├── LICENSE
├── README.md
├── graphs
├── exp14.png
├── exp20.png
└── exp24.png
├── logPartition.c
├── logsort.h
└── test.c
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2022-2024 aphitorite
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | ## Introduction
3 |
4 | The well-known Quicksort is a O(n log n) algorithm that uses O(n) partitioning to sort data. Such partitioning schemes are easily done in-place (O(1) extra space) but are not stable, or do not preserve the order of equal elements. Stable Quicksorts can also be done in O(n log n) time, but they use an extra O(n) space for stable partitioning and are no longer in-place.
5 |
6 | Logsort is a novel practical O(n log n) quicksort that is both in-place and stable. The algorithm stably partitions data in O(n) time using O(log n) space, hence the name, which many already consider to be in-place despite not being the optimal O(1). Unlike well-known in-place stable sorts which are O(n log² n), such as std::stable_sort, Logsort is asymptotically optimal.
7 |
8 | To see Logsort's practical performance, jump to [Results](https://github.com/aphitorite/Logsort#Results).
9 |
10 | > [!NOTE]
11 | > **Usage:** define `VAR` element type and `CMP` comparison function.
12 |
13 | ## Visualization
14 |
15 | (Youtube) Logsort visualized on N = 2049 with 9 extra space allocated.
16 |
17 | [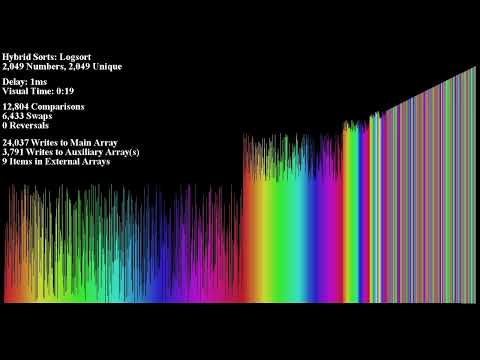](https://www.youtube.com/watch?v=be9dpGwciUo)
18 |
19 | ## Motivation
20 |
21 | O(n log n) in-place stable sorting is hard to achieve for sorting algorithms. Bubble Sort and Insertion Sort are stable and in-place but suboptimal. Efficient sorts, such as Quicksort and Heapsort, are in-place and O(n log n) but unstable.
22 |
23 | One class of sorting algorithms that achieve both in-place, stability, and O(n log n) time is Block Sort (a.k.a. Block Merge Sorts), such as [Wikisort](https://github.com/BonzaiThePenguin/WikiSort) and [Grailsort](https://github.com/Mrrl/GrailSort), which are in-place merge sorts. However, they are incredibly complicated and hard to implement. In addition, in-place stable partitioning is a rather obscure problem in sorting. Katajainen & Pasanen 1992 describes an O(1) space O(n) time partitioning algorithm, but it's only of theoretical interest and not practical.
24 |
25 | Logsort is a new sorting algorithm that aims to provide a simple and practical O(n log n) in-place stable sort implementation like alternatives such as Block Sort. The algorithm uses a novel O(n) in-place stable partitioning algorithm different than Katajainen & Pasanen 1992 and borrows ideas from [Aeos Quicksort](https://www.youtube.com/watch?v=_YTl2VJnQ4s) (stable quicksort with O(sqrt n) size blocking). By sorting recursively using this partition, we get an O(n log n) sorting algorithm.
26 |
27 | ## Algorithm
28 |
29 | Partitioning is analogous to sorting an array of 0's and 1's, where elements smaller than the pivot are 0 and elements larger are 1. (Munro et al. 1990) Logsort sorts 0's and 1's stably in O(n) time and O(log n) space via its partition.
30 |
31 | In brief, Logsort groups 0's and 1's elements into blocks of size O(log n) using its available space. By swapping elements among the 0 and 1 blocks, each block is assigned a unique index with O(log n) bits. An LL block swap partition is performed on the blocks which preserves the order of one partition but not the other. Using the assigned indices from earlier, the order of the blocks in the scrambled partition are restored. Lastly, the leftover 0's not divisible by the block length are shifted into place, and the Logsort partition is completed in O(n) time and O(log n) space.
32 |
33 | The four phases of the partition algorithm in more detail along with proofs:
34 | 1. [Grouping elements into blocks](https://github.com/aphitorite/Logsort#grouping-phase)
35 | 2. [Bit encoding the blocks](https://github.com/aphitorite/Logsort#bit-encoding)
36 | 3. [Swapping the blocks](https://github.com/aphitorite/Logsort#swapping-the-blocks)
37 | 4. [Sorting the blocks](https://github.com/aphitorite/Logsort#sorting-the-blocks) (+ [cleanup](https://github.com/aphitorite/Logsort#cleaning-up))
38 |
39 | The entire partition is implemented in about 100 lines of C code: [logPartition.c](https://github.com/aphitorite/Logsort/blob/main/logPartition.c)
40 |
41 | ## Grouping phase
42 |
43 | Given an unordered list of 0's and 1's, we group them into blocks of a fixed size where each block contains either only 0's or 1's. Given two buckets of B extra space, one can easily group blocks of size B (Katajainen & Pasanen 1992):
44 |
45 | ```
46 | Grouping blocks of size 2:
47 |
48 | ↓ move to ones bucket
49 | array: [1, 0, 1, 1, 0, 0, 1, 1]
50 | zeros: [ , ]
51 | ones: [ , ]
52 |
53 | ↓ move to zeros bucket
54 | array: [ , 0, 1, 1, 0, 0, 1, 1]
55 | zeros: [ , ]
56 | ones: [1, ]
57 |
58 | ↓ move to ones bucket
59 | array: [ , , 1, 1, 0, 0, 1, 1]
60 | zeros: [0, ]
61 | ones: [1, ]
62 |
63 | array: [ , , , 1, 0, 0, 1, 1]
64 | zeros: [0, ]
65 | ones: [1, 1] ← ones bucket full: output back into array
66 |
67 | ↓ ↓ first block created: continue looping
68 | array: [1, 1, , 1, 0, 0, 1, 1]
69 | zeros: [0, ]
70 | ones: [ , ]
71 | ```
72 |
73 | It's almost guaranteed we end up with partially filled buckets at the end of this phase. In that case, we output the 0 elements followed by the 1's at the end of the array.
74 |
75 | ```
76 | ↓ output zeros
77 | array: [1, 1, 0, 0, 1, 1, , ]
78 | zeros: [0, ]
79 | ones: [1, ]
80 |
81 | ↓ output ones
82 | array: [1, 1, 0, 0, 1, 1, 0, ]
83 | zeros: [ , ]
84 | ones: [1, ]
85 |
86 |
87 | array: [1, 1, 0, 0, 1, 1, 0, 1]
88 |
89 | ┌──── blocks ────┐ ↓ leftover zeros
90 | [1, 1][0, 0][1, 1][0][1]
91 | ```
92 |
93 | At the end of the phase, we are left with some leftover zeros that don't make a complete block. We handle them in the very last step of the partition.
94 |
95 | Logsort's O(log n) space usage comes from grouping blocks of size O(log n), and this will be important in the encoding phase. In the actual implementation, a space optimization from Aeos Quicksort is used which only needs one bucket instead of two. (Anonymous0726 2021) Like Wikisort and Grailsort, Logsort's external buffer size can be configured, given it's at least Ω(log n).
96 |
97 | > Since each element is moved a constant amount of times, once to the bucket and once back to the array, the grouping phase is O(n) regardless of block size but requires O(block size) extra space.
98 |
99 | ## Bit encoding
100 |
101 | 0's and 1's can also be concatenated to make binary numbers, so we can encode numbers in blocks by swapping elements between 0 blocks and 1 blocks. Decoding a number in a block requires a scan of the block which costs O(log n) comparisons. Since Logsort's blocks are O(log n) in size, there are enough bits to assign a unique index to each block.
102 |
103 | > There are at most O(n/log n) encodable blocks which require log(n/log n) = O(log n) bits to represent a number range from 0 to O(n/log n).
104 |
105 | ```
106 | Encode decimal number 13 = 0b1101:
107 |
108 | [0, 0, 0, 0, 0] [1, 1, 1, 1, 1]
109 | ↑ ↑ ↑ ↑ ↑ ↑
110 | 1 2 3 1 2 3 ← swap the following
111 |
112 | ┌─── 13 ───┐ ┌── ~13 ───┐
113 | [1, 1, 0, 1, 0] [0, 0, 1, 0, 1] ← the pair of blocks are now encoded with 13
114 | ↑ ↑
115 | last bit reserved to determine 0 or 1 block
116 | ```
117 |
118 | Using this technique, pairs of 0 and 1 block are encoded with a unique index during the encoding phase. We maintain two iterators: one for 0 blocks and 1 blocks respectively:
119 |
120 | ```
121 | Encode blocks:
122 |
123 | (0) (0)
124 | [ 0 ][ 1 ][ 1 ][ 1 ][ 0 ][ 1 ][ 0 ][ 1 ]
125 | └───┘└───┘ encode 0
126 |
127 | (0) (0) (1) (1)
128 | [ 0 ][ 1 ][ 1 ][ 1 ][ 0 ][ 1 ][ 0 ][ 1 ]
129 | └───┘ └───┘ encode 1
130 |
131 | (0) (0) (1) (2) (1) (2)
132 | [ 0 ][ 1 ][ 1 ][ 1 ][ 0 ][ 1 ][ 0 ][ 1 ]
133 | └───┘ └───┘ encode 2 and finish
134 | ```
135 |
136 | In this example, there were fewer 0 blocks, so all 0 blocks get encoded leaving some 1 blocks untouched. These leftover blocks will be handled in the swapping phase.
137 |
138 | > Encoding an index costs O(log n) swaps. Since each block is size O(log n), there are O(n/log n) blocks, so this phase is O(n/log n) \* O(log n) = O(n).
139 |
140 | ## Swapping the blocks
141 |
142 | Once the blocks are encoded, we swap the blocks belonging to the larger partition. In our example, there are more 1 blocks than 0 blocks so we scan the blocks' reserved bit and swap the 1 blocks to the right into their correct place:
143 |
144 | ```
145 | Swap blocks:
146 |
147 | (0) (0) (1) (2) (1) (2)
148 | [ 0a ][ 1a ][ 1b ][ 1c ][ 0b ][ 1d ][ 0c ][ 1e ]
149 | └────┘└────┘ block swap
150 |
151 | (0) (0) (1) (2) (1) (2)
152 | [ 0a ][ 1a ][ 1b ][ 1c ][ 0b ][ 0c ][ 1d ][ 1e ]
153 | └────┘ └────┘ block swap
154 |
155 | (0) (0) (1) (2) (1) (2)
156 | [ 0a ][ 1a ][ 1b ][ 0c ][ 0b ][ 1c ][ 1d ][ 1e ]
157 | └────┘ └────┘ block swap
158 |
159 | (0) (0) (1) (2) (1) (2)
160 | [ 0a ][ 1a ][ 0b ][ 0c ][ 1b ][ 1c ][ 1d ][ 1e ]
161 | └────┘ └────┘ block swap
162 |
163 | (0) (2) (1) (0) (1) (2)
164 | [ 0a ][ 0c ][ 0b ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
165 | (finished block swapping)
166 | ```
167 |
168 | Swapping blocks in this fashion preserves the order of the 1 blocks. If there were more 0 blocks, we would swap them to the left. In this example, after swapping, the 1's partition is stably ordered. However, the order of the 0 blocks is now scrambled. Using the encoded indices in the 0 blocks, we can reorder them stably in the sorting phase.
169 |
170 | > Each block in the phase is swapped once. Since each block swap costs O(log n) swaps and there are at most O(n/log n) blocks swapped, the swapping phase is O(n/log n) \* O(log n) = O(n).
171 |
172 | ## Sorting the blocks
173 |
174 | Reordering the scrambled blocks is quite easy: simply iterate across the blocks. If the current block's index is not equal to the iterator, block swap the current block to the read index. Repeat this step until the current block's index matches the iterator and move on to the next block.
175 |
176 | ```
177 | Sort blocks:
178 |
179 | (0)← (2) (1) (0) (1) (2)
180 | [ 0a ][ 0c ][ 0b ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
181 | └────┘ 0th block == 0 ? -> Yes: go to next block
182 |
183 | (0) (2)← (1) (0) (1) (2)
184 | [ 0a ][ 0c ][ 0b ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
185 | └────┘ 1st block == 2 ? -> No: swap with 2nd block
186 |
187 | (0) (1) (2) (0) (1) (2)
188 | [ 0a ][ 0b ][ 0c ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
189 | └────┘└────┘
190 |
191 | (0) (1)← (2) (0) (1) (2)
192 | [ 0a ][ 0b ][ 0c ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
193 | └────┘ 1st block == 1 ? -> Yes: go to next block
194 |
195 | (0) (1) (2)← (0) (1) (2)
196 | [ 0a ][ 0b ][ 0c ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
197 | └────┘ 2nd block == 2 ? -> Yes: finish
198 | ```
199 |
200 | In pseudocode:
201 |
202 | ```
203 | for each index from 0 to blocks.count - 1:
204 | current = blocks[index].decode()
205 | while current != index:
206 | block swap blocks[current] and blocks[index]
207 | current = blocks[index].decode()
208 | ```
209 |
210 | It's worth noting in our example we sorted the blocks belonging to the 0 partition. However, recall that the encoding of 1 blocks is the bit flip of 0 blocks, so we would need to bit flip the results of the decoding beforehand in the case of sorting 1 blocks.
211 |
212 | > Each time a block is swapped, it ends up in its final destination, therefore a block is swapped at most once. The blocks are also decoded at most twice: once per block swap and once per iterated block.
213 | >
214 | > Combined, the operations on a block are O(log n). Since there are at most O(n/log n) scrambled blocks, the sorting phase is O(n/log n) \* O(log n) = O(n).
215 |
216 | ### Cleaning up
217 |
218 | After the sorting phase, the blocks are now partitioned stably in O(n) time. However, some elements between blocks are still swapped from the encoding phase, and we want to restore the original states of the blocks. Since both 0 blocks and 1 blocks are in order, we can easily reaccess the original encoded block pairs along with their indices in ascending order. We then can "uncode" them by applying the encode algorithm again with the same index. After iterating and uncoding the block pairs, we complete the partition on the blocks.
219 |
220 | ```
221 | Uncode blocks:
222 |
223 | (0) (1) (2) (0) (1) (2)
224 | [ 0a ][ 0b ][ 0c ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
225 | └────┘ └────┘ uncode 0 (encode 0)
226 |
227 | (1) (2) (1) (2)
228 | [ 0a ][ 0b ][ 0c ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
229 | └────┘ └────┘ uncode 1 (encode 1)
230 |
231 | (2) (2)
232 | [ 0a ][ 0b ][ 0c ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
233 | └────┘ └────┘ uncode 2 (encode 2)
234 |
235 | [ 0a ][ 0b ][ 0c ][ 1a ][ 1b ][ 1c ][ 1d ][ 1e ]
236 | [ 0 ][ 1 ]
237 |
238 | blocks and underlying elements partitioned stably!
239 | ```
240 |
241 | We are not done yet and still have a leftover chunk of 0's that did not make a complete block from the grouping phase. Simply copy the 0 leftovers, shift the 1's partition to the right, and copy the leftovers back:
242 |
243 | ```
244 | Clean up:
245 |
246 | [0 0 0 0 0][1 1 1 1 1 1 1 1 1 1 1 1][0 0 0][1 1 1]
247 | └─────┘ copy out
248 |
249 | [0 0 0 0 0][1 1 1 1 1 1 1 1 1 1 1 1] [1 1 1]
250 | └───────────────────────┘ shift --->
251 |
252 | [0 0 0 0 0] [1 1 1 1 1 1 1 1 1 1 1 1][1 1 1]
253 | └─────┘ copy in
254 |
255 | [0 0 0 0 0][0 0 0][1 1 1 1 1 1 1 1 1 1 1 1][1 1 1]
256 | └─────── 0 ──────┘└────────────── 1 ─────────────┘
257 |
258 | partition complete!
259 | ```
260 |
261 | Finally, we've stably partitioned the list in O(n) time and O(log n) space.
262 |
263 | > There are O(n/log n) pairs of blocks that need to be uncoded. Since each uncoding operation is O(log n), it costs O(n/log n) \* O(log n) = O(n) operations.
264 | >
265 | > Copying the leftovers and shifting the 1's partition is O(n) + O(log n) = O(n).
266 |
267 | ## Results
268 |
269 | An O(n log n) in-place stable sort in theory sounds great, but how does it compare against existing sorts? In the following benchmarks, we test Logsort's practicality against four other stable sorting algorithms:
270 |
271 | - [**Grailsort**](https://github.com/Mrrl/GrailSort) +512 aux (Block Merge Sort)
272 | - [**Octosort**](https://github.com/scandum/octosort) +512 aux (Block Merge Sort, optimized [Wikisort](https://github.com/BonzaiThePenguin/WikiSort))
273 | - [**Sqrtsort**](https://github.com/Mrrl/SqrtSort) +√N aux (Block Merge Sort)
274 | - [**Blitsort**](https://github.com/scandum/blitsort) +512 aux (Fast Rotate Merge/Quick Sort, O(n log² n))
275 |
276 | All sorts are compiled with `gcc -O3` using GCC 11.4.0 and ran on Ubuntu 22.04 using WSL. The algorithms sort a random linear distribution of 32-bit integers containing N unique, √N unique, and 4 unique values respectively. The average time among 100 trials is recorded.
277 |
278 | 
279 | 
280 | 
281 |
282 | Data table
283 |
284 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
285 | |---------------|---------|---------|--------------|--------------|------|---------------|
286 | |Blitsort (512) |16384 |4 bytes |71 |84 |100 |4 unique |
287 | |Sqrtsort (√N) |16384 |4 bytes |482 |509 |100 |4 unique |
288 | |Octosort (512) |16384 |4 bytes |437 |463 |100 |4 unique |
289 | |Grailsort (512)|16384 |4 bytes |855 |923 |100 |4 unique |
290 | |Logsort (512) |16384 |4 bytes |107 |119 |100 |4 unique |
291 |
292 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
293 | |---------------|---------|---------|--------------|--------------|------|---------------|
294 | |Blitsort (512) |16384 |4 bytes |211 |227 |100 |128 unique |
295 | |Sqrtsort (√N) |16384 |4 bytes |764 |791 |100 |128 unique |
296 | |Octosort (512) |16384 |4 bytes |844 |872 |100 |128 unique |
297 | |Grailsort (512)|16384 |4 bytes |1533 |1590 |100 |128 unique |
298 | |Logsort (512) |16384 |4 bytes |375 |397 |100 |128 unique |
299 |
300 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
301 | |---------------|---------|---------|--------------|--------------|------|---------------|
302 | |Blitsort (512) |16384 |4 bytes |416 |435 |100 |16384 unique |
303 | |Sqrtsort (√N) |16384 |4 bytes |947 |972 |100 |16384 unique |
304 | |Octosort (512) |16384 |4 bytes |989 |1012 |100 |16384 unique |
305 | |Grailsort (512)|16384 |4 bytes |1036 |1064 |100 |16384 unique |
306 | |Logsort (512) |16384 |4 bytes |402 |424 |100 |16384 unique |
307 |
308 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
309 | |---------------|---------|---------|--------------|--------------|------|---------------|
310 | |Blitsort (512) |1048576 |4 bytes |5171 |5964 |100 |4 unique |
311 | |Sqrtsort (√N) |1048576 |4 bytes |37006 |38549 |100 |4 unique |
312 | |Octosort (512) |1048576 |4 bytes |30248 |32028 |100 |4 unique |
313 | |Grailsort (512)|1048576 |4 bytes |56563 |58549 |100 |4 unique |
314 | |Logsort (512) |1048576 |4 bytes |7098 |7527 |100 |4 unique |
315 |
316 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
317 | |---------------|---------|---------|--------------|--------------|------|---------------|
318 | |Blitsort (512) |1048576 |4 bytes |20459 |20896 |100 |1024 unique |
319 | |Sqrtsort (√N) |1048576 |4 bytes |66212 |68995 |100 |1024 unique |
320 | |Octosort (512) |1048576 |4 bytes |75614 |78219 |100 |1024 unique |
321 | |Grailsort (512)|1048576 |4 bytes |129576 |133018 |100 |1024 unique |
322 | |Logsort (512) |1048576 |4 bytes |22834 |23245 |100 |1024 unique |
323 |
324 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
325 | |---------------|---------|---------|--------------|--------------|------|---------------|
326 | |Blitsort (512) |1048576 |4 bytes |37693 |39161 |100 |1048576 unique |
327 | |Sqrtsort (√N) |1048576 |4 bytes |87581 |90788 |100 |1048576 unique |
328 | |Octosort (512) |1048576 |4 bytes |96464 |99214 |100 |1048576 unique |
329 | |Grailsort (512)|1048576 |4 bytes |92196 |95436 |100 |1048576 unique |
330 | |Logsort (512) |1048576 |4 bytes |37343 |38983 |100 |1048576 unique |
331 |
332 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
333 | |---------------|---------|---------|--------------|--------------|------|---------------|
334 | |Blitsort (512) |16777216 |4 bytes |431614 |462105 |100 |4 unique |
335 | |Sqrtsort (√N) |16777216 |4 bytes |885925 |904531 |100 |4 unique |
336 | |Octosort (512) |16777216 |4 bytes |657904 |671961 |100 |4 unique |
337 | |Grailsort (512)|16777216 |4 bytes |1059679 |1126016 |100 |4 unique |
338 | |Logsort (512) |16777216 |4 bytes |149899 |161879 |100 |4 unique |
339 |
340 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
341 | |---------------|---------|---------|--------------|--------------|------|---------------|
342 | |Blitsort (512) |16777216 |4 bytes |854276 |860791 |100 |4096 unique |
343 | |Sqrtsort (√N) |16777216 |4 bytes |1463341 |1499482 |100 |4096 unique |
344 | |Octosort (512) |16777216 |4 bytes |1682796 |1727569 |100 |4096 unique |
345 | |Grailsort (512)|16777216 |4 bytes |2744438 |2954750 |100 |4096 unique |
346 | |Logsort (512) |16777216 |4 bytes |484517 |490591 |100 |4096 unique |
347 |
348 | |Sort |List Size|Data Type|Best Time (µs)|Avg. Time (µs)|Trials|Distribution |
349 | |---------------|---------|---------|--------------|--------------|------|---------------|
350 | |Blitsort (512) |16777216 |4 bytes |1021487 |1030391 |100 |16777216 unique|
351 | |Sqrtsort (√N) |16777216 |4 bytes |1873933 |1988718 |100 |16777216 unique|
352 | |Octosort (512) |16777216 |4 bytes |2123259 |2267619 |100 |16777216 unique|
353 | |Grailsort (512)|16777216 |4 bytes |1965213 |2043090 |100 |16777216 unique|
354 | |Logsort (512) |16777216 |4 bytes |812568 |851833 |100 |16777216 unique|
355 |
356 |