├── .VERSION
├── .github
└── workflows
│ ├── ci.yml
│ └── publish.yml
├── .gitignore
├── LICENSE
├── README.md
├── codenav
├── __init__.py
├── agents
│ ├── __init__.py
│ ├── agent.py
│ ├── cohere
│ │ ├── __init__.py
│ │ └── agent.py
│ ├── gpt4
│ │ ├── __init__.py
│ │ └── agent.py
│ ├── interaction_formatters.py
│ └── llm_chat_agent.py
├── codenav_run.py
├── constants.py
├── default_eval_spec.py
├── environments
│ ├── __init__.py
│ ├── abstractions.py
│ ├── code_env.py
│ ├── code_summary_env.py
│ ├── done_env.py
│ └── retrieval_env.py
├── interaction
│ ├── __init__.py
│ ├── episode.py
│ └── messages.py
├── prompts
│ ├── __init__.py
│ ├── codenav
│ │ └── repo_description.txt
│ ├── default
│ │ ├── action__code.txt
│ │ ├── action__done.txt
│ │ ├── action__es_search.txt
│ │ ├── action__guidelines.txt
│ │ ├── action__preamble.txt
│ │ ├── overview.txt
│ │ ├── repo_description.txt
│ │ ├── response__code.txt
│ │ ├── response__done.txt
│ │ ├── response__es_search.txt
│ │ ├── response__preamble.txt
│ │ └── workflow.txt
│ ├── query_prompt.py
│ └── restart_prompt.py
├── retrieval
│ ├── __init__.py
│ ├── code_blocks.py
│ ├── code_summarizer.py
│ └── elasticsearch
│ │ ├── README.md
│ │ ├── __init__.py
│ │ ├── create_index.py
│ │ ├── debug_add_item_to_index.py
│ │ ├── elasticsearch.yml
│ │ ├── elasticsearch_constants.py
│ │ ├── elasticsearch_retriever.py
│ │ ├── index_codebase.py
│ │ └── install_elasticsearch.py
└── utils
│ ├── __init__.py
│ ├── config_params.py
│ ├── eval_types.py
│ ├── evaluator.py
│ ├── hashing_utils.py
│ ├── linting_and_type_checking_utils.py
│ ├── llm_utils.py
│ ├── logging_utils.py
│ ├── omegaconf_utils.py
│ ├── parsing_utils.py
│ ├── prompt_utils.py
│ └── string_utils.py
├── codenav_examples
├── create_code_env.py
├── create_episode.py
├── create_index.py
├── create_prompt.py
└── parallel_evaluation.py
├── playground
└── .gitignore
├── pyproject.toml
├── requirements.txt
├── scripts
└── release.py
└── setup.py
/.VERSION:
--------------------------------------------------------------------------------
1 | 0.0.1
--------------------------------------------------------------------------------
/.github/workflows/ci.yml:
--------------------------------------------------------------------------------
1 | name: CI
2 |
3 | concurrency:
4 | group: ${{ github.workflow }}-${{ github.ref }}
5 | cancel-in-progress: true
6 |
7 | on:
8 | pull_request:
9 | branches:
10 | - main
11 | push:
12 | branches:
13 | - main
14 |
15 | env:
16 | # Change this to invalidate existing cache.
17 | CACHE_PREFIX: v0
18 | PYTHON_PATH: ./
19 |
20 | jobs:
21 | checks:
22 | name: python ${{ matrix.python }} - ${{ matrix.task.name }}
23 | runs-on: [ubuntu-latest]
24 | timeout-minutes: 30
25 | strategy:
26 | fail-fast: false
27 | matrix:
28 | python: [3.9]
29 | task:
30 | - name: Style
31 | run: |
32 | black --check .
33 |
34 | # TODO: Add testing back in after fixing the tests for use with GH actions.
35 | # - name: Test
36 | # run: |
37 | # pytest -v --color=yes tests/
38 |
39 | steps:
40 | - uses: actions/checkout@v3
41 |
42 | - name: Setup Python
43 | uses: actions/setup-python@v4
44 | with:
45 | python-version: ${{ matrix.python }}
46 |
47 | - name: Install prerequisites
48 | run: |
49 | pip install --upgrade pip setuptools wheel virtualenv
50 |
51 | - name: Set build variables
52 | shell: bash
53 | run: |
54 | # Get the exact Python version to use in the cache key.
55 | echo "PYTHON_VERSION=$(python --version)" >> $GITHUB_ENV
56 | echo "RUNNER_ARCH=$(uname -m)" >> $GITHUB_ENV
57 | # Use week number in cache key so we can refresh the cache weekly.
58 | echo "WEEK_NUMBER=$(date +%V)" >> $GITHUB_ENV
59 |
60 | - uses: actions/cache@v3
61 | id: virtualenv-cache
62 | with:
63 | path: .venv
64 | key: ${{ env.CACHE_PREFIX }}-${{ env.WEEK_NUMBER }}-${{ runner.os }}-${{ env.RUNNER_ARCH }}-${{ env.PYTHON_VERSION }}-${{ hashFiles('requirements.txt') }}
65 | restore-keys: |
66 | ${{ env.CACHE_PREFIX }}-${{ env.WEEK_NUMBER }}-${{ runner.os }}-${{ env.RUNNER_ARCH }}-${{ env.PYTHON_VERSION }}-
67 |
68 | - name: Setup virtual environment (no cache hit)
69 | if: steps.virtualenv-cache.outputs.cache-hit != 'true'
70 | run: |
71 | test -d .venv || virtualenv -p $(which python) --copies --reset-app-data .venv
72 | . .venv/bin/activate
73 | pip install -e .[dev]
74 |
75 | - name: Setup virtual environment (cache hit)
76 | if: steps.virtualenv-cache.outputs.cache-hit == 'true'
77 | run: |
78 | . .venv/bin/activate
79 | pip install --no-deps -e .[dev]
80 |
81 | - name: Show environment info
82 | run: |
83 | . .venv/bin/activate
84 | which python
85 | python --version
86 | pip freeze
87 |
88 | - name: ${{ matrix.task.name }}
89 | run: |
90 | . .venv/bin/activate
91 | ${{ matrix.task.run }}
92 |
93 | - name: Clean up
94 | if: always()
95 | run: |
96 | . .venv/bin/activate
97 | pip uninstall -y codenav
98 |
--------------------------------------------------------------------------------
/.github/workflows/publish.yml:
--------------------------------------------------------------------------------
1 | # This workflow will upload the codenav package using Twine (after manually triggering it)
2 | # For more information see: https://help.github.com/en/actions/language-and-framework-guides/using-python-with-github-actions#publishing-to-package-registries
3 |
4 | name: Publish PYPI Packages
5 |
6 | on:
7 | workflow_dispatch:
8 |
9 | jobs:
10 | deploy:
11 |
12 | runs-on: ubuntu-latest
13 |
14 | steps:
15 | - uses: actions/checkout@v2
16 | - name: Set up Python
17 | uses: actions/setup-python@v2
18 | with:
19 | python-version: '3.9'
20 | - name: Install dependencies
21 | run: |
22 | python -m pip install --upgrade pip
23 | pip install setuptools twine
24 | - name: Build and publish
25 | env:
26 | TWINE_PASSWORD: ${{ secrets.PYPI_PASSWORD }}
27 | run: |
28 | python scripts/release.py
29 | twine upload -u __token__ dist/*
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # poetry
98 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
99 | # This is especially recommended for binary packages to ensure reproducibility, and is more
100 | # commonly ignored for libraries.
101 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
102 | #poetry.lock
103 |
104 | # pdm
105 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
106 | #pdm.lock
107 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
108 | # in version control.
109 | # https://pdm.fming.dev/#use-with-ide
110 | .pdm.toml
111 |
112 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
113 | __pypackages__/
114 |
115 | # Celery stuff
116 | celerybeat-schedule
117 | celerybeat.pid
118 |
119 | # SageMath parsed files
120 | *.sage.py
121 |
122 | # Environments
123 | .env
124 | .venv
125 | env/
126 | venv/
127 | ENV/
128 | env.bak/
129 | venv.bak/
130 |
131 | # Spyder project settings
132 | .spyderproject
133 | .spyproject
134 |
135 | # Rope project settings
136 | .ropeproject
137 |
138 | # mkdocs documentation
139 | /site
140 |
141 | # mypy
142 | .mypy_cache/
143 | .dmypy.json
144 | dmypy.json
145 |
146 | # Pyre type checker
147 | .pyre/
148 |
149 | # pytype static type analyzer
150 | .pytype/
151 |
152 | # Cython debug symbols
153 | cython_debug/
154 |
155 | # PyCharm
156 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
157 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
158 | # and can be added to the global gitignore or merged into this file. For a more nuclear
159 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
160 | #.idea/
161 |
162 | rag_cache
163 | __tmp*
164 | wandb
165 | tmp
166 | external_src
167 | codenav/external_src
168 | file_lock
169 | tmp.py
170 | *.jpg
171 | *.png
172 | rsync-to-*
173 | results
174 | *_out
175 | .vscode
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | Copyright 2024 Allen Institute for AI
179 |
180 | Licensed under the Apache License, Version 2.0 (the "License");
181 | you may not use this file except in compliance with the License.
182 | You may obtain a copy of the License at
183 |
184 | http://www.apache.org/licenses/LICENSE-2.0
185 |
186 | Unless required by applicable law or agreed to in writing, software
187 | distributed under the License is distributed on an "AS IS" BASIS,
188 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
189 | See the License for the specific language governing permissions and
190 | limitations under the License.
191 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # [CodeNav: Beyond tool-use to using real-world codebases with LLM agents 🚀](https://codenav.allenai.org/)
2 |
3 |
4 |
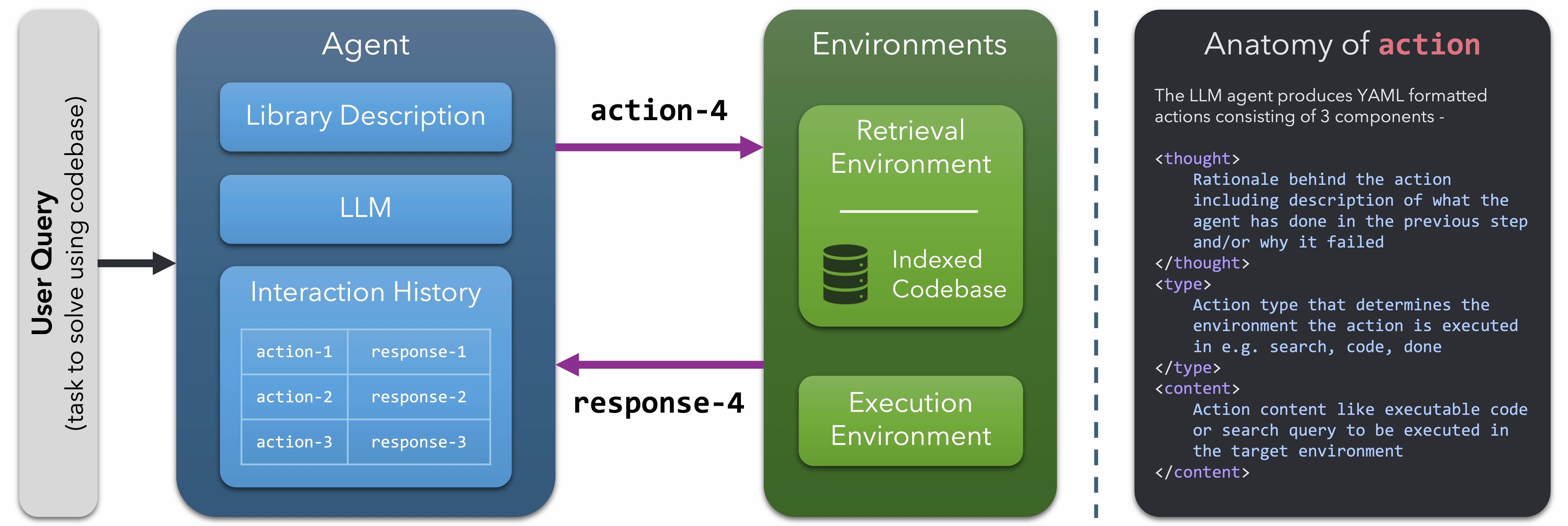
5 |
46 | Click to see DoneEnv.py contents
47 |
48 | class DoneEnv(CodeNavEnv):
49 | """
50 | DoneEnv is an environment class that handles the 'done' action in the CodeNav framework.
51 |
52 | Methods:
53 | check_action_validity(action: CodeNavAction) -> Tuple[bool, str]:
54 | Checks if the given action is valid for the 'done' action.
55 |
56 | step(action: CodeNavAction) -> None:
57 | Executes the 'done' action.
58 | """
59 | def check_action_validity(self, action: CodeNavAction) -> Tuple[bool, str]:
60 | """
61 | Checks if the given action is valid for the 'done' action.
62 |
63 | Args:
64 | action (CodeNavAction): The action to be validated.
65 |
66 | Returns:
67 | Tuple[bool, str]: A tuple containing a boolean indicating validity and an error message if invalid.
68 | """
69 | assert action.content is not None
70 |
71 | if action.content.strip().lower() in ["true", "false"]:
72 | return True, ""
73 | else:
74 | return (
75 | False,
76 | "When executing the done action, the content must be either 'True' or 'False'",
77 | )
78 |
79 | def step(self, action: CodeNavAction) -> None:
80 | """
81 | Executes the 'done' action.
82 |
83 | Args:
84 | action (CodeNavAction): The action to be executed.
85 | """
86 | return None
87 |
88 |
89 | Note: the `codenav` command line tool is simply an alias for running the [codenav_run.py](codenav%2Fcodenav_run.py) so
90 | you can replace `codenav ...` with `python -m codenav.codenav_run ...`
91 | or `python /path/to/codenav/codenav_run.py ...` and obtain the same results.
92 |
93 | Here's a more detailed description of the arguments you can pass to `codenav query` or `python -m codenav.codenav_run query`:
94 | | Argument | Type | Description |
95 | | --- | --- | --- |
96 | | `--code_dir` | str | The path to the codebase you want CodeNav to use. By default all files in this directory will get indexed with relative file paths. For instance, if you set `--code_dir /Users/tanmay/codebase` which contains a `computer_vision/tool.py` file then this file will be indexed with relative path `computer_vision/tools.py` |
97 | | `--force_subdir` | str | If you wish to only index a subdirectory within the code_dir then set this to the name of the sub directory |
98 | | `--module` | str | If you have a module installed e.g. via `pip install transformers` and you want CodeNav to use this module, you can simply set `--module transformers` instead of providing `--code_dir` |
99 | | `--repo_description_path` | str | If you have a README file or a file with a description of the codebase you are using, you can provide the path to this file here. You may use this file to point out to CodeNav the high-level purpose and structure of the codebase (e.g. highlight important directories, files, classes or functions) |
100 | | `--force_reindex` | bool | Set this flag if you want to force CodeNav to reindex the codebase. Otherwise, CodeNav will reuse an existing index if it exists or create one if it doesn't |
101 | | `--playground_dir` | str | The path specified here will work as the current directory for CodeNav's execution environment |
102 | | `--query` | str | The query you want CodeNav to solve using the codebase |
103 | | `--query_file` | str | If your query is long, you may want to save it to a txt file and provide the path to the text file here |
104 | | `--max_steps` | int | The maximum number of interactions to allow between CodeNav agent and environments |
105 |
106 |
107 | ### CodeNav as a library
108 |
109 | If you'd like to use CodeNav programmatically, you can do so by importing the `codenav` module and using the various
110 | functions/classes we provide. To get a sense of how this is done, we provide a number of example scripts
111 | under the [codenav_examples](codenav_examples) directory:
112 | - [create_index.py](codenav_examples%2Fcreate_index.py): Creates an Elasticsearch index for this codebase and then uses the `RetrievalEnv` environment to search for a code snippet.
113 | - [create_episode.py](codenav_examples%2Fcreate_episode.py): Creates an `OpenAICodeNavAgent` agent and then uses it to generate a solution for the query `"Find the DoneEnv and instantiate it"` **on this codebase** (i.e. executes a CodeNav agent on the CodeNav codebase). Be sure to run the `create_index.py` script above to generate the index before running this script.
114 | - [create_code_env.py](codenav_examples%2Fcreate_code_env.py)): Creates a `PythonCodeEnv` object and then executes a given code string in this environemnt
115 | - [create_prompt.py](codenav_examples%2Fcreate_prompt.py): Creates a custom prompt and instantiates and CodeNav agent with that prompt.
116 | - [parallel_evaluation.py](codenav_examples%2Fparallel_evaluation.py): Demonstrates how to run multiple CodeNav agents in parallel. This is useful for evaluating on a dataset of queries using multiple processes. The EvalSpec abstraction also helps you organize the code a little better!
117 |
118 | **Note** - You will still need to launch ElasticSearch server before running any of the above. To do so run
119 | ```
120 | python -m codenav.codenav_run init
121 | ```
122 |
123 | ## Elasticsearch & Indexing Gotchas 🤔
124 |
125 | When running CodeNav you must start an Elasticsearch index on your machine (e.g. by running `codenav init`)
126 | and once you run a query on a given codebase, CodeNav will index that codebase exactly once.
127 | This process means there are two things you should keep in mind:
128 | 1. You must manually shut off the Elasticsearch index once you are done with it. You can do this by running `codenav stop`.
129 | 2. If you modify/update the codebase you are asking CodeNav to use the Elasticsearch index will not automatically update and thus CodeNav will be writing code using stale information. In this case, you should add the `--force_reindex` flag when running `codenav query`, this will force CodeNav to reindex the codebase.
130 | 3. If you run CodeNav and find that it is unable to search for a file, you may want to make sure the file was indexed correctly. You can inspect all indexed files using Elasticsearch's Kibana interface at `http://localhost:5601/`. To view all the indices index by CodeNav, go to `http://localhost:5601/app/management/data/index_management`. Then click on the index you want to inspect and the click on "Discover Index" on the top-right side of the page. This will show you all the code blocks stored in this index. You can now use the UI to run queries against this index and see if the file your are looking for is present in the index and if it has the correct file path.
131 |
132 | ## Warning ⚠️
133 |
134 | CodeNav is a research project and may make errors. As CodeNav can potentially execute ANY code
135 | it wants, it is not suitable for security sensitive applications. We strongly recommend
136 | that you run CodeNav in a sandboxed environment where data loss or security breaches are not a concern.
137 |
138 | ## Authors ✍️
139 | - [Tanmay Gupta](https://tanmaygupta.info/)
140 | - [Luca Weihs](https://lucaweihs.github.io/)
141 | - [Aniruddha Kembhavi](https://anikem.github.io/)
142 |
143 | ## License 📄
144 | This project is licensed under the Apache 2.0 License.
145 |
146 | ## Citation
147 | ```bibtex
148 | @misc{gupta2024codenavtooluseusingrealworld,
149 | title={CodeNav: Beyond tool-use to using real-world codebases with LLM agents},
150 | author={Tanmay Gupta and Luca Weihs and Aniruddha Kembhavi},
151 | year={2024},
152 | eprint={2406.12276},
153 | archivePrefix={arXiv},
154 | primaryClass={cs.AI},
155 | url={https://arxiv.org/abs/2406.12276},
156 | }
157 | ```
158 |
159 | CodeNav builds along the research direction we started exploring with VisProg (CVPR 2023 Best Paper). For more context please visit [https://github.com/allenai/visprog/blob/main/README.md](https://github.com/allenai/visprog/blob/main/README.md).
160 |
--------------------------------------------------------------------------------
/codenav/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/__init__.py
--------------------------------------------------------------------------------
/codenav/agents/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/agents/__init__.py
--------------------------------------------------------------------------------
/codenav/agents/agent.py:
--------------------------------------------------------------------------------
1 | import abc
2 | from typing import Optional, Sequence, List, Dict, Any
3 |
4 | import codenav.interaction.messages as msg
5 | from codenav.agents.interaction_formatters import InteractionFormatter
6 |
7 |
8 | class CodeNavAgent(abc.ABC):
9 | max_tokens: int
10 | interaction_formatter: InteractionFormatter
11 | model: str
12 |
13 | def __init__(self, allowed_action_types: Sequence[msg.ACTION_TYPES]):
14 | self.allowed_action_types = allowed_action_types
15 | # self.reset()
16 |
17 | def reset(self):
18 | """Reset episode state. Must be called before starting a new episode."""
19 | self.episode_state = self.init_episode_state()
20 |
21 | @abc.abstractmethod
22 | def init_episode_state(self) -> msg.EpisodeState:
23 | """Build system prompt and initialize the episode state with it"""
24 | raise NotImplementedError
25 |
26 | def update_state(self, interaction: msg.Interaction):
27 | self.episode_state.update(interaction)
28 |
29 | @property
30 | def system_prompt_str(self) -> str:
31 | return self.episode_state.system_prompt.content
32 |
33 | @property
34 | def user_query_prompt_str(self) -> str:
35 | queries = [
36 | i.response
37 | for i in self.episode_state.interactions
38 | if isinstance(i.response, msg.UserQueryToAgent)
39 | ]
40 | assert len(queries) == 1
41 | return queries[0].message
42 |
43 | @abc.abstractmethod
44 | def get_action(self) -> msg.CodeNavAction:
45 | raise NotImplementedError
46 |
47 | @abc.abstractmethod
48 | def summarize_episode_state_for_restart(
49 | self, episode_state: msg.EpisodeState, max_tokens: Optional[int]
50 | ) -> str:
51 | raise NotImplementedError
52 |
53 | @property
54 | @abc.abstractmethod
55 | def all_queries_and_responses(self) -> List[Dict[str, Any]]:
56 | raise NotImplementedError
57 |
--------------------------------------------------------------------------------
/codenav/agents/cohere/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/agents/cohere/__init__.py
--------------------------------------------------------------------------------
/codenav/agents/cohere/agent.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import time
3 | from typing import List, Literal, Optional, Sequence
4 |
5 | from cohere import ChatMessage, InternalServerError, TooManyRequestsError
6 |
7 | import codenav.interaction.messages as msg
8 | from codenav.agents.interaction_formatters import InteractionFormatter
9 | from codenav.agents.llm_chat_agent import LLMChatCodeNavAgent, LlmChatMessage
10 | from codenav.constants import COHERE_CLIENT
11 |
12 |
13 | class CohereCodeNavAgent(LLMChatCodeNavAgent):
14 | def __init__(
15 | self,
16 | prompt: str,
17 | model: Literal["command-r", "command-r-plus"] = "command-r",
18 | max_tokens: int = 50000,
19 | allowed_action_types: Sequence[msg.ACTION_TYPES] = (
20 | "code",
21 | "done",
22 | "search",
23 | "reset",
24 | ),
25 | prompt_set: str = "default",
26 | interaction_formatter: Optional[InteractionFormatter] = None,
27 | ):
28 | super().__init__(
29 | model=model,
30 | prompt=prompt,
31 | max_tokens=max_tokens,
32 | allowed_action_types=allowed_action_types,
33 | interaction_formatter=interaction_formatter,
34 | )
35 |
36 | @property
37 | def client(self):
38 | return COHERE_CLIENT
39 |
40 | def query_llm(
41 | self,
42 | messages: List[LlmChatMessage],
43 | model: Optional[str] = None,
44 | max_tokens: Optional[int] = None,
45 | ) -> str:
46 | if model is None:
47 | model = self.model
48 |
49 | if max_tokens is None:
50 | max_tokens = self.max_tokens
51 |
52 | output = None
53 | nretries = 50
54 | for retry in range(nretries):
55 | try:
56 | output = self.client.chat(
57 | message=messages[-1]["message"],
58 | model=model,
59 | chat_history=messages[:-1],
60 | prompt_truncation="OFF",
61 | temperature=0.0,
62 | max_input_tokens=max_tokens,
63 | max_tokens=3000,
64 | )
65 | break
66 | except (TooManyRequestsError, InternalServerError):
67 | pass
68 |
69 | if retry >= nretries - 1:
70 | raise RuntimeError(f"Hit max retries ({nretries})")
71 |
72 | time.sleep(5)
73 |
74 | self._all_queries_and_responses.append(
75 | {
76 | "input": copy.deepcopy(messages),
77 | "output": output.text,
78 | "input_tokens": output.meta.billed_units.input_tokens,
79 | "output_tokens": output.meta.billed_units.output_tokens,
80 | }
81 | )
82 | return output.text
83 |
84 | def create_message_from_text(self, text: str, role: str) -> ChatMessage:
85 | role = {
86 | "assistant": "CHATBOT",
87 | "user": "USER",
88 | "system": "SYSTEM",
89 | }[role]
90 |
91 | return dict(role=role, message=text)
92 |
--------------------------------------------------------------------------------
/codenav/agents/gpt4/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/agents/gpt4/__init__.py
--------------------------------------------------------------------------------
/codenav/agents/gpt4/agent.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, Sequence
2 |
3 | import codenav.interaction.messages as msg
4 | from codenav.agents.interaction_formatters import InteractionFormatter
5 | from codenav.agents.llm_chat_agent import LLMChatCodeNavAgent, LlmChatMessage
6 | from codenav.constants import DEFAULT_OPENAI_MODEL, OPENAI_CLIENT
7 | from codenav.utils.llm_utils import create_openai_message
8 |
9 |
10 | class OpenAICodeNavAgent(LLMChatCodeNavAgent):
11 | def __init__(
12 | self,
13 | prompt: str,
14 | model: str = DEFAULT_OPENAI_MODEL,
15 | max_tokens: int = 50000,
16 | allowed_action_types: Sequence[msg.ACTION_TYPES] = (
17 | "code",
18 | "done",
19 | "search",
20 | "reset",
21 | ),
22 | interaction_formatter: Optional[InteractionFormatter] = None,
23 | ):
24 | super().__init__(
25 | model=model,
26 | prompt=prompt,
27 | max_tokens=max_tokens,
28 | allowed_action_types=allowed_action_types,
29 | interaction_formatter=interaction_formatter,
30 | )
31 |
32 | @property
33 | def client(self):
34 | return OPENAI_CLIENT
35 |
36 | def create_message_from_text(self, text: str, role: str) -> LlmChatMessage:
37 | return create_openai_message(text=text, role=role)
38 |
--------------------------------------------------------------------------------
/codenav/agents/interaction_formatters.py:
--------------------------------------------------------------------------------
1 | import abc
2 | from types import MappingProxyType
3 | from typing import Mapping, Literal
4 |
5 | from codenav.interaction.messages import (
6 | CodeNavAction,
7 | RESPONSE_TYPES,
8 | Interaction,
9 | MultiRetrievalResult,
10 | RetrievalResult,
11 | )
12 | from codenav.retrieval.elasticsearch.create_index import es_doc_to_string
13 |
14 | DEFAULT_ACTION_FORMAT_KWARGS = MappingProxyType(
15 | dict(include_header=True),
16 | )
17 |
18 | DEFAULT_RESPONSE_FORMAT_KWARGS = MappingProxyType(
19 | dict(
20 | include_code=False,
21 | display_updated_vars=True,
22 | include_query=True,
23 | include_header=True,
24 | )
25 | )
26 |
27 |
28 | class InteractionFormatter(abc.ABC):
29 | def format_action(self, action: CodeNavAction):
30 | raise NotImplementedError
31 |
32 | def format_response(self, response: RESPONSE_TYPES):
33 | raise NotImplementedError
34 |
35 |
36 | class DefaultInteractionFormatter(InteractionFormatter):
37 | def __init__(
38 | self,
39 | action_format_kwargs: Mapping[str, bool] = DEFAULT_ACTION_FORMAT_KWARGS,
40 | response_format_kwargs: Mapping[str, bool] = DEFAULT_RESPONSE_FORMAT_KWARGS,
41 | ):
42 | self.action_format_kwargs = action_format_kwargs
43 | self.response_format_kwargs = response_format_kwargs
44 |
45 | def format_action(self, action: CodeNavAction):
46 | return Interaction.format_action(
47 | action,
48 | **self.action_format_kwargs,
49 | )
50 |
51 | def format_response(self, response: RESPONSE_TYPES):
52 | return Interaction.format_response(
53 | response,
54 | **self.response_format_kwargs,
55 | )
56 |
57 |
58 | class CustomRetrievalInteractionFormatter(DefaultInteractionFormatter):
59 | def __init__(
60 | self, use_summary: Literal["ifshorter", "always", "never", "prototype"]
61 | ):
62 | super().__init__()
63 | self.use_summary = use_summary
64 |
65 | def format_retrieval_result(self, rr: RetrievalResult, include_query=True):
66 | res_str = ""
67 | if include_query:
68 | res_str += f"QUERY:\n{rr.query}\n\n"
69 |
70 | res_str += "CODE BLOCKS:\n"
71 |
72 | if len(rr.es_docs) == 0:
73 | if rr.failure_reason is not None:
74 | res_str += f"Failed to retrieve code blocks: {rr.failure_reason}\n"
75 | else:
76 | res_str += "No code blocks found.\n"
77 |
78 | return res_str
79 |
80 | for doc in rr.es_docs[: rr.max_expanded]:
81 | if self.use_summary == "prototype":
82 | doc = {**doc}
83 | doc["text"] = doc["prototype"] or doc["text"]
84 |
85 | use_summary = "never"
86 | else:
87 | use_summary = self.use_summary
88 |
89 | res_str += f"---\n{es_doc_to_string(doc, use_summary=use_summary)}\n"
90 |
91 | res_str += "---\n"
92 |
93 | unexpanded_docs = rr.es_docs[rr.max_expanded :]
94 | if len(unexpanded_docs) <= rr.max_expanded:
95 | res_str += "(All code blocks matching the query were returned.)\n"
96 | else:
97 | res_str += (
98 | f"({len(unexpanded_docs)} additional code blocks not shown."
99 | f" Search again with the same query to see additional results.)\n\n"
100 | )
101 |
102 | if rr.max_prototype > 0:
103 | prototypes_docs = [
104 | doc
105 | for doc in unexpanded_docs
106 | if doc["type"] in {"CLASS", "FUNCTION"}
107 | ]
108 | num_prototype_docs_shown = min(len(prototypes_docs), rr.max_prototype)
109 | res_str += (
110 | f"Prototypes for the next {num_prototype_docs_shown} out of"
111 | f" {len(prototypes_docs)} classes/functions found in unexpanded results"
112 | f" (search again with the same query to see details):\n"
113 | )
114 | for doc in prototypes_docs[:num_prototype_docs_shown]:
115 | res_str += f"{es_doc_to_string(doc, prototype=True)}\n"
116 |
117 | return res_str
118 |
119 | def format_response(self, response: RESPONSE_TYPES):
120 | if not isinstance(response, MultiRetrievalResult):
121 | return super(CustomRetrievalInteractionFormatter, self).format_response(
122 | response
123 | )
124 | else:
125 | res_str = ""
126 | for res in response.retrieval_results:
127 | res_str += self.format_retrieval_result(res, include_query=True)
128 | res_str += "\n"
129 |
130 | return res_str
131 |
--------------------------------------------------------------------------------
/codenav/agents/llm_chat_agent.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import traceback
3 | from typing import Any, Dict, List, Optional, Sequence, Union, cast
4 |
5 | from openai.types.chat import (
6 | ChatCompletionAssistantMessageParam,
7 | ChatCompletionSystemMessageParam,
8 | ChatCompletionUserMessageParam,
9 | )
10 |
11 | import codenav.interaction.messages as msg
12 | from codenav.agents.agent import CodeNavAgent
13 | from codenav.agents.interaction_formatters import (
14 | DefaultInteractionFormatter,
15 | InteractionFormatter,
16 | )
17 | from codenav.constants import (
18 | TOGETHER_CLIENT,
19 | )
20 | from codenav.prompts.restart_prompt import RESTART_PROMPT
21 | from codenav.utils.llm_utils import MaxTokensExceededError, query_gpt
22 |
23 | LlmChatMessage = Union[
24 | ChatCompletionSystemMessageParam,
25 | ChatCompletionUserMessageParam,
26 | ChatCompletionAssistantMessageParam,
27 | ]
28 |
29 |
30 | class LLMChatCodeNavAgent(CodeNavAgent):
31 | def __init__(
32 | self,
33 | model: str,
34 | prompt: str,
35 | max_tokens: int = 50000,
36 | allowed_action_types: Sequence[msg.ACTION_TYPES] = (
37 | "code",
38 | "done",
39 | "search",
40 | "reset",
41 | ),
42 | interaction_formatter: Optional[InteractionFormatter] = None,
43 | ):
44 | super().__init__(allowed_action_types=allowed_action_types)
45 | self.model = model
46 | self.prompt = prompt
47 | self.max_tokens = max_tokens
48 |
49 | if interaction_formatter is None:
50 | self.interaction_formatter = DefaultInteractionFormatter()
51 | else:
52 | self.interaction_formatter = interaction_formatter
53 |
54 | self._all_queries_and_responses: List[Dict] = []
55 |
56 | @property
57 | def client(self):
58 | return TOGETHER_CLIENT
59 |
60 | def query_llm(
61 | self,
62 | messages: List[LlmChatMessage],
63 | model: Optional[str] = None,
64 | max_tokens: Optional[int] = None,
65 | ) -> str:
66 | if model is None:
67 | model = self.model
68 |
69 | if max_tokens is None:
70 | max_tokens = self.max_tokens
71 |
72 | response_dict = query_gpt(
73 | messages=messages,
74 | model=model,
75 | max_tokens=max_tokens,
76 | client=self.client,
77 | return_input_output_tokens=True,
78 | )
79 | self._all_queries_and_responses.append(
80 | {"input": copy.deepcopy(messages), **response_dict}
81 | )
82 | return response_dict["output"]
83 |
84 | @property
85 | def all_queries_and_responses(self) -> List[Dict[str, Any]]:
86 | return copy.deepcopy(self._all_queries_and_responses)
87 |
88 | def init_episode_state(self) -> msg.EpisodeState:
89 | return msg.EpisodeState(system_prompt=msg.SystemPrompt(content=self.prompt))
90 |
91 | def create_message_from_text(self, text: str, role: str) -> LlmChatMessage:
92 | return cast(LlmChatMessage, {"role": role, "content": text})
93 |
94 | def build_chat_context(
95 | self,
96 | episode_state: msg.EpisodeState,
97 | ) -> List[LlmChatMessage]:
98 | chat_messages: List[LlmChatMessage] = [
99 | self.create_message_from_text(
100 | text=episode_state.system_prompt.content, role="system"
101 | ),
102 | ]
103 | for interaction in episode_state.interactions:
104 | if interaction.hidden:
105 | continue
106 |
107 | if interaction.action is not None:
108 | chat_messages.append(
109 | self.create_message_from_text(
110 | text=self.interaction_formatter.format_action(
111 | interaction.action
112 | ),
113 | role="assistant",
114 | )
115 | )
116 |
117 | if interaction.response is not None:
118 | chat_messages.append(
119 | self.create_message_from_text(
120 | text=self.interaction_formatter.format_response(
121 | interaction.response,
122 | ),
123 | role="user",
124 | )
125 | )
126 |
127 | return chat_messages
128 |
129 | def summarize_episode_state_for_restart(
130 | self, episode_state: msg.EpisodeState, max_tokens: Optional[int]
131 | ) -> str:
132 | if max_tokens is None:
133 | max_tokens = self.max_tokens
134 |
135 | chat_messages = self.build_chat_context(episode_state)
136 |
137 | current_env_var_names = {
138 | var_name
139 | for i in episode_state.interactions
140 | if isinstance(i.response, msg.ExecutionResult)
141 | for var_name in (i.response.updated_vars or {}).keys()
142 | }
143 |
144 | chat_messages.append(
145 | self.create_message_from_text(
146 | text=RESTART_PROMPT.format(
147 | current_env_var_names=", ".join(sorted(list(current_env_var_names)))
148 | ),
149 | role="user",
150 | )
151 | )
152 |
153 | return self.query_llm(messages=chat_messages, max_tokens=max_tokens)
154 |
155 | def get_action(self) -> msg.CodeNavAction:
156 | chat_messages = self.build_chat_context(self.episode_state)
157 | try:
158 | output = self.query_llm(messages=chat_messages)
159 | return msg.CodeNavAction.from_text(output)
160 | except MaxTokensExceededError:
161 | if "reset" in self.allowed_action_types:
162 | summary = self.summarize_episode_state_for_restart(
163 | episode_state=self.episode_state, max_tokens=2 * self.max_tokens
164 | )
165 | for interaction in self.episode_state.interactions:
166 | if not isinstance(interaction.response, msg.UserQueryToAgent):
167 | if not interaction.hidden:
168 | interaction.hidden_at_index = len(
169 | self.episode_state.interactions
170 | )
171 | interaction.hidden = True
172 | action = msg.CodeNavAction.from_text(summary)
173 | action.type = "reset"
174 | return action
175 |
176 | return msg.CodeNavAction(
177 | thought=f"Max tokens exceeded:\n{traceback.format_exc()}",
178 | type="done",
179 | content="False",
180 | )
181 |
--------------------------------------------------------------------------------
/codenav/codenav_run.py:
--------------------------------------------------------------------------------
1 | import importlib
2 | import os
3 | import re
4 | import subprocess
5 | import time
6 | from argparse import ArgumentParser
7 | from typing import Any, Dict, Optional, Sequence
8 |
9 | import attrs
10 | from elasticsearch import Elasticsearch
11 |
12 | from codenav.default_eval_spec import run_codenav_on_query
13 | from codenav.interaction.episode import Episode
14 | from codenav.retrieval.elasticsearch.index_codebase import (
15 | DEFAULT_ES_HOST,
16 | DEFAULT_ES_PORT,
17 | DEFAULT_KIBANA_PORT,
18 | build_index,
19 | )
20 | from codenav.retrieval.elasticsearch.install_elasticsearch import (
21 | ES_PATH,
22 | KIBANA_PATH,
23 | install_elasticsearch,
24 | is_es_installed,
25 | )
26 |
27 |
28 | def is_port_in_use(port: int) -> bool:
29 | import socket
30 |
31 | with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
32 | return s.connect_ex(("localhost", port)) == 0
33 |
34 |
35 | def is_es_running():
36 | es = Elasticsearch(DEFAULT_ES_HOST)
37 | return es.ping()
38 |
39 |
40 | def run_init():
41 | es = Elasticsearch(DEFAULT_ES_HOST)
42 | if es.ping():
43 | print(
44 | "Initialization complete, Elasticsearch is already running at http://localhost:9200."
45 | )
46 | return
47 |
48 | if not is_es_installed():
49 | print("Elasticsearch installation not found, downloading...")
50 | install_elasticsearch()
51 |
52 | if not is_es_installed():
53 | raise ValueError("Elasticsearch installation failed")
54 |
55 | if is_port_in_use(DEFAULT_ES_PORT) or is_port_in_use(DEFAULT_KIBANA_PORT):
56 | raise ValueError(
57 | f"The ports {DEFAULT_ES_PORT} and {DEFAULT_KIBANA_PORT} are already in use,"
58 | f" to start elasticsearch we require that these ports are free."
59 | )
60 |
61 | cmd = os.path.join(ES_PATH, "bin", "elasticsearch")
62 | print(f"Starting Elasticsearch server with command: {cmd}")
63 | es_process = subprocess.Popen(
64 | [cmd], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL
65 | )
66 |
67 | cmd = os.path.join(KIBANA_PATH, "bin", "kibana")
68 | print(f"Starting Kibana server with command: {cmd}")
69 | kibana_process = subprocess.Popen(
70 | [cmd], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL
71 | )
72 |
73 | es_started = False
74 | kibana_started = False
75 | try:
76 | for _ in range(10):
77 | es_started = es.ping()
78 | kibana_started = is_port_in_use(DEFAULT_KIBANA_PORT)
79 |
80 | if not es_started:
81 | print("Elasticsearch server not started yet...")
82 |
83 | if not kibana_started:
84 | print("Kibana server not started yet...")
85 |
86 | if es_started and kibana_started:
87 | break
88 |
89 | print("Waiting 10 seconds...")
90 | time.sleep(10)
91 |
92 | if not (es_started and kibana_started):
93 | raise RuntimeError("Elasticsearch failed to start")
94 |
95 | finally:
96 | if not (es_started and kibana_started):
97 | es_process.kill()
98 | kibana_process.kill()
99 |
100 | # noinspection PyUnreachableCode
101 | print(
102 | f"Initialization complete. "
103 | f" Elasticsearch server started successfully (PID {es_process.pid}) and can be accessed at {DEFAULT_ES_PORT}."
104 | f" You can also access the Kibana dashboard (PID {kibana_process.pid}) at {DEFAULT_KIBANA_PORT}."
105 | f" You will need to manually stop these processes when you are done with them."
106 | )
107 |
108 |
109 | def main():
110 | parser = ArgumentParser()
111 | parser.add_argument(
112 | "command",
113 | help="command to be executed",
114 | choices=["init", "stop", "query"],
115 | )
116 | parser.add_argument(
117 | "--code_dir",
118 | type=str,
119 | default=None,
120 | help="Path to the codebase to use. Only one of `code_dir` or `module` should be provided.",
121 | )
122 | parser.add_argument(
123 | "--module",
124 | type=str,
125 | default=None,
126 | help="Module to use for the codebase. Only one of `code_dir` or `module` should be provided.",
127 | )
128 |
129 | parser.add_argument(
130 | "--playground_dir",
131 | type=str,
132 | default=None,
133 | help="The working directory for the agent.",
134 | )
135 | parser.add_argument(
136 | "--max_steps",
137 | type=int,
138 | default=20,
139 | help="Maximum number of rounds of interaction.",
140 | )
141 | parser.add_argument(
142 | "-q",
143 | "--q",
144 | "--query",
145 | type=str,
146 | help="A description of the problem you want the the agent to solve (using `code_dir`).",
147 | )
148 | parser.add_argument(
149 | "-f",
150 | "--query_file",
151 | type=str,
152 | default=None,
153 | help="A path to a file containing your query (useful for long/detailed queries that are hard to enter on the commandline).",
154 | )
155 | parser.add_argument(
156 | "--force_reindex",
157 | action="store_true",
158 | help="Will delete the existing index (if any) and refresh it.",
159 | )
160 |
161 | parser.add_argument(
162 | "--force_subdir",
163 | type=str,
164 | default=None,
165 | help="Index only a subdirectory of the code_dir",
166 | )
167 |
168 | parser.add_argument(
169 | "--repo_description_path",
170 | type=str,
171 | default=None,
172 | help="Path to a file containing a description of the codebase.",
173 | )
174 |
175 | args = parser.parse_args()
176 |
177 | if args.command == "init":
178 | run_init()
179 | elif args.command == "stop":
180 | # Find all processes that start with ES_PATH and KIBANA_PATH and kill them
181 | for path in [ES_PATH, KIBANA_PATH]:
182 | cmd = f"ps aux | grep {path} | grep -v grep | awk '{{print $2}}' | xargs kill "
183 | subprocess.run(cmd, shell=True)
184 | elif args.command == "query":
185 | if not is_es_running():
186 | raise ValueError(
187 | "Elasticsearch not running, please run `codenav init` first."
188 | )
189 |
190 | assert (args.q is None) != (
191 | args.query_file is None
192 | ), "Exactly one of `q` or `query_file` should be provided"
193 |
194 | if args.query_file is not None:
195 | print(args.query_file)
196 | with open(args.query_file, "r") as f:
197 | args.q = f.read()
198 |
199 | if args.q is None:
200 | raise ValueError("No query provided")
201 |
202 | if args.code_dir is None == args.module is None:
203 | raise ValueError("Exactly one of `code_dir` or `module` should be provided")
204 |
205 | if args.code_dir is None and args.module is None:
206 | raise ValueError("No code_dir or module provided")
207 |
208 | if args.playground_dir is None:
209 | raise ValueError("No playground_dir provided")
210 |
211 | if args.code_dir is None:
212 | path_to_module = os.path.abspath(
213 | os.path.dirname(importlib.import_module(args.module).__file__)
214 | )
215 | args.code_dir = os.path.dirname(path_to_module)
216 | code_name = os.path.basename(path_to_module)
217 | force_subdir = code_name
218 | sys_path = os.path.dirname(path_to_module)
219 | else:
220 | force_subdir = args.force_subdir
221 | args.code_dir = os.path.abspath(args.code_dir)
222 | sys_path = args.code_dir
223 | code_name = os.path.basename(args.code_dir)
224 |
225 | args.playground_dir = os.path.abspath(args.playground_dir)
226 |
227 | if args.force_reindex or not Elasticsearch(DEFAULT_ES_HOST).indices.exists(
228 | index=code_name
229 | ):
230 | print(f"Index {code_name} not found, creating index...")
231 | build_index(
232 | code_dir=args.code_dir,
233 | index_uid=code_name,
234 | delete_index=args.force_reindex,
235 | force_subdir=force_subdir,
236 | )
237 |
238 | run_codenav_on_query(
239 | exp_name=re.sub("[^A-Za-z0–9 ]", "", args.q).replace(" ", "_")[:30],
240 | out_dir=args.playground_dir,
241 | query=args.q,
242 | code_dir=args.code_dir if args.module is None else args.module,
243 | sys_paths=[sys_path],
244 | index_name=code_name,
245 | working_dir=args.playground_dir,
246 | max_steps=args.max_steps,
247 | repo_description_path=args.repo_description_path,
248 | )
249 |
250 | else:
251 | raise ValueError(f"Unrecognized command: {args.command}")
252 |
253 |
254 | if __name__ == "__main__":
255 | main()
256 |
--------------------------------------------------------------------------------
/codenav/constants.py:
--------------------------------------------------------------------------------
1 | import os
2 | import warnings
3 | from pathlib import Path
4 | from typing import Optional
5 |
6 | ABS_PATH_OF_CODENAV_DIR = os.path.abspath(os.path.dirname(Path(__file__)))
7 | PROMPTS_DIR = os.path.join(ABS_PATH_OF_CODENAV_DIR, "prompts")
8 |
9 | DEFAULT_OPENAI_MODEL = "gpt-4o-2024-05-13"
10 | DEFAULT_RETRIEVAL_PER_QUERY = 3
11 |
12 |
13 | def get_env_var(name: str) -> Optional[str]:
14 | if name in os.environ:
15 | return os.environ[name]
16 | else:
17 | return None
18 |
19 |
20 | OPENAI_API_KEY = get_env_var("OPENAI_API_KEY")
21 | OPENAI_ORG = get_env_var("OPENAI_ORG")
22 | OPENAI_CLIENT = None
23 | try:
24 | from openai import OpenAI
25 |
26 | if OPENAI_API_KEY is not None and OPENAI_ORG is not None:
27 | OPENAI_CLIENT = OpenAI(
28 | api_key=OPENAI_API_KEY,
29 | organization=OPENAI_ORG,
30 | )
31 | else:
32 | warnings.warn(
33 | "OpenAI_API_KEY and OPENAI_ORG not set. OpenAI API will not work."
34 | )
35 | except ImportError:
36 | warnings.warn("openai package not found. OpenAI API will not work.")
37 |
38 |
39 | TOGETHER_API_KEY = get_env_var("TOGETHER_API_KEY")
40 | TOGETHER_CLIENT = None
41 | try:
42 | from together import Together
43 |
44 | if TOGETHER_API_KEY is not None:
45 | TOGETHER_CLIENT = Together(api_key=TOGETHER_API_KEY)
46 | else:
47 | warnings.warn("TOGETHER_API_KEY not set. Together API will not work.")
48 | except ImportError:
49 | warnings.warn("together package not found. Together API will not work.")
50 |
51 |
52 | COHERE_API_KEY = get_env_var("COHERE_API_KEY")
53 | COHERE_CLIENT = None
54 | try:
55 | import cohere
56 |
57 | if COHERE_API_KEY is not None:
58 | COHERE_CLIENT = cohere.Client(api_key=COHERE_API_KEY)
59 | else:
60 | warnings.warn("COHERE_API_KEY not set. Cohere API will not work.")
61 | except ImportError:
62 | warnings.warn("cohere package not found. Cohere API will not work.")
63 |
--------------------------------------------------------------------------------
/codenav/default_eval_spec.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import Any, List, Optional
3 |
4 | from codenav.agents.gpt4.agent import OpenAICodeNavAgent
5 | from codenav.constants import ABS_PATH_OF_CODENAV_DIR, DEFAULT_OPENAI_MODEL
6 | from codenav.environments.code_env import PythonCodeEnv
7 | from codenav.environments.done_env import DoneEnv
8 | from codenav.environments.retrieval_env import EsCodeRetriever, RetrievalEnv
9 | from codenav.interaction.episode import Episode
10 | from codenav.retrieval.elasticsearch.elasticsearch_constants import RESERVED_CHARACTERS
11 | from codenav.retrieval.elasticsearch.index_codebase import DEFAULT_ES_HOST
12 | from codenav.utils.eval_types import EvalInput, EvalSpec, Str2AnyDict
13 | from codenav.utils.evaluator import CodenavEvaluator
14 | from codenav.utils.prompt_utils import PROMPTS_DIR, PromptBuilder
15 |
16 |
17 | class DefaultEvalSpec(EvalSpec):
18 | def __init__(
19 | self,
20 | episode_kwargs: Str2AnyDict,
21 | interaction_kwargs: Str2AnyDict,
22 | logging_kwargs: Str2AnyDict,
23 | ):
24 | super().__init__(episode_kwargs, interaction_kwargs, logging_kwargs)
25 |
26 | @staticmethod
27 | def build_episode(
28 | eval_input: EvalInput,
29 | episode_kwargs: Optional[Str2AnyDict] = None,
30 | ) -> Episode:
31 | assert episode_kwargs is not None
32 |
33 | prompt_builder = PromptBuilder(
34 | prompt_dirs=episode_kwargs["prompt_dirs"],
35 | repo_description=episode_kwargs["repo_description"],
36 | )
37 | prompt = prompt_builder.build(
38 | dict(
39 | AVAILABLE_ACTIONS=episode_kwargs["allowed_actions"],
40 | RESERVED_CHARACTERS=RESERVED_CHARACTERS,
41 | RETRIEVALS_PER_KEYWORD=episode_kwargs["retrievals_per_keyword"],
42 | )
43 | )
44 |
45 | return Episode(
46 | agent=OpenAICodeNavAgent(
47 | prompt=prompt,
48 | model=episode_kwargs["llm"],
49 | allowed_action_types=episode_kwargs["allowed_actions"],
50 | ),
51 | action_type_to_env=dict(
52 | code=PythonCodeEnv(
53 | code_dir=episode_kwargs["code_dir"],
54 | sys_paths=episode_kwargs["sys_paths"],
55 | working_dir=episode_kwargs["working_dir"],
56 | ),
57 | search=RetrievalEnv(
58 | code_retriever=EsCodeRetriever(
59 | index_name=episode_kwargs["index_name"],
60 | host=episode_kwargs["host"],
61 | ),
62 | expansions_per_query=episode_kwargs["retrievals_per_keyword"],
63 | prototypes_per_query=episode_kwargs["prototypes_per_keyword"],
64 | summarize_code=False,
65 | ),
66 | done=DoneEnv(),
67 | ),
68 | user_query_str=eval_input.query,
69 | )
70 |
71 | @staticmethod
72 | def run_interaction(
73 | episode: Episode,
74 | interaction_kwargs: Optional[Str2AnyDict] = None,
75 | ) -> Str2AnyDict:
76 | assert interaction_kwargs is not None
77 | episode.step_until_max_steps_or_success(
78 | max_steps=interaction_kwargs["max_steps"],
79 | verbose=interaction_kwargs["verbose"],
80 | )
81 | ipynb_str = episode.to_notebook(cur_dir=episode.code_env.working_dir)
82 | return dict(ipynb_str=ipynb_str)
83 |
84 | @staticmethod
85 | def log_output(
86 | interaction_output: Str2AnyDict,
87 | eval_input: EvalInput,
88 | logging_kwargs: Optional[Str2AnyDict] = None,
89 | ) -> Any:
90 | assert logging_kwargs is not None
91 |
92 | outfile = os.path.join(logging_kwargs["out_dir"], f"{eval_input.uid}.ipynb")
93 | with open(outfile, "w") as f:
94 | f.write(interaction_output["ipynb_str"])
95 |
96 | return outfile
97 |
98 |
99 | def run_codenav_on_query(
100 | exp_name: str,
101 | out_dir: str,
102 | query: str,
103 | code_dir: str,
104 | index_name: str,
105 | working_dir: str = os.path.join(
106 | os.path.dirname(ABS_PATH_OF_CODENAV_DIR), "playground"
107 | ),
108 | sys_paths: Optional[List[str]] = None,
109 | repo_description_path: Optional[str] = None,
110 | es_host: str = DEFAULT_ES_HOST,
111 | max_steps: int = 20,
112 | ):
113 | prompt_dirs = [PROMPTS_DIR]
114 | repo_description = "default/repo_description.txt"
115 | if repo_description_path is not None:
116 | prompt_dir, repo_description = os.path.split(repo_description_path)
117 | conflict_path = os.path.join(PROMPTS_DIR, repo_description)
118 | if os.path.exists(conflict_path):
119 | raise ValueError(
120 | f"Prompt conflict detected: {repo_description} already exists in {PROMPTS_DIR}. "
121 | f"Please rename the {repo_description_path} file to resolve this conflict."
122 | )
123 | # append to front
124 | prompt_dirs.append(prompt_dir)
125 |
126 | episode_kwargs = dict(
127 | allowed_actions=["done", "code", "search"],
128 | repo_description=repo_description,
129 | retrievals_per_keyword=3,
130 | prototypes_per_keyword=7,
131 | llm=DEFAULT_OPENAI_MODEL,
132 | code_dir=code_dir,
133 | sys_paths=[] if sys_paths is None else sys_paths,
134 | working_dir=working_dir,
135 | index_name=index_name,
136 | host=es_host,
137 | prompt_dirs=prompt_dirs,
138 | )
139 | interaction_kwargs = dict(max_steps=max_steps, verbose=True)
140 | logging_kwargs = dict(out_dir=out_dir)
141 |
142 | # Run CodeNav on the query
143 | outfile = CodenavEvaluator.evaluate_input(
144 | eval_input=EvalInput(uid=exp_name, query=query),
145 | eval_spec=DefaultEvalSpec(
146 | episode_kwargs=episode_kwargs,
147 | interaction_kwargs=interaction_kwargs,
148 | logging_kwargs=logging_kwargs,
149 | ),
150 | )
151 |
152 | print("Output saved to ", outfile)
153 |
--------------------------------------------------------------------------------
/codenav/environments/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/environments/__init__.py
--------------------------------------------------------------------------------
/codenav/environments/abstractions.py:
--------------------------------------------------------------------------------
1 | import abc
2 | from typing import Tuple, Optional, Union
3 |
4 | from codenav.interaction.messages import (
5 | CodeNavAction,
6 | InvalidAction,
7 | MultiRetrievalResult,
8 | ExecutionResult,
9 | UserMessageToAgent,
10 | )
11 |
12 |
13 | class CodeNavEnv(abc.ABC):
14 | @abc.abstractmethod
15 | def check_action_validity(self, action: CodeNavAction) -> Tuple[bool, str]:
16 | raise NotImplementedError
17 |
18 | @abc.abstractmethod
19 | def step(
20 | self, action: CodeNavAction
21 | ) -> Optional[
22 | Union[InvalidAction, MultiRetrievalResult, ExecutionResult, UserMessageToAgent]
23 | ]:
24 | raise NotImplementedError
25 |
--------------------------------------------------------------------------------
/codenav/environments/code_summary_env.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, Tuple
2 |
3 | from codenav.environments.abstractions import CodeNavEnv
4 | from codenav.interaction.messages import CodeNavAction, UserMessageToAgent
5 |
6 |
7 | class CodeSummaryEnv(CodeNavEnv):
8 | def __init__(self) -> None:
9 | self.summary: Optional[str] = None
10 |
11 | def check_action_validity(self, action: CodeNavAction) -> Tuple[bool, str]:
12 | if action.content is None or action.content.strip() == "":
13 | return False, "No summary found in the action content."
14 |
15 | return True, ""
16 |
17 | def step(self, action: CodeNavAction) -> UserMessageToAgent:
18 | assert action.content is not None
19 | self.summary = action.content.strip()
20 | return UserMessageToAgent(message="Summary received and stored.")
21 |
--------------------------------------------------------------------------------
/codenav/environments/done_env.py:
--------------------------------------------------------------------------------
1 | from typing import Tuple
2 |
3 | from codenav.environments.abstractions import CodeNavEnv
4 | from codenav.interaction.messages import CodeNavAction
5 |
6 |
7 | class DoneEnv(CodeNavEnv):
8 | def check_action_validity(self, action: CodeNavAction) -> Tuple[bool, str]:
9 | assert action.content is not None
10 |
11 | if action.content.strip().lower() in ["true", "false"]:
12 | return True, ""
13 | else:
14 | return (
15 | False,
16 | "When executing the done action, the content must be either 'True' or 'False'",
17 | )
18 |
19 | def step(self, action: CodeNavAction) -> None:
20 | return None
21 |
--------------------------------------------------------------------------------
/codenav/environments/retrieval_env.py:
--------------------------------------------------------------------------------
1 | import os
2 | import traceback
3 | from typing import Dict, List, Sequence, Tuple, Union
4 |
5 | import codenav.interaction.messages as msg
6 | from codenav.environments.abstractions import CodeNavEnv
7 | from codenav.interaction.messages import CodeNavAction
8 | from codenav.retrieval.code_blocks import CodeBlockType
9 | from codenav.retrieval.elasticsearch.create_index import EsDocument, es_doc_to_hash
10 | from codenav.retrieval.elasticsearch.elasticsearch_retriever import (
11 | EsCodeRetriever,
12 | parallel_add_summary_to_es_docs,
13 | )
14 |
15 |
16 | def reorder_es_docs(es_docs: List[EsDocument]) -> List[EsDocument]:
17 | scores = []
18 | for es_doc in es_docs:
19 | t = es_doc["type"]
20 | proto = es_doc.get("prototype") or ""
21 |
22 | if t in [
23 | CodeBlockType.FUNCTION.name,
24 | CodeBlockType.CLASS.name,
25 | CodeBlockType.DOCUMENTATION.name,
26 | ]:
27 | score = 0.0
28 | elif t in [CodeBlockType.IMPORT.name, CodeBlockType.ASSIGNMENT.name]:
29 | score = 1.0
30 | else:
31 | score = 2.0
32 |
33 | if (
34 | os.path.basename(es_doc["file_path"]).lower().startswith("test_")
35 | or os.path.basename(es_doc["file_path"]).lower().endswith("_test.py")
36 | or (proto is not None and "test_" in proto.lower() or "Test" in proto)
37 | ):
38 | score += 2.0
39 |
40 | scores.append(score)
41 |
42 | return [
43 | es_doc for _, es_doc in sorted(list(zip(scores, es_docs)), key=lambda x: x[0])
44 | ]
45 |
46 |
47 | class RetrievalEnv(CodeNavEnv):
48 | def __init__(
49 | self,
50 | code_retriever: EsCodeRetriever,
51 | expansions_per_query: int,
52 | prototypes_per_query: int,
53 | max_per_query: int = 100,
54 | summarize_code: bool = True,
55 | overwrite_existing_summary: bool = False,
56 | ):
57 | self.code_retriever = code_retriever
58 | self.expansions_per_query = expansions_per_query
59 | self.prototypes_per_query = prototypes_per_query
60 | self.max_per_query = max_per_query
61 | self.summarize_code = summarize_code
62 | self.overwrite_existing_summary = overwrite_existing_summary
63 |
64 | self.retrieved_es_docs: Dict[str, EsDocument] = {}
65 |
66 | def reset(self):
67 | self.retrieved_es_docs = dict()
68 |
69 | def check_action_validity(self, action: CodeNavAction) -> Tuple[bool, str]:
70 | return True, ""
71 |
72 | def _get_retrieval_result(self, query: str):
73 | query = query.strip()
74 |
75 | try:
76 | es_docs = self.code_retriever.search(
77 | query=query, default_n=self.max_per_query
78 | )
79 | except:
80 | error_msg = traceback.format_exc()
81 | print(error_msg)
82 | if "Failed to parse query" in error_msg:
83 | error_msg = (
84 | f"Failed to parse search query: {query}\n"
85 | f"Please check the syntax and try again (be careful to escape any reserved characters)."
86 | )
87 |
88 | return msg.RetrievalResult(
89 | query=query,
90 | es_docs=[],
91 | failure_reason=error_msg,
92 | )
93 |
94 | filtered_es_docs = [
95 | es_doc
96 | for es_doc in es_docs
97 | if es_doc_to_hash(es_doc) not in self.retrieved_es_docs
98 | ]
99 |
100 | failure_reason = None
101 | if len(filtered_es_docs) == 0 and len(es_docs) > 0:
102 | failure_reason = (
103 | f"All code blocks matching the query have already been returned."
104 | )
105 |
106 | filtered_es_docs = reorder_es_docs(filtered_es_docs)
107 |
108 | # todo: add summaries to filtered_es_docs if jit_summarize is True
109 | if self.summarize_code:
110 | parallel_add_summary_to_es_docs(
111 | es_docs=filtered_es_docs[: self.expansions_per_query],
112 | es=self.code_retriever.es,
113 | index_name=self.code_retriever.index_name,
114 | code_summarizer=self.code_retriever.code_summarizer,
115 | overwrite_existing=self.overwrite_existing_summary,
116 | )
117 |
118 | for es_doc in filtered_es_docs[: self.expansions_per_query]:
119 | self.retrieved_es_docs[es_doc_to_hash(es_doc)] = es_doc
120 |
121 | return msg.RetrievalResult(
122 | query=query,
123 | es_docs=filtered_es_docs,
124 | failure_reason=failure_reason,
125 | max_expanded=self.expansions_per_query,
126 | max_prototype=self.prototypes_per_query,
127 | )
128 |
129 | def step(
130 | self, action: Union[CodeNavAction, str, Sequence[str]]
131 | ) -> msg.MultiRetrievalResult:
132 | if isinstance(action, str):
133 | queries = [q.strip() for q in action.split("\n") if q.strip() != ""]
134 | elif isinstance(action, CodeNavAction):
135 | if action.content is None:
136 | queries = []
137 | else:
138 | queries = [
139 | q.strip() for q in action.content.split("\n") if q.strip() != ""
140 | ]
141 | else:
142 | queries = [q.strip() for q in action if q.strip() != ""]
143 |
144 | retrieval_results: List[msg.RetrievalResult] = [
145 | self._get_retrieval_result(query=query) for query in queries
146 | ]
147 |
148 | return msg.MultiRetrievalResult(retrieval_results=retrieval_results)
149 |
--------------------------------------------------------------------------------
/codenav/interaction/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/interaction/__init__.py
--------------------------------------------------------------------------------
/codenav/interaction/episode.py:
--------------------------------------------------------------------------------
1 | from typing import Any, Dict, Optional, Tuple
2 |
3 | import pandas as pd
4 |
5 | import codenav.interaction.messages as msg
6 | from codenav.agents.agent import CodeNavAgent
7 | from codenav.agents.interaction_formatters import (
8 | DefaultInteractionFormatter,
9 | InteractionFormatter,
10 | )
11 | from codenav.environments.abstractions import CodeNavEnv
12 | from codenav.environments.code_env import PythonCodeEnv
13 | from codenav.environments.retrieval_env import RetrievalEnv
14 | from codenav.prompts.query_prompt import create_user_query_message
15 | from codenav.prompts.restart_prompt import PICKUP_PROMPT
16 |
17 |
18 | class Episode:
19 | def __init__(
20 | self,
21 | agent: CodeNavAgent,
22 | action_type_to_env: Dict[msg.ACTION_TYPES, CodeNavEnv],
23 | user_query_str: str,
24 | ):
25 | self.agent = agent
26 | self.action_type_to_env = action_type_to_env
27 |
28 | self.user_query_str = user_query_str
29 | self.agent.reset()
30 | # self.agent.reset(action_type_to_env=self.action_type_to_env)
31 |
32 | assert all(k in action_type_to_env for k in ["done", "code"])
33 |
34 | @property
35 | def code_env(self) -> PythonCodeEnv:
36 | code_envs = [
37 | env
38 | for env in self.action_type_to_env.values()
39 | if isinstance(env, PythonCodeEnv)
40 | ]
41 | assert len(code_envs) == 1
42 | return code_envs[0]
43 |
44 | def check_action_validity(self, action: msg.CodeNavAction) -> Tuple[bool, str]:
45 | is_valid = True
46 | error_msg = ""
47 |
48 | if action.type == "reset":
49 | return True, ""
50 |
51 | if action.thought is None:
52 | is_valid = False
53 | error_msg += "Action should always contain thought.\n"
54 |
55 | if action.type not in self.action_type_to_env:
56 | is_valid = False
57 | error_msg += f"Action type {action.type} is not supported.\n"
58 | return is_valid, error_msg
59 |
60 | assert action.type is not None
61 | env = self.action_type_to_env[action.type]
62 |
63 | content_valid, error_msg_content = env.check_action_validity(action)
64 |
65 | is_valid = is_valid and content_valid
66 | error_msg += error_msg_content
67 |
68 | return is_valid, error_msg
69 |
70 | def step(self) -> msg.Interaction:
71 | if len(self.agent.episode_state.interactions) == 0:
72 | assert self.code_env.code_dir is not None
73 |
74 | # Start of episode, add user query
75 | self.agent.update_state(
76 | msg.Interaction(
77 | action=None,
78 | response=create_user_query_message(
79 | user_query_str=self.user_query_str,
80 | code_dir=self.code_env.code_dir,
81 | working_dir=self.code_env.working_dir,
82 | added_paths=self.code_env.sys_paths,
83 | ),
84 | )
85 | )
86 |
87 | action = self.agent.get_action()
88 |
89 | action_is_valid, action_error_msg = self.check_action_validity(action)
90 |
91 | response: Optional[msg.RESPONSE_TYPES]
92 | if action_is_valid and action.type == "reset":
93 | response = msg.UserMessageToAgent(message=PICKUP_PROMPT)
94 | for env in self.action_type_to_env.values():
95 | if isinstance(env, RetrievalEnv):
96 | env.reset()
97 |
98 | elif action_is_valid:
99 | assert action.type is not None
100 | try:
101 | response = self.action_type_to_env[action.type].step(action)
102 | except KeyboardInterrupt:
103 | print(
104 | f"Keyboard interrupt occurred while attempting to execute code:{{\n{action.content}\n}}\n"
105 | f"String of notebook before interrupt: {self.to_notebook(cur_dir=self.code_env.working_dir)}\n",
106 | flush=True,
107 | )
108 | raise
109 | else:
110 | response = msg.InvalidAction(reason=action_error_msg)
111 |
112 | interaction = msg.Interaction(action=action, response=response)
113 | self.agent.update_state(interaction=interaction)
114 |
115 | return interaction
116 |
117 | def step_until_max_steps_or_success(self, max_steps: int, verbose: bool = True):
118 | for i in range(max_steps):
119 | interaction = self.step()
120 | if verbose:
121 | print("*" * 80)
122 | print(f"Step {i+1}")
123 | print("*" * 80)
124 | print("")
125 | print(
126 | Episode.format_interaction(
127 | interaction, self.agent.interaction_formatter
128 | )
129 | )
130 | if (
131 | interaction.action is not None
132 | and interaction.action.type == "done"
133 | and not isinstance(interaction.response, msg.InvalidAction)
134 | ):
135 | break
136 |
137 | @staticmethod
138 | def get_record(
139 | interaction: msg.Interaction, formatter: InteractionFormatter
140 | ) -> dict[str, Any]:
141 | if formatter is None:
142 | formatter = DefaultInteractionFormatter()
143 |
144 | if interaction.response is None:
145 | response_text = None
146 | else:
147 | response_text = formatter.format_response(
148 | interaction.response,
149 | )
150 |
151 | action = (
152 | msg.CodeNavAction() if interaction.action is None else interaction.action
153 | )
154 | return {
155 | "action/thought": action.thought,
156 | "action/type": str(action.type),
157 | "action/content": action.content,
158 | "response": response_text,
159 | "hidden": interaction.hidden,
160 | }
161 |
162 | def tabulate_interactions(self) -> pd.DataFrame:
163 | records = []
164 | for interaction in self.agent.episode_state.interactions:
165 | records.append(
166 | Episode.get_record(interaction, self.agent.interaction_formatter)
167 | )
168 |
169 | return pd.DataFrame.from_records(records)
170 |
171 | def tabulate_exec_trace(self) -> pd.DataFrame:
172 | return self.code_env.tabulate()
173 |
174 | def tabulate_prompts(self) -> pd.DataFrame:
175 | return pd.DataFrame.from_dict(
176 | dict(
177 | prompt_type=["QUERY", "SYSTEM_PROMPT"],
178 | prompt_content=[
179 | self.agent.user_query_prompt_str,
180 | self.agent.system_prompt_str,
181 | ],
182 | )
183 | )
184 |
185 | def to_notebook(self, cur_dir: str) -> str:
186 | import nbformat
187 | from nbformat import v4 as nbf
188 |
189 | nb = nbf.new_notebook()
190 | for i, row in self.tabulate_interactions().iterrows():
191 | thought = row["action/thought"]
192 | action_type = row["action/type"]
193 | content = row["action/content"]
194 | response = row["response"]
195 | thought, action_type, content, response = (
196 | x if x is not None else "None"
197 | for x in (thought, action_type, content, response)
198 | )
199 |
200 | if i == 0:
201 | nb.cells.append(
202 | nbf.new_markdown_cell(
203 | "\n\n".join(
204 | [
205 | "# Instruction to CodeNav",
206 | self.agent.user_query_prompt_str,
207 | "# Interactions",
208 | ]
209 | )
210 | )
211 | )
212 | continue
213 |
214 | nb.cells.append(
215 | nbf.new_markdown_cell(
216 | "\n\n".join(
217 | [
218 | f"## Step {i}: {action_type}",
219 | thought,
220 | ]
221 | )
222 | )
223 | )
224 |
225 | if action_type == "done":
226 | output = nbf.new_output(
227 | output_type="stream",
228 | text="Ending episode since the agent has issued a 'done' action.",
229 | )
230 | elif action_type == "code":
231 | output = nbf.new_output(
232 | output_type="execute_result",
233 | data={"text/plain": response},
234 | )
235 | else:
236 | output = nbf.new_output(
237 | output_type="stream",
238 | text=response,
239 | )
240 |
241 | nb.cells.append(nbf.new_code_cell(content, outputs=[output]))
242 | nb.cells.append(nbf.new_markdown_cell("---"))
243 |
244 | return nbformat.writes(nb)
245 |
246 | @staticmethod
247 | def format_interaction(
248 | interaction: msg.Interaction, interaction_formatter: InteractionFormatter
249 | ) -> str:
250 | record = Episode.get_record(interaction, formatter=interaction_formatter)
251 | return Episode.format_record(record)
252 |
253 | @staticmethod
254 | def format_record(record: dict[str, Any]) -> str:
255 | inter_str = "------Action------"
256 |
257 | inter_str += f"\nTHOUGHT:\n{record['action/thought']}"
258 |
259 | inter_str += f"\nACTION TYPE:\n{record.get('action/type')}"
260 |
261 | inter_str += f"\nACTION CONTENT:\n{record.get('action/content')}"
262 |
263 | inter_str += "\n\n-----Response-----"
264 | inter_str += f"\n{record['response']}"
265 | return inter_str
266 |
--------------------------------------------------------------------------------
/codenav/interaction/messages.py:
--------------------------------------------------------------------------------
1 | import abc
2 | from typing import Any, Dict, List, Literal, Optional, Sequence, Union, get_args
3 |
4 | import attrs
5 |
6 | from codenav.retrieval.elasticsearch.create_index import EsDocument, es_doc_to_string
7 | from codenav.utils.linting_and_type_checking_utils import (
8 | CodeAnalysisError,
9 | LintingError,
10 | TypeCheckingError,
11 | )
12 | from codenav.utils.string_utils import get_tag_content_from_text
13 |
14 |
15 | class CodeNavMessage:
16 | @abc.abstractmethod
17 | def format(self, *args, **kwargs) -> str:
18 | raise NotImplementedError
19 |
20 |
21 | @attrs.define
22 | class SystemPrompt(CodeNavMessage):
23 | content: str
24 |
25 | def format(self) -> str:
26 | return self.content
27 |
28 |
29 | ACTION_TYPES = Literal[
30 | "done", "code", "search", "reset", "code_summary", "request_user_message"
31 | ]
32 |
33 |
34 | @attrs.define
35 | class CodeNavAction(CodeNavMessage):
36 | thought: Optional[str] = None
37 | type: Optional[ACTION_TYPES] = None
38 | content: Optional[str] = None
39 |
40 | @staticmethod
41 | def get_tag_content_from_text(
42 | text: str,
43 | tag: Literal[
44 | "thought",
45 | "type",
46 | "content",
47 | "reset",
48 | "code",
49 | ],
50 | ) -> Optional[str]:
51 | return get_tag_content_from_text(text=text, tag=tag)
52 |
53 | @staticmethod
54 | def from_text(text: str) -> "CodeNavAction":
55 | thought = CodeNavAction.get_tag_content_from_text(text, "thought")
56 | type = CodeNavAction.get_tag_content_from_text(text, "type") # type: ignore
57 | content = CodeNavAction.get_tag_content_from_text(text, "content")
58 |
59 | assert type is None or type in get_args(
60 | ACTION_TYPES
61 | ), f"Invalid action type: {type} (valid types are {get_args(ACTION_TYPES)})"
62 |
63 | return CodeNavAction(
64 | thought=thought,
65 | type=type, # type: ignore
66 | content=content,
67 | )
68 |
69 | def to_tagged_text(self) -> str:
70 | return (
71 | f"\n{self.thought}\n"
72 | f"\n\n{self.type}\n"
73 | f"\n\n{self.content}\n"
74 | )
75 |
76 | def format(self) -> str:
77 | return self.to_tagged_text()
78 |
79 |
80 | @attrs.define
81 | class InvalidAction(CodeNavMessage):
82 | reason: str
83 |
84 | def format(self) -> str:
85 | return str(self)
86 |
87 |
88 | @attrs.define
89 | class ExecutionResult(CodeNavMessage):
90 | code_str: str
91 | stdout: str
92 | updated_vars: Optional[Dict[str, Any]] = None
93 | exec_error: Optional[str] = None
94 | linting_errors: Optional[List[LintingError]] = None
95 | type_checking_errors: Optional[List[TypeCheckingError]] = None
96 |
97 | @staticmethod
98 | def format_vars_with_max_len(vars: Dict[str, Any], max_len: int) -> str:
99 | """Format local variables with a maximum length per string representation."""
100 |
101 | l = []
102 | for k, v in vars.items():
103 | str_v = str(v)
104 | if len(str_v) > max_len:
105 | str_v = str_v[:max_len] + "..."
106 | l.append(f'"{k}": {str_v}')
107 |
108 | return "{" + ", ".join(l) + "}"
109 |
110 | def format(
111 | self,
112 | include_code: bool,
113 | display_updated_vars: bool,
114 | max_local_var_len: int = 500,
115 | ) -> str:
116 | res_str = ""
117 |
118 | if include_code:
119 | res_str = f"```\n{self.code_str}\n```\n"
120 |
121 | if self.stdout is not None and len(self.stdout) > 0:
122 | if len(self.stdout) > 2000:
123 | stdout_start = self.stdout[:1000]
124 | stdout_end = self.stdout[-1000:]
125 | msg = "STDOUT was too long. Showing only the start and end separated by ellipsis."
126 | res_str += f"STDOUT ({msg}):\n{stdout_start}\n\n...\n\n{stdout_end}\n"
127 | else:
128 | res_str += f"STDOUT:\n{self.stdout}\n"
129 |
130 | if self.exec_error is not None:
131 | res_str += f"EXECUTION ERROR:\n{self.exec_error}\n"
132 | elif self.stdout is None or len(self.stdout) == 0:
133 | # If there was no error or stdout, want to print something to tell the agent
134 | # that the code was executed
135 | res_str += "CODE EXECUTED WITHOUT ERROR, STDOUT WAS EMPTY\n"
136 |
137 | if (
138 | display_updated_vars
139 | and self.updated_vars is not None
140 | and len(self.updated_vars) > 0
141 | ):
142 | res_str += (
143 | f"RELEVANT VARIABLES (only shown if string rep. has changed after code exec):"
144 | f"\n{ExecutionResult.format_vars_with_max_len(self.updated_vars, max_len=max_local_var_len)}\n"
145 | )
146 |
147 | analysis_errors: List[CodeAnalysisError] = []
148 |
149 | if self.linting_errors is not None:
150 | analysis_errors.extend(self.linting_errors)
151 |
152 | if self.type_checking_errors is not None:
153 | analysis_errors.extend(self.type_checking_errors)
154 |
155 | if len(analysis_errors) > 0:
156 | res_str += "STATIC ANALYSIS ERRORS:\n"
157 | for err in analysis_errors:
158 | res_str += f"{err}\n"
159 |
160 | return res_str
161 |
162 |
163 | @attrs.define
164 | class RetrievalResult:
165 | query: str
166 | es_docs: Sequence[EsDocument]
167 | failure_reason: Optional[str] = None
168 | max_expanded: int = 3
169 | max_prototype: int = 10
170 |
171 | def format(
172 | self,
173 | include_query: bool = True,
174 | ) -> str:
175 | res_str = ""
176 | if include_query:
177 | res_str += f"QUERY:\n{self.query}\n\n"
178 |
179 | res_str += "CODE BLOCKS:\n"
180 |
181 | if len(self.es_docs) == 0:
182 | if self.failure_reason is not None:
183 | res_str += f"Failed to retrieve code blocks: {self.failure_reason}\n"
184 | else:
185 | res_str += "No code blocks found.\n"
186 |
187 | return res_str
188 |
189 | for doc in self.es_docs[: self.max_expanded]:
190 | res_str += "---\n{}\n".format(es_doc_to_string(doc, prototype=False))
191 |
192 | res_str += "---\n"
193 |
194 | unexpanded_docs = self.es_docs[self.max_expanded :]
195 | if len(unexpanded_docs) <= 0:
196 | res_str += "(All code blocks matching the query were returned.)\n"
197 | else:
198 | res_str += (
199 | f"({len(unexpanded_docs)} additional code blocks not shown."
200 | f" Search again with the same query to see additional results.)\n\n"
201 | )
202 |
203 | if self.max_prototype > 0:
204 | prototypes_docs = [
205 | doc
206 | for doc in unexpanded_docs
207 | if doc["type"] in {"CLASS", "FUNCTION"}
208 | ]
209 | num_prototype_docs_shown = min(len(prototypes_docs), self.max_prototype)
210 | res_str += (
211 | f"Prototypes for the next {num_prototype_docs_shown} out of"
212 | f" {len(prototypes_docs)} classes/functions found in unexpanded results"
213 | f" (search again with the same query to see details):\n"
214 | )
215 | for doc in prototypes_docs[:num_prototype_docs_shown]:
216 | res_str += "{}\n".format(es_doc_to_string(doc, prototype=True))
217 |
218 | return res_str
219 |
220 |
221 | @attrs.define
222 | class MultiRetrievalResult(CodeNavMessage):
223 | retrieval_results: Sequence[RetrievalResult]
224 |
225 | def format(
226 | self,
227 | include_query: bool = True,
228 | ) -> str:
229 | res_str = ""
230 | for res in self.retrieval_results:
231 | res_str += res.format(include_query)
232 | res_str += "\n"
233 |
234 | return res_str
235 |
236 |
237 | @attrs.define
238 | class UserMessageToAgent(CodeNavMessage):
239 | message: str
240 |
241 | def format(self) -> str:
242 | return self.message
243 |
244 |
245 | class UserQueryToAgent(UserMessageToAgent):
246 | pass
247 |
248 |
249 | RESPONSE_TYPES = Union[
250 | InvalidAction, MultiRetrievalResult, ExecutionResult, UserMessageToAgent
251 | ]
252 |
253 |
254 | @attrs.define
255 | class Interaction:
256 | action: Optional[CodeNavAction]
257 | response: Optional[RESPONSE_TYPES] = None
258 | hidden: bool = False
259 | hidden_at_index: bool = -1
260 |
261 | @staticmethod
262 | def format_action(action: CodeNavAction, include_header=True) -> str:
263 | if include_header:
264 | return "ACTION:\n" + action.format()
265 |
266 | return action.format()
267 |
268 | @staticmethod
269 | def format_response(
270 | response: RESPONSE_TYPES,
271 | include_code,
272 | display_updated_vars,
273 | include_query,
274 | include_header,
275 | ) -> str:
276 | if isinstance(response, ExecutionResult):
277 | response_type = "Execution Result"
278 | response_text = response.format(
279 | include_code=include_code,
280 | display_updated_vars=display_updated_vars,
281 | )
282 | elif isinstance(response, InvalidAction):
283 | response_type = "Invalid Action"
284 | response_text = response.format()
285 | elif isinstance(response, MultiRetrievalResult):
286 | response_type = "Retrieval Result"
287 | response_text = response.format(include_query=include_query)
288 | elif isinstance(response, UserMessageToAgent):
289 | response_type = "User Message"
290 | response_text = response.format()
291 | else:
292 | raise NotImplementedError()
293 |
294 | if include_header:
295 | return f"RESPONSE ({response_type}):\n" + response_text
296 |
297 | return response_text
298 |
299 |
300 | class EpisodeState:
301 | def __init__(self, system_prompt: SystemPrompt):
302 | self.system_prompt = system_prompt
303 | self.interactions: List[Interaction] = []
304 |
305 | def update(self, interaction: Interaction):
306 | self.interactions.append(interaction)
307 |
308 |
309 | def format_reponse(
310 | response: RESPONSE_TYPES,
311 | include_code=False,
312 | display_updated_vars=True,
313 | include_query=True,
314 | ) -> str:
315 | if isinstance(response, ExecutionResult):
316 | response_text = response.format(
317 | include_code=include_code,
318 | display_updated_vars=display_updated_vars,
319 | )
320 | elif isinstance(response, InvalidAction):
321 | response_text = response.format()
322 | elif isinstance(response, MultiRetrievalResult):
323 | response_text = response.format(include_query=include_query)
324 | elif isinstance(response, UserMessageToAgent):
325 | response_text = response.format()
326 | else:
327 | raise NotImplementedError()
328 |
329 | return "ACTION RESPONSE:\n" + response_text
330 |
--------------------------------------------------------------------------------
/codenav/prompts/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/prompts/__init__.py
--------------------------------------------------------------------------------
/codenav/prompts/codenav/repo_description.txt:
--------------------------------------------------------------------------------
1 | ## Repo description and user requirements
2 |
3 | The codebase you will use is called `codenav`. It is a library for creating LLM agents that can interact with one of the avilable environments to solve the user queries that require using an external codebase. For example, an agent can interact with "PythonCodeEnv" for code execution, and with "RetrievalEnv" for retrieving code snippets from an ElasticSearch index. It provides an "Episode" class for running this interaction with a specific agent and a set of environments. Here's the directory structure:
4 |
5 | codenav/agents/ - contains subdirectories that store implementations of LLM agents implemented with different LLMs
6 | codenav/environments/ - contains environments that the agent can interact with
7 | codenav/interaction/ - contains Episode and messages implementations (messages is how agent interacts with environments)
8 | codenav/prompts/ - stores various system prompts for the LLM agent
9 | codenav/retrieval/ - various files related to creating elastic search index and retrieving items from the index
10 | codenav/utils/ - contains various utility python files
11 | codenav/constants.py - contains important constants
--------------------------------------------------------------------------------
/codenav/prompts/default/action__code.txt:
--------------------------------------------------------------------------------
1 | ## ACTION TYPE: code
2 |
3 | In this case ... should include your Python code to execute. Do not enclose this code in ```.
--------------------------------------------------------------------------------
/codenav/prompts/default/action__done.txt:
--------------------------------------------------------------------------------
1 | ## ACTION TYPE: done
2 |
3 | In this case ... should contain ONLY the string True or False indicating whether you have been successful or not.
--------------------------------------------------------------------------------
/codenav/prompts/default/action__es_search.txt:
--------------------------------------------------------------------------------
1 | ## ACTION TYPE: search
2 |
3 | In this case ... should include one elasticsearch "query string" per line, these queries will be used to search an elasticsearch index of the codebase. Elasticsearch's reserved characters are {RESERVED_CHARACTERS} these should be escaped with a \ if you are trying to search for them explicitly (< and > can never be escaped). The index has fields
4 |
5 | - file_path # The path of the file relative the codebase's root (not absolute)
6 | - type # The of the text block (FUNCTION, CLASS, ASSIGNMENT, IMPORT, or DOCUMENTATION)
7 | - lines # The line numbers of the block in the file
8 | - text # The code as a string
9 |
10 | You may search with ANY valid query string. Example queries:
11 |
12 | text: (classification OR "detection model") # Finds blocks containing "classification" or "detection model". The quotes ensure "detection model" is treated as a single phrase.
13 |
14 | (text: classification) AND NOT (text: linear) # Finds blocks containing "classification" but not containing "linear"
15 |
16 | ((type: FUNCTION) OR (type: CLASS)) AND (file_path: *rel\/path\/to\/code.py) # Finds all functions or classes in the file at *rel/path/to/code.py
17 |
18 | 1. Rather than searching for `def function_name` or `class ClassName` you should use prefer to use the `type` field (i.e. search for `(type: FUNCTION) AND (text: function_name)` or `(type: CLASS) AND (text: ClassName)`).
19 | 2. When searching for a file_path, forward slashes MUST BE ESCAPED (ie all / should be replaced with \/).
20 | 3. If you are searching with a (file_path: rel\/path\/to\/code.py) and not retrieving relevant results, try broadening the search using a *, ie (file_path: *path\/to\/code.py)
21 | 3. Start with simple queries and only add extra constraints if the returned results are too broad.
22 |
--------------------------------------------------------------------------------
/codenav/prompts/default/action__guidelines.txt:
--------------------------------------------------------------------------------
1 | ## ACTION GUIDELINES
2 |
3 | Five guidelines that you should always follow are:
4 |
5 | 1. Do not ask the user to verify your results: do your best to verify your own results by coding or searching.
6 | 2. Before using a function or class from the code base, search for it to read its implementation.
7 | 3. Do not produce all code at once. Break down the problem into small steps and write code step by step. Before writing the next step, wait for user to execute the code and return the results. Iterate.
8 | 4. If the user query asks for you to do things a certain way, do not make assumptions or change the requirements to make it easier for you. It is better to fail following the requirements than to succeed solving a problem that should not have been solved.
9 |
--------------------------------------------------------------------------------
/codenav/prompts/default/action__preamble.txt:
--------------------------------------------------------------------------------
1 | # AGENT ACTIONS
2 |
3 | Always produce your output in the format:
4 | ```
5 |
6 | Rationale for your action describing what you've done, where the answer is, or why you have failed. Must ALWAYS be present, be concise.
7 |
8 |
9 | The type of action you're taking, this should be one of: {AVAILABLE_ACTIONS}
10 |
11 |
12 | The content of your action corresponding to the type. How this content must be formatted for each action type is described below.
13 |
14 | ```
15 | Do not include any text outside of the above tags.
16 |
--------------------------------------------------------------------------------
/codenav/prompts/default/overview.txt:
--------------------------------------------------------------------------------
1 | # OVERVIEW
2 |
3 | You are an expert Python Programmer. You will solve a user's query by writing Python code. In particular, the user will direct you to use a specific code base. We will now describe the workflow of your interaction with the user (Section "WORKFLOW"), the kinds of outputs you are allowed to produce (Section "AGENT ACTIONS"), and the responses you might expect from the user (Section "USER RESPONSES")
4 |
--------------------------------------------------------------------------------
/codenav/prompts/default/repo_description.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/prompts/default/repo_description.txt
--------------------------------------------------------------------------------
/codenav/prompts/default/response__code.txt:
--------------------------------------------------------------------------------
1 | ## USER RESPONSE TO code
2 |
3 | If you output code, the user will execute the code and return an ExecutionResult object. This object contains the result of executing the code (stdout and new variables), python execution errors, linting errors (from flake8), and type checking errors (from mypy). Pay attention to the errors - you might need to fix them in subsequent steps. Execution errors are the most important and you must fix them or try a different approach. Linting and type checking errors can be ignored if benign.
--------------------------------------------------------------------------------
/codenav/prompts/default/response__done.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/prompts/default/response__done.txt
--------------------------------------------------------------------------------
/codenav/prompts/default/response__es_search.txt:
--------------------------------------------------------------------------------
1 | ## USER RESPONSE TO search
2 |
3 | If you output search queries, the user will search the code base using your queries and return results in the format:
4 |
5 | ---
6 | file_path=,
7 | lines=[, ],
8 | type=,
9 | content={{
10 |
11 | }}
12 | ---
13 | ... # Up to {RETRIEVALS_PER_KEYWORD} code blocks per query.
14 |
15 | Use these text blocks as reference for generating code in subsequent steps. By default the user will return {RETRIEVALS_PER_KEYWORD} code blocks per query. If you would like to see more code blocks for the same query then simply output the same query again. The user will return the next {RETRIEVALS_PER_KEYWORD} text blocks.
16 |
17 | If a code block has already been retrieved before, it will not show up in the search results again. So if you are search is not returning the desired result, it is possible the code block has already been returned in the past.
--------------------------------------------------------------------------------
/codenav/prompts/default/response__preamble.txt:
--------------------------------------------------------------------------------
1 | # USER RESPONSES
2 |
3 | The user will respond to your actions with one of the following responses:
--------------------------------------------------------------------------------
/codenav/prompts/default/workflow.txt:
--------------------------------------------------------------------------------
1 | # WORKFLOW
2 |
3 | To solve the user's query, you might need multiple rounds of interaction with the user:
4 |
5 | First, the user will give you a query and information about the code repository they want you to use. The user will tell you the absolute path to the code repo as well as your current directory (the directory in which your code would be executed). All necessary dependencies should already be installed, do not try to install missing python dependencies. If you are missing a critical dependency, write "MISSING DEPENDENCY" in your thought and take the done action with content being "False".
6 |
7 | Given this initial task information, you will interact with the user to solve the task. The interaction may consist of multiple rounds. Each round consists of an action (ie output) from you and a response to that action from the user.
8 |
--------------------------------------------------------------------------------
/codenav/prompts/query_prompt.py:
--------------------------------------------------------------------------------
1 | from typing import Sequence
2 |
3 | from codenav.interaction.messages import UserQueryToAgent
4 |
5 | PATHS = """\
6 | Use the code base located at `{CODE_DIR}` to solve this query. Your current directory is `{WORKING_DIR}`.
7 | """
8 |
9 | ADDED_TO_PATH = """\
10 | The code base path has either been installed via pip or has been already been added to the system path via
11 | ```
12 | import sys
13 | sys.path.extend({ADDED_PATH})
14 | ```
15 | """
16 |
17 | # Import instructions might be different in case of an installed library rather than a local code repo. For now, we assume that the code repo is local and not installed.
18 | IMPORT_INSTRUCTIONS = """\
19 | If the import path in retrieved code block says `testing/dir_name/file_name.py` and you want to import variable, function or class called `obj` from this file, then import using `from testing.dir_name.file_name import obj`.
20 | """
21 |
22 |
23 | def create_user_query_message(
24 | user_query_str: str,
25 | code_dir: str,
26 | working_dir: str,
27 | added_paths: Sequence[str],
28 | ):
29 | return UserQueryToAgent(
30 | message=f"USER QUERY:\n\n{user_query_str}\n\nPATHS AND IMPORT INSTRUCTIONS:"
31 | + (f"\n" f"\n{PATHS}" f"\n{IMPORT_INSTRUCTIONS}" f"\n{ADDED_TO_PATH}").format(
32 | CODE_DIR=code_dir, WORKING_DIR=working_dir, ADDED_PATH=list(added_paths)
33 | ),
34 | )
35 |
--------------------------------------------------------------------------------
/codenav/prompts/restart_prompt.py:
--------------------------------------------------------------------------------
1 | RESTART_PROMPT = """\
2 | This task is about to be handed off to another AI agent. The agent will be given the same prompt you were and will be expected to continue your work in the same Python environment. The other agent will only be shown your single next response and will not have access to your previous thoughts, keywords, code, execution results, or retrieved code blocks. With this in mind, please respond in the format:
3 |
4 |
5 | A summary of everything you have done and learned so far relevant to the task. You should be concise but thorough.
6 |
7 |
8 | Code that, if run, would result in the Python environment being in its current state. This should include all necessary imports, definitions, and any other necessary setup. Ideally, this code should not produce any errors. Add comments when necessary explaining the code and describing the state of the environment. In this code do not define any variables/functions or import any libraries that are not available in the current environment state. For reference, the current variables defined in the environment are:\n{current_env_var_names}
9 |
10 | """
11 |
12 | PICKUP_PROMPT = """\
13 | You are picking up where another AI agent left off. The previous agent has provided a summary of their work and a code snippet that, if run, would result in the Python environment being in its current state.
14 | """
15 |
--------------------------------------------------------------------------------
/codenav/retrieval/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/retrieval/__init__.py
--------------------------------------------------------------------------------
/codenav/retrieval/code_blocks.py:
--------------------------------------------------------------------------------
1 | import ast
2 | import os
3 | from enum import Enum
4 | from typing import Dict, Iterable, List, Optional, Set
5 |
6 |
7 | class CodeBlockType(Enum):
8 | ASSIGNMENT = 1
9 | FUNCTION = 2
10 | CLASS = 3
11 | FILE = 4
12 | IMPORT = 5
13 | CONDITIONAL = 6
14 | DOCUMENTATION = 7
15 | OTHER = 8
16 |
17 |
18 | AST_TYPE_TO_CODE_BLOCK_TYPE = {
19 | ast.Module: CodeBlockType.FILE,
20 | ast.FunctionDef: CodeBlockType.FUNCTION,
21 | ast.ClassDef: CodeBlockType.CLASS,
22 | ast.Assign: CodeBlockType.ASSIGNMENT,
23 | ast.Import: CodeBlockType.IMPORT,
24 | ast.ImportFrom: CodeBlockType.IMPORT,
25 | ast.If: CodeBlockType.CONDITIONAL,
26 | ast.For: CodeBlockType.CONDITIONAL,
27 | }
28 |
29 |
30 | CODE_BLOCK_TEMPLATE = """file_path={file_path},
31 | lines=[{start_lineno}, {end_lineno}],
32 | type={type},
33 | content={{
34 | {code}
35 | }}"""
36 |
37 |
38 | DEFAULT_CODEBLOCK_TYPES = {
39 | CodeBlockType.FUNCTION,
40 | CodeBlockType.CLASS,
41 | CodeBlockType.ASSIGNMENT,
42 | CodeBlockType.IMPORT,
43 | CodeBlockType.CONDITIONAL,
44 | CodeBlockType.DOCUMENTATION,
45 | }
46 |
47 |
48 | class FilePath:
49 | def __init__(self, path: str, base_dir: str = "/"):
50 | self.path = os.path.abspath(path)
51 | self.base_dir = base_dir
52 |
53 | @property
54 | def file_name(self) -> str:
55 | """root/base_dir/path/to/file.py -> file.py"""
56 | return os.path.basename(self.path)
57 |
58 | @property
59 | def ext(self) -> str:
60 | """root/base_dir/path/to/file.py -> .py"""
61 | return os.path.splitext(self.path)[1]
62 |
63 | @property
64 | def rel_path(self) -> str:
65 | """root/base_dir/path/to/file.py -> path/to/file.py"""
66 | return os.path.relpath(self.path, self.base_dir)
67 |
68 | @property
69 | def import_path(self) -> str:
70 | """root/base_dir/path/to/file.py -> base_dir/path/to/file.py"""
71 | return os.path.join(os.path.basename(self.base_dir), self.rel_path)
72 |
73 | @property
74 | def abs_path(self) -> str:
75 | """root/base_dir/path/to/file.py -> /root/base_dir/path/to/file.py"""
76 | return self.path
77 |
78 | def __repr__(self) -> str:
79 | """FilePath(base_dir=root/base_dir, rel_path=path/to/file.py)"""
80 | return f"FilePath(base_dir={self.base_dir}, rel_path={self.rel_path})"
81 |
82 | def __eq__(self, other: object) -> bool:
83 | if not isinstance(other, FilePath):
84 | return NotImplemented
85 | return self.path == other.path and self.base_dir == other.base_dir
86 |
87 | def __hash__(self):
88 | return hash(str(self))
89 |
90 |
91 | def get_file_list(dir_path: str) -> list[FilePath]:
92 | file_list = []
93 | for root, dirs, files in os.walk(dir_path, followlinks=True):
94 | for file in files:
95 | file_list.append(FilePath(path=os.path.join(root, file), base_dir=dir_path))
96 | return file_list
97 |
98 |
99 | def filter_by_extension(
100 | file_list: list[FilePath], valid_extensions: Iterable[str] = (".py",)
101 | ) -> list[FilePath]:
102 | return [file_path for file_path in file_list if file_path.ext in valid_extensions]
103 |
104 |
105 | class CodeBlockASTNode:
106 | def __init__(
107 | self,
108 | ast_node: ast.AST,
109 | parent: Optional["CodeBlockASTNode"] = None,
110 | tree: Optional["CodeBlockAST"] = None,
111 | ):
112 | self.ast_node = ast_node
113 | self.parent = parent
114 | self.tree = tree
115 | self.code_summary: Optional[str] = None
116 |
117 | @staticmethod
118 | def format_code_block(
119 | file_path: str,
120 | start_lineno: Optional[int],
121 | end_lineno: Optional[int],
122 | type: str,
123 | code: str,
124 | ) -> str:
125 | return CODE_BLOCK_TEMPLATE.format(
126 | file_path=file_path,
127 | start_lineno=start_lineno,
128 | end_lineno=end_lineno,
129 | type=type,
130 | code=code,
131 | )
132 |
133 | def __repr__(self) -> str:
134 | if self.tree is None or self.tree.file_path is None:
135 | file_path = "None"
136 | else:
137 | file_path = self.tree.file_path.rel_path
138 |
139 | return self.format_code_block(
140 | file_path=file_path,
141 | start_lineno=self.ast_node.lineno - 1,
142 | end_lineno=self.ast_node.end_lineno,
143 | type=self.block_type.name,
144 | code=self.code if self.code_summary is None else self.code_summary,
145 | )
146 |
147 | @property
148 | def block_type(self) -> CodeBlockType:
149 | return AST_TYPE_TO_CODE_BLOCK_TYPE.get(type(self.ast_node), CodeBlockType.OTHER)
150 |
151 | @property
152 | def code(self):
153 | return "\n".join(
154 | self.tree.code_lines[self.ast_node.lineno - 1 : self.ast_node.end_lineno]
155 | )
156 |
157 | def children(
158 | self, included_types: Optional[Set[CodeBlockType]] = None
159 | ) -> List["CodeBlockASTNode"]:
160 | if self.tree is None:
161 | raise RuntimeError(
162 | "Cannot call children on a node that is not part of a tree."
163 | )
164 |
165 | return [
166 | self.tree.ast_node_to_node[child]
167 | for child in ast.iter_child_nodes(self.ast_node)
168 | if included_types is None
169 | or self.tree.ast_node_to_node[child].block_type in included_types
170 | ]
171 |
172 |
173 | class CodeBlockAST:
174 | def __init__(self, code: str, file_path: Optional[FilePath]):
175 | self.code = code
176 | self.code_lines = code.splitlines()
177 | self.file_path = file_path
178 | self.ast_root = ast.parse(self.code)
179 | self.ast_node_to_node: Dict[ast.AST, "CodeBlockASTNode"] = {}
180 | self._build_tree(
181 | CodeBlockASTNode(
182 | ast_node=self.ast_root,
183 | parent=None,
184 | tree=self,
185 | )
186 | )
187 |
188 | @property
189 | def root(self) -> CodeBlockASTNode:
190 | return self.ast_node_to_node[self.ast_root]
191 |
192 | @staticmethod
193 | def from_file_path(file_path: FilePath) -> "CodeBlockAST":
194 | with open(file_path.path, "r") as f:
195 | code = f.read()
196 |
197 | return CodeBlockAST(
198 | code=code,
199 | file_path=file_path,
200 | )
201 |
202 | def _build_tree(self, node: CodeBlockASTNode):
203 | self.ast_node_to_node[node.ast_node] = node
204 | for child in ast.iter_child_nodes(node.ast_node):
205 | child_node = CodeBlockASTNode(ast_node=child, parent=node, tree=self)
206 | self._build_tree(child_node)
207 |
208 | def __repr__(self) -> str:
209 | return ast.dump(self.ast_root)
210 |
--------------------------------------------------------------------------------
/codenav/retrieval/code_summarizer.py:
--------------------------------------------------------------------------------
1 | import ast
2 | import re
3 |
4 | from codenav.constants import DEFAULT_OPENAI_MODEL, OPENAI_CLIENT
5 | from codenav.utils.llm_utils import create_openai_message, query_gpt
6 | from codenav.utils.string_utils import get_tag_content_from_text
7 |
8 | SUMMARIZATION_PROMPT = """\
9 | You are an expert python programmer. Given a user provided code snippet that represents a function or a class definition, you will document that code. Your documentation should be concise as possible while still being sufficient to fully understand how the code behaves. Never mention that the code is being documented by an AI model or that it is in any particular style.
10 |
11 | If you are given a class definition which, for example, defines functions func1, func2, ..., funcN, you response should be formatted as:
12 | ```
13 |
14 | Doc string of the class, should include Attributes (if any).
15 |
16 |
17 |
18 | Google-style doc string of func1, should include Args, Returns, Yields, Raises, and Examples if applicable.
19 |
20 |
21 | (Doc strings for func2, ..., funcN, each in their own block)
22 | ```
23 |
24 | If you are given a function called func, then format similarly as:
25 | ```
26 |
27 | Doc string of func, should include Args, Returns, Yields, Raises, and Examples if applicable.
28 |
29 | ```
30 |
31 | Do not include starting or ending ``` in your response. Ensure you document the __init__ function if defined. Your output should start with including the < and > characters.
32 | """
33 |
34 |
35 | class DocstringTransformer(ast.NodeTransformer):
36 | def __init__(self, docstring_map):
37 | self.docstring_map = docstring_map
38 |
39 | def indent_docstring(self, docstring: str, offset: int = 0):
40 | indentation = " " * offset
41 | if "\n" in docstring:
42 | lines = docstring.split("\n") + [""]
43 | return "\n" + "\n".join([f"{indentation}{line}" for line in lines])
44 |
45 | def visit_ClassDef(self, node):
46 | # Update class docstring
47 | if node.name in self.docstring_map:
48 | docstring = self.indent_docstring(
49 | self.docstring_map[node.name], offset=node.col_offset + 4
50 | )
51 | if (
52 | node.body
53 | and isinstance(node.body[0], ast.Expr)
54 | and isinstance(node.body[0].value, (ast.Str, ast.Constant))
55 | ):
56 | # Replace the existing docstring
57 | node.body[0] = ast.Expr(value=ast.Str(s=docstring))
58 | else:
59 | # Insert new docstring if none exists
60 | node.body.insert(0, ast.Expr(value=ast.Str(s=docstring)))
61 | # node.body.insert(0, ast.Expr(value=ast.Str(s=docstring)))
62 | self.generic_visit(node) # Process methods
63 | return node
64 |
65 | def visit_FunctionDef(self, node):
66 | # Update method docstring and replace body
67 | if node.name in self.docstring_map:
68 | docstring = self.indent_docstring(
69 | self.docstring_map[node.name], offset=node.col_offset + 4
70 | )
71 | node.body = [
72 | ast.Expr(value=ast.Constant(value=docstring)),
73 | ast.parse("...").body,
74 | ]
75 | else:
76 | node.body = [ast.parse("...").body]
77 | return node
78 |
79 |
80 | def rewrite_docstring(code, docstring_map):
81 | tree = ast.parse(code)
82 | transformer = DocstringTransformer(docstring_map)
83 | transformed_tree = transformer.visit(tree)
84 | return ast.unparse(transformed_tree)
85 |
86 |
87 | class CodeSummarizer:
88 | def __init__(
89 | self,
90 | model: str = DEFAULT_OPENAI_MODEL,
91 | max_tokens: int = 50000,
92 | ):
93 | self.model = model
94 | self.max_tokens = max_tokens
95 |
96 | def generate_tagged_summary(self, code: str) -> str:
97 | # Use OpenAI to summarize the code
98 | messages = [
99 | create_openai_message(text=SUMMARIZATION_PROMPT, role="system"),
100 | create_openai_message(text=code, role="user"),
101 | ]
102 | return query_gpt(
103 | messages=messages,
104 | model=self.model,
105 | max_tokens=self.max_tokens,
106 | client=OPENAI_CLIENT,
107 | )
108 |
109 | def summarize(self, code: str) -> str:
110 | tagged_summary = self.generate_tagged_summary(code)
111 | tags = [t.strip() for t in re.findall(r"<([^/]*?)>", tagged_summary)]
112 | docstring_map = dict()
113 | for tag in tags:
114 | docstring_map[tag] = get_tag_content_from_text(tagged_summary, tag=tag)
115 |
116 | return rewrite_docstring(code, docstring_map)
117 |
118 |
119 | if __name__ == "__main__":
120 | import inspect
121 | import sys
122 | import importlib
123 |
124 | func_or_class = sys.argv[1]
125 |
126 | m = importlib.import_module(".".join(func_or_class.split(".")[:-1]))
127 | to_doc = inspect.getsource(getattr(m, func_or_class.split(".")[-1]))
128 |
129 | summarizer = CodeSummarizer()
130 | print(summarizer.summarize(to_doc))
131 |
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/README.md:
--------------------------------------------------------------------------------
1 | # Elasticsearch
2 |
3 | ## Download
4 |
5 | You can download Elasticsearch by running
6 | ```bash
7 | python -m codenav.retrieval.elasticsearch.install_elasticsearch
8 | ```
9 | This will save Elastic search to `codenav/external_src/elasticsearch-8.12.0`.
10 |
11 | ## Start
12 |
13 | Once downloaded, you can start the Elasticsearch server by running:
14 | ```bash
15 | bash codenav/external_src/elasticsearch-8.12.0/bin/elasticsearch
16 | ```
17 |
18 | ## Graphical interface
19 |
20 | It can be useful to use Kibana, an GUI for Elasticsearch, so you can do things like
21 | deleting an index without running commands via Python. Kibana will automatically be downloaded when you run the above
22 | install script. You can start Kibana by running:
23 | ```bash
24 | bash codenav/external_src/kibana-8.12.0/bin/kibana
25 | ```
26 | and you can access the web interface by navigating to [http://localhost:5601](http://localhost:5601) in your browser.
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/retrieval/elasticsearch/__init__.py
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/create_index.py:
--------------------------------------------------------------------------------
1 | from typing import Optional, TypedDict, Union, Literal
2 |
3 | import tiktoken
4 | from elasticsearch import Elasticsearch
5 |
6 | from codenav.utils.hashing_utils import md5_hash_str
7 |
8 |
9 | class EsDocument(TypedDict):
10 | text: str
11 | file_path: str
12 | lines: dict
13 | type: str # Will be string corresponding to one of the CodeBlockType types.
14 | prototype: str
15 | text_vector: Optional[list[float]]
16 | text_summary: Optional[str]
17 |
18 |
19 | def es_doc_to_string(
20 | doc: EsDocument,
21 | prototype: bool = False,
22 | use_summary: Union[bool, Literal["ifshorter", "always", "never"]] = "ifshorter",
23 | ) -> str:
24 | if prototype:
25 | return doc["prototype"] + " # " + doc["file_path"]
26 |
27 | code: Optional[str] = doc["text"]
28 | summary = doc.get("text_summary", code)
29 |
30 | if isinstance(use_summary, str):
31 | if use_summary == "ifshorter":
32 | encode_count = lambda m: len(
33 | tiktoken.get_encoding("cl100k_base").encode(m, disallowed_special=[])
34 | )
35 |
36 | use_summary = encode_count(code) >= encode_count(summary)
37 | elif use_summary == "always":
38 | use_summary = True
39 | elif use_summary == "never":
40 | use_summary = False
41 | else:
42 | raise ValueError("Invalid value for use_summary")
43 |
44 | doc_str = [
45 | f"file_path={doc['file_path']}",
46 | f"lines=[{doc['lines']['gte']}, {doc['lines']['lt']}]",
47 | f"type={doc['type']}",
48 | f"content={{\n{summary if use_summary else code}\n}}",
49 | ]
50 |
51 | return "\n".join(doc_str)
52 |
53 |
54 | def es_doc_to_hash(doc: EsDocument) -> str:
55 | return md5_hash_str(es_doc_to_string(doc, prototype=False, use_summary=False))
56 |
57 |
58 | class EsHit(TypedDict):
59 | _index: str
60 | _type: str
61 | _id: str
62 | _score: float
63 | _source: EsDocument
64 |
65 |
66 | CODENAV_INDEX_SETTINGS = {
67 | "settings": {
68 | "number_of_shards": 1,
69 | "number_of_replicas": 0,
70 | "analysis": {
71 | "tokenizer": {
72 | "code_ngram_3_4_tokenizer": {
73 | "type": "ngram",
74 | "min_gram": 3,
75 | "max_gram": 4,
76 | "token_chars": ["letter", "digit", "punctuation", "symbol"],
77 | }
78 | },
79 | "analyzer": {
80 | "code_ngram_3_4_analyzer": {
81 | "type": "custom",
82 | "tokenizer": "code_ngram_3_4_tokenizer",
83 | "filter": ["lowercase"], # You can include other filters as needed
84 | }
85 | },
86 | },
87 | },
88 | "mappings": {
89 | "properties": {
90 | "file_path": {"type": "keyword"},
91 | "type": {"type": "keyword"},
92 | "lines": {"type": "integer_range"}, # Using integer_range for line numbers
93 | "text": {
94 | "type": "text",
95 | "analyzer": "code_ngram_3_4_analyzer",
96 | },
97 | "prototype": {
98 | "type": "text",
99 | "analyzer": "code_ngram_3_4_analyzer",
100 | },
101 | "text_vector": {
102 | "type": "dense_vector",
103 | "dims": 1536, # Adjust the dimension according to your vector
104 | "index": "true",
105 | "similarity": "cosine",
106 | },
107 | "text_summary": {
108 | "type": "text",
109 | "analyzer": "code_ngram_3_4_analyzer",
110 | },
111 | }
112 | },
113 | }
114 |
115 |
116 | def create_empty_index(
117 | es: Elasticsearch,
118 | index_name: str,
119 | embedding_dim: int,
120 | ):
121 | assert embedding_dim == 1536, "Only 1536-dimensional vectors are supported"
122 | # Create the index
123 | es.indices.create(
124 | index=index_name, body=CODENAV_INDEX_SETTINGS, request_timeout=120
125 | )
126 |
127 |
128 | def create_file_path_hash_index(es: Elasticsearch, index_name: str):
129 | if es.indices.exists(index=index_name):
130 | return
131 |
132 | # Define the index settings and mappings
133 | index_body = {
134 | "settings": {"number_of_shards": 1, "number_of_replicas": 0},
135 | "mappings": {
136 | "properties": {
137 | "md5hash": {"type": "keyword"},
138 | "code_uuid": {"type": "keyword"},
139 | "file_path": {"type": "keyword"},
140 | "doc_count": {"type": "integer"},
141 | }
142 | },
143 | }
144 |
145 | # Create the index
146 | es.indices.create(index=index_name, body=index_body)
147 |
148 |
149 | if __name__ == "__main__":
150 | # Connect to the local Elasticsearch instance
151 | es = Elasticsearch(hosts="http://localhost:9200/")
152 |
153 | create_empty_index(es=es, index_name="code_repository", embedding_dim=1536)
154 |
155 | # Example document
156 | doc = {
157 | "text": "def example_function():\n pass",
158 | "file_path": "/path/to/file.py",
159 | "lines": {"gte": 5, "lte": 30},
160 | "type": "function",
161 | "text_vector": [0.1] * 768, # Example vector, replace with actual data
162 | }
163 |
164 | # Index the document
165 | es.index(index="code_repository", document=doc)
166 |
167 | query = {"query": {"match": {"type": "function"}}}
168 |
169 | res = es.search(index="code_repository", body=query)
170 | print(res["hits"]["hits"])
171 |
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/debug_add_item_to_index.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/retrieval/elasticsearch/debug_add_item_to_index.py
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/elasticsearch.yml:
--------------------------------------------------------------------------------
1 | # ======================== Elasticsearch Configuration =========================
2 | #
3 | # NOTE: Elasticsearch comes with reasonable defaults for most settings.
4 | # Before you set out to tweak and tune the configuration, make sure you
5 | # understand what are you trying to accomplish and the consequences.
6 | #
7 | # The primary way of configuring a node is via this file. This template lists
8 | # the most important settings you may want to configure for a production cluster.
9 | #
10 | # Please consult the documentation for further information on configuration options:
11 | # https://www.elastic.co/guide/en/elasticsearch/reference/index.html
12 | #
13 | # ---------------------------------- Cluster -----------------------------------
14 | #
15 | # Use a descriptive name for your cluster:
16 | #
17 | #cluster.name: my-application
18 | #
19 | # ------------------------------------ Node ------------------------------------
20 | #
21 | # Use a descriptive name for the node:
22 | #
23 | #node.name: node-1
24 | #
25 | # Add custom attributes to the node:
26 | #
27 | #node.attr.rack: r1
28 | #
29 | # ----------------------------------- Paths ------------------------------------
30 | #
31 | # Path to directory where to store the data (separate multiple locations by comma):
32 | #
33 | #path.data: /path/to/data
34 | #
35 | # Path to log files:
36 | #
37 | #path.logs: /path/to/logs
38 | #
39 | # ----------------------------------- Memory -----------------------------------
40 | #
41 | # Lock the memory on startup:
42 | #
43 | #bootstrap.memory_lock: true
44 | #
45 | # Make sure that the heap size is set to about half the memory available
46 | # on the system and that the owner of the process is allowed to use this
47 | # limit.
48 | #
49 | # Elasticsearch performs poorly when the system is swapping the memory.
50 | #
51 | # ---------------------------------- Network -----------------------------------
52 | #
53 | # By default Elasticsearch is only accessible on localhost. Set a different
54 | # address here to expose this node on the network:
55 | #
56 | #network.host: 192.168.0.1
57 | #
58 | # By default Elasticsearch listens for HTTP traffic on the first free port it
59 | # finds starting at 9200. Set a specific HTTP port here:
60 | #
61 | #http.port: 9200
62 | #
63 | # For more information, consult the network module documentation.
64 | #
65 | # --------------------------------- Discovery ----------------------------------
66 | #
67 | # Pass an initial list of hosts to perform discovery when this node is started:
68 | # The default list of hosts is ["127.0.0.1", "[::1]"]
69 | #
70 | #discovery.seed_hosts: ["host1", "host2"]
71 | #
72 | # Bootstrap the cluster using an initial set of master-eligible nodes:
73 | #
74 | #cluster.initial_master_nodes: ["node-1", "node-2"]
75 | #
76 | # For more information, consult the discovery and cluster formation module documentation.
77 | #
78 | # ---------------------------------- Various -----------------------------------
79 | #
80 | # Allow wildcard deletion of indices:
81 | #
82 | #action.destructive_requires_name: false
83 |
84 | #----------------------- BEGIN SECURITY AUTO CONFIGURATION -----------------------
85 | #
86 | # The following settings, TLS certificates, and keys have been automatically
87 | # generated to configure Elasticsearch security features on 01-02-2024 00:31:46
88 | #
89 | # --------------------------------------------------------------------------------
90 |
91 | # Enable security features
92 | xpack.security.enabled: false
93 |
94 | xpack.security.enrollment.enabled: false
95 |
96 | # Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
97 | xpack.security.http.ssl:
98 | enabled: false
99 | # keystore.path: certs/http.p12
100 |
101 | # Enable encryption and mutual authentication between cluster nodes
102 | xpack.security.transport.ssl:
103 | enabled: false
104 | # verification_mode: certificate
105 | # keystore.path: certs/transport.p12
106 | # truststore.path: certs/transport.p12
107 |
108 | # Create a new cluster with the current node only
109 | # Additional nodes can still join the cluster later
110 | #cluster.initial_master_nodes: ["ip-172-16-20-86.us-west-2.compute.internal"]
111 |
112 | # cluster.routing.allocation.disk.watermark.high: "95%"
113 | cluster.routing.allocation.disk.threshold_enabled: false # Getting rid of high disk utilization errors
114 |
115 | # Allow HTTP API connections from anywhere
116 | # Connections are encrypted and require user authentication
117 | http.host: 0.0.0.0
118 |
119 | # Allow other nodes to join the cluster from anywhere
120 | # Connections are encrypted and mutually authenticated
121 | #transport.host: 0.0.0.0
122 |
123 | #----------------------- END SECURITY AUTO CONFIGURATION -------------------------
124 |
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/elasticsearch_constants.py:
--------------------------------------------------------------------------------
1 | RESERVED_CHARACTERS = """+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /"""
2 |
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/elasticsearch_retriever.py:
--------------------------------------------------------------------------------
1 | from concurrent.futures.thread import ThreadPoolExecutor
2 | from typing import List
3 |
4 | from elasticsearch import Elasticsearch
5 |
6 | from codenav.retrieval.code_blocks import CodeBlockType
7 | from codenav.retrieval.code_summarizer import CodeSummarizer
8 | from codenav.retrieval.elasticsearch.create_index import EsDocument, es_doc_to_hash
9 |
10 |
11 | class EsCodeRetriever:
12 | def __init__(self, index_name: str, host: str):
13 | self.index_name = index_name
14 | assert (
15 | index_name is not None and index_name != ""
16 | ), "Index name cannot be empty."
17 |
18 | self.host = host
19 | self.es = Elasticsearch(hosts=host)
20 |
21 | if not self.es.ping():
22 | raise ValueError(
23 | f"Elasticsearch is not running or could not be reached at {host}."
24 | )
25 |
26 | self.code_summarizer = CodeSummarizer()
27 |
28 | def search(self, query: str, default_n: int = 10) -> List[EsDocument]:
29 | body = {"query": {"query_string": {"query": query}}, "size": default_n}
30 | hits = self.es.search(index=self.index_name, body=body)["hits"]["hits"]
31 | return [hit["_source"] for hit in hits]
32 |
33 |
34 | def add_summary_to_es_doc(
35 | es_doc: EsDocument,
36 | es: Elasticsearch,
37 | index_name: str,
38 | code_summarizer: CodeSummarizer,
39 | overwrite_existing: bool = False,
40 | ):
41 | if es_doc["type"] == CodeBlockType.DOCUMENTATION.name:
42 | return
43 |
44 | if "text_summary" in es_doc and es_doc["text_summary"] is not None:
45 | if not overwrite_existing:
46 | return
47 |
48 | summary = code_summarizer.summarize(es_doc["text"])
49 | es_doc["text_summary"] = summary
50 | es.update(
51 | index=index_name,
52 | id=es_doc_to_hash(es_doc),
53 | body={"doc": {"text_summary": summary}},
54 | )
55 |
56 |
57 | def parallel_add_summary_to_es_docs(
58 | es_docs: List[EsDocument],
59 | es: Elasticsearch,
60 | index_name: str,
61 | code_summarizer: CodeSummarizer,
62 | overwrite_existing: bool = False,
63 | ):
64 | n = len(es_docs)
65 | with ThreadPoolExecutor() as executor:
66 | executor.map(
67 | add_summary_to_es_doc,
68 | es_docs,
69 | [es] * n,
70 | [index_name] * n,
71 | [code_summarizer] * n,
72 | [overwrite_existing] * n,
73 | )
74 |
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/index_codebase.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import os.path
3 | import time
4 | from typing import List, Optional, Tuple
5 |
6 | from elasticsearch import Elasticsearch
7 | from elasticsearch.helpers import bulk
8 |
9 | from codenav.retrieval.code_blocks import (
10 | CodeBlockAST,
11 | CodeBlockType,
12 | filter_by_extension,
13 | get_file_list,
14 | )
15 | from codenav.retrieval.elasticsearch.create_index import (
16 | EsDocument,
17 | create_empty_index,
18 | es_doc_to_hash,
19 | )
20 | from codenav.utils.llm_utils import num_tokens_from_string
21 | from codenav.utils.parsing_utils import get_class_or_function_prototype
22 |
23 | DEFAULT_ES_PORT = 9200
24 | DEFAULT_KIBANA_PORT = 5601
25 | DEFAULT_ES_HOST = f"http://localhost:{DEFAULT_ES_PORT}"
26 | DEFAULT_KIBANA_HOST = f"http://localhost:{DEFAULT_KIBANA_PORT}"
27 |
28 |
29 | def parse_args():
30 | parser = argparse.ArgumentParser(description="Index codebase")
31 | parser.add_argument(
32 | "--code_dir",
33 | type=str,
34 | required=True,
35 | help="Path to the codebase to index",
36 | )
37 | parser.add_argument(
38 | "--index_uid",
39 | type=str,
40 | required=True,
41 | help="Unique identifier for the index",
42 | )
43 | parser.add_argument(
44 | "--delete_index",
45 | action="store_true",
46 | help="Delete the index if it already exists",
47 | )
48 | parser.add_argument(
49 | "--host",
50 | type=str,
51 | default=DEFAULT_ES_HOST,
52 | help="Elasticsearch host",
53 | )
54 | parser.add_argument(
55 | "--force_subdir",
56 | type=str,
57 | default=None,
58 | help="If provided, only index files in this subdirectory of code_dir. Their path in the index will still be the"
59 | " path relative to code_dir.",
60 | )
61 | return parser.parse_args()
62 |
63 |
64 | def split_markdown_documentation_into_parts(
65 | docstring: str, min_tokens: int = 100, split_after_ntokens: int = 1000
66 | ) -> Tuple[List[str], List[Tuple[int, int]]]:
67 | parts: List[str] = []
68 | line_nums: List[Tuple[int, int]] = []
69 | current_lines: List[str] = []
70 | current_line_nums: List[int] = []
71 |
72 | lines = docstring.split("\n")
73 | for cur_line_idx, line in enumerate(lines):
74 | line = line.rstrip()
75 |
76 | if line == "" and len(current_lines) == 0:
77 | # Skip leading empty lines
78 | continue
79 |
80 | if len(line) == 0:
81 | current_lines.append("")
82 | current_line_nums.append(cur_line_idx)
83 | continue
84 |
85 | if (
86 | line.lstrip().startswith("#")
87 | and (len(line) == 1 or line[1] != "#")
88 | and (num_tokens_from_string("\n".join(current_lines)) > min_tokens)
89 | ):
90 | # We're at a top-level header, and we have enough tokens to split
91 | parts.append("\n".join(current_lines))
92 | line_nums.append((current_line_nums[0], current_line_nums[-1]))
93 | current_lines = []
94 | current_line_nums = []
95 |
96 | current_lines.append(line)
97 | current_line_nums.append(cur_line_idx)
98 |
99 | # We should split if we're at the end of the document or if we've reached the token limit
100 | if (
101 | len(lines) - 1 == cur_line_idx
102 | or num_tokens_from_string("\n".join(current_lines)) > split_after_ntokens
103 | ):
104 | parts.append("\n".join(current_lines))
105 | line_nums.append((current_line_nums[0], current_line_nums[-1]))
106 | current_lines = []
107 | current_line_nums = []
108 |
109 | return parts, line_nums
110 |
111 |
112 | def _should_skip_python_file(file_path: str):
113 | with open(file_path, "r") as f:
114 | first_line = f.readline().strip("\n #").lower()
115 |
116 | if first_line.startswith("index:"):
117 | return first_line.split(":")[1].strip().lower() == "false"
118 |
119 | return False
120 |
121 |
122 | def get_es_docs(code_dir: str, force_subdir: Optional[str]):
123 | all_files = get_file_list(code_dir)
124 | docs = []
125 |
126 | if force_subdir is not None:
127 | force_subdir = os.path.abspath(os.path.join(code_dir, force_subdir))
128 | if force_subdir[-1] != "/":
129 | force_subdir += "/"
130 |
131 | all_files = [
132 | file_path
133 | for file_path in all_files
134 | if file_path.abs_path.startswith(force_subdir)
135 | ]
136 |
137 | python_files = filter_by_extension(all_files, valid_extensions=[".py"])
138 | for file_path in python_files:
139 | if _should_skip_python_file(file_path.abs_path):
140 | print(f"Skipping {file_path} as it has `index: false` in the first line.")
141 | continue
142 |
143 | try:
144 | code_block_ast = CodeBlockAST.from_file_path(file_path)
145 | except SyntaxError:
146 | print(f"Syntax error in {file_path}, skipping...")
147 | continue
148 |
149 | for block in code_block_ast.root.children():
150 | # noinspection PyTypeChecker
151 | docs.append(
152 | EsDocument(
153 | file_path=file_path.rel_path,
154 | type=block.block_type.name,
155 | lines=dict(
156 | gte=block.ast_node.lineno - 1, lt=block.ast_node.end_lineno
157 | ),
158 | text=block.code,
159 | prototype=get_class_or_function_prototype(
160 | block.ast_node, include_init=False
161 | ),
162 | )
163 | )
164 |
165 | doc_files = filter_by_extension(all_files, valid_extensions=[".md"])
166 | for file_path in doc_files:
167 | with open(file_path.abs_path, "r") as f:
168 | for part, line_nums in zip(
169 | *split_markdown_documentation_into_parts(f.read())
170 | ):
171 | docs.append(
172 | EsDocument(
173 | file_path=file_path.rel_path,
174 | type=CodeBlockType.DOCUMENTATION.name,
175 | lines=dict(gte=line_nums[0], lt=line_nums[1] + 1),
176 | text=part,
177 | )
178 | )
179 |
180 | return docs
181 |
182 |
183 | def build_index(
184 | code_dir: str,
185 | index_uid: str,
186 | delete_index: bool,
187 | host: str = DEFAULT_ES_HOST,
188 | force_subdir: Optional[str] = None,
189 | ):
190 | code_dir = os.path.abspath(code_dir)
191 | print(f"Indexing codebase at {code_dir} with index_uid {index_uid}")
192 |
193 | assert os.path.exists(code_dir), f"{code_dir} does not exist"
194 |
195 | docs = get_es_docs(code_dir, force_subdir=force_subdir)
196 | bulk_insert = [
197 | {
198 | "_op_type": "index",
199 | "_index": index_uid,
200 | "_id": es_doc_to_hash(doc),
201 | "_source": doc,
202 | }
203 | for doc in docs
204 | ]
205 |
206 | if delete_index:
207 | es = Elasticsearch(host)
208 | if es.indices.exists(index=index_uid):
209 | print("Deleting existing index...")
210 | es.indices.delete(index=index_uid)
211 |
212 | assert len(bulk_insert) > 0, f"No documents to index in {code_dir}."
213 |
214 | print(f"Indexing {len(bulk_insert)} documents...")
215 | es = Elasticsearch(host)
216 | create_empty_index(es=es, index_name=index_uid, embedding_dim=1536)
217 | bulk(es, bulk_insert)
218 |
219 | time.sleep(2) # to allow for indexing to finish
220 |
221 |
222 | if __name__ == "__main__":
223 | args = parse_args()
224 | build_index(
225 | code_dir=args.code_dir,
226 | index_uid=args.index_uid,
227 | delete_index=args.delete_index,
228 | host=args.host,
229 | force_subdir=args.force_subdir,
230 | )
231 |
--------------------------------------------------------------------------------
/codenav/retrieval/elasticsearch/install_elasticsearch.py:
--------------------------------------------------------------------------------
1 | import hashlib
2 | import os
3 | import shutil
4 | import sys
5 | import urllib
6 | import urllib.request
7 | from pathlib import Path
8 |
9 | ABS_PATH_OF_ES_DIR = os.path.abspath(os.path.dirname(Path(__file__)))
10 |
11 | DOWNLOAD_DIR = os.path.join(os.path.expanduser("~/.cache/codenav/elasticsearch"))
12 |
13 | ES_VERSION = "8.12.1"
14 | KIBANA_VERSION = ES_VERSION
15 |
16 | ES_PATH = os.path.join(DOWNLOAD_DIR, f"elasticsearch-{ES_VERSION}")
17 | KIBANA_PATH = os.path.join(DOWNLOAD_DIR, f"kibana-{ES_VERSION}")
18 |
19 | PLATFORM_TO_ES_URL = {
20 | "linux-x86_64": f"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-{ES_VERSION}-linux-x86_64.tar.gz",
21 | "darwin-aarch64": f"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-{ES_VERSION}-darwin-aarch64.tar.gz",
22 | "darwin-x86_64": f"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-{ES_VERSION}-darwin-x86_64.tar.gz",
23 | }
24 |
25 | PLATFORM_TO_KIBANA_URL = {
26 | "linux-x86_64": f"https://artifacts.elastic.co/downloads/kibana/kibana-{KIBANA_VERSION}-linux-x86_64.tar.gz",
27 | "darwin-aarch64": f"https://artifacts.elastic.co/downloads/kibana/kibana-{KIBANA_VERSION}-darwin-aarch64.tar.gz",
28 | "darwin-x86_64": f"https://artifacts.elastic.co/downloads/kibana/kibana-{KIBANA_VERSION}-darwin-x86_64.tar.gz",
29 | }
30 |
31 |
32 | def compute_sha512(file_path: str):
33 | sha512_hash = hashlib.sha512()
34 | with open(file_path, "rb") as f:
35 | # Read and update hash string value in blocks of 4K
36 | for byte_block in iter(lambda: f.read(4096), b""):
37 | sha512_hash.update(byte_block)
38 | return sha512_hash.hexdigest()
39 |
40 |
41 | def install_from_url(url: str) -> None:
42 | print(f"Downloading {url}")
43 |
44 | os.makedirs(DOWNLOAD_DIR, exist_ok=True)
45 |
46 | name = "-".join(url.split("/")[-1].split("-")[:2])
47 |
48 | if os.path.exists(os.path.join(DOWNLOAD_DIR, name)):
49 | print(f"{name} already exists. Skipping download...")
50 | return
51 |
52 | tar_path = os.path.join(DOWNLOAD_DIR, f"{name}.tar.gz")
53 | tar_hash_path = tar_path + ".sha512"
54 |
55 | urllib.request.urlretrieve(url, tar_path)
56 | urllib.request.urlretrieve(
57 | url + ".sha512",
58 | tar_hash_path,
59 | )
60 | print("Download complete")
61 |
62 | # Checking SHA512
63 | print("Checking SHA512")
64 | sha512 = compute_sha512(tar_path)
65 | with open(tar_hash_path, "r") as f:
66 | expected_sha512 = f.read().strip().split(" ")[0]
67 |
68 | if sha512 != expected_sha512:
69 | raise ValueError(f"SHA512 mismatch. Expected {expected_sha512}, got {sha512}")
70 |
71 | print(f"Extracting {tar_path} to {DOWNLOAD_DIR}")
72 | os.system(f"tar -xzf {tar_path} -C {DOWNLOAD_DIR}")
73 |
74 | assert os.path.join(ES_PATH)
75 |
76 | os.remove(tar_path)
77 | os.remove(tar_hash_path)
78 |
79 | print(f"{name} installation complete")
80 |
81 |
82 | def install_elasticsearch():
83 | if sys.platform == "darwin":
84 | if os.uname().machine == "arm64":
85 | platform = "darwin-aarch64"
86 | else:
87 | platform = "darwin-x86_64"
88 | else:
89 | assert sys.platform == "linux"
90 | platform = "linux-x86_64"
91 |
92 | install_from_url(PLATFORM_TO_ES_URL[platform])
93 |
94 | # Copy the elasticsearch config file to the elasticsearch directory
95 | es_config_file = os.path.join(ABS_PATH_OF_ES_DIR, "elasticsearch.yml")
96 | shutil.copy(es_config_file, os.path.join(ES_PATH, "config"))
97 |
98 | install_from_url(PLATFORM_TO_KIBANA_URL[platform])
99 |
100 |
101 | def is_es_installed():
102 | return os.path.exists(ES_PATH) and os.path.exists(KIBANA_PATH)
103 |
104 |
105 | if __name__ == "__main__":
106 | if not is_es_installed():
107 | install_elasticsearch()
108 | else:
109 | print(f"Elasticsearch already installed at {ES_PATH}")
110 |
--------------------------------------------------------------------------------
/codenav/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/utils/__init__.py
--------------------------------------------------------------------------------
/codenav/utils/config_params.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/allenai/codenav/2f200d9de2ee15cc82e232b8414765fe5f2fb617/codenav/utils/config_params.py
--------------------------------------------------------------------------------
/codenav/utils/eval_types.py:
--------------------------------------------------------------------------------
1 | from abc import ABC, abstractmethod
2 | from typing import Any, Dict, Optional, Union
3 |
4 | import attrs
5 |
6 | from codenav.interaction.episode import Episode
7 |
8 |
9 | @attrs.define
10 | class EvalInput:
11 | uid: Union[str, int]
12 | query: str
13 | metadata: Optional[Any] = None
14 |
15 |
16 | Str2AnyDict = Dict[str, Any]
17 |
18 |
19 | class EvalSpec(ABC):
20 | def __init__(
21 | self,
22 | episode_kwargs: Str2AnyDict,
23 | interaction_kwargs: Str2AnyDict,
24 | logging_kwargs: Str2AnyDict,
25 | ):
26 | self.episode_kwargs = episode_kwargs
27 | self.interaction_kwargs = interaction_kwargs
28 | self.logging_kwargs = logging_kwargs
29 |
30 | @staticmethod
31 | @abstractmethod
32 | def build_episode(
33 | eval_input: EvalInput,
34 | episode_kwargs: Optional[Str2AnyDict] = None,
35 | ) -> Episode:
36 | pass
37 |
38 | @staticmethod
39 | @abstractmethod
40 | def run_interaction(
41 | episode: Episode,
42 | interaction_kwargs: Optional[Str2AnyDict] = None,
43 | ) -> Optional[Str2AnyDict]:
44 | pass
45 |
46 | @staticmethod
47 | @abstractmethod
48 | def log_output(
49 | interaction_output: Str2AnyDict,
50 | eval_input: EvalInput,
51 | logging_kwargs: Optional[Str2AnyDict] = None,
52 | ) -> Any:
53 | pass
54 |
--------------------------------------------------------------------------------
/codenav/utils/evaluator.py:
--------------------------------------------------------------------------------
1 | import copy
2 | import multiprocessing as mp
3 | import sys
4 | import time
5 | import traceback
6 | from queue import Empty
7 | from typing import Any, Iterator, Sequence
8 |
9 | from codenav.utils.eval_types import EvalInput, EvalSpec
10 |
11 | if sys.platform.lower() == "darwin":
12 | mp = mp.get_context("spawn")
13 | else:
14 | mp = mp.get_context("forkserver")
15 |
16 |
17 | def _parallel_worker(task_queue: mp.Queue, result_queue: mp.Queue, eval_spec: EvalSpec):
18 | while True:
19 | try:
20 | eval_input: EvalInput = task_queue.get(timeout=1)
21 | print(f"Starting task: {eval_input.uid}")
22 | try:
23 | result = CodenavEvaluator.evaluate_input(
24 | eval_input=eval_input, eval_spec=copy.deepcopy(eval_spec)
25 | )
26 | except:
27 | result = ("failure", eval_input, traceback.format_exc())
28 | result_queue.put(result)
29 | raise
30 | result_queue.put(result)
31 | except Empty:
32 | break
33 |
34 |
35 | class CodenavEvaluator:
36 | def __init__(self, eval_spec: EvalSpec):
37 | self.eval_spec = eval_spec
38 |
39 | @staticmethod
40 | def evaluate_input(
41 | eval_input: EvalInput,
42 | eval_spec: EvalSpec,
43 | ) -> Any:
44 | episode = eval_spec.build_episode(
45 | eval_input=eval_input, episode_kwargs=eval_spec.episode_kwargs
46 | )
47 | interaction_output = eval_spec.run_interaction(
48 | episode=episode, interaction_kwargs=eval_spec.interaction_kwargs
49 | )
50 | assert interaction_output is not None
51 | return eval_spec.log_output(
52 | interaction_output=interaction_output,
53 | eval_input=eval_input,
54 | logging_kwargs=eval_spec.logging_kwargs,
55 | )
56 |
57 | def evaluate_in_sequence(self, inputs: Sequence[EvalInput]) -> Iterator[Any]:
58 | for input in inputs:
59 | yield CodenavEvaluator.evaluate_input(input, self.eval_spec)
60 |
61 | def evaluate_in_parallel(
62 | self, inputs: Sequence[EvalInput], n_procs: int
63 | ) -> Iterator[Any]:
64 | task_queue: mp.Queue[EvalInput] = mp.Queue()
65 | result_queue: mp.Queue[Any] = mp.Queue()
66 |
67 | for input in inputs:
68 | task_queue.put(input)
69 |
70 | procs = []
71 | for proc_idx in range(n_procs):
72 | p = mp.Process(
73 | target=_parallel_worker, args=(task_queue, result_queue, self.eval_spec)
74 | )
75 | p.start()
76 | procs.append(p)
77 |
78 | for _ in range(len(inputs)):
79 | yield result_queue.get()
80 |
81 | for proc in procs:
82 | proc.join(1)
83 |
84 | def evaluate(self, samples: Sequence[EvalInput], n_procs: int = 1) -> Iterator[Any]:
85 | start_time = time.time()
86 |
87 | if n_procs > 1:
88 | yield from self.evaluate_in_parallel(samples, n_procs)
89 | else:
90 | yield from self.evaluate_in_sequence(samples)
91 |
92 | print(f"Time taken in evaluation: {time.time() - start_time}")
93 |
--------------------------------------------------------------------------------
/codenav/utils/hashing_utils.py:
--------------------------------------------------------------------------------
1 | import hashlib
2 |
3 |
4 | def md5_hash_str(to_hash: str) -> str:
5 | return hashlib.md5(to_hash.encode()).hexdigest()
6 |
7 |
8 | def md5_hash_file(to_hash_path: str):
9 | with open(to_hash_path, "r") as f:
10 | return md5_hash_str(f.read())
11 |
--------------------------------------------------------------------------------
/codenav/utils/linting_and_type_checking_utils.py:
--------------------------------------------------------------------------------
1 | import subprocess
2 | import tempfile
3 | from typing import List, Optional, Tuple
4 |
5 | import black
6 | import mypy.api
7 |
8 |
9 | def black_format_code(code: str) -> Tuple[str, Optional[str]]:
10 | """Format code using black."""
11 | error_str: Optional[str] = None
12 | formatted_code: str = ""
13 | try:
14 | formatted_code = black.format_str(code, mode=black.FileMode())
15 | except Exception as error:
16 | formatted_code = code
17 | error_str = str(error)
18 | return formatted_code, error_str
19 |
20 |
21 | def run_mypy(code: str) -> Tuple[str, str, int]:
22 | """
23 | Run mypy (static type checker) on code.
24 |
25 | Returns:
26 | stdout (str): output of mypy, errors found etc
27 | stderr (str): errors generated by mypy itself
28 | exit_code (int): 0 means no type errors, non-zero implies type errors
29 | """
30 | return mypy.api.run(
31 | [
32 | "--ignore-missing-imports",
33 | "--no-namespace-packages",
34 | "--follow_imports",
35 | "silent",
36 | "-c",
37 | code,
38 | ]
39 | )
40 |
41 |
42 | def run_flake8(code: str) -> Tuple[str, str]:
43 | """
44 | Run flake8 (linter) on code.
45 |
46 | Returns:
47 | stdout (str): output of flake8, errors found etc
48 | stderr (str): errors generated by flake8 itself
49 | """
50 | with tempfile.NamedTemporaryFile(suffix=".py", mode="w", delete=True) as temp_file:
51 | temp_file.write(code)
52 | temp_file.flush() # Make sure all data is flushed to disk
53 | result = subprocess.run(
54 | ["flake8", temp_file.name], capture_output=True, text=True
55 | )
56 |
57 | return result.stdout, result.stderr
58 |
59 |
60 | class CodeAnalysisError:
61 | """Represents a code analysis error."""
62 |
63 | def __init__(
64 | self, code_ref: str, line_num: int, error: str, prefix: str = "CodeAnalysis"
65 | ):
66 | self.code_ref = code_ref
67 | self.line_num = line_num
68 | self.error = error
69 | self.prefix = prefix
70 |
71 | def __repr__(self) -> str:
72 | return f'{self.prefix}Error(code_ref="{self.code_ref}", line_num={self.line_num}, error="{self.error}")'
73 |
74 |
75 | class TypeCheckingError(CodeAnalysisError):
76 | """Represents a type checking error."""
77 |
78 | def __init__(self, code_ref: str, line_num: int, error: str):
79 | super().__init__(code_ref, line_num, error, prefix="TypeChecking")
80 |
81 |
82 | class LintingError(CodeAnalysisError):
83 | """Represents a linting error."""
84 |
85 | def __init__(self, code_ref: str, line_num: int, error: str):
86 | super().__init__(code_ref, line_num, error, prefix="Linting")
87 |
88 |
89 | def parse_mypy_output(mypy_output: str, code: str) -> List[TypeCheckingError]:
90 | """Parse mypy output."""
91 | if mypy_output == "":
92 | return []
93 |
94 | code_lines = code.split("\n")
95 | parse = []
96 | # skip last two items after split because - the second last is a count of error &
97 | # the last is an empty string
98 | lines = mypy_output.split("\n")
99 | assert lines[-2].startswith("Found ") or lines[-2].startswith("Success")
100 | assert lines[-1] == ""
101 | for line in lines[:-2]:
102 | path, line_num, error_type, error = line.split(":", maxsplit=3)
103 | parse.append(
104 | TypeCheckingError(
105 | code_ref=code_lines[int(line_num) - 1],
106 | line_num=int(line_num),
107 | error=error.strip(),
108 | )
109 | )
110 |
111 | return parse
112 |
113 |
114 | def parse_flake8_output(flake8_output: str, code: str) -> List[LintingError]:
115 | """Parse flake8 output."""
116 | if parse_flake8_output == "":
117 | return []
118 |
119 | code_lines = code.split("\n")
120 | parse = []
121 | # skip last item after split because it's an empty string
122 | lines = flake8_output.split("\n")
123 | assert lines[-1] == ""
124 | for line in lines[:-1]:
125 | path, line_num, col, error = line.split(":", maxsplit=3)
126 | parse.append(
127 | LintingError(
128 | code_ref=code_lines[int(line_num) - 1],
129 | line_num=int(line_num),
130 | error=error.strip(),
131 | )
132 | )
133 |
134 | return parse
135 |
136 |
137 | def get_linting_errors(
138 | code: str, skip_codes: List[str] = ["E402", "E501"]
139 | ) -> List[LintingError]:
140 | """Get linting errors."""
141 | lint_errs = parse_flake8_output(run_flake8(code)[0], code)
142 | to_return: List[LintingError] = []
143 | for err in lint_errs:
144 | if not any([code in err.error for code in skip_codes]):
145 | to_return.append(err)
146 |
147 | return to_return
148 |
149 |
150 | def get_type_checking_errors(code: str) -> List[TypeCheckingError]:
151 | """Get type checking errors."""
152 | type_errs = parse_mypy_output(run_mypy(code)[0], code)
153 | to_return: List[TypeCheckingError] = []
154 | for err in type_errs:
155 | if "no-redef" not in err.error:
156 | to_return.append(err)
157 |
158 | return to_return
159 |
--------------------------------------------------------------------------------
/codenav/utils/llm_utils.py:
--------------------------------------------------------------------------------
1 | import base64
2 | import json
3 | import math
4 | import time
5 | import traceback
6 | from typing import List, Literal, Optional, Sequence, Union, cast, Any, Dict
7 |
8 | import numpy as np
9 | import tiktoken
10 | import tqdm
11 | from PIL import Image
12 | from openai import InternalServerError, OpenAI, RateLimitError
13 | from openai.resources import Chat
14 | from openai.types.chat import (
15 | ChatCompletionAssistantMessageParam,
16 | ChatCompletionMessageParam,
17 | ChatCompletionSystemMessageParam,
18 | ChatCompletionUserMessageParam,
19 | )
20 |
21 | MODEL_STR_TO_PRICE_PER_1M_INPUT_TOKENS = {
22 | # Together models, input tokens cost same as output
23 | "mistralai/Mistral-7B-Instruct-v0.2": 0.2,
24 | "mistralai/Mixtral-8x7B-Instruct-v0.1": 0.6,
25 | "mistralai/Mixtral-8x22B-Instruct-v0.1": 1.2,
26 | "Qwen/Qwen1.5-72B-Chat": 1.0,
27 | "Qwen/Qwen1.5-110B-Chat": 1.8,
28 | "meta-llama/Llama-3-70b-chat-hf": 0.9,
29 | # OpenAI models
30 | "gpt-3.5-turbo-0301": 1.5,
31 | "gpt-3.5-turbo-0125": 1.5,
32 | "gpt-4-1106-preview": 10.0,
33 | "gpt-4o-2024-05-13": 5.0,
34 | # Cohere
35 | "command-r": 0.5,
36 | "command-r-plus": 3.0,
37 | }
38 |
39 | MODEL_STR_TO_PRICE_PER_1M_OUTPUT_TOKENS = {
40 | # Together models, input tokens cost same as output
41 | "mistralai/Mistral-7B-Instruct-v0.2": 0.2,
42 | "mistralai/Mixtral-8x7B-Instruct-v0.1": 0.6,
43 | "mistralai/Mixtral-8x22B-Instruct-v0.1": 1.2,
44 | "Qwen/Qwen1.5-72B-Chat": 1.0,
45 | "Qwen/Qwen1.5-110B-Chat": 1.8,
46 | "meta-llama/Llama-3-70b-chat-hf": 0.9,
47 | # OpenAI models
48 | "gpt-3.5-turbo-0301": 2.0,
49 | "gpt-3.5-turbo-0125": 2.0,
50 | "gpt-4o-2024-05-13": 15.0,
51 | "gpt-4-1106-preview": 30.0,
52 | # Cohere
53 | "command-r": 1.5,
54 | "command-r-plus": 15.0,
55 | }
56 |
57 |
58 | class MaxTokensExceededError(Exception):
59 | pass
60 |
61 |
62 | def num_tokens_from_messages(
63 | messages,
64 | skip_images: bool,
65 | model="gpt-3.5-turbo-0301",
66 | ):
67 | """Returns the number of tokens used by a list of messages."""
68 | assert skip_images, "skip_images=False is not presently supported"
69 |
70 | try:
71 | encoding = tiktoken.encoding_for_model(model)
72 | except KeyError:
73 | encoding = tiktoken.get_encoding("cl100k_base")
74 |
75 | if model in [
76 | "gpt-3.5-turbo-0301",
77 | "gpt-3.5-turbo-0125",
78 | "gpt-4-1106-preview",
79 | "gpt-4-0125-preview",
80 | ]: # note: future models may deviate from this
81 | num_tokens = 0
82 | for message in messages:
83 | num_tokens += (
84 | 4 # every message follows {role/name}\n{content}\n
85 | )
86 | for key, value in message.items():
87 | if key == "content":
88 | if isinstance(value, str):
89 | num_tokens += len(encoding.encode(value, disallowed_special=[]))
90 | elif isinstance(value, List):
91 | for piece in value:
92 | if piece["type"] == "text":
93 | num_tokens += len(
94 | encoding.encode(
95 | piece["text"], disallowed_special=[]
96 | )
97 | )
98 | else:
99 | assert skip_images
100 | else:
101 | raise NotImplementedError
102 | elif key == "name": # if there's a name, the role is omitted
103 | num_tokens += -1 # role is always required and always 1 token
104 | else:
105 | num_tokens += len(encoding.encode(value, disallowed_special=[]))
106 | num_tokens += 2 # every reply is primed with assistant
107 | return num_tokens
108 | else:
109 | raise NotImplementedError(
110 | f"""num_tokens_from_messages() is not presently implemented for model {model}.
111 | See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens."""
112 | )
113 |
114 |
115 | def image_height_width_from_path(image_path: str):
116 | with Image.open(image_path) as img:
117 | # Load only image metadata (not pixel data)
118 | img.load()
119 |
120 | # Get dimensions
121 | width, height = img.size
122 |
123 | return height, width
124 |
125 |
126 | def num_tokens_from_string(string: str, encoding_name: str = "cl100k_base") -> int:
127 | """Returns the number of tokens in a text string."""
128 | import tiktoken
129 |
130 | encoding = tiktoken.get_encoding(encoding_name)
131 | num_tokens = len(encoding.encode(string, disallowed_special=[]))
132 | return num_tokens
133 |
134 |
135 | def compute_token_count_for_image(image: Union[str, np.ndarray]):
136 | # From https://platform.openai.com/docs/guides/vision
137 | if isinstance(image, str):
138 | h, w = image_height_width_from_path(image)
139 | else:
140 | h, w, _ = image.shape
141 |
142 | # First rescaled to be within 2048x2048
143 | scale = 2048 / max([2048, h, w])
144 | h = h * scale
145 | w = w * scale
146 |
147 | # Then rescaled so shortest edge is 768
148 | h, w = 768 * h / min(h, w), 768 * w / min(h, w)
149 |
150 | return math.ceil(h / 512) * math.ceil(w / 512) * 170 + 85
151 |
152 |
153 | def partition_sequence(seq: Sequence, parts: int) -> List:
154 | assert 0 < parts, f"parts [{parts}] must be greater > 0"
155 | assert parts <= len(seq), f"parts [{parts}] > len(seq) [{len(seq)}]"
156 | n = len(seq)
157 |
158 | quotient = n // parts
159 | remainder = n % parts
160 | counts = [quotient + (i < remainder) for i in range(parts)]
161 | inds = np.cumsum([0] + counts)
162 | return [seq[ind0:ind1] for ind0, ind1 in zip(inds[:-1], inds[1:])]
163 |
164 |
165 | def encode_image(image_path: str):
166 | with open(image_path, "rb") as image_file:
167 | return base64.b64encode(image_file.read()).decode("utf-8")
168 |
169 |
170 | class NumpyJSONEncoder(json.JSONEncoder):
171 | """JSON encoder for numpy objects.
172 |
173 | Based off the stackoverflow answer by Jie Yang here: https://stackoverflow.com/a/57915246.
174 | The license for this code is [BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
175 | """
176 |
177 | def default(self, obj):
178 | if isinstance(obj, np.void):
179 | return None
180 | elif isinstance(obj, np.bool_):
181 | return bool(obj)
182 | elif isinstance(obj, np.integer):
183 | return int(obj)
184 | elif isinstance(obj, np.floating):
185 | return float(obj)
186 | elif isinstance(obj, np.ndarray):
187 | return obj.tolist()
188 | else:
189 | return super(NumpyJSONEncoder, self).default(obj)
190 |
191 |
192 | def compute_llm_cost(input_tokens: int, output_tokens: int, model: str):
193 | assert (
194 | model in MODEL_STR_TO_PRICE_PER_1M_INPUT_TOKENS
195 | and model in MODEL_STR_TO_PRICE_PER_1M_OUTPUT_TOKENS
196 | ), f"model [{model}] must be in both MODEL_STR_TO_PRICE_PER_1M_INPUT_TOKENS and MODEL_STR_TO_PRICE_PER_1M_OUTPUT_TOKENS"
197 |
198 | input_token_cost_per_1m = MODEL_STR_TO_PRICE_PER_1M_INPUT_TOKENS[model]
199 | output_token_cost_per_1m = MODEL_STR_TO_PRICE_PER_1M_OUTPUT_TOKENS[model]
200 |
201 | return (
202 | input_tokens * input_token_cost_per_1m
203 | + output_tokens * output_token_cost_per_1m
204 | ) / 1e6
205 |
206 |
207 | def compute_cost_for_queries_and_responses(
208 | queries_and_responses: Sequence[Dict[str, Union[str, List[Dict[str, Any]]]]],
209 | model: str,
210 | encoding_name: Optional[str] = "cl100k_base",
211 | ):
212 | input_tokens = 0
213 | output_tokens = 0
214 | for query_and_response in queries_and_responses:
215 | if "input_tokens" in query_and_response:
216 | input_tokens += query_and_response["input_tokens"]
217 | else:
218 | input_tokens += num_tokens_from_messages(
219 | query_and_response["input"], model=model, skip_images=True
220 | )
221 |
222 | if "output_tokens" in query_and_response:
223 | output_tokens += query_and_response["output_tokens"]
224 | else:
225 | output_str = query_and_response["output"]
226 | output_tokens += len(
227 | tiktoken.get_encoding(encoding_name).encode(
228 | output_str, disallowed_special=[]
229 | )
230 | )
231 |
232 | return (
233 | compute_llm_cost(input_tokens, output_tokens, model=model),
234 | input_tokens,
235 | output_tokens,
236 | )
237 |
238 |
239 | def create_openai_message(
240 | text: str, role: Literal["user", "system", "assistant"] = "user"
241 | ) -> Union[
242 | ChatCompletionSystemMessageParam,
243 | ChatCompletionUserMessageParam,
244 | ChatCompletionAssistantMessageParam,
245 | ]:
246 | return { # type: ignore
247 | "role": role,
248 | "content": [
249 | {
250 | "type": "text",
251 | "text": text,
252 | },
253 | ],
254 | }
255 |
256 |
257 | def query_gpt(
258 | messages: Sequence[ChatCompletionMessageParam],
259 | model: str,
260 | client: OpenAI,
261 | pbar: Optional[tqdm.tqdm] = None,
262 | sec_wait_between_retries: float = 10,
263 | max_tokens: int = 3000,
264 | return_input_output_tokens: bool = False,
265 | ) -> Optional[Union[str, Dict[str, Union[str, int]]]]:
266 | """Query the OpenAI API with the given messages."""
267 | num_tokens = num_tokens_from_messages(messages, skip_images=True)
268 | if num_tokens > max_tokens:
269 | raise MaxTokensExceededError(
270 | f"num_tokens [{num_tokens}] > max_tokens [{max_tokens}]"
271 | )
272 |
273 | if pbar:
274 | pbar.write(f"Num tokens: {num_tokens}")
275 |
276 | response = None
277 | for retry in range(10):
278 | try:
279 | response = cast(Chat, client.chat).completions.create(
280 | model=model,
281 | messages=cast(List[ChatCompletionMessageParam], messages),
282 | max_tokens=3000, # Max number of output tokens
283 | temperature=0.0,
284 | )
285 | break
286 | except RateLimitError:
287 | if pbar:
288 | pbar.write(
289 | f"Rate limit error, waiting {sec_wait_between_retries} seconds..."
290 | )
291 | except InternalServerError:
292 | if pbar:
293 | pbar.write(
294 | f"Internal server error, waiting {sec_wait_between_retries} seconds..."
295 | )
296 | except:
297 | m = traceback.format_exc().lower()
298 | if "ratelimit" in m or "rate limit" in m:
299 | if pbar:
300 | pbar.write(
301 | f"Rate limit error, waiting {sec_wait_between_retries} seconds..."
302 | )
303 | else:
304 | raise
305 |
306 | if response is not None:
307 | break
308 |
309 | if retry >= 9:
310 | if pbar:
311 | pbar.write(f"Hit max retries, raising exception.")
312 | raise RuntimeError("Hit max retries")
313 |
314 | if pbar:
315 | pbar.write(
316 | f"Retry {retry} failed, sleeping for {sec_wait_between_retries} seconds"
317 | )
318 |
319 | time.sleep(sec_wait_between_retries)
320 |
321 | if response is None:
322 | return None
323 |
324 | output = response.choices[0].message.content
325 |
326 | if return_input_output_tokens:
327 | return {
328 | "output": output,
329 | "input_tokens": response.usage.prompt_tokens,
330 | "output_tokens": response.usage.completion_tokens,
331 | }
332 | else:
333 | return output
334 |
--------------------------------------------------------------------------------
/codenav/utils/logging_utils.py:
--------------------------------------------------------------------------------
1 | import json
2 | import logging
3 | import multiprocessing as mp
4 | import os
5 | import signal
6 | import tempfile
7 | from queue import Empty
8 | from typing import Dict, Any, Set
9 |
10 | import attrs
11 | import wandb
12 |
13 |
14 | @attrs.define
15 | class StringAsFileArtifact:
16 | string: str
17 | file_name: str
18 | artifact_info: Dict[str, Any]
19 |
20 |
21 | class WandbClient:
22 | def __init__(self, queue: mp.Queue, client_index: int):
23 | self.queue = queue
24 | self.client_index = client_index
25 |
26 | self.Table = wandb.Table
27 | self.Image = wandb.Image
28 | self.Video = wandb.Video
29 | self.Audio = wandb.Audio
30 | self.Html = wandb.Html
31 |
32 | self._started = False
33 | self._closed = False
34 |
35 | def _check_is_start_and_notclosed(self):
36 | if not self._started:
37 | raise ValueError("WandbClient not been started yet. Call .init() first.")
38 |
39 | if self._closed:
40 | raise ValueError("WandbClient is closed.")
41 |
42 | def init(self):
43 | if self._started:
44 | raise ValueError("WandbClient is already started, cannot init again.")
45 |
46 | if self._closed:
47 | raise ValueError("WandbClient is closed, cannot init.")
48 |
49 | self._started = True
50 |
51 | def log(self, data: Dict[str, Any]):
52 | self._check_is_start_and_notclosed()
53 | self.queue.put((self.client_index, False, data))
54 |
55 | def log_artifact(self, artifact):
56 | self._check_is_start_and_notclosed()
57 | self.queue.put((self.client_index, False, artifact))
58 |
59 | def log_string_as_file_artifact(self, saa: StringAsFileArtifact):
60 | self._check_is_start_and_notclosed()
61 | self.queue.put((self.client_index, False, saa))
62 |
63 | def close(self):
64 | if not self._closed:
65 | self.queue.put((self.client_index, True, None))
66 | self._closed = True
67 |
68 | def __del__(self):
69 | if self._started and not self._closed:
70 | self.close()
71 |
72 |
73 | class WandbServer:
74 | def __init__(self, queue: mp.Queue, **wandb_kwargs):
75 | self.queue = queue
76 | self._num_clients_created = 0
77 | self._open_clients: Set[int] = set()
78 |
79 | wandb.init(**wandb_kwargs)
80 |
81 | def finish(self):
82 | assert not self.any_open_clients()
83 | wandb.finish()
84 |
85 | def create_client(self):
86 | wc = WandbClient(self.queue, client_index=self._num_clients_created)
87 | self._num_clients_created += 1
88 | self._open_clients.add(wc.client_index)
89 | return wc
90 |
91 | def any_open_clients(self):
92 | return len(self._open_clients) > 0
93 |
94 | @property
95 | def num_closed_clients(self):
96 | return self._num_clients_created - len(self._open_clients)
97 |
98 | def log(self, timeout: int, verbose: bool = False):
99 | logged_data = []
100 | while True:
101 | try:
102 | client_ind, closing, data = self.queue.get(timeout=timeout)
103 |
104 | assert client_ind in self._open_clients
105 |
106 | if closing:
107 | if verbose:
108 | print(f"Closing client {client_ind}")
109 |
110 | self._open_clients.remove(client_ind)
111 | continue
112 |
113 | if verbose:
114 | print(f"Logging [from client {client_ind}]: {data}")
115 |
116 | if isinstance(data, wandb.Artifact):
117 | wandb.log_artifact(data)
118 | elif isinstance(data, StringAsFileArtifact):
119 | td = tempfile.TemporaryDirectory()
120 | with td as temp_dir:
121 | with open(
122 | os.path.join(temp_dir, data.file_name), "w"
123 | ) as temp_file:
124 | temp_file.write(data.string)
125 |
126 | artifact = wandb.Artifact(**data.artifact_info)
127 | artifact.add_file(os.path.join(temp_dir, data.file_name))
128 |
129 | wandb.log_artifact(artifact)
130 | else:
131 | try:
132 | wandb.log(data)
133 | except TypeError:
134 | if isinstance(data, dict):
135 | new_data = {}
136 | for k, v in data.items():
137 | try:
138 | json.dumps(v)
139 | new_data[k] = v
140 | except:
141 | new_data[k] = str(v)
142 |
143 | wandb.log(new_data)
144 | else:
145 | raise
146 |
147 | logged_data.append(data)
148 | except Empty:
149 | break
150 |
151 | return logged_data
152 |
153 |
154 | class DelayedKeyboardInterrupt:
155 | def __enter__(self):
156 | self.signal_received = False
157 | self.old_handler = signal.signal(signal.SIGINT, self.handler)
158 |
159 | def handler(self, sig, frame):
160 | self.signal_received = (sig, frame)
161 | logging.debug(
162 | "SIGINT received. Delaying KeyboardInterrupt as critical code is running."
163 | )
164 |
165 | def __exit__(self, type, value, traceback):
166 | signal.signal(signal.SIGINT, self.old_handler)
167 | if self.signal_received:
168 | self.old_handler(*self.signal_received)
169 |
--------------------------------------------------------------------------------
/codenav/utils/omegaconf_utils.py:
--------------------------------------------------------------------------------
1 | import ast
2 | import copy
3 | import json
4 | import os.path
5 | import sys
6 | from typing import Optional, Sequence
7 |
8 | from omegaconf import OmegaConf, DictConfig, MissingMandatoryValue
9 | from omegaconf.errors import InterpolationKeyError
10 |
11 |
12 | def recursive_merge(base: DictConfig, other: DictConfig) -> DictConfig:
13 | base = copy.deepcopy(base)
14 |
15 | if all(key not in base for key in other):
16 | return OmegaConf.merge(base, other)
17 |
18 | for key in other:
19 | try:
20 | value = other[key]
21 | except InterpolationKeyError:
22 | value = other._get_node(key)._value()
23 | except MissingMandatoryValue:
24 | value = other._get_node(key)._value()
25 |
26 | if (
27 | key in base
28 | and isinstance(base[key], DictConfig)
29 | and isinstance(value, DictConfig)
30 | ):
31 | base[key] = recursive_merge(base[key], value)
32 | else:
33 | base[key] = value
34 |
35 | return base
36 |
37 |
38 | def load_config_from_file(config_path: str, at_key: Optional[str] = None) -> DictConfig:
39 | config_path = os.path.abspath(config_path)
40 | if not os.path.exists(config_path):
41 | raise FileNotFoundError(f"Config file not found: {config_path}")
42 |
43 | base_dir = os.path.dirname(os.path.abspath(config_path))
44 |
45 | main_conf = OmegaConf.load(config_path)
46 |
47 | defaults_paths = main_conf.get("_defaults_", [])
48 | if "_self_" not in defaults_paths:
49 | defaults_paths.insert(0, "_self_")
50 |
51 | main_conf.pop("_defaults_", None)
52 |
53 | config = OmegaConf.create()
54 | for p in defaults_paths:
55 | if p == "_self_":
56 | config = recursive_merge(config, main_conf)
57 | else:
58 | key = None
59 | if "@" in p:
60 | p, key = p.split("@")
61 |
62 | if not os.path.isabs(p):
63 | p = os.path.join(base_dir, p)
64 |
65 | other_conf = load_config_from_file(p, at_key=key)
66 |
67 | config = recursive_merge(config, other_conf)
68 |
69 | if at_key is not None:
70 | top = OmegaConf.create()
71 | cur = top
72 | sub_keys = at_key.split(".")
73 | for sub_key in sub_keys[:-1]:
74 | cur[sub_key] = OmegaConf.create()
75 | cur = cur[sub_key]
76 | cur[sub_keys[-1]] = config
77 | config = top
78 |
79 | return config
80 |
81 |
82 | def parse_omegaconf(
83 | base_config_path: Optional[str],
84 | args: Optional[Sequence[str]] = None,
85 | ) -> DictConfig:
86 | """
87 | Parses and merges configuration files and command line arguments using OmegaConf.
88 |
89 | This function loads a base configuration file (if provided), processes command line
90 | arguments to override configuration values or load additional files, and returns
91 | the final merged configuration.
92 |
93 | Basics:
94 | OmegaConf is a flexible and powerful configuration management library for Python.
95 | It supports hierarchical configurations, interpolation, and merging of configuration files.
96 | Key features of OmegaConf include:
97 | - Hierarchical Configuration: Allows configurations to be organized in nested structures.
98 | - Interpolation: Supports references to other values within the configuration.
99 | - Merging: Combines multiple configurations, with later configurations overriding earlier ones.
100 |
101 | YAML file overriding with `_defaults_`:
102 | You can use the `_defaults_` field in a YAML file to specify a list
103 | of other YAML files that should be loaded and merged. The `_defaults_` field allows
104 | you to control the order in which configurations are applied, with later files in
105 | the list overriding earlier ones.
106 |
107 | Example YAML files:
108 |
109 | ```yaml
110 | # logging.yaml
111 | log_level: info
112 | ```
113 |
114 | ```yaml
115 | # database.yaml
116 | database:
117 | host: localhost
118 | port: 5432
119 | ```
120 |
121 | ```yaml
122 | # base.yaml
123 | _defaults_:
124 | - logging.yaml@logging
125 | - database.yaml
126 |
127 | database:
128 | port: 3306
129 | ```
130 |
131 | Running `parse_omegaconf("base.yaml")` will result in the following configuration:
132 | ```yaml
133 | logging:
134 | log_level: info
135 | database:
136 | host: localhost
137 | port: 5432
138 | ```
139 |
140 | How overriding works:
141 | 1. When loading the main configuration file, `base.yaml`, the configurations listed in `_defaults_` are loaded
142 | in the order specified.
143 | 2. The main configuration file (the one containing `_defaults_`) IS LOADED FIRST BY DEFAULT.
144 | 3. If there are conflicting keys, the values in the later files override the earlier ones.
145 | 4. If a default yaml file is post-fixed with `@key`, the configuration will be placed at the specified key. Notice
146 | that logging.yaml@logging results in log_level: info being placed under the logging key in the final configuration.
147 | 5. By default, the fields in the main configuration file ARE OVERWRITTEN by the fields in the files listed in `_defaults_`
148 | as they are loaded first. If you'd prefer a different order, you can add _self_ to the list of defaults. E.g.
149 | ```yaml
150 | _defaults_:
151 | - logging.yaml
152 | - _self_
153 | - database.yaml
154 | ```
155 | will result in database.yaml overriding fields in base.yaml resulting in the merged configuration:
156 | ```yaml
157 | logging:
158 | log_level: info
159 | database:
160 | host: localhost
161 | port: 5432
162 | ```
163 |
164 | Command line overrides:
165 | Command line arguments can be used to override configuration values. Overrides can
166 | be specified directly or by using the `_file_` keyword to load additional configuration files.
167 |
168 | Direct overrides:
169 | ```bash
170 | python script.py database.port=1234
171 | ```
172 |
173 | `_file_` override:
174 | The `_file_` override allows you to specify an additional YAML file to be merged
175 | into the existing configuration:
176 | ```bash
177 | python script.py _file_=extra_config.yaml
178 | ```
179 |
180 | `_file_` with key specification:
181 | To load a file and merge it at a specific key:
182 | ```bash
183 | python script.py _file_=extra_config.yaml@some.key
184 | ```
185 |
186 | Comparing `parse_omegaconf` with the `hydra` library:
187 | Hydra is a popular configuration management library built on top of OmegaConf. Which provides a large
188 | collection of additional features for managing complex configurations. Hydra is designed to be a
189 | comprehensive solution for configuration management, including support for running and managing
190 | multiple job executions. `parse_omegaconf` is a much simpler function that focuses solely on configuration
191 | loading and merging, without the additional features provided by Hydra. We wrote this function as
192 | a lightweight alternative which is less opinionated about how configurations should be structured, loaded,
193 | and used.
194 |
195 | Args:
196 | base_config_path (Optional[str]): The path to the base configuration file.
197 | If None, an empty configuration will be created.
198 | args (Optional[Sequence[str]]): A list of command line arguments to override
199 | configuration values. If None, `sys.argv[1:]` will be used.
200 |
201 | Returns:
202 | omegaconf.DictConfig: The final merged configuration.
203 |
204 | Raises:
205 | FileNotFoundError: If the specified base configuration file does not exist.
206 | ValueError: If a command line argument is not formatted as `key=value`.
207 | KeyError: If attempting to override a non-existent key without using the `+` prefix.
208 | """
209 | if base_config_path is not None:
210 | config = load_config_from_file(base_config_path)
211 | else:
212 | config = OmegaConf.create()
213 |
214 | if args is None:
215 | args = sys.argv[1:]
216 |
217 | while len(args) > 0:
218 | arg = args.pop(0)
219 |
220 | try:
221 | key, value = arg.split("=", maxsplit=1)
222 | except ValueError:
223 | raise ValueError(f"Invalid argument: {arg}. Must be formatted as key=value")
224 |
225 | if arg.startswith("_file_="):
226 | sub_key = None
227 | if "@" in value:
228 | value, sub_key = value.split("@")
229 | config = recursive_merge(
230 | config, load_config_from_file(value, at_key=sub_key)
231 | )
232 | else:
233 | try:
234 | value = ast.literal_eval(value)
235 | except (SyntaxError, ValueError):
236 | try:
237 | value = json.loads(value)
238 | except json.JSONDecodeError:
239 | pass
240 |
241 | if key.startswith("+"):
242 | key = key[1:]
243 | else:
244 | key_parts = key.split(".")
245 | sub_config = config
246 | err_msg = (
247 | f"Cannot override value for key {key} in config to {value} using a command line argument"
248 | f" as the key {key} does not already exist in the config. If you'd like to to add a"
249 | f" key that does not already exist, please use the format +key=value rather than just key=value."
250 | )
251 | for key_part in key_parts[:-1]:
252 | if key_part not in sub_config:
253 | raise KeyError(err_msg)
254 | sub_config = sub_config[key_part]
255 |
256 | if sub_config._get_node(key_parts[-1]) is None:
257 | raise KeyError(err_msg)
258 |
259 | OmegaConf.update(config, key, value)
260 |
261 | return config
262 |
--------------------------------------------------------------------------------
/codenav/utils/parsing_utils.py:
--------------------------------------------------------------------------------
1 | import ast
2 | from _ast import AST
3 | from typing import Union, cast
4 |
5 |
6 | def get_class_or_function_prototype(
7 | code: Union[str, ast.ClassDef, ast.FunctionDef],
8 | include_init: bool = True,
9 | ) -> str:
10 | """
11 | Summarizes the given Python class or function definition code.
12 |
13 | For classes by, this will occur by keeping the class name and its __init__ method signature,
14 | replacing the body of __init__ with an ellipsis (...).
15 |
16 | For functions, this will occur by keeping the function name and its signature, replacing the body with an ellipsis (...).
17 |
18 | Args:
19 | - code: A string containing the Python class definition.
20 |
21 | Returns:
22 | - A summary string of the form "class ClassName(BaseClass): def __init__(self, arg1: Type, arg2: Type, ...): ..."
23 | for a class definition, or "def function_name(arg1: Type, arg2: Type, ...) -> Type: ..." for a function definition.
24 | """
25 | if isinstance(code, str):
26 | tree = ast.parse(code)
27 | func_or_class = [
28 | node
29 | for node in ast.iter_child_nodes(tree)
30 | if isinstance(node, (ast.ClassDef, ast.FunctionDef))
31 | ]
32 | assert (
33 | len(func_or_class) == 1
34 | ), "The given code should contain exactly one class or function definition."
35 | node = func_or_class[0]
36 | else:
37 | node = code
38 |
39 | summary = ""
40 | if isinstance(node, ast.ClassDef):
41 | # Format class definition
42 | base_classes = [ast.unparse(base) for base in node.bases]
43 | class_header = f"class {node.name}({', '.join(base_classes)}):"
44 | summary += class_header
45 |
46 | if include_init:
47 | for item in node.body:
48 | if isinstance(item, ast.FunctionDef) and item.name == "__init__":
49 | # Format __init__ method signature
50 | init_signature = ast.unparse(item.args)
51 | summary += f" def __init__({init_signature}): ..."
52 | break
53 | else:
54 | summary += " ..."
55 | elif isinstance(node, ast.FunctionDef):
56 | # Format function definition
57 | function_signature = ast.unparse(node.args)
58 |
59 | try:
60 | return_suff = f" -> {ast.unparse(cast(AST, node.returns))}"
61 | except:
62 | return_suff = ""
63 |
64 | summary += f"def {node.name}({function_signature}){return_suff}: ..."
65 |
66 | return summary
67 |
--------------------------------------------------------------------------------
/codenav/utils/prompt_utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 | from collections import defaultdict
4 | from typing import Any, Dict, List, Sequence, Tuple
5 |
6 | import attrs
7 |
8 | from codenav.constants import PROMPTS_DIR
9 |
10 |
11 | def extract_placeholders(s):
12 | pattern = r"(? str:
48 | found_path = None
49 | for prompt_dir in self.prompt_dirs:
50 | prompt_path = os.path.join(prompt_dir, rel_path)
51 | if os.path.exists(prompt_path):
52 | found_path = prompt_path
53 | break
54 |
55 | if found_path is None:
56 | raise FileNotFoundError(
57 | f"Prompt file with relative path: '{rel_path}' not found "
58 | f"in any of the prompt directories: {self.prompt_dirs}"
59 | )
60 |
61 | with open(found_path, "r") as f:
62 | prompt_str = f.read()
63 | placeholders = extract_placeholders(prompt_str)
64 | for pl in placeholders:
65 | self.placeholder_to_paths[pl].append(found_path)
66 |
67 | return prompt_str
68 |
69 | def get_action_prompts(self) -> Sequence[str]:
70 | return [
71 | self.get_prompt(getattr(self.action_prompts, action))
72 | for action in self.actions_to_enable
73 | ]
74 |
75 | def get_response_prompts(self) -> Sequence[str]:
76 | return [
77 | self.get_prompt(getattr(self.response_prompts, action))
78 | for action in self.actions_to_enable
79 | ]
80 |
81 | def build_template(self) -> Tuple[str, Dict[str, List[str]]]:
82 | self.placeholder_to_paths = defaultdict(list)
83 | prompts = [
84 | self.get_prompt(self.overview),
85 | self.get_prompt(self.workflow),
86 | self.get_prompt(self.action_prompts.preamble),
87 | *self.get_action_prompts(),
88 | self.get_prompt(self.action_prompts.guidelines),
89 | self.get_prompt(self.response_prompts.preamble),
90 | *self.get_response_prompts(),
91 | self.get_prompt(self.repo_description),
92 | ]
93 |
94 | return "\n\n".join(prompts), dict(self.placeholder_to_paths)
95 |
96 | def build(self, placeholder_values: Dict[str, Any]) -> str:
97 | return self.build_template()[0].format(**placeholder_values)
98 |
--------------------------------------------------------------------------------
/codenav/utils/string_utils.py:
--------------------------------------------------------------------------------
1 | import re
2 | from typing import Optional
3 |
4 |
5 | def get_tag_content_from_text(
6 | text: str,
7 | tag: str,
8 | ) -> Optional[str]:
9 | pattern = f"<{tag}>" + r"\s*(.*?)\s*" + f""
10 | match = re.search(pattern, text, re.DOTALL)
11 | content = match.group(1) if match else None
12 | if content == "":
13 | return None
14 | return content
15 |
16 |
17 | def str2bool(s: str):
18 | s = s.lower().strip()
19 | if s in ["yes", "true", "t", "y", "1"]:
20 | return True
21 | elif s in ["no", "false", "f", "n", "0"]:
22 | return False
23 | else:
24 | raise NotImplementedError
25 |
--------------------------------------------------------------------------------
/codenav_examples/create_code_env.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from codenav.environments.code_env import PythonCodeEnv
4 |
5 | project_dir = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
6 | print(f"Project directory: {project_dir}")
7 | env = PythonCodeEnv(
8 | sys_paths=[project_dir],
9 | working_dir=os.path.join(project_dir, "playground"),
10 | enable_type_checking=True,
11 | )
12 |
13 | exec_output1 = env.step("from codenav.interaction.messages import ACTION_TYPES")
14 | print(exec_output1.format(include_code=True, display_updated_vars=True))
15 |
16 | exec_output2 = env.step("print(ACTION_TYPES)")
17 | print(exec_output2.format(include_code=True, display_updated_vars=True))
18 |
--------------------------------------------------------------------------------
/codenav_examples/create_episode.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | from codenav.agents.gpt4.agent import OpenAICodeNavAgent
4 | from codenav.constants import ABS_PATH_OF_CODENAV_DIR, DEFAULT_OPENAI_MODEL
5 | from codenav.environments.code_env import PythonCodeEnv
6 | from codenav.environments.done_env import DoneEnv
7 | from codenav.environments.retrieval_env import EsCodeRetriever, RetrievalEnv
8 | from codenav.interaction.episode import Episode
9 | from codenav.retrieval.elasticsearch.elasticsearch_constants import RESERVED_CHARACTERS
10 | from codenav.retrieval.elasticsearch.index_codebase import DEFAULT_ES_HOST
11 | from codenav.utils.prompt_utils import PromptBuilder
12 |
13 | ALLOWED_ACTIONS = ["done", "code", "search"]
14 | CODE_DIR = ABS_PATH_OF_CODENAV_DIR
15 | PARENT_DIR = os.path.dirname(CODE_DIR)
16 |
17 | # create prompt
18 | prompt_builder = PromptBuilder(repo_description="codenav/repo_description.txt")
19 | prompt = prompt_builder.build(
20 | dict(
21 | AVAILABLE_ACTIONS=ALLOWED_ACTIONS,
22 | RESERVED_CHARACTERS=RESERVED_CHARACTERS,
23 | RETRIEVALS_PER_KEYWORD=3,
24 | )
25 | )
26 |
27 | # create environments
28 | code_env = PythonCodeEnv(
29 | code_dir=CODE_DIR,
30 | sys_paths=[PARENT_DIR],
31 | working_dir=os.path.join(PARENT_DIR, "playground"),
32 | )
33 |
34 | retrieval_env = RetrievalEnv(
35 | code_retriever=EsCodeRetriever(
36 | index_name="codenav",
37 | host=DEFAULT_ES_HOST,
38 | ),
39 | expansions_per_query=3,
40 | prototypes_per_query=7,
41 | )
42 |
43 | done_env = DoneEnv()
44 |
45 |
46 | # create agent using prompt
47 | agent = OpenAICodeNavAgent(
48 | prompt=prompt,
49 | model=DEFAULT_OPENAI_MODEL,
50 | allowed_action_types=ALLOWED_ACTIONS,
51 | )
52 |
53 | # create environments:
54 | episode = Episode(
55 | agent,
56 | action_type_to_env=dict(
57 | code=code_env,
58 | search=retrieval_env,
59 | done=done_env,
60 | ),
61 | user_query_str="Find the DoneEnv and instantiate it",
62 | )
63 |
64 | episode.step_until_max_steps_or_success(max_steps=5)
65 |
--------------------------------------------------------------------------------
/codenav_examples/create_index.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 |
4 | import pandas as pd
5 | from elasticsearch import Elasticsearch
6 |
7 | from codenav.environments.retrieval_env import RetrievalEnv
8 | from codenav.retrieval.elasticsearch.elasticsearch_retriever import EsCodeRetriever
9 | from codenav.retrieval.elasticsearch.index_codebase import DEFAULT_ES_HOST, build_index
10 |
11 | print(f"Looking for a running Elasticsearch server at {DEFAULT_ES_HOST}...")
12 | es = Elasticsearch(DEFAULT_ES_HOST)
13 | if es.ping():
14 | print(f"Elasticsearch server is running at {DEFAULT_ES_HOST}")
15 | else:
16 | print(
17 | f"Elasticsearch server not found at {DEFAULT_ES_HOST}\n"
18 | "\tStart the server before running this script\n"
19 | "\tTo start the Elasticsearch server, run `condenav init` or `python -m condenav.codenav_run init`"
20 | )
21 | sys.exit(1)
22 |
23 |
24 | CODE_DIR = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))
25 | SUBDIR = "codenav"
26 | print(f"Building index from subdir='{SUBDIR}' of code_dir='{CODE_DIR}' ...")
27 | build_index(
28 | code_dir=CODE_DIR,
29 | force_subdir=SUBDIR,
30 | delete_index=True,
31 | index_uid="codenav",
32 | host=DEFAULT_ES_HOST,
33 | )
34 |
35 | print("Creating EsCodeRetriever which can search the index...")
36 | es_code_retriever = EsCodeRetriever(index_name="codenav", host=DEFAULT_ES_HOST)
37 |
38 | print("Searching the ES index using `prototype: CodeEnv`...")
39 | search_query = "prototype: CodeSummaryEnv"
40 | raw_search_res = es_code_retriever.search(search_query)
41 |
42 | raw_search_res_df = pd.DataFrame.from_records(raw_search_res)
43 | print(raw_search_res_df)
44 |
45 | print("Creating retrieval environment that adds state logic...")
46 | env = RetrievalEnv(
47 | code_retriever=es_code_retriever,
48 | expansions_per_query=3,
49 | prototypes_per_query=5,
50 | summarize_code=False,
51 | )
52 | response = env.step(search_query)
53 | print(response.format())
54 |
--------------------------------------------------------------------------------
/codenav_examples/create_prompt.py:
--------------------------------------------------------------------------------
1 | from codenav.agents.gpt4.agent import DEFAULT_OPENAI_MODEL, OpenAICodeNavAgent
2 | from codenav.retrieval.elasticsearch.elasticsearch_constants import RESERVED_CHARACTERS
3 | from codenav.utils.prompt_utils import PromptBuilder
4 |
5 | # Prompt builder puts together a prompt template from text files
6 | # The template may contain placeholders for values
7 | prompt_builder = PromptBuilder(repo_description="codenav/repo_description.txt")
8 | prompt_template, placeholder_to_paths = prompt_builder.build_template()
9 |
10 | # see placeholders and the file paths they appear in
11 | print("Placeholders in template:\n", placeholder_to_paths)
12 |
13 | # provide values for these placeholders
14 | ALLOWED_ACTIONS = ["done", "code", "search"]
15 | placeholder_values = dict(
16 | AVAILABLE_ACTIONS=ALLOWED_ACTIONS,
17 | RESERVED_CHARACTERS=RESERVED_CHARACTERS,
18 | RETRIEVALS_PER_KEYWORD=3,
19 | )
20 | print("Provided values:\n", placeholder_values)
21 |
22 | # build prompt using values
23 | # the following is equivalent to prompt_template.format(**placeholder_values)
24 | prompt = prompt_builder.build(placeholder_values)
25 |
26 | # create agent using prompt
27 | agent = OpenAICodeNavAgent(
28 | prompt=prompt,
29 | model=DEFAULT_OPENAI_MODEL,
30 | allowed_action_types=ALLOWED_ACTIONS,
31 | )
32 |
--------------------------------------------------------------------------------
/codenav_examples/parallel_evaluation.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import Any, List, Optional
3 |
4 | from codenav.agents.gpt4.agent import OpenAICodeNavAgent
5 | from codenav.constants import ABS_PATH_OF_CODENAV_DIR, DEFAULT_OPENAI_MODEL
6 | from codenav.environments.code_env import PythonCodeEnv
7 | from codenav.environments.done_env import DoneEnv
8 | from codenav.environments.retrieval_env import EsCodeRetriever, RetrievalEnv
9 | from codenav.interaction.episode import Episode
10 | from codenav.retrieval.elasticsearch.elasticsearch_constants import RESERVED_CHARACTERS
11 | from codenav.retrieval.elasticsearch.index_codebase import DEFAULT_ES_HOST
12 | from codenav.utils.eval_types import EvalInput, EvalSpec, Str2AnyDict
13 | from codenav.utils.evaluator import CodenavEvaluator
14 | from codenav.utils.prompt_utils import PromptBuilder
15 |
16 |
17 | # EvalSpec defines the components for running an evaluation
18 | # EvalSpec is then used by the CodenavEvaluator to run CodeNav on inputs using 1 or more processes
19 | # EvalSpec requires defining 3 methods: build_episode, run_interaction, log_output
20 | class CodenavEvalSpec(EvalSpec):
21 | def __init__(
22 | self,
23 | episode_kwargs: Str2AnyDict,
24 | interaction_kwargs: Str2AnyDict,
25 | logging_kwargs: Str2AnyDict,
26 | ):
27 | super().__init__(episode_kwargs, interaction_kwargs, logging_kwargs)
28 |
29 | @staticmethod
30 | def build_episode(
31 | eval_input: EvalInput,
32 | episode_kwargs: Optional[Str2AnyDict] = None,
33 | ) -> Episode:
34 | assert episode_kwargs is not None
35 | prompt_builder = PromptBuilder(
36 | repo_description=episode_kwargs["repo_description"]
37 | )
38 | prompt = prompt_builder.build(
39 | dict(
40 | AVAILABLE_ACTIONS=episode_kwargs["allowed_actions"],
41 | RESERVED_CHARACTERS=RESERVED_CHARACTERS,
42 | RETRIEVALS_PER_KEYWORD=episode_kwargs["retrievals_per_keyword"],
43 | )
44 | )
45 |
46 | return Episode(
47 | agent=OpenAICodeNavAgent(
48 | prompt=prompt,
49 | model=episode_kwargs["llm"],
50 | allowed_action_types=episode_kwargs["allowed_actions"],
51 | ),
52 | action_type_to_env=dict(
53 | code=PythonCodeEnv(
54 | code_dir=episode_kwargs["code_dir"],
55 | sys_paths=episode_kwargs["sys_paths"],
56 | working_dir=episode_kwargs["working_dir"],
57 | ),
58 | search=RetrievalEnv(
59 | code_retriever=EsCodeRetriever(
60 | index_name=episode_kwargs["index_name"],
61 | host=episode_kwargs["host"],
62 | ),
63 | expansions_per_query=episode_kwargs["retrievals_per_keyword"],
64 | prototypes_per_query=episode_kwargs["prototypes_per_keyword"],
65 | ),
66 | done=DoneEnv(),
67 | ),
68 | user_query_str=eval_input.query,
69 | )
70 |
71 | @staticmethod
72 | def run_interaction(
73 | episode: Episode,
74 | interaction_kwargs: Optional[Str2AnyDict] = None,
75 | ) -> Str2AnyDict:
76 | assert interaction_kwargs is not None
77 | episode.step_until_max_steps_or_success(
78 | max_steps=interaction_kwargs["max_steps"],
79 | verbose=interaction_kwargs["verbose"],
80 | )
81 | ipynb_str = episode.to_notebook(cur_dir=episode.code_env.working_dir)
82 | return dict(ipynb_str=ipynb_str)
83 |
84 | @staticmethod
85 | def log_output(
86 | interaction_output: Str2AnyDict,
87 | eval_input: EvalInput,
88 | logging_kwargs: Optional[Str2AnyDict] = None,
89 | ) -> Any:
90 | assert logging_kwargs is not None
91 |
92 | outfile = os.path.join(logging_kwargs["out_dir"], f"{eval_input.uid}.ipynb")
93 | with open(outfile, "w") as f:
94 | f.write(interaction_output["ipynb_str"])
95 |
96 | return outfile
97 |
98 |
99 | def run_parallel_evaluation(
100 | eval_inputs: List[EvalInput],
101 | episode_kwargs: Str2AnyDict,
102 | interaction_kwargs: Str2AnyDict,
103 | logging_kwargs: Str2AnyDict,
104 | num_processes: int = 2,
105 | ):
106 | # create an instance of the CodenavEvaluator using the eval spec
107 | evaluator = CodenavEvaluator(
108 | eval_spec=CodenavEvalSpec(
109 | episode_kwargs=episode_kwargs,
110 | interaction_kwargs=interaction_kwargs,
111 | logging_kwargs=logging_kwargs,
112 | )
113 | )
114 |
115 | # Get outputs from the output queue
116 | num_inputs = len(eval_inputs)
117 | for i, output in enumerate(evaluator.evaluate(eval_inputs, n_procs=2)):
118 | print(
119 | f"Evaluated {i+1}/{num_inputs} | Input uid: {eval_inputs[i].uid} | Output saved to ",
120 | output,
121 | )
122 |
123 |
124 | if __name__ == "__main__":
125 | episode_kwargs = dict(
126 | allowed_actions=["done", "code", "search"],
127 | repo_description="codenav/repo_description.txt",
128 | retrievals_per_keyword=3,
129 | prototypes_per_keyword=7,
130 | llm=DEFAULT_OPENAI_MODEL,
131 | code_dir=ABS_PATH_OF_CODENAV_DIR,
132 | sys_paths=[os.path.dirname(ABS_PATH_OF_CODENAV_DIR)],
133 | working_dir=os.path.join(
134 | os.path.dirname(ABS_PATH_OF_CODENAV_DIR), "playground"
135 | ),
136 | index_name="codenav",
137 | host=DEFAULT_ES_HOST,
138 | )
139 | interaction_kwargs = dict(max_steps=10, verbose=True)
140 | logging_kwargs = dict(out_dir="/Users/tanmayg/Code/codenav_test/outputs")
141 |
142 | # Define the inputs to evaluate using EvalInput
143 | # Each EvalInput instance consists of a unique id (uid), a query, and optionally any metadata
144 | eval_inputs = [
145 | EvalInput(uid=1, query="Find the DoneEnv and instantiate it"),
146 | EvalInput(
147 | uid=2,
148 | query="Build the prompt template using PromptBuilder and print all the placeholders",
149 | ),
150 | ]
151 | run_parallel_evaluation(
152 | eval_inputs,
153 | episode_kwargs,
154 | interaction_kwargs,
155 | logging_kwargs,
156 | num_processes=2,
157 | )
158 |
--------------------------------------------------------------------------------
/playground/.gitignore:
--------------------------------------------------------------------------------
1 | *
2 | !.gitignore
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.black]
2 | extend-exclude = '''
3 | (
4 | eval_codebases/hf_transformers
5 | |eval_codebases/DAMO-ConvAI
6 | |.venv
7 | |external_src
8 | )
9 | '''
10 |
11 | [tool.mypy]
12 | exclude = [
13 | "^eval_codebases/llama2-webui.*",
14 | "^eval_codebases/hf_transformers.*",
15 | "^eval_codebases/cvxpy.*",
16 | "^eval_codebases/flask.*",
17 | "^eval_codebases/mnm.*",
18 | "^eval_codebases/sympy.*",
19 | "^eval_codebases/scikit-learn.*",
20 | "^eval_codebases/src.*",
21 | "^external_src.*",
22 | "tmp.py"
23 | ]
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | openai
2 | together
3 | cohere
4 | tiktoken
5 | black==23.12.1
6 | mypy
7 | flake8
8 | pillow
9 | numpy<2.0.0
10 | pandas
11 | wandb
12 | matplotlib
13 | nbformat
14 | notebook
15 | jupyterlab
16 | elasticsearch
17 | compress_json
18 | omegaconf
19 | hydra-core
20 | attrs
21 | tqdm
22 |
--------------------------------------------------------------------------------
/scripts/release.py:
--------------------------------------------------------------------------------
1 | import os
2 | import sys
3 | from pathlib import Path
4 | from subprocess import getoutput
5 |
6 | PKG_NAME = "codenav"
7 |
8 |
9 | def make_package(verbose=False):
10 | """Prepares sdist for codenav."""
11 |
12 | orig_dir = os.getcwd()
13 |
14 | base_dir = os.path.dirname(os.path.abspath(os.path.dirname(Path(__file__))))
15 | os.chdir(base_dir)
16 |
17 | with open(".VERSION", "r") as f:
18 | __version__ = f.readline().strip()
19 |
20 | # generate sdist via setuptools
21 | output = getoutput(f"{sys.executable} setup.py sdist")
22 | if verbose:
23 | print(output)
24 |
25 | os.chdir(os.path.join(base_dir, "dist"))
26 |
27 | # uncompress the tar.gz sdist
28 | output = getoutput(f"tar zxvf {PKG_NAME}-{__version__}.tar.gz")
29 | if verbose:
30 | print(output)
31 |
32 | # create new source file with version
33 | getoutput(
34 | f"printf '__version__ = \"{__version__}\"\n' >> {PKG_NAME}-{__version__}/{PKG_NAME}/_version.py"
35 | )
36 | # include it in sources
37 | getoutput(
38 | f'printf "\ncodenav/_version.py" >> {PKG_NAME}-{__version__}/{PKG_NAME}.egg-info/SOURCES.txt'
39 | )
40 |
41 | # recompress tar.gz
42 | output = getoutput(
43 | f"tar zcvf {PKG_NAME}-{__version__}.tar.gz {PKG_NAME}-{__version__}/"
44 | )
45 | if verbose:
46 | print(output)
47 |
48 | # remove temporary directory
49 | output = getoutput(f"rm -r {PKG_NAME}-{__version__}")
50 | if verbose:
51 | print(output)
52 |
53 | os.chdir(orig_dir)
54 |
55 |
56 | if __name__ == "__main__":
57 | make_package(verbose=False)
58 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | import os
2 | from pathlib import Path
3 |
4 | from setuptools import find_packages, setup
5 |
6 |
7 | def parse_req_file(fname, initial=None):
8 | """Reads requires.txt file generated by setuptools and outputs a
9 | new/updated dict of extras as keys and corresponding lists of dependencies
10 | as values.
11 |
12 | The input file's contents are similar to a `ConfigParser` file, e.g.
13 | pkg_1
14 | pkg_2
15 | pkg_3
16 |
17 | [extras1]
18 | pkg_4
19 | pkg_5
20 |
21 | [extras2]
22 | pkg_6
23 | pkg_7
24 | """
25 | reqs = {} if initial is None else initial
26 | cline = None
27 | with open(fname, "r") as f:
28 | for line in f.readlines():
29 | line = line[:-1].strip()
30 | if len(line) == 0:
31 | continue
32 | if line[0] == "[":
33 | # Add new key for current extras (if missing in dict)
34 | cline = line[1:-1].strip()
35 | if cline not in reqs:
36 | reqs[cline] = []
37 | else:
38 | # Only keep dependencies from extras
39 | if cline is not None:
40 | reqs[cline].append(line)
41 | return reqs
42 |
43 |
44 | def get_version(fname):
45 | """Reads PKG-INFO file generated by setuptools and extracts the Version
46 | number."""
47 | res = "UNK"
48 | with open(fname, "r") as f:
49 | for line in f.readlines():
50 | line = line[:-1]
51 | if line.startswith("Version:"):
52 | res = line.replace("Version:", "").strip()
53 | break
54 | if res in ["UNK", ""]:
55 | raise ValueError(f"Missing Version number in {fname}")
56 | return res
57 |
58 |
59 | def read_requirements(filename: str):
60 | with open(filename) as requirements_file:
61 | import re
62 |
63 | def fix_url_dependencies(req: str) -> str:
64 | """Pip and setuptools disagree about how URL dependencies should be handled."""
65 | m = re.match(
66 | r"^(git\+)?(https|ssh)://(git@)?github\.com/([\w-]+)/(?P[\w-]+)\.git",
67 | req,
68 | )
69 | if m is None:
70 | return req
71 | else:
72 | return f"{m.group('name')} @ {req}"
73 |
74 | requirements = []
75 | for line in requirements_file:
76 | line = line.strip()
77 | if line.startswith("#") or line.startswith("-e") or len(line) <= 0:
78 | continue
79 | requirements.append(fix_url_dependencies(line))
80 | return requirements
81 |
82 |
83 | def _do_setup():
84 | base_dir = os.path.abspath(os.path.dirname(Path(__file__)))
85 |
86 | if not os.path.exists(
87 | os.path.join(base_dir, "codenav.egg-info/dependency_links.txt")
88 | ):
89 | # Build mode for sdist
90 | os.chdir(base_dir)
91 |
92 | version_path = os.path.abspath(".VERSION")
93 | print(version_path)
94 | with open(version_path, "r") as f:
95 | __version__ = f.readline().strip()
96 |
97 | # Extra dependencies for development (actually unnecessary)
98 | extras = {}
99 | if os.path.exists("dev_requirements.txt"):
100 | extras = {
101 | "dev": [
102 | l.strip()
103 | for l in open("dev_requirements.txt", "r").readlines()
104 | if l.strip() != ""
105 | ]
106 | }
107 | else:
108 | # Install mode from sdist
109 | __version__ = get_version(os.path.join(base_dir, "codenav.egg-info/PKG-INFO"))
110 | extras = parse_req_file(os.path.join(base_dir, "codenav.egg-info/requires.txt"))
111 |
112 | setup(
113 | name="codenav",
114 | version=__version__,
115 | description=(
116 | "CodeNav is a LLM-powered agent that can answer queries about code."
117 | ),
118 | long_description=open("README.md").read(),
119 | long_description_content_type="text/markdown",
120 | classifiers=[
121 | "Intended Audience :: Science/Research",
122 | "Development Status :: 3 - Alpha",
123 | "License :: OSI Approved :: Apache Software License",
124 | "Programming Language :: Python :: 3",
125 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
126 | ],
127 | keywords=["code understanding", "LLM", "large language models"],
128 | url="https://github.com/allenai/codenav",
129 | author="Allen Institute for Artificial Intelligence",
130 | author_email="lucaw@allenai.org",
131 | packages=find_packages(
132 | include=["codenav", "codenav.*"],
133 | exclude=["*.tests", "*.tests.*", "tests.*", "tests"],
134 | ),
135 | license="Apache 2.0",
136 | package_data={
137 | "codenav": ["prompts/default/*"],
138 | },
139 | install_requires=read_requirements("requirements.txt"),
140 | python_requires=">=3.9",
141 | entry_points={"console_scripts": ["codenav=codenav.codenav_run:main"]},
142 | # scripts=["codenav/codenav_run.py"],
143 | # setup_requires=["pytest-runner"],
144 | # tests_require=["pytest", "pytest-cov"],
145 | extras_require=extras,
146 | )
147 |
148 |
149 | if __name__ == "__main__":
150 | _do_setup()
151 |
--------------------------------------------------------------------------------