├── .vscode
└── settings.json
├── .DS_Store
├── README.md
├── docs
├── .vitepress
│ ├── cache
│ │ └── deps
│ │ │ ├── package.json
│ │ │ ├── _metadata.json
│ │ │ ├── @theme_index.js.map
│ │ │ └── @theme_index.js
│ └── config.ts
├── algorithm
│ ├── sort
│ │ ├── countSort.md
│ │ ├── quickSort.md
│ │ ├── selectionSort.md
│ │ ├── mergeSort.md
│ │ ├── heapSort.md
│ │ ├── insertSort.md
│ │ ├── shellSort.md
│ │ └── bubbleSort.md
│ ├── math.md
│ ├── 链表
│ │ ├── 反转链表.md
│ │ ├── 移除链表元素.md
│ │ ├── 删除链表的倒数第n个结点.md
│ │ ├── k个一组翻转链表.md
│ │ ├── 相交链表.md
│ │ └── 环形链表II.md
│ ├── 字符串
│ │ ├── 反转字符串II.md
│ │ ├── 最长不含重复字符的子字符串.md
│ │ ├── 千位分隔数.md
│ │ ├── 字符串的排列.md
│ │ ├── 回文系列.md
│ │ └── 最小覆盖子串.md
│ ├── 回溯
│ │ ├── 总结.md
│ │ ├── 子集.md
│ │ ├── 子集II.md
│ │ ├── 字符串的排列.md
│ │ ├── 组合总和.md
│ │ ├── N皇后.md
│ │ ├── 回溯分割.md
│ │ └── 回溯排列.md
│ ├── 动态规划
│ │ ├── 动态规划理论基础.md
│ │ ├── 背包系列.md
│ │ ├── 爬楼梯.md
│ │ ├── 连续.md
│ │ ├── 不同路径.md
│ │ ├── 买卖股票的最佳时机.md
│ │ └── 打家劫舍系列.md
│ ├── 数组
│ │ ├── 两数之和.md
│ │ ├── 长度最小的子数组.md
│ │ ├── 合并两个有序数组.md
│ │ └── 双指针.md
│ ├── 二叉树
│ │ ├── 二叉树其他题目.md
│ │ ├── 二叉树的公共祖先.md
│ │ ├── 二叉树的遍历方式.md
│ │ ├── 二叉树的修改与构造2.md
│ │ ├── 求二叉搜索树的属性.md
│ │ ├── 二叉树的修改与构造.md
│ │ └── 二叉树的属性.md
│ ├── 深度遍历
│ │ ├── 岛屿数量.md
│ │ ├── 单词搜索.md
│ │ └── 螺旋矩阵.md
│ ├── bfs-dfs.md
│ ├── binarySearch.md
│ ├── 贪心算法
│ │ └── 贪心入门.md
│ └── index.md
├── network-protocol
│ ├── cdn.md
│ ├── index.md
│ ├── 12.http优缺点.md
│ ├── 06.tcp和udp的区别.md
│ ├── 15.https的tsl连接过程.md
│ ├── 13.http队头阻塞.md
│ ├── 01.网络模型.md
│ ├── dns.md
│ ├── 07.http报文结构.md
│ ├── 05.tcp中syn攻击.md
│ ├── 02.tcp报文.md
│ ├── 10.http请求体和请求头.md
│ ├── 09.http状态码.md
│ ├── 18.http2剖析.md
│ ├── 04.tcp四次挥手.md
│ ├── 03.tcp三次握手.md
│ ├── 11.cookie.md
│ ├── 08.http的请求方法.md
│ ├── 17.http2新功能.md
│ ├── 16.https证书.md
│ ├── 14.https改进了什么.md
│ ├── 20.http3.md
│ └── 19.http2服务器推送功能.md
├── index.md
└── ai
│ └── index.md
├── pnpm-workspace.yaml
├── .gitignore
├── package.json
├── .github
└── workflows
│ └── deploy.yml
└── quick-push.py
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "editor.formatOnSave": true,
3 | }
--------------------------------------------------------------------------------
/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/alvin0216/note/HEAD/.DS_Store
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Hello World
2 |
3 | Hi, I'm Alvin, a front-end developer.
4 |
--------------------------------------------------------------------------------
/docs/.vitepress/cache/deps/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "type": "module"
3 | }
4 |
--------------------------------------------------------------------------------
/pnpm-workspace.yaml:
--------------------------------------------------------------------------------
1 | packages:
2 | - 'code/*'
3 | # all packages in direct subdirs of packages/
4 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | node_modules
2 | yarn.lock
3 | yarn.error
4 | /public
5 | .cache
6 | dist
7 | /docs/.vitepress/cache
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "devDependencies": {
3 | "@vitejs/plugin-vue-jsx": "^3.0.1",
4 | "vitepress": "1.0.0-alpha.61"
5 | },
6 | "scripts": {
7 | "dev": "vitepress dev docs",
8 | "build": "vitepress build docs",
9 | "push": "node push.js"
10 | }
11 | }
12 |
--------------------------------------------------------------------------------
/docs/algorithm/sort/countSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 基数排序
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | 动画来源
13 |
14 | ---
15 |
16 | - [图解面试算法](https://github.com/MisterBooo/LeetCodeAnimation)
17 |
--------------------------------------------------------------------------------
/docs/algorithm/math.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 数学推算
3 | date: 2020-05-24 23:37:51
4 | sidebar: auto
5 | tags:
6 | - 数学推算
7 | categories:
8 | - 算法与数据结构
9 | ---
10 |
11 | ## 求和
12 |
13 | 求和公式 1+2+…+n
14 |
15 | ```js
16 | ((1 + n) * n) / 2;
17 | ```
18 |
19 | 1+2+3+4+5 = (1 + 5) + (2 + 4) + 3 =....
20 |
--------------------------------------------------------------------------------
/docs/network-protocol/cdn.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: CDN
3 | date: 2018-09-28 17:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - cdn
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 
12 |
13 | - [高性能利器:CDN 我建议你好好学一下!](https://juejin.cn/post/7002781373014474759)
14 |
--------------------------------------------------------------------------------
/docs/algorithm/链表/反转链表.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 反转链表
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 链表
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ```js
12 | /**
13 | * @param {ListNode} head
14 | * @return {ListNode}
15 | */
16 | var reverseList = function (head) {
17 | let cur = head;
18 | let prev = null;
19 |
20 | while (cur) {
21 | const next = cur.next;
22 | cur.next = prev;
23 | prev = cur;
24 | cur = next;
25 | }
26 |
27 | return prev;
28 | };
29 | ```
30 |
--------------------------------------------------------------------------------
/docs/network-protocol/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HTTP 脑图
3 | date: 2020-12-16 20:09:24
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 图片来源 [六张图从 HTTP/0.9 进化到 HTTP3.0](https://juejin.im/post/6856036933723521032?utm_source=gold_browser_extension)
12 |
13 | ## HTTP1.1
14 |
15 | 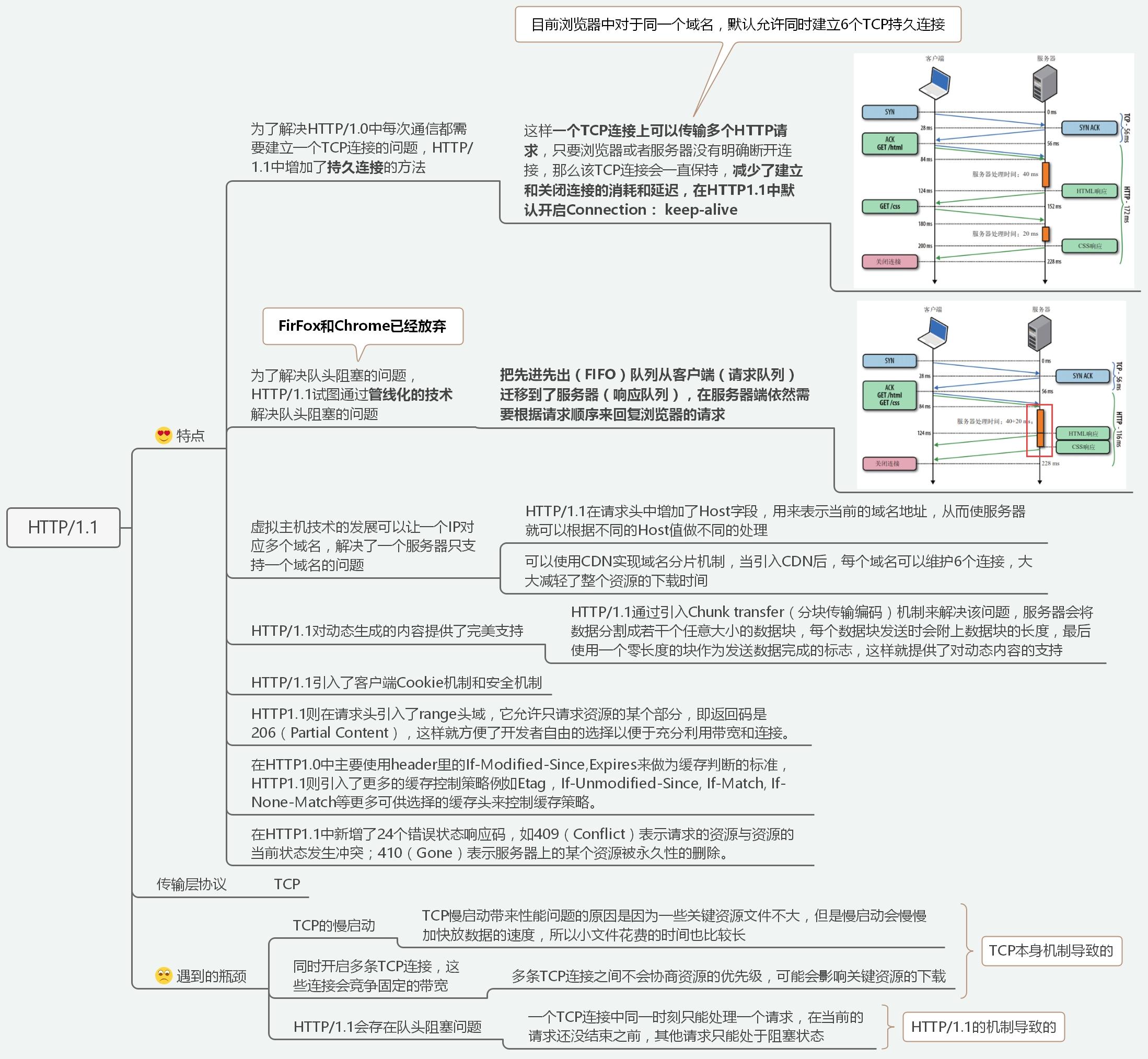
16 |
17 | ## HTTP2
18 |
19 | 
20 |
21 | ## HTTP3
22 |
23 | 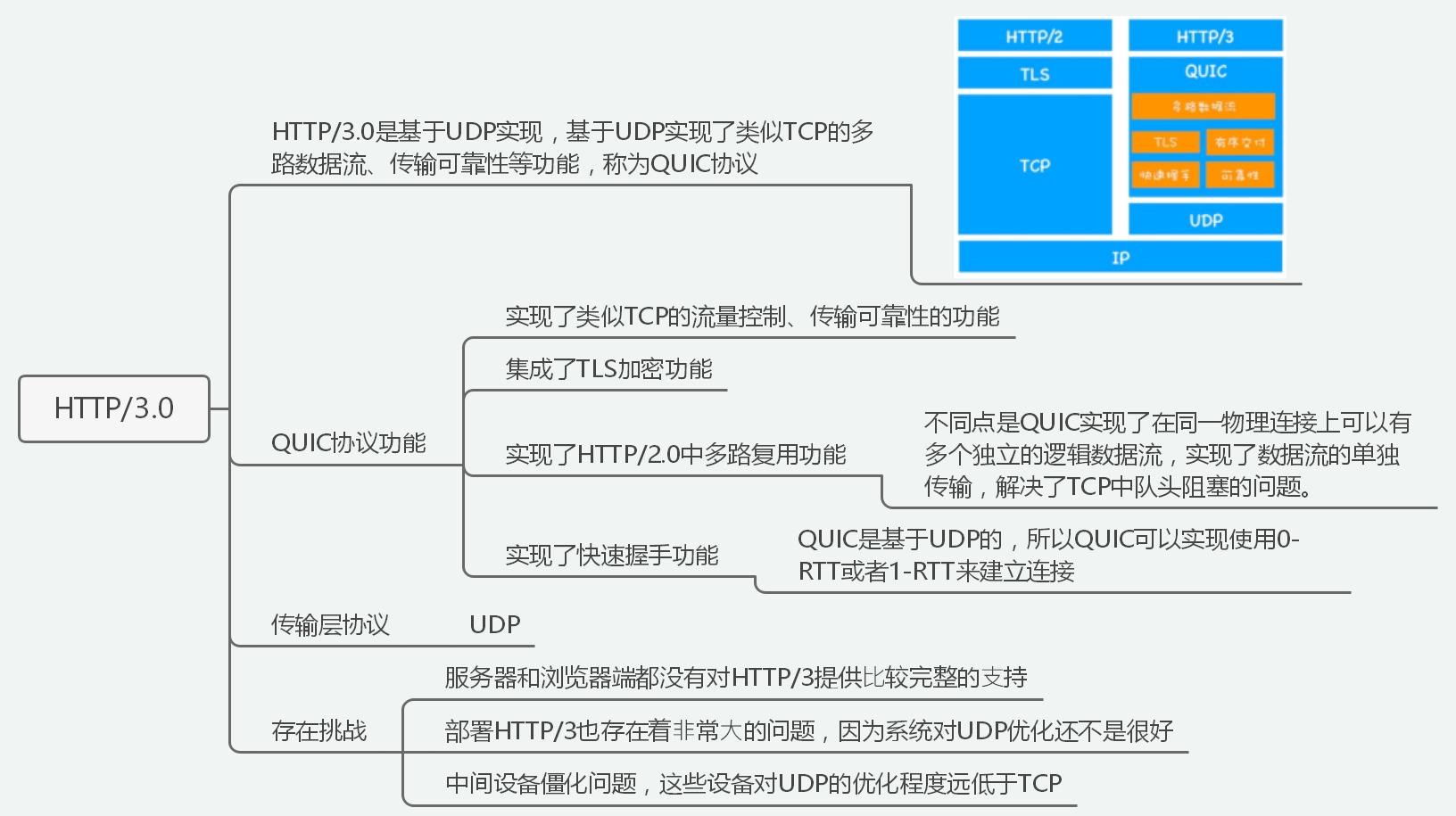
24 |
--------------------------------------------------------------------------------
/docs/network-protocol/12.http优缺点.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 简要概括一下 HTTP 的优缺点?
3 | date: 2018-09-17 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | ## HTTP 优点
12 |
13 | 1. 灵活可扩展:不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。
14 | 2. 可靠传输:HTTP 基于 TCP/IP,因此把这一特性继承了下来。这属于 TCP 的特性,不具体介绍了。
15 | 3. 请求-应答:也就是一发一收、有来有回,
16 | 4. 无状态:这服务器没有状态差异,可以很容易地组成集群。
17 |
18 | ## HTTP 缺点
19 |
20 | 1. 无状态:无法记录请求的对象信息,为此 cookie 存在的意义。。
21 | 2. 明文传输:容易被抓包,窃取、篡改、冒充。
22 | 3. 队头阻塞问题:由 HTTP 基本的“请求 - 应答”模型所导致的,因为 HTTP 规定报文必须是“一发一收”,这就形成了一个先进先出的“串行”队列。这个问题将
23 |
24 | 在如何解决 HTTP 的队头阻塞问题特殊讲解
25 |
--------------------------------------------------------------------------------
/docs/algorithm/字符串/反转字符串II.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 反转字符串II
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 字符串
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ```js
12 | /**
13 | * @param {string} s
14 | * @param {number} k
15 | * @return {string}
16 | */
17 | var reverseStr = function (s, k) {
18 | let arr = s.split('');
19 |
20 | for (let i = 0; i < s.length; i += 2 * k) {
21 | let y = Math.min(i + k, s.length) - 1;
22 | for (let x = i; x < y; x++, y--) {
23 | [arr[x], arr[y]] = [arr[y], arr[x]];
24 | }
25 | }
26 |
27 | return arr.join('');
28 | };
29 | ```
30 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/总结.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 回溯法总结
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | - [代码随想录](https://programmercarl.com/)
12 |
13 | ## 模板
14 |
15 | ```js
16 | result = [];
17 |
18 | function backtrack(路径, 选择列表) {
19 | if ('满足结束条件') {
20 | // 这里就是对答案做更新,依据实际题目出发
21 | result.push(路径);
22 | return;
23 | } else {
24 | for (let i = 0; i < 选择列表.length; i++) {
25 | // 对一个选择列表做相应的选择
26 |
27 | 做选择;
28 |
29 | backtrack(路径, 选择列表);
30 |
31 | // 既然是回溯算法,那么在一次分岔路做完选择后
32 | // 需要回退我们之前做的操作
33 |
34 | 撤销选择;
35 | }
36 | }
37 | }
38 | ```
39 |
--------------------------------------------------------------------------------
/docs/algorithm/链表/移除链表元素.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 移除链表元素
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 链表
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ```js
12 | /**
13 | * @param {ListNode} head
14 | * @param {number} val
15 | * @return {ListNode}
16 | */
17 | var removeElements = function (head, val) {
18 | let prev = new ListNode(undefined, head); //
19 | let cur = prev;
20 | // 我们以下个节点的值作为评判标准
21 | // 命中 则 cur.next = cur.next.next
22 | // 所以我们可以构造前置节点 来排除头节点的情况
23 | while (cur.next) {
24 | if (cur.next.val === val) cur.next = cur.next.next;
25 | else cur = cur.next;
26 | }
27 |
28 | return prev.next;
29 | };
30 | ```
31 |
--------------------------------------------------------------------------------
/docs/network-protocol/06.tcp和udp的区别.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: TCP 和 UDP 的区别概述
3 | date: 2018-09-28 15:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - tcp
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | - `TCP` 是一个面向连接的、可靠的、基于字节流的传输层协议。
12 | - 而 `UDP` 是一个面向无连接的传输层协议。
13 |
14 | 1. **面向连接**。所谓的连接,指的是客户端和服务器的连接,在双方互相通信之前,TCP 需要三次握手建立连接,而 UDP 没有相应建立连接的过程。
15 | 2. **可靠性**。TCP 花了非常多的功夫保证连接的可靠,这个可靠性体现在哪些方面呢?一个是有状态,另一个是可控制。
16 |
17 | TCP 会精准记录哪些数据发送了,哪些数据被对方接收了,哪些没有被接收到,而且保证数据包按序到达,不允许半点差错。这是**有状态**。
18 |
19 | 当意识到丢包了或者网络环境不佳,TCP 会根据具体情况调整自己的行为,控制自己的发送速度或者重发。这是**可控制**。
20 |
21 | 相应的,UDP 就是无状态, 不可控的。
22 |
23 | 3. **面向字节流**。UDP 的数据传输是基于数据报的,这是因为仅仅只是继承了 IP 层的特性,而 TCP 为了维护状态,将一个个 IP 包变成了字节流。
24 |
--------------------------------------------------------------------------------
/docs/algorithm/链表/删除链表的倒数第n个结点.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 删除链表的倒数第n个结点
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 链表
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ```js
12 | /**
13 | * @param {ListNode} head
14 | * @param {number} n
15 | * @return {ListNode}
16 | */
17 | var removeNthFromEnd = function (head, n) {
18 | let fast = head;
19 | while (n-- && fast) {
20 | fast = fast.next;
21 | }
22 |
23 | let prev = new ListNode(undefined, head);
24 | let slow = prev;
25 |
26 | while (fast) {
27 | fast = fast.next;
28 | slow = slow.next;
29 | }
30 |
31 | slow.next = slow.next.next;
32 |
33 | return prev.next;
34 | };
35 | ```
36 |
--------------------------------------------------------------------------------
/docs/.vitepress/cache/deps/_metadata.json:
--------------------------------------------------------------------------------
1 | {
2 | "hash": "f78c0ae0",
3 | "browserHash": "55079684",
4 | "optimized": {
5 | "vue": {
6 | "src": "../../../../node_modules/.pnpm/vue@3.4.27/node_modules/vue/dist/vue.runtime.esm-bundler.js",
7 | "file": "vue.js",
8 | "fileHash": "f7341a93",
9 | "needsInterop": false
10 | },
11 | "@theme/index": {
12 | "src": "../../../../node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/index.js",
13 | "file": "@theme_index.js",
14 | "fileHash": "3a6b41bf",
15 | "needsInterop": false
16 | }
17 | },
18 | "chunks": {}
19 | }
--------------------------------------------------------------------------------
/docs/algorithm/sort/quickSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 快速排序(基准)
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | 和归并一样,采用分治思想。不同的是,快排不是将数组一分为二,而是采用一个 “基准” 值。
13 |
14 | 也即 `[...rec(left), 基准, ...rec(right)]`,算法复杂度 $O(nlog(n))$
15 |
16 | ```js
17 | function quickSort(arr) {
18 | let len = arr.length;
19 | if (len < 2) return arr; // 临界条件
20 |
21 | const pivot = arr[0];
22 | const left = [];
23 | const right = [];
24 |
25 | // 分治
26 | for (let i = 1; i < len; i++) {
27 | arr[i] < pivot ? left.push(arr[i]) : right.push(arr[i]);
28 | }
29 |
30 | return [...quickSort(left), pivot, ...quickSort(right)];
31 | }
32 | ```
33 |
--------------------------------------------------------------------------------
/docs/algorithm/动态规划/动态规划理论基础.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 动态规划理论基础
3 | date: 2022-03-31 20:56:00
4 | sidebar: auto
5 | tags:
6 | - 动态规划
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | 个人理解动态规划是递推公式,是后面的结果需要依赖前面的计算结果才能成立。
12 |
13 | 举个例子 [打家劫舍 I](./打家劫舍系列.md)
14 |
15 | 求小偷偷到最大金额。
16 |
17 | ```js
18 | [1, 2, 3, 4];
19 | // 只有 1 间房可以偷: 1
20 | // 只有 2 间房可以偷: Math.max(1, 2)
21 | // 只有 3 间房可以偷: 1 + 3 > 2 => 4
22 | // 第 i 间房:dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i])
23 | // Math.max(隔壁那间房,相邻那件房 + 现在这间房)
24 | ```
25 |
26 | 递推得公式:
27 |
28 | ```js
29 | var rob = function (nums) {
30 | let dp = [nums[0], Math.max(nums[0], nums[1])];
31 | let len = nums.length;
32 | for (let i = 2; i < len; i++) {
33 | dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
34 | }
35 | return dp[len - 1];
36 | };
37 | ```
38 |
--------------------------------------------------------------------------------
/docs/algorithm/动态规划/背包系列.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 背包系列
3 | date: 2022-06-05 12:32:19
4 | sidebar: auto
5 | tags:
6 | - 动态规划
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 416. 分割等和子集
12 |
13 | [力扣题目链接](https://leetcode-cn.com/problems/partition-equal-subset-sum/): 给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
14 |
15 | 注意: 每个数组中的元素不会超过 100,数组的大小不会超过 200
16 |
17 | ```js
18 | 示例 1:
19 | 输入: [1, 5, 11, 5]
20 | 输出: true
21 | 解释: 数组可以分割成 [1, 5, 5] 和 [11].
22 |
23 | 示例 2:
24 | 输入: [1, 2, 3, 5]
25 | 输出: false
26 | 解释: 数组不能分割成两个元素和相等的子集.
27 | ```
28 |
29 | 提示:
30 |
31 | - 1 <= nums.length <= 200
32 | - 1 <= nums[i] <= 100
33 |
34 | ### 思路
35 |
36 | 本题可以看成是 0-1 背包问题,给一个可装载重量为 `sum / 2` 的背包和 N 个物品,每个物品的重量记录在 nums 数组中,问是否在一种装法,能够恰好将背包装满?`dp[i][j]`表示前 i 个物品是否能装满容积为 j 的背包,当 `dp[i][j]`为 true 时表示恰好可以装满。每个数都有放入背包和不放入两种情况,分析方法和 0-1 背包问题一样。
37 |
--------------------------------------------------------------------------------
/docs/algorithm/链表/k个一组翻转链表.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: k个一组翻转链表
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 链表
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ```js
12 | /**
13 | * @param {ListNode} head
14 | * @param {number} k
15 | * @return {ListNode}
16 | */
17 | var reverseKGroup = function (head, k) {
18 | let p = head,
19 | len = 0;
20 | while (p) {
21 | p = p.next;
22 | len++;
23 | }
24 |
25 | function dfs(node, len) {
26 | if (len < k) return node;
27 |
28 | // 反转链表
29 | let prev = null,
30 | cur = node;
31 | for (let i = 0; i < k; i++) {
32 | let next = cur.next;
33 | cur.next = prev;
34 | prev = cur;
35 | cur = next;
36 | }
37 |
38 | node.next = dfs(cur, len - k);
39 | return prev;
40 | }
41 |
42 | return dfs(head, len);
43 | };
44 | ```
45 |
--------------------------------------------------------------------------------
/docs/network-protocol/15.https的tsl连接过程.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: tsl 握手的过程(1.2)
3 | date: 2018-09-28 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - https
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | > 最终是使用会话密钥的方式进行对称加密的密文传输,所以拿到服务器的公钥加密随机数,让两端生成绘话密钥尤为重要!
12 |
13 | 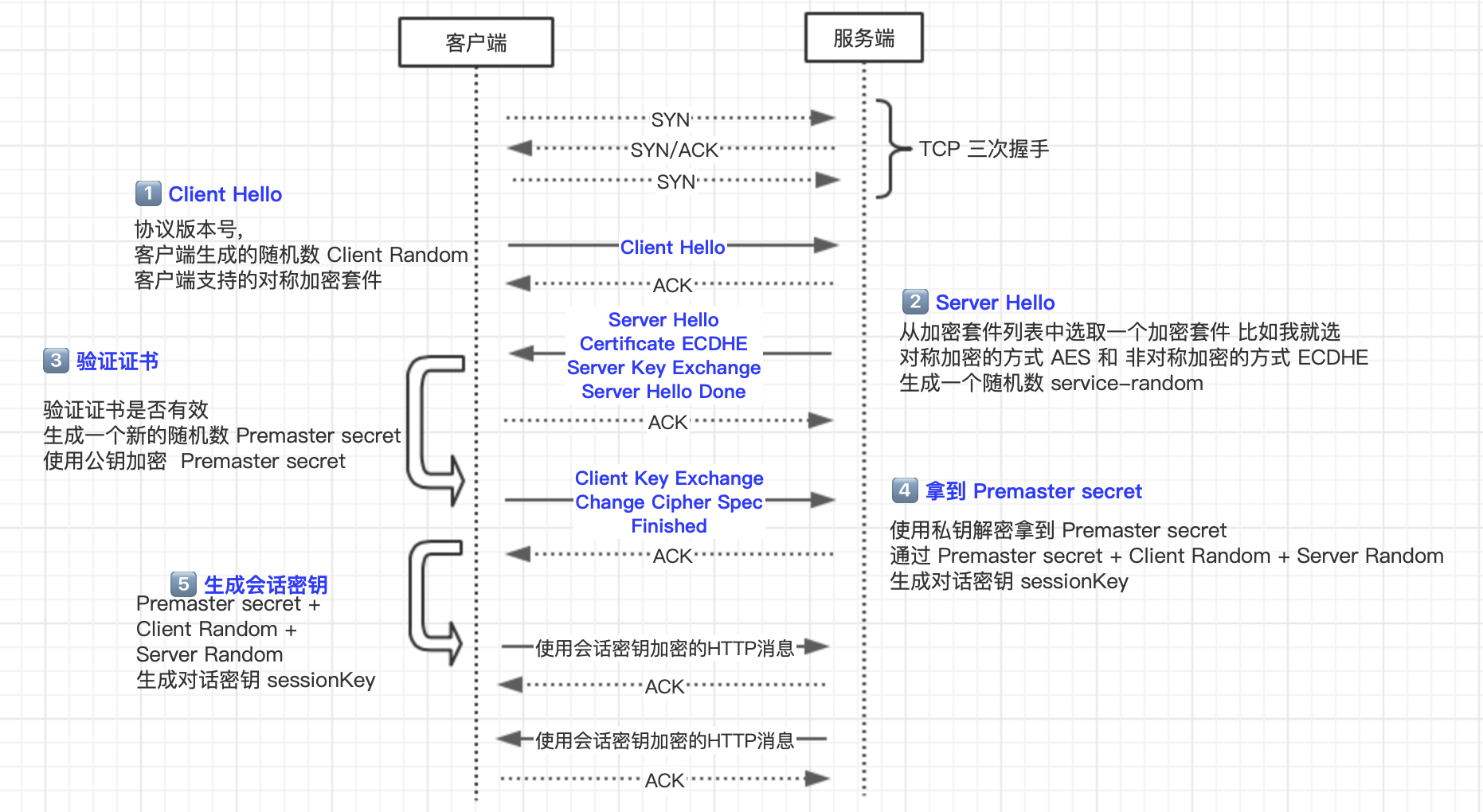
14 |
15 | - web `- client hellow ->` server
16 | - 客户端:我生成一个随机数 A,还有我支持的加密套件有哪些给你知道,当前我用的是 tsl 1.2 版本
17 | - web `<- server hello -` server
18 | - 服务端:我也生成一个随机数 B,我挑了一个加密套件 咱们使用这个套件进行加密
19 | - web `<- server key exchange -` server
20 | - 服务端:我给你发个证书,里面有我的公钥,你可以用公钥加密,黑客破解不了。
21 | - web `<- server hello done -` server
22 | - 服务端:通知一下你 我完成啦
23 | - web `- client key exchange ->` server
24 | - 客户端:检查了一下你的证书是有效的,拿到了公钥。我在生成了一个随机数 C,用你给我的公钥加密 发给你了
25 | - 服务端:我拿到了第三个随机数,我们使用同样的加密方式生成我们的会话密钥。以后咱们使用这个密钥进行通信吧
26 | - 客户端:好的,会话密钥只应用于当前会话,咱们传输很安全了。
27 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/子集.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 子集
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [力扣题目链接](https://leetcode-cn.com/problems/subsets/)
12 |
13 | 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
14 |
15 | 说明:解集不能包含重复的子集。
16 |
17 | ```js
18 | 输入: nums = [1, 2, 3];
19 | 输出: [[3], [1], [2], [1, 2, 3], [1, 3], [2, 3], [1, 2], []];
20 | ```
21 |
22 | ```js
23 | /**
24 | * @param {number[]} nums
25 | * @return {number[][]}
26 | */
27 | var subsets = function (nums) {
28 | let result = [];
29 | function backtrack(track, idx) {
30 | result.push([...track]);
31 |
32 | for (var i = idx; i < nums.length; i++) {
33 | track.push(nums[i]);
34 | backtrack(track, i + 1);
35 | track.pop();
36 | }
37 | }
38 |
39 | backtrack([], 0);
40 |
41 | return result;
42 | };
43 | ```
44 |
--------------------------------------------------------------------------------
/docs/network-protocol/13.http队头阻塞.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 如何解决 HTTP 的队头阻塞问题?
3 | date: 2018-09-15 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | - 队头阻塞
8 | categories:
9 | - 网络协议
10 | ---
11 |
12 | ## 什么是队头阻塞
13 |
14 | **http1.x 采用长连接(Connection:keep-alive),可以在一个 TCP 请求上,发送多个 http 请求。**
15 |
16 | 因为 HTTP 规定报文必须是 “**一发一收**”,这就形成了一个先进先出的“串行”队列。
17 |
18 | 队列里的请求没有轻重缓急的优先级,只有入队的先后顺序,排在最前面的请求被最优先处理。
19 |
20 | 如果队首的请求因为处理的太慢耽误了时间,那么队列里后面的所有请求也不得不跟着一起等待,结果就是其他的请求承担了不应有的时间成本。
21 |
22 | ## 并发连接
23 |
24 | 浏览器一个域名采用 `6-8` 个 TCP 连接,并发 `HTTP` 请求.
25 |
26 | 但其实,即使是提高了并发连接,还是不能满足人们对性能的需求。
27 |
28 | ## 域名分片
29 |
30 | 一个域名不是可以并发 6 个长连接吗?那我就多分几个域名。比如 content1.alvin.run 、content2.alvin.run。
31 |
32 | 这样一个 `alvin.run` 域名下可以分出非常多的二级域名,而它们都指向同样的一台服务器,能够并发的长连接数更多了,事实上也更好地解决了队头阻塞的问题。
33 |
34 | :::danger http1.1 没有真正解决了队头阻塞问题
35 |
36 | 即使使用上面的方式,也是治标不治本,http2 采用了**多路复用的方式**解决了这个问题,请看后续。
37 |
38 | :::
39 |
--------------------------------------------------------------------------------
/docs/algorithm/数组/两数之和.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 两数之和
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 哈希
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [力扣题目链接](https://leetcode-cn.com/problems/two-sum/)
12 |
13 | 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
14 |
15 | 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
16 |
17 | **示例:**
18 |
19 | ```js
20 | 给定 nums = [2, 7, 11, 15], target = 9
21 |
22 | 因为 nums[0] + nums[1] = 2 + 7 = 9
23 |
24 | 所以返回 [0, 1]
25 | ```
26 |
27 | 非常简单,看代码吧:
28 |
29 | ```js
30 | /**
31 | * @param {number[]} nums
32 | * @param {number} target
33 | * @return {number[]}
34 | */
35 | var twoSum = function (nums, target) {
36 | let map = new Map();
37 | for (let i = 0; i < nums.length; i++) {
38 | if (map.has(target - nums[i])) {
39 | return [map.get(target - nums[i]), i];
40 | }
41 | map.set(nums[i], i);
42 | }
43 | return [];
44 | };
45 | ```
46 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/子集II.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 子集II
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [力扣题目链接](https://leetcode-cn.com/problems/subsets-ii/)
12 |
13 | 给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
14 |
15 | 说明:解集不能包含重复的子集。
16 |
17 | 示例:
18 |
19 | ```js
20 | - 输入: [1,2,2]
21 | - 输出: [[2], [1], [1, 2, 2], [2, 2], [1, 2], []];
22 | ```
23 |
24 | ```js
25 | /**
26 | * @param {number[]} nums
27 | * @return {number[][]}
28 | */
29 | var subsetsWithDup = function (nums) {
30 | let result = [];
31 | nums.sort((a, b) => a - b);
32 | function backtrack(track, idx) {
33 | result.push([...track]);
34 |
35 | for (var i = idx; i < nums.length; i++) {
36 | if (nums[i] === nums[i - 1] && i > idx) continue;
37 | track.push(nums[i]);
38 | backtrack(track, i + 1);
39 | track.pop();
40 | }
41 | }
42 |
43 | backtrack([], 0);
44 |
45 | return result;
46 | };
47 | ```
48 |
--------------------------------------------------------------------------------
/docs/algorithm/二叉树/二叉树其他题目.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 二叉树其他题目
3 | date: 2022-05-14 22:22:39
4 | sidebar: auto
5 | tags:
6 | - 二叉树
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 求根节点到叶节点数字之和
12 |
13 | [leetcode](https://leetcode.cn/problems/sum-root-to-leaf-numbers)
14 |
15 | 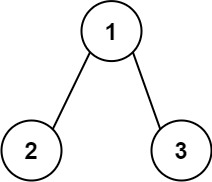
16 |
17 | ```js
18 | 输入:root = [1,2,3]
19 | 输出:25
20 | 解释:
21 | 从根到叶子节点路径 1->2 代表数字 12
22 | 从根到叶子节点路径 1->3 代表数字 13
23 | 因此,数字总和 = 12 + 13 = 25
24 | ```
25 |
26 | ```js
27 | /**
28 | * @param {TreeNode} root
29 | * @return {number}
30 | */
31 | var sumNumbers = function (root) {
32 | if (!root) return 0;
33 | let sum = 0;
34 | function dfs(root, value) {
35 | if (!root) return;
36 | let v = `${value}${root.val}`;
37 |
38 | if (!root.left && !root.right) {
39 | sum += Number(v);
40 | return;
41 | }
42 | dfs(root.left, v);
43 | dfs(root.right, v);
44 | }
45 |
46 | dfs(root, '');
47 |
48 | return sum;
49 | };
50 | ```
51 |
--------------------------------------------------------------------------------
/docs/network-protocol/01.网络模型.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 网络模型
3 | date: 2018-09-28 18:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 数据链路层(mac) -> 网络层(IP)-> 传输层(TCP/UDP)-> 应用层(HTTP、SMTP、FTP)
12 |
13 | 
14 |
15 | ## 数据链路层(Mac)
16 |
17 | 负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 `MAC` 地址来标记网络上的设备,所以有时候也叫 `MAC` 层。
18 |
19 | ## 网络层(IP)
20 |
21 | IP 协议就处在这一层。因为 IP 协议定义了“IP 地址”的概念,所以就可以在“链接层”的基础上,用 IP 地址取代 MAC 地址,把许许多多的局域网、广域网连接成一个虚拟的巨大网络,在这个网络里找设备时只要把 IP 地址再“翻译”成 MAC 地址就可以了。
22 |
23 | ## 传输层(TCP/UDP)
24 |
25 | 传输层负责为两台主机中的进程提供通信服务,它使用 16 位的端口号来标识端口,当两个计算机中的进程要进行通讯时,除了要知道对方的 IP 地址外,还需要知道对方的端口。该层主要有以下两个协议:用户数据报协议(UDP,User Datagram Protocol)和传输控制协议(TCP,Transmission Control Protocol):
26 |
27 | ## 应用层(HTTP/SMTP/FTP...)
28 |
29 | 由于下面的三层把基础打得非常好,所以在这一层就“百花齐放”了,有各种面向具体应用的协议。例如 Telnet、SSH、FTP、SMTP 等等,当然还有我们的 HTTP。
30 |
31 | 相关链接 [详解 四层、五层、七层 计算机网络模型](https://juejin.im/post/6844904049800642568)
32 |
--------------------------------------------------------------------------------
/.github/workflows/deploy.yml:
--------------------------------------------------------------------------------
1 | name: Deploy
2 |
3 | on:
4 | push:
5 | branches:
6 | - master
7 |
8 | jobs:
9 | deploy:
10 | runs-on: ubuntu-latest
11 | steps:
12 | - name: Checkout
13 | uses: actions/checkout@v4
14 | with:
15 | fetch-depth: 0 # 获取所有历史记录以便更好的 git 信息
16 |
17 | - name: Setup pnpm
18 | uses: pnpm/action-setup@v4
19 | with:
20 | version: latest # 或指定版本如 8.x
21 |
22 | - name: Setup Node.js
23 | uses: actions/setup-node@v4
24 | with:
25 | node-version: '20' # 推荐使用 LTS 版本
26 | cache: 'pnpm'
27 |
28 | - name: Install dependencies
29 | run: pnpm install --filter .
30 |
31 | - name: Build
32 | run: pnpm run build
33 | working-directory: ./docs
34 |
35 | - name: Deploy
36 | uses: peaceiris/actions-gh-pages@v3
37 | with:
38 | github_token: ${{ secrets.GITHUB_TOKEN }}
39 | publish_dir: docs/.vitepress/dist
40 |
--------------------------------------------------------------------------------
/docs/algorithm/sort/selectionSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 选择排序
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | 选择排序是外层循环,内循环找到最小或者最大的值的 index, 如果当前的元素不等于 index,则交换位置,算法复杂度 $O(n^2)$
13 |
14 | ```TS
15 | function swap(arr, i, j) {
16 | [arr[i], arr[j]] = [arr[j], arr[i]]
17 | }
18 |
19 | function selectionSort(arr) {
20 | for (let i = 0; i < arr.length; i++) {
21 | let minIndex = i
22 |
23 | for (let j = i + 1; j < arr.length; j++) {
24 | if (arr[minIndex] > arr[j]) {
25 | minIndex = j
26 | }
27 | }
28 |
29 | if (minIndex !== i) swap(arr, minIndex, i)
30 | }
31 | return arr
32 | }
33 |
34 |
35 | // test
36 | let arr = [4, 2, 3, 6, 5]
37 | console.log(selectionSort(arr)) // [ 2, 3, 4, 5, 6 ]
38 | ```
39 |
40 | 
41 |
42 | - 动画来源 [图解面试算法](https://github.com/MisterBooo/LeetCodeAnimation)
43 | - 参考 [优雅的 JavaScript 排序算法(ES6)](https://juejin.im/post/5ab62ec36fb9a028cf326c49)
44 |
--------------------------------------------------------------------------------
/docs/network-protocol/dns.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: DNS 解析
3 | date: 2018-09-28 17:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - dns
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 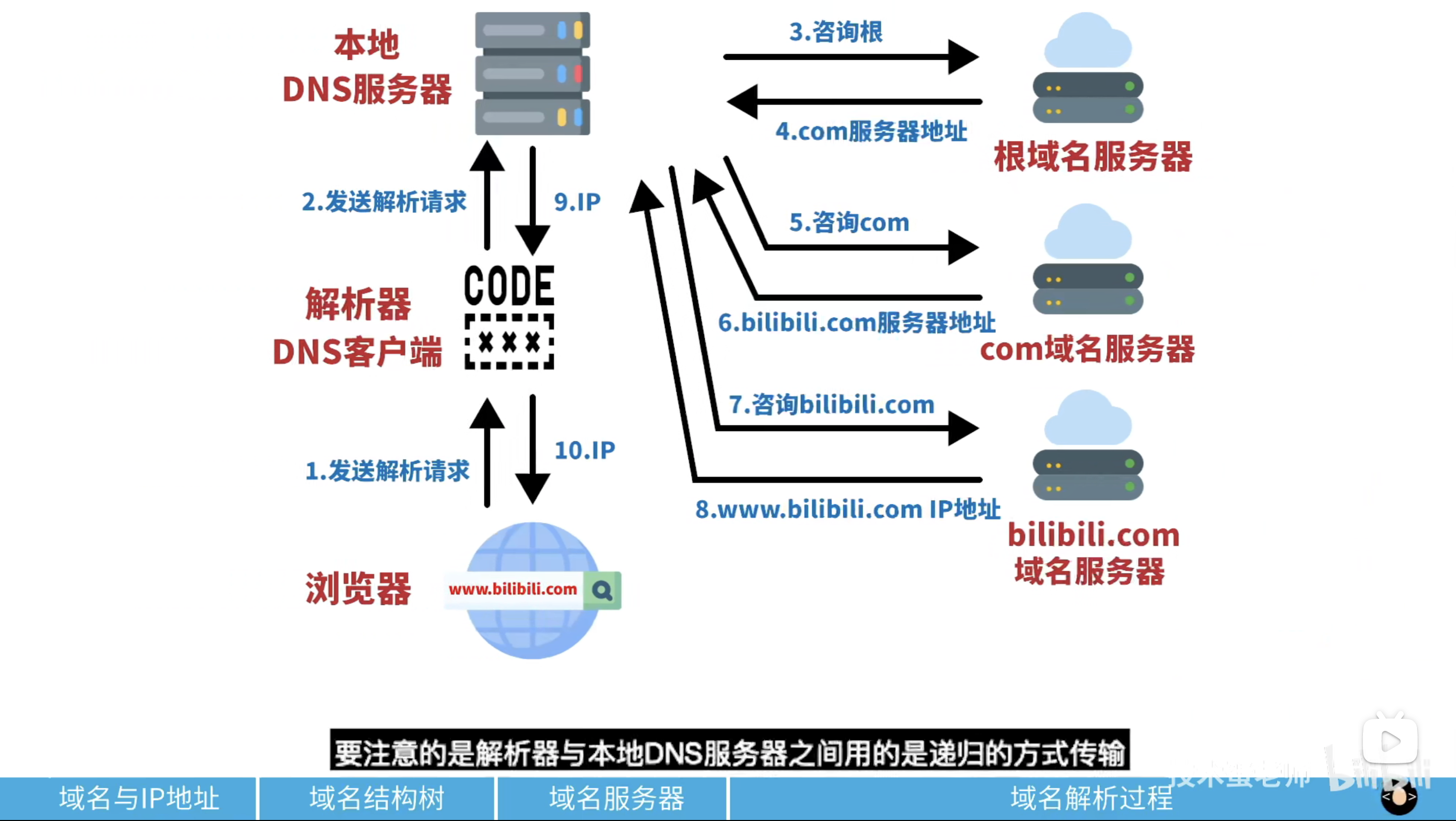
12 |
13 | ## 域名结构
14 |
15 | 就以 `mail.baidu.com` 域名为例,域名最后一个.的右侧部分我们称之为顶级域名,倒数第二个.右侧部分称之为二级域名,以此类推,就会有三级域名,四级域名等等。
16 |
17 | 在 `mail.baidu.com` 的域名中,`com` 成为顶级域名,`baidu.com` 称为二级域名,`mail.baidu.com` 称为三级域名。
18 |
19 | 域名由两个或两个以上的词组成,常见域名为二级域名+顶级域名组成,所以一般我们会将域名分为顶级域名、二级域名,除此之外,还有国家代码顶级域名。
20 |
21 | ## 查询顺序
22 |
23 | 现在我们来看看怎么去根据域名查询一台服务器的 IP 地址。
24 |
25 | 1. **检查浏览器缓存**中是否存在该域名与 IP 地址的映射关系,如果有则解析结束,没有则继续
26 | 2. 到系统本地查找映射关系,一般在 **hosts 文件**中,如果有则解析结束,否则继续
27 | 3. 到**本地域名服务器**去查询,有则结束,否则继续
28 | 4. **本地域名服务器查询根域名服务器**,该过程并不会返回映射关系,只会告诉你去下级服务器(顶级域名服务器)查询
29 | 5. **本地域名服务器查询顶级域名服务器**(即 com 服务器),同样不会返回映射关系,只会引导你去二级域名服务器查询
30 | 6. **本地域名服务器查询二级域名服务器**(即 `baidu.com` 服务器),引导去三级域名服务器查询
31 | 7. **本地域名服务器查询三级域名服务器**(即 mail.baidu.com 服务器),此时已经是最后一级了,如果有则返回映射关系,则本地域名服务器加入自身的映射表中,方便下次查询或其他用户查找,同时返回给该用户的计算机,没有找到则网页报错
32 |
33 | - [浏览器之 DNS 解析过程详解](https://juejin.cn/post/6909041150728863752)
34 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/字符串的排列.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 字符串的排列
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [剑指 Offer 38. 字符串的排列](https://leetcode-cn.com/problems/zi-fu-chuan-de-pai-lie-lcof/)
12 |
13 | ```js
14 | 输入:s = "abc"
15 | 输出:["abc","acb","bac","bca","cab","cba"]
16 | ```
17 |
18 | ```js
19 | /**
20 | * @param {string} s
21 | * @return {string[]}
22 | */
23 | var permutation = function (s) {
24 | let result = [];
25 | let visited = [];
26 |
27 | s = s.split('').sort((a, b) => a.charCodeAt() - b.charCodeAt());
28 |
29 | function backtrack(track) {
30 | if (track.length === s.length) {
31 | result.push([...track].join(''));
32 | return;
33 | }
34 |
35 | for (let i = 0; i < s.length; i++) {
36 | if (visited[i] || (!visited[i - 1] && s[i] === s[i - 1])) continue;
37 | track.push(s[i]);
38 | visited[i] = true;
39 | backtrack(track);
40 | track.pop();
41 | visited[i] = false;
42 | }
43 | }
44 |
45 | backtrack([]);
46 | return result;
47 | };
48 |
49 | console.log(permutation('abb'));
50 | ```
51 |
--------------------------------------------------------------------------------
/docs/algorithm/字符串/最长不含重复字符的子字符串.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 最长不含重复字符的子串
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 字符串
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ```js
12 | 输入: "abcabcbb"
13 | 输出: 3
14 | 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
15 |
16 | 输入: "bbbbb"
17 | 输出: 1
18 | 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
19 |
20 | 输入: "pwwkew"
21 | 输出: 3
22 | 解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
23 | 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
24 | ```
25 |
26 | ## 思路
27 |
28 | 1. 这里用哈希 + 双指针。end++,记录每次字符出现的位置
29 | 2. 如果发现字符在 map 里面,表示当前重复了,那么需要更新 start 指针
30 |
31 | ## 代码
32 |
33 | ```js
34 | /**
35 | * @param {string} s
36 | * @return {number}
37 | */
38 | var lengthOfLongestSubstring = function (s) {
39 | let start = 0,
40 | end = 0,
41 | max = 0,
42 | map = new Map();
43 |
44 | while (end < s.length) {
45 | if (map.has(s[end])) {
46 | // 更新左指针
47 | // 因为上次 char 的记录 可能未更新,所以判断 l 指针每次都是向前的!
48 | start = Math.max(start, map.get(s[end]) + 1);
49 | }
50 | map.set(s[end], end);
51 | end++;
52 | max = Math.max(max, end - start);
53 | }
54 |
55 | return max;
56 | };
57 | ```
58 |
--------------------------------------------------------------------------------
/docs/network-protocol/07.http报文结构.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HTTP 报文结构是怎样的?
3 | date: 2018-09-22 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 对于 TCP 而言,在传输的时候分为两个部分: **TCP 头**和**数据部分**。
12 |
13 | 而 HTTP 类似,也是 `header + body` 的结构,具体而言:
14 |
15 | ```ts
16 | 起始行 + 头部 + 空行 + 实体;
17 | ```
18 |
19 | :::details
20 |
21 | 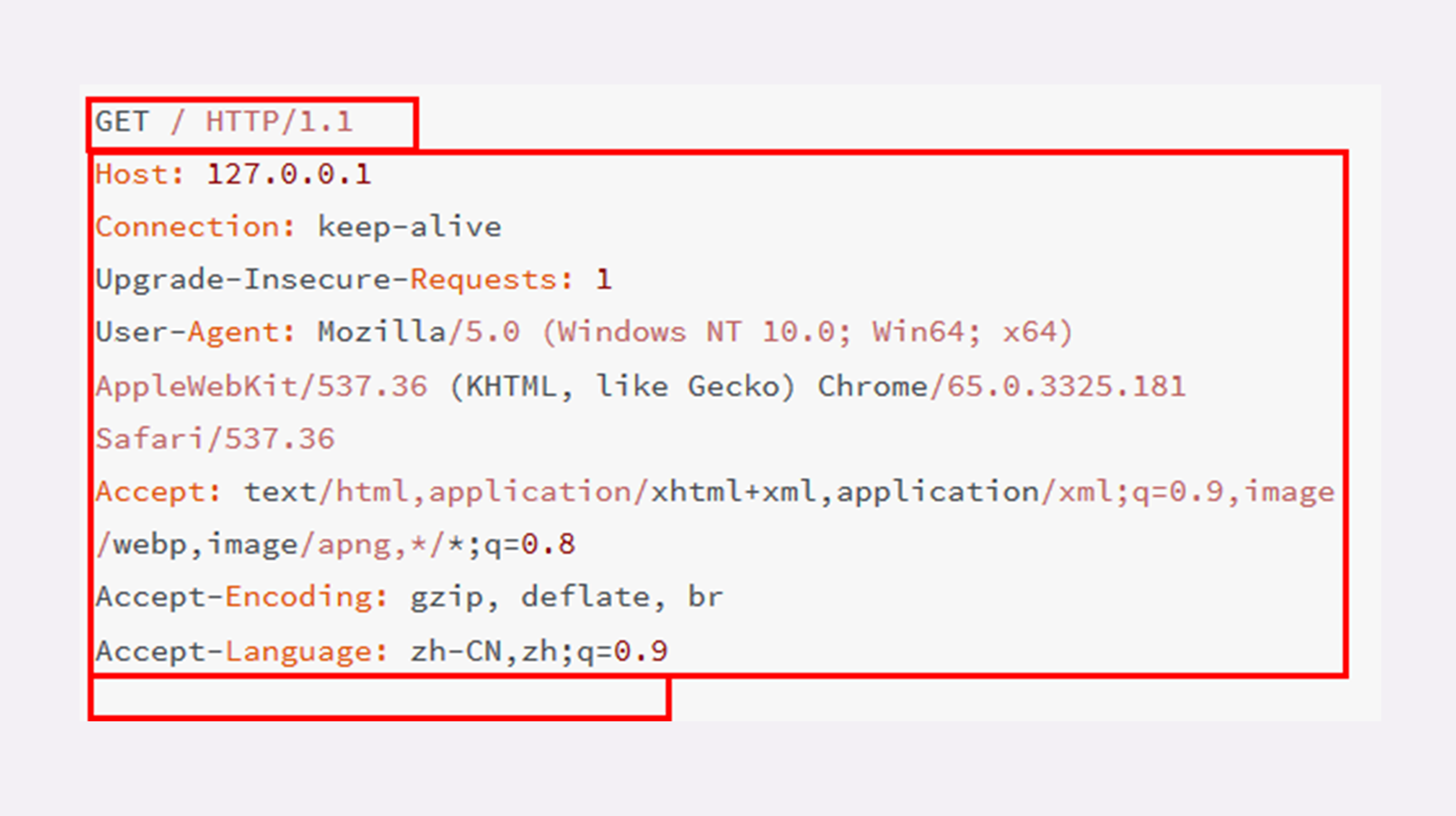
22 |
23 | :::
24 |
25 | ## 起始行
26 |
27 | 对于请求报文来说:
28 |
29 | ```ts
30 | GET /home HTTP/1.1
31 | ```
32 |
33 | 也就是`方法` + `路径` + `http 版本`。
34 |
35 | 对于响应报文来说,起始行一般长这个样:
36 |
37 | ```ts
38 | HTTP/1.1 200 OK
39 | ```
40 |
41 | `http 版本` + `状态码` + `原因`。
42 |
43 | ## 头部
44 |
45 | 
46 |
47 | 不管是请求头还是响应头,其中的字段是相当多的,而且牵扯到 http 非常多的特性,这里就不一一列举的,重点看看这些头部字段的格式:
48 |
49 | - 字段名不区分大小写
50 | - 字段名不允许出现空格,不可以出现下划线 `_`
51 | - 字段名后面必须紧接着 `:`
52 |
53 | ## 空行
54 |
55 | `空行` 用于区分**头部**和**实体**
56 |
57 | :::warning 如果说在头部中间故意加一个空行会怎么样?
58 |
59 | 那么空行后的内容全部被视为实体。
60 |
61 | :::
62 |
63 | ## 实体
64 |
65 | 就是具体的数据了,也就是 body 部分。请求报文对应请求体, 响应报文对应响应体。
66 |
--------------------------------------------------------------------------------
/docs/algorithm/sort/mergeSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 归并排序(分治)
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 |
13 |
14 | 用到分治算法,将大数组二分为一为两个小数组,递归去比较排序。算法复杂度 $O(nlog(n))$
15 |
16 | ```js
17 | var mergeSort = function (arr) {
18 | const len = arr.length;
19 | if (len === 1) return arr;
20 | const mid = Math.floor(len / 2);
21 |
22 | // 分
23 | const left = mergeSort(arr.slice(0, mid));
24 | const right = mergeSort(arr.slice(mid));
25 |
26 | // 治
27 | let res = [];
28 | while (left.length > 0 || right.length > 0) {
29 | // shift 推出
30 | if (left.length > 0 && right.length > 0) {
31 | res.push(left[0] < right[0] ? left.shift() : right.shift());
32 | } else if (left.length > 0) {
33 | res.push(left.shift());
34 | } else {
35 | res.push(right.shift());
36 | }
37 | }
38 |
39 | return res;
40 | };
41 | ```
42 |
43 | - 动画来源 [图解面试算法](https://github.com/MisterBooo/LeetCodeAnimation)
44 | - 参考 [优雅的 JavaScript 排序算法(ES6)](https://juejin.im/post/5ab62ec36fb9a028cf326c49)
45 |
--------------------------------------------------------------------------------
/docs/network-protocol/05.tcp中syn攻击.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 半连接队列和 SYN Flood 攻击
3 | date: 2018-09-28 14:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - tcp
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | ## 半连接队列
12 |
13 | 三次握手时,服务器第一次收到客户端的 SYN 之后,就会处于 SYN_RCVD 状态,此时双方还没有完全建立其连接,服务器会把此种状态下请求连接放在一个队列里,我们把这种队列称之为半连接队列。
14 |
15 | 当然还有一个全连接队列,就是已经完成三次握手,建立起连接的就会放在全连接队列中。如果队列满了就有可能会出现丢包现象。
16 |
17 | 这里在补充一点关于 **SYN-ACK 重传次数**的问题:
18 | 服务器发送完 `SYN-ACK` 包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传。如果重传次数超过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。
19 | 注意,每次重传等待的时间不一定相同,一般会是指数增长,例如间隔时间为 1s,2s,4s,8s......
20 |
21 | ## SYN 攻击
22 |
23 | 服务器端的资源分配是在二次握手时分配的,而客户端的资源是在完成三次握手时分配的,所以服务器容易受到 `SYN 洪泛攻击`。
24 |
25 | :::warning SYN 攻击是一种典型的 DoS/DDoS 攻击。
26 | SYN 攻击就是 Client 在短时间内伪造大量不存在的 IP 地址,并向 Server 不断地发送 SYN 包,Server 则回复确认包,并等待 Client 确认,由于源地址不存在,因此 Server 需要不断重发直至超时,这些伪造的 SYN 包将长时间占用未连接队列,导致正常的 SYN 请求因为队列满而被丢弃,从而引起网络拥塞甚至系统瘫痪。
27 | :::
28 |
29 | 检测 SYN 攻击非常的方便,当你在服务器上看到大量的半连接状态时,特别是源 IP 地址是随机的,基本上可以断定这是一次 SYN 攻击。在 `Linux/Unix` 上可以使用系统自带的 `netstats` 命令来检测 SYN 攻击。
30 |
31 | ```bash
32 | netstat -n -p TCP | grep SYN_RECV
33 | ```
34 |
35 | 常见的防御 SYN 攻击的方法有如下几种:
36 |
37 | - 缩短超时(SYN Timeout)时间
38 | - 增加最大半连接数
39 | - 过滤网关防护
40 | - SYN cookies 技术
41 |
--------------------------------------------------------------------------------
/docs/algorithm/字符串/千位分隔数.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 千位分隔数
3 | date: 2022-05-14 17:40:58
4 | sidebar: auto
5 | tags:
6 | - 字符串
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | 给你一个整数 n,请你每隔三位添加点(即 "." 符号)作为千位分隔符,并将结果以字符串格式返回。
12 |
13 | ```js
14 | 输入:n = 987
15 | 输出:"987"
16 |
17 | 输入:n = 1234
18 | 输出:"1.234"
19 |
20 | 输入:n = 123456789
21 | 输出:"123.456.789"
22 |
23 | 输入:n = 0
24 | 输出:"0"
25 | ```
26 |
27 | 无情的 api 杀手!
28 |
29 | ```js
30 | /**
31 | * @param {number} n
32 | * @return {string}
33 | */
34 | var thousandSeparator = function (n) {
35 | return n.toLocaleString(3).replace(/,/g, '.');
36 | };
37 | ```
38 |
39 | 当然不,正规解法:
40 |
41 | ```js
42 | /**
43 | * @param {number} n
44 | * @return {string}
45 | */
46 | var thousandSeparator = function (n) {
47 | let s = n.toString();
48 | let j = s.length;
49 | let result = [];
50 | while (j - 3 > 0) {
51 | result.unshift(s.slice(j - 3, j));
52 | j -= 3;
53 | }
54 | // 前面的数 也要判断
55 | if (j > 0) result.unshift(s.slice(0, j));
56 |
57 | return result.join('.');
58 | };
59 | ```
60 |
61 | Better
62 |
63 | ```js
64 | function thousandSeparator(n: number): string {
65 | const rec = (v: string) => (v.length <= 3 ? v : rec(v.slice(0, -3)) + '.' + v.slice(-3));
66 | return rec(String(n));
67 | }
68 | ```
69 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/组合总和.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 组合总和
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [力扣题目链接](https://leetcode-cn.com/problems/combination-sum/)
12 |
13 | 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
14 |
15 | candidates 中的数字可以无限制重复被选取。
16 |
17 | 说明:
18 |
19 | 所有数字(包括 target)都是正整数。
20 | 解集不能包含重复的组合。
21 |
22 | ```js
23 | 示例 1: 输入:candidates = [2,3,6,7], target = 7, 所求解集为: [ [7], [2,2,3] ]
24 |
25 | 示例 2: 输入:candidates = [2,3,5], target = 8, 所求解集为: [ [2,2,2,2], [2,3,3], [3,5] ]
26 | ```
27 |
28 | ```js
29 | /**
30 | * @param {number[]} candidates
31 | * @param {number} target
32 | * @return {number[][]}
33 | */
34 | var combinationSum = function (candidates, target) {
35 | let result = [];
36 |
37 | function backtrack(track, idx, sum) {
38 | if (sum === target) return result.push([...track]);
39 | if (sum > target) return;
40 |
41 | for (let i = idx; i < candidates.length; i++) {
42 | if (candidates[i] > target - sum) continue;
43 | track.push(candidates[i]);
44 | sum += candidates[i];
45 | backtrack(track, i, sum);
46 | sum -= candidates[i];
47 | track.pop();
48 | }
49 | }
50 |
51 | backtrack([], 0, 0);
52 | return result;
53 | };
54 | ```
55 |
--------------------------------------------------------------------------------
/docs/algorithm/字符串/字符串的排列.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 字符串的排列
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 字符串
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [567. 字符串的排列](https://leetcode.cn/problems/permutation-in-string): 给你两个字符串 `s1` 和 `s2` ,写一个函数来判断 `s2` 是否包含 `s1` 的排列。如果是,返回 `true` ;否则,返回 `false` 。
12 |
13 | 换句话说,s1 的排列之一是 s2 的 子串 。
14 |
15 | ```js
16 | 输入:s1 = "ab" s2 = "eidbaooo"
17 | 输出:true
18 | 解释:s2 包含 s1 的排列之一 ("ba").
19 |
20 | 输入:s1= "ab" s2 = "eidboaoo"
21 | 输出:false
22 | ```
23 |
24 | ```js
25 | /**
26 | * @param {string} s1
27 | * @param {string} s2
28 | * @return {boolean}
29 | */
30 | var checkInclusion = function (s1, s2) {
31 | let map = {};
32 | for (let char of s1) {
33 | if (map[char]) map[char] += 1;
34 | else map[char] = 1;
35 | }
36 |
37 | let slider = {};
38 | let start = 0;
39 | let end = 0;
40 | while (end < s2.length) {
41 | let char = s2[end];
42 |
43 | if (slider[char]) slider[char] += 1;
44 | else slider[char] = 1;
45 |
46 | end++;
47 |
48 | // 调整窗口,判断左侧窗口是否要收缩
49 | if (end - start > s1.length) {
50 | slider[s2[start]]--;
51 | start++;
52 | }
53 |
54 | if (Object.entries(map).every(([key, value]) => slider[key] === value)) {
55 | return true;
56 | }
57 | }
58 |
59 | return false;
60 | };
61 | ```
62 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | # layout: home
3 |
4 | title: VitePress
5 | titleTemplate: Vite & Vue Powered Static Site Generator
6 |
7 | hero:
8 | name: VitePress
9 | text: Vite & Vue Powered Static Site Generator
10 | tagline: Simple, powerful, and performant. Meet the modern SSG framework you've always wanted.
11 | actions:
12 | - theme: brand
13 | text: Get Started
14 | link: /home/accessibility
15 | - theme: alt
16 | text: View on GitHub
17 | link: https://github.com/vuejs/vitepress
18 | imgage:
19 | src: https://vitepress.dev/vitepress-logo-large.webp
20 |
21 | features:
22 | - title: "Vite: The DX that can't be beat"
23 | details: Feel the speed of Vite. Instant server start and lightning fast HMR that stays fast regardless of the app size.
24 | - title: Designed to be simplicity first
25 | details: With Markdown-centered content, it's built to help you focus on writing and deployed with minimum configuration.
26 | - title: Power of Vue meets Markdown
27 | details: Enhance your content with all the features of Vue in Markdown, while being able to customize your site with Vue.
28 | - title: Fully static yet still dynamic
29 | details: Go wild with true SSG + SPA architecture. Static on page load, but engage users with 100% interactivity from there.
30 | ---
31 |
32 | World's really stomping on your dreams, huh?
33 |
--------------------------------------------------------------------------------
/docs/algorithm/数组/长度最小的子数组.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 长度最小的子数组
3 | date: 2022-05-15 11:44:48
4 | sidebar: auto
5 | tags:
6 | - 数组
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | 给定一个含有 n 个正整数的数组和一个正整数 target 。
12 |
13 | 找出该数组中满足其和 ≥ target 的长度最小的 连续子数组 [numsl, numsl+1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。
14 |
15 | ```js
16 | 输入:target = 7, nums = [2,3,1,2,4,3]
17 | 输出:2
18 | 解释:子数组 [4,3] 是该条件下的长度最小的子数组。
19 |
20 | 输入:target = 4, nums = [1,4,4]
21 | 输出:1
22 |
23 | 输入:target = 11, nums = [1,1,1,1,1,1,1,1]
24 | 输出:0
25 | ```
26 |
27 | - 1 <= target <= 109
28 | - 1 <= nums.length <= 105
29 | - 1 <= nums[i] <= 105
30 |
31 | 进阶:
32 |
33 | 如果你已经实现 O(n) 时间复杂度的解法, 请尝试设计一个 O(n log(n)) 时间复杂度的解法。
34 |
35 | ## O(n) 解法
36 |
37 | 从左往右滑; 满足条件了就压缩左边界,不满足条件就扩大右
38 |
39 | ```js
40 | /**
41 | * @param {number} target
42 | * @param {number[]} nums
43 | * @return {number}
44 | */
45 | var minSubArrayLen = function (target, nums) {
46 | let sum = 0;
47 | let i = 0,
48 | j = 0,
49 | min = 0;
50 |
51 | while (j < nums.length) {
52 | // 主旋律是扩张,找可行解
53 | sum += nums[j];
54 |
55 | // 间歇性收缩,优化可行解
56 | while (sum >= target) {
57 | if (min === 0) min = j - i + 1;
58 | else min = Math.min(min, j - i + 1);
59 | sum -= nums[i];
60 | i++;
61 | }
62 |
63 | j++;
64 | }
65 |
66 | return min;
67 | };
68 | ```
69 |
70 | ## O(n log(n))
71 |
--------------------------------------------------------------------------------
/docs/algorithm/深度遍历/岛屿数量.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 岛屿数量
3 | date: 2022-05-10 15:27:04
4 | sidebar: auto
5 | tags:
6 | - 深度遍历
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [leetcode](https://leetcode.cn/problems/number-of-islands): 给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
12 |
13 | 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
14 |
15 | 此外,你可以假设该网格的四条边均被水包围。
16 |
17 | ```js
18 | 输入:grid = [
19 | ["1","1","1","1","0"],
20 | ["1","1","0","1","0"],
21 | ["1","1","0","0","0"],
22 | ["0","0","0","0","0"]
23 | ]
24 | 输出:1
25 |
26 | 输入:grid = [
27 | ["1","1","0","0","0"],
28 | ["1","1","0","0","0"],
29 | ["0","0","1","0","0"],
30 | ["0","0","0","1","1"]
31 | ]
32 | 输出:3
33 | ```
34 |
35 | ```js
36 | /**
37 | * @param {character[][]} grid
38 | * @return {number}
39 | */
40 | var numIslands = function (grid) {
41 | let count = 0;
42 | let [m, n] = [grid.length, grid[0].length];
43 |
44 | function toZero(i, j) {
45 | if (i < 0 || i >= m || j < 0 || j >= n || grid[i][j] === '0') return;
46 | grid[i][j] = '0';
47 | toZero(i + 1, j);
48 | toZero(i - 1, j);
49 | toZero(i, j + 1);
50 | toZero(i, j - 1);
51 | }
52 |
53 | for (let i = 0; i < m; i++) {
54 | for (let j = 0; j < n; j++) {
55 | if (grid[i][j] === '1') {
56 | count++;
57 | toZero(i, j);
58 | }
59 | }
60 | }
61 |
62 | return count;
63 | };
64 | ```
65 |
--------------------------------------------------------------------------------
/docs/algorithm/bfs-dfs.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: DFS & BFS
3 | date: 2020-05-24 23:37:51
4 | sidebar: auto
5 | tags:
6 | - 深度优先遍历
7 | - 广度优先遍历
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | ## DFS 深度优先遍历 递归实现
13 |
14 | ```js
15 | /**
16 | * Definition for a binary tree node.
17 | * function TreeNode(val) {
18 | * this.val = val;
19 | * this.left = this.right = null;
20 | * }
21 | */
22 |
23 | // 3
24 | // / \
25 | // 1 4
26 | // \
27 | // 2
28 | // 输出: 1 2 3 4
29 |
30 | function dfs(node) {
31 | if (!node) return;
32 | node.left && dfs(node.left);
33 | console.log(node.val); // 中序遍历
34 | node.right && dfs(node.right);
35 | }
36 | ```
37 |
38 | ## DFS 深度优先遍历 栈实现
39 |
40 | ```js
41 | function dfs(root) {
42 | const stack = [];
43 | let nums = [];
44 | let current = root;
45 |
46 | while (current || stack.length > 0) {
47 | while (current) {
48 | stack.push(current);
49 | current = current.left;
50 | }
51 | current = stack.pop();
52 | nums.push(current.val);
53 | current = current.right;
54 | }
55 |
56 | console.log(nums); // [ 1, 2, 3, 4 ]
57 | }
58 | ```
59 |
60 | ## BFS 广度优先遍历 队列实现
61 |
62 | ```js
63 | // 3
64 | // / \
65 | // 1 4
66 | // \
67 | // 2
68 | // 输出: 3 1 4 2
69 | function bfs(root) {
70 | let queue = [root];
71 |
72 | while (queue.length) {
73 | const node = queue.shift();
74 | console.log(node.val); //
75 | node.left && queue.push(node.left);
76 | node.right && queue.push(node.right);
77 | }
78 | }
79 | ```
80 |
--------------------------------------------------------------------------------
/docs/algorithm/链表/相交链表.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 相交链表
3 | date: 2022-05-15 11:02:11
4 | sidebar: auto
5 | tags:
6 | - 链表
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
12 |
13 | 图示两个链表在节点 c1 开始相交:
14 |
15 | 
16 |
17 | 题目数据 保证 整个链式结构中不存在环。
18 |
19 | 注意,函数返回结果后,链表必须 保持其原始结构 。
20 |
21 | ## 哈希解法
22 |
23 | ```js
24 | /**
25 | * Definition for singly-linked list.
26 | * function ListNode(val) {
27 | * this.val = val;
28 | * this.next = null;
29 | * }
30 | */
31 |
32 | /**
33 | * @param {ListNode} headA
34 | * @param {ListNode} headB
35 | * @return {ListNode}
36 | */
37 | var getIntersectionNode = function (headA, headB) {
38 | // hash
39 | let set = new Set();
40 | let cur = headA;
41 | while (cur) {
42 | set.add(cur);
43 | cur = cur.next;
44 | }
45 | cur = headB;
46 | while (cur) {
47 | if (set.has(cur)) return cur;
48 | cur = cur.next;
49 | }
50 |
51 | return null;
52 | };
53 | ```
54 |
55 | ## 双指针
56 |
57 | 若相交,链表 A: `a+c`, 链表 B : `b+c`. `a+c+b+c = b+c+a+c` 。则会在公共处 `c` 起点相遇。若不相交,`a +b = b+a` 。因此相遇处是 NULL
58 |
59 | ```js
60 | pA:1->2->3->4->5->6->null->9->5->6->null
61 | pB:9->5->6->null->1->2->3->4->5->6->null
62 | ```
63 |
64 | ```js
65 | var getIntersectionNode = function (headA, headB) {
66 | if (!headA || !headB) return null;
67 |
68 | let pA = headA,
69 | pB = headB;
70 | while (pA !== pB) {
71 | pA = pA ? pA.next : headB;
72 | pB = pB ? pB.next : headA;
73 | }
74 | \
75 | return pA;
76 | };
77 | ```
78 |
--------------------------------------------------------------------------------
/docs/algorithm/链表/环形链表II.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 环形链表II
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 链表
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [力扣题目链接](https://leetcode-cn.com/problems/linked-list-cycle-ii/)
12 |
13 | 题意:
14 | 给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
15 |
16 | 为了表示给定链表中的环,使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
17 |
18 | **说明**:不允许修改给定的链表。
19 |
20 | 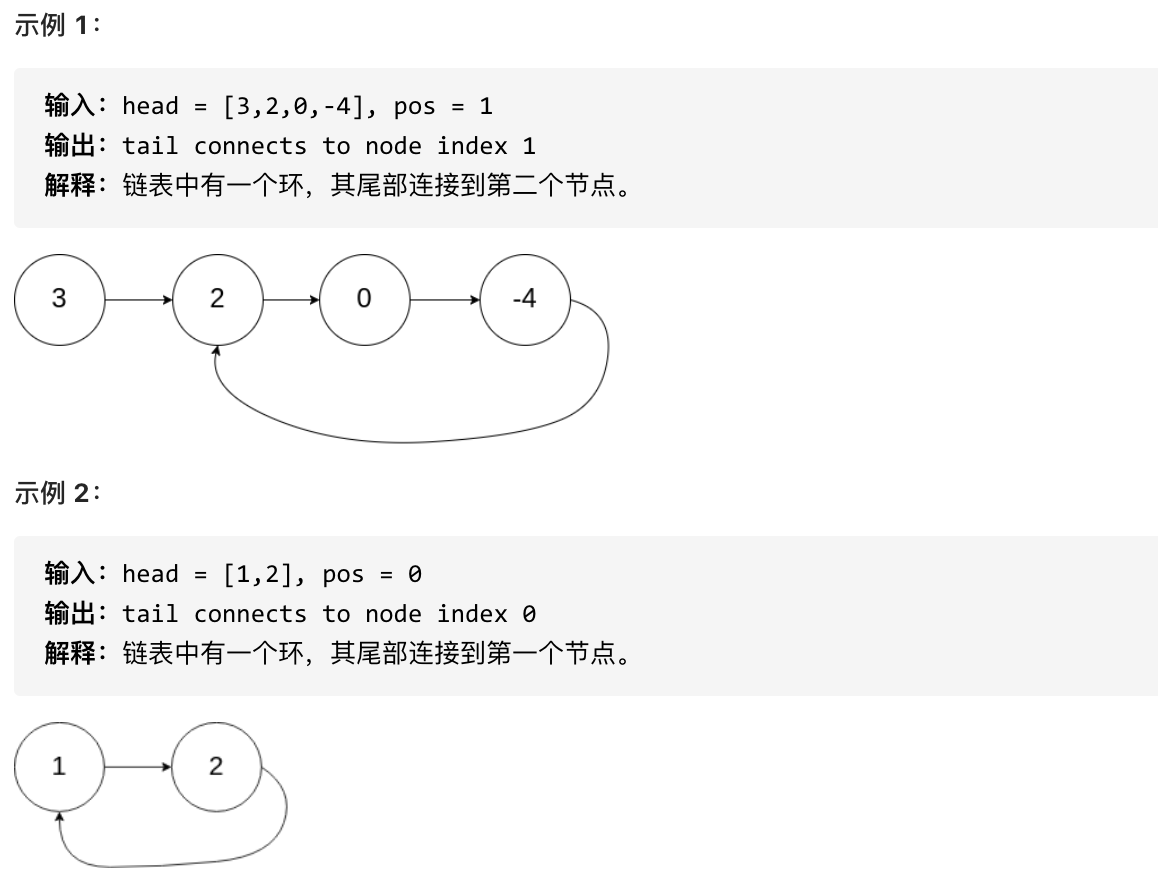
21 |
22 | ## 思路
23 |
24 | 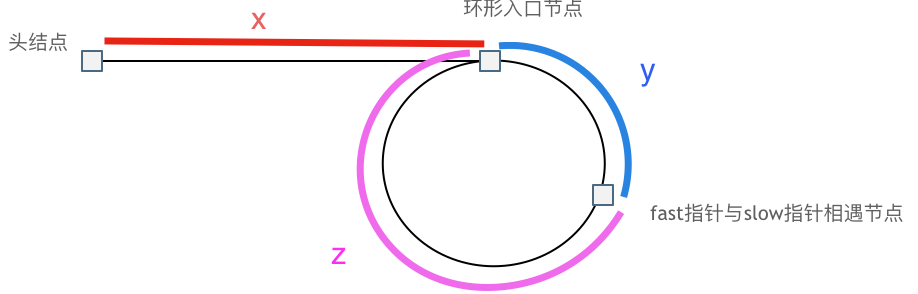
25 |
26 | 指针 slow 每次走一步,fast 每次走两步,如果有环,则一定会出现相遇的情况,注意这里是要返回环链接的起始位置。那么可以进行推断。
27 |
28 | 第一次相遇时
29 |
30 | - `slow` 走了 `x + y`
31 | - `fast` 走了 `x + y + n(y + z)`, n 指的是 fast 走了 n 次环
32 |
33 | 指针 slow 每次走一步,fast 每次走两步,得到公式 `2(x + y) = x + y + n(y + z)` , 也即 `x= n(y + z) - y`
34 |
35 | 整理公式之后为如下公式: `x = (n - 1)(y + z) + z`
36 |
37 | 先拿 n 为 1 的情况来举例,意味着 fast 指针在环形里转了一圈之后,就遇到了 slow 指针了。
38 |
39 | 当 n 为 1 的时候,公式就化解为 x = z,
40 |
41 | 这就意味着,**从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点**。
42 |
43 | ## 代码
44 |
45 | ```js
46 | /**
47 | * @param {ListNode} head
48 | * @return {ListNode}
49 | */
50 | var detectCycle = function (head) {
51 | let slow = head;
52 | let fast = head;
53 |
54 | while (fast && fast.next) {
55 | fast = fast.next.next;
56 | slow = slow.next;
57 | if (fast === slow) {
58 | // 相遇,但这里要求的是环的起始节点
59 | let slow = head;
60 | // slow 重头继续走,和相遇过的 fast 指针一样,每次只走一步,肯定会再头节点相遇
61 | while (slow !== fast) {
62 | slow = slow.next;
63 | fast = fast.next;
64 | }
65 | return slow;
66 | }
67 | }
68 |
69 | return null;
70 | };
71 | ```
72 |
--------------------------------------------------------------------------------
/docs/network-protocol/02.tcp报文.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: TCP 报文结构
3 | date: 2018-09-28 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - tcp
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | TCP 报文是 TCP 层传输的数据单元,也叫报文段。
12 |
13 | 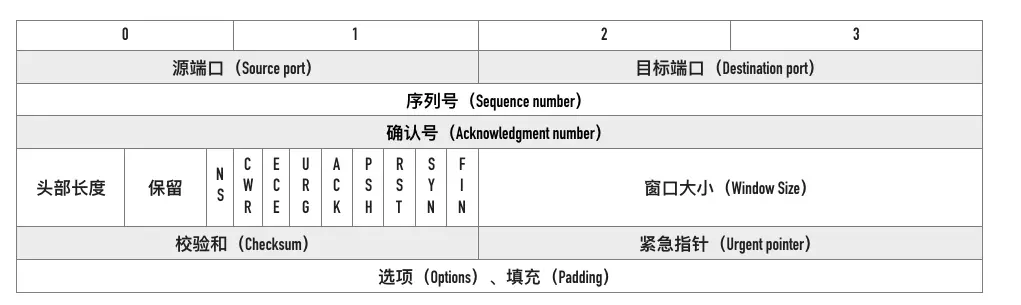
14 |
15 | ## 源端口、目标端口
16 |
17 | 如何标识唯一标识一个连接?答案是 TCP 连接的四元组——源 **IP、源端口、目标 IP 和目标端口。**
18 |
19 | 那 TCP 报文怎么没有源 IP 和目标 IP 呢?这是因为在 IP 层就已经处理了 IP 。TCP 只需要记录两者的端口即可。
20 |
21 | ## 序列号
22 |
23 | 即 `Sequence number`, 指的是本报文段第一个字节的序列号。
24 |
25 | 序列号在 TCP 通信的过程中有两个作用:
26 |
27 | - 在 SYN 报文中交换彼此的初始序列号。
28 | - 保证数据包按正确的顺序组装。
29 |
30 | ## ISN
31 |
32 | 即 `Initial Sequence Number`(初始序列号),在三次握手的过程当中,双方会用过 SYN 报文来交换彼此的 ISN。
33 |
34 | ISN 并不是一个固定的值,而是每 4 ms 加一,溢出则回到 0,这个算法使得猜测 ISN 变得很困难。那为什么要这么做?
35 |
36 | 如果 ISN 被攻击者预测到,要知道源 IP 和源端口号都是很容易伪造的,当攻击者猜测 ISN 之后,直接伪造一个 RST 后,就可以强制连接关闭的,这是非常危险的。
37 |
38 | 而动态增长的 ISN 大大提高了猜测 ISN 的难度。
39 |
40 | ## 确认号
41 |
42 | 即 `ACK`(Acknowledgment number)。用来告知对方下一个期望接收的序列号,小于 ACK 的所有字节已经全部收到。
43 |
44 | ## 标记位
45 |
46 | 常见的标记位有 `SYN`,`ACK`,`FIN`,`RST`,`PSH`。
47 |
48 | `SYN` 和 `ACK` 已经在上文说过,后三个解释如下: FIN: 即 Finish,表示发送方准备断开连接。
49 |
50 | `RST`:即 `Reset`,用来强制断开连接。
51 |
52 | `PSH`: 即 `Push`, 告知对方这些数据包收到后应该马上交给上层的应用,不能缓存。
53 |
54 | ## 窗口大小
55 |
56 | 占用两个字节,也就是 16 位,但实际上是不够用的。因此 TCP 引入了窗口缩放的选项,作为窗口缩放的比例因子,这个比例因子的范围在 0 ~ 14,比例因子可以将窗口的值扩大为原来的 2 ^ n 次方。
57 |
58 | ## 校验和
59 |
60 | 占用两个字节,防止传输过程中数据包有损坏,如果遇到校验和有差错的报文,TCP 直接丢弃之,等待重传。
61 |
62 | ## 可选项
63 |
64 | 可选项的格式如下:
65 |
66 | 
67 |
68 | 常用的可选项有以下几个:
69 |
70 | - TimeStamp: TCP 时间戳,后面详细介绍。
71 | - MSS: 指的是 TCP 允许的从对方接收的最大报文段。
72 | - SACK: 选择确认选项。
73 | - Window Scale: 窗口缩放选项。
74 |
--------------------------------------------------------------------------------
/docs/algorithm/sort/heapSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 堆排序
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | ## 简明解释
13 |
14 | 堆的定义
15 |
16 | 堆其实是一种特殊的树。只要满足这两点,它就是一个堆。
17 |
18 | 堆排序可以认为是选择排序的改进版,像选择排序一样将输入划分为已排序和待排序。
19 |
20 | 不一样的是堆排序利用堆这种近似完全二叉树的良好的数据结构来实现排序,本质上使用了二分的思想。
21 |
22 | 
23 |
24 | ## 算法步骤
25 |
26 | - 创建一个堆 H[0……n-1];
27 | - 把堆首(最大值)和堆尾互换;
28 | - 把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
29 | - 重复步骤 2,直到堆的尺寸为 1。
30 |
31 | ## 基本实现
32 |
33 | ```js
34 | function heapSort(arr) {
35 | let size = arr.length;
36 |
37 | // 初始化堆,i 从最后一个父节点开始调整,直到节点均调整完毕
38 | for (let i = Math.floor(size / 2) - 1; i >= 0; i--) {
39 | heapify(arr, i, size);
40 | }
41 | // 堆排序:先将第一个元素和已拍好元素前一位作交换,再重新调整,直到排序完毕
42 | for (let i = size - 1; i > 0; i--) {
43 | swap(arr, 0, i);
44 | size -= 1;
45 | heapify(arr, 0, size);
46 | }
47 |
48 | return arr;
49 | }
50 |
51 | function heapify(arr, index, size) {
52 | let largest = index;
53 | let left = 2 * index + 1;
54 | let right = 2 * index + 2;
55 |
56 | if (left < size && arr[left] > arr[largest]) {
57 | largest = left;
58 | }
59 | if (right < size && arr[right] > arr[largest]) {
60 | largest = right;
61 | }
62 | if (largest !== index) {
63 | swap(arr, index, largest);
64 | heapify(arr, largest, size);
65 | }
66 | }
67 |
68 | // test
69 | const arr = [91, 60, 96, 7, 35, 65, 10, 65, 9, 30, 20, 31, 77, 81, 24];
70 | console.log(heapSort(arr));
71 | ```
72 |
73 | ---
74 |
75 | - 动画来源 [图解面试算法](https://github.com/MisterBooo/LeetCodeAnimation)
76 | - 参考 [优雅的 JavaScript 排序算法(ES6)](https://juejin.im/post/5ab62ec36fb9a028cf326c49)
77 |
--------------------------------------------------------------------------------
/docs/algorithm/深度遍历/单词搜索.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 单词搜索
3 | date: 2022-05-17 16:21:09
4 | sidebar: auto
5 | tags:
6 | - 深度遍历
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 单词搜索
12 |
13 | 给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
14 |
15 | 单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
16 |
17 | 
18 |
19 | ```js
20 | 输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
21 | 输出:true
22 | ```
23 |
24 | 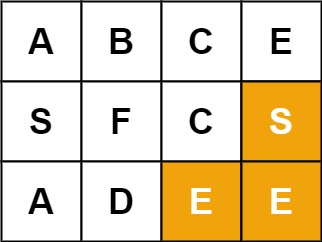
25 |
26 | ```js
27 | 输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
28 | 输出:true
29 | ```
30 |
31 | 
32 |
33 | ```js
34 | 输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
35 | 输出:false
36 | ```
37 |
38 | ```js
39 | /**
40 | * @param {character[][]} board
41 | * @param {string} word
42 | * @return {boolean}
43 | */
44 | var exist = function (board, word) {
45 | let n = board.length,
46 | m = board[0].length;
47 |
48 | function dfs(i, j, word) {
49 | if (!word) return true;
50 | if (i < 0 || i >= n || j < 0 || j >= m) return false;
51 | let char = word[0];
52 | let next = word.slice(1);
53 | if (board[i][j] !== char) return false;
54 | board[i][j] = undefined;
55 | let res = dfs(i - 1, j, next) || dfs(i + 1, j, next) || dfs(i, j + 1, next) || dfs(i, j - 1, next);
56 | board[i][j] = char;
57 | return res;
58 | }
59 |
60 | for (let i = 0; i < n; i++) {
61 | for (let j = 0; j < m; j++) {
62 | if (dfs(i, j, word)) return true;
63 | }
64 | }
65 | return false;
66 | };
67 | ```
68 |
--------------------------------------------------------------------------------
/docs/algorithm/数组/合并两个有序数组.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 合并两个有序数组
3 | date: 2022-05-14 12:15:34
4 | sidebar: auto
5 | tags:
6 | - 数组
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [leetcode](https://leetcode.cn/problems/merge-sorted-array): 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
12 |
13 | 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
14 |
15 | 最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n
16 |
17 | ```js
18 | 输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
19 | 输出:[1,2,2,3,5,6]
20 | 解释:需要合并 [1,2,3] 和 [2,5,6] 。
21 | 合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
22 |
23 | 输入:nums1 = [1], m = 1, nums2 = [], n = 0
24 | 输出:[1]
25 | 解释:需要合并 [1] 和 [] 。
26 | 合并结果是 [1] 。
27 |
28 | 输入:nums1 = [0], m = 0, nums2 = [1], n = 1
29 | 输出:[1]
30 | 解释:需要合并的数组是 [] 和 [1] 。
31 | 合并结果是 [1] 。
32 | 注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
33 | ```
34 |
35 | [题解](https://leetcode.cn/problems/merge-sorted-array/solution/ni-xiang-shuang-zhi-zhen-he-bing-liang-g-ucgj/)
36 |
37 | ---
38 |
39 | 思路 后面往前合并
40 |
41 | 
42 |
43 | ```js
44 | /**
45 | * @param {number[]} nums1
46 | * @param {number} m
47 | * @param {number[]} nums2
48 | * @param {number} n
49 | * @return {void} Do not return anything, modify nums1 in-place instead.
50 | */
51 | var merge = function (nums1, m, nums2, n) {
52 | let i = m - 1,
53 | j = n - 1,
54 | k = nums1.length - 1;
55 |
56 | while (i >= 0 && j >= 0) {
57 | if (nums1[i] > nums2[j]) nums1[k--] = nums1[i--];
58 | else nums1[k--] = nums2[j--];
59 | }
60 |
61 | // 到最后 nums2 还有数据,继续插入 nums1 前面
62 | while (j >= 0) {
63 | nums1[k--] = nums2[j--];
64 | }
65 | };
66 | ```
67 |
--------------------------------------------------------------------------------
/docs/network-protocol/10.http请求体和请求头.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 请求体以及 Accept
3 | date: 2018-09-18 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | ## 数据格式
12 |
13 | HTTP 它支持非常多的数据格式,那么这么多格式的数据一起到达客户端,客户端怎么知道它的格式呢?
14 |
15 | 具体体现在 `MIME`(Multipurpose Internet Mail Extensions, 多用途互联网邮件扩展)。它首先用在电子邮件系统中,让邮件可以发任意类型的数据,这对于 HTTP 来说也是通用的。
16 |
17 | 因此,HTTP 从 `MIME type` 取了一部分来标记报文 body 部分的数据类型,这些类型体现在 `Content-Type` 这个字段,当然这是针对于发送端而言,接收端想要收到特定类型的数据,也可以用 `Accept` 字段。
18 |
19 | 具体而言,这两个字段的取值可以分为下面几类:
20 |
21 | - `text`: text/html, text/plain, text/css 等
22 | - `image`: image/gif, image/jpeg, image/png 等
23 | - `audio/video`: audio/mpeg, video/mp4 等
24 | - `application`: application/json, application/javascript, application/pdf, application/octet-stream
25 |
26 | ## 压缩方式
27 |
28 | 当然一般这些数据都是会进行编码压缩的,采取什么样的压缩方式就体现在了发送方的 `Content-Encoding` 字段上, 同样的,接收什么样的压缩方式体现在了接受方的 `Accept-Encoding` 字段上。这个字段的取值有下面几种:
29 |
30 | - gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式;
31 | - deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
32 | - br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
33 |
34 | ```js
35 | // 发送端
36 | Content-Encoding: gzip
37 | // 接收端
38 | Accept-Encoding: gzip
39 | ```
40 |
41 | ## 支持语言
42 |
43 | 对于发送方而言,还有一个 `Content-Language` 字段,在需要实现国际化的方案当中,可以用来指定支持的语言,在接受方对应的字段为 `Accept-Language`。如:
44 |
45 | ```js
46 | // 发送端
47 | Content-Language: zh-CN, zh, en
48 | // 接收端
49 | Accept-Language: zh-CN, zh, en
50 | ```
51 |
52 | ## 字符集
53 |
54 | 最后是一个比较特殊的字段, 在接收端对应为 `Accept-Charset`,指定可以接受的字符集,而在发送端并没有对应的 `Content-Charset`, 而是直接放在了 `Content-Type` 中,以 `charset` 属性指定。如:
55 |
56 | ```js
57 | // 发送端
58 | Content-Type: text/html; charset=utf-8
59 | // 接收端
60 | Accept-Charset: charset=utf-8
61 | ```
62 |
63 | 最后以一张图来总结一下吧:
64 |
65 | 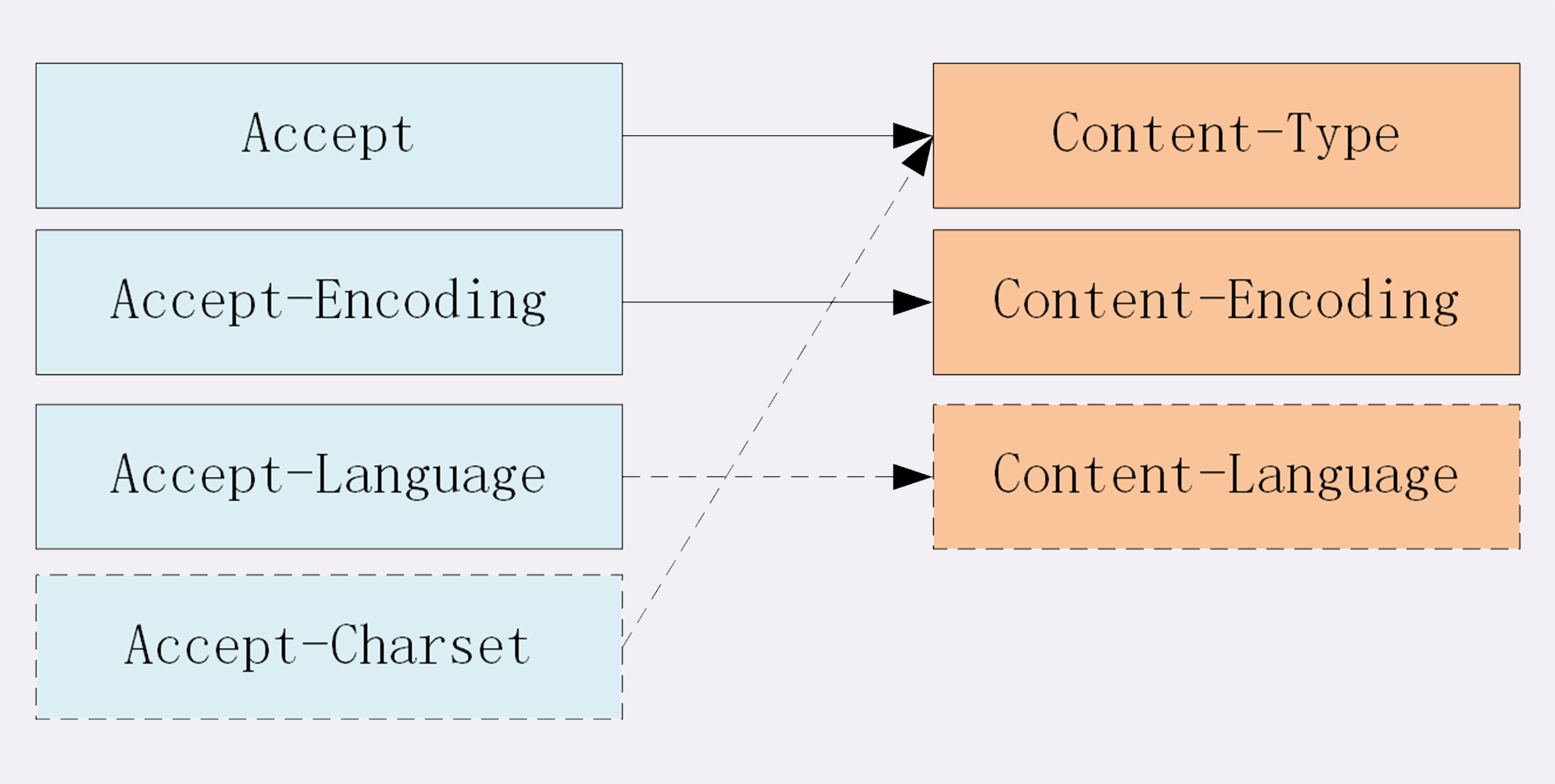
66 |
--------------------------------------------------------------------------------
/docs/algorithm/二叉树/二叉树的公共祖先.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 二叉树的公共祖先
3 | date: 2022-05-13 22:20:58
4 | sidebar: auto
5 | tags:
6 | - 二叉树
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 二叉树的最近公共祖先
12 |
13 | [leetcode](https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree)给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
14 |
15 | 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
16 |
17 | 
18 |
19 | ```js
20 | 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
21 | 输出:3
22 | 解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
23 |
24 | 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
25 | 输出:5
26 | 解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
27 |
28 | 输入:root = [1,2], p = 1, q = 2
29 | 输出:1
30 | ```
31 |
32 | ---
33 |
34 | 思考:中序遍历 有公共节点 就会有路径重复的情况...
35 |
36 | ```js
37 | /**
38 | * @param {TreeNode} root
39 | * @param {TreeNode} p
40 | * @param {TreeNode} q
41 | * @return {TreeNode}
42 | */
43 | var lowestCommonAncestor = function (root, p, q) {
44 | // 当前节点就是 p 或者 q 直接返回
45 | if (!root || root === p || root === q) return root;
46 |
47 | // 都不是,继续递归
48 | let left = lowestCommonAncestor(root.left, p, q);
49 | let right = lowestCommonAncestor(root.right, p, q);
50 |
51 | // 当前节点为公共节点
52 | if (left && right) return root;
53 |
54 | // 返回其中一个节点
55 | return left || right;
56 | };
57 | ```
58 |
59 | ## 二叉搜索树的最近公共祖先
60 |
61 | ```js
62 | var lowestCommonAncestor = function (root, p, q) {
63 | if (!root || root === p || root === q) return root;
64 | // 都不是,继续递归
65 | let left = lowestCommonAncestor(root.left, p, q);
66 | let right = lowestCommonAncestor(root.right, p, q);
67 |
68 | // 当前节点为公共节点
69 | if (left && right) return root;
70 |
71 | // 返回其中一个节点
72 | return left || right;
73 | };
74 | ```
75 |
--------------------------------------------------------------------------------
/docs/ai/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: AI
3 | date: 2025-12-15 12:32:19
4 | sidebar: auto
5 | tags:
6 | - AI
7 | categories:
8 | - AI
9 | ---
10 |
11 | ### Awesome
12 |
13 | https://mmh1.top/#/ai-tutorial
14 |
15 | 理解模型的核心概念确实是实践前的重要一步。下面我用一个表格来清晰解释你提到的这几个关键术语。
16 |
17 | ### 📖 核心概念解析
18 |
19 | | 概念 | 核心定义 | 类比解释 | 关键原因/意义 | 关联实践 |
20 | | :----------------------- | :----------------------------------------------------------------------------------------- | :--------------------------------------------------------------------------------- | :--------------------------------------------------------------------------------- | :-------------------------------------------------------------------------- |
21 | | **大模型 (LLM)** | 参数量巨大(通常数十亿以上)、基于海量数据训练、能处理多种复杂任务的自然语言处理模型。 | 像一个**博览群书的超级学者**,通识能力极强,能回答广泛问题、写作、编程等。 | 其涌现能力(未经专门训练就能完成新任务)是 AI 发展的突破,成为当前 AI 应用的基础。 | 直接使用(提问/对话),或作为基座模型进行**微调**。 |
22 | | **微调 (Fine-tuning)** | 在预训练好的**大模型**基础上,用特定领域的小规模数据继续训练,使其适应专门任务。 | 让“超级学者”**攻读一个专业学位**(如法律、医疗),成为该领域的专家。 | 以较低成本让通用模型获得专业能力,是定制化 AI 应用的主要方法。 | 需要准备领域数据,使用框架(如 PyTorch)或平台(如 Hugging Face)进行。 |
23 | | **过拟合 (Overfitting)** | 模型在训练数据上表现完美,但在未见过的测试数据上表现很差,即“**学得太死,不会举一反三**”。 | 学生**死记硬背了所有习题答案**,但考题稍一变化就不会做。 | 是模型训练中的核心挑战,衡量模型是否真正学会了“规律”而非“记忆”。 | 通过划分训练/验证集、早停、正则化、数据增强等技术来避免。 |
24 | | **Transformer** | 一种基于**自注意力机制**的神经网络架构,是现代**大模型**(如 GPT、BERT)的**核心引擎**。 | 像一个**超级高效的阅读理解系统**,能同时权衡句子中所有词之间的关系,捕捉长远依赖。 | 解决了传统模型(如 RNN)处理长文本的瓶颈,并行计算效率高,成为大模型的基石。 | 理解其结构是深入 NLP 的关键;实际中我们直接调用基于它构建的模型(如 GPT)。 |
25 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/N皇后.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: N皇后
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [力扣题目链接](https://leetcode-cn.com/problems/n-queens/)
12 |
13 | n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
14 |
15 | 给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
16 |
17 | 每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
18 |
19 | 示例 1:
20 |
21 | 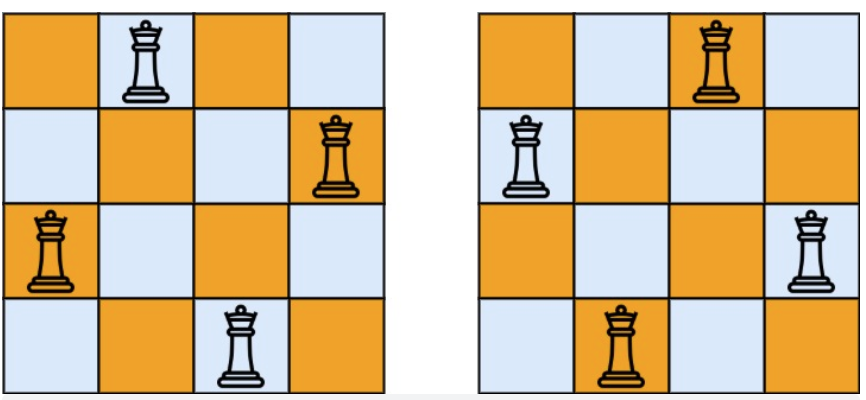
22 |
23 | ```js
24 | - 输入:n = 4
25 | - 输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
26 | - 解释:如上图所示,4 皇后问题存在两个不同的解法。
27 | ```
28 |
29 | 示例 2:
30 |
31 | ```js
32 | - 输入:n = 1
33 | - 输出:[["Q"]]
34 | ```
35 |
36 | ```js
37 | /**
38 | * @param {number} n
39 | * @return {string[][]}
40 | */
41 | var solveNQueens = function (n) {
42 | let result = [];
43 |
44 | // 初始化棋盘
45 | let chessBoard = new Array(n).fill([]).map(() => new Array(n).fill('.'));
46 |
47 | function backtrack(chessBoard, row) {
48 | if (row === n) {
49 | // end 终止条件
50 |
51 | result.push(chessBoard.map((item) => item.join(''))); // 推入res数组
52 | return;
53 | }
54 |
55 | for (let col = 0; col < n; col++) {
56 | // isVaild
57 | if (!isVaild(chessBoard, row, col)) continue;
58 |
59 | chessBoard[row][col] = 'Q';
60 | backtrack(chessBoard, row + 1);
61 | chessBoard[row][col] = '.';
62 | }
63 | }
64 |
65 | // 皇后不能处于同一行 同一列 统一斜角上!
66 | function isVaild(chessBoard, row, col) {
67 | // 之前的行
68 | for (let i = 0; i < row; i++) {
69 | // 所有的列
70 | for (let j = 0; j < n; j++) {
71 | if (
72 | chessBoard[i][j] == 'Q' && // 发现了皇后,并且和自己同列/对角线
73 | (j === col || i === row || i + j === row + col || i - j === row - col)
74 | ) {
75 | return false; // 不是合法的选择
76 | }
77 | }
78 | }
79 | return true;
80 | }
81 |
82 | backtrack(chessBoard, 0);
83 | console.log(result);
84 | return result;
85 | };
86 | ```
87 |
--------------------------------------------------------------------------------
/quick-push.py:
--------------------------------------------------------------------------------
1 | import subprocess
2 | from datetime import datetime
3 | import os
4 |
5 |
6 | def git_auto_commit_time():
7 | """
8 | 自动提交并附带时间戳的提交信息
9 | """
10 | try:
11 | # 检查是否有需要提交的更改
12 | result = subprocess.run(
13 | ["git", "status", "--porcelain"], capture_output=True, text=True
14 | )
15 |
16 | if not result.stdout.strip():
17 | print("📭 没有需要提交的更改")
18 | return True
19 |
20 | # 获取当前时间
21 | current_time = datetime.now()
22 |
23 | # 格式化时间选项(多种格式)
24 | time_formats = {
25 | "standard": current_time.strftime("%Y-%m-%d %H:%M:%S"),
26 | "compact": current_time.strftime("%Y%m%d_%H%M%S"),
27 | "readable": current_time.strftime("%b %d %Y, %I:%M %p"),
28 | "timestamp": str(int(current_time.timestamp())),
29 | }
30 |
31 | # 使用标准格式
32 | time_str = time_formats["standard"]
33 |
34 | # 获取当天提交次数(用于生成序列号)
35 | log_result = subprocess.run(
36 | ["git", "log", "--oneline", "--since=midnight", "--pretty=format:%s"],
37 | capture_output=True,
38 | text=True,
39 | )
40 |
41 | # 生成提交信息(带序号)
42 | commit_message = f"Auto commit at {time_str}"
43 |
44 | # 执行git操作
45 | print(f"🕒 提交时间: {time_str}")
46 | print(f"📝 提交信息: {commit_message}")
47 |
48 | subprocess.run(["git", "add", "."], check=True)
49 | subprocess.run(["git", "commit", "-m", commit_message], check=True)
50 |
51 | # 尝试推送
52 | push_result = subprocess.run(["git", "push"], capture_output=True, text=True)
53 |
54 | if push_result.returncode == 0:
55 | print("✅ 提交并推送成功")
56 | return True
57 | else:
58 | print("⚠️ 提交成功但推送失败")
59 | print(f" 错误信息: {push_result.stderr[:100]}...")
60 | return False
61 |
62 | except Exception as e:
63 | print(f"❌ 操作失败: {e}")
64 | return False
65 |
66 |
67 | # 使用示例
68 | if __name__ == "__main__":
69 | git_auto_commit_time()
70 |
--------------------------------------------------------------------------------
/docs/network-protocol/09.http状态码.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 如何理解 HTTP 状态码?
3 | date: 2018-09-20 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | - 状态码
8 | categories:
9 | - 网络协议
10 | ---
11 |
12 | RFC 标准把状态码分成了五类
13 |
14 | - 1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
15 | - 2××:成功,报文已经收到并被正确处理;
16 | - 3××:重定向,资源位置发生变动,需要客户端重新发送请求;
17 | - 4××:客户端错误,请求报文有误,服务器无法处理;
18 | - 5××:服务器错误,服务器在处理请求时内部发生了错误。
19 |
20 | ## 1××
21 |
22 | 1×× 类状态码属于提示信息,是协议处理的中间状态,实际能够用到的时候很少。
23 |
24 | **101 Switching Protocols**。在 `HTTP` 升级为 `WebSocket` 的时候,如果服务器同意变更,就会发送状态码 101。
25 |
26 | ## 2××
27 |
28 | | 状态码 | 描述 |
29 | | ------------------- | ---------------------------------------------------------------------------------------------------- |
30 | | 200 OK | 是最常见的成功状态码,通常在响应体中放有数据。 |
31 | | 204 No Content | 表示成功,但是响应体中没有 body 数据。 |
32 | | 206 Partial Content | 表示部分内容,它的使用场景为 HTTP 分块下载和断电续传,当然也会带上相应的响应头字段 `Content-Range`。 |
33 |
34 | ## 3××
35 |
36 | | 状态码 | 描述 |
37 | | ------ | -------------------------- |
38 | | 301 | 永久重定向 |
39 | | 302 | 临时重定向,不会做缓存优化 |
40 | | 304 | 协商缓存 |
41 |
42 | ## 4xx
43 |
44 | | 状态码 | 描述 |
45 | | ------ | -------------------------------- |
46 | | 400 | 笼统的错误码 |
47 | | 401 | 用户没有访问权限 |
48 | | 403 | Forbidden 表示服务器禁止访问资源 |
49 | | 404 | 资源在本服务器上未找到 |
50 | | 405 | 请求方法不被服务器端允许 |
51 | | 409 | 多个请求发生了冲突 |
52 | | 413 | 请求体的数据过大 |
53 |
54 | ## 5××
55 |
56 | | 状态码 | 描述 |
57 | | ------ | -------------------------------------------------------- |
58 | | 500 | 笼统的错误码 |
59 | | 501 | 表示客户端请求的功能还不支持 |
60 | | 502 | 服务器自身是正常的,但访问的时候出错了,啥错误咱也不知道 |
61 | | 503 | 表示服务器当前很忙,暂时无法响应服务 |
62 |
--------------------------------------------------------------------------------
/docs/network-protocol/18.http2剖析.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HTTP2 内核剖析
3 | date: 2018-09-23 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http2
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 下面的这张图对比了 HTTP/1、HTTPS 和 HTTP/2 的协议栈,你可以清晰地看到,HTTP/2 是建立在“HPack”“Stream”“TLS1.2”基础之上的,比 HTTP/1、HTTPS 复杂了一些。
12 |
13 | 
14 |
15 | ## 连接前言
16 |
17 | 由于 HTTP/2“事实上”是基于 TLS,所以在正式收发数据之前,会有 TCP 握手和 TLS 握手,这两个步骤相信你一定已经很熟悉了,所以这里就略过去不再细说。
18 |
19 | TLS 握手成功之后,客户端必须要发送一个“**连接前言**”(connection preface),用来确认建立 HTTP/2 连接。
20 |
21 | 这个“连接前言”是标准的 HTTP/1 请求报文,使用纯文本的 ASCII 码格式,请求方法是特别注册的一个关键字“PRI”,全文只有 24 个字节:
22 |
23 | ```js
24 | PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
25 | ```
26 |
27 | 只要服务器收到这个“有魔力的字符串”,就知道客户端在 TLS 上想要的是 HTTP/2 协议,而不是其他别的协议,后面就会都使用 HTTP/2 的数据格式。
28 |
29 | :::details nginx 开启 http2 也比较简单
30 |
31 | ```yaml
32 | server {
33 | listen 443 http2 ssl; # 443 端口 http2 ssl
34 | server_name alvin.run;
35 | #... 这是是上面的配置
36 | }
37 | ```
38 |
39 | :::
40 |
41 | ## 头部压缩 (略)
42 |
43 | 上文讲过
44 |
45 | ## 二进制帧
46 |
47 | HTTP/2 中传输的帧结构如下图所示
48 |
49 | 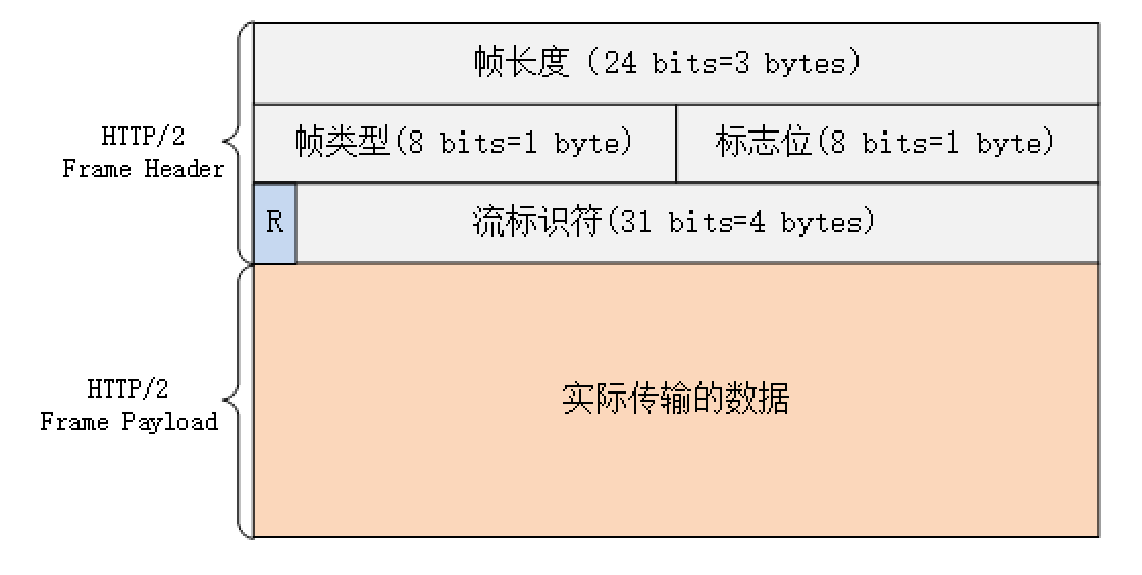
50 |
51 | 每个帧分为**帧头**和**帧体**。先是三个字节的帧长度,这个长度表示的是**帧体**的长度。
52 |
53 | 然后是帧类型,大概可以分为**数据帧**和**控制帧**两种。数据帧用来存放 HTTP 报文,控制帧用来管理流的传输。
54 |
55 | 接下来的一个字节是**帧标志**,里面一共有 8 个标志位,常用的有 `END_HEADERS` 表示头数据结束,`END_STREAM` 表示单方向数据发送结束。
56 |
57 | 后 4 个字节是 `Stream ID`, 也就是**流标识符**,有了它,接收方就能从乱序的二进制帧中选择出 ID 相同的帧,按顺序组装成请求/响应报文。
58 |
59 | ### 流的状态变化
60 |
61 | 从前面可以知道,在 HTTP/2 中,**所谓的流,其实就是二进制帧的双向传输的序列**。那么在 HTTP/2 请求和响应的过程中,流的状态是如何变化的呢?
62 |
63 | HTTP/2 其实也是借鉴了 TCP 状态变化的思想,根据帧的标志位来实现具体的状态改变。这里我们以一个普通的请求-响应过程为例来说明:
64 |
65 | 
66 |
67 | 最开始两者都是空闲状态,当客户端发送 Headers 帧后,开始分配 `Stream ID`, 此时客户端的流打开, 服务端接收之后服务端的流也打开,两端的流都打开之后,就可以互相传递数据帧和控制帧了。
68 |
69 | 当客户端要关闭时,向服务端发送 `END_STREAM` 帧,进入半关闭状态, 这个时候客户端只能接收数据,而不能发送数据。
70 |
71 | 服务端收到这个 END_STREAM 帧后也进入半关闭状态,不过此时服务端的情况是只能发送数据,而不能接收数据。随后服务端也向客户端发送 END_STREAM 帧,表示数据发送完毕,双方进入关闭状态。
72 |
73 | 如果下次要开启新的流,流 ID 需要自增,直到上限为止,到达上限后开一个新的 TCP 连接重头开始计数。由于流 ID 字段长度为 4 个字节,最高位又被保留,因此范围是 0 ~ 2 的 31 次方,大约 21 亿个。
74 |
--------------------------------------------------------------------------------
/docs/network-protocol/04.tcp四次挥手.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: TCP 四次挥手的过程
3 | date: 2018-09-28 16:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - tcp
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 四次挥手即终止 TCP 连接,就是指断开一个 TCP 连接时,需要客户端和服务端总共发送 4 个包以确认连接的断开。
12 |
13 | 
14 |
15 | ## 挥手过程
16 |
17 | 假设客户端发起关闭连接请求
18 |
19 | | 挥手 | 描述 |
20 | | :--: | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
21 | | 1️⃣ | 客户端发送 `FIN,ACK` 包给服务端,告诉他我要关闭请求了,此时进入 `FIN_WAIT` 状态 |
22 | | 2️⃣ | 服务端接收到关闭请求后,发送 `ACK` 包给客户端,告诉他我知道了。
但是我还不确定数据传输完了没,等我确定或者处理完,我这边就发个关闭请求包给你。
此时客户端进入 `FIN_WAIT2` 状态,服务端进入 `CLOSE_WAIT` 状态 |
23 | | 3️⃣ | 服务端传输完数据了,发送 `FIN,ACK` 给客户端,告诉他 我传输完数据了,你可以关闭了。 |
24 | | 4️⃣ | 客户端收到服务端的关闭请求包后,发送 `ACK` 包给服务端,告诉他我知道了,你可以关闭了。
服务端收到后,则进入 `CLOSED` 状态。
由于不确定服务端是否关闭了,客户端还需等待 `2MSL` 后才关闭连接 |
25 |
26 | ## 挥手为什么需要四次?
27 |
28 | 由于 TCP 协议是一种面向连接的、可靠的、基于字节流的运输层通信协议,TCP 是**全双工模式**。
29 |
30 | 这就意味着,关闭连接时,当 Client 端发出 FIN 报文段时,只是表示 Client 端告诉 Server 端数据已经发送完毕了。
31 |
32 | 当 Server 端收到 FIN 报文并返回 ACK 报文段,表示它已经知道 Client 端没有数据发送了,但是 Server 端还是可以发送数据到 Client 端的,所以 Server 很可能并不会立即关闭 SOCKET,直到 Server 端把数据也发送完毕。
33 |
34 | 当 Server 端也发送了 FIN 报文段时,这个时候就表示 Server 端也没有数据要发送了,就会告诉 Client 端,我也没有数据要发送了,之后彼此就会愉快的中断这次 TCP 连接。
35 |
36 | ## 四次挥手释放连接时,等待 2MSL 的意义?
37 |
38 | 如果不等待,客户端直接跑路,当服务端还有很多数据包要给客户端发,且还在路上的时候,若客户端的端口此时刚好被新的应用占用,那么就接收到了无用数据包,造成数据包混乱。所以,最保险的做法是等服务器发来的数据包都死翘翘再启动新的应用。
39 | 那,照这样说一个 MSL 不就不够了吗,为什么要等待 2 MSL?
40 |
41 | - **1 个 MSL 确保四次挥手中主动关闭方最后的 ACK 报文最终能达到对端**
42 | - **1 个 MSL 确保对端没有收到 ACK 重传的 FIN 报文可以到达**
43 |
44 | 这就是等待 2MSL 的意义。
45 |
--------------------------------------------------------------------------------
/docs/algorithm/深度遍历/螺旋矩阵.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 螺旋矩阵
3 | date: 2022-05-17 16:21:09
4 | sidebar: auto
5 | tags:
6 | - 深度遍历
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 螺旋矩阵
12 |
13 | 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
14 |
15 | 
16 |
17 | ```js
18 | 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
19 | 输出:[1,2,3,6,9,8,7,4,5]
20 | ```
21 |
22 | 维护四个状态值即可:
23 |
24 | ```js
25 | /**
26 | * @param {number[][]} matrix
27 | * @return {number[]}
28 | */
29 | var spiralOrder = function (matrix) {
30 | let [l, r, t, b] = [0, matrix[0].length - 1, 0, matrix.length - 1];
31 | let result = [];
32 | let len = matrix[0].length * matrix.length;
33 |
34 | while (result.length < len) {
35 | // l -> r
36 | for (let i = l; i <= r && result.length < len; i++) result.push(matrix[t][i]);
37 | t++;
38 | // t -> b
39 | for (let i = t; i <= b && result.length < len; i++) result.push(matrix[i][r]);
40 | r--;
41 | // r -> l
42 | for (let i = r; i >= l && result.length < len; i--) result.push(matrix[b][i]);
43 | b--;
44 | // b -> t
45 | for (let i = b; i >= t && result.length < len; i--) result.push(matrix[i][l]);
46 | l++;
47 | }
48 |
49 | return result;
50 | };
51 | ```
52 |
53 | ## 螺旋矩阵 II
54 |
55 | 给你一个正整数 n ,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的 n x n 正方形矩阵 matrix 。
56 |
57 | 
58 |
59 | ```js
60 | 输入:n = 3
61 | 输出:[[1,2,3],[8,9,4],[7,6,5]]
62 | ```
63 |
64 | 同理
65 |
66 | ```js
67 | /**
68 | * @param {number} n
69 | * @return {number[][]}
70 | */
71 | var generateMatrix = function (n) {
72 | let [l, r, t, b] = [0, n - 1, 0, n - 1];
73 | let matrix = new Array(n).fill().map(() => new Array(n).fill(undefined));
74 | let num = 1;
75 | let endNum = n * n;
76 | while (num <= endNum) {
77 | for (let i = l; i <= r; i++) matrix[t][i] = num++; // left to right.
78 | t++;
79 | for (let i = t; i <= b; i++) matrix[i][r] = num++; // top to bottom.
80 | r--;
81 | for (let i = r; i >= l; i--) matrix[b][i] = num++; // right to left .
82 | b--;
83 | for (let i = b; i >= t; i--) matrix[i][l] = num++; // bottom to top.
84 | l++;
85 | }
86 |
87 | return matrix;
88 | };
89 | ```
90 |
--------------------------------------------------------------------------------
/docs/algorithm/字符串/回文系列.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 回文系列
3 | date: 2022-05-14 16:43:54
4 | sidebar: auto
5 | tags:
6 | - 字符串
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 最长回文串
12 |
13 | [leetcode](https://leetcode.cn/problems/longest-palindrome) 给定一个包含大写字母和小写字母的字符串 s ,返回通过这些字母构造成的 **最长的回文串** 。
14 |
15 | 在构造过程中,请注意 **区分大小写** 。比如 "Aa" 不能当做一个回文字符串。
16 |
17 | ```js
18 | 输入:s = "abccccdd"
19 | 输出:7
20 | 解释: 我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
21 |
22 | 输入:s = "a"
23 | 输入:1
24 |
25 | 输入:s = "bb"
26 | 输入: 2
27 | ```
28 |
29 | ### 思路
30 |
31 | 解体的关键在于计算有多少对相同的字符。**就类似于打牌,抽到一对牌就打出来。当所有的牌都抽完了,手里如果还有剩余的未成对的牌,我能还能抽出一张**。
32 |
33 | 这里我用 map 来存放抽到的牌,如果当前抽到的牌已经在手里有了,那么把手里的那个牌和当前的牌凑成一对打出来,结果+2。最后如果手里还有牌,结果+1
34 |
35 | ---
36 |
37 | 1. 回文串的特点是都是成双成对的(除了奇数回文串中心节点之外,其它字符都是成双成对的)
38 | 2. 现在给我们一个字符串,让我们用这个字符串来构建回文串
39 | 3. 关键在于计算有多少对相同的字符
40 |
41 | ### 代码
42 |
43 | ```js
44 | /**
45 | * @param {string} s
46 | * @return {number}
47 | */
48 | var longestPalindrome = function (s) {
49 | let map = new Map();
50 | let sum = 0;
51 | for (let char of s) {
52 | if (map.has(char)) {
53 | sum += 2;
54 | map.delete(char);
55 | } else {
56 | map.set(char);
57 | }
58 | }
59 |
60 | // 如果手上还有牌,则 + 1
61 | let temp = map.size > 0 ? 1 : 0;
62 | return sum + temp;
63 | };
64 | ```
65 |
66 | ## 最长回文子串
67 |
68 | 给你一个字符串 s,找到 s 中最长的回文子串。
69 |
70 | ```js
71 | 输入:s = "babad"
72 | 输出:"bab"
73 | 解释:"aba" 同样是符合题意的答案。
74 |
75 | 输入:s = "cbbd"
76 | 输出:"bb"
77 | ```
78 |
79 | ```js
80 | /**
81 | * @param {string} s
82 | * @return {string}
83 | */
84 | var longestPalindrome = function (s) {
85 | let res = s[0];
86 | let len = s.length;
87 | for (let i = 1; i < len; i++) {
88 | let [l, r] = [i, i];
89 | // 左回文 bb 情况
90 | while (l > 0 && s[i] === s[l - 1]) l--;
91 |
92 | // 右回文
93 | while (r < len - 1 && s[i] === s[r + 1]) r++;
94 |
95 | // 左右回文 bab 情况
96 | while (l > 0 && r < len - 1 && s[l - 1] === s[r + 1]) {
97 | l--;
98 | r++;
99 | }
100 |
101 | if (l < r) {
102 | let cur = s.slice(l, r + 1);
103 | res = cur.length > res.length ? cur : res;
104 | }
105 | }
106 |
107 | return res;
108 | };
109 | ```
110 |
--------------------------------------------------------------------------------
/docs/algorithm/sort/insertSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 插入排序
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | ## 算法步骤
13 |
14 | 1. 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
15 | 2. 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
16 |
17 | 
18 |
19 | ## 基本实现
20 |
21 | ```js
22 | function insertSort(arr) {
23 | for (let i = 1; i < arr.length; i++) {
24 | let current = arr[i];
25 | let prevIndex = i - 1;
26 |
27 | while (arr[prevIndex] > current) {
28 | arr[prevIndex + 1] = arr[prevIndex]; // 如果前一个比 current 大,则往后移动一位,prevIndex-- 继续循环
29 | prevIndex--;
30 | }
31 | arr[prevIndex + 1] = current; // 插入
32 | }
33 |
34 | return arr;
35 | }
36 | ```
37 |
38 | ## 使用二分查找
39 |
40 | 首先把二分查找算法做一点小修改,以适应我们的插入排序:
41 |
42 | ```js
43 | function binarySearch(arr, maxIndex, value) {
44 | let min = 0;
45 | let max = maxIndex;
46 |
47 | while (min <= max) {
48 | const mid = Math.floor((min + max) / 2);
49 |
50 | if (arr[mid] <= value) {
51 | min = mid + 1;
52 | } else {
53 | max = mid - 1;
54 | }
55 | }
56 |
57 | return min;
58 | }
59 | ```
60 |
61 | 然后在查找插入位置时使用二分查找的方式来优化性能:
62 |
63 | ```js
64 | function insertionSort2(arr) {
65 | for (let i = 1, len = arr.length; i < len; i++) {
66 | const current = arr[i];
67 | const insertIndex = binarySearch(arr, i - 1, current); // 找到当前需要插入的 index
68 |
69 | for (let prevIndex = i - 1; prevIndex >= insertIndex; prevIndex--) {
70 | arr[prevIndex + 1] = arr[prevIndex];
71 | }
72 | arr[insertIndex] = current; // 恢复
73 | }
74 |
75 | return arr;
76 | }
77 |
78 | // test
79 | const arr = [91, 60, 96, 7, 35, 65, 10, 65, 9, 30, 20, 31, 77, 81, 24];
80 | console.log(insertionSort2(arr));
81 | ```
82 |
83 | - 稳定
84 | - 适合场景:对快要排序完成的数组时间复杂度为 O(n)
85 | - 非常低的开销
86 | - 时间复杂度 `O(n²)`
87 |
88 | > 由于它的优点(自适应,低开销,稳定,几乎排序时的 `O(n)`时间),插入排序通常用作递归基本情况(当问题规模较小时)针对较高开销分而治之排序算法, 如希尔排序或快速排序。
89 |
90 | - 高性能(特别是接近排序完毕时的数组),低开销,且稳定
91 | - 利用二分查找来优化
92 |
93 | ---
94 |
95 | - 动画来源 [图解面试算法](https://github.com/MisterBooo/LeetCodeAnimation)
96 | - 参考 [优雅的 JavaScript 排序算法(ES6)](https://juejin.im/post/5ab62ec36fb9a028cf326c49)
97 |
--------------------------------------------------------------------------------
/docs/.vitepress/cache/deps/@theme_index.js.map:
--------------------------------------------------------------------------------
1 | {
2 | "version": 3,
3 | "sources": ["../../../../node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/index.js", "../../../../node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/without-fonts.js"],
4 | "sourcesContent": ["import './styles/fonts.css';\nexport * from './without-fonts';\nexport { default as default } from './without-fonts';\n", "import './styles/vars.css';\nimport './styles/base.css';\nimport './styles/utils.css';\nimport './styles/components/custom-block.css';\nimport './styles/components/vp-code.css';\nimport './styles/components/vp-code-group.css';\nimport './styles/components/vp-doc.css';\nimport './styles/components/vp-sponsor.css';\nimport VPBadge from './components/VPBadge.vue';\nimport Layout from './Layout.vue';\n// Note: if we add more optional components here, i.e. components that are not\n// used in the theme by default unless the user imports them, make sure to update\n// the `lazyDefaultThemeComponentsRE` regex in src/node/build/bundle.ts.\nexport { default as VPHomeHero } from './components/VPHomeHero.vue';\nexport { default as VPHomeFeatures } from './components/VPHomeFeatures.vue';\nexport { default as VPHomeSponsors } from './components/VPHomeSponsors.vue';\nexport { default as VPDocAsideSponsors } from './components/VPDocAsideSponsors.vue';\nexport { default as VPTeamPage } from './components/VPTeamPage.vue';\nexport { default as VPTeamPageTitle } from './components/VPTeamPageTitle.vue';\nexport { default as VPTeamPageSection } from './components/VPTeamPageSection.vue';\nexport { default as VPTeamMembers } from './components/VPTeamMembers.vue';\nconst theme = {\n Layout,\n enhanceApp: ({ app }) => {\n app.component('Badge', VPBadge);\n }\n};\nexport default theme;\n"],
5 | "mappings": ";AAAA,OAAO;;;ACAP,OAAO;AACP,OAAO;AACP,OAAO;AACP,OAAO;AACP,OAAO;AACP,OAAO;AACP,OAAO;AACP,OAAO;AACP,OAAO,aAAa;AACpB,OAAO,YAAY;AAInB,SAAoB,WAAXA,gBAA6B;AACtC,SAAoB,WAAXA,gBAAiC;AAC1C,SAAoB,WAAXA,gBAAiC;AAC1C,SAAoB,WAAXA,gBAAqC;AAC9C,SAAoB,WAAXA,gBAA6B;AACtC,SAAoB,WAAXA,gBAAkC;AAC3C,SAAoB,WAAXA,gBAAoC;AAC7C,SAAoB,WAAXA,gBAAgC;AACzC,IAAM,QAAQ;AAAA,EACV;AAAA,EACA,YAAY,CAAC,EAAE,IAAI,MAAM;AACrB,QAAI,UAAU,SAAS,OAAO;AAAA,EAClC;AACJ;AACA,IAAO,wBAAQ;",
6 | "names": ["default"]
7 | }
8 |
--------------------------------------------------------------------------------
/docs/algorithm/binarySearch.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 二分查找
3 | date: 2020-05-24 23:37:51
4 | sidebar: auto
5 | ---
6 |
7 | ## 模板 1 【左区右闭】
8 |
9 | ```js
10 | function binarySearch(nums, target) {
11 | let l = 0,
12 | r = target.length - 1,
13 | mid = undefined;
14 |
15 | while (l <= r) {
16 | mid = (l + r) >>> 1;
17 | if (nums[mid] === target) return mid;
18 | else if (nums[mid] < target) l = mid + 1;
19 | else r = mid - 1;
20 | }
21 |
22 | return -1;
23 | }
24 | ```
25 |
26 | ## 模板 2 【左区右开】
27 |
28 | 主要是找极值用的多,比如找元素最左的位置
29 |
30 | ```js
31 | function getTargetLeft(nums, target) {
32 | let l = 0,
33 | r = nums.length,
34 | mid = undefined;
35 |
36 | while (l < r) {
37 | mid = (l + r) >>> 1;
38 | // target <= mid r
39 | if (nums[mid] >= target) r = mid;
40 | else l = mid + 1;
41 | }
42 |
43 | return nums[l] === target ? l : -1;
44 | }
45 |
46 | getTargetLeft([5, 7, 7, 8, 8, 10], 8); // 3
47 | ```
48 |
49 | 找元素最右的位置
50 |
51 | ```js
52 | function getTargeRight(nums, target) {
53 | let l = 0,
54 | r = nums.length,
55 | mid = undefined;
56 |
57 | while (l < r) {
58 | mid = (l + r) >>> 1;
59 | // target < mid r
60 | if (nums[mid] > target) r = mid;
61 | else l = mid + 1;
62 | }
63 | // 终止条件 l = r
64 | return nums[l - 1] === target ? l - 1 : -1;
65 | }
66 |
67 | getTargeRight([5, 7, 7, 8, 8, 10], 8); // 4
68 | ```
69 |
70 | ## 搜索旋转排序数组
71 |
72 | [题目链接](https://leetcode-cn.com/problems/search-in-rotated-sorted-array/)
73 |
74 | 输入:nums = [4,5,6,7,0,1,2], target = 0
75 | 输出:4
76 |
77 | 输入:nums = [4,5,6,7,0,1,2], target = 3
78 | 输出:-1
79 |
80 | ```js
81 | /**
82 | * @param {number[]} nums
83 | * @param {number} target
84 | * @return {number}
85 | */
86 | var search = function (nums, target) {
87 | let l = 0,
88 | r = nums.length - 1,
89 | mid = undefined;
90 |
91 | while (l <= r) {
92 | mid = (l + r) >>> 1;
93 | if (nums[mid] === target) return mid;
94 | // 右递增
95 | if (nums[mid] < nums[r]) {
96 | // 注意 target <= nums[r]
97 | if (nums[mid] < target && target <= nums[r]) l = mid + 1;
98 | else r = mid - 1;
99 | } else {
100 | if (nums[l] <= target && target < nums[mid]) r = mid - 1;
101 | else l = mid + 1;
102 | }
103 | }
104 |
105 | return -1;
106 | };
107 | ```
108 |
--------------------------------------------------------------------------------
/docs/algorithm/动态规划/爬楼梯.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 爬楼梯系列
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 动态规划
7 | categories:
8 | - leetcode
9 | ---
10 |
11 |
24 |
25 | ## 爬楼梯
26 |
27 | 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
28 |
29 | 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
30 |
31 | ```js
32 | var climbStairs = function (n) {
33 | let dp = [1, 1];
34 |
35 | for (let i = 2; i <= n; i++) {
36 | dp[i] = dp[i - 1] + dp[i - 2];
37 | }
38 |
39 | return dp[n];
40 | };
41 | ```
42 |
43 | ## 使用最小花费爬楼梯
44 |
45 | [leetcode](https://leetcode.cn/problems/min-cost-climbing-stairs): 给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
46 |
47 | 你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
48 |
49 | 请你计算并返回达到楼梯顶部的最低花费。
50 |
51 | ```js
52 | 输入:cost = [10,15,20]
53 | 输出:15
54 | 解释:你将从下标为 1 的台阶开始。
55 | - 支付 15 ,向上爬两个台阶,到达楼梯顶部。
56 | 总花费为 15 。
57 |
58 | 输入:cost = [1,100,1,1,1,100,1,1,100,1]
59 | 输出:6
60 | 解释:你将从下标为 0 的台阶开始。
61 | - 支付 1 ,向上爬两个台阶,到达下标为 2 的台阶。
62 | - 支付 1 ,向上爬两个台阶,到达下标为 4 的台阶。
63 | - 支付 1 ,向上爬两个台阶,到达下标为 6 的台阶。
64 | - 支付 1 ,向上爬一个台阶,到达下标为 7 的台阶。
65 | - 支付 1 ,向上爬两个台阶,到达下标为 9 的台阶。
66 | - 支付 1 ,向上爬一个台阶,到达楼梯顶部。
67 | 总花费为 6 。
68 | ```
69 |
70 | 思路
71 |
72 | 第 i 个台阶可以由**第 i 个台阶** 或者 **第 i -1 个台阶** 到达。
73 |
74 | 要到达 第 i 个台阶,则取决于前面两次 dp 结果:`dp[i] = Math.min(dp[i - 1], dp[i - 2]) + cost[i]`
75 |
76 | 最终比较 i i-1 即可。
77 |
78 | ```js
79 | /**
80 | * @param {number[]} cost
81 | * @return {number}
82 | */
83 | var minCostClimbingStairs = function (cost) {
84 | // dp[i] = Math.min()
85 | let len = cost.length;
86 | let dp = [cost[0], cost[1]];
87 | for (let i = 2; i < len; i++) {
88 | dp[i] = Math.min(dp[i - 1], dp[i - 2]) + cost[i];
89 | }
90 |
91 | //已经在楼顶了,在前两步中找花费最少的
92 | return Math.min(dp[len - 1], dp[len - 2]);
93 | };
94 | ```
95 |
96 | 优化空间复杂度:
97 |
98 | ```js
99 | /**
100 | * @param {number[]} cost
101 | * @return {number}
102 | */
103 | var minCostClimbingStairs = function (cost) {
104 | let dp = [cost[0], cost[1]];
105 | for (let i = 2; i < cost.length; i++) {
106 | let dpi = Math.min(dp[0], dp[1]) + cost[i];
107 | dp[0] = dp[1];
108 | dp[1] = dpi;
109 | }
110 |
111 | //已经在楼顶了,在前两步中找花费最少的
112 | return Math.min(dp[0], dp[1]);
113 | };
114 | ```
115 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/回溯分割.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 回溯分割系列
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 分割回文串
12 |
13 | [分割回文串](https://leetcode-cn.com/problems/palindrome-partitioning/)
14 |
15 | ```js
16 | 输入:s = "aab"
17 | 输出:[["a","a","b"],["aa","b"]]
18 | ```
19 |
20 | ```js
21 | /**
22 | * @param {string} s
23 | * @return {string[][]}
24 | */
25 | var partition = function (s) {
26 | let result = [];
27 |
28 | function backtrack(track, i) {
29 | if (i >= s.length) {
30 | result.push([...track]);
31 | return;
32 | }
33 |
34 | for (let j = i; j < s.length; j++) {
35 | if (!isHuiWen(s.slice(i, j + 1))) continue;
36 |
37 | // 判断是否回文
38 | track.push(s.slice(i, j + 1));
39 | backtrack(track, j + 1);
40 | track.pop();
41 | }
42 | }
43 |
44 | function isHuiWen(s) {
45 | let tmp = s.split('');
46 | while (tmp.length > 1) {
47 | if (tmp.pop() !== tmp.shift()) return false;
48 | }
49 | return true;
50 | }
51 |
52 | backtrack([], 0);
53 |
54 | return result;
55 | };
56 | ```
57 |
58 | ## 复原 IP 地址
59 |
60 | 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 '.' 分隔。
61 |
62 | 例如:"0.1.2.201" 和 "192.168.1.1" 是 有效 IP 地址,但是 "0.011.255.245"、"192.168.1.312" 和 "192.168@1.1" 是 无效 IP 地址。
63 | 给定一个只包含数字的字符串 s ,用以表示一个 IP 地址,返回所有可能的有效 IP 地址,这些地址可以通过在 s 中插入 '.' 来形成。你 不能 重新排序或删除 s 中的任何数字。你可以按 任何 顺序返回答案。
64 |
65 | ```js
66 | 输入:s = "25525511135"
67 | 输出:["255.255.11.135","255.255.111.35"]
68 |
69 | 输入:s = "0000"
70 | 输出:["0.0.0.0"]
71 |
72 | 输入:s = "101023"
73 | 输出:["1.0.10.23","1.0.102.3","10.1.0.23","10.10.2.3","101.0.2.3"]
74 | ```
75 |
76 | ```js
77 | /**
78 | * @param {string} s
79 | * @return {string[]}
80 | */
81 | var restoreIpAddresses = function (s) {
82 | let result = [];
83 | let path = [];
84 |
85 | function backtracking(i) {
86 | const len = path.length;
87 | if (len > 4) return;
88 | if (len === 4 && i === s.length) {
89 | result.push(path.join('.'));
90 | return;
91 | }
92 | for (let j = i; j < s.length; j++) {
93 | let str = s.slice(i, j + 1);
94 | if (str.length > 3 || Number(str) > 255) break;
95 | if (str.length > 1 && str[0] === '0') break; // 如果当前字符超过1位,但是前导位是0 则跳过
96 | path.push(str);
97 | backtracking(j + 1);
98 | path.pop();
99 | }
100 | }
101 | backtracking(0);
102 | return result;
103 | };
104 | ```
105 |
--------------------------------------------------------------------------------
/docs/algorithm/动态规划/连续.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 动态规划 - 连续
3 | date: 2022-05-10 14:56:33
4 | sidebar: auto
5 | tags:
6 | - 动态规划
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 最大子数组和
12 |
13 | 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
14 |
15 | 子数组 是数组中的一个连续部分。
16 |
17 | ```js
18 | 输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
19 | 输出:6
20 | 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
21 |
22 | 输入:nums = [1]
23 | 输出:1
24 |
25 | 输入:nums = [5,4,-1,7,8]
26 | 输出:23
27 | ```
28 |
29 | ---
30 |
31 | 动态规划 `dp[i] = Math.max(nums[i], dp[i - 1] + nums[i]);`
32 |
33 | ```js
34 | /**
35 | * @param {number[]} nums
36 | * @return {number}
37 | */
38 | var maxSubArray = function (nums) {
39 | let dp = [nums[0]];
40 | let len = nums.length;
41 |
42 | for (let i = 1; i < len; i++) {
43 | dp[i] = Math.max(nums[i], dp[i - 1] + nums[i]);
44 | }
45 |
46 | return Math.max(...dp);
47 | };
48 | ```
49 |
50 | 代码优化
51 |
52 | ```js
53 | var maxSubArray = function (nums) {
54 | let max = nums[0];
55 | let pre = max;
56 | let len = nums.length;
57 | for (let i = 1; i < len; i++) {
58 | pre = Math.max(pre + nums[i], nums[i]);
59 | max = Math.max(max, pre);
60 | }
61 |
62 | return max;
63 | };
64 | ```
65 |
66 | ## 最长重复子数组
67 |
68 | [力扣题目链接](https://leetcode-cn.com/problems/maximum-length-of-repeated-subarray/): 给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
69 |
70 | ```js
71 | 输入:
72 | A: [1,2,3,2,1]
73 | B: [3,2,1,4,7]
74 | 输出:3
75 | 解释:长度最长的公共子数组是 [3, 2, 1] 。
76 | ```
77 |
78 | ### 动态规划
79 |
80 | 
81 |
82 | ```js
83 | const findLength = (A, B) => {
84 | const m = A.length;
85 | const n = B.length;
86 | const dp = new Array(m + 1);
87 | for (let i = 0; i <= m; i++) {
88 | // 初始化整个dp矩阵,每个值为0
89 | dp[i] = new Array(n + 1).fill(0);
90 | }
91 | let res = 0;
92 | // i=0或j=0的base case,初始化时已经包括
93 | for (let i = 1; i <= m; i++) {
94 | // 从1开始遍历
95 | for (let j = 1; j <= n; j++) {
96 | // 从1开始遍历
97 | if (A[i - 1] == B[j - 1]) {
98 | dp[i][j] = dp[i - 1][j - 1] + 1;
99 | } // A[i-1]!=B[j-1]的情况,初始化时已包括了
100 | res = Math.max(dp[i][j], res);
101 | }
102 | }
103 | return res;
104 | };
105 | ```
106 |
107 | ### 滑动窗口解法
108 |
109 | 非常好理解,想象两把尺子,错开之后比较相同的部分,找最长相同的串就好了。
110 |
111 | 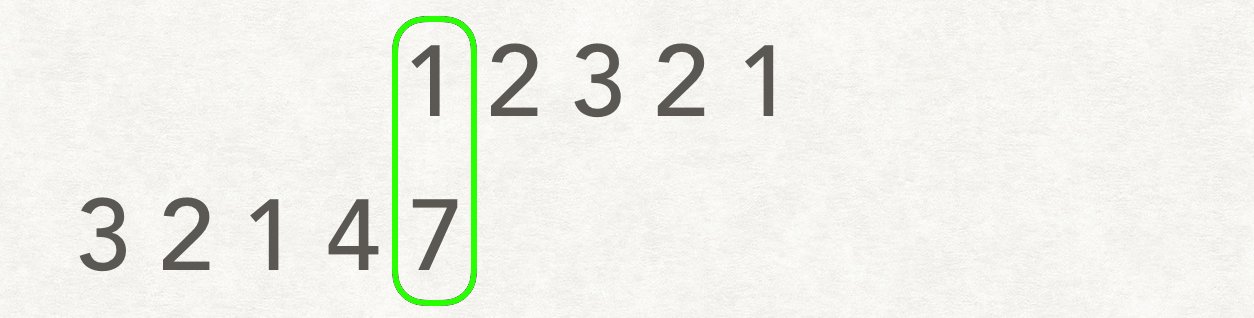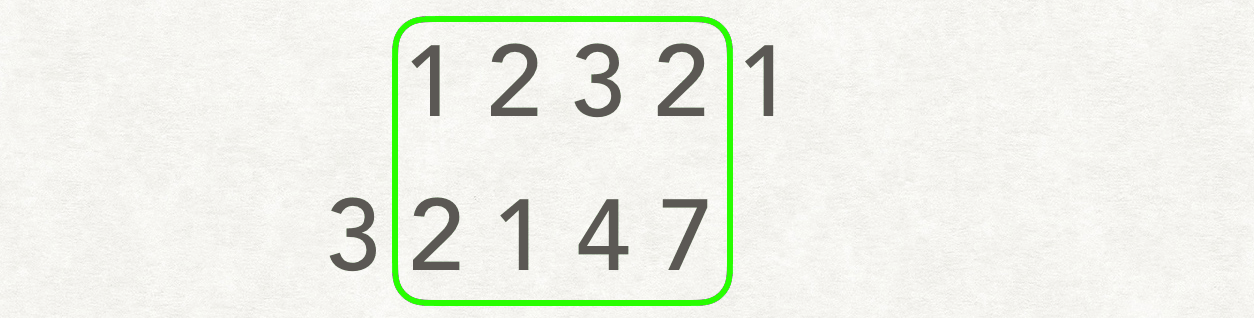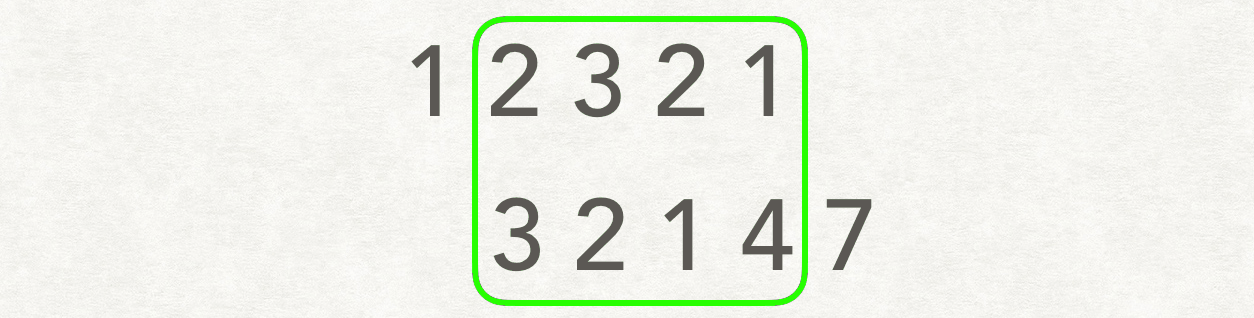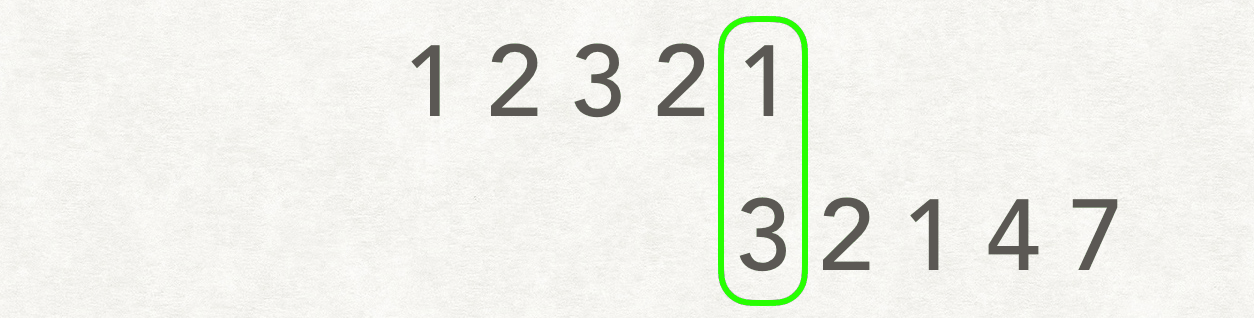
112 |
--------------------------------------------------------------------------------
/docs/algorithm/二叉树/二叉树的遍历方式.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 二叉树遍历方式
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 二叉树
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ```js
12 | // 3
13 | // / \
14 | // 1 4
15 | // \
16 | // 2
17 | ```
18 |
19 | - 中序遍历(左根右):`1 2 3 4`
20 | - 前序遍历(根左右):`3 1 2 4`
21 | - 后序遍历(左右根):`2 1 4 3`
22 |
23 | ---
24 |
25 | - dfs 通过栈实现(x 序遍历)
26 | - bfs 通过队列实现(层序遍历)
27 |
28 | ## 二叉树的前序遍历
29 |
30 | 给你二叉树的根节点 root ,返回它节点值的 前序 遍历。
31 |
32 | ### 递归版本
33 |
34 | ```js
35 | /**
36 | * @param {TreeNode} root
37 | * @return {number[]}
38 | */
39 | var preorderTraversal = function (root) {
40 | if (!root) return [];
41 | return [root.val, ...preorderTraversal(root.left), ...preorderTraversal(root.right)];
42 | };
43 | ```
44 |
45 | ### 栈版本
46 |
47 | ```js
48 | var preorderTraversal = function (root) {
49 | if (!root) return [];
50 | let stack = [root];
51 | let result = [];
52 | while (stack.length) {
53 | const node = stack.pop();
54 | result.push(node.val);
55 | node.right && stack.push(node.right); // 注意 先进后出 这里是右节点先进,然后后出
56 | node.left && stack.push(node.left);
57 | }
58 | return result;
59 | };
60 | ```
61 |
62 | ## 二叉树的后序遍历
63 |
64 | ```js
65 | var postorderTraversal = function (root) {
66 | if (!root) return [];
67 | return [...postorderTraversal(root.left), ...postorderTraversal(root.right), root.val];
68 | };
69 | ```
70 |
71 | ## 二叉树的中序遍历
72 |
73 | ```js
74 | var inorderTraversal = function (root) {
75 | if (!root) return [];
76 | return [...inorderTraversal(root.left), root.val, ...inorderTraversal(root.right)];
77 | };
78 | ```
79 |
80 | ## 二叉树的层序遍历
81 |
82 | - [leetcode](https://leetcode-cn.com/problems/binary-tree-level-order-traversal/):给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
83 |
84 | 
85 |
86 | ```js
87 | 输入:root = [3,9,20,null,null,15,7]
88 | 输出:[[3],[9,20],[15,7]]
89 | ```
90 |
91 | ```js
92 | /**
93 | * @param {TreeNode} root
94 | * @return {number[][]}
95 | */
96 | var levelOrder = function (root) {
97 | if (!root) return [];
98 | let result = [];
99 | let queue = [root];
100 |
101 | while (queue.length) {
102 | let len = queue.length;
103 | let temp = [];
104 | for (let i = 0; i < len; i++) {
105 | let node = queue.shift();
106 | temp.push(node.val);
107 | node.left && queue.push(node.left);
108 | node.right && queue.push(node.right);
109 | }
110 | result.push(temp);
111 | }
112 | return result;
113 | };
114 | ```
115 |
--------------------------------------------------------------------------------
/docs/network-protocol/03.tcp三次握手.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 三次握手的过程是怎样的?
3 | date: 2018-09-15 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - tcp
7 | - 三次握手
8 | categories:
9 | - 网络协议
10 | ---
11 |
12 | TCP 的三次握手,也是需要确认双方的两样能力: 发送的能力和接收的能力。于是便会有下面的三次握手的过程:
13 |
14 | 
15 |
16 | ## 握手过程
17 |
18 | 刚开始客户端处于 `Closed` 的状态,服务端处于 `Listen` 状态。 进行三次握手:
19 |
20 | | 握手 | 描述 |
21 | | ---- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
22 | | 1️⃣ | 客户端给服务端发一个 `SYN` 报文,并指明客户端的初始化序列号 ISN(c)。此时客户端处于 `SYN_SEND` 状态。 |
23 | | 2️⃣ | 服务器收到客户端的 SYN 报文之后,会以自己的 `SYN + ACK` 报文作为应答,并且也是指定了自己的初始化序列号 ISN(s)。 同时会把客户端的 ISN + 1 作为 ACK 的值,表示自己已经收到了客户端的 SYN,此时服务器处于 `SYN_REVD` 的状态。 |
24 | | 3️⃣ | 客户端收到 SYN 报文之后,会发送一个 `ACK` 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 `ESTABLISHED` 状态。服务器收到 ACK 报文之后,也处于 `ESTABLISHED` 状态,此时,双方已建立起了连接。 |
25 |
26 | 从图中可以看出,SYN 是需要消耗一个序列号的,下次发送对应的 ACK 序列号要加 1,为什么呢?只需要记住一个规则:
27 |
28 | **凡是需要对端确认的,一定消耗 TCP 报文的序列号。**
29 |
30 | SYN 需要对端的确认, 而 ACK 并不需要,因此 SYN 消耗一个序列号而 ACK 不需要。
31 |
32 | ## 为什么需要三次握手,两次不行吗?
33 |
34 | 试想如果是用两次握手,则会出现下面这种情况:
35 |
36 | 如果是两次,你现在发了 SYN 报文想握手,但**是这个包滞留在了当前的网络中**迟迟没有到达,TCP 以为这是丢了包,于是重传,两次握手建立好了连接。
37 |
38 | 看似没有问题,但是连接关闭后,如果这个滞留在网路中的包到达了服务端呢?这时候由于是两次握手,服务端只要接收到然后发送相应的数据包,就默认建立连接,但是现在客户端已经断开了。
39 |
40 | 看到问题的吧,这就带来了连接资源的浪费。
41 |
42 | ## 三次握手过程中可以携带数据吗?
43 |
44 | **第三次握手的时候,可以携带。前两次握手不能携带数据。**
45 |
46 | 如果前两次握手能够携带数据,那么一旦有人想攻击服务器,那么他只需要在第一次握手中的 SYN 报文中放大量数据,那么服务器势必会消耗更多的时间和内存空间去处理这些数据,增大了服务器被攻击的风险。
47 |
48 | 第三次握手的时候,客户端已经处于 `ESTABLISHED` 状态,并且已经能够确认服务器的接收、发送能力正常,这个时候相对安全了,可以携带数据。
49 |
50 | ## 同时打开会怎样?
51 |
52 | 如果双方同时发 `SYN` 报文,状态变化会是怎样的呢?
53 |
54 | 这是一个可能会发生的情况。
55 |
56 | 状态变迁如下:
57 |
58 |  59 |
60 | 在发送方给接收方发 `SYN` 报文的同时,接收方也给发送方发 `SYN` 报文,两个人刚上了!
61 |
62 | 发完 SYN,两者的状态都变为 `SYN-SENT`。
63 |
64 | 在各自收到对方的 `SYN` 后,两者状态都变为 `SYN-REVD`。
65 |
66 | 接着会回复对应的 `ACK + SYN`,这个报文在对方接收之后,两者状态一起变为 `ESTABLISHED`。
67 |
68 | 这就是同时打开情况下的状态变迁。
69 |
--------------------------------------------------------------------------------
/docs/algorithm/字符串/最小覆盖子串.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 最小覆盖子串
3 | date: 2022-05-14 10:09:26
4 | sidebar: auto
5 | tags:
6 | - 字符串
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [leetcode](https://leetcode.cn/problems/minimum-window-substring) 给你一个字符串 `s` 、一个字符串 `t` 。返回 `s` 中涵盖 `t` 所有字符的最小子串。如果 `s` 中不存在涵盖 `t` 所有字符的子串,则返回空字符串 "" 。
12 |
13 | 注意
14 |
15 | - 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
16 | - 如果 s 中存在这样的子串,我们保证它是唯一的答案。
17 |
18 | ```js
19 | 输入:s = "ADOBECODEBANC", t = "ABC"
20 | 输出:"BANC"
21 |
22 | 输入:s = "a", t = "a"
23 | 输出:"a"
24 |
25 | 输入: s = "a", t = "aa"
26 | 输出: ""
27 | 解释: t 中两个字符 'a' 均应包含在 s 的子串中,
28 | 因此没有符合条件的子字符串,返回空字符串。
29 | ```
30 |
31 | ## 思路
32 |
33 | 使用滑动窗口
34 |
35 | 用 i,j 表示滑动窗口的左边界和右边界,通过改变 i,j 来扩展和收缩滑动窗口,可以想象成一个窗口在字符串上游走,当这个窗口包含的元素满足条件,即包含字符串 T 的所有元素,记录下这个滑动窗口的长度 j-i+1,这些长度中的最小值就是要求的结果。
36 |
37 | 1. 不断增加 j 使滑动窗口增大,直到窗口包含了 T 的所有元素
38 | 2. 不断增加 i 使滑动窗口缩小,因为是要求最小字串,所以将不必要的元素排除在外,使长度减小,直到碰到一个必须包含的元素,这个时候不能再扔了,再扔就不满足条件了,记录此时滑动窗口的长度,并保存最小值
39 | 3. 让 i 再增加一个位置,这个时候滑动窗口肯定不满足条件了,那么继续从步骤一开始执行,寻找新的满足条件的滑动窗口,如此反复,直到 j 超出了字符串 S 范围。
40 |
41 | 图示
42 |
43 | 以 S="DOABECODEBANC",T="ABC" 为例
44 |
45 | 初始状态:
46 |
47 | 
48 |
49 | 步骤一:不断增加 j 使滑动窗口增大,直到窗口包含了 T 的所有元素
50 |
51 | 
52 |
53 | 步骤二:不断增加 i 使滑动窗口缩小,直到碰到一个必须包含的元素 A,此时记录长度更新结果
54 |
55 | 
56 |
57 | 步骤三:让 i 再增加一个位置,开始寻找下一个满足条件的滑动窗口
58 |
59 | 
60 |
61 | ## 代码
62 |
63 | ```js
64 | /**
65 | * @param {string} s
66 | * @param {string} t
67 | * @return {string}
68 | */
69 | var minWindow = function (s, t) {
70 | // 双指针滑动窗口问题
71 | let i = 0;
72 | let j = 0;
73 | let result = '';
74 |
75 | let map = {};
76 | for (const c of t) {
77 | map[c] = map[c] ? map[c] + 1 : 1;
78 | }
79 |
80 | let count = Object.keys(map).length;
81 |
82 | // 右移指针
83 | while (j < s.length) {
84 | const char = s[j];
85 | if (map[char] !== undefined) map[char]--;
86 | // 如果匹配到一个字符,需要再匹配的数量减 1
87 | if (map[char] === 0) count--;
88 |
89 | while (count === 0) {
90 | const matchStr = s.slice(i, j + 1);
91 | if (!result || matchStr.length < result.length) result = matchStr;
92 |
93 | // 如果当前左指针匹配中了
94 | if (map[s[i]] !== undefined) {
95 | map[s[i]]++;
96 | // 注意!这里 count++ 的条件基于当前 map[s[i]] === 1, 否则可能会重复
97 | if (map[s[i]] === 1) count++;
98 | }
99 |
100 | i++;
101 | }
102 | j++;
103 | }
104 |
105 | return result;
106 | };
107 | ```
108 |
109 | 需要注意的细节点
110 |
111 | ```js
112 | if (map[char] === 0) count--;
113 | if (map[char] === 1) count++;
114 | ```
115 |
--------------------------------------------------------------------------------
/docs/algorithm/贪心算法/贪心入门.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 贪心入门
3 | date: 2022-05-20 00:52:14
4 | sidebar: auto
5 | tags:
6 | - 贪心算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 什么是贪心
12 |
13 | **贪心的本质是选择每一阶段的局部最优,从而达到全局最优。**
14 |
15 | 这么说有点抽象,来举一个例子:
16 |
17 | 例如,有一堆钞票,你可以拿走十张,如果想达到最大的金额,你要怎么拿?
18 |
19 | 指定每次拿最大的,最终结果就是拿走最大数额的钱。
20 |
21 | 每次拿最大的就是局部最优,最后拿走最大数额的钱就是推出全局最优。
22 |
23 | 再举一个例子如果是 有一堆盒子,你有一个背包体积为 n,如何把背包尽可能装满,如果还每次选最大的盒子,就不行了。这时候就需要动态规划。
24 |
25 | ## 分发饼干
26 |
27 | 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
28 |
29 | 对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。**你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。**
30 |
31 | ```js
32 | 输入: g = [1,2,3], s = [1,1]
33 | 输出: 1
34 | 解释: 你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
35 | 虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
36 | 所以你应该输出1。
37 |
38 | 输入: g = [1,2], s = [1,2,3]
39 | 输出: 2
40 | 解释: 你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
41 | 你拥有的饼干数量和尺寸都足以让所有孩子满足。
42 | 所以你应该输出2.
43 | ```
44 |
45 | ---
46 |
47 | **思路**
48 |
49 | 为了满足更多的小孩,就不要造成饼干尺寸的浪费。
50 |
51 | 大尺寸的饼干既可以满足胃口大的孩子也可以满足胃口小的孩子,那么就应该优先满足胃口大的。
52 |
53 | **这里的局部最优就是大饼干喂给胃口大的,充分利用饼干尺寸喂饱一个,全局最优就是喂饱尽可能多的小孩。**
54 |
55 | 可以尝试使用贪心策略,先将饼干数组和小孩数组排序。然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量。
56 |
57 | ---
58 |
59 | ```js
60 | /**
61 | * @param {number[]} g
62 | * @param {number[]} s
63 | * @return {number}
64 | */
65 | var findContentChildren = function (g, s) {
66 | g.sort((a, b) => a - b);
67 | s.sort((a, b) => a - b);
68 |
69 | let count = 0;
70 | let [i, j] = [g.length - 1, s.length - 1];
71 | while (i >= 0) {
72 | if (j >= 0 && s[j] >= g[i]) {
73 | count++;
74 | j--; // 消耗一个饼干
75 | }
76 | i--;
77 | }
78 |
79 | return count;
80 | };
81 | ```
82 |
83 | ## 柠檬水找零
84 |
85 | 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
86 |
87 | 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
88 |
89 | 注意,一开始你手头没有任何零钱。
90 |
91 | 给你一个整数数组 bills ,其中 `bills[i]` 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
92 |
93 | ```js
94 | 输入:bills = [5,5,5,10,20]
95 | 输出:true
96 | 解释:
97 | 前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
98 | 第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
99 | 第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
100 | 由于所有客户都得到了正确的找零,所以我们输出 true。
101 | ```
102 |
103 | ---
104 |
105 | 贪心思路:有大额零钱先找大额零钱,没有再找小额零钱。比如 20 找 15,如果手头有一张 10 块和 5 块,和手头有一张 10 块,3 张五块。那么为了让自己零钱最大,则要优先采取第一个方案。
106 |
107 | ```js
108 | /**
109 | * @param {number[]} bills
110 | * @return {boolean}
111 | */
112 | var lemonadeChange = function (bills) {
113 | let [five, ten] = [0, 0];
114 | for (let bill of bills) {
115 | if (bill === 5) five++;
116 | else if (bill === 10) {
117 | if (five === 0) return false; // 没钱找
118 | five--;
119 | ten++;
120 | } else {
121 | // 优先找 10 块的
122 | if (five && ten) [five, ten] = [five - 1, ten - 1];
123 | else if (five >= 3) five -= 3;
124 | else return false;
125 | }
126 | }
127 |
128 | return true;
129 | };
130 | ```
131 |
132 | ## K 次取反后最大化的数组和
133 |
--------------------------------------------------------------------------------
/docs/network-protocol/11.cookie.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Cookie 有哪些属性和功能?
3 | date: 2018-09-16 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | - cookie
8 | categories:
9 | - 网络协议
10 | ---
11 |
12 | ## cookie 简介
13 |
14 | 基于 HTTP 传输是无状态的,也就是每次 HTTP 请求服务端和客户端都不知道数据是哪来的,而 `cookie` 服务器拥有“记忆能力”。
15 |
16 | :::: tabs
17 |
18 | ::: tab 简述
19 |
20 | 第一次访问网站的时候,浏览器发出请求,服务器响应请求后,会将 `cookie` 放入到响应请求中,在浏览器第二次发请求的时候,会把 `cookie` 带过去,服务端会辨别用户身份,当然服务器也可以修改 `cookie` 内容
21 |
22 | :::
23 |
24 | ::: tab 流程图
25 |
26 | 
27 |
28 | :::
29 |
30 | ::: tab 设置 cookie 代码示例
31 |
32 | ```js
33 | const http = require('http');
34 |
35 | http
36 | .createServer(function (request, response) {
37 | if (request.url === '/') {
38 | response.writeHead(200, {
39 | 'Content-Type': 'text/html;charset=utf-8',
40 | 'Set-Cookie': 'id=123',
41 | });
42 | response.end(`
43 |
59 |
60 | 在发送方给接收方发 `SYN` 报文的同时,接收方也给发送方发 `SYN` 报文,两个人刚上了!
61 |
62 | 发完 SYN,两者的状态都变为 `SYN-SENT`。
63 |
64 | 在各自收到对方的 `SYN` 后,两者状态都变为 `SYN-REVD`。
65 |
66 | 接着会回复对应的 `ACK + SYN`,这个报文在对方接收之后,两者状态一起变为 `ESTABLISHED`。
67 |
68 | 这就是同时打开情况下的状态变迁。
69 |
--------------------------------------------------------------------------------
/docs/algorithm/字符串/最小覆盖子串.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 最小覆盖子串
3 | date: 2022-05-14 10:09:26
4 | sidebar: auto
5 | tags:
6 | - 字符串
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | [leetcode](https://leetcode.cn/problems/minimum-window-substring) 给你一个字符串 `s` 、一个字符串 `t` 。返回 `s` 中涵盖 `t` 所有字符的最小子串。如果 `s` 中不存在涵盖 `t` 所有字符的子串,则返回空字符串 "" 。
12 |
13 | 注意
14 |
15 | - 对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
16 | - 如果 s 中存在这样的子串,我们保证它是唯一的答案。
17 |
18 | ```js
19 | 输入:s = "ADOBECODEBANC", t = "ABC"
20 | 输出:"BANC"
21 |
22 | 输入:s = "a", t = "a"
23 | 输出:"a"
24 |
25 | 输入: s = "a", t = "aa"
26 | 输出: ""
27 | 解释: t 中两个字符 'a' 均应包含在 s 的子串中,
28 | 因此没有符合条件的子字符串,返回空字符串。
29 | ```
30 |
31 | ## 思路
32 |
33 | 使用滑动窗口
34 |
35 | 用 i,j 表示滑动窗口的左边界和右边界,通过改变 i,j 来扩展和收缩滑动窗口,可以想象成一个窗口在字符串上游走,当这个窗口包含的元素满足条件,即包含字符串 T 的所有元素,记录下这个滑动窗口的长度 j-i+1,这些长度中的最小值就是要求的结果。
36 |
37 | 1. 不断增加 j 使滑动窗口增大,直到窗口包含了 T 的所有元素
38 | 2. 不断增加 i 使滑动窗口缩小,因为是要求最小字串,所以将不必要的元素排除在外,使长度减小,直到碰到一个必须包含的元素,这个时候不能再扔了,再扔就不满足条件了,记录此时滑动窗口的长度,并保存最小值
39 | 3. 让 i 再增加一个位置,这个时候滑动窗口肯定不满足条件了,那么继续从步骤一开始执行,寻找新的满足条件的滑动窗口,如此反复,直到 j 超出了字符串 S 范围。
40 |
41 | 图示
42 |
43 | 以 S="DOABECODEBANC",T="ABC" 为例
44 |
45 | 初始状态:
46 |
47 | 
48 |
49 | 步骤一:不断增加 j 使滑动窗口增大,直到窗口包含了 T 的所有元素
50 |
51 | 
52 |
53 | 步骤二:不断增加 i 使滑动窗口缩小,直到碰到一个必须包含的元素 A,此时记录长度更新结果
54 |
55 | 
56 |
57 | 步骤三:让 i 再增加一个位置,开始寻找下一个满足条件的滑动窗口
58 |
59 | 
60 |
61 | ## 代码
62 |
63 | ```js
64 | /**
65 | * @param {string} s
66 | * @param {string} t
67 | * @return {string}
68 | */
69 | var minWindow = function (s, t) {
70 | // 双指针滑动窗口问题
71 | let i = 0;
72 | let j = 0;
73 | let result = '';
74 |
75 | let map = {};
76 | for (const c of t) {
77 | map[c] = map[c] ? map[c] + 1 : 1;
78 | }
79 |
80 | let count = Object.keys(map).length;
81 |
82 | // 右移指针
83 | while (j < s.length) {
84 | const char = s[j];
85 | if (map[char] !== undefined) map[char]--;
86 | // 如果匹配到一个字符,需要再匹配的数量减 1
87 | if (map[char] === 0) count--;
88 |
89 | while (count === 0) {
90 | const matchStr = s.slice(i, j + 1);
91 | if (!result || matchStr.length < result.length) result = matchStr;
92 |
93 | // 如果当前左指针匹配中了
94 | if (map[s[i]] !== undefined) {
95 | map[s[i]]++;
96 | // 注意!这里 count++ 的条件基于当前 map[s[i]] === 1, 否则可能会重复
97 | if (map[s[i]] === 1) count++;
98 | }
99 |
100 | i++;
101 | }
102 | j++;
103 | }
104 |
105 | return result;
106 | };
107 | ```
108 |
109 | 需要注意的细节点
110 |
111 | ```js
112 | if (map[char] === 0) count--;
113 | if (map[char] === 1) count++;
114 | ```
115 |
--------------------------------------------------------------------------------
/docs/algorithm/贪心算法/贪心入门.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 贪心入门
3 | date: 2022-05-20 00:52:14
4 | sidebar: auto
5 | tags:
6 | - 贪心算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 什么是贪心
12 |
13 | **贪心的本质是选择每一阶段的局部最优,从而达到全局最优。**
14 |
15 | 这么说有点抽象,来举一个例子:
16 |
17 | 例如,有一堆钞票,你可以拿走十张,如果想达到最大的金额,你要怎么拿?
18 |
19 | 指定每次拿最大的,最终结果就是拿走最大数额的钱。
20 |
21 | 每次拿最大的就是局部最优,最后拿走最大数额的钱就是推出全局最优。
22 |
23 | 再举一个例子如果是 有一堆盒子,你有一个背包体积为 n,如何把背包尽可能装满,如果还每次选最大的盒子,就不行了。这时候就需要动态规划。
24 |
25 | ## 分发饼干
26 |
27 | 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
28 |
29 | 对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。**你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。**
30 |
31 | ```js
32 | 输入: g = [1,2,3], s = [1,1]
33 | 输出: 1
34 | 解释: 你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
35 | 虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
36 | 所以你应该输出1。
37 |
38 | 输入: g = [1,2], s = [1,2,3]
39 | 输出: 2
40 | 解释: 你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
41 | 你拥有的饼干数量和尺寸都足以让所有孩子满足。
42 | 所以你应该输出2.
43 | ```
44 |
45 | ---
46 |
47 | **思路**
48 |
49 | 为了满足更多的小孩,就不要造成饼干尺寸的浪费。
50 |
51 | 大尺寸的饼干既可以满足胃口大的孩子也可以满足胃口小的孩子,那么就应该优先满足胃口大的。
52 |
53 | **这里的局部最优就是大饼干喂给胃口大的,充分利用饼干尺寸喂饱一个,全局最优就是喂饱尽可能多的小孩。**
54 |
55 | 可以尝试使用贪心策略,先将饼干数组和小孩数组排序。然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量。
56 |
57 | ---
58 |
59 | ```js
60 | /**
61 | * @param {number[]} g
62 | * @param {number[]} s
63 | * @return {number}
64 | */
65 | var findContentChildren = function (g, s) {
66 | g.sort((a, b) => a - b);
67 | s.sort((a, b) => a - b);
68 |
69 | let count = 0;
70 | let [i, j] = [g.length - 1, s.length - 1];
71 | while (i >= 0) {
72 | if (j >= 0 && s[j] >= g[i]) {
73 | count++;
74 | j--; // 消耗一个饼干
75 | }
76 | i--;
77 | }
78 |
79 | return count;
80 | };
81 | ```
82 |
83 | ## 柠檬水找零
84 |
85 | 在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
86 |
87 | 每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
88 |
89 | 注意,一开始你手头没有任何零钱。
90 |
91 | 给你一个整数数组 bills ,其中 `bills[i]` 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
92 |
93 | ```js
94 | 输入:bills = [5,5,5,10,20]
95 | 输出:true
96 | 解释:
97 | 前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
98 | 第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
99 | 第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
100 | 由于所有客户都得到了正确的找零,所以我们输出 true。
101 | ```
102 |
103 | ---
104 |
105 | 贪心思路:有大额零钱先找大额零钱,没有再找小额零钱。比如 20 找 15,如果手头有一张 10 块和 5 块,和手头有一张 10 块,3 张五块。那么为了让自己零钱最大,则要优先采取第一个方案。
106 |
107 | ```js
108 | /**
109 | * @param {number[]} bills
110 | * @return {boolean}
111 | */
112 | var lemonadeChange = function (bills) {
113 | let [five, ten] = [0, 0];
114 | for (let bill of bills) {
115 | if (bill === 5) five++;
116 | else if (bill === 10) {
117 | if (five === 0) return false; // 没钱找
118 | five--;
119 | ten++;
120 | } else {
121 | // 优先找 10 块的
122 | if (five && ten) [five, ten] = [five - 1, ten - 1];
123 | else if (five >= 3) five -= 3;
124 | else return false;
125 | }
126 | }
127 |
128 | return true;
129 | };
130 | ```
131 |
132 | ## K 次取反后最大化的数组和
133 |
--------------------------------------------------------------------------------
/docs/network-protocol/11.cookie.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: Cookie 有哪些属性和功能?
3 | date: 2018-09-16 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | - cookie
8 | categories:
9 | - 网络协议
10 | ---
11 |
12 | ## cookie 简介
13 |
14 | 基于 HTTP 传输是无状态的,也就是每次 HTTP 请求服务端和客户端都不知道数据是哪来的,而 `cookie` 服务器拥有“记忆能力”。
15 |
16 | :::: tabs
17 |
18 | ::: tab 简述
19 |
20 | 第一次访问网站的时候,浏览器发出请求,服务器响应请求后,会将 `cookie` 放入到响应请求中,在浏览器第二次发请求的时候,会把 `cookie` 带过去,服务端会辨别用户身份,当然服务器也可以修改 `cookie` 内容
21 |
22 | :::
23 |
24 | ::: tab 流程图
25 |
26 | 
27 |
28 | :::
29 |
30 | ::: tab 设置 cookie 代码示例
31 |
32 | ```js
33 | const http = require('http');
34 |
35 | http
36 | .createServer(function (request, response) {
37 | if (request.url === '/') {
38 | response.writeHead(200, {
39 | 'Content-Type': 'text/html;charset=utf-8',
40 | 'Set-Cookie': 'id=123',
41 | });
42 | response.end(`
43 | Cookie
44 |
47 | `);
48 | }
49 | })
50 | .listen(3300);
51 |
52 | console.log('http://127.0.0.1:3300');
53 | ```
54 |
55 | 如果你要设置多个 Cookie 可以这样
56 |
57 | ```js
58 | response.writeHead(200, {
59 | 'Content-Type': 'text/html;charset=utf-8',
60 | 'Set-Cookie': ['id=123', 'age=18'],
61 | });
62 | ```
63 |
64 | :::
65 |
66 | ::: tab network 面板示例
67 |
68 | 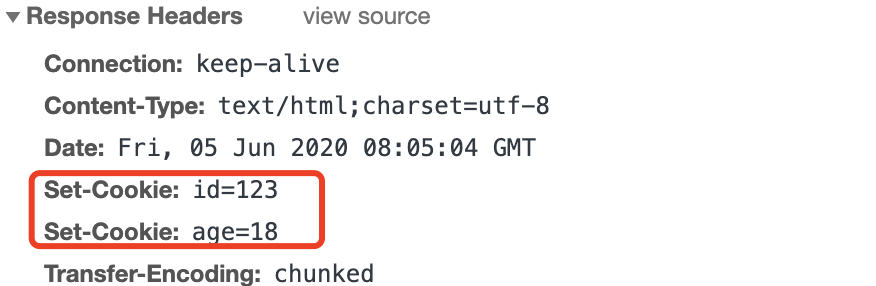
69 |
70 | :::
71 |
72 | ::::
73 |
74 | ## cookie 属性
75 |
76 | ### 生命周期
77 |
78 | Cookie 的有效期可以通过 `Expires` 和`Max-Age` 两个属性来设置。
79 |
80 | 若 Cookie 过期,则这个 Cookie 会被删除,并不会发送给服务端。
81 |
82 | ### 作用域
83 |
84 | 关于作用域也有两个属性: `Domain` 和 `path`, 给 Cookie 绑定了域名和路径,在发送请求之前,发现域名或者路径和这两个属性不匹配,那么就不会带上 Cookie。值得注意的是,对于路径来说,`/` 表示域名下的任意路径都允许使用 Cookie。
85 |
86 | ### 安全相关
87 |
88 | - **加强安全**: `Secure`,说明只能通过 HTTPS 传输 cookie。
89 | - **预防 xss 攻击**:带上 `HttpOnly` 属性 如果这个属性设置为 true,就不能通过 js 脚本来获取 cookie 的值,能有效的防止 xss 攻击
90 | - **预防 CSRF 攻击**:使用 `SameSite` 属性。
91 |
92 | | SameSite | 作用 |
93 | | -------- | -------------------------------------------------------------------------------------------------------------------- |
94 | | Strict | 浏览器完全禁止第三方请求携带 Cookie |
95 | | Lax | 就宽松一点了,但是只能在 **get 方法提交表单**况或者 **a 标签发送 get 请求**的情况下可以携带 Cookie,其他情况均不能。 |
96 | | None | 默认自动携带 Cookie |
97 |
98 | ## Cookie 的缺点
99 |
100 | 1. 容量缺陷。Cookie 的体积上限只有 **4KB**,只能用来存储少量的信息。
101 | 2. 性能缺陷。Cookie 紧跟域名,不管域名下面的某一个地址需不需要这个 Cookie ,请求都会携带上完整的 Cookie,这样随着请求数的增多,其实会造成巨大的性能浪费的,因为请求携带了很多不必要的内容。但可以通过 `Domain` 和 `Path` 指定作用域来解决。
102 | 3. 安全缺陷。由于 Cookie 以纯文本的形式在浏览器和服务器中传递,很容易被非法用户截获,然后进行一系列的篡改,在 Cookie 的有效期内重新发送给服务器,这是相当危险的。另外,在 HttpOnly 为 false 的情况下,Cookie 信息能直接通过 JS 脚本来读取。
103 |
--------------------------------------------------------------------------------
/docs/network-protocol/08.http的请求方法.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 如何理解 HTTP 的请求方法?
3 | date: 2018-09-19 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | | 请求方法 | 作用 |
12 | | --------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------- |
13 | | `GET` | 通常用于请求服务器发送某些资源 |
14 | | `HEAD` | 请求资源的头部信息, 并且这些头部与 HTTP GET 方法请求时返回的一致. 该请求方法的一个使用场景是在下载一个大文件前先获取其大小再决定是否要下载, 以此可以节约带宽资源 |
15 | | `OPTIONS` | 用于获取目的资源所支持的通信选项 |
16 | | `POST` | 发送数据给服务器 |
17 | | `PUT` | 用于新增资源或者使用请求中的有效负载替换目标资源的表现形式 |
18 | | `DELETE` | 用于删除指定的资源 |
19 | | `PATCH` | 用于对资源进行部分修改 |
20 | | `CONNECT` | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器 |
21 | | `TRACE` | 回显服务器收到的请求,主要用于测试或诊断 |
22 |
23 | ## GET 和 POST 有什么区别?
24 |
25 | | 角度 | 描述 |
26 | | ---------- | ------------------------------------------------------------------------ |
27 | | **缓存** | GET 请求会被浏览器主动缓存下来,留下历史记录,而 POST 默认不会。 |
28 | | **编码** | GET 只能进行 URL 编码,只能接收 ASCII 字符,而 POST 没有限制。 |
29 | | **参数** | GET 一般放在 URL 中,因此不安全,POST 放在请求体中,更适合传输敏感信息。 |
30 | | **幂等性** | GET 是幂等的,而 POST 不是。 |
31 |
32 | :::details 什么是幂等?
33 |
34 | 幂等的概念是指同一个请求方法执行多次和仅执行一次的效果完全相同。
35 |
36 | 比如 get 获取资源,get 几次都不会服务器都不会发生变化,而 POST 上传数据,会新增资源。
37 |
38 | - 按照 RFC 里的语义,POST 是“新增或提交数据”,多次提交数据会创建多个资源,所以不是幂等的;
39 | - 而 PUT 是“替换或更新数据”,多次更新一个资源,资源还是会第一次更新的状态,所以是幂等的。
40 |
41 | :::
42 |
43 | ## PUT 和 POST 都是给服务器发送新增资源,有什么区别?
44 |
45 | PUT 和 POST 方法的区别是,PUT 方法是幂等的:连续调用一次或者多次的效果相同(无副作用),而 POST 方法是非幂等的。
46 |
47 | 『POST 表示创建资源,PUT 表示更新资源』这种说法是错误的,两个都能创建资源,根本区别就在于幂等性
48 |
49 | ## PUT 和 PATCH 都是给服务器发送修改资源,有什么区别?
50 |
51 | PUT 和 PATCH 都是更新资源,**而 PATCH 用来对已知资源进行局部更新**。
52 |
53 | 比如我们修改个人信息
54 |
55 | ```json
56 | {
57 | "name": "alvin",
58 | "age": 18
59 | }
60 | ```
61 |
62 | 我们要修改年龄时
63 |
64 | ```json
65 | // 使用 PUT 覆盖资源
66 | {
67 | name: 'alvin',
68 | age: 20
69 | }
70 |
71 | // 使用 PATCH 局部更新
72 | { age: 20 }
73 | ```
74 |
--------------------------------------------------------------------------------
/docs/algorithm/sort/shellSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 希尔排序
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | 希尔排序是插入排序的改进版,它**克服了插入排序只能移动一个相邻位置的缺陷**(希尔排序可以一次移动 `gap` 个距离),利用了插入排序在排序几乎已经排序好的数组的非常快的优点。
13 |
14 | 使用可以动态定义的 gap 来渐进式排序,先排序距离较远的元素,再逐渐递进,而实际上排序中元素最终位置距离初始位置远的概率是很大的,所以希尔排序大大提升了性能(**尤其是 reverse 的时候非常快**,想象一下这时候冒泡排序和插入排序的速度)。
15 |
16 | 而且希尔排序不仅效率较高(比冒泡和插入高),它的代码相对要简短,低开销(继承插入排序的优点),追求这些特点(效率要求过得去就好,代码简短,开销低,且数据量较小)的时候希尔排序是好的 `O(n·log(n))` 算法的替代品。
17 |
18 | 总而言之:希尔排序的性能优化来自增量队列的输入和 `gap` 的设定。
19 |
20 | ## 属性
21 |
22 | - 不稳定
23 | - 在快要排序完成的数组有 `O(n·log(n))` 的时间复杂度(并且它对于反转数组的速度非常快)
24 | - `O(n^3/2)` time as shown (想要了解更多细节,请查阅 [wikipedia Shellsor](https://en.wikipedia.org/wiki/Shellsort#Applications))
25 |
26 | ::: warning 关于不稳定
27 | 我们知道, 单次直接插入排序是稳定的,它不会改变相同元素之间的相对顺序,但在多次不同的插入排序过程中, 相同的元素可能在各自的插入排序中移动,可能导致相同元素相对顺序发生变化。因此, 希尔排序并不稳定。
28 | :::
29 |
30 | ## 核心概念
31 |
32 | 希尔排序是基于**插入排序**的以下两点性质而提出改进方法的:
33 |
34 | 1. **插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到 `O(n)` 的效率**;
35 | 2. 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位 ;
36 |
37 | 其中 `gap`(增量)的选择是希尔排序的重要部分。只要最终 `gap` 为 1 任何 `gap` 序列都可以工作。算法最开始以一定的 `gap` 进行排序。然后会继续以一定 `gap` 进行排序,直到 `gap = 1` 时,算法变为插入排序。
38 |
39 | ## 算法步骤
40 |
41 | - 选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
42 | - 按增量序列个数 k,对序列进行 k 趟排序;
43 | - 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
44 |
45 | 
46 |
47 | ## 第一版:基本实现
48 |
49 | Donald Shell 的最初建议(`gap = n / 2`)版代码(方便理解):
50 |
51 | ```js
52 | function shellSort(arr) {
53 | const len = arr.length;
54 | let gap = Math.floor(len / 2);
55 |
56 | while (gap > 0) {
57 | // 注意下面这段 for 循环和插入排序极为相似
58 | for (let i = gap; i < len; i++) {
59 | const temp = arr[i];
60 | let preIndex = i - gap;
61 |
62 | while (arr[preIndex] > temp) {
63 | arr[preIndex + gap] = arr[preIndex];
64 | preIndex -= gap;
65 | }
66 | arr[preIndex + gap] = temp;
67 | }
68 | gap = Math.floor(gap / 2);
69 | }
70 |
71 | return arr;
72 | }
73 | ```
74 |
75 | ## 第二版:Knuth's increment sequence
76 |
77 | 常见的、易生成的、优化 `gap` 的序列方法(来自 Algorithms (4th Edition) ,有些更快的方法但序列不容易生成,因为用到了比较深奥的数学公式):
78 |
79 | ```js
80 | function shellSort(arr) {
81 | const len = arr.length;
82 | let gap = 1;
83 |
84 | while (gap < len / 3) {
85 | gap = gap * 3 + 1;
86 | }
87 | while (gap > 0) {
88 | for (let i = gap; i < len; i++) {
89 | const temp = arr[i];
90 | let preIndex = i - gap;
91 |
92 | while (arr[preIndex] > temp) {
93 | arr[preIndex + gap] = arr[preIndex];
94 | preIndex -= gap;
95 | }
96 | arr[preIndex + gap] = temp;
97 | }
98 | gap = Math.floor(gap / 2);
99 | }
100 |
101 | return arr;
102 | }
103 |
104 | // test
105 | const arr = [91, 60, 96, 7, 35, 65, 10, 65, 9, 30, 20, 31, 77, 81, 24];
106 | console.log(shellSort(arr));
107 | ```
108 |
109 | ---
110 |
111 | - 动画来源 [图解面试算法](https://github.com/MisterBooo/LeetCodeAnimation)
112 | - 参考 [优雅的 JavaScript 排序算法(ES6)](https://juejin.im/post/5ab62ec36fb9a028cf326c49)
113 |
--------------------------------------------------------------------------------
/docs/network-protocol/17.http2新功能.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HTTP2 做了哪些改进?
3 | date: 2018-09-24 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http2
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 由于 HTTPS 在安全方面已经做的非常好了,HTTP 改进的关注点放在了性能方面。主要区别有:
12 |
13 | | feature | description |
14 | | ---------------------- | --------------------------------------------------------------------------------- |
15 | | **头部压缩** | hpack + 哈夫曼编码压缩 |
16 | | **多路复用** | 报文转为二进制,生成 steam 在一个 tcp 乱序传输,但是同一个 Stream ID 的帧有序传输 |
17 | | **服务器推送** | 新建“流”主动向客户端发送消息 |
18 | | **可以设置请求优先级** |
19 |
20 | ## 头部压缩
21 |
22 | HTTP1.1 有着对请求体的压缩 `Content-Encoding`
23 |
24 | ```js
25 | // 发送端
26 | Content-Encoding: gzip
27 | // 接收端
28 | Accept-Encoding: gzip
29 | ```
30 |
31 | 但报文的另一个组成部分——`Header` 却被无视了,没有针对它的优化手段。
32 |
33 | - 当请求字段非常复杂的时候,尤其对于 GET 请求,请求报文几乎全是请求头,这个时候还是存在非常大的优化空间的。
34 | - 成千上万的请求响应报文里有很多字段值都是重复的,非常浪费,“长尾效应”导致大量带宽消耗在了这些冗余度极高的数据上。
35 |
36 | HTTP2 针对头部字段,也采用了对应的压缩算法——**HPACK**,对请求头进行压缩。
37 |
38 | :::: tabs
39 | ::: tab 1. 废除了原有的起始行概念
40 | 为了方便管理和压缩,HTTP/2 废除了原有的起始行概念
41 |
42 | 把起始行里面的请求方法、URI、状态码等统一转换成了头字段的形式,并且给这些“不是头字段的头字段”起了个特别的名字——“伪头字段”(pseudo-header fields)。而起始行里的版本号和错误原因短语因为没什么大用,顺便也给废除了。
43 |
44 | 为了与“真头字段”区分开来,这些“**伪头字段**”会在名字前加一个“:”,比如“:authority” “:method” “:status”,分别表示的是域名、请求方法和状态码。
45 |
46 | 现在 HTTP 报文头就简单了,全都是“Key-Value”形式的字段,
47 | :::
48 |
49 | ::: tab 2. 在服务器和客户端之间建立哈希表
50 |
51 | 将用到的字段存放在这张表中,那么在传输的时候对于之前出现过的值,只需要把**索引**(比如 0,1,2,...)传给对方即可,对方拿到索引查表就行了。这种传索引的方式,可以说让请求头字段得到极大程度的精简和复用。
52 |
53 | 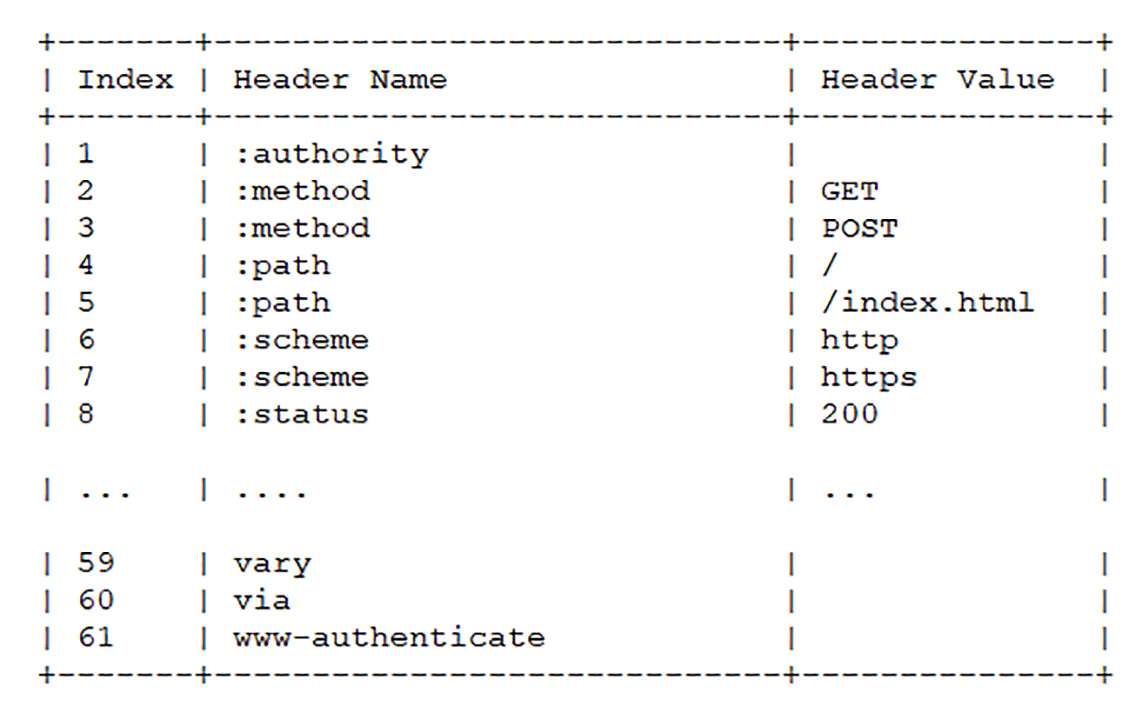
54 |
55 | :::
56 |
57 | ::: tab 3. 对于整数和字符串进行哈夫曼编码
58 | 哈夫曼编码的原理就是先将所有出现的字符建立一张索引表,然后让出现次数多的字符对应的索引尽可能短,传输的时候也是传输这样的索引序列,可以达到非常高的压缩率。
59 | :::
60 | ::::
61 |
62 | 头部数据压缩之后,HTTP2 就要把报文拆成二进制的帧准备发送。
63 |
64 | ## 多路复用
65 |
66 | ### 什么是 HTTP 队头阻塞?
67 |
68 | 我们之前讨论了 HTTP 队头阻塞的问题,其根本原因在于 HTTP 基于请求-响应的模型,在同一个 TCP 长连接中,前面的请求没有得到响应,后面的请求就会被阻塞。
69 |
70 | 后面我们又讨论到用并发连接和域名分片的方式来解决这个问题,但这并没有真正从 HTTP 本身的层面解决问题,只是增加了 TCP 连接,分摊风险而已。而且这么做也有弊端,多条 TCP 连接会竞争有限的带宽,让真正优先级高的请求不能优先处理。
71 |
72 | 而 HTTP/2 便从 HTTP 协议本身解决了队头阻塞问题。注意,这里并不是指的 TCP 队头阻塞,而是 HTTP 队头阻塞,两者并不是一回事。TCP 的队头阻塞是在数据包层面,单位是数据包,前一个报文没有收到便不会将后面收到的报文上传给 HTTP,而 HTTP 的队头阻塞是在 HTTP 请求-响应层面,前一个请求没处理完,后面的请求就要阻塞住。两者所在的层次不一样。
73 |
74 | 那么 HTTP/2 如何来解决所谓的队头阻塞呢?
75 |
76 | ### 二进制分帧
77 |
78 | 首先,HTTP/2 认为明文传输对机器而言太麻烦了,不方便计算机的解析,因为对于文本而言会有多义性的字符,比如回车换行到底是内容还是分隔符,在内部需要用到状态机去识别,效率比较低。于是 HTTP/2 干脆把报文全部换成二进制格式,全部传输 01 串,方便了机器的解析。
79 |
80 | 原来 Headers + Body 的报文格式如今被拆分成了一个个二进制的帧,用 **Headers 帧**存放头部字段,**Data 帧**存放请求体数据。分帧之后,服务器看到的不再是一个个完整的 HTTP 请求报文,而是一堆乱序的二进制帧。这些二进制帧不存在先后关系,因此也就不会排队等待,也就没有了 HTTP 的队头阻塞问题。
81 |
82 | 通信双方都可以给对方发送二进制帧,这种二进制帧的双向传输的序列,也叫做流(Stream)。**HTTP/2 用流来在一个 TCP 连接上来进行多个数据帧的通信,这就是多路复用的概念。**
83 |
84 | 可能你会有一个疑问,既然是乱序首发,那最后如何来处理这些乱序的数据帧呢?
85 |
86 | 首先要声明的是,所谓的乱序,指的是不同 ID 的 Stream 是乱序的,但同一个 Stream ID 的帧一定是按顺序传输的。二进制帧到达后对方会将 Stream ID 相同的二进制帧组装成完整的请求报文和响应报文。当然,在二进制帧当中还有其他的一些字段,实现了优先级和流量控制等功能,我们放到下一节再来介绍。
87 |
88 | ## 服务器推送
89 |
90 | HTTP/2 还在一定程度上改变了传统的“请求 - 应答”工作模式,服务器不再是完全被动地响应请求,也可以新建“流”主动向客户端发送消息。比如,在浏览器刚请求 HTML 的时候就提前把可能会用到的 JS、CSS 文件发给客户端,减少等待的延迟,这被称为“**服务器推送**”(Server Push,也叫 Cache Push)。
91 |
--------------------------------------------------------------------------------
/docs/algorithm/动态规划/不同路径.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 不同路径系列
3 | date: 2022-05-09 21:37:20
4 | sidebar: auto
5 | tags:
6 | - 动态规划
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 不同路径 I
12 |
13 | [力扣题目链接](https://leetcode-cn.com/problems/unique-paths/):一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
14 |
15 | 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
16 |
17 | 问总共有多少条不同的路径?
18 |
19 | 
20 |
21 | ```js
22 | 输入:m = 3, n = 7
23 | 输出:28
24 | ```
25 |
26 | ### 思路
27 |
28 | 
29 |
30 | 状态转移方程 `dp[i][j] = dp[i][j] = dp[i - 1][j] + dp[i][j - 1]`
31 |
32 | ### 代码
33 |
34 | ```js
35 | /**
36 | * @param {number} m
37 | * @param {number} n
38 | * @return {number}
39 | */
40 | var uniquePaths = function (m, n) {
41 | let dp = new Array(m).fill().map(() => new Array(n).fill(0));
42 | for (let i = 0; i < m; i++) {
43 | dp[i][0] = 1;
44 | }
45 |
46 | for (let i = 0; i < n; i++) {
47 | dp[0][i] = 1;
48 | }
49 | // i = 0 || j = 0 default 1
50 |
51 | for (let i = 1; i < m; i++) {
52 | for (let j = 1; j < n; j++) {
53 | dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
54 | }
55 | }
56 |
57 | return dp[m - 1][n - 1];
58 | };
59 | ```
60 |
61 | ## 不同路径 II
62 |
63 | [力扣题目链接](https://leetcode-cn.com/problems/unique-paths-ii/)
64 |
65 | 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
66 |
67 | 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
68 |
69 | 现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
70 |
71 | 
72 |
73 | 网格中的障碍物和空位置分别用 1 和 0 来表示。
74 |
75 | 示例 1:
76 |
77 | 
78 |
79 | ```js
80 | - 输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]]
81 | - 输出:2
82 | 解释:
83 | - 3x3 网格的正中间有一个障碍物。
84 | - 从左上角到右下角一共有 2 条不同的路径:
85 | 1. 向右 -> 向右 -> 向下 -> 向下
86 | 2. 向下 -> 向下 -> 向右 -> 向右
87 | ```
88 |
89 | 示例 2:
90 |
91 | 
92 |
93 | ```js
94 | - 输入:obstacleGrid = [[0,1],[0,0]]
95 | - 输出:1
96 |
97 | 提示:
98 |
99 | - m == obstacleGrid.length
100 | - n == obstacleGrid[i].length
101 | - 1 <= m, n <= 100
102 | - obstacleGrid[i][j] 为 0 或 1
103 | ```
104 |
105 | ### 思路
106 |
107 | 有障碍的话,其实就是标记对应的 dp table(dp 数组)保持初始值(0)就可以了。注意遇到障碍物跳过 dp 循环即可
108 |
109 | ```js
110 | for (let i = 1; i < m; i++) {
111 | for (let j = 1; j < n; j++) {
112 | if (obstacleGrid[i][j] == 1) continue;
113 | dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
114 | }
115 | }
116 | ```
117 |
118 | ### 代码
119 |
120 | ```js
121 | /**
122 | * @param {number[][]} obstacleGrid
123 | * @return {number}
124 | */
125 | var uniquePathsWithObstacles = function (obstacleGrid) {
126 | let m = obstacleGrid.length;
127 | let n = obstacleGrid[0].length;
128 | let dp = new Array(m).fill().map(() => new Array(n).fill(0));
129 |
130 | for (let i = 0; i < m && obstacleGrid[i][0] === 0; i++) {
131 | dp[i][0] = 1;
132 | }
133 |
134 | for (let i = 0; i < n && obstacleGrid[0][i] === 0; i++) {
135 | dp[0][i] = 1;
136 | }
137 |
138 | for (let i = 1; i < m; i++) {
139 | for (let j = 1; j < n; j++) {
140 | if (obstacleGrid[i][j] == 1) continue;
141 | dp[i][j] = dp[i - 1][j] + dp[i][j - 1];
142 | }
143 | }
144 |
145 | return dp[m - 1][n - 1];
146 | };
147 | ```
148 |
--------------------------------------------------------------------------------
/docs/network-protocol/16.https证书.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 证书为什么可以防冒充?
3 | date: 2018-09-26 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - https
7 | categories:
8 | - 网络协议
9 | author: 在下晨溪
10 | ---
11 |
12 | 基于**为什么 CA 的证书可以使得公钥正确传输给客户端**,不是很好理解,这里再解析一下。转自 [看完还不懂 HTTPS 我直播吃翔](https://zhuanlan.zhihu.com/p/25976060)
13 |
14 | https 通信完整流程图:
15 |
16 | 
17 |
18 | ## 第一层(安全传输数据)
19 |
20 | 假如我们要实现一个功能:一个用户 A 给一个用户 B 发消息,但是要保证这个消息的内容只能被 A 和 B 知道,其他的无论是墨渊上神还是太上老君都没办法破解或者篡改消息的内容。
21 |
22 | 由于消息不想被其他人看到,所以我们自然而然就会想到为消息加密,并且只有 A 和 B 才有解密的密钥。这里需要考虑几点:
23 |
24 | 1. 使用什么加密方式?
25 | 2. 密钥怎么告知对方?
26 |
27 | 对于第一个问题,加密算法分为两类:对称加密和非对称加密,这里我们选择对称机密,原因有如下几个:
28 |
29 | 1. 对称加密速度快,加密时 CPU 资源消耗少;
30 | 2. 非对称加密对待加密的数据的长度有比较严格的要求,不能太长,但是实际中消息可能会很长,因此非对称加密就满足不了;
31 |
32 | 对于第二个问题,这是导致整个 https 通信过程很复杂的根本原因。 如果 A 或 B 直接把他们之间用于解密的密钥通过互联网传输给对方,那一旦密钥被第三者劫持,第三者就能正确解密 A,B 之间的通信数据。
33 |
34 | ## 第二层(安全传输密钥)
35 |
36 | 通过第一层的描述,第二层需要解决的问题是:**安全地传输 A,B 之间用于解密数据的密钥**。
37 |
38 | 因为如果传输过程中这把密钥被第三者拿到了,就能解密传通信数据,所以,这把密钥必须得加密,就算第三者劫持到这把加密过的密钥,他也不能解密,得到真正的密钥。
39 |
40 | 那就是用非对称加密咯,那如何应用非对称加密来加密那把密钥呢?
41 |
42 | 考虑如下方式:
43 |
44 | 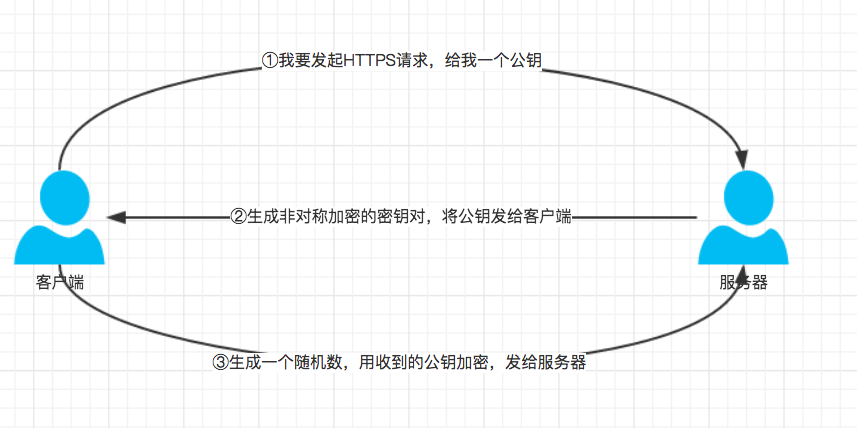
45 |
46 | 分析一下上面步骤的可行性:
47 |
48 | - 上述步骤中最终用于加密数据的密钥是客户端生成并且用公钥加密之后传给服务器的,因为私钥只有服务器才有,所以也就只有服务器才能解开客户端上报的密钥;
49 | - 要保证传输的密钥只能被服务器解密,就得保证用于加密密钥的公钥一定是服务器下发的,绝对不可能被第三方篡改过;
50 |
51 | 因为还可能存在一种"中间人攻击"的情况,如下图:
52 |
53 | 
54 |
55 | 这种情况下,客户端和服务器之间通信的数据就完全被坏人破解了。
56 |
57 | ## 第三层(安全传输公钥)🌟
58 |
59 | 从上一层可以知道,要保证数据的安全,就必须得保证服务器给客户端下发的公钥是真正的公钥,而不是中间人伪造的公钥。那怎么保证呢?
60 |
61 | 那就得引入数字证书了,数字证书是服务器主动去权威机构申请的,证书中包含了上一个图中的加密过的 A 公钥和权威机构的信息,所以服务器只需要给客户端下发数字证书即可。现在流程图如下:
62 |
63 | 
64 |
65 | 那数字证书中的 A 公钥是如何加密的呢?
66 |
67 | 答案是非对称加密,只不过这里是使用只有权威机构自己才有的私钥加密。
68 |
69 | 等一下,既然 A 公钥被权威机构的私钥加密了,那客户端收到证书之后怎么解密证书中的 A 公钥呢?需要有权威机构的公钥才能解密啊!那这个权威机构的公钥又是怎么安全地传输给客户端的呢?感觉进入了鸡生蛋,蛋生鸡的悖论了~~
70 |
71 | 别慌,**答案是权威机构的公钥不需要传输,因为权威机构会和主流的浏览器或操作系统合作,将他们的公钥内置在浏览器或操作系统环境中**。客户端收到证书之后,只需要从证书中找到权威机构的信息,并从本地环境中找到权威机构的公钥,就能正确解密 A 公钥。
72 |
73 | 这样就绝对安全了吗?既然权威技能能给服务器签发数字证书,那为什么就不可能给中间人签发数字证书呢?毕竟赚钱的生意权威机构也不会拒绝的呀。
74 |
75 | 试想一下:
76 |
77 | 服务器给客户端下发数字证书时证书被中间人劫持了,中间人将服务器的证书替换成自己的证书下发给客户端,客户端收到之后能够通过权威机构的公钥解密证书内容(因为中间人的证书也是权威机构私钥加密的),从而获取公钥,但是,这里的公钥并不是服务器原本的 A 公钥,而是中间人自己证书中的 B 公钥。从第二层可知,如果不能保证客户端收到的公钥是服务器下发的,那整个通信数据的安全就没法保证。简单总结就是证书被调包~
78 |
79 | 所以,还得保证客户端收到的证书就是服务器下发的证书,没有被中间人篡改过。
80 |
81 | ## 第四层(安全传输证书)🌟
82 |
83 | 这一层,我们的任务是:**保证客户端收到的证书是服务器下发的证书,没有被中间人篡改过**。
84 |
85 | 所以,这里就有两个需求:
86 |
87 | - 证明证书内容没有被第三方篡改过;
88 | - 证明证书是服务器下发的
89 |
90 | 其实这些问题,数字证书本身已经提供方案了,数字证书中除了包含加密之后的服务器公钥,权威机构的信息之外,还包含了证书内容的签名
91 |
92 | 先通过 Hash 函数计算得到证书数字摘要,然后用权威机构私钥加密数字摘要得到数字签名,签名计算方法以及证书对应的域名。这样一来,客户端收到证书之后:
93 |
94 | - 使用权威机构的公钥解密数字证书,得到证书内容(服务器的公钥)以及证书的数字签名,然后根据证书上描述的计算证书签名的方法计算一下当前证书的签名,与收到的签名作对比,如果一样,表示证书一定是服务器下发的,没有被中间人篡改过。
95 | - 因为中间人虽然有权威机构的公钥,能够解析证书内容并篡改,但是篡改完成之后中间人需要将证书重新加密,但是中间人没有权威机构的私钥,无法加密,强行加密只会导致客户端无法解密,如果中间人强行乱修改证书,就会导致证书内容和证书签名不匹配。**所以证书签名就能判断证书是否被篡改**
96 | - 除非黑客足够牛逼,能申请一份一模一样的证书,并且被加到浏览器的信任证书列表里,还要通过证书透明度服务的监督
97 | - 再考虑证书被掉包的情况:中间人同样可以向权威机构申请一份证书,然后在服务器给客户端下发证书的时候劫持原证书,将自己的假证书下发给客户端,客户端收到之后依然能够使用权威机构的公钥解密证书,并且证书签名也没问题。但是这个时候客户端还需要检查证书中的域名和当前访问的域名是否一致。如果不一致,会发出警告!
98 |
99 | 从上面的分析可以看到,数字证书中的信息确实能让客户端辨别证书的真伪。
100 |
101 | ---
102 |
103 | 整个过程都是客户端怎么核实证书是否有效,有效则证明公钥是正确的。证书到手,权威机构的公钥不需要传输,因为权威机构会和主流的浏览器或操作系统合作,将他们的公钥内置在浏览器或操作系统环境中。所以浏览器内置公钥,可以解密。
104 |
105 | 黑客也想拿到公钥,见上。CA 证书不会乱颁发,所以黑客拿到证书也无可奈何。
106 |
107 | 至于服务端怎么确认客户端身份、token 域名那些就可以确认了。
108 |
--------------------------------------------------------------------------------
/docs/algorithm/动态规划/买卖股票的最佳时机.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 买卖股票的最佳时机系列
3 | date: 2022-03-31 20:56:00
4 | sidebar: auto
5 | tags:
6 | - 动态规划
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 买卖股票的最佳时机
12 |
13 | 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
14 |
15 | 你只能选择 **某一天** 买入这只股票,并选择在 **未来的某一个不同的日子卖出该股票**。设计一个算法来计算你所能获取的最大利润。返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
16 |
17 | ```js
18 | 输入:[7,1,5,3,6,4]
19 | 输出:5
20 | 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
21 | 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票
22 | ```
23 |
24 | ```js
25 | 输入:prices = [7,6,4,3,1]
26 | 输出:0
27 | 解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
28 | ```
29 |
30 | ```js
31 | /**
32 | * @param {number[]} prices
33 | * @return {number}
34 | * 最后一个值 减去之前的最小值 就是最大值
35 | */
36 | var maxProfit = function (prices) {
37 | let min = prices[0];
38 | let max = 0;
39 | for (const p of prices) {
40 | min = Math.min(min, p);
41 | max = Math.max(max, p - min);
42 | }
43 | return max;
44 | };
45 | ```
46 |
47 | ## 买卖股票的最佳时机 II
48 |
49 | [leetcode](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii):给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
50 |
51 | 在每一天,你可以决定是否购买和/或出售股票。你在任何时候最多只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
52 |
53 | 返回 你能获得的 最大 利润 。
54 |
55 | ```js
56 | 输入:prices = [7,1,5,3,6,4]
57 | 输出:7
58 | 解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
59 | 随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3 。
60 | 总利润为 4 + 3 = 7 。
61 |
62 | 输入:prices = [1,2,3,4,5]
63 | 输出:4
64 | 解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4 。
65 | 总利润为 4 。
66 |
67 | 输入:prices = [7,6,4,3,1]
68 | 输出:0
69 | 解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0 。
70 | ```
71 |
72 | 不断买入卖出,取上坡值即可
73 |
74 | ```js
75 | /**
76 | * @param {number[]} prices
77 | * @return {number}
78 | */
79 | var maxProfit = function (prices) {
80 | let max = 0;
81 |
82 | for (let i = 1; i < prices.length; i++) {
83 | const sum = prices[i] - prices[i - 1];
84 |
85 | if (sum > 0) max += sum;
86 | }
87 |
88 | return max;
89 | };
90 | ```
91 |
92 | ## 买卖股票的最佳时机 III
93 |
94 | [力扣题目链接 hard](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iii/):给定一个数组,它的第 `i` 个元素是一支给定的股票在第 `i` 天的价格。设计一个算法来计算你所能获取的最大利润。你最多可以完成 **两笔** 交易。
95 |
96 | ```js
97 | 输入:prices = [3,3,5,0,0,3,1,4]
98 | 输出:6
99 | 解释:在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。
100 | 随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3。
101 |
102 | 输入:prices = [1,2,3,4,5]
103 | 输出:4
104 | 解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4。
105 | 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。
106 |
107 | 输入:prices = [7,6,4,3,1]
108 | 输出:0
109 | 解释:在这个情况下, 没有交易完成, 所以最大利润为 0。
110 |
111 | 输入:prices = [1]
112 | 输出:0
113 | ```
114 |
115 | [题解](https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iii/solution/mai-mai-gu-piao-de-zui-jia-shi-ji-iii-by-wrnt/)
116 |
117 | ```js
118 | /**
119 | * @param {number[]} prices
120 | * @return {number}
121 | */
122 | const maxProfit = function (prices) {
123 | let buy_1 = -prices[0],
124 | sell_1 = 0;
125 | let buy_2 = -prices[0],
126 | sell_2 = 0;
127 | let n = prices.length;
128 | for (let i = 1; i < n; i++) {
129 | // 第二次买入卖出的利润
130 | sell_2 = Math.max(sell_2, buy_2 + prices[i]);
131 | buy_2 = Math.max(buy_2, sell_1 - prices[i]); // 第二次买入,依赖上次利润
132 |
133 | // 第一次买入卖出的利润
134 | sell_1 = Math.max(sell_1, buy_1 + prices[i]);
135 | buy_1 = Math.max(buy_1, -prices[i]);
136 | }
137 | return sell_2;
138 | };
139 | ```
140 |
--------------------------------------------------------------------------------
/docs/algorithm/sort/bubbleSort.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 冒泡排序
3 | date: 2020-05-19 15:05:55
4 | sidebar: auto
5 | tags:
6 | - 算法与数据结构
7 | - 排序算法
8 | categories:
9 | - 算法与数据结构
10 | ---
11 |
12 | 稳定 时间复杂度 `O(n²)`
13 |
14 | ## 算法步骤
15 |
16 | - 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
17 | - 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
18 | - 针对所有的元素重复以上的步骤,除了最后一个。
19 | - 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
20 |
21 | 
22 |
23 | ## 第一版:基本实现
24 |
25 | 定义一个辅助函数,用于交换数组中的值。
26 |
27 | ```TS
28 | function swap(arr, i, j) {
29 | [arr[i], arr[j]] = [arr[j], arr[i]]
30 | }
31 | ```
32 |
33 | ```js
34 | function bubbleSort(arr) {
35 | for (let i = arr.length - 1; i > 0; i--) {
36 | for (let j = 0; j < i; j++) {
37 | if (arr[j] > arr[j + 1]) {
38 | swap(arr, j, j + 1);
39 | }
40 | }
41 | }
42 | return arr;
43 | }
44 | ```
45 |
46 | 测试
47 |
48 | ```js
49 | let array = [5, 2, 4, 3, 8];
50 |
51 | console.log(bubbleSort(array)); // [ 2, 3, 4, 5, 8 ]
52 | ```
53 |
54 | ## 第二版:缓存 pos
55 |
56 | 设置一标志性变量 pos,用于记录每趟排序中最后一次进行交换的位置。 由于 pos 位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到 pos 位置即可。
57 |
58 | ```js {5,9,14}
59 | function bubbleSort2(arr) {
60 | let i = arr.length - 1;
61 |
62 | while (i > 0) {
63 | let pos = 0;
64 |
65 | for (let j = 0; j < i; j++) {
66 | if (arr[j] > arr[j + 1]) {
67 | pos = j;
68 | swap(arr, j, j + 1);
69 | }
70 | }
71 |
72 | i = pos;
73 | }
74 |
75 | return arr;
76 | }
77 | ```
78 |
79 | - 如果循环一次,发现没有发生交换事件,代表数组升序,pos = 0,算法复杂度 `O(n)`
80 | - 只要有交换,pos 值就更新,直到没有发生交换为止。所以可以大大地简化了算法复杂度。
81 |
82 | ## 第三版:双向遍历
83 |
84 | 传统冒泡排序中每一趟排序操作只能找到一个最大值或最小值, 我们可以 **在每趟排序中进行正向和反向两遍冒泡** , 一次可以得到两个最终值(最大和最小) , 从而使外排序趟数几乎减少了一半。
85 |
86 | ```js
87 | function bubbleSort3(arr) {
88 | let start = 0;
89 | let end = arr.length - 1;
90 |
91 | while (start < end) {
92 | for (let i = 0; i < end; i++) {
93 | if (arr[i] > arr[i + 1]) {
94 | swap(arr, i, i + 1);
95 | }
96 | }
97 |
98 | end--;
99 |
100 | for (let j = end; j > start; j--) {
101 | if (arr[j - 1] > arr[j]) {
102 | swap(arr, j, j - 1);
103 | }
104 | }
105 |
106 | start++;
107 | }
108 | return arr;
109 | }
110 | ```
111 |
112 | ## 第四版:结合 2&3
113 |
114 | 前两种优化方式`(缓存 pos、双向遍历)`的结合:
115 |
116 | ```js
117 | function bubbleSort4(arr) {
118 | let start = 0;
119 | let end = arr.length - 1;
120 |
121 | while (start < end) {
122 | let startPos = 0;
123 | let endPos = 0;
124 |
125 | for (let i = 0; i < end; i++) {
126 | if (arr[i] > arr[i + 1]) {
127 | swap(arr, i, i + 1);
128 | startPos = i;
129 | }
130 | }
131 | start = startPos;
132 |
133 | for (let j = end; j > 0; j--) {
134 | if (arr[j - 1] > arr[j]) {
135 | swap(arr, j, j - 1);
136 | endPos = j;
137 | }
138 | }
139 | end = endPos;
140 | }
141 | return arr;
142 | }
143 | ```
144 |
145 | ## 蚂蚁金服面试 模拟 Array.prototype.sort
146 |
147 | 来自于蚂蚁金服的一道面试题:
148 |
149 | > 对于冒泡排序来说,能不能传入第二个参数(参数为函数),来控制升序和降序?(联想一下 `array.sort()`)
150 |
151 | ```js
152 | function bubbleSort(arr, compareFunc) {
153 | for (let i = arr.length - 1; i > 0; i--) {
154 | for (let j = 0; j < i; j++) {
155 | if (compareFunc(arr[j], arr[j + 1]) > 0) {
156 | swap(arr, j, j + 1);
157 | }
158 | }
159 | }
160 | return arr;
161 | }
162 |
163 | console.log(bubbleSort(array, (a, b) => a - b));
164 | console.log(bubbleSort(array, (a, b) => b - a));
165 | ```
166 |
167 | - 动画来源 [图解面试算法](https://github.com/MisterBooo/LeetCodeAnimation)
168 | - 参考 [优雅的 JavaScript 排序算法(ES6)](https://juejin.im/post/5ab62ec36fb9a028cf326c49)
169 |
--------------------------------------------------------------------------------
/docs/algorithm/二叉树/二叉树的修改与构造2.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 二叉树的修改与构造 II
3 | date: 2022-05-13 00:16:41
4 | sidebar: auto
5 | tags:
6 | - 二叉树
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 二叉搜索树中的插入操作
12 |
13 | [力扣题目链接](https://leetcode-cn.com/problems/insert-into-a-binary-search-tree/): 给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据保证,新值和原始二叉搜索树中的任意节点值都不同。
14 |
15 | 注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回任意有效的结果。
16 |
17 | 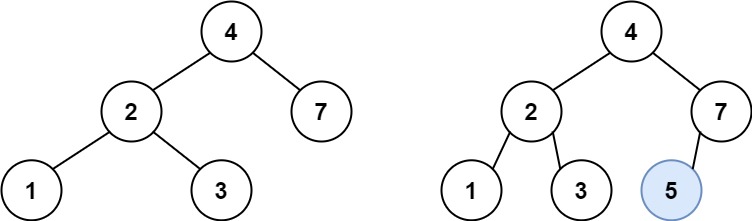
18 |
19 | ```js
20 | 输入:root = [4,2,7,1,3], val = 5
21 | 输出:[4,2,7,1,3,5]
22 | ```
23 |
24 | ```js
25 | var insertIntoBST = function (root, val) {
26 | let insertNode = new TreeNode(val);
27 | function dfs(node) {
28 | if (!node) return;
29 | if (val > node.val) {
30 | if (!node.right) node.right = insertNode;
31 | else dfs(node.right);
32 | } else {
33 | if (!node.left) node.left = insertNode;
34 | else dfs(node.left);
35 | }
36 | }
37 | dfs(root);
38 | return root || insertNode;
39 | };
40 | ```
41 |
42 | ## 删除二叉搜索树中的节点
43 |
44 | [力扣题目链接](https://leetcode-cn.com/problems/delete-node-in-a-bst/)
45 |
46 | 给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
47 |
48 | 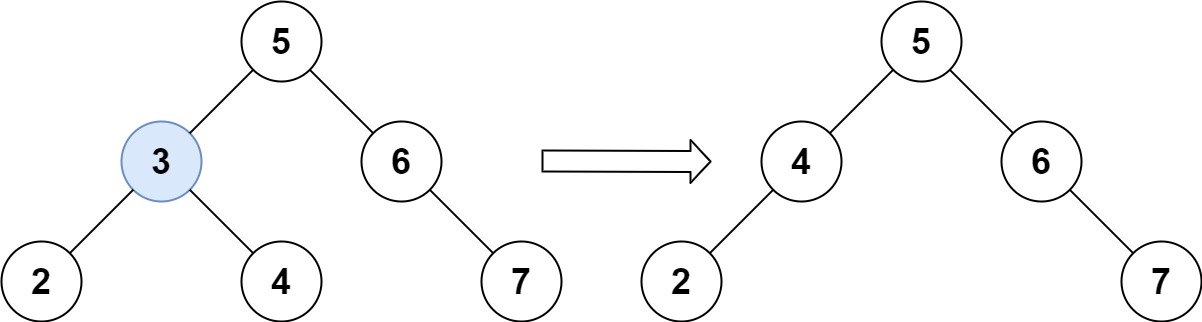
49 |
50 | ---
51 |
52 | 根据二叉搜索树的性质
53 |
54 | - 如果目标节点大于当前节点值,则去右子树中删除;
55 | - 如果目标节点小于当前节点值,则去左子树中删除;
56 | - 如果目标节点就是当前节点,分为以下三种情况:
57 | - 其无左子:其右子顶替其位置,删除了该节点;
58 | - 其无右子:其左子顶替其位置,删除了该节点;
59 | - 其左右子节点都有:其左子树转移到其右子树的最左节点的左子树上,然后右子树顶替其位置,由此删除了该节点
60 |
61 | 其左右子节点都有情况比较复杂,可以看动画实现:
62 |
63 | 
64 |
65 | ```js
66 | var deleteNode = function (root, key) {
67 | if (!root) return null;
68 | if (key > root.val) root.right = deleteNode(root.right, key);
69 | else if (key < root.val) root.left = deleteNode(root.left, key);
70 | // 删除的是当前节点
71 | else {
72 | if (!root.left) return root.right;
73 | else if (!root.right) return root.left;
74 | else {
75 | // 左右子树都存在的情况下
76 | let newRoot = root.right;
77 |
78 | // 找到右子树下的最左子树,将原本的 root.left 指向这个节点
79 | let cur = root.right;
80 | while (cur.left) {
81 | cur = cur.left;
82 | }
83 | cur.left = root.left;
84 |
85 | return newRoot;
86 | }
87 | }
88 |
89 | return root;
90 | };
91 | ```
92 |
93 | ## 修剪二叉搜索树
94 |
95 | 
96 |
97 | ```js
98 | 输入:root = [1,0,2], low = 1, high = 2
99 | 输出:[1,null,2]
100 | ```
101 |
102 | ```js
103 | /**
104 | * @param {TreeNode} root
105 | * @param {number} low
106 | * @param {number} high
107 | * @return {TreeNode}
108 | */
109 | var trimBST = function (root, low, high) {
110 | if (!root) return null;
111 | if (root.val < low) return trimBST(root.right, low, high);
112 | else if (root.val > high) return trimBST(root.left, low, high);
113 | else {
114 | root.left = trimBST(root.left, low, high);
115 | root.right = trimBST(root.right, low, high);
116 | }
117 | return root;
118 | };
119 | ```
120 |
121 | ## 将有序数组转换为二叉搜索树
122 |
123 | [力扣题目链接](https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/)
124 |
125 | 将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
126 |
127 | 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
128 |
129 | 
130 |
131 | ---
132 |
133 | 思路
134 |
135 | 题目中说要转换为一棵高度平衡二叉搜索树。这和转换为一棵普通二叉搜索树有什么差别呢?
136 |
137 | 其实这里不用强调平衡二叉搜索树,数组构造二叉树,构成平衡树是自然而然的事情,因为大家默认都是从数组中间位置取值作为节点元素,一般不会随机取,所以想构成不平衡的二叉树是自找麻烦。
138 |
139 | **本质就是寻找分割点,分割点作为当前节点,然后递归左区间和右区间。**
140 |
141 | **将一个按照升序排列的有序数组**:中序遍历,左根右,从小 ➡️ 大
142 |
143 | 1. 先要找到数组中最大的值和对应的下标, 最大的值构造根节点,下标用来下一步分割数组。
144 | 2. 最大值所在的下标左区间 构造左子树
145 | 3. 最大值所在的下标右区间 构造右子树
146 |
147 | ---
148 |
149 | 代码
150 |
151 | ```js
152 | var sortedArrayToBST = function (nums) {
153 | function buildTree(nums, l, r) {
154 | if (l > r) return null;
155 |
156 | let mid = (l + r) >>> 1;
157 |
158 | let root = new TreeNode(nums[mid]);
159 |
160 | root.left = buildTree(nums, l, mid - 1);
161 | root.right = buildTree(nums, mid + 1, r);
162 |
163 | return root;
164 | }
165 |
166 | return buildTree(nums, 0, nums.length - 1);
167 | };
168 | ```
169 |
--------------------------------------------------------------------------------
/docs/algorithm/二叉树/求二叉搜索树的属性.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 求二叉搜索树的属性
3 | date: 2022-05-13 10:52:45
4 | sidebar: auto
5 | tags:
6 | - 二叉树
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | > 遇到二叉搜索树请记住,中序遍历是有序数组!!!左右根
12 |
13 | ## 二叉搜索树中的搜索
14 |
15 | 
16 |
17 | ```js
18 | 输入:root = [4,2,7,1,3], val = 2
19 | 输出:[2,1,3]
20 | ```
21 |
22 | ```js
23 | /**
24 | * @param {TreeNode} root
25 | * @param {number} val
26 | * @return {TreeNode}
27 | */
28 | var searchBST = function (root, val) {
29 | if (!root) return null;
30 | if (root.val === val) return root;
31 | else if (val > root.val) return searchBST(root.right, val);
32 | else return searchBST(root.left, val);
33 | };
34 | ```
35 |
36 | ## 验证二叉搜索树
37 |
38 | [leetcode](https://leetcode.cn/problems/validate-binary-search-tree): 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
39 |
40 | 有效 二叉搜索树定义如下:
41 |
42 | - 节点的左子树只包含 小于 当前节点的数。
43 | - 节点的右子树只包含 大于 当前节点的数。
44 | - 所有左子树和右子树自身必须也是二叉搜索树。
45 |
46 | 思路:**二叉搜索树的中序遍历是从小到大的, 左右根**
47 |
48 | ```js
49 | var isValidBST = function (root) {
50 | // 二叉搜索树的中序遍历是从小到大的
51 | function inorder(node) {
52 | if (!node) return [];
53 | return [...inorder(node.left), node.val, ...inorder(node.right)];
54 | }
55 | let arr = inorder(root);
56 |
57 | for (let i = 1; i < arr.length; i++) {
58 | if (arr[i] <= arr[i - 1]) return false;
59 | }
60 |
61 | return true;
62 | };
63 | ```
64 |
65 | 优化 递归 提前减少遍历!
66 |
67 | ```js
68 | var isValidBST = function (root) {
69 | // 二叉搜索树的中序遍历是从小到大的
70 | let pre = -Infinity;
71 |
72 | function check(node) {
73 | if (!node) return true;
74 | // check left
75 | let left = check(node.left);
76 | // check current
77 | if (node.val < pre) return false;
78 | pre = node.val;
79 | // check right
80 | let right = check(node.right);
81 | return left && right;
82 | }
83 | return check(root);
84 | };
85 | ```
86 |
87 | ## 二叉搜索树的最小绝对差
88 |
89 | [力扣题目链接](https://leetcode-cn.com/problems/minimum-absolute-difference-in-bst/)
90 |
91 | 给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。
92 |
93 | 示例:
94 |
95 | 
96 |
97 | 提示:树中至少有 2 个节点。
98 |
99 | ```js
100 | var getMinimumDifference = function (root) {
101 | function inorderLoop(node) {
102 | if (!node) return [];
103 | return [...inorderLoop(node.left), node.val, ...inorderLoop(node.right)];
104 | }
105 |
106 | let inorder = inorderLoop(root);
107 |
108 | let min = Infinity;
109 |
110 | for (let i = 1; i < inorder.length; i++) {
111 | min = Math.min(min, inorder[i] - inorder[i - 1]);
112 | }
113 |
114 | return min;
115 | };
116 | ```
117 |
118 | ## 二叉搜索树中的众数
119 |
120 | [力扣题目链接](https://leetcode-cn.com/problems/find-mode-in-binary-search-tree/solution/)
121 |
122 | 给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。
123 |
124 | 假定 BST 有如下定义:
125 |
126 | - 结点左子树中所含结点的值小于等于当前结点的值
127 | - 结点右子树中所含结点的值大于等于当前结点的值
128 | - 左子树和右子树都是二叉搜索树
129 |
130 | 例如:
131 |
132 | 给定 BST [1,null,2,2],
133 |
134 | 
135 |
136 | ```js
137 | 输入:root = [1,null,2,2]
138 | 输出:[2]
139 | ```
140 |
141 | ---
142 |
143 | ```js
144 | var findMode = function (root) {
145 | let map = {};
146 | function dfs(node) {
147 | if (!node) return;
148 | dfs(node.left);
149 | dfs(node.right);
150 | if (!map[node.val]) map[node.val] = 1;
151 | else map[node.val]++;
152 | }
153 | dfs(root);
154 | const max = Math.max(...Object.values(map));
155 | return Object.keys(map).filter((key) => map[key] === max);
156 | };
157 | ```
158 |
159 | ---
160 |
161 | **进阶**:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内
162 |
163 | todo...
164 |
165 | ## 把二叉搜索树转换为累加树
166 |
167 | [leetcode](https://leetcode.cn/problems/convert-bst-to-greater-tree) 给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
168 |
169 | > BST 的中序遍历就是从小到大,那么反过来就是从大到小,然后累加就好了.
170 |
171 | ```js
172 | /**
173 | * @param {TreeNode} root
174 | * @return {TreeNode}
175 | */
176 | var convertBST = function (root) {
177 | let num = 0;
178 | function dfs(node) {
179 | if (!node) return null;
180 | dfs(node.right);
181 | node.val = node.val + num;
182 | num = node.val;
183 | dfs(node.left);
184 | return node;
185 | }
186 | return dfs(root);
187 | };
188 | ```
189 |
--------------------------------------------------------------------------------
/docs/algorithm/数组/双指针.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 双指针系列
3 | date: 2022-05-18 21:48:34
4 | sidebar: auto
5 | tags:
6 | - 双指针
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 下一个排列
12 |
13 | [leetcode](https://leetcode.cn/problems/next-permutation/) 大意就是
14 |
15 | - 例如,`arr = [1,2,3]` 的下一个排列是 `[1,3,2]` 。
16 | - 类似地,`arr = [2,3,1]` 的下一个排列是 `[3,1,2]` 。
17 | - 而 `arr = [3,2,1]` 的下一个排列是 `[1,2,3]` ,因为 `[3,2,1]` 不存在一个字典序更大的排列。
18 |
19 | 必须 原地 修改,只允许使用额外常数空间。
20 |
21 | ```js
22 | 输入:nums = [1,2,3]
23 | 输出:[1,3,2]
24 |
25 | 输入:nums = [3,2,1]
26 | 输出:[1,2,3]
27 |
28 | 输入:nums = [1,1,5]
29 | 输出:[1,5,1]
30 | ```
31 |
32 | ### 思路
33 |
34 | - 如何变大:从低位挑一个大一点的数,交换前面一个小一点的数。
35 | - 变大的幅度要尽量小。
36 |
37 | 像 [3,2,1] 这样递减的,没有下一个排列,已经稳定了,没法变大。
38 |
39 | 像 [1,5,2,4,3,2] 这种,怎么稍微变大?
40 |
41 | - 从右往左,**寻找第一个比右邻居小的数**,把它换到后面去
42 | - “第一个”意味着尽量是低位,“比右邻居小”意味着它是从右往左的第一个波谷
43 | - 比如,1 5 **(2)** 4 3 2,中间这个 2。
44 | - 接着还是从右往左,寻找第一个比这个 2 大的数。15 **(2)** 4 **(3)** 2,交换后:15 **(3)** 4 **(2)** 2。
45 | - 还没结束!变大的幅度可以再小一点,仟位微变大了,后三位可以再小一点。
46 | - 后三位肯定是递减的,翻转,变成[1,5,3,2,2,4],即为所求。
47 |
48 | 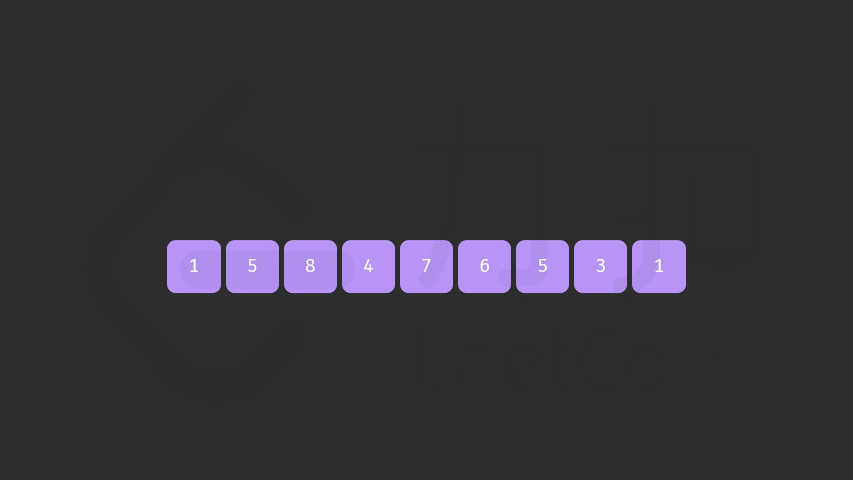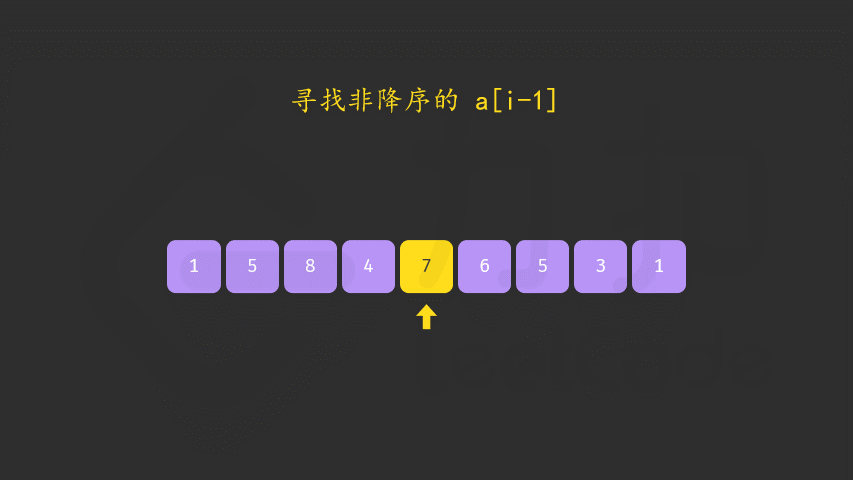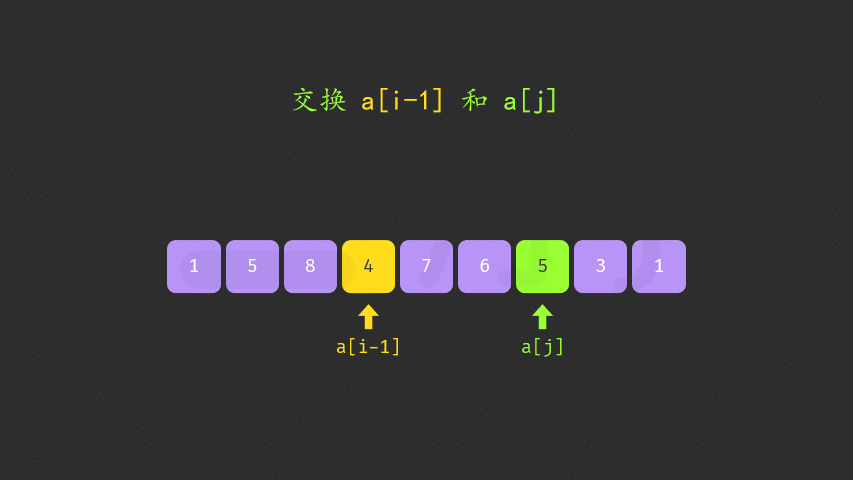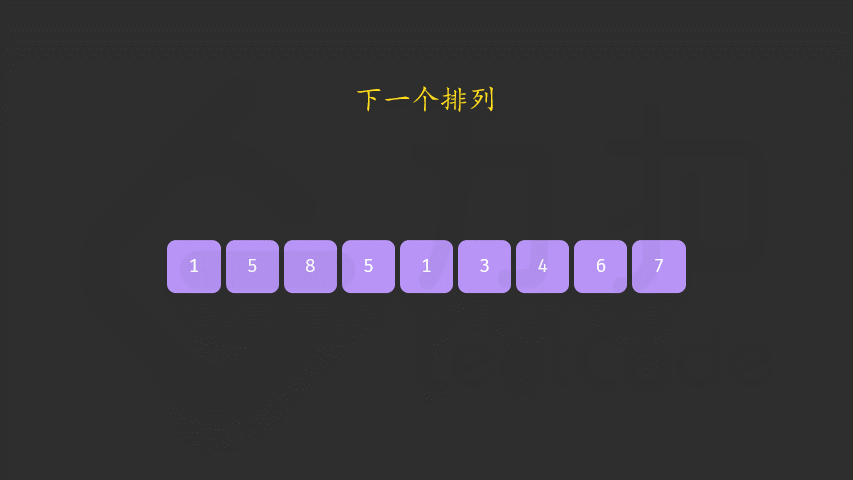
49 |
50 | ### 代码
51 |
52 | ```js
53 | /**
54 | * @param {number[]} nums
55 | * @return {void} Do not return anything, modify nums in-place instead.
56 | */
57 | function nextPermutation(nums) {
58 | let i = nums.length - 2; // 向左遍历,i从倒数第二开始是为了nums[i+1]要存在
59 | while (i >= 0 && nums[i] >= nums[i + 1]) i--; // 寻找第一个小于右邻居的数
60 |
61 | // 当前的 i 是存在的 从它身后挑一个数,和它换
62 | if (i >= 0) {
63 | let j = nums.length - 1;
64 | while (j >= 0 && nums[j] <= nums[i]) j--; // 寻找第一个大于 nums[i] 的数
65 | [nums[i], nums[j]] = [nums[j], nums[i]]; // 两数交换,实现变大
66 | }
67 |
68 | // 如果 i = -1,说明是递减排列,如 3 2 1,没有下一排列,直接翻转为最小排列:1 2 3
69 | let l = i + 1;
70 | let r = nums.length - 1;
71 | while (l < r) {
72 | // i 右边的数进行翻转,使得变大的幅度小一些
73 | [nums[l], nums[r]] = [nums[r], nums[l]];
74 | l++;
75 | r--;
76 | }
77 | }
78 | ```
79 |
80 | ## 三数之和
81 |
82 | [力扣题目链接](https://leetcode-cn.com/problems/3sum/): 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 `a + b + c = 0` ?请你找出所有满足条件且不重复的三元组。
83 |
84 | **注意:** 答案中不可以包含重复的三元组。
85 |
86 | ```js
87 | 给定数组 nums = [-1, 0, 1, 2, -1, -4],
88 | 满足要求的三元组集合为: [ [-1, 0, 1], [-1, -1, 2] ]
89 | ```
90 |
91 | ### 思路
92 |
93 | 1. 做排序,如果 i > 0 后面也没有要遍历下去的必要
94 | 2. 当前 i,定义指针 `l = i + 1, r = len - 1`, 当 l < r 情况下,计算 sum 值
95 | 1. sum > 0, r--
96 | 2. sum < 0, l++
97 | 3. sum === 0
98 | 1. 因为要求不含重复的三元组,这里再次对相同的元素值进行过滤
99 | 2. l++ && r--
100 |
101 | ### 代码
102 |
103 | ```js
104 | /**
105 | * @param {number[]} nums
106 | * @return {number[][]}
107 | */
108 | var threeSum = function (nums) {
109 | nums.sort((a, b) => a - b); // 排序
110 | let len = nums.length;
111 | let result = [];
112 | for (let i = 0; i < len; i++) {
113 | // 如果当前数字大于0,则三数之和一定大于0,所以结束循环
114 | if (nums[i] > 0) break;
115 | if (i > 0 && nums[i] == nums[i - 1]) continue; // 去重
116 |
117 | let [l, r] = [i + 1, len - 1];
118 | while (l < r) {
119 | let sum = nums[i] + nums[l] + nums[r];
120 | if (sum > 0) r--;
121 | else if (sum < 0) l++;
122 | else {
123 | // sum
124 | result.push([nums[i], nums[l], nums[r]]);
125 | while (l < r && nums[l] === nums[l + 1]) l++; // 去重
126 | while (l < r && nums[r] === nums[r - 1]) r--; // 去重
127 | l++;
128 | r--;
129 | }
130 | }
131 | }
132 |
133 | return result;
134 | };
135 | ```
136 |
137 | ## 接雨水
138 |
139 | [leetcode](https://leetcode-cn.com/problems/trapping-rain-water/)
140 |
141 | ```js
142 | 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
143 | 输出:6
144 | 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)
145 | ```
146 |
147 | ### 思路
148 |
149 | 我们先明确几个变量的含义
150 |
151 | ```js
152 | leftMax: 左边的最大值,它是从左往右遍历找到的
153 | rightMax: 右边的最大值,它是从右往左遍历找到的
154 | left: 从左往右处理的当前下标
155 | right: 从右往左处理的当前下标
156 | ```
157 |
158 | 
159 |
160 | 在某个位置 i 处,它能存的水,取决于它左右两边的最大值中较小的一个,这点很好理解,和木桶原理类似,取决于短板。
161 |
162 | 如图,当 i = 4,他能存储的水量取决于左右两根柱子的最小高度
163 |
164 | ### 代码
165 |
166 | ```js
167 | /**
168 | * @param {number[]} height
169 | * @return {number}
170 | */
171 | var trap = function (height) {
172 | let sum = 0;
173 | let [left, right, leftMax, rightMax] = [0, height.length - 1, 0, 0];
174 |
175 | while (left < right) {
176 | leftMax = Math.max(leftMax, height[left]);
177 | rightMax = Math.max(rightMax, height[right]);
178 |
179 | // 以左边为准
180 | if (leftMax <= rightMax) {
181 | sum += leftMax - height[left];
182 | left++;
183 | } else {
184 | sum += rightMax - height[right];
185 | right--;
186 | }
187 | }
188 |
189 | return sum;
190 | };
191 | ```
192 |
--------------------------------------------------------------------------------
/docs/network-protocol/14.https改进了什么.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HTTPS 做了什么?
3 | date: 2018-09-27 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - https
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | HTTP 报文是通过明文传输,这样很容易造成信息泄漏。(例如大家都熟悉的抓包工具:`Wireshark` 就可以截获 HTTP 请求)
12 |
13 | | 风险 | 描述 | 策略 |
14 | | ------------ | ------------------------------ | ---------------- |
15 | | **窃听风险** | 第三方可以获知通信内容 | 对称和非对称加密 |
16 | | **篡改风险** | 第三方可以修改通信内容 | 摘要算法 |
17 | | **冒充风险** | 第三方可以冒充他人身份参与通信 | 证书校验 |
18 |
19 | ## 在 tcp 基础上套了 ssl
20 |
21 | HTTPS 默认端口 `443`, 和 HTTP 不同之处在于 HTTPS 的下层协议套多了一层 `SSL/TSL` 协议。
22 |
23 | 
24 |
25 | - SSL:(Secure Socket Layer,安全套接字层),位于可靠的面向连接的网络层协议和应用层协议之间的一种协议层。SSL 通过互相认证、使用数字签名确保完整性、使用加密确保私密性,以实现客户端和服务器之间的安全通讯。该协议由两层组成:SSL 记录协议和 SSL 握手协议。
26 | - TLS:(Transport Layer Security,传输层安全协议),用于两个应用程序之间提供保密性和数据完整性。该协议由两层组成:TLS 记录协议和 TLS 握手协议。
27 |
28 | 也就是说掌握 HTTPS 关键之处还是掌握 SSL/TSL 是怎么解决三大风险的。
29 |
30 | - 防窃听,基于对称加密和非对称加密混合实现,使得密文无法被破解。
31 | - 篡改:通过摘要算法生成唯一值,只要有修改立马就可以发现。
32 | - 身份证书:则是通过数字签名和 CA 证书。
33 |
34 | 
35 |
36 | ## 防窃听
37 |
38 | 那就是加密,黑客即使截获你的报文也无法知道里面的信息
39 |
40 | ### 对称加密
41 |
42 | “对称加密”很好理解,客户端双方都有密钥,这两个密钥一样,用来加密/解密报文。常见算法为 `AES` 和 `ChaCha20`。
43 |
44 | 下面是一个通过 `AES` 算法加密的传输过程:
45 |
46 | 
47 |
48 | 这样黑客截获了密文后也无法得知里面的内容,除非他也有密钥。
49 |
50 | 对称加密看上去没问题了,但其中有一个很大的问题:**如何把密钥安全地传递给对方**,术语叫“**密钥交换**”。
51 |
52 | :::theorem 对称加密为什么要进行密钥交换?对称加密就一个密钥,客户端服务端各保存一份就可以了,为啥要传输交换呢?
53 |
54 | - 关键是“如何各保存一份”,两边加密通信必须要使用相同的密钥才行,不交换如何才能保持一致呢?
55 | - 而且简单的一对一还好说,现实情况是网站要面对成千上万的用户,如何与这么多的客户端保持一致?
56 | - 还有,如果总使用一个密钥,就很容易被破解,风险高,需要定期更换,最好是一次一密。
57 | - 所以,为了安全起见,每次通信前双方都要交换密钥,这样就实现了“各保存一份”,用完就扔掉,下次重新交换。
58 |
59 | :::
60 |
61 | ### 非对称加密
62 |
63 | 非对称加密可以解决“**密钥交换**”的问题。网站秘密保管私钥,在网上任意分发公钥,你想要登录网站只要用公钥加密就行了,密文只能由私钥持有者才能解密。而黑客因为没有私钥,所以就无法破解密文。
64 |
65 | 特点:
66 |
67 | - 任何经过 A 的公钥进行加密的信息,只有 A 的私钥才能解密
68 | - 任何有公钥的人可以确认对方发送的消息是被私钥加密过的
69 | - 非对称加密解密计算开销远远大于对称加密
70 | - 公钥加密私钥可以解密,反过来私钥加密公钥是可以解密的
71 |
72 | 下面是非对称加密的过程:
73 |
74 | 
75 |
76 | 由于黑客不知道后面的密钥是什么,所以也解密不出来。但是非对称加密也面临着风险:
77 |
78 | 首先非对称加密面临着性能开销的问题,,但因为它们都是基于复杂的数学难题,运算速度很慢,如果仅用非对称加密,虽然保证了安全,但通信速度有如乌龟、蜗牛,实用性就变成了零。
79 |
80 | 其次,服务端如何和客户端安全通信?
81 |
82 | 1. 通过公钥加密,客户端没有私钥无法解密。
83 | 2. 通过私钥加密,客户端有公钥可以解密。黑客也知道公钥,因为公钥是公开的,所以也不行。
84 |
85 | ### 混合加密
86 |
87 | 下面也是一个混合加密的例子:
88 |
89 | 
90 |
91 | 1. 客户端索要公钥
92 | 2. 服务端返回公钥
93 | 3. 客户端用伪随机数成会话秘钥,就是我们对称加密生成的密钥
94 | 4. 它用公钥加密之后进行传递(**这个时候被加密的不是数据 是这个会话秘钥 等于把钥匙加密了**) 这里的公钥就是非对称加密中的公钥 他是由服务器传递过去的。
95 | 5. 服务端用非对称加密的私钥去解密 拿到我们的会话秘钥
96 | 6. 客户端和服务端都能用同一个会话秘钥进行加解密了(使用的对称加密)
97 |
98 | 这样就算传输过程被攻击者截取到了被加密的会话秘钥 他没有服务器的私钥是无法得到会话秘钥的。
99 |
100 | ## 防篡改(摘要算法)
101 |
102 | HTTPS 第二个目的是对网站服务器进行真实身份认证
103 |
104 | 先来看一个问题 上一步我们已经解决了数据加密的问题 虽然攻击者无法解密数据 但是他可以**篡改数据** 我们怎么知道数据没被动过呢
105 |
106 | :::details 那就用到了摘要算法,常见算法 MD5, SHA-2
107 |
108 | - 摘要算法: 特殊的“单向”加密算法,它只有算法,没有密钥,加密后的数据无法解密,不能从摘要逆推出原文。
109 | - 因为摘要算法对输入具有“单向性”和“雪崩效应”,输入的微小不同会导致输出的剧烈变化,所以也被 TLS 用来生成伪随机数
110 | - 你可以把摘要算法近似地理解成一种特殊的压缩算法,它能够把任意长度的数据“压缩”成固定长度、而且独一无二的“摘要”字符串,就好像是给这段数据生成了一个数字“指纹”。
111 |
112 | :::
113 |
114 | 摘要算法保证了“数字摘要”和原文是完全等价的。所以,我们只要在原文后附上它的摘要,就能够保证数据的完整性。
115 |
116 | 1. 客户端发送用 Hash 函数生成消息摘要。`MD5(data)...`
117 | 2. 服务端收到后使用同样的方法计算信息的摘要,如果一致,就说明消息是完整可信的,没有被修改。
118 |
119 | :::danger
120 |
121 | 使用摘要算法后同样存在一个问题:黑客可以把**摘要也一起修改**了,就像一开始所说的,黑客可以伪装成网站来窃取信息。而反过来,他也可以伪装成你,向网站发送支付、转账等消息,网站没有办法确认你的身份,钱可能就这么被偷走了。
122 |
123 | :::
124 |
125 | ## 防冒充(ca 证书)
126 |
127 | 其实最后还有一个很关键的点是 我们刚刚所有的假设都基于 客户端的公钥是服务器传递过来的 那如果攻击者伪造了服务器的公钥怎么办呢
128 |
129 | 
130 |
131 | 解决上述身份验证问题的关键是确保获取的公钥途径是合法的,能够验证服务器的身份信息,为此需要引入权威的第三方机构 CA。
132 |
133 | 1. 服务方 S 向第三方机构 CA 提交公钥、组织信息、个人信息(域名)等信息并申请认证;
134 | 2. CA 通过线上、线下等多种手段验证申请者提供信息的真实性,如组织是否存在、企业是否合法,是否拥有域名的所有权等;
135 | 3. 如信息审核通过,CA 会向申请者签发认证文件-证书。
136 |
137 | - 客户端 C 向服务器 S 发出请求时,S 返回证书文件;- 证书包含以下信息:申请者公钥、申请者的组织信息和个人信息、签发机构 CA 的信息、有效时间、证书序列号等信息的明文,同时包含一个签名;
138 | - 签名的产生算法:首先,使用散列函数计算公开的明文信息的信息摘要,然后,采用 CA 的私钥对信息摘要进行加密,密文即签名;
139 |
140 | 4. 客户端 C 向服务器 S 发出请求时,S 返回证书文件;
141 | 5. 客户端 C 读取证书中的相关的明文信息,采用相同的散列函数计算得到信息摘要,然后,利用对应 CA 的公钥解密签名数据,对比证书的信息摘要,如果一致,则可以确认证书的合法性,即公钥合法;
142 | 6. 客户端然后验证证书相关的域名信息、有效时间等信息;
143 | 7. 客户端会内置信任 CA 的证书信息(包含公钥),如果 CA 不被信任,则找不到对应 CA 的证书,证书也会被判定非法。
144 |
145 | 在这个过程注意几点:
146 |
147 | 1. 申请证书不需要提供私钥,确保私钥永远只能服务器掌握;
148 | 2. 证书的合法性仍然依赖于非对称加密算法,证书主要是增加了服务器信息以及签名;
149 | 3. 内置 CA 对应的证书称为根证书,颁发者和使用者相同,自己为自己签名,即自签名证书(为什么说"部署自签 SSL 证书非常不安全")
150 | 4. 证书=公钥+申请者与颁发者信息+签名;
151 |
--------------------------------------------------------------------------------
/docs/.vitepress/cache/deps/@theme_index.js:
--------------------------------------------------------------------------------
1 | // node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/index.js
2 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/fonts.css";
3 |
4 | // node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/without-fonts.js
5 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/vars.css";
6 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/base.css";
7 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/utils.css";
8 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/components/custom-block.css";
9 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/components/vp-code.css";
10 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/components/vp-code-group.css";
11 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/components/vp-doc.css";
12 | import "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/styles/components/vp-sponsor.css";
13 | import VPBadge from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPBadge.vue";
14 | import Layout from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/Layout.vue";
15 | import { default as default2 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPHomeHero.vue";
16 | import { default as default3 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPHomeFeatures.vue";
17 | import { default as default4 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPHomeSponsors.vue";
18 | import { default as default5 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPDocAsideSponsors.vue";
19 | import { default as default6 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPTeamPage.vue";
20 | import { default as default7 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPTeamPageTitle.vue";
21 | import { default as default8 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPTeamPageSection.vue";
22 | import { default as default9 } from "C:/Users/guosw5/Desktop/codes/note/node_modules/.pnpm/vitepress@1.0.0-alpha.61_@a_b03ddc81f2f192b764cbb197b970210d/node_modules/vitepress/dist/client/theme-default/components/VPTeamMembers.vue";
23 | var theme = {
24 | Layout,
25 | enhanceApp: ({ app }) => {
26 | app.component("Badge", VPBadge);
27 | }
28 | };
29 | var without_fonts_default = theme;
30 | export {
31 | default5 as VPDocAsideSponsors,
32 | default3 as VPHomeFeatures,
33 | default2 as VPHomeHero,
34 | default4 as VPHomeSponsors,
35 | default9 as VPTeamMembers,
36 | default6 as VPTeamPage,
37 | default8 as VPTeamPageSection,
38 | default7 as VPTeamPageTitle,
39 | without_fonts_default as default
40 | };
41 | //# sourceMappingURL=@theme_index.js.map
42 |
--------------------------------------------------------------------------------
/docs/algorithm/回溯/回溯排列.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 回溯排列系列
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 回溯算法
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 全排列
12 |
13 | [力扣题目链接](https://leetcode-cn.com/problems/permutations/):给定一个 **没有重复** 数字的序列,返回其所有可能的全排列。
14 |
15 | ```js
16 | 输入: [1, 2, 3];
17 | 输出: [
18 | [1, 2, 3],
19 | [1, 3, 2],
20 | [2, 1, 3],
21 | [2, 3, 1],
22 | [3, 1, 2],
23 | [3, 2, 1],
24 | ];
25 | ```
26 |
27 | ```js
28 | /**
29 | * @param {number[]} nums
30 | * @return {number[][]}
31 | */
32 | var permute = function (nums) {
33 | let result = [];
34 | let used = [];
35 |
36 | function backtrack(track) {
37 | // 结束条件
38 | if (track.length == nums.length) {
39 | // 位置1:利用es6的'... 展开运算符'进行浅拷贝
40 | result.push([...track]);
41 | return;
42 | }
43 |
44 | for (let i = 0; i < nums.length; i++) {
45 | if (used[i]) continue; // 跳过本次循环
46 | track.push(nums[i]);
47 | used[i] = true;
48 | backtrack(track);
49 | track.pop(); // 删除路径
50 | used[i] = false;
51 | }
52 | }
53 |
54 | backtrack([]);
55 |
56 | return result;
57 | };
58 | ```
59 |
60 | ## 全排列 II
61 |
62 | [力扣题目链接](https://leetcode-cn.com/problems/permutations-ii/):给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
63 |
64 | ```js
65 | - 输入:nums = [1,1,2]
66 | - 输出:[[1,1,2],[1,2,1],[2,1,1]]
67 |
68 | - 输入:nums = [1,2,3]
69 | - 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
70 | ```
71 |
72 | ```js
73 | /**
74 | * @param {number[]} nums
75 | * @return {number[][]}
76 | *
77 | * ! 不同于全排列1 这里需要考虑重复的情况,所以回溯的时候加入
78 | * ! nums[i] == nums[i - 1] && !visited[i - 1] 进行判断(需要对数组先行排序)
79 | *
80 | */
81 | var permuteUnique = function (nums) {
82 | let result = [],
83 | len = nums.length,
84 | visited = new Array(len).fill(false); // 用于剪枝
85 |
86 | nums.sort((a, b) => a - b); // 排序
87 |
88 | function backtrack(path) {
89 | // 判断终止条件
90 | if (path.length === len) {
91 | result.push(path.slice());
92 | return;
93 | }
94 |
95 | for (let i = 0; i < len; i++) {
96 | if (visited[i] || (nums[i] == nums[i - 1] && !visited[i - 1])) continue; // 跳过
97 |
98 | // 加入当前数字并置状态位为已加入选择
99 | path.push(nums[i]);
100 | visited[i] = true;
101 | // 继续回溯
102 | backtrack(path);
103 |
104 | // 撤销选择并还原状态位
105 | path.pop();
106 | visited[i] = false;
107 | }
108 | }
109 |
110 | backtrack([]);
111 |
112 | return result;
113 | };
114 | ```
115 |
116 | ## 字符串的排列
117 |
118 | [剑指 Offer 38. 字符串的排列](https://leetcode-cn.com/problems/zi-fu-chuan-de-pai-lie-lcof/)
119 |
120 | ```js
121 | 输入:s = "abc"
122 | 输出:["abc","acb","bac","bca","cab","cba"]
123 | ```
124 |
125 | ```js
126 | /**
127 | * @param {string} s
128 | * @return {string[]}
129 | */
130 | var permutation = function (s) {
131 | let result = [];
132 | let visited = [];
133 |
134 | s = s.split('').sort((a, b) => a.charCodeAt() - b.charCodeAt());
135 |
136 | function backtrack(track) {
137 | if (track.length === s.length) {
138 | result.push([...track].join(''));
139 | return;
140 | }
141 |
142 | for (let i = 0; i < s.length; i++) {
143 | if (visited[i] || (!visited[i - 1] && s[i] === s[i - 1])) continue;
144 | track.push(s[i]);
145 | visited[i] = true;
146 | backtrack(track);
147 | track.pop();
148 | visited[i] = false;
149 | }
150 | }
151 |
152 | backtrack([]);
153 | return result;
154 | };
155 |
156 | console.log(permutation('abb'));
157 | ```
158 |
159 | ## 字母大小写全排列
160 |
161 | [字母大小写全排列](https://leetcode-cn.com/problems/letter-case-permutation/)
162 |
163 | ```js
164 | 输入:s = "a1b2
165 | 输出:["a1b2", "a1B2", "A1b2", "A1B2"]
166 | ```
167 |
168 | ```js
169 | /**
170 | * @param {string} s
171 | * @return {string[]}
172 | */
173 | var letterCasePermutation = function (s) {
174 | let result = [];
175 | function dfs(i, str) {
176 | if (i === s.length) {
177 | result.push(str);
178 | return;
179 | }
180 | if (/\d/.test(s[i])) dfs(i + 1, str + s[i]);
181 | else {
182 | dfs(i + 1, str + s[i].toLowerCase());
183 | dfs(i + 1, str + s[i].toUpperCase());
184 | }
185 | }
186 |
187 | dfs(0, '');
188 |
189 | return result;
190 | };
191 |
192 | // 使用回溯
193 | var letterCasePermutation = function (s) {
194 | let result = [];
195 |
196 | function backtrack(s, idx) {
197 | result.push(s);
198 | for (let i = idx; i < s.length; i++) {
199 | // 数字 跳过
200 | if (/\d/.test(s[i])) continue;
201 | // 字母, 反转字母大小写
202 | s = s.slice(0, i) + reverseStr(s[i]) + s.slice(i + 1);
203 |
204 | backtrack(s, i + 1);
205 |
206 | // 回溯, 将字母大小写反转回来
207 | s = s.slice(0, i) + reverseStr(s[i]) + s.slice(i + 1);
208 | }
209 | }
210 |
211 | function reverseStr(s) {
212 | return /[a-z]/.test(s) ? s.toUpperCase() : s.toLowerCase();
213 | }
214 |
215 | backtrack(s, 0);
216 | return result;
217 | };
218 | ```
219 |
--------------------------------------------------------------------------------
/docs/network-protocol/20.http3.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HTTP3 展望
3 | date: 2018-09-25 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http2
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | 在前面的两讲里,我们一起学习了 HTTP/2,你也应该看到了 HTTP/2 做出的许多努力,比如头部压缩、二进制分帧、虚拟的“流”与多路复用,性能方面比 HTTP/1 有了很大的提升,“基本上”解决了“队头阻塞”这个“老大难”问题。
12 |
13 | ## HTTP/2 的“队头阻塞”
14 |
15 | 等等,你可能要发出疑问了:为什么说是“基本上”,而不是“完全”解决了呢?
16 |
17 | 这是因为 HTTP/2 虽然使用“帧”“流”“多路复用”,没有了“队头阻塞”,但这些手段都是在应用层里,而在下层,也就是 TCP 协议里,还是会发生“队头阻塞”
18 |
19 | 这是怎么回事呢?
20 |
21 | 让我们从协议栈的角度来仔细看一下。在 HTTP/2 把多个“请求 - 响应”分解成流,交给 TCP 后,TCP 会再拆成更小的包依次发送(其实在 TCP 里应该叫 segment,也就是“段”)。
22 |
23 | 在网络良好的情况下,包可以很快送达目的地。但如果网络质量比较差,像手机上网的时候,就有可能会丢包。而 TCP 为了保证可靠传输,有个特别的“**丢包重传**”机制,丢失的包必须要等待重新传输确认,其他的包即使已经收到了,也只能放在缓冲区里,上层的应用拿不出来,只能“干着急”。
24 |
25 | 我举个简单的例子:
26 |
27 | 客户端用 TCP 发送了三个包,但服务器所在的操作系统只收到了后两个包,第一个包丢了。那么内核里的 TCP 协议栈就只能把已经收到的包暂存起来,“停下”等着客户端重传那个丢失的包,这样就又出现了“队头阻塞”。
28 |
29 | 由于这种“队头阻塞”是 TCP 协议固有的,所以 HTTP/2 即使设计出再多的“花样”也无法解决。
30 |
31 | Google 在推 SPDY 的时候就已经意识到了这个问题,于是就又发明了一个新的“QUIC”协议,让 HTTP 跑在 QUIC 上而不是 TCP 上。
32 |
33 | 而这个“HTTP over QUIC”就是 HTTP 协议的下一个大版本,HTTP/3。它在 HTTP/2 的基础上又实现了质的飞跃,真正“完美”地解决了“队头阻塞”问题。
34 |
35 | 这里先贴一下 HTTP/3 的协议栈图,让你对它有个大概的了解。
36 |
37 | 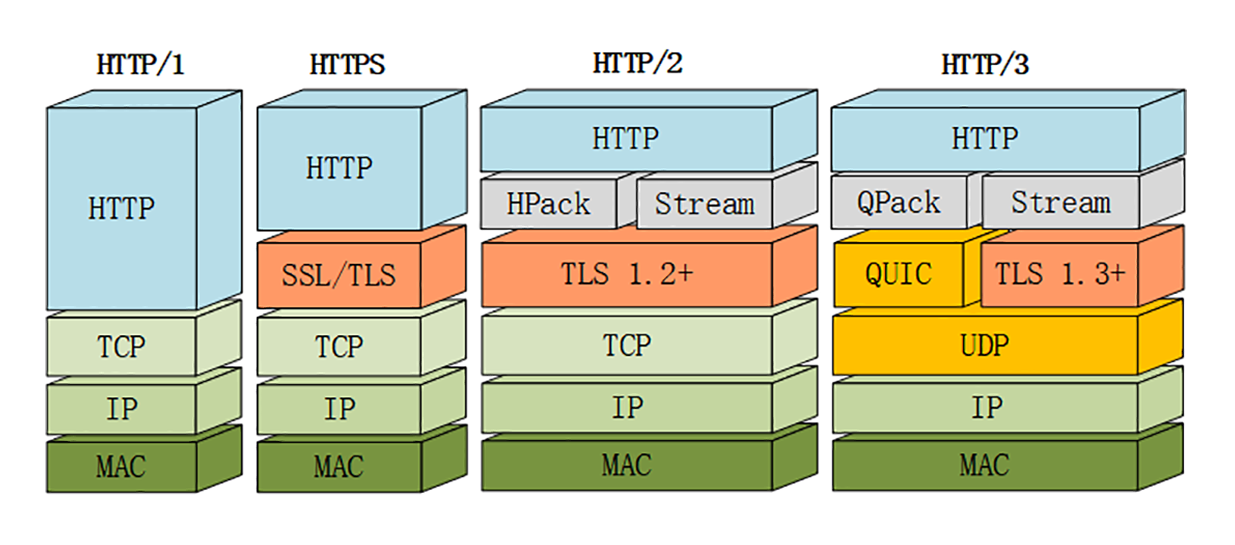
38 |
39 | ## QUIC 协议
40 |
41 | 从这张图里,你可以看到 HTTP/3 有一个关键的改变,那就是它把下层的 TCP“抽掉”了,换成了 UDP。因为 UDP 是无序的,包之间没有依赖关系,所以就从根本上解决了“队头阻塞”。
42 |
43 | 你一定知道,**UDP 是一个简单、不可靠的传输协议**,只是对 IP 协议的一层很薄的包装,和 TCP 相比,它实际应用的较少。
44 |
45 | 不过正是因为它简单,**不需要建连和断连**,通信成本低,也就非常灵活、高效,“可塑性”很强。
46 |
47 | 所以,QUIC 就选定了 UDP,在它之上把 TCP 的那一套连接管理、拥塞窗口、流量控制等“搬”了过来,“去其糟粕,取其精华”,打造出了一个全新的可靠传输协议,可以认为是“**新时代的 TCP**”。
48 |
49 | gQUIC 混合了 UDP、TLS、HTTP,是一个应用层的协议。而 IETF 则对 gQUIC 做了“清理”,把应用部分分离出来,形成了 HTTP/3,原来的 UDP 部分“下放”到了传输层,所以 iQUIC 有时候也叫“QUIC-transport”
50 |
51 | 接下来要说的 QUIC 都是指 iQUIC,要记住,它与早期的 gQUIC 不同,是一个传输层的协议,和 TCP 是平级的。
52 |
53 | ## QUIC 的特点
54 |
55 | QUIC 基于 UDP,而 UDP 是“无连接”的,根本就不需要“握手”和“挥手”,所以天生就要比 TCP 快。
56 |
57 | 就像 TCP 在 IP 的基础上实现了可靠传输一样,QUIC 也基于 UDP 实现了可靠传输,**保证数据一定能够抵达目的地**。它还引入了类似 HTTP/2 的“流”和“多路复用”,单个“流”是有序的,可能会因为丢包而阻塞,但其他“流”不会受到影响。
58 |
59 | 为了防止网络上的中间设备(Middle Box)识别协议的细节,QUIC 全面采用加密通信,可以很好地抵御窜改和“协议僵化”(ossification)。
60 |
61 | 而且,因为 TLS1.3 已经在去年(2018)正式发布,所以 QUIC 就直接应用了 TLS1.3,顺便也就获得了 0-RTT、1-RTT 连接的好处。
62 |
63 | 但 QUIC 并不是建立在 TLS 之上,而是内部“包含”了 TLS。它使用自己的帧“接管”了 TLS 里的“记录”,握手消息、警报消息都不使用 TLS 记录,直接封装成 QUIC 的帧发送,省掉了一次开销。
64 |
65 | ## QUIC 内部细节
66 |
67 | 由于 QUIC 在协议栈里比较偏底层,所以我只简略介绍两个内部的关键知识点。
68 |
69 | QUIC 的基本数据传输单位是**包**(packet)和**帧**(frame),一个包由多个帧组成,包面向的是“连接”,帧面向的是“流”。
70 |
71 | QUIC 使用不透明的“**连接 ID**”来标记通信的两个端点,客户端和服务器可以自行选择一组 ID 来标记自己,这样就解除了 TCP 里连接对“IP 地址 + 端口”(即常说的四元组)的强绑定,支持“**连接迁移**”(Connection Migration)。
72 |
73 | 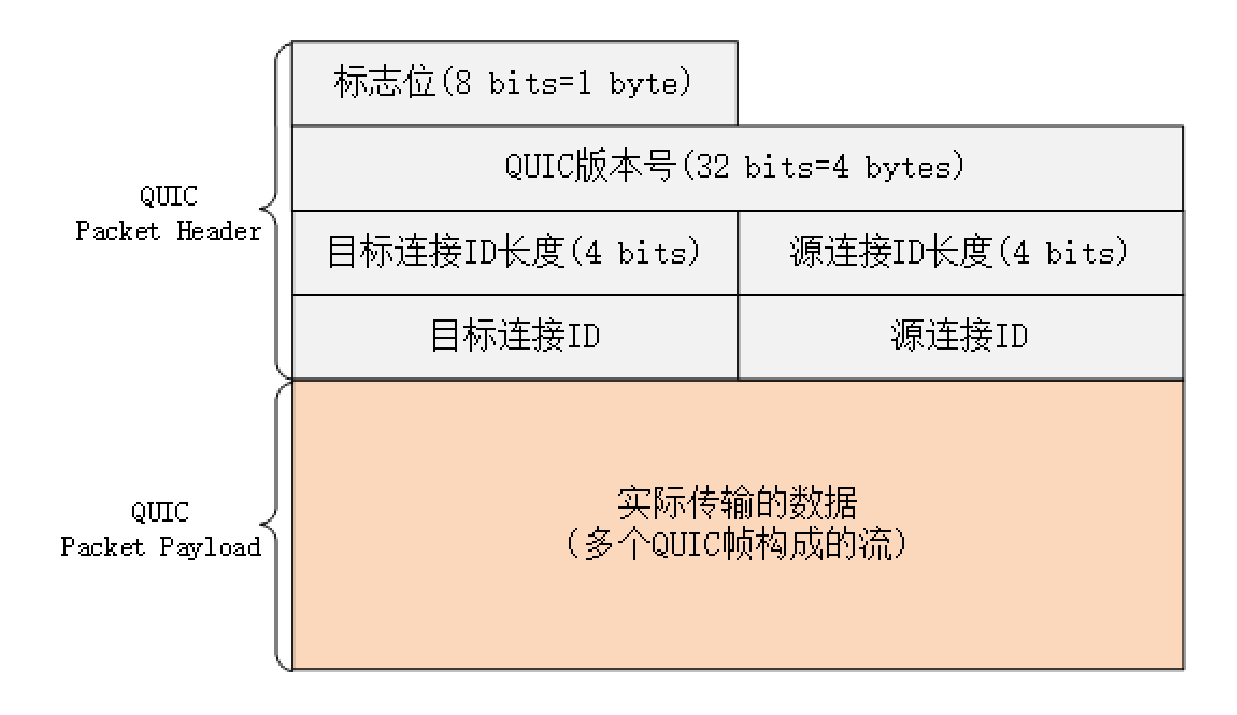
74 |
75 | 比如你下班回家,手机会自动由 4G 切换到 WiFi。这时 IP 地址会发生变化,TCP 就必须重新建立连接。而 QUIC 连接里的两端连接 ID 不会变,所以连接在“逻辑上”没有中断,它就可以在新的 IP 地址上继续使用之前的连接,消除重连的成本,实现连接的无缝迁移。
76 |
77 | QUIC 的帧里有多种类型,PING、ACK 等帧用于管理连接,而 STREAM 帧专门用来实现流。
78 |
79 | QUIC 里的流与 HTTP/2 的流非常相似,也是帧的序列,你可以对比着来理解。但 HTTP/2 里的流都是双向的,而 QUIC 则分为双向流和单向流。
80 |
81 | 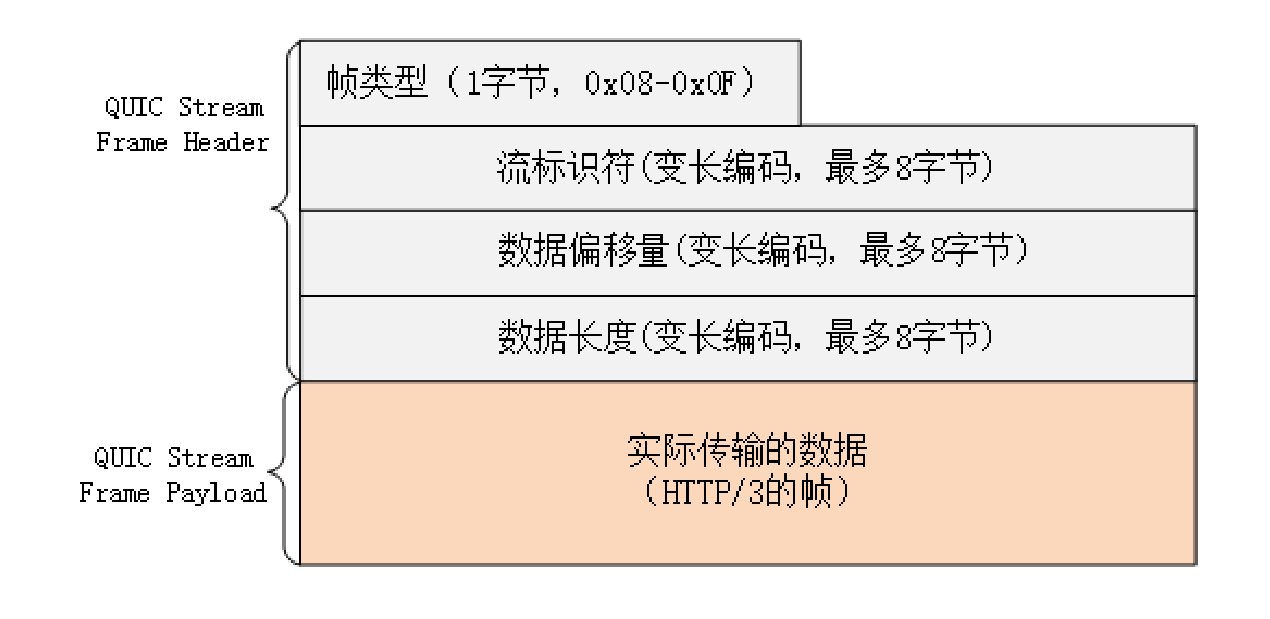
82 |
83 | QUIC 帧普遍采用变长编码,最少只要 1 个字节,最多有 8 个字节。流 ID 的最大可用位数是 62,数量上比 HTTP/2 的 2^31 大大增加。
84 |
85 | 流 ID 还保留了最低两位用作标志,第 1 位标记流的发起者,0 表示客户端,1 表示服务器;第 2 位标记流的方向,0 表示双向流,1 表示单向流。
86 |
87 | 所以 QUIC 流 ID 的奇偶性质和 HTTP/2 刚好相反,客户端的 ID 是偶数,从 0 开始计数。
88 |
89 | ## HTTP/3 协议
90 |
91 | 了解了 QUIC 之后,再来看 HTTP/3 就容易多了。
92 |
93 | 因为 QUIC 本身就已经支持了加密、流和多路复用,所以 HTTP/3 的工作减轻了很多,把流控制都交给 QUIC 去做。调用的不再是 TLS 的安全接口,也不是 Socket API,而是专门的 QUIC 函数。不过这个“QUIC 函数”还没有形成标准,必须要绑定到某一个具体的实现库。
94 |
95 | HTTP/3 里仍然使用流来发送“请求 - 响应”,但它自身不需要像 HTTP/2 那样再去定义流,而是直接使用 QUIC 的流,相当于做了一个“概念映射”。
96 |
97 | HTTP/3 里的“双向流”可以完全对应到 HTTP/2 的流,而“单向流”在 HTTP/3 里用来实现控制和推送,近似地对应 HTTP/2 的 0 号流。
98 |
99 | 由于流管理被“下放”到了 QUIC,所以 HTTP/3 里帧的结构也变简单了。
100 |
101 | 帧头只有两个字段:类型和长度,而且同样都采用变长编码,最小只需要两个字节。
102 |
103 | 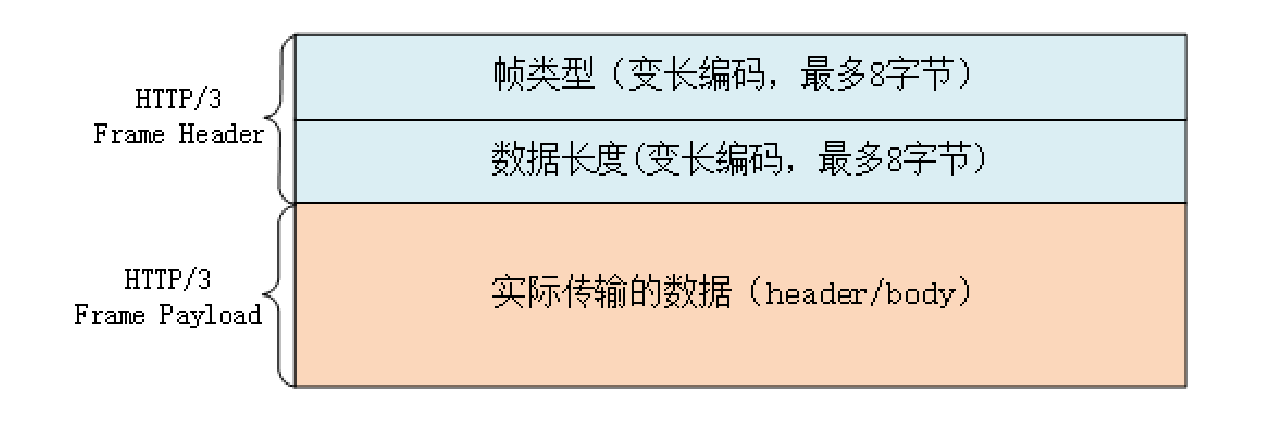
104 |
105 | HTTP/3 里的帧仍然分成数据帧和控制帧两类,HEADERS 帧和 DATA 帧传输数据,但其他一些帧因为在下层的 QUIC 里有了替代,所以在 HTTP/3 里就都消失了,比如 RST_STREAM、WINDOW_UPDATE、PING 等。
106 |
107 | 头部压缩算法在 HTTP/3 里升级成了“**QPACK**”,使用方式上也做了改变。虽然也分成静态表和动态表,但在流上发送 HEADERS 帧时不能更新字段,只能引用,索引表的更新需要在专门的单向流上发送指令来管理,解决了 HPACK 的“队头阻塞”问题。
108 |
109 | 另外,QPACK 的字典也做了优化,静态表由之前的 61 个增加到了 98 个,而且序号从 0 开始,也就是说“:authority”的编号是 0。
110 |
111 | ## HTTP/3 服务发现
112 |
113 | 讲了这么多,不知道你注意到了没有:HTTP/3 没有指定默认的端口号,也就是说不一定非要在 UDP 的 80 或者 443 上提供 HTTP/3 服务。
114 |
115 | 那么,该怎么“发现”HTTP/3 呢?
116 |
117 | 这就要用到 HTTP/2 里的“扩展帧”了。浏览器需要先用 HTTP/2 协议连接服务器,然后服务器可以在启动 HTTP/2 连接后发送一个“Alt-Svc”帧,包含一个“h3=host:port”的字符串,告诉浏览器在另一个端点上提供等价的 HTTP/3 服务。
118 |
119 | 浏览器收到“Alt-Svc”帧,会使用 QUIC 异步连接指定的端口,如果连接成功,就会断开 HTTP/2 连接,改用新的 HTTP/3 收发数据。
120 |
121 | ## 小结
122 |
123 | HTTP/3 基于 QUIC 协议,完全解决了“队头阻塞”问题,弱网环境下的表现会优于 HTTP/2;
124 |
125 | QUIC 是一个新的传输层协议,建立在 UDP 之上,实现了可靠传输;
126 |
127 | QUIC 内含了 TLS1.3,只能加密通信,支持 0-RTT 快速建连;
128 |
129 | QUIC 的连接使用“不透明”的连接 ID,不绑定在“IP 地址 + 端口”上,支持“连接迁移”;
130 |
131 | QUIC 的流与 HTTP/2 的流很相似,但分为双向流和单向流;
132 |
133 | HTTP/3 没有指定默认端口号,需要用 HTTP/2 的扩展帧“Alt-Svc”来发现。
134 |
--------------------------------------------------------------------------------
/docs/algorithm/动态规划/打家劫舍系列.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 打家劫舍系列
3 | date: 2022-03-31 20:56:00
4 | sidebar: auto
5 | tags:
6 | - 动态规划
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 打家劫舍
12 |
13 | [leetcode](https://leetcode-cn.com/problems/house-robber/):你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
14 |
15 | 给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
16 |
17 | ```js
18 | 输入:[1,2,3,1]
19 | 输出:4
20 | 解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
21 | 偷窃到的最高金额 = 1 + 3 = 4 。
22 | ```
23 |
24 | ### 思路
25 |
26 | - 偷第一间房:`nums[0]`
27 | - 偷第二间房:`Math.max(nums[0], nums[1])`
28 | - 偷第三间房:`Math.max(nums[1], nums[0] + nums[2]);`
29 | - 偷第 i 间房:`dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);`
30 |
31 | ### 代码
32 |
33 | ```js
34 | var rob = function (nums) {
35 | let dp = [nums[0], Math.max(nums[0], nums[1])];
36 | let len = nums.length;
37 | for (let i = 2; i < len; i++) {
38 | dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
39 | }
40 | return dp[len - 1];
41 | };
42 | ```
43 |
44 | ## 打家劫舍 II
45 |
46 | [leetcode](https://leetcode-cn.com/problems/house-robber-ii/submissions/):你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 **围成一圈** ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,**如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。**
47 |
48 | 给定一个代表每个房屋存放金额的非负整数数组,计算你 **在不触动警报装置的情况下** ,今晚能够偷窃到的最高金额。
49 |
50 | ```js
51 | 输入:nums = [2,3,2]
52 | 输出:3
53 | 解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
54 |
55 | 输入:nums = [1,2,3,1]
56 | 输出:4
57 | 解释:你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。
58 | 偷窃到的最高金额 = 1 + 3 = 4 。
59 |
60 | 输入:nums = [1,2,3]
61 | 输出:3
62 | ```
63 |
64 | ### 思路
65 |
66 | 对于一个数组,按照题意也就是首尾不能同时存在,那么拆分两种情况比较就可以了比如:
67 |
68 | ```js
69 | [1, 2, 3, 4, 5]
70 | 情况1 不包含尾元素 [1, 2, 3, 4] 最大值 2 + 4 = 6;
71 | 情况2 包含尾元素 [2, 3, 4, 5] 最大值 3 + 5 = 8;
72 | 那么取最大值即可!
73 | ```
74 |
75 | ### 代码
76 |
77 | ```js
78 | /**
79 | * @param {number[]} nums
80 | * @return {number}
81 | */
82 | var rob = function (nums) {
83 | let len = nums.length;
84 |
85 | if (len === 0) return 0;
86 | if (len === 1) return nums[0];
87 |
88 | function fn(nums) {
89 | let _len = nums.length;
90 | let dp = [nums[0], Math.max(nums[0], nums[1])];
91 | for (let i = 2; i < _len; i++) {
92 | dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
93 | }
94 | return dp[_len - 1];
95 | }
96 |
97 | return Math.max(fn(nums.slice(0, len - 1)), fn(nums.slice(1)));
98 | };
99 | ```
100 |
101 | ## 打家劫舍 III
102 |
103 | [leetcode](https://leetcode.cn/problems/house-robber-iii):小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
104 |
105 | 除了 `root` 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
106 |
107 | 给定二叉树的 `root` 。返回在不触动警报的情况下 ,小偷能够盗取的最高金额。
108 |
109 | 
110 |
111 | ```js
112 | 输入: root = [3,2,3,null,3,null,1]
113 | 输出: 7
114 | 解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
115 | ```
116 |
117 | 
118 |
119 | ```js
120 | 输入: root = [3,4,5,1,3,null,1]
121 | 输出: 9
122 | 解释: 小偷一晚能够盗取的最高金额 4 + 5 = 9
123 | ```
124 |
125 | ### 思路
126 |
127 | 这里刚开始做的时候,存在误区,认为进行层序遍历后,再通过 dp 进行计算最大值。如下(不通过的):
128 |
129 | ```js
130 | var rob = function (root) {
131 | if (!root) return 0;
132 | let nums = [];
133 | // 二叉树的层序遍历
134 | let queue = [root];
135 | while (queue.length) {
136 | let len = queue.length;
137 | let sum = 0;
138 | for (let i = 0; i < len; i++) {
139 | let node = queue.shift();
140 | sum += node.val;
141 | node.left && queue.push(node.left);
142 | node.right && queue.push(node.right);
143 | }
144 | nums.push(sum);
145 | }
146 |
147 | // 打家劫舍
148 | function robRoom(nums) {
149 | let len = nums.length;
150 | let dp = [nums[0], Math.max(nums[0], nums[1])];
151 | for (let i = 2; i < len; i++) {
152 | dp[i] = Math.max(dp[i - 1], dp[i - 2] + nums[i]);
153 | }
154 | return dp[len - 1];
155 | }
156 |
157 | return robRoom(nums);
158 | };
159 | ```
160 |
161 | 更多思路可以见 [四种写法:递归、记忆化递归、树形 DP、降维优化 | 337. 打家劫舍 III](https://leetcode.cn/problems/house-robber-iii/solution/si-chong-xie-fa-di-gui-ji-yi-hua-di-gui-shu-xing-d/)
162 |
163 | 这里理解到递归思路:
164 |
165 | 打不打劫根节点,会影响打劫一棵树的收益:
166 |
167 | 1. 打劫根节点,则不能打劫左右子节点,但是能打劫左右子节点的四个子树(如果有)。
168 | 2. 不打劫根节点,则能打劫左子节点和右子节点,收益是打劫左右子树的收益之和。
169 |
170 | ### 代码
171 |
172 | ```js
173 | var rob = function (root) {
174 | let memo = new Map(); // 这里没剪枝,如果不加 map 测试用例通过不了,超时了!
175 | function dfs(root) {
176 | if (!root) return 0;
177 | if (memo.has(root)) return memo.get(root);
178 | // 1. 打劫节点下的左右子树
179 | const value1 = dfs(root.left) + dfs(root.right);
180 |
181 | // 2. 打结根节点 + 叶子节点
182 | const value2 =
183 | root.val +
184 | // 左叶子结点
185 | dfs(root.left?.left) +
186 | dfs(root.left?.right) +
187 | // 右叶子结点
188 | dfs(root.right?.left) +
189 | dfs(root.right?.right);
190 |
191 | const res = Math.max(value1, value2);
192 | // 保存当前子树的计算结果
193 | memo.set(root, res);
194 | return res;
195 | }
196 |
197 | return dfs(root);
198 | };
199 | ```
200 |
--------------------------------------------------------------------------------
/docs/algorithm/二叉树/二叉树的修改与构造.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 二叉树的修改与构造
3 | date: 2022-05-11 23:59:03
4 | sidebar: auto
5 | tags:
6 | - 二叉树
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 翻转二叉树
12 |
13 | [leetcode easy](https://leetcode-cn.com/problems/invert-binary-tree/):给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
14 |
15 | 
16 |
17 | ```js
18 | 输入:root = [4,2,7,1,3,6,9]
19 | 输出:[4,7,2,9,6,3,1]
20 | ```
21 |
22 | code:
23 |
24 | ```js
25 | /**
26 | * @param {TreeNode} root
27 | * @return {TreeNode}
28 | */
29 | var invertTree = function (root) {
30 | if (!root) return null;
31 | let left = root.left;
32 | root.left = invertTree(root.right);
33 | root.right = invertTree(left);
34 | return root;
35 | };
36 | ```
37 |
38 | ## 从中序与后序遍历序列构造二叉树
39 |
40 | [leetcode](https://leetcode.cn/problems/construct-binary-tree-from-inorder-and-postorder-traversal):给定两个整数数组 `inorder` 和 `postorder` ,其中 `inorder` 是二叉树的中序遍历, `postorder` 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
41 |
42 | 
43 |
44 | ```js
45 | 输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
46 | 输出:[3,9,20,null,null,15,7]
47 | ```
48 |
49 | 思路:首先推导
50 |
51 | ```js
52 | var buildTree = function (inorder, postorder) {
53 | if (!inorder.length || postorder.length) return null;
54 | // inorder 左根右 postorder 左右根
55 | // 推导根 postorder[postorder.length - 1]
56 | let rootValue = postorder[postorder.length - 1];
57 | const root = new TreeNode(rootValue);
58 |
59 | root.left = buildTree(leftInoder, leftPostorder);
60 | root.right = buildTree(rightInoder, rightPostorder);
61 | return root;
62 | };
63 | ```
64 |
65 | ```js
66 | function TreeNode(val, left, right) {
67 | this.val = val === undefined ? 0 : val;
68 | this.left = left === undefined ? null : left;
69 | this.right = right === undefined ? null : right;
70 | }
71 |
72 | /**
73 | * Definition for a binary tree node.
74 | * function TreeNode(val, left, right) {
75 | * this.val = (val===undefined ? 0 : val)
76 | * this.left = (left===undefined ? null : left)
77 | * this.right = (right===undefined ? null : right)
78 | * }
79 | */
80 | /**
81 | * @param {number[]} inorder
82 | * @param {number[]} postorder
83 | * @return {TreeNode}
84 | */
85 | var buildTree = function (inorder, postorder) {
86 | if (!inorder.length || !postorder.length) return null;
87 |
88 | // inorder 左根右 postorder 左右根
89 | // 推导根 postorder[postorder.length - 1]
90 |
91 | const root = new TreeNode(postorder[postorder.length - 1]);
92 |
93 | // 分割点
94 | const index = inorder.findIndex((v) => root.val === v);
95 |
96 | // 左子树的中序遍历
97 | const leftInroder = inorder.slice(0, index);
98 | // 左子树的后续遍历
99 | const leftPostorder = postorder.slice(0, index);
100 |
101 | // 右子树的中序遍历
102 | const rightInroder = inorder.slice(index + 1);
103 | // 右子树的后续遍历
104 | const rightPostorder = postorder.slice(index, postorder.length - 1);
105 |
106 | root.left = buildTree(leftInroder, leftPostorder);
107 | root.right = buildTree(rightInroder, rightPostorder);
108 |
109 | return root;
110 | };
111 | ```
112 |
113 | ## 重建二叉树
114 |
115 | [leetcode](https://leetcode.cn/problems/zhong-jian-er-cha-shu-lcof): 输入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。
116 |
117 | 假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
118 |
119 | 
120 |
121 | ```js
122 | Input: (preorder = [3, 9, 20, 15, 7]), (inorder = [9, 3, 15, 20, 7]);
123 | Output: [3, 9, 20, null, null, 15, 7];
124 | ```
125 |
126 | ```js
127 | var buildTree = function (preorder, inorder) {
128 | if (!preorder.length) return null;
129 |
130 | let root = new TreeNode(preorder[0]);
131 | // 分割点
132 | let index = inorder.findIndex((v) => v === root.val);
133 |
134 | // first index = 1;
135 |
136 | // preorder 根左右 [右,根,左]
137 | // inorder 左根右 [左, 根, 右]
138 |
139 | root.left = buildTree(preorder.slice(1, index + 1), inorder.slice(0, index));
140 | root.right = buildTree(preorder.slice(index + 1), inorder.slice(index + 1));
141 |
142 | return root;
143 | };
144 | ```
145 |
146 | ## 最大二叉树
147 |
148 | [力扣题目地址](https://leetcode-cn.com/problems/maximum-binary-tree/) 给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
149 |
150 | - 二叉树的根是数组中的最大元素。
151 | - 左子树是通过数组中最大值左边部分构造出的最大二叉树。
152 | - 右子树是通过数组中最大值右边部分构造出的最大二叉树。
153 |
154 | 通过给定的数组构建最大二叉树,并且输出这个树的根节点。
155 |
156 | 
157 |
158 | ```js
159 | 输入:nums = [3,2,1,6,0,5]
160 | 输出:[6,3,5,null,2,0,null,null,1]
161 | 解释:递归调用如下所示:
162 | - [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。
163 | - [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。
164 | - 空数组,无子节点。
165 | - [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。
166 | - 空数组,无子节点。
167 | - 只有一个元素,所以子节点是一个值为 1 的节点。
168 | - [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。
169 | - 只有一个元素,所以子节点是一个值为 0 的节点。
170 | - 空数组,无子节点。
171 | ```
172 |
173 | ```js
174 | /**
175 | * @param {number[]} nums
176 | * @return {TreeNode}
177 | */
178 | var constructMaximumBinaryTree = function (nums) {
179 | if (nums.length == 0) return null;
180 |
181 | let maxNum = Math.max(...nums);
182 | let index = nums.indexOf(maxNum);
183 | return new TreeNode(
184 | maxNum,
185 | constructMaximumBinaryTree(nums.slice(0, index)),
186 | constructMaximumBinaryTree(nums.slice(index + 1))
187 | );
188 | };
189 | ```
190 |
191 | ## 合并二叉树
192 |
193 | [力扣题目链接](https://leetcode-cn.com/problems/merge-two-binary-trees/)
194 |
195 | 给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
196 |
197 | 你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
198 |
199 | 注意: 合并必须从两个树的根节点开始。
200 |
201 | 
202 |
203 | ```js
204 | 输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
205 | 输出:[3,4,5,5,4,null,7]
206 | ```
207 |
208 | ```js
209 | var mergeTrees = function (root1, root2) {
210 | if (!root1) return root2;
211 | if (!root2) return root1;
212 |
213 | return new TreeNode(root1.val + root2.val, mergeTrees(root1.left, root2.left), mergeTrees(root1.right, root2.right));
214 | };
215 | ```
216 |
--------------------------------------------------------------------------------
/docs/.vitepress/config.ts:
--------------------------------------------------------------------------------
1 | import { defineConfig } from 'vitepress';
2 | import vueJsx from '@vitejs/plugin-vue-jsx';
3 |
4 | export default defineConfig({
5 | vite: {
6 | plugins: [
7 | vueJsx(), //插件使用
8 | ],
9 | },
10 | title: "Alvin's note",
11 | description: 'Peace and love...',
12 | lastUpdated: true,
13 | base: '/note/',
14 | themeConfig: {
15 | algolia: {
16 | appId: '4QUKK9AB99',
17 | apiKey: '859dce261164de50e0989b1b9e819711',
18 | indexName: 'alvin0216io',
19 | },
20 | nav: [
21 | { text: 'AI', link: '/ai/' },
22 | { text: '网络协议', link: '/network-protocol/' },
23 | { text: '算法', link: '/algorithm/' },
24 | ],
25 | sidebar: {
26 | '/ai/': [
27 | {
28 | text: 'Awsome',
29 | items: [{ text: 'ChatGPT', link: '/ai/chatgpt' }],
30 | },
31 | ],
32 | '/network-protocol/': [
33 | {
34 | text: 'Awsome',
35 | items: [
36 | { text: 'DNS', link: '/network-protocol/dns' },
37 | { text: 'CDN', link: '/network-protocol/cdn' },
38 | { text: '网络模型', link: '/network-protocol/01.网络模型' },
39 | ],
40 | },
41 | {
42 | text: 'TCP',
43 | collapsed: true,
44 | items: [
45 | { text: 'tcp报文', link: '/network-protocol/02.tcp报文' },
46 | { text: 'tcp三次握手', link: '/network-protocol/03.tcp三次握手' },
47 | { text: 'tcp四次挥手', link: '/network-protocol/04.tcp四次挥手' },
48 | { text: 'tcp中syn攻击', link: '/network-protocol/05.tcp中syn攻击' },
49 | { text: 'tcp和udp的区别', link: '/network-protocol/06.tcp和udp的区别' },
50 | ],
51 | },
52 |
53 | {
54 | text: 'HTTP',
55 | items: [
56 | { text: 'http报文结构', link: '/network-protocol/07.http报文结构' },
57 | { text: 'http的请求方法', link: '/network-protocol/08.http的请求方法' },
58 | { text: 'http状态码', link: '/network-protocol/09.http状态码' },
59 | { text: 'http请求体和请求头', link: '/network-protocol/10.http请求体和请求头' },
60 | { text: 'cookie', link: '/network-protocol/11.cookie' },
61 | { text: 'http优缺点', link: '/network-protocol/12.http优缺点' },
62 | { text: 'http队头阻塞', link: '/network-protocol/13.http队头阻塞' },
63 | ],
64 | },
65 | {
66 | text: 'HTTPS',
67 | items: [
68 | { text: 'https改进了什么', link: '/network-protocol/14.https改进了什么' },
69 | { text: 'https的tsl连接过程', link: '/network-protocol/15.https的tsl连接过程' },
70 | { text: 'https证书', link: '/network-protocol/16.https证书' },
71 | ],
72 | },
73 | {
74 | text: 'HTTP2',
75 | items: [
76 | { text: 'http2新功能', link: '/network-protocol/17.http2新功能' },
77 | { text: 'http2剖析', link: '/network-protocol/18.http2剖析' },
78 | { text: 'http2服务器推送功能', link: '/network-protocol/19.http2服务器推送功能' },
79 | { text: 'http3', link: '/network-protocol/20.http3' },
80 | ],
81 | },
82 | ],
83 | '/algorithm/': [
84 | {
85 | text: '字符串',
86 | collapsed: true,
87 | items: [
88 | { text: '千位分隔数', link: '/algorithm/字符串/千位分隔数' },
89 | { text: '反转字符串II', link: '/algorithm/字符串/反转字符串II' },
90 | { text: '最长不含重复字符的子字符串', link: '/algorithm/字符串/最长不含重复字符的子字符串' },
91 | { text: '字符串的排列', link: '/algorithm/字符串/字符串的排列' },
92 | { text: '最小覆盖子串', link: '/algorithm/字符串/最小覆盖子串' },
93 | { text: '回文系列', link: '/algorithm/字符串/回文系列' },
94 | ],
95 | },
96 | {
97 | text: '数组',
98 | collapsed: true,
99 | items: [
100 | { text: '两数之和', link: '/algorithm/数组/两数之和' },
101 | { text: '合并两个有序数组', link: '/algorithm/数组/合并两个有序数组' },
102 | { text: '长度最小的子数组', link: '/algorithm/数组/长度最小的子数组' },
103 | { text: '双指针', link: '/algorithm/数组/双指针' },
104 | ],
105 | },
106 | {
107 | text: '链表',
108 | collapsed: true,
109 | items: [
110 | { text: '移除链表元素', link: '/algorithm/链表/移除链表元素' },
111 | { text: '删除链表的倒数第n个结点', link: '/algorithm/链表/删除链表的倒数第n个结点' },
112 | { text: '反转链表', link: '/algorithm/链表/反转链表' },
113 | { text: '环形链表II', link: '/algorithm/链表/环形链表II' },
114 | { text: '相交链表', link: '/algorithm/链表/相交链表' },
115 | { text: 'k个一组翻转链表', link: '/algorithm/链表/k个一组翻转链表' },
116 | ],
117 | },
118 | {
119 | text: '二叉树',
120 | collapsed: true,
121 | items: [
122 | { text: '二叉树的遍历方式', link: '/algorithm/二叉树/二叉树的遍历方式' },
123 | { text: '二叉树的属性', link: '/algorithm/二叉树/二叉树的属性' },
124 | { text: '二叉树的修改与构造', link: '/algorithm/二叉树/二叉树的修改与构造' },
125 | { text: '二叉树的修改与构造2', link: '/algorithm/二叉树/二叉树的修改与构造2' },
126 | { text: '求二叉搜索树的属性', link: '/algorithm/二叉树/求二叉搜索树的属性' },
127 | { text: '二叉树的公共祖先', link: '/algorithm/二叉树/二叉树的公共祖先' },
128 | { text: '二叉树其他题目', link: '/algorithm/二叉树/二叉树其他题目' },
129 | ],
130 | },
131 | {
132 | text: '动态规划',
133 | collapsed: true,
134 | items: [
135 | { text: '动态规划理论基础', link: '/algorithm/动态规划/动态规划理论基础' },
136 | { text: '爬楼梯', link: '/algorithm/动态规划/爬楼梯' },
137 | { text: '不同路径', link: '/algorithm/动态规划/不同路径' },
138 | { text: '打家劫舍系列', link: '/algorithm/动态规划/打家劫舍系列' },
139 | { text: '买卖股票的最佳时机', link: '/algorithm/动态规划/买卖股票的最佳时机' },
140 | { text: '背包系列', link: '/algorithm/动态规划/背包系列' },
141 | { text: '连续', link: '/algorithm/动态规划/连续' },
142 | ],
143 | },
144 | {
145 | text: '回溯算法',
146 | collapsed: true,
147 | items: [
148 | { text: '回溯算法', link: '/algorithm/回溯/回溯算法' },
149 | { text: '回溯排列', link: '/algorithm/回溯/回溯排列' },
150 | { text: '回溯分割', link: '/algorithm/回溯/回溯分割' },
151 | { text: '子集', link: '/algorithm/回溯/子集' },
152 | { text: '子集II', link: '/algorithm/回溯/子集II' },
153 | { text: '组合总和', link: '/algorithm/回溯/组合总和' },
154 | { text: 'N皇后', link: '/algorithm/回溯/N皇后' },
155 | ],
156 | },
157 | {
158 | text: '深度遍历',
159 | collapsed: true,
160 | items: [
161 | { text: '岛屿数量', link: '/algorithm/深度遍历/岛屿数量' },
162 | { text: '单词搜索', link: '/algorithm/深度遍历/单词搜索' },
163 | { text: '螺旋矩阵', link: '/algorithm/深度遍历/螺旋矩阵' },
164 | ],
165 | },
166 | {
167 | text: '贪心算法',
168 | collapsed: true,
169 | items: [{ text: '贪心入门', link: '/algorithm/贪心算法/贪心入门' }],
170 | },
171 | {
172 | text: '排序算法',
173 | collapsed: true,
174 | items: [
175 | { text: '冒泡排序', link: '/algorithm/sort/bubbleSort' },
176 | { text: '选择排序', link: '/algorithm/sort/selectionSort' },
177 | { text: '插入排序', link: '/algorithm/sort/insertSort' },
178 | { text: '归并排序', link: '/algorithm/sort/mergeSort' },
179 | { text: '快速排序', link: '/algorithm/sort/quickSort' },
180 | { text: '希尔排序', link: '/algorithm/sort/shellSort' },
181 | { text: '堆排序', link: '/algorithm/sort/heapSort' },
182 | ],
183 | },
184 | ],
185 | },
186 |
187 | editLink: {
188 | pattern: 'https://github.com/alvin0216/note//blob/master/docs/:path',
189 | text: 'Edit this page on GitHub',
190 | },
191 | socialLinks: [{ icon: 'github', link: 'https://github.com/alvin0216/note/blob/master' }],
192 |
193 | footer: {
194 | message: 'Released under the MIT License.',
195 | copyright: 'Copyright © 2019-present Alvin',
196 | },
197 | },
198 | });
199 |
--------------------------------------------------------------------------------
/docs/algorithm/二叉树/二叉树的属性.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 二叉树的属性
3 | date: 2022-03-31 20:46:00
4 | sidebar: auto
5 | tags:
6 | - 二叉树
7 | categories:
8 | - leetcode
9 | ---
10 |
11 | ## 对称二叉树
12 |
13 | [leetcode](https://leetcode-cn.com/problems/symmetric-tree/): 给你一个二叉树的根节点 root,检查它是否轴对称。
14 |
15 | 
16 |
17 | ```js
18 | 输入:root = [1,2,2,3,4,4,3]
19 | 输出:true
20 | ```
21 |
22 | code:
23 |
24 | ```js
25 | /**
26 | * @param {TreeNode} root
27 | * @return {boolean}
28 | */
29 | var isSymmetric = function (root) {
30 | const check = (left, right) => {
31 | if (!left && !right) return true; // 左右子树都不存在 也是对称的
32 | if (left && right) {
33 | // 左右子树都存在,要继续判断
34 | return (
35 | left.val === right.val && // 左右子树的顶点值要相等
36 | check(left.left, right.right) && // 左子树的left和右子树的right相等
37 | check(left.right, right.left) // 左子树的right和右子树的left相等
38 | );
39 | }
40 | // 左右子树中的一个不存在,一个存在,不是对称的
41 | return false;
42 | };
43 | return !root || check(root.left, root.right); // root为null也是对称的
44 | };
45 | ```
46 |
47 | ## 二叉树的最大深度
48 |
49 | [leetcode](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/): 给定一个二叉树,找出其最大深度。
50 |
51 | 二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
52 |
53 | 说明: 叶子节点是指没有子节点的节点。
54 |
55 | ```js
56 | 3
57 | / \
58 | 9 20
59 | / \
60 | 15 7
61 | // 3
62 | ```
63 |
64 | 我的答案:
65 |
66 | ```js
67 | var maxDepth = function (root) {
68 | let deep = 0;
69 | function dfs(node, len) {
70 | if (node) {
71 | deep = Math.max(deep, len + 1);
72 | node.left && dfs(node.left, len + 1);
73 | node.right && dfs(node.right, len + 1);
74 | }
75 | }
76 |
77 | dfs(root, 0);
78 | return deep;
79 | };
80 | ```
81 |
82 | 别人的答案:
83 |
84 | ```js
85 | var maxDepth = function (root) {
86 | if (!root) return 0;
87 | return 1 + Math.max(maxDepth(root.left), maxDepth(root.right));
88 | };
89 | ```
90 |
91 | ## 二叉树的最小深度
92 |
93 | [leetcode](https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/):给定一个二叉树,找出其最小深度。
94 |
95 | 最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
96 |
97 | 说明:叶子节点是指没有子节点的节点。
98 |
99 | ```js
100 | /**
101 | * @param {TreeNode} root
102 | * @return {number}
103 | */
104 | var minDepth = function (root) {
105 | if (!root) return 0;
106 | // 到叶子节点 返回 1 终止条件!
107 | if (!root.left && !root.right) return 1;
108 | // 只有右节点时 递归右节点
109 | if (!root.left) return 1 + minDepth(root.right);
110 | // 只有左节点时 递归左节点
111 | if (!root.right) return 1 + minDepth(root.left);
112 | return Math.min(minDepth(root.left), minDepth(root.right)) + 1;
113 | };
114 | ```
115 |
116 | ## 平衡二叉树
117 |
118 | [leetcode](https://leetcode-cn.com/problems/balanced-binary-tree/):给定一个二叉树,判断它是否是高度平衡的二叉树。
119 |
120 | 本题中,一棵高度平衡二叉树定义为:
121 |
122 | **一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。**
123 |
124 | 
125 |
126 | true
127 |
128 | 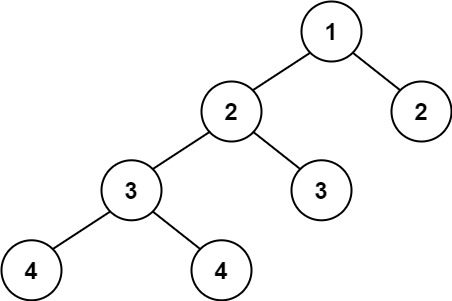
129 |
130 | false
131 |
132 | ```js
133 | /**
134 | * @param {TreeNode} root
135 | * @return {boolean}
136 | */
137 | var isBalanced = function (root) {
138 | if (!root) return true;
139 | if (Math.abs(getDeep(root.left) - getDeep(root.right)) > 1) return false;
140 | return isBalanced(root.left) && isBalanced(root.right);
141 | };
142 |
143 | function getDeep(node) {
144 | if (!node) return 0;
145 | return 1 + Math.max(getDeep(node.left), getDeep(node.right));
146 | }
147 | ```
148 |
149 | ## 完全二叉树的节点个数
150 |
151 | 其实就是计算有多少个节点
152 |
153 | ```js
154 | 输入:root = [1,2,3,4,5,6]
155 | 输出:6
156 | ```
157 |
158 | ```js
159 | /**
160 | * @param {TreeNode} root
161 | * @return {number}
162 | */
163 | var countNodes = function (root) {
164 | function dfs(node) {
165 | if (!node) return 0;
166 | return 1 + dfs(node.left) + dfs(node.right);
167 | }
168 | return dfs(root);
169 | };
170 | ```
171 |
172 | ## 二叉树的所有路径
173 |
174 | 给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
175 |
176 | 叶子节点 是指没有子节点的节点。
177 |
178 | 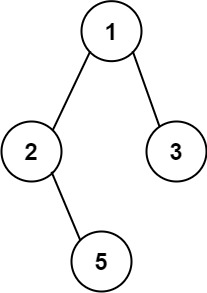
179 |
180 | ```js
181 | 输入:root = [1,2,3,null,5]
182 | 输出:["1->2->5","1->3"]
183 | ```
184 |
185 | 显而易见,深度优先遍历啦
186 |
187 | ```js
188 | /**
189 | * @param {TreeNode} root
190 | * @return {string[]}
191 | */
192 | var binaryTreePaths = function (root) {
193 | let result = [];
194 | function dfs(node, path = []) {
195 | if (!node) return;
196 | if (!node.left && !node.right) {
197 | result.push([...path, node.val].join('->'));
198 | } else {
199 | dfs(node.left, [...path, node.val]);
200 | dfs(node.right, [...path, node.val]);
201 | }
202 | }
203 |
204 | dfs(root);
205 | return result;
206 | };
207 | ```
208 |
209 | ## 左叶子之和
210 |
211 | 给定二叉树的根节点 root ,返回所有左叶子之和。
212 |
213 | 
214 |
215 | ```js
216 | 输入: root = [3,9,20,null,null,15,7]
217 | 输出: 24
218 | 解释: 在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24
219 | ```
220 |
221 | 也是 dfs,比较简单
222 |
223 | ```js
224 | /**
225 | * @param {TreeNode} root
226 | * @return {number}
227 | */
228 | var sumOfLeftLeaves = function (root) {
229 | // 左叶子
230 | // !node.left && !node.right && parent.left === node;
231 | let sum = 0;
232 | function dfs(node, parent) {
233 | if (!node) return;
234 | if (parent && parent.left === node && !node.left && !node.right) sum += node.val;
235 | dfs(node.left, node);
236 | dfs(node.right, node);
237 | }
238 | dfs(root);
239 | return sum;
240 | };
241 | ```
242 |
243 | ## 找树左下角的值
244 |
245 | 给定一个二叉树的 **根节点 root**,请找出该二叉树的 **最底层 最左边** 节点的值。
246 |
247 | 假设二叉树中至少有一个节点。
248 |
249 | 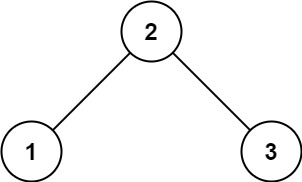
250 |
251 | ```js
252 | 输入: root = [2, 1, 3];
253 | 输出: 1;
254 | ```
255 |
256 | 我这里第一步思路是通过 bfs 做的,关于层序遍历可以看 [二叉树的层序遍历](./二叉树的遍历方式.md#二叉树的层序遍历)
257 |
258 | 二维数组最后一个序号,第一个数就是最左的叶子 🍃!
259 |
260 | ```js
261 | /**
262 | * @param {TreeNode} root
263 | * @return {number}
264 | */
265 | var findBottomLeftValue = function (root) {
266 | let queue = [root]; // 至少有一个节点
267 | let bfsResult = [];
268 | while (queue.length) {
269 | let len = queue.length;
270 | let temp = [];
271 | for (let i = 0; i < len; i++) {
272 | const node = queue.shift();
273 | temp.push(node.val);
274 | node.left && queue.push(node.left);
275 | node.right && queue.push(node.right);
276 | }
277 | bfsResult.push(temp);
278 | }
279 |
280 | return bfsResult[bfsResult.length - 1][0];
281 | };
282 | ```
283 |
284 | dfs 解法
285 |
286 | ```js
287 | var findBottomLeftValue = function (root) {
288 | let res;
289 | let maxDepth = 0;
290 | function dfs(node, deepth = 1) {
291 | if (!node) return;
292 | if (!node.left && !node.right) {
293 | if (deepth > maxDepth) {
294 | res = node.val;
295 | maxDepth = deepth;
296 | }
297 | }
298 | dfs(node.left, deepth + 1);
299 | dfs(node.right, deepth + 1);
300 | }
301 | dfs(root);
302 | return res;
303 | };
304 | ```
305 |
306 | ## 路径总和
307 |
308 | [leetcode](https://leetcode.cn/problems/path-sum)给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
309 |
310 | 叶子节点 是指没有子节点的节点
311 |
312 | 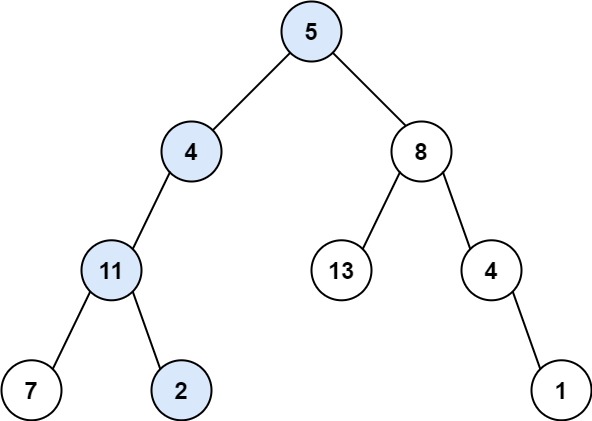
313 |
314 | ```js
315 | 输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
316 | 输出:true
317 | 解释:等于目标和的根节点到叶节点路径如上图所示。
318 | ```
319 |
320 | 
321 |
322 | ```js
323 | 输入:root = [1,2,3], targetSum = 5
324 | 输出:false
325 | 解释:树中存在两条根节点到叶子节点的路径:
326 | (1 --> 2): 和为 3
327 | (1 --> 3): 和为 4
328 | 不存在 sum = 5 的根节点到叶子节点的路径。
329 | ```
330 |
331 | ```js
332 | 输入:root = [], targetSum = 0
333 | 输出:false
334 | 解释:由于树是空的,所以不存在根节点到叶子节点的路径。
335 | ```
336 |
337 | dfs 递归搞定
338 |
339 | ```js
340 | var hasPathSum = function (root, targetSum) {
341 | if (!root) return false;
342 | if (!root.left && !root.right && root.val === targetSum) return true;
343 | return hasPathSum(root.left, targetSum - root.val) || hasPathSum(root.right, targetSum - root.val);
344 | };
345 | ```
346 |
--------------------------------------------------------------------------------
/docs/network-protocol/19.http2服务器推送功能.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: HTTP2 服务端推送功能实操
3 | date: 2019-09-25 13:00:28
4 | sidebar: 'auto'
5 | tags:
6 | - http2
7 | categories:
8 | - 网络协议
9 | ---
10 |
11 | ## 服务器推送功能解决了什么痛点?
12 |
13 | 客户端发送请求给服务器,服务器返回请求的资源,通常是 HTML 文件,HTML 文件包含一些资源链接(比如.js, .css 等)。浏览器解析 HTML 文件,获取资源链接,然后分别请求这些资源。
14 |
15 | 这一机制的问题在于,它迫使用户等待这样一个过程:**直到一个 HTML 文档下载完毕后,浏览器才能发现和获取页面的关键资源。从而延缓了页面渲染,拉长了页面加载时间**。
16 |
17 | 有了 Server Push,就有了解决上述问题的方案。Server Push 能让服务器在用户没有明确询问下,抢先地“推送”一些网站资源给客户端。只要正确地使用,我们可以根据用户正在访问的页面,给用户发送一些即将被使用的资源。
18 |
19 | ## 代码实操
20 |
21 | - [HTTP/2 Server Push with Node.js](https://blog.risingstack.com/node-js-http-2-push/)
22 |
23 | 使用内置的 `http2` 模块,我们可以创建一个 `http2` 服务器。有趣的一点在于,当 `index.htm`l 被请求时,我们会主动推送其他资源:`bundle1.js` 和 `bundle2.js`。这样的话,`bundle1.js` 和 `bundle2.js` 可以在浏览器请求它们之前就推送过去了。
24 |
25 | 
26 |
27 | 目录
28 |
29 | ```bash
30 | ├── package.json
31 | ├── public
32 | │ ├── bundle1.js
33 | │ ├── bundle2.js
34 | │ └── index.html
35 | ├── src
36 | │ ├── helper.js
37 | │ └── server.js
38 | └── ssl
39 | ├── cert.pem
40 | └── key.pem
41 | ```
42 |
43 | index.html
44 |
45 | ```html
46 |
47 |
48 | HTTP2 Push!
49 |
50 |
51 |
52 |
53 | ```
54 |
55 | server.js 主要是 `pushStream`
56 |
57 | ```js
58 | const http2 = require('http2');
59 | const server = http2.createSecureServer({ cert, key }, requestHandler);
60 |
61 | function push(stream, filePath) {
62 | const { file, headers } = getFile(filePath);
63 | const pushHeaders = { [HTTP2_HEADER_PATH]: filePath };
64 |
65 | stream.pushStream(pushHeaders, (pushStream) => {
66 | pushStream.respondWithFD(file, headers);
67 | });
68 | }
69 |
70 | function requestHandler(req, res) {
71 | // Push files with index.html
72 | if (reqPath === '/index.html') {
73 | push(res.stream, 'bundle1.js');
74 | push(res.stream, 'bundle2.js');
75 | }
76 |
77 | // Serve file
78 | res.stream.respondWithFD(file.fileDescriptor, file.headers);
79 | }
80 | ```
81 |
82 | ::: details src
83 |
84 | **server.js**
85 |
86 | ```js
87 | const fs = require('fs');
88 | const path = require('path');
89 | const http2 = require('http2');
90 | const helper = require('./helper');
91 |
92 | const { HTTP2_HEADER_PATH } = http2.constants;
93 | const PORT = process.env.PORT || 3000;
94 | const PUBLIC_PATH = path.join(__dirname, '../public');
95 |
96 | const publicFiles = helper.getFiles(PUBLIC_PATH);
97 | const server = http2.createSecureServer(
98 | {
99 | cert: fs.readFileSync(path.join(__dirname, '../ssl/cert.pem')),
100 | key: fs.readFileSync(path.join(__dirname, '../ssl/key.pem')),
101 | },
102 | requestHandler
103 | );
104 |
105 | // Push file
106 | function push(stream, path) {
107 | const file = publicFiles.get(path);
108 |
109 | if (!file) {
110 | return;
111 | }
112 |
113 | stream.pushStream({ [HTTP2_HEADER_PATH]: path }, (pushStream) => {
114 | pushStream.respondWithFD(file.fileDescriptor, file.headers);
115 | });
116 | }
117 |
118 | // Request handler
119 | function requestHandler(req, res) {
120 | const reqPath = req.url === '/' ? '/index.html' : req.url;
121 | const file = publicFiles.get(reqPath);
122 |
123 | // File not found
124 | if (!file) {
125 | res.statusCode = 404;
126 | res.end();
127 | return;
128 | }
129 |
130 | // Push with index.html
131 | if (reqPath === '/index.html') {
132 | push(res.stream, '/bundle1.js');
133 | push(res.stream, '/bundle2.js');
134 | }
135 |
136 | // Serve file
137 | res.stream.respondWithFD(file.fileDescriptor, file.headers);
138 | }
139 |
140 | server.listen(PORT, (err) => {
141 | console.log(`Server listening on ${PORT}`);
142 | });
143 | ```
144 |
145 | **helper**
146 |
147 | ```js
148 | const fs = require('fs');
149 | const path = require('path');
150 | const mime = require('mime');
151 |
152 | function getFiles(baseDir) {
153 | const files = new Map();
154 |
155 | fs.readdirSync(baseDir).forEach((fileName) => {
156 | const filePath = path.join(baseDir, fileName);
157 | const fileDescriptor = fs.openSync(filePath, 'r');
158 | const stat = fs.fstatSync(fileDescriptor);
159 | const contentType = mime.lookup(filePath);
160 |
161 | files.set(`/${fileName}`, {
162 | fileDescriptor,
163 | headers: {
164 | 'content-length': stat.size,
165 | 'last-modified': stat.mtime.toUTCString(),
166 | 'content-type': contentType,
167 | },
168 | });
169 | });
170 |
171 | return files;
172 | }
173 |
174 | module.exports = { getFiles };
175 | ```
176 |
177 | :::
178 |
179 | :::details public
180 |
181 | **bandle1**
182 |
183 | ```js
184 | console.log('Bundle 1');
185 | document.body.innerHTML += 'Bundle 1 loaded
';
186 | ```
187 |
188 | **bandle2**
189 |
190 | ```js
191 | console.log('Bundle 2');
192 | document.body.innerHTML += 'Bundle 2 loaded
';
193 | ```
194 |
195 | :::
196 |
197 | ::: details ssl
198 |
199 | **cert.pem**
200 |
201 | ```js
202 | -----BEGIN CERTIFICATE-----
203 | MIIDtTCCAp2gAwIBAgIJAN9jdYICeY33MA0GCSqGSIb3DQEBBQUAMEUxCzAJBgNV
204 | BAYTAkFVMRMwEQYDVQQIEwpTb21lLVN0YXRlMSEwHwYDVQQKExhJbnRlcm5ldCBX
205 | aWRnaXRzIFB0eSBMdGQwHhcNMTcwODE2MTMyNDA2WhcNMjcwODE0MTMyNDA2WjBF
206 | MQswCQYDVQQGEwJBVTETMBEGA1UECBMKU29tZS1TdGF0ZTEhMB8GA1UEChMYSW50
207 | ZXJuZXQgV2lkZ2l0cyBQdHkgTHRkMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIB
208 | CgKCAQEA4NGiIEgDf3NdOlpGAROY8ZNPJrhR6gNPTAIZKz314wDUJTF54a8ioeUn
209 | rsKL0Z5H67MmZ5LcsZO9jprrBaSFAIyFdiqQKOSWkXA+LZCEhqaCR0cOIOy0TEKb
210 | MxsABW+6hSoBXk1tK3IQntEcs22qQZll+Y++jUBck+XaCwAmpsk4ofqfLPHcvidj
211 | gHOYkKQg/fFIm81M1NKgdbQpW2/akob56kdh4scZrpwa6MxEylKppTjZ0jfF0cnv
212 | rrs4QTWvoIowfAMrrd/TJV5P8Ei5KcckJe8shlgoEOxtRrAjhIEUmZOT0yho7BcA
213 | C+Zudul0XJhcAPjbHirQ0+G4Agy3FwIDAQABo4GnMIGkMB0GA1UdDgQWBBQqMeql
214 | vTY7xAXbu5YXhnD4lBK1xjB1BgNVHSMEbjBsgBQqMeqlvTY7xAXbu5YXhnD4lBK1
215 | xqFJpEcwRTELMAkGA1UEBhMCQVUxEzARBgNVBAgTClNvbWUtU3RhdGUxITAfBgNV
216 | BAoTGEludGVybmV0IFdpZGdpdHMgUHR5IEx0ZIIJAN9jdYICeY33MAwGA1UdEwQF
217 | MAMBAf8wDQYJKoZIhvcNAQEFBQADggEBAEm90w4C0rFqxVVVojAYXrcvLD0E5iwA
218 | 3eEn+uD1dMy56he0LZNXlf3s3mZlRYE8+oGvydcMuXrmisVcvIuFQlES2M6y8S2b
219 | CW6xeir4+VKWR97c3p+M48rUfV8YGb2d6YBLNlekAT/S55Bhfy15sYWt+9LIi4i+
220 | ToqywlIfiMcwpBZLD1UTPs7b66Rx7LHmMFXpNfDugp8JHphLJRmXFNgZNNmi0Re0
221 | vDMgUWlgVzV9oMTjp0Ioafbtqcykg0JS+3KsXHWVQPWrw1wsBjje4XJLIIY1+W75
222 | tHBk3PL42xP5vPgRJ/8X22pFXnC/0MK6fKg5VdvwJQDBlYxbpcM3W+g=
223 | -----END CERTIFICATE-----
224 | ```
225 |
226 | **key.pem**
227 |
228 | ```js
229 | -----BEGIN RSA PRIVATE KEY-----
230 | MIIEpAIBAAKCAQEA4NGiIEgDf3NdOlpGAROY8ZNPJrhR6gNPTAIZKz314wDUJTF5
231 | 4a8ioeUnrsKL0Z5H67MmZ5LcsZO9jprrBaSFAIyFdiqQKOSWkXA+LZCEhqaCR0cO
232 | IOy0TEKbMxsABW+6hSoBXk1tK3IQntEcs22qQZll+Y++jUBck+XaCwAmpsk4ofqf
233 | LPHcvidjgHOYkKQg/fFIm81M1NKgdbQpW2/akob56kdh4scZrpwa6MxEylKppTjZ
234 | 0jfF0cnvrrs4QTWvoIowfAMrrd/TJV5P8Ei5KcckJe8shlgoEOxtRrAjhIEUmZOT
235 | 0yho7BcAC+Zudul0XJhcAPjbHirQ0+G4Agy3FwIDAQABAoIBAHHi4B04PcVffHel
236 | 6VZ8RfsCY5M6xgwklxPq8DMOlTPkZJNex95CqOmYOwz1cnzCkK5et3K6W9/89oZ6
237 | Bdp66AFKLgWZNCPzAC82y9irH+dSDCbtYMPfBMqo5xPxdoZKfhMdH0pVMJtUkgTR
238 | 65cdU6UdfyH35lCJrRwi0NzHu8y6qMyH5tOcNOIXwn/LfZ6ZwVx2lKAjthmac2z0
239 | 35qknvCNfgadrsl5PLWZBYwy3qx208pUUojMciL9RtfO17F6ofMhueOoChnaHv6h
240 | Lra3NpcuJlYdTTt3tgkTvfMXiZCMsWoV9q1+y9AcSojDJk4V6qiy0Nu8uQmSCRX8
241 | g/2ilqECgYEA/9yejCxaUfgHlA6LkFFMNNkgh3AwHxfIiEBzCDxkUPlu0J1z+65S
242 | UJLGLIgQoZN0UmN6a0YHHDxh0oxIvxoq+wc4PPIr9mmSsEt6YTUjYbYNIJ/5978b
243 | CH+41VGCszqzd0NSJTW7aKL3XFE34kDascgTiDd82KmqaC5chShCoZECgYEA4PC4
244 | qoNnAzILI9yM9hJcolrW9hf4pUXqG9orO7pr5/ETDVi74pNdKkb7MKE1snjTQBdu
245 | rV5q09wu9+Owa5AoHLkvTify+EXlUrc4UeVxEdlOfoc/laONZkGaENxn4DTH4rMj
246 | 6nlzMNPcR0Hxud/UqLpWiI20I+dJwVzBA3z3eicCgYEAqNb+LQPLqlGhNpuOj3KG
247 | dk1dwOJQbwQzyW22OxYXILQo4zMz6T50hUUFzzcOuoDifse0bfutD33tE5KNIsZy
248 | 3Go8O0OXrSinqvxzypfVPFJ1QTUwL8OFZEtcPjBmrj0rVqUvHOzjOb5ouxvBY+Vm
249 | K3EbKoVrNlJn6A3H8frKVXECgYEAsnQnfRdcbTuRfPTnW/07Qo6gxYJFABGUZl5S
250 | OENwggVOoSMJg/p3Sigf9fefWyTiK5Gre51RURz4oi8f8mXefNMpxW6KIw+InHPB
251 | Ga/WYVuuG1F/T17+ueZHrSK+wi/9eEu4rbeGfHFH67xUYqtB0k5qglExXd6LM/07
252 | H2JQD7cCgYAeU4FtW0VZdEtUkBLJhHHZ0l/UBtN/XhkpFjdrG9uJryX/2rnA8Zoh
253 | vKhSG5iWdTDak4R2dt9yJrTr1sriI5P176t76eAR4jg0F3xeRpiaDDk7wdznwh9F
254 | OKOJlLEHd9G2gryXAtUU4KPii3/Awgj/Kd37j7fssuMTQLB9bWIygQ==
255 | -----END RSA PRIVATE KEY-----
256 | ```
257 |
258 | :::
259 |
260 | Node.js 8.4.0 已经开始支持 HTTP/2,执行 node 命令时,加上 `--expose-http2` 选项就可以使用了。
261 |
--------------------------------------------------------------------------------
/docs/algorithm/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: 🔥 Algorithms
3 | date: 2020-07-22 09:23:33
4 | sidebar: auto
5 | ---
6 |
7 | ## 字符串
8 |
9 | - [1556. 千位分隔数](./字符串/千位分隔数.md)
10 | - [反转字符串 II](./字符串/反转字符串II.md)
11 | - [字符串的排列](./字符串/字符串的排列.md)
12 | - [🌟 最长不含重复字符的子字符串](./字符串/最长不含重复字符的子字符串.md)
13 | - [🌟 76. 最小覆盖子串](./字符串/最小覆盖子串.md)
14 | - 回文系列
15 | - [409. 最长回文串](./字符串/回文系列.md#最长回文串)
16 | - [5. 最长回文子串](./字符串/回文系列.md#最长回文子串)
17 |
18 | ## 数组
19 |
20 | - [两数之和](./数组/两数之和.md)
21 | - [合并两个有序数组](./数组/合并两个有序数组.md)
22 | - [长度最小的子数组](./数组/长度最小的子数组.md)
23 | - 双指针
24 | - [🌟 31. 下一个排列](./数组/双指针.md#下一个排列)
25 | - [🌟 15. 三数之和](./数组/双指针.md#三数之和)
26 | - [🌟 42. 接雨水](./数组/双指针.md#接雨水)
27 |
28 | ## 链表
29 |
30 | - [移除链表元素](./链表/移除链表元素.md)
31 | - [删除链表的倒数第 n 个结点](./链表/删除链表的倒数第n个结点.md)
32 | - [反转链表](./链表/反转链表.md)
33 | - [环形链表 II](./链表/环形链表II.md)
34 | - [160. 相交链表](./链表/相交链表.md)
35 | - [k 个一组翻转链表](./链表/k个一组翻转链表.md)
36 |
37 | ## 二叉树
38 |
39 | - 遍历方式
40 | - [144. 二叉树的前序遍历](./二叉树/二叉树的遍历方式.md#二叉树的前序遍历)
41 | - [145. 二叉树的后序遍历](./二叉树/二叉树的遍历方式.md#二叉树的后序遍历)
42 | - [94. 二叉树的中序遍历](./二叉树/二叉树的遍历方式.md#二叉树的中序遍历)
43 | - [🌟 102. 二叉树的层序遍历](./二叉树/二叉树的遍历方式.md#二叉树的层序遍历)
44 | - 二叉树的属性
45 | - [101. 对称二叉树](./二叉树/二叉树的属性.md#对称二叉树)
46 | - [104. 二叉树的最大深度](./二叉树/二叉树的属性.md#二叉树的最大深度)
47 | - [111. 二叉树的最小深度](./二叉树/二叉树的属性.md#二叉树的最小深度)
48 | - [222. 完全二叉树的节点个数](./二叉树/二叉树的属性.md#完全二叉树的节点个数)
49 | - [110. 平衡二叉树](./二叉树/二叉树的属性.md#平衡二叉树)
50 | - [257. 二叉树的所有路径](./二叉树/二叉树的属性.md#二叉树的所有路径)
51 | - [513. 找树左下角的值](./二叉树/二叉树的属性.md#找树左下角的值)
52 | - [112. 路径总和](./二叉树/二叉树的属性.md#路径总和)
53 | - 二叉树的修改与构造
54 | - [226. 翻转二叉树](./二叉树/二叉树的修改与构造.md#翻转二叉树)
55 | - [🌟 106. 从中序与后序遍历序列构造二叉树](./二叉树/二叉树的修改与构造.md#从中序与后序遍历序列构造二叉树)
56 | - [🌟 【剑指】 07. 重建二叉树](./二叉树/二叉树的修改与构造.md#重建二叉树)
57 | - [654. 最大二叉树](./二叉树/二叉树的修改与构造.md#最大二叉树)
58 | - [617. 合并二叉树](./二叉树/二叉树的修改与构造.md#合并二叉树)
59 | - 二叉树的修改与构造 II
60 | - [701. 二叉搜索树中的插入操作](./二叉树/二叉树的修改与构造2.md#二叉搜索树中的插入操作)
61 | - [🌟 450. 删除二叉搜索树中的节点](./二叉树/二叉树的修改与构造2.md#删除二叉搜索树中的节点)
62 | - [🌟 669. 修剪二叉搜索树](./二叉树/二叉树的修改与构造2.md#修剪二叉搜索树)
63 | - [🌟 108. 将有序数组转换为二叉搜索树](./二叉树/二叉树的修改与构造2.md#将有序数组转换为二叉搜索树)
64 | - 求二叉搜索树的属性
65 | - [700. 二叉搜索树中的搜索](./二叉树/求二叉搜索树的属性.md#二叉搜索树中的搜索)
66 | - [530. 二叉搜索树的最小绝对差](./二叉树/求二叉搜索树的属性.md#二叉搜索树的最小绝对差)
67 | - [510. 二叉搜索树中的众数](./二叉树/求二叉搜索树的属性.md#二叉搜索树中的众数)
68 | - [538. 把二叉搜索树转换为累加树](./二叉树/求二叉搜索树的属性.md#把二叉搜索树转换为累加树)
69 | - 二叉树的公共祖先
70 | - [236. 二叉树的最近公共祖先](./二叉树/二叉树的公共祖先.md#二叉树的最近公共祖先)
71 | - [235. 二叉搜索树的最近公共祖先](./二叉树/二叉树的公共祖先.md#二叉搜索树的最近公共祖先)
72 | - 二叉树其他题目
73 | - [129. 求根到叶子节点数字之和](./二叉树/二叉树其他题目.md#求根到叶子节点数字之和)
74 |
75 | ## 动态规划
76 |
77 | - [动态规划理论基础](./动态规划/动态规划理论基础.md)
78 | - 基础入门
79 | - [70. 爬楼梯](./动态规划/爬楼梯.md#爬楼梯)
80 | - [746. 使用最小花费爬楼梯](./动态规划/爬楼梯.md#使用最小花费爬楼梯)
81 | - [62. 不同路径](./动态规划/不同路径.md)
82 | - [63. 不同路径 II](./动态规划/不同路径.md#不同路径-ii)
83 | - 打家劫舍
84 | - [198. 打家劫舍 I](./动态规划/打家劫舍系列.md)
85 | - [213. 打家劫舍 II](./动态规划/打家劫舍系列.md#打家劫舍-ii)
86 | - [337. 打家劫舍 III](./动态规划/打家劫舍系列.md#打家劫舍-iii)
87 | - 买卖股票的最佳时机
88 | - [121. 买卖股票的最佳时机](./动态规划/买卖股票的最佳时机.md)
89 | - [122. 买卖股票的最佳时机 II](./动态规划/买卖股票的最佳时机.md#买卖股票的最佳时机-ii)
90 | - [123. 买卖股票的最佳时机 III](./动态规划/买卖股票的最佳时机.md#买卖股票的最佳时机-iii)
91 | - 背包问题
92 | - 背包系列
93 | - 完全背包
94 | - 多重背包
95 | - 子序列问题
96 | - 不连续
97 | - 最长上升子序列
98 | - 最长公共子序列
99 | - 不想交的线
100 | - 连续
101 | - 最长连续递增序列
102 | - [53. 最大子数组和](./动态规划/连续.md#最大子数组和)
103 | - [718. 最长重复子数组](./动态规划/连续.md#最长重复子数组)
104 | - 最大子序和
105 | - 编辑距离
106 | - 判断子序列
107 | - 不同的子序列
108 | - 两个字符串的删除操作
109 | - 编辑距离
110 | - 回文
111 | - 回文子串
112 | - 最长回文序列
113 |
114 | ## 回溯算法
115 |
116 | - [总结](./回溯/总结.md)
117 | - 回溯排列
118 | - [46. 全排列](./回溯/回溯排列.md#全排列)
119 | - [47. 全排列 II](./回溯/回溯排列.md#全排列-ii)
120 | - [剑指 38. 字符串的排列](./回溯/回溯排列.md#字符串的排列)
121 | - [784. 字母大小写全排列](./回溯/回溯排列.md#字母大小写全排列)
122 | - 回溯分割
123 | - [131. 分割回文串](./回溯/回溯分割.md#分割回文串)
124 | - [93. 复原 IP 地址](./回溯/回溯分割.md#复原-ip-地址)
125 | - 子集
126 | - [78. 子集](./回溯/子集.md)
127 | - [90. 子集 II](./回溯/子集II.md)
128 | - [组合总和](./回溯/组合总和.md)
129 |
130 | - [N 皇后](./回溯/N皇后.md)
131 |
132 | ## 贪心算法
133 |
134 | - 贪心入门
135 | - [455. 分发饼干](./贪心算法/贪心入门.md#分发饼干)
136 | - [860. 柠檬水找零](./贪心算法/贪心入门.md#柠檬水找零)
137 | - [1005. K 次取反后最大化的数组和](./贪心算法/贪心入门.md#K-次取反后最大化的数组和)
138 |
139 | ## DFS 遍历
140 |
141 | - [200. 岛屿数量](./深度遍历/岛屿数量.md)
142 | - [79. 单词搜索](./深度遍历/单词搜索.md)
143 | - [54. 螺旋矩阵](./深度遍历/螺旋矩阵.md)
144 | - [5. 螺旋矩阵 II](./深度遍历/螺旋矩阵.md#螺旋矩阵-ii)
145 | - 岛屿的周长
146 | - 岛屿的最大面积
147 |
148 | ## leetcode top 100
149 |
150 | | 题目 | 出现次数 | 链接 |
151 | | --------------------------------------------- | -------- | -------------------------------------------------------------------------------------------------- |
152 | | ✅ 3. 无重复字符的最长子串 | 18 | https://leetcode-cn.com/problems/longest-substring-without-repeating-characters |
153 | | ✅ 88. 合并两个有序数组 | 17 | https://leetcode-cn.com/problems/merge-sorted-array |
154 | | ✅ 129. 求根到叶子节点数字之和 | 15 | https://leetcode-cn.com/problems/sum-root-to-leaf-numbers |
155 | | ✅ 112. 路径总和 | 13 | https://leetcode-cn.com/problems/path-sum |
156 | | ✅ 53. 最大子序和 | 12 | https://leetcode-cn.com/problems/maximum-subarray |
157 | | ✅ 1. 两数之和 | 11 | https://leetcode-cn.com/problems/two-sum |
158 | | ✅ 165. 比较版本号 | 11 | https://leetcode-cn.com/problems/compare-version-numbers |
159 | | 215. 数组中的第 K 个最大元素 | 10 | https://leetcode-cn.com/problems/kth-largest-element-in-an-array |
160 | | ✅ 209. 长度最小的子数组 | 8 | https://leetcode-cn.com/problems/minimum-size-subarray-sum |
161 | | ✅ 剑指 Offer 22. 链表中倒数第 k 个节点 | 8 | https://leetcode-cn.com/problems/lian-biao-zhong-dao-shu-di-kge-jie-dian-lcof |
162 | | ✅ 415. 字符串相加 | 8 | https://leetcode-cn.com/problems/add-strings |
163 | | ✅ 46. 全排列 | 8 | https://leetcode-cn.com/problems/permutations |
164 | | ✅ 206. 反转链表 | 7 | https://leetcode-cn.com/problems/reverse-linked-list |
165 | | ✅ 102. 二叉树的层序遍历 | 6 | https://leetcode-cn.com/problems/binary-tree-level-order-traversal |
166 | | ✅ 70. 爬楼梯 | 6 | https://leetcode-cn.com/problems/climbing-stairs |
167 | | ✅ 54. 螺旋矩阵 | 6 | https://leetcode-cn.com/problems/spiral-matrix |
168 | | ✅ 93. 复原 IP 地址 | 5 | https://leetcode-cn.com/problems/restore-ip-addresses |
169 | | ✅ 200. 岛屿数量 | 5 | https://leetcode-cn.com/problems/number-of-islands |
170 | | ✅ 230. 二叉搜索树中第 K 小的元素 | 5 | https://leetcode-cn.com/problems/kth-smallest-element-in-a-bst |
171 | | ✅ 15. 三数之和 | 5 | https://leetcode-cn.com/problems/3sum |
172 | | ✅ 141. 环形链表 | 5 | https://leetcode-cn.com/problems/linked-list-cycle |
173 | | ✅ 429. N 叉树的层序遍历 | 5 | https://leetcode-cn.com/problems/n-ary-tree-level-order-traversal |
174 | | ✅ 226. 翻转二叉树 | 4 | https://leetcode-cn.com/problems/invert-binary-tree |
175 | | ✅ 121. 买卖股票的最佳时机 | 4 | https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock |
176 | | ✅ 718. 最长重复子数组 | 4 | https://leetcode-cn.com/problems/maximum-length-of-repeated-subarray |
177 | | ✅ 160. 相交链表 | 4 | https://leetcode-cn.com/problems/intersection-of-two-linked-lists |
178 | | ✅ 695. 岛屿的最大面积 | 4 | https://leetcode-cn.com/problems/max-area-of-island |
179 | | ✅ 62. 不同路径 | 4 | https://leetcode-cn.com/problems/unique-paths |
180 | | 剑指 Offer 62. 圆圈中最后剩下的数字 | 4 | https://leetcode-cn.com/problems/yuan-quan-zhong-zui-hou-sheng-xia-de-shu-zi-lcof |
181 | | ✅ 94. 二叉树的中序遍历 | 3 | https://leetcode-cn.com/problems/binary-tree-inorder-traversal |
182 | | ✅ 104. 二叉树的最大深度 | 3 | https://leetcode-cn.com/problems/maximum-depth-of-binary-tree |
183 | | ✅ 21. 合并两个有序链表 | 3 | https://leetcode-cn.com/problems/merge-two-sorted-lists |
184 | | ✅ 509. 斐波那契数 | 3 | https://leetcode-cn.com/problems/fibonacci-number |
185 | | ✅ 113. 路径总和 II | 3 | https://leetcode-cn.com/problems/path-sum-ii |
186 | | ✅ 468. 验证 IP 地址 | 3 | https://leetcode-cn.com/problems/validate-ip-address |
187 | | ✅ 31. 下一个排列 | 3 | https://leetcode-cn.com/problems/next-permutation |
188 | | ✅ 20. 有效的括号 | 3 | https://leetcode-cn.com/problems/valid-parentheses |
189 | | ✅ 349. 两个数组的交集 | 3 | https://leetcode-cn.com/problems/intersection-of-two-arrays |
190 | | ✅ 5. 最长回文子串 | 3 | https://leetcode-cn.com/problems/longest-palindromic-substring |
191 | | ✅ 236. 二叉树的最近公共祖先 | 3 | https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree |
192 | | ✅ 146. LRU 缓存机制 | 3 | https://leetcode-cn.com/problems/lru-cache |
193 | | ✅ 322. 零钱兑换 | 2 | https://leetcode-cn.com/problems/coin-change |
194 | | 394. 字符串解码 | 2 | https://leetcode-cn.com/problems/decode-string |
195 | | ✅ 19. 删除链表的倒数第 N 个节点 | 2 | https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list |
196 | | ✅ 剑指 Offer 24. 反转链表 | 2 | https://leetcode-cn.com/problems/fan-zhuan-lian-biao-lcof |
197 | | ✅ 42. 接雨水 | 2 | https://leetcode-cn.com/problems/trapping-rain-water |
198 | | 155. 最小栈 | 2 | https://leetcode-cn.com/problems/min-stack |
199 | | 169. 多数元素 | 2 | https://leetcode-cn.com/problems/majority-element |
200 | | 剑指 Offer 21. 调整数组顺序使奇数位于偶数前面 | 2 | https://leetcode-cn.com/problems/diao-zheng-shu-zu-shun-xu-shi-qi-shu-wei-yu-ou-shu-qian-mian-lcof |
201 | | 67. 二进制求和 | 2 | https://leetcode-cn.com/problems/add-binary |
202 | | 144. 二叉树的前序遍历 | 2 | https://leetcode-cn.com/problems/binary-tree-preorder-traversal |
203 | | 198. 打家劫舍 | 2 | https://leetcode-cn.com/problems/house-robber |
204 | | 14. 最长公共前缀 | 2 | https://leetcode-cn.com/problems/longest-common-prefix |
205 | | 补充题 3. 求区间最小数乘区间和的最大值 | 2 | https://mp.weixin.qq.com/s/UFv7pt_djjZoK_gzUBrRXA |
206 | | 199. 二叉树的右视图 | 2 | https://leetcode-cn.com/problems/binary-tree-right-side-view |
207 | | 剑指 Offer 09. 用两个栈实现队列 | 2 | https://leetcode-cn.com/problems/yong-liang-ge-zhan-shi-xian-dui-lie-lcof |
208 | | 56. 合并区间 | 2 | https://leetcode-cn.com/problems/merge-intervals |
209 | | 300. 最长上升子序列 | 2 | https://leetcode-cn.com/problems/longest-increasing-subsequence |
210 | | 剑指 Offer 38. 字符串的排列 | 2 | https://leetcode-cn.com/problems/zi-fu-chuan-de-pai-lie-lcof |
211 | | 补充题 14. 阿拉伯数字转中文数字 | 2 | |
212 | | 400. 第 N 个数字 | 2 | https://leetcode-cn.com/problems/nth-digit |
213 | | 101. 对称二叉树 | 2 | https://leetcode-cn.com/problems/symmetric-tree |
214 | | 剑指 Offer 48. 最长不含重复字符的子字符串 | 1 | https://leetcode-cn.com/problems/zui-chang-bu-han-zhong-fu-zi-fu-de-zi-zi-fu-chuan-lcof |
215 | | 680. 验证回文字符串 Ⅱ | 1 | https://leetcode-cn.com/problems/valid-palindrome-ii |
216 | | 124. 二叉树中的最大路径和 | 1 | https://leetcode-cn.com/problems/binary-tree-maximum-path-sum |
217 | | 221. 最大正方形 | 1 | https://leetcode-cn.com/problems/maximal-square |
218 | | 98. 验证二叉搜索树 | 1 | https://leetcode-cn.com/problems/validate-binary-search-tree |
219 | | 1047. 删除字符串中的所有相邻重复项 | 1 | https://leetcode-cn.com/problems/remove-all-adjacent-duplicates-in-string |
220 | | 44. 通配符匹配 | 1 | https://leetcode-cn.com/problems/wildcard-matching |
221 | | 130. 被围绕的区域 | 1 | https://leetcode-cn.com/problems/surrounded-regions |
222 | | 16. 最接近的三数之和 | 1 | https://leetcode-cn.com/problems/3sum-closest |
223 | | 498. 对角线遍历 | 1 | https://leetcode-cn.com/problems/diagonal-traverse |
224 | | 224. 基本计算器 | 1 | https://leetcode-cn.com/problems/basic-calculator |
225 | | 227. 基本计算器 II | 1 | https://leetcode-cn.com/problems/basic-calculator-ii |
226 | | 剑指 Offer 04. 二维数组中的查找 | 1 | https://leetcode-cn.com/problems/er-wei-shu-zu-zhong-de-cha-zhao-lcof |
227 | | 443. 压缩字符串 | 1 | https://leetcode-cn.com/problems/string-compression |
228 | | ✅ 142. 环形链表 II | 1 | https://leetcode-cn.com/problems/linked-list-cycle-ii |
229 | | 984. 不含 AAA 或 BBB 的字符串 | 1 | https://leetcode-cn.com/problems/string-without-aaa-or-bbb |
230 | | 151. 翻转字符串里的单词 | 1 | https://leetcode-cn.com/problems/reverse-words-in-a-string |
231 | | 213. 打家劫舍 II | 1 | https://leetcode-cn.com/problems/house-robber-ii |
232 | | 114. 二叉树展开为链表 | 1 | https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list |
233 | | 109. 有序链表转换二叉搜索树 | 1 | https://leetcode-cn.com/problems/convert-sorted-list-to-binary-search-tree |
234 | | 242. 有效的字母异位词 | 1 | https://leetcode-cn.com/problems/valid-anagram |
235 | | 862. 和至少为 K 的最短子数组 | 1 | https://leetcode-cn.com/problems/shortest-subarray-with-sum-at-least-k |
236 | | 1498. 满足条件的子序列数目 | 1 | https://leetcode-cn.com/problems/number-of-subsequences-that-satisfy-the-given-sum-condition |
237 | | 257. 二叉树的所有路径 | 1 | https://leetcode-cn.com/problems/binary-tree-paths |
238 | | 63. 不同路径 II | 1 | https://leetcode-cn.com/problems/unique-paths-ii |
239 | | 609. 在系统中查找重复文件 | 1 | https://leetcode-cn.com/problems/find-duplicate-file-in-system |
240 | | 232. 用栈实现队列 | 1 | https://leetcode-cn.com/problems/implement-queue-using-stacks |
241 | | 39. 组合总和 | 1 | https://leetcode-cn.com/problems/combination-sum |
242 | | 剑指 Offer 10- I. 斐波那契数列 | 1 | https://leetcode-cn.com/problems/fei-bo-na-qi-shu-lie-lcof |
243 | | 361. 轰炸敌人 | 1 | https://leetcode-cn.com/problems/bomb-enemy |
244 | | 525. 连续数组 | 1 | https://leetcode-cn.com/problems/contiguous-array |
245 | | 96. 不同的二叉搜索树 | 1 | https://leetcode-cn.com/problems/unique-binary-search-trees |
246 | | 103. 二叉树的锯齿形层次遍历 | 1 | https://leetcode-cn.com/problems/binary-tree-zigzag-level-order-traversal |
247 | | 717. 1 比特与 2 比特字符 | 1 | https://leetcode-cn.com/problems/1-bit-and-2-bit-characters |
248 | | 1353. 最多可以参加的会议数目 | 1 | https://leetcode-cn.com/problems/maximum-number-of-events-that-can-be-attended |
249 | | 剑指 Offer 63. 股票的最大利润 | 1 | https://leetcode-cn.com/problems/gu-piao-de-zui-da-li-run-lcof |
250 | | 剑指 Offer 27. 二叉树的镜像 | 1 | https://leetcode-cn.com/problems/er-cha-shu-de-jing-xiang-lcof |
251 | | LCP 04. 覆盖 | 1 | https://leetcode-cn.com/problems/broken-board-dominoes |
252 | | 剑指 Offer 39. 数组中出现次数超过一半的数字 | 1 | https://leetcode-cn.com/problems/shu-zu-zhong-chu-xian-ci-shu-chao-guo-yi-ban-de-shu-zi-lcof |
253 | | 剑指 Offer 07. 重建二叉树 | 1 | https://leetcode-cn.com/problems/zhong-jian-er-cha-shu-lcof |
254 | | 829. 连续整数求和 | 1 | https://leetcode-cn.com/problems/consecutive-numbers-sum |
255 | | 1356. 根据数字二进制下 1 的数目排序 | 1 | https://leetcode-cn.com/problems/sort-integers-by-the-number-of-1-bits |
256 | | 6. Z 字形变换 | 1 | https://leetcode-cn.com/problems/zigzag-conversion |
257 | | 704. 二分查找 | 1 | https://leetcode-cn.com/problems/binary-search |
258 | | 111. 二叉树的最小深度 | 1 | https://leetcode-cn.com/problems/minimum-depth-of-binary-tree |
259 | | 105. 从前序与中序遍历序列构造二叉树 | 1 | https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal |
260 | | 783. 二叉搜索树节点最小距离 | 1 | https://leetcode-cn.com/problems/minimum-distance-between-bst-nodes |
261 | | 剑指 Offer 42. 连续子数组的最大和 | 1 | https://leetcode-cn.com/problems/lian-xu-zi-shu-zu-de-zui-da-he-lcof |
262 | | 55. 跳跃游戏 | 1 | https://leetcode-cn.com/problems/jump-game |
263 | | 2. 两数相加 | 1 | https://leetcode-cn.com/problems/add-two-numbers |
264 | | 1410. HTML 实体解析器 | 1 | https://leetcode-cn.com/problems/html-entity-parser |
265 | | 125. 验证回文串 | 1 | https://leetcode-cn.com/problems/valid-palindrome |
266 | | 12. 整数转罗马数字 | 1 | https://leetcode-cn.com/problems/integer-to-roman |
267 | | 45. 跳跃游戏 II | 1 | https://leetcode-cn.com/problems/jump-game-ii |
268 | | 43. 字符串相乘 | 1 | https://leetcode-cn.com/problems/multiply-strings |
269 |
--------------------------------------------------------------------------------