├── pixelcnn
├── __init__.py
├── conv_layers.py
└── model.py
├── .images
├── gated_block.png
├── architecture.png
├── mnist_samples_1.png
├── mnist_samples_2.png
├── mnist_samples_3.png
└── masked_convolution.png
├── .gitignore
├── requirements.txt
├── sample.py
├── utils.py
├── train.py
└── README.md
/pixelcnn/__init__.py:
--------------------------------------------------------------------------------
1 | from pixelcnn.model import PixelCNN
2 |
3 | __all__ = ['PixelCNN']
--------------------------------------------------------------------------------
/.images/gated_block.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anordertoreclaim/PixelCNN/HEAD/.images/gated_block.png
--------------------------------------------------------------------------------
/.images/architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anordertoreclaim/PixelCNN/HEAD/.images/architecture.png
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | *.ipynb
2 | .ipynb_checkpoints
3 | .idea
4 | .data
5 | __pycache__/
6 | venv
7 | wandb
8 | train_samples
--------------------------------------------------------------------------------
/.images/mnist_samples_1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anordertoreclaim/PixelCNN/HEAD/.images/mnist_samples_1.png
--------------------------------------------------------------------------------
/.images/mnist_samples_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anordertoreclaim/PixelCNN/HEAD/.images/mnist_samples_2.png
--------------------------------------------------------------------------------
/.images/mnist_samples_3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anordertoreclaim/PixelCNN/HEAD/.images/mnist_samples_3.png
--------------------------------------------------------------------------------
/.images/masked_convolution.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anordertoreclaim/PixelCNN/HEAD/.images/masked_convolution.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | argh==0.26.2
2 | certifi==2019.6.16
3 | chardet==3.0.4
4 | Click==7.0
5 | docker-pycreds==0.4.0
6 | gitdb2==2.0.5
7 | GitPython==2.1.13
8 | gql==0.1.0
9 | graphql-core==2.2.1
10 | idna==2.8
11 | numpy==1.17.0
12 | nvidia-ml-py3==7.352.0
13 | pathtools==0.1.2
14 | Pillow==8.1.1
15 | promise==2.2.1
16 | psutil==5.6.6
17 | python-dateutil==2.8.0
18 | PyYAML==5.4
19 | requests==2.22.0
20 | Rx==1.6.1
21 | sentry-sdk==0.10.2
22 | shortuuid==0.5.0
23 | six==1.12.0
24 | smmap2==2.0.5
25 | subprocess32==3.5.4
26 | torch==1.1.0.post2
27 | torchvision==0.3.0
28 | tqdm==4.32.2
29 | urllib3==1.26.5
30 | wandb==0.8.6
31 | watchdog==0.9.0
32 |
--------------------------------------------------------------------------------
/pixelcnn/conv_layers.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 | import numpy as np
5 |
6 |
7 | class CroppedConv2d(nn.Conv2d):
8 | def __init__(self, *args, **kwargs):
9 | super(CroppedConv2d, self).__init__(*args, **kwargs)
10 |
11 | def forward(self, x):
12 | x = super(CroppedConv2d, self).forward(x)
13 |
14 | kernel_height, _ = self.kernel_size
15 | res = x[:, :, 1:-kernel_height, :]
16 | shifted_up_res = x[:, :, :-kernel_height-1, :]
17 |
18 | return res, shifted_up_res
19 |
20 |
21 | class MaskedConv2d(nn.Conv2d):
22 | def __init__(self, *args, mask_type, data_channels, **kwargs):
23 | super(MaskedConv2d, self).__init__(*args, **kwargs)
24 |
25 | assert mask_type in ['A', 'B'], 'Invalid mask type.'
26 |
27 | out_channels, in_channels, height, width = self.weight.size()
28 | yc, xc = height // 2, width // 2
29 |
30 | mask = np.zeros(self.weight.size(), dtype=np.float32)
31 | mask[:, :, :yc, :] = 1
32 | mask[:, :, yc, :xc + 1] = 1
33 |
34 | def cmask(out_c, in_c):
35 | a = (np.arange(out_channels) % data_channels == out_c)[:, None]
36 | b = (np.arange(in_channels) % data_channels == in_c)[None, :]
37 | return a * b
38 |
39 | for o in range(data_channels):
40 | for i in range(o + 1, data_channels):
41 | mask[cmask(o, i), yc, xc] = 0
42 |
43 | if mask_type == 'A':
44 | for c in range(data_channels):
45 | mask[cmask(c, c), yc, xc] = 0
46 |
47 | mask = torch.from_numpy(mask).float()
48 |
49 | self.register_buffer('mask', mask)
50 |
51 | def forward(self, x):
52 | self.weight.data *= self.mask
53 | x = super(MaskedConv2d, self).forward(x)
54 | return x
55 |
--------------------------------------------------------------------------------
/sample.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | from pixelcnn import PixelCNN
4 |
5 | import argparse
6 | from utils import str2bool, save_samples
7 |
8 | OUTPUT_DIRNAME = 'samples'
9 |
10 |
11 | def main():
12 | parser = argparse.ArgumentParser(description='PixelCNN')
13 |
14 | parser.add_argument('--causal-ksize', type=int, default=7,
15 | help='Kernel size of causal convolution')
16 | parser.add_argument('--hidden-ksize', type=int, default=7,
17 | help='Kernel size of hidden layers convolutions')
18 |
19 | parser.add_argument('--color-levels', type=int, default=2,
20 | help='Number of levels to quantisize value of each channel of each pixel into')
21 |
22 | parser.add_argument('--hidden-fmaps', type=int, default=30,
23 | help='Number of feature maps in hidden layer')
24 | parser.add_argument('--out-hidden-fmaps', type=int, default=10,
25 | help='Number of feature maps in outer hidden layer')
26 | parser.add_argument('--hidden-layers', type=int, default=6,
27 | help='Number of layers of gated convolutions with mask of type "B"')
28 |
29 | parser.add_argument('--cuda', type=str2bool, default=True,
30 | help='Flag indicating whether CUDA should be used')
31 | parser.add_argument('--model-path', '-m',
32 | help="Path to model's saved parameters")
33 | parser.add_argument('--output-fname', type=str, default='samples.png',
34 | help='Name of output file (.png format)')
35 |
36 | parser.add_argument('--label', '--l', type=int, default=-1,
37 | help='Label of sampled images. -1 indicates random labels.')
38 |
39 | parser.add_argument('--count', '-c', type=int, default=64,
40 | help='Number of images to generate')
41 | parser.add_argument('--height', type=int, default=28, help='Output image height')
42 | parser.add_argument('--width', type=int, default=28, help='Output image width')
43 |
44 | cfg = parser.parse_args()
45 | OUTPUT_FILENAME = cfg.output_fname
46 |
47 | model = PixelCNN(cfg=cfg)
48 | model.eval()
49 |
50 | device = torch.device("cuda" if torch.cuda.is_available() and cfg.cuda else "cpu")
51 | model.to(device)
52 |
53 | model.load_state_dict(torch.load(cfg.model_path))
54 |
55 | label = None if cfg.label == -1 else cfg.label
56 | samples = model.sample((3, cfg.height, cfg.width), cfg.count, label=label, device=device)
57 | save_samples(samples, OUTPUT_DIRNAME, OUTPUT_FILENAME)
58 |
59 |
60 | if __name__ == '__main__':
61 | main()
62 |
63 |
--------------------------------------------------------------------------------
/utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import argparse
3 | import os
4 |
5 | from torchvision.utils import save_image
6 | from torch.utils.data import DataLoader
7 | from torchvision import datasets, transforms
8 |
9 |
10 | def quantisize(image, levels):
11 | return np.digitize(image, np.arange(levels) / levels) - 1
12 |
13 |
14 | def str2bool(s):
15 | if isinstance(s, bool):
16 | return s
17 | if s.lower() in ('yes', 'true', 't', 'y', '1'):
18 | return True
19 | elif s.lower() in ('no', 'false', 'f', 'n', '0'):
20 | return False
21 | else:
22 | raise argparse.ArgumentTypeError('Boolean value expected')
23 |
24 |
25 | def nearest_square(num):
26 | return round(np.sqrt(num))**2
27 |
28 |
29 | def save_samples(samples, dirname, filename):
30 | if not os.path.exists(dirname):
31 | os.mkdir(dirname)
32 |
33 | count = samples.size()[0]
34 |
35 | count_sqrt = int(count ** 0.5)
36 | if count_sqrt ** 2 == count:
37 | nrow = count_sqrt
38 | else:
39 | nrow = count
40 |
41 | save_image(samples, os.path.join(dirname, filename), nrow=nrow)
42 |
43 |
44 | def get_loaders(dataset_name, batch_size, color_levels, train_root, test_root):
45 | normalize = transforms.Lambda(lambda image: np.array(image) / 255)
46 |
47 | discretize = transforms.Compose([
48 | transforms.Lambda(lambda image: quantisize(image, color_levels)),
49 | transforms.ToTensor()
50 | ])
51 |
52 | to_rgb = transforms.Compose([
53 | discretize,
54 | transforms.Lambda(lambda image_tensor: image_tensor.repeat(3, 1, 1))
55 | ])
56 |
57 | dataset_mappings = {'mnist': 'MNIST', 'fashionmnist': 'FashionMNIST', 'cifar': 'CIFAR10'}
58 | transform_mappings = {'mnist': to_rgb, 'fashionmnist': to_rgb, 'cifar': transforms.Compose([normalize, discretize])}
59 | hw_mappings = {'mnist': (28, 28), 'fashionmnist': (28, 28), 'cifar': (32, 32)}
60 |
61 | try:
62 | dataset = dataset_mappings[dataset_name]
63 | transform = transform_mappings[dataset_name]
64 |
65 | train_dataset = getattr(datasets, dataset)(root=train_root, train=True, download=True, transform=transform)
66 | test_dataset = getattr(datasets, dataset)(root=test_root, train=False, download=True, transform=transform)
67 |
68 | h, w = hw_mappings[dataset_name]
69 | except KeyError:
70 | raise AttributeError("Unsupported dataset")
71 |
72 | train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, pin_memory=True, drop_last=True)
73 | test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, pin_memory=True, drop_last=True)
74 |
75 | return train_loader, test_loader, h, w
76 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.optim as optim
3 | import torch.nn.functional as F
4 | from torch.nn.utils import clip_grad_norm_
5 | import numpy as np
6 |
7 | import argparse
8 | import os
9 | from utils import str2bool, save_samples, get_loaders
10 |
11 | from tqdm import tqdm
12 | import wandb
13 |
14 | from pixelcnn import PixelCNN
15 |
16 | TRAIN_DATASET_ROOT = '.data/train/'
17 | TEST_DATASET_ROOT = '.data/test/'
18 |
19 | MODEL_PARAMS_OUTPUT_DIR = 'model'
20 | MODEL_PARAMS_OUTPUT_FILENAME = 'params.pth'
21 |
22 | TRAIN_SAMPLES_DIR = 'train_samples'
23 |
24 |
25 | def train(cfg, model, device, train_loader, optimizer, scheduler, epoch):
26 | model.train()
27 |
28 | for images, labels in tqdm(train_loader, desc='Epoch {}/{}'.format(epoch + 1, cfg.epochs)):
29 | optimizer.zero_grad()
30 |
31 | images = images.to(device, non_blocking=True)
32 | labels = labels.to(device, non_blocking=True)
33 |
34 | normalized_images = images.float() / (cfg.color_levels - 1)
35 |
36 | outputs = model(normalized_images, labels)
37 | loss = F.cross_entropy(outputs, images)
38 | loss.backward()
39 |
40 | clip_grad_norm_(model.parameters(), max_norm=cfg.max_norm)
41 |
42 | optimizer.step()
43 |
44 | scheduler.step()
45 |
46 |
47 | def test_and_sample(cfg, model, device, test_loader, height, width, losses, params, epoch):
48 | test_loss = 0
49 |
50 | model.eval()
51 | with torch.no_grad():
52 | for images, labels in test_loader:
53 | images = images.to(device, non_blocking=True)
54 | labels = labels.to(device, non_blocking=True)
55 |
56 | normalized_images = images.float() / (cfg.color_levels - 1)
57 | outputs = model(normalized_images, labels)
58 |
59 | test_loss += F.cross_entropy(outputs, images, reduction='none')
60 |
61 | test_loss = test_loss.mean().cpu() / len(test_loader.dataset)
62 |
63 | wandb.log({
64 | "Test loss": test_loss
65 | })
66 | print("Average test loss: {}".format(test_loss))
67 |
68 | losses.append(test_loss)
69 | params.append(model.state_dict())
70 |
71 | samples = model.sample((3, height, width), cfg.epoch_samples, device=device)
72 | save_samples(samples, TRAIN_SAMPLES_DIR, 'epoch{}_samples.png'.format(epoch + 1))
73 |
74 |
75 | def main():
76 | parser = argparse.ArgumentParser(description='PixelCNN')
77 |
78 | parser.add_argument('--epochs', type=int, default=25,
79 | help='Number of epochs to train model for')
80 | parser.add_argument('--batch-size', type=int, default=32,
81 | help='Number of images per mini-batch')
82 | parser.add_argument('--dataset', type=str, default='mnist',
83 | help='Dataset to train model on. Either mnist, fashionmnist or cifar.')
84 |
85 | parser.add_argument('--causal-ksize', type=int, default=7,
86 | help='Kernel size of causal convolution')
87 | parser.add_argument('--hidden-ksize', type=int, default=7,
88 | help='Kernel size of hidden layers convolutions')
89 |
90 | parser.add_argument('--color-levels', type=int, default=2,
91 | help='Number of levels to quantisize value of each channel of each pixel into')
92 |
93 | parser.add_argument('--hidden-fmaps', type=int, default=30,
94 | help='Number of feature maps in hidden layer (must be divisible by 3)')
95 | parser.add_argument('--out-hidden-fmaps', type=int, default=10,
96 | help='Number of feature maps in outer hidden layer')
97 | parser.add_argument('--hidden-layers', type=int, default=6,
98 | help='Number of layers of gated convolutions with mask of type "B"')
99 |
100 | parser.add_argument('--learning-rate', '--lr', type=float, default=0.0001,
101 | help='Learning rate of optimizer')
102 | parser.add_argument('--weight-decay', type=float, default=0.0001,
103 | help='Weight decay rate of optimizer')
104 | parser.add_argument('--max-norm', type=float, default=1.,
105 | help='Max norm of the gradients after clipping')
106 |
107 | parser.add_argument('--epoch-samples', type=int, default=25,
108 | help='Number of images to sample each epoch')
109 |
110 | parser.add_argument('--cuda', type=str2bool, default=True,
111 | help='Flag indicating whether CUDA should be used')
112 |
113 | cfg = parser.parse_args()
114 |
115 | wandb.init(project="PixelCNN")
116 | wandb.config.update(cfg)
117 | torch.manual_seed(42)
118 |
119 | EPOCHS = cfg.epochs
120 |
121 | model = PixelCNN(cfg=cfg)
122 |
123 | device = torch.device("cuda" if torch.cuda.is_available() and cfg.cuda else "cpu")
124 | model.to(device)
125 |
126 | train_loader, test_loader, HEIGHT, WIDTH = get_loaders(cfg.dataset, cfg.batch_size, cfg.color_levels, TRAIN_DATASET_ROOT, TEST_DATASET_ROOT)
127 |
128 | optimizer = optim.Adam(model.parameters(), lr=cfg.learning_rate, weight_decay=cfg.weight_decay)
129 | scheduler = optim.lr_scheduler.CyclicLR(optimizer, cfg.learning_rate, 10*cfg.learning_rate, cycle_momentum=False)
130 |
131 | wandb.watch(model)
132 |
133 | losses = []
134 | params = []
135 |
136 | for epoch in range(EPOCHS):
137 | train(cfg, model, device, train_loader, optimizer, scheduler, epoch)
138 | test_and_sample(cfg, model, device, test_loader, HEIGHT, WIDTH, losses, params, epoch)
139 |
140 | print('\nBest test loss: {}'.format(np.amin(np.array(losses))))
141 | print('Best epoch: {}'.format(np.argmin(np.array(losses)) + 1))
142 | best_params = params[np.argmin(np.array(losses))]
143 |
144 | if not os.path.exists(MODEL_PARAMS_OUTPUT_DIR):
145 | os.mkdir(MODEL_PARAMS_OUTPUT_DIR)
146 | MODEL_PARAMS_OUTPUT_FILENAME = '{}_cks{}hks{}cl{}hfm{}ohfm{}hl{}_params.pth'\
147 | .format(cfg.dataset, cfg.causal_ksize, cfg.hidden_ksize, cfg.color_levels, cfg.hidden_fmaps, cfg.out_hidden_fmaps, cfg.hidden_layers)
148 | torch.save(best_params, os.path.join(MODEL_PARAMS_OUTPUT_DIR, MODEL_PARAMS_OUTPUT_FILENAME))
149 |
150 |
151 | if __name__ == '__main__':
152 | main()
153 |
--------------------------------------------------------------------------------
/pixelcnn/model.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from .conv_layers import MaskedConv2d, CroppedConv2d
5 |
6 |
7 | class CausalBlock(nn.Module):
8 | def __init__(self, in_channels, out_channels, kernel_size, data_channels):
9 | super(CausalBlock, self).__init__()
10 | self.split_size = out_channels
11 |
12 | self.v_conv = CroppedConv2d(in_channels,
13 | 2 * out_channels,
14 | (kernel_size // 2 + 1, kernel_size),
15 | padding=(kernel_size // 2 + 1, kernel_size // 2))
16 | self.v_fc = nn.Conv2d(in_channels,
17 | 2 * out_channels,
18 | (1, 1))
19 | self.v_to_h = nn.Conv2d(2 * out_channels,
20 | 2 * out_channels,
21 | (1, 1))
22 |
23 | self.h_conv = MaskedConv2d(in_channels,
24 | 2 * out_channels,
25 | (1, kernel_size),
26 | mask_type='A',
27 | data_channels=data_channels,
28 | padding=(0, kernel_size // 2))
29 | self.h_fc = MaskedConv2d(out_channels,
30 | out_channels,
31 | (1, 1),
32 | mask_type='A',
33 | data_channels=data_channels)
34 |
35 | def forward(self, image):
36 | v_out, v_shifted = self.v_conv(image)
37 | v_out += self.v_fc(image)
38 | v_out_tanh, v_out_sigmoid = torch.split(v_out, self.split_size, dim=1)
39 | v_out = torch.tanh(v_out_tanh) * torch.sigmoid(v_out_sigmoid)
40 |
41 | h_out = self.h_conv(image)
42 | v_shifted = self.v_to_h(v_shifted)
43 | h_out += v_shifted
44 | h_out_tanh, h_out_sigmoid = torch.split(h_out, self.split_size, dim=1)
45 | h_out = torch.tanh(h_out_tanh) * torch.sigmoid(h_out_sigmoid)
46 | h_out = self.h_fc(h_out)
47 |
48 | return v_out, h_out
49 |
50 |
51 | class GatedBlock(nn.Module):
52 | def __init__(self, in_channels, out_channels, kernel_size, data_channels):
53 | super(GatedBlock, self).__init__()
54 | self.split_size = out_channels
55 |
56 | self.v_conv = CroppedConv2d(in_channels,
57 | 2 * out_channels,
58 | (kernel_size // 2 + 1, kernel_size),
59 | padding=(kernel_size // 2 + 1, kernel_size // 2))
60 | self.v_fc = nn.Conv2d(in_channels,
61 | 2 * out_channels,
62 | (1, 1))
63 | self.v_to_h = MaskedConv2d(2 * out_channels,
64 | 2 * out_channels,
65 | (1, 1),
66 | mask_type='B',
67 | data_channels=data_channels)
68 |
69 | self.h_conv = MaskedConv2d(in_channels,
70 | 2 * out_channels,
71 | (1, kernel_size),
72 | mask_type='B',
73 | data_channels=data_channels,
74 | padding=(0, kernel_size // 2))
75 | self.h_fc = MaskedConv2d(out_channels,
76 | out_channels,
77 | (1, 1),
78 | mask_type='B',
79 | data_channels=data_channels)
80 |
81 | self.h_skip = MaskedConv2d(out_channels,
82 | out_channels,
83 | (1, 1),
84 | mask_type='B',
85 | data_channels=data_channels)
86 |
87 | self.label_embedding = nn.Embedding(10, 2*out_channels)
88 |
89 | def forward(self, x):
90 | v_in, h_in, skip, label = x[0], x[1], x[2], x[3]
91 |
92 | label_embedded = self.label_embedding(label).unsqueeze(2).unsqueeze(3)
93 |
94 | v_out, v_shifted = self.v_conv(v_in)
95 | v_out += self.v_fc(v_in)
96 | v_out += label_embedded
97 | v_out_tanh, v_out_sigmoid = torch.split(v_out, self.split_size, dim=1)
98 | v_out = torch.tanh(v_out_tanh) * torch.sigmoid(v_out_sigmoid)
99 |
100 | h_out = self.h_conv(h_in)
101 | v_shifted = self.v_to_h(v_shifted)
102 | h_out += v_shifted
103 | h_out += label_embedded
104 | h_out_tanh, h_out_sigmoid = torch.split(h_out, self.split_size, dim=1)
105 | h_out = torch.tanh(h_out_tanh) * torch.sigmoid(h_out_sigmoid)
106 |
107 | # skip connection
108 | skip = skip + self.h_skip(h_out)
109 |
110 | h_out = self.h_fc(h_out)
111 |
112 | # residual connections
113 | h_out = h_out + h_in
114 | v_out = v_out + v_in
115 |
116 | return {0: v_out, 1: h_out, 2: skip, 3: label}
117 |
118 |
119 | class PixelCNN(nn.Module):
120 | def __init__(self, cfg):
121 | super(PixelCNN, self).__init__()
122 |
123 | DATA_CHANNELS = 3
124 |
125 | self.hidden_fmaps = cfg.hidden_fmaps
126 | self.color_levels = cfg.color_levels
127 |
128 | self.causal_conv = CausalBlock(DATA_CHANNELS,
129 | cfg.hidden_fmaps,
130 | cfg.causal_ksize,
131 | data_channels=DATA_CHANNELS)
132 |
133 | self.hidden_conv = nn.Sequential(
134 | *[GatedBlock(cfg.hidden_fmaps, cfg.hidden_fmaps, cfg.hidden_ksize, DATA_CHANNELS) for _ in range(cfg.hidden_layers)]
135 | )
136 |
137 | self.label_embedding = nn.Embedding(10, self.hidden_fmaps)
138 |
139 | self.out_hidden_conv = MaskedConv2d(cfg.hidden_fmaps,
140 | cfg.out_hidden_fmaps,
141 | (1, 1),
142 | mask_type='B',
143 | data_channels=DATA_CHANNELS)
144 |
145 | self.out_conv = MaskedConv2d(cfg.out_hidden_fmaps,
146 | DATA_CHANNELS * cfg.color_levels,
147 | (1, 1),
148 | mask_type='B',
149 | data_channels=DATA_CHANNELS)
150 |
151 | def forward(self, image, label):
152 | count, data_channels, height, width = image.size()
153 |
154 | v, h = self.causal_conv(image)
155 |
156 | _, _, out, _ = self.hidden_conv({0: v,
157 | 1: h,
158 | 2: image.new_zeros((count, self.hidden_fmaps, height, width), requires_grad=True),
159 | 3: label}).values()
160 |
161 | label_embedded = self.label_embedding(label).unsqueeze(2).unsqueeze(3)
162 |
163 | # add label bias
164 | out += label_embedded
165 | out = F.relu(out)
166 | out = F.relu(self.out_hidden_conv(out))
167 | out = self.out_conv(out)
168 |
169 | out = out.view(count, self.color_levels, data_channels, height, width)
170 |
171 | return out
172 |
173 | def sample(self, shape, count, label=None, device='cuda'):
174 | channels, height, width = shape
175 |
176 | samples = torch.zeros(count, *shape).to(device)
177 | if label is None:
178 | labels = torch.randint(high=10, size=(count,)).to(device)
179 | else:
180 | labels = (label*torch.ones(count)).to(device).long()
181 |
182 | with torch.no_grad():
183 | for i in range(height):
184 | for j in range(width):
185 | for c in range(channels):
186 | unnormalized_probs = self.forward(samples, labels)
187 | pixel_probs = torch.softmax(unnormalized_probs[:, :, c, i, j], dim=1)
188 | sampled_levels = torch.multinomial(pixel_probs, 1).squeeze().float() / (self.color_levels - 1)
189 | samples[:, c, i, j] = sampled_levels
190 |
191 | return samples
192 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # PixelCNN
2 |
3 | This repository is a PyTorch implementation of [PixelCNN](https://arxiv.org/abs/1601.06759) in its [gated](https://arxiv.org/abs/1606.05328) form.
4 | The main goals I've pursued while doing it is to dive deeper into PyTorch and the network's architecture itself, which I've found both interesting and challenging to grasp. The repo might help someone, too!
5 |
6 | A lot of ideas were taken from [rampage644](https://github.com/rampage644)'s, [blog](http://sergeiturukin.com). Useful links also include [this](https://wiki.math.uwaterloo.ca/statwiki/index.php?title=STAT946F17/Conditional_Image_Generation_with_PixelCNN_Decoders), [this](http://www.scottreed.info/files/iclr2017.pdf) and [this](https://github.com/kundan2510/pixelCNN).
7 |
8 | # Model architecture
9 | Here I am going to sum up the main idea behind the architecture. I won't go deep into implementation details and how convolutions work, because it would be too much text and visuals. Visit the links above in order to have a more detailed look on the inner workings of the architecture. Then come here for a summary :)
10 |
11 | At first this architecture was an attempt to speed up the learning process of a RNN implementation of the same idea, which is a generative model that learns an explicit joint distribution of image's pixels by modeling it using simple chain rule:
12 |
13 |
14 |  15 |
15 |
16 |
17 | The order is row-wise i.e. value of each pixel depends on values of all pixels above and to the left of it. Here is an explanatory image:
18 |
19 |
20 | 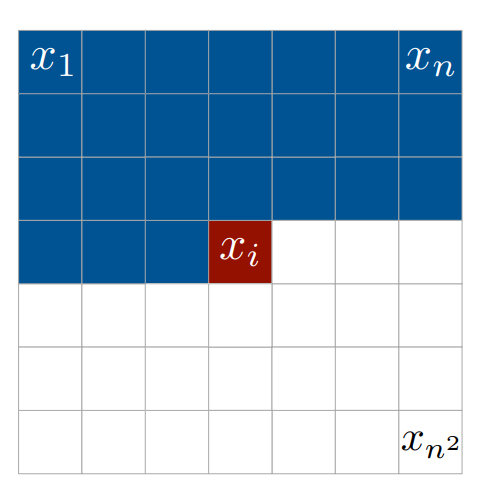 21 |
21 |
22 | In order to achieve this property authors of the papers used simple masked convolutions, which in the case of 1-channel black and white images look like this:
23 |
24 |
25 | 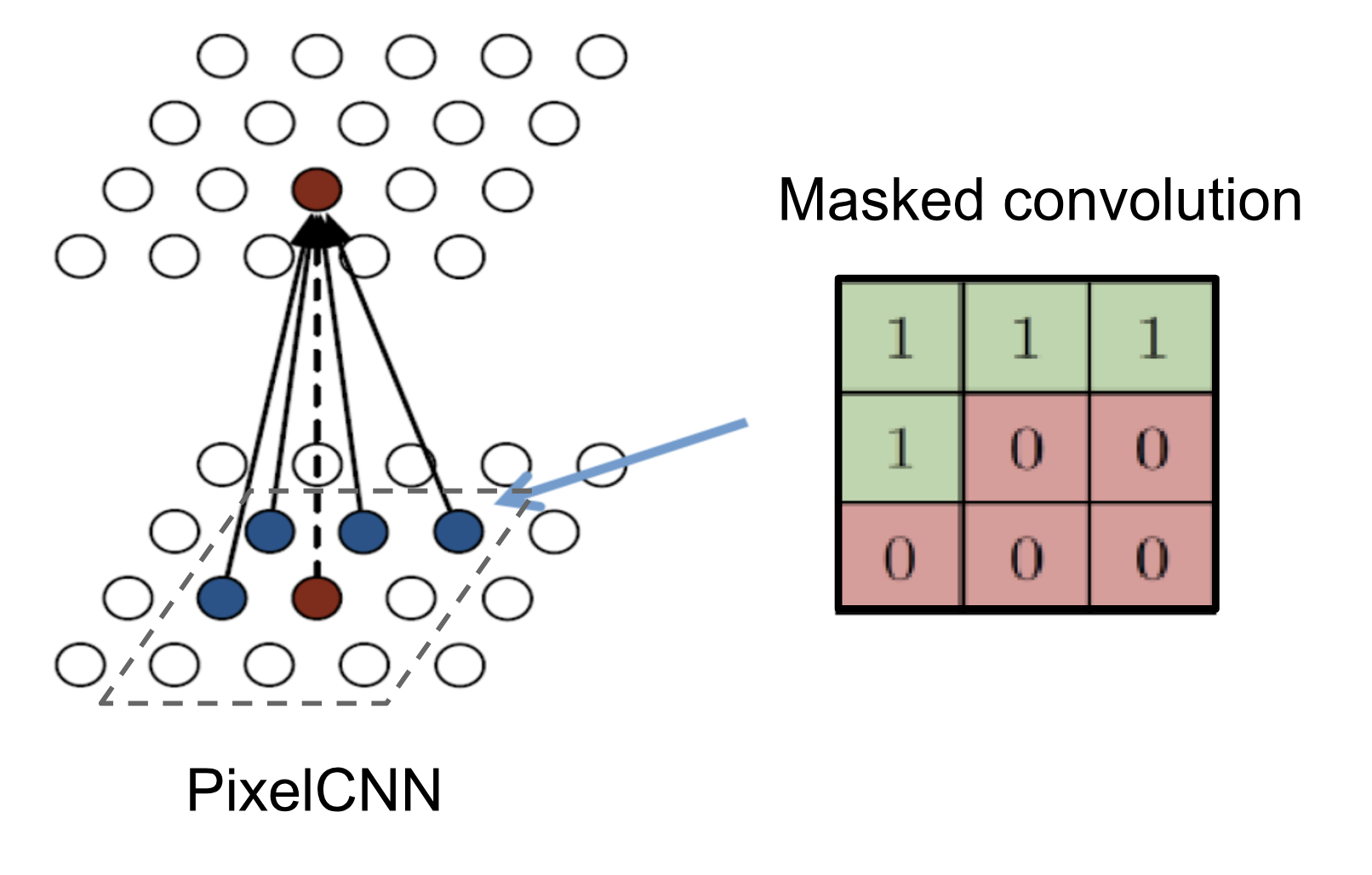 26 |
26 |
27 | (i. e. convolutional filters are multiplied by this mask before being applied to images)
28 |
29 |
30 | There are 2 types of masks: A and B. Masked convolution of type A can only see previously generated pixels, while mask of type B allows taking value of a pixel being predicted into consideration. Applying B-masked convolution after A-masked one preserves the causality, work it out! In the case of 3 data channels, types of masks are depicted on this image:
31 |
32 |
33 | 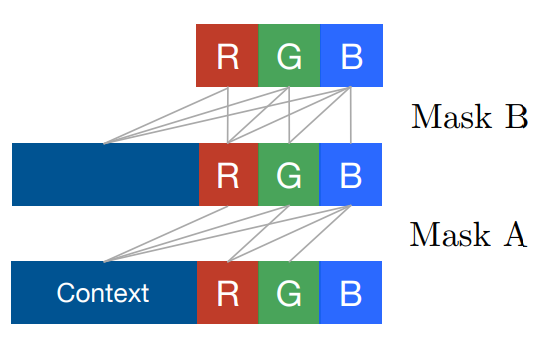 34 |
34 |
35 |
36 |
37 | The problem with a simple masking approach was the blind spot: when predicting some pixels, a portion of the image did not influence the prediction. This was fixed by introducing 2 separate convolutions: horizontal and vertical. Vertical convolution performs a simple unmasked convolution and sends its outputs to a horizontal convolution, which performs a masked 1-by-N convolution. They also added conditioning on labels and gates in order to increase the predicting power of the model.
38 |
39 | ## Gated block
40 | The main submodel of PixelCNN is a gated block, several of which are used in the network. Here is how it looks:
41 |
42 | 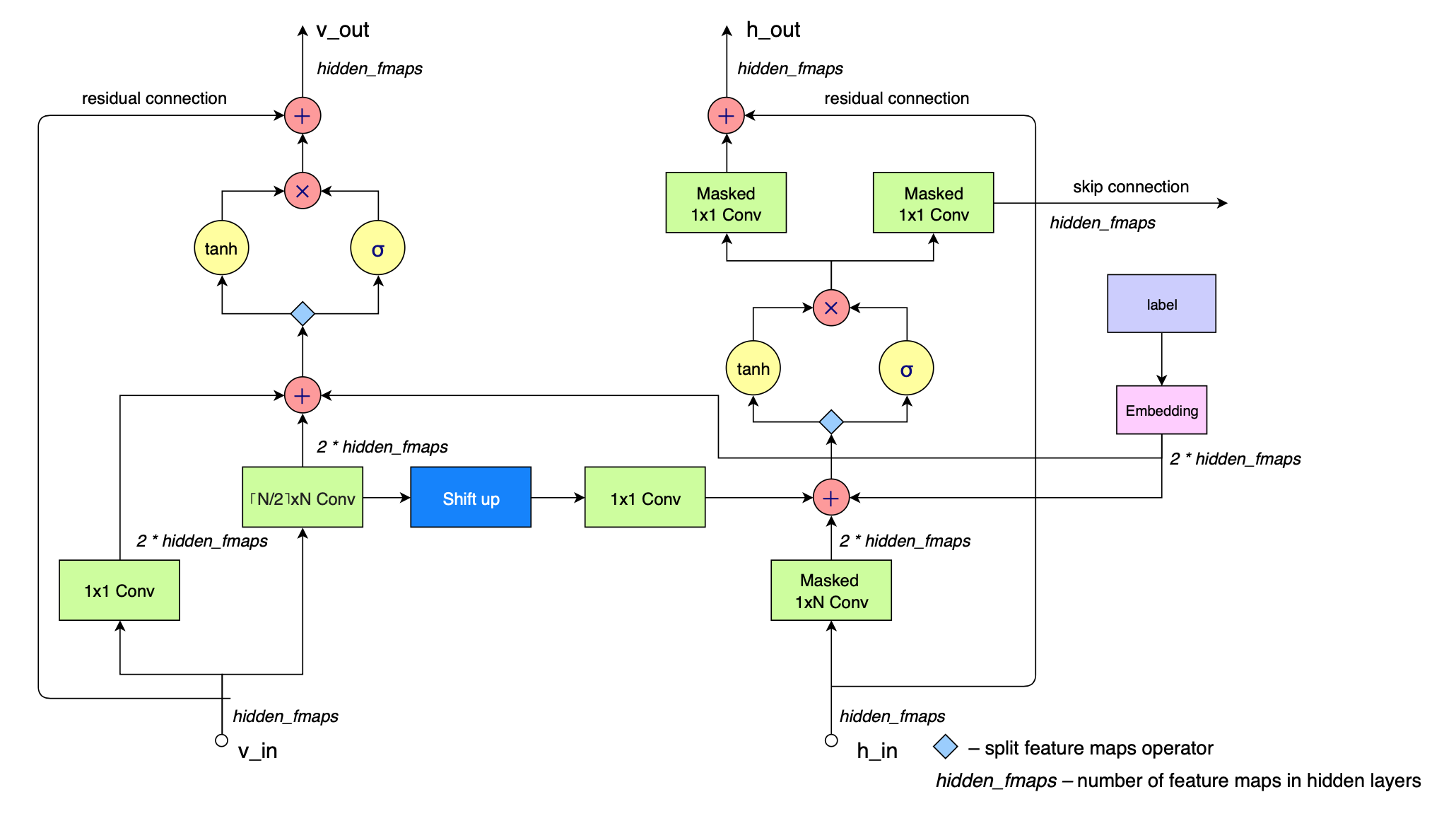
43 |
44 | ## High level architecture
45 | Here is what the whole architecture looks like:
46 |
47 | 
48 |
49 | Causal block is the same as gated block, except that it has neither residual nor skip connections, its input is image instead of a tensor with depth of *hidden_fmaps*, it uses mask of type A instead of B of a usual gated block and it doesn't incorporate label bias.
50 |
51 | Skip results are summed and ran through a ReLu – 1x1 Conv – ReLu block. Then the final convolutional layer is applied, which outputs a tensor that represents unnormalized probabilities of each color level for each color channel of each pixel in the image.
52 |
53 | # Training and sampling
54 | ### Train
55 | In order to train the model, use the `python train.py` command and set optional arguments if needed.
56 |
57 | Model's state dictionary is saved to `model` folder by default. Samples which are generated during training are saved to `train_samples` folder by default.
58 |
59 | Run `wandb login` in order to monitor hardware usage and each layer's gradients' distribution.
60 | ```
61 | $ python train.py -h
62 | usage: train.py [-h] [--epochs EPOCHS] [--batch-size BATCH_SIZE]
63 | [--dataset DATASET] [--causal-ksize CAUSAL_KSIZE]
64 | [--hidden-ksize HIDDEN_KSIZE] [--data-channels DATA_CHANNELS]
65 | [--color-levels COLOR_LEVELS] [--hidden-fmaps HIDDEN_FMAPS]
66 | [--out-hidden-fmaps OUT_HIDDEN_FMAPS]
67 | [--hidden-layers HIDDEN_LAYERS]
68 | [--learning-rate LEARNING_RATE] [--weight-decay WEIGHT_DECAY]
69 | [--max-norm MAX_NORM] [--epoch-samples EPOCH_SAMPLES]
70 | [--cuda CUDA]
71 |
72 | PixelCNN
73 |
74 | optional arguments:
75 | -h, --help show this help message and exit
76 | --epochs EPOCHS Number of epochs to train model for
77 | --batch-size BATCH_SIZE
78 | Number of images per mini-batch
79 | --dataset DATASET Dataset to train model on. Either mnist, fashionmnist
80 | or cifar.
81 | --causal-ksize CAUSAL_KSIZE
82 | Kernel size of causal convolution
83 | --hidden-ksize HIDDEN_KSIZE
84 | Kernel size of hidden layers convolutions
85 | --color-levels COLOR_LEVELS
86 | Number of levels to quantisize value of each channel
87 | of each pixel into
88 | --hidden-fmaps HIDDEN_FMAPS
89 | Number of feature maps in hidden layer (must be
90 | divisible by 3)
91 | --out-hidden-fmaps OUT_HIDDEN_FMAPS
92 | Number of feature maps in outer hidden layer
93 | --hidden-layers HIDDEN_LAYERS
94 | Number of layers of gated convolutions with mask of
95 | type "B"
96 | --learning-rate LEARNING_RATE, --lr LEARNING_RATE
97 | Learning rate of optimizer
98 | --weight-decay WEIGHT_DECAY
99 | Weight decay rate of optimizer
100 | --max-norm MAX_NORM Max norm of the gradients after clipping
101 | --epoch-samples EPOCH_SAMPLES
102 | Number of images to sample each epoch
103 | --cuda CUDA Flag indicating whether CUDA should be used
104 | ```
105 | ### Sample
106 | Sampling is performed similarly with `python sample.py`. Path to model's saved parameters must be defined.
107 |
108 | Samples are saved to `samples/samples.png` by default.
109 | ```
110 | $ python sample.py -h
111 | usage: sample.py [-h] [--causal-ksize CAUSAL_KSIZE]
112 | [--hidden-ksize HIDDEN_KSIZE] [--data-channels DATA_CHANNELS]
113 | [--color-levels COLOR_LEVELS] [--hidden-fmaps HIDDEN_FMAPS]
114 | [--out-hidden-fmaps OUT_HIDDEN_FMAPS]
115 | [--hidden-layers HIDDEN_LAYERS] [--cuda CUDA]
116 | [--model-path MODEL_PATH] [--output-fname OUTPUT_FNAME]
117 | [--label LABEL] [--count COUNT] [--height HEIGHT]
118 | [--width WIDTH]
119 |
120 | PixelCNN
121 |
122 | optional arguments:
123 | -h, --help show this help message and exit
124 | --causal-ksize CAUSAL_KSIZE
125 | Kernel size of causal convolution
126 | --hidden-ksize HIDDEN_KSIZE
127 | Kernel size of hidden layers convolutions
128 | --color-levels COLOR_LEVELS
129 | Number of levels to quantisize value of each channel
130 | of each pixel into
131 | --hidden-fmaps HIDDEN_FMAPS
132 | Number of feature maps in hidden layer
133 | --out-hidden-fmaps OUT_HIDDEN_FMAPS
134 | Number of feature maps in outer hidden layer
135 | --hidden-layers HIDDEN_LAYERS
136 | Number of layers of gated convolutions with mask of
137 | type "B"
138 | --cuda CUDA Flag indicating whether CUDA should be used
139 | --model-path MODEL_PATH, -m MODEL_PATH
140 | Path to model's saved parameters
141 | --output-fname OUTPUT_FNAME
142 | Name of output file (.png format)
143 | --label LABEL, --l LABEL
144 | Label of sampled images. -1 indicates random labels.
145 | --count COUNT, -c COUNT
146 | Number of images to generate
147 | --height HEIGHT Output image height
148 | --width WIDTH Output image width
149 | ```
150 | # Examples of samples
151 | The biggest challenge is to make the network converge to a good set of parameters. I've experimented with hyperparameters and here are the results I've managed to obtain for N-way MNIST using different models.
152 |
153 | Generally, in order for model to converge to a good set of parameters, one needs to go with a small learning rate (about 1e-4). I've also found that bigger kernel sizes in hidden layers work better.
154 |
155 | A very simple model, `python train.py --epochs 2 --color-levels 2 --hidden-fmaps 21 --lr 0.002 --max-norm 2` (all others are default values), trained for just 2 epochs, managed to produce these samples on a binary MNIST:
156 |
157 | 
158 |
159 | `python train.py --lr 0.0002` (quite a simple model, too) produced these results:
160 |
161 | 
162 |
163 | A more complex model, `python train.py --color-levels 10 --hidden-fmaps 120 --out-hidden-fmaps 60 --lr 0.0002`, managed to produce these on a 10-way MNIST:
164 |
165 | 
166 |
167 | ### I was trying to train the network on CIFAR-10, but I haven't managed to get any meaningful results. If you have, please contact me.
168 |
--------------------------------------------------------------------------------