├── .gitignore
├── Data
└── .gitignore
├── LICENSE
├── Literature
├── base_paper.pdf
├── copy_network.pdf
├── decoder_part.odt
├── doubts
└── graves2016.pdf
├── README.md
├── TensorFlow_implementation
├── .gitignore
├── Data_Preprocessor.ipynb
├── Summary_Generator
│ ├── Model.py
│ ├── Tensorflow_Graph
│ │ ├── __init__.py
│ │ ├── order_planner_with_copynet.py
│ │ ├── order_planner_without_copynet.py
│ │ └── utils.py
│ ├── Text_Preprocessing_Helpers
│ │ ├── __init__.py
│ │ ├── pickling_tools.py
│ │ └── utils.py
│ └── __init__.py
├── fast_data_preprocessor_part1.py
├── fast_data_preprocessor_part2.py
├── inferencer.py
├── pre_processing_op.ipynb
├── seq2seq
│ ├── __init__.py
│ ├── configurable.py
│ ├── contrib
│ │ ├── __init__.py
│ │ ├── experiment.py
│ │ ├── rnn_cell.py
│ │ └── seq2seq
│ │ │ ├── __init__.py
│ │ │ ├── decoder.py
│ │ │ └── helper.py
│ ├── data
│ │ ├── __init__.py
│ │ ├── input_pipeline.py
│ │ ├── parallel_data_provider.py
│ │ ├── postproc.py
│ │ ├── sequence_example_decoder.py
│ │ ├── split_tokens_decoder.py
│ │ └── vocab.py
│ ├── decoders
│ │ ├── __init__.py
│ │ ├── attention.py
│ │ ├── attention_decoder.py
│ │ ├── basic_decoder.py
│ │ ├── beam_search_decoder.py
│ │ └── rnn_decoder.py
│ ├── encoders
│ │ ├── __init__.py
│ │ ├── conv_encoder.py
│ │ ├── encoder.py
│ │ ├── image_encoder.py
│ │ ├── pooling_encoder.py
│ │ └── rnn_encoder.py
│ ├── global_vars.py
│ ├── graph_module.py
│ ├── graph_utils.py
│ ├── inference
│ │ ├── __init__.py
│ │ ├── beam_search.py
│ │ └── inference.py
│ ├── losses.py
│ ├── metrics
│ │ ├── __init__.py
│ │ ├── bleu.py
│ │ ├── metric_specs.py
│ │ └── rouge.py
│ ├── models
│ │ ├── __init__.py
│ │ ├── attention_seq2seq.py
│ │ ├── basic_seq2seq.py
│ │ ├── bridges.py
│ │ ├── image2seq.py
│ │ ├── model_base.py
│ │ └── seq2seq_model.py
│ ├── tasks
│ │ ├── __init__.py
│ │ ├── decode_text.py
│ │ ├── dump_attention.py
│ │ ├── dump_beams.py
│ │ └── inference_task.py
│ ├── test
│ │ ├── __init__.py
│ │ ├── attention_test.py
│ │ ├── beam_search_test.py
│ │ ├── bridges_test.py
│ │ ├── conv_encoder_test.py
│ │ ├── data_test.py
│ │ ├── decoder_test.py
│ │ ├── example_config_test.py
│ │ ├── hooks_test.py
│ │ ├── input_pipeline_test.py
│ │ ├── losses_test.py
│ │ ├── metrics_test.py
│ │ ├── models_test.py
│ │ ├── pipeline_test.py
│ │ ├── pooling_encoder_test.py
│ │ ├── rnn_cell_test.py
│ │ ├── rnn_encoder_test.py
│ │ ├── train_utils_test.py
│ │ ├── utils.py
│ │ └── vocab_test.py
│ └── training
│ │ ├── __init__.py
│ │ ├── hooks.py
│ │ └── utils.py
├── trainer_with_copy_net.py
└── trainer_without_copy_net.py
├── Visualizations
├── first_run_of_both.png
└── projector_pic.png
└── architecture_diagram.jpeg
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | env/
12 | build/
13 | develop-eggs/
14 | dist/
15 | downloads/
16 | eggs/
17 | .eggs/
18 | lib/
19 | lib64/
20 | parts/
21 | sdist/
22 | var/
23 | wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 |
28 | # PyInstaller
29 | # Usually these files are written by a python script from a template
30 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
31 | *.manifest
32 | *.spec
33 |
34 | # Installer logs
35 | pip-log.txt
36 | pip-delete-this-directory.txt
37 |
38 | # Unit test / coverage reports
39 | htmlcov/
40 | .tox/
41 | .coverage
42 | .coverage.*
43 | .cache
44 | nosetests.xml
45 | coverage.xml
46 | *.cover
47 | .hypothesis/
48 |
49 | # Translations
50 | *.mo
51 | *.pot
52 |
53 | # Django stuff:
54 | *.log
55 | local_settings.py
56 |
57 | # Flask stuff:
58 | instance/
59 | .webassets-cache
60 |
61 | # Scrapy stuff:
62 | .scrapy
63 |
64 | # Sphinx documentation
65 | docs/_build/
66 |
67 | # PyBuilder
68 | target/
69 |
70 | # Jupyter Notebook
71 | .ipynb_checkpoints
72 |
73 | # pyenv
74 | .python-version
75 |
76 | # celery beat schedule file
77 | celerybeat-schedule
78 |
79 | # SageMath parsed files
80 | *.sage.py
81 |
82 | # dotenv
83 | .env
84 |
85 | # virtualenv
86 | .venv
87 | venv/
88 | ENV/
89 |
90 | # Spyder project settings
91 | .spyderproject
92 | .spyproject
93 |
94 | # Rope project settings
95 | .ropeproject
96 |
97 | # mkdocs documentation
98 | /site
99 |
100 | # mypy
101 | .mypy_cache/
102 |
103 | # ignore pycharm setup
104 | .idea/
105 |
--------------------------------------------------------------------------------
/Data/.gitignore:
--------------------------------------------------------------------------------
1 | # ignore the full version of the wikipedia-biography-dataset
2 | wikipedia-biography-dataset/
3 |
4 | # ignore link as well
5 | wikipedia-biography-dataset
6 |
7 | # ignore the three full dataset files
8 | *.nb
9 | *.sent
10 | *.box
11 |
12 | # ignore the pickle files
13 | *.pickle
14 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2017 Animesh Karnewar
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Literature/base_paper.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/Literature/base_paper.pdf
--------------------------------------------------------------------------------
/Literature/copy_network.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/Literature/copy_network.pdf
--------------------------------------------------------------------------------
/Literature/decoder_part.odt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/Literature/decoder_part.odt
--------------------------------------------------------------------------------
/Literature/doubts:
--------------------------------------------------------------------------------
1 | 1.) In link based attention, how is the link matrix implemented?
2 |
3 | 2.) Equation 8, what is the first alpha(t - 1)
4 |
5 | 3.) Equation 8, how is the product of Link matrix with the alpha(t - 1) dimensionally correct?
6 |
7 | 4.) alpha_t_link is used for computing zt and also for computing alpha_hybrid
8 |
9 | 5.) how is the vocabulary calculated programmatically?
10 |
11 |
12 |
--------------------------------------------------------------------------------
/Literature/graves2016.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/Literature/graves2016.pdf
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Natural-Language-Summary-Generation-From-Structured-Data
2 | Implementation (Personal) of the paper titled
3 | `"Order-Planning Neural Text Generation From Structured Data"`. The dataset
4 | for this project can be found at ->
5 | [WikiBio](https://github.com/DavidGrangier/wikipedia-biography-dataset)
6 |
7 | Requirements for training:
8 | * `python 3+`
9 | * `tensorflow-gpu` (preferable; CPU will take forever)
10 | * `Host Memory 12GB+` (this will be addressed soon)
11 |
12 | ## Architecture
13 |
14 | 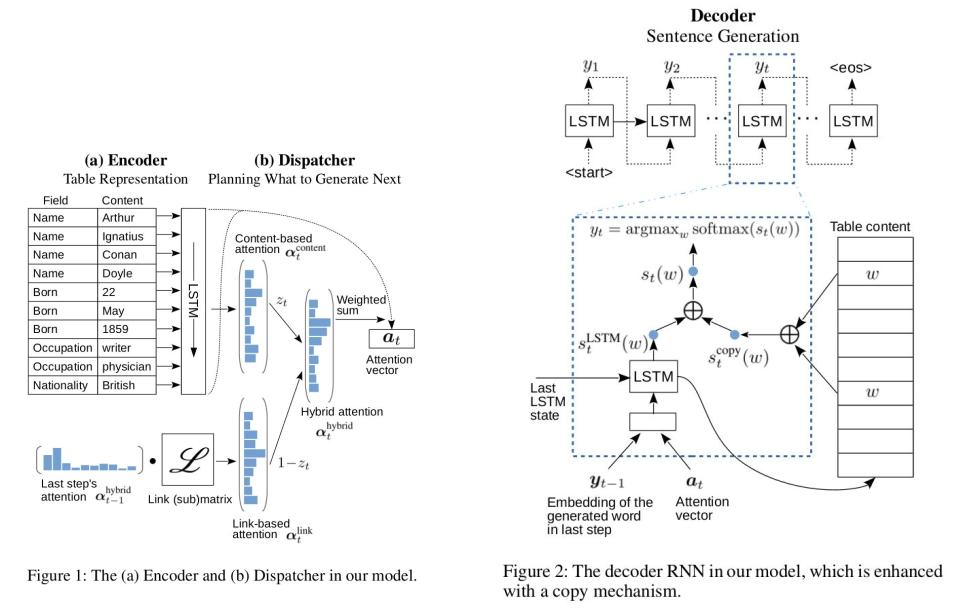 15 |
15 |
16 |
17 | ## Running the Code
18 | Process of using this code is slightly involved presently.
19 | This will be addressed in further development (perhaps with collaboration).
20 |
21 | #### 1. Preprocessing:
22 | Please refer to the `/TensorFlow_implementation/Data_Preprocessor.ipynb`
23 | for info about what steps are performed in preprocessing the data. Using
24 | the notebook on the full data for preprocessing will be very slow,
25 | so please use the following procedure for it.
26 |
27 | Step 1:
28 | (your_venv)$ python fast_data_preprocessor_part1.py
29 |
30 | Note that all the tweakable parameters are declared at the
31 | beginning of the script (Change them as per your requirement).
32 | This will generate a `temp.pickle` file in the same directory. Do not delete
33 | it even after full preprocessing. This is like a backup of the
34 | preprocessing pipeline; i.e. if you decide to change something later,
35 | you would'nt have to run the entire preprocessing again.
36 |
37 | Step 2:
38 | (your_venv)$ python fast_data_preprocessor_part12.py
39 |
40 | This will create the following file: `/Data/plug_and_play.pickle`. Again,
41 | tweakable parameters are at the beginning of the script.
42 | **Please Note that this process requires RAM 12GB+.
43 | If you have < 12GB Host memory, please use a subset of
44 | the dataset instead of the entire dataset
45 | (change `data_limit` in the script).**
46 |
47 | #### 2. Training:
48 |
49 | Once preprocessing is done, simply run one of the two training Scripts.
50 |
51 | (your_venv)$ python trainer_with_copy_net.py
52 | OR
53 | (your_venv)$ python trainer_without_copy_net.py
54 |
55 | Again all the hyperparameters are present at the beginning of the script.
56 | Example `trainer_without_copy_net.py`:
57 |
58 | ''' Name of the model: '''
59 | # This can be changed to create new models in the directory
60 | model_name = "Model_1(without_copy_net)"
61 |
62 | '''
63 | ========================================================
64 | || All Tweakable hyper-parameters
65 | ========================================================
66 | '''
67 | # constants for this script
68 | no_of_epochs = 500
69 | train_percentage = 100
70 | batch_size = 8
71 | checkpoint_factor = 100
72 | learning_rate = 3e-4 # for learning rate
73 | # but I have noticed that this learning rate works quite well.
74 | momentum = 0.9
75 |
76 | # Memory usage fraction:
77 | gpu_memory_usage_fraction = 1
78 |
79 | # Embeddings size:
80 | field_embedding_size = 100
81 | content_label_embedding_size = 400 # This is a much bigger
82 | # vocabulary compared to the field_name's vocabulary
83 |
84 | # LSTM hidden state sizes
85 | lstm_cell_state_size = hidden_state_size = 500 # they are
86 | # same (for now)
87 | '''
88 | ========================================================
89 | '''
90 |
91 | ## Test Runs:
92 | Once training is started, log-dirs are created for Tensorboard.
93 | Start your `tensorboard` server pointing to the log-dir.
94 |
95 | #### Loss monitor:
96 |
97 |
98 | 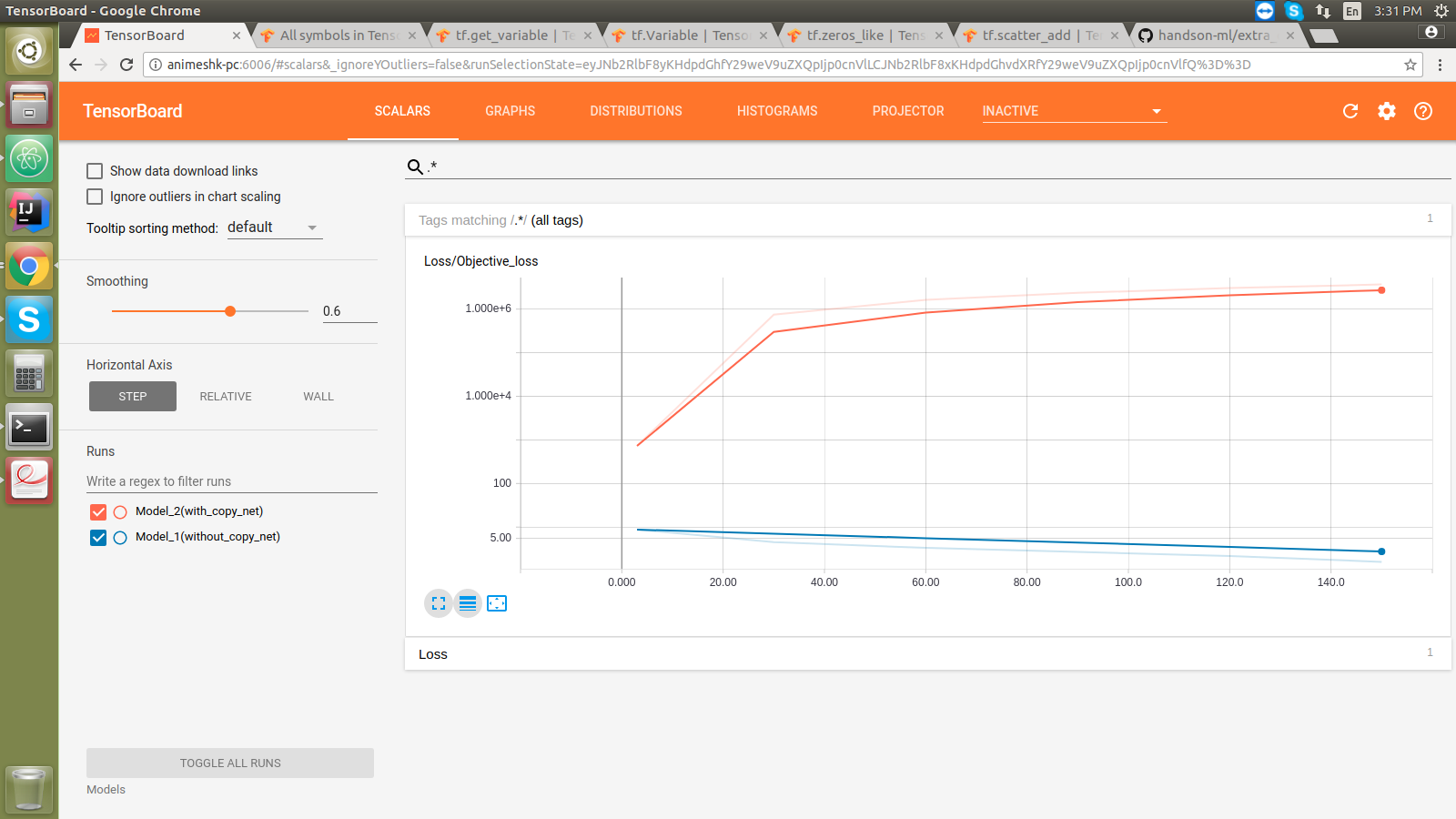 100 |
100 |
101 |
102 | #### Embedding projector:
103 |
104 |
105 | 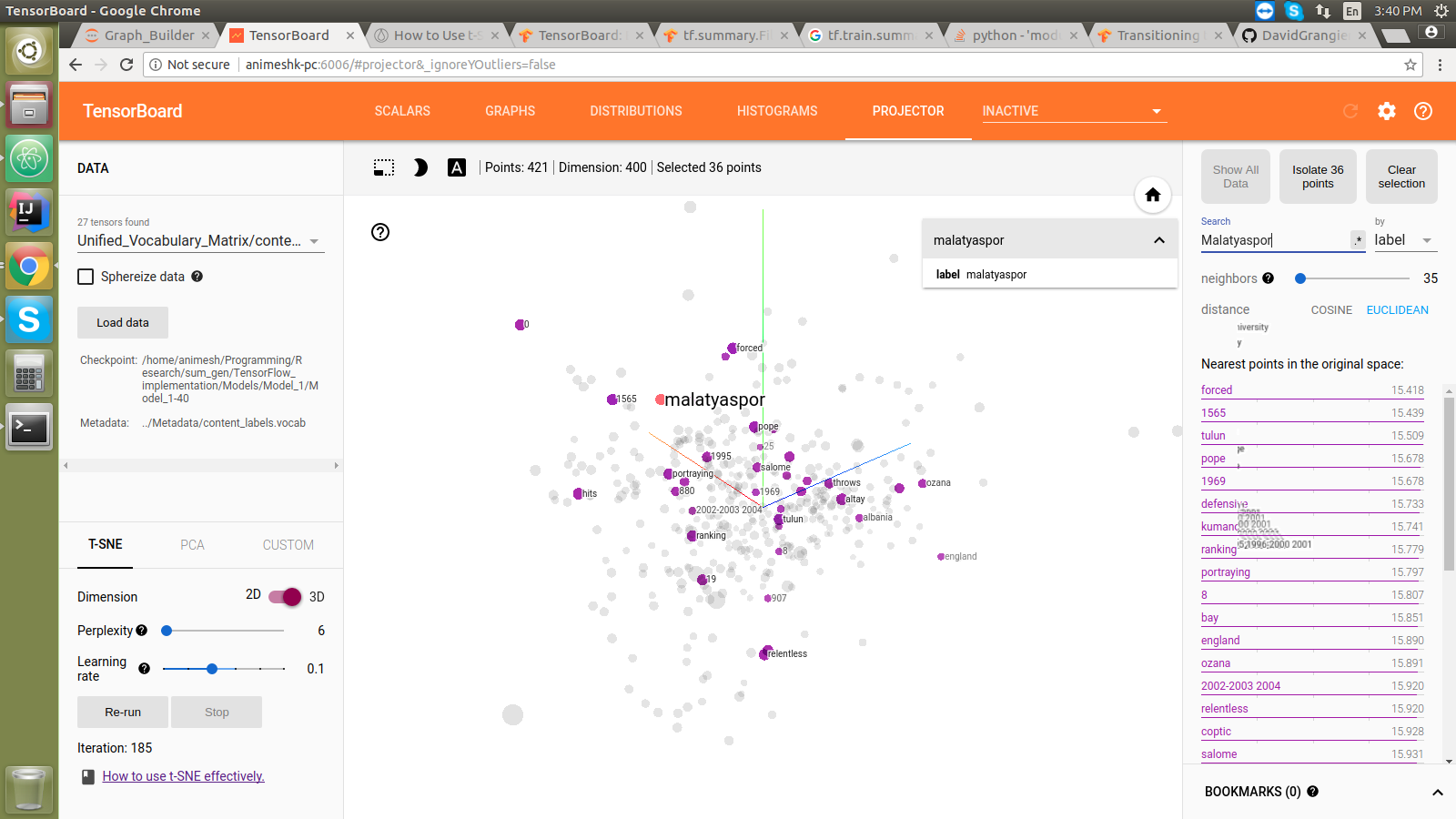 107 |
107 |
108 |
109 | * **Trained models coming soon ...**
110 |
111 | ## Thanks
112 | Please feel free to open PRs (contribute)/ issues / comments (feedback) here.
113 |
114 |
115 | Best regards,
116 | @akanimax :)
--------------------------------------------------------------------------------
/TensorFlow_implementation/.gitignore:
--------------------------------------------------------------------------------
1 | # ignore the pickle files
2 | *.pickle
3 |
4 | # ignore the Models directory
5 | Models/
6 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/Summary_Generator/Tensorflow_Graph/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/TensorFlow_implementation/Summary_Generator/Tensorflow_Graph/__init__.py
--------------------------------------------------------------------------------
/TensorFlow_implementation/Summary_Generator/Tensorflow_Graph/utils.py:
--------------------------------------------------------------------------------
1 | '''
2 | Library of helper tools for training and creating the Tensorflow graph of the
3 | system
4 | '''
5 |
6 | import numpy as np
7 |
8 | # Obtain the sequence lengths for the given input field_encodings / content_encodings (To feed to the RNN encoder)
9 | def get_lengths(sequences):
10 | '''
11 | Function to obtain the lengths of the given encodings. This allows for variable length sequences in the
12 | RNN encoder.
13 | @param
14 | sequences = [2d] list of integer encoded sequences, padded to the max_length of the batch
15 |
16 | @return
17 | lengths = [1d] list containing the lengths of the sequences
18 | '''
19 | return list(map(lambda x: len(x), sequences))
20 |
21 |
22 | def pad_sequences(seqs, pad_value = 0):
23 | '''
24 | funtion for padding the list of sequences and return a tensor that has all the sequences padded
25 | with leading 0s (for the bucketing phase)
26 | @param
27 | seqs => the list of integer sequences
28 | pad_value => the integer used as the padding value (defaults to zero)
29 | @return => padded tensor for this batch
30 | '''
31 |
32 | # find the maximum length among the given sequences
33 | max_length = max(map(lambda x: len(x), seqs))
34 |
35 | # create a list denoting the values with which the sequences need to be padded:
36 | padded_seqs = [] # initialize to empty list
37 | for seq in seqs:
38 | seq_len = len(seq) # obtain the length of current sequences
39 | diff = max_length - seq_len # calculate the padding amount for this seq
40 | padded_seqs.append(seq + [pad_value for _ in range(diff)])
41 |
42 |
43 | # return the padded seqs tensor
44 | return np.array(padded_seqs)
45 |
46 |
47 |
48 | # function to perform synchronous random shuffling of the training data
49 | def synch_random_shuffle_non_np(X, Y):
50 | '''
51 | ** This function takes in the parameters that are non numpy compliant dtypes such as list, tuple, etc.
52 | Although this function works on numpy arrays as well, this is not as performant enough
53 | @param
54 | X, Y => The data to be shuffled
55 | @return => The shuffled data
56 | '''
57 | combined = list(zip(X, Y))
58 |
59 | # shuffle the combined list in place
60 | np.random.shuffle(combined)
61 |
62 | # extract the data back from the combined list
63 | X, Y = list(zip(*combined))
64 |
65 | # return the shuffled data:
66 | return X, Y
67 |
68 |
69 |
70 | # function to split the data into train - dev sets:
71 | def split_train_dev(X, Y, train_percentage):
72 | '''
73 | function to split the given data into two small datasets (train - dev)
74 | @param
75 | X, Y => the data to be split
76 | (** Make sure the train dimension is the first one)
77 | train_percentage => the percentage which should be in the training set.
78 | (**this should be in 100% not decimal)
79 | @return => train_X, train_Y, test_X, test_Y
80 | '''
81 | m_examples = len(X)
82 | assert train_percentage <= 100, "Train percentage cannot be greater than 100! NOOB!"
83 | partition_point = int((m_examples * (float(train_percentage) / 100)) + 0.5) # 0.5 is added for rounding
84 |
85 | # construct the train_X, train_Y, test_X, test_Y sets:
86 | train_X = X[: partition_point]; train_Y = Y[: partition_point]
87 | test_X = X[partition_point: ]; test_Y = Y[partition_point: ]
88 |
89 | assert len(train_X) + len(test_X) == m_examples, "Something wrong in X splitting"
90 | assert len(train_Y) + len(test_Y) == m_examples, "Something wrong in Y splitting"
91 |
92 | # return the constructed sets
93 | return train_X, train_Y, test_X, test_Y
94 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/Summary_Generator/Text_Preprocessing_Helpers/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/TensorFlow_implementation/Summary_Generator/Text_Preprocessing_Helpers/__init__.py
--------------------------------------------------------------------------------
/TensorFlow_implementation/Summary_Generator/Text_Preprocessing_Helpers/pickling_tools.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function
2 |
3 | import _pickle as pickle # pickle module in python
4 | import os # for path related operations
5 |
6 | '''
7 | Simple function to perform pickling of the given object. This fucntion may fail if the size of the object exceeds
8 | the max size of the pickling protocol used. Although this is highly rare, One might then have to resort to some other
9 | strategy to pickle the data.
10 | The second function available is to unpickle a file located at the specified path
11 | '''
12 |
13 | # coded by botman
14 |
15 | # function to pickle an object
16 | def pickleIt(obj, save_path):
17 | '''
18 | function to pickle the given object.
19 | @param
20 | obj => the python object to be pickled
21 | save_path => the path where the pickled file is to be saved
22 | @return => nothing (the pickle file gets saved at the given location)
23 | '''
24 | if(not os.path.isfile(save_path)):
25 | with open(save_path, 'wb') as dumping:
26 | pickle.dump(obj, dumping)
27 |
28 | print("The file has been pickled at:", save_path)
29 |
30 | else:
31 | print("The pickle file already exists: ", save_path)
32 |
33 |
34 | # function to unpickle the given file and load the obj back into the python environment
35 | def unPickleIt(pickle_path): # might throw the file not found exception
36 | '''
37 | function to unpickle the object from the given path
38 | @param
39 | pickle_path => the path where the pickle file is located
40 | @return => the object extracted from the saved path
41 | '''
42 |
43 | with open(pickle_path, 'rb') as dumped_pickle:
44 | obj = pickle.load(dumped_pickle)
45 |
46 | return obj # return the unpickled object
47 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/Summary_Generator/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/TensorFlow_implementation/Summary_Generator/__init__.py
--------------------------------------------------------------------------------
/TensorFlow_implementation/fast_data_preprocessor_part1.py:
--------------------------------------------------------------------------------
1 | '''
2 | script for preprocessing the data from the files
3 | This script is optimized for producing the processed data faster
4 | '''
5 | from __future__ import print_function
6 | import numpy as np
7 | import os
8 | from Summary_Generator.Text_Preprocessing_Helpers.pickling_tools import *
9 |
10 | # set the data_path
11 | data_path = "../Data"
12 |
13 | data_files_paths = {
14 | "table_content": os.path.join(data_path, "train.box"),
15 | "nb_sentences" : os.path.join(data_path, "train.nb"),
16 | "train_sentences": os.path.join(data_path, "train.sent")
17 | }
18 |
19 | # generate the lists for all the samples in the dataset by reading the file once
20 |
21 |
22 | #=======================================================================================================================
23 | # Read the file for field_names and content_names
24 | #=======================================================================================================================
25 |
26 |
27 | print("Reading from the train.box file ...")
28 | with open(data_files_paths["table_content"]) as t_file:
29 | # read all the lines from the file:
30 | table_contents = t_file.readlines()
31 |
32 | # split all the lines at tab to generate the list of field_value pairs
33 | table_contents = map(lambda x: x.strip().split('\t'), table_contents)
34 |
35 |
36 | print("splitting the samples into field_names and content_words ...")
37 | # convert this list of string pairs into list of lists of tuples
38 | table_contents = map(lambda y: map(lambda x: tuple(x.split(":")), y), table_contents)
39 |
40 | # write a loop to separate out the field_names and the content_words
41 | count = 0; field_names = []; content_words = [] # initialize these to empty lists
42 | for sample in table_contents:
43 | # unzip the list:
44 | fields, contents = zip(*sample)
45 |
46 | # modify the fields to discard the _1, _2 labels
47 | fields = map(lambda x: x.split("_")[0], fields)
48 |
49 | # append the lists to appropriate lists
50 | field_names.append(list(fields)); content_words.append(list(contents))
51 |
52 | # increment the counter
53 | count += 1
54 |
55 | # give a feed_back for 1,00,000 samples:
56 | if(count % 100000 == 0):
57 | print("seperated", count, "samples")
58 |
59 | print("\nfield_names:\n", field_names[: 3], "\n\ncontent_words:\n", content_words[: 3])
60 |
61 |
62 |
63 | #==================================================================================================================
64 | # Read the file for the labels now
65 | #==================================================================================================================
66 | print("\n\nReading from the train.nb and the train.sent files ...")
67 | (labels, label_lengths) = (open(data_files_paths["train_sentences"]), open(data_files_paths["nb_sentences"]))
68 | label_words = labels.readlines(); lab_lengths = label_lengths.readlines()
69 | # close the files:
70 | labels.close(); label_lengths.close()
71 |
72 | print(label_words[: 3])
73 |
74 | # now perfrom the map_reduce operation to receive the a data structure similar to the field_names and content_words
75 | print("grouping lines in train.sent according to the train.nb ... ")
76 | count = 0; label_sentences = [] # initialize to empty list
77 |
78 | for length in lab_lengths:
79 | temp = []; cnt = 0;
80 | while(cnt < int(length)):
81 | sent = label_words.pop(0)
82 | # print("sent", sent)
83 | temp += sent.strip().split(' ')
84 | cnt += 1
85 | # print("temp ", temp)
86 |
87 | # append the temp to the label_sentences
88 | label_sentences.append(temp)
89 |
90 | # increment the counter
91 | count += 1
92 |
93 | # print a feedback for 1000 samples:
94 | if(count % 1000 == 0):
95 | print("grouped", count, "label_sentences")
96 |
97 |
98 | print(label_sentences[-3:])
99 |
100 |
101 | print("pickling the stuff generated till now ... ")
102 | # finally pickle the objects into a temporary pickle file:
103 | # temp_pickle object definition:
104 | temp_pickle = {
105 | "fields": field_names,
106 | "content": content_words,
107 | "label": label_sentences
108 | }
109 |
110 | pickleIt(temp_pickle, "temp.pickle")
111 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/fast_data_preprocessor_part2.py:
--------------------------------------------------------------------------------
1 | '''
2 | This script picks up from where we left in the first part.
3 | '''
4 |
5 | from __future__ import print_function
6 | from Summary_Generator.Text_Preprocessing_Helpers.pickling_tools import *
7 | from Summary_Generator.Text_Preprocessing_Helpers.utils import *
8 |
9 |
10 | # obtain the data from the pickle file generated as an entailment of the preprocessing part 1.
11 | temp_pickle_file_path = "temp.pickle"
12 |
13 | # set the limit on the samples to be trained on:
14 | limit = 600000 # no limit for now
15 |
16 | # unpickle the object from this file
17 | print("unpickling the data ...")
18 | temp_obj = unPickleIt(temp_pickle_file_path)
19 |
20 | # extract the three lists from this temp_obj
21 | field_names = temp_obj['fields'][:limit]
22 | content_words = temp_obj['content'][:limit]
23 | label_words = temp_obj['label'][:limit]
24 |
25 | # print first three elements from this list to verify the sanity:
26 | print("\nField_names:", field_names[: 3]); print("\nContent_words:", content_words[: 3]), print("\nLabel_words:", label_words[: 3])
27 |
28 | # tokenize the field_names:
29 | print("\n\nTokenizing the field_names ...")
30 | field_sequences, field_dict, rev_field_dict, field_vocab_size = prepare_tokenizer(field_names)
31 |
32 | print("Encoded field_sequences:", field_sequences[: 3])
33 |
34 |
35 | #Last part is to tokenize the content and the label sequences together:
36 | # note the length of the content_words:
37 | content_split_point = len(content_words)
38 |
39 | # attach them together
40 | # transform the label_words to add and tokens to all the sentences
41 | for i in range(len(label_words)):
42 | label_words[i] = [''] + label_words[i] + ['']
43 |
44 | unified_content_label_list = content_words + label_words
45 |
46 | # tokenize the unified_content_and_label_words:
47 | print("\n\nTokenizing the content and the label names ...")
48 | unified_sequences, content_label_dict, rev_content_label_dict, content_label_vocab_size = prepare_tokenizer(unified_content_label_list, max_word_length = 20000)
49 |
50 | print("Encoded content_label_sequences:", unified_sequences[: 3])
51 |
52 | # obtain the content and label sequences by separating it from the unified_sequences
53 | content_sequences = unified_sequences[: content_split_point]; label_sequences = unified_sequences[content_split_point: ]
54 |
55 | # Finally, pickle all of it together:
56 | pickle_obj = {
57 | # ''' Input structured data: '''
58 |
59 | # field_encodings and related data:
60 | 'field_encodings': field_sequences,
61 | 'field_dict': field_dict,
62 | 'field_rev_dict': rev_field_dict,
63 | 'field_vocab_size': field_vocab_size,
64 |
65 | # content encodings and related data:
66 | 'content_encodings': content_sequences,
67 |
68 | # ''' Label summary sentences: '''
69 |
70 | # label encodings and related data:
71 | 'label_encodings': label_sequences,
72 |
73 | # V union C related data:
74 | 'content_union_label_dict': content_label_dict,
75 | 'rev_content_union_label_dict': rev_content_label_dict,
76 | 'content_label_vocab_size': content_label_vocab_size
77 | }
78 |
79 | # call the pickling function to perform the pickling:
80 | print("\nPickling the processed data ...")
81 | pickleIt(pickle_obj, "../Data/plug_and_play.pickle")
82 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/inferencer.py:
--------------------------------------------------------------------------------
1 | '''
2 | Script for checking if the Inference computations run properly for the trained graph.
3 | '''
4 |
5 | from Summary_Generator.Tensorflow_Graph import order_planner_without_copynet
6 | from Summary_Generator.Text_Preprocessing_Helpers.pickling_tools import *
7 | from Summary_Generator.Tensorflow_Graph.utils import *
8 | from Summary_Generator.Model import *
9 | import numpy as np
10 | import tensorflow as tf
11 |
12 |
13 | # random_seed value for consistent debuggable behaviour
14 | seed_value = 3
15 |
16 | np.random.seed(seed_value) # set this seed for a device independant consistent behaviour
17 |
18 | ''' Set the constants for the script '''
19 | # various paths of the files
20 | data_path = "../Data" # the data path
21 |
22 | data_files_paths = {
23 | "table_content": os.path.join(data_path, "train.box"),
24 | "nb_sentences" : os.path.join(data_path, "train.nb"),
25 | "train_sentences": os.path.join(data_path, "train.sent")
26 | }
27 |
28 | base_model_path = "Models"
29 | plug_and_play_data_file = os.path.join(data_path, "plug_and_play.pickle")
30 |
31 |
32 | # Set the train_percentage mark here.
33 | train_percentage = 90
34 |
35 |
36 |
37 | ''' Extract and setup the data '''
38 | # Obtain the data:
39 | data = unPickleIt(plug_and_play_data_file)
40 |
41 | field_encodings = data['field_encodings']
42 | field_dict = data['field_dict']
43 |
44 | content_encodings = data['content_encodings']
45 |
46 | label_encodings = data['label_encodings']
47 | content_label_dict = data['content_union_label_dict']
48 | rev_content_label_dict = data['rev_content_union_label_dict']
49 |
50 | # vocabulary sizes
51 | field_vocab_size = data['field_vocab_size']
52 | content_label_vocab_size = data['content_label_vocab_size']
53 |
54 |
55 | X, Y = synch_random_shuffle_non_np(zip(field_encodings, content_encodings), label_encodings)
56 |
57 | train_X, train_Y, dev_X, dev_Y = split_train_dev(X, Y, train_percentage)
58 | train_X_field, train_X_content = zip(*train_X)
59 | train_X_field = list(train_X_field); train_X_content = list(train_X_content)
60 |
61 | # Free up the resources by deleting non required stuff
62 | del X, Y, field_encodings, content_encodings, train_X
63 |
64 | # print train_X_field, train_X_content, train_Y, dev_X, dev_Y
65 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | seq2seq library base module
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | from seq2seq.graph_module import GraphModule
23 |
24 | from seq2seq import contrib
25 | from seq2seq import data
26 | from seq2seq import decoders
27 | from seq2seq import encoders
28 | from seq2seq import global_vars
29 | from seq2seq import graph_utils
30 | from seq2seq import inference
31 | from seq2seq import losses
32 | from seq2seq import metrics
33 | from seq2seq import models
34 | from seq2seq import test
35 | from seq2seq import training
36 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/configurable.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Abstract base class for objects that are configurable using
16 | a parameters dictionary.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | import abc
24 | import copy
25 | from pydoc import locate
26 |
27 | import six
28 | import yaml
29 |
30 | import tensorflow as tf
31 |
32 |
33 | class abstractstaticmethod(staticmethod): #pylint: disable=C0111,C0103
34 | """Decorates a method as abstract and static"""
35 | __slots__ = ()
36 |
37 | def __init__(self, function):
38 | super(abstractstaticmethod, self).__init__(function)
39 | function.__isabstractmethod__ = True
40 |
41 | __isabstractmethod__ = True
42 |
43 |
44 | def _create_from_dict(dict_, default_module, *args, **kwargs):
45 | """Creates a configurable class from a dictionary. The dictionary must have
46 | "class" and "params" properties. The class can be either fully qualified, or
47 | it is looked up in the modules passed via `default_module`.
48 | """
49 | class_ = locate(dict_["class"]) or getattr(default_module, dict_["class"])
50 | params = {}
51 | if "params" in dict_:
52 | params = dict_["params"]
53 | instance = class_(params, *args, **kwargs)
54 | return instance
55 |
56 |
57 | def _maybe_load_yaml(item):
58 | """Parses `item` only if it is a string. If `item` is a dictionary
59 | it is returned as-is.
60 | """
61 | if isinstance(item, six.string_types):
62 | return yaml.load(item)
63 | elif isinstance(item, dict):
64 | return item
65 | else:
66 | raise ValueError("Got {}, expected YAML string or dict", type(item))
67 |
68 |
69 | def _deep_merge_dict(dict_x, dict_y, path=None):
70 | """Recursively merges dict_y into dict_x.
71 | """
72 | if path is None: path = []
73 | for key in dict_y:
74 | if key in dict_x:
75 | if isinstance(dict_x[key], dict) and isinstance(dict_y[key], dict):
76 | _deep_merge_dict(dict_x[key], dict_y[key], path + [str(key)])
77 | elif dict_x[key] == dict_y[key]:
78 | pass # same leaf value
79 | else:
80 | dict_x[key] = dict_y[key]
81 | else:
82 | dict_x[key] = dict_y[key]
83 | return dict_x
84 |
85 |
86 | def _parse_params(params, default_params):
87 | """Parses parameter values to the types defined by the default parameters.
88 | Default parameters are used for missing values.
89 | """
90 | # Cast parameters to correct types
91 | if params is None:
92 | params = {}
93 | result = copy.deepcopy(default_params)
94 | for key, value in params.items():
95 | # If param is unknown, drop it to stay compatible with past versions
96 | if key not in default_params:
97 | raise ValueError("%s is not a valid model parameter" % key)
98 | # Param is a dictionary
99 | if isinstance(value, dict):
100 | default_dict = default_params[key]
101 | if not isinstance(default_dict, dict):
102 | raise ValueError("%s should not be a dictionary", key)
103 | if default_dict:
104 | value = _parse_params(value, default_dict)
105 | else:
106 | # If the default is an empty dict we do not typecheck it
107 | # and assume it's done downstream
108 | pass
109 | if value is None:
110 | continue
111 | if default_params[key] is None:
112 | result[key] = value
113 | else:
114 | result[key] = type(default_params[key])(value)
115 | return result
116 |
117 |
118 | @six.add_metaclass(abc.ABCMeta)
119 | class Configurable(object):
120 | """Interface for all classes that are configurable
121 | via a parameters dictionary.
122 |
123 | Args:
124 | params: A dictionary of parameters.
125 | mode: A value in tf.contrib.learn.ModeKeys
126 | """
127 |
128 | def __init__(self, params, mode):
129 | self._params = _parse_params(params, self.default_params())
130 | self._mode = mode
131 | self._print_params()
132 |
133 | def _print_params(self):
134 | """Logs parameter values"""
135 | classname = self.__class__.__name__
136 | tf.logging.info("Creating %s in mode=%s", classname, self._mode)
137 | tf.logging.info("\n%s", yaml.dump({classname: self._params}))
138 |
139 | @property
140 | def mode(self):
141 | """Returns a value in tf.contrib.learn.ModeKeys.
142 | """
143 | return self._mode
144 |
145 | @property
146 | def params(self):
147 | """Returns a dictionary of parsed parameters.
148 | """
149 | return self._params
150 |
151 | @abstractstaticmethod
152 | def default_params():
153 | """Returns a dictionary of default parameters. The default parameters
154 | are used to define the expected type of passed parameters. Missing
155 | parameter values are replaced with the defaults returned by this method.
156 | """
157 | raise NotImplementedError
158 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/contrib/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/contrib/experiment.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """A patched tf.learn Experiment class to handle GPU memory
16 | sharing issues.
17 | """
18 |
19 | import tensorflow as tf
20 |
21 | class Experiment(tf.contrib.learn.Experiment):
22 | """A patched tf.learn Experiment class to handle GPU memory
23 | sharing issues."""
24 |
25 | def __init__(self, train_steps_per_iteration=None, *args, **kwargs):
26 | super(Experiment, self).__init__(*args, **kwargs)
27 | self._train_steps_per_iteration = train_steps_per_iteration
28 |
29 | def _has_training_stopped(self, eval_result):
30 | """Determines whether the training has stopped."""
31 | if not eval_result:
32 | return False
33 |
34 | global_step = eval_result.get(tf.GraphKeys.GLOBAL_STEP)
35 | return global_step and self._train_steps and (
36 | global_step >= self._train_steps)
37 |
38 | def continuous_train_and_eval(self,
39 | continuous_eval_predicate_fn=None):
40 | """Interleaves training and evaluation.
41 |
42 | The frequency of evaluation is controlled by the `train_steps_per_iteration`
43 | (via constructor). The model will be first trained for
44 | `train_steps_per_iteration`, and then be evaluated in turns.
45 |
46 | This differs from `train_and_evaluate` as follows:
47 | 1. The procedure will have train and evaluation in turns. The model
48 | will be trained for a number of steps (usuallly smaller than `train_steps`
49 | if provided) and then be evaluated. `train_and_evaluate` will train the
50 | model for `train_steps` (no small training iteraions).
51 |
52 | 2. Due to the different approach this schedule takes, it leads to two
53 | differences in resource control. First, the resources (e.g., memory) used
54 | by training will be released before evaluation (`train_and_evaluate` takes
55 | double resources). Second, more checkpoints will be saved as a checkpoint
56 | is generated at the end of each small trainning iteration.
57 |
58 | Args:
59 | continuous_eval_predicate_fn: A predicate function determining whether to
60 | continue after each iteration. `predicate_fn` takes the evaluation
61 | results as its arguments. At the beginning of evaluation, the passed
62 | eval results will be None so it's expected that the predicate function
63 | handles that gracefully. When `predicate_fn` is not specified, this will
64 | run in an infinite loop or exit when global_step reaches `train_steps`.
65 |
66 | Returns:
67 | A tuple of the result of the `evaluate` call to the `Estimator` and the
68 | export results using the specified `ExportStrategy`.
69 |
70 | Raises:
71 | ValueError: if `continuous_eval_predicate_fn` is neither None nor
72 | callable.
73 | """
74 |
75 | if (continuous_eval_predicate_fn is not None and
76 | not callable(continuous_eval_predicate_fn)):
77 | raise ValueError(
78 | "`continuous_eval_predicate_fn` must be a callable, or None.")
79 |
80 | eval_result = None
81 |
82 | # Set the default value for train_steps_per_iteration, which will be
83 | # overriden by other settings.
84 | train_steps_per_iteration = 1000
85 | if self._train_steps_per_iteration is not None:
86 | train_steps_per_iteration = self._train_steps_per_iteration
87 | elif self._train_steps is not None:
88 | # train_steps_per_iteration = int(self._train_steps / 10)
89 | train_steps_per_iteration = min(
90 | self._min_eval_frequency, self._train_steps)
91 |
92 | while (not continuous_eval_predicate_fn or
93 | continuous_eval_predicate_fn(eval_result)):
94 |
95 | if self._has_training_stopped(eval_result):
96 | # Exits once max steps of training is satisfied.
97 | tf.logging.info("Stop training model as max steps reached")
98 | break
99 |
100 | tf.logging.info("Training model for %s steps", train_steps_per_iteration)
101 | self._estimator.fit(
102 | input_fn=self._train_input_fn,
103 | steps=train_steps_per_iteration,
104 | monitors=self._train_monitors)
105 |
106 | tf.logging.info("Evaluating model now.")
107 | eval_result = self._estimator.evaluate(
108 | input_fn=self._eval_input_fn,
109 | steps=self._eval_steps,
110 | metrics=self._eval_metrics,
111 | name="one_pass",
112 | hooks=self._eval_hooks)
113 |
114 | return eval_result, self._maybe_export(eval_result)
115 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/contrib/rnn_cell.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of RNN Cells
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 | from __future__ import unicode_literals
21 |
22 | import sys
23 | import inspect
24 |
25 | import tensorflow as tf
26 | from tensorflow.python.ops import array_ops # pylint: disable=E0611
27 | from tensorflow.python.util import nest # pylint: disable=E0611
28 | from tensorflow.contrib.rnn import MultiRNNCell # pylint: disable=E0611
29 |
30 | # Import all cell classes from Tensorflow
31 | TF_CELL_CLASSES = [
32 | x for x in tf.contrib.rnn.__dict__.values()
33 | if inspect.isclass(x) and issubclass(x, tf.contrib.rnn.RNNCell)
34 | ]
35 | for cell_class in TF_CELL_CLASSES:
36 | setattr(sys.modules[__name__], cell_class.__name__, cell_class)
37 |
38 |
39 | class ExtendedMultiRNNCell(MultiRNNCell):
40 | """Extends the Tensorflow MultiRNNCell with residual connections"""
41 |
42 | def __init__(self,
43 | cells,
44 | residual_connections=False,
45 | residual_combiner="add",
46 | residual_dense=False):
47 | """Create a RNN cell composed sequentially of a number of RNNCells.
48 |
49 | Args:
50 | cells: list of RNNCells that will be composed in this order.
51 | state_is_tuple: If True, accepted and returned states are n-tuples, where
52 | `n = len(cells)`. If False, the states are all
53 | concatenated along the column axis. This latter behavior will soon be
54 | deprecated.
55 | residual_connections: If true, add residual connections between all cells.
56 | This requires all cells to have the same output_size. Also, iff the
57 | input size is not equal to the cell output size, a linear transform
58 | is added before the first layer.
59 | residual_combiner: One of "add" or "concat". To create inputs for layer
60 | t+1 either "add" the inputs from the prev layer or concat them.
61 | residual_dense: Densely connect each layer to all other layers
62 |
63 | Raises:
64 | ValueError: if cells is empty (not allowed), or at least one of the cells
65 | returns a state tuple but the flag `state_is_tuple` is `False`.
66 | """
67 | super(ExtendedMultiRNNCell, self).__init__(cells, state_is_tuple=True)
68 | assert residual_combiner in ["add", "concat", "mean"]
69 |
70 | self._residual_connections = residual_connections
71 | self._residual_combiner = residual_combiner
72 | self._residual_dense = residual_dense
73 |
74 | def __call__(self, inputs, state, scope=None):
75 | """Run this multi-layer cell on inputs, starting from state."""
76 | if not self._residual_connections:
77 | return super(ExtendedMultiRNNCell, self).__call__(
78 | inputs, state, (scope or "extended_multi_rnn_cell"))
79 |
80 | with tf.variable_scope(scope or "extended_multi_rnn_cell"):
81 | # Adding Residual connections are only possible when input and output
82 | # sizes are equal. Optionally transform the initial inputs to
83 | # `cell[0].output_size`
84 | if self._cells[0].output_size != inputs.get_shape().as_list()[1] and \
85 | (self._residual_combiner in ["add", "mean"]):
86 | inputs = tf.contrib.layers.fully_connected(
87 | inputs=inputs,
88 | num_outputs=self._cells[0].output_size,
89 | activation_fn=None,
90 | scope="input_transform")
91 |
92 | # Iterate through all layers (code from MultiRNNCell)
93 | cur_inp = inputs
94 | prev_inputs = [cur_inp]
95 | new_states = []
96 | for i, cell in enumerate(self._cells):
97 | with tf.variable_scope("cell_%d" % i):
98 | if not nest.is_sequence(state):
99 | raise ValueError(
100 | "Expected state to be a tuple of length %d, but received: %s" %
101 | (len(self.state_size), state))
102 | cur_state = state[i]
103 | next_input, new_state = cell(cur_inp, cur_state)
104 |
105 | # Either combine all previous inputs or only the current input
106 | input_to_combine = prev_inputs[-1:]
107 | if self._residual_dense:
108 | input_to_combine = prev_inputs
109 |
110 | # Add Residual connection
111 | if self._residual_combiner == "add":
112 | next_input = next_input + sum(input_to_combine)
113 | if self._residual_combiner == "mean":
114 | combined_mean = tf.reduce_mean(tf.stack(input_to_combine), 0)
115 | next_input = next_input + combined_mean
116 | elif self._residual_combiner == "concat":
117 | next_input = tf.concat([next_input] + input_to_combine, 1)
118 | cur_inp = next_input
119 | prev_inputs.append(cur_inp)
120 |
121 | new_states.append(new_state)
122 | new_states = (tuple(new_states)
123 | if self._state_is_tuple else array_ops.concat(new_states, 1))
124 | return cur_inp, new_states
125 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/contrib/seq2seq/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/data/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of input-related utlities.
15 | """
16 |
17 | from seq2seq.data import input_pipeline
18 | from seq2seq.data import parallel_data_provider
19 | from seq2seq.data import postproc
20 | from seq2seq.data import split_tokens_decoder
21 | from seq2seq.data import vocab
22 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/data/parallel_data_provider.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """A Data Provder that reads parallel (aligned) data.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 | from __future__ import unicode_literals
21 |
22 | import numpy as np
23 |
24 | import tensorflow as tf
25 | from tensorflow.contrib.slim.python.slim.data import data_provider
26 | from tensorflow.contrib.slim.python.slim.data import parallel_reader
27 |
28 | from seq2seq.data import split_tokens_decoder
29 |
30 |
31 | def make_parallel_data_provider(data_sources_source,
32 | data_sources_target,
33 | reader=tf.TextLineReader,
34 | num_samples=None,
35 | source_delimiter=" ",
36 | target_delimiter=" ",
37 | **kwargs):
38 | """Creates a DataProvider that reads parallel text data.
39 |
40 | Args:
41 | data_sources_source: A list of data sources for the source text files.
42 | data_sources_target: A list of data sources for the target text files.
43 | Can be None for inference mode.
44 | num_samples: Optional, number of records in the dataset
45 | delimiter: Split tokens in the data on this delimiter. Defaults to space.
46 | kwargs: Additional arguments (shuffle, num_epochs, etc) that are passed
47 | to the data provider
48 |
49 | Returns:
50 | A DataProvider instance
51 | """
52 |
53 | decoder_source = split_tokens_decoder.SplitTokensDecoder(
54 | tokens_feature_name="source_tokens",
55 | length_feature_name="source_len",
56 | append_token="SEQUENCE_END",
57 | delimiter=source_delimiter)
58 |
59 | dataset_source = tf.contrib.slim.dataset.Dataset(
60 | data_sources=data_sources_source,
61 | reader=reader,
62 | decoder=decoder_source,
63 | num_samples=num_samples,
64 | items_to_descriptions={})
65 |
66 | dataset_target = None
67 | if data_sources_target is not None:
68 | decoder_target = split_tokens_decoder.SplitTokensDecoder(
69 | tokens_feature_name="target_tokens",
70 | length_feature_name="target_len",
71 | prepend_token="SEQUENCE_START",
72 | append_token="SEQUENCE_END",
73 | delimiter=target_delimiter)
74 |
75 | dataset_target = tf.contrib.slim.dataset.Dataset(
76 | data_sources=data_sources_target,
77 | reader=reader,
78 | decoder=decoder_target,
79 | num_samples=num_samples,
80 | items_to_descriptions={})
81 |
82 | return ParallelDataProvider(
83 | dataset1=dataset_source, dataset2=dataset_target, **kwargs)
84 |
85 |
86 | class ParallelDataProvider(data_provider.DataProvider):
87 | """Creates a ParallelDataProvider. This data provider reads two datasets
88 | in parallel, keeping them aligned.
89 |
90 | Args:
91 | dataset1: The first dataset. An instance of the Dataset class.
92 | dataset2: The second dataset. An instance of the Dataset class.
93 | Can be None. If None, only `dataset1` is read.
94 | num_readers: The number of parallel readers to use.
95 | shuffle: Whether to shuffle the data sources and common queue when
96 | reading.
97 | num_epochs: The number of times each data source is read. If left as None,
98 | the data will be cycled through indefinitely.
99 | common_queue_capacity: The capacity of the common queue.
100 | common_queue_min: The minimum number of elements in the common queue after
101 | a dequeue.
102 | seed: The seed to use if shuffling.
103 | """
104 |
105 | def __init__(self,
106 | dataset1,
107 | dataset2,
108 | shuffle=True,
109 | num_epochs=None,
110 | common_queue_capacity=4096,
111 | common_queue_min=1024,
112 | seed=None):
113 |
114 | if seed is None:
115 | seed = np.random.randint(10e8)
116 |
117 | _, data_source = parallel_reader.parallel_read(
118 | dataset1.data_sources,
119 | reader_class=dataset1.reader,
120 | num_epochs=num_epochs,
121 | num_readers=1,
122 | shuffle=False,
123 | capacity=common_queue_capacity,
124 | min_after_dequeue=common_queue_min,
125 | seed=seed)
126 |
127 | data_target = ""
128 | if dataset2 is not None:
129 | _, data_target = parallel_reader.parallel_read(
130 | dataset2.data_sources,
131 | reader_class=dataset2.reader,
132 | num_epochs=num_epochs,
133 | num_readers=1,
134 | shuffle=False,
135 | capacity=common_queue_capacity,
136 | min_after_dequeue=common_queue_min,
137 | seed=seed)
138 |
139 | # Optionally shuffle the data
140 | if shuffle:
141 | shuffle_queue = tf.RandomShuffleQueue(
142 | capacity=common_queue_capacity,
143 | min_after_dequeue=common_queue_min,
144 | dtypes=[tf.string, tf.string],
145 | seed=seed)
146 | enqueue_ops = []
147 | enqueue_ops.append(shuffle_queue.enqueue([data_source, data_target]))
148 | tf.train.add_queue_runner(
149 | tf.train.QueueRunner(shuffle_queue, enqueue_ops))
150 | data_source, data_target = shuffle_queue.dequeue()
151 |
152 | # Decode source items
153 | items = dataset1.decoder.list_items()
154 | tensors = dataset1.decoder.decode(data_source, items)
155 |
156 | if dataset2 is not None:
157 | # Decode target items
158 | items2 = dataset2.decoder.list_items()
159 | tensors2 = dataset2.decoder.decode(data_target, items2)
160 |
161 | # Merge items and results
162 | items = items + items2
163 | tensors = tensors + tensors2
164 |
165 | super(ParallelDataProvider, self).__init__(
166 | items_to_tensors=dict(zip(items, tensors)),
167 | num_samples=dataset1.num_samples)
168 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/data/postproc.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 |
16 | """
17 | A collection of commonly used post-processing functions.
18 | """
19 |
20 | from __future__ import absolute_import
21 | from __future__ import division
22 | from __future__ import print_function
23 | from __future__ import unicode_literals
24 |
25 | def strip_bpe(text):
26 | """Deodes text that was processed using BPE from
27 | https://github.com/rsennrich/subword-nmt"""
28 | return text.replace("@@ ", "").strip()
29 |
30 | def decode_sentencepiece(text):
31 | """Decodes text that uses https://github.com/google/sentencepiece encoding.
32 | Assumes that pieces are separated by a space"""
33 | return "".join(text.split(" ")).replace("▁", " ").strip()
34 |
35 | def slice_text(text,
36 | eos_token="SEQUENCE_END",
37 | sos_token="SEQUENCE_START"):
38 | """Slices text from SEQUENCE_START to SEQUENCE_END, not including
39 | these special tokens.
40 | """
41 | eos_index = text.find(eos_token)
42 | text = text[:eos_index] if eos_index > -1 else text
43 | sos_index = text.find(sos_token)
44 | text = text[sos_index+len(sos_token):] if sos_index > -1 else text
45 | return text.strip()
46 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/data/sequence_example_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """A decoder for tf.SequenceExample"""
15 |
16 | import tensorflow as tf
17 | from tensorflow.contrib.slim.python.slim.data import data_decoder
18 |
19 |
20 | class TFSEquenceExampleDecoder(data_decoder.DataDecoder):
21 | """A decoder for TensorFlow Examples.
22 | Decoding Example proto buffers is comprised of two stages: (1) Example parsing
23 | and (2) tensor manipulation.
24 | In the first stage, the tf.parse_example function is called with a list of
25 | FixedLenFeatures and SparseLenFeatures. These instances tell TF how to parse
26 | the example. The output of this stage is a set of tensors.
27 | In the second stage, the resulting tensors are manipulated to provide the
28 | requested 'item' tensors.
29 | To perform this decoding operation, an ExampleDecoder is given a list of
30 | ItemHandlers. Each ItemHandler indicates the set of features for stage 1 and
31 | contains the instructions for post_processing its tensors for stage 2.
32 | """
33 |
34 | def __init__(self, context_keys_to_features, sequence_keys_to_features,
35 | items_to_handlers):
36 | """Constructs the decoder.
37 | Args:
38 | keys_to_features: a dictionary from TF-Example keys to either
39 | tf.VarLenFeature or tf.FixedLenFeature instances. See tensorflow's
40 | parsing_ops.py.
41 | items_to_handlers: a dictionary from items (strings) to ItemHandler
42 | instances. Note that the ItemHandler's are provided the keys that they
43 | use to return the final item Tensors.
44 | """
45 | self._context_keys_to_features = context_keys_to_features
46 | self._sequence_keys_to_features = sequence_keys_to_features
47 | self._items_to_handlers = items_to_handlers
48 |
49 | def list_items(self):
50 | """See base class."""
51 | return list(self._items_to_handlers.keys())
52 |
53 | def decode(self, serialized_example, items=None):
54 | """Decodes the given serialized TF-example.
55 | Args:
56 | serialized_example: a serialized TF-example tensor.
57 | items: the list of items to decode. These must be a subset of the item
58 | keys in self._items_to_handlers. If `items` is left as None, then all
59 | of the items in self._items_to_handlers are decoded.
60 | Returns:
61 | the decoded items, a list of tensor.
62 | """
63 | context, sequence = tf.parse_single_sequence_example(
64 | serialized_example, self._context_keys_to_features,
65 | self._sequence_keys_to_features)
66 |
67 | # Merge context and sequence features
68 | example = {}
69 | example.update(context)
70 | example.update(sequence)
71 |
72 | all_features = {}
73 | all_features.update(self._context_keys_to_features)
74 | all_features.update(self._sequence_keys_to_features)
75 |
76 | # Reshape non-sparse elements just once:
77 | for k, value in all_features.items():
78 | if isinstance(value, tf.FixedLenFeature):
79 | example[k] = tf.reshape(example[k], value.shape)
80 |
81 | if not items:
82 | items = self._items_to_handlers.keys()
83 |
84 | outputs = []
85 | for item in items:
86 | handler = self._items_to_handlers[item]
87 | keys_to_tensors = {key: example[key] for key in handler.keys}
88 | outputs.append(handler.tensors_to_item(keys_to_tensors))
89 | return outputs
90 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/data/split_tokens_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """A decoder that splits a string into tokens and returns the
15 | individual tokens and the length.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | from tensorflow.contrib.slim.python.slim.data import data_decoder
25 |
26 |
27 | class SplitTokensDecoder(data_decoder.DataDecoder):
28 | """A DataProvider that splits a string tensor into individual tokens and
29 | returns the tokens and the length.
30 | Optionally prepends or appends special tokens.
31 |
32 | Args:
33 | delimiter: Delimiter to split on. Must be a single character.
34 | tokens_feature_name: A descriptive feature name for the token values
35 | length_feature_name: A descriptive feature name for the length value
36 | """
37 |
38 | def __init__(self,
39 | delimiter=" ",
40 | tokens_feature_name="tokens",
41 | length_feature_name="length",
42 | prepend_token=None,
43 | append_token=None):
44 | self.delimiter = delimiter
45 | self.tokens_feature_name = tokens_feature_name
46 | self.length_feature_name = length_feature_name
47 | self.prepend_token = prepend_token
48 | self.append_token = append_token
49 |
50 | def decode(self, data, items):
51 | decoded_items = {}
52 |
53 | # Split tokens
54 | tokens = tf.string_split([data], delimiter=self.delimiter).values
55 |
56 | # Optionally prepend a special token
57 | if self.prepend_token is not None:
58 | tokens = tf.concat([[self.prepend_token], tokens], 0)
59 |
60 | # Optionally append a special token
61 | if self.append_token is not None:
62 | tokens = tf.concat([tokens, [self.append_token]], 0)
63 |
64 | decoded_items[self.length_feature_name] = tf.size(tokens)
65 | decoded_items[self.tokens_feature_name] = tokens
66 | return [decoded_items[_] for _ in items]
67 |
68 | def list_items(self):
69 | return [self.tokens_feature_name, self.length_feature_name]
70 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/data/vocab.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Vocabulary related functions.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import collections
22 | import tensorflow as tf
23 | from tensorflow import gfile
24 |
25 | SpecialVocab = collections.namedtuple("SpecialVocab",
26 | ["UNK", "SEQUENCE_START", "SEQUENCE_END"])
27 |
28 |
29 | class VocabInfo(
30 | collections.namedtuple("VocbabInfo",
31 | ["path", "vocab_size", "special_vocab"])):
32 | """Convenience structure for vocabulary information.
33 | """
34 |
35 | @property
36 | def total_size(self):
37 | """Returns size the the base vocabulary plus the size of extra vocabulary"""
38 | return self.vocab_size + len(self.special_vocab)
39 |
40 |
41 | def get_vocab_info(vocab_path):
42 | """Creates a `VocabInfo` instance that contains the vocabulary size and
43 | the special vocabulary for the given file.
44 |
45 | Args:
46 | vocab_path: Path to a vocabulary file with one word per line.
47 |
48 | Returns:
49 | A VocabInfo tuple.
50 | """
51 | with gfile.GFile(vocab_path) as file:
52 | vocab_size = sum(1 for _ in file)
53 | special_vocab = get_special_vocab(vocab_size)
54 | return VocabInfo(vocab_path, vocab_size, special_vocab)
55 |
56 |
57 | def get_special_vocab(vocabulary_size):
58 | """Returns the `SpecialVocab` instance for a given vocabulary size.
59 | """
60 | return SpecialVocab(*range(vocabulary_size, vocabulary_size + 3))
61 |
62 |
63 | def create_vocabulary_lookup_table(filename, default_value=None):
64 | """Creates a lookup table for a vocabulary file.
65 |
66 | Args:
67 | filename: Path to a vocabulary file containg one word per line.
68 | Each word is mapped to its line number.
69 | default_value: UNK tokens will be mapped to this id.
70 | If None, UNK tokens will be mapped to [vocab_size]
71 |
72 | Returns:
73 | A tuple (vocab_to_id_table, id_to_vocab_table,
74 | word_to_count_table, vocab_size). The vocab size does not include
75 | the UNK token.
76 | """
77 | if not gfile.Exists(filename):
78 | raise ValueError("File does not exist: {}".format(filename))
79 |
80 | # Load vocabulary into memory
81 | with gfile.GFile(filename) as file:
82 | vocab = list(line.strip("\n") for line in file)
83 | vocab_size = len(vocab)
84 |
85 | has_counts = len(vocab[0].split("\t")) == 2
86 | if has_counts:
87 | vocab, counts = zip(*[_.split("\t") for _ in vocab])
88 | counts = [float(_) for _ in counts]
89 | vocab = list(vocab)
90 | else:
91 | counts = [-1. for _ in vocab]
92 |
93 | # Add special vocabulary items
94 | special_vocab = get_special_vocab(vocab_size)
95 | vocab += list(special_vocab._fields)
96 | vocab_size += len(special_vocab)
97 | counts += [-1. for _ in list(special_vocab._fields)]
98 |
99 | if default_value is None:
100 | default_value = special_vocab.UNK
101 |
102 | tf.logging.info("Creating vocabulary lookup table of size %d", vocab_size)
103 |
104 | vocab_tensor = tf.constant(vocab)
105 | count_tensor = tf.constant(counts, dtype=tf.float32)
106 | vocab_idx_tensor = tf.range(vocab_size, dtype=tf.int64)
107 |
108 | # Create ID -> word mapping
109 | id_to_vocab_init = tf.contrib.lookup.KeyValueTensorInitializer(
110 | vocab_idx_tensor, vocab_tensor, tf.int64, tf.string)
111 | id_to_vocab_table = tf.contrib.lookup.HashTable(id_to_vocab_init, "UNK")
112 |
113 | # Create word -> id mapping
114 | vocab_to_id_init = tf.contrib.lookup.KeyValueTensorInitializer(
115 | vocab_tensor, vocab_idx_tensor, tf.string, tf.int64)
116 | vocab_to_id_table = tf.contrib.lookup.HashTable(vocab_to_id_init,
117 | default_value)
118 |
119 | # Create word -> count mapping
120 | word_to_count_init = tf.contrib.lookup.KeyValueTensorInitializer(
121 | vocab_tensor, count_tensor, tf.string, tf.float32)
122 | word_to_count_table = tf.contrib.lookup.HashTable(word_to_count_init, -1)
123 |
124 | return vocab_to_id_table, id_to_vocab_table, word_to_count_table, vocab_size
125 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/decoders/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of decoders and decoder-related functions.
15 | """
16 |
17 | from seq2seq.decoders.rnn_decoder import *
18 | from seq2seq.decoders.attention import *
19 | from seq2seq.decoders.basic_decoder import *
20 | from seq2seq.decoders.attention_decoder import *
21 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/decoders/attention.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """ Implementations of attention layers.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 | from __future__ import unicode_literals
21 |
22 | import abc
23 | import six
24 |
25 | import tensorflow as tf
26 | from tensorflow.python.framework import function # pylint: disable=E0611
27 |
28 | from seq2seq.graph_module import GraphModule
29 | from seq2seq.configurable import Configurable
30 |
31 |
32 | @function.Defun(
33 | tf.float32,
34 | tf.float32,
35 | tf.float32,
36 | func_name="att_sum_bahdanau",
37 | noinline=True)
38 | def att_sum_bahdanau(v_att, keys, query):
39 | """Calculates a batch- and timweise dot product with a variable"""
40 | return tf.reduce_sum(v_att * tf.tanh(keys + tf.expand_dims(query, 1)), [2])
41 |
42 |
43 | @function.Defun(tf.float32, tf.float32, func_name="att_sum_dot", noinline=True)
44 | def att_sum_dot(keys, query):
45 | """Calculates a batch- and timweise dot product"""
46 | return tf.reduce_sum(keys * tf.expand_dims(query, 1), [2])
47 |
48 |
49 | @six.add_metaclass(abc.ABCMeta)
50 | class AttentionLayer(GraphModule, Configurable):
51 | """
52 | Attention layer according to https://arxiv.org/abs/1409.0473.
53 |
54 | Params:
55 | num_units: Number of units used in the attention layer
56 | """
57 |
58 | def __init__(self, params, mode, name="attention"):
59 | GraphModule.__init__(self, name)
60 | Configurable.__init__(self, params, mode)
61 |
62 | @staticmethod
63 | def default_params():
64 | return {"num_units": 128}
65 |
66 | @abc.abstractmethod
67 | def score_fn(self, keys, query):
68 | """Computes the attention score"""
69 | raise NotImplementedError
70 |
71 | def _build(self, query, keys, values, values_length):
72 | """Computes attention scores and outputs.
73 |
74 | Args:
75 | query: The query used to calculate attention scores.
76 | In seq2seq this is typically the current state of the decoder.
77 | A tensor of shape `[B, ...]`
78 | keys: The keys used to calculate attention scores. In seq2seq, these
79 | are typically the outputs of the encoder and equivalent to `values`.
80 | A tensor of shape `[B, T, ...]` where each element in the `T`
81 | dimension corresponds to the key for that value.
82 | values: The elements to compute attention over. In seq2seq, this is
83 | typically the sequence of encoder outputs.
84 | A tensor of shape `[B, T, input_dim]`.
85 | values_length: An int32 tensor of shape `[B]` defining the sequence
86 | length of the attention values.
87 |
88 | Returns:
89 | A tuple `(scores, context)`.
90 | `scores` is vector of length `T` where each element is the
91 | normalized "score" of the corresponding `inputs` element.
92 | `context` is the final attention layer output corresponding to
93 | the weighted inputs.
94 | A tensor fo shape `[B, input_dim]`.
95 | """
96 | values_depth = values.get_shape().as_list()[-1]
97 |
98 | # Fully connected layers to transform both keys and query
99 | # into a tensor with `num_units` units
100 | att_keys = tf.contrib.layers.fully_connected(
101 | inputs=keys,
102 | num_outputs=self.params["num_units"],
103 | activation_fn=None,
104 | scope="att_keys")
105 | att_query = tf.contrib.layers.fully_connected(
106 | inputs=query,
107 | num_outputs=self.params["num_units"],
108 | activation_fn=None,
109 | scope="att_query")
110 |
111 | scores = self.score_fn(att_keys, att_query)
112 |
113 | # Replace all scores for padded inputs with tf.float32.min
114 | num_scores = tf.shape(scores)[1]
115 | scores_mask = tf.sequence_mask(
116 | lengths=tf.to_int32(values_length),
117 | maxlen=tf.to_int32(num_scores),
118 | dtype=tf.float32)
119 | scores = scores * scores_mask + ((1.0 - scores_mask) * tf.float32.min)
120 |
121 | # Normalize the scores
122 | scores_normalized = tf.nn.softmax(scores, name="scores_normalized")
123 |
124 | # Calculate the weighted average of the attention inputs
125 | # according to the scores
126 | context = tf.expand_dims(scores_normalized, 2) * values
127 | context = tf.reduce_sum(context, 1, name="context")
128 | context.set_shape([None, values_depth])
129 |
130 |
131 | return (scores_normalized, context)
132 |
133 |
134 | class AttentionLayerDot(AttentionLayer):
135 | """An attention layer that calculates attention scores using
136 | a dot product.
137 | """
138 |
139 | def score_fn(self, keys, query):
140 | return att_sum_dot(keys, query)
141 |
142 |
143 | class AttentionLayerBahdanau(AttentionLayer):
144 | """An attention layer that calculates attention scores using
145 | a parameterized multiplication."""
146 |
147 | def score_fn(self, keys, query):
148 | v_att = tf.get_variable(
149 | "v_att", shape=[self.params["num_units"]], dtype=tf.float32)
150 | return att_sum_bahdanau(v_att, keys, query)
151 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/decoders/basic_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | A basic sequence decoder that performs a softmax based on the RNN state.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | from seq2seq.decoders.rnn_decoder import RNNDecoder, DecoderOutput
25 |
26 |
27 | class BasicDecoder(RNNDecoder):
28 | """Simple RNN decoder that performed a softmax operations on the cell output.
29 | """
30 |
31 | def __init__(self, params, mode, vocab_size, name="basic_decoder"):
32 | super(BasicDecoder, self).__init__(params, mode, name)
33 | self.vocab_size = vocab_size
34 |
35 | def compute_output(self, cell_output):
36 | """Computes the decoder outputs."""
37 | return tf.contrib.layers.fully_connected(
38 | inputs=cell_output, num_outputs=self.vocab_size, activation_fn=None)
39 |
40 | @property
41 | def output_size(self):
42 | return DecoderOutput(
43 | logits=self.vocab_size,
44 | predicted_ids=tf.TensorShape([]),
45 | cell_output=self.cell.output_size)
46 |
47 | @property
48 | def output_dtype(self):
49 | return DecoderOutput(
50 | logits=tf.float32, predicted_ids=tf.int32, cell_output=tf.float32)
51 |
52 | def initialize(self, name=None):
53 | finished, first_inputs = self.helper.initialize()
54 | return finished, first_inputs, self.initial_state
55 |
56 | def step(self, time_, inputs, state, name=None):
57 | cell_output, cell_state = self.cell(inputs, state)
58 | logits = self.compute_output(cell_output)
59 | sample_ids = self.helper.sample(
60 | time=time_, outputs=logits, state=cell_state)
61 | outputs = DecoderOutput(
62 | logits=logits, predicted_ids=sample_ids, cell_output=cell_output)
63 | finished, next_inputs, next_state = self.helper.next_inputs(
64 | time=time_, outputs=outputs, state=cell_state, sample_ids=sample_ids)
65 | return (outputs, next_state, next_inputs, finished)
66 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/decoders/rnn_decoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Base class for sequence decoders.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import abc
24 | from collections import namedtuple
25 |
26 | import six
27 | import tensorflow as tf
28 | from tensorflow.python.util import nest # pylint: disable=E0611
29 |
30 | from seq2seq.graph_module import GraphModule
31 | from seq2seq.configurable import Configurable
32 | from seq2seq.contrib.seq2seq.decoder import Decoder, dynamic_decode
33 | from seq2seq.encoders.rnn_encoder import _default_rnn_cell_params
34 | from seq2seq.encoders.rnn_encoder import _toggle_dropout
35 | from seq2seq.training import utils as training_utils
36 |
37 |
38 | class DecoderOutput(
39 | namedtuple("DecoderOutput", ["logits", "predicted_ids", "cell_output"])):
40 | """Output of an RNN decoder.
41 |
42 | Note that we output both the logits and predictions because during
43 | dynamic decoding the predictions may not correspond to max(logits).
44 | For example, we may be sampling from the logits instead.
45 | """
46 | pass
47 |
48 |
49 | @six.add_metaclass(abc.ABCMeta)
50 | class RNNDecoder(Decoder, GraphModule, Configurable):
51 | """Base class for RNN decoders.
52 |
53 | Args:
54 | cell: An instance of ` tf.contrib.rnn.RNNCell`
55 | helper: An instance of `tf.contrib.seq2seq.Helper` to assist decoding
56 | initial_state: A tensor or tuple of tensors used as the initial cell
57 | state.
58 | name: A name for this module
59 | """
60 |
61 | def __init__(self, params, mode, name):
62 | GraphModule.__init__(self, name)
63 | Configurable.__init__(self, params, mode)
64 | self.params["rnn_cell"] = _toggle_dropout(self.params["rnn_cell"], mode)
65 | self.cell = training_utils.get_rnn_cell(**self.params["rnn_cell"])
66 | # Not initialized yet
67 | self.initial_state = None
68 | self.helper = None
69 |
70 | @abc.abstractmethod
71 | def initialize(self, name=None):
72 | raise NotImplementedError
73 |
74 | @abc.abstractmethod
75 | def step(self, name=None):
76 | raise NotImplementedError
77 |
78 | @property
79 | def batch_size(self):
80 | return tf.shape(nest.flatten([self.initial_state])[0])[0]
81 |
82 | def _setup(self, initial_state, helper):
83 | """Sets the initial state and helper for the decoder.
84 | """
85 | self.initial_state = initial_state
86 | self.helper = helper
87 |
88 | def finalize(self, outputs, final_state):
89 | """Applies final transformation to the decoder output once decoding is
90 | finished.
91 | """
92 | #pylint: disable=R0201
93 | return (outputs, final_state)
94 |
95 | @staticmethod
96 | def default_params():
97 | return {
98 | "max_decode_length": 100,
99 | "rnn_cell": _default_rnn_cell_params(),
100 | "init_scale": 0.04,
101 | }
102 |
103 | def _build(self, initial_state, helper):
104 | if not self.initial_state:
105 | self._setup(initial_state, helper)
106 |
107 | scope = tf.get_variable_scope()
108 | scope.set_initializer(tf.random_uniform_initializer(
109 | -self.params["init_scale"],
110 | self.params["init_scale"]))
111 |
112 | maximum_iterations = None
113 | if self.mode == tf.contrib.learn.ModeKeys.INFER:
114 | maximum_iterations = self.params["max_decode_length"]
115 |
116 | outputs, final_state = dynamic_decode(
117 | decoder=self,
118 | output_time_major=True,
119 | impute_finished=False,
120 | maximum_iterations=maximum_iterations)
121 | return self.finalize(outputs, final_state)
122 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/encoders/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Collection of encoders"""
15 |
16 | import seq2seq.encoders.encoder
17 | import seq2seq.encoders.rnn_encoder
18 |
19 | from seq2seq.encoders.rnn_encoder import *
20 | from seq2seq.encoders.image_encoder import *
21 | from seq2seq.encoders.pooling_encoder import PoolingEncoder
22 | from seq2seq.encoders.conv_encoder import ConvEncoder
23 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/encoders/conv_encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | An encoder that pools over embeddings, as described in
16 | https://arxiv.org/abs/1611.02344.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | from pydoc import locate
24 |
25 | import tensorflow as tf
26 |
27 | from seq2seq.encoders.encoder import Encoder, EncoderOutput
28 | from seq2seq.encoders.pooling_encoder import _create_position_embedding
29 |
30 |
31 | class ConvEncoder(Encoder):
32 | """A deep convolutional encoder, as described in
33 | https://arxiv.org/abs/1611.02344. The encoder supports optional positions
34 | embeddings.
35 |
36 | Params:
37 | attention_cnn.units: Number of units in `cnn_a`. Same in each layer.
38 | attention_cnn.kernel_size: Kernel size for `cnn_a`.
39 | attention_cnn.layers: Number of layers in `cnn_a`.
40 | embedding_dropout_keep_prob: Dropout keep probability
41 | applied to the embeddings.
42 | output_cnn.units: Number of units in `cnn_c`. Same in each layer.
43 | output_cnn.kernel_size: Kernel size for `cnn_c`.
44 | output_cnn.layers: Number of layers in `cnn_c`.
45 | position_embeddings.enable: If true, add position embeddings to the
46 | inputs before pooling.
47 | position_embeddings.combiner_fn: Function used to combine the
48 | position embeddings with the inputs. For example, `tensorflow.add`.
49 | position_embeddings.num_positions: Size of the position embedding matrix.
50 | This should be set to the maximum sequence length of the inputs.
51 | """
52 |
53 | def __init__(self, params, mode, name="conv_encoder"):
54 | super(ConvEncoder, self).__init__(params, mode, name)
55 | self._combiner_fn = locate(self.params["position_embeddings.combiner_fn"])
56 |
57 | @staticmethod
58 | def default_params():
59 | return {
60 | "attention_cnn.units": 512,
61 | "attention_cnn.kernel_size": 3,
62 | "attention_cnn.layers": 15,
63 | "embedding_dropout_keep_prob": 0.8,
64 | "output_cnn.units": 256,
65 | "output_cnn.kernel_size": 3,
66 | "output_cnn.layers": 5,
67 | "position_embeddings.enable": True,
68 | "position_embeddings.combiner_fn": "tensorflow.multiply",
69 | "position_embeddings.num_positions": 100,
70 | }
71 |
72 | def encode(self, inputs, sequence_length):
73 | if self.params["position_embeddings.enable"]:
74 | positions_embed = _create_position_embedding(
75 | embedding_dim=inputs.get_shape().as_list()[-1],
76 | num_positions=self.params["position_embeddings.num_positions"],
77 | lengths=sequence_length,
78 | maxlen=tf.shape(inputs)[1])
79 | inputs = self._combiner_fn(inputs, positions_embed)
80 |
81 | # Apply dropout to embeddings
82 | inputs = tf.contrib.layers.dropout(
83 | inputs=inputs,
84 | keep_prob=self.params["embedding_dropout_keep_prob"],
85 | is_training=self.mode == tf.contrib.learn.ModeKeys.TRAIN)
86 |
87 | with tf.variable_scope("cnn_a"):
88 | cnn_a_output = inputs
89 | for layer_idx in range(self.params["attention_cnn.layers"]):
90 | next_layer = tf.contrib.layers.conv2d(
91 | inputs=cnn_a_output,
92 | num_outputs=self.params["attention_cnn.units"],
93 | kernel_size=self.params["attention_cnn.kernel_size"],
94 | padding="SAME",
95 | activation_fn=None)
96 | # Add a residual connection, except for the first layer
97 | if layer_idx > 0:
98 | next_layer += cnn_a_output
99 | cnn_a_output = tf.tanh(next_layer)
100 |
101 | with tf.variable_scope("cnn_c"):
102 | cnn_c_output = inputs
103 | for layer_idx in range(self.params["output_cnn.layers"]):
104 | next_layer = tf.contrib.layers.conv2d(
105 | inputs=cnn_c_output,
106 | num_outputs=self.params["output_cnn.units"],
107 | kernel_size=self.params["output_cnn.kernel_size"],
108 | padding="SAME",
109 | activation_fn=None)
110 | # Add a residual connection, except for the first layer
111 | if layer_idx > 0:
112 | next_layer += cnn_c_output
113 | cnn_c_output = tf.tanh(next_layer)
114 |
115 | final_state = tf.reduce_mean(cnn_c_output, 1)
116 |
117 | return EncoderOutput(
118 | outputs=cnn_a_output,
119 | final_state=final_state,
120 | attention_values=cnn_c_output,
121 | attention_values_length=sequence_length)
122 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/encoders/encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Abstract base class for encoders.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import abc
23 | from collections import namedtuple
24 |
25 | import six
26 |
27 | from seq2seq.configurable import Configurable
28 | from seq2seq.graph_module import GraphModule
29 |
30 | EncoderOutput = namedtuple(
31 | "EncoderOutput",
32 | "outputs final_state attention_values attention_values_length")
33 |
34 |
35 | @six.add_metaclass(abc.ABCMeta)
36 | class Encoder(GraphModule, Configurable):
37 | """Abstract encoder class. All encoders should inherit from this.
38 |
39 | Args:
40 | params: A dictionary of hyperparameters for the encoder.
41 | name: A variable scope for the encoder graph.
42 | """
43 |
44 | def __init__(self, params, mode, name):
45 | GraphModule.__init__(self, name)
46 | Configurable.__init__(self, params, mode)
47 |
48 | def _build(self, inputs, *args, **kwargs):
49 | return self.encode(inputs, *args, **kwargs)
50 |
51 | @abc.abstractmethod
52 | def encode(self, *args, **kwargs):
53 | """
54 | Encodes an input sequence.
55 |
56 | Args:
57 | inputs: The inputs to encode. A float32 tensor of shape [B, T, ...].
58 | sequence_length: The length of each input. An int32 tensor of shape [T].
59 |
60 | Returns:
61 | An `EncoderOutput` tuple containing the outputs and final state.
62 | """
63 | raise NotImplementedError
64 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/encoders/image_encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Image encoder classes
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import tensorflow as tf
23 | from tensorflow.contrib.slim.python.slim.nets.inception_v3 \
24 | import inception_v3_base
25 |
26 | from seq2seq.encoders.encoder import Encoder, EncoderOutput
27 |
28 |
29 | class InceptionV3Encoder(Encoder):
30 | """
31 | A unidirectional RNN encoder. Stacking should be performed as
32 | part of the cell.
33 |
34 | Params:
35 | resize_height: Resize the image to this height before feeding it
36 | into the convolutional network.
37 | resize_width: Resize the image to this width before feeding it
38 | into the convolutional network.
39 | """
40 |
41 | def __init__(self, params, mode, name="image_encoder"):
42 | super(InceptionV3Encoder, self).__init__(params, mode, name)
43 |
44 | @staticmethod
45 | def default_params():
46 | return {
47 | "resize_height": 299,
48 | "resize_width": 299,
49 | }
50 |
51 | def encode(self, inputs):
52 | inputs = tf.image.resize_images(
53 | images=inputs,
54 | size=[self.params["resize_height"], self.params["resize_width"]],
55 | method=tf.image.ResizeMethod.BILINEAR)
56 |
57 | outputs, _ = inception_v3_base(tf.to_float(inputs))
58 | output_shape = outputs.get_shape() #pylint: disable=E1101
59 | shape_list = output_shape.as_list()
60 |
61 | # Take attentin over output elemnts in width and height dimension:
62 | # Shape: [B, W*H, ...]
63 | outputs_flat = tf.reshape(outputs, [shape_list[0], -1, shape_list[-1]])
64 |
65 | # Final state is the pooled output
66 | # Shape: [B, W*H*...]
67 | final_state = tf.contrib.slim.avg_pool2d(
68 | outputs, output_shape[1:3], padding="VALID", scope="pool")
69 | final_state = tf.contrib.slim.flatten(outputs, scope="flatten")
70 |
71 | return EncoderOutput(
72 | outputs=outputs_flat,
73 | final_state=final_state,
74 | attention_values=outputs_flat,
75 | attention_values_length=tf.shape(outputs_flat)[1])
76 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/encoders/pooling_encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | An encoder that pools over embeddings, as described in
16 | https://arxiv.org/abs/1611.02344.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | from pydoc import locate
24 |
25 | import numpy as np
26 | import tensorflow as tf
27 |
28 | from seq2seq.encoders.encoder import Encoder, EncoderOutput
29 |
30 |
31 | def position_encoding(sentence_size, embedding_size):
32 | """
33 | Position Encoding described in section 4.1 of
34 | End-To-End Memory Networks (https://arxiv.org/abs/1503.08895).
35 |
36 | Args:
37 | sentence_size: length of the sentence
38 | embedding_size: dimensionality of the embeddings
39 |
40 | Returns:
41 | A numpy array of shape [sentence_size, embedding_size] containing
42 | the fixed position encodings for each sentence position.
43 | """
44 | encoding = np.ones((sentence_size, embedding_size), dtype=np.float32)
45 | ls = sentence_size + 1
46 | le = embedding_size + 1
47 | for k in range(1, le):
48 | for j in range(1, ls):
49 | encoding[j-1, k-1] = (1.0 - j/float(ls)) - (
50 | k / float(le)) * (1. - 2. * j/float(ls))
51 | return encoding
52 |
53 |
54 | def _create_position_embedding(embedding_dim, num_positions, lengths, maxlen):
55 | """Creates position embeddings.
56 |
57 | Args:
58 | embedding_dim: Dimensionality of the embeddings. An integer.
59 | num_positions: The number of positions to be embedded. For example,
60 | if you have inputs of length up to 100, this should be 100. An integer.
61 | lengths: The lengths of the inputs to create position embeddings for.
62 | An int32 tensor of shape `[batch_size]`.
63 | maxlen: The maximum length of the input sequence to create position
64 | embeddings for. An int32 tensor.
65 |
66 | Returns:
67 | A tensor of shape `[batch_size, maxlen, embedding_dim]` that contains
68 | embeddings for each position. All elements past `lengths` are zero.
69 | """
70 | # Create constant position encodings
71 | position_encodings = tf.constant(
72 | position_encoding(num_positions, embedding_dim),
73 | name="position_encoding")
74 |
75 | # Slice to size of current sequence
76 | pe_slice = position_encodings[:maxlen, :]
77 | # Replicate encodings for each element in the batch
78 | batch_size = tf.shape(lengths)[0]
79 | pe_batch = tf.tile([pe_slice], [batch_size, 1, 1])
80 |
81 | # Mask out positions that are padded
82 | positions_mask = tf.sequence_mask(
83 | lengths=lengths, maxlen=maxlen, dtype=tf.float32)
84 | positions_embed = pe_batch * tf.expand_dims(positions_mask, 2)
85 |
86 | return positions_embed
87 |
88 | class PoolingEncoder(Encoder):
89 | """An encoder that pools over embeddings, as described in
90 | https://arxiv.org/abs/1611.02344. The encoder supports optional positions
91 | embeddings and a configurable pooling window.
92 |
93 | Params:
94 | dropout_keep_prob: Dropout keep probability applied to the embeddings.
95 | pooling_fn: The 1-d pooling function to use, e.g.
96 | `tensorflow.layers.average_pooling1d`.
97 | pool_size: The pooling window, passed as `pool_size` to
98 | the pooling function.
99 | strides: The stride during pooling, passed as `strides`
100 | the pooling function.
101 | position_embeddings.enable: If true, add position embeddings to the
102 | inputs before pooling.
103 | position_embeddings.combiner_fn: Function used to combine the
104 | position embeddings with the inputs. For example, `tensorflow.add`.
105 | position_embeddings.num_positions: Size of the position embedding matrix.
106 | This should be set to the maximum sequence length of the inputs.
107 | """
108 |
109 | def __init__(self, params, mode, name="pooling_encoder"):
110 | super(PoolingEncoder, self).__init__(params, mode, name)
111 | self._pooling_fn = locate(self.params["pooling_fn"])
112 | self._combiner_fn = locate(self.params["position_embeddings.combiner_fn"])
113 |
114 | @staticmethod
115 | def default_params():
116 | return {
117 | "dropout_keep_prob": 0.8,
118 | "pooling_fn": "tensorflow.layers.average_pooling1d",
119 | "pool_size": 5,
120 | "strides": 1,
121 | "position_embeddings.enable": True,
122 | "position_embeddings.combiner_fn": "tensorflow.multiply",
123 | "position_embeddings.num_positions": 100,
124 | }
125 |
126 | def encode(self, inputs, sequence_length):
127 | if self.params["position_embeddings.enable"]:
128 | positions_embed = _create_position_embedding(
129 | embedding_dim=inputs.get_shape().as_list()[-1],
130 | num_positions=self.params["position_embeddings.num_positions"],
131 | lengths=sequence_length,
132 | maxlen=tf.shape(inputs)[1])
133 | inputs = self._combiner_fn(inputs, positions_embed)
134 |
135 | # Apply dropout
136 | inputs = tf.contrib.layers.dropout(
137 | inputs=inputs,
138 | keep_prob=self.params["dropout_keep_prob"],
139 | is_training=self.mode == tf.contrib.learn.ModeKeys.TRAIN)
140 |
141 | outputs = self._pooling_fn(
142 | inputs=inputs,
143 | pool_size=self.params["pool_size"],
144 | strides=self.params["strides"],
145 | padding="SAME")
146 |
147 | # Final state is the average representation of the pooled embeddings
148 | final_state = tf.reduce_mean(outputs, 1)
149 |
150 | return EncoderOutput(
151 | outputs=outputs,
152 | final_state=final_state,
153 | attention_values=inputs,
154 | attention_values_length=sequence_length)
155 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/encoders/rnn_encoder.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Collection of RNN encoders.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 |
22 | import copy
23 | import tensorflow as tf
24 | from tensorflow.contrib.rnn.python.ops import rnn
25 |
26 | from seq2seq.encoders.encoder import Encoder, EncoderOutput
27 | from seq2seq.training import utils as training_utils
28 |
29 |
30 | def _unpack_cell(cell):
31 | """Unpack the cells because the stack_bidirectional_dynamic_rnn
32 | expects a list of cells, one per layer."""
33 | if isinstance(cell, tf.contrib.rnn.MultiRNNCell):
34 | return cell._cells #pylint: disable=W0212
35 | else:
36 | return [cell]
37 |
38 |
39 | def _default_rnn_cell_params():
40 | """Creates default parameters used by multiple RNN encoders.
41 | """
42 | return {
43 | "cell_class": "BasicLSTMCell",
44 | "cell_params": {
45 | "num_units": 128
46 | },
47 | "dropout_input_keep_prob": 1.0,
48 | "dropout_output_keep_prob": 1.0,
49 | "num_layers": 1,
50 | "residual_connections": False,
51 | "residual_combiner": "add",
52 | "residual_dense": False
53 | }
54 |
55 |
56 | def _toggle_dropout(cell_params, mode):
57 | """Disables dropout during eval/inference mode
58 | """
59 | cell_params = copy.deepcopy(cell_params)
60 | if mode != tf.contrib.learn.ModeKeys.TRAIN:
61 | cell_params["dropout_input_keep_prob"] = 1.0
62 | cell_params["dropout_output_keep_prob"] = 1.0
63 | return cell_params
64 |
65 |
66 | class UnidirectionalRNNEncoder(Encoder):
67 | """
68 | A unidirectional RNN encoder. Stacking should be performed as
69 | part of the cell.
70 |
71 | Args:
72 | cell: An instance of tf.contrib.rnn.RNNCell
73 | name: A name for the encoder
74 | """
75 |
76 | def __init__(self, params, mode, name="forward_rnn_encoder"):
77 | super(UnidirectionalRNNEncoder, self).__init__(params, mode, name)
78 | self.params["rnn_cell"] = _toggle_dropout(self.params["rnn_cell"], mode)
79 |
80 | @staticmethod
81 | def default_params():
82 | return {
83 | "rnn_cell": _default_rnn_cell_params(),
84 | "init_scale": 0.04,
85 | }
86 |
87 | def encode(self, inputs, sequence_length, **kwargs):
88 | scope = tf.get_variable_scope()
89 | scope.set_initializer(tf.random_uniform_initializer(
90 | -self.params["init_scale"],
91 | self.params["init_scale"]))
92 |
93 | cell = training_utils.get_rnn_cell(**self.params["rnn_cell"])
94 | outputs, state = tf.nn.dynamic_rnn(
95 | cell=cell,
96 | inputs=inputs,
97 | sequence_length=sequence_length,
98 | dtype=tf.float32,
99 | **kwargs)
100 | return EncoderOutput(
101 | outputs=outputs,
102 | final_state=state,
103 | attention_values=outputs,
104 | attention_values_length=sequence_length)
105 |
106 |
107 | class BidirectionalRNNEncoder(Encoder):
108 | """
109 | A bidirectional RNN encoder. Uses the same cell for both the
110 | forward and backward RNN. Stacking should be performed as part of
111 | the cell.
112 |
113 | Args:
114 | cell: An instance of tf.contrib.rnn.RNNCell
115 | name: A name for the encoder
116 | """
117 |
118 | def __init__(self, params, mode, name="bidi_rnn_encoder"):
119 | super(BidirectionalRNNEncoder, self).__init__(params, mode, name)
120 | self.params["rnn_cell"] = _toggle_dropout(self.params["rnn_cell"], mode)
121 |
122 | @staticmethod
123 | def default_params():
124 | return {
125 | "rnn_cell": _default_rnn_cell_params(),
126 | "init_scale": 0.04,
127 | }
128 |
129 | def encode(self, inputs, sequence_length, **kwargs):
130 | scope = tf.get_variable_scope()
131 | scope.set_initializer(tf.random_uniform_initializer(
132 | -self.params["init_scale"],
133 | self.params["init_scale"]))
134 |
135 | cell_fw = training_utils.get_rnn_cell(**self.params["rnn_cell"])
136 | cell_bw = training_utils.get_rnn_cell(**self.params["rnn_cell"])
137 | outputs, states = tf.nn.bidirectional_dynamic_rnn(
138 | cell_fw=cell_fw,
139 | cell_bw=cell_bw,
140 | inputs=inputs,
141 | sequence_length=sequence_length,
142 | dtype=tf.float32,
143 | **kwargs)
144 |
145 | # Concatenate outputs and states of the forward and backward RNNs
146 | outputs_concat = tf.concat(outputs, 2)
147 |
148 | return EncoderOutput(
149 | outputs=outputs_concat,
150 | final_state=states,
151 | attention_values=outputs_concat,
152 | attention_values_length=sequence_length)
153 |
154 |
155 | class StackBidirectionalRNNEncoder(Encoder):
156 | """
157 | A stacked bidirectional RNN encoder. Uses the same cell for both the
158 | forward and backward RNN. Stacking should be performed as part of
159 | the cell.
160 |
161 | Args:
162 | cell: An instance of tf.contrib.rnn.RNNCell
163 | name: A name for the encoder
164 | """
165 |
166 | def __init__(self, params, mode, name="stacked_bidi_rnn_encoder"):
167 | super(StackBidirectionalRNNEncoder, self).__init__(params, mode, name)
168 | self.params["rnn_cell"] = _toggle_dropout(self.params["rnn_cell"], mode)
169 |
170 | @staticmethod
171 | def default_params():
172 | return {
173 | "rnn_cell": _default_rnn_cell_params(),
174 | "init_scale": 0.04,
175 | }
176 |
177 | def encode(self, inputs, sequence_length, **kwargs):
178 | scope = tf.get_variable_scope()
179 | scope.set_initializer(tf.random_uniform_initializer(
180 | -self.params["init_scale"],
181 | self.params["init_scale"]))
182 |
183 | cell_fw = training_utils.get_rnn_cell(**self.params["rnn_cell"])
184 | cell_bw = training_utils.get_rnn_cell(**self.params["rnn_cell"])
185 |
186 | cells_fw = _unpack_cell(cell_fw)
187 | cells_bw = _unpack_cell(cell_bw)
188 |
189 | result = rnn.stack_bidirectional_dynamic_rnn(
190 | cells_fw=cells_fw,
191 | cells_bw=cells_bw,
192 | inputs=inputs,
193 | dtype=tf.float32,
194 | sequence_length=sequence_length,
195 | **kwargs)
196 | outputs_concat, _output_state_fw, _output_state_bw = result
197 | final_state = (_output_state_fw, _output_state_bw)
198 | return EncoderOutput(
199 | outputs=outputs_concat,
200 | final_state=final_state,
201 | attention_values=outputs_concat,
202 | attention_values_length=sequence_length)
203 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/global_vars.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Collection of global variables.
16 | """
17 |
18 | SYNC_REPLICAS_OPTIMIZER = None
19 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/graph_module.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | All graph components that create Variables should inherit from this
16 | base class defined in this file.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 |
23 | import tensorflow as tf
24 |
25 |
26 | class GraphModule(object):
27 | """
28 | Convenience class that makes it easy to share variables.
29 | Each insance of this class creates its own set of variables, but
30 | each subsequent execution of an instance will re-use its variables.
31 |
32 | Graph components that define variables should inherit from this class
33 | and implement their logic in the `_build` method.
34 | """
35 |
36 | def __init__(self, name):
37 | """
38 | Initialize the module. Each subclass must call this constructor with a name.
39 |
40 | Args:
41 | name: Name of this module. Used for `tf.make_template`.
42 | """
43 | self.name = name
44 | self._template = tf.make_template(name, self._build, create_scope_now_=True)
45 | # Docstrings for the class should be the docstring for the _build method
46 | self.__doc__ = self._build.__doc__
47 | # pylint: disable=E1101
48 | self.__call__.__func__.__doc__ = self._build.__doc__
49 |
50 | def _build(self, *args, **kwargs):
51 | """Subclasses should implement their logic here.
52 | """
53 | raise NotImplementedError
54 |
55 | def __call__(self, *args, **kwargs):
56 | # pylint: disable=missing-docstring
57 | return self._template(*args, **kwargs)
58 |
59 | def variable_scope(self):
60 | """Returns the proper variable scope for this module.
61 | """
62 | return tf.variable_scope(self._template.variable_scope)
63 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/graph_utils.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Miscellaneous utility function.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import tensorflow as tf
22 |
23 |
24 | def templatemethod(name_):
25 | """This decorator wraps a method with `tf.make_template`. For example,
26 |
27 | @templatemethod
28 | def my_method():
29 | # Create variables
30 | """
31 |
32 | def template_decorator(func):
33 | """Inner decorator function"""
34 |
35 | def func_wrapper(*args, **kwargs):
36 | """Inner wrapper function"""
37 | templated_func = tf.make_template(name_, func)
38 | return templated_func(*args, **kwargs)
39 |
40 | return func_wrapper
41 |
42 | return template_decorator
43 |
44 |
45 | def add_dict_to_collection(dict_, collection_name):
46 | """Adds a dictionary to a graph collection.
47 |
48 | Args:
49 | dict_: A dictionary of string keys to tensor values
50 | collection_name: The name of the collection to add the dictionary to
51 | """
52 | key_collection = collection_name + "_keys"
53 | value_collection = collection_name + "_values"
54 | for key, value in dict_.items():
55 | tf.add_to_collection(key_collection, key)
56 | tf.add_to_collection(value_collection, value)
57 |
58 |
59 | def get_dict_from_collection(collection_name):
60 | """Gets a dictionary from a graph collection.
61 |
62 | Args:
63 | collection_name: A collection name to read a dictionary from
64 |
65 | Returns:
66 | A dictionary with string keys and tensor values
67 | """
68 | key_collection = collection_name + "_keys"
69 | value_collection = collection_name + "_values"
70 | keys = tf.get_collection(key_collection)
71 | values = tf.get_collection(value_collection)
72 | return dict(zip(keys, values))
73 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/inference/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Modules related to running model inference.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | from seq2seq.inference.inference import *
22 | import seq2seq.inference.beam_search
23 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/inference/inference.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """ Generates model predictions.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import tensorflow as tf
22 |
23 | from seq2seq.training import utils as training_utils
24 |
25 |
26 | def create_inference_graph(model, input_pipeline, batch_size=32):
27 | """Creates a graph to perform inference.
28 |
29 | Args:
30 | task: An `InferenceTask` instance.
31 | input_pipeline: An instance of `InputPipeline` that defines
32 | how to read and parse data.
33 | batch_size: The batch size used for inference
34 |
35 | Returns:
36 | The return value of the model function, typically a tuple of
37 | (predictions, loss, train_op).
38 | """
39 |
40 | # TODO: This doesn't really belong here.
41 | # How to get rid of this?
42 | if hasattr(model, "use_beam_search"):
43 | if model.use_beam_search:
44 | tf.logging.info("Setting batch size to 1 for beam search.")
45 | batch_size = 1
46 |
47 | input_fn = training_utils.create_input_fn(
48 | pipeline=input_pipeline,
49 | batch_size=batch_size,
50 | allow_smaller_final_batch=True)
51 |
52 | # Build the graph
53 | features, labels = input_fn()
54 | return model(features=features, labels=labels, params=None)
55 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/losses.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Operations related to calculating sequence losses.
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
21 | import tensorflow as tf
22 |
23 |
24 | def cross_entropy_sequence_loss(logits, targets, sequence_length):
25 | """Calculates the per-example cross-entropy loss for a sequence of logits and
26 | masks out all losses passed the sequence length.
27 |
28 | Args:
29 | logits: Logits of shape `[T, B, vocab_size]`
30 | targets: Target classes of shape `[T, B]`
31 | sequence_length: An int32 tensor of shape `[B]` corresponding
32 | to the length of each input
33 |
34 | Returns:
35 | A tensor of shape [T, B] that contains the loss per example, per time step.
36 | """
37 | with tf.name_scope("cross_entropy_sequence_loss"):
38 | losses = tf.nn.sparse_softmax_cross_entropy_with_logits(
39 | logits=logits, labels=targets)
40 |
41 | # Mask out the losses we don't care about
42 | loss_mask = tf.sequence_mask(
43 | tf.to_int32(sequence_length), tf.to_int32(tf.shape(targets)[0]))
44 | losses = losses * tf.transpose(tf.to_float(loss_mask), [1, 0])
45 |
46 | return losses
47 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/metrics/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """ Collection of metric-related functions
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/metrics/bleu.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """BLEU metric implementation.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import os
24 | import re
25 | import subprocess
26 | import tempfile
27 | import numpy as np
28 |
29 | from six.moves import urllib
30 | import tensorflow as tf
31 |
32 |
33 | def moses_multi_bleu(hypotheses, references, lowercase=False):
34 | """Calculate the bleu score for hypotheses and references
35 | using the MOSES ulti-bleu.perl script.
36 |
37 | Args:
38 | hypotheses: A numpy array of strings where each string is a single example.
39 | references: A numpy array of strings where each string is a single example.
40 | lowercase: If true, pass the "-lc" flag to the multi-bleu script
41 |
42 | Returns:
43 | The BLEU score as a float32 value.
44 | """
45 |
46 | if np.size(hypotheses) == 0:
47 | return np.float32(0.0)
48 |
49 | # Get MOSES multi-bleu script
50 | try:
51 | multi_bleu_path, _ = urllib.request.urlretrieve(
52 | "https://raw.githubusercontent.com/moses-smt/mosesdecoder/"
53 | "master/scripts/generic/multi-bleu.perl")
54 | os.chmod(multi_bleu_path, 0o755)
55 | except: #pylint: disable=W0702
56 | tf.logging.info("Unable to fetch multi-bleu.perl script, using local.")
57 | metrics_dir = os.path.dirname(os.path.realpath(__file__))
58 | bin_dir = os.path.abspath(os.path.join(metrics_dir, "..", "..", "bin"))
59 | multi_bleu_path = os.path.join(bin_dir, "tools/multi-bleu.perl")
60 |
61 | # Dump hypotheses and references to tempfiles
62 | hypothesis_file = tempfile.NamedTemporaryFile()
63 | hypothesis_file.write("\n".join(hypotheses).encode("utf-8"))
64 | hypothesis_file.write(b"\n")
65 | hypothesis_file.flush()
66 | reference_file = tempfile.NamedTemporaryFile()
67 | reference_file.write("\n".join(references).encode("utf-8"))
68 | reference_file.write(b"\n")
69 | reference_file.flush()
70 |
71 | # Calculate BLEU using multi-bleu script
72 | with open(hypothesis_file.name, "r") as read_pred:
73 | bleu_cmd = [multi_bleu_path]
74 | if lowercase:
75 | bleu_cmd += ["-lc"]
76 | bleu_cmd += [reference_file.name]
77 | try:
78 | bleu_out = subprocess.check_output(
79 | bleu_cmd, stdin=read_pred, stderr=subprocess.STDOUT)
80 | bleu_out = bleu_out.decode("utf-8")
81 | bleu_score = re.search(r"BLEU = (.+?),", bleu_out).group(1)
82 | bleu_score = float(bleu_score)
83 | except subprocess.CalledProcessError as error:
84 | if error.output is not None:
85 | tf.logging.warning("multi-bleu.perl script returned non-zero exit code")
86 | tf.logging.warning(error.output)
87 | bleu_score = np.float32(0.0)
88 |
89 | # Close temp files
90 | hypothesis_file.close()
91 | reference_file.close()
92 |
93 | return np.float32(bleu_score)
94 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/models/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """This module contains various Encoder-Decoder models
15 | """
16 |
17 | from seq2seq.models.basic_seq2seq import BasicSeq2Seq
18 | from seq2seq.models.attention_seq2seq import AttentionSeq2Seq
19 | from seq2seq.models.image2seq import Image2Seq
20 |
21 | import seq2seq.models.bridges
22 | import seq2seq.models.model_base
23 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/models/attention_seq2seq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Sequence to Sequence model with attention
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from pydoc import locate
24 |
25 | import tensorflow as tf
26 |
27 | from seq2seq import decoders
28 | from seq2seq.models.basic_seq2seq import BasicSeq2Seq
29 |
30 |
31 | class AttentionSeq2Seq(BasicSeq2Seq):
32 | """Sequence2Sequence model with attention mechanism.
33 |
34 | Args:
35 | source_vocab_info: An instance of `VocabInfo`
36 | for the source vocabulary
37 | target_vocab_info: An instance of `VocabInfo`
38 | for the target vocabulary
39 | params: A dictionary of hyperparameters
40 | """
41 |
42 | def __init__(self, params, mode, name="att_seq2seq"):
43 | super(AttentionSeq2Seq, self).__init__(params, mode, name)
44 |
45 | @staticmethod
46 | def default_params():
47 | params = BasicSeq2Seq.default_params().copy()
48 | params.update({
49 | "attention.class": "AttentionLayerBahdanau",
50 | "attention.params": {}, # Arbitrary attention layer parameters
51 | "bridge.class": "seq2seq.models.bridges.ZeroBridge",
52 | "encoder.class": "seq2seq.encoders.BidirectionalRNNEncoder",
53 | "encoder.params": {}, # Arbitrary parameters for the encoder
54 | "decoder.class": "seq2seq.decoders.AttentionDecoder",
55 | "decoder.params": {} # Arbitrary parameters for the decoder
56 | })
57 | return params
58 |
59 | def _create_decoder(self, encoder_output, features, _labels):
60 | attention_class = locate(self.params["attention.class"]) or \
61 | getattr(decoders.attention, self.params["attention.class"])
62 | attention_layer = attention_class(
63 | params=self.params["attention.params"], mode=self.mode)
64 |
65 | # If the input sequence is reversed we also need to reverse
66 | # the attention scores.
67 | reverse_scores_lengths = None
68 | if self.params["source.reverse"]:
69 | reverse_scores_lengths = features["source_len"]
70 | if self.use_beam_search:
71 | reverse_scores_lengths = tf.tile(
72 | input=reverse_scores_lengths,
73 | multiples=[self.params["inference.beam_search.beam_width"]])
74 |
75 | return self.decoder_class(
76 | params=self.params["decoder.params"],
77 | mode=self.mode,
78 | vocab_size=self.target_vocab_info.total_size,
79 | attention_values=encoder_output.attention_values,
80 | attention_values_length=encoder_output.attention_values_length,
81 | attention_keys=encoder_output.outputs,
82 | attention_fn=attention_layer,
83 | reverse_scores_lengths=reverse_scores_lengths)
84 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/models/basic_seq2seq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Definition of a basic seq2seq model
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from pydoc import locate
24 | import tensorflow as tf
25 | from seq2seq.contrib.seq2seq import helper as tf_decode_helper
26 |
27 | from seq2seq.models.seq2seq_model import Seq2SeqModel
28 | from seq2seq.graph_utils import templatemethod
29 | from seq2seq.models import bridges
30 |
31 |
32 | class BasicSeq2Seq(Seq2SeqModel):
33 | """Basic Sequence2Sequence model with a unidirectional encoder and decoder.
34 | The last encoder state is used to initialize the decoder and thus both
35 | must share the same type of RNN cell.
36 |
37 | Args:
38 | source_vocab_info: An instance of `VocabInfo`
39 | for the source vocabulary
40 | target_vocab_info: An instance of `VocabInfo`
41 | for the target vocabulary
42 | params: A dictionary of hyperparameters
43 | """
44 |
45 | def __init__(self, params, mode, name="basic_seq2seq"):
46 | super(BasicSeq2Seq, self).__init__(params, mode, name)
47 | self.encoder_class = locate(self.params["encoder.class"])
48 | self.decoder_class = locate(self.params["decoder.class"])
49 |
50 | @staticmethod
51 | def default_params():
52 | params = Seq2SeqModel.default_params().copy()
53 | params.update({
54 | "bridge.class": "seq2seq.models.bridges.InitialStateBridge",
55 | "bridge.params": {},
56 | "encoder.class": "seq2seq.encoders.UnidirectionalRNNEncoder",
57 | "encoder.params": {}, # Arbitrary parameters for the encoder
58 | "decoder.class": "seq2seq.decoders.BasicDecoder",
59 | "decoder.params": {} # Arbitrary parameters for the decoder
60 | })
61 | return params
62 |
63 | def _create_bridge(self, encoder_outputs, decoder_state_size):
64 | """Creates the bridge to be used between encoder and decoder"""
65 | bridge_class = locate(self.params["bridge.class"]) or \
66 | getattr(bridges, self.params["bridge.class"])
67 | return bridge_class(
68 | encoder_outputs=encoder_outputs,
69 | decoder_state_size=decoder_state_size,
70 | params=self.params["bridge.params"],
71 | mode=self.mode)
72 |
73 | def _create_decoder(self, _encoder_output, _features, _labels):
74 | """Creates a decoder instance based on the passed parameters."""
75 | return self.decoder_class(
76 | params=self.params["decoder.params"],
77 | mode=self.mode,
78 | vocab_size=self.target_vocab_info.total_size)
79 |
80 | def _decode_train(self, decoder, bridge, _encoder_output, _features, labels):
81 | """Runs decoding in training mode"""
82 | target_embedded = tf.nn.embedding_lookup(self.target_embedding,
83 | labels["target_ids"])
84 | helper_train = tf_decode_helper.TrainingHelper(
85 | inputs=target_embedded[:, :-1],
86 | sequence_length=labels["target_len"] - 1)
87 | decoder_initial_state = bridge()
88 | return decoder(decoder_initial_state, helper_train)
89 |
90 | def _decode_infer(self, decoder, bridge, _encoder_output, features, labels):
91 | """Runs decoding in inference mode"""
92 | batch_size = self.batch_size(features, labels)
93 | if self.use_beam_search:
94 | batch_size = self.params["inference.beam_search.beam_width"]
95 |
96 | target_start_id = self.target_vocab_info.special_vocab.SEQUENCE_START
97 | helper_infer = tf_decode_helper.GreedyEmbeddingHelper(
98 | embedding=self.target_embedding,
99 | start_tokens=tf.fill([batch_size], target_start_id),
100 | end_token=self.target_vocab_info.special_vocab.SEQUENCE_END)
101 | decoder_initial_state = bridge()
102 | return decoder(decoder_initial_state, helper_infer)
103 |
104 | @templatemethod("encode")
105 | def encode(self, features, labels):
106 | source_embedded = tf.nn.embedding_lookup(self.source_embedding,
107 | features["source_ids"])
108 | encoder_fn = self.encoder_class(self.params["encoder.params"], self.mode)
109 | return encoder_fn(source_embedded, features["source_len"])
110 |
111 | @templatemethod("decode")
112 | def decode(self, encoder_output, features, labels):
113 | decoder = self._create_decoder(encoder_output, features, labels)
114 | if self.use_beam_search:
115 | decoder = self._get_beam_search_decoder(decoder)
116 |
117 | bridge = self._create_bridge(
118 | encoder_outputs=encoder_output,
119 | decoder_state_size=decoder.cell.state_size)
120 | if self.mode == tf.contrib.learn.ModeKeys.INFER:
121 | return self._decode_infer(decoder, bridge, encoder_output, features,
122 | labels)
123 | else:
124 | return self._decode_train(decoder, bridge, encoder_output, features,
125 | labels)
126 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/models/bridges.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """A collection of bridges between encoder and decoder. A bridge defines
15 | how encoder information are passed to the decoder.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import abc
24 | from pydoc import locate
25 |
26 | import six
27 | import numpy as np
28 |
29 | import tensorflow as tf
30 | from tensorflow.python.util import nest # pylint: disable=E0611
31 |
32 | from seq2seq.configurable import Configurable
33 |
34 |
35 | def _total_tensor_depth(tensor):
36 | """Returns the size of a tensor without the first (batch) dimension"""
37 | return np.prod(tensor.get_shape().as_list()[1:])
38 |
39 |
40 | @six.add_metaclass(abc.ABCMeta)
41 | class Bridge(Configurable):
42 | """An abstract bridge class. A bridge defines how state is passed
43 | between encoder and decoder.
44 |
45 | All logic is contained in the `_create` method, which returns an
46 | initial state for the decoder.
47 |
48 | Args:
49 | encoder_outputs: A namedtuple that corresponds to the the encoder outputs.
50 | decoder_state_size: An integer or tuple of integers defining the
51 | state size of the decoder.
52 | """
53 |
54 | def __init__(self, encoder_outputs, decoder_state_size, params, mode):
55 | Configurable.__init__(self, params, mode)
56 | self.encoder_outputs = encoder_outputs
57 | self.decoder_state_size = decoder_state_size
58 | self.batch_size = tf.shape(
59 | nest.flatten(self.encoder_outputs.final_state)[0])[0]
60 |
61 | def __call__(self):
62 | """Runs the bridge function.
63 |
64 | Returns:
65 | An initial decoder_state tensor or tuple of tensors.
66 | """
67 | return self._create()
68 |
69 | @abc.abstractmethod
70 | def _create(self):
71 | """ Implements the logic for this bridge.
72 | This function should be implemented by child classes.
73 |
74 | Returns:
75 | A tuple initial_decoder_state tensor or tuple of tensors.
76 | """
77 | raise NotImplementedError("Must be implemented by child class")
78 |
79 |
80 | class ZeroBridge(Bridge):
81 | """A bridge that does not pass any information between encoder and decoder
82 | and sets the initial decoder state to 0. The input function is not modified.
83 | """
84 |
85 | @staticmethod
86 | def default_params():
87 | return {}
88 |
89 | def _create(self):
90 | zero_state = nest.map_structure(
91 | lambda x: tf.zeros([self.batch_size, x], dtype=tf.float32),
92 | self.decoder_state_size)
93 | return zero_state
94 |
95 |
96 | class PassThroughBridge(Bridge):
97 | """Passes the encoder state through to the decoder as-is. This bridge
98 | can only be used if encoder and decoder have the exact same state size, i.e.
99 | use the same RNN cell.
100 | """
101 |
102 | @staticmethod
103 | def default_params():
104 | return {}
105 |
106 | def _create(self):
107 | nest.assert_same_structure(self.encoder_outputs.final_state,
108 | self.decoder_state_size)
109 | return self.encoder_outputs.final_state
110 |
111 |
112 | class InitialStateBridge(Bridge):
113 | """A bridge that creates an initial decoder state based on the output
114 | of the encoder. This state is created by passing the encoder outputs
115 | through an additional layer to match them to the decoder state size.
116 | The input function remains unmodified.
117 |
118 | Args:
119 | encoder_outputs: A namedtuple that corresponds to the the encoder outputs.
120 | decoder_state_size: An integer or tuple of integers defining the
121 | state size of the decoder.
122 | bridge_input: Which attribute of the `encoder_outputs` to use for the
123 | initial state calculation. For example, "final_state" means that
124 | `encoder_outputs.final_state` will be used.
125 | activation_fn: An optional activation function for the extra
126 | layer inserted between encoder and decoder. A string for a function
127 | name contained in `tf.nn`, e.g. "tanh".
128 | """
129 |
130 | def __init__(self, encoder_outputs, decoder_state_size, params, mode):
131 | super(InitialStateBridge, self).__init__(encoder_outputs,
132 | decoder_state_size, params, mode)
133 |
134 | if not hasattr(encoder_outputs, self.params["bridge_input"]):
135 | raise ValueError("Invalid bridge_input not in encoder outputs.")
136 |
137 | self._bridge_input = getattr(encoder_outputs, self.params["bridge_input"])
138 | self._activation_fn = locate(self.params["activation_fn"])
139 |
140 | @staticmethod
141 | def default_params():
142 | return {
143 | "bridge_input": "final_state",
144 | "activation_fn": "tensorflow.identity",
145 | }
146 |
147 | def _create(self):
148 | # Concat bridge inputs on the depth dimensions
149 | bridge_input = nest.map_structure(
150 | lambda x: tf.reshape(x, [self.batch_size, _total_tensor_depth(x)]),
151 | self._bridge_input)
152 | bridge_input_flat = nest.flatten([bridge_input])
153 | bridge_input_concat = tf.concat(bridge_input_flat, 1)
154 |
155 | state_size_splits = nest.flatten(self.decoder_state_size)
156 | total_decoder_state_size = sum(state_size_splits)
157 |
158 | # Pass bridge inputs through a fully connected layer layer
159 | initial_state_flat = tf.contrib.layers.fully_connected(
160 | inputs=bridge_input_concat,
161 | num_outputs=total_decoder_state_size,
162 | activation_fn=self._activation_fn)
163 |
164 | # Shape back into required state size
165 | initial_state = tf.split(initial_state_flat, state_size_splits, axis=1)
166 | return nest.pack_sequence_as(self.decoder_state_size, initial_state)
167 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/models/image2seq.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Definition of a basic seq2seq model
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 |
25 | from seq2seq import graph_utils
26 | from seq2seq.data import vocab
27 | from seq2seq.graph_utils import templatemethod
28 | from seq2seq.models.model_base import ModelBase
29 | from seq2seq.models.attention_seq2seq import AttentionSeq2Seq
30 |
31 |
32 | class Image2Seq(AttentionSeq2Seq):
33 | """A model that encodes an image and produces a sequence
34 | of tokens.
35 | """
36 |
37 | def __init__(self, params, mode, name="image_seq2seq"):
38 | super(Image2Seq, self).__init__(params, mode, name)
39 | self.params["source.reverse"] = False
40 | self.params["embedding.share"] = False
41 |
42 | @staticmethod
43 | def default_params():
44 | params = ModelBase.default_params()
45 | params.update({
46 | "attention.class": "AttentionLayerBahdanau",
47 | "attention.params": {
48 | "num_units": 128
49 | },
50 | "bridge.class": "seq2seq.models.bridges.ZeroBridge",
51 | "bridge.params": {},
52 | "encoder.class": "seq2seq.encoders.InceptionV3Encoder",
53 | "encoder.params": {}, # Arbitrary parameters for the encoder
54 | "decoder.class": "seq2seq.decoders.AttentionDecoder",
55 | "decoder.params": {}, # Arbitrary parameters for the decoder
56 | "target.max_seq_len": 50,
57 | "embedding.dim": 100,
58 | "inference.beam_search.beam_width": 0,
59 | "inference.beam_search.length_penalty_weight": 0.0,
60 | "inference.beam_search.choose_successors_fn": "choose_top_k",
61 | "vocab_target": "",
62 | })
63 | return params
64 |
65 | @templatemethod("encode")
66 | def encode(self, features, _labels):
67 | encoder_fn = self.encoder_class(self.params["encoder.params"], self.mode)
68 | return encoder_fn(features["image"])
69 |
70 | def batch_size(self, features, _labels):
71 | return tf.shape(features["image"])[0]
72 |
73 | def _preprocess(self, features, labels):
74 | """Model-specific preprocessing for features and labels:
75 |
76 | - Creates vocabulary lookup tables for target vocab
77 | - Converts tokens into vocabulary ids
78 | - Prepends a speical "SEQUENCE_START" token to the target
79 | - Appends a speical "SEQUENCE_END" token to the target
80 | """
81 |
82 | # Create vocabulary look for target
83 | target_vocab_to_id, target_id_to_vocab, target_word_to_count, _ = \
84 | vocab.create_vocabulary_lookup_table(self.target_vocab_info.path)
85 |
86 | # Add vocab tables to graph colection so that we can access them in
87 | # other places.
88 | graph_utils.add_dict_to_collection({
89 | "target_vocab_to_id": target_vocab_to_id,
90 | "target_id_to_vocab": target_id_to_vocab,
91 | "target_word_to_count": target_word_to_count
92 | }, "vocab_tables")
93 |
94 | if labels is None:
95 | return features, None
96 |
97 | labels = labels.copy()
98 |
99 | # Slices targets to max length
100 | if self.params["target.max_seq_len"] is not None:
101 | labels["target_tokens"] = labels["target_tokens"][:, :self.params[
102 | "target.max_seq_len"]]
103 | labels["target_len"] = tf.minimum(labels["target_len"],
104 | self.params["target.max_seq_len"])
105 |
106 | # Look up the target ids in the vocabulary
107 | labels["target_ids"] = target_vocab_to_id.lookup(labels["target_tokens"])
108 |
109 | labels["target_len"] = tf.to_int32(labels["target_len"])
110 | tf.summary.histogram("target_len", tf.to_float(labels["target_len"]))
111 |
112 | # Add to graph collection for later use
113 | graph_utils.add_dict_to_collection(features, "features")
114 | if labels:
115 | graph_utils.add_dict_to_collection(labels, "labels")
116 |
117 | return features, labels
118 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/models/model_base.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Base class for models"""
15 |
16 | from __future__ import absolute_import
17 | from __future__ import division
18 | from __future__ import print_function
19 | from __future__ import unicode_literals
20 |
21 | import collections
22 | import tensorflow as tf
23 |
24 | from seq2seq.configurable import Configurable
25 | from seq2seq.training import utils as training_utils
26 | from seq2seq import global_vars
27 |
28 |
29 | def _flatten_dict(dict_, parent_key="", sep="."):
30 | """Flattens a nested dictionary. Namedtuples within
31 | the dictionary are converted to dicts.
32 |
33 | Args:
34 | dict_: The dictionary to flatten.
35 | parent_key: A prefix to prepend to each key.
36 | sep: Separator between parent and child keys, a string. For example
37 | { "a": { "b": 3 } } will become { "a.b": 3 } if the separator is ".".
38 |
39 | Returns:
40 | A new flattened dictionary.
41 | """
42 | items = []
43 | for key, value in dict_.items():
44 | new_key = parent_key + sep + key if parent_key else key
45 | if isinstance(value, collections.MutableMapping):
46 | items.extend(_flatten_dict(value, new_key, sep=sep).items())
47 | elif isinstance(value, tuple) and hasattr(value, "_asdict"):
48 | dict_items = collections.OrderedDict(zip(value._fields, value))
49 | items.extend(_flatten_dict(dict_items, new_key, sep=sep).items())
50 | else:
51 | items.append((new_key, value))
52 | return dict(items)
53 |
54 |
55 | class ModelBase(Configurable):
56 | """Abstract base class for models.
57 |
58 | Args:
59 | params: A dictionary of hyperparameter values
60 | name: A name for this model to be used as a variable scope
61 | """
62 |
63 | def __init__(self, params, mode, name):
64 | self.name = name
65 | Configurable.__init__(self, params, mode)
66 |
67 | def _clip_gradients(self, grads_and_vars):
68 | """Clips gradients by global norm."""
69 | gradients, variables = zip(*grads_and_vars)
70 | clipped_gradients, _ = tf.clip_by_global_norm(
71 | gradients, self.params["optimizer.clip_gradients"])
72 | return list(zip(clipped_gradients, variables))
73 |
74 | def _create_optimizer(self):
75 | """Creates the optimizer"""
76 | name = self.params["optimizer.name"]
77 | optimizer = tf.contrib.layers.OPTIMIZER_CLS_NAMES[name](
78 | learning_rate=self.params["optimizer.learning_rate"],
79 | **self.params["optimizer.params"])
80 |
81 | # Optionally wrap with SyncReplicasOptimizer
82 | if self.params["optimizer.sync_replicas"] > 0:
83 | optimizer = tf.train.SyncReplicasOptimizer(
84 | opt=optimizer,
85 | replicas_to_aggregate=self.params[
86 | "optimizer.sync_replicas_to_aggregate"],
87 | total_num_replicas=self.params["optimizer.sync_replicas"])
88 | # This is really ugly, but we need to do this to make the optimizer
89 | # accessible outside of the model.
90 | global_vars.SYNC_REPLICAS_OPTIMIZER = optimizer
91 |
92 | return optimizer
93 |
94 | def _build_train_op(self, loss):
95 | """Creates the training operation"""
96 | learning_rate_decay_fn = training_utils.create_learning_rate_decay_fn(
97 | decay_type=self.params["optimizer.lr_decay_type"] or None,
98 | decay_steps=self.params["optimizer.lr_decay_steps"],
99 | decay_rate=self.params["optimizer.lr_decay_rate"],
100 | start_decay_at=self.params["optimizer.lr_start_decay_at"],
101 | stop_decay_at=self.params["optimizer.lr_stop_decay_at"],
102 | min_learning_rate=self.params["optimizer.lr_min_learning_rate"],
103 | staircase=self.params["optimizer.lr_staircase"])
104 |
105 | optimizer = self._create_optimizer()
106 | train_op = tf.contrib.layers.optimize_loss(
107 | loss=loss,
108 | global_step=tf.contrib.framework.get_global_step(),
109 | learning_rate=self.params["optimizer.learning_rate"],
110 | learning_rate_decay_fn=learning_rate_decay_fn,
111 | clip_gradients=self._clip_gradients,
112 | optimizer=optimizer,
113 | summaries=["learning_rate", "loss", "gradients", "gradient_norm"])
114 |
115 | return train_op
116 |
117 | @staticmethod
118 | def default_params():
119 | """Returns a dictionary of default parameters for this model."""
120 | return {
121 | "optimizer.name": "Adam",
122 | "optimizer.learning_rate": 1e-4,
123 | "optimizer.params": {}, # Arbitrary parameters for the optimizer
124 | "optimizer.lr_decay_type": "",
125 | "optimizer.lr_decay_steps": 100,
126 | "optimizer.lr_decay_rate": 0.99,
127 | "optimizer.lr_start_decay_at": 0,
128 | "optimizer.lr_stop_decay_at": tf.int32.max,
129 | "optimizer.lr_min_learning_rate": 1e-12,
130 | "optimizer.lr_staircase": False,
131 | "optimizer.clip_gradients": 5.0,
132 | "optimizer.sync_replicas": 0,
133 | "optimizer.sync_replicas_to_aggregate": 0,
134 | }
135 |
136 | def batch_size(self, features, labels):
137 | """Returns the batch size for a batch of examples"""
138 | raise NotImplementedError()
139 |
140 | def __call__(self, features, labels, params):
141 | """Creates the model graph. See the model_fn documentation in
142 | tf.contrib.learn.Estimator class for a more detailed explanation.
143 | """
144 | with tf.variable_scope("model"):
145 | with tf.variable_scope(self.name):
146 | return self._build(features, labels, params)
147 |
148 | def _build(self, features, labels, params):
149 | """Subclasses should implement this method. See the `model_fn` documentation
150 | in tf.contrib.learn.Estimator class for a more detailed explanation.
151 | """
152 | raise NotImplementedError
153 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/tasks/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Collection of task types.
16 | """
17 |
18 | from seq2seq.tasks.inference_task import InferenceTask
19 | from seq2seq.tasks.decode_text import DecodeText
20 | from seq2seq.tasks.dump_attention import DumpAttention
21 | from seq2seq.tasks.dump_beams import DumpBeams
22 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/tasks/dump_attention.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Task where both the input and output sequence are plain text.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import os
24 |
25 | import numpy as np
26 | from matplotlib import pyplot as plt
27 |
28 | import tensorflow as tf
29 | from tensorflow import gfile
30 |
31 | from seq2seq.tasks.decode_text import _get_prediction_length
32 | from seq2seq.tasks.inference_task import InferenceTask, unbatch_dict
33 |
34 |
35 | def _get_scores(predictions_dict):
36 | """Returns the attention scores, sliced by source and target length.
37 | """
38 | prediction_len = _get_prediction_length(predictions_dict)
39 | source_len = predictions_dict["features.source_len"]
40 | return predictions_dict["attention_scores"][:prediction_len, :source_len]
41 |
42 |
43 | def _create_figure(predictions_dict):
44 | """Creates and returns a new figure that visualizes
45 | attention scores for for a single model predictions.
46 | """
47 |
48 | # Find out how long the predicted sequence is
49 | target_words = list(predictions_dict["predicted_tokens"])
50 |
51 | prediction_len = _get_prediction_length(predictions_dict)
52 |
53 | # Get source words
54 | source_len = predictions_dict["features.source_len"]
55 | source_words = predictions_dict["features.source_tokens"][:source_len]
56 |
57 | # Plot
58 | fig = plt.figure(figsize=(8, 8))
59 | plt.imshow(
60 | X=predictions_dict["attention_scores"][:prediction_len, :source_len],
61 | interpolation="nearest",
62 | cmap=plt.cm.Blues)
63 | plt.xticks(np.arange(source_len), source_words, rotation=45)
64 | plt.yticks(np.arange(prediction_len), target_words, rotation=-45)
65 | fig.tight_layout()
66 |
67 | return fig
68 |
69 |
70 | class DumpAttention(InferenceTask):
71 | """Defines inference for tasks where both the input and output sequences
72 | are plain text.
73 |
74 | Params:
75 | delimiter: Character by which tokens are delimited. Defaults to space.
76 | unk_replace: If true, enable unknown token replacement based on attention
77 | scores.
78 | unk_mapping: If `unk_replace` is true, this can be the path to a file
79 | defining a dictionary to improve UNK token replacement. Refer to the
80 | documentation for more details.
81 | dump_attention_dir: Save attention scores and plots to this directory.
82 | dump_attention_no_plot: If true, only save attention scores, not
83 | attention plots.
84 | dump_beams: Write beam search debugging information to this file.
85 | """
86 |
87 | def __init__(self, params):
88 | super(DumpAttention, self).__init__(params)
89 | self._attention_scores_accum = []
90 | self._idx = 0
91 |
92 | if not self.params["output_dir"]:
93 | raise ValueError("Must specify output_dir for DumpAttention")
94 |
95 | @staticmethod
96 | def default_params():
97 | params = {}
98 | params.update({"output_dir": "", "dump_plots": True})
99 | return params
100 |
101 | def begin(self):
102 | super(DumpAttention, self).begin()
103 | gfile.MakeDirs(self.params["output_dir"])
104 |
105 | def before_run(self, _run_context):
106 | fetches = {}
107 | fetches["predicted_tokens"] = self._predictions["predicted_tokens"]
108 | fetches["features.source_len"] = self._predictions["features.source_len"]
109 | fetches["features.source_tokens"] = self._predictions[
110 | "features.source_tokens"]
111 | fetches["attention_scores"] = self._predictions["attention_scores"]
112 | return tf.train.SessionRunArgs(fetches)
113 |
114 | def after_run(self, _run_context, run_values):
115 | fetches_batch = run_values.results
116 | for fetches in unbatch_dict(fetches_batch):
117 | # Convert to unicode
118 | fetches["predicted_tokens"] = np.char.decode(
119 | fetches["predicted_tokens"].astype("S"), "utf-8")
120 | fetches["features.source_tokens"] = np.char.decode(
121 | fetches["features.source_tokens"].astype("S"), "utf-8")
122 |
123 | if self.params["dump_plots"]:
124 | output_path = os.path.join(self.params["output_dir"],
125 | "{:05d}.png".format(self._idx))
126 | _create_figure(fetches)
127 | plt.savefig(output_path)
128 | plt.close()
129 | tf.logging.info("Wrote %s", output_path)
130 | self._idx += 1
131 | self._attention_scores_accum.append(_get_scores(fetches))
132 |
133 | def end(self, _session):
134 | scores_path = os.path.join(self.params["output_dir"],
135 | "attention_scores.npz")
136 | np.savez(scores_path, *self._attention_scores_accum)
137 | tf.logging.info("Wrote %s", scores_path)
138 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/tasks/dump_beams.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Task where both the input and output sequence are plain text.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import numpy as np
24 |
25 | import tensorflow as tf
26 |
27 | from seq2seq.tasks.inference_task import InferenceTask, unbatch_dict
28 |
29 |
30 | class DumpBeams(InferenceTask):
31 | """Defines inference for tasks where both the input and output sequences
32 | are plain text.
33 |
34 | Params:
35 | file: File to write beam search information to.
36 | """
37 |
38 | def __init__(self, params):
39 | super(DumpBeams, self).__init__(params)
40 | self._beam_accum = {
41 | "predicted_ids": [],
42 | "beam_parent_ids": [],
43 | "scores": [],
44 | "log_probs": []
45 | }
46 |
47 | if not self.params["file"]:
48 | raise ValueError("Must specify file for DumpBeams")
49 |
50 | @staticmethod
51 | def default_params():
52 | params = {}
53 | params.update({"file": "",})
54 | return params
55 |
56 | def before_run(self, _run_context):
57 | fetches = {}
58 | fetches["beam_search_output.predicted_ids"] = self._predictions[
59 | "beam_search_output.predicted_ids"]
60 | fetches["beam_search_output.beam_parent_ids"] = self._predictions[
61 | "beam_search_output.beam_parent_ids"]
62 | fetches["beam_search_output.scores"] = self._predictions[
63 | "beam_search_output.scores"]
64 | fetches["beam_search_output.log_probs"] = self._predictions[
65 | "beam_search_output.log_probs"]
66 | return tf.train.SessionRunArgs(fetches)
67 |
68 | def after_run(self, _run_context, run_values):
69 | fetches_batch = run_values.results
70 | for fetches in unbatch_dict(fetches_batch):
71 | self._beam_accum["predicted_ids"].append(fetches[
72 | "beam_search_output.predicted_ids"])
73 | self._beam_accum["beam_parent_ids"].append(fetches[
74 | "beam_search_output.beam_parent_ids"])
75 | self._beam_accum["scores"].append(fetches["beam_search_output.scores"])
76 | self._beam_accum["log_probs"].append(fetches[
77 | "beam_search_output.log_probs"])
78 |
79 | def end(self, _session):
80 | np.savez(self.params["file"], **self._beam_accum)
81 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/tasks/inference_task.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Abstract base class for inference tasks.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import abc
24 |
25 | import six
26 | import tensorflow as tf
27 |
28 | from seq2seq import graph_utils
29 | from seq2seq.configurable import Configurable, abstractstaticmethod
30 |
31 |
32 | def unbatch_dict(dict_):
33 | """Converts a dictionary of batch items to a batch/list of
34 | dictionary items.
35 | """
36 | batch_size = list(dict_.values())[0].shape[0]
37 | for i in range(batch_size):
38 | yield {key: value[i] for key, value in dict_.items()}
39 |
40 |
41 | @six.add_metaclass(abc.ABCMeta)
42 | class InferenceTask(tf.train.SessionRunHook, Configurable):
43 | """
44 | Abstract base class for inference tasks. Defines the logic used to make
45 | predictions for a specific type of task.
46 |
47 | Params:
48 | model_class: The model class to instantiate. If undefined,
49 | re-uses the class used during training.
50 | model_params: Model hyperparameters. Specified hyperparameters will
51 | overwrite those used during training.
52 |
53 | Args:
54 | params: See Params above.
55 | """
56 |
57 | def __init__(self, params):
58 | Configurable.__init__(self, params, tf.contrib.learn.ModeKeys.INFER)
59 | self._predictions = None
60 |
61 | def begin(self):
62 | self._predictions = graph_utils.get_dict_from_collection("predictions")
63 |
64 | @abstractstaticmethod
65 | def default_params():
66 | raise NotImplementedError()
67 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Tests and testing utilities
15 | """
16 |
17 | from seq2seq.test import utils
18 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/attention_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Unit tests for attention functions.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | import numpy as np
25 |
26 | from seq2seq.decoders.attention import AttentionLayerDot
27 | from seq2seq.decoders.attention import AttentionLayerBahdanau
28 |
29 |
30 | class AttentionLayerTest(tf.test.TestCase):
31 | """
32 | Tests the AttentionLayer module.
33 | """
34 |
35 | def setUp(self):
36 | super(AttentionLayerTest, self).setUp()
37 | tf.logging.set_verbosity(tf.logging.INFO)
38 | self.batch_size = 8
39 | self.attention_dim = 128
40 | self.input_dim = 16
41 | self.seq_len = 10
42 | self.state_dim = 32
43 |
44 | def _create_layer(self):
45 | """Creates the attention layer. Should be implemented by child classes"""
46 | raise NotImplementedError
47 |
48 | def _test_layer(self):
49 | """Tests Attention layer with a given score type"""
50 | inputs_pl = tf.placeholder(tf.float32, (None, None, self.input_dim))
51 | inputs_length_pl = tf.placeholder(tf.int32, [None])
52 | state_pl = tf.placeholder(tf.float32, (None, self.state_dim))
53 | attention_fn = self._create_layer()
54 | scores, context = attention_fn(
55 | query=state_pl,
56 | keys=inputs_pl,
57 | values=inputs_pl,
58 | values_length=inputs_length_pl)
59 |
60 | with self.test_session() as sess:
61 | sess.run(tf.global_variables_initializer())
62 | feed_dict = {}
63 | feed_dict[inputs_pl] = np.random.randn(self.batch_size, self.seq_len,
64 | self.input_dim)
65 | feed_dict[state_pl] = np.random.randn(self.batch_size, self.state_dim)
66 | feed_dict[inputs_length_pl] = np.arange(self.batch_size) + 1
67 | scores_, context_ = sess.run([scores, context], feed_dict)
68 |
69 | np.testing.assert_array_equal(scores_.shape,
70 | [self.batch_size, self.seq_len])
71 | np.testing.assert_array_equal(context_.shape,
72 | [self.batch_size, self.input_dim])
73 |
74 | for idx, batch in enumerate(scores_, 1):
75 | # All scores that are padded should be zero
76 | np.testing.assert_array_equal(batch[idx:], np.zeros_like(batch[idx:]))
77 |
78 | # Scores should sum to 1
79 | scores_sum = np.sum(scores_, axis=1)
80 | np.testing.assert_array_almost_equal(scores_sum, np.ones([self.batch_size]))
81 |
82 |
83 | class AttentionLayerDotTest(AttentionLayerTest):
84 | """Tests the AttentionLayerDot class"""
85 |
86 | def _create_layer(self):
87 | return AttentionLayerDot(
88 | params={"num_units": self.attention_dim},
89 | mode=tf.contrib.learn.ModeKeys.TRAIN)
90 |
91 | def test_layer(self):
92 | self._test_layer()
93 |
94 |
95 | class AttentionLayerBahdanauTest(AttentionLayerTest):
96 | """Tests the AttentionLayerBahdanau class"""
97 |
98 | def _create_layer(self):
99 | return AttentionLayerBahdanau(
100 | params={"num_units": self.attention_dim},
101 | mode=tf.contrib.learn.ModeKeys.TRAIN)
102 |
103 | def test_layer(self):
104 | self._test_layer()
105 |
106 |
107 | if __name__ == "__main__":
108 | tf.test.main()
109 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/bridges_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Tests for Encoder-Decoder bridges.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from collections import namedtuple
24 | import numpy as np
25 |
26 | import tensorflow as tf
27 | from tensorflow.python.util import nest # pylint: disable=E0611
28 |
29 | from seq2seq.encoders.encoder import EncoderOutput
30 | from seq2seq.models.bridges import ZeroBridge, InitialStateBridge
31 | from seq2seq.models.bridges import PassThroughBridge
32 |
33 | DecoderOutput = namedtuple("DecoderOutput", ["predicted_ids"])
34 |
35 |
36 | class BridgeTest(tf.test.TestCase):
37 | """Abstract class for bridge tests"""
38 |
39 | def setUp(self):
40 | super(BridgeTest, self).setUp()
41 | self.batch_size = 4
42 | self.encoder_cell = tf.contrib.rnn.MultiRNNCell(
43 | [tf.contrib.rnn.GRUCell(4), tf.contrib.rnn.GRUCell(8)])
44 | self.decoder_cell = tf.contrib.rnn.MultiRNNCell(
45 | [tf.contrib.rnn.LSTMCell(16), tf.contrib.rnn.GRUCell(8)])
46 | final_encoder_state = nest.map_structure(
47 | lambda x: tf.convert_to_tensor(
48 | value=np.random.randn(self.batch_size, x),
49 | dtype=tf.float32),
50 | self.encoder_cell.state_size)
51 | self.encoder_outputs = EncoderOutput(
52 | outputs=tf.convert_to_tensor(
53 | value=np.random.randn(self.batch_size, 10, 16), dtype=tf.float32),
54 | attention_values=tf.convert_to_tensor(
55 | value=np.random.randn(self.batch_size, 10, 16), dtype=tf.float32),
56 | attention_values_length=np.full([self.batch_size], 10),
57 | final_state=final_encoder_state)
58 |
59 | def _create_bridge(self):
60 | """Creates the bridge class to be tests. Must be implemented by
61 | child classes"""
62 | raise NotImplementedError()
63 |
64 | def _assert_correct_outputs(self):
65 | """Asserts bridge outputs are correct. Must be implemented by
66 | child classes"""
67 | raise NotImplementedError()
68 |
69 | def _run(self, scope=None, **kwargs):
70 | """Runs the bridge with the given arguments
71 | """
72 |
73 | with tf.variable_scope(scope or "bridge"):
74 | bridge = self._create_bridge(**kwargs)
75 | initial_state = bridge()
76 |
77 | with self.test_session() as sess:
78 | sess.run(tf.global_variables_initializer())
79 | initial_state_ = sess.run(initial_state)
80 |
81 | return initial_state_
82 |
83 |
84 | class TestZeroBridge(BridgeTest):
85 | """Tests for the ZeroBridge class"""
86 |
87 | def _create_bridge(self, **kwargs):
88 | return ZeroBridge(
89 | encoder_outputs=self.encoder_outputs,
90 | decoder_state_size=self.decoder_cell.state_size,
91 | params=kwargs,
92 | mode=tf.contrib.learn.ModeKeys.TRAIN)
93 |
94 | def _assert_correct_outputs(self, initial_state_):
95 | initial_state_flat_ = nest.flatten(initial_state_)
96 | for element in initial_state_flat_:
97 | np.testing.assert_array_equal(element, np.zeros_like(element))
98 |
99 | def test_zero_bridge(self):
100 | self._assert_correct_outputs(self._run())
101 |
102 |
103 | class TestPassThroughBridge(BridgeTest):
104 | """Tests for the ZeroBridge class"""
105 |
106 | def _create_bridge(self, **kwargs):
107 | return PassThroughBridge(
108 | encoder_outputs=self.encoder_outputs,
109 | decoder_state_size=self.decoder_cell.state_size,
110 | params=kwargs,
111 | mode=tf.contrib.learn.ModeKeys.TRAIN)
112 |
113 | def _assert_correct_outputs(self, initial_state_):
114 | nest.assert_same_structure(initial_state_, self.decoder_cell.state_size)
115 | nest.assert_same_structure(initial_state_, self.encoder_outputs.final_state)
116 |
117 | encoder_state_flat = nest.flatten(self.encoder_outputs.final_state)
118 | with self.test_session() as sess:
119 | encoder_state_flat_ = sess.run(encoder_state_flat)
120 |
121 | initial_state_flat_ = nest.flatten(initial_state_)
122 | for e_dec, e_enc in zip(initial_state_flat_, encoder_state_flat_):
123 | np.testing.assert_array_equal(e_dec, e_enc)
124 |
125 | def test_passthrough_bridge(self):
126 | self.decoder_cell = self.encoder_cell
127 | self._assert_correct_outputs(self._run())
128 |
129 |
130 | class TestInitialStateBridge(BridgeTest):
131 | """Tests for the InitialStateBridge class"""
132 |
133 | def _create_bridge(self, **kwargs):
134 | return InitialStateBridge(
135 | encoder_outputs=self.encoder_outputs,
136 | decoder_state_size=self.decoder_cell.state_size,
137 | params=kwargs,
138 | mode=tf.contrib.learn.ModeKeys.TRAIN)
139 |
140 | def _assert_correct_outputs(self, initial_state_):
141 | nest.assert_same_structure(initial_state_, self.decoder_cell.state_size)
142 |
143 | def test_with_final_state(self):
144 | self._assert_correct_outputs(self._run(bridge_input="final_state"))
145 |
146 | def test_with_outputs(self):
147 | self._assert_correct_outputs(self._run(bridge_input="outputs"))
148 |
149 | def test_with_activation_fn(self):
150 | self._assert_correct_outputs(
151 | self._run(
152 | bridge_input="final_state", activation_fn="tanh"))
153 |
154 |
155 | if __name__ == "__main__":
156 | tf.test.main()
157 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/conv_encoder_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Test Cases for PoolingEncoder.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | import numpy as np
25 |
26 | from seq2seq.encoders import ConvEncoder
27 |
28 |
29 | class ConvEncoderTest(tf.test.TestCase):
30 | """
31 | Tests the ConvEncoder class.
32 | """
33 |
34 | def setUp(self):
35 | super(ConvEncoderTest, self).setUp()
36 | self.batch_size = 4
37 | self.sequence_length = 16
38 | self.input_depth = 10
39 | self.mode = tf.contrib.learn.ModeKeys.TRAIN
40 |
41 | def _test_with_params(self, params):
42 | """Tests the encoder with a given parameter configuration"""
43 | inputs = tf.random_normal(
44 | [self.batch_size, self.sequence_length, self.input_depth])
45 | example_length = tf.ones(
46 | self.batch_size, dtype=tf.int32) * self.sequence_length
47 |
48 | encode_fn = ConvEncoder(params, self.mode)
49 | encoder_output = encode_fn(inputs, example_length)
50 |
51 | with self.test_session() as sess:
52 | sess.run(tf.global_variables_initializer())
53 | encoder_output_ = sess.run(encoder_output)
54 |
55 | att_value_units = encode_fn.params["attention_cnn.units"]
56 | output_units = encode_fn.params["output_cnn.units"]
57 |
58 | np.testing.assert_array_equal(
59 | encoder_output_.outputs.shape,
60 | [self.batch_size, self.sequence_length, att_value_units])
61 | np.testing.assert_array_equal(
62 | encoder_output_.attention_values.shape,
63 | [self.batch_size, self.sequence_length, output_units])
64 | np.testing.assert_array_equal(
65 | encoder_output_.final_state.shape,
66 | [self.batch_size, output_units])
67 |
68 | def test_encode_with_pos(self):
69 | self._test_with_params({
70 | "position_embeddings.enable": True,
71 | "position_embeddings.num_positions": self.sequence_length,
72 | "attention_cnn.units": 5,
73 | "output_cnn.units": 6
74 | })
75 |
76 | if __name__ == "__main__":
77 | tf.test.main()
78 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/data_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """
16 | Unit tests for input-related operations.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import tempfile
25 | import tensorflow as tf
26 | import numpy as np
27 |
28 | from seq2seq.data import split_tokens_decoder
29 | from seq2seq.data.parallel_data_provider import make_parallel_data_provider
30 |
31 |
32 | class SplitTokensDecoderTest(tf.test.TestCase):
33 | """Tests the SplitTokensDecoder class
34 | """
35 |
36 | def test_decode(self):
37 | decoder = split_tokens_decoder.SplitTokensDecoder(
38 | delimiter=" ",
39 | tokens_feature_name="source_tokens",
40 | length_feature_name="source_len")
41 |
42 | self.assertEqual(decoder.list_items(), ["source_tokens", "source_len"])
43 |
44 | data = tf.constant("Hello world ! 笑w")
45 |
46 | decoded_tokens = decoder.decode(data, ["source_tokens"])
47 | decoded_length = decoder.decode(data, ["source_len"])
48 | decoded_both = decoder.decode(data, decoder.list_items())
49 |
50 | with self.test_session() as sess:
51 | decoded_tokens_ = sess.run(decoded_tokens)[0]
52 | decoded_length_ = sess.run(decoded_length)[0]
53 | decoded_both_ = sess.run(decoded_both)
54 |
55 | self.assertEqual(decoded_length_, 4)
56 | np.testing.assert_array_equal(
57 | np.char.decode(decoded_tokens_.astype("S"), "utf-8"),
58 | ["Hello", "world", "!", "笑w"])
59 |
60 | self.assertEqual(decoded_both_[1], 4)
61 | np.testing.assert_array_equal(
62 | np.char.decode(decoded_both_[0].astype("S"), "utf-8"),
63 | ["Hello", "world", "!", "笑w"])
64 |
65 |
66 | class ParallelDataProviderTest(tf.test.TestCase):
67 | """Tests the ParallelDataProvider class
68 | """
69 |
70 | def setUp(self):
71 | super(ParallelDataProviderTest, self).setUp()
72 | # Our data
73 | self.source_lines = ["Hello", "World", "!", "笑"]
74 | self.target_lines = ["1", "2", "3", "笑"]
75 | self.source_to_target = dict(zip(self.source_lines, self.target_lines))
76 |
77 | # Create two parallel text files
78 | self.source_file = tempfile.NamedTemporaryFile()
79 | self.target_file = tempfile.NamedTemporaryFile()
80 | self.source_file.write("\n".join(self.source_lines).encode("utf-8"))
81 | self.source_file.flush()
82 | self.target_file.write("\n".join(self.target_lines).encode("utf-8"))
83 | self.target_file.flush()
84 |
85 | def tearDown(self):
86 | super(ParallelDataProviderTest, self).tearDown()
87 | self.source_file.close()
88 | self.target_file.close()
89 |
90 | def test_reading(self):
91 | num_epochs = 50
92 | data_provider = make_parallel_data_provider(
93 | data_sources_source=[self.source_file.name],
94 | data_sources_target=[self.target_file.name],
95 | num_epochs=num_epochs,
96 | shuffle=True)
97 |
98 | item_keys = list(data_provider.list_items())
99 | item_values = data_provider.get(item_keys)
100 | items_dict = dict(zip(item_keys, item_values))
101 |
102 | self.assertEqual(
103 | set(item_keys),
104 | set(["source_tokens", "source_len", "target_tokens", "target_len"]))
105 |
106 | with self.test_session() as sess:
107 | sess.run(tf.global_variables_initializer())
108 | sess.run(tf.local_variables_initializer())
109 | with tf.contrib.slim.queues.QueueRunners(sess):
110 | item_dicts_ = [sess.run(items_dict) for _ in range(num_epochs * 3)]
111 |
112 | for item_dict in item_dicts_:
113 | item_dict["target_tokens"] = np.char.decode(
114 | item_dict["target_tokens"].astype("S"), "utf-8")
115 | item_dict["source_tokens"] = np.char.decode(
116 | item_dict["source_tokens"].astype("S"), "utf-8")
117 |
118 | # Source is Data + SEQUENCE_END
119 | self.assertEqual(item_dict["source_len"], 2)
120 | self.assertEqual(item_dict["source_tokens"][-1], "SEQUENCE_END")
121 | # Target is SEQUENCE_START + Data + SEQUENCE_END
122 | self.assertEqual(item_dict["target_len"], 3)
123 | self.assertEqual(item_dict["target_tokens"][0], "SEQUENCE_START")
124 | self.assertEqual(item_dict["target_tokens"][-1], "SEQUENCE_END")
125 |
126 | # Make sure data is aligned
127 | source_joined = " ".join(item_dict["source_tokens"][:-1])
128 | expected_target = self.source_to_target[source_joined]
129 | np.testing.assert_array_equal(
130 | item_dict["target_tokens"],
131 | ["SEQUENCE_START"] + expected_target.split(" ") + ["SEQUENCE_END"])
132 |
133 | def test_reading_without_targets(self):
134 | num_epochs = 50
135 | data_provider = make_parallel_data_provider(
136 | data_sources_source=[self.source_file.name],
137 | data_sources_target=None,
138 | num_epochs=num_epochs,
139 | shuffle=True)
140 |
141 | item_keys = list(data_provider.list_items())
142 | item_values = data_provider.get(item_keys)
143 | items_dict = dict(zip(item_keys, item_values))
144 |
145 | self.assertEqual(set(item_keys), set(["source_tokens", "source_len"]))
146 |
147 | with self.test_session() as sess:
148 | sess.run(tf.global_variables_initializer())
149 | sess.run(tf.local_variables_initializer())
150 | with tf.contrib.slim.queues.QueueRunners(sess):
151 | item_dicts_ = [sess.run(items_dict) for _ in range(num_epochs * 3)]
152 |
153 | for item_dict in item_dicts_:
154 | self.assertEqual(item_dict["source_len"], 2)
155 | item_dict["source_tokens"] = np.char.decode(
156 | item_dict["source_tokens"].astype("S"), "utf-8")
157 | self.assertEqual(item_dict["source_tokens"][-1], "SEQUENCE_END")
158 |
159 |
160 | if __name__ == "__main__":
161 | tf.test.main()
162 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/example_config_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """
16 | Test Cases for example configuration files.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import os
25 | from pydoc import locate
26 |
27 | import yaml
28 |
29 | import tensorflow as tf
30 | from tensorflow import gfile
31 |
32 | from seq2seq.test.models_test import EncoderDecoderTests
33 | from seq2seq import models
34 |
35 | EXAMPLE_CONFIG_DIR = os.path.abspath(
36 | os.path.join(os.path.dirname(__file__), "../../example_configs"))
37 |
38 |
39 | def _load_model_from_config(config_path, hparam_overrides, vocab_file, mode):
40 | """Loads model from a configuration file"""
41 | with gfile.GFile(config_path) as config_file:
42 | config = yaml.load(config_file)
43 | model_cls = locate(config["model"]) or getattr(models, config["model"])
44 | model_params = config["model_params"]
45 | if hparam_overrides:
46 | model_params.update(hparam_overrides)
47 | # Change the max decode length to make the test run faster
48 | model_params["decoder.params"]["max_decode_length"] = 5
49 | model_params["vocab_source"] = vocab_file
50 | model_params["vocab_target"] = vocab_file
51 | return model_cls(params=model_params, mode=mode)
52 |
53 |
54 | class ExampleConfigTest(object):
55 | """Interface for configuration-based tests"""
56 |
57 | def __init__(self, *args, **kwargs):
58 | super(ExampleConfigTest, self).__init__(*args, **kwargs)
59 | self.vocab_file = None
60 |
61 | def _config_path(self):
62 | """Returns the path to the configuration to be tested"""
63 | raise NotImplementedError()
64 |
65 | def create_model(self, mode, params=None):
66 | """Creates the model"""
67 | return _load_model_from_config(
68 | config_path=self._config_path(),
69 | hparam_overrides=params,
70 | vocab_file=self.vocab_file.name,
71 | mode=mode)
72 |
73 |
74 | class TestNMTLarge(ExampleConfigTest, EncoderDecoderTests):
75 | """Tests nmt_large.yml"""
76 |
77 | def _config_path(self):
78 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_large.yml")
79 |
80 |
81 | class TestNMTMedium(ExampleConfigTest, EncoderDecoderTests):
82 | """Tests nmt_medium.yml"""
83 |
84 | def _config_path(self):
85 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_medium.yml")
86 |
87 |
88 | class TestNMTSmall(ExampleConfigTest, EncoderDecoderTests):
89 | """Tests nmt_small.yml"""
90 |
91 | def _config_path(self):
92 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_small.yml")
93 |
94 | class TestNMTConv(ExampleConfigTest, EncoderDecoderTests):
95 | """Tests nmt_small.yml"""
96 |
97 | def _config_path(self):
98 | return os.path.join(EXAMPLE_CONFIG_DIR, "nmt_conv.yml")
99 |
100 |
101 | if __name__ == "__main__":
102 | tf.test.main()
103 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/hooks_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """Tests for SessionRunHooks.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import os
24 | import tempfile
25 | import shutil
26 | import time
27 |
28 | import tensorflow as tf
29 | from tensorflow.python.training import monitored_session # pylint: disable=E0611
30 | from tensorflow import gfile
31 |
32 | from seq2seq import graph_utils
33 | from seq2seq.training import hooks
34 |
35 |
36 | class TestPrintModelAnalysisHook(tf.test.TestCase):
37 | """Tests the `PrintModelAnalysisHook` hook"""
38 |
39 | def test_begin(self):
40 | model_dir = tempfile.mkdtemp()
41 | outfile = tempfile.NamedTemporaryFile()
42 | tf.get_variable("weigths", [128, 128])
43 | hook = hooks.PrintModelAnalysisHook(
44 | params={}, model_dir=model_dir, run_config=tf.contrib.learn.RunConfig())
45 | hook.begin()
46 |
47 | with gfile.GFile(os.path.join(model_dir, "model_analysis.txt")) as file:
48 | file_contents = file.read().strip()
49 |
50 | self.assertEqual(file_contents.decode(), "_TFProfRoot (--/16.38k params)\n"
51 | " weigths (128x128, 16.38k/16.38k params)")
52 | outfile.close()
53 |
54 |
55 | class TestTrainSampleHook(tf.test.TestCase):
56 | """Tests `TrainSampleHook` class.
57 | """
58 |
59 | def setUp(self):
60 | super(TestTrainSampleHook, self).setUp()
61 | self.model_dir = tempfile.mkdtemp()
62 | self.sample_dir = os.path.join(self.model_dir, "samples")
63 |
64 | # The hook expects these collections to be in the graph
65 | pred_dict = {}
66 | pred_dict["predicted_tokens"] = tf.constant([["Hello", "World", "笑w"]])
67 | pred_dict["labels.target_tokens"] = tf.constant([["Hello", "World", "笑w"]])
68 | pred_dict["labels.target_len"] = tf.constant(2),
69 | graph_utils.add_dict_to_collection(pred_dict, "predictions")
70 |
71 | def tearDown(self):
72 | super(TestTrainSampleHook, self).tearDown()
73 | shutil.rmtree(self.model_dir)
74 |
75 | def test_sampling(self):
76 | hook = hooks.TrainSampleHook(
77 | params={"every_n_steps": 10}, model_dir=self.model_dir,
78 | run_config=tf.contrib.learn.RunConfig())
79 |
80 | global_step = tf.contrib.framework.get_or_create_global_step()
81 | no_op = tf.no_op()
82 | hook.begin()
83 | with self.test_session() as sess:
84 | sess.run(tf.global_variables_initializer())
85 | sess.run(tf.local_variables_initializer())
86 | sess.run(tf.tables_initializer())
87 |
88 | #pylint: disable=W0212
89 | mon_sess = monitored_session._HookedSession(sess, [hook])
90 | # Should trigger for step 0
91 | sess.run(tf.assign(global_step, 0))
92 | mon_sess.run(no_op)
93 |
94 | outfile = os.path.join(self.sample_dir, "samples_000000.txt")
95 | with open(outfile, "rb") as readfile:
96 | self.assertIn("Prediction followed by Target @ Step 0",
97 | readfile.read().decode("utf-8"))
98 |
99 | # Should not trigger for step 9
100 | sess.run(tf.assign(global_step, 9))
101 | mon_sess.run(no_op)
102 | outfile = os.path.join(self.sample_dir, "samples_000009.txt")
103 | self.assertFalse(os.path.exists(outfile))
104 |
105 | # Should trigger for step 10
106 | sess.run(tf.assign(global_step, 10))
107 | mon_sess.run(no_op)
108 | outfile = os.path.join(self.sample_dir, "samples_000010.txt")
109 | with open(outfile, "rb") as readfile:
110 | self.assertIn("Prediction followed by Target @ Step 10",
111 | readfile.read().decode("utf-8"))
112 |
113 |
114 | class TestMetadataCaptureHook(tf.test.TestCase):
115 | """Test for the MetadataCaptureHook"""
116 |
117 | def setUp(self):
118 | super(TestMetadataCaptureHook, self).setUp()
119 | self.model_dir = tempfile.mkdtemp()
120 |
121 | def tearDown(self):
122 | super(TestMetadataCaptureHook, self).tearDown()
123 | shutil.rmtree(self.model_dir)
124 |
125 | def test_capture(self):
126 | global_step = tf.contrib.framework.get_or_create_global_step()
127 | # Some test computation
128 | some_weights = tf.get_variable("weigths", [2, 128])
129 | computation = tf.nn.softmax(some_weights)
130 |
131 | hook = hooks.MetadataCaptureHook(
132 | params={"step": 5}, model_dir=self.model_dir,
133 | run_config=tf.contrib.learn.RunConfig())
134 | hook.begin()
135 |
136 | with self.test_session() as sess:
137 | sess.run(tf.global_variables_initializer())
138 | #pylint: disable=W0212
139 | mon_sess = monitored_session._HookedSession(sess, [hook])
140 | # Should not trigger for step 0
141 | sess.run(tf.assign(global_step, 0))
142 | mon_sess.run(computation)
143 | self.assertEqual(gfile.ListDirectory(self.model_dir), [])
144 | # Should trigger *after* step 5
145 | sess.run(tf.assign(global_step, 5))
146 | mon_sess.run(computation)
147 | self.assertEqual(gfile.ListDirectory(self.model_dir), [])
148 | mon_sess.run(computation)
149 | self.assertEqual(
150 | set(gfile.ListDirectory(self.model_dir)),
151 | set(["run_meta", "tfprof_log", "timeline.json"]))
152 |
153 | if __name__ == "__main__":
154 | tf.test.main()
155 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/input_pipeline_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """
16 | Unit tests for input-related operations.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import tensorflow as tf
25 | import numpy as np
26 | import yaml
27 |
28 | from seq2seq.data import input_pipeline
29 | from seq2seq.test import utils as test_utils
30 |
31 |
32 | class TestInputPipelineDef(tf.test.TestCase):
33 | """Tests InputPipeline string definitions"""
34 |
35 | def test_without_extra_args(self):
36 | pipeline_def = yaml.load("""
37 | class: ParallelTextInputPipeline
38 | params:
39 | source_files: ["file1"]
40 | target_files: ["file2"]
41 | num_epochs: 1
42 | shuffle: True
43 | """)
44 | pipeline = input_pipeline.make_input_pipeline_from_def(
45 | pipeline_def, tf.contrib.learn.ModeKeys.TRAIN)
46 | self.assertIsInstance(pipeline, input_pipeline.ParallelTextInputPipeline)
47 | #pylint: disable=W0212
48 | self.assertEqual(pipeline.params["source_files"], ["file1"])
49 | self.assertEqual(pipeline.params["target_files"], ["file2"])
50 | self.assertEqual(pipeline.params["num_epochs"], 1)
51 | self.assertEqual(pipeline.params["shuffle"], True)
52 |
53 | def test_with_extra_args(self):
54 | pipeline_def = yaml.load("""
55 | class: ParallelTextInputPipeline
56 | params:
57 | source_files: ["file1"]
58 | target_files: ["file2"]
59 | num_epochs: 1
60 | shuffle: True
61 | """)
62 | pipeline = input_pipeline.make_input_pipeline_from_def(
63 | def_dict=pipeline_def,
64 | mode=tf.contrib.learn.ModeKeys.TRAIN,
65 | num_epochs=5,
66 | shuffle=False)
67 | self.assertIsInstance(pipeline, input_pipeline.ParallelTextInputPipeline)
68 | #pylint: disable=W0212
69 | self.assertEqual(pipeline.params["source_files"], ["file1"])
70 | self.assertEqual(pipeline.params["target_files"], ["file2"])
71 | self.assertEqual(pipeline.params["num_epochs"], 5)
72 | self.assertEqual(pipeline.params["shuffle"], False)
73 |
74 |
75 | class TFRecordsInputPipelineTest(tf.test.TestCase):
76 | """
77 | Tests Data Provider operations.
78 | """
79 |
80 | def setUp(self):
81 | super(TFRecordsInputPipelineTest, self).setUp()
82 | tf.logging.set_verbosity(tf.logging.INFO)
83 |
84 | def test_pipeline(self):
85 | tfrecords_file = test_utils.create_temp_tfrecords(
86 | sources=["Hello World . 笑"], targets=["Bye 泣"])
87 |
88 | pipeline = input_pipeline.TFRecordInputPipeline(
89 | params={
90 | "files": [tfrecords_file.name],
91 | "source_field": "source",
92 | "target_field": "target",
93 | "num_epochs": 5,
94 | "shuffle": False
95 | },
96 | mode=tf.contrib.learn.ModeKeys.TRAIN)
97 |
98 | data_provider = pipeline.make_data_provider()
99 |
100 | features = pipeline.read_from_data_provider(data_provider)
101 |
102 | with self.test_session() as sess:
103 | sess.run(tf.global_variables_initializer())
104 | sess.run(tf.local_variables_initializer())
105 | with tf.contrib.slim.queues.QueueRunners(sess):
106 | res = sess.run(features)
107 |
108 | self.assertEqual(res["source_len"], 5)
109 | self.assertEqual(res["target_len"], 4)
110 | np.testing.assert_array_equal(
111 | np.char.decode(res["source_tokens"].astype("S"), "utf-8"),
112 | ["Hello", "World", ".", "笑", "SEQUENCE_END"])
113 | np.testing.assert_array_equal(
114 | np.char.decode(res["target_tokens"].astype("S"), "utf-8"),
115 | ["SEQUENCE_START", "Bye", "泣", "SEQUENCE_END"])
116 |
117 |
118 | class ParallelTextInputPipelineTest(tf.test.TestCase):
119 | """
120 | Tests Data Provider operations.
121 | """
122 |
123 | def setUp(self):
124 | super(ParallelTextInputPipelineTest, self).setUp()
125 | tf.logging.set_verbosity(tf.logging.INFO)
126 |
127 | def test_pipeline(self):
128 | file_source, file_target = test_utils.create_temp_parallel_data(
129 | sources=["Hello World . 笑"], targets=["Bye 泣"])
130 |
131 | pipeline = input_pipeline.ParallelTextInputPipeline(
132 | params={
133 | "source_files": [file_source.name],
134 | "target_files": [file_target.name],
135 | "num_epochs": 5,
136 | "shuffle": False
137 | },
138 | mode=tf.contrib.learn.ModeKeys.TRAIN)
139 |
140 | data_provider = pipeline.make_data_provider()
141 |
142 | features = pipeline.read_from_data_provider(data_provider)
143 |
144 | with self.test_session() as sess:
145 | sess.run(tf.global_variables_initializer())
146 | sess.run(tf.local_variables_initializer())
147 | with tf.contrib.slim.queues.QueueRunners(sess):
148 | res = sess.run(features)
149 |
150 | self.assertEqual(res["source_len"], 5)
151 | self.assertEqual(res["target_len"], 4)
152 | np.testing.assert_array_equal(
153 | np.char.decode(res["source_tokens"].astype("S"), "utf-8"),
154 | ["Hello", "World", ".", "笑", "SEQUENCE_END"])
155 | np.testing.assert_array_equal(
156 | np.char.decode(res["target_tokens"].astype("S"), "utf-8"),
157 | ["SEQUENCE_START", "Bye", "泣", "SEQUENCE_END"])
158 |
159 |
160 | if __name__ == "__main__":
161 | tf.test.main()
162 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/losses_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Unit tests for loss-related operations.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | from seq2seq import losses as seq2seq_losses
24 | import tensorflow as tf
25 | import numpy as np
26 |
27 |
28 | class CrossEntropySequenceLossTest(tf.test.TestCase):
29 | """
30 | Test for `sqe2seq.losses.sequence_mask`.
31 | """
32 |
33 | def setUp(self):
34 | super(CrossEntropySequenceLossTest, self).setUp()
35 | tf.logging.set_verbosity(tf.logging.INFO)
36 | self.batch_size = 4
37 | self.sequence_length = 10
38 | self.vocab_size = 50
39 |
40 | def test_op(self):
41 | logits = np.random.randn(self.sequence_length, self.batch_size,
42 | self.vocab_size)
43 | logits = logits.astype(np.float32)
44 | sequence_length = np.array([1, 2, 3, 4])
45 | targets = np.random.randint(0, self.vocab_size,
46 | [self.sequence_length, self.batch_size])
47 | losses = seq2seq_losses.cross_entropy_sequence_loss(logits, targets,
48 | sequence_length)
49 |
50 | with self.test_session() as sess:
51 | losses_ = sess.run(losses)
52 |
53 | # Make sure all losses not past the sequence length are > 0
54 | np.testing.assert_array_less(np.zeros_like(losses_[:1, 0]), losses_[:1, 0])
55 | np.testing.assert_array_less(np.zeros_like(losses_[:2, 1]), losses_[:2, 1])
56 | np.testing.assert_array_less(np.zeros_like(losses_[:3, 2]), losses_[:3, 2])
57 |
58 | # Make sure all losses past the sequence length are 0
59 | np.testing.assert_array_equal(losses_[1:, 0], np.zeros_like(losses_[1:, 0]))
60 | np.testing.assert_array_equal(losses_[2:, 1], np.zeros_like(losses_[2:, 1]))
61 | np.testing.assert_array_equal(losses_[3:, 2], np.zeros_like(losses_[3:, 2]))
62 |
63 |
64 | if __name__ == "__main__":
65 | tf.test.main()
66 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/pooling_encoder_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | Test Cases for PoolingEncoder.
16 | """
17 |
18 | from __future__ import absolute_import
19 | from __future__ import division
20 | from __future__ import print_function
21 | from __future__ import unicode_literals
22 |
23 | import tensorflow as tf
24 | import numpy as np
25 |
26 | from seq2seq.encoders import PoolingEncoder
27 |
28 |
29 | class PoolingEncoderTest(tf.test.TestCase):
30 | """
31 | Tests the PoolingEncoder class.
32 | """
33 |
34 | def setUp(self):
35 | super(PoolingEncoderTest, self).setUp()
36 | self.batch_size = 4
37 | self.sequence_length = 16
38 | self.input_depth = 10
39 | self.mode = tf.contrib.learn.ModeKeys.TRAIN
40 |
41 | def _test_with_params(self, params):
42 | """Tests the encoder with a given parameter configuration"""
43 | inputs = tf.random_normal(
44 | [self.batch_size, self.sequence_length, self.input_depth])
45 | example_length = tf.ones(
46 | self.batch_size, dtype=tf.int32) * self.sequence_length
47 |
48 | encode_fn = PoolingEncoder(params, self.mode)
49 | encoder_output = encode_fn(inputs, example_length)
50 |
51 | with self.test_session() as sess:
52 | sess.run(tf.global_variables_initializer())
53 | encoder_output_ = sess.run(encoder_output)
54 |
55 | np.testing.assert_array_equal(
56 | encoder_output_.outputs.shape,
57 | [self.batch_size, self.sequence_length, self.input_depth])
58 | np.testing.assert_array_equal(
59 | encoder_output_.attention_values.shape,
60 | [self.batch_size, self.sequence_length, self.input_depth])
61 | np.testing.assert_array_equal(encoder_output_.final_state.shape,
62 | [self.batch_size, self.input_depth])
63 |
64 | def test_encode_with_pos(self):
65 | self._test_with_params({
66 | "position_embeddings.enable": True,
67 | "position_embeddings.num_positions": self.sequence_length
68 | })
69 |
70 | def test_encode_without_pos(self):
71 | self._test_with_params({
72 | "position_embeddings.enable": False,
73 | "position_embeddings.num_positions": 0
74 | })
75 |
76 | if __name__ == "__main__":
77 | tf.test.main()
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/rnn_cell_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """
16 | Unit tests for input-related operations.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import tensorflow as tf
25 | from seq2seq.contrib import rnn_cell
26 |
27 | import numpy as np
28 |
29 |
30 | class ExtendedMultiRNNCellTest(tf.test.TestCase):
31 | """Tests the ExtendedMultiRNNCell"""
32 |
33 | def test_without_residuals(self):
34 | inputs = tf.constant(np.random.randn(1, 2))
35 | state = (tf.constant(np.random.randn(1, 2)),
36 | tf.constant(np.random.randn(1, 2)))
37 |
38 | with tf.variable_scope("root", initializer=tf.constant_initializer(0.5)):
39 | standard_cell = tf.contrib.rnn.MultiRNNCell(
40 | [tf.contrib.rnn.GRUCell(2) for _ in range(2)], state_is_tuple=True)
41 | res_standard = standard_cell(inputs, state, scope="standard")
42 |
43 | test_cell = rnn_cell.ExtendedMultiRNNCell(
44 | [tf.contrib.rnn.GRUCell(2) for _ in range(2)])
45 | res_test = test_cell(inputs, state, scope="test")
46 |
47 | with self.test_session() as sess:
48 | sess.run([tf.global_variables_initializer()])
49 | res_standard_, res_test_, = sess.run([res_standard, res_test])
50 |
51 | # Make sure it produces the same results as the standard cell
52 | self.assertAllClose(res_standard_[0], res_test_[0])
53 | self.assertAllClose(res_standard_[1][0], res_test_[1][0])
54 | self.assertAllClose(res_standard_[1][1], res_test_[1][1])
55 |
56 | def _test_with_residuals(self, inputs, **kwargs):
57 | """Runs the cell in a session"""
58 | inputs = tf.convert_to_tensor(inputs)
59 | state = (tf.constant(np.random.randn(1, 2)),
60 | tf.constant(np.random.randn(1, 2)))
61 |
62 | with tf.variable_scope("root", initializer=tf.constant_initializer(0.5)):
63 | test_cell = rnn_cell.ExtendedMultiRNNCell(
64 | [tf.contrib.rnn.GRUCell(2) for _ in range(2)],
65 | residual_connections=True,
66 | **kwargs)
67 | res_test = test_cell(inputs, state, scope="test")
68 |
69 | with self.test_session() as sess:
70 | sess.run([tf.global_variables_initializer()])
71 | return sess.run(res_test)
72 |
73 | def _test_constant_shape(self, combiner):
74 | """Tests a residual combiner whose shape doesn't change
75 | with depth"""
76 | inputs = np.random.randn(1, 2)
77 | with tf.variable_scope("same_input_size"):
78 | res_ = self._test_with_residuals(inputs, residual_combiner=combiner)
79 | self.assertEqual(res_[0].shape, (1, 2))
80 | self.assertEqual(res_[1][0].shape, (1, 2))
81 | self.assertEqual(res_[1][1].shape, (1, 2))
82 |
83 | inputs = np.random.randn(1, 5)
84 | with tf.variable_scope("diff_input_size"):
85 | res_ = self._test_with_residuals(inputs, residual_combiner=combiner)
86 | self.assertEqual(res_[0].shape, (1, 2))
87 | self.assertEqual(res_[1][0].shape, (1, 2))
88 | self.assertEqual(res_[1][1].shape, (1, 2))
89 |
90 | with tf.variable_scope("same_input_size_dense"):
91 | res_ = self._test_with_residuals(
92 | inputs, residual_combiner=combiner, residual_dense=True)
93 | self.assertEqual(res_[0].shape, (1, 2))
94 | self.assertEqual(res_[1][0].shape, (1, 2))
95 | self.assertEqual(res_[1][1].shape, (1, 2))
96 |
97 | inputs = np.random.randn(1, 5)
98 | with tf.variable_scope("diff_input_size_dense"):
99 | res_ = self._test_with_residuals(
100 | inputs, residual_combiner=combiner, residual_dense=True)
101 | self.assertEqual(res_[0].shape, (1, 2))
102 | self.assertEqual(res_[1][0].shape, (1, 2))
103 | self.assertEqual(res_[1][1].shape, (1, 2))
104 |
105 | def test_residuals_mean(self):
106 | self._test_constant_shape(combiner="mean")
107 |
108 | def test_residuals_add(self):
109 | self._test_constant_shape(combiner="add")
110 |
111 | def test_residuals_concat(self):
112 | inputs = np.random.randn(1, 2)
113 | with tf.variable_scope("same_input_size"):
114 | res_ = self._test_with_residuals(inputs, residual_combiner="concat")
115 | self.assertEqual(res_[0].shape, (1, 6))
116 | self.assertEqual(res_[1][0].shape, (1, 2))
117 | self.assertEqual(res_[1][1].shape, (1, 2))
118 |
119 | inputs = np.random.randn(1, 5)
120 | with tf.variable_scope("diff_input_size"):
121 | res_ = self._test_with_residuals(inputs, residual_combiner="concat")
122 | self.assertEqual(res_[0].shape, (1, 5 + 2 + 2))
123 | self.assertEqual(res_[1][0].shape, (1, 2))
124 | self.assertEqual(res_[1][1].shape, (1, 2))
125 |
126 | inputs = np.random.randn(1, 2)
127 | with tf.variable_scope("same_input_size_dense"):
128 | res_ = self._test_with_residuals(
129 | inputs, residual_combiner="concat", residual_dense=True)
130 | self.assertEqual(res_[0].shape, (1, 2 + 4 + 2))
131 | self.assertEqual(res_[1][0].shape, (1, 2))
132 | self.assertEqual(res_[1][1].shape, (1, 2))
133 |
134 | inputs = np.random.randn(1, 5)
135 | with tf.variable_scope("diff_input_size_dense"):
136 | res_ = self._test_with_residuals(
137 | inputs, residual_combiner="concat", residual_dense=True)
138 | self.assertEqual(res_[0].shape, (1, 2 + (5 + 2) + 5))
139 | self.assertEqual(res_[1][0].shape, (1, 2))
140 | self.assertEqual(res_[1][1].shape, (1, 2))
141 |
142 |
143 | if __name__ == "__main__":
144 | tf.test.main()
145 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/utils.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Various testing utilities
15 | """
16 |
17 | from __future__ import absolute_import
18 | from __future__ import division
19 | from __future__ import print_function
20 | from __future__ import unicode_literals
21 |
22 | import tempfile
23 | import tensorflow as tf
24 |
25 |
26 | def create_temp_parallel_data(sources, targets):
27 | """
28 | Creates a temporary TFRecords file.
29 |
30 | Args:
31 | source: List of source sentences
32 | target: List of target sentences
33 |
34 | Returns:
35 | A tuple (sources_file, targets_file).
36 | """
37 | file_source = tempfile.NamedTemporaryFile()
38 | file_target = tempfile.NamedTemporaryFile()
39 | file_source.write("\n".join(sources).encode("utf-8"))
40 | file_source.flush()
41 | file_target.write("\n".join(targets).encode("utf-8"))
42 | file_target.flush()
43 | return file_source, file_target
44 |
45 |
46 | def create_temp_tfrecords(sources, targets):
47 | """
48 | Creates a temporary TFRecords file.
49 |
50 | Args:
51 | source: List of source sentences
52 | target: List of target sentences
53 |
54 | Returns:
55 | A tuple (sources_file, targets_file).
56 | """
57 |
58 | output_file = tempfile.NamedTemporaryFile()
59 | writer = tf.python_io.TFRecordWriter(output_file.name)
60 | for source, target in zip(sources, targets):
61 | ex = tf.train.Example()
62 | #pylint: disable=E1101
63 | ex.features.feature["source"].bytes_list.value.extend(
64 | [source.encode("utf-8")])
65 | ex.features.feature["target"].bytes_list.value.extend(
66 | [target.encode("utf-8")])
67 | writer.write(ex.SerializeToString())
68 | writer.close()
69 |
70 | return output_file
71 |
72 |
73 | def create_temporary_vocab_file(words, counts=None):
74 | """
75 | Creates a temporary vocabulary file.
76 |
77 | Args:
78 | words: List of words in the vocabulary
79 |
80 | Returns:
81 | A temporary file object with one word per line
82 | """
83 | vocab_file = tempfile.NamedTemporaryFile()
84 | if counts is None:
85 | for token in words:
86 | vocab_file.write((token + "\n").encode("utf-8"))
87 | else:
88 | for token, count in zip(words, counts):
89 | vocab_file.write("{}\t{}\n".format(token, count).encode("utf-8"))
90 | vocab_file.flush()
91 | return vocab_file
92 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/test/vocab_test.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # Copyright 2017 Google Inc.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """
16 | Unit tests for input-related operations.
17 | """
18 |
19 | from __future__ import absolute_import
20 | from __future__ import division
21 | from __future__ import print_function
22 | from __future__ import unicode_literals
23 |
24 | import tensorflow as tf
25 | import numpy as np
26 |
27 | from seq2seq.data import vocab
28 | from seq2seq.test import utils as test_utils
29 |
30 |
31 | class VocabInfoTest(tf.test.TestCase):
32 | """Tests VocabInfo class"""
33 |
34 | def setUp(self):
35 | super(VocabInfoTest, self).setUp()
36 | tf.logging.set_verbosity(tf.logging.INFO)
37 | self.vocab_list = ["Hello", ".", "Bye"]
38 | self.vocab_file = test_utils.create_temporary_vocab_file(self.vocab_list)
39 |
40 | def tearDown(self):
41 | super(VocabInfoTest, self).tearDown()
42 | self.vocab_file.close()
43 |
44 | def test_vocab_info(self):
45 | vocab_info = vocab.get_vocab_info(self.vocab_file.name)
46 | self.assertEqual(vocab_info.vocab_size, 3)
47 | self.assertEqual(vocab_info.path, self.vocab_file.name)
48 | self.assertEqual(vocab_info.special_vocab.UNK, 3)
49 | self.assertEqual(vocab_info.special_vocab.SEQUENCE_START, 4)
50 | self.assertEqual(vocab_info.special_vocab.SEQUENCE_END, 5)
51 | self.assertEqual(vocab_info.total_size, 6)
52 |
53 |
54 | class CreateVocabularyLookupTableTest(tf.test.TestCase):
55 | """
56 | Tests Vocabulary lookup table operations.
57 | """
58 |
59 | def test_without_counts(self):
60 | vocab_list = ["Hello", ".", "笑"]
61 | vocab_file = test_utils.create_temporary_vocab_file(vocab_list)
62 |
63 | vocab_to_id_table, id_to_vocab_table, _, vocab_size = \
64 | vocab.create_vocabulary_lookup_table(vocab_file.name)
65 |
66 | self.assertEqual(vocab_size, 6)
67 |
68 | with self.test_session() as sess:
69 | sess.run(tf.global_variables_initializer())
70 | sess.run(tf.local_variables_initializer())
71 | sess.run(tf.tables_initializer())
72 |
73 | ids = vocab_to_id_table.lookup(
74 | tf.convert_to_tensor(["Hello", ".", "笑", "??", "xxx"]))
75 | ids = sess.run(ids)
76 | np.testing.assert_array_equal(ids, [0, 1, 2, 3, 3])
77 |
78 | words = id_to_vocab_table.lookup(
79 | tf.convert_to_tensor(
80 | [0, 1, 2, 3], dtype=tf.int64))
81 | words = sess.run(words)
82 | np.testing.assert_array_equal(
83 | np.char.decode(words.astype("S"), "utf-8"),
84 | ["Hello", ".", "笑", "UNK"])
85 |
86 | def test_with_counts(self):
87 | vocab_list = ["Hello", ".", "笑"]
88 | vocab_counts = [100, 200, 300]
89 | vocab_file = test_utils.create_temporary_vocab_file(vocab_list,
90 | vocab_counts)
91 |
92 | vocab_to_id_table, id_to_vocab_table, word_to_count_table, vocab_size = \
93 | vocab.create_vocabulary_lookup_table(vocab_file.name)
94 |
95 | self.assertEqual(vocab_size, 6)
96 |
97 | with self.test_session() as sess:
98 | sess.run(tf.global_variables_initializer())
99 | sess.run(tf.local_variables_initializer())
100 | sess.run(tf.tables_initializer())
101 |
102 | ids = vocab_to_id_table.lookup(
103 | tf.convert_to_tensor(["Hello", ".", "笑", "??", "xxx"]))
104 | ids = sess.run(ids)
105 | np.testing.assert_array_equal(ids, [0, 1, 2, 3, 3])
106 |
107 | words = id_to_vocab_table.lookup(
108 | tf.convert_to_tensor(
109 | [0, 1, 2, 3], dtype=tf.int64))
110 | words = sess.run(words)
111 | np.testing.assert_array_equal(
112 | np.char.decode(words.astype("S"), "utf-8"),
113 | ["Hello", ".", "笑", "UNK"])
114 |
115 | counts = word_to_count_table.lookup(
116 | tf.convert_to_tensor(["Hello", ".", "笑", "??", "xxx"]))
117 | counts = sess.run(counts)
118 | np.testing.assert_array_equal(counts, [100, 200, 300, -1, -1])
119 |
120 |
121 | if __name__ == "__main__":
122 | tf.test.main()
123 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/seq2seq/training/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """Operatations and wrappers to help with model training.
15 | """
16 |
17 | from seq2seq.training import hooks
18 | from seq2seq.training import utils
19 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/trainer_with_copy_net.py:
--------------------------------------------------------------------------------
1 | from Summary_Generator.Tensorflow_Graph import order_planner_with_copynet
2 | from Summary_Generator.Text_Preprocessing_Helpers.pickling_tools import *
3 | from Summary_Generator.Tensorflow_Graph.utils import *
4 | from Summary_Generator.Model import *
5 | import numpy as np
6 | import tensorflow as tf
7 |
8 | # random_seed value for consistent debuggable behaviour
9 | seed_value = 3
10 |
11 | np.random.seed(seed_value) # set this seed for a device independant consistent behaviour
12 |
13 | ''' Set the constants for the script '''
14 | # various paths of the files
15 | data_path = "../Data" # the data path
16 |
17 | data_files_paths = {
18 | "table_content": os.path.join(data_path, "train.box"),
19 | "nb_sentences" : os.path.join(data_path, "train.nb"),
20 | "train_sentences": os.path.join(data_path, "train.sent")
21 | }
22 |
23 | base_model_path = "Models"
24 | plug_and_play_data_file = os.path.join(data_path, "plug_and_play.pickle")
25 |
26 |
27 |
28 |
29 |
30 | ''' Name of the model: '''
31 | # This can be changed to create new models in the directory
32 | model_name = "Model_2(with_copy_net)"
33 |
34 | '''
35 | =========================================================================================================
36 | || All Tweakable hyper-parameters
37 | =========================================================================================================
38 | '''
39 | # constants for this script
40 | train_percentage = 99
41 | batch_size = 2
42 | checkpoint_factor = 100
43 | learning_rate = 3e-4 # for learning rate -> https://twitter.com/karpathy/status/801621764144971776?lang=en
44 | # I know the tweet was a joke, but I have noticed that this learning rate works quite well.
45 |
46 | # Memory usage fraction:
47 | gpu_memory_usage_fraction = 0.2
48 |
49 | no_of_epochs = 500
50 |
51 | # Embeddings size:
52 | field_embedding_size = 200
53 | content_label_embedding_size = 400 # This is a much bigger vocabulary compared to the field_name's vocabulary
54 |
55 | # LSTM hidden state sizes
56 | lstm_cell_state_size = hidden_state_size = 500 # they are same (for now)
57 | '''
58 | =========================================================================================================
59 | '''
60 |
61 |
62 |
63 |
64 | ''' Extract and setup the data '''
65 | # Obtain the data:\
66 | print("Unpickling the data from the disc ...")
67 | data = unPickleIt(plug_and_play_data_file)
68 |
69 | field_encodings = data['field_encodings']
70 | field_dict = data['field_dict']
71 |
72 | content_encodings = data['content_encodings']
73 |
74 | label_encodings = data['label_encodings']
75 | content_label_dict = data['content_union_label_dict']
76 | rev_content_label_dict = data['rev_content_union_label_dict']
77 |
78 | # vocabulary sizes
79 | field_vocab_size = data['field_vocab_size']
80 | content_label_vocab_size = data['content_label_vocab_size']
81 |
82 |
83 | X, Y = synch_random_shuffle_non_np(zip(field_encodings, content_encodings), label_encodings)
84 |
85 | train_X, train_Y, dev_X, dev_Y = split_train_dev(X, Y, train_percentage)
86 | train_X_field, train_X_content = zip(*train_X)
87 | train_X_field = list(train_X_field); train_X_content = list(train_X_content)
88 |
89 | # Free up the resources by deleting non required stuff
90 | del X, Y, field_encodings, content_encodings, train_X
91 | print("\nTotal_training_examples:", len(train_X_field))
92 |
93 |
94 |
95 |
96 | ''' Obtain the TensorFlow graph of the order_planner_without_copynet Network'''
97 | # just execute the get_computation_graph function here:
98 | graph, interface_dict = order_planner_with_copynet.get_computation_graph (
99 | seed_value = seed_value,
100 |
101 | # vocabulary sizes
102 | field_vocab_size = field_vocab_size,
103 | content_label_vocab_size = content_label_vocab_size,
104 |
105 | # Embeddings size:
106 | field_embedding_size = field_embedding_size,
107 | content_label_embedding_size = content_label_embedding_size,
108 |
109 | # LSTM hidden state sizes
110 | lstm_cell_state_size = lstm_cell_state_size,
111 | hidden_state_size = hidden_state_size, # they are same (for now)
112 | rev_content_label_dict = rev_content_label_dict
113 | )
114 |
115 | ''' Start the Training of the data '''
116 | # Create the model and start the training on it
117 | model_path = os.path.join(base_model_path, model_name)
118 | model = Model(graph, interface_dict, tf.train.AdamOptimizer(learning_rate), field_dict, content_label_dict)
119 | model.train((train_X_field, train_X_content), train_Y, batch_size, no_of_epochs, checkpoint_factor, model_path, model_name, mem_fraction=gpu_memory_usage_fraction)
120 |
--------------------------------------------------------------------------------
/TensorFlow_implementation/trainer_without_copy_net.py:
--------------------------------------------------------------------------------
1 | from Summary_Generator.Tensorflow_Graph import order_planner_without_copynet
2 | from Summary_Generator.Text_Preprocessing_Helpers.pickling_tools import *
3 | from Summary_Generator.Tensorflow_Graph.utils import *
4 | from Summary_Generator.Model import *
5 | import numpy as np
6 | import tensorflow as tf
7 |
8 | # random_seed value for consistent debuggable behaviour
9 | seed_value = 3
10 |
11 | np.random.seed(seed_value) # set this seed for a device independant consistent behaviour
12 |
13 | ''' Set the constants for the script '''
14 | # various paths of the files
15 | data_path = "../Data" # the data path
16 |
17 | data_files_paths = {
18 | "table_content": os.path.join(data_path, "train.box"),
19 | "nb_sentences" : os.path.join(data_path, "train.nb"),
20 | "train_sentences": os.path.join(data_path, "train.sent")
21 | }
22 |
23 | base_model_path = "Models"
24 | plug_and_play_data_file = os.path.join(data_path, "plug_and_play.pickle")
25 |
26 |
27 |
28 |
29 |
30 | ''' Name of the model: '''
31 | # This can be changed to create new models in the directory
32 | model_name = "Model_1(without_copy_net)"
33 |
34 | '''
35 | =========================================================================================================
36 | || All Tweakable hyper-parameters
37 | =========================================================================================================
38 | '''
39 | # constants for this script
40 | no_of_epochs = 500
41 | train_percentage = 100
42 | batch_size = 2
43 | checkpoint_factor = 100
44 | learning_rate = 3e-4 # for learning rate -> https://twitter.com/karpathy/status/801621764144971776?lang=en
45 | # I know the tweet was a joke, but I have noticed that this learning rate works quite well.
46 | momentum = 0.9
47 |
48 | # Memory usage fraction:
49 | gpu_memory_usage_fraction = 1
50 |
51 | # Embeddings size:
52 | field_embedding_size = 100
53 | content_label_embedding_size = 400 # This is a much bigger vocabulary compared to the field_name's vocabulary
54 |
55 | # LSTM hidden state sizes
56 | lstm_cell_state_size = hidden_state_size = 500 # they are same (for now)
57 | '''
58 | =========================================================================================================
59 | '''
60 |
61 |
62 |
63 |
64 |
65 | ''' Extract and setup the data '''
66 | # Obtain the data:
67 | print("unpickling the data from the disc ...")
68 | data = unPickleIt(plug_and_play_data_file)
69 |
70 | field_encodings = data['field_encodings']
71 | field_dict = data['field_dict']
72 |
73 | content_encodings = data['content_encodings']
74 |
75 | label_encodings = data['label_encodings']
76 | content_label_dict = data['content_union_label_dict']
77 | rev_content_label_dict = data['rev_content_union_label_dict']
78 |
79 | # vocabulary sizes
80 | field_vocab_size = data['field_vocab_size']
81 | content_label_vocab_size = data['content_label_vocab_size']
82 |
83 |
84 | X, Y = synch_random_shuffle_non_np(list(zip(field_encodings, content_encodings)), label_encodings)
85 |
86 | train_X, train_Y, dev_X, dev_Y = split_train_dev(X, Y, train_percentage)
87 | train_X_field, train_X_content = zip(*train_X)
88 | train_X_field = list(train_X_field); train_X_content = list(train_X_content)
89 |
90 | # Free up the resources by deleting non required stuff
91 | del X, Y, field_encodings, content_encodings, train_X
92 |
93 |
94 |
95 |
96 |
97 |
98 | ''' Obtain the TensorFlow graph of the order_planner_without_copynet Network'''
99 | # just execute the get_computation_graph function here:
100 | graph, interface_dict = order_planner_without_copynet.get_computation_graph (
101 | seed_value = seed_value,
102 |
103 | # vocabulary sizes
104 | field_vocab_size = field_vocab_size,
105 | content_label_vocab_size = content_label_vocab_size,
106 |
107 | # Embeddings size:
108 | field_embedding_size = field_embedding_size,
109 | content_label_embedding_size = content_label_embedding_size,
110 |
111 | # LSTM hidden state sizes
112 | lstm_cell_state_size = lstm_cell_state_size,
113 | hidden_state_size = hidden_state_size, # they are same (for now)
114 | rev_content_label_dict = rev_content_label_dict
115 | )
116 |
117 | ''' Start the Training of the data '''
118 | # Create the model and start the training on it
119 | model_path = os.path.join(base_model_path, model_name)
120 | model = Model(graph, interface_dict, tf.train.MomentumOptimizer(learning_rate, momentum), field_dict, content_label_dict)
121 | #model = Model(graph, interface_dict, tf.train.AdamOptimizer(learning_rate, momentum), field_dict, content_label_dict)
122 | #model.train((train_X_field, train_X_content), train_Y, batch_size, no_of_epochs, checkpoint_factor, model_path, model_name, mem_fraction=gpu_memory_usage_fraction)
123 | model.train((train_X_field, train_X_content), train_Y, batch_size, no_of_epochs, checkpoint_factor, model_path, model_name, mem_fraction=gpu_memory_usage_fraction)
124 |
--------------------------------------------------------------------------------
/Visualizations/first_run_of_both.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/Visualizations/first_run_of_both.png
--------------------------------------------------------------------------------
/Visualizations/projector_pic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/Visualizations/projector_pic.png
--------------------------------------------------------------------------------
/architecture_diagram.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/akanimax/natural-language-summary-generation-from-structured-data/b8cc906286f97e8523acc8306945c34a4f8ef17c/architecture_diagram.jpeg
--------------------------------------------------------------------------------