├── media
├── model.png
├── VAM_gif.gif
├── combined.png
├── glimpses.png
├── sampling.png
├── attention.png
├── glimpsesensor.png
├── 2cross_entropy.png
└── glimpsenetwork.png
├── weightdecay.py
├── LICENCE
├── glimpseSensor.py
├── visualize.py
├── train.py
├── network.py
└── README.md
/media/model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/model.png
--------------------------------------------------------------------------------
/media/VAM_gif.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/VAM_gif.gif
--------------------------------------------------------------------------------
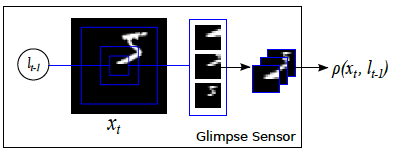
/media/combined.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/combined.png
--------------------------------------------------------------------------------
/media/glimpses.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/glimpses.png
--------------------------------------------------------------------------------
/media/sampling.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/sampling.png
--------------------------------------------------------------------------------
/media/attention.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/attention.png
--------------------------------------------------------------------------------
/media/glimpsesensor.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/glimpsesensor.png
--------------------------------------------------------------------------------
/media/2cross_entropy.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/2cross_entropy.png
--------------------------------------------------------------------------------
/media/glimpsenetwork.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alokwhitewolf/Visual-Attention-Model/HEAD/media/glimpsenetwork.png
--------------------------------------------------------------------------------
/weightdecay.py:
--------------------------------------------------------------------------------
1 | from chainer import training
2 |
3 | @training.make_extension(trigger=(400, 'epoch'))
4 | def lr_drop(trainer):
5 | trainer.updater.get_optimizer('main').lr *= 0.1
--------------------------------------------------------------------------------
/LICENCE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2018 Alok Kumar Bishoyi
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/glimpseSensor.py:
--------------------------------------------------------------------------------
1 | from chainer import cuda
2 | from chainer import function
3 | import numpy as np
4 |
5 |
6 | class GlimpseSensor(function.Function):
7 | def __init__(self, center, output_size,depth=1, scale=2, using_conv = False, ):
8 | if type(output_size) is not tuple:
9 | self.output_size = output_size
10 | else:
11 | assert output_size[0] == output_size[1],"Output dims must be same"
12 | self.output_size = output_size[0]
13 | self.center = center
14 | self.depth = depth
15 | self.scale = scale
16 | self.using_conv = using_conv
17 |
18 | def forward(self, images):
19 | xp = cuda.get_array_module(*images)
20 |
21 | n, c, h_i, w_i = images[0].shape
22 | assert h_i == w_i, "Image should be square"
23 | size_i = h_i
24 | size_o = self.output_size
25 |
26 | # [-1, 1]^2 -> [0, size_i - 1]x[0, size_i - 1]
27 | center = (0.5 * (self.center + 1) * (size_i - 1)).data # center:shape -> [n X 2]
28 | y = xp.zeros(shape=(n, c*self.depth, size_o, size_o), dtype=xp.float32)
29 |
30 | xmin = xp.zeros(shape=(self.depth, n), dtype=xp.int32)
31 | ymin = xp.zeros(shape=(self.depth, n), dtype=xp.int32)
32 | xmax = xp.zeros(shape=(self.depth, n), dtype=xp.int32)
33 | ymax = xp.zeros(shape=(self.depth, n), dtype=xp.int32)
34 |
35 | xstart = xp.zeros(shape=(self.depth, n), dtype=xp.int32)
36 | ystart = xp.zeros(shape=(self.depth, n), dtype=xp.int32)
37 |
38 |
39 | for depth in range(self.depth):
40 | xmin[depth] = xp.clip(xp.rint(center[:, 0]) - (0.5 * size_o * (np.power(self.scale,depth))), 0., size_i).astype(xp.int32)
41 | ymin[depth] = xp.clip(xp.rint(center[:, 1]) - (0.5 * size_o * (np.power(self.scale,depth))), 0., size_i).astype(xp.int32)
42 | xmax[depth] = xp.clip(xp.rint(center[:, 0]) + (0.5 * size_o * (np.power(self.scale,depth))), 0., size_i).astype(xp.int32)
43 | ymax[depth] = xp.clip(xp.rint(center[:, 1]) + (0.5 * size_o * (xp.power(self.scale,depth))), 0., size_i).astype(xp.int32)
44 |
45 | xstart[depth] = xmin[depth] - (xp.rint(center[:, 0]) - (0.5 * size_o * (np.power(self.scale,depth))))
46 | ystart[depth] = ymin[depth] - (xp.rint(center[:, 1]) - (0.5 * size_o * (np.power(self.scale,depth))))
47 |
48 | for i in range(n):
49 | for j in range(self.depth):
50 |
51 | cropped = images[0][i][:,xmin[j][i]:xmax[j][i], ymin[j][i]:ymax[j][i]]
52 | # TODO: resize images
53 |
54 | y[i][c*j: (c*j)+c, xstart[j][i]: xstart[j][i] + xmax[j][i] - xmin[j][i] ,
55 | ystart[j][i]: ystart[j][i] + ymax[j][i] - ymin[j][i]] += cropped
56 |
57 | if self.using_conv:
58 | return y,
59 | else:
60 | return y.reshape(n,-1),
61 |
62 | def backward(self, images, gy):
63 | #return zero grad
64 | xp = cuda.get_array_module(*images)
65 | n, c_in ,h_i, w_i = images[0].shape
66 | gx = xp.zeros(shape=(n, c_in, h_i, w_i), dtype=xp.float32)
67 | return gx,
68 |
69 |
70 | def getGlimpses(x, center, size, depth=1, scale=2, using_conv = False):
71 | return GlimpseSensor(center, size, depth, scale)(x)
72 |
73 |
74 |
75 |
--------------------------------------------------------------------------------
/visualize.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | import matplotlib.pyplot as plt
4 | from matplotlib import gridspec
5 | import chainer
6 | from chainer import serializers
7 | import PIL
8 | from PIL import ImageDraw
9 | import numpy as np
10 | import argparse
11 | import chainer.functions as F
12 | from network import RAM
13 |
14 |
15 | if __name__ == '__main__':
16 | parser = argparse.ArgumentParser(description='VAM in Chainer:MNIST')
17 | parser.add_argument('--batchsize', '-b', type=int, default=128,
18 | help='Number of images in each mini-batch')
19 | parser.add_argument('--gpu', '-g', type=int, default=-1,
20 | help='GPU ID (negative value indicates CPU)')
21 | parser.add_argument('--out', '-o', default='result',
22 | help='Directory to output the result')
23 | parser.add_argument('--unit', '-u', type=int, default=128,
24 | help='Dimension of locator, glimpse hidden state')
25 | parser.add_argument('--hidden','-hi', type=int, default=256,
26 | help='Dimension of lstm hidden state')
27 | parser.add_argument('--g_size', '-g_size', type=int, default=8,
28 | help='Dimension of output')
29 | parser.add_argument('--len_seq', '-l', type=int, default=6,
30 | help='Length of action sequence')
31 | parser.add_argument('--depth', '-d', type=int, default=1,
32 | help='no of depths/glimpses to be taken at once')
33 | parser.add_argument('--scale', '-s', type=float, default=2,
34 | help='subsequent scales of cropped image for sequential depths (int>1)')
35 | parser.add_argument('--sigma', '-si',type=float, default=0.03,
36 | help='sigma of location sampling model')
37 | parser.add_argument('--eval', '-eval', type=str, default=None,
38 | help='Evaluation mode: path to saved model file relative to current working dir')
39 | args = parser.parse_args()
40 |
41 | model = RAM(args.hidden, args.unit, args.sigma, args.g_size, args.len_seq, args.depth, args.scale)
42 | serializers.load_npz(os.getcwd() + args.eval, model)
43 | train, test = chainer.datasets.get_mnist()
44 | train_data, train_targets = np.array(train).transpose()
45 | test_data, test_targets = np.array(test).transpose()
46 | train_data = np.array(list(train_data)).reshape(train_data.shape[0], 1, 28, 28)
47 | test_data = np.array(list(test_data)).reshape(test_data.shape[0], 1, 28, 28)
48 | train_targets = np.array(train_targets).astype(np.int32)
49 | test_targets = np.array(test_targets).astype(np.int32)
50 | g_size = args.g_size
51 |
52 |
53 | def visualize(model):
54 | chainer.global_config.train = False
55 | index = np.random.randint(0, 9999)
56 | x_raw = train_data[index:index + 1]
57 | t_raw = train_targets[index]
58 | x = chainer.Variable(np.asarray(x_raw))
59 | t = chainer.Variable(np.asarray(t_raw))
60 | batchsize = x.data.shape[0]
61 | model.reset_state()
62 | ls = []
63 | probs = []
64 |
65 | l = np.random.uniform(-1, 1, size=(batchsize, 2)).astype(np.float32)
66 | l = chainer.Variable(np.asarray(l))
67 | ls.append(l.data)
68 | for i in range(6):
69 | l, ln_pi, y, b = model.forward(x, l, first=True)
70 | y = F.softmax(y)
71 | probs.append(y.data)
72 | ls.append(l.data)
73 | fig = plt.figure(figsize=(8, 6))
74 | gs = gridspec.GridSpec(1, 2, width_ratios=[3, 1])
75 | ax0 = plt.subplot(gs[0])
76 | image = PIL.Image.fromarray(train_data[index][0] * 255).convert('RGB')
77 | canvas = image.copy()
78 | draw = ImageDraw.Draw(canvas)
79 |
80 | locs = (((ls[i] + 1) / 2) * ((np.array([28, 28])) - 1))
81 |
82 | color = (0, 255, 0)
83 | xy = np.array([locs[0][0], locs[0][1], locs[0][0], locs[0][1]])
84 | wh = np.array([-g_size // 2, -g_size // 2, g_size // 2, g_size // 2])
85 | xys = [xy + np.power(2, s) * wh for s in range(args.depth)]
86 |
87 | for xy in xys:
88 | draw.rectangle(xy=list(xy), outline=color)
89 | del draw
90 |
91 | plt.imshow(canvas)
92 | plt.axis('off')
93 |
94 | y_ticks = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '0']
95 |
96 | bar_lengths = probs[i][0]
97 |
98 | ax1 = plt.subplot(gs[1])
99 | ax1.barh(y_ticks, bar_lengths, color='#006080')
100 | ax1.get_xaxis().set_ticks([])
101 | plt.tight_layout()
102 | plt.savefig(args.result+str(i) + '.png')
103 |
104 |
105 | visualize(model)
106 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import numpy as np
3 | import chainer
4 | from chainer import training, datasets, iterators, optimizers, serializers
5 | from chainer import reporter
6 | from network import RAM
7 | from chainer.training import extensions
8 | from weightdecay import lr_drop
9 |
10 |
11 | if __name__ == '__main__':
12 | parser = argparse.ArgumentParser(description='VAM in Chainer:MNIST')
13 | parser.add_argument('--batchsize', '-b', type=int, default=128,
14 | help='Number of images in each mini-batch')
15 | parser.add_argument('--epoch', '-e', type=int, default=1000,
16 | help='Number of sweeps over the dataset to train')
17 | parser.add_argument('--gpu', '-g', type=int, default=-1,
18 | help='GPU ID (negative value indicates CPU)')
19 | parser.add_argument('--out', '-o', default='result',
20 | help='Directory to output the result')
21 | parser.add_argument('--resume', '-r', default='',
22 | help='Resume the training from snapshot')
23 | parser.add_argument('--unit', '-u', type=int, default=128,
24 | help='Dimension of locator, glimpse hidden state')
25 | parser.add_argument('--hidden','-hi', type=int, default=256,
26 | help='Dimension of lstm hidden state')
27 | parser.add_argument('--g_size', '-g_size', type=int, default=8,
28 | help='Dimension of output')
29 | parser.add_argument('--len_seq', '-l', type=int, default=6,
30 | help='Length of action sequence')
31 | parser.add_argument('--depth', '-d', type=int, default=1,
32 | help='no of depths/glimpses to be taken at once')
33 | parser.add_argument('--scale', '-s', type=float, default=2,
34 | help='subsequent scales of cropped image for sequential depths (int>1)')
35 | parser.add_argument('--sigma', '-si',type=float, default=0.03,
36 | help='sigma of location sampling model')
37 | parser.add_argument('--evalm', '-evalm', type=str, default=None,
38 | help='Evaluation mode: path to saved model file')
39 | parser.add_argument('--evalo', '-eval0', type=str, default=None,
40 | help='Evaluation mode: path to saved optimizer file')
41 | args = parser.parse_args()
42 |
43 | print('GPU: {}'.format(args.gpu))
44 | print('# n_units: {}'.format(args.unit))
45 | print('# n_hidden: {}'.format(args.hidden))
46 | print('# Length of action sequence: {}'.format(args.len_seq))
47 | print('# sigma: {}'.format(args.sigma))
48 | print('# Minibatch-size: {}'.format(args.batchsize))
49 | print('# epoch: {}'.format(args.epoch))
50 | print('')
51 |
52 | train, test = chainer.datasets.get_mnist()
53 | train_data, train_targets = np.array(train).transpose()
54 | test_data, test_targets = np.array(test).transpose()
55 | train_data = np.array(list(train_data)).reshape(train_data.shape[0], 1, 28, 28)
56 | test_data = np.array(list(test_data)).reshape(test_data.shape[0], 1, 28, 28)
57 | train_targets = np.array(train_targets).astype(np.int32)
58 | test_targets = np.array(test_targets).astype(np.int32)
59 | if args.evalm is not None:
60 | chainer.global_config.train = False
61 |
62 | model = RAM(args.hidden, args.unit, args.sigma,
63 | args.g_size, args.len_seq, args.depth, args.scale, using_conv = False)
64 | #model.to_gpu()
65 | optimizer = optimizers.NesterovAG()
66 | if args.evalm is not None:
67 | serializers.load_npz(args.evalm, model)
68 | print('model loaded')
69 | if args.evalo is not None:
70 | serializers.load_npz(args.evalo, optimizer)
71 | print('optimizer loaded')
72 |
73 | if args.gpu>=0:
74 | model.to_gpu()
75 |
76 | optimizer.setup(model)
77 |
78 | train_dataset = datasets.TupleDataset(train_data, train_targets)
79 | train_iter = iterators.SerialIterator(train_dataset, args.batchsize)
80 | test_dataset = datasets.TupleDataset(test_data, test_targets)
81 | train_iter = iterators.SerialIterator(test_dataset, 128)
82 | stop_trigger = (args.epoch, 'epoch')
83 | updater = training.StandardUpdater(train_iter, optimizer, device=args.gpu)
84 | trainer = training.Trainer(updater, stop_trigger, out=args.out)
85 | trainer.extend(lr_drop)
86 | trainer.extend(extensions.snapshot_object(model, '2model{.updater.epoch}.npz'), trigger=(50,'epoch'))
87 | trainer.extend(extensions.snapshot_object(optimizer, '2opt{.updater.epoch}.npz'), trigger=(50, 'epoch'))
88 | trainer.extend(extensions.PlotReport(['main/training_accuracy'], 'epoch', trigger=(1, 'epoch'), file_name='2train_accuracy.png',
89 | marker="."))
90 | trainer.extend(extensions.PlotReport(['main/cross_entropy_loss'], 'epoch', trigger=(1, 'epoch'), file_name='2cross_entropy.png',
91 | marker="."))
92 | trainer.extend(extensions.ProgressBar((args.epoch,'epoch'),update_interval=50))
93 | trainer.run()
94 |
--------------------------------------------------------------------------------
/network.py:
--------------------------------------------------------------------------------
1 | import chainer
2 | from chainer import cuda, Variable
3 | import chainer.functions as F
4 | import chainer.links as L
5 | import numpy as np
6 | from glimpseSensor import getGlimpses
7 | from chainer import reporter
8 |
9 |
10 | class RAM(chainer.Chain):
11 | def __init__(self, n_hidden = 256, n_units = 128, sigma = 0.03,
12 | g_size=8, n_steps=6, n_depth=1, n_scale = 2, n_class = 10, using_conv = False):
13 |
14 | n_in = g_size * g_size * n_depth
15 | super(RAM, self).__init__(
16 | ll1=L.Linear(2, n_units), # 2 refers to x,y coordinate
17 | lrho1=L.Linear(n_in, n_units),
18 | lh1=L.Linear(n_units*2, n_hidden),
19 | lh2=L.Linear(n_hidden, n_hidden),
20 | lstm=L.LSTM(n_hidden, n_hidden),
21 | ly=L.Linear(n_hidden, n_class), # class/action output
22 | ll=L.Linear(n_hidden, 2), # location output
23 | lb=L.Linear(n_hidden, 1), # baseline output
24 | )
25 | self.g_size = g_size
26 | self.n_depth = n_depth
27 | self.n_scale = n_scale
28 | self.sigma = sigma
29 | self.n_steps = n_steps
30 | self.using_conv = using_conv
31 |
32 | def reset_state(self):
33 | self.lstm.reset_state()
34 |
35 | def get_location_loss(self, l, mean):
36 | if chainer.config.train:
37 | term1 = 0.5 * (l - mean) ** 2 * self.sigma ** -2
38 | return F.sum(term1, axis=1).reshape(-1,1)
39 | else:
40 | xp = cuda.get_array_module(l)
41 | return Variable(xp.zeros(l.shape[0]))
42 |
43 | def sample_location(self, l):
44 | """
45 | sample new location from center l_data
46 | """
47 | if chainer.global_config.train:
48 | l_data = l.data
49 | bs = l_data.shape[0]
50 | xp = cuda.get_array_module(l_data)
51 | randomness = (xp.random.normal(0, 1, size=(bs, 2))).astype(np.float32)
52 | l_sampled = l_data + np.sqrt(self.sigma) * randomness
53 | return Variable(xp.array(l_sampled))
54 | else:
55 | return l
56 |
57 | def forward(self, x, l, first=False):
58 | if not first:
59 | centers = self.sample_location(l)
60 | ln_pi = self.get_location_loss(centers, l)
61 |
62 |
63 | else:
64 | centers = l
65 | ln_pi = self.get_location_loss(l, l) # ==0's
66 | rho = getGlimpses(x, centers, self.g_size, self.n_depth, self.n_scale, self.using_conv)
67 |
68 | g0 = F.relu(self.ll1(centers))
69 | g1 = F.relu(self.lrho1(rho))
70 | h0 = F.concat([g0, g1], axis=1)
71 | h1 = F.relu(self.lh1(h0))
72 | h2 = F.relu(self.lh2(h1))
73 | h_out = self.lstm(h2)
74 | y = self.ly(h_out)
75 | l_out = F.tanh(self.ll(h_out))
76 | b = F.sigmoid(self.lb(h_out))
77 | return l_out, ln_pi, y, b
78 |
79 |
80 |
81 | def __call__(self, x, t):
82 |
83 | x = chainer.Variable(self.xp.asarray(x))
84 | t = chainer.Variable(self.xp.asarray(t))
85 | #print(x.shape)
86 | #print(t.shape)
87 | batchsize = x.data.shape[0]
88 | self.reset_state()
89 |
90 | # initial l
91 | l = np.random.uniform(-1, 1, size=(batchsize, 2)).astype(np.float32)
92 | l = chainer.Variable(self.xp.asarray(l))
93 |
94 | sum_ln_pi = Variable((self.xp.zeros((batchsize,1))))
95 | sum_ln_pi = F.cast(sum_ln_pi,'float32')
96 | l, ln_pi, y, b = self.forward(x, l, first=True)
97 | for i in range(1,self.n_steps):
98 | l, ln_pi, y, b = self.forward(x, l)
99 | sum_ln_pi += ln_pi
100 | self.loss_action = F.softmax_cross_entropy(y, t)
101 | self.loss = self.loss_action
102 | self.accuracy = F.accuracy(y, t)
103 | reporter.report({'accuracy': self.accuracy}, self)
104 | self.y = F.argmax(y, axis=1)
105 | if chainer.global_config.train:
106 |
107 | conditions = self.xp.argmax(y.data, axis=1) == t.data
108 | r = self.xp.where(conditions, 1., 0.).astype(self.xp.float32)
109 | r = self.xp.expand_dims(r, 1)
110 | # squared error between reward and baseline
111 | self.loss_baseline = F.mean_squared_error(r, b)
112 | self.loss += self.loss_baseline
113 | # loss with reinforce rule
114 | mean_ln_pi = sum_ln_pi / (self.n_steps - 1)
115 | a = F.sum(-mean_ln_pi * (r - b)) / batchsize
116 | self.reinforce_loss = F.sum(-mean_ln_pi * (r-b)) / batchsize
117 | self.loss += self.reinforce_loss
118 | reporter.report({'cross_entropy_loss': self.loss_action}, self)
119 | #reporter.report({'reinforce_loss': self.reinforce_loss}, self)
120 | #reporter.report({'total_loss': self.loss}, self)
121 | reporter.report({'training_accuracy': self.accuracy}, self)
122 |
123 | #print(self.loss)
124 | return self.loss
125 |
126 |
127 | if __name__ == "__main__":
128 | train, test = chainer.datasets.get_mnist(withlabel=True, ndim=3)
129 | train_data, train_targets = np.array(train).transpose()
130 | train_data = np.array(list(train_data)).reshape(train_data.shape[0], 1, 28, 28)
131 | train_targets = np.array(train_targets).astype(np.int32)
132 | x = train_data[0:2]
133 | t = train_targets[0:2]
134 | model = RAM()
135 | model.to_gpu()
136 | model(x, t)
137 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Visual Attention Model
2 | Chainer implementation of Deepmind's Recurrent Models of Visual Attention.
3 | 
4 | Humans do not tend to process a whole scene in its entirety at once. Instead we focus attention selectively on parts of the visual space to acquire information when and where it is needed, and combine information from different fixations over time to build up an internal representation of the scene.Focusing the computational resources on parts of a scene saves “bandwidth”
5 | as fewer “pixels” need to be processed.
6 | 
7 |
8 | The model is a recurrent neural network (RNN) which processes inputs sequentially, attending to
9 | different locations within the images (or video frames) one at a time, and incrementally combines
10 | information from these fixations to build up a dynamic internal representation of the scene or envi-
11 | ronment. Instead of processing an entire image or even bounding box at once, at each step, the model
12 | selects the next location to attend to based on past information
13 | and
14 | the demands of the task. Both
15 | the number of parameters in the model and the amount of computation it performs can be controlled
16 | independently of the size of the input image, which is in contrast to convolutional networks whose
17 | computational demands scale linearly with the number of image pixels.
18 | ## The Network Architecture
19 |
20 | Network Architecture image from Sunner Li's Blogpost
21 | Glimpse Sensor
22 |
23 |
24 |
25 | Glimpse Sensor is the implementation of RetinaThe idea is to allow our network to “take a glance” at the image around a given location, called a glimpse, then extract and resize this glimpse into various scales of image
26 | crops, but each scale is using the same resolution. For example, the glimpse in the above example contains 3 different scales, each scale has the same resolution (a.k.a. sensor bandwidth), e.g. 12x12. Therefore, the smallest
27 | scale of crop in the centre is most detailed, whereas the largest crop in the outer ring is most blurred. In summary, Glimpse Sensor takes a full-sized image and a location, outputs the “Retina-like” representation of the image
28 | around the given location.
29 |
30 | Glimpse Network
31 |
32 |
33 |
34 |
35 | Once we have defined glimpse sensor, Glimpse Network is simply a wrapped around Glimpse Sensor, to take a full-sized image and a location, extract a retina representation of the image via Glimpse Sensor, flatten, then combine the
36 | extracted retina representation with the glimpse location using hidden layers and ReLU, emitting a single vector g. This vector contains the information of both “what” (our retina representation) and “where” (the focused location within the image).
37 |
Recurrent Network
38 | Recurrent Network takes feature vector input from Glimpse Network, remembers the useful information via it’s hidden states (and memory cell).
39 |
40 | Location Network
41 | Location Network takes hidden states from Recurrent Network as input, and tries to predict the next location to look at. This location prediction will become input to the Glimpse Network in the next time step in the unrolled recurrent network. The Location Network is the key component in this whole idea since it directly determines where to pay attention to in the next time step. In order to maximize the performance of this Location Network, the paper introduce a stochastic process (i.e. gaussian distribution) to generate next location, and use reinforcement learning techniques to learn. It is also known as “hard” attention, since this stochastic process is non-differentiable (compared to “soft” attention). The intuition behind stochasticity is to balance between exploitation (to predict future using the history) and exploration (to try unprecedented stuff). Note that, this stochasticity makes the component non-differentiable, which will incur problem during back-propagation. And REINFORCE gradient policy algorithm is used to solve this problem.
42 |
Activation Network
43 | Activation Network takes hidden states from Recurrent Network as input, and tries to predict the digit. In addition, the prediction result is used to generate the reward point, which is used to train the Location Network (since the stochasticity makes it non-differentiable).
44 |
45 |
Architecture Combined
46 | Combining all the element illustrated above, we have our network architecture below.
47 | 
48 |
49 | ## Experiments
50 | - [x] MNIST
51 | 
52 | - [ ] Translated MNIST
53 | - [ ] Cluttered MNIST
54 | - [ ] SVHN
55 |
56 | ## Credits
57 | Some of the texts and images have been medium posts by Tristan and Sunner Li
58 |
--------------------------------------------------------------------------------

 23 |
24 |
23 |
24 | 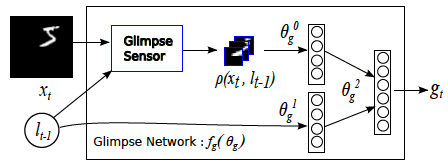 34 |
35 | Once we have defined glimpse sensor, Glimpse Network is simply a wrapped around Glimpse Sensor, to take a full-sized image and a location, extract a retina representation of the image via Glimpse Sensor, flatten, then combine the
36 | extracted retina representation with the glimpse location using hidden layers and ReLU, emitting a single vector g. This vector contains the information of both “what” (our retina representation) and “where” (the focused location within the image).
37 |
34 |
35 | Once we have defined glimpse sensor, Glimpse Network is simply a wrapped around Glimpse Sensor, to take a full-sized image and a location, extract a retina representation of the image via Glimpse Sensor, flatten, then combine the
36 | extracted retina representation with the glimpse location using hidden layers and ReLU, emitting a single vector g. This vector contains the information of both “what” (our retina representation) and “where” (the focused location within the image).
37 |