├── .DS_Store
├── .env_example
├── .gitignore
├── Dockerfile
├── LICENSE
├── README.md
├── app.py
├── assets
├── .DS_Store
├── current_rewards.png
├── historical_performance.png
├── historical_performance_2.png
└── logo.png
├── bootstrap_run.py
├── config.json
├── data
└── optimizer_log.json
├── docs
├── .DS_Store
├── 1. General.md
├── 2. Quickstart.md
├── 3. Usage and Parameters.md
├── 4. Indexing Rewards.md
├── 5. Architecture.md
├── 6. Developer.md
├── 7. Caution.md
├── 8. Changelog.md
├── 9. Roadmap.md
└── index.md
├── main.py
├── requirements.txt
├── script.txt
├── script_never.txt
└── src
├── __init__.py
├── alerting.py
├── automatic_allocation.py
├── fetch_allocations.py
├── filter_events.py
├── helpers.py
├── optimizer.py
├── performance_tracking.py
├── poi.py
├── queries.py
├── script_creation.py
├── subgraph_health_checks.py
├── webapp
├── __init__.py
├── about.py
├── display_optimizer.py
├── key_metrics.py
├── overview.py
└── sidebar.py
└── wip_caching.py
/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/.DS_Store
--------------------------------------------------------------------------------
/.env_example:
--------------------------------------------------------------------------------
1 | # RPC Connection
2 | RPC_URL = 'https://api.anyblock.tools/ethereum/ethereum/mainnet/rpc/XXXX-XXXX-XXXX-XXXX/'
3 |
4 | RPC_URL_TESTNET = 'https://api.anyblock.tools/ethereum/ethereum/rinkeby/rpc/XXXX-XXXX-XXXX-XXXX-XXXX/'
5 | # Mainnet Subgraph The Graph
6 | API_GATEWAY = "https://api.thegraph.com/subgraphs/name/graphprotocol/graph-network-mainnet"
7 | TESTNET_GATEWAY = "https://gateway.testnet.thegraph.com/network"
8 | # https://api.thegraph.com/subgraphs/name/graphprotocol/graph-network-mainnet -> Mainnet
9 | # https://gateway.network.thegraph.com/network
10 |
11 | # postgres credentials
12 | HOST="localhost"
13 | PORT=45432
14 | DATABASE="thegraph"
15 | DATABASE_USER="postgres"
16 | PASSWORD="YOUR POSTGRES PASSWORD"
17 |
18 |
19 | # REWARD_MANAGER AND CONTRACT
20 | REWARD_MANAGER = "0x9Ac758AB77733b4150A901ebd659cbF8cB93ED66"
21 |
22 | # Contract for Allocations
23 | ALLOCATION_MANAGER_MAINNET = "0xf55041e37e12cd407ad00ce2910b8269b01263b9"
24 | ALLOCATION_MANAGER_TESTNET = "0x2d44C0e097F6cD0f514edAC633d82E01280B4A5c"
25 |
26 | # Anyblock Analytics Indexer
27 | ANYBLOCK_ANALYTICS_ID = "0x453b5e165cf98ff60167ccd3560ebf8d436ca86c"
28 |
29 | # slack integration
30 | SLACK_WEBHOOK_URL = 'WEB HOOK'
31 | SLACK_CHANNEL = "#alerting"
32 |
33 | # Indexer Agent Management Endpoint
34 | INDEXER_MANAGEMENT_ENDPOINT = "http://127.0.0.1:18000/"
35 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | pip-wheel-metadata/
24 | share/python-wheels/
25 | *.egg-info/
26 | .installed.cfg
27 | *.egg
28 | MANIFEST
29 |
30 | # PyInstaller
31 | # Usually these files are written by a python script from a template
32 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
33 | *.manifest
34 | *.spec
35 |
36 | # Installer logs
37 | pip-log.txt
38 | pip-delete-this-directory.txt
39 |
40 | # Unit test / coverage reports
41 | htmlcov/
42 | .tox/
43 | .nox/
44 | .coverage
45 | .coverage.*
46 | .cache
47 | nosetests.xml
48 | coverage.xml
49 | *.cover
50 | *.py,cover
51 | .hypothesis/
52 | .pytest_cache/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | local_settings.py
60 | db.sqlite3
61 | db.sqlite3-journal
62 |
63 | # Flask stuff:
64 | instance/
65 | .webassets-cache
66 |
67 | # Scrapy stuff:
68 | .scrapy
69 |
70 | # Sphinx documentation
71 | docs/_build/
72 |
73 | # PyBuilder
74 | target/
75 |
76 | # Jupyter Notebook
77 | .ipynb_checkpoints
78 |
79 | # IPython
80 | profile_default/
81 | ipython_config.py
82 |
83 | # pyenv
84 | .python-version
85 |
86 | # pipenv
87 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
88 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
89 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
90 | # install all needed dependencies.
91 | #Pipfile.lock
92 |
93 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
94 | __pypackages__/
95 |
96 | # Celery stuff
97 | celerybeat-schedule
98 | celerybeat.pid
99 |
100 | # SageMath parsed files
101 | *.sage.py
102 |
103 | # Environments
104 | .env
105 | .venv
106 | env/
107 | venv/
108 | ENV/
109 | env.bak/
110 | venv.bak/
111 |
112 | # Spyder project settings
113 | .spyderproject
114 | .spyproject
115 |
116 | # Rope project settings
117 | .ropeproject
118 |
119 | # mkdocs documentation
120 | /site
121 |
122 | # mypy
123 | .mypy_cache/
124 | .dmypy.json
125 | dmypy.json
126 |
127 | # Pyre type checker
128 | .pyre/
129 |
130 | # data logs
131 | archive/
132 | .idea/
--------------------------------------------------------------------------------
/Dockerfile:
--------------------------------------------------------------------------------
1 | FROM python:3.8-bullseye
2 | RUN apt update && apt-get install -y glpk-utils libglpk-dev glpk-doc python3-swiglpk
3 |
4 | RUN mkdir /src
5 | WORKDIR /src
6 |
7 | COPY requirements.txt /src
8 | RUN pip install -r requirements.txt
9 |
10 | COPY . /src
11 | COPY .env .env
12 | #ENV RPC_URL https://api.anyblock.tools/ethereum/ethereum/mainnet/rpc/XXXX-XXXXX-XXXX/
13 |
14 | ENTRYPOINT ["python","main.py"]
15 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # The Graph Allocation Optimization
2 | **[-> Navigate to the Documentation](https://enderym.github.io/allocation-optimization-doc/)**
3 |
4 | ## ⚠️ Automatic Allocations
5 |
6 | The possibility of running the allocation script automatically is now pushed to the main repository.
7 | But **be careful**, there are still many **edge cases** where the script doesn't work like desired.
8 | Allocations to broken subgraph leads to problems in the automatic deallocation. If broken allocations
9 | are created, you have to manually close these allocations with a 0x0 POI. See [The Graph Academy - Manually Closing Allocations](https://docs.thegraph.academy/technical-documentation/tips-and-tricks/manuallyclosingallocationsforfailedsubgraphs).
10 |
11 | It is recommended to use the semi-automated way of using the tooling. So for the cli tool set the flag --automation to false
12 | (default false). And in the dropdown in the web application set the automation to false.
13 |
14 | ## General
15 |
16 | Allocations are a very important tool for indexers. Depending on the amount of allocations and the distribution
17 | of allocations on different subgraphs the indexing reward is calculated. Of course, this could be done manually -
18 | or a rule for the distribution of the stake could be set in advance. However, this might lead to not getting the
19 | optimum indexing reward.
20 |
21 | Therefore, we developed a tool (contributions appreciated) that calculates the optimal allocation distribution using
22 | optimization algorithms. For this purpose, the relevant variables in the indexing reward formula are
23 | queried using the meta subgraph, these are transferred to a linear optimization model and the model
24 | calculates the optimal distribution of the allocations on the different subgraphs.
25 |
26 | The tool creates an allocation script (**script.txt**) that can be used to change the allocations. It is possible
27 | to supply different parameters such as **indexer address** , **parallel allocations**, **threshold**, **maximal
28 | allocation in % per Subgraph**. The thresholds can be set as the minimum percentage increase of the indexing rewards and
29 | also taking into account the transaction costs for reallocations.
30 |
31 | The **goal** is to provide TheGraph indexers a tool to gain the highest possible return of indexing rewards
32 | from their invested stake and to react to changes in the ecosystem in an automated way. The optimization process
33 | takes every allocation and distribution of allocations and signals into consideration.
34 | After every successful optimization the results for the next optimization will differ from the previous one.
35 | It is an **ever changing process of optimization** because the relevant variables for the formula change.
36 | Therefore everyone who would use our allocation optimization script would benefit from it.
37 | Manually keeping track of changing circumstances in the ecosystem and distribution would be too time consuming.
38 |
39 | ## Transparency, Caution and Risk
40 |
41 | We are aware that this optimization significantly interferes with the revenues of the respective indexers.
42 | This requires a lot of trust. From our side, it is therefore extremely important to bring forth a transparent approach
43 | to optimization. Still using this script is at your own risk. ALWAYS check the results of the optimization and check
44 | the **script.txt** if it is suitable for your use-case and setup.
45 |
46 | Following the script and how it is working will be explained in detail. We purposely created the script in a semi-automatic way, where the results of the optimization
47 | process are logged and human intervention is necessary for deploying the changes.
48 | In future updates we would like to extend the scope to an automatic optimization script and deploy a hosted version
49 | with visualizations (contributions appreciated).
50 |
51 | ## Feedback
52 |
53 | To improve the tool, we look forward to your feedback. We would like to know which additional parameters would be relevant for you to tailor the optimization process more to the individual indexer. Furthermore, we would be interested to know which additional metrics you would like to see to track the performance of the indexer.
54 | ## Anyblock Analytics and Contact
55 | Check out [anyblockanalytics.com](https://anyblockanalytics.com/). We started participating in TheGraph ecosystem in the incentivized testnet as both indexers and curators and are Mainnet indexers from the start. Besides professionally running blockchain infrastructure for rpc and data, we can provide benefits through our data analytics and visualization expertise as well as ecosystem tool building.
56 |
57 | **Contact:**
58 |
59 | Discord: yarkin#5659
60 | E-Mail: [yarkin@anyblockanalytics.com](mailto:yarkin@anyblockanalytics.com)
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | from src.webapp.overview import streamlitEntry
2 | import pyutilib.subprocess.GlobalData
3 |
4 | if __name__ == '__main__':
5 |
6 | pyutilib.subprocess.GlobalData.DEFINE_SIGNAL_HANDLERS_DEFAULT = False
7 | streamlitEntry()
--------------------------------------------------------------------------------
/assets/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/assets/.DS_Store
--------------------------------------------------------------------------------
/assets/current_rewards.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/assets/current_rewards.png
--------------------------------------------------------------------------------
/assets/historical_performance.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/assets/historical_performance.png
--------------------------------------------------------------------------------
/assets/historical_performance_2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/assets/historical_performance_2.png
--------------------------------------------------------------------------------
/assets/logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/assets/logo.png
--------------------------------------------------------------------------------
/bootstrap_run.py:
--------------------------------------------------------------------------------
1 | from streamlit import bootstrap
2 |
3 | real_script = 'app.py'
4 |
5 | bootstrap.run(real_script, f'run.py {real_script}', [], {})
--------------------------------------------------------------------------------
/config.json:
--------------------------------------------------------------------------------
1 | {
2 | "blacklist": [
3 | "QmUGRJSXZ3r6WSVUauwxjJm8ELEFDRRUszsNSVcimmBKUq",
4 | "Qmbp3yDXBKu7R8UZUx4PGo851Yr2fxckcj4yrDxEeZsxNK",
5 | "Qmbp3yDXBKu7R8UZUx4PGo851Yr2fxckcj4yrDxEeZsxNL",
6 | "QmTKsqg2wUwsuGkeEnyKY1iPMdyaMXDhtCgtHeAxAe4X9r",
7 | "QmdRQFrYxdiZsQAQgUPQgHBvFM7kqn9JPhTQ7pXugmVRyk",
8 | "Qmdpkd8yvD4XR3mQMZQmY5nqBQtjEac8gb8RoFFcWan7xE",
9 | "QmdMiyqe4jswZcTRqUS26U4U232tjvkkGLr4cx2ZXPaeR9",
10 | "QmTg2ALR2tkJrCwTrzqkGUMtC2ikWJv1r7wQmBZEv68Rdp",
11 | "QmS7VGsn5s8UTMrebMRVNub2qCBYK19Qvg4dGNdTqsHX4k",
12 | "QmPTvxu2JquArtLUvhuqMuPzBQMP9zzRBQ1X1Rm32Y3rFu",
13 | "QmVW6RHBa6kTYkUPhTXrQt2HCgbjZfdWLJwWFZrsAqNdhN",
14 | "QmUJwidYPoTfbyrx1YUgp3VzjCaSkWCrptKch2sJypEA4o",
15 | "QmRhYzT8HEZ9LziQhP6JfNfd4co9A7muUYQhPMJsMUojSF",
16 | "Qmaz1R8vcv9v3gUfksqiS9JUz7K9G8S5By3JYn8kTiiP5K",
17 | "QmVEV7RA2U6BJT9Ssjxcfyrk4YQUnVqSRNX4TvYagjzh9h",
18 | "Qmav8jkmAeKBLyxmngJVwprN3ZsJA9A57jeoikdCU2Dyrv",
19 | "QmQuaHpLbA7m9EWU1GDDVM2RVGNrHwpbXkZVdUFBtdCZnv",
20 | "QmSVcqmXU7iYqZv9pu3uH3hUyLP6EtMutoMdiVEUv6HTmk",
21 | "QmbvTyvmxqHLahZwS7fZtVWGM85VCpCiKHiagPxQJp5ktS",
22 | "QmUS5rLubxakXFqLgorg9pWN557Cn1AvT2Jw2vb3PXZQ4L",
23 | "QmekqcLE25A51MTpWyWhYqy5vRL25KmZVNRfMCkrStQh8k",
24 | "QmSGQsLs7Tpm4hGWULFcjVc7suYzZrtLz1M5nGq2SjT1kb",
25 | "QmfRKox2Ha3c2rqWJMehL9vrAJC6k2RjtyM85241p5G1om",
26 | "QmZLFFChgZu6j4q8twaJn8xF74WgGgZ1WKEG6Cigesr49R",
27 | "QmfWvW1C8EKFGMhe1cDh8jErpFepdarvDXAzBV3hyYK3yu",
28 | "QmSQq9XVP9MzZPtvwuzidKLYwWRyt1QhvfrfxY4Kzde6B5",
29 | "QmXMVgNEJ32tKU8S8F51YSyKTLxB9wZZWc8d878JQg5evZ",
30 | "QmQnYvyMHph78WzySWZ6DrFQQfQoxDyFx3y9b5bbb3FdjZ",
31 | "QmPVD4r9qA5yN6RyFeDHPoiwWm9wEYoHMDQfYvVLTaCnuE",
32 | "QmdoCBPnZJHEWdn3KhQ3tTRJyARpZcaehMjnEdW3Ef8XQh",
33 | "QmV54DSadWFb2nEkLzSFpsw9PVEfjJcJ8da2gmUpP8MPDM",
34 | "QmQCnh9hGhTHcamNgHiHtpG6gGS2MihqqeKStwKiCDP4cq",
35 | "QmWXF3jTLo6Wy9MxDZz6WKhET3GFcSFqn6vmrDDYPF7UHK",
36 | "QmQZ23e5ECyQuqPYWW5TLPvNTPJd4iuz3TYZyMUTZ2kdNN",
37 | "QmNRkaVUwUQAwPwWgdQHYvw53A5gh3CP3giWnWQZdA2BTE",
38 | "QmP7ZmWYHN9CTVZyEQ6zu1kuaJgi2AreAw3zFRjbgA5oMS",
39 | "QmPMorokG4bY5i3Ae1dht14dGFBUh1RixE4AkfSPzFsV6E",
40 | "QmPVjCWWZeaN7Mw5P6GEhbGixFbv8XKvqTa1oTv7RQsosM",
41 | "QmQEGuJtXiwWni2bsmDDPPor9U1nfQ8s2kbQ6XYCwNjojG",
42 | "QmQj3DDJzo9mS9m7bHriw8XdnU3od65HSThebeeDBQiujP",
43 | "QmRDGLp6BHwiH9HAE2NYEE3f7LrKuRqziHBv76trT4etgU",
44 | "QmTBxvMF6YnbT1eYeRx9XQpH4WvxTV53vdptCCZFiZSprg",
45 | "QmTKXLEdMD6Vq7Nwxo8XAfnHpG6H1TzL1AGwiqLpoae3Pb",
46 | "QmTj6fHgHjuKKm43YL3Sm2hMvMci4AkFzx22Mdo9W3dyn8",
47 | "QmTkM4Gxh7wctYdwvdicnRt6oP2V62b5FGGMEDupbWcb4k",
48 | "QmUVskWrz1ZiQZ76AtyhcfFDEH1ELnRpoyEhVL8p6NFTbR",
49 | "QmUqXdxB5f9f6EuDPYcSEASCwUCQTBMU1LbsVntuQjamkc",
50 | "QmUxkM4kkYDyVEcUcBGWrvhj5Y6f2uvUTkPTmPjtm76A6k",
51 | "QmUymJWopFUdPtYF6C5BSXhJWFGG9SbNqw5X9ZrYbGgSJu",
52 | "QmVTUfdp5sJR4uNLq8jM1zR6TLyepejz9gd38YpNT9We5Q",
53 | "QmVUGoP6yjUxf5NnXtKxVQuuNh2dAxepuRiUuCQHQ9a3jy",
54 | "QmWiFjHuEzoKk6GkgUWvUHo6bCwqAZwYWPAw6VyG5vtTwQ",
55 | "QmXAiVUP6EM6bVBwf7Nc2c3kSdDXvEuGBfgZgiw69H6SvB",
56 | "QmayKScii7cuLXSCZ3tdLk5Af7gEksk5wVKUgx4tciem4n",
57 | "QmNN3mAoPhkdS7Jiw4pivSMwAkcXEdxZU2rpzEVTdH5Cs3",
58 | "QmWkVS3Uzr2WsTwvxtte2dpHbSYJSQ1bTQMVciKXCWx7TM",
59 | "QmS8Tx83667tCDMYbDCSb5kK9K2cpTN2wctHqhY82z58N9",
60 | "QmTe4t3FL3ckKFbog1izTpr8ArpMfvjamX39aTvHd66dah",
61 | "QmVmJGqzEfEHYhBZ72LvS7KPn8JzHJnYW2nbQrYohe2D33",
62 | "QmdQdeuADAMpDgHkNRuGiAxBUY2fQzgRqVUNNMfstWYZ6A",
63 | "QmaYPKeVVF3DwHxSUEXGiBddgEmzJQtxEZq9NiZE2fPpYV",
64 | "QmR7d6jqCPRfNSBmZ4RcSdhrfFy2sA4uFF72HgDee7an4J",
65 | "QmSqu5Cn6thejvPsxh46hQEw5nW9jghXeXAveywFssxCZk",
66 | "QmPw3hDdAJCVDCuwWux1ToXNRVpPoVhz1Q2ikvHvUAmDEJ",
67 | "QmaRDMxDnp9xD2Y4jJ8KFaRePp5XwEVMJxfAnaQskDCVj5",
68 | "QmRXM4nxShREiqpM6QawikzWsvhGvAnu3vYmssrmVhnMLX",
69 | "QmRPXbekeTX85rbq1uhYnsrwn7BEYziceXnVQWsLSMVu1F",
70 | "Qmc6NtwtBvmjkFSpsCis8y4d8nHZd4AJGV9aFSDMLCM3aS",
71 | "QmZe1xZKXWMgy1EHAK8JqCdeBsqejJwv2GTpFmTSo4zxgg",
72 | "QmRU76bKXzrbeuFxgwMbmDxYYAxei1nFFqgex7oFTT6jLZ",
73 | "QmTpbn6BN7fMMY6aPWPDpWHQxoQqSqLDiRnNXZ6TzfB98s",
74 | "QmQPVzjjSQEHxBQQNkFvwRqXjMiLhCcW83yTHNBazwfFE6",
75 | "QmRPqFKeY2vw2yBtRCgfauYmWLUkHyzHvF17bTjk2F7AQb",
76 | "QmUMcV3ZdMPGCNSw6ziYMcbWTTZh7QbmwiBQBtDoeErnaP",
77 | "QmSbWGuJ1EVSWpxAHaMTcE2gsGPfENquW6bg5RX15gsSF2",
78 | "QmWGidPnL6rBWo9n5oiytPsrChem8cctGq94gmBFDhLCGT",
79 | "QmYDo65mggNh7hNJPKAj8oyMK5oULgSajan3g4kRpmhh8S",
80 | "QmXrqdNWNFF7cJuMBnC6obkd3rELYCnKjeCzMyAfT1F7Zo",
81 | "QmWjRzTz4bYfJu6id5wLpak6YNAPnNnPJPMXSjhKiNHEeR",
82 | "Qmf5Q122JKgVUTXy3k9SdiMb5evPXUYPyUY2L5dLWWErn1",
83 | "QmbXjoeTBmDtgE5mWkMvTFn3z3gUTXGyqJWFEPnnEauh9k",
84 | "QmfMUU8ibGjog5wN7Wj96onxnuGhXs4urGsypzvjpgYcEW",
85 | "QmVrt9czq9j5i9iVrhvBFBdoArpWTXfjPV5KmJFiCUgpzH",
86 | "Qmcw4PifJggPBf9aGgWM957JZKpvoSckKgG3KbPP4xRKqT",
87 | "QmRhWefdtpPvehVyoLiTJHKeXjHbFmEJEbUBRReSt6EJhs",
88 | "QmU5jhcfrZsCWUwmPXsu6pVm62FKomLdJY5DGJyuFdDBJA",
89 | "QmeC6UZBxeq763PHR8gz6SZ1AToihyBRimNakuHAA9EMR8",
90 | "QmQEwyRhWKDCwV9wjRmCZ7ZXi5t9CtFdGVFCseMjWZRZXZ",
91 | "QmQjugeao4BP1NLEHnbgmJhip2UvoP1s2v3k45fViFjov6",
92 | "QmZpw79TAU2kBvb9P7TyaUmSjmsJ9fB4niMmVPnvQR52yo",
93 | "QmbpWnZVhbrcKe6FK12WnTQDGukUfohT4CgphJz8scSZBb",
94 | "QmYr7USMvpFxo7Vfkpnn8b3efYThSo5TcQkxCQjg888PBN",
95 | "QmSXDWQU4RhVwV1Yar9aQBC6sQvvpeAhiRBpuXy74DhSAv",
96 | "QmNdE1V1p9CNjK38Xs4nJUBQyvuQu2aZvxm7oyFioWrM9u",
97 | "QmNmzGSbhdxK9hyyarCDVV8eruAmT6kDkbQjomXn754qYQ",
98 | "QmNxaCqSfQCLRc4yWFTUCvzau2xG4dupfBJyVeysa3YaMg",
99 | "QmNyMvCsBstsri11dbC2kTcQSVBQJp5kqx9x3fzihyWPg7",
100 | "QmPodrZddjiX2BPPJv4siS9WPwbPDBhkHRDwz8FDGneQwZ",
101 | "QmQ44hgrWWt3Qf2X9XEX2fPyTbmQbChxwNm5c1t4mhKpGt",
102 | "QmQuaHpLbA7m9EWU1GDDVM2RVGNrHwpbXkZVdUFBtdCZnR",
103 | "QmR2rVWWY9xtSjuqLXbBUMvM71ZjBcDRoWUdBwL9F7DQ6t",
104 | "QmRgUHGMdg1mYhSDwJxDx4kQkE9dKt3Aueq9qk9UvVDtvx",
105 | "QmRz7PPku8vkWQCTJtisuBqQmsA68UdNujLjMcrN9aJSWk",
106 | "QmSZhMW1K9RZiswgbgxfu1QQZqj4KaGS9kzUqPiDUaSHuh",
107 | "QmSnGrtWuT4FVghKMcc5TemLgJSjH8TDCMKyedCsaXjDea",
108 | "QmNiU5YXnQk7ghyWfbqDrKG8ZH5b8ji389YYxhJCjYgeHu",
109 | "QmQQeCUjemEf6urSR5SUvvdRTn9ZXdctHwuxjPJoFJD6wR",
110 | "QmSqAS1zCsMgadZqXRwmAxMenz3erHMyK3eg4oP7QeyHXQ",
111 | "QmPTV3wHaqKKZ7GNRY7Y96nzV7hYdWmZVVANfVdzDeFvpk",
112 | "QmShykYBEhKUbZQSLdHZ3BGoMCL5aYtEVDYEz7NNLKy2dG",
113 | "QmRhLoEVF13KDzyWg9rmnHygBMcV6j9KotyMoFa6rugTgg",
114 | "QmP9a8FEBkkt5SCvcRyv35denC2RFSfWGoL2tgoo8LHpPy",
115 | "QmRab8e3AH4qteCS1qRA2vTirkkT56aGHaEmp3Vn7kiMuy",
116 | "QmPdLuKdpsW1WyrmRejX8dQPjVJJuMX74q5NpaNdpBJ7Fz",
117 | "QmPdejzo2ENKgPxBFUh6KJ66YVFnYxmmxXpZpMoAzyL2dY",
118 | "QmQXc8NHJ9ZbFkWBBJLiQtLuHBaVZtqaBy2cvm7VchULAM",
119 | "QmRHqzzP2VRcyKEpU7dertyAr5czZTFgbGkyAUa6H6duou",
120 | "QmRLE9ueEaDvBD57qsgUBANmyXwd7f8cybj8oTcVWC4KGb",
121 | "QmU3NicVe14LzQ3hNhyLQ1JCZu8uRyRjKejj1iD7oAKge1",
122 | "QmUddzLVFA3FDum6Xx9WPfgAqnBPbMM4q5r4WbUiu2T1F8",
123 | "QmVxQc55PE3NFeHLdrG2RuNp5wZstk4VaFaVyvjYekb15Y",
124 | "QmNrQtsd2PMn5EM8i1xHK2vskCvGPZiAHFGQQjupiEv2C1",
125 | "QmfWjxaEaaLDVpZssqXEX3aHvLMiWdxxwbS4n1Vc658q1M"
126 | ],
127 | "blacklisted_devs": [
128 | "0x03c65e533cc73cc65cd71a0cb65efa4b11e74c22"
129 | ],
130 | "indexed_subgraphs": [
131 | "QmNRkaVUwUQAwPwWgdQHYvw53A5gh3CP3giWnWQZdA2BTE",
132 | "QmRDGLp6BHwiH9HAE2NYEE3f7LrKuRqziHBv76trT4etgU",
133 | "QmRhYzT8HEZ9LziQhP6JfNfd4co9A7muUYQhPMJsMUojSF",
134 | "QmTKXLEdMD6Vq7Nwxo8XAfnHpG6H1TzL1AGwiqLpoae3Pb",
135 | "QmUghXvKf5cVjtayNNRHCd3RbHEwfbGBQ95s9vheJjN5hH",
136 | "QmVEV7RA2U6BJT9Ssjxcfyrk4YQUnVqSRNX4TvYagjzh9h",
137 | "QmZdsSbRwVD7VVVm5WGxZZC6HYvbjnFb4hcwvQ4fTs5bxA",
138 | "Qmaz1R8vcv9v3gUfksqiS9JUz7K9G8S5By3JYn8kTiiP5K",
139 | "QmbHg6vAJRD9ZWz5GTP9oMrfDyetnGTr5KWJBYAq59fm1W",
140 | "QmTBxvMF6YnbT1eYeRx9XQpH4WvxTV53vdptCCZFiZSprg",
141 | "Qmav8jkmAeKBLyxmngJVwprN3ZsJA9A57jeoikdCU2Dyrv",
142 | "QmTj6fHgHjuKKm43YL3Sm2hMvMci4AkFzx22Mdo9W3dyn8",
143 | "QmbYFfUKETrUwTQ7z8VD87KFoYJps8TGsSbM6m8bi6TaKG",
144 | "Qmf3qbX2SF58ifUQfMvWJKe99g9DavSKtRxm3evvCHocwS",
145 | "QmRhh7rFt3qxfRMTZvHRNK6jCobX4Gx5TkzWXhZkuj57w8"
146 | ],
147 | "nan_subgraphs": [
148 | "Qmf3qbX2SF58ifUQfMvWJKe99g9DavSKtRxm3evvCHocwS",
149 | "QmbHg6vAJRD9ZWz5GTP9oMrfDyetnGTr5KWJBYAq59fm1W",
150 | "QmTBxvMF6YnbT1eYeRx9XQpH4WvxTV53vdptCCZFiZSprg"
151 | ]
152 | }
--------------------------------------------------------------------------------
/docs/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/docs/.DS_Store
--------------------------------------------------------------------------------
/docs/1. General.md:
--------------------------------------------------------------------------------
1 | # General 🌝
2 | First of all, check out [[7. Caution]]. Check out the [[2. Quickstart]] Guide on how to get started with this application. The [[2. Quickstart#💫 Installation]] provides you with the necessary information to install this project on mac os or linux. In [[Usage and Parameters]] all relevant and optional parameters and use-cases are explained.
3 |
4 | Also feel free to check out the demo screencast of the [web application](https://i.imgur.com/3uLj7gv.gif) and the [CLI screencast](https://i.imgur.com/gGHVDyQ.gif).
5 |
6 | [[8. Changelog]] provides changes, enhancments and bug fixes for each released version. Navigate to the [[9. Roadmap]] to check out what is being worked on and what is yet to come.
7 |
8 | Do you want to get further insights into the indexing reward calcuation? Navigate to [[4. Indexing Rewards]]. [[6. Developer]] and [[5. Architecture]] show resources to better understand and contribute to the development and improve the tool.
9 | ## Impact and Goal
10 |
11 | Allocations are a very important tool for indexers. Depending on the amount of allocations and the distribution of allocations on different subgraphs the indexing reward is calculated. Of course, this could be done manually - or a rule for the distribution of the stake could be set in advance. However, this might lead to not getting the optimal indexing reward.
12 |
13 | Therefore, we developed a tool (contributions appreciated) that **calculates the optimal allocation distribution using optimization algorithms**. For this purpose, the relevant variables in the indexing reward formula are queried using the meta subgraph, these are transferred to a linear optimization model and the model calculates the optimal distribution of the allocations on the different subgraphs.
14 |
15 | The tool creates an allocation script (**script.txt**) that can be used to change the allocations. It is possible to supply different parameters such as **indexer address** , **parallel allocations**, **threshold**, **maximal allocation in % per Subgraph**. The thresholds can be set as the minimum percentage increase of the indexing rewards and also taking into account the transaction costs for reallocations.
16 |
17 | The **goal** is to provide TheGraph indexers a tool to gain the highest possible return of indexing rewards from their invested stake and to react to changes in the ecosystem in an automated way. The optimization process takes every allocation and distribution of allocations and signals into consideration. After every successful optimization the results for the next optimization will differ from the previous one. It is an **ever changing process of optimization** because the relevant variables for the formula change. Therefore everyone who would use our allocation optimization script would benefit from it. Manually keeping track of changing circumstances in the ecosystem and distribution would be too time consuming.
18 |
19 | The goal is to provide indexers with automation and value in the allocation process without having to worry much about the allocation distribution and indexing reward formula.
20 |
21 | This would simplify the work and optimize the outcome of one aspect of being in indexer, making this role more accessible and attractive, therefore helping to decentralize this part of the ecosystem even more. All participants would benefit, as their costs decrease / profits would increase and they would be relieved of the work of manual allocation.
22 |
23 | As an additional benefit for the ecosystem, the optimized allocation distribution in the subgraphs improves. The ecosystem would benefit because an optimal distribution would not give a few subgraphs the most allocations (the best known or largest projects), but the indexing rewards formula can also make it worthwhile to allocate to smaller subgraphs, which is time-consuming to calculate manually.
24 |
25 | ## Feedback
26 |
27 | To improve the tool, we look forward to your feedback. We would like to know which additional parameters would be relevant for you to tailor the optimization process more to the individual indexer. Furthermore, we would be interested to know which additional metrics you would like to see to track the performance of the indexer.
28 | ## Anyblock Analytics and Contact
29 | Check out [anyblockanalytics.com](https://anyblockanalytics.com/). We started participating in TheGraph ecosystem in the incentivized testnet as both indexers and curators and are Mainnet indexers from the start. Besides professionally running blockchain infrastructure for rpc and data, we can provide benefits through our data analytics and visualization expertise as well as ecosystem tool building.
30 |
31 | **Contact:**
32 |
33 | Discord: yarkin#5659
34 | E-Mail: [yarkin@anyblockanalytics.com](mailto:yarkin@anyblockanalytics.com)
--------------------------------------------------------------------------------
/docs/2. Quickstart.md:
--------------------------------------------------------------------------------
1 | # 🚀Quickstart
2 | There are different options to run the allocation optimization script. You can either run the optimization via a CLI script or with the **Streamlit Web Application**. If you are interested in a more visual presentation of the optimization process, it is recommended to use the streamlit web application.
3 |
4 | Currently a docker container is work in progress. This quickstart explains the **local installation** of the allocation script.
5 |
6 | **Demo Web Application:**
7 | ****
8 |
9 | **Demo CLI tool:**
10 | 
11 |
12 |
13 | ## 💫 Installation
14 |
15 |
16 | ### 🍏 Mac OS
17 |
18 | 1. Make sure to install [Homebrew](https://brew.sh/)
19 | 2. Install [GLPK](https://www.gnu.org/software/glpk/) (GNU Linear Programming Kit). It is a open source library used for large-scale linear programming, mixed integer programming and other mathematical problems.
20 |
21 | ```shell
22 | brew install glpk
23 | ```
24 |
25 | ### 🐧 Linux
26 | 1. Open a Terminal
27 | 2. Install [GLPK](https://www.gnu.org/software/glpk/) (GNU Linear Programming Kit). It is an open source library used for large-scale linear programming, mixed integer programming and other mathematical problems. It also requires some dependencies to be installed.
28 | ```shell
29 | sudo apt-get install glpk-utils libglpk-dev glpk-doc python-glpk
30 | ```
31 |
32 | ### General
33 | 1. If Python is not installed on your system yet, it is necessary to install it either directly via the command line or to [download](https://www.python.org/downloads/) the installation file from the web. Subsequently, it is necessary to install the Python package manager pip. Best, open a command line and execute the following command:
34 | ```shell
35 | python3 -m pip install --user --upgrade pip
36 | ```
37 | 2. Make sure python and pip is installed correctly.
38 |
39 | ```shell
40 | python ––version
41 | pip3 --version
42 | ```
43 | 3. It is always recommended to create new projects in virtual environments. This way the packages can be managed separately, you can create an isolated Python installation and you do not influence the system Python interpreter. Using virtual environments requires the installation of the “virtualenv” package (for further documentation, visit this [tutorial](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)).
44 | ```shell
45 | python3 -m pip install --user virtualenv
46 | ```
47 | 4. Clone the repository into the desired directory:
48 | ```shell
49 | git clone https://github.com/anyblockanalytics/thegraph-allocation-optimization.git
50 | ```
51 | 5. After creating the directory, we need to change to this folder and create a virtual environment.
52 |
53 | ```shell
54 | python3 -m venv env
55 | ```
56 | 6. And then the virtual environment can be activated
57 | ```shell
58 | source env/bin/activate
59 | ```
60 | 7. Now the requirments.txt file can be installed via pip
61 | ```shell
62 | pip install -r requirements.txt
63 | ```
64 | 8. Open the ```.env_example``` file and change the rpc key, postgres connection, slack alerting webhook (if a slack alerting is wanted) and the Indexer ID to your credentials. After changing the values, rename the file to ```.env```
65 | 9. Open the ```config.json```file. If you want to provide subgraphs to the blacklist manually, you can include the subgraphs or subgraph developers in this file.
66 | 10. Now everything should be installed. Start a terminal in the repository directory and run the script to check if everything works:
67 | ```shell
68 | python ./main.py --indexer_id 0x453b5e165cf98ff60167ccd3560ebf8d436ca86c --max_percentage 0.2 --threshold 20 --parallel_allocations 1 --no-subgraph-list --blacklist
69 | ```
70 | 11. Some Linux distros may require the following command:
71 | ```shell
72 | python3 ./main.py --indexer_id 0x453b5e165cf98ff60167ccd3560ebf8d436ca86c --max_percentage 0.2 --threshold 20 --parallel_allocations 1 --no-subgraph-list --blacklist
73 | ```
74 | 12. It is also possible to run the script on the The Graph Testnet:
75 | ```shell
76 | python ./main.py --indexer_id 0xbed8e8c97cf3accc3a9dfecc30700b49e30014f3 --max_percentage 0.2 --threshold 20 --parallel_allocations 1 --no-subgraph-list --network "testnet"
77 | ```
78 | 13. Start the streamlit server:
79 |
80 | ```shell
81 | streamlit run app.py
82 | ```
83 | 14. Open your web browser and navigate to ```http://localhost:8501/``` the streamlit web app should open.
84 |
85 | Navigate to [[Usage and Parameters]] for further configurations and explanation of all parameters.
86 |
87 | ### Docker
88 | You can create a docker container with the following command. But before building the docker container, be sure
89 | to change the .env_example file to .env example and add your RPC credentials.
90 |
91 | ````shell
92 | docker build -t allocation-optimization .
93 | ````
94 |
95 | Running the CLI Tool is possible with the command:
96 |
97 | ````shell
98 | docker container run allocation-optimization --indexer_id 0x453b5e165cf98ff60167ccd3560ebf8d436ca86c --max_percentage 0.2 --threshold 20 --parallel_allocations 1 --no-subgraph-list --app "script"
99 | ````
100 |
101 | The entrypoint of the docker container is "python", "main.py". Running the web app in the docker container can be achieved with:
102 | ````shell
103 | docker container run allocation-optimization --indexer_id 0x453b5e165cf98ff60167ccd3560ebf8d436ca86c --max_percentage 0.2 --threshold 20 --parallel_allocations 1 --no-subgraph-list --app "app"
104 | ````
--------------------------------------------------------------------------------
/docs/3. Usage and Parameters.md:
--------------------------------------------------------------------------------
1 | # Usage and Parameters
2 | In this part of the documentation the available parameters for the allocation optimization process are explained 💡 and use-cases are shown.
3 |
4 | The user of this allocation optimization script can adjust the allocation optimization process according to their wishes through some parameters. The following adjustments can be made:
5 |
6 | - A blacklist can be created. The subgraphs in the blacklist are not considered in the allocation process. The script creates a blacklist using various functions to avoid possible bot-bait subgraphs. The script can then blacklist specific subgraph developers, exclude subgraphs with error status or an outdated version, and blacklist subgraphs based on the sync status of the local indexer database.
7 |
8 | - A predefined subgraph list can be passed. Only these subgraphs should be considered in the allocation process and the stake should be distributed appropriately to these subgraphs.
9 |
10 | - Slack alerting can be integrated using webhooks. Each execution of the script creates an alert in a defined Slack channel if the threshold for a possible reallocation has been reached.
11 |
12 | - Threshold: With the threshold a percentage limit is determined. If this threshold is exceeded, a reallocation is appropriate and the tool creates a script.txt file containing the relevant commands for a reallocation.
13 |
14 | - And many more parameters which are described in the [[Usage and Parameters#Available Parameters]]
15 |
16 |
17 | The product to be built will allow for:
18 |
19 | - Visualization of the optimization process in a web app, which users can interact with to input various parameters such as the amount of stake to be allocated, maximum number of allocations, and maximum number of subgraphs on which to allocate, etc.
20 |
21 | - Visualization of the historic and current rewards from Indexing in the web app
22 |
23 | - Scheduling when such optimization processes should take place while automating the implementation of resulting suggestions.
24 |
25 |
26 |
27 | ## Available Parameters
28 | 1. **indexer_id** : It is necessary to supply the indexer address.
29 |
30 | 2. **max_percentage**: With max_percentage (a value between **0.0 - 1.0**) it is possible to set an upper limit in how much (percentage-wise) an allocation on one single subgraph can take. In the current status, the optimization often allocates the entire stake into one single subgraph (possibly this won't change, even when there are many subgraphs). The optimizations allocates the entire stake into one subgraph, because this (often) maximizes the indexing rewards. But sometimes it is not useful to allocate everything into one subgraph (risk diversification, ...). Therefore with max_percentage it is possible to limit the amount of stake one single subgraph can take. If it is set to 0.9, and you have a stake of 1.5M GRT, then the single subgraph can at most get 1.35M GRT allocated. The remainder is allocated to the next optimal subgraph, or is split among the rest. We at Anyblock like to diversify, so we set **max_percentage** to **0.2**
31 | 3. **threshold** : Set the threshold (in %) when an allocation script will be created. Takes a value between **0 - Infinity**. If your current **weekly** Indexing Rewards are 5000 and the threshold is set to **10**. The optimization has to atleast result in an increase of 10% in indexing rewards to create an allocation script. **BUT** the calculation of the threshold takes also the transaction costs into account. This means the indexing rewards have to be higher than 10% compared to the previous indexing rewards **AFTER** the transaction costs for the reallocation have been subtracted. Our **threshold** is **20**%.
32 | 5. **parallel_allocations**: Amoutn of parallel allocations (required for creating the script.txt file). Basically splits the allocation amount into subsets of the supplied parallel allocation amount. (SOON TO BE DEPRECIATED ⚠️)
33 | 6. **no-subgraph-list**: Disables the config.json, so no manual subgraph list is provided. (Default)
34 | 7. **subgraph-list**: utilizes the provided list in config.json as subgraphs that should be considered for the optimization.
35 | 8. **blacklist**: tells the script to ignore the blacklisted subgraphs in config.json. Also the blacklist will be created with the functions in **subgraphs_health_check.py**.
36 | 9. **threshold_interval:** Define the interval which is used for calculating the threshold requirment. Currently the recommended threshold interval is "weekly". Setting the threshold interval to weekly leads the optimization script to calculate threshold requirments based on weekly indexing rewards.
37 | 10. **reserve_stake:** Enables the indexer to define a dedicated amount of stake which should not be considered in the optimization. This reserve stake will not be allocated!
38 | 11. **min_allocation:** Set the minimum allocation in GRT per subgraph. If this value is above 0, every deployed subgraph will get the minimum allocation amount. **ATTENTION 🚨: Setting this value above 0 leads to massive increases in transaction costs**
39 | 12. **min_allocated_grt_subgraph:** Defines the minimum GRT allocation requirment for a subgraph to be considered in the optimization process. If a subgraph have less GRT allocated than the min_allocated_grt_subgraph, then it will not be considered in the optimization process.
40 | 13. **min_signalled_grt_subgraph:** Defines the minimum GRT signal requirment for a subgraph to be considered in the optimization process. If a subgraph have less GRT signalled than the min_signalled_grt_subgraph, then it will not be considered in the optimization process.
41 | 14. **slack_alerting:** Enables the user to configure a slack alerting in a dedicated slack channel. Outputs if the optimization reached the threshold and how much increase / decrease in rewards is expected after the optimization. Configure the webhook and channel in the **.env** file.
42 | 15. **network**: Select the network for the optimization run. Can either be set to "mainnet" (default) or "testnet".
43 |
44 | ## CLI - Tool
45 |
46 | 
47 |
48 | The CLI tool should be able to be used to automate the optimization and allocation process. In the future, the CLI tool will be executed with the help of a cron job in defined intervals and when the threshold is reached, the allocations will be automatically adjusted according to the optimization.
49 |
50 | The CLI tool is also used to run the optimization script without having to call a web interface. No streamlit web server is required to run the script.
51 |
52 | The CLI version supports the same parameterizations as the web interface.
53 |
54 | The script currently outputs two files: **script_never.txt** and **script.txt**. In future releases the optimization script will directly work with the indexer agent endpoint and communicate the allocation creation / closing with the help of graphQL mutations.
55 |
56 | ### script_never.txt
57 | The **script_never.txt** file contains the necessary commands that must be entered to drop all current allocations at the end of the current epoch. This is necessary to be able to use the script.txt and reallocate. The script_never.txt takes all subgraphs available into consideration and clears all allocations. It should be adapted if this is not the desired outcome.
58 |
59 | An example of a script_never.txt file:
60 | ```shell
61 | graph indexer rules set QmbYFfUKETrUwTQ7z8VD87KFoYJps8TGsSbM6m8bi6TaKG decisionBasis never && \
62 | graph indexer rules set QmTj6fHgHjuKKm43YL3Sm2hMvMci4AkFzx22Mdo9W3dyn8 decisionBasis never && \
63 | graph indexer rules get all --merged && \
64 | graph indexer cost get all
65 |
66 | ### [](https://github.com/anyblockanalytics/thegraph-allocation-optimization#scripttxt)
67 | ```
68 |
69 | ### script.txt
70 | The script file contains the necessary commands that must be entered to change the allocations and adjust them according to the optimization. The allocation script is general. It should be adapted according to the use-case.
71 |
72 | An example of a script.txt file:
73 |
74 | ```shell
75 | graph indexer rules set QmRhYzT8HEZ9LziQhP6JfNfd4co9A7muUYQhPMJsMUojSF allocationAmount 406350.00 parallelAllocations 4 decisionBasis always && \
76 | graph indexer cost set model QmRhYzT8HEZ9LziQhP6JfNfd4co9A7muUYQhPMJsMUojSF default.agora && \
77 | graph indexer cost set variables QmRhYzT8HEZ9LziQhP6JfNfd4co9A7muUYQhPMJsMUojSF '{}' && \
78 | graph indexer rules get all --merged && \graph indexer cost get all
79 | ```
80 | ## Streamlit App
81 | Check out the screencast of the web app:
82 |
83 | ****
84 |
85 | It is possible to parameterize the optimization run on the sidebar. After setting up the prefered settings, click on the button "run optimization". If the blacklist parameter is checked, the optimization run will take a while (**less than 2 minutes**).
86 |
87 | After running the optimization script, the dashboard is further populated.
88 |
89 |
90 | - Data from previous optimizations as JSON
91 | - Price Data (ETH-USD, GRT-USD, Gas Price in Gwei)
92 | - Historical performance for Closed/Active/Combined allocations
93 | - Data Table with allocation data by date
94 | - DIY Chart Builder (WIP)
95 | - Performance Metrics which visualize rewards per hour and optimized allocations on a timeline
96 | - Optimization run metrics:
97 | - Indexer stake, current rewards (hour/day/weekly/yearly)
98 | - Pending rewards, active allocations, average stake/signal ratio, average hourly rewards
99 | - Current allocation table
100 | - Distribution of rewards/stake signal ratio
101 | - Threshold pop up,
102 | - Information about the subgraphs the optimization tool recommends. (Boxes with dedicated image, description and metrics)
103 | - Output of allocation and allocation closing commands
104 |
105 | The web app makes it possible to follow the optimization process in a simple way. The results are visualized and recommendations for action are suggested. If the results are satisfactory, the commands can be copied for reallocation and executed in the Indexer CLI.
106 |
107 | The web app represents a semi-automated approach, where allocations are not yet set or closed automatically. The Web App also serves to build trust in the tool so that users know how the optimization works before they use the fully automated version.
108 |
109 |
110 |
--------------------------------------------------------------------------------
/docs/4. Indexing Rewards.md:
--------------------------------------------------------------------------------
1 | # Indexing Rewards
2 | ## General
3 | Indexer have a vital role to fulfill in The Graph ecosystem. This role is incentivized by **two revenue streams** for indexers. On the one hand, indexers are rewarded for their service in the ecosystem by receiving payments for serving queries in the networ (**query fee rebates**). And on the other hand, the 3% annual protocol-wide inflation is distributed to indexers who index subgraphs in the network. This second revenue stream are the **indexing rewards**. See [The Graph documentation](https://thegraph.com/docs/indexing#:~:text=Indexing%20rewards%20come%20from%20protocol,allocated%20stake%20on%20that%20subgraph.) for further information.
4 |
5 |
6 | >*Indexing rewards come from protocol inflation which is set to 3% annual issuance. **They are distributed across subgraphs based on the proportion of all curation signals on each, then distributed proportionally to indexers based on their allocated stake on that subgraph**. An allocation must be closed with a valid proof of indexing (POI) that meets the standards set by the arbitration charter to be eligible for rewards.*
7 | > -- [FAQ on The Graph Documentation](https://thegraph.com/docs/indexing#how-are-rewards-distributed):
8 |
9 | ## Equation
10 | Allocations are therefore a **core aspect of The Graph ecosystem for indexers to earn indexing rewards**. Based on the distribution and the amounts of allocations on different subgraphs, the indexing rewards are calculated using this formula:
11 | 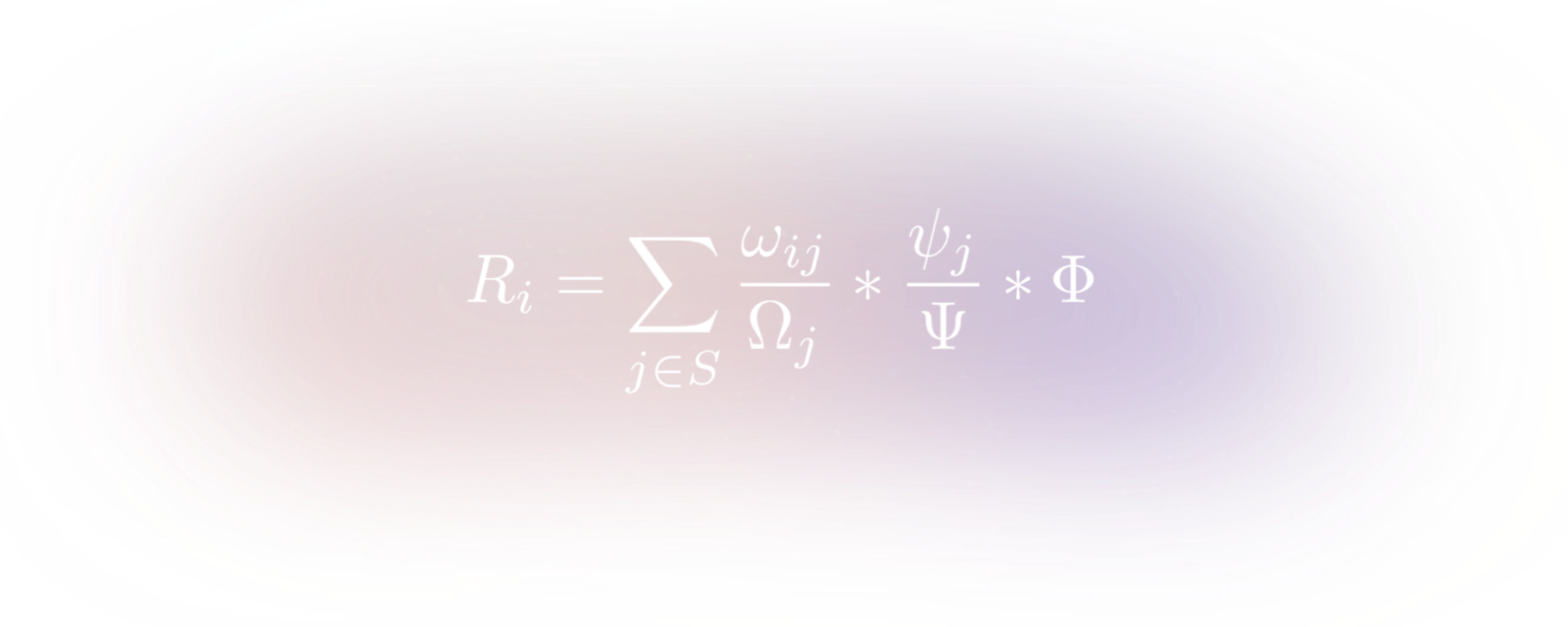
12 | where **ωij** is the amount that Indexer i has staked on subgraph j, Ωj is the total amount staked on subgraph j, ψj is the amount of GRT signaled for subgraph j, Ψ is the total amount signaled in the network and Φ is the total network indexer reward denominated in GRT.
13 |
14 | One could now calculate the indexing reward manually for each subgraph and distribute its stake accordingly. An alternative to this would be to define a rule that the indexer agent uses to distribute the allocations automatically. For example, one could distribute the stake equally among all subgraphs in the network. **However, this might lead to not getting the optimum indexing reward.**
15 |
16 | 
17 | (*Source: Discord stake-machine#1984*)
18 |
19 | **Problem Statement: How can indexing rewards be maximized so that the stake of indexers can be used most effectively without the time investment going to the extreme?**
20 |
21 | ## Optimizing Indexing Rewards
22 |
23 | Since this manual approach **does not yield the optimal rewards**, we use the Grant to develop a tool that computes the optimal allocation distribution using **optimization algorithms**. The relevant data for calculating the optimal allocation distribution is fetched using the *network subgraph* and other data sources and fed into the linear optimization model. This model then calculates the optimal distribution of allocations on the different subgraphs, **taking into account the preferences and parameterizations of the indexer**.
24 |
25 | The equation for calculating the indexing rewards is a perfect example of a linear optimization problem. The equation calculates the indexing rewards for each subgraph on which the indexer has an allocation. The sum of the indexing rewards per subgraph gives the total indexing rewards of the indexer.
26 |
27 | This tool optimizes the result of this calculation. The goal is to maximize the **indexing rewards**. So the value that is **left in the formula** (**Ri**). For this purpose the variable **ωij**, i.e. the allocations are optimized. The objective of the optimization is to maximize the indexing rewards. Thereby different constraints are considered.
28 |
29 | 1. The total allocations must not exceed the value of the indexer total stakes (minus the reserve stake).
30 | 2. For each subgraph that is optimized, the variable allocation must not be less than the min_allocation (parameter).
31 | 3. For each subgraph that is optimized, the variable allocation must not exceed the max_percentage (parameter) multiplied by the indexer total stake.
32 |
33 | For a programmatic explanation, look at this following code:
34 |
35 | ```python
36 | data = {(df.reset_index()['Name_y'].values[j], df.reset_index()['Address'].values[j], df['id'].values[j]): {
37 | 'Allocation': df['Allocation'].values[j],
38 | 'signalledTokensTotal': df['signalledTokensTotal'].values[j],
39 | 'stakedTokensTotal': df['stakedTokensTotal'].values[j],
40 | 'SignalledNetwork': int(total_tokens_signalled) / 10 ** 18,
41 | 'indexingRewardYear': indexing_reward_year,
42 | 'indexingRewardWeek': indexing_reward_week,
43 | 'indexingRewardDay': indexing_reward_day,
44 | 'indexingRewardHour': indexing_reward_hour,
45 | 'id': df['id'].values[j]} for j in set_J}
46 |
47 | # Initialize Pyomo Variables
48 | C = data.keys() # Name of Subgraphs
49 | model = pyomo.ConcreteModel()
50 |
51 | S = len(data) # amount subgraphs
52 | model.Subgraphs = range(S)
53 |
54 | # The Variable (Allocations) that should be changed to optimize rewards
55 | model.x = pyomo.Var(C, domain=pyomo.NonNegativeReals)
56 |
57 | # formula and model
58 | model.rewards = pyomo.Objective(
59 | expr=sum((model.x[c] / (data[c]['stakedTokensTotal'] + sliced_stake)) * (
60 | data[c]['signalledTokensTotal'] / data[c]['SignalledNetwork']) * data[c][reward_interval] for c in
61 | C), # Indexing Rewards Formula (Daily Rewards)
62 | sense=pyomo.maximize) # maximize Indexing Rewards
63 |
64 | # set constraint that allocations shouldn't be higher than total stake- reserce stake
65 | model.vol = pyomo.Constraint(expr=indexer_total_stake - reserve_stake >= sum(
66 | model.x[c] for c in C))
67 | model.bound_x = pyomo.ConstraintList()
68 |
69 | # iterate through subgraphs and set constraints
70 | for c in C:
71 | # Allocations per Subgraph should be higher than min_allocation
72 | model.bound_x.add(model.x[c] >= min_allocation)
73 | # Allocation per Subgraph can't be higher than x % of total Allocations
74 | model.bound_x.add(model.x[c] <= max_percentage * indexer_total_stake)
75 |
76 | # set solver to glpk -> In Future this could be changeable
77 | solver = pyomo.SolverFactory('glpk')
78 | solver.solve(model, keepfiles=True)
79 |
80 | ```
--------------------------------------------------------------------------------
/docs/5. Architecture.md:
--------------------------------------------------------------------------------
1 | # Architecture
2 | The tech stack for the allocation optimization tool contains different libraries as well as tools. The used programming language is **python**. Let's start with the Allocation Optimization Script itself. This core module of the application contains the relevant steps to optimize the allocations so that the highest indexing rewards can be achieved according to the given parameters.
3 | ## Core Functionality
4 |
5 | The script is based on the [Pyomo](http://www.pyomo.org/). optimization modeling language, which is based on Python and is open source. With the help of Pyomo, it is possible to use different open source and commercial optimizers for the optimization process. We use the open-source GLPK package ([GNU Linear Programming Kit](https://www.gnu.org/software/glpk/)). GLPK allows solving large-scale linear programming, mixed-integer programming, and other problems.
6 |
7 | The script utilizes GraphQL queries to the meta subgraph to retrieve the relevant information for the allocation optimization (current allocations, network information, etc.). Furthermore, open APIs are used to retrieve price data for the GRT token, ETH, and fiat currencies, as well as to get the current gas price. An ssh tunnel to the indexer graph node and the database server is used to gather information about the subgraph sync statuses and the latest valid POI for broken subgraphs. RPC calls to ethereum nodes are used to call the [rewards manager contract](https://etherscan.io/address/0x9Ac758AB77733b4150A901ebd659cbF8cB93ED66#readProxyContract) to get the pending rewards per subgraph.
8 |
9 | The data preprocessing, manipulation and preparation are performed using [pandas](https://pandas.pydata.org/). The allocation optimization script can be executed either in the command line or as a web application.
10 |
11 |
12 | ## Web Application
13 | The web application is based on streamlit. [Streamlit](https://streamlit.io/) is a python package that allows the development of data-driven applications. Visual charts are also displayed in this web interface using [plotly](https://plotly.com/).
14 |
15 | The web application takes the core logic from the **optimizer.py** file and displays the optimization process in a visual gui. The parameters are supplied via streamlit objects (checkboxes, sliders...) which are defined in the **./src/webapp/sidebar.py** file.
16 |
17 | The visualization of the optimization process is implemented in **./src/webapp/display_optimizer.py**. This includes functions to display further subgraph information, charts and data tables for the current optimization run.
18 |
19 | Further metrics, such as price metrics, the DIY chart builder, and historical performance charts are implemented in **./src/webapp/key_metrics.py**.
20 | ## Optimization Data
21 | The optimization runs are logged in a json file called "optimizer_log.json". It is located in the subdirectory ```./data/```. Each optimization run is sasved as a key value pair. Each runs key is the **datetime** of the run.
22 |
23 | Following metrics and data points are stored:
24 | * **Parameters:** for the run
25 | * **Price data**: gas price, grt-usd, eth-usd, grt-eth
26 | * **Network data:** total indexing rewards, grt_issuance ...
27 | * **Indexer data:** total stake, total allocated tokens
28 | * **Indexer's current allocations:** Saved as a key-value pair with the subgraph ipfs hash as key
29 | * **Current rewards:** hourly, daily, weekly, yearly
30 | * **Optimizer run data:** Threshold reached/not reached, which subgraphs to allocate to, expected returns...
31 |
32 | **Example:**
33 | ```json
34 | {
35 | "2021-09-06-10:43": {
36 | "datetime": "2021-09-06-10:43",
37 | "parameters": {
38 | "indexer_id": "0x453B5E165Cf98FF60167cCd3560EBf8D436ca86C",
39 | "blacklist": false,
40 | "parallel_allocations": 1,
41 | "max_percentage": 0.05,
42 | "threshold": 20,
43 | "subgraph_list_parameter": false,
44 | "threshold_interval": "weekly",
45 | "reserve_stake": 500,
46 | "min_allocation": 0,
47 | "min_signalled_grt_subgraph": 100,
48 | "min_allocated_grt_subgraph": 100,
49 | "app": "web",
50 | "slack_alerting": false
51 | },
52 | "price_data": {
53 | "gas_price_gwei": 105.928445249,
54 | "allocation_gas_usage": 270000,
55 | "ETH-USD": 3951.26,
56 | "GRT-USD": 1.04,
57 | "GRT-ETH": 0.00026276
58 | },
59 | "network_data": {
60 | "total_indexing_rewards": 196762472.49785247,
61 | "total_tokens_signalled": 3315140.590051623,
62 | "total_supply": 10180362807.536777,
63 | "total_tokens_allocated": 3105721872.4989176,
64 | "grt_issuance": 1000000012184945188,
65 | "yearly_inflation_percentage": 1.0300000002147995
66 | },
67 | "indexer": {
68 | "indexer_total_stake": 2389720.538838383,
69 | "indexer_total_allocated_tokens": 2389220.55
70 | },
71 | "current_allocations": {
72 | "QmRavjdwiaU7mFWT7Uum28Lf6y6cm397z6CdZPpLcFj9iR": {
73 | "Address": "0x303b502eba6fc9009263db01c6f1edeabe6427bb40a7e2e9be65f60760e5bb12",
74 | "Name_x": "Bot Bait v2",
75 | "Allocation": 477944.11000000004,
76 | "IndexingReward": 0.0,
77 | "allocation_id": "0x0505dc13c2440fc7ecfbdd8fb4576e47948cff17",
78 | "Name_y": "Bot Bait v2",
79 | "signalledTokensTotal": 3412.8412500000004,
80 | "stakedTokensTotal": 1697163.1099999999,
81 | "indexing_reward_hourly": 10.107526298208883,
82 | "indexing_reward_daily": 242.58237063492135,
83 | "indexing_reward_weekly": 1698.0754347925108,
84 | "indexing_reward_yearly": 88542.58093704746,
85 | "pending_rewards": 3884.652857838089
86 | },
87 | "QmT2McMyDQe5eVQJDESAXGygGU3yguwdREaLvq7ahGZiQ1": {
88 | "Address": "0x459aa5684fa2e9ce27420af9018f0317d9a58fd9e8d36bc065b6eebf7f546d2a",
89 | "Name_x": "dot-crypto-registry",
90 | "Allocation": 477444.11000000004,
91 | "IndexingReward": 0.0,
92 | "allocation_id": "0x07d048e19dd31c73777423bcb10a20f1b450d962",
93 | "Name_y": "dot-crypto-registry",
94 | "signalledTokensTotal": 7668.932316167791,
95 | "stakedTokensTotal": 5501770.109999999,
96 | "indexing_reward_hourly": 6.998907718194807,
97 | "indexing_reward_daily": 167.974989729743,
98 | "indexing_reward_weekly": 1175.8241251128225,
99 | "indexing_reward_yearly": 61310.8820917938,
100 | "pending_rewards": 2896.8974332849807
101 | },
102 | "QmU4yY98kYV4GUHJDYvpnrD9fqyB7HmvrTfq5KosWh8Lrh": {
103 | "Address": "0x55221e21ce7e608a8931f43a1704122501c58837cbb9aac6fdbb81bf4b507f26",
104 | "Name_x": "fei",
105 | "Allocation": 477944.11000000004,
106 | "IndexingReward": 0.0,
107 | "allocation_id": "0x547529b3fb503854cf2cc3b69b95e0b673d38d3b",
108 | "Name_y": "fei",
109 | "signalledTokensTotal": 1924.339946715805,
110 | "stakedTokensTotal": 997944.11,
111 | "indexing_reward_hourly": 9.692324634960048,
112 | "indexing_reward_daily": 232.61745926186728,
113 | "indexing_reward_weekly": 1628.3211028178537,
114 | "indexing_reward_yearly": 84905.387642787,
115 | "pending_rewards": 3724.8364730953094
116 | },
117 | "QmR6Sv5TPHktkK98GqZt4dhLNQ81CzXpASaqsibAxewv57": {
118 | "Address": "0x28ef98296776cf391293841a8f8a838cea705599b33d95dbd333049c631478c2",
119 | "Name_x": "makerdao-governance",
120 | "Allocation": 477944.11000000004,
121 | "IndexingReward": 0.0,
122 | "allocation_id": "0x93721ba038d1317464ebe2c9cf0dd4f569bae523",
123 | "Name_y": "makerdao-governance",
124 | "signalledTokensTotal": 2215.506462674542,
125 | "stakedTokensTotal": 1479250.1099999999,
126 | "indexing_reward_hourly": 7.528072394411027,
127 | "indexing_reward_daily": 180.67503302674024,
128 | "indexing_reward_weekly": 1264.7243674799313,
129 | "indexing_reward_yearly": 65946.39871480808,
130 | "pending_rewards": 3297.482606101014
131 | },
132 | "QmPXtp2UdoDsoryngUEMTsy1nPbVMuVrgozCMwyZjXUS8N": {
133 | "Address": "0x11bd056572a84f4f2700896fcd3a7434947cdb5a768ec4028f7935cd2cc2c687",
134 | "Name_x": "Totle Swap",
135 | "Allocation": 477944.11000000004,
136 | "IndexingReward": 0.0,
137 | "allocation_id": "0xcd39d994f0a7e22d24028e597041e1707a4a623a",
138 | "Name_y": "Totle Swap",
139 | "signalledTokensTotal": 1950.003419570772,
140 | "stakedTokensTotal": 1265417.11,
141 | "indexing_reward_hourly": 7.745581829774142,
142 | "indexing_reward_daily": 185.89529690823989,
143 | "indexing_reward_weekly": 1301.2661896952388,
144 | "indexing_reward_yearly": 67851.7953684505,
145 | "pending_rewards": 3402.7965587005338
146 | }
147 | },
148 | "current_rewards": {
149 | "indexing_reward_hourly": 42.072412875548906,
150 | "indexing_reward_daily": 1009.7451495615118,
151 | "indexing_reward_weekly": 7068.211219898357,
152 | "indexing_reward_yearly": 368557.0447548868
153 | },
154 | "optimizer": {
155 | "grt_per_allocation": 119461.02694191915,
156 | "allocations_total": 20.0,
157 | "stake_to_allocate": 2389220.538838383,
158 | "optimized_allocations": {
159 | "QmNNqS4Ftof3kGrTGrpynFYgeK5R6vVTEqADSN63vXEKC8": {
160 | "allocation_amount": 119486.026941919,
161 | "name": "Umbria",
162 | "address": "0x008f49562d4bdb43ae1b4b68097952d174fcec525019b0d270d2fe533a047d15",
163 | "signal_stake_ratio": 0.0019853511385943645
164 | },
165 | "QmNukFUkc6DspWQx8ZzRSvbpsBWaiPirQdbYPq6Qc4B4Wi": {
166 | "allocation_amount": 119486.026941919,
167 | "name": "Dummy Subgraph 1",
168 | "address": "0x087a6e8c03e01c5f29767e57ff2dd0ea619de26c46841ce4cf952e1c9cd64c07",
169 | "signal_stake_ratio": 0.0021272326548612175
170 | },
171 | "QmNyuWjzFxSaX9c9WCpWqVYYEo1TCtvfsL9gcqmhx7ArHy": {
172 | "allocation_amount": 119486.026941919,
173 | "name": "Bot Bait v1",
174 | "address": "0x098b3a9b9cb4299e66510822a1ce0c106c145a5724531509c3967077f659b8e4",
175 | "signal_stake_ratio": 0.0018682955005493798
176 | },
177 | "QmP7ZmWYHN9CTVZyEQ6zu1kuaJgi2AreAw3zFRjbgA5oMS": {
178 | "allocation_amount": 119486.026941919,
179 | "name": "Ribbon Finance",
180 | "address": "0x0b818c9b0a4eae4b7c2322636df77ce458ed9ff5e120a3d91524c66d1046f029",
181 | "signal_stake_ratio": 0.001792860095725464
182 | },
183 | "QmPU2gPVfovDGxDHt8FpXbhbxPq3dWNT6cNd9xqZYcD7uA": {
184 | "allocation_amount": 119486.026941919,
185 | "name": "elyfi",
186 | "address": "0x10bf983634fabedf30199c6c9c8960162a3b182ee8be3a7a4561e904bcbd0b19",
187 | "signal_stake_ratio": 0.002041595065280313
188 | },
189 | "QmPVjCWWZeaN7Mw5P6GEhbGixFbv8XKvqTa1oTv7RQsosM": {
190 | "allocation_amount": 119486.026941919,
191 | "name": "uniswap-v2-tokenHourData-subgraph",
192 | "address": "0x112efda0d0c6f9d853f3e0e5f7bc789003efbff0603c573fea0d79e63acc5720",
193 | "signal_stake_ratio": 0.0019880954256876657
194 | },
195 | "QmPdejzo2ENKgPxBFUh6KJ66YVFnYxmmxXpZpMoAzyL2dY": {
196 | "allocation_amount": 119486.026941919,
197 | "name": "Subgraph 21-QmPdejzo2ENKgPxBFUh6KJ66YVFnYxmmxXpZpMoAzyL2dY",
198 | "address": "0x133698f83f7ab5e98d36fb55f70ea4ceb121f284434bc232db1083e7a2067fc3",
199 | "signal_stake_ratio": 0.002045514850608105
200 | },
201 | "QmPhfSkFPbooXNJUMcQSWjMXoJYF3GnWT4JmHkxYXA85Zz": {
202 | "allocation_amount": 119486.026941919,
203 | "name": "Bancor",
204 | "address": "0x143db715c25f1e97631fd370a1db89108baace5ae71366da39fa44136b3567b1",
205 | "signal_stake_ratio": 0.001668356507081701
206 | },
207 | "QmQQeCUjemEf6urSR5SUvvdRTn9ZXdctHwuxjPJoFJD6wR": {
208 | "allocation_amount": 119486.026941919,
209 | "name": "renft",
210 | "address": "0x1ebd1e97a93bc8864e26088336ddd6b4e6f2bdc760ee1e29b3a9766921527cb8",
211 | "signal_stake_ratio": 0.0020115677900367354
212 | },
213 | "QmQXc8NHJ9ZbFkWBBJLiQtLuHBaVZtqaBy2cvm7VchULAM": {
214 | "allocation_amount": 119486.026941919,
215 | "name": "NFT Analytics BAYC",
216 | "address": "0x2085d7f6c1fcbfedff08446dc68104fd93f90f36d8247f217b6ead7983756d62",
217 | "signal_stake_ratio": 0.0017770638165785454
218 | },
219 | "QmQj3DDJzo9mS9m7bHriw8XdnU3od65HSThebeeDBQiujP": {
220 | "allocation_amount": 119486.026941919,
221 | "name": "Wrapped ETH",
222 | "address": "0x23739834f69676e56923f399b360beaf32cb222b1871dc85000ac7839b1c8682",
223 | "signal_stake_ratio": 0.0029928953473274764
224 | },
225 | "QmRWuFqUhuiggfSaSUsk4Z3BvZHwuwn66xw92k2fpNC2gF": {
226 | "allocation_amount": 119486.026941919,
227 | "name": "PAX",
228 | "address": "0x2f33513a1eafee12fd3f75bbe0c6a25348a74887b1e566f911e8cc55a04b9d70",
229 | "signal_stake_ratio": 0.002122135597897978
230 | },
231 | "QmRavjdwiaU7mFWT7Uum28Lf6y6cm397z6CdZPpLcFj9iR": {
232 | "allocation_amount": 119486.026941919,
233 | "name": "Bot Bait v2",
234 | "address": "0x303b502eba6fc9009263db01c6f1edeabe6427bb40a7e2e9be65f60760e5bb12",
235 | "signal_stake_ratio": 0.0018786721923364576
236 | },
237 | "QmRrHfw1Y1EZKUxd5MGTgmnbqf4hf8nynBG5F3ZQyjtVoF": {
238 | "allocation_amount": 118986.026941918,
239 | "name": "burny-boys",
240 | "address": "0x342ab2a85b6fe158b76f900e2c13c0aaef70c6c3671616046e0dfd0cd48345c2",
241 | "signal_stake_ratio": 0.0016565223849501901
242 | },
243 | "QmS7VGsn5s8UTMrebMRVNub2qCBYK19Qvg4dGNdTqsHX4k": {
244 | "allocation_amount": 119486.026941919,
245 | "name": "Test remove soon",
246 | "address": "0x380f876c05b7fce7bd8234de974bf0d5a0b262f7325bdb1a785ce4a120691831",
247 | "signal_stake_ratio": 0.0020431821109430093
248 | },
249 | "QmSjSH4EQHRNVbwGSkcEGQzDDRsBSmiDF4z63DMthsXf1M": {
250 | "allocation_amount": 119486.026941919,
251 | "name": "wildcards.world",
252 | "address": "0x41450cad731320fa6a709883e20bb2f8c6647e5b4937e7e59e0ed1373fa26efc",
253 | "signal_stake_ratio": 0.0017377616680302067
254 | },
255 | "QmSz8pavvfKeXXkSYsE5HH7UhD4LTKZ6szvnNohss5kxQz": {
256 | "allocation_amount": 119486.026941919,
257 | "name": "Keep network",
258 | "address": "0x4509060e1d1548bfd381baeacdadf0c163788e9dc472de48f523dbc4452742e3",
259 | "signal_stake_ratio": 0.0017188725044591292
260 | },
261 | "QmTKsqg2wUwsuGkeEnyKY1iPMdyaMXDhtCgtHeAxAe4X9r": {
262 | "allocation_amount": 119486.026941919,
263 | "name": "Cryptokitties",
264 | "address": "0x4a17b3535a7c534b1e65054a2cf8997ad7b76f3d56e9d3457ec09a75894ccfe1",
265 | "signal_stake_ratio": 0.002076849714983104
266 | },
267 | "QmU3MkEQCHCJbZ5U6sJbifpNLKwehSnYRgSGbeNUyY8Kb2": {
268 | "allocation_amount": 119486.026941919,
269 | "name": "Tacoswap Vision",
270 | "address": "0x54b81138d236538ce5098b45a63598cb6cc68f791fc67b239b63329db47b2d85",
271 | "signal_stake_ratio": 0.002465065297595677
272 | },
273 | "QmU4yY98kYV4GUHJDYvpnrD9fqyB7HmvrTfq5KosWh8Lrh": {
274 | "allocation_amount": 119486.026941919,
275 | "name": "fei",
276 | "address": "0x55221e21ce7e608a8931f43a1704122501c58837cbb9aac6fdbb81bf4b507f26",
277 | "signal_stake_ratio": 0.0017221506176195688
278 | },
279 | "indexingRewardHour": 49.90333067781851,
280 | "indexingRewardDay": 1197.679936267644,
281 | "indexingRewardWeek": 8383.752663117895,
282 | "indexingRewardYear": 437153.17673769005
283 | },
284 | "gas_costs_allocating_eth": 0.028600680217230005,
285 | "gas_costs_parallel_allocation_new_close_eth": 1.1440272086892003,
286 | "gas_costs_parallel_allocation_new_close_usd": 4520.3489486052895,
287 | "gas_costs_parallel_allocation_new_close_grt": 4353.886469360634,
288 | "increase_rewards_percentage": -42.99,
289 | "increase_rewards_fiat": -3159.88,
290 | "increase_rewards_grt": -3038.35,
291 | "threshold_reached": false
292 | }
293 | }
294 | },
295 | ```
--------------------------------------------------------------------------------
/docs/6. Developer.md:
--------------------------------------------------------------------------------
1 | # Developer Documentation
2 |
3 | ## Functioning
4 | First we grab all necessary The Graph data with a GraphQL Query to **"[https://gateway.network.thegraph.com/network](https://gateway.network.thegraph.com/network)"**. Here we define a variable input for the indexer id. This has to be supplied via the parameter indexer_id.
5 |
6 | The query is defined in *./src/queries.py* as the function ```getDataAllocationOptimizer()```
7 |
8 | ```python
9 | def getDataAllocationOptimizer(indexer_id, variables=None, ):
10 | """
11 | Grabs all relevant Data from the Mainnet Meta Subgraph which are used for the Optimizer
12 | Parameter ------- indexer_id : Address of Indexer to get the Data From Returns -------
13 | Dict with Subgraph Data (All Subgraphs with Name, SignalledTokens, Stakedtokens, Id), Indexer Data (Allocated Tokens Total and all Allocations), Graph Network Data (Total Tokens Allocated, total TokensStaked, Total Supply, GRT Issurance) """
14 | load_dotenv()
15 |
16 | API_GATEWAY = os.getenv('API_GATEWAY')
17 | OPTIMIZATION_DATA = """
18 | query MyQuery($input: String){ subgraphDeployments { originalName signalledTokens stakedTokens id } indexer(id: $input) { tokenCapacity allocatedTokens stakedTokens allocations { allocatedTokens id subgraphDeployment { originalName id } indexingRewards } account { defaultName { name } } } graphNetworks { totalTokensAllocated totalTokensStaked totalIndexingRewards totalTokensSignalled totalSupply networkGRTIssuance } } """ variables = {'input': indexer_id}
19 |
20 | request_json = {'query': OPTIMIZATION_DATA}
21 | if indexer_id:
22 | request_json['variables'] = variables
23 | resp = requests.post(API_GATEWAY, json=request_json)
24 | data = json.loads(resp.text)
25 | data = data['data']
26 |
27 | return data
28 | ```
29 |
30 | Furthermore we have to obtain price data with the functions ```getFiatPrice()``` and ```getGasPrice()```. We obtain fiat prices via the coingecko API. For the current gas price in gwei we use the Anyblock Analytics gas price API.
31 |
32 | Then we use the ```optimizeAllocations()``` function in **./src/optimizer.py** to run the optimization process. This function logs all relevant data for the allocation run in a variable called ```optimizer_results``` which is later translated to json and appended to **./data/optimizer_log.json**.
33 |
34 | If the blacklist paramter is set to ```True```, **createBlacklist** from **./src/subgraph_health_checks.py** is run. This populates the blacklist in the config.json.
35 |
36 | After grabbing the relevant data (price data, network data from the network subgraph) all indexing rewards (hourly,daily,weekly and yearly) are calculated for the currently open allocations.
37 |
38 | Furthermore the pending rewards for the open allocations are obtained via rpc calls to the **reward manager contract**. All relevant data is appended to the variable ```data```which is used for the optimization process. This dictionary includes key-value pairs, where the key is the subgraph and the value includes informations such as signalledTokensTotal and stakedTokensTotal.
39 |
40 | ```python
41 | # nested dictionary stored in data, key is SubgraphName,Address,ID
42 | data = {(df.reset_index()['Name_y'].values[j], df.reset_index()['Address'].values[j], df['id'].values[j]): {
43 | 'Allocation': df['Allocation'].values[j],
44 | 'signalledTokensTotal': df['signalledTokensTotal'].values[j],
45 | 'stakedTokensTotal': df['stakedTokensTotal'].values[j],
46 | 'SignalledNetwork': int(total_tokens_signalled) / 10 ** 18,
47 | 'indexingRewardYear': indexing_reward_year,
48 | 'indexingRewardWeek': indexing_reward_week,
49 | 'indexingRewardDay': indexing_reward_day,
50 | 'indexingRewardHour': indexing_reward_hour,
51 | 'id': df['id'].values[j]} for j in set_J}
52 | ```
53 |
54 | The optimization is run for every reward interval (Hourly, Daily, Weekly and Yearly). The objective of the optimization algorithm is to maximize the Indexing Rewards. Therefore it has to maximize the summation of the indexing reward formula.
55 |
56 | ```python
57 | # The Variable (Allocations) that should be changed to optimize rewards
58 | model.x = pyomo.Var(C, domain=pyomo.NonNegativeReals)
59 |
60 | # formula and model
61 | model.rewards = pyomo.Objective(
62 | expr=sum((model.x[c] / (data[c]['stakedTokensTotal'] + sliced_stake)) * (
63 | data[c]['signalledTokensTotal'] / data[c]['SignalledNetwork']) * data[c][reward_interval] for c in
64 | C), # Indexing Rewards Formula (Daily Rewards)
65 | sense=pyomo.maximize) # maximize Indexing Rewards
66 |
67 | # set constraint that allocations shouldn't be higher than total stake- reserce stake
68 | model.vol = pyomo.Constraint(expr=indexer_total_stake - reserve_stake >= sum(
69 | model.x[c] for c in C))
70 | model.bound_x = pyomo.ConstraintList()
71 |
72 | # iterate through subgraphs and set constraints
73 | for c in C:
74 | # Allocations per Subgraph should be higher than min_allocation
75 | model.bound_x.add(model.x[c] >= min_allocation)
76 | # Allocation per Subgraph can't be higher than x % of total Allocations
77 | model.bound_x.add(model.x[c] <= max_percentage * indexer_total_stake)
78 |
79 | # set solver to glpk -> In Future this could be changeable
80 | solver = pyomo.SolverFactory('glpk')
81 | solver.solve(model, keepfiles=True)
82 | ```
83 |
84 | The variable in this case is model.x[c], this is the variable allocation amount per Subgraph which has to be optimized to generate the maximum indexing reward. The equation takes the allocation per subgraph, the entire allocated stake on the specific subgraph and the signalled tokens on that subgraph into consideration.
85 |
86 | After the optimization was executed, the optimized rewards weekly / daily are stored in the variables ```optimized_reward_weekly``` and ```optimized_reward_daily```. This is used to calculate if the threshold is reached for reallocation.
87 |
88 | If slack alerting is enabled, the result of the optimization and if the threshold is reached is broadcasted to the desired slack channel. If the threshold is reached, a script.txt and script_never.txt file is created. If the threshold is not reached, these files are not created.
--------------------------------------------------------------------------------
/docs/7. Caution.md:
--------------------------------------------------------------------------------
1 | # Transparency, Caution and Risk ⚠️⛔️
2 |
3 | We are aware that this optimization significantly interferes with the revenues of the respective indexers. This requires a lot of trust. From our side, it is therefore extremely important to bring forth a transparent approach to optimization. Still using this script is at your own risk. ALWAYS check the results of the optimization and check the **script.txt** if it is suitable for your use-case and setup.
4 |
5 | Following the script and how it is working will be explained in detail. We purposely created the script in a semi-automatic way, where the results of the optimization process are logged and human intervention is necessary for deploying the changes. In future updates we would like to extend the scope to an automatic optimization script and deploy a hosted version with visualizations (contributions appreciated).
--------------------------------------------------------------------------------
/docs/8. Changelog.md:
--------------------------------------------------------------------------------
1 | # Changelog
2 |
3 | ## Release 1.0.1 beta📈
4 |
5 | ### Features
6 | * Added support for running the optimization on **testnet**. Checkout the **network** parameter in [[3. Usage and Parameters.md]]
7 | * Added support for testnet optimization in streamlit web application.
8 | * Refinement and addition of charts for historical performance tracking & GRT performance.
9 | 
10 | 
11 | 
12 |
13 | ## Release 1.0 beta 📤
14 |
15 | ### Features 🆕
16 |
17 | * Added **subgraph_health_checks.py** (optional: SSH tunnel on indexer local database). Allows indexers to fetch subgraphs that have errors, are not in sync, are depreciated or are from blacklisted subgraph developers. These functions, if applied, populate the config.json blacklist element automatically and helps mitigating bot-bait subgraphs.
18 | * Added automatic blacklisting for blacklisted subgraph developers. If there is a suspicious subgraph developer, the developer can be added to the config.json and the optimization script automatically blacklists all subgraphs released from this address
19 | * Added automatic blacklisting of inactive (active status: False) subgraphs
20 | * Added automatic blacklisting of subgraphs with bad health status (errors, not in sync
21 | * Added further parameters to change the behaviour of the allocation optimization script
22 | * **threshold_interval:** Define the interval which is used for calculating the threshold requirment. Currently the recommended threshold interval is "weekly". Setting the threshold interval to weekly leads the optimization script to calculate threshold requirments based on weekly indexing rewards.
23 | * **reserve_stake:** Enables the indexer to define a dedicated amount of stake which should not be considered in the optimization. This reserve stake will not be allocated!
24 | * **min_allocation:** Set the minimum allocation in GRT per subgraph. If this value is above 0, every deployed subgraph will get the minimum allocation amount. **ATTENTION 🚨: Setting this value above 0 leads to massive increases in transaction costs**
25 | * **min_allocated_grt_subgraph:** Defines the minimum GRT allocation requirment for a subgraph to be considered in the optimization process. If a subgraph have less GRT allocated than the min_allocated_grt_subgraph, then it will not be considered in the optimization process.
26 | * **min_signalled_grt_subgraph:** Defines the minimum GRT signal requirment for a subgraph to be considered in the optimization process. If a subgraph have less GRT signalled than the min_signalled_grt_subgraph, then it will not be considered in the optimization process.
27 | * **slack_alerting:** Enables the user to configure a slack alerting in a dedicated slack channel. Outputs if the optimization reached the threshold and how much increase / decrease in rewards is expected after the optimization. Configure the webhook and channel in the **.env** file.
28 | * Refactored the codebase. Now the script isn't bundled in one script.py file. A dedicated **src** directory is introduced, which also includes a **webapp** subdirectory for the streamlit application.
29 | * Included a **streamlit-based** web application for the optimization. The web application simplifies the usage of the optimization script. **Check out the [screencast of the web app](https://i.imgur.com/3uLj7gv.gif)**
30 | * Implemented historical performance tracking on daily granularity. For closed allocations the indexing rewards are calculated based on the network subgraph data. For active allocations the indexing rewards are calculated by gathering **pending rewards data with rpc calls from the reward manager contract**.
31 | * Implemented a **DIY Chart builder** based on plotly. This is **heavy work in progress** so expect errors.
32 | * Added key metrics from previous and current run
33 | * Abandoned tracking logic with log files for each run. Accumulated metrics of every optimization run in a optimizer_log.json with better structure and key-value pairs.
34 | * Added a POI fetching script (**poi.py**) to gather the latest acailable POIs for broken / bait subgraphs which are not correctly shown on the indexer agent. Requires a ssh tunnel to the indexer server or has to be run on the indexer server. **CAUTION ⚠️: Always crosscheck your POIs before manually closing allocations. If possible always use the indexer CLI**
35 | * Added Naive Method in Optimization Script to keep the ratio of signal / stake on a subgraph. In the model.reward optimization function we added the the part ```(data[c]['stakedTokensTotal'] + sliced_stake)```. This results in better optimizations. The script suggested to allocate large stakes to subgraphs with an awesome allocation / signal ratio. But the signals were not that high. When allocating a large stake on these subgraphs, the optimization "broke" the ratio and the rewards were not correctly calculated. With this addition we now add the stake which we allocate to the subgraphs into the formular.
36 | ```python
37 | model.rewards = pyomo.Objective(
38 | expr=sum((model.x[c] / (data[c]['stakedTokensTotal'] + sliced_stake))
39 | * (data[c]['signalledTokensTotal'] /
40 | data[c]['SignalledNetwork']) *
41 | data[c][reward_interval] for c in C),
42 | sense=pyomo.maximize)
43 | ```
44 | * Added Fetching Status of network subgraph (UP/DOWN) : Outputs a warning if the networ subgraph is down.
45 |
46 | ### Bugfixes 🐞
47 |
48 | - Subgraphs where allocations have been placed but the subgraph name is not available (anymore, because of updates to the subgraph), were not correctly recognized in the optimization process
49 | - Errors regarding mainnet launch were fixed
50 | - Fixed Error when running optimization script without active allocations
--------------------------------------------------------------------------------
/docs/9. Roadmap.md:
--------------------------------------------------------------------------------
1 | # Roadmap
2 |
3 | ## Backlog
4 |
5 | * Enhance **DIY chart builder**
6 | * Predefinied parameter settings for "strategies"
7 | * API Endpoint for the optimization
8 | * Alerting with Discord / Telegram
9 | * Detailed Historical Performance (hourly intervalls with caching)
10 | * Optimization of query fees (cobb-douglas-function)
11 | * Predictive modelling of subgraph signals -> which subgraph will get additional signal
12 | * Gas Optimization and Gas Estimation
13 |
14 | ## WIP
15 | * Dockerizing the application
16 | * Automatic allocation optimization and reallocation with cronjobs and communication with the indexe agent endpoint (requires graphQL mutations)
17 | * Styling, Fixing Bugs and enhancing charts in the streamlit web application
18 | * script_never.txt just populates the subgraphs that are reallocated, not removing all allocations
19 | * script.txt just allocating the changed allocations
20 | * Download performance data as .csv
21 |
22 | ## Done
23 | * Running the optimization script on testnet.
24 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 | # Allocation Optimization Tooling Documentation
2 | ## Table of Content
3 |
4 | - [[1. General]]
5 | - [[2. Quickstart]]
6 | - [[3. Usage and Parameters]]
7 | - [[4. Indexing Rewards]]
8 | - [[5. Architecture]]
9 | - [[6. Developer]]
10 | - [[7. Caution]]
11 | - [[8. Changelog]]
12 | - [[9. Roadmap]]
13 |
14 |
15 |
16 |
17 | ## Feedback
18 |
19 | To improve the tool, we look forward to your feedback. We would like to know which additional parameters would be relevant for you to tailor the optimization process more to the individual indexer. Furthermore, we would be interested to know which additional metrics you would like to see to track the performance of the indexer.
20 | ## Anyblock Analytics and Contact
21 | Check out [anyblockanalytics.com](https://anyblockanalytics.com/). We started participating in TheGraph ecosystem in the incentivized testnet as both indexers and curators and are Mainnet indexers from the start. Besides professionally running blockchain infrastructure for rpc and data, we can provide benefits through our data analytics and visualization expertise as well as ecosystem tool building.
22 |
23 | **Contact:**
24 |
25 | Discord: yarkin#5659
26 | E-Mail: [yarkin@anyblockanalytics.com](mailto:yarkin@anyblockanalytics.com)
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | from src.helpers import initializeParser
2 | from src.optimizer import optimizeAllocations
3 | from streamlit import bootstrap
4 | if __name__ == '__main__':
5 | """
6 | main.py script to execute for command line interface. Runs the optimizeAllocations function
7 | """
8 | my_parser = initializeParser()
9 | args = my_parser.parse_args()
10 | if args.app == "script":
11 | optimizeAllocations(indexer_id=args.indexer_id, blacklist_parameter=args.blacklist,
12 | parallel_allocations=args.parallel_allocations, max_percentage=args.max_percentage,
13 | threshold=args.threshold, subgraph_list_parameter=args.subgraph_list,
14 | threshold_interval=args.threshold_interval, reserve_stake=args.reserve_stake,
15 | min_allocation=args.min_allocation, min_allocated_grt_subgraph=args.min_allocated_grt_subgraph,
16 | min_signalled_grt_subgraph=args.min_signalled_grt_subgraph, app=args.app,
17 | slack_alerting=args.slack_alerting, network=args.network, automation=args.automation,
18 | ignore_tx_costs=args.ignore_tx_costs)
19 | if args.app == "app":
20 | real_script = 'app.py'
21 | bootstrap.run(real_script, f'streamlit run {real_script}', [], {})
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | attrs==20.3.0
2 | base58==2.1.0
3 | bitarray==1.2.2
4 | certifi==2020.12.5
5 | chardet==4.0.0
6 | cytoolz==0.11.0
7 | eth-abi==2.1.1
8 | eth-account==0.5.4
9 | eth-hash==0.3.1
10 | eth-keyfile==0.5.1
11 | eth-keys==0.3.3
12 | eth-rlp==0.2.1
13 | eth-typing==2.2.2
14 | eth-utils==1.10.0
15 | hexbytes==0.2.1
16 | idna==2.10
17 | ipfshttpclient==0.7.0a1
18 | jsonschema==3.2.0
19 | lru-dict==1.1.7
20 | multiaddr==0.0.9
21 | netaddr==0.8.0
22 | nose==1.3.7
23 | numpy==1.20.3
24 | pandas==1.2.5
25 | parsimonious==0.8.1
26 | pip==21.0.1
27 | ply==3.11
28 | protobuf==3.17.3
29 | pycoingecko==1.4.1
30 | pycryptodome==3.10.1
31 | Pyomo==5.7.3
32 | pyrsistent==0.17.3
33 | python-dateutil==2.8.1
34 | pytz==2021.1
35 | PyUtilib==6.0.0
36 | requests==2.25.1
37 | rlp==2.0.1
38 | setuptools==54.2.0
39 | six==1.15.0
40 | toolz==0.11.1
41 | urllib3==1.26.6
42 | varint==1.0.2
43 | web3==5.17.0
44 | websockets==8.1
45 | wheel==0.36.2
46 | redis
47 | httpx
48 | plotly-express
49 | streamlit
50 | millify
51 | streamlit-lottie
52 | aiohttp
53 | web3
54 | Web3
55 | python-dotenv
56 | psycopg2
--------------------------------------------------------------------------------
/script.txt:
--------------------------------------------------------------------------------
1 | graph indexer rules set QmfVsETfb3tZfUCtH4Ne4H2oVirR1zpsW57XwLtjqJP5Wz allocationAmount 477444.15 parallelAllocations 1 decisionBasis always && \
2 | graph indexer cost set model QmfVsETfb3tZfUCtH4Ne4H2oVirR1zpsW57XwLtjqJP5Wz default.agora && \
3 | graph indexer cost set variables QmfVsETfb3tZfUCtH4Ne4H2oVirR1zpsW57XwLtjqJP5Wz '{}' && \
4 | graph indexer rules set Qme8J5gnJtGWALnFvzRQS3NkffPGHHZr4XvjXLUjVfozzZ allocationAmount 477944.15 parallelAllocations 1 decisionBasis always && \
5 | graph indexer cost set model Qme8J5gnJtGWALnFvzRQS3NkffPGHHZr4XvjXLUjVfozzZ default.agora && \
6 | graph indexer cost set variables Qme8J5gnJtGWALnFvzRQS3NkffPGHHZr4XvjXLUjVfozzZ '{}' && \
7 | graph indexer rules set QmNNqS4Ftof3kGrTGrpynFYgeK5R6vVTEqADSN63vXEKC8 allocationAmount 477944.15 parallelAllocations 1 decisionBasis always && \
8 | graph indexer cost set model QmNNqS4Ftof3kGrTGrpynFYgeK5R6vVTEqADSN63vXEKC8 default.agora && \
9 | graph indexer cost set variables QmNNqS4Ftof3kGrTGrpynFYgeK5R6vVTEqADSN63vXEKC8 '{}' && \
10 | graph indexer rules set QmTtNENux7t81rWkxY58eDsHkqnABpwENahSaDPb39THfP allocationAmount 477944.15 parallelAllocations 1 decisionBasis always && \
11 | graph indexer cost set model QmTtNENux7t81rWkxY58eDsHkqnABpwENahSaDPb39THfP default.agora && \
12 | graph indexer cost set variables QmTtNENux7t81rWkxY58eDsHkqnABpwENahSaDPb39THfP '{}' && \
13 | graph indexer rules set QmT1nBfPJSSQpU6s4GaAfhhGLzZYjtEbqqFuPua2DtFc6M allocationAmount 477944.15 parallelAllocations 1 decisionBasis always && \
14 | graph indexer cost set model QmT1nBfPJSSQpU6s4GaAfhhGLzZYjtEbqqFuPua2DtFc6M default.agora && \
15 | graph indexer cost set variables QmT1nBfPJSSQpU6s4GaAfhhGLzZYjtEbqqFuPua2DtFc6M '{}' && \
16 | graph indexer rules get all --merged && \
17 | graph indexer cost get all
--------------------------------------------------------------------------------
/src/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/src/__init__.py
--------------------------------------------------------------------------------
/src/alerting.py:
--------------------------------------------------------------------------------
1 | import requests
2 | from dotenv import load_dotenv
3 | import os
4 |
5 | # Script for Alerting in Slack
6 | # Load Webhook URL and Channel from .env file
7 | load_dotenv()
8 | SLACK_WEBHOOK_URL = os.getenv('SLACK_WEBHOOK_URL')
9 | SLACK_CHANNEL = os.getenv('SLACK_CHANNEL')
10 |
11 | # ä Alert Map
12 | alert_map = {
13 | "emoji": {
14 | "threshold_reached": ":large_green_circle:",
15 | "threshold_not_reached": ":small_red_triangle_down:"
16 | },
17 | "text": {
18 | "threshold_reached": "THRESHOLD REACHED",
19 | "threshold_not_reached": "THRESHOLD NOT REACHED"
20 | },
21 | "message": {
22 | "threshold_reached": "Reallocating recommended",
23 | "threshold_not_reached": "Allocations are optimal"
24 | },
25 | "color": {
26 | "threshold_reached": "#32a852",
27 | "threshold_not_reached": "#ad1721"
28 | }
29 | }
30 |
31 |
32 | def alert_to_slack(status, threshold, threshold_interval, current_rewards, optimization_rewards, difference):
33 | data = {
34 | "text": "The Graph Optimization Alert Manager",
35 | "username": "Notifications",
36 | "channel": SLACK_CHANNEL,
37 | "attachments": [
38 | {
39 | "text": "{emoji} [*{state}*] ({threshold}%) Threshold Interval: {threshold_interval}\n {message}".format(
40 | emoji=alert_map["emoji"][status],
41 | state=alert_map["text"][status],
42 | threshold=threshold,
43 | threshold_interval=threshold_interval,
44 | message=alert_map["message"][
45 | status] + '\nCurrent GRT Rewards: ' +
46 | str(current_rewards) + '\nGRT Rewards after Optimization: ' + str(optimization_rewards) +
47 | '\n Difference in Rewards: ' + str(difference) + " GRT"
48 | ),
49 | "color": alert_map["color"][status],
50 | "attachment_type": "default",
51 |
52 | }]
53 | }
54 | r = requests.post(SLACK_WEBHOOK_URL, json=data)
55 | return r.status_code
56 |
--------------------------------------------------------------------------------
/src/automatic_allocation.py:
--------------------------------------------------------------------------------
1 | import requests
2 | import base58
3 | import json
4 | import os
5 | from dotenv import load_dotenv
6 | from src.queries import getActiveAllocations
7 | from src.filter_events import asyncFilterAllocationEvents
8 |
9 | def setIndexingRuleQuery(deployment, decision_basis = "never",
10 | allocation_amount = 0, parallel_allocations = 0):
11 | """
12 | Make Query against Indexer Management Endpoint to set Indexingrules
13 | """
14 |
15 | # Get Indexer Management Endpoint from .env file
16 | load_dotenv()
17 | url = os.getenv('INDEXER_MANAGEMENT_ENDPOINT')
18 |
19 | query = """
20 | mutation setIndexingRule($rule: IndexingRuleInput!){
21 | setIndexingRule(rule: $rule){
22 | deployment
23 | allocationAmount
24 | parallelAllocations
25 | maxAllocationPercentage
26 | minSignal
27 | maxSignal
28 | minStake
29 | minAverageQueryFees
30 | custom
31 | decisionBasis
32 | }
33 | }
34 | """
35 |
36 | if decision_basis == "never":
37 | allocation_input = {
38 | 'deployment' : deployment,
39 | 'decisionBasis' : decision_basis
40 | }
41 | if decision_basis == "always":
42 | allocation_input = {
43 | 'deployment' : deployment,
44 | 'decisionBasis' : decision_basis,
45 | 'allocationAmount': int(allocation_amount) * 10 ** 18,
46 | 'parallelAllocations' : parallel_allocations
47 |
48 | }
49 |
50 | variables = {'rule' : allocation_input}
51 |
52 | request = requests.post(url, json = {'query': query, 'variables': variables})
53 | if request.status_code == 200:
54 | return request.json()
55 | else:
56 | raise Exception("Query failed to run by returning code of {}. {}".format(request.status_code,query))
57 |
58 | def setIndexingRules(fixed_allocations, indexer_id,blacklist_parameter = True, parallel_allocations = 0 , network = "mainnet"):
59 | """
60 | setIndexingRule via indexer agent management endpoint (default :18000).
61 | Endpoint works with graphQL mutation. So the mutations are sent via a request.post
62 | method.
63 |
64 | returns: IndexingRule which was set via
65 | """
66 |
67 |
68 | print("YOU ARE IN AUTOMATION MODE")
69 |
70 | indexer_id = indexer_id.lower()
71 |
72 | # get relevant gateway for mainnet or testnet
73 | if network == 'mainnet':
74 | API_GATEWAY = os.getenv('API_GATEWAY')
75 | else:
76 | API_GATEWAY = os.getenv('TESTNET_GATEWAY')
77 | # get blacklisted subgraphs if wanted
78 |
79 | if blacklist_parameter:
80 | with open("./config.json", "r") as jsonfile:
81 | INVALID_SUBGRAPHS = json.load(jsonfile).get('blacklist')
82 | else:
83 | INVALID_SUBGRAPHS = False
84 |
85 | # set amount of parallel allocations per subgraph
86 | parallel_allocations = parallel_allocations
87 |
88 | # get the amount of GRT that should be allocated from the optimizer
89 | fixed_allocation_sum = sum(list(fixed_allocations.values())) * parallel_allocations
90 |
91 | # get relevant indexer data
92 | indexer_data = requests.post(
93 | API_GATEWAY,
94 | data='{"query":"{ indexer(id:\\"' + indexer_id + '\\") { account { defaultName { name } } stakedTokens delegatedTokens allocatedTokens tokenCapacity } }"}',
95 | headers={'content-type': 'application/json', 'Accept-Charset': 'UTF-8'}
96 | ).json()['data']['indexer']
97 |
98 | remaining_stake = int(indexer_data['tokenCapacity']) - int(fixed_allocation_sum)
99 | print(
100 | f"Processing subgraphs for indexer {indexer_data['account']['defaultName']['name'] if indexer_data['account']['defaultName'] else indexer_id}")
101 | print(f"Staked: {int(indexer_data['stakedTokens']) / 10 ** 18:,.2f}")
102 | print(f"Delegated: {int(indexer_data['delegatedTokens']) / 10 ** 18:,.2f}")
103 | print(f"Token Capacity: {int(indexer_data['tokenCapacity']) / 10 ** 18:,.2f}")
104 | print(f"Currently Allocated: {int(indexer_data['allocatedTokens']) / 10 ** 18:,.2f}")
105 | print(f"Fixed Allocation: {int(fixed_allocation_sum) / 10 ** 18:,.2f}")
106 | print(f"Remaining Stake: {remaining_stake / 10 ** 18:,.2f}")
107 | print('=' * 40)
108 |
109 | if (int(indexer_data['tokenCapacity']) - int(indexer_data['allocatedTokens']) < int(fixed_allocation_sum)):
110 | print("Not enough free stake for fixed allocation. Free to stake first")
111 | # sys.exit()
112 |
113 | subgraph_data = requests.post(
114 | API_GATEWAY,
115 | data='{"query":"{ subgraphDeployments(first: 1000) { id originalName stakedTokens signalledTokens } }"}',
116 | headers={'content-type': 'application/json', 'Accept-Charset': 'UTF-8'}
117 | ).json()['data']['subgraphDeployments']
118 |
119 | subgraphs = set()
120 | invalid_subgraphs = set()
121 | total_signal = 0
122 | total_stake = 0
123 | dynamic_allocation = 0
124 |
125 | for subgraph_deployment in subgraph_data:
126 | subgraph = base58.b58encode(bytearray.fromhex('1220' + subgraph_deployment['id'][2:])).decode("utf-8")
127 | if INVALID_SUBGRAPHS:
128 | if subgraph in INVALID_SUBGRAPHS:
129 | #print(f" Skipping invalid Subgraph: {subgraph_deployment['originalName']} ({subgraph})")
130 | invalid_subgraphs.add(subgraph)
131 | pass
132 | if subgraph in fixed_allocations.keys():
133 | if fixed_allocations[subgraph] > 0:
134 | print(
135 | f"{subgraph_deployment['originalName']} ({subgraph}) Total Stake: {int(subgraph_deployment['stakedTokens']) / 10 ** 18:,.2f} Total Signal: {int(subgraph_deployment['signalledTokens']) / 10 ** 18:,.2f} , Ratio: {(int(subgraph_deployment['stakedTokens']) / 10 ** 18) / ((int(subgraph_deployment['signalledTokens']) + 1) / 10 ** 18)}")
136 | subgraphs.add(subgraph)
137 | total_signal += int(subgraph_deployment['signalledTokens'])
138 | total_stake += int(subgraph_deployment['stakedTokens'])
139 | else:
140 | if subgraph in fixed_allocations.keys():
141 | if fixed_allocations[subgraph] > 0:
142 | print(
143 | f"{subgraph_deployment['originalName']} ({subgraph}) Total Stake: {int(subgraph_deployment['stakedTokens']) / 10 ** 18:,.2f} Total Signal: {int(subgraph_deployment['signalledTokens']) / 10 ** 18:,.2f} , Ratio: {(int(subgraph_deployment['stakedTokens']) / 10 ** 18) / ((int(subgraph_deployment['signalledTokens']) + 1) / 10 ** 18)}")
144 | subgraphs.add(subgraph)
145 | total_signal += int(subgraph_deployment['signalledTokens'])
146 | total_stake += int(subgraph_deployment['stakedTokens'])
147 |
148 | print(f"Total Signal: {total_signal / 10 ** 18:,.2f}")
149 | print(f"Total Stake: {total_stake / 10 ** 18:,.2f}")
150 | print('=' * 40)
151 |
152 | print(f"Subgraphs: {len(subgraphs)}")
153 | print(f"Fixed: {len(set(fixed_allocations.keys()))}")
154 | print(f"Dynamic: {len(subgraphs - set(fixed_allocations.keys()))}")
155 | print(f"Dynamic Allocation: {dynamic_allocation / 10 ** 18:,.2f}")
156 | print('=' * 40)
157 | print()
158 |
159 | # Closing Allocations via Indexer Agent Endpoint (localhost:18000), set decision_basis to never
160 |
161 | print("NOW CLOSING ALLOCATIONS AUTOMATICALLY VIA INDEXER MANAGEMENT ENDPOINT")
162 | active_allocations = getActiveAllocations(indexer_id = indexer_id, network = network)
163 | if active_allocations:
164 | active_allocations = active_allocations['allocations']
165 | allocation_ids = []
166 | for allocation in active_allocations:
167 | subgraph_hash = allocation["subgraphDeployment"]['id']
168 | allocation_amount = allocation["allocatedTokens"]
169 | print("CLOSING ALLOCATION FOR SUBGRAPH: " + str(subgraph_hash))
170 | print("SUBGRAPH IPFS HASH: " + allocation['subgraphDeployment']['ipfsHash'])
171 | print("ALLOCATION AMOUNT: " + str(allocation_amount))
172 | setIndexingRuleQuery(deployment = subgraph_hash, decision_basis = "never", parallel_allocations = parallel_allocations,
173 | allocation_amount = 0 )
174 |
175 | allocation_ids.append(allocation['id'])
176 | print("Closing Allocations amount: " + str(len(allocation_ids)))
177 | asyncFilterAllocationEvents(indexer_id = indexer_id, allocation_ids = allocation_ids, network= network, event_type = "closing" )
178 |
179 | # Allocating via Indexer Agent Endpoint (localhost:18000) set decision_basis to always
180 | print("NOW RUNNING THE AUTOMATIC ALLOCATION VIA INDEXER MANAGEMENT ENDPOINT")
181 | subgraph_deployment_ids = []
182 | for subgraph in subgraphs:
183 | if subgraph in fixed_allocations.keys():
184 | if fixed_allocations[subgraph] != 0:
185 | subgraph_hash = "0x"+base58.b58decode(subgraph).hex()[4:]
186 | subgraph_deployment_ids.append(subgraph_hash)
187 | allocation_amount = fixed_allocations[subgraph] / 10 ** 18
188 | print("ALLOCATING SUBGRAPH: " + "0x"+base58.b58decode(subgraph).hex()[4:])
189 | print("Allocation Amount: " + str(allocation_amount))
190 | print("")
191 | setIndexingRuleQuery(deployment = subgraph_hash, decision_basis = "always", parallel_allocations = parallel_allocations,
192 | allocation_amount = allocation_amount)
193 |
194 |
195 | asyncFilterAllocationEvents(indexer_id = indexer_id, allocation_ids = allocation_ids, network = network,
196 | subgraph_deployment_ids = subgraph_deployment_ids)
197 |
--------------------------------------------------------------------------------
/src/fetch_allocations.py:
--------------------------------------------------------------------------------
1 | import json
2 | import base58
3 | from eth_typing.evm import BlockNumber
4 | import requests
5 | import argparse
6 | from datetime import datetime, timedelta
7 | import datetime as dt
8 | from web3 import Web3
9 | from eth_utils import to_checksum_address
10 | import logging
11 | from dotenv import load_dotenv
12 | import os
13 | from collections import OrderedDict
14 |
15 | from web3.types import BlockIdentifier
16 |
17 | load_dotenv()
18 | RPC_URL = os.getenv('RPC_URL')
19 | API_GATEWAY = "https://api.thegraph.com/subgraphs/name/graphprotocol/graph-network-mainnet"
20 | ABI_JSON = """[{"anonymous":false,"inputs":[{"indexed":false,"internalType":"string","name":"param","type":"string"}],"name":"ParameterUpdated","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"indexer","type":"address"},{"indexed":true,"internalType":"address","name":"allocationID","type":"address"},{"indexed":false,"internalType":"uint256","name":"epoch","type":"uint256"},{"indexed":false,"internalType":"uint256","name":"amount","type":"uint256"}],"name":"RewardsAssigned","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"address","name":"indexer","type":"address"},{"indexed":true,"internalType":"address","name":"allocationID","type":"address"},{"indexed":false,"internalType":"uint256","name":"epoch","type":"uint256"}],"name":"RewardsDenied","type":"event"},{"anonymous":false,"inputs":[{"indexed":true,"internalType":"bytes32","name":"subgraphDeploymentID","type":"bytes32"},{"indexed":false,"internalType":"uint256","name":"sinceBlock","type":"uint256"}],"name":"RewardsDenylistUpdated","type":"event"},{"anonymous":false,"inputs":[{"indexed":false,"internalType":"address","name":"controller","type":"address"}],"name":"SetController","type":"event"},{"inputs":[],"name":"accRewardsPerSignal","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"accRewardsPerSignalLastBlockUpdated","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"contract IGraphProxy","name":"_proxy","type":"address"}],"name":"acceptProxy","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"contract IGraphProxy","name":"_proxy","type":"address"},{"internalType":"bytes","name":"_data","type":"bytes"}],"name":"acceptProxyAndCall","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes32","name":"","type":"bytes32"}],"name":"addressCache","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"controller","outputs":[{"internalType":"contract IController","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"bytes32","name":"","type":"bytes32"}],"name":"denylist","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"bytes32","name":"_subgraphDeploymentID","type":"bytes32"}],"name":"getAccRewardsForSubgraph","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"bytes32","name":"_subgraphDeploymentID","type":"bytes32"}],"name":"getAccRewardsPerAllocatedToken","outputs":[{"internalType":"uint256","name":"","type":"uint256"},{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"getAccRewardsPerSignal","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"getNewRewardsPerSignal","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"_allocationID","type":"address"}],"name":"getRewards","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"_controller","type":"address"},{"internalType":"uint256","name":"_issuanceRate","type":"uint256"}],"name":"initialize","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes32","name":"_subgraphDeploymentID","type":"bytes32"}],"name":"isDenied","outputs":[{"internalType":"bool","name":"","type":"bool"}],"stateMutability":"view","type":"function"},{"inputs":[],"name":"issuanceRate","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"bytes32","name":"_subgraphDeploymentID","type":"bytes32"}],"name":"onSubgraphAllocationUpdate","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes32","name":"_subgraphDeploymentID","type":"bytes32"}],"name":"onSubgraphSignalUpdate","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"_controller","type":"address"}],"name":"setController","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes32","name":"_subgraphDeploymentID","type":"bytes32"},{"internalType":"bool","name":"_deny","type":"bool"}],"name":"setDenied","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"bytes32[]","name":"_subgraphDeploymentID","type":"bytes32[]"},{"internalType":"bool[]","name":"_deny","type":"bool[]"}],"name":"setDeniedMany","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"uint256","name":"_issuanceRate","type":"uint256"}],"name":"setIssuanceRate","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[{"internalType":"address","name":"_subgraphAvailabilityOracle","type":"address"}],"name":"setSubgraphAvailabilityOracle","outputs":[],"stateMutability":"nonpayable","type":"function"},{"inputs":[],"name":"subgraphAvailabilityOracle","outputs":[{"internalType":"address","name":"","type":"address"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"bytes32","name":"","type":"bytes32"}],"name":"subgraphs","outputs":[{"internalType":"uint256","name":"accRewardsForSubgraph","type":"uint256"},{"internalType":"uint256","name":"accRewardsForSubgraphSnapshot","type":"uint256"},{"internalType":"uint256","name":"accRewardsPerSignalSnapshot","type":"uint256"},{"internalType":"uint256","name":"accRewardsPerAllocatedToken","type":"uint256"}],"stateMutability":"view","type":"function"},{"inputs":[{"internalType":"address","name":"_allocationID","type":"address"}],"name":"takeRewards","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"nonpayable","type":"function"},{"inputs":[],"name":"updateAccRewardsPerSignal","outputs":[{"internalType":"uint256","name":"","type":"uint256"}],"stateMutability":"nonpayable","type":"function"}]"""
21 | REWARD_MANAGER = "0x9Ac758AB77733b4150A901ebd659cbF8cB93ED66"
22 |
23 |
24 | def getGraphQuery(subgraph_url, indexer_id, variables=None, ):
25 | # use requests to get query results from POST Request and dump it into data
26 | """
27 | :param subgraph_url: 'https://api.thegraph.com/subgraphs/name/ppunky/hegic-v888'
28 | :param query: '{options(where: {status:"ACTIVE"}) {id symbol}}'
29 | :param variables:
30 | :return:
31 | """
32 |
33 | ALLOCATION_DATA = """
34 | query AllocationsByIndexer($input: ID!) {
35 | indexer(id: $input) {
36 | allocations(where: {status: Active}) {
37 | indexingRewards
38 | allocatedTokens
39 | status
40 | id
41 | createdAt
42 | subgraphDeployment {
43 | signalledTokens
44 | createdAt
45 | stakedTokens
46 | originalName
47 | id
48 | }
49 | createdAtEpoch
50 | createdAtBlockNumber
51 | }
52 | allocatedTokens
53 | stakedTokens
54 | delegatedTokens
55 | }
56 | }
57 | """
58 | variables = {'input': indexer_id}
59 |
60 | request_json = {'query': ALLOCATION_DATA}
61 | if indexer_id:
62 | request_json['variables'] = variables
63 | resp = requests.post(subgraph_url, json=request_json)
64 | response = json.loads(resp.text)
65 | response = response['data']
66 |
67 | return response
68 |
69 | def initialize_rpc():
70 | """Initializes RPC client.
71 |
72 | Returns
73 | -------
74 | object
75 | web3 instance
76 | """
77 | web3 = Web3(Web3.HTTPProvider(RPC_URL))
78 |
79 | logging.getLogger("web3.RequestManager").setLevel(logging.WARNING)
80 | logging.getLogger("web3.providers.HTTPProvider").setLevel(logging.WARNING)
81 |
82 | return web3
83 |
84 | def get_poi_data(subgraph_url):
85 | epoch_count = 219
86 | query = """
87 | query get_epoch_block($input: ID!) {
88 | graphNetwork(id: 1) {
89 | epochCount
90 | }
91 | epoch(id: $input) {
92 | startBlock
93 | }
94 | }
95 | """
96 |
97 | variables = {'input': epoch_count}
98 | request_json = {'query': query}
99 | if indexer_id:
100 | request_json['variables'] = variables
101 | resp = requests.post(subgraph_url, json=request_json)
102 | response = json.loads(resp.text)
103 |
104 | # epoch_count = response['data']['graphNetwork']['epochCount']
105 | epoch_count = 214
106 |
107 | variables = {'input': epoch_count}
108 | request_json = {'query': query}
109 | if indexer_id:
110 | request_json['variables'] = variables
111 | resp = requests.post(subgraph_url, json=request_json)
112 | response = json.loads(resp.text)
113 |
114 | start_block = response['data']['epoch']['startBlock']
115 |
116 | start_block_hash = web3.eth.getBlock(start_block)['hash'].hex()
117 |
118 | return start_block, start_block_hash
119 |
120 |
121 |
122 |
123 | if __name__ == '__main__':
124 |
125 | # datetime object containing current date and time
126 | now = datetime.now()
127 | DT_STRING = now.strftime("%d-%m-%Y %H:%M:%S")
128 | print("Script Execution on: ", DT_STRING)
129 |
130 | print(f"RPC initialized at: {RPC_URL}")
131 | web3 = initialize_rpc()
132 | abi = json.loads(ABI_JSON)
133 | contract = web3.eth.contract(address=REWARD_MANAGER, abi=abi)
134 |
135 | # initialize argument parser
136 | my_parser = argparse.ArgumentParser(description='The Graph Allocation script for determining the optimal Allocations \
137 | across different Subgraphs. outputs a script.txt which an be used \
138 | to allocate the results of the allocation script. The created Log Files\
139 | logs the run, with network information and if the threshold was reached.\
140 | Different Parameters can be supplied.')
141 |
142 | # Add the arguments
143 | # Indexer Address
144 | my_parser.add_argument('--indexer_id',
145 | metavar='indexer_id',
146 | type=str,
147 | help='The Graph Indexer Address',
148 | default="0x453b5e165cf98ff60167ccd3560ebf8d436ca86c")
149 |
150 | # Deployable stake amount
151 | my_parser.add_argument('--slices',
152 | metavar='slices',
153 | type=float,
154 | help='How many subgraphs you would like to spread your stake across',
155 | default="5")
156 |
157 | args = my_parser.parse_args()
158 | indexer_id = args.indexer_id # get indexer parameter input
159 | slices = args.slices # get number of slices input
160 |
161 | result = getGraphQuery(subgraph_url=API_GATEWAY, indexer_id=indexer_id)
162 | allocations = result['indexer']['allocations']
163 | allocated_tokens_total = int(result['indexer']['allocatedTokens'])/10**18
164 | staked_tokens = int(result['indexer']['stakedTokens'])/10**18
165 | delegated_tokens = int(result['indexer']['delegatedTokens'])/10**18
166 | total_tokens = staked_tokens + delegated_tokens
167 | sliced_stake = (total_tokens-5000) / slices
168 | print(f"Total allocated tokens: {round(total_tokens)} GRT with deployable {round(100 / slices)}% stake amounts of {round(sliced_stake)} GRT.")
169 |
170 | subgraphs = {}
171 | subgraphs_in_danger = []
172 | subgraphs_to_drop = []
173 |
174 | rate_best = 0
175 | pending_per_token_sum = 0
176 | pending_sum = 0
177 | average_historic_rate_hourly_sum = 0
178 | current_rate_sum = 0
179 |
180 | rewards_at_stake_from_broken_subgraphs = 0
181 |
182 | current_block = web3.eth.blockNumber
183 |
184 | for allocation in allocations:
185 | allocation_id = to_checksum_address(allocation['id'])
186 | subgraph_id = allocation['subgraphDeployment']['id']
187 | print(allocations.index(allocation), allocation_id)
188 | pending_rewards = contract.functions.getRewards(allocation_id).call() / 10**18
189 | pending_rewards_minus_1_hour = contract.functions.getRewards(allocation_id).call(block_identifier = current_block - 277) / 10**18
190 | pending_rewards_minus_5_minutes = contract.functions.getRewards(allocation_id).call(block_identifier = current_block - 23) / 10**18
191 |
192 | name = allocation['subgraphDeployment']['originalName']
193 | if name is None:
194 | name = f'Subgraph{allocations.index(allocation)}'
195 | created_at = allocation['createdAt']
196 | hours_since = dt.datetime.now() - datetime.fromtimestamp(created_at)
197 | hours_since = hours_since.total_seconds() / 3600
198 | subgraph_created_at = allocation['subgraphDeployment']['createdAt']
199 | subgraph_hours_since = dt.datetime.now() - datetime.fromtimestamp(created_at)
200 | subgraph_hours_since = subgraph_hours_since.total_seconds() / 3600
201 | allocated_tokens = int(allocation['allocatedTokens']) / 10**18
202 |
203 | # current_rate = pending_rewards - pending_rewards_minus_1_hour
204 | current_rate = pending_rewards - pending_rewards_minus_5_minutes
205 | current_rate_per_token = current_rate / allocated_tokens
206 |
207 | average_historic_rate_per_token = pending_rewards / allocated_tokens
208 | average_historic_rate_per_token_hourly = average_historic_rate_per_token / hours_since
209 | pending_rewards_hourly = pending_rewards / hours_since
210 |
211 | subgraph_signal = int(allocation['subgraphDeployment']['signalledTokens']) / 10**18
212 | subgraph_stake = int(allocation['subgraphDeployment']['stakedTokens']) / 10**18
213 |
214 | current_rate_all_indexers = current_rate / allocated_tokens * subgraph_stake
215 |
216 | b58 = base58.b58encode(bytearray.fromhex('1220' + subgraph_id[2:])).decode("utf-8")
217 | data = {
218 | 'name': name,
219 | 'subgraph_id': subgraph_id,
220 | 'subgraph_age_in_blocks': current_block - allocation['createdAtBlockNumber'],
221 | 'subgraph_age_in_hours': subgraph_hours_since,
222 | 'subgraph_age_in_days': subgraph_hours_since / 24,
223 | 'allocation_id': allocation_id,
224 | 'allocated_tokens': allocated_tokens,
225 | 'allocation_created_timestamp': created_at,
226 | 'allocation_created_epoch': allocation['createdAtEpoch'],
227 | 'allocation_status': allocation['status'],
228 | 'rewards_predicted_hourly_per_deployable_stake': 12* current_rate_all_indexers / (subgraph_stake + sliced_stake) * sliced_stake,
229 | 'rewards_pending': pending_rewards,
230 | 'rewards_pending_last_hour': current_rate,
231 | 'rewards_pending_per_token': pending_rewards / allocated_tokens,
232 | 'rewards_pending_last_hour_per_token': current_rate_per_token,
233 | 'rewards_pending_historic_per_token_average': average_historic_rate_per_token,
234 | 'rewards_pending_historic_per_token_hourly_average': average_historic_rate_per_token_hourly,
235 | 'subgraph_signal': subgraph_signal,
236 | 'subgraph_stake': subgraph_stake,
237 | 'subgraph_signal_ratio': subgraph_signal / subgraph_stake
238 | }
239 | subgraphs[b58] = data
240 |
241 | if current_rate == 0:
242 | subgraphs_to_drop.append(b58)
243 | rewards_at_stake_from_broken_subgraphs += pending_rewards
244 |
245 | if hours_since / 24 > 25:
246 | subgraphs_in_danger.append(b58)
247 |
248 | if current_rate_per_token > rate_best:
249 | rate_best = current_rate_per_token
250 | best_subgraph = b58
251 |
252 | pending_per_token_sum += pending_rewards / allocated_tokens
253 | pending_sum += pending_rewards
254 | average_historic_rate_hourly_sum += pending_rewards / hours_since
255 | current_rate_sum += current_rate
256 |
257 | pending_apy = average_historic_rate_hourly_sum * 24 * 12 * 365 * 100 / total_tokens
258 | forecast_apy = current_rate_sum * 24 * 12 * 365 * 100 / total_tokens
259 |
260 | # subgraphs = sorted(subgraphs.items(), key=lambda i: i[1]['rewards_forecast_per_token_hourly'], reverse=True)
261 | subgraphs = sorted(subgraphs.items(), key=lambda i: i[1]['rewards_pending'], reverse=True)
262 | # subgraphs = sorted(subgraphs.items(), key=lambda i: i[1]['rewards_predicted_hourly_per_deployable_stake'], reverse=True)
263 | # subgraphs = sorted(subgraphs.items(), key=lambda i: i[1]['allocated_tokens'], reverse=True)
264 | # Calculate optimization ratio
265 | optimized_hourly_rewards = 0.1
266 | for subgraph in subgraphs[:5]:
267 | optimized_hourly_rewards += subgraphs[0][1]['rewards_predicted_hourly_per_deployable_stake']
268 | optimization = current_rate_sum / optimized_hourly_rewards * 100
269 | # Convert back into dict
270 | subgraphs_dict = {k: v for k, v in subgraphs}
271 |
272 | print('')
273 | print(f"Best subgraph found at {subgraphs_dict[best_subgraph]['name']} ({best_subgraph}) at an hourly per token rate of {round(subgraphs_dict[best_subgraph]['rewards_pending_last_hour_per_token'],5)} GRT and a signal ratio of {round(subgraphs_dict[best_subgraph]['subgraph_signal_ratio']*100,8)}%. Current allocation: {subgraphs_dict[best_subgraph]['allocated_tokens']}")
274 | print(f"Indexing at {round(optimization,2)}% efficiency. Current pending: {round(pending_sum)} GRT. Naive method: {round(pending_sum / optimization * 100, 2)} GRT.")
275 | print(f"Indexing with {round(allocated_tokens_total)} GRT out of {round(total_tokens)} GRT ({round(allocated_tokens_total / total_tokens * 100)}%)")
276 | print(f"Per token efficiency: {pending_sum / total_tokens} GRT per GRT.")
277 | print(f"Average earnings of {round(average_historic_rate_hourly_sum,2)} GRT per hour ({round(current_rate_sum,2)} GRT based on last hour).")
278 | print(f"Indexing APY: {round(pending_apy, 2)}% APY. Last hour: {round(forecast_apy, 2)}% APY.")
279 | print('')
280 | # now write output to a file
281 | active_allocations = open("active_allocations.json", "w")
282 | # magic happens here to make it pretty-printed
283 | active_allocations.write(json.dumps(subgraphs, indent=4, sort_keys=True))
284 | active_allocations.close()
285 | print("Populated active_allocations.json for indexer", indexer_id)
286 |
287 | print('')
288 | if len(subgraphs_in_danger) > 0:
289 | print(f"WARNING: Your subgraphs are in danger of being closed with 0x0 POI: {subgraphs_in_danger}")
290 |
291 | print('')
292 | if len(subgraphs_to_drop) > 0:
293 | drops = len(subgraphs_to_drop)
294 | print(f"WARNING: {drops} of your allocated subgraphs are no longer active.")
295 | print(f"WARNING: {round(rewards_at_stake_from_broken_subgraphs)} GRT at stake without POI.")
296 |
297 | poi_block_number, poi_block_hash = get_poi_data(API_GATEWAY)
298 |
299 | # now write output to a file
300 | script_null_subgraphs = open("../script_null_subgraphs.txt", "w")
301 | for subgraph in subgraphs_to_drop:
302 | # magic happens here to make it pretty-printed
303 | script_null_subgraphs.write(f"http -b post http://localhost:8030/graphql \\\n")
304 | script_null_subgraphs.write("query='query poi { proofOfIndexing(\\\n")
305 | script_null_subgraphs.write(f"subgraph: \"{subgraph}\", blockNumber: {poi_block_number}, \\\n")
306 | script_null_subgraphs.write(f"blockHash: \"{poi_block_hash}\", \\\n")
307 | script_null_subgraphs.write(f"indexer: \"{indexer_id}\")" + "}'\n")
308 | script_null_subgraphs.write("\n")
309 | script_null_subgraphs.close()
310 |
311 | print("WARNING: Populated script_null_subgraphs.txt with recent POI closing scripts")
312 |
313 |
314 | DT_STRING = now.strftime("%d-%m-%Y %H:%M:%S")
315 | print("Script Completion on:", DT_STRING)
--------------------------------------------------------------------------------
/src/filter_events.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | from src.helpers import initialize_rpc_testnet, initialize_rpc, ALLOCATION_MANAGER_MAINNET, ALLOCATION_MANAGER_TESTNET, \
3 | ALLOCATION_MANAGER_ABI, ALLOCATION_MANAGER_ABI_TESTNET
4 | import json
5 | from web3.middleware import geth_poa_middleware
6 | from web3 import Web3
7 | import asyncio
8 |
9 | """
10 | def filterAllocationEvents(allocation_id, network = "mainnet", event_type = 'creation'):
11 | # Get All Events for AllocationClosed and AllocationCreated
12 | # Initialize web3 client, set network for allocation manager contract
13 |
14 | if network == "mainnet":
15 | web3 = initialize_rpc()
16 | allocation_manager = Web3.toChecksumAddress(ALLOCATION_MANAGER_MAINNET)
17 | # initialize contract with abi
18 | contract = web3.eth.contract(address=allocation_manager, abi=json.loads(ALLOCATION_MANAGER_ABI))
19 | if network == "testnet":
20 |
21 | web3 = initialize_rpc_testnet()
22 | allocation_manager = Web3.toChecksumAddress(ALLOCATION_MANAGER_TESTNET)
23 |
24 | # initialize contract with abi
25 | contract = web3.eth.contract(address=allocation_manager, abi=json.loads(ALLOCATION_MANAGER_ABI_TESTNET))
26 |
27 | # get current block and go back 12 blocks because of reorgs
28 | block = web3.eth.get_block('latest').number
29 | block_minus_12 = block -12
30 |
31 | # get start block for event filter
32 | block_minus_100 = block_minus_12 - 100
33 | if event_type == "creation":
34 | event_filter = contract.events.AllocationCreated.createFilter(fromBlock=block_minus_12,
35 | toBlock = block,
36 | argument_filters = {'allocationID':'0xb19f0920051c148e2d01ee263e881a8d8fc9d08e'.lower()})
37 | if len(event_filter.get_all_entries()) > 0:
38 | print("=" * 40)
39 | print(event_filter.get_all_entries())
40 | print("=" * 40)
41 | print('Event Succesfully Found for Allocation Opening of Allocation: ' + allocation_id)
42 | if event_type == "closing":
43 | event_filter = contract.events.AllocationClosed.createFilter(fromBlock=block_minus_12,
44 | toBlock = 'latest',
45 | argument_filters = {'allocationID':'0xFE282240De71e36D857AAD1b342a1075e13857A7'.lower()})
46 | if len(event_filter.get_all_entries()) > 0:
47 | print("=" * 40)
48 | print(event_filter.get_all_entries())
49 | print("=" * 40)
50 | print('Event Succesfully Found for Allocation Closing of Allocation: ' + allocation_id)
51 | """
52 | def asyncFilterAllocationEvents(indexer_id, allocation_ids = ["0xFE282240De71e36D857AAD1b342a1075e13857A7"], subgraph_deployment_ids = [], network = "mainnet", event_type = "creation", fromBlock= 'latest'):
53 |
54 | # Get All Events for AllocationClosed and AllocationCreated
55 | # Initialize web3 client, set network for allocation manager contract
56 | if network == "mainnet":
57 | web3 = initialize_rpc()
58 | allocation_manager = Web3.toChecksumAddress(ALLOCATION_MANAGER_MAINNET)
59 | # initialize contract with abi
60 | contract = web3.eth.contract(address=allocation_manager, abi=json.loads(ALLOCATION_MANAGER_ABI))
61 | if network == "testnet":
62 | web3 = initialize_rpc_testnet()
63 | allocation_manager = Web3.toChecksumAddress(ALLOCATION_MANAGER_TESTNET)
64 |
65 | web3.middleware_onion.inject(geth_poa_middleware, layer=0)
66 |
67 | # initialize contract with abi
68 | contract = web3.eth.contract(address=allocation_manager, abi=json.loads(ALLOCATION_MANAGER_ABI_TESTNET))
69 |
70 | # Initialize empty list where all relevant events will be added to
71 | events_found = []
72 |
73 |
74 | # get current block and go back 12 blocks because of reorgs
75 | block = web3.eth.get_block('latest').number
76 | block_minus_12 = block -12
77 |
78 | if fromBlock == 'latest':
79 | fromBlock = block_minus_12
80 | # define function to handle events and print to the console
81 | def handle_event(event):
82 | print(event)
83 | events_found.append(event)
84 |
85 |
86 | # asynchronous defined function to loop
87 | # this loop sets up an event filter and is looking for new entires for the "PairCreated" event
88 | # this loop runs on a poll interval
89 | async def log_loop(event_filter, poll_interval):
90 | # loop through events until event founds is the same length as allocation list supplied
91 | while len(events_found) != len(allocation_ids):
92 | for AllocationClosed in event_filter.get_new_entries():
93 | handle_event(AllocationClosed)
94 | await asyncio.sleep(poll_interval)
95 | print("="*40)
96 | print("All Allocation Events " + event_type + " found" )
97 |
98 |
99 | # when main is called
100 | # create a filter for the latest block and look for the "PairCreated" event for the uniswap factory contract
101 | # run an async loop
102 | # try to run the log_loop function above every 2 seconds
103 | if event_type == "closing":
104 | for allocation_id in allocation_ids:
105 | event_filter = contract.events.AllocationClosed.createFilter(fromBlock= fromBlock,
106 | argument_filters = {
107 | 'allocationID' : allocation_id
108 | })
109 | loop = asyncio.get_event_loop()
110 | try:
111 | loop.run_until_complete(
112 | asyncio.gather(
113 | log_loop(event_filter, 1)))
114 | finally:
115 | loop.close()
116 | asyncio.set_event_loop(asyncio.new_event_loop())
117 |
118 | if event_type == "creation":
119 | for subgraph_deployment_id in subgraph_deployment_ids:
120 | event_filter = contract.events.AllocationCreated.createFilter(fromBlock=fromBlock,
121 | argument_filters = {
122 | 'indexer' : indexer_id,
123 | 'subgraphDeploymentID': subgraph_deployment_id
124 | })
125 |
126 | loop = asyncio.get_event_loop()
127 | try:
128 | loop.run_until_complete(
129 | asyncio.gather(
130 | log_loop(event_filter, 1)))
131 | finally:
132 | loop.close()
133 | asyncio.set_event_loop(asyncio.new_event_loop())
134 | """
135 |
136 | for allocation_id in allocation_ids:
137 | if event_type == "creation":
138 | event_filter = contract.events.AllocationCreated.createFilter(fromBlock=fromBlock,
139 | argument_filters = {
140 | 'allocationID': allocation_id
141 | })
142 | if event_type == "closing":
143 | event_filter = contract.events.AllocationClosed.createFilter(fromBlock= fromBlock,
144 | argument_filters = {
145 | 'allocationID' : allocation_id
146 | })
147 | loop = asyncio.get_event_loop()
148 | try:
149 | loop.run_until_complete(
150 | asyncio.gather(
151 | log_loop(event_filter, 1)))
152 | finally:
153 | loop.close()
154 | asyncio.set_event_loop(asyncio.new_event_loop())
155 | """
156 | # Tests
157 |
158 |
159 | # asyncFilterAllocationEvents(indexer_id = "0xbed8e8c97cf3accc3a9dfecc30700b49e30014f3", subgraph_deployment_ids=["0x014e8a3184d5fad198123419a7b54d5f7c9f8a981116462591fbb1a922c39811"],
160 | # network="testnet",
161 | # event_type="creation",
162 | # fromBlock = 9307840
163 | # )
164 |
165 |
166 | # asyncFilterAllocationEvents(indexer_id = "0xbed8e8c97cf3accc3a9dfecc30700b49e30014f3", allocation_ids=["0xFE282240De71e36D857AAD1b342a1075e13857A7"],
167 | # network="testnet",
168 | # event_type="closing",
169 | # fromBlock=9308250 )
170 |
--------------------------------------------------------------------------------
/src/performance_tracking.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | from eth_utils import to_checksum_address
3 | import datetime as dt
4 | from src.queries import getAllAllocations, getActiveAllocations, getClosedAllocations, getAllocationDataById, \
5 | getCurrentBlock
6 | from src.helpers import initialize_rpc, initializeRewardManagerContract, ANYBLOCK_ANALYTICS_ID
7 | import pandas as pd
8 | import numpy as np
9 |
10 |
11 | def calculateRewardsActiveAllocation(allocation_id, interval=1):
12 | # initialize rewardManager Contract
13 | reward_manager_contract = initializeRewardManagerContract()
14 |
15 | # initialize web3 client
16 | web3 = initialize_rpc()
17 |
18 | # Grab allocation data by allocation_id
19 | allocation = getAllocationDataById(allocation_id)
20 | current_block = getCurrentBlock()
21 |
22 | allocation_id = to_checksum_address(allocation['id'])
23 | subgraph_id = allocation['subgraphDeployment']['id']
24 | allocation_creation_block = allocation['createdAtBlockNumber']
25 | subgraph_name = allocation['subgraphDeployment']['originalName']
26 |
27 | # If depreciated / broken and has no name, use ipfsHash as name
28 | if subgraph_name is None:
29 | subgraph_name = allocation['subgraphDeployment']['ipfsHash']
30 |
31 | # calculate the number of hours since the allocation took place
32 | allocation_created_at = allocation['createdAt']
33 | hours_since_allocation = dt.datetime.now() - datetime.fromtimestamp(allocation_created_at)
34 | hours_since_allocation = hours_since_allocation.total_seconds() / 3600
35 |
36 | # calculate the number of hours since the subgraph was created (age in hours)
37 | subgraph_created_at = allocation['subgraphDeployment']['createdAt']
38 | subgraph_hours_since_creation = dt.datetime.now() - datetime.fromtimestamp(subgraph_created_at)
39 | subgraph_hours_since_creation = subgraph_hours_since_creation.total_seconds() / 3600
40 |
41 | # get the amount of GRT allocated
42 | allocated_tokens = int(allocation['allocatedTokens']) / 10 ** 18
43 |
44 | # get the subgraph signal and stake
45 | subgraph_signal = int(allocation['subgraphDeployment']['signalledTokens']) / 10 ** 18
46 | subgraph_stake = int(allocation['subgraphDeployment']['stakedTokens']) / 10 ** 18
47 |
48 | # get the subgraph IPFS hash
49 | subgraph_ipfs_hash = allocation['subgraphDeployment']['ipfsHash']
50 |
51 | # Initialize a delta reward between current and previous interval reward
52 | accumulated_reward_minus_interval = 0
53 |
54 | # iterate through the range from allocation creation block to current block +1 in interval steps
55 | # we expect 270 Blocks per Hour. interval * 270 = Hour interval in blocks
56 |
57 | data = []
58 | temp_data = []
59 | for block in range(allocation_creation_block, current_block + 1, (24 * 270)):
60 | datetime_block = datetime.utcfromtimestamp(web3.eth.get_block(block).get('timestamp')).strftime(
61 | '%Y-%m-%d')
62 |
63 | try:
64 | accumulated_reward = reward_manager_contract.functions.getRewards(allocation_id).call(
65 | block_identifier=block) / 10 ** 18
66 | except:
67 | accumulated_reward = 0
68 |
69 | # calculate the difference between the accumulated reward and the reward from last interval and calc
70 | # the hourly rewards
71 | reward_rate_day = (accumulated_reward - accumulated_reward_minus_interval) / interval
72 | reward_rate_hour = reward_rate_day / 24
73 | reward_rate_hour_per_token = reward_rate_hour / allocated_tokens
74 |
75 | # set the currently accumulated reward fas the previous interval reward for next iteration
76 | accumulated_reward_minus_interval = accumulated_reward
77 | earnings_rate_all_indexers = reward_rate_hour / allocated_tokens * subgraph_stake
78 | try:
79 | stake_signal_ratio = subgraph_signal / subgraph_stake
80 | except:
81 | stake_signal_ratio = 0
82 |
83 | datetime_block = datetime.utcfromtimestamp(web3.eth.get_block(block).get('timestamp')).strftime(
84 | '%Y-%m-%d')
85 |
86 | # create list with entries
87 | temp_data.append({
88 | "datetime": datetime_block,
89 | "subgraph_name": subgraph_name,
90 | "subgraph_ipfs_hash": subgraph_ipfs_hash,
91 | "accumulated_reward": accumulated_reward,
92 | "reward_rate_day": reward_rate_day,
93 | "reward_rate_hour": reward_rate_hour,
94 | "reward_rate_hour_per_token": reward_rate_hour_per_token,
95 | "earnings_rate_all_indexers": earnings_rate_all_indexers,
96 | "subgraph_age_in_hours": subgraph_hours_since_creation,
97 | "subgraph_age_in_days": subgraph_hours_since_creation / 24,
98 | "subgraph_created_at": datetime.utcfromtimestamp(
99 | allocation['subgraphDeployment']['createdAt']).strftime('%Y-%m-%d'),
100 | "subgraph_signal": subgraph_signal,
101 | "subgraph_stake": subgraph_stake,
102 | "subgraph_signal_ratio": stake_signal_ratio,
103 | "block_height": block,
104 | "allocated_tokens": allocated_tokens,
105 | "allocation_id": allocation_id,
106 | "allocation_created_timestamp": datetime.utcfromtimestamp(allocation_created_at).strftime('%Y-%m-%d'),
107 | "allocation_created_epoch": allocation['createdAtEpoch'],
108 | "allocation_status": "Open",
109 | "timestamp": datetime.utcfromtimestamp(
110 | web3.eth.get_block(block).get('timestamp')).strftime('%Y-%m-%d'),
111 | })
112 | data.append(temp_data)
113 | df = pd.DataFrame(temp_data)
114 | return df
115 |
116 |
117 | def calculateRewardsAllActiveAllocations(indexer_id, interval=1):
118 | """Calculates the pending rewards in given interval for all active allocation
119 |
120 | Parameters
121 | -------
122 | interval (int): supply interval for pending rewards calculation in hours. Standard is 1h
123 | indexer_id (str) : supply indexer id for reward calculation on all allocations
124 | """
125 | # grab all active allocations
126 | active_allocations = getActiveAllocations(indexer_id=indexer_id)
127 | if active_allocations:
128 | active_allocations = active_allocations['allocations']
129 |
130 | df = pd.DataFrame(columns=["datetime",
131 | "subgraph_name",
132 | "subgraph_ipfs_hash",
133 | "accumulated_reward",
134 | "reward_rate_day",
135 | "reward_rate_hour",
136 | "reward_rate_hour_per_token",
137 | "earnings_rate_all_indexers",
138 | "subgraph_age_in_hours",
139 | "subgraph_age_in_days",
140 | "subgraph_created_at",
141 | "subgraph_signal",
142 | "subgraph_stake",
143 | "subgraph_signal_ratio",
144 | "block_height",
145 | "allocated_tokens",
146 | "allocation_id",
147 | "allocation_created_timestamp",
148 | "allocation_created_epoch",
149 | "allocation_status",
150 | "timestamp"
151 | ])
152 | # append all active allocations to a temp list with allocation ID
153 | for allocation in active_allocations:
154 | df_temp = calculateRewardsActiveAllocation(allocation_id=allocation['id'], interval=interval)
155 | df = df.append(df_temp)
156 | else:
157 | df = pd.DataFrame(columns=["datetime",
158 | "subgraph_name",
159 | "subgraph_ipfs_hash",
160 | "accumulated_reward",
161 | "reward_rate_day",
162 | "reward_rate_hour",
163 | "reward_rate_hour_per_token",
164 | "earnings_rate_all_indexers",
165 | "subgraph_age_in_hours",
166 | "subgraph_age_in_days",
167 | "subgraph_created_at",
168 | "subgraph_signal",
169 | "subgraph_stake",
170 | "subgraph_signal_ratio",
171 | "block_height",
172 | "allocated_tokens",
173 | "allocation_id",
174 | "allocation_created_timestamp",
175 | "allocation_created_epoch",
176 | "allocation_status",
177 | "timestamp"
178 | ])
179 | return df
180 |
181 |
182 | def calculateRewardsAllClosedAllocations(indexer_id):
183 | """Calculates the rewards and data for all closed Allocations.
184 |
185 | Parameters
186 | -------
187 | indexer_id (str) : supply indexer id for reward calculation on all allocations
188 | """
189 | # grab all active allocations
190 | closed_allocations = getClosedAllocations(indexer_id=indexer_id)
191 |
192 | temp_data = []
193 | if closed_allocations:
194 | for allocation in closed_allocations['totalAllocations']:
195 | if allocation.get('subgraphDeployment').get('signalledTokens'):
196 | subgraph_signal = int(allocation.get('subgraphDeployment').get('signalledTokens')) / 10 ** 18
197 | else:
198 | subgraph_signal = 0
199 |
200 | if allocation.get('subgraphDeployment').get('stakedTokens'):
201 | subgraph_stake = int(allocation.get('subgraphDeployment').get('stakedTokens')) / 10 ** 18
202 | else:
203 | subgraph_stake = 0
204 |
205 | try:
206 | subgraph_signal_ratio = subgraph_stake / subgraph_signal
207 | except ZeroDivisionError:
208 | subgraph_signal_ratio = 0
209 |
210 | subgraph_created_at = allocation['subgraphDeployment']['createdAt']
211 | subgraph_hours_since_creation = dt.datetime.now() - datetime.fromtimestamp(subgraph_created_at)
212 | subgraph_hours_since_creation = subgraph_hours_since_creation.total_seconds() / 3600
213 |
214 | created_at = datetime.utcfromtimestamp(
215 | allocation.get('createdAt')).strftime('%Y-%m-%d')
216 | closed_at = datetime.utcfromtimestamp(
217 | allocation.get('closedAt')).strftime('%Y-%m-%d')
218 |
219 | if (datetime.strptime(closed_at, "%Y-%m-%d") - datetime.strptime(created_at, "%Y-%m-%d")).days > 0:
220 | allocation_duration_days = (datetime.strptime(closed_at, "%Y-%m-%d") - datetime.strptime(created_at, "%Y-%m-%d")).days
221 | else:
222 | allocation_duration_days = 1
223 | reward_rate_day = (int(allocation.get('indexingRewards')) / 10 ** 18) / allocation_duration_days
224 |
225 | temp_data.append({
226 | 'created_at': created_at,
227 | 'closed_at': closed_at,
228 | "subgraph_name": allocation.get('subgraphDeployment').get('originalName'),
229 | "subgraph_ipfs_hash": allocation.get('subgraphDeployment').get('ipfsHash'),
230 | "accumulated_reward": int(allocation.get('indexingRewards')) / 10 ** 18,
231 | "reward_rate_day": reward_rate_day,
232 | "reward_rate_hour": reward_rate_day / 24,
233 | "reward_rate_hour_per_token": (reward_rate_day / 24) / (
234 | int(allocation.get('allocatedTokens')) / 10 ** 18),
235 | "earnings_rate_all_indexers": np.nan,
236 | "subgraph_age_in_hours": subgraph_hours_since_creation,
237 | "subgraph_age_in_days": subgraph_hours_since_creation / 24,
238 | "subgraph_created_at": datetime.utcfromtimestamp(
239 | allocation['subgraphDeployment']['createdAt']).strftime('%Y-%m-%d'),
240 | "subgraph_signal": subgraph_signal,
241 | "subgraph_stake": subgraph_stake,
242 | "subgraph_signal_ratio": subgraph_signal_ratio,
243 | "block_height": np.nan,
244 | "allocation_id": allocation.get('id'),
245 | "allocated_tokens": int(allocation.get('allocatedTokens')) / 10 ** 18,
246 | "allocation_created_timestamp": datetime.utcfromtimestamp(allocation.get('createdAt')).strftime(
247 | '%Y-%m-%d'),
248 | "allocation_created_epoch": allocation.get('createdAtEpoch'),
249 | "allocation_status": "Closed",
250 | "timestamp": datetime.utcfromtimestamp(
251 | allocation.get('closedAt')).strftime('%Y-%m-%d'),
252 | })
253 | df = pd.DataFrame(temp_data)
254 |
255 | # explode dataframe between each created_at and closed_at create rows
256 | df['day'] = df.apply(lambda row: pd.date_range(row['created_at'], row['closed_at'], freq='d'), axis=1)
257 | df = df.explode('day').reset_index() \
258 | .rename(columns={'day': 'datetime'}) \
259 | .drop(columns=['created_at', 'closed_at', 'index'])
260 |
261 | # Move Datetime to First column
262 | col = df.pop("datetime")
263 | df.insert(0, col.name, col)
264 |
265 | # Calculate accumulated reward from reward rate day
266 | df.sort_values(['allocation_id', 'datetime'], inplace=True)
267 |
268 | # get cumulative sum of rewards
269 | df_cumsum = df.groupby(by=['allocation_id', 'datetime'])['reward_rate_day'].sum() \
270 | .groupby(level='allocation_id').cumsum().reset_index(name='accumulated_reward')
271 |
272 | # drop previous accumulated_reward column
273 | df.drop(columns=['accumulated_reward'], inplace=True)
274 |
275 | # merge with main dataframe
276 | df = pd.merge(left=df, right=df_cumsum, how="left", left_on=['allocation_id', 'datetime'],
277 | right_on=["allocation_id", "datetime"])
278 |
279 | # col accumulated_rewards to 3 position
280 | col = df.pop("accumulated_reward")
281 | df.insert(3, col.name, col)
282 |
283 | # change datetime format
284 | df['datetime'] = df['datetime'].dt.strftime("%Y-%m-%d")
285 | else:
286 | df = pd.DataFrame(columns=['created_at',
287 | 'closed_at',
288 | "subgraph_name",
289 | "subgraph_ipfs_hash",
290 | "accumulated_reward",
291 | "reward_rate_day",
292 | "reward_rate_hour",
293 | "reward_rate_hour_per_token",
294 | "earnings_rate_all_indexers",
295 | "subgraph_age_in_hours",
296 | "subgraph_age_in_days",
297 | "subgraph_created_at",
298 | "subgraph_signal",
299 | "subgraph_stake",
300 | "subgraph_signal_ratio",
301 | "block_height",
302 | "allocation_id",
303 | "allocated_tokens",
304 | "allocation_created_timestamp",
305 | "allocation_created_epoch",
306 | "allocation_status",
307 | "timestamp"])
308 | return df
309 |
310 | # calculateRewardsAllClosedAllocations(ANYBLOCK_ANALYTICS_ID)
311 |
--------------------------------------------------------------------------------
/src/poi.py:
--------------------------------------------------------------------------------
1 | import json
2 | import base58
3 | from dotenv import load_dotenv
4 | import os
5 | import requests
6 | import time
7 | from src.queries import getCurrentEpoch, getStartBlockEpoch, getActiveAllocations
8 |
9 | # Indexer ID
10 | ANYBLOCK_ANALYTICS_ID = os.getenv('ANYBLOCK_ANALYTICS_ID')
11 |
12 |
13 | def getPoiQuery(indexerId, subgraphId, blockNumber, blockHash):
14 | """Get's the POI for a specified subgraph, blocknumber, and indexer
15 |
16 | Returns
17 | -------
18 | int
19 | POI
20 | """
21 |
22 | stream = os.popen("http -b post http://localhost:8030/graphql query='query poi {proofOfIndexing( \
23 | subgraph:" + '"' + str(subgraphId) + '"' + ", blockNumber:" + str(blockNumber) + ", \
24 | blockHash:" + '"' + str(blockHash) + '"' + ', \
25 | indexer:' + '"' + str(indexerId) + '"' + ")}'")
26 | output = stream.read()
27 | output
28 |
29 | return output
30 |
31 |
32 | def getValidPoi(indexerId, subgraphHash, start_epoch):
33 | """Get's the POI for an Allocation on one subgraph for a Indexer.
34 |
35 | Returns
36 | -------
37 | list
38 | With subgraphIpfsHash, epoch of POI, startBlock of Epoch, start Hash of Block, POI
39 | """
40 | # get startblock and startHash for all Epochs between Start and End Epoch
41 | listEpochs = list()
42 | for epoch in range(getCurrentEpoch(), start_epoch - 1, -1):
43 | startBlock, startHash = getStartBlockEpoch(epoch)
44 |
45 | # sleep so that the connection is not reset by peer
46 | time.sleep(0.01)
47 |
48 | subgraphIpfsHash = base58.b58encode(bytearray.fromhex('1220' + subgraphHash[2:])).decode("utf-8")
49 |
50 | poi = json.loads(getPoiQuery(indexerId, subgraphIpfsHash, blockNumber=startBlock, blockHash=startHash))
51 | # if no valid POI, return 0x000... POI
52 | allocationPOI = [subgraphHash, epoch, startBlock, startHash,
53 | "0x0000000000000000000000000000000000000000000000000000000000000000"]
54 |
55 | # if valid POI is found, return it with epoch, block etc.
56 | if poi['data']['proofOfIndexing'] is not None:
57 | print(
58 | f"Subgraph: {subgraphHash}, Epoch: {epoch}, startBlock: {startBlock}, startHash: {startHash}, poi: {poi['data']['proofOfIndexing']}")
59 | allocationPOI = [subgraphHash, epoch, startBlock, startHash, poi['data']['proofOfIndexing']]
60 | break
61 | return allocationPOI
62 |
63 |
64 | def getAllAllocationPois(indexerId):
65 | """Get's the POI for all Allocations of one Indexer.
66 |
67 | Returns
68 | -------
69 | list
70 | With subgraphIpfsHash, epoch of POI, startBlock of Epoch, start Hash of Block, POI, allocationId, allocationSubgraphName
71 | """
72 | print("Current Epoch: " + str(getCurrentEpoch()))
73 |
74 | # Grab all Active Allocations
75 | allocations = getActiveAllocations(indexer_id=indexerId)['allocations']
76 |
77 | # List of POIs to be returned
78 | allocationPoiList = list()
79 | allocationPoiDict = dict()
80 | shortAllocationPoiDict = dict()
81 |
82 | for allocation in allocations:
83 | allocationCreatedAtEpoch = allocation['createdAtEpoch']
84 | allocationId = allocation['id']
85 | allocationSubgraphName = allocation['subgraphDeployment']['originalName']
86 | allocationSubgraphHash = allocation['subgraphDeployment']['id']
87 | # If depreciated and no name is available
88 | if allocationSubgraphName is None:
89 | allocationSubgraphName = f'Subgraph{allocations.index(allocation)}'
90 |
91 | allocationPoi = getValidPoi(indexerId, subgraphHash=allocationSubgraphHash,
92 | start_epoch=allocationCreatedAtEpoch)
93 |
94 | allocationPoi.extend([allocationId, allocationSubgraphName])
95 | allocationPoiList.append(allocationPoi)
96 |
97 | data = {
98 | 'epoch': allocationPoi[1],
99 | 'startBlock': allocationPoi[2],
100 | 'startHash': allocationPoi[3],
101 | 'poi': allocationPoi[4],
102 | 'allocationId': allocationPoi[5],
103 | 'allocationSubgraphName': allocationPoi[6],
104 | }
105 | allocationPoiDict[allocationPoi[0]] = data
106 | shortAllocationPoiDict[allocationPoi[0]] = allocationPoi[4]
107 |
108 | # now write output to a file (Long Version)
109 | activeAllocationPois = open("../data/active_allocation_pois.json", "w")
110 |
111 | # magic happens here to make it pretty-printed
112 | activeAllocationPois.write(json.dumps(allocationPoiDict, indent=4, sort_keys=True))
113 | activeAllocationPois.close()
114 |
115 | # now write output to a file (Short Version
116 | shortActiveAllocationPois = open("../data/active_allocation_pois_short.json", "w")
117 |
118 | # magic happens here to make it pretty-printed
119 | shortActiveAllocationPois.write(json.dumps(shortAllocationPoiDict, indent=4, sort_keys=True))
120 | shortActiveAllocationPois.close()
121 |
122 | return allocationPoiList
123 |
124 | # pois = getAllAllocationPois(ANYBLOCK_ANALYTICS_ID)
125 | # print(pois)
126 |
--------------------------------------------------------------------------------
/src/script_creation.py:
--------------------------------------------------------------------------------
1 | import json
2 | import requests
3 | import base58
4 | import os
5 | from dotenv import load_dotenv
6 | def createAllocationScript(indexer_id, fixed_allocations, blacklist_parameter=True, parallel_allocations=1, network='mainnet'):
7 | """ Creates the script.txt file for reallocating based on the inputs of the optimizer
8 | script.
9 |
10 | parameters
11 | --------
12 | indexer_id : The Graph Indexer Wallet ID
13 | fixed_allocation : output set of optimizer
14 | blacklist_parameter: True/False , filter blacklisted subgraphs
15 | parallel_allocations : set amount of parallel allocations
16 |
17 |
18 | returns
19 | --------
20 | int : percentage increase rounded to two decimals
21 |
22 | """
23 | indexer_id = indexer_id.lower()
24 |
25 | load_dotenv()
26 | if network == 'mainnet':
27 | API_GATEWAY = os.getenv('API_GATEWAY')
28 | else:
29 | API_GATEWAY = os.getenv('TESTNET_GATEWAY')
30 | # get blacklisted subgraphs if wanted
31 | if blacklist_parameter:
32 | with open("./config.json", "r") as jsonfile:
33 | INVALID_SUBGRAPHS = json.load(jsonfile).get('blacklist')
34 | else:
35 | INVALID_SUBGRAPHS = False
36 | parallel_allocations = parallel_allocations
37 |
38 | # get the amount of GRT that should be allocated from the optimizer
39 | fixed_allocation_sum = sum(list(fixed_allocations.values())) * parallel_allocations
40 |
41 | # get relevant indexer data
42 | indexer_data = requests.post(
43 | API_GATEWAY,
44 | data='{"query":"{ indexer(id:\\"' + indexer_id + '\\") { account { defaultName { name } } stakedTokens delegatedTokens allocatedTokens tokenCapacity } }"}',
45 | headers={'content-type': 'application/json', 'Accept-Charset': 'UTF-8'}
46 | ).json()['data']['indexer']
47 |
48 | # calculate remaining stake after the fixed_allocation_sum
49 | remaining_stake = int(indexer_data['tokenCapacity']) - int(fixed_allocation_sum)
50 | print(
51 | f"Processing subgraphs for indexer {indexer_data['account']['defaultName']['name'] if indexer_data['account']['defaultName'] else indexer_id}")
52 | print(f"Staked: {int(indexer_data['stakedTokens']) / 10 ** 18:,.2f}")
53 | print(f"Delegated: {int(indexer_data['delegatedTokens']) / 10 ** 18:,.2f}")
54 | print(f"Token Capacity: {int(indexer_data['tokenCapacity']) / 10 ** 18:,.2f}")
55 | print(f"Currently Allocated: {int(indexer_data['allocatedTokens']) / 10 ** 18:,.2f}")
56 | print(f"Fixed Allocation: {int(fixed_allocation_sum) / 10 ** 18:,.2f}")
57 | print(f"Remaining Stake: {remaining_stake / 10 ** 18:,.2f}")
58 | print('=' * 40)
59 |
60 | if (int(indexer_data['tokenCapacity']) - int(indexer_data['allocatedTokens']) < int(fixed_allocation_sum)):
61 | print("Not enough free stake for fixed allocation. Free to stake first")
62 | # sys.exit()
63 |
64 | subgraph_data = requests.post(
65 | API_GATEWAY,
66 | data='{"query":"{ subgraphDeployments(first: 1000) { id originalName stakedTokens signalledTokens } }"}',
67 | headers={'content-type': 'application/json', 'Accept-Charset': 'UTF-8'}
68 | ).json()['data']['subgraphDeployments']
69 |
70 | subgraphs = set()
71 | invalid_subgraphs = set()
72 | total_signal = 0
73 | total_stake = 0
74 |
75 | for subgraph_deployment in subgraph_data:
76 | subgraph = base58.b58encode(bytearray.fromhex('1220' + subgraph_deployment['id'][2:])).decode("utf-8")
77 | if INVALID_SUBGRAPHS:
78 | if subgraph in INVALID_SUBGRAPHS:
79 | #print(f" Skipping invalid Subgraph: {subgraph_deployment['originalName']} ({subgraph})")
80 | invalid_subgraphs.add(subgraph)
81 | pass
82 | if subgraph in fixed_allocations.keys():
83 | print(
84 | f"{subgraph_deployment['originalName']} ({subgraph}) Total Stake: {int(subgraph_deployment['stakedTokens']) / 10 ** 18:,.2f} Total Signal: {int(subgraph_deployment['signalledTokens']) / 10 ** 18:,.2f} , Ratio: {(int(subgraph_deployment['stakedTokens']) / 10 ** 18) / ((int(subgraph_deployment['signalledTokens']) + 1) / 10 ** 18)}")
85 | subgraphs.add(subgraph)
86 | total_signal += int(subgraph_deployment['signalledTokens'])
87 | total_stake += int(subgraph_deployment['stakedTokens'])
88 | else:
89 | if subgraph in fixed_allocations.keys():
90 | print(
91 | f"{subgraph_deployment['originalName']} ({subgraph}) Total Stake: {int(subgraph_deployment['stakedTokens']) / 10 ** 18:,.2f} Total Signal: {int(subgraph_deployment['signalledTokens']) / 10 ** 18:,.2f} , Ratio: {(int(subgraph_deployment['stakedTokens']) / 10 ** 18) / ((int(subgraph_deployment['signalledTokens']) + 1) / 10 ** 18)}")
92 | subgraphs.add(subgraph)
93 | total_signal += int(subgraph_deployment['signalledTokens'])
94 | total_stake += int(subgraph_deployment['stakedTokens'])
95 |
96 | print(f"Total Signal: {total_signal / 10 ** 18:,.2f}")
97 | print(f"Total Stake: {total_stake / 10 ** 18:,.2f}")
98 | print('=' * 40)
99 | dynamic_allocation = 0
100 | # error
101 | """
102 | if remaining_stake != 0:
103 | if len(subgraphs) > 1:
104 | dynamic_allocation = math.floor(
105 | remaining_stake / (len(subgraphs - set(FIXED_ALLOCATION.keys()))) / PARALLEL_ALLOCATIONS / (
106 | 500 * 10 ** 18)) * (
107 | 500 * 10 ** 18)
108 | """
109 | print(f"Subgraphs: {len(subgraphs)}")
110 | print(f"Fixed: {len(set(fixed_allocations.keys()))}")
111 | print(f"Dynamic: {len(subgraphs - set(fixed_allocations.keys()))}")
112 | print(f"Dynamic Allocation: {dynamic_allocation / 10 ** 18:,.2f}")
113 | print('=' * 40)
114 | print()
115 | script_file = open("./script.txt", "w+")
116 | # print(
117 | # "graph indexer rules set global allocationAmount 10.0 parallelAllocations 2 minStake 500.0 decisionBasis rules && \\")
118 | for subgraph in subgraphs:
119 | # Delete rule -> reverts to default. This will trigger extra allocations!
120 | # print(f"graph indexer rules delete {subgraph} && \\")
121 | # Set fixed or dynamic allocation
122 | if subgraph in fixed_allocations.keys():
123 | if fixed_allocations[subgraph] != 0:
124 | script_file.write(
125 | f"graph indexer rules set {subgraph} allocationAmount {fixed_allocations[subgraph] / 10 ** 18:.2f} parallelAllocations {parallel_allocations} decisionBasis always && \\\n")
126 | script_file.write(f"graph indexer cost set model {subgraph} default.agora && \\\n")
127 | script_file.write(f"graph indexer cost set variables {subgraph} '{{}}' && \\\n")
128 |
129 | else:
130 |
131 | if dynamic_allocation != 0:
132 | script_file.write(
133 | f"graph indexer rules set {subgraph} allocationAmount {dynamic_allocation / 10 ** 18:.2f} parallelAllocations {parallel_allocations} decisionBasis always && \\\n")
134 | script_file.write(f"graph indexer cost set model {subgraph} default.agora && \\\n")
135 | script_file.write(f"graph indexer cost set variables {subgraph} '{{}}' && \\\n")
136 |
137 | script_file.write("graph indexer rules get all --merged && \\\n")
138 | script_file.write("graph indexer cost get all")
139 | script_file.close()
140 |
141 | # Disable rule -> this is required to "reset" allocations
142 | script_never = open("./script_never.txt", "w+")
143 |
144 | for subgraph in subgraphs:
145 | script_never.write(f"graph indexer rules set {subgraph} decisionBasis never && \\\n")
146 | for subgraph in invalid_subgraphs:
147 | script_never.write(f"graph indexer rules set {subgraph} decisionBasis never && \\\n")
148 | script_never.write("graph indexer rules get all --merged && \\\n")
149 | script_never.write("graph indexer cost get all")
150 | script_never.close()
151 | return
152 |
153 |
--------------------------------------------------------------------------------
/src/subgraph_health_checks.py:
--------------------------------------------------------------------------------
1 | import json
2 | from src.helpers import connectIndexerDatabase
3 | from src.queries import getSubgraphsFromDeveloper, getInactiveSubgraphs, getAllSubgraphDeployments, checkSubgraphStatus
4 |
5 |
6 | def getIndexedSubgraphsFromDatabase():
7 | # connect to postgres thegraph database
8 | pg_client = connectIndexerDatabase()
9 |
10 | # query for a list of subgraphs that are indexed, sorting by Failed and Lag
11 | cur = pg_client.cursor()
12 | query = '''
13 | SELECT
14 | d.deployment AS "deployment",
15 | d.synced AS "synced",
16 | d.failed AS "failed",
17 | a.node_id AS "node",
18 | (network.head_block_number - d.latest_ethereum_block_number) AS "lag"
19 | FROM
20 | subgraphs.subgraph_deployment AS d,
21 | subgraphs.subgraph_deployment_assignment AS a,
22 | public.ethereum_networks AS network
23 | WHERE a.id = d.id
24 | AND network.name = 'mainnet'
25 | AND a.node_id != 'removed'
26 | ORDER BY "lag" DESC, "deployment" DESC
27 | '''
28 |
29 | cur.execute(query)
30 | rows = cur.fetchall()
31 | return rows
32 |
33 |
34 | def fillBlacklistFromDatabaseBySyncAndError():
35 | rows = getIndexedSubgraphsFromDatabase()
36 |
37 | # open config.json and get blacklisted array
38 | with open("../config.json", "r") as jsonfile:
39 | config = json.load(jsonfile)
40 | blacklisted_subgraphs = config.get('blacklist')
41 |
42 | for row in rows:
43 | # print(f'Subgraph: {row[0]}, Synced: {row[1]}, Failed: {row[2]}, Node: {row[3]}, Lag: {row[4]}')
44 |
45 | # If Failed == True or Lag > 1000 append to blacklisted_subgraphs
46 | if row[2] == True or row[4] > 10000:
47 | print(row)
48 | blacklisted_subgraphs.append(row[0]) # append subgraph id to blacklist
49 |
50 | else:
51 | # remove all synced and not failed occurences from blacklist
52 | blacklisted_subgraphs = [subgraph for subgraph in blacklisted_subgraphs if subgraph != row[0]]
53 |
54 | config['blacklist'] = blacklisted_subgraphs
55 |
56 | # rewrite config.json file, keeps entrys that are already in there and are not changed by the conditions above
57 | with open("../config.json", "w") as f:
58 | f.write(json.dumps(config))
59 | f.close()
60 |
61 |
62 | def fillBlackListFromBlacklistedDevs(network):
63 | """Get's the blacklistede developers from the config.json file. Adds all Subgraphs that are
64 | deployed by the blacklisted developer to the blacklist (config.json['blacklist'])
65 |
66 | Returns
67 | -------
68 | print
69 | (Blacklisted Developer: Blacklisted Subgraphs)
70 | """
71 | # open config.json and get blacklisted array
72 | with open("./config.json", "r") as jsonfile:
73 | config = json.load(jsonfile)
74 |
75 | # Get List of Blacklisted Developers from config.json
76 | blacklisted_devs = config.get('blacklisted_devs')
77 |
78 | # gets the List of Blacklisted Subgraphs from config.json
79 | blacklisted_subgraphs = config.get('blacklist')
80 |
81 | # iterate through each blacklisted developer and append the subgraph IpfsHash to the blacklist
82 | for dev in blacklisted_devs:
83 | blacklisted_subgraphs_from_dev = getSubgraphsFromDeveloper(dev, network)
84 | for subgraph in blacklisted_subgraphs_from_dev:
85 | if subgraph not in blacklisted_subgraphs:
86 | blacklisted_subgraphs.append(subgraph) # append subgraph id to blacklist
87 | print(f"Blacklisted Developer {dev} and Subgraphs: {blacklisted_subgraphs_from_dev}")
88 |
89 | config['blacklist'] = blacklisted_subgraphs
90 |
91 | # rewrite config.json file, keeps entrys that are already in there and are not changed by the conditions above
92 | with open("../config.json", "w") as f:
93 | f.write(json.dumps(config, indent=4, sort_keys=True))
94 | f.close()
95 |
96 |
97 | def fillBlackListFromInactiveSubgraphs(network):
98 | """Get's the inactive subgraphs. Adds all Subgraphs that are
99 | inactive to the blacklist (config.json['blacklist'])
100 |
101 | Returns
102 | -------
103 | print
104 | (Blacklisted Subgraphs)
105 | """
106 | # open config.json and get blacklisted array
107 | with open("./config.json", "r") as jsonfile:
108 | config = json.load(jsonfile)
109 |
110 | # gets the List of Blacklisted Subgraphs from config.json
111 | blacklisted_subgraphs = config.get('blacklist')
112 |
113 | inactive_subgraph_list = getInactiveSubgraphs(network = network)
114 |
115 | # iterate through each inactive subgraph and append the subgraph IpfsHash to the blacklist
116 | for subgraph in inactive_subgraph_list:
117 | if subgraph not in blacklisted_subgraphs:
118 | blacklisted_subgraphs.append(subgraph) # append subgraph id to blacklist
119 |
120 | print(f"Blacklisted inactive Subgraphs: {inactive_subgraph_list}")
121 |
122 | config['blacklist'] = blacklisted_subgraphs
123 |
124 | # rewrite config.json file, keeps entrys that are already in there and are not changed by the conditions above
125 | with open("./config.json", "w") as f:
126 | f.write(json.dumps(config, indent=4, sort_keys=True))
127 | f.close()
128 |
129 |
130 |
131 | def isSubgraphHealthy(subgraph_id):
132 | """Checks Subgraph Health Status for Subgraph. Returns either
133 | True = Healthy, or False = Unhealthy
134 |
135 | Returns
136 | -------
137 |
138 | Bool (True / False)
139 |
140 | """
141 | subgraph_health = checkSubgraphStatus([subgraph_id])
142 | for status in subgraph_health:
143 | sync = status['synced']
144 | healthy = status['health']
145 |
146 | if status['fatalError']:
147 | error = True
148 | else:
149 | error = False
150 |
151 | # if status can not be found (depreciated subgraph) return False
152 | if not subgraph_health:
153 | return False
154 |
155 | # if subgraph not synced, return False
156 | elif not sync:
157 | return False
158 |
159 | # if subgraph not healthy, return False
160 | elif healthy == "failed":
161 | return False
162 | # if subgraph has errors, return False
163 |
164 | elif error:
165 | return False
166 |
167 | else:
168 | return True
169 |
170 |
171 | def fillBlackListFromSubgraphHealthStatus(network):
172 | """Fills Blacklist based on Subgraph Healt status for all SubgraphDeployments
173 |
174 | """
175 |
176 | # open config.json and get blacklisted array
177 | with open("./config.json", "r") as jsonfile:
178 | config = json.load(jsonfile)
179 |
180 | # gets the List of Blacklisted Subgraphs from config.json
181 | blacklisted_subgraphs = config.get('blacklist')
182 |
183 | subgraph_list = getAllSubgraphDeployments(network)
184 |
185 | # iterate through each subgraph
186 | for subgraph in subgraph_list:
187 | # check if subgraph is healthy
188 | subgraph_healthy = isSubgraphHealthy(subgraph)
189 |
190 | # if it is not healthy
191 | if not subgraph_healthy:
192 | # check if it is already in blacklist
193 | if subgraph not in blacklisted_subgraphs:
194 | # if it is not, append to it.
195 | blacklisted_subgraphs.append(subgraph) # append subgraph id to blacklist
196 | print(f"Blacklisted unhealthy Subgraphs: {subgraph}")
197 |
198 | config['blacklist'] = blacklisted_subgraphs
199 |
200 | # rewrite config.json file, keeps entrys that are already in there and are not changed by the conditions above
201 | with open("./config.json", "w") as f:
202 | f.write(json.dumps(config, indent=4, sort_keys=True))
203 | f.close()
204 |
205 |
206 | def checkMetaSubgraphHealth():
207 | """Checks Subgraph Health Status for Meta Subgraph for Mainnet (necessary to be healthy for reallocating)
208 |
209 | Returns
210 | -------
211 |
212 | Bool: True / False (Healthy if True, Broken if False)
213 |
214 | """
215 | #Qmf5XXWA8zhHbdvWqtPcR3jFkmb5FLR4MAefEYx8E3pHfr
216 | # old? : QmVbZAsN4NUxLDFS66JjmjUDWiYQVBAXPDQk26DGnLeRqz
217 | meta_subgraph_health = isSubgraphHealthy("Qmf5XXWA8zhHbdvWqtPcR3jFkmb5FLR4MAefEYx8E3pHfr")
218 | return meta_subgraph_health
219 |
220 |
221 | def createBlacklist(database=False, network='mainnet'):
222 | """creates Blacklist of Subgraphs from previous Subgraph Checks.
223 |
224 | Parameters:
225 | database: Boolean, if true checks postgres node database for not in sync / error Subgraphs
226 | """
227 | if database:
228 | fillBlacklistFromDatabaseBySyncAndError()
229 | fillBlackListFromBlacklistedDevs(network = network)
230 | fillBlackListFromInactiveSubgraphs(network = network)
231 | fillBlackListFromSubgraphHealthStatus(network = network)
232 |
233 | # createBlacklist()
234 |
--------------------------------------------------------------------------------
/src/webapp/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/anyblockanalytics/thegraph-allocation-optimization/d53927eccfc55f830f249126a950575dbfed2f9e/src/webapp/__init__.py
--------------------------------------------------------------------------------
/src/webapp/about.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 |
3 | def aboutTooling(col):
4 | with col.expander("Information about the Tooling 💡"):
5 | st.markdown(
6 | "# The Graph Allocation Optimization Tooling"
7 | "\nCheck out the [Documentation](https://enderym.github.io/allocation-optimization-doc/) "
8 | "\nThis web app provides metrics and functions to optimize allocations of indexers."
9 | )
10 |
--------------------------------------------------------------------------------
/src/webapp/key_metrics.py:
--------------------------------------------------------------------------------
1 | from src.queries import getFiatPrice, getGasPrice, getHistoricalPriceData
2 | import streamlit as st
3 | from millify import millify
4 | import json
5 | from src.performance_tracking import calculateRewardsAllActiveAllocations, calculateRewardsAllClosedAllocations
6 | import plotly.express as px
7 | import pandas as pd
8 | from plotly import graph_objs as go
9 | from plotly.subplots import make_subplots
10 | import numpy as np
11 | from datetime import datetime, timedelta
12 |
13 |
14 | def createMetricsOutput():
15 | # output interesting statistics
16 |
17 | col1, col2, col3 = st.columns(3)
18 | col1.metric("ETH-USD Price", millify(getFiatPrice('ETH-USD'), precision=2))
19 | col2.metric("GRT-USD Price", millify(getFiatPrice('GRT-USD'), precision=2))
20 | col3.metric("Gas Price (Gwei)", millify(getGasPrice(speed='fast')))
21 |
22 |
23 | def getPreviousRuns(col):
24 | # read optimization log
25 | with open("./data/optimizer_log.json") as optimization_log:
26 | log = json.load(optimization_log)
27 |
28 | # save all keys in list
29 | get_date_data = list()
30 | for entry in log:
31 | for key, value in entry.items():
32 | get_date_data.append(key)
33 |
34 | with col.expander("Data from Previous Optimizations:"):
35 | # selector for key (date) and then show values of optimization run
36 | options = st.selectbox(label="Select previous Optimization Data", options=get_date_data)
37 | for entry in log:
38 | if entry.get(options):
39 | st.write(entry)
40 |
41 |
42 | @st.cache
43 | def getActiveAllocationPerformance(indexer_id):
44 | # Load Historical performance for Active Allocations
45 |
46 | df = calculateRewardsAllActiveAllocations(indexer_id)
47 | return df
48 |
49 |
50 | @st.cache
51 | def getClosedAllocationPerformance(indexer_id):
52 | # Load Historical performance for Active Allocations
53 | df = calculateRewardsAllClosedAllocations(indexer_id)
54 | return df
55 |
56 |
57 | def mergeDatasetWithPrices(df, currency='usd'):
58 | # merge with historical price data
59 |
60 |
61 | start_datetime = datetime.today() - timedelta(days=900)
62 | end_datetime = datetime.today()
63 |
64 | start_datetime = datetime.combine(start_datetime, datetime.min.time())
65 | end_datetime = datetime.combine(end_datetime, datetime.max.time())
66 |
67 | # grab the price data
68 | eth_price_data = getHistoricalPriceData('the-graph', "usd", start_datetime, end_datetime)
69 |
70 | # Merge both dataframes
71 | df['datetime'] = pd.to_datetime(
72 | pd.to_datetime(df['datetime']),
73 | format='%Y-%m-%d').dt.date
74 |
75 | df = pd.merge(df, eth_price_data, left_on='datetime',
76 | right_on='datetime', how="left")
77 |
78 | # calculate prices with fiat
79 | df['accumulated_reward_fiat'] = df['accumulated_reward'] * df['close']
80 | df['reward_rate_hour_fiat'] = df['reward_rate_hour'] * df['close']
81 | return df
82 |
83 |
84 | def visualizePerformance(df_active, df_closed):
85 | # Show Historical Performance based on Selection of Data
86 | st.subheader("Historical Performance Metrics (Closed/Active/Combined):")
87 | if (df_active.size > 0) & (df_closed.size > 0):
88 |
89 | # combine both datasets
90 | df_combined = pd.concat([df_active, df_closed], axis=0, ignore_index=True)
91 |
92 | # create column for
93 | allocations_created_count_by_day = df_combined.groupby(["allocation_created_timestamp", "allocation_id"]) \
94 | .size().values
95 |
96 | col1, col2 = st.columns(2)
97 | options = col1.selectbox(label='Select Active, Closed or Combined Visualizations:',
98 | options=['Closed', 'Active', 'Combined'])
99 | currency_options = col2.selectbox("Fiat Currency", ('usd', 'eur'))
100 |
101 | map_options_df = {
102 | 'Closed': mergeDatasetWithPrices(df_closed, currency_options),
103 | 'Active': mergeDatasetWithPrices(df_active, currency_options),
104 | 'Combined': mergeDatasetWithPrices(df_combined, currency_options)
105 | }
106 |
107 | tableHistoricalPerformance(map_options_df[options], options)
108 | visualizeHistoricalPerformanceDiyChart(map_options_df[options])
109 | visualizeHistoricalPerformanceDedicatedCharts(map_options_df[options])
110 |
111 |
112 | def tableHistoricalPerformance(df, options):
113 | with st.expander(f"Data Table for Historical Performance {options}"):
114 | st.dataframe(df)
115 |
116 |
117 | def visualizeHistoricalPerformanceDiyChart(df):
118 | # Visualize Historical Performance
119 | with st.expander('DIY Chart Builder'):
120 | col1, col2, col3, col4 = st.columns(4)
121 | options = ["datetime",
122 | "subgraph_name",
123 | "subgraph_ipfs_hash",
124 | "accumulated_reward",
125 | "reward_rate_day",
126 | "reward_rate_hour",
127 | "reward_rate_hour_per_token",
128 | "earnings_rate_all_indexers",
129 | "subgraph_age_in_hours",
130 | "subgraph_created_at"
131 | "subgraph_age_in_days",
132 | "subgraph_signal",
133 | "subgraph_stake",
134 | "subgraph_signal_ratio",
135 | "block_height",
136 | "allocated_tokens",
137 | "allocation_created_timestamp",
138 | "allocation_created_epoch",
139 | "allocation_status",
140 | "timestamp"
141 | ]
142 | options_col_group = ['None', 'subgraph_name', 'subgraph_ipfs_hash', 'allocation_status']
143 | bar_type = ['bar', 'line', 'scatter', 'area']
144 | x_value = col1.selectbox(label="Select X - Value: ", options=options)
145 | y_value = col2.selectbox(label="Select Y - Value: ", options=options)
146 | col_value = col3.selectbox(label="Select Group By Color - Value", options=options_col_group)
147 | bar_value = col4.selectbox(label="Select Bar Type: ", options=bar_type)
148 | if col_value == 'None':
149 | col_value = None
150 | if bar_value == "line":
151 | fig = px.line(df, x=x_value, y=y_value,
152 | color=col_value, title='Visualization for: ' + str([x_value, y_value, col_value]),
153 | hover_name="subgraph_ipfs_hash")
154 | if bar_value == "bar":
155 | fig = px.bar(df, x=x_value, y=y_value,
156 | color=col_value, title='Visualization for: ' + str([x_value, y_value, col_value]),
157 | hover_name="subgraph_ipfs_hash")
158 | if bar_value == "scatter":
159 | fig = px.scatter(df, x=x_value, y=y_value,
160 | color=col_value, title='Visualization for: ' + str([x_value, y_value, col_value]),
161 | hover_name="subgraph_ipfs_hash")
162 | if bar_value == "area":
163 | fig = px.area(df, x=x_value, y=y_value,
164 | color=col_value, title='Visualization for: ' + str([x_value, y_value, col_value]),
165 | hover_name="subgraph_ipfs_hash")
166 | st.plotly_chart(fig, use_container_width=True)
167 |
168 |
169 | def visualizeHistoricalPerformanceDedicatedCharts(df):
170 | with st.expander('Performance Metrics'):
171 | # create dataframe for allocation created on datetime
172 | allocations_created_count_by_day = df[df['allocated_tokens'] > 1000].groupby(
173 | ["allocation_created_timestamp", "allocation_id"]) \
174 | .size().reset_index().groupby('allocation_created_timestamp').count().reset_index() \
175 | .rename(columns={"allocation_id": "amount_allocations"})
176 | df_specific = df
177 |
178 | # group by allocation
179 |
180 | df_specific = df_specific.groupby([df['datetime'], df['subgraph_name']], as_index=False).agg({
181 | 'datetime': 'max',
182 | 'allocated_tokens': 'sum',
183 | 'accumulated_reward': 'sum',
184 | 'reward_rate_day': 'sum',
185 | 'reward_rate_hour': 'sum',
186 | 'reward_rate_hour_fiat': 'sum',
187 | })
188 | # group data by date
189 | df = df.groupby(df['datetime'], as_index=False).agg({
190 | 'datetime': 'max',
191 | 'allocated_tokens': 'max',
192 | 'accumulated_reward': 'sum',
193 | 'accumulated_reward_fiat': 'sum',
194 | 'reward_rate_hour': 'sum',
195 | 'reward_rate_hour_fiat': 'sum',
196 | 'reward_rate_hour_per_token': 'sum',
197 | 'subgraph_signal_ratio': 'sum',
198 | 'close': 'max'
199 |
200 | })
201 | # merge with allocations created
202 | df = pd.merge(left=df, right=allocations_created_count_by_day, how="left", left_on="datetime",
203 | right_on="allocation_created_timestamp")
204 |
205 | visualizeHistoricalAggregatedPerformance(df, allocations_created_count_by_day)
206 |
207 | fig2 = visualizeHistoricalAccumuluatedRewards(df)
208 | fig3 = visualizeSubgraphPerformance(df_specific)
209 |
210 | st.plotly_chart(fig2, use_container_width=True)
211 | st.plotly_chart(fig3, use_container_width=True)
212 |
213 |
214 | def visualizeHistoricalAccumuluatedRewards(df):
215 | fig = make_subplots(specs=[[{"secondary_y": True}]])
216 | fig.add_trace(go.Scatter(x=df.datetime, y=df.accumulated_reward,
217 | marker=dict(
218 | color='rgba(50, 171, 96, 0.6)',
219 | line=dict(
220 | color='rgba(50, 171, 96, 1.0)',
221 | width=1),
222 | ),
223 | name='Accumulated Rewards in GRT per Day',
224 | orientation='h')
225 |
226 | )
227 | fig.add_trace(go.Scatter(x=df.datetime, y=df.accumulated_reward_fiat,
228 | marker=dict(
229 | color='rgba(216,191,216, 0.6)',
230 | line=dict(
231 | color='rgba(216,191,216, 1.0)',
232 | width=1),
233 | ),
234 | name='Accumulated Rewards in FIAT per Day',
235 | orientation='h'), secondary_y=False
236 |
237 | )
238 | fig.add_trace(go.Scatter(x=df.datetime, y=df.close,
239 | marker=dict(
240 | color='rgba(189,183,107, 0.6)',
241 | line=dict(
242 | color='rgba(189,183,107, 1.0)',
243 | width=1),
244 | ),
245 | name='GRT - Fiat Closing Price',
246 | orientation='h'), secondary_y=True
247 |
248 | )
249 | fig.update_layout(
250 | title='Historical Performance: Accumulated Indexing Rewards in GRT per Day',
251 | yaxis=dict(
252 | showgrid=False,
253 | showline=False,
254 | showticklabels=True,
255 | domain=[0, 0.85],
256 | ),
257 | yaxis2=dict(
258 | showgrid=False,
259 | showline=False,
260 | showticklabels=True,
261 | linecolor='rgba(102, 102, 102, 0.8)',
262 | linewidth=2,
263 | domain=[0.3, 0.5],
264 | range=[0, df['close'].max() + (
265 | df['close'].max() * 0.3)]
266 | ),
267 | xaxis=dict(
268 | zeroline=False,
269 | showline=False,
270 | showticklabels=True,
271 | showgrid=True,
272 | domain=[0, 1],
273 | ),
274 | legend=dict(x=0.029, y=1.038, font_size=12),
275 | margin=dict(l=100, r=20, t=70, b=70),
276 | paper_bgcolor='rgb(255, 255, 255)',
277 | plot_bgcolor='rgb(255, 255, 255)',
278 | font=dict(
279 | family="Courier New, monospace",
280 | ),
281 | height=600
282 | )
283 | # Set x-axis title
284 | fig.update_xaxes(title_text="Datetime")
285 |
286 | # Set y-axes titles
287 | fig.update_yaxes(title_text="Accumulated Indexing Rewards Daily (GRT) ")
288 | fig.update_yaxes(title_text="GRT-FIAT Closing Price", secondary_y=True)
289 |
290 | return fig
291 |
292 |
293 | def visualizeSubgraphPerformance(df):
294 | fig = make_subplots(specs=[[{"secondary_y": True}]])
295 | for c in df['subgraph_name'].unique():
296 | df_temp = df[df['subgraph_name'] == c]
297 |
298 | fig.add_trace(go.Scatter(x=df_temp.datetime, y=df_temp.reward_rate_hour,
299 | marker=dict(
300 | color='rgba(216,191,216, 0.6)',
301 | line=dict(
302 | color='rgba(216,191,216, 1.0)',
303 | width=1),
304 | ),
305 | name=c + ' Reward Rate',
306 | visible='legendonly',
307 | orientation='h'), secondary_y=False)
308 | fig.add_trace(go.Scatter(x=df_temp.datetime, y=df_temp.accumulated_reward,
309 | marker=dict(
310 | color='rgba(50, 171, 96, 0.6)',
311 | line=dict(
312 | color='rgba(50, 171, 96, 1.0)',
313 | width=1),
314 | ),
315 | name=c + ' Accumulated Rewards',
316 | visible='legendonly',
317 | orientation='h'), secondary_y=True)
318 | fig.update_layout(
319 |
320 | title='Historical Performance per Subgraph: Accumulated Indexing Rewards in GRT per Day and Reward Rate Hour',
321 | yaxis=dict(
322 | showgrid=False,
323 | showline=False,
324 | showticklabels=True,
325 | domain=[0, 0.85],
326 | ),
327 | yaxis2=dict(
328 | showgrid=False,
329 | showline=False,
330 | showticklabels=True,
331 | linecolor='rgba(102, 102, 102, 0.8)',
332 | linewidth=2,
333 | domain=[0.3, 0.5],
334 | range=[0, df['accumulated_reward'].max() + (
335 | df['accumulated_reward'].max() * 0.3)]
336 | ),
337 | xaxis=dict(
338 | zeroline=False,
339 | showline=False,
340 | showticklabels=True,
341 | showgrid=True,
342 | domain=[0, 0.9],
343 | ),
344 | legend=dict(font_size=12),
345 | margin=dict(l=100, r=20, t=70, b=70),
346 | paper_bgcolor='rgb(255, 255, 255)',
347 | plot_bgcolor='rgb(255, 255, 255)',
348 | font=dict(
349 | family="Courier New, monospace",
350 | ),
351 | height=600
352 | )
353 | # Set x-axis title
354 | fig.update_xaxes(title_text="Datetime")
355 |
356 | # Set y-axes titles
357 | fig.update_yaxes(title_text="Rewards Hourly (GRT) ")
358 | fig.update_yaxes(title_text="Rewards Accumulated (GRT)", secondary_y=True)
359 |
360 | return fig
361 |
362 |
363 | def visualizeHistoricalAggregatedPerformance(df, allocations_created_count_by_day):
364 | # get amount of created allocations per day
365 | """
366 | fig = px.area(df, x='datetime',
367 | y=["reward_rate_hour", "reward_rate_hour_per_token", "accumulated_reward",
368 | "subgraph_signal_ratio"],
369 | title='Rewards per Hour and Accumulated Rewards for Indexer',
370 | hover_name="datetime")
371 | fig.add_scatter(x=allocations_created_count_by_day['allocation_created_timestamp'],
372 | y=allocations_created_count_by_day['amount_allocations'],
373 | name="Allocations Opened (over 1000GRT")
374 | """
375 | fig = make_subplots(specs=[[{"secondary_y": True}]])
376 | fig.add_trace(go.Scatter(x=df.datetime, y=df.reward_rate_hour,
377 | marker=dict(
378 | color='rgba(50, 171, 96, 0.6)',
379 | line=dict(
380 | color='rgba(50, 171, 96, 1.0)',
381 | width=1),
382 | ),
383 | name='Hourly Indexing Rewards in GRT per Day',
384 | orientation='h'), secondary_y=False
385 |
386 | )
387 | fig.add_trace(go.Scatter(x=df.datetime, y=df.reward_rate_hour_fiat,
388 | marker=dict(
389 | color='rgba(216,191,216, 0.6)',
390 | line=dict(
391 | color='rgba(216,191,216, 1.0)',
392 | width=1),
393 | ),
394 | name='Hourly Indexing Rewards in FIAT per Day',
395 | orientation='h'), secondary_y=False
396 |
397 | )
398 | fig.add_trace(go.Scatter(
399 | x=allocations_created_count_by_day['allocation_created_timestamp'],
400 | y=allocations_created_count_by_day['amount_allocations'],
401 | mode='markers',
402 | marker=dict(size=allocations_created_count_by_day['amount_allocations'] * 7,
403 | color=np.random.randn(500),
404 | colorscale='Viridis'),
405 | line_color='rgb(128, 0, 128)',
406 | name='New Allocation Count per Day (allocations larger than 1000 GRT)'
407 | ), secondary_y=True)
408 |
409 | fig.update_layout(
410 | title='Historical Performance: Indexing Rewards per Hour in GRT and Amount of New Allocations per Day',
411 | yaxis=dict(
412 | showgrid=False,
413 | showline=False,
414 | showticklabels=True,
415 | domain=[0, 0.85],
416 | ),
417 | yaxis2=dict(
418 | showgrid=False,
419 | showline=False,
420 | showticklabels=True,
421 | linecolor='rgba(102, 102, 102, 0.8)',
422 | linewidth=2,
423 | domain=[0.3, 0.5],
424 | range=[0, allocations_created_count_by_day['amount_allocations'].max() + (
425 | allocations_created_count_by_day['amount_allocations'].max() * 0.3)]
426 | ),
427 | xaxis=dict(
428 | zeroline=False,
429 | showline=False,
430 | showticklabels=True,
431 | showgrid=True,
432 | domain=[0, 1],
433 | ),
434 | legend=dict(x=0.029, y=1.038, font_size=12),
435 | margin=dict(l=100, r=20, t=70, b=70),
436 | paper_bgcolor='rgb(255, 255, 255)',
437 | plot_bgcolor='rgb(255, 255, 255)',
438 | font=dict(
439 | family="Courier New, monospace",
440 | ),
441 | height=600
442 | )
443 | # Set x-axis title
444 | fig.update_xaxes(title_text="Datetime")
445 |
446 | # Set y-axes titles
447 | fig.update_yaxes(title_text="Indexing Rewards Hourly (GRT) ", secondary_y=False)
448 | fig.update_yaxes(title_text="New Allocations count (> 1000 GRT)", secondary_y=True)
449 |
450 | annotations = []
451 | for ydn, yd, xd in zip(allocations_created_count_by_day['amount_allocations'], df.reward_rate_hour,
452 | allocations_created_count_by_day['allocation_created_timestamp']):
453 | # labeling the scatter savings
454 | annotations.append(dict(xref='x', yref='y2',
455 | y=ydn + 0.2, x=xd,
456 | text='{:,}'.format(ydn) + 'Alloc.',
457 | font=dict(family='Arial', size=14,
458 | color='rgb(128, 0, 128)'),
459 | showarrow=True))
460 | fig.update_layout(annotations=annotations)
461 |
462 | st.plotly_chart(fig, use_container_width=True)
463 |
--------------------------------------------------------------------------------
/src/webapp/overview.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | import streamlit as st
3 | from src.webapp.sidebar import createSidebar
4 | from src.webapp.display_optimizer import createOptimizerOutput
5 | from src.webapp.key_metrics import createMetricsOutput, getPreviousRuns, \
6 | getActiveAllocationPerformance, getClosedAllocationPerformance, visualizePerformance
7 | from src.webapp.about import aboutTooling
8 | import copy
9 | def streamlitEntry():
10 | # set page width
11 | st.set_page_config(layout="wide")
12 | # set title and create sidebar
13 | st.title('The Graph Allocation Optimization Script')
14 | parameters = createSidebar()
15 |
16 | # show informations and previous runs
17 | col1, col2 = st.columns(2)
18 | aboutTooling(col1)
19 | getPreviousRuns(col2)
20 |
21 | # display key metrics
22 | createMetricsOutput()
23 |
24 |
25 | # historical performance
26 | indexer_id = parameters.get('indexer_id')
27 | df_active = getActiveAllocationPerformance(indexer_id)
28 | df_closed = getClosedAllocationPerformance(indexer_id)
29 |
30 | visualizePerformance(df_active,df_closed)
31 |
32 | st.markdown("""---""")
33 |
34 | # create Optimizer Output
35 | createOptimizerOutput(parameters)
36 |
--------------------------------------------------------------------------------
/src/webapp/sidebar.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | from src.helpers import img_to_bytes
3 | def createSidebar():
4 | # create Sidebar with Parameters
5 | with st.sidebar:
6 | # set sidbar title and subtitle
7 | st.header('Allocation Optimization Tool')
8 |
9 |
10 |
11 | st.markdown(
12 | f' ',
13 | unsafe_allow_html=True)
14 |
15 | st.subheader('Parameters:')
16 | # create form to submit data for optimization
17 | with st.form(key='columns_in_form'):
18 | # indexer id field
19 | indexer_id = st.text_input('Indexer Address', value="0x453b5e165cf98ff60167ccd3560ebf8d436ca86c",
20 | key='indexer_id')
21 | cols = st.columns(2)
22 | network = cols[0].selectbox('Network', options=['mainnet', 'testnet'])
23 | automation = cols[1].selectbox('Automation', options=[False,True])
24 |
25 | cols = st.columns(2)
26 | blacklist_parameter = cols[0].checkbox(label='Blacklist', key='blacklist_parameter', value=True)
27 | subgraph_list_parameter = cols[1].checkbox(label='Subgraphlist', key='subgraph_list_parameter', value=False)
28 |
29 | cols = st.columns(2)
30 | slack_alerting = cols[0].checkbox(label='Slack Alerting', key='slack_alerting', value=False)
31 | discord_alerting = cols[1].checkbox(label='Discord Alerting', key='discord_alerting', value=False)
32 |
33 | cols = st.columns(2)
34 |
35 | threshold = cols[0].slider(label="Threshold", min_value=0, max_value=100, value=20, step=5, key='threshold')
36 | parallel_allocations = cols[1].slider(label="parallel_allocations", min_value=1, max_value=20, value=1,
37 | step=1,
38 | key='parallel_allocations')
39 |
40 | max_percentage = st.slider(label="Max Percentage", min_value=0.0, max_value=1.0, value=0.2, step=0.05,
41 | key='max_percentage')
42 |
43 | threshold_interval = st.selectbox(label="Threshold Interval", options=['daily', 'weekly'],
44 | key="threshold_interval")
45 | ignore_tx_costs = st.selectbox('Ignore TX Gas costs', options= [False,True])
46 |
47 | reserve_stake = st.number_input(label="Reserve Stake", min_value=0, value=500, step=100,
48 | key="reserve_stake")
49 | min_allocation = st.number_input(label="Min. Allocation", min_value=0, value=0, step=100,
50 | key="min_allocation")
51 | min_signalled_grt_subgraph = st.number_input(label="Min. Signalled GRT per Subgaph", min_value=0, value=100,
52 | step=100,
53 | key="min_signalled_grt_subgraph")
54 | min_allocated_grt_subgraph = st.number_input(label="Min. Allocated GRT per Subgaph", min_value=0, value=100,
55 | step=100,
56 | key="min_allocated_grt_subgraph")
57 |
58 | submitted = st.form_submit_button('Run Optimizer')
59 |
60 | return_dict = {
61 | 'indexer_id': indexer_id,
62 | 'blacklist_parameter': blacklist_parameter,
63 | 'subgraph_list_parameter': subgraph_list_parameter,
64 | 'threshold': threshold,
65 | 'parallel_allocations': parallel_allocations,
66 | 'max_percentage': max_percentage,
67 | 'threshold_interval': threshold_interval,
68 | 'reserve_stake': reserve_stake,
69 | 'min_allocation': min_allocation,
70 | 'min_signalled_grt_subgraph': min_signalled_grt_subgraph,
71 | 'min_allocated_grt_subgraph': min_allocated_grt_subgraph,
72 | 'submitted': submitted,
73 | 'slack_alerting': slack_alerting,
74 | 'discord_alerting': discord_alerting,
75 | 'network': network,
76 | 'automation': automation,
77 | 'ignore_tx_costs' : ignore_tx_costs
78 |
79 | }
80 | return return_dict
81 |
--------------------------------------------------------------------------------
/src/wip_caching.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | from eth_utils import to_checksum_address
3 | import datetime as dt
4 | import json
5 | from src.queries import getAllAllocations, getActiveAllocations, getClosedAllocations, getAllocationDataById, \
6 | getCurrentBlock
7 | from src.helpers import initialize_rpc, initializeRewardManagerContract, ANYBLOCK_ANALYTICS_ID, conntectRedis, \
8 | get_routes_from_cache, set_routes_to_cache, getLastKeyFromDate
9 | import pandas as pd
10 | import aiohttp
11 | import asyncio
12 |
13 | def cacheCalculateRewardsActiveAllocation(allocation_id, interval=1, initial_run=False):
14 | """Calculates the pending rewards in given interval for active allocation and dumps results with more metrics into
15 | the redis cache.
16 |
17 | Parameters
18 | -------
19 | interval (int): supply interval for pending rewards calculation in hours. Standard is 1h
20 | allocation (str) : supply allocation id for reward calculation
21 |
22 | Returns
23 | -------
24 | rewards (dict): Key is datetime, Values are Sub Dict with 'allocation_id', 'subgraph_id', 'subgraph_name', 'rewards'
25 | ...
26 | """
27 | # initialize rewardManager Contract
28 | reward_manager_contract = initializeRewardManagerContract()
29 |
30 | # initialize web3 client
31 | web3 = initialize_rpc()
32 |
33 | # initialize redis client
34 | redis = conntectRedis()
35 |
36 | # Grab allocation data by allocation_id
37 | allocation = getAllocationDataById(allocation_id)
38 | current_block = getCurrentBlock()
39 |
40 | allocation_id = to_checksum_address(allocation['id'])
41 | subgraph_id = allocation['subgraphDeployment']['id']
42 | allocation_creation_block = allocation['createdAtBlockNumber']
43 |
44 | if allocation['closedAtBlockNumber']:
45 | allocation_closing_block = allocation['closedAtBlockNumber']
46 | closed_allocation = True
47 | else:
48 | closed_allocation = False
49 |
50 | subgraph_name = allocation['subgraphDeployment']['originalName']
51 |
52 | # If depreciated / broken and has no name, use ipfsHash as name
53 | if subgraph_name is None:
54 | subgraph_name = allocation['subgraphDeployment']['ipfsHash']
55 |
56 | # calculate the number of hours since the allocation took place
57 | allocation_created_at = allocation['createdAt']
58 | hours_since_allocation = dt.datetime.now() - datetime.fromtimestamp(allocation_created_at)
59 | hours_since_allocation = hours_since_allocation.total_seconds() / 3600
60 |
61 | # calculate the number of hours since the subgraph was created (age in hours)
62 | subgraph_created_at = allocation['subgraphDeployment']['createdAt']
63 | subgraph_hours_since_creation = dt.datetime.now() - datetime.fromtimestamp(subgraph_created_at)
64 | subgraph_hours_since_creation = subgraph_hours_since_creation.total_seconds() / 3600
65 |
66 | # get the amount of GRT allocated
67 | allocated_tokens = int(allocation['allocatedTokens']) / 10 ** 18
68 |
69 | # get the subgraph signal and stake
70 | subgraph_signal = int(allocation['subgraphDeployment']['signalledTokens']) / 10 ** 18
71 | subgraph_stake = int(allocation['subgraphDeployment']['stakedTokens']) / 10 ** 18
72 |
73 | # get the subgraph IPFS hash
74 | subgraph_ipfs_hash = allocation['subgraphDeployment']['ipfsHash']
75 |
76 | # Initialize a delta reward between current and previous interval reward
77 | accumulated_reward_minus_interval = 0
78 |
79 | # iterate through the range from allocation creation block to current block +1 in interval steps
80 | # we expect 270 Blocks per Hour. interval * 270 = Hour interval in blocks
81 |
82 | data = dict()
83 |
84 | if initial_run:
85 |
86 | for block in range(current_block if not closed_allocation else allocation_closing_block,
87 | allocation_creation_block - 1, -(24 * 270)):
88 | datetime_block = datetime.utcfromtimestamp(web3.eth.get_block(block).get('timestamp')).strftime(
89 | '%Y-%m-%d')
90 |
91 | # First it looks for the data in redis cache
92 | allocation_redis_key_hour = datetime_block + "-" + subgraph_ipfs_hash + "-" + allocation_id
93 | data = get_routes_from_cache(key=allocation_redis_key_hour)
94 |
95 | # If cache is found then serves the data from cache
96 | if data is not None:
97 | data = json.loads(data)
98 | data["cache"] = True
99 | data = json.dumps(data)
100 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
101 | continue
102 | else:
103 | try:
104 | accumulated_reward = reward_manager_contract.functions.getRewards(allocation_id).call(
105 | block_identifier=block) / 10 ** 18
106 | except:
107 | accumulated_reward = 0
108 |
109 | # calculate the difference between the accumulated reward and the reward from last interval and calc
110 | # the hourly rewards
111 | reward_rate_hour = (accumulated_reward - accumulated_reward_minus_interval) / interval
112 | reward_rate_hour_per_token = reward_rate_hour / allocated_tokens
113 |
114 | # set the currently accumulated reward fas the previous interval reward for next iteration
115 | accumulated_reward_minus_interval = accumulated_reward
116 |
117 | """
118 | # not sure about this one
119 | # calculate earnings of all indexers in this interval
120 | earnings_rate_all_indexers = reward_rate_hour / allocated_tokens * subgraph_stake
121 | """
122 | data = {}
123 | # set json like structure and structure by hourly datetime
124 | data[allocation_redis_key_hour] = {}
125 | data[allocation_redis_key_hour]['subgraph_name'] = subgraph_name
126 | data[allocation_redis_key_hour]['subgraph_ipfs_hash'] = subgraph_ipfs_hash
127 | data[allocation_redis_key_hour]['subgraph_age_in_hours'] = subgraph_hours_since_creation
128 | data[allocation_redis_key_hour]['subgraph_age_in_days'] = subgraph_hours_since_creation / 24
129 | data[allocation_redis_key_hour]['subgraph_signal'] = subgraph_signal
130 | data[allocation_redis_key_hour]['subgraph_stake'] = subgraph_stake
131 | try:
132 | data[allocation_redis_key_hour]['subgraph_signal_ratio'] = subgraph_signal / subgraph_stake
133 | except:
134 | data[allocation_redis_key_hour]['subgraph_signal_ratio'] = 0
135 | data[allocation_redis_key_hour][allocation_id] = {}
136 | data[allocation_redis_key_hour][allocation_id]['block_height'] = block
137 | data[allocation_redis_key_hour][allocation_id]['allocated_tokens'] = allocated_tokens
138 | data[allocation_redis_key_hour][allocation_id]['allocation_created_timestamp'] = allocation_created_at
139 | data[allocation_redis_key_hour][allocation_id]['allocation_created_epoch'] = allocation[
140 | 'createdAtEpoch']
141 | data[allocation_redis_key_hour][allocation_id]['allocation_status'] = "Closed"
142 | data[allocation_redis_key_hour][allocation_id]['timestamp'] = web3.eth.get_block(block).get('timestamp')
143 | data[allocation_redis_key_hour][allocation_id]['accumulated_reward'] = accumulated_reward
144 | data[allocation_redis_key_hour][allocation_id]['reward_rate_hour'] = reward_rate_hour
145 | data[allocation_redis_key_hour][allocation_id][
146 | 'reward_rate_hour_per_token'] = reward_rate_hour_per_token
147 |
148 | data["cache"] = False
149 | data = json.dumps(data)
150 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
151 |
152 | # if state is True:
153 | # return json.loads(data)
154 | else:
155 | # grab the most current key for the latest datetime and get the block number
156 | if closed_allocation:
157 | last_date_key = datetime.utcfromtimestamp(web3.eth.get_block(allocation_closing_block).get('timestamp'))
158 | else:
159 | last_date_key = datetime.now()
160 | # get latest key, if non is found return None
161 | latest_key = getLastKeyFromDate(subgraph_ipfs_hash=subgraph_ipfs_hash, date=last_date_key,
162 | allocation_id=allocation_id)
163 |
164 | if latest_key:
165 | latest_data = json.loads(get_routes_from_cache(key=latest_key))
166 | # iterate through latest key for latest date and get the block number
167 | for key_2, value in latest_data[(latest_key.decode('ascii'))].items():
168 | if "0x" in key_2:
169 | latest_block_with_data = value['block_height']
170 | break
171 | # if no key is found, set latest_block_with_data to allocation_creation_block
172 | if not latest_key:
173 | latest_block_with_data = allocation_creation_block
174 |
175 | for block in range(current_block if not closed_allocation else allocation_closing_block,
176 | latest_block_with_data - 1, -(24 * 270)):
177 | if (closed_allocation):
178 | if latest_block_with_data == allocation_closing_block:
179 | break
180 | datetime_block = datetime.utcfromtimestamp(web3.eth.get_block(block).get('timestamp')).strftime('%Y-%m-%d')
181 |
182 | # First it looks for the data in redis cache
183 | allocation_redis_key_hour = datetime_block + "-" + subgraph_ipfs_hash + "-" + allocation_id
184 | data = get_routes_from_cache(key=allocation_redis_key_hour)
185 |
186 | # If cache is found then serves the data from cache
187 | if data is not None:
188 | data = json.loads(data)
189 | data["cache"] = True
190 | data = json.dumps(data)
191 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
192 | continue
193 | else:
194 | try:
195 | accumulated_reward = reward_manager_contract.functions.getRewards(allocation_id).call(
196 | block_identifier=block) / 10 ** 18
197 | except web3.exceptions.ContractLogicError:
198 | accumulated_reward = 0
199 |
200 | # calculate the difference between the accumulated reward and the reward from last interval and calc
201 | # the hourly rewards
202 | reward_rate_hour = (accumulated_reward - accumulated_reward_minus_interval) / interval
203 | reward_rate_hour_per_token = reward_rate_hour / allocated_tokens
204 |
205 | # set the currently accumulated reward fas the previous interval reward for next iteration
206 | accumulated_reward_minus_interval = accumulated_reward
207 |
208 | """
209 | # not sure about this one
210 | # calculate earnings of all indexers in this interval
211 | earnings_rate_all_indexers = reward_rate_hour / allocated_tokens * subgraph_stake
212 | """
213 | data = {}
214 | # set json like structure and structure by hourly datetime
215 | data[allocation_redis_key_hour] = {}
216 | data[allocation_redis_key_hour]['subgraph_name'] = subgraph_name
217 | data[allocation_redis_key_hour]['subgraph_ipfs_hash'] = subgraph_ipfs_hash
218 | data[allocation_redis_key_hour]['subgraph_age_in_hours'] = subgraph_hours_since_creation
219 | data[allocation_redis_key_hour]['subgraph_age_in_days'] = subgraph_hours_since_creation / 24
220 | data[allocation_redis_key_hour]['subgraph_signal'] = subgraph_signal
221 | data[allocation_redis_key_hour]['subgraph_stake'] = subgraph_stake
222 | data[allocation_redis_key_hour]['subgraph_signal_ratio'] = subgraph_signal / subgraph_stake
223 | data[allocation_redis_key_hour][allocation_id] = {}
224 | data[allocation_redis_key_hour][allocation_id]['block_height'] = block
225 | data[allocation_redis_key_hour][allocation_id]['allocated_tokens'] = allocated_tokens
226 | data[allocation_redis_key_hour][allocation_id]['allocation_created_timestamp'] = allocation_created_at
227 | data[allocation_redis_key_hour][allocation_id]['allocation_created_epoch'] = allocation[
228 | 'createdAtEpoch']
229 | data[allocation_redis_key_hour][allocation_id]['allocation_status'] = "Closed"
230 | data[allocation_redis_key_hour][allocation_id]['timestamp'] = web3.eth.get_block(block).get('timestamp')
231 | data[allocation_redis_key_hour][allocation_id]['accumulated_reward'] = accumulated_reward
232 | data[allocation_redis_key_hour][allocation_id]['reward_rate_hour'] = reward_rate_hour
233 | data[allocation_redis_key_hour][allocation_id][
234 | 'reward_rate_hour_per_token'] = reward_rate_hour_per_token
235 |
236 | data["cache"] = False
237 | data = json.dumps(data)
238 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
239 |
240 | # if state is True:
241 | # return json.loads(data)
242 | return data
243 |
244 |
245 | def cacheCalculateRewardsAllActiveAllocations(indexer_id, interval=1, initial_run=False):
246 | """Calculates the pending rewards in given interval for all active allocation
247 |
248 | Parameters
249 | -------
250 | interval (int): supply interval for pending rewards calculation in hours. Standard is 1h
251 | indexer_id (str) : supply indexer id for reward calculation on all allocations
252 | """
253 | redis = conntectRedis()
254 | # grab all active allocations
255 | active_allocations = getActiveAllocations(indexer_id=indexer_id)
256 | active_allocations = active_allocations['allocations']
257 |
258 | # grab all allocations
259 | all_allocations = getAllAllocations(indexer_id=indexer_id)
260 | all_allocations = all_allocations['totalAllocations']
261 | allocation_id_temp_list = list()
262 |
263 | # append all active allocations to a temp list with allocation ID
264 | for allocation in active_allocations:
265 | # calculateRewardsActiveAllocation(allocation_id=allocation['id'], interval=1)
266 | allocation_id_temp_list.append(to_checksum_address(allocation['id']))
267 |
268 | # iterate through all allocations and calculate rewards
269 | for allocation in all_allocations:
270 | calculateRewardsActiveAllocation(allocation_id=allocation['id'], interval=1, initial_run=initial_run)
271 |
272 | # iterate through all keys and check if allocation id is in key, if yes it is an active allocation
273 | # if it is an active allocation, set status of allocation_status to "Active"
274 | for key in redis.scan_iter():
275 | if key.decode('ascii').split("-")[-1] in allocation_id_temp_list:
276 | data = get_routes_from_cache(key=key)
277 | data = json.loads(data)
278 | for key_2, value in data[(key.decode('ascii'))].items():
279 | if "0x" in key_2:
280 | data[(key.decode('ascii'))][key_2]['allocation_status'] = "Active"
281 | data = json.dumps(data)
282 | state = set_routes_to_cache(key=key, value=data)
283 |
284 |
285 | def cacheGetRewardsActiveAllocationsSpecificSubgraph(subgraph_hash="QmPXtp2UdoDsoryngUEMTsy1nPbVMuVrgozCMwyZjXUS8N"):
286 | """Grabs the Rewards for a specific Subgraph from the redis cache and creates a pandas dataframe from it
287 | calculates metrics such as reward_rate_hour and reward_rate_hour_token
288 |
289 | Parameters
290 | -------
291 | subgraph_hash (str): subgraph ipfs hash
292 | """
293 | redis = conntectRedis()
294 | temp_data_list = []
295 |
296 | # iterate through redis cache and get all keys
297 | for key in redis.scan_iter():
298 | # decode key and search for keys where subgraph hash is in it
299 | if subgraph_hash in key.decode('ascii'):
300 |
301 | # load data of key
302 | data = json.loads(get_routes_from_cache(key=key))
303 |
304 | # Append Data and Sub Keys to temp_data_list
305 | for key_2, value in data[(key.decode('ascii'))].items():
306 | if "0x" in key_2:
307 | temp_data_list.append({
308 | "datetime": datetime.utcfromtimestamp(value['timestamp']).strftime('%Y-%m-%d %H'),
309 | "subgraph_name": data[(key.decode('ascii'))]['subgraph_name'],
310 | "allocation_status": value['allocation_status'],
311 | "allocation_id": key.decode('ascii').split("-")[-1],
312 | "accumulated_reward": value['accumulated_reward'],
313 | "block_height": value['block_height'],
314 | "allocation_created_epoch": value['allocation_created_epoch'],
315 | "allocation_created_timestamp": value['allocation_created_timestamp'],
316 | "allocated_tokens": value['allocated_tokens']})
317 |
318 | # create dataframe, preprocess date column and create key metrics (reward_rate_hour and reward_rate_hour_per_token"
319 | df = pd.DataFrame(temp_data_list)
320 | df['datetime'] = pd.to_datetime(df['datetime'], format='%Y%m%d', errors='ignore')
321 | df.sort_values(by=['datetime'], inplace=True)
322 | df = pd.concat([df,
323 | df[['accumulated_reward']]
324 | .diff().rename({'accumulated_reward': 'reward_rate_hour'}, axis=1)], axis=1)
325 | df['reward_rate_hour_per_token'] = df['reward_rate_hour'] / df['allocated_tokens']
326 |
327 | return df
328 |
329 |
330 | def getRewardsActiveAllocationsAllSubgraphs():
331 | """Grabs the Rewards for all Subgraphs from the redis cache and creates a pandas dataframe from it
332 | calculates metrics such as reward_rate_hour and reward_rate_hour_token
333 |
334 | Parameters
335 | -------
336 | subgraph_hash (str): subgraph ipfs hash
337 | """
338 | redis = conntectRedis()
339 | temp_data_list = []
340 |
341 | # iterate through redis cache and get all keys
342 | for key in redis.scan_iter():
343 | # load data of key
344 | data = json.loads(get_routes_from_cache(key=key))
345 |
346 | # Append Data and Sub Keys to temp_data_list
347 | for key_2, value in data[(key.decode('ascii'))].items():
348 | if "0x" in key_2:
349 | temp_data_list.append({
350 | "datetime": datetime.utcfromtimestamp(value['timestamp']).strftime('%Y-%m-%d %H'),
351 | "subgraph_name": data[(key.decode('ascii'))]['subgraph_name'],
352 | "allocation_status": value['allocation_status'],
353 | "allocation_id": key.decode('ascii').split("-")[-1],
354 | "subgraph_hash": key.decode('ascii').split("-")[-2],
355 | "accumulated_reward": value['accumulated_reward'],
356 | "block_height": value['block_height'],
357 | "allocation_created_epoch": value['allocation_created_epoch'],
358 | "allocation_created_timestamp": value['allocation_created_timestamp'],
359 | "allocated_tokens": value['allocated_tokens']})
360 |
361 | # create dataframe, preprocess date column and create key metrics (reward_rate_hour and reward_rate_hour_per_token"
362 | df = pd.DataFrame(temp_data_list)
363 | df['datetime'] = pd.to_datetime(df['datetime'], format='%Y%m%d %H', errors='ignore')
364 | df.sort_values(by=['datetime'], inplace=True)
365 | df = pd.concat([df,
366 | df.groupby('allocation_id')[['accumulated_reward']]
367 | .diff().rename({'accumulated_reward': 'reward_rate_hour'}, axis=1)], axis=1)
368 | df['reward_rate_hour_per_token'] = df['reward_rate_hour'] / df['allocated_tokens']
369 |
370 | return df
--------------------------------------------------------------------------------
',
13 | unsafe_allow_html=True)
14 |
15 | st.subheader('Parameters:')
16 | # create form to submit data for optimization
17 | with st.form(key='columns_in_form'):
18 | # indexer id field
19 | indexer_id = st.text_input('Indexer Address', value="0x453b5e165cf98ff60167ccd3560ebf8d436ca86c",
20 | key='indexer_id')
21 | cols = st.columns(2)
22 | network = cols[0].selectbox('Network', options=['mainnet', 'testnet'])
23 | automation = cols[1].selectbox('Automation', options=[False,True])
24 |
25 | cols = st.columns(2)
26 | blacklist_parameter = cols[0].checkbox(label='Blacklist', key='blacklist_parameter', value=True)
27 | subgraph_list_parameter = cols[1].checkbox(label='Subgraphlist', key='subgraph_list_parameter', value=False)
28 |
29 | cols = st.columns(2)
30 | slack_alerting = cols[0].checkbox(label='Slack Alerting', key='slack_alerting', value=False)
31 | discord_alerting = cols[1].checkbox(label='Discord Alerting', key='discord_alerting', value=False)
32 |
33 | cols = st.columns(2)
34 |
35 | threshold = cols[0].slider(label="Threshold", min_value=0, max_value=100, value=20, step=5, key='threshold')
36 | parallel_allocations = cols[1].slider(label="parallel_allocations", min_value=1, max_value=20, value=1,
37 | step=1,
38 | key='parallel_allocations')
39 |
40 | max_percentage = st.slider(label="Max Percentage", min_value=0.0, max_value=1.0, value=0.2, step=0.05,
41 | key='max_percentage')
42 |
43 | threshold_interval = st.selectbox(label="Threshold Interval", options=['daily', 'weekly'],
44 | key="threshold_interval")
45 | ignore_tx_costs = st.selectbox('Ignore TX Gas costs', options= [False,True])
46 |
47 | reserve_stake = st.number_input(label="Reserve Stake", min_value=0, value=500, step=100,
48 | key="reserve_stake")
49 | min_allocation = st.number_input(label="Min. Allocation", min_value=0, value=0, step=100,
50 | key="min_allocation")
51 | min_signalled_grt_subgraph = st.number_input(label="Min. Signalled GRT per Subgaph", min_value=0, value=100,
52 | step=100,
53 | key="min_signalled_grt_subgraph")
54 | min_allocated_grt_subgraph = st.number_input(label="Min. Allocated GRT per Subgaph", min_value=0, value=100,
55 | step=100,
56 | key="min_allocated_grt_subgraph")
57 |
58 | submitted = st.form_submit_button('Run Optimizer')
59 |
60 | return_dict = {
61 | 'indexer_id': indexer_id,
62 | 'blacklist_parameter': blacklist_parameter,
63 | 'subgraph_list_parameter': subgraph_list_parameter,
64 | 'threshold': threshold,
65 | 'parallel_allocations': parallel_allocations,
66 | 'max_percentage': max_percentage,
67 | 'threshold_interval': threshold_interval,
68 | 'reserve_stake': reserve_stake,
69 | 'min_allocation': min_allocation,
70 | 'min_signalled_grt_subgraph': min_signalled_grt_subgraph,
71 | 'min_allocated_grt_subgraph': min_allocated_grt_subgraph,
72 | 'submitted': submitted,
73 | 'slack_alerting': slack_alerting,
74 | 'discord_alerting': discord_alerting,
75 | 'network': network,
76 | 'automation': automation,
77 | 'ignore_tx_costs' : ignore_tx_costs
78 |
79 | }
80 | return return_dict
81 |
--------------------------------------------------------------------------------
/src/wip_caching.py:
--------------------------------------------------------------------------------
1 | from datetime import datetime
2 | from eth_utils import to_checksum_address
3 | import datetime as dt
4 | import json
5 | from src.queries import getAllAllocations, getActiveAllocations, getClosedAllocations, getAllocationDataById, \
6 | getCurrentBlock
7 | from src.helpers import initialize_rpc, initializeRewardManagerContract, ANYBLOCK_ANALYTICS_ID, conntectRedis, \
8 | get_routes_from_cache, set_routes_to_cache, getLastKeyFromDate
9 | import pandas as pd
10 | import aiohttp
11 | import asyncio
12 |
13 | def cacheCalculateRewardsActiveAllocation(allocation_id, interval=1, initial_run=False):
14 | """Calculates the pending rewards in given interval for active allocation and dumps results with more metrics into
15 | the redis cache.
16 |
17 | Parameters
18 | -------
19 | interval (int): supply interval for pending rewards calculation in hours. Standard is 1h
20 | allocation (str) : supply allocation id for reward calculation
21 |
22 | Returns
23 | -------
24 | rewards (dict): Key is datetime, Values are Sub Dict with 'allocation_id', 'subgraph_id', 'subgraph_name', 'rewards'
25 | ...
26 | """
27 | # initialize rewardManager Contract
28 | reward_manager_contract = initializeRewardManagerContract()
29 |
30 | # initialize web3 client
31 | web3 = initialize_rpc()
32 |
33 | # initialize redis client
34 | redis = conntectRedis()
35 |
36 | # Grab allocation data by allocation_id
37 | allocation = getAllocationDataById(allocation_id)
38 | current_block = getCurrentBlock()
39 |
40 | allocation_id = to_checksum_address(allocation['id'])
41 | subgraph_id = allocation['subgraphDeployment']['id']
42 | allocation_creation_block = allocation['createdAtBlockNumber']
43 |
44 | if allocation['closedAtBlockNumber']:
45 | allocation_closing_block = allocation['closedAtBlockNumber']
46 | closed_allocation = True
47 | else:
48 | closed_allocation = False
49 |
50 | subgraph_name = allocation['subgraphDeployment']['originalName']
51 |
52 | # If depreciated / broken and has no name, use ipfsHash as name
53 | if subgraph_name is None:
54 | subgraph_name = allocation['subgraphDeployment']['ipfsHash']
55 |
56 | # calculate the number of hours since the allocation took place
57 | allocation_created_at = allocation['createdAt']
58 | hours_since_allocation = dt.datetime.now() - datetime.fromtimestamp(allocation_created_at)
59 | hours_since_allocation = hours_since_allocation.total_seconds() / 3600
60 |
61 | # calculate the number of hours since the subgraph was created (age in hours)
62 | subgraph_created_at = allocation['subgraphDeployment']['createdAt']
63 | subgraph_hours_since_creation = dt.datetime.now() - datetime.fromtimestamp(subgraph_created_at)
64 | subgraph_hours_since_creation = subgraph_hours_since_creation.total_seconds() / 3600
65 |
66 | # get the amount of GRT allocated
67 | allocated_tokens = int(allocation['allocatedTokens']) / 10 ** 18
68 |
69 | # get the subgraph signal and stake
70 | subgraph_signal = int(allocation['subgraphDeployment']['signalledTokens']) / 10 ** 18
71 | subgraph_stake = int(allocation['subgraphDeployment']['stakedTokens']) / 10 ** 18
72 |
73 | # get the subgraph IPFS hash
74 | subgraph_ipfs_hash = allocation['subgraphDeployment']['ipfsHash']
75 |
76 | # Initialize a delta reward between current and previous interval reward
77 | accumulated_reward_minus_interval = 0
78 |
79 | # iterate through the range from allocation creation block to current block +1 in interval steps
80 | # we expect 270 Blocks per Hour. interval * 270 = Hour interval in blocks
81 |
82 | data = dict()
83 |
84 | if initial_run:
85 |
86 | for block in range(current_block if not closed_allocation else allocation_closing_block,
87 | allocation_creation_block - 1, -(24 * 270)):
88 | datetime_block = datetime.utcfromtimestamp(web3.eth.get_block(block).get('timestamp')).strftime(
89 | '%Y-%m-%d')
90 |
91 | # First it looks for the data in redis cache
92 | allocation_redis_key_hour = datetime_block + "-" + subgraph_ipfs_hash + "-" + allocation_id
93 | data = get_routes_from_cache(key=allocation_redis_key_hour)
94 |
95 | # If cache is found then serves the data from cache
96 | if data is not None:
97 | data = json.loads(data)
98 | data["cache"] = True
99 | data = json.dumps(data)
100 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
101 | continue
102 | else:
103 | try:
104 | accumulated_reward = reward_manager_contract.functions.getRewards(allocation_id).call(
105 | block_identifier=block) / 10 ** 18
106 | except:
107 | accumulated_reward = 0
108 |
109 | # calculate the difference between the accumulated reward and the reward from last interval and calc
110 | # the hourly rewards
111 | reward_rate_hour = (accumulated_reward - accumulated_reward_minus_interval) / interval
112 | reward_rate_hour_per_token = reward_rate_hour / allocated_tokens
113 |
114 | # set the currently accumulated reward fas the previous interval reward for next iteration
115 | accumulated_reward_minus_interval = accumulated_reward
116 |
117 | """
118 | # not sure about this one
119 | # calculate earnings of all indexers in this interval
120 | earnings_rate_all_indexers = reward_rate_hour / allocated_tokens * subgraph_stake
121 | """
122 | data = {}
123 | # set json like structure and structure by hourly datetime
124 | data[allocation_redis_key_hour] = {}
125 | data[allocation_redis_key_hour]['subgraph_name'] = subgraph_name
126 | data[allocation_redis_key_hour]['subgraph_ipfs_hash'] = subgraph_ipfs_hash
127 | data[allocation_redis_key_hour]['subgraph_age_in_hours'] = subgraph_hours_since_creation
128 | data[allocation_redis_key_hour]['subgraph_age_in_days'] = subgraph_hours_since_creation / 24
129 | data[allocation_redis_key_hour]['subgraph_signal'] = subgraph_signal
130 | data[allocation_redis_key_hour]['subgraph_stake'] = subgraph_stake
131 | try:
132 | data[allocation_redis_key_hour]['subgraph_signal_ratio'] = subgraph_signal / subgraph_stake
133 | except:
134 | data[allocation_redis_key_hour]['subgraph_signal_ratio'] = 0
135 | data[allocation_redis_key_hour][allocation_id] = {}
136 | data[allocation_redis_key_hour][allocation_id]['block_height'] = block
137 | data[allocation_redis_key_hour][allocation_id]['allocated_tokens'] = allocated_tokens
138 | data[allocation_redis_key_hour][allocation_id]['allocation_created_timestamp'] = allocation_created_at
139 | data[allocation_redis_key_hour][allocation_id]['allocation_created_epoch'] = allocation[
140 | 'createdAtEpoch']
141 | data[allocation_redis_key_hour][allocation_id]['allocation_status'] = "Closed"
142 | data[allocation_redis_key_hour][allocation_id]['timestamp'] = web3.eth.get_block(block).get('timestamp')
143 | data[allocation_redis_key_hour][allocation_id]['accumulated_reward'] = accumulated_reward
144 | data[allocation_redis_key_hour][allocation_id]['reward_rate_hour'] = reward_rate_hour
145 | data[allocation_redis_key_hour][allocation_id][
146 | 'reward_rate_hour_per_token'] = reward_rate_hour_per_token
147 |
148 | data["cache"] = False
149 | data = json.dumps(data)
150 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
151 |
152 | # if state is True:
153 | # return json.loads(data)
154 | else:
155 | # grab the most current key for the latest datetime and get the block number
156 | if closed_allocation:
157 | last_date_key = datetime.utcfromtimestamp(web3.eth.get_block(allocation_closing_block).get('timestamp'))
158 | else:
159 | last_date_key = datetime.now()
160 | # get latest key, if non is found return None
161 | latest_key = getLastKeyFromDate(subgraph_ipfs_hash=subgraph_ipfs_hash, date=last_date_key,
162 | allocation_id=allocation_id)
163 |
164 | if latest_key:
165 | latest_data = json.loads(get_routes_from_cache(key=latest_key))
166 | # iterate through latest key for latest date and get the block number
167 | for key_2, value in latest_data[(latest_key.decode('ascii'))].items():
168 | if "0x" in key_2:
169 | latest_block_with_data = value['block_height']
170 | break
171 | # if no key is found, set latest_block_with_data to allocation_creation_block
172 | if not latest_key:
173 | latest_block_with_data = allocation_creation_block
174 |
175 | for block in range(current_block if not closed_allocation else allocation_closing_block,
176 | latest_block_with_data - 1, -(24 * 270)):
177 | if (closed_allocation):
178 | if latest_block_with_data == allocation_closing_block:
179 | break
180 | datetime_block = datetime.utcfromtimestamp(web3.eth.get_block(block).get('timestamp')).strftime('%Y-%m-%d')
181 |
182 | # First it looks for the data in redis cache
183 | allocation_redis_key_hour = datetime_block + "-" + subgraph_ipfs_hash + "-" + allocation_id
184 | data = get_routes_from_cache(key=allocation_redis_key_hour)
185 |
186 | # If cache is found then serves the data from cache
187 | if data is not None:
188 | data = json.loads(data)
189 | data["cache"] = True
190 | data = json.dumps(data)
191 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
192 | continue
193 | else:
194 | try:
195 | accumulated_reward = reward_manager_contract.functions.getRewards(allocation_id).call(
196 | block_identifier=block) / 10 ** 18
197 | except web3.exceptions.ContractLogicError:
198 | accumulated_reward = 0
199 |
200 | # calculate the difference between the accumulated reward and the reward from last interval and calc
201 | # the hourly rewards
202 | reward_rate_hour = (accumulated_reward - accumulated_reward_minus_interval) / interval
203 | reward_rate_hour_per_token = reward_rate_hour / allocated_tokens
204 |
205 | # set the currently accumulated reward fas the previous interval reward for next iteration
206 | accumulated_reward_minus_interval = accumulated_reward
207 |
208 | """
209 | # not sure about this one
210 | # calculate earnings of all indexers in this interval
211 | earnings_rate_all_indexers = reward_rate_hour / allocated_tokens * subgraph_stake
212 | """
213 | data = {}
214 | # set json like structure and structure by hourly datetime
215 | data[allocation_redis_key_hour] = {}
216 | data[allocation_redis_key_hour]['subgraph_name'] = subgraph_name
217 | data[allocation_redis_key_hour]['subgraph_ipfs_hash'] = subgraph_ipfs_hash
218 | data[allocation_redis_key_hour]['subgraph_age_in_hours'] = subgraph_hours_since_creation
219 | data[allocation_redis_key_hour]['subgraph_age_in_days'] = subgraph_hours_since_creation / 24
220 | data[allocation_redis_key_hour]['subgraph_signal'] = subgraph_signal
221 | data[allocation_redis_key_hour]['subgraph_stake'] = subgraph_stake
222 | data[allocation_redis_key_hour]['subgraph_signal_ratio'] = subgraph_signal / subgraph_stake
223 | data[allocation_redis_key_hour][allocation_id] = {}
224 | data[allocation_redis_key_hour][allocation_id]['block_height'] = block
225 | data[allocation_redis_key_hour][allocation_id]['allocated_tokens'] = allocated_tokens
226 | data[allocation_redis_key_hour][allocation_id]['allocation_created_timestamp'] = allocation_created_at
227 | data[allocation_redis_key_hour][allocation_id]['allocation_created_epoch'] = allocation[
228 | 'createdAtEpoch']
229 | data[allocation_redis_key_hour][allocation_id]['allocation_status'] = "Closed"
230 | data[allocation_redis_key_hour][allocation_id]['timestamp'] = web3.eth.get_block(block).get('timestamp')
231 | data[allocation_redis_key_hour][allocation_id]['accumulated_reward'] = accumulated_reward
232 | data[allocation_redis_key_hour][allocation_id]['reward_rate_hour'] = reward_rate_hour
233 | data[allocation_redis_key_hour][allocation_id][
234 | 'reward_rate_hour_per_token'] = reward_rate_hour_per_token
235 |
236 | data["cache"] = False
237 | data = json.dumps(data)
238 | state = set_routes_to_cache(key=allocation_redis_key_hour, value=data)
239 |
240 | # if state is True:
241 | # return json.loads(data)
242 | return data
243 |
244 |
245 | def cacheCalculateRewardsAllActiveAllocations(indexer_id, interval=1, initial_run=False):
246 | """Calculates the pending rewards in given interval for all active allocation
247 |
248 | Parameters
249 | -------
250 | interval (int): supply interval for pending rewards calculation in hours. Standard is 1h
251 | indexer_id (str) : supply indexer id for reward calculation on all allocations
252 | """
253 | redis = conntectRedis()
254 | # grab all active allocations
255 | active_allocations = getActiveAllocations(indexer_id=indexer_id)
256 | active_allocations = active_allocations['allocations']
257 |
258 | # grab all allocations
259 | all_allocations = getAllAllocations(indexer_id=indexer_id)
260 | all_allocations = all_allocations['totalAllocations']
261 | allocation_id_temp_list = list()
262 |
263 | # append all active allocations to a temp list with allocation ID
264 | for allocation in active_allocations:
265 | # calculateRewardsActiveAllocation(allocation_id=allocation['id'], interval=1)
266 | allocation_id_temp_list.append(to_checksum_address(allocation['id']))
267 |
268 | # iterate through all allocations and calculate rewards
269 | for allocation in all_allocations:
270 | calculateRewardsActiveAllocation(allocation_id=allocation['id'], interval=1, initial_run=initial_run)
271 |
272 | # iterate through all keys and check if allocation id is in key, if yes it is an active allocation
273 | # if it is an active allocation, set status of allocation_status to "Active"
274 | for key in redis.scan_iter():
275 | if key.decode('ascii').split("-")[-1] in allocation_id_temp_list:
276 | data = get_routes_from_cache(key=key)
277 | data = json.loads(data)
278 | for key_2, value in data[(key.decode('ascii'))].items():
279 | if "0x" in key_2:
280 | data[(key.decode('ascii'))][key_2]['allocation_status'] = "Active"
281 | data = json.dumps(data)
282 | state = set_routes_to_cache(key=key, value=data)
283 |
284 |
285 | def cacheGetRewardsActiveAllocationsSpecificSubgraph(subgraph_hash="QmPXtp2UdoDsoryngUEMTsy1nPbVMuVrgozCMwyZjXUS8N"):
286 | """Grabs the Rewards for a specific Subgraph from the redis cache and creates a pandas dataframe from it
287 | calculates metrics such as reward_rate_hour and reward_rate_hour_token
288 |
289 | Parameters
290 | -------
291 | subgraph_hash (str): subgraph ipfs hash
292 | """
293 | redis = conntectRedis()
294 | temp_data_list = []
295 |
296 | # iterate through redis cache and get all keys
297 | for key in redis.scan_iter():
298 | # decode key and search for keys where subgraph hash is in it
299 | if subgraph_hash in key.decode('ascii'):
300 |
301 | # load data of key
302 | data = json.loads(get_routes_from_cache(key=key))
303 |
304 | # Append Data and Sub Keys to temp_data_list
305 | for key_2, value in data[(key.decode('ascii'))].items():
306 | if "0x" in key_2:
307 | temp_data_list.append({
308 | "datetime": datetime.utcfromtimestamp(value['timestamp']).strftime('%Y-%m-%d %H'),
309 | "subgraph_name": data[(key.decode('ascii'))]['subgraph_name'],
310 | "allocation_status": value['allocation_status'],
311 | "allocation_id": key.decode('ascii').split("-")[-1],
312 | "accumulated_reward": value['accumulated_reward'],
313 | "block_height": value['block_height'],
314 | "allocation_created_epoch": value['allocation_created_epoch'],
315 | "allocation_created_timestamp": value['allocation_created_timestamp'],
316 | "allocated_tokens": value['allocated_tokens']})
317 |
318 | # create dataframe, preprocess date column and create key metrics (reward_rate_hour and reward_rate_hour_per_token"
319 | df = pd.DataFrame(temp_data_list)
320 | df['datetime'] = pd.to_datetime(df['datetime'], format='%Y%m%d', errors='ignore')
321 | df.sort_values(by=['datetime'], inplace=True)
322 | df = pd.concat([df,
323 | df[['accumulated_reward']]
324 | .diff().rename({'accumulated_reward': 'reward_rate_hour'}, axis=1)], axis=1)
325 | df['reward_rate_hour_per_token'] = df['reward_rate_hour'] / df['allocated_tokens']
326 |
327 | return df
328 |
329 |
330 | def getRewardsActiveAllocationsAllSubgraphs():
331 | """Grabs the Rewards for all Subgraphs from the redis cache and creates a pandas dataframe from it
332 | calculates metrics such as reward_rate_hour and reward_rate_hour_token
333 |
334 | Parameters
335 | -------
336 | subgraph_hash (str): subgraph ipfs hash
337 | """
338 | redis = conntectRedis()
339 | temp_data_list = []
340 |
341 | # iterate through redis cache and get all keys
342 | for key in redis.scan_iter():
343 | # load data of key
344 | data = json.loads(get_routes_from_cache(key=key))
345 |
346 | # Append Data and Sub Keys to temp_data_list
347 | for key_2, value in data[(key.decode('ascii'))].items():
348 | if "0x" in key_2:
349 | temp_data_list.append({
350 | "datetime": datetime.utcfromtimestamp(value['timestamp']).strftime('%Y-%m-%d %H'),
351 | "subgraph_name": data[(key.decode('ascii'))]['subgraph_name'],
352 | "allocation_status": value['allocation_status'],
353 | "allocation_id": key.decode('ascii').split("-")[-1],
354 | "subgraph_hash": key.decode('ascii').split("-")[-2],
355 | "accumulated_reward": value['accumulated_reward'],
356 | "block_height": value['block_height'],
357 | "allocation_created_epoch": value['allocation_created_epoch'],
358 | "allocation_created_timestamp": value['allocation_created_timestamp'],
359 | "allocated_tokens": value['allocated_tokens']})
360 |
361 | # create dataframe, preprocess date column and create key metrics (reward_rate_hour and reward_rate_hour_per_token"
362 | df = pd.DataFrame(temp_data_list)
363 | df['datetime'] = pd.to_datetime(df['datetime'], format='%Y%m%d %H', errors='ignore')
364 | df.sort_values(by=['datetime'], inplace=True)
365 | df = pd.concat([df,
366 | df.groupby('allocation_id')[['accumulated_reward']]
367 | .diff().rename({'accumulated_reward': 'reward_rate_hour'}, axis=1)], axis=1)
368 | df['reward_rate_hour_per_token'] = df['reward_rate_hour'] / df['allocated_tokens']
369 |
370 | return df
--------------------------------------------------------------------------------