├── LICENSE
├── README.md
├── favicon.ico
├── job_template_launch
├── README.md
├── app.yaml
├── appengine_config.py
├── create_template.py
├── cron.yaml
├── dfpipe
│ ├── __init__.py
│ └── pipe.py
├── main.py
├── setup.py
└── standard_requirements.txt
└── sdk_launch
├── Dockerfile
├── README.md
├── app.yaml
├── appengine_config.py
├── backend.yaml
├── cron.yaml
├── dfpipe
├── __init__.py
└── pipe.py
├── dispatch.yaml
├── main.py
├── main_df.py
├── main_test.py
├── requirements.txt
├── setup.py
└── standard_requirements.txt
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
203 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | # Running Dataflow jobs from Google App Engine
3 |
4 | This directory contains two different examples that show how you can run
5 | [Cloud Dataflow](https://cloud.google.com/dataflow/) pipelines from
6 | [App Engine](https://cloud.google.com/appengine/) apps, as a replacement
7 | for the older
8 | [GAE Python MapReduce libraries](https://github.com/GoogleCloudPlatform/appengine-mapreduce),
9 | as well as do much more.
10 |
11 | The examples show how to periodically launch a Python Dataflow pipeline from GAE, to
12 | analyze data stored in Cloud Datastore; in this case, tweets from Twitter.
13 |
14 | The example in [`sdk_launch`](./sdk_launch) shows how to launch Dataflow jobs via the Dataflow SDK. This requires the use of an App Engine Flex [service](https://cloud.google.com/appengine/docs/standard/python/an-overview-of-app-engine) to launch the pipeline.
15 |
16 | The example in [`job_template_launch`](./job_template_launch) shows how to launch Dataflow jobs via job [Templates](https://cloud.google.com/dataflow/docs/templates/overview). This can be done using only App Engine Standard.
17 | Prior to deploying the app, you create a pipeline template (via your local command line, in this example) for the app to use.
18 |
19 | ## Contributions
20 |
21 | Contributions are not currently accepted. This is not an official Google product.
22 |
--------------------------------------------------------------------------------
/favicon.ico:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/amygdala/gae-dataflow/ff6305b21f319d5c879708b0b48577233e44a451/favicon.ico
--------------------------------------------------------------------------------
/job_template_launch/README.md:
--------------------------------------------------------------------------------
1 |
2 | # Introduction
3 |
4 | This code example shows how you can run
5 | [Cloud Dataflow](https://cloud.google.com/dataflow/) pipelines from
6 | [App Engine](https://cloud.google.com/appengine/) apps, as a replacement
7 | for the older
8 | [GAE Python MapReduce libraries](https://github.com/GoogleCloudPlatform/appengine-mapreduce),
9 | as well as do much more.
10 |
11 | The example shows how to periodically launch a Python Dataflow pipeline from GAE, to
12 | analyze data stored in Cloud Datastore; in this case, tweets from Twitter.
13 |
14 | This example uses [Dataflow Templates](https://cloud.google.com/dataflow/docs/templates/overview) to launch the pipeline jobs. Since we're simply calling the Templates REST API to launch the jobs, we can build an App Engine standard app.
15 | For an example that uses the same pipeline, but uses the Dataflow SDK to launch the pipeline jobs, see the [`sdk_launch`](../sdk_launch) directory. Because of its use of the SDK, that example requires App Engine Flex.
16 | Now that Dataflow Templates are available for Python Dataflow, they are often the more straightforward option for this type of use case. See the Templates documentation for more detail.
17 |
18 | ### The Dataflow pipeline
19 |
20 | The Python Dataflow pipeline reads recent tweets from the past N days from Cloud Datastore, then
21 | essentially splits into three processing branches. It finds the top N most popular words in terms of
22 | the percentage of tweets they were found in, calculates the top N most popular URLs in terms of
23 | their count, and then derives relevant word co-occurrences (bigrams) using an
24 | approximation to a [tf*idf](https://en.wikipedia.org/wiki/Tf%E2%80%93idf)
25 | ranking metric. It writes the results to three BigQuery tables.
26 |
27 |
28 |
29 |
30 | ## Prerequisites for running the example
31 |
32 | ### 1. Basic GCP setup
33 |
34 | Follow the "Before you begin" steps on
35 | [this page](https://cloud.google.com/dataflow/docs/quickstarts/quickstart-python#before-you-begin).
36 | Note your project and bucket name; you will need them in a moment.
37 |
38 | Then, follow the next section on the same page to
39 | [install pip and the Dataflow SDK](https://cloud.google.com/dataflow/docs/quickstarts/quickstart-
40 | python#Setup). We'll need this to create our Dataflow Template.
41 |
42 |
43 | ### 2. Create a BigQuery dataset in your project
44 |
45 | The app will write its analytic results to BigQuery. In your project, [create a new
46 | dataset](https://cloud.google.com/bigquery/quickstart-web-ui#create_a_dataset) to use for this
47 | purpose, or note the name of an existing dataset that you will use.
48 |
49 | ### 3. Create a Twitter App
50 |
51 | [Create a Twitter application.](https://apps.twitter.com/). Note the credentials under the 'Keys
52 | and Access Tokens' tag: 'Consumer Key (API Key)', 'Consumer Secret (API Secret)', 'Access Token',
53 | and 'Access Token Secret'. You'll need these in moment.
54 |
55 | ### 4. Library installation
56 |
57 | We need to 'vendor' the libraries used by the app's frontend.
58 | Install the dependencies into the app's `lib` subdirectory like this:
59 |
60 | ```sh
61 | pip install --target=lib -r standard_requirements.txt
62 | ```
63 |
64 | (Take a look at `appengine_config.py` to see where we specify to GAE to add those libs).
65 |
66 |
67 | ### 5. Template Creation
68 |
69 | Now we're set to run the template creation script. It expects `PROJECT`, `BUCKET`, and `DATASET` environment variables to be set. Edit the following and paste at the command line:
70 |
71 | ```sh
72 | export DATASET=your-dataset
73 | export BUCKET=your-bucket
74 | export PROJECT=your-project
75 | ```
76 |
77 | Then, run the [template creation script](create_template.py):
78 |
79 | ```sh
80 | python create_template.py
81 | ```
82 |
83 | Note the resulting [Google Cloud Storage (GCS)](https://cloud.google.com/storage/)
84 | template path that is output to the command line. By default the GCS filename should be:
85 | ` + '-twproc_tmpl'`, but you can change that in the script if you like.
86 |
87 | The template creation script accesses the pipeline definition in [`dfpipe/pipe.py`](dfpipe/pipe.py) to build the template. As part of the pipeline definition, it's specified that the pipeline takes a
88 | [runtime argument](https://cloud.google.com/dataflow/docs/templates/creating-templates#modifying-your-code-to-use-runtime-parameters),
89 | `timestamp`. (This value is used to filter out tweets N days older than the timestamp, so that the analysis is only run over recent activity).
90 |
91 | ```python
92 | class UserOptions(PipelineOptions):
93 | @classmethod
94 | def _add_argparse_args(cls, parser):
95 | parser.add_value_provider_argument('--timestamp', type=str)
96 | ```
97 |
98 | Then, the pipeline code can access that runtime parameter, e.g.:
99 |
100 | ```python
101 | user_options = pipeline_options.view_as(UserOptions)
102 | ...
103 | wc_records = top_percents | 'format' >> beam.FlatMap(
104 | lambda x: [{'word': xx[0], 'percent': xx[1],
105 | 'ts': user_options.timestamp.get()} for xx in x])
106 | ```
107 |
108 | #### Optional sanity check: run your template-based Dataflow pipeline from the Cloud Console
109 |
110 | Now that you've created a pipeline template, you can test it out by launching a job based on that template from the [Cloud Console](https://console.cloud.google.com). (You could also do this via the `gcloud` command-line tool).
111 | While it's not strictly necessary to do this prior to deploying your GAE app, it's a good sanity check.
112 | Note that the pipeline won't do anything interesting unless you already have tweet data in the Datastore.
113 |
114 | Go to the [Dataflow pane](https://console.cloud.google.com/dataflow) of the Cloud Console, and click on "Create Job From Template".
115 |
116 |
117 |
118 | _Creating a Dataflow job from a template._
119 |
120 |
121 | Select "Custom Template", then browse to your new template's location in GCS. This info was output when you ran
122 | `create_template.py`. (The pulldown menu includes some predefined templates as well, that you may want to explore).
123 |
124 |
125 |
126 | _Select "Custom Template", and indicate the path to it._
127 |
128 |
129 | Finally, set your pipeline's runtime parameter(s). In this case, we have one: `timestamp`. The pipeline is expecting a value in a format like this: `2017-10-22 10:18:13.491543` (you can generate such a string in python via
130 | `str(datetime.datetime.now())`).
131 |
132 |
133 |
134 | _Set your pipeline's runtime parameter(s) before running the job._
135 |
136 |
137 | Note that while we don't show it here, [you can extend your templates with additional metadata](https://cloud.google.com/dataflow/docs/templates/creating-templates#metadata) so that custom parameters may be validated when the template is executed.
138 |
139 | Once you click 'Run', you should be able to see your job running in the Cloud Console.
140 |
141 | ### 6. Edit app.yaml
142 |
143 | Finally, edit `app.yaml`. Add the Twitter app credentials that you generated above. Then, fill in your PROJECT, DATASET, and BUCKET names.
144 |
145 | Next, add your TEMPLATE name. By default, it will be `-twproc_templ`, where `` is replaced with your project name.
146 |
147 | ## Deploy the app
148 |
149 | Now we're ready to deploy the GAE app. Deploy the `app.yaml` spec:
150 |
151 | ```sh
152 | $ gcloud app deploy app.yaml
153 | ```
154 |
155 | .. and then the `cron.yaml` spec:
156 |
157 | ```sh
158 | $ gcloud app deploy cron.yaml
159 | ```
160 |
161 |
162 | ## Test your deployment
163 |
164 | To test your deployment, manually trigger the cron jobs. To do this, go to the
165 | [cloud console](https://console.cloud.google.com) for your project,
166 | and visit the [App Engine pane](https://console.cloud.google.com/appengine).
167 | Then, click on 'Task Queues' in the left navbar, then the 'Cron Jobs' tab in the center pane.
168 |
169 | Then, click `Run now` for the `/timeline` cron job. This is the job that fetches tweets and stores
170 | them in the Datastore. After it runs, you should be able to see `Tweet` entities in the Datastore.
171 | Visit the [Datastore](https://console.cloud.google.com/datastore/entities) pane in the Cloud
172 | Console, and select `Tweet` from the 'Entities' pull-down menu. You can also try a GQL query:
173 |
174 | ```
175 | select * from Tweet order by created_at desc
176 | ```
177 |
178 | Once you know that the 'fetch tweets' cron is running successfully and populating the Datastore,
179 | click `Run now` for the
180 | `/launchtemplatejob` cron. This should kick off a Dataflow job and return within a few seconds. You
181 | should be able to see the job running in the [Dataflow pane](https://console.cloud.google.com/dataflow)
182 | of the Cloud Console. It should finish in a few minutes. Check that it finishes without error.
183 |
184 | Once it has finished, you ought to see three new tables in your BigQuery dataset: `urls`,
185 | `word_counts`, and `word_cooccur`.
186 |
187 | If you see any problems, make sure that you've configured the `app.yaml` as described above, and check the logs for clues.
188 |
189 | Note: the `/launchtemplatejob` request handler is configured to return without launching the pipeline
190 | if the request has not originated as a cron request. You can comment out that logic in `main.py`,
191 | in the `LaunchJob` class, if you'd like to override that behavior.
192 |
193 | ## Exploring the analytics results in BigQuery
194 |
195 | Once our example app is up and running, it periodically writes the results of its analysis to BigQuery. Then, we can run some fun queries on the data.
196 |
197 | For example, we can find recent word co-occurrences that are 'interesting' by our metric:
198 |
199 |
200 |
201 | Or look for emerging word pairs, that have become 'interesting' in the last day or so (as of early April 2017):
202 |
203 |
204 |
205 | We can contrast the 'interesting' word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):
206 |
207 |
208 |
209 | Or, find the most often-tweeted URLs from the past few days (some URLs are truncated in the output):
210 |
211 |
212 |
213 |
214 | ## What next?
215 |
216 | This example walks through how you can programmatically launch Dataflow pipelines — that read from Datastore — directly from your App Engine app, in order to support a range of processing and analytics tasks.
217 |
218 | There are lots of interesting ways that this example could be extended. For example, you could add
219 | a user-facing frontend to the web app, that fetches and displays results from BigQuery. You might
220 | also look at trends over time (e.g. for bigrams) -- either from BigQuery, or by extending the
221 | Dataflow pipeline.
222 |
223 | ## Contributions
224 |
225 | Contributions are not currently accepted. This is not an official Google product.
--------------------------------------------------------------------------------
/job_template_launch/app.yaml:
--------------------------------------------------------------------------------
1 | runtime: python27
2 | api_version: 1
3 | threadsafe: true
4 |
5 | handlers:
6 | - url: /.*
7 | script: main.app
8 | login: admin
9 |
10 | libraries:
11 | - name: ssl
12 | version: latest
13 |
14 | env_variables:
15 | CONSUMER_KEY: 'xxx'
16 | CONSUMER_SECRET: 'xxx'
17 | ACCESS_TOKEN: 'xxx'
18 | ACCESS_TOKEN_SECRET: 'xxx'
19 | PROJECT: 'YOUR-PROJECT-ID'
20 | DATASET: 'xxx'
21 | BUCKET: 'xxx'
22 | TEMPLATE_NAME: 'YOUR-PROJECT-ID-twproc_tmpl'
23 |
--------------------------------------------------------------------------------
/job_template_launch/appengine_config.py:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | from google.appengine.ext import vendor
16 |
17 | # Add any libraries installed in the "lib" folder.
18 | vendor.add('lib')
19 |
--------------------------------------------------------------------------------
/job_template_launch/create_template.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | The app for the 'backend' service, which handles cron job requests to
17 | launch a Dataflow pipeline to analyze recent tweets stored in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import logging
23 | import os
24 |
25 | from apache_beam.options.pipeline_options import PipelineOptions
26 |
27 | import dfpipe.pipe as pipe
28 |
29 |
30 | PROJECT = os.environ['PROJECT']
31 | BUCKET = os.environ['BUCKET']
32 | DATASET = os.environ['DATASET']
33 |
34 | pipeline_options = {
35 | 'project': PROJECT,
36 | 'staging_location': 'gs://' + BUCKET + '/staging',
37 | 'runner': 'DataflowRunner',
38 | 'setup_file': './setup.py',
39 | 'job_name': PROJECT + '-twcount',
40 | 'temp_location': 'gs://' + BUCKET + '/temp',
41 | 'template_location': 'gs://' + BUCKET + '/templates/' + PROJECT + '-twproc_tmpl'
42 | }
43 | # define and launch the pipeline (non-blocking), which will create the template.
44 | pipeline_options = PipelineOptions.from_dictionary(pipeline_options)
45 | pipe.process_datastore_tweets(PROJECT, DATASET, pipeline_options)
46 |
--------------------------------------------------------------------------------
/job_template_launch/cron.yaml:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | cron:
16 | - description: fetch tweets
17 | url: /timeline
18 | schedule: every 17 minutes
19 | target: default
20 | - description: launch dataflow pipeline
21 | url: /launchtemplatejob
22 | schedule: every 5 hours
23 | target: default
24 |
--------------------------------------------------------------------------------
/job_template_launch/dfpipe/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/job_template_launch/dfpipe/pipe.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | Define and launch a Dataflow pipeline to analyze recent tweets stored
17 | in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import datetime
23 | import json
24 | import logging
25 | import re
26 |
27 | import apache_beam as beam
28 | from apache_beam import combiners
29 | from apache_beam.io.gcp.bigquery import parse_table_schema_from_json
30 | from apache_beam.io.gcp.datastore.v1.datastoreio import ReadFromDatastore
31 | from apache_beam.pvalue import AsDict
32 | from apache_beam.pvalue import AsSingleton
33 | from apache_beam.options.pipeline_options import PipelineOptions
34 |
35 |
36 | from google.cloud.proto.datastore.v1 import query_pb2
37 | from googledatastore import helper as datastore_helper, PropertyFilter
38 |
39 |
40 | logging.basicConfig(level=logging.INFO)
41 |
42 | class FilterDate(beam.DoFn):
43 | """Filter Tweet datastore entities based on timestamp."""
44 |
45 | def __init__(self, opts, days):
46 | super(FilterDate, self).__init__()
47 | self.opts = opts
48 | self.days = days
49 | self.earlier = None
50 |
51 | def start_bundle(self):
52 | before = datetime.datetime.strptime(self.opts.timestamp.get(),
53 | '%Y-%m-%d %H:%M:%S.%f')
54 | self.earlier = before - datetime.timedelta(days=self.days)
55 |
56 | def process(self, element):
57 |
58 | created_at = element.properties.get('created_at', None)
59 | cav = None
60 | if created_at:
61 | cav = created_at.timestamp_value
62 | cseconds = cav.seconds
63 | else:
64 | return
65 | crdt = datetime.datetime.fromtimestamp(cseconds)
66 | logging.warn("crdt: %s", crdt)
67 | logging.warn("earlier: %s", self.earlier)
68 | if crdt > self.earlier:
69 | # return only the elements (datastore entities) with a 'created_at' date
70 | # within the last self.days days.
71 | yield element
72 |
73 |
74 | class WordExtractingDoFn(beam.DoFn):
75 | """Parse each tweet text into words, removing some 'stopwords'."""
76 |
77 | def process(self, element):
78 | content_value = element.properties.get('text', None)
79 | text_line = ''
80 | if content_value:
81 | text_line = content_value.string_value
82 |
83 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
84 | # You can add more stopwords if you want. These words are not included
85 | # in the analysis.
86 | stopwords = [
87 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
88 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
89 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
90 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
91 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your'
92 | 'who', 'when', 'via']
93 | stopwords += list(map(chr, range(97, 123)))
94 | return list(words - set(stopwords))
95 |
96 |
97 | class CoOccurExtractingDoFn(beam.DoFn):
98 | """Parse each tweet text into words, and after removing some 'stopwords',
99 | emit the bigrams.
100 | """
101 |
102 | def process(self, element):
103 | content_value = element.properties.get('text', None)
104 | text_line = ''
105 | if content_value:
106 | text_line = content_value.string_value
107 |
108 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
109 | # You can add more stopwords if you want. These words are not included
110 | # in the analysis.
111 | stopwords = [
112 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
113 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
114 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
115 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
116 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your',
117 | 'who', 'when', 'via']
118 | stopwords += list(map(chr, range(97, 123)))
119 | pruned_words = list(words - set(stopwords))
120 | pruned_words.sort()
121 | import itertools
122 | return list(itertools.combinations(pruned_words, 2))
123 |
124 |
125 | class URLExtractingDoFn(beam.DoFn):
126 | """Extract the urls from each tweet."""
127 |
128 | def process(self, element):
129 | url_content = element.properties.get('urls', None)
130 | if url_content:
131 | urls = url_content.array_value.values
132 | links = []
133 | for u in urls:
134 | links.append(u.string_value.lower())
135 | return links
136 |
137 |
138 |
139 | class QueryDatastore(beam.PTransform):
140 | """Generate a Datastore query, then read from the Datastore.
141 | """
142 |
143 | def __init__(self, project, days):
144 | super(QueryDatastore, self).__init__()
145 | self.project = project
146 | self.days = days
147 |
148 |
149 | # it's not currently supported to use template runtime value providers for
150 | # the Datastore input source, so we can't use runtime values to
151 | # construct our query. However, we can still statically filter based on time
152 | # of template construction, which lets us make the query a bit more
153 | # efficient.
154 | def expand(self, pcoll):
155 | query = query_pb2.Query()
156 | query.kind.add().name = 'Tweet'
157 | now = datetime.datetime.now()
158 | # The 'earlier' var will be set to a static value on template creation.
159 | # That is, because of the way that templates work, the value is defined
160 | # at template compile time, not runtime.
161 | # But defining a filter based on this value will still serve to make the
162 | # query more efficient than if we didn't filter at all.
163 | earlier = now - datetime.timedelta(days=self.days)
164 | datastore_helper.set_property_filter(query.filter, 'created_at',
165 | PropertyFilter.GREATER_THAN,
166 | earlier)
167 |
168 | return (pcoll
169 | | 'read from datastore' >> ReadFromDatastore(self.project,
170 | query, None))
171 |
172 |
173 | class UserOptions(PipelineOptions):
174 | @classmethod
175 | def _add_argparse_args(cls, parser):
176 | parser.add_value_provider_argument('--timestamp', type=str)
177 |
178 |
179 | def process_datastore_tweets(project, dataset, pipeline_options):
180 | """Creates a pipeline that reads tweets from Cloud Datastore from the last
181 | N days. The pipeline finds the top most-used words, the top most-tweeted
182 | URLs, ranks word co-occurrences by an 'interestingness' metric (similar to
183 | on tf* idf).
184 | """
185 |
186 | user_options = pipeline_options.view_as(UserOptions)
187 | DAYS = 4
188 |
189 | p = beam.Pipeline(options=pipeline_options)
190 |
191 | # Read entities from Cloud Datastore into a PCollection, then filter to get
192 | # only the entities from the last DAYS days.
193 | lines = (p | QueryDatastore(project, DAYS)
194 | | beam.ParDo(FilterDate(user_options, DAYS))
195 | )
196 |
197 | global_count = AsSingleton(
198 | lines
199 | | 'global count' >> beam.combiners.Count.Globally())
200 |
201 | # Count the occurrences of each word.
202 | percents = (lines
203 | | 'split' >> (beam.ParDo(WordExtractingDoFn())
204 | .with_output_types(unicode))
205 | | 'pair_with_one' >> beam.Map(lambda x: (x, 1))
206 | | 'group' >> beam.GroupByKey()
207 | | 'count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
208 | | 'in tweets percent' >> beam.Map(
209 | lambda (word, wsum), gc: (word, float(wsum) / gc), global_count))
210 | top_percents = (percents
211 | | 'top 500' >> combiners.Top.Of(500, lambda x, y: x[1] < y[1])
212 | )
213 | # Count the occurrences of each expanded url in the tweets
214 | url_counts = (lines
215 | | 'geturls' >> (beam.ParDo(URLExtractingDoFn())
216 | .with_output_types(unicode))
217 | | 'urls_pair_with_one' >> beam.Map(lambda x: (x, 1))
218 | | 'urls_group' >> beam.GroupByKey()
219 | | 'urls_count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
220 | | 'urls top 300' >> combiners.Top.Of(300, lambda x, y: x[1] < y[1])
221 | )
222 |
223 | # Define some inline helper functions.
224 |
225 | def join_cinfo(cooccur, percents):
226 | """Calculate a co-occurence ranking."""
227 | import math
228 |
229 | word1 = cooccur[0][0]
230 | word2 = cooccur[0][1]
231 | try:
232 | word1_percent = percents[word1]
233 | weight1 = 1 / word1_percent
234 | word2_percent = percents[word2]
235 | weight2 = 1 / word2_percent
236 | return (cooccur[0], cooccur[1], cooccur[1] *
237 | math.log(min(weight1, weight2)))
238 | except:
239 | return 0
240 |
241 | def generate_cooccur_schema():
242 | """BigQuery schema for the word co-occurrence table."""
243 | json_str = json.dumps({'fields': [
244 | {'name': 'w1', 'type': 'STRING', 'mode': 'NULLABLE'},
245 | {'name': 'w2', 'type': 'STRING', 'mode': 'NULLABLE'},
246 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
247 | {'name': 'log_weight', 'type': 'FLOAT', 'mode': 'NULLABLE'},
248 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
249 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
250 | return parse_table_schema_from_json(json_str)
251 |
252 | def generate_url_schema():
253 | """BigQuery schema for the urls count table."""
254 | json_str = json.dumps({'fields': [
255 | {'name': 'url', 'type': 'STRING', 'mode': 'NULLABLE'},
256 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
257 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
258 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
259 | return parse_table_schema_from_json(json_str)
260 |
261 | def generate_wc_schema():
262 | """BigQuery schema for the word count table."""
263 | json_str = json.dumps({'fields': [
264 | {'name': 'word', 'type': 'STRING', 'mode': 'NULLABLE'},
265 | {'name': 'percent', 'type': 'FLOAT', 'mode': 'NULLABLE'},
266 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
267 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
268 | return parse_table_schema_from_json(json_str)
269 |
270 | # Now build the rest of the pipeline.
271 | # Calculate the word co-occurence scores.
272 | cooccur_rankings = (lines
273 | | 'getcooccur' >> (beam.ParDo(CoOccurExtractingDoFn()))
274 | | 'co_pair_with_one' >> beam.Map(lambda x: (x, 1))
275 | | 'co_group' >> beam.GroupByKey()
276 | | 'co_count' >> beam.Map(lambda (wordts, ones): (wordts, sum(ones)))
277 | | 'weights' >> beam.Map(join_cinfo, AsDict(percents))
278 | | 'co top 300' >> combiners.Top.Of(300, lambda x, y: x[2] < y[2])
279 | )
280 |
281 | # Format the counts into a PCollection of strings.
282 | wc_records = top_percents | 'format' >> beam.FlatMap(
283 | lambda x: [{'word': xx[0], 'percent': xx[1],
284 | 'ts': user_options.timestamp.get()} for xx in x])
285 |
286 | url_records = url_counts | 'urls_format' >> beam.FlatMap(
287 | lambda x: [{'url': xx[0], 'count': xx[1],
288 | 'ts': user_options.timestamp.get()} for xx in x])
289 |
290 | co_records = cooccur_rankings | 'co_format' >> beam.FlatMap(
291 | lambda x: [{'w1': xx[0][0], 'w2': xx[0][1], 'count': xx[1],
292 | 'log_weight': xx[2],
293 | 'ts': user_options.timestamp.get()} for xx in x])
294 |
295 | # Write the results to three BigQuery tables.
296 | wc_records | 'wc_write_bq' >> beam.io.Write(
297 | beam.io.BigQuerySink(
298 | '%s:%s.word_counts' % (project, dataset),
299 | schema=generate_wc_schema(),
300 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
301 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
302 |
303 | url_records | 'urls_write_bq' >> beam.io.Write(
304 | beam.io.BigQuerySink(
305 | '%s:%s.urls' % (project, dataset),
306 | schema=generate_url_schema(),
307 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
308 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
309 |
310 | co_records | 'co_write_bq' >> beam.io.Write(
311 | beam.io.BigQuerySink(
312 | '%s:%s.word_cooccur' % (project, dataset),
313 | schema=generate_cooccur_schema(),
314 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
315 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
316 |
317 | # Actually run the pipeline.
318 | return p.run()
319 |
320 |
321 |
--------------------------------------------------------------------------------
/job_template_launch/main.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | The app for the 'frontend' service, which handles cron job requests to
16 | fetch tweets and store them in the Datastore.
17 | """
18 |
19 | import datetime
20 | import logging
21 | import os
22 |
23 | from google.appengine.ext import ndb
24 | import twitter
25 | import webapp2
26 |
27 | from googleapiclient.discovery import build
28 | from oauth2client.client import GoogleCredentials
29 |
30 |
31 | class Tweet(ndb.Model):
32 | """Define the Tweet model."""
33 | user = ndb.StringProperty()
34 | text = ndb.StringProperty()
35 | created_at = ndb.DateTimeProperty()
36 | tid = ndb.IntegerProperty()
37 | urls = ndb.StringProperty(repeated=True)
38 |
39 |
40 | class LaunchJob(webapp2.RequestHandler):
41 | """Launch the Dataflow pipeline using a job template."""
42 |
43 | def get(self):
44 | is_cron = self.request.headers.get('X-Appengine-Cron', False)
45 | # logging.info("is_cron is %s", is_cron)
46 | # Comment out the following check to allow non-cron-initiated requests.
47 | if not is_cron:
48 | return 'Blocked.'
49 | # These env vars are set in app.yaml.
50 | PROJECT = os.environ['PROJECT']
51 | BUCKET = os.environ['BUCKET']
52 | TEMPLATE = os.environ['TEMPLATE_NAME']
53 |
54 | # Because we're using the same job name each time, if you try to launch one
55 | # job while another is still running, the second will fail.
56 | JOBNAME = PROJECT + '-twproc-template'
57 |
58 | credentials = GoogleCredentials.get_application_default()
59 | service = build('dataflow', 'v1b3', credentials=credentials)
60 |
61 | BODY = {
62 | "jobName": "{jobname}".format(jobname=JOBNAME),
63 | "gcsPath": "gs://{bucket}/templates/{template}".format(
64 | bucket=BUCKET, template=TEMPLATE),
65 | "parameters": {"timestamp": str(datetime.datetime.utcnow())},
66 | "environment": {
67 | "tempLocation": "gs://{bucket}/temp".format(bucket=BUCKET),
68 | "zone": "us-central1-f"
69 | }
70 | }
71 |
72 | dfrequest = service.projects().templates().create(
73 | projectId=PROJECT, body=BODY)
74 | dfresponse = dfrequest.execute()
75 | logging.info(dfresponse)
76 | self.response.write('Done')
77 |
78 |
79 | class FetchTweets(webapp2.RequestHandler):
80 | """Fetch home timeline tweets from the given twitter account."""
81 |
82 | def get(self):
83 |
84 | # set up the twitter client. These env vars are set in app.yaml.
85 | consumer_key = os.environ['CONSUMER_KEY']
86 | consumer_secret = os.environ['CONSUMER_SECRET']
87 | access_token = os.environ['ACCESS_TOKEN']
88 | access_token_secret = os.environ['ACCESS_TOKEN_SECRET']
89 |
90 | api = twitter.Api(consumer_key=consumer_key,
91 | consumer_secret=consumer_secret,
92 | access_token_key=access_token,
93 | access_token_secret=access_token_secret)
94 |
95 | last_id = None
96 | public_tweets = None
97 |
98 | # see if we can get the id of the most recent tweet stored.
99 | tweet_entities = ndb.gql('select * from Tweet order by tid desc limit 1')
100 | last_id = None
101 | for te in tweet_entities:
102 | last_id = te.tid
103 | break
104 | if last_id:
105 | logging.info("last id is: %s", last_id)
106 |
107 | public_tweets = []
108 | # grab tweets from the home timeline of the auth'd account.
109 | try:
110 | if last_id:
111 | public_tweets = api.GetHomeTimeline(count=200, since_id=last_id)
112 | else:
113 | public_tweets = api.GetHomeTimeline(count=20)
114 | logging.warning("Could not get last tweet id from datastore.")
115 | except Exception as e:
116 | logging.warning("Error getting tweets: %s", e)
117 |
118 | # store the retrieved tweets in the datastore
119 | logging.info("got %s tweets", len(public_tweets))
120 | for tweet in public_tweets:
121 | tw = Tweet()
122 | # logging.info("text: %s, %s", tweet.text, tweet.user.screen_name)
123 | tw.text = tweet.text
124 | tw.user = tweet.user.screen_name
125 | tw.created_at = datetime.datetime.strptime(
126 | tweet.created_at, "%a %b %d %H:%M:%S +0000 %Y")
127 | tw.tid = tweet.id
128 | urls = tweet.urls
129 | urllist = []
130 | for u in urls:
131 | urllist.append(u.expanded_url)
132 | tw.urls = urllist
133 | tw.key = ndb.Key(Tweet, tweet.id)
134 | tw.put()
135 |
136 | self.response.write('Done')
137 |
138 |
139 | class MainPage(webapp2.RequestHandler):
140 | def get(self):
141 | self.response.write('nothing to see.')
142 |
143 |
144 | app = webapp2.WSGIApplication(
145 | [('/', MainPage), ('/timeline', FetchTweets),
146 | ('/launchtemplatejob', LaunchJob)],
147 | debug=True)
148 |
--------------------------------------------------------------------------------
/job_template_launch/setup.py:
--------------------------------------------------------------------------------
1 | #
2 | # Licensed to the Apache Software Foundation (ASF) under one or more
3 | # contributor license agreements. See the NOTICE file distributed with
4 | # this work for additional information regarding copyright ownership.
5 | # The ASF licenses this file to You under the Apache License, Version 2.0
6 | # (the "License"); you may not use this file except in compliance with
7 | # the License. You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | #
17 |
18 | """Setup.py module for the workflow's worker utilities.
19 |
20 | All the workflow related code is gathered in a package that will be built as a
21 | source distribution, staged in the staging area for the workflow being run and
22 | then installed in the workers when they start running.
23 |
24 | This behavior is triggered by specifying the --setup_file command line option
25 | when running the workflow for remote execution.
26 | """
27 |
28 | from distutils.command.build import build as _build
29 | import subprocess
30 |
31 | import setuptools
32 |
33 |
34 | # This class handles the pip install mechanism.
35 | class build(_build): # pylint: disable=invalid-name
36 | """A build command class that will be invoked during package install.
37 |
38 | The package built using the current setup.py will be staged and later
39 | installed in the worker using `pip install package'. This class will be
40 | instantiated during install for this specific scenario and will trigger
41 | running the custom commands specified.
42 | """
43 | sub_commands = _build.sub_commands + [('CustomCommands', None)]
44 |
45 |
46 | # Some custom command to run during setup. The command is not essential for this
47 | # workflow. It is used here as an example. Each command will spawn a child
48 | # process. Typically, these commands will include steps to install non-Python
49 | # packages. For instance, to install a C++-based library libjpeg62 the following
50 | # two commands will have to be added:
51 | #
52 | # ['apt-get', 'update'],
53 | # ['apt-get', '--assume-yes', install', 'libjpeg62'],
54 | #
55 | # First, note that there is no need to use the sudo command because the setup
56 | # script runs with appropriate access.
57 | # Second, if apt-get tool is used then the first command needs to be 'apt-get
58 | # update' so the tool refreshes itself and initializes links to download
59 | # repositories. Without this initial step the other apt-get install commands
60 | # will fail with package not found errors. Note also --assume-yes option which
61 | # shortcuts the interactive confirmation.
62 | #
63 | # The output of custom commands (including failures) will be logged in the
64 | # worker-startup log.
65 | CUSTOM_COMMANDS = [
66 | ['echo', 'Custom command worked!']]
67 |
68 |
69 | class CustomCommands(setuptools.Command):
70 | """A setuptools Command class able to run arbitrary commands."""
71 |
72 | def initialize_options(self):
73 | pass
74 |
75 | def finalize_options(self):
76 | pass
77 |
78 | def RunCustomCommand(self, command_list):
79 | print 'Running command: %s' % command_list
80 | p = subprocess.Popen(
81 | command_list,
82 | stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
83 | # Can use communicate(input='y\n'.encode()) if the command run requires
84 | # some confirmation.
85 | stdout_data, _ = p.communicate()
86 | print 'Command output: %s' % stdout_data
87 | if p.returncode != 0:
88 | raise RuntimeError(
89 | 'Command %s failed: exit code: %s' % (command_list, p.returncode))
90 |
91 | def run(self):
92 | for command in CUSTOM_COMMANDS:
93 | self.RunCustomCommand(command)
94 |
95 |
96 | # Configure the required packages and scripts to install.
97 | # Note that the Python Dataflow containers come with numpy already installed
98 | # so this dependency will not trigger anything to be installed unless a version
99 | # restriction is specified.
100 | REQUIRED_PACKAGES = [
101 | # 'numpy',
102 | ]
103 |
104 |
105 | setuptools.setup(
106 | name='dfpipe',
107 | version='0.0.1',
108 | description='dfpipe workflow package.',
109 | install_requires=REQUIRED_PACKAGES,
110 | packages=setuptools.find_packages(),
111 | cmdclass={
112 | # Command class instantiated and run during pip install scenarios.
113 | 'build': build,
114 | 'CustomCommands': CustomCommands,
115 | }
116 | )
117 |
--------------------------------------------------------------------------------
/job_template_launch/standard_requirements.txt:
--------------------------------------------------------------------------------
1 | python-twitter
2 | requests-toolbelt
3 | google-api-python-client
4 |
5 |
--------------------------------------------------------------------------------
/sdk_launch/Dockerfile:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | FROM gcr.io/google_appengine/python
16 |
17 | RUN apt-get update
18 | RUN pip install --upgrade pip
19 | RUN pip install --upgrade setuptools
20 | RUN apt-get install -y curl
21 |
22 | # You may later want to change this download as the Cloud SDK version is updated.
23 | RUN curl https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-sdk-176.0.0-linux-x86_64.tar.gz | tar xvz
24 | RUN ./google-cloud-sdk/install.sh -q
25 | RUN ./google-cloud-sdk/bin/gcloud components install beta
26 |
27 | ADD . /app/
28 | RUN pip install -r requirements.txt
29 | ENV PATH /home/vmagent/app/google-cloud-sdk/bin:$PATH
30 | # CHANGE THIS: Edit the following 3 lines to use your settings.
31 | ENV PROJECT your-project
32 | ENV BUCKET your-bucket-name
33 | ENV DATASET your-dataset-name
34 |
35 | EXPOSE 8080
36 | WORKDIR /app
37 |
38 | CMD gunicorn -b :$PORT main_df:app
39 |
40 |
--------------------------------------------------------------------------------
/sdk_launch/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Introduction
4 |
5 | This code example shows how you can run
6 | [Cloud Dataflow](https://cloud.google.com/dataflow/) pipelines from
7 | [App Engine](https://cloud.google.com/appengine/) apps, as a replacement
8 | for the older
9 | [GAE Python MapReduce libraries](https://github.com/GoogleCloudPlatform/appengine-mapreduce),
10 | as well as do much more.
11 |
12 | The example shows how to periodically launch a Python Dataflow pipeline from GAE, to
13 | analyze data stored in Cloud Datastore; in this case, tweets from Twitter.
14 |
15 | This example uses the Dataflow SDK to launch the pipeline jobs. Because of its use of the SDK, it requires App Engine Flex.
16 | For an example that uses the same pipeline, but uses [Dataflow Templates](https://cloud.google.com/dataflow/docs/templates/overview) to launch the pipeline jobs, see the ['job_template_launch'](../job_template_launch) directory, which uses App Engine Standard.
17 | Now that Dataflow Templates are available, they are likely the more straightforward option for this type of task in most cases, so you may want to start with the ['job_template_launch'](../job_template_launch) directory.
18 |
19 | The example is a GAE app with two [services (previously, 'modules')](https://cloud.google.com/appengine/docs/standard/python/an-overview-of-app-engine#services_the_building_blocks_of_app_engine):
20 |
21 | - a [GAE Standard](https://cloud.google.com/appengine/docs/standard/) service that periodically pulls in timeline tweets from Twitter and stores them in Datastore; and
22 |
23 | - a [GAE Flexible](https://cloud.google.com/appengine/docs/flexible/) service that periodically launches a Python Dataflow pipeline to analyze the tweet data in the Datastore.
24 |
25 |
26 | ### The Dataflow pipeline
27 |
28 | The Python Dataflow pipeline reads recent tweets from the past N days from Cloud Datastore, then
29 | essentially splits into three processing branches. It finds the top N most popular words in terms of
30 | the percentage of tweets they were found in, calculates the top N most popular URLs in terms of
31 | their count, and then derives relevant word co-occurrences (bigrams) using an
32 | approximation to a [tf*idf](https://en.wikipedia.org/wiki/Tf%E2%80%93idf)
33 | ranking metric. It writes the results to three BigQuery tables.
34 |
35 |
36 |
37 | ## Prerequisites for running the example
38 |
39 | ### 1. Basic GCP setup
40 |
41 | Follow the "Before you begin" steps on
42 | [this page](https://cloud.google.com/dataflow/docs/quickstarts/quickstart-python#before-you-begin).
43 | Note your project and bucket name; you will need them in a moment.
44 |
45 | For local testing (not required, but may be useful), follow the next section on the same page to
46 | [install pip and the Dataflow SDK](https://cloud.google.com/dataflow/docs/quickstarts/quickstart-
47 | python#Setup).
48 |
49 |
50 | ### 2. Create a BigQuery dataset in your project
51 |
52 | The app will write its analytic results to BigQuery. In your project, [create a new
53 | dataset](https://cloud.google.com/bigquery/quickstart-web-ui#create_a_dataset) to use for this
54 | purpose, or note the name of an existing dataset that you will use.
55 |
56 | ### 3. Create a Twitter App
57 |
58 | [Create a Twitter application.](https://apps.twitter.com/). Note the credentials under the 'Keys
59 | and Access Tokens' tag: 'Consumer Key (API Key)', 'Consumer Secret (API Secret)', 'Access Token',
60 | and 'Access Token Secret'. You'll need these in moment.
61 |
62 | ### 4. Library installation and config
63 |
64 | 1. We need to 'vendor' the libraries used by the app's frontend.
65 | Install the dependencies into the app's `lib` subdirectory like this:
66 |
67 | ```sh
68 | pip install --target=lib -r standard_requirements.txt
69 | ```
70 |
71 | (Take a look at `appengine_config.py` to see where we specify to GAE to add those libs).
72 |
73 | 2. Then, edit `app.yaml` to add the Twitter app credentials that you generated above.
74 |
75 | 3. Edit the `Dockerfile` to specify the env vars for your `PROJECT`, GCS `BUCKET`, and `DATASET`
76 | names, created as described above. (For the bucket, do NOT add the 'gs://' prefix; just use the
77 | name).
78 |
79 | ## Deploying the App
80 |
81 | The example app is essentially 'headless', with no user-facing frontend. It would be
82 | straightforward to add user-facing content, but as is, it just runs two app [cron](https://cloud.google.com/appengine/docs/flexible/python/scheduling-jobs-with-cron-yaml) jobs: one to
83 | periodically pull tweets from Twitter and add them to the Datastore, and one to periodically
84 | analyze the tweet data. The analysis results are written to BigQuery.
85 |
86 | More specifically, the app consists of two services: a GAE Standard service, which fetches tweets
87 | and stores them in the Datastore; and a GAE Flex service, which launches a Dataflow pipeline to
88 | analyze the tweet data. Both are triggered by App Engine cron jobs.
89 |
90 | So, the app has four .yaml files.
91 | There is one for each service: [`app.yaml`]('app.yaml') (which
92 | uses [`main.py`](main.py)) and [`backend.yaml`](backend.yaml) (which uses [`main_df.py`](main_df.py)).
93 | The GAE flex service is a [custom runtime](https://cloud.google.com/appengine/docs/flexible/custom-runtimes/),
94 | and it uses the [`Dockerfile`](Dockerfile) and [`requirements.txt`](requirements.txt)
95 | in this directory when it builds and deploys.
96 |
97 | Then, the app has a [`dispatch.yaml`](dispatch.yaml) file that specifies how to route requests to
98 | the two services; and a [`cron.yaml`](cron.yaml) file that defines the cron jobs.
99 |
100 | Deploy the parts of the app like this, in this order:
101 |
102 | ```
103 | gcloud app deploy app.yaml
104 | gcloud app deploy backend.yaml
105 | gcloud app deploy dispatch.yaml
106 | gcloud app deploy cron.yaml
107 | ```
108 |
109 | If you change something in either service's script, you only need to re-deploy that `.yaml` file.
110 | You don't need to redeploy the dispatch file again unless you change the routing. If you should want
111 | to change the cron job timings, just edit and redeploy the `cron.yaml` file.
112 |
113 | ## Testing your deployment
114 |
115 | To test your deployment, manually trigger the cron jobs. To do this, go to the
116 | [cloud console](https://console.cloud.google.com) for your project,
117 | and visit the [App Engine pane](https://console.cloud.google.com/appengine).
118 | Then, click on 'Task Queues' in the left navbar, then the 'Cron Jobs' tab in the center pane.
119 |
120 | Then, click `Run now` for the `/timeline` cron job. This is the job that fetches tweets and stores
121 | them in the Datastore. After it runs, you should be able to see `Tweet` entities in the Datastore.
122 | Visit the [Datastore](https://console.cloud.google.com/datastore/entities) pane in the Cloud
123 | Console, and select `Tweet` from the 'Entities' pull-down menu. You can also try a GQL query:
124 |
125 | ```
126 | select * from Tweet order by created_at desc
127 | ```
128 |
129 |
130 | Once you know that the 'fetch tweets' cron is running successfully, click `Run now` for the
131 | `/launchpipeline` cron. This should kick off a Dataflow job and return within a few seconds. You
132 | should be able to see it running in the [Dataflow pane](https://console.cloud.google.com/dataflow)
133 | of the Cloud Console. It should finish in a few minutes. Check that it finishes without error.
134 |
135 | Once it has finished, you ought to see three new tables in your BigQuery dataset: `urls`,
136 | `word_counts`, and `word_cooccur`.
137 |
138 | If you see any problems, make sure that you've configured the `app.yaml` and `Dockerfile` as
139 | described above, and check the logs for clues.
140 |
141 | Note: the `/launchpipeline` request handler is configured to return without launching the pipeline
142 | if the request has not originated as a cron request. You can comment out that logic in `main_df.py`,
143 | in the `launch()` function, if you'd like to override that behavior.
144 |
145 |
146 | ## Running the 'backend' script locally
147 |
148 | If you'd like, you can directly run the `main_df.py` script, which launches the Dataflow pipeline,
149 | locally. You might find this easier if you're trying to debug some change you've made. To do this,
150 | first make sure you've followed
151 | [these](https://cloud.google.com/dataflow/docs/quickstarts/quickstart-python#Setup) instructions.
152 | Make sure you have all the required dependencies by running
153 | the following in your virtual environment:
154 |
155 | ```sh
156 | pip install --target=lib -r requirements.txt
157 | ```
158 |
159 | Then, set the necessary environment vars in your shell (changing the following for your correct values):
160 |
161 | ```sh
162 | export PROJECT=your-project
163 | export BUCKET=your-bucket-name
164 | export DATASET=your-dataset-name
165 | ```
166 |
167 | Then, edit `main_df.py` and in `launch()`, comment out the code that checks that the request has
168 | the `'X-Appengine-Cron'`header.
169 |
170 | Then run:
171 |
172 | ```sh
173 | python main_df.py
174 | ```
175 |
176 | The script will start a web server on `localhost` port 8080.
177 | Visit [http://localhost:8080/launchpipeline](http://localhost:8080/launchpipeline).
178 | That should kick off the Dataflow pipeline deployment.
179 |
180 |
181 | ## Exploring the analytics results in BigQuery
182 |
183 | Once our example app is up and running, it periodically writes the results of its analysis to BigQuery. Then, we can run some fun queries on the data.
184 |
185 | For example, we can find recent word co-occurrences that are 'interesting' by our metric:
186 |
187 |
188 |
189 | Or look for emerging word pairs, that have become 'interesting' in the last day or so (as of early April 2017):
190 |
191 |
192 |
193 | We can contrast the 'interesting' word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):
194 |
195 |
196 |
197 | Or, find the most often-tweeted URLs from the past few days (some URLs are truncated in the output):
198 |
199 |
200 |
201 |
202 | ## What next?
203 |
204 | This example walks through how you can programmatically launch Dataflow pipelines — that read from Datastore — directly from your App Engine app, in order to support a range of processing and analytics tasks.
205 |
206 | There are lots of interesting ways that this example could be extended. For example, you could add
207 | a user-facing frontend to the web app, that fetches and displays results from BigQuery. You might
208 | also look at trends over time (e.g. for bigrams) -- either from BigQuery, or by extending the
209 | Dataflow pipeline.
210 |
211 | ## Contributions
212 |
213 | Contributions are not currently accepted. This is not an official Google product.
214 |
--------------------------------------------------------------------------------
/sdk_launch/app.yaml:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | runtime: python27
16 | api_version: 1
17 | threadsafe: true
18 |
19 | handlers:
20 | - url: /.*
21 | script: main.app
22 | login: admin
23 |
24 | libraries:
25 | - name: ssl
26 | version: latest
27 |
28 | env_variables:
29 | CONSUMER_KEY: 'xxxx'
30 | CONSUMER_SECRET: 'xxxx'
31 | ACCESS_TOKEN: 'xxxx'
32 | ACCESS_TOKEN_SECRET: 'xxxx'
--------------------------------------------------------------------------------
/sdk_launch/appengine_config.py:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | from google.appengine.ext import vendor
16 |
17 | # Add any libraries installed in the "lib" folder.
18 | vendor.add('lib')
19 |
--------------------------------------------------------------------------------
/sdk_launch/backend.yaml:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | service: backend
16 | runtime: custom
17 | env: flex
18 |
19 | manual_scaling:
20 | instances: 1
21 |
--------------------------------------------------------------------------------
/sdk_launch/cron.yaml:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | cron:
16 | - description: fetch tweets
17 | url: /timeline
18 | schedule: every 17 minutes
19 | target: default
20 | - description: launch dataflow pipeline
21 | url: /launchpipeline
22 | schedule: every 5 hours
23 | target: backend
24 |
--------------------------------------------------------------------------------
/sdk_launch/dfpipe/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/sdk_launch/dfpipe/pipe.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | Define and launch a Dataflow pipeline to analyze recent tweets stored
17 | in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import datetime
23 | import json
24 | import logging
25 | import re
26 |
27 | import apache_beam as beam
28 | from apache_beam import combiners
29 | from apache_beam.io.gcp.bigquery import parse_table_schema_from_json
30 | from apache_beam.io.gcp.datastore.v1.datastoreio import ReadFromDatastore
31 | from apache_beam.pvalue import AsDict
32 | from apache_beam.pvalue import AsSingleton
33 |
34 | from google.cloud.proto.datastore.v1 import query_pb2
35 | from googledatastore import helper as datastore_helper, PropertyFilter
36 |
37 |
38 | logging.basicConfig(level=logging.INFO)
39 |
40 |
41 | class WordExtractingDoFn(beam.DoFn):
42 | """Parse each tweet text into words, removing some 'stopwords'."""
43 |
44 | def process(self, element):
45 | content_value = element.properties.get('text', None)
46 | text_line = ''
47 | if content_value:
48 | text_line = content_value.string_value
49 |
50 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
51 | # You can add more stopwords if you want. These words are not included
52 | # in the analysis.
53 | stopwords = [
54 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
55 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
56 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
57 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
58 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your'
59 | 'who', 'when', 'via']
60 | stopwords += list(map(chr, range(97, 123)))
61 | return list(words - set(stopwords))
62 |
63 |
64 | class CoOccurExtractingDoFn(beam.DoFn):
65 | """Parse each tweet text into words, and after removing some 'stopwords',
66 | emit the bigrams.
67 | """
68 |
69 | def process(self, element):
70 | content_value = element.properties.get('text', None)
71 | text_line = ''
72 | if content_value:
73 | text_line = content_value.string_value
74 |
75 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
76 | # You can add more stopwords if you want. These words are not included
77 | # in the analysis.
78 | stopwords = [
79 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
80 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
81 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
82 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
83 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your',
84 | 'who', 'when', 'via']
85 | stopwords += list(map(chr, range(97, 123)))
86 | pruned_words = list(words - set(stopwords))
87 | pruned_words.sort()
88 | import itertools
89 | return list(itertools.combinations(pruned_words, 2))
90 |
91 |
92 | class URLExtractingDoFn(beam.DoFn):
93 | """Extract the urls from each tweet."""
94 |
95 | def process(self, element):
96 | url_content = element.properties.get('urls', None)
97 | if url_content:
98 | urls = url_content.array_value.values
99 | links = []
100 | for u in urls:
101 | links.append(u.string_value.lower())
102 | return links
103 |
104 |
105 | def make_query(kind):
106 | """Creates a Cloud Datastore query to retrieve all entities with a
107 | 'created_at' date > N days ago.
108 | """
109 | days = 4
110 | now = datetime.datetime.now()
111 | earlier = now - datetime.timedelta(days=days)
112 |
113 | query = query_pb2.Query()
114 | query.kind.add().name = kind
115 |
116 | datastore_helper.set_property_filter(query.filter, 'created_at',
117 | PropertyFilter.GREATER_THAN,
118 | earlier)
119 |
120 | return query
121 |
122 |
123 | def process_datastore_tweets(project, dataset, pipeline_options):
124 | """Creates a pipeline that reads tweets from Cloud Datastore from the last
125 | N days. The pipeline finds the top most-used words, the top most-tweeted
126 | URLs, ranks word co-occurrences by an 'interestingness' metric (similar to
127 | on tf* idf).
128 | """
129 | ts = str(datetime.datetime.utcnow())
130 | p = beam.Pipeline(options=pipeline_options)
131 | # Create a query to read entities from datastore.
132 | query = make_query('Tweet')
133 |
134 | # Read entities from Cloud Datastore into a PCollection.
135 | lines = (p
136 | | 'read from datastore' >> ReadFromDatastore(project, query, None))
137 |
138 | global_count = AsSingleton(
139 | lines
140 | | 'global count' >> beam.combiners.Count.Globally())
141 |
142 | # Count the occurrences of each word.
143 | percents = (lines
144 | | 'split' >> (beam.ParDo(WordExtractingDoFn())
145 | .with_output_types(unicode))
146 | | 'pair_with_one' >> beam.Map(lambda x: (x, 1))
147 | | 'group' >> beam.GroupByKey()
148 | | 'count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
149 | | 'in tweets percent' >> beam.Map(
150 | lambda (word, wsum), gc: (word, float(wsum) / gc), global_count))
151 | top_percents = (percents
152 | | 'top 500' >> combiners.Top.Of(500, lambda x, y: x[1] < y[1])
153 | )
154 | # Count the occurrences of each expanded url in the tweets
155 | url_counts = (lines
156 | | 'geturls' >> (beam.ParDo(URLExtractingDoFn())
157 | .with_output_types(unicode))
158 | | 'urls_pair_with_one' >> beam.Map(lambda x: (x, 1))
159 | | 'urls_group' >> beam.GroupByKey()
160 | | 'urls_count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
161 | | 'urls top 300' >> combiners.Top.Of(300, lambda x, y: x[1] < y[1])
162 | )
163 |
164 | # Define some inline helper functions.
165 |
166 | def join_cinfo(cooccur, percents):
167 | """Calculate a co-occurence ranking."""
168 | import math
169 |
170 | word1 = cooccur[0][0]
171 | word2 = cooccur[0][1]
172 | try:
173 | word1_percent = percents[word1]
174 | weight1 = 1 / word1_percent
175 | word2_percent = percents[word2]
176 | weight2 = 1 / word2_percent
177 | return (cooccur[0], cooccur[1], cooccur[1] *
178 | math.log(min(weight1, weight2)))
179 | except:
180 | return 0
181 |
182 | def generate_cooccur_schema():
183 | """BigQuery schema for the word co-occurrence table."""
184 | json_str = json.dumps({'fields': [
185 | {'name': 'w1', 'type': 'STRING', 'mode': 'NULLABLE'},
186 | {'name': 'w2', 'type': 'STRING', 'mode': 'NULLABLE'},
187 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
188 | {'name': 'log_weight', 'type': 'FLOAT', 'mode': 'NULLABLE'},
189 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
190 | return parse_table_schema_from_json(json_str)
191 |
192 | def generate_url_schema():
193 | """BigQuery schema for the urls count table."""
194 | json_str = json.dumps({'fields': [
195 | {'name': 'url', 'type': 'STRING', 'mode': 'NULLABLE'},
196 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
197 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
198 | return parse_table_schema_from_json(json_str)
199 |
200 | def generate_wc_schema():
201 | """BigQuery schema for the word count table."""
202 | json_str = json.dumps({'fields': [
203 | {'name': 'word', 'type': 'STRING', 'mode': 'NULLABLE'},
204 | {'name': 'percent', 'type': 'FLOAT', 'mode': 'NULLABLE'},
205 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
206 | return parse_table_schema_from_json(json_str)
207 |
208 | # Now build the rest of the pipeline.
209 | # Calculate the word co-occurence scores.
210 | cooccur_rankings = (lines
211 | | 'getcooccur' >> (beam.ParDo(CoOccurExtractingDoFn()))
212 | | 'co_pair_with_one' >> beam.Map(lambda x: (x, 1))
213 | | 'co_group' >> beam.GroupByKey()
214 | | 'co_count' >> beam.Map(lambda (wordts, ones): (wordts, sum(ones)))
215 | | 'weights' >> beam.Map(join_cinfo, AsDict(percents))
216 | | 'co top 300' >> combiners.Top.Of(300, lambda x, y: x[2] < y[2])
217 | )
218 |
219 | # Format the counts into a PCollection of strings.
220 | wc_records = top_percents | 'format' >> beam.FlatMap(
221 | lambda x: [{'word': xx[0], 'percent': xx[1], 'ts': ts} for xx in x])
222 |
223 | url_records = url_counts | 'urls_format' >> beam.FlatMap(
224 | lambda x: [{'url': xx[0], 'count': xx[1], 'ts': ts} for xx in x])
225 |
226 | co_records = cooccur_rankings | 'co_format' >> beam.FlatMap(
227 | lambda x: [{'w1': xx[0][0], 'w2': xx[0][1], 'count': xx[1],
228 | 'log_weight': xx[2], 'ts': ts} for xx in x])
229 |
230 | # Write the results to three BigQuery tables.
231 | wc_records | 'wc_write_bq' >> beam.io.Write(
232 | beam.io.BigQuerySink(
233 | '%s:%s.word_counts' % (project, dataset),
234 | schema=generate_wc_schema(),
235 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
236 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
237 |
238 | url_records | 'urls_write_bq' >> beam.io.Write(
239 | beam.io.BigQuerySink(
240 | '%s:%s.urls' % (project, dataset),
241 | schema=generate_url_schema(),
242 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
243 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
244 |
245 | co_records | 'co_write_bq' >> beam.io.Write(
246 | beam.io.BigQuerySink(
247 | '%s:%s.word_cooccur' % (project, dataset),
248 | schema=generate_cooccur_schema(),
249 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
250 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
251 |
252 | # Actually run the pipeline.
253 | return p.run()
254 |
255 |
256 |
--------------------------------------------------------------------------------
/sdk_launch/dispatch.yaml:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | dispatch:
16 |
17 | - url: "*/favicon.ico"
18 | service: default
19 |
20 | - url: "*/timeline*"
21 | service: default
22 |
23 | - url: "*/launchpipeline*"
24 | service: backend
25 |
26 |
--------------------------------------------------------------------------------
/sdk_launch/main.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | The app for the 'frontend' service, which handles cron job requests to
17 | fetch tweets and store them in the Datastore.
18 | """
19 |
20 | import datetime
21 | import logging
22 | import os
23 |
24 | from google.appengine.ext import ndb
25 | import twitter
26 | import webapp2
27 |
28 |
29 | class Tweet(ndb.Model):
30 | """Define the Tweet model."""
31 | user = ndb.StringProperty()
32 | text = ndb.StringProperty()
33 | created_at = ndb.DateTimeProperty()
34 | tid = ndb.IntegerProperty()
35 | urls = ndb.StringProperty(repeated=True)
36 |
37 |
38 | class FetchTweets(webapp2.RequestHandler):
39 | """Fetch home timeline tweets from the given twitter account."""
40 |
41 | def get(self):
42 |
43 | # set up the twitter client. These env vars are set in app.yaml.
44 | consumer_key = os.environ['CONSUMER_KEY']
45 | consumer_secret = os.environ['CONSUMER_SECRET']
46 | access_token = os.environ['ACCESS_TOKEN']
47 | access_token_secret = os.environ['ACCESS_TOKEN_SECRET']
48 |
49 | api = twitter.Api(consumer_key=consumer_key,
50 | consumer_secret=consumer_secret,
51 | access_token_key=access_token,
52 | access_token_secret=access_token_secret)
53 |
54 | last_id = None
55 | public_tweets = None
56 |
57 | # see if we can get the id of the most recent tweet stored.
58 | tweet_entities = ndb.gql('select * from Tweet order by tid desc limit 1')
59 | last_id = None
60 | for te in tweet_entities:
61 | last_id = te.tid
62 | break
63 | if last_id:
64 | logging.info("last id is: %s", last_id)
65 |
66 | public_tweets = []
67 | # grab tweets from the home timeline of the auth'd account.
68 | try:
69 | if last_id:
70 | public_tweets = api.GetHomeTimeline(count=200, since_id=last_id)
71 | else:
72 | public_tweets = api.GetHomeTimeline(count=20)
73 | logging.warning("Could not get last tweet id from datastore.")
74 | except Exception as e:
75 | logging.warning("Error getting tweets: %s", e)
76 |
77 | # store the retrieved tweets in the datastore
78 | logging.info("got %s tweets", len(public_tweets))
79 | for tweet in public_tweets:
80 | tw = Tweet()
81 | # logging.info("text: %s, %s", tweet.text, tweet.user.screen_name)
82 | tw.text = tweet.text
83 | tw.user = tweet.user.screen_name
84 | tw.created_at = datetime.datetime.strptime(tweet.created_at, "%a %b %d %H:%M:%S +0000 %Y")
85 | tw.tid = tweet.id
86 | urls = tweet.urls
87 | urllist = []
88 | for u in urls:
89 | urllist.append(u.expanded_url)
90 | tw.urls = urllist
91 | tw.key = ndb.Key(Tweet, tweet.id)
92 | tw.put()
93 |
94 | self.response.write('Done')
95 |
96 |
97 | class MainPage(webapp2.RequestHandler):
98 | def get(self):
99 | self.response.write('nothing to see.')
100 |
101 |
102 | app = webapp2.WSGIApplication(
103 | [('/', MainPage), ('/timeline', FetchTweets)], debug=True)
104 |
--------------------------------------------------------------------------------
/sdk_launch/main_df.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | The app for the 'backend' service, which handles cron job requests to
17 | launch a Dataflow pipeline to analyze recent tweets stored in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import logging
23 | import os
24 |
25 | from apache_beam.options.pipeline_options import PipelineOptions
26 |
27 | from flask import Flask
28 | from flask import request
29 |
30 | import dfpipe.pipe as pipe
31 |
32 |
33 | logging.basicConfig(level=logging.INFO)
34 | app = Flask(__name__)
35 |
36 | PROJECT = os.environ['PROJECT']
37 | BUCKET = os.environ['BUCKET']
38 | DATASET = os.environ['DATASET']
39 |
40 |
41 | # Route the incoming app requests.
42 |
43 | @app.route('/')
44 | def hello():
45 | """A no-op."""
46 | return 'nothing to see.'
47 |
48 |
49 | @app.route('/launchpipeline')
50 | def launch():
51 | """Launch the Dataflow pipeline."""
52 | is_cron = request.headers.get('X-Appengine-Cron', False)
53 | logging.info("is_cron is %s", is_cron)
54 | # Comment out the following test to allow non cron-initiated requests.
55 | if not is_cron:
56 | return 'Blocked.'
57 | pipeline_options = {
58 | 'project': PROJECT,
59 | 'staging_location': 'gs://' + BUCKET + '/staging',
60 | 'runner': 'DataflowRunner',
61 | 'setup_file': './setup.py',
62 | 'job_name': PROJECT + '-twcount',
63 | 'max_num_workers': 10,
64 | 'temp_location': 'gs://' + BUCKET + '/temp'
65 | }
66 | # define and launch the pipeline (non-blocking).
67 | pipe.process_datastore_tweets(PROJECT, DATASET,
68 | PipelineOptions.from_dictionary(pipeline_options))
69 |
70 | return 'Done.'
71 |
72 |
73 | if __name__ == '__main__':
74 | app.run(host='0.0.0.0', port=8080, debug=True)
75 |
--------------------------------------------------------------------------------
/sdk_launch/main_test.py:
--------------------------------------------------------------------------------
1 | # Copyright 2015 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | import webtest
16 |
17 | import main
18 |
19 |
20 | def test_app(testbed):
21 | app = webtest.TestApp(main.app)
22 | response = app.get('/')
23 | assert response.status_int == 200
24 |
--------------------------------------------------------------------------------
/sdk_launch/requirements.txt:
--------------------------------------------------------------------------------
1 | Flask==0.11.1
2 | gunicorn==19.6.0
3 | google-cloud-dataflow==2.0.0
4 |
--------------------------------------------------------------------------------
/sdk_launch/setup.py:
--------------------------------------------------------------------------------
1 | #
2 | # Licensed to the Apache Software Foundation (ASF) under one or more
3 | # contributor license agreements. See the NOTICE file distributed with
4 | # this work for additional information regarding copyright ownership.
5 | # The ASF licenses this file to You under the Apache License, Version 2.0
6 | # (the "License"); you may not use this file except in compliance with
7 | # the License. You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | #
17 |
18 | """Setup.py module for the workflow's worker utilities.
19 |
20 | All the workflow related code is gathered in a package that will be built as a
21 | source distribution, staged in the staging area for the workflow being run and
22 | then installed in the workers when they start running.
23 |
24 | This behavior is triggered by specifying the --setup_file command line option
25 | when running the workflow for remote execution.
26 | """
27 |
28 | from distutils.command.build import build as _build
29 | import subprocess
30 |
31 | import setuptools
32 |
33 |
34 | # This class handles the pip install mechanism.
35 | class build(_build): # pylint: disable=invalid-name
36 | """A build command class that will be invoked during package install.
37 |
38 | The package built using the current setup.py will be staged and later
39 | installed in the worker using `pip install package'. This class will be
40 | instantiated during install for this specific scenario and will trigger
41 | running the custom commands specified.
42 | """
43 | sub_commands = _build.sub_commands + [('CustomCommands', None)]
44 |
45 |
46 | # Some custom command to run during setup. The command is not essential for this
47 | # workflow. It is used here as an example. Each command will spawn a child
48 | # process. Typically, these commands will include steps to install non-Python
49 | # packages. For instance, to install a C++-based library libjpeg62 the following
50 | # two commands will have to be added:
51 | #
52 | # ['apt-get', 'update'],
53 | # ['apt-get', '--assume-yes', install', 'libjpeg62'],
54 | #
55 | # First, note that there is no need to use the sudo command because the setup
56 | # script runs with appropriate access.
57 | # Second, if apt-get tool is used then the first command needs to be 'apt-get
58 | # update' so the tool refreshes itself and initializes links to download
59 | # repositories. Without this initial step the other apt-get install commands
60 | # will fail with package not found errors. Note also --assume-yes option which
61 | # shortcuts the interactive confirmation.
62 | #
63 | # The output of custom commands (including failures) will be logged in the
64 | # worker-startup log.
65 | CUSTOM_COMMANDS = [
66 | ['echo', 'Custom command worked!']]
67 |
68 |
69 | class CustomCommands(setuptools.Command):
70 | """A setuptools Command class able to run arbitrary commands."""
71 |
72 | def initialize_options(self):
73 | pass
74 |
75 | def finalize_options(self):
76 | pass
77 |
78 | def RunCustomCommand(self, command_list):
79 | print 'Running command: %s' % command_list
80 | p = subprocess.Popen(
81 | command_list,
82 | stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
83 | # Can use communicate(input='y\n'.encode()) if the command run requires
84 | # some confirmation.
85 | stdout_data, _ = p.communicate()
86 | print 'Command output: %s' % stdout_data
87 | if p.returncode != 0:
88 | raise RuntimeError(
89 | 'Command %s failed: exit code: %s' % (command_list, p.returncode))
90 |
91 | def run(self):
92 | for command in CUSTOM_COMMANDS:
93 | self.RunCustomCommand(command)
94 |
95 |
96 | # Configure the required packages and scripts to install.
97 | # Note that the Python Dataflow containers come with numpy already installed
98 | # so this dependency will not trigger anything to be installed unless a version
99 | # restriction is specified.
100 | REQUIRED_PACKAGES = [
101 | # 'numpy',
102 | ]
103 |
104 |
105 | setuptools.setup(
106 | name='dfpipe',
107 | version='0.0.1',
108 | description='dfpipe workflow package.',
109 | install_requires=REQUIRED_PACKAGES,
110 | packages=setuptools.find_packages(),
111 | cmdclass={
112 | # Command class instantiated and run during pip install scenarios.
113 | 'build': build,
114 | 'CustomCommands': CustomCommands,
115 | }
116 | )
117 |
--------------------------------------------------------------------------------
/sdk_launch/standard_requirements.txt:
--------------------------------------------------------------------------------
1 | python-twitter
2 | requests-toolbelt
3 |
--------------------------------------------------------------------------------

 118 |
118 | 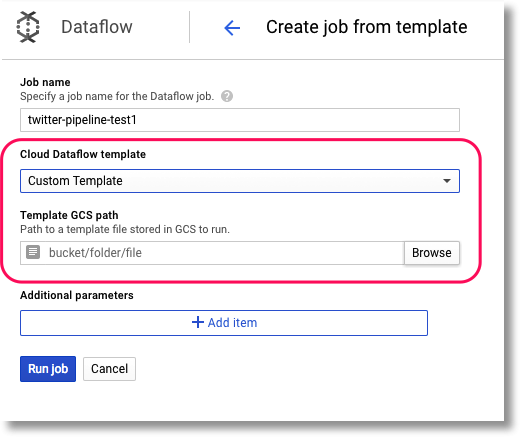 126 |
126 | 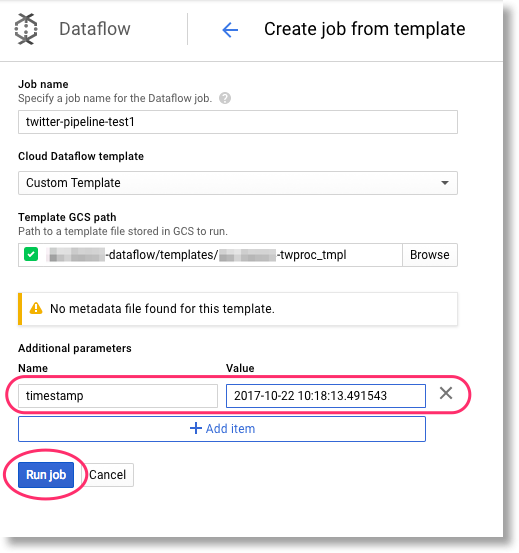 134 |
134 |  200 |
201 | Or look for emerging word pairs, that have become 'interesting' in the last day or so (as of early April 2017):
202 |
203 |
200 |
201 | Or look for emerging word pairs, that have become 'interesting' in the last day or so (as of early April 2017):
202 |
203 |  204 |
205 | We can contrast the 'interesting' word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):
206 |
207 |
204 |
205 | We can contrast the 'interesting' word pairs with the words that are simply the most popular within a given period (you can see that most of these words are common, but not particularly newsworthy):
206 |
207 |  208 |
209 | Or, find the most often-tweeted URLs from the past few days (some URLs are truncated in the output):
210 |
211 |
208 |
209 | Or, find the most often-tweeted URLs from the past few days (some URLs are truncated in the output):
210 |
211 | 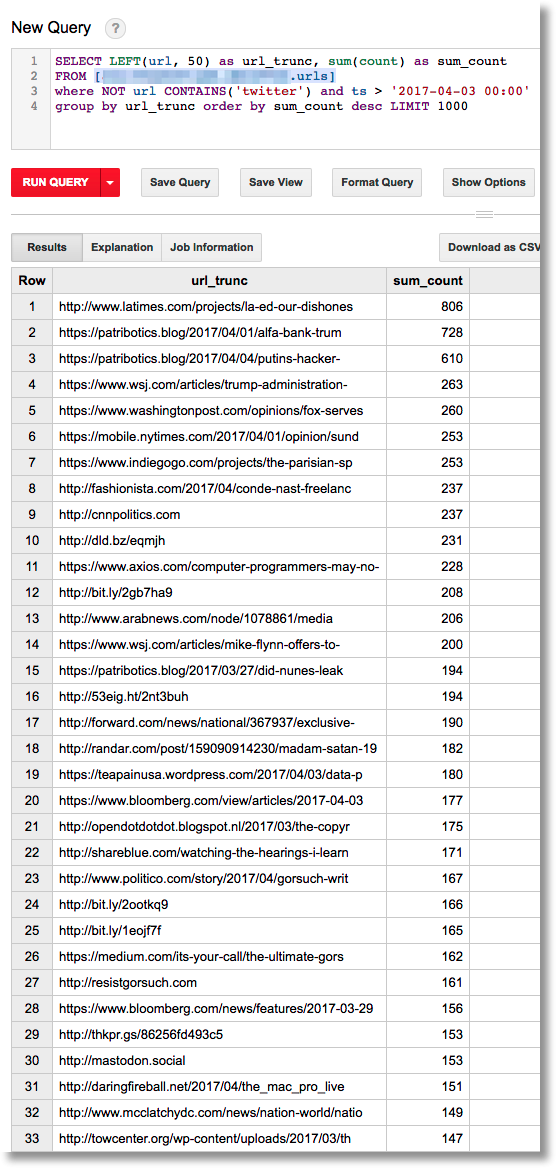 212 |
213 |
214 | ## What next?
215 |
216 | This example walks through how you can programmatically launch Dataflow pipelines — that read from Datastore — directly from your App Engine app, in order to support a range of processing and analytics tasks.
217 |
218 | There are lots of interesting ways that this example could be extended. For example, you could add
219 | a user-facing frontend to the web app, that fetches and displays results from BigQuery. You might
220 | also look at trends over time (e.g. for bigrams) -- either from BigQuery, or by extending the
221 | Dataflow pipeline.
222 |
223 | ## Contributions
224 |
225 | Contributions are not currently accepted. This is not an official Google product.
--------------------------------------------------------------------------------
/job_template_launch/app.yaml:
--------------------------------------------------------------------------------
1 | runtime: python27
2 | api_version: 1
3 | threadsafe: true
4 |
5 | handlers:
6 | - url: /.*
7 | script: main.app
8 | login: admin
9 |
10 | libraries:
11 | - name: ssl
12 | version: latest
13 |
14 | env_variables:
15 | CONSUMER_KEY: 'xxx'
16 | CONSUMER_SECRET: 'xxx'
17 | ACCESS_TOKEN: 'xxx'
18 | ACCESS_TOKEN_SECRET: 'xxx'
19 | PROJECT: 'YOUR-PROJECT-ID'
20 | DATASET: 'xxx'
21 | BUCKET: 'xxx'
22 | TEMPLATE_NAME: 'YOUR-PROJECT-ID-twproc_tmpl'
23 |
--------------------------------------------------------------------------------
/job_template_launch/appengine_config.py:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | from google.appengine.ext import vendor
16 |
17 | # Add any libraries installed in the "lib" folder.
18 | vendor.add('lib')
19 |
--------------------------------------------------------------------------------
/job_template_launch/create_template.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | The app for the 'backend' service, which handles cron job requests to
17 | launch a Dataflow pipeline to analyze recent tweets stored in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import logging
23 | import os
24 |
25 | from apache_beam.options.pipeline_options import PipelineOptions
26 |
27 | import dfpipe.pipe as pipe
28 |
29 |
30 | PROJECT = os.environ['PROJECT']
31 | BUCKET = os.environ['BUCKET']
32 | DATASET = os.environ['DATASET']
33 |
34 | pipeline_options = {
35 | 'project': PROJECT,
36 | 'staging_location': 'gs://' + BUCKET + '/staging',
37 | 'runner': 'DataflowRunner',
38 | 'setup_file': './setup.py',
39 | 'job_name': PROJECT + '-twcount',
40 | 'temp_location': 'gs://' + BUCKET + '/temp',
41 | 'template_location': 'gs://' + BUCKET + '/templates/' + PROJECT + '-twproc_tmpl'
42 | }
43 | # define and launch the pipeline (non-blocking), which will create the template.
44 | pipeline_options = PipelineOptions.from_dictionary(pipeline_options)
45 | pipe.process_datastore_tweets(PROJECT, DATASET, pipeline_options)
46 |
--------------------------------------------------------------------------------
/job_template_launch/cron.yaml:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | cron:
16 | - description: fetch tweets
17 | url: /timeline
18 | schedule: every 17 minutes
19 | target: default
20 | - description: launch dataflow pipeline
21 | url: /launchtemplatejob
22 | schedule: every 5 hours
23 | target: default
24 |
--------------------------------------------------------------------------------
/job_template_launch/dfpipe/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/job_template_launch/dfpipe/pipe.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | Define and launch a Dataflow pipeline to analyze recent tweets stored
17 | in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import datetime
23 | import json
24 | import logging
25 | import re
26 |
27 | import apache_beam as beam
28 | from apache_beam import combiners
29 | from apache_beam.io.gcp.bigquery import parse_table_schema_from_json
30 | from apache_beam.io.gcp.datastore.v1.datastoreio import ReadFromDatastore
31 | from apache_beam.pvalue import AsDict
32 | from apache_beam.pvalue import AsSingleton
33 | from apache_beam.options.pipeline_options import PipelineOptions
34 |
35 |
36 | from google.cloud.proto.datastore.v1 import query_pb2
37 | from googledatastore import helper as datastore_helper, PropertyFilter
38 |
39 |
40 | logging.basicConfig(level=logging.INFO)
41 |
42 | class FilterDate(beam.DoFn):
43 | """Filter Tweet datastore entities based on timestamp."""
44 |
45 | def __init__(self, opts, days):
46 | super(FilterDate, self).__init__()
47 | self.opts = opts
48 | self.days = days
49 | self.earlier = None
50 |
51 | def start_bundle(self):
52 | before = datetime.datetime.strptime(self.opts.timestamp.get(),
53 | '%Y-%m-%d %H:%M:%S.%f')
54 | self.earlier = before - datetime.timedelta(days=self.days)
55 |
56 | def process(self, element):
57 |
58 | created_at = element.properties.get('created_at', None)
59 | cav = None
60 | if created_at:
61 | cav = created_at.timestamp_value
62 | cseconds = cav.seconds
63 | else:
64 | return
65 | crdt = datetime.datetime.fromtimestamp(cseconds)
66 | logging.warn("crdt: %s", crdt)
67 | logging.warn("earlier: %s", self.earlier)
68 | if crdt > self.earlier:
69 | # return only the elements (datastore entities) with a 'created_at' date
70 | # within the last self.days days.
71 | yield element
72 |
73 |
74 | class WordExtractingDoFn(beam.DoFn):
75 | """Parse each tweet text into words, removing some 'stopwords'."""
76 |
77 | def process(self, element):
78 | content_value = element.properties.get('text', None)
79 | text_line = ''
80 | if content_value:
81 | text_line = content_value.string_value
82 |
83 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
84 | # You can add more stopwords if you want. These words are not included
85 | # in the analysis.
86 | stopwords = [
87 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
88 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
89 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
90 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
91 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your'
92 | 'who', 'when', 'via']
93 | stopwords += list(map(chr, range(97, 123)))
94 | return list(words - set(stopwords))
95 |
96 |
97 | class CoOccurExtractingDoFn(beam.DoFn):
98 | """Parse each tweet text into words, and after removing some 'stopwords',
99 | emit the bigrams.
100 | """
101 |
102 | def process(self, element):
103 | content_value = element.properties.get('text', None)
104 | text_line = ''
105 | if content_value:
106 | text_line = content_value.string_value
107 |
108 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
109 | # You can add more stopwords if you want. These words are not included
110 | # in the analysis.
111 | stopwords = [
112 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
113 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
114 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
115 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
116 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your',
117 | 'who', 'when', 'via']
118 | stopwords += list(map(chr, range(97, 123)))
119 | pruned_words = list(words - set(stopwords))
120 | pruned_words.sort()
121 | import itertools
122 | return list(itertools.combinations(pruned_words, 2))
123 |
124 |
125 | class URLExtractingDoFn(beam.DoFn):
126 | """Extract the urls from each tweet."""
127 |
128 | def process(self, element):
129 | url_content = element.properties.get('urls', None)
130 | if url_content:
131 | urls = url_content.array_value.values
132 | links = []
133 | for u in urls:
134 | links.append(u.string_value.lower())
135 | return links
136 |
137 |
138 |
139 | class QueryDatastore(beam.PTransform):
140 | """Generate a Datastore query, then read from the Datastore.
141 | """
142 |
143 | def __init__(self, project, days):
144 | super(QueryDatastore, self).__init__()
145 | self.project = project
146 | self.days = days
147 |
148 |
149 | # it's not currently supported to use template runtime value providers for
150 | # the Datastore input source, so we can't use runtime values to
151 | # construct our query. However, we can still statically filter based on time
152 | # of template construction, which lets us make the query a bit more
153 | # efficient.
154 | def expand(self, pcoll):
155 | query = query_pb2.Query()
156 | query.kind.add().name = 'Tweet'
157 | now = datetime.datetime.now()
158 | # The 'earlier' var will be set to a static value on template creation.
159 | # That is, because of the way that templates work, the value is defined
160 | # at template compile time, not runtime.
161 | # But defining a filter based on this value will still serve to make the
162 | # query more efficient than if we didn't filter at all.
163 | earlier = now - datetime.timedelta(days=self.days)
164 | datastore_helper.set_property_filter(query.filter, 'created_at',
165 | PropertyFilter.GREATER_THAN,
166 | earlier)
167 |
168 | return (pcoll
169 | | 'read from datastore' >> ReadFromDatastore(self.project,
170 | query, None))
171 |
172 |
173 | class UserOptions(PipelineOptions):
174 | @classmethod
175 | def _add_argparse_args(cls, parser):
176 | parser.add_value_provider_argument('--timestamp', type=str)
177 |
178 |
179 | def process_datastore_tweets(project, dataset, pipeline_options):
180 | """Creates a pipeline that reads tweets from Cloud Datastore from the last
181 | N days. The pipeline finds the top most-used words, the top most-tweeted
182 | URLs, ranks word co-occurrences by an 'interestingness' metric (similar to
183 | on tf* idf).
184 | """
185 |
186 | user_options = pipeline_options.view_as(UserOptions)
187 | DAYS = 4
188 |
189 | p = beam.Pipeline(options=pipeline_options)
190 |
191 | # Read entities from Cloud Datastore into a PCollection, then filter to get
192 | # only the entities from the last DAYS days.
193 | lines = (p | QueryDatastore(project, DAYS)
194 | | beam.ParDo(FilterDate(user_options, DAYS))
195 | )
196 |
197 | global_count = AsSingleton(
198 | lines
199 | | 'global count' >> beam.combiners.Count.Globally())
200 |
201 | # Count the occurrences of each word.
202 | percents = (lines
203 | | 'split' >> (beam.ParDo(WordExtractingDoFn())
204 | .with_output_types(unicode))
205 | | 'pair_with_one' >> beam.Map(lambda x: (x, 1))
206 | | 'group' >> beam.GroupByKey()
207 | | 'count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
208 | | 'in tweets percent' >> beam.Map(
209 | lambda (word, wsum), gc: (word, float(wsum) / gc), global_count))
210 | top_percents = (percents
211 | | 'top 500' >> combiners.Top.Of(500, lambda x, y: x[1] < y[1])
212 | )
213 | # Count the occurrences of each expanded url in the tweets
214 | url_counts = (lines
215 | | 'geturls' >> (beam.ParDo(URLExtractingDoFn())
216 | .with_output_types(unicode))
217 | | 'urls_pair_with_one' >> beam.Map(lambda x: (x, 1))
218 | | 'urls_group' >> beam.GroupByKey()
219 | | 'urls_count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
220 | | 'urls top 300' >> combiners.Top.Of(300, lambda x, y: x[1] < y[1])
221 | )
222 |
223 | # Define some inline helper functions.
224 |
225 | def join_cinfo(cooccur, percents):
226 | """Calculate a co-occurence ranking."""
227 | import math
228 |
229 | word1 = cooccur[0][0]
230 | word2 = cooccur[0][1]
231 | try:
232 | word1_percent = percents[word1]
233 | weight1 = 1 / word1_percent
234 | word2_percent = percents[word2]
235 | weight2 = 1 / word2_percent
236 | return (cooccur[0], cooccur[1], cooccur[1] *
237 | math.log(min(weight1, weight2)))
238 | except:
239 | return 0
240 |
241 | def generate_cooccur_schema():
242 | """BigQuery schema for the word co-occurrence table."""
243 | json_str = json.dumps({'fields': [
244 | {'name': 'w1', 'type': 'STRING', 'mode': 'NULLABLE'},
245 | {'name': 'w2', 'type': 'STRING', 'mode': 'NULLABLE'},
246 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
247 | {'name': 'log_weight', 'type': 'FLOAT', 'mode': 'NULLABLE'},
248 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
249 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
250 | return parse_table_schema_from_json(json_str)
251 |
252 | def generate_url_schema():
253 | """BigQuery schema for the urls count table."""
254 | json_str = json.dumps({'fields': [
255 | {'name': 'url', 'type': 'STRING', 'mode': 'NULLABLE'},
256 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
257 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
258 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
259 | return parse_table_schema_from_json(json_str)
260 |
261 | def generate_wc_schema():
262 | """BigQuery schema for the word count table."""
263 | json_str = json.dumps({'fields': [
264 | {'name': 'word', 'type': 'STRING', 'mode': 'NULLABLE'},
265 | {'name': 'percent', 'type': 'FLOAT', 'mode': 'NULLABLE'},
266 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
267 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
268 | return parse_table_schema_from_json(json_str)
269 |
270 | # Now build the rest of the pipeline.
271 | # Calculate the word co-occurence scores.
272 | cooccur_rankings = (lines
273 | | 'getcooccur' >> (beam.ParDo(CoOccurExtractingDoFn()))
274 | | 'co_pair_with_one' >> beam.Map(lambda x: (x, 1))
275 | | 'co_group' >> beam.GroupByKey()
276 | | 'co_count' >> beam.Map(lambda (wordts, ones): (wordts, sum(ones)))
277 | | 'weights' >> beam.Map(join_cinfo, AsDict(percents))
278 | | 'co top 300' >> combiners.Top.Of(300, lambda x, y: x[2] < y[2])
279 | )
280 |
281 | # Format the counts into a PCollection of strings.
282 | wc_records = top_percents | 'format' >> beam.FlatMap(
283 | lambda x: [{'word': xx[0], 'percent': xx[1],
284 | 'ts': user_options.timestamp.get()} for xx in x])
285 |
286 | url_records = url_counts | 'urls_format' >> beam.FlatMap(
287 | lambda x: [{'url': xx[0], 'count': xx[1],
288 | 'ts': user_options.timestamp.get()} for xx in x])
289 |
290 | co_records = cooccur_rankings | 'co_format' >> beam.FlatMap(
291 | lambda x: [{'w1': xx[0][0], 'w2': xx[0][1], 'count': xx[1],
292 | 'log_weight': xx[2],
293 | 'ts': user_options.timestamp.get()} for xx in x])
294 |
295 | # Write the results to three BigQuery tables.
296 | wc_records | 'wc_write_bq' >> beam.io.Write(
297 | beam.io.BigQuerySink(
298 | '%s:%s.word_counts' % (project, dataset),
299 | schema=generate_wc_schema(),
300 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
301 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
302 |
303 | url_records | 'urls_write_bq' >> beam.io.Write(
304 | beam.io.BigQuerySink(
305 | '%s:%s.urls' % (project, dataset),
306 | schema=generate_url_schema(),
307 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
308 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
309 |
310 | co_records | 'co_write_bq' >> beam.io.Write(
311 | beam.io.BigQuerySink(
312 | '%s:%s.word_cooccur' % (project, dataset),
313 | schema=generate_cooccur_schema(),
314 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
315 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
316 |
317 | # Actually run the pipeline.
318 | return p.run()
319 |
320 |
321 |
--------------------------------------------------------------------------------
/job_template_launch/main.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | The app for the 'frontend' service, which handles cron job requests to
16 | fetch tweets and store them in the Datastore.
17 | """
18 |
19 | import datetime
20 | import logging
21 | import os
22 |
23 | from google.appengine.ext import ndb
24 | import twitter
25 | import webapp2
26 |
27 | from googleapiclient.discovery import build
28 | from oauth2client.client import GoogleCredentials
29 |
30 |
31 | class Tweet(ndb.Model):
32 | """Define the Tweet model."""
33 | user = ndb.StringProperty()
34 | text = ndb.StringProperty()
35 | created_at = ndb.DateTimeProperty()
36 | tid = ndb.IntegerProperty()
37 | urls = ndb.StringProperty(repeated=True)
38 |
39 |
40 | class LaunchJob(webapp2.RequestHandler):
41 | """Launch the Dataflow pipeline using a job template."""
42 |
43 | def get(self):
44 | is_cron = self.request.headers.get('X-Appengine-Cron', False)
45 | # logging.info("is_cron is %s", is_cron)
46 | # Comment out the following check to allow non-cron-initiated requests.
47 | if not is_cron:
48 | return 'Blocked.'
49 | # These env vars are set in app.yaml.
50 | PROJECT = os.environ['PROJECT']
51 | BUCKET = os.environ['BUCKET']
52 | TEMPLATE = os.environ['TEMPLATE_NAME']
53 |
54 | # Because we're using the same job name each time, if you try to launch one
55 | # job while another is still running, the second will fail.
56 | JOBNAME = PROJECT + '-twproc-template'
57 |
58 | credentials = GoogleCredentials.get_application_default()
59 | service = build('dataflow', 'v1b3', credentials=credentials)
60 |
61 | BODY = {
62 | "jobName": "{jobname}".format(jobname=JOBNAME),
63 | "gcsPath": "gs://{bucket}/templates/{template}".format(
64 | bucket=BUCKET, template=TEMPLATE),
65 | "parameters": {"timestamp": str(datetime.datetime.utcnow())},
66 | "environment": {
67 | "tempLocation": "gs://{bucket}/temp".format(bucket=BUCKET),
68 | "zone": "us-central1-f"
69 | }
70 | }
71 |
72 | dfrequest = service.projects().templates().create(
73 | projectId=PROJECT, body=BODY)
74 | dfresponse = dfrequest.execute()
75 | logging.info(dfresponse)
76 | self.response.write('Done')
77 |
78 |
79 | class FetchTweets(webapp2.RequestHandler):
80 | """Fetch home timeline tweets from the given twitter account."""
81 |
82 | def get(self):
83 |
84 | # set up the twitter client. These env vars are set in app.yaml.
85 | consumer_key = os.environ['CONSUMER_KEY']
86 | consumer_secret = os.environ['CONSUMER_SECRET']
87 | access_token = os.environ['ACCESS_TOKEN']
88 | access_token_secret = os.environ['ACCESS_TOKEN_SECRET']
89 |
90 | api = twitter.Api(consumer_key=consumer_key,
91 | consumer_secret=consumer_secret,
92 | access_token_key=access_token,
93 | access_token_secret=access_token_secret)
94 |
95 | last_id = None
96 | public_tweets = None
97 |
98 | # see if we can get the id of the most recent tweet stored.
99 | tweet_entities = ndb.gql('select * from Tweet order by tid desc limit 1')
100 | last_id = None
101 | for te in tweet_entities:
102 | last_id = te.tid
103 | break
104 | if last_id:
105 | logging.info("last id is: %s", last_id)
106 |
107 | public_tweets = []
108 | # grab tweets from the home timeline of the auth'd account.
109 | try:
110 | if last_id:
111 | public_tweets = api.GetHomeTimeline(count=200, since_id=last_id)
112 | else:
113 | public_tweets = api.GetHomeTimeline(count=20)
114 | logging.warning("Could not get last tweet id from datastore.")
115 | except Exception as e:
116 | logging.warning("Error getting tweets: %s", e)
117 |
118 | # store the retrieved tweets in the datastore
119 | logging.info("got %s tweets", len(public_tweets))
120 | for tweet in public_tweets:
121 | tw = Tweet()
122 | # logging.info("text: %s, %s", tweet.text, tweet.user.screen_name)
123 | tw.text = tweet.text
124 | tw.user = tweet.user.screen_name
125 | tw.created_at = datetime.datetime.strptime(
126 | tweet.created_at, "%a %b %d %H:%M:%S +0000 %Y")
127 | tw.tid = tweet.id
128 | urls = tweet.urls
129 | urllist = []
130 | for u in urls:
131 | urllist.append(u.expanded_url)
132 | tw.urls = urllist
133 | tw.key = ndb.Key(Tweet, tweet.id)
134 | tw.put()
135 |
136 | self.response.write('Done')
137 |
138 |
139 | class MainPage(webapp2.RequestHandler):
140 | def get(self):
141 | self.response.write('nothing to see.')
142 |
143 |
144 | app = webapp2.WSGIApplication(
145 | [('/', MainPage), ('/timeline', FetchTweets),
146 | ('/launchtemplatejob', LaunchJob)],
147 | debug=True)
148 |
--------------------------------------------------------------------------------
/job_template_launch/setup.py:
--------------------------------------------------------------------------------
1 | #
2 | # Licensed to the Apache Software Foundation (ASF) under one or more
3 | # contributor license agreements. See the NOTICE file distributed with
4 | # this work for additional information regarding copyright ownership.
5 | # The ASF licenses this file to You under the Apache License, Version 2.0
6 | # (the "License"); you may not use this file except in compliance with
7 | # the License. You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | #
17 |
18 | """Setup.py module for the workflow's worker utilities.
19 |
20 | All the workflow related code is gathered in a package that will be built as a
21 | source distribution, staged in the staging area for the workflow being run and
22 | then installed in the workers when they start running.
23 |
24 | This behavior is triggered by specifying the --setup_file command line option
25 | when running the workflow for remote execution.
26 | """
27 |
28 | from distutils.command.build import build as _build
29 | import subprocess
30 |
31 | import setuptools
32 |
33 |
34 | # This class handles the pip install mechanism.
35 | class build(_build): # pylint: disable=invalid-name
36 | """A build command class that will be invoked during package install.
37 |
38 | The package built using the current setup.py will be staged and later
39 | installed in the worker using `pip install package'. This class will be
40 | instantiated during install for this specific scenario and will trigger
41 | running the custom commands specified.
42 | """
43 | sub_commands = _build.sub_commands + [('CustomCommands', None)]
44 |
45 |
46 | # Some custom command to run during setup. The command is not essential for this
47 | # workflow. It is used here as an example. Each command will spawn a child
48 | # process. Typically, these commands will include steps to install non-Python
49 | # packages. For instance, to install a C++-based library libjpeg62 the following
50 | # two commands will have to be added:
51 | #
52 | # ['apt-get', 'update'],
53 | # ['apt-get', '--assume-yes', install', 'libjpeg62'],
54 | #
55 | # First, note that there is no need to use the sudo command because the setup
56 | # script runs with appropriate access.
57 | # Second, if apt-get tool is used then the first command needs to be 'apt-get
58 | # update' so the tool refreshes itself and initializes links to download
59 | # repositories. Without this initial step the other apt-get install commands
60 | # will fail with package not found errors. Note also --assume-yes option which
61 | # shortcuts the interactive confirmation.
62 | #
63 | # The output of custom commands (including failures) will be logged in the
64 | # worker-startup log.
65 | CUSTOM_COMMANDS = [
66 | ['echo', 'Custom command worked!']]
67 |
68 |
69 | class CustomCommands(setuptools.Command):
70 | """A setuptools Command class able to run arbitrary commands."""
71 |
72 | def initialize_options(self):
73 | pass
74 |
75 | def finalize_options(self):
76 | pass
77 |
78 | def RunCustomCommand(self, command_list):
79 | print 'Running command: %s' % command_list
80 | p = subprocess.Popen(
81 | command_list,
82 | stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
83 | # Can use communicate(input='y\n'.encode()) if the command run requires
84 | # some confirmation.
85 | stdout_data, _ = p.communicate()
86 | print 'Command output: %s' % stdout_data
87 | if p.returncode != 0:
88 | raise RuntimeError(
89 | 'Command %s failed: exit code: %s' % (command_list, p.returncode))
90 |
91 | def run(self):
92 | for command in CUSTOM_COMMANDS:
93 | self.RunCustomCommand(command)
94 |
95 |
96 | # Configure the required packages and scripts to install.
97 | # Note that the Python Dataflow containers come with numpy already installed
98 | # so this dependency will not trigger anything to be installed unless a version
99 | # restriction is specified.
100 | REQUIRED_PACKAGES = [
101 | # 'numpy',
102 | ]
103 |
104 |
105 | setuptools.setup(
106 | name='dfpipe',
107 | version='0.0.1',
108 | description='dfpipe workflow package.',
109 | install_requires=REQUIRED_PACKAGES,
110 | packages=setuptools.find_packages(),
111 | cmdclass={
112 | # Command class instantiated and run during pip install scenarios.
113 | 'build': build,
114 | 'CustomCommands': CustomCommands,
115 | }
116 | )
117 |
--------------------------------------------------------------------------------
/job_template_launch/standard_requirements.txt:
--------------------------------------------------------------------------------
1 | python-twitter
2 | requests-toolbelt
3 | google-api-python-client
4 |
5 |
--------------------------------------------------------------------------------
/sdk_launch/Dockerfile:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | FROM gcr.io/google_appengine/python
16 |
17 | RUN apt-get update
18 | RUN pip install --upgrade pip
19 | RUN pip install --upgrade setuptools
20 | RUN apt-get install -y curl
21 |
22 | # You may later want to change this download as the Cloud SDK version is updated.
23 | RUN curl https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-sdk-176.0.0-linux-x86_64.tar.gz | tar xvz
24 | RUN ./google-cloud-sdk/install.sh -q
25 | RUN ./google-cloud-sdk/bin/gcloud components install beta
26 |
27 | ADD . /app/
28 | RUN pip install -r requirements.txt
29 | ENV PATH /home/vmagent/app/google-cloud-sdk/bin:$PATH
30 | # CHANGE THIS: Edit the following 3 lines to use your settings.
31 | ENV PROJECT your-project
32 | ENV BUCKET your-bucket-name
33 | ENV DATASET your-dataset-name
34 |
35 | EXPOSE 8080
36 | WORKDIR /app
37 |
38 | CMD gunicorn -b :$PORT main_df:app
39 |
40 |
--------------------------------------------------------------------------------
/sdk_launch/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Introduction
4 |
5 | This code example shows how you can run
6 | [Cloud Dataflow](https://cloud.google.com/dataflow/) pipelines from
7 | [App Engine](https://cloud.google.com/appengine/) apps, as a replacement
8 | for the older
9 | [GAE Python MapReduce libraries](https://github.com/GoogleCloudPlatform/appengine-mapreduce),
10 | as well as do much more.
11 |
12 | The example shows how to periodically launch a Python Dataflow pipeline from GAE, to
13 | analyze data stored in Cloud Datastore; in this case, tweets from Twitter.
14 |
15 | This example uses the Dataflow SDK to launch the pipeline jobs. Because of its use of the SDK, it requires App Engine Flex.
16 | For an example that uses the same pipeline, but uses [Dataflow Templates](https://cloud.google.com/dataflow/docs/templates/overview) to launch the pipeline jobs, see the ['job_template_launch'](../job_template_launch) directory, which uses App Engine Standard.
17 | Now that Dataflow Templates are available, they are likely the more straightforward option for this type of task in most cases, so you may want to start with the ['job_template_launch'](../job_template_launch) directory.
18 |
19 | The example is a GAE app with two [services (previously, 'modules')](https://cloud.google.com/appengine/docs/standard/python/an-overview-of-app-engine#services_the_building_blocks_of_app_engine):
20 |
21 | - a [GAE Standard](https://cloud.google.com/appengine/docs/standard/) service that periodically pulls in timeline tweets from Twitter and stores them in Datastore; and
22 |
23 | - a [GAE Flexible](https://cloud.google.com/appengine/docs/flexible/) service that periodically launches a Python Dataflow pipeline to analyze the tweet data in the Datastore.
24 |
25 |
26 | ### The Dataflow pipeline
27 |
28 | The Python Dataflow pipeline reads recent tweets from the past N days from Cloud Datastore, then
29 | essentially splits into three processing branches. It finds the top N most popular words in terms of
30 | the percentage of tweets they were found in, calculates the top N most popular URLs in terms of
31 | their count, and then derives relevant word co-occurrences (bigrams) using an
32 | approximation to a [tf*idf](https://en.wikipedia.org/wiki/Tf%E2%80%93idf)
33 | ranking metric. It writes the results to three BigQuery tables.
34 |
35 |
212 |
213 |
214 | ## What next?
215 |
216 | This example walks through how you can programmatically launch Dataflow pipelines — that read from Datastore — directly from your App Engine app, in order to support a range of processing and analytics tasks.
217 |
218 | There are lots of interesting ways that this example could be extended. For example, you could add
219 | a user-facing frontend to the web app, that fetches and displays results from BigQuery. You might
220 | also look at trends over time (e.g. for bigrams) -- either from BigQuery, or by extending the
221 | Dataflow pipeline.
222 |
223 | ## Contributions
224 |
225 | Contributions are not currently accepted. This is not an official Google product.
--------------------------------------------------------------------------------
/job_template_launch/app.yaml:
--------------------------------------------------------------------------------
1 | runtime: python27
2 | api_version: 1
3 | threadsafe: true
4 |
5 | handlers:
6 | - url: /.*
7 | script: main.app
8 | login: admin
9 |
10 | libraries:
11 | - name: ssl
12 | version: latest
13 |
14 | env_variables:
15 | CONSUMER_KEY: 'xxx'
16 | CONSUMER_SECRET: 'xxx'
17 | ACCESS_TOKEN: 'xxx'
18 | ACCESS_TOKEN_SECRET: 'xxx'
19 | PROJECT: 'YOUR-PROJECT-ID'
20 | DATASET: 'xxx'
21 | BUCKET: 'xxx'
22 | TEMPLATE_NAME: 'YOUR-PROJECT-ID-twproc_tmpl'
23 |
--------------------------------------------------------------------------------
/job_template_launch/appengine_config.py:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | from google.appengine.ext import vendor
16 |
17 | # Add any libraries installed in the "lib" folder.
18 | vendor.add('lib')
19 |
--------------------------------------------------------------------------------
/job_template_launch/create_template.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | The app for the 'backend' service, which handles cron job requests to
17 | launch a Dataflow pipeline to analyze recent tweets stored in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import logging
23 | import os
24 |
25 | from apache_beam.options.pipeline_options import PipelineOptions
26 |
27 | import dfpipe.pipe as pipe
28 |
29 |
30 | PROJECT = os.environ['PROJECT']
31 | BUCKET = os.environ['BUCKET']
32 | DATASET = os.environ['DATASET']
33 |
34 | pipeline_options = {
35 | 'project': PROJECT,
36 | 'staging_location': 'gs://' + BUCKET + '/staging',
37 | 'runner': 'DataflowRunner',
38 | 'setup_file': './setup.py',
39 | 'job_name': PROJECT + '-twcount',
40 | 'temp_location': 'gs://' + BUCKET + '/temp',
41 | 'template_location': 'gs://' + BUCKET + '/templates/' + PROJECT + '-twproc_tmpl'
42 | }
43 | # define and launch the pipeline (non-blocking), which will create the template.
44 | pipeline_options = PipelineOptions.from_dictionary(pipeline_options)
45 | pipe.process_datastore_tweets(PROJECT, DATASET, pipeline_options)
46 |
--------------------------------------------------------------------------------
/job_template_launch/cron.yaml:
--------------------------------------------------------------------------------
1 | # Copyright 2016 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | cron:
16 | - description: fetch tweets
17 | url: /timeline
18 | schedule: every 17 minutes
19 | target: default
20 | - description: launch dataflow pipeline
21 | url: /launchtemplatejob
22 | schedule: every 5 hours
23 | target: default
24 |
--------------------------------------------------------------------------------
/job_template_launch/dfpipe/__init__.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
--------------------------------------------------------------------------------
/job_template_launch/dfpipe/pipe.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | """
16 | Define and launch a Dataflow pipeline to analyze recent tweets stored
17 | in the Datastore.
18 | """
19 |
20 | from __future__ import absolute_import
21 |
22 | import datetime
23 | import json
24 | import logging
25 | import re
26 |
27 | import apache_beam as beam
28 | from apache_beam import combiners
29 | from apache_beam.io.gcp.bigquery import parse_table_schema_from_json
30 | from apache_beam.io.gcp.datastore.v1.datastoreio import ReadFromDatastore
31 | from apache_beam.pvalue import AsDict
32 | from apache_beam.pvalue import AsSingleton
33 | from apache_beam.options.pipeline_options import PipelineOptions
34 |
35 |
36 | from google.cloud.proto.datastore.v1 import query_pb2
37 | from googledatastore import helper as datastore_helper, PropertyFilter
38 |
39 |
40 | logging.basicConfig(level=logging.INFO)
41 |
42 | class FilterDate(beam.DoFn):
43 | """Filter Tweet datastore entities based on timestamp."""
44 |
45 | def __init__(self, opts, days):
46 | super(FilterDate, self).__init__()
47 | self.opts = opts
48 | self.days = days
49 | self.earlier = None
50 |
51 | def start_bundle(self):
52 | before = datetime.datetime.strptime(self.opts.timestamp.get(),
53 | '%Y-%m-%d %H:%M:%S.%f')
54 | self.earlier = before - datetime.timedelta(days=self.days)
55 |
56 | def process(self, element):
57 |
58 | created_at = element.properties.get('created_at', None)
59 | cav = None
60 | if created_at:
61 | cav = created_at.timestamp_value
62 | cseconds = cav.seconds
63 | else:
64 | return
65 | crdt = datetime.datetime.fromtimestamp(cseconds)
66 | logging.warn("crdt: %s", crdt)
67 | logging.warn("earlier: %s", self.earlier)
68 | if crdt > self.earlier:
69 | # return only the elements (datastore entities) with a 'created_at' date
70 | # within the last self.days days.
71 | yield element
72 |
73 |
74 | class WordExtractingDoFn(beam.DoFn):
75 | """Parse each tweet text into words, removing some 'stopwords'."""
76 |
77 | def process(self, element):
78 | content_value = element.properties.get('text', None)
79 | text_line = ''
80 | if content_value:
81 | text_line = content_value.string_value
82 |
83 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
84 | # You can add more stopwords if you want. These words are not included
85 | # in the analysis.
86 | stopwords = [
87 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
88 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
89 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
90 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
91 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your'
92 | 'who', 'when', 'via']
93 | stopwords += list(map(chr, range(97, 123)))
94 | return list(words - set(stopwords))
95 |
96 |
97 | class CoOccurExtractingDoFn(beam.DoFn):
98 | """Parse each tweet text into words, and after removing some 'stopwords',
99 | emit the bigrams.
100 | """
101 |
102 | def process(self, element):
103 | content_value = element.properties.get('text', None)
104 | text_line = ''
105 | if content_value:
106 | text_line = content_value.string_value
107 |
108 | words = set([x.lower() for x in re.findall(r'[A-Za-z\']+', text_line)])
109 | # You can add more stopwords if you want. These words are not included
110 | # in the analysis.
111 | stopwords = [
112 | 'a', 'amp', 'an', 'and', 'are', 'as', 'at', 'be', 'been',
113 | 'but', 'by', 'co', 'do', 'for', 'has', 'have', 'he', 'her', 'his',
114 | 'https', 'if', 'in', 'is', 'it', 'me', 'my', 'no', 'not', 'of', 'on',
115 | 'or', 'rt', 's', 'she', 'so', 't', 'than', 'that', 'the', 'they',
116 | 'this', 'to', 'us', 'was', 'we', 'what', 'with', 'you', 'your',
117 | 'who', 'when', 'via']
118 | stopwords += list(map(chr, range(97, 123)))
119 | pruned_words = list(words - set(stopwords))
120 | pruned_words.sort()
121 | import itertools
122 | return list(itertools.combinations(pruned_words, 2))
123 |
124 |
125 | class URLExtractingDoFn(beam.DoFn):
126 | """Extract the urls from each tweet."""
127 |
128 | def process(self, element):
129 | url_content = element.properties.get('urls', None)
130 | if url_content:
131 | urls = url_content.array_value.values
132 | links = []
133 | for u in urls:
134 | links.append(u.string_value.lower())
135 | return links
136 |
137 |
138 |
139 | class QueryDatastore(beam.PTransform):
140 | """Generate a Datastore query, then read from the Datastore.
141 | """
142 |
143 | def __init__(self, project, days):
144 | super(QueryDatastore, self).__init__()
145 | self.project = project
146 | self.days = days
147 |
148 |
149 | # it's not currently supported to use template runtime value providers for
150 | # the Datastore input source, so we can't use runtime values to
151 | # construct our query. However, we can still statically filter based on time
152 | # of template construction, which lets us make the query a bit more
153 | # efficient.
154 | def expand(self, pcoll):
155 | query = query_pb2.Query()
156 | query.kind.add().name = 'Tweet'
157 | now = datetime.datetime.now()
158 | # The 'earlier' var will be set to a static value on template creation.
159 | # That is, because of the way that templates work, the value is defined
160 | # at template compile time, not runtime.
161 | # But defining a filter based on this value will still serve to make the
162 | # query more efficient than if we didn't filter at all.
163 | earlier = now - datetime.timedelta(days=self.days)
164 | datastore_helper.set_property_filter(query.filter, 'created_at',
165 | PropertyFilter.GREATER_THAN,
166 | earlier)
167 |
168 | return (pcoll
169 | | 'read from datastore' >> ReadFromDatastore(self.project,
170 | query, None))
171 |
172 |
173 | class UserOptions(PipelineOptions):
174 | @classmethod
175 | def _add_argparse_args(cls, parser):
176 | parser.add_value_provider_argument('--timestamp', type=str)
177 |
178 |
179 | def process_datastore_tweets(project, dataset, pipeline_options):
180 | """Creates a pipeline that reads tweets from Cloud Datastore from the last
181 | N days. The pipeline finds the top most-used words, the top most-tweeted
182 | URLs, ranks word co-occurrences by an 'interestingness' metric (similar to
183 | on tf* idf).
184 | """
185 |
186 | user_options = pipeline_options.view_as(UserOptions)
187 | DAYS = 4
188 |
189 | p = beam.Pipeline(options=pipeline_options)
190 |
191 | # Read entities from Cloud Datastore into a PCollection, then filter to get
192 | # only the entities from the last DAYS days.
193 | lines = (p | QueryDatastore(project, DAYS)
194 | | beam.ParDo(FilterDate(user_options, DAYS))
195 | )
196 |
197 | global_count = AsSingleton(
198 | lines
199 | | 'global count' >> beam.combiners.Count.Globally())
200 |
201 | # Count the occurrences of each word.
202 | percents = (lines
203 | | 'split' >> (beam.ParDo(WordExtractingDoFn())
204 | .with_output_types(unicode))
205 | | 'pair_with_one' >> beam.Map(lambda x: (x, 1))
206 | | 'group' >> beam.GroupByKey()
207 | | 'count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
208 | | 'in tweets percent' >> beam.Map(
209 | lambda (word, wsum), gc: (word, float(wsum) / gc), global_count))
210 | top_percents = (percents
211 | | 'top 500' >> combiners.Top.Of(500, lambda x, y: x[1] < y[1])
212 | )
213 | # Count the occurrences of each expanded url in the tweets
214 | url_counts = (lines
215 | | 'geturls' >> (beam.ParDo(URLExtractingDoFn())
216 | .with_output_types(unicode))
217 | | 'urls_pair_with_one' >> beam.Map(lambda x: (x, 1))
218 | | 'urls_group' >> beam.GroupByKey()
219 | | 'urls_count' >> beam.Map(lambda (word, ones): (word, sum(ones)))
220 | | 'urls top 300' >> combiners.Top.Of(300, lambda x, y: x[1] < y[1])
221 | )
222 |
223 | # Define some inline helper functions.
224 |
225 | def join_cinfo(cooccur, percents):
226 | """Calculate a co-occurence ranking."""
227 | import math
228 |
229 | word1 = cooccur[0][0]
230 | word2 = cooccur[0][1]
231 | try:
232 | word1_percent = percents[word1]
233 | weight1 = 1 / word1_percent
234 | word2_percent = percents[word2]
235 | weight2 = 1 / word2_percent
236 | return (cooccur[0], cooccur[1], cooccur[1] *
237 | math.log(min(weight1, weight2)))
238 | except:
239 | return 0
240 |
241 | def generate_cooccur_schema():
242 | """BigQuery schema for the word co-occurrence table."""
243 | json_str = json.dumps({'fields': [
244 | {'name': 'w1', 'type': 'STRING', 'mode': 'NULLABLE'},
245 | {'name': 'w2', 'type': 'STRING', 'mode': 'NULLABLE'},
246 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
247 | {'name': 'log_weight', 'type': 'FLOAT', 'mode': 'NULLABLE'},
248 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
249 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
250 | return parse_table_schema_from_json(json_str)
251 |
252 | def generate_url_schema():
253 | """BigQuery schema for the urls count table."""
254 | json_str = json.dumps({'fields': [
255 | {'name': 'url', 'type': 'STRING', 'mode': 'NULLABLE'},
256 | {'name': 'count', 'type': 'INTEGER', 'mode': 'NULLABLE'},
257 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
258 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
259 | return parse_table_schema_from_json(json_str)
260 |
261 | def generate_wc_schema():
262 | """BigQuery schema for the word count table."""
263 | json_str = json.dumps({'fields': [
264 | {'name': 'word', 'type': 'STRING', 'mode': 'NULLABLE'},
265 | {'name': 'percent', 'type': 'FLOAT', 'mode': 'NULLABLE'},
266 | {'name': 'ts', 'type': 'TIMESTAMP', 'mode': 'NULLABLE'}]})
267 | # {'name': 'ts', 'type': 'STRING', 'mode': 'NULLABLE'}]})
268 | return parse_table_schema_from_json(json_str)
269 |
270 | # Now build the rest of the pipeline.
271 | # Calculate the word co-occurence scores.
272 | cooccur_rankings = (lines
273 | | 'getcooccur' >> (beam.ParDo(CoOccurExtractingDoFn()))
274 | | 'co_pair_with_one' >> beam.Map(lambda x: (x, 1))
275 | | 'co_group' >> beam.GroupByKey()
276 | | 'co_count' >> beam.Map(lambda (wordts, ones): (wordts, sum(ones)))
277 | | 'weights' >> beam.Map(join_cinfo, AsDict(percents))
278 | | 'co top 300' >> combiners.Top.Of(300, lambda x, y: x[2] < y[2])
279 | )
280 |
281 | # Format the counts into a PCollection of strings.
282 | wc_records = top_percents | 'format' >> beam.FlatMap(
283 | lambda x: [{'word': xx[0], 'percent': xx[1],
284 | 'ts': user_options.timestamp.get()} for xx in x])
285 |
286 | url_records = url_counts | 'urls_format' >> beam.FlatMap(
287 | lambda x: [{'url': xx[0], 'count': xx[1],
288 | 'ts': user_options.timestamp.get()} for xx in x])
289 |
290 | co_records = cooccur_rankings | 'co_format' >> beam.FlatMap(
291 | lambda x: [{'w1': xx[0][0], 'w2': xx[0][1], 'count': xx[1],
292 | 'log_weight': xx[2],
293 | 'ts': user_options.timestamp.get()} for xx in x])
294 |
295 | # Write the results to three BigQuery tables.
296 | wc_records | 'wc_write_bq' >> beam.io.Write(
297 | beam.io.BigQuerySink(
298 | '%s:%s.word_counts' % (project, dataset),
299 | schema=generate_wc_schema(),
300 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
301 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
302 |
303 | url_records | 'urls_write_bq' >> beam.io.Write(
304 | beam.io.BigQuerySink(
305 | '%s:%s.urls' % (project, dataset),
306 | schema=generate_url_schema(),
307 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
308 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
309 |
310 | co_records | 'co_write_bq' >> beam.io.Write(
311 | beam.io.BigQuerySink(
312 | '%s:%s.word_cooccur' % (project, dataset),
313 | schema=generate_cooccur_schema(),
314 | create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
315 | write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
316 |
317 | # Actually run the pipeline.
318 | return p.run()
319 |
320 |
321 |
--------------------------------------------------------------------------------
/job_template_launch/main.py:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | """
15 | The app for the 'frontend' service, which handles cron job requests to
16 | fetch tweets and store them in the Datastore.
17 | """
18 |
19 | import datetime
20 | import logging
21 | import os
22 |
23 | from google.appengine.ext import ndb
24 | import twitter
25 | import webapp2
26 |
27 | from googleapiclient.discovery import build
28 | from oauth2client.client import GoogleCredentials
29 |
30 |
31 | class Tweet(ndb.Model):
32 | """Define the Tweet model."""
33 | user = ndb.StringProperty()
34 | text = ndb.StringProperty()
35 | created_at = ndb.DateTimeProperty()
36 | tid = ndb.IntegerProperty()
37 | urls = ndb.StringProperty(repeated=True)
38 |
39 |
40 | class LaunchJob(webapp2.RequestHandler):
41 | """Launch the Dataflow pipeline using a job template."""
42 |
43 | def get(self):
44 | is_cron = self.request.headers.get('X-Appengine-Cron', False)
45 | # logging.info("is_cron is %s", is_cron)
46 | # Comment out the following check to allow non-cron-initiated requests.
47 | if not is_cron:
48 | return 'Blocked.'
49 | # These env vars are set in app.yaml.
50 | PROJECT = os.environ['PROJECT']
51 | BUCKET = os.environ['BUCKET']
52 | TEMPLATE = os.environ['TEMPLATE_NAME']
53 |
54 | # Because we're using the same job name each time, if you try to launch one
55 | # job while another is still running, the second will fail.
56 | JOBNAME = PROJECT + '-twproc-template'
57 |
58 | credentials = GoogleCredentials.get_application_default()
59 | service = build('dataflow', 'v1b3', credentials=credentials)
60 |
61 | BODY = {
62 | "jobName": "{jobname}".format(jobname=JOBNAME),
63 | "gcsPath": "gs://{bucket}/templates/{template}".format(
64 | bucket=BUCKET, template=TEMPLATE),
65 | "parameters": {"timestamp": str(datetime.datetime.utcnow())},
66 | "environment": {
67 | "tempLocation": "gs://{bucket}/temp".format(bucket=BUCKET),
68 | "zone": "us-central1-f"
69 | }
70 | }
71 |
72 | dfrequest = service.projects().templates().create(
73 | projectId=PROJECT, body=BODY)
74 | dfresponse = dfrequest.execute()
75 | logging.info(dfresponse)
76 | self.response.write('Done')
77 |
78 |
79 | class FetchTweets(webapp2.RequestHandler):
80 | """Fetch home timeline tweets from the given twitter account."""
81 |
82 | def get(self):
83 |
84 | # set up the twitter client. These env vars are set in app.yaml.
85 | consumer_key = os.environ['CONSUMER_KEY']
86 | consumer_secret = os.environ['CONSUMER_SECRET']
87 | access_token = os.environ['ACCESS_TOKEN']
88 | access_token_secret = os.environ['ACCESS_TOKEN_SECRET']
89 |
90 | api = twitter.Api(consumer_key=consumer_key,
91 | consumer_secret=consumer_secret,
92 | access_token_key=access_token,
93 | access_token_secret=access_token_secret)
94 |
95 | last_id = None
96 | public_tweets = None
97 |
98 | # see if we can get the id of the most recent tweet stored.
99 | tweet_entities = ndb.gql('select * from Tweet order by tid desc limit 1')
100 | last_id = None
101 | for te in tweet_entities:
102 | last_id = te.tid
103 | break
104 | if last_id:
105 | logging.info("last id is: %s", last_id)
106 |
107 | public_tweets = []
108 | # grab tweets from the home timeline of the auth'd account.
109 | try:
110 | if last_id:
111 | public_tweets = api.GetHomeTimeline(count=200, since_id=last_id)
112 | else:
113 | public_tweets = api.GetHomeTimeline(count=20)
114 | logging.warning("Could not get last tweet id from datastore.")
115 | except Exception as e:
116 | logging.warning("Error getting tweets: %s", e)
117 |
118 | # store the retrieved tweets in the datastore
119 | logging.info("got %s tweets", len(public_tweets))
120 | for tweet in public_tweets:
121 | tw = Tweet()
122 | # logging.info("text: %s, %s", tweet.text, tweet.user.screen_name)
123 | tw.text = tweet.text
124 | tw.user = tweet.user.screen_name
125 | tw.created_at = datetime.datetime.strptime(
126 | tweet.created_at, "%a %b %d %H:%M:%S +0000 %Y")
127 | tw.tid = tweet.id
128 | urls = tweet.urls
129 | urllist = []
130 | for u in urls:
131 | urllist.append(u.expanded_url)
132 | tw.urls = urllist
133 | tw.key = ndb.Key(Tweet, tweet.id)
134 | tw.put()
135 |
136 | self.response.write('Done')
137 |
138 |
139 | class MainPage(webapp2.RequestHandler):
140 | def get(self):
141 | self.response.write('nothing to see.')
142 |
143 |
144 | app = webapp2.WSGIApplication(
145 | [('/', MainPage), ('/timeline', FetchTweets),
146 | ('/launchtemplatejob', LaunchJob)],
147 | debug=True)
148 |
--------------------------------------------------------------------------------
/job_template_launch/setup.py:
--------------------------------------------------------------------------------
1 | #
2 | # Licensed to the Apache Software Foundation (ASF) under one or more
3 | # contributor license agreements. See the NOTICE file distributed with
4 | # this work for additional information regarding copyright ownership.
5 | # The ASF licenses this file to You under the Apache License, Version 2.0
6 | # (the "License"); you may not use this file except in compliance with
7 | # the License. You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | #
17 |
18 | """Setup.py module for the workflow's worker utilities.
19 |
20 | All the workflow related code is gathered in a package that will be built as a
21 | source distribution, staged in the staging area for the workflow being run and
22 | then installed in the workers when they start running.
23 |
24 | This behavior is triggered by specifying the --setup_file command line option
25 | when running the workflow for remote execution.
26 | """
27 |
28 | from distutils.command.build import build as _build
29 | import subprocess
30 |
31 | import setuptools
32 |
33 |
34 | # This class handles the pip install mechanism.
35 | class build(_build): # pylint: disable=invalid-name
36 | """A build command class that will be invoked during package install.
37 |
38 | The package built using the current setup.py will be staged and later
39 | installed in the worker using `pip install package'. This class will be
40 | instantiated during install for this specific scenario and will trigger
41 | running the custom commands specified.
42 | """
43 | sub_commands = _build.sub_commands + [('CustomCommands', None)]
44 |
45 |
46 | # Some custom command to run during setup. The command is not essential for this
47 | # workflow. It is used here as an example. Each command will spawn a child
48 | # process. Typically, these commands will include steps to install non-Python
49 | # packages. For instance, to install a C++-based library libjpeg62 the following
50 | # two commands will have to be added:
51 | #
52 | # ['apt-get', 'update'],
53 | # ['apt-get', '--assume-yes', install', 'libjpeg62'],
54 | #
55 | # First, note that there is no need to use the sudo command because the setup
56 | # script runs with appropriate access.
57 | # Second, if apt-get tool is used then the first command needs to be 'apt-get
58 | # update' so the tool refreshes itself and initializes links to download
59 | # repositories. Without this initial step the other apt-get install commands
60 | # will fail with package not found errors. Note also --assume-yes option which
61 | # shortcuts the interactive confirmation.
62 | #
63 | # The output of custom commands (including failures) will be logged in the
64 | # worker-startup log.
65 | CUSTOM_COMMANDS = [
66 | ['echo', 'Custom command worked!']]
67 |
68 |
69 | class CustomCommands(setuptools.Command):
70 | """A setuptools Command class able to run arbitrary commands."""
71 |
72 | def initialize_options(self):
73 | pass
74 |
75 | def finalize_options(self):
76 | pass
77 |
78 | def RunCustomCommand(self, command_list):
79 | print 'Running command: %s' % command_list
80 | p = subprocess.Popen(
81 | command_list,
82 | stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
83 | # Can use communicate(input='y\n'.encode()) if the command run requires
84 | # some confirmation.
85 | stdout_data, _ = p.communicate()
86 | print 'Command output: %s' % stdout_data
87 | if p.returncode != 0:
88 | raise RuntimeError(
89 | 'Command %s failed: exit code: %s' % (command_list, p.returncode))
90 |
91 | def run(self):
92 | for command in CUSTOM_COMMANDS:
93 | self.RunCustomCommand(command)
94 |
95 |
96 | # Configure the required packages and scripts to install.
97 | # Note that the Python Dataflow containers come with numpy already installed
98 | # so this dependency will not trigger anything to be installed unless a version
99 | # restriction is specified.
100 | REQUIRED_PACKAGES = [
101 | # 'numpy',
102 | ]
103 |
104 |
105 | setuptools.setup(
106 | name='dfpipe',
107 | version='0.0.1',
108 | description='dfpipe workflow package.',
109 | install_requires=REQUIRED_PACKAGES,
110 | packages=setuptools.find_packages(),
111 | cmdclass={
112 | # Command class instantiated and run during pip install scenarios.
113 | 'build': build,
114 | 'CustomCommands': CustomCommands,
115 | }
116 | )
117 |
--------------------------------------------------------------------------------
/job_template_launch/standard_requirements.txt:
--------------------------------------------------------------------------------
1 | python-twitter
2 | requests-toolbelt
3 | google-api-python-client
4 |
5 |
--------------------------------------------------------------------------------
/sdk_launch/Dockerfile:
--------------------------------------------------------------------------------
1 | # Copyright 2017 Google Inc.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 |
15 | FROM gcr.io/google_appengine/python
16 |
17 | RUN apt-get update
18 | RUN pip install --upgrade pip
19 | RUN pip install --upgrade setuptools
20 | RUN apt-get install -y curl
21 |
22 | # You may later want to change this download as the Cloud SDK version is updated.
23 | RUN curl https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-sdk-176.0.0-linux-x86_64.tar.gz | tar xvz
24 | RUN ./google-cloud-sdk/install.sh -q
25 | RUN ./google-cloud-sdk/bin/gcloud components install beta
26 |
27 | ADD . /app/
28 | RUN pip install -r requirements.txt
29 | ENV PATH /home/vmagent/app/google-cloud-sdk/bin:$PATH
30 | # CHANGE THIS: Edit the following 3 lines to use your settings.
31 | ENV PROJECT your-project
32 | ENV BUCKET your-bucket-name
33 | ENV DATASET your-dataset-name
34 |
35 | EXPOSE 8080
36 | WORKDIR /app
37 |
38 | CMD gunicorn -b :$PORT main_df:app
39 |
40 |
--------------------------------------------------------------------------------
/sdk_launch/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ## Introduction
4 |
5 | This code example shows how you can run
6 | [Cloud Dataflow](https://cloud.google.com/dataflow/) pipelines from
7 | [App Engine](https://cloud.google.com/appengine/) apps, as a replacement
8 | for the older
9 | [GAE Python MapReduce libraries](https://github.com/GoogleCloudPlatform/appengine-mapreduce),
10 | as well as do much more.
11 |
12 | The example shows how to periodically launch a Python Dataflow pipeline from GAE, to
13 | analyze data stored in Cloud Datastore; in this case, tweets from Twitter.
14 |
15 | This example uses the Dataflow SDK to launch the pipeline jobs. Because of its use of the SDK, it requires App Engine Flex.
16 | For an example that uses the same pipeline, but uses [Dataflow Templates](https://cloud.google.com/dataflow/docs/templates/overview) to launch the pipeline jobs, see the ['job_template_launch'](../job_template_launch) directory, which uses App Engine Standard.
17 | Now that Dataflow Templates are available, they are likely the more straightforward option for this type of task in most cases, so you may want to start with the ['job_template_launch'](../job_template_launch) directory.
18 |
19 | The example is a GAE app with two [services (previously, 'modules')](https://cloud.google.com/appengine/docs/standard/python/an-overview-of-app-engine#services_the_building_blocks_of_app_engine):
20 |
21 | - a [GAE Standard](https://cloud.google.com/appengine/docs/standard/) service that periodically pulls in timeline tweets from Twitter and stores them in Datastore; and
22 |
23 | - a [GAE Flexible](https://cloud.google.com/appengine/docs/flexible/) service that periodically launches a Python Dataflow pipeline to analyze the tweet data in the Datastore.
24 |
25 |
26 | ### The Dataflow pipeline
27 |
28 | The Python Dataflow pipeline reads recent tweets from the past N days from Cloud Datastore, then
29 | essentially splits into three processing branches. It finds the top N most popular words in terms of
30 | the percentage of tweets they were found in, calculates the top N most popular URLs in terms of
31 | their count, and then derives relevant word co-occurrences (bigrams) using an
32 | approximation to a [tf*idf](https://en.wikipedia.org/wiki/Tf%E2%80%93idf)
33 | ranking metric. It writes the results to three BigQuery tables.
34 |
35 |