 | self.traj_max_factor = traj_max_factor
42 |
43 | self.random_seq_len = random_seq_len
44 | self.random_first_frame = random_first_frame
45 | self.random_frame_rate = random_frame_rate
46 | self.random_number_traj = random_number_traj
47 | self.shuffle_frames = shuffle_frames
48 | self.pad_bounds = [10, 100]
49 | self.resize_lim = [0.25, 2.0] # sample resizes from here
50 | self.resize_delta = 0.2
51 | self.max_crop_offset = 50
52 |
53 | folder_names = Path(data_root).glob('*/*/')
54 | folder_names = [str(fn) for fn in folder_names]
55 | folder_names = sorted(folder_names)
56 | # print('folder_names', folder_names)
57 | if shuffle:
58 | random.shuffle(folder_names)
59 |
60 | self.seq_names = []
61 | for fi, fol in enumerate(folder_names):
62 | npy_path = os.path.join(fol, "annot.npy")
63 | rgb_path = os.path.join(fol, "frames")
64 | if os.path.isdir(rgb_path) and os.path.isfile(npy_path):
65 | img_paths = sorted(os.listdir(rgb_path))
66 | if len(img_paths)>=seq_len:
67 | self.seq_names.append(fol)
68 | else:
69 | pass
70 | else:
71 | pass
72 |
73 | print("found %d unique videos in %s" % (len(self.seq_names), self.data_root))
74 |
75 | def getitem_helper(self, index):
76 | gotit = True
77 | fol = self.seq_names[index]
78 | npy_path = os.path.join(fol, "annot.npy")
79 | rgb_path = os.path.join(fol, "frames")
80 |
81 | seq_name = fol.split('/')[-1]
82 |
83 | img_paths = sorted(os.listdir(rgb_path))
84 | rgbs = []
85 | for i, img_path in enumerate(img_paths):
86 | rgbs.append(imageio.v2.imread(os.path.join(rgb_path, img_path)))
87 |
88 | rgbs = np.stack(rgbs)
89 | annot_dict = np.load(npy_path, allow_pickle=True).item()
90 | trajs = annot_dict["point_xys"]
91 | visibs = annot_dict["point_visibs"]
92 | valids = annot_dict["point_xys_valid"]
93 |
94 | S = len(rgbs)
95 | # ensure all valid, and then discard valids tensor
96 | all_valid = np.nonzero(np.sum(valids, axis=0)==S)[0]
97 | trajs = trajs[:,all_valid]
98 | visibs = visibs[:,all_valid]
99 |
100 | if self.use_augs and np.random.rand() < 0.5: # time flip
101 | # time flip
102 | rgbs = np.flip(rgbs, axis=[0]).copy()
103 | trajs = np.flip(trajs, axis=[0]).copy()
104 | visibs = np.flip(visibs, axis=[0]).copy()
105 |
106 | if self.shuffle_frames and np.random.rand() < 0.01:
107 | # shuffle the frames
108 | perm = np.random.permutation(rgbs.shape[0])
109 | rgbs = rgbs[perm]
110 | trajs = trajs[perm]
111 | visibs = visibs[perm]
112 |
113 | frame_rate = 1
114 | final_num_traj = self.traj_per_sample
115 | crop_size = self.crop_size
116 |
117 | # randomize time slice
118 | min_num_traj = 1
119 | assert self.traj_per_sample >= min_num_traj
120 | if self.random_seq_len and self.random_number_traj:
121 | final_num_traj = np.random.randint(min_num_traj, self.traj_per_sample)
122 | alpha = final_num_traj / float(self.traj_per_sample)
123 | seq_len = int(alpha * 10 + (1 - alpha) * self.seq_len)
124 | seq_len = np.random.randint(seq_len - 2, seq_len + 2)
125 | if self.random_frame_rate:
126 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
127 | elif self.random_number_traj:
128 | final_num_traj = np.random.randint(min_num_traj, self.traj_per_sample)
129 | alpha = final_num_traj / float(self.traj_per_sample)
130 | seq_len = 8 * int(alpha * 2 + (1 - alpha) * self.seq_len // 8)
131 | # seq_len = np.random.randint(seq_len , seq_len + 2)
132 | if self.random_frame_rate:
133 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
134 | elif self.random_seq_len:
135 | seq_len = np.random.randint(int(self.seq_len / 2), self.seq_len)
136 | if self.random_frame_rate:
137 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
138 | else:
139 | seq_len = self.seq_len
140 | if self.random_frame_rate:
141 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
142 | if seq_len < len(rgbs):
143 | if self.random_first_frame:
144 | ind0 = np.random.choice(len(rgbs))
145 | rgb0 = rgbs[ind0]
146 | traj0 = trajs[ind0]
147 | visib0 = visibs[ind0]
148 |
149 | if seq_len * frame_rate < len(rgbs):
150 | start_ind = np.random.choice(len(rgbs) - (seq_len * frame_rate), 1)[0]
151 | else:
152 | start_ind = 0
153 | # print('slice %d:%d:%d' % (start_ind, start_ind+seq_len*frame_rate, frame_rate))
154 | rgbs = rgbs[start_ind : start_ind + seq_len * frame_rate : frame_rate]
155 | trajs = trajs[start_ind : start_ind + seq_len * frame_rate : frame_rate]
156 | visibs = visibs[start_ind : start_ind + seq_len * frame_rate : frame_rate]
157 |
158 | if self.random_first_frame:
159 | rgbs[0] = rgb0
160 | trajs[0] = traj0
161 | visibs[0] = visib0
162 |
163 | assert seq_len == len(rgbs)
164 |
165 | # ensure no crazy values
166 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs).astype(np.float64), axis=-1)<100000, axis=0)==seq_len)[0]
167 | trajs = trajs[:,all_valid]
168 | visibs = visibs[:,all_valid]
169 |
170 | if self.use_augs and np.random.rand() < 0.98:
171 | rgbs, trajs, visibs = self.add_photometric_augs(rgbs, trajs, visibs, replace=False)
172 | rgbs, trajs = self.add_spatial_augs(rgbs, trajs, visibs, crop_size)
173 | else:
174 | rgbs, trajs = self.crop(rgbs, trajs, crop_size)
175 |
176 | visibs[trajs[:, :, 0] > crop_size[1] - 1] = False
177 | visibs[trajs[:, :, 0] < 0] = False
178 | visibs[trajs[:, :, 1] > crop_size[0] - 1] = False
179 | visibs[trajs[:, :, 1] < 0] = False
180 |
181 | # ensure no crazy values
182 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs), axis=-1)<100000, axis=0)==seq_len)[0]
183 | trajs = trajs[:,all_valid]
184 | visibs = visibs[:,all_valid]
185 |
186 | if self.shuffle_frames and np.random.rand() < 0.01:
187 | # shuffle the frames (again)
188 | perm = np.random.permutation(rgbs.shape[0])
189 | rgbs = rgbs[perm]
190 | trajs = trajs[perm]
191 | visibs = visibs[perm]
192 |
193 | if self.only_first:
194 | vis_ok = np.nonzero(visibs[0]==1)[0]
195 | trajs = trajs[:,vis_ok]
196 | visibs = visibs[:,vis_ok]
197 |
198 | visibs = torch.from_numpy(visibs)
199 | trajs = torch.from_numpy(trajs)
200 |
201 | crop_tensor = torch.tensor(crop_size).flip(0)[None, None] / 2.0
202 | close_pts_inds = torch.all(
203 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < 1000.0,
204 | dim=0,
205 | )
206 | trajs = trajs[:, close_pts_inds]
207 | visibs = visibs[:, close_pts_inds]
208 | N = trajs.shape[1]
209 |
210 | assert self.only_first
211 |
212 | N = trajs.shape[1]
213 | point_inds = torch.randperm(N)[:self.traj_per_sample*self.traj_max_factor]
214 |
215 | if len(point_inds) < self.traj_per_sample:
216 | gotit = False
217 |
218 | trajs = trajs[:, point_inds]
219 | visibs = visibs[:, point_inds]
220 | valids = torch.ones_like(visibs)
221 |
222 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
223 |
224 | trajs = trajs[:, :self.traj_per_sample*self.traj_max_factor]
225 | visibs = visibs[:, :self.traj_per_sample*self.traj_max_factor]
226 | valids = valids[:, :self.traj_per_sample*self.traj_max_factor]
227 |
228 | sample = utils.data.VideoData(
229 | video=rgbs,
230 | trajs=trajs,
231 | visibs=visibs,
232 | valids=valids,
233 | seq_name=seq_name,
234 | dname=self.dname,
235 | )
236 | return sample, gotit
237 |
238 | def __len__(self):
239 | return len(self.seq_names)
240 |
--------------------------------------------------------------------------------
/utils/misc.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 |
4 | def get_1d_sincos_pos_embed_from_grid(embed_dim, positions):
5 | assert embed_dim % 2 == 0
6 | omega = torch.arange(embed_dim // 2, dtype=torch.double)
7 | omega /= embed_dim / 2.0
8 | omega = 1.0 / 10000**omega # (D/2,)
9 |
10 | positions = positions.reshape(-1) # (M,)
11 | out = torch.einsum("m,d->md", positions, omega) # (M, D/2), outer product
12 |
13 | emb_sin = torch.sin(out) # (M, D/2)
14 | emb_cos = torch.cos(out) # (M, D/2)
15 |
16 | emb = torch.cat([emb_sin, emb_cos], dim=1) # (M, D)
17 | return emb[None].float()
18 |
19 |
20 | class SimplePool():
21 | def __init__(self, pool_size, version='pt', min_size=1):
22 | self.pool_size = pool_size
23 | self.version = version
24 | self.items = []
25 | self.min_size = min_size
26 |
27 | if not (version=='pt' or version=='np'):
28 | print('version = %s; please choose pt or np')
29 | assert(False) # please choose pt or np
30 |
31 | def __len__(self):
32 | return len(self.items)
33 |
34 | def mean(self, min_size=None):
35 | if min_size is None:
36 | pool_size_thresh = self.min_size
37 | elif min_size=='half':
38 | pool_size_thresh = self.pool_size/2
39 | else:
40 | pool_size_thresh = min_size
41 |
42 | if self.version=='np':
43 | if len(self.items) >= pool_size_thresh:
44 | return np.sum(self.items)/float(len(self.items))
45 | else:
46 | return np.nan
47 | if self.version=='pt':
48 | if len(self.items) >= pool_size_thresh:
49 | return torch.sum(self.items)/float(len(self.items))
50 | else:
51 | return torch.from_numpy(np.nan)
52 |
53 | def sample(self, with_replacement=True):
54 | idx = np.random.randint(len(self.items))
55 | if with_replacement:
56 | return self.items[idx]
57 | else:
58 | return self.items.pop(idx)
59 |
60 | def fetch(self, num=None):
61 | if self.version=='pt':
62 | item_array = torch.stack(self.items)
63 | elif self.version=='np':
64 | item_array = np.stack(self.items)
65 | if num is not None:
66 | # there better be some items
67 | assert(len(self.items) >= num)
68 |
69 | # if there are not that many elements just return however many there are
70 | if len(self.items) < num:
71 | return item_array
72 | else:
73 | idxs = np.random.randint(len(self.items), size=num)
74 | return item_array[idxs]
75 | else:
76 | return item_array
77 |
78 | def is_full(self):
79 | full = len(self.items)==self.pool_size
80 | return full
81 |
82 | def empty(self):
83 | self.items = []
84 |
85 | def have_min_size(self):
86 | return len(self.items) >= self.min_size
87 |
88 |
89 | def update(self, items):
90 | for item in items:
91 | if len(self.items) < self.pool_size:
92 | # the pool is not full, so let's add this in
93 | self.items.append(item)
94 | else:
95 | # the pool is full
96 | # pop from the front
97 | self.items.pop(0)
98 | # add to the back
99 | self.items.append(item)
100 | return self.items
101 |
102 | def compute_tapvid_metrics(
103 | query_points: np.ndarray,
104 | gt_occluded: np.ndarray,
105 | gt_tracks: np.ndarray,
106 | pred_occluded: np.ndarray,
107 | pred_tracks: np.ndarray,
108 | query_mode: str,
109 | crop_size: tuple = (256, 256),
110 | ):
111 | """Computes TAP-Vid metrics (Jaccard, Pts. Within Thresh, Occ. Acc.)
112 | See the TAP-Vid paper for details on the metric computation. All inputs are
113 | given in raster coordinates. The first three arguments should be the direct
114 | outputs of the reader: the 'query_points', 'occluded', and 'target_points'.
115 | The paper metrics assume these are scaled relative to 256x256 images.
116 | pred_occluded and pred_tracks are your algorithm's predictions.
117 | This function takes a batch of inputs, and computes metrics separately for
118 | each video. The metrics for the full benchmark are a simple mean of the
119 | metrics across the full set of videos. These numbers are between 0 and 1,
120 | but the paper multiplies them by 100 to ease reading.
121 | Args:
122 | query_points: The query points, an in the format [t, y, x]. Its size is
123 | [b, n, 3], where b is the batch size and n is the number of queries
124 | gt_occluded: A boolean array of shape [b, n, t], where t is the number
125 | of frames. True indicates that the point is occluded.
126 | gt_tracks: The target points, of shape [b, n, t, 2]. Each point is
127 | in the format [x, y]
128 | pred_occluded: A boolean array of predicted occlusions, in the same
129 | format as gt_occluded.
130 | pred_tracks: An array of track predictions from your algorithm, in the
131 | same format as gt_tracks.
132 | query_mode: Either 'first' or 'strided', depending on how queries are
133 | sampled. If 'first', we assume the prior knowledge that all points
134 | before the query point are occluded, and these are removed from the
135 | evaluation.
136 | Returns:
137 | A dict with the following keys:
138 | occlusion_accuracy: Accuracy at predicting occlusion.
139 | pts_within_{x} for x in [1, 2, 4, 8, 16]: Fraction of points
140 | predicted to be within the given pixel threshold, ignoring occlusion
141 | prediction.
142 | jaccard_{x} for x in [1, 2, 4, 8, 16]: Jaccard metric for the given
143 | threshold
144 | average_pts_within_thresh: average across pts_within_{x}
145 | average_jaccard: average across jaccard_{x}
146 | """
147 |
148 | metrics = {}
149 | # Fixed bug is described in:
150 | # https://github.com/facebookresearch/co-tracker/issues/20
151 | eye = np.eye(gt_tracks.shape[2], dtype=np.int32)
152 |
153 | if query_mode == "first":
154 | # evaluate frames after the query frame
155 | query_frame_to_eval_frames = np.cumsum(eye, axis=1) - eye
156 | elif query_mode == "strided":
157 | # evaluate all frames except the query frame
158 | query_frame_to_eval_frames = 1 - eye
159 | else:
160 | raise ValueError("Unknown query mode " + query_mode)
161 |
162 | query_frame = query_points[..., 0]
163 | query_frame = np.round(query_frame).astype(np.int32)
164 | evaluation_points = query_frame_to_eval_frames[query_frame] > 0
165 |
166 | # Occlusion accuracy is simply how often the predicted occlusion equals the
167 | # ground truth.
168 | occ_acc = np.sum(
169 | np.equal(pred_occluded, gt_occluded) & evaluation_points,
170 | axis=(1, 2),
171 | ) / np.sum(evaluation_points)
172 | metrics["occlusion_accuracy"] = occ_acc
173 |
174 | # Next, convert the predictions and ground truth positions into pixel
175 | # coordinates.
176 | visible = np.logical_not(gt_occluded)
177 | pred_visible = np.logical_not(pred_occluded)
178 | all_frac_within = []
179 | all_jaccard = []
180 | sx_ = (crop_size[1] - 1) / 255.0
181 | sy_ = (crop_size[0] - 1) / 255.0
182 | sc_pt = np.array([sx_, sy_]).reshape([1, 1, 1, 2])
183 |
184 | for thresh in [1, 2, 4, 8, 16]:
185 | # True positives are points that are within the threshold and where both
186 | # the prediction and the ground truth are listed as visible.
187 | within_dist = np.sum(
188 | np.square(pred_tracks / sc_pt - gt_tracks / sc_pt),
189 | axis=-1,
190 | ) < np.square(thresh)
191 | is_correct = np.logical_and(within_dist, visible)
192 |
193 | # Compute the frac_within_threshold, which is the fraction of points
194 | # within the threshold among points that are visible in the ground truth,
195 | # ignoring whether they're predicted to be visible.
196 | count_correct = np.sum(
197 | is_correct & evaluation_points,
198 | axis=(1, 2),
199 | )
200 | count_visible_points = np.sum(visible & evaluation_points, axis=(1, 2))
201 | frac_correct = count_correct / count_visible_points
202 | metrics["pts_within_" + str(thresh)] = frac_correct
203 | all_frac_within.append(frac_correct)
204 |
205 | true_positives = np.sum(
206 | is_correct & pred_visible & evaluation_points, axis=(1, 2)
207 | )
208 |
209 | # The denominator of the jaccard metric is the true positives plus
210 | # false positives plus false negatives. However, note that true positives
211 | # plus false negatives is simply the number of points in the ground truth
212 | # which is easier to compute than trying to compute all three quantities.
213 | # Thus we just add the number of points in the ground truth to the number
214 | # of false positives.
215 | #
216 | # False positives are simply points that are predicted to be visible,
217 | # but the ground truth is not visible or too far from the prediction.
218 | gt_positives = np.sum(visible & evaluation_points, axis=(1, 2))
219 | false_positives = (~visible) & pred_visible
220 | false_positives = false_positives | ((~within_dist) & pred_visible)
221 | false_positives = np.sum(false_positives & evaluation_points, axis=(1, 2))
222 | jaccard = true_positives / (gt_positives + false_positives)
223 | metrics["jaccard_" + str(thresh)] = jaccard
224 | all_jaccard.append(jaccard)
225 | metrics["average_jaccard"] = np.mean(
226 | np.stack(all_jaccard, axis=1),
227 | axis=1,
228 | )
229 | metrics["average_pts_within_thresh"] = np.mean(
230 | np.stack(all_frac_within, axis=1),
231 | axis=1,
232 | )
233 | return metrics
234 |
235 |
--------------------------------------------------------------------------------
/demo.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import cv2
3 | import argparse
4 | import utils.saveload
5 | import utils.basic
6 | import utils.improc
7 | import PIL.Image
8 | import numpy as np
9 | import os
10 | from prettytable import PrettyTable
11 | import time
12 |
13 | def read_mp4(name_path):
14 | vidcap = cv2.VideoCapture(name_path)
15 | framerate = int(round(vidcap.get(cv2.CAP_PROP_FPS)))
16 | print('framerate', framerate)
17 | frames = []
18 | while vidcap.isOpened():
19 | ret, frame = vidcap.read()
20 | if ret == False:
21 | break
22 | frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
23 | frames.append(frame)
24 | vidcap.release()
25 | return frames, framerate
26 |
27 | def draw_pts_gpu(rgbs, trajs, visibs, colormap, rate=1, bkg_opacity=0.5):
28 | device = rgbs.device
29 | T, C, H, W = rgbs.shape
30 | trajs = trajs.permute(1,0,2) # N,T,2
31 | visibs = visibs.permute(1,0) # N,T
32 | N = trajs.shape[0]
33 | colors = torch.tensor(colormap, dtype=torch.float32, device=device) # [N,3]
34 |
35 | rgbs = rgbs * bkg_opacity # darken, to see the point tracks better
36 |
37 | opacity = 1.0
38 | if rate==1:
39 | radius = 1
40 | opacity = 0.9
41 | elif rate==2:
42 | radius = 1
43 | elif rate== 4:
44 | radius = 2
45 | elif rate== 8:
46 | radius = 4
47 | else:
48 | radius = 6
49 | sharpness = 0.15 + 0.05 * np.log2(rate)
50 |
51 | D = radius * 2 + 1
52 | y = torch.arange(D, device=device).float()[:, None] - radius
53 | x = torch.arange(D, device=device).float()[None, :] - radius
54 | dist2 = x**2 + y**2
55 | icon = torch.clamp(1 - (dist2 - (radius**2) / 2.0) / (radius * 2 * sharpness), 0, 1) # [D,D]
56 | icon = icon.view(1, D, D)
57 | dx = torch.arange(-radius, radius + 1, device=device)
58 | dy = torch.arange(-radius, radius + 1, device=device)
59 | disp_y, disp_x = torch.meshgrid(dy, dx, indexing="ij") # [D,D]
60 | for t in range(T):
61 | mask = visibs[:, t] # [N]
62 | if mask.sum() == 0:
63 | continue
64 | xy = trajs[mask, t] + 0.5 # [N,2]
65 | xy[:, 0] = xy[:, 0].clamp(0, W - 1)
66 | xy[:, 1] = xy[:, 1].clamp(0, H - 1)
67 | colors_now = colors[mask] # [N,3]
68 | N = xy.shape[0]
69 | cx = xy[:, 0].long() # [N]
70 | cy = xy[:, 1].long()
71 | x_grid = cx[:, None, None] + disp_x # [N,D,D]
72 | y_grid = cy[:, None, None] + disp_y # [N,D,D]
73 | valid = (x_grid >= 0) & (x_grid < W) & (y_grid >= 0) & (y_grid < H)
74 | x_valid = x_grid[valid] # [K]
75 | y_valid = y_grid[valid]
76 | icon_weights = icon.expand(N, D, D)[valid] # [K]
77 | colors_valid = colors_now[:, :, None, None].expand(N, 3, D, D).permute(1, 0, 2, 3)[
78 | :, valid
79 | ] # [3, K]
80 | idx_flat = (y_valid * W + x_valid).long() # [K]
81 |
82 | accum = torch.zeros_like(rgbs[t]) # [3, H, W]
83 | weight = torch.zeros(1, H * W, device=device) # [1, H*W]
84 | img_flat = accum.view(C, -1) # [3, H*W]
85 | weighted_colors = colors_valid * icon_weights # [3, K]
86 | img_flat.scatter_add_(1, idx_flat.unsqueeze(0).expand(C, -1), weighted_colors)
87 | weight.scatter_add_(1, idx_flat.unsqueeze(0), icon_weights.unsqueeze(0))
88 | weight = weight.view(1, H, W)
89 |
90 | alpha = weight.clamp(0, 1) * opacity
91 | accum = accum / (weight + 1e-6) # [3, H, W]
92 | rgbs[t] = rgbs[t] * (1 - alpha) + accum * alpha
93 | rgbs = rgbs.clamp(0, 255).byte().permute(0, 2, 3, 1).cpu().numpy() # T,H,W,3
94 | if bkg_opacity==0.0:
95 | for t in range(T):
96 | hsv_frame = cv2.cvtColor(rgbs[t], cv2.COLOR_RGB2HSV)
97 | saturation_factor = 1.5
98 | hsv_frame[..., 1] = np.clip(hsv_frame[..., 1] * saturation_factor, 0, 255)
99 | rgbs[t] = cv2.cvtColor(hsv_frame, cv2.COLOR_HSV2RGB)
100 | return rgbs
101 |
102 | def count_parameters(model):
103 | table = PrettyTable(["Modules", "Parameters"])
104 | total_params = 0
105 | for name, parameter in model.named_parameters():
106 | if not parameter.requires_grad:
107 | continue
108 | param = parameter.numel()
109 | if param > 100000:
110 | table.add_row([name, param])
111 | total_params+=param
112 | print(table)
113 | print('total params: %.2f M' % (total_params/1000000.0))
114 | return total_params
115 |
116 | def forward_video(rgbs, framerate, model, args):
117 |
118 | B,T,C,H,W = rgbs.shape
119 | assert C == 3
120 | device = rgbs.device
121 | assert(B==1)
122 |
123 | grid_xy = utils.basic.gridcloud2d(1, H, W, norm=False, device='cuda:0').float() # 1,H*W,2
124 | grid_xy = grid_xy.permute(0,2,1).reshape(1,1,2,H,W) # 1,1,2,H,W
125 |
126 | torch.cuda.empty_cache()
127 | print('starting forward...')
128 | f_start_time = time.time()
129 |
130 | flows_e, visconf_maps_e, _, _ = \
131 | model.forward_sliding(rgbs[:, args.query_frame:], iters=args.inference_iters, sw=None, is_training=False)
132 | traj_maps_e = flows_e.cuda() + grid_xy # B,Tf,2,H,W
133 | if args.query_frame > 0:
134 | backward_flows_e, backward_visconf_maps_e, _, _ = \
135 | model.forward_sliding(rgbs[:, :args.query_frame+1].flip([1]), iters=args.inference_iters, sw=None, is_training=False)
136 | backward_traj_maps_e = backward_flows_e.cuda() + grid_xy # B,Tb,2,H,W, reversed
137 | backward_traj_maps_e = backward_traj_maps_e.flip([1])[:, :-1] # flip time and drop the overlapped frame
138 | backward_visconf_maps_e = backward_visconf_maps_e.flip([1])[:, :-1] # flip time and drop the overlapped frame
139 | traj_maps_e = torch.cat([backward_traj_maps_e, traj_maps_e], dim=1) # B,T,2,H,W
140 | visconf_maps_e = torch.cat([backward_visconf_maps_e, visconf_maps_e], dim=1) # B,T,2,H,W
141 | ftime = time.time()-f_start_time
142 | print('finished forward; %.2f seconds / %d frames; %d fps' % (ftime, T, round(T/ftime)))
143 | utils.basic.print_stats('traj_maps_e', traj_maps_e)
144 | utils.basic.print_stats('visconf_maps_e', visconf_maps_e)
145 |
146 | # subsample to make the vis more readable
147 | rate = args.rate
148 | trajs_e = traj_maps_e[:,:,:,::rate,::rate].reshape(B,T,2,-1).permute(0,1,3,2) # B,T,N,2
149 | visconfs_e = visconf_maps_e[:,:,:,::rate,::rate].reshape(B,T,2,-1).permute(0,1,3,2) # B,T,N,2
150 |
151 | xy0 = trajs_e[0,0].cpu().numpy()
152 | colors = utils.improc.get_2d_colors(xy0, H, W)
153 |
154 | fn = args.mp4_path.split('/')[-1].split('.')[0]
155 | rgb_out_f = './pt_vis_%s_rate%d_q%d.mp4' % (fn, rate, args.query_frame)
156 | print('rgb_out_f', rgb_out_f)
157 | temp_dir = 'temp_pt_vis_%s_rate%d_q%d' % (fn, rate, args.query_frame)
158 | utils.basic.mkdir(temp_dir)
159 | vis = []
160 |
161 | frames = draw_pts_gpu(rgbs[0].to('cuda:0'), trajs_e[0], visconfs_e[0,:,:,1] > args.conf_thr,
162 | colors, rate=rate, bkg_opacity=args.bkg_opacity)
163 | print('frames', frames.shape)
164 |
165 | if args.vstack:
166 | frames_top = rgbs[0].clamp(0, 255).byte().permute(0, 2, 3, 1).cpu().numpy() # T,H,W,3
167 | frames = np.concatenate([frames_top, frames], axis=1)
168 | elif args.hstack:
169 | frames_left = rgbs[0].clamp(0, 255).byte().permute(0, 2, 3, 1).cpu().numpy() # T,H,W,3
170 | frames = np.concatenate([frames_left, frames], axis=2)
171 |
172 | print('writing frames to disk')
173 | f_start_time = time.time()
174 | for ti in range(T):
175 | temp_out_f = '%s/%03d.jpg' % (temp_dir, ti)
176 | im = PIL.Image.fromarray(frames[ti])
177 | im.save(temp_out_f)#, "PNG", subsampling=0, quality=80)
178 | ftime = time.time()-f_start_time
179 | print('finished writing; %.2f seconds / %d frames; %d fps' % (ftime, T, round(T/ftime)))
180 |
181 | print('writing mp4')
182 | os.system('/usr/bin/ffmpeg -y -hide_banner -loglevel error -f image2 -framerate %d -pattern_type glob -i "./%s/*.jpg" -c:v libx264 -crf 20 -pix_fmt yuv420p %s' % (framerate, temp_dir, rgb_out_f))
183 |
184 | # # flow vis
185 | # rgb_out_f = './flow_vis.mp4'
186 | # temp_dir = 'temp_flow_vis'
187 | # utils.basic.mkdir(temp_dir)
188 | # vis = []
189 | # for ti in range(T):
190 | # flow_vis = utils.improc.flow2color(flows_e[0:1,ti])
191 | # vis.append(flow_vis)
192 | # for ti in range(T):
193 | # temp_out_f = '%s/%03d.png' % (temp_dir, ti)
194 | # im = PIL.Image.fromarray(vis[ti][0].permute(1,2,0).cpu().numpy())
195 | # im.save(temp_out_f, "PNG", subsampling=0, quality=100)
196 | # os.system('/usr/bin/ffmpeg -y -hide_banner -loglevel error -f image2 -framerate 24 -pattern_type glob -i "./%s/*.png" -c:v libx264 -crf 1 -pix_fmt yuv420p %s' % (temp_dir, rgb_out_f))
197 |
198 | return None
199 |
200 | def run(model, args):
201 | log_dir = './logs_demo'
202 |
203 | global_step = 0
204 |
205 | if args.ckpt_init:
206 | _ = utils.saveload.load(
207 | None,
208 | args.ckpt_init,
209 | model,
210 | optimizer=None,
211 | scheduler=None,
212 | ignore_load=None,
213 | strict=True,
214 | verbose=False,
215 | weights_only=False,
216 | )
217 | print('loaded weights from', args.ckpt_init)
218 | else:
219 | if args.tiny:
220 | url = "https://huggingface.co/aharley/alltracker/resolve/main/alltracker_tiny.pth"
221 | else:
222 | url = "https://huggingface.co/aharley/alltracker/resolve/main/alltracker.pth"
223 | state_dict = torch.hub.load_state_dict_from_url(url, map_location='cpu')
224 | model.load_state_dict(state_dict['model'], strict=True)
225 | print('loaded weights from', url)
226 |
227 | model.cuda()
228 | for n, p in model.named_parameters():
229 | p.requires_grad = False
230 | model.eval()
231 |
232 | rgbs, framerate = read_mp4(args.mp4_path)
233 | print('rgbs[0]', rgbs[0].shape)
234 | H,W = rgbs[0].shape[:2]
235 |
236 | # shorten & shrink the video, in case the gpu is small
237 | if args.max_frames:
238 | rgbs = rgbs[:args.max_frames]
239 | scale = min(int(args.image_size)/H, int(args.image_size)/W)
240 | H, W = int(H*scale), int(W*scale)
241 | H, W = H//8 * 8, W//8 * 8 # make it divisible by 8
242 | rgbs = [cv2.resize(rgb, dsize=(W, H), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
243 | print('rgbs[0]', rgbs[0].shape)
244 |
245 | # move to gpu
246 | rgbs = [torch.from_numpy(rgb).permute(2,0,1) for rgb in rgbs]
247 | rgbs = torch.stack(rgbs, dim=0).unsqueeze(0).float() # 1,T,C,H,W
248 | print('rgbs', rgbs.shape)
249 |
250 | with torch.no_grad():
251 | metrics = forward_video(rgbs, framerate, model, args)
252 |
253 | return None
254 |
255 | if __name__ == "__main__":
256 | torch.set_grad_enabled(False)
257 |
258 | parser = argparse.ArgumentParser()
259 | parser.add_argument("--ckpt_init", type=str, default='') # the ckpt we want (else default)
260 | parser.add_argument("--mp4_path", type=str, default='./demo_video/monkey.mp4') # input video
261 | parser.add_argument("--query_frame", type=int, default=0) # which frame to track from
262 | parser.add_argument("--image_size", type=int, default=1024) # max dimension of a video frame (upsample to this)
263 | parser.add_argument("--max_frames", type=int, default=400) # trim the video to this length
264 | parser.add_argument("--inference_iters", type=int, default=4) # number of inference steps per forward
265 | parser.add_argument("--window_len", type=int, default=16) # model hyperparam
266 | parser.add_argument("--rate", type=int, default=2) # vis hyp
267 | parser.add_argument("--conf_thr", type=float, default=0.1) # vis hyp
268 | parser.add_argument("--bkg_opacity", type=float, default=0.5) # vis hyp
269 | parser.add_argument("--vstack", action='store_true', default=False) # whether to stack the input and output in the mp4
270 | parser.add_argument("--hstack", action='store_true', default=False) # whether to stack the input and output in the mp4
271 | parser.add_argument("--tiny", action='store_true', default=False) # whether to use the tiny model
272 | args = parser.parse_args()
273 |
274 | from nets.alltracker import Net;
275 | if args.tiny:
276 | model = Net(args.window_len, use_basicencoder=True, no_split=True)
277 | else:
278 | model = Net(args.window_len)
279 | count_parameters(model)
280 |
281 | run(model, args)
282 |
283 |
--------------------------------------------------------------------------------
/datasets/exportdataset.py:
--------------------------------------------------------------------------------
1 | from numpy import random
2 | import torch
3 | import numpy as np
4 | import os
5 | import random
6 | import imageio
7 | from pathlib import Path
8 | import matplotlib.pyplot as plt
9 | from utils.basic import print_stats
10 | from PIL import Image
11 | import cv2
12 | import utils.py
13 | import torch.nn.functional as F
14 | import torchvision.transforms.functional as tvF
15 | from torchvision.transforms import ColorJitter, GaussianBlur
16 | from datasets.pointdataset import PointDataset
17 |
18 | class ExportDataset(PointDataset):
19 | def __init__(self,
20 | data_root='../datasets/alltrack_export',
21 | version='bs',
22 | dsets=None,
23 | dsets_exclude=None,
24 | seq_len=64,
25 | crop_size=(384,512),
26 | shuffle_frames=False,
27 | shuffle=True,
28 | use_augs=False,
29 | is_training=True,
30 | backwards=False,
31 | traj_per_sample=256, # min number of trajs
32 | traj_max_factor=24, # multiplier on traj_per_sample
33 | random_seq_len=False,
34 | random_frame_rate=False,
35 | random_number_traj=False,
36 | only_first=False,
37 | ):
38 | super(ExportDataset, self).__init__(
39 | data_root=data_root,
40 | crop_size=crop_size,
41 | seq_len=seq_len,
42 | traj_per_sample=traj_per_sample,
43 | use_augs=use_augs,
44 | )
45 | print('loading export...')
46 |
47 | self.shuffle_frames = shuffle_frames
48 | self.pad_bounds = [10, 100]
49 | self.resize_lim = [0.25, 2.0] # sample resizes from here
50 | self.resize_delta = 0.2
51 | self.max_crop_offset = 50
52 | self.only_first = only_first
53 | self.traj_max_factor = traj_max_factor
54 |
55 | self.S = seq_len
56 |
57 | self.use_augs = use_augs
58 | self.is_training = is_training
59 |
60 | self.dataset_location = Path(data_root) / version
61 |
62 | dataset_names = self.dataset_location.glob('*/')
63 | self.dataset_names = [str(fn.stem) for fn in dataset_names]
64 | self.dataset_names = ['%s%d' % (dname, self.S) for dname in self.dataset_names]
65 | print('dataset_names', self.dataset_names)
66 |
67 | folder_names = self.dataset_location.glob('*/*/*/')
68 | folder_names = [str(fn) for fn in folder_names]
69 | # print('folder_names', folder_names)
70 |
71 | print('found {:d} {} folders in {}'.format(len(folder_names), version, self.dataset_location))
72 |
73 | if dsets is not None:
74 | print('dsets', dsets)
75 | new_folder_names = []
76 | for fn in folder_names:
77 | for dset in dsets:
78 | if dset in fn:
79 | new_folder_names.append(fn)
80 | break
81 | folder_names = new_folder_names
82 | print('filtered to %d folders' % len(folder_names))
83 |
84 | if backwards:
85 | new_folder_names = []
86 | for fn in folder_names:
87 | chunk = fn.split('/')[-2]
88 | if 'b' in chunk:
89 | new_folder_names.append(fn)
90 | folder_names = new_folder_names
91 | print('filtered to %d folders with backward motion' % len(folder_names))
92 |
93 | if dsets_exclude is not None:
94 | print('dsets_exclude', dsets_exclude)
95 | new_folder_names = []
96 | for fn in folder_names:
97 | keep = True
98 | for dset in dsets_exclude:
99 | if dset in fn:
100 | keep = False
101 | break
102 | if keep:
103 | new_folder_names.append(fn)
104 | folder_names = new_folder_names
105 | print('filtered to %d folders' % len(folder_names))
106 |
107 | # if quick:
108 | # folder_names = sorted(folder_names)
109 | # folder_names = folder_names[:201]
110 | # print('folder_names', folder_names)
111 |
112 | if shuffle:
113 | random.shuffle(folder_names)
114 | else:
115 | folder_names = sorted(list(folder_names))
116 |
117 | self.all_folders = folder_names
118 | # # step through once and make sure all of the npys are there
119 | # print('stepping through...')
120 | # self.all_folders = []
121 | # for fi, fol in enumerate(folder_names):
122 | # npy_path = os.path.join(fol, "annot.npy")
123 | # rgb_path = os.path.join(fol, "frames")
124 | # if os.path.isdir(rgb_path) and os.path.isfile(npy_path):
125 | # img_paths = sorted(os.listdir(rgb_path))
126 | # if len(img_paths)>=self.S:
127 | # self.all_folders.append(fol)
128 | # else:
129 | # pass
130 | # else:
131 | # pass
132 | # print('ok done stepping; got %d' % len(self.all_folders))
133 |
134 |
135 | def getitem_helper(self, index):
136 | # cH, cW = self.cH, self.cW
137 |
138 | fol = self.all_folders[index]
139 | npy_path = os.path.join(fol, "annot.npy")
140 | rgb_path = os.path.join(fol, "frames")
141 |
142 | mid = str(fol)[len(str(self.dataset_location))+1:]
143 | dname = mid.split('/')[0]
144 | # print('dname', dname)
145 |
146 | img_paths = sorted(os.listdir(rgb_path))
147 | rgbs = []
148 | try:
149 | for i, img_path in enumerate(img_paths):
150 | rgbs.append(imageio.v2.imread(os.path.join(rgb_path, img_path)))
151 | except:
152 | print('some exception when reading rgbs')
153 |
154 | if len(rgbs) self.S:
189 | surplus = trajs.shape[0] - self.S
190 | ind = np.random.randint(surplus)+1
191 | rgbs = rgbs[ind:ind+self.S]
192 | trajs = trajs[ind:ind+self.S]
193 | visibs = visibs[ind:ind+self.S]
194 | assert(trajs.shape[0] == self.S)
195 |
196 | if self.only_first:
197 | vis_ok = np.nonzero(visibs[0]==1)[0]
198 | trajs = trajs[:,vis_ok]
199 | visibs = visibs[:,vis_ok]
200 |
201 | N = trajs.shape[1]
202 | if N < self.traj_per_sample:
203 | print('exp: %s; N after vis0: %d' % (dname, N))
204 | return None, False
205 |
206 | # print('rgbs', rgbs.shape)
207 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
208 | scale = 0.5
209 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
210 | H, W = rgbs[0].shape[:2]
211 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
212 | trajs = trajs * scale
213 | # print('resized rgbs', rgbs.shape)
214 |
215 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
216 | scale = 0.5
217 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
218 | H, W = rgbs[0].shape[:2]
219 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
220 | trajs = trajs * scale
221 | # print('resized rgbs', rgbs.shape)
222 |
223 | if self.use_augs and np.random.rand() < 0.98:
224 | rgbs, trajs, visibs = self.add_photometric_augs(
225 | rgbs, trajs, visibs, replace=False,
226 | )
227 | if np.random.rand() < 0.2:
228 | rgbs, trajs = self.add_spatial_augs(rgbs, trajs, visibs, self.crop_size)
229 | else:
230 | rgbs, trajs = self.follow_crop(rgbs, trajs, visibs, self.crop_size)
231 | if np.random.rand() < self.rot_prob:
232 | # note this is OK since B==1
233 | # otw we would do it before this func
234 | rgbs = [np.transpose(rgb, (1,0,2)).copy() for rgb in rgbs]
235 | rgbs = np.stack(rgbs)
236 | trajs = np.flip(trajs, axis=2).copy()
237 | H, W = rgbs[0].shape[:2]
238 | if np.random.rand() < self.h_flip_prob:
239 | rgbs = [rgb[:, ::-1].copy() for rgb in rgbs]
240 | trajs[:, :, 0] = W - trajs[:, :, 0]
241 | rgbs = np.stack(rgbs)
242 | if np.random.rand() < self.v_flip_prob:
243 | rgbs = [rgb[::-1].copy() for rgb in rgbs]
244 | trajs[:, :, 1] = H - trajs[:, :, 1]
245 | rgbs = np.stack(rgbs)
246 | else:
247 | rgbs, trajs = self.crop(rgbs, trajs, self.crop_size)
248 |
249 | if self.shuffle_frames and np.random.rand() < 0.01:
250 | # shuffle the frames (again)
251 | perm = np.random.permutation(rgbs.shape[0])
252 | rgbs = rgbs[perm]
253 | trajs = trajs[perm]
254 | visibs = visibs[perm]
255 |
256 | H,W = rgbs[0].shape[:2]
257 |
258 | visibs[trajs[:, :, 0] > W-1] = False
259 | visibs[trajs[:, :, 0] < 0] = False
260 | visibs[trajs[:, :, 1] > H-1] = False
261 | visibs[trajs[:, :, 1] < 0] = False
262 |
263 | N = trajs.shape[1]
264 | # print('N8', N)
265 |
266 | # ensure no crazy values
267 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs), axis=-1)<100000, axis=0)==self.S)[0]
268 | trajs = trajs[:,all_valid]
269 | visibs = visibs[:,all_valid]
270 |
271 | if self.only_first:
272 | vis_ok = np.nonzero(visibs[0]==1)[0]
273 | trajs = trajs[:,vis_ok]
274 | visibs = visibs[:,vis_ok]
275 | N = trajs.shape[1]
276 |
277 | if N < self.traj_per_sample:
278 | print('exp: %s; N after aug: %d' % (dname, N))
279 | return None, False
280 |
281 | N = trajs.shape[1]
282 |
283 | seq_len = S
284 | visibs = torch.from_numpy(visibs)
285 | trajs = torch.from_numpy(trajs)
286 |
287 | # discard tracks that go far OOB
288 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
289 | close_pts_inds = torch.all(
290 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
291 | dim=0,
292 | )
293 | trajs = trajs[:, close_pts_inds]
294 | visibs = visibs[:, close_pts_inds]
295 |
296 | visible_pts_inds = (visibs[0]).nonzero(as_tuple=False)[:, 0]
297 | point_inds = torch.randperm(len(visible_pts_inds))[:self.traj_per_sample*self.traj_max_factor]
298 | if len(point_inds) < self.traj_per_sample:
299 | # print('not enough trajs')
300 | # gotit = False
301 | return None, False
302 |
303 | visible_inds_sampled = visible_pts_inds[point_inds]
304 |
305 | trajs = trajs[:, visible_inds_sampled].float()
306 | visibs = visibs[:, visible_inds_sampled].float()
307 | valids = torch.ones_like(visibs).float()
308 |
309 | trajs = trajs[:, :self.traj_per_sample*self.traj_max_factor]
310 | visibs = visibs[:, :self.traj_per_sample*self.traj_max_factor]
311 | valids = valids[:, :self.traj_per_sample*self.traj_max_factor]
312 |
313 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
314 |
315 | dname += '%d' % (self.S)
316 |
317 | sample = utils.data.VideoData(
318 | video=rgbs,
319 | trajs=trajs,
320 | visibs=visibs,
321 | valids=valids,
322 | seq_name=None,
323 | dname=dname,
324 | )
325 | return sample, True
326 |
327 | def __len__(self):
328 | return len(self.all_folders)
329 |
--------------------------------------------------------------------------------
/datasets/pointdataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import cv2
4 | import imageio
5 | import numpy as np
6 | from torchvision.transforms import ColorJitter, GaussianBlur
7 | from PIL import Image
8 | import utils.data
9 |
10 | class PointDataset(torch.utils.data.Dataset):
11 | def __init__(
12 | self,
13 | data_root,
14 | crop_size=(384, 512),
15 | seq_len=24,
16 | traj_per_sample=768,
17 | use_augs=False,
18 | ):
19 | super(PointDataset, self).__init__()
20 | self.data_root = data_root
21 | self.seq_len = seq_len
22 | self.traj_per_sample = traj_per_sample
23 | self.use_augs = use_augs
24 | # photometric augmentation
25 | self.photo_aug = ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.25 / 3.14)
26 | self.blur_aug = GaussianBlur(11, sigma=(0.1, 2.0))
27 | self.blur_aug_prob = 0.25
28 | self.color_aug_prob = 0.25
29 |
30 | # occlusion augmentation
31 | self.eraser_aug_prob = 0.5
32 | self.eraser_bounds = [2, 100]
33 | self.eraser_max = 10
34 |
35 | # occlusion augmentation
36 | self.replace_aug_prob = 0.5
37 | self.replace_bounds = [2, 100]
38 | self.replace_max = 10
39 |
40 | # spatial augmentations
41 | self.pad_bounds = [10, 100]
42 | self.crop_size = crop_size
43 | self.resize_lim = [0.25, 2.0] # sample resizes from here
44 | self.resize_delta = 0.2
45 | self.max_crop_offset = 50
46 |
47 | self.h_flip_prob = 0.5
48 | self.v_flip_prob = 0.5
49 | self.rot_prob = 0.5
50 |
51 | def getitem_helper(self, index):
52 | return NotImplementedError
53 |
54 | def __getitem__(self, index):
55 | gotit = False
56 | fails = 0
57 | while not gotit and fails < 4:
58 | sample, gotit = self.getitem_helper(index)
59 | if gotit:
60 | return sample, gotit
61 | else:
62 | fails += 1
63 | index = np.random.randint(len(self))
64 | del sample
65 | if fails > 1:
66 | print('note: sampling failed %d times' % fails)
67 |
68 | if self.seq_len is not None:
69 | S = self.seq_len
70 | else:
71 | S = 11
72 | # fake sample, so we can still collate
73 | sample = utils.data.VideoData(
74 | video=torch.zeros((S, 3, self.crop_size[0], self.crop_size[1])),
75 | trajs=torch.zeros((S, self.traj_per_sample, 2)),
76 | visibs=torch.zeros((S, self.traj_per_sample)),
77 | valids=torch.zeros((S, self.traj_per_sample)),
78 | )
79 | return sample, gotit
80 |
81 | def add_photometric_augs(self, rgbs, trajs, visibles, eraser=True, replace=True, augscale=1.0):
82 | T, N, _ = trajs.shape
83 |
84 | S = len(rgbs)
85 | H, W = rgbs[0].shape[:2]
86 | assert S == T
87 |
88 | if eraser:
89 | ############ eraser transform (per image after the first) ############
90 | eraser_bounds = [eb*augscale for eb in self.eraser_bounds]
91 | rgbs = [rgb.astype(np.float32) for rgb in rgbs]
92 | for i in range(1, S):
93 | if np.random.rand() < self.eraser_aug_prob:
94 | for _ in range(np.random.randint(1, self.eraser_max + 1)):
95 | # number of times to occlude
96 | xc = np.random.randint(0, W)
97 | yc = np.random.randint(0, H)
98 | dx = np.random.randint(eraser_bounds[0], eraser_bounds[1])
99 | dy = np.random.randint(eraser_bounds[0], eraser_bounds[1])
100 | x0 = np.clip(xc - dx / 2, 0, W - 1).round().astype(np.int32)
101 | x1 = np.clip(xc + dx / 2, 0, W - 1).round().astype(np.int32)
102 | y0 = np.clip(yc - dy / 2, 0, H - 1).round().astype(np.int32)
103 | y1 = np.clip(yc + dy / 2, 0, H - 1).round().astype(np.int32)
104 |
105 | mean_color = np.mean(
106 | rgbs[i][y0:y1, x0:x1, :].reshape(-1, 3), axis=0
107 | )
108 | rgbs[i][y0:y1, x0:x1, :] = mean_color
109 |
110 | occ_inds = np.logical_and(
111 | np.logical_and(trajs[i, :, 0] >= x0, trajs[i, :, 0] < x1),
112 | np.logical_and(trajs[i, :, 1] >= y0, trajs[i, :, 1] < y1),
113 | )
114 | visibles[i, occ_inds] = 0
115 | rgbs = [rgb.astype(np.uint8) for rgb in rgbs]
116 |
117 | if replace:
118 | rgbs_alt = [np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
119 | rgbs_alt = [np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs_alt]
120 |
121 | ############ replace transform (per image after the first) ############
122 | rgbs = [rgb.astype(np.float32) for rgb in rgbs]
123 | rgbs_alt = [rgb.astype(np.float32) for rgb in rgbs_alt]
124 | replace_bounds = [rb*augscale for rb in self.replace_bounds]
125 | for i in range(1, S):
126 | if np.random.rand() < self.replace_aug_prob:
127 | for _ in range(
128 | np.random.randint(1, self.replace_max + 1)
129 | ): # number of times to occlude
130 | xc = np.random.randint(0, W)
131 | yc = np.random.randint(0, H)
132 | dx = np.random.randint(replace_bounds[0], replace_bounds[1])
133 | dy = np.random.randint(replace_bounds[0], replace_bounds[1])
134 | x0 = np.clip(xc - dx / 2, 0, W - 1).round().astype(np.int32)
135 | x1 = np.clip(xc + dx / 2, 0, W - 1).round().astype(np.int32)
136 | y0 = np.clip(yc - dy / 2, 0, H - 1).round().astype(np.int32)
137 | y1 = np.clip(yc + dy / 2, 0, H - 1).round().astype(np.int32)
138 |
139 | wid = x1 - x0
140 | hei = y1 - y0
141 | y00 = np.random.randint(0, H - hei)
142 | x00 = np.random.randint(0, W - wid)
143 | fr = np.random.randint(0, S)
144 | rep = rgbs_alt[fr][y00 : y00 + hei, x00 : x00 + wid, :]
145 | rgbs[i][y0:y1, x0:x1, :] = rep
146 |
147 | occ_inds = np.logical_and(
148 | np.logical_and(trajs[i, :, 0] >= x0, trajs[i, :, 0] < x1),
149 | np.logical_and(trajs[i, :, 1] >= y0, trajs[i, :, 1] < y1),
150 | )
151 | visibles[i, occ_inds] = 0
152 | rgbs = [rgb.astype(np.uint8) for rgb in rgbs]
153 |
154 | ############ photometric augmentation ############
155 | if np.random.rand() < self.color_aug_prob:
156 | # random per-frame amount of aug
157 | rgbs = [np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
158 |
159 | if np.random.rand() < self.blur_aug_prob:
160 | # random per-frame amount of blur
161 | rgbs = [np.array(self.blur_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
162 |
163 | return rgbs, trajs, visibles
164 |
165 |
166 | def add_spatial_augs(self, rgbs, trajs, visibles, crop_size, augscale=1.0):
167 | T, N, __ = trajs.shape
168 |
169 | S = len(rgbs)
170 | H, W = rgbs[0].shape[:2]
171 | assert S == T
172 |
173 | rgbs = [rgb.astype(np.float32) for rgb in rgbs]
174 |
175 | trajs = trajs.astype(np.float64)
176 |
177 | target_H, target_W = crop_size
178 | if target_H > H or target_W > W:
179 | scale = max(target_H / H, target_W / W)
180 | new_H, new_W = int(np.ceil(H * scale)), int(np.ceil(W * scale))
181 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
182 | trajs = trajs * scale
183 |
184 | ############ spatial transform ############
185 |
186 | # padding
187 | pad_bounds = [int(pb*augscale) for pb in self.pad_bounds]
188 | pad_x0 = np.random.randint(pad_bounds[0], pad_bounds[1])
189 | pad_x1 = np.random.randint(pad_bounds[0], pad_bounds[1])
190 | pad_y0 = np.random.randint(pad_bounds[0], pad_bounds[1])
191 | pad_y1 = np.random.randint(pad_bounds[0], pad_bounds[1])
192 |
193 | rgbs = [np.pad(rgb, ((pad_y0, pad_y1), (pad_x0, pad_x1), (0, 0))) for rgb in rgbs]
194 | trajs[:, :, 0] += pad_x0
195 | trajs[:, :, 1] += pad_y0
196 | H, W = rgbs[0].shape[:2]
197 |
198 | # scaling + stretching
199 | scale = np.random.uniform(self.resize_lim[0], self.resize_lim[1])
200 | scale_x = scale
201 | scale_y = scale
202 | H_new = H
203 | W_new = W
204 |
205 | scale_delta_x = 0.0
206 | scale_delta_y = 0.0
207 |
208 | rgbs_scaled = []
209 | resize_delta = self.resize_delta * augscale
210 | for s in range(S):
211 | if s == 1:
212 | scale_delta_x = np.random.uniform(-resize_delta, resize_delta)
213 | scale_delta_y = np.random.uniform(-resize_delta, resize_delta)
214 | elif s > 1:
215 | scale_delta_x = (
216 | scale_delta_x * 0.8
217 | + np.random.uniform(-resize_delta, resize_delta) * 0.2
218 | )
219 | scale_delta_y = (
220 | scale_delta_y * 0.8
221 | + np.random.uniform(-resize_delta, resize_delta) * 0.2
222 | )
223 | scale_x = scale_x + scale_delta_x
224 | scale_y = scale_y + scale_delta_y
225 |
226 | # bring h/w closer
227 | scale_xy = (scale_x + scale_y) * 0.5
228 | scale_x = scale_x * 0.5 + scale_xy * 0.5
229 | scale_y = scale_y * 0.5 + scale_xy * 0.5
230 |
231 | # don't get too crazy
232 | scale_x = np.clip(scale_x, 0.2, 2.0)
233 | scale_y = np.clip(scale_y, 0.2, 2.0)
234 |
235 | H_new = int(H * scale_y)
236 | W_new = int(W * scale_x)
237 |
238 | # make it at least slightly bigger than the crop area,
239 | # so that the random cropping can add diversity
240 | H_new = np.clip(H_new, crop_size[0] + 10, None)
241 | W_new = np.clip(W_new, crop_size[1] + 10, None)
242 | # recompute scale in case we clipped
243 | scale_x = (W_new - 1) / float(W - 1)
244 | scale_y = (H_new - 1) / float(H - 1)
245 | rgbs_scaled.append(
246 | cv2.resize(rgbs[s], (W_new, H_new), interpolation=cv2.INTER_LINEAR)
247 | )
248 | trajs[s, :, 0] *= scale_x
249 | trajs[s, :, 1] *= scale_y
250 | rgbs = rgbs_scaled
251 | ok_inds = visibles[0, :] > 0
252 | vis_trajs = trajs[:, ok_inds] # S,?,2
253 |
254 | if vis_trajs.shape[1] > 0:
255 | mid_x = np.mean(vis_trajs[0, :, 0])
256 | mid_y = np.mean(vis_trajs[0, :, 1])
257 | else:
258 | mid_y = crop_size[0]
259 | mid_x = crop_size[1]
260 |
261 | x0 = int(mid_x - crop_size[1] // 2)
262 | y0 = int(mid_y - crop_size[0] // 2)
263 |
264 | offset_x = 0
265 | offset_y = 0
266 | max_crop_offset = int(self.max_crop_offset*augscale)
267 |
268 | for s in range(S):
269 | # on each frame, shift a bit more
270 | if s == 1:
271 | offset_x = np.random.randint(-max_crop_offset, max_crop_offset)
272 | offset_y = np.random.randint(-max_crop_offset, max_crop_offset)
273 | elif s > 1:
274 | offset_x = int(
275 | offset_x * 0.8
276 | + np.random.randint(-max_crop_offset, max_crop_offset + 1)
277 | * 0.2
278 | )
279 | offset_y = int(
280 | offset_y * 0.8
281 | + np.random.randint(-max_crop_offset, max_crop_offset + 1)
282 | * 0.2
283 | )
284 | x0 = x0 + offset_x
285 | y0 = y0 + offset_y
286 |
287 | H_new, W_new = rgbs[s].shape[:2]
288 | if H_new == crop_size[0]:
289 | y0 = 0
290 | else:
291 | y0 = min(max(0, y0), H_new - crop_size[0] - 1)
292 |
293 | if W_new == crop_size[1]:
294 | x0 = 0
295 | else:
296 | x0 = min(max(0, x0), W_new - crop_size[1] - 1)
297 |
298 | rgbs[s] = rgbs[s][y0 : y0 + crop_size[0], x0 : x0 + crop_size[1]]
299 | trajs[s, :, 0] -= x0
300 | trajs[s, :, 1] -= y0
301 |
302 | H = crop_size[0]
303 | W = crop_size[1]
304 |
305 | if np.random.rand() < self.h_flip_prob:
306 | rgbs = [rgb[:, ::-1].copy() for rgb in rgbs]
307 | trajs[:, :, 0] = W-1 - trajs[:, :, 0]
308 | if np.random.rand() < self.v_flip_prob:
309 | rgbs = [rgb[::-1].copy() for rgb in rgbs]
310 | trajs[:, :, 1] = H-1 - trajs[:, :, 1]
311 | return np.stack(rgbs), trajs.astype(np.float32)
312 |
313 | def crop(self, rgbs, trajs, crop_size):
314 | T, N, _ = trajs.shape
315 |
316 | S = len(rgbs)
317 | H, W = rgbs[0].shape[:2]
318 | assert S == T
319 |
320 | target_H, target_W = crop_size
321 | if target_H > H or target_W > W:
322 | scale = max(target_H / H, target_W / W)
323 | new_H, new_W = int(np.ceil(H * scale)), int(np.ceil(W * scale))
324 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
325 | trajs = trajs * scale
326 | H, W = rgbs[0].shape[:2]
327 |
328 | # simple random crop
329 | y0 = 0 if crop_size[0] >= H else (H - crop_size[0]) // 2
330 | x0 = 0 if crop_size[1] >= W else np.random.randint(0, W - crop_size[1])
331 | rgbs = [rgb[y0 : y0 + crop_size[0], x0 : x0 + crop_size[1]] for rgb in rgbs]
332 |
333 | trajs[:, :, 0] -= x0
334 | trajs[:, :, 1] -= y0
335 |
336 | return np.stack(rgbs), trajs
337 |
338 | def follow_crop(self, rgbs, trajs, visibs, crop_size):
339 | T, N, _ = trajs.shape
340 |
341 | rgbs = [rgb for rgb in rgbs] # unstack so we can change them one by one
342 |
343 | S = len(rgbs)
344 | H, W = rgbs[0].shape[:2]
345 | assert S == T
346 |
347 | vels = trajs[1:]-trajs[:-1]
348 | accels = vels[1:]-vels[:-1]
349 | vis_ = visibs[1:]*visibs[:-1]
350 | vis__ = vis_[1:]*vis_[:-1]
351 | travel = np.sum(np.sum(np.abs(accels)*vis__[:,:,None], axis=2), axis=0)
352 | num_interesting = np.sum(travel > 0).round()
353 | inds = np.argsort(-travel)[:max(num_interesting//32,32)]
354 |
355 | trajs_interesting = trajs[:,inds] # S,?,2
356 |
357 | # pick a random one to focus on, for variety
358 | smooth_xys = trajs_interesting[:,np.random.randint(len(inds))]
359 |
360 | crop_H, crop_W = crop_size
361 |
362 | smooth_xys = np.clip(smooth_xys, [crop_W // 2, crop_H // 2], [W - crop_W // 2, H - crop_H // 2])
363 |
364 | def smooth_path(xys, num_passes):
365 | kernel = np.array([0.25, 0.5, 0.25])
366 | for _ in range(num_passes):
367 | padded = np.pad(xys, ((1, 1), (0, 0)), mode='edge')
368 | xys = (
369 | kernel[0] * padded[:-2] +
370 | kernel[1] * padded[1:-1] +
371 | kernel[2] * padded[2:]
372 | )
373 | return xys
374 | num_passes = np.random.randint(4, S) # 1 is perfect follow; S is near linear
375 | smooth_xys = smooth_path(smooth_xys, num_passes)
376 |
377 | for si in range(S):
378 | x0, y0 = smooth_xys[si].round().astype(np.int32)
379 | x0 -= crop_W//2
380 | y0 -= crop_H//2
381 | rgbs[si] = rgbs[si][y0:y0+crop_H, x0:x0+crop_W]
382 | trajs[si,:,0] -= x0
383 | trajs[si,:,1] -= y0
384 |
385 | return np.stack(rgbs), trajs
386 |
387 |
--------------------------------------------------------------------------------
/datasets/dynrep_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gzip
3 | import torch
4 | import numpy as np
5 | import torch.utils.data as data
6 | from collections import defaultdict
7 | from typing import List, Optional, Any, Dict, Tuple, IO, TypeVar, Type, get_args, get_origin, Union, Any
8 | from datasets.pointdataset import PointDataset
9 | import json
10 | import dataclasses
11 | from dataclasses import dataclass, Field, MISSING
12 | import utils.data
13 | import cv2
14 | import random
15 |
16 | _X = TypeVar("_X")
17 |
18 |
19 | def load_dataclass(f: IO, cls: Type[_X], binary: bool = False) -> _X:
20 | """
21 | Loads to a @dataclass or collection hierarchy including dataclasses
22 | from a json recursively.
23 | Call it like load_dataclass(f, typing.List[FrameAnnotationAnnotation]).
24 | raises KeyError if json has keys not mapping to the dataclass fields.
25 |
26 | Args:
27 | f: Either a path to a file, or a file opened for writing.
28 | cls: The class of the loaded dataclass.
29 | binary: Set to True if `f` is a file handle, else False.
30 | """
31 | if binary:
32 | asdict = json.loads(f.read().decode("utf8"))
33 | else:
34 | asdict = json.load(f)
35 |
36 | # in the list case, run a faster "vectorized" version
37 | cls = get_args(cls)[0]
38 | res = list(_dataclass_list_from_dict_list(asdict, cls))
39 |
40 | return res
41 |
42 |
43 | def _resolve_optional(type_: Any) -> Tuple[bool, Any]:
44 | """Check whether `type_` is equivalent to `typing.Optional[T]` for some T."""
45 | if get_origin(type_) is Union:
46 | args = get_args(type_)
47 | if len(args) == 2 and args[1] == type(None): # noqa E721
48 | return True, args[0]
49 | if type_ is Any:
50 | return True, Any
51 |
52 | return False, type_
53 |
54 |
55 | def _unwrap_type(tp):
56 | # strips Optional wrapper, if any
57 | if get_origin(tp) is Union:
58 | args = get_args(tp)
59 | if len(args) == 2 and any(a is type(None) for a in args): # noqa: E721
60 | # this is typing.Optional
61 | return args[0] if args[1] is type(None) else args[1] # noqa: E721
62 | return tp
63 |
64 |
65 | def _get_dataclass_field_default(field: Field) -> Any:
66 | if field.default_factory is not MISSING:
67 | # pyre-fixme[29]: `Union[dataclasses._MISSING_TYPE,
68 | # dataclasses._DefaultFactory[typing.Any]]` is not a function.
69 | return field.default_factory()
70 | elif field.default is not MISSING:
71 | return field.default
72 | else:
73 | return None
74 |
75 |
76 | def _dataclass_list_from_dict_list(dlist, typeannot):
77 | """
78 | Vectorised version of `_dataclass_from_dict`.
79 | The output should be equivalent to
80 | `[_dataclass_from_dict(d, typeannot) for d in dlist]`.
81 |
82 | Args:
83 | dlist: list of objects to convert.
84 | typeannot: type of each of those objects.
85 | Returns:
86 | iterator or list over converted objects of the same length as `dlist`.
87 |
88 | Raises:
89 | ValueError: it assumes the objects have None's in consistent places across
90 | objects, otherwise it would ignore some values. This generally holds for
91 | auto-generated annotations, but otherwise use `_dataclass_from_dict`.
92 | """
93 |
94 | cls = get_origin(typeannot) or typeannot
95 |
96 | if typeannot is Any:
97 | return dlist
98 | if all(obj is None for obj in dlist): # 1st recursion base: all None nodes
99 | return dlist
100 | if any(obj is None for obj in dlist):
101 | # filter out Nones and recurse on the resulting list
102 | idx_notnone = [(i, obj) for i, obj in enumerate(dlist) if obj is not None]
103 | idx, notnone = zip(*idx_notnone)
104 | converted = _dataclass_list_from_dict_list(notnone, typeannot)
105 | res = [None] * len(dlist)
106 | for i, obj in zip(idx, converted):
107 | res[i] = obj
108 | return res
109 |
110 | is_optional, contained_type = _resolve_optional(typeannot)
111 | if is_optional:
112 | return _dataclass_list_from_dict_list(dlist, contained_type)
113 |
114 | # otherwise, we dispatch by the type of the provided annotation to convert to
115 | if issubclass(cls, tuple) and hasattr(cls, "_fields"): # namedtuple
116 | # For namedtuple, call the function recursively on the lists of corresponding keys
117 | types = cls.__annotations__.values()
118 | dlist_T = zip(*dlist)
119 | res_T = [
120 | _dataclass_list_from_dict_list(key_list, tp) for key_list, tp in zip(dlist_T, types)
121 | ]
122 | return [cls(*converted_as_tuple) for converted_as_tuple in zip(*res_T)]
123 | elif issubclass(cls, (list, tuple)):
124 | # For list/tuple, call the function recursively on the lists of corresponding positions
125 | types = get_args(typeannot)
126 | if len(types) == 1: # probably List; replicate for all items
127 | types = types * len(dlist[0])
128 | dlist_T = zip(*dlist)
129 | res_T = (
130 | _dataclass_list_from_dict_list(pos_list, tp) for pos_list, tp in zip(dlist_T, types)
131 | )
132 | if issubclass(cls, tuple):
133 | return list(zip(*res_T))
134 | else:
135 | return [cls(converted_as_tuple) for converted_as_tuple in zip(*res_T)]
136 | elif issubclass(cls, dict):
137 | # For the dictionary, call the function recursively on concatenated keys and vertices
138 | key_t, val_t = get_args(typeannot)
139 | all_keys_res = _dataclass_list_from_dict_list(
140 | [k for obj in dlist for k in obj.keys()], key_t
141 | )
142 | all_vals_res = _dataclass_list_from_dict_list(
143 | [k for obj in dlist for k in obj.values()], val_t
144 | )
145 | indices = np.cumsum([len(obj) for obj in dlist])
146 | assert indices[-1] == len(all_keys_res)
147 |
148 | keys = np.split(list(all_keys_res), indices[:-1])
149 | all_vals_res_iter = iter(all_vals_res)
150 | return [cls(zip(k, all_vals_res_iter)) for k in keys]
151 | elif not dataclasses.is_dataclass(typeannot):
152 | return dlist
153 |
154 | # dataclass node: 2nd recursion base; call the function recursively on the lists
155 | # of the corresponding fields
156 | assert dataclasses.is_dataclass(cls)
157 | fieldtypes = {
158 | f.name: (_unwrap_type(f.type), _get_dataclass_field_default(f))
159 | for f in dataclasses.fields(typeannot)
160 | }
161 |
162 | # NOTE the default object is shared here
163 | key_lists = (
164 | _dataclass_list_from_dict_list([obj.get(k, default) for obj in dlist], type_)
165 | for k, (type_, default) in fieldtypes.items()
166 | )
167 | transposed = zip(*key_lists)
168 | return [cls(*vals_as_tuple) for vals_as_tuple in transposed]
169 |
170 |
171 | @dataclass
172 | class ImageAnnotation:
173 | # path to jpg file, relative w.r.t. dataset_root
174 | path: str
175 | # H x W
176 | size: Tuple[int, int]
177 |
178 | @dataclass
179 | class DynamicReplicaFrameAnnotation:
180 | """A dataclass used to load annotations from json."""
181 |
182 | # can be used to join with `SequenceAnnotation`
183 | sequence_name: str
184 | # 0-based, continuous frame number within sequence
185 | frame_number: int
186 | # timestamp in seconds from the video start
187 | frame_timestamp: float
188 |
189 | image: ImageAnnotation
190 | meta: Optional[Dict[str, Any]] = None
191 |
192 | camera_name: Optional[str] = None
193 | trajectories: Optional[str] = None
194 |
195 |
196 | class DynamicReplicaDataset(PointDataset):
197 | def __init__(
198 | self,
199 | data_root,
200 | split="train",
201 | traj_per_sample=256,
202 | traj_max_factor=24, # multiplier on traj_per_sample
203 | crop_size=None,
204 | use_augs=False,
205 | seq_len=64,
206 | strides=[2,3],
207 | shuffle_frames=False,
208 | shuffle=False,
209 | only_first=False,
210 | ):
211 | super(DynamicReplicaDataset, self).__init__(
212 | data_root=data_root,
213 | crop_size=crop_size,
214 | seq_len=seq_len,
215 | traj_per_sample=traj_per_sample,
216 | use_augs=use_augs,
217 | )
218 | print('loading dynamicreplica dataset...')
219 | self.data_root = data_root
220 | self.only_first = only_first
221 | self.traj_max_factor = traj_max_factor
222 | self.seq_len = seq_len
223 | self.split = split
224 | self.traj_per_sample = traj_per_sample
225 | self.crop_size = crop_size
226 | self.shuffle_frames = shuffle_frames
227 | frame_annotations_file = f"frame_annotations_{split}.jgz"
228 | self.sample_list = []
229 | with gzip.open(
230 | os.path.join(data_root, split, frame_annotations_file), "rt", encoding="utf8"
231 | ) as zipfile:
232 | frame_annots_list = load_dataclass(zipfile, List[DynamicReplicaFrameAnnotation])
233 | seq_annot = defaultdict(list)
234 | for frame_annot in frame_annots_list:
235 | if frame_annot.camera_name == "left":
236 | seq_annot[frame_annot.sequence_name].append(frame_annot)
237 | # if os.path.isfile(traj_2d_file) and os.path.isfile(visib_file) and os.path.isfile(valid_file):
238 | # self.sequences.append(seq)
239 |
240 | clip_step = 64
241 |
242 | for seq_name in seq_annot.keys():
243 | S_local = len(seq_annot[seq_name])
244 | # print(seq_name, 'S_local', S_local)
245 |
246 | traj_path = os.path.join(self.data_root, self.split, seq_annot[seq_name][0].trajectories['path'])
247 | if os.path.isfile(traj_path):
248 | for stride in strides:
249 | for ref_idx in range(0, S_local-seq_len*stride, clip_step):
250 | full_idx = ref_idx + np.arange(seq_len)*stride
251 | full_idx = [ij for ij in full_idx if ij < S_local]
252 | full_idx = np.array(full_idx).astype(np.int32)
253 | if len(full_idx)==seq_len:
254 | sample = [seq_annot[seq_name][fi] for fi in full_idx]
255 | self.sample_list.append(sample)
256 | print('found %d unique videos in %s (split=%s)' % (len(self.sample_list), data_root, split))
257 | self.dname = 'dynrep%d' % seq_len
258 |
259 | if shuffle:
260 | random.shuffle(self.sample_list)
261 |
262 | def __len__(self):
263 | return len(self.sample_list)
264 |
265 | def getitem_helper(self, index):
266 | sample = self.sample_list[index]
267 | T = len(sample)
268 | rgbs, visibs, trajs = [], [], []
269 |
270 | H, W = sample[0].image.size
271 | image_size = (H, W)
272 |
273 | for i in range(T):
274 | traj_path = os.path.join(self.data_root, self.split, sample[i].trajectories["path"])
275 | traj = torch.load(traj_path, weights_only=False)
276 |
277 | visibs.append(traj["verts_inds_vis"].numpy())
278 |
279 | rgbs.append(traj["img"].numpy())
280 | trajs.append(traj["traj_2d"].numpy()[..., :2])
281 |
282 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
283 | trajs = np.stack(trajs)
284 | visibs = np.stack(visibs)
285 | T, N, D = trajs.shape
286 |
287 | H,W = rgbs[0].shape[:2]
288 | visibs[trajs[:, :, 0] > W-1] = False
289 | visibs[trajs[:, :, 0] < 0] = False
290 | visibs[trajs[:, :, 1] > H-1] = False
291 | visibs[trajs[:, :, 1] < 0] = False
292 |
293 |
294 | if self.use_augs and np.random.rand() < 0.5:
295 | # time flip
296 | rgbs = np.flip(rgbs, axis=[0]).copy()
297 | trajs = np.flip(trajs, axis=[0]).copy()
298 | visibs = np.flip(visibs, axis=[0]).copy()
299 |
300 | if self.shuffle_frames and np.random.rand() < 0.01:
301 | # shuffle the frames
302 | perm = np.random.permutation(rgbs.shape[0])
303 | rgbs = rgbs[perm]
304 | trajs = trajs[perm]
305 | visibs = visibs[perm]
306 |
307 | assert(trajs.shape[0] == self.seq_len)
308 |
309 | if self.only_first:
310 | vis_ok = np.nonzero(visibs[0]==1)[0]
311 | trajs = trajs[:,vis_ok]
312 | visibs = visibs[:,vis_ok]
313 |
314 | N = trajs.shape[1]
315 | if N < self.traj_per_sample:
316 | print('dyn: N after vis0', N)
317 | return None, False
318 |
319 | # the data is quite big: 720x1280
320 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
321 | scale = 0.5
322 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
323 | H, W = rgbs[0].shape[:2]
324 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
325 | trajs = trajs * scale
326 | # print('resized rgbs', rgbs.shape)
327 |
328 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
329 | scale = 0.5
330 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
331 | H, W = rgbs[0].shape[:2]
332 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
333 | trajs = trajs * scale
334 | # print('resized rgbs', rgbs.shape)
335 |
336 | if self.use_augs and np.random.rand() < 0.98:
337 | H, W = rgbs[0].shape[:2]
338 |
339 | rgbs, trajs, visibs = self.add_photometric_augs(
340 | rgbs, trajs, visibs, replace=False,
341 | )
342 | if np.random.rand() < 0.2:
343 | rgbs, trajs = self.add_spatial_augs(rgbs, trajs, visibs, self.crop_size)
344 | else:
345 | rgbs, trajs = self.follow_crop(rgbs, trajs, visibs, self.crop_size)
346 | if np.random.rand() < self.rot_prob:
347 | # note this is OK since B==1
348 | # otw we would do it before this func
349 | rgbs = [np.transpose(rgb, (1,0,2)).copy() for rgb in rgbs]
350 | rgbs = np.stack(rgbs)
351 | trajs = np.flip(trajs, axis=2).copy()
352 | H, W = rgbs[0].shape[:2]
353 | if np.random.rand() < self.h_flip_prob:
354 | rgbs = [rgb[:, ::-1].copy() for rgb in rgbs]
355 | trajs[:, :, 0] = W - trajs[:, :, 0]
356 | rgbs = np.stack(rgbs)
357 | if np.random.rand() < self.v_flip_prob:
358 | rgbs = [rgb[::-1].copy() for rgb in rgbs]
359 | trajs[:, :, 1] = H - trajs[:, :, 1]
360 | rgbs = np.stack(rgbs)
361 | else:
362 | rgbs, trajs = self.crop(rgbs, trajs, self.crop_size)
363 |
364 | if self.shuffle_frames and np.random.rand() < 0.01:
365 | # shuffle the frames (again)
366 | perm = np.random.permutation(rgbs.shape[0])
367 | rgbs = rgbs[perm]
368 | trajs = trajs[perm]
369 | visibs = visibs[perm]
370 |
371 | H,W = rgbs[0].shape[:2]
372 |
373 | visibs[trajs[:, :, 0] > W-1] = False
374 | visibs[trajs[:, :, 0] < 0] = False
375 | visibs[trajs[:, :, 1] > H-1] = False
376 | visibs[trajs[:, :, 1] < 0] = False
377 |
378 | # ensure no crazy values
379 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs), axis=-1)<100000, axis=0)==self.seq_len)[0]
380 | trajs = trajs[:,all_valid]
381 | visibs = visibs[:,all_valid]
382 |
383 | if self.only_first:
384 | vis_ok = np.nonzero(visibs[0]==1)[0]
385 | trajs = trajs[:,vis_ok]
386 | visibs = visibs[:,vis_ok]
387 |
388 | N = trajs.shape[1]
389 | if N < self.traj_per_sample:
390 | print('dyn: N after aug', N)
391 | return None, False
392 |
393 | trajs = torch.from_numpy(trajs)
394 | visibs = torch.from_numpy(visibs)
395 |
396 | rgbs = np.stack(rgbs, 0)
397 | rgbs = torch.from_numpy(rgbs).reshape(T, H, W, 3).permute(0, 3, 1, 2).float()
398 |
399 | # discard tracks that go far OOB
400 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
401 | close_pts_inds = torch.all(
402 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
403 | dim=0,
404 | )
405 | trajs = trajs[:, close_pts_inds]
406 | visibs = visibs[:, close_pts_inds]
407 |
408 | visible_pts_inds = (visibs[0]).nonzero(as_tuple=False)[:, 0]
409 | point_inds = torch.randperm(len(visible_pts_inds))[:self.traj_per_sample*self.traj_max_factor]
410 | if len(point_inds) < self.traj_per_sample:
411 | # print('not enough trajs')
412 | return None, False
413 |
414 | visible_inds_sampled = visible_pts_inds[point_inds]
415 | trajs = trajs[:, visible_inds_sampled].float()
416 | visibs = visibs[:, visible_inds_sampled]
417 | valids = torch.ones_like(visibs)
418 |
419 | trajs = trajs[:, :self.traj_per_sample*self.traj_max_factor]
420 | visibs = visibs[:, :self.traj_per_sample*self.traj_max_factor]
421 | valids = valids[:, :self.traj_per_sample*self.traj_max_factor]
422 |
423 | sample = utils.data.VideoData(
424 | video=rgbs,
425 | trajs=trajs,
426 | visibs=visibs,
427 | valids=valids,
428 | dname=self.dname,
429 | )
430 | return sample, True
431 |
--------------------------------------------------------------------------------
/test_dense_on_sparse.py:
--------------------------------------------------------------------------------
1 | import os
2 | import random
3 | import torch
4 | import torch.nn.functional as F
5 | import numpy as np
6 | import argparse
7 | import utils.loss
8 | import utils.data
9 | import utils.improc
10 | import utils.misc
11 | import utils.saveload
12 | from tensorboardX import SummaryWriter
13 | import datetime
14 | import time
15 |
16 | torch.set_float32_matmul_precision('medium')
17 |
18 | from prettytable import PrettyTable
19 | def count_parameters(model):
20 | table = PrettyTable(["Modules", "Parameters"])
21 | total_params = 0
22 | for name, parameter in model.named_parameters():
23 | if not parameter.requires_grad:
24 | continue
25 | param = parameter.numel()
26 | if param > 100000:
27 | table.add_row([name, param])
28 | total_params += param
29 | # print(table)
30 | print('total params: %.2f M' % (total_params/1000000.0))
31 | return total_params
32 |
33 | def get_parameter_names(model, forbidden_layer_types):
34 | result = []
35 | for name, child in model.named_children():
36 | result += [
37 | f"{name}.{n}"
38 | for n in get_parameter_names(child, forbidden_layer_types)
39 | if not isinstance(child, tuple(forbidden_layer_types))
40 | ]
41 | result += list(model._parameters.keys())
42 | return result
43 |
44 | def get_dataset(dname, args):
45 | if dname=='bad':
46 | dataset_names = ['bad']
47 | from datasets import badjadataset
48 | dataset = badjadataset.BadjaDataset(
49 | data_root=os.path.join(args.dataset_root, 'badja2'),
50 | crop_size=args.image_size,
51 | only_first=False,
52 | )
53 | elif dname=='cro':
54 | dataset_names = ['cro']
55 | from datasets import crohddataset
56 | dataset = crohddataset.CrohdDataset(
57 | data_root=os.path.join(args.dataset_root, 'crohd'),
58 | crop_size=args.image_size,
59 | seq_len=None,
60 | only_first=True,
61 | )
62 | elif dname=='dav':
63 | dataset_names = ['dav']
64 | from datasets import davisdataset
65 | dataset = davisdataset.DavisDataset(
66 | data_root=os.path.join(args.dataset_root, 'tapvid_davis'),
67 | crop_size=args.image_size,
68 | only_first=False,
69 | )
70 | elif dname=='dri':
71 | dataset_names = ['dri']
72 | from datasets import drivetrackdataset
73 | dataset = drivetrackdataset.DrivetrackDataset(
74 | data_root=os.path.join(args.dataset_root, 'drivetrack'),
75 | crop_size=args.image_size,
76 | seq_len=None,
77 | traj_per_sample=768,
78 | only_first=True,
79 | )
80 | elif dname=='ego':
81 | dataset_names = ['ego']
82 | from datasets import egopointsdataset
83 | dataset = egopointsdataset.EgoPointsDataset(
84 | data_root=os.path.join(args.dataset_root, 'ego_points'),
85 | crop_size=args.image_size,
86 | only_first=True,
87 | )
88 | elif dname=='hor':
89 | dataset_names = ['hor']
90 | from datasets import horsedataset
91 | dataset = horsedataset.HorseDataset(
92 | data_root=os.path.join(args.dataset_root, 'horse10'),
93 | crop_size=args.image_size,
94 | seq_len=None,
95 | only_first=True,
96 | )
97 | elif dname=='kin':
98 | dataset_names = ['kin']
99 | from datasets import kineticsdataset
100 | dataset = kineticsdataset.KineticsDataset(
101 | data_root=os.path.join(args.dataset_root, 'tapvid_kinetics'),
102 | crop_size=args.image_size,
103 | only_first=True,
104 | )
105 | elif dname=='rgb':
106 | dataset_names = ['rgb']
107 | from datasets import rgbstackingdataset
108 | dataset = rgbstackingdataset.RGBStackingDataset(
109 | data_root=os.path.join(args.dataset_root, 'tapvid_rgb_stacking'),
110 | crop_size=args.image_size,
111 | only_first=False,
112 | )
113 | elif dname=='rob':
114 | dataset_names = ['rob']
115 | from datasets import robotapdataset
116 | dataset = robotapdataset.RobotapDataset(
117 | data_root=os.path.join(args.dataset_root, 'robotap'),
118 | crop_size=args.image_size,
119 | only_first=True,
120 | )
121 | return dataset, dataset_names
122 |
123 | def create_pools(args, n_pool=10000, min_size=1):
124 | pools = {}
125 | n_pool = max(n_pool, 10)
126 | thrs = [1,2,4,8,16]
127 | for thr in thrs:
128 | pools['d_%d' % thr] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
129 | pools['jac_%d' % thr] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
130 | pools['d_avg'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
131 | pools['aj'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
132 | pools['oa'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
133 | return pools
134 |
135 | def forward_batch(batch, model, args, sw):
136 | rgbs = batch.video
137 | trajs_g = batch.trajs
138 | vis_g = batch.visibs
139 | valids = batch.valids
140 | dname = batch.dname
141 | # print('rgbs', rgbs.shape, rgbs.dtype, rgbs.device)
142 | # print('trajs_g', trajs_g.shape, trajs_g.device)
143 | # print('vis_g', vis_g.shape, vis_g.device)
144 |
145 | B, T, C, H, W = rgbs.shape
146 | assert C == 3
147 | B, T, N, D = trajs_g.shape
148 | device = rgbs.device
149 | assert(B==1)
150 |
151 | trajs_g = trajs_g.cuda()
152 | vis_g = vis_g.cuda()
153 | valids = valids.cuda()
154 | __, first_positive_inds = torch.max(vis_g, dim=1)
155 |
156 | grid_xy = utils.basic.gridcloud2d(1, H, W, norm=False, device='cuda:0').float() # 1,H*W,2
157 | grid_xy = grid_xy.permute(0,2,1).reshape(1,1,2,H,W) # 1,1,2,H,W
158 |
159 | trajs_e = torch.zeros([B, T, N, 2], device='cuda:0')
160 | visconfs_e = torch.zeros([B, T, N, 2], device='cuda:0')
161 | query_points_all = []
162 | with torch.no_grad():
163 | for first_positive_ind in torch.unique(first_positive_inds):
164 | chunk_pt_idxs = torch.nonzero(first_positive_inds[0]==first_positive_ind, as_tuple=False)[:, 0] # K
165 | chunk_pts = trajs_g[:, first_positive_ind[None].repeat(chunk_pt_idxs.shape[0]), chunk_pt_idxs] # B, K, 2
166 | query_points_all.append(torch.cat([first_positive_inds[:, chunk_pt_idxs, None], chunk_pts], dim=2))
167 |
168 | traj_maps_e = grid_xy.repeat(1,T,1,1,1) # B,T,2,H,W
169 | visconf_maps_e = torch.zeros_like(traj_maps_e)
170 | if first_positive_ind < T-1:
171 | if T > 128: # forward_sliding is a little safer memory-wise
172 | forward_flow_e, forward_visconf_e, forward_flow_preds, forward_visconf_preds = \
173 | model.forward_sliding(rgbs[:, first_positive_ind:], iters=args.inference_iters, sw=sw, is_training=False)
174 | else:
175 | forward_flow_e, forward_visconf_e, forward_flow_preds, forward_visconf_preds = \
176 | model(rgbs[:, first_positive_ind:], iters=args.inference_iters, sw=sw, is_training=False)
177 |
178 | del forward_flow_preds
179 | del forward_visconf_preds
180 | forward_traj_maps_e = forward_flow_e.cuda() + grid_xy # B,Tf,2,H,W, when T = 2, flow has no T dim, but we broadcast
181 | traj_maps_e[:,first_positive_ind:] = forward_traj_maps_e
182 | visconf_maps_e[:,first_positive_ind:] = forward_visconf_e
183 | if not sw.save_this:
184 | del forward_flow_e
185 | del forward_visconf_e
186 | del forward_traj_maps_e
187 |
188 | xyt = trajs_g[:,first_positive_ind].round().long()[0, chunk_pt_idxs] # K,2
189 | trajs_e_chunk = traj_maps_e[:, :, :, xyt[:,1], xyt[:,0]] # B,T,2,K
190 | trajs_e_chunk = trajs_e_chunk.permute(0,1,3,2) # B,T,K,2
191 | trajs_e.scatter_add_(2, chunk_pt_idxs[None, None, :, None].repeat(1, trajs_e_chunk.shape[1], 1, 2), trajs_e_chunk)
192 |
193 | visconfs_e_chunk = visconf_maps_e[:, :, :, xyt[:,1], xyt[:,0]] # B,T,2,K
194 | visconfs_e_chunk = visconfs_e_chunk.permute(0,1,3,2) # B,T,K,2
195 | visconfs_e.scatter_add_(2, chunk_pt_idxs[None, None, :, None].repeat(1, visconfs_e_chunk.shape[1], 1, 2), visconfs_e_chunk)
196 |
197 | visconfs_e[..., 0] *= visconfs_e[..., 1]
198 | assert (torch.all(visconfs_e >= 0) and torch.all(visconfs_e <= 1))
199 | vis_thr = 0.6
200 | query_points_all = torch.cat(query_points_all, dim=1)[..., [0, 2, 1]]
201 | gt_occluded = (vis_g < .5).bool().transpose(1, 2)
202 | gt_tracks = trajs_g.transpose(1, 2)
203 | pred_occluded = (visconfs_e[..., 0] < vis_thr).bool().transpose(1, 2)
204 | pred_tracks = trajs_e.transpose(1, 2)
205 |
206 | metrics = utils.misc.compute_tapvid_metrics(
207 | query_points=query_points_all.cpu().numpy(),
208 | gt_occluded=gt_occluded.cpu().numpy(),
209 | gt_tracks=gt_tracks.cpu().numpy(),
210 | pred_occluded=pred_occluded.cpu().numpy(),
211 | pred_tracks=pred_tracks.cpu().numpy(),
212 | query_mode='first',
213 | crop_size=args.image_size
214 | )
215 | for thr in [1, 2, 4, 8, 16]:
216 | metrics['d_%d' % thr] = metrics['pts_within_' + str(thr)]
217 | metrics['jac_%d' % thr] = metrics['jaccard_' + str(thr)]
218 | metrics['d_avg'] = metrics['average_pts_within_thresh']
219 | metrics['aj'] = metrics['average_jaccard']
220 | metrics['oa'] = metrics['occlusion_accuracy']
221 |
222 | return metrics
223 |
224 |
225 | def run(dname, model, args):
226 | def seed_everything(seed: int):
227 | random.seed(seed)
228 | os.environ["PYTHONHASHSEED"] = str(seed)
229 | np.random.seed(seed)
230 | torch.manual_seed(seed)
231 | torch.cuda.manual_seed(seed)
232 | torch.backends.cudnn.deterministic = True
233 | torch.backends.cudnn.benchmark = False
234 | def seed_worker(worker_id):
235 | worker_seed = torch.initial_seed() % 2**32
236 | np.random.seed(worker_seed + worker_id)
237 | random.seed(worker_seed + worker_id)
238 | seed = 42
239 | seed_everything(seed)
240 | g = torch.Generator()
241 | g.manual_seed(seed)
242 |
243 | B_ = args.batch_size * torch.cuda.device_count()
244 | assert(B_==1)
245 | model_name = "%dx%d" % (int(args.image_size[0]), int(args.image_size[1]))
246 | model_name += "i%d" % (args.inference_iters)
247 | model_name += "_%s" % args.init_dir
248 | model_name += "_%s" % dname
249 | if args.only_first:
250 | model_name += "_first"
251 | model_name += "_%s" % args.exp
252 | model_date = datetime.datetime.now().strftime('%M%S')
253 | model_name = model_name + '_' + model_date
254 |
255 | save_dir = '%s/%s' % (args.ckpt_dir, model_name)
256 |
257 | dataset, dataset_names = get_dataset(dname, args)
258 | dataloader = torch.utils.data.DataLoader(
259 | dataset,
260 | batch_size=1,
261 | shuffle=False,
262 | num_workers=args.num_workers,
263 | worker_init_fn=seed_worker,
264 | generator=g,
265 | pin_memory=True,
266 | drop_last=True,
267 | collate_fn=utils.data.collate_fn_train,
268 | )
269 | iterloader = iter(dataloader)
270 | print('len(dataloader)', len(dataloader))
271 |
272 | log_dir = './logs_test_dense_on_sparse'
273 | overpools_t = create_pools(args)
274 | writer_t = SummaryWriter(log_dir + '/' + args.model_type + '-' + model_name + '/t', max_queue=10, flush_secs=60)
275 |
276 | global_step = 0
277 | if args.init_dir:
278 | load_dir = '%s/%s' % (args.ckpt_dir, args.init_dir)
279 | _ = utils.saveload.load(
280 | None,
281 | load_dir,
282 | model,
283 | optimizer=None,
284 | scheduler=None,
285 | ignore_load=None,
286 | strict=True,
287 | verbose=False,
288 | weights_only=False,
289 | )
290 | model.cuda()
291 | for n, p in model.named_parameters():
292 | p.requires_grad = False
293 | model.eval()
294 |
295 | max_steps = min(args.max_steps, len(dataloader))
296 |
297 | while global_step < max_steps:
298 | torch.cuda.empty_cache()
299 | iter_start_time = time.time()
300 | try:
301 | batch = next(iterloader)
302 | except StopIteration:
303 | iterloader = iter(dataloader)
304 | batch = next(iterloader)
305 |
306 | batch, gotit = batch
307 | if not all(gotit):
308 | continue
309 |
310 | sw_t = utils.improc.Summ_writer(
311 | writer=writer_t,
312 | global_step=global_step,
313 | log_freq=args.log_freq,
314 | fps=8,
315 | scalar_freq=1,
316 | just_gif=True)
317 | if args.log_freq == 9999:
318 | sw_t.save_this = False
319 |
320 | rtime = time.time()-iter_start_time
321 |
322 | if batch.trajs.shape[2] == 0:
323 | global_step += 1
324 | continue
325 |
326 | metrics = forward_batch(batch, model, args, sw_t)
327 |
328 | # update stats
329 | for key in list(overpools_t.keys()):
330 | if key in metrics:
331 | overpools_t[key].update([metrics[key]])
332 | # plot stats
333 | for key in list(overpools_t.keys()):
334 | sw_t.summ_scalar('_/%s' % (key), overpools_t[key].mean())
335 |
336 | global_step += 1
337 |
338 | itime = time.time()-iter_start_time
339 |
340 | info_str = '%s; step %06d/%d; rtime %.2f; itime %.2f' % (
341 | model_name, global_step, max_steps, rtime, itime)
342 | info_str += '; dname %s; d_avg %.1f aj %.1f oa %.1f' % (
343 | dname, overpools_t['d_avg'].mean()*100.0, overpools_t['aj'].mean()*100.0, overpools_t['oa'].mean()*100.0
344 | )
345 | if sw_t.save_this:
346 | print('model_name', model_name)
347 |
348 | if not args.print_less:
349 | print(info_str, flush=True)
350 |
351 |
352 | if args.print_less:
353 | print(info_str, flush=True)
354 |
355 | writer_t.close()
356 |
357 | del iterloader
358 | del dataloader
359 | del dataset
360 |
361 | return overpools_t['d_avg'].mean()*100.0, overpools_t['aj'].mean()*100.0, overpools_t['oa'].mean()*100.0
362 |
363 | if __name__ == "__main__":
364 | torch.set_grad_enabled(False)
365 | init_dir = ''
366 |
367 | exp = ''
368 |
369 | parser = argparse.ArgumentParser()
370 | parser.add_argument("--exp", default=exp)
371 | parser.add_argument("--dname", type=str, nargs='+', default=None, help="Dataset names, written as a single string or list of strings")
372 | parser.add_argument("--init_dir", type=str, default=init_dir)
373 | parser.add_argument("--ckpt_dir", type=str, default='')
374 | parser.add_argument("--batch_size", type=int, default=1)
375 | parser.add_argument("--num_workers", type=int, default=1)
376 | parser.add_argument("--max_steps", type=int, default=1500)
377 | parser.add_argument("--log_freq", type=int, default=9999)
378 | parser.add_argument("--dataset_root", type=str, default='/orion/group')
379 | parser.add_argument("--inference_iters", type=int, default=4)
380 | parser.add_argument("--window_len", type=int, default=16)
381 | parser.add_argument("--stride", type=int, default=8)
382 | parser.add_argument("--image_size", nargs="+", default=[384, 512]) # resizing arg
383 | parser.add_argument("--backwards", default=False)
384 | parser.add_argument("--mixed_precision", action='store_true', default=False)
385 | parser.add_argument("--only_first", action='store_true', default=False)
386 | parser.add_argument("--no_split", action='store_true', default=False)
387 | parser.add_argument("--print_less", action='store_true', default=False)
388 | parser.add_argument("--use_basicencoder", action='store_true', default=False)
389 | parser.add_argument("--conf", action='store_true', default=False)
390 | parser.add_argument("--model_type", choices=['ours', 'raft', 'searaft', 'accflow', 'delta'], default='ours')
391 | args = parser.parse_args()
392 | # allow dname to be a comma-separated string (e.g., "rgb,bad,dav")
393 | if args.dname is not None and len(args.dname) == 1 and ',' in args.dname[0]:
394 | args.dname = args.dname[0].split(',')
395 | if args.dname is None:
396 | args.dname = ['bad', 'cro', 'dav', 'dri', 'hor', 'kin', 'rgb', 'rob']
397 | dataset_names = args.dname
398 | args.image_size = [int(args.image_size[0]), int(args.image_size[1])]
399 | full_start_time = time.time()
400 |
401 | from nets.alltracker import Net; model = Net(16)
402 | url = "https://huggingface.co/aharley/alltracker/resolve/main/alltracker.pth"
403 | state_dict = torch.hub.load_state_dict_from_url(url, map_location='cpu')
404 | model.load_state_dict(state_dict['model'], strict=True)
405 | print('loaded weights from', url)
406 |
407 | das, ajs, oas = [], [], []
408 | for dname in dataset_names:
409 | if dname==dataset_names[0]:
410 | count_parameters(model)
411 | da, aj, oa = run(dname, model, args)
412 | das.append(da)
413 | ajs.append(aj)
414 | oas.append(oa)
415 | for (data, name) in zip([dataset_names, das, ajs, oas], ['dn', 'da', 'aj', 'oa']):
416 | st = name + ': '
417 | for dat in data:
418 | if isinstance(dat, str):
419 | st += '%s,' % dat
420 | else:
421 | st += '%.1f,' % dat
422 | print(st)
423 | full_time = time.time()-full_start_time
424 | print('full_time %.1f' % full_time)
425 |
--------------------------------------------------------------------------------
/utils/py.py:
--------------------------------------------------------------------------------
1 | import glob, math
2 | import numpy as np
3 | # from scipy import misc
4 | # from scipy import linalg
5 | from PIL import Image
6 | import io
7 | import matplotlib.pyplot as plt
8 | EPS = 1e-6
9 |
10 |
11 | XMIN = -64.0 # right (neg is left)
12 | XMAX = 64.0 # right
13 | YMIN = -64.0 # down (neg is up)
14 | YMAX = 64.0 # down
15 | ZMIN = -64.0 # forward
16 | ZMAX = 64.0 # forward
17 |
18 | def print_stats(name, tensor):
19 | tensor = tensor.astype(np.float32)
20 | print('%s min = %.2f, mean = %.2f, max = %.2f' % (name, np.min(tensor), np.mean(tensor), np.max(tensor)), tensor.shape)
21 |
22 | def reduce_masked_mean(x, mask, axis=None, keepdims=False):
23 | # x and mask are the same shape
24 | # returns shape-1
25 | # axis can be a list of axes
26 | prod = x*mask
27 | numer = np.sum(prod, axis=axis, keepdims=keepdims)
28 | denom = EPS+np.sum(mask, axis=axis, keepdims=keepdims)
29 | mean = numer/denom
30 | return mean
31 |
32 | def reduce_masked_sum(x, mask, axis=None, keepdims=False):
33 | # x and mask are the same shape
34 | # returns shape-1
35 | # axis can be a list of axes
36 | prod = x*mask
37 | numer = np.sum(prod, axis=axis, keepdims=keepdims)
38 | return numer
39 |
40 | def reduce_masked_median(x, mask, keep_batch=False):
41 | # x and mask are the same shape
42 | # returns shape-1
43 | # axis can be a list of axes
44 |
45 | if not (x.shape == mask.shape):
46 | print('reduce_masked_median: these shapes should match:', x.shape, mask.shape)
47 | assert(False)
48 | # assert(x.shape == mask.shape)
49 |
50 | B = list(x.shape)[0]
51 |
52 | if keep_batch:
53 | x = np.reshape(x, [B, -1])
54 | mask = np.reshape(mask, [B, -1])
55 | meds = np.zeros([B], np.float32)
56 | for b in list(range(B)):
57 | xb = x[b]
58 | mb = mask[b]
59 | if np.sum(mb) > 0:
60 | xb = xb[mb > 0]
61 | meds[b] = np.median(xb)
62 | else:
63 | meds[b] = np.nan
64 | return meds
65 | else:
66 | x = np.reshape(x, [-1])
67 | mask = np.reshape(mask, [-1])
68 | if np.sum(mask) > 0:
69 | x = x[mask > 0]
70 | med = np.median(x)
71 | else:
72 | med = np.nan
73 | med = np.array([med], np.float32)
74 | return med
75 |
76 | def get_nFiles(path):
77 | return len(glob.glob(path))
78 |
79 | def get_file_list(path):
80 | return glob.glob(path)
81 |
82 | def rotm2eul(R):
83 | # R is 3x3
84 | sy = math.sqrt(R[0,0] * R[0,0] + R[1,0] * R[1,0])
85 | if sy > 1e-6: # singular
86 | x = math.atan2(R[2,1] , R[2,2])
87 | y = math.atan2(-R[2,0], sy)
88 | z = math.atan2(R[1,0], R[0,0])
89 | else:
90 | x = math.atan2(-R[1,2], R[1,1])
91 | y = math.atan2(-R[2,0], sy)
92 | z = 0
93 | return x, y, z
94 |
95 | def rad2deg(rad):
96 | return rad*180.0/np.pi
97 |
98 | def deg2rad(deg):
99 | return deg/180.0*np.pi
100 |
101 | def eul2rotm(rx, ry, rz):
102 | # copy of matlab, but order of inputs is different
103 | # R = [ cy*cz sy*sx*cz-sz*cx sy*cx*cz+sz*sx
104 | # cy*sz sy*sx*sz+cz*cx sy*cx*sz-cz*sx
105 | # -sy cy*sx cy*cx]
106 | sinz = np.sin(rz)
107 | siny = np.sin(ry)
108 | sinx = np.sin(rx)
109 | cosz = np.cos(rz)
110 | cosy = np.cos(ry)
111 | cosx = np.cos(rx)
112 | r11 = cosy*cosz
113 | r12 = sinx*siny*cosz - cosx*sinz
114 | r13 = cosx*siny*cosz + sinx*sinz
115 | r21 = cosy*sinz
116 | r22 = sinx*siny*sinz + cosx*cosz
117 | r23 = cosx*siny*sinz - sinx*cosz
118 | r31 = -siny
119 | r32 = sinx*cosy
120 | r33 = cosx*cosy
121 | r1 = np.stack([r11,r12,r13],axis=-1)
122 | r2 = np.stack([r21,r22,r23],axis=-1)
123 | r3 = np.stack([r31,r32,r33],axis=-1)
124 | r = np.stack([r1,r2,r3],axis=0)
125 | return r
126 |
127 | def wrap2pi(rad_angle):
128 | # puts the angle into the range [-pi, pi]
129 | return np.arctan2(np.sin(rad_angle), np.cos(rad_angle))
130 |
131 | def rot2view(rx,ry,rz,x,y,z):
132 | # takes rot angles and 3d position as input
133 | # returns viewpoint angles as output
134 | # (all in radians)
135 | # it will perform strangely if z <= 0
136 | az = wrap2pi(ry - (-np.arctan2(z, x) - 1.5*np.pi))
137 | el = -wrap2pi(rx - (-np.arctan2(z, y) - 1.5*np.pi))
138 | th = -rz
139 | return az, el, th
140 |
141 | def invAxB(a,b):
142 | """
143 | Compute the relative 3d transformation between a and b.
144 |
145 | Input:
146 | a -- first pose (homogeneous 4x4 matrix)
147 | b -- second pose (homogeneous 4x4 matrix)
148 |
149 | Output:
150 | Relative 3d transformation from a to b.
151 | """
152 | return np.dot(np.linalg.inv(a),b)
153 |
154 | def merge_rt(r, t):
155 | # r is 3 x 3
156 | # t is 3 or maybe 3 x 1
157 | t = np.reshape(t, [3, 1])
158 | rt = np.concatenate((r,t), axis=1)
159 | # rt is 3 x 4
160 | br = np.reshape(np.array([0,0,0,1], np.float32), [1, 4])
161 | # br is 1 x 4
162 | rt = np.concatenate((rt, br), axis=0)
163 | # rt is 4 x 4
164 | return rt
165 |
166 | def split_rt(rt):
167 | r = rt[:3,:3]
168 | t = rt[:3,3]
169 | r = np.reshape(r, [3, 3])
170 | t = np.reshape(t, [3, 1])
171 | return r, t
172 |
173 | def split_intrinsics(K):
174 | # K is 3 x 4 or 4 x 4
175 | fx = K[0,0]
176 | fy = K[1,1]
177 | x0 = K[0,2]
178 | y0 = K[1,2]
179 | return fx, fy, x0, y0
180 |
181 | def merge_intrinsics(fx, fy, x0, y0):
182 | # inputs are shaped []
183 | K = np.eye(4)
184 | K[0,0] = fx
185 | K[1,1] = fy
186 | K[0,2] = x0
187 | K[1,2] = y0
188 | # K is shaped 4 x 4
189 | return K
190 |
191 | def scale_intrinsics(K, sx, sy):
192 | fx, fy, x0, y0 = split_intrinsics(K)
193 | fx *= sx
194 | fy *= sy
195 | x0 *= sx
196 | y0 *= sy
197 | return merge_intrinsics(fx, fy, x0, y0)
198 |
199 | # def meshgrid(H, W):
200 | # x = np.linspace(0, W-1, W)
201 | # y = np.linspace(0, H-1, H)
202 | # xv, yv = np.meshgrid(x, y)
203 | # return xv, yv
204 |
205 | def compute_distance(transform):
206 | """
207 | Compute the distance of the translational component of a 4x4 homogeneous matrix.
208 | """
209 | return numpy.linalg.norm(transform[0:3,3])
210 |
211 | def radian_l1_dist(e, g):
212 | # if our angles are in [0, 360] we can follow this stack overflow answer:
213 | # https://gamedev.stackexchange.com/questions/4467/comparing-angles-and-working-out-the-difference
214 | # wrap2pi brings the angles to [-180, 180]; adding pi puts them in [0, 360]
215 | e = wrap2pi(e)+np.pi
216 | g = wrap2pi(g)+np.pi
217 | l = np.abs(np.pi - np.abs(np.abs(e-g) - np.pi))
218 | return l
219 |
220 | def apply_pix_T_cam(pix_T_cam, xyz):
221 | fx, fy, x0, y0 = split_intrinsics(pix_T_cam)
222 | # xyz is shaped B x H*W x 3
223 | # returns xy, shaped B x H*W x 2
224 | N, C = xyz.shape
225 | x, y, z = np.split(xyz, 3, axis=-1)
226 | EPS = 1e-4
227 | z = np.clip(z, EPS, None)
228 | x = (x*fx)/(z)+x0
229 | y = (y*fy)/(z)+y0
230 | xy = np.concatenate([x, y], axis=-1)
231 | return xy
232 |
233 | def apply_4x4(RT, XYZ):
234 | # RT is 4 x 4
235 | # XYZ is N x 3
236 |
237 | # put into homogeneous coords
238 | X, Y, Z = np.split(XYZ, 3, axis=1)
239 | ones = np.ones_like(X)
240 | XYZ1 = np.concatenate([X, Y, Z, ones], axis=1)
241 | # XYZ1 is N x 4
242 |
243 | XYZ1_t = np.transpose(XYZ1)
244 | # this is 4 x N
245 |
246 | XYZ2_t = np.dot(RT, XYZ1_t)
247 | # this is 4 x N
248 |
249 | XYZ2 = np.transpose(XYZ2_t)
250 | # this is N x 4
251 |
252 | XYZ2 = XYZ2[:,:3]
253 | # this is N x 3
254 |
255 | return XYZ2
256 |
257 | def Ref2Mem(xyz, Z, Y, X):
258 | # xyz is N x 3, in ref coordinates
259 | # transforms ref coordinates into mem coordinates
260 | N, C = xyz.shape
261 | assert(C==3)
262 | mem_T_ref = get_mem_T_ref(Z, Y, X)
263 | xyz = apply_4x4(mem_T_ref, xyz)
264 | return xyz
265 |
266 | # def Mem2Ref(xyz_mem, MH, MW, MD):
267 | # # xyz is B x N x 3, in mem coordinates
268 | # # transforms mem coordinates into ref coordinates
269 | # B, N, C = xyz_mem.get_shape().as_list()
270 | # ref_T_mem = get_ref_T_mem(B, MH, MW, MD)
271 | # xyz_ref = utils_geom.apply_4x4(ref_T_mem, xyz_mem)
272 | # return xyz_ref
273 |
274 | def get_mem_T_ref(Z, Y, X):
275 | # sometimes we want the mat itself
276 | # note this is not a rigid transform
277 |
278 | # for interpretability, let's construct this in two steps...
279 |
280 | # translation
281 | center_T_ref = np.eye(4, dtype=np.float32)
282 | center_T_ref[0,3] = -XMIN
283 | center_T_ref[1,3] = -YMIN
284 | center_T_ref[2,3] = -ZMIN
285 |
286 | VOX_SIZE_X = (XMAX-XMIN)/float(X)
287 | VOX_SIZE_Y = (YMAX-YMIN)/float(Y)
288 | VOX_SIZE_Z = (ZMAX-ZMIN)/float(Z)
289 |
290 | # scaling
291 | mem_T_center = np.eye(4, dtype=np.float32)
292 | mem_T_center[0,0] = 1./VOX_SIZE_X
293 | mem_T_center[1,1] = 1./VOX_SIZE_Y
294 | mem_T_center[2,2] = 1./VOX_SIZE_Z
295 |
296 | mem_T_ref = np.dot(mem_T_center, center_T_ref)
297 | return mem_T_ref
298 |
299 | def safe_inverse(a):
300 | r, t = split_rt(a)
301 | t = np.reshape(t, [3, 1])
302 | r_transpose = r.T
303 | inv = np.concatenate([r_transpose, -np.matmul(r_transpose, t)], 1)
304 | bottom_row = a[3:4, :] # this is [0, 0, 0, 1]
305 | inv = np.concatenate([inv, bottom_row], 0)
306 | return inv
307 |
308 | def get_ref_T_mem(Z, Y, X):
309 | mem_T_ref = get_mem_T_ref(X, Y, X)
310 | # note safe_inverse is inapplicable here,
311 | # since the transform is nonrigid
312 | ref_T_mem = np.linalg.inv(mem_T_ref)
313 | return ref_T_mem
314 |
315 | def voxelize_xyz(xyz_ref, Z, Y, X):
316 | # xyz_ref is N x 3
317 | xyz_mem = Ref2Mem(xyz_ref, Z, Y, X)
318 | # this is N x 3
319 | voxels = get_occupancy(xyz_mem, Z, Y, X)
320 | voxels = np.reshape(voxels, [Z, Y, X, 1])
321 | return voxels
322 |
323 | def get_inbounds(xyz, Z, Y, X, already_mem=False):
324 | # xyz is H*W x 3
325 |
326 | if not already_mem:
327 | xyz = Ref2Mem(xyz, Z, Y, X)
328 |
329 | x_valid = np.logical_and(
330 | np.greater_equal(xyz[:,0], -0.5),
331 | np.less(xyz[:,0], float(X)-0.5))
332 | y_valid = np.logical_and(
333 | np.greater_equal(xyz[:,1], -0.5),
334 | np.less(xyz[:,1], float(Y)-0.5))
335 | z_valid = np.logical_and(
336 | np.greater_equal(xyz[:,2], -0.5),
337 | np.less(xyz[:,2], float(Z)-0.5))
338 | inbounds = np.logical_and(np.logical_and(x_valid, y_valid), z_valid)
339 | return inbounds
340 |
341 | def sub2ind3d_zyx(depth, height, width, d, h, w):
342 | # same as sub2ind3d, but inputs in zyx order
343 | # when gathering/scattering with these inds, the tensor should be Z x Y x X
344 | return d*height*width + h*width + w
345 |
346 | def sub2ind3d_yxz(height, width, depth, h, w, d):
347 | return h*width*depth + w*depth + d
348 |
349 | # def ind2sub(height, width, ind):
350 | # # int input
351 | # y = int(ind / height)
352 | # x = ind % height
353 | # return y, x
354 |
355 | def get_occupancy(xyz_mem, Z, Y, X):
356 | # xyz_mem is N x 3
357 | # we want to fill a voxel tensor with 1's at these inds
358 |
359 | inbounds = get_inbounds(xyz_mem, Z, Y, X, already_mem=True)
360 | inds = np.where(inbounds)
361 |
362 | xyz_mem = np.reshape(xyz_mem[inds], [-1, 3])
363 | # xyz_mem is N x 3
364 |
365 | # this is more accurate than a cast/floor, but runs into issues when Y==0
366 | xyz_mem = np.round(xyz_mem).astype(np.int32)
367 | x = xyz_mem[:,0]
368 | y = xyz_mem[:,1]
369 | z = xyz_mem[:,2]
370 |
371 | voxels = np.zeros([Z, Y, X], np.float32)
372 | voxels[z, y, x] = 1.0
373 |
374 | return voxels
375 |
376 | def pixels2camera(x,y,z,fx,fy,x0,y0):
377 | # x and y are locations in pixel coordinates, z is a depth image in meters
378 | # their shapes are H x W
379 | # fx, fy, x0, y0 are scalar camera intrinsics
380 | # returns xyz, sized [B,H*W,3]
381 |
382 | H, W = z.shape
383 |
384 | fx = np.reshape(fx, [1,1])
385 | fy = np.reshape(fy, [1,1])
386 | x0 = np.reshape(x0, [1,1])
387 | y0 = np.reshape(y0, [1,1])
388 |
389 | # unproject
390 | x = ((z+EPS)/fx)*(x-x0)
391 | y = ((z+EPS)/fy)*(y-y0)
392 |
393 | x = np.reshape(x, [-1])
394 | y = np.reshape(y, [-1])
395 | z = np.reshape(z, [-1])
396 | xyz = np.stack([x,y,z], axis=1)
397 | return xyz
398 |
399 | def depth2pointcloud(z, pix_T_cam):
400 | H = z.shape[0]
401 | W = z.shape[1]
402 | y, x = meshgrid2d(H, W)
403 | z = np.reshape(z, [H, W])
404 |
405 | fx, fy, x0, y0 = split_intrinsics(pix_T_cam)
406 | xyz = pixels2camera(x, y, z, fx, fy, x0, y0)
407 | return xyz
408 |
409 | def meshgrid2d(Y, X):
410 | grid_y = np.linspace(0.0, Y-1, Y)
411 | grid_y = np.reshape(grid_y, [Y, 1])
412 | grid_y = np.tile(grid_y, [1, X])
413 |
414 | grid_x = np.linspace(0.0, X-1, X)
415 | grid_x = np.reshape(grid_x, [1, X])
416 | grid_x = np.tile(grid_x, [Y, 1])
417 |
418 | # outputs are Y x X
419 | return grid_y, grid_x
420 |
421 | def gridcloud3d(Y, X, Z):
422 | x_ = np.linspace(0, X-1, X)
423 | y_ = np.linspace(0, Y-1, Y)
424 | z_ = np.linspace(0, Z-1, Z)
425 | y, x, z = np.meshgrid(y_, x_, z_, indexing='ij')
426 | x = np.reshape(x, [-1])
427 | y = np.reshape(y, [-1])
428 | z = np.reshape(z, [-1])
429 | xyz = np.stack([x,y,z], axis=1).astype(np.float32)
430 | return xyz
431 |
432 | def gridcloud2d(Y, X):
433 | x_ = np.linspace(0, X-1, X)
434 | y_ = np.linspace(0, Y-1, Y)
435 | y, x = np.meshgrid(y_, x_, indexing='ij')
436 | x = np.reshape(x, [-1])
437 | y = np.reshape(y, [-1])
438 | xy = np.stack([x,y], axis=1).astype(np.float32)
439 | return xy
440 |
441 | def normalize(im):
442 | im = im - np.min(im)
443 | im = im / np.max(im)
444 | return im
445 |
446 | def wrap2pi(rad_angle):
447 | # rad_angle can be any shape
448 | # puts the angle into the range [-pi, pi]
449 | return np.arctan2(np.sin(rad_angle), np.cos(rad_angle))
450 |
451 | def convert_occ_to_height(occ):
452 | Z, Y, X, C = occ.shape
453 | assert(C==1)
454 |
455 | height = np.linspace(float(Y), 1.0, Y)
456 | height = np.reshape(height, [1, Y, 1, 1])
457 | height = np.max(occ*height, axis=1)/float(Y)
458 | height = np.reshape(height, [Z, X, C])
459 | return height
460 |
461 | def create_depth_image(xy, Z, H, W):
462 |
463 | # turn the xy coordinates into image inds
464 | xy = np.round(xy)
465 |
466 | # lidar reports a sphere of measurements
467 | # only use the inds that are within the image bounds
468 | # also, only use forward-pointing depths (Z > 0)
469 | valid = (xy[:,0] < W-1) & (xy[:,1] < H-1) & (xy[:,0] >= 0) & (xy[:,1] >= 0) & (Z[:] > 0)
470 |
471 | # gather these up
472 | xy = xy[valid]
473 | Z = Z[valid]
474 |
475 | inds = sub2ind(H,W,xy[:,1],xy[:,0])
476 | depth = np.zeros((H*W), np.float32)
477 |
478 | for (index, replacement) in zip(inds, Z):
479 | depth[index] = replacement
480 | depth[np.where(depth == 0.0)] = 70.0
481 | depth = np.reshape(depth, [H, W])
482 |
483 | return depth
484 |
485 | def vis_depth(depth, maxdepth=80.0, log_vis=True):
486 | depth[depth<=0.0] = maxdepth
487 | if log_vis:
488 | depth = np.log(depth)
489 | depth = np.clip(depth, 0, np.log(maxdepth))
490 | else:
491 | depth = np.clip(depth, 0, maxdepth)
492 | depth = (depth*255.0).astype(np.uint8)
493 | return depth
494 |
495 | def preprocess_color(x):
496 | return x.astype(np.float32) * 1./255 - 0.5
497 |
498 | def convert_box_to_ref_T_obj(boxes):
499 | shape = boxes.shape
500 | boxes = boxes.reshape(-1,9)
501 | rots = [eul2rotm(rx,ry,rz)
502 | for rx,ry,rz in boxes[:,6:]]
503 | rots = np.stack(rots,axis=0)
504 | trans = boxes[:,:3]
505 | ref_T_objs = [merge_rt(rot,tran)
506 | for rot,tran in zip(rots,trans)]
507 | ref_T_objs = np.stack(ref_T_objs,axis=0)
508 | ref_T_objs = ref_T_objs.reshape(shape[:-1]+(4,4))
509 | ref_T_objs = ref_T_objs.astype(np.float32)
510 | return ref_T_objs
511 |
512 | def get_rot_from_delta(delta, yaw_only=False):
513 | dx = delta[:,0]
514 | dy = delta[:,1]
515 | dz = delta[:,2]
516 |
517 | bot_hyp = np.sqrt(dz**2 + dx**2)
518 | # top_hyp = np.sqrt(bot_hyp**2 + dy**2)
519 |
520 | pitch = -np.arctan2(dy, bot_hyp)
521 | yaw = np.arctan2(dz, dx)
522 |
523 | if yaw_only:
524 | rot = [eul2rotm(0,y,0) for y in yaw]
525 | else:
526 | rot = [eul2rotm(0,y,p) for (p,y) in zip(pitch,yaw)]
527 |
528 | rot = np.stack(rot)
529 | # rot is B x 3 x 3
530 | return rot
531 |
532 | def im2col(im, psize):
533 | n_channels = 1 if len(im.shape) == 2 else im.shape[0]
534 | (n_channels, rows, cols) = (1,) * (3 - len(im.shape)) + im.shape
535 |
536 | im_pad = np.zeros((n_channels,
537 | int(math.ceil(1.0 * rows / psize) * psize),
538 | int(math.ceil(1.0 * cols / psize) * psize)))
539 | im_pad[:, 0:rows, 0:cols] = im
540 |
541 | final = np.zeros((im_pad.shape[1], im_pad.shape[2], n_channels,
542 | psize, psize))
543 | for c in np.arange(n_channels):
544 | for x in np.arange(psize):
545 | for y in np.arange(psize):
546 | im_shift = np.vstack(
547 | (im_pad[c, x:], im_pad[c, :x]))
548 | im_shift = np.column_stack(
549 | (im_shift[:, y:], im_shift[:, :y]))
550 | final[x::psize, y::psize, c] = np.swapaxes(
551 | im_shift.reshape(int(im_pad.shape[1] / psize), psize,
552 | int(im_pad.shape[2] / psize), psize), 1, 2)
553 |
554 | return np.squeeze(final[0:rows - psize + 1, 0:cols - psize + 1])
555 |
556 | def filter_discontinuities(depth, filter_size=9, thresh=10):
557 | H, W = list(depth.shape)
558 |
559 | # Ensure that filter sizes are okay
560 | assert filter_size % 2 == 1, "Can only use odd filter sizes."
561 |
562 | # Compute discontinuities
563 | offset = int((filter_size - 1) / 2)
564 | patches = 1.0 * im2col(depth, filter_size)
565 | mids = patches[:, :, offset, offset]
566 | mins = np.min(patches, axis=(2, 3))
567 | maxes = np.max(patches, axis=(2, 3))
568 |
569 | discont = np.maximum(np.abs(mins - mids),
570 | np.abs(maxes - mids))
571 | mark = discont > thresh
572 |
573 | # Account for offsets
574 | final_mark = np.zeros((H, W), dtype=np.uint16)
575 | final_mark[offset:offset + mark.shape[0],
576 | offset:offset + mark.shape[1]] = mark
577 |
578 | return depth * (1 - final_mark)
579 |
580 | def argmax2d(tensor):
581 | Y, X = list(tensor.shape)
582 | # flatten the Tensor along the height and width axes
583 | flat_tensor = tensor.reshape(-1)
584 | # argmax of the flat tensor
585 | argmax = np.argmax(flat_tensor)
586 |
587 | # convert the indices into 2d coordinates
588 | argmax_y = argmax // X # row
589 | argmax_x = argmax % X # col
590 |
591 | return argmax_y, argmax_x
592 |
593 | def plot_traj_3d(traj):
594 | # traj is S x 3
595 |
596 | # print('traj', traj.shape)
597 | S, C = list(traj.shape)
598 | assert(C==3)
599 |
600 | fig = plt.figure()
601 | ax = fig.add_subplot(111, projection='3d')
602 |
603 | colors = [plt.cm.RdYlBu(i) for i in np.linspace(0,1,S)]
604 | # print('colors', colors)
605 |
606 | xs = traj[:,0]
607 | ys = -traj[:,1]
608 | zs = traj[:,2]
609 |
610 | ax.scatter(xs, zs, ys, s=30, c=colors, marker='o', alpha=1.0, edgecolors=(0,0,0))#, color=color_map[n])
611 |
612 | ax.set_xlabel('X')
613 | ax.set_ylabel('Z')
614 | ax.set_zlabel('Y')
615 |
616 | ax.set_xlim(0,1)
617 | ax.set_ylim(0,1) # this is really Z
618 | ax.set_zlim(-1,0) # this is really Y
619 |
620 | buf = io.BytesIO()
621 | plt.savefig(buf, format='png')
622 | buf.seek(0)
623 | image = np.array(Image.open(buf)) # H x W x 4
624 | image = image[:,:,:3]
625 |
626 | plt.close()
627 | return image
628 |
629 | def camera2pixels(xyz, pix_T_cam):
630 | # xyz is shaped N x 3
631 | # returns xy, shaped N x 2
632 |
633 | fx, fy, x0, y0 = split_intrinsics(pix_T_cam)
634 | x, y, z = xyz[:,0], xyz[:,1], xyz[:,2]
635 |
636 | EPS = 1e-4
637 | z = np.clip(z, EPS, None)
638 | x = (x*fx)/z + x0
639 | y = (y*fy)/z + y0
640 | xy = np.stack([x, y], axis=-1)
641 | return xy
642 |
643 | def make_colorwheel():
644 | """
645 | Generates a color wheel for optical flow visualization as presented in:
646 | Baker et al. "A Database and Evaluation Methodology for Optical Flow" (ICCV, 2007)
647 | URL: http://vision.middlebury.edu/flow/flowEval-iccv07.pdf
648 |
649 | Code follows the original C++ source code of Daniel Scharstein.
650 | Code follows the the Matlab source code of Deqing Sun.
651 |
652 | Returns:
653 | np.ndarray: Color wheel
654 | """
655 |
656 | RY = 15
657 | YG = 6
658 | GC = 4
659 | CB = 11
660 | BM = 13
661 | MR = 6
662 |
663 | ncols = RY + YG + GC + CB + BM + MR
664 | colorwheel = np.zeros((ncols, 3))
665 | col = 0
666 |
667 | # RY
668 | colorwheel[0:RY, 0] = 255
669 | colorwheel[0:RY, 1] = np.floor(255*np.arange(0,RY)/RY)
670 | col = col+RY
671 | # YG
672 | colorwheel[col:col+YG, 0] = 255 - np.floor(255*np.arange(0,YG)/YG)
673 | colorwheel[col:col+YG, 1] = 255
674 | col = col+YG
675 | # GC
676 | colorwheel[col:col+GC, 1] = 255
677 | colorwheel[col:col+GC, 2] = np.floor(255*np.arange(0,GC)/GC)
678 | col = col+GC
679 | # CB
680 | colorwheel[col:col+CB, 1] = 255 - np.floor(255*np.arange(CB)/CB)
681 | colorwheel[col:col+CB, 2] = 255
682 | col = col+CB
683 | # BM
684 | colorwheel[col:col+BM, 2] = 255
685 | colorwheel[col:col+BM, 0] = np.floor(255*np.arange(0,BM)/BM)
686 | col = col+BM
687 | # MR
688 | colorwheel[col:col+MR, 2] = 255 - np.floor(255*np.arange(MR)/MR)
689 | colorwheel[col:col+MR, 0] = 255
690 | return colorwheel
691 |
692 | def flow_uv_to_colors(u, v, convert_to_bgr=False):
693 | """
694 | Applies the flow color wheel to (possibly clipped) flow components u and v.
695 |
696 | According to the C++ source code of Daniel Scharstein
697 | According to the Matlab source code of Deqing Sun
698 |
699 | Args:
700 | u (np.ndarray): Input horizontal flow of shape [H,W]
701 | v (np.ndarray): Input vertical flow of shape [H,W]
702 | convert_to_bgr (bool, optional): Convert output image to BGR. Defaults to False.
703 |
704 | Returns:
705 | np.ndarray: Flow visualization image of shape [H,W,3]
706 | """
707 | flow_image = np.zeros((u.shape[0], u.shape[1], 3), np.uint8)
708 | colorwheel = make_colorwheel() # shape [55x3]
709 | ncols = colorwheel.shape[0]
710 | rad = np.sqrt(np.square(u) + np.square(v))
711 | a = np.arctan2(-v, -u)/np.pi
712 | fk = (a+1) / 2*(ncols-1)
713 | k0 = np.floor(fk).astype(np.int32)
714 | k1 = k0 + 1
715 | k1[k1 == ncols] = 0
716 | f = fk - k0
717 | for i in range(colorwheel.shape[1]):
718 | tmp = colorwheel[:,i]
719 | col0 = tmp[k0] / 255.0
720 | col1 = tmp[k1] / 255.0
721 | col = (1-f)*col0 + f*col1
722 | idx = (rad <= 1)
723 | col[idx] = 1 - rad[idx] * (1-col[idx])
724 | col[~idx] = col[~idx] * 0.75 # out of range
725 | # Note the 2-i => BGR instead of RGB
726 | ch_idx = 2-i if convert_to_bgr else i
727 | flow_image[:,:,ch_idx] = np.floor(255 * col)
728 | return flow_image
729 |
730 | def flow_to_image(flow_uv, clip_flow=None, convert_to_bgr=False):
731 | """
732 | Expects a two dimensional flow image of shape.
733 |
734 | Args:
735 | flow_uv (np.ndarray): Flow UV image of shape [H,W,2]
736 | clip_flow (float, optional): Clip maximum of flow values. Defaults to None.
737 | convert_to_bgr (bool, optional): Convert output image to BGR. Defaults to False.
738 |
739 | Returns:
740 | np.ndarray: Flow visualization image of shape [H,W,3]
741 | """
742 | assert flow_uv.ndim == 3, 'input flow must have three dimensions'
743 | assert flow_uv.shape[2] == 2, 'input flow must have shape [H,W,2]'
744 | if clip_flow is not None:
745 | flow_uv = np.clip(flow_uv, -clip_flow, clip_flow) / clip_flow
746 | # flow_uv = np.clamp(flow, -clip, clip)/clip
747 |
748 | u = flow_uv[:,:,0]
749 | v = flow_uv[:,:,1]
750 | rad = np.sqrt(np.square(u) + np.square(v))
751 | rad_max = np.max(rad)
752 | epsilon = 1e-5
753 | u = u / (rad_max + epsilon)
754 | v = v / (rad_max + epsilon)
755 | return flow_uv_to_colors(u, v, convert_to_bgr)
756 |
--------------------------------------------------------------------------------
/train_stage1.py:
--------------------------------------------------------------------------------
1 | import os
2 | import random
3 | import torch
4 | import torch.nn.functional as F
5 | import numpy as np
6 | import argparse
7 | from lightning_fabric import Fabric
8 | import utils.loss
9 | import utils.samp
10 | import utils.data
11 | import utils.improc
12 | import utils.misc
13 | import utils.saveload
14 | from tensorboardX import SummaryWriter
15 | import datetime
16 | import time
17 | from nets.blocks import bilinear_sampler
18 |
19 | torch.set_float32_matmul_precision('medium')
20 |
21 | def get_parameter_names(model, forbidden_layer_types):
22 | """
23 | Returns the names of the model parameters that are not inside a forbidden layer.
24 | """
25 | result = []
26 | for name, child in model.named_children():
27 | result += [
28 | f"{name}.{n}"
29 | for n in get_parameter_names(child, forbidden_layer_types)
30 | if not isinstance(child, tuple(forbidden_layer_types))
31 | ]
32 | result += list(model._parameters.keys())
33 | return result
34 |
35 | def get_sparse_dataset(args, crop_size, N, T, random_first=False, version='kubric_au'):
36 | from datasets import kubric_movif_dataset
37 | dataset = kubric_movif_dataset.KubricMovifDataset(
38 | data_root=os.path.join(args.data_dir, version),
39 | crop_size=crop_size,
40 | seq_len=T,
41 | traj_per_sample=N,
42 | use_augs=args.use_augs,
43 | random_seq_len=args.random_seq_len,
44 | random_first_frame=random_first,
45 | random_frame_rate=args.random_frame_rate,
46 | random_number_traj=args.random_number_traj,
47 | shuffle_frames=args.shuffle_frames,
48 | shuffle=True,
49 | only_first=True,
50 | )
51 | dataset_names = [dataset.dname]
52 | return dataset, dataset_names
53 |
54 | def create_pools(n_pool=50, min_size=10):
55 | pools = {}
56 |
57 | n_pool = max(n_pool, 10)
58 |
59 | thrs = [1,2,4,8,16]
60 | for thr in thrs:
61 | pools['d_%d' % thr] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
62 | pools['d_avg'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
63 |
64 | pool_names = [
65 | 'seq_loss_visible',
66 | 'seq_loss_invisible',
67 | 'vis_loss',
68 | 'conf_loss',
69 | 'total_loss',
70 | ]
71 | for pool_name in pool_names:
72 | pools[pool_name] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
73 |
74 | return pools
75 |
76 | def fetch_optimizer(args, model):
77 | """Create the optimizer and learning rate scheduler"""
78 |
79 | total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
80 | print(f"Total number of parameters: {total_params}")
81 |
82 | decay_parameters = get_parameter_names(model, [torch.nn.LayerNorm])
83 | decay_parameters = [name for name in decay_parameters if not ("bias" in name)]
84 | nondecay_parameters = [n for n, p in model.named_parameters() if n not in decay_parameters]
85 | optimizer_grouped_parameters = [
86 | {
87 | "params": [p for n, p in model.named_parameters() if n in decay_parameters],
88 | "lr": args.lr,
89 | "weight_decay": args.wdecay,
90 | },
91 | {
92 | "params": [p for n, p in model.named_parameters() if n in nondecay_parameters],
93 | "lr": args.lr,
94 | "weight_decay": 0.0,
95 | },
96 | ]
97 | optimizer = torch.optim.AdamW(params=optimizer_grouped_parameters, lr=args.lr, weight_decay=args.wdecay)
98 |
99 | if args.use_scheduler:
100 | scheduler = torch.optim.lr_scheduler.OneCycleLR(
101 | optimizer,
102 | args.lr,
103 | args.max_steps+100,
104 | pct_start=0.05,
105 | cycle_momentum=False,
106 | anneal_strategy="cos",
107 | )
108 | else:
109 | scheduler = None
110 |
111 | return optimizer, scheduler
112 |
113 | def forward_batch_sparse(batch, model, args, sw, inference_iters):
114 | rgbs = batch.video
115 | trajs_g = batch.trajs
116 | vis_g = batch.visibs # B,S,N
117 | valids = batch.valids
118 | dname = batch.dname
119 |
120 | B, T, C, H, W = rgbs.shape
121 | assert C == 3
122 | B, T, N, D = trajs_g.shape
123 | device = rgbs.device
124 | S = 16
125 |
126 | if N==0 or torch.any(vis_g[:,0].reshape(-1)==0):
127 | print('vis_g', vis_g.shape)
128 | return None, None
129 |
130 | all_flow_e, all_visconf_e, all_flow_preds, all_visconf_preds = model(rgbs, iters=inference_iters, sw=sw, is_training=True)
131 |
132 | grid_xy = utils.basic.gridcloud2d(1, H, W, norm=False, device=device).float() # 1,H*W,2
133 | grid_xy = grid_xy.permute(0,2,1).reshape(1,1,2,H,W) # 1,1,2,H,W
134 | traj_maps_e = all_flow_e + grid_xy # B,T,2,H,W
135 | xy0 = trajs_g[:,0] # B,N,2
136 | xy0[:,:,0] = xy0[:,:,0].clamp(0,W-1)
137 | xy0[:,:,1] = xy0[:,:,1].clamp(0,H-1)
138 |
139 | traj_maps_e_ = traj_maps_e.reshape(B*T,2,H,W)
140 | xy0_ = xy0.reshape(B,1,N,2).repeat(1,T,1,1).reshape(B*T,N,1,2)
141 | trajs_e_ = utils.samp.bilinear_sampler(traj_maps_e_, xy0_) # B*T,2,N,1
142 | trajs_e = trajs_e_.reshape(B,T,2,N).permute(0,1,3,2) # B,T,N,2
143 |
144 | xy0_ = xy0.reshape(B,1,N,2).repeat(1,S,1,1).reshape(B*S,N,1,2)
145 |
146 | coord_predictions = []
147 | assert(B==1)
148 | for fpl in all_flow_preds:
149 | cps = []
150 | for fp in fpl:
151 | traj_map = fp + grid_xy # B,S,2,H,W
152 | traj_map_ = traj_map.reshape(B*S,2,H,W)
153 | traj_e_ = utils.samp.bilinear_sampler(traj_map_, xy0_) # B*T,2,N,1
154 | traj_e = traj_e_.reshape(B,S,2,N).permute(0,1,3,2) # B,S,N,2
155 | cps.append(traj_e)
156 | coord_predictions.append(cps)
157 |
158 | # visconf is upset when i bilinearly sample. says the data is outside [0,1]
159 | # so here we do NN sampling
160 | assert(B==1)
161 | x0, y0 = xy0[0,:,0], xy0[0,:,1] # N
162 | x0 = torch.clamp(x0, 0, W-1).round().long()
163 | y0 = torch.clamp(y0, 0, H-1).round().long()
164 | vis_predictions, confidence_predictions = [], []
165 | for vcl in all_visconf_preds:
166 | vps = []
167 | cps = []
168 | for vc in vcl:
169 | vc = vc[:,:,:,y0,x0] # B,S,2,N
170 | vps.append(vc[:,:,0]) # B,S,N
171 | cps.append(vc[:,:,1]) # B,S,N
172 | vis_predictions.append(vps)
173 | confidence_predictions.append(cps)
174 |
175 | vis_gts = []
176 | invis_gts = []
177 | traj_gts = []
178 | valids_gts = []
179 |
180 | for ind in range(0, T - S // 2, S // 2):
181 | vis_gts.append(vis_g[:, ind : ind + S])
182 | invis_gts.append(1 - vis_g[:, ind : ind + S])
183 | traj_gts.append(trajs_g[:, ind : ind + S, :, :2])
184 | valids_gts.append(valids[:, ind : ind + S])
185 |
186 | total_loss = torch.tensor(0.0, requires_grad=True, device=device)
187 | metrics = {}
188 |
189 | seq_loss_visible = utils.loss.sequence_loss(
190 | coord_predictions,
191 | traj_gts,
192 | valids_gts,
193 | vis=vis_gts,
194 | gamma=0.8,
195 | use_huber_loss=args.use_huber_loss,
196 | loss_only_for_visible=True,
197 | )
198 | confidence_loss = utils.loss.sequence_prob_loss(
199 | coord_predictions, confidence_predictions, traj_gts, vis_gts
200 | )
201 | vis_loss = utils.loss.sequence_BCE_loss(vis_predictions, vis_gts)
202 |
203 | seq_loss_invisible = utils.loss.sequence_loss(
204 | coord_predictions,
205 | traj_gts,
206 | valids_gts,
207 | vis=invis_gts,
208 | gamma=0.8,
209 | use_huber_loss=args.use_huber_loss,
210 | loss_only_for_visible=True,
211 | )
212 |
213 | total_loss = seq_loss_visible.mean()*0.05 + seq_loss_invisible.mean()*0.01 + vis_loss.mean() + confidence_loss.mean()
214 |
215 | if sw is not None and sw.save_scalar:
216 | dn = dname[0]
217 | metrics['dname'] = dn
218 | metrics['seq_loss_visible'] = seq_loss_visible.mean().item()
219 | metrics['seq_loss_invisible'] = seq_loss_invisible.mean().item()
220 | metrics['vis_loss'] = vis_loss.item()
221 | metrics['conf_loss'] = confidence_loss.mean().item()
222 | thrs = [1,2,4,8,16]
223 | sx_ = (W-1) / 255.0
224 | sy_ = (H-1) / 255.0
225 | sc_py = np.array([sx_, sy_]).reshape([1,1,1,2])
226 | sc_pt = torch.from_numpy(sc_py).float().to(device)
227 | d_sum = 0.0
228 | for thr in thrs:
229 | d_ = (torch.norm(trajs_e/sc_pt - trajs_g/sc_pt, dim=-1) < thr).float().mean().item()
230 | d_sum += d_
231 | metrics['d_%d' % thr] = d_
232 | d_avg = d_sum / len(thrs)
233 | metrics['d_avg'] = d_avg
234 | metrics['total_loss'] = total_loss.item()
235 |
236 | if sw is not None and sw.save_this:
237 | utils.basic.print_stats('rgbs', rgbs)
238 | prep_rgbs = utils.basic.normalize(rgbs[0:1])-0.5
239 | prep_grays = prep_rgbs.mean(dim=2, keepdim=True).repeat(1,1,3,1,1)
240 | sw.summ_rgb('0_inputs/rgb0', prep_rgbs[:,0], frame_str=dname[0], frame_id=torch.sum(vis_g[0,0]).item())
241 | sw.summ_traj2ds_on_rgb('0_inputs/trajs_g_on_rgb0', trajs_g[0:1], prep_rgbs[:,0], cmap='winter', linewidth=1)
242 | trajs_clamp = trajs_g.clone()
243 | trajs_clamp[:,:,:,0] = trajs_clamp[:,:,:,0].clip(0,W-1)
244 | trajs_clamp[:,:,:,1] = trajs_clamp[:,:,:,1].clip(0,H-1)
245 | inds = np.random.choice(trajs_g.shape[2], 1024)
246 | outs = sw.summ_pts_on_rgbs(
247 | '',
248 | trajs_clamp[0:1,:,inds],
249 | prep_grays[0:1],
250 | valids=valids[0:1,:,inds],
251 | cmap='winter', linewidth=3, only_return=True)
252 | sw.summ_pts_on_rgbs(
253 | '0_inputs/kps_gv_on_rgbs',
254 | trajs_clamp[0:1,:,inds],
255 | utils.improc.preprocess_color(outs),
256 | valids=valids[0:1,:,inds]*vis_g[0:1,:,inds],
257 | cmap='spring', linewidth=2,
258 | frame_ids=list(range(T)))
259 |
260 | out = utils.improc.preprocess_color(sw.summ_traj2ds_on_rgb('', trajs_g[0:1,:,inds], prep_rgbs[:,0], cmap='winter', linewidth=1, only_return=True))
261 | sw.summ_traj2ds_on_rgb('2_outputs/trajs_e_on_g', trajs_e[0:1,:,inds], out, cmap='spring', linewidth=1)
262 |
263 | trajs_e_clamp = trajs_e.clone()
264 | trajs_e_clamp[:,:,:,0] = trajs_e_clamp[:,:,:,0].clip(0,W-1)
265 | trajs_e_clamp[:,:,:,1] = trajs_e_clamp[:,:,:,1].clip(0,H-1)
266 | inds_e = np.random.choice(trajs_e.shape[2], 1024)
267 | outs = sw.summ_pts_on_rgbs(
268 | '',
269 | trajs_clamp[0:1,:,inds],
270 | prep_grays[0:1],
271 | valids=valids[0:1,:,inds]*vis_g[0:1,:,inds],
272 | cmap='winter', linewidth=2,
273 | only_return=True)
274 | sw.summ_pts_on_rgbs(
275 | '2_outputs/kps_ge_on_rgbs',
276 | trajs_e_clamp[0:1,:,inds],
277 | utils.improc.preprocess_color(outs),
278 | valids=valids[0:1,:,inds]*vis_g[0:1,:,inds],
279 | cmap='spring', linewidth=2,
280 | frame_ids=list(range(T)))
281 |
282 | return total_loss, metrics
283 |
284 |
285 | def run(model, args):
286 | fabric = Fabric(
287 | devices="auto",
288 | num_nodes=1,
289 | strategy="ddp",
290 | accelerator="cuda",
291 | precision="bf16-mixed" if args.mixed_precision else "32-true",
292 | )
293 | fabric.launch() # enable multi-gpu
294 |
295 | def seed_everything(seed: int):
296 | random.seed(seed)
297 | os.environ["PYTHONHASHSEED"] = str(seed)
298 | np.random.seed(seed)
299 | torch.manual_seed(seed)
300 | torch.cuda.manual_seed(seed)
301 | torch.backends.cudnn.deterministic = True
302 | torch.backends.cudnn.benchmark = False
303 | def seed_worker(worker_id):
304 | worker_seed = torch.initial_seed() % 2**32
305 | np.random.seed(worker_seed + worker_id)
306 | random.seed(worker_seed + worker_id)
307 | random_data = os.urandom(4)
308 | seed = int.from_bytes(random_data, byteorder="big")
309 | seed_everything(seed)
310 | g = torch.Generator()
311 | g.manual_seed(seed)
312 |
313 | B_ = args.batch_size * torch.cuda.device_count()
314 | model_name = "%d" % (B_)
315 | if args.use_augs:
316 | model_name += "A"
317 | if args.only_short:
318 | model_name += "i%d" % (args.inference_iters_24)
319 | elif args.no_short:
320 | model_name += "i%d" % (args.inference_iters_56)
321 | else:
322 | model_name += "i%d" % (args.inference_iters_24)
323 | model_name += "i%d" % (args.inference_iters_56)
324 | lrn = utils.basic.get_lr_str(args.lr) # e.g., 5e-4
325 | model_name += "_%s" % lrn
326 | if args.mixed_precision:
327 | model_name += "m"
328 | if args.use_huber_loss:
329 | model_name += "h"
330 | model_name += "_%s" % args.exp
331 | model_date = datetime.datetime.now().strftime('%M%S')
332 | model_name = model_name + '_' + model_date
333 | print('model_name', model_name)
334 |
335 | save_dir = '%s/%s' % (args.ckpt_dir, model_name)
336 |
337 | model.cuda()
338 |
339 | dataset_names = []
340 |
341 | if fabric.world_size==2:
342 | if args.only_short:
343 | ranks_56 = []
344 | ranks_24 = [0,1]
345 | log_ranks = [0]
346 | elif args.no_short:
347 | ranks_56 = [0,1]
348 | ranks_24 = []
349 | log_ranks = [0]
350 | else:
351 | ranks_56 = [0]
352 | ranks_24 = [1]
353 | log_ranks = [0,1]
354 | elif fabric.world_size==8:
355 | ranks_56 = [0,1,2,3]
356 | ranks_24 = [4,5,6,7]
357 | log_ranks = [0,4]
358 | else:
359 | ranks_24 = [0]
360 | ranks_56 = []
361 | log_ranks = [0]
362 | print('assuming we are debugging with 1 gpu...')
363 |
364 | if fabric.global_rank in ranks_56:
365 | sparse_dataset56, sparse_dataset_names56 = get_sparse_dataset(
366 | args, crop_size=args.crop_size_56, T=56, N=args.traj_per_sample_56, random_first=False, version='ce64/kublong')
367 | sparse_loader56 = torch.utils.data.DataLoader(
368 | sparse_dataset56,
369 | batch_size=args.batch_size,
370 | shuffle=True,
371 | num_workers=args.num_workers_56,
372 | worker_init_fn=seed_worker,
373 | generator=g,
374 | pin_memory=False,
375 | collate_fn=utils.data.collate_fn_train,
376 | drop_last=True,
377 | )
378 | sparse_loader56 = fabric.setup_dataloaders(sparse_loader56, move_to_device=False)
379 | print('len(sparse_loader56)', len(sparse_loader56))
380 | sparse_iterloader56 = iter(sparse_loader56)
381 | dataset_names += sparse_dataset_names56
382 | else:
383 | sparse_dataset24, sparse_dataset_names24 = get_sparse_dataset(
384 | args, crop_size=args.crop_size_24, T=24, N=args.traj_per_sample_24, random_first=args.random_first_frame, version='kubric_au')
385 | sparse_loader24 = torch.utils.data.DataLoader(
386 | sparse_dataset24,
387 | batch_size=args.batch_size,
388 | shuffle=True,
389 | num_workers=args.num_workers_24,
390 | worker_init_fn=seed_worker,
391 | generator=g,
392 | pin_memory=False,
393 | collate_fn=utils.data.collate_fn_train,
394 | drop_last=True,
395 | )
396 | sparse_loader24 = fabric.setup_dataloaders(sparse_loader24, move_to_device=False)
397 | print('len(sparse_loader24)', len(sparse_loader24))
398 | sparse_iterloader24 = iter(sparse_loader24)
399 | dataset_names += sparse_dataset_names24
400 |
401 | optimizer, scheduler = fetch_optimizer(args, model)
402 |
403 | if fabric.global_rank in log_ranks:
404 | log_dir = './logs_train'
405 | pools_t = {}
406 | for dname in dataset_names:
407 | if not (dname in pools_t):
408 | print('creating pools for', dname)
409 | pools_t[dname] = create_pools()
410 | overpools_t = create_pools()
411 | writer_t = SummaryWriter(log_dir + '/' + model_name + '/t', max_queue=10, flush_secs=60)
412 |
413 | global_step = 0
414 | if args.init_dir:
415 | load_dir = '%s/%s' % (args.ckpt_dir, args.init_dir)
416 | loaded_global_step = utils.saveload.load(
417 | fabric,
418 | load_dir,
419 | model,
420 | optimizer=optimizer if args.load_optimizer else None,
421 | scheduler=scheduler if args.load_scheduler else None,
422 | ignore_load=None,
423 | strict=True)
424 | if args.load_optimizer and not args.use_scheduler:
425 | assert(optimizer.param_groups[-1]["lr"] == args.lr)
426 | if args.load_step:
427 | global_step = loaded_global_step
428 | if args.use_scheduler and args.load_step and (not args.load_optimizer):
429 | # advance the scheduler to catch up with global_step
430 | for ii in range(global_step):
431 | scheduler.step()
432 |
433 | model, optimizer = fabric.setup(model, optimizer, move_to_device=False)
434 | model.train()
435 |
436 | while global_step < args.max_steps+10:
437 | global_step += 1
438 |
439 | f_start_time = time.time()
440 |
441 | optimizer.zero_grad(set_to_none=True)
442 | assert model.training
443 |
444 | if fabric.global_rank in log_ranks:
445 | sw_t = utils.improc.Summ_writer(
446 | writer=writer_t,
447 | global_step=global_step,
448 | log_freq=args.log_freq,
449 | fps=8,
450 | scalar_freq=min(53,args.log_freq),
451 | just_gif=True)
452 | else:
453 | sw_t = None
454 |
455 | metrics = None
456 |
457 | gotit = [False, False]
458 | while not all(gotit):
459 | if fabric.global_rank in ranks_56:
460 | try:
461 | batch = next(sparse_iterloader56)
462 | except StopIteration:
463 | sparse_iterloader56 = iter(sparse_loader56)
464 | batch = next(sparse_iterloader56)
465 | else:
466 | try:
467 | batch = next(sparse_iterloader24)
468 | except StopIteration:
469 | sparse_iterloader24 = iter(sparse_loader24)
470 | batch = next(sparse_iterloader24)
471 | batch, gotit = batch
472 |
473 | rtime = time.time()-f_start_time
474 |
475 | if fabric.global_rank in ranks_56:
476 | inference_iters = args.inference_iters_56
477 | else:
478 | inference_iters = args.inference_iters_24
479 |
480 | utils.data.dataclass_to_cuda_(batch)
481 | total_loss, metrics = forward_batch_sparse(batch, model, args, sw_t, inference_iters)
482 | ftime = time.time()-f_start_time
483 | fabric.barrier() # wait for all gpus to finish their fwd
484 |
485 | b_start_time = time.time()
486 | if metrics is not None:
487 | if fabric.global_rank in log_ranks and sw_t.save_scalar:
488 | sw_t.summ_scalar('_/current_lr', optimizer.param_groups[-1]["lr"])
489 | sw_t.summ_scalar('total_loss', metrics['total_loss'])
490 |
491 | # update stats
492 | dname = metrics['dname']
493 | if dname in dataset_names:
494 | for key in list(pools_t[dname].keys()):
495 | if key in metrics:
496 | pools_t[dname][key].update([metrics[key]])
497 | overpools_t[key].update([metrics[key]])
498 | # plot stats
499 | for key in list(overpools_t.keys()):
500 | for dname in dataset_names:
501 | sw_t.summ_scalar('%s/%s' % (dname, key), pools_t[dname][key].mean())
502 | sw_t.summ_scalar('_/%s' % (key), overpools_t[key].mean())
503 |
504 | if args.mixed_precision:
505 | fabric.backward(total_loss)
506 | fabric.clip_gradients(model, optimizer, max_norm=1.0, norm_type=2, error_if_nonfinite=False)
507 | optimizer.step()
508 | if args.use_scheduler:
509 | scheduler.step()
510 | else:
511 | fabric.backward(total_loss)
512 | fabric.clip_gradients(model, optimizer, max_norm=1.0, norm_type=2, error_if_nonfinite=False)
513 | optimizer.step()
514 | if args.use_scheduler:
515 | scheduler.step()
516 | btime = time.time()-b_start_time
517 | fabric.barrier() # wait for all gpus to finish their bwd
518 |
519 | itime = ftime + btime
520 |
521 | if global_step % args.save_freq == 0:
522 | if fabric.global_rank == 0:
523 | utils.saveload.save(save_dir, model.module, optimizer, scheduler, global_step, keep_latest=2)
524 |
525 | info_str = '%s; step %06d/%d; rtime %.2f; itime %.2f' % (
526 | model_name, global_step, args.max_steps, rtime, itime)
527 | if fabric.global_rank in log_ranks:
528 | if overpools_t['total_loss'].have_min_size():
529 | info_str += '; loss_t %.2f; d_avg %.1f' % (
530 | overpools_t['total_loss'].mean(),
531 | overpools_t['d_avg'].mean()*100.0,
532 | )
533 | info_str += '; (rank %d)' % fabric.global_rank
534 | print(info_str)
535 | print('done!')
536 |
537 | if fabric.global_rank in log_ranks:
538 | writer_t.close()
539 |
540 | if __name__ == "__main__":
541 | init_dir = ''
542 |
543 | # this file is for training alltracker in "stage 1",
544 | # which involves kubric-only training.
545 | # this is also the file to execute all ablations.
546 |
547 | from nets.alltracker import Net; exp = 'stage1' # clean up for release
548 |
549 | parser = argparse.ArgumentParser()
550 | parser.add_argument("--exp", default=exp)
551 | parser.add_argument("--init_dir", type=str, default=init_dir)
552 | parser.add_argument("--load_optimizer", default=False, action='store_true')
553 | parser.add_argument("--load_scheduler", default=False, action='store_true')
554 | parser.add_argument("--load_step", default=False, action='store_true')
555 | parser.add_argument("--ckpt_dir", type=str, default='./checkpoints')
556 | parser.add_argument("--data_dir", type=str, default='/data')
557 | parser.add_argument("--batch_size", type=int, default=1)
558 | parser.add_argument("--num_nodes", type=int, default=1)
559 | parser.add_argument("--num_workers_24", type=int, default=2)
560 | parser.add_argument("--num_workers_56", type=int, default=6)
561 | parser.add_argument("--mixed_precision", default=False, action='store_true')
562 | parser.add_argument("--lr", type=float, default=5e-4)
563 | parser.add_argument("--wdecay", type=float, default=0.0005)
564 | parser.add_argument("--max_steps", type=int, default=100000)
565 | parser.add_argument("--use_scheduler", default=True)
566 | parser.add_argument("--save_freq", type=int, default=2000)
567 | parser.add_argument("--log_freq", type=int, default=997) # prime number
568 | parser.add_argument("--traj_per_sample_24", type=int, default=256) # note we allow 1-24x this amount
569 | parser.add_argument("--traj_per_sample_56", type=int, default=256) # note we allow 1-24x this amount
570 | parser.add_argument("--inference_iters_24", type=int, default=4)
571 | parser.add_argument("--inference_iters_56", type=int, default=3)
572 | parser.add_argument("--random_frame_rate", default=False, action='store_true')
573 | parser.add_argument("--random_first_frame", default=False, action='store_true')
574 | parser.add_argument("--shuffle_frames", default=False, action='store_true')
575 | parser.add_argument("--use_augs", default=True)
576 | parser.add_argument("--seqlen", type=int, default=16)
577 | parser.add_argument("--crop_size_24", nargs="+", default=[384,512])
578 | parser.add_argument("--crop_size_56", nargs="+", default=[256,384])
579 | parser.add_argument("--random_number_traj", default=False, action='store_true')
580 | parser.add_argument("--use_huber_loss", default=False, action='store_true')
581 | parser.add_argument("--debug", default=False, action='store_true')
582 | parser.add_argument("--random_seq_len", default=False, action='store_true')
583 | parser.add_argument("--no_attn", default=False, action='store_true')
584 | parser.add_argument("--use_mixer", default=False, action='store_true')
585 | parser.add_argument("--use_conv", default=False, action='store_true')
586 | parser.add_argument("--use_convb", default=False, action='store_true')
587 | parser.add_argument("--use_basicencoder", default=False, action='store_true')
588 | parser.add_argument("--only_short", default=False, action='store_true')
589 | parser.add_argument("--no_short", default=False, action='store_true')
590 | parser.add_argument("--no_space", default=False, action='store_true')
591 | parser.add_argument("--no_time", default=False, action='store_true')
592 | parser.add_argument("--no_split", default=False, action='store_true')
593 | parser.add_argument("--no_ctx", default=False, action='store_true')
594 | parser.add_argument("--full_split", default=False, action='store_true')
595 | parser.add_argument("--use_sinmotion", default=False, action='store_true')
596 | parser.add_argument("--use_relmotion", default=False, action='store_true')
597 | parser.add_argument("--use_sinrelmotion", default=False, action='store_true')
598 | parser.add_argument("--use_feats8", default=False, action='store_true')
599 | parser.add_argument("--no_init", default=False, action='store_true')
600 | parser.add_argument("--num_blocks", type=int, default=3)
601 | parser.add_argument("--corr_radius", type=int, default=4)
602 | parser.add_argument("--corr_levels", type=int, default=5)
603 | parser.add_argument("--dim", type=int, default=128)
604 | parser.add_argument("--hdim", type=int, default=128)
605 |
606 | args = parser.parse_args()
607 |
608 | # fix up integers
609 | args.crop_size_24 = (int(args.crop_size_24[0]), int(args.crop_size_24[1]))
610 | args.crop_size_56 = (int(args.crop_size_56[0]), int(args.crop_size_56[1]))
611 |
612 | model = Net(
613 | 16,
614 | dim=args.dim,
615 | hdim=args.hdim,
616 | use_attn=(not args.no_attn),
617 | use_mixer=args.use_mixer,
618 | use_conv=args.use_conv,
619 | use_convb=args.use_convb,
620 | use_basicencoder=args.use_basicencoder,
621 | no_space=args.no_space,
622 | no_time=args.no_time,
623 | use_sinmotion=args.use_sinmotion,
624 | use_relmotion=args.use_relmotion,
625 | use_sinrelmotion=args.use_sinrelmotion,
626 | use_feats8=args.use_feats8,
627 | no_split=args.no_split,
628 | no_ctx=args.no_ctx,
629 | full_split=args.full_split,
630 | num_blocks=args.num_blocks,
631 | corr_radius=args.corr_radius,
632 | corr_levels=args.corr_levels,
633 | init_weights=(not args.no_init),
634 | )
635 |
636 | run(model, args)
637 |
638 |
--------------------------------------------------------------------------------
6 |
7 | **AllTracker is a point tracking model which is faster and more accurate than other similar models, while also producing dense output at high resolution.**
8 |
9 | AllTracker estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame.
10 |
11 | We are actively adding to this repo, but please ping or open an issue if you notice something missing or broken. The demo (at least) should work for everyone!
12 |
13 |
14 | ## Env setup
15 |
16 | Install miniconda:
17 | ```
18 | mkdir -p ~/miniconda3
19 | wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
20 | bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
21 | rm ~/miniconda3/miniconda.sh
22 | source ~/miniconda3/bin/activate
23 | conda init
24 | ```
25 |
26 | Set up a fresh conda environment for AllTracker:
27 |
28 | ```
29 | conda create -n alltracker python=3.12.8
30 | conda activate alltracker
31 | pip install -r requirements.txt
32 | ```
33 |
34 | ## Running the demo
35 |
36 | Download the sample video:
37 | ```
38 | cd demo_video
39 | sh download_video.sh
40 | cd ..
41 | ```
42 |
43 | Run the demo:
44 | ```
45 | python demo.py --mp4_path ./demo_video/monkey.mp4
46 | ```
47 | The demo script will automatically download the model weights from [huggingface](https://huggingface.co/aharley/alltracker/tree/main) if needed.
48 |
49 | For a fancier visualization, giving a side-by-side view of the input and output, try this:
50 | ```
51 | python demo.py --mp4_path ./demo_video/monkey.mp4 --query_frame 32 --conf_thr 0.01 --bkg_opacity 0.0 --rate 2 --hstack --query_frame 16
52 | ```
53 |
54 |
55 |
56 |
57 | ## Training
58 |
59 | AllTracker is trained in two stages: Stage 1 is kubric alone; Stage 2 is a mix of datasets. This 2-stage regime enables fair comparisons with models that train only on Kubric.
60 |
61 | ### Data prep
62 |
63 | Start by downloding Kubric.
64 |
65 | - 24-frame data: [kubric_au.tar.gz](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/kubric_au.tar.gz?download=true)
66 |
67 | - 64-frame data: [part1](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/ce64_kub_aa?download=true), [part2](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/ce64_kub_ab?download=true), [part3](https://huggingface.co/datasets/aharley/alltracker_data/resolve/main/ce64_kub_ac?download=true)
68 |
69 | Merge the parts by concatenating:
70 | ```
71 | cat ce64_kub_aa ce64_kub_ab ce64_kub_ac > ce64_kub.tar.gz
72 | ```
73 |
74 | The 24-frame Kubric data is a torch export of the official `kubric-public/tfds/movi_f/512x512` data.
75 |
76 | With Kubric, you can skip the other datasets and start training Stage 1.
77 |
78 | Download the rest of the point tracking datasets from [here](https://huggingface.co/datasets/aharley/alltracker_data/tree/main). There you will find 24-frame datasets, `ce24*.tar.gz`, and 64-frame datasets, `ce64*.tar.gz`. Some of the datasets are large, and they are split into parts, so you need to create the full files by concatenating.
79 |
80 | On disk, the point tracking datasets should look like this:
81 | ```
82 | data/
83 | ├── ce24/
84 | │ ├── drivingpt/
85 | │ ├── fltpt/
86 | │ ├── monkapt/
87 | │ ├── springpt/
88 | ├── ce64/
89 | │ ├── drivingpt/
90 | │ ├── kublong/
91 | │ ├── monkapt/
92 | │ ├── podlong/
93 | │ ├── springpt/
94 | ├── dynamicreplica/
95 | ├── kubric_au/
96 | ```
97 |
98 | Download the optical flow datasets from the official websites: [FlyingChairs, FlyingThings3D, Monkaa, Driving](https://lmb.informatik.uni-freiburg.de/resources/datasets) [AutoFlow](https://autoflow-google.github.io/), [SPRING](https://spring-benchmark.org/), [VIPER](https://playing-for-benchmarks.org/download/), [HD1K](http://hci-benchmark.iwr.uni-heidelberg.de/), [KITTI](https://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=flow), [TARTANAIR](https://theairlab.org/tartanair-dataset/).
99 |
100 |
101 | ### Stage 1
102 |
103 | Stage 1 is to train the model for 200k steps on Kubric.
104 |
105 | ```
106 | export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7; python train_stage1.py --mixed_precision --lr 5e-4 --max_steps 200000 --data_dir /data --exp "stage1abc"
107 | ```
108 |
109 | This should produce a tensorboard log in `./logs_train/`, and checkpoints in `./checkpoints/`, in folder names similar to "64Ai4i3_5e-4m_stage1abc_1318". (The 4-digit string at the end is a timecode indicating when the run began, to help make the filepaths unique.)
110 |
111 | ### Stage 2
112 |
113 | Stage 2 is to train the model for 400k steps on a mix of point tracking datasets and optical flow datasets. This stage initializes from the output of Stage 1.
114 |
115 | ```
116 | export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7; python train_stage2.py --mixed_precision --init_dir '64Ai4i3_5e-4m_stage1abc_1318' --lr 1e-5 --max_steps 400000 --exp 'stage2abc'
117 | ```
118 |
119 | ## Evaluation
120 |
121 | Test the model on point tracking datasets with a command like:
122 |
123 | ```
124 | python test_dense_on_sparse.py --dname 'dav'
125 | ```
126 |
127 | At the end, you should see:
128 | ```
129 | da: 76.3,
130 | aj: 63.3,
131 | oa: 90.0,
132 | ```
133 | which represent `d_avg` (accuracy), Average Jaccard, and Occlusion Accuracy. We find that small numerical issues (even across GPUs) may cause +- 0.1 fluctuation on these metrics.
134 |
135 | Test it at higher resolution with the `image_size` arg, like: `--image_size 448 768`, which should produce `da: 78.8, aj: 65.9, oa: 90.2` or `--image_size 768 1024`, which should produce `da: 80.6, aj: 67.2, oa: 89.7`.
136 |
137 | Note that AJ and OA are not reliable metrics in all datasets, because not all datasets follow the same rules about visibility annotation.
138 |
139 | Dataloaders for all test datasets are in the repo, and can be run in sequence with a command like:
140 | ```
141 | python test_dense_on_sparse.py --dname 'bad,cro,dav,dri,ego,hor,kin,rgb,rob'
142 | ```
143 | but if you have multiple GPUs, we recomend running the tests in parallel.
144 |
145 |
146 | ## Citation
147 |
148 | If you use this code for your research, please cite:
149 |
150 | ```
151 | Adam W. Harley, Yang You, Xinglong Sun, Yang Zheng, Nikhil Raghuraman, Yunqi Gu, Sheldon Liang, Wen-Hsuan Chu, Achal Dave, Pavel Tokmakov, Suya You, Rares Ambrus, Katerina Fragkiadaki, Leonidas J. Guibas. AllTracker: Efficient Dense Point Tracking at High Resolution. ICCV 2025.
152 | ```
153 |
154 | Bibtex:
155 | ```
156 | @inproceedings{harley2025alltracker,
157 | author = {Adam W. Harley and Yang You and Xinglong Sun and Yang Zheng and Nikhil Raghuraman and Yunqi Gu and Sheldon Liang and Wen-Hsuan Chu and Achal Dave and Pavel Tokmakov and Suya You and Rares Ambrus and Katerina Fragkiadaki and Leonidas J. Guibas},
158 | title = {All{T}racker: {E}fficient Dense Point Tracking at High Resolution}
159 | booktitle = {ICCV},
160 | year = {2025}
161 | }
162 | ```
163 |
--------------------------------------------------------------------------------
/utils/samp.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import utils.basic
3 | import torch.nn.functional as F
4 |
5 | def bilinear_sampler(input, coords, align_corners=True, padding_mode="border"):
6 | r"""Sample a tensor using bilinear interpolation
7 |
8 | `bilinear_sampler(input, coords)` samples a tensor :attr:`input` at
9 | coordinates :attr:`coords` using bilinear interpolation. It is the same
10 | as `torch.nn.functional.grid_sample()` but with a different coordinate
11 | convention.
12 |
13 | The input tensor is assumed to be of shape :math:`(B, C, H, W)`, where
14 | :math:`B` is the batch size, :math:`C` is the number of channels,
15 | :math:`H` is the height of the image, and :math:`W` is the width of the
16 | image. The tensor :attr:`coords` of shape :math:`(B, H_o, W_o, 2)` is
17 | interpreted as an array of 2D point coordinates :math:`(x_i,y_i)`.
18 |
19 | Alternatively, the input tensor can be of size :math:`(B, C, T, H, W)`,
20 | in which case sample points are triplets :math:`(t_i,x_i,y_i)`. Note
21 | that in this case the order of the components is slightly different
22 | from `grid_sample()`, which would expect :math:`(x_i,y_i,t_i)`.
23 |
24 | If `align_corners` is `True`, the coordinate :math:`x` is assumed to be
25 | in the range :math:`[0,W-1]`, with 0 corresponding to the center of the
26 | left-most image pixel :math:`W-1` to the center of the right-most
27 | pixel.
28 |
29 | If `align_corners` is `False`, the coordinate :math:`x` is assumed to
30 | be in the range :math:`[0,W]`, with 0 corresponding to the left edge of
31 | the left-most pixel :math:`W` to the right edge of the right-most
32 | pixel.
33 |
34 | Similar conventions apply to the :math:`y` for the range
35 | :math:`[0,H-1]` and :math:`[0,H]` and to :math:`t` for the range
36 | :math:`[0,T-1]` and :math:`[0,T]`.
37 |
38 | Args:
39 | input (Tensor): batch of input images.
40 | coords (Tensor): batch of coordinates.
41 | align_corners (bool, optional): Coordinate convention. Defaults to `True`.
42 | padding_mode (str, optional): Padding mode. Defaults to `"border"`.
43 |
44 | Returns:
45 | Tensor: sampled points.
46 | """
47 |
48 | sizes = input.shape[2:]
49 |
50 | assert len(sizes) in [2, 3]
51 |
52 | if len(sizes) == 3:
53 | # t x y -> x y t to match dimensions T H W in grid_sample
54 | coords = coords[..., [1, 2, 0]]
55 |
56 | if align_corners:
57 | coords = coords * torch.tensor(
58 | [2 / max(size - 1, 1) for size in reversed(sizes)], device=coords.device
59 | )
60 | else:
61 | coords = coords * torch.tensor(
62 | [2 / size for size in reversed(sizes)], device=coords.device
63 | )
64 |
65 | coords -= 1
66 |
67 | return F.grid_sample(
68 | input, coords, align_corners=align_corners, padding_mode=padding_mode
69 | )
70 |
71 |
72 | def sample_features4d(input, coords):
73 | r"""Sample spatial features
74 |
75 | `sample_features4d(input, coords)` samples the spatial features
76 | :attr:`input` represented by a 4D tensor :math:`(B, C, H, W)`.
77 |
78 | The field is sampled at coordinates :attr:`coords` using bilinear
79 | interpolation. :attr:`coords` is assumed to be of shape :math:`(B, R,
80 | 3)`, where each sample has the format :math:`(x_i, y_i)`. This uses the
81 | same convention as :func:`bilinear_sampler` with `align_corners=True`.
82 |
83 | The output tensor has one feature per point, and has shape :math:`(B,
84 | R, C)`.
85 |
86 | Args:
87 | input (Tensor): spatial features.
88 | coords (Tensor): points.
89 |
90 | Returns:
91 | Tensor: sampled features.
92 | """
93 |
94 | B, _, _, _ = input.shape
95 |
96 | # B R 2 -> B R 1 2
97 | coords = coords.unsqueeze(2)
98 |
99 | # B C R 1
100 | feats = bilinear_sampler(input, coords)
101 |
102 | return feats.permute(0, 2, 1, 3).view(
103 | B, -1, feats.shape[1] * feats.shape[3]
104 | ) # B C R 1 -> B R C
105 |
106 |
107 | def sample_features5d(input, coords):
108 | r"""Sample spatio-temporal features
109 |
110 | `sample_features5d(input, coords)` works in the same way as
111 | :func:`sample_features4d` but for spatio-temporal features and points:
112 | :attr:`input` is a 5D tensor :math:`(B, T, C, H, W)`, :attr:`coords` is
113 | a :math:`(B, R1, R2, 3)` tensor of spatio-temporal point :math:`(t_i,
114 | x_i, y_i)`. The output tensor has shape :math:`(B, R1, R2, C)`.
115 |
116 | Args:
117 | input (Tensor): spatio-temporal features.
118 | coords (Tensor): spatio-temporal points.
119 |
120 | Returns:
121 | Tensor: sampled features.
122 | """
123 |
124 | B, T, _, _, _ = input.shape
125 |
126 | # B T C H W -> B C T H W
127 | input = input.permute(0, 2, 1, 3, 4)
128 |
129 | # B R1 R2 3 -> B R1 R2 1 3
130 | coords = coords.unsqueeze(3)
131 |
132 | # B C R1 R2 1
133 | feats = bilinear_sampler(input, coords)
134 |
135 | return feats.permute(0, 2, 3, 1, 4).view(
136 | B, feats.shape[2], feats.shape[3], feats.shape[1]
137 | ) # B C R1 R2 1 -> B R1 R2 C
138 |
139 |
140 | def bilinear_sample2d(im, x, y, return_inbounds=False):
141 | # x and y are each B, N
142 | # output is B, C, N
143 | B, C, H, W = list(im.shape)
144 | N = list(x.shape)[1]
145 |
146 | x = x.float()
147 | y = y.float()
148 | H_f = torch.tensor(H, dtype=torch.float32)
149 | W_f = torch.tensor(W, dtype=torch.float32)
150 |
151 | # inbound_mask = (x>-0.5).float()*(y>-0.5).float()*(x -0.5).byte() & (x < float(W_f - 0.5)).byte()
208 | y_valid = (y > -0.5).byte() & (y < float(H_f - 0.5)).byte()
209 | inbounds = (x_valid & y_valid).float()
210 | inbounds = inbounds.reshape(B, N) # something seems wrong here for B>1; i'm getting an error here (or downstream if i put -1)
211 | return output, inbounds
212 |
213 | return output # B, C, N
214 |
--------------------------------------------------------------------------------
/datasets/drivetrackdataset.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 | import os
4 | import glob
5 | import cv2
6 | from datasets.pointdataset import PointDataset
7 | import pickle
8 | import utils.data
9 | from pathlib import Path
10 |
11 | class DrivetrackDataset(PointDataset):
12 | def __init__(
13 | self,
14 | data_root='../datasets/drivetrack',
15 | crop_size=(384, 512),
16 | seq_len=None,
17 | traj_per_sample=512,
18 | only_first=False,
19 | ):
20 | super(DrivetrackDataset, self).__init__(
21 | data_root=data_root,
22 | crop_size=crop_size,
23 | seq_len=seq_len,
24 | traj_per_sample=traj_per_sample,
25 | )
26 | print("loading drivetrack dataset...")
27 |
28 | self.dname = 'drivetrack'
29 | self.only_first = only_first
30 | S = seq_len
31 |
32 | self.dataset_location = Path(data_root)
33 | self.S = S
34 | video_fns = sorted(list(self.dataset_location.glob('*.npz')))
35 |
36 | self.video_fns = []
37 | for video_fn in video_fns[:100]: # drivetrack is huge and self-similar, so we trim to 100
38 | ds = np.load(video_fn, allow_pickle=True)
39 | rgbs, trajs, visibs = ds['video'], ds['tracks'], ds['visibles']
40 | # rgbs is T,1280,1920,3
41 | # trajs is N,T,2
42 | # visibs is N,T
43 |
44 | trajs = np.transpose(trajs, (1,0,2)).astype(np.float32) # S,N,2
45 | visibs = np.transpose(visibs, (1,0)).astype(np.float32) # S,N
46 | valids = visibs.copy()
47 | # print('N0', trajs.shape[1])
48 |
49 | # discard tracks with any inf/nan
50 | idx = np.nonzero(np.isfinite(trajs.sum(0).sum(1)))[0] # N
51 | trajs = trajs[:,idx]
52 | visibs = visibs[:,idx]
53 | valids = valids[:,idx]
54 | # print('N1', trajs.shape[1])
55 |
56 | if trajs.shape[1] < self.traj_per_sample:
57 | continue
58 |
59 | # shuffle and trim
60 | inds = np.random.permutation(trajs.shape[1])
61 | inds = inds[:10000]
62 | trajs = trajs[:,inds]
63 | visibs = visibs[:,inds]
64 | valids = valids[:,inds]
65 | # print('N2', trajs.shape[1])
66 |
67 | S,H,W,C = rgbs.shape
68 |
69 | # set OOB to invisible
70 | visibs[trajs[:, :, 0] > W-1] = False
71 | visibs[trajs[:, :, 0] < 0] = False
72 | visibs[trajs[:, :, 1] > H-1] = False
73 | visibs[trajs[:, :, 1] < 0] = False
74 |
75 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
76 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
77 | # print('N3', trajs.shape[1])
78 |
79 | if trajs.shape[1] < self.traj_per_sample:
80 | continue
81 |
82 | trajs = torch.from_numpy(trajs)
83 | visibs = torch.from_numpy(visibs)
84 | valids = torch.from_numpy(valids)
85 | # discard tracks that go far OOB
86 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
87 | close_pts_inds = torch.all(
88 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
89 | dim=0,
90 | )
91 | trajs = trajs[:, close_pts_inds]
92 | visibs = visibs[:, close_pts_inds]
93 | valids = valids[:, close_pts_inds]
94 | # print('N4', trajs.shape[1])
95 |
96 | if trajs.shape[1] < self.traj_per_sample:
97 | continue
98 |
99 | visible_inds = (valids[0]*visibs[0]).nonzero(as_tuple=False)[:, 0]
100 | trajs = trajs[:, visible_inds].float()
101 | visibs = visibs[:, visible_inds].float()
102 | valids = valids[:, visible_inds].float()
103 | # print('N5', trajs.shape[1])
104 |
105 | if trajs.shape[1] >= self.traj_per_sample:
106 | self.video_fns.append(video_fn)
107 |
108 | print(f"found {len(self.video_fns)} unique videos in {self.dataset_location}")
109 |
110 | def getitem_helper(self, index):
111 | video_fn = self.video_fns[index]
112 | ds = np.load(video_fn, allow_pickle=True)
113 | rgbs, trajs, visibs = ds['video'], ds['tracks'], ds['visibles']
114 | # rgbs is T,1280,1920,3
115 | # trajs is N,T,2
116 | # visibs is N,T
117 |
118 | trajs = np.transpose(trajs, (1,0,2)).astype(np.float32) # S,N,2
119 | visibs = np.transpose(visibs, (1,0)).astype(np.float32) # S,N
120 | valids = visibs.copy()
121 |
122 | # discard inf/nan
123 | idx = np.nonzero(np.isfinite(trajs.sum(0).sum(1)))[0] # N
124 | trajs = trajs[:,idx]
125 | visibs = visibs[:,idx]
126 | valids = valids[:,idx]
127 |
128 | # shuffle and trim
129 | inds = np.random.permutation(trajs.shape[1])
130 | inds = inds[:10000]
131 | trajs = trajs[:,inds]
132 | visibs = visibs[:,inds]
133 | valids = valids[:,inds]
134 | N = trajs.shape[1]
135 | # print('N2', trajs.shape[1])
136 |
137 | S,H,W,C = rgbs.shape
138 | # set OOB to invisible
139 | visibs[trajs[:, :, 0] > W-1] = False
140 | visibs[trajs[:, :, 0] < 0] = False
141 | visibs[trajs[:, :, 1] > H-1] = False
142 | visibs[trajs[:, :, 1] < 0] = False
143 |
144 | rgbs, trajs, visibs, valids = utils.data.standardize_test_data(
145 | rgbs, trajs, visibs, valids, only_first=self.only_first, seq_len=self.seq_len)
146 |
147 | H, W = rgbs[0].shape[:2]
148 | trajs[:,:,0] /= W-1
149 | trajs[:,:,1] /= H-1
150 | rgbs = [cv2.resize(rgb, (self.crop_size[1], self.crop_size[0]), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
151 | rgbs = np.stack(rgbs)
152 | H,W = rgbs[0].shape[:2]
153 | trajs[:,:,0] *= W-1
154 | trajs[:,:,1] *= H-1
155 |
156 | trajs = torch.from_numpy(trajs)
157 | visibs = torch.from_numpy(visibs)
158 | valids = torch.from_numpy(valids)
159 |
160 | # discard tracks that go far OOB
161 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
162 | close_pts_inds = torch.all(
163 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
164 | dim=0,
165 | )
166 | trajs = trajs[:, close_pts_inds]
167 | visibs = visibs[:, close_pts_inds]
168 | valids = valids[:, close_pts_inds]
169 | # print('N3', trajs.shape[1])
170 |
171 | visible_pts_inds = (valids[0]*visibs[0]).nonzero(as_tuple=False)[:, 0]
172 | point_inds = torch.randperm(len(visible_pts_inds))[: self.traj_per_sample]
173 | if len(point_inds) < self.traj_per_sample:
174 | return None, False
175 | visible_inds_sampled = visible_pts_inds[point_inds]
176 | trajs = trajs[:, visible_inds_sampled].float()
177 | visibs = visibs[:, visible_inds_sampled].float()
178 | valids = valids[:, visible_inds_sampled].float()
179 | # print('N4', trajs.shape[1])
180 |
181 | trajs = trajs[:, :self.traj_per_sample]
182 | visibs = visibs[:, :self.traj_per_sample]
183 | valids = valids[:, :self.traj_per_sample]
184 | # print('N5', trajs.shape[1])
185 |
186 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
187 |
188 | sample = utils.data.VideoData(
189 | video=rgbs,
190 | trajs=trajs,
191 | visibs=visibs,
192 | valids=valids,
193 | dname=self.dname,
194 | )
195 | return sample, True
196 |
197 | def __len__(self):
198 | return len(self.video_fns)
199 |
--------------------------------------------------------------------------------
/utils/loss.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn.functional as F
3 | import torch.nn as nn
4 | from typing import List
5 | import utils.basic
6 |
7 |
8 | def sequence_loss(
9 | flow_preds,
10 | flow_gt,
11 | valids,
12 | vis=None,
13 | gamma=0.8,
14 | use_huber_loss=False,
15 | loss_only_for_visible=False,
16 | ):
17 | """Loss function defined over sequence of flow predictions"""
18 | total_flow_loss = 0.0
19 | for j in range(len(flow_gt)):
20 | B, S, N, D = flow_gt[j].shape
21 | B, S2, N = valids[j].shape
22 | assert S == S2
23 | n_predictions = len(flow_preds[j])
24 | flow_loss = 0.0
25 | for i in range(n_predictions):
26 | i_weight = gamma ** (n_predictions - i - 1)
27 | flow_pred = flow_preds[j][i]
28 | if use_huber_loss:
29 | i_loss = huber_loss(flow_pred, flow_gt[j], delta=6.0)
30 | else:
31 | i_loss = (flow_pred - flow_gt[j]).abs() # B, S, N, 2
32 | i_loss = torch.mean(i_loss, dim=3) # B, S, N
33 | valid_ = valids[j].clone()
34 | if loss_only_for_visible:
35 | valid_ = valid_ * vis[j]
36 | flow_loss += i_weight * utils.basic.reduce_masked_mean(i_loss, valid_)
37 | flow_loss = flow_loss / n_predictions
38 | total_flow_loss += flow_loss
39 | return total_flow_loss / len(flow_gt)
40 |
41 | def sequence_loss_dense(
42 | flow_preds,
43 | flow_gt,
44 | valids,
45 | vis=None,
46 | gamma=0.8,
47 | use_huber_loss=False,
48 | loss_only_for_visible=False,
49 | ):
50 | """Loss function defined over sequence of flow predictions"""
51 | total_flow_loss = 0.0
52 | for j in range(len(flow_gt)):
53 | # print('flow_gt[j]', flow_gt[j].shape)
54 | B, S, D, H, W = flow_gt[j].shape
55 | B, S2, _, H, W = valids[j].shape
56 | assert S == S2
57 | n_predictions = len(flow_preds[j])
58 | flow_loss = 0.0
59 | # import ipdb; ipdb.set_trace()
60 | for i in range(n_predictions):
61 | # print('flow_e[j][i]', flow_preds[j][i].shape)
62 | i_weight = gamma ** (n_predictions - i - 1)
63 | flow_pred = flow_preds[j][i] # B,S,2,H,W
64 | if use_huber_loss:
65 | i_loss = huber_loss(flow_pred, flow_gt[j], delta=6.0) # B,S,2,H,W
66 | else:
67 | i_loss = (flow_pred - flow_gt[j]).abs() # B,S,2,H,W
68 | i_loss_ = torch.mean(i_loss, dim=2) # B,S,H,W
69 | valid_ = valids[j].reshape(B,S,H,W)
70 | # print(' (%d,%d) i_loss_' % (i,j), i_loss_.shape)
71 | # print(' (%d,%d) valid_' % (i,j), valid_.shape)
72 | if loss_only_for_visible:
73 | valid_ = valid_ * vis[j].reshape(B,-1,H,W) # usually B,S,H,W, but maybe B,1,H,W
74 | flow_loss += i_weight * utils.basic.reduce_masked_mean(i_loss_, valid_, broadcast=True)
75 | # import ipdb; ipdb.set_trace()
76 | flow_loss = flow_loss / n_predictions
77 | total_flow_loss += flow_loss
78 | return total_flow_loss / len(flow_gt)
79 |
80 |
81 | def huber_loss(x, y, delta=1.0):
82 | """Calculate element-wise Huber loss between x and y"""
83 | diff = x - y
84 | abs_diff = diff.abs()
85 | flag = (abs_diff <= delta).float()
86 | return flag * 0.5 * diff**2 + (1 - flag) * delta * (abs_diff - 0.5 * delta)
87 |
88 |
89 | def sequence_BCE_loss(vis_preds, vis_gts, valids=None, use_logits=False):
90 | total_bce_loss = 0.0
91 | # all_vis_preds = [torch.stack(vp) for vp in vis_preds]
92 | # all_vis_preds = torch.stack(all_vis_preds)
93 | # utils.basic.print_stats('all_vis_preds', all_vis_preds)
94 | for j in range(len(vis_preds)):
95 | n_predictions = len(vis_preds[j])
96 | bce_loss = 0.0
97 | for i in range(n_predictions):
98 | # utils.basic.print_stats('vis_preds[%d][%d]' % (j,i), vis_preds[j][i])
99 | # utils.basic.print_stats('vis_gts[%d]' % (i), vis_gts[i])
100 | if use_logits:
101 | loss = F.binary_cross_entropy_with_logits(vis_preds[j][i], vis_gts[j], reduction='none')
102 | else:
103 | loss = F.binary_cross_entropy(vis_preds[j][i], vis_gts[j], reduction='none')
104 | if valids is None:
105 | bce_loss += loss.mean()
106 | else:
107 | bce_loss += (loss * valids[j]).mean()
108 | bce_loss = bce_loss / n_predictions
109 | total_bce_loss += bce_loss
110 | return total_bce_loss / len(vis_preds)
111 |
112 |
113 | # def sequence_BCE_loss_dense(vis_preds, vis_gts):
114 | # total_bce_loss = 0.0
115 | # for j in range(len(vis_preds)):
116 | # n_predictions = len(vis_preds[j])
117 | # bce_loss = 0.0
118 | # for i in range(n_predictions):
119 | # vis_e = vis_preds[j][i]
120 | # vis_g = vis_gts[j]
121 | # print('vis_e', vis_e.shape, 'vis_g', vis_g.shape)
122 | # vis_loss = F.binary_cross_entropy(vis_e, vis_g)
123 | # bce_loss += vis_loss
124 | # bce_loss = bce_loss / n_predictions
125 | # total_bce_loss += bce_loss
126 | # return total_bce_loss / len(vis_preds)
127 |
128 |
129 | def sequence_prob_loss(
130 | tracks: torch.Tensor,
131 | confidence: torch.Tensor,
132 | target_points: torch.Tensor,
133 | visibility: torch.Tensor,
134 | expected_dist_thresh: float = 12.0,
135 | use_logits=False,
136 | ):
137 | """Loss for classifying if a point is within pixel threshold of its target."""
138 | # Points with an error larger than 12 pixels are likely to be useless; marking
139 | # them as occluded will actually improve Jaccard metrics and give
140 | # qualitatively better results.
141 | total_logprob_loss = 0.0
142 | for j in range(len(tracks)):
143 | n_predictions = len(tracks[j])
144 | logprob_loss = 0.0
145 | for i in range(n_predictions):
146 | err = torch.sum((tracks[j][i].detach() - target_points[j]) ** 2, dim=-1)
147 | valid = (err <= expected_dist_thresh**2).float()
148 | if use_logits:
149 | loss = F.binary_cross_entropy_with_logits(confidence[j][i], valid, reduction="none")
150 | else:
151 | loss = F.binary_cross_entropy(confidence[j][i], valid, reduction="none")
152 | loss *= visibility[j]
153 | loss = torch.mean(loss, dim=[1, 2])
154 | logprob_loss += loss
155 | logprob_loss = logprob_loss / n_predictions
156 | total_logprob_loss += logprob_loss
157 | return total_logprob_loss / len(tracks)
158 |
159 | def sequence_prob_loss_dense(
160 | tracks: torch.Tensor,
161 | confidence: torch.Tensor,
162 | target_points: torch.Tensor,
163 | visibility: torch.Tensor,
164 | expected_dist_thresh: float = 12.0,
165 | use_logits=False,
166 | ):
167 | """Loss for classifying if a point is within pixel threshold of its target."""
168 | # Points with an error larger than 12 pixels are likely to be useless; marking
169 | # them as occluded will actually improve Jaccard metrics and give
170 | # qualitatively better results.
171 |
172 | # all_confidence = [torch.stack(vp) for vp in confidence]
173 | # all_confidence = torch.stack(all_confidence)
174 | # utils.basic.print_stats('all_confidence', all_confidence)
175 |
176 | total_logprob_loss = 0.0
177 | for j in range(len(tracks)):
178 | n_predictions = len(tracks[j])
179 | logprob_loss = 0.0
180 | for i in range(n_predictions):
181 | # print('trajs_e', tracks[j][i].shape)
182 | # print('trajs_g', target_points[j].shape)
183 | err = torch.sum((tracks[j][i].detach() - target_points[j]) ** 2, dim=2)
184 | positive = (err <= expected_dist_thresh**2).float()
185 | # print('conf', confidence[j][i].shape, 'positive', positive.shape)
186 | if use_logits:
187 | loss = F.binary_cross_entropy_with_logits(confidence[j][i].squeeze(2), positive, reduction="none")
188 | else:
189 | loss = F.binary_cross_entropy(confidence[j][i].squeeze(2), positive, reduction="none")
190 | loss *= visibility[j].squeeze(2) # B,S,H,W
191 | loss = torch.mean(loss, dim=[1,2,3])
192 | logprob_loss += loss
193 | logprob_loss = logprob_loss / n_predictions
194 | total_logprob_loss += logprob_loss
195 | return total_logprob_loss / len(tracks)
196 |
197 |
198 | def masked_mean(data, mask, dim):
199 | if mask is None:
200 | return data.mean(dim=dim, keepdim=True)
201 | mask = mask.float()
202 | mask_sum = torch.sum(mask, dim=dim, keepdim=True)
203 | mask_mean = torch.sum(data * mask, dim=dim, keepdim=True) / torch.clamp(
204 | mask_sum, min=1.0
205 | )
206 | return mask_mean
207 |
208 |
209 | def masked_mean_var(data: torch.Tensor, mask: torch.Tensor, dim: List[int]):
210 | if mask is None:
211 | return data.mean(dim=dim, keepdim=True), data.var(dim=dim, keepdim=True)
212 | mask = mask.float()
213 | mask_sum = torch.sum(mask, dim=dim, keepdim=True)
214 | mask_mean = torch.sum(data * mask, dim=dim, keepdim=True) / torch.clamp(
215 | mask_sum, min=1.0
216 | )
217 | mask_var = torch.sum(
218 | mask * (data - mask_mean) ** 2, dim=dim, keepdim=True
219 | ) / torch.clamp(mask_sum, min=1.0)
220 | return mask_mean.squeeze(dim), mask_var.squeeze(dim)
221 |
--------------------------------------------------------------------------------
/datasets/kubric_movif_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import cv2
4 | import imageio
5 | import numpy as np
6 | import glob
7 | from pathlib import Path
8 | import utils.data
9 | from datasets.pointdataset import PointDataset
10 | import random
11 |
12 | class KubricMovifDataset(PointDataset):
13 | def __init__(
14 | self,
15 | data_root,
16 | crop_size=(384, 512),
17 | seq_len=24,
18 | traj_per_sample=768,
19 | traj_max_factor=24, # multiplier on traj_per_sample
20 | use_augs=False,
21 | random_seq_len=False,
22 | random_first_frame=False,
23 | random_frame_rate=False,
24 | random_number_traj=False,
25 | shuffle_frames=False,
26 | shuffle=True,
27 | only_first=False,
28 | ):
29 | super(KubricMovifDataset, self).__init__(
30 | data_root=data_root,
31 | crop_size=crop_size,
32 | seq_len=seq_len,
33 | traj_per_sample=traj_per_sample,
34 | use_augs=use_augs,
35 | )
36 | print('loading kubric S%d dataset...' % seq_len)
37 |
38 | self.dname = 'kubric%d' % seq_len
39 |
40 | self.only_first = only_first
41 | self.traj_max_factor = traj_max_factor
42 |
43 | self.random_seq_len = random_seq_len
44 | self.random_first_frame = random_first_frame
45 | self.random_frame_rate = random_frame_rate
46 | self.random_number_traj = random_number_traj
47 | self.shuffle_frames = shuffle_frames
48 | self.pad_bounds = [10, 100]
49 | self.resize_lim = [0.25, 2.0] # sample resizes from here
50 | self.resize_delta = 0.2
51 | self.max_crop_offset = 50
52 |
53 | folder_names = Path(data_root).glob('*/*/')
54 | folder_names = [str(fn) for fn in folder_names]
55 | folder_names = sorted(folder_names)
56 | # print('folder_names', folder_names)
57 | if shuffle:
58 | random.shuffle(folder_names)
59 |
60 | self.seq_names = []
61 | for fi, fol in enumerate(folder_names):
62 | npy_path = os.path.join(fol, "annot.npy")
63 | rgb_path = os.path.join(fol, "frames")
64 | if os.path.isdir(rgb_path) and os.path.isfile(npy_path):
65 | img_paths = sorted(os.listdir(rgb_path))
66 | if len(img_paths)>=seq_len:
67 | self.seq_names.append(fol)
68 | else:
69 | pass
70 | else:
71 | pass
72 |
73 | print("found %d unique videos in %s" % (len(self.seq_names), self.data_root))
74 |
75 | def getitem_helper(self, index):
76 | gotit = True
77 | fol = self.seq_names[index]
78 | npy_path = os.path.join(fol, "annot.npy")
79 | rgb_path = os.path.join(fol, "frames")
80 |
81 | seq_name = fol.split('/')[-1]
82 |
83 | img_paths = sorted(os.listdir(rgb_path))
84 | rgbs = []
85 | for i, img_path in enumerate(img_paths):
86 | rgbs.append(imageio.v2.imread(os.path.join(rgb_path, img_path)))
87 |
88 | rgbs = np.stack(rgbs)
89 | annot_dict = np.load(npy_path, allow_pickle=True).item()
90 | trajs = annot_dict["point_xys"]
91 | visibs = annot_dict["point_visibs"]
92 | valids = annot_dict["point_xys_valid"]
93 |
94 | S = len(rgbs)
95 | # ensure all valid, and then discard valids tensor
96 | all_valid = np.nonzero(np.sum(valids, axis=0)==S)[0]
97 | trajs = trajs[:,all_valid]
98 | visibs = visibs[:,all_valid]
99 |
100 | if self.use_augs and np.random.rand() < 0.5: # time flip
101 | # time flip
102 | rgbs = np.flip(rgbs, axis=[0]).copy()
103 | trajs = np.flip(trajs, axis=[0]).copy()
104 | visibs = np.flip(visibs, axis=[0]).copy()
105 |
106 | if self.shuffle_frames and np.random.rand() < 0.01:
107 | # shuffle the frames
108 | perm = np.random.permutation(rgbs.shape[0])
109 | rgbs = rgbs[perm]
110 | trajs = trajs[perm]
111 | visibs = visibs[perm]
112 |
113 | frame_rate = 1
114 | final_num_traj = self.traj_per_sample
115 | crop_size = self.crop_size
116 |
117 | # randomize time slice
118 | min_num_traj = 1
119 | assert self.traj_per_sample >= min_num_traj
120 | if self.random_seq_len and self.random_number_traj:
121 | final_num_traj = np.random.randint(min_num_traj, self.traj_per_sample)
122 | alpha = final_num_traj / float(self.traj_per_sample)
123 | seq_len = int(alpha * 10 + (1 - alpha) * self.seq_len)
124 | seq_len = np.random.randint(seq_len - 2, seq_len + 2)
125 | if self.random_frame_rate:
126 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
127 | elif self.random_number_traj:
128 | final_num_traj = np.random.randint(min_num_traj, self.traj_per_sample)
129 | alpha = final_num_traj / float(self.traj_per_sample)
130 | seq_len = 8 * int(alpha * 2 + (1 - alpha) * self.seq_len // 8)
131 | # seq_len = np.random.randint(seq_len , seq_len + 2)
132 | if self.random_frame_rate:
133 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
134 | elif self.random_seq_len:
135 | seq_len = np.random.randint(int(self.seq_len / 2), self.seq_len)
136 | if self.random_frame_rate:
137 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
138 | else:
139 | seq_len = self.seq_len
140 | if self.random_frame_rate:
141 | frame_rate = np.random.randint(1, int((120 / seq_len)) + 1)
142 | if seq_len < len(rgbs):
143 | if self.random_first_frame:
144 | ind0 = np.random.choice(len(rgbs))
145 | rgb0 = rgbs[ind0]
146 | traj0 = trajs[ind0]
147 | visib0 = visibs[ind0]
148 |
149 | if seq_len * frame_rate < len(rgbs):
150 | start_ind = np.random.choice(len(rgbs) - (seq_len * frame_rate), 1)[0]
151 | else:
152 | start_ind = 0
153 | # print('slice %d:%d:%d' % (start_ind, start_ind+seq_len*frame_rate, frame_rate))
154 | rgbs = rgbs[start_ind : start_ind + seq_len * frame_rate : frame_rate]
155 | trajs = trajs[start_ind : start_ind + seq_len * frame_rate : frame_rate]
156 | visibs = visibs[start_ind : start_ind + seq_len * frame_rate : frame_rate]
157 |
158 | if self.random_first_frame:
159 | rgbs[0] = rgb0
160 | trajs[0] = traj0
161 | visibs[0] = visib0
162 |
163 | assert seq_len == len(rgbs)
164 |
165 | # ensure no crazy values
166 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs).astype(np.float64), axis=-1)<100000, axis=0)==seq_len)[0]
167 | trajs = trajs[:,all_valid]
168 | visibs = visibs[:,all_valid]
169 |
170 | if self.use_augs and np.random.rand() < 0.98:
171 | rgbs, trajs, visibs = self.add_photometric_augs(rgbs, trajs, visibs, replace=False)
172 | rgbs, trajs = self.add_spatial_augs(rgbs, trajs, visibs, crop_size)
173 | else:
174 | rgbs, trajs = self.crop(rgbs, trajs, crop_size)
175 |
176 | visibs[trajs[:, :, 0] > crop_size[1] - 1] = False
177 | visibs[trajs[:, :, 0] < 0] = False
178 | visibs[trajs[:, :, 1] > crop_size[0] - 1] = False
179 | visibs[trajs[:, :, 1] < 0] = False
180 |
181 | # ensure no crazy values
182 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs), axis=-1)<100000, axis=0)==seq_len)[0]
183 | trajs = trajs[:,all_valid]
184 | visibs = visibs[:,all_valid]
185 |
186 | if self.shuffle_frames and np.random.rand() < 0.01:
187 | # shuffle the frames (again)
188 | perm = np.random.permutation(rgbs.shape[0])
189 | rgbs = rgbs[perm]
190 | trajs = trajs[perm]
191 | visibs = visibs[perm]
192 |
193 | if self.only_first:
194 | vis_ok = np.nonzero(visibs[0]==1)[0]
195 | trajs = trajs[:,vis_ok]
196 | visibs = visibs[:,vis_ok]
197 |
198 | visibs = torch.from_numpy(visibs)
199 | trajs = torch.from_numpy(trajs)
200 |
201 | crop_tensor = torch.tensor(crop_size).flip(0)[None, None] / 2.0
202 | close_pts_inds = torch.all(
203 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < 1000.0,
204 | dim=0,
205 | )
206 | trajs = trajs[:, close_pts_inds]
207 | visibs = visibs[:, close_pts_inds]
208 | N = trajs.shape[1]
209 |
210 | assert self.only_first
211 |
212 | N = trajs.shape[1]
213 | point_inds = torch.randperm(N)[:self.traj_per_sample*self.traj_max_factor]
214 |
215 | if len(point_inds) < self.traj_per_sample:
216 | gotit = False
217 |
218 | trajs = trajs[:, point_inds]
219 | visibs = visibs[:, point_inds]
220 | valids = torch.ones_like(visibs)
221 |
222 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
223 |
224 | trajs = trajs[:, :self.traj_per_sample*self.traj_max_factor]
225 | visibs = visibs[:, :self.traj_per_sample*self.traj_max_factor]
226 | valids = valids[:, :self.traj_per_sample*self.traj_max_factor]
227 |
228 | sample = utils.data.VideoData(
229 | video=rgbs,
230 | trajs=trajs,
231 | visibs=visibs,
232 | valids=valids,
233 | seq_name=seq_name,
234 | dname=self.dname,
235 | )
236 | return sample, gotit
237 |
238 | def __len__(self):
239 | return len(self.seq_names)
240 |
--------------------------------------------------------------------------------
/utils/misc.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import numpy as np
3 |
4 | def get_1d_sincos_pos_embed_from_grid(embed_dim, positions):
5 | assert embed_dim % 2 == 0
6 | omega = torch.arange(embed_dim // 2, dtype=torch.double)
7 | omega /= embed_dim / 2.0
8 | omega = 1.0 / 10000**omega # (D/2,)
9 |
10 | positions = positions.reshape(-1) # (M,)
11 | out = torch.einsum("m,d->md", positions, omega) # (M, D/2), outer product
12 |
13 | emb_sin = torch.sin(out) # (M, D/2)
14 | emb_cos = torch.cos(out) # (M, D/2)
15 |
16 | emb = torch.cat([emb_sin, emb_cos], dim=1) # (M, D)
17 | return emb[None].float()
18 |
19 |
20 | class SimplePool():
21 | def __init__(self, pool_size, version='pt', min_size=1):
22 | self.pool_size = pool_size
23 | self.version = version
24 | self.items = []
25 | self.min_size = min_size
26 |
27 | if not (version=='pt' or version=='np'):
28 | print('version = %s; please choose pt or np')
29 | assert(False) # please choose pt or np
30 |
31 | def __len__(self):
32 | return len(self.items)
33 |
34 | def mean(self, min_size=None):
35 | if min_size is None:
36 | pool_size_thresh = self.min_size
37 | elif min_size=='half':
38 | pool_size_thresh = self.pool_size/2
39 | else:
40 | pool_size_thresh = min_size
41 |
42 | if self.version=='np':
43 | if len(self.items) >= pool_size_thresh:
44 | return np.sum(self.items)/float(len(self.items))
45 | else:
46 | return np.nan
47 | if self.version=='pt':
48 | if len(self.items) >= pool_size_thresh:
49 | return torch.sum(self.items)/float(len(self.items))
50 | else:
51 | return torch.from_numpy(np.nan)
52 |
53 | def sample(self, with_replacement=True):
54 | idx = np.random.randint(len(self.items))
55 | if with_replacement:
56 | return self.items[idx]
57 | else:
58 | return self.items.pop(idx)
59 |
60 | def fetch(self, num=None):
61 | if self.version=='pt':
62 | item_array = torch.stack(self.items)
63 | elif self.version=='np':
64 | item_array = np.stack(self.items)
65 | if num is not None:
66 | # there better be some items
67 | assert(len(self.items) >= num)
68 |
69 | # if there are not that many elements just return however many there are
70 | if len(self.items) < num:
71 | return item_array
72 | else:
73 | idxs = np.random.randint(len(self.items), size=num)
74 | return item_array[idxs]
75 | else:
76 | return item_array
77 |
78 | def is_full(self):
79 | full = len(self.items)==self.pool_size
80 | return full
81 |
82 | def empty(self):
83 | self.items = []
84 |
85 | def have_min_size(self):
86 | return len(self.items) >= self.min_size
87 |
88 |
89 | def update(self, items):
90 | for item in items:
91 | if len(self.items) < self.pool_size:
92 | # the pool is not full, so let's add this in
93 | self.items.append(item)
94 | else:
95 | # the pool is full
96 | # pop from the front
97 | self.items.pop(0)
98 | # add to the back
99 | self.items.append(item)
100 | return self.items
101 |
102 | def compute_tapvid_metrics(
103 | query_points: np.ndarray,
104 | gt_occluded: np.ndarray,
105 | gt_tracks: np.ndarray,
106 | pred_occluded: np.ndarray,
107 | pred_tracks: np.ndarray,
108 | query_mode: str,
109 | crop_size: tuple = (256, 256),
110 | ):
111 | """Computes TAP-Vid metrics (Jaccard, Pts. Within Thresh, Occ. Acc.)
112 | See the TAP-Vid paper for details on the metric computation. All inputs are
113 | given in raster coordinates. The first three arguments should be the direct
114 | outputs of the reader: the 'query_points', 'occluded', and 'target_points'.
115 | The paper metrics assume these are scaled relative to 256x256 images.
116 | pred_occluded and pred_tracks are your algorithm's predictions.
117 | This function takes a batch of inputs, and computes metrics separately for
118 | each video. The metrics for the full benchmark are a simple mean of the
119 | metrics across the full set of videos. These numbers are between 0 and 1,
120 | but the paper multiplies them by 100 to ease reading.
121 | Args:
122 | query_points: The query points, an in the format [t, y, x]. Its size is
123 | [b, n, 3], where b is the batch size and n is the number of queries
124 | gt_occluded: A boolean array of shape [b, n, t], where t is the number
125 | of frames. True indicates that the point is occluded.
126 | gt_tracks: The target points, of shape [b, n, t, 2]. Each point is
127 | in the format [x, y]
128 | pred_occluded: A boolean array of predicted occlusions, in the same
129 | format as gt_occluded.
130 | pred_tracks: An array of track predictions from your algorithm, in the
131 | same format as gt_tracks.
132 | query_mode: Either 'first' or 'strided', depending on how queries are
133 | sampled. If 'first', we assume the prior knowledge that all points
134 | before the query point are occluded, and these are removed from the
135 | evaluation.
136 | Returns:
137 | A dict with the following keys:
138 | occlusion_accuracy: Accuracy at predicting occlusion.
139 | pts_within_{x} for x in [1, 2, 4, 8, 16]: Fraction of points
140 | predicted to be within the given pixel threshold, ignoring occlusion
141 | prediction.
142 | jaccard_{x} for x in [1, 2, 4, 8, 16]: Jaccard metric for the given
143 | threshold
144 | average_pts_within_thresh: average across pts_within_{x}
145 | average_jaccard: average across jaccard_{x}
146 | """
147 |
148 | metrics = {}
149 | # Fixed bug is described in:
150 | # https://github.com/facebookresearch/co-tracker/issues/20
151 | eye = np.eye(gt_tracks.shape[2], dtype=np.int32)
152 |
153 | if query_mode == "first":
154 | # evaluate frames after the query frame
155 | query_frame_to_eval_frames = np.cumsum(eye, axis=1) - eye
156 | elif query_mode == "strided":
157 | # evaluate all frames except the query frame
158 | query_frame_to_eval_frames = 1 - eye
159 | else:
160 | raise ValueError("Unknown query mode " + query_mode)
161 |
162 | query_frame = query_points[..., 0]
163 | query_frame = np.round(query_frame).astype(np.int32)
164 | evaluation_points = query_frame_to_eval_frames[query_frame] > 0
165 |
166 | # Occlusion accuracy is simply how often the predicted occlusion equals the
167 | # ground truth.
168 | occ_acc = np.sum(
169 | np.equal(pred_occluded, gt_occluded) & evaluation_points,
170 | axis=(1, 2),
171 | ) / np.sum(evaluation_points)
172 | metrics["occlusion_accuracy"] = occ_acc
173 |
174 | # Next, convert the predictions and ground truth positions into pixel
175 | # coordinates.
176 | visible = np.logical_not(gt_occluded)
177 | pred_visible = np.logical_not(pred_occluded)
178 | all_frac_within = []
179 | all_jaccard = []
180 | sx_ = (crop_size[1] - 1) / 255.0
181 | sy_ = (crop_size[0] - 1) / 255.0
182 | sc_pt = np.array([sx_, sy_]).reshape([1, 1, 1, 2])
183 |
184 | for thresh in [1, 2, 4, 8, 16]:
185 | # True positives are points that are within the threshold and where both
186 | # the prediction and the ground truth are listed as visible.
187 | within_dist = np.sum(
188 | np.square(pred_tracks / sc_pt - gt_tracks / sc_pt),
189 | axis=-1,
190 | ) < np.square(thresh)
191 | is_correct = np.logical_and(within_dist, visible)
192 |
193 | # Compute the frac_within_threshold, which is the fraction of points
194 | # within the threshold among points that are visible in the ground truth,
195 | # ignoring whether they're predicted to be visible.
196 | count_correct = np.sum(
197 | is_correct & evaluation_points,
198 | axis=(1, 2),
199 | )
200 | count_visible_points = np.sum(visible & evaluation_points, axis=(1, 2))
201 | frac_correct = count_correct / count_visible_points
202 | metrics["pts_within_" + str(thresh)] = frac_correct
203 | all_frac_within.append(frac_correct)
204 |
205 | true_positives = np.sum(
206 | is_correct & pred_visible & evaluation_points, axis=(1, 2)
207 | )
208 |
209 | # The denominator of the jaccard metric is the true positives plus
210 | # false positives plus false negatives. However, note that true positives
211 | # plus false negatives is simply the number of points in the ground truth
212 | # which is easier to compute than trying to compute all three quantities.
213 | # Thus we just add the number of points in the ground truth to the number
214 | # of false positives.
215 | #
216 | # False positives are simply points that are predicted to be visible,
217 | # but the ground truth is not visible or too far from the prediction.
218 | gt_positives = np.sum(visible & evaluation_points, axis=(1, 2))
219 | false_positives = (~visible) & pred_visible
220 | false_positives = false_positives | ((~within_dist) & pred_visible)
221 | false_positives = np.sum(false_positives & evaluation_points, axis=(1, 2))
222 | jaccard = true_positives / (gt_positives + false_positives)
223 | metrics["jaccard_" + str(thresh)] = jaccard
224 | all_jaccard.append(jaccard)
225 | metrics["average_jaccard"] = np.mean(
226 | np.stack(all_jaccard, axis=1),
227 | axis=1,
228 | )
229 | metrics["average_pts_within_thresh"] = np.mean(
230 | np.stack(all_frac_within, axis=1),
231 | axis=1,
232 | )
233 | return metrics
234 |
235 |
--------------------------------------------------------------------------------
/demo.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import cv2
3 | import argparse
4 | import utils.saveload
5 | import utils.basic
6 | import utils.improc
7 | import PIL.Image
8 | import numpy as np
9 | import os
10 | from prettytable import PrettyTable
11 | import time
12 |
13 | def read_mp4(name_path):
14 | vidcap = cv2.VideoCapture(name_path)
15 | framerate = int(round(vidcap.get(cv2.CAP_PROP_FPS)))
16 | print('framerate', framerate)
17 | frames = []
18 | while vidcap.isOpened():
19 | ret, frame = vidcap.read()
20 | if ret == False:
21 | break
22 | frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
23 | frames.append(frame)
24 | vidcap.release()
25 | return frames, framerate
26 |
27 | def draw_pts_gpu(rgbs, trajs, visibs, colormap, rate=1, bkg_opacity=0.5):
28 | device = rgbs.device
29 | T, C, H, W = rgbs.shape
30 | trajs = trajs.permute(1,0,2) # N,T,2
31 | visibs = visibs.permute(1,0) # N,T
32 | N = trajs.shape[0]
33 | colors = torch.tensor(colormap, dtype=torch.float32, device=device) # [N,3]
34 |
35 | rgbs = rgbs * bkg_opacity # darken, to see the point tracks better
36 |
37 | opacity = 1.0
38 | if rate==1:
39 | radius = 1
40 | opacity = 0.9
41 | elif rate==2:
42 | radius = 1
43 | elif rate== 4:
44 | radius = 2
45 | elif rate== 8:
46 | radius = 4
47 | else:
48 | radius = 6
49 | sharpness = 0.15 + 0.05 * np.log2(rate)
50 |
51 | D = radius * 2 + 1
52 | y = torch.arange(D, device=device).float()[:, None] - radius
53 | x = torch.arange(D, device=device).float()[None, :] - radius
54 | dist2 = x**2 + y**2
55 | icon = torch.clamp(1 - (dist2 - (radius**2) / 2.0) / (radius * 2 * sharpness), 0, 1) # [D,D]
56 | icon = icon.view(1, D, D)
57 | dx = torch.arange(-radius, radius + 1, device=device)
58 | dy = torch.arange(-radius, radius + 1, device=device)
59 | disp_y, disp_x = torch.meshgrid(dy, dx, indexing="ij") # [D,D]
60 | for t in range(T):
61 | mask = visibs[:, t] # [N]
62 | if mask.sum() == 0:
63 | continue
64 | xy = trajs[mask, t] + 0.5 # [N,2]
65 | xy[:, 0] = xy[:, 0].clamp(0, W - 1)
66 | xy[:, 1] = xy[:, 1].clamp(0, H - 1)
67 | colors_now = colors[mask] # [N,3]
68 | N = xy.shape[0]
69 | cx = xy[:, 0].long() # [N]
70 | cy = xy[:, 1].long()
71 | x_grid = cx[:, None, None] + disp_x # [N,D,D]
72 | y_grid = cy[:, None, None] + disp_y # [N,D,D]
73 | valid = (x_grid >= 0) & (x_grid < W) & (y_grid >= 0) & (y_grid < H)
74 | x_valid = x_grid[valid] # [K]
75 | y_valid = y_grid[valid]
76 | icon_weights = icon.expand(N, D, D)[valid] # [K]
77 | colors_valid = colors_now[:, :, None, None].expand(N, 3, D, D).permute(1, 0, 2, 3)[
78 | :, valid
79 | ] # [3, K]
80 | idx_flat = (y_valid * W + x_valid).long() # [K]
81 |
82 | accum = torch.zeros_like(rgbs[t]) # [3, H, W]
83 | weight = torch.zeros(1, H * W, device=device) # [1, H*W]
84 | img_flat = accum.view(C, -1) # [3, H*W]
85 | weighted_colors = colors_valid * icon_weights # [3, K]
86 | img_flat.scatter_add_(1, idx_flat.unsqueeze(0).expand(C, -1), weighted_colors)
87 | weight.scatter_add_(1, idx_flat.unsqueeze(0), icon_weights.unsqueeze(0))
88 | weight = weight.view(1, H, W)
89 |
90 | alpha = weight.clamp(0, 1) * opacity
91 | accum = accum / (weight + 1e-6) # [3, H, W]
92 | rgbs[t] = rgbs[t] * (1 - alpha) + accum * alpha
93 | rgbs = rgbs.clamp(0, 255).byte().permute(0, 2, 3, 1).cpu().numpy() # T,H,W,3
94 | if bkg_opacity==0.0:
95 | for t in range(T):
96 | hsv_frame = cv2.cvtColor(rgbs[t], cv2.COLOR_RGB2HSV)
97 | saturation_factor = 1.5
98 | hsv_frame[..., 1] = np.clip(hsv_frame[..., 1] * saturation_factor, 0, 255)
99 | rgbs[t] = cv2.cvtColor(hsv_frame, cv2.COLOR_HSV2RGB)
100 | return rgbs
101 |
102 | def count_parameters(model):
103 | table = PrettyTable(["Modules", "Parameters"])
104 | total_params = 0
105 | for name, parameter in model.named_parameters():
106 | if not parameter.requires_grad:
107 | continue
108 | param = parameter.numel()
109 | if param > 100000:
110 | table.add_row([name, param])
111 | total_params+=param
112 | print(table)
113 | print('total params: %.2f M' % (total_params/1000000.0))
114 | return total_params
115 |
116 | def forward_video(rgbs, framerate, model, args):
117 |
118 | B,T,C,H,W = rgbs.shape
119 | assert C == 3
120 | device = rgbs.device
121 | assert(B==1)
122 |
123 | grid_xy = utils.basic.gridcloud2d(1, H, W, norm=False, device='cuda:0').float() # 1,H*W,2
124 | grid_xy = grid_xy.permute(0,2,1).reshape(1,1,2,H,W) # 1,1,2,H,W
125 |
126 | torch.cuda.empty_cache()
127 | print('starting forward...')
128 | f_start_time = time.time()
129 |
130 | flows_e, visconf_maps_e, _, _ = \
131 | model.forward_sliding(rgbs[:, args.query_frame:], iters=args.inference_iters, sw=None, is_training=False)
132 | traj_maps_e = flows_e.cuda() + grid_xy # B,Tf,2,H,W
133 | if args.query_frame > 0:
134 | backward_flows_e, backward_visconf_maps_e, _, _ = \
135 | model.forward_sliding(rgbs[:, :args.query_frame+1].flip([1]), iters=args.inference_iters, sw=None, is_training=False)
136 | backward_traj_maps_e = backward_flows_e.cuda() + grid_xy # B,Tb,2,H,W, reversed
137 | backward_traj_maps_e = backward_traj_maps_e.flip([1])[:, :-1] # flip time and drop the overlapped frame
138 | backward_visconf_maps_e = backward_visconf_maps_e.flip([1])[:, :-1] # flip time and drop the overlapped frame
139 | traj_maps_e = torch.cat([backward_traj_maps_e, traj_maps_e], dim=1) # B,T,2,H,W
140 | visconf_maps_e = torch.cat([backward_visconf_maps_e, visconf_maps_e], dim=1) # B,T,2,H,W
141 | ftime = time.time()-f_start_time
142 | print('finished forward; %.2f seconds / %d frames; %d fps' % (ftime, T, round(T/ftime)))
143 | utils.basic.print_stats('traj_maps_e', traj_maps_e)
144 | utils.basic.print_stats('visconf_maps_e', visconf_maps_e)
145 |
146 | # subsample to make the vis more readable
147 | rate = args.rate
148 | trajs_e = traj_maps_e[:,:,:,::rate,::rate].reshape(B,T,2,-1).permute(0,1,3,2) # B,T,N,2
149 | visconfs_e = visconf_maps_e[:,:,:,::rate,::rate].reshape(B,T,2,-1).permute(0,1,3,2) # B,T,N,2
150 |
151 | xy0 = trajs_e[0,0].cpu().numpy()
152 | colors = utils.improc.get_2d_colors(xy0, H, W)
153 |
154 | fn = args.mp4_path.split('/')[-1].split('.')[0]
155 | rgb_out_f = './pt_vis_%s_rate%d_q%d.mp4' % (fn, rate, args.query_frame)
156 | print('rgb_out_f', rgb_out_f)
157 | temp_dir = 'temp_pt_vis_%s_rate%d_q%d' % (fn, rate, args.query_frame)
158 | utils.basic.mkdir(temp_dir)
159 | vis = []
160 |
161 | frames = draw_pts_gpu(rgbs[0].to('cuda:0'), trajs_e[0], visconfs_e[0,:,:,1] > args.conf_thr,
162 | colors, rate=rate, bkg_opacity=args.bkg_opacity)
163 | print('frames', frames.shape)
164 |
165 | if args.vstack:
166 | frames_top = rgbs[0].clamp(0, 255).byte().permute(0, 2, 3, 1).cpu().numpy() # T,H,W,3
167 | frames = np.concatenate([frames_top, frames], axis=1)
168 | elif args.hstack:
169 | frames_left = rgbs[0].clamp(0, 255).byte().permute(0, 2, 3, 1).cpu().numpy() # T,H,W,3
170 | frames = np.concatenate([frames_left, frames], axis=2)
171 |
172 | print('writing frames to disk')
173 | f_start_time = time.time()
174 | for ti in range(T):
175 | temp_out_f = '%s/%03d.jpg' % (temp_dir, ti)
176 | im = PIL.Image.fromarray(frames[ti])
177 | im.save(temp_out_f)#, "PNG", subsampling=0, quality=80)
178 | ftime = time.time()-f_start_time
179 | print('finished writing; %.2f seconds / %d frames; %d fps' % (ftime, T, round(T/ftime)))
180 |
181 | print('writing mp4')
182 | os.system('/usr/bin/ffmpeg -y -hide_banner -loglevel error -f image2 -framerate %d -pattern_type glob -i "./%s/*.jpg" -c:v libx264 -crf 20 -pix_fmt yuv420p %s' % (framerate, temp_dir, rgb_out_f))
183 |
184 | # # flow vis
185 | # rgb_out_f = './flow_vis.mp4'
186 | # temp_dir = 'temp_flow_vis'
187 | # utils.basic.mkdir(temp_dir)
188 | # vis = []
189 | # for ti in range(T):
190 | # flow_vis = utils.improc.flow2color(flows_e[0:1,ti])
191 | # vis.append(flow_vis)
192 | # for ti in range(T):
193 | # temp_out_f = '%s/%03d.png' % (temp_dir, ti)
194 | # im = PIL.Image.fromarray(vis[ti][0].permute(1,2,0).cpu().numpy())
195 | # im.save(temp_out_f, "PNG", subsampling=0, quality=100)
196 | # os.system('/usr/bin/ffmpeg -y -hide_banner -loglevel error -f image2 -framerate 24 -pattern_type glob -i "./%s/*.png" -c:v libx264 -crf 1 -pix_fmt yuv420p %s' % (temp_dir, rgb_out_f))
197 |
198 | return None
199 |
200 | def run(model, args):
201 | log_dir = './logs_demo'
202 |
203 | global_step = 0
204 |
205 | if args.ckpt_init:
206 | _ = utils.saveload.load(
207 | None,
208 | args.ckpt_init,
209 | model,
210 | optimizer=None,
211 | scheduler=None,
212 | ignore_load=None,
213 | strict=True,
214 | verbose=False,
215 | weights_only=False,
216 | )
217 | print('loaded weights from', args.ckpt_init)
218 | else:
219 | if args.tiny:
220 | url = "https://huggingface.co/aharley/alltracker/resolve/main/alltracker_tiny.pth"
221 | else:
222 | url = "https://huggingface.co/aharley/alltracker/resolve/main/alltracker.pth"
223 | state_dict = torch.hub.load_state_dict_from_url(url, map_location='cpu')
224 | model.load_state_dict(state_dict['model'], strict=True)
225 | print('loaded weights from', url)
226 |
227 | model.cuda()
228 | for n, p in model.named_parameters():
229 | p.requires_grad = False
230 | model.eval()
231 |
232 | rgbs, framerate = read_mp4(args.mp4_path)
233 | print('rgbs[0]', rgbs[0].shape)
234 | H,W = rgbs[0].shape[:2]
235 |
236 | # shorten & shrink the video, in case the gpu is small
237 | if args.max_frames:
238 | rgbs = rgbs[:args.max_frames]
239 | scale = min(int(args.image_size)/H, int(args.image_size)/W)
240 | H, W = int(H*scale), int(W*scale)
241 | H, W = H//8 * 8, W//8 * 8 # make it divisible by 8
242 | rgbs = [cv2.resize(rgb, dsize=(W, H), interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
243 | print('rgbs[0]', rgbs[0].shape)
244 |
245 | # move to gpu
246 | rgbs = [torch.from_numpy(rgb).permute(2,0,1) for rgb in rgbs]
247 | rgbs = torch.stack(rgbs, dim=0).unsqueeze(0).float() # 1,T,C,H,W
248 | print('rgbs', rgbs.shape)
249 |
250 | with torch.no_grad():
251 | metrics = forward_video(rgbs, framerate, model, args)
252 |
253 | return None
254 |
255 | if __name__ == "__main__":
256 | torch.set_grad_enabled(False)
257 |
258 | parser = argparse.ArgumentParser()
259 | parser.add_argument("--ckpt_init", type=str, default='') # the ckpt we want (else default)
260 | parser.add_argument("--mp4_path", type=str, default='./demo_video/monkey.mp4') # input video
261 | parser.add_argument("--query_frame", type=int, default=0) # which frame to track from
262 | parser.add_argument("--image_size", type=int, default=1024) # max dimension of a video frame (upsample to this)
263 | parser.add_argument("--max_frames", type=int, default=400) # trim the video to this length
264 | parser.add_argument("--inference_iters", type=int, default=4) # number of inference steps per forward
265 | parser.add_argument("--window_len", type=int, default=16) # model hyperparam
266 | parser.add_argument("--rate", type=int, default=2) # vis hyp
267 | parser.add_argument("--conf_thr", type=float, default=0.1) # vis hyp
268 | parser.add_argument("--bkg_opacity", type=float, default=0.5) # vis hyp
269 | parser.add_argument("--vstack", action='store_true', default=False) # whether to stack the input and output in the mp4
270 | parser.add_argument("--hstack", action='store_true', default=False) # whether to stack the input and output in the mp4
271 | parser.add_argument("--tiny", action='store_true', default=False) # whether to use the tiny model
272 | args = parser.parse_args()
273 |
274 | from nets.alltracker import Net;
275 | if args.tiny:
276 | model = Net(args.window_len, use_basicencoder=True, no_split=True)
277 | else:
278 | model = Net(args.window_len)
279 | count_parameters(model)
280 |
281 | run(model, args)
282 |
283 |
--------------------------------------------------------------------------------
/datasets/exportdataset.py:
--------------------------------------------------------------------------------
1 | from numpy import random
2 | import torch
3 | import numpy as np
4 | import os
5 | import random
6 | import imageio
7 | from pathlib import Path
8 | import matplotlib.pyplot as plt
9 | from utils.basic import print_stats
10 | from PIL import Image
11 | import cv2
12 | import utils.py
13 | import torch.nn.functional as F
14 | import torchvision.transforms.functional as tvF
15 | from torchvision.transforms import ColorJitter, GaussianBlur
16 | from datasets.pointdataset import PointDataset
17 |
18 | class ExportDataset(PointDataset):
19 | def __init__(self,
20 | data_root='../datasets/alltrack_export',
21 | version='bs',
22 | dsets=None,
23 | dsets_exclude=None,
24 | seq_len=64,
25 | crop_size=(384,512),
26 | shuffle_frames=False,
27 | shuffle=True,
28 | use_augs=False,
29 | is_training=True,
30 | backwards=False,
31 | traj_per_sample=256, # min number of trajs
32 | traj_max_factor=24, # multiplier on traj_per_sample
33 | random_seq_len=False,
34 | random_frame_rate=False,
35 | random_number_traj=False,
36 | only_first=False,
37 | ):
38 | super(ExportDataset, self).__init__(
39 | data_root=data_root,
40 | crop_size=crop_size,
41 | seq_len=seq_len,
42 | traj_per_sample=traj_per_sample,
43 | use_augs=use_augs,
44 | )
45 | print('loading export...')
46 |
47 | self.shuffle_frames = shuffle_frames
48 | self.pad_bounds = [10, 100]
49 | self.resize_lim = [0.25, 2.0] # sample resizes from here
50 | self.resize_delta = 0.2
51 | self.max_crop_offset = 50
52 | self.only_first = only_first
53 | self.traj_max_factor = traj_max_factor
54 |
55 | self.S = seq_len
56 |
57 | self.use_augs = use_augs
58 | self.is_training = is_training
59 |
60 | self.dataset_location = Path(data_root) / version
61 |
62 | dataset_names = self.dataset_location.glob('*/')
63 | self.dataset_names = [str(fn.stem) for fn in dataset_names]
64 | self.dataset_names = ['%s%d' % (dname, self.S) for dname in self.dataset_names]
65 | print('dataset_names', self.dataset_names)
66 |
67 | folder_names = self.dataset_location.glob('*/*/*/')
68 | folder_names = [str(fn) for fn in folder_names]
69 | # print('folder_names', folder_names)
70 |
71 | print('found {:d} {} folders in {}'.format(len(folder_names), version, self.dataset_location))
72 |
73 | if dsets is not None:
74 | print('dsets', dsets)
75 | new_folder_names = []
76 | for fn in folder_names:
77 | for dset in dsets:
78 | if dset in fn:
79 | new_folder_names.append(fn)
80 | break
81 | folder_names = new_folder_names
82 | print('filtered to %d folders' % len(folder_names))
83 |
84 | if backwards:
85 | new_folder_names = []
86 | for fn in folder_names:
87 | chunk = fn.split('/')[-2]
88 | if 'b' in chunk:
89 | new_folder_names.append(fn)
90 | folder_names = new_folder_names
91 | print('filtered to %d folders with backward motion' % len(folder_names))
92 |
93 | if dsets_exclude is not None:
94 | print('dsets_exclude', dsets_exclude)
95 | new_folder_names = []
96 | for fn in folder_names:
97 | keep = True
98 | for dset in dsets_exclude:
99 | if dset in fn:
100 | keep = False
101 | break
102 | if keep:
103 | new_folder_names.append(fn)
104 | folder_names = new_folder_names
105 | print('filtered to %d folders' % len(folder_names))
106 |
107 | # if quick:
108 | # folder_names = sorted(folder_names)
109 | # folder_names = folder_names[:201]
110 | # print('folder_names', folder_names)
111 |
112 | if shuffle:
113 | random.shuffle(folder_names)
114 | else:
115 | folder_names = sorted(list(folder_names))
116 |
117 | self.all_folders = folder_names
118 | # # step through once and make sure all of the npys are there
119 | # print('stepping through...')
120 | # self.all_folders = []
121 | # for fi, fol in enumerate(folder_names):
122 | # npy_path = os.path.join(fol, "annot.npy")
123 | # rgb_path = os.path.join(fol, "frames")
124 | # if os.path.isdir(rgb_path) and os.path.isfile(npy_path):
125 | # img_paths = sorted(os.listdir(rgb_path))
126 | # if len(img_paths)>=self.S:
127 | # self.all_folders.append(fol)
128 | # else:
129 | # pass
130 | # else:
131 | # pass
132 | # print('ok done stepping; got %d' % len(self.all_folders))
133 |
134 |
135 | def getitem_helper(self, index):
136 | # cH, cW = self.cH, self.cW
137 |
138 | fol = self.all_folders[index]
139 | npy_path = os.path.join(fol, "annot.npy")
140 | rgb_path = os.path.join(fol, "frames")
141 |
142 | mid = str(fol)[len(str(self.dataset_location))+1:]
143 | dname = mid.split('/')[0]
144 | # print('dname', dname)
145 |
146 | img_paths = sorted(os.listdir(rgb_path))
147 | rgbs = []
148 | try:
149 | for i, img_path in enumerate(img_paths):
150 | rgbs.append(imageio.v2.imread(os.path.join(rgb_path, img_path)))
151 | except:
152 | print('some exception when reading rgbs')
153 |
154 | if len(rgbs) self.S:
189 | surplus = trajs.shape[0] - self.S
190 | ind = np.random.randint(surplus)+1
191 | rgbs = rgbs[ind:ind+self.S]
192 | trajs = trajs[ind:ind+self.S]
193 | visibs = visibs[ind:ind+self.S]
194 | assert(trajs.shape[0] == self.S)
195 |
196 | if self.only_first:
197 | vis_ok = np.nonzero(visibs[0]==1)[0]
198 | trajs = trajs[:,vis_ok]
199 | visibs = visibs[:,vis_ok]
200 |
201 | N = trajs.shape[1]
202 | if N < self.traj_per_sample:
203 | print('exp: %s; N after vis0: %d' % (dname, N))
204 | return None, False
205 |
206 | # print('rgbs', rgbs.shape)
207 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
208 | scale = 0.5
209 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
210 | H, W = rgbs[0].shape[:2]
211 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
212 | trajs = trajs * scale
213 | # print('resized rgbs', rgbs.shape)
214 |
215 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
216 | scale = 0.5
217 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
218 | H, W = rgbs[0].shape[:2]
219 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
220 | trajs = trajs * scale
221 | # print('resized rgbs', rgbs.shape)
222 |
223 | if self.use_augs and np.random.rand() < 0.98:
224 | rgbs, trajs, visibs = self.add_photometric_augs(
225 | rgbs, trajs, visibs, replace=False,
226 | )
227 | if np.random.rand() < 0.2:
228 | rgbs, trajs = self.add_spatial_augs(rgbs, trajs, visibs, self.crop_size)
229 | else:
230 | rgbs, trajs = self.follow_crop(rgbs, trajs, visibs, self.crop_size)
231 | if np.random.rand() < self.rot_prob:
232 | # note this is OK since B==1
233 | # otw we would do it before this func
234 | rgbs = [np.transpose(rgb, (1,0,2)).copy() for rgb in rgbs]
235 | rgbs = np.stack(rgbs)
236 | trajs = np.flip(trajs, axis=2).copy()
237 | H, W = rgbs[0].shape[:2]
238 | if np.random.rand() < self.h_flip_prob:
239 | rgbs = [rgb[:, ::-1].copy() for rgb in rgbs]
240 | trajs[:, :, 0] = W - trajs[:, :, 0]
241 | rgbs = np.stack(rgbs)
242 | if np.random.rand() < self.v_flip_prob:
243 | rgbs = [rgb[::-1].copy() for rgb in rgbs]
244 | trajs[:, :, 1] = H - trajs[:, :, 1]
245 | rgbs = np.stack(rgbs)
246 | else:
247 | rgbs, trajs = self.crop(rgbs, trajs, self.crop_size)
248 |
249 | if self.shuffle_frames and np.random.rand() < 0.01:
250 | # shuffle the frames (again)
251 | perm = np.random.permutation(rgbs.shape[0])
252 | rgbs = rgbs[perm]
253 | trajs = trajs[perm]
254 | visibs = visibs[perm]
255 |
256 | H,W = rgbs[0].shape[:2]
257 |
258 | visibs[trajs[:, :, 0] > W-1] = False
259 | visibs[trajs[:, :, 0] < 0] = False
260 | visibs[trajs[:, :, 1] > H-1] = False
261 | visibs[trajs[:, :, 1] < 0] = False
262 |
263 | N = trajs.shape[1]
264 | # print('N8', N)
265 |
266 | # ensure no crazy values
267 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs), axis=-1)<100000, axis=0)==self.S)[0]
268 | trajs = trajs[:,all_valid]
269 | visibs = visibs[:,all_valid]
270 |
271 | if self.only_first:
272 | vis_ok = np.nonzero(visibs[0]==1)[0]
273 | trajs = trajs[:,vis_ok]
274 | visibs = visibs[:,vis_ok]
275 | N = trajs.shape[1]
276 |
277 | if N < self.traj_per_sample:
278 | print('exp: %s; N after aug: %d' % (dname, N))
279 | return None, False
280 |
281 | N = trajs.shape[1]
282 |
283 | seq_len = S
284 | visibs = torch.from_numpy(visibs)
285 | trajs = torch.from_numpy(trajs)
286 |
287 | # discard tracks that go far OOB
288 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
289 | close_pts_inds = torch.all(
290 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
291 | dim=0,
292 | )
293 | trajs = trajs[:, close_pts_inds]
294 | visibs = visibs[:, close_pts_inds]
295 |
296 | visible_pts_inds = (visibs[0]).nonzero(as_tuple=False)[:, 0]
297 | point_inds = torch.randperm(len(visible_pts_inds))[:self.traj_per_sample*self.traj_max_factor]
298 | if len(point_inds) < self.traj_per_sample:
299 | # print('not enough trajs')
300 | # gotit = False
301 | return None, False
302 |
303 | visible_inds_sampled = visible_pts_inds[point_inds]
304 |
305 | trajs = trajs[:, visible_inds_sampled].float()
306 | visibs = visibs[:, visible_inds_sampled].float()
307 | valids = torch.ones_like(visibs).float()
308 |
309 | trajs = trajs[:, :self.traj_per_sample*self.traj_max_factor]
310 | visibs = visibs[:, :self.traj_per_sample*self.traj_max_factor]
311 | valids = valids[:, :self.traj_per_sample*self.traj_max_factor]
312 |
313 | rgbs = torch.from_numpy(rgbs).permute(0, 3, 1, 2).float()
314 |
315 | dname += '%d' % (self.S)
316 |
317 | sample = utils.data.VideoData(
318 | video=rgbs,
319 | trajs=trajs,
320 | visibs=visibs,
321 | valids=valids,
322 | seq_name=None,
323 | dname=dname,
324 | )
325 | return sample, True
326 |
327 | def __len__(self):
328 | return len(self.all_folders)
329 |
--------------------------------------------------------------------------------
/datasets/pointdataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import torch
3 | import cv2
4 | import imageio
5 | import numpy as np
6 | from torchvision.transforms import ColorJitter, GaussianBlur
7 | from PIL import Image
8 | import utils.data
9 |
10 | class PointDataset(torch.utils.data.Dataset):
11 | def __init__(
12 | self,
13 | data_root,
14 | crop_size=(384, 512),
15 | seq_len=24,
16 | traj_per_sample=768,
17 | use_augs=False,
18 | ):
19 | super(PointDataset, self).__init__()
20 | self.data_root = data_root
21 | self.seq_len = seq_len
22 | self.traj_per_sample = traj_per_sample
23 | self.use_augs = use_augs
24 | # photometric augmentation
25 | self.photo_aug = ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.25 / 3.14)
26 | self.blur_aug = GaussianBlur(11, sigma=(0.1, 2.0))
27 | self.blur_aug_prob = 0.25
28 | self.color_aug_prob = 0.25
29 |
30 | # occlusion augmentation
31 | self.eraser_aug_prob = 0.5
32 | self.eraser_bounds = [2, 100]
33 | self.eraser_max = 10
34 |
35 | # occlusion augmentation
36 | self.replace_aug_prob = 0.5
37 | self.replace_bounds = [2, 100]
38 | self.replace_max = 10
39 |
40 | # spatial augmentations
41 | self.pad_bounds = [10, 100]
42 | self.crop_size = crop_size
43 | self.resize_lim = [0.25, 2.0] # sample resizes from here
44 | self.resize_delta = 0.2
45 | self.max_crop_offset = 50
46 |
47 | self.h_flip_prob = 0.5
48 | self.v_flip_prob = 0.5
49 | self.rot_prob = 0.5
50 |
51 | def getitem_helper(self, index):
52 | return NotImplementedError
53 |
54 | def __getitem__(self, index):
55 | gotit = False
56 | fails = 0
57 | while not gotit and fails < 4:
58 | sample, gotit = self.getitem_helper(index)
59 | if gotit:
60 | return sample, gotit
61 | else:
62 | fails += 1
63 | index = np.random.randint(len(self))
64 | del sample
65 | if fails > 1:
66 | print('note: sampling failed %d times' % fails)
67 |
68 | if self.seq_len is not None:
69 | S = self.seq_len
70 | else:
71 | S = 11
72 | # fake sample, so we can still collate
73 | sample = utils.data.VideoData(
74 | video=torch.zeros((S, 3, self.crop_size[0], self.crop_size[1])),
75 | trajs=torch.zeros((S, self.traj_per_sample, 2)),
76 | visibs=torch.zeros((S, self.traj_per_sample)),
77 | valids=torch.zeros((S, self.traj_per_sample)),
78 | )
79 | return sample, gotit
80 |
81 | def add_photometric_augs(self, rgbs, trajs, visibles, eraser=True, replace=True, augscale=1.0):
82 | T, N, _ = trajs.shape
83 |
84 | S = len(rgbs)
85 | H, W = rgbs[0].shape[:2]
86 | assert S == T
87 |
88 | if eraser:
89 | ############ eraser transform (per image after the first) ############
90 | eraser_bounds = [eb*augscale for eb in self.eraser_bounds]
91 | rgbs = [rgb.astype(np.float32) for rgb in rgbs]
92 | for i in range(1, S):
93 | if np.random.rand() < self.eraser_aug_prob:
94 | for _ in range(np.random.randint(1, self.eraser_max + 1)):
95 | # number of times to occlude
96 | xc = np.random.randint(0, W)
97 | yc = np.random.randint(0, H)
98 | dx = np.random.randint(eraser_bounds[0], eraser_bounds[1])
99 | dy = np.random.randint(eraser_bounds[0], eraser_bounds[1])
100 | x0 = np.clip(xc - dx / 2, 0, W - 1).round().astype(np.int32)
101 | x1 = np.clip(xc + dx / 2, 0, W - 1).round().astype(np.int32)
102 | y0 = np.clip(yc - dy / 2, 0, H - 1).round().astype(np.int32)
103 | y1 = np.clip(yc + dy / 2, 0, H - 1).round().astype(np.int32)
104 |
105 | mean_color = np.mean(
106 | rgbs[i][y0:y1, x0:x1, :].reshape(-1, 3), axis=0
107 | )
108 | rgbs[i][y0:y1, x0:x1, :] = mean_color
109 |
110 | occ_inds = np.logical_and(
111 | np.logical_and(trajs[i, :, 0] >= x0, trajs[i, :, 0] < x1),
112 | np.logical_and(trajs[i, :, 1] >= y0, trajs[i, :, 1] < y1),
113 | )
114 | visibles[i, occ_inds] = 0
115 | rgbs = [rgb.astype(np.uint8) for rgb in rgbs]
116 |
117 | if replace:
118 | rgbs_alt = [np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
119 | rgbs_alt = [np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs_alt]
120 |
121 | ############ replace transform (per image after the first) ############
122 | rgbs = [rgb.astype(np.float32) for rgb in rgbs]
123 | rgbs_alt = [rgb.astype(np.float32) for rgb in rgbs_alt]
124 | replace_bounds = [rb*augscale for rb in self.replace_bounds]
125 | for i in range(1, S):
126 | if np.random.rand() < self.replace_aug_prob:
127 | for _ in range(
128 | np.random.randint(1, self.replace_max + 1)
129 | ): # number of times to occlude
130 | xc = np.random.randint(0, W)
131 | yc = np.random.randint(0, H)
132 | dx = np.random.randint(replace_bounds[0], replace_bounds[1])
133 | dy = np.random.randint(replace_bounds[0], replace_bounds[1])
134 | x0 = np.clip(xc - dx / 2, 0, W - 1).round().astype(np.int32)
135 | x1 = np.clip(xc + dx / 2, 0, W - 1).round().astype(np.int32)
136 | y0 = np.clip(yc - dy / 2, 0, H - 1).round().astype(np.int32)
137 | y1 = np.clip(yc + dy / 2, 0, H - 1).round().astype(np.int32)
138 |
139 | wid = x1 - x0
140 | hei = y1 - y0
141 | y00 = np.random.randint(0, H - hei)
142 | x00 = np.random.randint(0, W - wid)
143 | fr = np.random.randint(0, S)
144 | rep = rgbs_alt[fr][y00 : y00 + hei, x00 : x00 + wid, :]
145 | rgbs[i][y0:y1, x0:x1, :] = rep
146 |
147 | occ_inds = np.logical_and(
148 | np.logical_and(trajs[i, :, 0] >= x0, trajs[i, :, 0] < x1),
149 | np.logical_and(trajs[i, :, 1] >= y0, trajs[i, :, 1] < y1),
150 | )
151 | visibles[i, occ_inds] = 0
152 | rgbs = [rgb.astype(np.uint8) for rgb in rgbs]
153 |
154 | ############ photometric augmentation ############
155 | if np.random.rand() < self.color_aug_prob:
156 | # random per-frame amount of aug
157 | rgbs = [np.array(self.photo_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
158 |
159 | if np.random.rand() < self.blur_aug_prob:
160 | # random per-frame amount of blur
161 | rgbs = [np.array(self.blur_aug(Image.fromarray(rgb)), dtype=np.uint8) for rgb in rgbs]
162 |
163 | return rgbs, trajs, visibles
164 |
165 |
166 | def add_spatial_augs(self, rgbs, trajs, visibles, crop_size, augscale=1.0):
167 | T, N, __ = trajs.shape
168 |
169 | S = len(rgbs)
170 | H, W = rgbs[0].shape[:2]
171 | assert S == T
172 |
173 | rgbs = [rgb.astype(np.float32) for rgb in rgbs]
174 |
175 | trajs = trajs.astype(np.float64)
176 |
177 | target_H, target_W = crop_size
178 | if target_H > H or target_W > W:
179 | scale = max(target_H / H, target_W / W)
180 | new_H, new_W = int(np.ceil(H * scale)), int(np.ceil(W * scale))
181 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
182 | trajs = trajs * scale
183 |
184 | ############ spatial transform ############
185 |
186 | # padding
187 | pad_bounds = [int(pb*augscale) for pb in self.pad_bounds]
188 | pad_x0 = np.random.randint(pad_bounds[0], pad_bounds[1])
189 | pad_x1 = np.random.randint(pad_bounds[0], pad_bounds[1])
190 | pad_y0 = np.random.randint(pad_bounds[0], pad_bounds[1])
191 | pad_y1 = np.random.randint(pad_bounds[0], pad_bounds[1])
192 |
193 | rgbs = [np.pad(rgb, ((pad_y0, pad_y1), (pad_x0, pad_x1), (0, 0))) for rgb in rgbs]
194 | trajs[:, :, 0] += pad_x0
195 | trajs[:, :, 1] += pad_y0
196 | H, W = rgbs[0].shape[:2]
197 |
198 | # scaling + stretching
199 | scale = np.random.uniform(self.resize_lim[0], self.resize_lim[1])
200 | scale_x = scale
201 | scale_y = scale
202 | H_new = H
203 | W_new = W
204 |
205 | scale_delta_x = 0.0
206 | scale_delta_y = 0.0
207 |
208 | rgbs_scaled = []
209 | resize_delta = self.resize_delta * augscale
210 | for s in range(S):
211 | if s == 1:
212 | scale_delta_x = np.random.uniform(-resize_delta, resize_delta)
213 | scale_delta_y = np.random.uniform(-resize_delta, resize_delta)
214 | elif s > 1:
215 | scale_delta_x = (
216 | scale_delta_x * 0.8
217 | + np.random.uniform(-resize_delta, resize_delta) * 0.2
218 | )
219 | scale_delta_y = (
220 | scale_delta_y * 0.8
221 | + np.random.uniform(-resize_delta, resize_delta) * 0.2
222 | )
223 | scale_x = scale_x + scale_delta_x
224 | scale_y = scale_y + scale_delta_y
225 |
226 | # bring h/w closer
227 | scale_xy = (scale_x + scale_y) * 0.5
228 | scale_x = scale_x * 0.5 + scale_xy * 0.5
229 | scale_y = scale_y * 0.5 + scale_xy * 0.5
230 |
231 | # don't get too crazy
232 | scale_x = np.clip(scale_x, 0.2, 2.0)
233 | scale_y = np.clip(scale_y, 0.2, 2.0)
234 |
235 | H_new = int(H * scale_y)
236 | W_new = int(W * scale_x)
237 |
238 | # make it at least slightly bigger than the crop area,
239 | # so that the random cropping can add diversity
240 | H_new = np.clip(H_new, crop_size[0] + 10, None)
241 | W_new = np.clip(W_new, crop_size[1] + 10, None)
242 | # recompute scale in case we clipped
243 | scale_x = (W_new - 1) / float(W - 1)
244 | scale_y = (H_new - 1) / float(H - 1)
245 | rgbs_scaled.append(
246 | cv2.resize(rgbs[s], (W_new, H_new), interpolation=cv2.INTER_LINEAR)
247 | )
248 | trajs[s, :, 0] *= scale_x
249 | trajs[s, :, 1] *= scale_y
250 | rgbs = rgbs_scaled
251 | ok_inds = visibles[0, :] > 0
252 | vis_trajs = trajs[:, ok_inds] # S,?,2
253 |
254 | if vis_trajs.shape[1] > 0:
255 | mid_x = np.mean(vis_trajs[0, :, 0])
256 | mid_y = np.mean(vis_trajs[0, :, 1])
257 | else:
258 | mid_y = crop_size[0]
259 | mid_x = crop_size[1]
260 |
261 | x0 = int(mid_x - crop_size[1] // 2)
262 | y0 = int(mid_y - crop_size[0] // 2)
263 |
264 | offset_x = 0
265 | offset_y = 0
266 | max_crop_offset = int(self.max_crop_offset*augscale)
267 |
268 | for s in range(S):
269 | # on each frame, shift a bit more
270 | if s == 1:
271 | offset_x = np.random.randint(-max_crop_offset, max_crop_offset)
272 | offset_y = np.random.randint(-max_crop_offset, max_crop_offset)
273 | elif s > 1:
274 | offset_x = int(
275 | offset_x * 0.8
276 | + np.random.randint(-max_crop_offset, max_crop_offset + 1)
277 | * 0.2
278 | )
279 | offset_y = int(
280 | offset_y * 0.8
281 | + np.random.randint(-max_crop_offset, max_crop_offset + 1)
282 | * 0.2
283 | )
284 | x0 = x0 + offset_x
285 | y0 = y0 + offset_y
286 |
287 | H_new, W_new = rgbs[s].shape[:2]
288 | if H_new == crop_size[0]:
289 | y0 = 0
290 | else:
291 | y0 = min(max(0, y0), H_new - crop_size[0] - 1)
292 |
293 | if W_new == crop_size[1]:
294 | x0 = 0
295 | else:
296 | x0 = min(max(0, x0), W_new - crop_size[1] - 1)
297 |
298 | rgbs[s] = rgbs[s][y0 : y0 + crop_size[0], x0 : x0 + crop_size[1]]
299 | trajs[s, :, 0] -= x0
300 | trajs[s, :, 1] -= y0
301 |
302 | H = crop_size[0]
303 | W = crop_size[1]
304 |
305 | if np.random.rand() < self.h_flip_prob:
306 | rgbs = [rgb[:, ::-1].copy() for rgb in rgbs]
307 | trajs[:, :, 0] = W-1 - trajs[:, :, 0]
308 | if np.random.rand() < self.v_flip_prob:
309 | rgbs = [rgb[::-1].copy() for rgb in rgbs]
310 | trajs[:, :, 1] = H-1 - trajs[:, :, 1]
311 | return np.stack(rgbs), trajs.astype(np.float32)
312 |
313 | def crop(self, rgbs, trajs, crop_size):
314 | T, N, _ = trajs.shape
315 |
316 | S = len(rgbs)
317 | H, W = rgbs[0].shape[:2]
318 | assert S == T
319 |
320 | target_H, target_W = crop_size
321 | if target_H > H or target_W > W:
322 | scale = max(target_H / H, target_W / W)
323 | new_H, new_W = int(np.ceil(H * scale)), int(np.ceil(W * scale))
324 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
325 | trajs = trajs * scale
326 | H, W = rgbs[0].shape[:2]
327 |
328 | # simple random crop
329 | y0 = 0 if crop_size[0] >= H else (H - crop_size[0]) // 2
330 | x0 = 0 if crop_size[1] >= W else np.random.randint(0, W - crop_size[1])
331 | rgbs = [rgb[y0 : y0 + crop_size[0], x0 : x0 + crop_size[1]] for rgb in rgbs]
332 |
333 | trajs[:, :, 0] -= x0
334 | trajs[:, :, 1] -= y0
335 |
336 | return np.stack(rgbs), trajs
337 |
338 | def follow_crop(self, rgbs, trajs, visibs, crop_size):
339 | T, N, _ = trajs.shape
340 |
341 | rgbs = [rgb for rgb in rgbs] # unstack so we can change them one by one
342 |
343 | S = len(rgbs)
344 | H, W = rgbs[0].shape[:2]
345 | assert S == T
346 |
347 | vels = trajs[1:]-trajs[:-1]
348 | accels = vels[1:]-vels[:-1]
349 | vis_ = visibs[1:]*visibs[:-1]
350 | vis__ = vis_[1:]*vis_[:-1]
351 | travel = np.sum(np.sum(np.abs(accels)*vis__[:,:,None], axis=2), axis=0)
352 | num_interesting = np.sum(travel > 0).round()
353 | inds = np.argsort(-travel)[:max(num_interesting//32,32)]
354 |
355 | trajs_interesting = trajs[:,inds] # S,?,2
356 |
357 | # pick a random one to focus on, for variety
358 | smooth_xys = trajs_interesting[:,np.random.randint(len(inds))]
359 |
360 | crop_H, crop_W = crop_size
361 |
362 | smooth_xys = np.clip(smooth_xys, [crop_W // 2, crop_H // 2], [W - crop_W // 2, H - crop_H // 2])
363 |
364 | def smooth_path(xys, num_passes):
365 | kernel = np.array([0.25, 0.5, 0.25])
366 | for _ in range(num_passes):
367 | padded = np.pad(xys, ((1, 1), (0, 0)), mode='edge')
368 | xys = (
369 | kernel[0] * padded[:-2] +
370 | kernel[1] * padded[1:-1] +
371 | kernel[2] * padded[2:]
372 | )
373 | return xys
374 | num_passes = np.random.randint(4, S) # 1 is perfect follow; S is near linear
375 | smooth_xys = smooth_path(smooth_xys, num_passes)
376 |
377 | for si in range(S):
378 | x0, y0 = smooth_xys[si].round().astype(np.int32)
379 | x0 -= crop_W//2
380 | y0 -= crop_H//2
381 | rgbs[si] = rgbs[si][y0:y0+crop_H, x0:x0+crop_W]
382 | trajs[si,:,0] -= x0
383 | trajs[si,:,1] -= y0
384 |
385 | return np.stack(rgbs), trajs
386 |
387 |
--------------------------------------------------------------------------------
/datasets/dynrep_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import gzip
3 | import torch
4 | import numpy as np
5 | import torch.utils.data as data
6 | from collections import defaultdict
7 | from typing import List, Optional, Any, Dict, Tuple, IO, TypeVar, Type, get_args, get_origin, Union, Any
8 | from datasets.pointdataset import PointDataset
9 | import json
10 | import dataclasses
11 | from dataclasses import dataclass, Field, MISSING
12 | import utils.data
13 | import cv2
14 | import random
15 |
16 | _X = TypeVar("_X")
17 |
18 |
19 | def load_dataclass(f: IO, cls: Type[_X], binary: bool = False) -> _X:
20 | """
21 | Loads to a @dataclass or collection hierarchy including dataclasses
22 | from a json recursively.
23 | Call it like load_dataclass(f, typing.List[FrameAnnotationAnnotation]).
24 | raises KeyError if json has keys not mapping to the dataclass fields.
25 |
26 | Args:
27 | f: Either a path to a file, or a file opened for writing.
28 | cls: The class of the loaded dataclass.
29 | binary: Set to True if `f` is a file handle, else False.
30 | """
31 | if binary:
32 | asdict = json.loads(f.read().decode("utf8"))
33 | else:
34 | asdict = json.load(f)
35 |
36 | # in the list case, run a faster "vectorized" version
37 | cls = get_args(cls)[0]
38 | res = list(_dataclass_list_from_dict_list(asdict, cls))
39 |
40 | return res
41 |
42 |
43 | def _resolve_optional(type_: Any) -> Tuple[bool, Any]:
44 | """Check whether `type_` is equivalent to `typing.Optional[T]` for some T."""
45 | if get_origin(type_) is Union:
46 | args = get_args(type_)
47 | if len(args) == 2 and args[1] == type(None): # noqa E721
48 | return True, args[0]
49 | if type_ is Any:
50 | return True, Any
51 |
52 | return False, type_
53 |
54 |
55 | def _unwrap_type(tp):
56 | # strips Optional wrapper, if any
57 | if get_origin(tp) is Union:
58 | args = get_args(tp)
59 | if len(args) == 2 and any(a is type(None) for a in args): # noqa: E721
60 | # this is typing.Optional
61 | return args[0] if args[1] is type(None) else args[1] # noqa: E721
62 | return tp
63 |
64 |
65 | def _get_dataclass_field_default(field: Field) -> Any:
66 | if field.default_factory is not MISSING:
67 | # pyre-fixme[29]: `Union[dataclasses._MISSING_TYPE,
68 | # dataclasses._DefaultFactory[typing.Any]]` is not a function.
69 | return field.default_factory()
70 | elif field.default is not MISSING:
71 | return field.default
72 | else:
73 | return None
74 |
75 |
76 | def _dataclass_list_from_dict_list(dlist, typeannot):
77 | """
78 | Vectorised version of `_dataclass_from_dict`.
79 | The output should be equivalent to
80 | `[_dataclass_from_dict(d, typeannot) for d in dlist]`.
81 |
82 | Args:
83 | dlist: list of objects to convert.
84 | typeannot: type of each of those objects.
85 | Returns:
86 | iterator or list over converted objects of the same length as `dlist`.
87 |
88 | Raises:
89 | ValueError: it assumes the objects have None's in consistent places across
90 | objects, otherwise it would ignore some values. This generally holds for
91 | auto-generated annotations, but otherwise use `_dataclass_from_dict`.
92 | """
93 |
94 | cls = get_origin(typeannot) or typeannot
95 |
96 | if typeannot is Any:
97 | return dlist
98 | if all(obj is None for obj in dlist): # 1st recursion base: all None nodes
99 | return dlist
100 | if any(obj is None for obj in dlist):
101 | # filter out Nones and recurse on the resulting list
102 | idx_notnone = [(i, obj) for i, obj in enumerate(dlist) if obj is not None]
103 | idx, notnone = zip(*idx_notnone)
104 | converted = _dataclass_list_from_dict_list(notnone, typeannot)
105 | res = [None] * len(dlist)
106 | for i, obj in zip(idx, converted):
107 | res[i] = obj
108 | return res
109 |
110 | is_optional, contained_type = _resolve_optional(typeannot)
111 | if is_optional:
112 | return _dataclass_list_from_dict_list(dlist, contained_type)
113 |
114 | # otherwise, we dispatch by the type of the provided annotation to convert to
115 | if issubclass(cls, tuple) and hasattr(cls, "_fields"): # namedtuple
116 | # For namedtuple, call the function recursively on the lists of corresponding keys
117 | types = cls.__annotations__.values()
118 | dlist_T = zip(*dlist)
119 | res_T = [
120 | _dataclass_list_from_dict_list(key_list, tp) for key_list, tp in zip(dlist_T, types)
121 | ]
122 | return [cls(*converted_as_tuple) for converted_as_tuple in zip(*res_T)]
123 | elif issubclass(cls, (list, tuple)):
124 | # For list/tuple, call the function recursively on the lists of corresponding positions
125 | types = get_args(typeannot)
126 | if len(types) == 1: # probably List; replicate for all items
127 | types = types * len(dlist[0])
128 | dlist_T = zip(*dlist)
129 | res_T = (
130 | _dataclass_list_from_dict_list(pos_list, tp) for pos_list, tp in zip(dlist_T, types)
131 | )
132 | if issubclass(cls, tuple):
133 | return list(zip(*res_T))
134 | else:
135 | return [cls(converted_as_tuple) for converted_as_tuple in zip(*res_T)]
136 | elif issubclass(cls, dict):
137 | # For the dictionary, call the function recursively on concatenated keys and vertices
138 | key_t, val_t = get_args(typeannot)
139 | all_keys_res = _dataclass_list_from_dict_list(
140 | [k for obj in dlist for k in obj.keys()], key_t
141 | )
142 | all_vals_res = _dataclass_list_from_dict_list(
143 | [k for obj in dlist for k in obj.values()], val_t
144 | )
145 | indices = np.cumsum([len(obj) for obj in dlist])
146 | assert indices[-1] == len(all_keys_res)
147 |
148 | keys = np.split(list(all_keys_res), indices[:-1])
149 | all_vals_res_iter = iter(all_vals_res)
150 | return [cls(zip(k, all_vals_res_iter)) for k in keys]
151 | elif not dataclasses.is_dataclass(typeannot):
152 | return dlist
153 |
154 | # dataclass node: 2nd recursion base; call the function recursively on the lists
155 | # of the corresponding fields
156 | assert dataclasses.is_dataclass(cls)
157 | fieldtypes = {
158 | f.name: (_unwrap_type(f.type), _get_dataclass_field_default(f))
159 | for f in dataclasses.fields(typeannot)
160 | }
161 |
162 | # NOTE the default object is shared here
163 | key_lists = (
164 | _dataclass_list_from_dict_list([obj.get(k, default) for obj in dlist], type_)
165 | for k, (type_, default) in fieldtypes.items()
166 | )
167 | transposed = zip(*key_lists)
168 | return [cls(*vals_as_tuple) for vals_as_tuple in transposed]
169 |
170 |
171 | @dataclass
172 | class ImageAnnotation:
173 | # path to jpg file, relative w.r.t. dataset_root
174 | path: str
175 | # H x W
176 | size: Tuple[int, int]
177 |
178 | @dataclass
179 | class DynamicReplicaFrameAnnotation:
180 | """A dataclass used to load annotations from json."""
181 |
182 | # can be used to join with `SequenceAnnotation`
183 | sequence_name: str
184 | # 0-based, continuous frame number within sequence
185 | frame_number: int
186 | # timestamp in seconds from the video start
187 | frame_timestamp: float
188 |
189 | image: ImageAnnotation
190 | meta: Optional[Dict[str, Any]] = None
191 |
192 | camera_name: Optional[str] = None
193 | trajectories: Optional[str] = None
194 |
195 |
196 | class DynamicReplicaDataset(PointDataset):
197 | def __init__(
198 | self,
199 | data_root,
200 | split="train",
201 | traj_per_sample=256,
202 | traj_max_factor=24, # multiplier on traj_per_sample
203 | crop_size=None,
204 | use_augs=False,
205 | seq_len=64,
206 | strides=[2,3],
207 | shuffle_frames=False,
208 | shuffle=False,
209 | only_first=False,
210 | ):
211 | super(DynamicReplicaDataset, self).__init__(
212 | data_root=data_root,
213 | crop_size=crop_size,
214 | seq_len=seq_len,
215 | traj_per_sample=traj_per_sample,
216 | use_augs=use_augs,
217 | )
218 | print('loading dynamicreplica dataset...')
219 | self.data_root = data_root
220 | self.only_first = only_first
221 | self.traj_max_factor = traj_max_factor
222 | self.seq_len = seq_len
223 | self.split = split
224 | self.traj_per_sample = traj_per_sample
225 | self.crop_size = crop_size
226 | self.shuffle_frames = shuffle_frames
227 | frame_annotations_file = f"frame_annotations_{split}.jgz"
228 | self.sample_list = []
229 | with gzip.open(
230 | os.path.join(data_root, split, frame_annotations_file), "rt", encoding="utf8"
231 | ) as zipfile:
232 | frame_annots_list = load_dataclass(zipfile, List[DynamicReplicaFrameAnnotation])
233 | seq_annot = defaultdict(list)
234 | for frame_annot in frame_annots_list:
235 | if frame_annot.camera_name == "left":
236 | seq_annot[frame_annot.sequence_name].append(frame_annot)
237 | # if os.path.isfile(traj_2d_file) and os.path.isfile(visib_file) and os.path.isfile(valid_file):
238 | # self.sequences.append(seq)
239 |
240 | clip_step = 64
241 |
242 | for seq_name in seq_annot.keys():
243 | S_local = len(seq_annot[seq_name])
244 | # print(seq_name, 'S_local', S_local)
245 |
246 | traj_path = os.path.join(self.data_root, self.split, seq_annot[seq_name][0].trajectories['path'])
247 | if os.path.isfile(traj_path):
248 | for stride in strides:
249 | for ref_idx in range(0, S_local-seq_len*stride, clip_step):
250 | full_idx = ref_idx + np.arange(seq_len)*stride
251 | full_idx = [ij for ij in full_idx if ij < S_local]
252 | full_idx = np.array(full_idx).astype(np.int32)
253 | if len(full_idx)==seq_len:
254 | sample = [seq_annot[seq_name][fi] for fi in full_idx]
255 | self.sample_list.append(sample)
256 | print('found %d unique videos in %s (split=%s)' % (len(self.sample_list), data_root, split))
257 | self.dname = 'dynrep%d' % seq_len
258 |
259 | if shuffle:
260 | random.shuffle(self.sample_list)
261 |
262 | def __len__(self):
263 | return len(self.sample_list)
264 |
265 | def getitem_helper(self, index):
266 | sample = self.sample_list[index]
267 | T = len(sample)
268 | rgbs, visibs, trajs = [], [], []
269 |
270 | H, W = sample[0].image.size
271 | image_size = (H, W)
272 |
273 | for i in range(T):
274 | traj_path = os.path.join(self.data_root, self.split, sample[i].trajectories["path"])
275 | traj = torch.load(traj_path, weights_only=False)
276 |
277 | visibs.append(traj["verts_inds_vis"].numpy())
278 |
279 | rgbs.append(traj["img"].numpy())
280 | trajs.append(traj["traj_2d"].numpy()[..., :2])
281 |
282 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
283 | trajs = np.stack(trajs)
284 | visibs = np.stack(visibs)
285 | T, N, D = trajs.shape
286 |
287 | H,W = rgbs[0].shape[:2]
288 | visibs[trajs[:, :, 0] > W-1] = False
289 | visibs[trajs[:, :, 0] < 0] = False
290 | visibs[trajs[:, :, 1] > H-1] = False
291 | visibs[trajs[:, :, 1] < 0] = False
292 |
293 |
294 | if self.use_augs and np.random.rand() < 0.5:
295 | # time flip
296 | rgbs = np.flip(rgbs, axis=[0]).copy()
297 | trajs = np.flip(trajs, axis=[0]).copy()
298 | visibs = np.flip(visibs, axis=[0]).copy()
299 |
300 | if self.shuffle_frames and np.random.rand() < 0.01:
301 | # shuffle the frames
302 | perm = np.random.permutation(rgbs.shape[0])
303 | rgbs = rgbs[perm]
304 | trajs = trajs[perm]
305 | visibs = visibs[perm]
306 |
307 | assert(trajs.shape[0] == self.seq_len)
308 |
309 | if self.only_first:
310 | vis_ok = np.nonzero(visibs[0]==1)[0]
311 | trajs = trajs[:,vis_ok]
312 | visibs = visibs[:,vis_ok]
313 |
314 | N = trajs.shape[1]
315 | if N < self.traj_per_sample:
316 | print('dyn: N after vis0', N)
317 | return None, False
318 |
319 | # the data is quite big: 720x1280
320 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
321 | scale = 0.5
322 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
323 | H, W = rgbs[0].shape[:2]
324 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
325 | trajs = trajs * scale
326 | # print('resized rgbs', rgbs.shape)
327 |
328 | if H > self.crop_size[0]*2 and W > self.crop_size[1]*2 and np.random.rand() < 0.5:
329 | scale = 0.5
330 | rgbs = [cv2.resize(rgb, None, fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR) for rgb in rgbs]
331 | H, W = rgbs[0].shape[:2]
332 | rgbs = np.stack(rgbs, axis=0) # S,H,W,3
333 | trajs = trajs * scale
334 | # print('resized rgbs', rgbs.shape)
335 |
336 | if self.use_augs and np.random.rand() < 0.98:
337 | H, W = rgbs[0].shape[:2]
338 |
339 | rgbs, trajs, visibs = self.add_photometric_augs(
340 | rgbs, trajs, visibs, replace=False,
341 | )
342 | if np.random.rand() < 0.2:
343 | rgbs, trajs = self.add_spatial_augs(rgbs, trajs, visibs, self.crop_size)
344 | else:
345 | rgbs, trajs = self.follow_crop(rgbs, trajs, visibs, self.crop_size)
346 | if np.random.rand() < self.rot_prob:
347 | # note this is OK since B==1
348 | # otw we would do it before this func
349 | rgbs = [np.transpose(rgb, (1,0,2)).copy() for rgb in rgbs]
350 | rgbs = np.stack(rgbs)
351 | trajs = np.flip(trajs, axis=2).copy()
352 | H, W = rgbs[0].shape[:2]
353 | if np.random.rand() < self.h_flip_prob:
354 | rgbs = [rgb[:, ::-1].copy() for rgb in rgbs]
355 | trajs[:, :, 0] = W - trajs[:, :, 0]
356 | rgbs = np.stack(rgbs)
357 | if np.random.rand() < self.v_flip_prob:
358 | rgbs = [rgb[::-1].copy() for rgb in rgbs]
359 | trajs[:, :, 1] = H - trajs[:, :, 1]
360 | rgbs = np.stack(rgbs)
361 | else:
362 | rgbs, trajs = self.crop(rgbs, trajs, self.crop_size)
363 |
364 | if self.shuffle_frames and np.random.rand() < 0.01:
365 | # shuffle the frames (again)
366 | perm = np.random.permutation(rgbs.shape[0])
367 | rgbs = rgbs[perm]
368 | trajs = trajs[perm]
369 | visibs = visibs[perm]
370 |
371 | H,W = rgbs[0].shape[:2]
372 |
373 | visibs[trajs[:, :, 0] > W-1] = False
374 | visibs[trajs[:, :, 0] < 0] = False
375 | visibs[trajs[:, :, 1] > H-1] = False
376 | visibs[trajs[:, :, 1] < 0] = False
377 |
378 | # ensure no crazy values
379 | all_valid = np.nonzero(np.sum(np.sum(np.abs(trajs), axis=-1)<100000, axis=0)==self.seq_len)[0]
380 | trajs = trajs[:,all_valid]
381 | visibs = visibs[:,all_valid]
382 |
383 | if self.only_first:
384 | vis_ok = np.nonzero(visibs[0]==1)[0]
385 | trajs = trajs[:,vis_ok]
386 | visibs = visibs[:,vis_ok]
387 |
388 | N = trajs.shape[1]
389 | if N < self.traj_per_sample:
390 | print('dyn: N after aug', N)
391 | return None, False
392 |
393 | trajs = torch.from_numpy(trajs)
394 | visibs = torch.from_numpy(visibs)
395 |
396 | rgbs = np.stack(rgbs, 0)
397 | rgbs = torch.from_numpy(rgbs).reshape(T, H, W, 3).permute(0, 3, 1, 2).float()
398 |
399 | # discard tracks that go far OOB
400 | crop_tensor = torch.tensor(self.crop_size).flip(0)[None, None] / 2.0
401 | close_pts_inds = torch.all(
402 | torch.linalg.vector_norm(trajs[..., :2] - crop_tensor, dim=-1) < max(H,W)*2,
403 | dim=0,
404 | )
405 | trajs = trajs[:, close_pts_inds]
406 | visibs = visibs[:, close_pts_inds]
407 |
408 | visible_pts_inds = (visibs[0]).nonzero(as_tuple=False)[:, 0]
409 | point_inds = torch.randperm(len(visible_pts_inds))[:self.traj_per_sample*self.traj_max_factor]
410 | if len(point_inds) < self.traj_per_sample:
411 | # print('not enough trajs')
412 | return None, False
413 |
414 | visible_inds_sampled = visible_pts_inds[point_inds]
415 | trajs = trajs[:, visible_inds_sampled].float()
416 | visibs = visibs[:, visible_inds_sampled]
417 | valids = torch.ones_like(visibs)
418 |
419 | trajs = trajs[:, :self.traj_per_sample*self.traj_max_factor]
420 | visibs = visibs[:, :self.traj_per_sample*self.traj_max_factor]
421 | valids = valids[:, :self.traj_per_sample*self.traj_max_factor]
422 |
423 | sample = utils.data.VideoData(
424 | video=rgbs,
425 | trajs=trajs,
426 | visibs=visibs,
427 | valids=valids,
428 | dname=self.dname,
429 | )
430 | return sample, True
431 |
--------------------------------------------------------------------------------
/test_dense_on_sparse.py:
--------------------------------------------------------------------------------
1 | import os
2 | import random
3 | import torch
4 | import torch.nn.functional as F
5 | import numpy as np
6 | import argparse
7 | import utils.loss
8 | import utils.data
9 | import utils.improc
10 | import utils.misc
11 | import utils.saveload
12 | from tensorboardX import SummaryWriter
13 | import datetime
14 | import time
15 |
16 | torch.set_float32_matmul_precision('medium')
17 |
18 | from prettytable import PrettyTable
19 | def count_parameters(model):
20 | table = PrettyTable(["Modules", "Parameters"])
21 | total_params = 0
22 | for name, parameter in model.named_parameters():
23 | if not parameter.requires_grad:
24 | continue
25 | param = parameter.numel()
26 | if param > 100000:
27 | table.add_row([name, param])
28 | total_params += param
29 | # print(table)
30 | print('total params: %.2f M' % (total_params/1000000.0))
31 | return total_params
32 |
33 | def get_parameter_names(model, forbidden_layer_types):
34 | result = []
35 | for name, child in model.named_children():
36 | result += [
37 | f"{name}.{n}"
38 | for n in get_parameter_names(child, forbidden_layer_types)
39 | if not isinstance(child, tuple(forbidden_layer_types))
40 | ]
41 | result += list(model._parameters.keys())
42 | return result
43 |
44 | def get_dataset(dname, args):
45 | if dname=='bad':
46 | dataset_names = ['bad']
47 | from datasets import badjadataset
48 | dataset = badjadataset.BadjaDataset(
49 | data_root=os.path.join(args.dataset_root, 'badja2'),
50 | crop_size=args.image_size,
51 | only_first=False,
52 | )
53 | elif dname=='cro':
54 | dataset_names = ['cro']
55 | from datasets import crohddataset
56 | dataset = crohddataset.CrohdDataset(
57 | data_root=os.path.join(args.dataset_root, 'crohd'),
58 | crop_size=args.image_size,
59 | seq_len=None,
60 | only_first=True,
61 | )
62 | elif dname=='dav':
63 | dataset_names = ['dav']
64 | from datasets import davisdataset
65 | dataset = davisdataset.DavisDataset(
66 | data_root=os.path.join(args.dataset_root, 'tapvid_davis'),
67 | crop_size=args.image_size,
68 | only_first=False,
69 | )
70 | elif dname=='dri':
71 | dataset_names = ['dri']
72 | from datasets import drivetrackdataset
73 | dataset = drivetrackdataset.DrivetrackDataset(
74 | data_root=os.path.join(args.dataset_root, 'drivetrack'),
75 | crop_size=args.image_size,
76 | seq_len=None,
77 | traj_per_sample=768,
78 | only_first=True,
79 | )
80 | elif dname=='ego':
81 | dataset_names = ['ego']
82 | from datasets import egopointsdataset
83 | dataset = egopointsdataset.EgoPointsDataset(
84 | data_root=os.path.join(args.dataset_root, 'ego_points'),
85 | crop_size=args.image_size,
86 | only_first=True,
87 | )
88 | elif dname=='hor':
89 | dataset_names = ['hor']
90 | from datasets import horsedataset
91 | dataset = horsedataset.HorseDataset(
92 | data_root=os.path.join(args.dataset_root, 'horse10'),
93 | crop_size=args.image_size,
94 | seq_len=None,
95 | only_first=True,
96 | )
97 | elif dname=='kin':
98 | dataset_names = ['kin']
99 | from datasets import kineticsdataset
100 | dataset = kineticsdataset.KineticsDataset(
101 | data_root=os.path.join(args.dataset_root, 'tapvid_kinetics'),
102 | crop_size=args.image_size,
103 | only_first=True,
104 | )
105 | elif dname=='rgb':
106 | dataset_names = ['rgb']
107 | from datasets import rgbstackingdataset
108 | dataset = rgbstackingdataset.RGBStackingDataset(
109 | data_root=os.path.join(args.dataset_root, 'tapvid_rgb_stacking'),
110 | crop_size=args.image_size,
111 | only_first=False,
112 | )
113 | elif dname=='rob':
114 | dataset_names = ['rob']
115 | from datasets import robotapdataset
116 | dataset = robotapdataset.RobotapDataset(
117 | data_root=os.path.join(args.dataset_root, 'robotap'),
118 | crop_size=args.image_size,
119 | only_first=True,
120 | )
121 | return dataset, dataset_names
122 |
123 | def create_pools(args, n_pool=10000, min_size=1):
124 | pools = {}
125 | n_pool = max(n_pool, 10)
126 | thrs = [1,2,4,8,16]
127 | for thr in thrs:
128 | pools['d_%d' % thr] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
129 | pools['jac_%d' % thr] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
130 | pools['d_avg'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
131 | pools['aj'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
132 | pools['oa'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
133 | return pools
134 |
135 | def forward_batch(batch, model, args, sw):
136 | rgbs = batch.video
137 | trajs_g = batch.trajs
138 | vis_g = batch.visibs
139 | valids = batch.valids
140 | dname = batch.dname
141 | # print('rgbs', rgbs.shape, rgbs.dtype, rgbs.device)
142 | # print('trajs_g', trajs_g.shape, trajs_g.device)
143 | # print('vis_g', vis_g.shape, vis_g.device)
144 |
145 | B, T, C, H, W = rgbs.shape
146 | assert C == 3
147 | B, T, N, D = trajs_g.shape
148 | device = rgbs.device
149 | assert(B==1)
150 |
151 | trajs_g = trajs_g.cuda()
152 | vis_g = vis_g.cuda()
153 | valids = valids.cuda()
154 | __, first_positive_inds = torch.max(vis_g, dim=1)
155 |
156 | grid_xy = utils.basic.gridcloud2d(1, H, W, norm=False, device='cuda:0').float() # 1,H*W,2
157 | grid_xy = grid_xy.permute(0,2,1).reshape(1,1,2,H,W) # 1,1,2,H,W
158 |
159 | trajs_e = torch.zeros([B, T, N, 2], device='cuda:0')
160 | visconfs_e = torch.zeros([B, T, N, 2], device='cuda:0')
161 | query_points_all = []
162 | with torch.no_grad():
163 | for first_positive_ind in torch.unique(first_positive_inds):
164 | chunk_pt_idxs = torch.nonzero(first_positive_inds[0]==first_positive_ind, as_tuple=False)[:, 0] # K
165 | chunk_pts = trajs_g[:, first_positive_ind[None].repeat(chunk_pt_idxs.shape[0]), chunk_pt_idxs] # B, K, 2
166 | query_points_all.append(torch.cat([first_positive_inds[:, chunk_pt_idxs, None], chunk_pts], dim=2))
167 |
168 | traj_maps_e = grid_xy.repeat(1,T,1,1,1) # B,T,2,H,W
169 | visconf_maps_e = torch.zeros_like(traj_maps_e)
170 | if first_positive_ind < T-1:
171 | if T > 128: # forward_sliding is a little safer memory-wise
172 | forward_flow_e, forward_visconf_e, forward_flow_preds, forward_visconf_preds = \
173 | model.forward_sliding(rgbs[:, first_positive_ind:], iters=args.inference_iters, sw=sw, is_training=False)
174 | else:
175 | forward_flow_e, forward_visconf_e, forward_flow_preds, forward_visconf_preds = \
176 | model(rgbs[:, first_positive_ind:], iters=args.inference_iters, sw=sw, is_training=False)
177 |
178 | del forward_flow_preds
179 | del forward_visconf_preds
180 | forward_traj_maps_e = forward_flow_e.cuda() + grid_xy # B,Tf,2,H,W, when T = 2, flow has no T dim, but we broadcast
181 | traj_maps_e[:,first_positive_ind:] = forward_traj_maps_e
182 | visconf_maps_e[:,first_positive_ind:] = forward_visconf_e
183 | if not sw.save_this:
184 | del forward_flow_e
185 | del forward_visconf_e
186 | del forward_traj_maps_e
187 |
188 | xyt = trajs_g[:,first_positive_ind].round().long()[0, chunk_pt_idxs] # K,2
189 | trajs_e_chunk = traj_maps_e[:, :, :, xyt[:,1], xyt[:,0]] # B,T,2,K
190 | trajs_e_chunk = trajs_e_chunk.permute(0,1,3,2) # B,T,K,2
191 | trajs_e.scatter_add_(2, chunk_pt_idxs[None, None, :, None].repeat(1, trajs_e_chunk.shape[1], 1, 2), trajs_e_chunk)
192 |
193 | visconfs_e_chunk = visconf_maps_e[:, :, :, xyt[:,1], xyt[:,0]] # B,T,2,K
194 | visconfs_e_chunk = visconfs_e_chunk.permute(0,1,3,2) # B,T,K,2
195 | visconfs_e.scatter_add_(2, chunk_pt_idxs[None, None, :, None].repeat(1, visconfs_e_chunk.shape[1], 1, 2), visconfs_e_chunk)
196 |
197 | visconfs_e[..., 0] *= visconfs_e[..., 1]
198 | assert (torch.all(visconfs_e >= 0) and torch.all(visconfs_e <= 1))
199 | vis_thr = 0.6
200 | query_points_all = torch.cat(query_points_all, dim=1)[..., [0, 2, 1]]
201 | gt_occluded = (vis_g < .5).bool().transpose(1, 2)
202 | gt_tracks = trajs_g.transpose(1, 2)
203 | pred_occluded = (visconfs_e[..., 0] < vis_thr).bool().transpose(1, 2)
204 | pred_tracks = trajs_e.transpose(1, 2)
205 |
206 | metrics = utils.misc.compute_tapvid_metrics(
207 | query_points=query_points_all.cpu().numpy(),
208 | gt_occluded=gt_occluded.cpu().numpy(),
209 | gt_tracks=gt_tracks.cpu().numpy(),
210 | pred_occluded=pred_occluded.cpu().numpy(),
211 | pred_tracks=pred_tracks.cpu().numpy(),
212 | query_mode='first',
213 | crop_size=args.image_size
214 | )
215 | for thr in [1, 2, 4, 8, 16]:
216 | metrics['d_%d' % thr] = metrics['pts_within_' + str(thr)]
217 | metrics['jac_%d' % thr] = metrics['jaccard_' + str(thr)]
218 | metrics['d_avg'] = metrics['average_pts_within_thresh']
219 | metrics['aj'] = metrics['average_jaccard']
220 | metrics['oa'] = metrics['occlusion_accuracy']
221 |
222 | return metrics
223 |
224 |
225 | def run(dname, model, args):
226 | def seed_everything(seed: int):
227 | random.seed(seed)
228 | os.environ["PYTHONHASHSEED"] = str(seed)
229 | np.random.seed(seed)
230 | torch.manual_seed(seed)
231 | torch.cuda.manual_seed(seed)
232 | torch.backends.cudnn.deterministic = True
233 | torch.backends.cudnn.benchmark = False
234 | def seed_worker(worker_id):
235 | worker_seed = torch.initial_seed() % 2**32
236 | np.random.seed(worker_seed + worker_id)
237 | random.seed(worker_seed + worker_id)
238 | seed = 42
239 | seed_everything(seed)
240 | g = torch.Generator()
241 | g.manual_seed(seed)
242 |
243 | B_ = args.batch_size * torch.cuda.device_count()
244 | assert(B_==1)
245 | model_name = "%dx%d" % (int(args.image_size[0]), int(args.image_size[1]))
246 | model_name += "i%d" % (args.inference_iters)
247 | model_name += "_%s" % args.init_dir
248 | model_name += "_%s" % dname
249 | if args.only_first:
250 | model_name += "_first"
251 | model_name += "_%s" % args.exp
252 | model_date = datetime.datetime.now().strftime('%M%S')
253 | model_name = model_name + '_' + model_date
254 |
255 | save_dir = '%s/%s' % (args.ckpt_dir, model_name)
256 |
257 | dataset, dataset_names = get_dataset(dname, args)
258 | dataloader = torch.utils.data.DataLoader(
259 | dataset,
260 | batch_size=1,
261 | shuffle=False,
262 | num_workers=args.num_workers,
263 | worker_init_fn=seed_worker,
264 | generator=g,
265 | pin_memory=True,
266 | drop_last=True,
267 | collate_fn=utils.data.collate_fn_train,
268 | )
269 | iterloader = iter(dataloader)
270 | print('len(dataloader)', len(dataloader))
271 |
272 | log_dir = './logs_test_dense_on_sparse'
273 | overpools_t = create_pools(args)
274 | writer_t = SummaryWriter(log_dir + '/' + args.model_type + '-' + model_name + '/t', max_queue=10, flush_secs=60)
275 |
276 | global_step = 0
277 | if args.init_dir:
278 | load_dir = '%s/%s' % (args.ckpt_dir, args.init_dir)
279 | _ = utils.saveload.load(
280 | None,
281 | load_dir,
282 | model,
283 | optimizer=None,
284 | scheduler=None,
285 | ignore_load=None,
286 | strict=True,
287 | verbose=False,
288 | weights_only=False,
289 | )
290 | model.cuda()
291 | for n, p in model.named_parameters():
292 | p.requires_grad = False
293 | model.eval()
294 |
295 | max_steps = min(args.max_steps, len(dataloader))
296 |
297 | while global_step < max_steps:
298 | torch.cuda.empty_cache()
299 | iter_start_time = time.time()
300 | try:
301 | batch = next(iterloader)
302 | except StopIteration:
303 | iterloader = iter(dataloader)
304 | batch = next(iterloader)
305 |
306 | batch, gotit = batch
307 | if not all(gotit):
308 | continue
309 |
310 | sw_t = utils.improc.Summ_writer(
311 | writer=writer_t,
312 | global_step=global_step,
313 | log_freq=args.log_freq,
314 | fps=8,
315 | scalar_freq=1,
316 | just_gif=True)
317 | if args.log_freq == 9999:
318 | sw_t.save_this = False
319 |
320 | rtime = time.time()-iter_start_time
321 |
322 | if batch.trajs.shape[2] == 0:
323 | global_step += 1
324 | continue
325 |
326 | metrics = forward_batch(batch, model, args, sw_t)
327 |
328 | # update stats
329 | for key in list(overpools_t.keys()):
330 | if key in metrics:
331 | overpools_t[key].update([metrics[key]])
332 | # plot stats
333 | for key in list(overpools_t.keys()):
334 | sw_t.summ_scalar('_/%s' % (key), overpools_t[key].mean())
335 |
336 | global_step += 1
337 |
338 | itime = time.time()-iter_start_time
339 |
340 | info_str = '%s; step %06d/%d; rtime %.2f; itime %.2f' % (
341 | model_name, global_step, max_steps, rtime, itime)
342 | info_str += '; dname %s; d_avg %.1f aj %.1f oa %.1f' % (
343 | dname, overpools_t['d_avg'].mean()*100.0, overpools_t['aj'].mean()*100.0, overpools_t['oa'].mean()*100.0
344 | )
345 | if sw_t.save_this:
346 | print('model_name', model_name)
347 |
348 | if not args.print_less:
349 | print(info_str, flush=True)
350 |
351 |
352 | if args.print_less:
353 | print(info_str, flush=True)
354 |
355 | writer_t.close()
356 |
357 | del iterloader
358 | del dataloader
359 | del dataset
360 |
361 | return overpools_t['d_avg'].mean()*100.0, overpools_t['aj'].mean()*100.0, overpools_t['oa'].mean()*100.0
362 |
363 | if __name__ == "__main__":
364 | torch.set_grad_enabled(False)
365 | init_dir = ''
366 |
367 | exp = ''
368 |
369 | parser = argparse.ArgumentParser()
370 | parser.add_argument("--exp", default=exp)
371 | parser.add_argument("--dname", type=str, nargs='+', default=None, help="Dataset names, written as a single string or list of strings")
372 | parser.add_argument("--init_dir", type=str, default=init_dir)
373 | parser.add_argument("--ckpt_dir", type=str, default='')
374 | parser.add_argument("--batch_size", type=int, default=1)
375 | parser.add_argument("--num_workers", type=int, default=1)
376 | parser.add_argument("--max_steps", type=int, default=1500)
377 | parser.add_argument("--log_freq", type=int, default=9999)
378 | parser.add_argument("--dataset_root", type=str, default='/orion/group')
379 | parser.add_argument("--inference_iters", type=int, default=4)
380 | parser.add_argument("--window_len", type=int, default=16)
381 | parser.add_argument("--stride", type=int, default=8)
382 | parser.add_argument("--image_size", nargs="+", default=[384, 512]) # resizing arg
383 | parser.add_argument("--backwards", default=False)
384 | parser.add_argument("--mixed_precision", action='store_true', default=False)
385 | parser.add_argument("--only_first", action='store_true', default=False)
386 | parser.add_argument("--no_split", action='store_true', default=False)
387 | parser.add_argument("--print_less", action='store_true', default=False)
388 | parser.add_argument("--use_basicencoder", action='store_true', default=False)
389 | parser.add_argument("--conf", action='store_true', default=False)
390 | parser.add_argument("--model_type", choices=['ours', 'raft', 'searaft', 'accflow', 'delta'], default='ours')
391 | args = parser.parse_args()
392 | # allow dname to be a comma-separated string (e.g., "rgb,bad,dav")
393 | if args.dname is not None and len(args.dname) == 1 and ',' in args.dname[0]:
394 | args.dname = args.dname[0].split(',')
395 | if args.dname is None:
396 | args.dname = ['bad', 'cro', 'dav', 'dri', 'hor', 'kin', 'rgb', 'rob']
397 | dataset_names = args.dname
398 | args.image_size = [int(args.image_size[0]), int(args.image_size[1])]
399 | full_start_time = time.time()
400 |
401 | from nets.alltracker import Net; model = Net(16)
402 | url = "https://huggingface.co/aharley/alltracker/resolve/main/alltracker.pth"
403 | state_dict = torch.hub.load_state_dict_from_url(url, map_location='cpu')
404 | model.load_state_dict(state_dict['model'], strict=True)
405 | print('loaded weights from', url)
406 |
407 | das, ajs, oas = [], [], []
408 | for dname in dataset_names:
409 | if dname==dataset_names[0]:
410 | count_parameters(model)
411 | da, aj, oa = run(dname, model, args)
412 | das.append(da)
413 | ajs.append(aj)
414 | oas.append(oa)
415 | for (data, name) in zip([dataset_names, das, ajs, oas], ['dn', 'da', 'aj', 'oa']):
416 | st = name + ': '
417 | for dat in data:
418 | if isinstance(dat, str):
419 | st += '%s,' % dat
420 | else:
421 | st += '%.1f,' % dat
422 | print(st)
423 | full_time = time.time()-full_start_time
424 | print('full_time %.1f' % full_time)
425 |
--------------------------------------------------------------------------------
/utils/py.py:
--------------------------------------------------------------------------------
1 | import glob, math
2 | import numpy as np
3 | # from scipy import misc
4 | # from scipy import linalg
5 | from PIL import Image
6 | import io
7 | import matplotlib.pyplot as plt
8 | EPS = 1e-6
9 |
10 |
11 | XMIN = -64.0 # right (neg is left)
12 | XMAX = 64.0 # right
13 | YMIN = -64.0 # down (neg is up)
14 | YMAX = 64.0 # down
15 | ZMIN = -64.0 # forward
16 | ZMAX = 64.0 # forward
17 |
18 | def print_stats(name, tensor):
19 | tensor = tensor.astype(np.float32)
20 | print('%s min = %.2f, mean = %.2f, max = %.2f' % (name, np.min(tensor), np.mean(tensor), np.max(tensor)), tensor.shape)
21 |
22 | def reduce_masked_mean(x, mask, axis=None, keepdims=False):
23 | # x and mask are the same shape
24 | # returns shape-1
25 | # axis can be a list of axes
26 | prod = x*mask
27 | numer = np.sum(prod, axis=axis, keepdims=keepdims)
28 | denom = EPS+np.sum(mask, axis=axis, keepdims=keepdims)
29 | mean = numer/denom
30 | return mean
31 |
32 | def reduce_masked_sum(x, mask, axis=None, keepdims=False):
33 | # x and mask are the same shape
34 | # returns shape-1
35 | # axis can be a list of axes
36 | prod = x*mask
37 | numer = np.sum(prod, axis=axis, keepdims=keepdims)
38 | return numer
39 |
40 | def reduce_masked_median(x, mask, keep_batch=False):
41 | # x and mask are the same shape
42 | # returns shape-1
43 | # axis can be a list of axes
44 |
45 | if not (x.shape == mask.shape):
46 | print('reduce_masked_median: these shapes should match:', x.shape, mask.shape)
47 | assert(False)
48 | # assert(x.shape == mask.shape)
49 |
50 | B = list(x.shape)[0]
51 |
52 | if keep_batch:
53 | x = np.reshape(x, [B, -1])
54 | mask = np.reshape(mask, [B, -1])
55 | meds = np.zeros([B], np.float32)
56 | for b in list(range(B)):
57 | xb = x[b]
58 | mb = mask[b]
59 | if np.sum(mb) > 0:
60 | xb = xb[mb > 0]
61 | meds[b] = np.median(xb)
62 | else:
63 | meds[b] = np.nan
64 | return meds
65 | else:
66 | x = np.reshape(x, [-1])
67 | mask = np.reshape(mask, [-1])
68 | if np.sum(mask) > 0:
69 | x = x[mask > 0]
70 | med = np.median(x)
71 | else:
72 | med = np.nan
73 | med = np.array([med], np.float32)
74 | return med
75 |
76 | def get_nFiles(path):
77 | return len(glob.glob(path))
78 |
79 | def get_file_list(path):
80 | return glob.glob(path)
81 |
82 | def rotm2eul(R):
83 | # R is 3x3
84 | sy = math.sqrt(R[0,0] * R[0,0] + R[1,0] * R[1,0])
85 | if sy > 1e-6: # singular
86 | x = math.atan2(R[2,1] , R[2,2])
87 | y = math.atan2(-R[2,0], sy)
88 | z = math.atan2(R[1,0], R[0,0])
89 | else:
90 | x = math.atan2(-R[1,2], R[1,1])
91 | y = math.atan2(-R[2,0], sy)
92 | z = 0
93 | return x, y, z
94 |
95 | def rad2deg(rad):
96 | return rad*180.0/np.pi
97 |
98 | def deg2rad(deg):
99 | return deg/180.0*np.pi
100 |
101 | def eul2rotm(rx, ry, rz):
102 | # copy of matlab, but order of inputs is different
103 | # R = [ cy*cz sy*sx*cz-sz*cx sy*cx*cz+sz*sx
104 | # cy*sz sy*sx*sz+cz*cx sy*cx*sz-cz*sx
105 | # -sy cy*sx cy*cx]
106 | sinz = np.sin(rz)
107 | siny = np.sin(ry)
108 | sinx = np.sin(rx)
109 | cosz = np.cos(rz)
110 | cosy = np.cos(ry)
111 | cosx = np.cos(rx)
112 | r11 = cosy*cosz
113 | r12 = sinx*siny*cosz - cosx*sinz
114 | r13 = cosx*siny*cosz + sinx*sinz
115 | r21 = cosy*sinz
116 | r22 = sinx*siny*sinz + cosx*cosz
117 | r23 = cosx*siny*sinz - sinx*cosz
118 | r31 = -siny
119 | r32 = sinx*cosy
120 | r33 = cosx*cosy
121 | r1 = np.stack([r11,r12,r13],axis=-1)
122 | r2 = np.stack([r21,r22,r23],axis=-1)
123 | r3 = np.stack([r31,r32,r33],axis=-1)
124 | r = np.stack([r1,r2,r3],axis=0)
125 | return r
126 |
127 | def wrap2pi(rad_angle):
128 | # puts the angle into the range [-pi, pi]
129 | return np.arctan2(np.sin(rad_angle), np.cos(rad_angle))
130 |
131 | def rot2view(rx,ry,rz,x,y,z):
132 | # takes rot angles and 3d position as input
133 | # returns viewpoint angles as output
134 | # (all in radians)
135 | # it will perform strangely if z <= 0
136 | az = wrap2pi(ry - (-np.arctan2(z, x) - 1.5*np.pi))
137 | el = -wrap2pi(rx - (-np.arctan2(z, y) - 1.5*np.pi))
138 | th = -rz
139 | return az, el, th
140 |
141 | def invAxB(a,b):
142 | """
143 | Compute the relative 3d transformation between a and b.
144 |
145 | Input:
146 | a -- first pose (homogeneous 4x4 matrix)
147 | b -- second pose (homogeneous 4x4 matrix)
148 |
149 | Output:
150 | Relative 3d transformation from a to b.
151 | """
152 | return np.dot(np.linalg.inv(a),b)
153 |
154 | def merge_rt(r, t):
155 | # r is 3 x 3
156 | # t is 3 or maybe 3 x 1
157 | t = np.reshape(t, [3, 1])
158 | rt = np.concatenate((r,t), axis=1)
159 | # rt is 3 x 4
160 | br = np.reshape(np.array([0,0,0,1], np.float32), [1, 4])
161 | # br is 1 x 4
162 | rt = np.concatenate((rt, br), axis=0)
163 | # rt is 4 x 4
164 | return rt
165 |
166 | def split_rt(rt):
167 | r = rt[:3,:3]
168 | t = rt[:3,3]
169 | r = np.reshape(r, [3, 3])
170 | t = np.reshape(t, [3, 1])
171 | return r, t
172 |
173 | def split_intrinsics(K):
174 | # K is 3 x 4 or 4 x 4
175 | fx = K[0,0]
176 | fy = K[1,1]
177 | x0 = K[0,2]
178 | y0 = K[1,2]
179 | return fx, fy, x0, y0
180 |
181 | def merge_intrinsics(fx, fy, x0, y0):
182 | # inputs are shaped []
183 | K = np.eye(4)
184 | K[0,0] = fx
185 | K[1,1] = fy
186 | K[0,2] = x0
187 | K[1,2] = y0
188 | # K is shaped 4 x 4
189 | return K
190 |
191 | def scale_intrinsics(K, sx, sy):
192 | fx, fy, x0, y0 = split_intrinsics(K)
193 | fx *= sx
194 | fy *= sy
195 | x0 *= sx
196 | y0 *= sy
197 | return merge_intrinsics(fx, fy, x0, y0)
198 |
199 | # def meshgrid(H, W):
200 | # x = np.linspace(0, W-1, W)
201 | # y = np.linspace(0, H-1, H)
202 | # xv, yv = np.meshgrid(x, y)
203 | # return xv, yv
204 |
205 | def compute_distance(transform):
206 | """
207 | Compute the distance of the translational component of a 4x4 homogeneous matrix.
208 | """
209 | return numpy.linalg.norm(transform[0:3,3])
210 |
211 | def radian_l1_dist(e, g):
212 | # if our angles are in [0, 360] we can follow this stack overflow answer:
213 | # https://gamedev.stackexchange.com/questions/4467/comparing-angles-and-working-out-the-difference
214 | # wrap2pi brings the angles to [-180, 180]; adding pi puts them in [0, 360]
215 | e = wrap2pi(e)+np.pi
216 | g = wrap2pi(g)+np.pi
217 | l = np.abs(np.pi - np.abs(np.abs(e-g) - np.pi))
218 | return l
219 |
220 | def apply_pix_T_cam(pix_T_cam, xyz):
221 | fx, fy, x0, y0 = split_intrinsics(pix_T_cam)
222 | # xyz is shaped B x H*W x 3
223 | # returns xy, shaped B x H*W x 2
224 | N, C = xyz.shape
225 | x, y, z = np.split(xyz, 3, axis=-1)
226 | EPS = 1e-4
227 | z = np.clip(z, EPS, None)
228 | x = (x*fx)/(z)+x0
229 | y = (y*fy)/(z)+y0
230 | xy = np.concatenate([x, y], axis=-1)
231 | return xy
232 |
233 | def apply_4x4(RT, XYZ):
234 | # RT is 4 x 4
235 | # XYZ is N x 3
236 |
237 | # put into homogeneous coords
238 | X, Y, Z = np.split(XYZ, 3, axis=1)
239 | ones = np.ones_like(X)
240 | XYZ1 = np.concatenate([X, Y, Z, ones], axis=1)
241 | # XYZ1 is N x 4
242 |
243 | XYZ1_t = np.transpose(XYZ1)
244 | # this is 4 x N
245 |
246 | XYZ2_t = np.dot(RT, XYZ1_t)
247 | # this is 4 x N
248 |
249 | XYZ2 = np.transpose(XYZ2_t)
250 | # this is N x 4
251 |
252 | XYZ2 = XYZ2[:,:3]
253 | # this is N x 3
254 |
255 | return XYZ2
256 |
257 | def Ref2Mem(xyz, Z, Y, X):
258 | # xyz is N x 3, in ref coordinates
259 | # transforms ref coordinates into mem coordinates
260 | N, C = xyz.shape
261 | assert(C==3)
262 | mem_T_ref = get_mem_T_ref(Z, Y, X)
263 | xyz = apply_4x4(mem_T_ref, xyz)
264 | return xyz
265 |
266 | # def Mem2Ref(xyz_mem, MH, MW, MD):
267 | # # xyz is B x N x 3, in mem coordinates
268 | # # transforms mem coordinates into ref coordinates
269 | # B, N, C = xyz_mem.get_shape().as_list()
270 | # ref_T_mem = get_ref_T_mem(B, MH, MW, MD)
271 | # xyz_ref = utils_geom.apply_4x4(ref_T_mem, xyz_mem)
272 | # return xyz_ref
273 |
274 | def get_mem_T_ref(Z, Y, X):
275 | # sometimes we want the mat itself
276 | # note this is not a rigid transform
277 |
278 | # for interpretability, let's construct this in two steps...
279 |
280 | # translation
281 | center_T_ref = np.eye(4, dtype=np.float32)
282 | center_T_ref[0,3] = -XMIN
283 | center_T_ref[1,3] = -YMIN
284 | center_T_ref[2,3] = -ZMIN
285 |
286 | VOX_SIZE_X = (XMAX-XMIN)/float(X)
287 | VOX_SIZE_Y = (YMAX-YMIN)/float(Y)
288 | VOX_SIZE_Z = (ZMAX-ZMIN)/float(Z)
289 |
290 | # scaling
291 | mem_T_center = np.eye(4, dtype=np.float32)
292 | mem_T_center[0,0] = 1./VOX_SIZE_X
293 | mem_T_center[1,1] = 1./VOX_SIZE_Y
294 | mem_T_center[2,2] = 1./VOX_SIZE_Z
295 |
296 | mem_T_ref = np.dot(mem_T_center, center_T_ref)
297 | return mem_T_ref
298 |
299 | def safe_inverse(a):
300 | r, t = split_rt(a)
301 | t = np.reshape(t, [3, 1])
302 | r_transpose = r.T
303 | inv = np.concatenate([r_transpose, -np.matmul(r_transpose, t)], 1)
304 | bottom_row = a[3:4, :] # this is [0, 0, 0, 1]
305 | inv = np.concatenate([inv, bottom_row], 0)
306 | return inv
307 |
308 | def get_ref_T_mem(Z, Y, X):
309 | mem_T_ref = get_mem_T_ref(X, Y, X)
310 | # note safe_inverse is inapplicable here,
311 | # since the transform is nonrigid
312 | ref_T_mem = np.linalg.inv(mem_T_ref)
313 | return ref_T_mem
314 |
315 | def voxelize_xyz(xyz_ref, Z, Y, X):
316 | # xyz_ref is N x 3
317 | xyz_mem = Ref2Mem(xyz_ref, Z, Y, X)
318 | # this is N x 3
319 | voxels = get_occupancy(xyz_mem, Z, Y, X)
320 | voxels = np.reshape(voxels, [Z, Y, X, 1])
321 | return voxels
322 |
323 | def get_inbounds(xyz, Z, Y, X, already_mem=False):
324 | # xyz is H*W x 3
325 |
326 | if not already_mem:
327 | xyz = Ref2Mem(xyz, Z, Y, X)
328 |
329 | x_valid = np.logical_and(
330 | np.greater_equal(xyz[:,0], -0.5),
331 | np.less(xyz[:,0], float(X)-0.5))
332 | y_valid = np.logical_and(
333 | np.greater_equal(xyz[:,1], -0.5),
334 | np.less(xyz[:,1], float(Y)-0.5))
335 | z_valid = np.logical_and(
336 | np.greater_equal(xyz[:,2], -0.5),
337 | np.less(xyz[:,2], float(Z)-0.5))
338 | inbounds = np.logical_and(np.logical_and(x_valid, y_valid), z_valid)
339 | return inbounds
340 |
341 | def sub2ind3d_zyx(depth, height, width, d, h, w):
342 | # same as sub2ind3d, but inputs in zyx order
343 | # when gathering/scattering with these inds, the tensor should be Z x Y x X
344 | return d*height*width + h*width + w
345 |
346 | def sub2ind3d_yxz(height, width, depth, h, w, d):
347 | return h*width*depth + w*depth + d
348 |
349 | # def ind2sub(height, width, ind):
350 | # # int input
351 | # y = int(ind / height)
352 | # x = ind % height
353 | # return y, x
354 |
355 | def get_occupancy(xyz_mem, Z, Y, X):
356 | # xyz_mem is N x 3
357 | # we want to fill a voxel tensor with 1's at these inds
358 |
359 | inbounds = get_inbounds(xyz_mem, Z, Y, X, already_mem=True)
360 | inds = np.where(inbounds)
361 |
362 | xyz_mem = np.reshape(xyz_mem[inds], [-1, 3])
363 | # xyz_mem is N x 3
364 |
365 | # this is more accurate than a cast/floor, but runs into issues when Y==0
366 | xyz_mem = np.round(xyz_mem).astype(np.int32)
367 | x = xyz_mem[:,0]
368 | y = xyz_mem[:,1]
369 | z = xyz_mem[:,2]
370 |
371 | voxels = np.zeros([Z, Y, X], np.float32)
372 | voxels[z, y, x] = 1.0
373 |
374 | return voxels
375 |
376 | def pixels2camera(x,y,z,fx,fy,x0,y0):
377 | # x and y are locations in pixel coordinates, z is a depth image in meters
378 | # their shapes are H x W
379 | # fx, fy, x0, y0 are scalar camera intrinsics
380 | # returns xyz, sized [B,H*W,3]
381 |
382 | H, W = z.shape
383 |
384 | fx = np.reshape(fx, [1,1])
385 | fy = np.reshape(fy, [1,1])
386 | x0 = np.reshape(x0, [1,1])
387 | y0 = np.reshape(y0, [1,1])
388 |
389 | # unproject
390 | x = ((z+EPS)/fx)*(x-x0)
391 | y = ((z+EPS)/fy)*(y-y0)
392 |
393 | x = np.reshape(x, [-1])
394 | y = np.reshape(y, [-1])
395 | z = np.reshape(z, [-1])
396 | xyz = np.stack([x,y,z], axis=1)
397 | return xyz
398 |
399 | def depth2pointcloud(z, pix_T_cam):
400 | H = z.shape[0]
401 | W = z.shape[1]
402 | y, x = meshgrid2d(H, W)
403 | z = np.reshape(z, [H, W])
404 |
405 | fx, fy, x0, y0 = split_intrinsics(pix_T_cam)
406 | xyz = pixels2camera(x, y, z, fx, fy, x0, y0)
407 | return xyz
408 |
409 | def meshgrid2d(Y, X):
410 | grid_y = np.linspace(0.0, Y-1, Y)
411 | grid_y = np.reshape(grid_y, [Y, 1])
412 | grid_y = np.tile(grid_y, [1, X])
413 |
414 | grid_x = np.linspace(0.0, X-1, X)
415 | grid_x = np.reshape(grid_x, [1, X])
416 | grid_x = np.tile(grid_x, [Y, 1])
417 |
418 | # outputs are Y x X
419 | return grid_y, grid_x
420 |
421 | def gridcloud3d(Y, X, Z):
422 | x_ = np.linspace(0, X-1, X)
423 | y_ = np.linspace(0, Y-1, Y)
424 | z_ = np.linspace(0, Z-1, Z)
425 | y, x, z = np.meshgrid(y_, x_, z_, indexing='ij')
426 | x = np.reshape(x, [-1])
427 | y = np.reshape(y, [-1])
428 | z = np.reshape(z, [-1])
429 | xyz = np.stack([x,y,z], axis=1).astype(np.float32)
430 | return xyz
431 |
432 | def gridcloud2d(Y, X):
433 | x_ = np.linspace(0, X-1, X)
434 | y_ = np.linspace(0, Y-1, Y)
435 | y, x = np.meshgrid(y_, x_, indexing='ij')
436 | x = np.reshape(x, [-1])
437 | y = np.reshape(y, [-1])
438 | xy = np.stack([x,y], axis=1).astype(np.float32)
439 | return xy
440 |
441 | def normalize(im):
442 | im = im - np.min(im)
443 | im = im / np.max(im)
444 | return im
445 |
446 | def wrap2pi(rad_angle):
447 | # rad_angle can be any shape
448 | # puts the angle into the range [-pi, pi]
449 | return np.arctan2(np.sin(rad_angle), np.cos(rad_angle))
450 |
451 | def convert_occ_to_height(occ):
452 | Z, Y, X, C = occ.shape
453 | assert(C==1)
454 |
455 | height = np.linspace(float(Y), 1.0, Y)
456 | height = np.reshape(height, [1, Y, 1, 1])
457 | height = np.max(occ*height, axis=1)/float(Y)
458 | height = np.reshape(height, [Z, X, C])
459 | return height
460 |
461 | def create_depth_image(xy, Z, H, W):
462 |
463 | # turn the xy coordinates into image inds
464 | xy = np.round(xy)
465 |
466 | # lidar reports a sphere of measurements
467 | # only use the inds that are within the image bounds
468 | # also, only use forward-pointing depths (Z > 0)
469 | valid = (xy[:,0] < W-1) & (xy[:,1] < H-1) & (xy[:,0] >= 0) & (xy[:,1] >= 0) & (Z[:] > 0)
470 |
471 | # gather these up
472 | xy = xy[valid]
473 | Z = Z[valid]
474 |
475 | inds = sub2ind(H,W,xy[:,1],xy[:,0])
476 | depth = np.zeros((H*W), np.float32)
477 |
478 | for (index, replacement) in zip(inds, Z):
479 | depth[index] = replacement
480 | depth[np.where(depth == 0.0)] = 70.0
481 | depth = np.reshape(depth, [H, W])
482 |
483 | return depth
484 |
485 | def vis_depth(depth, maxdepth=80.0, log_vis=True):
486 | depth[depth<=0.0] = maxdepth
487 | if log_vis:
488 | depth = np.log(depth)
489 | depth = np.clip(depth, 0, np.log(maxdepth))
490 | else:
491 | depth = np.clip(depth, 0, maxdepth)
492 | depth = (depth*255.0).astype(np.uint8)
493 | return depth
494 |
495 | def preprocess_color(x):
496 | return x.astype(np.float32) * 1./255 - 0.5
497 |
498 | def convert_box_to_ref_T_obj(boxes):
499 | shape = boxes.shape
500 | boxes = boxes.reshape(-1,9)
501 | rots = [eul2rotm(rx,ry,rz)
502 | for rx,ry,rz in boxes[:,6:]]
503 | rots = np.stack(rots,axis=0)
504 | trans = boxes[:,:3]
505 | ref_T_objs = [merge_rt(rot,tran)
506 | for rot,tran in zip(rots,trans)]
507 | ref_T_objs = np.stack(ref_T_objs,axis=0)
508 | ref_T_objs = ref_T_objs.reshape(shape[:-1]+(4,4))
509 | ref_T_objs = ref_T_objs.astype(np.float32)
510 | return ref_T_objs
511 |
512 | def get_rot_from_delta(delta, yaw_only=False):
513 | dx = delta[:,0]
514 | dy = delta[:,1]
515 | dz = delta[:,2]
516 |
517 | bot_hyp = np.sqrt(dz**2 + dx**2)
518 | # top_hyp = np.sqrt(bot_hyp**2 + dy**2)
519 |
520 | pitch = -np.arctan2(dy, bot_hyp)
521 | yaw = np.arctan2(dz, dx)
522 |
523 | if yaw_only:
524 | rot = [eul2rotm(0,y,0) for y in yaw]
525 | else:
526 | rot = [eul2rotm(0,y,p) for (p,y) in zip(pitch,yaw)]
527 |
528 | rot = np.stack(rot)
529 | # rot is B x 3 x 3
530 | return rot
531 |
532 | def im2col(im, psize):
533 | n_channels = 1 if len(im.shape) == 2 else im.shape[0]
534 | (n_channels, rows, cols) = (1,) * (3 - len(im.shape)) + im.shape
535 |
536 | im_pad = np.zeros((n_channels,
537 | int(math.ceil(1.0 * rows / psize) * psize),
538 | int(math.ceil(1.0 * cols / psize) * psize)))
539 | im_pad[:, 0:rows, 0:cols] = im
540 |
541 | final = np.zeros((im_pad.shape[1], im_pad.shape[2], n_channels,
542 | psize, psize))
543 | for c in np.arange(n_channels):
544 | for x in np.arange(psize):
545 | for y in np.arange(psize):
546 | im_shift = np.vstack(
547 | (im_pad[c, x:], im_pad[c, :x]))
548 | im_shift = np.column_stack(
549 | (im_shift[:, y:], im_shift[:, :y]))
550 | final[x::psize, y::psize, c] = np.swapaxes(
551 | im_shift.reshape(int(im_pad.shape[1] / psize), psize,
552 | int(im_pad.shape[2] / psize), psize), 1, 2)
553 |
554 | return np.squeeze(final[0:rows - psize + 1, 0:cols - psize + 1])
555 |
556 | def filter_discontinuities(depth, filter_size=9, thresh=10):
557 | H, W = list(depth.shape)
558 |
559 | # Ensure that filter sizes are okay
560 | assert filter_size % 2 == 1, "Can only use odd filter sizes."
561 |
562 | # Compute discontinuities
563 | offset = int((filter_size - 1) / 2)
564 | patches = 1.0 * im2col(depth, filter_size)
565 | mids = patches[:, :, offset, offset]
566 | mins = np.min(patches, axis=(2, 3))
567 | maxes = np.max(patches, axis=(2, 3))
568 |
569 | discont = np.maximum(np.abs(mins - mids),
570 | np.abs(maxes - mids))
571 | mark = discont > thresh
572 |
573 | # Account for offsets
574 | final_mark = np.zeros((H, W), dtype=np.uint16)
575 | final_mark[offset:offset + mark.shape[0],
576 | offset:offset + mark.shape[1]] = mark
577 |
578 | return depth * (1 - final_mark)
579 |
580 | def argmax2d(tensor):
581 | Y, X = list(tensor.shape)
582 | # flatten the Tensor along the height and width axes
583 | flat_tensor = tensor.reshape(-1)
584 | # argmax of the flat tensor
585 | argmax = np.argmax(flat_tensor)
586 |
587 | # convert the indices into 2d coordinates
588 | argmax_y = argmax // X # row
589 | argmax_x = argmax % X # col
590 |
591 | return argmax_y, argmax_x
592 |
593 | def plot_traj_3d(traj):
594 | # traj is S x 3
595 |
596 | # print('traj', traj.shape)
597 | S, C = list(traj.shape)
598 | assert(C==3)
599 |
600 | fig = plt.figure()
601 | ax = fig.add_subplot(111, projection='3d')
602 |
603 | colors = [plt.cm.RdYlBu(i) for i in np.linspace(0,1,S)]
604 | # print('colors', colors)
605 |
606 | xs = traj[:,0]
607 | ys = -traj[:,1]
608 | zs = traj[:,2]
609 |
610 | ax.scatter(xs, zs, ys, s=30, c=colors, marker='o', alpha=1.0, edgecolors=(0,0,0))#, color=color_map[n])
611 |
612 | ax.set_xlabel('X')
613 | ax.set_ylabel('Z')
614 | ax.set_zlabel('Y')
615 |
616 | ax.set_xlim(0,1)
617 | ax.set_ylim(0,1) # this is really Z
618 | ax.set_zlim(-1,0) # this is really Y
619 |
620 | buf = io.BytesIO()
621 | plt.savefig(buf, format='png')
622 | buf.seek(0)
623 | image = np.array(Image.open(buf)) # H x W x 4
624 | image = image[:,:,:3]
625 |
626 | plt.close()
627 | return image
628 |
629 | def camera2pixels(xyz, pix_T_cam):
630 | # xyz is shaped N x 3
631 | # returns xy, shaped N x 2
632 |
633 | fx, fy, x0, y0 = split_intrinsics(pix_T_cam)
634 | x, y, z = xyz[:,0], xyz[:,1], xyz[:,2]
635 |
636 | EPS = 1e-4
637 | z = np.clip(z, EPS, None)
638 | x = (x*fx)/z + x0
639 | y = (y*fy)/z + y0
640 | xy = np.stack([x, y], axis=-1)
641 | return xy
642 |
643 | def make_colorwheel():
644 | """
645 | Generates a color wheel for optical flow visualization as presented in:
646 | Baker et al. "A Database and Evaluation Methodology for Optical Flow" (ICCV, 2007)
647 | URL: http://vision.middlebury.edu/flow/flowEval-iccv07.pdf
648 |
649 | Code follows the original C++ source code of Daniel Scharstein.
650 | Code follows the the Matlab source code of Deqing Sun.
651 |
652 | Returns:
653 | np.ndarray: Color wheel
654 | """
655 |
656 | RY = 15
657 | YG = 6
658 | GC = 4
659 | CB = 11
660 | BM = 13
661 | MR = 6
662 |
663 | ncols = RY + YG + GC + CB + BM + MR
664 | colorwheel = np.zeros((ncols, 3))
665 | col = 0
666 |
667 | # RY
668 | colorwheel[0:RY, 0] = 255
669 | colorwheel[0:RY, 1] = np.floor(255*np.arange(0,RY)/RY)
670 | col = col+RY
671 | # YG
672 | colorwheel[col:col+YG, 0] = 255 - np.floor(255*np.arange(0,YG)/YG)
673 | colorwheel[col:col+YG, 1] = 255
674 | col = col+YG
675 | # GC
676 | colorwheel[col:col+GC, 1] = 255
677 | colorwheel[col:col+GC, 2] = np.floor(255*np.arange(0,GC)/GC)
678 | col = col+GC
679 | # CB
680 | colorwheel[col:col+CB, 1] = 255 - np.floor(255*np.arange(CB)/CB)
681 | colorwheel[col:col+CB, 2] = 255
682 | col = col+CB
683 | # BM
684 | colorwheel[col:col+BM, 2] = 255
685 | colorwheel[col:col+BM, 0] = np.floor(255*np.arange(0,BM)/BM)
686 | col = col+BM
687 | # MR
688 | colorwheel[col:col+MR, 2] = 255 - np.floor(255*np.arange(MR)/MR)
689 | colorwheel[col:col+MR, 0] = 255
690 | return colorwheel
691 |
692 | def flow_uv_to_colors(u, v, convert_to_bgr=False):
693 | """
694 | Applies the flow color wheel to (possibly clipped) flow components u and v.
695 |
696 | According to the C++ source code of Daniel Scharstein
697 | According to the Matlab source code of Deqing Sun
698 |
699 | Args:
700 | u (np.ndarray): Input horizontal flow of shape [H,W]
701 | v (np.ndarray): Input vertical flow of shape [H,W]
702 | convert_to_bgr (bool, optional): Convert output image to BGR. Defaults to False.
703 |
704 | Returns:
705 | np.ndarray: Flow visualization image of shape [H,W,3]
706 | """
707 | flow_image = np.zeros((u.shape[0], u.shape[1], 3), np.uint8)
708 | colorwheel = make_colorwheel() # shape [55x3]
709 | ncols = colorwheel.shape[0]
710 | rad = np.sqrt(np.square(u) + np.square(v))
711 | a = np.arctan2(-v, -u)/np.pi
712 | fk = (a+1) / 2*(ncols-1)
713 | k0 = np.floor(fk).astype(np.int32)
714 | k1 = k0 + 1
715 | k1[k1 == ncols] = 0
716 | f = fk - k0
717 | for i in range(colorwheel.shape[1]):
718 | tmp = colorwheel[:,i]
719 | col0 = tmp[k0] / 255.0
720 | col1 = tmp[k1] / 255.0
721 | col = (1-f)*col0 + f*col1
722 | idx = (rad <= 1)
723 | col[idx] = 1 - rad[idx] * (1-col[idx])
724 | col[~idx] = col[~idx] * 0.75 # out of range
725 | # Note the 2-i => BGR instead of RGB
726 | ch_idx = 2-i if convert_to_bgr else i
727 | flow_image[:,:,ch_idx] = np.floor(255 * col)
728 | return flow_image
729 |
730 | def flow_to_image(flow_uv, clip_flow=None, convert_to_bgr=False):
731 | """
732 | Expects a two dimensional flow image of shape.
733 |
734 | Args:
735 | flow_uv (np.ndarray): Flow UV image of shape [H,W,2]
736 | clip_flow (float, optional): Clip maximum of flow values. Defaults to None.
737 | convert_to_bgr (bool, optional): Convert output image to BGR. Defaults to False.
738 |
739 | Returns:
740 | np.ndarray: Flow visualization image of shape [H,W,3]
741 | """
742 | assert flow_uv.ndim == 3, 'input flow must have three dimensions'
743 | assert flow_uv.shape[2] == 2, 'input flow must have shape [H,W,2]'
744 | if clip_flow is not None:
745 | flow_uv = np.clip(flow_uv, -clip_flow, clip_flow) / clip_flow
746 | # flow_uv = np.clamp(flow, -clip, clip)/clip
747 |
748 | u = flow_uv[:,:,0]
749 | v = flow_uv[:,:,1]
750 | rad = np.sqrt(np.square(u) + np.square(v))
751 | rad_max = np.max(rad)
752 | epsilon = 1e-5
753 | u = u / (rad_max + epsilon)
754 | v = v / (rad_max + epsilon)
755 | return flow_uv_to_colors(u, v, convert_to_bgr)
756 |
--------------------------------------------------------------------------------
/train_stage1.py:
--------------------------------------------------------------------------------
1 | import os
2 | import random
3 | import torch
4 | import torch.nn.functional as F
5 | import numpy as np
6 | import argparse
7 | from lightning_fabric import Fabric
8 | import utils.loss
9 | import utils.samp
10 | import utils.data
11 | import utils.improc
12 | import utils.misc
13 | import utils.saveload
14 | from tensorboardX import SummaryWriter
15 | import datetime
16 | import time
17 | from nets.blocks import bilinear_sampler
18 |
19 | torch.set_float32_matmul_precision('medium')
20 |
21 | def get_parameter_names(model, forbidden_layer_types):
22 | """
23 | Returns the names of the model parameters that are not inside a forbidden layer.
24 | """
25 | result = []
26 | for name, child in model.named_children():
27 | result += [
28 | f"{name}.{n}"
29 | for n in get_parameter_names(child, forbidden_layer_types)
30 | if not isinstance(child, tuple(forbidden_layer_types))
31 | ]
32 | result += list(model._parameters.keys())
33 | return result
34 |
35 | def get_sparse_dataset(args, crop_size, N, T, random_first=False, version='kubric_au'):
36 | from datasets import kubric_movif_dataset
37 | dataset = kubric_movif_dataset.KubricMovifDataset(
38 | data_root=os.path.join(args.data_dir, version),
39 | crop_size=crop_size,
40 | seq_len=T,
41 | traj_per_sample=N,
42 | use_augs=args.use_augs,
43 | random_seq_len=args.random_seq_len,
44 | random_first_frame=random_first,
45 | random_frame_rate=args.random_frame_rate,
46 | random_number_traj=args.random_number_traj,
47 | shuffle_frames=args.shuffle_frames,
48 | shuffle=True,
49 | only_first=True,
50 | )
51 | dataset_names = [dataset.dname]
52 | return dataset, dataset_names
53 |
54 | def create_pools(n_pool=50, min_size=10):
55 | pools = {}
56 |
57 | n_pool = max(n_pool, 10)
58 |
59 | thrs = [1,2,4,8,16]
60 | for thr in thrs:
61 | pools['d_%d' % thr] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
62 | pools['d_avg'] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
63 |
64 | pool_names = [
65 | 'seq_loss_visible',
66 | 'seq_loss_invisible',
67 | 'vis_loss',
68 | 'conf_loss',
69 | 'total_loss',
70 | ]
71 | for pool_name in pool_names:
72 | pools[pool_name] = utils.misc.SimplePool(n_pool, version='np', min_size=min_size)
73 |
74 | return pools
75 |
76 | def fetch_optimizer(args, model):
77 | """Create the optimizer and learning rate scheduler"""
78 |
79 | total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
80 | print(f"Total number of parameters: {total_params}")
81 |
82 | decay_parameters = get_parameter_names(model, [torch.nn.LayerNorm])
83 | decay_parameters = [name for name in decay_parameters if not ("bias" in name)]
84 | nondecay_parameters = [n for n, p in model.named_parameters() if n not in decay_parameters]
85 | optimizer_grouped_parameters = [
86 | {
87 | "params": [p for n, p in model.named_parameters() if n in decay_parameters],
88 | "lr": args.lr,
89 | "weight_decay": args.wdecay,
90 | },
91 | {
92 | "params": [p for n, p in model.named_parameters() if n in nondecay_parameters],
93 | "lr": args.lr,
94 | "weight_decay": 0.0,
95 | },
96 | ]
97 | optimizer = torch.optim.AdamW(params=optimizer_grouped_parameters, lr=args.lr, weight_decay=args.wdecay)
98 |
99 | if args.use_scheduler:
100 | scheduler = torch.optim.lr_scheduler.OneCycleLR(
101 | optimizer,
102 | args.lr,
103 | args.max_steps+100,
104 | pct_start=0.05,
105 | cycle_momentum=False,
106 | anneal_strategy="cos",
107 | )
108 | else:
109 | scheduler = None
110 |
111 | return optimizer, scheduler
112 |
113 | def forward_batch_sparse(batch, model, args, sw, inference_iters):
114 | rgbs = batch.video
115 | trajs_g = batch.trajs
116 | vis_g = batch.visibs # B,S,N
117 | valids = batch.valids
118 | dname = batch.dname
119 |
120 | B, T, C, H, W = rgbs.shape
121 | assert C == 3
122 | B, T, N, D = trajs_g.shape
123 | device = rgbs.device
124 | S = 16
125 |
126 | if N==0 or torch.any(vis_g[:,0].reshape(-1)==0):
127 | print('vis_g', vis_g.shape)
128 | return None, None
129 |
130 | all_flow_e, all_visconf_e, all_flow_preds, all_visconf_preds = model(rgbs, iters=inference_iters, sw=sw, is_training=True)
131 |
132 | grid_xy = utils.basic.gridcloud2d(1, H, W, norm=False, device=device).float() # 1,H*W,2
133 | grid_xy = grid_xy.permute(0,2,1).reshape(1,1,2,H,W) # 1,1,2,H,W
134 | traj_maps_e = all_flow_e + grid_xy # B,T,2,H,W
135 | xy0 = trajs_g[:,0] # B,N,2
136 | xy0[:,:,0] = xy0[:,:,0].clamp(0,W-1)
137 | xy0[:,:,1] = xy0[:,:,1].clamp(0,H-1)
138 |
139 | traj_maps_e_ = traj_maps_e.reshape(B*T,2,H,W)
140 | xy0_ = xy0.reshape(B,1,N,2).repeat(1,T,1,1).reshape(B*T,N,1,2)
141 | trajs_e_ = utils.samp.bilinear_sampler(traj_maps_e_, xy0_) # B*T,2,N,1
142 | trajs_e = trajs_e_.reshape(B,T,2,N).permute(0,1,3,2) # B,T,N,2
143 |
144 | xy0_ = xy0.reshape(B,1,N,2).repeat(1,S,1,1).reshape(B*S,N,1,2)
145 |
146 | coord_predictions = []
147 | assert(B==1)
148 | for fpl in all_flow_preds:
149 | cps = []
150 | for fp in fpl:
151 | traj_map = fp + grid_xy # B,S,2,H,W
152 | traj_map_ = traj_map.reshape(B*S,2,H,W)
153 | traj_e_ = utils.samp.bilinear_sampler(traj_map_, xy0_) # B*T,2,N,1
154 | traj_e = traj_e_.reshape(B,S,2,N).permute(0,1,3,2) # B,S,N,2
155 | cps.append(traj_e)
156 | coord_predictions.append(cps)
157 |
158 | # visconf is upset when i bilinearly sample. says the data is outside [0,1]
159 | # so here we do NN sampling
160 | assert(B==1)
161 | x0, y0 = xy0[0,:,0], xy0[0,:,1] # N
162 | x0 = torch.clamp(x0, 0, W-1).round().long()
163 | y0 = torch.clamp(y0, 0, H-1).round().long()
164 | vis_predictions, confidence_predictions = [], []
165 | for vcl in all_visconf_preds:
166 | vps = []
167 | cps = []
168 | for vc in vcl:
169 | vc = vc[:,:,:,y0,x0] # B,S,2,N
170 | vps.append(vc[:,:,0]) # B,S,N
171 | cps.append(vc[:,:,1]) # B,S,N
172 | vis_predictions.append(vps)
173 | confidence_predictions.append(cps)
174 |
175 | vis_gts = []
176 | invis_gts = []
177 | traj_gts = []
178 | valids_gts = []
179 |
180 | for ind in range(0, T - S // 2, S // 2):
181 | vis_gts.append(vis_g[:, ind : ind + S])
182 | invis_gts.append(1 - vis_g[:, ind : ind + S])
183 | traj_gts.append(trajs_g[:, ind : ind + S, :, :2])
184 | valids_gts.append(valids[:, ind : ind + S])
185 |
186 | total_loss = torch.tensor(0.0, requires_grad=True, device=device)
187 | metrics = {}
188 |
189 | seq_loss_visible = utils.loss.sequence_loss(
190 | coord_predictions,
191 | traj_gts,
192 | valids_gts,
193 | vis=vis_gts,
194 | gamma=0.8,
195 | use_huber_loss=args.use_huber_loss,
196 | loss_only_for_visible=True,
197 | )
198 | confidence_loss = utils.loss.sequence_prob_loss(
199 | coord_predictions, confidence_predictions, traj_gts, vis_gts
200 | )
201 | vis_loss = utils.loss.sequence_BCE_loss(vis_predictions, vis_gts)
202 |
203 | seq_loss_invisible = utils.loss.sequence_loss(
204 | coord_predictions,
205 | traj_gts,
206 | valids_gts,
207 | vis=invis_gts,
208 | gamma=0.8,
209 | use_huber_loss=args.use_huber_loss,
210 | loss_only_for_visible=True,
211 | )
212 |
213 | total_loss = seq_loss_visible.mean()*0.05 + seq_loss_invisible.mean()*0.01 + vis_loss.mean() + confidence_loss.mean()
214 |
215 | if sw is not None and sw.save_scalar:
216 | dn = dname[0]
217 | metrics['dname'] = dn
218 | metrics['seq_loss_visible'] = seq_loss_visible.mean().item()
219 | metrics['seq_loss_invisible'] = seq_loss_invisible.mean().item()
220 | metrics['vis_loss'] = vis_loss.item()
221 | metrics['conf_loss'] = confidence_loss.mean().item()
222 | thrs = [1,2,4,8,16]
223 | sx_ = (W-1) / 255.0
224 | sy_ = (H-1) / 255.0
225 | sc_py = np.array([sx_, sy_]).reshape([1,1,1,2])
226 | sc_pt = torch.from_numpy(sc_py).float().to(device)
227 | d_sum = 0.0
228 | for thr in thrs:
229 | d_ = (torch.norm(trajs_e/sc_pt - trajs_g/sc_pt, dim=-1) < thr).float().mean().item()
230 | d_sum += d_
231 | metrics['d_%d' % thr] = d_
232 | d_avg = d_sum / len(thrs)
233 | metrics['d_avg'] = d_avg
234 | metrics['total_loss'] = total_loss.item()
235 |
236 | if sw is not None and sw.save_this:
237 | utils.basic.print_stats('rgbs', rgbs)
238 | prep_rgbs = utils.basic.normalize(rgbs[0:1])-0.5
239 | prep_grays = prep_rgbs.mean(dim=2, keepdim=True).repeat(1,1,3,1,1)
240 | sw.summ_rgb('0_inputs/rgb0', prep_rgbs[:,0], frame_str=dname[0], frame_id=torch.sum(vis_g[0,0]).item())
241 | sw.summ_traj2ds_on_rgb('0_inputs/trajs_g_on_rgb0', trajs_g[0:1], prep_rgbs[:,0], cmap='winter', linewidth=1)
242 | trajs_clamp = trajs_g.clone()
243 | trajs_clamp[:,:,:,0] = trajs_clamp[:,:,:,0].clip(0,W-1)
244 | trajs_clamp[:,:,:,1] = trajs_clamp[:,:,:,1].clip(0,H-1)
245 | inds = np.random.choice(trajs_g.shape[2], 1024)
246 | outs = sw.summ_pts_on_rgbs(
247 | '',
248 | trajs_clamp[0:1,:,inds],
249 | prep_grays[0:1],
250 | valids=valids[0:1,:,inds],
251 | cmap='winter', linewidth=3, only_return=True)
252 | sw.summ_pts_on_rgbs(
253 | '0_inputs/kps_gv_on_rgbs',
254 | trajs_clamp[0:1,:,inds],
255 | utils.improc.preprocess_color(outs),
256 | valids=valids[0:1,:,inds]*vis_g[0:1,:,inds],
257 | cmap='spring', linewidth=2,
258 | frame_ids=list(range(T)))
259 |
260 | out = utils.improc.preprocess_color(sw.summ_traj2ds_on_rgb('', trajs_g[0:1,:,inds], prep_rgbs[:,0], cmap='winter', linewidth=1, only_return=True))
261 | sw.summ_traj2ds_on_rgb('2_outputs/trajs_e_on_g', trajs_e[0:1,:,inds], out, cmap='spring', linewidth=1)
262 |
263 | trajs_e_clamp = trajs_e.clone()
264 | trajs_e_clamp[:,:,:,0] = trajs_e_clamp[:,:,:,0].clip(0,W-1)
265 | trajs_e_clamp[:,:,:,1] = trajs_e_clamp[:,:,:,1].clip(0,H-1)
266 | inds_e = np.random.choice(trajs_e.shape[2], 1024)
267 | outs = sw.summ_pts_on_rgbs(
268 | '',
269 | trajs_clamp[0:1,:,inds],
270 | prep_grays[0:1],
271 | valids=valids[0:1,:,inds]*vis_g[0:1,:,inds],
272 | cmap='winter', linewidth=2,
273 | only_return=True)
274 | sw.summ_pts_on_rgbs(
275 | '2_outputs/kps_ge_on_rgbs',
276 | trajs_e_clamp[0:1,:,inds],
277 | utils.improc.preprocess_color(outs),
278 | valids=valids[0:1,:,inds]*vis_g[0:1,:,inds],
279 | cmap='spring', linewidth=2,
280 | frame_ids=list(range(T)))
281 |
282 | return total_loss, metrics
283 |
284 |
285 | def run(model, args):
286 | fabric = Fabric(
287 | devices="auto",
288 | num_nodes=1,
289 | strategy="ddp",
290 | accelerator="cuda",
291 | precision="bf16-mixed" if args.mixed_precision else "32-true",
292 | )
293 | fabric.launch() # enable multi-gpu
294 |
295 | def seed_everything(seed: int):
296 | random.seed(seed)
297 | os.environ["PYTHONHASHSEED"] = str(seed)
298 | np.random.seed(seed)
299 | torch.manual_seed(seed)
300 | torch.cuda.manual_seed(seed)
301 | torch.backends.cudnn.deterministic = True
302 | torch.backends.cudnn.benchmark = False
303 | def seed_worker(worker_id):
304 | worker_seed = torch.initial_seed() % 2**32
305 | np.random.seed(worker_seed + worker_id)
306 | random.seed(worker_seed + worker_id)
307 | random_data = os.urandom(4)
308 | seed = int.from_bytes(random_data, byteorder="big")
309 | seed_everything(seed)
310 | g = torch.Generator()
311 | g.manual_seed(seed)
312 |
313 | B_ = args.batch_size * torch.cuda.device_count()
314 | model_name = "%d" % (B_)
315 | if args.use_augs:
316 | model_name += "A"
317 | if args.only_short:
318 | model_name += "i%d" % (args.inference_iters_24)
319 | elif args.no_short:
320 | model_name += "i%d" % (args.inference_iters_56)
321 | else:
322 | model_name += "i%d" % (args.inference_iters_24)
323 | model_name += "i%d" % (args.inference_iters_56)
324 | lrn = utils.basic.get_lr_str(args.lr) # e.g., 5e-4
325 | model_name += "_%s" % lrn
326 | if args.mixed_precision:
327 | model_name += "m"
328 | if args.use_huber_loss:
329 | model_name += "h"
330 | model_name += "_%s" % args.exp
331 | model_date = datetime.datetime.now().strftime('%M%S')
332 | model_name = model_name + '_' + model_date
333 | print('model_name', model_name)
334 |
335 | save_dir = '%s/%s' % (args.ckpt_dir, model_name)
336 |
337 | model.cuda()
338 |
339 | dataset_names = []
340 |
341 | if fabric.world_size==2:
342 | if args.only_short:
343 | ranks_56 = []
344 | ranks_24 = [0,1]
345 | log_ranks = [0]
346 | elif args.no_short:
347 | ranks_56 = [0,1]
348 | ranks_24 = []
349 | log_ranks = [0]
350 | else:
351 | ranks_56 = [0]
352 | ranks_24 = [1]
353 | log_ranks = [0,1]
354 | elif fabric.world_size==8:
355 | ranks_56 = [0,1,2,3]
356 | ranks_24 = [4,5,6,7]
357 | log_ranks = [0,4]
358 | else:
359 | ranks_24 = [0]
360 | ranks_56 = []
361 | log_ranks = [0]
362 | print('assuming we are debugging with 1 gpu...')
363 |
364 | if fabric.global_rank in ranks_56:
365 | sparse_dataset56, sparse_dataset_names56 = get_sparse_dataset(
366 | args, crop_size=args.crop_size_56, T=56, N=args.traj_per_sample_56, random_first=False, version='ce64/kublong')
367 | sparse_loader56 = torch.utils.data.DataLoader(
368 | sparse_dataset56,
369 | batch_size=args.batch_size,
370 | shuffle=True,
371 | num_workers=args.num_workers_56,
372 | worker_init_fn=seed_worker,
373 | generator=g,
374 | pin_memory=False,
375 | collate_fn=utils.data.collate_fn_train,
376 | drop_last=True,
377 | )
378 | sparse_loader56 = fabric.setup_dataloaders(sparse_loader56, move_to_device=False)
379 | print('len(sparse_loader56)', len(sparse_loader56))
380 | sparse_iterloader56 = iter(sparse_loader56)
381 | dataset_names += sparse_dataset_names56
382 | else:
383 | sparse_dataset24, sparse_dataset_names24 = get_sparse_dataset(
384 | args, crop_size=args.crop_size_24, T=24, N=args.traj_per_sample_24, random_first=args.random_first_frame, version='kubric_au')
385 | sparse_loader24 = torch.utils.data.DataLoader(
386 | sparse_dataset24,
387 | batch_size=args.batch_size,
388 | shuffle=True,
389 | num_workers=args.num_workers_24,
390 | worker_init_fn=seed_worker,
391 | generator=g,
392 | pin_memory=False,
393 | collate_fn=utils.data.collate_fn_train,
394 | drop_last=True,
395 | )
396 | sparse_loader24 = fabric.setup_dataloaders(sparse_loader24, move_to_device=False)
397 | print('len(sparse_loader24)', len(sparse_loader24))
398 | sparse_iterloader24 = iter(sparse_loader24)
399 | dataset_names += sparse_dataset_names24
400 |
401 | optimizer, scheduler = fetch_optimizer(args, model)
402 |
403 | if fabric.global_rank in log_ranks:
404 | log_dir = './logs_train'
405 | pools_t = {}
406 | for dname in dataset_names:
407 | if not (dname in pools_t):
408 | print('creating pools for', dname)
409 | pools_t[dname] = create_pools()
410 | overpools_t = create_pools()
411 | writer_t = SummaryWriter(log_dir + '/' + model_name + '/t', max_queue=10, flush_secs=60)
412 |
413 | global_step = 0
414 | if args.init_dir:
415 | load_dir = '%s/%s' % (args.ckpt_dir, args.init_dir)
416 | loaded_global_step = utils.saveload.load(
417 | fabric,
418 | load_dir,
419 | model,
420 | optimizer=optimizer if args.load_optimizer else None,
421 | scheduler=scheduler if args.load_scheduler else None,
422 | ignore_load=None,
423 | strict=True)
424 | if args.load_optimizer and not args.use_scheduler:
425 | assert(optimizer.param_groups[-1]["lr"] == args.lr)
426 | if args.load_step:
427 | global_step = loaded_global_step
428 | if args.use_scheduler and args.load_step and (not args.load_optimizer):
429 | # advance the scheduler to catch up with global_step
430 | for ii in range(global_step):
431 | scheduler.step()
432 |
433 | model, optimizer = fabric.setup(model, optimizer, move_to_device=False)
434 | model.train()
435 |
436 | while global_step < args.max_steps+10:
437 | global_step += 1
438 |
439 | f_start_time = time.time()
440 |
441 | optimizer.zero_grad(set_to_none=True)
442 | assert model.training
443 |
444 | if fabric.global_rank in log_ranks:
445 | sw_t = utils.improc.Summ_writer(
446 | writer=writer_t,
447 | global_step=global_step,
448 | log_freq=args.log_freq,
449 | fps=8,
450 | scalar_freq=min(53,args.log_freq),
451 | just_gif=True)
452 | else:
453 | sw_t = None
454 |
455 | metrics = None
456 |
457 | gotit = [False, False]
458 | while not all(gotit):
459 | if fabric.global_rank in ranks_56:
460 | try:
461 | batch = next(sparse_iterloader56)
462 | except StopIteration:
463 | sparse_iterloader56 = iter(sparse_loader56)
464 | batch = next(sparse_iterloader56)
465 | else:
466 | try:
467 | batch = next(sparse_iterloader24)
468 | except StopIteration:
469 | sparse_iterloader24 = iter(sparse_loader24)
470 | batch = next(sparse_iterloader24)
471 | batch, gotit = batch
472 |
473 | rtime = time.time()-f_start_time
474 |
475 | if fabric.global_rank in ranks_56:
476 | inference_iters = args.inference_iters_56
477 | else:
478 | inference_iters = args.inference_iters_24
479 |
480 | utils.data.dataclass_to_cuda_(batch)
481 | total_loss, metrics = forward_batch_sparse(batch, model, args, sw_t, inference_iters)
482 | ftime = time.time()-f_start_time
483 | fabric.barrier() # wait for all gpus to finish their fwd
484 |
485 | b_start_time = time.time()
486 | if metrics is not None:
487 | if fabric.global_rank in log_ranks and sw_t.save_scalar:
488 | sw_t.summ_scalar('_/current_lr', optimizer.param_groups[-1]["lr"])
489 | sw_t.summ_scalar('total_loss', metrics['total_loss'])
490 |
491 | # update stats
492 | dname = metrics['dname']
493 | if dname in dataset_names:
494 | for key in list(pools_t[dname].keys()):
495 | if key in metrics:
496 | pools_t[dname][key].update([metrics[key]])
497 | overpools_t[key].update([metrics[key]])
498 | # plot stats
499 | for key in list(overpools_t.keys()):
500 | for dname in dataset_names:
501 | sw_t.summ_scalar('%s/%s' % (dname, key), pools_t[dname][key].mean())
502 | sw_t.summ_scalar('_/%s' % (key), overpools_t[key].mean())
503 |
504 | if args.mixed_precision:
505 | fabric.backward(total_loss)
506 | fabric.clip_gradients(model, optimizer, max_norm=1.0, norm_type=2, error_if_nonfinite=False)
507 | optimizer.step()
508 | if args.use_scheduler:
509 | scheduler.step()
510 | else:
511 | fabric.backward(total_loss)
512 | fabric.clip_gradients(model, optimizer, max_norm=1.0, norm_type=2, error_if_nonfinite=False)
513 | optimizer.step()
514 | if args.use_scheduler:
515 | scheduler.step()
516 | btime = time.time()-b_start_time
517 | fabric.barrier() # wait for all gpus to finish their bwd
518 |
519 | itime = ftime + btime
520 |
521 | if global_step % args.save_freq == 0:
522 | if fabric.global_rank == 0:
523 | utils.saveload.save(save_dir, model.module, optimizer, scheduler, global_step, keep_latest=2)
524 |
525 | info_str = '%s; step %06d/%d; rtime %.2f; itime %.2f' % (
526 | model_name, global_step, args.max_steps, rtime, itime)
527 | if fabric.global_rank in log_ranks:
528 | if overpools_t['total_loss'].have_min_size():
529 | info_str += '; loss_t %.2f; d_avg %.1f' % (
530 | overpools_t['total_loss'].mean(),
531 | overpools_t['d_avg'].mean()*100.0,
532 | )
533 | info_str += '; (rank %d)' % fabric.global_rank
534 | print(info_str)
535 | print('done!')
536 |
537 | if fabric.global_rank in log_ranks:
538 | writer_t.close()
539 |
540 | if __name__ == "__main__":
541 | init_dir = ''
542 |
543 | # this file is for training alltracker in "stage 1",
544 | # which involves kubric-only training.
545 | # this is also the file to execute all ablations.
546 |
547 | from nets.alltracker import Net; exp = 'stage1' # clean up for release
548 |
549 | parser = argparse.ArgumentParser()
550 | parser.add_argument("--exp", default=exp)
551 | parser.add_argument("--init_dir", type=str, default=init_dir)
552 | parser.add_argument("--load_optimizer", default=False, action='store_true')
553 | parser.add_argument("--load_scheduler", default=False, action='store_true')
554 | parser.add_argument("--load_step", default=False, action='store_true')
555 | parser.add_argument("--ckpt_dir", type=str, default='./checkpoints')
556 | parser.add_argument("--data_dir", type=str, default='/data')
557 | parser.add_argument("--batch_size", type=int, default=1)
558 | parser.add_argument("--num_nodes", type=int, default=1)
559 | parser.add_argument("--num_workers_24", type=int, default=2)
560 | parser.add_argument("--num_workers_56", type=int, default=6)
561 | parser.add_argument("--mixed_precision", default=False, action='store_true')
562 | parser.add_argument("--lr", type=float, default=5e-4)
563 | parser.add_argument("--wdecay", type=float, default=0.0005)
564 | parser.add_argument("--max_steps", type=int, default=100000)
565 | parser.add_argument("--use_scheduler", default=True)
566 | parser.add_argument("--save_freq", type=int, default=2000)
567 | parser.add_argument("--log_freq", type=int, default=997) # prime number
568 | parser.add_argument("--traj_per_sample_24", type=int, default=256) # note we allow 1-24x this amount
569 | parser.add_argument("--traj_per_sample_56", type=int, default=256) # note we allow 1-24x this amount
570 | parser.add_argument("--inference_iters_24", type=int, default=4)
571 | parser.add_argument("--inference_iters_56", type=int, default=3)
572 | parser.add_argument("--random_frame_rate", default=False, action='store_true')
573 | parser.add_argument("--random_first_frame", default=False, action='store_true')
574 | parser.add_argument("--shuffle_frames", default=False, action='store_true')
575 | parser.add_argument("--use_augs", default=True)
576 | parser.add_argument("--seqlen", type=int, default=16)
577 | parser.add_argument("--crop_size_24", nargs="+", default=[384,512])
578 | parser.add_argument("--crop_size_56", nargs="+", default=[256,384])
579 | parser.add_argument("--random_number_traj", default=False, action='store_true')
580 | parser.add_argument("--use_huber_loss", default=False, action='store_true')
581 | parser.add_argument("--debug", default=False, action='store_true')
582 | parser.add_argument("--random_seq_len", default=False, action='store_true')
583 | parser.add_argument("--no_attn", default=False, action='store_true')
584 | parser.add_argument("--use_mixer", default=False, action='store_true')
585 | parser.add_argument("--use_conv", default=False, action='store_true')
586 | parser.add_argument("--use_convb", default=False, action='store_true')
587 | parser.add_argument("--use_basicencoder", default=False, action='store_true')
588 | parser.add_argument("--only_short", default=False, action='store_true')
589 | parser.add_argument("--no_short", default=False, action='store_true')
590 | parser.add_argument("--no_space", default=False, action='store_true')
591 | parser.add_argument("--no_time", default=False, action='store_true')
592 | parser.add_argument("--no_split", default=False, action='store_true')
593 | parser.add_argument("--no_ctx", default=False, action='store_true')
594 | parser.add_argument("--full_split", default=False, action='store_true')
595 | parser.add_argument("--use_sinmotion", default=False, action='store_true')
596 | parser.add_argument("--use_relmotion", default=False, action='store_true')
597 | parser.add_argument("--use_sinrelmotion", default=False, action='store_true')
598 | parser.add_argument("--use_feats8", default=False, action='store_true')
599 | parser.add_argument("--no_init", default=False, action='store_true')
600 | parser.add_argument("--num_blocks", type=int, default=3)
601 | parser.add_argument("--corr_radius", type=int, default=4)
602 | parser.add_argument("--corr_levels", type=int, default=5)
603 | parser.add_argument("--dim", type=int, default=128)
604 | parser.add_argument("--hdim", type=int, default=128)
605 |
606 | args = parser.parse_args()
607 |
608 | # fix up integers
609 | args.crop_size_24 = (int(args.crop_size_24[0]), int(args.crop_size_24[1]))
610 | args.crop_size_56 = (int(args.crop_size_56[0]), int(args.crop_size_56[1]))
611 |
612 | model = Net(
613 | 16,
614 | dim=args.dim,
615 | hdim=args.hdim,
616 | use_attn=(not args.no_attn),
617 | use_mixer=args.use_mixer,
618 | use_conv=args.use_conv,
619 | use_convb=args.use_convb,
620 | use_basicencoder=args.use_basicencoder,
621 | no_space=args.no_space,
622 | no_time=args.no_time,
623 | use_sinmotion=args.use_sinmotion,
624 | use_relmotion=args.use_relmotion,
625 | use_sinrelmotion=args.use_sinrelmotion,
626 | use_feats8=args.use_feats8,
627 | no_split=args.no_split,
628 | no_ctx=args.no_ctx,
629 | full_split=args.full_split,
630 | num_blocks=args.num_blocks,
631 | corr_radius=args.corr_radius,
632 | corr_levels=args.corr_levels,
633 | init_weights=(not args.no_init),
634 | )
635 |
636 | run(model, args)
637 |
638 |
--------------------------------------------------------------------------------