├── NSF_1.gif
├── NSF_2.gif
├── NSF_3.gif
├── README.md
├── config.py
├── evaluate.py
├── generating_queries
├── generate_test_PCL_baseline_sets.py
├── generate_test_PCL_ours_sets.py
├── generate_test_PCL_supervise_sets.py
├── generate_test_RGB_baseline_sets.py
├── generate_test_RGB_ours_sets.py
├── generate_test_RGB_real_baseline_sets.py
├── generate_test_RGB_real_ours_sets.py
├── generate_test_RGB_real_supervise_sets.py
├── generate_test_RGB_supervise_sets.py
├── generate_training_tuples_PCL_baseline.py
├── generate_training_tuples_PCL_ours.py
├── generate_training_tuples_PCL_supervise.py
├── generate_training_tuples_RGB_baseline.py
├── generate_training_tuples_RGB_ours.py
├── generate_training_tuples_RGB_real_baseline.py
├── generate_training_tuples_RGB_real_ours.py
├── generate_training_tuples_RGB_real_supervise.py
├── generate_training_tuples_RGB_supervise.py
└── set_path.py
├── get_embeddings_ours.py
├── loading_pointclouds.py
├── loss
└── pointnetvlad_loss.py
├── models
├── ImageNetVlad.py
├── PointNetVlad.py
├── Verification_PCL.py
├── Verification_RGB.py
├── Verification_RGB_real.py
└── resnet_mod.py
├── requirements.txt
├── results
└── .DS_Store
├── set_path.py
├── train_netvlad_RGB_baseline.py
├── train_netvlad_RGB_ours.py
├── train_netvlad_RGB_real_baseline.py
├── train_netvlad_RGB_real_ours.py
├── train_netvlad_RGB_real_supervise.py
├── train_netvlad_RGB_supervise.py
├── train_pointnetvlad_PCL_baseline.py
├── train_pointnetvlad_PCL_ours.py
└── train_pointnetvlad_PCL_supervise.py
/NSF_1.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ai4ce/TF-VPR/83a4fbf59c1e51c0024c97943788db82fca9da7d/NSF_1.gif
--------------------------------------------------------------------------------
/NSF_2.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ai4ce/TF-VPR/83a4fbf59c1e51c0024c97943788db82fca9da7d/NSF_2.gif
--------------------------------------------------------------------------------
/NSF_3.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ai4ce/TF-VPR/83a4fbf59c1e51c0024c97943788db82fca9da7d/NSF_3.gif
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Self-Supervised Visual Place Recognition by Mining Temporal and Feature Neighborhoods
2 | [Chao Chen](https://scholar.google.com/citations?hl=en&user=WOBQbwQAAAAJ), [Xinhao Liu](https://gaaaavin.github.io), [Xuchu Xu](https://www.xuchuxu.com), [Yiming Li](https://scholar.google.com/citations?user=i_aajNoAAAAJ), [Li Ding](https://www.hajim.rochester.edu/ece/lding6/), [Ruoyu Wang](https://github.com/ruoyuwangeel4930), [Chen Feng](https://scholar.google.com/citations?user=YeG8ZM0AAAAJ)
3 |
4 | **"A Novel self-supervised VPR model capable of retrieving positives from various orientations."**
5 |
6 | 
7 | [](https://svgshare.com/i/Zhy.svg)
8 | [](https://github.com/Joechencc/TF-VPR)
9 | [](https://github.com/Joechencc/TF-VPR/stargazers/)
10 |
11 |
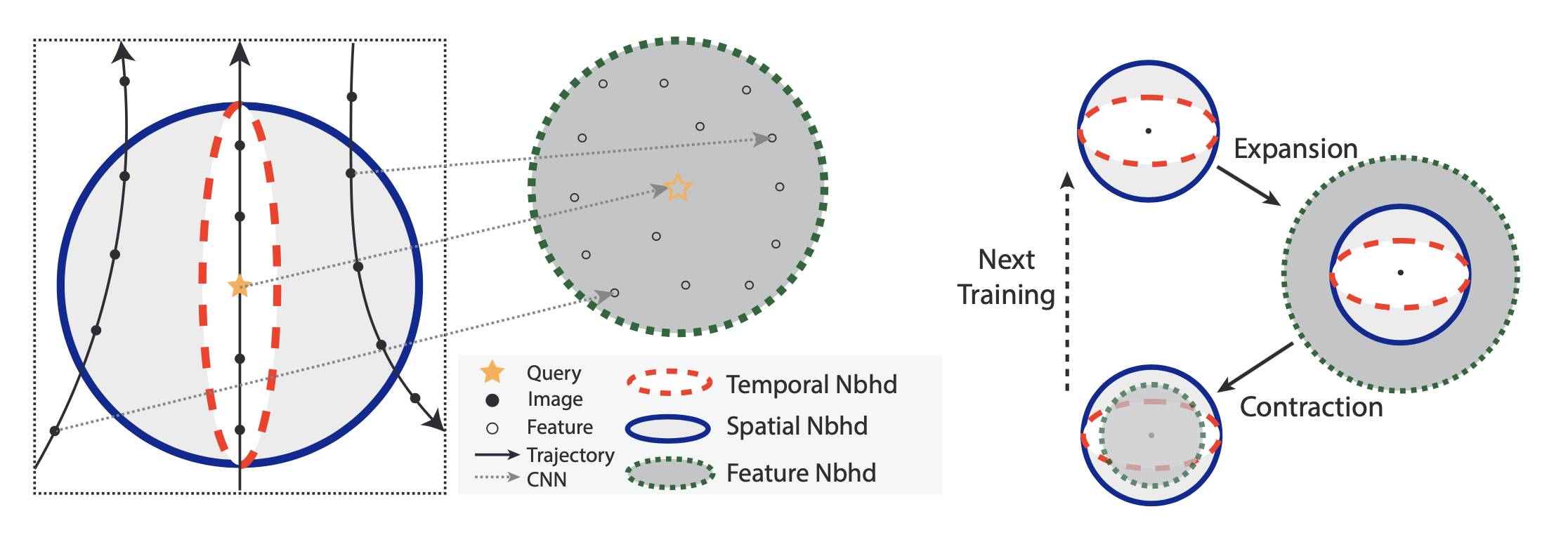
12 |
14 |
15 | ## Abstract
16 |
17 | Visual place recognition (VPR) using deep networks has achieved state-of-the-art performance. However, most of the related approaches require a training set with ground truth sensor poses to obtain the positive and negative samples of each observation's spatial neighborhoods. When such knowledge is unknown, the temporal neighborhoods from a sequentially collected data stream could be exploited for self-supervision, although with suboptimal performance. Inspired by noisy label learning, we propose a novel self-supervised VPR framework that uses both the temporal neighborhoods and the learnable feature neighborhoods to discover the unknown spatial neighborhoods. Our method follows an iterative training paradigm which alternates between: (1) representation learning with data augmentation, (2) positive set expansion to include the current feature space neighbors, and (3) positive set contraction via geometric verification. We conduct comprehensive experiments on both simulated and real datasets, with input of both images and point clouds. The results demonstrate that our method outperforms the baselines in both recall rate, robustness, and a novel metric we proposed for VPR, the orientation diversity.
18 |
19 | ## Dataset
20 |
21 | Download links:
22 | - For Pointcloud: Please refer to DeepMapping paper, https://github.com/ai4ce/PointCloudSimulator
23 | - For NYU-VPR-360 dataset: https://drive.google.com/drive/u/0/folders/1ErXzIx0je5aGSRFbo5jP7oR8gPrdersO
24 |
25 | You could find more detailed documents on our [website](https://ai4ce.github.io/TF-VPR/)!
26 |
27 | # Data Structure
28 | ```
29 | Data_folder
30 | ├── 000001.pcd or 000001.RGB # Dataset
31 | ├── 000002.pcd or 000002.RGB # Dataset
32 | | ...
33 | ├── 00nnnn.pcd or 00nnnn.RGB # Dataset
34 | ├── gt_pose.mat # ground truth mat file contains the geographical information for evaluation
35 | ```
36 |
37 | ## Folder Structure
38 |
39 | TF-VPR follows the same file structure as the [PointNetVLAD](https://github.com/mikacuy/pointnetvlad):
40 | ```
41 | TF-VPR
42 | ├── loss # loss function
43 | ├── models # network model
44 | | ├── PointNetVlad.py # PointNetVLAD network model
45 | | ├── ImageNetVLAD.py # NetVLAD network model
46 | | ├── resnet_mod.py # ResNet network model
47 | | ├── Verification_PCL.py # Verification for PCL data
48 | | ├── Verification_RGB.py # Verification for RGB data
49 | | ├── Verification_RGB_real.py # Verification for RGB_real data
50 | | ...
51 | ├── generating_queries # Preprocess the data, initial the label, and generate Pickle file
52 | | ├── generate_test_PCL_baseline_sets.py # Generate the test pickle file for PCL baseline
53 | | ├── generate_test_PCL_ours_sets.py # Generate the test pickle file for PCL TF-VPR
54 | | ├── generate_test_PCL_supervise_sets.py # Generate the test pickle file for PCL supervise
55 | | ├── generate_test_RGB_baseline_sets.py # Generate the test pickle file for Habitat-sim baseline
56 | | ├── generate_test_RGB_ours_sets.py # Generate the test pickle file for Habitat-sim TF-VPR
57 | | ├── generate_test_RGB_supervise_sets.py # Generate the test pickle file for Habitat-sim supervise
58 | | ├── generate_test_RGB_real_baseline_sets.py # Generate the test pickle file for NYU-VPR-360 baseline
59 | | ├── generate_test_RGB_real_ours_sets.py # Generate the test pickle file for NYU-VPR-360 TF-VPR
60 | | ├── generate_test_RGB_real_supervise_sets.py # Generate the test pickle file for NYU-VPR-360 supervise
61 | | ├── generate_training_tuples_PCL_baseline.py # Generate the train pickle file for PCL baseline
62 | | ├── generate_training_tuples_PCL_ours.py # Generate the train pickle file for PCL TF-VPR
63 | | ├── generate_training_tuples_PCL_supervise.py # Generate the train pickle file for PCL supervise
64 | | ├── generate_training_tuples_RGB_baseline.py # Generate the train pickle file for Habitat-sim baseline
65 | | ├── generate_training_tuples_RGB_ours.py # Generate the train pickle file for Habitat-sim TF-VPR
66 | | ├── generate_training_tuples_RGB_supervise.py # Generate the train pickle file for Habitat-sim supervise
67 | | ├── generate_training_tuples_RGB_supervise.py # Generate the train pickle file for NYU-VPR-360 baseline
68 | | ├── generate_training_tuples_RGB_real_ours.py # Generate the train pickle file for NYU-VPR-360 TF-VPR
69 | | ├── generate_training_tuples_RGB_real_supervise.py # Generate the train pickle file for NYU-VPR-360 supervise
70 | | ...
71 | ├── results # Results are saved here
72 | ├── config.py # Config file
73 | ├── evaluate.py # evaluate file
74 | ├── loading_pointcloud.py # file loading script
75 | ├── train_pointnetvlad_PCL_baseline.py # Main file to train PCL baseline
76 | ├── train_pointnetvlad_PCL_ours.py # Main file to train PCL TF-VPR
77 | ├── train_pointnetvlad_PCL_supervise.py # Main file to train PCL supervise
78 | ├── train_netvlad_RGB_baseline.py # Main file to train Hatbitat-sim baseline
79 | ├── train_netvlad_RGB_ours.py # Main file to train Hatbitat-sim TF-VPR
80 | ├── train_netvlad_RGB_supervise.py # Main file to train Hatbitat-sim supervise
81 | ├── train_netvlad_RGB_real_baseline.py # Main file to train NYU-VPR-360 baseline
82 | ├── train_netvlad_RGB_real_ours.py # Main file to train NYU-VPR-360 TF-VPR
83 | ├── train_netvlad_RGB_real_supervise.py # Main file to train NYU-VPR-360 supervise
84 | | ...
85 | ```
86 | Point cloud TF-VPR result:
87 |
88 | 
89 |
90 | RGB TF-VPR result:
91 |
92 | 
93 |
94 | NYU-VPR-360 TF-VPR result:
95 |
96 | 
97 |
98 | # Note
99 |
100 | I kept almost everything not related to tensorflow as the original implementation. The main differences are:
101 | * Multi-GPU support
102 | * Configuration file (config.py)
103 | * Evaluation on the eval dataset after every epochs
104 |
105 | ### Pre-Requisites
106 | - Python 3.6
107 | - PyTorch >=1.10.0
108 | - tensorboardX
109 | - open3d-python 0.4
110 | - scipy
111 | - matplotlib
112 | - numpy
113 | - pandas
114 | - scikit-learn
115 | - pickle5
116 | - torchvision
117 | - opencv-contrib-python
118 |
119 | ### Generate pickle files
120 | ```
121 | cd generating_queries/
122 | ### For Pointcloud data
123 |
124 | # To create pickle file for PCL baseline method
125 | python generate_training_tuples_PCL_baseline.py
126 |
127 | # To create pickle file for PCL TF-VPR method
128 | python generate_training_tuples_PCL_ours.py
129 |
130 | # To create pickle file for PCL supervise method
131 | python generate_training_tuples_PCL_supervise.py
132 |
133 | # To create pickle file for PCL baseline evaluation pickle
134 | python generate_test_PCL_baseline_sets.py
135 |
136 | # To create pickle file for PCL TF-VPR evaluation pickle
137 | python generate_test_PCL_ours_sets.py
138 |
139 | # To create pickle file for PCL supervise evaluation pickle
140 | python generate_test_PCL_supervise_sets.py
141 | ```
142 |
143 | ```
144 | cd generating_queries/
145 | ### For Habitat-sim data
146 |
147 | # For training tuples in our RGB baseline network
148 | python generate_training_tuples_RGB_baseline.py
149 |
150 | # For training tuples in our RGB baseline network
151 | python generate_training_tuples_RGB_ours.py
152 |
153 | # For training tuples in our RGB baseline network
154 | python generate_training_tuples_RGB_supervise.py
155 |
156 | # For RGB network evaluation
157 | python generate_test_RGB_baseline_sets.py
158 |
159 | # For RGB network evaluation
160 | python generate_test_RGB_ours_sets.py
161 |
162 | # For RGB network evaluation
163 | python generate_test_RGB_supervise_sets.py
164 | ```
165 |
166 | ```
167 | cd generating_queries/
168 | ### For NYU-VPR-360 data
169 |
170 | # For training tuples in our RGB baseline network
171 | python generate_training_tuples_RGB_real_baseline.py
172 |
173 | # For training tuples in our RGB baseline network
174 | python generate_training_tuples_RGB_real_ours.py
175 |
176 | # For training tuples in our RGB baseline network
177 | python generate_training_tuples_RGB_real_supervise.py
178 |
179 | # For RGB network evaluation
180 | python generate_test_RGB_baseline_real_sets.py
181 |
182 | # For RGB network evaluation
183 | python generate_test_RGB_real_ours_sets.py
184 |
185 | # For RGB network evaluation
186 | python generate_test_RGB_real_supervise_sets.py
187 | ```
188 |
189 | ### Verification threshold
190 | ```
191 | ### For point cloud
192 |
193 | python Verification_PCL.py # you can create max and min threshold using this command. For RGB, we calculate the threshold on Verification stage, no need to precalculate
194 | ```
195 |
196 | ### Train
197 | ```
198 | ### For point cloud
199 |
200 | python train_pointnetvlad_PCL_baseline.py # Train baseline for PCL data
201 | python train_pointnetvlad_PCL_ours.py # Train ours for PCL data
202 | python train_pointnetvlad_PCL_supervise.py # Train supervise for PCL data
203 |
204 | ### For Habitat-sim
205 |
206 | python train_pointnetvlad_RGBL_baseline.py # Train baseline for Habitat-sim data
207 | python train_pointnetvlad_RGB_ours.py # Train ours for Habitat-sim data
208 | python train_pointnetvlad_RGB_supervise.py # Train supervise for Habitat-sim data
209 |
210 | ### For point cloud
211 |
212 | python train_pointnetvlad_RGB_real_baseline.py # Train baseline for NYU-VPR-360 data
213 | python train_pointnetvlad_RGB_real_ours.py # Train baseline for NYU-VPR-360 data
214 | python train_pointnetvlad_RGB_real_supervise.py # Train baseline for NYU-VPR-360 data
215 | ```
216 |
217 | ### Evaluate (You don't need to run it separately. For every epoch, evaluation will be run automatically)
218 | ```
219 | python evaluate.py
220 | ```
221 |
222 | Take a look at train_pointnetvlad.py and evaluate.py for more parameters
223 |
224 | ## Benchmark
225 |
226 | We implement SPTM, TF-VPR, and supervise version, please check the other branches for reference
227 |
228 | ## Citation
229 |
230 | If you find TF-VPR useful in your research, please cite:
231 |
232 | ```bibtex
233 | @article{Chen2022arxiv,
234 | author = {Chen, Chao and Liu, Xinhao and Xu, Xuchu and Li, Yiming and Ding, Li and Wang, Ruoyu and Feng, Chen},
235 | title = {Self-Supervised Visual Place Recognition by Mining Temporal and Feature Neighborhoods},
236 | journal = {arxiv},
237 | year = {2022}
238 |
239 | }
240 | ```
241 |
242 | ## Acknowledgements
243 |
244 | Chen Feng is the corresponding author. The research is supported by NSF Future Manufacturing program under CMMI-1932187, CNS-2121391, and EEC-2036870. Chao Chen gratefully thanks the help from Bhargav Makwana.
245 |
--------------------------------------------------------------------------------
/config.py:
--------------------------------------------------------------------------------
1 | # GLOBAL
2 | NUM_POINTS = 256
3 | FEATURE_OUTPUT_DIM = 512
4 | PICKLE_FOLDER = "train_pickle/"
5 | RESULTS_FOLDER = "results/"
6 | OUTPUT_FILE = "results/results.txt"
7 | SIZED_GRID_X = 64*4
8 | SIZED_GRID_Y = 64
9 | GRID_X = 1080
10 | GRID_Y = 1920
11 | file_name = "Goffs"
12 |
13 | LOG_DIR = 'log/'
14 | MODEL_FILENAME = "model.ckpt"
15 |
16 | DATASET_FOLDER = '/home/cc/dm_data'
17 | DATASET_FOLDER_RGB = '/mnt/NAS/home/cc/data/habitat_4/train'
18 | DATASET_FOLDER_RGB_REAL = '/mnt/NAS/data/cc_data/2D_RGB_real_full3'
19 |
20 | # TRAIN
21 | BATCH_NUM_QUERIES = 2
22 | TRAIN_POSITIVES_PER_QUERY = 2
23 | TRAIN_NEGATIVES_PER_QUERY = 18
24 | DECAY_STEP = 200000
25 | DECAY_RATE = 0.7
26 | BASE_LEARNING_RATE = 0.000005
27 | MOMENTUM = 0.9
28 | OPTIMIZER = 'ADAM'
29 | MAX_EPOCH = 20
30 | FOLD_NUM = 18
31 |
32 | MARGIN_1 = 0.5
33 | MARGIN_2 = 0.2
34 |
35 | BN_INIT_DECAY = 0.5
36 | BN_DECAY_DECAY_RATE = 0.5
37 | BN_DECAY_CLIP = 0.99
38 |
39 | RESUME = False
40 | ROT_NUM = 8
41 |
42 | EVAL_NEAREST = 16
43 | INIT_TRUST = 2
44 | INIT_TRUST_SCALAR = 1
45 | NEIGHBOR = 4
46 |
47 | TRAIN_FILE = 'generating_queries/training_queries_baseline.pickle'
48 | TEST_FILE = 'generating_queries/test_queries_baseline.pickle'
49 | scene_list = ['Goffs','Nimmons','Reyno','Spotswood','Springhill','Stilwell']
50 |
51 | # LOSS
52 | LOSS_FUNCTION = 'quadruplet'
53 | LOSS_FUNCTION_RGB = 'triplet'
54 |
55 | LOSS_LAZY = True
56 | TRIPLET_USE_BEST_POSITIVES = False
57 | LOSS_IGNORE_ZERO_BATCH = False
58 |
59 | # EVAL6
60 | EVAL_BATCH_SIZE = 2
61 | EVAL_POSITIVES_PER_QUERY = 4
62 | EVAL_NEGATIVES_PER_QUERY = 12
63 |
64 | EVAL_DATABASE_FILE = 'generating_queries/evaluation_database.pickle'
65 | EVAL_QUERY_FILE = 'generating_queries/evaluation_query.pickle'
66 |
67 |
68 | def cfg_str():
69 | out_string = ""
70 | for name in globals():
71 | if not name.startswith("__") and not name.__contains__("cfg_str"):
72 | #print(name, "=", globals()[name])
73 | out_string = out_string + "cfg." + name + \
74 | "=" + str(globals()[name]) + "\n"
75 | return out_string
76 |
--------------------------------------------------------------------------------
/generating_queries/generate_test_PCL_baseline_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import random
4 | import set_path
5 |
6 | import numpy as np
7 | import pandas as pd
8 | from sklearn.neighbors import KDTree
9 |
10 | import config as cfg
11 |
12 | import scipy.io as sio
13 | import torch
14 |
15 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
16 | base_path = cfg.DATASET_FOLDER
17 |
18 | runs_folder = "dm_data"
19 | filename = "gt_pose.mat"
20 | pointcloud_fols = "/pointcloud_20m_10overlap/"
21 | test_num = 10
22 |
23 | print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
24 |
25 | cc_dir = "/home/cc/"
26 | all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
27 | file_size_ = 2048
28 | folders = []
29 |
30 | # All runs are used for training (both full and partial)
31 | index_list = [11,14,15,17]
32 | print("Number of runs: "+str(len(index_list)))
33 | for index in index_list:
34 | folders.append(all_folders[index])
35 | print(folders)
36 |
37 |
38 | #####For training and test data split#####
39 | def output_to_file(output, filename):
40 | with open(filename, 'wb') as handle:
41 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
42 | print("Done ", filename)
43 |
44 | #########################################
45 | def construct_query_dict(df_centroids, df_database, folder_num, filename_train, filename_test, test=False):
46 | database_trees = []
47 | test_trees = []
48 | tree = KDTree(df_centroids[['x','y']])
49 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=15)
50 | ind_r = tree.query_radius(df_centroids[['x','y']], r=50)
51 | queries_sets = []
52 | database_sets = []
53 | for folder in range(folder_num):
54 | queries = {}
55 | for i in range(len(df_centroids)//folder_num):
56 | temp_indx = folder*(len(df_centroids)//folder_num) + i
57 | query = df_centroids.iloc[temp_indx]["file"]
58 | #print("folder:"+str(folder))
59 | #print("query:"+str(query))
60 | queries[len(queries.keys())] = {"query":query,
61 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
62 | queries_sets.append(queries)
63 | test_tree = KDTree(df_centroids[folder*test_num:(folder+1)*test_num][['x','y']])
64 | test_trees.append(test_tree)
65 |
66 | for folder in range(folder_num):
67 | dataset = {}
68 | for i in range(len(df_database)//folder_num):
69 | temp_indx = folder*len(df_database)//folder_num + i
70 | data = df_database.iloc[temp_indx]["file"]
71 | dataset[len(dataset.keys())] = {"query":data,
72 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y'])}
73 |
74 | database_sets.append(dataset)
75 | database_tree = KDTree(df_database[folder*file_size_:(folder+1)*file_size_][['x','y']])
76 | database_trees.append(database_tree)
77 |
78 | if test:
79 | for i in range(len(database_sets)):
80 | tree = database_trees[i]
81 | for j in range(len(queries_sets)):
82 | if(i == j):
83 | continue
84 | for key in range(len(queries_sets[j].keys())):
85 | coor = np.array(
86 | [[queries_sets[j][key]["x"],queries_sets[j][key]["y"]]])
87 | index = tree.query_radius(coor, r=25)
88 | # indices of the positive matches in database i of each query (key) in test set j
89 | queries_sets[j][key][i] = index[0].tolist()
90 |
91 | output_to_file(queries_sets, filename_test)
92 | output_to_file(database_sets, filename_train)
93 |
94 | # Initialize pandas DataFrame
95 | df_train = pd.DataFrame(columns=['file','x','y'])
96 | df_test = pd.DataFrame(columns=['file','x','y'])
97 |
98 | df_files_test = []
99 | df_files_train =[]
100 |
101 | df_locations_tr_x = []
102 | df_locations_tr_y = []
103 | df_locations_ts_x = []
104 | df_locations_ts_y = []
105 |
106 | for folder in folders:
107 | df_locations = sio.loadmat(os.path.join(
108 | cc_dir,runs_folder,folder,filename))
109 |
110 | df_locations = df_locations['pose']
111 | df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
112 |
113 | #2038 Training 10 testing
114 | test_index = list(sorted(random.sample(range(len(df_locations)), k=test_num)))
115 | train_index = list(range(df_locations.shape[0]))
116 | #for i in test_index:
117 | # train_index.pop(i)
118 |
119 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
120 | df_locations_tr_y.extend(list(df_locations[train_index,1]))
121 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
122 | df_locations_ts_y.extend(list(df_locations[test_index,1]))
123 |
124 | all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
125 | all_files.remove('gt_pose.mat')
126 | all_files.remove('gt_pose.png')
127 |
128 | for (indx, file_) in enumerate(all_files):
129 | if indx in test_index:
130 | df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
131 | df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
132 |
133 |
134 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
135 | columns =['file','x', 'y'])
136 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
137 | columns =['file','x', 'y'])
138 |
139 | print("Number of training submaps: "+str(len(df_train['file'])))
140 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
141 |
142 | print("df_train:"+str(len(df_train)))
143 | print("len(folders):"+str(len(folders)))
144 |
145 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
146 | construct_query_dict(df_test, df_train, len(folders),"evaluation_database.pickle", "evaluation_query.pickle", True)
147 |
--------------------------------------------------------------------------------
/generating_queries/generate_test_PCL_ours_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import random
4 | import set_path
5 |
6 | import numpy as np
7 | import pandas as pd
8 | from sklearn.neighbors import KDTree
9 |
10 | import config as cfg
11 |
12 | import scipy.io as sio
13 | import torch
14 |
15 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
16 | base_path = cfg.DATASET_FOLDER
17 |
18 | runs_folder = "dm_data"
19 | filename = "gt_pose.mat"
20 | pointcloud_fols = "/pointcloud_20m_10overlap/"
21 | test_num = 10
22 |
23 | evaluate_all = True
24 | print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
25 |
26 | for i in range(2):
27 | if i==1:
28 | evaluate_all = False
29 | cc_dir = "/home/cc/"
30 | all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
31 | file_size_ = 2048
32 | folders = []
33 |
34 | # All runs are used for training (both full and partial)
35 | if evaluate_all:
36 | index_list = list(range(18))
37 | else:
38 | index_list = [5,6,7,9]#,11,14,18,19,29,31,32,34,36,40,44,46,49,51,53,54,57,59,61,63,65,68,69,72,75,77,79,83,85,88,91,93,94]
39 | print("Number of runs: "+str(len(index_list)))
40 | for index in index_list:
41 | folders.append(all_folders[index])
42 | print(folders)
43 |
44 |
45 | #####For training and test data split#####
46 | def output_to_file(output, filename):
47 | with open(filename, 'wb') as handle:
48 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
49 | print("Done ", filename)
50 |
51 | #########################################
52 | def construct_query_dict(df_centroids, df_database, folder_num, filename_train, filename_test, test=False):
53 | database_trees = []
54 | test_trees = []
55 | tree = KDTree(df_centroids[['x','y']])
56 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=15)
57 | ind_r = tree.query_radius(df_centroids[['x','y']], r=50)
58 | queries_sets = []
59 | database_sets = []
60 | for folder in range(folder_num):
61 | queries = {}
62 | for i in range(len(df_centroids)//folder_num):
63 | temp_indx = folder*(len(df_centroids)//folder_num) + i
64 | query = df_centroids.iloc[temp_indx]["file"]
65 | #print("folder:"+str(folder))
66 | #print("query:"+str(query))
67 | queries[len(queries.keys())] = {"query":query,
68 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
69 | queries_sets.append(queries)
70 | test_tree = KDTree(df_centroids[folder*test_num:(folder+1)*test_num][['x','y']])
71 | test_trees.append(test_tree)
72 |
73 | for folder in range(folder_num):
74 | dataset = {}
75 | for i in range(len(df_database)//folder_num):
76 | temp_indx = folder*len(df_database)//folder_num + i
77 | data = df_database.iloc[temp_indx]["file"]
78 | dataset[len(dataset.keys())] = {"query":data,
79 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y'])}
80 |
81 | database_sets.append(dataset)
82 | database_tree = KDTree(df_database[folder*file_size_:(folder+1)*file_size_][['x','y']])
83 | database_trees.append(database_tree)
84 |
85 | if test:
86 | for i in range(len(database_sets)):
87 | tree = database_trees[i]
88 | for j in range(len(queries_sets)):
89 | if(i == j):
90 | continue
91 | for key in range(len(queries_sets[j].keys())):
92 | coor = np.array(
93 | [[queries_sets[j][key]["x"],queries_sets[j][key]["y"]]])
94 | index = tree.query_radius(coor, r=25)
95 | # indices of the positive matches in database i of each query (key) in test set j
96 | queries_sets[j][key][i] = index[0].tolist()
97 |
98 | output_to_file(queries_sets, filename_test)
99 | output_to_file(database_sets, filename_train)
100 |
101 | # Initialize pandas DataFrame
102 | df_train = pd.DataFrame(columns=['file','x','y'])
103 | df_test = pd.DataFrame(columns=['file','x','y'])
104 |
105 | df_files_test = []
106 | df_files_train =[]
107 |
108 | df_locations_tr_x = []
109 | df_locations_tr_y = []
110 | df_locations_ts_x = []
111 | df_locations_ts_y = []
112 |
113 | for folder in folders:
114 | df_locations = sio.loadmat(os.path.join(
115 | cc_dir,runs_folder,folder,filename))
116 |
117 | df_locations = df_locations['pose']
118 | df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
119 |
120 | #2038 Training 10 testing
121 | test_index = list(sorted(random.sample(range(len(df_locations)), k=test_num)))
122 | train_index = list(range(df_locations.shape[0]))
123 | #for i in test_index:
124 | # train_index.pop(i)
125 |
126 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
127 | df_locations_tr_y.extend(list(df_locations[train_index,1]))
128 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
129 | df_locations_ts_y.extend(list(df_locations[test_index,1]))
130 |
131 | all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
132 | all_files.remove('gt_pose.mat')
133 | all_files.remove('gt_pose.png')
134 |
135 | for (indx, file_) in enumerate(all_files):
136 | if indx in test_index:
137 | df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
138 | df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
139 |
140 |
141 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
142 | columns =['file','x', 'y'])
143 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
144 | columns =['file','x', 'y'])
145 |
146 | print("Number of training submaps: "+str(len(df_train['file'])))
147 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
148 |
149 | print("df_train:"+str(len(df_train)))
150 | print("len(folders):"+str(len(folders)))
151 |
152 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
153 | if not evaluate_all:
154 | construct_query_dict(df_test, df_train, len(folders),"evaluation_database.pickle", "evaluation_query.pickle", True)
155 | else:
156 | construct_query_dict(df_test, df_train, len(folders),"evaluation_database_full.pickle", "evaluation_query_full.pickle", True)
--------------------------------------------------------------------------------
/generating_queries/generate_test_PCL_supervise_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import random
4 | import set_path
5 |
6 | import numpy as np
7 | import pandas as pd
8 | from sklearn.neighbors import KDTree
9 |
10 | import config as cfg
11 |
12 | import scipy.io as sio
13 | import torch
14 |
15 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
16 | base_path = cfg.DATASET_FOLDER
17 |
18 | runs_folder = "dm_data"
19 | filename = "gt_pose.mat"
20 | pointcloud_fols = "/pointcloud_20m_10overlap/"
21 | test_num = 4
22 |
23 | evaluate_all = False
24 | for k in range(2):
25 | if k == 1:
26 | evaluate_all = True
27 | print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
28 |
29 | cc_dir = "/home/cc/"
30 | all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
31 | file_size_ = 2048
32 | folders = []
33 |
34 | # All runs are used for training (both full and partial)
35 | if evaluate_all:
36 | index_list = list(range(18))
37 | else:
38 | index_list = [5,6,7,9]
39 | print("Number of runs: "+str(len(index_list)))
40 | for index in index_list:
41 | folders.append(all_folders[index])
42 | print(folders)
43 |
44 |
45 | #####For training and test data split#####
46 | def output_to_file(output, filename):
47 | with open(filename, 'wb') as handle:
48 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
49 | print("Done ", filename)
50 |
51 | #########################################
52 | def construct_query_dict(df_centroids, df_database, folder_num, filename_train, filename_test, test=False):
53 | database_trees = []
54 | test_trees = []
55 | tree = KDTree(df_centroids[['x','y']])
56 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=15)
57 | ind_r = tree.query_radius(df_centroids[['x','y']], r=50)
58 | queries_sets = []
59 | database_sets = []
60 | for folder in range(folder_num):
61 | queries = {}
62 | for i in range(len(df_centroids)//folder_num):
63 | temp_indx = folder*(len(df_centroids)//folder_num) + i
64 | query = df_centroids.iloc[temp_indx]["file"]
65 | #print("folder:"+str(folder))
66 | #print("query:"+str(query))
67 | queries[len(queries.keys())] = {"query":query,
68 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
69 | queries_sets.append(queries)
70 | test_tree = KDTree(df_centroids[folder*test_num:(folder+1)*test_num][['x','y']])
71 | test_trees.append(test_tree)
72 |
73 | for folder in range(folder_num):
74 | dataset = {}
75 | for i in range(len(df_database)//folder_num):
76 | temp_indx = folder*len(df_database)//folder_num + i
77 | data = df_database.iloc[temp_indx]["file"]
78 | dataset[len(dataset.keys())] = {"query":data,
79 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y'])}
80 |
81 | database_sets.append(dataset)
82 | database_tree = KDTree(df_database[folder*file_size_:(folder+1)*file_size_][['x','y']])
83 | database_trees.append(database_tree)
84 |
85 | if test:
86 | for i in range(len(database_sets)):
87 | tree = database_trees[i]
88 | for j in range(len(queries_sets)):
89 | if(i == j):
90 | continue
91 | for key in range(len(queries_sets[j].keys())):
92 | coor = np.array(
93 | [[queries_sets[j][key]["x"],queries_sets[j][key]["y"]]])
94 | index = tree.query_radius(coor, r=25)
95 | # indices of the positive matches in database i of each query (key) in test set j
96 | queries_sets[j][key][i] = index[0].tolist()
97 |
98 | output_to_file(queries_sets, filename_test)
99 | output_to_file(database_sets, filename_train)
100 |
101 | # Initialize pandas DataFrame
102 | df_train = pd.DataFrame(columns=['file','x','y'])
103 | df_test = pd.DataFrame(columns=['file','x','y'])
104 |
105 | df_files_test = []
106 | df_files_train =[]
107 |
108 | df_locations_tr_x = []
109 | df_locations_tr_y = []
110 | df_locations_ts_x = []
111 | df_locations_ts_y = []
112 |
113 | for folder in folders:
114 | df_locations = sio.loadmat(os.path.join(
115 | cc_dir,runs_folder,folder,filename))
116 |
117 | df_locations = df_locations['pose']
118 | df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
119 |
120 | #2038 Training 10 testing
121 | test_index = list(sorted(random.sample(range(len(df_locations)), k=test_num)))
122 | train_index = list(range(df_locations.shape[0]))
123 | #for i in test_index:
124 | # train_index.pop(i)
125 |
126 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
127 | df_locations_tr_y.extend(list(df_locations[train_index,1]))
128 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
129 | df_locations_ts_y.extend(list(df_locations[test_index,1]))
130 |
131 | all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
132 | all_files.remove('gt_pose.mat')
133 | all_files.remove('gt_pose.png')
134 |
135 | for (indx, file_) in enumerate(all_files):
136 | if indx in test_index:
137 | df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
138 | df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
139 |
140 |
141 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
142 | columns =['file','x', 'y'])
143 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
144 | columns =['file','x', 'y'])
145 |
146 | print("Number of training submaps: "+str(len(df_train['file'])))
147 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
148 |
149 | print("df_train:"+str(len(df_train)))
150 |
151 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
152 | if not evaluate_all:
153 | construct_query_dict(df_test, df_train, len(folders),"evaluation_database.pickle", "evaluation_query.pickle", True)
154 | else:
155 | construct_query_dict(df_test, df_train, len(folders),"evaluation_database_full.pickle", "evaluation_query_full.pickle", True)
--------------------------------------------------------------------------------
/generating_queries/generate_test_RGB_baseline_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 | import json
16 |
17 | ##########################################
18 |
19 | def output_to_file(output, filename):
20 | with open(filename, 'wb') as handle:
21 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
22 | print("Done ", filename)
23 |
24 | #########################################
25 | def construct_query_dict(df_centroids, df_database, folder_num, traj_len, filename_train, filename_test, nn_ind, r_mid, r_ind, test=False, evaluate_all=False):
26 | database_trees = []
27 | test_trees = []
28 | if not evaluate_all:
29 | tree = KDTree(df_centroids[['x','y']])
30 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
31 | ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
32 | queries_sets = []
33 | database_sets = []
34 |
35 | #for folder in range(folder_num):
36 | queries = {}
37 | for i in range(len(df_centroids)):
38 | #temp_indx = folder*len(df_centroids)//folder_num + i
39 | temp_indx = i
40 | query = df_centroids.iloc[temp_indx]["file"]
41 | #print("folder:"+str(folder))
42 | #print("query:"+str(query))
43 | if not evaluate_all:
44 | queries[len(queries.keys())] = {"query":query,
45 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
46 | else:
47 | queries[len(queries.keys())] = {"query":query}
48 |
49 | queries_sets.append(queries)
50 | if not evaluate_all:
51 | test_tree = KDTree(df_centroids[['x','y']])
52 | test_trees.append(test_tree)
53 |
54 | ###############################
55 | #for folder in range(folder_num):
56 | dataset = {}
57 | for i in range(len(df_database)):
58 | #temp_indx = folder*len(df_database)//folder_num + i
59 | temp_indx = i
60 | data = df_database.iloc[temp_indx]["file"]
61 | if not evaluate_all:
62 | dataset[len(dataset.keys())] = {"query":data,
63 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y']) }
64 | else:
65 | dataset[len(dataset.keys())] = {"query":data}
66 | database_sets.append(dataset)
67 | if not evaluate_all:
68 | database_tree = KDTree(df_database[['x','y']])
69 | database_trees.append(database_tree)
70 | ##################################
71 | if test:
72 | if not evaluate_all:
73 | #for i in range(len(database_sets)):
74 | tree = database_trees[0]
75 | #for j in range(len(queries_sets)):
76 | #if(i == j):
77 | # continue
78 | #print("len(queries_sets[j].keys():"+str(len(queries_sets[j].keys())))
79 | #assert(0)
80 | for key in range(len(queries_sets[0].keys())):
81 | coor = np.array(
82 | [[queries_sets[0][key]["x"],queries_sets[0][key]["y"]]])
83 | index = tree.query_radius(coor, r=r_mid)
84 | # indices of the positive matches in database i of each query (key) in test set j
85 | queries_sets[0][key][0] = index[0].tolist()
86 | else:
87 | pass
88 |
89 | output_to_file(queries_sets, filename_test)
90 | output_to_file(database_sets, filename_train)
91 |
92 | def generate(scene_index, evaluate_all = False, inside=True):
93 | base_path = "/mnt/NAS/home/cc/data/habitat_4/train"
94 | runs_folder = cfg.scene_list[scene_index]
95 | #runs_folder = "Goffs"
96 | pre_dir = os.path.join(base_path, runs_folder)
97 |
98 | nn_ind = 0.2
99 | r_mid = 0.2
100 | r_ind = 0.6
101 |
102 | filename = "gt_pose.mat"
103 |
104 | folders = list(sorted(os.listdir(pre_dir)))
105 |
106 | if evaluate_all == False:
107 | index_list = list(range(len(folders)))
108 | else:
109 | index_list = list(range(len(folders)))
110 |
111 | fold_list = []
112 | for index in index_list:
113 | fold_list.append(folders[index])
114 |
115 | all_files = []
116 | for fold in fold_list:
117 | files_ = []
118 | files = list(sorted(os.listdir(os.path.join(pre_dir, fold))))
119 | files.remove('gt_pose.mat')
120 | # print("len(files):"+str(len(files)))
121 | for ind in range(len(files)):
122 | file_ = "panoimg_"+str(ind)+".png"
123 | files_.append(os.path.join(pre_dir, fold, file_))
124 | all_files.extend(files_)
125 | # all_files.remove('trajectory.mp4')
126 | # all_files = [i for i in all_files if not i.endswith(".npy")]
127 |
128 | traj_len = len(all_files)
129 | file_size = traj_len/len(fold_list)
130 |
131 | # Initialize pandas DataFrame
132 | if evaluate_all:
133 | df_train = pd.DataFrame(columns=['file'])
134 | df_test = pd.DataFrame(columns=['file'])
135 | else:
136 | df_train = pd.DataFrame(columns=['file','x','y'])
137 | df_test = pd.DataFrame(columns=['file','x','y'])
138 |
139 | if not evaluate_all:
140 | df_files_test = []
141 | df_files_train =[]
142 |
143 | df_locations_tr_x = []
144 | df_locations_tr_y = []
145 |
146 | df_locations_ts_x = []
147 | df_locations_ts_y = []
148 |
149 | # print("os.path.join(pre_dir,filename):"+str(os.path.join(pre_dir,filename)))
150 | df_locations = torch.zeros((traj_len, 3), dtype = torch.float)
151 | for count, fold in enumerate(fold_list):
152 | data = sio.loadmat(os.path.join(pre_dir,fold,filename))
153 | df_location = data['pose']
154 | df_locations[int(count*file_size):int((count+1)*file_size)] = torch.tensor(df_location, dtype = torch.float)
155 |
156 | # df_locations = df_locations['pose']
157 | # df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
158 | else:
159 | df_files_test = []
160 | df_files_train =[]
161 |
162 | #n-40 Training 40 testing
163 | test_sample = len(fold_list)*10
164 | test_index = random.choices(range(traj_len), k=test_sample)
165 | train_index = list(range(traj_len))
166 | #for i in test_index:
167 | # train_index.pop(i)
168 | if not evaluate_all:
169 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
170 | df_locations_tr_y.extend(list(df_locations[train_index,2]))
171 |
172 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
173 | df_locations_ts_y.extend(list(df_locations[test_index,2]))
174 |
175 | for indx in range(traj_len):
176 | # file_ = 'panoimg_'+str(indx)+'.png'
177 | if indx in test_index:
178 | df_files_test.append(all_files[indx])
179 | df_files_train.append(all_files[indx])
180 |
181 | if not evaluate_all:
182 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
183 | columns =['file','x', 'y'])
184 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
185 | columns =['file','x', 'y'])
186 | else:
187 | df_train = pd.DataFrame(list(zip(df_files_train)),
188 | columns =['file'])
189 | df_test = pd.DataFrame(list(zip(df_files_test)),
190 | columns =['file'])
191 | print("Number of training submaps: "+str(len(df_train['file'])))
192 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
193 |
194 |
195 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
196 | if inside == False:
197 | if not evaluate_all:
198 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database.pickle", "generating_queries/evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
199 | else:
200 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database_full.pickle", "generating_queries/evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
201 | else:
202 | if not evaluate_all:
203 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database.pickle", "evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
204 | else:
205 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database_full.pickle", "evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
206 | if __name__ == "__main__":
207 | generate(1, evaluate_all=False)
208 |
--------------------------------------------------------------------------------
/generating_queries/generate_test_RGB_ours_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 | import json
16 |
17 | ##########################################
18 |
19 | def output_to_file(output, filename):
20 | with open(filename, 'wb') as handle:
21 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
22 | print("Done ", filename)
23 |
24 | #########################################
25 | def construct_query_dict(df_centroids, df_database, folder_num, traj_len, filename_train, filename_test, nn_ind, r_mid, r_ind, test=False, evaluate_all=False):
26 | database_trees = []
27 | test_trees = []
28 | if not evaluate_all:
29 | tree = KDTree(df_centroids[['x','y']])
30 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
31 | ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
32 | queries_sets = []
33 | database_sets = []
34 |
35 | queries = {}
36 | for i in range(len(df_centroids)):
37 | temp_indx = i
38 | query = df_centroids.iloc[temp_indx]["file"]
39 |
40 | if not evaluate_all:
41 | queries[len(queries.keys())] = {"query":query,
42 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
43 | else:
44 | queries[len(queries.keys())] = {"query":query}
45 |
46 | queries_sets.append(queries)
47 | if not evaluate_all:
48 | test_tree = KDTree(df_centroids[['x','y']])
49 | test_trees.append(test_tree)
50 |
51 | ###############################
52 | dataset = {}
53 | for i in range(len(df_database)):
54 | temp_indx = i
55 | data = df_database.iloc[temp_indx]["file"]
56 | if not evaluate_all:
57 | dataset[len(dataset.keys())] = {"query":data,
58 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y']) }
59 | else:
60 | dataset[len(dataset.keys())] = {"query":data}
61 | database_sets.append(dataset)
62 | if not evaluate_all:
63 | database_tree = KDTree(df_database[['x','y']])
64 | database_trees.append(database_tree)
65 | ##################################
66 | if test:
67 | if not evaluate_all:
68 | tree = database_trees[0]
69 |
70 | for key in range(len(queries_sets[0].keys())):
71 | coor = np.array(
72 | [[queries_sets[0][key]["x"],queries_sets[0][key]["y"]]])
73 | index = tree.query_radius(coor, r=r_mid)
74 | queries_sets[0][key][0] = index[0].tolist()
75 | else:
76 | pass
77 |
78 | output_to_file(queries_sets, filename_test)
79 | output_to_file(database_sets, filename_train)
80 |
81 | def generate(scene_index, evaluate_all = False, inside=True):
82 | base_path = "/mnt/NAS/home/cc/data/habitat_4/train"
83 | runs_folder = cfg.scene_list[scene_index]
84 | pre_dir = os.path.join(base_path, runs_folder)
85 |
86 | nn_ind = 0.2
87 | r_mid = 0.2
88 | r_ind = 0.6
89 |
90 | filename = "gt_pose.mat"
91 |
92 | folders = list(sorted(os.listdir(pre_dir)))
93 | if evaluate_all == False:
94 | index_list = list(range(len(folders)))
95 | else:
96 | index_list = list(range(len(folders)))
97 |
98 | fold_list = []
99 | for index in index_list:
100 | fold_list.append(folders[index])
101 |
102 | all_files = []
103 | for fold in fold_list:
104 | files_ = []
105 | files = list(sorted(os.listdir(os.path.join(pre_dir, fold))))
106 | files.remove('gt_pose.mat')
107 | # print("len(files):"+str(len(files)))
108 | for ind in range(len(files)):
109 | file_ = "panoimg_"+str(ind)+".png"
110 | files_.append(os.path.join(pre_dir, fold, file_))
111 | all_files.extend(files_)
112 |
113 | traj_len = len(all_files)
114 | file_size = traj_len/len(fold_list)
115 |
116 | # Initialize pandas DataFrame
117 | if evaluate_all:
118 | df_train = pd.DataFrame(columns=['file'])
119 | df_test = pd.DataFrame(columns=['file'])
120 | else:
121 | df_train = pd.DataFrame(columns=['file','x','y'])
122 | df_test = pd.DataFrame(columns=['file','x','y'])
123 |
124 | if not evaluate_all:
125 | df_files_test = []
126 | df_files_train =[]
127 |
128 | df_locations_tr_x = []
129 | df_locations_tr_y = []
130 |
131 | df_locations_ts_x = []
132 | df_locations_ts_y = []
133 |
134 | df_locations = torch.zeros((traj_len, 3), dtype = torch.float)
135 | for count, fold in enumerate(fold_list):
136 | data = sio.loadmat(os.path.join(pre_dir,fold,filename))
137 | df_location = data['pose']
138 | df_locations[int(count*file_size):int((count+1)*file_size)] = torch.tensor(df_location, dtype = torch.float)
139 |
140 | else:
141 | df_files_test = []
142 | df_files_train =[]
143 |
144 | #n-40 Training 40 testing
145 | test_sample = len(fold_list)*10
146 | test_index = random.choices(range(traj_len), k=test_sample)
147 | train_index = list(range(traj_len))
148 |
149 | if not evaluate_all:
150 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
151 | df_locations_tr_y.extend(list(df_locations[train_index,2]))
152 |
153 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
154 | df_locations_ts_y.extend(list(df_locations[test_index,2]))
155 |
156 | for indx in range(traj_len):
157 | if indx in test_index:
158 | df_files_test.append(all_files[indx])
159 | df_files_train.append(all_files[indx])
160 |
161 | if not evaluate_all:
162 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
163 | columns =['file','x', 'y'])
164 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
165 | columns =['file','x', 'y'])
166 | else:
167 | df_train = pd.DataFrame(list(zip(df_files_train)),
168 | columns =['file'])
169 | df_test = pd.DataFrame(list(zip(df_files_test)),
170 | columns =['file'])
171 | print("Number of training submaps: "+str(len(df_train['file'])))
172 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
173 |
174 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
175 | if inside == False:
176 | if not evaluate_all:
177 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database.pickle", "generating_queries/evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
178 | else:
179 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database_full.pickle", "generating_queries/evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
180 | else:
181 | if not evaluate_all:
182 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database.pickle", "evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
183 | else:
184 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database_full.pickle", "evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
185 | if __name__ == "__main__":
186 | generate(0, evaluate_all=False)
187 | generate(0, evaluate_all=True)
--------------------------------------------------------------------------------
/generating_queries/generate_test_RGB_real_baseline_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 | import json
16 |
17 | ##########################################
18 |
19 | def output_to_file(output, filename):
20 | with open(filename, 'wb') as handle:
21 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
22 | print("Done ", filename)
23 |
24 | #########################################
25 | def construct_query_dict(df_centroids, df_database, folder_num, traj_len, filename_train, filename_test, nn_ind, r_mid, r_ind, test=False, evaluate_all=False):
26 | database_trees = []
27 | test_trees = []
28 | if not evaluate_all:
29 | tree = KDTree(df_centroids[['x','y']])
30 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
31 | ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
32 | queries_sets = []
33 | database_sets = []
34 |
35 | #for folder in range(folder_num):
36 | queries = {}
37 | for i in range(len(df_centroids)):
38 | #temp_indx = folder*len(df_centroids)//folder_num + i
39 | temp_indx = i
40 | query = df_centroids.iloc[temp_indx]["file"]
41 | #print("folder:"+str(folder))
42 | #print("query:"+str(query))
43 | if not evaluate_all:
44 | queries[len(queries.keys())] = {"query":query,
45 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
46 | else:
47 | queries[len(queries.keys())] = {"query":query}
48 |
49 | queries_sets.append(queries)
50 | if not evaluate_all:
51 | test_tree = KDTree(df_centroids[['x','y']])
52 | test_trees.append(test_tree)
53 |
54 | ###############################
55 | #for folder in range(folder_num):
56 | dataset = {}
57 | for i in range(len(df_database)):
58 | #temp_indx = folder*len(df_database)//folder_num + i
59 | temp_indx = i
60 | data = df_database.iloc[temp_indx]["file"]
61 | if not evaluate_all:
62 | dataset[len(dataset.keys())] = {"query":data,
63 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y']) }
64 | else:
65 | dataset[len(dataset.keys())] = {"query":data}
66 | database_sets.append(dataset)
67 | if not evaluate_all:
68 | database_tree = KDTree(df_database[['x','y']])
69 | database_trees.append(database_tree)
70 | ##################################
71 | if test:
72 | if not evaluate_all:
73 | #for i in range(len(database_sets)):
74 | tree = database_trees[0]
75 | #for j in range(len(queries_sets)):
76 | #if(i == j):
77 | # continue
78 | #print("len(queries_sets[j].keys():"+str(len(queries_sets[j].keys())))
79 | #assert(0)
80 | for key in range(len(queries_sets[0].keys())):
81 | coor = np.array(
82 | [[queries_sets[0][key]["x"],queries_sets[0][key]["y"]]])
83 | index = tree.query_radius(coor, r=r_mid)
84 | # indices of the positive matches in database i of each query (key) in test set j
85 | queries_sets[0][key][0] = index[0].tolist()
86 | #print("index[0].tolist():"+str(len(index[0].tolist())))
87 | else:
88 | pass
89 |
90 | output_to_file(queries_sets, filename_test)
91 | output_to_file(database_sets, filename_train)
92 |
93 | def generate(scene_index, evaluate_all = False, inside=True):
94 | base_path = "/mnt/NAS/data/cc_data/2D_RGB_real_edited3"
95 | #runs_folder = cfg.scene_names[scene_index]
96 | #runs_folder = "Goffs"
97 | pre_dir = base_path #os.path.join(base_path, runs_folder)
98 |
99 | nn_ind = 0.003
100 | r_mid = 0.003
101 | r_ind = 0.006
102 |
103 | filename = "gt_pose.mat"
104 |
105 | folders = list(sorted(os.listdir(pre_dir)))
106 | if evaluate_all == False:
107 | index_list = [0]
108 | else:
109 | index_list = list(range(len(folders)))
110 |
111 | fold_list = []
112 | for index in index_list:
113 | fold_list.append(folders[index])
114 |
115 | all_files = []
116 | for fold in fold_list:
117 | files_ = []
118 | files = list(sorted(os.listdir(os.path.join(pre_dir, fold))))
119 | files.remove('gt_pose.mat')
120 | # print("len(files):"+str(len(files)))
121 | for ind in range(len(files)):
122 | file_ = "panoimg_"+str(ind)+".jpg"
123 | files_.append(os.path.join(pre_dir, fold, file_))
124 | all_files.extend(files_)
125 | # all_files.remove('trajectory.mp4')
126 | # all_files = [i for i in all_files if not i.endswith(".npy")]
127 |
128 | traj_len = len(all_files)
129 | file_size = traj_len/len(fold_list)
130 |
131 | # Initialize pandas DataFrame
132 | if evaluate_all:
133 | df_train = pd.DataFrame(columns=['file'])
134 | df_test = pd.DataFrame(columns=['file'])
135 | else:
136 | df_train = pd.DataFrame(columns=['file','x','y'])
137 | df_test = pd.DataFrame(columns=['file','x','y'])
138 |
139 | if not evaluate_all:
140 | df_files_test = []
141 | df_files_train =[]
142 |
143 | df_locations_tr_x = []
144 | df_locations_tr_y = []
145 |
146 | df_locations_ts_x = []
147 | df_locations_ts_y = []
148 |
149 | # print("os.path.join(pre_dir,filename):"+str(os.path.join(pre_dir,filename)))
150 | df_locations = torch.zeros((traj_len, 2), dtype = torch.float)
151 | for count, fold in enumerate(fold_list):
152 | data = sio.loadmat(os.path.join(pre_dir,fold,filename))
153 | df_location = data['pose']
154 | df_locations[int(count*file_size):int((count+1)*file_size)] = torch.tensor(df_location, dtype = torch.float)
155 |
156 | # df_locations = df_locations['pose']
157 | # df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
158 | else:
159 | df_files_test = []
160 | df_files_train =[]
161 |
162 | #n-40 Training 40 testing
163 | test_sample = len(fold_list)*10
164 | test_index = random.choices(range(traj_len), k=test_sample)
165 | train_index = list(range(traj_len))
166 | #for i in test_index:
167 | # train_index.pop(i)
168 | if not evaluate_all:
169 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
170 | df_locations_tr_y.extend(list(df_locations[train_index,1]))
171 |
172 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
173 | df_locations_ts_y.extend(list(df_locations[test_index,1]))
174 |
175 | for indx in range(traj_len):
176 | # file_ = 'panoimg_'+str(indx)+'.png'
177 | if indx in test_index:
178 | df_files_test.append(all_files[indx])
179 | df_files_train.append(all_files[indx])
180 |
181 | if not evaluate_all:
182 | #print("df_files_train:"+str((df_files_train)))
183 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
184 | columns =['file','x', 'y'])
185 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
186 | columns =['file','x', 'y'])
187 | else:
188 | df_train = pd.DataFrame(list(zip(df_files_train)),
189 | columns =['file'])
190 | df_test = pd.DataFrame(list(zip(df_files_test)),
191 | columns =['file'])
192 | print("Number of training submaps: "+str(len(df_train['file'])))
193 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
194 |
195 |
196 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
197 | if inside == False:
198 | if not evaluate_all:
199 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database.pickle", "generating_queries/evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
200 | else:
201 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database_full.pickle", "generating_queries/evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
202 | else:
203 | if not evaluate_all:
204 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database.pickle", "evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
205 | else:
206 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database_full.pickle", "evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
207 | if __name__ == "__main__":
208 | generate(1, evaluate_all=False)
--------------------------------------------------------------------------------
/generating_queries/generate_test_RGB_real_ours_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 | import json
16 |
17 | ##########################################
18 |
19 | def output_to_file(output, filename):
20 | with open(filename, 'wb') as handle:
21 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
22 | print("Done ", filename)
23 |
24 | #########################################
25 | def construct_query_dict(df_centroids, df_database, folder_num, traj_len, filename_train, filename_test, nn_ind, r_mid, r_ind, test=False, evaluate_all=False):
26 | database_trees = []
27 | test_trees = []
28 | if not evaluate_all:
29 | tree = KDTree(df_centroids[['x','y']])
30 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
31 | ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
32 | queries_sets = []
33 | database_sets = []
34 |
35 | #for folder in range(folder_num):
36 | queries = {}
37 | for i in range(len(df_centroids)):
38 | #temp_indx = folder*len(df_centroids)//folder_num + i
39 | temp_indx = i
40 | query = df_centroids.iloc[temp_indx]["file"]
41 | #print("folder:"+str(folder))
42 | #print("query:"+str(query))
43 | if not evaluate_all:
44 | queries[len(queries.keys())] = {"query":query,
45 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
46 | else:
47 | queries[len(queries.keys())] = {"query":query}
48 |
49 | queries_sets.append(queries)
50 | if not evaluate_all:
51 | test_tree = KDTree(df_centroids[['x','y']])
52 | test_trees.append(test_tree)
53 |
54 | ###############################
55 | #for folder in range(folder_num):
56 | dataset = {}
57 | for i in range(len(df_database)):
58 | #temp_indx = folder*len(df_database)//folder_num + i
59 | temp_indx = i
60 | data = df_database.iloc[temp_indx]["file"]
61 | if not evaluate_all:
62 | dataset[len(dataset.keys())] = {"query":data,
63 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y']) }
64 | else:
65 | dataset[len(dataset.keys())] = {"query":data}
66 | database_sets.append(dataset)
67 | if not evaluate_all:
68 | database_tree = KDTree(df_database[['x','y']])
69 | database_trees.append(database_tree)
70 | ##################################
71 | if test:
72 | if not evaluate_all:
73 | #for i in range(len(database_sets)):
74 | tree = database_trees[0]
75 | #for j in range(len(queries_sets)):
76 | #if(i == j):
77 | # continue
78 | #print("len(queries_sets[j].keys():"+str(len(queries_sets[j].keys())))
79 | #assert(0)
80 | for key in range(len(queries_sets[0].keys())):
81 | coor = np.array(
82 | [[queries_sets[0][key]["x"],queries_sets[0][key]["y"]]])
83 | index = tree.query_radius(coor, r=r_mid)
84 | # indices of the positive matches in database i of each query (key) in test set j
85 | queries_sets[0][key][0] = index[0].tolist()
86 | #print("index[0].tolist():"+str(len(index[0].tolist())))
87 | else:
88 | pass
89 |
90 | output_to_file(queries_sets, filename_test)
91 | output_to_file(database_sets, filename_train)
92 |
93 | def generate(scene_index, evaluate_all = False, inside=True):
94 | if not evaluate_all:
95 | base_path = "/mnt/NAS/data/cc_data/2D_RGB_real_edited3"
96 | else:
97 | base_path = "/mnt/NAS/data/cc_data/2D_RGB_real_full3"
98 | #runs_folder = cfg.scene_names[scene_index]
99 | #runs_folder = "Goffs"
100 | pre_dir = base_path #os.path.join(base_path, runs_folder)
101 |
102 | nn_ind = 0.003
103 | r_mid = 0.003
104 | r_ind = 0.006
105 |
106 | filename = "gt_pose.mat"
107 |
108 | folders = list(sorted(os.listdir(pre_dir)))
109 | if evaluate_all == False:
110 | index_list = [0]
111 | else:
112 | index_list = list(range(len(folders)))
113 |
114 | fold_list = []
115 | for index in index_list:
116 | fold_list.append(folders[index])
117 |
118 | all_files = []
119 | for fold in fold_list:
120 | files_ = []
121 | files = list(sorted(os.listdir(os.path.join(pre_dir, fold))))
122 | if not evaluate_all:
123 | files.remove('gt_pose.mat')
124 | else:
125 | pass
126 | # print("len(files):"+str(len(files)))
127 | for ind in range(len(files)):
128 | file_ = "panoimg_"+str(ind)+".jpg"
129 | files_.append(os.path.join(pre_dir, fold, file_))
130 | all_files.extend(files_)
131 | # all_files.remove('trajectory.mp4')
132 | # all_files = [i for i in all_files if not i.endswith(".npy")]
133 |
134 | traj_len = len(all_files)
135 | file_size = traj_len/len(fold_list)
136 |
137 | # Initialize pandas DataFrame
138 | if evaluate_all:
139 | df_train = pd.DataFrame(columns=['file'])
140 | df_test = pd.DataFrame(columns=['file'])
141 | else:
142 | df_train = pd.DataFrame(columns=['file','x','y'])
143 | df_test = pd.DataFrame(columns=['file','x','y'])
144 |
145 | if not evaluate_all:
146 | df_files_test = []
147 | df_files_train =[]
148 |
149 | df_locations_tr_x = []
150 | df_locations_tr_y = []
151 |
152 | df_locations_ts_x = []
153 | df_locations_ts_y = []
154 |
155 | # print("os.path.join(pre_dir,filename):"+str(os.path.join(pre_dir,filename)))
156 | df_locations = torch.zeros((traj_len, 2), dtype = torch.float)
157 | for count, fold in enumerate(fold_list):
158 | data = sio.loadmat(os.path.join(pre_dir,fold,filename))
159 | df_location = data['pose']
160 | df_locations[int(count*file_size):int((count+1)*file_size)] = torch.tensor(df_location, dtype = torch.float)
161 |
162 | # df_locations = df_locations['pose']
163 | # df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
164 | else:
165 | df_files_test = []
166 | df_files_train =[]
167 |
168 | #n-40 Training 40 testing
169 | test_sample = len(fold_list)*10
170 | test_index = random.choices(range(traj_len), k=test_sample)
171 | train_index = list(range(traj_len))
172 | #for i in test_index:
173 | # train_index.pop(i)
174 | if not evaluate_all:
175 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
176 | df_locations_tr_y.extend(list(df_locations[train_index,1]))
177 |
178 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
179 | df_locations_ts_y.extend(list(df_locations[test_index,1]))
180 |
181 | for indx in range(traj_len):
182 | # file_ = 'panoimg_'+str(indx)+'.png'
183 | if indx in test_index:
184 | df_files_test.append(all_files[indx])
185 | df_files_train.append(all_files[indx])
186 |
187 | if not evaluate_all:
188 | #print("df_files_train:"+str((df_files_train)))
189 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
190 | columns =['file','x', 'y'])
191 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
192 | columns =['file','x', 'y'])
193 | else:
194 | df_train = pd.DataFrame(list(zip(df_files_train)),
195 | columns =['file'])
196 | df_test = pd.DataFrame(list(zip(df_files_test)),
197 | columns =['file'])
198 | print("Number of training submaps: "+str(len(df_train['file'])))
199 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
200 |
201 |
202 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
203 | if inside == False:
204 | if not evaluate_all:
205 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database.pickle", "generating_queries/evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
206 | else:
207 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database_full.pickle", "generating_queries/evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
208 | else:
209 | if not evaluate_all:
210 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database.pickle", "evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
211 | else:
212 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database_full.pickle", "evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
213 | if __name__ == "__main__":
214 | generate(1, evaluate_all=True)
215 | generate(1, evaluate_all=False)
--------------------------------------------------------------------------------
/generating_queries/generate_test_RGB_real_supervise_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 | import json
16 |
17 | ##########################################
18 |
19 | def output_to_file(output, filename):
20 | with open(filename, 'wb') as handle:
21 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
22 | print("Done ", filename)
23 |
24 | #########################################
25 | def construct_query_dict(df_centroids, df_database, folder_num, traj_len, filename_train, filename_test, nn_ind, r_mid, r_ind, test=False, evaluate_all=False):
26 | database_trees = []
27 | test_trees = []
28 | if not evaluate_all:
29 | tree = KDTree(df_centroids[['x','y']])
30 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
31 | ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
32 | queries_sets = []
33 | database_sets = []
34 |
35 | #for folder in range(folder_num):
36 | queries = {}
37 | for i in range(len(df_centroids)):
38 | #temp_indx = folder*len(df_centroids)//folder_num + i
39 | temp_indx = i
40 | query = df_centroids.iloc[temp_indx]["file"]
41 | #print("folder:"+str(folder))
42 | #print("query:"+str(query))
43 | if not evaluate_all:
44 | queries[len(queries.keys())] = {"query":query,
45 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
46 | else:
47 | queries[len(queries.keys())] = {"query":query}
48 |
49 | queries_sets.append(queries)
50 | if not evaluate_all:
51 | test_tree = KDTree(df_centroids[['x','y']])
52 | test_trees.append(test_tree)
53 |
54 | ###############################
55 | #for folder in range(folder_num):
56 | dataset = {}
57 | for i in range(len(df_database)):
58 | #temp_indx = folder*len(df_database)//folder_num + i
59 | temp_indx = i
60 | data = df_database.iloc[temp_indx]["file"]
61 | if not evaluate_all:
62 | dataset[len(dataset.keys())] = {"query":data,
63 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y']) }
64 | else:
65 | dataset[len(dataset.keys())] = {"query":data}
66 | database_sets.append(dataset)
67 | if not evaluate_all:
68 | database_tree = KDTree(df_database[['x','y']])
69 | database_trees.append(database_tree)
70 | ##################################
71 | if test:
72 | if not evaluate_all:
73 | #for i in range(len(database_sets)):
74 | tree = database_trees[0]
75 | #for j in range(len(queries_sets)):
76 | #if(i == j):
77 | # continue
78 | #print("len(queries_sets[j].keys():"+str(len(queries_sets[j].keys())))
79 | #assert(0)
80 | for key in range(len(queries_sets[0].keys())):
81 | coor = np.array(
82 | [[queries_sets[0][key]["x"],queries_sets[0][key]["y"]]])
83 | index = tree.query_radius(coor, r=r_mid)
84 | # indices of the positive matches in database i of each query (key) in test set j
85 | queries_sets[0][key][0] = index[0].tolist()
86 | else:
87 | pass
88 |
89 | output_to_file(queries_sets, filename_test)
90 | output_to_file(database_sets, filename_train)
91 |
92 | def generate(evaluate_all = False, inside=True):
93 | base_path = "/mnt/NAS/data/cc_data/2D_RGB_real_edited3"
94 | # runs_folder = cfg.scene_list[scene_index]
95 | #runs_folder = "Goffs"
96 | pre_dir = os.path.join(base_path)
97 |
98 | nn_ind = 0.2
99 | r_mid = 0.2
100 | r_ind = 0.6
101 |
102 | filename = "gt_pose.mat"
103 |
104 | folders = list(sorted(os.listdir(pre_dir)))
105 | if evaluate_all == False:
106 | index_list = list(range(len(folders)))
107 | else:
108 | index_list = list(range(len(folders)))
109 |
110 | fold_list = []
111 | for index in index_list:
112 | fold_list.append(folders[index])
113 |
114 | all_files = []
115 | for fold in fold_list:
116 | files_ = []
117 | files = list(sorted(os.listdir(os.path.join(pre_dir, fold))))
118 | files.remove('gt_pose.mat')
119 | # print("len(files):"+str(len(files)))
120 | for ind in range(len(files)):
121 | file_ = "panoimg_"+str(ind)+".jpg"
122 | files_.append(os.path.join(pre_dir, fold, file_))
123 | all_files.extend(files_)
124 | # all_files.remove('trajectory.mp4')
125 | # all_files = [i for i in all_files if not i.endswith(".npy")]
126 |
127 | traj_len = len(all_files)
128 | file_size = traj_len/len(fold_list)
129 |
130 | # Initialize pandas DataFrame
131 | if evaluate_all:
132 | df_train = pd.DataFrame(columns=['file'])
133 | df_test = pd.DataFrame(columns=['file'])
134 | else:
135 | df_train = pd.DataFrame(columns=['file','x','y'])
136 | df_test = pd.DataFrame(columns=['file','x','y'])
137 |
138 | if not evaluate_all:
139 | df_files_test = []
140 | df_files_train =[]
141 |
142 | df_locations_tr_x = []
143 | df_locations_tr_y = []
144 |
145 | df_locations_ts_x = []
146 | df_locations_ts_y = []
147 |
148 | # print("os.path.join(pre_dir,filename):"+str(os.path.join(pre_dir,filename)))
149 | df_locations = torch.zeros((traj_len, 2), dtype = torch.float)
150 | for count, fold in enumerate(fold_list):
151 | data = sio.loadmat(os.path.join(pre_dir,fold,filename))
152 | df_location = data['pose']
153 | df_locations[int(count*file_size):int((count+1)*file_size)] = torch.tensor(df_location, dtype = torch.float)
154 |
155 | # df_locations = df_locations['pose']
156 | # df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
157 | else:
158 | df_files_test = []
159 | df_files_train =[]
160 |
161 | #n-40 Training 40 testing
162 | test_sample = len(fold_list)*10
163 | test_index = random.choices(range(traj_len), k=test_sample)
164 | train_index = list(range(traj_len))
165 | #for i in test_index:
166 | # train_index.pop(i)
167 | if not evaluate_all:
168 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
169 | df_locations_tr_y.extend(list(df_locations[train_index,1]))
170 |
171 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
172 | df_locations_ts_y.extend(list(df_locations[test_index,1]))
173 |
174 | for indx in range(traj_len):
175 | # file_ = 'panoimg_'+str(indx)+'.png'
176 | if indx in test_index:
177 | df_files_test.append(all_files[indx])
178 | df_files_train.append(all_files[indx])
179 |
180 | if not evaluate_all:
181 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
182 | columns =['file','x', 'y'])
183 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
184 | columns =['file','x', 'y'])
185 | else:
186 | df_train = pd.DataFrame(list(zip(df_files_train)),
187 | columns =['file'])
188 | df_test = pd.DataFrame(list(zip(df_files_test)),
189 | columns =['file'])
190 | print("Number of training submaps: "+str(len(df_train['file'])))
191 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
192 |
193 |
194 | #construct_query_dict(df_train,len(folders),"evaluation_database.pickle",False)
195 | if inside == False:
196 | if not evaluate_all:
197 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database.pickle", "generating_queries/evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
198 | else:
199 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database_full.pickle", "generating_queries/evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
200 | else:
201 | if not evaluate_all:
202 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database.pickle", "evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
203 | else:
204 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database_full.pickle", "evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
205 | if __name__ == "__main__":
206 | generate(evaluate_all=False)
--------------------------------------------------------------------------------
/generating_queries/generate_test_RGB_supervise_sets.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 | import json
16 |
17 | ##########################################
18 |
19 | def output_to_file(output, filename):
20 | with open(filename, 'wb') as handle:
21 | pickle.dump(output, handle, protocol=pickle.HIGHEST_PROTOCOL)
22 | print("Done ", filename)
23 |
24 | #########################################
25 | def construct_query_dict(df_centroids, df_database, folder_num, traj_len, filename_train, filename_test, nn_ind, r_mid, r_ind, test=False, evaluate_all=False):
26 | database_trees = []
27 | test_trees = []
28 | if not evaluate_all:
29 | tree = KDTree(df_centroids[['x','y']])
30 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
31 | ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
32 | queries_sets = []
33 | database_sets = []
34 |
35 | queries = {}
36 | for i in range(len(df_centroids)):
37 | temp_indx = i
38 | query = df_centroids.iloc[temp_indx]["file"]
39 |
40 | if not evaluate_all:
41 | queries[len(queries.keys())] = {"query":query,
42 | "x":float(df_centroids.iloc[temp_indx]['x']),"y":float(df_centroids.iloc[temp_indx]['y'])}
43 | else:
44 | queries[len(queries.keys())] = {"query":query}
45 |
46 | queries_sets.append(queries)
47 | if not evaluate_all:
48 | test_tree = KDTree(df_centroids[['x','y']])
49 | test_trees.append(test_tree)
50 |
51 | ###############################
52 | dataset = {}
53 | for i in range(len(df_database)):
54 | temp_indx = i
55 | data = df_database.iloc[temp_indx]["file"]
56 | if not evaluate_all:
57 | dataset[len(dataset.keys())] = {"query":data,
58 | "x":float(df_database.iloc[temp_indx]['x']),"y":float(df_database.iloc[temp_indx]['y']) }
59 | else:
60 | dataset[len(dataset.keys())] = {"query":data}
61 | database_sets.append(dataset)
62 | if not evaluate_all:
63 | database_tree = KDTree(df_database[['x','y']])
64 | database_trees.append(database_tree)
65 | ##################################
66 | if test:
67 | if not evaluate_all:
68 | tree = database_trees[0]
69 |
70 | for key in range(len(queries_sets[0].keys())):
71 | coor = np.array(
72 | [[queries_sets[0][key]["x"],queries_sets[0][key]["y"]]])
73 | index = tree.query_radius(coor, r=r_mid)
74 | # indices of the positive matches in database i of each query (key) in test set j
75 | queries_sets[0][key][0] = index[0].tolist()
76 | else:
77 | pass
78 |
79 | output_to_file(queries_sets, filename_test)
80 | output_to_file(database_sets, filename_train)
81 |
82 | def generate(scene_index, evaluate_all = False, inside=True):
83 | base_path = "/mnt/NAS/home/cc/data/habitat_4/train"
84 | runs_folder = cfg.scene_list[scene_index]
85 | pre_dir = os.path.join(base_path, runs_folder)
86 |
87 | nn_ind = 0.2
88 | r_mid = 0.2
89 | r_ind = 0.6
90 |
91 | filename = "gt_pose.mat"
92 |
93 | folders = list(sorted(os.listdir(pre_dir)))
94 | if evaluate_all == False:
95 | index_list = list(range(len(folders)))
96 | else:
97 | index_list = list(range(len(folders)))
98 |
99 | fold_list = []
100 | for index in index_list:
101 | fold_list.append(folders[index])
102 |
103 | all_files = []
104 | for fold in fold_list:
105 | files_ = []
106 | files = list(sorted(os.listdir(os.path.join(pre_dir, fold))))
107 | files.remove('gt_pose.mat')
108 | # print("len(files):"+str(len(files)))
109 | for ind in range(len(files)):
110 | file_ = "panoimg_"+str(ind)+".png"
111 | files_.append(os.path.join(pre_dir, fold, file_))
112 | all_files.extend(files_)
113 |
114 | traj_len = len(all_files)
115 | file_size = traj_len/len(fold_list)
116 |
117 | # Initialize pandas DataFrame
118 | if evaluate_all:
119 | df_train = pd.DataFrame(columns=['file'])
120 | df_test = pd.DataFrame(columns=['file'])
121 | else:
122 | df_train = pd.DataFrame(columns=['file','x','y'])
123 | df_test = pd.DataFrame(columns=['file','x','y'])
124 |
125 | if not evaluate_all:
126 | df_files_test = []
127 | df_files_train =[]
128 |
129 | df_locations_tr_x = []
130 | df_locations_tr_y = []
131 |
132 | df_locations_ts_x = []
133 | df_locations_ts_y = []
134 |
135 | df_locations = torch.zeros((traj_len, 3), dtype = torch.float)
136 | for count, fold in enumerate(fold_list):
137 | data = sio.loadmat(os.path.join(pre_dir,fold,filename))
138 | df_location = data['pose']
139 | df_locations[int(count*file_size):int((count+1)*file_size)] = torch.tensor(df_location, dtype = torch.float)
140 |
141 | else:
142 | df_files_test = []
143 | df_files_train =[]
144 |
145 | #n-40 Training 40 testing
146 | test_sample = len(fold_list)*10
147 | test_index = random.choices(range(traj_len), k=test_sample)
148 | train_index = list(range(traj_len))
149 | if not evaluate_all:
150 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
151 | df_locations_tr_y.extend(list(df_locations[train_index,2]))
152 |
153 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
154 | df_locations_ts_y.extend(list(df_locations[test_index,2]))
155 |
156 | for indx in range(traj_len):
157 | if indx in test_index:
158 | df_files_test.append(all_files[indx])
159 | df_files_train.append(all_files[indx])
160 |
161 | if not evaluate_all:
162 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
163 | columns =['file','x', 'y'])
164 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
165 | columns =['file','x', 'y'])
166 | else:
167 | df_train = pd.DataFrame(list(zip(df_files_train)),
168 | columns =['file'])
169 | df_test = pd.DataFrame(list(zip(df_files_test)),
170 | columns =['file'])
171 | print("Number of training submaps: "+str(len(df_train['file'])))
172 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
173 |
174 |
175 | if inside == False:
176 | if not evaluate_all:
177 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database.pickle", "generating_queries/evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
178 | else:
179 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"generating_queries/evaluation_database_full.pickle", "generating_queries/evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
180 | else:
181 | if not evaluate_all:
182 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database.pickle", "evaluation_query.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
183 | else:
184 | construct_query_dict(df_train, df_train, len(fold_list), traj_len,"evaluation_database_full.pickle", "evaluation_query_full.pickle", nn_ind, r_mid, r_ind, True, evaluate_all)
185 | if __name__ == "__main__":
186 | generate(1, evaluate_all=False)
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_PCL_baseline.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import random
4 | import set_path
5 |
6 | import numpy as np
7 | import pandas as pd
8 | from sklearn.neighbors import KDTree
9 |
10 | import config as cfg
11 |
12 | import scipy.io as sio
13 | import torch
14 |
15 |
16 | #####For training and test data split#####
17 |
18 |
19 | def construct_dict(df_files, df_indices, filename, folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest):
20 | pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
21 | mid_index_range = list(range(-k_nearest, (k_nearest)+1))
22 | pos_index_range.remove(0)
23 | replace_counts = 0
24 | queries = {}
25 | for num in range(folder_num):
26 | for index in range(len(df_indices)//folder_num):
27 | df_indice = df_indices[num * (len(df_indices)//folder_num) + index]
28 | positive_l = []
29 | negative_l = list(range(num*folder_size,(num+1)*folder_size,1))
30 | for index_pos in pos_index_range:
31 | if (index_pos + df_indice >= 0) and (index_pos + df_indice <= folder_size -1):
32 | positive_l.append(index_pos + df_indice+folder_size*num)
33 | for index_pos in mid_index_range:
34 | if (index_pos + df_indice >= 0) and (index_pos + df_indice <= folder_size -1):
35 | negative_l.remove(index_pos + df_indice+folder_size*num)
36 | queries[num * (len(df_indices)//folder_num) + index] = {"query":df_files[num * (len(df_indices)//folder_num) + index],
37 | "positives":positive_l,"negatives":negative_l}
38 |
39 | #print("replace_counts:"+str(replace_counts))
40 | #print("queries:"+str(queries[0][0]))
41 |
42 | with open(filename, 'wb') as handle:
43 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
44 |
45 | print("Done ", filename)
46 |
47 | def generate(data_index):
48 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
49 | base_path = cfg.DATASET_FOLDER
50 | runs_folder = "dm_data/"
51 | print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
52 |
53 | cc_dir = "/home/cc/"
54 | all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
55 |
56 | folders = []
57 | # All runs are used for training (both full and partial)
58 | index_list = range(len(all_folders))
59 | print("Number of runs: "+str(len(index_list)))
60 | for index in index_list:
61 | folders.append(all_folders[index])
62 |
63 | # Initialize pandas DataFrame
64 | k_nearest = 10
65 | k_furthest = 50
66 |
67 | df_train = pd.DataFrame(columns=['file','positives','negatives'])
68 | df_test = pd.DataFrame(columns=['file','positives','negatives'])
69 |
70 | df_files_test = []
71 | df_files_train =[]
72 | df_files_all =[]
73 |
74 | df_indices_train = []
75 | df_indices_test = []
76 | df_indices_all = []
77 |
78 | folder_num = len(folders)
79 |
80 | for folder in folders:
81 | all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
82 | all_files.remove('gt_pose.mat')
83 | all_files.remove('gt_pose.png')
84 |
85 | folder_size = len(all_files)
86 | test_index = random.sample(range(folder_size), k=2)
87 | train_index = list(range(folder_size))
88 | for ts_ind in test_index:
89 | train_index.remove(ts_ind)
90 |
91 | for (indx, file_) in enumerate(all_files):
92 | if indx in test_index:
93 | df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
94 | df_indices_test.append(indx)
95 | else:
96 | df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
97 | df_indices_train.append(indx)
98 |
99 | df_files_all.append(os.path.join(cc_dir,runs_folder,folder,file_))
100 | df_indices_all.append(indx)
101 | pre_dir = os.path.join(cc_dir,runs_folder)
102 |
103 | if not os.path.exists(cfg.PICKLE_FOLDER):
104 | os.mkdir(cfg.PICKLE_FOLDER)
105 |
106 | construct_dict(df_files_train, df_indices_train, "train_pickle/training_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest)
107 | construct_dict(df_files_test, df_indices_test, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest)
108 | construct_dict(df_files_all, df_indices_all, "train_pickle/all_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest)
109 | if __name__ == "__main__":
110 | for i in range(1):
111 | generate(i)
112 |
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_PCL_ours.py:
--------------------------------------------------------------------------------
1 |
2 | import os
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 |
16 |
17 | #####For training and test data split#####
18 |
19 |
20 | def construct_dict(df_files, df_indices, filename, folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest, definite_positives=None):
21 | pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
22 | mid_index_range = list(range(-k_nearest, (k_nearest)+1))
23 | pos_index_range.remove(0)
24 |
25 | replace_counts = 0
26 | queries = {}
27 | for num in range(folder_num):
28 |
29 | for index in range(len(df_indices)//folder_num):
30 | df_indice = df_indices[num * (len(df_indices)//folder_num) + index]
31 | positive_l = []
32 | negative_l = list(range(num*folder_size,(num+1)*folder_size,1))
33 | for index_pos in pos_index_range:
34 | if (index_pos + df_indice >= 0) and (index_pos + df_indice <= folder_size -1):
35 | positive_l.append(index_pos + df_indice+folder_size*num)
36 | for index_pos in mid_index_range:
37 | if (index_pos + df_indice >= 0) and (index_pos + df_indice <= folder_size -1):
38 | negative_l.remove(index_pos + df_indice+folder_size*num)
39 | if definite_positives is not None:
40 |
41 | if ((np.array(definite_positives[num][df_indice]).ndim) == 2) and (np.array(definite_positives[num][df_indice]).shape[0]!=0):
42 | extend_element = definite_positives[num][df_indice][0]
43 | else:
44 | # print("extend_element_pre:"+str(definite_positives[num][df_indice]))
45 | extend_element = definite_positives[num][df_indice]
46 |
47 | positive_l.extend(extend_element)
48 | # print("positive_l:"+str(positive_l))
49 | positive_l = list(set(positive_l))
50 | negative_l = [i for i in negative_l if i not in extend_element]
51 |
52 | queries[num * (len(df_indices)//folder_num) + index] = {"query":df_files[num * (len(df_indices)//folder_num) + index],
53 | "positives":positive_l,"negatives":negative_l}
54 |
55 | #print("replace_counts:"+str(replace_counts))
56 | #print("queries:"+str(queries[0][0]))
57 |
58 | with open(filename, 'wb') as handle:
59 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
60 |
61 | print("Done ", filename)
62 |
63 | def generate(data_index, definite_positives=None, inside=True):
64 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
65 | base_path = cfg.DATASET_FOLDER
66 | runs_folder = "dm_data/"
67 | print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
68 |
69 | cc_dir = "/home/cc/"
70 | all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
71 |
72 | folders = []
73 | # All runs are used for training (both full and partial)
74 | index_list = range(len(all_folders))
75 | print("Number of runs: "+str(len(index_list)))
76 | for index in index_list:
77 | folders.append(all_folders[index])
78 |
79 | # Initialize pandas DataFrame
80 | k_nearest = 10
81 | k_furthest = 50
82 |
83 | df_train = pd.DataFrame(columns=['file','positives','negatives'])
84 | df_test = pd.DataFrame(columns=['file','positives','negatives'])
85 |
86 | df_files_test = []
87 | df_files_train =[]
88 | df_files = []
89 |
90 | df_indices_train = []
91 | df_indices_test = []
92 | df_indices = []
93 |
94 | folder_num = len(folders)
95 |
96 | for folder in folders:
97 | all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
98 | all_files.remove('gt_pose.mat')
99 | all_files.remove('gt_pose.png')
100 |
101 | folder_size = len(all_files)
102 | test_index = random.sample(range(folder_size), k=2)
103 | train_index = list(range(folder_size))
104 | for ts_ind in test_index:
105 | train_index.remove(ts_ind)
106 |
107 | for (indx, file_) in enumerate(all_files):
108 | if indx in test_index:
109 | df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
110 | df_indices_test.append(indx)
111 | else:
112 | df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
113 | df_indices_train.append(indx)
114 | df_files.append(os.path.join(cc_dir,runs_folder,folder,file_))
115 | df_indices.append(indx)
116 |
117 | pre_dir = os.path.join(cc_dir,runs_folder)
118 |
119 | if not os.path.exists(cfg.PICKLE_FOLDER):
120 | os.mkdir(cfg.PICKLE_FOLDER)
121 |
122 | if inside == True:
123 | construct_dict(df_files_train, df_indices_train, "train_pickle/training_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest)
124 | construct_dict(df_files_test, df_indices_test, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest)
125 | construct_dict(df_files, df_indices, "train_pickle/db_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest)
126 |
127 | else:
128 | construct_dict(df_files_train, df_indices_train, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest, definite_positives=definite_positives)
129 | construct_dict(df_files_test, df_indices_test, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest, definite_positives=definite_positives)
130 | construct_dict(df_files, df_indices, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", folder_size, folder_num, all_folders, pre_dir, k_nearest, k_furthest, definite_positives=definite_positives)
131 |
132 | if __name__ == "__main__":
133 | for i in range(1):
134 | generate(i)
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_PCL_supervise.py:
--------------------------------------------------------------------------------
1 | import os
2 | import pickle
3 | import random
4 | import set_path
5 |
6 | import numpy as np
7 | import pandas as pd
8 | from sklearn.neighbors import KDTree
9 |
10 | import config as cfg
11 |
12 | import scipy.io as sio
13 | import torch
14 |
15 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
16 | base_path = cfg.DATASET_FOLDER
17 |
18 | runs_folder = "dm_data/"
19 | filename = "gt_pose.mat"
20 | pointcloud_fols = "/pointcloud_20m_10overlap/"
21 |
22 | print("cfg.DATASET_FOLDER:"+str(cfg.DATASET_FOLDER))
23 |
24 | cc_dir = "/home/cc/"
25 | all_folders = sorted(os.listdir(os.path.join(cc_dir,runs_folder)))
26 |
27 | folders = []
28 |
29 | # All runs are used for training (both full and partial)
30 | index_list = range(18)
31 | print("Number of runs: "+str(len(index_list)))
32 | for index in index_list:
33 | folders.append(all_folders[index])
34 | print(folders)
35 |
36 |
37 | #####For training and test data split#####
38 |
39 |
40 | def construct_query_dict(df_centroids, train_index, test_index, filename_train, filename_test):
41 | tree = KDTree(df_centroids[['x','y']])
42 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=15)
43 | ind_r = tree.query_radius(df_centroids[['x','y']], r=50)
44 | queries = {}
45 | queries_test = {}
46 |
47 | #for i in range(len(ind_nn)):
48 | for i in train_index:
49 | query = df_centroids.iloc[i]["file"]
50 | positives = np.setdiff1d(ind_nn[i],[i]).tolist()
51 | negatives = np.setdiff1d(
52 | df_centroids.index.values.tolist(),ind_r[i]).tolist()
53 | random.shuffle(negatives)
54 | queries[i] = {"query":df_centroids.iloc[i]['file'],
55 | "positives":positives,"negatives":negatives}
56 |
57 | for i in test_index:
58 | query = df_centroids.iloc[i]["file"]
59 | positives = np.setdiff1d(ind_nn[i],[i]).tolist()
60 | negatives = np.setdiff1d(
61 | df_centroids.index.values.tolist(),ind_r[i]).tolist()
62 | random.shuffle(negatives)
63 | queries_test[i] = {"query":df_centroids.iloc[i]['file'],
64 | "positives":positives,"negatives":negatives}
65 |
66 | with open(filename_train, 'wb') as handle:
67 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
68 | with open(filename_test, 'wb') as handle:
69 | pickle.dump(queries_test, handle, protocol=pickle.HIGHEST_PROTOCOL)
70 |
71 | print("Done ", filename_train)
72 | print("Done ", filename_test)
73 |
74 | if not os.path.exists(cfg.PICKLE_FOLDER):
75 | os.mkdir(cfg.PICKLE_FOLDER)
76 |
77 | # Initialize pandas DataFrame
78 | df_train = pd.DataFrame(columns=['file','x','y'])
79 | df_test = pd.DataFrame(columns=['file','x','y'])
80 | df_file = pd.DataFrame(columns=['file','x','y'])
81 |
82 | df_files_test = []
83 | df_files_train =[]
84 | df_files = []
85 |
86 | df_indice_test = []
87 | df_indice_train = []
88 | df_indice = []
89 |
90 | df_locations_tr_x = []
91 | df_locations_tr_y = []
92 | df_locations_ts_x = []
93 | df_locations_ts_y = []
94 | df_locations_db_x = []
95 | df_locations_db_y = []
96 |
97 | count = 0
98 | for folder in folders:
99 | df_locations = sio.loadmat(os.path.join(
100 | cc_dir,runs_folder,folder,filename))
101 |
102 | df_locations = df_locations['pose']
103 | df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
104 |
105 | #2038 Training 10 testing
106 | test_index = random.sample(range(len(df_locations)), k=10)
107 | df_indice_test.extend(np.array(test_index)+count*2048)
108 | train_index = list(range(df_locations.shape[0]))
109 | df_indice_train.extend(np.array(train_index)+count*2048)
110 | db_index = list(range(df_locations.shape[0]))
111 | count=count+1
112 | for i in test_index:
113 | train_index.remove(i)
114 |
115 | df_locations_tr_x.extend(list(df_locations[train_index,0]))
116 | df_locations_tr_y.extend(list(df_locations[train_index,1]))
117 | df_locations_ts_x.extend(list(df_locations[test_index,0]))
118 | df_locations_ts_y.extend(list(df_locations[test_index,1]))
119 | df_locations_db_x.extend(list(df_locations[db_index,0]))
120 | df_locations_db_y.extend(list(df_locations[db_index,1]))
121 |
122 | all_files = list(sorted(os.listdir(os.path.join(cc_dir,runs_folder,folder))))
123 | all_files.remove('gt_pose.mat')
124 | all_files.remove('gt_pose.png')
125 |
126 | for (indx, file_) in enumerate(all_files):
127 | if indx in test_index:
128 | df_files_test.append(os.path.join(cc_dir,runs_folder,folder,file_))
129 | else:
130 | df_files_train.append(os.path.join(cc_dir,runs_folder,folder,file_))
131 | df_files.append(os.path.join(cc_dir,runs_folder,folder,file_))
132 |
133 |
134 | print("df_locations_tr_x:"+str(len(df_locations_tr_x)))
135 | print("df_files_test:"+str(len(df_files_test)))
136 |
137 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
138 | columns =['file','x', 'y'])
139 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
140 | columns =['file','x', 'y'])
141 | df_file = pd.DataFrame(list(zip(df_files, df_locations_db_x, df_locations_db_y)),
142 | columns =['file','x', 'y'])
143 |
144 |
145 | print("Number of training submaps: "+str(len(df_train['file'])))
146 | print("Number of non-disjoint test submaps: "+str(len(df_test['file'])))
147 |
148 | construct_query_dict(df_file, df_indice_train, df_indice_test, "training_queries_baseline.pickle", "test_queries_baseline.pickle")
149 | #construct_query_dict(df_test,"test_queries_baseline.pickle")
150 |
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_RGB_baseline.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 |
16 | #####For training and test data split#####
17 |
18 | def construct_dict(folder_num, df_files, df_files_all, df_indices, filename, pre_dir, k_nearest, k_furthest, traj_len, definite_positives=None):
19 | pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
20 | mid_index_range = list(range(-k_nearest, (k_nearest)+1))
21 | queries = {}
22 | count = 0
23 | traj_len = int(len(df_files_all)/folder_num)
24 | for df_indice in df_indices:
25 | cur_fold_num = int(df_indice//traj_len)
26 | file_index = int(df_indice%traj_len)
27 | positive_l = []
28 | negative_l = list(range(cur_fold_num*traj_len, (cur_fold_num+1)*traj_len, 1))
29 |
30 | cur_indice = df_indice % traj_len
31 |
32 | for index_pos in pos_index_range:
33 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
34 | positive_l.append(index_pos + df_indice)
35 | for index_pos in mid_index_range:
36 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
37 | negative_l.remove(index_pos + df_indice)
38 | #positive_l.append(df_indice)
39 | #positive_l.append(df_indice)
40 | #negative_l.remove(df_indice)
41 |
42 | if definite_positives is not None:
43 | if len(definite_positives)==1:
44 | if definite_positives[0][df_indice].ndim ==2:
45 | positive_l.extend(definite_positives[0][df_indice][0])
46 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice][0]]
47 | else:
48 | positive_l.extend(definite_positives[0][df_indice])
49 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice]]
50 | else:
51 | positive_l.extend(definite_positives[df_indice])
52 | positive_l = list(set(positive_l))
53 | negative_l = [i for i in negative_l if i not in definite_positives[df_indice]]
54 |
55 | queries[count] = {"query":df_files[count],
56 | "positives":positive_l,"negatives":negative_l}
57 | count = count + 1
58 |
59 | with open(filename, 'wb') as handle:
60 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
61 |
62 | print("Done ", filename)
63 |
64 | def generate(scene_index, data_index, definite_positives=None, inside=True):
65 | base_path = "/mnt/NAS/home/cc/data/habitat_4/train/"
66 | run_folder = cfg.scene_list[scene_index]
67 | base_path = os.path.join(base_path,run_folder)
68 | pre_dir = base_path
69 | '''
70 | runs_folder = cfg.scene_names[scene_index]
71 | print("runs_folder2:"+str(runs_folder))
72 |
73 | pre_dir = os.path.join(base_path, runs_folder)
74 | print("pre_dir:"+str(pre_dir))
75 | '''
76 | filename = "gt_pose.mat"
77 |
78 | # Initialize pandas DataFrame
79 | k_nearest = 10
80 | k_furthest = 50
81 |
82 | df_train = pd.DataFrame(columns=['file','positives','negatives'])
83 | df_test = pd.DataFrame(columns=['file','positives','negatives'])
84 |
85 | df_files_test = []
86 | df_files_train =[]
87 | df_files = []
88 |
89 | df_indices_train = []
90 | df_indices_test = []
91 | df_indices = []
92 |
93 | fold_list = list(sorted(os.listdir(base_path)))
94 | all_files = []
95 | for fold in fold_list:
96 | files_ = []
97 | files = list(sorted(os.listdir(os.path.join(base_path, fold))))
98 | files.remove('gt_pose.mat')
99 | # print("len(files):"+str(len(files)))
100 | for ind in range(len(files)):
101 | file_ = "panoimg_"+str(ind)+".png"
102 | files_.append(os.path.join(base_path, fold, file_))
103 | all_files.extend(files_)
104 |
105 | traj_len = len(all_files)
106 |
107 | #n Training 10 testing
108 | test_sample = len(fold_list)*10
109 | file_index = list(range(traj_len))
110 | test_index = random.sample(range(traj_len), k=test_sample)
111 | train_index = list(range(traj_len))
112 | for ts_ind in test_index:
113 | train_index.remove(ts_ind)
114 |
115 | for indx in range(traj_len):
116 | # file_ = 'panoimg_'+str(indx)+'.png'
117 | if indx in test_index:
118 | df_files_test.append(all_files[indx])
119 | df_indices_test.append(indx)
120 | else:
121 | df_files_train.append(all_files[indx])
122 | df_indices_train.append(indx)
123 | df_files.append(all_files[indx])
124 | df_indices.append(indx)
125 |
126 | if not os.path.exists(cfg.PICKLE_FOLDER):
127 | os.mkdir(cfg.PICKLE_FOLDER)
128 |
129 | if inside == True:
130 | construct_dict(len(fold_list),df_files_train, df_files,df_indices_train, "train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
131 | construct_dict(len(fold_list), df_files_test, df_files,df_indices_test, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
132 | construct_dict(len(fold_list), df_files,df_files, df_indices, "train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
133 |
134 | else:
135 | construct_dict(len(fold_list), df_files_train,df_files, df_indices_train, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
136 | construct_dict(len(fold_list), df_files_test,df_files, df_indices_test, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
137 | construct_dict(len(fold_list), df_files,df_files, df_indices, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
138 |
139 | if __name__ == "__main__":
140 | for i in range(1):
141 | generate(0,i)
142 |
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_RGB_ours.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 |
16 | #####For training and test data split#####
17 |
18 | def construct_dict(folder_num, df_files, df_files_all, df_indices, filename, pre_dir, k_nearest, k_furthest, traj_len, definite_positives=None):
19 | pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
20 | mid_index_range = list(range(-k_nearest, (k_nearest)+1))
21 | queries = {}
22 | count = 0
23 | traj_len = int(len(df_files_all)/folder_num)
24 | for df_indice in df_indices:
25 | cur_fold_num = int(df_indice//traj_len)
26 | file_index = int(df_indice%traj_len)
27 | positive_l = []
28 | negative_l = list(range(cur_fold_num*traj_len, (cur_fold_num+1)*traj_len, 1))
29 |
30 | cur_indice = df_indice % traj_len
31 |
32 | for index_pos in pos_index_range:
33 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
34 | positive_l.append(index_pos + df_indice)
35 | for index_pos in mid_index_range:
36 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
37 | negative_l.remove(index_pos + df_indice)
38 |
39 | if definite_positives is not None:
40 | if len(definite_positives)==1:
41 | if definite_positives[0][df_indice].ndim ==2:
42 | positive_l.extend(definite_positives[0][df_indice][0])
43 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice][0]]
44 | else:
45 | positive_l.extend(definite_positives[0][df_indice])
46 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice]]
47 | else:
48 | positive_l.extend(definite_positives[df_indice])
49 | positive_l = list(set(positive_l))
50 | negative_l = [i for i in negative_l if i not in definite_positives[df_indice]]
51 |
52 | queries[count] = {"query":df_files[count],
53 | "positives":positive_l,"negatives":negative_l}
54 | count = count + 1
55 |
56 | with open(filename, 'wb') as handle:
57 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
58 |
59 | print("Done ", filename)
60 |
61 | def generate(scene_index, data_index, definite_positives=None, inside=True):
62 | base_path = "/mnt/NAS/home/cc/data/habitat_4/train/"#Goffs/"
63 | base_path = os.path.join(base_path,cfg.scene_list[scene_index])
64 | pre_dir = base_path
65 |
66 | filename = "gt_pose.mat"
67 |
68 | # Initialize pandas DataFrame
69 | k_nearest = 10
70 | k_furthest = 50
71 |
72 | df_train = pd.DataFrame(columns=['file','positives','negatives'])
73 | df_test = pd.DataFrame(columns=['file','positives','negatives'])
74 |
75 | df_files_test = []
76 | df_files_train =[]
77 | df_files = []
78 |
79 | df_indices_train = []
80 | df_indices_test = []
81 | df_indices = []
82 |
83 | fold_list = list(sorted(os.listdir(base_path)))
84 | all_files = []
85 | for fold in fold_list:
86 | files_ = []
87 | files = list(sorted(os.listdir(os.path.join(base_path, fold))))
88 | files.remove('gt_pose.mat')
89 | # print("len(files):"+str(len(files)))
90 | for ind in range(len(files)):
91 | file_ = "panoimg_"+str(ind)+".png"
92 | files_.append(os.path.join(base_path, fold, file_))
93 | all_files.extend(files_)
94 |
95 | traj_len = len(all_files)
96 |
97 | #n Training 10 testing
98 | test_sample = len(fold_list)*10
99 | file_index = list(range(traj_len))
100 | test_index = random.sample(range(traj_len), k=test_sample)
101 | train_index = list(range(traj_len))
102 |
103 | for indx in range(traj_len):
104 | if indx in test_index:
105 | df_files_test.append(all_files[indx])
106 | df_indices_test.append(indx)
107 | else:
108 | df_files_train.append(all_files[indx])
109 | df_indices_train.append(indx)
110 | df_files.append(all_files[indx])
111 | df_indices.append(indx)
112 |
113 | if not os.path.exists(cfg.PICKLE_FOLDER):
114 | os.mkdir(cfg.PICKLE_FOLDER)
115 |
116 | if inside == True:
117 | construct_dict(len(fold_list),df_files_train, df_files,df_indices_train, "train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
118 | construct_dict(len(fold_list), df_files_test, df_files,df_indices_test, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
119 | construct_dict(len(fold_list), df_files,df_files, df_indices, "train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
120 |
121 | else:
122 | construct_dict(len(fold_list), df_files_train,df_files, df_indices_train, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
123 | construct_dict(len(fold_list), df_files_test,df_files, df_indices_test, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
124 | construct_dict(len(fold_list), df_files,df_files, df_indices, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
125 |
126 | if __name__ == "__main__":
127 | for i in range(1):
128 | generate(0,i)
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_RGB_real_baseline.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 |
16 | #####For training and test data split#####
17 |
18 | def construct_dict(folder_num, df_files, df_files_all, df_indices, filename, pre_dir, k_nearest, k_furthest, traj_len, definite_positives=None):
19 | pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
20 | pos_index_range.remove(0)
21 | mid_index_range = list(range(-k_furthest//2, (k_furthest)//2+1))
22 | queries = {}
23 | count = 0
24 | traj_len = int(len(df_files_all)/folder_num)
25 | for df_indice in df_indices:
26 | cur_fold_num = int(df_indice//traj_len)
27 | file_index = int(df_indice%traj_len)
28 | positive_l = []
29 | negative_l = list(range(cur_fold_num*traj_len, (cur_fold_num+1)*traj_len, 1))
30 |
31 | cur_indice = df_indice % traj_len
32 |
33 | for index_pos in pos_index_range:
34 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
35 | positive_l.append(index_pos + df_indice)
36 | for index_pos in mid_index_range:
37 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
38 | negative_l.remove(index_pos + df_indice)
39 | #positive_l.append(df_indice)
40 | #positive_l.append(df_indice)
41 | #negative_l.remove(df_indice)
42 |
43 | if definite_positives is not None:
44 | if len(definite_positives)==1:
45 | if definite_positives[0][df_indice].ndim ==2:
46 | positive_l.extend(definite_positives[0][df_indice][0])
47 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice][0]]
48 | else:
49 | positive_l.extend(definite_positives[0][df_indice])
50 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice]]
51 | else:
52 | positive_l.extend(definite_positives[df_indice])
53 | positive_l = list(set(positive_l))
54 | negative_l = [i for i in negative_l if i not in definite_positives[df_indice]]
55 |
56 | queries[count] = {"query":df_files[count],
57 | "positives":positive_l,"negatives":negative_l}
58 | #print("query:"+str(df_files[count]))
59 | #print("positives:"+str(positive_l))
60 | count = count + 1
61 |
62 | with open(filename, 'wb') as handle:
63 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
64 |
65 | print("Done ", filename)
66 |
67 | def generate(scene_index, data_index, definite_positives=None, inside=True):
68 | base_path = "/mnt/NAS/data/cc_data/2D_RGB_real_full3"
69 | pre_dir = base_path
70 | '''
71 | runs_folder = cfg.scene_names[scene_index]
72 | print("runs_folder2:"+str(runs_folder))
73 |
74 | pre_dir = os.path.join(base_path, runs_folder)
75 | print("pre_dir:"+str(pre_dir))
76 | '''
77 | filename = "gt_pose.mat"
78 |
79 | # Initialize pandas DataFrame
80 | k_nearest = 10
81 | k_furthest = 200
82 |
83 | df_train = pd.DataFrame(columns=['file','positives','negatives'])
84 | df_test = pd.DataFrame(columns=['file','positives','negatives'])
85 |
86 | df_files_test = []
87 | df_files_train =[]
88 | df_files = []
89 |
90 | df_indices_train = []
91 | df_indices_test = []
92 | df_indices = []
93 |
94 | fold_list = list(sorted(os.listdir(base_path)))
95 | all_files = []
96 | for fold in fold_list:
97 | files_ = []
98 | files = list(sorted(os.listdir(os.path.join(base_path, fold))))
99 | #files.remove('gt_pose.mat')
100 | # print("len(files):"+str(len(files)))
101 | for ind in range(len(files)):
102 | file_ = "panoimg_"+str(ind)+".jpg"
103 | files_.append(os.path.join(base_path, fold, file_))
104 | all_files.extend(files_)
105 |
106 | traj_len = len(all_files)
107 |
108 | #n Training 10 testing
109 | test_sample = len(fold_list)*10
110 | file_index = list(range(traj_len))
111 | test_index = random.sample(range(traj_len), k=test_sample)
112 | train_index = list(range(traj_len))
113 | for ts_ind in test_index:
114 | train_index.remove(ts_ind)
115 |
116 | for indx in range(traj_len):
117 | # file_ = 'panoimg_'+str(indx)+'.png'
118 | if indx in test_index:
119 | df_files_test.append(all_files[indx])
120 | df_indices_test.append(indx)
121 | else:
122 | df_files_train.append(all_files[indx])
123 | df_indices_train.append(indx)
124 | df_files.append(all_files[indx])
125 | df_indices.append(indx)
126 |
127 | if not os.path.exists(cfg.PICKLE_FOLDER):
128 | os.mkdir(cfg.PICKLE_FOLDER)
129 |
130 | if inside == True:
131 | construct_dict(len(fold_list),df_files_train, df_files,df_indices_train, "train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
132 | construct_dict(len(fold_list), df_files_test, df_files,df_indices_test, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
133 | construct_dict(len(fold_list), df_files,df_files, df_indices, "train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
134 |
135 | else:
136 | construct_dict(len(fold_list), df_files_train,df_files, df_indices_train, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
137 | construct_dict(len(fold_list), df_files_test,df_files, df_indices_test, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
138 | construct_dict(len(fold_list), df_files,df_files, df_indices, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
139 |
140 | if __name__ == "__main__":
141 | for i in range(1):
142 | generate(0,i)
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_RGB_real_ours.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 |
16 | #####For training and test data split#####
17 |
18 | def construct_dict(folder_num, df_files, df_files_all, df_indices, filename, pre_dir, k_nearest, k_furthest, traj_len, definite_positives=None):
19 | pos_index_range = list(range(-k_nearest//2, (k_nearest//2)+1))
20 | pos_index_range.remove(0)
21 | mid_index_range = list(range(-k_nearest, (k_nearest)+1))
22 | queries = {}
23 | count = 0
24 | traj_len = int(len(df_files_all)/folder_num)
25 | for df_indice in df_indices:
26 | cur_fold_num = int(df_indice//traj_len)
27 | file_index = int(df_indice%traj_len)
28 | positive_l = []
29 | negative_l = list(range(cur_fold_num*traj_len, (cur_fold_num+1)*traj_len, 1))
30 |
31 | cur_indice = df_indice % traj_len
32 |
33 | for index_pos in pos_index_range:
34 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
35 | positive_l.append(index_pos + df_indice)
36 | for index_pos in mid_index_range:
37 | if (index_pos + cur_indice >= 0) and (index_pos + cur_indice <= traj_len -1):
38 | negative_l.remove(index_pos + df_indice)
39 | #positive_l.append(df_indice)
40 | #positive_l.append(df_indice)
41 | #negative_l.remove(df_indice)
42 |
43 | if definite_positives is not None:
44 | if len(definite_positives)==1:
45 | if (definite_positives[0][df_indice].ndim ==2) and (definite_positives[0][df_indice].shape[0]!=0) :
46 | positive_l.extend(definite_positives[0][df_indice][0])
47 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice][0]]
48 | else:
49 | positive_l.extend(definite_positives[0][df_indice])
50 | negative_l = [i for i in negative_l if i not in definite_positives[0][df_indice]]
51 | else:
52 | positive_l.extend(definite_positives[df_indice])
53 | positive_l = list(set(positive_l))
54 | negative_l = [i for i in negative_l if i not in definite_positives[df_indice]]
55 |
56 | queries[count] = {"query":df_files[count],
57 | "positives":positive_l,"negatives":negative_l}
58 | count = count + 1
59 |
60 | with open(filename, 'wb') as handle:
61 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
62 |
63 | print("Done ", filename)
64 |
65 | def generate(scene_index, data_index, definite_positives=None, inside=True):
66 | base_path = "/mnt/NAS/data/cc_data/2D_RGB_real_full3"
67 | pre_dir = base_path
68 | '''
69 | runs_folder = cfg.scene_names[scene_index]
70 | print("runs_folder2:"+str(runs_folder))
71 |
72 | pre_dir = os.path.join(base_path, runs_folder)
73 | print("pre_dir:"+str(pre_dir))
74 | '''
75 | filename = "gt_pose.mat"
76 |
77 | # Initialize pandas DataFrame
78 | k_nearest = 10
79 | k_furthest = 100
80 |
81 | df_train = pd.DataFrame(columns=['file','positives','negatives'])
82 | df_test = pd.DataFrame(columns=['file','positives','negatives'])
83 |
84 | df_files_test = []
85 | df_files_train =[]
86 | df_files = []
87 |
88 | df_indices_train = []
89 | df_indices_test = []
90 | df_indices = []
91 |
92 | fold_list = list(sorted(os.listdir(base_path)))
93 | all_files = []
94 | for fold in fold_list:
95 | files_ = []
96 | files = list(sorted(os.listdir(os.path.join(base_path, fold))))
97 | #files.remove('gt_pose.mat')
98 | # print("len(files):"+str(len(files)))
99 | for ind in range(len(files)):
100 | file_ = "panoimg_"+str(ind)+".jpg"
101 | files_.append(os.path.join(base_path, fold, file_))
102 | all_files.extend(files_)
103 |
104 | traj_len = len(all_files)
105 |
106 | #n Training 10 testing
107 | test_sample = len(fold_list)*10
108 | file_index = list(range(traj_len))
109 | test_index = random.sample(range(traj_len), k=test_sample)
110 | train_index = list(range(traj_len))
111 | #for ts_ind in test_index:
112 | # train_index.remove(ts_ind)
113 |
114 | for indx in range(traj_len):
115 | # file_ = 'panoimg_'+str(indx)+'.png'
116 | if indx in test_index:
117 | df_files_test.append(all_files[indx])
118 | df_indices_test.append(indx)
119 | else:
120 | df_files_train.append(all_files[indx])
121 | df_indices_train.append(indx)
122 | df_files.append(all_files[indx])
123 | df_indices.append(indx)
124 |
125 | if not os.path.exists(cfg.PICKLE_FOLDER):
126 | os.mkdir(cfg.PICKLE_FOLDER)
127 |
128 | if inside == True:
129 | construct_dict(len(fold_list),df_files_train, df_files,df_indices_train, "train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
130 | construct_dict(len(fold_list), df_files_test, df_files,df_indices_test, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
131 | construct_dict(len(fold_list), df_files,df_files, df_indices, "train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)))
132 |
133 | else:
134 | construct_dict(len(fold_list), df_files_train,df_files, df_indices_train, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
135 | construct_dict(len(fold_list), df_files_test,df_files, df_indices_test, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
136 | construct_dict(len(fold_list), df_files,df_files, df_indices, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir, k_nearest, k_furthest, int(traj_len/len(fold_list)), definite_positives=definite_positives)
137 |
138 | if __name__ == "__main__":
139 | for i in range(1):
140 | generate(0,i)
141 |
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_RGB_real_supervise.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 |
16 | #####For training and test data split#####
17 |
18 | def construct_dict(folder_num, df_f, df_all, df_files, df_files_all, df_indices, df_indices_all, df_locations_x_all, df_locations_y_all, df_locations_x, df_locations_y, filename, pre_dir):
19 | nn_ind = 0.005
20 | r_mid = 0.005
21 | r_ind = 0.015
22 |
23 | queries = {}
24 | count = 0
25 |
26 | df_centroids = df_all
27 | df_folder_index = df_indices
28 |
29 | tree = KDTree(df_centroids[['x','y']])
30 | ind_r = tree.query_radius(df_centroids[['x','y']], r=r_ind)
31 | ind_nn = tree.query_radius(df_centroids[['x','y']],r=nn_ind)
32 |
33 | for i in df_indices:
34 | query = df_centroids.iloc[i]["file"]
35 | positives = np.setdiff1d(ind_nn[i],[i]).tolist()
36 | negatives = np.setdiff1d(
37 | df_centroids.index.values.tolist(),ind_r[i]).tolist()
38 | random.shuffle(negatives)
39 | if len(positives)<2:
40 | positives = []
41 | positives.append(i+1)
42 | positives.append(i-1)
43 | positives = np.array(positives)
44 | # print(len(positives))
45 | # assert(len(positives)<=1000)
46 |
47 | queries[i] = {"query":df_centroids.iloc[i]['file'],
48 | "positives":positives,"negatives":negatives}
49 |
50 |
51 | with open(filename, 'wb') as handle:
52 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
53 |
54 | print("Done ", filename)
55 |
56 | def generate(data_index, definite_positives=None, inside=True):
57 | base_path = "/mnt/NAS/data/cc_data/2D_RGB_real_edited3"
58 | base_path = os.path.join(base_path)
59 | pre_dir = base_path
60 | '''
61 | runs_folder = cfg.scene_names[scene_index]
62 | print("runs_folder2:"+str(runs_folder))
63 |
64 | pre_dir = os.path.join(base_path, runs_folder)
65 | print("pre_dir:"+str(pre_dir))
66 | '''
67 | filename = "gt_pose.mat"
68 |
69 | # Initialize pandas DataFrame
70 |
71 | df_train = pd.DataFrame(columns=['file','x','y'])
72 | df_test = pd.DataFrame(columns=['file','x','y'])
73 | df_all = pd.DataFrame(columns=['file','x','y'])
74 |
75 | df_files_test = []
76 | df_files_train =[]
77 | df_files = []
78 |
79 | df_indices_train = []
80 | df_indices_test = []
81 | df_indices = []
82 |
83 | df_locations_tr_x = []
84 | df_locations_tr_y = []
85 | # df_locations_tr_z = []
86 |
87 | df_locations_ts_x = []
88 | df_locations_ts_y = []
89 | # df_locations_ts_z = []
90 |
91 | df_locations_x = []
92 | df_locations_y = []
93 | # df_locations_z = []
94 |
95 | fold_list = list(sorted(os.listdir(base_path)))
96 | all_files = []
97 | for ind, fold in enumerate(fold_list):
98 | files_ = []
99 | files = list(sorted(os.listdir(os.path.join(base_path, fold))))
100 | files.remove('gt_pose.mat')
101 | # print("len(files):"+str(len(files)))
102 | for ind_f in range(len(files)):
103 | file_ = "panoimg_"+str(ind_f)+".jpg"
104 | files_.append(os.path.join(base_path, fold, file_))
105 | df_files.extend(files_)
106 | df_locations = sio.loadmat(os.path.join(base_path,fold,filename))
107 | df_locations = df_locations['pose']
108 | #df_locations = torch.tensor(df_locations, dtype = torch.float).cpu()
109 | # print(df_locations.shape)
110 | # assert()
111 | file_index = list(range(df_locations.shape[0]))
112 |
113 | df_locations_x.extend(list(df_locations[file_index,0]))
114 | # df_locations_z.extend(list(df_locations[file_index,1]))
115 | df_locations_y.extend(list(df_locations[file_index,1]))
116 | test_sample = 10
117 | test_index_temp = random.sample(range(df_locations.shape[0]), k=test_sample)
118 | test_index = list(np.array(test_index_temp)+ind * df_locations.shape[0])
119 |
120 | df_indices_test.extend(test_index)
121 | train_index_temp = list(range(df_locations.shape[0]))
122 | train_index = list(np.array(train_index_temp)+ind * len(files_))
123 | df_indices.extend(train_index)
124 | files_ = []
125 | for ts_ind in test_index:
126 | train_index.remove(ts_ind)
127 | file_ = "panoimg_"+str(ts_ind)+".jpg"
128 | files_.append(os.path.join(base_path, fold, file_))
129 | df_indices_train.extend(train_index)
130 | df_files_test.extend(files_)
131 | files_ = []
132 | for tr_ind in train_index:
133 | file_ = "panoimg_"+str(tr_ind)+".jpg"
134 | files_.append(os.path.join(base_path, fold, file_))
135 | df_files_train.extend(files_)
136 |
137 | df_locations_tr_x.extend(list(df_locations[train_index_temp,0]))
138 | # df_locations_tr_z.extend(list(df_locations[train_index_temp,1]))
139 | df_locations_tr_y.extend(list(df_locations[train_index_temp,1]))
140 |
141 | df_locations_ts_x.extend(list(df_locations[test_index_temp,0]))
142 | # df_locations_ts_z.extend(list(df_locations[test_index_temp,1]))
143 | df_locations_ts_y.extend(list(df_locations[test_index_temp,1]))
144 |
145 | traj_len = len(all_files)
146 |
147 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y)),
148 | columns =['file','x', 'y'])
149 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y)),
150 | columns =['file','x', 'y'])
151 | df_all = pd.DataFrame(list(zip(df_files, df_locations_x, df_locations_y)),
152 | columns =['file','x', 'y'])
153 | #n Training 10 testing
154 | if not os.path.exists(cfg.PICKLE_FOLDER):
155 | os.mkdir(cfg.PICKLE_FOLDER)
156 |
157 | if inside == True:
158 | construct_dict(len(fold_list),df_train,df_all,df_files_train,df_files,df_indices_train, df_indices,df_locations_x,df_locations_y,df_locations_tr_x,df_locations_tr_y,"train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir)
159 | construct_dict(len(fold_list),df_test,df_all,df_files_test,df_files,df_indices_test,df_indices,df_locations_x,df_locations_y,df_locations_ts_x,df_locations_ts_y, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir)
160 | construct_dict(len(fold_list),df_all,df_all,df_files,df_files,df_indices,df_indices,df_locations_x,df_locations_y,df_locations_x,df_locations_y,"train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir)
161 |
162 | else:
163 | construct_dict(len(fold_list),df_train,df_all,df_files_train,df_files,df_indices_train,df_indices,df_locations_x,df_locations_y,df_locations_tr_x,df_locations_tr_y, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir)
164 | construct_dict(len(fold_list),df_test,df_all,df_files_test,df_files, df_indices_test,df_indices,df_locations_x,df_locations_y,df_locations_ts_x,df_locations_ts_y, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir)
165 | construct_dict(len(fold_list),df_all,df_all,df_files,df_files, df_indices, df_indices, df_locations_x,df_locations_y,df_locations_x,df_locations_y, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir)
166 |
167 | if __name__ == "__main__":
168 | for i in range(1):
169 | generate(i)
--------------------------------------------------------------------------------
/generating_queries/generate_training_tuples_RGB_supervise.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | import pickle
4 | import random
5 | import set_path
6 |
7 | import numpy as np
8 | import pandas as pd
9 | from sklearn.neighbors import KDTree
10 |
11 | import config as cfg
12 |
13 | import scipy.io as sio
14 | import torch
15 |
16 | #####For training and test data split#####
17 |
18 | def construct_dict(folder_num, df_f, df_all, df_files, df_files_all, df_indices, df_indices_all, df_locations_x_all, df_locations_y_all, df_locations_z_all, df_locations_x, df_locations_y, df_locations_z, filename, pre_dir):
19 | nn_ind = 0.4
20 | r_mid = 0.4
21 | r_ind = 1.2
22 |
23 | queries = {}
24 | count = 0
25 |
26 | df_centroids = df_all
27 | df_folder_index = df_indices
28 |
29 | tree = KDTree(df_centroids[['x','y','z']])
30 | ind_r = tree.query_radius(df_centroids[['x','y','z']], r=r_ind)
31 | ind_nn = tree.query_radius(df_centroids[['x','y','z']],r=nn_ind)
32 |
33 | for i in df_indices:
34 | query = df_centroids.iloc[i]["file"]
35 | positives = np.setdiff1d(ind_nn[i],[i]).tolist()
36 | negatives = np.setdiff1d(
37 | df_centroids.index.values.tolist(),ind_r[i]).tolist()
38 | random.shuffle(negatives)
39 |
40 | if len(positives)<2:
41 | print("i:"+str(i))
42 | print("len(positives):"+str(len(positives)))
43 | assert(len(positives)>=2)
44 |
45 | queries[i] = {"query":df_centroids.iloc[i]['file'],
46 | "positives":positives,"negatives":negatives}
47 |
48 |
49 | with open(filename, 'wb') as handle:
50 | pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL)
51 |
52 | print("Done ", filename)
53 |
54 | def generate(scene_index, data_index, definite_positives=None, inside=True):
55 | base_path = "/mnt/NAS/home/cc/data/habitat_4/train/"
56 | base_path = os.path.join(base_path, cfg.scene_list[scene_index])
57 | pre_dir = base_path
58 |
59 | filename = "gt_pose.mat"
60 |
61 | # Initialize pandas DataFrame
62 |
63 | df_train = pd.DataFrame(columns=['file','x','y','z'])
64 | df_test = pd.DataFrame(columns=['file','x','y','z'])
65 | df_all = pd.DataFrame(columns=['file','x','y','z'])
66 |
67 | df_files_test = []
68 | df_files_train =[]
69 | df_files = []
70 |
71 | df_indices_train = []
72 | df_indices_test = []
73 | df_indices = []
74 |
75 | df_locations_tr_x = []
76 | df_locations_tr_y = []
77 | df_locations_tr_z = []
78 |
79 | df_locations_ts_x = []
80 | df_locations_ts_y = []
81 | df_locations_ts_z = []
82 |
83 | df_locations_x = []
84 | df_locations_y = []
85 | df_locations_z = []
86 |
87 | fold_list = list(sorted(os.listdir(base_path)))
88 | all_files = []
89 | for ind, fold in enumerate(fold_list):
90 | files_ = []
91 | files = list(sorted(os.listdir(os.path.join(base_path, fold))))
92 | files.remove('gt_pose.mat')
93 | for ind_f in range(len(files)):
94 | file_ = "panoimg_"+str(ind_f)+".png"
95 | files_.append(os.path.join(base_path, fold, file_))
96 | df_files.extend(files_)
97 | df_locations = sio.loadmat(os.path.join(base_path,fold,filename))
98 | df_locations = df_locations['pose']
99 | file_index = list(range(df_locations.shape[0]))
100 |
101 | df_locations_x.extend(list(df_locations[file_index,0]))
102 | df_locations_z.extend(list(df_locations[file_index,1]))
103 | df_locations_y.extend(list(df_locations[file_index,2]))
104 | test_sample = 10
105 | test_index_temp = random.sample(range(df_locations.shape[0]), k=test_sample)
106 | test_index = list(np.array(test_index_temp)+ind * df_locations.shape[0])
107 |
108 | df_indices_test.extend(test_index)
109 | train_index_temp = list(range(df_locations.shape[0]))
110 | train_index = list(np.array(train_index_temp)+ind * len(files_))
111 | df_indices.extend(train_index)
112 | files_ = []
113 | for ts_ind in test_index:
114 | train_index.remove(ts_ind)
115 | file_ = "panoimg_"+str(ts_ind)+".png"
116 | files_.append(os.path.join(base_path, fold, file_))
117 | df_indices_train.extend(train_index)
118 | df_files_test.extend(files_)
119 | files_ = []
120 | for tr_ind in train_index:
121 | file_ = "panoimg_"+str(tr_ind)+".png"
122 | files_.append(os.path.join(base_path, fold, file_))
123 | df_files_train.extend(files_)
124 |
125 | df_locations_tr_x.extend(list(df_locations[train_index_temp,0]))
126 | df_locations_tr_z.extend(list(df_locations[train_index_temp,1]))
127 | df_locations_tr_y.extend(list(df_locations[train_index_temp,2]))
128 |
129 | df_locations_ts_x.extend(list(df_locations[test_index_temp,0]))
130 | df_locations_ts_z.extend(list(df_locations[test_index_temp,1]))
131 | df_locations_ts_y.extend(list(df_locations[test_index_temp,2]))
132 |
133 | traj_len = len(all_files)
134 |
135 | df_train = pd.DataFrame(list(zip(df_files_train, df_locations_tr_x, df_locations_tr_y, df_locations_tr_z)),
136 | columns =['file','x', 'y', 'z'])
137 | df_test = pd.DataFrame(list(zip(df_files_test, df_locations_ts_x, df_locations_ts_y, df_locations_ts_z)),
138 | columns =['file','x', 'y', 'z'])
139 | df_all = pd.DataFrame(list(zip(df_files, df_locations_x, df_locations_y, df_locations_z)),
140 | columns =['file','x', 'y', 'z'])
141 | #n Training 10 testing
142 | if not os.path.exists(cfg.PICKLE_FOLDER):
143 | os.mkdir(cfg.PICKLE_FOLDER)
144 |
145 | if inside == True:
146 | construct_dict(len(fold_list),df_train,df_all,df_files_train,df_files,df_indices_train, df_indices,df_locations_x,df_locations_y,df_locations_z,df_locations_tr_x,df_locations_tr_y,df_locations_tr_z,"train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir)
147 | construct_dict(len(fold_list),df_test,df_all,df_files_test,df_files,df_indices_test,df_indices,df_locations_x,df_locations_y,df_locations_z,df_locations_ts_x,df_locations_ts_y,df_locations_ts_z, "train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir)
148 | construct_dict(len(fold_list),df_all,df_all,df_files,df_files,df_indices,df_indices,df_locations_x,df_locations_y,df_locations_z,df_locations_x,df_locations_y,df_locations_z,"train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir)
149 |
150 | else:
151 | construct_dict(len(fold_list),df_train,df_all,df_files_train,df_files,df_indices_train,df_indices,df_locations_x,df_locations_y,df_locations_z,df_locations_tr_x,df_locations_tr_y,df_locations_tr_z, "generating_queries/train_pickle/training_queries_baseline_"+str(data_index)+".pickle", pre_dir)
152 | construct_dict(len(fold_list),df_test,df_all,df_files_test,df_files, df_indices_test,df_indices,df_locations_x,df_locations_y,df_locations_z,df_locations_ts_x,df_locations_ts_y,df_locations_ts_z, "generating_queries/train_pickle/test_queries_baseline_"+str(data_index)+".pickle", pre_dir)
153 | construct_dict(len(fold_list),df_all,df_all,df_files,df_files, df_indices, df_indices, df_locations_x,df_locations_y,df_locations_z,df_locations_x,df_locations_y,df_locations_z, "generating_queries/train_pickle/db_queries_baseline_"+str(data_index)+".pickle", pre_dir)
154 |
155 | if __name__ == "__main__":
156 | for i in range(1):
157 | generate(0,i)
--------------------------------------------------------------------------------
/generating_queries/set_path.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | sys.path.insert(0, '../')
4 |
--------------------------------------------------------------------------------
/get_embeddings_ours.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os
3 | import sys
4 |
5 | import numpy as np
6 |
7 | import config as cfg
8 | import models.PointNetVlad as PNV
9 | import torch
10 | from loading_pointclouds import *
11 | from torch.backends import cudnn
12 | from tqdm import tqdm
13 |
14 | #os.environ["CUDA_VISIBLE_DEVICES"] = "0"
15 |
16 |
17 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
18 | sys.path.append(BASE_DIR)
19 |
20 | cudnn.enabled = True
21 |
22 | parser = argparse.ArgumentParser()
23 | parser.add_argument('--log_dir', default='log/', help='Log dir [default: log]')
24 | parser.add_argument('--results_dir', default='results/',
25 | help='results dir [default: results/]')
26 | parser.add_argument('--positives_per_query', type=int, default=2,
27 | help='Number of potential positives in each training tuple [default: 2]')
28 | parser.add_argument('--negatives_per_query', type=int, default=18,
29 | help='Number of definite negatives in each training tuple [default: 18]')
30 | parser.add_argument('--max_epoch', type=int, default=100,
31 | help='Epoch to run [default: 100]')
32 | parser.add_argument('--batch_num_queries', type=int, default=2,
33 | help='Batch Size during training [default: 2]')
34 | parser.add_argument('--learning_rate', type=float, default=0.000005,
35 | help='Initial learning rate [default: 0.000005]')
36 | parser.add_argument('--momentum', type=float, default=0.9,
37 | help='Initial learning rate [default: 0.9]')
38 | parser.add_argument('--optimizer', default='adam',
39 | help='adam or momentum [default: adam]')
40 | parser.add_argument('--decay_step', type=int, default=200000,
41 | help='Decay step for lr decay [default: 200000]')
42 | parser.add_argument('--decay_rate', type=float, default=0.7,
43 | help='Decay rate for lr decay [default: 0.7]')
44 | parser.add_argument('--margin_1', type=float, default=0.5,
45 | help='Margin for hinge loss [default: 0.5]')
46 | parser.add_argument('--margin_2', type=float, default=0.2,
47 | help='Margin for hinge loss [default: 0.2]')
48 | parser.add_argument('--loss_function', default='quadruplet', choices=[
49 | 'triplet', 'quadruplet'], help='triplet or quadruplet [default: quadruplet]')
50 | parser.add_argument('--loss_not_lazy', action='store_false',
51 | help='If present, do not use lazy variant of loss')
52 | parser.add_argument('--loss_ignore_zero_batch', action='store_true',
53 | help='If present, mean only batches with loss > 0.0')
54 | parser.add_argument('--triplet_use_best_positives', action='store_true',
55 | help='If present, use best positives, otherwise use hardest positives')
56 | parser.add_argument('--resume', action='store_true',
57 | help='If present, restore checkpoint and resume training')
58 | parser.add_argument('--dataset_folder', default='../../dataset/',
59 | help='PointNetVlad Dataset Folder')
60 |
61 | FLAGS = parser.parse_args()
62 | cfg.BATCH_NUM_QUERIES = FLAGS.batch_num_queries
63 | #cfg.EVAL_BATCH_SIZE = 12
64 | cfg.NUM_POINTS = 256
65 | cfg.TRAIN_POSITIVES_PER_QUERY = FLAGS.positives_per_query
66 | cfg.TRAIN_NEGATIVES_PER_QUERY = FLAGS.negatives_per_query
67 | cfg.MAX_EPOCH = FLAGS.max_epoch
68 | cfg.BASE_LEARNING_RATE = FLAGS.learning_rate
69 | cfg.MOMENTUM = FLAGS.momentum
70 | cfg.OPTIMIZER = FLAGS.optimizer
71 | cfg.DECAY_STEP = FLAGS.decay_step
72 | cfg.DECAY_RATE = FLAGS.decay_rate
73 | cfg.MARGIN1 = FLAGS.margin_1
74 | cfg.MARGIN2 = FLAGS.margin_2
75 | cfg.FEATURE_OUTPUT_DIM = 256
76 |
77 | cfg.LOSS_FUNCTION = FLAGS.loss_function
78 | cfg.TRIPLET_USE_BEST_POSITIVES = FLAGS.triplet_use_best_positives
79 | cfg.LOSS_LAZY = FLAGS.loss_not_lazy
80 | cfg.LOSS_IGNORE_ZERO_BATCH = FLAGS.loss_ignore_zero_batch
81 |
82 |
83 | cfg.LOG_DIR = FLAGS.log_dir
84 | if not os.path.exists(cfg.LOG_DIR):
85 | os.mkdir(cfg.LOG_DIR)
86 | LOG_FOUT = open(os.path.join(cfg.LOG_DIR, 'log_train.txt'), 'w')
87 | LOG_FOUT.write(str(FLAGS) + '\n')
88 |
89 | cfg.RESULTS_FOLDER = FLAGS.results_dir
90 | print("cfg.RESULTS_FOLDER:"+str(cfg.RESULTS_FOLDER))
91 |
92 | cfg.DATASET_FOLDER = FLAGS.dataset_folder
93 |
94 |
95 | cfg.BN_INIT_DECAY = 0.5
96 | cfg.BN_DECAY_DECAY_RATE = 0.5
97 | BN_DECAY_DECAY_STEP = float(cfg.DECAY_STEP)
98 | cfg.BN_DECAY_CLIP = 0.99
99 |
100 | HARD_NEGATIVES = {}
101 | TRAINING_LATENT_VECTORS = []
102 |
103 | TOTAL_ITERATIONS = 0
104 |
105 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
106 |
107 | print(f'cfg.BATCH_NUM_QUERIES : {cfg.BATCH_NUM_QUERIES}')
108 |
109 | def get_bn_decay(batch):
110 | bn_momentum = cfg.BN_INIT_DECAY * \
111 | (cfg.BN_DECAY_DECAY_RATE **
112 | (batch * cfg.BATCH_NUM_QUERIES // BN_DECAY_DECAY_STEP))
113 | return min(cfg.BN_DECAY_CLIP, 1 - bn_momentum)
114 |
115 |
116 | def log_string(out_str):
117 | LOG_FOUT.write(out_str + '\n')
118 | LOG_FOUT.flush()
119 | print(out_str)
120 |
121 | # learning rate halfed every 5 epoch
122 | def get_learning_rate(epoch):
123 | learning_rate = cfg.BASE_LEARNING_RATE * ((0.9) ** (epoch // 5))
124 | learning_rate = max(learning_rate, 0.00001) # CLIP THE LEARNING RATE!
125 | return learning_rate
126 |
127 |
128 | def get_feature_representation(filename, model):
129 | model.eval()
130 | queries = load_pc_files([filename],True)
131 | queries = np.expand_dims(queries, axis=1)
132 | with torch.no_grad():
133 | q = torch.from_numpy(queries).float()
134 | q = q.to(device)
135 | output = model(q)
136 | output = output.detach().cpu().numpy()
137 | output = np.squeeze(output)
138 | model.train()
139 | return output
140 |
141 |
142 | def train():
143 | learning_rate = get_learning_rate(0)
144 |
145 | model = PNV.PointNetVlad(global_feat=True, feature_transform=True,
146 | max_pool=False, output_dim=cfg.FEATURE_OUTPUT_DIM, num_points=cfg.NUM_POINTS)
147 | model = model.to(device)
148 |
149 | parameters = filter(lambda p: p.requires_grad, model.parameters())
150 |
151 | if cfg.OPTIMIZER == 'momentum':
152 | optimizer = torch.optim.SGD(
153 | parameters, learning_rate, momentum=cfg.MOMENTUM)
154 | elif cfg.OPTIMIZER == 'adam':
155 | optimizer = torch.optim.Adam(parameters, learning_rate)
156 | else:
157 | optimizer = None
158 | exit(0)
159 |
160 | model_path = cfg.RESULTS_FOLDER + "checkpoints.pth.tar"
161 |
162 | print("Loading model from ", model_path)
163 |
164 | checkpoint = torch.load(model_path)
165 | print(checkpoint.keys())
166 | saved_state_dict = checkpoint['state_dict']
167 | starting_epoch = checkpoint['epoch']
168 |
169 | model.load_state_dict(saved_state_dict)
170 | optimizer.load_state_dict(checkpoint['optimizer'])
171 |
172 | data_path = "data/"
173 |
174 | files = sorted(os.listdir(data_path))
175 | train_file_idxs = np.arange(0, len(files))
176 |
177 | print(f'Length of train ids : {len(train_file_idxs)}')
178 |
179 | queries = []
180 |
181 | for i in tqdm(train_file_idxs):
182 | path = os.path.join(data_path, files[i])
183 | query = get_feature_representation(path, model)
184 | queries.append(query)
185 |
186 | queries = np.array(queries)
187 |
188 | save_file = cfg.RESULTS_FOLDER + "embeddings.npy"
189 | np.save(save_file, queries)
190 |
191 | print(queries.shape)
192 |
193 | train()
194 |
--------------------------------------------------------------------------------
/loss/pointnetvlad_loss.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import math
3 | import torch
4 |
5 |
6 | def best_pos_distance(query, pos_vecs):
7 | num_pos = pos_vecs.shape[1]
8 | query_copies = query.repeat(1, int(num_pos), 1)
9 | diff = ((pos_vecs - query_copies) ** 2).sum(2)
10 | min_pos, _ = diff.min(1)
11 | max_pos, _ = diff.max(1)
12 | return min_pos, max_pos
13 |
14 |
15 | def triplet_loss(q_vec, pos_vecs, neg_vecs, margin, use_min=False, lazy=False, ignore_zero_loss=False):
16 | min_pos, max_pos = best_pos_distance(q_vec, pos_vecs)
17 |
18 | # PointNetVLAD official code use min_pos, but i think max_pos should be used
19 | if use_min:
20 | positive = min_pos
21 | else:
22 | positive = max_pos
23 |
24 | num_neg = neg_vecs.shape[1]
25 | batch = q_vec.shape[0]
26 | query_copies = q_vec.repeat(1, int(num_neg), 1)
27 | positive = positive.view(-1, 1)
28 | positive = positive.repeat(1, int(num_neg))
29 |
30 | loss = margin + positive - ((neg_vecs - query_copies) ** 2).sum(2)
31 | loss = loss.clamp(min=0.0)
32 | if lazy:
33 | triplet_loss = loss.max(1)[0]
34 | else:
35 | triplet_loss = loss.sum(1)
36 | if ignore_zero_loss:
37 | hard_triplets = torch.gt(triplet_loss, 1e-16).float()
38 | num_hard_triplets = torch.sum(hard_triplets)
39 | triplet_loss = triplet_loss.sum() / (num_hard_triplets + 1e-16)
40 | else:
41 | triplet_loss = triplet_loss.mean()
42 | return triplet_loss
43 |
44 |
45 | def triplet_loss_wrapper(q_vec, pos_vecs, neg_vecs, other_neg, m1, m2, use_min=False, lazy=False, ignore_zero_loss=False):
46 | return triplet_loss(q_vec, pos_vecs, neg_vecs, m1, use_min, lazy, ignore_zero_loss)
47 |
48 |
49 | def quadruplet_loss(q_vec, pos_vecs, neg_vecs, other_neg, m1, m2, use_min=False, lazy=False, ignore_zero_loss=False):
50 | min_pos, max_pos = best_pos_distance(q_vec, pos_vecs)
51 |
52 | # PointNetVLAD official code use min_pos, but i think max_pos should be used
53 | if use_min:
54 | positive = min_pos
55 | else:
56 | positive = max_pos
57 |
58 | num_neg = neg_vecs.shape[1]
59 | batch = q_vec.shape[0]
60 | query_copies = q_vec.repeat(1, int(num_neg), 1)
61 | positive = positive.view(-1, 1)
62 | positive = positive.repeat(1, int(num_neg))
63 |
64 | loss = m1 + positive - ((neg_vecs - query_copies) ** 2).sum(2)
65 | loss = loss.clamp(min=0.0)
66 | if lazy:
67 | triplet_loss = loss.max(1)[0]
68 | else:
69 | triplet_loss = loss.sum(1)
70 | if ignore_zero_loss:
71 | hard_triplets = torch.gt(triplet_loss, 1e-16).float()
72 | num_hard_triplets = torch.sum(hard_triplets)
73 | triplet_loss = triplet_loss.sum() / (num_hard_triplets + 1e-16)
74 | else:
75 | triplet_loss = triplet_loss.mean()
76 |
77 | other_neg_copies = other_neg.repeat(1, int(num_neg), 1)
78 | second_loss = m2 + positive - ((neg_vecs - other_neg_copies) ** 2).sum(2)
79 | second_loss = second_loss.clamp(min=0.0)
80 | if lazy:
81 | second_loss = second_loss.max(1)[0]
82 | else:
83 | second_loss = second_loss.sum(1)
84 |
85 | if ignore_zero_loss:
86 | hard_second = torch.gt(second_loss, 1e-16).float()
87 | num_hard_second = torch.sum(hard_second)
88 | second_loss = second_loss.sum() / (num_hard_second + 1e-16)
89 | else:
90 | second_loss = second_loss.mean()
91 |
92 | total_loss = triplet_loss + second_loss
93 | return total_loss
94 |
--------------------------------------------------------------------------------
/models/ImageNetVlad.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.parallel
5 | import torch.utils.data
6 | from torch.autograd import Variable
7 | import numpy as np
8 | import torch.nn.functional as F
9 | import math
10 | import torchvision.models as models
11 |
12 | class NetVLAD_Image(nn.Module):
13 | """NetVLAD layer implementation"""
14 | def __init__(self, num_clusters=64, dim=128,
15 | normalize_input=True, vladv2=False):
16 |
17 | """
18 | Args:
19 | num_clusters : int
20 | The number of clusters
21 |
22 | dim : int
23 | Dimension of descriptors
24 |
25 | alpha : float
26 | Parameter of initialization. Larger value is harder assignment.
27 |
28 | normalize_input : bool
29 | If true, descriptor-wise L2 normalization is applied to input.
30 |
31 | vladv2 : bool
32 | If true, use vladv2 otherwise use vladv1
33 | """
34 |
35 | super(NetVLAD_Image, self).__init__()
36 | self.num_clusters = num_clusters
37 | self.dim = dim
38 | self.alpha = 0
39 | self.vladv2 = vladv2
40 | self.normalize_input = normalize_input
41 | self.conv = nn.Conv2d(dim, num_clusters, kernel_size=(1, 1), bias=vladv2)
42 | self.centroids = nn.Parameter(torch.rand(num_clusters, dim))
43 |
44 | def init_params(self, clsts, traindescs):
45 |
46 | #TODO replace numpy ops with pytorch ops
47 | if self.vladv2 == False:
48 | clstsAssign = clsts / np.linalg.norm(clsts, axis=1, keepdims=True)
49 | dots = np.dot(clstsAssign, traindescs.T)
50 | dots.sort(0)
51 | dots = dots[::-1, :] # sort, descending
52 |
53 | self.alpha = (-np.log(0.01) / np.mean(dots[0,:] - dots[1,:])).item()
54 | self.centroids = nn.Parameter(torch.from_numpy(clsts))
55 | self.conv.weight = nn.Parameter(torch.from_numpy(self.alpha*clstsAssign).unsqueeze(2).unsqueeze(3))
56 | self.conv.bias = None
57 | else:
58 | knn = NearestNeighbors(n_jobs=-1) #TODO faiss?
59 | knn.fit(traindescs)
60 | del traindescs
61 | dsSq = np.square(knn.kneighbors(clsts, 2)[1])
62 | del knn
63 | self.alpha = (-np.log(0.01) / np.mean(dsSq[:,1] - dsSq[:,0])).item()
64 | self.centroids = nn.Parameter(torch.from_numpy(clsts))
65 | del clsts, dsSq
66 |
67 | self.conv.weight = nn.Parameter(
68 | (2.0 * self.alpha * self.centroids).unsqueeze(-1).unsqueeze(-1)
69 | )
70 |
71 | self.conv.bias = nn.Parameter(
72 | - self.alpha * self.centroids.norm(dim=1)
73 | )
74 |
75 | def forward(self, x):
76 | N, C = x.shape[:2]
77 |
78 | if self.normalize_input:
79 | x = F.normalize(x, p=2, dim=1) # across descriptor dim
80 |
81 | # soft-assignment
82 | soft_assign = self.conv(x).view(N, self.num_clusters, -1)
83 | soft_assign = F.softmax(soft_assign, dim=1)
84 | x_flatten = x.view(N, C, -1)
85 |
86 | # calculate residuals to each clusters
87 | vlad = torch.zeros([N, self.num_clusters, C], dtype=x.dtype, layout=x.layout, device=x.device)
88 | for C in range(self.num_clusters): # slower than non-looped, but lower memory usage
89 | residual = x_flatten.unsqueeze(0).permute(1, 0, 2, 3) - \
90 | self.centroids[C:C+1, :].expand(x_flatten.size(-1), -1, -1).permute(1, 2, 0).unsqueeze(0)
91 | residual *= soft_assign[:,C:C+1,:].unsqueeze(2)
92 | vlad[:,C:C+1,:] = residual.sum(dim=-1)
93 |
94 | vlad = F.normalize(vlad, p=2, dim=2) # intra-normalization
95 | vlad = vlad.view(x.size(0), -1) # flatten
96 | vlad = F.normalize(vlad, p=2, dim=1) # L2 normalize
97 |
98 | return vlad
99 |
100 | class NetVLAD_Image2(nn.Module):
101 | """NetVLAD layer implementation"""
102 | def __init__(self, num_clusters=64, dim=128, alpha=100.0,
103 | normalize_input=True):
104 | """
105 | Args:
106 | num_clusters : int
107 | The number of clusters
108 | dim : int
109 | Dimension of descriptors
110 | alpha : float
111 | Parameter of initialization. Larger value is harder assignment.
112 | normalize_input : bool
113 | If true, descriptor-wise L2 normalization is applied to input.
114 | """
115 | super(NetVLAD_Image, self).__init__()
116 | self.num_clusters = num_clusters
117 | self.dim = dim
118 | self.alpha = alpha
119 | self.normalize_input = normalize_input
120 | self.conv = nn.Conv2d(dim, num_clusters, kernel_size=(1, 1), bias=True)
121 | self.centroids = nn.Parameter(torch.rand(num_clusters, dim))
122 | self._init_params()
123 |
124 | def _init_params(self):
125 | self.conv.weight = nn.Parameter(
126 | (2.0 * self.alpha * self.centroids).unsqueeze(-1).unsqueeze(-1)
127 | )
128 |
129 | self.conv.bias = nn.Parameter(
130 | - self.alpha * self.centroids.norm(dim=1)
131 | )
132 |
133 | def forward(self, x):
134 | N, C = x.shape[:2]
135 | if self.normalize_input:
136 | x = F.normalize(x, p=2, dim=1) # across descriptor dim
137 |
138 | # soft-assignment
139 | soft_assign = self.conv(x).view(N, self.num_clusters, -1)
140 | soft_assign = F.softmax(soft_assign, dim=1)
141 | x_flatten = x.view(N, C, -1)
142 |
143 | # calculate residuals to each clusters
144 | residual = x_flatten.expand(self.num_clusters, -1, -1, -1).permute(1, 0, 2, 3) - \
145 | self.centroids.expand(x_flatten.size(-1), -1, -1).permute(1, 2, 0).unsqueeze(0)
146 | residual *= soft_assign.unsqueeze(2)
147 |
148 | vlad = residual.sum(dim=-1)
149 | vlad = F.normalize(vlad, p=2, dim=2) # intra-normalization
150 | vlad = vlad.view(x.size(0), -1) # flatten
151 | vlad = F.normalize(vlad, p=2, dim=1) # L2 normalize
152 | return vlad
153 |
154 | class NetVLADLoupe(nn.Module):
155 | def __init__(self, feature_size, max_samples, cluster_size, output_dim,
156 | gating=True, add_batch_norm=True, is_training=True):
157 | super(NetVLADLoupe, self).__init__()
158 | self.feature_size = feature_size
159 | self.max_samples = max_samples
160 | self.output_dim = output_dim
161 | self.is_training = is_training
162 | self.gating = gating
163 | self.add_batch_norm = add_batch_norm
164 | self.cluster_size = cluster_size
165 | self.softmax = nn.Softmax(dim=-1)
166 | self.cluster_weights = nn.Parameter(torch.randn(
167 | feature_size, cluster_size) * 1 / math.sqrt(feature_size))
168 | self.cluster_weights2 = nn.Parameter(torch.randn(
169 | 1, feature_size, cluster_size) * 1 / math.sqrt(feature_size))
170 | self.hidden1_weights = nn.Parameter(
171 | torch.randn(cluster_size * feature_size, output_dim) * 1 / math.sqrt(feature_size))
172 |
173 | if add_batch_norm:
174 | self.cluster_biases = None
175 | self.bn1 = nn.BatchNorm1d(cluster_size)
176 | else:
177 | self.cluster_biases = nn.Parameter(torch.randn(
178 | cluster_size) * 1 / math.sqrt(feature_size))
179 | self.bn1 = None
180 |
181 | self.bn2 = nn.BatchNorm1d(output_dim)
182 |
183 | if gating:
184 | self.context_gating = GatingContext(
185 | output_dim, add_batch_norm=add_batch_norm)
186 |
187 | def forward(self, x):
188 | x = x.transpose(1, 3).contiguous()
189 | x = x.view((-1, self.max_samples, self.feature_size))
190 | activation = torch.matmul(x, self.cluster_weights)
191 | if self.add_batch_norm:
192 | # activation = activation.transpose(1,2).contiguous()
193 | activation = activation.view(-1, self.cluster_size)
194 | activation = self.bn1(activation)
195 | activation = activation.view(-1,
196 | self.max_samples, self.cluster_size)
197 | # activation = activation.transpose(1,2).contiguous()
198 | else:
199 | activation = activation + self.cluster_biases
200 | activation = self.softmax(activation)
201 | activation = activation.view((-1, self.max_samples, self.cluster_size))
202 |
203 | a_sum = activation.sum(-2, keepdim=True)
204 | a = a_sum * self.cluster_weights2
205 |
206 | activation = torch.transpose(activation, 2, 1)
207 | x = x.view((-1, self.max_samples, self.feature_size))
208 | vlad = torch.matmul(activation, x)
209 | vlad = torch.transpose(vlad, 2, 1)
210 | vlad = vlad - a
211 |
212 | vlad = F.normalize(vlad, dim=1, p=2)
213 | vlad = vlad.view((-1, self.cluster_size * self.feature_size))
214 | vlad = F.normalize(vlad, dim=1, p=2)
215 |
216 | vlad = torch.matmul(vlad, self.hidden1_weights)
217 |
218 | vlad = self.bn2(vlad)
219 |
220 | if self.gating:
221 | vlad = self.context_gating(vlad)
222 |
223 | return vlad
224 |
225 |
226 | class GatingContext(nn.Module):
227 | def __init__(self, dim, add_batch_norm=True):
228 | super(GatingContext, self).__init__()
229 | self.dim = dim
230 | self.add_batch_norm = add_batch_norm
231 | self.gating_weights = nn.Parameter(
232 | torch.randn(dim, dim) * 1 / math.sqrt(dim))
233 | self.sigmoid = nn.Sigmoid()
234 |
235 | if add_batch_norm:
236 | self.gating_biases = None
237 | self.bn1 = nn.BatchNorm1d(dim)
238 | else:
239 | self.gating_biases = nn.Parameter(
240 | torch.randn(dim) * 1 / math.sqrt(dim))
241 | self.bn1 = None
242 |
243 | def forward(self, x):
244 | gates = torch.matmul(x, self.gating_weights)
245 |
246 | if self.add_batch_norm:
247 | gates = self.bn1(gates)
248 | else:
249 | gates = gates + self.gating_biases
250 |
251 | gates = self.sigmoid(gates)
252 |
253 | activation = x * gates
254 |
255 | return activation
256 |
257 |
258 | class Flatten(nn.Module):
259 | def __init__(self):
260 | nn.Module.__init__(self)
261 |
262 | def forward(self, input):
263 | return input.view(input.size(0), -1)
264 |
265 |
266 | class STN2d(nn.Module):
267 | def __init__(self, num_points=256, k=2, use_bn=True):
268 | super(STN2d, self).__init__()
269 | self.k = k
270 | self.kernel_size = 2 if k == 2 else 1
271 | self.channels = 1 if k == 2 else k
272 | self.num_points = num_points
273 | self.use_bn = use_bn
274 | self.conv1 = torch.nn.Conv2d(self.channels, 64, (1, self.kernel_size))
275 | self.conv2 = torch.nn.Conv2d(64, 128, (1,1))
276 | self.conv3 = torch.nn.Conv2d(128, 1024, (1,1))
277 | self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
278 | self.fc1 = nn.Linear(1024, 512)
279 | self.fc2 = nn.Linear(512, 256)
280 | self.fc3 = nn.Linear(256, k*k)
281 | self.fc3.weight.data.zero_()
282 | self.fc3.bias.data.zero_()
283 | self.relu = nn.ReLU()
284 |
285 | if use_bn:
286 | self.bn1 = nn.BatchNorm2d(64)
287 | self.bn2 = nn.BatchNorm2d(128)
288 | self.bn3 = nn.BatchNorm2d(1024)
289 | self.bn4 = nn.BatchNorm1d(512)
290 | self.bn5 = nn.BatchNorm1d(256)
291 |
292 | def forward(self, x):
293 | batchsize = x.size()[0]
294 | if self.use_bn:
295 | x = F.relu(self.bn1(self.conv1(x)))
296 | x = F.relu(self.bn2(self.conv2(x)))
297 | x = F.relu(self.bn3(self.conv3(x)))
298 | else:
299 | x = F.relu(self.conv1(x))
300 | x = F.relu(self.conv2(x))
301 | x = F.relu(self.conv3(x))
302 | x = self.mp1(x)
303 | x = x.view(-1, 1024)
304 |
305 | if self.use_bn:
306 | x = F.relu(self.bn4(self.fc1(x)))
307 | x = F.relu(self.bn5(self.fc2(x)))
308 | else:
309 | x = F.relu(self.fc1(x))
310 | x = F.relu(self.fc2(x))
311 | x = self.fc3(x)
312 |
313 | iden = Variable(torch.from_numpy(np.eye(self.k).astype(np.float32))).view(
314 | 1, self.k*self.k).repeat(batchsize, 1)
315 | if x.is_cuda:
316 | iden = iden.cuda()
317 | x = x + iden
318 | x = x.view(-1, self.k, self.k)
319 | return x
320 |
321 |
322 | class STN3d(nn.Module):
323 | def __init__(self, num_points=2500, k=3, use_bn=True):
324 | super(STN3d, self).__init__()
325 | self.k = k
326 | self.kernel_size = 3 if k == 3 else 1
327 | self.channels = 1 if k == 3 else k
328 | self.num_points = num_points
329 | self.use_bn = use_bn
330 | self.conv1 = torch.nn.Conv2d(self.channels, 64, (1, self.kernel_size))
331 | self.conv2 = torch.nn.Conv2d(64, 128, (1,1))
332 | self.conv3 = torch.nn.Conv2d(128, 1024, (1,1))
333 | self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
334 | self.fc1 = nn.Linear(1024, 512)
335 | self.fc2 = nn.Linear(512, 256)
336 | self.fc3 = nn.Linear(256, k*k)
337 | self.fc3.weight.data.zero_()
338 | self.fc3.bias.data.zero_()
339 | self.relu = nn.ReLU()
340 |
341 | if use_bn:
342 | self.bn1 = nn.BatchNorm2d(64)
343 | self.bn2 = nn.BatchNorm2d(128)
344 | self.bn3 = nn.BatchNorm2d(1024)
345 | self.bn4 = nn.BatchNorm1d(512)
346 | self.bn5 = nn.BatchNorm1d(256)
347 |
348 | def forward(self, x):
349 | batchsize = x.size()[0]
350 | if self.use_bn:
351 | x = F.relu(self.bn1(self.conv1(x)))
352 | x = F.relu(self.bn2(self.conv2(x)))
353 | x = F.relu(self.bn3(self.conv3(x)))
354 | else:
355 | x = F.relu(self.conv1(x))
356 | x = F.relu(self.conv2(x))
357 | x = F.relu(self.conv3(x))
358 | x = self.mp1(x)
359 | x = x.view(-1, 1024)
360 |
361 | if self.use_bn:
362 | x = F.relu(self.bn4(self.fc1(x)))
363 | x = F.relu(self.bn5(self.fc2(x)))
364 | else:
365 | x = F.relu(self.fc1(x))
366 | x = F.relu(self.fc2(x))
367 | x = self.fc3(x)
368 |
369 | iden = Variable(torch.from_numpy(np.eye(self.k).astype(np.float32))).view(
370 | 1, self.k*self.k).repeat(batchsize, 1)
371 | if x.is_cuda:
372 | iden = iden.cuda()
373 | x = x + iden
374 | x = x.view(-1, self.k, self.k)
375 | return x
376 |
377 |
378 | class ObsFeatAVD(nn.Module):
379 | """Feature extractor for 2D organized point clouds"""
380 | def __init__(self, n_out=1024, num_points=2500, global_feat=True, feature_transform=False, max_pool=True):
381 | super(ObsFeatAVD, self).__init__()
382 | self.n_out = n_out
383 | self.global_feature = global_feat
384 | self.feature_transform = feature_transform
385 | self.max_pool = max_pool
386 | k = 3
387 | p = int(np.floor(k / 2)) + 2
388 | self.stn = STN3d(num_points=num_points, k=3, use_bn=False)
389 | self.feature_trans = STN3d(num_points=num_points, k=64, use_bn=False)
390 | self.conv1 = nn.Conv2d(3,64,kernel_size=k,padding=p,dilation=3)
391 | self.conv2 = nn.Conv2d(64,128,kernel_size=k,padding=p,dilation=3)
392 | self.conv3 = nn.Conv2d(128,256,kernel_size=k,padding=p,dilation=3)
393 | self.conv7 = nn.Conv2d(256,self.n_out,kernel_size=k,padding=p,dilation=3)
394 | self.amp = nn.AdaptiveMaxPool2d(1)
395 |
396 | def forward(self, x):
397 | batchsize = x.size()[0]
398 | trans = self.stn(x)
399 | x = torch.matmul(torch.squeeze(x), trans)
400 | x = x.view(batchsize, 1, -1, 3)
401 | x = x.permute(0,3,1,2)
402 | assert(x.shape[1]==3),"the input size must be "
403 | x = F.relu(self.conv1(x))
404 | x = F.relu(self.conv2(x))
405 | x = F.relu(self.conv3(x))
406 | x = self.conv7(x)
407 | if self.max_pool:
408 | x = self.amp(x)
409 | #x = x.view(-1,self.n_out) #
410 | x = x.permute(0,2,3,1)
411 | return x
412 |
413 | class ImageNetfeat(nn.Module):
414 | def __init__(self, global_feat=True, feature_transform=False, max_pool=True):
415 | super(ImageNetfeat, self).__init__()
416 | encoder = models.vgg16(pretrained=True)
417 | layers = list(encoder.features.children())[:-2]
418 |
419 | self.base_model = nn.Sequential(*layers)
420 |
421 | def forward(self, x):
422 | B,_,g_x,g_y,_ = x.shape
423 | result = self.base_model(x.reshape(B,3,g_x,g_y))
424 | return result
425 |
426 | class ImageNetVlad(nn.Module):
427 | def __init__(self, grid_x=256, grid_y=256, global_feat=True, feature_transform=False, max_pool=True, output_dim=1024):
428 | super(ImageNetVlad, self).__init__()
429 |
430 | self.obs_feat_extractor = ImageNetfeat(global_feat=global_feat,
431 | feature_transform=feature_transform, max_pool=max_pool)
432 |
433 | dim = list(self.obs_feat_extractor.parameters())[-1].shape[0]
434 | self.net_vlad = NetVLAD_Image(num_clusters=32, dim=512, vladv2=True)
435 | self.fc1 = nn.Linear(16384, 4096)
436 | self.bn1 = nn.BatchNorm1d(4096)
437 | self.fc2 = nn.Linear(4096, output_dim)
438 | self.bn2 = nn.BatchNorm1d(output_dim)
439 | self.relu = nn.ReLU()
440 |
441 | def forward(self, x):
442 | x = self.obs_feat_extractor(x)
443 | x = self.net_vlad(x)
444 | x = self.relu(self.bn1(self.fc1(x)))
445 | x = self.relu(self.bn2(self.fc2(x)))
446 |
447 | return x
448 |
449 |
450 | if __name__ == '__main__':
451 | num_points = 256
452 | sim_data = Variable(torch.rand(44, 1, num_points, 3))
453 | sim_data = sim_data.cuda()
454 |
455 | pnv = PointNetVlad.PointNetVlad(global_feat=True, feature_transform=True, max_pool=False,
456 | output_dim=256, num_points=num_points).cuda()
457 | pnv.train()
458 | out3 = pnv(sim_data)
459 | print('pnv', out3.size())
--------------------------------------------------------------------------------
/models/PointNetVlad.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 | import torch
3 | import torch.nn as nn
4 | import torch.nn.parallel
5 | import torch.utils.data
6 | from torch.autograd import Variable
7 | import numpy as np
8 | import torch.nn.functional as F
9 | import math
10 | import random
11 | from .resnet_mod import *
12 |
13 | class NetVLADLoupe(nn.Module):
14 | def __init__(self, feature_size, max_samples, cluster_size, output_dim,
15 | gating=True, add_batch_norm=True, is_training=True):
16 | super(NetVLADLoupe, self).__init__()
17 | self.feature_size = feature_size
18 | self.max_samples = max_samples
19 | self.output_dim = output_dim
20 | self.is_training = is_training
21 | self.gating = gating
22 | self.add_batch_norm = add_batch_norm
23 | self.cluster_size = cluster_size
24 | self.softmax = nn.Softmax(dim=-1)
25 | self.cluster_weights = nn.Parameter(torch.randn(
26 | feature_size, cluster_size) * 1 / math.sqrt(feature_size))
27 | self.cluster_weights2 = nn.Parameter(torch.randn(
28 | 1, feature_size, cluster_size) * 1 / math.sqrt(feature_size))
29 | self.hidden1_weights = nn.Parameter(
30 | torch.randn(cluster_size * feature_size, output_dim) * 1 / math.sqrt(feature_size))
31 |
32 | if add_batch_norm:
33 | self.cluster_biases = None
34 | self.bn1 = nn.BatchNorm1d(cluster_size)
35 | else:
36 | self.cluster_biases = nn.Parameter(torch.randn(
37 | cluster_size) * 1 / math.sqrt(feature_size))
38 | self.bn1 = None
39 |
40 | self.bn2 = nn.BatchNorm1d(output_dim)
41 |
42 | if gating:
43 | self.context_gating = GatingContext(
44 | output_dim, add_batch_norm=add_batch_norm)
45 |
46 | def forward(self, x):
47 | x = x.transpose(1, 3).contiguous()
48 | x = x.view((-1, self.max_samples, self.feature_size))
49 | activation = torch.matmul(x, self.cluster_weights)
50 | if self.add_batch_norm:
51 | # activation = activation.transpose(1,2).contiguous()
52 | activation = activation.view(-1, self.cluster_size)
53 | activation = self.bn1(activation)
54 | activation = activation.view(-1,
55 | self.max_samples, self.cluster_size)
56 | # activation = activation.transpose(1,2).contiguous()
57 | else:
58 | activation = activation + self.cluster_biases
59 | activation = self.softmax(activation)
60 | activation = activation.view((-1, self.max_samples, self.cluster_size))
61 |
62 | a_sum = activation.sum(-2, keepdim=True)
63 | a = a_sum * self.cluster_weights2
64 |
65 | activation = torch.transpose(activation, 2, 1)
66 | x = x.view((-1, self.max_samples, self.feature_size))
67 | vlad = torch.matmul(activation, x)
68 | vlad = torch.transpose(vlad, 2, 1)
69 | vlad = vlad - a
70 |
71 | vlad = F.normalize(vlad, dim=1, p=2)
72 | vlad = vlad.reshape((-1, self.cluster_size * self.feature_size))
73 | vlad = F.normalize(vlad, dim=1, p=2)
74 |
75 | vlad = torch.matmul(vlad, self.hidden1_weights)
76 |
77 | vlad = self.bn2(vlad)
78 |
79 | if self.gating:
80 | vlad = self.context_gating(vlad)
81 |
82 | return vlad
83 |
84 |
85 | class GatingContext(nn.Module):
86 | def __init__(self, dim, add_batch_norm=True):
87 | super(GatingContext, self).__init__()
88 | self.dim = dim
89 | self.add_batch_norm = add_batch_norm
90 | self.gating_weights = nn.Parameter(
91 | torch.randn(dim, dim) * 1 / math.sqrt(dim))
92 | self.sigmoid = nn.Sigmoid()
93 |
94 | if add_batch_norm:
95 | self.gating_biases = None
96 | self.bn1 = nn.BatchNorm1d(dim)
97 | else:
98 | self.gating_biases = nn.Parameter(
99 | torch.randn(dim) * 1 / math.sqrt(dim))
100 | self.bn1 = None
101 |
102 | def forward(self, x):
103 | gates = torch.matmul(x, self.gating_weights)
104 |
105 | if self.add_batch_norm:
106 | gates = self.bn1(gates)
107 | else:
108 | gates = gates + self.gating_biases
109 |
110 | gates = self.sigmoid(gates)
111 |
112 | activation = x * gates
113 |
114 | return activation
115 |
116 |
117 | class Flatten(nn.Module):
118 | def __init__(self):
119 | nn.Module.__init__(self)
120 |
121 | def forward(self, input):
122 | return input.view(input.size(0), -1)
123 |
124 |
125 | class STN2d(nn.Module):
126 | def __init__(self, num_points=256, k=2, use_bn=True):
127 | super(STN2d, self).__init__()
128 | self.k = k
129 | self.kernel_size = 2 if k == 2 else 1
130 | self.channels = 1 if k == 2 else k
131 | self.num_points = num_points
132 | self.use_bn = use_bn
133 | self.conv1 = torch.nn.Conv2d(self.channels, 64, (1, self.kernel_size))
134 | self.conv2 = torch.nn.Conv2d(64, 128, (1,1))
135 | self.conv3 = torch.nn.Conv2d(128, 1024, (1,1))
136 | self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
137 | self.fc1 = nn.Linear(1024, 512)
138 | self.fc2 = nn.Linear(512, 256)
139 | self.fc3 = nn.Linear(256, k*k)
140 | self.fc3.weight.data.zero_()
141 | self.fc3.bias.data.zero_()
142 | self.relu = nn.ReLU()
143 |
144 | if use_bn:
145 | self.bn1 = nn.BatchNorm2d(64)
146 | self.bn2 = nn.BatchNorm2d(128)
147 | self.bn3 = nn.BatchNorm2d(1024)
148 | self.bn4 = nn.BatchNorm1d(512)
149 | self.bn5 = nn.BatchNorm1d(256)
150 |
151 | def forward(self, x):
152 | batchsize = x.size()[0]
153 | if self.use_bn:
154 | x = F.relu(self.bn1(self.conv1(x)))
155 | x = F.relu(self.bn2(self.conv2(x)))
156 | x = F.relu(self.bn3(self.conv3(x)))
157 | else:
158 | x = F.relu(self.conv1(x))
159 | x = F.relu(self.conv2(x))
160 | x = F.relu(self.conv3(x))
161 | x = self.mp1(x)
162 | x = x.view(-1, 1024)
163 |
164 | if self.use_bn:
165 | x = F.relu(self.bn4(self.fc1(x)))
166 | x = F.relu(self.bn5(self.fc2(x)))
167 | else:
168 | x = F.relu(self.fc1(x))
169 | x = F.relu(self.fc2(x))
170 | x = self.fc3(x)
171 |
172 | iden = Variable(torch.from_numpy(np.eye(self.k).astype(np.float32))).view(
173 | 1, self.k*self.k).repeat(batchsize, 1)
174 | if x.is_cuda:
175 | iden = iden.cuda()
176 | x = x + iden
177 | x = x.view(-1, self.k, self.k)
178 | return x
179 |
180 |
181 | class STN3d(nn.Module):
182 | def __init__(self, num_points=2500, k=3, use_bn=True):
183 | super(STN3d, self).__init__()
184 | self.k = k
185 | self.kernel_size = 3 if k == 3 else 1
186 | self.channels = 1 if k == 3 else k
187 | self.num_points = num_points
188 | self.use_bn = use_bn
189 | self.conv1 = torch.nn.Conv2d(self.channels, 64, (1, self.kernel_size))
190 | self.conv2 = torch.nn.Conv2d(64, 128, (1,1))
191 | self.conv3 = torch.nn.Conv2d(128, 1024, (1,1))
192 | self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
193 | self.fc1 = nn.Linear(1024, 512)
194 | self.fc2 = nn.Linear(512, 256)
195 | self.fc3 = nn.Linear(256, k*k)
196 | self.fc3.weight.data.zero_()
197 | self.fc3.bias.data.zero_()
198 | self.relu = nn.ReLU()
199 |
200 | if use_bn:
201 | self.bn1 = nn.BatchNorm2d(64)
202 | self.bn2 = nn.BatchNorm2d(128)
203 | self.bn3 = nn.BatchNorm2d(1024)
204 | self.bn4 = nn.BatchNorm1d(512)
205 | self.bn5 = nn.BatchNorm1d(256)
206 |
207 | def forward(self, x):
208 | batchsize = x.size()[0]
209 | if self.use_bn:
210 | x = F.relu(self.bn1(self.conv1(x)))
211 | x = F.relu(self.bn2(self.conv2(x)))
212 | x = F.relu(self.bn3(self.conv3(x)))
213 | else:
214 | x = F.relu(self.conv1(x))
215 | x = F.relu(self.conv2(x))
216 | x = F.relu(self.conv3(x))
217 | x = self.mp1(x)
218 | x = x.view(-1, 1024)
219 |
220 | if self.use_bn:
221 | x = F.relu(self.bn4(self.fc1(x)))
222 | x = F.relu(self.bn5(self.fc2(x)))
223 | else:
224 | x = F.relu(self.fc1(x))
225 | x = F.relu(self.fc2(x))
226 | x = self.fc3(x)
227 |
228 | iden = Variable(torch.from_numpy(np.eye(self.k).astype(np.float32))).view(
229 | 1, self.k*self.k).repeat(batchsize, 1)
230 | if x.is_cuda:
231 | iden = iden.cuda()
232 | x = x + iden
233 | x = x.view(-1, self.k, self.k)
234 | return x
235 |
236 |
237 | class ObsFeatAVD(nn.Module):
238 | """Feature extractor for 2D organized point clouds"""
239 | def __init__(self, n_out=1024, num_points=2500, global_feat=True, feature_transform=False, max_pool=True):
240 | super(ObsFeatAVD, self).__init__()
241 | self.n_out = n_out
242 | self.global_feature = global_feat
243 | self.feature_transform = feature_transform
244 | self.max_pool = max_pool
245 | k = 3
246 | p = int(np.floor(k / 2)) + 2
247 | self.stn = STN3d(num_points=num_points, k=3, use_bn=False)
248 | self.feature_trans = STN3d(num_points=num_points, k=64, use_bn=False)
249 | self.conv1 = nn.Conv2d(3,64,kernel_size=k,padding=p,dilation=3)
250 | self.conv2 = nn.Conv2d(64,128,kernel_size=k,padding=p,dilation=3)
251 | self.conv3 = nn.Conv2d(128,256,kernel_size=k,padding=p,dilation=3)
252 | self.conv7 = nn.Conv2d(256,self.n_out,kernel_size=k,padding=p,dilation=3)
253 | self.amp = nn.AdaptiveMaxPool2d(1)
254 |
255 | def forward(self, x):
256 | batchsize = x.size()[0]
257 | trans = self.stn(x)
258 | x = torch.matmul(torch.squeeze(x), trans)
259 | x = x.view(batchsize, 1, -1, 3)
260 | x = x.permute(0,3,1,2)
261 | assert(x.shape[1]==3),"the input size must be "
262 | x = F.relu(self.conv1(x))
263 | x = F.relu(self.conv2(x))
264 | x = F.relu(self.conv3(x))
265 | x = self.conv7(x)
266 | if self.max_pool:
267 | x = self.amp(x)
268 | #x = x.view(-1,self.n_out) #
269 | x = x.permute(0,2,3,1)
270 | return x
271 |
272 | class PointNetfeat(nn.Module):
273 | def __init__(self, num_points=256, global_feat=True, feature_transform=False, max_pool=True):
274 | super(PointNetfeat, self).__init__()
275 | self.stn = STN2d(num_points=num_points, k=2, use_bn=False)
276 | self.feature_trans = STN2d(num_points=num_points, k=64, use_bn=False)
277 | self.apply_feature_trans = feature_transform
278 | self.conv1 = torch.nn.Conv1d(1, 64, (1, 2))
279 | self.conv2 = torch.nn.Conv1d(64, 64, (1, 1))
280 | self.conv3 = torch.nn.Conv1d(64, 64, (1, 1))
281 | self.conv4 = torch.nn.Conv1d(64, 128, (1, 1))
282 | self.conv5 = torch.nn.Conv2d(128, 1024, (1, 1))
283 | self.bn1 = nn.BatchNorm2d(64)
284 | self.bn2 = nn.BatchNorm2d(64)
285 | self.bn3 = nn.BatchNorm2d(64)
286 | self.bn4 = nn.BatchNorm2d(128)
287 | self.bn5 = nn.BatchNorm2d(1024)
288 | self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
289 | self.num_points = num_points
290 | self.global_feat = global_feat
291 | self.max_pool = max_pool
292 |
293 | def forward(self, x):
294 | x = x[:,:,:,:2]
295 | batchsize = x.size()[0]
296 | trans = self.stn(x)
297 | x = torch.matmul(torch.squeeze(x), trans)
298 | x = x.view(batchsize, 1, -1, 2)
299 | #x = x.transpose(2,1)
300 | #x = torch.bmm(x, trans)
301 | #x = x.transpose(2,1)
302 | x = F.relu(self.bn1(self.conv1(x)))
303 | x = F.relu(self.bn2(self.conv2(x)))
304 | pointfeat = x
305 | if self.apply_feature_trans:
306 | f_trans = self.feature_trans(x)
307 | x = torch.squeeze(x)
308 | if batchsize == 1:
309 | x = torch.unsqueeze(x, 0)
310 | x = torch.matmul(x.transpose(1, 2), f_trans)
311 | x = x.transpose(1, 2).contiguous()
312 | x = x.view(batchsize, 64, -1, 1)
313 | x = F.relu(self.bn3(self.conv3(x)))
314 | x = F.relu(self.bn4(self.conv4(x)))
315 | x = self.bn5(self.conv5(x))
316 | if not self.max_pool:
317 | return x
318 | else:
319 | x = self.mp1(x)
320 | x = x.view(-1, 1024)
321 | if self.global_feat:
322 | return x, trans
323 | else:
324 | x = x.view(-1, 1024, 1).repeat(1, 1, self.num_points)
325 | return torch.cat([x, pointfeat], 1), trans
326 |
327 |
328 | class PointNetfeatCNN(nn.Module):
329 | def __init__(self, num_points=256, global_feat=True, feature_transform=False, max_pool=True):
330 | super(PointNetfeatCNN, self).__init__()
331 | self.stn = STN2d(num_points=num_points, k=2, use_bn=False)
332 | self.feature_trans = STN2d(num_points=num_points, k=64, use_bn=False)
333 | self.apply_feature_trans = feature_transform
334 | self.conv1 = torch.nn.Conv2d(1, 64, kernel_size=(3,4), stride=1, padding=(1,1),
335 | bias=False, padding_mode='circular')
336 |
337 | self.conv2 = torch.nn.Conv2d(64, 64, kernel_size=(3,3), stride=1, padding=(1,1),
338 | bias=False, padding_mode='circular')
339 | self.conv3 = torch.nn.Conv2d(64, 64, kernel_size=(3,3), stride=1, padding=(1,1),
340 | bias=False, padding_mode='circular')
341 | self.conv4 = torch.nn.Conv2d(64, 128, kernel_size=(3,3), stride=1, padding=(1,1),
342 | bias=False, padding_mode='circular')
343 | self.conv5 = torch.nn.Conv2d(128, 1024, kernel_size=(3,3), stride=1, padding=(1,1),
344 | bias=False, padding_mode='circular')
345 | self.bn1 = nn.BatchNorm2d(64)
346 | self.bn2 = nn.BatchNorm2d(64)
347 | self.bn3 = nn.BatchNorm2d(64)
348 | self.bn4 = nn.BatchNorm2d(128)
349 | self.bn5 = nn.BatchNorm2d(1024)
350 | self.mp1 = torch.nn.MaxPool2d((num_points, 1), 1)
351 | self.num_points = num_points
352 | self.global_feat = global_feat
353 | self.max_pool = max_pool
354 |
355 | def process_data(self,ob,low_th = -20,high_th = 20):
356 | for i in range(ob.size()[0]):
357 | seed = random.randint(low_th, high_th)
358 | ob[i] = torch.roll(ob[i], seed, dims=1)
359 | return ob
360 |
361 | def forward(self, x):
362 | x = x[:,:,:,:2]
363 | batchsize = x.size()[0]
364 | threshold = batchsize//2
365 | x = self.process_data(x, low_th=-threshold, high_th=threshold)
366 | #trans = self.stn(x)
367 | #x = torch.matmul(torch.squeeze(x), trans)
368 | x = x.view(batchsize, 1, -1, 2)
369 | x = F.relu(self.bn1(self.conv1(x)))
370 | x = F.relu(self.bn2(self.conv2(x)))
371 |
372 | pointfeat = x
373 |
374 | if self.apply_feature_trans:
375 | f_trans = self.feature_trans(x)
376 | x = torch.squeeze(x)
377 | if batchsize == 1:
378 | x = torch.unsqueeze(x, 0)
379 | x = torch.matmul(x.transpose(1, 2), f_trans)
380 | x = x.transpose(1, 2).contiguous()
381 | x = x.view(batchsize, 64, -1, 1)
382 | x = F.relu(self.bn3(self.conv3(x)))
383 | x = F.relu(self.bn4(self.conv4(x)))
384 | x = self.bn5(self.conv5(x))
385 | if not self.max_pool:
386 | return x
387 | else:
388 | x = self.mp1(x)
389 | x = x.view(-1, 1024)
390 |
391 | if self.global_feat:
392 | return x, trans
393 | else:
394 | x = x.view(-1, 1024, 1).repeat(1, 1, self.num_points)
395 | return torch.cat([x, pointfeat], 1), trans
396 |
397 | class PointNetVlad(nn.Module):
398 | def __init__(self, num_points=256, global_feat=True, feature_transform=False, max_pool=True, output_dim=1024):
399 | super(PointNetVlad, self).__init__()
400 | #self.point_net = PointNetfeat(num_points=num_points, global_feat=global_feat,
401 | # feature_transform=feature_transform, max_pool=max_pool)
402 | #self.obs_feat_extractor = ObsFeatAVD(n_out=1024, num_points=num_points, global_feat=global_feat,
403 | # feature_transform=feature_transform, max_pool=max_pool)
404 | self.obs_feat_extractor = PointNetfeatCNN(num_points=num_points, global_feat=global_feat,
405 | feature_transform=feature_transform, max_pool=max_pool)
406 | self.net_vlad = NetVLADLoupe(feature_size=1024, max_samples=num_points, cluster_size=64,
407 | output_dim=output_dim, gating=True, add_batch_norm=True,
408 | is_training=True)
409 |
410 | def forward(self, x):
411 | #x = self.point_net(x)
412 | x = self.obs_feat_extractor(x)
413 | x = self.net_vlad(x)
414 | return x
415 |
416 |
417 | if __name__ == '__main__':
418 | num_points = 256
419 | sim_data = Variable(torch.rand(44, 1, num_points, 3))
420 | sim_data = sim_data.cuda()
421 |
422 | pnv = PointNetVlad.PointNetVlad(global_feat=True, feature_transform=True, max_pool=False,
423 | output_dim=256, num_points=num_points).cuda()
424 | pnv.train()
425 | out3 = pnv(sim_data)
426 | print('pnv', out3.size())
427 |
--------------------------------------------------------------------------------
/models/resnet_mod.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | # from .utils import load_state_dict_from_url
4 |
5 |
6 | __all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101',
7 | 'resnet152', 'resnext50_32x4d', 'resnext101_32x8d',
8 | 'wide_resnet50_2', 'wide_resnet101_2']
9 |
10 |
11 | model_urls = {
12 | 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
13 | 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
14 | 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
15 | 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
16 | 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
17 | 'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
18 | 'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
19 | 'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
20 | 'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
21 | }
22 |
23 |
24 | def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
25 | """3x3 convolution with padding"""
26 | return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
27 | padding=dilation, groups=groups, bias=False, dilation=dilation, padding_mode='circular')
28 |
29 |
30 | def conv1x1(in_planes, out_planes, stride=1):
31 | """1x1 convolution"""
32 | return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
33 |
34 |
35 | class BasicBlock(nn.Module):
36 | expansion = 1
37 | __constants__ = ['downsample']
38 |
39 | def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
40 | base_width=64, dilation=1, norm_layer=None):
41 | super(BasicBlock, self).__init__()
42 | if norm_layer is None:
43 | norm_layer = nn.BatchNorm2d
44 | if groups != 1 or base_width != 64:
45 | raise ValueError('BasicBlock only supports groups=1 and base_width=64')
46 | if dilation > 1:
47 | raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
48 | # Both self.conv1 and self.downsample layers downsample the input when stride != 1
49 | self.conv1 = conv3x3(inplanes, planes, stride)
50 | self.bn1 = norm_layer(planes)
51 | self.relu = nn.ReLU(inplace=True)
52 | self.conv2 = conv3x3(planes, planes)
53 | self.bn2 = norm_layer(planes)
54 | self.downsample = downsample
55 | self.stride = stride
56 |
57 | def forward(self, x):
58 | identity = x
59 |
60 | out = self.conv1(x)
61 | out = self.bn1(out)
62 | out = self.relu(out)
63 |
64 | out = self.conv2(out)
65 | out = self.bn2(out)
66 |
67 | if self.downsample is not None:
68 | identity = self.downsample(x)
69 |
70 | out += identity
71 | out = self.relu(out)
72 |
73 | return out
74 |
75 |
76 | class Bottleneck(nn.Module):
77 | expansion = 4
78 | __constants__ = ['downsample']
79 |
80 | def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
81 | base_width=64, dilation=1, norm_layer=None):
82 | super(Bottleneck, self).__init__()
83 | if norm_layer is None:
84 | norm_layer = nn.BatchNorm2d
85 | width = int(planes * (base_width / 64.)) * groups
86 | # Both self.conv2 and self.downsample layers downsample the input when stride != 1
87 | self.conv1 = conv1x1(inplanes, width)
88 | self.bn1 = norm_layer(width)
89 | self.conv2 = conv3x3(width, width, stride, groups, dilation)
90 | self.bn2 = norm_layer(width)
91 | self.conv3 = conv1x1(width, planes * self.expansion)
92 | self.bn3 = norm_layer(planes * self.expansion)
93 | self.relu = nn.ReLU(inplace=True)
94 | self.downsample = downsample
95 | self.stride = stride
96 |
97 | def forward(self, x):
98 | identity = x
99 |
100 | out = self.conv1(x)
101 | out = self.bn1(out)
102 | out = self.relu(out)
103 |
104 | out = self.conv2(out)
105 | out = self.bn2(out)
106 | out = self.relu(out)
107 |
108 | out = self.conv3(out)
109 | out = self.bn3(out)
110 |
111 | if self.downsample is not None:
112 | identity = self.downsample(x)
113 |
114 | out += identity
115 | out = self.relu(out)
116 |
117 | return out
118 |
119 |
120 | class ResNet(nn.Module):
121 |
122 | def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
123 | groups=1, width_per_group=64, replace_stride_with_dilation=None,
124 | norm_layer=None):
125 | super(ResNet, self).__init__()
126 | if norm_layer is None:
127 | norm_layer = nn.BatchNorm2d
128 | self._norm_layer = norm_layer
129 |
130 | self.inplanes = 64
131 | self.dilation = 1
132 | if replace_stride_with_dilation is None:
133 | # each element in the tuple indicates if we should replace
134 | # the 2x2 stride with a dilated convolution instead
135 | replace_stride_with_dilation = [False, False, False]
136 | if len(replace_stride_with_dilation) != 3:
137 | raise ValueError("replace_stride_with_dilation should be None "
138 | "or a 3-element tuple, got {}".format(replace_stride_with_dilation))
139 | self.groups = groups
140 | self.base_width = width_per_group
141 | self.conv1 = nn.Conv2d(1, self.inplanes, kernel_size=7, stride=2, padding=3,
142 | bias=False, padding_mode='circular')
143 | self.bn1 = norm_layer(self.inplanes)
144 | self.relu = nn.ReLU(inplace=True)
145 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
146 | self.layer1 = self._make_layer(block, 64, layers[0])
147 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
148 | dilate=replace_stride_with_dilation[0])
149 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
150 | dilate=replace_stride_with_dilation[1])
151 | self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
152 | dilate=replace_stride_with_dilation[2])
153 | self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
154 | self.fc = nn.Linear(512 * block.expansion, num_classes)
155 |
156 | for m in self.modules():
157 | if isinstance(m, nn.Conv2d):
158 | nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
159 | elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
160 | nn.init.constant_(m.weight, 1)
161 | nn.init.constant_(m.bias, 0)
162 |
163 | # Zero-initialize the last BN in each residual branch,
164 | # so that the residual branch starts with zeros, and each residual block behaves like an identity.
165 | # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
166 | if zero_init_residual:
167 | for m in self.modules():
168 | if isinstance(m, Bottleneck):
169 | nn.init.constant_(m.bn3.weight, 0)
170 | elif isinstance(m, BasicBlock):
171 | nn.init.constant_(m.bn2.weight, 0)
172 |
173 | def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
174 | norm_layer = self._norm_layer
175 | downsample = None
176 | previous_dilation = self.dilation
177 | if dilate:
178 | self.dilation *= stride
179 | stride = 1
180 | if stride != 1 or self.inplanes != planes * block.expansion:
181 | downsample = nn.Sequential(
182 | conv1x1(self.inplanes, planes * block.expansion, stride),
183 | norm_layer(planes * block.expansion),
184 | )
185 |
186 | layers = []
187 | layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
188 | self.base_width, previous_dilation, norm_layer))
189 | self.inplanes = planes * block.expansion
190 | for _ in range(1, blocks):
191 | layers.append(block(self.inplanes, planes, groups=self.groups,
192 | base_width=self.base_width, dilation=self.dilation,
193 | norm_layer=norm_layer))
194 |
195 | return nn.Sequential(*layers)
196 |
197 | def _forward_impl(self, x):
198 | # See note [TorchScript super()]
199 | print("x:"+str(x.shape))
200 | x = self.conv1(x)
201 | print("x2:"+str(x.shape))
202 | x = self.bn1(x)
203 | print("x3:"+str(x.shape))
204 | x = self.relu(x)
205 | print("x4:"+str(x.shape))
206 | x = self.maxpool(x)
207 | print("x5:"+str(x.shape))
208 | x = self.layer1(x)
209 | x = self.layer2(x)
210 | x = self.layer3(x)
211 | x = self.layer4(x)
212 |
213 | x = self.avgpool(x)
214 | x = torch.flatten(x, 1)
215 | x = self.fc(x)
216 |
217 | return x
218 |
219 | def forward(self, x):
220 | return self._forward_impl(x)
221 |
222 |
223 | def _resnet(arch, block, layers, pretrained, progress, **kwargs):
224 | model = ResNet(block, layers, **kwargs)
225 | # if pretrained:
226 | # state_dict = load_state_dict_from_url(model_urls[arch],
227 | # progress=progress)
228 | # model.load_state_dict(state_dict)
229 | return model
230 |
231 |
232 | def resnet18(pretrained=False, progress=True, **kwargs):
233 | r"""ResNet-18 model from
234 | `"Deep Residual Learning for Image Recognition" `_
235 | Args:
236 | pretrained (bool): If True, returns a model pre-trained on ImageNet
237 | progress (bool): If True, displays a progress bar of the download to stderr
238 | """
239 | return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
240 | **kwargs)
241 |
242 |
243 | def resnet34(pretrained=False, progress=True, **kwargs):
244 | r"""ResNet-34 model from
245 | `"Deep Residual Learning for Image Recognition" `_
246 | Args:
247 | pretrained (bool): If True, returns a model pre-trained on ImageNet
248 | progress (bool): If True, displays a progress bar of the download to stderr
249 | """
250 | return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
251 | **kwargs)
252 |
253 |
254 | def resnet50(pretrained=False, progress=True, **kwargs):
255 | r"""ResNet-50 model from
256 | `"Deep Residual Learning for Image Recognition" `_
257 | Args:
258 | pretrained (bool): If True, returns a model pre-trained on ImageNet
259 | progress (bool): If True, displays a progress bar of the download to stderr
260 | """
261 | return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
262 | **kwargs)
263 |
264 |
265 | def resnet101(pretrained=False, progress=True, **kwargs):
266 | r"""ResNet-101 model from
267 | `"Deep Residual Learning for Image Recognition" `_
268 | Args:
269 | pretrained (bool): If True, returns a model pre-trained on ImageNet
270 | progress (bool): If True, displays a progress bar of the download to stderr
271 | """
272 | return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,
273 | **kwargs)
274 |
275 |
276 | def resnet152(pretrained=False, progress=True, **kwargs):
277 | r"""ResNet-152 model from
278 | `"Deep Residual Learning for Image Recognition" `_
279 | Args:
280 | pretrained (bool): If True, returns a model pre-trained on ImageNet
281 | progress (bool): If True, displays a progress bar of the download to stderr
282 | """
283 | return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress,
284 | **kwargs)
285 |
286 |
287 | def resnext50_32x4d(pretrained=False, progress=True, **kwargs):
288 | r"""ResNeXt-50 32x4d model from
289 | `"Aggregated Residual Transformation for Deep Neural Networks" `_
290 | Args:
291 | pretrained (bool): If True, returns a model pre-trained on ImageNet
292 | progress (bool): If True, displays a progress bar of the download to stderr
293 | """
294 | kwargs['groups'] = 32
295 | kwargs['width_per_group'] = 4
296 | return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
297 | pretrained, progress, **kwargs)
298 |
299 |
300 | def resnext101_32x8d(pretrained=False, progress=True, **kwargs):
301 | r"""ResNeXt-101 32x8d model from
302 | `"Aggregated Residual Transformation for Deep Neural Networks" `_
303 | Args:
304 | pretrained (bool): If True, returns a model pre-trained on ImageNet
305 | progress (bool): If True, displays a progress bar of the download to stderr
306 | """
307 | kwargs['groups'] = 32
308 | kwargs['width_per_group'] = 8
309 | return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],
310 | pretrained, progress, **kwargs)
311 |
312 |
313 | def wide_resnet50_2(pretrained=False, progress=True, **kwargs):
314 | """Wide ResNet-50-2 model from
315 | `"Wide Residual Networks" `_
316 | The model is the same as ResNet except for the bottleneck number of channels
317 | which is twice larger in every block. The number of channels in outer 1x1
318 | convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
319 | channels, and in Wide ResNet-50-2 has 2048-1024-2048.
320 | Args:
321 | pretrained (bool): If True, returns a model pre-trained on ImageNet
322 | progress (bool): If True, displays a progress bar of the download to stderr
323 | """
324 | kwargs['width_per_group'] = 64 * 2
325 | return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3],
326 | pretrained, progress, **kwargs)
327 |
328 |
329 | def wide_resnet101_2(pretrained=False, progress=True, **kwargs):
330 | r"""Wide ResNet-101-2 model from
331 | `"Wide Residual Networks" `_
332 | The model is the same as ResNet except for the bottleneck number of channels
333 | which is twice larger in every block. The number of channels in outer 1x1
334 | convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048
335 | channels, and in Wide ResNet-50-2 has 2048-1024-2048.
336 | Args:
337 | pretrained (bool): If True, returns a model pre-trained on ImageNet
338 | progress (bool): If True, displays a progress bar of the download to stderr
339 | """
340 | kwargs['width_per_group'] = 64 * 2
341 | return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3],
342 | pretrained, progress, **kwargs)
343 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.10.1
2 | tensorboardX
3 | open3d-python==0.4
4 | scipy
5 | matplotlib
6 | numpy
7 | pandas
8 | scikit-learn
9 | pickle5
10 | opencv-python
11 | torchvision
12 | opencv-contrib-python
13 |
--------------------------------------------------------------------------------
/results/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/ai4ce/TF-VPR/83a4fbf59c1e51c0024c97943788db82fca9da7d/results/.DS_Store
--------------------------------------------------------------------------------
/set_path.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import os
3 | sys.path.insert(0, './')
4 |
--------------------------------------------------------------------------------
/train_netvlad_RGB_real_supervise.py:
--------------------------------------------------------------------------------
1 | import datetime
2 | #import torch
3 | #device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
4 | import argparse
5 | import importlib
6 | import math
7 | import os
8 | import socket
9 | import sys
10 |
11 | import numpy as np
12 | from sklearn.neighbors import KDTree, NearestNeighbors
13 | import generating_queries.generate_training_tuples_RGB_real_supervise as generate_dataset_tt
14 | import generating_queries.generate_test_RGB_real_supervise_sets as generate_dataset_eval
15 |
16 | import config as cfg
17 | import evaluate
18 | import loss.pointnetvlad_loss as PNV_loss
19 | import models.Verification_RGB_real as VFC
20 | import models.ImageNetVlad as INV
21 | import torch
22 | import torch.nn as nn
23 | from loading_pointclouds import *
24 | from tensorboardX import SummaryWriter
25 | from torch.autograd import Variable
26 | from torch.backends import cudnn
27 | import scipy.io as sio
28 |
29 | BASE_DIR = os.path.dirname(os.path.abspath(__file__))
30 | sys.path.append(BASE_DIR)
31 |
32 |
33 |
34 | cudnn.enabled = True
35 |
36 | parser = argparse.ArgumentParser()
37 | parser.add_argument('--log_dir', default='log/', help='Log dir [default: log]')
38 | parser.add_argument('--results_dir', default='results/',
39 | help='results dir [default: results]')
40 | parser.add_argument('--positives_per_query', type=int, default=2,
41 | help='Number of potential positives in each training tuple [default: 2]')
42 | parser.add_argument('--negatives_per_query', type=int, default=18,
43 | help='Number of definite negatives in each training tuple [default: 18]')
44 | parser.add_argument('--max_epoch', type=int, default=30,
45 | help='Epoch to run [default: 100]')
46 | parser.add_argument('--batch_num_queries', type=int, default=2,
47 | help='Batch Size during training [default: 2]')
48 | parser.add_argument('--learning_rate', type=float, default=0.000005,
49 | help='Initial learning rate [default: 0.000005]')
50 | parser.add_argument('--momentum', type=float, default=0.9,
51 | help='Initial learning rate [default: 0.9]')
52 | parser.add_argument('--optimizer', default='adam',
53 | help='adam or momentum [default: adam]')
54 | parser.add_argument('--decay_step', type=int, default=200000,
55 | help='Decay step for lr decay [default: 200000]')
56 | parser.add_argument('--decay_rate', type=float, default=0.7,
57 | help='Decay rate for lr decay [default: 0.7]')
58 | parser.add_argument('--margin_1', type=float, default=0.5,
59 | help='Margin for hinge loss [default: 0.5]')
60 | parser.add_argument('--margin_2', type=float, default=0.2,
61 | help='Margin for hinge loss [default: 0.2]')
62 | parser.add_argument('--loss_function', default='triplet', choices=[
63 | 'triplet', 'quadruplet'], help='triplet or quadruplet [default: quadruplet]')
64 | parser.add_argument('--loss_not_lazy', action='store_false',
65 | help='If present, do not use lazy variant of loss')
66 | parser.add_argument('--loss_ignore_zero_batch', action='store_true',
67 | help='If present, mean only batches with loss > 0.0')
68 | parser.add_argument('--triplet_use_best_positives', action='store_true',
69 | help='If present, use best positives, otherwise use hardest positives')
70 | parser.add_argument('--resume', action='store_true',
71 | help='If present, restore checkpoint and resume training')
72 | parser.add_argument('--dataset_folder', default='/mnt/NAS/data/cc_data/2D_RGB_real_full3',
73 | help='PointNetVlad Dataset Folder')
74 |
75 | FLAGS = parser.parse_args()
76 | #cfg.EVAL_BATCH_SIZE = 12
77 | cfg.GRID_X = 1080
78 | cfg.GRID_Y = 1920
79 | cfg.BASE_LEARNING_RATE = FLAGS.learning_rate
80 | cfg.MOMENTUM = FLAGS.momentum
81 | cfg.OPTIMIZER = FLAGS.optimizer
82 | cfg.DECAY_STEP = FLAGS.decay_step
83 | cfg.DECAY_RATE = FLAGS.decay_rate
84 | cfg.MARGIN1 = FLAGS.margin_1
85 | cfg.MARGIN2 = FLAGS.margin_2
86 |
87 | cfg.TRIPLET_USE_BEST_POSITIVES = FLAGS.triplet_use_best_positives
88 | cfg.LOSS_LAZY = FLAGS.loss_not_lazy
89 | cfg.LOSS_IGNORE_ZERO_BATCH = FLAGS.loss_ignore_zero_batch
90 |
91 | cfg.TRAIN_FILE = 'generating_queries/train_pickle/training_queries_baseline_0.pickle'
92 | cfg.TEST_FILE = 'generating_queries/train_pickle/test_queries_baseline_0.pickle'
93 | cfg.DB_FILE = 'generating_queries/train_pickle/db_queries_baseline_0.pickle'
94 |
95 | cfg.LOG_DIR = FLAGS.log_dir
96 | if not os.path.exists(cfg.LOG_DIR):
97 | os.mkdir(cfg.LOG_DIR)
98 | LOG_FOUT = open(os.path.join(cfg.LOG_DIR, 'log_train.txt'), 'w')
99 | LOG_FOUT.write(str(FLAGS) + '\n')
100 |
101 | cfg.RESULTS_FOLDER = FLAGS.results_dir
102 | print("cfg.RESULTS_FOLDER:"+str(cfg.RESULTS_FOLDER))
103 |
104 | # Load dictionary of training queries
105 | TRAINING_QUERIES = get_queries_dict(cfg.TRAIN_FILE)
106 | TEST_QUERIES = get_queries_dict(cfg.TEST_FILE)
107 | DB_QUERIES = get_queries_dict(cfg.DB_FILE)
108 |
109 | cfg.BN_INIT_DECAY = 0.5
110 | cfg.BN_DECAY_DECAY_RATE = 0.5
111 | BN_DECAY_DECAY_STEP = float(cfg.DECAY_STEP)
112 | cfg.BN_DECAY_CLIP = 0.99
113 |
114 | HARD_NEGATIVES = {}
115 | TRAINING_LATENT_VECTORS = []
116 |
117 | TOTAL_ITERATIONS = 0
118 |
119 | device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
120 | cfg.margin = 0.1
121 |
122 | def get_bn_decay(batch):
123 | bn_momentum = cfg.BN_INIT_DECAY * \
124 | (cfg.BN_DECAY_DECAY_RATE **
125 | (batch * cfg.BATCH_NUM_QUERIES // BN_DECAY_DECAY_STEP))
126 | return min(cfg.BN_DECAY_CLIP, 1 - bn_momentum)
127 |
128 |
129 | def log_string(out_str):
130 | LOG_FOUT.write(out_str + '\n')
131 | LOG_FOUT.flush()
132 | print(out_str)
133 |
134 | # learning rate halfed every 5 epoch
135 |
136 | def get_learning_rate(epoch):
137 | learning_rate = cfg.BASE_LEARNING_RATE * ((0.9) ** (epoch // 5))
138 | learning_rate = max(learning_rate, 0.00001) # CLIP THE LEARNING RATE!
139 | return learning_rate
140 |
141 |
142 | def train():
143 | global HARD_NEGATIVES, TOTAL_ITERATIONS, TRAINING_QUERIES
144 | bn_decay = get_bn_decay(0)
145 |
146 | TRAINING_QUERIES = get_queries_dict(cfg.TRAIN_FILE)
147 | TEST_QUERIES = get_queries_dict(cfg.TEST_FILE)
148 | DB_QUERIES = get_queries_dict(cfg.DB_FILE)
149 |
150 | cfg.RESULTS_FOLDER = os.path.join("results/", 'scene2')
151 | if not os.path.isdir(cfg.RESULTS_FOLDER):
152 | os.mkdir(cfg.RESULTS_FOLDER)
153 | if cfg.LOSS_FUNCTION_RGB == 'quadruplet':
154 | loss_function = PNV_loss.quadruplet_loss
155 | elif cfg.LOSS_FUNCTION_RGB == 'triplet_RI':
156 | loss_function = PNV_loss.triplet_loss_RI
157 | else:
158 | loss_function = PNV_loss.triplet_loss
159 | learning_rate = get_learning_rate(0)
160 |
161 | train_writer = SummaryWriter(os.path.join(cfg.LOG_DIR, 'train'))
162 |
163 | model = INV.ImageNetVlad(global_feat=True, feature_transform=True,
164 | max_pool=False, output_dim=cfg.FEATURE_OUTPUT_DIM, grid_x = cfg.GRID_X, grid_y = cfg.GRID_Y)
165 | model = model.to(device)
166 |
167 | parameters = filter(lambda p: p.requires_grad, model.parameters())
168 |
169 | if cfg.OPTIMIZER == 'momentum':
170 | optimizer = torch.optim.SGD(
171 | parameters, learning_rate, momentum=cfg.MOMENTUM)
172 | elif cfg.OPTIMIZER == 'adam':
173 | optimizer = torch.optim.Adam(parameters, learning_rate)
174 | else:
175 | optimizer = None
176 | exit(0)
177 |
178 | if FLAGS.resume:
179 | resume_filename = cfg.LOG_DIR + "checkpoint.pth.tar"
180 | print("Resuming From ", resume_filename)
181 | checkpoint = torch.load(resume_filename)
182 | saved_state_dict = checkpoint['state_dict']
183 | starting_epoch = checkpoint['epoch']
184 | print("starting_epoch:"+str(starting_epoch))
185 | #starting_epoch = starting_epoch +1
186 | TOTAL_ITERATIONS = starting_epoch * len(TRAINING_QUERIES)
187 | starting_epoch = starting_epoch +1
188 | model.load_state_dict(saved_state_dict)
189 | optimizer.load_state_dict(checkpoint['optimizer'])
190 |
191 | else:
192 | starting_epoch = 0
193 |
194 |
195 | LOG_FOUT.write(cfg.cfg_str())
196 | LOG_FOUT.write("\n")
197 | LOG_FOUT.flush()
198 |
199 | try:
200 | potential_positives
201 | except NameError:
202 | potential_positives = None
203 | potential_distributions = None
204 | trusted_positives = None
205 |
206 | for epoch in range(starting_epoch, cfg.MAX_EPOCH):
207 | print(epoch)
208 | print()
209 |
210 | log_string('**** EPOCH %03d ****' % (epoch))
211 | sys.stdout.flush()
212 |
213 | train_one_epoch(model, optimizer, train_writer, loss_function, epoch, TRAINING_QUERIES, TEST_QUERIES, DB_QUERIES)
214 |
215 | log_string('EVALUATING...')
216 | cfg.OUTPUT_FILE = os.path.join(cfg.RESULTS_FOLDER , 'results_' + str(epoch) + '.txt')
217 | eval_recall_1, eval_recall_5, eval_recall_10 = evaluate.evaluate_model_RGB_real(model,optimizer,epoch,True)
218 |
219 | log_string('EVAL RECALL_1: %s' % str(eval_recall_1))
220 | log_string('EVAL RECALL_5: %s' % str(eval_recall_5))
221 | log_string('EVAL RECALL_10: %s' % str(eval_recall_10))
222 |
223 |
224 | def train_one_epoch(model, optimizer, train_writer, loss_function, epoch, TRAINING_QUERIES, TEST_QUERIES, DB_QUERIES):
225 | global HARD_NEGATIVES
226 | global TRAINING_LATENT_VECTORS, TOTAL_ITERATIONS
227 |
228 | is_training = True
229 | sampled_neg = 4000
230 | # number of hard negatives in the training tuple
231 | # which are taken from the sampled negatives
232 | num_to_take = 10
233 |
234 | # Shuffle train files
235 | train_file_idxs = np.arange(0, len(TRAINING_QUERIES.keys()))
236 | np.random.shuffle(train_file_idxs)
237 |
238 | for i in range(len(train_file_idxs)//cfg.BATCH_NUM_QUERIES):
239 | # for i in range(1):
240 | batch_keys = train_file_idxs[i *
241 | cfg.BATCH_NUM_QUERIES:(i+1)*cfg.BATCH_NUM_QUERIES]
242 | q_tuples = []
243 |
244 | faulty_tuple = False
245 | no_other_neg = False
246 | for j in range(cfg.BATCH_NUM_QUERIES):
247 | if (len(DB_QUERIES[batch_keys[j]]["positives"]) < cfg.TRAIN_POSITIVES_PER_QUERY):
248 | faulty_tuple = True
249 | break
250 | # no cached feature vectors
251 | if (len(TRAINING_LATENT_VECTORS) == 0):
252 | q_tuples.append(
253 | get_query_tuple_RGB_real_supervise(DB_QUERIES[batch_keys[j]], cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY,
254 | DB_QUERIES, hard_neg=[], other_neg=True))
255 | #print("q_tuples:"+str(q_tuples))
256 |
257 | elif (len(HARD_NEGATIVES.keys()) == 0):
258 | query = get_feature_representation(
259 | DB_QUERIES[batch_keys[j]]['query'], model)
260 | random.shuffle(DB_QUERIES[batch_keys[j]]['negatives'])
261 | negatives = DB_QUERIES[batch_keys[j]
262 | ]['negatives'][0:sampled_neg]
263 | hard_negs = get_random_hard_negatives(
264 | query, negatives, num_to_take)
265 | q_tuples.append(
266 | get_query_tuple_RGB_real_supervise(DB_QUERIES[batch_keys[j]], cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY,
267 | DB_QUERIES, hard_negs, other_neg=True))
268 | else:
269 | query = get_feature_representation(
270 | DB_QUERIES[batch_keys[j]]['query'], model)
271 | random.shuffle(DB_QUERIES[batch_keys[j]]['negatives'])
272 | negatives = DB_QUERIES[batch_keys[j]
273 | ]['negatives'][0:sampled_neg]
274 | hard_negs = get_random_hard_negatives(
275 | query, negatives, num_to_take)
276 | hard_negs = list(set().union(
277 | HARD_NEGATIVES[batch_keys[j]], hard_negs))
278 | q_tuples.append(
279 | get_query_tuple_RGB_real_supervise(DB_QUERIES[batch_keys[j]], cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY,
280 | DB_QUERIES, hard_negs, other_neg=True))
281 |
282 | if (q_tuples[j][3].shape[2] != 3):
283 | no_other_neg = True
284 | break
285 |
286 | if(faulty_tuple):
287 | log_string('----' + str(i) + '-----')
288 | log_string('----' + 'FAULTY TUPLE' + '-----')
289 | continue
290 |
291 | if(no_other_neg):
292 | log_string('----' + str(i) + '-----')
293 | log_string('----' + 'NO OTHER NEG' + '-----')
294 | continue
295 |
296 | queries = []
297 | positives = []
298 | negatives = []
299 | other_neg = []
300 | for k in range(len(q_tuples)):
301 | queries.append(q_tuples[k][0])
302 | positives.append(q_tuples[k][1])
303 | negatives.append(q_tuples[k][2])
304 | other_neg.append(q_tuples[k][3])
305 |
306 | queries = np.array(queries, dtype=np.float32)
307 | queries = np.expand_dims(queries, axis=1)
308 | other_neg = np.array(other_neg, dtype=np.float32)
309 | other_neg = np.expand_dims(other_neg, axis=1)
310 | positives = np.array(positives, dtype=np.float32)
311 | negatives = np.array(negatives, dtype=np.float32)
312 |
313 | log_string('----' + str(i) + '-----')
314 | if (len(queries.shape) != 5):
315 | log_string('----' + 'FAULTY QUERY' + '-----')
316 | continue
317 |
318 | model.train()
319 | optimizer.zero_grad()
320 |
321 | output_queries, output_positives, output_negatives, output_other_neg = run_model(
322 | model, queries, positives, negatives, other_neg)
323 |
324 | loss = loss_function(output_queries, output_positives, output_negatives, 0.1, use_min=cfg.TRIPLET_USE_BEST_POSITIVES, lazy=cfg.LOSS_LAZY, ignore_zero_loss=cfg.LOSS_IGNORE_ZERO_BATCH)
325 | #loss = loss_function(output_queries, output_positives, output_negatives, rot_output_queries, rot_output_positives, rot_output_negatives, 0.1, use_min=cfg.TRIPLET_USE_BEST_POSITIVES, lazy=False, ignore_zero_loss=cfg.LOSS_IGNORE_ZERO_BATCH)
326 | loss.backward()
327 | optimizer.step()
328 |
329 | log_string('batch loss: %f' % loss)
330 | train_writer.add_scalar("Loss", loss.cpu().item(), TOTAL_ITERATIONS)
331 | TOTAL_ITERATIONS += cfg.BATCH_NUM_QUERIES
332 |
333 | def get_feature_representation(filename, model):
334 | model.eval()
335 | queries = load_image_files([filename],False)
336 | queries = np.expand_dims(queries, axis=1)
337 |
338 | with torch.no_grad():
339 | q = torch.from_numpy(queries).float()
340 | q = q.to(device)
341 | output = model(q)
342 | output = output.detach().cpu().numpy()
343 | output = np.squeeze(output)
344 | model.train()
345 | return output
346 |
347 |
348 | def get_random_hard_negatives(query_vec, random_negs, num_to_take):
349 | global TRAINING_LATENT_VECTORS
350 |
351 | latent_vecs = []
352 | for j in range(len(random_negs)):
353 | latent_vecs.append(TRAINING_LATENT_VECTORS[random_negs[j]])
354 |
355 | latent_vecs = np.array(latent_vecs)
356 | nbrs = KDTree(latent_vecs)
357 | distances, indices = nbrs.query(np.array([query_vec]), k=num_to_take)
358 | hard_negs = np.squeeze(np.array(random_negs)[indices[0]])
359 | hard_negs = hard_negs.tolist()
360 | return hard_negs
361 |
362 |
363 | def get_latent_vectors(model, dict_to_process):
364 | train_file_idxs = np.arange(0, len(dict_to_process.keys()))
365 |
366 | batch_num = cfg.BATCH_NUM_QUERIES * \
367 | (1 + cfg.TRAIN_POSITIVES_PER_QUERY + cfg.TRAIN_NEGATIVES_PER_QUERY + 1)
368 | q_output = []
369 |
370 | model.eval()
371 |
372 | for q_index in range(len(train_file_idxs)//batch_num):
373 | file_indices = train_file_idxs[q_index *
374 | batch_num:(q_index+1)*(batch_num)]
375 | file_names = []
376 | for index in file_indices:
377 | file_names.append(dict_to_process[index]["query"])
378 | queries = load_image_files(file_names,False)
379 |
380 | feed_tensor = torch.from_numpy(queries).float()
381 | feed_tensor = feed_tensor.unsqueeze(1)
382 | feed_tensor = feed_tensor.to(device)
383 | with torch.no_grad():
384 | out = model(feed_tensor)
385 |
386 | out = out.detach().cpu().numpy()
387 | out = np.squeeze(out)
388 |
389 | q_output.append(out)
390 |
391 | q_output = np.array(q_output)
392 | if(len(q_output) != 0):
393 | q_output = q_output.reshape(-1, q_output.shape[-1])
394 |
395 | # handle edge case
396 | for q_index in range((len(train_file_idxs) // batch_num * batch_num), len(dict_to_process.keys())):
397 | index = train_file_idxs[q_index]
398 | queries = load_image_files([dict_to_process[index]["query"]],False)
399 | queries = np.expand_dims(queries, axis=1)
400 |
401 | with torch.no_grad():
402 | queries_tensor = torch.from_numpy(queries).float()
403 | o1 = model(queries_tensor.to(device))
404 |
405 | output = o1.detach().cpu().numpy()
406 | output = np.squeeze(output)
407 | if (q_output.shape[0] != 0):
408 | q_output = np.vstack((q_output, output))
409 | else:
410 | q_output = output
411 |
412 | model.train()
413 | return q_output
414 |
415 |
416 | def run_model(model, queries, positives, negatives, other_neg, require_grad=True):
417 | queries_tensor = torch.from_numpy(queries).float()
418 | positives_tensor = torch.from_numpy(positives).float()
419 | negatives_tensor = torch.from_numpy(negatives).float()
420 | other_neg_tensor = torch.from_numpy(other_neg).float()
421 | feed_tensor = torch.cat(
422 | (queries_tensor, positives_tensor, negatives_tensor, other_neg_tensor), 1)
423 | feed_tensor = feed_tensor.view((-1, 1, cfg.SIZED_GRID_X, cfg.SIZED_GRID_Y, 3))
424 |
425 | feed_tensor.requires_grad_(require_grad)
426 | feed_tensor = feed_tensor.to(device)
427 | if require_grad:
428 | output = model(feed_tensor)
429 | else:
430 | with torch.no_grad():
431 | output = model(feed_tensor)
432 |
433 | output = output.view(cfg.BATCH_NUM_QUERIES, -1, output.shape[-1])
434 | o1, o2, o3, o4 = torch.split(
435 | output, [1, cfg.TRAIN_POSITIVES_PER_QUERY, cfg.TRAIN_NEGATIVES_PER_QUERY, 1], dim=1)
436 | return o1, o2, o3, o4#, ro1, ro2, ro3, ro4
437 |
438 |
439 | if __name__ == "__main__":
440 | for i in range(1):
441 | train()
--------------------------------------------------------------------------------