├── LICENSE.md
├── README.md
├── ebb_dataset
└── .gitkeep
├── load_dataset.py
├── model.py
├── models
└── original
│ └── .gitkeep
├── results
└── full-resolution
│ └── .gitkeep
├── test_model.py
├── train_model.py
├── utils.py
├── vgg.py
├── vgg_pretrained
└── .gitkeep
└── visual_samples
├── depth_maps
├── 1.png
├── 10.png
├── 11.png
├── 12.png
├── 2.png
├── 3.png
├── 4.png
├── 5.png
├── 6.png
├── 7.png
├── 8.png
└── 9.png
└── images
├── 1.jpg
├── 10.jpg
├── 11.jpg
├── 12.jpg
├── 2.jpg
├── 3.jpg
├── 4.jpg
├── 5.jpg
├── 6.jpg
├── 7.jpg
├── 8.jpg
└── 9.jpg
/LICENSE.md:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/LICENSE.md
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | ## Rendering Natural Camera Bokeh Effect with Deep Learning
2 |
3 |
4 |
5 |  6 |
7 |
6 |
7 |
8 |
9 | #### 1. Overview [[Paper]](https://arxiv.org/pdf/2006.05698.pdf) [[Project Webpage]](http://people.ee.ethz.ch/~ihnatova/pynet-bokeh.html) [[PyNET PyTorch]](https://github.com/aiff22/PyNET-PyTorch)
10 |
11 | This repository provides the implementation of the deep learning-based bokeh effect rendering approach presented in [this paper](https://arxiv.org/pdf/2006.05698.pdf). The model is trained to map the standard **narrow-aperture images** into shallow depth-of-field photos captured with a professional Canon 7D DSLR camera. The presented approach is camera independent, **does not require any special hardware**, and can also be applied to the existing images. More visual results of this method on the presented EBB! dataset and its comparison to the **Portrait Mode** of the *Google Pixel Camera* app can be found [here](http://people.ee.ethz.ch/~ihnatova/pynet-bokeh.html#demo).
12 |
13 |
14 |
15 | #### 2. Prerequisites
16 |
17 | - Python: scipy, numpy, imageio and pillow packages
18 | - [TensorFlow 1.x / 2.x](https://www.tensorflow.org/install/) + [CUDA cuDNN](https://developer.nvidia.com/cudnn)
19 | - Nvidia GPU
20 |
21 |
22 |
23 | #### 3. First steps
24 |
25 | - Download the pre-trained [VGG-19 model](https://polybox.ethz.ch/index.php/s/7z5bHNg5r5a0g7k) and put it into `vgg_pretrained/` folder.
26 | - Download the pre-trained [PyNET model](https://data.vision.ee.ethz.ch/ihnatova/public/ebb/PyNET_Bokeh_pretrained.zip) and put it into `models/original/` folder.
27 | - Download the [EBB! dataset](http://people.ee.ethz.ch/~ihnatova/pynet-bokeh.html#dataset) and extract it into `ebb_dataset/` folder.
28 | This folder should contain two subfolders: `train/` and `test/`
29 |
30 | *Please note that Google Drive has a quota limiting the number of downloads per day. To avoid it, you can login to your Google account and press "Add to My Drive" button instead of a direct download. Please check [this issue](https://github.com/aiff22/PyNET/issues/4) for more information.*
31 |
32 |
33 |
34 |
35 | #### 4. PyNET CNN
36 |
37 |
38 |
39 | 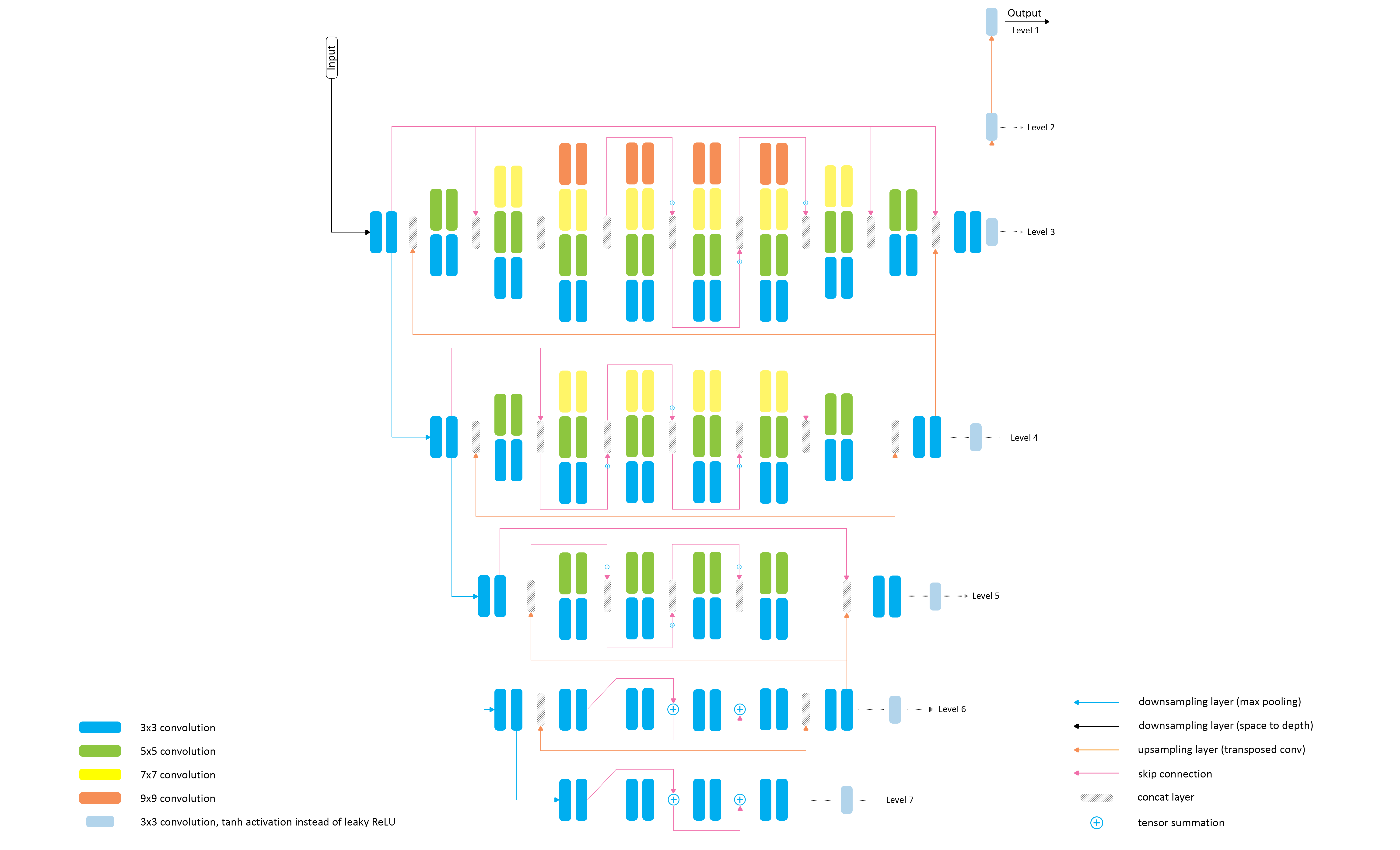 40 |
41 |
40 |
41 |
42 |
43 | The proposed PyNET-based architecture has an inverted pyramidal shape and is processing the images at **seven different scales** (levels). The model is trained sequentially, starting from the lowest 7th layer, which allows to achieve good semantically-driven reconstruction results at smaller scales that are working with images of very low resolution and thus performing mostly global image manipulations. After the bottom layer is pre-trained, the same procedure is applied to the next level till the training is done on the original resolution. Since each higher level is getting **upscaled high-quality features** from the lower part of the model, it mainly learns to reconstruct the missing low-level details and refines the results. In this work, we additionally use two transposed convolutional layers on top of the main model (Levels 1, 2) that upsample the images to their target size.
44 |
45 |
46 |
47 | #### 5. Training the model
48 |
49 | The model is trained level by level, starting from the lowest (7th) one:
50 |
51 | ```bash
52 | python train_model.py level=
53 | ```
54 |
55 | Obligatory parameters:
56 |
57 | >```level```: **```7, 6, 5, 4, 3, 2, 1```**
58 |
59 | Optional parameters and their default values:
60 |
61 | >```batch_size```: **```50```** - batch size [small values can lead to unstable training]
62 | >```train_size```: **```4894```** - the number of training images randomly loaded each 1000 iterations
63 | >```eval_step```: **```1000```** - each ```eval_step``` iterations the accuracy is computed and the model is saved
64 | >```learning_rate```: **```5e-5```** - learning rate
65 | >```restore_iter```: **```None```** - iteration to restore (when not specified, the last saved model for PyNET's ```level+1``` is loaded)
66 | >```num_train_iters```: **```5K, 5K, 20K, 20K, 30K, 80K, 100K (for levels 5 - 0)```** - the number of training iterations
67 | >```vgg_dir```: **```vgg_pretrained/imagenet-vgg-verydeep-19.mat```** - path to the pre-trained VGG-19 network
68 | >```dataset_dir```: **```ebb_dataset/```** - path to the folder with the **EBB! dataset**
69 |
70 |
71 |
72 | Below we provide the commands used for training the model on the Nvidia Tesla V100 GPU with 16GB of RAM. When using GPUs with smaller amount of memory, the batch size and the number of training iterations should be adjusted accordingly:
73 |
74 | ```bash
75 | python train_model.py level=7 batch_size=50 num_train_iters=5000
76 | python train_model.py level=6 batch_size=50 num_train_iters=5000
77 | python train_model.py level=5 batch_size=40 num_train_iters=20000
78 | python train_model.py level=4 batch_size=14 num_train_iters=20000
79 | python train_model.py level=3 batch_size=9 num_train_iters=30000
80 | python train_model.py level=2 batch_size=9 num_train_iters=80000
81 | python train_model.py level=1 batch_size=5 num_train_iters=100000
82 | ```
83 |
84 |
85 |
86 | #### 6. Test the provided pre-trained models on full-resolution test EBB! images
87 |
88 | ```bash
89 | python test_model.py orig=true
90 | ```
91 |
92 | Optional parameters:
93 |
94 | >```use_gpu```: **```true```**,**```false```** - run the model on GPU or CPU
95 | >```dataset_dir```: **```ebb_dataset/```** - path to the folder with the **EBB! dataset**
96 |
97 |
98 |
99 | #### 7. Validate the obtained model on full-resolution test EBB! images
100 |
101 | ```bash
102 | python test_model.py
103 | ```
104 | Optional parameters:
105 |
106 | >```restore_iter```: **```None```** - iteration to restore (when not specified, the last saved model for level=`````` is loaded)
107 | >```use_gpu```: **```true```**,**```false```** - run the model on GPU or CPU
108 | >```dataset_dir```: **```ebb_dataset/```** - path to the folder with the **EBB! dataset**
109 |
110 |
111 |
112 | #### 8. Folder structure
113 |
114 | >```models/``` - logs and models that are saved during the training process
115 | >```models/original/``` - the folder with the provided pre-trained PyNET model
116 | >```ebb_dataset/``` - the folder with the EBB! dataset
117 | >```results/``` - visual results for image crops that are saved while training
118 | >```results/full-resolution/``` - full-resolution image results saved during the testing
119 | >```vgg-pretrained/``` - the folder with the pre-trained VGG-19 network
120 |
121 | >```load_dataset.py``` - python script that loads training data
122 | >```model.py``` - PyNET implementation (TensorFlow)
123 | >```train_model.py``` - implementation of the training procedure
124 | >```test_model.py``` - applying the pre-trained model to full-resolution test images and computing the numerical results
125 | >```utils.py``` - auxiliary functions
126 | >```vgg.py``` - loading the pre-trained vgg-19 network
127 |
128 |
129 |
130 | #### 9. License
131 |
132 | Copyright (C) 2020 Andrey Ignatov. All rights reserved.
133 |
134 | Licensed under the [CC BY-NC-SA 4.0 (Attribution-NonCommercial-ShareAlike 4.0 International)](https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
135 |
136 | The code is released for academic research use only.
137 |
138 |
139 |
140 | #### 10. Citation
141 |
142 | ```
143 | @article{ignatov2020rendering,
144 | title={Rendering Natural Camera Bokeh Effect with Deep Learning},
145 | author={Ignatov, Andrey and Patel, Jagruti and Timofte, Radu},
146 | booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
147 | pages={0--0},
148 | year={2020}
149 | }
150 | ```
151 |
152 |
153 | #### 11. Any further questions?
154 |
155 | ```
156 | Please contact Andrey Ignatov (andrey@vision.ee.ethz.ch) for more information
157 | ```
158 |
--------------------------------------------------------------------------------
/ebb_dataset/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/ebb_dataset/.gitkeep
--------------------------------------------------------------------------------
/load_dataset.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020 by Andrey Ignatov. All Rights Reserved.
2 |
3 | from __future__ import print_function
4 | from scipy import misc
5 | from PIL import Image
6 | import imageio
7 | import os
8 | import numpy as np
9 |
10 |
11 | def load_test_data(dataset_dir, PATCH_WIDTH, PATCH_HEIGHT, DSLR_SCALE):
12 |
13 | test_directory_orig = dataset_dir + 'test/original/'
14 | test_directory_orig_depth = dataset_dir + 'test/original_depth/'
15 | test_directory_blur = dataset_dir + 'test/bokeh/'
16 |
17 | #NUM_TEST_IMAGES = 200
18 | NUM_TEST_IMAGES = len([name for name in os.listdir(test_directory_orig)
19 | if os.path.isfile(os.path.join(test_directory_orig, name))])
20 |
21 | test_data = np.zeros((NUM_TEST_IMAGES, PATCH_HEIGHT, PATCH_WIDTH, 4))
22 | test_answ = np.zeros((NUM_TEST_IMAGES, int(PATCH_HEIGHT * DSLR_SCALE), int(PATCH_WIDTH * DSLR_SCALE), 3))
23 |
24 | for i in range(0, NUM_TEST_IMAGES):
25 |
26 | I = misc.imread(test_directory_orig + str(i) + '.jpg')
27 | I_depth = misc.imread(test_directory_orig_depth + str(i) + '.png')
28 |
29 | # Downscaling the image by a factor of 2
30 | I = misc.imresize(I, 0.5, interp='bicubic')
31 |
32 | # Making sure that its width is multiple of 32
33 | new_width = int(I.shape[1]/32) * 32
34 | I = I[:, 0:new_width, :]
35 |
36 | # Stacking the image together with its depth map
37 | I_temp = np.zeros((I.shape[0], I.shape[1], 4))
38 | I_temp[:, :, 0:3] = I
39 | I_temp[:, :, 3] = I_depth
40 | I = I_temp
41 |
42 | h, w, d = I.shape
43 | y = np.random.randint(0, w - 512)
44 |
45 | # Extracting random patch of width PATCH_WIDTH
46 | I = np.float32(I[:, y:y + PATCH_WIDTH, :]) / 255.0
47 | test_data[i, :] = I
48 |
49 | I = misc.imread(test_directory_blur + str(i) + '.jpg')
50 | I = np.float32(misc.imresize(I[:, y*2:y*2 + 1024, :], DSLR_SCALE / 2, interp='bicubic')) / 255.0
51 | test_answ[i, :] = I
52 |
53 | return test_data, test_answ
54 |
55 |
56 | def load_training_batch(dataset_dir, PATCH_WIDTH, PATCH_HEIGHT, DSLR_SCALE, train_size):
57 |
58 | test_directory_orig = dataset_dir + 'train/original/'
59 | test_directory_orig_depth = dataset_dir + 'train/original_depth/'
60 | test_directory_blur = dataset_dir + 'train/bokeh/'
61 |
62 | # NUM_TRAINING_IMAGES = 4894
63 | NUM_TRAINING_IMAGES = len([name for name in os.listdir(test_directory_orig)
64 | if os.path.isfile(os.path.join(test_directory_orig, name))])
65 |
66 | TRAIN_IMAGES = np.random.choice(np.arange(0, NUM_TRAINING_IMAGES), train_size, replace=False)
67 |
68 | test_data = np.zeros((train_size, PATCH_HEIGHT, PATCH_WIDTH, 4))
69 | test_answ = np.zeros((train_size, int(PATCH_HEIGHT * DSLR_SCALE), int(PATCH_WIDTH * DSLR_SCALE), 3))
70 |
71 | i = 0
72 | for img in TRAIN_IMAGES:
73 |
74 | I = misc.imread(test_directory_orig + str(img) + '.jpg')
75 | I_depth = misc.imread(test_directory_orig_depth + str(img) + '.png')
76 |
77 | # Downscaling the image by a factor of 2
78 | I = misc.imresize(I, 0.5, interp='bicubic')
79 |
80 | # Making sure that its width is multiple of 32
81 | new_width = int(I.shape[1] / 32) * 32
82 | I = I[:, 0:new_width, :]
83 |
84 | # Stacking the image together with its depth map
85 | I_temp = np.zeros((I.shape[0], I.shape[1], 4))
86 | I_temp[:, :, 0:3] = I
87 | I_temp[:, :, 3] = I_depth
88 | I = I_temp
89 |
90 | h, w, d = I.shape
91 | y = np.random.randint(0, w - 512)
92 |
93 | # Extracting random patch of width PATCH_WIDTH
94 | I = np.float32(I[:, y:y + PATCH_WIDTH, :]) / 255.0
95 | test_data[i, :] = I
96 |
97 | I = misc.imread(test_directory_blur + str(img) + '.jpg')
98 | I = np.float32(misc.imresize(I[:, y * 2:y * 2 + 1024, :], DSLR_SCALE / 2, interp='bicubic')) / 255.0
99 | test_answ[i, :] = I
100 |
101 | i += 1
102 |
103 | return test_data, test_answ
104 |
105 |
106 | def load_input_image(image_dir, depth_maps_dir, photo):
107 |
108 | I = misc.imread(image_dir + photo)
109 | I_depth = misc.imread(depth_maps_dir + str(photo.split(".")[0]) + '.png')
110 |
111 | # Downscaling the image by a factor of 2
112 | I = misc.imresize(I, 0.5, interp='bicubic')
113 |
114 | # Making sure that its width is multiple of 32
115 | new_width = int(I.shape[1] / 32) * 32
116 | I = I[:, 0:new_width, :]
117 | I_depth = I_depth[:, 0:new_width]
118 |
119 | # Stacking the image together with its depth map
120 | I_temp = np.zeros((I.shape[0], I.shape[1], 4))
121 | I_temp[:, :, 0:3] = I
122 | I_temp[:, :, 3] = I_depth
123 |
124 | I = np.float32(I_temp) / 255.0
125 | I = np.reshape(I, [1, I.shape[0], I.shape[1], 4])
126 |
127 | return I
128 |
129 |
--------------------------------------------------------------------------------
/model.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 by Andrey Ignatov. All Rights Reserved.
2 |
3 | import tensorflow as tf
4 | import numpy as np
5 |
6 |
7 | def PyNET(input, instance_norm=True, instance_norm_level_1=False):
8 |
9 | # Note: the paper uses a different layer naming scheme.
10 | # In this code, layer N corresponds to layer N+2 from the article.
11 |
12 | with tf.compat.v1.variable_scope("generator"):
13 |
14 | # -----------------------------------------
15 | # Space-to-depth layer
16 |
17 | space2depth_l0 = tf.nn.space_to_depth(input, 2) # 512 -> 256
18 |
19 | # -----------------------------------------
20 | # Downsampling layers
21 |
22 | conv_l1_d1 = _conv_multi_block(space2depth_l0, 3, num_maps=32, instance_norm=False) # 256 -> 256
23 | pool1 = max_pool(conv_l1_d1, 2) # 256 -> 128
24 |
25 | conv_l2_d1 = _conv_multi_block(pool1, 3, num_maps=64, instance_norm=instance_norm) # 128 -> 128
26 | pool2 = max_pool(conv_l2_d1, 2) # 128 -> 64
27 |
28 | conv_l3_d1 = _conv_multi_block(pool2, 3, num_maps=128, instance_norm=instance_norm) # 64 -> 64
29 | pool3 = max_pool(conv_l3_d1, 2) # 64 -> 32
30 |
31 | conv_l4_d1 = _conv_multi_block(pool3, 3, num_maps=256, instance_norm=instance_norm) # 32 -> 32
32 | pool4 = max_pool(conv_l4_d1, 2) # 32 -> 16
33 |
34 | # -----------------------------------------
35 | # Processing: Level 5, Input size: 16 x 16
36 |
37 | conv_l5_d1 = _conv_multi_block(pool4, 3, num_maps=512, instance_norm=instance_norm)
38 | conv_l5_d2 = _conv_multi_block(conv_l5_d1, 3, num_maps=512, instance_norm=instance_norm) + conv_l5_d1
39 | conv_l5_d3 = _conv_multi_block(conv_l5_d2, 3, num_maps=512, instance_norm=instance_norm) + conv_l5_d2
40 | conv_l5_d4 = _conv_multi_block(conv_l5_d3, 3, num_maps=512, instance_norm=instance_norm)
41 |
42 | conv_t4a = _conv_tranpose_layer(conv_l5_d4, 256, 3, 2) # 16 -> 32
43 | conv_t4b = _conv_tranpose_layer(conv_l5_d4, 256, 3, 2) # 16 -> 32
44 |
45 | # -> Output: Level 5
46 |
47 | conv_l5_out = _conv_layer(conv_l5_d4, 3, 3, 1, relu=False, instance_norm=False)
48 | output_l5 = tf.nn.tanh(conv_l5_out) * 0.58 + 0.5
49 |
50 | # -----------------------------------------
51 | # Processing: Level 4, Input size: 32 x 32
52 |
53 | conv_l4_d2 = stack(conv_l4_d1, conv_t4a)
54 | conv_l4_d3 = _conv_multi_block(conv_l4_d2, 3, num_maps=256, instance_norm=instance_norm)
55 | conv_l4_d4 = _conv_multi_block(conv_l4_d3, 3, num_maps=256, instance_norm=instance_norm) + conv_l4_d3
56 | conv_l4_d5 = _conv_multi_block(conv_l4_d4, 3, num_maps=256, instance_norm=instance_norm) + conv_l4_d4
57 | conv_l4_d6 = stack(_conv_multi_block(conv_l4_d5, 3, num_maps=256, instance_norm=instance_norm), conv_t4b)
58 |
59 | conv_l4_d7 = _conv_multi_block(conv_l4_d6, 3, num_maps=256, instance_norm=instance_norm)
60 |
61 | conv_t3a = _conv_tranpose_layer(conv_l4_d7, 128, 3, 2) # 32 -> 64
62 | conv_t3b = _conv_tranpose_layer(conv_l4_d7, 128, 3, 2) # 32 -> 64
63 |
64 | # -> Output: Level 4
65 |
66 | conv_l4_out = _conv_layer(conv_l4_d7, 3, 3, 1, relu=False, instance_norm=False)
67 | output_l4 = tf.nn.tanh(conv_l4_out) * 0.58 + 0.5
68 |
69 | # -----------------------------------------
70 | # Processing: Level 3, Input size: 64 x 64
71 |
72 | conv_l3_d2 = stack(conv_l3_d1, conv_t3a)
73 | conv_l3_d3 = _conv_multi_block(conv_l3_d2, 5, num_maps=128, instance_norm=instance_norm) + conv_l3_d2
74 | conv_l3_d4 = _conv_multi_block(conv_l3_d3, 5, num_maps=128, instance_norm=instance_norm) + conv_l3_d3
75 | conv_l3_d5 = _conv_multi_block(conv_l3_d4, 5, num_maps=128, instance_norm=instance_norm) + conv_l3_d4
76 | conv_l3_d6 = stack(_conv_multi_block(conv_l3_d5, 5, num_maps=128, instance_norm=instance_norm), conv_l3_d1)
77 | conv_l3_d7 = stack(conv_l3_d6, conv_t3b)
78 |
79 | conv_l3_d8 = _conv_multi_block(conv_l3_d7, 3, num_maps=128, instance_norm=instance_norm)
80 |
81 | conv_t2a = _conv_tranpose_layer(conv_l3_d8, 64, 3, 2) # 64 -> 128
82 | conv_t2b = _conv_tranpose_layer(conv_l3_d8, 64, 3, 2) # 64 -> 128
83 |
84 | # -> Output: Level 3
85 |
86 | conv_l3_out = _conv_layer(conv_l3_d8, 3, 3, 1, relu=False, instance_norm=False)
87 | output_l3 = tf.nn.tanh(conv_l3_out) * 0.58 + 0.5
88 |
89 | # -------------------------------------------
90 | # Processing: Level 2, Input size: 128 x 128
91 |
92 | conv_l2_d2 = stack(conv_l2_d1, conv_t2a)
93 | conv_l2_d3 = stack(_conv_multi_block(conv_l2_d2, 5, num_maps=64, instance_norm=instance_norm), conv_l2_d1)
94 |
95 | conv_l2_d4 = _conv_multi_block(conv_l2_d3, 7, num_maps=64, instance_norm=instance_norm) + conv_l2_d3
96 | conv_l2_d5 = _conv_multi_block(conv_l2_d4, 7, num_maps=64, instance_norm=instance_norm) + conv_l2_d4
97 | conv_l2_d6 = _conv_multi_block(conv_l2_d5, 7, num_maps=64, instance_norm=instance_norm) + conv_l2_d5
98 | conv_l2_d7 = stack(_conv_multi_block(conv_l2_d6, 7, num_maps=64, instance_norm=instance_norm), conv_l2_d1)
99 |
100 | conv_l2_d8 = stack(_conv_multi_block(conv_l2_d7, 5, num_maps=64, instance_norm=instance_norm), conv_t2b)
101 | conv_l2_d9 = _conv_multi_block(conv_l2_d8, 3, num_maps=64, instance_norm=instance_norm)
102 |
103 | conv_t1a = _conv_tranpose_layer(conv_l2_d9, 32, 3, 2) # 128 -> 256
104 | conv_t1b = _conv_tranpose_layer(conv_l2_d9, 32, 3, 2) # 128 -> 256
105 |
106 | # -> Output: Level 2
107 |
108 | conv_l2_out = _conv_layer(conv_l2_d9, 3, 3, 1, relu=False, instance_norm=False)
109 | output_l2 = tf.nn.tanh(conv_l2_out) * 0.58 + 0.5
110 |
111 | # -------------------------------------------
112 | # Processing: Level 1, Input size: 256 x 256
113 |
114 | conv_l1_d2 = stack(conv_l1_d1, conv_t1a)
115 | conv_l1_d3 = stack(_conv_multi_block(conv_l1_d2, 5, num_maps=32, instance_norm=False), conv_l1_d1)
116 |
117 | conv_l1_d4 = _conv_multi_block(conv_l1_d3, 7, num_maps=32, instance_norm=False)
118 |
119 | conv_l1_d5 = _conv_multi_block(conv_l1_d4, 9, num_maps=32, instance_norm=instance_norm_level_1)
120 | conv_l1_d6 = _conv_multi_block(conv_l1_d5, 9, num_maps=32, instance_norm=instance_norm_level_1) + conv_l1_d5
121 | conv_l1_d7 = _conv_multi_block(conv_l1_d6, 9, num_maps=32, instance_norm=instance_norm_level_1) + conv_l1_d6
122 | conv_l1_d8 = _conv_multi_block(conv_l1_d7, 9, num_maps=32, instance_norm=instance_norm_level_1) + conv_l1_d7
123 |
124 | conv_l1_d9 = stack(_conv_multi_block(conv_l1_d8, 7, num_maps=32, instance_norm=False), conv_l1_d1)
125 |
126 | conv_l1_d10 = stack(_conv_multi_block(conv_l1_d9, 5, num_maps=32, instance_norm=False), conv_t1b)
127 | conv_l1_d11 = stack(conv_l1_d10, conv_l1_d1)
128 |
129 | conv_l1_d12 = _conv_multi_block(conv_l1_d11, 3, num_maps=32, instance_norm=False)
130 |
131 | # -> Output: Level 1
132 |
133 | conv_l1_out = _conv_layer(conv_l1_d12, 3, 3, 1, relu=False, instance_norm=False)
134 | output_l1 = tf.nn.tanh(conv_l1_out) * 0.58 + 0.5
135 |
136 | # ----------------------------------------------------------
137 | # Processing: Level 0 (x2 upscaling), Input size: 256 x 256
138 |
139 | conv_l0 = _conv_tranpose_layer(conv_l1_d12, 8, 3, 2) # 256 -> 512
140 | conv_l0_out = _conv_layer(conv_l0, 3, 3, 1, relu=False, instance_norm=False)
141 | output_l0 = tf.nn.tanh(conv_l0_out) * 0.58 + 0.5
142 |
143 | # ----------------------------------------------------------
144 | # Processing: Level Up (x4 upscaling), Input size: 512 x 512
145 |
146 | conv_l_up = _conv_tranpose_layer(conv_l0_out, 3, 3, 2) # 512 -> 1024
147 | conv_l_up_out = _conv_layer(conv_l_up, 3, 3, 1, relu=False, instance_norm=False)
148 |
149 | output_l_up = tf.nn.tanh(conv_l_up_out) * 0.58 + 0.5
150 |
151 | return output_l_up, output_l0, output_l1, output_l2, output_l3, output_l4, output_l5
152 |
153 |
154 | def _conv_multi_block(input, max_size, num_maps, instance_norm):
155 |
156 | conv_3a = _conv_layer(input, num_maps, 3, 1, relu=True, instance_norm=instance_norm)
157 | conv_3b = _conv_layer(conv_3a, num_maps, 3, 1, relu=True, instance_norm=instance_norm)
158 |
159 | output_tensor = conv_3b
160 |
161 | if max_size >= 5:
162 |
163 | conv_5a = _conv_layer(input, num_maps, 5, 1, relu=True, instance_norm=instance_norm)
164 | conv_5b = _conv_layer(conv_5a, num_maps, 5, 1, relu=True, instance_norm=instance_norm)
165 |
166 | output_tensor = stack(output_tensor, conv_5b)
167 |
168 | if max_size >= 7:
169 |
170 | conv_7a = _conv_layer(input, num_maps, 7, 1, relu=True, instance_norm=instance_norm)
171 | conv_7b = _conv_layer(conv_7a, num_maps, 7, 1, relu=True, instance_norm=instance_norm)
172 |
173 | output_tensor = stack(output_tensor, conv_7b)
174 |
175 | if max_size >= 9:
176 |
177 | conv_9a = _conv_layer(input, num_maps, 9, 1, relu=True, instance_norm=instance_norm)
178 | conv_9b = _conv_layer(conv_9a, num_maps, 9, 1, relu=True, instance_norm=instance_norm)
179 |
180 | output_tensor = stack(output_tensor, conv_9b)
181 |
182 | return output_tensor
183 |
184 |
185 | def stack(x, y):
186 | return tf.concat([x, y], 3)
187 |
188 |
189 | def conv2d(x, W):
190 | return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
191 |
192 |
193 | def leaky_relu(x, alpha=0.2):
194 | return tf.maximum(alpha * x, x)
195 |
196 |
197 | def _conv_layer(net, num_filters, filter_size, strides, relu=True, instance_norm=False, padding='SAME'):
198 |
199 | weights_init = _conv_init_vars(net, num_filters, filter_size)
200 | strides_shape = [1, strides, strides, 1]
201 | bias = tf.Variable(tf.constant(0.01, shape=[num_filters]))
202 |
203 | net = tf.nn.conv2d(net, weights_init, strides_shape, padding=padding) + bias
204 |
205 | if instance_norm:
206 | net = _instance_norm(net)
207 |
208 | if relu:
209 | net = leaky_relu(net)
210 |
211 | return net
212 |
213 |
214 | def _instance_norm(net):
215 |
216 | batch, rows, cols, channels = [i.value for i in net.get_shape()]
217 | var_shape = [channels]
218 |
219 | mu, sigma_sq = tf.compat.v1.nn.moments(net, [1,2], keep_dims=True)
220 | shift = tf.Variable(tf.zeros(var_shape))
221 | scale = tf.Variable(tf.ones(var_shape))
222 |
223 | epsilon = 1e-3
224 | normalized = (net-mu)/(sigma_sq + epsilon)**(.5)
225 |
226 | return scale * normalized + shift
227 |
228 |
229 | def _conv_init_vars(net, out_channels, filter_size, transpose=False):
230 |
231 | _, rows, cols, in_channels = [i.value for i in net.get_shape()]
232 |
233 | if not transpose:
234 | weights_shape = [filter_size, filter_size, in_channels, out_channels]
235 | else:
236 | weights_shape = [filter_size, filter_size, out_channels, in_channels]
237 |
238 | weights_init = tf.Variable(tf.compat.v1.truncated_normal(weights_shape, stddev=0.01, seed=1), dtype=tf.float32)
239 | return weights_init
240 |
241 |
242 | def _conv_tranpose_layer(net, num_filters, filter_size, strides):
243 | weights_init = _conv_init_vars(net, num_filters, filter_size, transpose=True)
244 |
245 | net_shape = tf.shape(net)
246 | tf_shape = tf.stack([net_shape[0], net_shape[1] * strides, net_shape[2] * strides, num_filters])
247 |
248 | strides_shape = [1, strides, strides, 1]
249 | net = tf.nn.conv2d_transpose(net, weights_init, tf_shape, strides_shape, padding='SAME')
250 |
251 | return leaky_relu(net)
252 |
253 |
254 | def max_pool(x, n):
255 | return tf.nn.max_pool(x, ksize=[1, n, n, 1], strides=[1, n, n, 1], padding='VALID')
256 |
--------------------------------------------------------------------------------
/models/original/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/models/original/.gitkeep
--------------------------------------------------------------------------------
/results/full-resolution/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/results/full-resolution/.gitkeep
--------------------------------------------------------------------------------
/test_model.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020 by Andrey Ignatov. All Rights Reserved.
2 |
3 | from scipy import misc
4 | import numpy as np
5 | import tensorflow as tf
6 | import sys
7 | import os
8 |
9 | tf.compat.v1.disable_v2_behavior()
10 |
11 | from load_dataset import load_input_image
12 | from model import PyNET
13 | import utils
14 | import sys
15 |
16 | LEVEL, restore_iter, dataset_dir, use_gpu, orig_model = utils.process_test_model_args(sys.argv)
17 | DSLR_SCALE = float(1) / (2 ** (LEVEL - 2))
18 |
19 | # Disable gpu if specified
20 | config = tf.compat.v1.ConfigProto(device_count={'GPU': 0}) if use_gpu == "false" else None
21 |
22 |
23 | with tf.compat.v1.Session(config=config) as sess:
24 |
25 | # Placeholders for test data
26 | x_ = tf.compat.v1.placeholder(tf.float32, [1, None, None, 4])
27 | y_ = tf.compat.v1.placeholder(tf.float32, [1, None, None, 3])
28 |
29 | # generate bokeh image
30 |
31 | output_l1, output_l2, output_l3, output_l4, output_l5, output_l6, output_l7 = \
32 | PyNET(x_, instance_norm=True, instance_norm_level_1=False)
33 |
34 | if LEVEL < 1:
35 | print("Lvel number cannot be less than 1. Aborting.")
36 | sys.exit()
37 | if LEVEL > 3:
38 | print("Larger images are needed for computing PSNR / SSIM scores. Aborting.")
39 | sys.exit()
40 | if LEVEL == 3:
41 | bokeh_img = output_l3
42 | if LEVEL == 2:
43 | bokeh_img = output_l2
44 | if LEVEL == 1:
45 | bokeh_img = output_l1
46 |
47 | bokeh_img = tf.clip_by_value(bokeh_img, 0.0, 1.0)
48 |
49 | # Removing the boundary (32 px) from the resulting / target images
50 |
51 | crop_height_ = tf.compat.v1.placeholder(tf.int32)
52 | crop_width_ = tf.compat.v1.placeholder(tf.int32)
53 |
54 | bokeh_img_cropped = tf.image.crop_to_bounding_box(bokeh_img, 32, 32, crop_height_, crop_width_)
55 | y_cropped = tf.image.crop_to_bounding_box(y_, 32, 32, crop_height_, crop_width_)
56 |
57 | # Losses
58 |
59 | loss_psnr = tf.reduce_mean(tf.image.psnr(bokeh_img_cropped, y_cropped, 1.0))
60 | loss_ssim = tf.reduce_mean(tf.image.ssim(bokeh_img_cropped, y_cropped, 1.0))
61 | loss_ms_ssim = tf.reduce_mean(tf.image.ssim_multiscale(bokeh_img_cropped, y_cropped, 1.0))
62 |
63 | # Loading pre-trained model
64 |
65 | saver = tf.compat.v1.train.Saver()
66 |
67 | if orig_model == "true":
68 | saver.restore(sess, "models/original/pynet_bokeh_level_0")
69 | else:
70 | saver.restore(sess, "models/pynet_level_" + str(LEVEL) + "_iteration_" + str(restore_iter) + ".ckpt")
71 |
72 | # -------------------------------------------------
73 | # Part 1: Processing sample full-resolution images
74 |
75 | print("Generating sample visual results")
76 |
77 | sample_images_dir = "visual_samples/images/"
78 | sample_depth_maps_dir = "visual_samples/depth_maps/"
79 |
80 | sample_images = [f for f in os.listdir(sample_images_dir) if os.path.isfile(sample_images_dir + f)]
81 |
82 | for photo in sample_images:
83 |
84 | # Load image
85 |
86 | I = load_input_image(sample_images_dir, sample_depth_maps_dir, photo)
87 |
88 | # Run inference
89 |
90 | bokeh_tensor = sess.run(bokeh_img, feed_dict={x_: I})
91 | bokeh_image = np.reshape(bokeh_tensor, [int(I.shape[1] * DSLR_SCALE), int(I.shape[2] * DSLR_SCALE), 3])
92 |
93 | # Save the results as .png images
94 | photo_name = photo.rsplit(".", 1)[0]
95 | misc.imsave("results/full-resolution/" + photo_name + "_level_" + str(LEVEL) +
96 | "_iteration_" + str(restore_iter) + ".png", bokeh_image)
97 |
98 | # ------------------------------------------------------------------------
99 | # Part 1: Compute PSNR / SSIM scores on the test part of the EBB! dataset
100 |
101 | print("Performing quantitative evaluation")
102 |
103 | test_directory_orig = dataset_dir + 'test/original/'
104 | test_directory_orig_depth = dataset_dir + 'test/original_depth/'
105 | test_directory_blur = dataset_dir + 'test/bokeh/'
106 |
107 | test_images = [f for f in os.listdir(test_directory_orig) if os.path.isfile(os.path.join(test_directory_orig, f))]
108 |
109 | loss_psnr_ = 0.0
110 | loss_ssim_ = 0.0
111 | loss_msssim_ = 0.0
112 |
113 | test_size = len(test_images)
114 | iter_ = 0
115 |
116 | for photo in test_images:
117 |
118 | # Load image
119 |
120 | I = load_input_image(test_directory_orig, test_directory_orig_depth, photo)
121 |
122 | Y = misc.imread(test_directory_blur + photo) / 255.0
123 | Y = np.float32(misc.imresize(Y, DSLR_SCALE / 2, interp='bicubic')) / 255.0
124 | Y = np.reshape(Y, [1, Y.shape[0], Y.shape[1], 3])
125 |
126 | loss_psnr_temp, loss_ssim_temp, loss_msssim_temp = sess.run([loss_psnr, loss_ssim, loss_ms_ssim],
127 | feed_dict={x_: I, y_: Y, crop_height_: Y.shape[1] - 64, crop_width_: Y.shape[2] - 64})
128 |
129 | print(photo, iter_, loss_psnr_temp, loss_ssim_temp, loss_msssim_temp)
130 |
131 | loss_psnr_ += loss_psnr_temp / test_size
132 | loss_ssim_ += loss_ssim_temp / test_size
133 | loss_msssim_ += loss_msssim_temp / test_size
134 |
135 | iter_ += 1
136 |
137 | output_logs = "PSNR: %.4g, SSIM: %.4g, MS-SSIM: %.4g\n" % (loss_psnr_, loss_ssim_, loss_msssim_)
138 | print(output_logs)
139 |
--------------------------------------------------------------------------------
/train_model.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020 by Andrey Ignatov. All Rights Reserved.
2 |
3 | import tensorflow as tf
4 | from scipy import misc
5 | import numpy as np
6 | import sys
7 |
8 | tf.compat.v1.disable_v2_behavior()
9 |
10 | from load_dataset import load_training_batch, load_test_data
11 | from model import PyNET
12 | import utils
13 | import vgg
14 |
15 | # Processing command arguments
16 |
17 | LEVEL, batch_size, train_size, learning_rate, restore_iter, num_train_iters, dataset_dir, vgg_dir, eval_step = \
18 | utils.process_command_args(sys.argv)
19 |
20 | # Defining the size of the input and target image patches
21 |
22 | PATCH_WIDTH, PATCH_HEIGHT = 512, 512
23 | DSLR_SCALE = float(1) / (2 ** (LEVEL - 2))
24 |
25 | TARGET_WIDTH = int(PATCH_WIDTH * DSLR_SCALE)
26 | TARGET_HEIGHT = int(PATCH_HEIGHT * DSLR_SCALE)
27 | TARGET_DEPTH = 3
28 | TARGET_SIZE = TARGET_WIDTH * TARGET_HEIGHT * TARGET_DEPTH
29 |
30 | np.random.seed(0)
31 |
32 | # Defining the model architecture
33 |
34 | with tf.Graph().as_default(), tf.compat.v1.Session() as sess:
35 |
36 | # Placeholders for training data
37 |
38 | input_ = tf.compat.v1.placeholder(tf.float32, [batch_size, PATCH_HEIGHT, PATCH_WIDTH, 4])
39 | target_ = tf.compat.v1.placeholder(tf.float32, [batch_size, TARGET_HEIGHT, TARGET_WIDTH, TARGET_DEPTH])
40 |
41 | # Get the rendered bokeh image
42 |
43 | output_l1, output_l2, output_l3, output_l4, output_l5, output_l6, output_l7 = \
44 | PyNET(input_, instance_norm=True, instance_norm_level_1=False)
45 |
46 | if LEVEL == 7:
47 | bokeh_img = output_l7
48 | if LEVEL == 6:
49 | bokeh_img = output_l6
50 | if LEVEL == 5:
51 | bokeh_img = output_l5
52 | if LEVEL == 4:
53 | bokeh_img = output_l4
54 | if LEVEL == 3:
55 | bokeh_img = output_l3
56 | if LEVEL == 2:
57 | bokeh_img = output_l2
58 | if LEVEL == 1:
59 | bokeh_img = output_l1
60 |
61 | # Losses
62 |
63 | bokeh_img_flat = tf.reshape(bokeh_img, [-1, TARGET_SIZE])
64 | target_flat = tf.reshape(target_, [-1, TARGET_SIZE])
65 |
66 | # MSE loss
67 | loss_mse = tf.reduce_sum(tf.pow(target_flat - bokeh_img_flat, 2)) / (TARGET_SIZE * batch_size)
68 |
69 | # PSNR loss
70 | loss_psnr = 20 * utils.log10(1.0 / tf.sqrt(loss_mse))
71 |
72 | # SSIM loss
73 | loss_ssim = tf.reduce_mean(tf.image.ssim(bokeh_img, target_, 1.0))
74 |
75 | # MS-SSIM loss
76 | loss_ms_ssim = tf.reduce_mean(tf.image.ssim_multiscale(bokeh_img, target_, 1.0))
77 |
78 | # L1 loss
79 | loss_l1 = tf.compat.v1.losses.absolute_difference(bokeh_img, target_)
80 |
81 | # Content loss
82 | CONTENT_LAYER = 'relu5_4'
83 |
84 | bokeh_img_vgg = vgg.net(vgg_dir, vgg.preprocess(bokeh_img * 255))
85 | target_vgg = vgg.net(vgg_dir, vgg.preprocess(target_ * 255))
86 |
87 | content_size = utils._tensor_size(target_vgg[CONTENT_LAYER]) * batch_size
88 | loss_content = 2 * tf.nn.l2_loss(bokeh_img_vgg[CONTENT_LAYER] - target_vgg[CONTENT_LAYER]) / content_size
89 |
90 | # Final loss function
91 |
92 | if LEVEL > 1:
93 | loss_generator = loss_l1 * 100
94 | else:
95 | loss_generator = loss_l1 * 10 + loss_content * 0.1 + (1 - loss_ssim) * 10
96 |
97 | # Optimize network parameters
98 |
99 | generator_vars = [v for v in tf.compat.v1.global_variables() if v.name.startswith("generator")]
100 | train_step_gen = tf.compat.v1.train.AdamOptimizer(learning_rate).minimize(loss_generator)
101 |
102 | # Initialize and restore the variables
103 |
104 | print("Initializing variables")
105 | sess.run(tf.compat.v1.global_variables_initializer())
106 |
107 | saver = tf.compat.v1.train.Saver(var_list=generator_vars, max_to_keep=100)
108 |
109 | if LEVEL < 7:
110 | print("Restoring Variables")
111 | saver.restore(sess, "models/pynet_level_" + str(LEVEL + 1) + "_iteration_" + str(restore_iter) + ".ckpt")
112 |
113 | saver = tf.compat.v1.train.Saver(var_list=generator_vars, max_to_keep=100)
114 |
115 | # Loading training and test data
116 |
117 | print("Loading test data...")
118 | test_data, test_answ = load_test_data(dataset_dir, PATCH_WIDTH, PATCH_HEIGHT, DSLR_SCALE)
119 | print("Test data was loaded\n")
120 |
121 | print("Loading training data...")
122 | train_data, train_answ = load_training_batch(dataset_dir, PATCH_WIDTH, PATCH_HEIGHT, DSLR_SCALE, train_size)
123 | print("Training data was loaded\n")
124 |
125 | TEST_SIZE = test_data.shape[0]
126 | num_test_batches = int(test_data.shape[0] / batch_size)
127 |
128 | visual_crops_ids = np.random.randint(0, TEST_SIZE, batch_size)
129 | visual_test_crops = test_data[visual_crops_ids, :]
130 | visual_target_crops = test_answ[visual_crops_ids, :]
131 |
132 | print("Training network")
133 |
134 | logs = open("models/logs.txt", "w+")
135 | logs.close()
136 |
137 | training_loss = 0.0
138 |
139 | for i in range(num_train_iters + 1):
140 |
141 | # Train PyNET model
142 |
143 | idx_train = np.random.randint(0, train_size, batch_size)
144 |
145 | phone_images = train_data[idx_train]
146 | dslr_images = train_answ[idx_train]
147 |
148 | # Random flips and rotations
149 |
150 | for k in range(batch_size):
151 |
152 | random_rotate = np.random.randint(1, 100) % 4
153 | phone_images[k] = np.rot90(phone_images[k], random_rotate)
154 | dslr_images[k] = np.rot90(dslr_images[k], random_rotate)
155 | random_flip = np.random.randint(1, 100) % 2
156 |
157 | if random_flip == 1:
158 | phone_images[k] = np.flipud(phone_images[k])
159 | dslr_images[k] = np.flipud(dslr_images[k])
160 |
161 | # Training step
162 |
163 | [loss_temp, temp] = sess.run([loss_generator, train_step_gen], feed_dict={input_: phone_images, target_: dslr_images})
164 | training_loss += loss_temp / eval_step
165 |
166 | if i % eval_step == 0:
167 |
168 | # Evaluate PyNET model
169 |
170 | test_losses = np.zeros((1, 6 if LEVEL < 4 else 5))
171 |
172 | for j in range(num_test_batches):
173 |
174 | be = j * batch_size
175 | en = (j+1) * batch_size
176 |
177 | phone_images = test_data[be:en]
178 | dslr_images = test_answ[be:en]
179 |
180 | if LEVEL < 4:
181 | losses = sess.run([loss_generator, loss_content, loss_mse, loss_psnr, loss_l1, loss_ms_ssim], \
182 | feed_dict={input_: phone_images, target_: dslr_images})
183 | else:
184 | losses = sess.run([loss_generator, loss_content, loss_mse, loss_psnr, loss_l1], \
185 | feed_dict={input_: phone_images, target_: dslr_images})
186 |
187 | test_losses += np.asarray(losses) / num_test_batches
188 |
189 | if LEVEL < 4:
190 | logs_gen = "step %d | training: %.4g, test: %.4g | content: %.4g, mse: %.4g, psnr: %.4g, l1: %.4g, " \
191 | "ms-ssim: %.4g\n" % (i, training_loss, test_losses[0][0], test_losses[0][1],
192 | test_losses[0][2], test_losses[0][3], test_losses[0][4], test_losses[0][5])
193 | else:
194 | logs_gen = "step %d | training: %.4g, test: %.4g | content: %.4g, mse: %.4g, psnr: %.4g, l1: %.4g\n" % \
195 | (i, training_loss, test_losses[0][0], test_losses[0][1], test_losses[0][2], test_losses[0][3], test_losses[0][4])
196 | print(logs_gen)
197 |
198 | # Save the results to log file
199 |
200 | logs = open("models/logs.txt", "a")
201 | logs.write(logs_gen)
202 | logs.write('\n')
203 | logs.close()
204 |
205 | # Save visual results for several test images
206 |
207 | bokeh_crops = sess.run(bokeh_img, feed_dict={input_: visual_test_crops, target_: dslr_images})
208 |
209 | idx = 0
210 | for crop in bokeh_crops:
211 | if idx < 7:
212 | before_after = np.hstack((
213 | np.float32(misc.imresize(
214 | np.reshape(visual_test_crops[idx, :, :, 0:3] * 255, [PATCH_HEIGHT, PATCH_WIDTH, 3]),
215 | [TARGET_HEIGHT, TARGET_WIDTH])) / 255.0,
216 | crop,
217 | np.reshape(visual_target_crops[idx], [TARGET_HEIGHT, TARGET_WIDTH, TARGET_DEPTH])))
218 | misc.imsave("results/pynet_img_" + str(idx) + "_level_" + str(LEVEL) + "_iter_" + str(i) + ".jpg",
219 | before_after)
220 | idx += 1
221 |
222 | training_loss = 0.0
223 |
224 | # Saving the model that corresponds to the current iteration
225 | saver.save(sess, "models/pynet_level_" + str(LEVEL) + "_iteration_" + str(i) + ".ckpt", write_meta_graph=False)
226 |
227 | # Loading new training data
228 | if i % 1000 == 0:
229 |
230 | del train_data
231 | del train_answ
232 | train_data, train_answ = load_training_batch(dataset_dir, PATCH_WIDTH, PATCH_HEIGHT, DSLR_SCALE, train_size)
233 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | # Copyright 2020 by Andrey Ignatov. All Rights Reserved.
2 |
3 | from functools import reduce
4 | import tensorflow as tf
5 | import numpy as np
6 | import sys
7 | import os
8 |
9 | NUM_DEFAULT_TRAIN_ITERS = [-1, 100000, 80000, 30000, 20000, 20000, 5000, 5000]
10 |
11 |
12 | def process_command_args(arguments):
13 |
14 | # Specifying the default parameters
15 |
16 | level = 1
17 | batch_size = 50
18 |
19 | train_size = 4894
20 | learning_rate = 5e-5
21 |
22 | eval_step = 1000
23 | restore_iter = None
24 | num_train_iters = None
25 |
26 | dataset_dir = 'ebb_dataset/'
27 | vgg_dir = 'vgg_pretrained/imagenet-vgg-verydeep-19.mat'
28 |
29 | for args in arguments:
30 |
31 | if args.startswith("level"):
32 | level = int(args.split("=")[1])
33 |
34 | if args.startswith("batch_size"):
35 | batch_size = int(args.split("=")[1])
36 |
37 | if args.startswith("train_size"):
38 | train_size = int(args.split("=")[1])
39 |
40 | if args.startswith("learning_rate"):
41 | learning_rate = float(args.split("=")[1])
42 |
43 | if args.startswith("restore_iter"):
44 | restore_iter = int(args.split("=")[1])
45 |
46 | if args.startswith("num_train_iters"):
47 | num_train_iters = int(args.split("=")[1])
48 |
49 | # -----------------------------------
50 |
51 | if args.startswith("dataset_dir"):
52 | dataset_dir = args.split("=")[1]
53 |
54 | if args.startswith("vgg_dir"):
55 | vgg_dir = args.split("=")[1]
56 |
57 | if args.startswith("eval_step"):
58 | eval_step = int(args.split("=")[1])
59 |
60 | if restore_iter is None and level < 7:
61 | restore_iter = get_last_iter(level + 1)
62 | if restore_iter == -1:
63 | print("Error: Cannot find any pre-trained models for PyNET's level " + str(level + 1) + ".")
64 | print("Aborting the training.")
65 | sys.exit()
66 |
67 | if num_train_iters is None:
68 | num_train_iters = NUM_DEFAULT_TRAIN_ITERS[level]
69 |
70 | print("The following parameters will be applied for CNN training:")
71 |
72 | print("Training level: " + str(level))
73 | print("Batch size: " + str(batch_size))
74 | print("Learning rate: " + str(learning_rate))
75 | print("Training iterations: " + str(num_train_iters))
76 | print("Evaluation step: " + str(eval_step))
77 | print("Restore Iteration: " + str(restore_iter))
78 | print("Path to the dataset: " + dataset_dir)
79 | print("Path to VGG-19 network: " + vgg_dir)
80 |
81 | return level, batch_size, train_size, learning_rate, restore_iter, num_train_iters,\
82 | dataset_dir, vgg_dir, eval_step
83 |
84 |
85 | def process_test_model_args(arguments):
86 |
87 | level = 1
88 | restore_iter = None
89 |
90 | dataset_dir = 'ebb_dataset/'
91 | use_gpu = "true"
92 |
93 | orig_model = "false"
94 |
95 | for args in arguments:
96 |
97 | if args.startswith("level"):
98 | level = int(args.split("=")[1])
99 |
100 | if args.startswith("dataset_dir"):
101 | dataset_dir = args.split("=")[1]
102 |
103 | if args.startswith("restore_iter"):
104 | restore_iter = int(args.split("=")[1])
105 |
106 | if args.startswith("use_gpu"):
107 | use_gpu = args.split("=")[1]
108 |
109 | if args.startswith("orig"):
110 | orig_model = args.split("=")[1]
111 |
112 | if restore_iter is None and orig_model == "false":
113 | restore_iter = get_last_iter(level)
114 | if restore_iter == -1:
115 | print("Error: Cannot find any pre-trained models for PyNET's level " + str(level) + ".")
116 | sys.exit()
117 |
118 | return level, restore_iter, dataset_dir, use_gpu, orig_model
119 |
120 |
121 | def get_last_iter(level):
122 |
123 | saved_models = [int((model_file.split("_")[-1]).split(".")[0])
124 | for model_file in os.listdir("models/")
125 | if model_file.startswith("pynet_level_" + str(level))]
126 |
127 | if len(saved_models) > 0:
128 | return np.max(saved_models)
129 | else:
130 | return -1
131 |
132 |
133 | def log10(x):
134 | numerator = tf.compat.v1.log(x)
135 | denominator = tf.compat.v1.log(tf.constant(10, dtype=numerator.dtype))
136 | return numerator / denominator
137 |
138 |
139 | def _tensor_size(tensor):
140 | from operator import mul
141 | return reduce(mul, (d.value for d in tensor.get_shape()[1:]), 1)
142 |
143 |
--------------------------------------------------------------------------------
/vgg.py:
--------------------------------------------------------------------------------
1 | # Copyright 2019-2020 by Andrey Ignatov. All Rights Reserved.
2 |
3 | import tensorflow as tf
4 | import numpy as np
5 | import scipy.io
6 |
7 | IMAGE_MEAN = np.array([123.68, 116.779, 103.939])
8 |
9 |
10 | def net(path_to_vgg_net, input_image):
11 |
12 | layers = (
13 | 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1',
14 |
15 | 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
16 |
17 | 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3',
18 | 'relu3_3', 'conv3_4', 'relu3_4', 'pool3',
19 |
20 | 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3',
21 | 'relu4_3', 'conv4_4', 'relu4_4', 'pool4',
22 |
23 | 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3',
24 | 'relu5_3', 'conv5_4', 'relu5_4'
25 | )
26 |
27 | data = scipy.io.loadmat(path_to_vgg_net)
28 | weights = data['layers'][0]
29 |
30 | net = {}
31 | current = input_image
32 | for i, name in enumerate(layers):
33 | layer_type = name[:4]
34 | if layer_type == 'conv':
35 | kernels, bias = weights[i][0][0][0][0]
36 | kernels = np.transpose(kernels, (1, 0, 2, 3))
37 | bias = bias.reshape(-1)
38 | current = _conv_layer(current, kernels, bias)
39 | elif layer_type == 'relu':
40 | current = tf.nn.relu(current)
41 | elif layer_type == 'pool':
42 | current = _pool_layer(current)
43 | net[name] = current
44 |
45 | return net
46 |
47 |
48 | def _conv_layer(input, weights, bias):
49 | conv = tf.nn.conv2d(input, tf.constant(weights), strides=(1, 1, 1, 1), padding='SAME')
50 | return tf.nn.bias_add(conv, bias)
51 |
52 |
53 | def _pool_layer(input):
54 | return tf.nn.max_pool(input, ksize=(1, 2, 2, 1), strides=(1, 2, 2, 1), padding='SAME')
55 |
56 |
57 | def preprocess(image):
58 | return image - IMAGE_MEAN
59 |
--------------------------------------------------------------------------------
/vgg_pretrained/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/vgg_pretrained/.gitkeep
--------------------------------------------------------------------------------
/visual_samples/depth_maps/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/1.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/10.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/11.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/12.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/2.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/3.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/4.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/5.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/6.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/7.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/8.png
--------------------------------------------------------------------------------
/visual_samples/depth_maps/9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/depth_maps/9.png
--------------------------------------------------------------------------------
/visual_samples/images/1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/1.jpg
--------------------------------------------------------------------------------
/visual_samples/images/10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/10.jpg
--------------------------------------------------------------------------------
/visual_samples/images/11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/11.jpg
--------------------------------------------------------------------------------
/visual_samples/images/12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/12.jpg
--------------------------------------------------------------------------------
/visual_samples/images/2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/2.jpg
--------------------------------------------------------------------------------
/visual_samples/images/3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/3.jpg
--------------------------------------------------------------------------------
/visual_samples/images/4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/4.jpg
--------------------------------------------------------------------------------
/visual_samples/images/5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/5.jpg
--------------------------------------------------------------------------------
/visual_samples/images/6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/6.jpg
--------------------------------------------------------------------------------
/visual_samples/images/7.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/7.jpg
--------------------------------------------------------------------------------
/visual_samples/images/8.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/8.jpg
--------------------------------------------------------------------------------
/visual_samples/images/9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aiff22/PyNET-Bokeh/98942b9b9c4206b2b8712d317bc2f79b685d50ea/visual_samples/images/9.jpg
--------------------------------------------------------------------------------