├── shekar
├── data
│ ├── files
│ │ ├── __init__.py
│ │ ├── offensive_words.csv
│ │ ├── stopwords.csv
│ │ └── informal_words.csv
│ ├── masks
│ │ ├── __init__.py
│ │ ├── bulb.png
│ │ ├── cat.png
│ │ ├── cloud.png
│ │ ├── head.png
│ │ ├── heart.png
│ │ └── iran.png
│ ├── fonts
│ │ ├── sahel.ttf
│ │ └── parastoo.ttf
│ └── readme.md
├── visualization
│ └── __init__.py
├── ner
│ ├── __init__.py
│ └── base.py
├── pos
│ ├── __init__.py
│ ├── base.py
│ └── albert_pos.py
├── keyword_extraction
│ ├── __init__.py
│ ├── base.py
│ └── rake.py
├── transforms
│ ├── __init__.py
│ ├── flatten.py
│ └── ngram_extractor.py
├── embeddings
│ ├── __init__.py
│ ├── contextual_embedder.py
│ ├── albert_embedder.py
│ ├── base.py
│ └── word_embedder.py
├── spelling
│ ├── __init__.py
│ └── checker.py
├── sentiment_analysis
│ ├── __init__.py
│ ├── base.py
│ └── albert_sentiment_binary.py
├── toxicity
│ ├── __init__.py
│ ├── base_offensive.py
│ └── logistic_offensive_classifier.py
├── morphology
│ ├── __init__.py
│ ├── lemmatizer.py
│ └── stemmer.py
├── tokenization
│ ├── __init__.py
│ ├── base.py
│ ├── word_tokenizer.py
│ ├── sentence_tokenizer.py
│ └── albert_tokenizer.py
├── __init__.py
├── preprocessing
│ ├── normalizers
│ │ ├── __init__.py
│ │ ├── ya_normalizer.py
│ │ ├── repeated_letter_normalizer.py
│ │ ├── arabic_unicode_normalizer.py
│ │ ├── punctuation_normalizer.py
│ │ ├── digit_normalizer.py
│ │ └── alphabet_normalizer.py
│ ├── maskers
│ │ ├── hashtag_masker.py
│ │ ├── mention_masker.py
│ │ ├── digit_masker.py
│ │ ├── diacritic_masker.py
│ │ ├── html_tag_masker.py
│ │ ├── url_masker.py
│ │ ├── email_masker.py
│ │ ├── emoji_masker.py
│ │ ├── punctuation_masker.py
│ │ ├── offensive_word_masker.py
│ │ ├── stopword_masker.py
│ │ ├── non_persian_letter_masker.py
│ │ └── __init__.py
│ └── __init__.py
├── normalizer.py
├── utils.py
└── hub.py
├── .coveragerc
├── assets
├── banner.png
└── wordcloud_example.png
├── docs
├── assets
│ ├── images
│ │ ├── favicon.ico
│ │ ├── favicon.png
│ │ └── embeddings_visualization.png
│ ├── fonts
│ │ └── Vazirmatn-Regular.ttf
│ ├── stylesheets
│ │ └── extra.css
│ └── overrides
│ │ └── partials
│ │ └── footer.html
└── en
│ ├── tutorials
│ ├── spell_checking.md
│ ├── keyword_extraction.md
│ ├── pos.md
│ ├── visualization.md
│ ├── tokenization.md
│ ├── cli.md
│ └── ner.md
│ └── getting_started
│ ├── installation.md
│ └── quick_start.md
├── .gitignore
├── lab
├── spm_train.py
├── export_fasttext_to_bin.py
├── train_fasttext_gensim.py
└── train_albert_mlm.py
├── tests
├── test_utils.py
└── unit
│ ├── tokenization
│ ├── test_word_tokenizer.py
│ ├── test_sentence_tokenizer.py
│ ├── test_albert_tokenizer.py
│ └── test_base_tokenizer.py
│ ├── keyword_extraction
│ ├── test_rake.py
│ └── test_base_keyword_extractor.py
│ ├── ner
│ ├── test_base_ner.py
│ └── test_albert_ner.py
│ ├── spelling
│ ├── test_base_checker.py
│ └── test_statistical_checker.py
│ ├── toxicity
│ ├── test_toxicity_base.py
│ └── test_logistic_offensive.py
│ ├── pos
│ ├── test_base_pos.py
│ └── test_albert_pos.py
│ ├── visualization
│ └── test_wordcloud.py
│ ├── embeddings
│ ├── test_contextual_embedder.py
│ ├── test_albert_embedder.py
│ ├── test_word_embedder.py
│ └── test_base_embedder.py
│ ├── base
│ ├── test_base.py
│ └── test_base_text_transformer.py
│ ├── morphology
│ ├── test_lemmatizer.py
│ ├── test_stemmer.py
│ └── test_inflector.py
│ └── sentiment_analysis
│ └── test_base_sentiment.py
├── .github
└── workflows
│ ├── publish.yml
│ └── test.yml
├── .gitattributes
├── CITATION.cff
├── LICENSE
├── examples
├── pos_tagging.ipynb
└── keyword_extraction.ipynb
├── pyproject.toml
├── mkdocs.yml
└── paper.bib
/shekar/data/files/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/shekar/data/masks/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/.coveragerc:
--------------------------------------------------------------------------------
1 | [run]
2 | omit =
3 | tests/*
4 | */tests/*
--------------------------------------------------------------------------------
/assets/banner.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/assets/banner.png
--------------------------------------------------------------------------------
/shekar/visualization/__init__.py:
--------------------------------------------------------------------------------
1 | from .word_cloud import WordCloud
2 |
3 | __all__ = ["WordCloud"]
4 |
--------------------------------------------------------------------------------
/shekar/data/fonts/sahel.ttf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/fonts/sahel.ttf
--------------------------------------------------------------------------------
/shekar/data/masks/bulb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/masks/bulb.png
--------------------------------------------------------------------------------
/shekar/data/masks/cat.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/masks/cat.png
--------------------------------------------------------------------------------
/shekar/data/masks/cloud.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/masks/cloud.png
--------------------------------------------------------------------------------
/shekar/data/masks/head.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/masks/head.png
--------------------------------------------------------------------------------
/shekar/data/masks/heart.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/masks/heart.png
--------------------------------------------------------------------------------
/shekar/data/masks/iran.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/masks/iran.png
--------------------------------------------------------------------------------
/assets/wordcloud_example.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/assets/wordcloud_example.png
--------------------------------------------------------------------------------
/docs/assets/images/favicon.ico:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/docs/assets/images/favicon.ico
--------------------------------------------------------------------------------
/docs/assets/images/favicon.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/docs/assets/images/favicon.png
--------------------------------------------------------------------------------
/shekar/data/fonts/parastoo.ttf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/shekar/data/fonts/parastoo.ttf
--------------------------------------------------------------------------------
/shekar/data/readme.md:
--------------------------------------------------------------------------------
1 | #### Vocabulary
2 |
3 |
4 | #### Persian Stop Words
5 |
6 |
7 |
8 |
9 |
10 |
--------------------------------------------------------------------------------
/docs/assets/fonts/Vazirmatn-Regular.ttf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/docs/assets/fonts/Vazirmatn-Regular.ttf
--------------------------------------------------------------------------------
/shekar/ner/__init__.py:
--------------------------------------------------------------------------------
1 | from .albert_ner import AlbertNER
2 | from .base import NER
3 |
4 |
5 | __all__ = ["AlbertNER", "NER"]
6 |
--------------------------------------------------------------------------------
/shekar/pos/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import POSTagger
2 | from .albert_pos import AlbertPOS
3 |
4 | __all__ = ["POSTagger", "AlbertPOS"]
5 |
--------------------------------------------------------------------------------
/docs/assets/images/embeddings_visualization.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amirivojdan/shekar/HEAD/docs/assets/images/embeddings_visualization.png
--------------------------------------------------------------------------------
/shekar/keyword_extraction/__init__.py:
--------------------------------------------------------------------------------
1 | from .rake import RAKE
2 | from .base import KeywordExtractor
3 |
4 | __all__ = ["RAKE", "KeywordExtractor"]
5 |
--------------------------------------------------------------------------------
/shekar/transforms/__init__.py:
--------------------------------------------------------------------------------
1 | from .ngram_extractor import NGramExtractor
2 | from .flatten import Flatten
3 |
4 | __all__ = [
5 | "NGramExtractor",
6 | "Flatten",
7 | ]
8 |
--------------------------------------------------------------------------------
/shekar/embeddings/__init__.py:
--------------------------------------------------------------------------------
1 | from .word_embedder import WordEmbedder
2 | from .contextual_embedder import ContextualEmbedder
3 |
4 |
5 | __all__ = ["WordEmbedder", "ContextualEmbedder"]
6 |
--------------------------------------------------------------------------------
/shekar/spelling/__init__.py:
--------------------------------------------------------------------------------
1 | from .statistical_checker import StatisticalSpellChecker
2 | from .checker import SpellChecker
3 |
4 | __all__ = ["StatisticalSpellChecker", "SpellChecker"]
5 |
--------------------------------------------------------------------------------
/shekar/sentiment_analysis/__init__.py:
--------------------------------------------------------------------------------
1 | from .base import SentimentClassifier
2 | from .albert_sentiment_binary import AlbertBinarySentimentClassifier
3 |
4 | __all__ = ["SentimentClassifier", "AlbertBinarySentimentClassifier"]
5 |
--------------------------------------------------------------------------------
/shekar/toxicity/__init__.py:
--------------------------------------------------------------------------------
1 | from .base_offensive import OffensiveLanguageClassifier
2 | from .logistic_offensive_classifier import LogisticOffensiveClassifier
3 |
4 | __all__ = ["OffensiveLanguageClassifier", "LogisticOffensiveClassifier"]
5 |
--------------------------------------------------------------------------------
/shekar/morphology/__init__.py:
--------------------------------------------------------------------------------
1 | from .conjugator import Conjugator
2 | from .inflector import Inflector
3 | from .stemmer import Stemmer
4 | from .lemmatizer import Lemmatizer
5 |
6 | __all__ = ["Conjugator", "Inflector", "Stemmer", "Lemmatizer"]
7 |
--------------------------------------------------------------------------------
/shekar/tokenization/__init__.py:
--------------------------------------------------------------------------------
1 | from .albert_tokenizer import AlbertTokenizer
2 | from .sentence_tokenizer import SentenceTokenizer
3 | from .word_tokenizer import WordTokenizer
4 | from .base import Tokenizer
5 |
6 | __all__ = ["AlbertTokenizer", "SentenceTokenizer", "WordTokenizer", "Tokenizer"]
7 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Python-generated files
2 | __pycache__/
3 | *.py[oc]
4 | build/
5 | dist/
6 | wheels/
7 | *.egg-info
8 |
9 | # Virtual environments
10 | .venv
11 | .pytest_cache
12 | .python-version
13 |
14 | # Jupyter Notebook
15 | .ipynb_checkpoints
16 | notebooks/
17 |
18 | site/
19 |
20 | .coverage
21 |
22 | htmlcov/
23 | .ruff_cache/
--------------------------------------------------------------------------------
/lab/spm_train.py:
--------------------------------------------------------------------------------
1 | import sentencepiece as spm
2 |
3 | spm.SentencePieceTrainer.train(
4 | input="./corpus.txt",
5 | model_prefix="sp_unigram",
6 | vocab_size=32000,
7 | model_type="unigram",
8 | normalization_rule_name="identity",
9 | character_coverage=1.0,
10 | byte_fallback=True,
11 | train_extremely_large_corpus=True,
12 | )
13 |
--------------------------------------------------------------------------------
/tests/test_utils.py:
--------------------------------------------------------------------------------
1 | from shekar.utils import is_informal
2 |
3 |
4 | def test_is_informal():
5 | input_text = "میخوام برم خونه، تو نمیای؟"
6 | expected_output = True
7 | assert is_informal(input_text) == expected_output
8 |
9 | input_text = "دیگه چه خبر؟"
10 | expected_output = True
11 | assert is_informal(input_text) == expected_output
12 |
--------------------------------------------------------------------------------
/docs/assets/stylesheets/extra.css:
--------------------------------------------------------------------------------
1 | @font-face {
2 | font-family: 'Vazirmatn';
3 | src: url('../fonts/Vazirmatn-Regular.ttf') format('truetype');
4 | font-weight: normal;
5 | font-style: normal;
6 | font-display: swap;
7 |
8 | }
9 |
10 | body {
11 | font-family: 'Vazirmatn', sans-serif;
12 |
13 | }
14 |
15 | :root {
16 | --md-primary-fg-color: #00A693;
17 | --md-primary-fg-color--light: #00A693;
18 | --md-primary-fg-color--dark: #00A693;
19 | }
20 |
21 |
--------------------------------------------------------------------------------
/shekar/ner/base.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from .albert_ner import AlbertNER
3 |
4 | NER_REGISTRY = {
5 | "albert": AlbertNER,
6 | }
7 |
8 |
9 | class NER(BaseTransform):
10 | def __init__(self, model: str = "albert", model_path=None):
11 | model = model.lower()
12 | if model not in NER_REGISTRY:
13 | raise ValueError(
14 | f"Unknown NER model '{model}'. Available: {list(NER_REGISTRY.keys())}"
15 | )
16 |
17 | self.model = NER_REGISTRY[model](model_path=model_path)
18 |
19 | def transform(self, X: str) -> list:
20 | return self.model.transform(X)
21 |
--------------------------------------------------------------------------------
/.github/workflows/publish.yml:
--------------------------------------------------------------------------------
1 | name: Publish to PyPI
2 |
3 | on:
4 | release:
5 | types: [published]
6 |
7 | permissions:
8 | contents: read
9 |
10 | jobs:
11 | release:
12 | runs-on: ubuntu-latest
13 | environment: pypi
14 | permissions:
15 | id-token: write
16 | steps:
17 | - uses: actions/checkout@v4
18 |
19 | - name: Install uv and setup the python version
20 | uses: astral-sh/setup-uv@v5
21 |
22 | - name: Install the project
23 | run: uv sync --all-groups
24 |
25 | - name: Build wheel
26 | run: uv build
27 |
28 | - name: Publish package
29 | run: uv publish
30 |
--------------------------------------------------------------------------------
/shekar/pos/base.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from .albert_pos import AlbertPOS
3 |
4 | POS_REGISTRY = {
5 | "albert": AlbertPOS,
6 | }
7 |
8 |
9 | class POSTagger(BaseTransform):
10 | def __init__(self, model: str = "albert", model_path=None):
11 | model = model.lower()
12 | if model not in POS_REGISTRY:
13 | raise ValueError(
14 | f"Unknown POS model '{model}'. Available: {list(POS_REGISTRY.keys())}"
15 | )
16 |
17 | self.model = POS_REGISTRY[model](model_path=model_path)
18 |
19 | def transform(self, X: str) -> list:
20 | return self.model.transform(X)
21 |
--------------------------------------------------------------------------------
/.gitattributes:
--------------------------------------------------------------------------------
1 | # Default: text files use LF
2 | # on Windows run "git config --global core.autocrlf false"
3 | # to renomalize line endings, run: "git add --renormalize ."
4 |
5 | * text=auto eol=lf
6 |
7 | # Common binary types that must never be touched
8 | *.png binary
9 | *.jpg binary
10 | *.jpeg binary
11 | *.gif binary
12 | *.bmp binary
13 | *.ico binary
14 | *.pdf binary
15 | *.zip binary
16 | *.gz binary
17 | *.tar binary
18 | *.7z binary
19 | *.mp4 binary
20 | *.mov binary
21 | *.avi binary
22 | *.mp3 binary
23 | *.wav binary
24 | *.ogg binary
25 | *.ttf binary
26 | *.otf binary
27 | *.woff binary
28 | *.woff2 binary
29 | *.eot binary
30 | *.exe binary
31 | *.dll binary
32 |
--------------------------------------------------------------------------------
/docs/en/tutorials/spell_checking.md:
--------------------------------------------------------------------------------
1 | # Spell Checking
2 |
3 | The `SpellChecker` class provides simple and effective spelling correction for Persian text. It can automatically detect and fix common errors such as extra characters, spacing mistakes, or misspelled words. You can use it directly as a callable on a sentence to clean up the text, or call `suggest()` to get a ranked list of correction candidates for a single word.
4 |
5 | **Example Usage**
6 |
7 | ```python
8 | from shekar import SpellChecker
9 |
10 | spell_checker = SpellChecker()
11 | print(spell_checker("سسلام بر ششما ددوست من"))
12 |
13 | print(spell_checker.suggest("درود"))
14 | ```
15 |
16 | ```output
17 | سلام بر شما دوست من
18 | ['درود', 'درصد', 'ورود', 'درد', 'درون']
19 | ```
--------------------------------------------------------------------------------
/shekar/toxicity/base_offensive.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from .logistic_offensive_classifier import LogisticOffensiveClassifier
3 |
4 | OFFENSIVE_REGISTRY = {
5 | "logistic": LogisticOffensiveClassifier,
6 | }
7 |
8 |
9 | class OffensiveLanguageClassifier(BaseTransform):
10 | def __init__(self, model: str = "logistic", model_path=None):
11 | model = model.lower()
12 | if model not in OFFENSIVE_REGISTRY:
13 | raise ValueError(
14 | f"Unknown model '{model}'. Available: {list(OFFENSIVE_REGISTRY.keys())}"
15 | )
16 |
17 | self.model = OFFENSIVE_REGISTRY[model](model_path=model_path)
18 |
19 | def transform(self, X: str):
20 | return self.model.transform(X)
21 |
--------------------------------------------------------------------------------
/shekar/keyword_extraction/base.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from .rake import RAKE
3 |
4 | KEYWORD_EXTRACTION_REGISTRY = {
5 | "rake": RAKE,
6 | }
7 |
8 |
9 | class KeywordExtractor(BaseTransform):
10 | def __init__(self, model: str = "rake", max_length=3, top_n=5):
11 | model = model.lower()
12 | if model not in KEYWORD_EXTRACTION_REGISTRY:
13 | raise ValueError(
14 | f"Unknown keyword extraction model '{model}'. Available: {list(KEYWORD_EXTRACTION_REGISTRY.keys())}"
15 | )
16 |
17 | self.model = KEYWORD_EXTRACTION_REGISTRY[model](
18 | max_length=max_length, top_n=top_n
19 | )
20 |
21 | def fit(self, X, y=None):
22 | return self.model.fit(X, y)
23 |
24 | def transform(self, X: str) -> list:
25 | return self.model.transform(X)
26 |
--------------------------------------------------------------------------------
/tests/unit/tokenization/test_word_tokenizer.py:
--------------------------------------------------------------------------------
1 | from shekar.tokenization import WordTokenizer
2 |
3 |
4 | def test_word_tokenizer():
5 | tokenizer = WordTokenizer()
6 | text = "چه سیبهای قشنگی! حیات نشئهٔ تنهایی است."
7 | expected_output = [
8 | "چه",
9 | "سیبهای",
10 | "قشنگی",
11 | "!",
12 | "حیات",
13 | "نشئهٔ",
14 | "تنهایی",
15 | "است",
16 | ".",
17 | ]
18 | print(tokenizer.tokenize(text))
19 | assert list(tokenizer.tokenize(text)) == expected_output
20 |
21 | text = "سلام دنیا"
22 | expected_output = ["سلام", "دنیا"]
23 | assert list(tokenizer.tokenize(text)) == expected_output
24 |
25 | text = "این یک متن آزمایشی است."
26 | expected_output = ["این", "یک", "متن", "آزمایشی", "است", "."]
27 | assert list(tokenizer.tokenize(text)) == expected_output
28 |
--------------------------------------------------------------------------------
/shekar/tokenization/base.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from .word_tokenizer import WordTokenizer
3 | from .sentence_tokenizer import SentenceTokenizer
4 | from .albert_tokenizer import AlbertTokenizer
5 |
6 | TOKENIZATION_REGISTRY = {
7 | "word": WordTokenizer,
8 | "sentence": SentenceTokenizer,
9 | "albert": AlbertTokenizer,
10 | }
11 |
12 |
13 | class Tokenizer(BaseTransform):
14 | def __init__(self, model: str = "word"):
15 | model = model.lower()
16 | if model not in TOKENIZATION_REGISTRY:
17 | raise ValueError(
18 | f"Unknown tokenizer model '{model}'. Available: {list(TOKENIZATION_REGISTRY.keys())}"
19 | )
20 |
21 | self.model = TOKENIZATION_REGISTRY[model]()
22 |
23 | def fit(self, X, y=None):
24 | return self.model.fit(X, y)
25 |
26 | def transform(self, X: str) -> str:
27 | return self.model.transform(X)
28 |
--------------------------------------------------------------------------------
/shekar/transforms/flatten.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from typing import Iterable
3 |
4 |
5 | class Flatten(BaseTransform):
6 | """
7 | A transformer that flattens a nested iterable of strings into a generator of strings.
8 | """
9 |
10 | def transform(self, X: Iterable) -> Iterable[str]:
11 | """
12 | Flattens a nested iterable structure into a generator of strings.
13 |
14 | Args:
15 | X: An iterable that may contain nested iterables of strings
16 |
17 | Returns:
18 | Iterable[str]: A generator yielding all string items
19 | """
20 |
21 | def _flatten(items):
22 | for item in items:
23 | if isinstance(item, str):
24 | yield item
25 | elif isinstance(item, Iterable) and not isinstance(item, (str, bytes)):
26 | yield from _flatten(item)
27 |
28 | return _flatten(X)
29 |
--------------------------------------------------------------------------------
/docs/en/getting_started/installation.md:
--------------------------------------------------------------------------------
1 | # Installing shekar
2 |
3 | ## PyPI
4 |
5 | You can install Shekar with pip. By default, the `CPU` runtime of ONNX is included, which works on all platforms.
6 |
7 | ### CPU Installation (All Platforms)
8 |
9 |
10 | ```bash
11 | $ pip install shekar
12 | ---> 100%
13 | Successfully installed shekar!
14 | ```
15 | This works on **Windows**, **Linux**, and **macOS** (including Apple Silicon M1/M2/M3).
16 |
17 | ### GPU Acceleration (NVIDIA CUDA)
18 | If you have an NVIDIA GPU and want hardware acceleration, you need to replace the CPU runtime with the GPU version.
19 |
20 | **Prerequisites**
21 |
22 | - NVIDIA GPU with CUDA support
23 | - Appropriate CUDA Toolkit installed
24 | - Compatible NVIDIA drivers
25 |
26 |
27 | ```bash
28 | $ pip install shekar \
29 | && pip uninstall -y onnxruntime \
30 | && pip install onnxruntime-gpu
31 | ---> 100%
32 | Successfully installed shekar!
33 | ```
--------------------------------------------------------------------------------
/shekar/spelling/checker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from .statistical_checker import StatisticalSpellChecker
3 |
4 | SPELL_CHECKING_REGISTRY = {
5 | "statistical": StatisticalSpellChecker,
6 | }
7 |
8 |
9 | class SpellChecker(BaseTransform):
10 | def __init__(self, model: str = "statistical"):
11 | model = model.lower()
12 | if model not in SPELL_CHECKING_REGISTRY:
13 | raise ValueError(
14 | f"Unknown spell checking model '{model}'. Available: {list(SPELL_CHECKING_REGISTRY.keys())}"
15 | )
16 |
17 | self.model = SPELL_CHECKING_REGISTRY[model]()
18 |
19 | def suggest(self, word, n_best=5):
20 | return self.model.suggest(word, n_best=n_best)
21 |
22 | def correct(self, text):
23 | return self.model.correct(text)
24 |
25 | def fit(self, X, y=None):
26 | return self.model.fit(X, y)
27 |
28 | def transform(self, X: str) -> str:
29 | return self.model.transform(X)
30 |
--------------------------------------------------------------------------------
/shekar/__init__.py:
--------------------------------------------------------------------------------
1 | from .pipeline import Pipeline
2 | from .base import BaseTransform, BaseTextTransform
3 | from .normalizer import Normalizer
4 | from .tokenization import WordTokenizer, SentenceTokenizer, Tokenizer
5 | from .keyword_extraction import KeywordExtractor
6 | from .ner import NER
7 | from .pos import POSTagger
8 | from .sentiment_analysis import SentimentClassifier
9 | from .embeddings import WordEmbedder, ContextualEmbedder
10 | from .spelling import SpellChecker
11 | from .morphology import Conjugator, Inflector, Stemmer, Lemmatizer
12 | from .hub import Hub
13 |
14 | __all__ = [
15 | "Hub",
16 | "Pipeline",
17 | "BaseTransform",
18 | "BaseTextTransform",
19 | "Normalizer",
20 | "KeywordExtractor",
21 | "NER",
22 | "POSTagger",
23 | "SentimentClassifier",
24 | "SpellChecker",
25 | "Tokenizer",
26 | "WordEmbedder",
27 | "ContextualEmbedder",
28 | "WordTokenizer",
29 | "SentenceTokenizer",
30 | "Conjugator",
31 | "Inflector",
32 | "Stemmer",
33 | "Lemmatizer",
34 | ]
35 |
--------------------------------------------------------------------------------
/CITATION.cff:
--------------------------------------------------------------------------------
1 | cff-version: "1.2.0"
2 | authors:
3 | - family-names: Amirivojdan
4 | given-names: Ahmad
5 | orcid: "https://orcid.org/0000-0003-3741-3979"
6 | contact:
7 | - family-names: Amirivojdan
8 | given-names: Ahmad
9 | orcid: "https://orcid.org/0000-0003-3741-3979"
10 | doi: 10.5281/zenodo.17408443
11 | message: If you use this software, please cite our article in the
12 | Journal of Open Source Software.
13 | preferred-citation:
14 | authors:
15 | - family-names: Amirivojdan
16 | given-names: Ahmad
17 | orcid: "https://orcid.org/0000-0003-3741-3979"
18 | date-published: 2025-10-21
19 | doi: 10.21105/joss.09128
20 | issn: 2475-9066
21 | issue: 114
22 | journal: Journal of Open Source Software
23 | publisher:
24 | name: Open Journals
25 | start: 9128
26 | title: "Shekar: A Python Toolkit for Persian Natural Language
27 | Processing"
28 | type: article
29 | url: "https://joss.theoj.org/papers/10.21105/joss.09128"
30 | volume: 10
31 | title: "Shekar: A Python Toolkit for Persian Natural Language
32 | Processing"
33 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2024 Ahmad Amirivojdan
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/shekar/embeddings/contextual_embedder.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from .base import BaseEmbedder
3 | from .albert_embedder import AlbertEmbedder
4 |
5 | CONTEXTUAL_EMBEDDING_REGISTRY = {
6 | "albert": AlbertEmbedder,
7 | }
8 |
9 |
10 | class ContextualEmbedder(BaseEmbedder):
11 | """ContextualEmbedder class for embedding sentences using pre-trained models.
12 | Args:
13 | model (str): Name of the word embedding model to use.
14 | model_path (str, optional): Path to the pre-trained model file. If None, it will be downloaded from the hub.
15 | Raises:
16 | ValueError: If the specified model is not found in the registry.
17 | """
18 |
19 | def __init__(self, model: str = "albert"):
20 | model = model.lower()
21 | if model not in CONTEXTUAL_EMBEDDING_REGISTRY:
22 | raise ValueError(
23 | f"Unknown contextual embedding model '{model}'. Available: {list(CONTEXTUAL_EMBEDDING_REGISTRY.keys())}"
24 | )
25 |
26 | self.embedder = CONTEXTUAL_EMBEDDING_REGISTRY[model]()
27 |
28 | def embed(self, phrase: str) -> np.ndarray:
29 | return self.embedder(phrase)
30 |
31 | def transform(self, X: str) -> np.ndarray:
32 | return self.embed(X)
33 |
--------------------------------------------------------------------------------
/shekar/preprocessing/normalizers/__init__.py:
--------------------------------------------------------------------------------
1 | from .alphabet_normalizer import AlphabetNormalizer
2 | from .arabic_unicode_normalizer import ArabicUnicodeNormalizer
3 | from .digit_normalizer import DigitNormalizer
4 | from .punctuation_normalizer import PunctuationNormalizer
5 | from .spacing_normalizer import SpacingNormalizer
6 | from .ya_normalizer import YaNormalizer
7 | from .repeated_letter_normalizer import RepeatedLetterNormalizer
8 |
9 | # aliases
10 | NormalizeDigits = DigitNormalizer
11 | NormalizePunctuations = PunctuationNormalizer
12 | NormalizeArabicUnicodes = ArabicUnicodeNormalizer
13 | NormalizeYas = YaNormalizer
14 | NormalizeSpacings = SpacingNormalizer
15 | NormalizeAlphabets = AlphabetNormalizer
16 | NormalizeRepeatedLetters = RepeatedLetterNormalizer
17 |
18 | __all__ = [
19 | "AlphabetNormalizer",
20 | "ArabicUnicodeNormalizer",
21 | "DigitNormalizer",
22 | "PunctuationNormalizer",
23 | "SpacingNormalizer",
24 | "YaNormalizer",
25 | "RepeatedLetterNormalizer",
26 | # aliases
27 | "NormalizeDigits",
28 | "NormalizePunctuations",
29 | "NormalizeArabicUnicodes",
30 | "NormalizeSpacings",
31 | "NormalizeAlphabets",
32 | "NormalizeYas",
33 | "NormalizeRepeatedLetters",
34 | ]
35 |
--------------------------------------------------------------------------------
/tests/unit/keyword_extraction/test_rake.py:
--------------------------------------------------------------------------------
1 | from shekar.keyword_extraction.rake import RAKE
2 |
3 |
4 | def test_rake_instantiates_with_defaults():
5 | extractor = RAKE()
6 | assert extractor.top_n == 5
7 | assert callable(extractor.transform)
8 |
9 |
10 | def test_rake_fit_returns_self():
11 | rake = RAKE()
12 | result = rake.fit(["نمونه متن برای آزمایش"])
13 | assert result is rake
14 |
15 |
16 | def test_rake_extract_keywords_basic():
17 | rake = RAKE(top_n=5)
18 | text = "هوش مصنوعی یکی از مهمترین فناوریهای قرن حاضر است. یادگیری ماشین نیز زیرمجموعهای از آن محسوب میشود."
19 |
20 | keywords = rake.transform(text)
21 |
22 | assert isinstance(keywords, list)
23 | assert len(keywords) <= 5
24 | assert all(isinstance(kw, str) for kw in keywords)
25 | assert all(len(kw) > 0 for kw in keywords)
26 |
27 |
28 | def test_rake_top_n_limit():
29 | rake = RAKE(top_n=2)
30 | text = "مهندسی، ریاضی و فیزیک از پایههای اصلی علوم پایه هستند."
31 |
32 | keywords = rake.transform(text)
33 |
34 | assert isinstance(keywords, list)
35 | assert len(keywords) <= 2
36 |
37 |
38 | def test_rake_handles_empty_text_gracefully():
39 | rake = RAKE()
40 | keywords = rake.transform("")
41 | assert isinstance(keywords, list)
42 | assert keywords == []
43 |
--------------------------------------------------------------------------------
/shekar/preprocessing/normalizers/ya_normalizer.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class YaNormalizer(BaseTextTransform):
5 | """
6 | Normalizes Ya in the text regarding the offical Persian script standard published by the Iranian Academy of Language and Literature.
7 | reference: https://apll.ir/
8 |
9 | There are two styles available:
10 | - "standard": Follows the official Persian script standard.
11 | - "joda" (default): Follows the Joda script style.
12 |
13 | Examples:
14 | >>> ya_normalizer = YaNormalizer(style="standard")
15 | >>> ya_normalizer("خانهی ما")
16 | "خانۀ ما"
17 | >>> ya_normalizer = YaNormalizer(style="joda")
18 | >>> ya_normalizer("خانۀ ما")
19 | "خانهی ما"
20 | """
21 |
22 | def __init__(self, style="joda"):
23 | super().__init__()
24 | if style == "standard":
25 | self._ya_mappings = [
26 | (r"هی", "ۀ"),
27 | (r"ه ی", "ۀ"),
28 | ]
29 | elif style == "joda":
30 | self._ya_mappings = [
31 | (r"ۀ", "هی"),
32 | (r"ه ی", "هی"),
33 | ]
34 |
35 | self._patterns = self._compile_patterns(self._ya_mappings)
36 |
37 | def _function(self, text: str) -> str:
38 | return self._map_patterns(text, self._patterns).strip()
39 |
--------------------------------------------------------------------------------
/tests/unit/tokenization/test_sentence_tokenizer.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.tokenization import SentenceTokenizer
3 |
4 |
5 | @pytest.fixture
6 | def tokenizer():
7 | return SentenceTokenizer()
8 |
9 |
10 | def test_tokenize_simple_sentence(tokenizer):
11 | text = "زنده باد ایران!"
12 | expected = ["زنده باد ایران!"]
13 | assert list(tokenizer.tokenize(text)) == expected
14 |
15 |
16 | def test_tokenize_multiple_sentences(tokenizer):
17 | text = "چه سیبهای قشنگی! حیات نشئه تنهایی است."
18 | expected = ["چه سیبهای قشنگی!", "حیات نشئه تنهایی است."]
19 | assert list(tokenizer(text)) == expected
20 |
21 |
22 | def test_tokenize_multiple_sentences_with_space(tokenizer):
23 | text = "چه سیبهای قشنگی! حیات نشئه تنهایی است. "
24 | expected = ["چه سیبهای قشنگی!", "حیات نشئه تنهایی است."]
25 | assert list(tokenizer.tokenize(text)) == expected
26 |
27 |
28 | def test_tokenize_multiple_sentences_with_newline(tokenizer):
29 | text = "چه سیبهای قشنگی! \n\n \n \nحیات نشئه تنهایی است. "
30 | expected = ["چه سیبهای قشنگی!", "حیات نشئه تنهایی است."]
31 | assert list(tokenizer(text)) == expected
32 |
33 |
34 | def test_tokenize_multiple_sentences_with_question_mark(tokenizer):
35 | text = "ما چه کردیم؟ و چه خواهیم کرد در این فرصت کم!؟"
36 | expected = ["ما چه کردیم؟", "و چه خواهیم کرد در این فرصت کم!؟"]
37 | assert list(tokenizer.tokenize(text)) == expected
38 |
--------------------------------------------------------------------------------
/docs/en/tutorials/keyword_extraction.md:
--------------------------------------------------------------------------------
1 | # Keyword Extraction
2 |
3 | [](examples/keyword_extraction.ipynb) [](https://colab.research.google.com/github/amirivojdan/shekar/blob/main/examples/keyword_extraction.ipynb)
4 |
5 | The `shekar.keyword_extraction` module provides tools for automatically identifying and extracting key terms and phrases from Persian text. These algorithms help highlight the most important concepts and topics within documents for tasks such as document summarization, topic modeling, and information retrieval.
6 |
7 | Currently, **RAKE (Rapid Automatic Keyword Extraction)** is used as the **default** keyword extraction model.
8 |
9 |
10 | ```python
11 | from shekar import KeywordExtractor
12 |
13 | extractor = KeywordExtractor(max_length=2, top_n=10)
14 |
15 | input_text = (
16 | "زبان فارسی یکی از زبانهای مهم منطقه و جهان است که تاریخچهای کهن دارد. "
17 | "زبان فارسی با داشتن ادبیاتی غنی و شاعرانی برجسته، نقشی بیبدیل در گسترش فرهنگ ایرانی ایفا کرده است. "
18 | "از دوران فردوسی و شاهنامه تا دوران معاصر، زبان فارسی همواره ابزار بیان اندیشه، احساس و هنر بوده است. "
19 | )
20 |
21 | keywords = extractor(input_text)
22 |
23 | for kw in keywords:
24 | print(kw)
25 | ```
26 | ```shell
27 | فرهنگ ایرانی
28 | گسترش فرهنگ
29 | ایرانی ایفا
30 | زبان فارسی
31 | تاریخچهای کهن
32 | ```
--------------------------------------------------------------------------------
/lab/export_fasttext_to_bin.py:
--------------------------------------------------------------------------------
1 | from gensim.models import FastText
2 | import pickle
3 | import numpy as np
4 |
5 | model = FastText.load("fasttext_d300_w10_v250k_cbow_naab.model")
6 |
7 | embedding = model.wv["سلام"]
8 | print(embedding)
9 |
10 |
11 | similarity = model.wv.similarity("سلام", "درود")
12 | print(f"Similarity between 'سلام' and 'درود': {similarity}")
13 |
14 | top_similar = model.wv.most_similar("سلام", topn=5)
15 | print("Top 5 most similar words to 'سلام':")
16 | for word, score in top_similar:
17 | print(f"{word}: {score}")
18 |
19 | words = np.array(list(model.wv.index_to_key))
20 | embeddings = np.array([model.wv[word] for word in words])
21 |
22 | model_export = {
23 | "words": words,
24 | "embeddings": embeddings,
25 | "vector_size": model.vector_size,
26 | "window": model.window,
27 | "model": "fasttext-" + ("cbow" if model.sg == 0 else "skipgram"),
28 | "epochs": model.epochs,
29 | "dataset": "SLPL/naab"
30 | }
31 |
32 | with open("fasttext_d300_w10_v250k_cbow_naab.bin", "wb") as f:
33 | pickle.dump(model_export, f)
34 |
35 | with open("fasttext_d300_w10_v250k_cbow_naab.bin", "rb") as f:
36 | loaded_model_export = pickle.load(f)
37 | new_embedding = loaded_model_export["embeddings"][np.where(loaded_model_export["words"] == "سلام")[0][0]]
38 |
39 | if np.array_equal(embedding, new_embedding):
40 | print("The embeddings match!")
41 | else:
42 | print("The embeddings do not match.")
--------------------------------------------------------------------------------
/tests/unit/ner/test_base_ner.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.ner import NER
3 | from shekar.ner.albert_ner import AlbertNER
4 |
5 |
6 | def test_ner_default_model_is_albert():
7 | ner = NER()
8 | assert isinstance(ner.model, AlbertNER)
9 |
10 |
11 | def test_ner_invalid_model_raises():
12 | with pytest.raises(ValueError, match="Unknown NER model 'foobar'"):
13 | NER("foobar")
14 |
15 |
16 | def test_ner_transform_outputs_entities():
17 | ner = NER()
18 | text = "من علیرضا امیری هستم و در دانشگاه تهران تحصیل میکنم."
19 |
20 | entities = ner.transform(text)
21 |
22 | # Should be a list of tuples or dicts
23 | assert isinstance(entities, list)
24 | assert all(isinstance(ent, tuple) for ent in entities)
25 |
26 | # Check format: (text, label)
27 | for ent in entities:
28 | assert isinstance(ent[0], str) # entity text
29 | assert isinstance(ent[1], str) # entity label
30 |
31 |
32 | def test_ner_fit_returns_model():
33 | ner = NER()
34 | result = ner.fit(["متن تست"], [["O", "B-PER", "I-PER"]])
35 | assert result is ner
36 |
37 |
38 | def test_ner_detects_known_entities():
39 | ner = NER()
40 | text = "دکتر علیرضا امیری در دانشگاه تهران تدریس میکند."
41 | entities = ner.transform(text)
42 | print(entities)
43 | entity_texts = [e[0] for e in entities]
44 | assert "دکتر علیرضا امیری" in entity_texts
45 | assert "دانشگاه تهران" in entity_texts
46 |
--------------------------------------------------------------------------------
/tests/unit/ner/test_albert_ner.py:
--------------------------------------------------------------------------------
1 | from shekar.ner.albert_ner import AlbertNER
2 |
3 |
4 | def test_albert_ner_model_loads_successfully():
5 | model = AlbertNER()
6 | assert model.session is not None
7 | assert hasattr(model, "transform")
8 | assert callable(model.transform)
9 | assert isinstance(model.id2tag, dict)
10 | assert "B-PER" in model.id2tag.values()
11 |
12 |
13 | def test_albert_ner_transform_output_format():
14 | model = AlbertNER()
15 | text = "من علیرضا امیری هستم و در دانشگاه تهران تحصیل میکنم."
16 |
17 | output = model.transform(text)
18 |
19 | assert isinstance(output, list)
20 | assert all(isinstance(ent, tuple) and len(ent) == 2 for ent in output)
21 |
22 | for entity, label in output:
23 | assert isinstance(entity, str)
24 | assert isinstance(label, str)
25 | assert label in {"DAT", "EVE", "LOC", "ORG", "PER"}
26 |
27 |
28 | def test_albert_ner_detects_known_entities():
29 | model = AlbertNER()
30 | text = "دکتر علیرضا امیری در دانشگاه تهران تحصیل میکند."
31 | output = model.transform(text)
32 | entities = {e[0]: e[1] for e in output}
33 |
34 | assert "دکتر علیرضا امیری" in entities
35 | assert entities["دکتر علیرضا امیری"] == "PER"
36 |
37 | assert "دانشگاه تهران" in entities
38 | assert entities["دانشگاه تهران"] == "LOC"
39 |
40 |
41 | def test_albert_ner_fit_returns_self():
42 | model = AlbertNER()
43 | result = model.fit(["dummy text"])
44 | assert result is model
45 |
--------------------------------------------------------------------------------
/shekar/data/files/offensive_words.csv:
--------------------------------------------------------------------------------
1 | بیشرف
2 | گوه
3 | کیری
4 | کسکش
5 | پدرسگ
6 | بیپدر
7 | جنده
8 | کیر
9 | کس
10 | بی ناموس
11 | کص تپل
12 | خار کیونی
13 | خواهر کیونی
14 | خواهر جنده
15 | خار جنده
16 | خار کسده
17 | خار کصده
18 | مادر جنده
19 | زن جنده
20 | بکنمت
21 | بکن توش
22 | بکن تو کونت
23 | سکس
24 | سکسی
25 | سکسیی
26 | کیر
27 | دختر جنده
28 | کس ننت
29 | کص ننت
30 | کس ننه
31 | کص ننه
32 | کس مادر
33 | کص مادر
34 | کیردوست
35 | مادر کونی
36 | خواهر کونی
37 | خوار کونی
38 | خارکسده
39 | خارکس ده
40 | کیروکس
41 | کس و کیر
42 | زنازاده
43 | ولدزنا
44 | خانم جنده
45 | کس خیس
46 | گاییدن
47 | بچه کونی
48 | کسشعر
49 | کصشعر
50 | کسشر
51 | سرکیر
52 | کس کردن
53 | کس دادن
54 | بکن بکن
55 | کس لیسیدن
56 | کس لیس
57 | کص لیسیدن
58 | کص لیس
59 | آب کیر
60 | جنده خانه
61 | کس کش
62 | کیرمکیدن
63 | لاکونی
64 | بی غیرت
65 | کله کیری
66 | کیرناز
67 | کسکیر
68 | کیردراز
69 | سکسیم
70 | ساکونی
71 | سکسی باش
72 | کسخل
73 | کصخل
74 | کصکلک بازی
75 | کصکش
76 | حرومزاده
77 | حروم زاده
78 | کونی
79 | مادر جنده
80 | کص
81 | خارکسّه
82 | دیوث
83 | کس خور
84 | کس خل
85 | کص لیس
86 | کس لیس
87 | خارکونی
88 | کونی مقام
89 | کیری مقام
90 | خار سولاخی
91 | خارتو
92 | کصپدر
93 | جنده پولی
94 | زاخار
95 | بی پدرو مادر
96 | بی پدر مادر
97 | کیرم دهنت
98 | بکیرم
99 | کیر خر
100 | ننه مرده
101 | حروملقمه
102 | مادر فاکر
103 | کصپولی
104 | ننه هزار کیر
105 | ننه کیر دزد
106 | دهنتو گاییدم
107 | کصپولی
108 | کسقلمبه
109 | کصقلمبه
110 | کص قلمبه
111 | سگ کص پدر
112 | سگ بگاد
113 | تاپاله
114 | کص تاپاله
--------------------------------------------------------------------------------
/shekar/morphology/lemmatizer.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 | from .stemmer import Stemmer
3 | from shekar import data
4 | from .conjugator import get_conjugated_verbs
5 |
6 |
7 | class Lemmatizer(BaseTextTransform):
8 | """
9 | A rule-based lemmatizer for Persian text.
10 |
11 | This class reduces words to their lemma (dictionary form) using a combination
12 | of verb conjugation mappings, a stemming algorithm, and a vocabulary lookup.
13 | It prioritizes explicit mappings of conjugated verbs, then falls back to a
14 | stemmer and vocabulary checks.
15 |
16 | Example:
17 | >>> lemmatizer = Lemmatizer()
18 | >>> lemmatizer("رفتند")
19 | 'رفت/رو'
20 | >>> lemmatizer("کتابها")
21 | 'کتاب'
22 |
23 | """
24 |
25 | def __init__(self, return_infinitive=False):
26 | super().__init__()
27 | self.stemmer = Stemmer()
28 | self.return_infinitive = return_infinitive
29 |
30 | def _function(self, text):
31 | conjugated_verbs = get_conjugated_verbs()
32 |
33 | if text in conjugated_verbs:
34 | (past_stem, present_stem) = conjugated_verbs[text]
35 | if past_stem is None:
36 | return present_stem
37 | if self.return_infinitive:
38 | return past_stem + "ن"
39 | return past_stem + "/" + present_stem
40 |
41 | stem = self.stemmer(text)
42 | if stem and stem in data.vocab:
43 | return stem
44 |
45 | if text in data.vocab:
46 | return text
47 |
48 | return text
49 |
--------------------------------------------------------------------------------
/shekar/embeddings/albert_embedder.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | import onnxruntime
3 | import numpy as np
4 | from shekar.hub import Hub
5 | from .base import BaseEmbedder
6 | from shekar.tokenization import AlbertTokenizer
7 | from shekar.utils import get_onnx_providers
8 |
9 |
10 | class AlbertEmbedder(BaseEmbedder):
11 | def __init__(self, model_path: str | Path = None):
12 | super().__init__()
13 | resource_name = "albert_persian_mlm_embeddings.onnx"
14 | if model_path is None or not Path(model_path).exists():
15 | model_path = Hub.get_resource(file_name=resource_name)
16 | self.session = onnxruntime.InferenceSession(
17 | model_path, providers=get_onnx_providers()
18 | )
19 | self.tokenizer = AlbertTokenizer(enable_padding=True, enable_truncation=True)
20 | self.vector_size = 768
21 |
22 | def embed(self, phrase: str) -> np.ndarray:
23 | inputs = self.tokenizer(phrase)
24 |
25 | logits, last_hidden_state = self.session.run(None, inputs)
26 |
27 | mask = inputs["attention_mask"].astype(last_hidden_state.dtype)[:, :, None]
28 |
29 | # drop special tokens
30 | # if "input_ids" in inputs:
31 | # ids = inputs["input_ids"]
32 | # for tid in [cls_id, sep_id]: # define these ids if available
33 | # if tid is not None:
34 | # mask[ids == tid] = 0
35 |
36 | sum_all = (last_hidden_state * mask).sum(axis=(0, 1)) # (H,)
37 | count = np.clip(mask.sum(), 1e-9, None) # scalar
38 |
39 | return (sum_all / count).astype(np.float32)
40 |
--------------------------------------------------------------------------------
/shekar/normalizer.py:
--------------------------------------------------------------------------------
1 | from typing import Iterable
2 | from shekar import Pipeline
3 | from shekar.preprocessing import (
4 | PunctuationNormalizer,
5 | AlphabetNormalizer,
6 | DigitNormalizer,
7 | SpacingNormalizer,
8 | MaskEmojis,
9 | MaskEmails,
10 | MaskURLs,
11 | RemoveDiacritics,
12 | # NonPersianLetterMasker,
13 | MaskHTMLTags,
14 | RepeatedLetterNormalizer,
15 | ArabicUnicodeNormalizer,
16 | YaNormalizer,
17 | )
18 |
19 |
20 | class Normalizer(Pipeline):
21 | def __init__(self, steps=None):
22 | if steps is None:
23 | steps = [
24 | ("AlphabetNormalizer", AlphabetNormalizer()),
25 | ("ArabicUnicodeNormalizer", ArabicUnicodeNormalizer()),
26 | ("DigitNormalizer", DigitNormalizer()),
27 | ("PunctuationNormalizer", PunctuationNormalizer()),
28 | ("EmailMasker", MaskEmails(mask_token=" ")),
29 | ("URLMasker", MaskURLs(mask_token=" ")),
30 | ("EmojiMasker", MaskEmojis(mask_token=" ")),
31 | ("HTMLTagMasker", MaskHTMLTags(mask_token=" ")),
32 | ("DiacriticRemover", RemoveDiacritics()),
33 | ("RepeatedLetterNormalizer", RepeatedLetterNormalizer()),
34 | # ("NonPersianLetterFilter", NonPersianLetterFilter()),
35 | ("SpacingNormalizer", SpacingNormalizer()),
36 | ("YaNormalizer", YaNormalizer(style="joda")),
37 | ]
38 | super().__init__(steps=steps)
39 |
40 | def normalize(self, text: Iterable[str] | str):
41 | return self(text)
42 |
--------------------------------------------------------------------------------
/tests/unit/tokenization/test_albert_tokenizer.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from shekar.tokenization import AlbertTokenizer
3 |
4 |
5 | def test_albert_tokenizer_real_loads_successfully():
6 | tokenizer = AlbertTokenizer()
7 | assert tokenizer.tokenizer is not None
8 | assert hasattr(tokenizer, "transform")
9 |
10 |
11 | def test_albert_tokenizer_transform_output():
12 | tokenizer = AlbertTokenizer()
13 |
14 | text = "من عاشق برنامهنویسی هستم."
15 | output = tokenizer.transform(text)
16 |
17 | # Check keys
18 | assert isinstance(output, dict)
19 | assert set(output.keys()) == {"input_ids", "attention_mask", "token_type_ids"}
20 |
21 | # Check shapes and types
22 | input_ids = output["input_ids"]
23 | attention_mask = output["attention_mask"]
24 | token_type_ids = output["token_type_ids"]
25 |
26 | assert isinstance(input_ids, np.ndarray)
27 | assert input_ids.dtype == np.int64
28 | assert input_ids.shape[0] == 1
29 |
30 | assert isinstance(attention_mask, np.ndarray)
31 | assert attention_mask.shape == input_ids.shape
32 |
33 | assert isinstance(token_type_ids, np.ndarray)
34 | assert token_type_ids.shape == input_ids.shape
35 | assert np.all(token_type_ids == 0)
36 |
37 |
38 | def test_albert_tokenizer_multiple_sentences():
39 | tokenizer = AlbertTokenizer()
40 |
41 | texts = ["سلام دنیا", "او به دانشگاه تهران رفت.", "کتابها روی میز هستند."]
42 |
43 | for text in texts:
44 | output = tokenizer.transform(text)
45 | assert isinstance(output, dict)
46 | assert output["input_ids"].shape[1] > 0 # Non-empty sequence
47 |
--------------------------------------------------------------------------------
/tests/unit/keyword_extraction/test_base_keyword_extractor.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.keyword_extraction import KeywordExtractor
3 | from shekar.keyword_extraction.rake import RAKE
4 |
5 |
6 | def test_keyword_extractor_default_model_is_rake():
7 | extractor = KeywordExtractor()
8 | assert isinstance(extractor.model, RAKE)
9 |
10 |
11 | def test_keyword_extractor_invalid_model_raises():
12 | with pytest.raises(ValueError, match="Unknown keyword extraction model 'invalid'"):
13 | KeywordExtractor(model="invalid")
14 |
15 |
16 | def test_keyword_extractor_fit_returns_model():
17 | extractor = KeywordExtractor()
18 | result = extractor.fit(["متن تست"])
19 | assert result is extractor.model
20 |
21 |
22 | def test_keyword_extractor_transform_returns_keywords():
23 | extractor = KeywordExtractor(top_n=5, max_length=3)
24 | text = "امروز هوا بسیار خوب و آفتابی است و من به پارک رفتم تا قدم بزنم."
25 |
26 | output = extractor.transform(text)
27 |
28 | assert isinstance(output, list)
29 | assert len(output) <= 5
30 |
31 | for item in output:
32 | # Accept either list of strings or list of (phrase, score)
33 | if isinstance(item, tuple):
34 | phrase, score = item
35 | assert isinstance(phrase, str)
36 | assert isinstance(score, (int, float))
37 | else:
38 | assert isinstance(item, str)
39 |
40 |
41 | def test_keyword_extractor_respects_top_n_limit():
42 | extractor = KeywordExtractor(top_n=2)
43 | text = "کتابخانه مرکزی دانشگاه تهران بسیار بزرگ و مجهز است."
44 |
45 | keywords = extractor.transform(text)
46 |
47 | assert len(keywords) <= 2
48 |
--------------------------------------------------------------------------------
/tests/unit/spelling/test_base_checker.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from unittest.mock import patch, MagicMock
3 | from shekar.spelling import SpellChecker
4 |
5 |
6 | def test_spellchecker_initialization_default_model():
7 | # Patch where it's used, not where it's defined!
8 | with patch(
9 | "shekar.spelling.checker.SPELL_CHECKING_REGISTRY",
10 | {"statistical": MagicMock()},
11 | ) as fake_registry:
12 | spell = SpellChecker()
13 | assert callable(spell.model) or hasattr(spell.model, "transform")
14 |
15 | fake_registry.keys
16 |
17 |
18 | def test_spellchecker_invalid_model():
19 | with pytest.raises(ValueError) as exc_info:
20 | SpellChecker(model="unknown")
21 | assert "Unknown spell checking model" in str(exc_info.value)
22 |
23 |
24 | def test_spellchecker_fit_calls_underlying_model():
25 | fake_model = MagicMock()
26 | with patch(
27 | "shekar.spelling.checker.SPELL_CHECKING_REGISTRY",
28 | {"statistical": lambda: fake_model},
29 | ):
30 | spell = SpellChecker()
31 | X = ["متن تستی"]
32 | spell.fit(X)
33 | fake_model.fit.assert_called_once_with(X, None)
34 |
35 |
36 | def test_spellchecker_transform_calls_underlying_model():
37 | fake_model = MagicMock()
38 | fake_model.transform.return_value = "متن اصلاحشده"
39 | with patch(
40 | "shekar.spelling.checker.SPELL_CHECKING_REGISTRY",
41 | {"statistical": lambda: fake_model},
42 | ):
43 | spell = SpellChecker()
44 | result = spell.transform("متن تستی")
45 | fake_model.transform.assert_called_once_with("متن تستی")
46 | assert result == "متن اصلاحشده"
47 |
--------------------------------------------------------------------------------
/tests/unit/toxicity/test_toxicity_base.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.toxicity import OffensiveLanguageClassifier
3 |
4 |
5 | class TestOffensiveLanguageClassifier:
6 | def test_init_default_model(self):
7 | classifier = OffensiveLanguageClassifier()
8 | assert classifier.model is not None
9 |
10 | def test_init_logistic_model(self):
11 | classifier = OffensiveLanguageClassifier(model="logistic")
12 | assert classifier.model is not None
13 |
14 | def test_init_logistic_model_uppercase(self):
15 | classifier = OffensiveLanguageClassifier(model="LOGISTIC")
16 | assert classifier.model is not None
17 |
18 | def test_init_invalid_model(self):
19 | with pytest.raises(ValueError, match="Unknown model 'invalid'"):
20 | OffensiveLanguageClassifier(model="invalid")
21 |
22 | def test_init_with_model_path(self):
23 | classifier = OffensiveLanguageClassifier(model_path="/path/to/model")
24 | assert classifier.model is not None
25 |
26 | def test_transform_persian_clean_text(self):
27 | classifier = OffensiveLanguageClassifier()
28 | result = classifier.transform("زبان فارسی میهن من است!")
29 | assert isinstance(result, tuple)
30 |
31 | def test_transform_persian_offensive_text(self):
32 | classifier = OffensiveLanguageClassifier()
33 | result = classifier.transform("تو خیلی احمق و بیشرفی!")
34 | assert isinstance(result, tuple)
35 |
36 | def test_callable_interface(self):
37 | classifier = OffensiveLanguageClassifier()
38 | result = classifier("زبان فارسی میهن من است!")
39 | assert isinstance(result, tuple)
40 |
--------------------------------------------------------------------------------
/docs/en/tutorials/pos.md:
--------------------------------------------------------------------------------
1 | # Part-of-Speech Tagging
2 |
3 | [](examples/pos_tagging.ipynb) [](https://colab.research.google.com/github/amirivojdan/shekar/blob/main/examples/pos_tagging.ipynb)
4 |
5 | Part-of-Speech (POS) tagging assigns a grammatical tag to each word in a sentence. The `POSTagger` class in Shekar uses a transformer-based model (default: **ALBERT**) to generate POS tags based on the **Universal Dependencies (UD) standard**.
6 |
7 | Each word is assigned a single tag, such as `NOUN`, `VERB`, or `ADJ`, enabling downstream tasks like syntactic parsing, chunking, and information extraction.
8 |
9 | **Features**
10 |
11 | - **Transformer-based model** for high accuracy
12 | - **Universal POS tags** following the UD standard
13 | - Easy-to-use Python interface
14 |
15 | **Example Usage**
16 |
17 | ```python
18 | from shekar import POSTagger
19 |
20 | # Initialize the POS tagger
21 | pos_tagger = POSTagger()
22 |
23 | text = "نوروز، جشن سال نو ایرانی، بیش از سه هزار سال قدمت دارد و در کشورهای مختلف جشن گرفته میشود."
24 |
25 | # Get POS tags
26 | result = pos_tagger(text)
27 |
28 | # Print each word with its tag
29 | for word, tag in result:
30 | print(f"{word}: {tag}")
31 | ```
32 |
33 | ```shell
34 | نوروز: PROPN
35 | ،: PUNCT
36 | جشن: NOUN
37 | سال: NOUN
38 | نو: ADJ
39 | ایرانی: ADJ
40 | ،: PUNCT
41 | بیش: ADJ
42 | از: ADP
43 | سه: NUM
44 | هزار: NUM
45 | سال: NOUN
46 | قدمت: NOUN
47 | دارد: VERB
48 | و: CCONJ
49 | در: ADP
50 | کشورهای: NOUN
51 | مختلف: ADJ
52 | جشن: NOUN
53 | گرفته: VERB
54 | میشود: VERB
55 | .: PUNCT
56 | ```
--------------------------------------------------------------------------------
/tests/unit/tokenization/test_base_tokenizer.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.tokenization import (
3 | Tokenizer,
4 | WordTokenizer,
5 | SentenceTokenizer,
6 | AlbertTokenizer,
7 | )
8 | import collections.abc
9 |
10 |
11 | def test_tokenizer_default_model_is_word():
12 | tokenizer = Tokenizer()
13 | assert isinstance(tokenizer.model, WordTokenizer)
14 |
15 |
16 | def test_tokenizer_initializes_correct_model():
17 | assert isinstance(Tokenizer("word").model, WordTokenizer)
18 | assert isinstance(Tokenizer("sentence").model, SentenceTokenizer)
19 | assert isinstance(Tokenizer("albert").model, AlbertTokenizer)
20 |
21 |
22 | def test_tokenizer_invalid_model_raises():
23 | with pytest.raises(ValueError, match="Unknown tokenizer model 'foobar'"):
24 | Tokenizer("foobar")
25 |
26 |
27 | @pytest.mark.parametrize("model_name", ["word", "sentence", "albert"])
28 | def test_tokenizer_transform_returns_expected_type(model_name):
29 | tokenizer = Tokenizer(model_name)
30 | text = "سلام دنیا. من علی هستم."
31 |
32 | output = tokenizer.transform(text)
33 |
34 | if model_name == "albert":
35 | assert isinstance(output, dict)
36 | assert {"input_ids", "attention_mask", "token_type_ids"} <= output.keys()
37 | else:
38 | assert isinstance(output, collections.abc.Iterable)
39 | output_list = list(output)
40 | assert all(isinstance(t, str) for t in output_list)
41 |
42 |
43 | @pytest.mark.parametrize("model_name", ["word", "sentence", "albert"])
44 | def test_tokenizer_fit_delegation(model_name):
45 | tokenizer = Tokenizer(model_name)
46 | assert tokenizer.fit(["test sentence"]) is tokenizer.model
47 |
--------------------------------------------------------------------------------
/shekar/sentiment_analysis/base.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from .albert_sentiment_binary import AlbertBinarySentimentClassifier
3 |
4 | SENTIMENT_REGISTRY = {
5 | "albert-binary": AlbertBinarySentimentClassifier,
6 | }
7 |
8 |
9 | class SentimentClassifier(BaseTransform):
10 | """A wrapper class for sentiment analysis models.
11 | Currently, it supports only the "albert-binary" model.
12 | Args:
13 | model (str): The sentiment analysis model to use. Default is "albert-binary".
14 | model_path (str, optional): Path to a custom model file. If None, the default model will be used.
15 | """
16 |
17 | def __init__(self, model: str = "albert-binary", model_path=None):
18 | model = model.lower()
19 | if model not in SENTIMENT_REGISTRY:
20 | raise ValueError(
21 | f"Unknown sentiment model '{model}'. Available: {list(SENTIMENT_REGISTRY.keys())}"
22 | )
23 |
24 | self.model = SENTIMENT_REGISTRY[model](model_path=model_path)
25 |
26 | def transform(self, X: str) -> tuple:
27 | """Perform sentiment analysis on the input text.
28 | Args:
29 | X (str): Input text.
30 | Returns:
31 | tuple: A tuple containing the predicted sentiment label and its confidence score.
32 |
33 | Example:
34 | >>> model = AlbertBinarySentimentClassifier()
35 | >>> model.transform("فیلم ۳۰۰ افتضاح بود.")
36 | ('negative', 0.998765468120575)
37 | >>> model.transform("سریال قصههای مجید عالی بود!")
38 | ('positive', 0.9976541996002197)
39 | """
40 | return self.model.transform(X)
41 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/hashtag_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class HashtagMasker(BaseTextTransform):
5 | """
6 | A text transformation class for removing hashtags from the text.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to identify
9 | and remove hashtags from the text. It ensures a clean representation of the text by
10 | eliminating all hashtags.
11 |
12 | The `HashtagMasker` class includes `fit` and `fit_transform` methods, and it
13 | is callable, allowing direct application to text data.
14 |
15 | Methods:
16 |
17 | fit(X, y=None):
18 | Fits the transformer to the input data.
19 | transform(X, y=None):
20 | Transforms the input data by removing hashtags.
21 | fit_transform(X, y=None):
22 | Fits the transformer to the input data and applies the transformation.
23 |
24 | __call__(text: str) -> str:
25 | Allows the class to be called as a function, applying the transformation
26 | to the input text.
27 |
28 | Example:
29 | >>> hashtag_masker = HashtagMasker()
30 | >>> cleaned_text = hashtag_masker("#سلام #خوش_آمدید")
31 | >>> print(cleaned_text)
32 | "سلام خوش_آمدید"
33 | """
34 |
35 | def __init__(self, mask_token: str = " "):
36 | super().__init__()
37 | self._hashtag_mappings = [
38 | (r"#([^\s]+)", mask_token),
39 | ]
40 |
41 | self._patterns = self._compile_patterns(self._hashtag_mappings)
42 |
43 | def _function(self, text: str) -> str:
44 | return self._map_patterns(text, self._patterns).strip()
45 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/mention_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class MentionMasker(BaseTextTransform):
5 | """
6 | A text transformation class for removing mentions from the text.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to identify
9 | and remove mentions from the text. It ensures a clean representation of the text by
10 | eliminating all mentions.
11 |
12 | The `MentionMasker` class includes `fit` and `fit_transform` methods, and it
13 | is callable, allowing direct application to text data.
14 |
15 | Methods:
16 |
17 | fit(X, y=None):
18 | Fits the transformer to the input data.
19 | transform(X, y=None):
20 | Transforms the input data by removing mentions.
21 | fit_transform(X, y=None):
22 | Fits the transformer to the input data and applies the transformation.
23 |
24 | __call__(text: str) -> str:
25 | Allows the class to be called as a function, applying the transformation
26 | to the input text.
27 |
28 | Example:
29 | >>> mention_masker = MentionMasker()
30 | >>> cleaned_text = mention_masker("سلام @user! چطوری؟")
31 | >>> print(cleaned_text)
32 | "سلام ! چطوری؟"
33 | """
34 |
35 | def __init__(self, mask_token: str = " "):
36 | super().__init__()
37 | self._mention_mappings = [
38 | (r"@([^\s]+)", mask_token),
39 | ]
40 |
41 | self._patterns = self._compile_patterns(self._mention_mappings)
42 |
43 | def _function(self, text: str) -> str:
44 | return self._map_patterns(text, self._patterns).strip()
45 |
--------------------------------------------------------------------------------
/shekar/tokenization/word_tokenizer.py:
--------------------------------------------------------------------------------
1 | import re
2 | from typing import Iterable
3 | from shekar import data, BaseTextTransform
4 |
5 |
6 | class WordTokenizer(BaseTextTransform):
7 | """
8 | A class used to tokenize text into words based on spaces and punctuation marks.
9 | Methods:
10 | tokenize(text: str) -> List[str]: Tokenizes the input text into a list of words.
11 | Example:
12 | >>> tokenizer = WordTokenizer()
13 | >>> text = "چه سیبهای قشنگی! حیات نشئه تنهایی است."
14 | >>> tokenizer.tokenize(text)
15 | ['چه', 'سیبهای', 'قشنگی', '!', 'حیات', 'نشئه', 'تنهایی', 'است', '.']
16 | """
17 |
18 | def __init__(self):
19 | super().__init__()
20 | self.pattern = re.compile(rf"([{re.escape(data.punctuations)}])|\s+")
21 |
22 | def tokenize(self, text: str) -> Iterable[str]:
23 | """
24 | Tokenizes the input text into a list of words, keeping punctuations as separate tokens.
25 |
26 | Args:
27 | text (str): The input text to be tokenized.
28 |
29 | Returns:
30 | Iterable[str]: A Iterable of tokenized words and punctuations.
31 | """
32 | return self._function(text)
33 |
34 | def _function(self, text: str) -> Iterable[str]:
35 | """
36 | Tokenizes the input text into a list of words, keeping punctuations as separate tokens.
37 |
38 | Args:
39 | text (str): The input text to be tokenized.
40 |
41 | Returns:
42 | List[str]: A list of tokenized words and punctuations.
43 | """
44 | tokens = self.pattern.split(text)
45 | return (token for token in tokens if token and not token.isspace())
46 |
--------------------------------------------------------------------------------
/lab/train_fasttext_gensim.py:
--------------------------------------------------------------------------------
1 | from pprint import pprint as print
2 | from gensim.models.fasttext import FastText
3 | import multiprocessing
4 | from shekar import Normalizer
5 | from shekar.tokenization import WordTokenizer, SentenceTokenizer
6 | from datasets import load_dataset
7 |
8 | hf_dataset = "SLPL/naab"
9 |
10 | class DatasetIter:
11 | def __init__(self, hf_dataset):
12 |
13 | self.word_tokenizer = WordTokenizer()
14 | self.sentence_tokenizer = SentenceTokenizer()
15 | self.normalizer = Normalizer()
16 | self.dataset = load_dataset(hf_dataset, split="train")
17 |
18 | def __iter__(self):
19 | for example in self.dataset:
20 | text = self.normalizer(example["text"])
21 | sentences = self.sentence_tokenizer(text)
22 | for sentence in sentences:
23 | words = self.word_tokenizer(sentence)
24 | yield [word for word in words]
25 |
26 | dataset_iter = DatasetIter(hf_dataset)
27 |
28 | cpu_count = multiprocessing.cpu_count()
29 | print(f"CPU count: {cpu_count}")
30 |
31 | d=300
32 | w=10
33 | vs=250
34 | ds= hf_dataset.split("/")[-1]
35 | model_type = "cbow"
36 |
37 | model = FastText(vector_size=d,
38 | window=w,
39 | sorted_vocab=1,
40 | max_final_vocab=vs*1000,
41 | workers=cpu_count-10,
42 | sg=0 if model_type == "cbow" else 1,
43 | epochs=3)
44 |
45 | model.build_vocab(corpus_iterable=dataset_iter, progress_per=10000)
46 | print(f"Vocabulary size: {len(model.wv)}")
47 |
48 | model.train(corpus_iterable=dataset_iter, total_examples=model.corpus_count, epochs=model.epochs)
49 | model.save(f"fasttext_d{d}_w{w}_v{vs}k_{model_type}_{ds}.model")
--------------------------------------------------------------------------------
/.github/workflows/test.yml:
--------------------------------------------------------------------------------
1 | name: Test
2 | on: push
3 | jobs:
4 | test:
5 | runs-on: ${{ matrix.os }}
6 | strategy:
7 | matrix:
8 | os: [ubuntu-latest, windows-latest, macos-latest]
9 | python-version: ["3.10", "3.11", "3.12", "3.13"]
10 | steps:
11 | - name: Checkout
12 | uses: actions/checkout@v4
13 |
14 | - name: Set up Python ${{ matrix.python-version }}
15 | uses: actions/setup-python@v5
16 | with:
17 | python-version: ${{ matrix.python-version }}
18 |
19 | - name: Setup uv
20 | uses: astral-sh/setup-uv@v4
21 | with:
22 | version: "0.4.15"
23 | enable-cache: true
24 | cache-dependency-glob: |
25 | requirements**.txt
26 | pyproject.toml
27 |
28 | - name: setup venv
29 | run: uv venv
30 |
31 | - name: Upgrade hatch
32 | run: uv pip install --upgrade hatch hatchling
33 |
34 | - name: Install all dependencies
35 | run: uv pip install -e ".[all]"
36 |
37 | - name: Install base + dev dependencies
38 | run: uv pip install -e ".[dev]"
39 |
40 | - name: Install Ruff
41 | run: uv pip install ruff
42 |
43 | - name: Run Ruff Format Check
44 | run: uv run ruff format shekar tests --check --diff
45 |
46 | - name: Run Ruff Lint
47 | run: uv run ruff check shekar tests
48 |
49 | - name: Install Pytest
50 | run: uv pip install pytest pytest-cov
51 |
52 | - name: Run Tests
53 | run: uv run pytest --cov --cov-branch --cov-report=xml
54 |
55 | - name: Upload results to Codecov
56 | uses: codecov/codecov-action@v5
57 | with:
58 | token: ${{ secrets.CODECOV_TOKEN }}
59 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/digit_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 | from shekar import data
3 |
4 |
5 | class DigitMasker(BaseTextTransform):
6 | """
7 | A text transformation class for filtering numbers from the text.
8 |
9 | This class inherits from `BaseTextTransform` and provides functionality to remove or replace
10 | all numeric characters from the text. It uses predefined mappings to eliminate
11 | Arabic, English, and other Unicode numbers, ensuring a clean and normalized text representation.
12 |
13 | The `DigitMasker` class includes `fit` and `fit_transform` methods, and it
14 | is callable, allowing direct application to text data.
15 |
16 | Methods:
17 |
18 | fit(X, y=None):
19 | Fits the transformer to the input data.
20 | transform(X, y=None):
21 | Transforms the input data by removing numbers.
22 | fit_transform(X, y=None):
23 | Fits the transformer to the input data and applies the transformation.
24 |
25 | __call__(text: str) -> str:
26 | Allows the class to be called as a function, applying the transformation
27 | to the input text.
28 |
29 | Example:
30 | >>> digit_masker = DigitMasker()
31 | >>> cleaned_text = digit_masker("این متن 1234 شامل اعداد است.")
32 | >>> print(cleaned_text)
33 | "این متن شامل اعداد است."
34 | """
35 |
36 | def __init__(self, mask_token: str = ""):
37 | super().__init__()
38 | self._number_mappings = [
39 | (rf"[{data.numbers}]", mask_token),
40 | ]
41 |
42 | self._patterns = self._compile_patterns(self._number_mappings)
43 |
44 | def _function(self, text: str) -> str:
45 | return self._map_patterns(text, self._patterns).strip()
46 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/diacritic_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 | from shekar import data
3 |
4 |
5 | class DiacriticMasker(BaseTextTransform):
6 | """
7 | A text transformation class for removing Arabic diacritics from the text.
8 |
9 | This class inherits from `BaseTextTransform` and provides functionality to remove
10 | Arabic diacritics from the text. It uses predefined mappings to eliminate diacritics
11 | such as "َ", "ً", "ُ", and others, ensuring a clean and normalized text representation.
12 |
13 | The `DiacriticMasker` class includes `fit` and `fit_transform` methods, and it
14 | is callable, allowing direct application to text data.
15 |
16 | Methods:
17 |
18 | fit(X, y=None):
19 | Fits the transformer to the input data.
20 | transform(X, y=None):
21 | Transforms the input data by removing diacritics.
22 | fit_transform(X, y=None):
23 | Fits the transformer to the input data and applies the transformation.
24 |
25 | __call__(text: str) -> str:
26 | Allows the class to be called as a function, applying the transformation
27 | to the input text.
28 |
29 | Example:
30 | >>> diacritic_masker = DiacriticMasker()
31 | >>> cleaned_text = diacritic_masker("کُجا نِشانِ قَدَم ناتَمام خواهَد ماند؟")
32 | >>> print(cleaned_text)
33 | "کجا نشان قدم ناتمام خواهد ماند؟"
34 | """
35 |
36 | def __init__(self):
37 | super().__init__()
38 | self._diacritic_mappings = [
39 | (rf"[{data.diacritics}]", ""),
40 | ]
41 |
42 | self._patterns = self._compile_patterns(self._diacritic_mappings)
43 |
44 | def _function(self, text: str) -> str:
45 | return self._map_patterns(text, self._patterns).strip()
46 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/html_tag_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 | import html
3 |
4 |
5 | class HTMLTagMasker(BaseTextTransform):
6 | """
7 | A text transformation class for removing HTML tags and entities from the text.
8 |
9 | This class inherits from `BaseTextTransform` and provides functionality to identify
10 | and remove HTML tags and entities from the text. It ensures a clean and tag-free
11 | representation of the text by unescaping HTML entities and removing all HTML tags.
12 |
13 | The `HTMLTagMasker` class includes `fit` and `fit_transform` methods, and it
14 | is callable, allowing direct application to text data.
15 |
16 | Methods:
17 |
18 | fit(X, y=None):
19 | Fits the transformer to the input data.
20 | transform(X, y=None):
21 | Transforms the input data by removing HTML tags and entities.
22 | fit_transform(X, y=None):
23 | Fits the transformer to the input data and applies the transformation.
24 |
25 | __call__(text: str) -> str:
26 | Allows the class to be called as a function, applying the transformation
27 | to the input text.
28 |
29 | Example:
30 | >>> html_tag_masker = HTMLTagMasker()
31 | >>> cleaned_text = html_tag_masker("این یک متن نمونه است.
")
32 | >>> print(cleaned_text)
33 | "این یک متن نمونه است."
34 | """
35 |
36 | def __init__(self, mask_token: str = " "):
37 | super().__init__()
38 | self._html_tag_mappings = [
39 | (r"<[^>]+>", mask_token),
40 | ]
41 |
42 | self._patterns = self._compile_patterns(self._html_tag_mappings)
43 |
44 | def _function(self, text: str) -> str:
45 | text = html.unescape(text)
46 | return self._map_patterns(text, self._patterns).strip()
47 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/url_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class URLMasker(BaseTextTransform):
5 | """
6 | A text transformation class for masking URLs in the text.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to identify
9 | and mask URLs in the text. It replaces URLs with a specified mask, ensuring privacy
10 | and anonymization of sensitive information.
11 |
12 | The `URLMasker` class includes `fit` and `fit_transform` methods, and it
13 | is callable, allowing direct application to text data.
14 |
15 | Args:
16 | mask (str): The mask to replace the URLs with. Default is "".
17 |
18 | Methods:
19 |
20 | fit(X, y=None):
21 | Fits the transformer to the input data.
22 | transform(X, y=None):
23 | Transforms the input data by masking URLs.
24 | fit_transform(X, y=None):
25 | Fits the transformer to the input data and applies the transformation.
26 |
27 | __call__(text: str) -> str:
28 | Allows the class to be called as a function, applying the transformation
29 | to the input text.
30 | Example:
31 | >>> url_masker = URLMasker(mask="")
32 | >>> masked_text = url_masker("برای اطلاعات بیشتر به https://shekar.io مراجعه کنید.")
33 | >>> print(masked_text)
34 | "برای اطلاعات بیشتر به مراجعه کنید."
35 | """
36 |
37 | def __init__(self, mask_token: str = ""):
38 | super().__init__()
39 | self._mask_token = mask_token
40 | self._url_mappings = [
41 | (r"(https?://[^\s]+)", self._mask_token),
42 | ]
43 | self._patterns = self._compile_patterns(self._url_mappings)
44 |
45 | def _function(self, text: str) -> str:
46 | return self._map_patterns(text, self._patterns).strip()
47 |
--------------------------------------------------------------------------------
/docs/en/tutorials/visualization.md:
--------------------------------------------------------------------------------
1 | # Visualization
2 |
3 | ## WordCloud
4 |
5 | [](examples/word_cloud.ipynb) [](https://colab.research.google.com/github/amirivojdan/shekar/blob/main/examples/word_cloud.ipynb)
6 |
7 |
8 | The `WordCloud` class in Shekar provides a simple and customizable way to generate visually rich Persian word clouds. It supports right-to-left rendering, Persian fonts, custom shape masks, and color maps for elegant and accurate visualization of word frequencies.
9 |
10 | **Example Usage**
11 |
12 | ```python
13 | import requests
14 | from collections import Counter
15 |
16 | from shekar import WordCloud
17 | from shekar import WordTokenizer
18 | from shekar.preprocessing import (
19 | HTMLTagRemover,
20 | PunctuationRemover,
21 | StopWordRemover,
22 | NonPersianRemover,
23 | )
24 | preprocessing_pipeline = HTMLTagRemover() | PunctuationRemover() | StopWordRemover() | NonPersianRemover()
25 |
26 |
27 | url = f"https://ganjoor.net/ferdousi/shahname/siavosh/sh9"
28 | response = requests.get(url)
29 | html_content = response.text
30 | clean_text = preprocessing_pipeline(html_content)
31 |
32 | word_tokenizer = WordTokenizer()
33 | tokens = word_tokenizer(clean_text)
34 |
35 | word_freqs = Counter(tokens)
36 |
37 | wordCloud = WordCloud(
38 | mask="Iran",
39 | width=1000,
40 | height=500,
41 | max_font_size=220,
42 | min_font_size=5,
43 | bg_color="white",
44 | contour_color="black",
45 | contour_width=3,
46 | color_map="Set2",
47 | )
48 |
49 | # if shows disconnect words, try again with bidi_reshape=True
50 | image = wordCloud.generate(word_freqs, bidi_reshape=False)
51 | image.show()
52 | ```
53 |
54 | 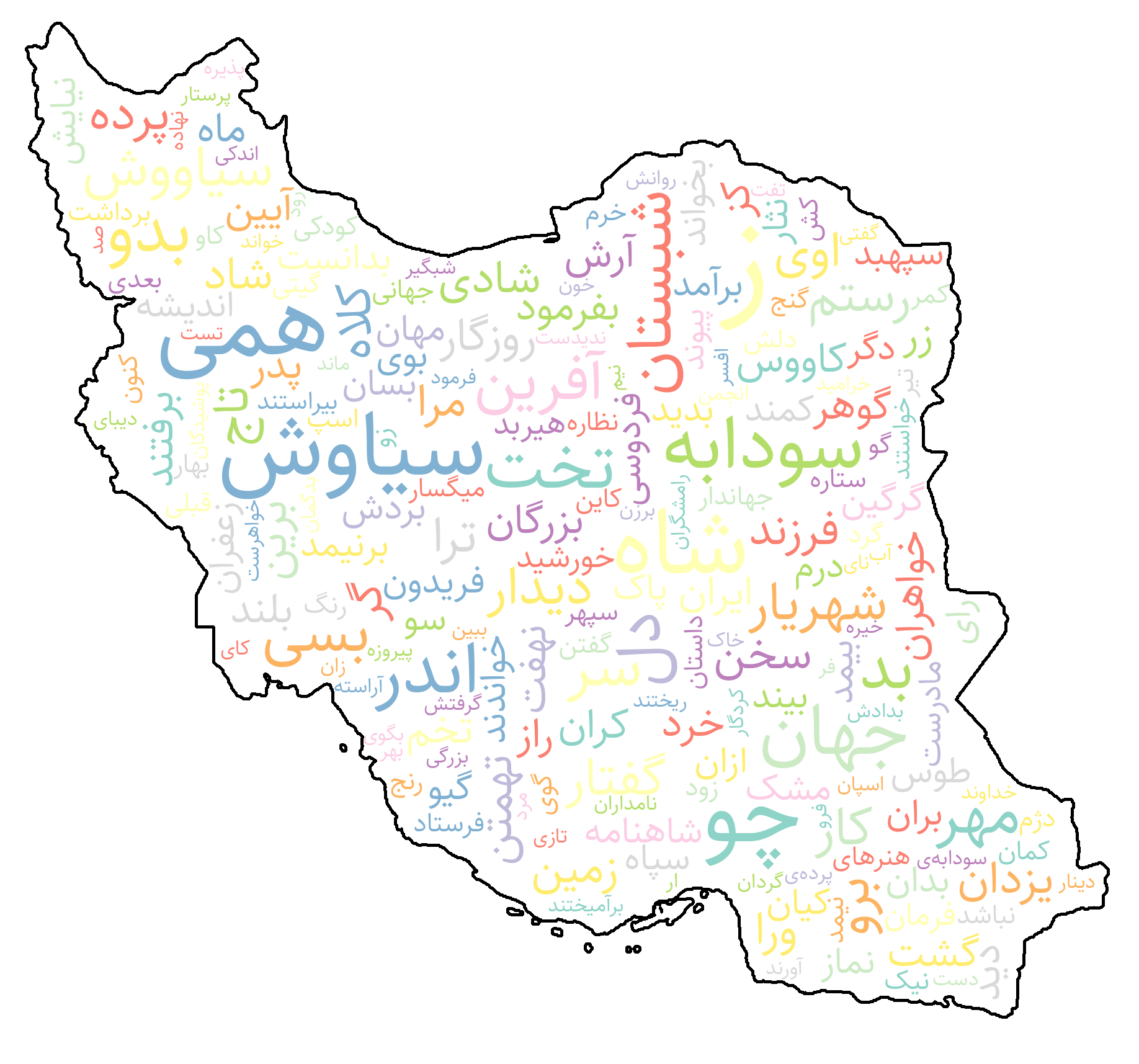
--------------------------------------------------------------------------------
/shekar/preprocessing/normalizers/repeated_letter_normalizer.py:
--------------------------------------------------------------------------------
1 | from shekar import BaseTextTransform
2 |
3 |
4 | class RepeatedLetterNormalizer(BaseTextTransform):
5 | """
6 | A text transformation class for removing redundant characters from the text.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to identify
9 | and remove redundant characters from the text. It removes more than two repeated letters
10 | and eliminates every keshida (ـ) from the text, ensuring a clean and normalized representation.
11 |
12 | The `RedundantCharacterRemover` class includes `fit` and `fit_transform` methods, and it
13 | is callable, allowing direct application to text data.
14 |
15 | Methods:
16 |
17 | fit(X, y=None):
18 | Fits the transformer to the input data.
19 | transform(X, y=None):
20 | Transforms the input data by removing redundant characters.
21 | fit_transform(X, y=None):
22 | Fits the transformer to the input data and applies the transformation.
23 |
24 | __call__(text: str) -> str:
25 | Allows the class to be called as a function, applying the transformation
26 | to the input text.
27 |
28 | Example:
29 | >>> redundant_char_remover = RedundantCharacterRemover()
30 | >>> cleaned_text = redundant_char_remover("اینــــجاااا یکــــــ متنــــــ نمونه است.")
31 | >>> print(cleaned_text)
32 | "اینجاا یک متن نمونه است."
33 | """
34 |
35 | def __init__(self):
36 | super().__init__()
37 | self._redundant_mappings = [
38 | (r"[ـ]", ""), # remove keshida
39 | (r"([^\s])\1{2,}", r"\1\1"), # remove more than two repeated letters
40 | ]
41 |
42 | self._patterns = self._compile_patterns(self._redundant_mappings)
43 |
44 | def _function(self, text: str) -> str:
45 | return self._map_patterns(text, self._patterns).strip()
46 |
--------------------------------------------------------------------------------
/examples/pos_tagging.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "id": "752b5183",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "!pip install shekar"
11 | ]
12 | },
13 | {
14 | "cell_type": "code",
15 | "execution_count": 1,
16 | "id": "f97522ed",
17 | "metadata": {},
18 | "outputs": [
19 | {
20 | "name": "stdout",
21 | "output_type": "stream",
22 | "text": [
23 | "نوروز: PROPN\n",
24 | "،: PUNCT\n",
25 | "جشن: NOUN\n",
26 | "سال: NOUN\n",
27 | "نو: ADJ\n",
28 | "ایرانی: ADJ\n",
29 | "،: PUNCT\n",
30 | "بیش: ADJ\n",
31 | "از: ADP\n",
32 | "سه: NUM\n",
33 | "هزار: NUM\n",
34 | "سال: NOUN\n",
35 | "قدمت: NOUN\n",
36 | "دارد: VERB\n",
37 | "و: CCONJ\n",
38 | "در: ADP\n",
39 | "کشورهای: NOUN\n",
40 | "مختلف: ADJ\n",
41 | "جشن: NOUN\n",
42 | "گرفته: VERB\n",
43 | "میشود: VERB\n",
44 | ".: PUNCT\n"
45 | ]
46 | }
47 | ],
48 | "source": [
49 | "from shekar import POSTagger\n",
50 | "\n",
51 | "pos_tagger = POSTagger()\n",
52 | "text = \"نوروز، جشن سال نو ایرانی، بیش از سه هزار سال قدمت دارد و در کشورهای مختلف جشن گرفته میشود.\"\n",
53 | "\n",
54 | "result = pos_tagger(text)\n",
55 | "for word, tag in result:\n",
56 | " print(f\"{word}: {tag}\")"
57 | ]
58 | }
59 | ],
60 | "metadata": {
61 | "kernelspec": {
62 | "display_name": "shekar",
63 | "language": "python",
64 | "name": "python3"
65 | },
66 | "language_info": {
67 | "codemirror_mode": {
68 | "name": "ipython",
69 | "version": 3
70 | },
71 | "file_extension": ".py",
72 | "mimetype": "text/x-python",
73 | "name": "python",
74 | "nbconvert_exporter": "python",
75 | "pygments_lexer": "ipython3",
76 | "version": "3.10.16"
77 | }
78 | },
79 | "nbformat": 4,
80 | "nbformat_minor": 5
81 | }
82 |
--------------------------------------------------------------------------------
/shekar/tokenization/sentence_tokenizer.py:
--------------------------------------------------------------------------------
1 | import re
2 | from typing import Iterable
3 | from shekar import data, BaseTextTransform
4 |
5 |
6 | class SentenceTokenizer(BaseTextTransform):
7 | """
8 | A class used to tokenize text into sentences based on punctuation marks.
9 | Attributes:
10 | pattern (Pattern): A compiled regular expression pattern used to identify sentence-ending punctuation.
11 | Methods:
12 | tokenize(text: str) -> List[str]: Tokenizes the input text into a list of sentences.
13 | Example:
14 | >>> tokenizer = SentenceTokenizer()
15 | >>> text = "چه سیبهای قشنگی! حیات نشئه تنهایی است."
16 | >>> tokenizer.tokenize(text)
17 | ['.چه سیبهای قشنگی!', 'حیات نشئه تنهایی است']
18 | """
19 |
20 | def __init__(self):
21 | super().__init__()
22 | self.pattern = re.compile(
23 | f"([{re.escape(data.end_sentence_punctuations)}]+)", re.UNICODE
24 | )
25 |
26 | def _function(self, text: str) -> Iterable[str]:
27 | """
28 | Tokenizes the input text into a list of sentences.
29 |
30 | Args:
31 | text (str): The input text to be tokenized.
32 |
33 | Returns:
34 | List[str]: A list of tokenized sentences.
35 | """
36 |
37 | tokens = self.pattern.split(text)
38 | for i in range(0, len(tokens) - 1, 2):
39 | if tokens[i].strip() or tokens[i + 1].strip():
40 | yield tokens[i].strip() + tokens[i + 1].strip()
41 | if len(tokens) % 2 == 1 and tokens[-1].strip():
42 | yield tokens[-1].strip()
43 |
44 | def tokenize(self, text: str) -> Iterable[str]:
45 | """
46 | Tokenizes the input text into a list of sentences.
47 |
48 | Args:
49 | text (str): The input text to be tokenized.
50 |
51 | Returns:
52 | List[str]: A list of tokenized sentences.
53 | """
54 | return self._function(text)
55 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/email_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class EmailMasker(BaseTextTransform):
5 | """
6 | A text transformation class for masking email addresses in the text.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to identify
9 | and mask email addresses in the text. It replaces email addresses with a specified
10 | mask, ensuring privacy and anonymization of sensitive information.
11 |
12 | The `EmailMasker` class includes `fit` and `fit_transform` methods, and it
13 | is callable, allowing direct application to text data.
14 |
15 | Args:
16 | mask (str): The mask to replace the email addresses with. Default is "".
17 |
18 | Methods:
19 |
20 | fit(X, y=None):
21 | Fits the transformer to the input data.
22 | transform(X, y=None):
23 | Transforms the input data by masking email addresses.
24 | fit_transform(X, y=None):
25 | Fits the transformer to the input data and applies the transformation.
26 |
27 | __call__(text: str) -> str:
28 | Allows the class to be called as a function, applying the transformation
29 | to the input text.
30 |
31 | Example:
32 | >>> email_masker = EmailMasker(mask="")
33 | >>> masked_text = email_masker("برای تماس با ما به info@shekar.io ایمیل بزنید.")
34 | >>> print(masked_text)
35 | "برای تماس با ما به ایمیل بزنید."
36 | """
37 |
38 | def __init__(self, mask_token: str = ""):
39 | super().__init__()
40 | self._mask_token = mask_token
41 | self._email_mappings = [
42 | (r"([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,})", self._mask_token),
43 | ]
44 | self._patterns = self._compile_patterns(self._email_mappings)
45 |
46 | def _function(self, text: str) -> str:
47 | return self._map_patterns(text, self._patterns).strip()
48 |
--------------------------------------------------------------------------------
/shekar/toxicity/logistic_offensive_classifier.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from shekar.hub import Hub
3 | from pathlib import Path
4 | import onnxruntime
5 | import numpy as np
6 | from shekar.utils import get_onnx_providers
7 | from shekar.preprocessing import StopWordRemover
8 |
9 |
10 | class LogisticOffensiveClassifier(BaseTransform):
11 | """Logistic model for offensive language detection.
12 | This model is trained on Naseza(ناسزا) Persian offensive language dataset.
13 | Args:
14 | model_path (str | Path, optional): Path to a custom model file. If None, the default model will be used.
15 |
16 | Example:
17 | >>> model = LogisticOffensiveClassifier()
18 | >>> model.transform("این یک متن معمولی است.")
19 | ('neutral', 0.987654321)
20 | >>> model.transform("تو خیلی احمق و بیشرفی!")
21 | ('offensive', 0.9987654321)
22 | """
23 |
24 | def __init__(self, model_path: str | Path = None):
25 | super().__init__()
26 | resource_name = "tfidf_logistic_offensive.onnx"
27 | if model_path is None or not Path(model_path).exists():
28 | model_path = Hub.get_resource(file_name=resource_name)
29 |
30 | self.session = onnxruntime.InferenceSession(
31 | model_path, providers=get_onnx_providers()
32 | )
33 |
34 | self.id2label = {0: "neutral", 1: "offensive"}
35 | self.stopword_remover = StopWordRemover()
36 |
37 | def transform(self, X: str) -> tuple:
38 | X = self.stopword_remover(X)
39 |
40 | in_name = self.session.get_inputs()[0].name
41 | out_names = [o.name for o in self.session.get_outputs()]
42 | arr = np.array([[X]], dtype=object)
43 | onnx_label, onnx_proba = self.session.run(out_names, {in_name: arr})
44 |
45 | if onnx_proba.ndim != 2:
46 | onnx_label, onnx_proba = onnx_proba, onnx_label
47 |
48 | return (self.id2label[onnx_label[0]], float(onnx_proba[0][onnx_label[0]]))
49 |
--------------------------------------------------------------------------------
/tests/unit/spelling/test_statistical_checker.py:
--------------------------------------------------------------------------------
1 | from collections import Counter
2 | from shekar.spelling.statistical_checker import StatisticalSpellChecker
3 |
4 |
5 | def test_generate_1edits_has_reasonable_variants():
6 | word = "کتاب"
7 | edits = StatisticalSpellChecker.generate_1edits(word)
8 | assert isinstance(edits, set)
9 | assert any(len(e) == len(word) for e in edits) # replacements or transposes
10 | assert any(len(e) == len(word) - 1 for e in edits) # deletions
11 | assert any(len(e) == len(word) + 1 for e in edits) # insertions
12 |
13 |
14 | def test_generate_n_edits_expands_with_n():
15 | word = "کتاب"
16 | edits_1 = StatisticalSpellChecker.generate_n_edits(word, n=1)
17 | edits_2 = StatisticalSpellChecker.generate_n_edits(word, n=2)
18 | assert edits_2.issuperset(edits_1)
19 | assert len(edits_2) > len(edits_1)
20 |
21 |
22 | def test_correct_returns_known_word_if_exists():
23 | checker = StatisticalSpellChecker()
24 | assert checker.correct("سلام")[0] == "سلام"
25 |
26 |
27 | def test_correct_returns_best_match_for_misspelled_word():
28 | words = Counter({"سلام": 10, "سللم": 1})
29 | checker = StatisticalSpellChecker(words=words)
30 | suggestions = checker.correct("سلاا")
31 | assert isinstance(suggestions, list)
32 | assert "سلام" in suggestions
33 |
34 |
35 | def test_correct_text_with_mixed_words():
36 | words = Counter({"سلام": 5, "علیکم": 3, "دوست": 2})
37 | checker = StatisticalSpellChecker(words=words)
38 | text = "سلاام علیکم دوصت"
39 | corrected = checker.correct_text(text)
40 | assert "سلام" in corrected
41 | assert "علیکم" in corrected
42 | assert "دوست" in corrected
43 |
44 |
45 | def test_transform_applies_correction_to_sentence():
46 | checker = StatisticalSpellChecker()
47 | input_text = "سلاام بر شوم"
48 | corrected = checker.transform(input_text)
49 | assert isinstance(corrected, str)
50 | assert len(corrected.split()) == len(input_text.split())
51 |
--------------------------------------------------------------------------------
/docs/en/tutorials/tokenization.md:
--------------------------------------------------------------------------------
1 | # Tokenization
2 |
3 | Tokenization is the process of breaking down text into smaller units called tokens. These tokens can be sentences, words, or even characters. Tokenization is a crucial step in natural language processing (NLP) as it helps in understanding and analyzing the structure of the text. It is commonly used in text preprocessing for machine learning models, search engines, and text analysis tools.
4 |
5 | ## WordTokenizer
6 |
7 | The `WordTokenizer` class splits text into individual words and punctuation marks. It is useful for tasks such as part-of-speech tagging, keyword extraction, and any NLP pipeline where token-level analysis is required. The tokenizer handles Persian-specific punctuation, spacing, and diacritics to produce accurate token boundaries.
8 |
9 | Below is an example of how to use the `WordTokenizer`:
10 |
11 | ```python
12 | from shekar import WordTokenizer
13 |
14 | text = "چه سیبهای قشنگی! حیات نشئهٔ تنهایی است."
15 | tokenizer = WordTokenizer()
16 | tokens = tokenizer.tokenize(text)
17 |
18 | print(list(tokens))
19 | ```
20 |
21 | ```shell
22 | ['چه', 'سیبهای', 'قشنگی', '!', 'حیات', 'نشئهٔ', 'تنهایی', 'است', '.']
23 | ```
24 |
25 | ## SentenceTokenizer
26 |
27 | The `SentenceTokenizer` class is designed to split a given text into individual sentences. This class is particularly useful in natural language processing tasks where understanding the structure and meaning of sentences is important. The `SentenceTokenizer` class can handle various punctuation marks and language-specific rules to accurately identify sentence boundaries.
28 |
29 | Below is an example of how to use the `SentenceTokenizer`:
30 |
31 | ```python
32 | from shekar import SentenceTokenizer
33 |
34 | text = "هدف ما کمک به یکدیگر است! ما میتوانیم با هم کار کنیم."
35 | tokenizer = SentenceTokenizer()
36 | sentences = tokenizer(text)
37 |
38 | for sentence in sentences:
39 | print(sentence)
40 | ```
41 |
42 | ```shell
43 | هدف ما کمک به یکدیگر است!
44 | ما میتوانیم با هم کار کنیم.
45 | ```
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/emoji_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class EmojiMasker(BaseTextTransform):
5 | """
6 | A text transformation class for removing emojis from the text.
7 | This class inherits from `BaseTextTransform` and provides functionality to remove
8 | emojis from the text. It identifies and eliminates a wide range of emojis, ensuring a clean and emoji-free text representation.
9 | The `EmojiMasker` class includes `fit` and `fit_transform` methods, and it
10 | is callable, allowing direct application to text data.
11 |
12 | Methods:
13 |
14 | fit(X, y=None):
15 | Fits the transformer to the input data.
16 | transform(X, y=None):
17 | Transforms the input data by removing emojis.
18 | fit_transform(X, y=None):
19 | Fits the transformer to the input data and applies the transformation.
20 |
21 | __call__(text: str) -> str:
22 | Allows the class to be called as a function, applying the transformation
23 | to the input text.
24 |
25 | Example:
26 | >>> emoji_masker = EmojiMasker()
27 | >>> cleaned_text = emoji_masker("درود بر شما😊!🌟")
28 | >>> print(cleaned_text)
29 | "درود بر شما!"
30 | """
31 |
32 | def __init__(self, mask_token: str = ""):
33 | super().__init__()
34 | self._mask_token = mask_token
35 |
36 | self._emoji_mappings = [
37 | (
38 | r"(?:"
39 | r"\p{Extended_Pictographic}(?:\p{Emoji_Modifier})?(?:\uFE0F)?"
40 | r"(?:\u200D\p{Extended_Pictographic}(?:\p{Emoji_Modifier})?(?:\uFE0F)?)*"
41 | r"|"
42 | r"(?:\p{Regional_Indicator}{2})" # country flags
43 | r")",
44 | self._mask_token,
45 | ),
46 | ]
47 |
48 | self._patterns = self._compile_patterns(self._emoji_mappings)
49 |
50 | def _function(self, text: str) -> str:
51 | return self._map_patterns(text, self._patterns).strip()
52 |
--------------------------------------------------------------------------------
/docs/assets/overrides/partials/footer.html:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/shekar/embeddings/base.py:
--------------------------------------------------------------------------------
1 | from abc import abstractmethod
2 | from shekar.base import BaseTransform
3 | import numpy as np
4 |
5 |
6 | class BaseEmbedder(BaseTransform):
7 | def _cosine_similarity(self, vec1: np.ndarray, vec2: np.ndarray) -> float:
8 | """Calculate cosine similarity between two vectors.
9 | Args:
10 | vec1 (np.ndarray): First vector.
11 | vec2 (np.ndarray): Second vector.
12 | Returns:
13 | float: Cosine similarity between the two vectors.
14 | """
15 |
16 | if (
17 | vec1 is None
18 | or not isinstance(vec1, np.ndarray)
19 | or (vec2 is None or not isinstance(vec2, np.ndarray))
20 | ):
21 | return 0.0
22 |
23 | dot_product = np.dot(vec1, vec2)
24 | norm1 = np.linalg.norm(vec1)
25 | norm2 = np.linalg.norm(vec2)
26 |
27 | if norm1 == 0 or norm2 == 0:
28 | return 0.0
29 |
30 | return float(dot_product / (norm1 * norm2))
31 |
32 | @abstractmethod
33 | def embed(self, text: str) -> np.ndarray:
34 | """Embed a given text/token into a vector representation.
35 | Args:
36 | text (str): Input text to be embedded.
37 | Returns:
38 | np.ndarray: Vector representation of the input text.
39 | """
40 | pass
41 |
42 | def transform(self, X: str) -> np.ndarray:
43 | """Transform the input text into its embedded vector representation.
44 | Args:
45 | X (str): Input text to be transformed.
46 | Returns:
47 | np.ndarray: Embedded vector representation of the input text.
48 | """
49 | return self.embed(X)
50 |
51 | def similarity(self, text1: str, text2: str) -> float:
52 | """Calculate cosine similarity between two texts.
53 | Args:
54 | text1 (str): First text.
55 | text2 (str): Second text.
56 | Returns:
57 | float: Cosine similarity between the embeddings of the two texts.
58 | """
59 |
60 | vec1 = self.embed(text1)
61 | vec2 = self.embed(text2)
62 | return self._cosine_similarity(vec1, vec2)
63 |
--------------------------------------------------------------------------------
/shekar/preprocessing/normalizers/arabic_unicode_normalizer.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class ArabicUnicodeNormalizer(BaseTextTransform):
5 | """
6 | A text transformation class for normalizing special Arabic Unicode characters to their Persian equivalents.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to replace
9 | various special Arabic Unicode characters with their Persian equivalents. It uses predefined mappings
10 | to substitute characters such as "﷽", "﷼", and other Arabic ligatures with their standard Persian representations.
11 |
12 | The `ArabicUnicodeNormalizer` class includes `fit` and `fit_transform` methods, and it
13 | is callable, allowing direct application to text data.
14 |
15 | Methods:
16 |
17 | fit(X, y=None):
18 | Fits the transformer to the input data.
19 | transform(X, y=None):
20 | Transforms the input data by normalizing special Arabic Unicode characters.
21 | fit_transform(X, y=None):
22 | Fits the transformer to the input data and applies the transformation.
23 |
24 | __call__(text: str) -> str:
25 | Allows the class to be called as a function, applying the transformation
26 | to the input text.
27 |
28 | Example:
29 | >>> unicode_normalizer = ArabicUnicodeNormalizer()
30 | >>> normalized_text = unicode_normalizer("﷽ ﷼ ﷴ")
31 | >>> print(normalized_text)
32 | "بسم الله الرحمن الرحیم ریال محمد"
33 | """
34 |
35 | def __init__(self):
36 | super().__init__()
37 | self.unicode_mappings = [
38 | ("﷽", "بسم الله الرحمن الرحیم"),
39 | ("﷼", "ریال"),
40 | ("(ﷰ|ﷹ)", "صلی"),
41 | ("ﷲ", "الله"),
42 | ("ﷳ", "اکبر"),
43 | ("ﷴ", "محمد"),
44 | ("ﷵ", "صلعم"),
45 | ("ﷶ", "رسول"),
46 | ("ﷷ", "علیه"),
47 | ("ﷸ", "وسلم"),
48 | ("ﻵ|ﻶ|ﻷ|ﻸ|ﻹ|ﻺ|ﻻ|ﻼ", "لا"),
49 | ]
50 |
51 | self._patterns = self._compile_patterns(self.unicode_mappings)
52 |
53 | def _function(self, X, y=None):
54 | return self._map_patterns(X, self._patterns)
55 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/punctuation_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 | from shekar import data
3 | import re
4 | import string
5 |
6 |
7 | class PunctuationMasker(BaseTextTransform):
8 | """
9 | A text transformation class for filtering out specified punctuation characters from the text.
10 | This class inherits from `BaseTextTransform` and provides functionality to remove
11 | various punctuation symbols based on user-defined or default settings. It uses regular
12 | expressions to identify and replace specified punctuation characters with a given replacement string.
13 | The `PunctuationMasker` class includes `fit` and `fit_transform` methods, and it
14 | is callable, allowing direct application to text data.
15 | Methods:
16 |
17 | fit(X, y=None):
18 | Fits the transformer to the input data.
19 | transform(X, y=None):
20 | Transforms the input data by filtering out specified punctuation characters.
21 | fit_transform(X, y=None):
22 | Fits the transformer to the input data and applies the transformation.
23 |
24 | __call__(text: str) -> str:
25 | Allows the class to be called as a function, applying the transformation
26 | to the input text.
27 | Example:
28 | >>> punctuation_masker = PunctuationMasker()
29 | >>> filtered_text = punctuation_masker("دریغ است ایران که ویران شود!")
30 | >>> print(filtered_text)
31 | "دریغ است ایران که ویران شود"
32 | """
33 |
34 | def __init__(self, punctuations: str | None = None, mask_token: str = ""):
35 | super().__init__()
36 | if not punctuations:
37 | self._punctuation_mappings = [
38 | (rf"[{re.escape(data.punctuations)}]", mask_token),
39 | (rf"[{re.escape(string.punctuation)}]", mask_token),
40 | ]
41 |
42 | else:
43 | self._punctuation_mappings = [
44 | (rf"[{re.escape(punctuations)}]", mask_token),
45 | ]
46 |
47 | self._patterns = self._compile_patterns(self._punctuation_mappings)
48 |
49 | def _function(self, text: str) -> str:
50 | return self._map_patterns(text, self._patterns).strip()
51 |
--------------------------------------------------------------------------------
/tests/unit/pos/test_base_pos.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from unittest.mock import patch
3 | from shekar.pos.albert_pos import AlbertPOS
4 | from shekar.pos.base import POSTagger, POS_REGISTRY
5 |
6 |
7 | class TestPOSTagger:
8 | def test_init_with_valid_model(self):
9 | # Test initialization with a valid model
10 | tagger = POSTagger(model="albert")
11 | assert isinstance(tagger.model, AlbertPOS)
12 |
13 | def test_init_with_custom_model_path(self):
14 | # Test initialization with a custom model path
15 | custom_path = "custom/model/path"
16 | tagger = POSTagger(model="albert", model_path=custom_path)
17 | assert isinstance(tagger.model, AlbertPOS)
18 | # We can't directly check the model_path without exposing it in the AlbertPOS class
19 |
20 | def test_init_with_invalid_model(self):
21 | # Test initialization with an invalid model name
22 | with pytest.raises(ValueError) as exc_info:
23 | POSTagger(model="invalid_model")
24 | assert "Unknown POS model 'invalid_model'" in str(exc_info.value)
25 | assert str(list(POS_REGISTRY.keys())) in str(exc_info.value)
26 |
27 | def test_init_with_case_insensitive_model_name(self):
28 | # Test that model name is case-insensitive
29 | tagger = POSTagger(model="AlBeRt")
30 | assert isinstance(tagger.model, AlbertPOS)
31 |
32 | @patch.object(AlbertPOS, "transform")
33 | def test_transform_delegates_to_model(self, mock_transform):
34 | # Test that transform method delegates to the model's transform method
35 | mock_transform.return_value = [("word", "POS")]
36 | tagger = POSTagger()
37 | text = "Sample text"
38 | result = tagger.transform(text)
39 |
40 | mock_transform.assert_called_once_with(text)
41 | assert result == [("word", "POS")]
42 |
43 | def test_integration_with_model(self):
44 | # This is a more integration-style test
45 | tagger = POSTagger()
46 | # Assuming the model.transform returns list of (word, pos) tuples
47 | result = tagger.transform("سلام بر شما.")
48 | assert isinstance(result, list)
49 | # Further assertions would depend on the actual implementation of AlbertPOS
50 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/offensive_word_masker.py:
--------------------------------------------------------------------------------
1 | from typing import Iterable
2 | from shekar import data
3 | from shekar.base import BaseTextTransform
4 | import re
5 |
6 |
7 | class OffensiveWordMasker(BaseTextTransform):
8 | """
9 | A text transformation class for removing Persian offensive words from the text.
10 |
11 | This class inherits from `WordMasker` and provides functionality to identify
12 | and remove Persian offensive words from the text. It uses a predefined list of offensive words
13 | to filter out inappropriate content from the text.
14 |
15 | The `OffensiveWordMasker` class includes `fit` and `fit_transform` methods, and it
16 | is callable, allowing direct application to text data.
17 |
18 | Args:
19 | offensive_words (Iterable[str], optional): A list of offensive words to be removed from the text.
20 | If not provided, a default list of Persian offensive words will be used.
21 |
22 | Methods:
23 |
24 | fit(X, y=None):
25 | Fits the transformer to the input data.
26 | transform(X, y=None):
27 | Transforms the input data by removing stopwords.
28 | fit_transform(X, y=None):
29 | Fits the transformer to the input data and applies the transformation.
30 |
31 | __call__(text: str) -> str:
32 | Allows the class to be called as a function, applying the transformation
33 | to the input text.
34 | Example:
35 | >>> offensive_word_masker = OffensiveWordMasker(offensive_words=["تاپاله","فحش", "بد", "زشت"], mask_token="[بوق]")
36 | >>> cleaned_text = offensive_word_masker("عجب آدم تاپالهای هستی!")
37 | >>> print(cleaned_text)
38 | "عجب آدم [بوق]ای هستی!"
39 | """
40 |
41 | def __init__(self, words: Iterable[str] = None, mask_token: str = ""):
42 | super().__init__()
43 | if words is None:
44 | words = data.offensive_words
45 | self._mask_token = mask_token
46 | self._word_mappings = []
47 | self._word_mappings.append(
48 | (rf"\b({'|'.join(map(re.escape, words))})\b", mask_token)
49 | )
50 |
51 | self._patterns = self._compile_patterns(self._word_mappings)
52 |
53 | def _function(self, text: str) -> str:
54 | return self._map_patterns(text, self._patterns).strip()
55 |
--------------------------------------------------------------------------------
/tests/unit/visualization/test_wordcloud.py:
--------------------------------------------------------------------------------
1 | import pytest
2 |
3 | pytest.importorskip("wordcloud")
4 | pytest.importorskip("matplotlib")
5 | pytest.importorskip("arabic_reshaper")
6 | pytest.importorskip("bidi")
7 | pytest.importorskip("PIL")
8 |
9 | from shekar.visualization import WordCloud
10 | from PIL import Image
11 | from collections import Counter
12 | import numpy as np
13 | import os
14 | from importlib import resources
15 | from shekar import data
16 |
17 |
18 | @pytest.fixture
19 | def wordcloud_instance():
20 | return WordCloud()
21 |
22 |
23 | def test_wordcloud_default_initialization(wordcloud_instance):
24 | assert wordcloud_instance.wc is not None
25 | assert wordcloud_instance.mask is None
26 |
27 |
28 | def test_wordcloud_custom_mask():
29 | mask_path = resources.files(data).joinpath("masks") / "iran.png"
30 | if not os.path.exists(mask_path):
31 | pytest.skip("Custom mask file does not exist.")
32 | wc_instance = WordCloud(mask=str(mask_path))
33 | assert wc_instance.mask is not None
34 | assert isinstance(wc_instance.mask, np.ndarray)
35 |
36 |
37 | def test_wordcloud_invalid_mask():
38 | with pytest.raises(FileNotFoundError):
39 | WordCloud(mask="invalid_path.png")
40 |
41 |
42 | def test_wordcloud_generate_valid_frequencies(wordcloud_instance):
43 | frequencies = Counter({"ایران": 10, "خاک": 5, "دلیران": 15})
44 | image = wordcloud_instance.generate(frequencies)
45 | assert isinstance(image, Image.Image)
46 |
47 |
48 | def test_wordcloud_generate_invalid_frequencies(wordcloud_instance):
49 | with pytest.raises(ValueError):
50 | wordcloud_instance.generate({"word1": "invalid_frequency"})
51 |
52 |
53 | def test_wordcloud_generate_empty_frequencies(wordcloud_instance):
54 | frequencies = Counter()
55 | with pytest.raises(ValueError):
56 | wordcloud_instance.generate(frequencies)
57 |
58 |
59 | def test_wordcloud_font_path():
60 | wc_instance = WordCloud(font="parastoo")
61 | assert "parastoo.ttf" in str(wc_instance.wc.font_path)
62 |
63 |
64 | def test_wordcloud_invalid_font_path():
65 | with pytest.raises(FileNotFoundError):
66 | WordCloud(font="invalid_font.ttf")
67 |
68 |
69 | def test_wordcloud_invalid_color_map():
70 | wc_instance = WordCloud(color_map="invalid_colormap")
71 | assert wc_instance.wc.colormap == "Set3"
72 |
--------------------------------------------------------------------------------
/shekar/preprocessing/normalizers/punctuation_normalizer.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class PunctuationNormalizer(BaseTextTransform):
5 | """
6 | A text transformation class for normalizing punctuation marks in text.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to replace
9 | various punctuation symbols with their normalized equivalents. It uses predefined
10 | mappings to substitute characters such as dashes, underscores, question marks,
11 | exclamation marks, and others with consistent representations.
12 |
13 | The `PunctuationNormalizer` class includes `fit` and `fit_transform` methods, and it
14 | is callable, allowing direct application to text data.
15 |
16 | Methods:
17 |
18 | fit(X, y=None):
19 | Fits the transformer to the input data.
20 | transform(X, y=None):
21 | Transforms the input data by normalizing punctuation marks.
22 | fit_transform(X, y=None):
23 | Fits the transformer to the input data and applies the transformation.
24 |
25 | __call__(text: str) -> str:
26 | Allows the class to be called as a function, applying the transformation
27 | to the input text.
28 |
29 | Example:
30 | >>> punc_normalizer = PunctuationNormalizer()
31 | >>> normalized_text = punc_normalizer("فارسی شکر است❕نوشته کیست?")
32 | >>> print(normalized_text)
33 | "فارسی شکر است! نوشته کیست؟"
34 | """
35 |
36 | def __init__(self):
37 | super().__init__()
38 | self.punctuation_mappings = [
39 | (r"[▕❘❙❚▏│]", "|"),
40 | (r"[ㅡ一—–ー̶]", "-"),
41 | (r"[▁_̲]", "_"),
42 | (r"[❔?�؟ʕʔ🏻\x08\x97\x9d]", "؟"),
43 | (r"[❕!]", "!"),
44 | (r"[⁉]", "!؟"),
45 | (r"[‼]", "!!"),
46 | (r"[℅%]", "٪"),
47 | (r"[÷]", "/"),
48 | (r"[×]", "*"),
49 | (r"[:]", ":"),
50 | (r"[›]", ">"),
51 | (r"[‹<]", "<"),
52 | (r"[《]", "«"),
53 | (r"[》]", "»"),
54 | (r"[•]", "."),
55 | (r"[٬,]", "،"),
56 | (r"[;;]", "؛"),
57 | ]
58 |
59 | self._patterns = self._compile_patterns(self.punctuation_mappings)
60 |
61 | def _function(self, X, y=None):
62 | return self._map_patterns(X, self._patterns)
63 |
--------------------------------------------------------------------------------
/docs/en/getting_started/quick_start.md:
--------------------------------------------------------------------------------
1 | # Quick Start Guide
2 |
3 | Welcome to **Shekar**, a Python library for Persian Natural Language Processing. This guide will walk you through the most essential components so you can get started quickly with preprocessing, tokenization, pipelines, normalization, and embeddings.
4 |
5 | ---
6 |
7 | ## 1. Normalize Your Text
8 |
9 | The built-in `Normalizer` class provides a ready-to-use pipeline that combines the most common filters and normalization steps, offering a default configuration that covers the majority of use cases.
10 |
11 | ```python
12 | from shekar import Normalizer
13 |
14 | normalizer = Normalizer()
15 | text = "«فارسی شِکَر است» نام داستان ڪوتاه طنز آمێزی از محمد علی جمالــــــــزاده می باشد که در سال 1921 منتشر شده است و آغاز ڱر تحول بزرگی در ادَبێات معاصر ایران 🇮🇷 بۃ شمار میرود."
16 |
17 | print(normalizer(text))
18 | ```
19 |
20 | ```shell
21 | «فارسی شکر است» نام داستان کوتاه طنزآمیزی از محمدعلی جمالزاده میباشد که در سال ۱۹۲۱ منتشر شدهاست و آغازگر تحول بزرگی در ادبیات معاصر ایران به شمار میرود.
22 | ```
23 |
24 | ---
25 |
26 | ## 2. Use Preprocessing Components
27 |
28 | Import and use individual text cleaners like `EmojiRemover`, `DiacriticsRemover`, or `URLMasker`.
29 |
30 | ```python
31 | from shekar.preprocessing import EmojiRemover
32 |
33 | text = "سلام 🌹😊"
34 | print(EmojiRemover()(text)) # Output: "سلام"
35 | ```
36 |
37 | See the full list of components in `shekar.preprocessing`.
38 |
39 | ---
40 |
41 | ## 3. Build Custom Pipelines
42 |
43 | Create your own pipeline by chaining any number of preprocessing steps:
44 |
45 | ```python
46 | from shekar import Pipeline
47 | from shekar.preprocessing import EmojiRemover, PunctuationRemover
48 |
49 | pipeline = Pipeline([
50 | ("emoji", EmojiRemover()),
51 | ("punct", PunctuationRemover())
52 | ])
53 |
54 | text = "پرندههای 🐔 قفسی، عادت دارن به بیکسی!"
55 | print(pipeline(text)) # Output: "پرندههای قفسی عادت دارن به بیکسی"
56 | ```
57 |
58 | Supports:
59 | - Single strings or batches
60 | - Function decorators for auto-cleaning input arguments
61 |
62 | ---
63 |
64 | ## 4. Tokenize Text into Sentences
65 |
66 | Use `SentenceTokenizer` to split text into sentences:
67 |
68 | ```python
69 | from shekar import SentenceTokenizer
70 |
71 | text = "هدف ما کمک به یکدیگر است! ما میتوانیم با هم کار کنیم."
72 | sentences = SentenceTokenizer()(text)
73 |
74 | for s in sentences:
75 | print(s)
76 | ```
77 |
--------------------------------------------------------------------------------
/tests/unit/embeddings/test_contextual_embedder.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | import numpy as np
3 | from unittest.mock import Mock, patch
4 | from shekar.embeddings.contextual_embedder import (
5 | ContextualEmbedder,
6 | CONTEXTUAL_EMBEDDING_REGISTRY,
7 | )
8 |
9 |
10 | class TestContextualEmbedder:
11 | def test_init_with_default_model(self):
12 | """Test initialization with default model."""
13 | embedder = ContextualEmbedder()
14 | assert isinstance(embedder.embedder, CONTEXTUAL_EMBEDDING_REGISTRY["albert"])
15 |
16 | def test_init_with_uppercase_model_name(self):
17 | """Test initialization with uppercase model name."""
18 | embedder = ContextualEmbedder(model="ALBERT")
19 | assert isinstance(embedder.embedder, CONTEXTUAL_EMBEDDING_REGISTRY["albert"])
20 |
21 | def test_init_with_invalid_model(self):
22 | """Test initialization with invalid model raises ValueError."""
23 | with pytest.raises(ValueError) as excinfo:
24 | ContextualEmbedder(model="nonexistent_model")
25 |
26 | assert "Unknown contextual embedding model" in str(excinfo.value)
27 | assert "Available: ['albert']" in str(excinfo.value)
28 |
29 | @patch("shekar.embeddings.contextual_embedder.CONTEXTUAL_EMBEDDING_REGISTRY")
30 | def test_embed_calls_embedder(self, mock_registry):
31 | """Test that embed method calls the underlying embedder."""
32 | mock_embedder = Mock()
33 | mock_embedder.return_value = np.array([0.1, 0.2, 0.3])
34 | mock_registry.__getitem__.return_value = lambda: mock_embedder
35 | mock_registry.__contains__.return_value = True
36 | mock_registry.keys.return_value = ["albert"]
37 |
38 | embedder = ContextualEmbedder()
39 | result = embedder.embed("test phrase")
40 |
41 | mock_embedder.assert_called_once_with("test phrase")
42 | assert np.array_equal(result, np.array([0.1, 0.2, 0.3]))
43 |
44 | @patch("shekar.embeddings.contextual_embedder.ContextualEmbedder.embed")
45 | def test_transform_calls_embed(self, mock_embed):
46 | """Test that transform method calls the embed method."""
47 | mock_embed.return_value = np.array([0.4, 0.5, 0.6])
48 |
49 | embedder = ContextualEmbedder()
50 | result = embedder.transform("test sentence")
51 |
52 | mock_embed.assert_called_once_with("test sentence")
53 | assert np.array_equal(result, np.array([0.4, 0.5, 0.6]))
54 |
--------------------------------------------------------------------------------
/shekar/sentiment_analysis/albert_sentiment_binary.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from shekar.tokenization import AlbertTokenizer
3 | from shekar.hub import Hub
4 | from pathlib import Path
5 | import onnxruntime
6 | import numpy as np
7 | from shekar.utils import get_onnx_providers
8 |
9 |
10 | class AlbertBinarySentimentClassifier(BaseTransform):
11 | """Albert model for binary sentiment classification (positive/negative).
12 | This model is fine-tuned on the snapfood dataset.
13 | Args:
14 | model_path (str | Path, optional): Path to a custom model file. If None, the default model will be used.
15 | """
16 |
17 | def __init__(self, model_path: str | Path = None):
18 | super().__init__()
19 | resource_name = "albert_persian_sentiment_binary_q8.onnx"
20 | if model_path is None or not Path(model_path).exists():
21 | model_path = Hub.get_resource(file_name=resource_name)
22 |
23 | self.session = onnxruntime.InferenceSession(
24 | model_path, providers=get_onnx_providers()
25 | )
26 | self.tokenizer = AlbertTokenizer()
27 |
28 | self.id2tag = {0: "negative", 1: "positive"}
29 |
30 | def transform(self, X: str) -> tuple:
31 | """Perform sentiment analysis on the input text.
32 | Args:
33 | X (str): Input text.
34 | Returns:
35 | tuple: A tuple containing the predicted sentiment label and its confidence score.
36 | Example:
37 | >>> model = AlbertBinarySentimentClassifier()
38 | >>> model.transform("فیلم ۳۰۰ افتضاح بود.")
39 | ('negative', 0.998765468120575)
40 | >>> model.transform("سریال قصههای مجید عالی بود!")
41 | ('positive', 0.9976541996002197)
42 | """
43 | batched = self.tokenizer(X) # dict with (num_chunks, L) arrays
44 | input_ids = batched["input_ids"] # (B, L)
45 | attention_mask = batched["attention_mask"] # (B, L)
46 |
47 | inputs = {
48 | "input_ids": input_ids,
49 | "attention_mask": attention_mask,
50 | }
51 | outputs = self.session.run(None, inputs)
52 | logits = outputs[0]
53 | scores = np.exp(logits) / np.exp(logits).sum(-1, keepdims=True)
54 | predicted_class = int(np.argmax(logits, axis=1)[0])
55 | predicted_class_score = float(scores[0, predicted_class])
56 |
57 | return (self.id2tag[predicted_class], predicted_class_score)
58 |
--------------------------------------------------------------------------------
/tests/unit/base/test_base.py:
--------------------------------------------------------------------------------
1 | # test_base_transformer.py
2 | import pytest
3 | from shekar.base import BaseTransform
4 | from shekar.pipeline import Pipeline
5 |
6 |
7 | # Covers the abstract NotImplementedError lines directly
8 | def test_transform_abstract_error():
9 | with pytest.raises(NotImplementedError):
10 | BaseTransform.transform(None, [1, 2, 3]) # directly call on class
11 |
12 |
13 | # Covers fit_transform and __call__ via a concrete subclass
14 | class DummyTransformer(BaseTransform):
15 | def fit(self, X, y=None):
16 | self.was_fitted = True
17 | return self
18 |
19 | def transform(self, X):
20 | assert hasattr(self, "was_fitted")
21 | return X
22 |
23 |
24 | class DummyTransformerA(BaseTransform):
25 | def fit(self, X, y=None):
26 | return self
27 |
28 | def transform(self, X):
29 | return X
30 |
31 |
32 | class DummyTransformerB(BaseTransform):
33 | def fit(self, X, y=None):
34 | return self
35 |
36 | def transform(self, X):
37 | return X
38 |
39 |
40 | def test_fit_transform_works():
41 | d = DummyTransformer()
42 | out = d.fit_transform([1, 2, 3])
43 | assert out == [1, 2, 3]
44 |
45 |
46 | def test_call_works():
47 | d = DummyTransformer()
48 | out = d([4, 5, 6])
49 | assert out == [4, 5, 6]
50 |
51 |
52 | def test_or_with_pipeline():
53 | d1 = DummyTransformerA()
54 | d2 = DummyTransformerB()
55 | pipe = Pipeline(steps=[("DummyTransformerB", d2)])
56 | combined_pipe = d1 | pipe
57 | assert isinstance(combined_pipe, Pipeline)
58 | assert combined_pipe.steps[0][0] == "DummyTransformerA"
59 | assert isinstance(combined_pipe.steps[0][1], DummyTransformerA)
60 | assert combined_pipe.steps[1][0] == "DummyTransformerB"
61 | assert isinstance(combined_pipe.steps[1][1], DummyTransformerB)
62 |
63 |
64 | def test_or_with_transformer():
65 | d1 = DummyTransformerA()
66 | d2 = DummyTransformerB()
67 | combined_pipe = d1 | d2
68 | assert isinstance(combined_pipe, Pipeline)
69 | assert combined_pipe.steps[0][0] == "DummyTransformerA"
70 | assert isinstance(combined_pipe.steps[0][1], DummyTransformerA)
71 | assert combined_pipe.steps[1][0] == "DummyTransformerB"
72 | assert isinstance(combined_pipe.steps[1][1], DummyTransformerB)
73 |
74 |
75 | def test_or_with_invalid_type():
76 | d1 = DummyTransformerA()
77 | with pytest.raises(TypeError):
78 | _ = d1 | 123 # not a Pipeline or BaseTransformer
79 |
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [build-system]
2 | requires = ["hatchling"]
3 | build-backend = "hatchling.build"
4 |
5 | [project]
6 | name = "shekar"
7 | version = "1.3.0"
8 | description = "Simplifying Persian NLP for Modern Applications"
9 | readme = "README.md"
10 | license = "MIT"
11 |
12 | authors = [{ name = "Ahmad Amirivojdan", email = "amirivojdan@gmail.com" }]
13 | requires-python = ">=3.10"
14 |
15 | keywords = [
16 | "NLP",
17 | "Natural Language Processing",
18 | "Persian",
19 | "Shekar",
20 | "Text Processing",
21 | "Machine Learning",
22 | "Deep Learning",
23 | ]
24 |
25 | classifiers = [
26 | "Development Status :: 5 - Production/Stable",
27 | "Intended Audience :: Developers",
28 | "Intended Audience :: Science/Research",
29 | "Topic :: Scientific/Engineering :: Artificial Intelligence",
30 | "Topic :: Text Processing",
31 | "Topic :: Text Processing :: Linguistic",
32 | "License :: OSI Approved :: MIT License",
33 | "Natural Language :: Persian",
34 | "Programming Language :: Python",
35 | "Programming Language :: Python :: 3",
36 | "Programming Language :: Python :: 3.10",
37 | "Programming Language :: Python :: 3.11",
38 | "Programming Language :: Python :: 3.12",
39 | "Programming Language :: Python :: 3.13",
40 | "Programming Language :: Python :: 3 :: Only",
41 | "Operating System :: OS Independent",
42 | ]
43 |
44 | dependencies = [
45 | "click>=8.1.8",
46 | "numpy>=1.24.4",
47 | "regex>=2024.11.6",
48 | "tokenizers>=0.21.2",
49 | "tqdm>=4.67.1",
50 | "onnxruntime>=1.23.2",
51 | ]
52 |
53 | [project.optional-dependencies]
54 | viz = [
55 | "wordcloud>=1.9.4",
56 | "arabic-reshaper>=3.0.0",
57 | "python-bidi>=0.6.6",
58 | "pillow>=11.2.1",
59 | ]
60 |
61 | all = [
62 | "shekar[viz]"
63 | ]
64 |
65 | [dependency-groups]
66 | dev = [
67 | "mkdocs-material>=9.5.49",
68 | "mkdocs>=1.6.1",
69 | "mkdocstrings[python]>=0.26.1",
70 | "pytest>=8.3.4",
71 | "ipykernel>=6.29.5",
72 | "coverage>=7.8.0",
73 | "termynal>=0.13.0",
74 | "ruff>=0.12.5",
75 | "mkdocs-static-i18n>=1.3.0",
76 | ]
77 |
78 |
79 | [project.scripts]
80 | shekar = "shekar.cli:main"
81 |
82 | [project.urls]
83 | Homepage = "https://github.com/amirivojdan/shekar"
84 | Repository = "https://github.com/amirivojdan/shekar"
85 | Documentation = "https://lib.shekar.io"
86 | Issues = "https://github.com/amirivojdan/shekar/issues"
87 | Changelog = "https://github.com/amirivojdan/shekar/releases"
88 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/stopword_masker.py:
--------------------------------------------------------------------------------
1 | from typing import Iterable
2 | from shekar import data
3 | from shekar.base import BaseTextTransform
4 | import re
5 |
6 |
7 | class StopWordMasker(BaseTextTransform):
8 | """
9 | A text transformation class for removing Persian stopwords from the text.
10 |
11 | This class inherits from `WordMasker` and provides functionality to identify
12 | and remove Persian stopwords from the text. It uses a predefined list of stopwords
13 | to filter out common words that do not contribute significant meaning to the text.
14 |
15 | The `StopWordMasker` class includes `fit` and `fit_transform` methods, and it
16 | is callable, allowing direct application to text data.
17 |
18 | Args:
19 | stopwords (Iterable[str], optional): A list of stopwords to be removed from the text.
20 | If not provided, a default list of Persian stopwords will be used.
21 |
22 | Methods:
23 |
24 | fit(X, y=None):
25 | Fits the transformer to the input data.
26 | transform(X, y=None):
27 | Transforms the input data by removing stopwords.
28 | fit_transform(X, y=None):
29 | Fits the transformer to the input data and applies the transformation.
30 |
31 | __call__(text: str) -> str:
32 | Allows the class to be called as a function, applying the transformation
33 | to the input text.
34 | Example:
35 | >>> stopword_masker = StopWordMasker(stopwords=["و", "به", "از"])
36 | >>> cleaned_text = stopword_masker("این یک متن نمونه است و به شما کمک میکند.")
37 | >>> print(cleaned_text)
38 | "این یک متن نمونه است شما کمک میکند."
39 | """
40 |
41 | def __init__(self, stopwords: Iterable[str] = None, mask_token: str = ""):
42 | super().__init__()
43 |
44 | if stopwords is None:
45 | stopwords = data.stopwords
46 | self._mask_token = mask_token
47 | self._word_mappings = []
48 | for word in stopwords:
49 | escaped_word = re.escape(word)
50 | self._word_mappings.append(
51 | (
52 | rf"(? str:
60 | return self._map_patterns(text, self._patterns).strip()
61 |
--------------------------------------------------------------------------------
/tests/unit/morphology/test_lemmatizer.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.morphology.lemmatizer import Lemmatizer
3 | from shekar.morphology.conjugator import get_conjugated_verbs
4 | from shekar import data
5 |
6 |
7 | @pytest.fixture
8 | def lemmatizer():
9 | return Lemmatizer()
10 |
11 |
12 | def test_return_infinitive_option():
13 | lemmatizer = Lemmatizer(return_infinitive=True)
14 | assert lemmatizer("رفتند") == "رفتن"
15 | assert lemmatizer("میخونم") == "خواندن"
16 | assert lemmatizer("رفته بودم") == "رفتن"
17 | assert lemmatizer("خواهم رفت") == "رفتن"
18 |
19 |
20 | def test_conjugated_verb(lemmatizer, monkeypatch):
21 | conjugated_verbs = get_conjugated_verbs()
22 | # Example: "رفتند" -> "رفت/رو"
23 | monkeypatch.setitem(conjugated_verbs, "رفتند", ("رفت", "رو"))
24 | assert lemmatizer("رفتند") == "رفت/رو"
25 |
26 | # test هست
27 | monkeypatch.setitem(conjugated_verbs, "هستند", (None, "هست"))
28 | assert lemmatizer("هستند") == "هست"
29 |
30 |
31 | def test_informal_verb(lemmatizer, monkeypatch):
32 | assert lemmatizer("میخونم") == "خواند/خوان"
33 | assert lemmatizer("میخوابم") == "خوابید/خواب"
34 | assert lemmatizer("نمیرم") == "رفت/رو"
35 |
36 |
37 | def test_stemmer_and_vocab(lemmatizer, monkeypatch):
38 | # Example: "کتابها" -> "کتاب"
39 | # Simulate stemmer returning "کتاب" and "کتاب" in vocab
40 | monkeypatch.setattr(lemmatizer.stemmer, "__call__", lambda self, text: "کتاب")
41 | monkeypatch.setitem(data.vocab, "کتاب", True)
42 | assert lemmatizer("کتابها") == "کتاب"
43 |
44 |
45 | def test_vocab_only(lemmatizer, monkeypatch):
46 | # If word is in vocab, return as is
47 | monkeypatch.setitem(data.vocab, "مدرسه", True)
48 | assert lemmatizer("مدرسه") == "مدرسه"
49 |
50 |
51 | def test_no_match(lemmatizer, monkeypatch):
52 | # If word is not in conjugated_verbs, stemmer result not in vocab, and not in vocab
53 | monkeypatch.setattr(lemmatizer.stemmer, "__call__", lambda self, text: "ناشناخته")
54 | monkeypatch.setitem(data.vocab, "ناشناخته", False)
55 | assert lemmatizer("ناشناخته") == "ناشناخته"
56 |
57 |
58 | def test_prefixed_verbs(lemmatizer):
59 | assert lemmatizer("فراخواند") == "فراخواند/فراخوان"
60 | assert lemmatizer("فرابخوان") == "فراخواند/فراخوان"
61 | assert lemmatizer("فرا نخواهم خواند") == "فراخواند/فراخوان"
62 | assert lemmatizer("پسنمیانداخت") == "پس\u200cانداخت/پس\u200cانداز"
63 | assert lemmatizer("ورنیامد") == "ورآمد/ورآ"
64 | assert lemmatizer("باز نخواهم گشت") == "بازگشت/بازگرد"
65 |
--------------------------------------------------------------------------------
/tests/unit/embeddings/test_albert_embedder.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from shekar.embeddings.albert_embedder import AlbertEmbedder
3 |
4 |
5 | class TestAlbertEmbedder:
6 | def test_init_with_default_path(self):
7 | embedder = AlbertEmbedder()
8 | assert embedder.session is not None
9 | assert embedder.tokenizer is not None
10 | assert embedder.vector_size == 768
11 |
12 | def test_init_with_custom_path(self):
13 | # This will fall back to Hub.get_resource since path doesn't exist
14 | embedder = AlbertEmbedder(model_path="nonexistent_path.onnx")
15 | assert embedder.session is not None
16 | assert embedder.tokenizer is not None
17 | assert embedder.vector_size == 768
18 |
19 | def test_embed_single_word(self):
20 | embedder = AlbertEmbedder()
21 | result = embedder.embed("سلام")
22 | assert isinstance(result, np.ndarray)
23 | assert result.dtype == np.float32
24 | assert result.shape == (768,)
25 |
26 | def test_embed_sentence(self):
27 | embedder = AlbertEmbedder()
28 | result = embedder.embed("سلام دنیا چطوری؟")
29 | assert isinstance(result, np.ndarray)
30 | assert result.dtype == np.float32
31 | assert result.shape == (768,)
32 |
33 | def test_embed_empty_string(self):
34 | embedder = AlbertEmbedder()
35 | result = embedder.embed("")
36 | assert isinstance(result, np.ndarray)
37 | assert result.dtype == np.float32
38 | assert result.shape == (768,)
39 |
40 | def test_embed_long_text(self):
41 | embedder = AlbertEmbedder()
42 | long_text = "این یک متن طولانی است. " * 50
43 | result = embedder.embed(long_text)
44 | assert isinstance(result, np.ndarray)
45 | assert result.dtype == np.float32
46 | assert result.shape == (768,)
47 |
48 | def test_embed_consistency(self):
49 | embedder = AlbertEmbedder()
50 | text = "تست پایداری"
51 | result1 = embedder.embed(text)
52 | result2 = embedder.embed(text)
53 | np.testing.assert_array_equal(result1, result2)
54 |
55 | def test_embed_different_inputs_different_outputs(self):
56 | embedder = AlbertEmbedder()
57 | result1 = embedder.embed("متن اول")
58 | result2 = embedder.embed("متن دوم")
59 | assert not np.array_equal(result1, result2)
60 |
61 | def test_vector_size_property(self):
62 | embedder = AlbertEmbedder()
63 | assert embedder.vector_size == 768
64 | assert isinstance(embedder.vector_size, int)
65 |
--------------------------------------------------------------------------------
/shekar/preprocessing/normalizers/digit_normalizer.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class DigitNormalizer(BaseTextTransform):
5 | """
6 | A text transformation class for normalizing Arabic, English, and other Unicode number signs to Persian numbers.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to replace
9 | various numeric characters from Arabic, English, and other Unicode representations with their Persian equivalents.
10 | It uses predefined mappings to substitute characters such as "1", "٢", and other numeric signs with their standard Persian representations.
11 |
12 | The `NumericNormalizer` class includes `fit` and `fit_transform` methods, and it
13 | is callable, allowing direct application to text data.
14 |
15 | Methods:
16 |
17 | fit(X, y=None):
18 | Fits the transformer to the input data.
19 | transform(X, y=None):
20 | Transforms the input data by normalizing numbers.
21 | fit_transform(X, y=None):
22 | Fits the transformer to the input data and applies the transformation.
23 |
24 | __call__(text: str) -> str:
25 | Allows the class to be called as a function, applying the transformation
26 | to the input text.
27 |
28 | Example:
29 | >>> numeric_normalizer = NumericNormalizer()
30 | >>> normalized_text = numeric_normalizer("1𝟮3٤٥⓺")
31 | >>> print(normalized_text)
32 | "۱۲۳۴۵۶"
33 | """
34 |
35 | def __init__(self):
36 | super().__init__()
37 | self._number_mappings = [
38 | (r"[0٠𝟢𝟬]", "۰"),
39 | (r"[1١𝟣𝟭⑴⒈⓵①❶𝟙𝟷ı]", "۱"),
40 | (r"[2٢𝟤𝟮⑵⒉⓶②❷²𝟐𝟸𝟚ᒿշ]", "۲"),
41 | (r"[3٣𝟥𝟯⑶⒊⓷③❸³ვ]", "۳"),
42 | (r"[4٤𝟦𝟰⑷⒋⓸④❹⁴]", "۴"),
43 | (r"[5٥𝟧𝟱⑸⒌⓹⑤❺⁵]", "۵"),
44 | (r"[6٦𝟨𝟲⑹⒍⓺⑥❻⁶]", "۶"),
45 | (r"[7٧𝟩𝟳⑺⒎⓻⑦❼⁷]", "۷"),
46 | (r"[8٨𝟪𝟴⑻⒏⓼⑧❽⁸۸]", "۸"),
47 | (r"[9٩𝟫𝟵⑼⒐⓽⑨❾⁹]", "۹"),
48 | (r"[⑽⒑⓾⑩]", "۱۰"),
49 | (r"[⑾⒒⑪]", "۱۱"),
50 | (r"[⑿⒓⑫]", "۱۲"),
51 | (r"[⒀⒔⑬]", "۱۳"),
52 | (r"[⒁⒕⑭]", "۱۴"),
53 | (r"[⒂⒖⑮]", "۱۵"),
54 | (r"[⒃⒗⑯]", "۱۶"),
55 | (r"[⒄⒘⑰]", "۱۷"),
56 | (r"[⒅⒙⑱]", "۱۸"),
57 | (r"[⒆⒚⑲]", "۱۹"),
58 | (r"[⒇⒛⑳]", "۲۰"),
59 | ]
60 | self._patterns = self._compile_patterns(self._number_mappings)
61 |
62 | def _function(self, X, y=None):
63 | return self._map_patterns(X, self._patterns)
64 |
--------------------------------------------------------------------------------
/tests/unit/base/test_base_text_transformer.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | import re
3 | import regex
4 | from shekar.base import BaseTextTransform
5 |
6 |
7 | class TestBaseTextTransformer:
8 | class MockTextTransformer(BaseTextTransform):
9 | def _function(self, X: str, y=None) -> str:
10 | # Example implementation for testing purposes
11 | return X.replace("گربه", "سگ")
12 |
13 | @pytest.fixture
14 | def transformer(self):
15 | return self.MockTextTransformer()
16 |
17 | def test_transform_single_string(self, transformer):
18 | input_text = "گربه روی دیوار نشست."
19 | expected_output = "سگ روی دیوار نشست."
20 | assert transformer.transform(input_text) == expected_output
21 |
22 | def test_transform_iterable_strings(self, transformer):
23 | input_texts = ["گربه روی دیوار نشست.", "گربه در حیاط بود."]
24 | expected_output = ["سگ روی دیوار نشست.", "سگ در حیاط بود."]
25 | assert list(transformer.transform(input_texts)) == expected_output
26 |
27 | def test_transform_invalid_input(self, transformer):
28 | with pytest.raises(
29 | ValueError, match="Input must be a string or a Iterable of strings."
30 | ):
31 | transformer.transform(123)
32 |
33 | def test_fit(self, transformer):
34 | input_text = "گربه روی دیوار نشست."
35 | assert transformer.fit(input_text) is transformer
36 |
37 | def test_fit_transform(self, transformer):
38 | input_text = "گربه روی دیوار نشست."
39 | expected_output = "سگ روی دیوار نشست."
40 | assert transformer.fit_transform(input_text) == expected_output
41 |
42 | def test_compile_patterns(self):
43 | mappings = [
44 | (r"\bگربه\b", "سگ"),
45 | (r"\bدیوار\b", "حیاط"),
46 | ]
47 |
48 | compiled_patterns = BaseTextTransform._compile_patterns(mappings)
49 | print(compiled_patterns)
50 | assert len(compiled_patterns) == 2
51 | assert isinstance(compiled_patterns[0][0], (re.Pattern, regex.Pattern))
52 | assert compiled_patterns[0][1] == "سگ"
53 |
54 | def test_map_patterns(self):
55 | text = "گربه روی دیوار نشست."
56 | patterns = BaseTextTransform._compile_patterns(
57 | [("گربه", "سگ"), ("دیوار", "حیاط")]
58 | )
59 | expected_output = "سگ روی حیاط نشست."
60 | assert BaseTextTransform._map_patterns(text, patterns) == expected_output
61 |
62 | def test_abstract_function_error(self):
63 | with pytest.raises(NotImplementedError):
64 | BaseTextTransform._function(None, None)
65 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/non_persian_letter_masker.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 | from shekar import data
3 | import re
4 | import string
5 |
6 |
7 | class NonPersianLetterMasker(BaseTextTransform):
8 | """
9 | A text transformation class for removing non-Persian characters from the text.
10 |
11 | This class inherits from `BaseTextTransform` and provides functionality to identify
12 | and remove non-Persian characters from the text. It uses predefined character sets
13 | to filter out unwanted characters while optionally retaining English characters and diacritics.
14 |
15 | The `NonPersianLetterMasker` class includes `fit` and `fit_transform` methods, and it
16 | is callable, allowing direct application to text data.
17 |
18 | Args:
19 | keep_english (bool): If True, retains English characters. Default is False.
20 | keep_diacritics (bool): If True, retains diacritics. Default is False.
21 |
22 | Methods:
23 |
24 | fit(X, y=None):
25 | Fits the transformer to the input data.
26 | transform(X, y=None):
27 | Transforms the input data by removing non-Persian characters.
28 | fit_transform(X, y=None):
29 | Fits the transformer to the input data and applies the transformation.
30 |
31 | __call__(text: str) -> str:
32 | Allows the class to be called as a function, applying the transformation
33 | to the input text.
34 | Example:
35 | >>> non_persian_masker = NonPersianLetterMasker(keep_english=True, keep_diacritics=False)
36 | >>> cleaned_text = non_persian_masker("این یک متن نمونه است! Hello!")
37 | >>> print(cleaned_text)
38 | "این یک متن نمونه است! Hello!"
39 | """
40 |
41 | def __init__(self, keep_english=False, keep_diacritics=False):
42 | super().__init__()
43 |
44 | self.characters_to_keep = (
45 | data.persian_letters + data.spaces + data.persian_digits + data.punctuations
46 | )
47 |
48 | if keep_diacritics:
49 | self.characters_to_keep += data.diacritics
50 |
51 | if keep_english:
52 | self.characters_to_keep += (
53 | string.ascii_letters + string.digits + string.punctuation
54 | )
55 |
56 | allowed_chars = re.escape(self.characters_to_keep)
57 | self._filter_mappings = [(r"[^" + allowed_chars + r"]+", "")]
58 |
59 | self._patterns = self._compile_patterns(self._filter_mappings)
60 |
61 | def _function(self, text: str) -> str:
62 | return self._map_patterns(text, self._patterns).strip()
63 |
--------------------------------------------------------------------------------
/shekar/transforms/ngram_extractor.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 | from shekar.tokenization import WordTokenizer
3 |
4 |
5 | class NGramExtractor(BaseTextTransform):
6 | """
7 | A text transformation class for extracting n-grams from the text.
8 | This class inherits from `BaseTextTransformer` and provides functionality to extract
9 | n-grams from the text. It allows for the specification of the range of n-grams to be extracted,
10 | ensuring flexibility in the extraction process.
11 | The `NGramExtractor` class includes `fit` and `fit_transform` methods, and it
12 | is callable, allowing direct application to text data.
13 | Args:
14 | range (tuple[int, int]): The range of n-grams to be extracted. Default is (1, 2).
15 | Methods:
16 | fit(X, y=None):
17 | Fits the transformer to the input data.
18 | transform(X, y=None):
19 | Transforms the input data by extracting n-grams.
20 | fit_transform(X, y=None):
21 | Fits the transformer to the input data and applies the transformation.
22 | __call__(text: str) -> list[str]:
23 | Allows the class to be called as a function, applying the transformation
24 | to the input text and returning a list of n-grams.
25 | Example:
26 | >>> ngram_extractor = NGramExtractor(range=(1, 3))
27 | >>> ngrams = ngram_extractor("این یک متن نمونه است.")
28 | >>> print(ngrams)
29 | ["این", "یک", "متن", "نمونه", "است", "این یک", "یک متن", "متن نمونه", "نمونه است"]
30 | """
31 |
32 | def __init__(self, range: tuple[int, int] = (1, 1)):
33 | super().__init__()
34 | if not isinstance(range, tuple) or not all(isinstance(i, int) for i in range):
35 | raise TypeError("N-gram range must be a tuple tuple of integers.")
36 | elif len(range) != 2:
37 | raise ValueError("N-gram range must be a tuple of length 2.")
38 | elif range[0] < 1 or range[1] < 1:
39 | raise ValueError("N-gram range must be greater than 0.")
40 | elif range[0] > range[1]:
41 | raise ValueError("N-gram range must be in the form of (min, max).")
42 |
43 | self.range = range
44 | self.word_tokenizer = WordTokenizer()
45 |
46 | def _function(self, text: str) -> list[str]:
47 | tokens = list(self.word_tokenizer(text))
48 | ngrams = []
49 | for n in range(self.range[0], self.range[1] + 1):
50 | ngrams.extend(
51 | [" ".join(tokens[i : i + n]) for i in range(len(tokens) - n + 1)]
52 | )
53 | return ngrams
54 |
--------------------------------------------------------------------------------
/tests/unit/pos/test_albert_pos.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.pos.albert_pos import AlbertPOS
3 | from shekar.hub import Hub
4 |
5 |
6 | class TestAlbertPOS:
7 | @pytest.fixture
8 | def pos_tagger(self):
9 | return AlbertPOS()
10 |
11 | def test_initialization(self, pos_tagger):
12 | assert pos_tagger.session is not None
13 | assert pos_tagger.tokenizer is not None
14 | assert pos_tagger.word_tokenizer is not None
15 | assert isinstance(pos_tagger.id2tag, dict)
16 | assert (
17 | len(pos_tagger.id2tag) == 17
18 | ) # Verify the tag dictionary has all expected entries
19 |
20 | def test_transform_empty_text(self, pos_tagger):
21 | result = pos_tagger.transform("")
22 | assert isinstance(result, list)
23 | assert len(result) == 0
24 |
25 | def test_transform_simple_text(self, pos_tagger):
26 | text = "من به خانه رفتم."
27 | result = pos_tagger.transform(text)
28 |
29 | assert isinstance(result, list)
30 | assert len(result) > 0
31 |
32 | # Check structure of returned data
33 | for word_tag_pair in result:
34 | assert isinstance(word_tag_pair, tuple)
35 | assert len(word_tag_pair) == 2
36 | word, tag = word_tag_pair
37 | assert isinstance(word, str)
38 | assert isinstance(tag, str)
39 | assert tag in pos_tagger.id2tag.values()
40 |
41 | def test_transform_with_punctuation(self, pos_tagger):
42 | text = "سلام! این یک متن تست است. آیا همه چیز خوب است؟"
43 | result = pos_tagger.transform(text)
44 |
45 | # Check that punctuation is properly tagged
46 | punctuation_marks = {".", ",", "!", "؟", ":", ";", "«", "»"}
47 | for word, tag in result:
48 | if word in punctuation_marks:
49 | assert tag == "PUNCT"
50 |
51 | def test_custom_model_path(self, tmp_path):
52 | # This test will be skipped if the model file doesn't exist
53 | model_path = Hub.get_resource("albert_persian_pos_q8.onnx")
54 |
55 | # Create a POS tagger with explicit model path
56 | pos_tagger = AlbertPOS(model_path=model_path)
57 |
58 | # Verify it works
59 | result = pos_tagger.transform("این یک آزمون است.")
60 | assert isinstance(result, list)
61 | assert len(result) > 0
62 |
63 | def test_transform_consistency(self, pos_tagger):
64 | text = "من به مدرسه میروم."
65 |
66 | # Run the transform twice to check for consistency
67 | result1 = pos_tagger.transform(text)
68 | result2 = pos_tagger.transform(text)
69 |
70 | assert result1 == result2
71 |
--------------------------------------------------------------------------------
/tests/unit/morphology/test_stemmer.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.morphology.stemmer import Stemmer
3 | from shekar import data
4 |
5 |
6 | @pytest.fixture
7 | def stemmer():
8 | return Stemmer()
9 |
10 |
11 | def test_stemmer_removes_plural_suffix(stemmer):
12 | assert stemmer("کتابها") == "کتاب"
13 | assert stemmer("خانهها") == "خانه"
14 | assert stemmer("خونههامون") == "خانه"
15 | assert stemmer("حیوون") == "حیوان"
16 | assert stemmer("دوستان") == "دوست"
17 | assert stemmer("زورگیران") == "زورگیر"
18 | assert stemmer("مدیران") == "مدیر"
19 | assert stemmer("حیوانات") == "حیوان"
20 | assert stemmer("دانشآموزان") == "دانشآموز"
21 | assert stemmer("کشتهشدگان") == "کشتهشده"
22 | assert stemmer("رزمندگان") == "رزمنده"
23 |
24 | assert stemmer("زعفران") != "زعفر"
25 | assert stemmer("زعفرون") == "زعفران"
26 |
27 | assert stemmer("بیکران") == "بیکران"
28 | assert stemmer("شوکران") == "شوکران"
29 | assert stemmer("میهمان") == "میهمان"
30 | assert stemmer("ایران") == "ایران"
31 | assert stemmer("امان") == "امان"
32 | assert stemmer("پایان") == "پایان"
33 | assert stemmer("پهلوان") == "پهلوان"
34 |
35 | assert stemmer("شاتگان") != "شاته"
36 | assert stemmer("یگان") != "یه"
37 | assert stemmer("رایگان") != "رایه"
38 | assert stemmer("شایگان") != "شایه"
39 |
40 | assert stemmer("آقایون") == "آقا"
41 |
42 |
43 | def test_stemmer_removes_possessive_suffix(stemmer):
44 | assert stemmer("نوهام") == "نوه"
45 | assert stemmer("کتابم") == "کتاب"
46 | assert stemmer("خانهمان") == "خانه"
47 | assert stemmer("دوستت") == "دوست"
48 |
49 | assert stemmer("کتابهامون") == "کتاب"
50 | assert stemmer("کتابهام") == "کتاب"
51 | assert stemmer("رفیقهامون") == "رفیق"
52 |
53 |
54 | def test_stemmer_removes_comparative_superlative(stemmer):
55 | word = f"خوب{data.ZWNJ}ترین"
56 | assert stemmer(word) == "خوب"
57 |
58 | word2 = f"سریع{data.ZWNJ}تر"
59 | assert stemmer(word2) == "سریع"
60 |
61 | word3 = "دشوارترین"
62 | assert stemmer(word3) == "دشوار"
63 |
64 | word4 = "شدیدترین"
65 | assert stemmer(word4) == "شدید"
66 |
67 |
68 | def test_stemmer_removes_ezafe_after_zwnj(stemmer):
69 | word = f"خانه{data.ZWNJ}ی"
70 | assert stemmer(word) == "خانه"
71 |
72 | word = "پیتزایی"
73 | assert stemmer(word) == "پیتزا"
74 |
75 | word = "صهیونیستی"
76 | assert stemmer(word) == "صهیونیست"
77 |
78 | word = "شورای"
79 | assert stemmer(word) == "شورا"
80 |
81 | word = "هندویی"
82 | assert stemmer(word) == "هندو"
83 |
84 | word = "کمردردی"
85 | assert stemmer(word) == "کمردرد"
86 |
87 |
88 | def test_stemmer_no_change_for_no_suffix(stemmer):
89 | assert stemmer("کتاب") == "کتاب"
90 | assert stemmer("خانه") == "خانه"
91 |
--------------------------------------------------------------------------------
/docs/en/tutorials/cli.md:
--------------------------------------------------------------------------------
1 | # Command-Line Interface (CLI)
2 |
3 | Shekar includes a command-line interface (CLI) for quick text processing and visualization.
4 | You can normalize Persian text or generate wordclouds directly from files or inline strings.
5 |
6 | **Usage**
7 |
8 | ```console
9 | shekar [COMMAND] [OPTIONS]
10 | ```
11 |
12 | ### Commands
13 |
14 | 1. `normalize`
15 |
16 | Normalize Persian text by standardizing spacing, characters, and diacritics.
17 | Works with files or inline text.
18 |
19 | **Options**
20 |
21 | - `-i, --input` Path to an input text file
22 | - `-o, --output` Path to save normalized text. If not provided, results are printed to stdout
23 | - `-t, --text` Inline text instead of a file
24 | - `--encoding` Force a specific input file encoding
25 | - `--progress` Show progress bar (enabled by default)
26 |
27 | **Examples**
28 |
29 |
30 | ```console
31 | # Normalize a text file and save output
32 | shekar normalize -i ./corpus.txt -o ./normalized_corpus.txt
33 | ```
34 |
35 |
36 |
37 |
38 | ```console
39 | # Normalize inline text
40 | shekar normalize --text "درود پرودگار بر ایران و ایرانی"
41 | ```
42 |
43 | 1. `wordcloud`
44 |
45 | Generate a wordcloud image (PNG) from Persian text, either from a file or inline.
46 | Preprocessing automatically removes punctuation, diacritics, stopwords, non-Persian characters, and normalizes spacing.
47 |
48 | ---
49 |
50 | **Options**
51 |
52 | - `-i, --input` Input text file
53 | - `-t, --text` Inline text instead of a file
54 | - `-o, --output` **(required)** Path to output PNG file
55 | - `--bidi` Apply **bidi reshaping** for correct rendering of Persian text (default: `False`)
56 | - `--mask` Shape mask (`Iran`, `Heart`, `Bulb`, `Cat`, `Cloud`, `Head`) or custom image path
57 | - `--font` Font to use (`sahel`, `parastoo`, or custom TTF path)
58 | - `--width` Image width in pixels (default: 1000)
59 | - `--height` Image height in pixels (default: 500)
60 | - `--bg-color` Background color (default: white)
61 | - `--contour-color` Outline color (default: black)
62 | - `--contour-width` Outline thickness (default: 3)
63 | - `--color-map` Matplotlib colormap for words (default: Set2)
64 | - `--min-font-size` Minimum font size (default: 5)
65 | - `--max-font-size` Maximum font size (default: 220)
66 |
67 | ---
68 |
69 | **Examples**
70 |
71 |
72 | ```console
73 | # Generate a wordcloud from a text file
74 | shekar wordcloud -i ./corpus.txt -o ./word_cloud.png
75 | ```
76 |
77 |
78 |
79 |
80 | ```console
81 | # Generate a wordcloud from inline text with a custom mask
82 |
83 | shekar wordcloud --text "درود پرودگار بر ایران و ایرانی"
84 | \ -o ./word_cloud.png --mask Heart
85 | ```
86 |
87 | **Note:** If the letters in the generated wordcloud appear **separated**, use the `--bidi` option to enable proper Persian text shaping.
88 |
--------------------------------------------------------------------------------
/lab/train_albert_mlm.py:
--------------------------------------------------------------------------------
1 | import os
2 | from transformers import (
3 | AlbertTokenizer,
4 | AutoModelForMaskedLM,
5 | DataCollatorForLanguageModeling,
6 | Trainer,
7 | TrainingArguments,
8 | )
9 |
10 | from datasets import load_dataset
11 | from shekar import Normalizer
12 |
13 | normalizer = Normalizer()
14 | num_cpus = os.cpu_count() - 10
15 | datasets = load_dataset("SLPL/naab")
16 |
17 | tokenizer = AlbertTokenizer.from_pretrained(
18 | "shekar-ai/albert-base-v2-persian-zwnj-naab-mlm", use_fast=True
19 | )
20 |
21 | def tokenize_function(examples):
22 | # Normalize the text using shekar normalizer
23 | examples["text"] = [normalizer(text) for text in examples["text"]]
24 | # Apply the cleaning pipeline
25 | return tokenizer(examples["text"])
26 |
27 |
28 | tokenized_datasets = datasets.map(
29 | tokenize_function, batched=True, num_proc=num_cpus, remove_columns=["text"]
30 | )
31 |
32 | block_size = tokenizer.model_max_length
33 |
34 | def group_texts(examples):
35 | concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
36 | total_length = len(concatenated_examples[list(examples.keys())[0]])
37 |
38 | total_length = (total_length // block_size) * block_size
39 |
40 | result = {
41 | k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
42 | for k, t in concatenated_examples.items()
43 | }
44 | result["labels"] = result["input_ids"].copy()
45 | return result
46 |
47 |
48 | lm_datasets = tokenized_datasets.map(
49 | group_texts,
50 | batched=True,
51 | batch_size=1000,
52 | num_proc=num_cpus,
53 | )
54 |
55 | model = AutoModelForMaskedLM.from_pretrained(
56 | "shekar-ai/albert-base-v2-persian-zwnj-naab-mlm"
57 | )
58 | model.resize_token_embeddings(len(tokenizer))
59 | model_checkpoint = "shekar-ai/albert-base-v2-persian-zwnj-naab-mlm"
60 |
61 | training_args = TrainingArguments(
62 | model_checkpoint,
63 | overwrite_output_dir="True",
64 | eval_strategy="steps",
65 | save_steps=50000,
66 | eval_steps=50000,
67 | warmup_steps=10000,
68 | learning_rate=2e-5,
69 | weight_decay=0.01,
70 | save_strategy="steps",
71 | save_total_limit=1,
72 | push_to_hub=True,
73 | hub_model_id=model_checkpoint,
74 | num_train_epochs=3,
75 | per_device_train_batch_size=32,
76 | per_device_eval_batch_size=32,
77 | load_best_model_at_end=True,
78 | report_to="tensorboard",
79 | )
80 |
81 | data_collator = DataCollatorForLanguageModeling(
82 | tokenizer=tokenizer, mlm_probability=0.15
83 | )
84 |
85 | lm_datasets = lm_datasets["train"].train_test_split(test_size=0.02, seed=42)
86 |
87 | trainer = Trainer(
88 | model=model,
89 | args=training_args,
90 | train_dataset=lm_datasets["train"],
91 | eval_dataset=lm_datasets["test"],
92 | data_collator=data_collator,
93 | )
94 |
95 | trainer.train()
96 |
97 | trainer.push_to_hub(commit_message="Training complete", blocking=True)
98 |
--------------------------------------------------------------------------------
/docs/en/tutorials/ner.md:
--------------------------------------------------------------------------------
1 | # Named Entity Recognition (NER)
2 |
3 | [](examples/ner.ipynb) [](https://colab.research.google.com/github/amirivojdan/shekar/blob/main/examples/ner.ipynb)
4 |
5 |
6 | The `NER` module in **Shekar** provides a fast and quantized Named Entity Recognition pipeline powered by a fine-tuned ALBERT model (**default**) exported to ONNX format for efficient inference.
7 |
8 | It automatically identifies common Persian entities such as persons, locations, organizations, dates, and events. The NER pipeline is designed for speed and easy integration with other preprocessing components like normalization and tokenization.
9 |
10 |
11 | **Example usage**:
12 |
13 | ```python
14 | from shekar import NER
15 | from shekar import Normalizer
16 |
17 | input_text = (
18 | "شاهرخ مسکوب به سالِ ۱۳۰۴ در بابل زاده شد و دوره ابتدایی را در تهران و در مدرسه علمیه پشت "
19 | "مسجد سپهسالار گذراند. از کلاس پنجم ابتدایی مطالعه رمان و آثار ادبی را شروع کرد. از همان زمان "
20 | "در دبیرستان ادب اصفهان ادامه تحصیل داد. پس از پایان تحصیلات دبیرستان در سال ۱۳۲۴ از اصفهان به تهران رفت و "
21 | "در رشته حقوق دانشگاه تهران مشغول به تحصیل شد."
22 | )
23 |
24 | normalizer = Normalizer()
25 | normalized_text = normalizer(input_text)
26 |
27 | albert_ner = NER()
28 | entities = albert_ner(normalized_text)
29 |
30 | for text, label in entities:
31 | print(f"{text} → {label}")
32 | ```
33 |
34 | ```shell
35 | شاهرخ مسکوب → PER
36 | سال ۱۳۰۴ → DAT
37 | بابل → LOC
38 | دوره ابتدایی → DAT
39 | تهران → LOC
40 | مدرسه علمیه → LOC
41 | مسجد سپهسالار → LOC
42 | دبیرستان ادب اصفهان → LOC
43 | در سال ۱۳۲۴ → DAT
44 | اصفهان → LOC
45 | تهران → LOC
46 | دانشگاه تهران → ORG
47 | فرانسه → LOC
48 | ```
49 |
50 | ## Entity Tags
51 |
52 | The following table summarizes the entity types used by the model (aggregating B- and I- tags):
53 |
54 | | Tag | Description |
55 | | ------- | ---------------------------------------- |
56 | | **PER** | Person names |
57 | | **LOC** | Locations (cities, countries, landmarks) |
58 | | **ORG** | Organizations (companies, institutions) |
59 | | **DAT** | Dates and temporal expressions |
60 | | **EVE** | Events (festivals, historical events) |
61 | | **O** | Outside (non-entity text) |
62 |
63 | ## Chaining with Pipelines
64 |
65 | You can seamlessly chain `NER` with other components using the `|` operator:
66 |
67 | ```python
68 | from shekar import NER
69 | from shekar import Normalizer
70 |
71 | normalizer = Normalizer()
72 | albert_ner = NER()
73 |
74 | ner_pipeline = normalizer | albert_ner
75 | entities = ner_pipeline(input_text)
76 |
77 | for text, label in entities:
78 | print(f"{text} → {label}")
79 | ```
80 |
81 | This chaining enables clean and readable code, letting you build custom NLP flows with preprocessing and tagging in one pass.
--------------------------------------------------------------------------------
/tests/unit/morphology/test_inflector.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.morphology.inflector import Inflector
3 | from shekar import data
4 |
5 |
6 | class TestInflector:
7 | @pytest.fixture
8 | def inflector(self):
9 | return Inflector()
10 |
11 | # Tests for comparative method
12 | def test_comparative_irregular(self, inflector):
13 | assert inflector.comparative("خوب") == "بهتر"
14 | assert inflector.comparative("که") == "کهتر"
15 | assert inflector.comparative("به") == "بهتر"
16 | assert inflector.comparative("کم") == "کمتر"
17 | assert inflector.comparative("بیش") == "بیشتر"
18 | assert inflector.comparative("مه") == "مهتر"
19 |
20 | def test_comparative_with_zwnj(self, inflector):
21 | assert inflector.comparative("ناراحت") == f"ناراحت{data.ZWNJ}تر"
22 | assert inflector.comparative("بزرگ") == f"بزرگ{data.ZWNJ}تر"
23 |
24 | def test_comparative_without_zwnj(self, inflector):
25 | # Test with letters that don't need ZWNJ
26 | for letter in data.non_left_joiner_letters:
27 | test_word = "تست" + letter
28 | assert inflector.comparative(test_word) == test_word + "تر"
29 |
30 | # Tests for superlative method
31 | def test_superlative_irregular(self, inflector):
32 | assert inflector.superlative("خوب") == "بهترین"
33 | assert inflector.superlative("که") == "کهترین"
34 | assert inflector.superlative("به") == "بهترین"
35 | assert inflector.superlative("کم") == "کمترین"
36 | assert inflector.superlative("بیش") == "بیشترین"
37 | assert inflector.superlative("مه") == "مهترین"
38 |
39 | def test_superlative_with_zwnj(self, inflector):
40 | assert inflector.superlative("ناراحت") == f"ناراحت{data.ZWNJ}ترین"
41 | assert inflector.superlative("بزرگ") == f"بزرگ{data.ZWNJ}ترین"
42 |
43 | def test_superlative_without_zwnj(self, inflector):
44 | # Test with letters that don't need ZWNJ
45 | for letter in data.non_left_joiner_letters:
46 | test_word = "تست" + letter
47 | assert inflector.superlative(test_word) == test_word + "ترین"
48 |
49 | # Tests for plural method
50 | def test_plural_with_zwnj(self, inflector):
51 | assert inflector.plural("کتاب") == f"کتاب{data.ZWNJ}ها"
52 | assert inflector.plural("درخت") == f"درخت{data.ZWNJ}ها"
53 |
54 | def test_plural_without_zwnj(self, inflector):
55 | assert inflector.plural("میز") == "میزها"
56 |
57 | # Test with letters that don't need ZWNJ
58 | for letter in data.non_left_joiner_letters:
59 | test_word = "تست" + letter
60 | assert inflector.plural(test_word) == test_word + "ها"
61 |
62 | def test_all_irregular_adjectives(self, inflector):
63 | # Test that all irregular adjectives in the dictionary work correctly
64 | for adj, (comp, sup) in inflector.irregular_adjectives.items():
65 | assert inflector.comparative(adj) == comp
66 | assert inflector.superlative(adj) == sup
67 |
--------------------------------------------------------------------------------
/shekar/keyword_extraction/rake.py:
--------------------------------------------------------------------------------
1 | from shekar import BaseTransform
2 | from shekar.preprocessing import (
3 | RemoveStopWords,
4 | RemovePunctuations,
5 | RemoveDigits,
6 | )
7 |
8 | from shekar.transforms import (
9 | Flatten,
10 | NGramExtractor,
11 | )
12 |
13 | from collections import defaultdict
14 | from shekar.tokenization import SentenceTokenizer, WordTokenizer
15 |
16 |
17 | class RAKE(BaseTransform):
18 | """
19 | Extracts keywords from text using tokenization, filtering, and frequency-based scoring.
20 | """
21 |
22 | def __init__(self, max_length=3, top_n=5):
23 | self._sentence_tokenizer = SentenceTokenizer()
24 | self._word_tokenizer = WordTokenizer()
25 | self._preprocessor = (
26 | RemoveStopWords(mask_token="|")
27 | | RemovePunctuations(mask_token="|")
28 | | RemoveDigits(mask_token="|")
29 | )
30 | self._ngram_extractor = NGramExtractor(range=(1, max_length)) | Flatten()
31 | self.top_n = top_n
32 | super().__init__()
33 |
34 | def _extract_phrases(self, text: str) -> list[str]:
35 | phrases = []
36 | for sentence in self._sentence_tokenizer.tokenize(text):
37 | clean_sentence = self._preprocessor(sentence)
38 | for phrase in (p.strip() for p in clean_sentence.split("|")):
39 | if phrase:
40 | ngrams = list(self._ngram_extractor(phrase))
41 | phrases.extend([ng for ng in ngrams if len(ng) > 2])
42 | return phrases
43 |
44 | def _calculate_word_scores(self, phrases: list[str]) -> dict[str, float]:
45 | word_frequency = defaultdict(int)
46 | word_degree = defaultdict(int)
47 | for phrase in phrases:
48 | words = [
49 | w.strip() for w in self._word_tokenizer.tokenize(phrase) if len(w) > 2
50 | ]
51 | degree = len(words) - 1
52 | for word in words:
53 | word_frequency[word] += 1
54 | word_degree[word] += degree
55 | return {
56 | word: (word_degree[word] + word_frequency[word]) / word_frequency[word]
57 | for word in word_frequency
58 | }
59 |
60 | def _generate_candidate_keyword_scores(
61 | self, phrases: list[str], word_scores: dict[str, float]
62 | ) -> dict[str, float]:
63 | candidates = {}
64 | for phrase in phrases:
65 | words = [
66 | w.strip() for w in self._word_tokenizer.tokenize(phrase) if len(w) > 2
67 | ]
68 | candidates[phrase] = sum(word_scores.get(word, 0) for word in words)
69 | return candidates
70 |
71 | def transform(self, X: str) -> list[str]:
72 | phrases = self._extract_phrases(X)
73 | word_scores = self._calculate_word_scores(phrases)
74 | candidates = self._generate_candidate_keyword_scores(phrases, word_scores)
75 | return [
76 | kw
77 | for kw, score in sorted(
78 | candidates.items(), key=lambda x: x[1], reverse=True
79 | )[: self.top_n]
80 | ]
81 |
--------------------------------------------------------------------------------
/shekar/data/files/stopwords.csv:
--------------------------------------------------------------------------------
1 | آخرین
2 | آره
3 | آری
4 | آقا
5 | آقای
6 | آقایان
7 | آن
8 | آنان
9 | آنجا
10 | آنها
11 | آنچه
12 | آنکه
13 | آیا
14 | ابتدا
15 | اثر
16 | اجرا
17 | اخیر
18 | از
19 | اش
20 | اغلب
21 | افراد
22 | البته
23 | ام
24 | اما
25 | امر
26 | امروز
27 | امکان
28 | اند
29 | او
30 | اول
31 | اولین
32 | اکنون
33 | اگر
34 | اگه
35 | ای
36 | ایشان
37 | ایشون
38 | ایم
39 | این
40 | اینجا
41 | اینکه
42 | با
43 | بار
44 | باز
45 | باعث
46 | بالا
47 | بالای
48 | باید
49 | بجز
50 | بخش
51 | بخشی
52 | بدون
53 | بر
54 | برابر
55 | براساس
56 | برای
57 | برخی
58 | بروز
59 | بسیار
60 | بسیاری
61 | بطور
62 | بعد
63 | بعضی
64 | بله
65 | بلکه
66 | بلی
67 | بنابراین
68 | به
69 | بهتر
70 | بهترین
71 | بی
72 | بیرون
73 | بیش
74 | بیشتر
75 | بیشتری
76 | بین
77 | تا
78 | تان
79 | تاکنون
80 | تحت
81 | تر
82 | ترین
83 | تعداد
84 | تعیین
85 | تمام
86 | تموم
87 | تمامی
88 | تنها
89 | تو
90 | توسط
91 | توی
92 | جا
93 | جای
94 | جایی
95 | جدا
96 | جدی
97 | جز
98 | جلوی
99 | جمع
100 | جمعی
101 | جهت
102 | حاضر
103 | حال
104 | حالا
105 | حالی
106 | حتی
107 | حد
108 | حداقل
109 | حدود
110 | حقیقتا
111 | حین
112 | خاص
113 | خصوص
114 | خطر
115 | خوب
116 | خوبی
117 | خود
118 | خودش
119 | خودم
120 | خودمان
121 | خودمون
122 | خویش
123 | خیلی
124 | داخل
125 | دارای
126 | در
127 | درباره
128 | درون
129 | درین
130 | دو
131 | دوباره
132 | دور
133 | دوم
134 | دچار
135 | دیگر
136 | دیگران
137 | دیگری
138 | را
139 | رو
140 | روبه
141 | روش
142 | روند
143 | روی
144 | زمانی
145 | زمینه
146 | زیاد
147 | زیادی
148 | زیر
149 | زیرا
150 | سایر
151 | سبب
152 | سراسر
153 | سری
154 | سمت
155 | سه
156 | سهم
157 | سوم
158 | سوی
159 | سپس
160 | شامل
161 | شان
162 | شاید
163 | شش
164 | شما
165 | شمار
166 | صرف
167 | صورت
168 | ضد
169 | ضمن
170 | طبق
171 | طریق
172 | طور
173 | طول
174 | طی
175 | عالی
176 | عدم
177 | علاوه
178 | علت
179 | علیرغم
180 | علیه
181 | عمل
182 | عموما
183 | عین
184 | غیر
185 | فرد
186 | فردی
187 | فعلا
188 | فقط
189 | فوق
190 | قابل
191 | قبل
192 | قصد
193 | لازم
194 | لحاظ
195 | لذا
196 | لطفا
197 | ما
198 | مان
199 | مانند
200 | متاسفانه
201 | مثل
202 | مثلا
203 | محسوب
204 | مدت
205 | مدتی
206 | مربوط
207 | مرسی
208 | مشخص
209 | مقابل
210 | ممکن
211 | من
212 | منظور
213 | مهم
214 | مواجه
215 | موارد
216 | موجب
217 | مورد
218 | مگر
219 | می
220 | میان
221 | ناشی
222 | نباید
223 | نحوه
224 | نخست
225 | نخستین
226 | نزدیک
227 | نسبت
228 | نشان
229 | نظر
230 | نظیر
231 | نه
232 | نوع
233 | نوعی
234 | نیاز
235 | نیز
236 | ها
237 | هایی
238 | هر
239 | هرگز
240 | هم
241 | همان
242 | همه
243 | همواره
244 | همچنان
245 | همچنین
246 | همچون
247 | همیشه
248 | همین
249 | هنوز
250 | هنگام
251 | هنگامی
252 | هیچ
253 | و
254 | واقعی
255 | وجود
256 | وسط
257 | وضع
258 | وقتی
259 | وقتیکه
260 | ولی
261 | وی
262 | پخش
263 | پر
264 | پس
265 | پشت
266 | پنج
267 | پی
268 | پیدا
269 | پیش
270 | پیشین
271 | چرا
272 | چطور
273 | چنان
274 | چند
275 | چندین
276 | چنین
277 | چه
278 | چهارم
279 | چون
280 | چگونه
281 | چیز
282 | چیزی
283 | کامل
284 | کاملا
285 | کجا
286 | کدام
287 | کس
288 | کسانی
289 | کسی
290 | کل
291 | کلی
292 | کم
293 | کنار
294 | کنونی
295 | که
296 | کی
297 | یا
298 | یعنی
299 | یک
300 | یکدیگر
301 | یکی
--------------------------------------------------------------------------------
/tests/unit/toxicity/test_logistic_offensive.py:
--------------------------------------------------------------------------------
1 | from shekar.toxicity import LogisticOffensiveClassifier
2 |
3 |
4 | class TestLogisticOffensiveClassifier:
5 | def setup_method(self):
6 | """Set up test fixtures before each test method."""
7 | self.classifier = LogisticOffensiveClassifier()
8 |
9 | def test_init_default_model(self):
10 | """Test initialization with default model."""
11 | classifier = LogisticOffensiveClassifier()
12 | assert classifier.session is not None
13 | assert classifier.id2label == {0: "neutral", 1: "offensive"}
14 | assert classifier.stopword_remover is not None
15 |
16 | def test_init_custom_model_path_none(self):
17 | """Test initialization with None model path."""
18 | classifier = LogisticOffensiveClassifier(model_path=None)
19 | assert classifier.session is not None
20 |
21 | def test_transform_neutral_text(self):
22 | """Test transform with neutral text from docstring example."""
23 | result = self.classifier.transform("این یک متن معمولی است.")
24 | label, confidence = result
25 | assert isinstance(label, str)
26 | assert label in ["neutral", "offensive"]
27 | assert isinstance(confidence, float)
28 | assert 0.0 <= confidence <= 1.0
29 |
30 | def test_transform_offensive_text(self):
31 | """Test transform with offensive text from docstring example."""
32 | result = self.classifier.transform("تو خیلی احمق و بیشرفی!")
33 | label, confidence = result
34 | assert isinstance(label, str)
35 | assert label in ["neutral", "offensive"]
36 | assert isinstance(confidence, float)
37 | assert 0.0 <= confidence <= 1.0
38 |
39 | def test_transform_empty_string(self):
40 | """Test transform with empty string."""
41 | result = self.classifier.transform("")
42 | label, confidence = result
43 | assert isinstance(label, str)
44 | assert label in ["neutral", "offensive"]
45 | assert isinstance(confidence, float)
46 | assert 0.0 <= confidence <= 1.0
47 |
48 | def test_transform_return_type(self):
49 | """Test that transform returns a tuple with correct types."""
50 | result = self.classifier.transform("test text")
51 | assert isinstance(result, tuple)
52 | assert len(result) == 2
53 | label, confidence = result
54 | assert isinstance(label, str)
55 | assert isinstance(confidence, float)
56 |
57 | def test_transform_confidence_range(self):
58 | """Test that confidence scores are within valid range."""
59 | texts = ["سلام", "متن تست", "hello world"]
60 | for text in texts:
61 | _, confidence = self.classifier.transform(text)
62 | assert 0.0 <= confidence <= 1.0
63 |
64 | def test_multiple_transforms_consistency(self):
65 | """Test that multiple transforms of the same text return consistent results."""
66 | text = "این یک متن تست است"
67 | result1 = self.classifier.transform(text)
68 | result2 = self.classifier.transform(text)
69 | assert result1 == result2
70 |
--------------------------------------------------------------------------------
/tests/unit/embeddings/test_word_embedder.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | import numpy as np
3 | import pickle
4 |
5 | from shekar.embeddings.word_embedder import WordEmbedder
6 |
7 |
8 | @pytest.fixture
9 | def dummy_model_path(tmp_path):
10 | """Create a dummy embedding model pickle file for testing."""
11 | model_data = {
12 | "words": ["سیب", "موز", "هلو"],
13 | "embeddings": np.array(
14 | [[1.0, 0.0, 0.0], [0.0, 1.0, 0.0], [1.0, 1.0, 0.0]], dtype=np.float32
15 | ),
16 | "vector_size": 3,
17 | "window": 5,
18 | "model": "fasttext",
19 | "epochs": 10,
20 | "dataset": "dummy",
21 | }
22 | file_path = tmp_path / "dummy_model.pkl"
23 | with open(file_path, "wb") as f:
24 | pickle.dump(model_data, f)
25 | return file_path
26 |
27 |
28 | def test_invalid_model_name_raises():
29 | with pytest.raises(ValueError):
30 | WordEmbedder(model="unknown-model")
31 |
32 |
33 | def test_embed_known_token(dummy_model_path):
34 | we = WordEmbedder(model="fasttext-d100", model_path=dummy_model_path)
35 | vec = we.embed("سیب")
36 | assert isinstance(vec, np.ndarray)
37 | assert np.allclose(vec, np.array([1.0, 0.0, 0.0], dtype=np.float32))
38 |
39 |
40 | @pytest.mark.parametrize("oov_strategy", ["zero", "none", "error"])
41 | def test_embed_oov_strategies(dummy_model_path, oov_strategy):
42 | we = WordEmbedder(
43 | model="fasttext-d100", model_path=dummy_model_path, oov_strategy=oov_strategy
44 | )
45 | token = "ناشناخته"
46 | if oov_strategy == "zero":
47 | vec = we.embed(token)
48 | assert isinstance(vec, np.ndarray)
49 | assert np.allclose(vec, np.zeros(3))
50 | elif oov_strategy == "none":
51 | assert we.embed(token) is None
52 | elif oov_strategy == "error":
53 | with pytest.raises(KeyError):
54 | we.embed(token)
55 |
56 |
57 | def test_transform_is_alias_of_embed(dummy_model_path):
58 | we = WordEmbedder(model="fasttext-d100", model_path=dummy_model_path)
59 | token = "موز"
60 | assert np.allclose(we.transform(token), we.embed(token))
61 |
62 |
63 | def test_similarity_between_tokens(dummy_model_path):
64 | we = WordEmbedder(model="fasttext-d100", model_path=dummy_model_path)
65 | sim = we.similarity("سیب", "هلو")
66 | # Cosine similarity of [1,0,0] and [1,1,0] is 1 / sqrt(2)
67 | assert np.isclose(sim, 1 / np.sqrt(2), atol=1e-6)
68 |
69 |
70 | def test_most_similar_returns_sorted_list(dummy_model_path):
71 | we = WordEmbedder(model="fasttext-d100", model_path=dummy_model_path)
72 | result = we.most_similar("سیب", top_n=2)
73 | assert isinstance(result, list)
74 | assert all(isinstance(item, tuple) and len(item) == 2 for item in result)
75 | # Ensure it's sorted by similarity
76 | sims = [s for _, s in result]
77 | assert sims == sorted(sims, reverse=True)
78 | # Check top_n limit
79 | assert len(result) == 2
80 |
81 |
82 | def test_most_similar_empty_for_oov(dummy_model_path):
83 | we = WordEmbedder(
84 | model="fasttext-d100", model_path=dummy_model_path, oov_strategy="none"
85 | )
86 | assert we.most_similar("ناشناخته") == []
87 |
--------------------------------------------------------------------------------
/shekar/pos/albert_pos.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTransform
2 | from shekar.tokenization import AlbertTokenizer, WordTokenizer
3 | from shekar.hub import Hub
4 | from pathlib import Path
5 | import onnxruntime
6 | import numpy as np
7 | from shekar.utils import get_onnx_providers
8 |
9 |
10 | class AlbertPOS(BaseTransform):
11 | def __init__(self, model_path: str | Path = None):
12 | super().__init__()
13 | resource_name = "albert_persian_pos_q8.onnx"
14 | if model_path is None or not Path(model_path).exists():
15 | model_path = Hub.get_resource(file_name=resource_name)
16 |
17 | self.session = onnxruntime.InferenceSession(
18 | model_path, providers=get_onnx_providers()
19 | )
20 | self.tokenizer = AlbertTokenizer()
21 | self.word_tokenizer = WordTokenizer()
22 |
23 | self.id2tag = {
24 | 0: "ADJ",
25 | 1: "ADP",
26 | 2: "ADV",
27 | 3: "AUX",
28 | 4: "CCONJ",
29 | 5: "DET",
30 | 6: "INTJ",
31 | 7: "NOUN",
32 | 8: "NUM",
33 | 9: "PART",
34 | 10: "PRON",
35 | 11: "PROPN",
36 | 12: "PUNCT",
37 | 13: "SCONJ",
38 | 14: "VERB",
39 | 15: "X",
40 | 16: "_",
41 | }
42 |
43 | def transform(self, text: str) -> list:
44 | words = self.word_tokenizer(text)
45 | tokens = []
46 | word_ids = []
47 | for word in words:
48 | encoded = self.tokenizer.tokenizer.encode(word, add_special_tokens=False)
49 | tokens.extend(encoded.tokens)
50 | word_ids.extend([word] * len(encoded.tokens))
51 |
52 | # Convert to IDs
53 | input_ids = []
54 | for token in tokens:
55 | token_id = self.tokenizer.tokenizer.token_to_id(token)
56 | if token_id is None:
57 | token_id = self.tokenizer.pad_token_id
58 | input_ids.append(token_id)
59 |
60 | attention_mask = [1] * len(input_ids)
61 | # Pad to max length (optional or if needed)
62 | pad_len = self.tokenizer.model_max_length - len(input_ids)
63 | input_ids += (
64 | [self.tokenizer.pad_token_id] * pad_len
65 | ) # Using self.tokenizer.pad_token_id as the padding token ID for ALBERT
66 | attention_mask += [0] * pad_len
67 |
68 | inputs = {
69 | "input_ids": np.array([input_ids], dtype=np.int64),
70 | "attention_mask": np.array([attention_mask], dtype=np.int64),
71 | }
72 |
73 | outputs = self.session.run(None, inputs)
74 | logits = outputs[0]
75 | logits = logits[0, : len(tokens), :]
76 | tags_ids = np.argmax(logits, axis=-1)
77 | tags = [self.id2tag[tag] for tag in tags_ids]
78 |
79 | final_preds = []
80 | match_words = []
81 | prev_word = None
82 | for token, word, pred_tag in zip(tokens, word_ids, tags):
83 | if word != prev_word:
84 | final_preds.append(pred_tag)
85 | match_words.append(word)
86 | prev_word = word
87 |
88 | return list(zip(match_words, final_preds))
89 |
--------------------------------------------------------------------------------
/tests/unit/embeddings/test_base_embedder.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import pytest
3 |
4 |
5 | from shekar.embeddings.base import BaseEmbedder
6 |
7 |
8 | class DummyEmbedder(BaseEmbedder):
9 | """A tiny concrete embedder for testing."""
10 |
11 | def __init__(self, table=None, dim=3):
12 | self.table = table or {}
13 | self.dim = dim
14 | self.calls = 0
15 |
16 | def embed(self, text: str) -> np.ndarray:
17 | self.calls += 1
18 | vec = self.table.get(text)
19 | if vec is None:
20 | return np.zeros(self.dim, dtype=np.float32)
21 | return np.asarray(vec, dtype=np.float32)
22 |
23 | def transform(self, X):
24 | """Dummy implementation required by BaseTransform."""
25 | if isinstance(X, str):
26 | return self.embed(X)
27 | return [self.embed(x) for x in X]
28 |
29 |
30 | def test_base_embedder_is_abstract():
31 | with pytest.raises(TypeError):
32 | BaseEmbedder()
33 |
34 |
35 | @pytest.mark.parametrize(
36 | "v1, v2, expected",
37 | [
38 | (np.array([1.0, 0.0]), np.array([1.0, 0.0]), 1.0), # identical
39 | (np.array([1.0, 0.0]), np.array([0.0, 1.0]), 0.0), # orthogonal
40 | (
41 | np.array([1.0, 1.0]),
42 | np.array([2.0, 2.0]),
43 | 1.0,
44 | ), # same direction different magnitude
45 | ],
46 | )
47 | def test_cosine_similarity_basic(v1, v2, expected):
48 | e = DummyEmbedder()
49 | got = e._cosine_similarity(v1, v2)
50 | assert np.isclose(got, expected, atol=1e-7)
51 |
52 |
53 | def test_cosine_similarity_with_zero_vector_returns_0():
54 | e = DummyEmbedder()
55 | v1 = np.array([0.0, 0.0])
56 | v2 = np.array([1.0, 0.0])
57 | assert e._cosine_similarity(v1, v2) == 0.0
58 | assert e._cosine_similarity(v2, v1) == 0.0
59 |
60 |
61 | @pytest.mark.parametrize(
62 | "v1, v2",
63 | [
64 | (None, np.array([1.0, 0.0])),
65 | (np.array([1.0, 0.0]), None),
66 | (None, None),
67 | ([1.0, 0.0], np.array([1.0, 0.0])),
68 | ],
69 | )
70 | def test_cosine_similarity_invalid_inputs_return_0(v1, v2):
71 | e = DummyEmbedder()
72 | assert e._cosine_similarity(v1, v2) == 0.0
73 |
74 |
75 | def test_similarity_uses_embed_and_returns_expected_value():
76 | table = {
77 | "a": np.array([1.0, 0.0, 0.0]),
78 | "b": np.array([0.0, 1.0, 0.0]),
79 | "c": np.array([1.0, 0.0, 0.0]),
80 | }
81 | e = DummyEmbedder(table=table, dim=3)
82 |
83 | # a vs c should be 1.0, a vs b should be 0.0
84 | assert np.isclose(e.similarity("a", "c"), 1.0)
85 | assert np.isclose(e.similarity("a", "b"), 0.0)
86 |
87 | # OOV vs a -> zero vector vs a -> 0.0
88 | assert np.isclose(e.similarity("oov", "a"), 0.0)
89 |
90 | # embed must have been called twice for each similarity call
91 | # 3 similarity calls * 2 = 6
92 | assert e.calls == 6
93 |
94 |
95 | def test_similarity_returns_float():
96 | table = {"hello": np.array([1.0, 2.0, 3.0])}
97 | e = DummyEmbedder(table=table, dim=3)
98 | sim = e.similarity("hello", "hello")
99 | assert isinstance(sim, float)
100 |
--------------------------------------------------------------------------------
/shekar/utils.py:
--------------------------------------------------------------------------------
1 | import re
2 | import onnxruntime as ort
3 |
4 |
5 | def is_informal(text, threshold=1) -> bool:
6 | """
7 | Classifies Persian text into formal or informal based on predefined regex patterns and counts the number of informal matches.
8 | This function is an implementation of:
9 | https://fa.wikipedia.org/wiki/%D9%88%DB%8C%DA%A9%DB%8C%E2%80%8C%D9%BE%D8%AF%DB%8C%D8%A7:%D8%A7%D8%B4%D8%AA%D8%A8%D8%A7%D9%87%E2%80%8C%DB%8C%D8%A7%D8%A8/%D9%81%D9%87%D8%B1%D8%B3%D8%AA/%D8%BA%DB%8C%D8%B1%D8%B1%D8%B3%D9%85%DB%8C
10 |
11 | Args:
12 | text (str): The input Persian text.
13 |
14 | Returns:
15 | tuple: True or False
16 | """
17 | informal_patterns = [
18 | r"(?:ن?می? ?|ب|ن)(?:[یا]فشون|پاشون|پرورون|پرون|پوسون|پوشون|پیچون|تابون|تازون|ترسون|ترکون|تکون|تونست|جنبون|جوشون|چپون|چربون|چرخون|چرون|چسبون|چشون|چکون|چلون|خارون|خراشون|خشکون|خندون|خوابون|خورون|خون|خیسون|درخشون|رسون|رقصون|رنجون|رون|دون|سابون|ستون|سوزون|ش|شورون|غلتون|فهمون|کوبون|گذرون|گردون|گریون|گزین|گسترون|گنجون|لرزون|لغزون|لمبون|مالون|ا?نداز|نشون|هراسون|وزون)(?:م|ی|ه|یم|ید|ن)",
19 | r"(?:ن?می? ?|ب|ن)(?:چا|خا|خوا)(?:م|ی|د|یم|ید|ن)",
20 | r"(?:ن?می? ?|ب)(?:مون|شین|گ)(?:م|ی|ه|یم|ید|ن)",
21 | r"(?:ن?می? ?|ن)(?:دون|د|تون)(?:م|ی|ه|یم|ید|ن)",
22 | r"(?:نمی? ?|ن)(?:یا)(?:م|ه|یم|ید|ن)",
23 | r"(?:می? ?)(?:ر)(?:م|ی|ه|یم|ید|ن)",
24 | r"(?:ن?می? ?|ب|ن)(?:در|پا|کاه|گا|ایست)ن",
25 | r"(?:ن?می? ?|ب|ن)دون(?:م|ی|ه|یم|ید|ن)",
26 | r"(?:ازش|اونه?ا|ایشون|اینجوری?|این[وه]|بازم|باهاش|براتون|برام|بهش|بیخیال|تموم|چ?جوری|چیه|دیگه|کدوم|مونده|زبون|همینه)",
27 | r"(?:آروم|آشیونه|آشیون|اومدم|برم|اونه|اون|ایرونی|اینا|بادمجون|بدونیم|بذار|بریم|بشیم|بشین|بنداز|بچگونه|بیابون|بیگیر|تهرون|تونستم|خمیردندون|خودتون|خودشون|خودمونی|خودمون)",
28 | r"(?:خوروندن|خونه|خیابون|داره|داروخونه|داغون|دخترونه|دندون|رودخونه|زمونه|زنونه|سوزوندن|قلیون|مردونه|مهمون|موندم|میام|میونه|میون|میدونیم|نتونستم|ندونیم)",
29 | r"(?:نذار|نریم|نسوزوندن|نشونه|نشون|نموندم|نمیاد|نمیام|نمیان|نمیایم|نمیاین|نمیای|نمیدونید|نمیدونیم|نمیدونین|نیستن|نیومدم|هستن|همزبون|همشون|پسرونه|پشت بوم|کوچیک|تمومه)",
30 | ]
31 |
32 | match_count = 0
33 |
34 | for pattern in informal_patterns:
35 | matches = re.findall(pattern, text)
36 | match_count += len(matches)
37 |
38 | classification = True if match_count >= threshold else False
39 | return classification
40 |
41 |
42 | def get_onnx_providers() -> list[str]:
43 | """
44 | Get the list of available ONNX Runtime execution providers, prioritizing GPU providers if available.
45 | This function checks for the presence of various execution providers and returns a list ordered by preference.
46 | Returns:
47 | list: A list of available ONNX Runtime execution providers ordered by preference.
48 | """
49 |
50 | PREFERRED = [
51 | "TensorrtExecutionProvider", # NVIDIA TensorRT
52 | "CUDAExecutionProvider", # NVIDIA CUDA
53 | "ROCMExecutionProvider", # AMD ROCm (Linux)
54 | "DmlExecutionProvider", # Windows DirectML
55 | "OpenVINOExecutionProvider", # Intel CPU/iGPU
56 | "CoreMLExecutionProvider", # macOS
57 | "CPUExecutionProvider", # always last
58 | ]
59 |
60 | available = ort.get_available_providers()
61 | providers = [ep for ep in PREFERRED if ep in available]
62 | return providers
63 |
--------------------------------------------------------------------------------
/shekar/preprocessing/normalizers/alphabet_normalizer.py:
--------------------------------------------------------------------------------
1 | from shekar.base import BaseTextTransform
2 |
3 |
4 | class AlphabetNormalizer(BaseTextTransform):
5 | """
6 | A text transformation class for normalizing Arabic/Urdu characters to Persian characters.
7 |
8 | This class inherits from `BaseTextTransform` and provides functionality to replace
9 | various Arabic/Urdu characters with their Persian equivalents. It uses predefined mappings
10 | to substitute characters such as different forms of "ی", "ک", and other Arabic letters
11 | with their standard Persian representations.
12 |
13 | The `AlphabetNormalizer` class includes `fit` and `fit_transform` methods, and it
14 | is callable, allowing direct application to text data.
15 |
16 | Methods:
17 |
18 | fit(X, y=None):
19 | Fits the transformer to the input data.
20 | transform(X, y=None):
21 | Transforms the input data by normalizing Arabic/Urdu characters to Persian.
22 | fit_transform(X, y=None):
23 | Fits the transformer to the input data and applies the transformation.
24 |
25 | __call__(text: str) -> str:
26 | Allows the class to be called as a function, applying the transformation
27 | to the input text.
28 |
29 | Example:
30 | >>> alphabet_normalizer = AlphabetNormalizer()
31 | >>> normalized_text = alphabet_normalizer("ۿدف ما ػمګ بۃ ێڪډيڱڕ إښټ")
32 | >>> print(normalized_text)
33 | "هدف ما کمک به یکدیگر است"
34 | """
35 |
36 | def __init__(self):
37 | super().__init__()
38 | self.character_mappings = [
39 | (r"[ﺁﺂ]", "آ"),
40 | (r"[أٲٵ]", "أ"),
41 | (r"[ﭐﭑٳﺇﺈإٱ]", "ا"),
42 | (r"[ؠٮٻڀݐݒݔݕݖﭒﭕﺏﺒ]", "ب"),
43 | (r"[ﭖﭗﭘﭙﭚﭛﭜﭝ]", "پ"),
44 | (r"[ٹٺټٿݓﭞﭟﭠﭡﭦﭨﺕﺘ]", "ت"),
45 | (r"[ٽݑﺙﺚﺛﺜﭢﭤ]", "ث"),
46 | (r"[ڃڄﭲﭴﭵﭷﺝﺟﺠ]", "ج"),
47 | (r"[ڇڿﭺݘﭼﮀﮁݯ]", "چ"),
48 | (r"[ځڂڅݗݮﺡﺤ]", "ح"),
49 | (r"[ﺥﺦﺧ]", "خ"),
50 | (r"[ڈډڊڋڍۮݙݚﮂﮈﺩ]", "د"),
51 | (r"[ڌﱛﺫﺬڎڏڐﮅﮇ]", "ذ"),
52 | (r"[ڑڒړڔڕږۯݛﮌﺭ]", "ر"),
53 | (r"[ڗݫﺯﺰ]", "ز"),
54 | (r"[ڙﮊﮋ]", "ژ"),
55 | (r"[ښڛﺱﺴ]", "س"),
56 | (r"[ڜۺﺵﺸݜݭ]", "ش"),
57 | (r"[ڝڞﺹﺼ]", "ص"),
58 | (r"[ۻﺽﻀ]", "ض"),
59 | (r"[ﻁﻃﻄ]", "ط"),
60 | (r"[ﻅﻆﻈڟ]", "ظ"),
61 | (r"[ڠݝݞݟﻉﻊﻋ]", "ع"),
62 | (r"[ۼﻍﻎﻐ]", "غ"),
63 | (r"[ڡڢڣڤڥڦݠݡﭪﭫﭬﻑﻒﻓ]", "ف"),
64 | (r"[ٯڧڨﻕﻗ]", "ق"),
65 | (r"[كػؼڪګڬڭڮݢݣﮎﮐﯓﻙﻛ]", "ک"),
66 | (r"[ڰڱڲڳڴﮒﮔﮖ]", "گ"),
67 | (r"[ڵڶڷڸݪﻝﻠ]", "ل"),
68 | (r"[۾ݥݦﻡﻢﻣ]", "م"),
69 | (r"[ڹںڻڼڽݧݨݩﮞﻥﻧ]", "ن"),
70 | (r"[ﯝٷﯗﯘﺅٶ]", "ؤ"),
71 | (r"[ﯙﯚﯜﯞﯟۄۅۉۊۋۏﯠﻭפ]", "و"),
72 | (r"[ﮤۂ]", "ۀ"),
73 | (r"[ھۿہۃەﮦﮧﮨﮩﻩﻫة]", "ه"),
74 | (r"[ﮰﮱٸۓ]", "ئ"),
75 | (r"[ﯷﯹ]", "ئی"),
76 | (r"[ﯻ]", "ئد"),
77 | (r"[ﯫ]", "ئا"),
78 | (r"[ﯭ]", "ئه"),
79 | (r"[ﯰﯵﯳ]", "ئو"),
80 | (
81 | r"[ؽؾؿىيۍێېۑےﮮﮯﯤﯥﯦﯧﯼﯽﯾﯿﻯﻱﻳﯨﯩﱝ]",
82 | "ی",
83 | ),
84 | ]
85 |
86 | self._patterns = self._compile_patterns(self.character_mappings)
87 |
88 | def _function(self, X, y=None):
89 | return self._map_patterns(X, self._patterns)
90 |
--------------------------------------------------------------------------------
/mkdocs.yml:
--------------------------------------------------------------------------------
1 | site_name: shekar
2 | site_description: Simplifying Persian NLP for Modern Applications
3 | repo_url: https://github.com/amirivojdan/shekar/
4 | theme:
5 | name: material
6 | custom_dir: docs/assets/overrides
7 | features:
8 | - search.share
9 | - navigation.path
10 | - navigation.indexes
11 | - navigation.tabs
12 | - navigation.sections
13 | - navigation.expand
14 | - content.code.copy
15 | icon:
16 | repo: fontawesome/brands/github
17 | logo: assets/images/favicon.png
18 | palette:
19 | primary: custom
20 |
21 | extra_css:
22 | - assets/stylesheets/extra.css
23 |
24 | repo_name: amirivojdan/shekar
25 | nav:
26 | - Home:
27 | - Overview: index.md
28 | - Installation: getting_started/installation.md
29 | - Quick Start: getting_started/quick_start.md
30 | - CLI: tutorials/cli.md
31 | - Preprocessing: tutorials/preprocessing.md
32 | - Pipeline: tutorials/pipeline.md
33 | - Tokenization: tutorials/tokenization.md
34 | - Normalization: tutorials/normalization.md
35 | - Embeddings: tutorials/embeddings.md
36 | - Part-of-Speech Tagging: tutorials/pos.md
37 | - Named Entity Recognition: tutorials/ner.md
38 | - Keyword Extraction: tutorials/keyword_extraction.md
39 | - Spell Checking: tutorials/spell_checking.md
40 | - Visualization: tutorials/visualization.md
41 |
42 | plugins:
43 | - search
44 | - i18n:
45 | docs_structure: folder
46 | fallback_to_default: true
47 | reconfigure_material: true
48 | reconfigure_search: true
49 | languages:
50 | - locale: en
51 | name: English
52 | build: true
53 | default: true
54 | - locale: fa
55 | name: فارسی
56 | site_name: شکر
57 | site_description: سادهسازی پردازش زبان فارسی برای کاربردهای نوین
58 | build: true
59 | nav_translations:
60 | Home: خانه
61 | Overview: مرور کلی
62 | Installation: نصب
63 | Quick Start: شروع سریع
64 | CLI: رابط خط فرمان
65 | Preprocessing: پیشپردازش
66 | Pipeline: زنجیرۀ پردازش
67 | Tokenization: بخشبندی واژگانی/جملهای
68 | Normalization: یکنواختسازی متن
69 | Embeddings: بازنمایی واژهها و جملات
70 | Part-of-Speech Tagging: برچسبگذاری نقشهای دستوری
71 | Named Entity Recognition: شناسایی موجودیتهای نامدار
72 | Keyword Extraction: کلیدواژهیابی
73 | Spell Checking: غلطیابی املایی
74 | Visualization: بصریسازی
75 |
76 |
77 | - termynal:
78 | title: bash
79 | buttons: macos
80 | prompt_literal_start:
81 | - "$"
82 |
83 |
84 | markdown_extensions:
85 | - admonition
86 | - codehilite
87 | - pymdownx.highlight:
88 | anchor_linenums: true
89 | line_spans: __span
90 | pygments_lang_class: true
91 | - pymdownx.inlinehilite
92 | - pymdownx.snippets
93 | - pymdownx.superfences
94 | - pymdownx.highlight
95 | - pymdownx.inlinehilite
96 | - pymdownx.emoji:
97 | emoji_index: !!python/name:material.extensions.emoji.twemoji
98 | emoji_generator: !!python/name:material.extensions.emoji.to_svg
99 |
100 | extra:
101 | generator: false
102 | social:
103 | - icon: fontawesome/brands/github
104 | link: https://github.com/amirivojdan/shekar
105 | name: GitHub
106 |
--------------------------------------------------------------------------------
/examples/keyword_extraction.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "code",
5 | "execution_count": null,
6 | "id": "cae799c9",
7 | "metadata": {},
8 | "outputs": [],
9 | "source": [
10 | "!pip install shekar"
11 | ]
12 | },
13 | {
14 | "cell_type": "code",
15 | "execution_count": 6,
16 | "id": "d14df880",
17 | "metadata": {},
18 | "outputs": [
19 | {
20 | "name": "stdout",
21 | "output_type": "stream",
22 | "text": [
23 | "\n",
24 | "\n",
25 | "\n",
26 | "\n",
27 | ">> stemmer = Stemmer()
13 | >>> stemmer("کتابها")
14 | "کتاب"
15 | >>> stemmer("نوهام")
16 | "نوه"
17 |
18 | """
19 |
20 | def __init__(self):
21 | super().__init__()
22 |
23 | ZWNJ = re.escape(data.ZWNJ)
24 | NLJ_CLASS = "[" + "".join(map(re.escape, data.non_left_joiner_letters)) + "]"
25 |
26 | self._possessive_mappings = [
27 | # possessive clitics: remove if joined by ZWNJ or base ends with a non-left-joiner
28 | (rf"(?:(?:{ZWNJ})|(?<={NLJ_CLASS}))(?:مان|تان|ام|ات|شان)$", ""),
29 | (
30 | rf"(?:(?:{ZWNJ})|(?<={NLJ_CLASS}))(?:هایشان|هایش|هایت|هایم|هایتان|هایمان)$",
31 | "",
32 | ),
33 | (
34 | rf"(?:(?:{ZWNJ})|(?<={NLJ_CLASS}))(?:هاشون|هاش|هات|هام|هاتون|هامون)$",
35 | "",
36 | ), # informal plurals
37 | (rf"(?:{ZWNJ})?(?:م|ت|ش)$", ""),
38 | ]
39 |
40 | self._plural_mappings = [
41 | # plurals: remove if joined by ZWNJ or base ends with a non-left-joiner
42 | (rf"(?:(?:{ZWNJ})|(?<={NLJ_CLASS}))(?:هایی|های|ها)$", ""),
43 | (r"(?<=.{2})(? str:
73 | # special cases not plural but eding with "ان"
74 | if (
75 | text in data.vocab
76 | and text.endswith("ان")
77 | and not text.endswith("یان")
78 | and not text.endswith("گان")
79 | ):
80 | return text
81 |
82 | for patterns in self._all_patterns:
83 | stem = self._map_patterns(text, patterns)
84 |
85 | if stem != text and len(stem) > 2 and stem in data.vocab:
86 | if stem in data.informal_words:
87 | stem = data.informal_words[stem]
88 | return stem
89 |
90 | if text in data.informal_words:
91 | return data.informal_words[text]
92 |
93 | return text
94 |
--------------------------------------------------------------------------------
/shekar/preprocessing/maskers/__init__.py:
--------------------------------------------------------------------------------
1 | from .email_masker import EmailMasker
2 | from .url_masker import URLMasker
3 | from .diacritic_masker import DiacriticMasker
4 | from .non_persian_letter_masker import NonPersianLetterMasker
5 | from .emoji_masker import EmojiMasker
6 | from .punctuation_masker import PunctuationMasker
7 | from .stopword_masker import StopWordMasker
8 | from .hashtag_masker import HashtagMasker
9 | from .mention_masker import MentionMasker
10 | from .digit_masker import DigitMasker
11 | from .html_tag_masker import HTMLTagMasker
12 | from .offensive_word_masker import OffensiveWordMasker
13 |
14 | # aliases
15 | DiacriticRemover = DiacriticMasker
16 | EmojiRemover = EmojiMasker
17 | NonPersianRemover = NonPersianLetterMasker
18 | PunctuationRemover = PunctuationMasker
19 | StopWordRemover = StopWordMasker
20 | HashtagRemover = HashtagMasker
21 | MentionRemover = MentionMasker
22 | DigitRemover = DigitMasker
23 | HTMLTagRemover = HTMLTagMasker
24 | EmailRemover = EmailMasker
25 | URLRemover = URLMasker
26 | OffensiveWordRemover = OffensiveWordMasker
27 |
28 |
29 | # action-based remover aliases
30 | RemoveDiacritics = DiacriticMasker
31 | RemoveEmojis = EmojiMasker
32 | RemoveNonPersianLetters = NonPersianLetterMasker
33 | RemovePunctuations = PunctuationMasker
34 | RemoveStopWords = StopWordMasker
35 | RemoveHashtags = HashtagMasker
36 | RemoveMentions = MentionMasker
37 | RemoveDigits = DigitMasker
38 | RemoveHTMLTags = HTMLTagMasker
39 | RemoveEmails = EmailMasker
40 | RemoveURLs = URLMasker
41 | RemoveOffensiveWords = OffensiveWordMasker
42 |
43 | # action-based Masker aliases
44 | MaskEmails = EmailMasker
45 | MaskURLs = URLMasker
46 | MaskEmojis = EmojiMasker
47 | MaskDigits = DigitMasker
48 | MaskPunctuations = PunctuationMasker
49 | MaskNonPersianLetters = NonPersianLetterMasker
50 | MaskStopWords = StopWordMasker
51 | MaskHashtags = HashtagMasker
52 | MaskMentions = MentionMasker
53 | MaskDiacritics = DiacriticMasker
54 | MaskHTMLTags = HTMLTagMasker
55 | MaskOffensiveWords = OffensiveWordMasker
56 |
57 |
58 | __all__ = [
59 | "DiacriticMasker",
60 | "EmojiMasker",
61 | "NonPersianLetterMasker",
62 | "PunctuationMasker",
63 | "StopWordMasker",
64 | "HashtagMasker",
65 | "MentionMasker",
66 | "DigitMasker",
67 | "RepeatedLetterMasker",
68 | "HTMLTagMasker",
69 | "EmailMasker",
70 | "URLMasker",
71 | "OffensiveWordMasker",
72 | # aliases
73 | "DiacriticRemover",
74 | "EmojiRemover",
75 | "NonPersianRemover",
76 | "PunctuationRemover",
77 | "StopWordRemover",
78 | "HashtagRemover",
79 | "MentionRemover",
80 | "DigitRemover",
81 | "HTMLTagRemover",
82 | "EmailRemover",
83 | "URLRemover",
84 | "OffensiveWordRemover",
85 | # action-based aliases
86 | "RemoveDiacritics",
87 | "RemoveEmojis",
88 | "RemoveNonPersianLetters",
89 | "RemovePunctuations",
90 | "RemoveStopWords",
91 | "RemoveHashtags",
92 | "RemoveMentions",
93 | "RemoveDigits",
94 | "RemoveHTMLTags",
95 | "RemoveEmails",
96 | "RemoveURLs",
97 | "RemoveOffensiveWords",
98 | # Maskers
99 | "MaskEmails",
100 | "MaskURLs",
101 | "MaskEmojis",
102 | "MaskDigits",
103 | "MaskPunctuations",
104 | "MaskNonPersianLetters",
105 | "MaskStopWords",
106 | "MaskHashtags",
107 | "MaskMentions",
108 | "MaskDiacritics",
109 | "MaskHTMLTags",
110 | "MaskOffensiveWords",
111 | ]
112 |
--------------------------------------------------------------------------------
/shekar/tokenization/albert_tokenizer.py:
--------------------------------------------------------------------------------
1 | from pathlib import Path
2 | from typing import Optional, Dict, Any
3 | import numpy as np
4 | from tokenizers import Tokenizer
5 | from shekar.base import BaseTransform
6 | from shekar.hub import Hub
7 |
8 |
9 | class AlbertTokenizer(BaseTransform):
10 | """
11 | Tokenize text with an ALBERT tokenizer and return fixed-length chunks.
12 |
13 | - Splits long inputs into multiple chunks of size `model_max_length`
14 | - Adds special tokens per tokenizer's post-processor
15 | - Returns stacked NumPy arrays ready for model input
16 | """
17 |
18 | def __init__(
19 | self,
20 | model_path: Optional[str | Path] = None,
21 | enable_padding: bool = False,
22 | enable_truncation: bool = False,
23 | stride: int = 0,
24 | ):
25 | super().__init__()
26 | resource_name = "albert_persian_tokenizer.json"
27 |
28 | if model_path is None or not Path(model_path).exists():
29 | model_path = Hub.get_resource(file_name=resource_name)
30 |
31 | self.tokenizer = Tokenizer.from_file(str(model_path))
32 |
33 | self.pad_token = ""
34 | self.unk_token = ""
35 |
36 | pad_id = self.tokenizer.token_to_id(self.pad_token)
37 | if pad_id is None:
38 | # Safely register a pad token if it was not present in the vocab
39 | self.tokenizer.add_special_tokens([self.pad_token])
40 | pad_id = self.tokenizer.token_to_id(self.pad_token)
41 |
42 | self.pad_token_id = pad_id
43 | self.unk_token_id = self.tokenizer.token_to_id(self.unk_token)
44 | self.model_max_length = 512
45 | self.stride = stride
46 |
47 | if enable_truncation:
48 | self.tokenizer.enable_truncation(
49 | max_length=self.model_max_length,
50 | stride=self.stride,
51 | )
52 |
53 | if enable_padding:
54 | self.tokenizer.enable_padding(
55 | length=self.model_max_length,
56 | pad_id=self.pad_token_id,
57 | pad_token=self.pad_token,
58 | pad_type_id=0,
59 | direction="right",
60 | )
61 |
62 | def transform(self, X: str) -> Dict[str, Any]:
63 | """
64 | Tokenize `X` into one or more chunks of size `model_max_length`.
65 |
66 | Args:
67 | X: Input text.
68 |
69 | Returns:
70 | dict with:
71 | - input_ids: np.ndarray[int64] of shape (num_chunks, model_max_length)
72 | - attention_mask: np.ndarray[int64] of shape (num_chunks, model_max_length)
73 | - token_type_ids: np.ndarray[int64] of shape (num_chunks, model_max_length)
74 | - num_chunks: int
75 | """
76 |
77 | first = self.tokenizer.encode(X)
78 | overflow = list(getattr(first, "overflowing", []))
79 | encodings = [first] + overflow
80 |
81 | input_ids = np.stack(
82 | [np.asarray(enc.ids, dtype=np.int64) for enc in encodings], axis=0
83 | )
84 | attention_mask = np.stack(
85 | [np.asarray(enc.attention_mask, dtype=np.int64) for enc in encodings],
86 | axis=0,
87 | )
88 |
89 | token_type_ids = np.stack(
90 | [np.asarray(enc.type_ids, dtype=np.int64) for enc in encodings], axis=0
91 | )
92 |
93 | return {
94 | "input_ids": input_ids,
95 | "attention_mask": attention_mask,
96 | "token_type_ids": token_type_ids,
97 | }
98 |
--------------------------------------------------------------------------------
/shekar/data/files/informal_words.csv:
--------------------------------------------------------------------------------
1 | خونه,خانه
2 | بونه,بهانه
3 | بهونه,بهانه
4 | شونه,شانه
5 | لونه,لانه
6 | آشیونه,آشیانه
7 | پنهون,پنهان
8 | خندون,خندان
9 | تهرون,تهران
10 | شمرون,شمران
11 | طهرون,تهران
12 | حیرون,حیران
13 | حیون,حیوان
14 | حیوون,حیوان
15 | کاشون,کاشان
16 | پریشون,پریشان
17 | کرمون,کرمان
18 | گریون,گریان
19 | گلدون,گلدان
20 | گمون,گمان
21 | هذیون,هذیان
22 | قلیون,قلیان
23 | ریزون,ریزان
24 | چمدون,چمدان
25 | آسمون,آسمان
26 | ریسمون,ریسمان
27 | پهلوون,پهلوان
28 | پهلون,پهلوان
29 | جون,جان
30 | جوون,جوان
31 | نوجوون,نوجوان
32 | بوم,بام
33 | پشتبوم,پشتبام
34 | حموم,حمام
35 | آویزون,آویزان
36 | اویزون,آویزان
37 | نون,نان
38 | درمون,درمان
39 | چسبون,چسبان
40 | بادمجون,بادمجان
41 | جنبون,جنبان
42 | دونه,دانه
43 | نشون,نشان
44 | مهربون,مهربان
45 | داغون,داغان
46 | ویرون,ویران
47 | ویرونه,ویرانه
48 | خانوم,خانم
49 | تموم,تمام
50 | ناتموم,ناتمام
51 | سولاخ,سوراخ
52 | اگه,اگر
53 | آخه,آخر
54 | درخشون,درخشان
55 | پرسون,پرسان
56 | گردون,گردان
57 | چرخون,چرخان
58 | دندون,دندان
59 | زمونه,زمانه
60 | دهن,دهان
61 | مثلن,مثلا
62 | عملن,عملا
63 | رسمن,رسما
64 | شرعن,شرعا
65 | مخصوصن,مخصوصا
66 | نسبتن,نسبتا
67 | کلن,کلا
68 | دقیقن,دقیقا
69 | ذاتن,ذاتا
70 | شدیدن,شدیدا
71 | قطعن,قطعا
72 | ابدن,ابدا
73 | اولن,اولا
74 | دومن,دوما
75 | سومن,سوما
76 | بعدن,بعدا
77 | آروم,آرام
78 | ارزون,ارزان
79 | چقد,چقدر
80 | ایرون,ایران
81 | بارون,باران
82 | تومن,تومان
83 | تکون,تکان
84 | مردونه,مردانه
85 | دخترونه,دخترانه
86 | پسرونه,پسرانه
87 | زنونه,زنانه
88 | دردونه,دردانه
89 | زمستون,زمستان
90 | تابستون,تابستان
91 | مهمون,مهمان
92 | مهمونی,مهمانی
93 | چمدون,چمدان
94 | نردبون,نردبان
95 | کارخونه,کارخانه
96 | صابخونه,صاحبخانه
97 | کتابخونه,کتابخانه
98 | قهوه خونه,قهوهخانه
99 | مهمون خونه,مهمانخانه
100 | یه,یک
101 | یهو,یکباره
102 | ینواخت,یکنواخت
103 | شیطون,شیطان
104 | والا,والله
105 | چونه,چانه
106 | گشنه,گرسنه
107 | کوچیک,کوچک
108 | نشونی,نشانی
109 | تهرونی,تهرانی
110 | ایرونی,ایرانی
111 | حروم,حرام
112 | هندونه,هندوانه
113 | اونقدی,آنقدری
114 | انقدی,آنقدری
115 | انقد,آنقدر
116 | اونقد,آنقدر
117 | اونقدر,آنقدر
118 | انقدر,آنقدر
119 | جونور,جانوار
120 | مثه,مثل
121 | ارزون,ارزان
122 | تکون,تکان
123 | حدودن,حدودا
124 | دووم,دوام
125 | زبون,زبان
126 | نون,نان
127 | خونگی,خانگی
128 | ینی,یعنی
129 | کمون,کمان
130 | کمونه,کمانه
131 | زبون,زبان
132 | زبونه,زبانه
133 | آتیش,آتش
134 | شیش,شش
135 | پونصد,پانصد
136 | زعفرون,زعفران
137 | شونصد,ششصد
138 | پونزده,پانزده
139 | شونزده,شانزده
140 | کفتر,کبوتر
141 | دون,دانه
142 | دونه,دانه
143 | نادون,نادان
144 | خزون,خزان
145 | نمکدون,نمکدان
146 | قندون,قندان
147 | فسنجون,فسنجان
148 | رودخونه,رودخانه
149 | زورخونه,زورخانه
150 | کارخونه,کارخانه
151 | افشون,افشان
152 | ایمون,ایمان
153 | بادوم,بادام
154 | تابون,تابان
155 | تمبون,تمبان
156 | تنبون,تنبان
157 | کهکشون,کهکشان
158 | یخبندون,یخبندان
159 | یخبندون,یخبندان
160 | گوسفندچرون,گوسفندچران
161 | ابروکمون,ابروکمان
162 | اشکریزون,اشکریزان
163 | اصفاهان,اصفهان
164 | اصفهون,اصفهان
165 | اصفهونی,اصفهانی
166 | عقدکنون,عقدکنان
167 | بیابون,بیابان
168 | خیابون,خیابان
169 | میدون,میدان
170 | گرون,گران
171 | عاره,آره
172 | خونهتکونی,خانهتکانی
173 | خونهدار,خانهدار
174 | خونهنشین,خانهنشین
175 | سفرهخونه,سفرهخانه
176 | مکتبخونه,مکتبخانه
177 | همخونه,همخانه
178 | همخونه,همخانه
179 | چایخونه,چایخانه
180 | چایخونه,چایخانه
181 | یتیمخونه,یتیمخانه
182 | بالاخونه,بالاخانه
183 | سربازخونه,سربازخانه
184 | زورخونه,زورخانه
185 | سقاخونه,سقاخانه
186 | گلخونه,گلخانه
187 | پیشخون,پیشخوان
188 | خروسخون,خروسخوان
189 | خروسخون,خروسخوان
190 | زندونی,زندانی
191 | سگدونی,سگدانی
192 | نوندونی,ناندانی
193 | نادونی,نادانی
194 | اعیونی,اعیانی
195 | پیشونی,پیشانی
196 | سلمونی,سلمانی
197 | اوستا,استاد
198 |
--------------------------------------------------------------------------------
/shekar/preprocessing/__init__.py:
--------------------------------------------------------------------------------
1 | from .maskers import (
2 | DiacriticMasker,
3 | DigitMasker,
4 | EmojiMasker,
5 | HashtagMasker,
6 | HTMLTagMasker,
7 | MentionMasker,
8 | NonPersianLetterMasker,
9 | PunctuationMasker,
10 | StopWordMasker,
11 | EmailMasker,
12 | URLMasker,
13 | OffensiveWordMasker,
14 | # aliases
15 | DiacriticRemover,
16 | EmojiRemover,
17 | NonPersianRemover,
18 | PunctuationRemover,
19 | StopWordRemover,
20 | HashtagRemover,
21 | MentionRemover,
22 | DigitRemover,
23 | HTMLTagRemover,
24 | EmailRemover,
25 | URLRemover,
26 | OffensiveWordRemover,
27 | # action-based aliases
28 | RemoveDiacritics,
29 | RemoveEmojis,
30 | RemoveNonPersianLetters,
31 | RemovePunctuations,
32 | RemoveStopWords,
33 | RemoveHashtags,
34 | RemoveMentions,
35 | RemoveDigits,
36 | RemoveHTMLTags,
37 | RemoveEmails,
38 | RemoveURLs,
39 | RemoveOffensiveWords,
40 | # Maskers
41 | MaskEmails,
42 | MaskURLs,
43 | MaskEmojis,
44 | MaskDigits,
45 | MaskPunctuations,
46 | MaskNonPersianLetters,
47 | MaskStopWords,
48 | MaskHashtags,
49 | MaskMentions,
50 | MaskDiacritics,
51 | MaskHTMLTags,
52 | MaskOffensiveWords,
53 | )
54 |
55 | from .normalizers import (
56 | AlphabetNormalizer,
57 | ArabicUnicodeNormalizer,
58 | DigitNormalizer,
59 | PunctuationNormalizer,
60 | NormalizeDigits,
61 | NormalizePunctuations,
62 | NormalizeArabicUnicodes,
63 | NormalizeAlphabets,
64 | SpacingNormalizer,
65 | NormalizeSpacings,
66 | YaNormalizer,
67 | NormalizeYas,
68 | RepeatedLetterNormalizer,
69 | NormalizeRepeatedLetters,
70 | )
71 |
72 | __all__ = [
73 | # Maskers
74 | "DiacriticMasker",
75 | "EmojiMasker",
76 | "NonPersianLetterMasker",
77 | "PunctuationMasker",
78 | "StopWordMasker",
79 | "HashtagMasker",
80 | "MentionMasker",
81 | "DigitMasker",
82 | "RepeatedLetterMasker",
83 | "HTMLTagMasker",
84 | "EmailMasker",
85 | "URLMasker",
86 | "OffensiveWordMasker",
87 | # aliases
88 | "DiacriticRemover",
89 | "EmojiRemover",
90 | "NonPersianRemover",
91 | "PunctuationRemover",
92 | "StopWordRemover",
93 | "HashtagRemover",
94 | "MentionRemover",
95 | "DigitRemover",
96 | "HTMLTagRemover",
97 | "EmailRemover",
98 | "URLRemover",
99 | "OffensiveWordRemover",
100 | # action-based aliases
101 | "RemoveDiacritics",
102 | "RemoveEmojis",
103 | "RemoveNonPersianLetters",
104 | "RemovePunctuations",
105 | "RemoveStopWords",
106 | "RemoveHashtags",
107 | "RemoveMentions",
108 | "RemoveDigits",
109 | "RemoveHTMLTags",
110 | "RemoveEmails",
111 | "RemoveURLs",
112 | "RemoveOffensiveWords",
113 | # Maskers
114 | "MaskDiacritics",
115 | "MaskEmojis",
116 | "MaskNonPersianLetters",
117 | "MaskPunctuations",
118 | "MaskStopWords",
119 | "MaskHashtags",
120 | "MaskMentions",
121 | "MaskDigits",
122 | "MaskHTMLTags",
123 | "MaskEmails",
124 | "MaskURLs",
125 | "MaskOffensiveWords",
126 | # Normalizers
127 | "AlphabetNormalizer",
128 | "ArabicUnicodeNormalizer",
129 | "DigitNormalizer",
130 | "PunctuationNormalizer",
131 | "SpacingNormalizer",
132 | "YaNormalizer",
133 | "RepeatedLetterNormalizer",
134 | "NormalizeAlphabets",
135 | "NormalizeArabicUnicodes",
136 | "NormalizeDigits",
137 | "NormalizePunctuations",
138 | "NormalizeSpacings",
139 | "NormalizeYas",
140 | "NormalizeRepeatedLetters",
141 | ]
142 |
--------------------------------------------------------------------------------
/shekar/hub.py:
--------------------------------------------------------------------------------
1 | import urllib.request
2 | from pathlib import Path
3 | from tqdm import tqdm
4 | import hashlib
5 |
6 | MODEL_HASHES = {
7 | "albert_persian_tokenizer.json": "79716aa7d8aeee80d362835da4f33e2b36b69fe65c257ead32c5ecd850e9ed17",
8 | "albert_persian_sentiment_binary_q8.onnx": "377c322edc3c0de0c48bf3fd4420c7385158bd34492f5b157ea6978745c50e4a",
9 | "albert_persian_ner_q8.onnx": "a3d2b1d2c167abd01e6b663279d3f8c3bb1b3d0411f693515cd0b31a5a3d3e80",
10 | "albert_persian_pos_q8.onnx": "8b5a2761aae83911272763034e180345fe12b2cd45b6de0151db9fbf9d3d8b31",
11 | "albert_persian_mlm_embeddings.onnx": "6b2d987ba409fd6957764742e30bfbbe385ab33c210caeb313aa9a2eb9afa51a",
12 | "fasttext_d100_w5_v100k_cbow_wiki.bin": "27daf69dc030e028dda33465c488e25f72c2ea65a53b5c1e0695b883a8be061c",
13 | "fasttext_d300_w10_v250k_cbow_naab.bin": "8db1e1e50f4b889c7e1774501541be2832240892b9ca00053772f0af7cd2526b",
14 | "tfidf_logistic_offensive.onnx": "1ac778114c9e2ec1f94fe463df03008032ce75306c5ed494bb06c4542430df44",
15 | }
16 |
17 |
18 | class TqdmUpTo(tqdm):
19 | """Provides `update_to(n)` which uses `tqdm.update(delta_n)`."""
20 |
21 | def update_to(self, b=1, bsize=1, tsize=None):
22 | if tsize is not None:
23 | self.total = tsize
24 | self.update(b * bsize - self.n)
25 |
26 |
27 | class Hub:
28 | @staticmethod
29 | def compute_sha256_hash(path: str | Path, block_size=65536):
30 | """Compute the SHA-256 hash of a file."""
31 | sha256 = hashlib.sha256()
32 | with open(path, "rb") as f:
33 | for block in iter(lambda: f.read(block_size), b""):
34 | sha256.update(block)
35 | return sha256.hexdigest()
36 |
37 | @staticmethod
38 | def get_resource(file_name: str) -> Path:
39 | base_url = "https://shekar.ai/"
40 | cache_dir = Path.home() / ".shekar"
41 |
42 | if file_name not in MODEL_HASHES:
43 | raise ValueError(f"File {file_name} is not recognized.")
44 |
45 | model_path = cache_dir / file_name
46 |
47 | cache_dir.mkdir(parents=True, exist_ok=True)
48 |
49 | if not model_path.exists():
50 | if not Hub.download_file(base_url + file_name, model_path):
51 | model_path.unlink(missing_ok=True)
52 | raise FileNotFoundError(
53 | f"Failed to download {file_name} from {base_url}. "
54 | f"You can also download it manually from {base_url + file_name} and place it in {cache_dir}."
55 | )
56 |
57 | elif Hub.compute_sha256_hash(model_path) != MODEL_HASHES[file_name]:
58 | model_path.unlink(missing_ok=True)
59 | raise ValueError(
60 | f"Hash mismatch for {file_name}. Expected {MODEL_HASHES[file_name]}, got {Hub.compute_sha256_hash(model_path)}"
61 | )
62 | return model_path
63 |
64 | @staticmethod
65 | def download_file(url: str, dest_path: Path) -> bool:
66 | try:
67 | with TqdmUpTo(
68 | unit="B",
69 | unit_scale=True,
70 | unit_divisor=1024,
71 | miniters=1,
72 | desc="Downloading model: ",
73 | bar_format="{l_bar}{bar}| {n_fmt}/{total_fmt}",
74 | ) as t:
75 | urllib.request.urlretrieve(
76 | url, filename=dest_path, reporthook=t.update_to, data=None
77 | )
78 | t.total = t.n
79 | return True
80 | except Exception as e:
81 | print(f"Error downloading the file: {e}")
82 | return False
83 |
84 |
85 | if __name__ == "__main__":
86 | import sys
87 |
88 | if len(sys.argv) != 2:
89 | print("Usage: python hub.py ")
90 | sys.exit(1)
91 | file_path = sys.argv[1]
92 | print(Hub.compute_sha256_hash(file_path))
93 |
--------------------------------------------------------------------------------
/shekar/embeddings/word_embedder.py:
--------------------------------------------------------------------------------
1 | import pickle
2 |
3 | import numpy as np
4 | from shekar.hub import Hub
5 | from pathlib import Path
6 | from .base import BaseEmbedder
7 |
8 | WORD_EMBEDDING_REGISTRY = {
9 | "fasttext-d100": "fasttext_d100_w5_v100k_cbow_wiki.bin",
10 | "fasttext-d300": "fasttext_d300_w10_v250k_cbow_naab.bin",
11 | }
12 |
13 |
14 | class WordEmbedder(BaseEmbedder):
15 | """WordEmbedder class for embedding words using pre-trained models.
16 | Args:
17 | model (str): Name of the word embedding model to use.
18 | model_path (str, optional): Path to the pre-trained model file. If None, it will be downloaded from the hub.
19 | Raises:
20 | ValueError: If the specified model is not found in the registry.
21 | """
22 |
23 | def __init__(
24 | self, model: str = "fasttext-d100", model_path=None, oov_strategy: str = "zero"
25 | ):
26 | """Initialize the WordEmbedder with a specified model and path.
27 | Args:
28 |
29 | model (str): Name of the word embedding model to use.
30 | model_path (str, optional): Path to the pre-trained model file. If None,
31 | it will be downloaded from the hub.
32 | oov_strategy (str): Strategy for handling out-of-vocabulary words. Default is "zero". Can be "zero", "none", or "error".
33 | Raises:
34 | ValueError: If the specified model is not found in the registry.
35 | """
36 |
37 | super().__init__()
38 | self.oov_strategy = oov_strategy
39 | model = model.lower()
40 | if model not in WORD_EMBEDDING_REGISTRY:
41 | raise ValueError(
42 | f"Unknown word embedding model '{model}'. Available: {list(WORD_EMBEDDING_REGISTRY.keys())}"
43 | )
44 |
45 | resource_name = WORD_EMBEDDING_REGISTRY[model]
46 | if model_path is None or not Path(model_path).exists():
47 | model_path = Hub.get_resource(file_name=resource_name)
48 |
49 | model = pickle.load(open(model_path, "rb"))
50 | self.words = model["words"]
51 | self.embeddings = model["embeddings"]
52 | self.vector_size = model["vector_size"]
53 | self.window = model["window"]
54 | self.model_type = model["model"]
55 | self.epochs = model["epochs"]
56 | self.dataset = model["dataset"]
57 |
58 | self.token2idx = {word: idx for idx, word in enumerate(self.words)}
59 |
60 | def embed(self, token: str) -> np.ndarray:
61 | if token in self.token2idx:
62 | index = self.token2idx[token]
63 | return self.embeddings[index]
64 | else:
65 | if self.oov_strategy == "zero":
66 | return np.zeros(self.vector_size)
67 | elif self.oov_strategy == "none":
68 | return None
69 | elif self.oov_strategy == "error":
70 | raise KeyError(f"Token '{token}' not found in the vocabulary.")
71 |
72 | def transform(self, X: str) -> np.ndarray:
73 | return self.embed(X)
74 |
75 | def most_similar(self, token: str, top_n: int = 5) -> list:
76 | """Find the most similar tokens to a given token.
77 | Args:
78 | token (str): The token to find similar tokens for.
79 | top_n (int): Number of similar tokens to return.
80 | Returns:
81 | list: List of tuples containing similar tokens and their similarity scores.
82 | """
83 |
84 | vec = self.embed(token)
85 | if vec is None:
86 | return []
87 |
88 | similarities = []
89 | for other_token in self.words:
90 | if other_token != token:
91 | sim = self.similarity(token, other_token)
92 | similarities.append((other_token, sim))
93 |
94 | similarities.sort(key=lambda x: x[1], reverse=True)
95 | return similarities[:top_n]
96 |
--------------------------------------------------------------------------------
/tests/unit/sentiment_analysis/test_base_sentiment.py:
--------------------------------------------------------------------------------
1 | import pytest
2 | from shekar.sentiment_analysis.base import SentimentClassifier, SENTIMENT_REGISTRY
3 |
4 |
5 | class TestSentimentClassifier:
6 | def test_init_default_model(self):
7 | """Test initialization with default model."""
8 | classifier = SentimentClassifier()
9 | assert hasattr(classifier, "model")
10 | assert classifier.model is not None
11 |
12 | def test_init_with_valid_model(self):
13 | """Test initialization with valid model name."""
14 | classifier = SentimentClassifier(model="albert-binary")
15 | assert hasattr(classifier, "model")
16 | assert classifier.model is not None
17 |
18 | def test_init_case_insensitive(self):
19 | """Test that model name is case insensitive."""
20 | classifier = SentimentClassifier(model="ALBERT-BINARY")
21 | assert hasattr(classifier, "model")
22 | assert classifier.model is not None
23 |
24 | def test_init_with_invalid_model(self):
25 | """Test initialization with invalid model raises ValueError."""
26 | with pytest.raises(ValueError) as exc_info:
27 | SentimentClassifier(model="invalid-model")
28 |
29 | assert "Unknown sentiment model 'invalid-model'" in str(exc_info.value)
30 | assert "Available:" in str(exc_info.value)
31 |
32 | def test_init_with_model_path(self):
33 | """Test initialization with custom model path."""
34 | classifier = SentimentClassifier(
35 | model="albert-binary", model_path="/custom/path"
36 | )
37 | assert hasattr(classifier, "model")
38 | assert classifier.model is not None
39 |
40 | def test_transform_persian_positive_text(self):
41 | """Test sentiment analysis on Persian positive text."""
42 | classifier = SentimentClassifier()
43 | result = classifier.transform("سریال قصههای مجید عالی بود!")
44 |
45 | assert isinstance(result, tuple)
46 | assert len(result) == 2
47 |
48 | def test_transform_persian_negative_text(self):
49 | """Test sentiment analysis on Persian negative text."""
50 | classifier = SentimentClassifier()
51 | result = classifier.transform("فیلم ۳۰۰ افتضاح بود.")
52 |
53 | assert isinstance(result, tuple)
54 | assert len(result) == 2
55 |
56 | def test_transform_empty_string(self):
57 | """Test sentiment analysis on empty string."""
58 | classifier = SentimentClassifier()
59 | result = classifier.transform("")
60 |
61 | assert isinstance(result, tuple)
62 | assert len(result) == 2
63 |
64 | def test_transform_english_text(self):
65 | """Test sentiment analysis on English text."""
66 | classifier = SentimentClassifier()
67 | result = classifier.transform("This movie is great!")
68 |
69 | assert isinstance(result, tuple)
70 | assert len(result) == 2
71 | assert len(result) > 0
72 |
73 | def test_multiple_transforms_same_instance(self):
74 | """Test multiple transform calls on same instance."""
75 | classifier = SentimentClassifier()
76 |
77 | result1 = classifier.transform("متن مثبت")
78 | result2 = classifier.transform("متن منفی")
79 |
80 | assert isinstance(result1, tuple)
81 | assert isinstance(result2, tuple)
82 | assert len(result1) == 2
83 | assert len(result2) == 2
84 |
85 | def test_sentiment_registry_contains_albert_binary(self):
86 | """Test that SENTIMENT_REGISTRY contains expected models."""
87 | assert "albert-binary" in SENTIMENT_REGISTRY
88 | assert callable(SENTIMENT_REGISTRY["albert-binary"])
89 |
90 | def test_inheritance_from_base_transform(self):
91 | """Test that SentimentClassifier inherits from BaseTransform."""
92 | classifier = SentimentClassifier()
93 | assert hasattr(classifier, "transform")
94 |
--------------------------------------------------------------------------------
/paper.bib:
--------------------------------------------------------------------------------
1 | @inproceedings{jafari2025dadmatools,
2 | title={DadmaTools V2: an Adapter-Based Natural Language Processing Toolkit for the {P}ersian Language},
3 | author={Jafari, Sadegh and Farsi, Farhan and Ebrahimi, Navid and Sajadi, Mohamad Bagher and Eetemadi, Sauleh},
4 | booktitle={Proceedings of the 1st Workshop on NLP for Languages Using Arabic Script},
5 | pages={37--43},
6 | year={2025}
7 | }
8 |
9 | @inproceedings{mohtaj2018parsivar,
10 | title={Parsivar: A language processing toolkit for {P}ersian},
11 | author={Mohtaj, Salar and Roshanfekr, Behnam and Zafarian, Atefeh and Asghari, Habibollah},
12 | booktitle={Proceedings of the eleventh international conference on language resources and evaluation (lrec 2018)},
13 | year={2018}
14 | }
15 |
16 | @article{sabouri2022naab,
17 | title={naab: A ready-to-use plug-and-play corpus for {F}arsi},
18 | author={Sabouri, Sadra and Rahmati, Elnaz and Gooran, Soroush and Sameti, Hossein},
19 | journal={arXiv preprint arXiv:2208.13486},
20 | year={2022},
21 | doi={10.22034/jaiai.2024.480062.1016}
22 | }
23 |
24 | @inproceedings{qasemizadeh2006adaptive,
25 | title={Adaptive language independent spell checking using intelligent traverse on a tree},
26 | author={QasemiZadeh, Behrang and Ilkhani, Ali and Ganjeii, Amir},
27 | booktitle={2006 ieee conference on cybernetics and intelligent systems},
28 | pages={1--6},
29 | year={2006},
30 | organization={IEEE},
31 | doi={10.1109/ICCIS.2006.252325}
32 | }
33 |
34 | @inproceedings{eslami2004persian,
35 | title={Persian generative lexicon},
36 | author={Eslami, Moharam and Atashgah, M Sharifi and Alizadeh, LS and Zandi, T},
37 | booktitle={The first workshop on Persian language and computer. Tehran, Iran},
38 | year={2004}
39 | }
40 |
41 | @article{kudo2018sentencepiece,
42 | title={SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing},
43 | author={Kudo, Taku and Richardson, John},
44 | journal={arXiv preprint arXiv:1808.06226},
45 | year={2018},
46 | doi={10.48550/arXiv.1808.06226}
47 | }
48 |
49 | @article{rasooli2020persian,
50 | title={The {P}ersian dependency treebank made universal},
51 | author={Rasooli, Mohammad Sadegh and Safari, Pegah and Moloodi, Amirsaeid and Nourian, Alireza},
52 | journal={arXiv preprint arXiv:2009.10205},
53 | year={2020},
54 | doi={10.48550/arXiv.2009.10205}
55 | }
56 |
57 | @article{lan2019albert,
58 | title={{ALBERT}: A lite {BERT} for self-supervised learning of language representations},
59 | author={Lan, Zhenzhong and Chen, Mingda and Goodman, Sebastian and Gimpel, Kevin and Sharma, Piyush and Soricut, Radu},
60 | journal={arXiv preprint arXiv:1909.11942},
61 | year={2019},
62 | doi={10.48550/arXiv.1909.11942}
63 | }
64 |
65 | @article{rose2010automatic,
66 | title={Automatic keyword extraction from individual documents},
67 | author={Rose, Stuart and Engel, Dave and Cramer, Nick and Cowley, Wendy},
68 | journal={Text mining: applications and theory},
69 | pages={1--20},
70 | year={2010},
71 | publisher={Wiley Online Library},
72 | doi={10.1002/9780470689646.ch1}
73 | }
74 |
75 | @article{farahani2021parsbert,
76 | title={Parsbert: Transformer-based model for {P}ersian language understanding},
77 | author={Farahani, Mehrdad and Gharachorloo, Mohammad and Farahani, Marzieh and Manthouri, Mohammad},
78 | journal={Neural Processing Letters},
79 | volume={53},
80 | number={6},
81 | pages={3831--3847},
82 | year={2021},
83 | publisher={Springer},
84 | doi={10.1007/s11063-021-10528-4}
85 | }
86 |
87 | @dataset{amirivojdan_2025_naseza,
88 | author = {Ahmad Amirivojdan},
89 | title = {Naseza: A Large-Scale Dataset for {P}ersian Hate Speech and Offensive Language Detection},
90 | year = {2025},
91 | publisher = {Zenodo},
92 | version = {v1.0.0},
93 | doi = {10.5281/zenodo.17355123},
94 | url = {https://doi.org/10.5281/zenodo.17355123},
95 | license = {CC0-1.0}
96 | }
97 |
--------------------------------------------------------------------------------