├── .actor
├── Dockerfile
├── actor.json
└── input_schema.json
├── .dockerignore
├── .editorconfig
├── .eslintrc
├── .github
└── workflows
│ └── checks.yml
├── .gitignore
├── CHANGELOG.md
├── LICENSE.md
├── README.md
├── data
├── dataset_rag-web-browser_2024-09-02_2gb_maxResult_1.json
├── dataset_rag-web-browser_2024-09-02_2gb_maxResults_5.json
├── dataset_rag-web-browser_2024-09-02_4gb_maxResult_1.json
├── dataset_rag-web-browser_2024-09-02_4gb_maxResult_5.json
└── performance_measures.md
├── docs
├── apify-gpt-custom-action.png
├── aws-lambda-call-rag-web-browser.py
├── stand_by_rag_web_browser_example.py
└── standby-openapi-3.0.0.json
├── eslint.config.mjs
├── package-lock.json
├── package.json
├── src
├── const.ts
├── crawlers.ts
├── errors.ts
├── google-search
│ └── google-extractors-urls.ts
├── input.ts
├── main.ts
├── mcp
│ └── server.ts
├── performance-measures.ts
├── request-handler.ts
├── responses.ts
├── search.ts
├── server.ts
├── types.ts
├── utils.ts
└── website-content-crawler
│ ├── html-processing.ts
│ ├── markdown.ts
│ └── text-extractor.ts
├── tests
├── cheerio-crawler.content.test.ts
├── helpers
│ ├── html
│ │ └── basic.html
│ └── server.ts
├── playwright-crawler.content.test.ts
├── standby.test.ts
└── utils.test.ts
├── tsconfig.eslint.json
├── tsconfig.json
├── types
└── turndown-plugin-gfm.d.ts
└── vitest.config.ts
/.actor/Dockerfile:
--------------------------------------------------------------------------------
1 | # Specify the base Docker image. You can read more about
2 | # the available images at https://crawlee.dev/docs/guides/docker-images
3 | # You can also use any other image from Docker Hub.
4 | FROM apify/actor-node-playwright-chrome:22-1.46.0 AS builder
5 |
6 | # Copy just package.json and package-lock.json
7 | # to speed up the build using Docker layer cache.
8 | COPY --chown=myuser package*.json ./
9 |
10 | # Install all dependencies. Don't audit to speed up the installation.
11 | RUN npm install --include=dev --audit=false
12 |
13 | # Next, copy the source files using the user set
14 | # in the base image.
15 | COPY --chown=myuser . ./
16 |
17 | # Install all dependencies and build the project.
18 | # Don't audit to speed up the installation.
19 | RUN npm run build
20 |
21 | # Create final image
22 | FROM apify/actor-node-playwright-firefox:22-1.46.0
23 |
24 | # Copy just package.json and package-lock.json
25 | # to speed up the build using Docker layer cache.
26 | COPY --chown=myuser package*.json ./
27 |
28 | # Install NPM packages, skip optional and development dependencies to
29 | # keep the image small. Avoid logging too much and print the dependency
30 | # tree for debugging
31 | RUN npm --quiet set progress=false \
32 | && npm install --omit=dev --omit=optional \
33 | && echo "Installed NPM packages:" \
34 | && (npm list --omit=dev --all || true) \
35 | && echo "Node.js version:" \
36 | && node --version \
37 | && echo "NPM version:" \
38 | && npm --version \
39 | && rm -r ~/.npm
40 |
41 | # Remove the existing firefox installation
42 | RUN rm -rf ${PLAYWRIGHT_BROWSERS_PATH}/*
43 |
44 | # Install all required playwright dependencies for firefox
45 | RUN npx playwright install firefox
46 | # symlink the firefox binary to the root folder in order to bypass the versioning and resulting browser launch crashes.
47 | RUN ln -s ${PLAYWRIGHT_BROWSERS_PATH}/firefox-*/firefox/firefox ${PLAYWRIGHT_BROWSERS_PATH}/
48 |
49 | # Overrides the dynamic library used by Firefox to determine trusted root certificates with p11-kit-trust.so, which loads the system certificates.
50 | RUN rm $PLAYWRIGHT_BROWSERS_PATH/firefox-*/firefox/libnssckbi.so
51 | RUN ln -s /usr/lib/x86_64-linux-gnu/pkcs11/p11-kit-trust.so $(ls -d $PLAYWRIGHT_BROWSERS_PATH/firefox-*)/firefox/libnssckbi.so
52 |
53 | # Copy built JS files from builder image
54 | COPY --from=builder --chown=myuser /home/myuser/dist ./dist
55 |
56 | # Next, copy the remaining files and directories with the source code.
57 | # Since we do this after NPM install, quick build will be really fast
58 | # for most source file changes.
59 | COPY --chown=myuser . ./
60 |
61 | # Disable experimental feature warning from Node.js
62 | ENV NODE_NO_WARNINGS=1
63 |
64 | # Run the image.
65 | CMD npm run start:prod --silent
66 |
--------------------------------------------------------------------------------
/.actor/actor.json:
--------------------------------------------------------------------------------
1 | {
2 | "actorSpecification": 1,
3 | "name": "rag-web-browser",
4 | "title": "RAG Web browser",
5 | "description": "Web browser for OpenAI Assistants API and RAG pipelines, similar to a web browser in ChatGPT. It queries Google Search, scrapes the top N pages from the results, and returns their cleaned content as Markdown for further processing by an LLM.",
6 | "version": "1.0",
7 | "input": "./input_schema.json",
8 | "dockerfile": "./Dockerfile",
9 | "storages": {
10 | "dataset": {
11 | "actorSpecification": 1,
12 | "title": "RAG Web Browser",
13 | "description": "Too see all scraped properties, export the whole dataset or select All fields instead of Overview.",
14 | "views": {
15 | "overview": {
16 | "title": "Overview",
17 | "description": "An view showing just basic properties for simplicity.",
18 | "transformation": {
19 | "flatten": ["metadata", "searchResult"],
20 | "fields": [
21 | "metadata.url",
22 | "metadata.title",
23 | "searchResult.resultType",
24 | "markdown"
25 | ]
26 | },
27 | "display": {
28 | "component": "table",
29 | "properties": {
30 | "metadata.url": {
31 | "label": "Page URL",
32 | "format": "text"
33 | },
34 | "metadata.title": {
35 | "label": "Page title",
36 | "format": "text"
37 | },
38 | "searchResult.resultType": {
39 | "label": "Result type",
40 | "format": "text"
41 | },
42 | "text": {
43 | "label": "Extracted Markdown",
44 | "format": "text"
45 | }
46 | }
47 | }
48 | },
49 | "searchResults": {
50 | "title": "Search results",
51 | "description": "A view showing just the Google Search results, without the page content.",
52 | "transformation": {
53 | "flatten": ["searchResult"],
54 | "fields": [
55 | "searchResult.title",
56 | "searchResult.description",
57 | "searchResult.resultType",
58 | "searchResult.url"
59 | ]
60 | },
61 | "display": {
62 | "component": "table",
63 | "properties": {
64 | "searchResult.description": {
65 | "label": "Description",
66 | "format": "text"
67 | },
68 | "searchResult.title": {
69 | "label": "Title",
70 | "format": "text"
71 | },
72 | "searchResult.resultType": {
73 | "label": "Result type",
74 | "format": "text"
75 | },
76 | "searchResult.url": {
77 | "label": "URL",
78 | "format": "text"
79 | }
80 | }
81 | }
82 | }
83 | }
84 | }
85 | }
86 | }
87 |
--------------------------------------------------------------------------------
/.actor/input_schema.json:
--------------------------------------------------------------------------------
1 | {
2 | "title": "RAG Web Browser",
3 | "description": "Here you can test RAG Web Browser and its settings. Just enter the search terms or URL and click *Start ▶* to get results. In production applications, call the Actor via Standby HTTP server for fast response times.",
4 | "type": "object",
5 | "schemaVersion": 1,
6 | "properties": {
7 | "query": {
8 | "title": "Search term or URL",
9 | "type": "string",
10 | "description": "Enter Google Search keywords or a URL of a specific web page. The keywords might include the [advanced search operators](https://blog.apify.com/how-to-scrape-google-like-a-pro/). Examples:\n\n- san francisco weather\n- https://www.cnn.com\n- function calling site:openai.com",
11 | "prefill": "web browser for RAG pipelines -site:reddit.com",
12 | "editor": "textfield",
13 | "pattern": "[^\\s]+"
14 | },
15 | "maxResults": {
16 | "title": "Maximum results",
17 | "type": "integer",
18 | "description": "The maximum number of top organic Google Search results whose web pages will be extracted. If `query` is a URL, then this field is ignored and the Actor only fetches the specific web page.",
19 | "default": 3,
20 | "minimum": 1,
21 | "maximum": 100
22 | },
23 | "outputFormats": {
24 | "title": "Output formats",
25 | "type": "array",
26 | "description": "Select one or more formats to which the target web pages will be extracted and saved in the resulting dataset.",
27 | "editor": "select",
28 | "default": ["markdown"],
29 | "items": {
30 | "type": "string",
31 | "enum": ["text", "markdown", "html"],
32 | "enumTitles": ["Plain text", "Markdown", "HTML"]
33 | }
34 | },
35 | "requestTimeoutSecs": {
36 | "title": "Request timeout",
37 | "type": "integer",
38 | "description": "The maximum time in seconds available for the request, including querying Google Search and scraping the target web pages. For example, OpenAI allows only [45 seconds](https://platform.openai.com/docs/actions/production#timeouts) for custom actions. If a target page loading and extraction exceeds this timeout, the corresponding page will be skipped in results to ensure at least some results are returned within the timeout. If no page is extracted within the timeout, the whole request fails.",
39 | "minimum": 1,
40 | "maximum": 300,
41 | "default": 40,
42 | "unit": "seconds",
43 | "editor": "hidden"
44 | },
45 | "serpProxyGroup": {
46 | "title": "SERP proxy group",
47 | "type": "string",
48 | "description": "Enables overriding the default Apify Proxy group used for fetching Google Search results.",
49 | "editor": "select",
50 | "default": "GOOGLE_SERP",
51 | "enum": ["GOOGLE_SERP", "SHADER"],
52 | "sectionCaption": "Google Search scraping settings"
53 | },
54 | "serpMaxRetries": {
55 | "title": "SERP max retries",
56 | "type": "integer",
57 | "description": "The maximum number of times the Actor will retry fetching the Google Search results on error. If the last attempt fails, the entire request fails.",
58 | "minimum": 0,
59 | "maximum": 5,
60 | "default": 2
61 | },
62 | "proxyConfiguration": {
63 | "title": "Proxy configuration",
64 | "type": "object",
65 | "description": "Apify Proxy configuration used for scraping the target web pages.",
66 | "default": {
67 | "useApifyProxy": true
68 | },
69 | "prefill": {
70 | "useApifyProxy": true
71 | },
72 | "editor": "proxy",
73 | "sectionCaption": "Target pages scraping settings"
74 | },
75 | "scrapingTool": {
76 | "title": "Select a scraping tool",
77 | "type": "string",
78 | "description": "Select a scraping tool for extracting the target web pages. The Browser tool is more powerful and can handle JavaScript heavy websites, while the Plain HTML tool can't handle JavaScript but is about two times faster.",
79 | "editor": "select",
80 | "default": "raw-http",
81 | "enum": ["browser-playwright", "raw-http"],
82 | "enumTitles": ["Browser (uses Playwright)", "Raw HTTP"]
83 | },
84 | "removeElementsCssSelector": {
85 | "title": "Remove HTML elements (CSS selector)",
86 | "type": "string",
87 | "description": "A CSS selector matching HTML elements that will be removed from the DOM, before converting it to text, Markdown, or saving as HTML. This is useful to skip irrelevant page content. The value must be a valid CSS selector as accepted by the `document.querySelectorAll()` function. \n\nBy default, the Actor removes common navigation elements, headers, footers, modals, scripts, and inline image. You can disable the removal by setting this value to some non-existent CSS selector like `dummy_keep_everything`.",
88 | "editor": "textarea",
89 | "default": "nav, footer, script, style, noscript, svg, img[src^='data:'],\n[role=\"alert\"],\n[role=\"banner\"],\n[role=\"dialog\"],\n[role=\"alertdialog\"],\n[role=\"region\"][aria-label*=\"skip\" i],\n[aria-modal=\"true\"]",
90 | "prefill": "nav, footer, script, style, noscript, svg, img[src^='data:'],\n[role=\"alert\"],\n[role=\"banner\"],\n[role=\"dialog\"],\n[role=\"alertdialog\"],\n[role=\"region\"][aria-label*=\"skip\" i],\n[aria-modal=\"true\"]"
91 | },
92 | "htmlTransformer": {
93 | "title": "HTML transformer",
94 | "type": "string",
95 | "description": "Specify how to transform the HTML to extract meaningful content without any extra fluff, like navigation or modals. The HTML transformation happens after removing and clicking the DOM elements.\n\n- **None** (default) - Only removes the HTML elements specified via 'Remove HTML elements' option.\n\n- **Readable text** - Extracts the main contents of the webpage, without navigation and other fluff.",
96 | "default": "none",
97 | "prefill": "none",
98 | "editor": "hidden"
99 | },
100 | "desiredConcurrency": {
101 | "title": "Desired browsing concurrency",
102 | "type": "integer",
103 | "description": "The desired number of web browsers running in parallel. The system automatically scales the number based on the CPU and memory usage. If the initial value is `0`, the Actor picks the number automatically based on the available memory.",
104 | "minimum": 0,
105 | "maximum": 50,
106 | "default": 5,
107 | "editor": "hidden"
108 | },
109 | "maxRequestRetries": {
110 | "title": "Target page max retries",
111 | "type": "integer",
112 | "description": "The maximum number of times the Actor will retry loading the target web page on error. If the last attempt fails, the page will be skipped in the results.",
113 | "minimum": 0,
114 | "maximum": 3,
115 | "default": 1
116 | },
117 | "dynamicContentWaitSecs": {
118 | "title": "Target page dynamic content timeout",
119 | "type": "integer",
120 | "description": "The maximum time in seconds to wait for dynamic page content to load. The Actor considers the web page as fully loaded once this time elapses or when the network becomes idle.",
121 | "default": 10,
122 | "unit": "seconds"
123 | },
124 | "removeCookieWarnings": {
125 | "title": "Remove cookie warnings",
126 | "type": "boolean",
127 | "description": "If enabled, the Actor attempts to close or remove cookie consent dialogs to improve the quality of extracted text. Note that this setting increases the latency.",
128 | "default": true
129 | },
130 | "debugMode": {
131 | "title": "Enable debug mode",
132 | "type": "boolean",
133 | "description": "If enabled, the Actor will store debugging information into the resulting dataset under the `debug` field.",
134 | "default": false
135 | }
136 | },
137 | "required": ["query"]
138 | }
139 |
--------------------------------------------------------------------------------
/.dockerignore:
--------------------------------------------------------------------------------
1 | # configurations
2 | .idea
3 |
4 | # crawlee and apify storage folders
5 | apify_storage
6 | crawlee_storage
7 | storage
8 |
9 | # installed files
10 | node_modules
11 |
12 | # git folder
13 | .git
14 |
15 | # data
16 | data
17 | src/storage
18 | dist
19 |
--------------------------------------------------------------------------------
/.editorconfig:
--------------------------------------------------------------------------------
1 | root = true
2 |
3 | [*]
4 | indent_style = space
5 | indent_size = 4
6 | charset = utf-8
7 | trim_trailing_whitespace = true
8 | insert_final_newline = true
9 | end_of_line = lf
10 | max_line_length = 120
11 |
--------------------------------------------------------------------------------
/.eslintrc:
--------------------------------------------------------------------------------
1 | {
2 | "root": true,
3 | "env": {
4 | "browser": true,
5 | "es2020": true,
6 | "node": true
7 | },
8 | "extends": [
9 | "@apify/eslint-config-ts"
10 | ],
11 | "parserOptions": {
12 | "project": "./tsconfig.json",
13 | "ecmaVersion": 2020
14 | },
15 | "ignorePatterns": [
16 | "node_modules",
17 | "dist",
18 | "**/*.d.ts"
19 | ],
20 | "plugins": ["import"],
21 | "rules": {
22 | "import/order": [
23 | "error",
24 | {
25 | "groups": [
26 | ["builtin", "external"],
27 | "internal",
28 | ["parent", "sibling", "index"]
29 | ],
30 | "newlines-between": "always",
31 | "alphabetize": {
32 | "order": "asc",
33 | "caseInsensitive": true
34 | }
35 | }
36 | ],
37 | "max-len": ["error", { "code": 120, "ignoreUrls": true, "ignoreStrings": true, "ignoreTemplateLiterals": true }]
38 | }
39 | }
40 |
--------------------------------------------------------------------------------
/.github/workflows/checks.yml:
--------------------------------------------------------------------------------
1 | name: Code Checks
2 |
3 | on:
4 | push:
5 | branches: [ master ]
6 | pull_request:
7 | branches: [ master ]
8 |
9 | jobs:
10 | build-and-test:
11 | runs-on: ubuntu-latest
12 |
13 | steps:
14 | - uses: actions/checkout@v4
15 |
16 | - name: Setup Node.js
17 | uses: actions/setup-node@v4
18 | with:
19 | node-version: 'latest'
20 | cache: 'npm'
21 |
22 | - name: Install dependencies
23 | run: npm ci
24 |
25 | - name: Build
26 | run: npm run build
27 |
28 | - name: Lint
29 | run: npm run lint
30 |
31 | - name: Install Playwright
32 | run: npx playwright install
33 |
34 | - name: Test
35 | run: npm run test
36 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # This file tells Git which files shouldn't be added to source control
2 |
3 | .DS_Store
4 | .idea
5 | dist
6 | node_modules
7 | apify_storage
8 | storage
9 |
10 | # Added by Apify CLI
11 | .venv
12 | .aider*
13 |
14 | # Actor run input
15 | input.json
16 |
--------------------------------------------------------------------------------
/CHANGELOG.md:
--------------------------------------------------------------------------------
1 | This changelog summarizes all changes of the RAG Web Browser
2 |
3 | ### 1.0.15 (2025-03-27)
4 |
5 | 🐛 Bug Fixes
6 | - Cancel requests only in standby mode
7 |
8 | ### 1.0.13 (2025-03-27)
9 |
10 | 🐛 Bug Fixes
11 | - Cancel crawling requests from timed-out search queries
12 |
13 | ### 1.0.12 (2025-03-24)
14 |
15 | 🐛 Bug Fixes
16 | - Updated selector for organic search results and places
17 |
18 | ### 1.0.11 (2025-03-21)
19 |
20 | 🐛 Bug Fixes
21 | - Selector for organic search results
22 |
23 | ### 1.0.10 (2025-03-19)
24 |
25 | 🚀 Features
26 | - Handle all query parameters in the standby mode (including proxy)
27 |
28 | ### 1.0.9 (2025-03-14)
29 |
30 | 🚀 Features
31 | - Change default value for `scrapingTool` from 'browser-playwright' to 'raw-http' to improve latency.
32 |
33 | ### 1.0.8 (2025-03-07)
34 |
35 | 🚀 Features
36 | - Add a new `scrapingTool` input to allow users to choose between Browser scraper and raw HTTP scraper
37 |
38 | ### 1.0.7 (2025-02-20)
39 |
40 | 🚀 Features
41 | - Update Readme.md to include information about MCP
42 |
43 | ### 1.0.6 (2025-02-04)
44 |
45 | 🚀 Features
46 | - Handle double encoding of URLs
47 |
48 | ### 1.0.5 (2025-01-17)
49 |
50 | 🐛 Bug Fixes
51 | - Change default value of input query
52 | - Retry search if no results are found
53 |
54 | ### 1.0.4 (2025-01-04)
55 |
56 | 🚀 Features
57 | - Include Model Context Protocol in Standby Mode
58 |
59 | ### 1.0.3 (2024-11-13)
60 |
61 | 🚀 Features
62 | - Improve README.md and simplify configuration
63 | - Add an AWS Lambda function
64 | - Hide variables initialConcurrency, minConcurrency, and maxConcurrency in the Actor input and remove them from README.md
65 | - Remove requestTimeoutContentCrawlSecs and use only requestTimeoutSecs
66 | - Ensure there is enough time left to wait for dynamic content before the Actor timeout (normal mode)
67 | - Rename googleSearchResults to searchResults and searchProxyGroup to serpProxyGroup
68 | - Implement input validation
69 |
70 | ### 0.1.4 (2024-11-08)
71 |
72 | 🚀 Features
73 | - Add functionality to extract content from a specific URL
74 | - Update README.md to include new functionality and provide examples
75 |
76 | ### 0.0.32 (2024-10-17)
77 |
78 | 🚀 Features
79 | - Handle errors when request is added to Playwright queue.
80 | This will prevent the Cheerio crawler from repeating the same request multiple times.
81 | - Silence error: Could not parse CSS stylesheet as there is no way to fix it at our end
82 | - Set logLevel to INFO (debug level can be set using the `debugMode=true` input)
83 |
84 | ### 2024-10-11
85 |
86 | 🚀 Features
87 | - Increase the maximum number of results (`maxResults`) from 50 to 100
88 | - Explain better how to search a specific website using "llm site:apify.com"
89 |
90 | ### 2024-10-07
91 |
92 | 🚀 Features
93 | - Add a short description how to create a custom action
94 |
95 | ### 2024-09-24
96 |
97 | 🚀 Features
98 | - Updated README.md to include tips on improving latency
99 | - Set initialConcurrency to 5
100 | - Set minConcurrency to 3
101 |
102 | ### 2024-09-20
103 |
104 | 🐛 Bug Fixes
105 | - Fix response format when crawler fails
106 |
107 | ### 2024-09-24
108 |
109 | 🚀 Features
110 | - Add ability to create new crawlers using query parameters
111 | - Update Dockerfile to node version 22
112 |
113 | 🐛 Bug Fixes
114 | - Fix playwright key creation
115 |
116 | ### 2024-09-11
117 |
118 | 🚀 Features
119 | - Initial version of the RAG Web Browser
120 |
--------------------------------------------------------------------------------
/LICENSE.md:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "{}"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright 2024 Apify Technologies s.r.o.
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 🌐 RAG Web Browser
2 |
3 | [](https://apify.com/apify/rag-web-browser)
4 |
5 | This Actor provides web browsing functionality for AI agents and LLM applications,
6 | similar to the [web browsing](https://openai.com/index/introducing-chatgpt-search/) feature in ChatGPT.
7 | It accepts a search phrase or a URL, queries Google Search, then crawls web pages from the top search results, cleans the HTML, converts it to text or Markdown,
8 | and returns it back for processing by the LLM application.
9 | The extracted text can then be injected into prompts and retrieval augmented generation (RAG) pipelines, to provide your LLM application with up-to-date context from the web.
10 |
11 | ## Main features
12 |
13 | - 🚀 **Quick response times** for great user experience
14 | - ⚙️ Supports **dynamic JavaScript-heavy websites** using a headless browser
15 | - 🔄 **Flexible scraping** with Browser mode for complex websites or Plain HTML mode for faster scraping
16 | - 🕷 Automatically **bypasses anti-scraping protections** using proxies and browser fingerprints
17 | - 📝 Output formats include **Markdown**, plain text, and HTML
18 | - 🔌 Supports **OpenAPI and MCP** for easy integration
19 | - 🪟 It's **open source**, so you can review and modify it
20 |
21 | ## Example
22 |
23 | For a search query like `fast web browser in RAG pipelines`, the Actor will return an array with a content of top results from Google Search, which looks like this:
24 |
25 | ```json
26 | [
27 | {
28 | "crawl": {
29 | "httpStatusCode": 200,
30 | "httpStatusMessage": "OK",
31 | "loadedAt": "2024-11-25T21:23:58.336Z",
32 | "uniqueKey": "eM0RDxDQ3q",
33 | "requestStatus": "handled"
34 | },
35 | "searchResult": {
36 | "title": "apify/rag-web-browser",
37 | "description": "Sep 2, 2024 — The RAG Web Browser is designed for Large Language Model (LLM) applications or LLM agents to provide up-to-date ....",
38 | "url": "https://github.com/apify/rag-web-browser"
39 | },
40 | "metadata": {
41 | "title": "GitHub - apify/rag-web-browser: RAG Web Browser is an Apify Actor to feed your LLM applications ...",
42 | "description": "RAG Web Browser is an Apify Actor to feed your LLM applications ...",
43 | "languageCode": "en",
44 | "url": "https://github.com/apify/rag-web-browser"
45 | },
46 | "markdown": "# apify/rag-web-browser: RAG Web Browser is an Apify Actor ..."
47 | }
48 | ]
49 | ```
50 |
51 | If you enter a specific URL such as `https://openai.com/index/introducing-chatgpt-search/`, the Actor will extract
52 | the web page content directly like this:
53 |
54 | ```json
55 | [{
56 | "crawl": {
57 | "httpStatusCode": 200,
58 | "httpStatusMessage": "OK",
59 | "loadedAt": "2024-11-21T14:04:28.090Z"
60 | },
61 | "metadata": {
62 | "url": "https://openai.com/index/introducing-chatgpt-search/",
63 | "title": "Introducing ChatGPT search | OpenAI",
64 | "description": "Get fast, timely answers with links to relevant web sources",
65 | "languageCode": "en-US"
66 | },
67 | "markdown": "# Introducing ChatGPT search | OpenAI\n\nGet fast, timely answers with links to relevant web sources.\n\nChatGPT can now search the web in a much better way than before. ..."
68 | }]
69 | ```
70 |
71 | ## ⚙️ Usage
72 |
73 | The RAG Web Browser can be used in two ways: **as a standard Actor** by passing it an input object with the settings,
74 | or in the **Standby mode** by sending it an HTTP request.
75 |
76 | See the [Performance Optimization](#-performance-optimization) section below for detailed benchmarks and configuration recommendations to achieve optimal response times.
77 |
78 | ### Normal Actor run
79 |
80 | You can run the Actor "normally" via the Apify API, schedule, integrations, or manually in Console.
81 | On start, you pass the Actor an input JSON object with settings including the search phrase or URL,
82 | and it stores the results to the default dataset.
83 | This mode is useful for testing and evaluation, but might be too slow for production applications and RAG pipelines,
84 | because it takes some time to start the Actor's Docker container and a web browser.
85 | Also, one Actor run can only handle one query, which isn't efficient.
86 |
87 | ### Standby web server
88 |
89 | The Actor also supports the [**Standby mode**](https://docs.apify.com/platform/actors/running/standby),
90 | where it runs an HTTP web server that receives requests with the search phrases and responds with the extracted web content.
91 | This mode is preferred for production applications, because if the Actor is already running, it will
92 | return the results much faster. Additionally, in the Standby mode the Actor can handle multiple requests
93 | in parallel, and thus utilizes the computing resources more efficiently.
94 |
95 | To use RAG Web Browser in the Standby mode, simply send an HTTP GET request to the following URL:
96 |
97 | ```
98 | https://rag-web-browser.apify.actor/search?token=&query=hello+world
99 | ```
100 |
101 | where `` is your [Apify API token](https://console.apify.com/settings/integrations).
102 | Note that you can also pass the API token using the `Authorization` HTTP header with Basic authentication for increased security.
103 |
104 | The response is a JSON array with objects containing the web content from the found web pages, as shown in the example [above](#example).
105 |
106 | #### Query parameters
107 |
108 | The `/search` GET HTTP endpoint accepts all the input parameters [described on the Actor page](https://apify.com/apify/rag-web-browser/input-schema). Object parameters like `proxyConfiguration` should be passed as url-encoded JSON strings.
109 |
110 |
111 | ## 🔌 Integration with LLMs
112 |
113 | RAG Web Browser has been designed for easy integration with LLM applications, GPTs, OpenAI Assistants, and RAG pipelines using function calling.
114 |
115 | ### OpenAPI schema
116 |
117 | Here you can find the [OpenAPI 3.1.0 schema](https://apify.com/apify/rag-web-browser/api/openapi)
118 | or [OpenAPI 3.0.0 schema](https://raw.githubusercontent.com/apify/rag-web-browser/refs/heads/master/docs/standby-openapi-3.0.0.json)
119 | for the Standby web server. Note that the OpenAPI definition contains
120 | all available query parameters, but only `query` is required.
121 | You can remove all the others parameters from the definition if their default value is right for your application,
122 | in order to reduce the number of LLM tokens necessary and to reduce the risk of hallucinations in function calling.
123 |
124 | ### OpenAI Assistants
125 |
126 | While OpenAI's ChatGPT and GPTs support web browsing natively, [Assistants](https://platform.openai.com/docs/assistants/overview) currently don't.
127 | With RAG Web Browser, you can easily add the web search and browsing capability to your custom AI assistant and chatbots.
128 | For detailed instructions,
129 | see the [OpenAI Assistants integration](https://docs.apify.com/platform/integrations/openai-assistants#real-time-search-data-for-openai-assistant) in Apify documentation.
130 |
131 | ### OpenAI GPTs
132 |
133 | You can easily add the RAG Web Browser to your GPTs by creating a custom action. Here's a quick guide:
134 |
135 | 1. Go to [**My GPTs**](https://chatgpt.com/gpts/mine) on ChatGPT website and click **+ Create a GPT**.
136 | 2. Complete all required details in the form.
137 | 3. Under the **Actions** section, click **Create new action**.
138 | 4. In the Action settings, set **Authentication** to **API key** and choose Bearer as **Auth Type**.
139 | 5. In the **schema** field, paste the [OpenAPI 3.1.0 schema](https://raw.githubusercontent.com/apify/rag-web-browser/refs/heads/master/docs/standby-openapi-3.1.0.json)
140 | of the Standby web server HTTP API.
141 |
142 | 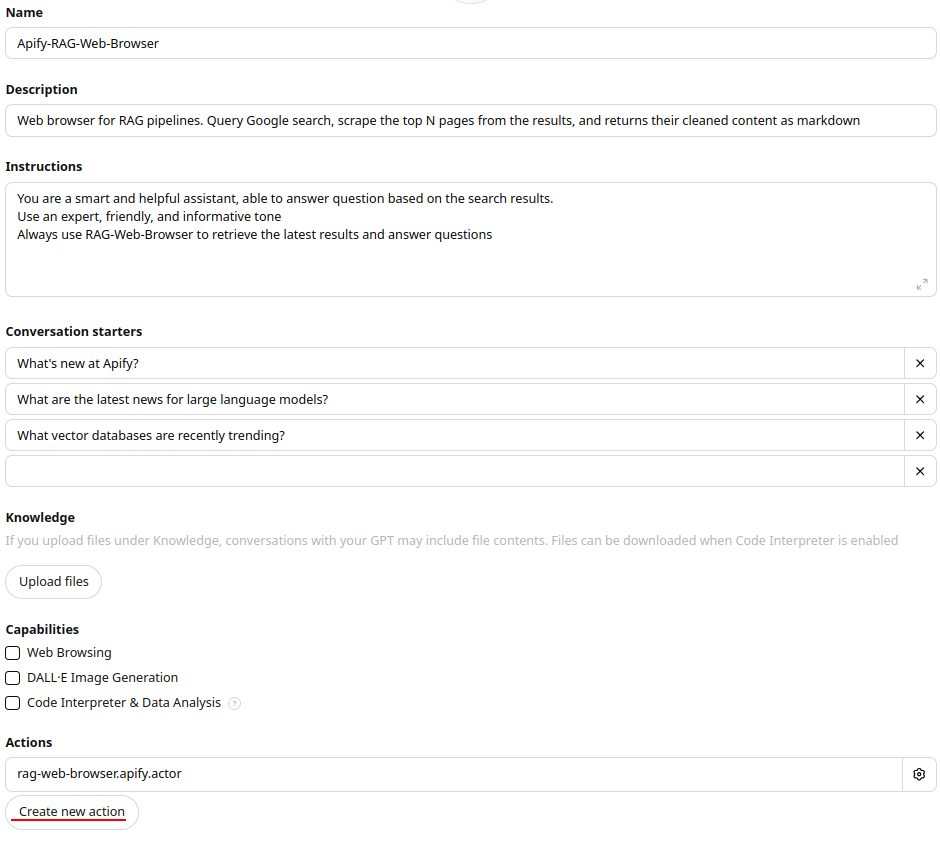
143 |
144 | Learn more about [adding custom actions to your GPTs with Apify Actors](https://blog.apify.com/add-custom-actions-to-your-gpts/) on Apify Blog.
145 |
146 | ### Anthropic: Model Context Protocol (MCP) Server
147 |
148 | The RAG Web Browser Actor can also be used as an [MCP server](https://github.com/modelcontextprotocol) and integrated with AI applications and agents, such as Claude Desktop.
149 | For example, in Claude Desktop, you can configure the MCP server in its settings to perform web searches and extract content.
150 | Alternatively, you can develop a custom MCP client to interact with the RAG Web Browser Actor.
151 |
152 | In the Standby mode, the Actor runs an HTTP server that supports the MCP protocol via SSE (Server-Sent Events).
153 |
154 | 1. Initiate SSE connection:
155 | ```shell
156 | curl https://rag-web-browser.apify.actor/sse?token=
157 | ```
158 | On connection, you'll receive a `sessionId`:
159 | ```text
160 | event: endpoint
161 | data: /message?sessionId=5b2
162 | ```
163 |
164 | 1. Send a message to the server by making a POST request with the `sessionId`, `APIFY-API-TOKEN` and your query:
165 | ```shell
166 | curl -X POST "https://rag-web-browser.apify.actor/message?session_id=5b2&token=" -H "Content-Type: application/json" -d '{
167 | "jsonrpc": "2.0",
168 | "id": 1,
169 | "method": "tools/call",
170 | "params": {
171 | "arguments": { "query": "recent news about LLMs", "maxResults": 1 },
172 | "name": "rag-web-browser"
173 | }
174 | }'
175 | ```
176 | For the POST request, the server will respond with:
177 | ```text
178 | Accepted
179 | ```
180 |
181 | 1. Receive a response at the initiated SSE connection:
182 | The server invoked `Actor` and its tool using the provided query and sent the response back to the client via SSE.
183 |
184 | ```text
185 | event: message
186 | data: {"result":{"content":[{"type":"text","text":"[{\"searchResult\":{\"title\":\"Language models recent news\",\"description\":\"Amazon Launches New Generation of LLM Foundation Model...\"}}
187 | ```
188 |
189 | You can try the MCP server using the [MCP Tester Client](https://apify.com/jiri.spilka/tester-mcp-client) available on Apify. In the MCP client, simply enter the URL `https://rag-web-browser.apify.actor/sse` in the Actor input field and click **Run** and interact with server in a UI.
190 | To learn more about MCP servers, check out the blog post [What is Anthropic's Model Context Protocol](https://blog.apify.com/what-is-model-context-protocol/).
191 |
192 | ## ⏳ Performance optimization
193 |
194 | To get the most value from RAG Web Browsers in your LLM applications,
195 | always use the Actor via the [Standby web server](#standby-web-server) as described above,
196 | and see the tips in the following sections.
197 |
198 | ### Scraping tool
199 |
200 | The **most critical performance decision** is selecting the appropriate scraping method for your use case:
201 |
202 | - **For static websites**: Use `scrapingTool=raw-http` to achieve up to 2x faster performance. This lightweight method directly fetches HTML without JavaScript processing.
203 |
204 | - **For dynamic websites**: Use the default `scrapingTool=browser-playwright` when targeting sites with JavaScript-rendered content or interactive elements
205 |
206 | This single parameter choice can significantly impact both response times and content quality, so select based on your target websites' characteristics.
207 |
208 | ### Request timeout
209 |
210 | Many user-facing RAG applications impose a time limit on external functions to provide a good user experience.
211 | For example, OpenAI Assistants and GPTs have a limit of [45 seconds](https://platform.openai.com/docs/actions/production#timeouts) for custom actions.
212 |
213 | To ensure the web search and content extraction is completed within the required timeout,
214 | you can set the `requestTimeoutSecs` query parameter.
215 | If this timeout is exceeded, **the Actor makes the best effort to return results it has scraped up to that point**
216 | in order to provide your LLM application with at least some context.
217 |
218 | Here are specific situations that might occur when the timeout is reached:
219 |
220 | - The Google Search query failed => the HTTP request fails with a 5xx error.
221 | - The requested `query` is a single URL that failed to load => the HTTP request fails with a 5xx error.
222 | - The requested `query` is a search term, but one of target web pages failed to load => the response contains at least
223 | the `searchResult` for the specific page contains a URL, title, and description.
224 | - One of the target pages hasn't loaded dynamic content (within the `dynamicContentWaitSecs` deadline)
225 | => the Actor extracts content from the currently loaded HTML
226 |
227 |
228 | ### Reducing response time
229 |
230 | For low-latency applications, it's recommended to run the RAG Web Browser in Standby mode
231 | with the default settings, i.e. with 8 GB of memory and maximum of 24 requests per run.
232 | Note that on the first request, the Actor takes a little time to respond (cold start).
233 |
234 | Additionally, you can adjust the following query parameters to reduce the response time:
235 |
236 | - `scrapingTool`: Use `raw-http` for static websites or `browser-playwright` for dynamic websites.
237 | - `maxResults`: The lower the number of search results to scrape, the faster the response time. Just note that the LLM application might not have sufficient context for the prompt.
238 | - `dynamicContentWaitSecs`: The lower the value, the faster the response time. However, the important web content might not be loaded yet, which will reduce the accuracy of your LLM application.
239 | - `removeCookieWarnings`: If the websites you're scraping don't have cookie warnings or if their presence can be tolerated, set this to `false` to slightly improve latency.
240 | - `debugMode`: If set to `true`, the Actor will store latency data to results so that you can see where it takes time.
241 |
242 |
243 | ### Cost vs. throughput
244 |
245 | When running the RAG Web Browser in Standby web server, the Actor can process a number of requests in parallel.
246 | This number is determined by the following [Standby mode](https://docs.apify.com/platform/actors/running/standby) settings:
247 |
248 | - **Max requests per run** and **Desired requests per run** - Determine how many requests can be sent by the system to one Actor run.
249 | - **Memory** - Determines how much memory and CPU resources the Actor run has available, and this how many web pages it can open and process in parallel.
250 |
251 | Additionally, the Actor manages its internal pool of web browsers to handle the requests.
252 | If the Actor memory or CPU is at capacity, the pool automatically scales down, and requests
253 | above the capacity are delayed.
254 |
255 | By default, these Standby mode settings are optimized for quick response time:
256 | 8 GB of memory and maximum of 24 requests per run gives approximately ~340 MB per web page.
257 | If you prefer to optimize the Actor for the cost, you can **Create task** for the Actor in Apify Console
258 | and override these settings. Just note that requests might take longer and so you should
259 | increase `requestTimeoutSecs` accordingly.
260 |
261 |
262 | ### Benchmark
263 |
264 | Below is a typical latency breakdown for RAG Web Browser with **maxResults** set to either `1` or `3`, and various memory settings.
265 | These settings allow for processing all search results in parallel.
266 | The numbers below are based on the following search terms: "apify", "Donald Trump", "boston".
267 | Results were averaged for the three queries.
268 |
269 | | Memory (GB) | Max results | Latency (sec) |
270 | |-------------|-------------|---------------|
271 | | 4 | 1 | 22 |
272 | | 4 | 3 | 31 |
273 | | 8 | 1 | 16 |
274 | | 8 | 3 | 17 |
275 |
276 | Please note the these results are only indicative and may vary based on the search term, target websites, and network latency.
277 |
278 | ## 💰 Pricing
279 |
280 | The RAG Web Browser is free of charge, and you only pay for the Apify platform consumption when it runs.
281 | The main driver of the price is the Actor compute units (CUs), which are proportional to the amount of Actor run memory
282 | and run time (1 CU = 1 GB memory x 1 hour).
283 |
284 | ## ⓘ Limitations and feedback
285 |
286 | The Actor uses [Google Search](https://www.google.com/) in the United States with English language,
287 | and so queries like "_best nearby restaurants_" will return search results from the US.
288 |
289 | If you need other regions or languages, or have some other feedback,
290 | please [submit an issue](https://console.apify.com/actors/3ox4R101TgZz67sLr/issues) in Apify Console to let us know.
291 |
292 |
293 | ## 👷🏼 Development
294 |
295 | The RAG Web Browser Actor has open source available on [GitHub](https://github.com/apify/rag-web-browser),
296 | so that you can modify and develop it yourself. Here are the steps how to run it locally on your computer.
297 |
298 | Download the source code:
299 |
300 | ```bash
301 | git clone https://github.com/apify/rag-web-browser
302 | cd rag-web-browser
303 | ```
304 |
305 | Install [Playwright](https://playwright.dev) with dependencies:
306 |
307 | ```bash
308 | npx playwright install --with-deps
309 | ```
310 |
311 | And then you can run it locally using [Apify CLI](https://docs.apify.com/cli) as follows:
312 |
313 | ```bash
314 | APIFY_META_ORIGIN=STANDBY apify run -p
315 | ```
316 |
317 | Server will start on `http://localhost:3000` and you can send requests to it, for example:
318 |
319 | ```bash
320 | curl "http://localhost:3000/search?query=example.com"
321 | ```
322 |
--------------------------------------------------------------------------------
/data/dataset_rag-web-browser_2024-09-02_4gb_maxResult_1.json:
--------------------------------------------------------------------------------
1 | [{
2 | "crawl": {
3 | "httpStatusCode": 200,
4 | "loadedAt": "2024-09-02T11:57:16.049Z",
5 | "uniqueKey": "6cca1227-3742-4544-b1c1-16cb13d2dba8",
6 | "requestStatus": "handled",
7 | "debug": {
8 | "timeMeasures": [
9 | {
10 | "event": "request-received",
11 | "timeMs": 0,
12 | "timeDeltaPrevMs": 0
13 | },
14 | {
15 | "event": "before-cheerio-queue-add",
16 | "timeMs": 143,
17 | "timeDeltaPrevMs": 143
18 | },
19 | {
20 | "event": "cheerio-request-handler-start",
21 | "timeMs": 2993,
22 | "timeDeltaPrevMs": 2850
23 | },
24 | {
25 | "event": "before-playwright-queue-add",
26 | "timeMs": 3011,
27 | "timeDeltaPrevMs": 18
28 | },
29 | {
30 | "event": "playwright-request-start",
31 | "timeMs": 15212,
32 | "timeDeltaPrevMs": 12201
33 | },
34 | {
35 | "event": "playwright-wait-dynamic-content",
36 | "timeMs": 22158,
37 | "timeDeltaPrevMs": 6946
38 | },
39 | {
40 | "event": "playwright-remove-cookie",
41 | "timeMs": 22331,
42 | "timeDeltaPrevMs": 173
43 | },
44 | {
45 | "event": "playwright-parse-with-cheerio",
46 | "timeMs": 23122,
47 | "timeDeltaPrevMs": 791
48 | },
49 | {
50 | "event": "playwright-process-html",
51 | "timeMs": 25226,
52 | "timeDeltaPrevMs": 2104
53 | },
54 | {
55 | "event": "playwright-before-response-send",
56 | "timeMs": 25433,
57 | "timeDeltaPrevMs": 207
58 | }
59 | ]
60 | }
61 | },
62 | "metadata": {
63 | "author": null,
64 | "title": "Apify: Full-stack web scraping and data extraction platform",
65 | "description": "Cloud platform for web scraping, browser automation, and data for AI. Use 2,000+ ready-made tools, code templates, or order a custom solution.",
66 | "keywords": "web scraper,web crawler,scraping,data extraction,API",
67 | "languageCode": "en",
68 | "url": "https://apify.com/"
69 | },
70 | "text": "Full-stack web scraping and data extraction platformStar apify/crawlee on GitHubProblem loading pageBack ButtonSearch IconFilter Icon\npowering the world's top data-driven teams\nSimplify scraping with\nCrawlee\nGive your crawlers an unfair advantage with Crawlee, our popular library for building reliable scrapers in Node.js.\n\nimport\n{\nPuppeteerCrawler,\nDataset\n}\nfrom 'crawlee';\nconst crawler = new PuppeteerCrawler(\n{\nasync requestHandler(\n{\nrequest, page,\nenqueueLinks\n}\n) \n{\nurl: request.url,\ntitle: await page.title(),\nawait enqueueLinks();\nawait crawler.run(['https://crawlee.dev']);\nUse your favorite libraries\nApify works great with both Python and JavaScript, with Playwright, Puppeteer, Selenium, Scrapy, or any other library.\nStart with our code templates\nfrom scrapy.spiders import CrawlSpider, Rule\nclass Scraper(CrawlSpider):\nname = \"scraper\"\nstart_urls = [\"https://the-coolest-store.com/\"]\ndef parse_item(self, response):\nitem = Item()\nitem[\"price\"] = response.css(\".price_color::text\").get()\nreturn item\nTurn your code into an Apify Actor\nActors are serverless microapps that are easy to develop, run, share, and integrate. The infra, proxies, and storages are ready to go.\nLearn more about Actors\nimport\n{ Actor\n}\nfrom 'apify'\nawait Actor.init();\nDeploy to the cloud\nNo config required. Use a single CLI command or build directly from GitHub.\nDeploy to Apify\n> apify push\nInfo: Deploying Actor 'computer-scraper' to Apify.\nRun: Updated version 0.0 for scraper Actor.\nRun: Building Actor scraper\nACTOR: Pushing Docker image to repository.\nACTOR: Build finished.\nActor build detail -> https://console.apify.com/actors#/builds/0.0.2\nSuccess: Actor was deployed to Apify cloud and built there.\nRun your Actors\nStart from Apify Console, CLI, via API, or schedule your Actor to start at any time. It’s your call.\nPOST/v2/acts/4cT0r1D/runs\nRun object\n{ \"id\": \"seHnBnyCTfiEnXft\", \"startedAt\": \"2022-12-01T13:42:00.364Z\", \"finishedAt\": null, \"status\": \"RUNNING\", \"options\": { \"build\": \"version-3\", \"timeoutSecs\": 3600, \"memoryMbytes\": 4096 }, \"defaultKeyValueStoreId\": \"EiGjhZkqseHnBnyC\", \"defaultDatasetId\": \"vVh7jTthEiGjhZkq\", \"defaultRequestQueueId\": \"TfiEnXftvVh7jTth\" }\nNever get blocked\nUse our large pool of datacenter and residential proxies. Rely on smart IP address rotation with human-like browser fingerprints.\nLearn more about Apify Proxy\nawait Actor.createProxyConfiguration(\n{\ncountryCode: 'US',\ngroups: ['RESIDENTIAL'],\nStore and share crawling results\nUse distributed queues of URLs to crawl. Store structured data or binary files. Export datasets in CSV, JSON, Excel or other formats.\nLearn more about Apify Storage\nGET/v2/datasets/d4T453t1D/items\nDataset items\n[ { \"title\": \"myPhone 99 Super Max\", \"description\": \"Such phone, max 99, wow!\", \"price\": 999 }, { \"title\": \"myPad Hyper Thin\", \"description\": \"So thin it's 2D.\", \"price\": 1499 } ]\nMonitor performance over time\nInspect all Actor runs, their logs, and runtime costs. Listen to events and get custom automated alerts.\nIntegrations. Everywhere.\nConnect to hundreds of apps right away using ready-made integrations, or set up your own with webhooks and our API.\nSee all integrations\nCrawls websites using raw HTTP requests, parses the HTML with the Cheerio library, and extracts data from the pages using a Node.js code. Supports both recursive crawling and lists of URLs. This actor is a high-performance alternative to apify/web-scraper for websites that do not require JavaScript.\nCrawls arbitrary websites using the Chrome browser and extracts data from pages using JavaScript code. The Actor supports both recursive crawling and lists of URLs and automatically manages concurrency for maximum performance. This is Apify's basic tool for web crawling and scraping.\nExtract data from hundreds of Google Maps locations and businesses. Get Google Maps data including reviews, images, contact info, opening hours, location, popular times, prices & more. Export scraped data, run the scraper via API, schedule and monitor runs, or integrate with other tools.\nYouTube crawler and video scraper. Alternative YouTube API with no limits or quotas. Extract and download channel name, likes, number of views, and number of subscribers.\nScrape Booking with this hotels scraper and get data about accommodation on Booking.com. You can crawl by keywords or URLs for hotel prices, ratings, addresses, number of reviews, stars. You can also download all that room and hotel data from Booking.com with a few clicks: CSV, JSON, HTML, and Excel\nCrawls websites with the headless Chrome and Puppeteer library using a provided server-side Node.js code. This crawler is an alternative to apify/web-scraper that gives you finer control over the process. Supports both recursive crawling and list of URLs. Supports login to website.\nUse this Amazon scraper to collect data based on URL and country from the Amazon website. Extract product information without using the Amazon API, including reviews, prices, descriptions, and Amazon Standard Identification Numbers (ASINs). Download data in various structured formats.\nScrape tweets from any Twitter user profile. Top Twitter API alternative to scrape Twitter hashtags, threads, replies, followers, images, videos, statistics, and Twitter history. Export scraped data, run the scraper via API, schedule and monitor runs or integrate with other tools.\nBrowse 2,000+ Actors",
71 | "markdown": "# Full-stack web scraping and data extraction platformStar apify/crawlee on GitHubProblem loading pageBack ButtonSearch IconFilter Icon\n\npowering the world's top data-driven teams\n\n#### \n\nSimplify scraping with\n\nCrawlee\n\nGive your crawlers an unfair advantage with Crawlee, our popular library for building reliable scrapers in Node.js.\n\n \n\nimport\n\n{\n\n \n\nPuppeteerCrawler,\n\n \n\nDataset\n\n}\n\n \n\nfrom 'crawlee';\n\nconst crawler = new PuppeteerCrawler(\n\n{\n\n \n\nasync requestHandler(\n\n{\n\n \n\nrequest, page,\n\n \n\nenqueueLinks\n\n}\n\n) \n\n{\n\nurl: request.url,\n\ntitle: await page.title(),\n\nawait enqueueLinks();\n\nawait crawler.run(\\['https://crawlee.dev'\\]);\n\n\n\n#### Use your favorite libraries\n\nApify works great with both Python and JavaScript, with Playwright, Puppeteer, Selenium, Scrapy, or any other library.\n\n[Start with our code templates](https://apify.com/templates)\n\nfrom scrapy.spiders import CrawlSpider, Rule\n\nclass Scraper(CrawlSpider):\n\nname = \"scraper\"\n\nstart\\_urls = \\[\"https://the-coolest-store.com/\"\\]\n\ndef parse\\_item(self, response):\n\nitem = Item()\n\nitem\\[\"price\"\\] = response.css(\".price\\_color::text\").get()\n\nreturn item\n\n#### Turn your code into an Apify Actor\n\nActors are serverless microapps that are easy to develop, run, share, and integrate. The infra, proxies, and storages are ready to go.\n\n[Learn more about Actors](https://apify.com/actors)\n\nimport\n\n{ Actor\n\n}\n\n from 'apify'\n\nawait Actor.init();\n\n\n\n#### Deploy to the cloud\n\nNo config required. Use a single CLI command or build directly from GitHub.\n\n[Deploy to Apify](https://console.apify.com/actors/new)\n\n\\> apify push\n\nInfo: Deploying Actor 'computer-scraper' to Apify.\n\nRun: Updated version 0.0 for scraper Actor.\n\nRun: Building Actor scraper\n\nACTOR: Pushing Docker image to repository.\n\nACTOR: Build finished.\n\nActor build detail -> https://console.apify.com/actors#/builds/0.0.2\n\nSuccess: Actor was deployed to Apify cloud and built there.\n\n\n\n#### Run your Actors\n\nStart from Apify Console, CLI, via API, or schedule your Actor to start at any time. It’s your call.\n\n```\nPOST/v2/acts/4cT0r1D/runs\n```\n\nRun object\n\n```\n{\n \"id\": \"seHnBnyCTfiEnXft\",\n \"startedAt\": \"2022-12-01T13:42:00.364Z\",\n \"finishedAt\": null,\n \"status\": \"RUNNING\",\n \"options\": {\n \"build\": \"version-3\",\n \"timeoutSecs\": 3600,\n \"memoryMbytes\": 4096\n },\n \"defaultKeyValueStoreId\": \"EiGjhZkqseHnBnyC\",\n \"defaultDatasetId\": \"vVh7jTthEiGjhZkq\",\n \"defaultRequestQueueId\": \"TfiEnXftvVh7jTth\"\n}\n```\n\n\n\n#### Never get blocked\n\nUse our large pool of datacenter and residential proxies. Rely on smart IP address rotation with human-like browser fingerprints.\n\n[Learn more about Apify Proxy](https://apify.com/proxy)\n\nawait Actor.createProxyConfiguration(\n\n{\n\ncountryCode: 'US',\n\ngroups: \\['RESIDENTIAL'\\],\n\n\n\n#### Store and share crawling results\n\nUse distributed queues of URLs to crawl. Store structured data or binary files. Export datasets in CSV, JSON, Excel or other formats.\n\n[Learn more about Apify Storage](https://apify.com/storage)\n\n```\nGET/v2/datasets/d4T453t1D/items\n```\n\nDataset items\n\n```\n[\n {\n \"title\": \"myPhone 99 Super Max\",\n \"description\": \"Such phone, max 99, wow!\",\n \"price\": 999\n },\n {\n \"title\": \"myPad Hyper Thin\",\n \"description\": \"So thin it's 2D.\",\n \"price\": 1499\n }\n]\n```\n\n\n\n#### Monitor performance over time\n\nInspect all Actor runs, their logs, and runtime costs. Listen to events and get custom automated alerts.\n\n\n\n#### Integrations. Everywhere.\n\nConnect to hundreds of apps right away using ready-made integrations, or set up your own with webhooks and our API.\n\n[See all integrations](https://apify.com/integrations)\n\n[\n\nCrawls websites using raw HTTP requests, parses the HTML with the Cheerio library, and extracts data from the pages using a Node.js code. Supports both recursive crawling and lists of URLs. This actor is a high-performance alternative to apify/web-scraper for websites that do not require JavaScript.\n\n](https://apify.com/apify/cheerio-scraper)[\n\nCrawls arbitrary websites using the Chrome browser and extracts data from pages using JavaScript code. The Actor supports both recursive crawling and lists of URLs and automatically manages concurrency for maximum performance. This is Apify's basic tool for web crawling and scraping.\n\n](https://apify.com/apify/web-scraper)[\n\nExtract data from hundreds of Google Maps locations and businesses. Get Google Maps data including reviews, images, contact info, opening hours, location, popular times, prices & more. Export scraped data, run the scraper via API, schedule and monitor runs, or integrate with other tools.\n\n](https://apify.com/compass/crawler-google-places)[\n\nYouTube crawler and video scraper. Alternative YouTube API with no limits or quotas. Extract and download channel name, likes, number of views, and number of subscribers.\n\n](https://apify.com/streamers/youtube-scraper)[\n\nScrape Booking with this hotels scraper and get data about accommodation on Booking.com. You can crawl by keywords or URLs for hotel prices, ratings, addresses, number of reviews, stars. You can also download all that room and hotel data from Booking.com with a few clicks: CSV, JSON, HTML, and Excel\n\n](https://apify.com/voyager/booking-scraper)[\n\nCrawls websites with the headless Chrome and Puppeteer library using a provided server-side Node.js code. This crawler is an alternative to apify/web-scraper that gives you finer control over the process. Supports both recursive crawling and list of URLs. Supports login to website.\n\n](https://apify.com/apify/puppeteer-scraper)[\n\nUse this Amazon scraper to collect data based on URL and country from the Amazon website. Extract product information without using the Amazon API, including reviews, prices, descriptions, and Amazon Standard Identification Numbers (ASINs). Download data in various structured formats.\n\n](https://apify.com/junglee/Amazon-crawler)[\n\nScrape tweets from any Twitter user profile. Top Twitter API alternative to scrape Twitter hashtags, threads, replies, followers, images, videos, statistics, and Twitter history. Export scraped data, run the scraper via API, schedule and monitor runs or integrate with other tools.\n\n](https://apify.com/quacker/twitter-scraper)\n\n[Browse 2,000+ Actors](https://apify.com/store)",
72 | "html": null
73 | },
74 | {
75 | "crawl": {
76 | "httpStatusCode": 200,
77 | "loadedAt": "2024-09-02T11:57:46.636Z",
78 | "uniqueKey": "8b63e9cc-700b-4c36-ae32-3622eb3dba76",
79 | "requestStatus": "handled",
80 | "debug": {
81 | "timeMeasures": [
82 | {
83 | "event": "request-received",
84 | "timeMs": 0,
85 | "timeDeltaPrevMs": 0
86 | },
87 | {
88 | "event": "before-cheerio-queue-add",
89 | "timeMs": 101,
90 | "timeDeltaPrevMs": 101
91 | },
92 | {
93 | "event": "cheerio-request-handler-start",
94 | "timeMs": 2726,
95 | "timeDeltaPrevMs": 2625
96 | },
97 | {
98 | "event": "before-playwright-queue-add",
99 | "timeMs": 2734,
100 | "timeDeltaPrevMs": 8
101 | },
102 | {
103 | "event": "playwright-request-start",
104 | "timeMs": 11707,
105 | "timeDeltaPrevMs": 8973
106 | },
107 | {
108 | "event": "playwright-wait-dynamic-content",
109 | "timeMs": 12790,
110 | "timeDeltaPrevMs": 1083
111 | },
112 | {
113 | "event": "playwright-remove-cookie",
114 | "timeMs": 13525,
115 | "timeDeltaPrevMs": 735
116 | },
117 | {
118 | "event": "playwright-parse-with-cheerio",
119 | "timeMs": 13914,
120 | "timeDeltaPrevMs": 389
121 | },
122 | {
123 | "event": "playwright-process-html",
124 | "timeMs": 14788,
125 | "timeDeltaPrevMs": 874
126 | },
127 | {
128 | "event": "playwright-before-response-send",
129 | "timeMs": 14899,
130 | "timeDeltaPrevMs": 111
131 | }
132 | ]
133 | }
134 | },
135 | "metadata": {
136 | "author": null,
137 | "title": "Home | Donald J. Trump",
138 | "description": "Certified Website of Donald J. Trump For President 2024. America's comeback starts right now. Join our movement to Make America Great Again!",
139 | "keywords": null,
140 | "languageCode": "en",
141 | "url": "https://www.donaldjtrump.com/"
142 | },
143 | "text": "Home | Donald J. Trump\n\"THEY’RE NOT AFTER ME, \nTHEY’RE AFTER YOU \n…I’M JUST STANDING \nIN THE WAY!”\nDONALD J. TRUMP, 45th President of the United States \nContribute VOLUNTEER \nAgenda47 Platform\nAmerica needs determined Republican Leadership at every level of Government to address the core threats to our very survival: Our disastrously Open Border, our weakened Economy, crippling restrictions on American Energy Production, our depleted Military, attacks on the American System of Justice, and much more. \nTo make clear our commitment, we offer to the American people the 2024 GOP Platform to Make America Great Again! It is a forward-looking Agenda that begins with the following twenty promises that we will accomplish very quickly when we win the White House and Republican Majorities in the House and Senate. \nPlatform \nI AM YOUR VOICE. AMERICA FIRST!\nPresident Trump Will Stop China From Owning America\nI will ensure America's future remains firmly in America's hands!\nPresident Donald J. Trump Calls for Probe into Intelligence Community’s Role in Online Censorship\nThe ‘Twitter Files’ prove that we urgently need my plan to dismantle the illegal censorship regime — a regime like nobody’s ever seen in the history of our country or most other countries for that matter,” President Trump said.\nPresident Donald J. Trump — Free Speech Policy Initiative\nPresident Donald J. Trump announced a new policy initiative aimed to dismantle the censorship cartel and restore free speech.\nPresident Donald J. Trump Declares War on Cartels\nJoe Biden prepares to make his first-ever trip to the southern border that he deliberately erased, President Trump announced that when he is president again, it will be the official policy of the United States to take down the drug cartels just as we took down ISIS.\nAgenda47: Ending the Nightmare of the Homeless, Drug Addicts, and Dangerously Deranged\nFor a small fraction of what we spend upon Ukraine, we could take care of every homeless veteran in America. Our veterans are being treated horribly.\nAgenda47: Liberating America from Biden’s Regulatory Onslaught\nNo longer will unelected members of the Washington Swamp be allowed to act as the fourth branch of our Republic.\nAgenda47: Firing the Radical Marxist Prosecutors Destroying America\nIf we cannot restore the fair and impartial rule of law, we will not be a free country.\nAgenda47: President Trump Announces Plan to Stop the America Last Warmongers and Globalists\nPresident Donald J. Trump announced his plan to defeat the America Last warmongers and globalists in the Deep State, the Pentagon, the State Department, and the national security industrial complex.\nAgenda47: President Trump Announces Plan to End Crime and Restore Law and Order\nPresident Donald J. Trump unveiled his new plan to stop out-of-control crime and keep all Americans safe. In his first term, President Trump reduced violent crime and stood strongly with America’s law enforcement. On Joe Biden’s watch, violent crime has skyrocketed and communities have become less safe as he defunded, defamed, and dismantled police forces. www.DonaldJTrump.com Text TRUMP to 88022\nAgenda47: President Trump on Making America Energy Independent Again\nBiden's War on Energy Is The Key Driver of the Worst Inflation in 58 Years! When I'm back in Office, We Will Eliminate Every Democrat Regulation That Hampers Domestic Enery Production!\nPresident Trump Will Build a New Missile Defense Shield\nWe must be able to defend our homeland, our allies, and our military assets around the world from the threat of hypersonic missiles, no matter where they are launched from. Just as President Trump rebuilt our military, President Trump will build a state-of-the-art next-generation missile defense shield to defend America from missile attack.\nPresident Trump Calls for Immediate De-escalation and Peace\nJoe Biden's weakness and incompetence has brought us to the brink of nuclear war and leading us to World War 3. It's time for all parties involved to pursue a peaceful end to the war in Ukraine before it spirals out of control and into nuclear war.\nPresident Trump’s Plan to Protect Children from Left-Wing Gender Insanity\nPresident Trump today announced his plan to stop the chemical, physical, and emotional mutilation of our youth.\nPresident Trump’s Plan to Save American Education and Give Power Back to Parents\nOur public schools have been taken over by the Radical Left Maniacs!\nWe Must Protect Medicare and Social Security\nUnder no circumstances should Republicans vote to cut a single penny from Medicare or Social Security\nPresident Trump Will Stop China From Owning America\nI will ensure America's future remains firmly in America's hands!\nPresident Donald J. Trump Calls for Probe into Intelligence Community’s Role in Online Censorship\nThe ‘Twitter Files’ prove that we urgently need my plan to dismantle the illegal censorship regime — a regime like nobody’s ever seen in the history of our country or most other countries for that matter,” President Trump said.\nPresident Donald J. Trump — Free Speech Policy Initiative\nPresident Donald J. Trump announced a new policy initiative aimed to dismantle the censorship cartel and restore free speech.\nPresident Donald J. Trump Declares War on Cartels\nJoe Biden prepares to make his first-ever trip to the southern border that he deliberately erased, President Trump announced that when he is president again, it will be the official policy of the United States to take down the drug cartels just as we took down ISIS.\nAgenda47: Ending the Nightmare of the Homeless, Drug Addicts, and Dangerously Deranged\nFor a small fraction of what we spend upon Ukraine, we could take care of every homeless veteran in America. Our veterans are being treated horribly.\nAgenda47: Liberating America from Biden’s Regulatory Onslaught\nNo longer will unelected members of the Washington Swamp be allowed to act as the fourth branch of our Republic.",
144 | "markdown": "# Home | Donald J. Trump\n\n## \"THEY’RE NOT AFTER ME, \nTHEY’RE AFTER YOU \n…I’M JUST STANDING \nIN THE WAY!”\n\nDONALD J. TRUMP, 45th President of the United States\n\n[Contribute](https://secure.winred.com/trump-national-committee-jfc/lp-website-contribute-button) [VOLUNTEER](https://www.donaldjtrump.com/join)\n\n## Agenda47 Platform\n\nAmerica needs determined Republican Leadership at every level of Government to address the core threats to our very survival: Our disastrously Open Border, our weakened Economy, crippling restrictions on American Energy Production, our depleted Military, attacks on the American System of Justice, and much more.\n\nTo make clear our commitment, we offer to the American people the 2024 GOP Platform to Make America Great Again! It is a forward-looking Agenda that begins with the following twenty promises that we will accomplish very quickly when we win the White House and Republican Majorities in the House and Senate.\n\n[Platform](https://www.donaldjtrump.com/platform)\n\n\n\n\n\n## I AM **YOUR VOICE**. AMERICA FIRST!\n\n[](https://rumble.com/embed/v23gkay/?rel=0)\n\n### President Trump Will Stop China From Owning America\n\nI will ensure America's future remains firmly in America's hands!\n\n[](https://rumble.com/embed/v22aczi/?rel=0)\n\n### President Donald J. Trump Calls for Probe into Intelligence Community’s Role in Online Censorship\n\nThe ‘Twitter Files’ prove that we urgently need my plan to dismantle the illegal censorship regime — a regime like nobody’s ever seen in the history of our country or most other countries for that matter,” President Trump said.\n\n[](https://rumble.com/embed/v1y7kp8/?rel=0)\n\n### President Donald J. Trump — Free Speech Policy Initiative\n\nPresident Donald J. Trump announced a new policy initiative aimed to dismantle the censorship cartel and restore free speech.\n\n[](https://rumble.com/embed/v21etrc/?rel=0)\n\n### President Donald J. Trump Declares War on Cartels\n\nJoe Biden prepares to make his first-ever trip to the southern border that he deliberately erased, President Trump announced that when he is president again, it will be the official policy of the United States to take down the drug cartels just as we took down ISIS.\n\n[](https://rumble.com/embed/v2g7i07/?rel=0)\n\n### Agenda47: Ending the Nightmare of the Homeless, Drug Addicts, and Dangerously Deranged\n\nFor a small fraction of what we spend upon Ukraine, we could take care of every homeless veteran in America. Our veterans are being treated horribly.\n\n[](https://rumble.com/embed/v2fmn6y/?rel=0)\n\n### Agenda47: Liberating America from Biden’s Regulatory Onslaught\n\nNo longer will unelected members of the Washington Swamp be allowed to act as the fourth branch of our Republic.\n\n[](https://rumble.com/embed/v2ff6i4/?rel=0)\n\n### Agenda47: Firing the Radical Marxist Prosecutors Destroying America\n\nIf we cannot restore the fair and impartial rule of law, we will not be a free country.\n\n[](https://rumble.com/embed/v27rnh8/?rel=0)\n\n### Agenda47: President Trump Announces Plan to Stop the America Last Warmongers and Globalists\n\nPresident Donald J. Trump announced his plan to defeat the America Last warmongers and globalists in the Deep State, the Pentagon, the State Department, and the national security industrial complex.\n\n[](https://rumble.com/embed/v27mkjo/?rel=0)\n\n### Agenda47: President Trump Announces Plan to End Crime and Restore Law and Order\n\nPresident Donald J. Trump unveiled his new plan to stop out-of-control crime and keep all Americans safe. In his first term, President Trump reduced violent crime and stood strongly with America’s law enforcement. On Joe Biden’s watch, violent crime has skyrocketed and communities have become less safe as he defunded, defamed, and dismantled police forces. www.DonaldJTrump.com Text TRUMP to 88022\n\n[](https://rumble.com/embed/v26a8h6/?rel=0)\n\n### Agenda47: President Trump on Making America Energy Independent Again\n\nBiden's War on Energy Is The Key Driver of the Worst Inflation in 58 Years! When I'm back in Office, We Will Eliminate Every Democrat Regulation That Hampers Domestic Enery Production!\n\n[](https://rumble.com/embed/v24rq6y/?rel=0)\n\n### President Trump Will Build a New Missile Defense Shield\n\nWe must be able to defend our homeland, our allies, and our military assets around the world from the threat of hypersonic missiles, no matter where they are launched from. Just as President Trump rebuilt our military, President Trump will build a state-of-the-art next-generation missile defense shield to defend America from missile attack.\n\n[](https://rumble.com/embed/v25d8w0/?rel=0)\n\n### President Trump Calls for Immediate De-escalation and Peace\n\nJoe Biden's weakness and incompetence has brought us to the brink of nuclear war and leading us to World War 3. It's time for all parties involved to pursue a peaceful end to the war in Ukraine before it spirals out of control and into nuclear war.\n\n[](https://rumble.com/embed/v2597vg/?rel=0)\n\n### President Trump’s Plan to Protect Children from Left-Wing Gender Insanity\n\nPresident Trump today announced his plan to stop the chemical, physical, and emotional mutilation of our youth.\n\n[](https://rumble.com/embed/v24n0j2/?rel=0)\n\n### President Trump’s Plan to Save American Education and Give Power Back to Parents\n\nOur public schools have been taken over by the Radical Left Maniacs!\n\n[](https://rumble.com/embed/v23qmwu/?rel=0)\n\n### We Must Protect Medicare and Social Security\n\nUnder no circumstances should Republicans vote to cut a single penny from Medicare or Social Security\n\n[](https://rumble.com/embed/v23gkay/?rel=0)\n\n### President Trump Will Stop China From Owning America\n\nI will ensure America's future remains firmly in America's hands!\n\n[](https://rumble.com/embed/v22aczi/?rel=0)\n\n### President Donald J. Trump Calls for Probe into Intelligence Community’s Role in Online Censorship\n\nThe ‘Twitter Files’ prove that we urgently need my plan to dismantle the illegal censorship regime — a regime like nobody’s ever seen in the history of our country or most other countries for that matter,” President Trump said.\n\n[](https://rumble.com/embed/v1y7kp8/?rel=0)\n\n### President Donald J. Trump — Free Speech Policy Initiative\n\nPresident Donald J. Trump announced a new policy initiative aimed to dismantle the censorship cartel and restore free speech.\n\n[](https://rumble.com/embed/v21etrc/?rel=0)\n\n### President Donald J. Trump Declares War on Cartels\n\nJoe Biden prepares to make his first-ever trip to the southern border that he deliberately erased, President Trump announced that when he is president again, it will be the official policy of the United States to take down the drug cartels just as we took down ISIS.\n\n[](https://rumble.com/embed/v2g7i07/?rel=0)\n\n### Agenda47: Ending the Nightmare of the Homeless, Drug Addicts, and Dangerously Deranged\n\nFor a small fraction of what we spend upon Ukraine, we could take care of every homeless veteran in America. Our veterans are being treated horribly.\n\n[](https://rumble.com/embed/v2fmn6y/?rel=0)\n\n### Agenda47: Liberating America from Biden’s Regulatory Onslaught\n\nNo longer will unelected members of the Washington Swamp be allowed to act as the fourth branch of our Republic.\n\n",
145 | "html": null
146 | },
147 | {
148 | "crawl": {
149 | "httpStatusCode": 200,
150 | "loadedAt": "2024-09-02T11:58:25.056Z",
151 | "uniqueKey": "be30f466-6a07-4b0f-86e9-8804c8ae2a91",
152 | "requestStatus": "handled",
153 | "debug": {
154 | "timeMeasures": [
155 | {
156 | "event": "request-received",
157 | "timeMs": 0,
158 | "timeDeltaPrevMs": 0
159 | },
160 | {
161 | "event": "before-cheerio-queue-add",
162 | "timeMs": 125,
163 | "timeDeltaPrevMs": 125
164 | },
165 | {
166 | "event": "cheerio-request-handler-start",
167 | "timeMs": 2561,
168 | "timeDeltaPrevMs": 2436
169 | },
170 | {
171 | "event": "before-playwright-queue-add",
172 | "timeMs": 2570,
173 | "timeDeltaPrevMs": 9
174 | },
175 | {
176 | "event": "playwright-request-start",
177 | "timeMs": 6948,
178 | "timeDeltaPrevMs": 4378
179 | },
180 | {
181 | "event": "playwright-wait-dynamic-content",
182 | "timeMs": 16957,
183 | "timeDeltaPrevMs": 10009
184 | },
185 | {
186 | "event": "playwright-remove-cookie",
187 | "timeMs": 17541,
188 | "timeDeltaPrevMs": 584
189 | },
190 | {
191 | "event": "playwright-parse-with-cheerio",
192 | "timeMs": 23250,
193 | "timeDeltaPrevMs": 5709
194 | },
195 | {
196 | "event": "playwright-process-html",
197 | "timeMs": 25265,
198 | "timeDeltaPrevMs": 2015
199 | },
200 | {
201 | "event": "playwright-before-response-send",
202 | "timeMs": 25276,
203 | "timeDeltaPrevMs": 11
204 | }
205 | ]
206 | }
207 | },
208 | "metadata": {
209 | "author": null,
210 | "title": "Boston.com: Local breaking news, sports, weather, and things to do",
211 | "description": "What Boston cares about right now: Get breaking updates on news, sports, and weather. Local alerts, things to do, and more on Boston.com.",
212 | "keywords": null,
213 | "languageCode": "en-US",
214 | "url": "https://www.boston.com/"
215 | },
216 | "text": "Local breaking news, sports, weather, and things to doBack ButtonSearch IconFilter IconUser-Sync\nSome areas of this page may shift around if you resize the browser window. Be sure to check heading and document order.\nUser-Sync",
217 | "markdown": "# Local breaking news, sports, weather, and things to doBack ButtonSearch IconFilter IconUser-Sync\n\nSome areas of this page may shift around if you resize the browser window. Be sure to check heading and document order.\n\n\n\n\n\nUser-Sync",
218 | "html": null
219 | }]
--------------------------------------------------------------------------------
/data/performance_measures.md:
--------------------------------------------------------------------------------
1 | # Memory 2GB, Max Results 1, Proxy: auto
2 |
3 | ```text
4 | 'request-received' => [ 0, 0, 0 ],
5 | 'before-cheerio-queue-add' => [ 147, 124, 115 ],
6 | 'cheerio-request-handler-start' => [ 2428, 2400, 2668 ],
7 | 'before-playwright-queue-add' => [ 91, 83, 86 ],
8 | 'playwright-request-start' => [ 29301, 9102, 8706 ],
9 | 'playwright-wait-dynamic-content' => [ 10086, 1001, 10000 ],
10 | 'playwright-remove-cookie' => [ 697, 422, 2100 ],
11 | 'playwright-parse-with-cheerio' => [ 2315, 484, 13892 ],
12 | 'playwright-process-html' => [ 4296, 2091, 5099 ],
13 | 'playwright-before-response-send' => [ 401, 297, 10 ]
14 |
15 | AVG:
16 | request-received: 0 s
17 | before-cheerio-queue-add: 129
18 | cheerio-request-handler-start: 2499
19 | before-playwright-queue-add: 87
20 | playwright-request-start: 15703
21 | playwright-wait-dynamic-content: 7029
22 | playwright-remove-cookie: 1073
23 | playwright-parse-with-cheerio: 5564
24 | playwright-process-html: 3829
25 | playwright-before-response-send: 236
26 | Time taken for each request: [ 49762, 16004, 42676 ]
27 | Time taken on average 36147.333333333336
28 |
29 | ```
30 |
31 | # Memory 2GB, Max Results 5, Proxy: auto
32 |
33 | ```text
34 | 'request-received' => [
35 | 0, 0, 0, 0, 0, 0,
36 | 0, 0, 0, 0, 0, 0,
37 | 0, 0, 0
38 | ],
39 | 'before-cheerio-queue-add' => [
40 | 117, 117, 117, 117,
41 | 117, 124, 124, 124,
42 | 124, 124, 192, 192,
43 | 192, 192, 192
44 | ],
45 | 'cheerio-request-handler-start' => [
46 | 4691, 4691, 4691, 4691,
47 | 4691, 2643, 2643, 2643,
48 | 2643, 2643, 2690, 2690,
49 | 2690, 2690, 2690
50 | ],
51 | 'before-playwright-queue-add' => [
52 | 131, 131, 131, 131, 131, 17,
53 | 17, 17, 17, 17, 70, 70,
54 | 70, 70, 70
55 | ],
56 | 'playwright-request-start' => [
57 | 30964, 30554, 73656,
58 | 85353, 118157, 26266,
59 | 29180, 75575, 88773,
60 | 90977, 20893, 18280,
61 | 66584, 74592, 103678
62 | ],
63 | 'playwright-wait-dynamic-content' => [
64 | 1207, 10297, 2595,
65 | 1008, 20897, 1010,
66 | 1004, 4799, 3204,
67 | 2204, 1186, 1009,
68 | 1006, 3197, 10001
69 | ],
70 | 'playwright-remove-cookie' => [
71 | 1181, 1600, 2812, 2897,
72 | 2409, 3498, 8494, 2298,
73 | 1091, 2986, 2312, 4193,
74 | 3240, 917, 601
75 | ],
76 | 'playwright-parse-with-cheerio' => [
77 | 2726, 21001, 24109,
78 | 35499, 3820, 2000,
79 | 6895, 2400, 1120,
80 | 1224, 24199, 5298,
81 | 952, 2383, 6331
82 | ],
83 | 'playwright-process-html' => [
84 | 4585, 6206, 10700,
85 | 14115, 2870, 2217,
86 | 15325, 1609, 1183,
87 | 4184, 2604, 14626,
88 | 302, 1812, 3482
89 | ],
90 | 'playwright-before-response-send' => [
91 | 113, 592, 478, 100, 17,
92 | 487, 7499, 189, 13, 106,
93 | 199, 4190, 3, 2, 90
94 | ]
95 | }
96 | request-received: 0
97 | before-cheerio-queue-add: 144
98 | cheerio-request-handler-start: 3341
99 | before-playwright-queue-add: 73
100 | playwright-request-start: 62232
101 | playwright-wait-dynamic-content: 4308
102 | playwright-remove-cookie: 2702
103 | playwright-parse-with-cheerio: 9330
104 | playwright-process-html: 5721
105 | playwright-before-response-send: 939
106 | Time taken for each request: [
107 | 45715, 75189, 119289,
108 | 143911, 153109, 38262,
109 | 71181, 89654, 98168,
110 | 104465, 54345, 50548,
111 | 75039, 85855, 127135
112 | ]
113 | ```
114 |
115 | # Memory 4GB, Max Results 1, Proxy: auto
116 |
117 | ```text
118 | 'request-received' => [ 0, 0, 0 ],
119 | 'before-cheerio-queue-add' => [ 143, 101, 125 ],
120 | 'cheerio-request-handler-start' => [ 2850, 2625, 2436 ],
121 | 'before-playwright-queue-add' => [ 18, 8, 9 ],
122 | 'playwright-request-start' => [ 12201, 8973, 4378 ],
123 | 'playwright-wait-dynamic-content' => [ 6946, 1083, 10009 ],
124 | 'playwright-remove-cookie' => [ 173, 735, 584 ],
125 | 'playwright-parse-with-cheerio' => [ 791, 389, 5709 ],
126 | 'playwright-process-html' => [ 2104, 874, 2015 ],
127 | 'playwright-before-response-send' => [ 207, 111, 11 ]
128 |
129 | AVG:
130 | request-received: 0
131 | before-cheerio-queue-add: 123
132 | cheerio-request-handler-start: 2637
133 | before-playwright-queue-add: 12
134 | playwright-request-start: 8517
135 | playwright-wait-dynamic-content: 6013
136 | playwright-remove-cookie: 497
137 | playwright-parse-with-cheerio: 2296
138 | playwright-process-html: 1664
139 | playwright-before-response-send: 110
140 | Time taken for each request: [ 25433, 14899, 25276 ]
141 | Time taken on average 21869.333333333332
142 | ```
143 |
144 | # Memory 4GB, Max Results 3, Proxy: auto
145 |
146 | ```text
147 | Average time for each time measure event: Map(10) {
148 | 'request-received' => [
149 | 0, 0, 0, 0, 0,
150 | 0, 0, 0, 0
151 | ],
152 | 'before-cheerio-queue-add' => [
153 | 157, 157, 157,
154 | 107, 107, 107,
155 | 122, 122, 122
156 | ],
157 | 'cheerio-request-handler-start' => [
158 | 1699, 1699, 1699,
159 | 4312, 4312, 4312,
160 | 2506, 2506, 2506
161 | ],
162 | 'before-playwright-queue-add' => [
163 | 10, 10, 10, 13, 13,
164 | 13, 5, 5, 5
165 | ],
166 | 'playwright-request-start' => [
167 | 16249, 17254, 26159,
168 | 6726, 9821, 11124,
169 | 7349, 8212, 29345
170 | ],
171 | 'playwright-wait-dynamic-content' => [
172 | 1110, 10080, 10076,
173 | 6132, 1524, 18367,
174 | 3077, 2508, 10001
175 | ],
176 | 'playwright-remove-cookie' => [
177 | 1883, 914, 133,
178 | 1176, 5072, 241,
179 | 793, 4234, 120
180 | ],
181 | 'playwright-parse-with-cheerio' => [
182 | 1203, 1490, 801,
183 | 698, 2919, 507,
184 | 798, 1378, 2756
185 | ],
186 | 'playwright-process-html' => [
187 | 2597, 1304, 1398,
188 | 1099, 6756, 1031,
189 | 2110, 5416, 2028
190 | ],
191 | 'playwright-before-response-send' => [
192 | 105, 112, 74,
193 | 501, 3381, 26,
194 | 101, 1570, 69
195 | ]
196 | }
197 | request-received: 0 s
198 | before-cheerio-queue-add: 129 s
199 | cheerio-request-handler-start: 2839 s
200 | before-playwright-queue-add: 9 s
201 | playwright-request-start: 14693 s
202 | playwright-wait-dynamic-content: 6986 s
203 | playwright-remove-cookie: 1618 s
204 | playwright-parse-with-cheerio: 1394 s
205 | playwright-process-html: 2638 s
206 | playwright-before-response-send: 660 s
207 | Time taken for each request: [
208 | 25013, 33020,
209 | 40507, 20764,
210 | 33905, 35728,
211 | 16861, 25951,
212 | 46952
213 | ]
214 | Time taken on average 30966.777777777777
215 | ```
216 |
217 | # Memory 4GB, Max Results 5, Proxy: auto
218 |
219 | ```text
220 | 'request-received' => [
221 | 0, 0, 0, 0, 0, 0,
222 | 0, 0, 0, 0, 0, 0,
223 | 0, 0, 0
224 | ],
225 | 'before-cheerio-queue-add' => [
226 | 195, 195, 195, 195,
227 | 195, 130, 130, 130,
228 | 130, 130, 109, 109,
229 | 109, 109, 109
230 | ],
231 | 'cheerio-request-handler-start' => [
232 | 2288, 2288, 2288, 2288,
233 | 2288, 2762, 2762, 2762,
234 | 2762, 2762, 4300, 4300,
235 | 4300, 4300, 4300
236 | ],
237 | 'before-playwright-queue-add' => [
238 | 103, 103, 103, 103, 103, 16,
239 | 16, 16, 16, 16, 5, 5,
240 | 5, 5, 5
241 | ],
242 | 'playwright-request-start' => [
243 | 17899, 18621, 37100,
244 | 56307, 61701, 6888,
245 | 12091, 36292, 35101,
246 | 44008, 9857, 12664,
247 | 36950, 44076, 42185
248 | ],
249 | 'playwright-wait-dynamic-content' => [
250 | 1004, 1001, 10001,
251 | 1001, 10000, 2999,
252 | 15808, 1094, 6002,
253 | 10002, 2809, 1088,
254 | 1001, 1002, 10000
255 | ],
256 | 'playwright-remove-cookie' => [
257 | 997, 4378, 1096, 1891,
258 | 546, 3698, 687, 1500,
259 | 1591, 104, 1189, 6905,
260 | 1299, 143, 105
261 | ],
262 | 'playwright-parse-with-cheerio' => [
263 | 1413, 4604, 3906, 5612,
264 | 2192, 2901, 538, 908,
265 | 398, 824, 1893, 2493,
266 | 514, 639, 1468
267 | ],
268 | 'playwright-process-html' => [
269 | 2524, 1717, 3692, 4489,
270 | 3889, 6667, 810, 1293,
271 | 302, 1278, 3518, 4522,
272 | 297, 636, 1136
273 | ],
274 | 'playwright-before-response-send' => [
275 | 94, 194, 7, 20, 187,
276 | 4733, 387, 12, 12, 7,
277 | 209, 2210, 191, 53, 57
278 | ]
279 | }
280 | request-received: 0 s
281 | before-cheerio-queue-add: 145
282 | cheerio-request-handler-start: 3117
283 | before-playwright-queue-add: 41
284 | playwright-request-start: 31449
285 | playwright-wait-dynamic-content: 4987
286 | playwright-remove-cookie: 1742
287 | playwright-parse-with-cheerio: 2020
288 | playwright-process-html: 2451
289 | playwright-before-response-send: 558
290 | Time taken for each request: [
291 | 26517, 33101, 58388,
292 | 71906, 81101, 30794,
293 | 33229, 44007, 46314,
294 | 59131, 23889, 34296,
295 | 44666, 50963, 59365
296 | ]
297 | Time taken on average 46511.13333333333
298 |
299 | ```
300 |
301 | # Memory 8GB, Max Results 1, Proxy: auto
302 |
303 | ```text
304 | Average time for each time measure event: Map(10) {
305 | 'request-received' => [ 0, 0, 0 ],
306 | 'before-cheerio-queue-add' => [ 132, 157, 128 ],
307 | 'cheerio-request-handler-start' => [ 2354, 2606, 2609 ],
308 | 'before-playwright-queue-add' => [ 13, 7, 12 ],
309 | 'playwright-request-start' => [ 7214, 8876, 5463 ],
310 | 'playwright-wait-dynamic-content' => [ 6502, 2432, 6927 ],
311 | 'playwright-remove-cookie' => [ 100, 114, 141 ],
312 | 'playwright-parse-with-cheerio' => [ 483, 388, 477 ],
313 | 'playwright-process-html' => [ 1056, 509, 724 ],
314 | 'playwright-before-response-send' => [ 124, 10, 21 ]
315 | }
316 | request-received: 0 s
317 | before-cheerio-queue-add: 139 s
318 | cheerio-request-handler-start: 2523 s
319 | before-playwright-queue-add: 11 s
320 | playwright-request-start: 7184 s
321 | playwright-wait-dynamic-content: 5287 s
322 | playwright-remove-cookie: 118 s
323 | playwright-parse-with-cheerio: 449 s
324 | playwright-process-html: 763 s
325 | playwright-before-response-send: 52 s
326 | Time taken for each request: [ 17978, 15099, 16502 ]
327 | Time taken on average 16526.333333333332
328 | ```
329 |
330 | # Memory 8GB, Max Results 3, Proxy: auto
331 |
332 | ```text
333 | Average time for each time measure event: Map(10) {
334 | 'request-received' => [
335 | 0, 0, 0, 0,
336 | 0, 0, 0, 0
337 | ],
338 | 'before-cheerio-queue-add' => [
339 | 148, 148, 178,
340 | 178, 178, 167,
341 | 167, 167
342 | ],
343 | 'cheerio-request-handler-start' => [
344 | 2421, 2421, 2486,
345 | 2486, 2486, 2474,
346 | 2474, 2474
347 | ],
348 | 'before-playwright-queue-add' => [
349 | 19, 19, 27, 27,
350 | 27, 9, 9, 9
351 | ],
352 | 'playwright-request-start' => [
353 | 11465, 12067,
354 | 5774, 4998,
355 | 14786, 4785,
356 | 5145, 9222
357 | ],
358 | 'playwright-wait-dynamic-content' => [
359 | 1826, 10001, 1003,
360 | 1309, 10001, 1001,
361 | 1196, 2051
362 | ],
363 | 'playwright-remove-cookie' => [
364 | 463, 99, 392,
365 | 2817, 136, 195,
366 | 102, 127
367 | ],
368 | 'playwright-parse-with-cheerio' => [
369 | 662, 497, 627,
370 | 490, 439, 154,
371 | 132, 86
372 | ],
373 | 'playwright-process-html' => [
374 | 1959, 1011, 1237,
375 | 3201, 301, 200,
376 | 513, 243
377 | ],
378 | 'playwright-before-response-send' => [
379 | 37, 98, 65,
380 | 1086, 42, 4,
381 | 102, 15
382 | ]
383 | }
384 | request-received: 0 s
385 | before-cheerio-queue-add: 166 s
386 | cheerio-request-handler-start: 2465 s
387 | before-playwright-queue-add: 18 s
388 | playwright-request-start: 8530 s
389 | playwright-wait-dynamic-content: 3549 s
390 | playwright-remove-cookie: 541 s
391 | playwright-parse-with-cheerio: 386 s
392 | playwright-process-html: 1083 s
393 | playwright-before-response-send: 181 s
394 | Time taken for each request: [
395 | 19000, 26361,
396 | 11789, 16592,
397 | 28396, 8989,
398 | 9840, 14394
399 | ]
400 | Time taken on average 16920.125
401 | ```
402 |
--------------------------------------------------------------------------------
/docs/apify-gpt-custom-action.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/apify/rag-web-browser/2fc2a69bc3cca722bc47609b8de3dd8b31d68fbb/docs/apify-gpt-custom-action.png
--------------------------------------------------------------------------------
/docs/aws-lambda-call-rag-web-browser.py:
--------------------------------------------------------------------------------
1 | """
2 | This is an example of an AWS Lambda function that calls the RAG Web Browser actor and returns text results.
3 |
4 | There is a limit of 25KB for the response body in AWS Bedrock, so we need to limit the number of results to 3
5 | and truncate the text whenever required.
6 | """
7 |
8 | import json
9 | import os
10 | import urllib.parse
11 | import urllib.request
12 |
13 | ACTOR_BASE_URL = "https://rag-web-browser.apify.actor" # Base URL from OpenAPI schema
14 | MAX_RESULTS = 3 # Limit the number of results to decrease response size, limit 25KB
15 | TRUNCATE_TEXT_LENGTH = 5000 # Truncate the response body to decrease the response size, limit 25KB
16 | OUTPUT_FORMATS = "markdown" # Default output format
17 |
18 | # Lambda function environment variable
19 | APIFY_API_TOKEN = os.getenv("APIFY_API_TOKEN")
20 |
21 |
22 | def lambda_handler(event, context):
23 | print("Received event", event)
24 |
25 | api_path = event["apiPath"]
26 | http_method = event["httpMethod"]
27 | parameters = event.get("parameters", [])
28 |
29 | url = f"{ACTOR_BASE_URL}{api_path}"
30 | headers = {"Authorization": f"Bearer {APIFY_API_TOKEN}"}
31 |
32 | query_params = {}
33 | for param in parameters:
34 | name = param["name"]
35 | value = param["value"]
36 | query_params[name] = value
37 |
38 | # Limit the number of results to decrease response size
39 | # Getting: lambda response exceeds maximum size 25KB: 66945
40 | print("Query params: ", query_params)
41 | query_params["maxResults"] = min(MAX_RESULTS, int(query_params.get("maxResults", MAX_RESULTS)))
42 |
43 | # Always return Markdown format
44 | query_params["outputFormats"] = query_params.get("outputFormats", OUTPUT_FORMATS) + f",{OUTPUT_FORMATS}"
45 | query_params["outputFormats"] = ",".join(set(query_params["outputFormats"].split(",")))
46 | print("Limited max results to: ", query_params["maxResults"])
47 |
48 | try:
49 | if query_params and http_method == "GET":
50 | url = f"{url}?{urllib.parse.urlencode(query_params)}"
51 | print(f"GET request to {url}")
52 | req = urllib.request.Request(url, headers=headers, method="GET")
53 | with urllib.request.urlopen(req) as response:
54 | response_body = response.read().decode("utf-8")
55 | print("Received response from RAG Web Browser", response_body)
56 |
57 | else:
58 | return {"statusCode": 400, "body": json.dumps({"message": f"HTTP method {http_method} not supported"})}
59 |
60 | response = json.loads(response_body)
61 |
62 | # Truncate the response body to decrease the response size, there is a limit of 25KB
63 | print("Truncating the response body")
64 | body = [d.get("markdown", "")[:TRUNCATE_TEXT_LENGTH] + "..." for d in response]
65 |
66 | # Handle the API response
67 | action_response = {
68 | "actionGroup": event["actionGroup"],
69 | "apiPath": api_path,
70 | "httpMethod": http_method,
71 | "httpStatusCode": 200,
72 | "responseBody": {"application/json": {"body": "\n".join(body)}},
73 | }
74 |
75 | dummy_api_response = {"response": action_response, "messageVersion": event["messageVersion"]}
76 | print("Response: {}".format(dummy_api_response))
77 |
78 | return dummy_api_response
79 |
80 | except Exception as e:
81 | print("Error occurred", e)
82 | return {"statusCode": 500, "body": json.dumps({"message": "Internal server error", "error": str(e)})}
83 |
84 |
85 | if __name__ == "__main__":
86 |
87 | test_event = {
88 | "apiPath": "/search",
89 | "httpMethod": "GET",
90 | "parameters": [
91 | {"name": "query", "type": "string", "value": "AI agents in healthcare"},
92 | {"name": "maxResults", "type": "integer", "value": "3"},
93 | ],
94 | "agent": "healthcare-agent",
95 | "actionGroup": "action-call-rag-web-browser",
96 | "sessionId": "031263542130667",
97 | "messageVersion": "1.0",
98 | }
99 | handler_response = lambda_handler(test_event, None)
100 |
--------------------------------------------------------------------------------
/docs/stand_by_rag_web_browser_example.py:
--------------------------------------------------------------------------------
1 | """
2 | This script demonstrates how to interact with the Rag-Web-Browser API in Standby mode. It includes a basic example of querying for information, processing results, and handling potential errors.
3 |
4 | The example usage in the __main__ block shows how to perform searches for both general topics and specific websites, outputting the results in different formats.
5 | """
6 |
7 | import os
8 | from typing import List
9 |
10 | import requests
11 | from dotenv import load_dotenv
12 |
13 | load_dotenv()
14 | API_TOKEN = os.getenv("APIFY_API_TOKEN")
15 |
16 | class RagWebBrowserClient:
17 | def __init__(self, api_token: str):
18 | self.api_token = api_token
19 | self.base_url = "https://rag-web-browser.apify.actor"
20 |
21 | def search(self,
22 | query: str,
23 | max_results: int = 3,
24 | output_formats: str = "markdown",
25 | request_timeout_secs: int = 30,
26 | dynamic_content_wait_secs: int = 10) -> List[dict]:
27 |
28 | # For info about params see: https://apify.com/apify/rag-web-browser#query-parameters
29 | params = {
30 | 'query': query,
31 | 'maxResults': max_results,
32 | 'outputFormats': output_formats,
33 | 'requestTimeoutSecs': request_timeout_secs,
34 | 'dynamicContentWaitSecs': dynamic_content_wait_secs
35 | }
36 |
37 | headers = {
38 | 'Authorization': f'Bearer {self.api_token}',
39 | 'Content-Type': 'application/json'
40 | }
41 |
42 | try:
43 | response = requests.get(
44 | f'{self.base_url}/search',
45 | params=params,
46 | headers=headers,
47 | timeout=request_timeout_secs
48 | )
49 | response.raise_for_status()
50 | return response.json()
51 |
52 | except requests.exceptions.RequestException as e:
53 | print(f"Error making request: {e}")
54 | return []
55 |
56 | if __name__ == "__main__":
57 |
58 | client = RagWebBrowserClient(API_TOKEN)
59 |
60 | queries = [
61 | "artificial intelligence latest developments", # Non-specific website query
62 | "https://www.example.com", # Specific website query
63 | ]
64 |
65 | for query in queries:
66 | print(f"\nSearching for: {query}")
67 | results = client.search(
68 | query=query,
69 | max_results=2,
70 | output_formats="text,markdown",
71 | request_timeout_secs=45
72 | )
73 |
74 | for i, result in enumerate(results, 1):
75 | print(f"\nResult {i}:")
76 | print(f"Title: {result["metadata"]["title"]}")
77 | print(f"URL: {result["metadata"]["url"]}")
78 | print("Content preview:", result.get('text', 'N/A')[:200] + "...")
--------------------------------------------------------------------------------
/docs/standby-openapi-3.0.0.json:
--------------------------------------------------------------------------------
1 | {
2 | "openapi": "3.0.0",
3 | "info": {
4 | "title": "RAG Web Browser",
5 | "description": "Web browser for OpenAI Assistants API and RAG pipelines, similar to a web browser in ChatGPT. It queries Google Search, scrapes the top N pages from the results, and returns their cleaned content as Markdown for further processing by an LLM.",
6 | "version": "v1"
7 | },
8 | "servers": [
9 | {
10 | "url": "https://rag-web-browser.apify.actor"
11 | }
12 | ],
13 | "paths": {
14 | "/search": {
15 | "get": {
16 | "operationId": "apify_rag-web-browser",
17 | "x-openai-isConsequential": false,
18 | "description": "Web browser for OpenAI Assistants API and RAG pipelines, similar to a web browser in ChatGPT. It queries Google Search, scrapes the top N pages from the results, and returns their cleaned content as Markdown for further processing by an LLM.",
19 | "summary": "Web browser for OpenAI Assistants API and RAG pipelines, similar to a web browser in ChatGPT. It queries Google Search, scrapes the top N pages from the results, and returns their cleaned content as Markdown for further processing by an LLM.",
20 | "parameters": [
21 | {
22 | "name": "query",
23 | "in": "query",
24 | "description": "Enter Google Search keywords or a URL of a specific web page. The keywords might include the [advanced search operators](https://blog.apify.com/how-to-scrape-google-like-a-pro/). Examples:\n\n- san francisco weather\n- https://www.cnn.com\n- function calling site:openai.com",
25 | "required": true,
26 | "schema": {
27 | "type": "string",
28 | "pattern": "[^\\s]+"
29 | }
30 | },
31 | {
32 | "name": "maxResults",
33 | "in": "query",
34 | "description": "The maximum number of top organic Google Search results whose web pages will be extracted. If `query` is a URL, then this field is ignored and the Actor only fetches the specific web page.",
35 | "required": false,
36 | "schema": {
37 | "type": "integer",
38 | "minimum": 1,
39 | "maximum": 100,
40 | "default": 3
41 | }
42 | },
43 | {
44 | "name": "outputFormats",
45 | "in": "query",
46 | "description": "Select one or more formats to which the target web pages will be extracted and saved in the resulting dataset.",
47 | "required": false,
48 | "schema": {
49 | "type": "array",
50 | "items": {
51 | "type": "string",
52 | "enum": [
53 | "text",
54 | "markdown",
55 | "html"
56 | ]
57 | },
58 | "default": [
59 | "markdown"
60 | ]
61 | },
62 | "style": "form",
63 | "explode": false
64 | },
65 | {
66 | "name": "requestTimeoutSecs",
67 | "in": "query",
68 | "description": "The maximum time in seconds available for the request, including querying Google Search and scraping the target web pages. For example, OpenAI allows only [45 seconds](https://platform.openai.com/docs/actions/production#timeouts) for custom actions. If a target page loading and extraction exceeds this timeout, the corresponding page will be skipped in results to ensure at least some results are returned within the timeout. If no page is extracted within the timeout, the whole request fails.",
69 | "required": false,
70 | "schema": {
71 | "type": "integer",
72 | "minimum": 1,
73 | "maximum": 600,
74 | "default": 40
75 | }
76 | },
77 | {
78 | "name": "serpProxyGroup",
79 | "in": "query",
80 | "description": "Enables overriding the default Apify Proxy group used for fetching Google Search results.",
81 | "required": false,
82 | "schema": {
83 | "type": "string",
84 | "enum": [
85 | "GOOGLE_SERP",
86 | "SHADER"
87 | ],
88 | "default": "GOOGLE_SERP"
89 | }
90 | },
91 | {
92 | "name": "serpMaxRetries",
93 | "in": "query",
94 | "description": "The maximum number of times the Actor will retry fetching the Google Search results on error. If the last attempt fails, the entire request fails.",
95 | "required": false,
96 | "schema": {
97 | "type": "integer",
98 | "minimum": 0,
99 | "maximum": 3,
100 | "default": 1
101 | }
102 | },
103 | {
104 | "name": "scrapingTool",
105 | "in": "query",
106 | "description": "Select a scraping tool for extracting the target web pages. The Browser tool is more powerful and can handle JavaScript heavy websites, while the Plain HTML tool can't handle JavaScript but is about two times faster.",
107 | "required": false,
108 | "schema": {
109 | "type": "string",
110 | "enum": [
111 | "browser-playwright",
112 | "raw-http"
113 | ],
114 | "default": "raw-http"
115 | }
116 | },
117 | {
118 | "name": "removeElementsCssSelector",
119 | "in": "query",
120 | "required": false,
121 | "description": "A CSS selector matching HTML elements that will be removed from the DOM, before converting it to text, Markdown, or saving as HTML. This is useful to skip irrelevant page content. The value must be a valid CSS selector as accepted by the `document.querySelectorAll()` function. \n\nBy default, the Actor removes common navigation elements, headers, footers, modals, scripts, and inline image. You can disable the removal by setting this value to some non-existent CSS selector like `dummy_keep_everything`.",
122 | "schema": {
123 | "type": "string",
124 | "default": "nav, footer, script, style, noscript, svg, img[src^='data:'],\n[role=\"alert\"],\n[role=\"banner\"],\n[role=\"dialog\"],\n[role=\"alertdialog\"],\n[role=\"region\"][aria-label*=\"skip\" i],\n[aria-modal=\"true\"]"
125 | }
126 | },
127 | {
128 | "name": "maxRequestRetries",
129 | "in": "query",
130 | "description": "The maximum number of times the Actor will retry loading the target web page on error. If the last attempt fails, the page will be skipped in the results.",
131 | "required": false,
132 | "schema": {
133 | "type": "integer",
134 | "minimum": 0,
135 | "maximum": 3,
136 | "default": 1
137 | }
138 | },
139 | {
140 | "name": "dynamicContentWaitSecs",
141 | "in": "query",
142 | "description": "The maximum time in seconds to wait for dynamic page content to load. The Actor considers the web page as fully loaded once this time elapses or when the network becomes idle.",
143 | "required": false,
144 | "schema": {
145 | "type": "integer",
146 | "default": 10
147 | }
148 | },
149 | {
150 | "name": "removeCookieWarnings",
151 | "in": "query",
152 | "description": "If enabled, the Actor attempts to close or remove cookie consent dialogs to improve the quality of extracted text. Note that this setting increases the latency.",
153 | "required": false,
154 | "schema": {
155 | "type": "boolean",
156 | "default": true
157 | }
158 | },
159 | {
160 | "name": "debugMode",
161 | "in": "query",
162 | "description": "If enabled, the Actor will store debugging information into the resulting dataset under the `debug` field.",
163 | "required": false,
164 | "schema": {
165 | "type": "boolean",
166 | "default": false
167 | }
168 | }
169 | ],
170 | "responses": {
171 | "200": {
172 | "description": "OK"
173 | }
174 | }
175 | }
176 | }
177 | }
178 | }
179 |
--------------------------------------------------------------------------------
/eslint.config.mjs:
--------------------------------------------------------------------------------
1 | import apifyTypescriptConfig from '@apify/eslint-config/ts.js';
2 |
3 | // eslint-disable-next-line import/no-default-export
4 | export default [
5 | { ignores: ['**/dist'] }, // Ignores need to happen first
6 | ...apifyTypescriptConfig,
7 | {
8 | languageOptions: {
9 | sourceType: 'module',
10 |
11 | parserOptions: {
12 | project: 'tsconfig.eslint.json', // Or your other tsconfig
13 | },
14 | },
15 | },
16 | ];
17 |
--------------------------------------------------------------------------------
/package.json:
--------------------------------------------------------------------------------
1 | {
2 | "name": "rag-web-browser",
3 | "version": "0.0.1",
4 | "type": "module",
5 | "description": "RAG Web Browser - run Google Search queries and extract content from the top search results.",
6 | "engines": {
7 | "node": ">=18.0.0"
8 | },
9 | "dependencies": {
10 | "@crawlee/memory-storage": "^3.11.1",
11 | "@modelcontextprotocol/sdk": "^1.0.4",
12 | "@mozilla/readability": "^0.5.0",
13 | "apify": "^3.2.6",
14 | "cheerio": "^1.0.0-rc.12",
15 | "crawlee": "^3.12.0",
16 | "express": "^4.21.2",
17 | "joplin-turndown-plugin-gfm": "^1.0.12",
18 | "jsdom": "^24.1.1",
19 | "playwright": "^1.47.0",
20 | "turndown": "^7.2.0"
21 | },
22 | "devDependencies": {
23 | "@apify/eslint-config": "^1.0.0",
24 | "@apify/tsconfig": "^0.1.0",
25 | "@eslint/compat": "^1.2.7",
26 | "@eslint/eslintrc": "^3.3.1",
27 | "@eslint/js": "^9.23.0",
28 | "@types/express": "^5.0.0",
29 | "@types/node": "^22.13.1",
30 | "@types/turndown": "^5.0.5",
31 | "eslint": "^9.23.0",
32 | "eslint-config-prettier": "^9.1.0",
33 | "eslint-plugin-import": "^2.29.1",
34 | "globals": "^16.0.0",
35 | "tsx": "^4.6.2",
36 | "typescript": "^5.3.3",
37 | "typescript-eslint": "^8.29.0",
38 | "vitest": "^3.0.5"
39 | },
40 | "scripts": {
41 | "start": "npm run start:dev",
42 | "start:prod": "node dist/src/main.js",
43 | "start:dev": "tsx src/main.ts",
44 | "build": "tsc",
45 | "lint": "eslint ./src --ext .ts",
46 | "lint:fix": "eslint ./src --ext .ts --fix",
47 | "test": "vitest run"
48 | },
49 | "author": "Apify",
50 | "license": "ISC"
51 | }
52 |
--------------------------------------------------------------------------------
/src/const.ts:
--------------------------------------------------------------------------------
1 | export enum ContentCrawlerStatus {
2 | PENDING = 'pending',
3 | HANDLED = 'handled',
4 | FAILED = 'failed',
5 | }
6 |
7 | export enum Routes {
8 | SEARCH = '/search',
9 | SSE = '/sse',
10 | MESSAGE = '/message',
11 | }
12 |
13 | export enum ContentCrawlerTypes {
14 | PLAYWRIGHT = 'playwright',
15 | CHEERIO = 'cheerio',
16 | }
17 |
18 | export const PLAYWRIGHT_REQUEST_TIMEOUT_NORMAL_MODE_SECS = 60;
19 |
--------------------------------------------------------------------------------
/src/crawlers.ts:
--------------------------------------------------------------------------------
1 | import { MemoryStorage } from '@crawlee/memory-storage';
2 | import { RequestQueue } from 'apify';
3 | import type { CheerioAPI } from 'cheerio';
4 | import {
5 | CheerioCrawler,
6 | type CheerioCrawlerOptions,
7 | type CheerioCrawlingContext,
8 | log,
9 | PlaywrightCrawler,
10 | type PlaywrightCrawlerOptions,
11 | type PlaywrightCrawlingContext,
12 | type RequestOptions,
13 | } from 'crawlee';
14 |
15 | import { ContentCrawlerTypes } from './const.js';
16 | import { scrapeOrganicResults } from './google-search/google-extractors-urls.js';
17 | import { failedRequestHandler, requestHandlerCheerio, requestHandlerPlaywright } from './request-handler.js';
18 | import { addEmptyResultToResponse, sendResponseError } from './responses.js';
19 | import type { ContentCrawlerOptions, ContentCrawlerUserData, SearchCrawlerUserData } from './types.js';
20 | import { addTimeMeasureEvent, createRequest } from './utils.js';
21 |
22 | const crawlers = new Map();
23 | const client = new MemoryStorage({ persistStorage: false });
24 |
25 | export function getCrawlerKey(crawlerOptions: CheerioCrawlerOptions | PlaywrightCrawlerOptions) {
26 | return JSON.stringify(crawlerOptions);
27 | }
28 |
29 | /**
30 | * Adds a content crawl request to selected content crawler.
31 | * Get existing crawler based on crawlerOptions and scraperSettings, if not present -> create new
32 | */
33 | export const addContentCrawlRequest = async (
34 | request: RequestOptions,
35 | responseId: string,
36 | contentCrawlerKey: string,
37 | ) => {
38 | const crawler = crawlers.get(contentCrawlerKey);
39 | const name = crawler instanceof PlaywrightCrawler ? 'playwright' : 'cheerio';
40 |
41 | if (!crawler) {
42 | log.error(`Content crawler not found: key ${contentCrawlerKey}`);
43 | return;
44 | }
45 | try {
46 | await crawler.requestQueue!.addRequest(request);
47 | // create an empty result in search request response
48 | // do not use request.uniqueKey as responseId as it is not id of a search request
49 | addEmptyResultToResponse(responseId, request);
50 | log.info(`Added request to the ${name}-content-crawler: ${request.url}`);
51 | } catch (err) {
52 | log.error(`Error adding request to ${name}-content-crawler: ${request.url}, error: ${err}`);
53 | }
54 | };
55 |
56 | /**
57 | * Creates and starts a Google search crawler with the provided configuration.
58 | * A crawler won't be created if it already exists.
59 | */
60 | export async function createAndStartSearchCrawler(
61 | searchCrawlerOptions: CheerioCrawlerOptions,
62 | startCrawler = true,
63 | ) {
64 | const key = getCrawlerKey(searchCrawlerOptions);
65 | if (crawlers.has(key)) {
66 | return { key, crawler: crawlers.get(key) };
67 | }
68 |
69 | log.info(`Creating new cheerio crawler with key ${key}`);
70 | const crawler = new CheerioCrawler({
71 | ...(searchCrawlerOptions as CheerioCrawlerOptions),
72 | requestQueue: await RequestQueue.open(key, { storageClient: client }),
73 | requestHandler: async ({ request, $: _$ }: CheerioCrawlingContext) => {
74 | // NOTE: we need to cast this to fix `cheerio` type errors
75 | addTimeMeasureEvent(request.userData!, 'cheerio-request-handler-start');
76 | const $ = _$ as CheerioAPI;
77 |
78 | log.info(`Search-crawler requestHandler: Processing URL: ${request.url}`);
79 | const organicResults = scrapeOrganicResults($);
80 |
81 | // filter organic results to get only results with URL
82 | let results = organicResults.filter((result) => result.url !== undefined);
83 | // remove results with URL starting with '/search?q=' (google return empty search results for images)
84 | results = results.filter((result) => !result.url!.startsWith('/search?q='));
85 |
86 | if (results.length === 0) {
87 | throw new Error(`No results found for search request: ${request.url}`);
88 | }
89 |
90 | // limit the number of search results to the maxResults
91 | results = results.slice(0, request.userData?.maxResults ?? results.length);
92 | log.info(`Extracted ${results.length} results: \n${results.map((r) => r.url).join('\n')}`);
93 |
94 | addTimeMeasureEvent(request.userData!, 'before-playwright-queue-add');
95 | const responseId = request.userData.responseId!;
96 | let rank = 1;
97 | for (const result of results) {
98 | result.rank = rank++;
99 | const r = createRequest(
100 | request.userData.query,
101 | result,
102 | responseId,
103 | request.userData.contentScraperSettings!,
104 | request.userData.timeMeasures!,
105 | );
106 | await addContentCrawlRequest(r, responseId, request.userData.contentCrawlerKey!);
107 | }
108 | },
109 | failedRequestHandler: async ({ request }, err) => {
110 | addTimeMeasureEvent(request.userData!, 'cheerio-failed-request');
111 | log.error(`Google-search-crawler failed to process request ${request.url}, error ${err.message}`);
112 | const errorResponse = { errorMessage: err.message };
113 | sendResponseError(request.uniqueKey, JSON.stringify(errorResponse));
114 | },
115 | });
116 | if (startCrawler) {
117 | crawler.run().then(
118 | () => log.warning('Google-search-crawler has finished'),
119 | // eslint-disable-next-line @typescript-eslint/no-empty-function
120 | () => { },
121 | );
122 | log.info('Google-search-crawler has started 🫡');
123 | }
124 | crawlers.set(key, crawler);
125 | log.info(`Number of crawlers ${crawlers.size}`);
126 | return { key, crawler };
127 | }
128 |
129 | /**
130 | * Creates and starts a content crawler with the provided configuration.
131 | * Either Playwright or Cheerio crawler will be created based on the provided crawler options.
132 | * A crawler won't be created if it already exists.
133 | */
134 | export async function createAndStartContentCrawler(
135 | contentCrawlerOptions: ContentCrawlerOptions,
136 | startCrawler = true,
137 | ) {
138 | const { type: crawlerType, crawlerOptions } = contentCrawlerOptions;
139 |
140 | const key = getCrawlerKey(crawlerOptions);
141 | if (crawlers.has(key)) {
142 | return { key, crawler: crawlers.get(key) };
143 | }
144 |
145 | const crawler = crawlerType === 'playwright'
146 | ? await createPlaywrightContentCrawler(crawlerOptions, key)
147 | : await createCheerioContentCrawler(crawlerOptions, key);
148 |
149 | if (startCrawler) {
150 | crawler.run().then(
151 | () => log.warning(`Crawler ${crawlerType} has finished`),
152 | // eslint-disable-next-line @typescript-eslint/no-empty-function
153 | () => {},
154 | );
155 | log.info(`Crawler ${crawlerType} has started 💪🏼`);
156 | }
157 | crawlers.set(key, crawler);
158 | log.info(`Number of crawlers ${crawlers.size}`);
159 | return { key, crawler };
160 | }
161 |
162 | async function createPlaywrightContentCrawler(
163 | crawlerOptions: PlaywrightCrawlerOptions,
164 | key: string,
165 | ): Promise {
166 | log.info(`Creating new playwright crawler with key ${key}`);
167 | return new PlaywrightCrawler({
168 | ...crawlerOptions,
169 | keepAlive: crawlerOptions.keepAlive,
170 | requestQueue: await RequestQueue.open(key, { storageClient: client }),
171 | requestHandler: (async (context) => {
172 | await requestHandlerPlaywright(context as unknown as PlaywrightCrawlingContext);
173 | }),
174 | failedRequestHandler: async ({ request }, err) => failedRequestHandler(request, err, ContentCrawlerTypes.PLAYWRIGHT),
175 | });
176 | }
177 |
178 | async function createCheerioContentCrawler(
179 | crawlerOptions: CheerioCrawlerOptions,
180 | key: string,
181 | ): Promise {
182 | log.info(`Creating new cheerio crawler with key ${key}`);
183 | return new CheerioCrawler({
184 | ...crawlerOptions,
185 | keepAlive: crawlerOptions.keepAlive,
186 | requestQueue: await RequestQueue.open(key, { storageClient: client }),
187 | requestHandler: (async (context) => {
188 | await requestHandlerCheerio(context as unknown as CheerioCrawlingContext,
189 | );
190 | }),
191 | failedRequestHandler: async ({ request }, err) => failedRequestHandler(request, err, ContentCrawlerTypes.CHEERIO),
192 | });
193 | }
194 |
195 | /**
196 | * Adds a search request to the Google search crawler.
197 | * Create a response for the request and set the desired number of results (maxResults).
198 | */
199 | export const addSearchRequest = async (
200 | request: RequestOptions,
201 | searchCrawlerOptions: CheerioCrawlerOptions,
202 | ) => {
203 | const key = getCrawlerKey(searchCrawlerOptions);
204 | const crawler = crawlers.get(key);
205 |
206 | if (!crawler) {
207 | log.error(`Cheerio crawler not found: key ${key}`);
208 | return;
209 | }
210 | addTimeMeasureEvent(request.userData!, 'before-cheerio-queue-add');
211 | await crawler.requestQueue!.addRequest(request);
212 | log.info(`Added request to cheerio-google-search-crawler: ${request.url}`);
213 | };
214 |
--------------------------------------------------------------------------------
/src/errors.ts:
--------------------------------------------------------------------------------
1 | export class UserInputError extends Error {
2 | constructor(message: string) {
3 | super(message);
4 | this.name = 'UserInputError';
5 | }
6 | }
7 |
--------------------------------------------------------------------------------
/src/google-search/google-extractors-urls.ts:
--------------------------------------------------------------------------------
1 | import type { CheerioAPI } from 'cheerio';
2 | import type { Element } from 'domhandler';
3 |
4 | import type { OrganicResult, SearchResultType } from '../types.js';
5 |
6 | /**
7 | * Deduplicates search results based on their title and URL (source @apify/google-search).
8 | */
9 | export const deduplicateResults = (results: T[]): T[] => {
10 | const deduplicatedResults = [];
11 | const resultHashes = new Set();
12 | for (const result of results) {
13 | // date defaults to now so it is not stable
14 | const hash = JSON.stringify({ title: result.title, url: result.url });
15 | if (!resultHashes.has(hash)) {
16 | deduplicatedResults.push(result);
17 | resultHashes.add(hash);
18 | }
19 | }
20 | return deduplicatedResults;
21 | };
22 |
23 | /**
24 | * Parses a single organic search result (source: @apify/google-search).
25 | */
26 | const parseResult = ($: CheerioAPI, el: Element) => {
27 | $(el).find('div.action-menu').remove();
28 |
29 | const descriptionSelector = '.VwiC3b';
30 | const searchResult: OrganicResult = {
31 | title: $(el).find('h3').first().text() || '',
32 | description: ($(el).find(descriptionSelector).text() || '').trim(),
33 | url: $(el).find('a').first().attr('href') || '',
34 | };
35 |
36 | return searchResult;
37 | };
38 |
39 | /**
40 | * Extracts search results from the given selectors (source: @apify/google-search).
41 | */
42 | const extractResultsFromSelectors = ($: CheerioAPI, selectors: string[]) => {
43 | const searchResults: OrganicResult[] = [];
44 | const selector = selectors.join(', ');
45 | for (const resultEl of $(selector)) {
46 | const results = $(resultEl).map((_i, el) => parseResult($, el as Element)).toArray();
47 | for (const result of results) {
48 | if (result.title && result.url) {
49 | searchResults.push(result);
50 | }
51 | }
52 | }
53 | return searchResults;
54 | };
55 |
56 | /**
57 | * If true, the results are not inherent to the given query, but to a similar suggested query
58 | */
59 | const areTheResultsSuggestions = ($: CheerioAPI) => {
60 | // Check if the message "No results found" is shown
61 | return $('div#topstuff > div.fSp71d').children().length > 0;
62 | };
63 |
64 | /**
65 | * Extracts organic search results from the given Cheerio instance (source: @apify/google-search).
66 | */
67 | export const scrapeOrganicResults = ($: CheerioAPI): OrganicResult[] => {
68 | const resultSelectors2023January = [
69 | '.hlcw0c', // Top result with site links
70 | '.g.Ww4FFb', // General search results
71 | '.MjjYud', // General search results 2025 March, this includes also images so we need to add a check that results has both title and url
72 | '.g .tF2Cxc>.yuRUbf', // old search selector 2021 January
73 | '.g [data-header-feature="0"]', // old search selector 2022 January
74 | '.g .rc', // very old selector
75 | '.sATSHe', // another new selector in March 2025
76 | ];
77 |
78 | const searchResults = extractResultsFromSelectors($, resultSelectors2023January);
79 | const deduplicatedResults = deduplicateResults(searchResults);
80 | let resultType: SearchResultType = 'ORGANIC';
81 | if (areTheResultsSuggestions($)) {
82 | resultType = 'SUGGESTED';
83 | }
84 | return deduplicatedResults.map((result) => ({
85 | ...result,
86 | resultType,
87 | }));
88 | };
89 |
--------------------------------------------------------------------------------
/src/input.ts:
--------------------------------------------------------------------------------
1 | import type { ProxyConfigurationOptions } from 'apify';
2 | import { Actor } from 'apify';
3 | import type { CheerioCrawlerOptions, ProxyConfiguration } from 'crawlee';
4 | import { BrowserName, log } from 'crawlee';
5 | import { firefox } from 'playwright';
6 |
7 | import inputSchema from '../.actor/input_schema.json' with { type: 'json' };
8 | import { ContentCrawlerTypes } from './const.js';
9 | import { UserInputError } from './errors.js';
10 | import type {
11 | ContentCrawlerOptions,
12 | ContentScraperSettings,
13 | Input,
14 | OutputFormats,
15 | ScrapingTool,
16 | SERPProxyGroup,
17 | } from './types.js';
18 |
19 | /**
20 | * Processes the input and returns an array of crawler settings. This is ideal for startup of STANDBY mode
21 | * because it makes it simple to start all crawlers at once.
22 | */
23 | export async function processStandbyInput(originalInput: Partial) {
24 | const { input, searchCrawlerOptions, contentScraperSettings } = await processInputInternal(originalInput, true);
25 |
26 | const proxy = await Actor.createProxyConfiguration(input.proxyConfiguration);
27 | const contentCrawlerOptions: ContentCrawlerOptions[] = [
28 | createPlaywrightCrawlerOptions(input, proxy),
29 | createCheerioCrawlerOptions(input, proxy),
30 | ];
31 |
32 | return { input, searchCrawlerOptions, contentCrawlerOptions, contentScraperSettings };
33 | }
34 |
35 | /**
36 | * Processes the input and returns the settings for the crawler.
37 | */
38 | export async function processInput(originalInput: Partial) {
39 | const { input, searchCrawlerOptions, contentScraperSettings } = await processInputInternal(originalInput);
40 |
41 | const proxy = await Actor.createProxyConfiguration(input.proxyConfiguration);
42 | const contentCrawlerOptions: ContentCrawlerOptions = input.scrapingTool === 'raw-http'
43 | ? createCheerioCrawlerOptions(input, proxy, false)
44 | : createPlaywrightCrawlerOptions(input, proxy, false);
45 |
46 | return { input, searchCrawlerOptions, contentCrawlerOptions, contentScraperSettings };
47 | }
48 |
49 | /**
50 | * Processes the input and returns the settings for the crawler (adapted from: Website Content Crawler).
51 | */
52 | async function processInputInternal(
53 | originalInput: Partial,
54 | standbyInit = false,
55 | ) {
56 | // const input = { ...defaults, ...originalInput } as Input;
57 |
58 | const input = validateAndFillInput(originalInput, standbyInit);
59 |
60 | const {
61 | debugMode,
62 | dynamicContentWaitSecs,
63 | serpMaxRetries,
64 | serpProxyGroup,
65 | outputFormats,
66 | readableTextCharThreshold,
67 | removeElementsCssSelector,
68 | htmlTransformer,
69 | removeCookieWarnings,
70 | } = input;
71 |
72 | log.setLevel(debugMode ? log.LEVELS.DEBUG : log.LEVELS.INFO);
73 |
74 | const proxySearch = await Actor.createProxyConfiguration({ groups: [serpProxyGroup] });
75 | const searchCrawlerOptions: CheerioCrawlerOptions = {
76 | keepAlive: standbyInit,
77 | maxRequestRetries: serpMaxRetries,
78 | proxyConfiguration: proxySearch,
79 | autoscaledPoolOptions: { desiredConcurrency: 1 },
80 | };
81 |
82 | const contentScraperSettings: ContentScraperSettings = {
83 | debugMode,
84 | dynamicContentWaitSecs,
85 | htmlTransformer,
86 | maxHtmlCharsToProcess: 1.5e6,
87 | outputFormats,
88 | readableTextCharThreshold,
89 | removeCookieWarnings,
90 | removeElementsCssSelector,
91 | };
92 |
93 | return { input, searchCrawlerOptions, contentScraperSettings };
94 | }
95 |
96 | function createPlaywrightCrawlerOptions(
97 | input: Input,
98 | proxy: ProxyConfiguration | undefined,
99 | keepAlive = true,
100 | ): ContentCrawlerOptions {
101 | const { maxRequestRetries, desiredConcurrency } = input;
102 |
103 | return {
104 | type: ContentCrawlerTypes.PLAYWRIGHT,
105 | crawlerOptions: {
106 | headless: true,
107 | keepAlive,
108 | maxRequestRetries,
109 | proxyConfiguration: proxy,
110 | requestHandlerTimeoutSecs: input.requestTimeoutSecs,
111 | launchContext: {
112 | launcher: firefox,
113 | },
114 | browserPoolOptions: {
115 | fingerprintOptions: {
116 | fingerprintGeneratorOptions: {
117 | browsers: [BrowserName.firefox],
118 | },
119 | },
120 | retireInactiveBrowserAfterSecs: 60,
121 | },
122 | autoscaledPoolOptions: {
123 | desiredConcurrency,
124 | },
125 | },
126 | };
127 | }
128 |
129 | function createCheerioCrawlerOptions(
130 | input: Input,
131 | proxy: ProxyConfiguration | undefined,
132 | keepAlive = true,
133 | ): ContentCrawlerOptions {
134 | const { maxRequestRetries, desiredConcurrency } = input;
135 |
136 | return {
137 | type: ContentCrawlerTypes.CHEERIO,
138 | crawlerOptions: {
139 | keepAlive,
140 | maxRequestRetries,
141 | proxyConfiguration: proxy,
142 | requestHandlerTimeoutSecs: input.requestTimeoutSecs,
143 | autoscaledPoolOptions: {
144 | desiredConcurrency,
145 | },
146 | },
147 | };
148 | }
149 |
150 | /**
151 | * Validates the input and fills in the default values where necessary.
152 | * Do not validate query parameter when standbyInit is true.
153 | * This is a bit ugly, but it's necessary to avoid throwing an error when the query is not provided in standby mode.
154 | */
155 | function validateAndFillInput(input: Partial, standbyInit: boolean): Input {
156 | /* eslint-disable no-param-reassign */
157 | const validateRange = (
158 | value: number | string | undefined,
159 | min: number,
160 | max: number,
161 | defaultValue: number,
162 | fieldName: string,
163 | ) => {
164 | // parse the value as a number to check if it's a valid number
165 | if (value === undefined) {
166 | log.info(`The \`${fieldName}\` parameter is not defined. Using the default value ${defaultValue}.`);
167 | return defaultValue;
168 | } if (typeof value === 'string') {
169 | value = Number(value);
170 | } if (value < min) {
171 | log.warning(`The \`${fieldName}\` parameter must be at least ${min}, but was ${fieldName}. Using ${min} instead.`);
172 | return min;
173 | } if (value > max) {
174 | log.warning(`The \`${fieldName}\` parameter must be at most ${max}, but was ${fieldName}. Using ${max} instead.`);
175 | return max;
176 | }
177 | return value;
178 | };
179 |
180 | // Throw an error if the query is not provided and standbyInit is false.
181 | if (!input.query && !standbyInit) {
182 | throw new UserInputError('The `query` parameter must be provided and non-empty.');
183 | }
184 |
185 | // Max results
186 | input.maxResults = validateRange(
187 | input.maxResults,
188 | inputSchema.properties.maxResults.minimum,
189 | inputSchema.properties.maxResults.maximum,
190 | inputSchema.properties.maxResults.default,
191 | 'maxResults',
192 | );
193 |
194 | // Output formats
195 | if (!input.outputFormats || input.outputFormats.length === 0) {
196 | input.outputFormats = inputSchema.properties.outputFormats.default as OutputFormats[];
197 | log.info(`The \`outputFormats\` parameter is not defined. Using default value \`${input.outputFormats}\`.`);
198 | } else if (input.outputFormats.some((format) => !['text', 'markdown', 'html'].includes(format))) {
199 | throw new UserInputError('The `outputFormats` array may only contain `text`, `markdown`, or `html`.');
200 | }
201 |
202 | // Request timout seconds
203 | input.requestTimeoutSecs = validateRange(
204 | input.requestTimeoutSecs,
205 | inputSchema.properties.requestTimeoutSecs.minimum,
206 | inputSchema.properties.requestTimeoutSecs.maximum,
207 | inputSchema.properties.requestTimeoutSecs.default,
208 | 'requestTimeoutSecs',
209 | );
210 |
211 | // SERP proxy group
212 | if (!input.serpProxyGroup || input.serpProxyGroup.length === 0) {
213 | input.serpProxyGroup = inputSchema.properties.serpProxyGroup.default as SERPProxyGroup;
214 | } else if (input.serpProxyGroup !== 'GOOGLE_SERP' && input.serpProxyGroup !== 'SHADER') {
215 | throw new UserInputError('The `serpProxyGroup` parameter must be either `GOOGLE_SERP` or `SHADER`.');
216 | }
217 |
218 | // SERP max retries
219 | input.serpMaxRetries = validateRange(
220 | input.serpMaxRetries,
221 | inputSchema.properties.serpMaxRetries.minimum,
222 | inputSchema.properties.serpMaxRetries.maximum,
223 | inputSchema.properties.serpMaxRetries.default,
224 | 'serpMaxRetries',
225 | );
226 |
227 | // Proxy configuration
228 | if (!input.proxyConfiguration) {
229 | input.proxyConfiguration = inputSchema.properties.proxyConfiguration.default as ProxyConfigurationOptions;
230 | }
231 |
232 | // Scraping tool
233 | if (!input.scrapingTool) {
234 | input.scrapingTool = inputSchema.properties.scrapingTool.default as ScrapingTool;
235 | } else if (input.scrapingTool !== 'browser-playwright' && input.scrapingTool !== 'raw-http') {
236 | throw new UserInputError('The `scrapingTool` parameter must be either `browser-playwright` or `raw-http`.');
237 | }
238 |
239 | // Remove elements CSS selector
240 | if (!input.removeElementsCssSelector) {
241 | input.removeElementsCssSelector = inputSchema.properties.removeElementsCssSelector.default;
242 | }
243 |
244 | // HTML transformer
245 | if (!input.htmlTransformer) {
246 | input.htmlTransformer = inputSchema.properties.htmlTransformer.default;
247 | }
248 |
249 | // Desired concurrency
250 | input.desiredConcurrency = validateRange(
251 | input.desiredConcurrency,
252 | inputSchema.properties.desiredConcurrency.minimum,
253 | inputSchema.properties.desiredConcurrency.maximum,
254 | inputSchema.properties.desiredConcurrency.default,
255 | 'desiredConcurrency',
256 | );
257 |
258 | // Max request retries
259 | input.maxRequestRetries = validateRange(
260 | input.maxRequestRetries,
261 | inputSchema.properties.maxRequestRetries.minimum,
262 | inputSchema.properties.maxRequestRetries.maximum,
263 | inputSchema.properties.maxRequestRetries.default,
264 | 'maxRequestRetries',
265 | );
266 |
267 | // Dynamic content wait seconds
268 | if (!input.dynamicContentWaitSecs || input.dynamicContentWaitSecs >= input.requestTimeoutSecs) {
269 | input.dynamicContentWaitSecs = Math.round(input.requestTimeoutSecs / 2);
270 | }
271 |
272 | // Remove cookie warnings
273 | if (input.removeCookieWarnings === undefined) {
274 | input.removeCookieWarnings = inputSchema.properties.removeCookieWarnings.default;
275 | }
276 |
277 | // Debug mode
278 | if (input.debugMode === undefined) {
279 | input.debugMode = inputSchema.properties.debugMode.default;
280 | }
281 |
282 | return input as Input;
283 | /* eslint-enable no-param-reassign */
284 | }
285 |
--------------------------------------------------------------------------------
/src/main.ts:
--------------------------------------------------------------------------------
1 | import { Actor } from 'apify';
2 | import { log } from 'crawlee';
3 |
4 | import { createAndStartContentCrawler, createAndStartSearchCrawler } from './crawlers.js';
5 | import { processInput, processStandbyInput } from './input.js';
6 | import { addTimeoutToAllResponses } from './responses.js';
7 | import { handleSearchNormalMode } from './search.js';
8 | import { createServer } from './server.js';
9 | import type { Input } from './types.js';
10 | import { isActorStandby } from './utils.js';
11 |
12 | await Actor.init();
13 |
14 | Actor.on('migrating', () => {
15 | addTimeoutToAllResponses(60);
16 | });
17 |
18 | const originalInput = await Actor.getInput>() ?? {} as Input;
19 |
20 | if (isActorStandby()) {
21 | log.info('Actor is running in the STANDBY mode.');
22 |
23 | const host = Actor.isAtHome() ? process.env.ACTOR_STANDBY_URL as string : 'http://localhost';
24 | const port = Actor.isAtHome() ? Number(process.env.ACTOR_STANDBY_PORT) : 3000;
25 |
26 | const {
27 | input,
28 | searchCrawlerOptions,
29 | contentCrawlerOptions,
30 | contentScraperSettings,
31 | } = await processStandbyInput(originalInput);
32 |
33 | log.info(`Loaded input: ${JSON.stringify(input)},
34 | cheerioCrawlerOptions: ${JSON.stringify(searchCrawlerOptions)},
35 | contentCrawlerOptions: ${JSON.stringify(contentCrawlerOptions)},
36 | contentScraperSettings ${JSON.stringify(contentScraperSettings)}
37 | `);
38 |
39 | const app = createServer();
40 |
41 | app.listen(port, async () => {
42 | const promises: Promise[] = [];
43 | promises.push(createAndStartSearchCrawler(searchCrawlerOptions));
44 | for (const settings of contentCrawlerOptions) {
45 | promises.push(createAndStartContentCrawler(settings));
46 | }
47 |
48 | await Promise.all(promises);
49 | log.info(`The Actor web server is listening for user requests at ${host}:${port}`);
50 | });
51 | } else {
52 | log.info('Actor is running in the NORMAL mode.');
53 |
54 | const {
55 | input,
56 | searchCrawlerOptions,
57 | contentCrawlerOptions,
58 | contentScraperSettings,
59 | } = await processInput(originalInput);
60 |
61 | log.info(`Loaded input: ${JSON.stringify(input)},
62 | cheerioCrawlerOptions: ${JSON.stringify(searchCrawlerOptions)},
63 | contentCrawlerOptions: ${JSON.stringify(contentCrawlerOptions)},
64 | contentScraperSettings ${JSON.stringify(contentScraperSettings)}
65 | `);
66 |
67 | try {
68 | await handleSearchNormalMode(input, searchCrawlerOptions, contentCrawlerOptions, contentScraperSettings);
69 | } catch (e) {
70 | const error = e as Error;
71 | await Actor.fail(error.message as string);
72 | }
73 | await Actor.exit();
74 | }
75 |
--------------------------------------------------------------------------------
/src/mcp/server.ts:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env node
2 |
3 | /**
4 | * Model Context Protocol (MCP) server for RAG Web Browser Actor
5 | */
6 |
7 | import { Server } from '@modelcontextprotocol/sdk/server/index.js';
8 | import type { Transport } from '@modelcontextprotocol/sdk/shared/transport.js';
9 | import { CallToolRequestSchema, ListToolsRequestSchema } from '@modelcontextprotocol/sdk/types.js';
10 |
11 | import inputSchema from '../../.actor/input_schema.json' with { type: 'json' };
12 | import { handleModelContextProtocol } from '../search.js';
13 | import type { Input } from '../types.js';
14 |
15 | const TOOL_SEARCH = inputSchema.title.toLowerCase().replace(/ /g, '-');
16 |
17 | const TOOLS = [
18 | {
19 | name: TOOL_SEARCH,
20 | description: inputSchema.description,
21 | inputSchema,
22 | },
23 | ];
24 |
25 | /**
26 | * Create an MCP server with a tool to call RAG Web Browser Actor
27 | */
28 | export class RagWebBrowserServer {
29 | private server: Server;
30 |
31 | constructor() {
32 | this.server = new Server(
33 | {
34 | name: 'mcp-server-rag-web-browser',
35 | version: '0.1.0',
36 | },
37 | {
38 | capabilities: {
39 | tools: {},
40 | },
41 | },
42 | );
43 | this.setupErrorHandling();
44 | this.setupToolHandlers();
45 | }
46 |
47 | private setupErrorHandling(): void {
48 | this.server.onerror = (error) => {
49 | console.error('[MCP Error]', error); // eslint-disable-line no-console
50 | };
51 | process.on('SIGINT', async () => {
52 | await this.server.close();
53 | process.exit(0);
54 | });
55 | }
56 |
57 | private setupToolHandlers(): void {
58 | this.server.setRequestHandler(ListToolsRequestSchema, async () => {
59 | return {
60 | tools: TOOLS,
61 | };
62 | });
63 | this.server.setRequestHandler(CallToolRequestSchema, async (request) => {
64 | const { name, arguments: args } = request.params;
65 | switch (name) {
66 | case TOOL_SEARCH: {
67 | const content = await handleModelContextProtocol(args as unknown as Input);
68 | return { content: content.map((message) => ({ type: 'text', text: JSON.stringify(message) })) };
69 | }
70 | default: {
71 | throw new Error(`Unknown tool: ${name}`);
72 | }
73 | }
74 | });
75 | }
76 |
77 | async connect(transport: Transport): Promise {
78 | await this.server.connect(transport);
79 | }
80 | }
81 |
--------------------------------------------------------------------------------
/src/performance-measures.ts:
--------------------------------------------------------------------------------
1 | import { Actor } from 'apify';
2 |
3 | /**
4 | * Compute average time for each time measure event
5 | */
6 |
7 | // const datasetId = 'aDnsnaBqGb8eTdpGv'; // 2GB, maxResults=1
8 | // const datasetId = 'giAPLL8dhd2PDqPlf'; // 2GB, maxResults=5
9 | // const datasetId = 'VKzel6raVqisgIYfe'; // 4GB, maxResults=1
10 | // const datasetId = 'KkTaLd70HbFgAO35y'; // 4GB, maxResults=3
11 | // const datasetId = 'fm9tO0GDBUagMT0df'; // 4GB, maxResults=5
12 | // const datasetId = '6ObH057Icr9z1bgXl'; // 8GB, maxResults=1
13 | const datasetId = 'lfItikr0vAXv7oXwH'; // 8GB, maxResults=3
14 |
15 | // set environment variables APIFY_TOKEN
16 | process.env.APIFY_TOKEN = '';
17 |
18 | const dataset = await Actor.openDataset(datasetId, { forceCloud: true });
19 | const remoteDataset = await dataset.getData();
20 |
21 | const timeMeasuresMap = new Map();
22 | const timeMeasuresTimeTaken = [];
23 |
24 | // compute average time for the timeMeasures
25 | for (const item of remoteDataset.items) {
26 | const { timeMeasures } = item.crawl.debug;
27 |
28 | for (const measure of timeMeasures) {
29 | if (!timeMeasuresMap.has(measure.event)) {
30 | timeMeasuresMap.set(measure.event, []);
31 | }
32 | timeMeasuresMap.set(measure.event, [...timeMeasuresMap.get(measure.event)!, measure.timeDeltaPrevMs]);
33 |
34 | if (measure.event === 'playwright-before-response-send') {
35 | timeMeasuresTimeTaken.push(measure.timeMs);
36 | }
37 | }
38 | }
39 | // eslint-disable-next-line no-console
40 | console.log('Average time for each time measure event:', timeMeasuresMap);
41 |
42 | for (const [key, value] of timeMeasuresMap) {
43 | const sum = value.reduce((a, b) => a + b, 0);
44 | const avg = sum / value.length;
45 | // eslint-disable-next-line no-console
46 | console.log(`${key}: ${avg.toFixed(0)} s`);
47 | }
48 |
49 | // eslint-disable-next-line no-console
50 | console.log('Time taken for each request:', timeMeasuresTimeTaken);
51 | // eslint-disable-next-line no-console
52 | console.log('Time taken on average', timeMeasuresTimeTaken.reduce((a, b) => a + b, 0) / timeMeasuresTimeTaken.length);
53 |
--------------------------------------------------------------------------------
/src/request-handler.ts:
--------------------------------------------------------------------------------
1 | import { Actor } from 'apify';
2 | import { load } from 'cheerio';
3 | import { type CheerioCrawlingContext, htmlToText, log, type PlaywrightCrawlingContext, type Request, sleep } from 'crawlee';
4 |
5 | import { ContentCrawlerStatus, ContentCrawlerTypes } from './const.js';
6 | import { addResultToResponse, responseData, sendResponseIfFinished } from './responses.js';
7 | import type { ContentCrawlerUserData, Output } from './types.js';
8 | import { addTimeMeasureEvent, isActorStandby, transformTimeMeasuresToRelative } from './utils.js';
9 | import { processHtml } from './website-content-crawler/html-processing.js';
10 | import { htmlToMarkdown } from './website-content-crawler/markdown.js';
11 |
12 | let ACTOR_TIMEOUT_AT: number | undefined;
13 | try {
14 | ACTOR_TIMEOUT_AT = process.env.ACTOR_TIMEOUT_AT ? new Date(process.env.ACTOR_TIMEOUT_AT).getTime() : undefined;
15 | } catch {
16 | ACTOR_TIMEOUT_AT = undefined;
17 | }
18 |
19 | /**
20 | * Waits for the `time` to pass, but breaks early if the page is loaded (source: Website Content Crawler).
21 | */
22 | async function waitForPlaywright({ page }: PlaywrightCrawlingContext, time: number) {
23 | // Early break is possible only after 1/3 of the time has passed (max 3 seconds) to avoid breaking too early.
24 | const hardDelay = Math.min(1000, Math.floor(0.3 * time));
25 | await sleep(hardDelay);
26 |
27 | return Promise.race([page.waitForLoadState('networkidle', { timeout: 0 }), sleep(time - hardDelay)]);
28 | }
29 |
30 | /**
31 | * Checks if the request should time out based on response timeout.
32 | * It verifies if the response data contains the responseId. If not, it sets the request's noRetry flag
33 | * to true and throws an error to cancel the request.
34 | *
35 | * @param {Request} request - The request object to be checked.
36 | * @param {string} responseId - The response ID to look for in the response data.
37 | * @throws {Error} Throws an error if the request times out.
38 | */
39 | function checkTimeoutAndCancelRequest(request: Request, responseId: string) {
40 | if (!responseData.has(responseId)) {
41 | request.noRetry = true;
42 | throw new Error('Timed out. Cancelling the request...');
43 | }
44 | }
45 |
46 | /**
47 | * Decide whether to wait based on the remaining time left for the Actor to run.
48 | * Always waits if the Actor is in the STANDBY_MODE.
49 | */
50 | export function hasTimeLeftToTimeout(time: number) {
51 | if (process.env.STANDBY_MODE) return true;
52 | if (!ACTOR_TIMEOUT_AT) return true;
53 |
54 | const timeLeft = ACTOR_TIMEOUT_AT - Date.now();
55 | if (timeLeft > time) return true;
56 |
57 | log.debug('Not enough time left to wait for dynamic content. Skipping');
58 | return false;
59 | }
60 |
61 | /**
62 | * Waits for the `time`, but checks the content length every half second and breaks early if it hasn't changed
63 | * in last 2 seconds (source: Website Content Crawler).
64 | */
65 | export async function waitForDynamicContent(context: PlaywrightCrawlingContext, time: number) {
66 | if (context.page && hasTimeLeftToTimeout(time)) {
67 | await waitForPlaywright(context, time);
68 | }
69 | }
70 |
71 | function isValidContentType(contentType: string | undefined) {
72 | return ['text', 'html', 'xml'].some((type) => contentType?.includes(type));
73 | }
74 |
75 | async function checkValidResponse(
76 | $: CheerioCrawlingContext['$'],
77 | contentType: string | undefined,
78 | context: PlaywrightCrawlingContext | CheerioCrawlingContext,
79 | ) {
80 | const { request, response } = context;
81 | const { responseId } = request.userData;
82 |
83 | if (!$ || !isValidContentType(contentType)) {
84 | log.info(`Skipping URL ${request.loadedUrl} as it could not be parsed.`, { contentType });
85 | const resultSkipped: Output = {
86 | crawl: {
87 | httpStatusCode: response?.status(),
88 | httpStatusMessage: "Couldn't parse the content",
89 | loadedAt: new Date(),
90 | uniqueKey: request.uniqueKey,
91 | requestStatus: ContentCrawlerStatus.FAILED,
92 | },
93 | metadata: { url: request.url },
94 | searchResult: request.userData.searchResult!,
95 | query: request.userData.query,
96 | text: '',
97 | };
98 | log.info(`Adding result to the Apify dataset, url: ${request.url}`);
99 | await context.pushData(resultSkipped);
100 | if (responseId) {
101 | addResultToResponse(responseId, request.uniqueKey, resultSkipped);
102 | sendResponseIfFinished(responseId);
103 | }
104 | return false;
105 | }
106 |
107 | return true;
108 | }
109 |
110 | async function handleContent(
111 | $: CheerioCrawlingContext['$'],
112 | crawlerType: ContentCrawlerTypes,
113 | statusCode: number | undefined,
114 | context: PlaywrightCrawlingContext | CheerioCrawlingContext,
115 | ) {
116 | const { request } = context;
117 | const { responseId, contentScraperSettings: settings } = request.userData;
118 |
119 | const $html = $('html');
120 | const html = $html.html()!;
121 | const processedHtml = await processHtml(html, request.url, settings, $);
122 | addTimeMeasureEvent(request.userData, `${crawlerType}-process-html`);
123 |
124 | const isTooLarge = processedHtml.length > settings.maxHtmlCharsToProcess;
125 | const text = isTooLarge ? load(processedHtml).text() : htmlToText(load(processedHtml));
126 |
127 | const result: Output = {
128 | crawl: {
129 | httpStatusCode: statusCode,
130 | httpStatusMessage: 'OK',
131 | loadedAt: new Date(),
132 | uniqueKey: request.uniqueKey,
133 | requestStatus: ContentCrawlerStatus.HANDLED,
134 | },
135 | searchResult: request.userData.searchResult!,
136 | metadata: {
137 | author: $('meta[name=author]').first().attr('content') ?? undefined,
138 | title: $('title').first().text(),
139 | description: $('meta[name=description]').first().attr('content') ?? undefined,
140 | languageCode: $html.first().attr('lang') ?? undefined,
141 | url: request.url,
142 | },
143 | query: request.userData.query,
144 | text: settings.outputFormats.includes('text') ? text : undefined,
145 | markdown: settings.outputFormats.includes('markdown') ? htmlToMarkdown(processedHtml) : undefined,
146 | html: settings.outputFormats.includes('html') ? processedHtml : undefined,
147 | };
148 |
149 | addTimeMeasureEvent(request.userData, `${crawlerType}-before-response-send`);
150 | if (settings.debugMode) {
151 | result.crawl.debug = { timeMeasures: transformTimeMeasuresToRelative(request.userData.timeMeasures!) };
152 | }
153 | log.info(`Adding result to the Apify dataset, url: ${request.url}`);
154 | await context.pushData(result);
155 |
156 | // Get responseId from the request.userData, which corresponds to the original search request
157 | if (responseId) {
158 | addResultToResponse(responseId, request.uniqueKey, result);
159 | sendResponseIfFinished(responseId);
160 | }
161 | }
162 |
163 | export async function requestHandlerPlaywright(
164 | context: PlaywrightCrawlingContext,
165 | ) {
166 | const { request, response, page, closeCookieModals } = context;
167 | const { contentScraperSettings: settings, responseId } = request.userData;
168 |
169 | if (isActorStandby()) checkTimeoutAndCancelRequest(request, responseId);
170 |
171 | log.info(`Processing URL: ${request.url}`);
172 | addTimeMeasureEvent(request.userData, 'playwright-request-start');
173 | if (settings.dynamicContentWaitSecs > 0) {
174 | await waitForDynamicContent(context, settings.dynamicContentWaitSecs * 1000);
175 | addTimeMeasureEvent(request.userData, 'playwright-wait-dynamic-content');
176 | }
177 |
178 | if (page && settings.removeCookieWarnings) {
179 | await closeCookieModals();
180 | addTimeMeasureEvent(request.userData, 'playwright-remove-cookie');
181 | }
182 |
183 | // Parsing the page after the dynamic content has been loaded / cookie warnings removed
184 | const $ = await context.parseWithCheerio();
185 | addTimeMeasureEvent(request.userData, 'playwright-parse-with-cheerio');
186 |
187 | const headers = response?.headers instanceof Function ? response.headers() : response?.headers;
188 | // @ts-expect-error false-positive?
189 | const isValidResponse = await checkValidResponse($, headers?.['content-type'], context);
190 | if (!isValidResponse) return;
191 |
192 | const statusCode = response?.status();
193 |
194 | await handleContent($, ContentCrawlerTypes.PLAYWRIGHT, statusCode, context);
195 | }
196 |
197 | export async function requestHandlerCheerio(
198 | context: CheerioCrawlingContext,
199 | ) {
200 | const { $, request, response } = context;
201 | const { responseId } = request.userData;
202 |
203 | if (isActorStandby()) checkTimeoutAndCancelRequest(request, responseId);
204 |
205 | log.info(`Processing URL: ${request.url}`);
206 | addTimeMeasureEvent(request.userData, 'cheerio-request-start');
207 |
208 | const isValidResponse = await checkValidResponse($, response.headers['content-type'], context);
209 | if (!isValidResponse) return;
210 |
211 | const statusCode = response?.statusCode;
212 |
213 | await handleContent($, ContentCrawlerTypes.CHEERIO, statusCode, context);
214 | }
215 |
216 | export async function failedRequestHandler(request: Request, err: Error, crawlerType: ContentCrawlerTypes) {
217 | log.error(`Content-crawler failed to process request ${request.url}, error ${err.message}`);
218 | request.userData.timeMeasures!.push({ event: `${crawlerType}-failed-request`, time: Date.now() });
219 | const { responseId } = request.userData;
220 | if (responseId) {
221 | const resultErr: Output = {
222 | crawl: {
223 | httpStatusCode: 500,
224 | httpStatusMessage: err.message,
225 | loadedAt: new Date(),
226 | uniqueKey: request.uniqueKey,
227 | requestStatus: ContentCrawlerStatus.FAILED,
228 | },
229 | searchResult: request.userData.searchResult!,
230 | metadata: {
231 | url: request.url,
232 | title: '',
233 | },
234 | text: '',
235 | };
236 | log.info(`Adding result to the Apify dataset, url: ${request.url}`);
237 | await Actor.pushData(resultErr);
238 | addResultToResponse(responseId, request.uniqueKey, resultErr);
239 | sendResponseIfFinished(responseId);
240 | }
241 | }
242 |
--------------------------------------------------------------------------------
/src/responses.ts:
--------------------------------------------------------------------------------
1 | import { log } from 'apify';
2 | import type { RequestOptions } from 'crawlee';
3 |
4 | import { ContentCrawlerStatus } from './const.js';
5 | import type { ContentCrawlerUserData, Output } from './types.js';
6 |
7 | type ResponseData = {
8 | resultsMap: Map;
9 | resolve: (value: Output[]) => void;
10 | reject: (reason?: unknown) => void;
11 | timeoutId?: NodeJS.Timeout;
12 | };
13 |
14 | export const responseData = new Map();
15 |
16 | /**
17 | * Helper function to get response object by responseId.
18 | */
19 | const getResponse = (responseId: string): ResponseData | null => {
20 | const res = responseData.get(responseId);
21 | if (res) return res;
22 |
23 | return null;
24 | };
25 |
26 | /**
27 | * Create a response promise
28 | * (for content crawler requests there is no need to create a response object).
29 | */
30 | export async function createResponsePromise(responseId: string, timeoutSecs: number): Promise {
31 | log.info(`Created responsePromise for response ID: ${responseId}`);
32 | return new Promise((resolve, reject) => {
33 | const data: ResponseData = {
34 | resultsMap: new Map(),
35 | resolve,
36 | reject,
37 | };
38 | responseData.set(responseId, data);
39 |
40 | // Set a timeout to reject the promise if it takes too long
41 | data.timeoutId = setTimeout(() => {
42 | sendResponseError(responseId, 'Timed out.');
43 | }, timeoutSecs * 1000);
44 | });
45 | }
46 |
47 | /**
48 | * Add empty result to response object when the content crawler request is created.
49 | * This is needed to keep track of all results and to know that all results have been handled.
50 | */
51 | export function addEmptyResultToResponse(responseId: string, request: RequestOptions) {
52 | const res = getResponse(responseId);
53 | if (!res) return;
54 |
55 | const result: Partial