 103 |
104 |
103 |
104 |  105 |
106 | + 下载我训练的一些模型(还有很多bug)
107 |
108 | ```
109 | cd AlphaPig/logs
110 | sh ./download_model.sh
111 | ```
112 |
113 | ## 致谢
114 |
115 | + 源工程请移步[junxiaosong/AlphaZero_Gomoku](https://github.com/junxiaosong/AlphaZero_Gomoku) ,特别感谢大V的很多issue和指导。
116 |
117 | + 特别感谢格灵深瞳提供的很多训练帮助(课程与训练资源上提供了很大支持),没有格灵深瞳的这些帮助,训练起来毫无头绪。
118 |
119 | + 感谢[Uloud](https://www.ucloud.cn/) 提供的P40 AI-train服务,1256小时/实例的训练,验证了不少想法。而且最后还免单了,中间没少打扰技术支持。特别感谢他们。
120 |
121 |
105 |
106 | + 下载我训练的一些模型(还有很多bug)
107 |
108 | ```
109 | cd AlphaPig/logs
110 | sh ./download_model.sh
111 | ```
112 |
113 | ## 致谢
114 |
115 | + 源工程请移步[junxiaosong/AlphaZero_Gomoku](https://github.com/junxiaosong/AlphaZero_Gomoku) ,特别感谢大V的很多issue和指导。
116 |
117 | + 特别感谢格灵深瞳提供的很多训练帮助(课程与训练资源上提供了很大支持),没有格灵深瞳的这些帮助,训练起来毫无头绪。
118 |
119 | + 感谢[Uloud](https://www.ucloud.cn/) 提供的P40 AI-train服务,1256小时/实例的训练,验证了不少想法。而且最后还免单了,中间没少打扰技术支持。特别感谢他们。
120 |
121 | 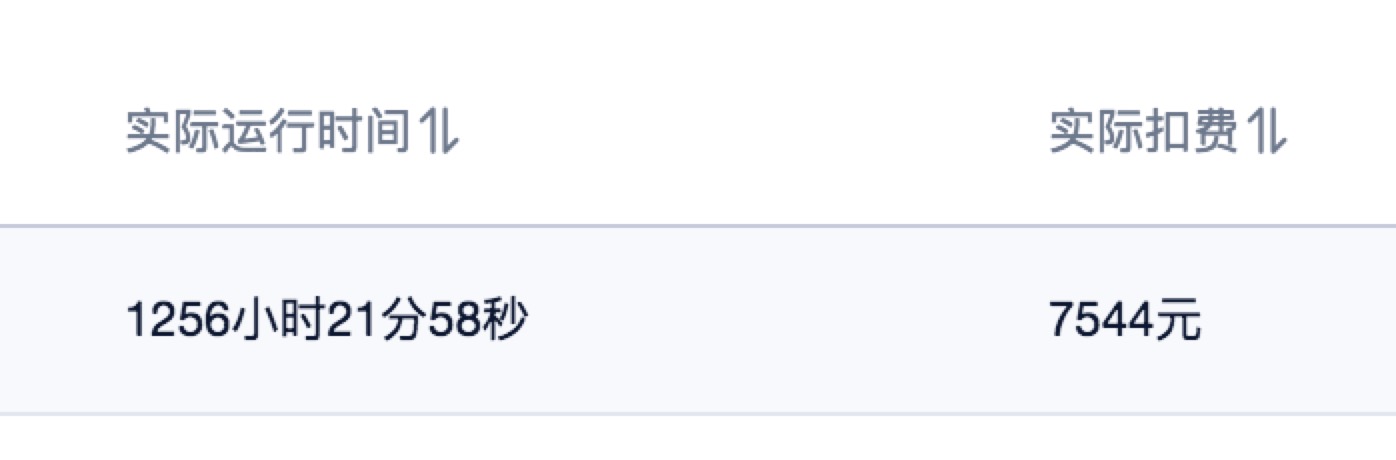 122 |
122 |  123 |
124 |
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | from . import game
3 | from . import mcts_pure
4 | from . import policy_value_net_mxnet
5 | from . import policy_value_net_mxnet_simple
6 |
--------------------------------------------------------------------------------
/ai_train.dockerfile:
--------------------------------------------------------------------------------
1 | From gospelslave/alphapig:v0.1.3
2 |
3 | WORKDIR /workspace
4 |
5 | ADD ./ /workspace
6 |
7 | RUN /bin/bash -c "source ~/.bashrc"
8 |
9 |
10 |
--------------------------------------------------------------------------------
/conf/train_config.yaml:
--------------------------------------------------------------------------------
1 | # 数据目录
2 | sgf_dir: './sgf_data'
3 | # AI对弈数据目录
4 | ai_data_dir: './pickle_ai_data'
5 | # 棋盘设置
6 | board_width: 15
7 | board_height: 15
8 | n_in_row: 5
9 | # 学习率
10 | learn_rate: 0.0004
11 | # 根据KL散度动态调整学习率
12 | lr_multiplier: 1.0
13 | temp: 1.0
14 | # 每次移动的simulations数
15 | n_playout: 400
16 | # TODO: 蒙特卡洛树模拟选择时更多的依靠先验,估值越精确,C就应该偏向深度(越小)
17 | c_puct: 5
18 | # 数据集最大量(双端队列长度)
19 | buffer_size: 2198800
20 | batch_size: 128
21 | epochs: 8
22 | play_batch_size: 1
23 | # KL散度
24 | kl_targ: 0.02
25 | # 每check_freq次 检测对弈成绩
26 | check_freq: 1000
27 | # 检测成绩用的mcts对手的思考深度
28 | pure_mcts_playout_num: 1000
29 | # 训练多少轮
30 | game_batch_num: 240000
31 |
32 |
33 | # 训练日志
34 | train_logging:
35 | version: 1
36 | formatters:
37 | simpleFormater:
38 | format: '%(asctime)s - %(levelname)s - %(name)s[line:%(lineno)d]: %(message)s'
39 | datefmt: '%Y-%m-%d %H:%M:%S'
40 | handlers:
41 | # 标准输出,只要级别在DEBUG以上就会输出
42 | console:
43 | class: logging.StreamHandler
44 | formatter: simpleFormater
45 | level: DEBUG
46 | stream: ext://sys.stdout
47 | # INFO以上,滚动文件,保留20个,每个最大100MB
48 | info_file_handler:
49 | class : logging.FileHandler
50 | formatter: simpleFormater
51 | level: INFO
52 | filename: ./logs/info.log
53 | # ERROR以上
54 | error_file_handler:
55 | class : logging.FileHandler
56 | formatter: simpleFormater
57 | level: ERROR
58 | filename: ./logs/error.log
59 | root:
60 | level: DEBUG
61 | handlers: [console, info_file_handler, error_file_handler]
62 |
--------------------------------------------------------------------------------
/cpu_train.sh:
--------------------------------------------------------------------------------
1 | docker run -it \
2 | -v /home/ubuntu/uai-sdk/examples/mxnet/train/AlphaPig:/data \
3 | -v /home/ubuntu/uai-sdk/examples/mxnet/train/AlphaPig/sgf_data:/data/data \
4 | -v /home/ubuntu/uai-sdk/examples/mxnet/train/AlphaPig/logs:/data/output \
5 | uhub.service.ucloud.cn/uaishare/cpu_uaitrain_ubuntu-14.04_python-2.7.6_mxnet-1.0.0:v1.0 \
6 | /bin/bash -c "cd /data && /usr/bin/python /data/train_mxnet.py --model-prefix=siler_Alpha --work_dir=/data --output_dir=/data/output"
7 |
8 |
9 |
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/docker-compose.yml:
--------------------------------------------------------------------------------
1 | version: "2.3"
2 |
3 | services:
4 | gobang_server:
5 | image: gospelslave/alphapig:v0.1.11
6 | entrypoint: /bin/bash run_server.sh
7 | privileged: true
8 | environment:
9 | - TZ=Asia/Shanghai
10 | ports:
11 | - 8888:8888
12 | restart: always
13 | logging:
14 | driver: json-file
15 | options:
16 | max-size: "10M"
17 | max-file: "5"
18 |
19 | gobang_ai:
20 | image: gospelslave/alphapig:v0.1.11
21 | entrypoint: /bin/bash run_ai.sh
22 | privileged: true
23 | environment:
24 | - TZ=Asia/Shanghai
25 | runtime: nvidia
26 | restart: always
27 | logging:
28 | driver: json-file
29 | options:
30 | max-size: "10M"
31 | max-file: "5"
32 |
--------------------------------------------------------------------------------
/evaluate/AICollection.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import time
3 | import ChessHelper
4 | import threading
5 | from ChessBoard import ChessBoard
6 | from Hall import GameRoom
7 | from Hall import User
8 | import random
9 | import os
10 | from ChessClient import ChessClient
11 |
12 |
13 | class GameStrategy(object):
14 | def __init__(self):
15 | import gobang
16 | self.searcher = gobang.searcher()
17 |
18 | def play_one_piece(self, user, gameboard):
19 | # user = User()
20 | # gameboard = ChessBoard()
21 | turn = user.game_role
22 | self.searcher.board = [[gameboard.get_piece(m, n) for n in xrange(gameboard.SIZE)] for m in
23 | xrange(gameboard.SIZE)]
24 | # gameboard=ChessBoard()
25 | # gameboard.move_history
26 | score, row, col = self.searcher.search(turn, 2)
27 | # print "score:", score
28 | return (row, col)
29 |
30 |
31 | class GameStrategy_yixin(object):
32 |
33 | def __init__(self):
34 | self.muid = str(random.randint(0, 1000000))
35 | self.comm_folder = 'yixin_comm/'
36 | if not os.path.exists(self.comm_folder):
37 | os.makedirs(self.comm_folder)
38 | self.chess_state_file = self.comm_folder + 'game_state_' + self.muid
39 | self.action_file = self.comm_folder + 'action_' + self.muid
40 |
41 | def play_one_piece(self, user, gameboard):
42 | # user = User()
43 | # gameboard = ChessBoard()
44 | with open(self.chess_state_file, 'w') as chess_state_file:
45 | for userrole, move_num, row, col in gameboard.move_history:
46 | chess_state_file.write('%d,%d\n' % (row, col))
47 | if os.path.exists(self.action_file):
48 | os.remove(self.action_file)
49 | os.system("yixin_ai\yixin.exe %s %s" % (self.chess_state_file, self.action_file))
50 | row, col = random.randint(0, 15), random.randint(0, 15)
51 | with open(self.action_file) as action_file:
52 | line = action_file.readline()
53 | row, col = line.strip().split(',')
54 | row, col = int(row), int(col)
55 |
56 | return (row, col)
57 |
58 |
59 | class GameStrategy_random(object):
60 | def __init__(self):
61 | self._chess_helper_move_set = []
62 | for i in range(15):
63 | for j in range(15):
64 | self._chess_helper_move_set.append((i, j))
65 | random.shuffle(self._chess_helper_move_set)
66 | self.try_step = 0
67 |
68 | def play_one_piece(self, user, gameboard):
69 | move = self._chess_helper_move_set[self.try_step]
70 | while gameboard.get_piece(move[0], move[1]) != 0 and self.try_step < 15 * 15:
71 | self.try_step += 1
72 | move = self._chess_helper_move_set[self.try_step]
73 | self.try_step += 1
74 | return move
75 |
76 |
77 | class GameCommunicator(threading.Thread):
78 | def __init__(self, roomid, stragegy, server_url):
79 | threading.Thread.__init__(self)
80 | self.room_id = roomid
81 | self.stragegy = stragegy;
82 | self.server_url = server_url
83 |
84 | def run(self):
85 | client = ChessClient(self.server_url)
86 | client.login_in_guest()
87 | client.join_room(self.room_id)
88 | client.join_game()
89 | exp_interval = 0.5
90 | max_exp_interval = 200
91 | while True:
92 | single_max_time = exp_interval * 100
93 | wait_time = client.wait_game_info_changed(interval=exp_interval, max_time=single_max_time)
94 | if wait_time > single_max_time:
95 | exp_interval *= 2
96 | else:
97 | exp_interval = 0.5
98 | if exp_interval > max_exp_interval:
99 | exp_interval = max_exp_interval
100 | room = client.get_room_info()
101 | user = client.get_user_info()
102 | gameboard = client.get_game_info()
103 | print 'waittime:',wait_time,',room_status:',room.get_status(),',ask_take_back:',room.ask_take_back
104 | if room.get_status() == 1 or room.get_status() == 2:
105 | continue
106 | elif room.get_status() == 3:
107 | if room.ask_take_back != 0 and room.ask_take_back != user.game_role:
108 | client.answer_take_back()
109 | continue
110 | if gameboard.get_current_user() == user.game_role:
111 | one_legal_piece = self.stragegy.play_one_piece(user, gameboard)
112 | action_result = client.put_piece(*one_legal_piece)
113 | client.wait_game_info_changed(interval=exp_interval, max_time=single_max_time)
114 | if action_result['id'] != 0:
115 | print ChessHelper.numToAlp(one_legal_piece[0]), ChessHelper.numToAlp(one_legal_piece[1])
116 | print action_result['info']
117 | break
118 | continue
119 | elif room.get_status() == 4:
120 | break
121 |
122 |
123 | class GameListener(object):
124 | def __init__(self, prefix_stategy_map, server_url):
125 | self.client = ChessClient(server_url)
126 | self.client.login_in_guest()
127 | self.prefix_stategy_map = prefix_stategy_map
128 | self.server_url = server_url
129 | self.accupied = set()
130 |
131 | def listen(self):
132 | while True:
133 | all_rooms = self.client.get_all_rooms()
134 | for room in all_rooms:
135 | room_name = room[0]
136 | room_status = room[1]
137 | for prefix in self.prefix_stategy_map:
138 | if room_name.startswith(prefix) and room_status == GameRoom.ROOM_STATUS_ONEWAITING:
139 | if room_name in self.accupied:
140 | continue
141 | print 'Evoke:', room_name
142 | strg = self.prefix_stategy_map[prefix]()
143 | self.accupied.add(room_name)
144 | commu = GameCommunicator(room_name, strg, self.server_url)
145 | commu.start()
146 | break
147 | time.sleep(4)
148 |
149 |
150 | def go_listen():
151 | import argparse
152 | parser = argparse.ArgumentParser()
153 | parser.add_argument('--server_url', default='http://120.132.59.147:11111')
154 | args = parser.parse_args()
155 |
156 |
157 | if args.server_url.endswith('/'):
158 | args.server_url = args.server_url[:-1]
159 | if not args.server_url.startswith('http://'):
160 | args.server_url = 'http://' + args.server_url
161 |
162 | prefix_stategy_map = {'ai_': lambda: GameStrategy(), 'yixin_': lambda: GameStrategy_yixin(),
163 | 'random_': lambda: GameStrategy_random()}
164 | listen = GameListener(prefix_stategy_map, args.server_url)
165 | listen.listen()
166 |
167 |
168 | if __name__ == "__main__":
169 | go_listen()
170 |
--------------------------------------------------------------------------------
/evaluate/ChessBoard.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import time
3 | import cPickle as pickle
4 |
5 |
6 | class ChessBoard(object):
7 | """ChessBoard
8 |
9 | Attributes:
10 | SIZE: The chess board's size.
11 | board: To store the board information.
12 | state: Indicate if the game is over.
13 | current_user: The user who put the next piece.
14 | """
15 |
16 | STATE_RUNNING = 0
17 | STATE_DONE = 1
18 | STATE_ABORT = 1
19 |
20 | PIECE_STATE_BLANK = 0
21 | PIECE_STATE_FIRST = 1
22 | PIECE_STATE_SECOND = 2
23 |
24 | PAD = 4
25 |
26 | CHECK_DIRECTION = [[[0, 1], [0, -1]], [[1, 0], [-1, 0]], [[1, 1], [-1, -1]], [[1, -1], [-1, 1]]]
27 |
28 | def __init__(self, size=15):
29 | self.SIZE = size
30 | self.board = np.zeros((self.SIZE + ChessBoard.PAD * 2, self.SIZE + ChessBoard.PAD * 2), dtype=np.uint8)
31 | self.state = ChessBoard.STATE_RUNNING
32 | self.current_user = ChessBoard.PIECE_STATE_FIRST
33 |
34 | self.move_num = 0
35 | self.move_history = []
36 |
37 | self.dump_cache = None
38 |
39 | def changed(func):
40 | def wrapper_func(self,*args, **kwargs):
41 | ret=func(self,*args, **kwargs)
42 | self.dump_cache = None
43 | return ret
44 |
45 | return wrapper_func
46 |
47 | def get_piece(self, row, col):
48 | return self.board[row + ChessBoard.PAD, col + ChessBoard.PAD]
49 |
50 | @changed
51 | def set_piece(self, row, col, user):
52 | self.board[row + ChessBoard.PAD, col + ChessBoard.PAD] = user
53 |
54 | @changed
55 | def put_piece(self, row, col, user):
56 | """Put a piece in the board and check if he wins.
57 | Returns:
58 | 0 successful move.
59 | 1 successful and win move.
60 | -1 move out of range.
61 | -2 piece has been occupied.
62 | -3 game is over
63 | -4 not your turn.
64 | """
65 | if row < 0 or row >= self.SIZE or col < 0 or col >= self.SIZE:
66 | return -1
67 | if self.get_piece(row, col) != ChessBoard.PIECE_STATE_BLANK:
68 | return -2
69 | if self.state != ChessBoard.STATE_RUNNING:
70 | return -3
71 | if user != self.current_user:
72 | return -4
73 |
74 | self.set_piece(row, col, user)
75 | self.move_num += 1
76 | self.move_history.append((user, self.move_num, row, col,))
77 | # self.last_move = (row, col)
78 |
79 | # check if win
80 | for dx in xrange(4):
81 | connected_piece_num = 1
82 | for dy in xrange(2):
83 | current_direct = ChessBoard.CHECK_DIRECTION[dx][dy]
84 | c_row = row
85 | c_col = col
86 |
87 | # if else realization
88 | for dz in xrange(4):
89 | c_row += current_direct[0]
90 | c_col += current_direct[1]
91 | if self.get_piece(c_row, c_col) == user:
92 | connected_piece_num += 1
93 | else:
94 | break
95 |
96 | # remove if, but not faster
97 | # p = 1
98 | # for dz in xrange(4):
99 | # c_row += current_direct[0]
100 | # c_col += current_direct[1]
101 | # p = p & (self.board[c_row, c_col] == user)
102 | # connected_piece_num += p
103 |
104 | if connected_piece_num >= 5:
105 | self.state = ChessBoard.STATE_DONE
106 | return 1
107 |
108 | if self.current_user == ChessBoard.PIECE_STATE_SECOND:
109 | self.current_user = ChessBoard.PIECE_STATE_FIRST
110 | else:
111 | self.current_user = ChessBoard.PIECE_STATE_SECOND
112 |
113 | if self.move_num == self.SIZE * self.SIZE:
114 | # self.state = ChessBoard.STATE_DONE
115 | self.state = ChessBoard.STATE_ABORT
116 |
117 | return 0
118 |
119 | def get_winner(self):
120 | return self.current_user if self.state == ChessBoard.STATE_DONE else -1
121 |
122 | def get_state(self):
123 | return self.state
124 |
125 | def get_current_user(self):
126 | return self.current_user
127 |
128 | def get_lastmove(self):
129 | return self.move_history[-1] if len(self.move_history) > 0 else (-1, -1, -1, -1)
130 |
131 | @changed
132 | def take_one_back(self):
133 | if len(self.move_history) > 0:
134 | last_move = self.move_history.pop()
135 | self.set_piece(last_move[-2], last_move[-1], ChessBoard.PIECE_STATE_BLANK)
136 | self.move_num -= 1
137 |
138 | if self.current_user == ChessBoard.PIECE_STATE_SECOND:
139 | self.current_user = ChessBoard.PIECE_STATE_FIRST
140 | else:
141 | self.current_user = ChessBoard.PIECE_STATE_SECOND
142 |
143 | def is_over(self):
144 | return self.state == ChessBoard.STATE_DONE or self.state == ChessBoard.STATE_ABORT
145 |
146 | def dumps(self):
147 | if self.dump_cache is None:
148 | self.dump_cache = pickle.dumps((self.SIZE, self.board, self.state, self.current_user, self.move_history))
149 | return self.dump_cache
150 |
151 | @changed
152 | def loads(self, chess_str):
153 | self.SIZE, self.board, self.state, self.current_user, self.move_history = pickle.loads(chess_str)
154 |
155 |
156 | @changed
157 | def reset(self):
158 | self.board = np.zeros((self.SIZE + ChessBoard.PAD * 2, self.SIZE + ChessBoard.PAD * 2), dtype=np.uint8)
159 | self.state = ChessBoard.STATE_RUNNING
160 | self.current_user = ChessBoard.PIECE_STATE_FIRST
161 | self.move_num = 0
162 | self.move_history = []
163 |
164 | @changed
165 | def abort(self):
166 | self.state = ChessBoard.STATE_ABORT
167 |
--------------------------------------------------------------------------------
/evaluate/ChessClient.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import requests
3 | import cookielib
4 | # import http.cookiejar
5 | from bs4 import BeautifulSoup
6 | import json
7 | import time
8 | import cPickle as pickle
9 | # import _pickle as pickle
10 | import ChessHelper
11 | from ChessBoard import ChessBoard
12 | from Hall import GameRoom
13 | from Hall import User
14 | import random
15 | import sys
16 | import os
17 | # 方便引入 AlphaPig
18 | abs_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), '../../')
19 | sys.path.insert(0, abs_path)
20 | import AlphaPig as gomoku_zm
21 |
22 |
23 | class ChessClient():
24 | def __init__(self, server_url):
25 | self.session = requests.Session()
26 | self.session.cookies = cookielib.CookieJar()
27 | agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36'
28 | self.headers = {
29 | "Host": server_url,
30 | "Origin": server_url,
31 | "Referer": server_url,
32 | 'User-Agent': agent
33 | }
34 | self.server_url = server_url
35 | self.board = ChessBoard()
36 | self.last_status_signature = ""
37 |
38 | def send_get(self, url):
39 | return self.session.get(self.server_url + url, headers=self.headers)
40 |
41 | def send_post(self, url, data):
42 | return self.session.post(self.server_url + url, data, headers=self.headers)
43 |
44 | def login_in_guest(self):
45 | response = self.send_get('/login?action=login_in_guest')
46 | soup = BeautifulSoup(response.content, "html.parser")
47 | username_span = soup.find('span', attrs={'id': 'username'})
48 | if username_span:
49 | return username_span.text
50 | else:
51 | return None
52 |
53 | def login(self, username, password):
54 | response = self.send_post('/login?action=login',
55 | data={'username': username, 'password': password})
56 | soup = BeautifulSoup(response.content, "html.parser")
57 | username_span = soup.find('span', attrs={'id': 'username'})
58 | if username_span:
59 | return username_span.text
60 | else:
61 | return None
62 |
63 | def logout(self):
64 | self.send_get('/login?action=logout')
65 |
66 | def join_room(self, roomid):
67 | response = self.send_post('/action?action=joinroom',
68 | data={'roomid': roomid})
69 | action_result = json.loads(response.content)
70 | return action_result
71 |
72 | def join_game(self, cur_role):
73 | #response = self.send_get('/action?action=joingame')
74 | response = self.send_post('/action?action=joingame',
75 | data={'position': str(cur_role)})
76 | action_result = json.loads(response.content)
77 | return action_result
78 |
79 | def put_piece(self, row, col):
80 | response = self.send_get(
81 | '/action?action=gameaction&actionid=%s&piece_i=%d&piece_j=%d' % ('put_piece', row, col))
82 | action_result = json.loads(response.content)
83 | return action_result
84 |
85 | def get_room_info(self):
86 | response = self.send_get(
87 | '/action?action=gameaction&actionid=%s' % 'get_room_info')
88 | action_result = json.loads(response.content)
89 | room = pickle.loads(str(action_result['info']))
90 | return room
91 |
92 | def get_game_info(self):
93 | response = self.send_get(
94 | '/action?action=gameaction&actionid=%s' % 'get_game_info')
95 | action_result = json.loads(response.content)
96 | room = pickle.loads(str(action_result['info']))
97 | return room
98 |
99 | def get_user_info(self):
100 | response = self.send_get(
101 | '/action?action=gameaction&actionid=%s' % 'get_user_info')
102 | action_result = json.loads(response.content)
103 | room = pickle.loads(str(action_result['info']))
104 | return room
105 |
106 | def wait_game_info_changed(self, interval=0.5, max_time=100):
107 | wait_time = 0
108 | assert interval > 0, "interval must be positive"
109 | while True:
110 | response = self.send_get(
111 | '/action?action=gameaction&actionid=%s' % ('get_status_signature'))
112 | action_result = json.loads(response.content)
113 | if action_result['id'] == 0:
114 | status_signature = action_result['info']
115 | if self.last_status_signature != status_signature:
116 | self.last_status_signature = status_signature
117 | break
118 | else:
119 | print("ERROR get_status_signature,", action_result['id'], action_result['info'])
120 | break
121 | time.sleep(interval)
122 | wait_time += interval
123 | if wait_time > max_time:
124 | break
125 |
126 | return wait_time
127 |
128 | def get_all_rooms(self):
129 | response = self.send_get(
130 | '/action?action=get_all_rooms')
131 | action_result = json.loads(response.content)
132 | all_rooms = action_result['info']
133 | return all_rooms
134 |
135 | def answer_take_back(self, agree=True):
136 | response = self.send_get(
137 | '/action?action=gameaction&actionid=answer_take_back&agree=' + ('true' if agree else 'false'))
138 | action_result = json.loads(response.content)
139 | return action_result
140 |
141 |
142 | class GameStrategy_random():
143 | def __init__(self):
144 | self._chess_helper_move_set = []
145 | for i in range(15):
146 | for j in range(15):
147 | self._chess_helper_move_set.append((i, j))
148 | random.shuffle(self._chess_helper_move_set)
149 | self.try_step = 0
150 |
151 | def play_one_piece(self, user, gameboard):
152 | move = self._chess_helper_move_set[self.try_step]
153 | while gameboard.get_piece(move[0], move[1]) != 0 and self.try_step < 15 * 15:
154 | self.try_step += 1
155 | move = self._chess_helper_move_set[self.try_step]
156 | self.try_step += 1
157 | return move
158 |
159 |
160 | class GameStrategy_MZhang():
161 | def __init__(self, startplayer=0, complex_='s'):
162 | abs_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), '../')
163 | # 普通卷积
164 | """
165 | model_file2 = os.path.join(abs_path, './logs/current_policy_tf_small.model')
166 | model_file1 = os.path.join(abs_path, './logs/best_policy_tf_10999.model')
167 | model_file3 = os.path.join(abs_path, './logs/current_policy_1024.model')
168 | # 残差5层
169 | model_file_res = os.path.join(abs_path, './logs/current_res_5.model')
170 | model_file_res10 = os.path.join(abs_path, './logs/current_res_10.model')
171 | """
172 | model_file1 = os.path.join(abs_path, "./logs/current_policy.model")
173 | model_file2 = os.path.join(abs_path, "./logs/current_policy.model")
174 | model_file3 = os.path.join(abs_path, "./logs/current_policy.model")
175 | model_file_res = os.path.join(abs_path, "./logs/current_policy.model")
176 | model_file_res10 = os.path.join(abs_path, "./logs/current_policy.model")
177 |
178 | policy_param = None
179 | self.height = 15
180 | self.width = 15
181 | if model_file1 is not None:
182 | print('loading...', model_file1)
183 | try:
184 | policy_param = pickle.load(open(model_file1, 'rb'))
185 | except:
186 | policy_param = pickle.load(open(model_file1, 'rb'), encoding='bytes')
187 |
188 | if complex_ == 's':
189 | policy_value_net = gomoku_zm.policy_value_net_mxnet_simple.PolicyValueNet(self.height, self.width, batch_size=16, model_params=policy_param)
190 | self.mcts_player = gomoku_zm.mcts_alphaZero.MCTSPlayer(policy_value_net.policy_value_fn, c_puct=3, n_playout=80) # n_playout: 160 太久了 改成 80
191 | # 500:50s 200:32s
192 | # 残差网络 5层
193 | elif complex_ == 'r':
194 | if model_file_res is not None:
195 | try:
196 | policy_param_res = pickle.load(open(model_file_res, 'rb'))
197 | except:
198 | policy_param_res = pickle.load(open(model_file_res, 'rb'), encoding='bytes')
199 | policy_value_net_res = gomoku_zm.policy_value_net_mxnet.PolicyValueNet(self.height, self.width, batch_size=16, n_blocks=5, n_filter=128, model_params=policy_param_res)
200 | self.mcts_player = gomoku_zm.mcts_alphaZero.MCTSPlayer(policy_value_net_res.policy_value_fn, c_puct=3, n_playout=1290)
201 | # 10层残差
202 | elif complex_ == 'r10':
203 | if model_file_res10 is not None:
204 | try:
205 | policy_param_res = pickle.load(open(model_file_res10, 'rb'))
206 | except:
207 | policy_param_res = pickle.load(open(model_file_res10, 'rb'), encoding='bytes')
208 | policy_value_net_res = gomoku_zm.policy_value_net_mxnet.PolicyValueNet(self.height, self.width, batch_size=16, n_blocks=10, n_filter=128, model_params=policy_param_res)
209 | self.mcts_player = gomoku_zm.mcts_alphaZero.MCTSPlayer(policy_value_net_res.policy_value_fn, c_puct=3, n_playout=990)
210 | else:
211 | print("*=*" * 20, ": 模型参数错误")
212 | self.board = gomoku_zm.game.Board(width=self.width, height=self.height, n_in_row=5)
213 | self.board.init_board(startplayer)
214 | self.game = gomoku_zm.game.Game(self.board)
215 | p1, p2 = self.board.players
216 | print('players:', p1, p2)
217 | self.mcts_player.set_player_ind(p1)
218 | pass
219 |
220 | def play_one_piece(self, user, gameboard):
221 | print('user:', gameboard.get_current_user())
222 | print('gameboard:', gameboard.move_history)
223 | lastm = gameboard.get_lastmove()
224 | if lastm[0] != -1:
225 | usr, n, row, col = lastm
226 | mv = (self.height-row-1)*self.height+col
227 | if not self.board.states.has_key(mv):
228 | self.board.do_move(mv)
229 |
230 | print('board:', self.board.states.items())
231 | move = self.mcts_player.get_action(self.board)
232 | print('***' * 10)
233 | print('move: ', move)
234 | print('\n')
235 | self.board.do_move(move)
236 | # self.game.graphic(self.board, *self.board.players)
237 | outmv = (self.height-move//self.height-1, move%self.width)
238 |
239 | return outmv
240 |
241 |
242 |
243 | def go_play(args):
244 |
245 | client = ChessClient(args.server_url)
246 | client.login_in_guest()
247 | client.join_room(args.room_name)
248 | client.join_game(args.cur_role)
249 | user = client.get_user_info()
250 | print("加入游戏成功,你是:" + ("黑方" if user.game_role == 1 else "白方"))
251 | print('model is: ', args.model)
252 |
253 | if args.ai == 'random':
254 | strategy = GameStrategy_MZhang(user.game_role-1, args.model)
255 | else:
256 | assert False, "No other ai, you can add one or import the AICollection's ai."
257 |
258 | while True:
259 | wait_time = client.wait_game_info_changed()
260 | print('wait_time:', wait_time)
261 |
262 | room = client.get_room_info()
263 | # room=GameRoom()
264 | user = client.get_user_info()
265 | # user=User()
266 | gameboard = client.get_game_info()
267 | # gameboard = ChessBoard()
268 |
269 | print('room.get_status():', room.get_status())
270 | print('user.game_status():', user.game_status)
271 | print('gameboard.game_status():')
272 | ChessHelper.printBoard(gameboard)
273 |
274 | if room.get_status() == GameRoom.ROOM_STATUS_NOONE or room.get_status() == GameRoom.ROOM_STATUS_ONEWAITING:
275 | print("等待另一个对手加入游戏:")
276 | continue
277 | elif room.get_status() == GameRoom.ROOM_STATUS_PLAYING:
278 | if room.ask_take_back != 0 and room.ask_take_back != user.game_role:
279 | client.answer_take_back()
280 | return 0
281 | # break
282 | if gameboard.get_current_user() == user.game_role:
283 | print("轮到你走:")
284 | current_time = time.time()
285 | one_legal_piece = strategy.play_one_piece(user, gameboard)
286 | action_result = client.put_piece(*one_legal_piece)
287 | print('***' * 20)
288 | print('COST TIME: %s' % (time.time() - current_time))
289 | if action_result['id'] != 0:
290 | print("走棋失败:")
291 | print(ChessHelper.numToAlp(one_legal_piece[0]), ChessHelper.numToAlp(one_legal_piece[1]))
292 | print(action_result['info'])
293 |
294 | else:
295 | print("轮到对手走....")
296 | continue
297 | elif room.get_status() == GameRoom.ROOM_STATUS_FINISH:
298 | print("游戏已经结束了," + ("黑方" if gameboard.get_winner() == 1 else "白方") + " 赢了")
299 | return 1
300 | # break
301 |
302 |
303 | if __name__ == "__main__":
304 | import argparse
305 | import time
306 | parser = argparse.ArgumentParser()
307 | # yixin_XX_X 格式将会进入和yixin的对战中
308 | temp_room_name = 'yixin_anxingle_' + str(time.time())
309 | parser.add_argument('--room_name', type=str, default=temp_room_name)
310 | parser.add_argument('--cur_role', default=1)
311 | parser.add_argument('--model', default='s')
312 | print('room_name: ', temp_room_name)
313 | parser.add_argument('--server_url', default='http://127.0.0.1:33512')
314 | parser.add_argument('--ai', default='random')
315 | args = parser.parse_args()
316 | while True:
317 | status = go_play(args)
318 | if status == 1:
319 | time.sleep(5)
320 | else:
321 | print("房间有人!")
322 | time.sleep(10)
323 |
--------------------------------------------------------------------------------
/evaluate/ChessHelper.py:
--------------------------------------------------------------------------------
1 | from ChessBoard import ChessBoard
2 | import random
3 | from line_profiler import LineProfiler
4 |
5 |
6 | def numToAlp(num):
7 | return chr(ord('A') + num)
8 |
9 |
10 | def transferSymbol(sym):
11 | if sym == 0:
12 | return "."
13 | if sym == 1:
14 | return "O"
15 | if sym == 2:
16 | return "X"
17 | return "E"
18 |
19 |
20 | def printBoard(chessboard):
21 | for i in range(chessboard.SIZE + 1):
22 | for j in range(chessboard.SIZE + 1):
23 | if i == 0 and j == 0:
24 | print(' ')
25 | elif i == 0:
26 | print(numToAlp(j - 1))
27 | elif j == 0:
28 | print(numToAlp(i - 1))
29 | else:
30 | print(transferSymbol(chessboard.get_piece(i - 1, j - 1)))
31 | print()
32 |
33 | def printBoard2Str(chessboard):
34 | info_array=[]
35 |
36 | for i in range(chessboard.SIZE + 1):
37 | info_str = ""
38 | for j in range(chessboard.SIZE + 1):
39 |
40 | if i == 0 and j == 0:
41 | info_str+= ' '
42 | elif i == 0:
43 | info_str += numToAlp(j - 1)
44 | elif j == 0:
45 | info_str +=numToAlp(i - 1)
46 | else:
47 | info_str +=transferSymbol(chessboard.get_piece(i - 1, j - 1))
48 | info_str += '\t'
49 | # info_str +='\n'
50 |
51 | info_array.append(info_str)
52 | return info_array
53 |
54 | def playRandomGame(chessboard):
55 | muser = 1
56 | _chess_helper_move_set = []
57 | for i in range(15):
58 | for j in range(15):
59 | _chess_helper_move_set.append((i, j))
60 | random.shuffle(_chess_helper_move_set)
61 | for move in _chess_helper_move_set:
62 | if chessboard.is_over():
63 | # print "No place to put."
64 | return -5
65 |
66 | r_row = move[0]
67 | r_col = move[1]
68 |
69 | return_value = chessboard.put_piece(r_row, r_col, muser)
70 | muser = 2 if muser == 1 else 1
71 | if return_value != 0:
72 | # print ("\n%s win one board. last move is %s %s, return value is %d" % (
73 | # transferSymbol(chessboard.get_winner()), numToAlp(r_row), numToAlp(r_col), return_value))
74 | return return_value
75 |
76 |
77 | if __name__ == '__main__':
78 | def linePro():
79 | lp = LineProfiler()
80 |
81 | # lp_wrapper = lp(cb.put_piece)
82 | # lp_wrapper(7, 7, 1)
83 |
84 | def playMuch(num):
85 | oi = 0
86 | for i in xrange(num):
87 | cb = ChessBoard()
88 | playRandomGame(cb)
89 | oi += cb.move_num
90 | print(oi / num)
91 |
92 | lp_wrapper = lp(playMuch)
93 | lp_wrapper(1000)
94 | lp.print_stats()
95 |
96 |
97 | def playRandom():
98 | cb = ChessBoard()
99 | return_value = playRandomGame(cb)
100 | printBoard(cb)
101 | print ("\n%s win one board. last move is %s %s, return value is %d" % (
102 | transferSymbol(cb.get_winner()), numToAlp(cb.get_lastmove()[0]), numToAlp(cb.get_lastmove()[1]),
103 | return_value))
104 |
105 |
106 | playRandom()
107 | #linePro()
108 |
--------------------------------------------------------------------------------
/evaluate/ChessServer.py:
--------------------------------------------------------------------------------
1 | import tornado.ioloop
2 | import tornado.web
3 | import os
4 | import argparse
5 |
6 | from Hall import Hall
7 | from Hall import GameRoom
8 | from Hall import User
9 |
10 | hall = Hall()
11 |
12 |
13 | class BaseHandler(tornado.web.RequestHandler):
14 | def get_current_user(self):
15 | return self.get_secure_cookie("username")
16 |
17 |
18 | class ChessHandler(BaseHandler):
19 |
20 | def get_post(self):
21 | info_ = ""
22 | user = hall.get_user_with_uid(self.current_user)
23 | room = user.game_room
24 | chess_board = room.board if room else None
25 | self.render("page/chessboard.html", username=self.current_user, room=room,
26 | chess_board=chess_board, user=user)
27 |
28 | @tornado.web.authenticated
29 | def get(self):
30 | self.get_post()
31 |
32 | @tornado.web.authenticated
33 | def post(self):
34 | self.get_post()
35 |
36 |
37 | class ActionHandler(BaseHandler):
38 |
39 | def get_post(self):
40 | action = self.get_argument("action", None)
41 | action_result = {"id": -1, "info": "Failure"}
42 |
43 | if action:
44 | if action == "joinroom":
45 | roomid = self.get_argument("roomid", None)
46 | if roomid:
47 | hall.join_room(self.current_user, roomid)
48 | action_result["id"] = 0
49 | action_result["info"] = "Join room success."
50 | else:
51 | action_result["id"] = -1
52 | action_result["info"] = "Not legal room id."
53 |
54 | elif action == "joingame":
55 | user_role = int(self.get_argument("position", -1))
56 |
57 | if hall.join_game(self.current_user, user_role) == 0:
58 | action_result["id"] = 0
59 | action_result["info"] = "Join game success."
60 |
61 | else:
62 | action_result["id"] = -1
63 | action_result["info"] = "Join game failed, join a room first or have joined game or game is full."
64 |
65 | elif action == "gameaction":
66 | actionid = self.get_argument("actionid", None)
67 | game_action_result = hall.game_action(self.current_user, actionid, self)
68 | if game_action_result.result_id == 0:
69 | action_result["id"] = 0
70 | action_result["info"] = game_action_result.result_info
71 | else:
72 | action_result["id"] = -1
73 | action_result["info"] = "Game action failed:" + str(
74 | game_action_result.result_id) + "," + game_action_result.result_info
75 | elif action == "getboardinfo":
76 | room = hall.get_room_with_user(self.current_user)
77 | # room=GameRoom()
78 | if room:
79 | action_result["id"] = 0
80 | action_result["info"] = room.board.dumps()
81 | else:
82 | action_result["id"] = -1
83 | action_result["info"] = "Not in room, please join one."
84 | elif action == "get_all_rooms":
85 | action_result["id"] = 0
86 | action_result["info"] = [[room_name, hall.id2room[room_name].get_status()] for room_name in
87 | hall.id2room]
88 | elif action == "reset_room":
89 | user = hall.get_user_with_uid(self.current_user)
90 | room = user.game_room
91 | # room=GameRoom()
92 | if room and room.get_status() == GameRoom.ROOM_STATUS_FINISH and user in room.play_users:
93 | room.reset_game()
94 | action_result["id"] = 0
95 | action_result["info"] = "reset success"
96 | else:
97 | action_result["id"] = -1
98 | action_result["info"] = "reset failed."
99 |
100 | else:
101 | action_result["id"] = -1
102 | action_result["info"] = "Not recognition action" + action
103 | else:
104 | action_result["info"] = "Not action arg set"
105 |
106 | # self.write(tornado.escape.json_encode(action_result))
107 | self.finish(action_result)
108 |
109 | @tornado.web.authenticated
110 | def get(self):
111 | self.get_post()
112 |
113 | @tornado.web.authenticated
114 | def post(self):
115 | self.get_post()
116 |
117 |
118 | class LoginHandler(BaseHandler):
119 |
120 | def get_post(self):
121 |
122 | action = self.get_argument("action", None)
123 |
124 | if action == "login":
125 | if self.current_user is not None:
126 | self.clear_cookie("username")
127 | hall.logout(self.current_user)
128 |
129 | username = self.get_argument("username")
130 | password = self.get_argument("password")
131 | username = hall.login(username, password)
132 | if username:
133 | self.set_secure_cookie("username", username)
134 | self.redirect("/")
135 | else:
136 | self.redirect("/login?status=wrong_password_or_name")
137 | elif action == "login_in_guest":
138 | if self.current_user is not None:
139 | self.clear_cookie("username")
140 | hall.logout(self.current_user)
141 |
142 | username = hall.login_in_guest()
143 | print(username)
144 | if username:
145 | self.set_secure_cookie("username", username)
146 | self.redirect("/")
147 | elif action == "logout":
148 | if self.current_user is not None:
149 | self.clear_cookie("username")
150 | hall.logout(self.current_user)
151 | self.redirect("/login")
152 | else:
153 | self.render('page/login.html')
154 |
155 | def get(self):
156 | self.get_post()
157 |
158 | def post(self):
159 | self.get_post()
160 |
161 |
162 | def main(listen_port):
163 | settings = {
164 | # "template_path": os.path.join(os.path.dirname(__file__), "templates"),
165 | "cookie_secret": "bZJc2sWbQLKos6GkHn/VB9oXwQt8S0R0kRvJ5/xJ89E=",
166 | # "xsrf_cookies": True,
167 | "login_url": "/login",
168 | "static_path": os.path.join(os.path.dirname(__file__), "static"),
169 | }
170 | app = tornado.web.Application([
171 | (r"/", ChessHandler),
172 | (r"/login", LoginHandler),
173 | (r"/action", ActionHandler),
174 | ], **settings)
175 | app.listen(listen_port)
176 | tornado.ioloop.IOLoop.current().start()
177 |
178 |
179 | if __name__ == "__main__":
180 | parser = argparse.ArgumentParser()
181 | parser.add_argument('--port', default=8888)
182 | args = parser.parse_args()
183 | main(args.port)
184 |
--------------------------------------------------------------------------------
/evaluate/Hall.py:
--------------------------------------------------------------------------------
1 | import sys
2 |
3 | from ChessBoard import ChessBoard
4 | import cPickle as pickle
5 | # import _pickle as pickle
6 | import random
7 | import string
8 | import os
9 |
10 |
11 | class User(object):
12 | def __init__(self, uid_, hall_):
13 | self.uid = uid_
14 | self.game_room = None
15 | self.hall = hall_
16 | self.game_status = User.USER_GAME_STATUS_NOJOIN
17 | self.game_role = -1
18 |
19 | USER_GAME_STATUS_NOJOIN = 0
20 | USER_GAME_STATUS_GAMEJOINED = 1
21 |
22 | def send_message(self):
23 | pass
24 |
25 | def receive_message(self, message):
26 | pass
27 |
28 | def send_game_state(self):
29 | pass
30 |
31 | def action(self, action):
32 | pass
33 |
34 | def join_room(self, room):
35 | if self.game_room is not None:
36 | self.leave_room()
37 |
38 | if room.join_room(self) == GameRoom.ACTION_SUCCESS:
39 | self.game_room = room
40 | else:
41 | return -1
42 |
43 | def join_game(self, user_role):
44 | if self.game_room is None:
45 | return -1
46 |
47 | if self.game_status == User.USER_GAME_STATUS_GAMEJOINED:
48 | return -1
49 | if self.game_room.join_game(self, user_role) == GameRoom.ACTION_SUCCESS:
50 | self.game_status = User.USER_GAME_STATUS_GAMEJOINED
51 | return 0
52 | else:
53 | return -1
54 |
55 | def leave_room(self):
56 | if self.game_room is None:
57 | return -1
58 | self.leave_game()
59 | self.game_room.leave_room(self)
60 |
61 | def leave_game(self):
62 | if self.game_room is None:
63 | return -1
64 | self.game_room.leave_game(self)
65 | self.game_status = User.USER_GAME_STATUS_NOJOIN
66 | self.game_role = -1
67 |
68 |
69 | class ActionResult(object):
70 | def __init__(self, result_id_=0, result_info_=""):
71 | self.result_id = result_id_
72 | self.result_info = result_info_
73 |
74 |
75 | class GameRoom(object):
76 | ACTION_SUCCESS = 0
77 | ACTION_FAILURE = -1
78 |
79 | def __init__(self, room_id_):
80 | self.play_users = []
81 | self.position2users = {} # 1 black role 2 white role
82 | self.room_id = room_id_
83 | self.users = []
84 | self.max_player_num = 2
85 | self.max_user_num = 10000
86 | self.board = ChessBoard()
87 | self.status_signature = None
88 | self.set_changed()
89 | self.chess_folder = 'chess_output'
90 | # self.game_status = GameRoom.GAME_STATUS_NOTBEGIN
91 | self.ask_take_back = 0
92 |
93 | def set_changed(self):
94 | self.status_signature = ''.join(random.sample(string.ascii_letters + string.digits, 8))
95 |
96 | def broadcast_message_to_all(self, message):
97 | self.set_changed()
98 | pass
99 |
100 | def send_message(self, to_user_id, message):
101 | self.set_changed()
102 | pass
103 |
104 | def get_last_move(self):
105 | (userrole, move_num, row, col) = self.board.get_lastmove()
106 | if userrole < 0:
107 | userrole = -1 * self.get_status() - 1
108 | last_move = {
109 | 'role': userrole,
110 | 'move_num': move_num,
111 | 'row': row,
112 | 'col': col,
113 | }
114 | return last_move
115 |
116 | # GAME_STATUS_NOTBEGIN = 0
117 | # GAME_STATUS_RUNING_HEIFANG = 1
118 | # GAME_STATUS_RUNING_BAIFANG = 2
119 | # GAME_STATUS_FINISH = 3
120 | # GAME_STATUS_ASKTAKEBACK_HEIFANG = 4
121 | # GAME_STATUS_ASKTAKEBACK_BAIFANG = 5
122 | # GAME_STATUS_ASKREBEGIN_HEIFANG = 6
123 | # GAME_STATUS_ASKREBEGIN_BAIFANG = 7
124 |
125 | def get_signature(self):
126 | return self.status_signature
127 |
128 | def action(self, user, action_code, action_args):
129 | if action_code == "put_piece":
130 | if self.ask_take_back != 0:
131 | return ActionResult(-1, "Wait take back answer before.")
132 | if not (user.game_role == 1) and not (user.game_role == 2):
133 | return ActionResult(-1, "Not the right time or role to put piece")
134 | piece_i = action_args.get_argument('piece_i', None)
135 | piece_j = action_args.get_argument('piece_j', None)
136 | if piece_i and piece_j:
137 | return_code = self.board.put_piece(int(piece_i), int(piece_j), user.game_role)
138 | if return_code >= 0:
139 | if return_code == 1:
140 | self.finish_game()
141 | self.set_changed()
142 | return ActionResult(0, "put_piece success:" + str(return_code));
143 | else:
144 | return ActionResult(-4, "put_piece failed, because " + str(return_code))
145 | else:
146 | return ActionResult(-3, "Not set the piece_i and piece_j")
147 | elif action_code == "getlastmove":
148 | return ActionResult(0, self.get_last_move())
149 | elif action_code == "get_status_signature":
150 | return ActionResult(0, self.get_signature())
151 | elif action_code == "get_room_info":
152 | return ActionResult(0, pickle.dumps(self))
153 | elif action_code == "get_game_info":
154 | return ActionResult(0, pickle.dumps(self.board))
155 | elif action_code == "get_user_info":
156 | return ActionResult(0, pickle.dumps(user))
157 | elif action_code == "ask_take_back":
158 | if self.ask_take_back != 0:
159 | return ActionResult(-1, "Not right time to ask take back.")
160 | if user.game_role != 1 and user.game_role != 2:
161 | return ActionResult(-1, "Not right role to ask take back.")
162 | self.ask_take_back = user.game_role
163 | self.set_changed()
164 | return ActionResult(0, "Ask take back success")
165 | elif action_code == "answer_take_back":
166 |
167 | if not (self.ask_take_back == 1 and user.game_role == 2) and not (
168 | self.ask_take_back == 2 and user.game_role == 1):
169 | return ActionResult(-1, "Not the right time or role to answer take back")
170 |
171 | agree = action_args.get_argument('agree', 'false')
172 | if agree == 'true':
173 | if self.ask_take_back == 1 and user.game_role == 2:
174 | if self.board.get_current_user() == 1:
175 | self.board.take_one_back()
176 | self.board.take_one_back()
177 |
178 | elif self.ask_take_back == 2 and user.game_role == 1:
179 | if self.board.get_current_user() == 2:
180 | self.board.take_one_back()
181 | self.board.take_one_back()
182 | self.ask_take_back = 0
183 | self.set_changed()
184 | return ActionResult(0, "answer take back success")
185 | else:
186 | return ActionResult(-2, "Not recognized game action")
187 |
188 | # def join(self, user):
189 | # if self.join_game(user) == GameRoom.ACTION_SUCCESS:
190 | # return GameRoom.ACTION_SUCCESS
191 | # return self.join_watch(user)
192 |
193 | def join_game(self, user, user_role):
194 | if user not in self.users:
195 | return GameRoom.ACTION_FAILURE
196 |
197 | if len(self.play_users) >= self.max_player_num:
198 | return GameRoom.ACTION_FAILURE
199 | idle_position = [i for i in range(1, self.max_player_num + 1) if i not in self.position2users]
200 | if len(idle_position) == 0:
201 | return GameRoom.ACTION_FAILURE
202 | if user_role is None or user_role == -1:
203 | user_role = idle_position[0]
204 | elif user_role == 0:
205 | random.shuffle(idle_position)
206 | user_role = idle_position[0]
207 | else:
208 | if user_role in self.position2users or user_role > self.max_player_num:
209 | return GameRoom.ACTION_FAILURE
210 | user.game_role = user_role
211 | self.position2users[user_role] = user
212 | self.play_users.append(user)
213 |
214 | self.set_changed()
215 | return GameRoom.ACTION_SUCCESS
216 |
217 | def join_room(self, user):
218 | if len(self.users) >= self.max_user_num:
219 | return GameRoom.ACTION_FAILURE
220 | self.users.append(user)
221 | self.set_changed()
222 | return GameRoom.ACTION_SUCCESS
223 |
224 | def leave_game(self, user):
225 | if user not in self.play_users:
226 | return
227 |
228 | if user in self.play_users:
229 | if self.get_status() == GameRoom.ROOM_STATUS_PLAYING:
230 | self.finish_game(state=-1)
231 | self.play_users.remove(user)
232 | if user.game_role in self.position2users:
233 | del self.position2users[user.game_role]
234 | self.set_changed()
235 |
236 | def leave_room(self, user):
237 | if user not in self.users:
238 | return
239 | self.leave_game(user)
240 | self.users.remove(user)
241 | self.set_changed()
242 |
243 | ROOM_STATUS_FINISH = 4
244 | ROOM_STATUS_NOONE = 1
245 | ROOM_STATUS_ONEWAITING = 2
246 | ROOM_STATUS_PLAYING = 3
247 | ROOM_STATUS_WRONG = -1
248 | ROOM_STATUS_NOTINROOM = 0
249 |
250 | def get_status(self):
251 | if self.board.is_over():
252 | return GameRoom.ROOM_STATUS_FINISH;
253 | if len(self.play_users) == 0:
254 | return GameRoom.ROOM_STATUS_NOONE;
255 | if len(self.play_users) == 1:
256 | return GameRoom.ROOM_STATUS_ONEWAITING;
257 | if len(self.play_users) == 2:
258 | return GameRoom.ROOM_STATUS_PLAYING;
259 | return GameRoom.ROOM_STATUS_WRONG;
260 |
261 | def reset_game(self):
262 | while len(self.play_users) > 0:
263 | self.play_users[0].leave_game()
264 | self.board.reset()
265 |
266 | def finish_game(self, state=0):
267 | if state == -1:
268 | self.board.abort()
269 |
270 | if not os.path.exists(self.chess_folder):
271 | os.makedirs(self.chess_folder)
272 | import datetime
273 | tm = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
274 | chess_file = self.chess_folder + '/' + self.room_id + '_[' + '|'.join(
275 | [user.uid for user in self.play_users]) + ']_' + tm + '.txt'
276 | with open(chess_file, 'w') as f:
277 | f.write(self.board.dumps())
278 |
279 | # def get_room_info(self):
280 | # room_info = {'status': 0, 'roomid': -1}
281 | # room_info['status'] = self.get_status()
282 | # room_info['roomid'] = self.room_id
283 | # room_info['room'] = self
284 | # room_info['users_uid'] = []
285 | # room_info['play_users_uid'] = []
286 | # room_info['users'] = []
287 | # room_info['play_users'] = []
288 | # for user in self.users:
289 | # room_info['users_uid'].append(user.uid)
290 | # room_info['users'].append(user)
291 | # for user in user.game_room.play_users:
292 | # room_info['play_users_uid'].append(user.uid)
293 | # room_info['play_users'].append(user)
294 |
295 |
296 | class Hall(object):
297 | def __init__(self):
298 | self.uid2user = {}
299 | self.id2room = {}
300 | self.MaxUserNum = 10000
301 | self.user_num = 0
302 |
303 | def login(self, username, password):
304 | if self.user_num > self.MaxUserNum:
305 | return None
306 | pass
307 |
308 | def login_in_guest(self):
309 | if self.user_num > self.MaxUserNum:
310 | return None
311 | import random
312 | username = "guest_"
313 | while True:
314 | rand_postfix = random.randint(10000, 1000000)
315 | username = "guest_" + str(rand_postfix)
316 | if username not in self.uid2user:
317 | break
318 | user = User(username, self)
319 | self.uid2user[username] = user
320 | return username
321 |
322 | def get_user_with_uid(self, userid):
323 | if userid not in self.uid2user:
324 | self.uid2user[userid] = User(userid, self)
325 | return self.uid2user[userid]
326 |
327 | def join_room(self, username, roomid):
328 | user = self.get_user_with_uid(username)
329 | if roomid not in self.id2room:
330 | self.id2room[roomid] = GameRoom(roomid)
331 | if user.game_room != self.id2room[roomid]:
332 | user.join_room(self.id2room[roomid])
333 |
334 | def get_room_info_with_user(self, username):
335 | room_info = {'status': 0, 'roomid': -1}
336 | user = self.get_user_with_uid(username)
337 | if user.game_room:
338 |
339 | room_info['status'] = user.game_room.get_status()
340 | room_info['roomid'] = user.game_room.room_id
341 | room_info['room'] = user.game_room
342 | room_info['users_uid'] = []
343 | room_info['play_users_uid'] = []
344 | room_info['users'] = []
345 | room_info['play_users'] = []
346 | for user in user.game_room.users:
347 | room_info['users_uid'].append(user.uid)
348 | room_info['users'].append(user)
349 | for user in user.game_room.play_users:
350 | room_info['play_users_uid'].append(user.uid)
351 | room_info['play_users'].append(user)
352 | return room_info
353 |
354 | def get_room_with_user(self, username):
355 | user = self.get_user_with_uid(username)
356 | if user.game_room:
357 | return user.game_room
358 | return None
359 |
360 | def join_game(self, username, user_role):
361 | user = self.get_user_with_uid(username)
362 | return user.join_game(user_role)
363 |
364 | def game_action(self, username, actionid, arg_pack):
365 | user = self.get_user_with_uid(username)
366 | if user.game_room:
367 | return user.game_room.action(user, actionid, arg_pack)
368 | else:
369 | return ActionResult(-1, "Not in any room")
370 |
371 | def logout(self, username):
372 | user = self.get_user_with_uid(username)
373 | if user.game_room:
374 | user.game_room.leave_room(user)
375 | self.uid2user.pop(username)
376 |
--------------------------------------------------------------------------------
/evaluate/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 使用指南
4 | ```
5 | cd AlphaPig/evaluate
6 | python ChessServer.py # 将会在本机11111端口启动对弈服务,浏览器打开localhost:11111即可
7 | ```
8 |
9 | # 与AI对弈
10 |
11 | 1.
12 | ```
13 | # AlphaPig/evaluate 目录下
14 | python ChessClient.py --model XXX.model --cur_role 1/2 --room_name ROOM_NAME --server_url 127.0.0.1:8888
15 | ```
16 | --cur_role 1是黑手,2是白手; —room_name是对弈的房间号码,server_url 是对弈服务器的地址(默认是本机喽)
17 |
18 | 如果是两个AI对弈,则双方出了--cur_role之外,都敲入相同的参数。如果是AI与人,则谁先进去先有优先选择权。
19 |
20 | # 人人对弈
21 |
22 | 直接打开浏览器,约定房间,没什么好说的。
--------------------------------------------------------------------------------
/evaluate/ai_listen_ucloud.bat:
--------------------------------------------------------------------------------
1 | c:\Python27\python.exe AICollection.py --server_url http://120.132.59.147:11111
--------------------------------------------------------------------------------
/evaluate/logs/error.log:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anxingle/AlphaPig/16257003c6fa33d3583b8d43919f4ec944f8b5bb/evaluate/logs/error.log
--------------------------------------------------------------------------------
/evaluate/logs/info.log:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anxingle/AlphaPig/16257003c6fa33d3583b8d43919f4ec944f8b5bb/evaluate/logs/info.log
--------------------------------------------------------------------------------
/evaluate/page/chessboard.html:
--------------------------------------------------------------------------------
1 |
2 | {% from Hall import GameRoom %}
3 |
4 |
5 |
6 |
123 |
124 |
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | from . import game
3 | from . import mcts_pure
4 | from . import policy_value_net_mxnet
5 | from . import policy_value_net_mxnet_simple
6 |
--------------------------------------------------------------------------------
/ai_train.dockerfile:
--------------------------------------------------------------------------------
1 | From gospelslave/alphapig:v0.1.3
2 |
3 | WORKDIR /workspace
4 |
5 | ADD ./ /workspace
6 |
7 | RUN /bin/bash -c "source ~/.bashrc"
8 |
9 |
10 |
--------------------------------------------------------------------------------
/conf/train_config.yaml:
--------------------------------------------------------------------------------
1 | # 数据目录
2 | sgf_dir: './sgf_data'
3 | # AI对弈数据目录
4 | ai_data_dir: './pickle_ai_data'
5 | # 棋盘设置
6 | board_width: 15
7 | board_height: 15
8 | n_in_row: 5
9 | # 学习率
10 | learn_rate: 0.0004
11 | # 根据KL散度动态调整学习率
12 | lr_multiplier: 1.0
13 | temp: 1.0
14 | # 每次移动的simulations数
15 | n_playout: 400
16 | # TODO: 蒙特卡洛树模拟选择时更多的依靠先验,估值越精确,C就应该偏向深度(越小)
17 | c_puct: 5
18 | # 数据集最大量(双端队列长度)
19 | buffer_size: 2198800
20 | batch_size: 128
21 | epochs: 8
22 | play_batch_size: 1
23 | # KL散度
24 | kl_targ: 0.02
25 | # 每check_freq次 检测对弈成绩
26 | check_freq: 1000
27 | # 检测成绩用的mcts对手的思考深度
28 | pure_mcts_playout_num: 1000
29 | # 训练多少轮
30 | game_batch_num: 240000
31 |
32 |
33 | # 训练日志
34 | train_logging:
35 | version: 1
36 | formatters:
37 | simpleFormater:
38 | format: '%(asctime)s - %(levelname)s - %(name)s[line:%(lineno)d]: %(message)s'
39 | datefmt: '%Y-%m-%d %H:%M:%S'
40 | handlers:
41 | # 标准输出,只要级别在DEBUG以上就会输出
42 | console:
43 | class: logging.StreamHandler
44 | formatter: simpleFormater
45 | level: DEBUG
46 | stream: ext://sys.stdout
47 | # INFO以上,滚动文件,保留20个,每个最大100MB
48 | info_file_handler:
49 | class : logging.FileHandler
50 | formatter: simpleFormater
51 | level: INFO
52 | filename: ./logs/info.log
53 | # ERROR以上
54 | error_file_handler:
55 | class : logging.FileHandler
56 | formatter: simpleFormater
57 | level: ERROR
58 | filename: ./logs/error.log
59 | root:
60 | level: DEBUG
61 | handlers: [console, info_file_handler, error_file_handler]
62 |
--------------------------------------------------------------------------------
/cpu_train.sh:
--------------------------------------------------------------------------------
1 | docker run -it \
2 | -v /home/ubuntu/uai-sdk/examples/mxnet/train/AlphaPig:/data \
3 | -v /home/ubuntu/uai-sdk/examples/mxnet/train/AlphaPig/sgf_data:/data/data \
4 | -v /home/ubuntu/uai-sdk/examples/mxnet/train/AlphaPig/logs:/data/output \
5 | uhub.service.ucloud.cn/uaishare/cpu_uaitrain_ubuntu-14.04_python-2.7.6_mxnet-1.0.0:v1.0 \
6 | /bin/bash -c "cd /data && /usr/bin/python /data/train_mxnet.py --model-prefix=siler_Alpha --work_dir=/data --output_dir=/data/output"
7 |
8 |
9 |
10 |
11 |
12 |
13 |
--------------------------------------------------------------------------------
/docker-compose.yml:
--------------------------------------------------------------------------------
1 | version: "2.3"
2 |
3 | services:
4 | gobang_server:
5 | image: gospelslave/alphapig:v0.1.11
6 | entrypoint: /bin/bash run_server.sh
7 | privileged: true
8 | environment:
9 | - TZ=Asia/Shanghai
10 | ports:
11 | - 8888:8888
12 | restart: always
13 | logging:
14 | driver: json-file
15 | options:
16 | max-size: "10M"
17 | max-file: "5"
18 |
19 | gobang_ai:
20 | image: gospelslave/alphapig:v0.1.11
21 | entrypoint: /bin/bash run_ai.sh
22 | privileged: true
23 | environment:
24 | - TZ=Asia/Shanghai
25 | runtime: nvidia
26 | restart: always
27 | logging:
28 | driver: json-file
29 | options:
30 | max-size: "10M"
31 | max-file: "5"
32 |
--------------------------------------------------------------------------------
/evaluate/AICollection.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import time
3 | import ChessHelper
4 | import threading
5 | from ChessBoard import ChessBoard
6 | from Hall import GameRoom
7 | from Hall import User
8 | import random
9 | import os
10 | from ChessClient import ChessClient
11 |
12 |
13 | class GameStrategy(object):
14 | def __init__(self):
15 | import gobang
16 | self.searcher = gobang.searcher()
17 |
18 | def play_one_piece(self, user, gameboard):
19 | # user = User()
20 | # gameboard = ChessBoard()
21 | turn = user.game_role
22 | self.searcher.board = [[gameboard.get_piece(m, n) for n in xrange(gameboard.SIZE)] for m in
23 | xrange(gameboard.SIZE)]
24 | # gameboard=ChessBoard()
25 | # gameboard.move_history
26 | score, row, col = self.searcher.search(turn, 2)
27 | # print "score:", score
28 | return (row, col)
29 |
30 |
31 | class GameStrategy_yixin(object):
32 |
33 | def __init__(self):
34 | self.muid = str(random.randint(0, 1000000))
35 | self.comm_folder = 'yixin_comm/'
36 | if not os.path.exists(self.comm_folder):
37 | os.makedirs(self.comm_folder)
38 | self.chess_state_file = self.comm_folder + 'game_state_' + self.muid
39 | self.action_file = self.comm_folder + 'action_' + self.muid
40 |
41 | def play_one_piece(self, user, gameboard):
42 | # user = User()
43 | # gameboard = ChessBoard()
44 | with open(self.chess_state_file, 'w') as chess_state_file:
45 | for userrole, move_num, row, col in gameboard.move_history:
46 | chess_state_file.write('%d,%d\n' % (row, col))
47 | if os.path.exists(self.action_file):
48 | os.remove(self.action_file)
49 | os.system("yixin_ai\yixin.exe %s %s" % (self.chess_state_file, self.action_file))
50 | row, col = random.randint(0, 15), random.randint(0, 15)
51 | with open(self.action_file) as action_file:
52 | line = action_file.readline()
53 | row, col = line.strip().split(',')
54 | row, col = int(row), int(col)
55 |
56 | return (row, col)
57 |
58 |
59 | class GameStrategy_random(object):
60 | def __init__(self):
61 | self._chess_helper_move_set = []
62 | for i in range(15):
63 | for j in range(15):
64 | self._chess_helper_move_set.append((i, j))
65 | random.shuffle(self._chess_helper_move_set)
66 | self.try_step = 0
67 |
68 | def play_one_piece(self, user, gameboard):
69 | move = self._chess_helper_move_set[self.try_step]
70 | while gameboard.get_piece(move[0], move[1]) != 0 and self.try_step < 15 * 15:
71 | self.try_step += 1
72 | move = self._chess_helper_move_set[self.try_step]
73 | self.try_step += 1
74 | return move
75 |
76 |
77 | class GameCommunicator(threading.Thread):
78 | def __init__(self, roomid, stragegy, server_url):
79 | threading.Thread.__init__(self)
80 | self.room_id = roomid
81 | self.stragegy = stragegy;
82 | self.server_url = server_url
83 |
84 | def run(self):
85 | client = ChessClient(self.server_url)
86 | client.login_in_guest()
87 | client.join_room(self.room_id)
88 | client.join_game()
89 | exp_interval = 0.5
90 | max_exp_interval = 200
91 | while True:
92 | single_max_time = exp_interval * 100
93 | wait_time = client.wait_game_info_changed(interval=exp_interval, max_time=single_max_time)
94 | if wait_time > single_max_time:
95 | exp_interval *= 2
96 | else:
97 | exp_interval = 0.5
98 | if exp_interval > max_exp_interval:
99 | exp_interval = max_exp_interval
100 | room = client.get_room_info()
101 | user = client.get_user_info()
102 | gameboard = client.get_game_info()
103 | print 'waittime:',wait_time,',room_status:',room.get_status(),',ask_take_back:',room.ask_take_back
104 | if room.get_status() == 1 or room.get_status() == 2:
105 | continue
106 | elif room.get_status() == 3:
107 | if room.ask_take_back != 0 and room.ask_take_back != user.game_role:
108 | client.answer_take_back()
109 | continue
110 | if gameboard.get_current_user() == user.game_role:
111 | one_legal_piece = self.stragegy.play_one_piece(user, gameboard)
112 | action_result = client.put_piece(*one_legal_piece)
113 | client.wait_game_info_changed(interval=exp_interval, max_time=single_max_time)
114 | if action_result['id'] != 0:
115 | print ChessHelper.numToAlp(one_legal_piece[0]), ChessHelper.numToAlp(one_legal_piece[1])
116 | print action_result['info']
117 | break
118 | continue
119 | elif room.get_status() == 4:
120 | break
121 |
122 |
123 | class GameListener(object):
124 | def __init__(self, prefix_stategy_map, server_url):
125 | self.client = ChessClient(server_url)
126 | self.client.login_in_guest()
127 | self.prefix_stategy_map = prefix_stategy_map
128 | self.server_url = server_url
129 | self.accupied = set()
130 |
131 | def listen(self):
132 | while True:
133 | all_rooms = self.client.get_all_rooms()
134 | for room in all_rooms:
135 | room_name = room[0]
136 | room_status = room[1]
137 | for prefix in self.prefix_stategy_map:
138 | if room_name.startswith(prefix) and room_status == GameRoom.ROOM_STATUS_ONEWAITING:
139 | if room_name in self.accupied:
140 | continue
141 | print 'Evoke:', room_name
142 | strg = self.prefix_stategy_map[prefix]()
143 | self.accupied.add(room_name)
144 | commu = GameCommunicator(room_name, strg, self.server_url)
145 | commu.start()
146 | break
147 | time.sleep(4)
148 |
149 |
150 | def go_listen():
151 | import argparse
152 | parser = argparse.ArgumentParser()
153 | parser.add_argument('--server_url', default='http://120.132.59.147:11111')
154 | args = parser.parse_args()
155 |
156 |
157 | if args.server_url.endswith('/'):
158 | args.server_url = args.server_url[:-1]
159 | if not args.server_url.startswith('http://'):
160 | args.server_url = 'http://' + args.server_url
161 |
162 | prefix_stategy_map = {'ai_': lambda: GameStrategy(), 'yixin_': lambda: GameStrategy_yixin(),
163 | 'random_': lambda: GameStrategy_random()}
164 | listen = GameListener(prefix_stategy_map, args.server_url)
165 | listen.listen()
166 |
167 |
168 | if __name__ == "__main__":
169 | go_listen()
170 |
--------------------------------------------------------------------------------
/evaluate/ChessBoard.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import time
3 | import cPickle as pickle
4 |
5 |
6 | class ChessBoard(object):
7 | """ChessBoard
8 |
9 | Attributes:
10 | SIZE: The chess board's size.
11 | board: To store the board information.
12 | state: Indicate if the game is over.
13 | current_user: The user who put the next piece.
14 | """
15 |
16 | STATE_RUNNING = 0
17 | STATE_DONE = 1
18 | STATE_ABORT = 1
19 |
20 | PIECE_STATE_BLANK = 0
21 | PIECE_STATE_FIRST = 1
22 | PIECE_STATE_SECOND = 2
23 |
24 | PAD = 4
25 |
26 | CHECK_DIRECTION = [[[0, 1], [0, -1]], [[1, 0], [-1, 0]], [[1, 1], [-1, -1]], [[1, -1], [-1, 1]]]
27 |
28 | def __init__(self, size=15):
29 | self.SIZE = size
30 | self.board = np.zeros((self.SIZE + ChessBoard.PAD * 2, self.SIZE + ChessBoard.PAD * 2), dtype=np.uint8)
31 | self.state = ChessBoard.STATE_RUNNING
32 | self.current_user = ChessBoard.PIECE_STATE_FIRST
33 |
34 | self.move_num = 0
35 | self.move_history = []
36 |
37 | self.dump_cache = None
38 |
39 | def changed(func):
40 | def wrapper_func(self,*args, **kwargs):
41 | ret=func(self,*args, **kwargs)
42 | self.dump_cache = None
43 | return ret
44 |
45 | return wrapper_func
46 |
47 | def get_piece(self, row, col):
48 | return self.board[row + ChessBoard.PAD, col + ChessBoard.PAD]
49 |
50 | @changed
51 | def set_piece(self, row, col, user):
52 | self.board[row + ChessBoard.PAD, col + ChessBoard.PAD] = user
53 |
54 | @changed
55 | def put_piece(self, row, col, user):
56 | """Put a piece in the board and check if he wins.
57 | Returns:
58 | 0 successful move.
59 | 1 successful and win move.
60 | -1 move out of range.
61 | -2 piece has been occupied.
62 | -3 game is over
63 | -4 not your turn.
64 | """
65 | if row < 0 or row >= self.SIZE or col < 0 or col >= self.SIZE:
66 | return -1
67 | if self.get_piece(row, col) != ChessBoard.PIECE_STATE_BLANK:
68 | return -2
69 | if self.state != ChessBoard.STATE_RUNNING:
70 | return -3
71 | if user != self.current_user:
72 | return -4
73 |
74 | self.set_piece(row, col, user)
75 | self.move_num += 1
76 | self.move_history.append((user, self.move_num, row, col,))
77 | # self.last_move = (row, col)
78 |
79 | # check if win
80 | for dx in xrange(4):
81 | connected_piece_num = 1
82 | for dy in xrange(2):
83 | current_direct = ChessBoard.CHECK_DIRECTION[dx][dy]
84 | c_row = row
85 | c_col = col
86 |
87 | # if else realization
88 | for dz in xrange(4):
89 | c_row += current_direct[0]
90 | c_col += current_direct[1]
91 | if self.get_piece(c_row, c_col) == user:
92 | connected_piece_num += 1
93 | else:
94 | break
95 |
96 | # remove if, but not faster
97 | # p = 1
98 | # for dz in xrange(4):
99 | # c_row += current_direct[0]
100 | # c_col += current_direct[1]
101 | # p = p & (self.board[c_row, c_col] == user)
102 | # connected_piece_num += p
103 |
104 | if connected_piece_num >= 5:
105 | self.state = ChessBoard.STATE_DONE
106 | return 1
107 |
108 | if self.current_user == ChessBoard.PIECE_STATE_SECOND:
109 | self.current_user = ChessBoard.PIECE_STATE_FIRST
110 | else:
111 | self.current_user = ChessBoard.PIECE_STATE_SECOND
112 |
113 | if self.move_num == self.SIZE * self.SIZE:
114 | # self.state = ChessBoard.STATE_DONE
115 | self.state = ChessBoard.STATE_ABORT
116 |
117 | return 0
118 |
119 | def get_winner(self):
120 | return self.current_user if self.state == ChessBoard.STATE_DONE else -1
121 |
122 | def get_state(self):
123 | return self.state
124 |
125 | def get_current_user(self):
126 | return self.current_user
127 |
128 | def get_lastmove(self):
129 | return self.move_history[-1] if len(self.move_history) > 0 else (-1, -1, -1, -1)
130 |
131 | @changed
132 | def take_one_back(self):
133 | if len(self.move_history) > 0:
134 | last_move = self.move_history.pop()
135 | self.set_piece(last_move[-2], last_move[-1], ChessBoard.PIECE_STATE_BLANK)
136 | self.move_num -= 1
137 |
138 | if self.current_user == ChessBoard.PIECE_STATE_SECOND:
139 | self.current_user = ChessBoard.PIECE_STATE_FIRST
140 | else:
141 | self.current_user = ChessBoard.PIECE_STATE_SECOND
142 |
143 | def is_over(self):
144 | return self.state == ChessBoard.STATE_DONE or self.state == ChessBoard.STATE_ABORT
145 |
146 | def dumps(self):
147 | if self.dump_cache is None:
148 | self.dump_cache = pickle.dumps((self.SIZE, self.board, self.state, self.current_user, self.move_history))
149 | return self.dump_cache
150 |
151 | @changed
152 | def loads(self, chess_str):
153 | self.SIZE, self.board, self.state, self.current_user, self.move_history = pickle.loads(chess_str)
154 |
155 |
156 | @changed
157 | def reset(self):
158 | self.board = np.zeros((self.SIZE + ChessBoard.PAD * 2, self.SIZE + ChessBoard.PAD * 2), dtype=np.uint8)
159 | self.state = ChessBoard.STATE_RUNNING
160 | self.current_user = ChessBoard.PIECE_STATE_FIRST
161 | self.move_num = 0
162 | self.move_history = []
163 |
164 | @changed
165 | def abort(self):
166 | self.state = ChessBoard.STATE_ABORT
167 |
--------------------------------------------------------------------------------
/evaluate/ChessClient.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | import requests
3 | import cookielib
4 | # import http.cookiejar
5 | from bs4 import BeautifulSoup
6 | import json
7 | import time
8 | import cPickle as pickle
9 | # import _pickle as pickle
10 | import ChessHelper
11 | from ChessBoard import ChessBoard
12 | from Hall import GameRoom
13 | from Hall import User
14 | import random
15 | import sys
16 | import os
17 | # 方便引入 AlphaPig
18 | abs_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), '../../')
19 | sys.path.insert(0, abs_path)
20 | import AlphaPig as gomoku_zm
21 |
22 |
23 | class ChessClient():
24 | def __init__(self, server_url):
25 | self.session = requests.Session()
26 | self.session.cookies = cookielib.CookieJar()
27 | agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/5.1.2.3000 Chrome/55.0.2883.75 Safari/537.36'
28 | self.headers = {
29 | "Host": server_url,
30 | "Origin": server_url,
31 | "Referer": server_url,
32 | 'User-Agent': agent
33 | }
34 | self.server_url = server_url
35 | self.board = ChessBoard()
36 | self.last_status_signature = ""
37 |
38 | def send_get(self, url):
39 | return self.session.get(self.server_url + url, headers=self.headers)
40 |
41 | def send_post(self, url, data):
42 | return self.session.post(self.server_url + url, data, headers=self.headers)
43 |
44 | def login_in_guest(self):
45 | response = self.send_get('/login?action=login_in_guest')
46 | soup = BeautifulSoup(response.content, "html.parser")
47 | username_span = soup.find('span', attrs={'id': 'username'})
48 | if username_span:
49 | return username_span.text
50 | else:
51 | return None
52 |
53 | def login(self, username, password):
54 | response = self.send_post('/login?action=login',
55 | data={'username': username, 'password': password})
56 | soup = BeautifulSoup(response.content, "html.parser")
57 | username_span = soup.find('span', attrs={'id': 'username'})
58 | if username_span:
59 | return username_span.text
60 | else:
61 | return None
62 |
63 | def logout(self):
64 | self.send_get('/login?action=logout')
65 |
66 | def join_room(self, roomid):
67 | response = self.send_post('/action?action=joinroom',
68 | data={'roomid': roomid})
69 | action_result = json.loads(response.content)
70 | return action_result
71 |
72 | def join_game(self, cur_role):
73 | #response = self.send_get('/action?action=joingame')
74 | response = self.send_post('/action?action=joingame',
75 | data={'position': str(cur_role)})
76 | action_result = json.loads(response.content)
77 | return action_result
78 |
79 | def put_piece(self, row, col):
80 | response = self.send_get(
81 | '/action?action=gameaction&actionid=%s&piece_i=%d&piece_j=%d' % ('put_piece', row, col))
82 | action_result = json.loads(response.content)
83 | return action_result
84 |
85 | def get_room_info(self):
86 | response = self.send_get(
87 | '/action?action=gameaction&actionid=%s' % 'get_room_info')
88 | action_result = json.loads(response.content)
89 | room = pickle.loads(str(action_result['info']))
90 | return room
91 |
92 | def get_game_info(self):
93 | response = self.send_get(
94 | '/action?action=gameaction&actionid=%s' % 'get_game_info')
95 | action_result = json.loads(response.content)
96 | room = pickle.loads(str(action_result['info']))
97 | return room
98 |
99 | def get_user_info(self):
100 | response = self.send_get(
101 | '/action?action=gameaction&actionid=%s' % 'get_user_info')
102 | action_result = json.loads(response.content)
103 | room = pickle.loads(str(action_result['info']))
104 | return room
105 |
106 | def wait_game_info_changed(self, interval=0.5, max_time=100):
107 | wait_time = 0
108 | assert interval > 0, "interval must be positive"
109 | while True:
110 | response = self.send_get(
111 | '/action?action=gameaction&actionid=%s' % ('get_status_signature'))
112 | action_result = json.loads(response.content)
113 | if action_result['id'] == 0:
114 | status_signature = action_result['info']
115 | if self.last_status_signature != status_signature:
116 | self.last_status_signature = status_signature
117 | break
118 | else:
119 | print("ERROR get_status_signature,", action_result['id'], action_result['info'])
120 | break
121 | time.sleep(interval)
122 | wait_time += interval
123 | if wait_time > max_time:
124 | break
125 |
126 | return wait_time
127 |
128 | def get_all_rooms(self):
129 | response = self.send_get(
130 | '/action?action=get_all_rooms')
131 | action_result = json.loads(response.content)
132 | all_rooms = action_result['info']
133 | return all_rooms
134 |
135 | def answer_take_back(self, agree=True):
136 | response = self.send_get(
137 | '/action?action=gameaction&actionid=answer_take_back&agree=' + ('true' if agree else 'false'))
138 | action_result = json.loads(response.content)
139 | return action_result
140 |
141 |
142 | class GameStrategy_random():
143 | def __init__(self):
144 | self._chess_helper_move_set = []
145 | for i in range(15):
146 | for j in range(15):
147 | self._chess_helper_move_set.append((i, j))
148 | random.shuffle(self._chess_helper_move_set)
149 | self.try_step = 0
150 |
151 | def play_one_piece(self, user, gameboard):
152 | move = self._chess_helper_move_set[self.try_step]
153 | while gameboard.get_piece(move[0], move[1]) != 0 and self.try_step < 15 * 15:
154 | self.try_step += 1
155 | move = self._chess_helper_move_set[self.try_step]
156 | self.try_step += 1
157 | return move
158 |
159 |
160 | class GameStrategy_MZhang():
161 | def __init__(self, startplayer=0, complex_='s'):
162 | abs_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), '../')
163 | # 普通卷积
164 | """
165 | model_file2 = os.path.join(abs_path, './logs/current_policy_tf_small.model')
166 | model_file1 = os.path.join(abs_path, './logs/best_policy_tf_10999.model')
167 | model_file3 = os.path.join(abs_path, './logs/current_policy_1024.model')
168 | # 残差5层
169 | model_file_res = os.path.join(abs_path, './logs/current_res_5.model')
170 | model_file_res10 = os.path.join(abs_path, './logs/current_res_10.model')
171 | """
172 | model_file1 = os.path.join(abs_path, "./logs/current_policy.model")
173 | model_file2 = os.path.join(abs_path, "./logs/current_policy.model")
174 | model_file3 = os.path.join(abs_path, "./logs/current_policy.model")
175 | model_file_res = os.path.join(abs_path, "./logs/current_policy.model")
176 | model_file_res10 = os.path.join(abs_path, "./logs/current_policy.model")
177 |
178 | policy_param = None
179 | self.height = 15
180 | self.width = 15
181 | if model_file1 is not None:
182 | print('loading...', model_file1)
183 | try:
184 | policy_param = pickle.load(open(model_file1, 'rb'))
185 | except:
186 | policy_param = pickle.load(open(model_file1, 'rb'), encoding='bytes')
187 |
188 | if complex_ == 's':
189 | policy_value_net = gomoku_zm.policy_value_net_mxnet_simple.PolicyValueNet(self.height, self.width, batch_size=16, model_params=policy_param)
190 | self.mcts_player = gomoku_zm.mcts_alphaZero.MCTSPlayer(policy_value_net.policy_value_fn, c_puct=3, n_playout=80) # n_playout: 160 太久了 改成 80
191 | # 500:50s 200:32s
192 | # 残差网络 5层
193 | elif complex_ == 'r':
194 | if model_file_res is not None:
195 | try:
196 | policy_param_res = pickle.load(open(model_file_res, 'rb'))
197 | except:
198 | policy_param_res = pickle.load(open(model_file_res, 'rb'), encoding='bytes')
199 | policy_value_net_res = gomoku_zm.policy_value_net_mxnet.PolicyValueNet(self.height, self.width, batch_size=16, n_blocks=5, n_filter=128, model_params=policy_param_res)
200 | self.mcts_player = gomoku_zm.mcts_alphaZero.MCTSPlayer(policy_value_net_res.policy_value_fn, c_puct=3, n_playout=1290)
201 | # 10层残差
202 | elif complex_ == 'r10':
203 | if model_file_res10 is not None:
204 | try:
205 | policy_param_res = pickle.load(open(model_file_res10, 'rb'))
206 | except:
207 | policy_param_res = pickle.load(open(model_file_res10, 'rb'), encoding='bytes')
208 | policy_value_net_res = gomoku_zm.policy_value_net_mxnet.PolicyValueNet(self.height, self.width, batch_size=16, n_blocks=10, n_filter=128, model_params=policy_param_res)
209 | self.mcts_player = gomoku_zm.mcts_alphaZero.MCTSPlayer(policy_value_net_res.policy_value_fn, c_puct=3, n_playout=990)
210 | else:
211 | print("*=*" * 20, ": 模型参数错误")
212 | self.board = gomoku_zm.game.Board(width=self.width, height=self.height, n_in_row=5)
213 | self.board.init_board(startplayer)
214 | self.game = gomoku_zm.game.Game(self.board)
215 | p1, p2 = self.board.players
216 | print('players:', p1, p2)
217 | self.mcts_player.set_player_ind(p1)
218 | pass
219 |
220 | def play_one_piece(self, user, gameboard):
221 | print('user:', gameboard.get_current_user())
222 | print('gameboard:', gameboard.move_history)
223 | lastm = gameboard.get_lastmove()
224 | if lastm[0] != -1:
225 | usr, n, row, col = lastm
226 | mv = (self.height-row-1)*self.height+col
227 | if not self.board.states.has_key(mv):
228 | self.board.do_move(mv)
229 |
230 | print('board:', self.board.states.items())
231 | move = self.mcts_player.get_action(self.board)
232 | print('***' * 10)
233 | print('move: ', move)
234 | print('\n')
235 | self.board.do_move(move)
236 | # self.game.graphic(self.board, *self.board.players)
237 | outmv = (self.height-move//self.height-1, move%self.width)
238 |
239 | return outmv
240 |
241 |
242 |
243 | def go_play(args):
244 |
245 | client = ChessClient(args.server_url)
246 | client.login_in_guest()
247 | client.join_room(args.room_name)
248 | client.join_game(args.cur_role)
249 | user = client.get_user_info()
250 | print("加入游戏成功,你是:" + ("黑方" if user.game_role == 1 else "白方"))
251 | print('model is: ', args.model)
252 |
253 | if args.ai == 'random':
254 | strategy = GameStrategy_MZhang(user.game_role-1, args.model)
255 | else:
256 | assert False, "No other ai, you can add one or import the AICollection's ai."
257 |
258 | while True:
259 | wait_time = client.wait_game_info_changed()
260 | print('wait_time:', wait_time)
261 |
262 | room = client.get_room_info()
263 | # room=GameRoom()
264 | user = client.get_user_info()
265 | # user=User()
266 | gameboard = client.get_game_info()
267 | # gameboard = ChessBoard()
268 |
269 | print('room.get_status():', room.get_status())
270 | print('user.game_status():', user.game_status)
271 | print('gameboard.game_status():')
272 | ChessHelper.printBoard(gameboard)
273 |
274 | if room.get_status() == GameRoom.ROOM_STATUS_NOONE or room.get_status() == GameRoom.ROOM_STATUS_ONEWAITING:
275 | print("等待另一个对手加入游戏:")
276 | continue
277 | elif room.get_status() == GameRoom.ROOM_STATUS_PLAYING:
278 | if room.ask_take_back != 0 and room.ask_take_back != user.game_role:
279 | client.answer_take_back()
280 | return 0
281 | # break
282 | if gameboard.get_current_user() == user.game_role:
283 | print("轮到你走:")
284 | current_time = time.time()
285 | one_legal_piece = strategy.play_one_piece(user, gameboard)
286 | action_result = client.put_piece(*one_legal_piece)
287 | print('***' * 20)
288 | print('COST TIME: %s' % (time.time() - current_time))
289 | if action_result['id'] != 0:
290 | print("走棋失败:")
291 | print(ChessHelper.numToAlp(one_legal_piece[0]), ChessHelper.numToAlp(one_legal_piece[1]))
292 | print(action_result['info'])
293 |
294 | else:
295 | print("轮到对手走....")
296 | continue
297 | elif room.get_status() == GameRoom.ROOM_STATUS_FINISH:
298 | print("游戏已经结束了," + ("黑方" if gameboard.get_winner() == 1 else "白方") + " 赢了")
299 | return 1
300 | # break
301 |
302 |
303 | if __name__ == "__main__":
304 | import argparse
305 | import time
306 | parser = argparse.ArgumentParser()
307 | # yixin_XX_X 格式将会进入和yixin的对战中
308 | temp_room_name = 'yixin_anxingle_' + str(time.time())
309 | parser.add_argument('--room_name', type=str, default=temp_room_name)
310 | parser.add_argument('--cur_role', default=1)
311 | parser.add_argument('--model', default='s')
312 | print('room_name: ', temp_room_name)
313 | parser.add_argument('--server_url', default='http://127.0.0.1:33512')
314 | parser.add_argument('--ai', default='random')
315 | args = parser.parse_args()
316 | while True:
317 | status = go_play(args)
318 | if status == 1:
319 | time.sleep(5)
320 | else:
321 | print("房间有人!")
322 | time.sleep(10)
323 |
--------------------------------------------------------------------------------
/evaluate/ChessHelper.py:
--------------------------------------------------------------------------------
1 | from ChessBoard import ChessBoard
2 | import random
3 | from line_profiler import LineProfiler
4 |
5 |
6 | def numToAlp(num):
7 | return chr(ord('A') + num)
8 |
9 |
10 | def transferSymbol(sym):
11 | if sym == 0:
12 | return "."
13 | if sym == 1:
14 | return "O"
15 | if sym == 2:
16 | return "X"
17 | return "E"
18 |
19 |
20 | def printBoard(chessboard):
21 | for i in range(chessboard.SIZE + 1):
22 | for j in range(chessboard.SIZE + 1):
23 | if i == 0 and j == 0:
24 | print(' ')
25 | elif i == 0:
26 | print(numToAlp(j - 1))
27 | elif j == 0:
28 | print(numToAlp(i - 1))
29 | else:
30 | print(transferSymbol(chessboard.get_piece(i - 1, j - 1)))
31 | print()
32 |
33 | def printBoard2Str(chessboard):
34 | info_array=[]
35 |
36 | for i in range(chessboard.SIZE + 1):
37 | info_str = ""
38 | for j in range(chessboard.SIZE + 1):
39 |
40 | if i == 0 and j == 0:
41 | info_str+= ' '
42 | elif i == 0:
43 | info_str += numToAlp(j - 1)
44 | elif j == 0:
45 | info_str +=numToAlp(i - 1)
46 | else:
47 | info_str +=transferSymbol(chessboard.get_piece(i - 1, j - 1))
48 | info_str += '\t'
49 | # info_str +='\n'
50 |
51 | info_array.append(info_str)
52 | return info_array
53 |
54 | def playRandomGame(chessboard):
55 | muser = 1
56 | _chess_helper_move_set = []
57 | for i in range(15):
58 | for j in range(15):
59 | _chess_helper_move_set.append((i, j))
60 | random.shuffle(_chess_helper_move_set)
61 | for move in _chess_helper_move_set:
62 | if chessboard.is_over():
63 | # print "No place to put."
64 | return -5
65 |
66 | r_row = move[0]
67 | r_col = move[1]
68 |
69 | return_value = chessboard.put_piece(r_row, r_col, muser)
70 | muser = 2 if muser == 1 else 1
71 | if return_value != 0:
72 | # print ("\n%s win one board. last move is %s %s, return value is %d" % (
73 | # transferSymbol(chessboard.get_winner()), numToAlp(r_row), numToAlp(r_col), return_value))
74 | return return_value
75 |
76 |
77 | if __name__ == '__main__':
78 | def linePro():
79 | lp = LineProfiler()
80 |
81 | # lp_wrapper = lp(cb.put_piece)
82 | # lp_wrapper(7, 7, 1)
83 |
84 | def playMuch(num):
85 | oi = 0
86 | for i in xrange(num):
87 | cb = ChessBoard()
88 | playRandomGame(cb)
89 | oi += cb.move_num
90 | print(oi / num)
91 |
92 | lp_wrapper = lp(playMuch)
93 | lp_wrapper(1000)
94 | lp.print_stats()
95 |
96 |
97 | def playRandom():
98 | cb = ChessBoard()
99 | return_value = playRandomGame(cb)
100 | printBoard(cb)
101 | print ("\n%s win one board. last move is %s %s, return value is %d" % (
102 | transferSymbol(cb.get_winner()), numToAlp(cb.get_lastmove()[0]), numToAlp(cb.get_lastmove()[1]),
103 | return_value))
104 |
105 |
106 | playRandom()
107 | #linePro()
108 |
--------------------------------------------------------------------------------
/evaluate/ChessServer.py:
--------------------------------------------------------------------------------
1 | import tornado.ioloop
2 | import tornado.web
3 | import os
4 | import argparse
5 |
6 | from Hall import Hall
7 | from Hall import GameRoom
8 | from Hall import User
9 |
10 | hall = Hall()
11 |
12 |
13 | class BaseHandler(tornado.web.RequestHandler):
14 | def get_current_user(self):
15 | return self.get_secure_cookie("username")
16 |
17 |
18 | class ChessHandler(BaseHandler):
19 |
20 | def get_post(self):
21 | info_ = ""
22 | user = hall.get_user_with_uid(self.current_user)
23 | room = user.game_room
24 | chess_board = room.board if room else None
25 | self.render("page/chessboard.html", username=self.current_user, room=room,
26 | chess_board=chess_board, user=user)
27 |
28 | @tornado.web.authenticated
29 | def get(self):
30 | self.get_post()
31 |
32 | @tornado.web.authenticated
33 | def post(self):
34 | self.get_post()
35 |
36 |
37 | class ActionHandler(BaseHandler):
38 |
39 | def get_post(self):
40 | action = self.get_argument("action", None)
41 | action_result = {"id": -1, "info": "Failure"}
42 |
43 | if action:
44 | if action == "joinroom":
45 | roomid = self.get_argument("roomid", None)
46 | if roomid:
47 | hall.join_room(self.current_user, roomid)
48 | action_result["id"] = 0
49 | action_result["info"] = "Join room success."
50 | else:
51 | action_result["id"] = -1
52 | action_result["info"] = "Not legal room id."
53 |
54 | elif action == "joingame":
55 | user_role = int(self.get_argument("position", -1))
56 |
57 | if hall.join_game(self.current_user, user_role) == 0:
58 | action_result["id"] = 0
59 | action_result["info"] = "Join game success."
60 |
61 | else:
62 | action_result["id"] = -1
63 | action_result["info"] = "Join game failed, join a room first or have joined game or game is full."
64 |
65 | elif action == "gameaction":
66 | actionid = self.get_argument("actionid", None)
67 | game_action_result = hall.game_action(self.current_user, actionid, self)
68 | if game_action_result.result_id == 0:
69 | action_result["id"] = 0
70 | action_result["info"] = game_action_result.result_info
71 | else:
72 | action_result["id"] = -1
73 | action_result["info"] = "Game action failed:" + str(
74 | game_action_result.result_id) + "," + game_action_result.result_info
75 | elif action == "getboardinfo":
76 | room = hall.get_room_with_user(self.current_user)
77 | # room=GameRoom()
78 | if room:
79 | action_result["id"] = 0
80 | action_result["info"] = room.board.dumps()
81 | else:
82 | action_result["id"] = -1
83 | action_result["info"] = "Not in room, please join one."
84 | elif action == "get_all_rooms":
85 | action_result["id"] = 0
86 | action_result["info"] = [[room_name, hall.id2room[room_name].get_status()] for room_name in
87 | hall.id2room]
88 | elif action == "reset_room":
89 | user = hall.get_user_with_uid(self.current_user)
90 | room = user.game_room
91 | # room=GameRoom()
92 | if room and room.get_status() == GameRoom.ROOM_STATUS_FINISH and user in room.play_users:
93 | room.reset_game()
94 | action_result["id"] = 0
95 | action_result["info"] = "reset success"
96 | else:
97 | action_result["id"] = -1
98 | action_result["info"] = "reset failed."
99 |
100 | else:
101 | action_result["id"] = -1
102 | action_result["info"] = "Not recognition action" + action
103 | else:
104 | action_result["info"] = "Not action arg set"
105 |
106 | # self.write(tornado.escape.json_encode(action_result))
107 | self.finish(action_result)
108 |
109 | @tornado.web.authenticated
110 | def get(self):
111 | self.get_post()
112 |
113 | @tornado.web.authenticated
114 | def post(self):
115 | self.get_post()
116 |
117 |
118 | class LoginHandler(BaseHandler):
119 |
120 | def get_post(self):
121 |
122 | action = self.get_argument("action", None)
123 |
124 | if action == "login":
125 | if self.current_user is not None:
126 | self.clear_cookie("username")
127 | hall.logout(self.current_user)
128 |
129 | username = self.get_argument("username")
130 | password = self.get_argument("password")
131 | username = hall.login(username, password)
132 | if username:
133 | self.set_secure_cookie("username", username)
134 | self.redirect("/")
135 | else:
136 | self.redirect("/login?status=wrong_password_or_name")
137 | elif action == "login_in_guest":
138 | if self.current_user is not None:
139 | self.clear_cookie("username")
140 | hall.logout(self.current_user)
141 |
142 | username = hall.login_in_guest()
143 | print(username)
144 | if username:
145 | self.set_secure_cookie("username", username)
146 | self.redirect("/")
147 | elif action == "logout":
148 | if self.current_user is not None:
149 | self.clear_cookie("username")
150 | hall.logout(self.current_user)
151 | self.redirect("/login")
152 | else:
153 | self.render('page/login.html')
154 |
155 | def get(self):
156 | self.get_post()
157 |
158 | def post(self):
159 | self.get_post()
160 |
161 |
162 | def main(listen_port):
163 | settings = {
164 | # "template_path": os.path.join(os.path.dirname(__file__), "templates"),
165 | "cookie_secret": "bZJc2sWbQLKos6GkHn/VB9oXwQt8S0R0kRvJ5/xJ89E=",
166 | # "xsrf_cookies": True,
167 | "login_url": "/login",
168 | "static_path": os.path.join(os.path.dirname(__file__), "static"),
169 | }
170 | app = tornado.web.Application([
171 | (r"/", ChessHandler),
172 | (r"/login", LoginHandler),
173 | (r"/action", ActionHandler),
174 | ], **settings)
175 | app.listen(listen_port)
176 | tornado.ioloop.IOLoop.current().start()
177 |
178 |
179 | if __name__ == "__main__":
180 | parser = argparse.ArgumentParser()
181 | parser.add_argument('--port', default=8888)
182 | args = parser.parse_args()
183 | main(args.port)
184 |
--------------------------------------------------------------------------------
/evaluate/Hall.py:
--------------------------------------------------------------------------------
1 | import sys
2 |
3 | from ChessBoard import ChessBoard
4 | import cPickle as pickle
5 | # import _pickle as pickle
6 | import random
7 | import string
8 | import os
9 |
10 |
11 | class User(object):
12 | def __init__(self, uid_, hall_):
13 | self.uid = uid_
14 | self.game_room = None
15 | self.hall = hall_
16 | self.game_status = User.USER_GAME_STATUS_NOJOIN
17 | self.game_role = -1
18 |
19 | USER_GAME_STATUS_NOJOIN = 0
20 | USER_GAME_STATUS_GAMEJOINED = 1
21 |
22 | def send_message(self):
23 | pass
24 |
25 | def receive_message(self, message):
26 | pass
27 |
28 | def send_game_state(self):
29 | pass
30 |
31 | def action(self, action):
32 | pass
33 |
34 | def join_room(self, room):
35 | if self.game_room is not None:
36 | self.leave_room()
37 |
38 | if room.join_room(self) == GameRoom.ACTION_SUCCESS:
39 | self.game_room = room
40 | else:
41 | return -1
42 |
43 | def join_game(self, user_role):
44 | if self.game_room is None:
45 | return -1
46 |
47 | if self.game_status == User.USER_GAME_STATUS_GAMEJOINED:
48 | return -1
49 | if self.game_room.join_game(self, user_role) == GameRoom.ACTION_SUCCESS:
50 | self.game_status = User.USER_GAME_STATUS_GAMEJOINED
51 | return 0
52 | else:
53 | return -1
54 |
55 | def leave_room(self):
56 | if self.game_room is None:
57 | return -1
58 | self.leave_game()
59 | self.game_room.leave_room(self)
60 |
61 | def leave_game(self):
62 | if self.game_room is None:
63 | return -1
64 | self.game_room.leave_game(self)
65 | self.game_status = User.USER_GAME_STATUS_NOJOIN
66 | self.game_role = -1
67 |
68 |
69 | class ActionResult(object):
70 | def __init__(self, result_id_=0, result_info_=""):
71 | self.result_id = result_id_
72 | self.result_info = result_info_
73 |
74 |
75 | class GameRoom(object):
76 | ACTION_SUCCESS = 0
77 | ACTION_FAILURE = -1
78 |
79 | def __init__(self, room_id_):
80 | self.play_users = []
81 | self.position2users = {} # 1 black role 2 white role
82 | self.room_id = room_id_
83 | self.users = []
84 | self.max_player_num = 2
85 | self.max_user_num = 10000
86 | self.board = ChessBoard()
87 | self.status_signature = None
88 | self.set_changed()
89 | self.chess_folder = 'chess_output'
90 | # self.game_status = GameRoom.GAME_STATUS_NOTBEGIN
91 | self.ask_take_back = 0
92 |
93 | def set_changed(self):
94 | self.status_signature = ''.join(random.sample(string.ascii_letters + string.digits, 8))
95 |
96 | def broadcast_message_to_all(self, message):
97 | self.set_changed()
98 | pass
99 |
100 | def send_message(self, to_user_id, message):
101 | self.set_changed()
102 | pass
103 |
104 | def get_last_move(self):
105 | (userrole, move_num, row, col) = self.board.get_lastmove()
106 | if userrole < 0:
107 | userrole = -1 * self.get_status() - 1
108 | last_move = {
109 | 'role': userrole,
110 | 'move_num': move_num,
111 | 'row': row,
112 | 'col': col,
113 | }
114 | return last_move
115 |
116 | # GAME_STATUS_NOTBEGIN = 0
117 | # GAME_STATUS_RUNING_HEIFANG = 1
118 | # GAME_STATUS_RUNING_BAIFANG = 2
119 | # GAME_STATUS_FINISH = 3
120 | # GAME_STATUS_ASKTAKEBACK_HEIFANG = 4
121 | # GAME_STATUS_ASKTAKEBACK_BAIFANG = 5
122 | # GAME_STATUS_ASKREBEGIN_HEIFANG = 6
123 | # GAME_STATUS_ASKREBEGIN_BAIFANG = 7
124 |
125 | def get_signature(self):
126 | return self.status_signature
127 |
128 | def action(self, user, action_code, action_args):
129 | if action_code == "put_piece":
130 | if self.ask_take_back != 0:
131 | return ActionResult(-1, "Wait take back answer before.")
132 | if not (user.game_role == 1) and not (user.game_role == 2):
133 | return ActionResult(-1, "Not the right time or role to put piece")
134 | piece_i = action_args.get_argument('piece_i', None)
135 | piece_j = action_args.get_argument('piece_j', None)
136 | if piece_i and piece_j:
137 | return_code = self.board.put_piece(int(piece_i), int(piece_j), user.game_role)
138 | if return_code >= 0:
139 | if return_code == 1:
140 | self.finish_game()
141 | self.set_changed()
142 | return ActionResult(0, "put_piece success:" + str(return_code));
143 | else:
144 | return ActionResult(-4, "put_piece failed, because " + str(return_code))
145 | else:
146 | return ActionResult(-3, "Not set the piece_i and piece_j")
147 | elif action_code == "getlastmove":
148 | return ActionResult(0, self.get_last_move())
149 | elif action_code == "get_status_signature":
150 | return ActionResult(0, self.get_signature())
151 | elif action_code == "get_room_info":
152 | return ActionResult(0, pickle.dumps(self))
153 | elif action_code == "get_game_info":
154 | return ActionResult(0, pickle.dumps(self.board))
155 | elif action_code == "get_user_info":
156 | return ActionResult(0, pickle.dumps(user))
157 | elif action_code == "ask_take_back":
158 | if self.ask_take_back != 0:
159 | return ActionResult(-1, "Not right time to ask take back.")
160 | if user.game_role != 1 and user.game_role != 2:
161 | return ActionResult(-1, "Not right role to ask take back.")
162 | self.ask_take_back = user.game_role
163 | self.set_changed()
164 | return ActionResult(0, "Ask take back success")
165 | elif action_code == "answer_take_back":
166 |
167 | if not (self.ask_take_back == 1 and user.game_role == 2) and not (
168 | self.ask_take_back == 2 and user.game_role == 1):
169 | return ActionResult(-1, "Not the right time or role to answer take back")
170 |
171 | agree = action_args.get_argument('agree', 'false')
172 | if agree == 'true':
173 | if self.ask_take_back == 1 and user.game_role == 2:
174 | if self.board.get_current_user() == 1:
175 | self.board.take_one_back()
176 | self.board.take_one_back()
177 |
178 | elif self.ask_take_back == 2 and user.game_role == 1:
179 | if self.board.get_current_user() == 2:
180 | self.board.take_one_back()
181 | self.board.take_one_back()
182 | self.ask_take_back = 0
183 | self.set_changed()
184 | return ActionResult(0, "answer take back success")
185 | else:
186 | return ActionResult(-2, "Not recognized game action")
187 |
188 | # def join(self, user):
189 | # if self.join_game(user) == GameRoom.ACTION_SUCCESS:
190 | # return GameRoom.ACTION_SUCCESS
191 | # return self.join_watch(user)
192 |
193 | def join_game(self, user, user_role):
194 | if user not in self.users:
195 | return GameRoom.ACTION_FAILURE
196 |
197 | if len(self.play_users) >= self.max_player_num:
198 | return GameRoom.ACTION_FAILURE
199 | idle_position = [i for i in range(1, self.max_player_num + 1) if i not in self.position2users]
200 | if len(idle_position) == 0:
201 | return GameRoom.ACTION_FAILURE
202 | if user_role is None or user_role == -1:
203 | user_role = idle_position[0]
204 | elif user_role == 0:
205 | random.shuffle(idle_position)
206 | user_role = idle_position[0]
207 | else:
208 | if user_role in self.position2users or user_role > self.max_player_num:
209 | return GameRoom.ACTION_FAILURE
210 | user.game_role = user_role
211 | self.position2users[user_role] = user
212 | self.play_users.append(user)
213 |
214 | self.set_changed()
215 | return GameRoom.ACTION_SUCCESS
216 |
217 | def join_room(self, user):
218 | if len(self.users) >= self.max_user_num:
219 | return GameRoom.ACTION_FAILURE
220 | self.users.append(user)
221 | self.set_changed()
222 | return GameRoom.ACTION_SUCCESS
223 |
224 | def leave_game(self, user):
225 | if user not in self.play_users:
226 | return
227 |
228 | if user in self.play_users:
229 | if self.get_status() == GameRoom.ROOM_STATUS_PLAYING:
230 | self.finish_game(state=-1)
231 | self.play_users.remove(user)
232 | if user.game_role in self.position2users:
233 | del self.position2users[user.game_role]
234 | self.set_changed()
235 |
236 | def leave_room(self, user):
237 | if user not in self.users:
238 | return
239 | self.leave_game(user)
240 | self.users.remove(user)
241 | self.set_changed()
242 |
243 | ROOM_STATUS_FINISH = 4
244 | ROOM_STATUS_NOONE = 1
245 | ROOM_STATUS_ONEWAITING = 2
246 | ROOM_STATUS_PLAYING = 3
247 | ROOM_STATUS_WRONG = -1
248 | ROOM_STATUS_NOTINROOM = 0
249 |
250 | def get_status(self):
251 | if self.board.is_over():
252 | return GameRoom.ROOM_STATUS_FINISH;
253 | if len(self.play_users) == 0:
254 | return GameRoom.ROOM_STATUS_NOONE;
255 | if len(self.play_users) == 1:
256 | return GameRoom.ROOM_STATUS_ONEWAITING;
257 | if len(self.play_users) == 2:
258 | return GameRoom.ROOM_STATUS_PLAYING;
259 | return GameRoom.ROOM_STATUS_WRONG;
260 |
261 | def reset_game(self):
262 | while len(self.play_users) > 0:
263 | self.play_users[0].leave_game()
264 | self.board.reset()
265 |
266 | def finish_game(self, state=0):
267 | if state == -1:
268 | self.board.abort()
269 |
270 | if not os.path.exists(self.chess_folder):
271 | os.makedirs(self.chess_folder)
272 | import datetime
273 | tm = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
274 | chess_file = self.chess_folder + '/' + self.room_id + '_[' + '|'.join(
275 | [user.uid for user in self.play_users]) + ']_' + tm + '.txt'
276 | with open(chess_file, 'w') as f:
277 | f.write(self.board.dumps())
278 |
279 | # def get_room_info(self):
280 | # room_info = {'status': 0, 'roomid': -1}
281 | # room_info['status'] = self.get_status()
282 | # room_info['roomid'] = self.room_id
283 | # room_info['room'] = self
284 | # room_info['users_uid'] = []
285 | # room_info['play_users_uid'] = []
286 | # room_info['users'] = []
287 | # room_info['play_users'] = []
288 | # for user in self.users:
289 | # room_info['users_uid'].append(user.uid)
290 | # room_info['users'].append(user)
291 | # for user in user.game_room.play_users:
292 | # room_info['play_users_uid'].append(user.uid)
293 | # room_info['play_users'].append(user)
294 |
295 |
296 | class Hall(object):
297 | def __init__(self):
298 | self.uid2user = {}
299 | self.id2room = {}
300 | self.MaxUserNum = 10000
301 | self.user_num = 0
302 |
303 | def login(self, username, password):
304 | if self.user_num > self.MaxUserNum:
305 | return None
306 | pass
307 |
308 | def login_in_guest(self):
309 | if self.user_num > self.MaxUserNum:
310 | return None
311 | import random
312 | username = "guest_"
313 | while True:
314 | rand_postfix = random.randint(10000, 1000000)
315 | username = "guest_" + str(rand_postfix)
316 | if username not in self.uid2user:
317 | break
318 | user = User(username, self)
319 | self.uid2user[username] = user
320 | return username
321 |
322 | def get_user_with_uid(self, userid):
323 | if userid not in self.uid2user:
324 | self.uid2user[userid] = User(userid, self)
325 | return self.uid2user[userid]
326 |
327 | def join_room(self, username, roomid):
328 | user = self.get_user_with_uid(username)
329 | if roomid not in self.id2room:
330 | self.id2room[roomid] = GameRoom(roomid)
331 | if user.game_room != self.id2room[roomid]:
332 | user.join_room(self.id2room[roomid])
333 |
334 | def get_room_info_with_user(self, username):
335 | room_info = {'status': 0, 'roomid': -1}
336 | user = self.get_user_with_uid(username)
337 | if user.game_room:
338 |
339 | room_info['status'] = user.game_room.get_status()
340 | room_info['roomid'] = user.game_room.room_id
341 | room_info['room'] = user.game_room
342 | room_info['users_uid'] = []
343 | room_info['play_users_uid'] = []
344 | room_info['users'] = []
345 | room_info['play_users'] = []
346 | for user in user.game_room.users:
347 | room_info['users_uid'].append(user.uid)
348 | room_info['users'].append(user)
349 | for user in user.game_room.play_users:
350 | room_info['play_users_uid'].append(user.uid)
351 | room_info['play_users'].append(user)
352 | return room_info
353 |
354 | def get_room_with_user(self, username):
355 | user = self.get_user_with_uid(username)
356 | if user.game_room:
357 | return user.game_room
358 | return None
359 |
360 | def join_game(self, username, user_role):
361 | user = self.get_user_with_uid(username)
362 | return user.join_game(user_role)
363 |
364 | def game_action(self, username, actionid, arg_pack):
365 | user = self.get_user_with_uid(username)
366 | if user.game_room:
367 | return user.game_room.action(user, actionid, arg_pack)
368 | else:
369 | return ActionResult(-1, "Not in any room")
370 |
371 | def logout(self, username):
372 | user = self.get_user_with_uid(username)
373 | if user.game_room:
374 | user.game_room.leave_room(user)
375 | self.uid2user.pop(username)
376 |
--------------------------------------------------------------------------------
/evaluate/README.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | # 使用指南
4 | ```
5 | cd AlphaPig/evaluate
6 | python ChessServer.py # 将会在本机11111端口启动对弈服务,浏览器打开localhost:11111即可
7 | ```
8 |
9 | # 与AI对弈
10 |
11 | 1.
12 | ```
13 | # AlphaPig/evaluate 目录下
14 | python ChessClient.py --model XXX.model --cur_role 1/2 --room_name ROOM_NAME --server_url 127.0.0.1:8888
15 | ```
16 | --cur_role 1是黑手,2是白手; —room_name是对弈的房间号码,server_url 是对弈服务器的地址(默认是本机喽)
17 |
18 | 如果是两个AI对弈,则双方出了--cur_role之外,都敲入相同的参数。如果是AI与人,则谁先进去先有优先选择权。
19 |
20 | # 人人对弈
21 |
22 | 直接打开浏览器,约定房间,没什么好说的。
--------------------------------------------------------------------------------
/evaluate/ai_listen_ucloud.bat:
--------------------------------------------------------------------------------
1 | c:\Python27\python.exe AICollection.py --server_url http://120.132.59.147:11111
--------------------------------------------------------------------------------
/evaluate/logs/error.log:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anxingle/AlphaPig/16257003c6fa33d3583b8d43919f4ec944f8b5bb/evaluate/logs/error.log
--------------------------------------------------------------------------------
/evaluate/logs/info.log:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anxingle/AlphaPig/16257003c6fa33d3583b8d43919f4ec944f8b5bb/evaluate/logs/info.log
--------------------------------------------------------------------------------
/evaluate/page/chessboard.html:
--------------------------------------------------------------------------------
1 |
2 | {% from Hall import GameRoom %}
3 |
4 |
5 |
6 | | 147 | {% elif chess_board.get_piece(i, j)==1 %} 148 | | 149 | {% if i== chess_board.get_lastmove()[-2] and j== chess_board.get_lastmove()[-1]%} 150 | Last 151 | {% end %} 152 | | 153 | {% elif chess_board.get_piece(i , j)==2 %} 154 |155 | {% if i== chess_board.get_lastmove()[-2] and j== chess_board.get_lastmove()[-1]%} 156 | Last 157 | {% end %} 158 | | 159 | {% else %} 160 | not legal {{chess_board.get_piece(i , j)}} 161 | {% end%} 162 | {% end%} 163 |