├── .streamlit
└── config.toml
├── README.md
├── main.py
├── prospects.csv
├── requirements.txt
└── template.pptx
/.streamlit/config.toml:
--------------------------------------------------------------------------------
1 | [theme]
2 | base="dark"
3 | primaryColor="FF8C00"
4 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | [](https://arsentievalex-instant-insight-web-app-main-gz753r.streamlit.app/)
2 |
3 | # Instant Insight Web App (3rd place in Streamlit Hackathon for Snowflake Summit 2023)
4 |
5 | This app is designed to generate an instant company research.
6 |
7 | In a matter of few clicks, a user gets a PowerPoint presentation with the company overview, SWOT analysis, financials, and value propostion tailored for the selling product. The app works with the US public companies.
8 |
9 |
10 | Firstly, filter and select a company:
11 |
12 | 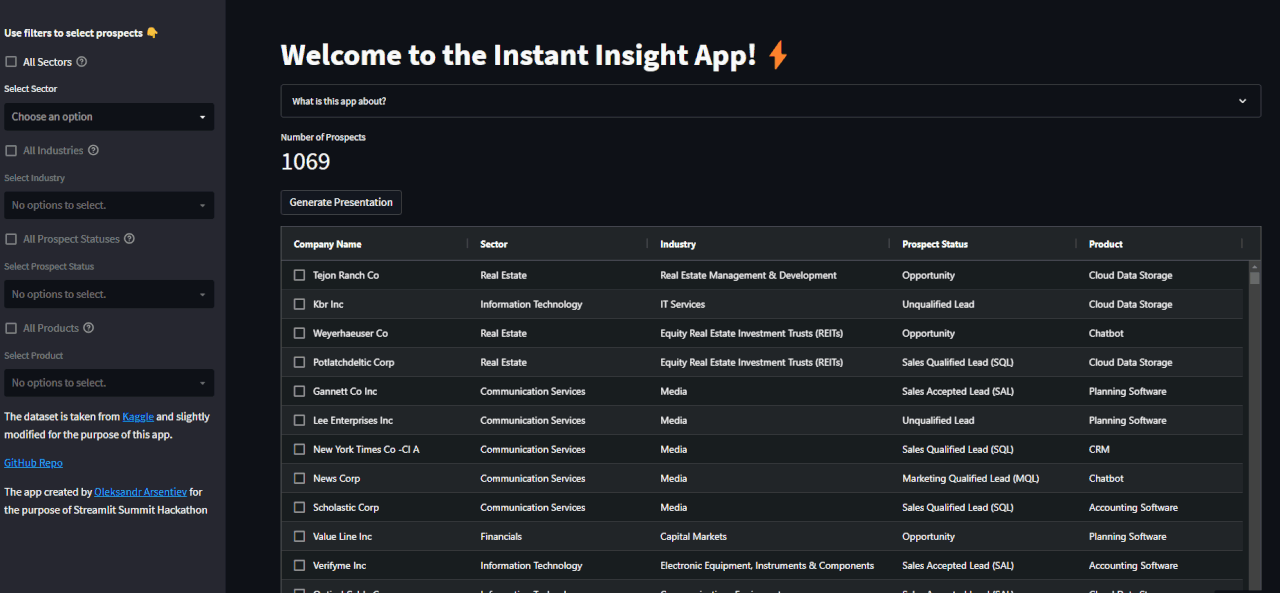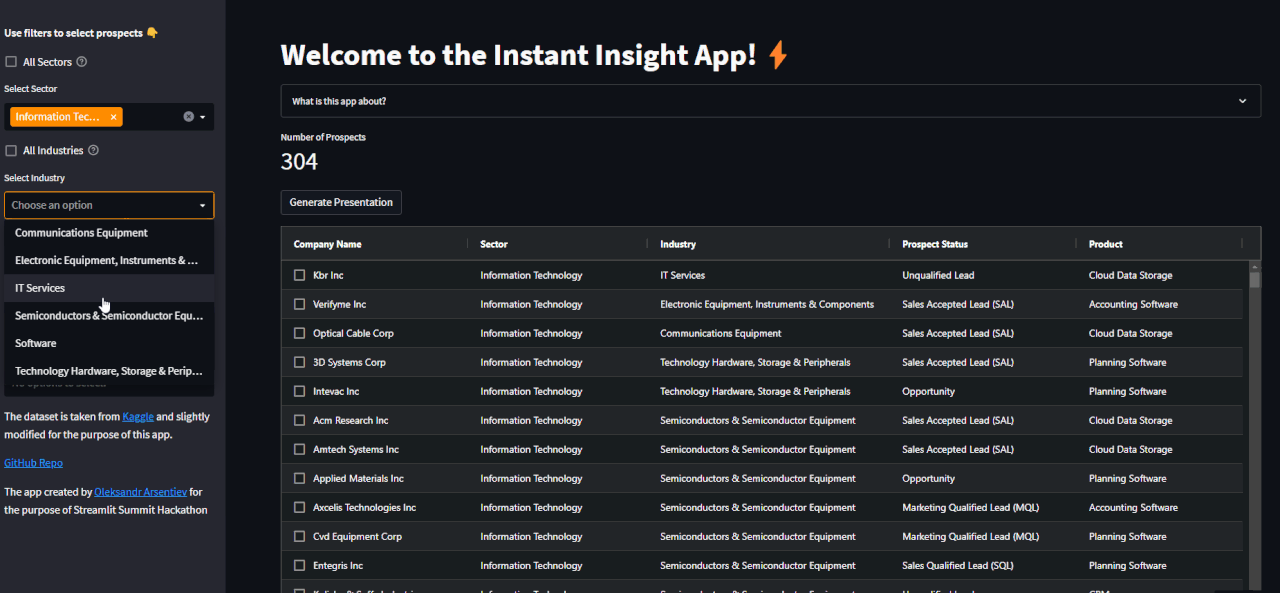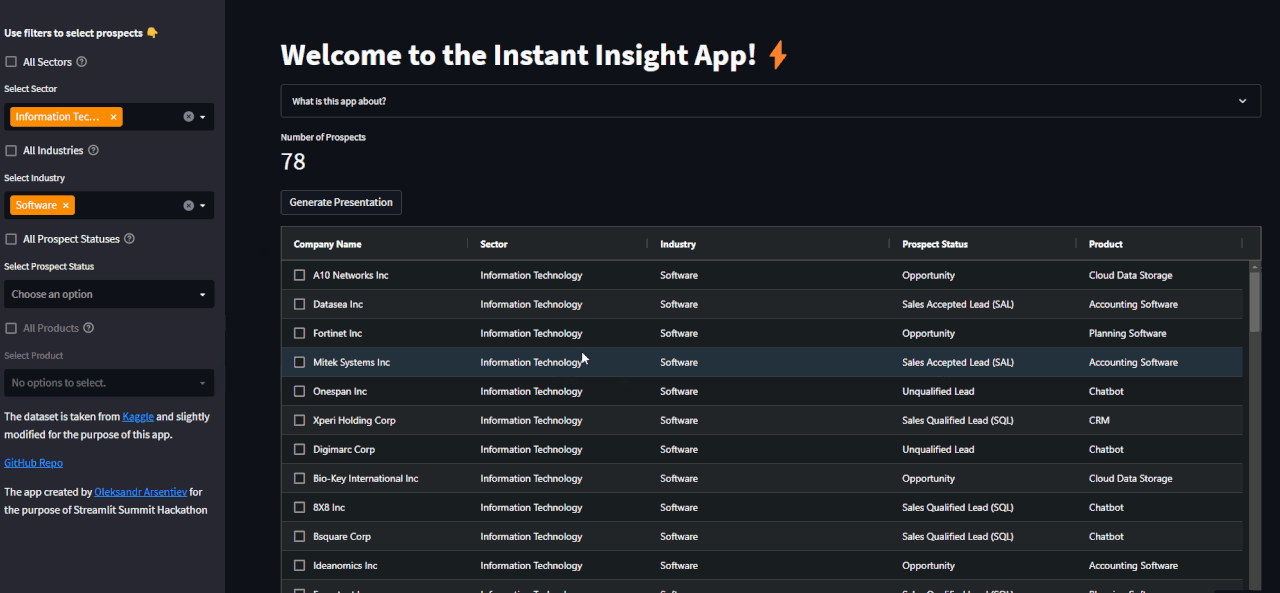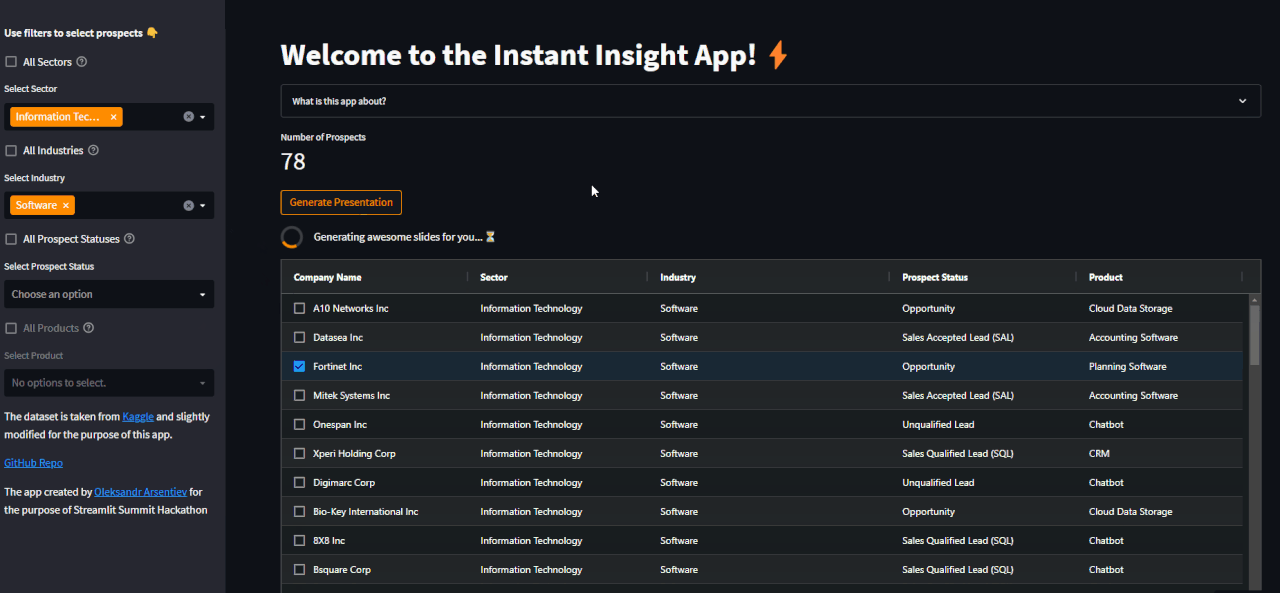 13 |
14 | Wait for up to 30 sec and download a PowerPoint:
15 |
16 |
13 |
14 | Wait for up to 30 sec and download a PowerPoint:
15 |
16 | 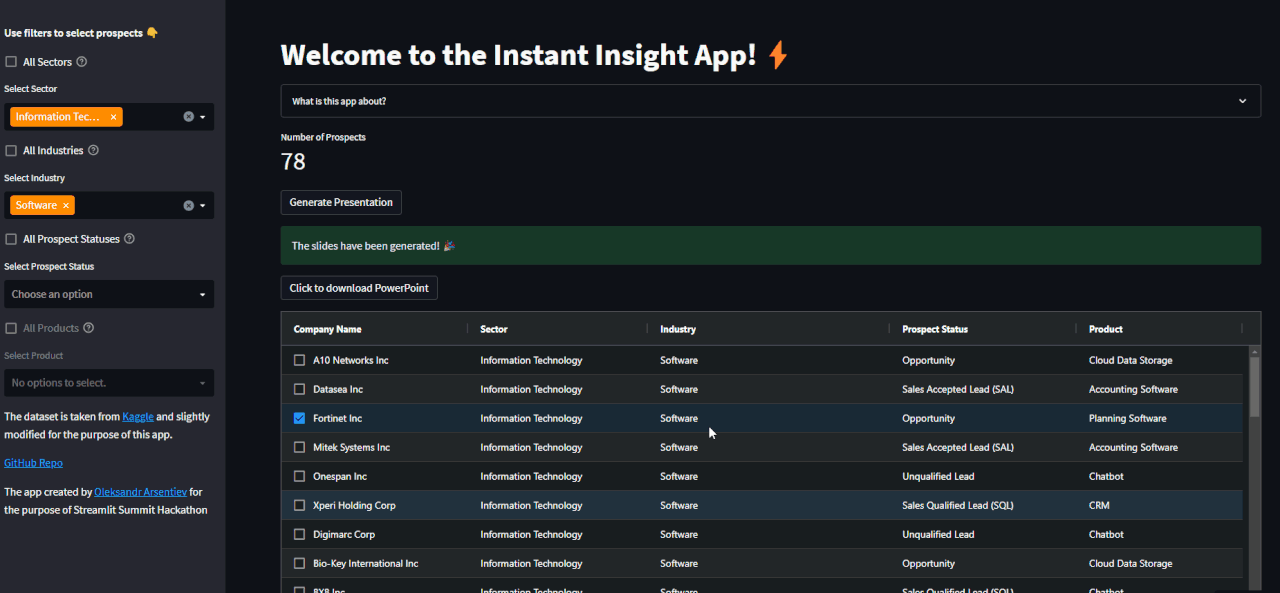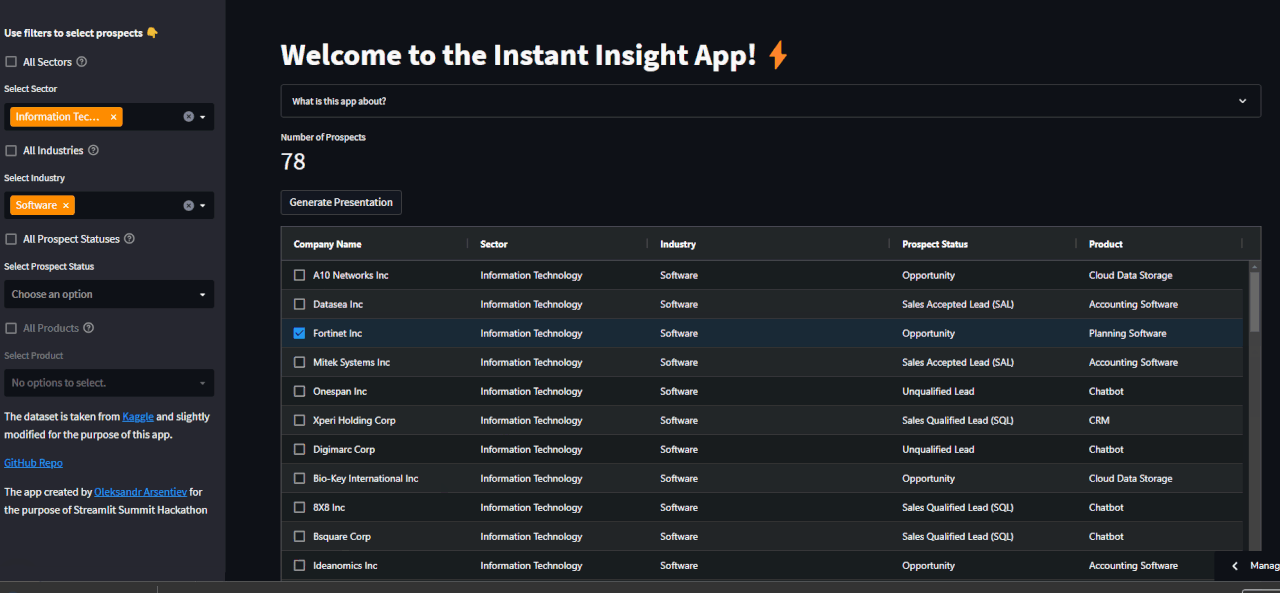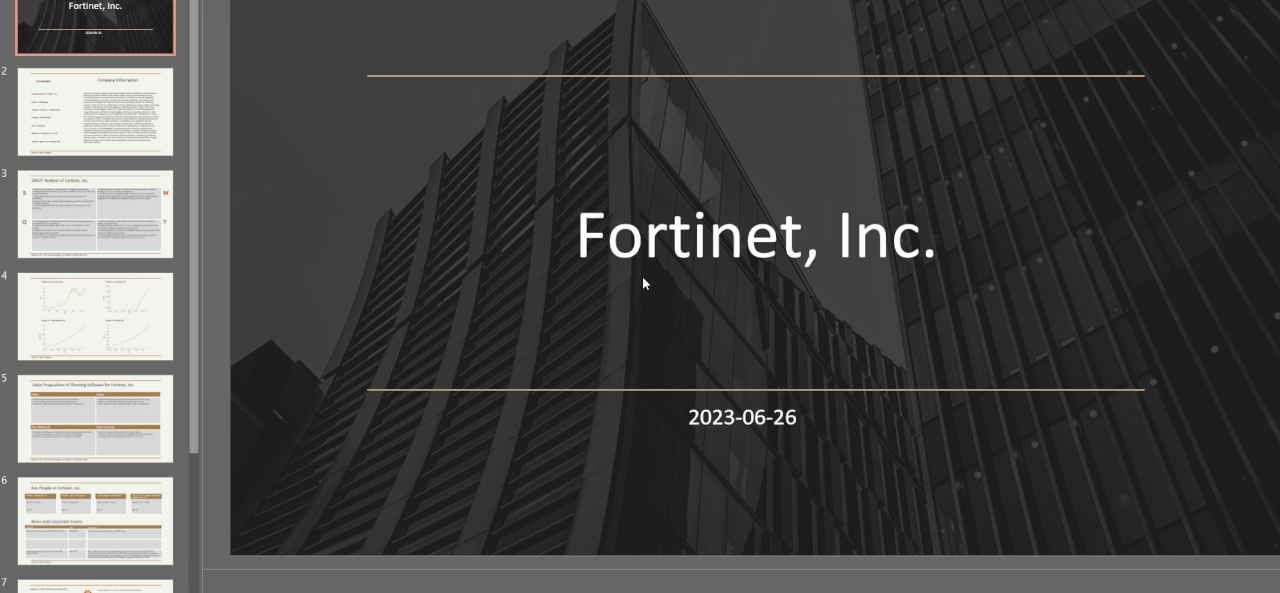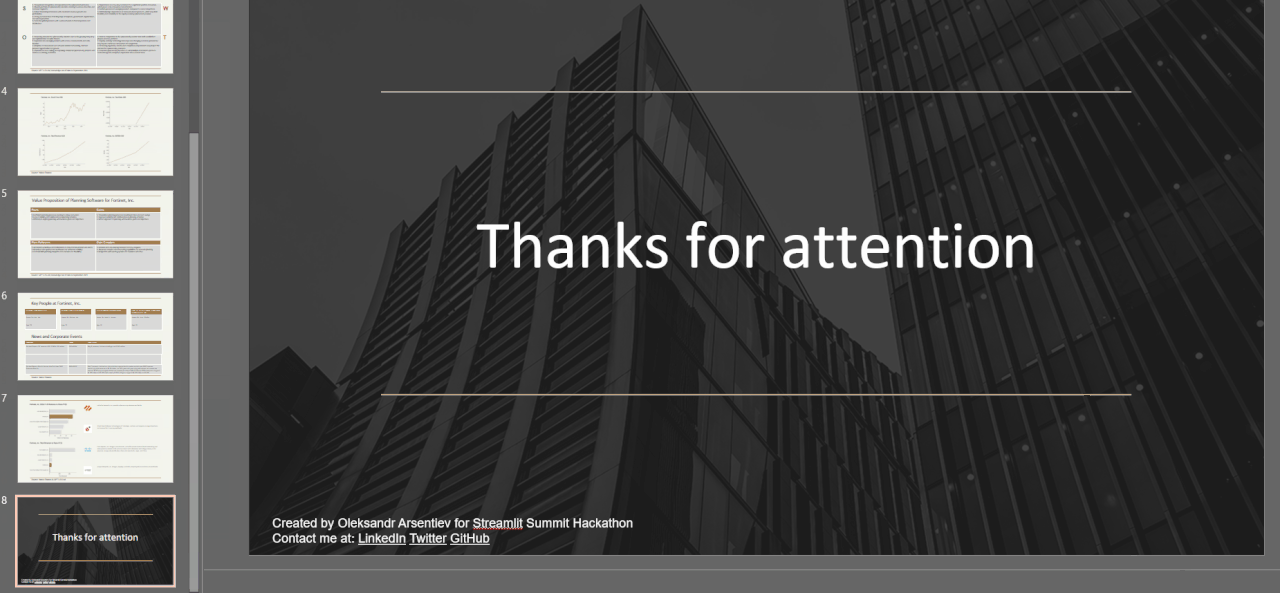 17 |
18 |
19 | [App's URL](https://arsentievalex-instant-insight-web-app-main-gz753r.streamlit.app/)
20 |
21 | Tech Stack:
22 |
23 | • Database - Snowflake via Snowflake Connector
24 |
25 | • Data Processing - Pandas
26 |
27 | • Research Data - Yahoo Finance via Yahooquery, GPT 3.5 via LangChain
28 |
29 | • Visualization - Plotly
30 |
31 | • Frontend - Streamlit, AgGrid
32 |
33 | • Presentation - Python-pptx
34 |
35 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | #import snowflake.connector
3 | import streamlit as st
4 | from streamlit_dynamic_filters import DynamicFilters
5 | from st_aggrid import AgGrid
6 | from st_aggrid.grid_options_builder import GridOptionsBuilder
7 | from st_aggrid import GridUpdateMode, DataReturnMode
8 | import warnings
9 | from yahooquery import Ticker
10 | import plotly.express as px
11 | import plotly.graph_objects as go
12 | from pptx import Presentation
13 | from pptx.util import Inches
14 | from datetime import date
15 | from PIL import Image
16 | import requests
17 | import os
18 | from io import BytesIO
19 | from langchain.chat_models import ChatOpenAI
20 | from langchain.schema import HumanMessage, SystemMessage
21 | import traceback
22 | import re
23 | import ast
24 |
25 | # hide future warnings (caused by st_aggrid)
26 | warnings.simplefilter(action='ignore', category=FutureWarning)
27 |
28 | # set page layout and define basic variables
29 | st.set_page_config(layout="wide", page_icon='⚡', page_title="Instant Insight")
30 | path = os.path.dirname(__file__)
31 | today = date.today()
32 |
33 |
34 | def resize_image(url):
35 | """function to resize logos while keeping aspect ratio. Accepts URL as an argument and return an image object"""
36 |
37 | # Open the image file
38 | image = Image.open(requests.get(url, stream=True).raw)
39 |
40 | # if a logo is too high or too wide then make the background container twice as big
41 | if image.height > 140:
42 | container_width = 220 * 2
43 | container_height = 140 * 2
44 |
45 | elif image.width > 220:
46 | container_width = 220 * 2
47 | container_height = 140 * 2
48 | else:
49 | container_width = 220
50 | container_height = 140
51 |
52 | # Create a new image with the same aspect ratio as the original image
53 | new_image = Image.new('RGBA', (container_width, container_height))
54 |
55 | # Calculate the position to paste the image so that it is centered
56 | x = (container_width - image.width) // 2
57 | y = (container_height - image.height) // 2
58 |
59 | # Paste the image onto the new image
60 | new_image.paste(image, (x, y))
61 | return new_image
62 |
63 |
64 | def add_image(slide, image, left, top, width):
65 | """function to add an image to the PowerPoint slide and specify its position and width"""
66 | slide.shapes.add_picture(image, left=left, top=top, width=width)
67 |
68 |
69 | def replace_text(replacements, slide):
70 | """function to replace text on a PowerPoint slide. Takes dict of {match: replacement, ... } and replaces all matches"""
71 | # Iterate through all shapes in the slide
72 | for shape in slide.shapes:
73 | for match, replacement in replacements.items():
74 | if shape.has_text_frame:
75 | if (shape.text.find(match)) != -1:
76 | text_frame = shape.text_frame
77 | for paragraph in text_frame.paragraphs:
78 | whole_text = "".join(run.text for run in paragraph.runs)
79 | whole_text = whole_text.replace(str(match), str(replacement))
80 | for idx, run in enumerate(paragraph.runs):
81 | if idx != 0:
82 | p = paragraph._p
83 | p.remove(run._r)
84 | if bool(paragraph.runs):
85 | paragraph.runs[0].text = whole_text
86 |
87 |
88 | def get_stock(ticker, period, interval):
89 | """function to get stock data from Yahoo Finance. Takes ticker, period and interval as arguments and returns a DataFrame"""
90 | hist = ticker.history(period=period, interval=interval)
91 | hist = hist.reset_index()
92 | # capitalize column names
93 | hist.columns = [x.capitalize() for x in hist.columns]
94 | return hist
95 |
96 |
97 | def plot_graph(df, x, y, title, name):
98 | """function to plot a line graph. Takes DataFrame, x and y axis, title and name as arguments and returns a Plotly figure"""
99 | fig = px.line(df, x=x, y=y, template='simple_white',
100 | title='{} {}'.format(name, title))
101 | fig.update_traces(line_color='#A27D4F')
102 | fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
103 | return fig
104 |
105 |
106 | def peers_plot(df, name, metric):
107 | """function to plot a bar chart with peers. Takes DataFrame, name, metric and ticker as arguments and returns a Plotly figure"""
108 |
109 | # drop rows with missing metrics
110 | df.dropna(subset=[metric], inplace=True)
111 |
112 | df_sorted = df.sort_values(metric, ascending=False)
113 |
114 | # iterate over the labels and add the colors to the color mapping dictionary, hightlight the selected ticker
115 | color_map = {}
116 | for label in df_sorted['Company Name']:
117 | if label == name:
118 | color_map[label] = '#A27D4F'
119 | else:
120 | color_map[label] = '#D9D9D9'
121 |
122 | fig = px.bar(df_sorted, y='Company Name', x=metric, template='simple_white', color='Company Name',
123 | color_discrete_map=color_map,
124 | orientation='h',
125 | title='{} {} vs Peers FY22'.format(name, metric))
126 | fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', showlegend=False, yaxis_title='')
127 | return fig
128 |
129 |
130 | def esg_plot(name, df):
131 | # Define colors for types
132 | colors = {name: '#A27D4F', 'Peer Group': '#D9D9D9'}
133 |
134 | # Creating the bar chart
135 | fig = go.Figure()
136 | for type in df['Type'].unique():
137 | fig.add_trace(go.Bar(
138 | x=df[df['Type'] == type]['variable'],
139 | y=df[df['Type'] == type]['value'],
140 | name=type,
141 | text=df[df['Type'] == type]['value'],
142 | textposition='outside',
143 | marker_color=colors[type]
144 | ))
145 | fig.update_layout(
146 | height=700,
147 | width=1000,
148 | barmode='group',
149 | title="ESG Score vs Peers Average",
150 | xaxis_title="",
151 | yaxis_title="Score",
152 | legend_title="Type",
153 | xaxis=dict(tickangle=0),
154 | paper_bgcolor='rgba(0,0,0,0)',
155 | plot_bgcolor='rgba(0,0,0,0)')
156 | return fig
157 |
158 |
159 | def get_financials(df, col_name, metric_name):
160 | """function to get financial metrics from a DataFrame. Takes DataFrame, column name and metric name as arguments and returns a DataFrame"""
161 | metric = df.loc[:, ['asOfDate', col_name]]
162 | metric_df = pd.DataFrame(metric).reset_index()
163 | metric_df.columns = ['Symbol', 'Year', metric_name]
164 |
165 | return metric_df
166 |
167 |
168 | def generate_gpt_response(gpt_input, max_tokens, api_key, llm_model):
169 | """function to generate a response from GPT-3. Takes input and max tokens as arguments and returns a response"""
170 | # Create an instance of the OpenAI class
171 | chat = ChatOpenAI(openai_api_key=api_key, model=llm_model,
172 | temperature=0, max_tokens=max_tokens)
173 |
174 | # Generate a response from the model
175 | response = chat.predict_messages(
176 | [SystemMessage(content='You are a helpful expert in finance, market and company research.'
177 | 'You also have exceptional skills in selling B2B software products.'),
178 | HumanMessage(
179 | content=gpt_input)])
180 |
181 | return response.content.strip()
182 |
183 |
184 | def dict_from_string(response):
185 | """function to parse GPT response with competitors tickers and convert it to a dict"""
186 | # Find a substring that starts with '{' and ends with '}', across multiple lines
187 | match = re.search(r'\{.*?\}', response, re.DOTALL)
188 |
189 | dictionary = None
190 | if match:
191 | try:
192 | # Try to convert substring to dict
193 | dictionary = ast.literal_eval(match.group())
194 | except (ValueError, SyntaxError):
195 | # Not a dictionary
196 | return None
197 | return dictionary
198 |
199 |
200 | def extract_comp_financials(tkr, comp_name, dict):
201 | """function to extract financial metrics for competitors. Takes a ticker as an argument and appends financial metrics to dict"""
202 | ticker = Ticker(tkr)
203 | income_df = ticker.income_statement(frequency='a', trailing=False)
204 |
205 | subset = income_df.loc[:, ['asOfDate', 'TotalRevenue', 'SellingGeneralAndAdministration']].reset_index()
206 |
207 | # keep only 2022 data
208 | subset = subset[subset['asOfDate'].dt.year == 2022].sort_values(by='asOfDate', ascending=False).head(1)
209 |
210 | # get values
211 | total_revenue = subset['TotalRevenue'].values[0]
212 | sg_and_a = subset['SellingGeneralAndAdministration'].values[0]
213 |
214 | # calculate sg&a as a percentage of total revenue
215 | sg_and_a_pct = round(sg_and_a / total_revenue * 100, 2)
216 |
217 | # add values to dictionary
218 | dict[comp_name]['Total Revenue'] = total_revenue
219 | dict[comp_name]['SG&A % Of Revenue'] = sg_and_a_pct
220 |
221 |
222 | def convert_to_nested_dict(input_dict, nested_key):
223 | """function to convert a dictionary to a nested dictionary. Takes a dictionary and a nested key as arguments and returns a dictionary"""
224 | output_dict = {}
225 | for key, value in input_dict.items():
226 | output_dict[key] = {nested_key: value}
227 | return output_dict
228 |
229 |
230 | def shorten_summary(text):
231 | # Split the text into sentences using a regular expression pattern
232 | sentences = re.split(r'(?
17 |
18 |
19 | [App's URL](https://arsentievalex-instant-insight-web-app-main-gz753r.streamlit.app/)
20 |
21 | Tech Stack:
22 |
23 | • Database - Snowflake via Snowflake Connector
24 |
25 | • Data Processing - Pandas
26 |
27 | • Research Data - Yahoo Finance via Yahooquery, GPT 3.5 via LangChain
28 |
29 | • Visualization - Plotly
30 |
31 | • Frontend - Streamlit, AgGrid
32 |
33 | • Presentation - Python-pptx
34 |
35 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | import pandas as pd
2 | #import snowflake.connector
3 | import streamlit as st
4 | from streamlit_dynamic_filters import DynamicFilters
5 | from st_aggrid import AgGrid
6 | from st_aggrid.grid_options_builder import GridOptionsBuilder
7 | from st_aggrid import GridUpdateMode, DataReturnMode
8 | import warnings
9 | from yahooquery import Ticker
10 | import plotly.express as px
11 | import plotly.graph_objects as go
12 | from pptx import Presentation
13 | from pptx.util import Inches
14 | from datetime import date
15 | from PIL import Image
16 | import requests
17 | import os
18 | from io import BytesIO
19 | from langchain.chat_models import ChatOpenAI
20 | from langchain.schema import HumanMessage, SystemMessage
21 | import traceback
22 | import re
23 | import ast
24 |
25 | # hide future warnings (caused by st_aggrid)
26 | warnings.simplefilter(action='ignore', category=FutureWarning)
27 |
28 | # set page layout and define basic variables
29 | st.set_page_config(layout="wide", page_icon='⚡', page_title="Instant Insight")
30 | path = os.path.dirname(__file__)
31 | today = date.today()
32 |
33 |
34 | def resize_image(url):
35 | """function to resize logos while keeping aspect ratio. Accepts URL as an argument and return an image object"""
36 |
37 | # Open the image file
38 | image = Image.open(requests.get(url, stream=True).raw)
39 |
40 | # if a logo is too high or too wide then make the background container twice as big
41 | if image.height > 140:
42 | container_width = 220 * 2
43 | container_height = 140 * 2
44 |
45 | elif image.width > 220:
46 | container_width = 220 * 2
47 | container_height = 140 * 2
48 | else:
49 | container_width = 220
50 | container_height = 140
51 |
52 | # Create a new image with the same aspect ratio as the original image
53 | new_image = Image.new('RGBA', (container_width, container_height))
54 |
55 | # Calculate the position to paste the image so that it is centered
56 | x = (container_width - image.width) // 2
57 | y = (container_height - image.height) // 2
58 |
59 | # Paste the image onto the new image
60 | new_image.paste(image, (x, y))
61 | return new_image
62 |
63 |
64 | def add_image(slide, image, left, top, width):
65 | """function to add an image to the PowerPoint slide and specify its position and width"""
66 | slide.shapes.add_picture(image, left=left, top=top, width=width)
67 |
68 |
69 | def replace_text(replacements, slide):
70 | """function to replace text on a PowerPoint slide. Takes dict of {match: replacement, ... } and replaces all matches"""
71 | # Iterate through all shapes in the slide
72 | for shape in slide.shapes:
73 | for match, replacement in replacements.items():
74 | if shape.has_text_frame:
75 | if (shape.text.find(match)) != -1:
76 | text_frame = shape.text_frame
77 | for paragraph in text_frame.paragraphs:
78 | whole_text = "".join(run.text for run in paragraph.runs)
79 | whole_text = whole_text.replace(str(match), str(replacement))
80 | for idx, run in enumerate(paragraph.runs):
81 | if idx != 0:
82 | p = paragraph._p
83 | p.remove(run._r)
84 | if bool(paragraph.runs):
85 | paragraph.runs[0].text = whole_text
86 |
87 |
88 | def get_stock(ticker, period, interval):
89 | """function to get stock data from Yahoo Finance. Takes ticker, period and interval as arguments and returns a DataFrame"""
90 | hist = ticker.history(period=period, interval=interval)
91 | hist = hist.reset_index()
92 | # capitalize column names
93 | hist.columns = [x.capitalize() for x in hist.columns]
94 | return hist
95 |
96 |
97 | def plot_graph(df, x, y, title, name):
98 | """function to plot a line graph. Takes DataFrame, x and y axis, title and name as arguments and returns a Plotly figure"""
99 | fig = px.line(df, x=x, y=y, template='simple_white',
100 | title='{} {}'.format(name, title))
101 | fig.update_traces(line_color='#A27D4F')
102 | fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
103 | return fig
104 |
105 |
106 | def peers_plot(df, name, metric):
107 | """function to plot a bar chart with peers. Takes DataFrame, name, metric and ticker as arguments and returns a Plotly figure"""
108 |
109 | # drop rows with missing metrics
110 | df.dropna(subset=[metric], inplace=True)
111 |
112 | df_sorted = df.sort_values(metric, ascending=False)
113 |
114 | # iterate over the labels and add the colors to the color mapping dictionary, hightlight the selected ticker
115 | color_map = {}
116 | for label in df_sorted['Company Name']:
117 | if label == name:
118 | color_map[label] = '#A27D4F'
119 | else:
120 | color_map[label] = '#D9D9D9'
121 |
122 | fig = px.bar(df_sorted, y='Company Name', x=metric, template='simple_white', color='Company Name',
123 | color_discrete_map=color_map,
124 | orientation='h',
125 | title='{} {} vs Peers FY22'.format(name, metric))
126 | fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', showlegend=False, yaxis_title='')
127 | return fig
128 |
129 |
130 | def esg_plot(name, df):
131 | # Define colors for types
132 | colors = {name: '#A27D4F', 'Peer Group': '#D9D9D9'}
133 |
134 | # Creating the bar chart
135 | fig = go.Figure()
136 | for type in df['Type'].unique():
137 | fig.add_trace(go.Bar(
138 | x=df[df['Type'] == type]['variable'],
139 | y=df[df['Type'] == type]['value'],
140 | name=type,
141 | text=df[df['Type'] == type]['value'],
142 | textposition='outside',
143 | marker_color=colors[type]
144 | ))
145 | fig.update_layout(
146 | height=700,
147 | width=1000,
148 | barmode='group',
149 | title="ESG Score vs Peers Average",
150 | xaxis_title="",
151 | yaxis_title="Score",
152 | legend_title="Type",
153 | xaxis=dict(tickangle=0),
154 | paper_bgcolor='rgba(0,0,0,0)',
155 | plot_bgcolor='rgba(0,0,0,0)')
156 | return fig
157 |
158 |
159 | def get_financials(df, col_name, metric_name):
160 | """function to get financial metrics from a DataFrame. Takes DataFrame, column name and metric name as arguments and returns a DataFrame"""
161 | metric = df.loc[:, ['asOfDate', col_name]]
162 | metric_df = pd.DataFrame(metric).reset_index()
163 | metric_df.columns = ['Symbol', 'Year', metric_name]
164 |
165 | return metric_df
166 |
167 |
168 | def generate_gpt_response(gpt_input, max_tokens, api_key, llm_model):
169 | """function to generate a response from GPT-3. Takes input and max tokens as arguments and returns a response"""
170 | # Create an instance of the OpenAI class
171 | chat = ChatOpenAI(openai_api_key=api_key, model=llm_model,
172 | temperature=0, max_tokens=max_tokens)
173 |
174 | # Generate a response from the model
175 | response = chat.predict_messages(
176 | [SystemMessage(content='You are a helpful expert in finance, market and company research.'
177 | 'You also have exceptional skills in selling B2B software products.'),
178 | HumanMessage(
179 | content=gpt_input)])
180 |
181 | return response.content.strip()
182 |
183 |
184 | def dict_from_string(response):
185 | """function to parse GPT response with competitors tickers and convert it to a dict"""
186 | # Find a substring that starts with '{' and ends with '}', across multiple lines
187 | match = re.search(r'\{.*?\}', response, re.DOTALL)
188 |
189 | dictionary = None
190 | if match:
191 | try:
192 | # Try to convert substring to dict
193 | dictionary = ast.literal_eval(match.group())
194 | except (ValueError, SyntaxError):
195 | # Not a dictionary
196 | return None
197 | return dictionary
198 |
199 |
200 | def extract_comp_financials(tkr, comp_name, dict):
201 | """function to extract financial metrics for competitors. Takes a ticker as an argument and appends financial metrics to dict"""
202 | ticker = Ticker(tkr)
203 | income_df = ticker.income_statement(frequency='a', trailing=False)
204 |
205 | subset = income_df.loc[:, ['asOfDate', 'TotalRevenue', 'SellingGeneralAndAdministration']].reset_index()
206 |
207 | # keep only 2022 data
208 | subset = subset[subset['asOfDate'].dt.year == 2022].sort_values(by='asOfDate', ascending=False).head(1)
209 |
210 | # get values
211 | total_revenue = subset['TotalRevenue'].values[0]
212 | sg_and_a = subset['SellingGeneralAndAdministration'].values[0]
213 |
214 | # calculate sg&a as a percentage of total revenue
215 | sg_and_a_pct = round(sg_and_a / total_revenue * 100, 2)
216 |
217 | # add values to dictionary
218 | dict[comp_name]['Total Revenue'] = total_revenue
219 | dict[comp_name]['SG&A % Of Revenue'] = sg_and_a_pct
220 |
221 |
222 | def convert_to_nested_dict(input_dict, nested_key):
223 | """function to convert a dictionary to a nested dictionary. Takes a dictionary and a nested key as arguments and returns a dictionary"""
224 | output_dict = {}
225 | for key, value in input_dict.items():
226 | output_dict[key] = {nested_key: value}
227 | return output_dict
228 |
229 |
230 | def shorten_summary(text):
231 | # Split the text into sentences using a regular expression pattern
232 | sentences = re.split(r'(?