├── CPU.md
├── Java
├── dubbo.md
├── 一次使用多线程所引发的惨案.md
├── 我是一个线程池.md
├── 一个故事看懂对象的创建过程.md
├── 为什么线程崩溃不会导致JVM崩溃.md
├── Java线程模型.md
├── ConrrentHashMap是强一致性的吗.md
├── 字节码剖析.md
└── 多线程使用不当引发的惨案.md
├── 学习指南
├── 美团2017-2020年技术文章.md
└── 谷歌师兄刷题笔记.md
├── 程序人生
├── 我创业啦!!!.md
├── 我是如何晋升专家岗的.md
├── 面试了十几位前端有感.md
├── 与一位全职转行做滴滴司机的前程序员对话引发的思考.md
├── 谈谈一些学习心得.md
└── 优秀的程序员应该具备哪些能力.md
├── 工程师效率
├── Gradlebuild慢?可能是你使用的姿势不对.md
└── Alfred有多强悍,我写了个一键上传图片的workflow来告诉你.md
├── README.md
├── 系统设计
├── 震惊!线上四台机器同一时间全部OOM,到底发生了什么?.md
├── 优秀程序员必备的四项能力.md
├── 你管这破玩意儿叫负载均衡.md
├── 金融监控实战.md
├── 从应用层到网络层排查Dubbo接口超时全记录.md
├── 高性能短链设计.md
├── keepalived工作原理.md
└── 高性能网关设计实践.md
├── ChatGPT
└── AI地图实践.md
├── 网络
├── 这个下载文件的问题困住了我至少三位同事.md
├── TCP:一个悲伤的故事.md
├── 20张图让你彻底弄懂HTTPS原理.md
└── 你管这破玩意儿叫token.md
├── 个人感悟
└── 随想.md
├── 算法
├── Trie树的妙用.md
├── 拜托,别再问我什么是B+树了.md
└── 提升逼格利器-位运算.md
├── MySQL
└── 深入浅出索引原理.md
└── 架构
└── 高可用.md
/CPU.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/Java/dubbo.md:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/学习指南/美团2017-2020年技术文章.md:
--------------------------------------------------------------------------------
1 | 给大家送一份很不错的资料,是美团技术团队送给技术人的年货,我过年期间看了几篇,确实是很扎实的年货。
2 | 美团 2017-2020 年发布的技术文章合集,我也给大家收集并汇总到一起了。
3 |
4 |
5 | 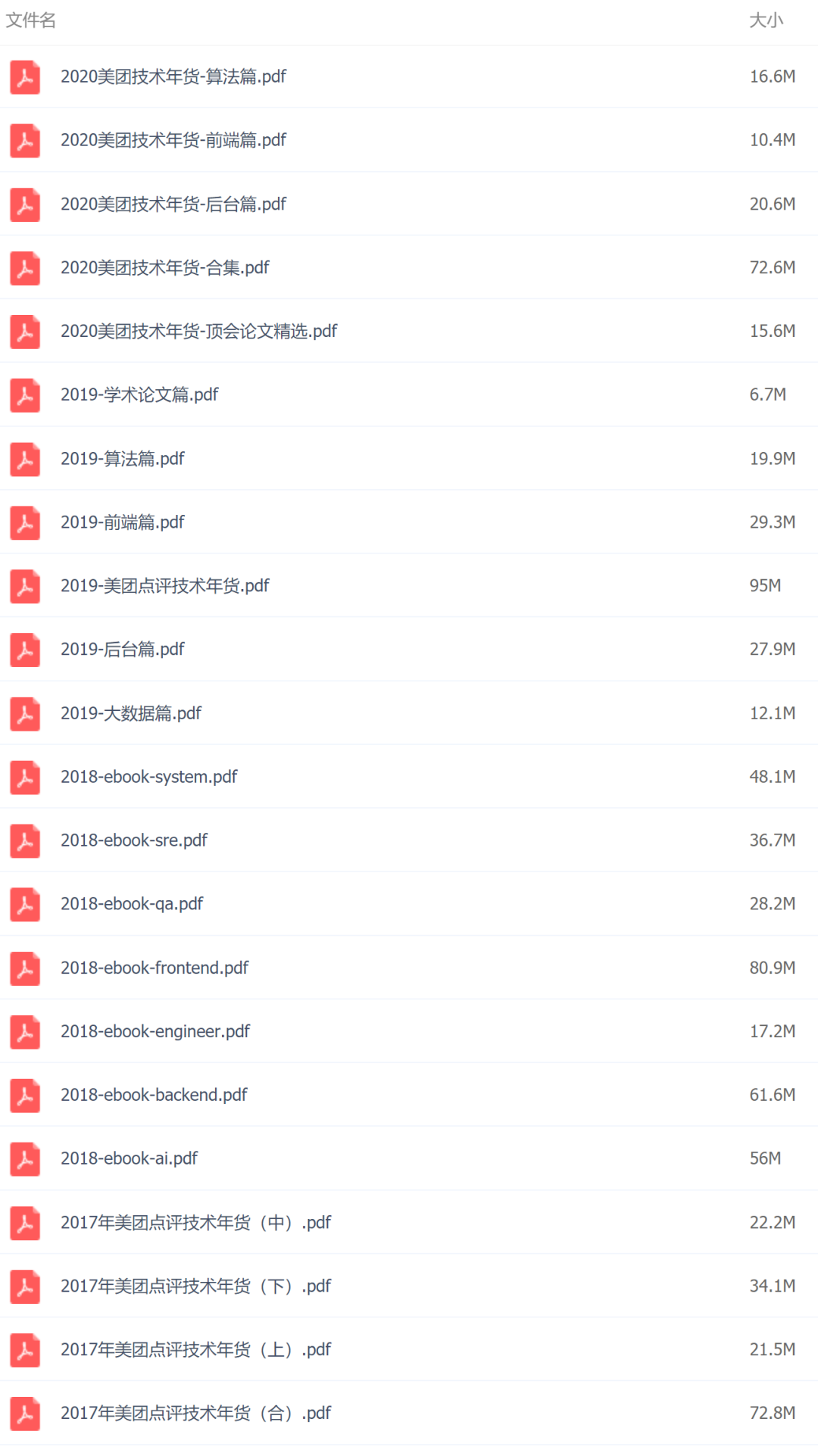
6 |
7 |
8 | 美团文章质量真的是很高,如果你也想看,可以扫一扫关注「码海」,回复关键字【java】,即可获得下载链接。
9 |
10 | 
--------------------------------------------------------------------------------
/学习指南/谷歌师兄刷题笔记.md:
--------------------------------------------------------------------------------
1 | 对于刷题相关的文章,在之前我也推荐过不少,今天在给大家推荐一份谷歌师兄的算法刷题笔记,这份笔记与以往的刷题有所区别,作者把 Leetcode 一千多道题都进行了系统的整理,并且对于每一道题的代码,都要求 beat 100%。
2 |
3 | 作者把所有题型分成了 13 个类别,截个图给大家看一下
4 |
5 | 
6 |
7 | 无论是为了面试,为了打比赛还是入门学习一些算法,我还是挺建议前期按照各类题型逐个击破,这份刷题笔记,或许可以给大家带来一些帮忙。
8 |
9 | 我简单看了一下每一个道题的解答,每个题并没有给出多种答案,基本都是直接给出最优解,代码写的挺简洁,所以呢,我觉得这份刷题笔记,大家还是可以收藏一份放在电脑里,时不时拿大神的代码出来参考一下。截几个图给大家看看
10 |
11 | 
12 |
13 | 
14 |
15 | 就算你现在不学算法,那么这份笔记也值得你收藏,万一有人问你 Leetcode 某道题解,或者有大神在讨论题解,咱打开这份笔记,不管三七二十一,直接把最优解扔给他,然后退出群聊
16 |
17 | 如何获取呢?
18 |
19 | 大家可以关注下面这个微信公众号「码海」回复「**刷题**」即可获取。
20 |
21 | 
22 |
23 | 另外大家可以star一下这个github地址: [easy-cs](https://github.com/allentofight/easy-cs),会持续更新文档哦
--------------------------------------------------------------------------------
/Java/一次使用多线程所引发的惨案.md:
--------------------------------------------------------------------------------
1 | 你好,我是坤哥
2 |
3 |
4 |
5 | 今天和大家分享一下前几天出现的一次使用多线程导致的线上故障,挺有代表性的,这个错误估计比较资深的程序员也会犯错,特此分享出来,相信大家看了肯定收获
6 |
7 |
8 |
9 | ### 问题背景
10 |
11 | 先简单介绍下此次使用多线程改造的业务背景,我们的平台是是返利平台,有一个搜索场景是用户在 app 上输入商品名称,传给 server 后 server 会根据此商品名称来查找其在各个平台(如淘宝,京东,拼多多)上对应的商品列表再返回给 app 进行展示,由于是单线程,显然 server 的处理时间和平台的数量成简单的线性关系(平台越多,server 的处理时间越多),由于各个平台的搜索接口是独立的,所以显然单线程是可以改成多线程的,如下
12 |
13 | 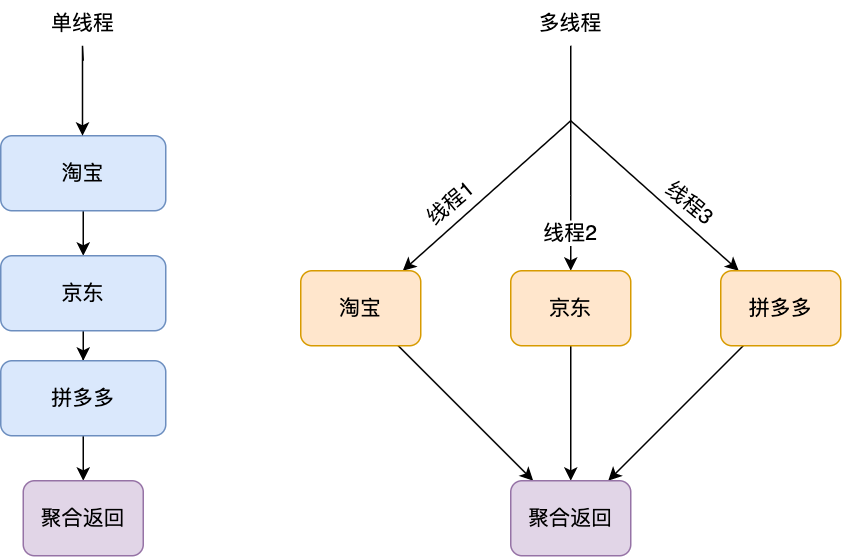
14 |
15 |
16 |
17 | 改成用多线程后,server 的处理时间只取决于商品搜索接口耗时最长的那一个平台了,显然效率得到了极大的提升,看起来这是一次完美的改造,不过这只是灾难的开始,上线后有大量用户反馈搜索接口不能用,经过定位后发现是因为 app 的版本号(version)无法获取,所以搜索接口会触发引导用户去升级 app 的提示,伪代码如下
18 |
19 | ```java
20 | static String getAppVersion() {
21 | String version = getVersion();
22 | if (StringUtils.isEmpty(version)) {
23 | throw new Exception("获取 version 失败,请升级");
24 | }
25 | return version;
26 | }
27 | ```
28 |
29 | 好了,原因找到了,那么问题来了,好好的 version 怎么突然间就找不到了呢,我们可以先思考一下这个 version 应该存在哪里比较合适
30 |
31 |
32 |
33 | ### threadlocal 简介
34 |
35 |
36 |
37 |
38 |
39 | 主要是为了提高性能将单线程改成多线程
--------------------------------------------------------------------------------
/程序人生/我创业啦!!!.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥。
2 |
3 | 今天要宣布一件大事,我要创业了!确切地说是我们部门要拆分成一个独立的公司,盈亏自负。
4 |
5 | 自从去年 leader 和我说部门要拆分之后就一直很期待,熟悉我的读者都知道去年我是从金融部门转向了返利业务,原因嘛其实很简单,金融受监管影响较大,在增长上遇到了较大瓶颈,而返利业务发展还不错,有奔头,本来属于无心插柳的试水业务,没想到发展比较迅猛,成了公司的扛把子部门!有很高的想象力。
6 |
7 | 为啥我对部门独立成公司这么期待,leader 让我选择后我毫不犹豫得就答应了呢?
8 |
9 | 主要有以下三个原因
10 |
11 | ### 1、 市场巨大,想象空间高
12 |
13 | 给大家看一下网上找到的一张图
14 |
15 | 
16 |
17 | 2019年淘宝联盟(阿里妈妈)全年支出淘客佣金 500 亿,官方的目标是希望在未来几年佣金能达到 1000 亿的规模!想象空间巨大,这是其一。其二,当前阿里,拼多多,京东等巨头厮杀激烈,必然在获客上会下大功夫,可以预见必然会大力扶持淘客,所以在可预见的未来对淘客而言都是很大的利好!
18 |
19 | ### 2、 团队现金流稳定
20 |
21 | 正向的现金流太重要了,多少创业公司死于缺钱这两字,这个问题在我们这不存在,我们已能实现正向的现金流,而且投资人看好,已融了一大笔钱(具体数额不便透露),第二轮融资也基本敲定,估值上亿,所以未来几年我们都不用为钱的事发愁,可以尝试一些方向。
22 |
23 | ### 3、 团队靠谱
24 |
25 | 团队成员太重要了,事在人为,投资人投你一方面是业务方向,另一方面毫无疑问是人,公司挺多人都觉得我们是最具创业精神的团队,而且我们产品总监(未来新公司的 CEO)连续两次把公司的试水业务做成了公司的战略级产品,眼光,产品思维确实让人佩服!团队可以说是我选择出去干的最重要原因了。
26 |
27 | ## 因为相信,所以看见
28 |
29 | 我想简单谈下我对创业的一点点想法,背靠大集团,确实安全感提升很多,可以旱涝保收,不过既然有机会实现 10 倍速的财富增长,为啥不去做呢,像字节,快手等早期员工有多少人因为选择的时机而实现了财富自由,而且基于对上述我说的几个理由的判断,不得不对新团队有这样高的期待! 我非常喜欢那句话「因为相信,所以看见」,因为基于对未来的判断,所以我们看见了这条路是可以走下去的,梦想总是要有的,万一实现了呢?
30 |
31 | 当然了,创业有风险,大家之后在选择创业公司时一定要擦亮眼睛,可以试试上文我所说的判断逻辑,从业务前景,现金流,团队人员配置这三项来判断,相信你能避开不少坑。
32 |
33 | ## 最后: 招人
34 |
35 | 目前新公司人员已经到位,不过独缺**前端**,如果你是前端开发人员,欢迎投简历给我,另外第二轮融资我们也基本敲定,到时可能会扩招后端等人员,欢迎大家扫一扫关注公号「码海」,添加我的微信:geekoftaste,我会第一时间把招聘消息发到朋友圈里,希望我们能共事
36 |
37 | 
38 |
39 |
--------------------------------------------------------------------------------
/工程师效率/Gradlebuild慢?可能是你使用的姿势不对.md:
--------------------------------------------------------------------------------
1 | 之前我司每个 Java 应用部署到预发都要等待漫长的编译打包时间,非常地痛苦!大项目编译时间常常达到接近 10 分钟,生命短暂啊,人生有多少个 10 分钟可以等待,于是我的效能团队针对编译作了一些优化,提速非常明显,对某个应用的测试来看,编译时间从 160 s 缩短到了 50 s 左右,提升近 70%,大家纷纷点赞,那么效能团队做了哪些措施来让编译速度提升这么明显呢?
2 |
3 | 首先要说的是我们用的 Gradle 来作为我们的构建工具,所以主要是针对 Gradle 的命令来作了一些优化
4 |
5 | ## 1、修改 gradle build 的参数
6 |
7 | * 使用 --build-cache
8 |
9 | 什么是 build cache(构建缓存),在 Gradle 中,每一个待编译的工程叫 Project,每一个 Project 在构建时都包含一系列的 task
10 |
11 | 
12 |
13 | 每个 task 的输入都可以作为下一个 task 的输出,build cache 做的事就是把可以缓存(注:并不是所有的 task 输出都能缓存)的 task 输出都缓存住,这样在构建过程中,如果发现这个 task 的输入不变,就没必要重新执行任务了,直接从 task ouput 缓存里拿即可,如下图示,Build 2 的构建输入直接从 Build Cache 中拿,这样 Build 1 就不用构建了。
14 |
15 | 
16 |
17 | 效果怎么样呢,看下图,下面图分别显示了 Gradle 持续集成时使用构建缓存和不使用构建缓存两种情况下的聚合的构建时间,可以看到使用了 cache 的 Gradle 构建速度明显快于不使用 cache 的情况
18 |
19 | 
20 |
21 |
22 | 更骚的是这个 Buiid Cache 支持分布式的,可以统一把这些 cache 丢到一台机器上,本地机器要编译时统一去这台机器拉 cache,这样如果我们切换分支时执行构建也能用 Build Cache 来加快构建速度
23 |
24 | --build-cache 的具有使用需要注意一些事项,比如得 Gradle 4.3 以上才有效,建议大家直接去官网查查看
25 |
26 | * 增加 --parallel 参数
27 |
28 | 并行执行在多项目编译的项目中能有效提升编译的速度,但是并行执行的前提是每个项目已经被模块化,每个项目之间没有耦合。
29 |
30 |
31 | * 移除 --refresh-dependencies 参数
32 |
33 | 原来 gradle build 有加这个参数,这个参数会忽略缓存,强制重新下载,显然是编译的瓶颈
34 |
35 | ## 2、任务并行
36 |
37 | 原来 Jenkins 中执行 Gradle 编译任务,每个 Task 是串行执行的,总编译耗时是每个任务执行时间的总和。
38 |
39 | 
40 |
41 | 现在把它改成了并行的
42 |
43 | 
44 | 显然并行执行会快得多
45 |
46 | ## 3、将大项目工程中的常用代码抽成 jar 包
47 |
48 | 对于业务方来说,采用这种方式也是提升编译速度的有效手段 ,将大量代码抽成 jar 包,意味着它们本身就是字段码了,在 gradle build 时就不用编译啦。
49 |
50 | 希望本文对你有帮助,记得点个在看哦 ^_^
51 |
52 | 欢迎关注公号,共同交流学习
53 |
54 | 
--------------------------------------------------------------------------------
/程序人生/我是如何晋升专家岗的.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥。
2 |
3 | 近期收至少不少读者私信咨询,最普通的困惑是「每天都在 CRUD。没啥竞争力,该怎么办」,我觉得这是一个很普遍的问题,也应该是很多人的困惑,我想讲讲我的经历,希望对大家能有所启发。
4 |
5 | 目前我虽然做的从事的是 Java 后端,不过其实我一开始做的是 iOS 客户端,16 年我司在移动端业务发展迅猛,业务都高歌猛进,随之而来的是 iOS APP 工程的急速膨胀,于是一个大问题就出现了:由于工程庞大,打包时间急遽上升,经常需要一小时以上,更恼人的是打包经常失败,这样的话从提测,到提交到 appstore 发布等流程都受到了严重影响,甚至影响到了整体的业务迭代流程。这事还惊动了我们的副总裁,问我们是否是 Mac mini 性能太差所致,是否可以换个高配的机器来解决。
6 |
7 | 当时我刚加入集团不久,做的也是某业务的负责人,其实做的也是 CRUD 的工作,听到这个消息,**立马意识到这是个巨大的机会**,解决好了不仅能让集团的业务迭代速度大大提升,更是能成为第二年的晋升的重要加成,于是就在业余时间着手调研解决方案,当时我们正在实行 iOS 的组件化方案,简单地说就是把一个工程拆分一个个以业务,功能划分的组件,这样的话组件之间的开发互不影响,能极大地提升业务的迭代速度。
8 |
9 | 
10 |
11 | **如图示:组件化示意图,有点类似于微服务架构中的服务拆分,只不过与微服务不同的是这些组件共同组成了一个 app,这些组件编译归档后会生成 ipa,也就是运行在大家手中的 app。**
12 |
13 | 经过观察不难发现从工程打包生成 ipa 99% 的耗时就在组件编译生成静态库这一步,所以解决方案很简单,提前将组件打包成静态库不就行了,这样 app 工程就由一个个组件的静态库组成,省去了编译这一步
14 |
15 | 
16 |
17 | 当然组件打包生成静态库这一步还要有工具来实现,调研了一下发现有现成的第三方库可用,于是将一整套方案整理成文档第一时间在 iOS 团队进行了分享,之后各个组件负责人一起加班加点地把这件事落实了下来。
18 |
19 | 效果也是很明显的,整个打包时间从一个多小时降低到了 3 分钟以内,生产力得到了巨大的提升,后续所有 iOS 打包方案也是用的这套方案,可以说彻底解决了打包的问题,第二年晋升我也将此项写到了我的述职报告中,并得到了评委的认可,当然能晋升还有其他的一些要素,但打包方案的提出可以说是一个重大加成。
20 |
21 | 仔细看打包的解决方案,你会发现,其实没啥技术含量,但我把握住了,而且发现痛点后第一时间调研提出解决方案,也取得了显著效果。
22 |
23 | 所以虽然说很多人都在担心一直在 CRUD,但我们其实能做很多来提升我们的技术,提升我们的影响力,我们可以及时发现痛点并解决它,关键是要**有心**,当时我司 iOS 开发人员有十几个,结果是我主动调研并第一时间先提出了解决方案,我觉得我自己的积极主动有很大的关系。
24 |
25 | 这件事对我们的启发是我觉得要**要争取成为解决方案的提出者**,提出者贡献最大,执行虽然重要,但没有方案,便无从下手,这就好比没有建筑图纸,如何施工。
26 |
27 | 所以我觉得虽然很多人都在 CRUD,但只要我们**有心**,一样可以提升自己的技术能力,就比如你做 CRUD,关心过接口性能吗,是否还有优化的空间(比如提升 20%等),上次我看到安琪拉在阿里做的事就颇多感慨,他把接口性能优化的耗时,从三十几毫秒下降到五毫秒,类似的接口还有十几个,都是核心接口,还有SQL性能的优化等等,如下是他优化后的效果:
28 |
29 | 
30 |
31 | 这样的话你做的每一个优化日积月累必然会给你带来出其不意的回报!
32 |
33 | 另一方面,我学得稍微大点的团队都会有技术分享,可以多去旁听下其他团队的解决方案,痛点以便看下是否能引入自己的团队中。
34 |
35 | 最后我想再说的是千万不要觉得 CRUD 就不能提高技术了,关键还在于你是否有心。
36 |
37 | 最后欢迎大家加我好友,一起交流,共同进步^_^
38 |
39 | 
40 |
--------------------------------------------------------------------------------
/程序人生/面试了十几位前端有感.md:
--------------------------------------------------------------------------------
1 | 创业后一直没招到合适的前端,一直都是后端干着前端的活,当然对技术尤其是创业公司而言,其实没必要分前后端这么细,但我们还是希望能招到一位比较有经验的前端,一是团队的人员配置更加合理,二是有一位有经验的前端可以给我们团队带来很大的帮助,提升我们的前端的整体 level,比如有时页面需要用一些复杂的交互动画或者碰到一些疑难杂症如果招一位有经验的前端能让问题更快速的解决。
2 |
3 |
4 |
5 | 基于以上的这些想法 ,我们打算招一位有经验的前端,由于之前委托过别人招聘过一位不合格的前端,所以这次招聘我们决定自己上阵,当然要求其实不会很高,能干活,有潜力,完整地参与过商业项目的开发即可,毕竟创业公司压力比较大(我们大小周),而且总的 package 确实不如大厂,如果再按大厂的要求来招聘那估计招不到多少人。
6 |
7 |
8 |
9 | 在面试中我发现一些共性的问题,这里简单总结下,最近正值金九银十,有不少读者让我帮忙看看简历或者说说面试中注意的事项,也顺带借此简单说下
10 |
11 | ### 1.简历的书写问题
12 |
13 | 这一块我发现主要有以下问题
14 |
15 | #### 简单罗列项目,未突出重点
16 |
17 | 不少人简历大段大段地介绍项目的功能,确实写了一些对应的技术栈,但面试官最关心的比如技术难点和自己承担的角色却只字未提,这样的简历其实是要打折扣的,面试官其实更关心的此项目的含金量,在我看来主要有以下两点
18 |
19 | * **项目中的难点与改进**: 这一点**尤其关键**,最好能有可量化的指标,比如说通过采用 xxx 等手段,让页面的加载速度提升了xxx s,通过对 xxx 开源项目的改造,解决了 xxx 的痛点等
20 | * **自己在项目中承担的角色**: 这一点也很重要,同样一个项目,承担的是核心还是边缘角色,这对个人的评价至关重要,如果是核心开发角色并承担了主要技术的攻关,无疑能让简历的份量大大提升,反之会逊色不少,但如果你承担的就是边缘角色呢,该怎么办,我觉得个人也得主要去了解整个项目的脉络,各个功能模块的实现原理,尤其是那些技术实现难点,最好也能把它们都摸透,这样能把项目的难点等说透在逻辑也能自洽
21 |
22 |
23 |
24 | ### 2. 简历上写的与自身能力不匹配
25 |
26 | 这一点是大忌,在面试中发现好几位有这样的问题,比如有一位说使用代理服务解决跨域问题,结果一问部署步骤说不出所以然,再问什么是跨域,也说不上来,再比如有一位说熟悉 TCP 协议,结果一问为什么需要三次握手,也说不出个所以然,这些都是比较忌讳的,面试官只能通过简历来了解你,如果简历上写的点与实际不符,他可能会很怀疑你简历你的真实性,或者认为你个人不够严谨,这样最后的结果往往不理想,不熟悉的就不要写,写上了就一定要了解掌握这些技术点的原理,至少要让你的能力与简历上的相符
27 |
28 |
29 |
30 | 接下来再来谈谈简历中的加分项,在我看来以下两点无疑会大大加分
31 |
32 | #### 主动解决问题的意识
33 |
34 | 项目中存在问题,如果自己能主动推进解决,这样的简历毫无疑问会大大加分,比如我之前就曾在[我是如何晋升专家岗](https://mp.weixin.qq.com/s/zElQzjft_cBoamb_5-GxfA)里提到主动去优化技术方案将打包时间从一个多小时降低到 3 分钟以内,这些没有人让你做,属于「无中生有」,如果能解决好这些问题那你的简历其实是非常亮眼的,可能有人说这样的机遇可遇而不可求,其实我觉得还是要看自己是否**有心**,比如我面过一个两年工作经验的前端,问到代码规范的问题,他说组内主要看个人的意识,这显然是有问题的,也不利于团队协作,最佳方式应该是靠工具的形式来约束,比如使用 VSCode + eslint 插件自动修复或者指出你的代码问题,光这样还不够,如果有些人不修复,写了一大堆 console.log 提交了怎么办?所以你还需要利用 git commit 的 pre hook 来校验代码规范,如果校验不通过那就不让提交,通过这样的方式就有力推进了代码规范,你看这就是一个很好的优化点,如果你能推进这方面工具化的落地,那说明你有一定的技术追求与代码规范和工具化意识,这在简历上无疑是一个比较大的亮点。
35 |
36 |
37 |
38 | 再比如一些候选人所在的公司在外包公司或者其他的一些小厂,一些发布流程不是那么自动化(碰到几个手动需要手动打包后再交给运维部署的), 那能否想办法把这个流程自动化呢(比如很多大厂里的发布流程都是一键点击自动化的),这样的话省去了人力之苦,而且也对项目是怎么跑起来的有一个清晰的认识,如果我们在项目中碰到这些不那么高效的活能把它自动化掉,那对团队的效率提升无疑是很大的,也能为你的履历添砖加瓦。
39 |
40 |
41 |
42 | #### 线上部署可演示的项目
43 |
44 | 这一点对于工作经验不足的开发者尤其有帮助,比如我发现其中一位候选人就做得很好,让我印象深刻,他业余时间自己做了一个如下皮卡丘的动画项目
45 |
46 | 
47 |
48 | 在线上可演示效果,并且还有代码滚动展示,这种意识确实非常棒,让人感觉更真实,收到的挺多简历都写着做过 xxx 系统,如果这些能在线上让面试官体验一下,确实是一个很大的亮点。
49 |
50 |
51 |
52 | 再比如秒杀系统在后端面试中经常出现,那我们能否去做一套这样的系统并部署上去呢,如果能让面试官体验一下,用户体验上无疑会好很多,怎么从 0 开始做秒杀项目呢,这里推荐几个我看过的质量很高的专栏和文章,可能对大家有帮助
53 |
54 | 1. 极客时间的《手把手带你搭建秒杀系统》从 0 到 1 带你打造一个百万 QPS 的秒杀项目,关于秒杀理论讲解得很到位,实践性也很强
55 | 2. github 上的 2.2w star 的秒杀项目:https://github.com/qiurunze123/miaosha
56 | 3. [秒杀系统实战总结](https://mp.weixin.qq.com/s/yWn_2OQV31zn5wJKKejGug),一位技术总监关于秒杀的总结,根据他们公司的秒杀项目估的总结,可以应付大部分的场景
57 |
58 |
59 |
60 | 部署一个完整的上线项目,一来可以让你对项目如何是跑起来的会有非常感性的认识,二来面试官线上可以有直观的体验,而且也能看到你的代码书写规范等,好处很多,挺多人说自己没有高并发经验,那就手动实践一下部署上去让面试官见证一下,这些经验不就有了吗,好处这么多,何乐而不为呢。
61 |
62 |
63 |
64 | 另外不少人抱怨说面试官喜欢问很多八股文,其实我想说的是如果项目经验足够硬核,技术含量足够高,没有人喜欢也没必要问那些八股文,直接顺着项目经验问你在项目中掌握的技术点就足以给你定级了。
65 |
66 | 
--------------------------------------------------------------------------------
/程序人生/与一位全职转行做滴滴司机的前程序员对话引发的思考.md:
--------------------------------------------------------------------------------
1 | 昨天晚上由于没赶上班车,所以打开了滴滴叫了一辆快车,上车后看这司机小伙子挺斯文的,简单聊了几句,没想到居然是位前程序员,一开始还以为是兼职,结果聊完之后才知道是全职,确实是大吃一惊,仔细一问原委才知道,原来是去年因为疫情原因被裁,但是之后一直没找到工作,但生活总得继续吧,最终选择了全职转行做滴滴这条路。由于我司到地铁只有几分钟的车程,很快就到站了,没法再继续细聊下去,但是听完之后,不胜唏嘘。
2 |
3 | 每个人都有自己的选择,旁人确实不好评价,可能在当时的情况下转行做滴滴是他作出的最利于摆脱当前困境的最佳选择,就像前段时间很热门有三位程序员相约考公成功上岸这事一样,在我们看来,他们放弃了程序员的高薪,可能难以理解,但对他们而言,他们摆脱了 996,每天准点下班,发季线低了,也能常和老婆孩子热炕头,这样的生活别提有多惬意了,都云作者痴, 谁解其中味?
4 |
5 | 虽然理解他们的选择,职业也并无贵贱之分,但肯定有好坏之别,那么什么样的职业是好,什么样的职业是坏呢?
6 |
7 | ## 好职业与坏职业
8 |
9 | 我觉得好工作应该是**上限高,有想象力的**,坏工作则是有上限,自己的未来一眼就能看穿,看得到头的,什么意思?
10 |
11 | 比如说吧以滴滴司机为例,每天的收入与你跑的单数成正比,可能每天都非常努力地跑单,拼死拼活一天能赚个一千多,但**当你停止接单时,你的收入也就停止了**,清洁工,餐饮里跑腿的也是一样,这一类工作只要你停止劳动了,你的收入也就戛然而止了,而且这类工作需要付出极大的体力消耗,每天劳累了一天,根本没有时间思考人生,第二天开始又**重复机械**地劳作,**可替代性极高**,而我们知道职场的收入与你的不可替代性是成正比的,所以这类工作我认为并不是好工作。
12 |
13 | 那么好工作又有哪些特性呢,我觉得有两点,一是能持续打造自己的稀缺性,比如程序员行业,随着你技能的不断精进,你的待遇,不可替代性自然会越来越强,二是想象空间足够高,比如说自媒体,可能你写的文章没人看,但也有可能写出 10w+ 的爆文,而且做自媒体长尾效应明显,只要你的文章/视频等足够好,在很长的时间内你都可以借此不断获得关注,长尾效应明显,在当今时代,流量就是钱啊,所以你用心写好文章,就可以借此获得源源不断地关注,认可,也就是说**当你停止写作时,你过去的作品还在不断地吸引很多人关注你,为你创造价值**,这就是为啥我一直坚持写作,也鼓励大家写作的原因,从这个角度来看,自媒体确实是一个好职业!
14 |
15 | ## 工程师如何抵御风险
16 |
17 | 为了避免别人觉得我在说教,我先简单亮一下自己的成绩,目前的被动收入(副业+理财等)已能 cover 包括房贷等在内的生活开支,老婆的一个投资项目每年也能稳定收益 20 w 左右,生活上只要不出现特别大的变故,可以说没有任何问题,所以我说的一些经验可能对大家有些借鉴意义,希望能给大家带来一些启发。
18 |
19 | 首先当然是把自己的本职工作做好,技术越强,职位越高,你的竞争力也就越强,现在虽然是寒冬时期,招聘标准越来越高,但从全局来看,技术优秀的候选者去头条,拼多多这样的大厂呆个十年运气好挣个千万依然不是什么大问题问题,但不得不承认的是,90% 的工程师想要拿到百万年薪确实很难,我司之前一位总裁就说过,P8 以下我们认为都是可以培养的,P8及以上看天赋,升职除了能力之外,可能多少也掺杂着些运气。
20 |
21 | 所以我们应该怎么办,之前有提过,这里再搬出之前 linkedln 和 paypal 的联合创始人ReidHoffman 提出的 ABZ 理论吧。
22 |
23 | A: 是你正在从事的工作,也是能长期从事下去的工作,值得你持续投入,并可以获得安全感,并且这份工作,你个人还很满意。
24 |
25 | B: 是除去 A 计划外,业余时间你给自己其他能力的培训,或者兴趣爱好或梦想,可以认为是副业,这样的话万一主业出现问题,哪天被机器人替代了,由于你有自己的副业,可以立马转为 A,可以让你从容应对。
26 |
27 | Z: 即个人资产,是你的保障,也是你的退路。假设有一天你的 AB 计划全部落空失败,你的 Z 计划,可以保证你在未来某一段时间内,可以继续保持现有的生活品质,能给你一次从头再来的机会。我的理解就是理财,比如基金,定投,股票,房产投资等,
28 |
29 | 在 IT 界并不是每个人都是人中龙凤,达到百万年薪并不是那么容易,那么我们是否可以考虑做斜杠青年呢,可能我们在某种能力上并不突出,但可以在沟通,写作,影响力上多向发展构建自己的 IP 矩阵,这些能力的关系可能是「能力 1 x 能力 2 x 能力 n」这样的乘法关系,无形中会让我们的竞争力大大提高,IT 人可能大部分人听过侯捷,翻译了很多畅销书,我记得业内有位大牛评论侯捷老师时说,单论技术能力算中上,离顶尖有距离,但他翻译的书非常好,基本都是畅销书,就就构建了强大的影响力,这就像现在技术公号领域最知名的博主 stormzhang 一样,技术并非顶尖,但通过投资,写作等构建了坚实的护城河,他们未必有顶尖的技术,但为读者提供了一流的服务,进而构建了自己影响力。
30 |
31 | 需要注意的是在斜杠青年的尝试中,这些能力最好是对主业有促进作用的,比如写作,通过写作你巩固了对知识点的理解,厘清了各个模糊的概念,由点及面构建了自己的知识体系,也锻炼了自己的写作,表达能力等,这对主业就有极大的促进作用,千万慎重考虑由程序员转行做滴滴这样的事,因为这是两个完全不同的行业,一旦转行,你之前行业的积累就没有,相当于从头开始,而且就我们以上的分析来看,滴滴这样的职业上限有限,一眼望得到头,不是一份好职业。
32 |
33 | 我最近做了淘客,一些朋友看来有点「不务正业」,但其实一来我的业务从之前负责的金融转到返利来了,从事淘客有助于我对本身的业务有更深的理解,二来淘客其实也是一个长尾效应很明显的行业,回报也是比较丰厚的(我看到最夸张的案例一个月躺赚 30w,你没有看错,是一个月 30w!),而且要做好淘客,你要懂得些拉新,精细化运营等思路,这样来看又锻炼了你的产品和运营思维,不管怎么看,都对你的主业有很大的促进作用!有这么多好处,为啥不做。
34 |
35 | 说了这么多最重要的我觉得是**不要给自己设限**,在保证自己主业的前提下多去尝试,尽量构建自己的能力矩阵。
36 |
37 | 再说投资,一般人可能想得到的投资就是股票,理财,还有房子,不过其实还有一种投资回报也很丰厚,比如投资「密室逃脱」这种新兴项目,上文我说的老婆投资每年能躺赚 20w 的项目就是这个,前期投资,后斯回本后躺赚的这种,当然这种投资需要有眼光,更需要勇气,我建议是不要超过家庭总收入的四分之一,这样万一失败也不至于影响到正常的家庭生活水平。
38 |
39 | ## 最后
40 |
41 | 希望本文对你有所启发,另外前几天在朋友圈分享了做淘客的一点心得,没想到这么多人感兴趣,本周将会在我的另一个号「程序员坤哥」上分享出来,希望对想做淘客的朋友一定会有帮助!如果想看的可以关注这个号哦。
42 |
43 | 另外欢迎大家扫描以下二维码,关注公众号「码海」共同进步
44 |
45 |
46 | 
47 |
--------------------------------------------------------------------------------
/Java/我是一个线程池.md:
--------------------------------------------------------------------------------
1 | ## 线程池的自我介绍
2 | 我是一个线程池(ThreadPoolExecutor),我的主要工作是管理在我这的多个线程(Thread),让他们能并发地执行多个任务的同时,又不会造成很大的的系统开销,有人不明白,创建线程有啥开销呢,不是只要 new 一个 Thread 出来让它跑就行了吗,这里我要简单解释下:
3 |
4 | 1. 其实 Java 中的中的线程模型是基于操作系统原生线程模型实现的,也就是说 Java 中的线程其实是基于内核线程实现的,线程的创建,析构与同步都需要进行系统调用,而系统调用需要在用户态与内核中来回切换,代价相对较高,线程的生命周期包括「线程创建时间」,「线程执行任务时间」,「线程销毁时间」,创建和销毁都需要导致系统调用。
5 |
6 | 2. 每个 Thread 都需要有一个内核线程的支持,也就意味着每个 Thread 都需要消耗一定的内核资源(如内核线程的栈空间),因为能创建的 Thread 是有限的,默认一个线程的线程栈大小是 1 M,如果每来一个任务就创建线程的话,1024 个任务就占用了 1 G 内存,很容易就系统崩溃了。
7 |
8 |
9 | ## corePoolSize
10 | 所以我的主要作用就是减少线程的**创建时间**和**销毁时间**,线程创建后不让它马上销毁,而是常驻在我这,随叫随到,我把这些常驻的线程叫做核心线程,核心线程数也不宜过多,所以我指定了它们的数量(corePoolSize),假定为 3 吧。
11 |
12 | 「线程池,这是我的一个任务,帮我执行一下吧」,主线程丢给我任务后立马返回,于是我赶紧调用 execute 方法来处理丢给我的这个任务(Runnable)
13 |
14 | ```java
15 | public interface Executor {
16 | void execute(Runnable command);
17 | }
18 | ```
19 | 由于我诞生后还没有执行过任务,核心线程一直为 0,于是在这个方法里我创建了一个线程作为核心线程。
20 |
21 | 「线程池,任务又来了,帮我执行一下吧」,又来任务了!于是我再次调用 了 execute,又创建了一个核心线程,此时核心线程数为 2。
22 |
23 | 过了一段时间,第一个核心线程已经执行完任务,空闲出来了,此时任务又来了。。。
24 |
25 | 「线程池,这是我的一个任务,帮我执行一下吧」主线程摞下一句话后又走了,此时是 1 个核心线程在忙碌,一个核心线程空闲,可能很多人误以为这里既然有一个核心线程在空闲,那就把任务交给这个线程处理即可,不用再创建核心线程了,但实际上只要**当前核心线程数少于当初设置的 corePoolSize,不管当前核心线程是否空闲,我依然会再创建一个核心线程**,主要是为了保证核心线程尽快达到我们设置的数量,这样如果之后有很多任务涌进来,这些已创建好的核心线程就可以马上准备好处理这些任务了,不需要再经过创建线程这种耗时的操作了。
26 |
27 | 经过上面的一番操作,核心线程数来到了最开始设置的数量 3 了。
28 |
29 | ## workQueue
30 |
31 | 「线程池,任务又来了,帮我执行一下吧」,熟悉的声音又来了,此时核心线程已经达到了我们设置的数量 3 个了,再创建线程当然可以,但又要造成一个系统调用,开销比较大,其实核心线程可能经过很短的时间又能马上空闲出来了,不如把任务放到放到一个队列里,让这些核心线程自己去取。
32 |
33 | 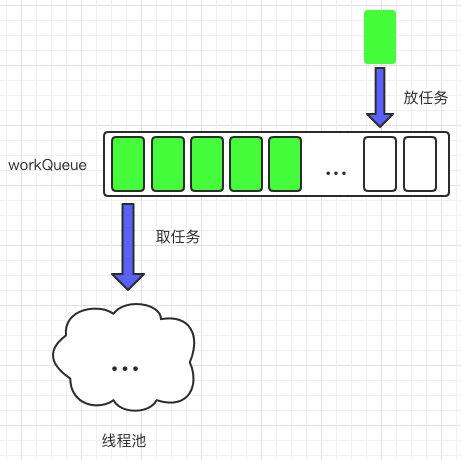
34 |
35 | 聪明的你一定发现了,这就是典型的生产者-消费者模型,线程池中的线程只要不断循环去 workQueue 队列获取任务即可,为了避免 workQueue 为空线程一直轮询导致的 CPU 资源被占用的问题,这里的 workQueue 采用了阻塞队列,所谓阻塞是指,如果 workQueue 为空,则获取元素的线程会等待队列变为非空,一旦有新的任务入队列,会唤醒等待中的线程。
36 | **画外音:线程等待是指调用 LockSupport.park 将线程从运行态变为阻塞态,此时线程就不占用 CPU 资源了**
37 |
38 | 可是好景不长, JVM 老大向我反馈出现 OOM 问题了,一看问题我就明白了,原来是哪个新手程序员在创建我的时候,声明使用了**无界队列**,导致核心线程无法及时处理任务,而任务又源源不断地添加进了 workQueue 中(即生产任务速度远大于消费任务速度),导致 workQueue 越来越大,最终产生了 OOM!
39 |
40 |
41 | 解决方式很简单,**使用有界队列即可**,这样当 workQueue 满时就无法添加任务了,不会导致 workQueue 无限增大导致 OOM。
42 | **画外音:所谓有界队列是指设定了固定大小的队列,当队列里的元素超过这个大小后就再也不能往这个队列里塞任务了,而无界队列由于没有设置固定大小 ,可以直接入队,直到溢出,容易造成 OOM,所以创建线程池时应该尽量使用有界队列**
43 |
44 | ## maximumPoolSize
45 |
46 | 将 workQueue 改用有界队列后,再也没出现过 OOM 了,不过由于主线程又源源不断地丢了一些耗时的任务过来,核心线程依然处理不过来,workQueue 很快又满了,这时我想起了另一个参数 maximumPoolSize,这个参数定义了我能创建的最大线程数,当其它线程要往队列塞任务,但发现 workQueue 满时,由于当前在我这的线程还未到达 maximumPoolSize(假设起初指定为 5),所以我又创建了线程来处理这个任务。
47 |
48 | **画外音: 在 workQueue 已满的条件下,如果当前线程池的线程数量 >= corePoolSize 且 <= maximumPoolSize,后续如果一直有其它线程丢任务进来,会一直创建线程,直到 maximumPoolSize。**
49 |
50 | ## RejectedExecutionHandler
51 | 某天,往我这丢任务的某个线程反馈收到异常了,我一看,我靠,workQueue 满了,线程数也达到了 maximumPoolSize,但此时依然有任务不断往 workQueue 中插,但这种情况下已经超出了我的处理能力了,只好执行默认的拒绝策略,抛出 RejectedExecutionException 异常让其他线程(往我这丢任务的线程)自己处理。
52 | **画外音:线程池提供了 AbortPolicy,DiscardPolicy,DiscardOldestPolicy,CallerRunsPolicy,自定义这五种拒绝策略,默认是 AbortPolicy**
53 |
54 | ## keepAliveTime
55 | 在线程们的努力之下,workQueue 队列中的任务很快被清空了,很长一段时间都没有任务进来了,线程们很快就无事可做,放着又占用资源,该怎么处理呢?此时我这有核心线程 3(corePoolSize = 3), 额外线程 2 (maximumPoolSize 为 5),
56 |
57 | 我是这么处理的,如果当前线程总数超过了 corePoolSize,在 keepAliveTime 这个时间内,如果池子里的线程一直空闲,就把这个线程给干掉,哪个线程空闲时间先到达 keepAliveTime,就干掉哪个,直到线程数减少到 corePoolSize。
58 |
59 | **画外音:线程池里没有核心线程和额外线程之分,只是为了讲述方便人为划分了一下,但其实线程池里的线程都是平等的,任何一个线程都可以被干掉**
60 |
61 | ## 总结
62 | 通过上文的自我介绍,我相信你已经对我的工作机制有了较为深入的了解,但这还不够,本周请看主人对我的另一篇深度剖析文,<<万字长文深度剖析线程池>>,敬请期待!
63 |
64 | 欢迎关注公号一起交流,共同进步
65 |
66 | 
67 |
68 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥,公众号「坤哥漫谈IT」号主,本人双非一本,非科班出身,目前就任某独角兽技术专家职位,相信很多人都和我一样有普通的出身,但希望能在计算机这个领域有所建树,希望我的一些学习经验能帮助到你。
2 |
3 | 不少读者反馈公号搜索文章不方便,所以响应大家号召,把文章整到了 github 上以方便大家查阅,仓库地址就叫 easy-cs 吧,致力于让天下没有难学的计算机,哈哈。
4 |
5 | 这些文章平均被转载 20 次以上,得到很多人的认可,相信看完之后无论是面试还是工作对你都会有很大的帮助,绝对精品!希望大家给个 **star** 支持一下,这是笔者持续更文的动力!目录如下
6 |
7 | * 学习指南PDF
8 | * [谷歌师兄刷题笔记](学习指南/谷歌师兄刷题笔记.md)
9 | * [美团2017-2020年技术文章](学习指南/美团2017-2020年技术文章.md)
10 | * 计算机基础
11 | * [从进入内核态看内存管理](计算机基础/从进入内核态看内存管理.md)
12 |
13 | * 网络
14 | * [20 张图让你彻底弄懂 HTTPS 原理!](网络/20张图让你彻底弄懂HTTPS原理.md)
15 | * [51 张图带你彻底弄懂HTTP](网络/51张图带你彻底弄懂HTTP.md)
16 | * [TCP:一个悲伤的故事](网络/TCP:一个悲伤的故事.md)
17 | * [你管这破玩意儿叫token](网络/你管这破玩意儿叫token.md)
18 | * [这个下载文件的问题困住了我至少三位同事](网络/这个下载文件的问题困住了我至少三位同事.md)
19 | * [一个数据包的互联网之旅](网络/一个数据包的互联网之旅.md)
20 | * [51 张图带你彻底弄懂HTTP](网络/51张图带你彻底弄懂HTTP.md)
21 | * 算法
22 | * [一文学会递归解题](算法/一文学会递归解题.md)
23 | * [一文学会动态规划解题技巧](算法/一文学会动态规划解题技巧.md)
24 | * [一文学会链表解题](算法/一文学会链表解题.md)
25 | * [一文看懂排列组合算法](算法/一文看懂排列组合算法.md)
26 | * [一文学会回溯算法解题技巧](算法/一文学会回溯算法解题技巧.md)
27 | * [红黑树杀人事件始末](算法/红黑树杀人事件始末.md)
28 | * [Trie树的妙用](算法/Trie树的妙用.md)
29 | * [图文详解bfs,dfs](算法/图文详解bfs,dfs.md)
30 | * [提升逼格利器-位运算](算法/提升逼格利器-位运算.md)
31 | * [拜托,别再问我什么是 B+ 树了](算法/拜托,别再问我什么是B+树了.md)
32 | * 系统设计
33 | * [震惊!线上四台机器同一时间全部 OOM,到底发生了什么?](系统设计/震惊!线上四台机器同一时间全部OOM,到底发生了什么?.md)
34 | * [ELK 性能优化实战](系统设计/ELK性能优化实战.md)
35 | * [keepalived工作原理](系统设计/keepalived工作原理.md)
36 | * [优秀程序员必备的四项能力](系统设计/优秀程序员必备的四项能力.md)
37 | * [金融监控实战](系统设计/金融监控实战.md)
38 | * [高性能短链设计](系统设计/高性能短链设计.md)
39 | * [高性能网关设计实践](系统设计/高性能网关设计实践.md)
40 | * [simhash实现机制](系统设计/simhash实现机制.md)
41 | * [从应用层到网络层排查Dubbo接口超时全记录.md](系统设计/从应用层到网络层排查Dubbo接口超时全记录.md)
42 | * [你管这破玩意儿叫负载均衡](系统设计/你管这破玩意儿叫负载均衡.md)
43 | * Java
44 | * [我是一个线程池](Java/我是一个线程池.md)
45 | * [2w字长文深度解析线程池](Java/2w字长文深度解析线程池.md)
46 | * [1.5w字,30图带你彻底掌握 AQS!](Java/1.5w字,30图带你彻底掌握AQS!.md)
47 | * [看完这篇垃圾回收,和面试官扯皮没问题了](Java/看完这篇垃圾回收,和面试官扯皮没问题了.md)
48 | * [垃圾回收-实战篇](Java/垃圾回收-实战篇.md)
49 | * [一文学会注解的正确使用姿势](Java/一文学会注解的正确使用姿势.md)
50 | * [Netty 架构与原理初探](Java/Netty架构与原理初探.md)
51 | * [Netty 源码剖析](Java/Netty源码剖析.md)
52 | * [Netty 应用篇](Java/Netty应用篇.md)
53 | * [Sharding-JDBC 的基本用法和基本原理](Java/Sharding-JDBC的基本用法和基本原理.md)
54 | * [aop造火箭事件始末](Java/aop造火箭事件始末.md)
55 | * [一个故事看懂对象的创建过程.md](Java/一个故事看懂对象的创建过程.md)
56 | * [字节码剖析.md](Java/字节码剖析.md)
57 | * [类加载机制.md](Java/类加载机制.md)
58 | * [为什么线程崩溃不会导致 JVM 崩溃](Java/为什么线程崩溃不会导致JVM崩溃.md)
59 | * [Java线程模型](Java/Java线程模型.md)
60 | * MySQL
61 | * [SQL 进阶使用技巧](MySQL/SQL进阶使用技巧.md)
62 | * [执行一条 SQL 后 MySQL 做了哪些事情](MySQL/执行一条SQL后MySQL做了哪些事情.md)
63 | * [深入浅出索引原理](MySQL/深入浅出索引原理.md)
64 | * 分布式
65 | * [分布式事务,看这篇真的够了!](分布式/分布式事务,看这篇真的够了!.md)
66 | * [40张图看懂分布式追踪系统原理及实践](分布式/40张图看懂分布式追踪系统原理及实践.md)
67 | * 工程师效率
68 | * [Alfred 有多强悍,我写了个一键上传图片的 workflow 来告诉你](工程师效率/Alfred有多强悍,我写了个一键上传图片的workflow来告诉你.md)
69 | * [Gradle build 慢?可能是你使用的姿势不对](工程师效率/Gradlebuild慢?可能是你使用的姿势不对.md)
70 | * 架构
71 | * [什么是高可用](架构/高可用.md)
72 | * 中间件
73 | * [深入浅出消息队列](中间件/MQ基本概念.md)
74 | * 设计模式
75 | * [我用 DCL 写出了单例模式,结果阿里面试官不满意!](设计模式/我用DCL写出了单例模式,结果阿里面试官不满意!.md)
76 | * 程序人生
77 | * [一位全职转行做滴滴司机的前程序员对话引发的思考](程序人生/一位全职转行做滴滴司机的前程序员对话引发的思考.md)
78 | * [谈谈一些学习心得](程序人生/谈谈一些学习心得.md)
79 | * [优秀的程序员应该具备哪些能力](程序人生/优秀的程序员应该具备哪些能力.md)
80 | * [我创业啦!!!](程序人生/我创业啦!!!.md)
81 | * [我是如何晋升专家岗的](程序人生/我是如何晋升专家岗的.md)
82 | * [面试了十几位前端有感](程序人生/面试了十几位前端有感.md)
83 | * 个人随想
84 | * [随想](个人感悟/随想.md)
85 |
86 | 更多精品文章,欢迎大家扫码关注「坤哥漫谈IT」
87 |
88 | 
89 |
90 | 也欢迎大家扫一扫加我好友(备注:github),拉你进学习交流群,里面有各位 BAT 大佬,可以提问,内推等,一起抱团取暖^_^
91 |
92 | 
93 |
--------------------------------------------------------------------------------
/系统设计/震惊!线上四台机器同一时间全部OOM,到底发生了什么?.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ### 案发现场
4 | 昨天晚上突然短信收到 APM (即 Application Performance Management 的简称,我们内部自己搭建了这样一套系统来对应用的性能、可靠性进行线上的监控和预警的一种机制)大量告警
5 |
6 | (画外音: 监控是一种非常重要的发现问题的手段,没有的话一定要及时建立哦)
7 |
8 | 紧接着运维打来电话告知线上部署的四台机器全部 OOM (out of memory, 内存不足),服务全部不可用,赶紧查看问题!
9 |
10 | ### 问题排查
11 | 首先运维先重启了机器,保证线上服务可用,然后再仔细地看了下线上的日志,确实是因为 OOM 导致服务不可用
12 | 
13 |
14 | 第一时间想到 dump 当时的内存状态,但由于为了让线上尽快恢复服务,运维重启了机器,导致无法 dump 出事发时的内存。所以我又看了下我们 APM 中对 JVM 的监控图表
15 |
16 | 画外音: 一种方式不行,尝试另外的角度切入!再次强调,监控非常重要!完善的监控能还原当时的事发现场,方便定位问题。
17 |
18 | 
19 |
20 |
21 |
22 |
23 | 不看不知道,一看吓一跳,从 16:00 开始应用中创建的线程居然每时每刻都在上升,一直到 3w 左右,重启后(蓝色箭头),线程也一直在不断增长),正常情况下的线程数是多少呢,600!问题找到了,应该是在下午 16:00 左右发了一段有问题的代码,导致线程一直在创建,且创建的线程一直未消亡!查看发布记录,发现发布记录只有这么一段可疑的代码 diff:在 HttpClient 初始化的时候额外加了一个 **evictExpiredConnections** 配置
24 |
25 | 
26 |
27 | 问题定位了,应该是就是这个配置导致的!(线程上升的时间点和发布时间点完全吻合!),于是先把这个新加的配置给干掉上线,上线之后线程数果然恢复正常了。那 **evictExpiredConnections** 做了什么导致线程数每时每刻在上升呢?这个配置又是为了解决什么问题而加上的呢?于是找到了相关同事来了解加这个配置的前因后果
28 |
29 | ### 还原事发经过
30 |
31 | 最近线上出现不少 **NoHttpResponseException** 的异常,那是什么导致了这个异常呢?
32 |
33 | 在说这个问题之前我们得先了解一下 http 的 keep-alive 机制。
34 |
35 | 先看下正常的一个 TCP 连接的生命周期
36 | 
37 |
38 | 可以看到每个 TCP 连接都要经过**三次握手**建立连接后才能发送数据,要经过**四次挥手**才能断开连接,如果每个 TCP 连接在 server 返回 response 后都立马断开,则发起多个 HTTP 请求就要多次创建断开 TCP, 这在 **Http 请求很多**的情况下无疑是很耗性能的, 如果在 server 返回 response 不立即断开 TCP 链接,而是**复用**这条链接进行下一次的 Http 请求,则无形中省略了很多创建 / 断开 TCP 的开销,性能上无疑会有很大提升。
39 |
40 | 如下图示,左图是不复用 TCP 发起多个 HTTP 请求的情况,右图是复用 TCP 的情况,可以看到发起三次 HTTP 请求,复用 TCP 的话可以省去两次建立 / 断开 TCP 的开销,理论上发起 一个应用只要启一个 TCP 连接即可,其他 HTTP 请求都可以复用这个 TCP 连接,这样 n 次 HTTP 请求可以省去 n-1 次创建 / 断开 TCP 的开销。这对性能的提升无疑是有巨大的帮助。
41 |
42 | 
43 |
44 | 回过头来看 keep-alive (又称持久连接,连接复用)做的就是复用连接, 保证连接持久有效。
45 |
46 | (画外音: Http 1.1 之后 keep-alive 才默认支持并开启,不过目前大部分网站都用了 http 1.1 了,也就是说大部分都默认支持链接复用了)
47 |
48 | **天下没有免费的午餐** ,虽然 keep-alive 省去了很多不必要的握手/挥手操作,但由于连接长期保活,如果一直没有 http 请求的话,这条连接也就长期闲着了,会占用系统资源,有时反而会比复用连接带来更大的性能消耗。 所以我们一般会为 keep-alive 设置一个 timeout, 这样如果连接在设置的 timeout 时间内一直处于空闲状态(未发生任何数据传输),经过 timeout 时间后,连接就会释放,就能节省系统开销。
49 |
50 | 看起来给 keep-alive 加 timeout 是完美了,但是又引入了新的问题(一波已平,一波又起!),考虑如下情况:
51 |
52 | 如果服务端关闭连接,发送 FIN 包(注:在设置的 timeout 时间内服务端如果一直未收到客户端的请求,服务端会主动发起带 Fin 标志的请求以断开连接释放资源),在这个 FIN 包发送但是还未到达客户端期间,客户端如果继续复用这个 TCP 连接发送 HTTP 请求报文的话,服务端会因为在四次挥手期间不接收报文而发送 RST 报文给客户端,客户端收到 RST 报文就会提示异常 (即 **NoHttpResponseException**)
53 |
54 |
55 | 我们再用流程图仔细梳理一下上述这种产生 **NoHttpResponseException** 的原因,这样能看得更明白一些
56 |
57 | 
58 |
59 | 费了这么大的功夫,我们终于知道了产生 ** **NoHttpResponseException**** 的原因,那该怎么解决呢,有两种策略
60 |
61 | 1. 重试,收到异常后,重试一两次,由于重试后客户端会用有效的连接去请求,所以可以避免这种情况,不过一次要注意重试次数,避免引起雪崩!
62 | 2. 设置一个定时线程,定时清理上述的闲置连接,可以将这个定时时间设置为 keep alive timeout 时间的一半以保证超时前回收。
63 |
64 | **evictExpiredConnections** 就是用的上述第二种策略,来看下官方用法使用说明
65 |
66 | ```java
67 | Makes this instance of HttpClient proactively evict idle connections from the
68 | connection pool using a background thread.
69 | ```
70 |
71 | 调用这个方法只会产生一个定时线程,那为啥应用中线程会一直增加呢,因为我们对每一个请求都创建了一个 HttpClient! 这样由于每一个 HttpClient 实例都会调用 **evictExpiredConnections** ,导致有多少请求都会创建多少个 定时线程!
72 |
73 | 还有一个问题,为啥线上四台机器几乎同一时间点全挂呢?
74 | 因为由于负载均衡,这四台机器的权重是一样的,硬件配置也一样,收到的请求其实也可以认为是差不多的,这样这四台机器由于创建 HttpClient 而生成的后台线程也在同一时间达到最高点,然后同时 OOM。
75 |
76 | ### 解决问题
77 | 所以针对以上提到的问题,我们首先把 HttpClient 改成了单例,这样保证服务启动后只会有一个定时清理线程,另外我们也让运维针对应用的线程数做了监控,如果超过某个阈值直接告警,这样能在应用 OOM 前及时发现处理。
78 | 画外音:再次强调,监控相当重要,能把问题扼杀在摇篮里!
79 |
80 |
81 | ### 总结
82 | 本文通过线上四台机器同时 OOM 的现象,来详细剖析产定位了产生问题的原因,可以看到我们在应用某个库时首先要对这个库要有充分的了了解(上述 HttpClient 的创建不用单例显然是个问题),其次必要的网络知识还是需要的,所以要成为一个合格的程序员,不关对语言本身有所了解,还要对网络,数据库等也要有所涉猎,这些对排查问题以及性能调优等会有非常大的帮助,再次,完善的监控非常重要,通过触发某个阈值提前告警,可以将问题扼杀在摇篮里!
83 |
84 | 
85 |
86 | 
--------------------------------------------------------------------------------
/ChatGPT/AI地图实践.md:
--------------------------------------------------------------------------------
1 |
2 | 大家好,我是坤哥
3 |
4 |
5 |
6 | AI 时代已至!在工作中我大量使用 ChatGPT 来提升工作效率,得到了很好的效果
7 |
8 | 今天我就给大家分享一个案例,来看一下我在工作中是利用 AI 把原本半天的工作量压缩到不到半小时的。希望能对职场人士尤其是程序员群体有所启发
9 |
10 |
11 |
12 | 最近我司要做一个 AI 工具地图,效果如下
13 |
14 |
15 |
16 | 
17 |
18 |
19 |
20 | 需求是把每个 AI 产品的图标分门别类地先合成一个小图,再把所有小图整合成一个 AI 大地图,注意每个图标下面的文字都是其对应的产品名哦,放大看某一类AI产品的效果如下:
21 |
22 |
23 |
24 | 
25 |
26 |
27 |
28 |
29 |
30 |
31 |
32 | 如果把所有的工作如包括下载图标,合成每个类别的 AI 产品,再到合成最后的大图都交给 UI,可想而知这样的工作量是非常巨大的,所以我们就想能不能尽可能地减轻 UI 的工作量,用技术的手段至少能先做到分门别类地合成小图,这样 UI 所要做的事就比较简单了,只要把小图拼成大图就行了
33 |
34 |
35 |
36 |
37 |
38 |
39 |
40 | 首先我们需要找到这样 AI 图标,毫无疑问 AI 导航网站最合适不过了,这些导航网站基本上分门别类地给你整理好了这些AI产品的图标,我们决定使用 https://ai-bot.cn/ 这个导航网站里的图标,它的首页截图如下
41 |
42 |
43 |
44 | 
45 |
46 |
47 |
48 | 好了再来明确我们的需求,首先需要获取每一类 AI 产品下的图标,并将图标命名为此 AI 对应的产品名,然后将这属于同一类AI产品的图标置于同一个文件夹下,如下
49 |
50 |
51 |
52 | 
53 |
54 |
55 |
56 |
57 |
58 |
59 |
60 | 图标有几百个,如果人工一个个下载图标并命名,工作量巨大不说,还很容易出错,最容易想到的当然是用脚本如 Js 或 Python 来爬取网页中的图标和文案,但是如果人工去写脚本,也挺费时的,而且很难一次性写对所有的代码, 需要花很多时间 来 debug,所以写脚本这样的重活最好让 ChatGPT 来帮我们写,又快又好,只要我们把需求写清楚,ChatGPT 基本一次性就能把脚本给我们写好。
61 |
62 |
63 |
64 |
65 |
66 |
67 |
68 | 我们首先观察网站的结构,注意到网站的结构很相似,基本都是 「AI 类别标题 + AI 类别图标集合」这样的组合结构,我们就取一个来观察
69 |
70 |
71 |
72 | 下图中绿框为AI 类别标题对应相应的 div,红框为标题下的图标集合对应相应的 div
73 |
74 |
75 |
76 | [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oYadyg7z-1691679560090)(/Users/ronaldo/Library/Application Support/typora-user-images/image-20230720103226947.png)]
77 |
78 |
79 |
80 |
81 |
82 |
83 |
84 | 继续观察,每一个类别的标题对应着 class 为 d-flex 的 `div > h4 > i` 中的文字
85 |
86 |
87 |
88 |
89 |
90 |
91 |
92 | 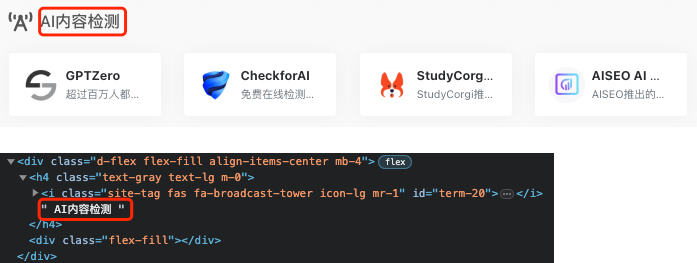
93 |
94 |
95 |
96 |
97 |
98 |
99 |
100 | 而每个 AI 图标的 url 和名称在 html 中的元素如下
101 |
102 |
103 |
104 | 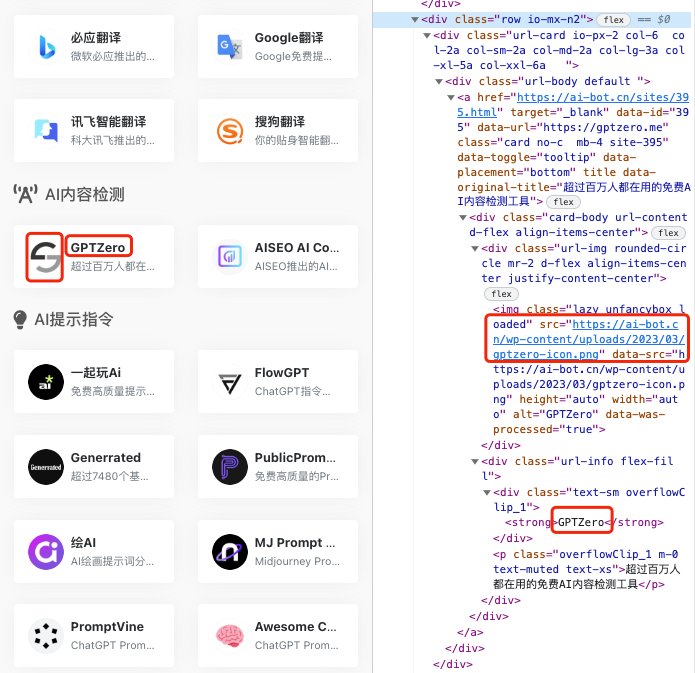
105 |
106 |
107 |
108 | `注意`:有一些AI产品分类如热门工具等不是这样的结构,不过结构都非常类似,用 Visual Studio 来将它们调整成以上的结构即可
109 |
110 |
111 |
112 |
113 |
114 |
115 |
116 | 了解了我们要提取的 html 结构后,我们就可以给 ChatGPT 下指令来让其为我们生成脚本来提取每一类 AI 产品下的图标并在下载后将其命名为相应的 AI 产品名了,指令如下(test.html 即网页的 html):
117 |
118 |
119 |
120 | 
121 |
122 |
123 |
124 | 最终它会给我生成类似以下的 Python 代码:
125 |
126 |
127 |
128 | 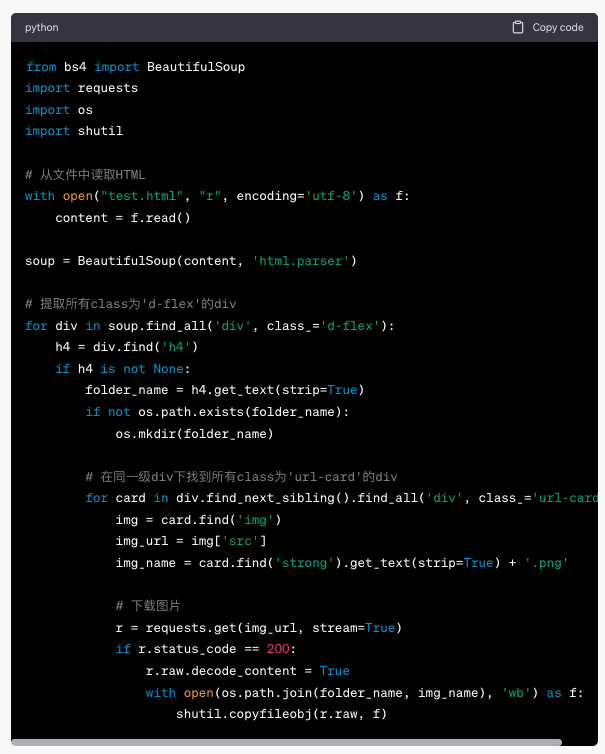
129 |
130 |
131 |
132 | 放在本地,下载对应的依赖后一键执行即可按要求提取每个分类下的AI图标,如下
133 |
134 |
135 |
136 | 
137 |
138 |
139 |
140 | 做到这一步还不够, 为了进一步减轻 UI 的工作量我们希望帮 UI 把每一个 AI 类别的图标合成一张大图,如下:
141 |
142 |
143 |
144 | 
145 |
146 |
147 |
148 | 合成图片这种工作 Python 也能做,指令如下:
149 |
150 |
151 |
152 |
153 |
154 |
155 |
156 | 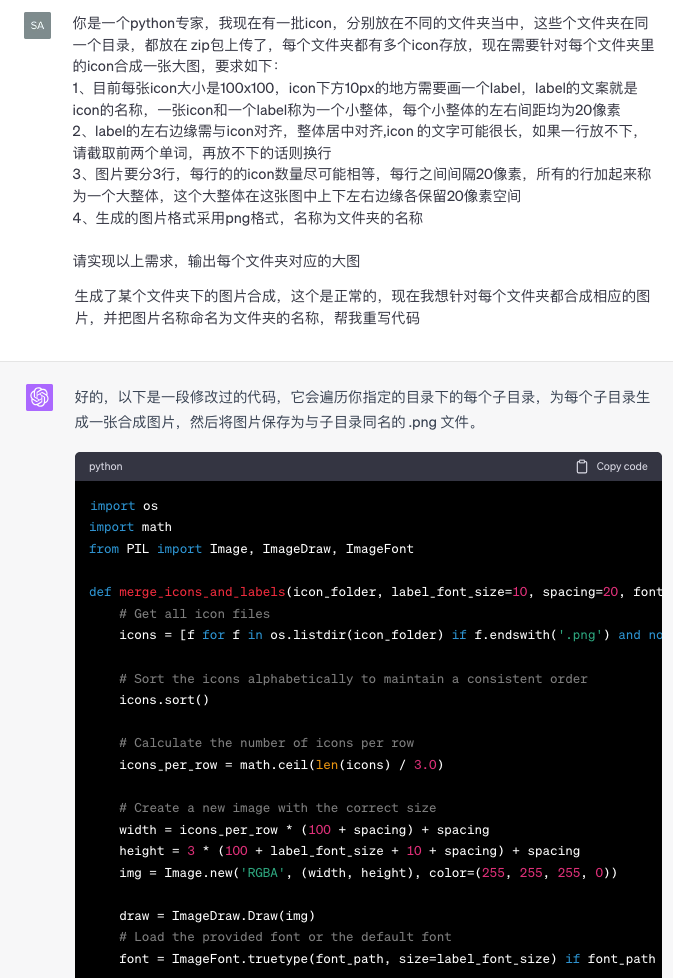
157 |
158 |
159 |
160 |
161 |
162 |
163 |
164 | 执行代码后效果如下:
165 |
166 |
167 |
168 | 
169 |
170 |
171 |
172 | 可以看到,每一类的图标都合成了一个大图
173 |
174 |
175 |
176 | 这样的话交付给UI的就是一些合成好的每个 AI 类别的小图了,他们拿到后再将其拼成一张大图就相对容易多了
177 |
178 |
179 |
180 |
181 |
182 | ### 总结
183 |
184 |
185 |
186 | 本文给大家展示了一个典型地利用 AI 来提效的案例,这只是其中之一,实际上在工作中我大量使用了 AI 来编码,以网站的后端代码为例上,90%的代码都是 AI 写的,当然指令还是我的下的,有人说 ChatGPT 的出现可能会替代程序员,但就我的大量实践经验来看,暂时还没达到这种程度,比如我一开始让它写后端,但它没给我处理跨域这种情况,这就需要程序员本人有相关的经验指引它补全,再比如我希望后端的很多接口都需要有用户身份的验证后才能进入具体的代码逻辑,但又不想每个接口都写重复的校验代码,那就需要指示 GPT 帮我封装校验逻辑,使用类似`export default withMiddleware(handler, cors, authenticate)`这样的责任链的方式来重用代码以提高代码的可扩展性,所以事在人为,对于程序员来说,你越资深,掌握的知识越多,就越能指示 ChatGPT 最大程序地发挥其功效, AI 能够帮我们处理那些重复的,不需要怎么动脑的工作,但更高层次的抽象还是需要程序员来指示它来完成。未来 AI 可能会进化,但至少当下我们能做的还是提升我们的功力以进一步利用释放 AI 的潜能
187 |
188 |
189 |
190 | 我建了一个 [AI 导航网站](https://ainavtech.com/),欢迎大家体验
191 |
--------------------------------------------------------------------------------
/程序人生/谈谈一些学习心得.md:
--------------------------------------------------------------------------------
1 | 最近不少读者加我探讨了一些算法,Java 或如何看书等学习方面的困惑,我觉得这些都挺有共性的,所以就想着结合自己的经历来谈谈有关学习的一些话题,希望能给读者一些启发。
2 |
3 | ## 提升自己的起点
4 | 先简单介绍我自己,我大学是双非普通一本,非科班出身,目前在某独角兽公司担任技术专家职位,相信大多数人的出身和我一样,普通院线毕业,想渴望着能一步步走上技术专家乃至更高级别的职位,那既然是普通院校毕业,与那些 985 院校科班出身的同学相比本身就有天然的劣势,所以我们就更要提升自己的起点了。
5 |
6 | 何谓提升自己的起点,比如对于技术人员来说搜索资料就应该用 Google, 而不是百度,查不到就去 Stackoverflow 提问,大部分资料用英文都能搜到,日积月累,你的英文水平就算再蹩脚也能完成华丽蜕变,为什么要强调英文水平呢,现在移动互联网时代,各大主流平台 iOS, Android,甚至一些领先的框架如 Flutter 等全是国外出的,第一手资料全是英文的,所以如何用英文查资料,无压力读取英文官方文档这是技术人的基本素质,再者就算是翻译难免也有瑕疵,所以一定要持续提升自己的英文水平,坚决用 Google!
7 |
8 | 再比如大多数人学习可能主要通过各种博客来学,这样确实可以学到不少东西,但是博客的问题是**各种知识点比较散**,而且多数是作者对知识的提炼和总结总结,总结的过程中可能省略了很多知识点,也漏掉了书中的一些精华,所以如果要提升自己,系统地构建自己的知识体系,一定要**看书**!看书确实是一件很费力地事,但长期来看,对你知识体系的构建大有裨益!看书一定要看好书,怎么去找好书呢,推荐大家看看图灵社区(https://www.ituring.com.cn/ ) 很多书都很经典,也可以去豆瓣上搜搜那些高分书籍,看看底下的评论到底好在哪,买东西我们都会货比三家,更何况一本好书对你的成长大有裨益,所以值得你多花点心思来挑本好书!另外值得一提的是一开始很多人入门可能摸不着门道,这时候看视频快速入门是没问题的,但后期一定要回归到书本的学习中来!看书是实现知识技能充分必要条件!
9 |
10 | 再举个我自己的例子吧,目前我一直在运营着公号,坚持原创!一周至少发一篇精品文章,其实我也可以多多转载下别人的文章多吸点粉,但我没有这样做,转载只需要五分钟,确实方便,但对我个人写作能力地提升没有任何帮助!所以我一直坚持着原创,努力地写文章,这样虽然很苦,但对自己写作能力的提升,逻辑思维的构建长远来看帮助很大!这就叫提升自己的起点。
11 |
12 | 提升自己的起点会带来什么效果,这里给大家介绍一下复利曲线
13 |
14 | 
15 |
16 | 前期的增长势头非常慢,但日积月累,到达某个拐点之后,增长就如火箭上升一般,势不可挡,就像我另一个做公号的朋友 cxuan 一样,前面几十篇文章无人问津,最近写得几篇文章带来的粉丝量突然爆发,其实也是因为之前的几十篇文章给他带来了足够强的写作能力,奠定了强大的写作基础,所以现在就像上面的后期的复利曲线一样,势不可挡。所以坚持提升自己的起点长期来看一定能给自己带来足够强的复利!
17 |
18 | ## 底层能力很重要
19 |
20 | 什么是底层能力,算法,数据结构,操作系统这些就属于底层能力,这些为什么重要,这些是上层语言,工具的根基!这些属于心法,内功,学好之后对你后期势能的爆发大有裨益!内功很重要,**工具不重要**!不少人误把工具用得熟练程序当作自己资本,甚至在 V 站上看到一个人对刚入职的同事不会用 git 而大加吐嘈,这是大错特错的,工具为什么不重要,想想杨过在武功大成后用玄铁重剑和木剑对他来说差别大吗,对于一个内功深厚的人来说,工具的掌握只要稍微看下文档,Google 一下即可掌握,信手拈来!内功决定程序员的上限,而工具的掌握甚至连下限都不算,内功最重要。
21 |
22 | 再举一个和大家工作息息相关的例子,曾经一个人来我司面试,我面了之后觉得不错,但上司面试之后觉得人不够聪明,所谓不够聪明指的是给出一道相关设计题,在多方引导下仍然没有思路,所以最后没拿到 offer,所以大厂为什么喜欢考虑算法,我在之前的[文章](https://mp.weixin.qq.com/s/DA4zHIPFP6ISzVeobdgdew)里也说过了,其实就是考你的构建模型,修改模型的能力,这样是判断一个人是否聪明的重要标准,所以掌握算法这些底层能力十分重要,算法的学习很枯燥。学习算法最好先掌握理论,掌握之后再去 leetcode 上多刷下题,学习算法理论建议大家可以学学极客时间上王争老师的「数据结构与算法」教程,对每个点讲得都很透彻!再结合吴师兄的动画题解与自己的多加练习,相信大家掌握算法不成问题。
23 |
24 | ## 多读源码
25 | 要掌握好一个框架,学习它的底层原理,读源码是必不可少的,这样才能在面对多个框架的选型时根据框架的优劣性做出取舍,同时多读框架的源码你还会对它底层的思想有更深刻的理解,能够做到知其然,更能知其所以然,举个简单地例子,在 Java 中有一个 **Arrays.sort** 的方法可以对数组进行排序,一开始我以为是个简单地快排,读它的源码之后才发现它虽然是用的快排,不过它用的是 dual-pivot 快排,这就让我产生了深厚的兴趣, 后来了解到这个 dual-pivot 快排比经典快排节省了 12% 的元素扫描,扫描元素的个数这种新的算法把内存的流量的因素考虑进去,比较适应新时代。看到一种框架可以不断地引出新的知识点,深挖这些新知识点,这样框架的优劣性也就吃透了。
26 |
27 | 曾经做 iOS 的时候国内优酷就有一个大神 ibireme 通读各类框架源码然后设计了 YYKit 等框架,引起轰动!甚至引来 Facebook 挖角,所以通读框架源码对于提升自己的能力非常有效!那怎么读一个框架源码呢,这又是一个大的话题,后面我会结合 HttpClient 的源码阅读来谈谈我的一些心得体会
28 |
29 | ## 以教为学
30 |
31 | 学完了某些知识点,怎么确定自己就掌握它了呢,可以试着把这些知识点写成博客,在写博客的过程中要反复思考这些知识点怎么让小白也看得懂,如果写出来之后小白也看懂了,那么基本可以肯定这些知识点可以算掌握了,同时在写博客的过程中,如果有问题,读者说不定也会帮你指出来,这样对自己知识的盲点是个很好的补充,写博客最好的时间是十年前,其次是现在!强烈建议读者现在都开始写博客,一方面是对自己知识体系的一个梳理,另一方面也能与读者探讨,一举两得!
32 |
33 | ## 再谈 Java 学习
34 | 由于我的主业是 Java ,所以也有不少人来和我交流 Java 的学习,这里推荐几本书吧
35 |
36 | **新手必备**
37 | 1、《Java 核心技术:卷 1 基础知识》
38 | 对于新手来说非常友好的一本技术书,也是 Sun 公司的官方用书,对 Java 的基础有深入剖析,初学者必读!
39 | 2、《Head first Java》
40 | Head first 公司出品的书都非常耐读, 这本书对 Java 的各种基本概念的讲解非常到位,清晰易懂!推荐阅读英文版哦,如果你英文不好,更要阅读这本书了,还记得我们上文提得:请提升自己的起点吗,刚好可以通过读取这本书要慢慢地养成读取英文书的习惯,技术书籍其实英文并不是很难,要多读读,养成读取英文版书籍的习惯
41 |
42 | **进阶**
43 | 1、《深入理解 Java 虚拟机》
44 | 要进阶一定要对垃圾回收原理, JVM 调优,字节码,Java 线程模型有较清晰地认识,这本书可以说是这些补齐这些知识点的不二之选!精典书籍,谁看谁知道!
45 | 2、《Effective Java》
46 | 这样书对如何写好 Java 总结了很多有用的知识点,也是精典书籍了,必看
47 | 3、 《Java编程思想》
48 | 这本书可以说是 Java 编程的圣经了,要学好 Java 就绕不开本书,豆瓣评分 9.1 分,也是必看书籍,不过不推荐小白一开始就看这本书,建议还是先看完上述所说的新手必备书籍后并且阅读一些框架的源码或工作过一段时间后再看,对里面的知识点体会会更深
49 |
50 | 暂时就推荐这么多吧,其还有一些像《Java并发编程实战》,netty 等书籍等进阶到一定阶段后其实也可以看看,不过这些都是后话了,大家啃完上面的几本书对于再去学其他书问题不大。
51 |
52 | 身为 Java 后端开发,只了解 Java 就够了吗, 至少你要对网络知识,MySql 这些也要做一定的了解吧,所以 《TCP/IP 详解》《高性能 Mysql》也是你进阶的不二书籍,至少要对 TCP 的慢启动,拥塞机制有所了解,要对索引,如何优化 Mysql 性能有一定的了解吧。可以先对后端工程师应该具备哪些能力画出一个技能树(如下图),然后再对这个技能树上的每个点再各个击破!
53 |
54 | 
55 |
56 | ## 再谈学习
57 |
58 | 前面说了多次看书的好处,这里也推荐大家学习一下极客时间的教程,我基本上每出一个教程必买,有人会说,你看得过来吗,其实我们都陷入了一个误区,买这些教程一定要看完吗,其实只要它的的某个知识点能帮助到你,你就赚了!能完整地看完当然更好,但如果暂时没时间,可以利用碎片化时间选择对自己有帮助的点先学习啊,只要某个点对你有启发,你就赚了!很多面不都是由这些点一个个组成的吗,将这些点串联起来,这样就能逐步构建自己的知识体系和学习框架。
59 |
60 | 
61 |
62 | ## 最后
63 | 前面谈了很多学习方面的一些个人体会,这只是我个人的一些学习感悟,欢迎大家扫码关注我公号回复「学习路线」,可以拿到相关的学习路线中的电子书
64 |
65 | 
--------------------------------------------------------------------------------
/Java/一个故事看懂对象的创建过程.md:
--------------------------------------------------------------------------------
1 | Java 帝国发生了一场危机,各个线程正在闹罢工。。。
2 |
3 | 「发生了什么事,听说各个线程最近正在闹罢工」国王老虚说道
4 |
5 | 「报告国王,最近各个线程反应创建对象太难了,要求王国进行变革」线程大臣启奏道
6 |
7 | 「创建对象有什么难的,我们不是用了 bump the pointer 机制吗,new 一下对象不就创建了吗」老虚大惑不解,「我们知道对象一般来说都是先分配在堆上的 Eden 区的,那么在堆上怎样才能快速地给对象分配空间呢?假设堆是内存是绝对规整的,用过的放一边,空闲的放另一边,中间放一个指针作为分界点,那么在分配对象时只需要将指针移动到与对象大小相等的距离即可,这样创建对象只要不断地移动指针就行啦。这就是我们所说说的 bump the pointer(指针碰撞)」老虚边说边画出了以下图示
8 |
9 | 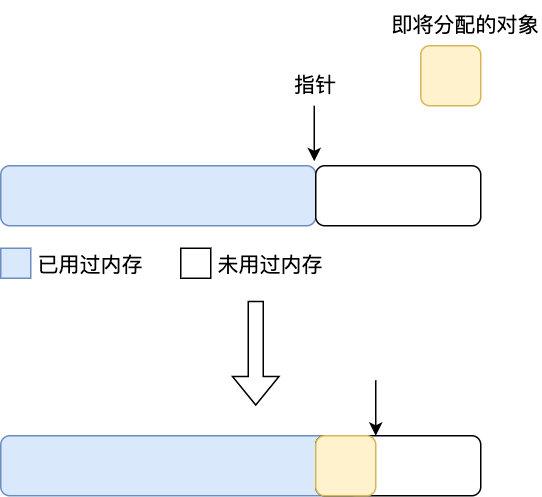
10 |
11 | 「指针碰撞我们当然知道,如果是单线程这样轻轻移动指针分配对象的方式当然很快,但如果是多线程呢,会产生严重的锁竞争呀」
12 |
13 | 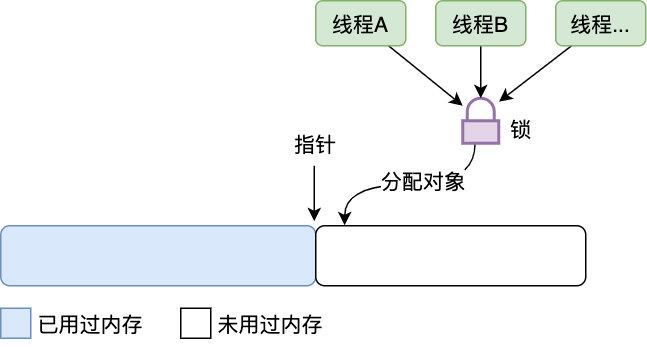
14 |
15 | 「这确实是个问题,锁在多线程下确实会产生比较严重的问题,虽然这里用的是 CAS 乐观锁,但在多线程对象分配上由于锁竞争关系也会有较严重的性能问题」老虚沉思道
16 |
17 | ### TLAB
18 |
19 | 「能否这样,我们知道对象一般是在 Eden 区分配的,为每个线程创建一块单独的区域,每个线程分配对象时只在自己的区域里分配,在自己的区域分配时也采用 bump the pointer 的方式来分配,这样既可以用 bump the pointer 的方式来加速了对象的创建,又避免了创建对象时的锁竞争,可谓一举双得!」线程大臣说道
20 |
21 | 「妙啊,我们给这块区域取个名字吧,就叫它 Thread Local Allocation Buffer(即线程本地分配缓存区),这块是线程专用的内存分配区域」老虚道
22 |
23 | 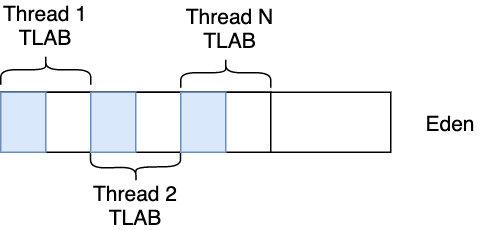
24 |
25 | 「还有一个问题,这块区域该分配多大呢,如果分配太大,可能一个线程根本就没有分配对象的需求或者分配对象很少,造成了空间的浪费,如果分配太小,则可能某些线程比较活跃,分配的对象比较多,那么就要重新分配一个 TLAB,或者直接在 Eden 上分配,这样频繁分配 TLAB 或者在 Eden 分配会造成资源与性能的浪费」不愧是国王,一眼看出问题的本质
26 |
27 | 「是的,TLAB 大小主要和两个因素有关:每个 gc 内需要对象分配的线程个数以及线程每次 gc 分配的内存,这两项指标显然也与历史值有关,所以我们需要根据历史值来算出当前应该分配的 TLAB 大小,有一种算法指数平均数算法(EMA)可以干这事」线程大臣也不赖,一眼就抓住了问题的关键
28 |
29 | 「如果 TLAB 满了咋办」老虚困惑道
30 |
31 | 「满了就针对此线程创建一个 TLAB,或者直接丢到 Eden 区呗,另外需要说明的是 TLAB 比较适用于小对象的分配,大对象一般直接分配到 Eden 区哦」线程大臣解释道
32 |
33 | ### 逃逸分析与标量替换
34 |
35 | 老虚采纳了线程大臣的建议实现了 TLAB,由于采用了 TLAB 机制,各个线程的工作效率瞬间提升,老虚笑开了花,可是好景不长,新的问题又出现了。。。
36 |
37 | 「老虚啊,我发现采用 TLAB 之后线程的工作效率确实提升了很多,但一些线程反映由于 GC 时的 STW(stop the word),导致他们啥也干不了,这个问题自 Java 帝国诞生起就出现了,能否解决一下」
38 |
39 | 「这没办法,STW 是必须的,总不能一边清理垃圾一边扔垃圾吧,那垃圾还怎么收拾地干净」
40 |
41 | 「STW 确实不能避免,但能否减少 GC 次数呢,GC 次数少了,STW 自然也少了,GC 发生在堆中,那只要对象不分配在堆中,GC 次数不就自然而然少了吗」线臣大臣说到
42 |
43 | 「难不成要把它分配在栈上?」老虚一听能减少 GC 次数,顿时来了精神
44 |
45 | 「没错,就是要把它分配在栈上!这样线程在调用栈销毁后对象也就销毁了」线程大臣看起来胸有成竹「但它首先必须满足一个条件:逃逸分析」
46 |
47 | 「什么是逃逸分析」老虚x疑惑道
48 |
49 | > 逃逸分析是指分析指针动态范围的方法,分析在程序的哪些地方可以访问到指针。当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它执行线程中,或是返回到调用者子程序。我们就说这个对象「逃逸」了,否则就说对象未逃逸,未逃逸的对象是可以分配在堆栈上的(采用标量替换的形式)的。
50 |
51 | 「Talk is cheap, show me your code,举几个例子来吧」老虚道
52 |
53 | ```
54 | public class EscapeTest {
55 |
56 | public static Object globalVariableObject;
57 |
58 | public Object instanceObject;
59 |
60 | public void globalVariableEscape(){
61 | globalVariableObject = new Object(); // 1.静态变量,外部线程可见,发生逃逸
62 | }
63 |
64 | public void instanceObjectEscape(){
65 | instanceObject = new Object(); // 2.赋值给堆中实例字段,外部线程可见,发生逃逸
66 | }
67 |
68 | public Object returnObjectEscape(){
69 | return new Object(); // 3.返回实例,外部线程可见,发生逃逸
70 | }
71 |
72 | public void noEscape(){
73 | //仅创建线程可见,对象无逃逸
74 | Object noEscape = new Object(); //4. 仅创建线程可见,对象无逃逸
75 | }
76 |
77 | }
78 | ```
79 |
80 | 我们可以看到,当对象符合以下两种条件时我们就说它逃逸了
81 |
82 | 1. 被赋值给了对象的字段或类的变量,因为很显然对象分配在堆中,是线程共享的,其他线程可能对其进行修改
83 |
84 |
85 |
86 | 2. 对象被传进了不确定的代码中去运行,比如返回给上一个调用栈赋值给其他对象的属性等
87 |
88 | 只有那种满足条件 4 的仅创建线程可见的对象,才能被判断为无逃逸,才能将对象分配到堆上
89 |
90 | 「未逃逸的对象怎样才能被分配在栈上呢?」老虚还是有点困惑
91 |
92 | 「我们先了解两个名词:**标量**和**聚合量**,标量就是不可进一步分解的量,像 Java 的基本类型如 int 等基本类型以及 reference 类型就是标量,聚合量就简单了,就是各个标量的组合,对象其实就是聚合量,所以让对象分配在栈上其实很简单,将其替换为各个标量即可」线程大臣顿了顿,给出了标量替换的 demo
93 |
94 | 
95 |
96 | 「妙啊,通过将对象打散为多个标量,由于标量是直接在栈上分配的,就避免了对象在堆中的分配」这个思路确实给力!老虚立即下令实行
97 |
98 | ### 锁消除
99 |
100 | 「老虚啊,我无意中发现未逃逸的对象还有锁消除功能」线程大臣兴奋地说
101 |
102 | 「啥是锁消除」老虚挺兴奋的
103 |
104 | 我们先来看看 StringBuffer 的 append 方法:
105 |
106 | ```
107 | @Override
108 | public synchronized StringBuffer append(Object obj) {
109 | toStringCache = null;
110 | super.append(String.valueOf(obj));
111 | return this;
112 | }
113 | ```
114 |
115 | 你看看是不是有个 synchronized 锁,那如果 StringBuffer 不是逃逸对象,比如下面这样
116 |
117 | ```
118 | public void test() {
119 | StringBuffer sb = new StringBuffer()
120 | sb.append(s1).append(s2)
121 | return sb.toString();
122 | }
123 | ```
124 |
125 | 那 append 方法的 Synchronized 锁就可以消除了对不对
126 |
127 | 「可以可以」老虚兴奋极了,完成之后 JVM 帝国的生产力又提升了一个新台阶。。。
--------------------------------------------------------------------------------
/网络/这个下载文件的问题困住了我至少三位同事.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 | 今天给大家分享两个比较有用的浏览器行为与预期不一致的现象,这两个问题其实并不是什么难题,但在工作中发现不少人被难住了,在我的印象中至少有三位同事在群里问这样的问题,上周又有同事被此现象困住了,所以我觉得这应该是个共性问题,在这里分享给大家,希望对大家有帮助
4 |
5 | ### 现象一、点击按钮无法实现文件下载
6 |
7 | 前端同事反馈在浏览器里点击实现好的「下载商品图片」按钮却无法下载(预期应该下载 zip 文件)
8 |
9 | 
10 |
11 | 但如果你在浏览器的地址栏里输入此下载地址却又能直接从浏览器里下载,这是为何?
12 |
13 | 我们可以打开调试工具「网络部分」,然后点击一下上面的「下载商品图片」,首先看一下网络请求是否正常。
14 |
15 | 1、 首先看请求头,可以看出状态码是 200,另外还有 content-disposition 与 Content-Type 这两个 response header
16 | 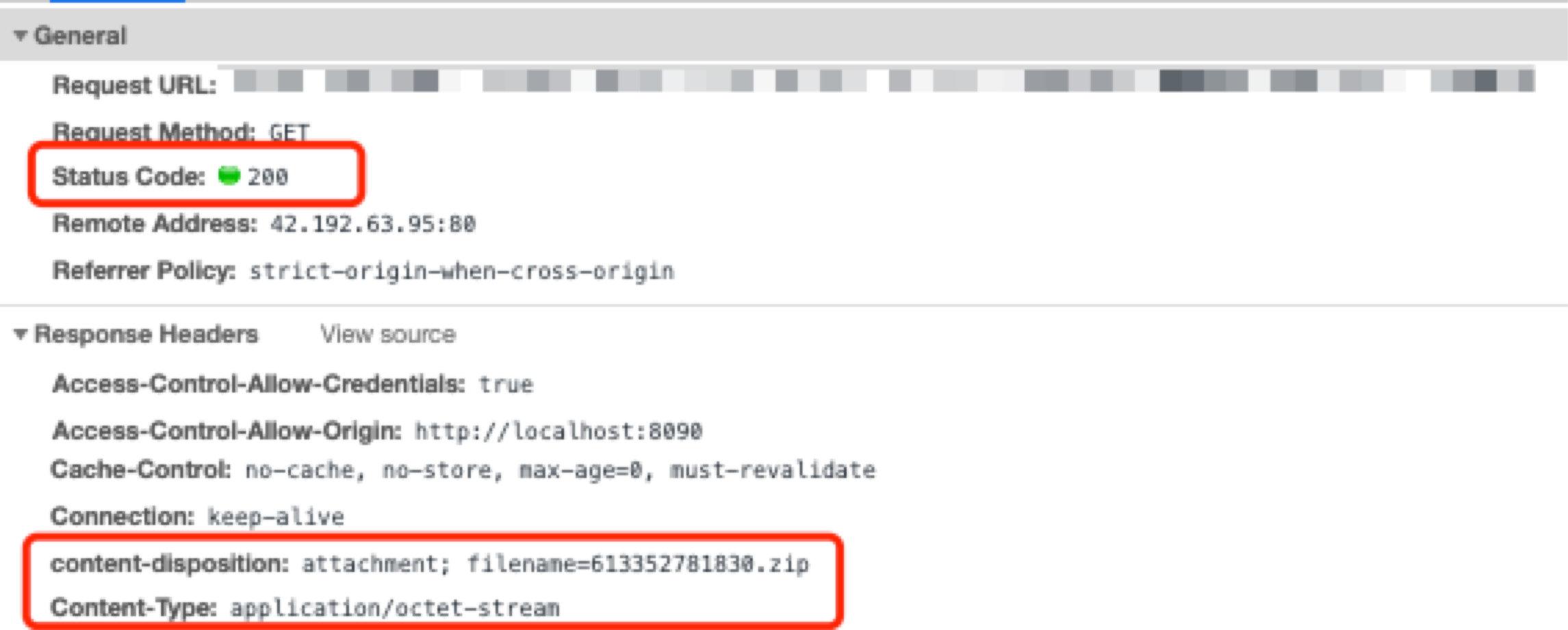
17 |
18 | 画外音:`Content-Type: application/octet-stream` 告诉客户端这是一个二进制文件,`content-disposition` 告诉客户端这是一个需要下载的附件并告诉浏览器该附件默认的文件名。
19 |
20 |
21 | 2、再看此请求的 response body,是否和步骤一的 **application/octet-stream** 相符:
22 |
23 | 
24 |
25 | 可以看到 response 就是一堆乱码,即文件的二进制流表现形式,所以从请求来看其实是没有问题的,文件是正常的返回的,但为啥文件却没有下载下来,下载下来的文件去哪里了呢,注意看上图的另一个红框 **XHR **,它的全称是 XMLHttpRequest,是 ajax 请求的一种表现形式。
26 |
27 | ajax 本身无法触发浏览器的下载功能, 它的 response 会交由 JavaScript 处理,使用 ajax 下载完成后,response 以字符串的形式存储在内存中,那使用 ajax 就没法下载了吗?不是的,我们看下浏览器为啥能下载
28 |
29 | 我们发现使用浏览器的 GET 请求(主要以 frame 加载, a 标签点击触发)或 POST请求(以 form 的形式存在)是可以下载文件的,因为这是浏览器的内置事件,下载的 response 会交由浏览器自己处理,浏览器如果识别到是二进制流数据则下载,如果识别到是可以打开的文件,如 xml, image 等则不会下载,会以预览的样式存在。
30 |
31 | 那么为啥 ajax 不能默认实现文件下载呢,这是浏览器的安全策略限制的,试想如果 ajax 可以下载文件,那就意味着 ajax 可以直接与磁盘交互,这会存在严重的安全隐患。
32 |
33 |
34 | 根据以上分析,要使用 ajax 下载文件我们也就有思路了,既然使用 a 标签(或 frame)的点击事件可以触发浏览器的内置下载行为,那我们在用 ajax 下载拿到 response 后,可以用 js 新建一个隐藏的 a 标签(标签的 href 指向文件的链接),执行它的 click 事件,这样就触发了浏览器的内置下载事件,就可以下载文件了,不过需要注意的事,创建的 a 标签中要添加一个 download 属性,如 下载。
35 |
36 | 这个 download 属性有啥用呢,对于浏览器能打开得文件,例如 html,xml 等,如果你不加 download,点击 a 标签就不是下载了,而是打开,(注意 download 属性目前只被火狐和谷歌兼容)
37 |
38 | 使用 ajax 来执行下载文件的代码示例如下:
39 |
40 | ```javascript
41 | const filename = response.headers['content-disposition'].match(
42 | /filename=(.*)/
43 | )[1]
44 | // 首先要创建一个 Blob 对象(表示不可变、原始数据的类文件对象)
45 | const blob = new Blob([response.data], {type: 'application/zip'});
46 | if (typeof window.navigator.msSaveBlob !== 'undefined') {
47 | // 兼容IE,window.navigator.msSaveBlob:以本地方式保存文件
48 | window.navigator.msSaveBlob(blob, decodeURI(filename))
49 | } else {
50 | let elink = document.createElement("a"); // 创建一个标签
51 | elink.style.display = "none"; // 隐藏标签
52 | elink.href = window.URL.createObjectURL(blob); // 配置href,指向本地文件的内存地址
53 | elink.download = filename;
54 | elink.click();
55 | URL.revokeObjectURL(elink.href); // 释放URL 对象
56 | document.body.removeChild(elink); // 移除标签
57 | }
58 | ```
59 |
60 |
61 | ### 现象二、在浏览器输入图片链接想预览,结果却变成了下载图片
62 |
63 | 这个问题其实经由上文分析,相信你不难猜出是咋回事,我们先抓包看一下:
64 |
65 | 
66 |
67 | 可以看到返回的 Content-Type 为 `octet-stream`,上文我们提到,它指任意类型的二进制流数据,一般下载文件返回的是这种类型,浏览器由于无法识别打开流数据,所以会下载,那为啥大多数图片在浏览器上是可以预览的呢,因为它返回的 Content-Type 是 image/png 或 image/jpeg 等浏览器可以直接识别打开的文件,这样就不会执行下载事件
68 |
69 | ### 总结
70 |
71 | 以上两个问题需要我们对浏览器的工作机制与 HTTP 协议有一定的了解,所以基础真的很重要啊,不然很可能你排查半天也无从下手,但如果你知道了这些原理,抓个包分析一下它们的 Content-Type,瞬间就豁然开朗了!另外对一些疑难杂症,了解 HTTP 协议与浏览器的工作机制也有助于帮助你快速定位解决问题。
72 |
73 | 比如上图的解决方案中我们通过 content-disposition 来获取文件的名称
74 |
75 | ```javascript
76 | const filename = response.headers['content-disposition'].match(
77 | /filename=(.*)/
78 | )[1]
79 | ```
80 | 但在最开始发现这段代码有问题,打印日志发现 response.headers['content-disposition'] 居然为空,可是打开浏览器的 network 会发现, content-disposition 明明存在啊
81 |
82 | 
83 |
84 | 那为啥在 reponse 的 header 里拿不到 content-disposition 呢?
85 |
86 | 一查发现原来还是 HTTP 协议的问题
87 |
88 | 默认情况下,header 只有七种 simple response headers (简单响应首部)可以暴露给外部:
89 |
90 | ```shell
91 | Cache-Control
92 | Content-Language
93 | Content-Length
94 | Content-Type
95 | Expires
96 | Last-Modified
97 | Pragma
98 | ```
99 |
100 | 这里的暴露给外部,意思是让客户端(比如 Chrome)可以访问得到,既可以在 Network 里看到,也可以在代码里获取到他们的值。
101 |
102 | 而 content-disposition 不在其中,所以即使服务器在协议回包里加了该字段,如下
103 |
104 | ```java
105 | response.setHeader("content-disposition", "attachment; filename=" + filename);
106 | ```
107 |
108 | 但因没“暴露”给外部,客户端就「看得到,吃不到」。
109 |
110 | 而响应首部 Access-Control-Expose-Headers 就是控制“暴露”的开关,它列出了哪些首部可以作为响应的一部分暴露给外部。
111 |
112 | 所以如果想要让客户端可以访问到其他的首部信息,服务器不仅要在 header 里加入该首部,还要将它们在 Access-Control-Expose-Headers 里面列出来,如下:
113 |
114 | ```java
115 | response.setHeader("Access-Control-Expose-Headers", "Content-Disposition");
116 | response.setHeader("content-disposition", "attachment; filename=" + filename);
117 | ```
118 |
119 | 这样的话 JS 的 response header 里就有 content-disposition 的值啦。
120 |
121 |
122 | 更多精品文章,欢迎大家扫码关注「码海」
123 |
124 | 
--------------------------------------------------------------------------------
/个人感悟/随想.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 | 不少读者私下对我说我的朋友圈对他们的帮助很大,所以想了一下把一些有价值的思考提炼出来分享出来,希望对大家有帮助,也欢迎大家扫码加我好友,围观朋友圈,共同进步^_^
4 |
5 | 
6 |
7 | ### 编程思维
8 |
9 | * 「分析源码第一步,先看一下单元测试用例。因为,一般单元测试中,每一个用例就是测试代码中的一个局部或者说是一个小流程。那对于一些比较完善的开源软件,它们的单元测试覆盖率都非常高,很容易找到我们关心的那个流程所对应的测试用例。我们的源码分析,就可以从这些测试用例入手,一步一步跟踪其方法调用链路,理清实现过程。」摘自极客时间,说得不错/:handclap
10 |
11 | * JAVA 网络,看到一个比喻挺不错的(有一些瑕疵,不过不影响整体理解),分享给大家:
12 | 例子:有一个养鸡的农场,里面养着来自各个农户(Thread)的鸡(Socket),每家农户都在农场中建立了自己的鸡舍(SocketChannel)
13 | 1、BIO:Block IO,每个农户盯着自己的鸡舍,一旦有鸡下蛋,就去做捡蛋处理;
14 | 2、NIO:No-Block IO-单Selector,农户们花钱请了一个饲养员(Selector),并告诉饲养员(register)如果哪家的鸡有任何情况(下蛋)均要向这家农户报告(select keys);
15 | 3、NIO:No-Block IO-多Selector,当农场中的鸡舍逐渐增多时,一个饲养员巡视(轮询)一次所需时间就会不断地加长,这样农户知道自己家的鸡有下蛋的情况就会发生较大的延迟。怎么解决呢?没错,多请几个饲养员(多Selector),每个饲养员分配管理鸡舍,这样就可以减轻一个饲养员的工作量,同时农户们可以更快的知晓自己家的鸡是否下蛋了;
16 | 4、Epoll模式:如果采用Epoll方式,农场问题应该如何改进呢?其实就是饲养员不需要再巡视鸡舍,而是听到哪间鸡舍的鸡打鸣了(活跃连接),就知道哪家农户的鸡下蛋了;
17 | 5、AIO:Asynchronous I/O, 鸡下蛋后,以前的NIO方式要求饲养员通知农户去取蛋,AIO模式出现以后,事情变得更加简单了,取蛋工作由饲养员自己负责,然后取完后,直接通知农户来拿即可,而不需要农户自己到鸡舍去取蛋。
18 |
19 | * 在看 ConcurrentHashMap 源码,看到 helpTransfer 的方法时,被一个地方卡住了,联系上下文,想了半天,总感觉这里有问题
20 |
21 | 
22 |
23 | 于是打开 https://bugs.java.com/bugdatabase/view_bug.do 搜了一下,果然是 bug!比较坑爹的是这个 bug 在 JDK 12 才解决,顺便感叹一句,搜了不少靠前的文章,都讲到这一段,但都没有发现这是 bug,怀疑还是很重要的,即便这是 Doug Lea 写的。源码要看,但要细看,指不定你哪天也在这上面提一下 bug,简历上可以增添一句:我是给 bugs.java.com 提过 bug 的男人,简历瞬间熠熠生辉😃
24 |
25 | * 看了一篇被誉为是"程序员史诗般必读文章"的论文,同时也是 Kafka 的起源论文,大受震憾,中文版:https://www.kancloud.cn/kancloud/log-real-time-datas-unifying/58711
26 |
27 | * 接手了一个很复杂的 PHP 转 Java 的工作,评估了一下工作量,如果硬转,估计一天都搞不定,这个功能其实用的很少,于是想到 Java 可以执行 shell,这样直接在 Java 里调用执行 php 脚本的命令(php xxx.php)就可拿到结果,处理后,10 分钟搞定,先思考再动手,结果会大不一样[Smirk]
28 |
29 | * 极客时间李智慧的《高并发架构实战课》确实给力!不管是秒杀还是短链设计虽然我之前我都写过,但这门课在这两节中依然给出了让我眼前一亮的思路,每一章节信息量都很大,比如短链设计中提到居然可以将 144 亿条 86.4GB 的短链提前生成保存在一个 HDFS 文件中!短链过期后还可以重复利用(过个一两年其实这些短链也就过期了),而我们之前短链的设计是连续递增,使用openrestry 等方案来实现高性能,看完这门课之后最大的感叹是原来高性能还可以用这些相对简单的技术来实现,设计思路都挺巧妙的/::,@
30 |
31 | * 美团的这篇垃圾回收写得太棒了!不过文章略长,2万多字,记笔记都记了好久,慢用/:,@P https://tech.meituan.com/2020/11/12/java-9-cms-gc.html
32 |
33 | * 发现一本神作《Inside Java Virtual Machine》,虽然是2000年出版的,但关于JVM的知识点讲得很细,不少东西依然不过时,是对《深入理解Java虚拟机》很好的补充
34 |
35 | * 非常好的一篇线上问题复盘文章,信息量很大,GET 到很多新技能,比如
36 |
37 | 1. 可以使用 OQL(类 SQL)来查找容量大于 xx 的对象
38 | 2. 在 FullGC 后新老年代都占用 700 M 的空间下,JVM 却依然持续进行 full GC,原因居然是 Vector 扩容引起的
39 |
40 | 最后的解决方案也是挺巧妙的,推荐看看
41 |
42 | https://tech.ebayinc.com/engineering/sre-case-study-triage-a-non-heap-jvm-out-of-memory-issue/
43 |
44 | * 最近看了一些秒杀方面的东西,收获颇丰,推荐几个很有技术含量的秒杀项目或文章,希望对大家有帮助
45 |
46 | 1. 极客时间的《手把手带你搭建秒杀系统》从 0 到 1 带你打造一个百万 QPS 的秒杀项目,关于秒杀理论讲解得很到位
47 | 2. 秒杀系统实战总结:https://mp.weixin.qq.com/s/yWn_2OQV31zn5wJKKejGug,一位技术总监关于秒杀的总结,实战性非常强
48 | 3. github 上的 2.2w 秒杀项目:https://github.com/qiurunze123/miaosha
49 |
50 | * 最近面试了不少前端,其中一位让我印象深刻,他在简历上写了一个可以演示的项目(计时展示一个皮卡丘的绘制过程,并且源码滚动展示),整体聊下来感觉非常好,其实说实话谁也不想问那些枯燥的八股文,如果有项目经验,顺着项目问相关知识点最舒服,如果可以演示就更棒了/:handclap
51 |
52 | * 提起IO多路复用,我们第一感觉是复用一个线程去处理大量的 Socket 连接,今天看到一个观点很受启发,复用更多的是指系统调用的复用,「因为在非阻塞 IO 时,就已经可以实现一个线程处理多个网络连接了,这个是由于其非阻塞而决定的(下图为非阻塞IO)多路复用主要复用的是通过有限次的系统调用来实现管理多个网络连接。最简单来说,我目前有 10 个连接,我可以通过一次系统调用将这 10 个连接都丢给内核,让内核告诉我,哪些连接上面数据准备好了,然后我再去读取每个就绪的连接上的数据。因此,IO 多路复用,复用的是系统调用。通过有限次系统调用判断海量连接是否数据准备好了」
53 |
54 | 
55 |
56 | * 推荐一门比较系统的计算机科学概览课程,在油管上非常火爆的计算机科学入门课程,累积千万播放,能够帮助我们在脑海中建立完整的计算机学科体系
57 |
58 | 很贴心的是,这个课程被一些计算机博主看到了之后,自发的组织起来,翻译了中文字幕,并将视频上传到了 B 站上,也建立了相应的 Github 项目,目前在 B 站的播放也有百万量级了。
59 |
60 | Github:https://github.com/1c7/Crash-Course-Computer-Science-Chinese
61 |
62 | Bilibili:https://www.bilibili.com/video/av21376839
63 |
64 | 每天在地铁上看几集,进步一点点[Smirk]
65 |
66 | * 网上不少博客说 disruptor 的 ringbuffer 满了之后会阻塞业务线程,差点我就信了,但转念一想 log4j2 用的也是 ringbuffer,它又是个如此常见的日志组件,这样的话岂不是打日志都得悠着点,看了一下源码,发现它有个 AsyncQueueFullPolicy 的选项,可以选择 discard 模式,这个 discard 模式用的是 disruptor 的 tryPublishEvent 的方法,用这个方法投递的话在 ringbuffer 满了之后并不会阻塞,而是会直接返回 false,而用 publishEvent 来投递的话则在 ringbuffer 满时会发生阻塞 1 纳秒现象。尽信书不如无书,确实要多探索一下,多读下源码,毕竟:源码之下无秘密!
67 |
68 | * 前端迟迟未招到合适的人,小程序的需求又特别多,于是这两周客串了一把前端,主要时间其实是花在界面的调整上,今天看需求准备开始搭页面时突然想到我们的 UI 稿是用 sketch 标的 html 页面,每个元素都有 css 等样式,是否可以写个脚本把这些 html 页面转成小程序代码,一搜居然还真有,阿里的 imgcook已经实现了,可以导出多端代码,试用了一下非常给力!导出的 css 还原度 100%!开发在导出的代码里稍作修改即可,大大减少了开发量和视觉走查成本,多思考,减少重复无效的工作,生活会更美好/:,@P,顺便说一句,阿里牛逼/::>
69 |
70 | 
71 |
72 |
73 |
74 | ### 商业思维
75 |
76 | 1. 近期看到几例创业卖房或者抵押房子最后失败的案例,实在让人唏嘘,余世维曾经说过一句话我觉得每一个创业者都应该谨记:我在外面打拼不管结局如何,但我始终不会动用留给家里的这栋房产。这就是底线思维,创业者应该要做最坏的打算,留有最基本的底线(不影响冢人体面的生活),当然说来容易做来难,毕竟公司就像自己的孩子一样,很难接受它半路胎死腹中,所以说大部分人都不适合创业,要承受极高的压力和极有可能一无所有的窘境,别没事想着创业,做一夜暴富的美梦,如果一定要创业,建议做轻资产创业,比如做自媒体等,这样成本就只有一台电脑还有个人时间,后果也可以承受
77 |
78 | 2. 晚上打车回家,1.2 公里等了 15 分钟,本来挺恼火的,上车一问为什么这么久,司机说他注册了好多个平台,没留意到接单通知,并且补充说现在每天的接单收入都不及油钱,主要是因为疫情,大家都不敢出来消费了,而且现在出现大量的工厂倒闭潮,大量的服装厂,做外贸的等倒闭了,大家都不好过,他因为有不少人脉,帮了不少老板介绍了工作,所以比较了解这这些,他自己则准备再干一周也转行。想起王兴 2019 年所说的那句话:今年是未来十年最好的一年,现在仔细一想,确实有先见之明,时刻准备着过冬
79 |
80 | 3. 年初亦仁说今天应该全力发力抖音,深以为然,这两个月我们在抖音直播带货取得了挺大的突破,这个月预计可以提前完成单品牌单月百万 GMV 的目标,为什么很多商家现在都布局抖音了呢,因为阿里电商遭遇了比较大的挑战,和我们合作的某 TOP 3 品牌也反馈他们在淘宝,天猫的销量下滑了30%~40%,而抖音的电商数据一直在稳步增长,抖音毫无疑问是个不容忽视的巨大的金矿!
81 | 4. 好几位读者反应公司在裁员中,最近确实是裁员滚滚,资本趋冷,加入有稳定现金流的公司太重要了,存量博杀的时代,活着才是王道
82 | 5. 上个月为某品牌带货卖了两万多,品牌方觉得有点少,于是他们自己播了一场,结果只卖了 80,终于明白了我们的直播相对专业,于是毫无保留的把最新款式等他们觉得比较有用的款式以及其他一些商品信息同步给了我们/:,@P,这一方面说明了把一些看似简单的事情做到极致也是很强的竞争力,另一方面我觉得更重要得是让客户觉得我们做这事是专业,有壁垒的/::,@
83 |
84 | ### 其他
85 |
86 | * 今日的乌克兰与当年的国民政府何其相似,民众都处在悲惨的境地,都沦为大国博弈的棋子,都有一个将自己命运寄托于其他大国的“领袖”,如此焉能不败!天幸中国有润之!
87 |
88 | * 磁盘空间满了,准备删些文件,发现 QQ 居然占了好几个 G,于是手起刀落,直接卸载,这玩意貌似一年多没用了,以后估计也不会再怎么用了,重要的人和事都保存在微信里,这就够了。顺便推荐一款清理 mac 很好用的工具 omniDiskSweeper,使用 GUI 的形式能帮你按容量大小列出本机上的所有文件并删除,体验很不错
89 |
90 | * 晚上第一次看话剧,《最后晚餐》,确实精彩,两个演员撑起了一场一个半小时的戏,很有感染力,听到现场挺多人的啜泣声,记得有一篇文章说看一个演员的水平高低没有什么统一的标准,但如果长时间经历过话剧表演的演员表演功力一般很深厚,原因很简单,话剧是现场表演,到某段台词需要哭,那你就得立马哭,不像电影那样可以后期剪辑或者使用催泪剂来达成效果,建议大家有机会看看话剧,感受下现场表演的魅力/:,@P
91 |
92 |
--------------------------------------------------------------------------------
/系统设计/优秀程序员必备的四项能力.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 一个优秀的程序员需要具备挺多特质的,比如好奇心,学习能力等,但在我看来一个优秀的程序员必须具备四项核心能力,哪四 项,先卖个关子,程序员最喜欢说的话是「Talk is Cheap, show me your code」,那我们先来看一道很常见的面试题
3 |
4 | > 如何快速定位IP对应的省份地址?
5 |
6 | 我们知道,每个省市都分配了一个 ip 段,如下
7 |
8 | ```shell
9 | [202.102.133.0, 202.102.133.255] 山东东营市
10 | [202.102.135.0, 202.102.136.255] 山东烟台
11 | [202.102.156.34, 202.102.157.255] 山东青岛
12 | [202.102.48.0, 202.102.48.255] 江苏宿迁
13 | [202.102.49.15, 202.102.51.251] 江苏泰州
14 | [202.102.56.0, 202.102.56.255] 江苏连云港
15 | ```
16 | 输入一个 ip 地址怎么做到秒级定位此 ip 所在的省市呢?
17 |
18 | 
19 |
20 | **如图示:在百度上输入一个 ip 地址,能做到秒级展示其所属地,怎么做到的呢,背后用到了什么原理**
21 |
22 | 这就引入了我们要谈的程序员需要具备的第一项能力: **抽象问题**或者说**数据建模**的能力
23 |
24 | ## 抽象问题的能力
25 | 所谓抽象问题或者说数据建模的能力,即能把一个问题抽象或归类为某种方案来解决,比如要实现负载均衡, 会想到一致性哈希算法,要实现最短路径,想到使用动态规划, 微服务下要保证服务可用引入降级机制等等,一句话就是把具体的问题抽象成到解决此问题背后的方法论,进而用相关的技术方案得以解决。
26 |
27 | 回归到如何快速定位 IP 对应的省份地址这道题来看,如果我们不具备抽象问题的能力,硬着头皮从头到尾把输入的ip 与所有区间段的 ip 都遍历对比一遍,然后判断它落到哪个区间,那么 ip 地址有 32 位,共有 2^32 个,约有 42.9 亿个,用暴力遍历法每查找一个 ip 最坏情况下要遍历约 42 亿次,这种方法显然是不可行的。
28 |
29 | 所以我们必须得把这个问题抽象为另一种可行的方法,即: **二分查找**, ip 地址查找怎么就跟二分查找扯上关系了,背后的逻辑是什么,我们一起来看看。
30 |
31 | ip 地址不容易比较,那我们首先把 ip 地址转成整数,于是每个省市对应的 ip 地址区间就变成了整数区间,假设为如下区间
32 |
33 | ```shell
34 | [1, 5]
35 | [11, 15]
36 | [16, 20]
37 | [6, 10]
38 | ....
39 | ```
40 |
41 | 再以每个整数区间的起始数字对这些区间进行排序,排序后的区间如下
42 |
43 | ```shell
44 | [1, 5]
45 | [6, 10]
46 | [11, 15]
47 | [16, 20]
48 | ...
49 | ```
50 | 看到这些排序后的区间,想到了啥,二分查找就是在一组有序的数字中进行查找!是不是找到相似点了?
51 |
52 | 这里给没听过二分查找的读者简单普及下啥是二分查找,小时候可能我们都玩过猜字游戏,在纸面上写一个 1 到 100 的数字,比如 70,让对方猜,怎样猜才能猜最快。
53 |
54 | 1. 首先猜 1 和 100 的**中间数字** (1+ 100) / 2 = 50(取整)
55 | 2. 50 < 70, 于是我们继续猜 50 和 100 的**中间数字** (50+100) / 2 = 75
56 | 3. 75 > 70,于是我们继续猜 50 和 75 的**中间数字** (50+75) / 2 = 62
57 | 4. 依次持续类似以上的步骤,不断地缩小范围,直至找到 70
58 |
59 | 
60 |
61 |
62 | 总共只猜了 7 次,比起我们从 1 猜到 100 效率高了十几倍,如果被猜字的范围从一扩大到成百上千万,提升的效率是指数级的!二分查找也叫折半查找(注意上文中加粗的**中间数字**),每查找一次,问题规模缩小一半,整体时间复杂度是O(logn),即使我们要在 42 亿的数字中查找数字,最多也只要查 32 次,所以采用二分查找对查找性能的提升无疑是巨大的!
63 |
64 | 二分查找是要在一堆有序的数字中精准地查找所要查找的数**是否存在**,而回过头来看已经排序好的以下 ip 段
65 |
66 | ```shell
67 | [1, 5]
68 | [6, 10]
69 | [11, 15]
70 | [16, 20]
71 | ...
72 | ```
73 |
74 | 我们要查找的是某个整数是否在一个有序数组的相邻两个数字的区间里,例如:取这些 ip 区间的起始地址组成一个数组 (1,6,11,16,....)(有序数组),如果我们要找的 ip 对应的整型为 14, 由于它在 [11,16) (11是闭区间,16是开区间) 之间,所以这个 ip 就落在 [11, 15] 这个 ip 区间,这样就找到了这个 ip 对应的省市了。
75 |
76 | 所以就由二分查找某个值是否存在转变成了查找某个值是否在有序数组中相邻的两个值之间了,这就引入了程序员要具备的第二层能力:举一反三或者说修改模型的能力
77 |
78 | ## 修改模型的能力
79 | 就像机器学习,现在其实有很多现成的模型可用,比如识别物的模型等等,我们需要的话可以直接拿来用,但是现有模型的准确率可能不是那么理想(比如只有80%),如果我们需要进一步地提升识别准确率,可能就需要对其参数进行进一步的调优,以进一步地优化模型,达到我们预期的值。
80 |
81 | 再比如当当网基于 Dubbo 的扩展版本开发的 Dubbox 也是由于原来的 Dubbo 功能不满足其团队需求而在其基础上修改扩展的。
82 |
83 | 回过头来看以上说的原来二分查找只是查找某个值是否存在,而我们现在要解决的问题是查找某个值是否在相邻的两个值之间,这本质是也是对模型的调优或修改,以进一步满足我们的要求。于是我们写下了如下代码
84 |
85 | ```java
86 | public static int bsearch(int[] a, int length, int value) {
87 | int low = 0;
88 | int high = length - 1;
89 | while (low <= high) {
90 | int mid = (low + high) / 2;
91 | if (a[mid] > value) {
92 | if (mid == 0) {
93 | return -1;
94 | }
95 | if (a[mid-1] <= value) {
96 | return mid-1;
97 | } else {
98 | high = mid-1;
99 | }
100 | }else {
101 | low = mid + 1;
102 | }
103 | }
104 | return -1;
105 | }
106 | ```
107 | 那这段代码有啥问题吗,或者说有哪些可以优化的空间,这就引入了程序员需要具备的第三项能力: 代码要有足够的健壮性
108 |
109 | ## 代码要有足够的健壮性
110 | 仔细看上文的代码,有两个地方有潜在隐患,一个是 length 可能是负数,而显然数组的长度不可能是负数,也就是说对这种异常数据应该**抛异常**。另外 **(low + higth) / 2** 这段代码中的 low+high 如果在数组很大的情况下比较容易造成溢出,所以可以改造成 low + (high - low) / 2, 另外为了提升性能可以把除以 2 改成位运算,即 **low + ((high - low) >> 1)**,于是代码变成了
111 |
112 | ```java
113 | public static int bsearch(int[] a, int length, int value) throws Exception {
114 |
115 | if (length < 0) {
116 | // 实际应该抛出一个继续自Exception的异常,这里为了方便直接抛出Exception
117 | throw new Exception("数据长度不合法");
118 | }
119 |
120 | int low = 0;
121 | int high = length - 1;
122 | while (low <= high) {
123 | int mid = low + ((high - low) >> 1);
124 | if (a[mid] > value) {
125 | if (mid == 0) {
126 | return -1;
127 | }
128 | if (a[mid-1] <= value) {
129 | return mid-1;
130 | } else {
131 | high = mid-1;
132 | }
133 | }else {
134 | low = mid + 1;
135 | }
136 | }
137 | return -1;
138 | }
139 | ```
140 | 有人可能觉得判断数组长度小于 0 过于严苛了,但是是人就会犯错误,这里也是为了强调我们对异常情况的处理要到位,说到代码的健壮性,这里再多说几句,在创业初期我司主要用的是 php,主要是创业团队追求快,用 PHP 这种弱类型语言开发确实效率高,不过不安全,线上多次出现因为变量可以随意赋值造成的多次线上故障,而 Java 这种强类型语言虽然开发效率上比 PHP 慢了不少,但强类型语言的特征保证了它的稳定,**足够安全**,所以后期随着人员的扩充,为了保证线上足够安全,我司去年把大部分的服务都 Java 化了,近年来有不少人唱衰 Java,但 Java 的安全,稳定性以及强大的生态能力注定了它的长久生命力。
141 |
142 | 代码写成这样看起来确实完美了,还能再优化吗,注意上文中的代码只适用于 int 的数组,如果我们想针对 short 或 long 型等类型的数组进行查找就无能为力了,所以这就引入了程序员需要具备的第四项能力: 代码要有足够的可扩展性
143 |
144 | ## 代码要有足够的可扩展性
145 | 怎么让 bsearch 这个二分查找也支持 long 型或 short 型数组呢,这里引入 Java 语言中的泛型,于是我们代码改造如下
146 |
147 | ```java
148 | public static int bsearch(T[] a, int length, T value) throws Exception {
149 | if (length < 0) {
150 | // 实际应该抛出一个继承自Exception的异常,这里为了方便直接抛出Exception
151 | throw new Exception("数据长度不合法");
152 | }
153 | int low = 0;
154 | int high = length - 1;
155 | while (low <= high) {
156 | int mid = low + ((high - low) >> 1);
157 | if (a[mid].compareTo(value) > 0) {
158 | if (mid == 0) {
159 | return -1;
160 | }
161 | if (a[mid-1].compareTo(value) <= 0) {
162 | return mid-1;
163 | } else {
164 | high = mid-1;
165 | }
166 | }else {
167 | low = mid + 1;
168 | }
169 | }
170 | return -1;
171 | }
172 | ```
173 |
174 | 写成这样,可以说我们的代码具有足够的健壮性与可扩展性了。
175 |
176 | ## 总结
177 | 本文通过一个常见的面试题来详细阐述了优秀程序员必须具备的四项核心能力: 抽象问题,修改模型,写出健壮性,可扩展性的代码!所以为什么面试中大厂喜欢考算法,主要是想详细地了解你是否具备解决此算法题背后的思想,即**抽象问题**的能力,面试官还喜欢对相应算法题进行各种变形,其实也是为了考察你是否具有**修改模型**的能力(比如一个翻转链表,可以引申出顺序每 k 个一组翻转,逆序每 k 个一组翻转),所以为了同时具备这两项能力,我们需要提前掌握大量的理论知识,做大量的刻意练习。共勉!
--------------------------------------------------------------------------------
/系统设计/你管这破玩意儿叫负载均衡.md:
--------------------------------------------------------------------------------
1 | 相信大家都听过这样的一道经典面试题:「请说出在淘宝网输入一个关键词到最终展示网页的整个流程,越详细越好」
2 |
3 | 这个问题其实很难,涉及到 HTTP,TCP,网关,LVS 等一系列相关的概念及工作机制,如果你能掌握到这其中的每个知识点,那将极大地点亮你的技能树,你对于网络是如何运作也会了然于胸,即便不能完全掌握,但知道流量怎么流转的对你排查定位问题会大有帮助,我之前就利用这些知识定位到不少问题,为了弄清楚整个流程,我查阅了很多资料也请教了不少人,相信应该可以把这个问题讲明白,不过写着写着发现篇幅实在太长,所以分为上下两篇来分别介绍一下,本篇先介绍流量在后端的的整体架构图,下一篇会深入剖析细节点,如 LVS 的工作细节,这其中会涉及到交换机,路由器的工作机制等
4 |
5 |
6 | 李大牛创业了,由于前期没啥流量,所以他只部署了一台 tomcat server,让客户端将请求直接打到这台 server 上
7 |
8 | 
9 |
10 | 这样部署一开始也没啥问题,因为业务量不是很大,单机足以扛住,但后来李大牛的业务踩中了风口,业务迅猛发展,于是单机的性能逐渐遇到了瓶颈,而且由于只部署了一台机器,这台机器挂掉了业务也就跌零了,这可不行,所以为了避免单机性能瓶颈与解决单点故障的隐患,李大牛决定多部署几台机器(假设为三台),这样可以让 client 随机打向其中的一台机器,这样就算其中一台机器挂了,另外的机器还存活,让 client 打向其它没有宕机的机器即可
11 |
12 |
13 |
14 | 
15 |
16 |
17 |
18 | 现在问题来了,client 到底该打向这三台机器的哪一台呢,如果让 client 来选择肯定不合适,因为如果让 client 来选择具体的 server,那么它必须知道有哪几台 server,然后再用轮询等方式随机连接其中一台机器,但如果其中某台 server 宕机了,client 是无法提前感知到的,那么很可能 client 会连接到这台挂掉的 server 上,所以选择哪台机器来连接的工作最好放在 server 中,具体怎么做呢,在架构设计中有个经典的共识:没有什么是加一层解决不了的,如果有那就再加一层,所以我们在 server 端再加一层,将其命名为 LB(Load Balance,负载均衡),由 LB 统一接收 client 的请求,然后再由它来决定具体与哪一个 server 通信,一般业界普遍使用 Nginx 作为 LB
19 |
20 |
21 |
22 |
23 |
24 | 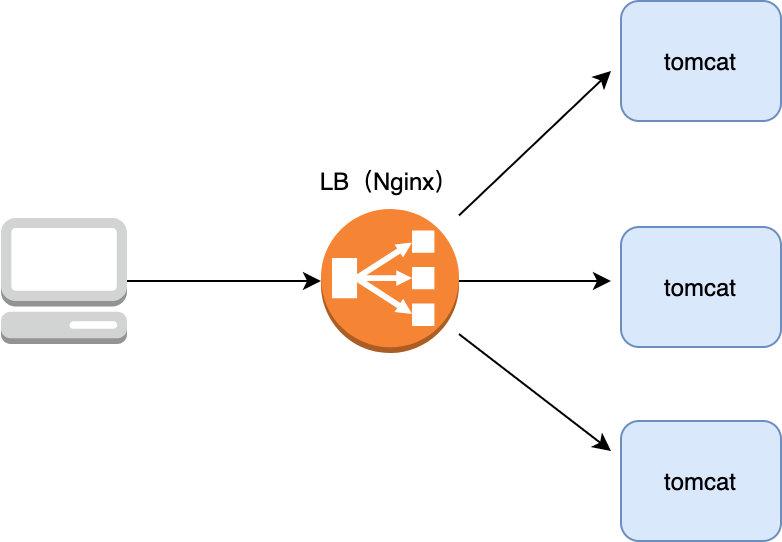
25 |
26 |
27 |
28 |
29 |
30 | 采用这样的架构设计总算支撑了业务的快速增长,但随后不久李大牛发现这样的架构有点问题:所有的流量都能打到 server 上,这显然是有问题的,不太安全,那能不能在流量打到 server 前再做一层鉴权操作呢,鉴权通过了我们才让它打到 server 上,我们把这一层叫做网关(为了避免单点故障,网关也要以集群的形式存在)
31 |
32 |
33 |
34 | 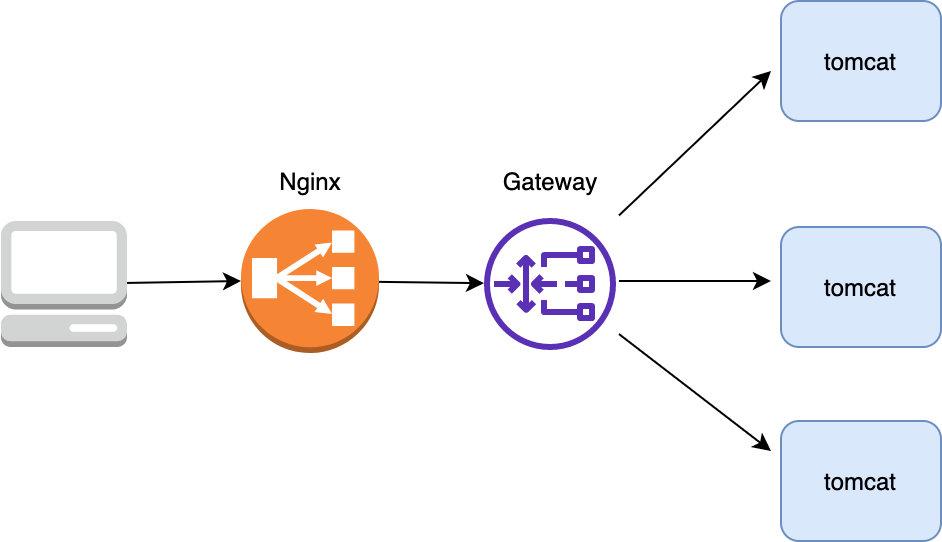
35 |
36 |
37 |
38 | 这样的话所有的流量在打到 server 前都要经过网关这一层,鉴权通过后才把流量转发到 server 中,否则就向 client 返回报错信息,除了鉴权外,网关还起到风控(防止羊毛党),协议转换(比如将 HTTP 转换成 Dubbo),流量控制等功能,以最大程度地保证转发给 server 的流量是安全的,可控的。
39 |
40 |
41 |
42 | 这样的设计持续了很长一段时间,但是后来李大牛发现这样的设计其实还是有问题,不管是动态请求,还是静态资源(如 js,css文件)请求都打到 tomcat 了,这样在流量大时会造成 tomcat 承受极大的压力,其实对于静态资源的处理 tomcat 不如 Nginx,tomcat 每次都要从磁盘加载文件比较影响性能,而 Nginx 有 proxy cache 等功能可以极大提升对静态资源的处理能力。
43 |
44 | **画外音:所谓的 proxy cache 是指 nginx 从静态资源服务器上获取资源后会缓存在本地的内存+磁盘中,下次请求如果命中缓存就从 Nginx 本机的 Cache 中直接返回了**
45 |
46 |
47 |
48 | 所以李大牛又作了如下优化:如果是动态请求,则经过 gateway 打到 tomcat,如果是静态请求,则打到静态资源服务器上
49 |
50 | 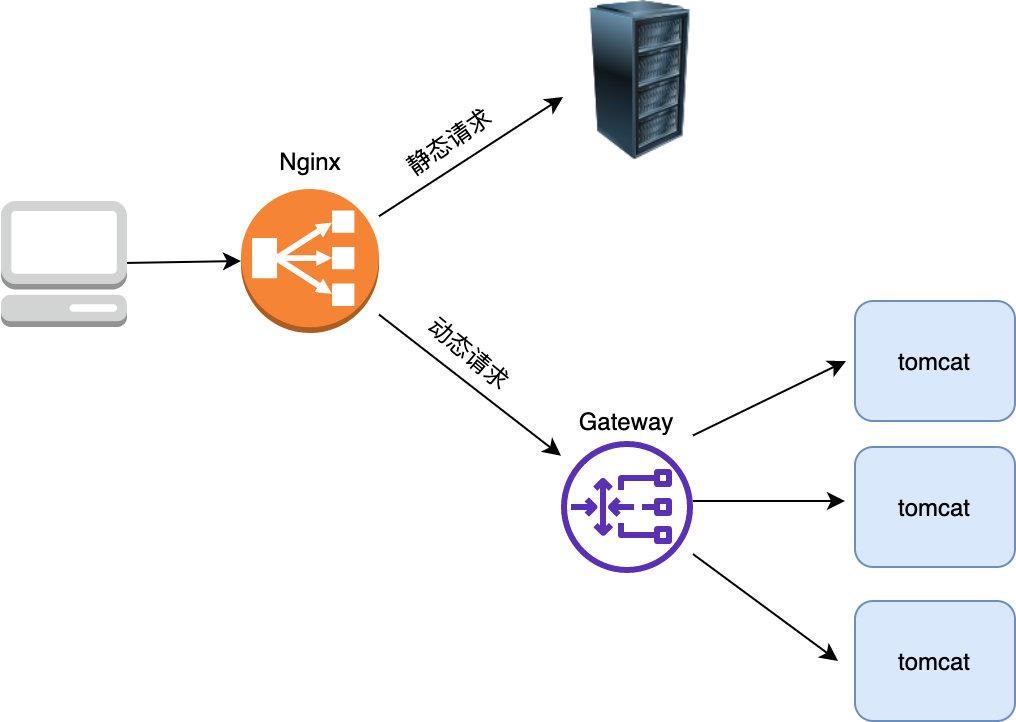
51 |
52 | 这就是我们所说的**动静分离**,将静态请求与动态请求分开,这样 tomcat 就可以专注于处理其擅长的动态请求,而静态资源由于利用到了 Nginx 的 proxy cache 等功能,后端的处理能力又上了一个台阶。
53 |
54 |
55 |
56 | 另外需要注意的是并不是所有的动态请求都需要经过网关,像我们的运营中心后台由于是内部员工使用的,所以它的鉴权与网关的 api 鉴权并不相同,所以我们直接部署了两台运营中心的 server ,直接让 Nginx 将运营中心的请求打到了这两台 server 上,绕过了网关。
57 |
58 | 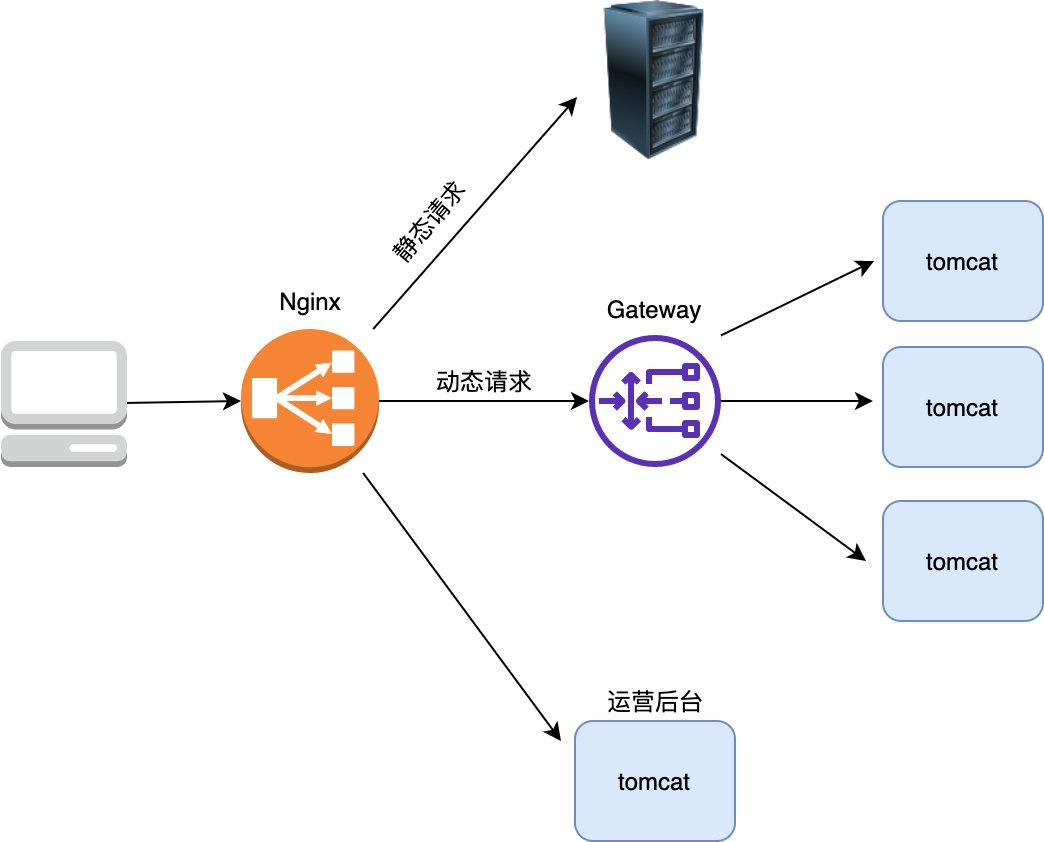
59 |
60 |
61 |
62 | 当然为了避免单点故障 Nginx 也需要部署至少两台机器,于是我们的架构变成了下面这样,Nginx 部署两台,以主备的形式存在,备 Nginx 会通过 keepalived 机制(发送心跳包) 来及时感知到主 Nginx 的存活,发现宕机自己就顶上充当主 Nginx 的角色
63 |
64 |
65 |
66 | 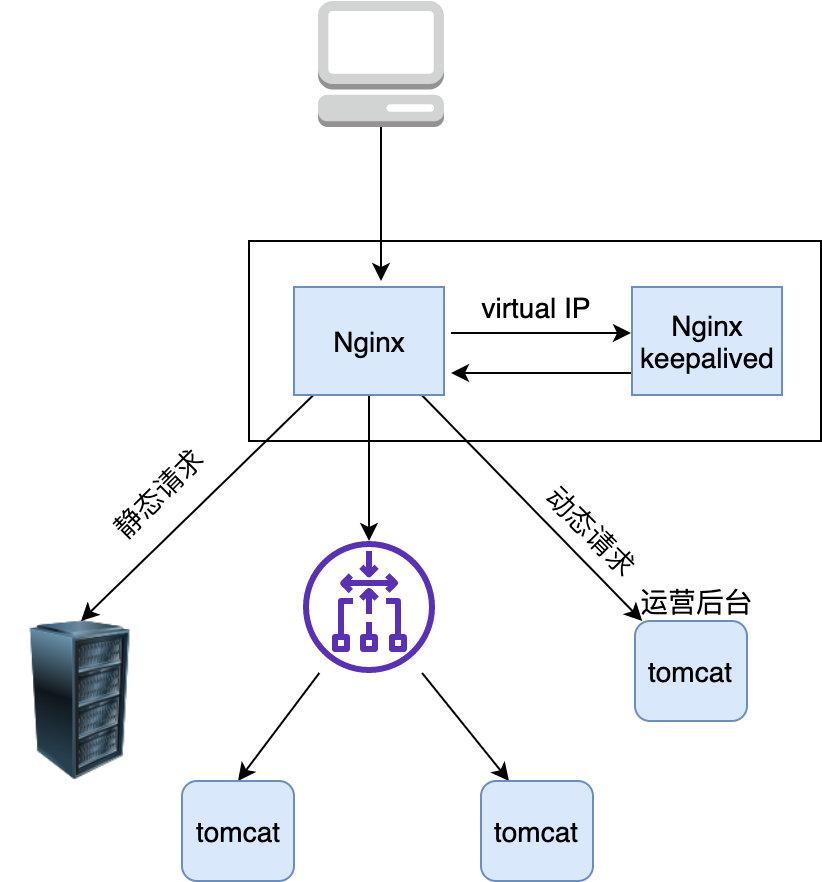
67 |
68 |
69 |
70 | 看起来这样的架构确实不错,但要注意的是 Nginx 是七层(即应用 层)负载均衡器 ,这意味着如果它要转发流量首先得和 client 建立一个 TCP 连接,并且转发的时候也要与转发到的上游 server 建立一个 TCP 连接,而我们知道建立 TCP 连接其实是需要耗费内存(TCP Socket,接收/发送缓存区等需要占用内存)的,客户端和上游服务器要发送数据都需要先发送暂存到到 Nginx 再经由另一端的 TCP 连接传给对方。
71 |
72 |
73 |
74 | 
75 |
76 |
77 |
78 | 所以 Nginx 的负载能力受限于机器I/O,CPU内存等一系列配置,一旦连接很多(比如达到百万)的话,Nginx 抗负载能力就会急遽下降。
79 |
80 |
81 |
82 | 经过分析可知 Nginx 的负载能力较差主要是因为它是七层负载均衡器必须要在上下游分别建立两个 TCP 所致,那么是否能设计一个类似路由器那样的只负载转发包但不需要建立连接的负载均衡器呢,这样由于不需要建立连接,只负责转发包,不需要维护额外的 TCP 连接,它的负载能力必然大大提升,于是四层负载均衡器 LVS 就诞生了,简单对比下两者的区别
83 |
84 | 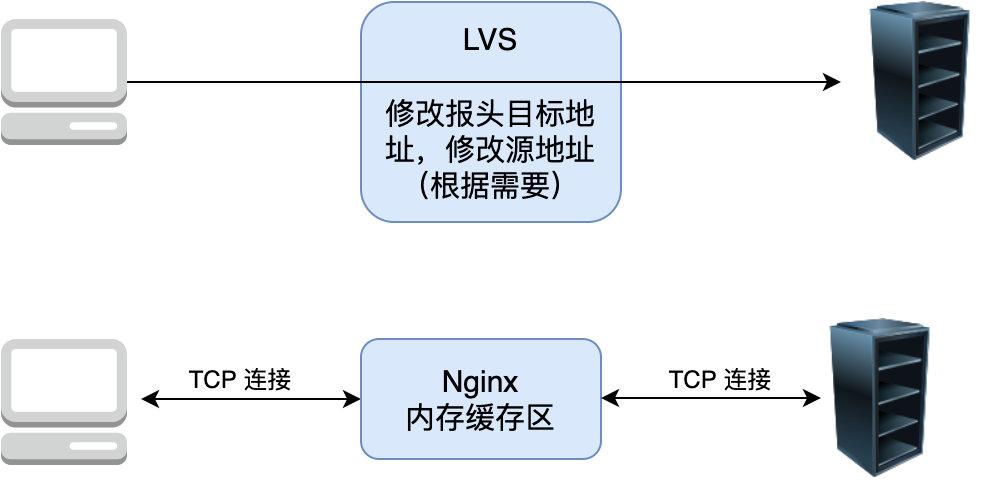
85 |
86 |
87 |
88 | 可以看到 LVS 只是单纯地转发包,不需要和上下游建立连接即可转发包,相比于 Nginx 它的抗负载能力强、*性能*高,能达到 F5 硬件的 60%;对内存和cpu资源消耗比较低
89 |
90 |
91 |
92 | > 那么四层负载均衡器是如何工作的呢
93 |
94 |
95 |
96 | 负载均衡设备在接收到第一个来自客户端的SYN 请求时,即通过负载均衡算法选择一个最佳的服务器,并对报文中目标IP地址进行修改(改为后端服务器 IP ),直接转发给该服务器。TCP 的连接建立,即三次握手是客户端和服务器直接建立的,负载均衡设备只是起到一个类似路由器的转发动作。在某些部署情况下,为保证服务器回包可以正确返回给负载均衡设备,在转发报文的同时可能还会对报文原来的源地址进行修改。
97 |
98 |
99 |
100 | 综上所述,我们在 Nginx 上再加了一层 LVS,以让它来承接我们的所有流量,当然为了保证 LVS 的可用性,我们也采用主备的方式部署 LVS,另外采用这种架构如果 Nginx 容量不够我们可以很方便地进行水平扩容,于是我们的架构改进如下:
101 |
102 |
103 |
104 | 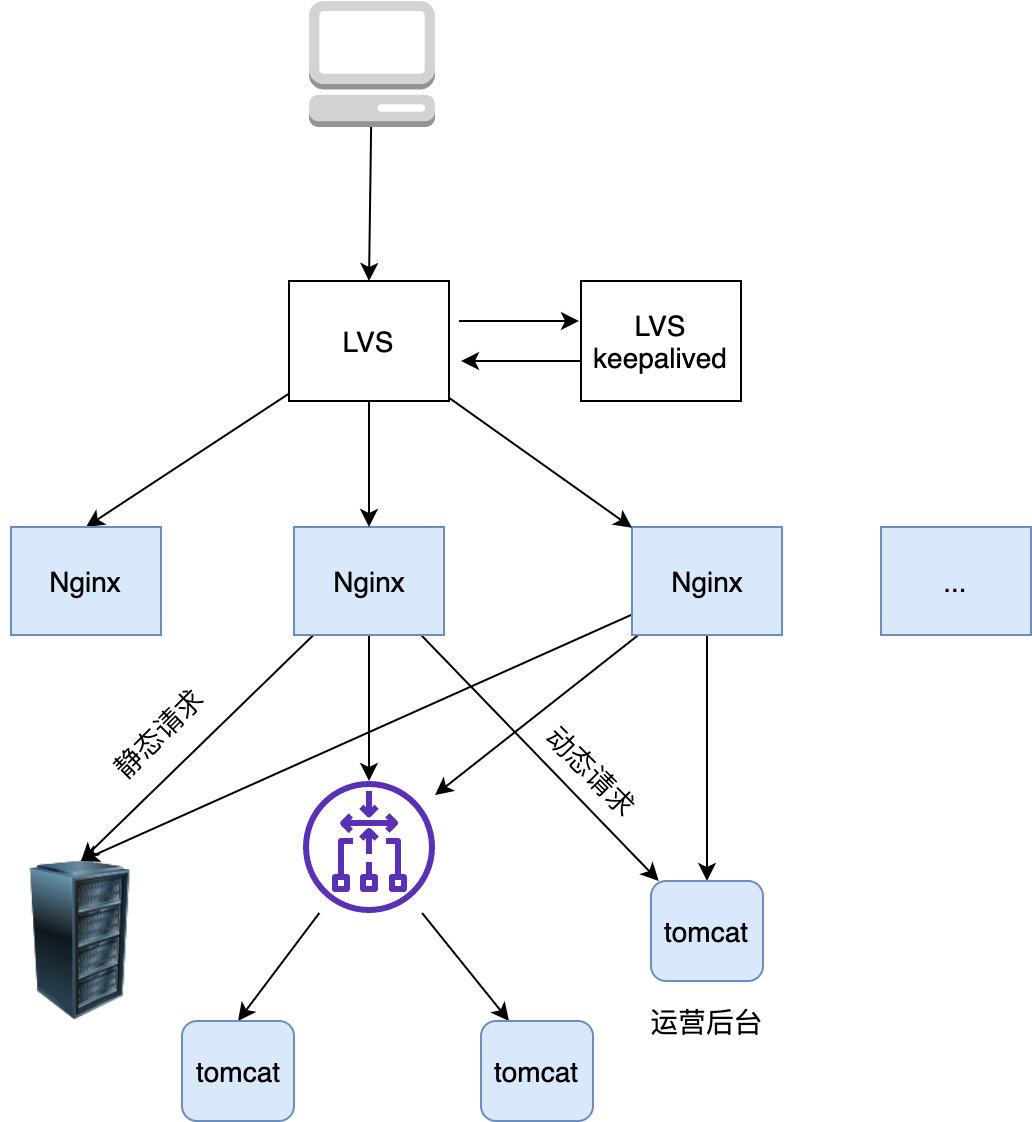
105 |
106 |
107 |
108 | 当然只有一台 LVS 的话在流量很大的情况下也是找不住的,怎么办,多加几台啊,使用 DNS 负载均衡在解析域名的时候随机打到其中一台不就行了
109 |
110 |
111 |
112 | 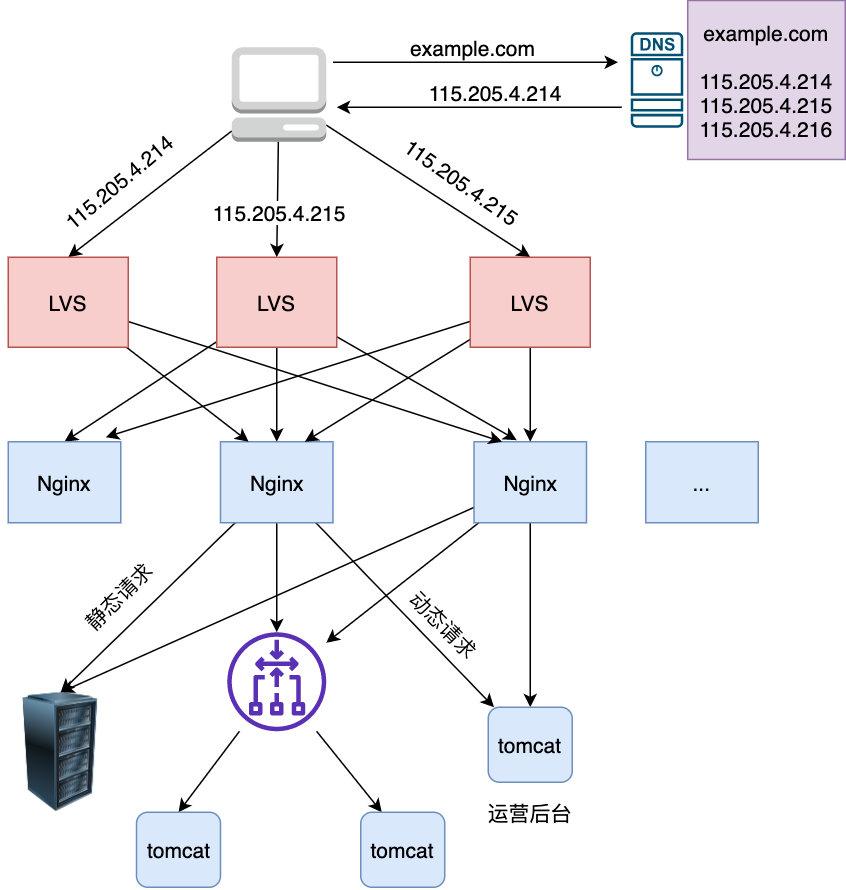
113 |
114 |
115 |
116 | 通过这样的方式终于可以让流量稳定流转了,有个点可能一些朋友会有疑问,下面我们一起来看看
117 |
118 |
119 |
120 | > 既然 LVS 可以采用部署多台的形式来避免单点故障,那 Nginx 也可以啊,而且 Nginx 在 1.9 之后也开始支持*四层负载*均衡了,所以貌似 LVS 不是很有必要?
121 |
122 | 如果不用 LVS 则架构图是这样的
123 |
124 | 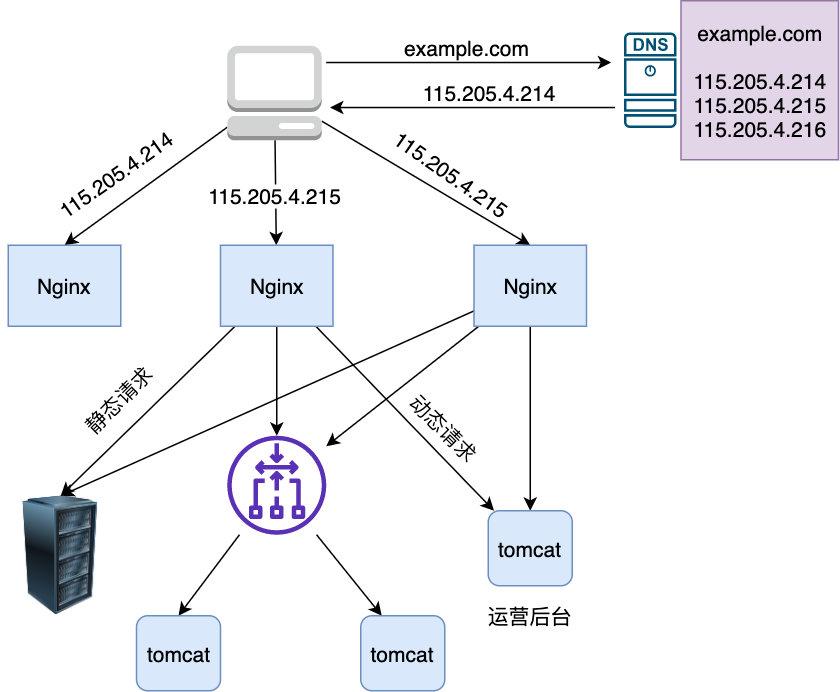
125 |
126 | 通过部署多台 Nginx 的方式在流量不是那么大的时候确实是可行,但 LVS 是 Linux 的内核模块,工作在内核态,而 Nginx 工作在用户态,也相对比较重,所以在性能和稳定性上 Nginx 是不如 LVS 的,这就是为什么我们要采用 LVS + Nginx 的部署方式。
127 |
128 |
129 |
130 | 另外相信大家也注意到了,如果流量很大时,静态资源应该部署在 CDN 上, CDN 会自动选择离用户最近的节点返回给用户,所以我们最终的架构改进如下
131 |
132 | 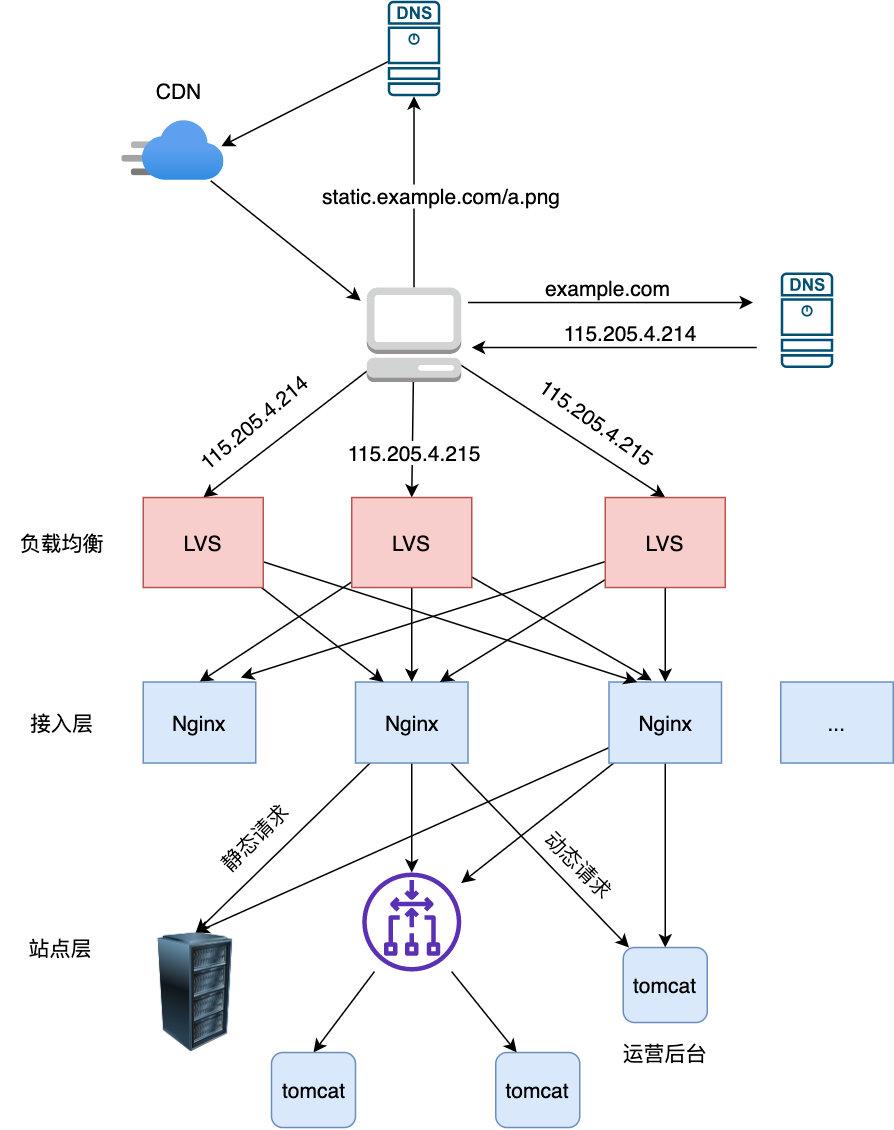
133 |
134 |
135 |
136 | ### 总结
137 |
138 | 架构一定要结合业务的实际情况来设计,脱离业务谈架构其实是耍流氓,可以看到上文每一个架构的衍化都与我们的业务发展息息相关,对于中小型流量没有那么大的公司,其实用 Nginx 作为负载均衡足够,在流量迅猛增长后则考虑使用 lvs+nginx,当然像美团这样的巨量流量(数十 Gbps的流量、上千万的并发连接),lvs 也不管用了(实测虽然使用了 lvs 但依然出现了不少丢包的现象)所以它们开发出了自己的一套四层负载均衡器 MGW
139 |
140 | 另外看了本文相信大家对分层的概念应该有更透彻的理解,没有什么是分层解决不了的事,如果有,那就再多加一层,分层使每个模块各司其职,功能解藕,而且方便扩展,大家很熟悉的 TCP/IP 就是个很好的例子,每层只管负责自己的事,至于下层是什么实现的上层是不 care 的
141 |
142 | 以上就是本文的全部内容,希望大家看了有收获^_^,下一篇我们再继续深入探究一个请求的往返链路,会深入剖析 LVS,交换机,路由器等的工作原理,敬请期待 ^_^
143 |
144 |
145 | 更多精品文章,欢迎大家扫码关注「码海」
146 |
147 | 
--------------------------------------------------------------------------------
/程序人生/优秀的程序员应该具备哪些能力.md:
--------------------------------------------------------------------------------
1 |
2 | 我认为以下特性是一个优秀程序员的必备素质。
3 | 1. 抽象问题或者说数据建模的问题:将复杂的问题转化为相应的方法论来解决,比如说打的时显示的导航按最短距离,最短用时等展示给用户,所用的解决方式就是用图论的方式来建模
4 | 2. 修改模型的能力:即对现成的模型进行修改以更好地满足业务需求,比如说对开源库进行修改以更好地适应业务的需求
5 | 3. 举一反三的能力:比如说你写了几年的 PHP,突然丢给你一个 Java 的项目,你能否在较短的时间内熟悉 Java 语法 ,快速上手,这项能力可以看出程序员的底层功底是否扎实,因为语言只是表现形式,只是工具,内功才是区分工程师是否优秀的重要特性,想想看杨过神功大成后,使用木剑还是使用玄铁重剑对他来说区别大吗。
6 | 4. 写出的代码要有足够的健壮性,可扩展性:比如你写个功能模块,是否考虑异常等场景,再比如产品需求变了,你的代码是否能够做到几乎不改动,因为我们知道代码越写隐藏的 bug 越多,所以如果可扩展性好的话极大避免了给队友埋坑的可能
7 |
8 | 说了这么多我相信大家还是觉得太理论化了,好,那我们就来看一道题来演练一下工程师的能力模型
9 |
10 | > 题目:如何快速定位IP对应的省份地址?
11 |
12 | 我们知道,每个省市都分配了一个 ip 段,如下
13 |
14 | ```shell
15 | [202.102.133.0, 202.102.133.255] 山东东营市
16 | [202.102.135.0, 202.102.136.255] 山东烟台
17 | [202.102.156.34, 202.102.157.255] 山东青岛
18 | [202.102.48.0, 202.102.48.255] 江苏宿迁
19 | [202.102.49.15, 202.102.51.251] 江苏泰州
20 | [202.102.56.0, 202.102.56.255] 江苏连云港
21 | ```
22 | 输入一个 ip 地址怎么做到秒级定位此 ip 所在的省市呢?
23 |
24 | 
25 |
26 | **如图示:在百度上输入一个 ip 地址,能做到秒级展示其所属地,怎么做到的呢,背后用到了什么原理**
27 |
28 | 这就引入了我们要谈的程序员需要具备的第一项能力: **抽象问题**或者说**数据建模**的能力
29 |
30 | ## 抽象问题的能力
31 | 所谓抽象问题或者说数据建模的能力,即能把一个问题抽象或归类为某种方案来解决,比如要实现负载均衡, 会想到一致性哈希算法,要实现最短路径,想到使用动态规划, 微服务下要保证服务可用引入降级机制等等,一句话就是把具体的问题抽象成到解决此问题背后的方法论,进而用相关的技术方案得以解决。
32 |
33 | 回归到如何快速定位 IP 对应的省份地址这道题来看,如果我们不具备抽象问题的能力,硬着头皮从头到尾把输入的ip 与所有区间段的 ip 都遍历对比一遍,然后判断它落到哪个区间,那么 ip 地址有 32 位,共有 2^32 个,约有 42.9 亿个,用暴力遍历法每查找一个 ip 最坏情况下要遍历约 42 亿次,这种方法显然是不可行的。
34 |
35 | 所以我们必须得把这个问题抽象为另一种可行的方法,即: **二分查找**, ip 地址查找怎么就跟二分查找扯上关系了,背后的逻辑是什么,我们一起来看看。
36 |
37 | ip 地址不容易比较,那我们首先把 ip 地址转成整数,于是每个省市对应的 ip 地址区间就变成了整数区间,假设为如下区间
38 |
39 | ```shell
40 | [1, 5]
41 | [11, 15]
42 | [16, 20]
43 | [6, 10]
44 | ....
45 | ```
46 |
47 | 再以每个整数区间的起始数字对这些区间进行排序,排序后的区间如下
48 |
49 | ```shell
50 | [1, 5]
51 | [6, 10]
52 | [11, 15]
53 | [16, 20]
54 | ...
55 | ```
56 | 看到这些排序后的区间,想到了啥,二分查找就是在一组有序的数字中进行查找!是不是找到相似点了?
57 |
58 | 这里给没听过二分查找的读者简单普及下啥是二分查找,小时候可能我们都玩过猜字游戏,在纸面上写一个 1 到 100 的数字,比如 70,让对方猜,怎样猜才能猜最快。
59 |
60 | 1. 首先猜 1 和 100 的**中间数字** (1+ 100) / 2 = 50(取整)
61 | 2. 50 < 70, 于是我们继续猜 50 和 100 的**中间数字** (50+100) / 2 = 75
62 | 3. 75 > 70,于是我们继续猜 50 和 75 的**中间数字** (50+75) / 2 = 62
63 | 4. 依次持续类似以上的步骤,不断地缩小范围,直至找到 70
64 |
65 | 
66 |
67 |
68 | 总共只猜了 7 次,比起我们从 1 猜到 100 效率高了十几倍,如果被猜字的范围从一扩大到成百上千万,提升的效率是指数级的!二分查找也叫折半查找(注意上文中加粗的**中间数字**),每查找一次,问题规模缩小一半,整体时间复杂度是O(logn),即使我们要在 42 亿的数字中查找数字,最多也只要查 32 次,所以采用二分查找对查找性能的提升无疑是巨大的!
69 |
70 | 二分查找是要在一堆有序的数字中精准地查找所要查找的数**是否存在**,而回过头来看已经排序好的以下 ip 段
71 |
72 | ```shell
73 | [1, 5]
74 | [6, 10]
75 | [11, 15]
76 | [16, 20]
77 | ...
78 | ```
79 |
80 | 我们要查找的是某个整数是否在一个有序数组的相邻两个数字的区间里,例如:取这些 ip 区间的起始地址组成一个数组 (1,6,11,16,....)(有序数组),如果我们要找的 ip 对应的整型为 14, 由于它在 [11,16) (11是闭区间,16是开区间) 之间,所以这个 ip 就落在 [11, 15] 这个 ip 区间,这样就找到了这个 ip 对应的省市了。
81 |
82 | 所以就由二分查找某个值是否存在转变成了查找某个值是否在有序数组中相邻的两个值之间了,这就引入了程序员要具备的第二层能力:举一反三或者说修改模型的能力
83 |
84 | ## 修改模型的能力
85 | 就像机器学习,现在其实有很多现成的模型可用,比如识别物的模型等等,我们需要的话可以直接拿来用,但是现有模型的准确率可能不是那么理想(比如只有80%),如果我们需要进一步地提升识别准确率,可能就需要对其参数进行进一步的调优,以进一步地优化模型,达到我们预期的值。
86 |
87 | 再比如当当网基于 Dubbo 的扩展版本开发的 Dubbox 也是由于原来的 Dubbo 功能不满足其团队需求而在其基础上修改扩展的。
88 |
89 | 回过头来看以上说的原来二分查找只是查找某个值是否存在,而我们现在要解决的问题是查找某个值是否在相邻的两个值之间,这本质是也是对模型的调优或修改,以进一步满足我们的要求。于是我们写下了如下代码
90 |
91 | ```java
92 | public static int bsearch(int[] a, int length, int value) {
93 | int low = 0;
94 | int high = length - 1;
95 | while (low <= high) {
96 | int mid = (low + high) / 2;
97 | if (a[mid] > value) {
98 | if (mid == 0) {
99 | return -1;
100 | }
101 | if (a[mid-1] <= value) {
102 | return mid-1;
103 | } else {
104 | high = mid-1;
105 | }
106 | }else {
107 | low = mid + 1;
108 | }
109 | }
110 | return -1;
111 | }
112 | ```
113 | 那这段代码有啥问题吗,或者说有哪些可以优化的空间,这就引入了程序员需要具备的第三项能力: 代码要有足够的健壮性
114 |
115 | ## 代码要有足够的健壮性
116 | 仔细看上文的代码,有两个地方有潜在隐患,一个是 length 可能是负数,而显然数组的长度不可能是负数,也就是说对这种异常数据应该**抛异常**。另外 **(low + higth) / 2** 这段代码中的 low+high 如果在数组很大的情况下比较容易造成溢出,所以可以改造成 low + (high - low) / 2, 另外为了提升性能可以把除以 2 改成位运算,即 **low + ((high - low) >> 1)**,于是代码变成了
117 |
118 | ```java
119 | public static int bsearch(int[] a, int length, int value) throws Exception {
120 |
121 | if (length < 0) {
122 | // 实际应该抛出一个继续自Exception的异常,这里为了方便直接抛出Exception
123 | throw new Exception("数据长度不合法");
124 | }
125 |
126 | int low = 0;
127 | int high = length - 1;
128 | while (low <= high) {
129 | int mid = low + ((high - low) >> 1);
130 | if (a[mid] > value) {
131 | if (mid == 0) {
132 | return -1;
133 | }
134 | if (a[mid-1] <= value) {
135 | return mid-1;
136 | } else {
137 | high = mid-1;
138 | }
139 | }else {
140 | low = mid + 1;
141 | }
142 | }
143 | return -1;
144 | }
145 | ```
146 | 有人可能觉得判断数组长度小于 0 过于严苛了,但是是人就会犯错误,这里也是为了强调我们对异常情况的处理要到位,说到代码的健壮性,这里再多说几句,在创业初期我司主要用的是 php,主要是创业团队追求快,用 PHP 这种弱类型语言开发确实效率高,不过不安全,线上多次出现因为变量可以随意赋值造成的多次线上故障,而 Java 这种强类型语言虽然开发效率上比 PHP 慢了不少,但强类型语言的特征保证了它的稳定,**足够安全**,所以后期随着人员的扩充,为了保证线上足够安全,我司去年把大部分的服务都 Java 化了,近年来有不少人唱衰 Java,但 Java 的安全,稳定性以及强大的生态能力注定了它的长久生命力。
147 |
148 | 代码写成这样看起来确实完美了,还能再优化吗,注意上文中的代码只适用于 int 的数组,如果我们想针对 short 或 long 型等类型的数组进行查找就无能为力了,所以这就引入了程序员需要具备的第四项能力: 代码要有足够的可扩展性
149 |
150 | ## 代码要有足够的可扩展性
151 | 怎么让 bsearch 这个二分查找也支持 long 型或 short 型数组呢,这里引入 Java 语言中的泛型,于是我们代码改造如下
152 |
153 | ```java
154 | public static int bsearch(T[] a, int length, T value) throws Exception {
155 | if (length < 0) {
156 | // 实际应该抛出一个继承自Exception的异常,这里为了方便直接抛出Exception
157 | throw new Exception("数据长度不合法");
158 | }
159 | int low = 0;
160 | int high = length - 1;
161 | while (low <= high) {
162 | int mid = low + ((high - low) >> 1);
163 | if (a[mid].compareTo(value) > 0) {
164 | if (mid == 0) {
165 | return -1;
166 | }
167 | if (a[mid-1].compareTo(value) <= 0) {
168 | return mid-1;
169 | } else {
170 | high = mid-1;
171 | }
172 | }else {
173 | low = mid + 1;
174 | }
175 | }
176 | return -1;
177 | }
178 | ```
179 |
180 | 写成这样,可以说我们的代码具有足够的健壮性与可扩展性了。
181 |
182 |
183 | 如果大家觉得不错,希望能点个赞支持一下,感谢!也欢迎关注我的微信公众号:「码海」,共同进步
--------------------------------------------------------------------------------
/系统设计/金融监控实战.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 从电商转金融 2 年多了,由于两者商业模式,流量的不同,期间踩了很多坑,尤其是在监控这一块,我们吃过不少苦头,前期由于监控缺失,造成了多起线上事故,经过一番摸索,我们实现了一些相对可行的监控方法,有效地保证了大盘及业务的稳定,在此总结出来分享给大家,希望能为大家提供一些金融场景下的监控思路,如果大家如有更好的思路,也欢迎共同探讨。
3 |
4 | 本文主要从以下几个方面来阐述:
5 |
6 | 1. 电商场景下的常用监控方式
7 | 2. 金融监控的难点
8 | 3. 金融场景下监控的几种可靠手段
9 |
10 | ## 电商场景下的常用监控方式
11 |
12 | 电商场景下的监控主要有两种,一种是流量监控(接口请求),一种是关键节点(如注册,下单)的监控
13 |
14 | 对于这两者监控来说,我们常用的手法就是打点,接口每请求一次或关键节点每生成一次打个点,这样我们就可以通过比较今天和昨天的打点数据来监控,以下为我们针对某一关键事件的打点数据
15 |
16 | 
17 |
18 | **如图示:绿色代表今天打点数据,黄色代表昨天**
19 |
20 | 有了昨天和今天的打点数据我们要做监控就很简单了,可以对比同一时间段两者的打点数据,如果今天的打点数据相对于昨天下跌超过比如 50%,那么这个关键节点的路径可能是有问题的,就可以触发告警,如下图示
21 |
22 | 
23 |
24 | 这两种监控之所以在电商场景下可行主要有两个原因:
25 |
26 | 一是因为电商场景下的流量比较大,流量大,那么每分钟的打点数据就比较大, 这样通过下跌百分比来触发告警误差相对较小,所以可行,另外流量大所以意味着有任何的风吹草动,比如因为页面不可用造成的投诉短时间内会暴增,或打点数据短时间的急剧下降,都能在较短的时候内提早预警,让我们及时发现问题所在。
27 |
28 | 二是因为电商下的关键节点相对比较少,主要无非就是「添加购物车」与「下单」等关键节点,关键节点少意味着只要关键节点出了问题了,通过上文所述的下跌百分比告警排查关键节点的路径是否出问题即可,由于关键节点少,整个需要关注的核心链路相对比较短,所以排查起来相对比较容易一些。
29 |
30 | ## 金融监控的难点
31 |
32 | 上节介绍的电商场景下的两种方案在金融场景上都不适用,原因主要是因为金融是一个低频操作,且电商场景下的日活通常能达到几十上百万,但金融场景下的日活要少个几十倍,这就意味着每个关键节点的打点每小时可能只有几十不到,可能在长达几十分钟内关键节点对应的打点都为 0,所以也就无法用这种下跌百分比的形式进行告警。为了更好地向大家介绍金融业务监控的痛点,还是先简单介绍一下金融业务。
33 |
34 | ### 金融业务简介
35 |
36 | 目前我们主要从事的是现金贷业务,属于助贷业务,所谓助贷,即平台方并不直接发放贷款,只是平台方利用自身的获客,贷后管理等优势为借款人撮合匹配资金方,以实现资金的融通,平台方收取相当的手续费。主要业务流程如下
37 |
38 | 
39 |
40 | 我们平台会为每一个用户挑选其中与之匹配的资金方进行授信,这些资金方的风控策略不同,所以授信通过率,借款通过率这些核心指标自然有较大的差异,像一些头部资金方如马上消金或 360 借钱等通过率比较高,我们会给予更多的流量,而一些不太知名的资金方这些关键指标表现不太如人意,给之分配的流量自然较少。
41 |
42 | 为每一个用户匹配申请资金方后,通常都要经历以下周期:
43 |
44 | 
45 |
46 | 1. 贷前:授信环节,资金方要给你额度,你总要提供身份证以及相关的学历等个人信息吧,这样资金方通过这些信息就可以评估你的信用,决定是否给你额度
47 | 2. 贷中:即借款环节,授信通过之后,用户就可以借款了
48 | 3. 贷后:即还款环节
49 |
50 | 可以看到对于每一步,尤其是贷前和贷中,核心流程的关键节点都非常多,关键节点多就意味着漏斗大,用户的转化就越低,关键节点的打点(如提交授信,提交借款)可能一天只有几千,平均到每分钟也就几次甚至没有,而且由于金融本身是个非常低频的操作,用户的行为具有很大的不确定性,可能今天 8~9 点提交授信人数有 50,但第二天 8~9 点提交授信人数又降到个位数了,这些在电商里肯定会触发告警的现象在金融里却再正常不过,所以初期常常出现这样一种现象:我们在监控图表上发现两天同一时间段某些资金方关键节点的打点(如提交授信,放款成功单数)相差巨大,但排查后发现链路却没有问题,搞得我们焦头烂额。
51 |
52 | 通过以上简介,相信大家不难理解电商场景下的监控不能照搬到金融场景中,我们必须要结合金融场景**低频**的特点来设计一套相应的监控体系。
53 |
54 |
55 | ## 金融场景下监控的几种可靠手段
56 |
57 | ### 1、针对每个资金方每个流程(贷前贷中贷后)成功数或成功率进行监控
58 |
59 | 针对以上所述金融低频的特点,我们设计了一套相对有效的监控系统,思路如下:虽然贷前,贷中,贷后每个流程的关键节点都很多,但其实我们没必要对所有的关键节点都进行监控,我们只需要对**每个资金方**的关键流程的成功结果(授信成功,借款成功,授信通过率,借款通过率)进行打点监控,因为如果授信或借款成功了,说明贷前和贷中的流程都没有问题了
60 |
61 | 
62 |
63 |
64 | 注意我们需要分别对**每个资金方**的授信成功和借款成功都进行打点监控,因为统计总数成功没有意义,每个资金的风控策略和流量分配是不一样的,以成功总数来判断流程是否正常很可能导致一些资金方某天风控策略调整(或其他 bug)导致授信或借款全部失败而未被发现。
65 |
66 | 当然上文也说了,每个资金方授信成功或借款成功的总数很可能在几十分钟内都为 0,那我们可以以小时的成功总数来告警。 我们记录下每天每小时的成功总数,每半小时比较今天和过去一周同一时间段(平均值)近 X 小时内的成功数,如果低于过去一周平均成功数的一半,说明可能链接出问题了,就告警,这个 X 怎么选择呢,如果最近一小时成功总数小于 20(这个阈值需要根据实际情况选取),那我们就选今天和过去一周同一时间段最近两小时的成功总数进行比较,如果还是小于 20 ,那就选最近三小时的成功总数进行比较。。。,直到最近 X 小时的成功总数达到 20,这样误差就比较小了,通过这种方式的告警有效率目前为止 100%! 也发现了线上多起问题,钉钉告警展示如下:
67 |
68 | 
69 |
70 | 优质资金方由于通过率高,分配的流量大,所以对应的每小时的成功数相对来说比较多,用这种与过去一周同一时间段平均值比较的方式来进行告警确实可行,但对于那些通过率较差的资金方呢,这些资金方可能一天总共才有几个成功数,用上面的告警方式误差较大,那我们就拉长一下时间线,统计近 8 个小时此资金方的成功数,如果为 0 ,说明可能有问题:
71 |
72 | 
73 |
74 | 通过这种方式我们也发现了多起因为资金方风控调整导致授信/放款成功数降低导致的问题,及时通知资金方解决了问题。
75 |
76 | ### 2、巧用切面及时发现解决资金方异常
77 |
78 | 迄今为止,我们总共接入了二十几家资金方,每个资金方都有自己的一套接口规范,每个资金方的接口都不一样,总共可能接入了几百上千个接口,这就带来了一些隐患,如果由于我们代码的 bug 或资金方内部问题导致接口请求失败(通常是接口返回的状态码为失败的状态码),我们很难发现,有人说这不简单吗,如果接口返回的是失败的状态码,针对此时的请求错误告警不就行了。
79 |
80 | 这里有两个问题:
81 |
82 | 一是这种告警代码应该写在哪里,有人说就写在每个资金方的请求底层啊,如果是这样的话,监控代码与业务代码紧藕合,而且我们接入了二十几家资金方,每一家的底层请求对应的文件里都要一个个的写告警代码,工作量巨大,且之后如果新接资金方很容易忘记把告警代码给加上。
83 |
84 | 二是并不是所有返回失败状态码的接口我们都要告警,有些是正常的请求失败,如「账户永久冻结」,「放款日当天不允许还款」,这些失败的请求并不是 bug 导致的失败,所以我们并不关心,就算给我们告警也没有意义,我们只对「姓名不能为空」这种会明显是 bug 导致的请求失败感兴趣,我们需要过滤过正常失败的告警。
85 |
86 |
87 | 先看第一个问题,每个资金方的底层接口请求伪代码如下
88 |
89 | ```java
90 | // 接口调用
91 | String result = httpPost();
92 | Response response = JSON.parseObject(result, Response.class);
93 | // 如果请求的状态码是失败的状态码
94 | if (!response.getCode().equals(SUCCESS_CODE)) {
95 | // 抛出异常,异常里带有为资金方返回的失败信息
96 | throw new Exception(ErrorCodeEnum.ERROR_REQUEST_EXCEPTION, response.getMessage());
97 | }
98 | ```
99 |
100 | 很显然如果能用切面拦截所有这些资金方抛出的异常,那我们就能把针对这些异常的告警统一写在切面里,不会对现有代码有任何入侵,且方便统一管理所有资金方的告警,也就完美解决了问题一。
101 |
102 | 
103 |
104 | 切面实现的伪代码如下:
105 |
106 | ```java
107 |
108 | @Aspect
109 | public class LoggingAspect {
110 | //只捕获所有资金方请求文件所在的包
111 | @AfterThrowing ("execution(* com.howtodoinjava.app.service.impl.*(..))", throwing = "ex")
112 | public void logAfterThrowingAllMethods(CustomException ex) throws Throwable {
113 | //发送抛出的错误信息至钉钉告警
114 | sendDingWarning(ex.getMessage());
115 | }
116 | }
117 | ```
118 |
119 | 再来看第二个问题,如何过滤过我们不关心的正常失败请求抛出的异常呢。思路也很简单,设置一个白名单机制,如果我们发现失败的请求是正常的失败,把这个失败的信息加入白名单里即可,这样如果某个资金方请求失败抛出异常了,我们只要看一下这个这个失败信息是否在白名单里即可,如果在,说明是正常的失败,不需要触发告警,如果不在白名单里,则触发告警。经过改造, 我们的告警流程变成了如下这样:
120 |
121 |
122 | 
123 |
124 | 这里有一个小问题需要注意一下,这个白名单该怎么配置呢,一开始我们并不知道哪些失败的请求是正常的失败请求,所以一开始只能把所有失败的请求都告警,每发现一个正常的失败请求,就把此失败信息加到白名单里,所以这个白名单是不断动态变化的,而且也是需要实时生效的,我们选择了 360 开源的 QConf 来配置我们的白名单。
125 |
126 | QConf 是一种基于 Zookeeper 的分布式管理服务,致力于将配置内容从代码中完全分离出来,及时可靠高效地提供配置访问和更新服务,使用 QConf 进行配置后,白名单的管理问题也解决了。
127 |
128 |
129 | ### 3、针对资金方实现熔断降级
130 |
131 | 在我们的业务场景中,一个用户请求很可能会请求多个资金方的接口,如果某个资金方的服务出现问题,依赖于这个资金方接口的用户请求也就挂了,实际上在我们的业务场景中几乎每个请求都要请求资金方的接口,这也意味着只要某个资金方的服务不可用,我们业务也就不可用了,显然这是不能接受的。
132 |
133 | 
134 |
135 | **如图示:某次用户请求要请求多个资金方,如果资金方 B 的接口服务挂了,很可能导致此次用户请求也挂!甚至导致整个业务不可用!**
136 |
137 |
138 | 所以我们必须引入熔断降级机制,当某个资金方服务出现异常时(如调用超时或其他异常比例升高),接下来的降级时间窗口内,对该资源的调用都自动熔断,快速失败,这样就避免了业务不可用的巨大隐患。
139 |
140 | 我们使用阿里的 Sentinel 来实现熔断降级,Sentinel 提供了几种方式来实现熔断,我们使用了 1 分钟内异常数超过阈值后进行熔断的这种方式,一旦触发了熔断,请求资金方接口就会抛出「DegradeException」,同样的也是在切面中捕获此异常,然后告警。
141 |
142 |
143 |
144 | ## 总结
145 | 本文总结分享了在金融这种低频业务场景下设计监控的几种方式,通过以上几种方式基本保证了大盘的稳定,不过其实第一种监控(针对成功数,成功率)如果换成机器学习中的行为预测效率应该会更高,也会更及时一些,不过团队里面没有这方面经验的人才,所以暂时用针对成功数/成功率的监控来替代,后续如果有机会引入机器学习的尝试,相信会有不错的效果。如果你有更好的监控方法可以分享,欢迎提出哦。
146 |
147 | 最后:欢迎大家关注我的公号,一起交流,共同进步!
148 |
149 | 
150 |
--------------------------------------------------------------------------------
/工程师效率/Alfred有多强悍,我写了个一键上传图片的workflow来告诉你.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 |
3 | 一直以来用的都是 MarkEditor 写作,它有一个比较重要的功能:能自动将拷贝到编辑器中的截图同步到图床,这样如果要将文章导出发到其他平台,由于本地的图片在导出后自动转成了链接,所以无需担心图片在其他平台的识别问题。
4 |
5 | 
6 |
7 |
8 |
9 | 但是最近发现文章同步到掘金或 CSDN 这些平台时,这些图片链接居然无法转存到他们的平台,应该是 markeditor 的图床用了防盗链技术导致图片无法转存。
10 |
11 | **画外音:在掘金,CSDN 这些第三方平台发文时,一般会将文中非本平台的图片链接转存为本平台的,防止第三方图片链接失效导致文章中的图片在平台展示有问题。**
12 |
13 | 那么该怎么解决呢,有两种方式
14 |
15 | 1. 一种是找到那些粘贴图片后可以自动上传图床并且生成的图片链接没有防盗链的平台,如 mdnice.com, 不过我试了一下 mdnice.com,貌似有 bug,Chrome 和 Safari 上粘贴图片后自动上传图片不起作用,360浏览器倒是可以。
16 | 2. 另一种是在 MarkEditor 里设置其他图床,比如七牛云等,这样可以配置七牛云的图片不采用防盗链技术,但是要配置七牛云这样的图床,一来要收费,二来要去注册帐号,申请域名备案等等,有点麻烦。
17 |
18 | 考虑之后我决定自己整一个自动上传到图床的工具,无它,自己实现比较 Cool,怎么做呢,一般本地图片要转成最终的图床链接有以下两步
19 |
20 | 1. 剪切或者复制图片
21 | 2. 将图片上传到云端,上传成功后会返回云端的图片链接
22 |
23 |
24 | 我希望这个工具能达到如下流程图所示的效果:
25 |
26 | 
27 |
28 |
29 |
30 | 复制图片/截图后,按下快捷键,自动完成之后上传图片到图床----->获取图片地址----->转成 markdown 中的图片地址(即** \!\[\](云端图片url) **这种形式)并将其 copy 到剪切板,这样我在 markdown 编辑器粘贴即可获取云端图片链接。
31 |
32 | ## 技术选型
33 |
34 | 使用一个快捷键就能完成后面的所有操作,第一时间我想到了 Alfred 的 workflow,Alfred 堪称是 Mac 的第一神器,它是一个用键盘通过热键、关键字、**自定义插件**来加快操作效率的工具,它不但是搜索工具,还是快速启动工具,甚至能够操作许多系统功能,扩充性极强,其中自定义插件是其核心功能,主要通过 workflow 实现, 什么是 workflow 呢,我们知道一个大的任务可以分解成一个个的小任务(work),这些小任务通过输入输出组合起来就能完成这个大任务,这样一个个 work 组合起来就形成了一个工作流(workflow)
35 |
36 | 
37 |
38 | 其中每一个 work 可以由 php, python 等多个编程语言编写,通过 workflow 可以串起各个 work 的输入输出,这样只要触发一下快捷键,workflow 就能自动执行,最终会得到一个结果,比如我之前就写了一个时间戳日期互相转换的 workflow,如下:
39 |
40 | 
41 |
42 | 在 workflow 中输入 ts(快捷键),后面跟着你要展示的时间戳/日期,即可将其转成日期/时间戳,非常方便。我们在日常中可以将一些重复的工作来用 workflow 实现,这样只要输入一个快捷键即可自动触发,能省下我们很多时间,不亦乐乎!
43 |
44 | ## 一键上传图片 workflow 实现思路
45 |
46 | 上节可知 workflow 确实强大,所以用它来实现我们的自动上传图片到图床的功能再合适不过了。
47 |
48 | 首先我选择了蛋壳(https://imgkr.com/)这个免费又稳定的图床,现在问题的关键是得看下上传图片到蛋壳拿到云端的图片逻辑该怎么写。我们可以打开 charles(或其他抓包工具)然后上传一张图片,成功后可以在 charles 看到上传图片的请求
49 |
50 | 
51 |
52 | 然后我们看看这个上传图片的请求到底是咋样的,按以下步骤,点击 Copy as cURL,可以看看这个 curl 请求长啥样
53 |
54 | 
55 |
56 | 拷贝出来后的 curl 请求长这样
57 |
58 | 
59 |
60 | 从图中可以看到, curl 请求的请求部分除了图片的二进制数据是动态变化,其他都是固定的,图片的二进制数据无疑是从剪切板中来的,于是问题转化为了如何从剪切板中获取图片数据。
61 |
62 | 如何从剪切板中获取图片数据呢,这里介绍一个工具: pngpaste, 它可以将图片从剪切板中导出到指定路径,先用 brew 安装一下这个工具
63 |
64 | ```shell
65 | brew install pngpaste
66 | ```
67 |
68 | 安装之后我们就可以用以下命令将剪切板中的图片导到指定路径了
69 |
70 | ```
71 | pngpaste 图片路径
72 | ```
73 |
74 | 于是问题转化成如何获取指定路径图片的二进制数据,shell 做不到,不过 php 可以做到,所以我们最终用 php 重写了上文中的 curl 请求,也就是说我们最终选择用 php 来完成最终的 workflow, 最终的 php 实现的思路如下:
75 |
76 | 
77 |
78 | 如有兴趣可以看下如下代码实现,注释写得很详尽了,相信大家应该能看懂
79 |
80 | ```php
81 | // 将剪切板中的图片拷贝到指定的路径
82 | $command = '/usr/local/bin/pngpaste /tmp/test.jpeg';
83 | $output = shell_exec($command);
84 |
85 | require 'workflows.php';
86 | $wf = new Workflows();
87 |
88 | // 加载图片二进制数据
89 | $data = file_get_contents('/tmp/test.jpeg');
90 |
91 |
92 | // 以下为上传图片逻辑
93 | $ch = curl_init('http://imgkr.com/api/v2/files/upload');
94 | $boundary = 'WebKitFormBoundaryCQV3KALJwjBXA5ue';
95 |
96 | $files = ['171f3cdebc5586.jpeg' => $data];
97 | $delimiter = '-------------' . $boundary;
98 | $data = '';
99 | foreach ($files as $name => $content) {
100 | $data .= "--" . $delimiter . "\r\n"
101 | . 'Content-Disposition: form-data; name="file"; filename="' . $name . '"' . "\r\nContent-Type: image/jpeg" . "\r\n\r\n"
102 | . $content . "\r\n";
103 | }
104 | $data .= "--" . $delimiter . "--\r\n";
105 | curl_setopt_array($ch, [
106 | CURLOPT_POST => true,
107 | CURLOPT_HTTPHEADER => [
108 | 'Content-Type: multipart/form-data; boundary=' . $delimiter,
109 | 'Content-Length: ' . strlen($data),
110 | 'Host: imgkr.com',
111 | 'User-Agent: Mozilla/5.0 (Macintosh, Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
112 | 'X-Requested-With: XMLHttpRequest',
113 | 'Accept: */*',
114 | 'Origin: https://imgkr.com',
115 | 'Sec-Fetch-Site: same-origin',
116 | 'Sec-Fetch-Mode: cors',
117 | 'Sec-Fetch-Dest: empty',
118 | 'Referer: https://imgkr.com/',
119 | 'Accept-Language: zh,en-US,q=0.9,en,q=0.8,zh-CN,q=0.7',
120 | 'Cookie: _ga=GA1.2.377288389.1594181932, _gid=GA1.2.851545805.1594809662, _gat=1',
121 | ],
122 | CURLOPT_POSTFIELDS => $data
123 | ]);
124 |
125 | curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
126 | curl_setopt($ch, CURLOPT_ENCODING, 'gzip, deflate');
127 | $test = json_decode(curl_exec($ch));
128 |
129 | // 以下三行为上传图片成功后,将其转化为 markdown 中的图片格式并将其写入剪切板中,这样最终在 markdown 中粘贴后即为对应的 markdown 图片链接
130 | $result = '\'\'';
131 | $copy = "echo $result | pbcopy";
132 | shell_exec($copy);
133 |
134 | $query = '';
135 | $result = '拷贝到剪切板成功!';
136 | $wf->result($query, $result, $result, $query, 'icon.png');
137 | echo $wf->toxml();
138 | ```
139 |
140 | **画外音:workflows.php 是用 php 写 workflow 的一个辅助插件,能在 Alfred 的下拉框中展示我们需要的结果,大家如有兴趣可以去 https://github.com/joetannenbaum/alfred-workflow 进一步了解一下**
141 |
142 |
143 | ## 配置 workflow
144 |
145 | 脚本既然写好,那配置 workflow 自然不在话下,新建的 workflow 如下:
146 |
147 | 
148 |
149 | 以上 workflow 表示当按下「shift+cmd+s」时(即图片中的 Hotkey),会自动执行对应的脚本(Script Filter)将剪切板中的图片上传到图床(执行图片中的脚本 Script Filter),并最终将云端图片转成 markdown 的图片url 并拷贝到剪切板。这样我们只要在编辑器执行一下粘贴命令即可得到我们想要的云端图片 url,效果如下图所示,workflow 成功执行后会在 Alfred 的下拉框中展示「拷贝到剪切板成功」这个信息。
150 |
151 | 
152 |
153 | 从此以后,如果我想截图并且获取此图片的链接即可一键搞定!再也不要机械的手动上传图片了!是不是很 Cool!
154 |
155 | ## 总结
156 |
157 | 工具化,自动化是工程师非常重要的思维方式,我们应该把重复低效的工作工具化,自动化,把有限的时候投入在更值得做的事情上去,就像现在的自动化测试等也是为了用工具化,自动化的思维帮助研发测试人员从重复低效的工作中解脱出来。workflow 无疑给我们提供了一个很好的手段,日常工作中,我们可以借助 workflow 来提升我们的工作效率!
158 |
159 | ## 彩蛋
160 |
161 | 文中的 workflow 我已经整好放在百度网盘了,大家在后台回复「666」即可获取,获取后双击即可使用,需要注意的是要使用 workflow 必须使用付费版的 Alfred,不过 Alfred 的强大功能绝对值得你的投入,我已经买了终身升级版了,使用 workflow 能省下你的很多时间,相信我,买它!绝对物超所值!!!如果链接失效请发我微信「geekoftaste」,我发你。
162 |
163 |
164 | 最后欢迎大家关注公号,加我私人微信「geekoftaste」,一起交流,共同进步!
165 |
166 | 
167 |
--------------------------------------------------------------------------------
/系统设计/从应用层到网络层排查Dubbo接口超时全记录.md:
--------------------------------------------------------------------------------
1 | 我们常说面试造火箭,很多人对此提出质疑,相信大家看了这篇文章会明白面试造火箭的道理,这篇排查问题的技巧涉及到索引,GC,容器,网络抓包,全链路追踪等基本技能,没有这些造火箭的本事,排查这类问题往往会无从下手,本篇也能回答不少朋友的问题:为什么学 Java 却要掌握网络,MySQL等其他知识体系,这会让你成为更出色的工程师哦。
2 |
3 |
4 | ## 一. 问题现象
5 |
6 | 商品团队反馈,会员部分 dubbo 接口偶现超时异常,而且时间不规律,几乎每天都有,商品服务超时报错如下图:
7 |
8 |
9 | 
10 |
11 | 超时的接口平时耗时极短,平均耗时 4-5 毫秒。查看 dubbo 的接口配置,商品调用会员接口超时时间是一秒,失败策略是failfast,快速失败不会重试。
12 |
13 | 会员共部署了8台机器,都是 Java 应用,Java 版本使用的是 JDK 8,都跑在 docker 容器中 。
14 |
15 |
16 | ## 二. 问题分析
17 |
18 | 开始以为只是简单的接口超时,着手排查。首先查看接口逻辑,只有简单的数据库调用,封装参数返回。SQL 走了索引查询,理应返回很快才是。
19 |
20 | 于是搜索 dubbo 的拦截器 ElapsedFilter 打印的耗时日志(ElapsedFilter 是 dubbo SPI 机制的扩展点之一,超过 300 毫秒的接口耗时都会打印),这个接口的部分时间耗时确实很长。
21 |
22 | 
23 |
24 | 再查询数据库的慢 SQL 平台,未发现慢 SQL。
25 |
26 |
27 |
28 | ### 1. 数据库超时?
29 |
30 | 怀疑是获取数据库连接耗时。代码中调用数据库查询可以分为两步,获取数据库连接和 SQL 查询,慢SQL 平台监测的 SQL 执行时间,既然慢 SQL 平台没有发现,那可能是建立连接耗时较长。
31 |
32 | 查看应用中使用了 Druid 连接池,数据库连接会在初始化使用时建立,而不是每次 SQL 查询再建立连接。Druid 配置的 initial-size(初始化链接数)是 5,max-active(最大连接池数量)是 50,但 min-idle(最小连接池数量)只有 1,猜测可能是连接长时间不被使用后都回收了,有新的请求进来后触发建立连接,耗时较长。
33 |
34 | 因此调整 min-idle 为 10,并加上了 Druid 连接池的使用情况日志,每隔 3 秒打印连接池的活跃数等信息,重新观察。
35 |
36 | 改动上线后,还是有超时发生,超时发生时查看连接池日志,连接数正常,连接池连接数也没什么波动。
37 |
38 | ### 2. STW?
39 |
40 | 因此重新回到报错日志观察,ElapsedFilter 打印的耗时日志已经消失。由于在业务方法的入口和出口,以及数据库操作的前后打印了日志,发现整个业务操作耗时极短,都在几毫秒内完成。
41 |
42 | 但是调用端隔一段时间开始超时报错,且并不是调用一个接口超时,而是调用好几个接口都同时超时。另外,调用端的几台机器都会同时报超时(可以在 elk 平台筛选 hostname 查看),而提供服务超时的机器是同一台。
43 |
44 | 这样问题就比较清晰了,**应该是某一时刻提供服务的某台机器出现比较全局性的问题导致几乎所有接口都超时**。
45 |
46 | 继续观察日志,抓了其中一个超时的请求从调用端到服务端的所有日志(理应有分布式 ID 可以追踪,context id 只能追踪单应用内的一个请求,跨应用就失效了,所以只能自己想办法,此处是根据调用IP+时间+接口+参数在 elk 定位)。
47 | 这次有了新的发现,服务端收到请求的时间比调用端发起调用的时间晚了一秒,比较严谨的说法是调用端的超时日志中 dubbo 有打印 startTime(记为T1)和 endTime,同时在服务端的接口方法入口加了日志,可以定位请求进来的时间(记为T2),比较这两个时间,发现 T2 比 T1 晚了一秒多,更长一点的有两到三秒。
48 | 内网调用网络时间几乎可以忽略不计,这个延迟时间极其不正常。很容易想到 Java 应用的 STW(Stop The World),其中,特别是垃圾回收会导致短暂的应用停顿,无法响应请求。
49 |
50 | 排查垃圾回收问题第一件事自然是打开垃圾回收日志(GC log),GC log 打印了 GC 发生的时间,GC 的类型,以及 GC 耗费的时间等。增加 JVM 启动参数
51 |
52 | > -XX:+PrintGCDetails -Xloggc:${APPLICATION_LOG_DIR}/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime。
53 |
54 | 为了方便排查,同时打印了所有应用的停顿时间。(除了垃圾回收会导致应用停顿,还有很多操作也会导致停顿,比如取消偏向锁等操作)。由于应用是在 docker 环境,因此每次应用发布都会导致 GC 日志被清除,写了个上报程序,定时把 GC log 上报到 elk 平台,方便观察。
55 |
56 | 以下是接口超时时 gc 的情况:
57 |
58 | 
59 |
60 | 可以看到,有次 GC 耗费的时间接近两秒,应用的停顿时间也接近两秒,而且此次的垃圾回收是ParNew 算法,也就是发生在新生代。所以基本可以确定,**是垃圾回收的停顿导致应用不可用,进而导致接口超时**。
61 |
62 | ### 2.1 安全点及 FinalReferecne
63 |
64 | 以下开始排查新生代垃圾回收耗时过长的问题。
65 | 首先,应用的 JVM 参数配置是
66 |
67 | > -Xmx5g -Xms5g -Xmn1g -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -Xss256k -XX:SurvivorRatio=8 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70
68 |
69 | 通过观察 marvin 平台(我们的监控平台),发现堆的利用率一直很低,GC 日志甚至没出现过一次 CMS GC,由此可以排除是堆大小不够用的问题。
70 |
71 | ParNew 回收算法较为简单,不像老年代使用的 CMS 那么复杂。ParNew 采用标记-复制算法,把新生代分为 Eden 和 Survivor 区,Survivor 区分为 S0 和 S1,新的对象先被分配到 Eden 和 S0 区,都满了无法分配的时候把存活的对象复制到 S1 区,清除剩下的对象,腾出空间。比较耗时的操作有三个地方,**找到并标记存活对象,回收对象,复制存活对象**(此处涉及到比较多垃圾回收的知识,详细部分就不展开说了)。
72 |
73 | 找到并标记存活对象前 JVM 需要暂停所有线程,这一步并不是一蹴而就的,需要等所有的线程都跑到安全点。部分线程可能由于执行较长的循环等操作无法马上响应安全点请求,JVM 有个参数可以打印所有安全点操作的耗时,加上参数
74 |
75 | > -XX:+PrintSafepointStatistics -XX: PrintSafepointStatisticsCount=1 -XX:+UnlockDiagnosticVMOptions -XX: -DisplayVMOutput -XX:+LogVMOutput -XX:LogFile=/opt/apps/logs/safepoint.log。
76 |
77 | 
78 |
79 | 安全点日志中 spin+block 时间是线程跑到安全点并响应的时间,从日志可以看出,此处耗时极短,大部分时间都消耗在 vmop 操作,也就是到达安全点之后的操作时间,排除线程等待进入安全点耗时过长的可能。
80 |
81 | 继续分析回收对象的耗时,根据引用强弱程度不通,Java 的对象类型可分为各类 Reference,其中FinalReference 较为特殊,对象有个 finalize 方法,可在对象被回收之前调用,给对象一个垂死挣扎的机会。有些框架会在对象 finalize 方法中做一些资源回收,关闭连接的操作,导致垃圾回收耗时增加。因此通过增加JVM参数 -XX:+PrintReferenceGC,打印各类 Reference 回收的时间。
82 |
83 | 
84 |
85 | 可以看到,FinalReference 的回收时间也极短。
86 |
87 | 最后看复制存活对象的耗时,复制的时间主要由存活下来的对象大小决定,从 GC log 可以看到,每次新生代回收基本可以回收百分之九十以上的对象,存活对象极少。因此基本可以排除这种可能。
88 | 问题的排查陷入僵局,ParNew 算法较为简单,因此 JVM 并没有更多的日志记录,所以排查更多是通过经验。
89 |
90 | ### 2.2 垃圾回收线程
91 |
92 | 不得已,开始求助网友,上 stackoverflow 发帖(链接见文末),有大神从 GC log 发现,有两次 GC 回收的对象大小几乎一样,但是耗时却相差十倍,因此建议确认下系统的 CPU 情况,是否是虚拟环境,可能存在激烈的 CPU 资源竞争。
93 |
94 | 其实之前已经怀疑是 CPU 资源问题,通过 marvin 监控发现,垃圾回收时 CPU 波动并不大。但运维发现我们应用的垃圾回收线程数有些问题(GC 线程数可以通过 jstack 命令打印线程堆栈查看),JVM 的 GC 线程数量是根据 CPU 的核数确定的,如果是八个核心以下,GC 线程数等于CPU 核心数,我们应用跑在 docker 容器,分配的核心是六核,但是新生代 GC 线程数却达到了 53个,这明显不正常。
95 | 最后发现,这个问题是 JVM 在 docker 环境中,获取到的 CPU 信息是宿主机的(容器中 /proc目录并未做隔离,各容器共享,CPU信息保存在该目录下),并不是指定的六核心,宿主机是八十核心,因此创建的垃圾回收线程数远大于 docker 环境的 CPU 资源,导致每次新生代回收线程间竞争激烈,耗时增加。
96 |
97 | 通过指定 JVM 垃圾回收线程数为 CPU 核心数,限制新生代垃圾回收线程,增加JVM参数
98 |
99 | > -XX:ParallelGCThreads=6 -XX:ConcGCThreads=6
100 |
101 |
102 | 
103 |
104 | 效果立竿见影!新生代垃圾回收时间基本降到 50 毫秒以下,成功解决垃圾回收耗时较长问题。
105 |
106 | ## 三. 问题重现
107 |
108 |
109 | 本以为超时问题应该彻底解决了,但还是收到了接口超时的报警。现象完全一样,同一时间多个接口同时超时。查看 GC 日志,发现已经没有超过一秒的停顿时间,甚至上百毫秒的都已经没有。
110 |
111 |
112 |
113 | ### 1. Arthas 和 Dubbo
114 |
115 | 回到代码,重新分析。开始对整个 Dubbo 接口接收请求过程进行拆解,打算借助阿里巴巴开源的Arthas 对请求进行 trace,打印全链路各个步骤的时间。(**Arthas 和 dubbo**)
116 | 服务端接收 dubbo 请求,从网络层开始再到应用层。具体是从 netty 的 worker 线程接收到请求,再投递到 dubbo 的业务线程池(应用使用的是 ALL 类型线程池),由于涉及到多个线程,只能分两段进行 trace,netty 接收请求的一段,dubbo 线程处理的一段。
117 | Arthas 的 trace 功能可以在后台运行,同时只打印耗时超过某个阈值的链路。(trace 采用的是instrument+ASM,会导致短暂的应用暂停,暂停时间取决于被植入的类的数量,需注意)
118 | 由于没有打印参数,无法准确定位超时的请求,而且 trace 只能看到调用第一层的耗时时间,结果都是业务处理时间过长,最后放弃了该trace方法。
119 |
120 | 受 GC 线程数思路的启发,由于应用运行基本不涉及刷盘的操作,都是 CPU 运算+内存读取,耗时仍旧应该是线程竞争或者锁引起的。重新回到 jstack 的堆栈进行排查,发现总线程数仍有 900+,处于一个较高的水平,其中 forkjoin 线程和 netty 的 worker 的线程数仍较多。于是重新搜索代码中线程数是通过CPU核心数设置(Runtime.getRuntime().availableProcessors())的地方,发现还是有不少框架使用这个参数,这部分无法通过设置JVM参数解决。
121 |
122 | 因此和容器组商量,是否能够给容器内应用传递正确的 CPU 核心数。容器组确认可以通过升级 JDK 版本和开启 CPU SET 技术限制容器使用的 CPU 数,从 Java 8u131 和 Java 9 开始,JVM 可以理解和利用 cpusets 来确定可用处理器的大小(**Java 和 cpu set 见文末参考链接**)。现在使用的也是JDK 8,小版本升级风险较小,因此测试没问题后,推动应用内8台容器升级到了 Java 8u221,并且开启了 cpu set,指定容器可使用的 CPU 数。
123 | 重新修改上线后,还是有超时情况发生。
124 |
125 | ### 2. 网络抓包
126 |
127 | 观察具体的超时机器和时间,发现并不是多台机器超时,而是一段时间有某台机器比较密集的超时,而且频率比之前密集了许多。以前的超时在各机器之间较为随机,而且频率低很多。比较奇怪的是,wukong 经过发布之后,原来超时的机器不超时了,而是其他的机器开始超时,看起来像是接力赛。(docker 应用的宿主机随着每次发布都可能变化)
128 |
129 | 面对如此奇怪的现象,只能怀疑是宿主机或者是网络问题了,因此开始网络抓包。
130 |
131 | 由于超时是发生在一台机器上,而且频率较为密集,因此直接进入该机器,使用 tcpdump 命令抓取host 是调用方进来的包并保存抓包记录,通过 wireshark 分析(wireshark 是抓包分析神器),抓到了一些异常包。
132 | 
133 | > 注意抓包中出现的 「TCP Out_of_Order」,「TCP Dup ACK」,「TCP Retransmission」,三者的释义如下:
134 | >
135 | >`TCP Out_of_Order`: 一般来说是网络拥塞,导致顺序包抵达时间不同,延时太长,或者包丢失,需要重新组合数据单元,因为他们可能是由不同的路径到达你的电脑上面。
136 | >
137 | >`TCP dup ack XXX#X`: 重复应答,#前的表示报文到哪个序号丢失,#后面的是表示第几次丢失
138 | >
139 | >`TCP Retransmission`: 超时引发的数据重传
140 | 终于,通过在 elk 中超时日志打印的 contextid,在 wireshark 过滤定位超时的 TCP 包,发现超时的时候有丢包和重传。抓了多个超时的日志都有丢包发生,确认是网络问题引起。
141 |
142 | 问题至此基本告一段落,接下来容器组继续排查网络偶发丢包问题。
143 |
144 |
145 | 巨人的肩膀
146 |
147 | * stackoverflow 提问帖子: http://aakn.cn/YbFsl
148 | * jstack 可视化分析工具:https://fastthread.io/
149 | * 2018年的 Docker 和 JVM:`https://www.jdon.com/51214
150 |
151 | 欢迎关注公众号与笔者共同交流哦^_^
152 |
153 | 
154 |
--------------------------------------------------------------------------------
/算法/Trie树的妙用.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 我们几乎每天都在用搜索引擎搜索信息,相信大家肯定有注意过这样一个细节:当输入某个字符的时候,搜索引框底下会出现多个推荐词,如下,输入「python」后,底下会出现挺多**以 python 为前缀**的推荐搜索文本,它是如何实现的呢?
3 |
4 | 
5 |
6 | 文章标题已经给出答案了,没错,用 Trie 树。本文将会从以下几个方面来简述一下 Trie 树的原理,以让大家对 Trie 树有一个比较全面的认识。
7 |
8 |
9 | * 什么是 Trie 树
10 | * Trie 树的实现
11 | * 如何实现搜索字符串自动提示
12 | * 再谈 Trie 树
13 |
14 | 相信大家看了肯定有收获
15 |
16 | ## 什么是 Trie 树
17 |
18 | Trie 树,又称前缀树,字段典树,或单词查找树,是一种树形结构,也是哈希表的变种,它是一种专门处理字段串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题,主要被搜索引擎用来做文本词频的统计。
19 |
20 | 画重点:快速字符串匹配,词频统计。
21 |
22 | 1、快速字符串匹配
23 |
24 | 假设想要在一串字符串如 a, to, tea, ted, ten, i, in, inn 中多次查找某个字符串是否存在,该怎么做呢,很直观的想法是用 hash,这种确实没问题,**如果 hash 函数设计得好的话**,如果 hash 函数设计得不好,很容易产生冲突,进而退化成字符串间的比较,另外,在英文中其实有很多单词有共同的前缀,比如中 tea, ted, ten 这三个单词有共同的前缀 te, 如果用 hash 的话,无疑这些共同前缀相当于重复存了多次,比较费空间。
25 |
26 | 如果用 Trie 树的话,能解决以上两个问题,先来看下 trie 树是如何表示的,以以上的一组字符串 a, to, tea, ted, ten, i, in, inn 为例,它们组成的 Trie 树如下:
27 |
28 |
29 | 
30 |
31 | 如果要查找某个字符串的话,从根节点出发,每次取待查找字符串中的一个字符往下遍历,即可找到,可以看到它的查找时间复杂度为 O(N) (N 为字符串长度),还是很快的(英文单词普遍比较短)。
32 |
33 | 2、词频统计
34 | 只要在每个结点上加一个计数器,遍历单词时,所有字符串的最后一个字符对应结点的计算器都加 1, 如以 a,an,and 构造的 Trie 树如下,每个结点计算器都为 1,代表以此结点存储字符为终止字符的单词分别为 1 个。
35 |
36 | 
37 |
38 |
39 |
40 |
41 |
42 | 从前面 Trie 树的图解可以看到 Trie 树的本质就是**前缀树**,通过提取出字符串的公共前缀(如果有的话),以达到快速匹配字符串的目的。
43 |
44 | 通过前缀匹配,使用 Trie 树查找字符串的效率大大提高!
45 |
46 | 从以上 Trie 树的图解我们可以得出 Trie 树的以下几个特点
47 |
48 | 1. 根节点不包含字符,除根节点外每个节点只包含一个字符
49 | 2. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。如上图中从根节点到结点 o,经过的字符为「t」和「o」,所以它表示单词 to。
50 | 3. 每个节点的所有子节点包含的字符都不相同,这一点也就保证了相同的前缀能够得到复用。
51 |
52 | 那么 Trie 树该怎么表示呢
53 |
54 | ## Trie 树的实现
55 |
56 | 从上文我们对 Trie 树的剖析可以很明显地看到 Trie 树是一颗多叉树,那么多叉树该怎么表示呢,假设字符串都是由 26 个小写字母组成,则显然 Trie 树应该是一颗 26 叉树,每个节点包含 26 个子节点,如下
57 |
58 | 
59 |
60 |
61 | 上图可以看出,26 个子节点我们可以用大小为 26 的数组表示,所以 Trie 树表示如下
62 |
63 | ```java
64 |
65 | /**
66 | * 26 个字母
67 | */
68 | static final int ALPHABET_SIZE = 26;
69 |
70 | /**
71 | * Trie 树的节点表示
72 | */
73 | static class TriedNode {
74 | /**
75 | * 根节点专用,存储 "/"
76 | */
77 | public char val;
78 |
79 | /**
80 | * 以此结点字符为终止字符的字符串的个数
81 | */
82 | public int frequency;
83 |
84 | /**
85 | * 节点指向的子节点
86 | */
87 | TriedNode[] children = new TriedNode[ALPHABET_SIZE];
88 |
89 | public TriedNode(char val) {
90 | this.val = val;
91 | }
92 | }
93 |
94 | /**
95 | * Trie 树
96 | */
97 | static class TrieTree {
98 | private TriedNode root = new TriedNode('/'); // 根节点
99 | }
100 | ```
101 |
102 | Trie 树的表现有了,现在我们来看下 Trie 树的两个主要操作
103 |
104 | 1. 根据一组字符串构造 Trie 树
105 | 2. 在 Trie 树中查找字符串是否存在
106 |
107 |
108 | 先来看如何根据一组字符串构造 Trie 树,首先如何根据一个单词来构造 Trie 树呢,假设我们以单词 「and」 为例来看下 Trie 树的表现形式
109 |
110 | 
111 |
112 | **注:图中的数字表示数组的元素位置**
113 |
114 | 可以看到构建 Trie 树的主要步骤如下
115 |
116 | 1. 构建根节点,此时根节点存有一个元素大小为 26 的数组
117 | 2. 遍历字符串「and」
118 | 3. 遍历第一个字符 a 时,将上述数组的第一个元素赋值为一个 TriedNode 实例(假设其名为 A)
119 | 4. 当遍历第二个字符 n 时,将 A 结点 TriedNode 数组下标为 n-a = 13 (a 的 ascii 为 97,n 的 ascii 码为 110) 的元素赋值为一个 TriedNode 实例(假设其名为 N)
120 | 5. 同理,当遍历第三个字符 d 时,将 N 结点 TriedNode 数组的第 4 个元素(下标为 3)赋值为一个 TriedNode 实例(假设其名为 D),同时也将其结点的 frequency 加一,代表以此字符为终止字符的字符串多了一个。
121 |
122 |
123 | 由以上分析不难写出根据字符串构建 Trie 树的代码,如下
124 |
125 |
126 | ```java
127 | /**
128 | * Trie 树
129 | */
130 | static class TrieTree {
131 | private TriedNode root = new TriedNode('/'); // 根节点
132 |
133 | /**
134 | * 以 String 为条件构建 Trie 树
135 | * @param s
136 | */
137 | public void insertString(String s) {
138 | TriedNode p = root;
139 | for (int i = 0; i < s.length(); i++){
140 | char c = s.charAt(i);
141 | int index = c-'a';
142 | if (p.children[index] == null) {
143 | p.children[index] = new TriedNode(c);
144 | }
145 | p = p.children[index];
146 | //Process char
147 | }
148 | p.frequency++;
149 | }
150 | }
151 | ```
152 |
153 | Trie 树构造好了,再在 Trie 树中查找某字符串是否存在就简单很多了,遍历字符串,查看每个字符在相应层级的数组位置的元素是否为空即可,如果是,说明不存在,如果不是,则继续遍历字符查找,直到遍历完成,代码如下
154 |
155 | ```java
156 | /**
157 | * 查找字符串是否在原字符串集合中
158 | * @param s
159 | * @return boolean
160 | */
161 | public boolean findStr(String s) {
162 | TriedNode p = root;
163 | for (int i = 0; i < s.length(); i++){
164 | // 当前被遍历的字符
165 | char c = s.charAt(i);
166 | int index = c-'a';
167 | if (p.children[index] == null) {
168 | // 如果字符对应位置的数组元素为空,说明肯定不存在此字符,终止之后的字符遍历
169 | return false;
170 | }
171 | // 如果存在,则继续往后遍历字符串
172 | p = p.children[index];
173 | }
174 | return true;
175 | }
176 | ```
177 |
178 | 由于在节点中也用 frequency 保存了单词数,所以如果在 Trie 树中最终发现字符串存在,也可以随便查找出此字符串的个数。
179 |
180 |
181 | ## 如何实现搜索字符串自动提示功能
182 |
183 | 有了 Trie 树,相信大家不难解决开篇的这个问题,首先搜索引擎根据用户的搜索词构建一颗 Trie 树,假设这个搜索词库是 a, to, tea, ted, ten, i, in, inn,则构建的 Trie 树为
184 |
185 | 
186 |
187 |
188 | 那么当用户在搜索框输入「te」的时候,根据 Trie 树的特性得知以 te 为前缀的字符串有 tea,ted,ten,则应该在搜索框提示词中展示这三个字符串。这里有一个小问题,一般搜索框只会展示 10 个搜索词,但以用户输入字符串为前缀的字符串可能远超 10 次,到底该展示哪 10 个呢,最简单的规则是展示搜索次数最多的 10 个字符串,于是问题就转化为了 TopK 问题,维护一个有 10 个元素的小顶堆,步骤如下
189 |
190 | 1. 先根据用户输入的前缀在树中找出含有此前缀的所有字符串
191 | 2. 我们知道在节点中保存了字符串的被搜索次数,所以利用小顶堆即可算出被搜索次数最多的 10 个字符串,即可得最终展示给用户的提示词。
192 |
193 | **注意:这里的求 TopK 要用是小顶堆,不是大顶堆哦,在[搜索引擎背后的经典数据结构和算法](https://mp.weixin.qq.com/s/wSWWz-W6325NPVKGWBiE6g)这篇文章中有读者提出了疑问,不要搞混了,小顶堆是求最大的 Top K 值,大顶堆是求最小的 TopK 值,由于我们要求最多的前 10 个搜索词,所以应该是用小顶堆)。**
194 |
195 |
196 | 这样就解决了,考虑以下现象:我们在输入搜索词的时候,搜索引擎给出的提示词**可能并不是以用户输入的字符串为前缀的**
197 |
198 | 
199 | 如图示:搜索引擎给出的搜索关键字并不包含有「brekfa」 前缀。
200 |
201 | 这种又是怎么实现的呢,它实际上用到了**字符串编辑距离**的思想,所谓字符串编辑距离是说一个字符串可以通过增删改查字符来变成另外一个字符串
202 |
203 | 
204 |
205 | **如图示: brekfa 添加 a 之后变成了 breakfa**
206 |
207 |
208 | 显然所作的增删改查次数越少,效率越高,经过**最少的**字符中编辑变成另一个合法的字符串后,就以此字符串为前缀去 Trie 树中查找提示词。
209 |
210 | 当然了,像 Google 这样的搜索引擎要实时显示这些结果,背后肯定经过了很多改造。不过原理都大同小异。
211 |
212 |
213 | ## 再谈 Trie 树
214 |
215 | 从前面的介绍中我们可以看到使用 Trie 树确实在能在快速查找字符串与词频统计上发挥重要作用,但天下没有免费的午餐,如果字符集比较大的话,用 Trie 树可能会造成空间的浪费,以上文中构建的 Trie 树为例
216 |
217 | 
218 |
219 | 每个结点维护一个 26 个元素大小的数组,共有 4 个数组,也就是分配了 26 x 4 = 104 个元素的空间,但实际上只有三个元素空间(a,n,d)被分配了,浪费了 101 个空间,空间利率率很低,所以一般更适用于字符串前缀重复比较多的情况,当然也可以考虑对 Trie 树进行如下**缩点优化**,能节省一些空间
220 |
221 |
222 | 
223 |
224 | 当然这么优化后也增加了代码的编码难度,所以要视情况而定。
225 |
226 | 另外如果用 Trie 树的话,一般需要我们自己编码,对工程师的编码能力要求较高,所以是否用 Trie 树我们一般建议如下:
227 |
228 | 1. 如果是字符串的**精确匹配查找**,我们一般建议使用散列表或红黑树来解决,毕竟很多语言的类库都有现成的,不需要自己实现,拿来即用
229 | 2. 如果需要进行**前缀匹配查找**,则用 Trie 树更合适一些
230 |
231 | ## 总结
232 |
233 | 本文通过搜索引擎字符串提示简要地概述了其实现原理,相信大家应该理解了,需要注意的是其使用场景,更推荐在需要前缀匹配查找的时候用 Trie 树,否则像一般的精确匹配查找等更推荐用散列表和红黑树这些很成熟的数据结构,毕竟这两数据结构实现一般在类库中都是实现了的,不需要自己实现,尽量不要重复造轮子。
234 |
235 |
236 | 感谢阅读,欢迎关注公众号一起交流,共同进步!
237 |
238 | 
--------------------------------------------------------------------------------
/算法/拜托,别再问我什么是B+树了.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 每当我们执行某个 SQL 发现很慢时,都会下意识地反应是否加了索引,那么大家是否有想过加了索引为啥会使数据查找更快呢,索引的底层一般又是用什么结构存储的呢,相信大家看了标题已经有答案了,没错!B+树!那么它相对于一般的链表,哈希等有何不同,为何多数存储引擎都使用它呢,今天我就来揭开 B+ 树的面纱,相信看了此文,B+ 树不再神秘,对你理解以下高频面试题会大有帮助!
3 |
4 | * 为啥索引常用 B+ 树作为底层的数据结构
5 | * 除了 B+ 树索引,你还知道什么索引
6 | * 为啥推荐自增 id 作为主键,自建主键不行吗
7 | * 什么是页分裂,页合并
8 | * 怎么根据索引查找行记录
9 |
10 | 本文将会从以下几个方面来讲解 B+ 树
11 |
12 | 1. 定义问题
13 | 2. 几种常见的数据结构对比
14 | 3. 创建索引有哪些需要考虑的问题,怎样更高效地建立索引
15 |
16 | ## 定义问题
17 |
18 | 要知道索引底层为啥使用 B+ 树,得看它解决了什么问题,我们可以想想,日常我们用到的比较多的 SQL 有哪些呢。
19 |
20 | 假设我们有一张以下的用户表:
21 |
22 | ```sql
23 | CREATE TABLE `user` (
24 | `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
25 | `name` varchar(20) DEFAULT NULL COMMENT '姓名',
26 | `idcard` varchar(20) DEFAULT NULL COMMENT '身份证号码',
27 | `age` tinyint(10) DEFAULT NULL COMMENT '年龄',
28 | PRIMARY KEY (`id`)
29 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户信息';
30 | ```
31 |
32 | 一般我们会有如下需求:
33 |
34 | **1、根据用户 id 查用户信息**
35 |
36 | ```sql
37 | select * from user where id = 123;
38 | ```
39 |
40 | **2、根据区间值来查找用户信息**
41 |
42 | ```sql
43 | select * from user where id > 123 and id < 234;
44 | ```
45 |
46 | **3、按 id 逆序排列,分页取出用户信息**
47 |
48 | ```sql
49 | select * from user where id < 1234 order by id desc limit 10;
50 | ```
51 |
52 | 从以上的几个常用 SQL 我们可以看到索引所用的数据结构必须满足以下三个条件
53 |
54 | 1. 根据某个值精确快速查找
55 | 2. 根据区间值的上下限来快速查找此区间的数据
56 | 3. 索引值需要排好序,并支持快速顺序查找和逆序查找
57 |
58 | 接下来我们以主键索引(id 索引)为例来看看如何用相应的数据结构来构造它
59 |
60 | ## 几种常见的数据结构对比
61 |
62 | 接下来我们想想有哪些数据结构满足以上的条件
63 |
64 | **1、散列表**
65 |
66 | 散列表(也称哈希表)是根据关键码值(Key value)而直接进行访问的数据结构,它让码值经过哈希函数的转换映射到散列表对应的位置上,查找效率非常高。哈希索引就是基于散列表实现的,假设我们对名字建立了哈希索引,则查找过程如下图所示:
67 |
68 |
69 | 
70 |
71 | 对于每一行数据,存储引擎都会对所有的索引列(上图中的 name 列)计算一个哈希码(上图散列表的位置),散列表里的每个元素指向数据行的指针,由于索引自身只存储对应的哈希值,所以索引的结构十分紧凑,这让哈希索引查找速度非常快!但是哈希索引也有它的劣势,如下:
72 |
73 | 1. 针对哈希索引,只有精确匹配索引所有列的查询才有效,比如我在列(A,B)上建立了哈希索引,如果只查询数据列 A,则无法使用该索引。
74 | 2. 哈希索引并不是按照索引值顺序存存储的,所以也就无法用于排序,也就是说无法根据区间快速查找
75 | 3. 哈希索引只包含哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行,不过,由于哈希索引多数是在内存中完成的,大部分情况下这一点不是问题
76 | 4. 哈希索引只支持等值比较查询,包括 =,IN(),不支持任何范围的查找,如 age > 17
77 |
78 | 综上所述,哈希索引只适用于特定场合, 如果用得对,确实能再带来很大的性能提升,如在 InnoDB 引擎中,有一种特殊的功能叫「自适应哈希索引」,如果 InnoDB 注意到某些索引列值被频繁使用时,它会在内存基于 B+ 树索引之上再创建一个哈希索引,这样就能让 B+树也具有哈希索引的优点,比如快速的哈希查找。
79 |
80 | **2、链表**
81 |
82 | 双向链表支持顺序查找和逆序查找,如图下
83 |
84 | 
85 |
86 | 但显然不支持我们说的按某个值或区间的**快速查找**,另外我们知道表中的数据是要不断增加的,索引也是要及时插入更新的,链表显然也不支持数据的快速插入,所以能否在链表的基础上改造一下,让它支持快速查找,更新,删除。有一种结构刚好能满足我们的需求,这里引入跳表的概念。
87 |
88 | 什么是跳表?简单地说,跳表是在链表之上加上多层索引构成的。如下图所示
89 |
90 | 
91 |
92 | 假设我们现在要查找区间 7- 13 的记录,再也不用从头开始查找了,只要在上图中的二级索引开始找即可,遍历三次即可找到链表的区间位置,时间复杂度是 O(logn),非常快,这样看来,跳表是能满足我们的需求的,实际上它的结构已经和 B+ 树非常接近了,只不过 B+ 树是从平衡二叉查找树演化而来的而已,接下来我们一步步来看下如何将平衡二叉查找树改造成 B+ 树。
93 |
94 | 先来看看什么是平衡二叉查找树,平衡二叉查找树具有如下性质:
95 |
96 | 1. 若左子树不空,则左子树上所有节点的值均小于它的根节点的值;
97 | 2. 若右子树不空,则右子树上所有节点的值均大于或等于它的根节点的值;
98 | 3. 每个非叶子节点的左右子树的高度之差的绝对值(平衡因子)最多为1。
99 |
100 | 下图就是一颗平衡二叉查找树
101 |
102 | 
103 |
104 | 从其特性就可以看到平衡二叉查找树查找节点的时间复杂度是 O(log2n)
105 |
106 |
107 | 现在我们将其改造成 B+ 树
108 |
109 | 
110 |
111 | 可以看到主要区别就是所有的节点值都在最后叶节点上用双向链表连接在了一起,仔细和跳表对比一下 ,是不是很像,现在如果我们要找15 ~ 27 这个区间的数只要先找到 15 这个节点(时间复杂度 logn = 3 次)再从前往后遍历直到 27 这个节点即可,即可找到这区间的节点,这样它完美地支持了我们提的三个需求:快速查找值,区间,顺序逆序查找。
112 |
113 | 假设有 1 亿个节点,每个节点要查询多少次呢,显然最多为 log21亿 = 27 次,如果这 1 亿个节点都在内存里,那 27 次显然不是问题,可以说是非常快了,但一个新的问题出现了,这 1 亿个节点在内存大小是多少呢,我们简单算一下,假设每个节点 16 byte,则 1 亿个节点大概要占用 1.5G 内存!对于内存这么宝贵的资源来说是非常可怕的空间消耗,这还只是一个索引,一般我们都会在表中定义多个索引,或者库中定义多张表,这样的话内存很快就爆满了!所以在内存中完全装载一个 B+ 树索引显然是有问题的,如何解决呢。
114 |
115 | 内存放不下, 我们可以把它放到磁盘嘛,磁盘空间比内存大多了,但新的问题又来了,我们知道内存与磁盘的读取速度相差太大了,通常内存是纳秒级的,而磁盘是毫秒级的,读取同样大小的数据,两者可能相差上万倍,于是上一步我们计算的 27 次查询如果放在磁盘中来看就非常要命了(查找一个节点可以认为是一次磁盘 IO,也就是说有 27 次磁盘 IO!),27 次查询是否可以优化?
116 |
117 | 可以很明显地观察到查询次数和树高有关,那树高和什么有关,很明显和每个节点的子节点个数有关,即 N 叉树中的 N,假设现在有 16 个数,我们分别用二叉树和五叉树来构建,看下树高分别是多少
118 |
119 | 
120 |
121 |
122 | 
123 |
124 | 可以看到如果用二叉树 ,要遍历 5 个节点,如果用五叉树 ,只要遍历 3 次,一下少了两次磁盘 IO,回过头来看 上文的一亿个节点,如果我们用 100 叉树来构建,需要几次 IO 呢
125 |
126 | 
127 |
128 | 可以看到,最多遍历五次(实际上根节点一般存在内存里的,所以可以认为是 4 次)!磁盘 IO 一下从 27 减少到了 5!性能可以说是大大提升了,有人说 5 次还是太多,是不是可以把 100 叉树改成 1000 或 10000 叉树呢,这样 IO 次数不就就能进一步减少了。
129 |
130 | 这里我们就需要了解页(page)的概念,在计算机里,无论是内存还是磁盘,操作系统都是按页的大小进行读取的(页大小通常为 4 kb),磁盘每次读取都会**预读**,会提前将连续的数据读入内存中,这样就避免了多次 IO,这就是计算机中有名的**局部性原理**,即我用到一块数据,很大可能这块数据附近的数据也会被用到,干脆一起加载,省得多次 IO 拖慢速度, 这个连续数据有多大呢,必须是是操作系统页大小的整数倍,这个连续数据就是 MySQL 的页,默认值为 16 KB,也就是说对于 B+ 树的节点,最好设置成页的大小(16 KB),这样一个 B+ 树上的节点就只会有一次 IO 读。
131 |
132 | 那有人就会问了,这个页大小是不是越大越好呢,设置大一点,节点可容纳的数据就越多,树高越小,IO 不就越小了吗,这里要注意,页大小并不是越大越好,InnoDB 是通过内存中的缓存池(pool buffer)来管理从磁盘中读取的页数据的。页太大的话,很快就把这个缓存池撑满了,可能会造成页在内存与磁盘间频繁换入换出,影响性能。
133 |
134 | 通过以上分析,相信我们不难猜测出 N 叉树中的 N 该怎么设置了,只要选的时候尽量保证每个节点的大小等于一个页(16kb)的大小即可。
135 |
136 | ## 页分裂与页合并
137 |
138 | 现在我们来看看开头的问题, 为啥推荐自增 id 作为主键,自建主键不行吗,有人可能会说用户的身份证是唯一的,可以用它来做主键,假设以身份证作主键,会有什么问题呢。
139 |
140 | B+ 树为了维护索引的有序性,每插入或更新一条记录的时候,会对索引进行更新。假设原来基于身份证作索引的 B+ 树如下(假设为二叉树 ,图中只列出了身份证的前四位)
141 |
142 | 
143 |
144 | 现在有一个开头是 3604 的身份证对应的记录插入 db ,此时要更新索引,按排序来更新的话,显然这个 3604 的身份证号应该插到左边节点 3504 后面(如下图示,假设为二叉树)
145 |
146 | 
147 |
148 | 如果把 3604 这个身份证号插入到 3504 后面的话,这个节点的元素个数就有 3 个了,显然不符合二叉树的条件,此时就会造成**页分裂**,就需要调整这个节点以让它符合二叉树的条件
149 |
150 | 
151 |
152 | **如图示:调整过后符合二叉树条件**
153 |
154 | 这种由于页分裂造成的调整必然导致性能的下降,尤其是以身份证作为主键的话,由于身份证的随机性,必然造成大量的随机结点中的插入,进而造成大量的页分裂,进而造成性能的急剧下降,那如果是以自增 id 作为主键呢,由于新插入的表中生成的 id 比索引中所有的值都大,所以它要么合到已存在的节点(元素个数未满)中,要么放入新建的节点中(如下图示)所以如果是以自增 id 作为主键,就不存在页分裂的问题了,推荐!
155 |
156 | 
157 |
158 |
159 | 有页分裂就必然有页合并,什么时候会发生页合并呢,当删除表记录的时候,索引也要删除,此时就有可能发生页合并,如图示
160 |
161 | 
162 |
163 | 当我们删除 id 为 7,9 对应行的时候,上图中的索引就要更新,把 7,9 删掉,此时 8,10 就应该合到一个节点,不然 8,10 分散在两个节点上,可能造成两次 IO 读,势必会影响查找效率! 那什么时候会发生页合并呢,我们可以定个阈值,比如对于 N 叉树来说,当节点的个数小于 N/2 的时候就应该和附近的节点合并,不过需要注意的是合并后节点里的元素大小可能会超过 N,造成页分裂,需要再对父节点等进行调整以让它满足 N 叉树的条件。
164 |
165 |
166 | ## 怎么根据索引查找行记录
167 |
168 | 相信大家看完以上的 B+ 树索引的介绍应该还有个疑惑,怎么根据对应的索引值查找行记录呢,其实相应的行记录就放在最后的叶子节点中,找到了索引值,也就找到了行记录。如图示
169 |
170 | 
171 |
172 | 可以看到,非叶子节点只存了索引值,只在最后一行才存放了行记录,这样极大地减小了索引了大小,而且只要找到索引值就找到了行记录,也提升了效率,
173 |
174 | 这种在叶节点存放一整行记录的索引被称为聚簇索引,其他的就称为非聚簇索引。
175 |
176 | ## 关于 B+ 树的总结
177 |
178 | 综上所述,B+树有以下特点:
179 |
180 | * 每个节点中子节点的个数不能超过 N,也不能小于 N/2(不然会造成页分裂或页合并)
181 | * 根节点的子节点个数可以不超过 m/2,这是一个例外
182 | * m 叉树只存储索引,并不真正存储数据,只有最后一行的叶子节点存储行数据。
183 | * 通过链表将叶子节点串联在一起,这样可以方便按区间查找
184 |
185 |
186 | ## 总结
187 | 本文由日常中常用的 SQL 由浅入深地总结了 B+ 树的特点,相信大家应该对 B+ 树索引有了比较清晰地认识,所以说为啥我们要掌握底层原来,学完了 B+ 树,再看开头提的几个问题,其实也不过如此,深挖底层,有时候确实能让你以不变应万变。
188 |
189 |
190 | 最后,欢迎大家关注我的公号「码海」,共同进步!
191 |
192 | 
193 |
194 |
195 | 巨人的肩膀
196 |
197 | http://www.rainybowe.com/blog/2016/05/10/mysql%E7%B4%A2%E5%BC%95/index.html
198 | https://time.geekbang.org/column/article/69236
--------------------------------------------------------------------------------
/网络/TCP:一个悲伤的故事.md:
--------------------------------------------------------------------------------
1 | >漫画描述了 TCP 协议的基本原理,为了提高可理解性,部分细节设计与真实的 TCP 协议有所差别,但总体思想与 TCP 一致。
2 | >如果读者想了解 TCP 的设计细节,请参考严肃学术材料和 RFC 文档
3 |
4 |
5 |
6 | 
7 |
8 | 
9 |
10 | 
11 |
12 | 
13 |
14 | 
15 |
16 | 
17 |
18 | 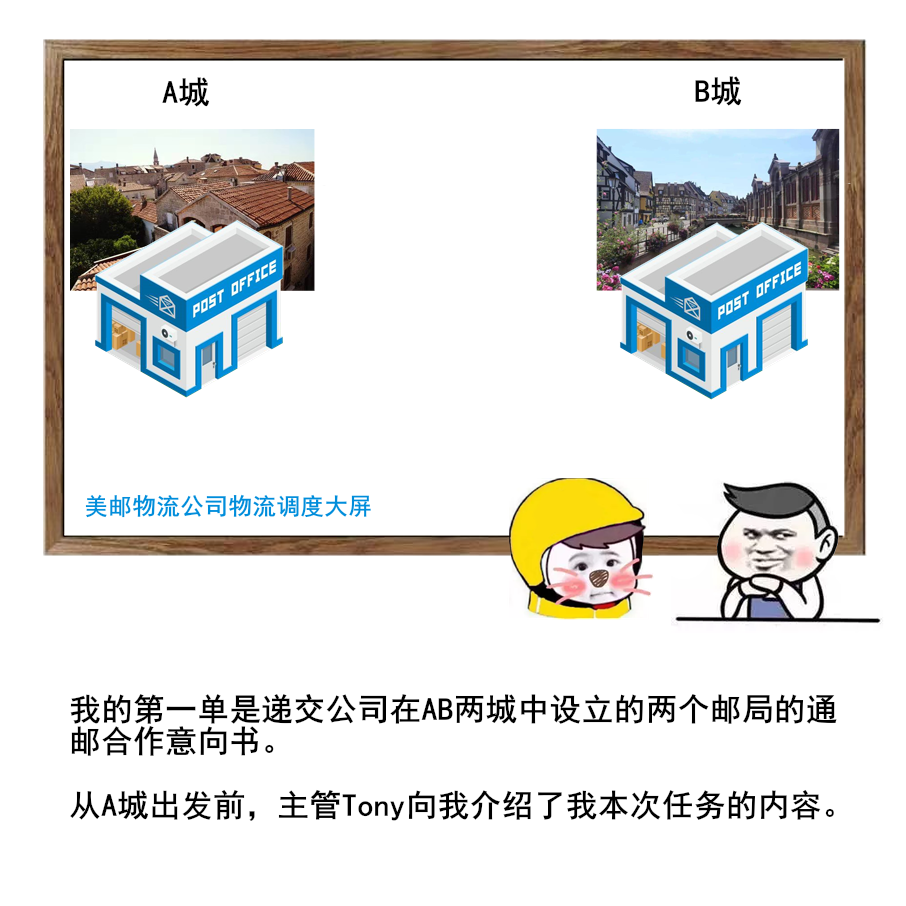
19 |
20 | 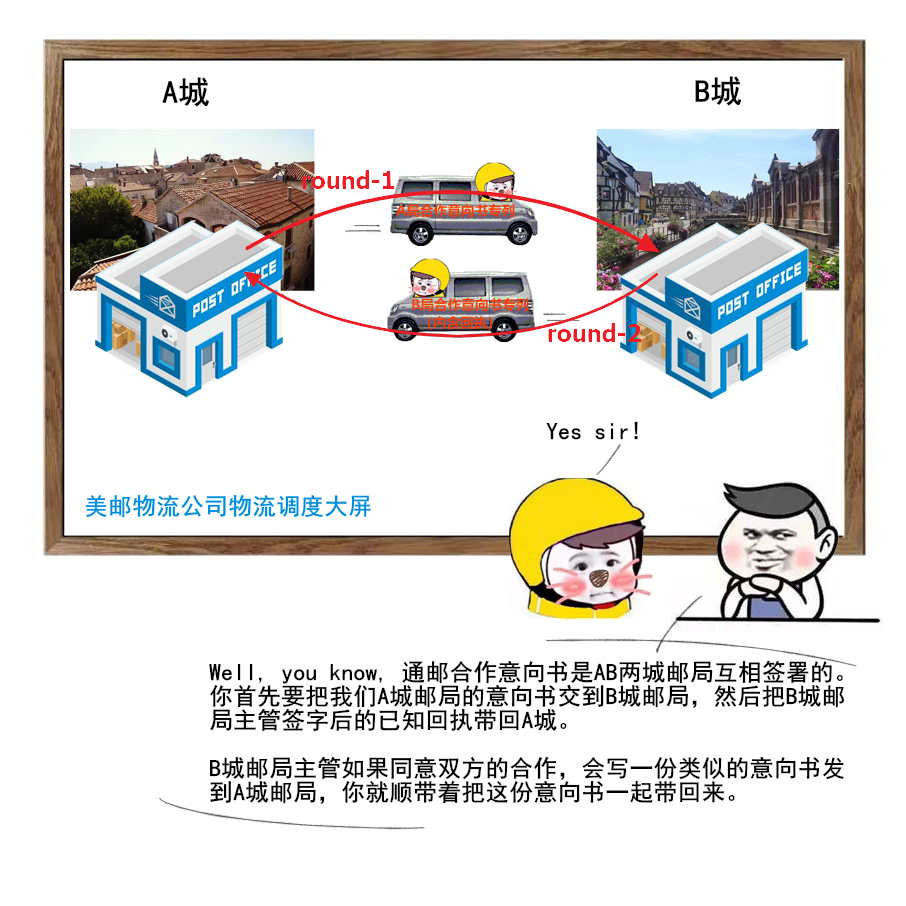
21 |
22 | 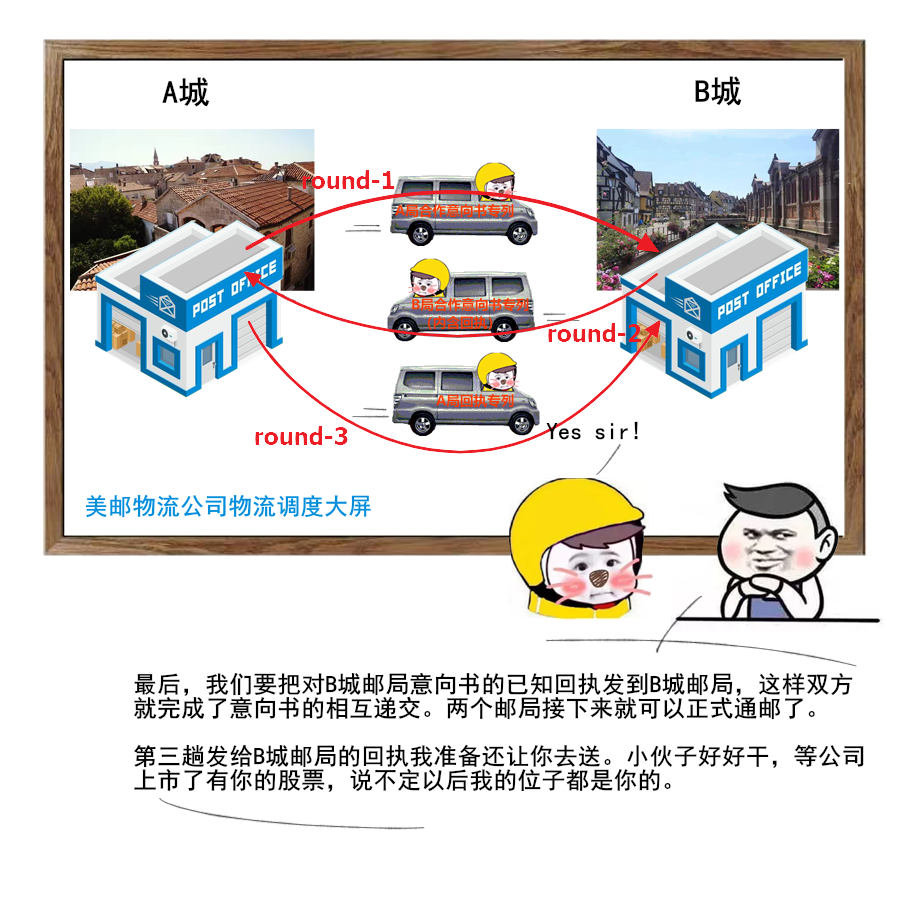
23 |
24 | 
25 |
26 | 
27 |
28 | 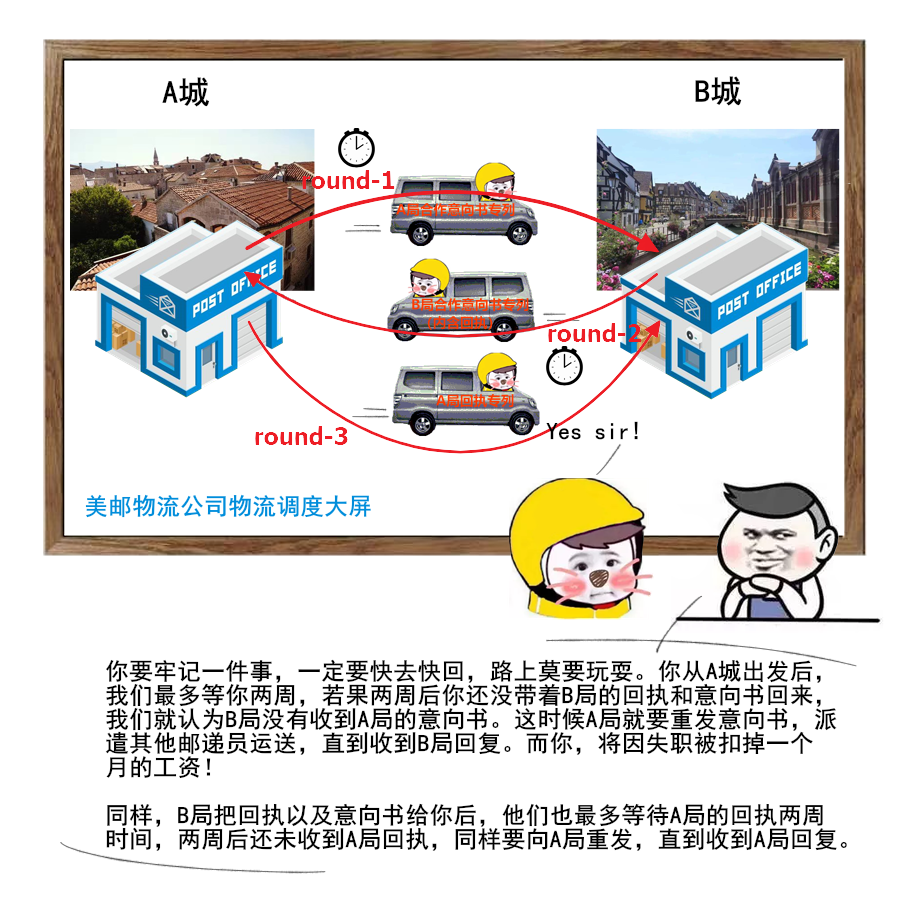
29 |
30 | 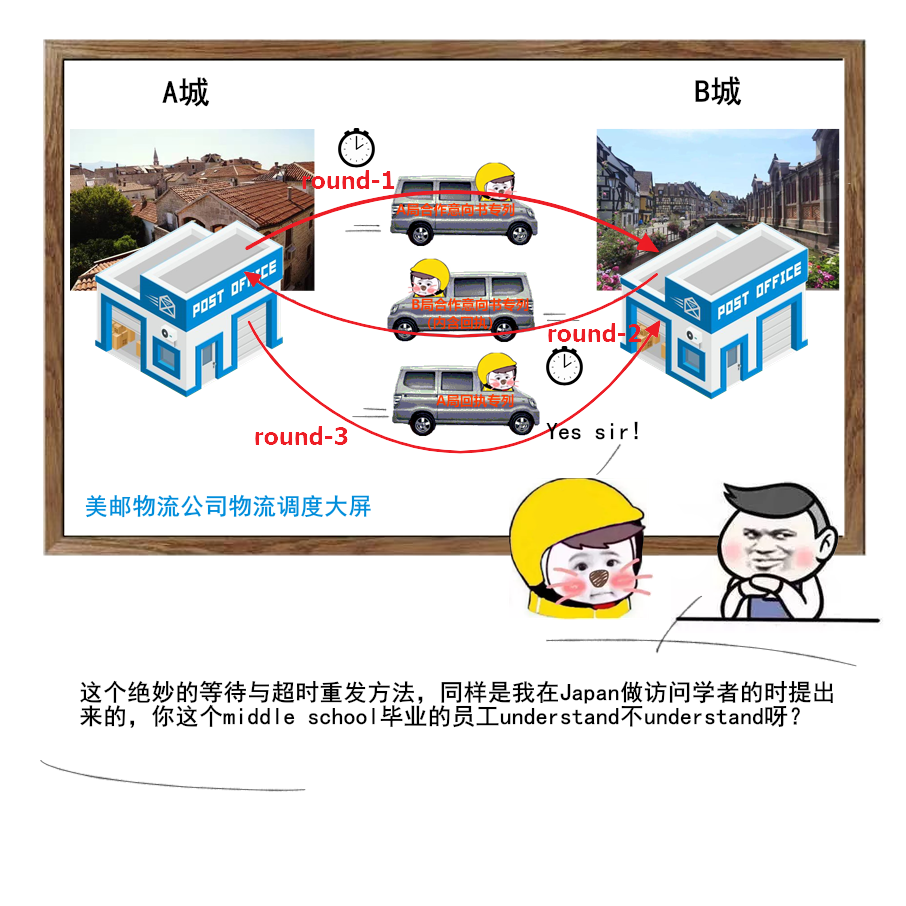
31 |
32 | 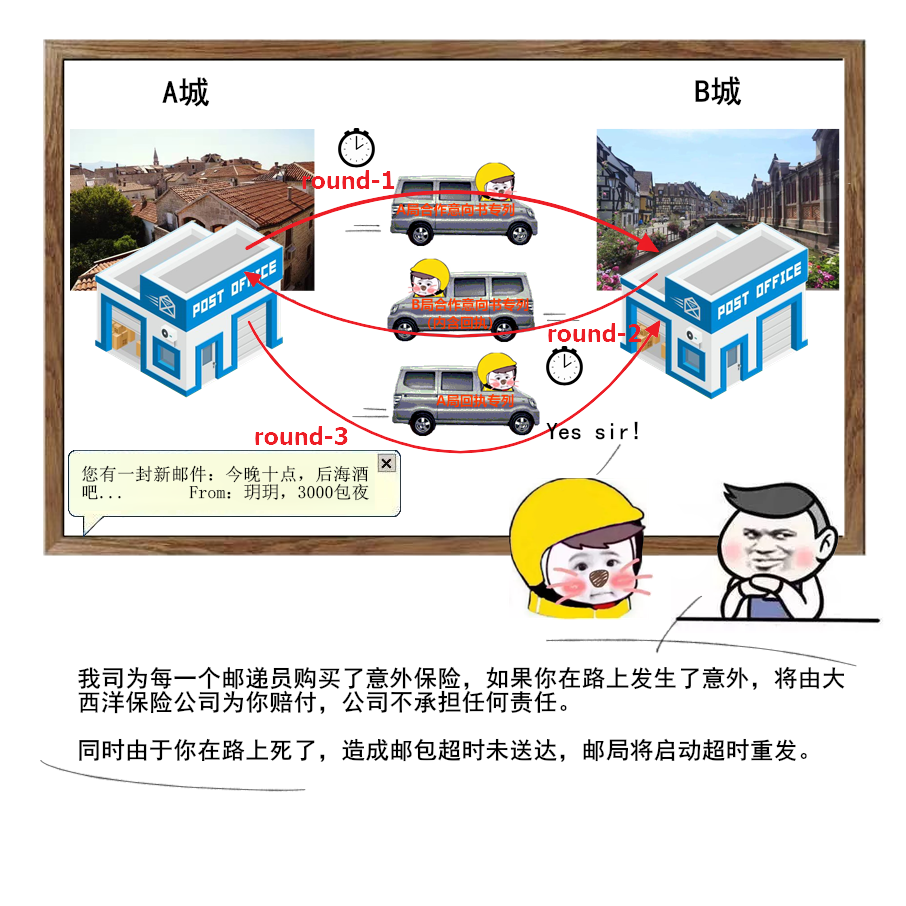
33 |
34 | 
35 |
36 | 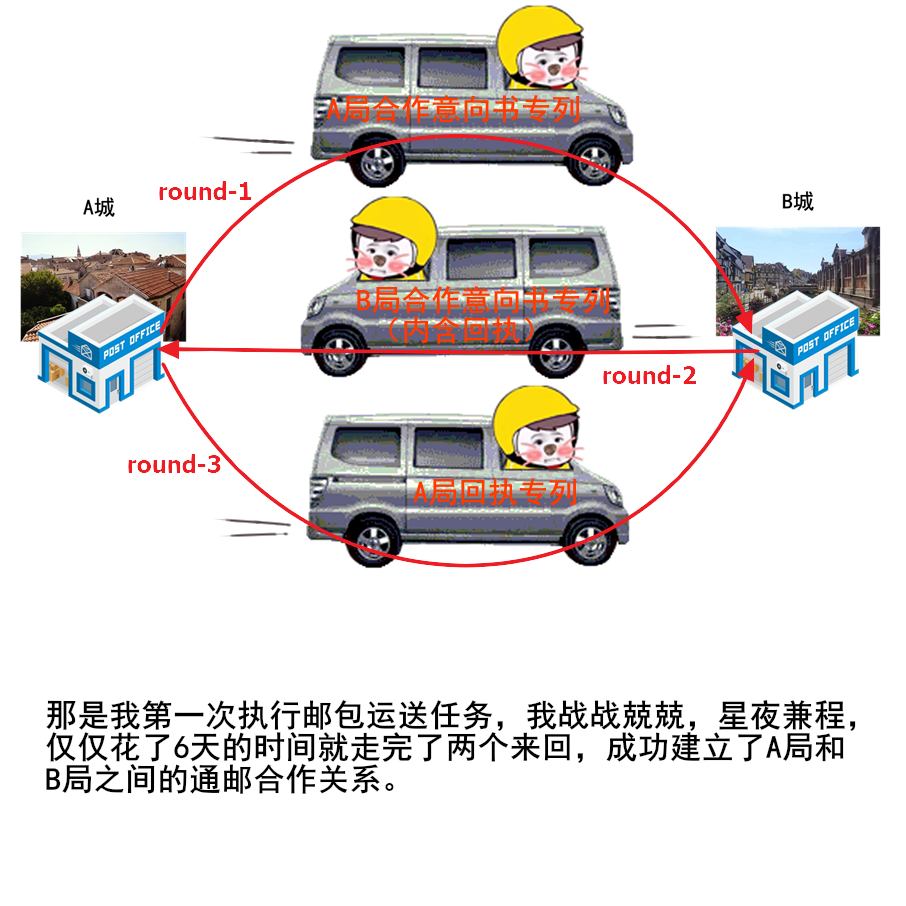
37 |
38 | 
39 |
40 | 
41 |
42 | 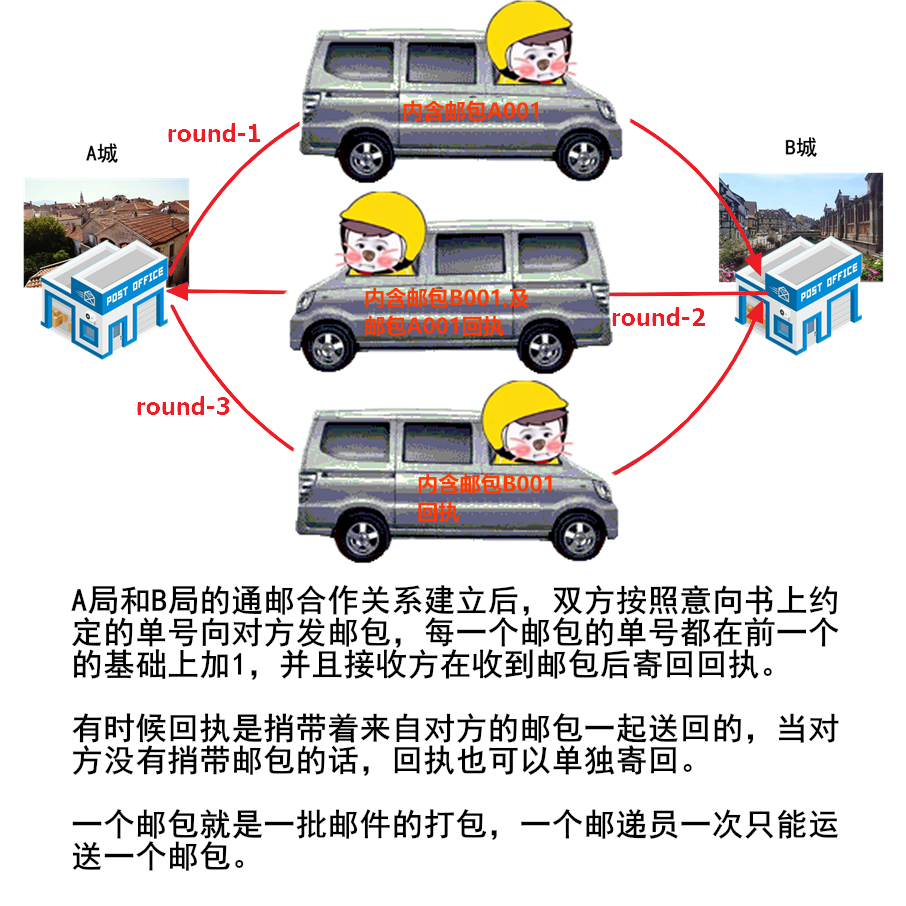
43 |
44 | 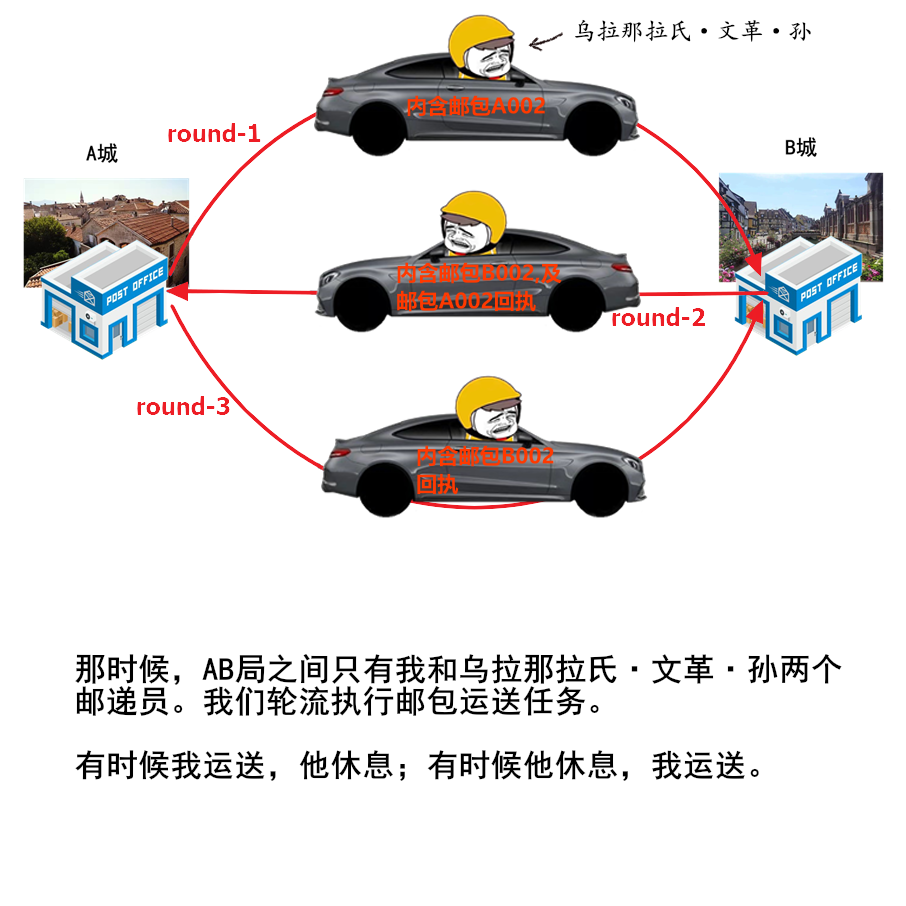
45 |
46 | 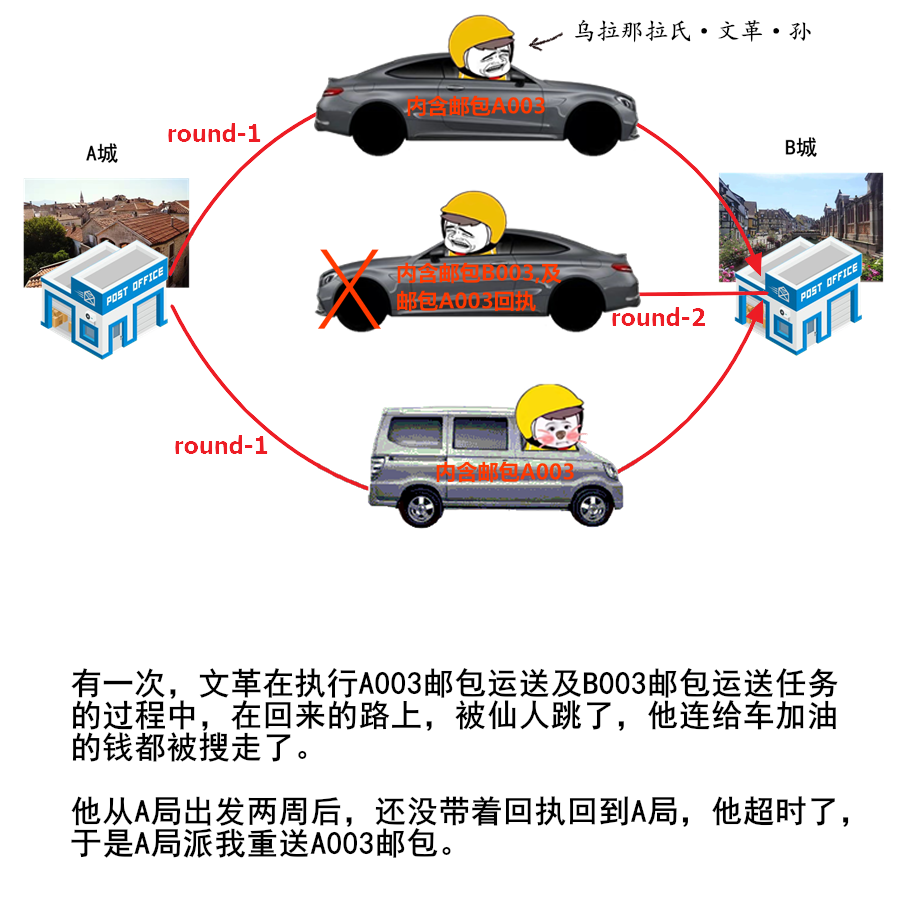
47 |
48 | 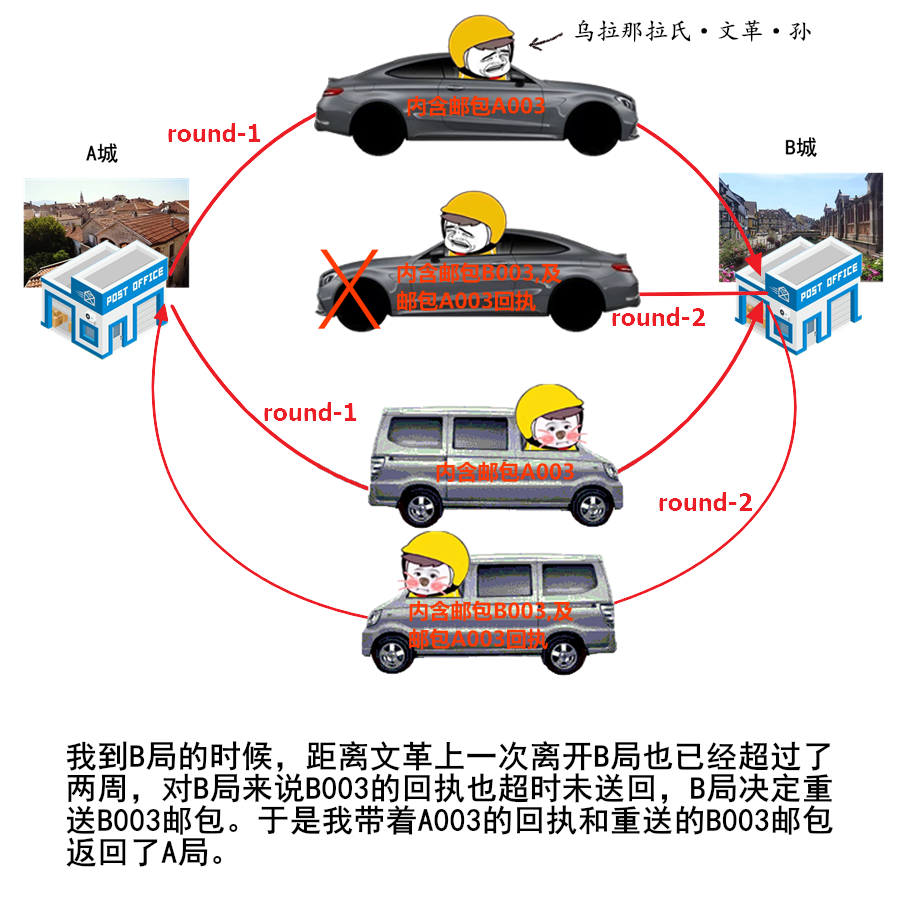
49 |
50 | 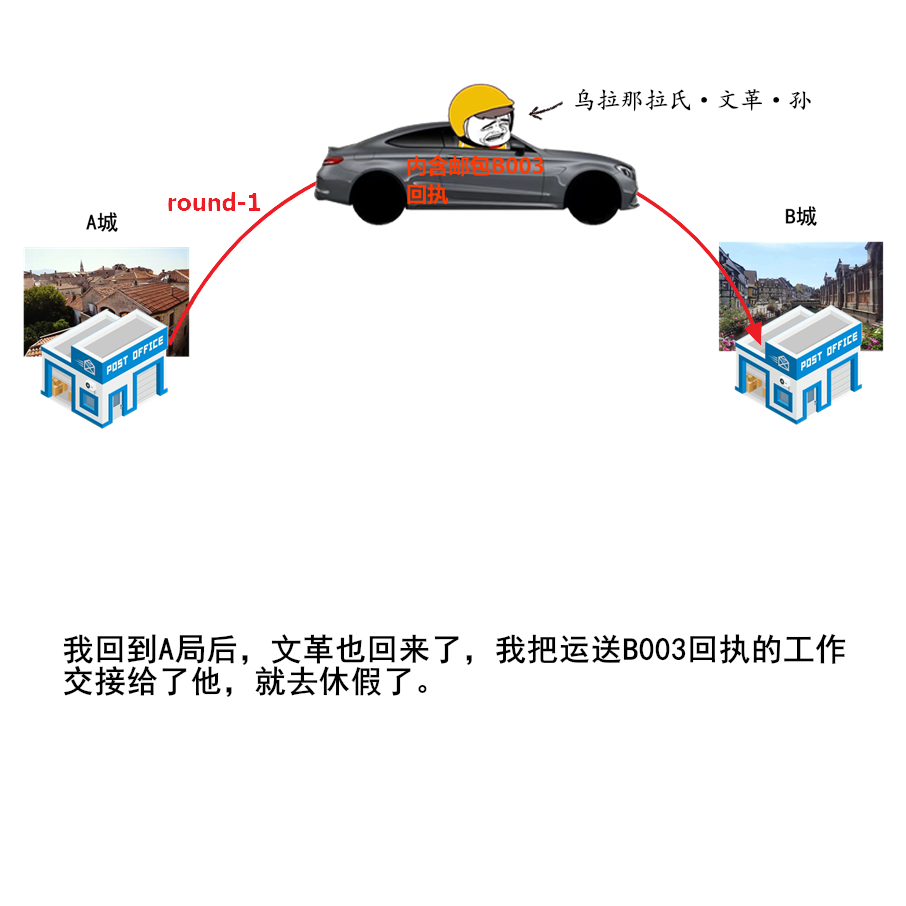
51 |
52 | 
53 |
54 | 
55 |
56 | 
57 |
58 | 
59 |
60 | 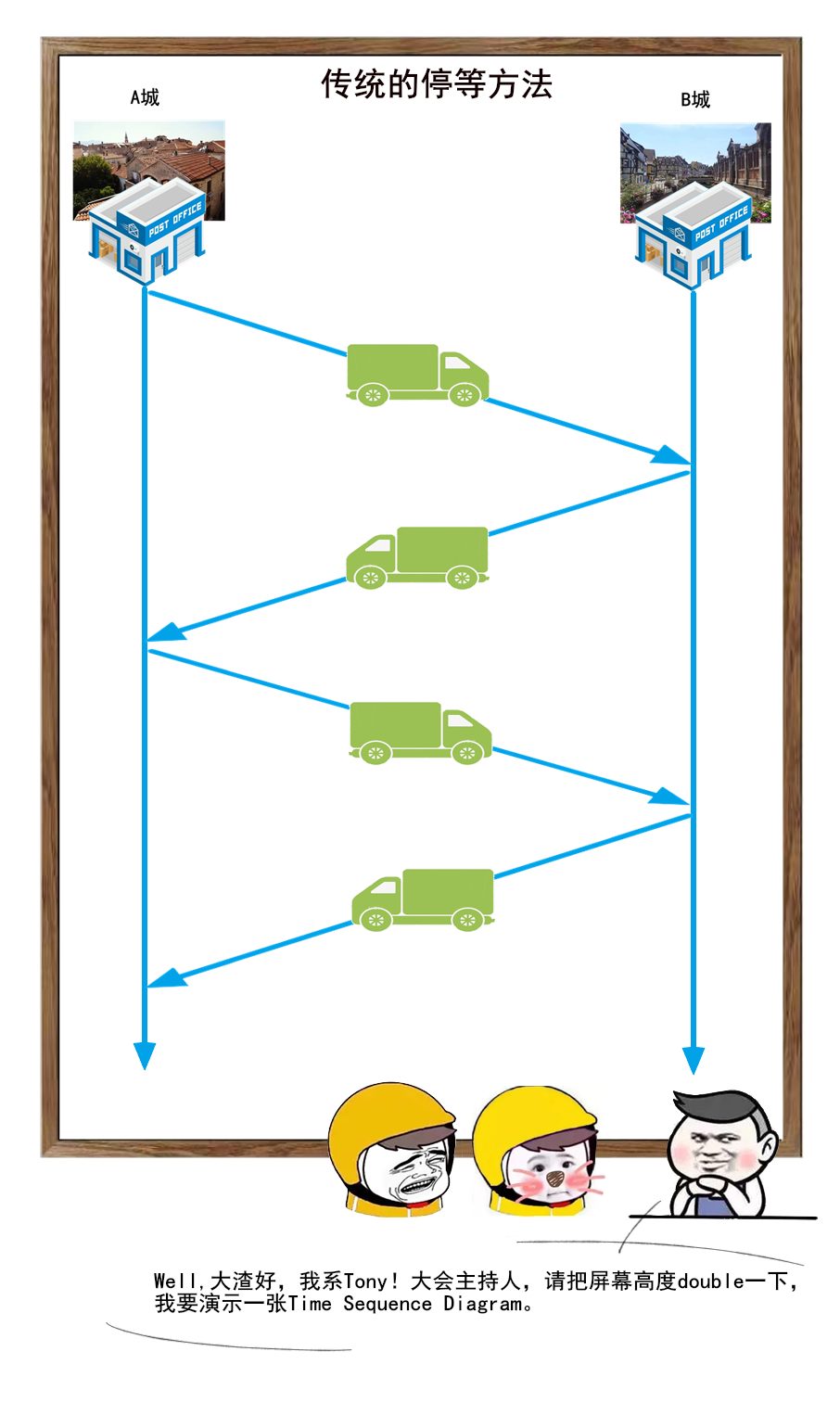
61 |
62 | 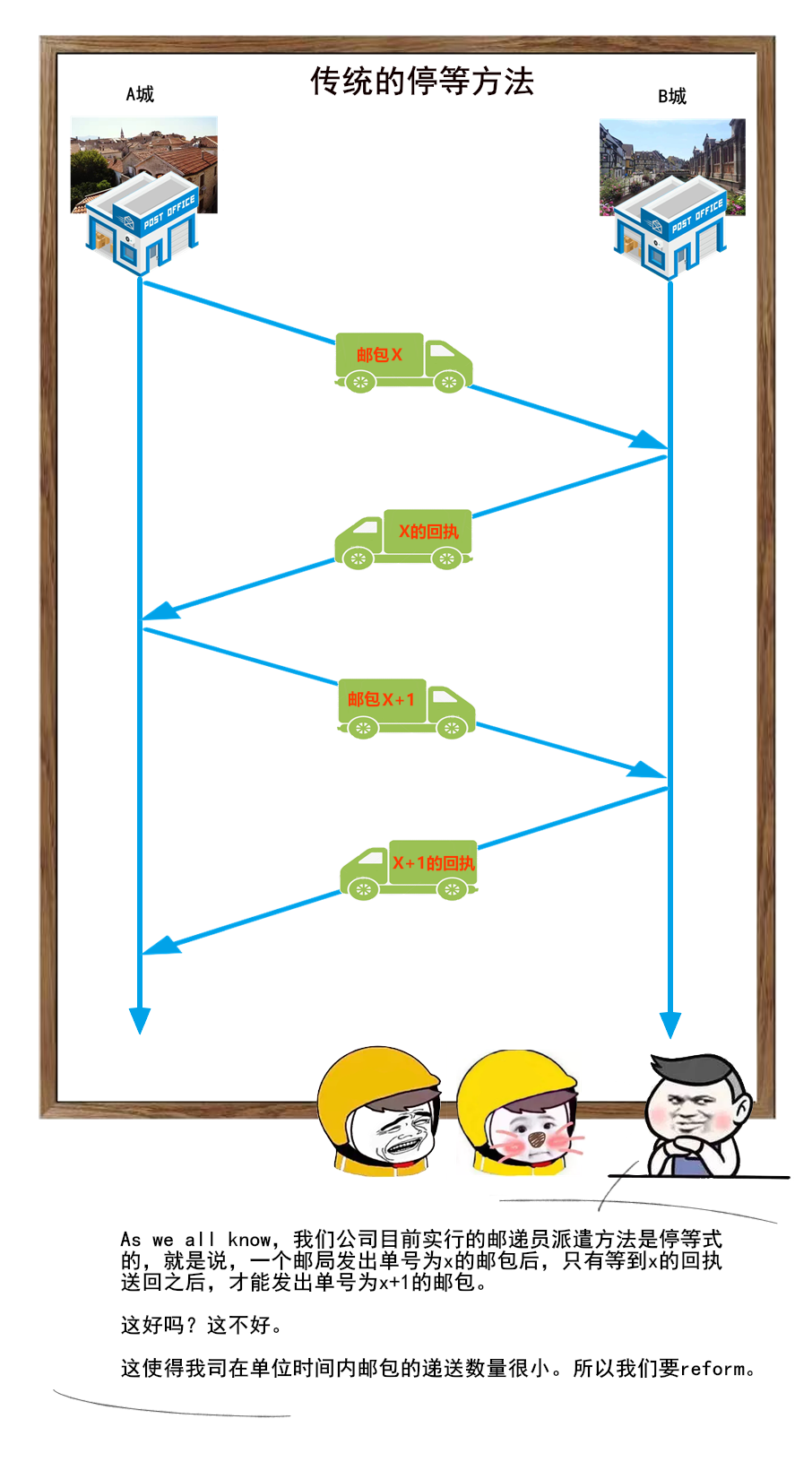
63 |
64 | 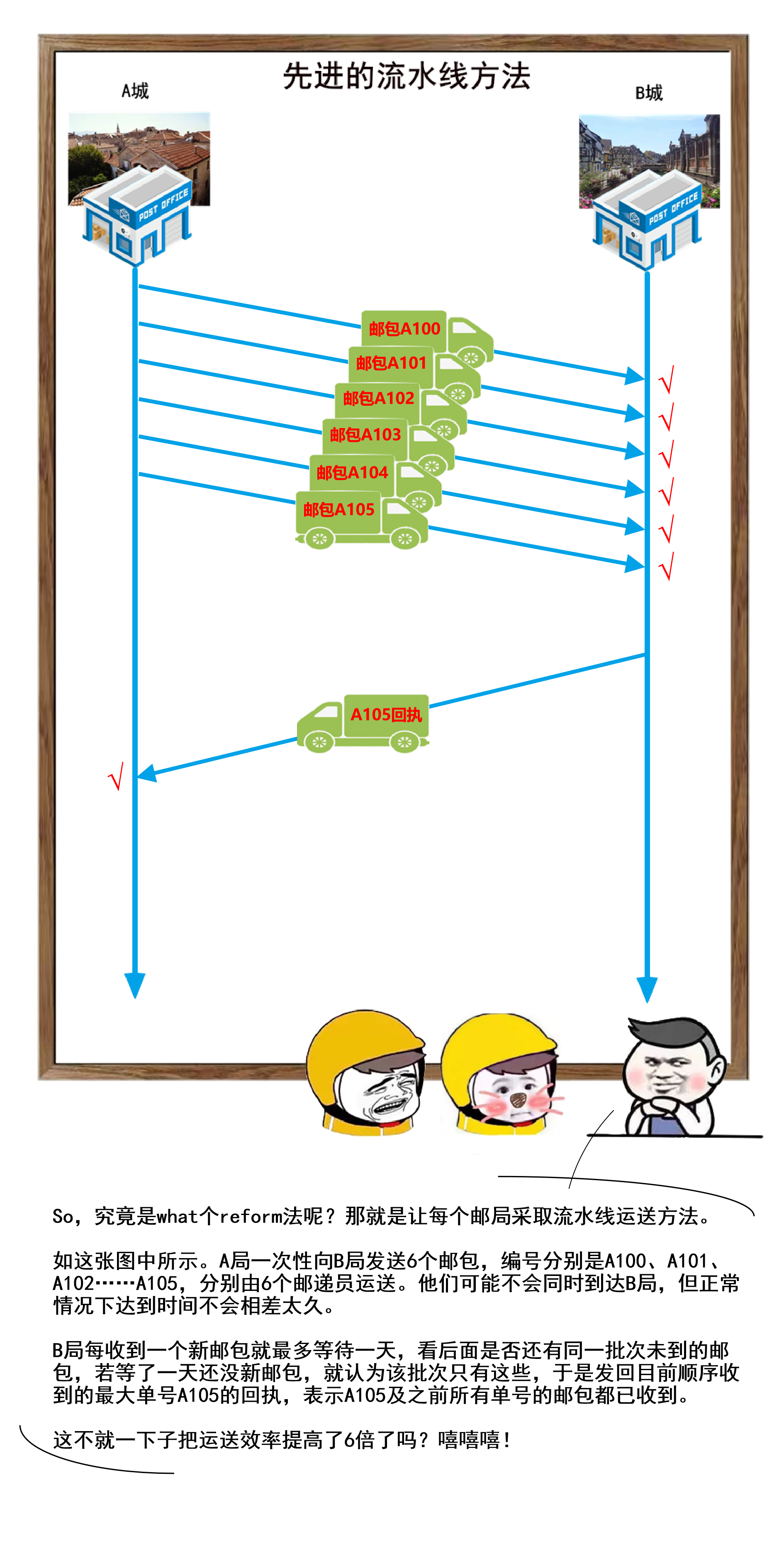
65 |
66 | 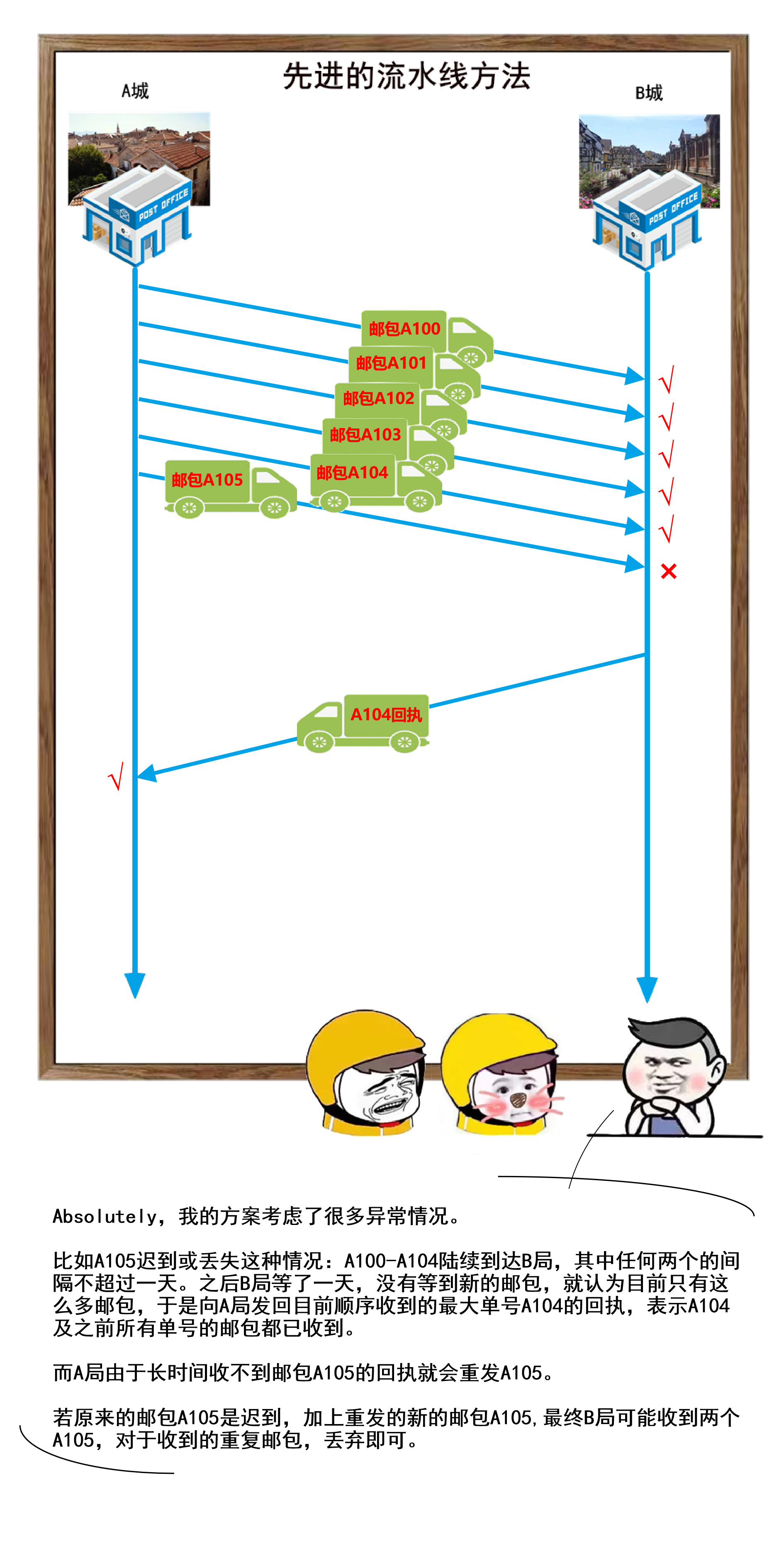
67 |
68 | 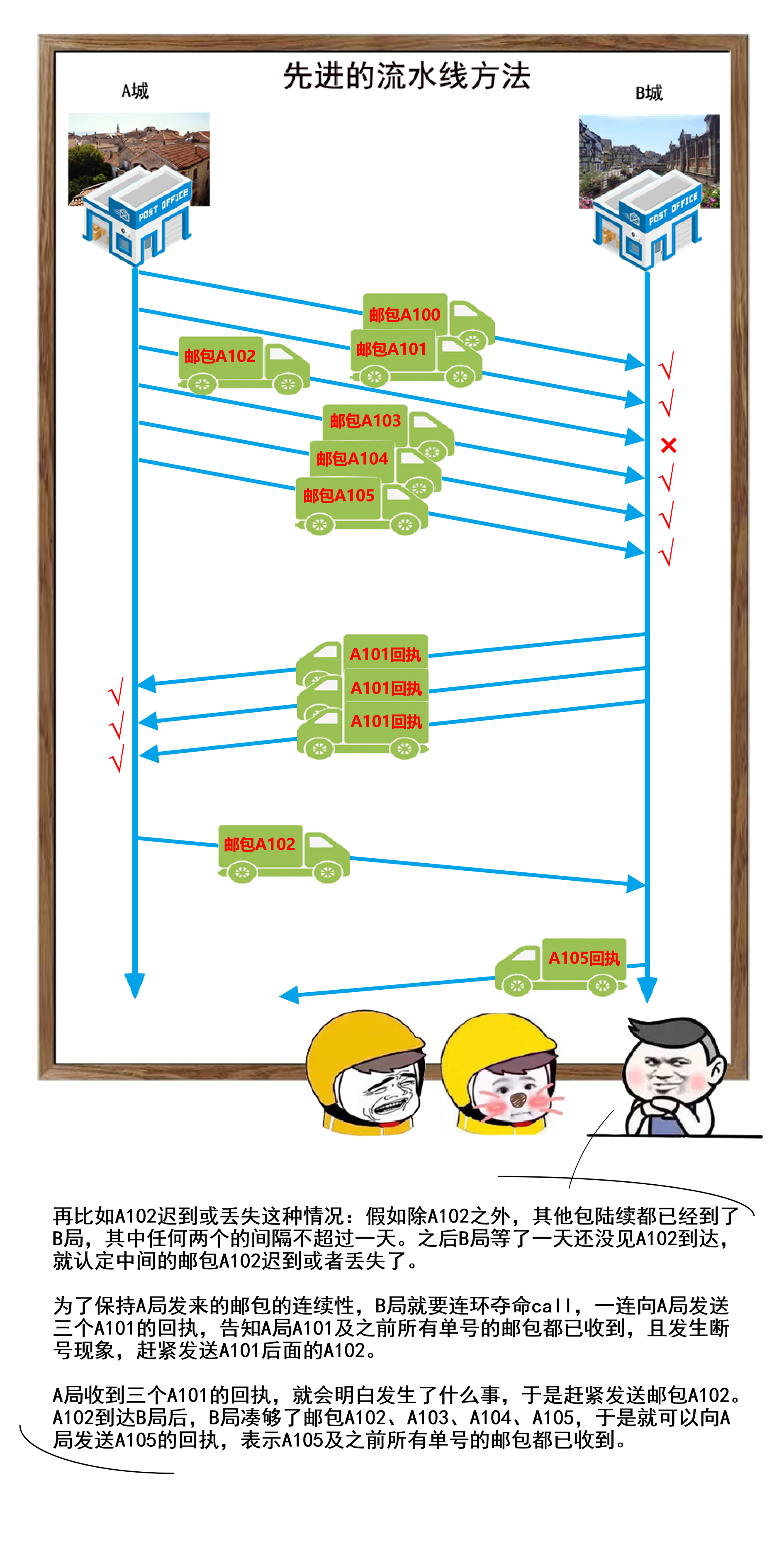
69 |
70 | 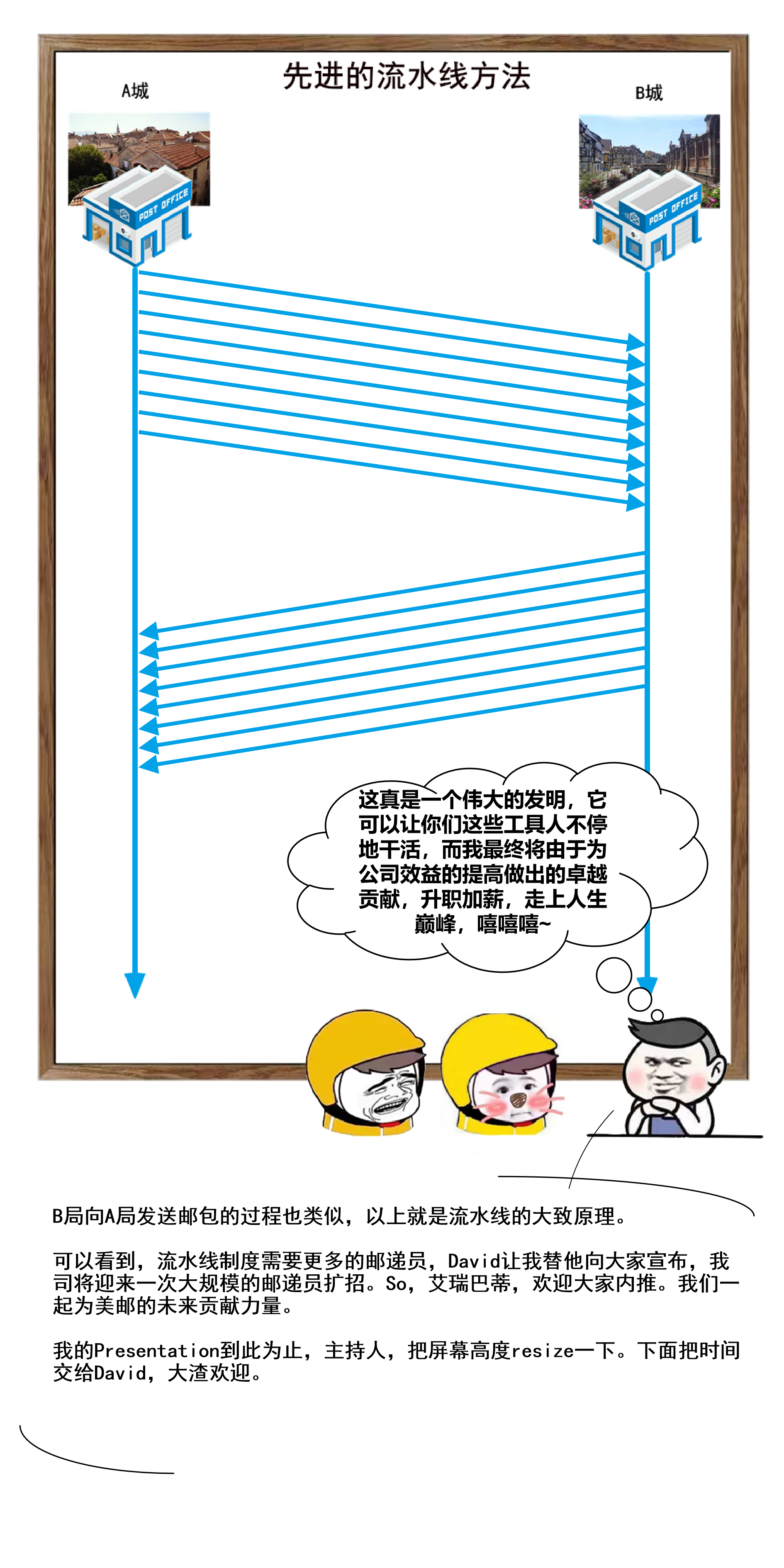
71 |
72 | 
73 |
74 | 
75 |
76 | 
77 |
78 | 
79 |
80 | 
81 |
82 | 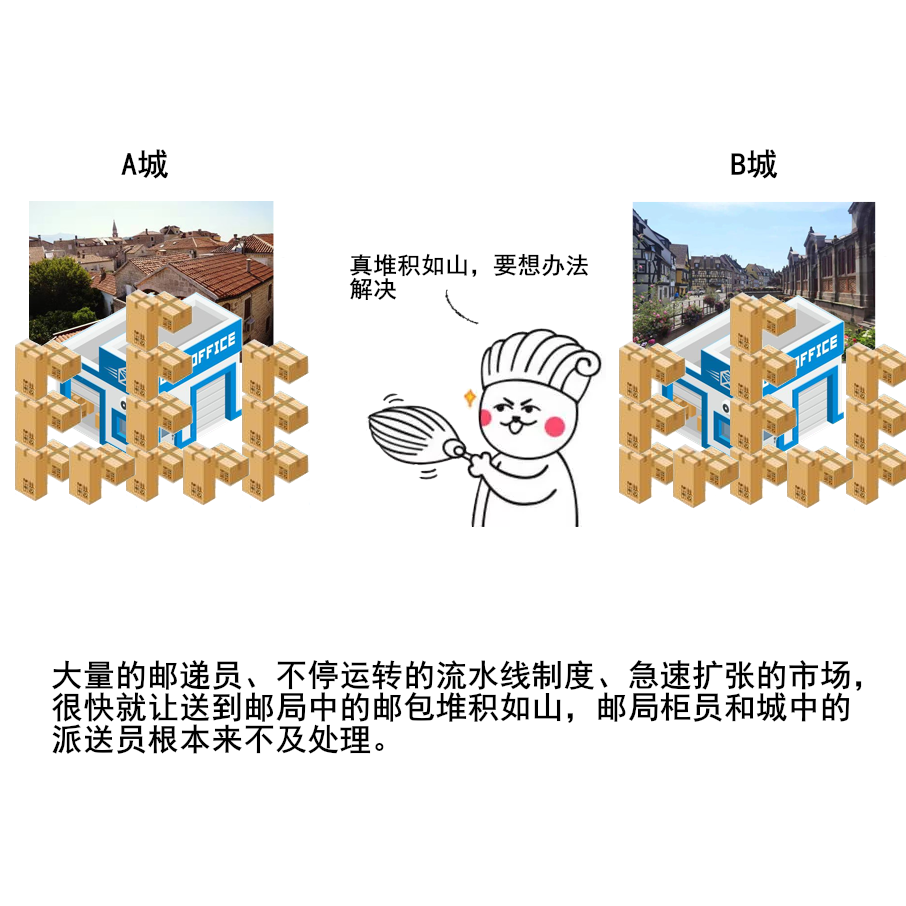
83 |
84 | 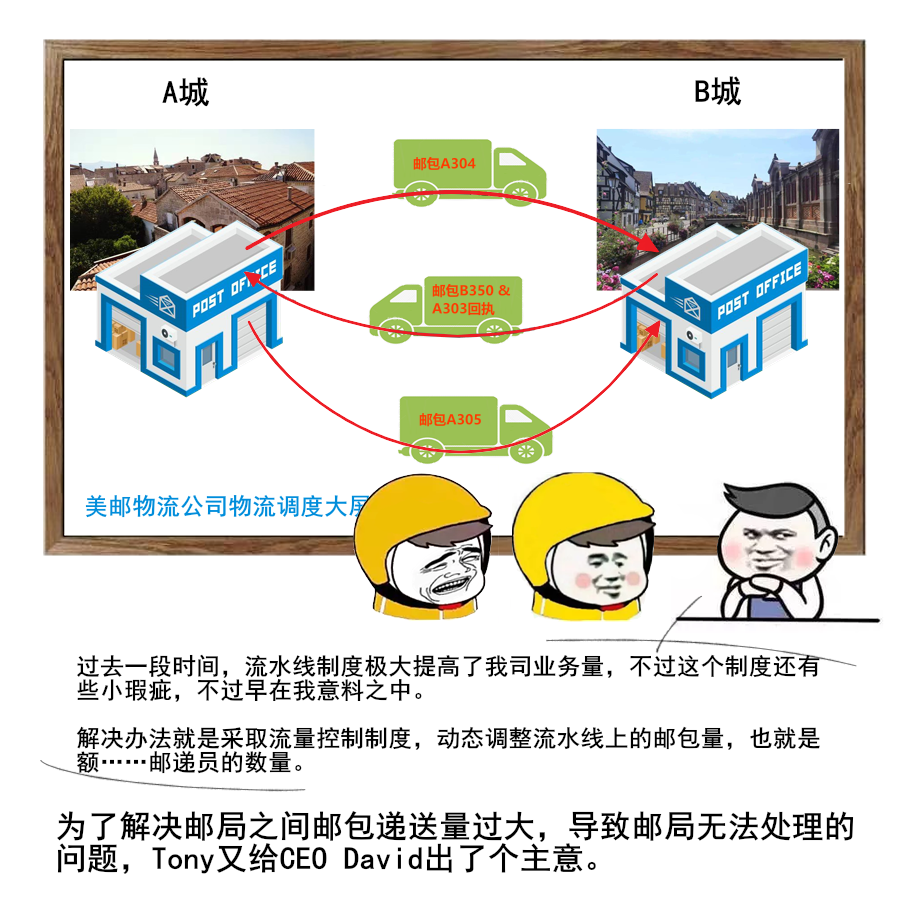
85 |
86 | 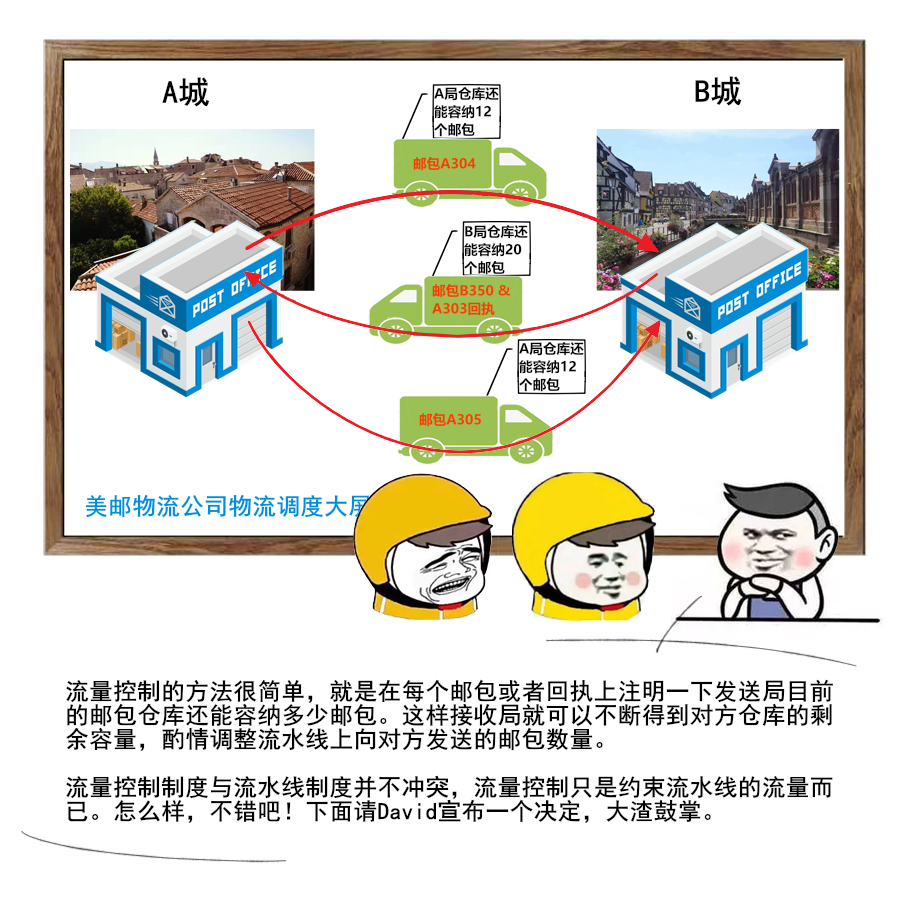
87 |
88 | 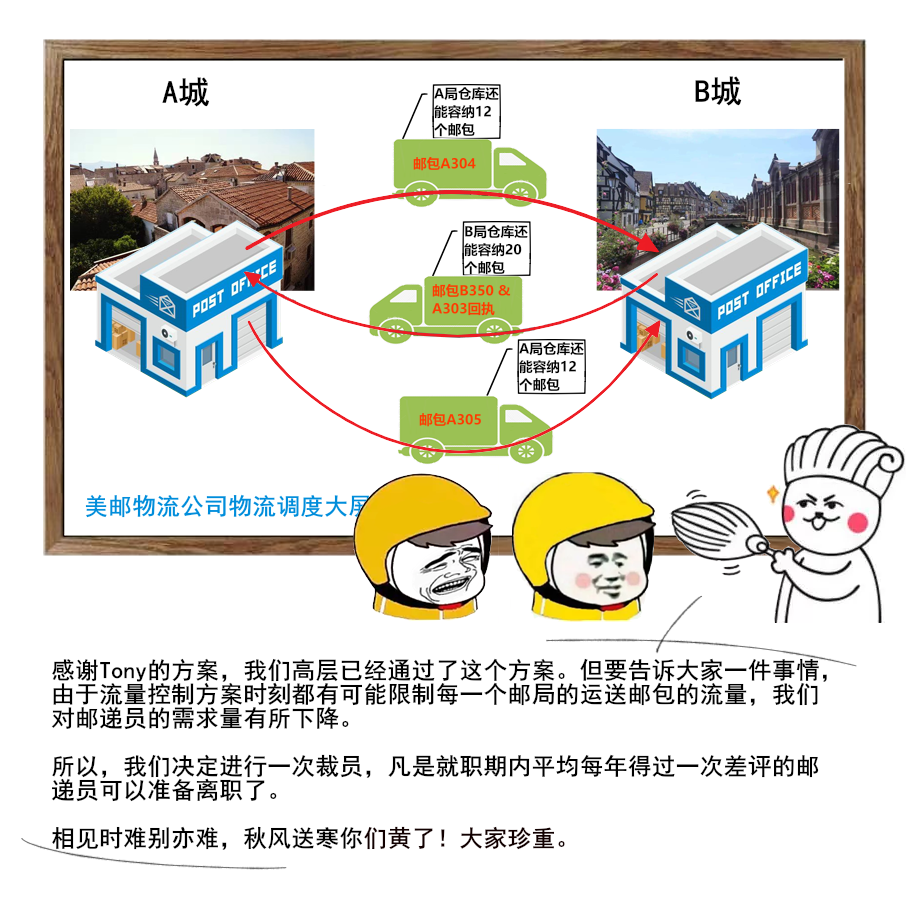
89 |
90 | 
91 |
92 | 
93 |
94 | 
95 |
96 | 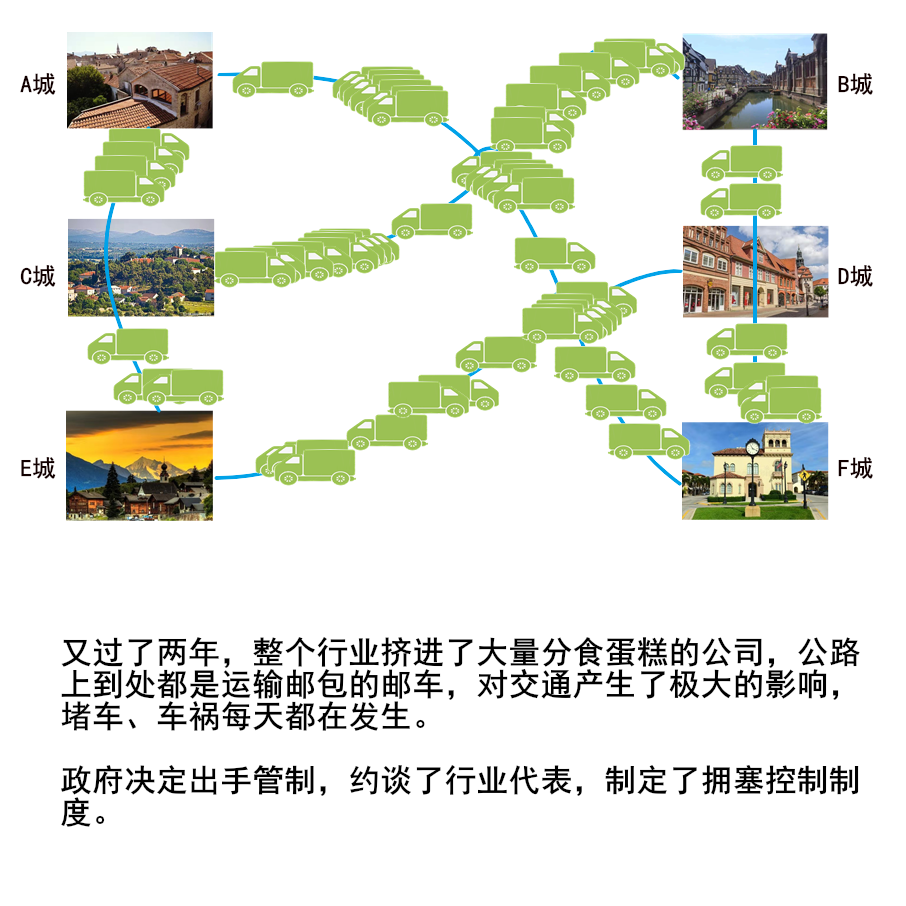
97 |
98 | 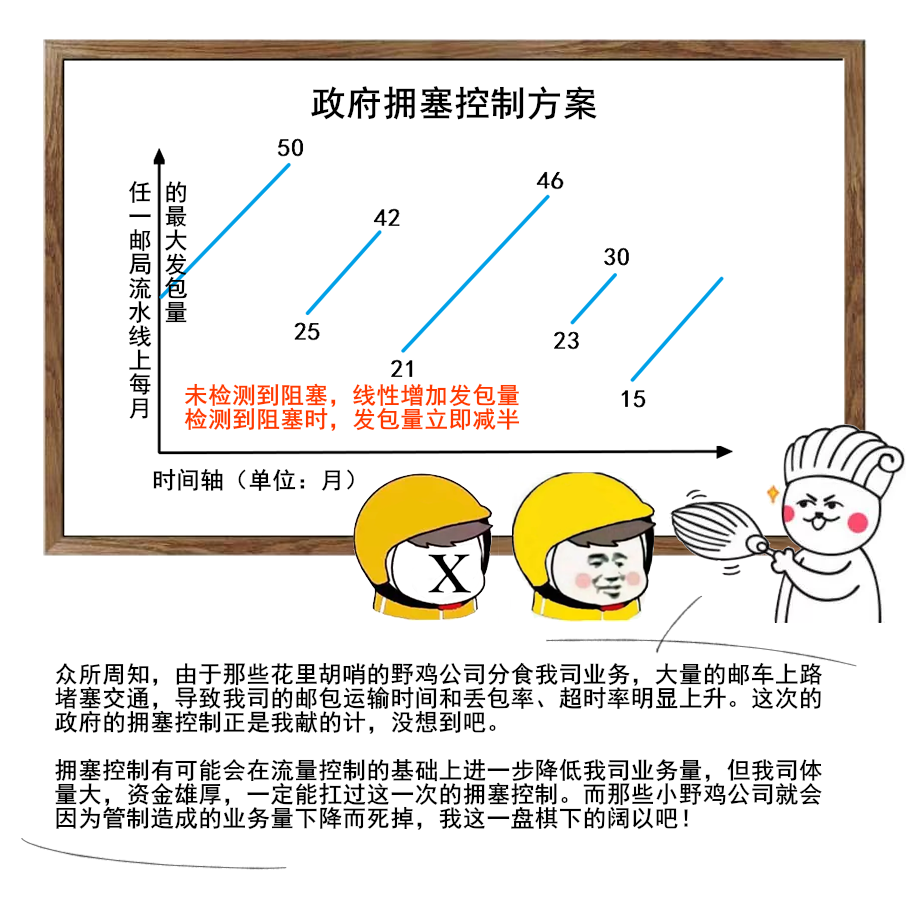
99 |
100 | 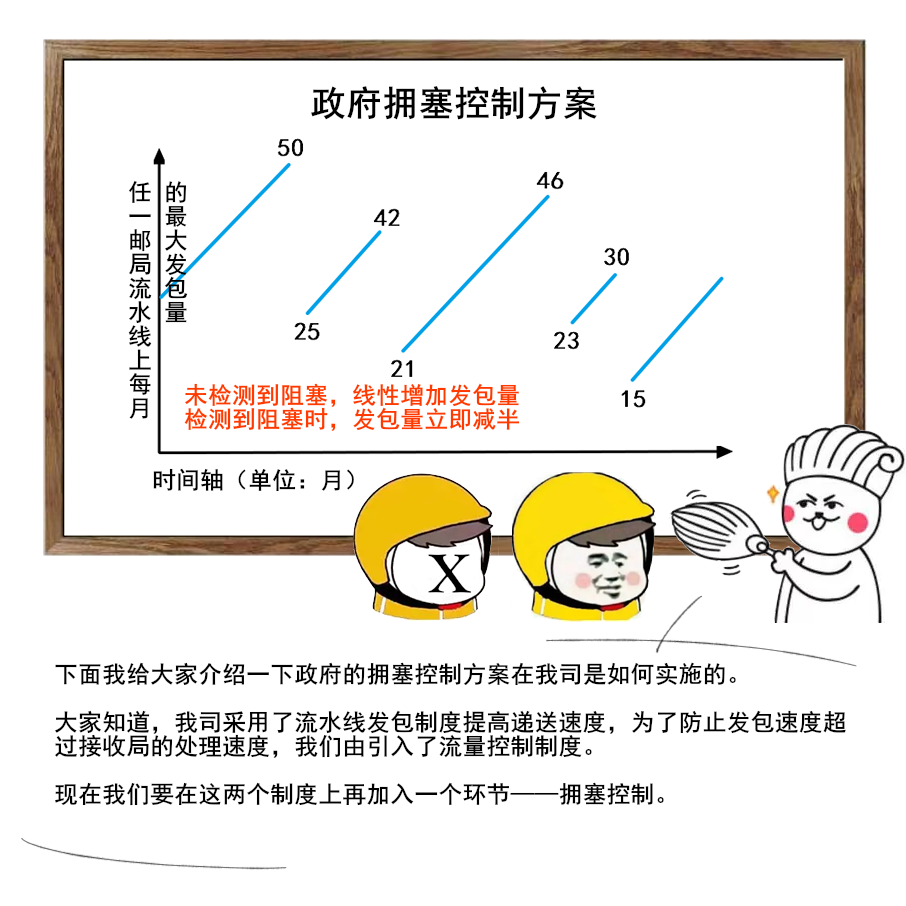
101 |
102 | 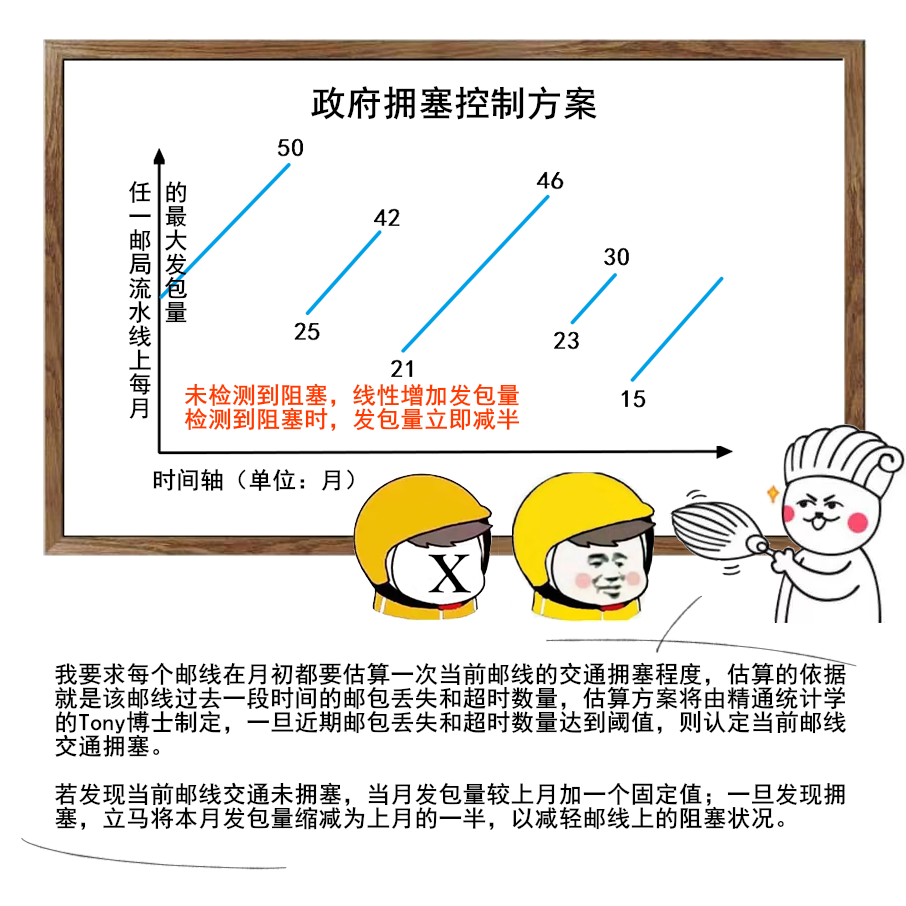
103 |
104 | 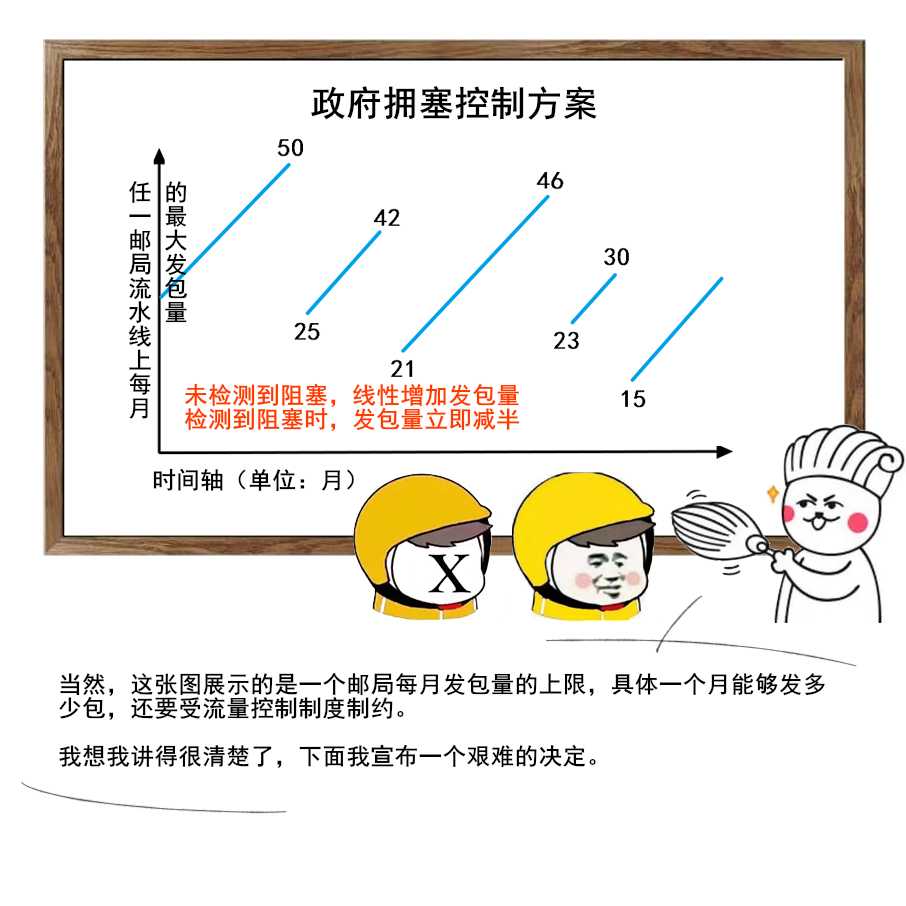
105 |
106 | 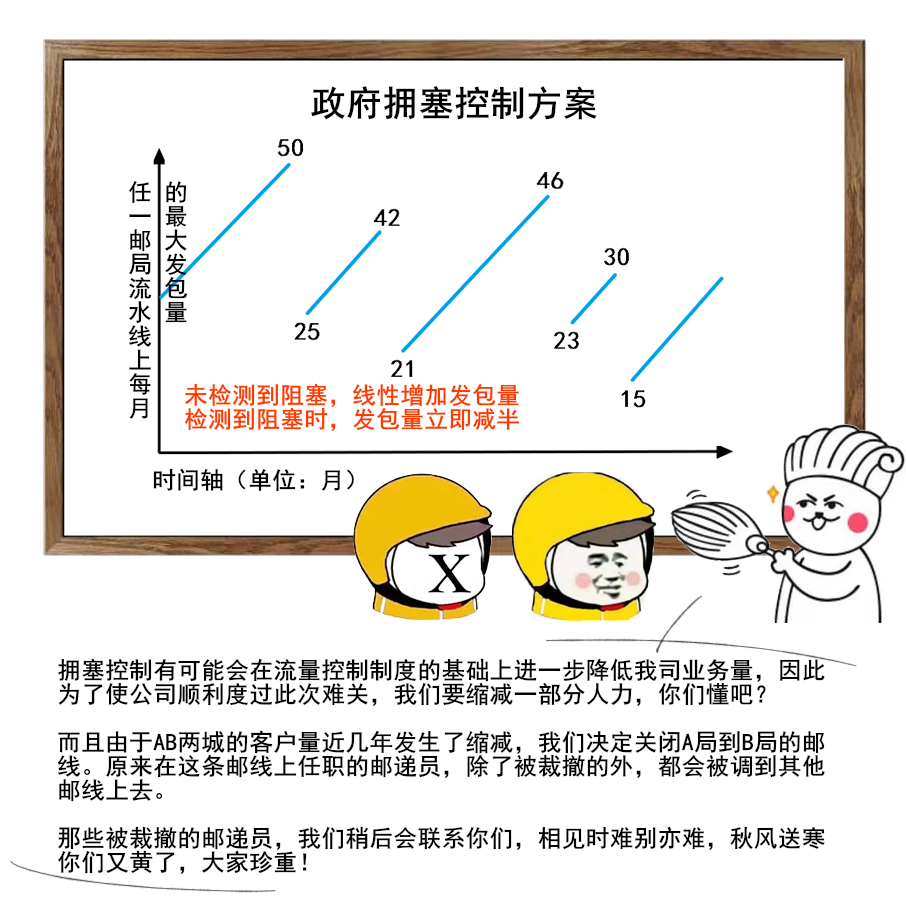
107 |
108 | 
109 |
110 | 
111 |
112 | 
113 |
114 | 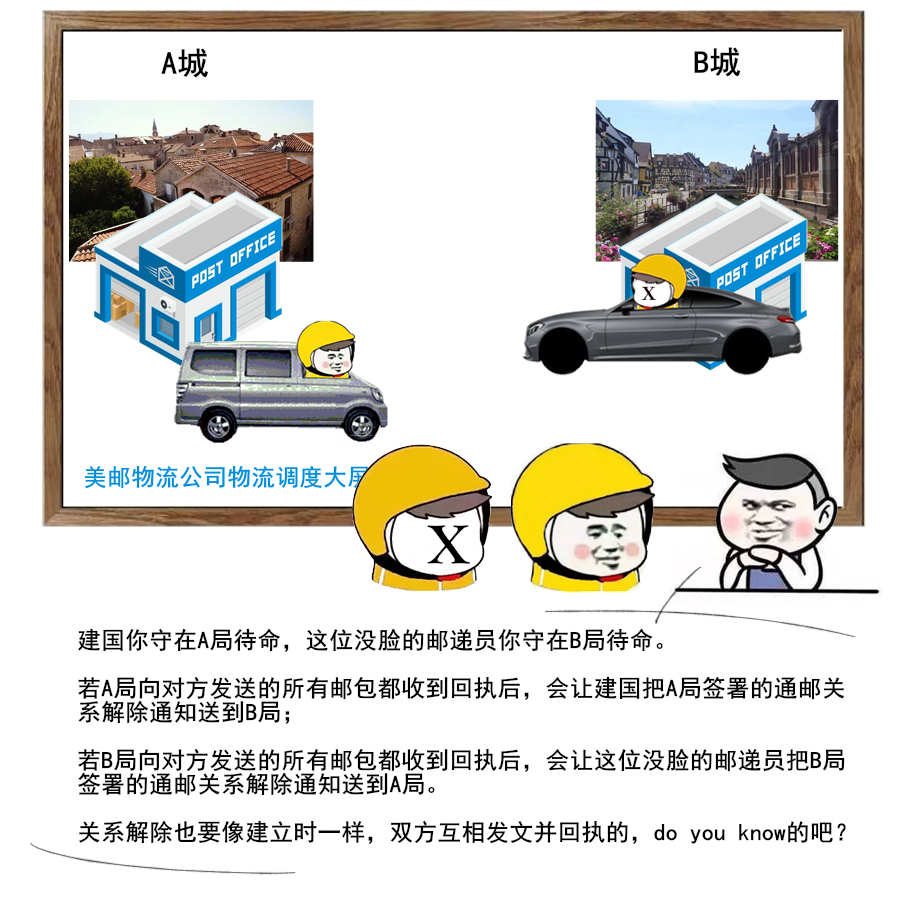
115 |
116 | 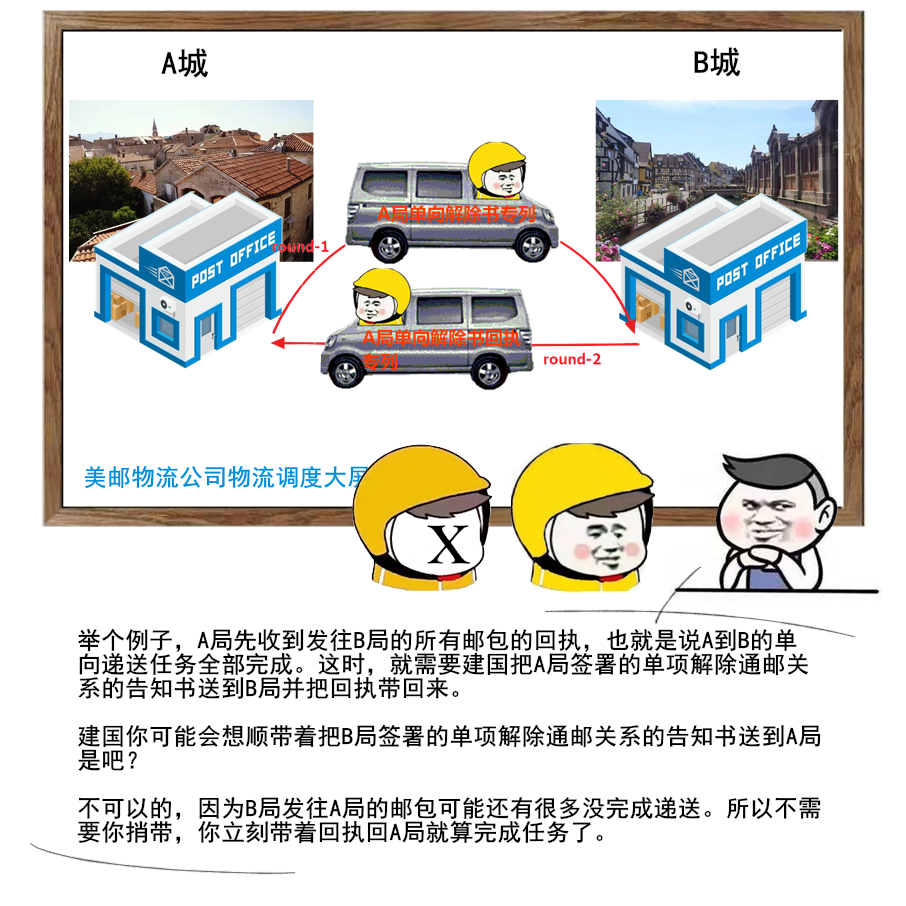
117 |
118 | 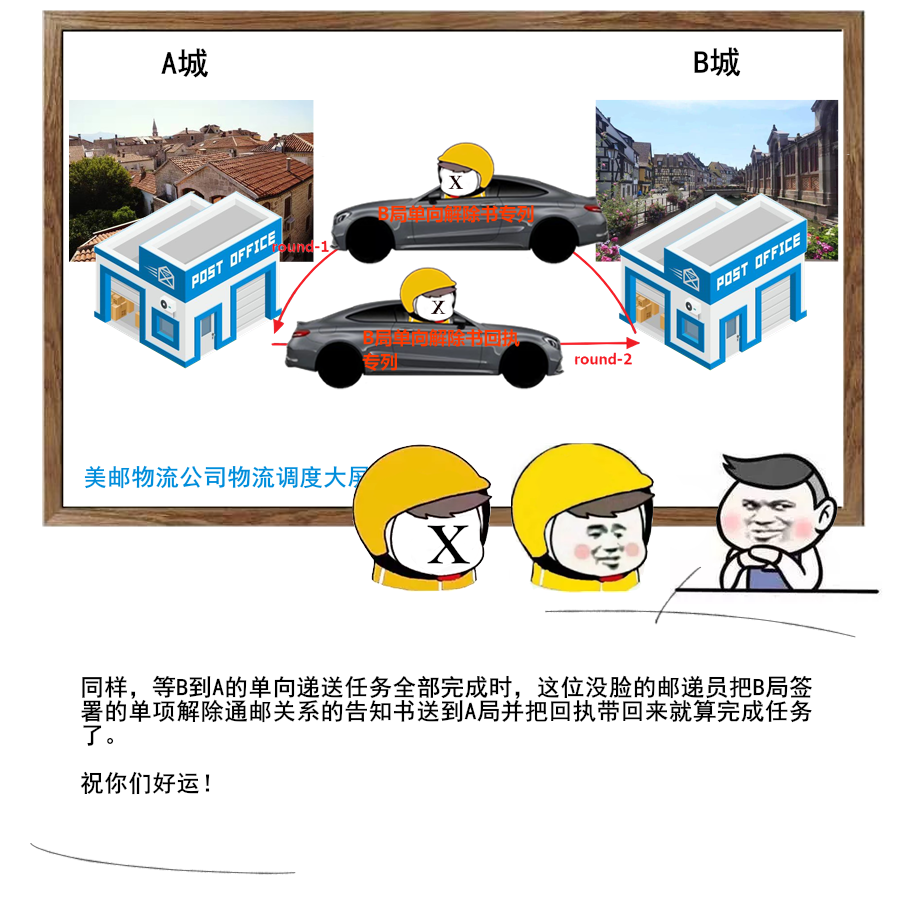
119 |
120 | 
121 |
122 | 
123 |
124 | 
125 |
126 | 欢迎大家大家关注「码海」,加我私人微信「geekoftaste」,拉你进技术交流群,群里有很多 BAT 的大咖,可以提问,互相交流,内推等,2020 的冬天有点冷,欢迎大家进群一起抱团取暖
127 |
128 | 
--------------------------------------------------------------------------------
/网络/20张图让你彻底弄懂HTTPS原理.md:
--------------------------------------------------------------------------------
1 | # 前言
2 | 近年来各大公司对信息安全传输越来越重视,也逐步把网站升级到 HTTPS 了,那么大家知道 HTTPS 的原理是怎样的吗,到底是它是如何确保信息安全传输的?网上挺多介绍 HTTPS,但我发现总是或多或少有些点有些遗漏,没有讲全,今天试图由浅入深地把 HTTPS 讲明白,相信大家看完一定能掌握 HTTPS 的原理,本文大纲如下:
3 |
4 | 1. HTTP 为什么不安全
5 | 2. 安全通信的四大原则
6 | 3. HTTPS 通信原理简述
7 | * 对称加密
8 | * 数字证书
9 | * 非对称加密
10 | * 数字签名
11 | 4. 其它 HTTPS 相关问题
12 |
13 | ## HTTP 为什么不安全
14 |
15 | HTTP 由于是明文传输,主要存在三大风险
16 |
17 | 1、 窃听风险
18 |
19 | 中间人可以获取到通信内容,由于内容是明文,所以获取明文后有安全风险
20 |
21 | 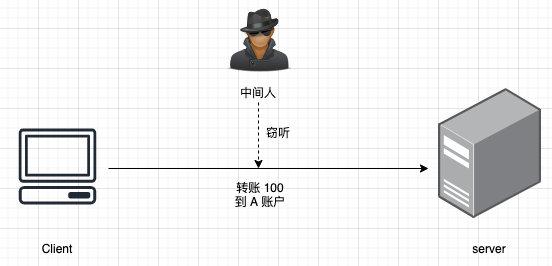
22 |
23 |
24 | 2、 篡改风险
25 |
26 | 中间人可以篡改报文内容后再发送给对方,风险极大
27 |
28 | 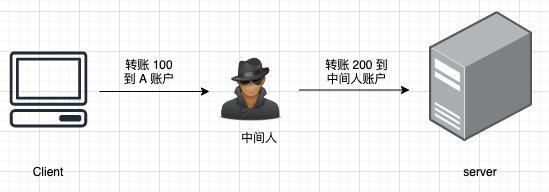
29 |
30 | 3、 冒充风险
31 |
32 | 比如你以为是在和某宝通信,但实际上是在和一个钓鱼网站通信。
33 |
34 | 
35 |
36 | HTTPS 显然是为了解决这三大风险而存在的,接下来我们看看 HTTPS 到底解决了什么问题。
37 |
38 | ## 安全通信的四大原则
39 |
40 | 看了上一节,不难猜到 HTTPS 就是为了解决上述三个风险而生的,一般我们认为安全的通信需要包括以下四个原则: **机密性**、**完整性**,**身份认证**和**不可否认**
41 |
42 | 1. **机密性**:即对数据加密,解决了窃听风险,因为即使被中间人窃听,由于数据是加密的,他也拿不到明文
43 | 2. **完整性**:指数据在传输过程中没有被篡改,不多不少,保持原样,中途如果哪怕改了一个标点符号,接收方也能识别出来,从来判定接收报文不合法
44 | 3. **身份认证**:确认对方的真实身份,即证明「你妈是你妈」的问题,这样就解决了冒充风险,用户不用担心访问的是某宝结果却在和钓鱼网站通信的问题
45 | 4. **不可否认**: 即不可否认已发生的行为,比如小明向小红借了 1000 元,但没打借条,或者打了借条但没有**签名**,就会造成小红的资金损失
46 |
47 | 接下来我们一步步来看看 HTTPS 是如何实现以满足以上四大安全通信原则的。
48 |
49 | ## HTTPS 通信原理简述
50 |
51 |
52 | ### 对称加密: HTTPS 的最终加密形式
53 | 既然 HTTP 是明文传输的,那我们给报文加密不就行了,既然要加密,我们肯定需要通信双方协商好密钥吧,一种是通信双方使用**同一把密钥**,即**对称加密**的方式来给报文进行加解密。
54 |
55 | 
56 |
57 | 如图示:使用对称加密的通信双方使用**同一把**密钥进行加解密。
58 |
59 | 对称加密具有加解密速度快,性能高的特点,也是 HTTPS 最终采用的加密形式,但是这里有一个关键问题,对称加密的通信双方要使用同一把密钥,这个密钥是如何协商出来的?如果通过报文的方式直接传输密钥,之后的通信其实还是在裸奔,因为这个密钥会被中间人截获甚至替换掉,这样中间人就可以用截获的密钥解密报文,甚至替换掉密钥以达到篡改报文的目的。
60 |
61 | 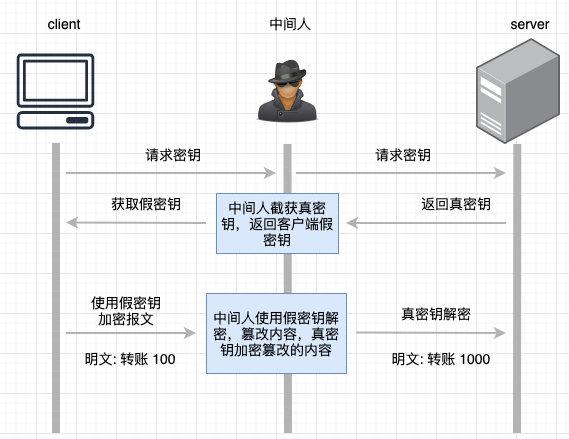
62 |
63 |
64 | 有人说对这个密钥加密不就完了,但对方如果要解密这个密钥还是要传加密密钥给对方,依然还是会被中间人截获的,这么看来直接传输密钥无论怎样都无法摆脱俄罗斯套娃的难题,是不可行的。
65 |
66 | ### 非对称加密:解决单向对称密钥的传输问题
67 |
68 | 直接传输密钥无论从哪一端传从上节分析来看是不行了,这里我们再看另一种加密方式:**非对称加密**。
69 |
70 | 非对称加密即加解密双方使用不同的密钥,一把作为公钥,可以公开的,一把作为私钥,不能公开,公钥加密的密文只有私钥可以解密,私钥加密的内容,也只有公钥可以解密。
71 |
72 | **注:私钥加密其实这个说法其实并不严谨,准确的说私钥加密应该叫私钥签名,因为私密加密的信息公钥是可以解密的,而公钥是公开的,任何人都可以拿到,用公钥解密叫做验签**
73 |
74 | 这样的话对于 server 来说,保管好私钥,发布公钥给其他 client, 其他 client 只要把对称加密的密钥加密传给 server 即可,如此一来由于公钥加密只有私钥能解密,而私钥只有 server 有,所以能保证 client 向 server 传输是安全的,server 解密后即可拿到对称加密密钥,这样交换了密钥之后就可以用对称加密密钥通信了。
75 |
76 | 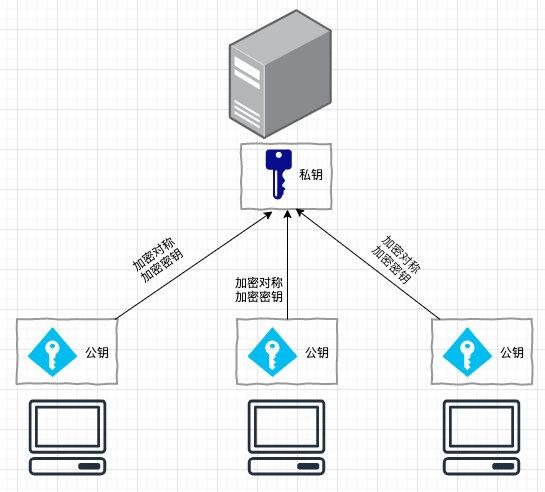
77 |
78 | 但是问题又来了, server 怎么把公钥**安全地**传输给 client 呢。如果直接传公钥,也会存在被中间人调包的风险。
79 |
80 | 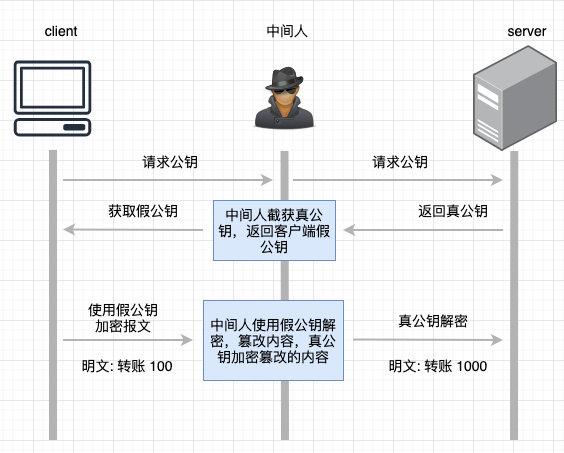
81 |
82 | ### 数字证书,解决公钥传输信任问题
83 |
84 | 如何解决公钥传输问题呢,从现实生活中的场景找答案,员工入职时,企业一般会要求提供学历证明,显然不是什么阿猫阿狗的本本都可称为学历,这个学历必须由**第三方权威机构(Certificate Authority,简称 CA)**即教育部颁发,同理,server 也可以向 CA 申请证书,**在证书中附上公钥**,然后将证书传给 client,证书由站点管理者向 CA 申请,申请的时候会提交 DNS 主机名等信息,CA 会根据这些信息生成证书
85 |
86 | 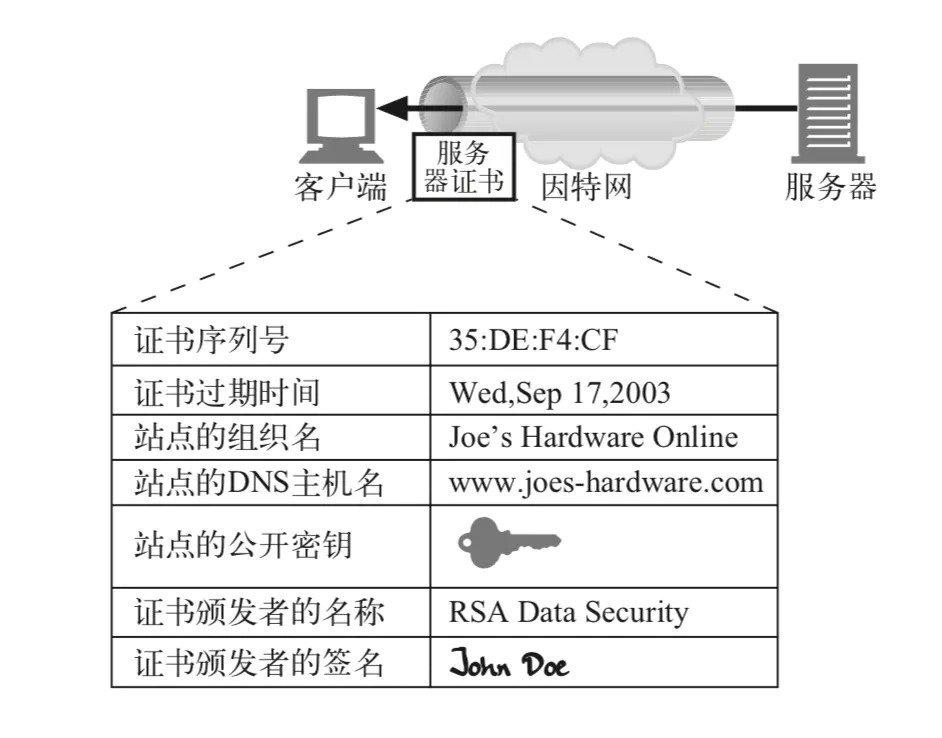
87 |
88 | 这样当 client 拿到证书后,就可以获得证书上的公钥,再用此公钥加密**对称加密密钥**传给 server 即可,看起来确实很完美,不过在这里大家要考虑两个问题
89 |
90 | **问题一、 如何验证证书的真实性,如何防止证书被篡改**
91 |
92 | 想象一下上文中我们提到的学历,企业如何认定你提供的学历证书是真是假呢,答案是用学历编号,企业拿到证书后用学历编号在学信网上一查就知道证书真伪了,学历编号其实就是我们常说的**数字签名**,可以防止证书造假。
93 |
94 | 回到 HTTPS 上,证书的数字签名该如何产生的呢,一图胜千言
95 |
96 | 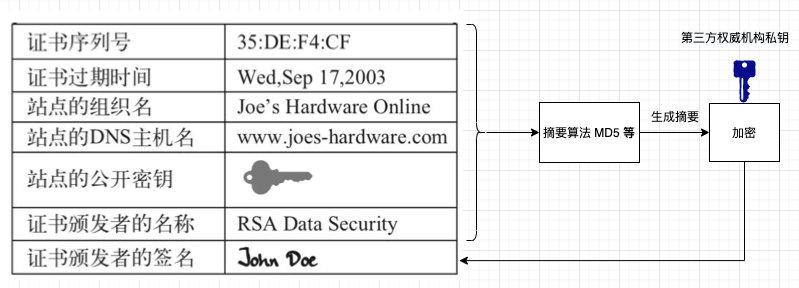
97 |
98 |
99 |
100 | 步骤如下
101 | 1、 首先使用一些摘要算法(如 MD5)将证书明文(如证书序列号,DNS主机名等)生成摘要,然后再用第三方权威机构的私钥对生成的摘要进行加密(签名)
102 |
103 | > 消息摘要是把任意长度的输入揉和而产生长度固定的伪随机输入的算法,无论输入的消息有多长,计算出来的消息摘要的长度总是固定的,一般来说,只要内容不同,产生的摘要必然不同(相同的概率可以认为接近于 0),所以可以验证内容是否被篡改了。
104 |
105 | 为啥要先生成摘要再加密呢,不能直接加密?
106 |
107 | 因为使用非对称加密是非常耗时的,如果把整个证书内容都加密生成签名的话,客户端验验签也需要把签名解密,证书明文较长,客户端验签就需要很长的时间,而用摘要的话,会把内容很长的明文压缩成小得多的定长字符串,客户端验签的话就会快得多。
108 |
109 |
110 | 2、客户端拿到证书后也用同样的摘要算法对证书明文计算摘要,两者一笔对就可以发现报文是否被篡改了,那为啥要用第三方权威机构(Certificate Authority,简称 CA)私钥对摘要加密呢,因为摘要算法是公开的,中间人可以替换掉证书明文,再根据证书上的摘要算法计算出摘要后把证书上的摘要也给替换掉!这样 client 拿到证书后计算摘要发现一样,误以为此证书是合法就中招了。所以必须要用 CA 的私钥给摘要进行加密生成签名,这样的话 client 得用 CA 的公钥来给签名解密,拿到的才是未经篡改合法的摘要(私钥签名,公钥才能解密)
111 |
112 | server 将证书传给 client 后,client 的验签过程如下
113 |
114 | 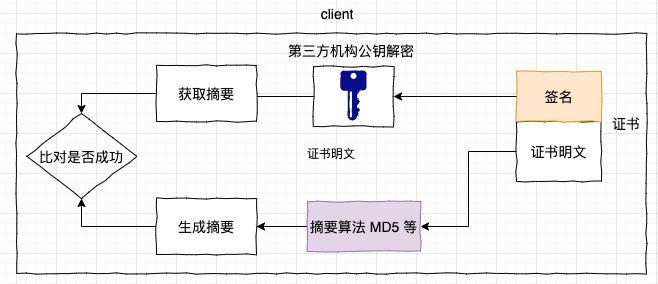
115 |
116 | 这样的话,由于只有 CA 的公钥才能解密签名,如果客户端收到一个假的证书,使用 CA 的公钥是无法解密的,如果客户端收到了真的证书,但证书上的内容被篡改了,摘要比对不成功的话,客户端也会认定此证书非法。
117 |
118 | 细心的你一定发现了问题,CA 公钥如何安全地传输到 client ?如果还是从 server 传输到 client,依然无法解决公钥被调包的风险,**实际上此公钥是存在于 CA 证书上,而此证书(也称 Root CA 证书)被操作系统信任,内置在操作系统上的,无需传输**,如果用的是 Mac 的同学,可以打开 keychain 查看一下,可以看到很多内置的被信任的证书。
119 |
120 | 
121 |
122 |
123 | server 传输 CA 颁发的证书,客户中收到证书后使用**内置 CA 证书中的公钥**来解密签名,验签即可,这样的话就解决了公钥传输过程中被调包的风险。
124 |
125 | **问题二、 如何防止证书被调包**
126 |
127 | 实际上任何站点都可以向第三方权威机构申请证书,中间人也不例外。
128 |
129 | 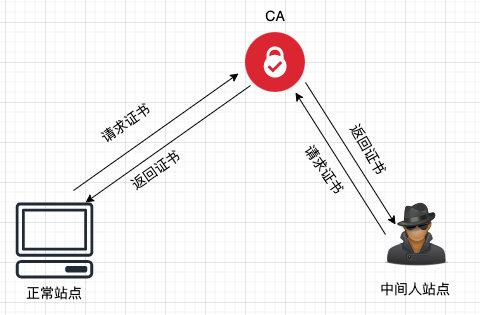
130 |
131 | 正常站点和中间人都可以向 CA 申请证书,获得认证的证书由于都是 CA 颁发的,所以都是合法的,那么此时中间人是否可以在传输过程中将正常站点发给 client 的证书替换成自己的证书呢,如下所示
132 |
133 | 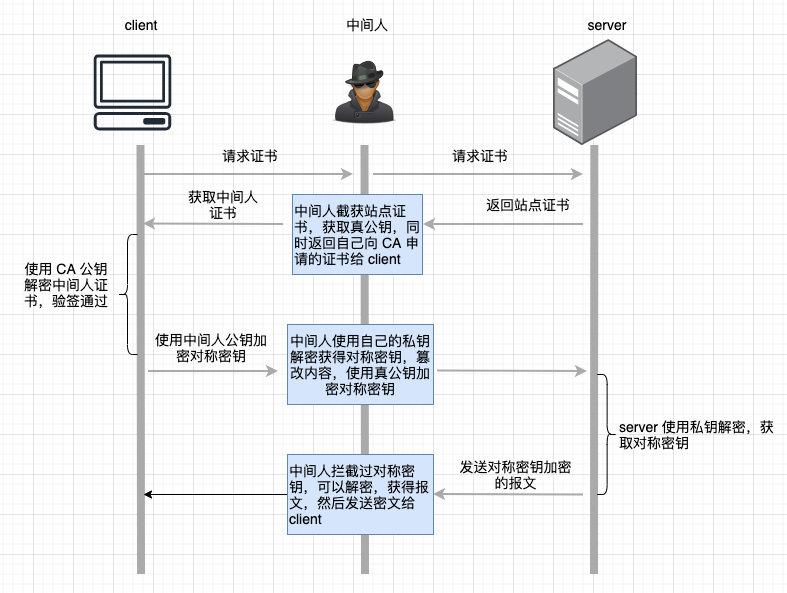
134 |
135 |
136 | 答案是不行,因为客户端除了通过验签的方式验证证书是否合法之外,**还需要验证证书上的域名与自己的请求域名是否一致**,中间人中途虽然可以替换自己向 CA 申请的合法证书,但此证书中的域名与 client 请求的域名不一致,client 会认定为不通过!
137 |
138 |
139 | 但是上面的证书调包给了我们一种思路,什么思路?大家想想, HTTPS 既然是加密的, charles 这些「中间人」为啥能抓到明文的包呢,其实就是用了证书调包这一手法,想想看,在用 charles 抓 HTTPS 的包之前我们先要做什么,当然是安装 charles 的证书
140 |
141 | 
142 |
143 |
144 | 这个证书里有 charles 的公钥,这样的话 charles 就可以将 server 传给 client 的证书调包成自己的证书,client 拿到后就可以用你安装的 charles 证书来验签等,验证通过之后就会用 charles 证书中的公钥来加密对称密钥了,整个流程如下
145 |
146 | 
147 |
148 | 由此可知,charles 这些中间人能抓取 HTTPS 包的前提是信任它们的 CA 证书,然后就可以通过替换证书的方式进行瞒天过海,所以我们千万不要随便信任第三方的证书,避免安全风险。
149 |
150 | ## 其它 HTTPS 相关问题
151 |
152 | > 什么是双向认证
153 | 以上的讲述过程中,我们只是在 client 端验证了 server 传输证书的合法性,但 server 如何验证 client 的合法性,还是用证书,我们在网上进行转账等操作时,想想看是不是要先将银行发给我们的 U 盾插到电脑上?其实也是因为 U 盾内置了证书,通信时将证书发给 server,server 验证通过之后即可开始通信。
154 | **画外音:身份认证只是 U 盾功能的一种,还有其他功能,比如加解密都是在 U 盾中执行,保证了密钥不会出现在内存中**
155 |
156 | > 什么是证书信任链
157 |
158 | 前文说了,我们可以向 CA 申请证书,但全世界的顶级 CA(Root CA) 就那么几个,每天都有很多人要向它申请证书,它也忙不过来啊,怎么办呢,想想看在一个公司里如果大家都找 CEO 办事,他是不是要疯了,那他能怎么办?授权,他会把权力交给 CTO,CFO 等,这样你们只要把 CTO 之类的就行了,CTO 如果也忙不过来呢,继续往下授权啊。
159 |
160 | 
161 |
162 | 同样的,既然顶级 CA 忙不过来,那它就向下一级,下下级 CA 授权即可,这样我们就只要找一级/二级/三级 CA 申请证书即可。怎么证明这些证书被 Root CA 授权过了呢,小一点的 CA 可以让大一点的 CA 来签名认证,比如一级 CA 让 Root CA 来签名认证,二级 CA 让一级 CA 来签名认证,Root CA 没有人给他签名认证,只能自己证明自己了,这个证书就叫「自签名证书」或者「根证书」,我们必须信任它,不然证书信任链是走不下去的(这个根证书前文我们提过,其实是是内置在操作系统中的)
163 |
164 | 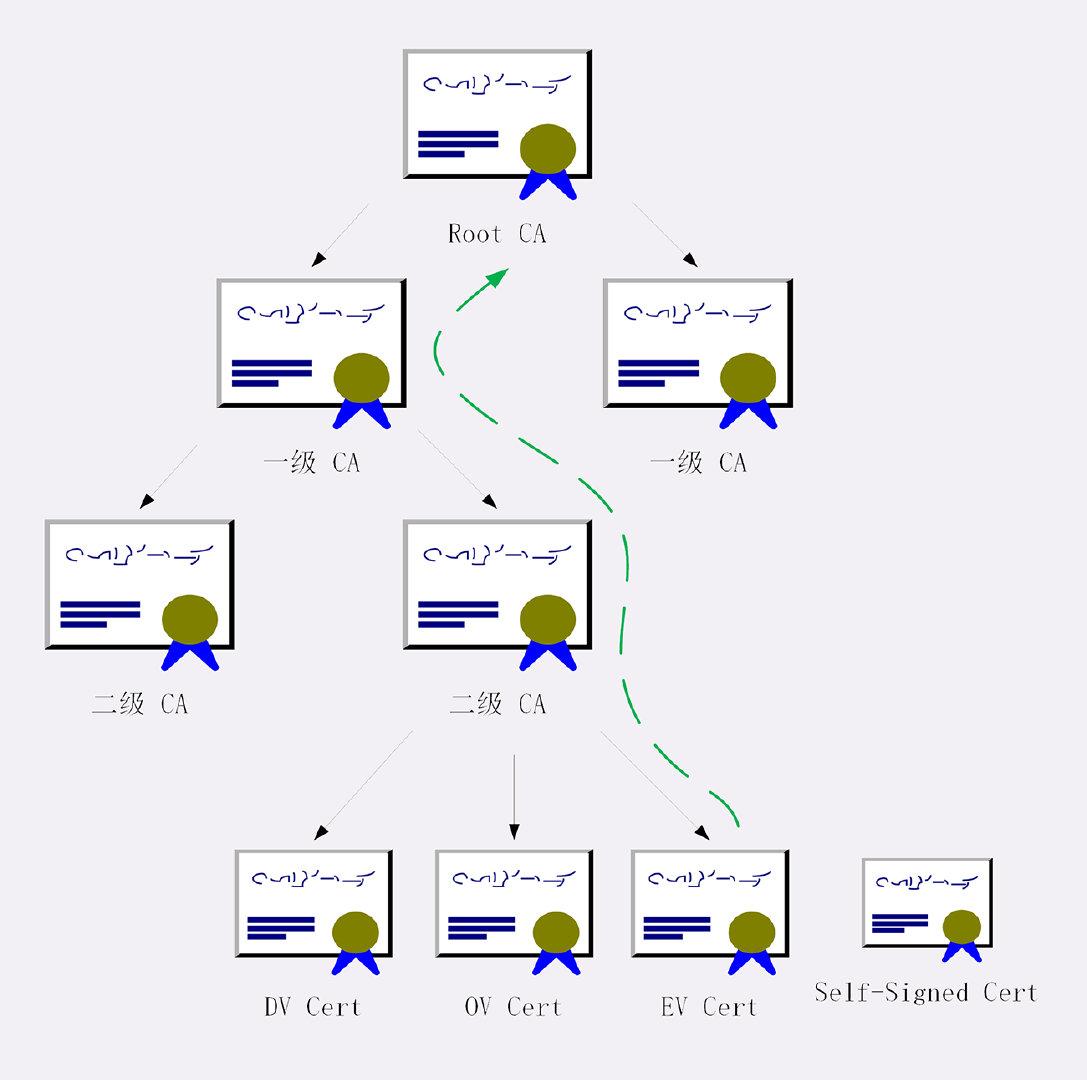
165 |
166 | 现在我们看看如果站点申请的是 二级 CA 颁发的证书,client 收到之后会如何验证这个证书呢,实际上 service 传了传给二级 CA 的证书外,**还会把证书信任链也一起传给客户端**,这样客户端会按如下步骤进行验证:
167 | 1. 浏览器就使用信任的根证书(根公钥)解析证书链的根证书得到一级证书的公钥+摘要验签
168 | 2. 拿一级证书的公钥解密一级证书,拿到二级证书的公钥和摘要验签
169 | 3. 再然后拿二级证书的公钥解密 server 传过来的二级证书,得到服务器的公钥和摘要验签,验证过程就结束了
170 |
171 |
172 | ## 总结
173 | 相信大家看完本文应该对 HTTPS 的原理有了很清楚的认识了, HTTPS 无非就是 HTTP + SSL/TLS
174 |
175 | 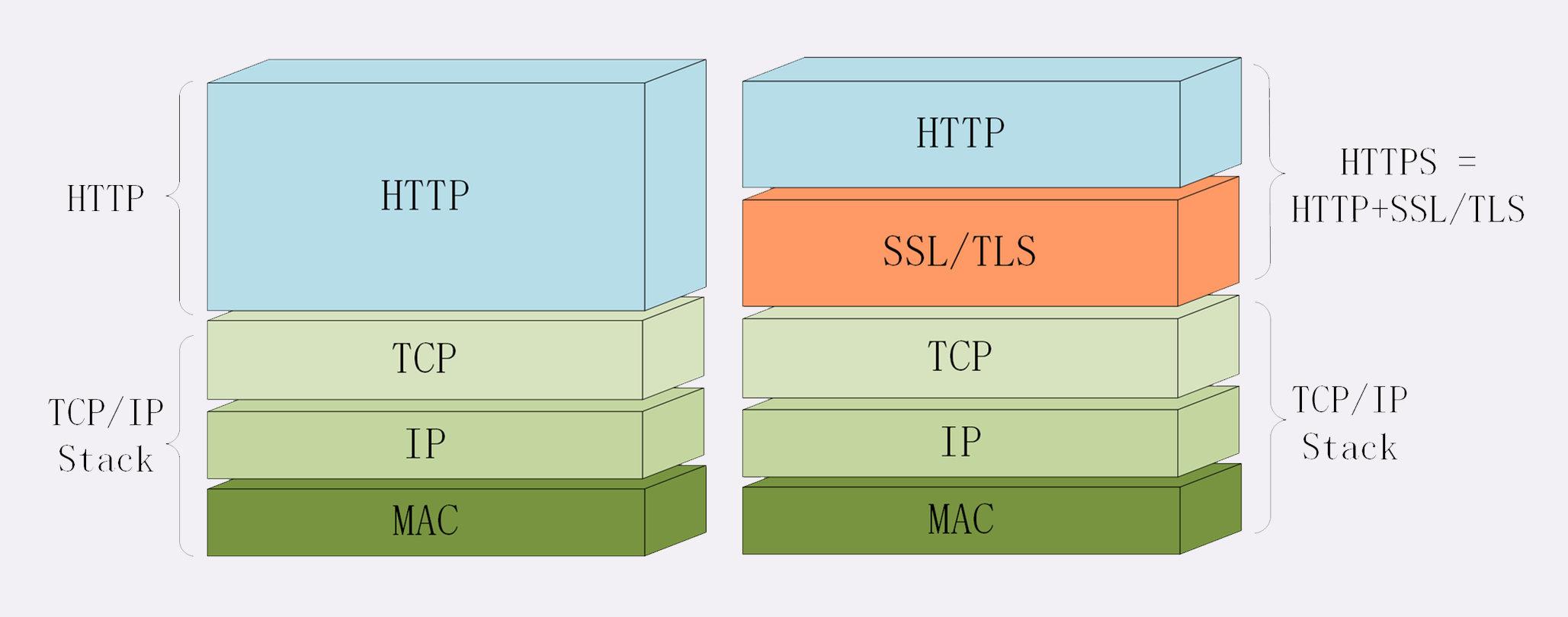
176 |
177 | 而 SSL/TLS 的功能其实本质上是**如何协商出安全的对称加密密钥以利用此密钥进行后续通讯的过程**,带着这个疑问相信你不难理解数字证书和数字签名这两个让人费解的含义,搞懂了这些也就明白了为啥 HTTPS 是加密的,charles 这些工具却能抓包出明文来。
178 |
179 | �巨人的肩膀
180 | * https://juejin.cn/post/6844903958863937550
181 | * https://showme.codes/2017-02-20/understand-https/
182 | * 极客时间,透视 HTTP 协议
183 | * https://zhuanlan.zhihu.com/p/67199487
184 |
185 | 欢迎关注公众号交流哦
186 |
187 | 
--------------------------------------------------------------------------------
/系统设计/高性能短链设计.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 今天,我们来谈谈如何设计一个高性能短链系统,短链系统设计看起来很简单,但每个点都能展开很多知识点,也是在面试中非常适合考察侯选人的一道设计题,本文将会结合我们生产上稳定运行两年之久的高性能短链系统给大家简单做下设计这套系统所涉及的一些思路,希望对大家能有一些帮助。
3 |
4 | 本文将会从以下几个方面来讲解,每个点包含的信息量都不少,相信大家看完肯定有收获
5 |
6 | * 短链有啥好处,为啥要设计它,用长链不香吗
7 | * 短链跳转的基本原理
8 | * 短链生成的几种方法
9 | * 短链的架构支撑
10 |
11 | **注:里面涉及到不少布隆过滤器,snowflake 等技术,由于不是本文重点,所以建议大家看完后再自己去深入了解,不然展开讲篇幅会很长**
12 |
13 | ## 短链有啥好处,用长链不香吗
14 |
15 | 来看下以下极客时间发我的营销短信,点击下方蓝色的链接(短链)
16 |
17 | 
18 |
19 | 浏览器的地址栏上最终会显示一条如下的长链。
20 |
21 | 
22 |
23 |
24 |
25 | 那么为啥要用短链表示,直接用长链不行吗,用短链的话有如下好外
26 |
27 | 1、链接变短,在对内容长度有限制的平台发文,可编辑的文字就变多了
28 |
29 | 最典型的就是微博,限定了只能发 140 个字,如果一串长链直接怼上去,其他可编辑的内容就所剩无几了,用短链的话,链接长度大大减少,自然可编辑的文字多了不少。
30 |
31 | 再比如一般短信发文有长度限度,如果用长链,一条短信很可能要拆分成两三条发,本来一条一毛的短信费变成了两三毛,何苦呢。另外用短链在内容排版上也更美观。
32 |
33 | 2、我们经常需要将链接转成二维码的形式分享给他人,如果是长链的话二维码密集难识别,短链就不存在这个问题了,如图示
34 |
35 | 
36 |
37 |
38 | 3、链接太长在有些平台上无法自动识别为超链接
39 |
40 | 如图示,在钉钉上,就无法识别如下长链接,只能识别部分,用短地址无此问题
41 |
42 | 
43 |
44 |
45 | ## 短链跳转的基本原理
46 |
47 | 从上文可知,短链好处多多,那么它是如何工作的呢。我们在浏览器抓下包看看
48 |
49 | 
50 |
51 | 可以看到请求后,返回了状态码 302(重定向)与 location 值为长链的响应,然后浏览器会再请求这个长链以得到最终的响应,整个交互流程图如下
52 |
53 | 
54 |
55 |
56 | 主要步骤就是访问短网址后重定向访问 B,那么问题来了,301 和 302 都是重定向,到底该用哪个,这里需要注意一下 301 和 302 的区别
57 |
58 | * 301,代表 **永久重定向**,也就是说第一次请求拿到长链接后,下次浏览器再去请求短链的话,不会向短网址服务器请求了,而是直接从浏览器的缓存里拿,这样在 server 层面就无法获取到短网址的点击数了,如果这个链接刚好是某个活动的链接,也就无法分析此活动的效果。所以我们一般不采用 301。
59 | * **302**,代表 **临时重定向**,也就是说每次去请求短链都会去请求短网址服务器(除非响应中用 Cache-Control 或 Expired 暗示浏览器缓存),这样就便于 server 统计点击数,所以虽然用 302 会给 server 增加一点压力,但在数据异常重要的今天,这点代码是值得的,所以推荐使用 302!
60 |
61 | ## 短链生成的几种方法
62 |
63 | ### 1、哈希算法
64 |
65 | 怎样才能生成短链,仔细观察上例中的短链,显然它是由固定短链域名 + 长链映射成的一串字母组成,那么长链怎么才能映射成一串字母呢,哈希函数不就用来干这事的吗,于是我们有了以下设计思路
66 |
67 | 
68 |
69 |
70 | 那么这个哈希函数该怎么取呢,相信肯定有很多人说用 MD5,SHA 等算法,其实这样做有点杀鸡用牛刀了,而且既然是加密就意味着性能上会有损失,我们其实不关心反向解密的难度,反而更关心的是哈希的运算速度和冲突概率。
71 |
72 | 能够满足这样的哈希算法有很多,这里推荐 Google 出品的 MurmurHash 算法,MurmurHash 是一种**非加密型**哈希函数,适用于一般的哈希检索操作。与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash 的随机分布特征表现更良好。非加密意味着着相比 MD5,SHA 这些函数它的性能肯定更高(实际上性能是 MD5 等加密算法的十倍以上),也正是由于它的这些优点,所以虽然它出现于 2008,但目前已经广泛应用到 Redis、MemCache、Cassandra、HBase、Lucene 等众多著名的软件中。
73 |
74 | **画外音:这里有个小插曲,MurmurHash 成名后,作者拿到了 Google 的 offer,所以多做些开源的项目,说不定成名后你也能不经意间收到 Google 的 offer ^_^。**
75 |
76 | MurmurHash 提供了两种长度的哈希值,32 bit,128 bit,为了让网址尽可通地短,我们选择 32 bit 的哈希值,32 bit 能表示的最大值近 43 亿,对于中小型公司的业务而言绰绰有余。对上文提到的极客长链做 MurmurHash 计算,得到的哈希值为 3002604296,于是我们现在得到的短链为 固定短链域名+哈希值 = http://gk.link/a/3002604296
77 |
78 | **如何缩短域名?**
79 |
80 | 有人说人这个域名还是有点长,还有一招,3002604296 得到的这个哈希值是十进制的,那我们把它转为 62 进制可缩短它的长度,10 进制转 62 进制如下:
81 |
82 | 
83 |
84 | 于是我们有 (3002604296)10 = (3hcCxy)62,一下从 10 位缩短到了 6 位!于是现在得到了我们的短链为 http://gk.link/a/3hcCxy
85 |
86 | **画外音:6 位 62 进制数可表示 568 亿的数,应付长链转换绰绰有余**
87 |
88 |
89 | **如何解决哈希冲突的问题?**
90 |
91 | 既然是哈希函数,不可避免地会产生哈希冲突(尽管概率很低),该怎么解决呢。
92 |
93 | 我们知道既然访问访问短链能跳转到长链,那么两者之前这种映射关系一定是要保存起来的,可以用 Redis 或 Mysql 等,这里我们选择用 Mysql 来存储。表结构应该如下所示
94 |
95 | ```shell
96 | CREATE TABLE `short_url_map` (
97 | `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
98 | `lurl` varchar(160) DEFAULT NULL COMMENT '长地址',
99 | `surl` varchar(10) DEFAULT NULL COMMENT '短地址',
100 | `gmt_create` int(11) DEFAULT NULL COMMENT '创建时间',
101 | PRIMARY KEY (`id`)
102 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
103 | ```
104 |
105 | 于是我们有了以下设计思路。
106 |
107 | 1. 将长链(lurl)经过 MurmurHash 后得到短链。
108 | 2. 再根据短链去 short_url_map 表中查找看是否存在相关记录,如果不存在,将长链与短链对应关系插入数据库中,存储。
109 | 3. 如果存在,说明已经有相关记录了,此时在长串上拼接一个自定义好的字段,比如「DUPLICATE」,然后再对接接的字段串「lurl + DUPLICATE」做第一步操作,如果最后还是重复呢,再拼一个字段串啊,只要到时根据短链取出长链的时候把这些自定义好的字符串移除即是原来的长链。
110 |
111 | 以上步骤显然是要优化的,插入一条记录居然要经过两次 sql 查询(根据短链查记录,将长短链对应关系插入数据库中),如果在高并发下,显然会成为瓶颈。
112 |
113 | **画外音:一般数据库和应用服务(只做计算不做存储)会部署在两台不同的 server 上,执行两条 sql 就需要两次网络通信,这两次网络通信与两次 sql 执行是整个短链系统的性能瓶颈所在!**
114 |
115 | 所以该怎么优化呢
116 |
117 | 1. 首先我们需要给短链字段 surl 加上唯一索引
118 | 2. 当长链经过 MurmurHash 得到短链后,直接将长短链对应关系插入 db 中,如果 db 里不含有此短链的记录,则插入,如果包含了,说明违反了唯一性索引,此时只要给长链再加上我们上文说的自定义字段「DUPLICATE」,重新 hash 再插入即可,看起来在违反唯一性索引的情况下是多执行了步骤,但我们要知道 MurmurHash 发生冲突的概率是非常低的,基本上不太可能发生,所以这种方案是可以接受的。
119 |
120 | 当然如果在数据量很大的情况下,冲突的概率会增大,此时我们可以加布隆过滤器来进行优化。
121 |
122 | 用所有生成的短网址构建布隆过滤器,当一个新的长链生成短链后,先将此短链在布隆过滤器中进行查找,如果不存在,说明 db 里不存在此短网址,可以插入!
123 |
124 | **画外音:布隆过滤器是一种非常省内存的数据结构,长度为 10 亿的布隆过滤器,只需要 125 M 的内存空间。**
125 |
126 | 综上,如果用哈希函数来设计,总体的设计思路如下
127 |
128 | 
129 |
130 |
131 | 用哈希算法生成的短链其实已经能满足我们的业务需求,接下来我们再来看看如何用自增序列的方式来生成短链
132 |
133 | ### 2、自增序列算法
134 |
135 | 我们可以维护一个 ID 自增生成器,比如 1,2,3 这样的整数递增 ID,当收到一个长链转短链的请求时,ID 生成器为其分配一个 ID,再将其转化为 62 进制,拼接到短链域名后面就得到了最终的短网址,那么这样的 ID 自增生成器该如何设计呢。如果在低峰期发号还好,高并发下,ID 自增生成器的的 ID 生成可能会系统瓶颈,所以它的设计就显得尤为重要。
136 |
137 | 主要有以下四种获取 id 的方法
138 |
139 | 1、类 uuid
140 |
141 | 简单地说就是用 **UUID uuid = UUID.randomUUID();** 这种方式生成的 UUID,UUID(Universally Unique Identifier)全局唯一标识符,是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的,但这种方式生成的 id 比较长,且无序,在插入 db 时可能会频繁导致**页分裂**,影响插入性能。
142 |
143 | 2、Redis
144 |
145 | 用 Redis 是个不错的选择,性能好,单机可支撑 10 w+ 请求,足以应付大部分的业务场景,但有人说如果一台机器扛不住呢,可以设置多台嘛,比如我布置 10 台机器,每台机器分别只生成尾号0,1,2,... 9 的 ID, 每次加 10即可,只要设置一个 ID 生成器代理随机分配给发号器生成 ID 就行了。
146 |
147 | 
148 |
149 |
150 |
151 | 不过用 Redis 这种方案,需要考虑持久化(短链 ID 总不能一样吧),灾备,成本有点高。
152 |
153 | 3、Snowflake
154 |
155 | 用 Snowflake 也是个不错的选择,不过 Snowflake 依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成 ID 冲突,或者 ID 乱序。
156 |
157 | 4、Mysql 自增主键
158 |
159 | 这种方式使用简单,扩展方便,所以我们使用 Mysql 的自增主键来作为短链的 id。简单总结如下:
160 |
161 |
162 | 
163 |
164 |
165 | 那么问题来了,如果用 Mysql 自增 id 作为短链 ID,在高并发下,db 的写压力会很大,这种情况该怎么办呢。
166 |
167 | 考虑一下,一定要在用到的时候去生成 id 吗,是否可以提前生成这些自增 id ?
168 |
169 | 方案如下:
170 |
171 | 设计一个专门的发号表,每插入一条记录,为短链 id 预留 (主键 id * 1000 - 999) 到 (主键 id * 1000) 的号段,如下
172 |
173 | 发号表:url_sender_num
174 |
175 | 
176 |
177 | **如图示:tmp_start_num 代表短链的起始 id,tmp_end_num 代表短链的终止 id。**
178 |
179 | 当长链转短链的请求打到某台机器时,先看这台机器是否分配了短链号段,未分配就往发号表插入一条记录,则这台机器将为短链分配范围在 tmp_start_num 到 tmp_end_num 之间的 id。从 tmp_start_num 开始分配,一直分配到 tmp_end_num,如果发号 id 达到了 tmp_end_num,说明这个区间段的 id 已经分配完了,则再往发号表插入一条记录就又获取了一个发号 id 区间。
180 |
181 | **画外音:思考一下这个自增短链 id 在机器上该怎么实现呢, 可以用 redis, 不过更简单的方案是用 AtomicLong,单机上性能不错,也保证了并发的安全性。**
182 |
183 | 整体设计图如下
184 |
185 | 
186 |
187 |
188 |
189 | 解决了发号器问题,接下来就简单了,从发号器拿过来的 id ,即为短链 id,接下来我们再创建一个长短链的映射表即可, 短链 id 即为主键,不过这里有个需要注意的地方,我们可能需要防止多次相同的长链生成不同的短链 id 这种情况,这就需要每次先根据长链来查找 db 看是否存在相关记录,一般的做法是根据长链做索引,但这样的话索引的空间会很大,所以我们可以对长链适当的压缩,比如 MD5,再对长链的 MD5 字段做索引,这样索引就会小很多。这样只要根据长链的 md5 去表里查是否存在相同的记录即可。所以我们设计的表如下
190 |
191 |
192 | ```sql
193 | CREATE TABLE `short_url_map` (
194 | `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '短链 id',
195 | `lurl` varchar(10) DEFAULT NULL COMMENT '长链',
196 | `md5` char(32) DEFAULT NULL COMMENT '长链md5',
197 | `gmt_create` int(11) DEFAULT NULL COMMENT '创建时间',
198 | PRIMARY KEY (`id`)
199 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
200 | ```
201 |
202 | 当然了,数据量如果很大的话,后期就需要分区或分库分表了。
203 |
204 | ## 请求短链的高并发架构设计
205 | 在电商公司,经常有很多活动,秒杀,抢红包等等,在某个时间点的 QPS 会很高,考虑到这种情况,我们引入了 openResty,它是一个基于 Nginx 与 Lua 的高性能 Web 平台,由于 Nginx 的非阻塞IO模型,使用 openResty 可以轻松支持 100 w + 的并发数,一般情况下你只要部署一台即可,同时 openResty 也自带了缓存机制,集成了 redis 这些缓存模块,也可以直接连 mysql。不需要再通过业务层连这些中间件,性能自然会高不少
206 |
207 | 
208 |
209 | 如图示,使用 openResty 省去了业务层这一步,直达缓存层与数据库层,也提升了不少性能。
210 |
211 | ## 总结
212 |
213 | 本文对短链设计方案作了详细地剖析,旨在给大家提供几种不同的短链设计思路,文中涉及到挺多像布隆过滤器,openRestry 等技术,文中没有展开讲,建议大家回头可以去再详细了解一下。再比如文中提到的 Mysql 页分裂也需要对底层使用的 B+ tree 数据结构,操作系统按页获取等知识有比较详细地了解,相信大家各个知识点都吃透后会收获不小。
214 |
215 | 巨人的肩膀
216 |
217 | https://www.cnblogs.com/rjzheng/p/11827426.html
218 | https://time.geekbang.org/column/article/80850
219 |
220 |
221 | 欢迎大家扫码关注公众号,一起探讨
222 |
223 | 
--------------------------------------------------------------------------------
/网络/你管这破玩意儿叫token.md:
--------------------------------------------------------------------------------
1 | 上周我们在团队内部首次采用了 jwt(Json Web Token) token 这种 no-session 的方式来作用户的账号验证,发现网上的文章对 token 的介绍很多都不对,所以对 cookie,session, token(以下 token 皆指 jwt token) 作了一下对比,相信大家看完肯定有收获!
2 |
3 | ### Cookie
4 | 1991 年 HTTP 0.9 诞生了,当时只是为了满足大家浏览 web 文档的要求 ,所以只有 GET 请求,浏览完了就走了,两个连接之间是没有任何联系的,这也是 HTTP 为无状态的原因,因为它诞生之初就没有这个需求。
5 |
6 | 但随着交互式 Web 的兴起(所谓交互式就是你不光可以浏览,还可以登录,发评论,购物等用户操作的行为),单纯地浏览 web 已经无法满足人们的要求,比如随着网上购物的兴起,需要记录用户的购物车记录,就需要有一个机制记录每个连接的关系,这样我们就知道加入购物车的商品到底属于谁了,于是 Cookie 就诞生了。
7 |
8 | > Cookie,有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行 Session 跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息 。
9 |
10 | 工作机制如下
11 | 
12 |
13 | 以加入购物车为例,每次浏览器请求后 server 都会将本次商品 id 存储在 Cookie 中返回给客户端,客户端会将 Cookie 保存在本地,下一次再将上次保存在本地的 Cookie 传给 server 就行了,这样每个 Cookie 都保存着用户的商品 id,购买记录也就不会丢失了
14 |
15 | 
16 |
17 | 仔细观察上图相信你不难发现随着购物车内的商品越来越多,每次请求的 cookie 也越来越大,这对每个请求来说是一个很大的负担,我只是想将一个商品加入购买车,为何要将历史的商品记录也一起返回给 server ?购物车信息其实已经记录在 server 了,浏览器这样的操作岂不是多此一举?怎么改进呢
18 |
19 | ### Session
20 |
21 | 仔细考虑下,由于用户的购物车信息都会保存在 Server 中,所以在 Cookie 里只要保存能识别用户身份的信息,知道是谁发起了加入购物车操作即可,这样每次请求后只要在 Cookie 里带上用户的身份信息,请求体里也只要带上本次加入购物车的商品 id,大大减少了 cookie 的体积大小,我们把这种能识别哪个请求由哪个用户发起的机制称为 Session(会话机制),生成的能识别用户身份信息的字符串称为 sessionId,它的工作机制如下
22 |
23 | 
24 |
25 |
26 | 1. 首先用户登录,server 会为用户生成一个 session,为其分配唯一的 sessionId,这个 sessionId 是与某个用户绑定的,也就是说根据此 sessionid(假设为 abc) 可以查询到它到底是哪个用户,然后将此 sessionid 通过 cookie 传给浏览器
27 | 2. 之后浏览器的每次添加购物车请求中只要在 cookie 里带上 sessionId=abc 这一个键值对即可,server 根据 sessionId 找到它对应的用户后,把传过来的商品 id 保存到 server 中对应用户的购物车即可
28 |
29 | 可以看到通过这种方式再也不需要在 cookie 里传所有的购物车的商品 id 了,大大减轻了请求的负担!
30 |
31 | 另外通过上文不难观察出 **cookie 是存储在 client 的,而 session 保存在 server**,sessionId 需要借助 cookie 的传递才有意义。
32 |
33 | ### session 的痛点
34 |
35 | 看起来通过 cookie + session 的方式是解决了问题, 但是我们忽略了一个问题,上述情况能正常工作是因为我们假设 server 是单机工作的,但实际在生产上,为了保障高可用,一般服务器至少需要两台机器,通过负载均衡的方式来决定到底请求该打到哪台机器上。
36 |
37 | 
38 |
39 | **如图示:客户端请求后,由负载均衡器(如 Nginx)来决定到底打到哪台机器**
40 |
41 |
42 | 假设登录请求打到了 A 机器,A 机器生成了 session 并在 cookie 里添加 sessionId 返回给了浏览器,那么问题来了:下次添加购物车时如果请求打到了 B 或者 C,由于 session 是在 A 机器生成的,此时的 B,C 是找不到 session 的,那么就会发生无法添加购物车的错误,就得重新登录了,此时请问该怎么办。主要有以下三种解决方案
43 |
44 | > 1、session 复制
45 |
46 | A 生成 session 后复制到 B, C,这样每台机器都有一份 session,无论添加购物车的请求打到哪台机器,由于 session 都能找到,故不会有问题
47 |
48 | 
49 |
50 | 这种方式虽然可行,但缺点也很明显:
51 |
52 | 1. 同一样的一份 session 保存了多份,数据冗余
53 | 2. 如果节点少还好,但如果节点多的话,特别是像阿里,微信这种由于 DAU 上亿,可能需要部署成千上万台机器,这样节点增多复制造成的性能消耗也会很大。
54 |
55 | > 2、session 粘连
56 |
57 | 这种方式是让每个客户端请求只打到固定的一台机器上,比如浏览器登录请求打到 A 机器后,后续所有的添加购物车请求也都打到 A 机器上,Nginx 的 sticky 模块可以支持这种方式,支持按 ip 或 cookie 粘连等等,如按 ip 粘连方式如下
58 |
59 |
60 | ```shell
61 | upstream tomcats {
62 | ip_hash;
63 | server 10.1.1.107:88;
64 | server 10.1.1.132:80;
65 | }
66 | ```
67 |
68 | 
69 |
70 | 这样的话每个 client 请求到达 Nginx 后,只要它的 ip 不变,根据 ip hash 算出来的值会打到固定的机器上,也就不存在 session 找不到的问题了,当然不难看出这种方式缺点也是很明显,对应的机器挂了怎么办?
71 |
72 | > 3、session 共享
73 |
74 | 这种方式也是目前各大公司普遍采用的方案,将 session 保存在 redis,memcached 等中间件中,请求到来时,各个机器去这些中间件取一下 session 即可。
75 |
76 | 
77 |
78 | 缺点其实也不难发现,就是每个请求都要去 redis 取一下 session,多了一次内部连接,消耗了一点性能,另外为了保证 redis 的高可用,必须做集群,当然了对于大公司来说, redis 集群基本都会部署,所以这方案可以说是大公司的首选了。
79 |
80 | ### Token:no session!
81 |
82 | 通过上文分析我们知道通过在服务端共享 session 的方式可以完成用户的身份定位,但是不难发现也有一个小小的瑕疵:搞个校验机制我还得搭个 redis 集群?大厂确实 redis 用得比较普遍,但对于小厂来说可能它的业务量还未达到用 redis 的程度,所以有没有其他不用 server 存储 session 的用户身份校验机制呢,这就是我们今天要介绍的主角:token。
83 |
84 | 首先请求方输入自己的用户名,密码,然后 server 据此生成 token,客户端拿到 token 后会保存到本地,之后向 server 请求时在请求头带上此 token 即可。
85 |
86 | 
87 |
88 | 相信大家看了上图会发现存在两个问题
89 |
90 | 1、 token 只存储在浏览器中,服务端却没有存储,这样的话我随便搞个 token 传给 server 也行?
91 |
92 | `答:server 会有一套校验机制,校验这个 token 是否合法。`
93 |
94 | 2、怎么不像 session 那样根据 sessionId 找到 userid 呢,这样的话怎么知道是哪个用户?
95 |
96 | `答:token 本身可以带 uid 信息,解密后就可以获取`
97 |
98 |
99 | 第一个问题,如何校验 token 呢?我们可以借鉴 HTTPS 的签名机制来校验。先来看 jwt token 的组成部分
100 |
101 | 
102 |
103 |
104 | 可以看到 token 主要由三部分组成
105 | 1. header:指定了签名算法
106 | 2. payload:可以指定用户 id,过期时间等非敏感数据
107 | 3. Signature: 签名,server 根据 header 知道它该用哪种签名算法,再用密钥根据此签名算法对 head + payload 生成签名,这样一个 token 就生成了。
108 |
109 | 当 server 收到浏览器传过来的 token 时,它会首先取出 token 中的 header + payload,根据密钥生成签名,然后再与 token 中的签名比对,如果成功则说明签名是合法的,即 token 是合法的。而且你会发现 payload 中存有我们的 userId,所以拿到 token 后直接在 payload 中就可获取 userid,避免了像 session 那样要从 redis 去取的开销
110 |
111 | **画外音:header, payload 实际上是以 base64 的形式存在的,文中为了描述方便,省去了这一步。**
112 |
113 |
114 | 你会发现这种方式确实很妙,只要 server 保证密钥不泄露,那么生成的 token 就是安全的,因为如果伪造 token 的话在签名验证环节是无法通过的,就此即可判定 token 非法。
115 |
116 | 可以看到通过这种方式有效地避免了 token 必须保存在 server 的弊端,实现了分布式存储,不过需要注意的是,token 一旦由 server 生成,它就是有效的,直到过期,无法让 token 失效,除非在 server 为 token 设立一个黑名单,在校验 token 前先过一遍此黑名单,如果在黑名单里则此 token 失效,但一旦这样做的话,那就意味着黑名单就必须保存在 server,这又回到了 session 的模式,那直接用 session 不香吗。所以一般的做法是当客户端登出要让 token 失效时,直接在本地移除 token 即可,下次登录重新生成 token 就好。
117 |
118 | 另外需要注意的是 Token 一般是放在 header 的 Authorization 自定义头里,不是放在 Cookie 里的,这主要是为了解决跨域不能共享 Cookie 的问题 (下文详述)
119 |
120 | ### Cookie 与 Token 的简单总结
121 |
122 | > Cookie 有哪些局限性?
123 |
124 | 1、 Cookie 跨站是不能共享的,这样的话如果你要实现多应用(多系统)的单点登录(SSO),使用 Cookie 来做需要的话就很困难了(要用比较复杂的 trick 来实现,有兴趣的话可以看文末参考链接)
125 |
126 | **画外音: 所谓单点登录,是指在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。**
127 |
128 | 但如果用 token 来实现 SSO 会非常简单,如下
129 |
130 | 
131 |
132 | 只要在 header 中的 authorize 字段(或其他自定义)加上 token 即可完成所有跨域站点的认证。
133 |
134 | 2、 在移动端原生请求是没有 cookie 之说的,而 sessionid 依赖于 cookie,sessionid 就不能用 cookie 来传了,如果用 token 的话,由于它是随着 header 的 authoriize 传过来的,也就不存在此问题,换句话说** token 天生支持移动平台**,天生就就支持所有平台,可扩展性好
135 |
136 | 综上所述,token 具有存储实现简单,扩展性好这些特点。
137 |
138 | > token 有哪些缺点
139 |
140 | 那有人就问了,既然 token 这么好,那为什么各个大公司几乎都采用共享 session 的方式呢,可能很多少人是第一次听到 token,token 不香吗,因为 token 有以下两点劣势:
141 |
142 | `1、 token 太长了`
143 |
144 | token 是 header, payload 编码后的样式,所以一般要比 sessionId 长很多,很有可能超出 cookie 的大小限制(cookie 一般有大小限制的,如 4kb),如果你在 token 中存储的信息越长,那么 token 本身也会越长,这样的话由于你每次请求都会带上 token,对请求来是个不小的负担
145 |
146 | `2、 不太安全`
147 |
148 | 网上很多文章说 token 更安全,其实不然,细心的你可能发现了,我们说 token 是存在浏览器的,再细问,存在浏览器的哪里?既然它太长放在 cookie 里可能导致 cookie 超限,那就只好放在 local storage 里,这样会造成严重的安全问题,因为 local storage 这类的本地存储是可以被 JS 直接读取的,另外由上文也提到,token 一旦生成无法让其失效,必须等到其过期才行,这样的话如果服务端检测到了一个安全威胁,也无法使相关的 token 失效。
149 |
150 | **所以 token 更适合一次性的命令认证,设置一个比较短的有效期**
151 |
152 | ### 一些误解: Cookie 相比 token 更不安全,比如 CSRF 攻击
153 |
154 | 首先我们需要解释下 CSRF 攻击是怎么回事
155 |
156 | 攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过(cookie 里带来 sessionId 等身份认证的信息),所以被访问的网站会认为是真正的用户操作而去运行。
157 |
158 | 比如用户登录了某银行网站(假设为 **http://www.examplebank.com/**,并且转账地址为 **http://www.examplebank.com/withdraw?amount=1000&transferTo=PayeeName**),登录后 cookie 里会包含登录用户的 sessionid,攻击者可以在另一个网站上放置如下代码
159 |
160 | ```html
161 |  162 | ```
163 |
164 | 那么如果正常的用户误点了上面这张图片,由于相同域名的请求会自动带上 cookie,而 cookie 里带有正常登录用户的 sessionid,类似上面这样的转账操作在 server 就会成功,会造成极大的安全风险
165 |
166 | 
167 |
168 | CSRF 攻击的根本原因在于对于同样域名的每个请求来说,它的 cookie 都会被自动带上,这个是浏览器的机制决定的,所以很多人据此认定 cookie 不安全。
169 |
170 | 使用 token 确实避免了CSRF 的问题,但正如上文所述,由于 token 保存在 local storage,它会被 JS 读取,**从存储角度来看**也不安全(实际上防护 CSRF 攻击的正确方式只有 CSRF token)
171 |
172 |
173 | 所以不管是 cookie 还是 token,从存储角度来看其实都不安全,我们所说的的安全更多的是强调传输中的安全,可以用 HTTPS 协议来传输, 这样的话请求头都能被加密,也就保证了传输中的安全。
174 |
175 |
176 |
177 | 其实我们把 cookie 和 token 比较本身就不合理,一个是存储方式,一个是验证方式,正确的比较应该是 session vs token。
178 |
179 | ## 总结
180 |
181 | session 和 token 本质上是没有区别的,都是对用户身份的认证机制,只是他们实现的校验机制不一样而已(一个保存在 server,通过在 redis 等中间件获取来校验,一个保存在 client,通过签名校验的方式来校验),多数场景上使用 session 会更合理,但如果在单点登录,一次性命令上使用 token 会更合适,最好在不同的业务场景中合理选型,才能达到事半功倍的效果。
182 |
183 |
184 | 巨人的肩膀
185 | * Cookie Session跨站无法共享问题(单点登录解决方案):https://blog.csdn.net/wtopps/article/details/75040224
186 | * Stop using JWT for sessions:http://cryto.net/~joepie91/blog/2016/06/13/stop-using-jwt-for-sessions/
187 | *
188 | 更多精品文章,欢迎大家扫码关注「码海」
189 |
190 | 
191 |
--------------------------------------------------------------------------------
/Java/为什么线程崩溃不会导致JVM崩溃.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 |
4 |
5 | 网上看到一个很有意思的据说是美团的面试题:为什么线程崩溃崩溃不会导致 JVM 崩溃,这个问题我看了不少回答,但都没答到根本原因,所以决定答一答,相信大家看完肯定会有收获,本文分以下几节来探讨
6 |
7 | 1. 线程崩溃,进程一定会崩溃吗
8 | 2. 进程是如何崩溃的-信号机制简介
9 | 3. 为什么在 JVM 中线程崩溃不会导致 JVM 进程崩溃
10 | 4. openJDK 源码解析
11 |
12 |
13 |
14 | ### 线程崩溃,进程一定会崩溃吗
15 |
16 | 一般来说如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃,为什么系统要让进程崩溃呢,这主要是因为在进程中,**各个线程的地址空间是共享的**,既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃
17 |
18 | 
19 |
20 |
21 |
22 | 非法访问内存有以下几种情况,我们以 C 语言举例来看看
23 |
24 | 1. 针对只读内存写入数据
25 |
26 | ```c
27 | #include
28 | #include
29 |
30 | int main() {
31 | char *s = "hello world";
32 | s[1] = 'H'; // 向只读内存写入数据,崩溃
33 | }
34 | ```
35 |
36 | 2. 访问了不属于进程地址空间的内存
37 |
38 | ```c
39 | #include
40 | #include
41 |
42 | int main() {
43 | int *p = (int *)0xC0000fff;
44 | *p = 10; // 针对不属于进程的内核空间写入数据,崩溃
45 | }
46 | ```
47 |
48 | 在 32 位虚拟地址空间中,p 指向的是内核空间,显然不具有写入权限,所以上述赋值操作会导致崩溃
49 |
50 | 3. 访问了不存在的内存,比如
51 |
52 | ```c
53 | #include
54 | #include
55 |
56 | int main() {
57 | int *a = NULL;
58 | *a = 1; // 访问了不存在的内存
59 | }
60 | ```
61 |
62 |
63 |
64 | 以上错误都是访问内存时的错误,所以统一会报 Segment Fault 错误(即段错误),这些都会导致进程崩溃
65 |
66 | ### 进程是如何崩溃的-信号机制简介
67 |
68 | 那么线程崩溃后,进程是如何崩溃的呢,这背后的机制到底是怎样的,答案是**信号**,大家想想要干掉一个正在运行的进程是不是经常用 kill -9 pid 这样的命令,这里的 kill 其实就是给指定 pid 发送终止信号的意思,其中的 9 就是信号,其实信号有很多类型的,在 Linux 中可以通过 `kill -l`查看所有可用的信号
69 |
70 | 
71 |
72 | 当然了发 kill 信号必须具有一定的权限,否则任意进程都可以通过发信号来终止其他进程,那显然是不合理的,实际上 kill 执行的是系统调用,将控制权转移给了内核(操作系统),由内核来给指定的进程发送信号
73 |
74 |
75 |
76 | 那么发个信号进程怎么就崩溃了呢,这背后的原理到底是怎样的?
77 |
78 | 其背后的机制如下
79 |
80 | 1. CPU 执行正常的进程指令
81 | 2. 调用 kill 系统调用向进程发送信号
82 | 3. 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
83 | 4. 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
84 | 5. **操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出**
85 |
86 | 注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,**但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行**
87 |
88 | ```c
89 | // 自定义信号处理函数示例
90 |
91 | #include
92 | #include
93 | #include
94 | // 自定义信号处理函数,处理自定义逻辑后再调用 exit 退出
95 | void sigHandler(int sig) {
96 | printf("Signal %d catched!\n", sig);
97 | exit(sig);
98 | }
99 | int main(void) {
100 | signal(SIGSEGV, sigHandler);
101 | int *p = (int *)0xC0000fff;
102 | *p = 10; // 针对不属于进程的内核空间写入数据,崩溃
103 | }
104 |
105 | // 以上结果输出: Signal 11 catched!
106 | ```
107 |
108 |
109 |
110 | **如代码所示**:注册信号处理函数后,当收到 SIGSEGV 信号后,先执行相关的逻辑再退出
111 |
112 |
113 |
114 | 另外当进程接收信号之后也可以不定义自己的信号处理函数,而是选择忽略信号,如下
115 |
116 | ```c
117 | #include
118 | #include
119 | #include
120 |
121 | int main(void) {
122 | // 忽略信号
123 | signal(SIGSEGV, SIG_IGN);
124 |
125 | // 产生一个 SIGSEGV 信号
126 | raise(SIGSEGV);
127 |
128 | printf("正常结束");
129 | }
130 | ```
131 |
132 |
133 |
134 | 也就是说虽然给进程发送了 kill 信号,但如果进程自己定义了信号处理函数或者无视信号就有机会逃出生天,当然了 kill -9 命令例外,不管进程是否定义了信号处理函数,都会马上被干掉
135 |
136 | 说到这大家是否想起了一道经典面试题:如何让正在运行的 Java 工程的优雅停机,通过上面的介绍大家不难发现,其实是 JVM 自己定义了信号处理函数,这样当发送 kill pid 命令(默认会传 15 也就是 SIGTERM)后,JVM 就可以在信号处理函数中执行一些资源清理之后再调用 exit 退出。这种场景显然不能用 kill -9,不然一下把进程干掉了资源就来不及清楚了
137 |
138 |
139 |
140 | ### 为什么线程崩溃不会导致 JVM 进程崩溃
141 |
142 | 现在我们再来看看开头这个问题,相信你多少会心中有数,想想看在 Java 中有哪些是觉见的由于非法访问内存而产生的 Exception 或 error 呢,常见的是大家熟悉的 StackoverflowError 或者 NPE(NullPointerException),NPE 我们都了解,属于是访问了不存在的内存
143 |
144 | 但为什么栈溢出(Stackoverflow)也属于非法访问内存呢,这得简单聊一下进程的虚拟空间,也就是前面提到的共享地址空间
145 |
146 | 现代操作系统为了保护进程之间不受影响,所以使用了虚拟地址空间来隔离进程,进程的寻址都是针对虚拟地址,每个进程的虚拟空间都是一样的,而线程会共用进程的地址空间,以 32 位虚拟空间,进程的虚拟空间分布如下
147 |
148 | 
149 |
150 | 那么 stackoverflow 是怎么发生的呢,进程每调用一个函数,都会分配一个栈桢,然后在栈桢里会分配函数里定义的各种局部变量,假设现在调用了一个无限递归的函数,那就会持续分配栈帧,但 stack 的大小是有限的(Linux 中默认为 8 M,可以通过 ulimit -a 查看),如果无限递归显然很快栈就会分配完了,此时再调用函数试图分配超出栈的大小内存,就会发生段错误,也就是 stackoverflowError
151 |
152 | 
153 |
154 |
155 |
156 | 好了,现在我们知道了 StackoverflowError 怎么产生的,那问题来了,既然 StackoverflowError 或者 NPE 都属于非法访问内存, JVM 为什么不会崩溃呢,有了上一节的铺垫,相信你不难回答,其实就是因为 JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃,怎么证明这个推测呢,我们来看下 JVM 的源码来一探究竟
157 |
158 |
159 |
160 | ### openJDK 源码解析
161 |
162 | HotSpot 虚拟机是目前使用范围最广的 Java 虚拟机,据 R 大所述, Oracle JDK 与 OpenJDK 里的 JVM 都是 HotSpot VM,从源码层面说,两者基本上是同一个东西,OpenJDK 是开源的,所以我们主要研究下 Java 8 的 OpenJDK 即可,地址如下:https://github.com/AdoptOpenJDK/openjdk-jdk8u,有兴趣的可以下载来看看
163 |
164 |
165 |
166 | 我们只研究 Linux 下的 JVM,为了便于说明,也方便大家查阅,我把其中关于信号处理的关键流程整理了下(忽略其中的次要代码)
167 |
168 | 
169 |
170 |
171 |
172 | 可以看到,在启动 JVM 的时候,也设置了信号处理函数,收到 SIGSEGV,SIGPIPE 等信号后最终会调用 JVM_handle_linux_signal 这个自定义信号处理函数,再来看下这个函数的主要逻辑
173 |
174 |
175 |
176 | ```c
177 | JVM_handle_linux_signal(int sig,
178 | siginfo_t* info,
179 | void* ucVoid,
180 | int abort_if_unrecognized) {
181 |
182 | // Must do this before SignalHandlerMark, if crash protection installed we will longjmp away
183 | // 这段代码里会调用 siglongjmp,主要做线程恢复之用
184 | os::ThreadCrashProtection::check_crash_protection(sig, t);
185 |
186 | if (info != NULL && uc != NULL && thread != NULL) {
187 | pc = (address) os::Linux::ucontext_get_pc(uc);
188 |
189 | // Handle ALL stack overflow variations here
190 | if (sig == SIGSEGV) {
191 | // Si_addr may not be valid due to a bug in the linux-ppc64 kernel (see
192 | // comment below). Use get_stack_bang_address instead of si_addr.
193 | address addr = ((NativeInstruction*)pc)->get_stack_bang_address(uc);
194 |
195 | // 判断是否栈溢出了
196 | if (addr < thread->stack_base() &&
197 | addr >= thread->stack_base() - thread->stack_size()) {
198 | if (thread->thread_state() == _thread_in_Java) {
199 | stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::STACK_OVERFLOW);
200 | }
201 | }
202 | }
203 | }
204 |
205 | if (sig == SIGSEGV &&
206 | !MacroAssembler::needs_explicit_null_check((intptr_t)info->si_addr)) {
207 | // 此处会做空指针检查
208 | stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
209 | }
210 |
211 |
212 | // 如果是栈溢出或者空指针最终会返回 true,不会走最后的 report_and_die,所以 JVM 不会退出
213 | if (stub != NULL) {
214 | // save all thread context in case we need to restore it
215 | if (thread != NULL) thread->set_saved_exception_pc(pc);
216 |
217 | uc->uc_mcontext.gregs[REG_PC] = (greg_t)stub;
218 | // 返回 true 代表 JVM 进程不会退出
219 | return true;
220 | }
221 |
222 | VMError err(t, sig, pc, info, ucVoid);
223 | // 生成 hs_err_pid_xxx.log 文件并退出
224 | err.report_and_die();
225 |
226 | ShouldNotReachHere();
227 | return true; // Mute compiler
228 |
229 | }
230 | ```
231 |
232 |
233 |
234 | 从以上代码我们可以知道以下信息
235 |
236 | 1. 发生 stackoverflow 还有空指针错误,确实都发送了 SIGSEGV,只是虚拟机不选择退出,而是自己内部作了额外的处理,其实是恢复了线程的执行,并抛出 StackoverflowError 和 NPE,这就是为什么 JVM 不会崩溃且我们能捕获这两个错误/异常的原因
237 |
238 | 2. 如果针对 SIGSEGV 等信号,在以上的函数中 JVM 没有做额外的处理,那么最终会走到 report_and_die 这个方法,这个方法主要做的事情是生成 hs_err_pid_xxx.log crash 文件(记录了一些堆栈信息或错误),然后退出
239 |
240 |
241 |
242 | 自此我相信大家已经明白了为什么发生了 StackoverflowError 和 NPE 这两个非法访问内存的错误,JVM 却没有崩溃的原因,原因其实就是虚拟机内部定义了信号处理函数,而在信号处理函数中对这两者做了额外的处理以让 JVM 不崩溃,另一方面也可以看出如果 JVM 不对信号做额外的处理,最后会自己退出并产生 crash 文件 hs_err_pid_xxx.log(可以通过 -XX:ErrorFile=/var/*log*/hs_err.log 这样的方式指定),这个文件记录了虚拟机崩溃的重要原因,所以也可以说,虚拟机是否崩溃只要看它是否会产生此崩溃日志文件
243 |
244 |
245 |
246 | ### 总结
247 |
248 | 正常情况下,操作系统为了保证系统安全,所以针对非法内存访问会发送一个 SIGSEGV 信号,而操作系统一般会调用默认的信号处理函数(一般会让相关的进程崩溃),但如果进程觉得"罪不致死",那么它也可以选择自定义一个信号处理函数,这样的话它就可以做一些自定义的逻辑,比如记录 crash 信息等有意义的事,回过头来看为什么虚拟机会针对 StackoverflowError 和 NullPointerException 做额外处理让线程恢复呢,针对 stackoverflow 其实它采用了一种栈回溯的方法保证线程可以一直执行下去,而捕获空指针错误主要是这个错误实在太普遍了,为了这一个很常见的错误而让 JVM 崩溃那线上的 JVM 要宕机多少次,所以与其这次倒不如让线程起死回生,并且将这两个错误/异常抛给用户来处理
249 |
250 |
251 |
252 | #### 巨人的肩膀
253 |
254 | Segmentation Fault in Linux: https://www.cnblogs.com/kaixin/archive/2010/06/07/1753133.html
255 |
256 | linux SIGSEGV 信号捕捉,保证发生段错误后程序不崩溃: https://blog.csdn.net/work_msh/article/details/8470277
257 |
258 |
259 |
260 | 更多精品文章,欢迎大家扫码关注「码海」
261 |
262 | 
--------------------------------------------------------------------------------
/Java/Java线程模型.md:
--------------------------------------------------------------------------------
1 | 上周[线程崩溃为什么不会导致 JVM 崩溃](https://mp.weixin.qq.com/s/JnlTdUk8Jvao8L6FAtKqhQ)在其他平台发出后,有一位小伙伴留言说有个地方不严谨
2 |
3 | 
4 |
5 | 他认为如果 JVM 中的主线程异常没有被捕获,JVM 还是会崩溃,那么这个说法是否正确呢,我们做个试验看看结果是否是他说的这样
6 |
7 | ```java
8 | public class Test {
9 | public static void main(String[] args) {
10 | TestThread testThread = new TestThread();
11 | TestThread.start();
12 | Integer p = null;
13 | // 这里会导致空指针异常
14 | if (p.equals(2)) {
15 | System.out.println("hahaha");
16 | }
17 | }
18 | }
19 |
20 | class TestThread extends Thread {
21 | @Override
22 | public void run() {
23 | while (true) {
24 | System.out.println("test");
25 | }
26 | }
27 | }
28 | ```
29 |
30 | 试验很简单,首先启动一个线程,在这个线程里搞一个 while true 不断打印, 然后在主线程中制造一个空指针异常,不捕获,然后看是否会一直打印 test
31 |
32 |
33 |
34 | 结果是会不断打印 test,说明**主线程崩溃,JVM 并没有崩溃**,这是怎么回事, JVM 又会在什么情况下完全退出呢?
35 |
36 |
37 |
38 | 其实在 Java 中并没有所谓主线程的概念,只是我们习惯把启动的线程作为主线程而已,所有线程其实都是平等的,不管什么线程崩溃都不会影响到其它线程的执行,注意我们这里说的线程崩溃是指由于未 catch 住 JVM 抛出的虚拟机错误(VirtualMachineError)而导致的崩溃,虚拟机错误包括 InternalError,OutOfMemoryError,StackOverflowError,UnknownError 这四大子类
39 |
40 | 
41 |
42 |
43 |
44 | JVM 抛出这些错误其实是一种防止整个进程崩溃的自我防护机制,这些错误其实是 JVM 内部定义了信号处理函数处理后抛出的,JVM 认为这些错误"罪不致死",所以选择恢复线程再给这些线程抛错误(就算线程不 catch 这些错误也不会崩溃)的方式来避免自身崩溃,但如果线程触发了一些其他的非法访问内存的错误,JVM 则会认为这些错误很严重,从而选择退出,比如下面这种非法访问内存的错误就会被认为是致命错误,JVM 就不会向上层抛错误,而会直接选择退出
45 |
46 | ```java
47 | Field f = Unsafe.class.getDeclaredField("theUnsafe");
48 | f.setAccessible(true);
49 | Unsafe unsafe = (Unsafe) f.get(null);
50 | unsafe.putAddress(0, 0);
51 | ```
52 |
53 | 回过头来看,除了这些致命性错误导致的 JVM 崩溃,还有哪些情况会导致 JVM 退出呢,在 javadoc 上说的很清楚
54 |
55 | 
56 |
57 | **The Java Virtual Machine exits when the only threads running are all daemon threads**
58 |
59 | 也就是说只有在 JVM 的所有线程都是守护线程(daemon thread)的时候才会完全退出,什么是守护线程?守护线程其实是为其他线程服务的线程,比如垃圾回收线程就是典型的守护线程,既然是为其他线程服务的,那么一旦其他线程都不存在了,守护线程也没有存在的意义了,于是 JVM 也就退出了,守护线程通常是 JVM 运行时帮我们创建好的,当然我们也可以自己设置,以开头的代码为例,在创建完 TestThread 后,调用 testThread.setDaemon(true) 方法即可将线程转为守护线程,然后再启动,这样在主线程退出后,JVM 就会退出了,大家可以试试
60 |
61 |
62 |
63 | ### Java 线程模型简介
64 |
65 | 我们可以看看 Java 的线程模型,这样大家对 JVM 的线程调度也会有一个更全面的认识,我们可以先从源码角度看看,启动一个 Thread 到底在 JVM 内部发生了什么,启动源码代码在 Thread#start 方法中
66 |
67 | ```java
68 | public class Thread {
69 |
70 | public synchronized void start() {
71 | ...
72 | start0();
73 | ...
74 | }
75 | private native void start0();
76 | }
77 | ```
78 |
79 | 可以看到最终会调用 start0 这个 native 方法,我们去下载一下 openJDK(地址:https://github.com/AdoptOpenJDK/openjdk-jdk8u) 来看看这个方法对应的逻辑
80 |
81 |
82 |
83 | 
84 |
85 | 可以看到 start0 对应的是 JVM_startThread 这个方法,我们主要观察在 Linux 下的线程启动情况,一路追踪下去
86 |
87 | ```c++
88 | // jvm.cpp
89 | JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
90 | native_thread = new JavaThread(&thread_entry, sz);
91 |
92 | // thread.cpp
93 | JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz)
94 | {
95 | os::create_thread(this, thr_type, stack_sz);
96 | }
97 |
98 | // os_linux.cpp
99 | bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
100 | int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
101 | }
102 | ```
103 |
104 | 可以看到最终是通过调用 pthread_create 来启动线程的,这个方法是一个 C 函数库实现的创建 native thread 的接口,是一个系统调用,由此可见 pthread_create 最终会创建一个 native thread,这个线程也叫**内核线程**,操作系统只能调度内核线程,于是我们知道了在 Java 中,Java 线程和内核线程是一对一的关系,Java 线程调度实际上是通过操作系统调度实现的,这种一对一的线程也叫 NPTL(Native POSIX Thread Library) 模型,如下
105 |
106 | 
107 |
108 | 那么这个内核线程在内核中又是怎么表示的呢, 其实在 Linux 中不管是进程还是线程都是通过一个 task_struct 的结构体来表示的, 这个结构体定义了进程需要的虚拟地址,文件描述符,寄存器,信号等资源
109 |
110 |
111 |
112 | 早期没有线程的概念,所以每次启动一个进程都需要调用 fork 创建进程,这个 fork 干的事其实就是 copy 父进程对应的 task_struct 的多数字段(pid 等除外),这在性能上显然是无法接受的。于是线程的概念被提出来了,线程除了有自己的栈和寄存器外,其他像虚拟地址,文件描述符等资源都可以共享
113 |
114 |
115 |
116 | 
117 |
118 |
119 |
120 | 于是针对线程,我们就可以指定在创建 task_struct 时,采用**共享**而不是复制字段的方式。其实不管是创建进程(fork)还是创建线程(pthread_create)最终都会通过调用 clone() 的形式来创建 task_struct,只不过 pthread_create 在调用 clone 时,指定了如下几个共享参数
121 |
122 | ```
123 | clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
124 | ```
125 |
126 | **画外音**:CLONE_VM 共享页表,CLONE_FS 共享文件系统信息,CLONE_FILES 共享文件句柄,CLONE_SIGHAND 共享信号
127 |
128 |
129 |
130 | 通过共享而不是复制资源的形式极大地加快了线程的创建,另外线程的调度开销也会更小,比如在(同一进程内)线程间切换的时候由于共享了虚拟地址空间,TLB 不会被刷新从而导致内存访问低效的问题
131 |
132 |
133 |
134 | 提到这相信你已经明白了教科书上的一句话:进程是资源分配的最小单元,而线程是程序执行的最小单位。在 Linux 中进程分配资源后,线程通过共享资源的方式来被调度的以提升线程的执行效率
135 |
136 |
137 |
138 | 由此可见,在 Linux 中所有的进程/线程都是用的 task_struct,**它们之间其实是平等的**,那怎么表示这些线程属于同一个进程的概念呢,毕竟线程之间也是要通信的,一组线程以及它们所共同引用的一组资源就是一个进程。, 它们还必须被视为一个整体。
139 |
140 |
141 |
142 | task_struct 中引入了线程组的概念,如果线程都是由同一个进程(即我们说的主线程)产生的, 那么它们的 tgid(线程组id) 是一样的,如果是主线程,则 pid = tgid,如果是主线程创建的线程,则这些线程的 tgid 会与主线程的 tgid 一致,
143 |
144 |
145 |
146 | 那么在 LInux 中进程,进程内的线程之间是如何通信或者管理的呢,其实 NPTL 是一种实现了 POSIX Thread 的标准 ,所以我们只需要看 POSIX Thread 的标准即可,以下列出了 POSIX Thread 的主要标准:
147 |
148 | 1. 查看进程列表的时候, 相关的一组 task_struct 应当被展现为列表中的一个节点(即进程内如果有多个线程,展示进程列表 `ps -ef` 时只会展示主线程,如果要查看线程的话可以用 `ps -T`)
149 | 2. 发送给这个进程的信号(对应 kill 系统调用), 将被对应的这一组 task_struct 所共享, 并且被其中的任意一个”线程”处理
150 | 3. 发送给某个线程的信号(对应 pthread_kill), 将只被对应的一个 task_struct 接收, 并且由它自己来处理
151 | 4. 当进程被停止或继续时(对应 SIGSTOP/SIGCONT 信号), 对应的这一组 task_struct 状态将改变
152 | 5. 当进程收到一个致命信号(比如由于段错误收到 SIGSEGV 信号), 对应的这一组 task_struct 将全部退出
153 |
154 | **画外音**: POSIX 即可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),是一种接口规范,如果系统都遵循这个标准,可以做到源码级的迁移,这就类似 Java 中的针对接口编程
155 |
156 |
157 |
158 | 这样就能很好地满足进程退出线程也退出,或者线程间通信等要求了
159 |
160 |
161 |
162 | ### NPTL 模型的缺点
163 |
164 | NPTL 是一种非常高效的模型,研究表明 NPTL 能够成功地在 IA-32 平台上在两秒种内生成 100,000 个线程,而 2.6 之前未采用 NPTL 的内核则需耗费 15 分钟左右,看起来 NPTL 确实很好地满足了我们的需求,但针对内核线程来调度其实还是有以下问题
165 |
166 |
167 |
168 | 1. 不管是进程还是线程,每次阻塞、切换都需要陷入系统调用(system call),系统调用开销其实挺大的,包括上下文切换(寄存器切换),特权模式切换等,而且还得先让 CPU 跑操作系统的调度程序,然后再由调度程序决定该跑哪一个进程(线程)
169 | 2. 不管是进程还是线程,都属于抢占式调度(高优先级线进程优先被调度),由于抢占式调度执行顺序无法确定的特点,使用线程时需要非常小心地处理同步问题
170 | 3. 线程虽然更轻量级,但这只是相对于进程而言,实际上使用线程所消耗的资源依然很大,比如在 linux 上,一个线程默认的栈大小是1M,创建几万个线程就吃不消了
171 |
172 |
173 |
174 | ### 协程
175 |
176 | NPTL 模型其实已经足够优秀了,上述问题本质上其实还是因为线程还是太“重”所致,那能否再在线程上抽出一个更轻量级的执行单元(可被 CPU 调度和分派的基本单位)呢,答案是肯定的,在线程之上我们可以再抽象出一个协程(coroutine)的概念,就像进程是由线程来调度的,同样线程也可以细化成一个个的协程来调度
177 |
178 |
179 |
180 | 
181 |
182 |
183 |
184 | 针对以上问题,协程都做了非常好的处理
185 |
186 | 1. 协程的调度处于用户态,也就没有了系统调用这些开销
187 | 2. 协程不属于抢占式调度,而是协作式调度,如何调度,在什么时间让出执行权给其它协程是由用户自己决定的,这样的话同步的问题也基本不存在,可以认为协程是无锁的,所以性能很高
188 | 3. 我们可以认为线程的执行是由一个个协程组成的,协程是更轻量的存在,内存使用大约只有线程的十分之一甚至是几十分之一,它是使用栈内存按需使用的,所以创建百万级的协程是非常轻松的事
189 |
190 |
191 |
192 | 协程是怎么做到上述这些的呢
193 |
194 |
195 |
196 | 协程(coroutine)可以分为两个角度来看,一个是 routine 即执行单元,一个是 co 即 cooperative 协作,也就是说线程可以依次顺序执行各个协程,但协程与线程不同之处在于,如果某个协程(假设为 A)内碰到了 IO 等阻塞事件,可以主动让出自己的调度权,即挂起(suspend),转而执行其他协程,等 IO 事件准备好了,再来调度协程 A
197 |
198 | 
199 |
200 |
201 |
202 | 这就好比我在看电视的时候碰到广告,那我可以先去倒杯水,等广告播完了再回来继续看电视。而如果是函数,那你必须看完广告再去倒水,显然协程的效率更高。那么协程之间是怎么协作的呢,我们可以在两个协程之间碰到 IO 等阻塞事件时随时将自己挂起(yield),然后唤醒(resume)对方以让对方执行,想象一下如果协程中有挺多 IO 等阻塞事件时,那这种协作调度是非常方便的
203 |
204 | 
205 |
206 | 不像函数必须执行完才能返回,协程可以在执行流中的**任意位置**由用户决定挂起和唤醒,无疑协程是更方便的
207 |
208 | 
209 |
210 |
211 |
212 | 更重要的一点是不像线程的挂起和唤醒等调度必须通过系统调用来让内核调度器来调度,**协程的挂起和唤醒完全是由用户决定的**,而且这个调度是在用户态,几乎没有开销!
213 |
214 |
215 |
216 | 前面我们一直提到一般我们在协程中碰到 IO 等阻塞事件时才会挂起并唤醒其他协程,所以可知**协程非常适合 IO 密集型的应用**,如果是计算密集型其实用线程反而更加合适
217 |
218 |
219 |
220 | 为什么 Go 语言这么最近这么火,一个很重要的原因就是因为因为它天生支持协程,可以轻而易举地创建成千上万个协程,而如果是创建线程的话,创建几百个估计就够呛了,不过比较遗憾的是 Java 原生并不支持协程,只能通过一些第三方库如 Quasar 来实现,2018 年 OpenJDK 官方创建了一个 loom 项目来推进协程的官方支持工作
221 |
222 |
223 |
224 | ### 总结
225 |
226 | 从进程,到线程再到协程,可知我们一直在想办法让执行单元变得更轻量级,一开始只有进程的概念,但是进程的创建在 Linux 下需要调用 fork 全部复制一遍资源,虽然后来引入了写时复制的概念,但进程的创建开销依然很大,于是提出了更轻量级的线程,在 Linux 中线程与进程其实都是用 task_struct 表示的,只是线程采用了共享资源的方式来创建,极大了提升了 task_struct 的创建与调度效率,但人们发现,线程的阻塞,唤醒都要通过系统调用陷入内核态才能被调度程度调度,如果线程频繁切换,开销无疑是很大的,于是人们提出了协程的概念,协程是根据栈内存按需求分配的,所需开销是线程的几十分之一,非常的轻量,而且调度是在用户态,并且它是协作式调度,可以很方便的挂起恢复其他协程的执行,在此期间,线程是不会被挂起的,所以无论是创建还是调度开销都很小,目前 Java 官方还不支持,不过支持协程应该是大势所趋,未来我们可以期待一下
227 |
--------------------------------------------------------------------------------
/系统设计/keepalived工作原理.md:
--------------------------------------------------------------------------------
1 | ### 问题初现
2 |
3 | 「滴~~~」,小章的钉钉突然响起了很多客服转发来的用户投诉信息,说是网络连接不上了,经过排查发现是其中一台机器(RS2)挂了
4 |
5 | 
6 |
7 | 但是 LVS 依然持续地把流量打到这台机器上,持续造成线上问题,小章首先把这台机器从 LVS 上摘除,**先保证线上正常**,然后为了避免之后出现类似问题,急忙找了 CEO 老梁来商讨方案。
8 |
9 | ### 应用层健康检查:HTTP 检测
10 |
11 | 老梁一眼看出了问题所在:「我们需要开发一个健康检查服务,部署在 LVS 上,这个服务可以定时检查其后的 RS 是否可用,如果不可用则将 RS 摘除,这样就可以保障线上服务正常了」
12 |
13 | 「妙啊,通过软件及时探测,摘除不可用的机器,避免了人工发现不及时的问题,那么该怎么做这个健康检查呢,需要满足什么条件呢」听说要开发这样的软件,小章顿时来了兴致。
14 |
15 | 「小章啊,仔细想想看,我们的服务在发布过程中其实也是有健康检查的,要保证一个工程可用,至少保证它是可访问的以及它用到的中间件,DAO 是正常的,所以它的健康代码如下
16 |
17 | ```
18 | @Service(protocol = {"rest"})
19 | public class HealthCheckServiceImpl implements HealthCheckService {
20 |
21 | @Resource
22 | private TestDAO TestDAO;
23 |
24 | @Resource
25 | private RebateClient rebateClient;
26 |
27 | @Override
28 | public String getHealthStatus() {
29 | List testDOS =
30 | TestDAO.getResult(123);
31 | Assert.isTrue(testDOS != null, "rebateMemberDOS null");
32 |
33 | // 此处省略 redis 检测
34 |
35 | // 此处省略其它检测
36 |
37 | return "health";
38 | }}
39 | ```
40 |
41 | 如以上代码所示,我们在工程里写了健康检查 HealthCheckService 类,暴露了一个 rest 服务,这样的话在部署的时候在服务部署脚本里首先访问一下此服务的 getHealthStatus 方法,如果返回的值为「health」,则说明此服务的 dubbo 服务,DAO,redis 等正常,说明此服务是没有问题的,如果返回的值不为 health,则说明此服务有问题,不能上线,这就是我们所说的**健康检查**,通过访问服务暴露的方法,来检测此服务是否可用。
42 |
43 | 所以我们要开发的检测服务也与此类似,只要定时访问此服务暴露的接口,看下此接口返回的值与我们期待的值是否一致即可,一致说明此服务正常,否则,说明此服务异常,将其剔除,当然了一次连接不通就判断为不可用可能有些问题,我们可以提供一个重试次数,比如 3 次,如果 3 次健康检测都失败,则认定此服务不可用!配置的伪代码如下:
44 |
45 | ```
46 | real_server 192.168.1.220 80 {
47 | HTTP_GET {
48 | url {
49 | path /healthCheck
50 | status_code 200
51 | }
52 | connect_timeout 3
53 | nb_get_retry 3 // 置超时重试次数
54 |
55 | }
56 | }
57 | ```
58 |
59 | 「妙啊,此法甚好!只要访问健康检查服务就可以很方便地查看此服务是否正常了,但是有个问题:如果这个健康检测方法写的检测逻辑很多,而 LVS 定时发检测请求比较频繁的话可能会有一定的性能问题,是否有更轻量级的检测方法呢」小章说道
60 |
61 | 「考虑得很周到!一般健康检测确实逻辑比较重,所以只在部署的的时候检测一次就够了,在生产上我们可以采用更轻量的检测方式:**TCP连接检测**」
62 |
63 | ### TCP连接检测
64 |
65 | TCP 连接检测原理很简单,我们知道要建立一个 TCP 连接,首先必须由 TCP 客户端发起 connect 请求,三次握手成功后才算建立起一个 TCP 链接,然后才能正常收发数据
66 |
67 | 
68 |
69 | 所以我们只要调用 connect 方法看它是否成功即可,成功即说明连接建立成功,说明服务是可用的,如果失败说明此服务有问题,直接摘除即可,当然了与 HTTP 检测一样,也要有超时机制,伪代码如下
70 |
71 | ```
72 | tcp连接检测
73 | TCP_CHECK {
74 | connect_port 80 // 指定端口
75 | connect_timeout 6 // 设置响应超时时间
76 | nb_get_retry 3 // 设置超时重试次数
77 | delay_before_retry 3 // 设置超时重试间隔时间
78 | }
79 | ```
80 |
81 | 小章按着老梁的思路把这两种健康检测思路给实现了,并且给这个服务取了个霸气的名字:**keepalived**,老梁很满意,不过他又发现了新的问题。。。
82 |
83 | ### 单点故障---高可用解决之道
84 |
85 | 「小章,健康检查做得很好,而且提供了两种检查方式,很全面,不过你这个架构还有个很致命的问题,不知你有没发现,那就是目前只有一台 LVS 在工作,如果这台 LVS 挂了,那我们业务就跌零了, 你还需要让 keepalived 支持 LVS 的高可用」
86 |
87 | 小章恍然大悟,「那该咋办呢」
88 |
89 | 「高可用的通用解决方案很简单,**冗余**+**故障自动发现转移**,我们可以按照这个思路来设计 LVS 高可用,具体方案如下:
90 |
91 | 我们可以为 LVS 准备几台备机,如果发现 LVS 挂了,就让备机顶上去,这样不就实现了高可用了吗」不愧是 CTO,一语中的
92 |
93 | 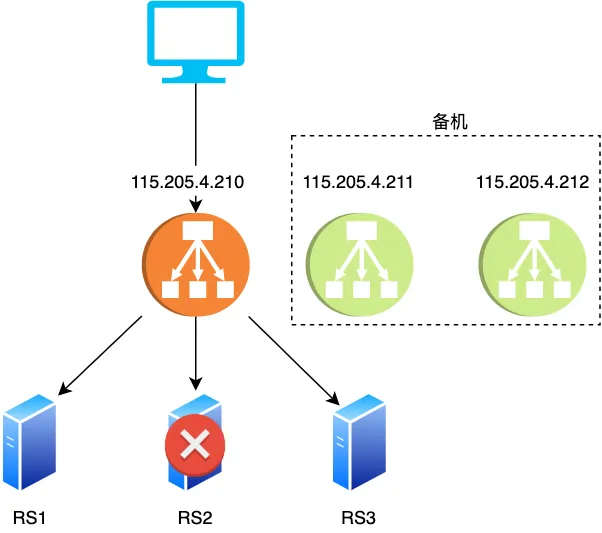
94 |
95 | 小章看了一眼架构图,提出了三个问题
96 |
97 | 1. 如果主机(以下简称 master)宕机,备机(以下简称 backup)顶上,那 IP 地址不是变了吗,此时客户端该怎么连接
98 | 2. 几台机器首次启动时,谁为 master,谁为 backup
99 | 3. master 宕机后,backup 是如何感知到的,多台 backup 又是如何竞选出主机的,这个和问题 2 有点类似
100 |
101 | 「这几个问题提的很好,正是实现高可用的关键,可以看出小伙子还是有经过深入思考的」老梁高兴地说,「这些问题不难化解,我们一一来看看」
102 |
103 | > 问题一:backup 成为 master 后,IP 地址变了怎么办?
104 |
105 | 答:IP 地址不能变,对外必须表现为一个 IP,我们通常称为「虚拟(virtual) IP」,通常简称为 VIP
106 |
107 | 
108 |
109 | 如果 master(即图中的 L1)工作,则此 VIP 在 master 上可用,若 master 宕机,如果 backup(比如 L2)竞选 master 成功,则 VIP 在 L2 上生效,**同时新的 master 需要发送一个携带有本机的 MAC 地址和 VIP 地址信息的 ARP 报文**,你会发现 VIP 从老的 master 转移到竞选 master 成功的 backup 上了,我们把这种现象称为 **IP 漂移**,这里有两个问题需要澄清
110 |
111 | 1. 一个主机如何才能有两个 IP
112 | 2. 为什么 VIP 在某台竞选 master 成功的 backup 上生效后要发一个携带有本机的 MAC 地址和 VIP 地址信息的 ARP 报文
113 |
114 | 先看第一个问题,主机如何才能拥有两个 IP ,毕竟一台机器成为主机后,除了本身机器被分配的 IP(115.205.4.210),VIP 也**漂移**到它身上了,此时它拥有两个 IP
115 |
116 | 我们知道计算机要上网,首先要把网线插入网卡,一个网卡其实就对应着一个 IP,所以一台主机配两个网卡就可以绑定两个 IP,一般 LVS 都会配置双网卡,一来每个网卡带宽都是有限的,双网卡相当于提升了一倍的带宽,二来两个网卡也起到了热备的作用,如果一个网卡坏了,另外一个可以顶上。
117 |
118 | 但有人说了,我就只有一个网卡,也想配置多个 IP,是否可以?
119 |
120 | **答案是可以的**,网卡一般分两种,一种是**物理网卡**,一种是**虚拟网卡**
121 |
122 | 1. `物理网卡`:可以插网线的网卡,如果有多个网卡,我们一般将其命名为 eth0,eth1。。。,如果一个网卡对应多个 IP,以 eth0 为例,一般将其命名为 eth0,eth0:0,eth0:1。。。eth0:x,比如一台机器只有一个网卡,但其对应两个 IP 192.168.1.2, 192.168.1.3,那么其绑定的网卡名称分别为 eth0,eth0:0
123 | 2. `虚拟网卡`:虚拟网卡通常被称为 loopback,一般命名为 lo,是一个特殊的网络接口,主要用于本机中各个应用之间的网络交互(哪怕网线拔了,本机各个应用之间通过 lo 也是能通信的),需要注意的是虚拟网卡和物理网卡一样,也可以绑定任意 IP 地址,如果在虚拟网卡配置了任何的 IP 地址,只要有物理网卡,就能到收到并处理目的 IP 为虚拟网卡上 IP 的数据包,lo 默认绑定了 127.0.0.1 这个本地 IP ,如果要绑定其他的 IP,对应的网卡命名一般为 lo:0,lo:1。。。
124 |
125 | 所以假设一台机器只有一个网卡,一般内网给它默认分配的 IP 绑定在 eth0 上,那么我们就可以把虚拟 IP 绑定在 eth0:0 上,这样的话外界就能正常访问此虚拟 IP 了,如果 master 挂掉了,keepalived 会让此 master 的 eth0:0 端口失效,同时让新 master 的 eth0:0 绑定虚拟 IP,这样就避免了对外暴露两个虚拟 IP。
126 |
127 | 再来看第二位问题,虚拟 IP 在某台机器生效后,为啥要发一个 ARP 请求呢,这个问题其实在之前的文章中提到过,这里为了照顾其他没看过之前文章的读者,再简单提一下,其实上面的架构图我们作了一定程度的简化,更详细的应该如下图所示
128 |
129 | 
130 |
131 | 如图示,三台 LVS 机器组成一个同一网段的以太网我们知道,以太网是以 mac 地址来寻址的,我们知道现在对外暴露的是虚拟 IP,那么当带有虚拟 IP 的包到达路由器时,它该怎么找到对应的机器呢?
132 |
133 | 一开始它啥也不知道,所以它在网址发了一个 ARP 广播包,相当于大吼一声:IP 地址为 115.205.4.213 的机器是谁啊,由于这个虚拟 IP 在 L1 上,所以只有 L1 响应了,L1 会把带有自己 mac 地址的响应包发回给路由器,路由器收到后会把 IP 地址与 L1 mac 地址的关系记在本地,然后在包的头部装上 L1 的 mac 地址发给交换机,交换机就能识别到应该发给 L1,下次当客户端再次发数据包到路由器时,路由器会首先在本地缓存(ARP 缓存)中查到 IP 对应的 mac(即 L1 的mac),命中后将包上的 mac 地址替换成 L1 的 mac 转发出去,至此相信你应该明白为啥虚拟 IP 生效后要发 ARP 报文了,就是**为了更新由器上的 ARP 缓存**,将虚拟 IP 对应的 mac 地址更新为竞选 master 成功的 backup 上的 mac,这样下次路由器就能正确将新 master 的 mac 附在数据包上,就能正确地转发到机器上了,否则,数据包会转发到老的 master 上,引起灾难性的后果!
134 |
135 | > 问题二:几台机器首次启动后,谁为 master,谁为 backup
136 |
137 | 这个问题其实很简单,谁的能力强,谁就优先成为 master,我们可以给各个机器设置不同的值为 0~255 的权重,权重越大,代表此机器越有可能成为 master(如果权重一样,则比较它们的 IP,IP 大的权重高),这里分几种情况
138 |
139 | 1. 每个机器启动后都处于 Initialize 状态,若某台机器接口(eth0)Up 之后,如果其权重为 255 且此时还没有 master 则其成为 master 并且让虚拟 IP 绑定在 eth0:0 端口上,如果此时已有 master 呢,分两种模式:**抢占**和**非抢占**模式,如果处于非抢占模式下,则它转为 backup 状态,否则它会重新竞争成为 master,此时一般能竞争成功,因为它处于最高权重(一般只有一台机器处于最高权限)
140 | 2. 如果某台机器权重不为 255,则**经过一段时间后**如果此时还没有 master ,那么它会竞争 master,如果此时有了 master,也和情况 1 一样,分抢占和非抢占模式,为啥要经过一段时间才竞争 master 呢,其实主要是为了优先让权重为 255 的机器成为 master
141 |
142 | 整体流程如下
143 |
144 | 
145 |
146 | > 问题三: master 宕机后,backup 是如何感知到的,多台 backup 又是如何竞选出主机的
147 |
148 | 当机器成为 master 后,它会定时发送广播给其他的 backup,让其他 backup 知道它还存活着,如果在指定时间内(一般我们称此时间为 Master_Down_Interval)backup 没有收到 master 的广播包,那么 backup 互相之间会发广播包通过比较权重竞争 master,某台 backup 竞选 master 成功后同样会让虚拟 IP 绑定在 eth0:0 端口上,并且发送 ARP 包让路由器等更新自己的 ARP 缓存,其他竞选失败的则转为 backup 状态
149 |
150 | 至此相信大家已经明白了 keepalived 的工作机制,所有上面说的这些工作只要配置一下 keepalived 的配置文件并启动后即可实现。
151 |
152 | 另外 keepalived 实现的高可用机制不光可以用在 LVS 上,也可以用在 MySQL 等高可用上,所以你内部工程连 MySQL 的地址一般是虚拟 IP。现在我相信你能看懂如下 LVS 的高可用工作图了
153 |
154 | 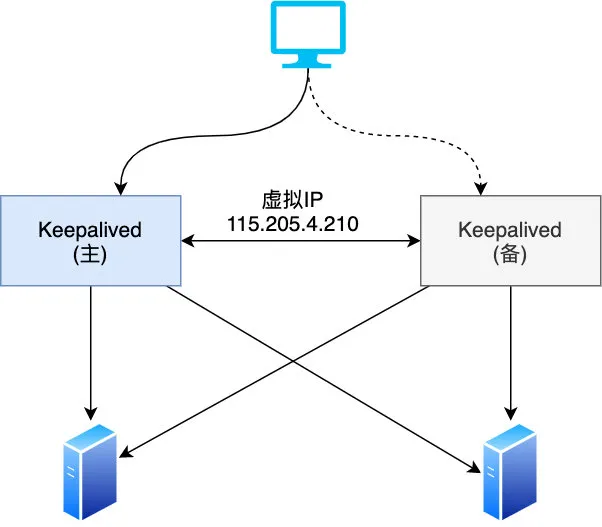
155 |
156 | **注**:不管是 master 还是 backup 都能对背后的 RS 作健康检查哦
157 |
158 | ### 总结
159 |
160 | 相信大家看完本文对 keepalived 的工作原理应该是了然于胸了,它的主要工作模式无非就两块:「健康检查」和「高可用」,健康检查我们只介绍了常见的两种,其实它还支持通过运行脚本来作健康检测,只是不太常用而已,另外 keepalived 的高可用可以说是大放异彩,除了用在 LVS 的高可用,还用在 Nginx ,MySQL 的高可用上,原理其实无非就是利用心跳检测+竞争 master + IP 漂移来实现,完整的 keepalived.conf 配置文件大家有兴趣可以看文末的参考链接,相信经过上面的原理讲解再去看此文件不是问题
161 |
162 | 另外不知大家是否注意到了,master 虽然可以定时向 backup 发送心跳,但如果此心跳链路坏了 backup 就会误认为 master 已经不可用了,从而去申请成为 master,这样就会造成两个 master 的出现,也就是我们常说的**脑裂**,怎么解决?可以同时用两条心跳线路,这样一条心跳检测线路坏了,另一条还是好的,依然能传送心跳消息。当然除了心跳链路坏了还有可能会有其他情况也会导致脑裂的发生,我们还是要做好多种预案,必要时人工及时介入,(关于脑裂的更多信息可以看文末的参考链接)
163 |
164 | #### 巨人的肩膀
165 |
166 | - keepalived.conf 配置文件详解: https://www.huaweicloud.com/articles/c37ca72e2dde50e91324471ea761d41b.html
167 | - 脑裂问题及解决:https://www.cnblogs.com/struggle-1216/p/12897981.html
168 |
169 | 欢迎关注公众号与笔者共同交流哦^_^
170 |
171 | 
--------------------------------------------------------------------------------
/Java/ConrrentHashMap是强一致性的吗.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 |
4 |
5 | 上周我在极客时间某个课程看到某个讲师在讨论 ConcurrentHashMap(以下简称 CHM)是强一致性还是弱一致性时,提到这么一段话
6 |
7 | 
8 |
9 | 这个解释网上也是流传甚广,那么到底对不对呢,在回答这个问题之前,我们得想清楚两个问题
10 |
11 | 1. 什么是强一致性,什么是弱一致性
12 | 2. 上文提到 get 没有加锁,所以没法即时获取 put 的数据,也就意味着如果加锁就可以立即获取到 put 的值了?那么除了加锁之外,还有其他办法可以立即获取到 put 的值吗
13 |
14 | ### 强一致性与弱一致性
15 |
16 | > 强一致性
17 |
18 | 首先我们先来看第一个问题,什么是强一致性
19 |
20 | 一致性(Consistency)是指多副本(Replications)问题中的数据一致性。可以分为强一致性、弱一致性。
21 |
22 | 强一致性也被可以被称做原子一致性(Atomic Consistency)或线性一致性(Linearizable Consistency),必须符合以下两个要求
23 |
24 | - 任何一次读都能**立即**读到某个数据的最近一次写的数据
25 | - 系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致
26 |
27 | 简单地说就是假定对同一个数据集合,分别有两个线程 A、B 进行操作,假定 A 首先进行了修改操作,那么从时序上在 A 这个操作之后发生的所有 B 的操作都应该能**立即**(或者说**实时**)看到 A 修改操作的结果。
28 |
29 |
30 |
31 | > 弱一致性
32 |
33 | 与强一致性相对的就是弱一致性,即数据更新之后,如果立即访问的话可能访问不到或者只能访问部分的数据。如果 A 线程更新数据后 B 线程**经过一段时间**后都能访问到此数据,则称这种情况为最终一致性,最终一致性也是弱一致性,只不过是弱一致性的一种特例而已
34 |
35 |
36 |
37 | 那么在 Java 中产生弱一致性的原因有哪些呢,或者说有哪些方式可以保证强一致呢,这就得先了解两个概念,可见性和有序性
38 |
39 |
40 |
41 | ### 一致性的根因:可见性与有序性
42 |
43 | #### 可见性
44 |
45 | 首先我们需要了解一下 Java 中的内存模型
46 |
47 | 
48 |
49 | 上图是 JVM 中的 Java 内存模型,可以看到,它主要由两部分组成,一部分是线程独有的`程序计数器`,`虚拟机栈`,`本地方法栈`,这部分的数据由于是线程独有的,所以不存在一致性问题(我们说的一致性问题往往指多线程间的数据一致性),一部分是线程共享的`堆`和`方法区`,我们重点看一下堆内存。
50 |
51 |
52 |
53 | 我们知道,线程执行是要占用 CPU 的,我们知道 CPU 是从寄存器里取数据的,寄存器里没有数据的话,就要从内存中取,而众所周知这两者的速度差异极大,可谓是一个天上一个地上,所以为了缓解这种矛盾,CPU 内置了三级缓存,每次线程执行需要数据时,就会把堆内存的数据以 cacheline(一般是 64 Byte) 的形式先加载到 CPU 的三级缓存中来,这样之后取数据就可以直接从缓存中取从而极大地提升了 CPU 的执行效率(如下图示)
54 |
55 |
56 |
57 | 
58 |
59 |
60 |
61 | 但是这样的话由于线程加载执行完数据后数据往往会缓存在 CPU 的寄存器中而不会马上刷新到内存中,从而导致其他线程执行如果需要堆内存中共享数据的话取到的就不会是最新数据了,从而导致数据的不一致
62 |
63 |
64 |
65 | 举个例子,以执行以下代码为例
66 |
67 | ```java
68 | //线程1执行的代码
69 | int i = 0;
70 | i = 10;
71 |
72 | //线程2执行的代码
73 | j = i;
74 | ```
75 |
76 | 在线程 1 执行完后 i 的值为 10,然后 2 开始执行,此时 j 的值很可能还是 0,因为线程 1 执行时,会先把 i = 0 的值从内存中加载到 CPU 缓存中,然后给 i 赋值 10,**此时的 10 是更新在 CPU 缓存中的**,而**未刷新到内存中**,当线程 2 开始执行时,首先会将 i 的值从内存中(其值为 0)加载到 CPU 中来,故其值依然为 0,而不是 10,这就是典型的由于 CPU 缓存而导致的数据不一致现象。
77 |
78 |
79 |
80 | 那么怎么解决可见性导致的数据不一致呢,其实只要让 CPU 修改共享变量时立即写回到内存中,同时通过总线协议(比如 MESI)通过其他 CPU 所读取的此数据所在 cacheline 无效以重新从内存中读取此值即可
81 |
82 | #### 有序性
83 |
84 | 除了可见性造成的数据不一致外,指令重排序也会造成数据不一致
85 |
86 | ```java
87 | int x = 1; ①
88 | boolean flag = true; ②
89 | int y = x + 1; ③
90 | ```
91 |
92 | 以上代码执行步骤可能很多人认为是按正常的 ①,②,③ 执行的,但实际上很可能编译器会将其调换一下位置,实际的执行顺序可能是 ①③②,或 ②①③,也就是说 ①③ 是紧邻的,为什么会这样呢,因为执行 1 后,CPU 会把 x = 1 从内存加载到寄存器中,如果此时直接调用 ③ 执行,那么 CPU 就可以直接读取 x 在寄存器中的值 1 进行计算,反之,如果先执行了语句 ②,那么有可能 x 在寄存器中的值被覆盖掉从而导致执行 ③ 后又要重新从内存中加载 x 的值,有人可能会说这样的指令重排序貌似也没有多大问题呀,那么考虑如下代码
93 |
94 |
95 |
96 | ```java
97 | public class Reordering {
98 |
99 | private static boolean flag;
100 | private static int num;
101 |
102 | public static void main(String[] args) {
103 | Thread t1 = new Thread(new Runnable() {
104 | @Override
105 | public void run() {
106 | while (!flag) {
107 | Thread.yield();
108 | }
109 |
110 | System.out.println(num);
111 | }
112 | }, "t1");
113 | t1.start();
114 | num = 5; ①
115 | flag = true; ②
116 | }
117 | }
118 | ```
119 |
120 | 以上代码最终输出的值正常情况下是 5,但如果上述 ① ,② 两行指令发生重排序,那么结果是有可能为 0 的,从而导致我们观察到的数据不一致的现象发生,所以显然解决方案是避免指令重排序的发生,也就是保证指令按我们看到的代码的顺序有序执行,也就是我们常说的有序性,一般是通过在指令之间添加内存屏障来避免指令的重排序
121 |
122 | > 那么如何保证可见性与有序性呢
123 |
124 | 相信大家都非常熟悉了,使用 volatile 可以保证可见性与有序性,只要在声明属性变量时添加上 volatile 就可以让此变量实现强一致性,也就是说上述的 Reordering 类的 flag 只要声明为 volatile,那么打印结果就永远是 5!
125 |
126 | 好了,现在问题来了,CHM 到底是不是强一致性呢,首先我们以 Java 8 为例来看下它的设计结构(和之前的版本相差不大,主要加上了红黑树提升了查询效率)
127 |
128 |
129 |
130 | 
131 |
132 | 来看下这个 table 数组和节点的声明方式(以下定义 8 和 之前的版本中都是一样的):
133 |
134 | ```java
135 | public class ConcurrentHashMap extends AbstractMap
136 | implements ConcurrentMap, Serializable {
137 | transient volatile Node[] table;
138 | ...
139 | }
140 |
141 | static class Node implements Map.Entry {
142 | final int hash;
143 | final K key;
144 | volatile V val;
145 | volatile Node next;
146 | ...
147 | }
148 | ```
149 |
150 | 可以看到 CHM 的 table 数组,Node 中的 值 val,下一个节点 next 都声明为了 volatile,于是有学员就提出了一个疑问
151 |
152 |
153 |
154 | 
155 |
156 | 讲师的回答也提到 CHM 为弱一致性的重要原因:即如果 table 中的某个槽位为空,此时某个线程执行了 key,value 的赋值操作,那么此槽位会**新增**一个 Node 节点,在 JDK 8 以前,CHM 是通过以下方式给槽位赋 Node 的
157 |
158 | ```java
159 | V put(K key, int hash, V value, boolean onlyIfAbsent) {
160 | lock();
161 | ...
162 | tab[index] = new HashEntry(...);
163 | ...
164 | unlock();
165 | }
166 | ```
167 |
168 | 然后是通过以下方式来根据 key 来读取 value 的
169 |
170 | ```java
171 | V get(Object key, int hash) {
172 | if (count != 0) { // read-volatile
173 | HashEntry e = getFirst(hash);
174 | while (e != null) {
175 | if (e.hash == hash && key.equals(e.key)) {
176 | V v = e.value;
177 | if (v != null)
178 | return v;
179 | return readValueUnderLock(e); // recheck
180 | }
181 | e = e.next;
182 | }
183 | }
184 | return null;
185 | }
186 | ```
187 |
188 | 可以看到 put 时是直接给数组中的元素赋值的,而由于 get 没有加锁,所以无法保证线程 A put 的新元素对执行 get 的线程可见。
189 |
190 |
191 |
192 | put 是有加锁的,所以其实如果 get 也加锁的话,那么毫无疑问 get 是可以立即拿到 put 的值的。为什么加锁也可以呢,其实这是 JLS(Java Language Specification Java 语言规范) 规定的几种情况,简单地说就是支持 happens before 语义的可以保证数据的强一致性,在官网(https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html)中列出了几种支持 Happens before 的情况,其中**指出使用 volatile,synchronize,lock 是可以确保 happens before 语义的**,也就是说使用这三者可以保证数据的强一致性,可能有人就问了,到底什么是 happens before 呢,**其实本质是一种能确保线程及时刷新数据到内存,另一线程能实时从内存读取最新数据以保证数据在线程之间保持一致性的一种机制**,我们以 lock 为例来简单解释下
193 |
194 |
195 |
196 | ```java
197 | public class LockDemo {
198 | private int x = 0;
199 |
200 | private void test() {
201 | lock();
202 | x++;
203 | unlock();
204 | }
205 | }
206 |
207 | ```
208 |
209 | 如果线程 1 执行 test,由于拿到了锁,所以首先会把数据(此例中为 x = 0)从内存中加载到 CPU 中执行,执行 x++ 后,x 在 CPU 中的值变为 1,然后解锁,解锁时会把 x = 1 的值立即刷新到内存中,这样下一个线程再执行 test 方法再次获取相同的锁时又从内存中获取 x 的最新值(即 1),**这就是我们通常说的对一个锁的解锁, happens-before 于随后对这个锁的加锁**,可以看到,通过这种方式可以保证数据的一致性
210 |
211 |
212 |
213 | 至此我们明白了:**在 Java 8 以前,CHM 的 get,put 确实是弱一致羽性**,可能有人会问为什么不对 get 加锁呢,加上了锁不就可以确保数据的一致性了吗,可以是可以,但别忘了 CHM 是为高并发设计而生的,加了锁不就导致并发性大幅度下降了么,那 CHM 存在的意义是啥?
214 |
215 |
216 |
217 | > 所以 put,get 就无法做到强一致性了吗?
218 |
219 |
220 |
221 | 我们在上文中已经知道,使用 volatile,synchronize,lock 是可以确保 happens before 语义的,同时经过分析我们知道使用 synchronize,lock 加锁的设计是不满足我们设计 CHM 的初衷的,那么只剩下 volatile 了,遗憾的是由于 Java 数组在元素层面的元数据设计上的缺失,是无法表达元素是 final、volatile 等语义的,所以 **volatile 可以修饰变量,却无法修饰数组中的元素**,还有其他办法吗?来看看 Java 8 是怎么处理的(这里只列出了写和读方法中的关键代码)
222 |
223 | ```java
224 | private static final sun.misc.Unsafe U;
225 |
226 | // 写
227 | final V putVal(K key, V value, boolean onlyIfAbsent) {
228 | ...
229 | for (Node[] tab = table;;) {
230 | if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
231 | if (casTabAt(tab, i, null,
232 | new Node(hash, key, value, null)))
233 | break;
234 | }
235 | }
236 | ...
237 | }
238 |
239 | static final boolean casTabAt(Node[] tab, int i,
240 | Node c, Node v) {
241 | return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
242 | }
243 |
244 |
245 | // 读
246 | public V get(Object key) {
247 |
248 | if ((tab = table) != null && (n = tab.length) > 0 &&
249 | (e = tabAt(tab, (n - 1) & h)) != null) {
250 | ...
251 | }
252 | return null;
253 | }
254 |
255 | @SuppressWarnings("unchecked")
256 | static final Node tabAt(Node[] tab, int i) {
257 | return (Node)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
258 | }
259 |
260 | ```
261 |
262 | 可以看到在 Java 8 中,CHM 使用了 unsafe 类来实现读写操作
263 |
264 | * 对于写首先使用 compareAndSwapObject(即我们熟悉的 CAS)来更新**内存中**数组中的元素
265 | * 对于读则使用了 getObjectVolatile 来读取**内存中**数组中的元素(在底层其实是用了 C++ 的 volatile 来实现 java 中的 volatile 效果,有兴趣可以看看)
266 |
267 | 由于读写都是直接对内存操作的,所以通过这样的方式可以保证 put,get 的强一致性,至此真相大白! Java 8 以后 put,get 是可以保证强一致性的!CHM 是通过 compareAndSwapObject 来取代对数组元素直接赋值的操作,通过 getObjectVolatile 来补上无法表达数组元素是 volatile 的坑来实现的
268 |
269 |
270 |
271 | 注意并不是说 CHM 所有的操作都是强一致性的,比如 Java 8 中计算容量的方法 size() 就是弱一致性(Java 7 中此方法反而是强一致性),所以我们说强/弱一致性一定要确定好前提(比如指定 Java 8 下 CHM 的 put,get 这种场景)
272 |
273 |
274 |
275 | ### 总结
276 |
277 | 其实 Java 8 对 CHM 进行了一番比较彻底的重构,让它的性能大幅度得到了提升,比如弃用 segment 这种设计,改用对每个槽位做分段锁,使用红黑树来降低查询时的复杂度,扩容时多个线程可以一起参与扩容等等,可以说 Java 8 的 CHM 的设计非常精妙,集 CAS,synchroinize,泛型等 Java 基础语法之大成,又有巧妙的算法设计,读后确实让人大开眼界,有机会我会再和大家分享一下其中的设计精髓,另外我们对某些知识点一定要多加思考,最好能自己去翻翻源码验证一下真伪,相信你会对网上的一些谬误会更容易看穿。
278 |
279 |
280 |
281 | 最后欢迎大家关注我的公号,加我好友:「geekoftaste」,一起交流,共同进步!
282 |
283 | 
284 |
285 |
--------------------------------------------------------------------------------
/MySQL/深入浅出索引原理.md:
--------------------------------------------------------------------------------
1 | 索引可以说是每个工程师的必备技能点,明白索引的原理对于写出高质量的 SQL 至关重要,今天我们就从 0 到 1 来理解下索引的原理,相信大家看完不关对索引还会对 MySQL 中 InnoDB 存储引擎的最小存储单位「页」会有更深刻的认识
2 |
3 | ### 从实际需求出发
4 |
5 | 假设有如下用户表:
6 |
7 | ```sql
8 | CREATE TABLE `user` (
9 | `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
10 | `name` int(11) DEFAULT NULL COMMENT '姓名',
11 | `age` tinyint(3) unsigned DEFAULT NULL COMMENT '年龄',
12 | `height` int(11) DEFAULT NULL COMMENT '身高',
13 | PRIMARY KEY (`id`)
14 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';
15 | ```
16 |
17 | 可以看到存储引擎使用的是 InnoDB,我们先来看针对此表而言工作中比较常用的 SQL 语句都有哪此,毕竟技术是要为业务需求服务的,
18 |
19 | ```sql
20 | 1. select * from user where id = xxx
21 | 2. select * from user order by id asc/desc
22 | 3. select * from user where age = xxx
23 | 4. select age from user where age = xxx
24 | 5. select age from user order by age asc/desc
25 | ```
26 |
27 | 既然要查询那我们首先插入一些数据吧,毕竟没有数据何来查询
28 |
29 | ```sql
30 | insert into user ('name', 'age', 'height') values ('张三', 20, 170);
31 | insert into user ('name', 'age', 'height') values ('李四', 21, 171);
32 | insert into user ('name', 'age', 'height') values ('王五', 22, 172);
33 | insert into user ('name', 'age', 'height') values ('赵六', 23, 173);
34 | insert into user ('name', 'age', 'height') values ('钱七', 24, 174);
35 | ```
36 |
37 | 插入后表中的数据如下:
38 |
39 |
40 |
41 | 
42 |
43 | 不知你有没发现我们在插入的时候并没有指定 id 值,但 InnoDB 为每条记录默认添加了一个 id 值,而且这个 id 值是递增的,每插入一条记录,id 递增 1,id 为什么要递增呢,主要是为了查询方便,每条记录按 id 由小到大的顺序用链表连接起来,这样每次查找 id = xxx 的值就从 id = 1 开始依次往后查找即可
44 |
45 | 
46 |
47 |
48 |
49 | 现在假设我们要执行以下 SQL 语句,MySQL 会怎么查询呢
50 |
51 | ```sql
52 | select * from user where id = 3
53 | ```
54 |
55 | ### 页
56 |
57 | 如前所述,首先从 id 最小的记录也就是 id = 1 读起,每次读一条记录,将其 id 值与要查询的值比较,连续读三次记录于是找到了记录 3,注意这个读的操作,是首先需要把存储在磁盘的记录读取到内存然后再比较 id 的,从磁盘读到内存算一次 IO,也就是说此过程中产生了三次 IO,如果只是几条记录还好,但如果要比较的条数多的话对性能是非常严重的挑战,如果我要查询为 id = 100 的记录那岂不是要产生 100 次 IO?既然瓶颈在 IO,那该怎么改进呢,很简单,我们现在的设计一次 IO 只能读一条记录,那改为一次 IO 能读取 100 条甚至更多不就只产生一次 IO 了吗,这背后的思想就是**程序局部性原理**:当用到了某项数据时,很可能会用到与之相邻的数据,所以干脆把相依的数据一起加载进去(你从 id = 1 开始读,那很可能用到 id = 1 紧随其后的元素,于是干脆把 id = 1 ~ id = 100 的记录都加载进去)
58 |
59 |
60 |
61 | 当然一次 IO 的读取记录也并不是多多益善,总不能为了一条查询记录而把很多无关的数据都加载到内存吧,那会造成资源的极大浪费,于是我们采用了一个比较折中的方案,我们规定一次 IO 读取 16 K 的数据,假设为 100 条数据好了,这样如果我们要查询 id = 100 的记录,只产生了一次 IO 读(id=1~id=100 的记录),比起原来的 100 次 IO 提升了 100 倍的性能
62 |
63 |
64 |
65 | 
66 |
67 | 我们把这 16KB 的记录组合称为一个**页**
68 |
69 | ### 页目录
70 |
71 | 一次 IO 会读取一个页,然后再在内存里查找页里的记录,在内存里查找确实比磁盘快多了,但我们仍不满意,因为如果要查找 id = 100 的记录,要先从 id = 1 的记录比较起,然后是id=2,...,id=100,需要比较 100 次,能否更快一点?
72 |
73 |
74 |
75 | 可以参照二分查找,先查找 id = (1+100)/2 = 50,由于 50 < 100,接着在 50~100 的记录中查,然后再在 75~100 中查,这样经过 7 次就可找到 id = 100 次的记录,比起原来的 100 次比较又提升了不少性能。但现在问题来了,第一次要找到 id = 50 的记录又得从 id = 1 开始遍历 50 次才能找到,能否一下就定位到 id=50 的记录呢,如果不能,哪怕第一次从 id = 30 或 40 开始查找也行啊
76 |
77 |
78 |
79 | 有什么数据结构能满足这种需求呢,还记得跳表不,每隔 n 个元素抽出一个组成一级索引,每隔 2*n 个元素组成二级索引。。。
80 |
81 |
82 |
83 | 
84 |
85 | 如图示,以建立一级索引为例,我们在查找的时候先在一级索引查找,在一级索引里定位到了再到链表里查找,比如我们要找 7 这个数字,如果不用跳表直接在链表里查,需要比较 7 次,而如果用了跳表我们先在一级索引查找,发现只要比较 3 次,减少了四次,所以我们可以利用跳表的思想来减少查询次数,具体操作如下,每 4 个元素为一组组成一个槽(slot),槽只记录本组元素最大的那条记录以及记录本组有几条记录
86 |
87 |
88 |
89 | 
90 |
91 |
92 |
93 | 现在我们假设我们想要定位 id = 9 的那条记录,该怎么做呢,很简单:**首先定位记录在哪个槽,然后遍历此槽中的元素**
94 |
95 |
96 |
97 | 1. 定位在哪个槽,首先取最小槽和最大槽对应的 id(分别为 4, 12),先通过二分查找取它们的中间值为 (4+12)/2 = 8,8 小于 9,且槽 2 的最大 id 为 12,所以可知 id = 9 的记录在槽 2 里
98 | 2. 遍历槽 2 中的元素,现在问题来了,我们知道每条记录都构成了一个单链表,而每个槽指向的是此分组中的最大 id 值,该怎么从此槽的第一个元素开始遍历呢,很简单,从槽 1 开始遍历不就行了,因为它指向元素的下一个元素即为槽 2 的起始元素,遍历后发现槽 2 的 第一个元素即为我们找到的 id 为 9 的元素
99 |
100 |
101 |
102 | 可以看到通过这种方式在页内很快把我们的元素定位出来了,MySQL 规定每个槽中的元素在 1~8 条,所以只要定位了在哪个槽,剩下的比较就不是什么问题了,当然一个页装的记录终究是有限的,如果页满了,就要要开辟另外的页来装记录了,页与页之间通过链表连接起来,但注意看下图,为啥要用双向链表连接起来呢,别忘了最开头我们列出的 「order by id asc 」和「order by id desc 」这两个查询条件,也就是说记录需要同时支持正序与逆序查找,这就是为什么要使用双向链表的原因
103 |
104 |
105 |
106 | 
107 |
108 |
109 |
110 | ### B+ 树的诞生
111 |
112 | 现在问题来了,如果有很多页,该怎么定位元素呢,如果元素刚好在前几个页还好,大不了遍历前几个页也很快,但如果要查 id = 100w 这样的元素一页页遍历的话就要遍历 1w 页(假设每页 100 条记录),那显然是不可接受的,如何改进呢,其实之前建的页内目录已经给了我们启发,既然在页内我们可以通过为记录建页目录的形式来先定位元素在哪个槽然后再找,那针对多页,能否先定位元素在哪个页呢,也就是说我们可以为页也建立一个目录,这个目录里的每一条记录都对应着页及页中的最小记录,当然这个目录也是以页的形式存在的,为了便于区分 ,我们把针对页生成的目录对应的页称为**目录页**,而之前存储**完整记录**的页称为**数据页**
113 |
114 |
115 |
116 | 
117 |
118 |
119 |
120 | **画外音**:目录页与数据页一样,内部也是有槽的,上文为了方便展示,没有画出,目录页和数据除了记录数据不一样,其他结构都是一致的
121 |
122 |
123 |
124 | 现在如果要查找 id = xxx 的记录就很简单了,只要先到目录页中定位它的起始页然后再依次查找即可,由于不管是目录页还是数据页里面都有槽,所以无论是定位目录页的页码还是定位数据页中的记录都是非常快的。
125 |
126 |
127 |
128 | 当然了,随着页的增多,目录页存放的记录也越来越多,目录页也终归会满的,那就再建一个目录页吧,于是现在问题来了,怎么定位要找的 id 是在哪个目录页呢,再次制定针对目录页的目录页不就行了,如下
129 |
130 | 
131 |
132 |
133 |
134 | 看到上面这个结构你想到了什么?没错,这就是一颗 B+ 树!到此相信你已经明白了 B+ 树的演进之路,也明白了它的原理,可以看到这颗 B+ 树有三层,我们把最顶层的目录页称为**根节点**,最下层的存储完整记录的页称为**叶子节点**,
135 |
136 | 现在我们再来看一下如何查找 id = 55 的记录,首先会加载根节点,发现应该在页码 30 的页中去找,于是加载页 30,在页 30 中又发现应该在页 4 中查中,于是再次把页 4 加载进内存中,然后在页 4 中依次遍历查找,可以看到总共经历了 3 次 IO(B+树有几层就会有几次 IO),页读取之后会缓存在内存中,再读的话如果命中内存中的页就会直接从内存中获取。有人可能会问,如果 B+ 树层数很多,那岂不是可能会有很多次 IO,我们简单的算一下,假设数据页可以存储 100 条记录,目录页可以存储 1000 条记录(目录页由于只存储了主键,不存储完整的数据,所以可以存储更多的记录),那么
137 |
138 |
139 |
140 | - 如果`B+`树只有 1 层,也就是只有 1 个用于存放用户记录的节点,最多能存放`100`条记录。
141 | - 如果`B+`树有 2 层,最多能存放`1000×100=100000`条记录。
142 | - 如果`B+`树有 3 层,最多能存放`1000×1000×100=100000000`条记录。
143 | - 如果`B+`树有 4 层,最多能存放`1000×1000×1000×100=100000000000`条记录!
144 |
145 | 所以一般3~4 层的 B+ 树足以满足我们的要求,而且每次读取后会缓存在内存中(当然也会根据一定的算法被换出内存),所以整体来看 3~4 层 B+ 树足以满足我们需求
146 |
147 |
148 |
149 | ### 聚簇索引与非聚簇索引
150 |
151 |
152 |
153 | 相信你已经发现了,上文中我们举的 B+ 树的例子针对的是 id 也就是主键的索引,不难发现主键索引中的叶子结点存储了完整的 SQL 记录,我们把这种存储了完整记录的索引称为聚簇索引,**只要你定义了主键,那么主键索引就是聚簇索引**。
154 |
155 |
156 |
157 | 那么如果是非主键的列创建的索引又是怎样的形式呢,非叶子节点的形式完全一样,但叶子节点的存储则有些不同,非主键列索引叶子节点上存储的是**索引列及主键值**,比如我们假设对 age 这个列建立了索引,那么它的索引树如下
158 |
159 | 
160 |
161 |
162 |
163 | 可以看到非叶子节点保存的是「age 值 + 页码」,而叶子节点保存的是 「age 值+主键值」,那么你可能就会疑惑了,如下 SQL 是怎么取出完整记录的呢
164 |
165 | ```sql
166 | select * from user where age = xxx
167 | ```
168 |
169 | 第一步大家都知道,上述 SQL 可以命中 age 列对应的索引,然后找到叶子节点上对应的记录(如果有的话),但叶子节点上的记录只有 age 和 id 这两列,而你用的是 select *,意味着要查找 user 的所有列信息,该怎么办呢,答案是根据拿到的 id 再到聚簇索引找 id 对应的完整记录,这就是我们所说的**回表**,如果回表多的话显然会造成一定的性能问题,因为 id 可能分布在不同的页中,这意味着要将不同的页从磁盘读入内存,这些页很可能不是相邻的,也就意味着会造成大量的**随机 IO**,会严重地影响性能,看到这相信大家不难明白一道高频面试题:**为什么设置了命中了索引但还是造成了全表扫描**,其中一个原因就是虽然命中了索引但在叶子节点查询到记录后还要大量的回表,导致优化器认为这种情况还不如全表扫描会更快些
170 |
171 |
172 |
173 | 有人可能会问,为啥都二级索引不存储完整的记录呢,当然是为了节省空间,毕竟完整的数据是很耗空间的,如果每加一个索引都要额外存储完整的记录,那会造成很多数据冗余。
174 |
175 |
176 |
177 | 怎么避免这种情况呢?**索引覆盖**,如果如下 SQL 满足你的需求,那么就建议采用如下形式
178 |
179 | ```sql
180 | select age from user where age = xxx
181 | select age,id from user where age = xxx
182 | ```
183 |
184 | 不难发现这种 SQL 的特点是要获取的列(age)就是索引列本身(包括 id),这样在根据 age 的索引查到叶子节上对应的记录后,由于记录本身就包含了这些列,就不需要回表了,能提升性能
185 |
186 |
187 |
188 | **磁盘预读**
189 |
190 | 接下来我们讨论一个网上很多人搞不拎清的一个问题,我们知道操作系统是以页为单位来管理内存的,在 Linux 中,一页的大小默认为 4 KB,也就是说无论是从磁盘载入数据到内存还是将内存写回磁盘,操作系统都会以页为单位进行操作,哪怕你只对一个空文件只写入了一个字节,操作系统也会为其分配一个页的大小( 4 KB)
191 |
192 | 
193 |
194 | `如图示,向磁盘写入了两个 byte ,但操作系统依然为其分配了一个页(4 KB)的大小`
195 |
196 |
197 |
198 | innoDB 也是以页为单位来存储与读取的,而 innoDB 页的默认大小为 16 KB,那么网上很多人的疑问是这是否意味着它需要执行 4 次 IO 才能把 innoDB 的页读完呢?不是的,只需要一次 IO,为什么?这需要理解一点磁盘读取数据的工作原理
199 |
200 |
201 |
202 |
203 |
204 | #### 磁盘的构造
205 |
206 | 首先我们来看看磁盘的物理结构
207 |
208 | 
209 |
210 |
211 |
212 |
213 |
214 | 硬盘内部主要部件为磁盘盘片、传动磁臂、读写磁头和转轴,数据主要写入磁盘的盘片上的,盘片又是由若干个**扇区**构成的,数据写入读取都是以扇区为基本单位的,另外以盘片中心为圆心,把盘片分成若干个同心圆,那每一个划分圆的“线条”,就称为**磁道**
215 |
216 | 那么数据是如何读取与写入的呢,主要有三步
217 |
218 |
219 |
220 | 1. **寻道**:既然数据是保存在扇区上的,那我首先我们需要知道它到底是在哪个扇区上吧,这就需要先让磁头移动到扇区所在的磁道上,我们把它称为寻道时间,平均寻道时间一般在3-15ms
221 | 2. **旋转延迟**: 磁盘移动到扇区所在的磁盘上时,此时的磁头对准的还不一定我们想要的数据对应的扇区,所以需要等待盘片旋转片刻,等到我们想要的数据对应的扇区落到磁头下,旋转延迟取决于磁盘转速,通常用磁盘旋转一周所需时间的1/2表示。比如:7200rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms,而转速为15000rpm的磁盘其平均旋转延迟为2ms
222 | 3. **数据传输**:经过前面的两步,磁头终于开始读写数据了,目前IDE/ATA能达到133MB/s,SATA II可达到300MB/s的接口数据传输率,**数据传输时间通常远小于前两部分消耗时间**。可忽略不计
223 |
224 | 注意数据传输中的忽略不计是有前提的,即是需要读取**连续相邻**的扇区,也就是我们常说的顺序 IO,磁盘顺序 IO 的读写速度可以媲美甚至超越内存的随机 IO,所以这部分时间可以忽略不计,(大家熟知的 Kafka 之所以性能强悍,有一个重要原因就是利用了磁盘的顺序读写),但如果要读取的数据是分布在不同的扇区的话,也就变成了随机 IO,随机 IO 毫无疑问增大了寻道时间和旋转延迟,性能是非常堪忧的(典型代表就是上文提到的 回表时大量 id 分布在不同的页上,造成了大量的随机 IO)
225 |
226 | 
227 |
228 | **如图示**:图片来自著名学术期刊 ACM Queue 上的性能对比图,可以看到磁盘顺序 IO(Sequential Disk)的速度比内存随机读写(Random memory)还快
229 |
230 |
231 |
232 | 那读取 innoDB 中的一个页为啥算一次 IO 呢,相信你已经猜到了,因为这一个页是连续分配的,也即意味着它们的扇区是相邻的,所以它是顺序 IO
233 |
234 |
235 |
236 | 操作系统是以页为单位来管理内存的,它可以一次加载整数倍的页,而 innoDB 的页大小为 16KB,刚好是操作系统页(4KB)的 4 倍,所以可以指定在读取的起始地址连续读取 4 个操作系统页,即 16 KB,这就是我们说的**磁盘预读**,至此相信大家不难明白为啥说读取一页其实只是一次 IO 而不是 4 次了
237 |
238 |
239 |
240 | ### 总结
241 |
242 | 看完本文相信大家能明白索引的由来了,此外对页以及磁盘预读对性能的提升应该也有不少了解,其实 MySQL 的页结构与我们推演的结构有些许出入,不过不影响整体的理解,如果大家有兴趣深入了解 MySQL 的页结构,强烈建议大家看看文末的<>这本书,讲解得非常细致
243 |
244 |
245 | * 巨人的肩膀
246 |
247 | 1. 磁盘I/O那些事: https://tech.meituan.com/2017/05/19/about-desk-io.html
248 | 2. 带你从头到尾捋一遍MySQL索引结构: https://blog.51cto.com/u_12302929/3290492
249 | 3. MySQL 是怎样运行的:从根儿上理解 MySQL
250 |
251 | 最后欢迎大家关注我的公众号「**码海**」,第一时间收到干货推文
--------------------------------------------------------------------------------
/系统设计/高性能网关设计实践.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 之前的[高性能短链设计](https://mp.weixin.qq.com/s/YTrBaERcyjvw7A0Fg2Iegw)一文颇受大家好评,共被转载 **47** 次,受宠若惊,在此感谢大家的认可!在文末简单提了一下 OpenResty,一些读者比较感兴趣,刚好我们接入层网关也是用的 OpenResty,所以希望通过对网关设计的介绍来简单总结一下 OpenResty 的相关知识点,争取让大家对 OpenResty 这种高性能 Web 平台有一个比较全面的了解。本文会从以下几个方面来讲解。
3 |
4 | * 网关的作用
5 | * 接入层网关架构设计与实现
6 | * 技术选型
7 | * OpenResty 原理剖析
8 |
9 |
10 | ## 网关的作用
11 |
12 | 网关作为所有请求的流量入口,主要承担着安全,限流,熔断降级,监控,日志,风控,鉴权等功能,网关主要有两种类型
13 |
14 | * 一种是接入层网关(access gateway),主要负责路由,WAF(防止SQL Injection, XSS, 路径遍历, 窃取敏感数据,CC攻击等),限流,日志,缓存等,这一层的网关主要承载着将请求路由到各个应用层网关的功能
15 |
16 | * 另一种是应用层网关,比如现在流行的微服务,各个服务可能是用不同的语言写的,如 PHP,Java 等,那么接入层就要将请求路由到相应的应用层集群,再由相应的应用层网关进行鉴权等处理,处理完之后再调用相应的微服务进行处理,应用层网关也起着路由,超时,重试,熔断等功能。
17 |
18 | 目前市面上比较流行的系统架构如下
19 |
20 | 
21 |
22 |
23 | 可以看到接入层网关承载着公司的所有流量,对性能有很高的要求,它的设计决定着整个系统的上限。所以我们今天主要谈谈接入层网关的设计。
24 |
25 | ## 接入层网关架构设计与实现
26 |
27 | 首先我们要明白接入层网关的核心功能是:**根据路由规则将请求分发到对应的后端集群**,所以要实现如下几个功能模型 。
28 |
29 | 1、 路由:根据请求的 host, url 等规则转发到指定的上游(相应的后端集群)
30 | 2、 路由策略插件化:这是网关的**灵魂所在**,路由中会有身份认证,限流限速,安全防护(如 IP 黑名单,refer异常,UA异常,需第一时间拒绝)等规则,这些规则以插件的形式互相组合起来以便只对某一类的请求生效,每个插件都即插即用,互不影响,这些插件应该是**动态可配置**的,动态生效的(无须重启服务),为啥要可动态可配置呢,因为每个请求对应的路由逻辑,限流规则,最终请求的后端集群等规则是不一样的
31 |
32 | 
33 |
34 | 如图示,两个请求对应的路由规则是不一样的,它们对应的路由规则(限流,rewrite)等通过各个规则插件组合在一起,可以看到,光两个请求 url 的路由规则就有挺多的,如果一个系统大到一定程度,url 会有不少,就会有不少规则,这样每个请求的规则就必须**可配置化**,**动态化**,最好能在管理端集中控制,统一下发。
35 |
36 | 3、后端集群的动态变更
37 |
38 | 路由规则的应用是为了确定某一类请求经过这些规则后最终到达哪一个集群,而我们知道请求肯定是要打到某一台集群的 ip 上的,而机器的扩缩容其实是比较常见的,所以必须支持动态变更,总不能我每次上下线机器的时候都要重启系统让它生效吧。
39 |
40 | 4、监控统计,请求量、错误率统计等等
41 |
42 | 这个比较好理解,在接入层作所有流量的请求,错误统计,便于打点,告警,分析。
43 |
44 | 要实现这些需求就必须对我们采用的技术:OpenResty 有比较详细的了解,所以下文会简单介绍一下 OpenResty 的知识点。
45 |
46 | ## 技术选型
47 |
48 | 有人可能第一眼想到用 Nginx,没错,由于 Nginx 采用了 epoll 模型(非阻塞 IO 模型),确实能满足大多数场景的需求(经过优化 100 w + 的并发数不是问题),但是 Nginx 更适合作为静态的 Web 服务器,因为对于 Nginx 来说,如果发生任何变化,都需要修改磁盘上的配置,然后重新加载才能生效,它并没有提供 API 来控制运行时的行为,而如上文所述,动态化是接入层网关非常重要的一个功能。所以经过一番调研,我们选择了 OpenResty,啥是 OpenResty 呢,来看下官网的定义:
49 |
50 | > OpenResty® 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
51 | > OpenResty® 的目标是让你的Web服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
52 |
53 | 可以简单理解为,OpenResty = Nginx + Lua, 通过 Lua 扩展 Nginx 实现的可伸缩的 Web 平台
54 | 。它利用了 Nginx 的高性能,又在其基础上添加了 Lua 的脚本语言来让 Nginx 也具有了动态的特性。通过 OpenResty 中 lua-Nginx-module 模块中提供的 Lua API,我们可以动态地控制路由、上游、SSL 证书、请求、响应等。甚至可以在不重启 OpenResty 的前提下,修改业务的处理逻辑,并不局限于 OpenResty 提供的 Lua API。
55 |
56 | 关于静态和动态有一个很合适的类比:如果把 Web 服务器当做是一个正在高速公路上飞驰的汽车,Nginx 需要停车才能更换轮胎,更换车漆颜色,而 OpenResty 中可以边跑边换轮胎,更换车漆,甚至更换发动机,直接让普通的汽车变成超跑!
57 |
58 |
59 | 除了以上的动态性,还有两个特性让 OpenResty 独出一格。
60 |
61 | **1、详尽的文档和测试用例**
62 |
63 | 作为开源项目,文档和测试毫无疑问是其是否靠谱的关键,它的文档非常详细,作者把每个注意的点都写在文档上了,多数时候只要看文档即可,每一个测试案例都包含完整的 Nginx 配置和 lua 代码。以及测试的输入数据和预期的输出数据。
64 |
65 | **2、同步非阻塞**
66 |
67 | OpenResty 在诞生之初就支持了协程,并且基于此实现了同步非阻塞的编程模型。
68 | **画外音:协程(coroutine)我们可以将它看成一个用户态的线程,只不过这个线程是我们自己调度的,而且不同协程的切换不需要陷入内核态,效率比较高。(一般我们说的线程是要指内核态线程,由内核调度,需要从用户空间陷入内核空间,相比协程,对性能会有不小的影响)**
69 |
70 | 啥是同步非阻塞呢。假设有以下两个两行代码:
71 |
72 | ```lua
73 | local res, err = query-mysql(sql)
74 | local value, err = query-redis(key)
75 | ```
76 |
77 | **同步**:必须执行完查询 mysql,才能执行下面的 redis 查询,如果不等 mysql 执行完成就能执行 redis 则是异步。
78 |
79 | **阻塞**:假设执行 sql 语句需要 1s,如果在这 1s 内,CPU 只能干等着不能做其它任何事,那就是阻塞,如果在 sql 执行期间可以做其他事(注意由于是同步的,所以不能执行以下的 redis 查询),则是非阻塞。
80 |
81 | 同步关注的是语句的先后执行顺序,如果上一个语句必须执行完才能执行下一个语句就是同步,如果不是,就是异步,阻塞关注的是线程是 CPU 是否需要在 IO 期间干等着,如果在 IO(或其他耗时操作期间)期间可以做其他事,那就是非阻塞,不能动,则是阻塞。
82 |
83 | 那么 OpenResty 的工作原理是怎样的呢,又是如何实现同步非阻塞的呢。
84 |
85 | ## OpenResty 原理剖析
86 |
87 | ### 工作原理剖析
88 | 由于 OpenResty 基于 Nginx 实现的,我们先来看看 Nginx 的工作原理
89 |
90 | 
91 |
92 | Nginx 启动后,会有一个 master 进程和多个 worker 进程 , master 进程接受管理员的信号量(如 Nginx -s reload, -s stop)来管理 worker 进程,master 本身并不接收 client 的请求,主要由 worker 进程来接收请求,不同于 apache 的每个请求会占用一个线程,且是同步IO,Nginx 是异步非阻塞的,每个 worker 可以同时处理的请求数只受限于内存大小,这里就要简单地了解一下 nginx 采用的 epoll 模型:
93 |
94 | epoll 采用多路复用模型,即同一时间虽然可能会有多个请求进来, 但只会用一个线程去监视,然后哪个请求数据准备好了,就调用相应的线程去处理,就像图中所示,同拨开关一样,同一时间只有一个线程在处理, epoll 是基于事件驱动模型的,每个请求进来注册事件并注册 callback 回调函数,等数据准入好了,就调用回调函数进行处理,它是异步非阻塞的,所以性能很高。
95 |
96 | 
97 |
98 |
99 | 打个简单的比方,我们都有订票的经验,当我们委托酒店订票时,接待员会先把我们的电话号码和相关信息等记下来(注册事件),挂断电话后接待员在操作期间我们就可以去做其他事了(非阻塞),当接待员把手续搞好后会主动打电话给我们通知我们票订好了(回调)。
100 |
101 |
102 | worker 进程是从 master fork 出来的,这意味着 worker 进程之间是互相独立的,这样不同 worker 进程之间处理并发请求几乎没有同步锁的限制,好处就是一个 worker 进程挂了,不会影响其他进程,我们一般把 worker 数量设置成和 CPU 的个数,这样可以减少不必要的 CPU 切换,提升性能,每个 worker 都是单线程执行的。
103 | 那么 LuaJIT 在 OpenResty 架构中的位置是怎样的呢。
104 |
105 | 
106 |
107 |
108 | 首先启动的 master 进程带有 LuaJIT 的机虚拟,而 worker 进程是从 master 进程 fork 出来的,在 worker 内进程的工作主要由 Lua 协程来完成,也就是说在同一个 worker 内的所有协程,都会共享这个 LuaJIT 虚拟机,每个 worker 进程里 lua 的执行也是在这个虚拟机中完成的。
109 |
110 | 同一个时间点,worker 进程只能处理一个用户请求,也就是说只有一个 lua 协程在运行,那为啥 OpenResty 能支持百万并发请求呢,这就需要了解 Lua 协程与 Nginx 事件机制是如何配合的了。
111 |
112 | 
113 |
114 | 如图示,当用 Lua 调用查询 MySQL 或 网络 IO 时,虚拟机会调用 Lua 协程的 yield 把自己挂起,在 Nginx 中注册回调,此时 worker 就可以处理另外的请求了(非阻塞),等到 IO 事件处理完了, Nginx 就会调用 resume 来唤醒 lua 协程。
115 |
116 | 事实上,由 OpenResty 提供的所有 API,都是非阻塞的,下文提到的与 MySQL,Redis 等交互,都是非阻塞的,所以性能很高。
117 |
118 |
119 |
120 |
121 | ### OpenResty 请求生命周期
122 |
123 | Nginx 的每个请求有 11 个阶段,OpenResty 也有11 个 \*_by_lua 的指令,如下图示:
124 |
125 | 
126 |
127 | 各个阶段 \*_by_lua 的解释如下
128 |
129 | ```shell
130 | set_by_lua:设置变量;
131 | rewrite_by_lua:转发、重定向等;
132 | access_by_lua:准入、权限等;
133 | content_by_lua:生成返回内容;
134 | header_filter_by_lua:应答头过滤处理;
135 | body_filter_by_lua:应答体过滤处理;
136 | log_by_lua:日志记录。
137 | ```
138 |
139 | 这样分阶段有啥好处呢,假设你原来的 API 请求都是明文的
140 |
141 | ```nginx
142 |
143 | # 明文协议版本
144 | location /request {
145 | content_by_lua '...'; # 处理请求
146 | }
147 | ```
148 |
149 | 现在需要对其加上加密和解密的机制,只需要在 access 阶段解密, 在 body filter 阶段加密即可,原来 content 的逻辑无需做任务改动,有效实现了代码的解藕。
150 |
151 | ```nginx
152 | # 加密协议版本
153 | location /request {
154 | access_by_lua '...'; # 请求体解密
155 | content_by_lua '...'; # 处理请求,不需要关心通信协议
156 | body_filter_by_lua '...'; # 应答体加密
157 | }
158 | ```
159 |
160 | 再比如我们不是要要上文提到网关的核心功能之一不是要监控日志吗,就可以统一在 log_by_lua 上报日志,不影响其他阶段的逻辑。
161 |
162 | ## worker 间共享数据的利器: shared dict
163 |
164 | worker 既然是互相独立的进程,就需要考虑其共享数据的问题, OpenResty 提供了一种高效的数据结构: shared dict ,可以实现在 worker 间共享数据,shared dict 对外提供了 20 多个 Lua API,都是原子操作的,避免了高并发下的竞争问题。
165 |
166 |
167 | ## 路由策略插件化实现
168 |
169 | 有了以上 OpenResty 点的铺垫,来看看上文提的网关核心功能 「路由策略插件化」,「后端集群的动态变更」如何实现
170 |
171 | 首先针对某个请求的路由策略大概是这样的
172 |
173 | 
174 |
175 | 整个插件化的步骤大致如下
176 |
177 | 1、每条策略由 url ,action, cluster 等组成,代表请求 url 在打到后端集群过程中最终经历了哪些路由规则,这些规则统一在我们的路由管理平台配置,存在 db 里。
178 |
179 | 2、OpenResty 启动时,在请求的 init 阶段 worker 进程会去拉取这些规则,将这些规则编译成一个个可执行的 lua 函数,这一个个函数就对应了一条条的规则。
180 |
181 | 
182 |
183 |
184 | 需要注意的是为了避免重复去 MySQL 中拉取数据,某个 worker 从 MySQL 拉取完规则(此步需要加锁,避免所有 worker 都去拉取)或者后端集群等配置信息后要将其保存在 shared dict 中,这样之后所有的 worker 请求只要从 shared dict 中获取这些规则,然后将其映射成对应模块的函数即可,如果配置规则有变动呢,配置后台通过接口通知 OpenResty 重新加载一下即可
185 |
186 | 
187 |
188 |
189 | 经过路由规则确定好每个请求对应要打的后端集群后,就需要根据 upstream 来确定最终打到哪个集群的哪台机器上,我们看看如何动态管理集群。
190 |
191 |
192 |
193 | ## 后端集群的动态配置
194 |
195 | 在 Nginx 中配置 upstream 的格式如下
196 |
197 | ```lua
198 | upstream backend {
199 | server backend1.example.com weight=5;
200 | server backend2.example.com;
201 | server 192.0.0.1 backup;
202 | }
203 | ```
204 | 以上这个示例是按照权重(weight)来划分的,6 个请求进来,5个请求打到 backend1.example.com, 1 个请求打到 backend2.example.com,如果这两台机器都不可用,就打到 192.0.0.1,这种静态配置的方式 upstream 的方式确实可行,但我们知道机器的扩缩容有时候比较频繁,如果每次机器上下线都要手动去改,并且改完之后还要重新去 reload 无疑是不可行的,出错的概率很大,而且每次配置都要 reload 对性能的损耗也是挺大的,为了解决这个问题,OpenResty 提供了一个 dyups 的模块来解决此问题, 它提供了一个 dyups api,可以动态增,删,创建 upsteam,所以在 init 阶段我们会先去拉取集群信息,构建 upstream,之后如果集群信息有变动,会通过如下形式调用 dyups api 来更新 upstream
205 |
206 | ```lua
207 |
208 | -- 动态配置 upstream 接口站点
209 | server {
210 | listen 127.0.0.1:81;
211 | location / {
212 | dyups_interface;
213 | }
214 | }
215 |
216 |
217 | -- 增加 upstream:user_backend
218 | curl -d "server 10.53.10.191;" 127.0.0.1:81/upstream/user_backend
219 |
220 | -- 删除 upstream:user_backend
221 | curl -i -X DELETE 127.0.0.1:81/upstream/user_backend
222 | ```
223 |
224 | 使用 dyups 就解决了动态配置 upstream 的问题
225 |
226 | ## 网关最终架构设计图
227 |
228 | 
229 |
230 | 通过这样的设计,最终实现了网关的配置化,动态化。
231 |
232 | ## 总结
233 |
234 | 网关作为承载公司所有流量的入口,对性能有着极高的要求,所以技术选型上还是要慎重,之所以选择 OpenResty,一是因为它高性能,二是目前也有小米,阿里,腾讯等大公司在用,是久经过市场考验的,本文通过对网关的总结简要介绍了 OpenResty 的相关知识点,相信大家对其主要功能点应该有所了解了,不过 OpenResty 的知识点远不止以上这些,大家如有兴趣,可以参考文末的学习教程深入学习,相信大家会有不少启发的。
235 |
236 |
237 | ## 题外话
238 |
239 | 「码海」历史精品文章已经做成电子书了,如有需要欢迎添加我的个人微信,除了发你电子书外,也可以加入我的读者群,一起探讨问题,共同进步!里面有不少技术总监等大咖,相信不管是职场进阶也好,个人困惑也好,都能对你有所帮助哦
240 |
241 |
242 | 欢迎关注公众号加我个人微信交流哦
243 |
244 | 
245 |
246 | 巨人的肩膀
247 | * 谈谈微服务中的 API 网关 https://www.cnblogs.com/savorboard/p/api-gateway.html
248 | * Openresty动态更新(无reload)TCP Upstream的原理和实现 https://developer.aliyun.com/article/745757
249 | * http://www.ttlsa.com/Nginx/Nginx-modules-ngx_http_dyups_module/
250 | * 极客时间 OpenResty 从入门到实战
251 |
252 | 欢迎关注公众号与笔者共同交流哦^_^
253 |
254 | 
--------------------------------------------------------------------------------
/Java/字节码剖析.md:
--------------------------------------------------------------------------------
1 | ### 前言
2 |
3 | 你好,我是坤哥
4 |
5 | 从今天起我打算整一个 Java 系列的进阶基础文章, 相信对大家会有帮助帮助,万丈高楼平地起,打好基础我们才能走得更好,举个例子,之前我在武哥的 Kafka 文章中看到这样的一句话「除此之外,页缓存(pageCache)还有一个巨大的优势。用过 Java 的人都知道:如果不用页缓存,而是用 JVM 进程中的缓存,对象的内存开销非常大(通常是真实数据大小的几倍甚至更多)」,如果你不了解 Java 对象的表示,看到这样的话会一脸懵逼:对象的开销到底有多巨大,反过来看,如果你掌握了 Java 中的对象布局,GC,NIO 等原理,理解这些框架的原理及其设计思路就不是什么难事
6 |
7 |
8 |
9 | 另一个让我下决心写这个系列的原因是经常有一些读者问一些学习路线的事,之前我写过一些大纲,但没有从点的层面展开,所以这次准备从点的思路来将各个知识点细细道来,然后再整理成 pdf,这样之后如果有人再问起,直接把这个 pdf 扔给他们就完事了 ^_^,欢迎大家加我微信:geekoftaste 一起探讨
10 |
11 |
12 |
13 | 每个系列都会以图文并茂的方式来讲解,争取做到深入浅出,举个例子,上面我们说了对象的开销很大,到底有多大呢,我会用图解的方式来带你一步步分析,看完后相信你会明白为什么 int\[128\]\[2\] 实例比 int[256] 实例多了 246% 的额外开销了,再比如我们都知道 Eden 区或 tenured(老年代区)满了会触发 yong gc 或 old gc,不过导致 gc 停顿时间过长的原因其实有挺多的,如果你看完我总结的这些通用的思路,相信你就能根据这套理论来快速地排查问题了,这个系列干货很多,相信对提升大家的 Java 内功有不少帮助,记得得文末点赞支持一下哦 ^_^
14 |
15 |
16 |
17 | Java 系列大纲如下:
18 |
19 |
20 |
21 | 
22 |
23 | 本篇我们先来学习下字节码 ,毕竟这是 Java 能跨平台的根本原因,而且通过了解字节码也可以彻底揭开 JVM 运行程序的秘密,整体会用问答的形式来讲解
24 |
25 |
26 |
27 | > 能否简单介绍一下 Java 的特性
28 |
29 | Java 是一门**面向对象**,**静态类型的**语言,具有跨平台的特点,与 C,C++ 这些需要手动管理内存,编译型的语言不同,它是解释型的,具有跨平台和自动垃圾回收的特点,那么它的跨平台到底是怎么实现的呢?
30 |
31 |
32 |
33 | 我们知道计算机只能识别二进制代码表示的机器语言,所以不管用的什么高级语言,最终都得翻译成机器语言才能被 CPU 识别并执行,对于 C++这些编译型语言来说是直接一步到位转为相应平台的可执行文件(即机器语言指令),而对 Java 来说,则首先由编译器将源文件编译成字节码,再在运行时由虚拟机(JVM)解释成机器指令来执行,我们可以看下下图
34 |
35 | 
36 |
37 | 也就是说 Java 的跨平台其实是通过先生成字节码,再由针对各个平台实现的 JVM 来解释执行实现的,JVM 屏蔽了 OS 的差异,我们知道 Java 工程都是以 Jar 包分发(一堆 class 文件的集合体)部署的,这就意味着 jar 包可以在各个平台上运行(由相应平台的 JVM 解释执行即可),这就是 Java 能实现跨平台的原因所在
38 |
39 | 这也是为什么 JVM 能运行 Scala、Groovy、Kotlin 这些语言的原因,并不是 JVM 直接来执行这些语言,而是这些语言最终都会生成符合 JVM 规范的字节码再由 JVM 执行,不知你是否注意到,使用字节码也利用了计算机科学中的分层理念,通过加入字节码这样的中间层,有效屏蔽了与上层的交互差异。
40 |
41 |
42 |
43 | > JVM 是怎么执行字节码的
44 |
45 | 在此之前我们先来看下 JVM 的整体内存结构,对其有一个宏观的认识,然后再来看 JVM 是如何执行字节码的
46 |
47 | 
48 |
49 |
50 |
51 | JVM 在内存中主要分为「栈」,「堆」,「非堆」以及 JVM 自身,堆主要用来分配类实例和数组,非堆包括「方法区」、「JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)」、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码
52 |
53 |
54 |
55 | 我们主要关注栈,我们知道线程是 cpu 调度的最小单位,在 JVM 中一旦创建一个线程,就会为其分配一个线程栈,线程会调用一个个方法,每个方法都会对应一个个的栈祯压到线程栈里,JVM 中的栈内存结构如下
56 |
57 |
58 |
59 | 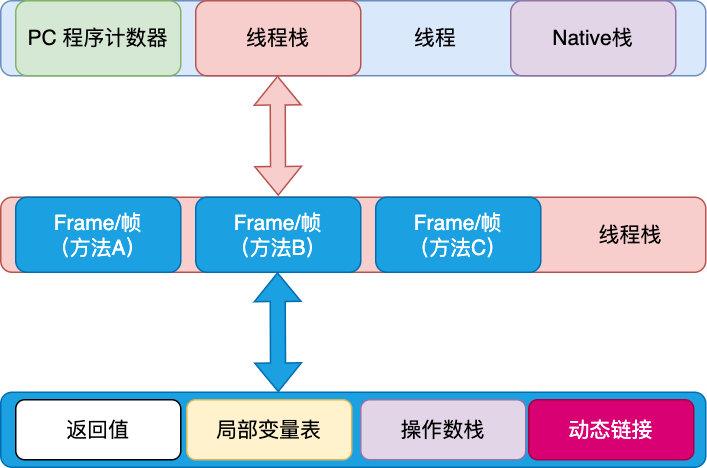
60 |
61 |
62 |
63 | 至此我们总算接近 JVM 执行的真相了,JVM 是以栈帧为单位执行的,栈帧由以下四个部分组成
64 |
65 | * 返回值
66 | * 局部变量表(Local Variables):存储方法用到的本地变量
67 | * 动态链接:在字节码中,所有的变量和方法都是以符号引用的形式保存在 class 文件的常量池中的,比如一个方法调用另外的方法,是通过常量池中指向方法的符号引用来表示的,动态链接的作用就是为了将这些符号引用转换为调用方法的直接引用,这么说可能有人还是不理解,所以我们先执行一下 `javap -verbose Demo.class `命令来查看一下字节码中的常量池是咋样的 
68 |
69 | 注意:以上只列出了常量池中的**部分符号引用**
70 |
71 |
72 |
73 | 可以看到 Object 的 init 方法是由 #4.#16 表示的,而 #4 又指向了 #19,#19 表示 Object,#16 又指向了 #7.#8,#7 指向了方法名,#8 指向了 ()V(表示方法的返回值为 void,且无方法参数),字节码加载后,会把类信息加载到元空间(Java 8 以后)中的方法区中,动态链接会把这些符号引用替换为调用方法的直接引用,如下图示
74 |
75 | 
76 |
77 |
78 |
79 | 那为什么要提供动态链接呢,通过上面这种方式绕了好几个弯才定位到具体的执行方法,效率不是低了很多吗,其实**主要是为了支持 Java 的多态**,比如我们声明一个 `Father f = new Son()`这样的变量,但执行 f.method() 的时候会绑定到 son 的 method(如果有的话),这就是用到了动态链接的技术,在运行时才能定位到具体该调用哪个方法,动态链接也称为后期绑定,与之相对的是静态链接(也称为前期绑定),即在编译期和运行期对象的方法都保持不变,静态链接发生在编译期,也就是说在程序执行前方法就已经被绑定,**java 当中的方法只有final、static、private和构造方法是前期绑定的**。而动态链接发生在运行时,**几乎所有的方法都是运行时绑定的**
80 |
81 |
82 |
83 | 举个例子来看看两者的区别,一目了解
84 |
85 | ```java
86 | class Animal{
87 | public void eat(){
88 | System.out.println("动物进食");
89 | }
90 | }
91 |
92 | class Cat extends Animal{
93 | @Override
94 | public void eat() {
95 | super.eat();//表现为早起绑定(静态链接)
96 | System.out.println("猫进食");
97 | }
98 | }
99 | public class AnimalTest {
100 | public void showAnimal(Animal animal){
101 | animal.eat();//表现为晚期绑定(动态链接)
102 | }
103 | }
104 |
105 | ```
106 |
107 |
108 |
109 | * `操作数栈(Operand Stack)`:程序主要由指令和操作数组成,指令用来说明这条操作做什么,比如是做加法还是乘法,操作数就是指令要执行的数据,那么指令怎么获取数据呢,指令集的架构模型分为**基于栈的指令集架构**和**基于寄存器的指令集架构**两种,JVM 中的指令集属于前者,也就是说任何操作都是用栈来管理,基于栈指令可以更好地实现跨平台,栈都是是在内存中分配的,而寄存器往往和硬件挂钩,不同的硬件架构是不一样的,不利于跨平台,当然于栈的指令集架构缺点也很明显,基于栈的实现需要更多指令才能完成(因为栈只是一个FILO结构,需要频繁压栈出栈),而寄存器是在CPU的高速缓存区,相较而言,**基于栈的速度要慢不少**,这也是为了跨平台而做出的一点性能牺牲,毕竟鱼和熊掌不可兼得。
110 |
111 |
112 |
113 | ### Java 字节码技术简介
114 |
115 | 注意线程中还有一个「PC 程序计数器」,是每个线程独有的,记录着当前线程所执行的字节码的行号指示器,也就是指向下一条指令的地址,也就是将执行的指令代码。由执行引擎读取下一条指令。我们先来看下看一下字节码长啥样。假设我们有以下 Java 代码
116 |
117 | ```java
118 | package com.mahai;
119 | public class Demo {
120 | private int a = 1;
121 | public static void foo() {
122 | int a = 1;
123 | int b = 2;
124 | int c = (a + b) * 5;
125 | }
126 | }
127 | ```
128 |
129 | 执行 javac Demo.java 后可以看到其字节码如下
130 |
131 | 
132 |
133 | 字节码是给 JVM 看的,所以我们需要将其翻译成人能看懂的代码,好在 JDK 提供了反解析工具 javap ,可以根据字节码反解析出 code 区(汇编指令)、本地变量表、异常表和代码行偏移量映射表、常量池等信息。我们执行以下命令来看下根据字节码反解析的文件长啥样(更详细的信息可以执行 javap -verbose 命令,在本例中我们重点关注 Code 区是如何执行的,所以使用了 javap -c 来执行
134 |
135 | ```
136 | javap -c Demo.class
137 | ```
138 |
139 | 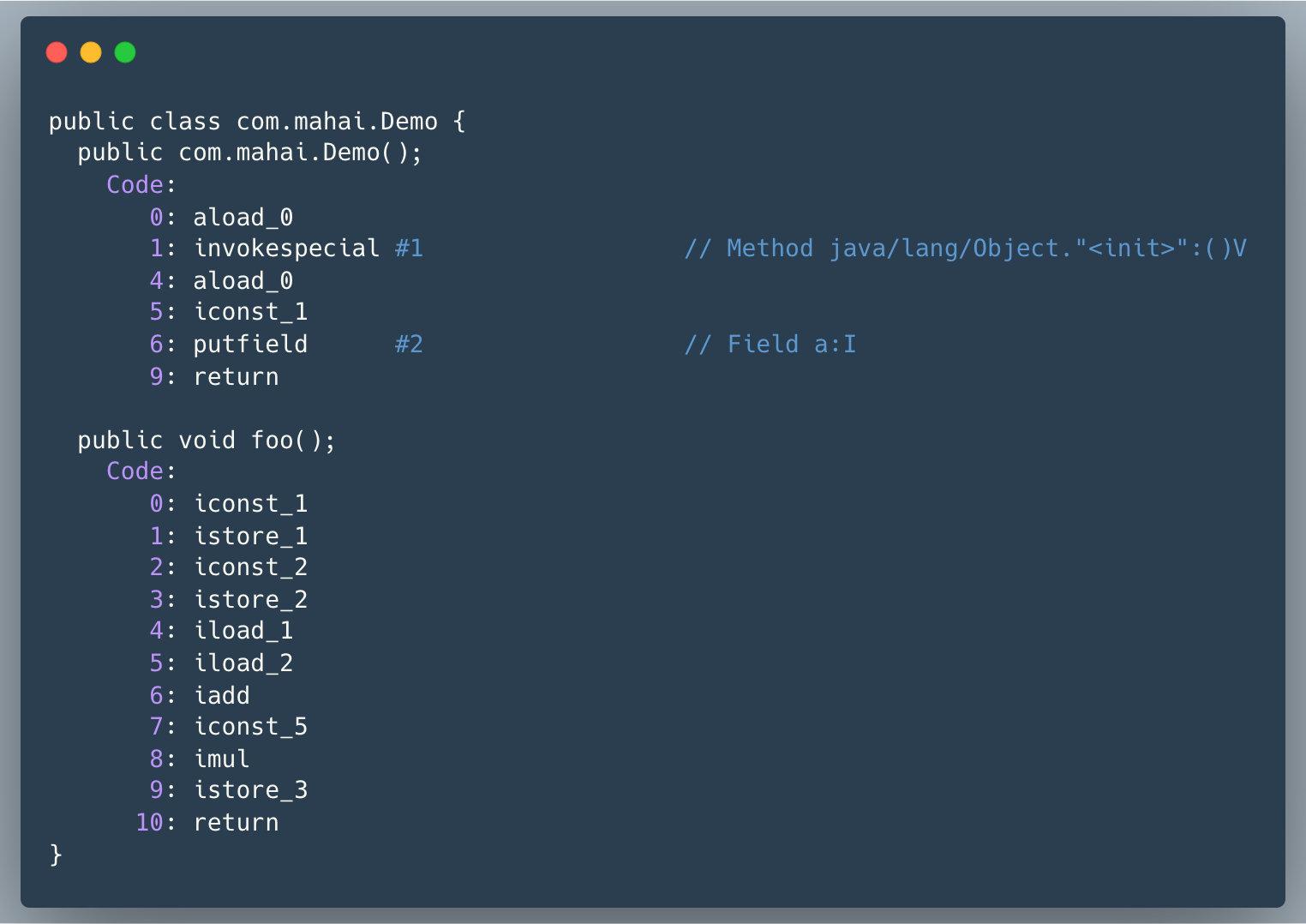
140 |
141 |
142 |
143 | 转换成这种形式可读性强了很多,那么aload_0,invokespecial 这些表示什么含义呢, javap 是怎么根据字节码来解析出这些指令出来的呢
144 |
145 |
146 |
147 | 首先我们需要明白什么是指令,**指令=操作码+操作数**,操作码表示这条指令要做什么,比如加减乘除,操作数即操作码操作的数,比如 1+ 2 这条指令,操作码其实是加法,1,2 为操作数,在 Java 中每个操作码都由一个字节表示,每个操作码都有对应类似 aload_0,invokespecial,iconst_1 这样的助记符,有些操作码本来就包含着操作数,比如字节码 0x04 对应的助记符为 iconst_1, 表示 将 int 型 1 推送至栈顶,这些操作码就相当于指令,而有些操作码需要配合操作数才能形成指令,如字节码 0x10 表示 bipush,后面需要跟着一个操作数,表示 `将单字节的常量值(-128~127)推送至栈顶`。以下为列出的几个字节码与助记符示例
148 |
149 | | 字节码 | 助记符 | 表示含义 |
150 | | ------ | ------------- | ------------------------------------------ |
151 | | 0x04 | iconst_1 | 将int型1推送至栈顶 |
152 | | 0xb7 | invokespecial | 调用超类构建方法, 实例初始化方法, 私有方法 |
153 | | 0x1a | iload_0 | 将第一个int型本地变量推送至栈顶 |
154 | | 0x10 | bipush | 将单字节的常量值(-128~127)推送至栈顶 |
155 |
156 | 至此我们不难明白 javap 的作用了,它主要就是找到字节码对应的的助记符然后再展示在我们面前的,我们简单看下上述的默认构造方法是如何根据字节码映射成助记符并最终呈现在我们面前的:
157 |
158 |
159 |
160 | 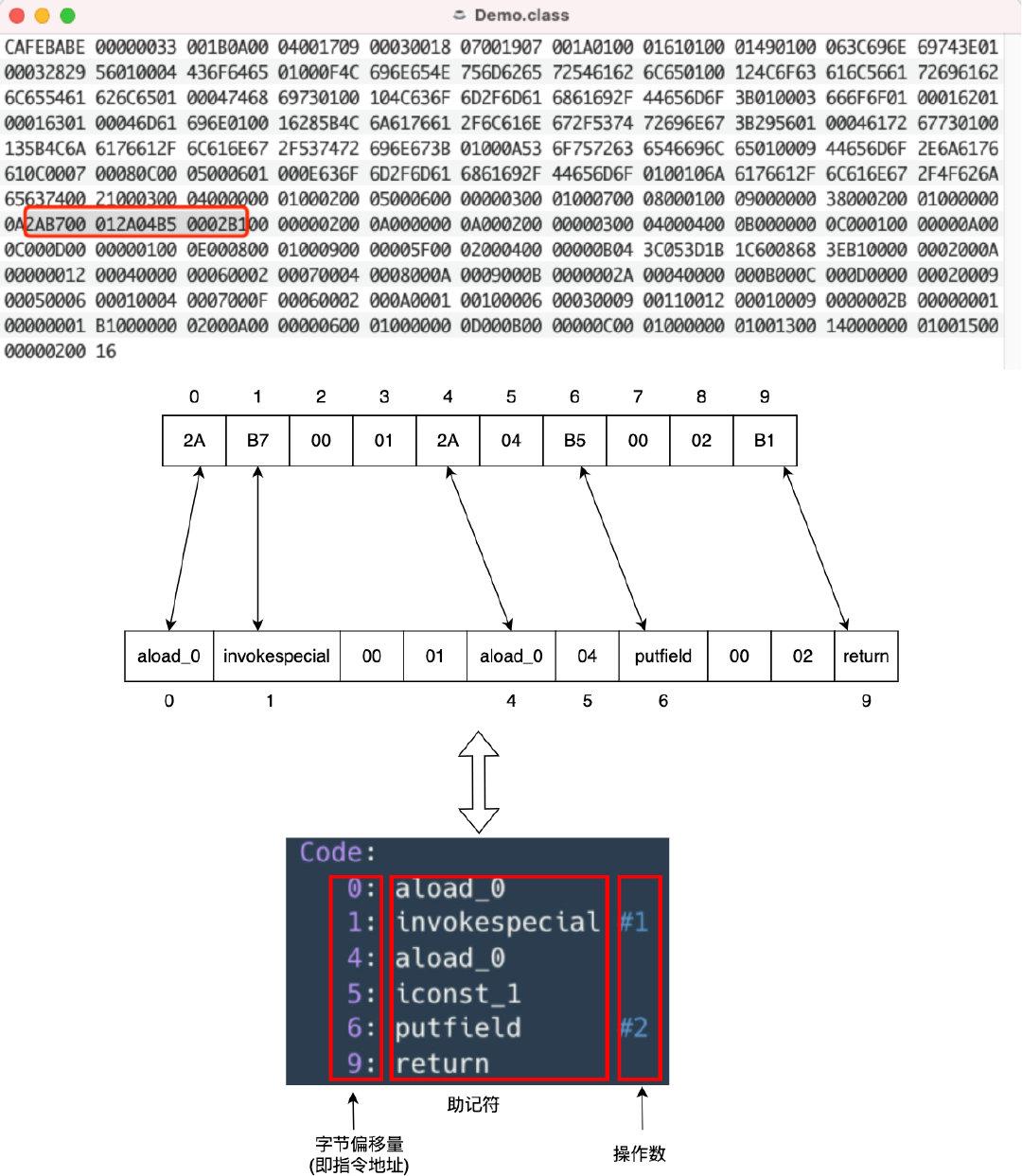
161 |
162 | 最左边的数字是 Code 区中每个字节的偏移量,这个是保存在 PC 的程序计数中的,比如如果当前指令指向 1,下一条就指向 4
163 |
164 |
165 |
166 | 另外大家不难发现,在源码中其实我们并没有定义默认构造函数,但在字节码中却生成了,而且你会发现我们在源码中定义了`private int a = 1;`但这个变量赋值的操作却是在构造方法中执行的(下文会分析到),这就是理解字节码的意义:**它可以反映 JVM 执行程序的真正逻辑**,而源码只是表象,要深入分析还得看字节码!
167 |
168 |
169 |
170 | 接下来我们就来瞧一瞧构造方法对应的指令是如何执行的,首先我们来看一下在 JVM 中指令是怎么执行的。
171 |
172 |
173 |
174 | 1. 首先 JVM 会为每个方法分配对应的局部变量表,可以认为它是一个数组,每个坑位(我们称为 slot)为方法中分配的变量,如果是实例方法,这些局部变量可以是 this, 方法参数,方法里分配的局部变量,这些局部变量的类型即我们熟知的 int,long 等八大基本,还有引用,返回地址,每个 slot 为 4 个字节,所以像 Long , Double 这种 8 个字节的要占用 2 个 slot, 如果这个方法为实例方法,则第一个 slot 为 this 指针, 如果是静态方法则没有 this 指针
175 |
176 | 2. 分配好局部变量表后,方法里如果涉及到赋值,加减乘除等操作,那么这些指令的运算就需要依赖于操作数栈了,将这些指令对应的操作数通过压栈,弹栈来完成指令的执行
177 |
178 | 比如有 `int i = 69` 这样的指令,对应的字码节指令如下
179 |
180 | ```
181 | 0:bipush 69
182 | 2:istore_0
183 | ```
184 |
185 | 其在内存中的操作过程如下
186 |
187 | 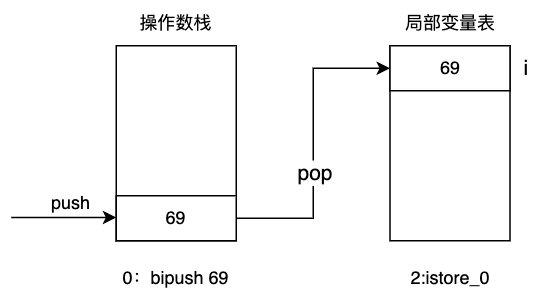
188 |
189 | 可以看到主要分两步:第一步首先把 69 这个 int 值压栈,然后再弹栈,把 69 弹出放到局部变量表 i 对应的位置,istore_0 表示弹栈,将其从操作数栈中弹出整型数字存储到本地变量中,0 表示本地变量在局部变量表的第 0 个 slot
190 |
191 |
192 |
193 | 理解了上面这个操作,我们再来看一下默认构造函数对应的字节码指令是如何执行的
194 |
195 | 
196 |
197 |
198 |
199 | 首先我们需要先来理解一下上面几个指令
200 |
201 | * aload_0:从局部变量表中加载第 0 个 slot 中的对象引用到操作数栈的栈顶,这里的 0 表示第 0 个位置,也就是 this
202 | * invokespecial:用来调用构造函数,但也可以用于调用同一个类中的 private 方法, 以及 可见的超类方法,在此例中表示调用父类的构造器(因为 #1 符号引用指向对应的 init 方法)
203 | * iconst_1:将 int 型 1推送至栈顶
204 | * putfield:它接受一个操作数,这个操作数引用的是运行时常量池里的一个字段,在这里这个字段是 a。赋给这个字段的值,以及包含这个字段的对象引用,在执行这条指令的时候,都会从操作数栈顶上 pop 出来。前面的 aload_0 指令已经把包含这个字段的对象(this)压到操作数栈上了,而后面的 iconst_1 又把 1 压到栈里。最后 putfield 指令会将这两个值从栈顶弹出。执行完的结果就是这个对象的 a 这个字段的值更新成了 1。
205 |
206 | 接下来我们来详细解释以上以上助记符代表的含义
207 |
208 |
209 |
210 | * 第一条命令 aload_0,表示从局部变量表中加载第 0 个 slot 中的对象引用到操作数栈的栈顶,也就是将 this 加载到栈顶,如下
211 |
212 | 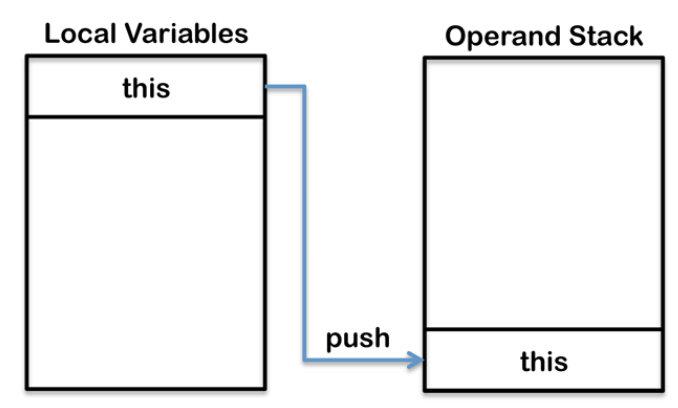
213 |
214 |
215 |
216 | * 第二步 invokespecial #1,表示弹栈并且执行 #1 对应的方法,#1 代表的含义可以从旁边的解释(`# Method java/lang/Object."":()V`)看出,即调用父类的初始化方法,这也印象了那句话:**子类初始化时会从初始化父类**
217 | * 之后的命令 `aload_0`,`iconst_1`,`putfied #2` 图解如下
218 |
219 | 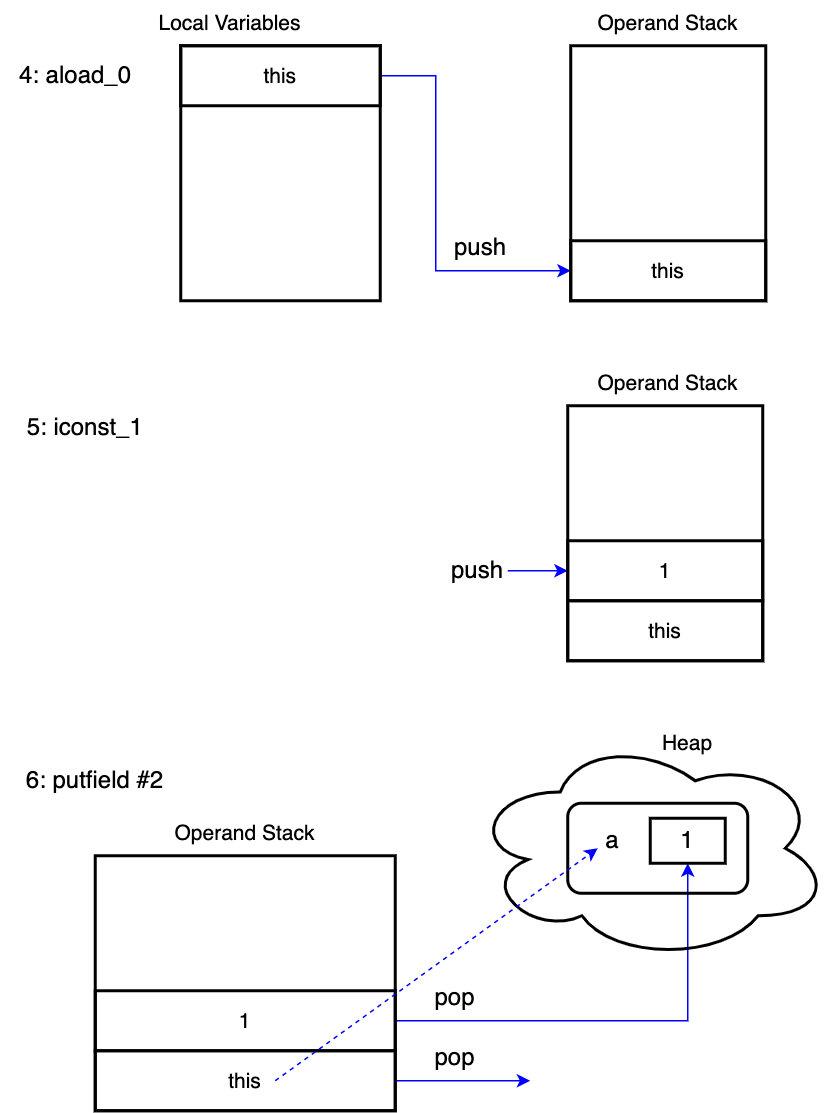
220 |
221 |
222 |
223 | 可能有人有些奇怪,上述 `6: putfield #2`命令中的 #2 怎么就代表 Demo 的私有成员 a 了,这就涉及到字节码中的常量池概念了,我们执行 `javap -verbose path/Demo.class` 可以看到这些字面量代表的含义,#1,#2 这种数字形式的表示形式也被称为符号引用,程序运行期会将符号引用转换为直接引用
224 |
225 | 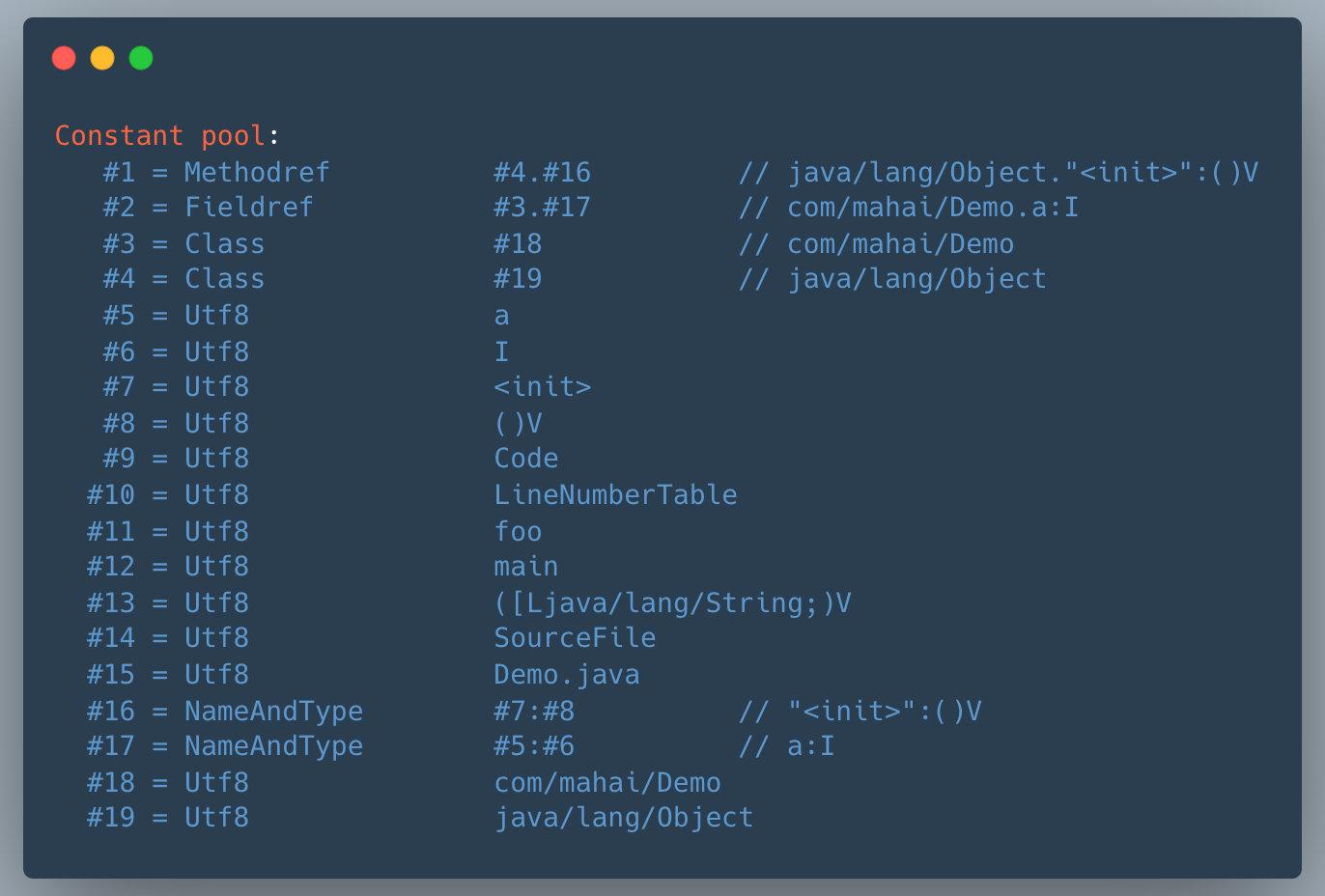
226 |
227 | 由此可知 #2 代表 Demo 类的 a 属性,如下
228 |
229 | 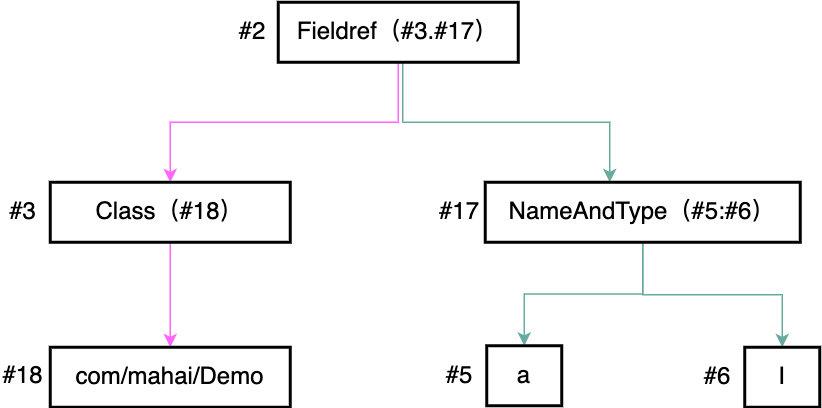
230 |
231 |
232 |
233 |
234 |
235 | 我们再来用动图看一下 foo 的执行流程,相信你现在能理解其含义了
236 |
237 | 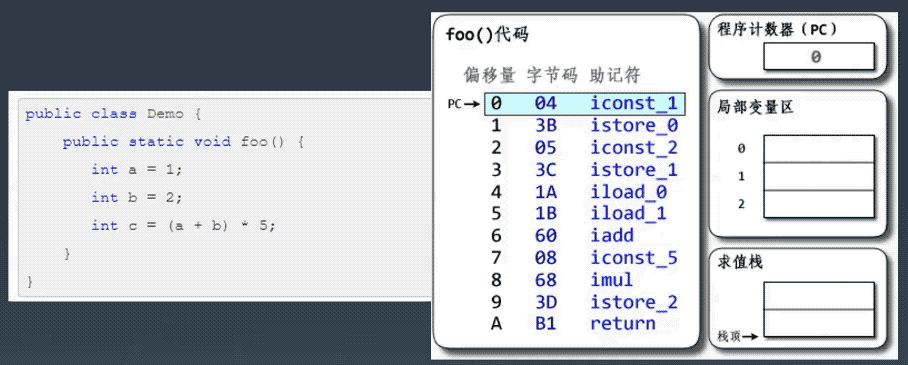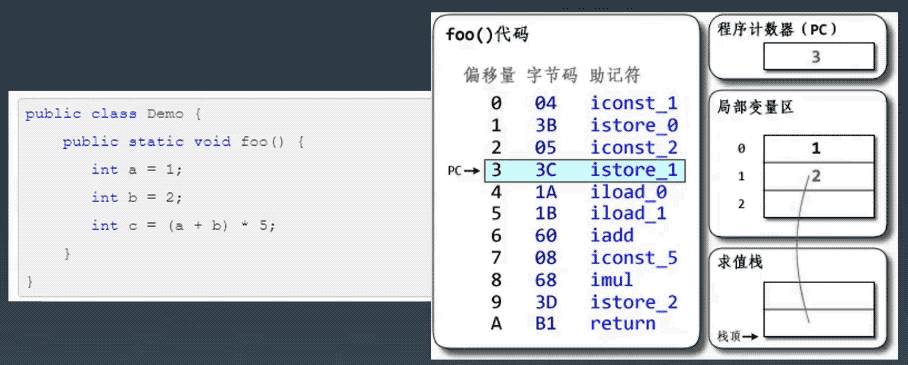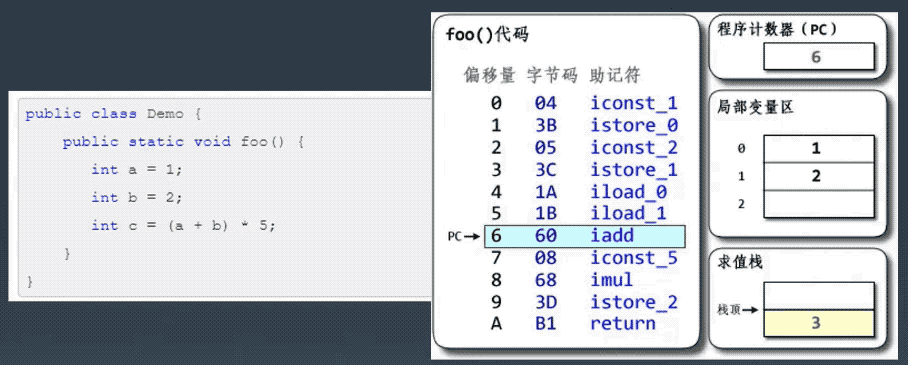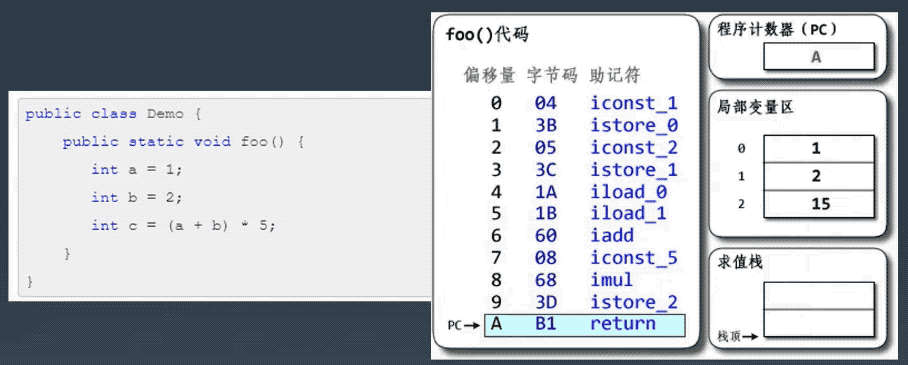
238 |
239 |
240 |
241 | 唯一需要注意的此例中的 foo 是个静态方法,所以局部变量区是没有 this 的。
242 |
243 |
244 |
245 | 相信你不难发现 JVM 执行字节码的流程与 CPU 执行机器码步骤如出一辙,都经历了「取指令」,「译码」,「执行」,「存储计算结果」这四步,首先程序计数器指向下一条要执行的指令,然后 JVM 获取指令,由本地执行引擎将字节码操作数转成机器码(译码)执行,执行后将值存储到局部变量区(存储计算结果)中
246 |
247 |
248 |
249 | 关于字节码我推荐两款工具
250 |
251 | * 一个是 Hex Fiend,一款很好的十六进制编辑器,可以用来查看字节码
252 | * 一款是 Intellij Idea 的插件 `jclasslib Bytecode viewer`,能为你展示 javap -verbose 命令对应的常量池,接口, Code 等数据,非常的直观,对于分析字节码非常有帮忙,如下
253 |
254 | 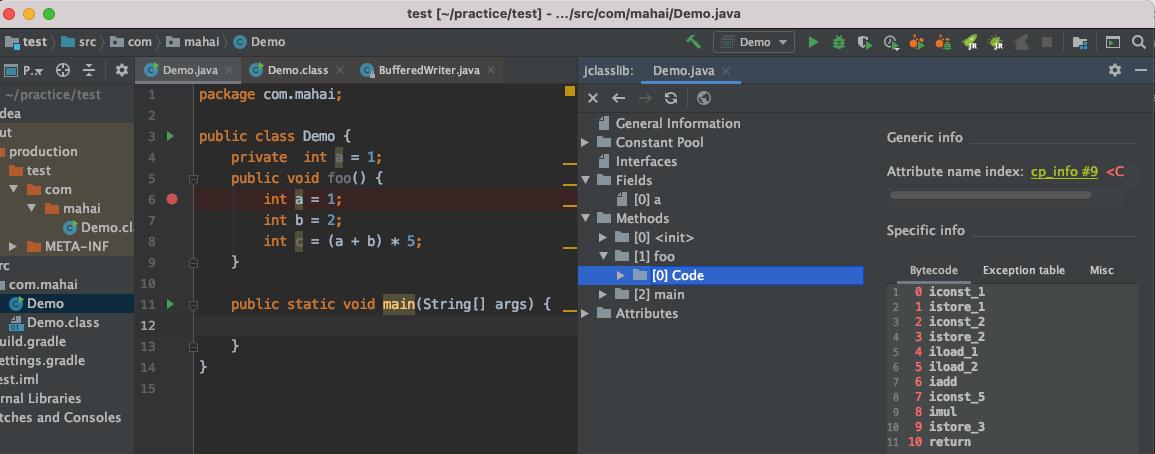
255 |
256 |
257 |
258 | 欢迎关注公号一起交流,共同进步
259 |
260 | 
261 |
262 | 下一篇我们继续聊字节码是如何被加载的
--------------------------------------------------------------------------------
/架构/高可用.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 | 今天我们来聊一下互联网三高(高并发、高性能、高可用)中的高可用,看完本文相信能解开你关于高可用设计的大部分困惑
4 |
5 | ### 前言
6 |
7 | 高可用(High availability,即 HA)的主要目的是为了保障「业务的连续性」,即在用户眼里,业务永远是正常(或者说基本正常)对外提供服务的。高可用主要是针对架构而言,那么要做好高可用,就要首先设计好架构,第一步我们一般会采用分层的思想将一个庞大的 IT 系统拆分成为应用层,中间件,数据存储层等独立的层,每一层再拆分成为更细粒度的组件,第二步就是让每个组件对外提供服务,毕竟每个组件都不是孤立存在的,都需要互相协作,对外提供服务才有意义。
8 |
9 |
10 |
11 | 要保证架构的高可用,就要保证架构中所有组件以及其对外暴露服务都要做高可用设计,任何一个组件或其服务没做高可用,都意味着系统存在风险。
12 |
13 |
14 |
15 | 那么这么多组件该怎么做高可用设计呢,其实任何组件要做高可用,都离不开「冗余」和「自动故障转移」,众所周知单点是高可用的大敌,所以组件一般是以集群(至少两台机器)的形式存在的,这样只要某台机器出现问题,集群中的其他机器就可以随时顶替,这就是「冗余」。简单计算一下,假设一台机器的可用性为 90%,则两台机器组成的集群可用性为 1-0.1*0.1 = 99%,所以显然冗余的机器越多,可用性越高。
16 |
17 |
18 |
19 | 但光有冗余还不够,如果机器出现问题,需要人工切换的话也是费时费力,而且容易出错,所以我们还需要借助第三方工具(即仲裁者)的力量来实现「自动」的故障转移,以达到实现**近实时**的故障转移的目的,**近实时的故障转移才是高可用的主要意义**
20 |
21 |
22 |
23 | 怎样的系统可以称之为高可用呢,业界一般用几个九来衡量系统的可用性,如下
24 |
25 | | 可用性级别 | 系统可用性% | 宕机时间/年 | 宕机时间/月 | 宕机时间/周 | 宕机时间/天 |
26 | | ---------- | ----------- | ----------- | ----------- | ----------- | ----------- |
27 | | 不可用 | 90% | 36.5 天 | 73 小时 | 16.8 小时 | 144 分钟 |
28 | | 基本可用 | 99% | 87.6 小时 | 7.3 小时 | 1.68 小时 | 14.4 分钟 |
29 | | 较高可用 | 99.9% | 8.76 小时 | 43.8 分钟 | 10.1 分钟 | 1.44 分钟 |
30 | | 高可用 | 99.99% | 52.56 分钟 | 4.38 分钟 | 1.01 秒 | 8.64 秒 |
31 | | 极高可用 | 99.999% | 5.26 分钟 | 26.28 秒 | 6.06 秒 | 0.86 秒 |
32 |
33 | 一般实现两个 9 很简单,毕竟每天宕机 14 分钟已经严重影响业务了,这样的公司迟早歇菜,大厂一般要求 4 个 9,其他要求严苛的业务要达到五个九以上,比如如果因为一个电脑的故障导致所有列车停驶,那么就会有数以万计的人正常生活受到阻碍,这种情况就要求五个九以上
34 |
35 |
36 |
37 | 接下来我们就来一起看看架构中的各个组件如何借助「冗余」和「自动故障转移」来实现高可用。
38 |
39 |
40 |
41 | ### 互联网架构剖析
42 |
43 | 目前多数互联网都会采用微服务架构,常见架构如下:
44 |
45 | 
46 |
47 | 可以看到架构主要分以下几层
48 |
49 | 1. 接入层:主要由 F5 硬件或 LVS 软件来承载所有的流量入口
50 | 2. 反向代理层:Nginx,主要负责根据 url 来分发流量,限流等
51 | 3. 网关:主要负责流控,风控,协议转换等
52 | 4. 站点层:主要负责调用会员,促销等基本服务来装配 json 等数据并返回给客户端
53 | 5. 基础 service:其实与站点层都属于微服务,是平级关系,只不过基础 service 属于基础设施,能被上层的各个业务层 server 调用而已
54 | 6. 存储层:也就是 DB,如 MySQL,Oracle 等,一般由基础 service 调用返回给站点层
55 | 7. 中间件:ZK,ES,Redis,MQ 等,主要起到加速访问数据等功能,在下文中我们会简单介绍下各个组件的作用
56 |
57 |
58 |
59 | 如前所述,要实现整体架构的高可用,必须要实现每一层组件的高可用,接下来我们就来分别看一下每一层的组件都是如何实现高可用的
60 |
61 | ### 接入层&反向代理层
62 |
63 | 这两层的高可用都和 keepalived 有关,所以我们结合起来一起看
64 |
65 | 
66 |
67 |
68 |
69 | 对外,两个 LVS 以主备的形式对外提供服务,注意只有 master 在工作(即此时的 VIP 在 master 上生效),另外一个 backup 在 master 宕机之后会接管 master 的工作,那么 backup 怎么知道 master 是否正常呢,答案是通过 keepalived,在主备机器上都装上 keepalived 软件,启动后就会通过心跳检测彼此的健康状况,一旦检测到 master 宕机,keepalived 会检测到,从而 backup 自动转成 master,对外提供服务,此时 VIP 地址(即图中的 115.204.94.139)即在 backup 上生效,也就是我们常说的「IP漂移」,通过这样的方式即解决了 LVS 的高可用。
70 |
71 |
72 |
73 | keepalived 的心跳检测主要通过发送 ICMP 报文,或者利用 TCP 的端口连接和扫描检测来检测的,同样的,它也可以用来检测 Nginx 暴露的端口,如果某些 Nginx 不正常 keepalived 也能检测到并将其从 LVS 能转发的服务列表中剔出。
74 |
75 |
76 |
77 | 借用 keepalived 这个第三方工具,同时实现了 LVS 和 Nginx 的高可用,同时在出现故障时也可以将宕机情况发送到对应开发人员的邮箱以让他们及时收到通知处理,确实很方便,keepalived 应用广泛,下文我们也能看到它也可以用在 MySQL 上来实现 MySQL 的高可用。
78 |
79 |
80 |
81 | ### 微服务
82 |
83 | 接下来我们再来看一下「网关」,「站点层」,「基础服务层」,这三者一般就是我们所说的微服务架构组件,当然这些微服务组件还需要通过一些 RPC 框架如 Dubbo 来支撑,所以微服务要实现高可用,就意味着 dubbo 这些 RPC 框架也要提供支撑微服务高可用的能力,我们就以 dubbo 为例来看下它是如何实现高可用的
84 |
85 |
86 |
87 | 我们先来简单地看下 dubbo 的基本架构
88 |
89 | 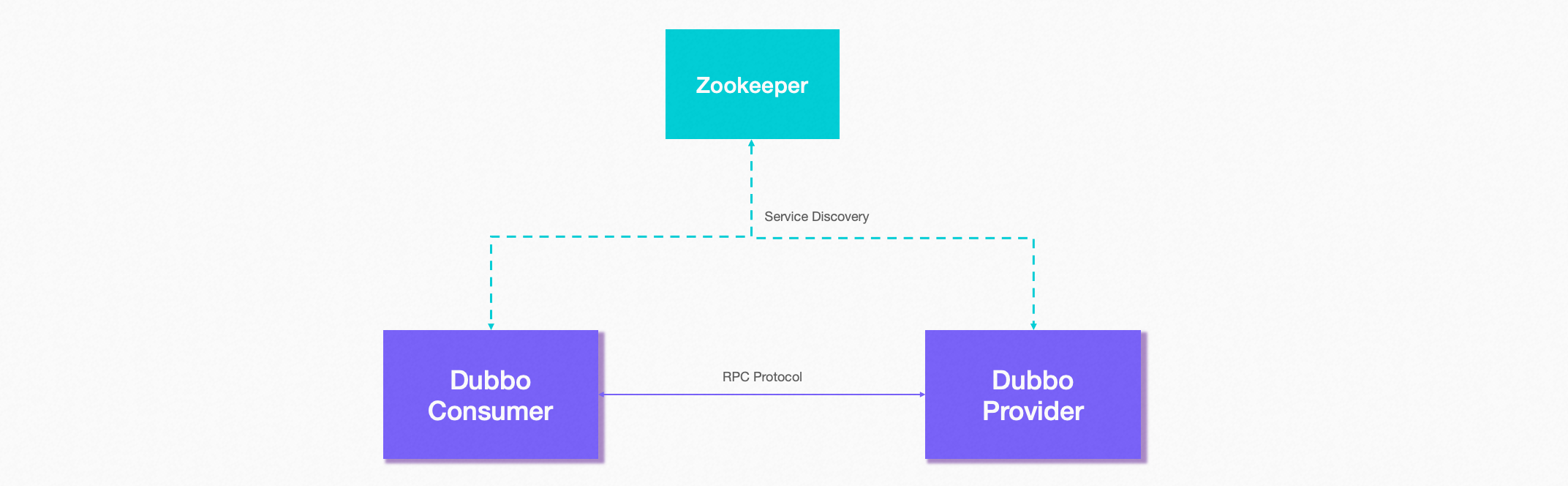
90 |
91 | 思路也很简单,首先是 Provider(服务提供者)向 Registry(注册中心,如 ZK 或 Nacos 等)注册服务,然后 Consumer(服务消费者)向注册中心订阅和拉取 Provider 服务列表,获取服务列表后,Consumer 就可以根据其负载均衡策略选择其中一个 Provider 来向其发出请求,当其中某个 Provider 不可用(下线或者因为 GC 阻塞等)时,会被注册中心及时监听(通过心跳机制)到,也会及时推送给 Consumer,这样 Consumer 就能将其从可用的 Provider 列表中剔除,也就实现了故障的自动转移,不难看出,注册中心就起到了类似 keepalived 的作用
92 |
93 |
94 |
95 | ### 中间件
96 |
97 | 我们再来看下这些中间件如 ZK,Redis 等是如何实现高可用的呢
98 |
99 |
100 |
101 | #### ZK
102 |
103 | 上一节微服务中我们提到了注册中心,那我们就以 ZK(ZooKeeper)为例来看看它的高可用是如何实现的,先来看下它的整体架构图如下
104 |
105 |
106 |
107 | 
108 |
109 |
110 |
111 | Zookeeper 中的主要角色如下
112 |
113 | * Leader: 即领导者,在集群中只有一个 Leader,主要承担了以下的功能
114 | 1. 事务请求的唯一调度和处理者,保证集群事物处理的顺序性,所有 Follower 的写请求都会转给 Leader 执行,用来保证事务的一致性
115 | 2. 集群内部各服务器的调度者:处理好事务请求后,会将数据广播同步到各个 Follower,统计 Follower 写入成功的数量,超过半数 Follower 写入成功,Leader 就会认为写请求提交成功,通知所有的 Follower commit 这个这与操作,保证事后哪怕是集群崩溃恢复或者重启,这个写操作也不会丢失。
116 | * Follower:
117 | 1. 处理客户端非事务请求、转发事务请求给 leader 服务器
118 | 2. 参与事物请求 Proposal 的投票(需要半数以上服务器通过才能通知 leader commit 数据; Leader 发起的提案,要求 Follower 投票)
119 | 3. 参与 Leader 选举的投票
120 |
121 | **画外音**:Zookeeper 3.0 之后新增了一种 Observer 的角色,不过与此处讨论的 ZK 高可用关系不是很大,为了简化问题,所以省略
122 |
123 | 可以看到由于只有一个 Leader,很显然,此 Leader 存在单点隐患,那么 ZK 是怎么解决此问题的呢,首先 Follower 与 Leader 会用心跳机制保持连接,如果 Leader 出现问题了(宕机或者因为 FullGC 等原因无法响应),Follower 就无法感知到 Leader 的心跳,就会认为 Leader 出问题了,于是它们就会发起投票选举,最终在多个 Follower 中选出一个 Leader 来(这里主要用到了 Zookeeper Atomic Broadcast,即 ZAB 协议,它是为 ZK 专门设计的一种支持崩溃恢复的一致性协议),选举的细节不是本文重点,就不在此详述了。
124 |
125 |
126 |
127 | 除了 ZAB 协议,业界上常用的还有 Paxos,Raft 等协议算法,也可以用在 Leader 选举上,也就是是在分布式架构中,这些协议算法承担了“第三者”也就是仲裁者的作用,以承担故障的自动转移
128 |
129 | #### Redis
130 |
131 | Redis 的高可用需要根据它的部署模式来看看,主要分为「主从模式」和「Cluster 分片模式」两种
132 |
133 | ##### 主从模式
134 |
135 | 先来看一下主从模式,架构如下
136 |
137 | 
138 |
139 |
140 |
141 | 主从模式即一主多从(一个或者多个从节点),其中主节点主要负责读和写,然后会将数据同步到多个从节点上,Client 也可以对多个从节点发起读请求,这样可以减轻主节点的压力,但和 ZK 一样,由于只有一个主节点,存在单点隐患,所以必须引入第三方仲裁者的机制来判定主节点是否宕机以及在判定主节点宕机后快速选出某个从节点来充当主节点的角色,这个第三方仲裁者在 Redis 中我们一般称其为「哨兵」(sentinel),当然哨兵进程本身也有可能挂掉,所以为了安全起见,需要部署多个哨兵(即哨兵集群)
142 |
143 | 
144 |
145 | 这些哨兵通过 gossip(流言) 协议来接收关于主服务器是否下线的信息,并在判定主节点宕机后使用 Raft 协议来选举出新的主节点
146 |
147 | ##### Cluster 分片集群
148 |
149 | 主从模式看似完美,但存在以下几个问题
150 |
151 | 1. 主节点写的压力难以降低:因为只有一个主节点能接收写请求,如果在高并发的情况下,写请求如果很高的话可能会把主节点的网卡打满,造成主节点对外无法服务
152 | 2. 主节点的存储能力受到单机存储容量的限制:因为不管是主节点还是从节点,存储的都是**全量**缓存数据,那么随着业务量的增长,缓存数据很可能直线上升,直到达到存储瓶颈
153 | 3. 同步风暴:因为数据都是从 master 同步到 slave 的,如果有多个从节点的话,master 节点的压力会很大
154 |
155 |
156 |
157 | 为了解决主从模式的以上问题,分片集群应运而生,所谓分片集群即将数据分片,每一个分片数据由相应的主节点负责读写,这样的话就有多个主节点来分担写的压力,并且每个节点只存储**部分数据**,也就解决了单机存储瓶颈的问题,但需要注意的是每个主节点都存在单点问题,所以需要针对每个主节点做高可用,整体架构如下
158 |
159 | 
160 |
161 | 原理也很简单,在 Proxy 收到 client 执行的 redis 的读写命令后,首先会对 key 进行计算得出一个值,如果这个值落在相应 master 负责的数值范围(一般将每个数字称为槽,Redis 一共有 16384 个槽)之内,那就把这条 redis 命令发给对应的 master 去执行,可以看到每个 master 节点只负责处理一部分的 redis 数据,同时为了避免每个 master 的单点问题,也为其配备了多个从节点以组成集群,当主节点宕机时,集群会通过 Raft 算法来从从节点中选举出一个主节点
162 |
163 |
164 |
165 | #### ES
166 |
167 | 再来看一下 ES 是如何实现高可用的,在 ES 中,数据是以分片(Shard)的形式存在的,如下图所示,一个节点中索引数据共分为三个分片存储
168 |
169 | 
170 |
171 | 但只有一个节点的话,显然存在和 Redis 的主从架构一样的单点问题,这个节点挂了,ES 也就挂了,所以显然需要创建多个节点
172 |
173 | 一旦创建了多个节点,分片的优势就体现出来了,可以将分片数据分布式存储到其它节点上,极大提升了数据的水平扩展能力,同时每个节点都能承担读写请求,采用负载均衡的形式避免了单点的读写压力
174 |
175 |
176 |
177 | > ES 的写机制与 Redis 和 MySQL 的主从架构有些差别(后两者的写都是直接向 master 节点发起写请求,而 ES 则不是),所以这里稍微解释一下 ES 的工作原理
178 | >
179 | > 首先说下节点的工作机制,节点(Node)分为主节点(Master Node)和从结点(Slave Node),主节点的主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点,主节点也只有一个,一般通过类 Bully 算法来选举出来,如果主节点不可用了,则其他从节点也可以通过此算法来选举以实现集群的高可用,任何节点都可以接收读写请求以达到负载均衡的目的
180 | >
181 | > 再说一下分片的工作原理,分片分为主分片(Primary Shard 如 P0,P1,P2)和副本分片(Replica Shard,如 R0,R1,R2),主分片负责数据的写操作,所以虽然任何节点可以接收读写请求,但如果此节点接收的是写请求并且没有写数据所在的主分片话,此节点会将写请求调度到主分片所在的节点上,写入主分片后,主分片会把数据复制到其他节点的副本分片上,以两个副本的集群为例,写操作如下
182 | >
183 | > 
184 |
185 | #### MQ
186 |
187 | ES 中利用数据分片来提升高可用和水平扩展能力的思想也应用在其他组件的架构设计上,我们以 MQ 中的 kafka 为例再来看下数据分片的应用
188 |
189 | 
190 |
191 | 如上是 Kafka 集群,可以看到每个 Topic 的 Partition 都分布式存储在其它消息服务器上,这样一旦某个 Partition 不可用,可以从其他 follower 选举出 leader 继续服务,不过与 ES 中的数据分片不同的是,follower Partition 属于**冷备**,也就是说在正常情况下不会对外服务,只有在 leader 挂掉之后从多个 follower 中选出leader 后才能对外提供服务
192 |
193 |
194 |
195 | ### 存储层
196 |
197 | 接下来我们再来看一下最后一层,存储层(DB),这里我们以 MySQL 为例来简单地讨论一下其高可用设计,其实大家如果看完了以上的高可用设计,会发现 MySQL 的高可用也不过如此,与 Redis 类似,它也分主从和分片(即我们常说的分库分表)两种架构
198 |
199 | 主从的话与 LVS 类似,一般使用 keepalived 的形式来实现高可用,如下所示
200 |
201 | 
202 |
203 |
204 |
205 | 如果 master 宕机了 ,Keepalived 也会及时发现,于是从库会升级主库,并且 VIP 也会“漂移”到原从库上生效,所以说大家在工程配置的 MySQL 地址一般是 VIP 以保证高可用
206 |
207 | 数据量大了之后就要分库分表了,于是就有了多主,就像 Redis 的分片集群一样,需要针对每个主配备多个从,如下
208 |
209 |
210 |
211 | 
212 |
213 |
214 |
215 | 之前有读者问分库分表之后为啥还要做主从,现在我想大家应该都明白了,不是为了解决读写性能问题,主要是为了实现高可用
216 |
217 | ### 总结
218 |
219 | 看完了架构层面的高可用设计,相信大家对高可用的核心思想「冗余」和「自动故障转移」会有更深刻的体会,观察以上架构中的组件你会发现冗余的主要原因是因为只有一主,为什么不能有多主呢,也不是不可以,但这样在分布式系统下要保证数据的一致性是非常困难的,尤其是节点多了的话,数据之间的同步更是一大难题,所以多数组件采用一主的形式,然后再在主和多从之间同步,多数组件之所以选择一主本质上是技术上的 tradeoff
220 |
221 |
222 |
223 | 那么做好每个组件的高可用之后是否整个架构就真的可用了呢,非也,这只能说迈出了第一步,在生产上还有很多突发情况会让我们的系统面临挑战,比如
224 |
225 | 1. 瞬时流量问题:比如我们可能会面临秒杀带来的瞬时流量激增导致系统的承载能力被压垮,这种情况可能影响日常交易等核心链路,所以需要做到系统之间的隔离,如单独为秒杀部署一套独立的集群
226 | 2. 安全问题:比如 DDOS 攻击,爬虫频繁请求甚至删库跑路等导致系统拒绝服务
227 | 3. 代码问题:比如代码 bug 引起内存泄露导致 FullGC 导致系统无法响应等
228 | 4. 部署问题:在发布过程中如果贸然中止当前正在运行的服务也是不行的,需要做到优雅停机,平滑发布
229 | 5. 第三方问题:比如我们之前的服务依赖第三方系统,第三方可能出问题导致影响我们的核心业务
230 | 6. 不可抗力:如机房断电,所以需要做好容灾,异地多活,之前我司业务就由于机房故障导致服务四小时不可用,损失惨重
231 |
232 | 所以除了做好架构的高可用之外,我们还需要在做好系统隔离,限流,熔断,风控,降级,对关键操作限制操作人权限等措施以保证系统的可用。
233 |
234 |
235 |
236 | 这里特别提一下降级,这是为了保证系统可用性采取的常用的措施,简单举几个例子
237 |
238 | 1. 我们之前对接过一个第三方资金方由于自身原因借款功能出了问题导致无法借款,这种情况为了避免引起用户恐慌,于是我们在用户申请第三方借款的时候返回了一个类似「为了提升你的额度,资金方正在系统升级」这样的文案,避免了客诉
239 | 2. 在流媒体领域,当用户观看直播出现严重卡顿时,很多企业的第一选择不是查 log 排查问题,而是为用户自动降码率。因为比起画质降低,卡的看不了显然会让用户更痛苦
240 | 3. 双十一零点高峰期,我们把用户的注册登录等非核心功能给停掉了,以保证下单等核心流程的顺利
241 |
242 |
243 |
244 | 另外我们最好能做到事前防御,在系统出问题前把它扼杀在摇篮里,所以我们需要做单元测试,做全链路压测等来发现问题,还需要针对 CPU,线程数等做好**监控**,当其达到我们设定的域值时就触发告警以让我们及时发现修复问题(我司之前就碰到过一个类似的[生产事故复盘](https://mp.weixin.qq.com/s/B1EplSO2hTEoDAcPNtsGwA)大家可以看一下),此外在做好单元测试的前提下,依然有可能因为代码的潜在 bug 引起线上问题,所以我们需要在关键时间(比如双十一期间)封网(也就是不让发布代码)
245 |
246 |
247 |
248 | 此外我们还需要在出事后能快速定位问题,快速回滚,这就需要记录每一次的发布时间,发布人等,这里的发布不仅包括工程的发布,还包括配置中心等的发布
249 |
250 | 
251 |
252 | **画外音**:上图是我司的发布记录,可以看到有代码变更,回滚等,这样如果发现有问题的话可以一键回滚
253 |
254 |
255 |
256 | 最后我们以一张图来总结一下高可用的常见手段
257 |
258 |
259 |
260 | 
261 |
262 |
263 |
264 |
265 |
266 | ### 参考
267 |
268 | * 《乔新亮的 CTO 成长复盘 --- 高可用设计,让产品没有后顾之忧》
269 |
270 |
--------------------------------------------------------------------------------
/Java/多线程使用不当引发的惨案.md:
--------------------------------------------------------------------------------
1 | 你好,我是坤哥
2 |
3 | 前些日子我们线上出现了一个比较严重的故障,这个故障是多线程使用不当引起的,挺有代表性的,所以分享给大家,希望能帮大家避坑
4 |
5 |
6 |
7 | ### 问题简述
8 |
9 | 先简单介绍一下问题产生的背景,我们有个返利业务,其中有个搜索场景,这个场景是用户在 app 输入搜索关键词,然后 server 会根据这个关键词到各个平台(如淘宝,京东,拼多多等)调一下搜索接口,聚合这些搜索结果后再返回给用户,最开始这个搜索场景处理是单线程的,但随着接入的平台越来越多,搜索请求耗时也越来越长,由于每个平台的搜索请求都是独立的,很显然,单线程是可以优化为多线程的,如下
10 |
11 | 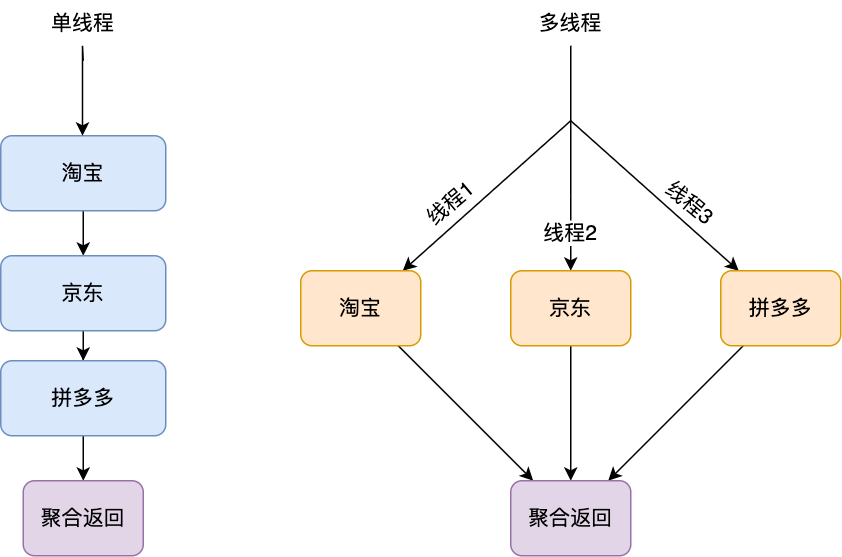
12 |
13 |
14 |
15 | 这样的话,搜索请求的耗时就只取决于搜索接口耗时最长的那个平台,所以使用多线程显然对接口性能是一个极大的优化,但使用多线程改造上线后,短时间内社群中有多名用户反馈前台展示「APP 需要升级的提示」,经定位后发现是因为在多线程中无法获取客户端信息,由于客户端信息缺失,导致返回给用户需要升级的提示,伪代码如下
16 |
17 | ```java
18 | // 开启多线程处理
19 | new Thread(new Runnable() {
20 | @Override
21 | public void run() {
22 | Map clientInfoMap = Context.getContext().getClientInfo();
23 | // 无法获取客户端信息,返回需要升级的信息
24 | if (clientInfoMap == null) {
25 | throw new Exception("版本号过低,请升级版本");
26 | }
27 | String version = clientInfoMap.get("version");
28 |
29 |
30 | // 以下正常逻辑
31 | ....
32 | }
33 | }).start();
34 | ```
35 |
36 | **画外音**:在生产中多线程使用的是线程池来实现,这里为了方便演示,直接 new Thread,效果都一样,大家知道即可
37 |
38 | 那么问题来了,改成多线程后客户端信息怎么就取不到了呢?要搞清楚这个问题,就得先了解客户端信息是如何存储的了
39 |
40 | ### Threadlocal 简介
41 |
42 | 不同客户端请求的客户端信息(wifi 还是 4G,机型,app名称,电量等)显然不一样,dubbo 业务线程拿到客户端请求后首先会将有用的请求信息提取出来(如本文中的 Map clientInfo),但这个 clientInfo 可能会在线程调用的各个方法中用到,于是如何存储就成为了一个现实的问题,相信有经验的朋友一下就想到了,没错,用 Threadlocal !为什么用它,它有什么优势,简单来说有两点
43 |
44 | 1. 无锁化提升并发性能
45 | 2. 简化变量的传递逻辑
46 |
47 |
48 |
49 | #### 1.无锁化提升并发性能
50 |
51 | 先说第一个,无锁化提升并发性能,影响并发的原因有很多,其中一个很重要的原因就是锁,为了防止对共享变量的竞用,不得不对共享变量加锁
52 |
53 | 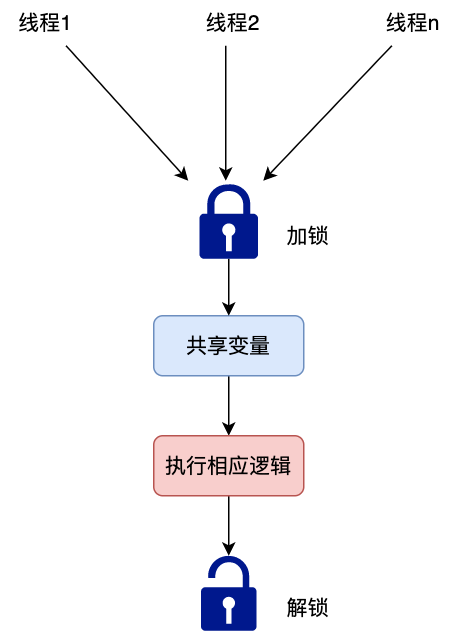
54 |
55 |
56 |
57 | 如果对共享变量争用的线程数增多,显然会严重影响系统的并发度,最好的办法就是使用“影分身术”为每个线程都创建一个线程本地变量,这样就避免了对共享变量的竞用,也就实现了无锁化
58 |
59 |
60 |
61 | 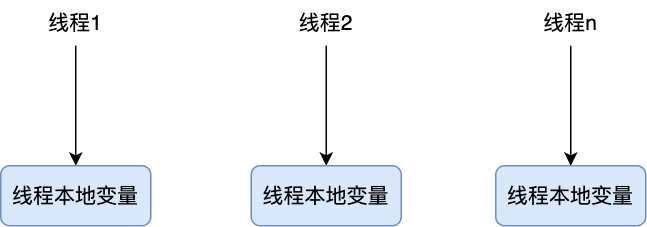
62 |
63 | ThreadLocal 即线程本地变量,它可以为每个线程创建一份线程本地变量,使用方法如下
64 |
65 | ```java
66 | static ThreadLocal threadLocal1 = new ThreadLocal() {
67 | @Override
68 | protected SimpleDateFormat initialValue() {
69 | return new SimpleDateFormat("yyyy-MM-dd");
70 | }
71 | };
72 |
73 | public String formatDate(Date date) {
74 | return threadLocal1.get().format(date);
75 | }
76 | ```
77 |
78 | 这样的话每个线程就独享一份与其他线程无关的 SimpleDateFormat 实例副本,它们调用 formatDate 时使用的 SimpleDateFormat 实例也是自己独有的副本,无论对副本怎么操作对其他线程都互不影响
79 |
80 |
81 |
82 | 通过以上例子我们可以看出,可以通过 `new ThreadLocal`+ `initialValue` 来为创建的 ThreadLocal 实例初始化本地变量(`initialValue` 方法会在首次调用 get 时被调用以初始化本地变量)。当然,如果之后需要修改本地变量的话,也可以用以下方式来修改
83 |
84 | ```java
85 | threadLocal1.set(new SimpleDateFormat("yyyy-MM-dd"))
86 | ```
87 |
88 | 而使用 `threadLocal1.get()`这样的方法即可获得线程本地变量
89 |
90 |
91 |
92 | 可能一些朋友会好奇线程本地变量是如何存储的,一图胜千言
93 |
94 | 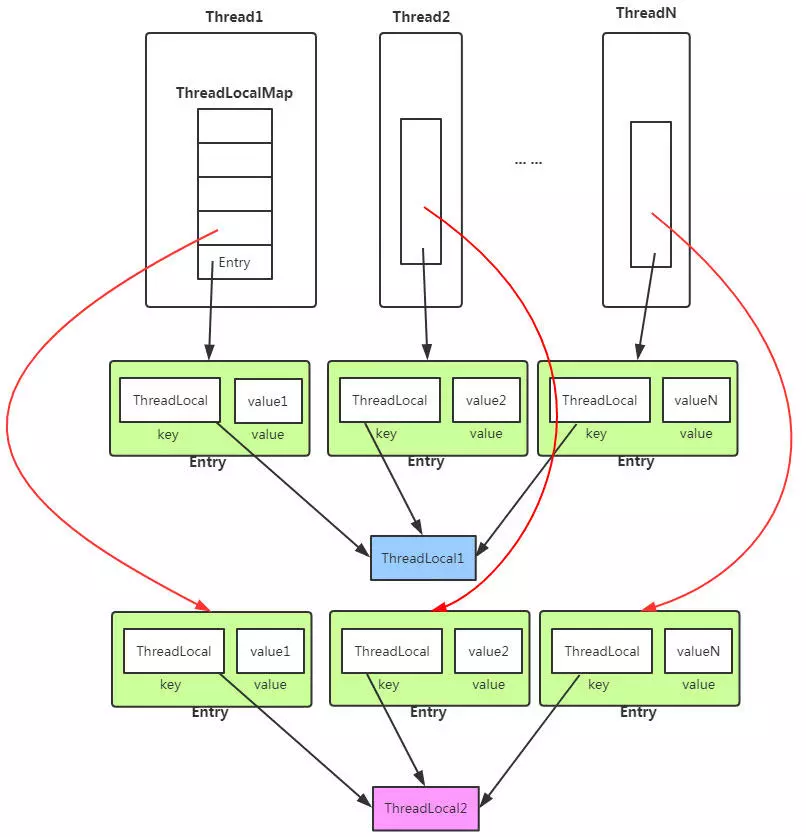
95 |
96 | 每一个线程(Thread)内部都有一个 ThreadLocalMap, ThreadLocal 的 get 和 set 操作其实在底层都是针对 ThreadLocalMap 进行操作的
97 |
98 | ```java
99 | public class Thread implements Runnable {
100 | /* ThreadLocal values pertaining to this thread. This map is maintained
101 | * by the ThreadLocal class. */
102 | ThreadLocal.ThreadLocalMap threadLocals = null;
103 | }
104 | ```
105 |
106 | 它与 HashMap 类似,存储的都是键值对,只不过每一项(Entry)中的 key 为 threadlocal 变量(如上文案例中的 threadLocal1),value 才为我们要存储的值(如上文中的 SimpleDateFormat 实例),此外它们在碰到 hash 冲突时的处理策略也不同,HashMap 在碰到 hash 冲突时采用的是链表法,而 ThreadLocalMap 采用的是线性探测法
107 |
108 |
109 |
110 | #### 2.简化变量的传递逻辑
111 |
112 | 接下来我们来看使用 ThreadLocal 的等二个好处,`简化变量的传递逻辑`,线程在处理业务逻辑时可能会调用几十个方法,如果这些方法中只有几个需要用到 clientInfo,难道要在这几十个方法中定义一个 clientInfo 参数来层层传递吗,显然不现实。那该怎么办呢,使用 ThreadLocal 即可解决此问题。由上文可知通过 ThreadLocal 设置的本地变量是同 threadlocal 一起保存在 Thread 的 ThreadLocalMap 这个内部类中的,所以可在线程调用的任意方法中取出,伪代码如下
113 |
114 | ```java
115 | public class ThreadLocalWithUserContext implements Runnable {
116 |
117 | private static ThreadLocal> threadLocal
118 | = new ThreadLocal<>();
119 |
120 | @Override
121 | public void run() {
122 | // clientInfo 初始化
123 | Map clientInfo = xxx;
124 | threadLocal.set(clientInfo);
125 | test1();
126 | }
127 |
128 | public void test1() {
129 | test2();
130 | }
131 |
132 | public void test2() {
133 | testX();
134 | }
135 | ...
136 |
137 | public void testX() {
138 | Map clientInfo = threadLocal.get();
139 | }
140 | }
141 | ```
142 |
143 | 中间定义的任何方法都无需为了传递 clientInfo 而定义一个额外的变量,代码优雅了不少
144 |
145 |
146 |
147 | 由以上分析可知,使用 ThreadLocal 确实比较方便,在此我们先停下来思考一个问题:如果线程在调用过程中只用到一个 clientInfo 这样的信息,只定义一个 ThreadLocal 变量当然就够了,但实际上在使用过程中我们可能要传递多个类似 clientInfo 这样的信息(如 userId,cookie,header),难道因此要定义多个 ThreadLocal 变量吗,这么做不是不可以,但不够优雅,更合适的做法是我们只定义一个 ThreadLocal 变量,变量存的是一个上下文对象,其他像 clientInfo,userId,header 等信息就作为此上下文对象的属性即可,代码如下
148 |
149 |
150 |
151 | ```java
152 | public final class Context {
153 |
154 | private static final ThreadLocal LOCAL = new ThreadLocal() {
155 | protected Context initialValue() {
156 | return new Context();
157 | }
158 | };
159 |
160 |
161 | private Long uid; // 用户uid
162 | private Map clientInfo; // 客户端信息
163 | private Map headers = null; // 请求头信息
164 | private Map> cookies = null; // 请求 cookie
165 |
166 | public static Context getContext() {
167 | return (Context) LOCAL.get();
168 | }
169 |
170 | }
171 | ```
172 |
173 | 这样的话我们可通过 `Context.getContext().getXXX()` 的形式来获取线程所需的信息,通过这样的方式我们不仅避免了定义无数 ThreadLocal 变量的烦恼,而且还收拢了上下文信息的管理
174 |
175 |
176 |
177 | 通过以上介绍相信大家也都知道了 clientInfo 其实是借由 ThreadLocal 存储的,认清了这个事实后那我们现在再回头看开头的生产问题:将单线程改成多线程后,为什么在新线程中就拿不到 clientInfo 了?
178 |
179 |
180 |
181 | ### 问题剖析
182 |
183 | 源码之下无秘密,我们查看一下源码来一探究竟,获取本地变量的值使用的是 ThreadLocal.get 方法,那就来看下这个方法
184 |
185 | ```java
186 | public class ThreadLocal {
187 | public T get() {
188 | // 1.先获取当前线程
189 | Thread t = Thread.currentThread();
190 | // 2.再获取当前线程的 ThreadLocalMap
191 | ThreadLocalMap map = getMap(t);
192 | if (map != null) {
193 | ThreadLocalMap.Entry e = map.getEntry(this);
194 | if (e != null) {
195 | T result = (T)e.value;
196 | return result;
197 | }
198 | }
199 | return setInitialValue();
200 | }
201 | }
202 | ```
203 |
204 | 可以看到 get 方法主要步骤如下
205 |
206 | 1. 首先需要获取当前线程
207 | 2. 其次获取当前线程的 ThreadLocalMap
208 | 3. 进而再去获取相应的本地变量值
209 | 4. 如果没有的话则调用 initiaValue 方法来初始化本地变量
210 |
211 | 由此可知当我们调用 threadlocal.get 时,会拿到**当前线程**的 ThreadLocalMap,然后再去拿 entry 中的本地变量,而对多线程来说,新线程的 ThreadLocalMap 里面的东西本来就未做任何设置,是空的,拿不到线程本地变量也就合情合理了
212 |
213 |
214 |
215 | ### 解决方案
216 |
217 | 问题清楚了,那怎么解决呢,不难得知主要有两种方案
218 |
219 | 1.我们之前是在新线程的执行方法中调用 threadlocal.get 方法,可以改成先从当前执行线程中调用 threadlocal.get 获得 clientInfo,然后再把 clientInfo 传入新线程,伪代码如下
220 |
221 | ```java
222 | // 先从当前线程的 Context 中获取 clientInfo
223 | Map clientInfoMap = Context.getContext().getClientInfo();
224 | new Thread(new Runnable() {
225 | @Override
226 | public void run() {
227 | // 此时的 clientInfoMap 由于是在新线程创建前获取的,肯定是有值的
228 | String version = clientInfoMap.get("version");
229 |
230 |
231 | // 以下正常逻辑
232 | ....
233 | }
234 | }).start();
235 | ```
236 |
237 | ####
238 |
239 | 2.只需把 ThreadLocal 换成 InheritableThreadLocal,如下
240 |
241 | ```java
242 | public final class Context {
243 | private static final InheritableThreadLocal LOCAL = new InheritableThreadLocal() {
244 | protected Context initialValue() {
245 | return new Context();
246 | }
247 | };
248 |
249 | public static Context getContext() {
250 | return (Context) LOCAL.get();
251 | }
252 | }
253 |
254 | new Thread(new Runnable() {
255 | @Override
256 | public void run() {
257 | // 此时的 clientInfo 能正常获取到
258 | Map clientInfo = Context.getContext().getClientInfo();
259 | String version = clientInfo.get("version");
260 | // 以下正常逻辑
261 | ....
262 | }
263 | }).start();
264 |
265 | ```
266 |
267 |
268 |
269 | 为什么 InheritableThreadLocal 能有这么神奇,背后的原理是什么?
270 |
271 |
272 |
273 | 由前文介绍我们得知,ThreadLocal 变量最终是存在 ThreadLocalMap 中的,那么能否在创建新线程的时候,把当前线程的 ThreadLocalMap 复制给新线程的 ThreadLocalMap 呢,这样的话即便你从新线程中调用 threadlocal.get 也照样能获得对应的本地变量,和 InheritableThreadLocal 相关的底层干的就是这个事,我们先来瞧一瞧 InheritableThreadLocal 长啥样
274 |
275 | ```java
276 | public class InheritableThreadLocal extends ThreadLocal {
277 |
278 | ThreadLocalMap getMap(Thread t) {
279 | return t.inheritableThreadLocals;
280 | }
281 |
282 | void createMap(Thread t, T firstValue) {
283 | t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue);
284 | }
285 | }
286 | ```
287 |
288 | 由此可知 InheritableThreadLocal 其实是继承自 ThreadLocal 类的,此外我们在 getMap 和 createMap 这两个方法中也发现它的底层其实是用 inheritableThreadLocals 来存储的,而 ThreadLocal 用的是 threadLocals 变量存储的
289 |
290 | ```java
291 | public class Thread implements Runnable {
292 | // ThreadLocal 实例的底层存储
293 | ThreadLocal.ThreadLocalMap threadLocals = null;
294 |
295 | // inheritableThreadLocals 实例的底层存储
296 | ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
297 | }
298 | ```
299 |
300 | 知道了这些,我们再来看下创建线程时涉及到的 inheritableThreadLocals 复制相关的关键代码如下:
301 |
302 | ```java
303 | public
304 | class Thread implements Runnable {
305 | public Thread() {
306 | init(null, null, "Thread-" + nextThreadNum(), 0);
307 | }
308 |
309 | private void init(ThreadGroup g, Runnable target, String name,
310 | long stackSize) {
311 | init(g, target, name, stackSize, null, true);
312 | }
313 |
314 | private void init(ThreadGroup g, Runnable target, String name,
315 | long stackSize, AccessControlContext acc,
316 | boolean inheritThreadLocals) {
317 | ...
318 | Thread parent = currentThread();
319 | if (inheritThreadLocals && parent.inheritableThreadLocals != null)
320 | // 将当前线程的 inheritableThreadLocals 复制给新创建线程的 inheritableThreadLocals
321 | this.inheritableThreadLocals =
322 | ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
323 | }
324 | }
325 | ```
326 |
327 | 由此可知,在创建新线程时,在初始化时其实相关逻辑是帮我们干了复制 inheritableThreadLocals 的操作,至此真相大白
328 |
329 |
330 |
331 | ### 总结
332 |
333 | 看完本文,相信大家对 Threadlocal 与 InheritableThreadLocal 的使用及其底层原理的掌握已不存在疑问,这也提醒我们熟练地掌握一个组件或一项技术最好的方式还是熟读它的源码,毕竟源码之下无秘密,当我们使用到别人封装好的组件或类时,最好可以也看一下它的源码,以本文为例,其实我们工程中多处地方都使用了 `Context.getContext().getClientInfo();`这样的获取客户端信息的形式,用惯了导致在多线程环境下没有引起警惕,以致踩了坑。
334 |
335 |
336 |
337 | 另外需要注意的是 ThreadLocal 使用不当可能导致内存泄漏,需要在线程结束后及时 remove 掉,这些技术细节不是本文重点,故而没有深入详解,有兴趣的大家可以去查阅相关资料,
338 |
--------------------------------------------------------------------------------
/算法/提升逼格利器-位运算.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 |
3 | 位运算在生产或算法解题中并不常见,不过如果你用得好,可以达到事半功倍的效果,而且位运算用得好,也可以极大地提升性能,如果在生产或面试中能看到使用位运算来解题,会让人眼前一亮,觉得你还是**有点逼格**的,巧用位运算,不仅会提升性能,还会让代码的可读性更好,达到四两拨千斤的效果,今天我们就来学学位运算在解题中的一些技巧,最后会用位运算来看看怎么解八皇后这道大 Boss 题,相信你看完肯定会有收获!
4 |
5 | 本文将会从以下几个方面来讲解位运算
6 |
7 | * 什么是位运算,位运算常见操作
8 | * 位运算使用技巧简介
9 | * 巧用位运算解算法题
10 |
11 | ## 什么是位运算,位运算常见操作
12 |
13 | 在现代计算机中所有的数据在内存中都是以二进制存在的,位运算就是直接对**整数**在内存中的二进制位进行操作,由于位运算直接对内存数据进行操作,无需转成十进制,因此使用位运算的处理速度是很快的。
14 |
15 | 举个简单的例子, 当我们要计算 6 & 4 的结果,在做位运算的时候首先要把 6,4 转成二进制,然后再做相应的位操作(与)。
16 |
17 | 
18 |
19 |
20 | 基本的位运算有与、或、异或、取反、左移、右移这6种,介绍如下:
21 |
22 | **& 与**:只有当两位都是 1 时结果才是 1,否则为 0 。
23 |
24 |
25 | ```shell
26 | 0110
27 | & 0100
28 | -----------
29 | 0100
30 | ```
31 |
32 |
33 | **| 或**:两位中只要有 1 位为 1 结果就是 1,两位都为 0 则结果为 0。
34 |
35 | ```shell
36 | 0110
37 | & 0110
38 | -----------
39 | 0110
40 | ```
41 |
42 |
43 | **^ 异或**:两个位相同则为 0,不同则为 1
44 |
45 | ```shell
46 | 0110
47 | ^ 0100
48 | -----------
49 | 0010
50 | ```
51 |
52 |
53 | **~ 取反**: 0 则变为 1,1 则变为 0
54 |
55 | ```shell
56 | ~ 0110
57 | -----------
58 | 1001
59 | ```
60 |
61 | **<< 左移**:向左进行移位操作,高位丢弃,低位补 0
62 |
63 | ```java
64 | int a = 8;
65 | a << 3;
66 | 移位前:0000 0000 0000 0000 0000 0000 0000 1000
67 | 移位后:0000 0000 0000 0000 0000 0000 0100 0000
68 | ```
69 |
70 | **>> 右移**:向右进行移位操作,对无符号数,高位补 0,对于有符号数,高位补符号位
71 |
72 | ```java
73 | unsigned int a = 8;
74 | a >> 3;
75 | 移位前:0000 0000 0000 0000 0000 0000 0000 1000
76 | 移位后:0000 0000 0000 0000 0000 0000 0000 0001
77 |
78 | int a = -8;
79 | a >> 3;
80 | 移位前:1111 1111 1111 1111 1111 1111 1111 1000
81 | 移位后:1111 1111 1111 1111 1111 1111 1111 1111
82 | ```
83 |
84 |
85 | ## 位运算使用技巧简介
86 | 接下来我们就由浅入深地来学习一下使用位运算的那些黑科技
87 |
88 | **1、 判断整型的奇偶性**
89 |
90 | 使用位运算操作如下
91 |
92 | ```c
93 | if((x & 1) == 0) {
94 | // 偶数
95 | } else {
96 | // 奇数
97 | }
98 | ```
99 |
100 | 这个例子相信大家都见过,只需判断整型的第一位是否是 1 即可,如果是说明是奇数,否则是偶数
101 |
102 | **2、 判断第 n 位是否设置为 1**
103 |
104 | ```c
105 | if (x & (1< 有 8 个一模一样的瓶子,其中有 7 瓶是普通的水,有一瓶是毒药。任何喝下毒药的生物都会在一星期之后死亡。现在,你只有 3 只小白鼠和一星期的时间,如何检验出哪个瓶子里有毒药?
168 |
169 | 解题步骤如下:
170 |
171 | 1、 把这 8 个瓶子从 0 到 7 进行编号,用二进制表示如下
172 |
173 | ```shell
174 | 000
175 | 001
176 | 010
177 | 011
178 | 100
179 | 101
180 | 110
181 | 111
182 | ```
183 |
184 | 2、 将 0 到 7 编号中第一位为 1 的所有瓶子(即 1,3,5,7)的水混在一起给老鼠 1 吃,第二位值为 1 的所有瓶子(即2,3,6,7)的水混在一起给老鼠 2 吃, 第三位值为 1 的所有瓶子(4,5,6,7)的水混在一起给老鼠 3 吃,现在假设老鼠 1,3 死了,那么有毒的瓶子编号中第 1,3 位肯定为 1,老鼠 2 没死,则有毒的瓶子编号中第 2 位肯定为 0,得到值 101 ,对应的编号是 5, 也就是第五瓶的水有毒。
185 |
186 | 这道题及其相关的变种在面试中出现地比较频繁,比如我现在把 8 瓶水换成 1000 瓶,问你至少需要几只老鼠才能测出有毒的瓶子,有了上述的思路相信应该不难,几只老鼠就相当于几个进制位,显然 2^10 = 1024 > 1000,即 10 只老鼠即可测出来。
187 |
188 | **2、 leetcode 232**
189 |
190 | > 给定一个数,判断它是否是可以用 2 的幂次方表示,可以返回 true,不可以返回 false,比如 8 = 2^3, 说明可以用 2 的幂次方表示,返回 true,9 不可以,所以返回 false。
191 |
192 | 解题分析:这题常规解法是做个循环不断地乘以 2 ,看下是否等于给定的值,如果等于说明是 2 的幂次方,否则如果不断累乘 2 后大于给定的值,说明不能用 2 的幂次方表示,时间复杂度是所做的累乘的次数,即 2^n >= 给定的值中的 n。
193 |
194 | 那是否有更快的解法呢?
195 |
196 | 上文的介绍中其实我们已经埋下伏笔了,没错用 x & (x-1),首先我们要发现能用 2 的幂次方表示的数的特点:它的所有位中有且仅有一位为 1,如
197 |
198 | ```shell
199 | 00001 2^0 = 1
200 | 00010 2^1 = 2
201 | 00100 2^2 = 4
202 | 01000 2^3 = 8
203 | 10000 2^3 = 16
204 | ```
205 |
206 | **如图示,所有 2 的幂次方最多只有一位为 1**
207 |
208 | 明白了这一点, 我们的思路就简单了,由于符合 2 的幂次方的数只有一位为 1,x & (x-1) 是把最后一位 1 置为 0,所以只要做一次 x & (x-1) 运算,看它的值是否等于 0 即可,如果是 0 说明它可以用 2 的幂次方表示,否则不可以,代码如下:
209 |
210 | ```c
211 | if(x&(x-1)) { //使用与运算判断一个数是否是2的幂次方
212 | printf("%d不是2的幂次方!\n", num);
213 | } else {
214 | printf("%d是2的%d次方!\n", num, log2(num));
215 | }
216 | ```
217 |
218 | 只用一行代码即可搞定,方便了很多!
219 |
220 |
221 | **3、 leetcode 232**
222 |
223 | > 给定一个非负整数 num. 对于 0 ≤ i ≤ num 范围中的每个数字 i, 计算其二进制数中 1 的数目并将它们作为数组返回。
224 | > 输入: 5 输出: [0,1,1,2,1,2]
225 |
226 | 这题的常规解法相信大家都能猜到,就是从 0 到 num 循环一遍,求出每个数字 i 中 1 的数目。
227 |
228 | 如果用位运算怎么做呢,先来看下解法,然后我们再来分析为啥这样写,非常巧妙!
229 |
230 | Python 代码
231 |
232 | ```Python
233 | vector countBits(int num) {
234 | vector bits(num+1, 0);
235 | for (int i = 1; i<= num; i++) {
236 | bits[i] += bits[i & (i-1)] + 1;
237 | }
238 | }
239 | ```
240 |
241 | Java 代码
242 |
243 | ```java
244 | public static int[] countBits(int num) {
245 | int[] bits = new int[num+1];
246 | Arrays.fill(bits, 0);
247 |
248 | for (int i = 1; i <= num; i++) {
249 | bits[i] = bits[i & (i-1)] + 1;
250 | }
251 | return bits;
252 | }
253 | ```
254 |
255 | 最关键的代码看这一行
256 |
257 | ```java
258 | bits[i] += bits[i & (i-1)] + 1;
259 | ```
260 |
261 | 这行代码是啥意思呢,i & (i-1) 是把 i 的最后一个值为 1 的位设为 0,不难发现整数「i & (i-1)」 中 1 的位数比 i 中 1 的位数少一个 ,所以要加 1(即 bits[i & (i-1)] + 1)。非常巧妙,这样从 1 开始走一遍循环即可,中间不要做任何针对变量 i 的 1 的个数的计算,只不过付出了一个 bits 数组的代价。 这里也是利用了以空间换时间的思想。
262 |
263 |
264 | **4、 利用位运算来解八皇后问题**
265 |
266 | 接下来我们来看看终级 Boss 题,如何用位运算来解八皇后问题,解题中运用到了非常多的位运算技巧,相信你学完会收获不少。
267 |
268 | > 在 8×8 格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上,问有多少种摆法
269 |
270 | 举个简单的下图所示的例子,如果在棋盘上放置一个皇后,则与这个皇后同一行,同一列,且皇后所在斜线经过的格子不能再放其他皇后。
271 |
272 | 
273 | 如图示,在其中任意一行放置一个皇后,则与此皇后同行,同列,同对角线的都不允许再放其他皇后,图中蓝色区块不允许放其他皇后。
274 |
275 | 一般我们用回溯法解八皇后。这里简单介绍一下啥是回溯法。
276 |
277 | 在第一行从左到右先选择一个位置放置皇后,由于第一行放了皇后,第二行可放皇后的位置受到了限制(下图蓝色区块表示对应行的格子不能放皇后)
278 | 
279 |
280 | **如图示,第二行放皇后的位置只能从第三个格子开始选**
281 |
282 | 第二行我们选第三个格子放皇后,选完开始在第三行选,第三方可选的位置也受到了第一,二行皇后所放位置的影响
283 |
284 | 
285 | **如图示,第三行只能从第五个格子开始放置皇后**
286 |
287 | 同理,第三,四,五行都从左到右选择符合条件的的格子放置皇后,选完后问题来了,第六行所在行没有可选的位置了!如图示
288 |
289 | 
290 |
291 | 怎么办呢,回溯!重新摆放第五行的皇后,将其放到第八格上
292 |
293 | 
294 |
295 | 重新摆放后发现第六行还是没有符合条件的行,咋办,我们知道第六行可摆放皇后的位置受第五行影响,而第五行受第四行摆放皇后位置的影响的,所以回溯到第四行,将皇后位置摆放到当前行的其他位置(第七格),再接着往下放 5,6,7,8 行的皇后。。。,只要不满足条件,改变上一层的的条件重新来,上一层调整后还是不符合条件,再调整上上层的。。。,调整完后重新往下递归选择,直到找到符合条件的,找到之后再在第一层换一个位置选皇后递归往下层选择执行,直到找到所有的解,这种不满足条件就回退上层调整再试的思想就是回溯法,可以看到回溯法一般是用递归实现的。
296 |
297 | 回溯算法有不少变种,这里我们重点介绍使用位运算的回溯算法,它是所有解法中最高效的!如果在面试中能使用位运算来解回溯算法,绝对会让面试官给你个大大的赞!
298 |
299 | 接下来是重点了,怎么用位运算来求解。
300 |
301 | 在以上回溯法的分析中,我们不难发现,在八皇后问题中,问题的关键是找出行可放皇后的格子。找到之后问题就解决了 90%,所以接下来我们就来看看怎么找这些可用的格子。
302 |
303 | 假设我们要求解第三行可放皇后的格子(说明一二行的皇后已放好了)那么第三行可放皇后的位置受到哪些条件的限制呢。显然在第一二行已放皇后的格子所在的列,左斜线,右斜线对应的方格都不能放皇后,如图示:
304 |
305 |
306 | 
307 |
308 | 我们以 column 来记录所有上方行已放置的皇后导致当前行格子不可用的集合,所在列如果放了皇后,则当前行格子对应的位置为 1,否则为 0,同理,以 pie(撇,左斜线) 记录所有已放置的皇后左斜方向导致当前行格子不可用的集合, na(捺,右斜线) 表示所有已放置的皇后右斜方向导致当前行不可用的集合。则对于第三行来说我们有:
309 |
310 | ```shell
311 | column = 10010000 (上图中的第一个图,第 1,4 列放了皇后,所以 1,4 位置为 1,其他位置为 0)
312 | pie = 00100000 (上图中的第二个图,左斜线经过第三行的第三个方格,所以第三位为 1)
313 | na = 00101000 (上图中的第三个图,右斜线经过第三行的第三, 五个方格,所以第三,五位为 1)
314 | ```
315 |
316 | 将这三个变量作或运算得到结果如下
317 |
318 | ```shell
319 | 10010000
320 | | 00100000
321 | | 00101000
322 | -----------------------
323 | 10111000
324 | ```
325 | 也就是说对于第三层来说第 1,3,4,5 个格子不能放皇后。如图示
326 |
327 | 
328 |
329 | 于是可知 column | pie | na 得到的结果中值为 0 的代表当前行对应的格子可放皇后, 1 代表不能放,但我们想改成 1 代表格子可放皇后, 0 代表不可放皇后,毕竟这样更符合我们的思维方式,怎么办,取反不就行了,于是我们有~(column| pie | na)。
330 |
331 | 问题来了,这样取反是有问题的,因为这三个变量都是定义的 int 型,为 32 位,取反之后高位的 0 全部变成了 1,而我们只想保留低 8 位(因为是 8 皇后),想把高位都置为 0,怎么办,这里就要用到位运算的黑科技了
332 |
333 | ```shell
334 | ~(column | pie | na) & ((1 << 8)-1)
335 | ```
336 | 后面的的 ((1<< 8) -1) 表示先把 1 往左移 8 位,值为 100000000,再减 1 ,则低 8 位全部为 1,高位全部为 0!(即 0011111111)再作与运算,即可保留低 8 位,去除高位。
337 |
338 | 费了这么大的劲,我们终于把当前行可放皇后的格子都找出来了(所有位值为 1 的格子可放置皇后)。接下来我们只要做个循环,遍历所有位为 1 的格子,每次取出可用格子放上皇后,再找下一层可放置皇后的格子,依此递归下去即可,直接所有行都遍历完毕。
339 |
340 | 于是现在问题转化为了已知当前行的 columne,pie,na,怎么确定下一行可放置皇后的格子。
341 |
342 | 上文可知,我们已经选出了当前行可用的格子(相应位为 1 对应的格子可用),假设我们在当前行选择了其中一个格子来放置皇后,此位置记为 p(如果是当前行的最后一个格子最后一个格子,则值为 1,如果放在倒数第二个,值为 10,倒数第三个则为 100,依此类推),则对于下一行来说,显然 column = column | p
343 |
344 | 那么 pie 呢,仔细看下图,显然应该为 (pie | p) << 1, 左斜线往下一行的格子延展时,相当于左移一位,
345 |
346 | 
347 |
348 | **如图示:下一行的 pie 显然为 (pie | p) << 1。**
349 |
350 | 同理 下一行的 na 应该为 (na | p) >> 1
351 |
352 |
353 | 有了以上详细地解析,我们就可以写出伪代码了
354 |
355 | ```c
356 | void queenSettle(row, col,pie,na) {
357 | N = 8; // 8皇后
358 | if (row >= N) {
359 | // 遍历到最后一行说明已经找到符合的条件了
360 | count++;return
361 | }
362 |
363 | // 取出当前行可放置皇后的格子
364 | bits = (~(col|pie|na)) & ((1 << N)-1)
365 |
366 | while(bits > 0) {
367 | // 每次从当前行可用的格子中取出最右边位为 1 的格子放置皇后
368 | p = bits & -bits
369 |
370 | // 紧接着在下一行继续放皇后
371 | queenSettle(row+1, col | p, (pie|p) << 1, (na | p) >> 1)
372 |
373 | // 当前行最右边格子已经选完了,将其置成 0,代表这个格子已遍历过
374 | bits = bits & (bits-1)
375 | }
376 | }
377 | ```
378 | 一开始传入 queenSettle(0,0,0,0) 这样即可得到最终的解。伪代码写得很清楚了,相信用相关语言不难实现,这里就留给大家作个练习吧。
379 |
380 |
381 | ## 总结
382 |
383 | 本文带大家由浅入深地完成了位运算的学习,掌握好位运算不仅仅是为了提升逼格,还能极大地提升效率,位运算也广泛地应用于代码编写中,运用得当能极大地简化代码,且可读性更好,限于篇幅关系,这里不展开,大家如有兴趣可参考文末的链接。
384 |
385 | 如有帮助,欢迎大家关注公号哦。之后将会讲解大量算法解题思路,希望我们一起攻克算法难题!
386 |
387 |
388 | 
389 |
390 |
391 | 巨人的肩膀
392 |
393 | http://graphics.stanford.edu/~seander/bithacks.html#OperationCounting
394 |
395 | https://catonmat.net/low-level-bit-hacks 位运算的那些骚操作
396 |
397 | https://www.zhihu.com/question/38206659/answer/736472332
398 |
399 | http://xxgblog.com/2013/09/15/java-bitmask/ Java位运算在程序设计中的使用
400 |
--------------------------------------------------------------------------------
162 | ```
163 |
164 | 那么如果正常的用户误点了上面这张图片,由于相同域名的请求会自动带上 cookie,而 cookie 里带有正常登录用户的 sessionid,类似上面这样的转账操作在 server 就会成功,会造成极大的安全风险
165 |
166 | 
167 |
168 | CSRF 攻击的根本原因在于对于同样域名的每个请求来说,它的 cookie 都会被自动带上,这个是浏览器的机制决定的,所以很多人据此认定 cookie 不安全。
169 |
170 | 使用 token 确实避免了CSRF 的问题,但正如上文所述,由于 token 保存在 local storage,它会被 JS 读取,**从存储角度来看**也不安全(实际上防护 CSRF 攻击的正确方式只有 CSRF token)
171 |
172 |
173 | 所以不管是 cookie 还是 token,从存储角度来看其实都不安全,我们所说的的安全更多的是强调传输中的安全,可以用 HTTPS 协议来传输, 这样的话请求头都能被加密,也就保证了传输中的安全。
174 |
175 |
176 |
177 | 其实我们把 cookie 和 token 比较本身就不合理,一个是存储方式,一个是验证方式,正确的比较应该是 session vs token。
178 |
179 | ## 总结
180 |
181 | session 和 token 本质上是没有区别的,都是对用户身份的认证机制,只是他们实现的校验机制不一样而已(一个保存在 server,通过在 redis 等中间件获取来校验,一个保存在 client,通过签名校验的方式来校验),多数场景上使用 session 会更合理,但如果在单点登录,一次性命令上使用 token 会更合适,最好在不同的业务场景中合理选型,才能达到事半功倍的效果。
182 |
183 |
184 | 巨人的肩膀
185 | * Cookie Session跨站无法共享问题(单点登录解决方案):https://blog.csdn.net/wtopps/article/details/75040224
186 | * Stop using JWT for sessions:http://cryto.net/~joepie91/blog/2016/06/13/stop-using-jwt-for-sessions/
187 | *
188 | 更多精品文章,欢迎大家扫码关注「码海」
189 |
190 | 
191 |
--------------------------------------------------------------------------------
/Java/为什么线程崩溃不会导致JVM崩溃.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 |
4 |
5 | 网上看到一个很有意思的据说是美团的面试题:为什么线程崩溃崩溃不会导致 JVM 崩溃,这个问题我看了不少回答,但都没答到根本原因,所以决定答一答,相信大家看完肯定会有收获,本文分以下几节来探讨
6 |
7 | 1. 线程崩溃,进程一定会崩溃吗
8 | 2. 进程是如何崩溃的-信号机制简介
9 | 3. 为什么在 JVM 中线程崩溃不会导致 JVM 进程崩溃
10 | 4. openJDK 源码解析
11 |
12 |
13 |
14 | ### 线程崩溃,进程一定会崩溃吗
15 |
16 | 一般来说如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃,为什么系统要让进程崩溃呢,这主要是因为在进程中,**各个线程的地址空间是共享的**,既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃
17 |
18 | 
19 |
20 |
21 |
22 | 非法访问内存有以下几种情况,我们以 C 语言举例来看看
23 |
24 | 1. 针对只读内存写入数据
25 |
26 | ```c
27 | #include
28 | #include
29 |
30 | int main() {
31 | char *s = "hello world";
32 | s[1] = 'H'; // 向只读内存写入数据,崩溃
33 | }
34 | ```
35 |
36 | 2. 访问了不属于进程地址空间的内存
37 |
38 | ```c
39 | #include
40 | #include
41 |
42 | int main() {
43 | int *p = (int *)0xC0000fff;
44 | *p = 10; // 针对不属于进程的内核空间写入数据,崩溃
45 | }
46 | ```
47 |
48 | 在 32 位虚拟地址空间中,p 指向的是内核空间,显然不具有写入权限,所以上述赋值操作会导致崩溃
49 |
50 | 3. 访问了不存在的内存,比如
51 |
52 | ```c
53 | #include
54 | #include
55 |
56 | int main() {
57 | int *a = NULL;
58 | *a = 1; // 访问了不存在的内存
59 | }
60 | ```
61 |
62 |
63 |
64 | 以上错误都是访问内存时的错误,所以统一会报 Segment Fault 错误(即段错误),这些都会导致进程崩溃
65 |
66 | ### 进程是如何崩溃的-信号机制简介
67 |
68 | 那么线程崩溃后,进程是如何崩溃的呢,这背后的机制到底是怎样的,答案是**信号**,大家想想要干掉一个正在运行的进程是不是经常用 kill -9 pid 这样的命令,这里的 kill 其实就是给指定 pid 发送终止信号的意思,其中的 9 就是信号,其实信号有很多类型的,在 Linux 中可以通过 `kill -l`查看所有可用的信号
69 |
70 | 
71 |
72 | 当然了发 kill 信号必须具有一定的权限,否则任意进程都可以通过发信号来终止其他进程,那显然是不合理的,实际上 kill 执行的是系统调用,将控制权转移给了内核(操作系统),由内核来给指定的进程发送信号
73 |
74 |
75 |
76 | 那么发个信号进程怎么就崩溃了呢,这背后的原理到底是怎样的?
77 |
78 | 其背后的机制如下
79 |
80 | 1. CPU 执行正常的进程指令
81 | 2. 调用 kill 系统调用向进程发送信号
82 | 3. 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
83 | 4. 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
84 | 5. **操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出**
85 |
86 | 注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,**但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行**
87 |
88 | ```c
89 | // 自定义信号处理函数示例
90 |
91 | #include
92 | #include
93 | #include
94 | // 自定义信号处理函数,处理自定义逻辑后再调用 exit 退出
95 | void sigHandler(int sig) {
96 | printf("Signal %d catched!\n", sig);
97 | exit(sig);
98 | }
99 | int main(void) {
100 | signal(SIGSEGV, sigHandler);
101 | int *p = (int *)0xC0000fff;
102 | *p = 10; // 针对不属于进程的内核空间写入数据,崩溃
103 | }
104 |
105 | // 以上结果输出: Signal 11 catched!
106 | ```
107 |
108 |
109 |
110 | **如代码所示**:注册信号处理函数后,当收到 SIGSEGV 信号后,先执行相关的逻辑再退出
111 |
112 |
113 |
114 | 另外当进程接收信号之后也可以不定义自己的信号处理函数,而是选择忽略信号,如下
115 |
116 | ```c
117 | #include
118 | #include
119 | #include
120 |
121 | int main(void) {
122 | // 忽略信号
123 | signal(SIGSEGV, SIG_IGN);
124 |
125 | // 产生一个 SIGSEGV 信号
126 | raise(SIGSEGV);
127 |
128 | printf("正常结束");
129 | }
130 | ```
131 |
132 |
133 |
134 | 也就是说虽然给进程发送了 kill 信号,但如果进程自己定义了信号处理函数或者无视信号就有机会逃出生天,当然了 kill -9 命令例外,不管进程是否定义了信号处理函数,都会马上被干掉
135 |
136 | 说到这大家是否想起了一道经典面试题:如何让正在运行的 Java 工程的优雅停机,通过上面的介绍大家不难发现,其实是 JVM 自己定义了信号处理函数,这样当发送 kill pid 命令(默认会传 15 也就是 SIGTERM)后,JVM 就可以在信号处理函数中执行一些资源清理之后再调用 exit 退出。这种场景显然不能用 kill -9,不然一下把进程干掉了资源就来不及清楚了
137 |
138 |
139 |
140 | ### 为什么线程崩溃不会导致 JVM 进程崩溃
141 |
142 | 现在我们再来看看开头这个问题,相信你多少会心中有数,想想看在 Java 中有哪些是觉见的由于非法访问内存而产生的 Exception 或 error 呢,常见的是大家熟悉的 StackoverflowError 或者 NPE(NullPointerException),NPE 我们都了解,属于是访问了不存在的内存
143 |
144 | 但为什么栈溢出(Stackoverflow)也属于非法访问内存呢,这得简单聊一下进程的虚拟空间,也就是前面提到的共享地址空间
145 |
146 | 现代操作系统为了保护进程之间不受影响,所以使用了虚拟地址空间来隔离进程,进程的寻址都是针对虚拟地址,每个进程的虚拟空间都是一样的,而线程会共用进程的地址空间,以 32 位虚拟空间,进程的虚拟空间分布如下
147 |
148 | 
149 |
150 | 那么 stackoverflow 是怎么发生的呢,进程每调用一个函数,都会分配一个栈桢,然后在栈桢里会分配函数里定义的各种局部变量,假设现在调用了一个无限递归的函数,那就会持续分配栈帧,但 stack 的大小是有限的(Linux 中默认为 8 M,可以通过 ulimit -a 查看),如果无限递归显然很快栈就会分配完了,此时再调用函数试图分配超出栈的大小内存,就会发生段错误,也就是 stackoverflowError
151 |
152 | 
153 |
154 |
155 |
156 | 好了,现在我们知道了 StackoverflowError 怎么产生的,那问题来了,既然 StackoverflowError 或者 NPE 都属于非法访问内存, JVM 为什么不会崩溃呢,有了上一节的铺垫,相信你不难回答,其实就是因为 JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃,怎么证明这个推测呢,我们来看下 JVM 的源码来一探究竟
157 |
158 |
159 |
160 | ### openJDK 源码解析
161 |
162 | HotSpot 虚拟机是目前使用范围最广的 Java 虚拟机,据 R 大所述, Oracle JDK 与 OpenJDK 里的 JVM 都是 HotSpot VM,从源码层面说,两者基本上是同一个东西,OpenJDK 是开源的,所以我们主要研究下 Java 8 的 OpenJDK 即可,地址如下:https://github.com/AdoptOpenJDK/openjdk-jdk8u,有兴趣的可以下载来看看
163 |
164 |
165 |
166 | 我们只研究 Linux 下的 JVM,为了便于说明,也方便大家查阅,我把其中关于信号处理的关键流程整理了下(忽略其中的次要代码)
167 |
168 | 
169 |
170 |
171 |
172 | 可以看到,在启动 JVM 的时候,也设置了信号处理函数,收到 SIGSEGV,SIGPIPE 等信号后最终会调用 JVM_handle_linux_signal 这个自定义信号处理函数,再来看下这个函数的主要逻辑
173 |
174 |
175 |
176 | ```c
177 | JVM_handle_linux_signal(int sig,
178 | siginfo_t* info,
179 | void* ucVoid,
180 | int abort_if_unrecognized) {
181 |
182 | // Must do this before SignalHandlerMark, if crash protection installed we will longjmp away
183 | // 这段代码里会调用 siglongjmp,主要做线程恢复之用
184 | os::ThreadCrashProtection::check_crash_protection(sig, t);
185 |
186 | if (info != NULL && uc != NULL && thread != NULL) {
187 | pc = (address) os::Linux::ucontext_get_pc(uc);
188 |
189 | // Handle ALL stack overflow variations here
190 | if (sig == SIGSEGV) {
191 | // Si_addr may not be valid due to a bug in the linux-ppc64 kernel (see
192 | // comment below). Use get_stack_bang_address instead of si_addr.
193 | address addr = ((NativeInstruction*)pc)->get_stack_bang_address(uc);
194 |
195 | // 判断是否栈溢出了
196 | if (addr < thread->stack_base() &&
197 | addr >= thread->stack_base() - thread->stack_size()) {
198 | if (thread->thread_state() == _thread_in_Java) {
199 | stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::STACK_OVERFLOW);
200 | }
201 | }
202 | }
203 | }
204 |
205 | if (sig == SIGSEGV &&
206 | !MacroAssembler::needs_explicit_null_check((intptr_t)info->si_addr)) {
207 | // 此处会做空指针检查
208 | stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
209 | }
210 |
211 |
212 | // 如果是栈溢出或者空指针最终会返回 true,不会走最后的 report_and_die,所以 JVM 不会退出
213 | if (stub != NULL) {
214 | // save all thread context in case we need to restore it
215 | if (thread != NULL) thread->set_saved_exception_pc(pc);
216 |
217 | uc->uc_mcontext.gregs[REG_PC] = (greg_t)stub;
218 | // 返回 true 代表 JVM 进程不会退出
219 | return true;
220 | }
221 |
222 | VMError err(t, sig, pc, info, ucVoid);
223 | // 生成 hs_err_pid_xxx.log 文件并退出
224 | err.report_and_die();
225 |
226 | ShouldNotReachHere();
227 | return true; // Mute compiler
228 |
229 | }
230 | ```
231 |
232 |
233 |
234 | 从以上代码我们可以知道以下信息
235 |
236 | 1. 发生 stackoverflow 还有空指针错误,确实都发送了 SIGSEGV,只是虚拟机不选择退出,而是自己内部作了额外的处理,其实是恢复了线程的执行,并抛出 StackoverflowError 和 NPE,这就是为什么 JVM 不会崩溃且我们能捕获这两个错误/异常的原因
237 |
238 | 2. 如果针对 SIGSEGV 等信号,在以上的函数中 JVM 没有做额外的处理,那么最终会走到 report_and_die 这个方法,这个方法主要做的事情是生成 hs_err_pid_xxx.log crash 文件(记录了一些堆栈信息或错误),然后退出
239 |
240 |
241 |
242 | 自此我相信大家已经明白了为什么发生了 StackoverflowError 和 NPE 这两个非法访问内存的错误,JVM 却没有崩溃的原因,原因其实就是虚拟机内部定义了信号处理函数,而在信号处理函数中对这两者做了额外的处理以让 JVM 不崩溃,另一方面也可以看出如果 JVM 不对信号做额外的处理,最后会自己退出并产生 crash 文件 hs_err_pid_xxx.log(可以通过 -XX:ErrorFile=/var/*log*/hs_err.log 这样的方式指定),这个文件记录了虚拟机崩溃的重要原因,所以也可以说,虚拟机是否崩溃只要看它是否会产生此崩溃日志文件
243 |
244 |
245 |
246 | ### 总结
247 |
248 | 正常情况下,操作系统为了保证系统安全,所以针对非法内存访问会发送一个 SIGSEGV 信号,而操作系统一般会调用默认的信号处理函数(一般会让相关的进程崩溃),但如果进程觉得"罪不致死",那么它也可以选择自定义一个信号处理函数,这样的话它就可以做一些自定义的逻辑,比如记录 crash 信息等有意义的事,回过头来看为什么虚拟机会针对 StackoverflowError 和 NullPointerException 做额外处理让线程恢复呢,针对 stackoverflow 其实它采用了一种栈回溯的方法保证线程可以一直执行下去,而捕获空指针错误主要是这个错误实在太普遍了,为了这一个很常见的错误而让 JVM 崩溃那线上的 JVM 要宕机多少次,所以与其这次倒不如让线程起死回生,并且将这两个错误/异常抛给用户来处理
249 |
250 |
251 |
252 | #### 巨人的肩膀
253 |
254 | Segmentation Fault in Linux: https://www.cnblogs.com/kaixin/archive/2010/06/07/1753133.html
255 |
256 | linux SIGSEGV 信号捕捉,保证发生段错误后程序不崩溃: https://blog.csdn.net/work_msh/article/details/8470277
257 |
258 |
259 |
260 | 更多精品文章,欢迎大家扫码关注「码海」
261 |
262 | 
--------------------------------------------------------------------------------
/Java/Java线程模型.md:
--------------------------------------------------------------------------------
1 | 上周[线程崩溃为什么不会导致 JVM 崩溃](https://mp.weixin.qq.com/s/JnlTdUk8Jvao8L6FAtKqhQ)在其他平台发出后,有一位小伙伴留言说有个地方不严谨
2 |
3 | 
4 |
5 | 他认为如果 JVM 中的主线程异常没有被捕获,JVM 还是会崩溃,那么这个说法是否正确呢,我们做个试验看看结果是否是他说的这样
6 |
7 | ```java
8 | public class Test {
9 | public static void main(String[] args) {
10 | TestThread testThread = new TestThread();
11 | TestThread.start();
12 | Integer p = null;
13 | // 这里会导致空指针异常
14 | if (p.equals(2)) {
15 | System.out.println("hahaha");
16 | }
17 | }
18 | }
19 |
20 | class TestThread extends Thread {
21 | @Override
22 | public void run() {
23 | while (true) {
24 | System.out.println("test");
25 | }
26 | }
27 | }
28 | ```
29 |
30 | 试验很简单,首先启动一个线程,在这个线程里搞一个 while true 不断打印, 然后在主线程中制造一个空指针异常,不捕获,然后看是否会一直打印 test
31 |
32 |
33 |
34 | 结果是会不断打印 test,说明**主线程崩溃,JVM 并没有崩溃**,这是怎么回事, JVM 又会在什么情况下完全退出呢?
35 |
36 |
37 |
38 | 其实在 Java 中并没有所谓主线程的概念,只是我们习惯把启动的线程作为主线程而已,所有线程其实都是平等的,不管什么线程崩溃都不会影响到其它线程的执行,注意我们这里说的线程崩溃是指由于未 catch 住 JVM 抛出的虚拟机错误(VirtualMachineError)而导致的崩溃,虚拟机错误包括 InternalError,OutOfMemoryError,StackOverflowError,UnknownError 这四大子类
39 |
40 | 
41 |
42 |
43 |
44 | JVM 抛出这些错误其实是一种防止整个进程崩溃的自我防护机制,这些错误其实是 JVM 内部定义了信号处理函数处理后抛出的,JVM 认为这些错误"罪不致死",所以选择恢复线程再给这些线程抛错误(就算线程不 catch 这些错误也不会崩溃)的方式来避免自身崩溃,但如果线程触发了一些其他的非法访问内存的错误,JVM 则会认为这些错误很严重,从而选择退出,比如下面这种非法访问内存的错误就会被认为是致命错误,JVM 就不会向上层抛错误,而会直接选择退出
45 |
46 | ```java
47 | Field f = Unsafe.class.getDeclaredField("theUnsafe");
48 | f.setAccessible(true);
49 | Unsafe unsafe = (Unsafe) f.get(null);
50 | unsafe.putAddress(0, 0);
51 | ```
52 |
53 | 回过头来看,除了这些致命性错误导致的 JVM 崩溃,还有哪些情况会导致 JVM 退出呢,在 javadoc 上说的很清楚
54 |
55 | 
56 |
57 | **The Java Virtual Machine exits when the only threads running are all daemon threads**
58 |
59 | 也就是说只有在 JVM 的所有线程都是守护线程(daemon thread)的时候才会完全退出,什么是守护线程?守护线程其实是为其他线程服务的线程,比如垃圾回收线程就是典型的守护线程,既然是为其他线程服务的,那么一旦其他线程都不存在了,守护线程也没有存在的意义了,于是 JVM 也就退出了,守护线程通常是 JVM 运行时帮我们创建好的,当然我们也可以自己设置,以开头的代码为例,在创建完 TestThread 后,调用 testThread.setDaemon(true) 方法即可将线程转为守护线程,然后再启动,这样在主线程退出后,JVM 就会退出了,大家可以试试
60 |
61 |
62 |
63 | ### Java 线程模型简介
64 |
65 | 我们可以看看 Java 的线程模型,这样大家对 JVM 的线程调度也会有一个更全面的认识,我们可以先从源码角度看看,启动一个 Thread 到底在 JVM 内部发生了什么,启动源码代码在 Thread#start 方法中
66 |
67 | ```java
68 | public class Thread {
69 |
70 | public synchronized void start() {
71 | ...
72 | start0();
73 | ...
74 | }
75 | private native void start0();
76 | }
77 | ```
78 |
79 | 可以看到最终会调用 start0 这个 native 方法,我们去下载一下 openJDK(地址:https://github.com/AdoptOpenJDK/openjdk-jdk8u) 来看看这个方法对应的逻辑
80 |
81 |
82 |
83 | 
84 |
85 | 可以看到 start0 对应的是 JVM_startThread 这个方法,我们主要观察在 Linux 下的线程启动情况,一路追踪下去
86 |
87 | ```c++
88 | // jvm.cpp
89 | JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
90 | native_thread = new JavaThread(&thread_entry, sz);
91 |
92 | // thread.cpp
93 | JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz)
94 | {
95 | os::create_thread(this, thr_type, stack_sz);
96 | }
97 |
98 | // os_linux.cpp
99 | bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
100 | int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
101 | }
102 | ```
103 |
104 | 可以看到最终是通过调用 pthread_create 来启动线程的,这个方法是一个 C 函数库实现的创建 native thread 的接口,是一个系统调用,由此可见 pthread_create 最终会创建一个 native thread,这个线程也叫**内核线程**,操作系统只能调度内核线程,于是我们知道了在 Java 中,Java 线程和内核线程是一对一的关系,Java 线程调度实际上是通过操作系统调度实现的,这种一对一的线程也叫 NPTL(Native POSIX Thread Library) 模型,如下
105 |
106 | 
107 |
108 | 那么这个内核线程在内核中又是怎么表示的呢, 其实在 Linux 中不管是进程还是线程都是通过一个 task_struct 的结构体来表示的, 这个结构体定义了进程需要的虚拟地址,文件描述符,寄存器,信号等资源
109 |
110 |
111 |
112 | 早期没有线程的概念,所以每次启动一个进程都需要调用 fork 创建进程,这个 fork 干的事其实就是 copy 父进程对应的 task_struct 的多数字段(pid 等除外),这在性能上显然是无法接受的。于是线程的概念被提出来了,线程除了有自己的栈和寄存器外,其他像虚拟地址,文件描述符等资源都可以共享
113 |
114 |
115 |
116 | 
117 |
118 |
119 |
120 | 于是针对线程,我们就可以指定在创建 task_struct 时,采用**共享**而不是复制字段的方式。其实不管是创建进程(fork)还是创建线程(pthread_create)最终都会通过调用 clone() 的形式来创建 task_struct,只不过 pthread_create 在调用 clone 时,指定了如下几个共享参数
121 |
122 | ```
123 | clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
124 | ```
125 |
126 | **画外音**:CLONE_VM 共享页表,CLONE_FS 共享文件系统信息,CLONE_FILES 共享文件句柄,CLONE_SIGHAND 共享信号
127 |
128 |
129 |
130 | 通过共享而不是复制资源的形式极大地加快了线程的创建,另外线程的调度开销也会更小,比如在(同一进程内)线程间切换的时候由于共享了虚拟地址空间,TLB 不会被刷新从而导致内存访问低效的问题
131 |
132 |
133 |
134 | 提到这相信你已经明白了教科书上的一句话:进程是资源分配的最小单元,而线程是程序执行的最小单位。在 Linux 中进程分配资源后,线程通过共享资源的方式来被调度的以提升线程的执行效率
135 |
136 |
137 |
138 | 由此可见,在 Linux 中所有的进程/线程都是用的 task_struct,**它们之间其实是平等的**,那怎么表示这些线程属于同一个进程的概念呢,毕竟线程之间也是要通信的,一组线程以及它们所共同引用的一组资源就是一个进程。, 它们还必须被视为一个整体。
139 |
140 |
141 |
142 | task_struct 中引入了线程组的概念,如果线程都是由同一个进程(即我们说的主线程)产生的, 那么它们的 tgid(线程组id) 是一样的,如果是主线程,则 pid = tgid,如果是主线程创建的线程,则这些线程的 tgid 会与主线程的 tgid 一致,
143 |
144 |
145 |
146 | 那么在 LInux 中进程,进程内的线程之间是如何通信或者管理的呢,其实 NPTL 是一种实现了 POSIX Thread 的标准 ,所以我们只需要看 POSIX Thread 的标准即可,以下列出了 POSIX Thread 的主要标准:
147 |
148 | 1. 查看进程列表的时候, 相关的一组 task_struct 应当被展现为列表中的一个节点(即进程内如果有多个线程,展示进程列表 `ps -ef` 时只会展示主线程,如果要查看线程的话可以用 `ps -T`)
149 | 2. 发送给这个进程的信号(对应 kill 系统调用), 将被对应的这一组 task_struct 所共享, 并且被其中的任意一个”线程”处理
150 | 3. 发送给某个线程的信号(对应 pthread_kill), 将只被对应的一个 task_struct 接收, 并且由它自己来处理
151 | 4. 当进程被停止或继续时(对应 SIGSTOP/SIGCONT 信号), 对应的这一组 task_struct 状态将改变
152 | 5. 当进程收到一个致命信号(比如由于段错误收到 SIGSEGV 信号), 对应的这一组 task_struct 将全部退出
153 |
154 | **画外音**: POSIX 即可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),是一种接口规范,如果系统都遵循这个标准,可以做到源码级的迁移,这就类似 Java 中的针对接口编程
155 |
156 |
157 |
158 | 这样就能很好地满足进程退出线程也退出,或者线程间通信等要求了
159 |
160 |
161 |
162 | ### NPTL 模型的缺点
163 |
164 | NPTL 是一种非常高效的模型,研究表明 NPTL 能够成功地在 IA-32 平台上在两秒种内生成 100,000 个线程,而 2.6 之前未采用 NPTL 的内核则需耗费 15 分钟左右,看起来 NPTL 确实很好地满足了我们的需求,但针对内核线程来调度其实还是有以下问题
165 |
166 |
167 |
168 | 1. 不管是进程还是线程,每次阻塞、切换都需要陷入系统调用(system call),系统调用开销其实挺大的,包括上下文切换(寄存器切换),特权模式切换等,而且还得先让 CPU 跑操作系统的调度程序,然后再由调度程序决定该跑哪一个进程(线程)
169 | 2. 不管是进程还是线程,都属于抢占式调度(高优先级线进程优先被调度),由于抢占式调度执行顺序无法确定的特点,使用线程时需要非常小心地处理同步问题
170 | 3. 线程虽然更轻量级,但这只是相对于进程而言,实际上使用线程所消耗的资源依然很大,比如在 linux 上,一个线程默认的栈大小是1M,创建几万个线程就吃不消了
171 |
172 |
173 |
174 | ### 协程
175 |
176 | NPTL 模型其实已经足够优秀了,上述问题本质上其实还是因为线程还是太“重”所致,那能否再在线程上抽出一个更轻量级的执行单元(可被 CPU 调度和分派的基本单位)呢,答案是肯定的,在线程之上我们可以再抽象出一个协程(coroutine)的概念,就像进程是由线程来调度的,同样线程也可以细化成一个个的协程来调度
177 |
178 |
179 |
180 | 
181 |
182 |
183 |
184 | 针对以上问题,协程都做了非常好的处理
185 |
186 | 1. 协程的调度处于用户态,也就没有了系统调用这些开销
187 | 2. 协程不属于抢占式调度,而是协作式调度,如何调度,在什么时间让出执行权给其它协程是由用户自己决定的,这样的话同步的问题也基本不存在,可以认为协程是无锁的,所以性能很高
188 | 3. 我们可以认为线程的执行是由一个个协程组成的,协程是更轻量的存在,内存使用大约只有线程的十分之一甚至是几十分之一,它是使用栈内存按需使用的,所以创建百万级的协程是非常轻松的事
189 |
190 |
191 |
192 | 协程是怎么做到上述这些的呢
193 |
194 |
195 |
196 | 协程(coroutine)可以分为两个角度来看,一个是 routine 即执行单元,一个是 co 即 cooperative 协作,也就是说线程可以依次顺序执行各个协程,但协程与线程不同之处在于,如果某个协程(假设为 A)内碰到了 IO 等阻塞事件,可以主动让出自己的调度权,即挂起(suspend),转而执行其他协程,等 IO 事件准备好了,再来调度协程 A
197 |
198 | 
199 |
200 |
201 |
202 | 这就好比我在看电视的时候碰到广告,那我可以先去倒杯水,等广告播完了再回来继续看电视。而如果是函数,那你必须看完广告再去倒水,显然协程的效率更高。那么协程之间是怎么协作的呢,我们可以在两个协程之间碰到 IO 等阻塞事件时随时将自己挂起(yield),然后唤醒(resume)对方以让对方执行,想象一下如果协程中有挺多 IO 等阻塞事件时,那这种协作调度是非常方便的
203 |
204 | 
205 |
206 | 不像函数必须执行完才能返回,协程可以在执行流中的**任意位置**由用户决定挂起和唤醒,无疑协程是更方便的
207 |
208 | 
209 |
210 |
211 |
212 | 更重要的一点是不像线程的挂起和唤醒等调度必须通过系统调用来让内核调度器来调度,**协程的挂起和唤醒完全是由用户决定的**,而且这个调度是在用户态,几乎没有开销!
213 |
214 |
215 |
216 | 前面我们一直提到一般我们在协程中碰到 IO 等阻塞事件时才会挂起并唤醒其他协程,所以可知**协程非常适合 IO 密集型的应用**,如果是计算密集型其实用线程反而更加合适
217 |
218 |
219 |
220 | 为什么 Go 语言这么最近这么火,一个很重要的原因就是因为因为它天生支持协程,可以轻而易举地创建成千上万个协程,而如果是创建线程的话,创建几百个估计就够呛了,不过比较遗憾的是 Java 原生并不支持协程,只能通过一些第三方库如 Quasar 来实现,2018 年 OpenJDK 官方创建了一个 loom 项目来推进协程的官方支持工作
221 |
222 |
223 |
224 | ### 总结
225 |
226 | 从进程,到线程再到协程,可知我们一直在想办法让执行单元变得更轻量级,一开始只有进程的概念,但是进程的创建在 Linux 下需要调用 fork 全部复制一遍资源,虽然后来引入了写时复制的概念,但进程的创建开销依然很大,于是提出了更轻量级的线程,在 Linux 中线程与进程其实都是用 task_struct 表示的,只是线程采用了共享资源的方式来创建,极大了提升了 task_struct 的创建与调度效率,但人们发现,线程的阻塞,唤醒都要通过系统调用陷入内核态才能被调度程度调度,如果线程频繁切换,开销无疑是很大的,于是人们提出了协程的概念,协程是根据栈内存按需求分配的,所需开销是线程的几十分之一,非常的轻量,而且调度是在用户态,并且它是协作式调度,可以很方便的挂起恢复其他协程的执行,在此期间,线程是不会被挂起的,所以无论是创建还是调度开销都很小,目前 Java 官方还不支持,不过支持协程应该是大势所趋,未来我们可以期待一下
227 |
--------------------------------------------------------------------------------
/系统设计/keepalived工作原理.md:
--------------------------------------------------------------------------------
1 | ### 问题初现
2 |
3 | 「滴~~~」,小章的钉钉突然响起了很多客服转发来的用户投诉信息,说是网络连接不上了,经过排查发现是其中一台机器(RS2)挂了
4 |
5 | 
6 |
7 | 但是 LVS 依然持续地把流量打到这台机器上,持续造成线上问题,小章首先把这台机器从 LVS 上摘除,**先保证线上正常**,然后为了避免之后出现类似问题,急忙找了 CEO 老梁来商讨方案。
8 |
9 | ### 应用层健康检查:HTTP 检测
10 |
11 | 老梁一眼看出了问题所在:「我们需要开发一个健康检查服务,部署在 LVS 上,这个服务可以定时检查其后的 RS 是否可用,如果不可用则将 RS 摘除,这样就可以保障线上服务正常了」
12 |
13 | 「妙啊,通过软件及时探测,摘除不可用的机器,避免了人工发现不及时的问题,那么该怎么做这个健康检查呢,需要满足什么条件呢」听说要开发这样的软件,小章顿时来了兴致。
14 |
15 | 「小章啊,仔细想想看,我们的服务在发布过程中其实也是有健康检查的,要保证一个工程可用,至少保证它是可访问的以及它用到的中间件,DAO 是正常的,所以它的健康代码如下
16 |
17 | ```
18 | @Service(protocol = {"rest"})
19 | public class HealthCheckServiceImpl implements HealthCheckService {
20 |
21 | @Resource
22 | private TestDAO TestDAO;
23 |
24 | @Resource
25 | private RebateClient rebateClient;
26 |
27 | @Override
28 | public String getHealthStatus() {
29 | List testDOS =
30 | TestDAO.getResult(123);
31 | Assert.isTrue(testDOS != null, "rebateMemberDOS null");
32 |
33 | // 此处省略 redis 检测
34 |
35 | // 此处省略其它检测
36 |
37 | return "health";
38 | }}
39 | ```
40 |
41 | 如以上代码所示,我们在工程里写了健康检查 HealthCheckService 类,暴露了一个 rest 服务,这样的话在部署的时候在服务部署脚本里首先访问一下此服务的 getHealthStatus 方法,如果返回的值为「health」,则说明此服务的 dubbo 服务,DAO,redis 等正常,说明此服务是没有问题的,如果返回的值不为 health,则说明此服务有问题,不能上线,这就是我们所说的**健康检查**,通过访问服务暴露的方法,来检测此服务是否可用。
42 |
43 | 所以我们要开发的检测服务也与此类似,只要定时访问此服务暴露的接口,看下此接口返回的值与我们期待的值是否一致即可,一致说明此服务正常,否则,说明此服务异常,将其剔除,当然了一次连接不通就判断为不可用可能有些问题,我们可以提供一个重试次数,比如 3 次,如果 3 次健康检测都失败,则认定此服务不可用!配置的伪代码如下:
44 |
45 | ```
46 | real_server 192.168.1.220 80 {
47 | HTTP_GET {
48 | url {
49 | path /healthCheck
50 | status_code 200
51 | }
52 | connect_timeout 3
53 | nb_get_retry 3 // 置超时重试次数
54 |
55 | }
56 | }
57 | ```
58 |
59 | 「妙啊,此法甚好!只要访问健康检查服务就可以很方便地查看此服务是否正常了,但是有个问题:如果这个健康检测方法写的检测逻辑很多,而 LVS 定时发检测请求比较频繁的话可能会有一定的性能问题,是否有更轻量级的检测方法呢」小章说道
60 |
61 | 「考虑得很周到!一般健康检测确实逻辑比较重,所以只在部署的的时候检测一次就够了,在生产上我们可以采用更轻量的检测方式:**TCP连接检测**」
62 |
63 | ### TCP连接检测
64 |
65 | TCP 连接检测原理很简单,我们知道要建立一个 TCP 连接,首先必须由 TCP 客户端发起 connect 请求,三次握手成功后才算建立起一个 TCP 链接,然后才能正常收发数据
66 |
67 | 
68 |
69 | 所以我们只要调用 connect 方法看它是否成功即可,成功即说明连接建立成功,说明服务是可用的,如果失败说明此服务有问题,直接摘除即可,当然了与 HTTP 检测一样,也要有超时机制,伪代码如下
70 |
71 | ```
72 | tcp连接检测
73 | TCP_CHECK {
74 | connect_port 80 // 指定端口
75 | connect_timeout 6 // 设置响应超时时间
76 | nb_get_retry 3 // 设置超时重试次数
77 | delay_before_retry 3 // 设置超时重试间隔时间
78 | }
79 | ```
80 |
81 | 小章按着老梁的思路把这两种健康检测思路给实现了,并且给这个服务取了个霸气的名字:**keepalived**,老梁很满意,不过他又发现了新的问题。。。
82 |
83 | ### 单点故障---高可用解决之道
84 |
85 | 「小章,健康检查做得很好,而且提供了两种检查方式,很全面,不过你这个架构还有个很致命的问题,不知你有没发现,那就是目前只有一台 LVS 在工作,如果这台 LVS 挂了,那我们业务就跌零了, 你还需要让 keepalived 支持 LVS 的高可用」
86 |
87 | 小章恍然大悟,「那该咋办呢」
88 |
89 | 「高可用的通用解决方案很简单,**冗余**+**故障自动发现转移**,我们可以按照这个思路来设计 LVS 高可用,具体方案如下:
90 |
91 | 我们可以为 LVS 准备几台备机,如果发现 LVS 挂了,就让备机顶上去,这样不就实现了高可用了吗」不愧是 CTO,一语中的
92 |
93 | 
94 |
95 | 小章看了一眼架构图,提出了三个问题
96 |
97 | 1. 如果主机(以下简称 master)宕机,备机(以下简称 backup)顶上,那 IP 地址不是变了吗,此时客户端该怎么连接
98 | 2. 几台机器首次启动时,谁为 master,谁为 backup
99 | 3. master 宕机后,backup 是如何感知到的,多台 backup 又是如何竞选出主机的,这个和问题 2 有点类似
100 |
101 | 「这几个问题提的很好,正是实现高可用的关键,可以看出小伙子还是有经过深入思考的」老梁高兴地说,「这些问题不难化解,我们一一来看看」
102 |
103 | > 问题一:backup 成为 master 后,IP 地址变了怎么办?
104 |
105 | 答:IP 地址不能变,对外必须表现为一个 IP,我们通常称为「虚拟(virtual) IP」,通常简称为 VIP
106 |
107 | 
108 |
109 | 如果 master(即图中的 L1)工作,则此 VIP 在 master 上可用,若 master 宕机,如果 backup(比如 L2)竞选 master 成功,则 VIP 在 L2 上生效,**同时新的 master 需要发送一个携带有本机的 MAC 地址和 VIP 地址信息的 ARP 报文**,你会发现 VIP 从老的 master 转移到竞选 master 成功的 backup 上了,我们把这种现象称为 **IP 漂移**,这里有两个问题需要澄清
110 |
111 | 1. 一个主机如何才能有两个 IP
112 | 2. 为什么 VIP 在某台竞选 master 成功的 backup 上生效后要发一个携带有本机的 MAC 地址和 VIP 地址信息的 ARP 报文
113 |
114 | 先看第一个问题,主机如何才能拥有两个 IP ,毕竟一台机器成为主机后,除了本身机器被分配的 IP(115.205.4.210),VIP 也**漂移**到它身上了,此时它拥有两个 IP
115 |
116 | 我们知道计算机要上网,首先要把网线插入网卡,一个网卡其实就对应着一个 IP,所以一台主机配两个网卡就可以绑定两个 IP,一般 LVS 都会配置双网卡,一来每个网卡带宽都是有限的,双网卡相当于提升了一倍的带宽,二来两个网卡也起到了热备的作用,如果一个网卡坏了,另外一个可以顶上。
117 |
118 | 但有人说了,我就只有一个网卡,也想配置多个 IP,是否可以?
119 |
120 | **答案是可以的**,网卡一般分两种,一种是**物理网卡**,一种是**虚拟网卡**
121 |
122 | 1. `物理网卡`:可以插网线的网卡,如果有多个网卡,我们一般将其命名为 eth0,eth1。。。,如果一个网卡对应多个 IP,以 eth0 为例,一般将其命名为 eth0,eth0:0,eth0:1。。。eth0:x,比如一台机器只有一个网卡,但其对应两个 IP 192.168.1.2, 192.168.1.3,那么其绑定的网卡名称分别为 eth0,eth0:0
123 | 2. `虚拟网卡`:虚拟网卡通常被称为 loopback,一般命名为 lo,是一个特殊的网络接口,主要用于本机中各个应用之间的网络交互(哪怕网线拔了,本机各个应用之间通过 lo 也是能通信的),需要注意的是虚拟网卡和物理网卡一样,也可以绑定任意 IP 地址,如果在虚拟网卡配置了任何的 IP 地址,只要有物理网卡,就能到收到并处理目的 IP 为虚拟网卡上 IP 的数据包,lo 默认绑定了 127.0.0.1 这个本地 IP ,如果要绑定其他的 IP,对应的网卡命名一般为 lo:0,lo:1。。。
124 |
125 | 所以假设一台机器只有一个网卡,一般内网给它默认分配的 IP 绑定在 eth0 上,那么我们就可以把虚拟 IP 绑定在 eth0:0 上,这样的话外界就能正常访问此虚拟 IP 了,如果 master 挂掉了,keepalived 会让此 master 的 eth0:0 端口失效,同时让新 master 的 eth0:0 绑定虚拟 IP,这样就避免了对外暴露两个虚拟 IP。
126 |
127 | 再来看第二位问题,虚拟 IP 在某台机器生效后,为啥要发一个 ARP 请求呢,这个问题其实在之前的文章中提到过,这里为了照顾其他没看过之前文章的读者,再简单提一下,其实上面的架构图我们作了一定程度的简化,更详细的应该如下图所示
128 |
129 | 
130 |
131 | 如图示,三台 LVS 机器组成一个同一网段的以太网我们知道,以太网是以 mac 地址来寻址的,我们知道现在对外暴露的是虚拟 IP,那么当带有虚拟 IP 的包到达路由器时,它该怎么找到对应的机器呢?
132 |
133 | 一开始它啥也不知道,所以它在网址发了一个 ARP 广播包,相当于大吼一声:IP 地址为 115.205.4.213 的机器是谁啊,由于这个虚拟 IP 在 L1 上,所以只有 L1 响应了,L1 会把带有自己 mac 地址的响应包发回给路由器,路由器收到后会把 IP 地址与 L1 mac 地址的关系记在本地,然后在包的头部装上 L1 的 mac 地址发给交换机,交换机就能识别到应该发给 L1,下次当客户端再次发数据包到路由器时,路由器会首先在本地缓存(ARP 缓存)中查到 IP 对应的 mac(即 L1 的mac),命中后将包上的 mac 地址替换成 L1 的 mac 转发出去,至此相信你应该明白为啥虚拟 IP 生效后要发 ARP 报文了,就是**为了更新由器上的 ARP 缓存**,将虚拟 IP 对应的 mac 地址更新为竞选 master 成功的 backup 上的 mac,这样下次路由器就能正确将新 master 的 mac 附在数据包上,就能正确地转发到机器上了,否则,数据包会转发到老的 master 上,引起灾难性的后果!
134 |
135 | > 问题二:几台机器首次启动后,谁为 master,谁为 backup
136 |
137 | 这个问题其实很简单,谁的能力强,谁就优先成为 master,我们可以给各个机器设置不同的值为 0~255 的权重,权重越大,代表此机器越有可能成为 master(如果权重一样,则比较它们的 IP,IP 大的权重高),这里分几种情况
138 |
139 | 1. 每个机器启动后都处于 Initialize 状态,若某台机器接口(eth0)Up 之后,如果其权重为 255 且此时还没有 master 则其成为 master 并且让虚拟 IP 绑定在 eth0:0 端口上,如果此时已有 master 呢,分两种模式:**抢占**和**非抢占**模式,如果处于非抢占模式下,则它转为 backup 状态,否则它会重新竞争成为 master,此时一般能竞争成功,因为它处于最高权重(一般只有一台机器处于最高权限)
140 | 2. 如果某台机器权重不为 255,则**经过一段时间后**如果此时还没有 master ,那么它会竞争 master,如果此时有了 master,也和情况 1 一样,分抢占和非抢占模式,为啥要经过一段时间才竞争 master 呢,其实主要是为了优先让权重为 255 的机器成为 master
141 |
142 | 整体流程如下
143 |
144 | 
145 |
146 | > 问题三: master 宕机后,backup 是如何感知到的,多台 backup 又是如何竞选出主机的
147 |
148 | 当机器成为 master 后,它会定时发送广播给其他的 backup,让其他 backup 知道它还存活着,如果在指定时间内(一般我们称此时间为 Master_Down_Interval)backup 没有收到 master 的广播包,那么 backup 互相之间会发广播包通过比较权重竞争 master,某台 backup 竞选 master 成功后同样会让虚拟 IP 绑定在 eth0:0 端口上,并且发送 ARP 包让路由器等更新自己的 ARP 缓存,其他竞选失败的则转为 backup 状态
149 |
150 | 至此相信大家已经明白了 keepalived 的工作机制,所有上面说的这些工作只要配置一下 keepalived 的配置文件并启动后即可实现。
151 |
152 | 另外 keepalived 实现的高可用机制不光可以用在 LVS 上,也可以用在 MySQL 等高可用上,所以你内部工程连 MySQL 的地址一般是虚拟 IP。现在我相信你能看懂如下 LVS 的高可用工作图了
153 |
154 | 
155 |
156 | **注**:不管是 master 还是 backup 都能对背后的 RS 作健康检查哦
157 |
158 | ### 总结
159 |
160 | 相信大家看完本文对 keepalived 的工作原理应该是了然于胸了,它的主要工作模式无非就两块:「健康检查」和「高可用」,健康检查我们只介绍了常见的两种,其实它还支持通过运行脚本来作健康检测,只是不太常用而已,另外 keepalived 的高可用可以说是大放异彩,除了用在 LVS 的高可用,还用在 Nginx ,MySQL 的高可用上,原理其实无非就是利用心跳检测+竞争 master + IP 漂移来实现,完整的 keepalived.conf 配置文件大家有兴趣可以看文末的参考链接,相信经过上面的原理讲解再去看此文件不是问题
161 |
162 | 另外不知大家是否注意到了,master 虽然可以定时向 backup 发送心跳,但如果此心跳链路坏了 backup 就会误认为 master 已经不可用了,从而去申请成为 master,这样就会造成两个 master 的出现,也就是我们常说的**脑裂**,怎么解决?可以同时用两条心跳线路,这样一条心跳检测线路坏了,另一条还是好的,依然能传送心跳消息。当然除了心跳链路坏了还有可能会有其他情况也会导致脑裂的发生,我们还是要做好多种预案,必要时人工及时介入,(关于脑裂的更多信息可以看文末的参考链接)
163 |
164 | #### 巨人的肩膀
165 |
166 | - keepalived.conf 配置文件详解: https://www.huaweicloud.com/articles/c37ca72e2dde50e91324471ea761d41b.html
167 | - 脑裂问题及解决:https://www.cnblogs.com/struggle-1216/p/12897981.html
168 |
169 | 欢迎关注公众号与笔者共同交流哦^_^
170 |
171 | 
--------------------------------------------------------------------------------
/Java/ConrrentHashMap是强一致性的吗.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 |
4 |
5 | 上周我在极客时间某个课程看到某个讲师在讨论 ConcurrentHashMap(以下简称 CHM)是强一致性还是弱一致性时,提到这么一段话
6 |
7 | 
8 |
9 | 这个解释网上也是流传甚广,那么到底对不对呢,在回答这个问题之前,我们得想清楚两个问题
10 |
11 | 1. 什么是强一致性,什么是弱一致性
12 | 2. 上文提到 get 没有加锁,所以没法即时获取 put 的数据,也就意味着如果加锁就可以立即获取到 put 的值了?那么除了加锁之外,还有其他办法可以立即获取到 put 的值吗
13 |
14 | ### 强一致性与弱一致性
15 |
16 | > 强一致性
17 |
18 | 首先我们先来看第一个问题,什么是强一致性
19 |
20 | 一致性(Consistency)是指多副本(Replications)问题中的数据一致性。可以分为强一致性、弱一致性。
21 |
22 | 强一致性也被可以被称做原子一致性(Atomic Consistency)或线性一致性(Linearizable Consistency),必须符合以下两个要求
23 |
24 | - 任何一次读都能**立即**读到某个数据的最近一次写的数据
25 | - 系统中的所有进程,看到的操作顺序,都和全局时钟下的顺序一致
26 |
27 | 简单地说就是假定对同一个数据集合,分别有两个线程 A、B 进行操作,假定 A 首先进行了修改操作,那么从时序上在 A 这个操作之后发生的所有 B 的操作都应该能**立即**(或者说**实时**)看到 A 修改操作的结果。
28 |
29 |
30 |
31 | > 弱一致性
32 |
33 | 与强一致性相对的就是弱一致性,即数据更新之后,如果立即访问的话可能访问不到或者只能访问部分的数据。如果 A 线程更新数据后 B 线程**经过一段时间**后都能访问到此数据,则称这种情况为最终一致性,最终一致性也是弱一致性,只不过是弱一致性的一种特例而已
34 |
35 |
36 |
37 | 那么在 Java 中产生弱一致性的原因有哪些呢,或者说有哪些方式可以保证强一致呢,这就得先了解两个概念,可见性和有序性
38 |
39 |
40 |
41 | ### 一致性的根因:可见性与有序性
42 |
43 | #### 可见性
44 |
45 | 首先我们需要了解一下 Java 中的内存模型
46 |
47 | 
48 |
49 | 上图是 JVM 中的 Java 内存模型,可以看到,它主要由两部分组成,一部分是线程独有的`程序计数器`,`虚拟机栈`,`本地方法栈`,这部分的数据由于是线程独有的,所以不存在一致性问题(我们说的一致性问题往往指多线程间的数据一致性),一部分是线程共享的`堆`和`方法区`,我们重点看一下堆内存。
50 |
51 |
52 |
53 | 我们知道,线程执行是要占用 CPU 的,我们知道 CPU 是从寄存器里取数据的,寄存器里没有数据的话,就要从内存中取,而众所周知这两者的速度差异极大,可谓是一个天上一个地上,所以为了缓解这种矛盾,CPU 内置了三级缓存,每次线程执行需要数据时,就会把堆内存的数据以 cacheline(一般是 64 Byte) 的形式先加载到 CPU 的三级缓存中来,这样之后取数据就可以直接从缓存中取从而极大地提升了 CPU 的执行效率(如下图示)
54 |
55 |
56 |
57 | 
58 |
59 |
60 |
61 | 但是这样的话由于线程加载执行完数据后数据往往会缓存在 CPU 的寄存器中而不会马上刷新到内存中,从而导致其他线程执行如果需要堆内存中共享数据的话取到的就不会是最新数据了,从而导致数据的不一致
62 |
63 |
64 |
65 | 举个例子,以执行以下代码为例
66 |
67 | ```java
68 | //线程1执行的代码
69 | int i = 0;
70 | i = 10;
71 |
72 | //线程2执行的代码
73 | j = i;
74 | ```
75 |
76 | 在线程 1 执行完后 i 的值为 10,然后 2 开始执行,此时 j 的值很可能还是 0,因为线程 1 执行时,会先把 i = 0 的值从内存中加载到 CPU 缓存中,然后给 i 赋值 10,**此时的 10 是更新在 CPU 缓存中的**,而**未刷新到内存中**,当线程 2 开始执行时,首先会将 i 的值从内存中(其值为 0)加载到 CPU 中来,故其值依然为 0,而不是 10,这就是典型的由于 CPU 缓存而导致的数据不一致现象。
77 |
78 |
79 |
80 | 那么怎么解决可见性导致的数据不一致呢,其实只要让 CPU 修改共享变量时立即写回到内存中,同时通过总线协议(比如 MESI)通过其他 CPU 所读取的此数据所在 cacheline 无效以重新从内存中读取此值即可
81 |
82 | #### 有序性
83 |
84 | 除了可见性造成的数据不一致外,指令重排序也会造成数据不一致
85 |
86 | ```java
87 | int x = 1; ①
88 | boolean flag = true; ②
89 | int y = x + 1; ③
90 | ```
91 |
92 | 以上代码执行步骤可能很多人认为是按正常的 ①,②,③ 执行的,但实际上很可能编译器会将其调换一下位置,实际的执行顺序可能是 ①③②,或 ②①③,也就是说 ①③ 是紧邻的,为什么会这样呢,因为执行 1 后,CPU 会把 x = 1 从内存加载到寄存器中,如果此时直接调用 ③ 执行,那么 CPU 就可以直接读取 x 在寄存器中的值 1 进行计算,反之,如果先执行了语句 ②,那么有可能 x 在寄存器中的值被覆盖掉从而导致执行 ③ 后又要重新从内存中加载 x 的值,有人可能会说这样的指令重排序貌似也没有多大问题呀,那么考虑如下代码
93 |
94 |
95 |
96 | ```java
97 | public class Reordering {
98 |
99 | private static boolean flag;
100 | private static int num;
101 |
102 | public static void main(String[] args) {
103 | Thread t1 = new Thread(new Runnable() {
104 | @Override
105 | public void run() {
106 | while (!flag) {
107 | Thread.yield();
108 | }
109 |
110 | System.out.println(num);
111 | }
112 | }, "t1");
113 | t1.start();
114 | num = 5; ①
115 | flag = true; ②
116 | }
117 | }
118 | ```
119 |
120 | 以上代码最终输出的值正常情况下是 5,但如果上述 ① ,② 两行指令发生重排序,那么结果是有可能为 0 的,从而导致我们观察到的数据不一致的现象发生,所以显然解决方案是避免指令重排序的发生,也就是保证指令按我们看到的代码的顺序有序执行,也就是我们常说的有序性,一般是通过在指令之间添加内存屏障来避免指令的重排序
121 |
122 | > 那么如何保证可见性与有序性呢
123 |
124 | 相信大家都非常熟悉了,使用 volatile 可以保证可见性与有序性,只要在声明属性变量时添加上 volatile 就可以让此变量实现强一致性,也就是说上述的 Reordering 类的 flag 只要声明为 volatile,那么打印结果就永远是 5!
125 |
126 | 好了,现在问题来了,CHM 到底是不是强一致性呢,首先我们以 Java 8 为例来看下它的设计结构(和之前的版本相差不大,主要加上了红黑树提升了查询效率)
127 |
128 |
129 |
130 | 
131 |
132 | 来看下这个 table 数组和节点的声明方式(以下定义 8 和 之前的版本中都是一样的):
133 |
134 | ```java
135 | public class ConcurrentHashMap extends AbstractMap
136 | implements ConcurrentMap, Serializable {
137 | transient volatile Node[] table;
138 | ...
139 | }
140 |
141 | static class Node implements Map.Entry {
142 | final int hash;
143 | final K key;
144 | volatile V val;
145 | volatile Node next;
146 | ...
147 | }
148 | ```
149 |
150 | 可以看到 CHM 的 table 数组,Node 中的 值 val,下一个节点 next 都声明为了 volatile,于是有学员就提出了一个疑问
151 |
152 |
153 |
154 | 
155 |
156 | 讲师的回答也提到 CHM 为弱一致性的重要原因:即如果 table 中的某个槽位为空,此时某个线程执行了 key,value 的赋值操作,那么此槽位会**新增**一个 Node 节点,在 JDK 8 以前,CHM 是通过以下方式给槽位赋 Node 的
157 |
158 | ```java
159 | V put(K key, int hash, V value, boolean onlyIfAbsent) {
160 | lock();
161 | ...
162 | tab[index] = new HashEntry(...);
163 | ...
164 | unlock();
165 | }
166 | ```
167 |
168 | 然后是通过以下方式来根据 key 来读取 value 的
169 |
170 | ```java
171 | V get(Object key, int hash) {
172 | if (count != 0) { // read-volatile
173 | HashEntry e = getFirst(hash);
174 | while (e != null) {
175 | if (e.hash == hash && key.equals(e.key)) {
176 | V v = e.value;
177 | if (v != null)
178 | return v;
179 | return readValueUnderLock(e); // recheck
180 | }
181 | e = e.next;
182 | }
183 | }
184 | return null;
185 | }
186 | ```
187 |
188 | 可以看到 put 时是直接给数组中的元素赋值的,而由于 get 没有加锁,所以无法保证线程 A put 的新元素对执行 get 的线程可见。
189 |
190 |
191 |
192 | put 是有加锁的,所以其实如果 get 也加锁的话,那么毫无疑问 get 是可以立即拿到 put 的值的。为什么加锁也可以呢,其实这是 JLS(Java Language Specification Java 语言规范) 规定的几种情况,简单地说就是支持 happens before 语义的可以保证数据的强一致性,在官网(https://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html)中列出了几种支持 Happens before 的情况,其中**指出使用 volatile,synchronize,lock 是可以确保 happens before 语义的**,也就是说使用这三者可以保证数据的强一致性,可能有人就问了,到底什么是 happens before 呢,**其实本质是一种能确保线程及时刷新数据到内存,另一线程能实时从内存读取最新数据以保证数据在线程之间保持一致性的一种机制**,我们以 lock 为例来简单解释下
193 |
194 |
195 |
196 | ```java
197 | public class LockDemo {
198 | private int x = 0;
199 |
200 | private void test() {
201 | lock();
202 | x++;
203 | unlock();
204 | }
205 | }
206 |
207 | ```
208 |
209 | 如果线程 1 执行 test,由于拿到了锁,所以首先会把数据(此例中为 x = 0)从内存中加载到 CPU 中执行,执行 x++ 后,x 在 CPU 中的值变为 1,然后解锁,解锁时会把 x = 1 的值立即刷新到内存中,这样下一个线程再执行 test 方法再次获取相同的锁时又从内存中获取 x 的最新值(即 1),**这就是我们通常说的对一个锁的解锁, happens-before 于随后对这个锁的加锁**,可以看到,通过这种方式可以保证数据的一致性
210 |
211 |
212 |
213 | 至此我们明白了:**在 Java 8 以前,CHM 的 get,put 确实是弱一致羽性**,可能有人会问为什么不对 get 加锁呢,加上了锁不就可以确保数据的一致性了吗,可以是可以,但别忘了 CHM 是为高并发设计而生的,加了锁不就导致并发性大幅度下降了么,那 CHM 存在的意义是啥?
214 |
215 |
216 |
217 | > 所以 put,get 就无法做到强一致性了吗?
218 |
219 |
220 |
221 | 我们在上文中已经知道,使用 volatile,synchronize,lock 是可以确保 happens before 语义的,同时经过分析我们知道使用 synchronize,lock 加锁的设计是不满足我们设计 CHM 的初衷的,那么只剩下 volatile 了,遗憾的是由于 Java 数组在元素层面的元数据设计上的缺失,是无法表达元素是 final、volatile 等语义的,所以 **volatile 可以修饰变量,却无法修饰数组中的元素**,还有其他办法吗?来看看 Java 8 是怎么处理的(这里只列出了写和读方法中的关键代码)
222 |
223 | ```java
224 | private static final sun.misc.Unsafe U;
225 |
226 | // 写
227 | final V putVal(K key, V value, boolean onlyIfAbsent) {
228 | ...
229 | for (Node[] tab = table;;) {
230 | if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
231 | if (casTabAt(tab, i, null,
232 | new Node(hash, key, value, null)))
233 | break;
234 | }
235 | }
236 | ...
237 | }
238 |
239 | static final boolean casTabAt(Node[] tab, int i,
240 | Node c, Node v) {
241 | return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
242 | }
243 |
244 |
245 | // 读
246 | public V get(Object key) {
247 |
248 | if ((tab = table) != null && (n = tab.length) > 0 &&
249 | (e = tabAt(tab, (n - 1) & h)) != null) {
250 | ...
251 | }
252 | return null;
253 | }
254 |
255 | @SuppressWarnings("unchecked")
256 | static final Node tabAt(Node[] tab, int i) {
257 | return (Node)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
258 | }
259 |
260 | ```
261 |
262 | 可以看到在 Java 8 中,CHM 使用了 unsafe 类来实现读写操作
263 |
264 | * 对于写首先使用 compareAndSwapObject(即我们熟悉的 CAS)来更新**内存中**数组中的元素
265 | * 对于读则使用了 getObjectVolatile 来读取**内存中**数组中的元素(在底层其实是用了 C++ 的 volatile 来实现 java 中的 volatile 效果,有兴趣可以看看)
266 |
267 | 由于读写都是直接对内存操作的,所以通过这样的方式可以保证 put,get 的强一致性,至此真相大白! Java 8 以后 put,get 是可以保证强一致性的!CHM 是通过 compareAndSwapObject 来取代对数组元素直接赋值的操作,通过 getObjectVolatile 来补上无法表达数组元素是 volatile 的坑来实现的
268 |
269 |
270 |
271 | 注意并不是说 CHM 所有的操作都是强一致性的,比如 Java 8 中计算容量的方法 size() 就是弱一致性(Java 7 中此方法反而是强一致性),所以我们说强/弱一致性一定要确定好前提(比如指定 Java 8 下 CHM 的 put,get 这种场景)
272 |
273 |
274 |
275 | ### 总结
276 |
277 | 其实 Java 8 对 CHM 进行了一番比较彻底的重构,让它的性能大幅度得到了提升,比如弃用 segment 这种设计,改用对每个槽位做分段锁,使用红黑树来降低查询时的复杂度,扩容时多个线程可以一起参与扩容等等,可以说 Java 8 的 CHM 的设计非常精妙,集 CAS,synchroinize,泛型等 Java 基础语法之大成,又有巧妙的算法设计,读后确实让人大开眼界,有机会我会再和大家分享一下其中的设计精髓,另外我们对某些知识点一定要多加思考,最好能自己去翻翻源码验证一下真伪,相信你会对网上的一些谬误会更容易看穿。
278 |
279 |
280 |
281 | 最后欢迎大家关注我的公号,加我好友:「geekoftaste」,一起交流,共同进步!
282 |
283 | 
284 |
285 |
--------------------------------------------------------------------------------
/MySQL/深入浅出索引原理.md:
--------------------------------------------------------------------------------
1 | 索引可以说是每个工程师的必备技能点,明白索引的原理对于写出高质量的 SQL 至关重要,今天我们就从 0 到 1 来理解下索引的原理,相信大家看完不关对索引还会对 MySQL 中 InnoDB 存储引擎的最小存储单位「页」会有更深刻的认识
2 |
3 | ### 从实际需求出发
4 |
5 | 假设有如下用户表:
6 |
7 | ```sql
8 | CREATE TABLE `user` (
9 | `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
10 | `name` int(11) DEFAULT NULL COMMENT '姓名',
11 | `age` tinyint(3) unsigned DEFAULT NULL COMMENT '年龄',
12 | `height` int(11) DEFAULT NULL COMMENT '身高',
13 | PRIMARY KEY (`id`)
14 | ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户表';
15 | ```
16 |
17 | 可以看到存储引擎使用的是 InnoDB,我们先来看针对此表而言工作中比较常用的 SQL 语句都有哪此,毕竟技术是要为业务需求服务的,
18 |
19 | ```sql
20 | 1. select * from user where id = xxx
21 | 2. select * from user order by id asc/desc
22 | 3. select * from user where age = xxx
23 | 4. select age from user where age = xxx
24 | 5. select age from user order by age asc/desc
25 | ```
26 |
27 | 既然要查询那我们首先插入一些数据吧,毕竟没有数据何来查询
28 |
29 | ```sql
30 | insert into user ('name', 'age', 'height') values ('张三', 20, 170);
31 | insert into user ('name', 'age', 'height') values ('李四', 21, 171);
32 | insert into user ('name', 'age', 'height') values ('王五', 22, 172);
33 | insert into user ('name', 'age', 'height') values ('赵六', 23, 173);
34 | insert into user ('name', 'age', 'height') values ('钱七', 24, 174);
35 | ```
36 |
37 | 插入后表中的数据如下:
38 |
39 |
40 |
41 | 
42 |
43 | 不知你有没发现我们在插入的时候并没有指定 id 值,但 InnoDB 为每条记录默认添加了一个 id 值,而且这个 id 值是递增的,每插入一条记录,id 递增 1,id 为什么要递增呢,主要是为了查询方便,每条记录按 id 由小到大的顺序用链表连接起来,这样每次查找 id = xxx 的值就从 id = 1 开始依次往后查找即可
44 |
45 | 
46 |
47 |
48 |
49 | 现在假设我们要执行以下 SQL 语句,MySQL 会怎么查询呢
50 |
51 | ```sql
52 | select * from user where id = 3
53 | ```
54 |
55 | ### 页
56 |
57 | 如前所述,首先从 id 最小的记录也就是 id = 1 读起,每次读一条记录,将其 id 值与要查询的值比较,连续读三次记录于是找到了记录 3,注意这个读的操作,是首先需要把存储在磁盘的记录读取到内存然后再比较 id 的,从磁盘读到内存算一次 IO,也就是说此过程中产生了三次 IO,如果只是几条记录还好,但如果要比较的条数多的话对性能是非常严重的挑战,如果我要查询为 id = 100 的记录那岂不是要产生 100 次 IO?既然瓶颈在 IO,那该怎么改进呢,很简单,我们现在的设计一次 IO 只能读一条记录,那改为一次 IO 能读取 100 条甚至更多不就只产生一次 IO 了吗,这背后的思想就是**程序局部性原理**:当用到了某项数据时,很可能会用到与之相邻的数据,所以干脆把相依的数据一起加载进去(你从 id = 1 开始读,那很可能用到 id = 1 紧随其后的元素,于是干脆把 id = 1 ~ id = 100 的记录都加载进去)
58 |
59 |
60 |
61 | 当然一次 IO 的读取记录也并不是多多益善,总不能为了一条查询记录而把很多无关的数据都加载到内存吧,那会造成资源的极大浪费,于是我们采用了一个比较折中的方案,我们规定一次 IO 读取 16 K 的数据,假设为 100 条数据好了,这样如果我们要查询 id = 100 的记录,只产生了一次 IO 读(id=1~id=100 的记录),比起原来的 100 次 IO 提升了 100 倍的性能
62 |
63 |
64 |
65 | 
66 |
67 | 我们把这 16KB 的记录组合称为一个**页**
68 |
69 | ### 页目录
70 |
71 | 一次 IO 会读取一个页,然后再在内存里查找页里的记录,在内存里查找确实比磁盘快多了,但我们仍不满意,因为如果要查找 id = 100 的记录,要先从 id = 1 的记录比较起,然后是id=2,...,id=100,需要比较 100 次,能否更快一点?
72 |
73 |
74 |
75 | 可以参照二分查找,先查找 id = (1+100)/2 = 50,由于 50 < 100,接着在 50~100 的记录中查,然后再在 75~100 中查,这样经过 7 次就可找到 id = 100 次的记录,比起原来的 100 次比较又提升了不少性能。但现在问题来了,第一次要找到 id = 50 的记录又得从 id = 1 开始遍历 50 次才能找到,能否一下就定位到 id=50 的记录呢,如果不能,哪怕第一次从 id = 30 或 40 开始查找也行啊
76 |
77 |
78 |
79 | 有什么数据结构能满足这种需求呢,还记得跳表不,每隔 n 个元素抽出一个组成一级索引,每隔 2*n 个元素组成二级索引。。。
80 |
81 |
82 |
83 | 
84 |
85 | 如图示,以建立一级索引为例,我们在查找的时候先在一级索引查找,在一级索引里定位到了再到链表里查找,比如我们要找 7 这个数字,如果不用跳表直接在链表里查,需要比较 7 次,而如果用了跳表我们先在一级索引查找,发现只要比较 3 次,减少了四次,所以我们可以利用跳表的思想来减少查询次数,具体操作如下,每 4 个元素为一组组成一个槽(slot),槽只记录本组元素最大的那条记录以及记录本组有几条记录
86 |
87 |
88 |
89 | 
90 |
91 |
92 |
93 | 现在我们假设我们想要定位 id = 9 的那条记录,该怎么做呢,很简单:**首先定位记录在哪个槽,然后遍历此槽中的元素**
94 |
95 |
96 |
97 | 1. 定位在哪个槽,首先取最小槽和最大槽对应的 id(分别为 4, 12),先通过二分查找取它们的中间值为 (4+12)/2 = 8,8 小于 9,且槽 2 的最大 id 为 12,所以可知 id = 9 的记录在槽 2 里
98 | 2. 遍历槽 2 中的元素,现在问题来了,我们知道每条记录都构成了一个单链表,而每个槽指向的是此分组中的最大 id 值,该怎么从此槽的第一个元素开始遍历呢,很简单,从槽 1 开始遍历不就行了,因为它指向元素的下一个元素即为槽 2 的起始元素,遍历后发现槽 2 的 第一个元素即为我们找到的 id 为 9 的元素
99 |
100 |
101 |
102 | 可以看到通过这种方式在页内很快把我们的元素定位出来了,MySQL 规定每个槽中的元素在 1~8 条,所以只要定位了在哪个槽,剩下的比较就不是什么问题了,当然一个页装的记录终究是有限的,如果页满了,就要要开辟另外的页来装记录了,页与页之间通过链表连接起来,但注意看下图,为啥要用双向链表连接起来呢,别忘了最开头我们列出的 「order by id asc 」和「order by id desc 」这两个查询条件,也就是说记录需要同时支持正序与逆序查找,这就是为什么要使用双向链表的原因
103 |
104 |
105 |
106 | 
107 |
108 |
109 |
110 | ### B+ 树的诞生
111 |
112 | 现在问题来了,如果有很多页,该怎么定位元素呢,如果元素刚好在前几个页还好,大不了遍历前几个页也很快,但如果要查 id = 100w 这样的元素一页页遍历的话就要遍历 1w 页(假设每页 100 条记录),那显然是不可接受的,如何改进呢,其实之前建的页内目录已经给了我们启发,既然在页内我们可以通过为记录建页目录的形式来先定位元素在哪个槽然后再找,那针对多页,能否先定位元素在哪个页呢,也就是说我们可以为页也建立一个目录,这个目录里的每一条记录都对应着页及页中的最小记录,当然这个目录也是以页的形式存在的,为了便于区分 ,我们把针对页生成的目录对应的页称为**目录页**,而之前存储**完整记录**的页称为**数据页**
113 |
114 |
115 |
116 | 
117 |
118 |
119 |
120 | **画外音**:目录页与数据页一样,内部也是有槽的,上文为了方便展示,没有画出,目录页和数据除了记录数据不一样,其他结构都是一致的
121 |
122 |
123 |
124 | 现在如果要查找 id = xxx 的记录就很简单了,只要先到目录页中定位它的起始页然后再依次查找即可,由于不管是目录页还是数据页里面都有槽,所以无论是定位目录页的页码还是定位数据页中的记录都是非常快的。
125 |
126 |
127 |
128 | 当然了,随着页的增多,目录页存放的记录也越来越多,目录页也终归会满的,那就再建一个目录页吧,于是现在问题来了,怎么定位要找的 id 是在哪个目录页呢,再次制定针对目录页的目录页不就行了,如下
129 |
130 | 
131 |
132 |
133 |
134 | 看到上面这个结构你想到了什么?没错,这就是一颗 B+ 树!到此相信你已经明白了 B+ 树的演进之路,也明白了它的原理,可以看到这颗 B+ 树有三层,我们把最顶层的目录页称为**根节点**,最下层的存储完整记录的页称为**叶子节点**,
135 |
136 | 现在我们再来看一下如何查找 id = 55 的记录,首先会加载根节点,发现应该在页码 30 的页中去找,于是加载页 30,在页 30 中又发现应该在页 4 中查中,于是再次把页 4 加载进内存中,然后在页 4 中依次遍历查找,可以看到总共经历了 3 次 IO(B+树有几层就会有几次 IO),页读取之后会缓存在内存中,再读的话如果命中内存中的页就会直接从内存中获取。有人可能会问,如果 B+ 树层数很多,那岂不是可能会有很多次 IO,我们简单的算一下,假设数据页可以存储 100 条记录,目录页可以存储 1000 条记录(目录页由于只存储了主键,不存储完整的数据,所以可以存储更多的记录),那么
137 |
138 |
139 |
140 | - 如果`B+`树只有 1 层,也就是只有 1 个用于存放用户记录的节点,最多能存放`100`条记录。
141 | - 如果`B+`树有 2 层,最多能存放`1000×100=100000`条记录。
142 | - 如果`B+`树有 3 层,最多能存放`1000×1000×100=100000000`条记录。
143 | - 如果`B+`树有 4 层,最多能存放`1000×1000×1000×100=100000000000`条记录!
144 |
145 | 所以一般3~4 层的 B+ 树足以满足我们的要求,而且每次读取后会缓存在内存中(当然也会根据一定的算法被换出内存),所以整体来看 3~4 层 B+ 树足以满足我们需求
146 |
147 |
148 |
149 | ### 聚簇索引与非聚簇索引
150 |
151 |
152 |
153 | 相信你已经发现了,上文中我们举的 B+ 树的例子针对的是 id 也就是主键的索引,不难发现主键索引中的叶子结点存储了完整的 SQL 记录,我们把这种存储了完整记录的索引称为聚簇索引,**只要你定义了主键,那么主键索引就是聚簇索引**。
154 |
155 |
156 |
157 | 那么如果是非主键的列创建的索引又是怎样的形式呢,非叶子节点的形式完全一样,但叶子节点的存储则有些不同,非主键列索引叶子节点上存储的是**索引列及主键值**,比如我们假设对 age 这个列建立了索引,那么它的索引树如下
158 |
159 | 
160 |
161 |
162 |
163 | 可以看到非叶子节点保存的是「age 值 + 页码」,而叶子节点保存的是 「age 值+主键值」,那么你可能就会疑惑了,如下 SQL 是怎么取出完整记录的呢
164 |
165 | ```sql
166 | select * from user where age = xxx
167 | ```
168 |
169 | 第一步大家都知道,上述 SQL 可以命中 age 列对应的索引,然后找到叶子节点上对应的记录(如果有的话),但叶子节点上的记录只有 age 和 id 这两列,而你用的是 select *,意味着要查找 user 的所有列信息,该怎么办呢,答案是根据拿到的 id 再到聚簇索引找 id 对应的完整记录,这就是我们所说的**回表**,如果回表多的话显然会造成一定的性能问题,因为 id 可能分布在不同的页中,这意味着要将不同的页从磁盘读入内存,这些页很可能不是相邻的,也就意味着会造成大量的**随机 IO**,会严重地影响性能,看到这相信大家不难明白一道高频面试题:**为什么设置了命中了索引但还是造成了全表扫描**,其中一个原因就是虽然命中了索引但在叶子节点查询到记录后还要大量的回表,导致优化器认为这种情况还不如全表扫描会更快些
170 |
171 |
172 |
173 | 有人可能会问,为啥都二级索引不存储完整的记录呢,当然是为了节省空间,毕竟完整的数据是很耗空间的,如果每加一个索引都要额外存储完整的记录,那会造成很多数据冗余。
174 |
175 |
176 |
177 | 怎么避免这种情况呢?**索引覆盖**,如果如下 SQL 满足你的需求,那么就建议采用如下形式
178 |
179 | ```sql
180 | select age from user where age = xxx
181 | select age,id from user where age = xxx
182 | ```
183 |
184 | 不难发现这种 SQL 的特点是要获取的列(age)就是索引列本身(包括 id),这样在根据 age 的索引查到叶子节上对应的记录后,由于记录本身就包含了这些列,就不需要回表了,能提升性能
185 |
186 |
187 |
188 | **磁盘预读**
189 |
190 | 接下来我们讨论一个网上很多人搞不拎清的一个问题,我们知道操作系统是以页为单位来管理内存的,在 Linux 中,一页的大小默认为 4 KB,也就是说无论是从磁盘载入数据到内存还是将内存写回磁盘,操作系统都会以页为单位进行操作,哪怕你只对一个空文件只写入了一个字节,操作系统也会为其分配一个页的大小( 4 KB)
191 |
192 | 
193 |
194 | `如图示,向磁盘写入了两个 byte ,但操作系统依然为其分配了一个页(4 KB)的大小`
195 |
196 |
197 |
198 | innoDB 也是以页为单位来存储与读取的,而 innoDB 页的默认大小为 16 KB,那么网上很多人的疑问是这是否意味着它需要执行 4 次 IO 才能把 innoDB 的页读完呢?不是的,只需要一次 IO,为什么?这需要理解一点磁盘读取数据的工作原理
199 |
200 |
201 |
202 |
203 |
204 | #### 磁盘的构造
205 |
206 | 首先我们来看看磁盘的物理结构
207 |
208 | 
209 |
210 |
211 |
212 |
213 |
214 | 硬盘内部主要部件为磁盘盘片、传动磁臂、读写磁头和转轴,数据主要写入磁盘的盘片上的,盘片又是由若干个**扇区**构成的,数据写入读取都是以扇区为基本单位的,另外以盘片中心为圆心,把盘片分成若干个同心圆,那每一个划分圆的“线条”,就称为**磁道**
215 |
216 | 那么数据是如何读取与写入的呢,主要有三步
217 |
218 |
219 |
220 | 1. **寻道**:既然数据是保存在扇区上的,那我首先我们需要知道它到底是在哪个扇区上吧,这就需要先让磁头移动到扇区所在的磁道上,我们把它称为寻道时间,平均寻道时间一般在3-15ms
221 | 2. **旋转延迟**: 磁盘移动到扇区所在的磁盘上时,此时的磁头对准的还不一定我们想要的数据对应的扇区,所以需要等待盘片旋转片刻,等到我们想要的数据对应的扇区落到磁头下,旋转延迟取决于磁盘转速,通常用磁盘旋转一周所需时间的1/2表示。比如:7200rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms,而转速为15000rpm的磁盘其平均旋转延迟为2ms
222 | 3. **数据传输**:经过前面的两步,磁头终于开始读写数据了,目前IDE/ATA能达到133MB/s,SATA II可达到300MB/s的接口数据传输率,**数据传输时间通常远小于前两部分消耗时间**。可忽略不计
223 |
224 | 注意数据传输中的忽略不计是有前提的,即是需要读取**连续相邻**的扇区,也就是我们常说的顺序 IO,磁盘顺序 IO 的读写速度可以媲美甚至超越内存的随机 IO,所以这部分时间可以忽略不计,(大家熟知的 Kafka 之所以性能强悍,有一个重要原因就是利用了磁盘的顺序读写),但如果要读取的数据是分布在不同的扇区的话,也就变成了随机 IO,随机 IO 毫无疑问增大了寻道时间和旋转延迟,性能是非常堪忧的(典型代表就是上文提到的 回表时大量 id 分布在不同的页上,造成了大量的随机 IO)
225 |
226 | 
227 |
228 | **如图示**:图片来自著名学术期刊 ACM Queue 上的性能对比图,可以看到磁盘顺序 IO(Sequential Disk)的速度比内存随机读写(Random memory)还快
229 |
230 |
231 |
232 | 那读取 innoDB 中的一个页为啥算一次 IO 呢,相信你已经猜到了,因为这一个页是连续分配的,也即意味着它们的扇区是相邻的,所以它是顺序 IO
233 |
234 |
235 |
236 | 操作系统是以页为单位来管理内存的,它可以一次加载整数倍的页,而 innoDB 的页大小为 16KB,刚好是操作系统页(4KB)的 4 倍,所以可以指定在读取的起始地址连续读取 4 个操作系统页,即 16 KB,这就是我们说的**磁盘预读**,至此相信大家不难明白为啥说读取一页其实只是一次 IO 而不是 4 次了
237 |
238 |
239 |
240 | ### 总结
241 |
242 | 看完本文相信大家能明白索引的由来了,此外对页以及磁盘预读对性能的提升应该也有不少了解,其实 MySQL 的页结构与我们推演的结构有些许出入,不过不影响整体的理解,如果大家有兴趣深入了解 MySQL 的页结构,强烈建议大家看看文末的<>这本书,讲解得非常细致
243 |
244 |
245 | * 巨人的肩膀
246 |
247 | 1. 磁盘I/O那些事: https://tech.meituan.com/2017/05/19/about-desk-io.html
248 | 2. 带你从头到尾捋一遍MySQL索引结构: https://blog.51cto.com/u_12302929/3290492
249 | 3. MySQL 是怎样运行的:从根儿上理解 MySQL
250 |
251 | 最后欢迎大家关注我的公众号「**码海**」,第一时间收到干货推文
--------------------------------------------------------------------------------
/系统设计/高性能网关设计实践.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 | 之前的[高性能短链设计](https://mp.weixin.qq.com/s/YTrBaERcyjvw7A0Fg2Iegw)一文颇受大家好评,共被转载 **47** 次,受宠若惊,在此感谢大家的认可!在文末简单提了一下 OpenResty,一些读者比较感兴趣,刚好我们接入层网关也是用的 OpenResty,所以希望通过对网关设计的介绍来简单总结一下 OpenResty 的相关知识点,争取让大家对 OpenResty 这种高性能 Web 平台有一个比较全面的了解。本文会从以下几个方面来讲解。
3 |
4 | * 网关的作用
5 | * 接入层网关架构设计与实现
6 | * 技术选型
7 | * OpenResty 原理剖析
8 |
9 |
10 | ## 网关的作用
11 |
12 | 网关作为所有请求的流量入口,主要承担着安全,限流,熔断降级,监控,日志,风控,鉴权等功能,网关主要有两种类型
13 |
14 | * 一种是接入层网关(access gateway),主要负责路由,WAF(防止SQL Injection, XSS, 路径遍历, 窃取敏感数据,CC攻击等),限流,日志,缓存等,这一层的网关主要承载着将请求路由到各个应用层网关的功能
15 |
16 | * 另一种是应用层网关,比如现在流行的微服务,各个服务可能是用不同的语言写的,如 PHP,Java 等,那么接入层就要将请求路由到相应的应用层集群,再由相应的应用层网关进行鉴权等处理,处理完之后再调用相应的微服务进行处理,应用层网关也起着路由,超时,重试,熔断等功能。
17 |
18 | 目前市面上比较流行的系统架构如下
19 |
20 | 
21 |
22 |
23 | 可以看到接入层网关承载着公司的所有流量,对性能有很高的要求,它的设计决定着整个系统的上限。所以我们今天主要谈谈接入层网关的设计。
24 |
25 | ## 接入层网关架构设计与实现
26 |
27 | 首先我们要明白接入层网关的核心功能是:**根据路由规则将请求分发到对应的后端集群**,所以要实现如下几个功能模型 。
28 |
29 | 1、 路由:根据请求的 host, url 等规则转发到指定的上游(相应的后端集群)
30 | 2、 路由策略插件化:这是网关的**灵魂所在**,路由中会有身份认证,限流限速,安全防护(如 IP 黑名单,refer异常,UA异常,需第一时间拒绝)等规则,这些规则以插件的形式互相组合起来以便只对某一类的请求生效,每个插件都即插即用,互不影响,这些插件应该是**动态可配置**的,动态生效的(无须重启服务),为啥要可动态可配置呢,因为每个请求对应的路由逻辑,限流规则,最终请求的后端集群等规则是不一样的
31 |
32 | 
33 |
34 | 如图示,两个请求对应的路由规则是不一样的,它们对应的路由规则(限流,rewrite)等通过各个规则插件组合在一起,可以看到,光两个请求 url 的路由规则就有挺多的,如果一个系统大到一定程度,url 会有不少,就会有不少规则,这样每个请求的规则就必须**可配置化**,**动态化**,最好能在管理端集中控制,统一下发。
35 |
36 | 3、后端集群的动态变更
37 |
38 | 路由规则的应用是为了确定某一类请求经过这些规则后最终到达哪一个集群,而我们知道请求肯定是要打到某一台集群的 ip 上的,而机器的扩缩容其实是比较常见的,所以必须支持动态变更,总不能我每次上下线机器的时候都要重启系统让它生效吧。
39 |
40 | 4、监控统计,请求量、错误率统计等等
41 |
42 | 这个比较好理解,在接入层作所有流量的请求,错误统计,便于打点,告警,分析。
43 |
44 | 要实现这些需求就必须对我们采用的技术:OpenResty 有比较详细的了解,所以下文会简单介绍一下 OpenResty 的知识点。
45 |
46 | ## 技术选型
47 |
48 | 有人可能第一眼想到用 Nginx,没错,由于 Nginx 采用了 epoll 模型(非阻塞 IO 模型),确实能满足大多数场景的需求(经过优化 100 w + 的并发数不是问题),但是 Nginx 更适合作为静态的 Web 服务器,因为对于 Nginx 来说,如果发生任何变化,都需要修改磁盘上的配置,然后重新加载才能生效,它并没有提供 API 来控制运行时的行为,而如上文所述,动态化是接入层网关非常重要的一个功能。所以经过一番调研,我们选择了 OpenResty,啥是 OpenResty 呢,来看下官网的定义:
49 |
50 | > OpenResty® 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
51 | > OpenResty® 的目标是让你的Web服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
52 |
53 | 可以简单理解为,OpenResty = Nginx + Lua, 通过 Lua 扩展 Nginx 实现的可伸缩的 Web 平台
54 | 。它利用了 Nginx 的高性能,又在其基础上添加了 Lua 的脚本语言来让 Nginx 也具有了动态的特性。通过 OpenResty 中 lua-Nginx-module 模块中提供的 Lua API,我们可以动态地控制路由、上游、SSL 证书、请求、响应等。甚至可以在不重启 OpenResty 的前提下,修改业务的处理逻辑,并不局限于 OpenResty 提供的 Lua API。
55 |
56 | 关于静态和动态有一个很合适的类比:如果把 Web 服务器当做是一个正在高速公路上飞驰的汽车,Nginx 需要停车才能更换轮胎,更换车漆颜色,而 OpenResty 中可以边跑边换轮胎,更换车漆,甚至更换发动机,直接让普通的汽车变成超跑!
57 |
58 |
59 | 除了以上的动态性,还有两个特性让 OpenResty 独出一格。
60 |
61 | **1、详尽的文档和测试用例**
62 |
63 | 作为开源项目,文档和测试毫无疑问是其是否靠谱的关键,它的文档非常详细,作者把每个注意的点都写在文档上了,多数时候只要看文档即可,每一个测试案例都包含完整的 Nginx 配置和 lua 代码。以及测试的输入数据和预期的输出数据。
64 |
65 | **2、同步非阻塞**
66 |
67 | OpenResty 在诞生之初就支持了协程,并且基于此实现了同步非阻塞的编程模型。
68 | **画外音:协程(coroutine)我们可以将它看成一个用户态的线程,只不过这个线程是我们自己调度的,而且不同协程的切换不需要陷入内核态,效率比较高。(一般我们说的线程是要指内核态线程,由内核调度,需要从用户空间陷入内核空间,相比协程,对性能会有不小的影响)**
69 |
70 | 啥是同步非阻塞呢。假设有以下两个两行代码:
71 |
72 | ```lua
73 | local res, err = query-mysql(sql)
74 | local value, err = query-redis(key)
75 | ```
76 |
77 | **同步**:必须执行完查询 mysql,才能执行下面的 redis 查询,如果不等 mysql 执行完成就能执行 redis 则是异步。
78 |
79 | **阻塞**:假设执行 sql 语句需要 1s,如果在这 1s 内,CPU 只能干等着不能做其它任何事,那就是阻塞,如果在 sql 执行期间可以做其他事(注意由于是同步的,所以不能执行以下的 redis 查询),则是非阻塞。
80 |
81 | 同步关注的是语句的先后执行顺序,如果上一个语句必须执行完才能执行下一个语句就是同步,如果不是,就是异步,阻塞关注的是线程是 CPU 是否需要在 IO 期间干等着,如果在 IO(或其他耗时操作期间)期间可以做其他事,那就是非阻塞,不能动,则是阻塞。
82 |
83 | 那么 OpenResty 的工作原理是怎样的呢,又是如何实现同步非阻塞的呢。
84 |
85 | ## OpenResty 原理剖析
86 |
87 | ### 工作原理剖析
88 | 由于 OpenResty 基于 Nginx 实现的,我们先来看看 Nginx 的工作原理
89 |
90 | 
91 |
92 | Nginx 启动后,会有一个 master 进程和多个 worker 进程 , master 进程接受管理员的信号量(如 Nginx -s reload, -s stop)来管理 worker 进程,master 本身并不接收 client 的请求,主要由 worker 进程来接收请求,不同于 apache 的每个请求会占用一个线程,且是同步IO,Nginx 是异步非阻塞的,每个 worker 可以同时处理的请求数只受限于内存大小,这里就要简单地了解一下 nginx 采用的 epoll 模型:
93 |
94 | epoll 采用多路复用模型,即同一时间虽然可能会有多个请求进来, 但只会用一个线程去监视,然后哪个请求数据准备好了,就调用相应的线程去处理,就像图中所示,同拨开关一样,同一时间只有一个线程在处理, epoll 是基于事件驱动模型的,每个请求进来注册事件并注册 callback 回调函数,等数据准入好了,就调用回调函数进行处理,它是异步非阻塞的,所以性能很高。
95 |
96 | 
97 |
98 |
99 | 打个简单的比方,我们都有订票的经验,当我们委托酒店订票时,接待员会先把我们的电话号码和相关信息等记下来(注册事件),挂断电话后接待员在操作期间我们就可以去做其他事了(非阻塞),当接待员把手续搞好后会主动打电话给我们通知我们票订好了(回调)。
100 |
101 |
102 | worker 进程是从 master fork 出来的,这意味着 worker 进程之间是互相独立的,这样不同 worker 进程之间处理并发请求几乎没有同步锁的限制,好处就是一个 worker 进程挂了,不会影响其他进程,我们一般把 worker 数量设置成和 CPU 的个数,这样可以减少不必要的 CPU 切换,提升性能,每个 worker 都是单线程执行的。
103 | 那么 LuaJIT 在 OpenResty 架构中的位置是怎样的呢。
104 |
105 | 
106 |
107 |
108 | 首先启动的 master 进程带有 LuaJIT 的机虚拟,而 worker 进程是从 master 进程 fork 出来的,在 worker 内进程的工作主要由 Lua 协程来完成,也就是说在同一个 worker 内的所有协程,都会共享这个 LuaJIT 虚拟机,每个 worker 进程里 lua 的执行也是在这个虚拟机中完成的。
109 |
110 | 同一个时间点,worker 进程只能处理一个用户请求,也就是说只有一个 lua 协程在运行,那为啥 OpenResty 能支持百万并发请求呢,这就需要了解 Lua 协程与 Nginx 事件机制是如何配合的了。
111 |
112 | 
113 |
114 | 如图示,当用 Lua 调用查询 MySQL 或 网络 IO 时,虚拟机会调用 Lua 协程的 yield 把自己挂起,在 Nginx 中注册回调,此时 worker 就可以处理另外的请求了(非阻塞),等到 IO 事件处理完了, Nginx 就会调用 resume 来唤醒 lua 协程。
115 |
116 | 事实上,由 OpenResty 提供的所有 API,都是非阻塞的,下文提到的与 MySQL,Redis 等交互,都是非阻塞的,所以性能很高。
117 |
118 |
119 |
120 |
121 | ### OpenResty 请求生命周期
122 |
123 | Nginx 的每个请求有 11 个阶段,OpenResty 也有11 个 \*_by_lua 的指令,如下图示:
124 |
125 | 
126 |
127 | 各个阶段 \*_by_lua 的解释如下
128 |
129 | ```shell
130 | set_by_lua:设置变量;
131 | rewrite_by_lua:转发、重定向等;
132 | access_by_lua:准入、权限等;
133 | content_by_lua:生成返回内容;
134 | header_filter_by_lua:应答头过滤处理;
135 | body_filter_by_lua:应答体过滤处理;
136 | log_by_lua:日志记录。
137 | ```
138 |
139 | 这样分阶段有啥好处呢,假设你原来的 API 请求都是明文的
140 |
141 | ```nginx
142 |
143 | # 明文协议版本
144 | location /request {
145 | content_by_lua '...'; # 处理请求
146 | }
147 | ```
148 |
149 | 现在需要对其加上加密和解密的机制,只需要在 access 阶段解密, 在 body filter 阶段加密即可,原来 content 的逻辑无需做任务改动,有效实现了代码的解藕。
150 |
151 | ```nginx
152 | # 加密协议版本
153 | location /request {
154 | access_by_lua '...'; # 请求体解密
155 | content_by_lua '...'; # 处理请求,不需要关心通信协议
156 | body_filter_by_lua '...'; # 应答体加密
157 | }
158 | ```
159 |
160 | 再比如我们不是要要上文提到网关的核心功能之一不是要监控日志吗,就可以统一在 log_by_lua 上报日志,不影响其他阶段的逻辑。
161 |
162 | ## worker 间共享数据的利器: shared dict
163 |
164 | worker 既然是互相独立的进程,就需要考虑其共享数据的问题, OpenResty 提供了一种高效的数据结构: shared dict ,可以实现在 worker 间共享数据,shared dict 对外提供了 20 多个 Lua API,都是原子操作的,避免了高并发下的竞争问题。
165 |
166 |
167 | ## 路由策略插件化实现
168 |
169 | 有了以上 OpenResty 点的铺垫,来看看上文提的网关核心功能 「路由策略插件化」,「后端集群的动态变更」如何实现
170 |
171 | 首先针对某个请求的路由策略大概是这样的
172 |
173 | 
174 |
175 | 整个插件化的步骤大致如下
176 |
177 | 1、每条策略由 url ,action, cluster 等组成,代表请求 url 在打到后端集群过程中最终经历了哪些路由规则,这些规则统一在我们的路由管理平台配置,存在 db 里。
178 |
179 | 2、OpenResty 启动时,在请求的 init 阶段 worker 进程会去拉取这些规则,将这些规则编译成一个个可执行的 lua 函数,这一个个函数就对应了一条条的规则。
180 |
181 | 
182 |
183 |
184 | 需要注意的是为了避免重复去 MySQL 中拉取数据,某个 worker 从 MySQL 拉取完规则(此步需要加锁,避免所有 worker 都去拉取)或者后端集群等配置信息后要将其保存在 shared dict 中,这样之后所有的 worker 请求只要从 shared dict 中获取这些规则,然后将其映射成对应模块的函数即可,如果配置规则有变动呢,配置后台通过接口通知 OpenResty 重新加载一下即可
185 |
186 | 
187 |
188 |
189 | 经过路由规则确定好每个请求对应要打的后端集群后,就需要根据 upstream 来确定最终打到哪个集群的哪台机器上,我们看看如何动态管理集群。
190 |
191 |
192 |
193 | ## 后端集群的动态配置
194 |
195 | 在 Nginx 中配置 upstream 的格式如下
196 |
197 | ```lua
198 | upstream backend {
199 | server backend1.example.com weight=5;
200 | server backend2.example.com;
201 | server 192.0.0.1 backup;
202 | }
203 | ```
204 | 以上这个示例是按照权重(weight)来划分的,6 个请求进来,5个请求打到 backend1.example.com, 1 个请求打到 backend2.example.com,如果这两台机器都不可用,就打到 192.0.0.1,这种静态配置的方式 upstream 的方式确实可行,但我们知道机器的扩缩容有时候比较频繁,如果每次机器上下线都要手动去改,并且改完之后还要重新去 reload 无疑是不可行的,出错的概率很大,而且每次配置都要 reload 对性能的损耗也是挺大的,为了解决这个问题,OpenResty 提供了一个 dyups 的模块来解决此问题, 它提供了一个 dyups api,可以动态增,删,创建 upsteam,所以在 init 阶段我们会先去拉取集群信息,构建 upstream,之后如果集群信息有变动,会通过如下形式调用 dyups api 来更新 upstream
205 |
206 | ```lua
207 |
208 | -- 动态配置 upstream 接口站点
209 | server {
210 | listen 127.0.0.1:81;
211 | location / {
212 | dyups_interface;
213 | }
214 | }
215 |
216 |
217 | -- 增加 upstream:user_backend
218 | curl -d "server 10.53.10.191;" 127.0.0.1:81/upstream/user_backend
219 |
220 | -- 删除 upstream:user_backend
221 | curl -i -X DELETE 127.0.0.1:81/upstream/user_backend
222 | ```
223 |
224 | 使用 dyups 就解决了动态配置 upstream 的问题
225 |
226 | ## 网关最终架构设计图
227 |
228 | 
229 |
230 | 通过这样的设计,最终实现了网关的配置化,动态化。
231 |
232 | ## 总结
233 |
234 | 网关作为承载公司所有流量的入口,对性能有着极高的要求,所以技术选型上还是要慎重,之所以选择 OpenResty,一是因为它高性能,二是目前也有小米,阿里,腾讯等大公司在用,是久经过市场考验的,本文通过对网关的总结简要介绍了 OpenResty 的相关知识点,相信大家对其主要功能点应该有所了解了,不过 OpenResty 的知识点远不止以上这些,大家如有兴趣,可以参考文末的学习教程深入学习,相信大家会有不少启发的。
235 |
236 |
237 | ## 题外话
238 |
239 | 「码海」历史精品文章已经做成电子书了,如有需要欢迎添加我的个人微信,除了发你电子书外,也可以加入我的读者群,一起探讨问题,共同进步!里面有不少技术总监等大咖,相信不管是职场进阶也好,个人困惑也好,都能对你有所帮助哦
240 |
241 |
242 | 欢迎关注公众号加我个人微信交流哦
243 |
244 | 
245 |
246 | 巨人的肩膀
247 | * 谈谈微服务中的 API 网关 https://www.cnblogs.com/savorboard/p/api-gateway.html
248 | * Openresty动态更新(无reload)TCP Upstream的原理和实现 https://developer.aliyun.com/article/745757
249 | * http://www.ttlsa.com/Nginx/Nginx-modules-ngx_http_dyups_module/
250 | * 极客时间 OpenResty 从入门到实战
251 |
252 | 欢迎关注公众号与笔者共同交流哦^_^
253 |
254 | 
--------------------------------------------------------------------------------
/Java/字节码剖析.md:
--------------------------------------------------------------------------------
1 | ### 前言
2 |
3 | 你好,我是坤哥
4 |
5 | 从今天起我打算整一个 Java 系列的进阶基础文章, 相信对大家会有帮助帮助,万丈高楼平地起,打好基础我们才能走得更好,举个例子,之前我在武哥的 Kafka 文章中看到这样的一句话「除此之外,页缓存(pageCache)还有一个巨大的优势。用过 Java 的人都知道:如果不用页缓存,而是用 JVM 进程中的缓存,对象的内存开销非常大(通常是真实数据大小的几倍甚至更多)」,如果你不了解 Java 对象的表示,看到这样的话会一脸懵逼:对象的开销到底有多巨大,反过来看,如果你掌握了 Java 中的对象布局,GC,NIO 等原理,理解这些框架的原理及其设计思路就不是什么难事
6 |
7 |
8 |
9 | 另一个让我下决心写这个系列的原因是经常有一些读者问一些学习路线的事,之前我写过一些大纲,但没有从点的层面展开,所以这次准备从点的思路来将各个知识点细细道来,然后再整理成 pdf,这样之后如果有人再问起,直接把这个 pdf 扔给他们就完事了 ^_^,欢迎大家加我微信:geekoftaste 一起探讨
10 |
11 |
12 |
13 | 每个系列都会以图文并茂的方式来讲解,争取做到深入浅出,举个例子,上面我们说了对象的开销很大,到底有多大呢,我会用图解的方式来带你一步步分析,看完后相信你会明白为什么 int\[128\]\[2\] 实例比 int[256] 实例多了 246% 的额外开销了,再比如我们都知道 Eden 区或 tenured(老年代区)满了会触发 yong gc 或 old gc,不过导致 gc 停顿时间过长的原因其实有挺多的,如果你看完我总结的这些通用的思路,相信你就能根据这套理论来快速地排查问题了,这个系列干货很多,相信对提升大家的 Java 内功有不少帮助,记得得文末点赞支持一下哦 ^_^
14 |
15 |
16 |
17 | Java 系列大纲如下:
18 |
19 |
20 |
21 | 
22 |
23 | 本篇我们先来学习下字节码 ,毕竟这是 Java 能跨平台的根本原因,而且通过了解字节码也可以彻底揭开 JVM 运行程序的秘密,整体会用问答的形式来讲解
24 |
25 |
26 |
27 | > 能否简单介绍一下 Java 的特性
28 |
29 | Java 是一门**面向对象**,**静态类型的**语言,具有跨平台的特点,与 C,C++ 这些需要手动管理内存,编译型的语言不同,它是解释型的,具有跨平台和自动垃圾回收的特点,那么它的跨平台到底是怎么实现的呢?
30 |
31 |
32 |
33 | 我们知道计算机只能识别二进制代码表示的机器语言,所以不管用的什么高级语言,最终都得翻译成机器语言才能被 CPU 识别并执行,对于 C++这些编译型语言来说是直接一步到位转为相应平台的可执行文件(即机器语言指令),而对 Java 来说,则首先由编译器将源文件编译成字节码,再在运行时由虚拟机(JVM)解释成机器指令来执行,我们可以看下下图
34 |
35 | 
36 |
37 | 也就是说 Java 的跨平台其实是通过先生成字节码,再由针对各个平台实现的 JVM 来解释执行实现的,JVM 屏蔽了 OS 的差异,我们知道 Java 工程都是以 Jar 包分发(一堆 class 文件的集合体)部署的,这就意味着 jar 包可以在各个平台上运行(由相应平台的 JVM 解释执行即可),这就是 Java 能实现跨平台的原因所在
38 |
39 | 这也是为什么 JVM 能运行 Scala、Groovy、Kotlin 这些语言的原因,并不是 JVM 直接来执行这些语言,而是这些语言最终都会生成符合 JVM 规范的字节码再由 JVM 执行,不知你是否注意到,使用字节码也利用了计算机科学中的分层理念,通过加入字节码这样的中间层,有效屏蔽了与上层的交互差异。
40 |
41 |
42 |
43 | > JVM 是怎么执行字节码的
44 |
45 | 在此之前我们先来看下 JVM 的整体内存结构,对其有一个宏观的认识,然后再来看 JVM 是如何执行字节码的
46 |
47 | 
48 |
49 |
50 |
51 | JVM 在内存中主要分为「栈」,「堆」,「非堆」以及 JVM 自身,堆主要用来分配类实例和数组,非堆包括「方法区」、「JVM内部处理或优化所需的内存(如JIT编译后的代码缓存)」、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码
52 |
53 |
54 |
55 | 我们主要关注栈,我们知道线程是 cpu 调度的最小单位,在 JVM 中一旦创建一个线程,就会为其分配一个线程栈,线程会调用一个个方法,每个方法都会对应一个个的栈祯压到线程栈里,JVM 中的栈内存结构如下
56 |
57 |
58 |
59 | 
60 |
61 |
62 |
63 | 至此我们总算接近 JVM 执行的真相了,JVM 是以栈帧为单位执行的,栈帧由以下四个部分组成
64 |
65 | * 返回值
66 | * 局部变量表(Local Variables):存储方法用到的本地变量
67 | * 动态链接:在字节码中,所有的变量和方法都是以符号引用的形式保存在 class 文件的常量池中的,比如一个方法调用另外的方法,是通过常量池中指向方法的符号引用来表示的,动态链接的作用就是为了将这些符号引用转换为调用方法的直接引用,这么说可能有人还是不理解,所以我们先执行一下 `javap -verbose Demo.class `命令来查看一下字节码中的常量池是咋样的 
68 |
69 | 注意:以上只列出了常量池中的**部分符号引用**
70 |
71 |
72 |
73 | 可以看到 Object 的 init 方法是由 #4.#16 表示的,而 #4 又指向了 #19,#19 表示 Object,#16 又指向了 #7.#8,#7 指向了方法名,#8 指向了 ()V(表示方法的返回值为 void,且无方法参数),字节码加载后,会把类信息加载到元空间(Java 8 以后)中的方法区中,动态链接会把这些符号引用替换为调用方法的直接引用,如下图示
74 |
75 | 
76 |
77 |
78 |
79 | 那为什么要提供动态链接呢,通过上面这种方式绕了好几个弯才定位到具体的执行方法,效率不是低了很多吗,其实**主要是为了支持 Java 的多态**,比如我们声明一个 `Father f = new Son()`这样的变量,但执行 f.method() 的时候会绑定到 son 的 method(如果有的话),这就是用到了动态链接的技术,在运行时才能定位到具体该调用哪个方法,动态链接也称为后期绑定,与之相对的是静态链接(也称为前期绑定),即在编译期和运行期对象的方法都保持不变,静态链接发生在编译期,也就是说在程序执行前方法就已经被绑定,**java 当中的方法只有final、static、private和构造方法是前期绑定的**。而动态链接发生在运行时,**几乎所有的方法都是运行时绑定的**
80 |
81 |
82 |
83 | 举个例子来看看两者的区别,一目了解
84 |
85 | ```java
86 | class Animal{
87 | public void eat(){
88 | System.out.println("动物进食");
89 | }
90 | }
91 |
92 | class Cat extends Animal{
93 | @Override
94 | public void eat() {
95 | super.eat();//表现为早起绑定(静态链接)
96 | System.out.println("猫进食");
97 | }
98 | }
99 | public class AnimalTest {
100 | public void showAnimal(Animal animal){
101 | animal.eat();//表现为晚期绑定(动态链接)
102 | }
103 | }
104 |
105 | ```
106 |
107 |
108 |
109 | * `操作数栈(Operand Stack)`:程序主要由指令和操作数组成,指令用来说明这条操作做什么,比如是做加法还是乘法,操作数就是指令要执行的数据,那么指令怎么获取数据呢,指令集的架构模型分为**基于栈的指令集架构**和**基于寄存器的指令集架构**两种,JVM 中的指令集属于前者,也就是说任何操作都是用栈来管理,基于栈指令可以更好地实现跨平台,栈都是是在内存中分配的,而寄存器往往和硬件挂钩,不同的硬件架构是不一样的,不利于跨平台,当然于栈的指令集架构缺点也很明显,基于栈的实现需要更多指令才能完成(因为栈只是一个FILO结构,需要频繁压栈出栈),而寄存器是在CPU的高速缓存区,相较而言,**基于栈的速度要慢不少**,这也是为了跨平台而做出的一点性能牺牲,毕竟鱼和熊掌不可兼得。
110 |
111 |
112 |
113 | ### Java 字节码技术简介
114 |
115 | 注意线程中还有一个「PC 程序计数器」,是每个线程独有的,记录着当前线程所执行的字节码的行号指示器,也就是指向下一条指令的地址,也就是将执行的指令代码。由执行引擎读取下一条指令。我们先来看下看一下字节码长啥样。假设我们有以下 Java 代码
116 |
117 | ```java
118 | package com.mahai;
119 | public class Demo {
120 | private int a = 1;
121 | public static void foo() {
122 | int a = 1;
123 | int b = 2;
124 | int c = (a + b) * 5;
125 | }
126 | }
127 | ```
128 |
129 | 执行 javac Demo.java 后可以看到其字节码如下
130 |
131 | 
132 |
133 | 字节码是给 JVM 看的,所以我们需要将其翻译成人能看懂的代码,好在 JDK 提供了反解析工具 javap ,可以根据字节码反解析出 code 区(汇编指令)、本地变量表、异常表和代码行偏移量映射表、常量池等信息。我们执行以下命令来看下根据字节码反解析的文件长啥样(更详细的信息可以执行 javap -verbose 命令,在本例中我们重点关注 Code 区是如何执行的,所以使用了 javap -c 来执行
134 |
135 | ```
136 | javap -c Demo.class
137 | ```
138 |
139 | 
140 |
141 |
142 |
143 | 转换成这种形式可读性强了很多,那么aload_0,invokespecial 这些表示什么含义呢, javap 是怎么根据字节码来解析出这些指令出来的呢
144 |
145 |
146 |
147 | 首先我们需要明白什么是指令,**指令=操作码+操作数**,操作码表示这条指令要做什么,比如加减乘除,操作数即操作码操作的数,比如 1+ 2 这条指令,操作码其实是加法,1,2 为操作数,在 Java 中每个操作码都由一个字节表示,每个操作码都有对应类似 aload_0,invokespecial,iconst_1 这样的助记符,有些操作码本来就包含着操作数,比如字节码 0x04 对应的助记符为 iconst_1, 表示 将 int 型 1 推送至栈顶,这些操作码就相当于指令,而有些操作码需要配合操作数才能形成指令,如字节码 0x10 表示 bipush,后面需要跟着一个操作数,表示 `将单字节的常量值(-128~127)推送至栈顶`。以下为列出的几个字节码与助记符示例
148 |
149 | | 字节码 | 助记符 | 表示含义 |
150 | | ------ | ------------- | ------------------------------------------ |
151 | | 0x04 | iconst_1 | 将int型1推送至栈顶 |
152 | | 0xb7 | invokespecial | 调用超类构建方法, 实例初始化方法, 私有方法 |
153 | | 0x1a | iload_0 | 将第一个int型本地变量推送至栈顶 |
154 | | 0x10 | bipush | 将单字节的常量值(-128~127)推送至栈顶 |
155 |
156 | 至此我们不难明白 javap 的作用了,它主要就是找到字节码对应的的助记符然后再展示在我们面前的,我们简单看下上述的默认构造方法是如何根据字节码映射成助记符并最终呈现在我们面前的:
157 |
158 |
159 |
160 | 
161 |
162 | 最左边的数字是 Code 区中每个字节的偏移量,这个是保存在 PC 的程序计数中的,比如如果当前指令指向 1,下一条就指向 4
163 |
164 |
165 |
166 | 另外大家不难发现,在源码中其实我们并没有定义默认构造函数,但在字节码中却生成了,而且你会发现我们在源码中定义了`private int a = 1;`但这个变量赋值的操作却是在构造方法中执行的(下文会分析到),这就是理解字节码的意义:**它可以反映 JVM 执行程序的真正逻辑**,而源码只是表象,要深入分析还得看字节码!
167 |
168 |
169 |
170 | 接下来我们就来瞧一瞧构造方法对应的指令是如何执行的,首先我们来看一下在 JVM 中指令是怎么执行的。
171 |
172 |
173 |
174 | 1. 首先 JVM 会为每个方法分配对应的局部变量表,可以认为它是一个数组,每个坑位(我们称为 slot)为方法中分配的变量,如果是实例方法,这些局部变量可以是 this, 方法参数,方法里分配的局部变量,这些局部变量的类型即我们熟知的 int,long 等八大基本,还有引用,返回地址,每个 slot 为 4 个字节,所以像 Long , Double 这种 8 个字节的要占用 2 个 slot, 如果这个方法为实例方法,则第一个 slot 为 this 指针, 如果是静态方法则没有 this 指针
175 |
176 | 2. 分配好局部变量表后,方法里如果涉及到赋值,加减乘除等操作,那么这些指令的运算就需要依赖于操作数栈了,将这些指令对应的操作数通过压栈,弹栈来完成指令的执行
177 |
178 | 比如有 `int i = 69` 这样的指令,对应的字码节指令如下
179 |
180 | ```
181 | 0:bipush 69
182 | 2:istore_0
183 | ```
184 |
185 | 其在内存中的操作过程如下
186 |
187 | 
188 |
189 | 可以看到主要分两步:第一步首先把 69 这个 int 值压栈,然后再弹栈,把 69 弹出放到局部变量表 i 对应的位置,istore_0 表示弹栈,将其从操作数栈中弹出整型数字存储到本地变量中,0 表示本地变量在局部变量表的第 0 个 slot
190 |
191 |
192 |
193 | 理解了上面这个操作,我们再来看一下默认构造函数对应的字节码指令是如何执行的
194 |
195 | 
196 |
197 |
198 |
199 | 首先我们需要先来理解一下上面几个指令
200 |
201 | * aload_0:从局部变量表中加载第 0 个 slot 中的对象引用到操作数栈的栈顶,这里的 0 表示第 0 个位置,也就是 this
202 | * invokespecial:用来调用构造函数,但也可以用于调用同一个类中的 private 方法, 以及 可见的超类方法,在此例中表示调用父类的构造器(因为 #1 符号引用指向对应的 init 方法)
203 | * iconst_1:将 int 型 1推送至栈顶
204 | * putfield:它接受一个操作数,这个操作数引用的是运行时常量池里的一个字段,在这里这个字段是 a。赋给这个字段的值,以及包含这个字段的对象引用,在执行这条指令的时候,都会从操作数栈顶上 pop 出来。前面的 aload_0 指令已经把包含这个字段的对象(this)压到操作数栈上了,而后面的 iconst_1 又把 1 压到栈里。最后 putfield 指令会将这两个值从栈顶弹出。执行完的结果就是这个对象的 a 这个字段的值更新成了 1。
205 |
206 | 接下来我们来详细解释以上以上助记符代表的含义
207 |
208 |
209 |
210 | * 第一条命令 aload_0,表示从局部变量表中加载第 0 个 slot 中的对象引用到操作数栈的栈顶,也就是将 this 加载到栈顶,如下
211 |
212 | 
213 |
214 |
215 |
216 | * 第二步 invokespecial #1,表示弹栈并且执行 #1 对应的方法,#1 代表的含义可以从旁边的解释(`# Method java/lang/Object."":()V`)看出,即调用父类的初始化方法,这也印象了那句话:**子类初始化时会从初始化父类**
217 | * 之后的命令 `aload_0`,`iconst_1`,`putfied #2` 图解如下
218 |
219 | 
220 |
221 |
222 |
223 | 可能有人有些奇怪,上述 `6: putfield #2`命令中的 #2 怎么就代表 Demo 的私有成员 a 了,这就涉及到字节码中的常量池概念了,我们执行 `javap -verbose path/Demo.class` 可以看到这些字面量代表的含义,#1,#2 这种数字形式的表示形式也被称为符号引用,程序运行期会将符号引用转换为直接引用
224 |
225 | 
226 |
227 | 由此可知 #2 代表 Demo 类的 a 属性,如下
228 |
229 | 
230 |
231 |
232 |
233 |
234 |
235 | 我们再来用动图看一下 foo 的执行流程,相信你现在能理解其含义了
236 |
237 | 
238 |
239 |
240 |
241 | 唯一需要注意的此例中的 foo 是个静态方法,所以局部变量区是没有 this 的。
242 |
243 |
244 |
245 | 相信你不难发现 JVM 执行字节码的流程与 CPU 执行机器码步骤如出一辙,都经历了「取指令」,「译码」,「执行」,「存储计算结果」这四步,首先程序计数器指向下一条要执行的指令,然后 JVM 获取指令,由本地执行引擎将字节码操作数转成机器码(译码)执行,执行后将值存储到局部变量区(存储计算结果)中
246 |
247 |
248 |
249 | 关于字节码我推荐两款工具
250 |
251 | * 一个是 Hex Fiend,一款很好的十六进制编辑器,可以用来查看字节码
252 | * 一款是 Intellij Idea 的插件 `jclasslib Bytecode viewer`,能为你展示 javap -verbose 命令对应的常量池,接口, Code 等数据,非常的直观,对于分析字节码非常有帮忙,如下
253 |
254 | 
255 |
256 |
257 |
258 | 欢迎关注公号一起交流,共同进步
259 |
260 | 
261 |
262 | 下一篇我们继续聊字节码是如何被加载的
--------------------------------------------------------------------------------
/架构/高可用.md:
--------------------------------------------------------------------------------
1 | 大家好,我是坤哥
2 |
3 | 今天我们来聊一下互联网三高(高并发、高性能、高可用)中的高可用,看完本文相信能解开你关于高可用设计的大部分困惑
4 |
5 | ### 前言
6 |
7 | 高可用(High availability,即 HA)的主要目的是为了保障「业务的连续性」,即在用户眼里,业务永远是正常(或者说基本正常)对外提供服务的。高可用主要是针对架构而言,那么要做好高可用,就要首先设计好架构,第一步我们一般会采用分层的思想将一个庞大的 IT 系统拆分成为应用层,中间件,数据存储层等独立的层,每一层再拆分成为更细粒度的组件,第二步就是让每个组件对外提供服务,毕竟每个组件都不是孤立存在的,都需要互相协作,对外提供服务才有意义。
8 |
9 |
10 |
11 | 要保证架构的高可用,就要保证架构中所有组件以及其对外暴露服务都要做高可用设计,任何一个组件或其服务没做高可用,都意味着系统存在风险。
12 |
13 |
14 |
15 | 那么这么多组件该怎么做高可用设计呢,其实任何组件要做高可用,都离不开「冗余」和「自动故障转移」,众所周知单点是高可用的大敌,所以组件一般是以集群(至少两台机器)的形式存在的,这样只要某台机器出现问题,集群中的其他机器就可以随时顶替,这就是「冗余」。简单计算一下,假设一台机器的可用性为 90%,则两台机器组成的集群可用性为 1-0.1*0.1 = 99%,所以显然冗余的机器越多,可用性越高。
16 |
17 |
18 |
19 | 但光有冗余还不够,如果机器出现问题,需要人工切换的话也是费时费力,而且容易出错,所以我们还需要借助第三方工具(即仲裁者)的力量来实现「自动」的故障转移,以达到实现**近实时**的故障转移的目的,**近实时的故障转移才是高可用的主要意义**
20 |
21 |
22 |
23 | 怎样的系统可以称之为高可用呢,业界一般用几个九来衡量系统的可用性,如下
24 |
25 | | 可用性级别 | 系统可用性% | 宕机时间/年 | 宕机时间/月 | 宕机时间/周 | 宕机时间/天 |
26 | | ---------- | ----------- | ----------- | ----------- | ----------- | ----------- |
27 | | 不可用 | 90% | 36.5 天 | 73 小时 | 16.8 小时 | 144 分钟 |
28 | | 基本可用 | 99% | 87.6 小时 | 7.3 小时 | 1.68 小时 | 14.4 分钟 |
29 | | 较高可用 | 99.9% | 8.76 小时 | 43.8 分钟 | 10.1 分钟 | 1.44 分钟 |
30 | | 高可用 | 99.99% | 52.56 分钟 | 4.38 分钟 | 1.01 秒 | 8.64 秒 |
31 | | 极高可用 | 99.999% | 5.26 分钟 | 26.28 秒 | 6.06 秒 | 0.86 秒 |
32 |
33 | 一般实现两个 9 很简单,毕竟每天宕机 14 分钟已经严重影响业务了,这样的公司迟早歇菜,大厂一般要求 4 个 9,其他要求严苛的业务要达到五个九以上,比如如果因为一个电脑的故障导致所有列车停驶,那么就会有数以万计的人正常生活受到阻碍,这种情况就要求五个九以上
34 |
35 |
36 |
37 | 接下来我们就来一起看看架构中的各个组件如何借助「冗余」和「自动故障转移」来实现高可用。
38 |
39 |
40 |
41 | ### 互联网架构剖析
42 |
43 | 目前多数互联网都会采用微服务架构,常见架构如下:
44 |
45 | 
46 |
47 | 可以看到架构主要分以下几层
48 |
49 | 1. 接入层:主要由 F5 硬件或 LVS 软件来承载所有的流量入口
50 | 2. 反向代理层:Nginx,主要负责根据 url 来分发流量,限流等
51 | 3. 网关:主要负责流控,风控,协议转换等
52 | 4. 站点层:主要负责调用会员,促销等基本服务来装配 json 等数据并返回给客户端
53 | 5. 基础 service:其实与站点层都属于微服务,是平级关系,只不过基础 service 属于基础设施,能被上层的各个业务层 server 调用而已
54 | 6. 存储层:也就是 DB,如 MySQL,Oracle 等,一般由基础 service 调用返回给站点层
55 | 7. 中间件:ZK,ES,Redis,MQ 等,主要起到加速访问数据等功能,在下文中我们会简单介绍下各个组件的作用
56 |
57 |
58 |
59 | 如前所述,要实现整体架构的高可用,必须要实现每一层组件的高可用,接下来我们就来分别看一下每一层的组件都是如何实现高可用的
60 |
61 | ### 接入层&反向代理层
62 |
63 | 这两层的高可用都和 keepalived 有关,所以我们结合起来一起看
64 |
65 | 
66 |
67 |
68 |
69 | 对外,两个 LVS 以主备的形式对外提供服务,注意只有 master 在工作(即此时的 VIP 在 master 上生效),另外一个 backup 在 master 宕机之后会接管 master 的工作,那么 backup 怎么知道 master 是否正常呢,答案是通过 keepalived,在主备机器上都装上 keepalived 软件,启动后就会通过心跳检测彼此的健康状况,一旦检测到 master 宕机,keepalived 会检测到,从而 backup 自动转成 master,对外提供服务,此时 VIP 地址(即图中的 115.204.94.139)即在 backup 上生效,也就是我们常说的「IP漂移」,通过这样的方式即解决了 LVS 的高可用。
70 |
71 |
72 |
73 | keepalived 的心跳检测主要通过发送 ICMP 报文,或者利用 TCP 的端口连接和扫描检测来检测的,同样的,它也可以用来检测 Nginx 暴露的端口,如果某些 Nginx 不正常 keepalived 也能检测到并将其从 LVS 能转发的服务列表中剔出。
74 |
75 |
76 |
77 | 借用 keepalived 这个第三方工具,同时实现了 LVS 和 Nginx 的高可用,同时在出现故障时也可以将宕机情况发送到对应开发人员的邮箱以让他们及时收到通知处理,确实很方便,keepalived 应用广泛,下文我们也能看到它也可以用在 MySQL 上来实现 MySQL 的高可用。
78 |
79 |
80 |
81 | ### 微服务
82 |
83 | 接下来我们再来看一下「网关」,「站点层」,「基础服务层」,这三者一般就是我们所说的微服务架构组件,当然这些微服务组件还需要通过一些 RPC 框架如 Dubbo 来支撑,所以微服务要实现高可用,就意味着 dubbo 这些 RPC 框架也要提供支撑微服务高可用的能力,我们就以 dubbo 为例来看下它是如何实现高可用的
84 |
85 |
86 |
87 | 我们先来简单地看下 dubbo 的基本架构
88 |
89 | 
90 |
91 | 思路也很简单,首先是 Provider(服务提供者)向 Registry(注册中心,如 ZK 或 Nacos 等)注册服务,然后 Consumer(服务消费者)向注册中心订阅和拉取 Provider 服务列表,获取服务列表后,Consumer 就可以根据其负载均衡策略选择其中一个 Provider 来向其发出请求,当其中某个 Provider 不可用(下线或者因为 GC 阻塞等)时,会被注册中心及时监听(通过心跳机制)到,也会及时推送给 Consumer,这样 Consumer 就能将其从可用的 Provider 列表中剔除,也就实现了故障的自动转移,不难看出,注册中心就起到了类似 keepalived 的作用
92 |
93 |
94 |
95 | ### 中间件
96 |
97 | 我们再来看下这些中间件如 ZK,Redis 等是如何实现高可用的呢
98 |
99 |
100 |
101 | #### ZK
102 |
103 | 上一节微服务中我们提到了注册中心,那我们就以 ZK(ZooKeeper)为例来看看它的高可用是如何实现的,先来看下它的整体架构图如下
104 |
105 |
106 |
107 | 
108 |
109 |
110 |
111 | Zookeeper 中的主要角色如下
112 |
113 | * Leader: 即领导者,在集群中只有一个 Leader,主要承担了以下的功能
114 | 1. 事务请求的唯一调度和处理者,保证集群事物处理的顺序性,所有 Follower 的写请求都会转给 Leader 执行,用来保证事务的一致性
115 | 2. 集群内部各服务器的调度者:处理好事务请求后,会将数据广播同步到各个 Follower,统计 Follower 写入成功的数量,超过半数 Follower 写入成功,Leader 就会认为写请求提交成功,通知所有的 Follower commit 这个这与操作,保证事后哪怕是集群崩溃恢复或者重启,这个写操作也不会丢失。
116 | * Follower:
117 | 1. 处理客户端非事务请求、转发事务请求给 leader 服务器
118 | 2. 参与事物请求 Proposal 的投票(需要半数以上服务器通过才能通知 leader commit 数据; Leader 发起的提案,要求 Follower 投票)
119 | 3. 参与 Leader 选举的投票
120 |
121 | **画外音**:Zookeeper 3.0 之后新增了一种 Observer 的角色,不过与此处讨论的 ZK 高可用关系不是很大,为了简化问题,所以省略
122 |
123 | 可以看到由于只有一个 Leader,很显然,此 Leader 存在单点隐患,那么 ZK 是怎么解决此问题的呢,首先 Follower 与 Leader 会用心跳机制保持连接,如果 Leader 出现问题了(宕机或者因为 FullGC 等原因无法响应),Follower 就无法感知到 Leader 的心跳,就会认为 Leader 出问题了,于是它们就会发起投票选举,最终在多个 Follower 中选出一个 Leader 来(这里主要用到了 Zookeeper Atomic Broadcast,即 ZAB 协议,它是为 ZK 专门设计的一种支持崩溃恢复的一致性协议),选举的细节不是本文重点,就不在此详述了。
124 |
125 |
126 |
127 | 除了 ZAB 协议,业界上常用的还有 Paxos,Raft 等协议算法,也可以用在 Leader 选举上,也就是是在分布式架构中,这些协议算法承担了“第三者”也就是仲裁者的作用,以承担故障的自动转移
128 |
129 | #### Redis
130 |
131 | Redis 的高可用需要根据它的部署模式来看看,主要分为「主从模式」和「Cluster 分片模式」两种
132 |
133 | ##### 主从模式
134 |
135 | 先来看一下主从模式,架构如下
136 |
137 | 
138 |
139 |
140 |
141 | 主从模式即一主多从(一个或者多个从节点),其中主节点主要负责读和写,然后会将数据同步到多个从节点上,Client 也可以对多个从节点发起读请求,这样可以减轻主节点的压力,但和 ZK 一样,由于只有一个主节点,存在单点隐患,所以必须引入第三方仲裁者的机制来判定主节点是否宕机以及在判定主节点宕机后快速选出某个从节点来充当主节点的角色,这个第三方仲裁者在 Redis 中我们一般称其为「哨兵」(sentinel),当然哨兵进程本身也有可能挂掉,所以为了安全起见,需要部署多个哨兵(即哨兵集群)
142 |
143 | 
144 |
145 | 这些哨兵通过 gossip(流言) 协议来接收关于主服务器是否下线的信息,并在判定主节点宕机后使用 Raft 协议来选举出新的主节点
146 |
147 | ##### Cluster 分片集群
148 |
149 | 主从模式看似完美,但存在以下几个问题
150 |
151 | 1. 主节点写的压力难以降低:因为只有一个主节点能接收写请求,如果在高并发的情况下,写请求如果很高的话可能会把主节点的网卡打满,造成主节点对外无法服务
152 | 2. 主节点的存储能力受到单机存储容量的限制:因为不管是主节点还是从节点,存储的都是**全量**缓存数据,那么随着业务量的增长,缓存数据很可能直线上升,直到达到存储瓶颈
153 | 3. 同步风暴:因为数据都是从 master 同步到 slave 的,如果有多个从节点的话,master 节点的压力会很大
154 |
155 |
156 |
157 | 为了解决主从模式的以上问题,分片集群应运而生,所谓分片集群即将数据分片,每一个分片数据由相应的主节点负责读写,这样的话就有多个主节点来分担写的压力,并且每个节点只存储**部分数据**,也就解决了单机存储瓶颈的问题,但需要注意的是每个主节点都存在单点问题,所以需要针对每个主节点做高可用,整体架构如下
158 |
159 | 
160 |
161 | 原理也很简单,在 Proxy 收到 client 执行的 redis 的读写命令后,首先会对 key 进行计算得出一个值,如果这个值落在相应 master 负责的数值范围(一般将每个数字称为槽,Redis 一共有 16384 个槽)之内,那就把这条 redis 命令发给对应的 master 去执行,可以看到每个 master 节点只负责处理一部分的 redis 数据,同时为了避免每个 master 的单点问题,也为其配备了多个从节点以组成集群,当主节点宕机时,集群会通过 Raft 算法来从从节点中选举出一个主节点
162 |
163 |
164 |
165 | #### ES
166 |
167 | 再来看一下 ES 是如何实现高可用的,在 ES 中,数据是以分片(Shard)的形式存在的,如下图所示,一个节点中索引数据共分为三个分片存储
168 |
169 | 
170 |
171 | 但只有一个节点的话,显然存在和 Redis 的主从架构一样的单点问题,这个节点挂了,ES 也就挂了,所以显然需要创建多个节点
172 |
173 | 一旦创建了多个节点,分片的优势就体现出来了,可以将分片数据分布式存储到其它节点上,极大提升了数据的水平扩展能力,同时每个节点都能承担读写请求,采用负载均衡的形式避免了单点的读写压力
174 |
175 |
176 |
177 | > ES 的写机制与 Redis 和 MySQL 的主从架构有些差别(后两者的写都是直接向 master 节点发起写请求,而 ES 则不是),所以这里稍微解释一下 ES 的工作原理
178 | >
179 | > 首先说下节点的工作机制,节点(Node)分为主节点(Master Node)和从结点(Slave Node),主节点的主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点,主节点也只有一个,一般通过类 Bully 算法来选举出来,如果主节点不可用了,则其他从节点也可以通过此算法来选举以实现集群的高可用,任何节点都可以接收读写请求以达到负载均衡的目的
180 | >
181 | > 再说一下分片的工作原理,分片分为主分片(Primary Shard 如 P0,P1,P2)和副本分片(Replica Shard,如 R0,R1,R2),主分片负责数据的写操作,所以虽然任何节点可以接收读写请求,但如果此节点接收的是写请求并且没有写数据所在的主分片话,此节点会将写请求调度到主分片所在的节点上,写入主分片后,主分片会把数据复制到其他节点的副本分片上,以两个副本的集群为例,写操作如下
182 | >
183 | > 
184 |
185 | #### MQ
186 |
187 | ES 中利用数据分片来提升高可用和水平扩展能力的思想也应用在其他组件的架构设计上,我们以 MQ 中的 kafka 为例再来看下数据分片的应用
188 |
189 | 
190 |
191 | 如上是 Kafka 集群,可以看到每个 Topic 的 Partition 都分布式存储在其它消息服务器上,这样一旦某个 Partition 不可用,可以从其他 follower 选举出 leader 继续服务,不过与 ES 中的数据分片不同的是,follower Partition 属于**冷备**,也就是说在正常情况下不会对外服务,只有在 leader 挂掉之后从多个 follower 中选出leader 后才能对外提供服务
192 |
193 |
194 |
195 | ### 存储层
196 |
197 | 接下来我们再来看一下最后一层,存储层(DB),这里我们以 MySQL 为例来简单地讨论一下其高可用设计,其实大家如果看完了以上的高可用设计,会发现 MySQL 的高可用也不过如此,与 Redis 类似,它也分主从和分片(即我们常说的分库分表)两种架构
198 |
199 | 主从的话与 LVS 类似,一般使用 keepalived 的形式来实现高可用,如下所示
200 |
201 | 
202 |
203 |
204 |
205 | 如果 master 宕机了 ,Keepalived 也会及时发现,于是从库会升级主库,并且 VIP 也会“漂移”到原从库上生效,所以说大家在工程配置的 MySQL 地址一般是 VIP 以保证高可用
206 |
207 | 数据量大了之后就要分库分表了,于是就有了多主,就像 Redis 的分片集群一样,需要针对每个主配备多个从,如下
208 |
209 |
210 |
211 | 
212 |
213 |
214 |
215 | 之前有读者问分库分表之后为啥还要做主从,现在我想大家应该都明白了,不是为了解决读写性能问题,主要是为了实现高可用
216 |
217 | ### 总结
218 |
219 | 看完了架构层面的高可用设计,相信大家对高可用的核心思想「冗余」和「自动故障转移」会有更深刻的体会,观察以上架构中的组件你会发现冗余的主要原因是因为只有一主,为什么不能有多主呢,也不是不可以,但这样在分布式系统下要保证数据的一致性是非常困难的,尤其是节点多了的话,数据之间的同步更是一大难题,所以多数组件采用一主的形式,然后再在主和多从之间同步,多数组件之所以选择一主本质上是技术上的 tradeoff
220 |
221 |
222 |
223 | 那么做好每个组件的高可用之后是否整个架构就真的可用了呢,非也,这只能说迈出了第一步,在生产上还有很多突发情况会让我们的系统面临挑战,比如
224 |
225 | 1. 瞬时流量问题:比如我们可能会面临秒杀带来的瞬时流量激增导致系统的承载能力被压垮,这种情况可能影响日常交易等核心链路,所以需要做到系统之间的隔离,如单独为秒杀部署一套独立的集群
226 | 2. 安全问题:比如 DDOS 攻击,爬虫频繁请求甚至删库跑路等导致系统拒绝服务
227 | 3. 代码问题:比如代码 bug 引起内存泄露导致 FullGC 导致系统无法响应等
228 | 4. 部署问题:在发布过程中如果贸然中止当前正在运行的服务也是不行的,需要做到优雅停机,平滑发布
229 | 5. 第三方问题:比如我们之前的服务依赖第三方系统,第三方可能出问题导致影响我们的核心业务
230 | 6. 不可抗力:如机房断电,所以需要做好容灾,异地多活,之前我司业务就由于机房故障导致服务四小时不可用,损失惨重
231 |
232 | 所以除了做好架构的高可用之外,我们还需要在做好系统隔离,限流,熔断,风控,降级,对关键操作限制操作人权限等措施以保证系统的可用。
233 |
234 |
235 |
236 | 这里特别提一下降级,这是为了保证系统可用性采取的常用的措施,简单举几个例子
237 |
238 | 1. 我们之前对接过一个第三方资金方由于自身原因借款功能出了问题导致无法借款,这种情况为了避免引起用户恐慌,于是我们在用户申请第三方借款的时候返回了一个类似「为了提升你的额度,资金方正在系统升级」这样的文案,避免了客诉
239 | 2. 在流媒体领域,当用户观看直播出现严重卡顿时,很多企业的第一选择不是查 log 排查问题,而是为用户自动降码率。因为比起画质降低,卡的看不了显然会让用户更痛苦
240 | 3. 双十一零点高峰期,我们把用户的注册登录等非核心功能给停掉了,以保证下单等核心流程的顺利
241 |
242 |
243 |
244 | 另外我们最好能做到事前防御,在系统出问题前把它扼杀在摇篮里,所以我们需要做单元测试,做全链路压测等来发现问题,还需要针对 CPU,线程数等做好**监控**,当其达到我们设定的域值时就触发告警以让我们及时发现修复问题(我司之前就碰到过一个类似的[生产事故复盘](https://mp.weixin.qq.com/s/B1EplSO2hTEoDAcPNtsGwA)大家可以看一下),此外在做好单元测试的前提下,依然有可能因为代码的潜在 bug 引起线上问题,所以我们需要在关键时间(比如双十一期间)封网(也就是不让发布代码)
245 |
246 |
247 |
248 | 此外我们还需要在出事后能快速定位问题,快速回滚,这就需要记录每一次的发布时间,发布人等,这里的发布不仅包括工程的发布,还包括配置中心等的发布
249 |
250 | 
251 |
252 | **画外音**:上图是我司的发布记录,可以看到有代码变更,回滚等,这样如果发现有问题的话可以一键回滚
253 |
254 |
255 |
256 | 最后我们以一张图来总结一下高可用的常见手段
257 |
258 |
259 |
260 | 
261 |
262 |
263 |
264 |
265 |
266 | ### 参考
267 |
268 | * 《乔新亮的 CTO 成长复盘 --- 高可用设计,让产品没有后顾之忧》
269 |
270 |
--------------------------------------------------------------------------------
/Java/多线程使用不当引发的惨案.md:
--------------------------------------------------------------------------------
1 | 你好,我是坤哥
2 |
3 | 前些日子我们线上出现了一个比较严重的故障,这个故障是多线程使用不当引起的,挺有代表性的,所以分享给大家,希望能帮大家避坑
4 |
5 |
6 |
7 | ### 问题简述
8 |
9 | 先简单介绍一下问题产生的背景,我们有个返利业务,其中有个搜索场景,这个场景是用户在 app 输入搜索关键词,然后 server 会根据这个关键词到各个平台(如淘宝,京东,拼多多等)调一下搜索接口,聚合这些搜索结果后再返回给用户,最开始这个搜索场景处理是单线程的,但随着接入的平台越来越多,搜索请求耗时也越来越长,由于每个平台的搜索请求都是独立的,很显然,单线程是可以优化为多线程的,如下
10 |
11 | 
12 |
13 |
14 |
15 | 这样的话,搜索请求的耗时就只取决于搜索接口耗时最长的那个平台,所以使用多线程显然对接口性能是一个极大的优化,但使用多线程改造上线后,短时间内社群中有多名用户反馈前台展示「APP 需要升级的提示」,经定位后发现是因为在多线程中无法获取客户端信息,由于客户端信息缺失,导致返回给用户需要升级的提示,伪代码如下
16 |
17 | ```java
18 | // 开启多线程处理
19 | new Thread(new Runnable() {
20 | @Override
21 | public void run() {
22 | Map clientInfoMap = Context.getContext().getClientInfo();
23 | // 无法获取客户端信息,返回需要升级的信息
24 | if (clientInfoMap == null) {
25 | throw new Exception("版本号过低,请升级版本");
26 | }
27 | String version = clientInfoMap.get("version");
28 |
29 |
30 | // 以下正常逻辑
31 | ....
32 | }
33 | }).start();
34 | ```
35 |
36 | **画外音**:在生产中多线程使用的是线程池来实现,这里为了方便演示,直接 new Thread,效果都一样,大家知道即可
37 |
38 | 那么问题来了,改成多线程后客户端信息怎么就取不到了呢?要搞清楚这个问题,就得先了解客户端信息是如何存储的了
39 |
40 | ### Threadlocal 简介
41 |
42 | 不同客户端请求的客户端信息(wifi 还是 4G,机型,app名称,电量等)显然不一样,dubbo 业务线程拿到客户端请求后首先会将有用的请求信息提取出来(如本文中的 Map clientInfo),但这个 clientInfo 可能会在线程调用的各个方法中用到,于是如何存储就成为了一个现实的问题,相信有经验的朋友一下就想到了,没错,用 Threadlocal !为什么用它,它有什么优势,简单来说有两点
43 |
44 | 1. 无锁化提升并发性能
45 | 2. 简化变量的传递逻辑
46 |
47 |
48 |
49 | #### 1.无锁化提升并发性能
50 |
51 | 先说第一个,无锁化提升并发性能,影响并发的原因有很多,其中一个很重要的原因就是锁,为了防止对共享变量的竞用,不得不对共享变量加锁
52 |
53 | 
54 |
55 |
56 |
57 | 如果对共享变量争用的线程数增多,显然会严重影响系统的并发度,最好的办法就是使用“影分身术”为每个线程都创建一个线程本地变量,这样就避免了对共享变量的竞用,也就实现了无锁化
58 |
59 |
60 |
61 | 
62 |
63 | ThreadLocal 即线程本地变量,它可以为每个线程创建一份线程本地变量,使用方法如下
64 |
65 | ```java
66 | static ThreadLocal threadLocal1 = new ThreadLocal() {
67 | @Override
68 | protected SimpleDateFormat initialValue() {
69 | return new SimpleDateFormat("yyyy-MM-dd");
70 | }
71 | };
72 |
73 | public String formatDate(Date date) {
74 | return threadLocal1.get().format(date);
75 | }
76 | ```
77 |
78 | 这样的话每个线程就独享一份与其他线程无关的 SimpleDateFormat 实例副本,它们调用 formatDate 时使用的 SimpleDateFormat 实例也是自己独有的副本,无论对副本怎么操作对其他线程都互不影响
79 |
80 |
81 |
82 | 通过以上例子我们可以看出,可以通过 `new ThreadLocal`+ `initialValue` 来为创建的 ThreadLocal 实例初始化本地变量(`initialValue` 方法会在首次调用 get 时被调用以初始化本地变量)。当然,如果之后需要修改本地变量的话,也可以用以下方式来修改
83 |
84 | ```java
85 | threadLocal1.set(new SimpleDateFormat("yyyy-MM-dd"))
86 | ```
87 |
88 | 而使用 `threadLocal1.get()`这样的方法即可获得线程本地变量
89 |
90 |
91 |
92 | 可能一些朋友会好奇线程本地变量是如何存储的,一图胜千言
93 |
94 | 
95 |
96 | 每一个线程(Thread)内部都有一个 ThreadLocalMap, ThreadLocal 的 get 和 set 操作其实在底层都是针对 ThreadLocalMap 进行操作的
97 |
98 | ```java
99 | public class Thread implements Runnable {
100 | /* ThreadLocal values pertaining to this thread. This map is maintained
101 | * by the ThreadLocal class. */
102 | ThreadLocal.ThreadLocalMap threadLocals = null;
103 | }
104 | ```
105 |
106 | 它与 HashMap 类似,存储的都是键值对,只不过每一项(Entry)中的 key 为 threadlocal 变量(如上文案例中的 threadLocal1),value 才为我们要存储的值(如上文中的 SimpleDateFormat 实例),此外它们在碰到 hash 冲突时的处理策略也不同,HashMap 在碰到 hash 冲突时采用的是链表法,而 ThreadLocalMap 采用的是线性探测法
107 |
108 |
109 |
110 | #### 2.简化变量的传递逻辑
111 |
112 | 接下来我们来看使用 ThreadLocal 的等二个好处,`简化变量的传递逻辑`,线程在处理业务逻辑时可能会调用几十个方法,如果这些方法中只有几个需要用到 clientInfo,难道要在这几十个方法中定义一个 clientInfo 参数来层层传递吗,显然不现实。那该怎么办呢,使用 ThreadLocal 即可解决此问题。由上文可知通过 ThreadLocal 设置的本地变量是同 threadlocal 一起保存在 Thread 的 ThreadLocalMap 这个内部类中的,所以可在线程调用的任意方法中取出,伪代码如下
113 |
114 | ```java
115 | public class ThreadLocalWithUserContext implements Runnable {
116 |
117 | private static ThreadLocal> threadLocal
118 | = new ThreadLocal<>();
119 |
120 | @Override
121 | public void run() {
122 | // clientInfo 初始化
123 | Map clientInfo = xxx;
124 | threadLocal.set(clientInfo);
125 | test1();
126 | }
127 |
128 | public void test1() {
129 | test2();
130 | }
131 |
132 | public void test2() {
133 | testX();
134 | }
135 | ...
136 |
137 | public void testX() {
138 | Map clientInfo = threadLocal.get();
139 | }
140 | }
141 | ```
142 |
143 | 中间定义的任何方法都无需为了传递 clientInfo 而定义一个额外的变量,代码优雅了不少
144 |
145 |
146 |
147 | 由以上分析可知,使用 ThreadLocal 确实比较方便,在此我们先停下来思考一个问题:如果线程在调用过程中只用到一个 clientInfo 这样的信息,只定义一个 ThreadLocal 变量当然就够了,但实际上在使用过程中我们可能要传递多个类似 clientInfo 这样的信息(如 userId,cookie,header),难道因此要定义多个 ThreadLocal 变量吗,这么做不是不可以,但不够优雅,更合适的做法是我们只定义一个 ThreadLocal 变量,变量存的是一个上下文对象,其他像 clientInfo,userId,header 等信息就作为此上下文对象的属性即可,代码如下
148 |
149 |
150 |
151 | ```java
152 | public final class Context {
153 |
154 | private static final ThreadLocal LOCAL = new ThreadLocal() {
155 | protected Context initialValue() {
156 | return new Context();
157 | }
158 | };
159 |
160 |
161 | private Long uid; // 用户uid
162 | private Map clientInfo; // 客户端信息
163 | private Map headers = null; // 请求头信息
164 | private Map> cookies = null; // 请求 cookie
165 |
166 | public static Context getContext() {
167 | return (Context) LOCAL.get();
168 | }
169 |
170 | }
171 | ```
172 |
173 | 这样的话我们可通过 `Context.getContext().getXXX()` 的形式来获取线程所需的信息,通过这样的方式我们不仅避免了定义无数 ThreadLocal 变量的烦恼,而且还收拢了上下文信息的管理
174 |
175 |
176 |
177 | 通过以上介绍相信大家也都知道了 clientInfo 其实是借由 ThreadLocal 存储的,认清了这个事实后那我们现在再回头看开头的生产问题:将单线程改成多线程后,为什么在新线程中就拿不到 clientInfo 了?
178 |
179 |
180 |
181 | ### 问题剖析
182 |
183 | 源码之下无秘密,我们查看一下源码来一探究竟,获取本地变量的值使用的是 ThreadLocal.get 方法,那就来看下这个方法
184 |
185 | ```java
186 | public class ThreadLocal {
187 | public T get() {
188 | // 1.先获取当前线程
189 | Thread t = Thread.currentThread();
190 | // 2.再获取当前线程的 ThreadLocalMap
191 | ThreadLocalMap map = getMap(t);
192 | if (map != null) {
193 | ThreadLocalMap.Entry e = map.getEntry(this);
194 | if (e != null) {
195 | T result = (T)e.value;
196 | return result;
197 | }
198 | }
199 | return setInitialValue();
200 | }
201 | }
202 | ```
203 |
204 | 可以看到 get 方法主要步骤如下
205 |
206 | 1. 首先需要获取当前线程
207 | 2. 其次获取当前线程的 ThreadLocalMap
208 | 3. 进而再去获取相应的本地变量值
209 | 4. 如果没有的话则调用 initiaValue 方法来初始化本地变量
210 |
211 | 由此可知当我们调用 threadlocal.get 时,会拿到**当前线程**的 ThreadLocalMap,然后再去拿 entry 中的本地变量,而对多线程来说,新线程的 ThreadLocalMap 里面的东西本来就未做任何设置,是空的,拿不到线程本地变量也就合情合理了
212 |
213 |
214 |
215 | ### 解决方案
216 |
217 | 问题清楚了,那怎么解决呢,不难得知主要有两种方案
218 |
219 | 1.我们之前是在新线程的执行方法中调用 threadlocal.get 方法,可以改成先从当前执行线程中调用 threadlocal.get 获得 clientInfo,然后再把 clientInfo 传入新线程,伪代码如下
220 |
221 | ```java
222 | // 先从当前线程的 Context 中获取 clientInfo
223 | Map clientInfoMap = Context.getContext().getClientInfo();
224 | new Thread(new Runnable() {
225 | @Override
226 | public void run() {
227 | // 此时的 clientInfoMap 由于是在新线程创建前获取的,肯定是有值的
228 | String version = clientInfoMap.get("version");
229 |
230 |
231 | // 以下正常逻辑
232 | ....
233 | }
234 | }).start();
235 | ```
236 |
237 | ####
238 |
239 | 2.只需把 ThreadLocal 换成 InheritableThreadLocal,如下
240 |
241 | ```java
242 | public final class Context {
243 | private static final InheritableThreadLocal LOCAL = new InheritableThreadLocal() {
244 | protected Context initialValue() {
245 | return new Context();
246 | }
247 | };
248 |
249 | public static Context getContext() {
250 | return (Context) LOCAL.get();
251 | }
252 | }
253 |
254 | new Thread(new Runnable() {
255 | @Override
256 | public void run() {
257 | // 此时的 clientInfo 能正常获取到
258 | Map clientInfo = Context.getContext().getClientInfo();
259 | String version = clientInfo.get("version");
260 | // 以下正常逻辑
261 | ....
262 | }
263 | }).start();
264 |
265 | ```
266 |
267 |
268 |
269 | 为什么 InheritableThreadLocal 能有这么神奇,背后的原理是什么?
270 |
271 |
272 |
273 | 由前文介绍我们得知,ThreadLocal 变量最终是存在 ThreadLocalMap 中的,那么能否在创建新线程的时候,把当前线程的 ThreadLocalMap 复制给新线程的 ThreadLocalMap 呢,这样的话即便你从新线程中调用 threadlocal.get 也照样能获得对应的本地变量,和 InheritableThreadLocal 相关的底层干的就是这个事,我们先来瞧一瞧 InheritableThreadLocal 长啥样
274 |
275 | ```java
276 | public class InheritableThreadLocal extends ThreadLocal {
277 |
278 | ThreadLocalMap getMap(Thread t) {
279 | return t.inheritableThreadLocals;
280 | }
281 |
282 | void createMap(Thread t, T firstValue) {
283 | t.inheritableThreadLocals = new ThreadLocalMap(this, firstValue);
284 | }
285 | }
286 | ```
287 |
288 | 由此可知 InheritableThreadLocal 其实是继承自 ThreadLocal 类的,此外我们在 getMap 和 createMap 这两个方法中也发现它的底层其实是用 inheritableThreadLocals 来存储的,而 ThreadLocal 用的是 threadLocals 变量存储的
289 |
290 | ```java
291 | public class Thread implements Runnable {
292 | // ThreadLocal 实例的底层存储
293 | ThreadLocal.ThreadLocalMap threadLocals = null;
294 |
295 | // inheritableThreadLocals 实例的底层存储
296 | ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
297 | }
298 | ```
299 |
300 | 知道了这些,我们再来看下创建线程时涉及到的 inheritableThreadLocals 复制相关的关键代码如下:
301 |
302 | ```java
303 | public
304 | class Thread implements Runnable {
305 | public Thread() {
306 | init(null, null, "Thread-" + nextThreadNum(), 0);
307 | }
308 |
309 | private void init(ThreadGroup g, Runnable target, String name,
310 | long stackSize) {
311 | init(g, target, name, stackSize, null, true);
312 | }
313 |
314 | private void init(ThreadGroup g, Runnable target, String name,
315 | long stackSize, AccessControlContext acc,
316 | boolean inheritThreadLocals) {
317 | ...
318 | Thread parent = currentThread();
319 | if (inheritThreadLocals && parent.inheritableThreadLocals != null)
320 | // 将当前线程的 inheritableThreadLocals 复制给新创建线程的 inheritableThreadLocals
321 | this.inheritableThreadLocals =
322 | ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
323 | }
324 | }
325 | ```
326 |
327 | 由此可知,在创建新线程时,在初始化时其实相关逻辑是帮我们干了复制 inheritableThreadLocals 的操作,至此真相大白
328 |
329 |
330 |
331 | ### 总结
332 |
333 | 看完本文,相信大家对 Threadlocal 与 InheritableThreadLocal 的使用及其底层原理的掌握已不存在疑问,这也提醒我们熟练地掌握一个组件或一项技术最好的方式还是熟读它的源码,毕竟源码之下无秘密,当我们使用到别人封装好的组件或类时,最好可以也看一下它的源码,以本文为例,其实我们工程中多处地方都使用了 `Context.getContext().getClientInfo();`这样的获取客户端信息的形式,用惯了导致在多线程环境下没有引起警惕,以致踩了坑。
334 |
335 |
336 |
337 | 另外需要注意的是 ThreadLocal 使用不当可能导致内存泄漏,需要在线程结束后及时 remove 掉,这些技术细节不是本文重点,故而没有深入详解,有兴趣的大家可以去查阅相关资料,
338 |
--------------------------------------------------------------------------------
/算法/提升逼格利器-位运算.md:
--------------------------------------------------------------------------------
1 | ## 前言
2 |
3 | 位运算在生产或算法解题中并不常见,不过如果你用得好,可以达到事半功倍的效果,而且位运算用得好,也可以极大地提升性能,如果在生产或面试中能看到使用位运算来解题,会让人眼前一亮,觉得你还是**有点逼格**的,巧用位运算,不仅会提升性能,还会让代码的可读性更好,达到四两拨千斤的效果,今天我们就来学学位运算在解题中的一些技巧,最后会用位运算来看看怎么解八皇后这道大 Boss 题,相信你看完肯定会有收获!
4 |
5 | 本文将会从以下几个方面来讲解位运算
6 |
7 | * 什么是位运算,位运算常见操作
8 | * 位运算使用技巧简介
9 | * 巧用位运算解算法题
10 |
11 | ## 什么是位运算,位运算常见操作
12 |
13 | 在现代计算机中所有的数据在内存中都是以二进制存在的,位运算就是直接对**整数**在内存中的二进制位进行操作,由于位运算直接对内存数据进行操作,无需转成十进制,因此使用位运算的处理速度是很快的。
14 |
15 | 举个简单的例子, 当我们要计算 6 & 4 的结果,在做位运算的时候首先要把 6,4 转成二进制,然后再做相应的位操作(与)。
16 |
17 | 
18 |
19 |
20 | 基本的位运算有与、或、异或、取反、左移、右移这6种,介绍如下:
21 |
22 | **& 与**:只有当两位都是 1 时结果才是 1,否则为 0 。
23 |
24 |
25 | ```shell
26 | 0110
27 | & 0100
28 | -----------
29 | 0100
30 | ```
31 |
32 |
33 | **| 或**:两位中只要有 1 位为 1 结果就是 1,两位都为 0 则结果为 0。
34 |
35 | ```shell
36 | 0110
37 | & 0110
38 | -----------
39 | 0110
40 | ```
41 |
42 |
43 | **^ 异或**:两个位相同则为 0,不同则为 1
44 |
45 | ```shell
46 | 0110
47 | ^ 0100
48 | -----------
49 | 0010
50 | ```
51 |
52 |
53 | **~ 取反**: 0 则变为 1,1 则变为 0
54 |
55 | ```shell
56 | ~ 0110
57 | -----------
58 | 1001
59 | ```
60 |
61 | **<< 左移**:向左进行移位操作,高位丢弃,低位补 0
62 |
63 | ```java
64 | int a = 8;
65 | a << 3;
66 | 移位前:0000 0000 0000 0000 0000 0000 0000 1000
67 | 移位后:0000 0000 0000 0000 0000 0000 0100 0000
68 | ```
69 |
70 | **>> 右移**:向右进行移位操作,对无符号数,高位补 0,对于有符号数,高位补符号位
71 |
72 | ```java
73 | unsigned int a = 8;
74 | a >> 3;
75 | 移位前:0000 0000 0000 0000 0000 0000 0000 1000
76 | 移位后:0000 0000 0000 0000 0000 0000 0000 0001
77 |
78 | int a = -8;
79 | a >> 3;
80 | 移位前:1111 1111 1111 1111 1111 1111 1111 1000
81 | 移位后:1111 1111 1111 1111 1111 1111 1111 1111
82 | ```
83 |
84 |
85 | ## 位运算使用技巧简介
86 | 接下来我们就由浅入深地来学习一下使用位运算的那些黑科技
87 |
88 | **1、 判断整型的奇偶性**
89 |
90 | 使用位运算操作如下
91 |
92 | ```c
93 | if((x & 1) == 0) {
94 | // 偶数
95 | } else {
96 | // 奇数
97 | }
98 | ```
99 |
100 | 这个例子相信大家都见过,只需判断整型的第一位是否是 1 即可,如果是说明是奇数,否则是偶数
101 |
102 | **2、 判断第 n 位是否设置为 1**
103 |
104 | ```c
105 | if (x & (1< 有 8 个一模一样的瓶子,其中有 7 瓶是普通的水,有一瓶是毒药。任何喝下毒药的生物都会在一星期之后死亡。现在,你只有 3 只小白鼠和一星期的时间,如何检验出哪个瓶子里有毒药?
168 |
169 | 解题步骤如下:
170 |
171 | 1、 把这 8 个瓶子从 0 到 7 进行编号,用二进制表示如下
172 |
173 | ```shell
174 | 000
175 | 001
176 | 010
177 | 011
178 | 100
179 | 101
180 | 110
181 | 111
182 | ```
183 |
184 | 2、 将 0 到 7 编号中第一位为 1 的所有瓶子(即 1,3,5,7)的水混在一起给老鼠 1 吃,第二位值为 1 的所有瓶子(即2,3,6,7)的水混在一起给老鼠 2 吃, 第三位值为 1 的所有瓶子(4,5,6,7)的水混在一起给老鼠 3 吃,现在假设老鼠 1,3 死了,那么有毒的瓶子编号中第 1,3 位肯定为 1,老鼠 2 没死,则有毒的瓶子编号中第 2 位肯定为 0,得到值 101 ,对应的编号是 5, 也就是第五瓶的水有毒。
185 |
186 | 这道题及其相关的变种在面试中出现地比较频繁,比如我现在把 8 瓶水换成 1000 瓶,问你至少需要几只老鼠才能测出有毒的瓶子,有了上述的思路相信应该不难,几只老鼠就相当于几个进制位,显然 2^10 = 1024 > 1000,即 10 只老鼠即可测出来。
187 |
188 | **2、 leetcode 232**
189 |
190 | > 给定一个数,判断它是否是可以用 2 的幂次方表示,可以返回 true,不可以返回 false,比如 8 = 2^3, 说明可以用 2 的幂次方表示,返回 true,9 不可以,所以返回 false。
191 |
192 | 解题分析:这题常规解法是做个循环不断地乘以 2 ,看下是否等于给定的值,如果等于说明是 2 的幂次方,否则如果不断累乘 2 后大于给定的值,说明不能用 2 的幂次方表示,时间复杂度是所做的累乘的次数,即 2^n >= 给定的值中的 n。
193 |
194 | 那是否有更快的解法呢?
195 |
196 | 上文的介绍中其实我们已经埋下伏笔了,没错用 x & (x-1),首先我们要发现能用 2 的幂次方表示的数的特点:它的所有位中有且仅有一位为 1,如
197 |
198 | ```shell
199 | 00001 2^0 = 1
200 | 00010 2^1 = 2
201 | 00100 2^2 = 4
202 | 01000 2^3 = 8
203 | 10000 2^3 = 16
204 | ```
205 |
206 | **如图示,所有 2 的幂次方最多只有一位为 1**
207 |
208 | 明白了这一点, 我们的思路就简单了,由于符合 2 的幂次方的数只有一位为 1,x & (x-1) 是把最后一位 1 置为 0,所以只要做一次 x & (x-1) 运算,看它的值是否等于 0 即可,如果是 0 说明它可以用 2 的幂次方表示,否则不可以,代码如下:
209 |
210 | ```c
211 | if(x&(x-1)) { //使用与运算判断一个数是否是2的幂次方
212 | printf("%d不是2的幂次方!\n", num);
213 | } else {
214 | printf("%d是2的%d次方!\n", num, log2(num));
215 | }
216 | ```
217 |
218 | 只用一行代码即可搞定,方便了很多!
219 |
220 |
221 | **3、 leetcode 232**
222 |
223 | > 给定一个非负整数 num. 对于 0 ≤ i ≤ num 范围中的每个数字 i, 计算其二进制数中 1 的数目并将它们作为数组返回。
224 | > 输入: 5 输出: [0,1,1,2,1,2]
225 |
226 | 这题的常规解法相信大家都能猜到,就是从 0 到 num 循环一遍,求出每个数字 i 中 1 的数目。
227 |
228 | 如果用位运算怎么做呢,先来看下解法,然后我们再来分析为啥这样写,非常巧妙!
229 |
230 | Python 代码
231 |
232 | ```Python
233 | vector countBits(int num) {
234 | vector bits(num+1, 0);
235 | for (int i = 1; i<= num; i++) {
236 | bits[i] += bits[i & (i-1)] + 1;
237 | }
238 | }
239 | ```
240 |
241 | Java 代码
242 |
243 | ```java
244 | public static int[] countBits(int num) {
245 | int[] bits = new int[num+1];
246 | Arrays.fill(bits, 0);
247 |
248 | for (int i = 1; i <= num; i++) {
249 | bits[i] = bits[i & (i-1)] + 1;
250 | }
251 | return bits;
252 | }
253 | ```
254 |
255 | 最关键的代码看这一行
256 |
257 | ```java
258 | bits[i] += bits[i & (i-1)] + 1;
259 | ```
260 |
261 | 这行代码是啥意思呢,i & (i-1) 是把 i 的最后一个值为 1 的位设为 0,不难发现整数「i & (i-1)」 中 1 的位数比 i 中 1 的位数少一个 ,所以要加 1(即 bits[i & (i-1)] + 1)。非常巧妙,这样从 1 开始走一遍循环即可,中间不要做任何针对变量 i 的 1 的个数的计算,只不过付出了一个 bits 数组的代价。 这里也是利用了以空间换时间的思想。
262 |
263 |
264 | **4、 利用位运算来解八皇后问题**
265 |
266 | 接下来我们来看看终级 Boss 题,如何用位运算来解八皇后问题,解题中运用到了非常多的位运算技巧,相信你学完会收获不少。
267 |
268 | > 在 8×8 格的国际象棋上摆放八个皇后,使其不能互相攻击,即任意两个皇后都不能处于同一行、同一列或同一斜线上,问有多少种摆法
269 |
270 | 举个简单的下图所示的例子,如果在棋盘上放置一个皇后,则与这个皇后同一行,同一列,且皇后所在斜线经过的格子不能再放其他皇后。
271 |
272 | 
273 | 如图示,在其中任意一行放置一个皇后,则与此皇后同行,同列,同对角线的都不允许再放其他皇后,图中蓝色区块不允许放其他皇后。
274 |
275 | 一般我们用回溯法解八皇后。这里简单介绍一下啥是回溯法。
276 |
277 | 在第一行从左到右先选择一个位置放置皇后,由于第一行放了皇后,第二行可放皇后的位置受到了限制(下图蓝色区块表示对应行的格子不能放皇后)
278 | 
279 |
280 | **如图示,第二行放皇后的位置只能从第三个格子开始选**
281 |
282 | 第二行我们选第三个格子放皇后,选完开始在第三行选,第三方可选的位置也受到了第一,二行皇后所放位置的影响
283 |
284 | 
285 | **如图示,第三行只能从第五个格子开始放置皇后**
286 |
287 | 同理,第三,四,五行都从左到右选择符合条件的的格子放置皇后,选完后问题来了,第六行所在行没有可选的位置了!如图示
288 |
289 | 
290 |
291 | 怎么办呢,回溯!重新摆放第五行的皇后,将其放到第八格上
292 |
293 | 
294 |
295 | 重新摆放后发现第六行还是没有符合条件的行,咋办,我们知道第六行可摆放皇后的位置受第五行影响,而第五行受第四行摆放皇后位置的影响的,所以回溯到第四行,将皇后位置摆放到当前行的其他位置(第七格),再接着往下放 5,6,7,8 行的皇后。。。,只要不满足条件,改变上一层的的条件重新来,上一层调整后还是不符合条件,再调整上上层的。。。,调整完后重新往下递归选择,直到找到符合条件的,找到之后再在第一层换一个位置选皇后递归往下层选择执行,直到找到所有的解,这种不满足条件就回退上层调整再试的思想就是回溯法,可以看到回溯法一般是用递归实现的。
296 |
297 | 回溯算法有不少变种,这里我们重点介绍使用位运算的回溯算法,它是所有解法中最高效的!如果在面试中能使用位运算来解回溯算法,绝对会让面试官给你个大大的赞!
298 |
299 | 接下来是重点了,怎么用位运算来求解。
300 |
301 | 在以上回溯法的分析中,我们不难发现,在八皇后问题中,问题的关键是找出行可放皇后的格子。找到之后问题就解决了 90%,所以接下来我们就来看看怎么找这些可用的格子。
302 |
303 | 假设我们要求解第三行可放皇后的格子(说明一二行的皇后已放好了)那么第三行可放皇后的位置受到哪些条件的限制呢。显然在第一二行已放皇后的格子所在的列,左斜线,右斜线对应的方格都不能放皇后,如图示:
304 |
305 |
306 | 
307 |
308 | 我们以 column 来记录所有上方行已放置的皇后导致当前行格子不可用的集合,所在列如果放了皇后,则当前行格子对应的位置为 1,否则为 0,同理,以 pie(撇,左斜线) 记录所有已放置的皇后左斜方向导致当前行格子不可用的集合, na(捺,右斜线) 表示所有已放置的皇后右斜方向导致当前行不可用的集合。则对于第三行来说我们有:
309 |
310 | ```shell
311 | column = 10010000 (上图中的第一个图,第 1,4 列放了皇后,所以 1,4 位置为 1,其他位置为 0)
312 | pie = 00100000 (上图中的第二个图,左斜线经过第三行的第三个方格,所以第三位为 1)
313 | na = 00101000 (上图中的第三个图,右斜线经过第三行的第三, 五个方格,所以第三,五位为 1)
314 | ```
315 |
316 | 将这三个变量作或运算得到结果如下
317 |
318 | ```shell
319 | 10010000
320 | | 00100000
321 | | 00101000
322 | -----------------------
323 | 10111000
324 | ```
325 | 也就是说对于第三层来说第 1,3,4,5 个格子不能放皇后。如图示
326 |
327 | 
328 |
329 | 于是可知 column | pie | na 得到的结果中值为 0 的代表当前行对应的格子可放皇后, 1 代表不能放,但我们想改成 1 代表格子可放皇后, 0 代表不可放皇后,毕竟这样更符合我们的思维方式,怎么办,取反不就行了,于是我们有~(column| pie | na)。
330 |
331 | 问题来了,这样取反是有问题的,因为这三个变量都是定义的 int 型,为 32 位,取反之后高位的 0 全部变成了 1,而我们只想保留低 8 位(因为是 8 皇后),想把高位都置为 0,怎么办,这里就要用到位运算的黑科技了
332 |
333 | ```shell
334 | ~(column | pie | na) & ((1 << 8)-1)
335 | ```
336 | 后面的的 ((1<< 8) -1) 表示先把 1 往左移 8 位,值为 100000000,再减 1 ,则低 8 位全部为 1,高位全部为 0!(即 0011111111)再作与运算,即可保留低 8 位,去除高位。
337 |
338 | 费了这么大的劲,我们终于把当前行可放皇后的格子都找出来了(所有位值为 1 的格子可放置皇后)。接下来我们只要做个循环,遍历所有位为 1 的格子,每次取出可用格子放上皇后,再找下一层可放置皇后的格子,依此递归下去即可,直接所有行都遍历完毕。
339 |
340 | 于是现在问题转化为了已知当前行的 columne,pie,na,怎么确定下一行可放置皇后的格子。
341 |
342 | 上文可知,我们已经选出了当前行可用的格子(相应位为 1 对应的格子可用),假设我们在当前行选择了其中一个格子来放置皇后,此位置记为 p(如果是当前行的最后一个格子最后一个格子,则值为 1,如果放在倒数第二个,值为 10,倒数第三个则为 100,依此类推),则对于下一行来说,显然 column = column | p
343 |
344 | 那么 pie 呢,仔细看下图,显然应该为 (pie | p) << 1, 左斜线往下一行的格子延展时,相当于左移一位,
345 |
346 | 
347 |
348 | **如图示:下一行的 pie 显然为 (pie | p) << 1。**
349 |
350 | 同理 下一行的 na 应该为 (na | p) >> 1
351 |
352 |
353 | 有了以上详细地解析,我们就可以写出伪代码了
354 |
355 | ```c
356 | void queenSettle(row, col,pie,na) {
357 | N = 8; // 8皇后
358 | if (row >= N) {
359 | // 遍历到最后一行说明已经找到符合的条件了
360 | count++;return
361 | }
362 |
363 | // 取出当前行可放置皇后的格子
364 | bits = (~(col|pie|na)) & ((1 << N)-1)
365 |
366 | while(bits > 0) {
367 | // 每次从当前行可用的格子中取出最右边位为 1 的格子放置皇后
368 | p = bits & -bits
369 |
370 | // 紧接着在下一行继续放皇后
371 | queenSettle(row+1, col | p, (pie|p) << 1, (na | p) >> 1)
372 |
373 | // 当前行最右边格子已经选完了,将其置成 0,代表这个格子已遍历过
374 | bits = bits & (bits-1)
375 | }
376 | }
377 | ```
378 | 一开始传入 queenSettle(0,0,0,0) 这样即可得到最终的解。伪代码写得很清楚了,相信用相关语言不难实现,这里就留给大家作个练习吧。
379 |
380 |
381 | ## 总结
382 |
383 | 本文带大家由浅入深地完成了位运算的学习,掌握好位运算不仅仅是为了提升逼格,还能极大地提升效率,位运算也广泛地应用于代码编写中,运用得当能极大地简化代码,且可读性更好,限于篇幅关系,这里不展开,大家如有兴趣可参考文末的链接。
384 |
385 | 如有帮助,欢迎大家关注公号哦。之后将会讲解大量算法解题思路,希望我们一起攻克算法难题!
386 |
387 |
388 | 
389 |
390 |
391 | 巨人的肩膀
392 |
393 | http://graphics.stanford.edu/~seander/bithacks.html#OperationCounting
394 |
395 | https://catonmat.net/low-level-bit-hacks 位运算的那些骚操作
396 |
397 | https://www.zhihu.com/question/38206659/answer/736472332
398 |
399 | http://xxgblog.com/2013/09/15/java-bitmask/ Java位运算在程序设计中的使用
400 |
--------------------------------------------------------------------------------