├── .github
└── workflows
│ └── mdbook.yml
├── .gitignore
├── README.md
├── book.toml
└── src
├── .DS_Store
├── README.md
├── SUMMARY.md
├── algostruct
├── README.md
├── array.md
├── crypto.md
├── graph.md
├── hashTable.md
├── probability.md
├── structBasics.md
├── tree.md
└── unsorted.md
├── architecture
├── README.md
├── architecturesPatterns.md
├── ddd.md
├── gof.md
├── microserices
│ ├── README.md
│ ├── integration.md
│ └── monolithSeparation.md
├── oopBase.md
├── principles.md
└── uncategorized.md
├── auth
├── README.md
├── steps
│ ├── README.md
│ ├── authentication.md
│ ├── authorization.md
│ └── identification.md
└── webAuth
│ ├── README.md
│ ├── cookieSessions.md
│ ├── httpBasic.md
│ ├── httpDigest.md
│ ├── oauth.md
│ ├── otp.md
│ └── token.md
├── checkList.md
├── db
├── .DS_Store
├── README.md
├── column
│ ├── README.md
│ ├── clickhouse.md
│ └── vertica.md
├── dBTheory
│ ├── README.md
│ ├── distrubedDb
│ │ ├── README.md
│ │ ├── replication.md
│ │ ├── sharding.md
│ │ └── unsorted.md
│ ├── normalForms.md
│ └── transactions.md
├── messages
│ ├── README.md
│ ├── kafka.md
│ ├── nats.md
│ └── rabbit.md
├── noSql
│ ├── README.md
│ ├── memcached.md
│ ├── mongo.md
│ ├── redis.md
│ └── tarantool.md
└── relational
│ ├── README.md
│ ├── mysql
│ ├── README.MD
│ ├── architecture.md
│ ├── concurency.md
│ ├── explain.md
│ ├── indexes.md
│ ├── sql.md
│ └── unsorted.md
│ └── postgreSql
│ ├── README.md
│ └── indexes.md
├── devmethods.md
├── devops
├── README.md
├── deployment.md
├── linux.md
├── load_balancing.md
├── observability.md
└── virtualization
│ ├── README.md
│ ├── docker.md
│ └── kubernetes.md
├── git.md
├── goLang
├── .DS_Store
├── README.md
├── concurrency
│ ├── .DS_Store
│ ├── README.md
│ ├── chanel.md
│ ├── context.md
│ ├── gouritine.md
│ ├── patterns.md
│ ├── scheduler.md
│ └── sync.md
├── ecosystem.md
├── memory.md
└── types
│ ├── README.md
│ ├── array_slice.md
│ ├── interface.md
│ ├── map.md
│ ├── scalar.md
│ └── struct.md
├── ib.md
├── javascript.md
├── media
├── .DS_Store
├── algostruct
│ ├── collision-resolving.png
│ ├── collision_chain.png
│ ├── collision_open_hash.png
│ └── hash-func.png
├── auth
│ └── webAuth
│ │ ├── accessRefreshJwt.png
│ │ ├── cookieSession.png
│ │ ├── httpBasic.png
│ │ ├── httpDigest.png
│ │ ├── jwt.png
│ │ └── token.png
├── bAndB+.png
├── bTreeExample.png
├── bTreeIndex.png
├── biHeap.png
├── cgi.jpeg
├── db
│ ├── .DS_Store
│ ├── specific
│ │ ├── .DS_Store
│ │ └── messages
│ │ │ ├── kaffka_prod_con.png
│ │ │ ├── kafka.jpg
│ │ │ ├── mcq.jpg
│ │ │ ├── nats.jpg
│ │ │ └── rabbit.jpg
│ └── theory
│ │ └── sharding
│ │ ├── consistent_hashing11.png
│ │ └── consistent_hashing4.png
├── gitLifeCycle.png
├── gitMergeRebase.jpeg
├── gitRebaseOnTo.png
├── go
│ ├── go_chan.png
│ ├── go_hash.png
│ ├── nilIface.png
│ ├── scheduler_grq_lrq.png
│ ├── scheduler_mpg.jpeg
│ ├── scheduler_mpg2.jpeg
│ ├── slice-1.png
│ ├── slice-2.png
│ ├── slice-array.png
│ ├── stack_heap1.jpeg
│ └── stack_heap2.jpeg
├── image1.jpeg
├── image10.png
├── image11.jpeg
├── image12.png
├── image14.png
├── image15.jpeg
├── image16.png
├── image2.png
├── image3.png
├── image4.png
├── image5.png
├── image9.png
├── joins.png
├── kolka.png
├── masterSlaveReplication.png
├── multiColumnIndex.png
├── multiSortIndex.png
├── mySqlArchitecture.png
├── network
│ ├── htpp_v.png
│ ├── tcp-vs-udp.png
│ ├── tcp_udp_format.jpeg
│ ├── tcp_udp_stack.jpeg
│ ├── tls-handshake.png
│ └── tls-internet.png
├── osi-tcp-ip.png
├── phpCache.png
├── redisTypes.jpg
├── replicationHl.jpg
├── replicationUpdate.jpg
└── rtree.png
├── network
├── README.md
├── dns.md
├── http.md
├── osi.md
├── realTime.md
├── tcp_ip.md
├── tls.md
└── whatHappenWhen.md
├── os.md
├── php
├── README.md
├── frameworks
│ ├── README.md
│ ├── laravel.md
│ └── symfony.md
├── innovations.md
├── internals.md
├── serverIteractions.md
└── uncategorized.md
├── styles
└── website.css
├── test.md
└── unsorted
├── README.md
├── bits.md
├── types.md
└── unicode.md
/.github/workflows/mdbook.yml:
--------------------------------------------------------------------------------
1 | # Sample workflow for building and deploying a mdBook site to GitHub Pages
2 | #
3 | # To get started with mdBook see: https://rust-lang.github.io/mdBook/index.html
4 | #
5 | name: Deploy mdBook site to Pages
6 |
7 | on:
8 | # Runs on pushes targeting the default branch
9 | push:
10 | branches: ["master"]
11 |
12 | # Allows you to run this workflow manually from the Actions tab
13 | workflow_dispatch:
14 |
15 | # Sets permissions of the GITHUB_TOKEN to allow deployment to GitHub Pages
16 | permissions:
17 | contents: read
18 | pages: write
19 | id-token: write
20 |
21 | # Allow only one concurrent deployment, skipping runs queued between the run in-progress and latest queued.
22 | # However, do NOT cancel in-progress runs as we want to allow these production deployments to complete.
23 | concurrency:
24 | group: "pages"
25 | cancel-in-progress: false
26 |
27 | jobs:
28 | # Build job
29 | build:
30 | runs-on: ubuntu-latest
31 | env:
32 | MDBOOK_VERSION: 0.4.21
33 | steps:
34 | - uses: actions/checkout@v3
35 | - name: Install mdBook
36 | run: |
37 | curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf -y | sh
38 | rustup update
39 | cargo install --version ${MDBOOK_VERSION} mdbook
40 | - name: Setup Pages
41 | id: pages
42 | uses: actions/configure-pages@v3
43 | - name: Build with mdBook
44 | run: mdbook build
45 | - name: Upload artifact
46 | uses: actions/upload-pages-artifact@v3
47 | with:
48 | path: ./book
49 |
50 | # Deployment job
51 | deploy:
52 | environment:
53 | name: github-pages
54 | url: ${{ steps.deployment.outputs.page_url }}
55 | runs-on: ubuntu-latest
56 | needs: build
57 | steps:
58 | - name: Deploy to GitHub Pages
59 | id: deployment
60 | uses: actions/deploy-pages@v4
61 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Node rules:
2 | ## Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)
3 | .grunt
4 |
5 | ## Dependency directory
6 | ## Commenting this out is preferred by some people, see
7 | ## https://docs.npmjs.com/misc/faq#should-i-check-my-node_modules-folder-into-git
8 | node_modules
9 |
10 | # Book build output
11 | /book
12 |
13 | # eBook build output
14 | *.epub
15 | *.mobi
16 | *.pdf
17 |
18 | #.DS_Store
19 | *.DS_Store
20 |
21 | /.idea
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Памятка Backend разработчику для подготовки к собеседованиям
2 |
3 | Это репозиторий с **.md** исходниками. Читать лучше здесь [backendinterview.ru](https://backendinterview.ru)
4 |
5 | Всем привет, меня зовут Артур Пантелеев и вы читаете мою "*книгу*" о собеседованиях.
6 |
7 | Это методичка(краткий справочник) по темам, знание которых может понадобиться при собеседовании на бэкендера (с уклоном в **Golang**/PHP) и на работе.
8 |
9 | **Не является** исчерпывающим руководством, а служит лишь **тезисным помощником** в повторении и подготовки к собеседованию и структурированию собственных знаний. Также много полезных ссылок на дополнительные материалы.
10 |
11 | Вопросы можно задать в чат [@phpgeeks](https://t.me/phpgeeks) или в лс [@arturpanteleev](https://t.me/arturpanteleev)
12 |
13 | Улучшения/дополнения шлите сюда [https://github.com/arturpanteleev/phpInterview](https://github.com/arturpanteleev/phpInterview)
14 |
15 | *P.S. Первый кирпич в создание пособия заложил, увековечив здесь своё имя, Сергей Пронин.*
16 |
17 |  --------------------------------------------------------------------------------
/book.toml:
--------------------------------------------------------------------------------
1 | [book]
2 | title = "Backend interview"
3 | description = "Книжка для подготовки к собеседованию на должность backend developer"
4 | authors = ["Artur Panteleev"]
5 | language = "ru"
6 |
7 |
8 | [output.html]
9 | mathjax-support = true
10 | site-url = "/book/"
11 | git-repository-url = "https://github.com/arturpanteleev/phpInterview"
12 |
--------------------------------------------------------------------------------
/src/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/.DS_Store
--------------------------------------------------------------------------------
/src/README.md:
--------------------------------------------------------------------------------
1 | # Памятка PHP/GoLang разработчику для подготовки к собеседованиям
2 |
3 | Всем привет, меня зовут Артур Пантелеев и вы читаете мою "*книгу*" о собеседованиях.
4 |
5 | Это методичка(краткий справочник) по темам, знание которых может понадобиться при собеседовании на бэкендера (с уклоном в **Golang**/PHP) и на работе.
6 |
7 | **Не является** исчерпывающим руководством, а служит лишь **тезисным помощником** в повторении и подготовки к собеседованию и структурированию собственных знаний. Также много полезных ссылок на дополнительные материалы.
8 |
9 | Вопросы можно задать в чат [@phpgeeks](https://t.me/phpgeeks) или в лс [@arturpanteleev](https://t.me/arturpanteleev)
10 |
11 | Улучшения/дополнения шлите сюда [GitHub - arturpanteleev/backendinterview: Памятка Backend разработчика по прохождению собеседованй](https://github.com/arturpanteleev/phpInterview)
12 |
13 | *P.S. Первый кирпич в создание пособия заложил, увековечив здесь своё имя, Сергей Пронин.
14 |
15 |
--------------------------------------------------------------------------------
/book.toml:
--------------------------------------------------------------------------------
1 | [book]
2 | title = "Backend interview"
3 | description = "Книжка для подготовки к собеседованию на должность backend developer"
4 | authors = ["Artur Panteleev"]
5 | language = "ru"
6 |
7 |
8 | [output.html]
9 | mathjax-support = true
10 | site-url = "/book/"
11 | git-repository-url = "https://github.com/arturpanteleev/phpInterview"
12 |
--------------------------------------------------------------------------------
/src/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/.DS_Store
--------------------------------------------------------------------------------
/src/README.md:
--------------------------------------------------------------------------------
1 | # Памятка PHP/GoLang разработчику для подготовки к собеседованиям
2 |
3 | Всем привет, меня зовут Артур Пантелеев и вы читаете мою "*книгу*" о собеседованиях.
4 |
5 | Это методичка(краткий справочник) по темам, знание которых может понадобиться при собеседовании на бэкендера (с уклоном в **Golang**/PHP) и на работе.
6 |
7 | **Не является** исчерпывающим руководством, а служит лишь **тезисным помощником** в повторении и подготовки к собеседованию и структурированию собственных знаний. Также много полезных ссылок на дополнительные материалы.
8 |
9 | Вопросы можно задать в чат [@phpgeeks](https://t.me/phpgeeks) или в лс [@arturpanteleev](https://t.me/arturpanteleev)
10 |
11 | Улучшения/дополнения шлите сюда [GitHub - arturpanteleev/backendinterview: Памятка Backend разработчика по прохождению собеседованй](https://github.com/arturpanteleev/phpInterview)
12 |
13 | *P.S. Первый кирпич в создание пособия заложил, увековечив здесь своё имя, Сергей Пронин.
14 |
15 |  --------------------------------------------------------------------------------
/src/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Оглавление
2 |
3 | [Введение](README.md)
4 |
5 | * [Алгоритмы и Структуры Данных](algostruct/README.md)
6 | * [Базовые структуры](algostruct/structBasics.md)
7 | * [Массив](algostruct/array.md)
8 | * [Хэш-Таблица](algostruct/hashTable.md)
9 | * [Дерево](algostruct/tree.md)
10 | * [Граф](algostruct/graph.md)
11 | * [Вероятностные](algostruct/probability.md)
12 | * [Криптография](algostruct/crypto.md)
13 | * [Разное](algostruct/unsorted.md)
14 | * [Базы Данных](db/README.md)
15 | * [Теория Баз Данных](db/dBTheory/README.md)
16 | * [Нормальные формы](db/dBTheory/normalForms.md)
17 | * [Транзакции](db/dBTheory/transactions.md)
18 | * [Распределенные БД](db/dBTheory/distrubedDb/README.md)
19 | * [Репликация](db/dBTheory/distrubedDb/replication.md)
20 | * [Шардинг](db/dBTheory/distrubedDb/sharding.md)
21 | * [Разное](db/dBTheory/distrubedDb/unsorted.md)
22 | * [Реляционные БД](db/relational/README.MD)
23 | * [MySql](db/relational/mysql/README.MD)
24 | * [Архитектура MySql](db/relational/mysql/architecture.md)
25 | * [Конкурентный доступ](db/relational/mysql/concurency.md)
26 | * [Индексы](db/relational/mysql/indexes.md)
27 | * [Основы SQL](db/relational/mysql/sql.md)
28 | * [Explain](db/relational/mysql/explain.md)
29 | * [Разное](db/relational/mysql/unsorted.md)
30 | * [PostgreSql](db/relational/postgreSql/README.md)
31 | * [Колоночные](db/column/README.md)
32 | * [ClickHouse](db/column/clickhouse.md)
33 | * [Vertica](db/column/vertica.md)
34 | * [NoSql](db/noSql/README.md)
35 | * [Memcached](db/noSql/memcached.md)
36 | * [Redis](db/noSql/redis.md)
37 | * [Tarantool](db/noSql/tarantool.md)
38 | * [Mongo](db/noSql/mongo.md)
39 | * [Message brokers](db/messages/README.md)
40 | * [Rabbit](db/messages/rabbit.md)
41 | * [Kafka](db/messages/kafka.md)
42 | * [Nats](db/messages/nats.md)
43 | * [Архитектура](architecture/README.md)
44 | * [Основы ООП](architecture/oopBase.md)
45 | * [Паттерны GoF(Банда 4)](architecture/gof.md)
46 | * [Принципы хорошей архитектуры](architecture/principles.md)
47 | * [Архитектурные паттерны](architecture/architecturesPatterns.md)
48 | * [DDD](architecture/ddd.md)
49 | * [Микросервисы](architecture/microserices/README.md)
50 | * [Паттерны и протоколы интеграции](architecture/microserices/integration.md)
51 | * [Способы распиливания монолита](architecture/microserices/monolithSeparation.md)
52 | * [Разное](architecture/uncategorized.md)
53 | * [Аутентификация](auth/README.md)
54 | * [Этапы входа в систему](auth/steps/README.md)
55 | * [Идентификация](auth/steps/identification.md)
56 | * [Аутентификация](auth/steps/authentication.md)
57 | * [Авторизация](auth/steps/authorization.md)
58 | * [Методы аутентификации](auth/webAuth/README.md)
59 | * [HTTP Basic](auth/webAuth/httpBasic.md)
60 | * [HTTP Digest](auth/webAuth/httpDigest.md)
61 | * [На основе Cookie и сессий](auth/webAuth/cookieSessions.md)
62 | * [На основе токенов](auth/webAuth/token.md)
63 | * [С помощью одноразовых паролей (One-Time Passwords, OTP)](auth/webAuth/otp.md)
64 | * [OAuth](auth/webAuth/oauth.md)
65 | * [GoLang](goLang/README.md)
66 | * [Типы данных](goLang/types/README.md)
67 | * [Скалярные](goLang/types/scalar.md)
68 | * [Массив и слайс](goLang/types/array_slice.md)
69 | * [Map](goLang/types/map.md)
70 | * [Структура](goLang/types/struct.md)
71 | * [Интерфейс](goLang/types/interface.md)
72 | * [Concurrency](goLang/concurrency/README.md)
73 | * [Каналы](goLang/concurrency/chanel.md)
74 | * [Планировщик](goLang/concurrency/scheduler.md)
75 | * [Goroutines](goLang/concurrency/gouritine.md)
76 | * [Context](goLang/concurrency/context.md)
77 | * [Sync](goLang/concurrency/sync.md)
78 | * [Паттерны](goLang/concurrency/patterns.md)
79 | * [Управление памятью](goLang/memory.md)
80 | * [Экосистема](goLang/ecosystem.md)
81 | * [PHP](php/README.md)
82 | * [Фичи новых версий](php/innovations.md)
83 | * [PHP Internals](php/internals.md)
84 | * [realTime взаимодействие с сервером](php/serverIteractions.md)
85 | * [Фреймворки](php/frameworks/README.md)
86 | * [Laravel](php/frameworks/laravel.md)
87 | * [Symfony](php/frameworks/symfony.md)
88 | * [Разное](php/uncategorized.md)
89 | * [JavaScript](javascript.md)
90 | * [Информационная безопасность](ib.md)
91 | * [Git](git.md)
92 | * [Основы сетей](network/README.md)
93 | * [OSI](network/osi.md)
94 | * [TCP/IP](network/tcp_ip.md)
95 | * [HTTP](network/http.md)
96 | * [TLS](network/tls.md)
97 | * [DNS](network/dns.md)
98 | * [Что происходит при нажатии на g](network/whatHappenWhen.md)
99 | * [Real time с веб-сервером](network/realTime.md)
100 | * [Операционные системы и устройство ПК](os.md)
101 | * [Системное администрирование](devops/README.md)
102 | * [Linux](devops/linux.md)
103 | * [Основы виртуализации](devops/virtualization/README.md)
104 | * [Docker](devops/virtualization/docker.md)
105 | * [Kubernetes](devops/virtualization/kubernetes.md)
106 | * [Deployment](devops/deployment.md)
107 | * [Observability](devops/observability.md)
108 | * [Load Balancing](devops/load_balancing.md)
109 | * [Тестирование](test.md)
110 | * [Разное](unsorted/README.md)
111 | * [Побитовые операции](unsorted/bits.md)
112 | * [Типизация](unsorted/types.md)
113 | * [Юникод](unsorted/unicode.md)
114 | * [Методологии разработки](devmethods.md)
115 | * [ЧекЛист](checkList.md)
116 |
--------------------------------------------------------------------------------
/src/algostruct/README.md:
--------------------------------------------------------------------------------
1 | # Алгоритмы и структуры данных
2 |
3 | Раздел **computer science**, который изучает различные методы и подходы к решению задач обработки данных. Он включает в себя изучение алгоритмов, которые представляют собой последовательность шагов для решения конкретной задачи, а также структур данных, которые представляют собой способы организации и хранения данных для эффективного доступа и манипуляций. Разбираться в алгоритмах и структурах данных важно по следующим причинам:
4 |
5 | + Эффективность и оптимизация: Использование правильных алгоритмов и структур данных может значительно повысить эффективность выполнения программы. Это может означать сокращение времени выполнения, уменьшение потребления памяти или оптимальное использование ресурсов компьютера.
6 | + Понимание основных принципов: Изучение алгоритмов и структур данных позволяет разработчикам понять основные принципы и концепции, которые лежат в основе компьютерных систем. Это помогает развить абстрактное мышление, логическое рассуждение и умение решать проблемы.
7 |
8 |
9 | - [Базовые структуры](structBasics.md)
10 | - [Массив](array.md)
11 | - [Хэш-Таблица](hashTable.md)
12 | - [Дерево](tree.md)
13 | - [Граф](graph.md)
14 | - [Криптография](crypto.md)
15 | - [Вероятностные](probability.md)
16 | - [Разные алгоритмы](unsorted.md)
17 |
18 |
--------------------------------------------------------------------------------
/src/algostruct/graph.md:
--------------------------------------------------------------------------------
1 | ## Граф
2 |
3 | Граф — это совокупность объектов со связями между ними. Объекты представляются как вершины, или узлы графа, а связи — как дуги, или рёбра. Для разных областей применения виды графов могут различаться направленностью, ограничениями на количество связей и дополнительными данными о вершинах или рёбрах. Граф называется:
4 |
5 | - **связным**, если для любых вершин u,v есть путь из u в v.
6 | - **деревом**, если он связный и не содержит простых циклов.
7 | - **полным**, если любые его две (различные, если не допускаются петли) вершины соединены ребром.
8 | - **двудольным**, если его вершины можно разбить на два непересекающихся подмножества V1 и V2 так, что всякое ребро соединяет вершину из V1 с вершиной из V2.
9 | - **планарным**, если граф можно изобразить диаграммой на плоскости без пересечений рёбер.
10 | - **ориентированным**, если рёбрам которого присвоено направление. Направленные рёбра именуются также *дугами*, а в некоторых источниках и просто рёбрами.
11 |
12 |
13 |
14 | ## Что такое обход графа?
15 |
16 |
17 | Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
18 |
19 | Двумя основными алгоритмами обхода графа являются поиск в глубину **(Depth-First Search, DFS)** и поиск в ширину **(Breadth-First Search, BFS)**.
20 |
21 | ### Поиск в глубину
22 |
23 | **Поиск в глубину(Depth-First Search, DFS)** находит такой путь от данной вершины, до нужной, что этот путь содержит минимальную сумму ребер графа. Например, если мы ищем на карте метро путь от Сокольников, до Парка Победы, требующий наименьшее время для переезда(расстояние между каждыми соседними станциями, будет весом ребра), то мы ищем в глубину.
24 |
25 | **DFS** следует концепции «погружайся глубже, головой вперед» («go deep, head first»). Идея заключается в том, что мы двигаемся от начальной вершины (точки, места) в определенном направлении (по определенному пути) до тех пор, пока не достигнем конца пути или пункта назначения (искомой вершины). Если мы достигли конца пути, но он не является пунктом назначения, то мы возвращаемся назад (к точке разветвления или расхождения путей) и идем по другому маршруту.
26 |
27 | ### Поиск в ширину
28 |
29 | **Поиск в ширину(Breadth-First Search, BFS)** — это один из основных алгоритмов на графах. В результате поиска в ширину находится путь кратчайшей длины в невзвешенном графе, т.е. путь, содержащий наименьшее число рёбер. Например, если мы ищем на карте метро путь от Сокольников, до Парка Победы, содержащий наименьшее число станций, то мы ищем в ширину.
30 |
31 | **BFS** следует концепции «расширяйся, поднимаясь на высоту птичьего полета» («go wide, bird’s eye-view»). Вместо того чтобы двигаться по определенному пути до конца, BFS предполагает движение вперед по одному соседу за раз.
32 |
33 | ## Алгори́тм Де́йкстры
34 |
35 | Алгори́тм Де́йкстры (Dijkstra’s algorithm) — алгоритм на графах, изобретённый нидерландским учёным Эдсгером Дейкстрой в 1959 году. Находит кратчайшие пути от одной из вершин графа до всех остальных. Алгоритм работает только для графов **без рёбер отрицательного веса**.
36 |
37 | Каждой вершине из V сопоставим метку — минимальное известное расстояние от этой вершины до a. Алгоритм работает пошагово — на каждом шаге он «посещает» одну вершину и пытается уменьшать метки. Работа алгоритма завершается, когда все вершины посещены.
38 |
39 | Инициализация. Метка самой вершины a полагается равной 0, метки остальных вершин — бесконечности. Это отражает то, что расстояния от a до других вершин пока неизвестны. Все вершины графа помечаются как не посещённые.
40 |
41 | Шаг алгоритма. Если все вершины посещены, алгоритм завершается. В противном случае из ещё не посещённых вершин выбирается вершина u, имеющая минимальную метку. Мы рассматриваем всевозможные маршруты, в которых u является предпоследним пунктом. Вершины, в которые ведут рёбра из u, назовём соседями этой вершины. Для каждого соседа вершины u, кроме отмеченных как посещённые, рассмотрим новую длину пути, равную сумме значений текущей метки u и длины ребра, соединяющего u с этим соседом. Если полученное значение длины меньше значения метки соседа, заменим значение метки полученным значением длины. Рассмотрев всех соседей, пометим вершину u как посещённую и повторим шаг алгоритма.
42 |
43 |
44 |
45 | *Дополнительно:*
46 |
47 | - [Обход графа: поиск в глубину и поиск в ширину простыми словами на примере JavaScript](https://habr.com/ru/post/504374/)
--------------------------------------------------------------------------------
/src/algostruct/hashTable.md:
--------------------------------------------------------------------------------
1 | # Хэш таблица
2 |
3 | **Хеш-таблица(hash table)** — структура данных, реализующая интерфейс ассоциативного массива, позволяет хранить пары `ключ => значение` и выполнять три операции:
4 |
5 | - добавление
6 | - поиск
7 | - удаление
8 |
9 | Главное свойство **hash table** — все операции(вставка, поиск и удаление) в среднем выполняются за **O(1)**, среднее время поиска по ней также равно **O(1)** и **O(n)** в худшем случае.
10 |
11 | Выполнение операции в хеш-таблице начинается с вычисления **хеш-функции** от ключа. Получающееся хеш-значение играет роль индекса. Затем выполняемая операция (добавление, удаление или поиск) перенаправляется объекту, который хранится в соответствующей ячейке массива. 
12 |
13 | Ситуация, когда для различных ключей получается одно и то же хеш-значение, называется коллизией. Существует несколько способов разрешения коллизий.
14 |
15 | 
16 |
17 | ### Метод цепочек
18 |
19 | Этот метод часто называют **открытым хешированием**. Его суть проста — элементы с одинаковым хешем попадают в одну ячейку в виде связного списка(возможны оптимизации, где вместо списка будет дерево). Каждая ячейка массива *H* является указателем на связный список(цепочку) пар ключ-значение, соответствующих одному и тому же хеш-значению ключа. Коллизии просто приводят к тому, что появляются цепочки длиной более одного элемента.
20 |
21 | 
22 |
23 | ### Открытая индексация (или закрытое хеширование)
24 |
25 | Метод открытой адресации (open addressing) представляет собой один из способов решения коллизий в хеш-таблицах. Вместо того чтобы создавать цепочки (списки) для элементов с одинаковыми хеш-значениями, метод открытой адресации предлагает разместить элементы в самой таблице, перемещая их на другие позиции, если возникают коллизии.
26 |
27 | При вставке нового элемента происходит попытка разместить его в таблице на соответствующей позиции, определенной хеш-функцией. Если позиция занята, то начинается поиск следующей свободной позиции в таблице. Этот процесс может включать в себя различные стратегии поиска, такие как линейное пробирование, квадратичное пробирование, двойное хеширование и др. Для успешной работы алгоритмов поиска последовательность проб должна быть такой, чтобы все ячейки хеш-таблицы оказались просмотренными ровно по одному разу.
28 |
29 | Алгоритм поиска просматривает ячейки хеш-таблицы в том же самом порядке, что и при вставке, до тех пор, пока не найдется либо элемент с искомым ключом, либо свободная ячейка (что означает отсутствие элемента в хеш-таблице). Этот порядок вычисляется на лету, что позволяет сэкономить на памяти для указателей, требующихся в хеш-таблицах с цепочками.
30 |
31 | 
32 |
33 |
34 |
35 | ### Рехеширование
36 |
37 | Рехеширование (rehashing) - это процесс изменения размера хеш-таблицы и перераспределения её элементов для уменьшения коллизий и обеспечения эффективной работы структуры данных. Оно может происходить при превышении определенной заполненности таблицы (например, 70% от максимальной) или по другим условиям.
38 |
39 | Основные шаги рехеширования в хеш-таблицах:
40 |
41 | 1. **Создание новой таблицы:** Сначала создается новая хеш-таблица с более большим или меньшим размером по сравнению с текущей таблицей. Выбор размера новой таблицы может зависеть от стратегии рехеширования.
42 | 2. **Перераспределение элементов:** Затем элементы из текущей таблицы перераспределяются в новую таблицу с использованием обновленных хеш-функций. Это может потребовать вычисления новых хеш-значений для каждого элемента и его перемещения в соответствующую позицию новой таблицы.
43 | 3. **Обновление ссылок:** Все ссылки на таблицу теперь должны указывать на новую таблицу, так чтобы последующие операции вставки, поиска и удаления работали с обновленной структурой данных.
44 |
45 | Существует несколько стратегий рехеширования:
46 |
47 | 1. **Удвоение размера:** При этой стратегии новая таблица имеет удвоенный размер по сравнению с текущей. Это позволяет более равномерно распределить элементы и обеспечить эффективную работу таблицы. Однако это требует дополнительной памяти.
48 | 2. **Уменьшение размера:** В некоторых случаях, если таблица стала слишком маленькой после множественных удалений, может потребоваться уменьшить её размер, чтобы сэкономить память.
49 | 3. **Двойное хеширование:** Это метод рехеширования, при котором элементы перераспределяются в таблицу нового размера с использованием другой хеш-функции. Это может помочь избежать кластеризации элементов, если первая хеш-функция вызывает коллизии.
50 |
51 | Преимущества рехеширования:
52 |
53 | - Уменьшение коллизий: Рехеширование позволяет более равномерно распределить элементы, уменьшая вероятность коллизий и улучшая производительность.
54 | - Динамическое изменение размера: Таблица может адаптироваться к изменяющейся нагрузке, увеличивая или уменьшая свой размер по мере необходимости.
55 |
56 | Недостатки рехеширования:
57 |
58 | - Дополнительные затраты: Рехеширование может потребовать выделения памяти для новой таблицы и перемещения элементов, что может быть дорогим по ресурсам.
59 | - Временная сложность: Процесс рехеширования может занять время, что может замедлить работу структуры данных на короткий срок.
60 |
61 | Выбор стратегии рехеширования и параметров (например, размера новой таблицы) зависит от конкретных потребностей и характеристик приложения.
62 |
63 |
64 |
65 | *Дополнительно:*
66 |
67 | - [Хэширование](http://aliev.me/runestone/SortSearch/Hashing.html)
68 | - [Хэш-Таблица](https://www.wikiwand.com/ru/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0)
--------------------------------------------------------------------------------
/src/algostruct/structBasics.md:
--------------------------------------------------------------------------------
1 | # Основные структуры данных
2 |
3 | ## Массивы (Arrays)
4 |
5 | Упорядоченная коллекция элементов, где каждый элемент имеет свой уникальный индекс. Позволяет эффективный доступ к элементам по индексу.
6 |
7 | ## Связанный список (Linked List)
8 |
9 | *Описание:* Связанный список - это структура данных, состоящая из узлов, каждый из которых содержит значение элемента и указатель на следующий узел в списке. Существуют односвязные списки, где каждый узел имеет указатель только на следующий узел, и двусвязные списки, где узлы имеют указатели на предыдущий и следующий узлы.
10 |
11 | *Преимущества:*
12 |
13 | - Динамическое изменение размера списка (в отличие от массивов)
14 | - Эффективное добавление и удаление элементов в начале или конце списка
15 | - Относительно простая реализация
16 |
17 | *Недостатки:*
18 |
19 | - Непостоянное время доступа к элементам (в отличие от массивов)
20 | - Больший объем занимаемой памяти по сравнению с массивами из-за хранения указателей на узлы
21 |
22 | *Применение:* Связанные списки подходят для реализации стеков, очередей, а также для задач, где требуется частое добавление или удаление элементов и не требуется быстрый доступ к элементам по индексу.
23 |
24 | ## Стэк(Stack)
25 |
26 | Cтруктура данных, организованная по принципу "последний пришел, первый ушел" (**LIFO**). Элементы добавляются и удаляются с одного конца структуры.
27 |
28 | *Преимущества:*
29 |
30 | - Простота реализации
31 | - Легкость использования в рекурсии и отката операций
32 |
33 | *Недостатки:*
34 |
35 | - Ограниченный доступ к элементам (только к вершине стека)
36 |
37 | *Применение:* Стеки полезны при выполнении рекурсивных функций, обработке скобочных последовательностей и отмене операций.
38 |
39 | ## Очередь (Queue)
40 |
41 | Структура данных, организованная по принципу "первый пришел, первый ушел" (**FIFO**). Элементы добавляются в конец очереди и удаляются из начала.
42 |
43 | *Преимущества:*
44 |
45 | - Поддержка естественного порядка обработки элементов
46 | - Применение в алгоритмах обхода и поиска
47 |
48 | *Недостатки:*
49 |
50 | - Ограниченный доступ к элементам (только к началу и концу очереди)
51 |
52 | *Применение:* Очереди используются в алгоритмах обхода в ширину, приоритетных очередях и многопоточных приложениях для обработки задач.
53 |
54 | ## Хэш-таблица (Hash Table)
55 |
56 | Структура данных, основанная на хэш-функции, которая преобразует ключ в индекс массива для хранения значения.
57 |
58 | *Преимущества:*
59 |
60 | - Быстрый доступ, вставка и удаление элементов (в среднем O(1))
61 | - Гибкость структуры
62 |
63 | *Недостатки:*
64 |
65 | - Возможность коллизий хэш-функции
66 | - Затраты памяти на хранение элементов и обработку коллизий
67 |
68 | *Применение:* Хэш-таблицы используются в поисковых алгоритмах, кэшировании данных, реализации ассоциативных массивов и словарей.
69 |
70 | ## Граф (Graph)
71 |
72 | Структура данных, состоящая из вершин (узлов) и ребер, которые соединяют эти вершины. Графы могут быть ориентированными (направленными) или неориентированными.
73 |
74 | *Преимущества:*
75 |
76 | - Отражение сложных отношений между элементами
77 | - Гибкость структуры
78 |
79 | *Недостатки:*
80 |
81 | - Сложность реализации и обработки
82 | - Большие затраты памяти
83 |
84 | *Применение:* Графы широко используются в транспортных сетях, социальных сетях, веб-технологиях и задачах оптимизации.
85 |
86 | ## Дерево (Tree)
87 |
88 | Иерархическая структура данных, состоящая из узлов, соединенных ребрами. У дерева есть корень и набор дочерних узлов, которые могут иметь свои дочерние узлы.
89 |
90 | *Преимущества:*
91 |
92 | - Иерархическая структура данных
93 | - Быстрый поиск, вставка и удаление элементов (для сбалансированных деревьев)
94 |
95 | *Недостатки:*
96 |
97 | - Сложность реализации и поддержания сбалансированности
98 |
99 | *Применение:* Деревья используются в файловых системах, синтаксических анализаторах, базах данных и поисковых алгоритмах.
100 |
101 | ## Двоичные кучи (Binary Heap)
102 |
103 | Структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом (например, максимальный по значению).
104 |
105 | ## Bit Arrays
106 |
107 | Массивы битов, где каждый бит представляет элемент данных. Часто используются для оптимизации использования памяти, когда нужно хранить множество флагов или булевых значений.
108 |
109 | *Дополнительно:*
110 | - [Структуры данных. Algolist](http://algolist.manual.ru/ds/index.php)
111 | - [Структуры данных в программировании](https://dzen.ru/a/ZE0wsb_h1yYEF8vx)
112 |
--------------------------------------------------------------------------------
/src/architecture/README.md:
--------------------------------------------------------------------------------
1 | # Архитектура ПО
2 |
3 | **Архитектура программного обеспечения** (software architecture) — совокупность важнейших решений об организации программной системы. Также это набор ограничений для достижения определенных целей.
4 |
5 | - [Основы ООП](oopBase.md)
6 | - [Паттерны GoF(Банда 4)](gof.md)
7 | - [Принципы хорошей архитектуры](principles.md)
8 | - [Архитектурные паттерны](architecturesPatterns.md)
9 | - [DDD](ddd.md)
10 | - [Микросервисы](microserices/README.md)
11 | - [Разное](uncategorized.md)
12 |
13 |
--------------------------------------------------------------------------------
/src/architecture/microserices/README.md:
--------------------------------------------------------------------------------
1 | # Микросервисная архитектура
2 |
3 | Микросервисная архитектура — вариант сервис-ориентированной архитектуры программного обеспечения, ориентированный на взаимодействие насколько это возможно небольших, слабо связанных и легко изменяемых модулей — микросервисов, получивший распространение в середине 2010-х годов в связи с развитием практик гибкой разработки и DevOps.
4 |
5 | Если в традиционных вариантах сервис-ориентированной архитектуры модули могут быть сами по себе достаточно сложными программными системами, а взаимодействие между ними зачастую полагается на стандартизованные тяжеловесные протоколы (такие, как SOAP, XML-RPC), в микросервисной архитектуре системы выстраиваются из компонентов, выполняющих относительно элементарные функции, и взаимодействующие с использованием экономичных сетевых коммуникационных протоколов. За счёт повышения гранулярности модулей архитектура нацелена на уменьшение степени зацепления и увеличение связности, что позволяет проще добавлять и изменять функции в системе в любое время.
6 |
7 | ## Преимущества микросервисов
8 |
9 | - **Независимые релизы** - Выдача компонентов по мере готовности благодаря декомпозиции решения и отделения различных процессов. Раздельные команды, циклы разработки, тестирование, деплоя. И конечно разделенные продуктовые команды - это важно, потому что большой командой, работающей над старым монолитом, сложно было управлять. Такая команда вынуждена была работать по строгому процессу, а хотелось больше творчества и независимости. Это могли позволить себе только небольшие команды.
10 |
11 | - **Гибкость развертывания и масштабирования** - Хотелось бы комбинировать сервисы так, как это необходимо нам, а не так, как заставляет код. Можно гораздо гибче масштабировать приложение, точечно балансируя число интсансов сервисов, которые не вывозят нагрузку.
12 |
13 | - **Технологическая независимость** - Можно выбирать инструмент под задачу. Тут заюзаем Go с хранением в памяти тут оставим java с полноценной субд. Гораздо легче внедрить новый инструмент.
14 |
15 | ## Недостатки микросервисов
16 |
17 | - Издержки на межсетевое взаимодействие
18 | - Трудности с распределенными транзакциями
19 | - Сложность эксплуатации
20 | - Риски получения зоопарка технологий
21 | - При неверном применении подхода, получим распределенный монолит.
22 |
23 |
24 |
25 | *Дополнительно:*
26 |
27 | - [Просто о микросервисах](https://habr.com/ru/company/raiffeisenbank/blog/346380/)
28 | - [Смерть микросервисного безумия в 2018 году](https://habr.com/ru/company/flant/blog/347518/)
29 | - [Переход от монолита к микросервисам: история и практика](https://habr.com/ru/company/raiffeisenbank/blog/458404/)
30 | - [Микросервисы — за и против](http://devopsru.com/news/2016-05-10-microservice-trade-offs.html)
--------------------------------------------------------------------------------
/src/architecture/microserices/integration.md:
--------------------------------------------------------------------------------
1 | # Протоколы межсервисного взаимодействия
2 |
3 | ### MQ vs. HTTP
4 |
5 | I was going through my old files and came across my notes on MQ and thought I’d share some reasons to use MQ vs. HTTP:
6 |
7 | - If your consumer processes at a fixed rate (i.e. can’t handle floods to the HTTP server [bursts]) then using **MQ provides the flexibility** for the service to buffer the other requests vs. bogging it down.
8 | - **Time independent processing** and **messaging exchange patterns** — if the thread is performing a fire-and-forget, then MQ is better suited for that pattern vs. HTTP.
9 | - **Long-lived processes are better suited for MQ** as you can send a request and have a seperate thread listening for responses (note WS-Addressing allows HTTP to process in this manner but requires both endpoints to support that capability).
10 | - **Loose coupling** where one process can continue to do work even if the other process is not available vs. HTTP having to retry.
11 | - **Request prioritization** where more important messages can jump to the front of the queue.
12 | - **XA transactions** – MQ is fully XA compliant – HTTP is not.
13 | - **Fault tolerance** – MQ messages survive server or network failures – HTTP does not.
14 | - MQ provides for **‘assured’ delivery** of messages once and only once, http does not.
15 | - MQ provides the ability to do **message segmentation** and message grouping for large messages – HTTP does not have that ability as it treats each transaction seperately.
16 | - MQ provides a **pub/sub interface** where-as HTTP is point-to-point.
17 |
18 | https://solace.com/blog/products-tech/experience-awesomeness-event-driven-microservices
19 |
20 | ## Синхронные
21 |
22 | RPC
23 |
24 | REST
25 |
26 | ## Асинхронные
27 |
28 |
29 |
30 |
--------------------------------------------------------------------------------
/src/architecture/microserices/monolithSeparation.md:
--------------------------------------------------------------------------------
1 | # Методы распиливания монолита
2 |
3 | При разделении монолитного приложения на микросервисы существует несколько распространенных паттернов, которые помогают
4 | достичь более гибкой, масштабируемой и поддерживаемой архитектуры. Вот некоторые основные паттерны разделения монолита
5 | на микросервисы:
6 |
7 | ## Decomposition by Domain (Разделение по доменам):
8 |
9 | В этом случае монолит разбивается на микросервисы вокруг отдельных доменов или областей функциональности.
10 | Каждый сервис полностью отвечает за определенный домен и содержит все необходимые компоненты (базу данных, логику и
11 | интерфейсы).
12 | Этот подход обеспечивает высокую коэксплуатацию и независимость доменов, но может потребовать управления распределенными
13 | транзакциями.
14 |
15 | ## Decomposition by Business Capability (Разделение по бизнес-возможностям):
16 |
17 | При этом подходе монолит разбивается на отдельные сервисы вокруг бизнес-возможностей или функций приложения.
18 | Каждый сервис отвечает за определенный бизнес-аспект и имеет свою собственную базу данных и логику.
19 | Этот подход способствует независимости разработки, масштабируемости и возможности быстрого внесения изменений.
20 |
21 | ## Decomposition by Data (Разделение по данным):
22 |
23 | В этом подходе монолит разбивается на микросервисы вокруг различных источников данных.
24 | Каждый сервис имеет собственную базу данных или отвечает за конкретный набор данных.
25 | Этот подход обеспечивает независимость данных и позволяет эффективно масштабировать и поддерживать различные аспекты
26 | приложения.
27 |
28 | ## Decomposition by UI (Разделение по пользовательскому интерфейсу):
29 |
30 | В этом случае монолит разбивается на микросервисы, каждый из которых отвечает за отдельный пользовательский интерфейс
31 | или экран.
32 | Каждый сервис предоставляет свои собственные API для взаимодействия с пользовательским интерфейсом.
33 | Этот подход обеспечивает независимость разработки, улучшенную масштабируемость и возможность использования разных
34 | технологий в разных сервисах.
35 |
36 | ## Decomposition by Deployment (Разделение по развертыванию):
37 |
38 | При этом подходе монолит разбивается на микросервисы в соответствии с их развертыванием и масштабированием.
39 | Каждый сервис может быть развернут и масштабирован независимо от других сервисов.
40 | Этот подход облегчает управление развертыванием, масштабированием и обновлением сервисов.
41 |
42 | ## Decomposition by Communication Protocol (Разделение по протоколу коммуникации):
43 |
44 | В этом случае монолит разбивается на микросервисы, которые общаются между собой посредством различных протоколов.
45 | Каждый сервис может быть реализован с использованием разных технологий и языков программирования.
46 | Этот подход позволяет гибко разрабатывать и масштабировать сервисы в соответствии с их требованиями коммуникации.
47 |
48 | Каждый из этих паттернов имеет свои преимущества и недостатки, и выбор определенного паттерна зависит от конкретных
49 | требований вашего приложения и контекста, в котором оно используется. Важно тщательно изучить и понять вашу систему и
50 | бизнес-потребности, прежде чем принимать решение о разделении монолита на микросервисы.
--------------------------------------------------------------------------------
/src/architecture/oopBase.md:
--------------------------------------------------------------------------------
1 | ## Основы ООП
2 |
3 | **Объе́ктно-ориенти́рованное программи́рование (ООП)** — методология программирования, основанная на представлении программы в виде совокупности объектов(структур данных, хранящих рядом сами данные и их поведение, т.е методы для работы с этими данными), каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования.
4 |
5 | **Инкапсуляция** — это фундаментальная объектно-ориентированная концепция, позволяющая упаковывать данные и поведение в единый компонент с разделением его на обособленные части — интерфейс и реализацию. Последнее осуществляется благодаря принципу изоляции решений разработки в ПО, известному как **сокрытие информации (information hiding)**.
6 |
7 | **Сокрытие информации** – это сокрытие деталей проектирования, которые могут измениться в будущем, для ограничения каскадных изменений в программной системе и для упрощения ее разработки и сопровождения.
8 |
9 | **Полиморфизм** – это свойство системы использовать разные объекты с одинаковым интерфейсом без информации о типе и внутренней структуре объекта(является следствием инкапсуляции).
10 |
11 | **Наследование** – это свойство системы, позволяющее описать новый класс на основе уже существующего с частично или полностью заимствующейся функциональностью. Класс, от которого производится наследование, называется базовым или родительским. Новый класс – потомком, наследником или производным классом.
12 |
13 | **Агрегирование** - В объектно-ориентированном программировании под агрегированием подразумевают методику создания нового класса из уже существующих классов путём включения, называемого также делегированием. Об агрегировании также часто говорят как об «отношении принадлежности» по принципу «у машины есть корпус, колёса и двигатель».
14 |
15 | Вложенные объекты нового класса обычно объявляются закрытыми, что делает их недоступными для прикладных программистов, работающих с классом. С другой стороны, создатель класса может изменять эти объекты, не нарушая при этом работы существующего клиентского кода. Кроме того, замена вложенных объектов на стадии выполнения программы позволяет динамически изменять её поведение. Механизм наследования такой гибкостью не обладает, поскольку для производных классов устанавливаются ограничения, проверяемые на стадии компиляции.
16 |
17 | На базе агрегирования реализуется методика делегирования, когда поставленная перед внешним объектом задача перепоручается внутреннему объекту, специализирующемуся на решении задач такого рода.
18 |
19 | **Агрегация (агрегирование по ссылке**) — отношение «часть-целое» между двумя равноправными объектами, когда один объект (контейнер) имеет ссылку на другой объект. Оба объекта могут существовать независимо: если контейнер будет уничтожен, то его содержимое — нет.
20 |
21 | **Композиция (агрегирование по значению)** — более строгий вариант агрегирования, когда включаемый объект может существовать только как часть контейнера. Если контейнер будет уничтожен, то и включённый объект тоже будет уничтожен.
--------------------------------------------------------------------------------
/src/architecture/uncategorized.md:
--------------------------------------------------------------------------------
1 | # Разные паттерны
2 |
3 | ## Шаблоны взаимодействия с клиентом
4 |
5 | - **Model-view-controller (MVC, «модель-представление-контроллер», «модель-вид-контроллер»)** — схема использования нескольких шаблонов проектирования, с помощью которых модель приложения, пользовательский интерфейс и взаимодействие с пользователем разделены на три отдельных компонента таким образом, чтобы модификация одного из компонентов оказывала минимальное воздействие на остальные. Данная схема проектирования часто используется для построения архитектурного каркаса, когда переходят от теории к реализации в конкретной предметной области.
6 | - **HMVC (*Hierarchical model–view–controller*)** — Иерархические Модель-Вид-Контроллер, одно из расширений архитектурного [*паттерна*](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F) [*MVC*](https://ru.wikipedia.org/wiki/Model-View-Controller), позволяющее решить некоторые проблемы масштабируемости приложений, имеющих классическую MVC-архитектуру. Согласно парадигме HMVC, каждая отдельная MVC триада используется в качестве слоя в иерархической структуре. При этом, каждая триада в этой иерархии независима от других, и может обратиться к контроллеру другой триады. Такой подход существенно облегчает и ускоряет разработку сложных приложений, облегчает их дальнейшую поддержку и масштабирование, способствует повторному использованию кода.
7 | - **Model Model-View-Presenter (MVP**) — шаблон проектирования, производный от MVC, который используется в основном для построения пользовательского интерфейса. Элемент Presenter в данном шаблоне берёт на себя функциональность посредника (аналогично контроллеру в MVC) и отвечает за управление событиями пользовательского интерфейса (например, использование мыши) так же, как в других шаблонах обычно отвечает представление.
8 | - **Model-View-ViewModel (MVVM)** — применяется при проектировании архитектуры приложения. используется для разделения модели и её представления, что необходимо для изменения их отдельно друг от друга. Например, разработчик задает логику работы с данными, а дизайнер соответственно работает с пользовательским интерфейсом. MVVM удобно использовать вместо классического MVC и ему подобных в тех случаях, когда в платформе, на которой ведётся разработка, присутствует «связывание данных». В шаблонах проектирования MVC/MVP изменения в пользовательском интерфейсе не влияют непосредственно на Модель, а предварительно идут через Контроллер (англ. Controller) или Presenter. В таких технологиях как WPF и Silverlight есть концепция «связывания данных», позволяющая связывать данные с визуальными элементами в обе стороны. Следовательно, при использовании этого приема применение модели MVC становится крайне неудобным из-за того, что привязка данных к представлению напрямую не укладывается в концепцию MVC/MVP.
9 | - **PageController** - В основе контроллера страниц лежит идея создания компонентов, которые будут выполнять роль контроллеров для каждой страницы Web-сайта.(много физических точек(файлов) входа)
10 | - **FrontController** - Один контроллер обрабатывает все запросы к веб-сайту(одна физическая точка входа)
11 |
12 | ## Шаблоны для работы с базами данных
13 |
14 | - **ActiveRecord** - реализует популярный подход объектно-реляционного проецирования (ORM). Каждый класс AR отражает таблицу (или представление) базы данных, экземпляр AR — строку в этой таблице, а общие операции CRUD реализованы как методы AR. В результате мы можем использовать более объектно-ориентированный подход доступа к данным
15 | - **Data Mapper** — это программная прослойка, разделяющая объект и БД. Его обязанность — пересылать данные между ними и изолировать их друг от друга. При использовании Data Mapper'а объекты не нуждаются в знании о существовании БД. Они не нуждаются в SQL-коде, и (естественно) в информации о структуре БД. Так как Data Mapper - это разновидность паттерна Mapper, сам объект-Mapper неизвестен объекту.
16 |
17 | ## Совсем разное
18 |
19 | - **Делегирование (Delegation)** — основной шаблон проектирования, в котором объект внешне выражает некоторое поведение, но в реальности передаёт ответственность за выполнение этого поведения связанному объекту. Шаблон делегирования является фундаментальной абстракцией, на основе которой реализованы другие шаблоны - композиция (также называемая агрегацией), примеси (mixins) и аспекты (aspects).
20 | - **Lazy Load (Ленивая Загрузка)** подразумевает отказ от загрузки дополнительных данных, когда в этом нет необходимости. Вместо этого ставится маркер о том, что данные не загружены и их надо загрузить в случае, если они понадобятся. Как известно, если Вы ленивы, то вы выигрываете в том случае, если дело, которое вы не делали на самом деле и не надо было делать.
21 | - **Registry**(реестр) — это ООП замена глобальным переменным, предназначена для хранения данных и передачи их между модулями системы. Соответственно, его наделяют стандартными свойствами — запись, чтение, удаление. Вот типовая реализация.
22 |
23 |
--------------------------------------------------------------------------------
/src/auth/README.md:
--------------------------------------------------------------------------------
1 | # Аутентификация
2 |
3 | * [Этапы входа в систему](steps/README.md)
4 | * [Идентификация](steps/identification.md)
5 | * [Аутентификация](steps/authentication.md)
6 | * [Авторизация](steps/authorization.md)
7 | * [Методы аутентификации](webAuth/README.md)
8 | * [HTTP Basic](webAuth/httpBasic.md)
9 | * [HTTP Digest](webAuth/httpDigest.md)
10 | * [На основе Cookie и сессий](webAuth/cookieSessions.md)
11 | * [На основе токенов](webAuth/token.md)
12 | * [С помощью одноразовых паролей (One-Time Passwords, OTP)](webAuth/otp.md)
13 | * [OAuth](webAuth/oauth.md)
14 |
15 |
--------------------------------------------------------------------------------
/src/auth/steps/README.md:
--------------------------------------------------------------------------------
1 | # Что такое идентификация, аутентификация, авторизация
2 |
3 | Идентификация, аутентификация и авторизация обычно представляют собой этапы единого процесса — входа в какую-либо систему.
4 |
5 | * [Идентификация](identification.md)
6 | * [Аутентификация](authentication.md)
7 | * [Авторизация](authorization.md)
8 |
--------------------------------------------------------------------------------
/src/auth/steps/authentication.md:
--------------------------------------------------------------------------------
1 | # Аутентификация
2 |
3 | Аутентификация — это второй этап входа, где система проверяет, что пользователь — это действительно он.
4 |
5 | Основные способы аутентификации:
6 | - **фактор знания**: сравнение пароля с сохранённым в базе;
7 | - **фактор владения**: предъявление USB-ключа или ввод кода с устройства;
8 | - **личный фактор**: биометрические данные (отпечаток, лицо) или поведенческие особенности.
9 |
10 | После успешной аутентификации система переходит к авторизации.
11 |
12 | В web-приложениях могут применяться различные [методы аутентификация](../webAuth/README.md).
--------------------------------------------------------------------------------
/src/auth/steps/authorization.md:
--------------------------------------------------------------------------------
1 | # Авторизация
2 |
3 | Авторизация — третий этап входа в систему. Заключается в предоставлении лицу или группе лиц прав на выполнение определённых действий.
--------------------------------------------------------------------------------
/src/auth/steps/identification.md:
--------------------------------------------------------------------------------
1 | # Идентификация
2 |
3 | **Идентификация** — это этап, когда системе предоставляется уникальный цифровой идентификатор (логин, email, номер телефона и т.д.) пользователя системы, под именем которого мы хотим зайти.
4 |
5 | Чтобы убедиться, что владелец идентификатора — настоящий, система проводит аутентификацию.
--------------------------------------------------------------------------------
/src/auth/webAuth/README.md:
--------------------------------------------------------------------------------
1 | # Методы аутентификации в веб-приложениях
2 |
3 | * [HTTP Basic](httpBasic.md)
4 | * [HTTP Digest](httpDigest.md)
5 | * [На основе Cookie и сессий](cookieSessions.md)
6 | * [На основе токенов](token.md)
7 | * [С помощью одноразовых паролей (One-Time Passwords, OTP)](otp.md)
8 | * [OAuth](oauth.md)
9 |
--------------------------------------------------------------------------------
/src/auth/webAuth/cookieSessions.md:
--------------------------------------------------------------------------------
1 | # Аутентификация на основе Cookie и сессий
2 |
3 | При сеансовой аутентификации состояние пользователя хранится на сервере. При первом входе сервер проверяет учётные данные, генерирует сессию и отправляет идентификатор сессии в браузер, который сохраняет его в cookie. Это позволяет пользователю не вводить имя и пароль при каждом обращении к сайту.
4 |
5 | Сеансовая аутентификация является stateful: сервер должен находить сохранённую сессию для связи идентификатора с пользователем.
6 |
7 | 
8 |
9 | ##### Преимущества и недостатки
10 |
11 | | Преимущества | Недостатки |
12 | | -------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
13 | | Более быстрый последующий вход в систему, так как не требуется вводить учётные данные. | Требует сохранения состояния (stateful). Сервер ведет учёт каждого сеанса на своей стороне. Хранилище информации о сеансе пользователей должно быть общим для нескольких сервисов, чтобы обеспечить аутентификацию. Из-за этого он не подходит для REST-сервисов, поскольку REST — это протокол без хранения состояния. |
14 | | Достаточно простая реализация. Многие фреймворки предоставляют эту возможность из коробки. | Без специальных настроек (domain, path , samesite) cookie отправляются при каждом запросе, даже если он не требует аутентификации. |
15 | | Удобнее для пользователя, поскольку ему не приходится каждый раз при обращении к серверу вводить имя и пароль. | Без правильной настройки безопасности метод может быть уязвим для CSRF-атак. |
16 |
--------------------------------------------------------------------------------
/src/auth/webAuth/httpBasic.md:
--------------------------------------------------------------------------------
1 | # Базовая HTTP аутентификация — HTTP Basic
2 |
3 | Это самая простая форма аутентификация, встроенная в протокол HTTP. Учётные данные для входа в систему передаются в заголовках запроса при каждом запросе:
4 |
5 | ```
6 | "Authorization: Basic dXNlcm5hbWU6cGFzc3dvcmQ=" your-website.com
7 | ```
8 |
9 | Имена пользователей и пароли не шифруются, а объединяются в строку **имя_пользователя:пароль** и кодируются с помощью **base64**.
10 |
11 | Метод является stateless, поэтому клиент должен предоставлять учётные данные при каждом запросе. Он подходит для вызовов API, а также для простых процессов аутентификации, не требующих постоянных сессий.
12 |
13 | 
14 |
15 | 1. Неавторизованный клиент запрашивает ограниченный ресурс.
16 | 2. Сервер отправляет HTTP **401 Unauthorized** и добавляет в ответ заголовок **WWW-Authenticate** со значением **Basic**.
17 | 3. Заголовок **WWW-Authenticate: Basic** заставляет браузер запросить имя пользователя и пароль.
18 | 4. После ввода учётных данных они передаются в заголовке с каждым запросом: **Authorization: Basic dcdvcmQ=**
19 | ##### Преимущества и недостатки
20 |
21 | | Преимущества | Недостатки |
22 | | --------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
23 | | Поскольку в этом методе не так много операций, аутентификация выполняется быстро. | Учётные данные передаются в base64, который, по сути, является другим представлением обычного текста. Закодированную в base64 информацию легко декодировать. В связи с этим обязательно использовать HTTPS/SSL. |
24 | | Простота реализации. | Учётные данные должны передаваться при каждом запросе. |
25 | | Поддерживается всеми основными браузерами. | |
26 |
--------------------------------------------------------------------------------
/src/auth/webAuth/httpDigest.md:
--------------------------------------------------------------------------------
1 | # HTTP Digest Authentication
2 |
3 | HTTP Digest Authentication (или Digest Access Authentication) — более безопасная форма базовой аутентификации. В отличие от Basic Auth, здесь пароль передается в виде хеша, что повышает уровень безопасности.
4 |
5 | 
6 |
7 | 1. Неаутентифицированный клиент запрашивает ресурс с ограниченным доступом.
8 |
9 | 2. Сервер генерирует случайное значение, называемое nonce, и отправляет обратно статус HTTP **401 Unauthorized** с заголовком **WWW-Authenticate**, имеющим значение **Digest** вместе с nonce:
10 | ```
11 | WWW-Authenticate: Digest
12 | realm="Access to the '/' path",
13 | nonce="e4549c0548886bc2",
14 | algorithm="MD5"
15 | ```
16 |
17 |
18 | 3. Получив ответ с заголовком **WWW-Authenticate**, браузер запрашивает у пользователя логин и пароль.
19 |
20 | 4. После ввода учётных данных браузер отправляет серверу ответ **Authorization**:
21 | ```
22 | Authorization: Digest username="User1",
23 | realm="Access to the '/' path",
24 | nonce="e4549c0548886bc2",
25 | uri="/",
26 | algorithm=MD5,
27 | response="6299988bb4f05c0d8ad44295873858cf"
28 | ```
29 |
30 | Значение response в ответе формируется следующим образом:
31 |
32 | ```
33 | response = H(HA1:nonce:HA2)
34 |
35 | HA1 = H(username:realm:password)
36 |
37 | HA2 = H(method:digestURI)
38 | ```
39 |
40 | Пример:
41 | ```
42 | response = SHA256(HA1:”e4549c0548886bc2”:HA2)
43 |
44 | HA1 = SHA256(”User1”:”/”:”User1Password”)
45 |
46 | HA2 = SHA256(”GET”:”/”)
47 | ```
48 |
49 | Актуальный стандарт HTTP **Digest Authentication** описывается в [RFC7616](https://httpwg.org/specs/rfc7616.html). Ответ **Authorization** может содержать дополнительные поля для дополнительной защиты (счётчик запросов **nc**, одноразовый номер клиента **cnonce**, качество кода защиты **qop**).
50 |
51 | Также **RFC7616** добавляет алгоритм хеширования **SHA256** на замену небезопасному алгоритму **MD5**, использование которого поддерживается, но не рекомендуется.
52 |
53 | 5. Получив ответ **Authorization**, сервер выполняет вычисляет свой вариант response и сравнивает его с тем, что получено от клиента.
54 |
55 | 6. Если хеши совпадают, пользователь получает доступ к запрошенному ресурсу.
56 |
57 | ##### Преимущества и недостатки
58 |
59 | |Преимущества|Недостатки|
60 | |---|---|
61 | |Более безопасен, чем Basic auth, поскольку пароль не передается открытым текстом.|Метод уязвим для атак типа «человек посередине» (man-in-the-middle), если не используется https.|
62 | |Простота реализации.|Учётные данные должны передаваться при каждом запросе.|
63 | |Поддерживается всеми основными браузерами.|
64 |
--------------------------------------------------------------------------------
/src/auth/webAuth/oauth.md:
--------------------------------------------------------------------------------
1 | # OAuth
2 |
3 | OAuth 2.0 — протокол аутентификации, позволяющий выдать одному сервису (приложению) права на доступ к ресурсам пользователя на другом сервисе. Протокол избавляет от необходимости доверять приложению логин и пароль, а также позволяет выдавать ограниченный набор прав, а не всё сразу.
4 |
5 | OAuth 2.0 основан на использовании базовых веб-технологий: HTTP-запросах, редиректах и т. п. Поэтому использование OAuth возможно на любой платформе с доступом к интернету и браузеру: на сайтах, в мобильных и desktop-приложениях, плагинах для браузеров.
6 |
7 | Клиент должен одним из четырёх способов получить от сервера авторизации (OAuth провайдера) токен доступа (Access Token). Далее клиент будет использовать этот Access Token в запросах к Серверу ресурсов, чтобы получать данные.
8 |
9 | ##### Особенности Access Token
10 |
11 | - Ограниченное время жизни.
12 | - Его можно отозвать. Если есть подозрение, что токен украли, то мы просто запрещаем получать данные с помощью этого токена.
13 | - Компрометация токена не значит компрометирование логина и пароля. Из токена никак не получить логин и пароль.
14 | - По токену может быть доступна только часть данных (**scope**). Клиент запрашивает список разрешений, которые необходимы ему для работы, а Владелец ресурсов, то есть пользователь, решает выдать такие права или нет. Например, можно выдать права только на просмотр списка контактов, тогда читать письма или редактировать контакты будет нельзя.
15 |
16 | Помимо Access Token сервер авторизации может выдавать также Refresh Token. Это токен, который позволяет запросить новый **access_token** без участия Владельца ресурсов. Время жизни у такого токена намного больше Access Token, и его потеря гораздо серьёзнее: используя Refresh Token, злоумышленник может запросить у Сервера авторизации новый токен доступа и войти в систему.
17 |
18 | Сервер авторизации должен располагать информацией о каждом клиенте, который делает к нему запрос, то есть каждый клиент должен быть зарегистрирован. Зарегистрировав клиента, мы получаем **client_id** и **client_secret** и обязаны передавать, как минимум **client_id** в каждом запросе.
19 |
20 | Не все клиенты могут гарантировать сохранность **client_secret**, поэтому он есть не у всех. Например, SPA без бэкенда, теоретически достать оттуда можно что угодно.
21 |
22 | ##### Способы получения Access Token
23 |
24 | 1. По данным клиента (**Client Credentials**). Получаем токен по **client_id** и **client_secre**t.
25 | 2. По логину и паролю пользователя (**Resource Owner Password Credential**). Только для безопасных клиентов, заслуживающих полного доверия.
26 | 3. По авторизационному коду (**Authorization Code Grant**). Самый сложный и самый надёжный способ.
27 | 4. Неявно (**Implicit Grant**)
28 |
29 | #### Client Credentials
30 | 1. API 1 передаёт серверу авторизации **client_id** и **client_secret**.
31 | 2. В ответ он получает **access_token**, с помощью которого может обратиться к API 2.
32 | 3. API 1 обращается к API 2.
33 | 4. API 2 получает запрос с **access_token** и обращается к серверу авторизации для проверки действительности переданного токена (**RFC 7662**).
34 | #### Resource Owner Password Credential
35 | 1. Владелец ресурсов передаёт свой логин и пароль Клиенту.
36 | 2. Клиент отправляет Авторизационному серверу логин и пароль клиента, а также свой **client_id** и **client_secret**.
37 | 3. 3. Если предоставленные пользователем учётные данные корректны, сервер авторизации вернёт ответ **application/json**, содержащий **access_token**.
38 | #### Authorization Code Grant
39 | 1. Пользователь на сайте нажимает кнопку авторизации, например через Facebook.
40 | 2. Происходит редирект на авторизационный сервер.
41 | 3. Если активной сессии нет, то пользователь должен залогиниться. Если активная сессия есть, то просто подтвердить авторизацию.
42 | 4. Если всё пойдёт хорошо, вы получите ответ **HTTP 302**. Код авторизации включён в конце URL-адреса: в параметре **?code=SplewFEFofer**
43 | 5. Теперь, когда у вас есть код авторизации, вы должны обменять его на токены. Используя извлеченный код авторизации из предыдущего шага, вам нужно будет выполнить **POST** на URL-адрес токена.
44 | 6. Если все пойдет хорошо, вы получите ответ **HTTP 200** с полезной нагрузкой, содержащей значения **access_token**, **refresh_token**, **id_token** и **token_type**.
45 | 7. Чтобы вызвать ваш API из обычного веб-приложения, приложение должно передать полученный токен доступа в заголовке авторизации вашего HTTP-запроса.
46 | #### Implicit Grant
47 | Используется на одностраничных сайтах без бэкенда.
48 | 1. Пользователь на сайте жмёт на кнопку, происходит редирект на сервер авторизации.
49 | 2. Пользователь вводит логин и пароль, если он не авторизован.
50 | 3. Происходит редирект обратно, но **access_token** возвращается в URL сразу:
51 | https://domain.com/back_path#access_token=8ijfwWEFFf0wefOofreW6rglk
52 |
--------------------------------------------------------------------------------
/src/auth/webAuth/otp.md:
--------------------------------------------------------------------------------
1 | # Одноразовые пароли (One-Time Passwords, OTP)
2 |
3 | Одноразовые пароли (OTP) используются для подтверждения аутентификации. Это случайно сгенерированные коды, которые проверяют, является ли пользователь тем, за кого себя выдает. Они часто применяются в двухфакторной аутентификации после проверки учётных данных.
4 |
5 | Для использования OTP необходима доверенная система, такая как проверенный адрес электронной почты или номер мобильного телефона. Наиболее распространённый тип — OTP с ограниченным временем действия (TOTP).
6 |
7 | OTP рекомендуется использовать в приложениях с конфиденциальными данными, например, в интернет-банкинге и финансовых сервисах.
8 |
9 | ##### Алгоритм использования OTP
10 |
11 | Традиционный способ реализации OTP:
12 |
13 | - Клиент отправляет имя пользователя и пароль.
14 | - После проверки учётных данных сервер генерирует случайный код, сохраняет его у себя и отправляет в доверенную систему.
15 | - Пользователь получает код в доверенной системе и вводит его в веб-приложение.
16 | - Сервер сверяет код с сохранённым и аутентифицирует пользователя.
17 |
18 | Как работают OTP-агенты (**Google Authenticator, Microsoft Authenticator** и F**reeOTP**):
19 |
20 | - При включённой двухфакторной аутентификации (2FA) сервер генерирует случайное начальное значение и отправляет его пользователю в виде уникального QR-кода.
21 | - Пользователь сканирует QR-код с помощью своего приложения 2FA для подтверждения доверенного устройства.
22 | - При необходимости ввода OTP пользователь проверяет наличие кода на своём устройстве и вводит его в веб-приложение.
23 | - Сервер проверяет код и предоставляет доступ.
24 |
25 | ##### Преимущества и недостатки
26 |
27 | | Преимущества | Недостатки |
28 | | -------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
29 | | Дополнительный уровень защиты. | Необходимо хранить начальные вектора (seeds), используемые для генерации OTP. |
30 | | Нет опасности, что украденный пароль может быть использован для работы с несколькими сайтами или сервисами, где также применяются OTP. | Если потерян код восстановления OTP, придётся выполнять полную процедуру восстановления доступа к учётной записи. |
31 | | | Проблемы возникают, когда доверенное устройство недоступно (севшая батарея, ошибка сети и т.д.). В этом случае, как правило, требуется резервное устройство, что создаёт дополнительный вектор атаки. |
--------------------------------------------------------------------------------
/src/auth/webAuth/token.md:
--------------------------------------------------------------------------------
1 | # Аутентификация на основе токенов
2 |
3 | Самый распространенный способ реализации аутентификации на основе токенов — использование JSON Web Tokens (JWTs).
4 |
5 | JWT — это открытый стандарт (RFC 7519), определяющий способ безопасной передачи информации между сторонами в виде объектов JSON.
6 |
7 | 
8 |
9 | После получения учётных данных от клиента сервер проверяет их и генерирует идентификационный токен JWT, содержащий информацию о пользователе. Токены идентифицируют пользователя и предоставляют данные о событии аутентификации. Они предназначены для клиента и имеют фиксированный формат, который позволяет извлекать идентификационную информацию.
10 |
11 | Чтобы предотвратить изменения или подделку, сервер формирует электронную подпись данных токена при его создании и добавляет её в токен. JWT используется в stateless приложениях и не хранится на сервере; клиент отправляет его с запросами.
12 |
13 | JWT состоит из трёх частей:
14 |
15 | - Заголовка с типом токена и алгоритмом шифрования.
16 | - Полезной нагрузки с данными для аутентификации и информацией о пользователе.
17 | - Подписи, содержащей хешированное значение header+payload+соль, которая подтверждает подлинность данных в полезной нагрузке.
18 |
19 | 
20 |
21 | Токен представляет из себя простую строку из символов, например:
22 |
23 | ```
24 | eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
25 | ```
26 |
27 | Этапы аутентификации с помощью токена:
28 |
29 | 1. Ввод логина и пароля.
30 | 2. Шифрование (преобразование логина и пароля в закодированную строку).
31 | 3. Передача шифрованных данных на сервер.
32 | 4. Генерация сервером токена доступа, с помощью которого веб-приложение будет обращаться к backend приложению для получения данных. Этот токен должен отправляться на сервер с каждым запросом.
33 | 5. Отправка токена обратно в браузер.
34 | 6. Сохранение токена на клиенте для дальнейшего использования.
35 |
36 | Суть в том, что мы один раз передаём приватные данные, а затем используем токен с публичными данными. Ключ для подписи токена хранится только на сервере, и клиент не имеет к нему доступа, что гарантирует, что только сервер может изменять токен. Декодировать токен и получить **header** и **payload** может любой, кто его получил, так как эти данные публичные.
37 |
38 | Когда сервер получает токен, он вычисляет подпись полезной нагрузки с помощью своего ключа и сравнивает её с подписью в токене. Если данные не совпадают или не удаётся декодировать токен, это указывает на возможное вмешательство, и запрос не проходит валидацию, возвращая ошибку.
39 |
40 | ##### Access и Refresh токены
41 |
42 | Подпись токена защищает его от изменений, но хакеры могут перехватить его и использовать для доступа к аккаунту, так как токен содержит все данные для аутентификации. Это делает любого, кто получил токен, равным настоящему владельцу аккаунта.
43 |
44 | Для решения этой проблемы используются Access и Refresh токены. Access Token остаётся, и добавляется Refresh токен с такой же структурой.
45 |
46 | Оба токена содержат обязательные поля в полезной нагрузке — **iat** и **exp**.
47 |
48 | 
49 |
50 | **iat** (issued at time) — время, когда токен сгенерирован.
51 | **exp** (expiration time) — время, до которого токен будет считаться валидным.
52 |
53 | ##### Алгоритм аутентификации с использованием Refresh и Access токенов
54 |
55 | 1. Пользователь вводит логин и пароль, которые отправляются на сервер.
56 | 2. Сервер создаёт или находит пользователя в базе данных и генерирует два токена с полями **iat** и **exp**: Access Token с коротким сроком действия (15-20 минут) и Refresh Token с более длительным (несколько дней или недель).
57 | 3. Сервер возвращает оба токена в браузер, где они сохраняются.
58 | 4. При запросе данных клиент проверяет срок действия Access Token. Если он не истёк, запрос отправляется; если истёк, необходимо обновить токен перед отправкой.
59 | 5. Для обновления Access Token клиент отправляет запрос с Refresh Token. Сервер генерирует новую пару токенов и возвращает их клиенту.
60 | 6. Если Refresh Token также истёк, возвращается ошибка, и пользователя просят ввести логин и пароль снова.
61 |
62 | *Дополнительно:*
63 | - https://jwt.io/
64 |
--------------------------------------------------------------------------------
/src/checkList.md:
--------------------------------------------------------------------------------
1 | # Чеклист подготовки
2 |
3 | Чеклист нужен для того, чтобы в максимально короткие сроки выявить пробелы в знаниях.
4 |
5 | ## Алгоритмы и Структуры Данных
6 | * Базовые структуры
7 | * Массив и его сортировки(сложность и реализация)
8 | * Пузырек
9 | * Вставками
10 | * Быстрая
11 | * Выборками
12 | * Хэш-Таблица
13 | * Хеш функция
14 | * Методы разрешения колизий
15 | * Метод цепочек
16 | * Последовательность проб
17 | * Дерево
18 | * Бинарное дерево поиска
19 | * B(balanced) Tree
20 | * B+ Tree
21 | * АВЛ
22 | * Красно черное
23 | * Поворот
24 | * Граф
25 | * Поиск в ширину, в глубину, алгоритм Дейкстры
26 | * Разное
27 | * Бинарный поиск
28 | * Динамическое программирование
29 | * Жадные алгоритмы
30 | * Побитовые операции
31 |
32 | ## Базы Данных
33 | * Теория Баз Данных
34 | * Транзакции
35 | * ACID
36 | * Проблемы параллельного чтения
37 | * Уровни изолированности транзакций
38 | * Нормальные формы(1-6 + бойса кода + доменная)
39 | * Распределенные БД
40 | * Репликация
41 | * Синхронная и асинхронная и полусинхронная
42 | * Master/Master & Master/Slave
43 | * Покомандная(логическая) & Построчная(физическая)
44 | * Шардинг
45 | * Статический и динамический + комбинированный, vitual bucket
46 | * Решардинг
47 | * Ключ шардирования
48 | * Паттерны поиска(умный клиент, прокси, координатор)
49 | * Консистентный хеш
50 | * Теорема САР
51 | * MapReduce
52 | * Конкретные реализации СУБД
53 | * MySql
54 | * Архитектура MySql
55 | * Конекшн
56 | * Парсер, оптимизатор, кеш и буфер, sql интерфейс
57 | * Движки(подсистемы хранения)
58 | * Файловая система
59 | * Конкурентный доступ
60 | * Блокировки
61 | * shared lock и exclusive loc
62 | * построчная и табличная
63 | * явные/неявные
64 | * SELECT… LOCK IN SHARE MODE
65 | * SELECT… FOR UPDATE
66 | * Блокировка индекса innoDB(record lock, gap lock, next key lock)
67 | * согласованное неблокирующее чтение
68 | * Deadlock
69 | * MVCC
70 | * Индексы
71 | * B Tree
72 | * B Tree
73 | * B+ Tree
74 | * Составной индекс
75 | * Устройство B Tree индекса изнутри
76 | * Hash
77 | * R-Tree
78 | * Селективность и кардинальность
79 | * Кластерные индексы
80 | * Покрывающие индексы
81 | * Основы SQL
82 | * CREATE, ALTER, DROP, SELECT, INSERT, UPDATE, DELETE, HAVING, GROUP BY, JOIN
83 | * Explain
84 | * Разное
85 | * Innodb vs MyIsam
86 | * Datetime vs Timestamp
87 | * PostgreSql
88 | * NoSql
89 | * Memcaced
90 | * Redis
91 | * Типы данных
92 | * Redis Cluster
93 | * Репликация и шардинг
94 | * Tarantool
95 | * Mongo
96 | * Брокеры сообщений
97 | * Rabbit
98 | * Kafka
99 | * Колоночные
100 | * ClickHouse
101 | * Vertica
102 | * Разное
103 | * Time-series
104 | * Blob-store
105 | * Сетевые
106 | * Графовые
107 |
108 | ## Архитектура
109 | * Основы ООП
110 | * Инкапсуляция
111 | * Полиморфзим
112 | * Наследование
113 | * Композиция/агрегация
114 | * Паттерны GoFБанда 4
115 | * Создающие
116 | * Поведенческие
117 | * Структурные
118 | * Принципы хорошей архитектуры
119 | * SOLID
120 | * GRASP
121 | * DRY
122 | * KISS
123 | * Архитектурные паттерны
124 | * Layer architecture
125 | * Onion architecture
126 | * Hexagonal architecture
127 | * CQRS
128 | * ES
129 | * Saga
130 | * DDD
131 | * Стратегические
132 | * Bounded context
133 | * Ubiquitous language
134 | * Subdomain
135 | * Тактические
136 | * Aggregate root
137 | * Entity
138 | * Value object
139 | * Api и Микросервисы
140 | * Rest
141 | * Rpc
142 | * JsonApi
143 | * GraphQL
144 | * gRpc
145 | * protobuf
146 |
147 | ## PHP
148 | * Фичи новых версий
149 | * PHP Internals
150 | * Zval
151 | * Union
152 | * CopyOnWrite
153 | * Стандартные функции
154 | * Фреймворки
155 | * Laravel
156 | * Symfony
157 | * Разное
158 |
159 | ## GoLang
160 | * scheduler
161 | * 3 сущности - горутина, поток, контекст привязанный к потоку
162 | * m : n (m задач на n потоках)
163 | * work stealing
164 | * указатели(передача по ссылке/значению)
165 | * arrays & slices
166 | * channels(небуферизированные/буферизированные) неблокирующее чтение
167 | * sync(mutex(r/w), atomic, once, pool, map, waitgrop)
168 | * рефлексия
169 | * unsafe
170 | * Error(), panic, deffer, recover
171 | * context.Context
172 |
173 | ## Информационная безопасность
174 | * SQL injection
175 | * XSS
176 | * CSRF
177 |
178 | ## Git
179 | * Rebase vs Merge
180 | * Checkout vs reset vs revert
181 |
182 | ## Основы сетей
183 | * Взаимодействие с веб-сервером
184 | * HTTP
185 | * SSL/TLS
186 | * DNS
187 | * Сетевые модели
188 | * realTime взаимодействие с сервером
189 | * Что происходит при нажатии на g
190 |
191 | ## Операционные системы
192 |
193 | - потоки и процессы
194 | - гринтреды
195 | - вытесняющая и кооперативная многозадачность
196 |
197 | ## Системное администрирование
198 | * Linux
199 | * Как убить процесс
200 | * Load Average
201 | * Docker
202 | * Теория виртуализации
203 | * Kubernetes
204 |
205 | ## Тестирование
206 | * Юнит тесты
207 | * Интеграционные тесты
208 | * Приемочные тесты
209 | * Системные
210 | * Мутационное тестирование
211 |
212 | ## Менеджмент и тимлидство
213 | * Обязанности тимлида
214 | * Resource Manager
215 | * Product Owner
216 | * Integrator
217 | * Technical Lead
218 | * Administrator
219 | * Методологии разработки
220 | * Водопад
221 | * Итеративные модели
222 | * Scrum
223 | * Kanban
224 | * Scrumban
--------------------------------------------------------------------------------
/src/db/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/db/.DS_Store
--------------------------------------------------------------------------------
/src/db/README.md:
--------------------------------------------------------------------------------
1 | # Базы данных
2 |
3 | В данном разделе рассказывается о классической теории баз данных + об особенностях работы и устройства конкретных реальных баз данных. Существующие базы данных, можно условно поделить на следующие группы - реляционные, документо-ориентированные, key=>value, временных рядов, колоночные, брокеры сообщений, blob-store, графовые, сетевые и т.д
4 |
5 | * [Теория Баз Данных](dBTheory/README.md)
6 | * [Реляционные БД](relational/README.MD)
7 | * [MySql](relational/mysql/README.MD)
8 | * [Архитектура MySql](relational/mysql/architecture.md)
9 | * [Конкурентный доступ](relational/mysql/concurency.md)
10 | * [Индексы](relational/mysql/indexes.md)
11 | * [Основы SQL](relational/mysql/sql.md)
12 | * [Explain](relational/mysql/explain.md)
13 | * [Разное](relational/mysql/unsorted.md)
14 | * [PostgreSql](relational/postgreSql/README.md)
15 | * [Колоночные](column/README.md)
16 | * [ClickHouse](column/clickhouse.md)
17 | * [Vertica](column/vertica.md)
18 | * [NoSql](noSql/README.md)
19 | * [Memcached](noSql/memcached.md)
20 | * [Redis](noSql/redis.md)
21 | * [Tarantool](noSql/tarantool.md)
22 | * [Mongo](noSql/mongo.md)
23 | * [Message brokers](messages/README.md)
24 | * [Rabbit](messages/rabbit.md)
25 | * [Kafka](messages/kafka.md)
26 | * [Nats](messages/nats.md)
27 |
--------------------------------------------------------------------------------
/src/db/column/README.md:
--------------------------------------------------------------------------------
1 | # Колоночные базы данных
2 |
3 | Колоночные базы данных (Columnar Databases) - это тип баз данных, где данные хранятся и организуются по колонкам, в отличие от традиционных реляционных баз данных, где данные хранятся по строкам. В колоночных базах данных каждая колонка содержит данные одного типа, и они компактно хранятся в сжатом формате.
4 |
5 | Преимущества колоночных баз данных включают более эффективное использование памяти, лучшую сжимаемость данных, быстрый доступ к определенным колонкам и поддержку агрегатных операций. Они обычно хорошо подходят для аналитических и OLAP (Online Analytical Processing) задач, где требуется обработка больших объемов данных.
6 |
7 | Некоторые известные колоночные базы данных: Apache Cassandra, Apache HBase, Google Bigtable и Vertica. Они широко используются в различных сценариях, включая аналитику, бизнес-интеллект и обработку больших данных.
--------------------------------------------------------------------------------
/src/db/column/vertica.md:
--------------------------------------------------------------------------------
1 | # Vertica
2 |
3 | Vertica - колоночная база данных, разработанная для обработки аналитических и OLAP-запросов на больших объемах данных. Вот некоторые особенности, отличительные черты, преимущества, недостатки и архитектура Vertica:
4 |
5 | Особенности и отличительные черты:
6 |
7 | 1. Колоночное хранение данных: Вертикальная организация данных по колонкам позволяет эффективно сжимать данные и ускоряет выполнение аналитических запросов, поскольку только необходимые колонки считываются с диска.
8 | 2. Распределенная архитектура: Vertica может работать в распределенном режиме на кластере серверов, где данные разделены и хранятся на разных узлах, обеспечивая высокую пропускную способность и масштабируемость.
9 | 3. Оптимизация для аналитических запросов: Vertica имеет множество встроенных функций и оптимизаций, таких как оптимизация запросов на основе статистики, параллельное выполнение запросов и сжатие данных, что позволяет обрабатывать сложные аналитические запросы быстро и эффективно.
10 |
11 | Преимущества:
12 |
13 | 1. Высокая производительность: Vertica обеспечивает быстрое выполнение аналитических запросов на больших объемах данных.
14 | 2. Горизонтальная масштабируемость: Vertica позволяет добавлять новые серверы в кластер для увеличения общей пропускной способности и хранения большего объема данных.
15 | 3. Встроенные аналитические функции: Vertica предлагает широкий набор встроенных функций для выполнения сложных аналитических операций и агрегирования данных.
16 |
17 | Недостатки:
18 |
19 | 1. Сложность установки и настройки: Установка и настройка Vertica может быть сложной и требует некоторых знаний и опыта в администрировании баз данных.
20 | 2. Высокие требования к аппаратному обеспечению: Vertica требует высокопроизводительного оборудования для достижения оптимальной производительности.
21 |
22 | Архитектура: Архитектура Vertica включает узлы хранения данных (Storage Nodes), узлы выполнения запросов (Query Nodes) и узлы управления (Management Nodes). Узлы хранения данных отвечают за хранение и управление данными, узлы выполнения запросов обрабатывают аналитические запросы, а узлы управления координируют работу кластера и управляют метаданными. Vertica также использует репликацию данных для обеспечения отказоустойчивости и доступности данных.
23 |
24 | Эта архитектура позволяет Vertica достигать высокой производительности и масштабируемости при обработке аналитических запросов на больших объемах данных.
--------------------------------------------------------------------------------
/src/db/dBTheory/README.md:
--------------------------------------------------------------------------------
1 | # Теория баз данных
2 |
3 | Классическая теория БД не привязанна к каким-либо конкретным системам хранения и обработки данных.
4 |
5 | База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины. Многие специалисты указывают на распространённую ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий.
6 |
7 |
--------------------------------------------------------------------------------
/src/db/dBTheory/distrubedDb/README.md:
--------------------------------------------------------------------------------
1 | # Распределенные системы
2 |
3 | - [Репликация](replication.md)
4 | - [Шардинг](sharding.md)
5 | - [Разное](unsorted.md)
--------------------------------------------------------------------------------
/src/db/messages/README.md:
--------------------------------------------------------------------------------
1 | # Брокеры сообщений
2 |
3 | ## Гарантии доставки
4 |
5 | - At-most-once delivery (“как максимум однократная доставка”). Это значит, что сообщение не может быть доставлено больше одного раза. При этом сообщение может быть потеряно.
6 | - At-least-once delivery (“как минимум однократная доставка”). Это значит, что сообщение никогда не будет потеряно. При этом сообщение может быть доставлено более одного раза.
7 | - Exactly-once delivery (“строго однократная доставка”). Святой грааль систем сообщений. Все сообщения доставляются строго единожды.
8 |
9 | * [Kafka](kafka.md)
10 | * [Rabbit](rabbit.md)
11 | * [Nats](nats.md)
--------------------------------------------------------------------------------
/src/db/messages/nats.md:
--------------------------------------------------------------------------------
1 | # Nats
2 |
3 |
--------------------------------------------------------------------------------
/src/SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Оглавление
2 |
3 | [Введение](README.md)
4 |
5 | * [Алгоритмы и Структуры Данных](algostruct/README.md)
6 | * [Базовые структуры](algostruct/structBasics.md)
7 | * [Массив](algostruct/array.md)
8 | * [Хэш-Таблица](algostruct/hashTable.md)
9 | * [Дерево](algostruct/tree.md)
10 | * [Граф](algostruct/graph.md)
11 | * [Вероятностные](algostruct/probability.md)
12 | * [Криптография](algostruct/crypto.md)
13 | * [Разное](algostruct/unsorted.md)
14 | * [Базы Данных](db/README.md)
15 | * [Теория Баз Данных](db/dBTheory/README.md)
16 | * [Нормальные формы](db/dBTheory/normalForms.md)
17 | * [Транзакции](db/dBTheory/transactions.md)
18 | * [Распределенные БД](db/dBTheory/distrubedDb/README.md)
19 | * [Репликация](db/dBTheory/distrubedDb/replication.md)
20 | * [Шардинг](db/dBTheory/distrubedDb/sharding.md)
21 | * [Разное](db/dBTheory/distrubedDb/unsorted.md)
22 | * [Реляционные БД](db/relational/README.MD)
23 | * [MySql](db/relational/mysql/README.MD)
24 | * [Архитектура MySql](db/relational/mysql/architecture.md)
25 | * [Конкурентный доступ](db/relational/mysql/concurency.md)
26 | * [Индексы](db/relational/mysql/indexes.md)
27 | * [Основы SQL](db/relational/mysql/sql.md)
28 | * [Explain](db/relational/mysql/explain.md)
29 | * [Разное](db/relational/mysql/unsorted.md)
30 | * [PostgreSql](db/relational/postgreSql/README.md)
31 | * [Колоночные](db/column/README.md)
32 | * [ClickHouse](db/column/clickhouse.md)
33 | * [Vertica](db/column/vertica.md)
34 | * [NoSql](db/noSql/README.md)
35 | * [Memcached](db/noSql/memcached.md)
36 | * [Redis](db/noSql/redis.md)
37 | * [Tarantool](db/noSql/tarantool.md)
38 | * [Mongo](db/noSql/mongo.md)
39 | * [Message brokers](db/messages/README.md)
40 | * [Rabbit](db/messages/rabbit.md)
41 | * [Kafka](db/messages/kafka.md)
42 | * [Nats](db/messages/nats.md)
43 | * [Архитектура](architecture/README.md)
44 | * [Основы ООП](architecture/oopBase.md)
45 | * [Паттерны GoF(Банда 4)](architecture/gof.md)
46 | * [Принципы хорошей архитектуры](architecture/principles.md)
47 | * [Архитектурные паттерны](architecture/architecturesPatterns.md)
48 | * [DDD](architecture/ddd.md)
49 | * [Микросервисы](architecture/microserices/README.md)
50 | * [Паттерны и протоколы интеграции](architecture/microserices/integration.md)
51 | * [Способы распиливания монолита](architecture/microserices/monolithSeparation.md)
52 | * [Разное](architecture/uncategorized.md)
53 | * [Аутентификация](auth/README.md)
54 | * [Этапы входа в систему](auth/steps/README.md)
55 | * [Идентификация](auth/steps/identification.md)
56 | * [Аутентификация](auth/steps/authentication.md)
57 | * [Авторизация](auth/steps/authorization.md)
58 | * [Методы аутентификации](auth/webAuth/README.md)
59 | * [HTTP Basic](auth/webAuth/httpBasic.md)
60 | * [HTTP Digest](auth/webAuth/httpDigest.md)
61 | * [На основе Cookie и сессий](auth/webAuth/cookieSessions.md)
62 | * [На основе токенов](auth/webAuth/token.md)
63 | * [С помощью одноразовых паролей (One-Time Passwords, OTP)](auth/webAuth/otp.md)
64 | * [OAuth](auth/webAuth/oauth.md)
65 | * [GoLang](goLang/README.md)
66 | * [Типы данных](goLang/types/README.md)
67 | * [Скалярные](goLang/types/scalar.md)
68 | * [Массив и слайс](goLang/types/array_slice.md)
69 | * [Map](goLang/types/map.md)
70 | * [Структура](goLang/types/struct.md)
71 | * [Интерфейс](goLang/types/interface.md)
72 | * [Concurrency](goLang/concurrency/README.md)
73 | * [Каналы](goLang/concurrency/chanel.md)
74 | * [Планировщик](goLang/concurrency/scheduler.md)
75 | * [Goroutines](goLang/concurrency/gouritine.md)
76 | * [Context](goLang/concurrency/context.md)
77 | * [Sync](goLang/concurrency/sync.md)
78 | * [Паттерны](goLang/concurrency/patterns.md)
79 | * [Управление памятью](goLang/memory.md)
80 | * [Экосистема](goLang/ecosystem.md)
81 | * [PHP](php/README.md)
82 | * [Фичи новых версий](php/innovations.md)
83 | * [PHP Internals](php/internals.md)
84 | * [realTime взаимодействие с сервером](php/serverIteractions.md)
85 | * [Фреймворки](php/frameworks/README.md)
86 | * [Laravel](php/frameworks/laravel.md)
87 | * [Symfony](php/frameworks/symfony.md)
88 | * [Разное](php/uncategorized.md)
89 | * [JavaScript](javascript.md)
90 | * [Информационная безопасность](ib.md)
91 | * [Git](git.md)
92 | * [Основы сетей](network/README.md)
93 | * [OSI](network/osi.md)
94 | * [TCP/IP](network/tcp_ip.md)
95 | * [HTTP](network/http.md)
96 | * [TLS](network/tls.md)
97 | * [DNS](network/dns.md)
98 | * [Что происходит при нажатии на g](network/whatHappenWhen.md)
99 | * [Real time с веб-сервером](network/realTime.md)
100 | * [Операционные системы и устройство ПК](os.md)
101 | * [Системное администрирование](devops/README.md)
102 | * [Linux](devops/linux.md)
103 | * [Основы виртуализации](devops/virtualization/README.md)
104 | * [Docker](devops/virtualization/docker.md)
105 | * [Kubernetes](devops/virtualization/kubernetes.md)
106 | * [Deployment](devops/deployment.md)
107 | * [Observability](devops/observability.md)
108 | * [Load Balancing](devops/load_balancing.md)
109 | * [Тестирование](test.md)
110 | * [Разное](unsorted/README.md)
111 | * [Побитовые операции](unsorted/bits.md)
112 | * [Типизация](unsorted/types.md)
113 | * [Юникод](unsorted/unicode.md)
114 | * [Методологии разработки](devmethods.md)
115 | * [ЧекЛист](checkList.md)
116 |
--------------------------------------------------------------------------------
/src/algostruct/README.md:
--------------------------------------------------------------------------------
1 | # Алгоритмы и структуры данных
2 |
3 | Раздел **computer science**, который изучает различные методы и подходы к решению задач обработки данных. Он включает в себя изучение алгоритмов, которые представляют собой последовательность шагов для решения конкретной задачи, а также структур данных, которые представляют собой способы организации и хранения данных для эффективного доступа и манипуляций. Разбираться в алгоритмах и структурах данных важно по следующим причинам:
4 |
5 | + Эффективность и оптимизация: Использование правильных алгоритмов и структур данных может значительно повысить эффективность выполнения программы. Это может означать сокращение времени выполнения, уменьшение потребления памяти или оптимальное использование ресурсов компьютера.
6 | + Понимание основных принципов: Изучение алгоритмов и структур данных позволяет разработчикам понять основные принципы и концепции, которые лежат в основе компьютерных систем. Это помогает развить абстрактное мышление, логическое рассуждение и умение решать проблемы.
7 |
8 |
9 | - [Базовые структуры](structBasics.md)
10 | - [Массив](array.md)
11 | - [Хэш-Таблица](hashTable.md)
12 | - [Дерево](tree.md)
13 | - [Граф](graph.md)
14 | - [Криптография](crypto.md)
15 | - [Вероятностные](probability.md)
16 | - [Разные алгоритмы](unsorted.md)
17 |
18 |
--------------------------------------------------------------------------------
/src/algostruct/graph.md:
--------------------------------------------------------------------------------
1 | ## Граф
2 |
3 | Граф — это совокупность объектов со связями между ними. Объекты представляются как вершины, или узлы графа, а связи — как дуги, или рёбра. Для разных областей применения виды графов могут различаться направленностью, ограничениями на количество связей и дополнительными данными о вершинах или рёбрах. Граф называется:
4 |
5 | - **связным**, если для любых вершин u,v есть путь из u в v.
6 | - **деревом**, если он связный и не содержит простых циклов.
7 | - **полным**, если любые его две (различные, если не допускаются петли) вершины соединены ребром.
8 | - **двудольным**, если его вершины можно разбить на два непересекающихся подмножества V1 и V2 так, что всякое ребро соединяет вершину из V1 с вершиной из V2.
9 | - **планарным**, если граф можно изобразить диаграммой на плоскости без пересечений рёбер.
10 | - **ориентированным**, если рёбрам которого присвоено направление. Направленные рёбра именуются также *дугами*, а в некоторых источниках и просто рёбрами.
11 |
12 |
13 |
14 | ## Что такое обход графа?
15 |
16 |
17 | Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
18 |
19 | Двумя основными алгоритмами обхода графа являются поиск в глубину **(Depth-First Search, DFS)** и поиск в ширину **(Breadth-First Search, BFS)**.
20 |
21 | ### Поиск в глубину
22 |
23 | **Поиск в глубину(Depth-First Search, DFS)** находит такой путь от данной вершины, до нужной, что этот путь содержит минимальную сумму ребер графа. Например, если мы ищем на карте метро путь от Сокольников, до Парка Победы, требующий наименьшее время для переезда(расстояние между каждыми соседними станциями, будет весом ребра), то мы ищем в глубину.
24 |
25 | **DFS** следует концепции «погружайся глубже, головой вперед» («go deep, head first»). Идея заключается в том, что мы двигаемся от начальной вершины (точки, места) в определенном направлении (по определенному пути) до тех пор, пока не достигнем конца пути или пункта назначения (искомой вершины). Если мы достигли конца пути, но он не является пунктом назначения, то мы возвращаемся назад (к точке разветвления или расхождения путей) и идем по другому маршруту.
26 |
27 | ### Поиск в ширину
28 |
29 | **Поиск в ширину(Breadth-First Search, BFS)** — это один из основных алгоритмов на графах. В результате поиска в ширину находится путь кратчайшей длины в невзвешенном графе, т.е. путь, содержащий наименьшее число рёбер. Например, если мы ищем на карте метро путь от Сокольников, до Парка Победы, содержащий наименьшее число станций, то мы ищем в ширину.
30 |
31 | **BFS** следует концепции «расширяйся, поднимаясь на высоту птичьего полета» («go wide, bird’s eye-view»). Вместо того чтобы двигаться по определенному пути до конца, BFS предполагает движение вперед по одному соседу за раз.
32 |
33 | ## Алгори́тм Де́йкстры
34 |
35 | Алгори́тм Де́йкстры (Dijkstra’s algorithm) — алгоритм на графах, изобретённый нидерландским учёным Эдсгером Дейкстрой в 1959 году. Находит кратчайшие пути от одной из вершин графа до всех остальных. Алгоритм работает только для графов **без рёбер отрицательного веса**.
36 |
37 | Каждой вершине из V сопоставим метку — минимальное известное расстояние от этой вершины до a. Алгоритм работает пошагово — на каждом шаге он «посещает» одну вершину и пытается уменьшать метки. Работа алгоритма завершается, когда все вершины посещены.
38 |
39 | Инициализация. Метка самой вершины a полагается равной 0, метки остальных вершин — бесконечности. Это отражает то, что расстояния от a до других вершин пока неизвестны. Все вершины графа помечаются как не посещённые.
40 |
41 | Шаг алгоритма. Если все вершины посещены, алгоритм завершается. В противном случае из ещё не посещённых вершин выбирается вершина u, имеющая минимальную метку. Мы рассматриваем всевозможные маршруты, в которых u является предпоследним пунктом. Вершины, в которые ведут рёбра из u, назовём соседями этой вершины. Для каждого соседа вершины u, кроме отмеченных как посещённые, рассмотрим новую длину пути, равную сумме значений текущей метки u и длины ребра, соединяющего u с этим соседом. Если полученное значение длины меньше значения метки соседа, заменим значение метки полученным значением длины. Рассмотрев всех соседей, пометим вершину u как посещённую и повторим шаг алгоритма.
42 |
43 |
44 |
45 | *Дополнительно:*
46 |
47 | - [Обход графа: поиск в глубину и поиск в ширину простыми словами на примере JavaScript](https://habr.com/ru/post/504374/)
--------------------------------------------------------------------------------
/src/algostruct/hashTable.md:
--------------------------------------------------------------------------------
1 | # Хэш таблица
2 |
3 | **Хеш-таблица(hash table)** — структура данных, реализующая интерфейс ассоциативного массива, позволяет хранить пары `ключ => значение` и выполнять три операции:
4 |
5 | - добавление
6 | - поиск
7 | - удаление
8 |
9 | Главное свойство **hash table** — все операции(вставка, поиск и удаление) в среднем выполняются за **O(1)**, среднее время поиска по ней также равно **O(1)** и **O(n)** в худшем случае.
10 |
11 | Выполнение операции в хеш-таблице начинается с вычисления **хеш-функции** от ключа. Получающееся хеш-значение играет роль индекса. Затем выполняемая операция (добавление, удаление или поиск) перенаправляется объекту, который хранится в соответствующей ячейке массива. 
12 |
13 | Ситуация, когда для различных ключей получается одно и то же хеш-значение, называется коллизией. Существует несколько способов разрешения коллизий.
14 |
15 | 
16 |
17 | ### Метод цепочек
18 |
19 | Этот метод часто называют **открытым хешированием**. Его суть проста — элементы с одинаковым хешем попадают в одну ячейку в виде связного списка(возможны оптимизации, где вместо списка будет дерево). Каждая ячейка массива *H* является указателем на связный список(цепочку) пар ключ-значение, соответствующих одному и тому же хеш-значению ключа. Коллизии просто приводят к тому, что появляются цепочки длиной более одного элемента.
20 |
21 | 
22 |
23 | ### Открытая индексация (или закрытое хеширование)
24 |
25 | Метод открытой адресации (open addressing) представляет собой один из способов решения коллизий в хеш-таблицах. Вместо того чтобы создавать цепочки (списки) для элементов с одинаковыми хеш-значениями, метод открытой адресации предлагает разместить элементы в самой таблице, перемещая их на другие позиции, если возникают коллизии.
26 |
27 | При вставке нового элемента происходит попытка разместить его в таблице на соответствующей позиции, определенной хеш-функцией. Если позиция занята, то начинается поиск следующей свободной позиции в таблице. Этот процесс может включать в себя различные стратегии поиска, такие как линейное пробирование, квадратичное пробирование, двойное хеширование и др. Для успешной работы алгоритмов поиска последовательность проб должна быть такой, чтобы все ячейки хеш-таблицы оказались просмотренными ровно по одному разу.
28 |
29 | Алгоритм поиска просматривает ячейки хеш-таблицы в том же самом порядке, что и при вставке, до тех пор, пока не найдется либо элемент с искомым ключом, либо свободная ячейка (что означает отсутствие элемента в хеш-таблице). Этот порядок вычисляется на лету, что позволяет сэкономить на памяти для указателей, требующихся в хеш-таблицах с цепочками.
30 |
31 | 
32 |
33 |
34 |
35 | ### Рехеширование
36 |
37 | Рехеширование (rehashing) - это процесс изменения размера хеш-таблицы и перераспределения её элементов для уменьшения коллизий и обеспечения эффективной работы структуры данных. Оно может происходить при превышении определенной заполненности таблицы (например, 70% от максимальной) или по другим условиям.
38 |
39 | Основные шаги рехеширования в хеш-таблицах:
40 |
41 | 1. **Создание новой таблицы:** Сначала создается новая хеш-таблица с более большим или меньшим размером по сравнению с текущей таблицей. Выбор размера новой таблицы может зависеть от стратегии рехеширования.
42 | 2. **Перераспределение элементов:** Затем элементы из текущей таблицы перераспределяются в новую таблицу с использованием обновленных хеш-функций. Это может потребовать вычисления новых хеш-значений для каждого элемента и его перемещения в соответствующую позицию новой таблицы.
43 | 3. **Обновление ссылок:** Все ссылки на таблицу теперь должны указывать на новую таблицу, так чтобы последующие операции вставки, поиска и удаления работали с обновленной структурой данных.
44 |
45 | Существует несколько стратегий рехеширования:
46 |
47 | 1. **Удвоение размера:** При этой стратегии новая таблица имеет удвоенный размер по сравнению с текущей. Это позволяет более равномерно распределить элементы и обеспечить эффективную работу таблицы. Однако это требует дополнительной памяти.
48 | 2. **Уменьшение размера:** В некоторых случаях, если таблица стала слишком маленькой после множественных удалений, может потребоваться уменьшить её размер, чтобы сэкономить память.
49 | 3. **Двойное хеширование:** Это метод рехеширования, при котором элементы перераспределяются в таблицу нового размера с использованием другой хеш-функции. Это может помочь избежать кластеризации элементов, если первая хеш-функция вызывает коллизии.
50 |
51 | Преимущества рехеширования:
52 |
53 | - Уменьшение коллизий: Рехеширование позволяет более равномерно распределить элементы, уменьшая вероятность коллизий и улучшая производительность.
54 | - Динамическое изменение размера: Таблица может адаптироваться к изменяющейся нагрузке, увеличивая или уменьшая свой размер по мере необходимости.
55 |
56 | Недостатки рехеширования:
57 |
58 | - Дополнительные затраты: Рехеширование может потребовать выделения памяти для новой таблицы и перемещения элементов, что может быть дорогим по ресурсам.
59 | - Временная сложность: Процесс рехеширования может занять время, что может замедлить работу структуры данных на короткий срок.
60 |
61 | Выбор стратегии рехеширования и параметров (например, размера новой таблицы) зависит от конкретных потребностей и характеристик приложения.
62 |
63 |
64 |
65 | *Дополнительно:*
66 |
67 | - [Хэширование](http://aliev.me/runestone/SortSearch/Hashing.html)
68 | - [Хэш-Таблица](https://www.wikiwand.com/ru/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0)
--------------------------------------------------------------------------------
/src/algostruct/structBasics.md:
--------------------------------------------------------------------------------
1 | # Основные структуры данных
2 |
3 | ## Массивы (Arrays)
4 |
5 | Упорядоченная коллекция элементов, где каждый элемент имеет свой уникальный индекс. Позволяет эффективный доступ к элементам по индексу.
6 |
7 | ## Связанный список (Linked List)
8 |
9 | *Описание:* Связанный список - это структура данных, состоящая из узлов, каждый из которых содержит значение элемента и указатель на следующий узел в списке. Существуют односвязные списки, где каждый узел имеет указатель только на следующий узел, и двусвязные списки, где узлы имеют указатели на предыдущий и следующий узлы.
10 |
11 | *Преимущества:*
12 |
13 | - Динамическое изменение размера списка (в отличие от массивов)
14 | - Эффективное добавление и удаление элементов в начале или конце списка
15 | - Относительно простая реализация
16 |
17 | *Недостатки:*
18 |
19 | - Непостоянное время доступа к элементам (в отличие от массивов)
20 | - Больший объем занимаемой памяти по сравнению с массивами из-за хранения указателей на узлы
21 |
22 | *Применение:* Связанные списки подходят для реализации стеков, очередей, а также для задач, где требуется частое добавление или удаление элементов и не требуется быстрый доступ к элементам по индексу.
23 |
24 | ## Стэк(Stack)
25 |
26 | Cтруктура данных, организованная по принципу "последний пришел, первый ушел" (**LIFO**). Элементы добавляются и удаляются с одного конца структуры.
27 |
28 | *Преимущества:*
29 |
30 | - Простота реализации
31 | - Легкость использования в рекурсии и отката операций
32 |
33 | *Недостатки:*
34 |
35 | - Ограниченный доступ к элементам (только к вершине стека)
36 |
37 | *Применение:* Стеки полезны при выполнении рекурсивных функций, обработке скобочных последовательностей и отмене операций.
38 |
39 | ## Очередь (Queue)
40 |
41 | Структура данных, организованная по принципу "первый пришел, первый ушел" (**FIFO**). Элементы добавляются в конец очереди и удаляются из начала.
42 |
43 | *Преимущества:*
44 |
45 | - Поддержка естественного порядка обработки элементов
46 | - Применение в алгоритмах обхода и поиска
47 |
48 | *Недостатки:*
49 |
50 | - Ограниченный доступ к элементам (только к началу и концу очереди)
51 |
52 | *Применение:* Очереди используются в алгоритмах обхода в ширину, приоритетных очередях и многопоточных приложениях для обработки задач.
53 |
54 | ## Хэш-таблица (Hash Table)
55 |
56 | Структура данных, основанная на хэш-функции, которая преобразует ключ в индекс массива для хранения значения.
57 |
58 | *Преимущества:*
59 |
60 | - Быстрый доступ, вставка и удаление элементов (в среднем O(1))
61 | - Гибкость структуры
62 |
63 | *Недостатки:*
64 |
65 | - Возможность коллизий хэш-функции
66 | - Затраты памяти на хранение элементов и обработку коллизий
67 |
68 | *Применение:* Хэш-таблицы используются в поисковых алгоритмах, кэшировании данных, реализации ассоциативных массивов и словарей.
69 |
70 | ## Граф (Graph)
71 |
72 | Структура данных, состоящая из вершин (узлов) и ребер, которые соединяют эти вершины. Графы могут быть ориентированными (направленными) или неориентированными.
73 |
74 | *Преимущества:*
75 |
76 | - Отражение сложных отношений между элементами
77 | - Гибкость структуры
78 |
79 | *Недостатки:*
80 |
81 | - Сложность реализации и обработки
82 | - Большие затраты памяти
83 |
84 | *Применение:* Графы широко используются в транспортных сетях, социальных сетях, веб-технологиях и задачах оптимизации.
85 |
86 | ## Дерево (Tree)
87 |
88 | Иерархическая структура данных, состоящая из узлов, соединенных ребрами. У дерева есть корень и набор дочерних узлов, которые могут иметь свои дочерние узлы.
89 |
90 | *Преимущества:*
91 |
92 | - Иерархическая структура данных
93 | - Быстрый поиск, вставка и удаление элементов (для сбалансированных деревьев)
94 |
95 | *Недостатки:*
96 |
97 | - Сложность реализации и поддержания сбалансированности
98 |
99 | *Применение:* Деревья используются в файловых системах, синтаксических анализаторах, базах данных и поисковых алгоритмах.
100 |
101 | ## Двоичные кучи (Binary Heap)
102 |
103 | Структура данных, позволяющая быстро (за логарифмическое время) добавлять элементы и извлекать элемент с максимальным приоритетом (например, максимальный по значению).
104 |
105 | ## Bit Arrays
106 |
107 | Массивы битов, где каждый бит представляет элемент данных. Часто используются для оптимизации использования памяти, когда нужно хранить множество флагов или булевых значений.
108 |
109 | *Дополнительно:*
110 | - [Структуры данных. Algolist](http://algolist.manual.ru/ds/index.php)
111 | - [Структуры данных в программировании](https://dzen.ru/a/ZE0wsb_h1yYEF8vx)
112 |
--------------------------------------------------------------------------------
/src/architecture/README.md:
--------------------------------------------------------------------------------
1 | # Архитектура ПО
2 |
3 | **Архитектура программного обеспечения** (software architecture) — совокупность важнейших решений об организации программной системы. Также это набор ограничений для достижения определенных целей.
4 |
5 | - [Основы ООП](oopBase.md)
6 | - [Паттерны GoF(Банда 4)](gof.md)
7 | - [Принципы хорошей архитектуры](principles.md)
8 | - [Архитектурные паттерны](architecturesPatterns.md)
9 | - [DDD](ddd.md)
10 | - [Микросервисы](microserices/README.md)
11 | - [Разное](uncategorized.md)
12 |
13 |
--------------------------------------------------------------------------------
/src/architecture/microserices/README.md:
--------------------------------------------------------------------------------
1 | # Микросервисная архитектура
2 |
3 | Микросервисная архитектура — вариант сервис-ориентированной архитектуры программного обеспечения, ориентированный на взаимодействие насколько это возможно небольших, слабо связанных и легко изменяемых модулей — микросервисов, получивший распространение в середине 2010-х годов в связи с развитием практик гибкой разработки и DevOps.
4 |
5 | Если в традиционных вариантах сервис-ориентированной архитектуры модули могут быть сами по себе достаточно сложными программными системами, а взаимодействие между ними зачастую полагается на стандартизованные тяжеловесные протоколы (такие, как SOAP, XML-RPC), в микросервисной архитектуре системы выстраиваются из компонентов, выполняющих относительно элементарные функции, и взаимодействующие с использованием экономичных сетевых коммуникационных протоколов. За счёт повышения гранулярности модулей архитектура нацелена на уменьшение степени зацепления и увеличение связности, что позволяет проще добавлять и изменять функции в системе в любое время.
6 |
7 | ## Преимущества микросервисов
8 |
9 | - **Независимые релизы** - Выдача компонентов по мере готовности благодаря декомпозиции решения и отделения различных процессов. Раздельные команды, циклы разработки, тестирование, деплоя. И конечно разделенные продуктовые команды - это важно, потому что большой командой, работающей над старым монолитом, сложно было управлять. Такая команда вынуждена была работать по строгому процессу, а хотелось больше творчества и независимости. Это могли позволить себе только небольшие команды.
10 |
11 | - **Гибкость развертывания и масштабирования** - Хотелось бы комбинировать сервисы так, как это необходимо нам, а не так, как заставляет код. Можно гораздо гибче масштабировать приложение, точечно балансируя число интсансов сервисов, которые не вывозят нагрузку.
12 |
13 | - **Технологическая независимость** - Можно выбирать инструмент под задачу. Тут заюзаем Go с хранением в памяти тут оставим java с полноценной субд. Гораздо легче внедрить новый инструмент.
14 |
15 | ## Недостатки микросервисов
16 |
17 | - Издержки на межсетевое взаимодействие
18 | - Трудности с распределенными транзакциями
19 | - Сложность эксплуатации
20 | - Риски получения зоопарка технологий
21 | - При неверном применении подхода, получим распределенный монолит.
22 |
23 |
24 |
25 | *Дополнительно:*
26 |
27 | - [Просто о микросервисах](https://habr.com/ru/company/raiffeisenbank/blog/346380/)
28 | - [Смерть микросервисного безумия в 2018 году](https://habr.com/ru/company/flant/blog/347518/)
29 | - [Переход от монолита к микросервисам: история и практика](https://habr.com/ru/company/raiffeisenbank/blog/458404/)
30 | - [Микросервисы — за и против](http://devopsru.com/news/2016-05-10-microservice-trade-offs.html)
--------------------------------------------------------------------------------
/src/architecture/microserices/integration.md:
--------------------------------------------------------------------------------
1 | # Протоколы межсервисного взаимодействия
2 |
3 | ### MQ vs. HTTP
4 |
5 | I was going through my old files and came across my notes on MQ and thought I’d share some reasons to use MQ vs. HTTP:
6 |
7 | - If your consumer processes at a fixed rate (i.e. can’t handle floods to the HTTP server [bursts]) then using **MQ provides the flexibility** for the service to buffer the other requests vs. bogging it down.
8 | - **Time independent processing** and **messaging exchange patterns** — if the thread is performing a fire-and-forget, then MQ is better suited for that pattern vs. HTTP.
9 | - **Long-lived processes are better suited for MQ** as you can send a request and have a seperate thread listening for responses (note WS-Addressing allows HTTP to process in this manner but requires both endpoints to support that capability).
10 | - **Loose coupling** where one process can continue to do work even if the other process is not available vs. HTTP having to retry.
11 | - **Request prioritization** where more important messages can jump to the front of the queue.
12 | - **XA transactions** – MQ is fully XA compliant – HTTP is not.
13 | - **Fault tolerance** – MQ messages survive server or network failures – HTTP does not.
14 | - MQ provides for **‘assured’ delivery** of messages once and only once, http does not.
15 | - MQ provides the ability to do **message segmentation** and message grouping for large messages – HTTP does not have that ability as it treats each transaction seperately.
16 | - MQ provides a **pub/sub interface** where-as HTTP is point-to-point.
17 |
18 | https://solace.com/blog/products-tech/experience-awesomeness-event-driven-microservices
19 |
20 | ## Синхронные
21 |
22 | RPC
23 |
24 | REST
25 |
26 | ## Асинхронные
27 |
28 |
29 |
30 |
--------------------------------------------------------------------------------
/src/architecture/microserices/monolithSeparation.md:
--------------------------------------------------------------------------------
1 | # Методы распиливания монолита
2 |
3 | При разделении монолитного приложения на микросервисы существует несколько распространенных паттернов, которые помогают
4 | достичь более гибкой, масштабируемой и поддерживаемой архитектуры. Вот некоторые основные паттерны разделения монолита
5 | на микросервисы:
6 |
7 | ## Decomposition by Domain (Разделение по доменам):
8 |
9 | В этом случае монолит разбивается на микросервисы вокруг отдельных доменов или областей функциональности.
10 | Каждый сервис полностью отвечает за определенный домен и содержит все необходимые компоненты (базу данных, логику и
11 | интерфейсы).
12 | Этот подход обеспечивает высокую коэксплуатацию и независимость доменов, но может потребовать управления распределенными
13 | транзакциями.
14 |
15 | ## Decomposition by Business Capability (Разделение по бизнес-возможностям):
16 |
17 | При этом подходе монолит разбивается на отдельные сервисы вокруг бизнес-возможностей или функций приложения.
18 | Каждый сервис отвечает за определенный бизнес-аспект и имеет свою собственную базу данных и логику.
19 | Этот подход способствует независимости разработки, масштабируемости и возможности быстрого внесения изменений.
20 |
21 | ## Decomposition by Data (Разделение по данным):
22 |
23 | В этом подходе монолит разбивается на микросервисы вокруг различных источников данных.
24 | Каждый сервис имеет собственную базу данных или отвечает за конкретный набор данных.
25 | Этот подход обеспечивает независимость данных и позволяет эффективно масштабировать и поддерживать различные аспекты
26 | приложения.
27 |
28 | ## Decomposition by UI (Разделение по пользовательскому интерфейсу):
29 |
30 | В этом случае монолит разбивается на микросервисы, каждый из которых отвечает за отдельный пользовательский интерфейс
31 | или экран.
32 | Каждый сервис предоставляет свои собственные API для взаимодействия с пользовательским интерфейсом.
33 | Этот подход обеспечивает независимость разработки, улучшенную масштабируемость и возможность использования разных
34 | технологий в разных сервисах.
35 |
36 | ## Decomposition by Deployment (Разделение по развертыванию):
37 |
38 | При этом подходе монолит разбивается на микросервисы в соответствии с их развертыванием и масштабированием.
39 | Каждый сервис может быть развернут и масштабирован независимо от других сервисов.
40 | Этот подход облегчает управление развертыванием, масштабированием и обновлением сервисов.
41 |
42 | ## Decomposition by Communication Protocol (Разделение по протоколу коммуникации):
43 |
44 | В этом случае монолит разбивается на микросервисы, которые общаются между собой посредством различных протоколов.
45 | Каждый сервис может быть реализован с использованием разных технологий и языков программирования.
46 | Этот подход позволяет гибко разрабатывать и масштабировать сервисы в соответствии с их требованиями коммуникации.
47 |
48 | Каждый из этих паттернов имеет свои преимущества и недостатки, и выбор определенного паттерна зависит от конкретных
49 | требований вашего приложения и контекста, в котором оно используется. Важно тщательно изучить и понять вашу систему и
50 | бизнес-потребности, прежде чем принимать решение о разделении монолита на микросервисы.
--------------------------------------------------------------------------------
/src/architecture/oopBase.md:
--------------------------------------------------------------------------------
1 | ## Основы ООП
2 |
3 | **Объе́ктно-ориенти́рованное программи́рование (ООП)** — методология программирования, основанная на представлении программы в виде совокупности объектов(структур данных, хранящих рядом сами данные и их поведение, т.е методы для работы с этими данными), каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования.
4 |
5 | **Инкапсуляция** — это фундаментальная объектно-ориентированная концепция, позволяющая упаковывать данные и поведение в единый компонент с разделением его на обособленные части — интерфейс и реализацию. Последнее осуществляется благодаря принципу изоляции решений разработки в ПО, известному как **сокрытие информации (information hiding)**.
6 |
7 | **Сокрытие информации** – это сокрытие деталей проектирования, которые могут измениться в будущем, для ограничения каскадных изменений в программной системе и для упрощения ее разработки и сопровождения.
8 |
9 | **Полиморфизм** – это свойство системы использовать разные объекты с одинаковым интерфейсом без информации о типе и внутренней структуре объекта(является следствием инкапсуляции).
10 |
11 | **Наследование** – это свойство системы, позволяющее описать новый класс на основе уже существующего с частично или полностью заимствующейся функциональностью. Класс, от которого производится наследование, называется базовым или родительским. Новый класс – потомком, наследником или производным классом.
12 |
13 | **Агрегирование** - В объектно-ориентированном программировании под агрегированием подразумевают методику создания нового класса из уже существующих классов путём включения, называемого также делегированием. Об агрегировании также часто говорят как об «отношении принадлежности» по принципу «у машины есть корпус, колёса и двигатель».
14 |
15 | Вложенные объекты нового класса обычно объявляются закрытыми, что делает их недоступными для прикладных программистов, работающих с классом. С другой стороны, создатель класса может изменять эти объекты, не нарушая при этом работы существующего клиентского кода. Кроме того, замена вложенных объектов на стадии выполнения программы позволяет динамически изменять её поведение. Механизм наследования такой гибкостью не обладает, поскольку для производных классов устанавливаются ограничения, проверяемые на стадии компиляции.
16 |
17 | На базе агрегирования реализуется методика делегирования, когда поставленная перед внешним объектом задача перепоручается внутреннему объекту, специализирующемуся на решении задач такого рода.
18 |
19 | **Агрегация (агрегирование по ссылке**) — отношение «часть-целое» между двумя равноправными объектами, когда один объект (контейнер) имеет ссылку на другой объект. Оба объекта могут существовать независимо: если контейнер будет уничтожен, то его содержимое — нет.
20 |
21 | **Композиция (агрегирование по значению)** — более строгий вариант агрегирования, когда включаемый объект может существовать только как часть контейнера. Если контейнер будет уничтожен, то и включённый объект тоже будет уничтожен.
--------------------------------------------------------------------------------
/src/architecture/uncategorized.md:
--------------------------------------------------------------------------------
1 | # Разные паттерны
2 |
3 | ## Шаблоны взаимодействия с клиентом
4 |
5 | - **Model-view-controller (MVC, «модель-представление-контроллер», «модель-вид-контроллер»)** — схема использования нескольких шаблонов проектирования, с помощью которых модель приложения, пользовательский интерфейс и взаимодействие с пользователем разделены на три отдельных компонента таким образом, чтобы модификация одного из компонентов оказывала минимальное воздействие на остальные. Данная схема проектирования часто используется для построения архитектурного каркаса, когда переходят от теории к реализации в конкретной предметной области.
6 | - **HMVC (*Hierarchical model–view–controller*)** — Иерархические Модель-Вид-Контроллер, одно из расширений архитектурного [*паттерна*](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F) [*MVC*](https://ru.wikipedia.org/wiki/Model-View-Controller), позволяющее решить некоторые проблемы масштабируемости приложений, имеющих классическую MVC-архитектуру. Согласно парадигме HMVC, каждая отдельная MVC триада используется в качестве слоя в иерархической структуре. При этом, каждая триада в этой иерархии независима от других, и может обратиться к контроллеру другой триады. Такой подход существенно облегчает и ускоряет разработку сложных приложений, облегчает их дальнейшую поддержку и масштабирование, способствует повторному использованию кода.
7 | - **Model Model-View-Presenter (MVP**) — шаблон проектирования, производный от MVC, который используется в основном для построения пользовательского интерфейса. Элемент Presenter в данном шаблоне берёт на себя функциональность посредника (аналогично контроллеру в MVC) и отвечает за управление событиями пользовательского интерфейса (например, использование мыши) так же, как в других шаблонах обычно отвечает представление.
8 | - **Model-View-ViewModel (MVVM)** — применяется при проектировании архитектуры приложения. используется для разделения модели и её представления, что необходимо для изменения их отдельно друг от друга. Например, разработчик задает логику работы с данными, а дизайнер соответственно работает с пользовательским интерфейсом. MVVM удобно использовать вместо классического MVC и ему подобных в тех случаях, когда в платформе, на которой ведётся разработка, присутствует «связывание данных». В шаблонах проектирования MVC/MVP изменения в пользовательском интерфейсе не влияют непосредственно на Модель, а предварительно идут через Контроллер (англ. Controller) или Presenter. В таких технологиях как WPF и Silverlight есть концепция «связывания данных», позволяющая связывать данные с визуальными элементами в обе стороны. Следовательно, при использовании этого приема применение модели MVC становится крайне неудобным из-за того, что привязка данных к представлению напрямую не укладывается в концепцию MVC/MVP.
9 | - **PageController** - В основе контроллера страниц лежит идея создания компонентов, которые будут выполнять роль контроллеров для каждой страницы Web-сайта.(много физических точек(файлов) входа)
10 | - **FrontController** - Один контроллер обрабатывает все запросы к веб-сайту(одна физическая точка входа)
11 |
12 | ## Шаблоны для работы с базами данных
13 |
14 | - **ActiveRecord** - реализует популярный подход объектно-реляционного проецирования (ORM). Каждый класс AR отражает таблицу (или представление) базы данных, экземпляр AR — строку в этой таблице, а общие операции CRUD реализованы как методы AR. В результате мы можем использовать более объектно-ориентированный подход доступа к данным
15 | - **Data Mapper** — это программная прослойка, разделяющая объект и БД. Его обязанность — пересылать данные между ними и изолировать их друг от друга. При использовании Data Mapper'а объекты не нуждаются в знании о существовании БД. Они не нуждаются в SQL-коде, и (естественно) в информации о структуре БД. Так как Data Mapper - это разновидность паттерна Mapper, сам объект-Mapper неизвестен объекту.
16 |
17 | ## Совсем разное
18 |
19 | - **Делегирование (Delegation)** — основной шаблон проектирования, в котором объект внешне выражает некоторое поведение, но в реальности передаёт ответственность за выполнение этого поведения связанному объекту. Шаблон делегирования является фундаментальной абстракцией, на основе которой реализованы другие шаблоны - композиция (также называемая агрегацией), примеси (mixins) и аспекты (aspects).
20 | - **Lazy Load (Ленивая Загрузка)** подразумевает отказ от загрузки дополнительных данных, когда в этом нет необходимости. Вместо этого ставится маркер о том, что данные не загружены и их надо загрузить в случае, если они понадобятся. Как известно, если Вы ленивы, то вы выигрываете в том случае, если дело, которое вы не делали на самом деле и не надо было делать.
21 | - **Registry**(реестр) — это ООП замена глобальным переменным, предназначена для хранения данных и передачи их между модулями системы. Соответственно, его наделяют стандартными свойствами — запись, чтение, удаление. Вот типовая реализация.
22 |
23 |
--------------------------------------------------------------------------------
/src/auth/README.md:
--------------------------------------------------------------------------------
1 | # Аутентификация
2 |
3 | * [Этапы входа в систему](steps/README.md)
4 | * [Идентификация](steps/identification.md)
5 | * [Аутентификация](steps/authentication.md)
6 | * [Авторизация](steps/authorization.md)
7 | * [Методы аутентификации](webAuth/README.md)
8 | * [HTTP Basic](webAuth/httpBasic.md)
9 | * [HTTP Digest](webAuth/httpDigest.md)
10 | * [На основе Cookie и сессий](webAuth/cookieSessions.md)
11 | * [На основе токенов](webAuth/token.md)
12 | * [С помощью одноразовых паролей (One-Time Passwords, OTP)](webAuth/otp.md)
13 | * [OAuth](webAuth/oauth.md)
14 |
15 |
--------------------------------------------------------------------------------
/src/auth/steps/README.md:
--------------------------------------------------------------------------------
1 | # Что такое идентификация, аутентификация, авторизация
2 |
3 | Идентификация, аутентификация и авторизация обычно представляют собой этапы единого процесса — входа в какую-либо систему.
4 |
5 | * [Идентификация](identification.md)
6 | * [Аутентификация](authentication.md)
7 | * [Авторизация](authorization.md)
8 |
--------------------------------------------------------------------------------
/src/auth/steps/authentication.md:
--------------------------------------------------------------------------------
1 | # Аутентификация
2 |
3 | Аутентификация — это второй этап входа, где система проверяет, что пользователь — это действительно он.
4 |
5 | Основные способы аутентификации:
6 | - **фактор знания**: сравнение пароля с сохранённым в базе;
7 | - **фактор владения**: предъявление USB-ключа или ввод кода с устройства;
8 | - **личный фактор**: биометрические данные (отпечаток, лицо) или поведенческие особенности.
9 |
10 | После успешной аутентификации система переходит к авторизации.
11 |
12 | В web-приложениях могут применяться различные [методы аутентификация](../webAuth/README.md).
--------------------------------------------------------------------------------
/src/auth/steps/authorization.md:
--------------------------------------------------------------------------------
1 | # Авторизация
2 |
3 | Авторизация — третий этап входа в систему. Заключается в предоставлении лицу или группе лиц прав на выполнение определённых действий.
--------------------------------------------------------------------------------
/src/auth/steps/identification.md:
--------------------------------------------------------------------------------
1 | # Идентификация
2 |
3 | **Идентификация** — это этап, когда системе предоставляется уникальный цифровой идентификатор (логин, email, номер телефона и т.д.) пользователя системы, под именем которого мы хотим зайти.
4 |
5 | Чтобы убедиться, что владелец идентификатора — настоящий, система проводит аутентификацию.
--------------------------------------------------------------------------------
/src/auth/webAuth/README.md:
--------------------------------------------------------------------------------
1 | # Методы аутентификации в веб-приложениях
2 |
3 | * [HTTP Basic](httpBasic.md)
4 | * [HTTP Digest](httpDigest.md)
5 | * [На основе Cookie и сессий](cookieSessions.md)
6 | * [На основе токенов](token.md)
7 | * [С помощью одноразовых паролей (One-Time Passwords, OTP)](otp.md)
8 | * [OAuth](oauth.md)
9 |
--------------------------------------------------------------------------------
/src/auth/webAuth/cookieSessions.md:
--------------------------------------------------------------------------------
1 | # Аутентификация на основе Cookie и сессий
2 |
3 | При сеансовой аутентификации состояние пользователя хранится на сервере. При первом входе сервер проверяет учётные данные, генерирует сессию и отправляет идентификатор сессии в браузер, который сохраняет его в cookie. Это позволяет пользователю не вводить имя и пароль при каждом обращении к сайту.
4 |
5 | Сеансовая аутентификация является stateful: сервер должен находить сохранённую сессию для связи идентификатора с пользователем.
6 |
7 | 
8 |
9 | ##### Преимущества и недостатки
10 |
11 | | Преимущества | Недостатки |
12 | | -------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
13 | | Более быстрый последующий вход в систему, так как не требуется вводить учётные данные. | Требует сохранения состояния (stateful). Сервер ведет учёт каждого сеанса на своей стороне. Хранилище информации о сеансе пользователей должно быть общим для нескольких сервисов, чтобы обеспечить аутентификацию. Из-за этого он не подходит для REST-сервисов, поскольку REST — это протокол без хранения состояния. |
14 | | Достаточно простая реализация. Многие фреймворки предоставляют эту возможность из коробки. | Без специальных настроек (domain, path , samesite) cookie отправляются при каждом запросе, даже если он не требует аутентификации. |
15 | | Удобнее для пользователя, поскольку ему не приходится каждый раз при обращении к серверу вводить имя и пароль. | Без правильной настройки безопасности метод может быть уязвим для CSRF-атак. |
16 |
--------------------------------------------------------------------------------
/src/auth/webAuth/httpBasic.md:
--------------------------------------------------------------------------------
1 | # Базовая HTTP аутентификация — HTTP Basic
2 |
3 | Это самая простая форма аутентификация, встроенная в протокол HTTP. Учётные данные для входа в систему передаются в заголовках запроса при каждом запросе:
4 |
5 | ```
6 | "Authorization: Basic dXNlcm5hbWU6cGFzc3dvcmQ=" your-website.com
7 | ```
8 |
9 | Имена пользователей и пароли не шифруются, а объединяются в строку **имя_пользователя:пароль** и кодируются с помощью **base64**.
10 |
11 | Метод является stateless, поэтому клиент должен предоставлять учётные данные при каждом запросе. Он подходит для вызовов API, а также для простых процессов аутентификации, не требующих постоянных сессий.
12 |
13 | 
14 |
15 | 1. Неавторизованный клиент запрашивает ограниченный ресурс.
16 | 2. Сервер отправляет HTTP **401 Unauthorized** и добавляет в ответ заголовок **WWW-Authenticate** со значением **Basic**.
17 | 3. Заголовок **WWW-Authenticate: Basic** заставляет браузер запросить имя пользователя и пароль.
18 | 4. После ввода учётных данных они передаются в заголовке с каждым запросом: **Authorization: Basic dcdvcmQ=**
19 | ##### Преимущества и недостатки
20 |
21 | | Преимущества | Недостатки |
22 | | --------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
23 | | Поскольку в этом методе не так много операций, аутентификация выполняется быстро. | Учётные данные передаются в base64, который, по сути, является другим представлением обычного текста. Закодированную в base64 информацию легко декодировать. В связи с этим обязательно использовать HTTPS/SSL. |
24 | | Простота реализации. | Учётные данные должны передаваться при каждом запросе. |
25 | | Поддерживается всеми основными браузерами. | |
26 |
--------------------------------------------------------------------------------
/src/auth/webAuth/httpDigest.md:
--------------------------------------------------------------------------------
1 | # HTTP Digest Authentication
2 |
3 | HTTP Digest Authentication (или Digest Access Authentication) — более безопасная форма базовой аутентификации. В отличие от Basic Auth, здесь пароль передается в виде хеша, что повышает уровень безопасности.
4 |
5 | 
6 |
7 | 1. Неаутентифицированный клиент запрашивает ресурс с ограниченным доступом.
8 |
9 | 2. Сервер генерирует случайное значение, называемое nonce, и отправляет обратно статус HTTP **401 Unauthorized** с заголовком **WWW-Authenticate**, имеющим значение **Digest** вместе с nonce:
10 | ```
11 | WWW-Authenticate: Digest
12 | realm="Access to the '/' path",
13 | nonce="e4549c0548886bc2",
14 | algorithm="MD5"
15 | ```
16 |
17 |
18 | 3. Получив ответ с заголовком **WWW-Authenticate**, браузер запрашивает у пользователя логин и пароль.
19 |
20 | 4. После ввода учётных данных браузер отправляет серверу ответ **Authorization**:
21 | ```
22 | Authorization: Digest username="User1",
23 | realm="Access to the '/' path",
24 | nonce="e4549c0548886bc2",
25 | uri="/",
26 | algorithm=MD5,
27 | response="6299988bb4f05c0d8ad44295873858cf"
28 | ```
29 |
30 | Значение response в ответе формируется следующим образом:
31 |
32 | ```
33 | response = H(HA1:nonce:HA2)
34 |
35 | HA1 = H(username:realm:password)
36 |
37 | HA2 = H(method:digestURI)
38 | ```
39 |
40 | Пример:
41 | ```
42 | response = SHA256(HA1:”e4549c0548886bc2”:HA2)
43 |
44 | HA1 = SHA256(”User1”:”/”:”User1Password”)
45 |
46 | HA2 = SHA256(”GET”:”/”)
47 | ```
48 |
49 | Актуальный стандарт HTTP **Digest Authentication** описывается в [RFC7616](https://httpwg.org/specs/rfc7616.html). Ответ **Authorization** может содержать дополнительные поля для дополнительной защиты (счётчик запросов **nc**, одноразовый номер клиента **cnonce**, качество кода защиты **qop**).
50 |
51 | Также **RFC7616** добавляет алгоритм хеширования **SHA256** на замену небезопасному алгоритму **MD5**, использование которого поддерживается, но не рекомендуется.
52 |
53 | 5. Получив ответ **Authorization**, сервер выполняет вычисляет свой вариант response и сравнивает его с тем, что получено от клиента.
54 |
55 | 6. Если хеши совпадают, пользователь получает доступ к запрошенному ресурсу.
56 |
57 | ##### Преимущества и недостатки
58 |
59 | |Преимущества|Недостатки|
60 | |---|---|
61 | |Более безопасен, чем Basic auth, поскольку пароль не передается открытым текстом.|Метод уязвим для атак типа «человек посередине» (man-in-the-middle), если не используется https.|
62 | |Простота реализации.|Учётные данные должны передаваться при каждом запросе.|
63 | |Поддерживается всеми основными браузерами.|
64 |
--------------------------------------------------------------------------------
/src/auth/webAuth/oauth.md:
--------------------------------------------------------------------------------
1 | # OAuth
2 |
3 | OAuth 2.0 — протокол аутентификации, позволяющий выдать одному сервису (приложению) права на доступ к ресурсам пользователя на другом сервисе. Протокол избавляет от необходимости доверять приложению логин и пароль, а также позволяет выдавать ограниченный набор прав, а не всё сразу.
4 |
5 | OAuth 2.0 основан на использовании базовых веб-технологий: HTTP-запросах, редиректах и т. п. Поэтому использование OAuth возможно на любой платформе с доступом к интернету и браузеру: на сайтах, в мобильных и desktop-приложениях, плагинах для браузеров.
6 |
7 | Клиент должен одним из четырёх способов получить от сервера авторизации (OAuth провайдера) токен доступа (Access Token). Далее клиент будет использовать этот Access Token в запросах к Серверу ресурсов, чтобы получать данные.
8 |
9 | ##### Особенности Access Token
10 |
11 | - Ограниченное время жизни.
12 | - Его можно отозвать. Если есть подозрение, что токен украли, то мы просто запрещаем получать данные с помощью этого токена.
13 | - Компрометация токена не значит компрометирование логина и пароля. Из токена никак не получить логин и пароль.
14 | - По токену может быть доступна только часть данных (**scope**). Клиент запрашивает список разрешений, которые необходимы ему для работы, а Владелец ресурсов, то есть пользователь, решает выдать такие права или нет. Например, можно выдать права только на просмотр списка контактов, тогда читать письма или редактировать контакты будет нельзя.
15 |
16 | Помимо Access Token сервер авторизации может выдавать также Refresh Token. Это токен, который позволяет запросить новый **access_token** без участия Владельца ресурсов. Время жизни у такого токена намного больше Access Token, и его потеря гораздо серьёзнее: используя Refresh Token, злоумышленник может запросить у Сервера авторизации новый токен доступа и войти в систему.
17 |
18 | Сервер авторизации должен располагать информацией о каждом клиенте, который делает к нему запрос, то есть каждый клиент должен быть зарегистрирован. Зарегистрировав клиента, мы получаем **client_id** и **client_secret** и обязаны передавать, как минимум **client_id** в каждом запросе.
19 |
20 | Не все клиенты могут гарантировать сохранность **client_secret**, поэтому он есть не у всех. Например, SPA без бэкенда, теоретически достать оттуда можно что угодно.
21 |
22 | ##### Способы получения Access Token
23 |
24 | 1. По данным клиента (**Client Credentials**). Получаем токен по **client_id** и **client_secre**t.
25 | 2. По логину и паролю пользователя (**Resource Owner Password Credential**). Только для безопасных клиентов, заслуживающих полного доверия.
26 | 3. По авторизационному коду (**Authorization Code Grant**). Самый сложный и самый надёжный способ.
27 | 4. Неявно (**Implicit Grant**)
28 |
29 | #### Client Credentials
30 | 1. API 1 передаёт серверу авторизации **client_id** и **client_secret**.
31 | 2. В ответ он получает **access_token**, с помощью которого может обратиться к API 2.
32 | 3. API 1 обращается к API 2.
33 | 4. API 2 получает запрос с **access_token** и обращается к серверу авторизации для проверки действительности переданного токена (**RFC 7662**).
34 | #### Resource Owner Password Credential
35 | 1. Владелец ресурсов передаёт свой логин и пароль Клиенту.
36 | 2. Клиент отправляет Авторизационному серверу логин и пароль клиента, а также свой **client_id** и **client_secret**.
37 | 3. 3. Если предоставленные пользователем учётные данные корректны, сервер авторизации вернёт ответ **application/json**, содержащий **access_token**.
38 | #### Authorization Code Grant
39 | 1. Пользователь на сайте нажимает кнопку авторизации, например через Facebook.
40 | 2. Происходит редирект на авторизационный сервер.
41 | 3. Если активной сессии нет, то пользователь должен залогиниться. Если активная сессия есть, то просто подтвердить авторизацию.
42 | 4. Если всё пойдёт хорошо, вы получите ответ **HTTP 302**. Код авторизации включён в конце URL-адреса: в параметре **?code=SplewFEFofer**
43 | 5. Теперь, когда у вас есть код авторизации, вы должны обменять его на токены. Используя извлеченный код авторизации из предыдущего шага, вам нужно будет выполнить **POST** на URL-адрес токена.
44 | 6. Если все пойдет хорошо, вы получите ответ **HTTP 200** с полезной нагрузкой, содержащей значения **access_token**, **refresh_token**, **id_token** и **token_type**.
45 | 7. Чтобы вызвать ваш API из обычного веб-приложения, приложение должно передать полученный токен доступа в заголовке авторизации вашего HTTP-запроса.
46 | #### Implicit Grant
47 | Используется на одностраничных сайтах без бэкенда.
48 | 1. Пользователь на сайте жмёт на кнопку, происходит редирект на сервер авторизации.
49 | 2. Пользователь вводит логин и пароль, если он не авторизован.
50 | 3. Происходит редирект обратно, но **access_token** возвращается в URL сразу:
51 | https://domain.com/back_path#access_token=8ijfwWEFFf0wefOofreW6rglk
52 |
--------------------------------------------------------------------------------
/src/auth/webAuth/otp.md:
--------------------------------------------------------------------------------
1 | # Одноразовые пароли (One-Time Passwords, OTP)
2 |
3 | Одноразовые пароли (OTP) используются для подтверждения аутентификации. Это случайно сгенерированные коды, которые проверяют, является ли пользователь тем, за кого себя выдает. Они часто применяются в двухфакторной аутентификации после проверки учётных данных.
4 |
5 | Для использования OTP необходима доверенная система, такая как проверенный адрес электронной почты или номер мобильного телефона. Наиболее распространённый тип — OTP с ограниченным временем действия (TOTP).
6 |
7 | OTP рекомендуется использовать в приложениях с конфиденциальными данными, например, в интернет-банкинге и финансовых сервисах.
8 |
9 | ##### Алгоритм использования OTP
10 |
11 | Традиционный способ реализации OTP:
12 |
13 | - Клиент отправляет имя пользователя и пароль.
14 | - После проверки учётных данных сервер генерирует случайный код, сохраняет его у себя и отправляет в доверенную систему.
15 | - Пользователь получает код в доверенной системе и вводит его в веб-приложение.
16 | - Сервер сверяет код с сохранённым и аутентифицирует пользователя.
17 |
18 | Как работают OTP-агенты (**Google Authenticator, Microsoft Authenticator** и F**reeOTP**):
19 |
20 | - При включённой двухфакторной аутентификации (2FA) сервер генерирует случайное начальное значение и отправляет его пользователю в виде уникального QR-кода.
21 | - Пользователь сканирует QR-код с помощью своего приложения 2FA для подтверждения доверенного устройства.
22 | - При необходимости ввода OTP пользователь проверяет наличие кода на своём устройстве и вводит его в веб-приложение.
23 | - Сервер проверяет код и предоставляет доступ.
24 |
25 | ##### Преимущества и недостатки
26 |
27 | | Преимущества | Недостатки |
28 | | -------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
29 | | Дополнительный уровень защиты. | Необходимо хранить начальные вектора (seeds), используемые для генерации OTP. |
30 | | Нет опасности, что украденный пароль может быть использован для работы с несколькими сайтами или сервисами, где также применяются OTP. | Если потерян код восстановления OTP, придётся выполнять полную процедуру восстановления доступа к учётной записи. |
31 | | | Проблемы возникают, когда доверенное устройство недоступно (севшая батарея, ошибка сети и т.д.). В этом случае, как правило, требуется резервное устройство, что создаёт дополнительный вектор атаки. |
--------------------------------------------------------------------------------
/src/auth/webAuth/token.md:
--------------------------------------------------------------------------------
1 | # Аутентификация на основе токенов
2 |
3 | Самый распространенный способ реализации аутентификации на основе токенов — использование JSON Web Tokens (JWTs).
4 |
5 | JWT — это открытый стандарт (RFC 7519), определяющий способ безопасной передачи информации между сторонами в виде объектов JSON.
6 |
7 | 
8 |
9 | После получения учётных данных от клиента сервер проверяет их и генерирует идентификационный токен JWT, содержащий информацию о пользователе. Токены идентифицируют пользователя и предоставляют данные о событии аутентификации. Они предназначены для клиента и имеют фиксированный формат, который позволяет извлекать идентификационную информацию.
10 |
11 | Чтобы предотвратить изменения или подделку, сервер формирует электронную подпись данных токена при его создании и добавляет её в токен. JWT используется в stateless приложениях и не хранится на сервере; клиент отправляет его с запросами.
12 |
13 | JWT состоит из трёх частей:
14 |
15 | - Заголовка с типом токена и алгоритмом шифрования.
16 | - Полезной нагрузки с данными для аутентификации и информацией о пользователе.
17 | - Подписи, содержащей хешированное значение header+payload+соль, которая подтверждает подлинность данных в полезной нагрузке.
18 |
19 | 
20 |
21 | Токен представляет из себя простую строку из символов, например:
22 |
23 | ```
24 | eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
25 | ```
26 |
27 | Этапы аутентификации с помощью токена:
28 |
29 | 1. Ввод логина и пароля.
30 | 2. Шифрование (преобразование логина и пароля в закодированную строку).
31 | 3. Передача шифрованных данных на сервер.
32 | 4. Генерация сервером токена доступа, с помощью которого веб-приложение будет обращаться к backend приложению для получения данных. Этот токен должен отправляться на сервер с каждым запросом.
33 | 5. Отправка токена обратно в браузер.
34 | 6. Сохранение токена на клиенте для дальнейшего использования.
35 |
36 | Суть в том, что мы один раз передаём приватные данные, а затем используем токен с публичными данными. Ключ для подписи токена хранится только на сервере, и клиент не имеет к нему доступа, что гарантирует, что только сервер может изменять токен. Декодировать токен и получить **header** и **payload** может любой, кто его получил, так как эти данные публичные.
37 |
38 | Когда сервер получает токен, он вычисляет подпись полезной нагрузки с помощью своего ключа и сравнивает её с подписью в токене. Если данные не совпадают или не удаётся декодировать токен, это указывает на возможное вмешательство, и запрос не проходит валидацию, возвращая ошибку.
39 |
40 | ##### Access и Refresh токены
41 |
42 | Подпись токена защищает его от изменений, но хакеры могут перехватить его и использовать для доступа к аккаунту, так как токен содержит все данные для аутентификации. Это делает любого, кто получил токен, равным настоящему владельцу аккаунта.
43 |
44 | Для решения этой проблемы используются Access и Refresh токены. Access Token остаётся, и добавляется Refresh токен с такой же структурой.
45 |
46 | Оба токена содержат обязательные поля в полезной нагрузке — **iat** и **exp**.
47 |
48 | 
49 |
50 | **iat** (issued at time) — время, когда токен сгенерирован.
51 | **exp** (expiration time) — время, до которого токен будет считаться валидным.
52 |
53 | ##### Алгоритм аутентификации с использованием Refresh и Access токенов
54 |
55 | 1. Пользователь вводит логин и пароль, которые отправляются на сервер.
56 | 2. Сервер создаёт или находит пользователя в базе данных и генерирует два токена с полями **iat** и **exp**: Access Token с коротким сроком действия (15-20 минут) и Refresh Token с более длительным (несколько дней или недель).
57 | 3. Сервер возвращает оба токена в браузер, где они сохраняются.
58 | 4. При запросе данных клиент проверяет срок действия Access Token. Если он не истёк, запрос отправляется; если истёк, необходимо обновить токен перед отправкой.
59 | 5. Для обновления Access Token клиент отправляет запрос с Refresh Token. Сервер генерирует новую пару токенов и возвращает их клиенту.
60 | 6. Если Refresh Token также истёк, возвращается ошибка, и пользователя просят ввести логин и пароль снова.
61 |
62 | *Дополнительно:*
63 | - https://jwt.io/
64 |
--------------------------------------------------------------------------------
/src/checkList.md:
--------------------------------------------------------------------------------
1 | # Чеклист подготовки
2 |
3 | Чеклист нужен для того, чтобы в максимально короткие сроки выявить пробелы в знаниях.
4 |
5 | ## Алгоритмы и Структуры Данных
6 | * Базовые структуры
7 | * Массив и его сортировки(сложность и реализация)
8 | * Пузырек
9 | * Вставками
10 | * Быстрая
11 | * Выборками
12 | * Хэш-Таблица
13 | * Хеш функция
14 | * Методы разрешения колизий
15 | * Метод цепочек
16 | * Последовательность проб
17 | * Дерево
18 | * Бинарное дерево поиска
19 | * B(balanced) Tree
20 | * B+ Tree
21 | * АВЛ
22 | * Красно черное
23 | * Поворот
24 | * Граф
25 | * Поиск в ширину, в глубину, алгоритм Дейкстры
26 | * Разное
27 | * Бинарный поиск
28 | * Динамическое программирование
29 | * Жадные алгоритмы
30 | * Побитовые операции
31 |
32 | ## Базы Данных
33 | * Теория Баз Данных
34 | * Транзакции
35 | * ACID
36 | * Проблемы параллельного чтения
37 | * Уровни изолированности транзакций
38 | * Нормальные формы(1-6 + бойса кода + доменная)
39 | * Распределенные БД
40 | * Репликация
41 | * Синхронная и асинхронная и полусинхронная
42 | * Master/Master & Master/Slave
43 | * Покомандная(логическая) & Построчная(физическая)
44 | * Шардинг
45 | * Статический и динамический + комбинированный, vitual bucket
46 | * Решардинг
47 | * Ключ шардирования
48 | * Паттерны поиска(умный клиент, прокси, координатор)
49 | * Консистентный хеш
50 | * Теорема САР
51 | * MapReduce
52 | * Конкретные реализации СУБД
53 | * MySql
54 | * Архитектура MySql
55 | * Конекшн
56 | * Парсер, оптимизатор, кеш и буфер, sql интерфейс
57 | * Движки(подсистемы хранения)
58 | * Файловая система
59 | * Конкурентный доступ
60 | * Блокировки
61 | * shared lock и exclusive loc
62 | * построчная и табличная
63 | * явные/неявные
64 | * SELECT… LOCK IN SHARE MODE
65 | * SELECT… FOR UPDATE
66 | * Блокировка индекса innoDB(record lock, gap lock, next key lock)
67 | * согласованное неблокирующее чтение
68 | * Deadlock
69 | * MVCC
70 | * Индексы
71 | * B Tree
72 | * B Tree
73 | * B+ Tree
74 | * Составной индекс
75 | * Устройство B Tree индекса изнутри
76 | * Hash
77 | * R-Tree
78 | * Селективность и кардинальность
79 | * Кластерные индексы
80 | * Покрывающие индексы
81 | * Основы SQL
82 | * CREATE, ALTER, DROP, SELECT, INSERT, UPDATE, DELETE, HAVING, GROUP BY, JOIN
83 | * Explain
84 | * Разное
85 | * Innodb vs MyIsam
86 | * Datetime vs Timestamp
87 | * PostgreSql
88 | * NoSql
89 | * Memcaced
90 | * Redis
91 | * Типы данных
92 | * Redis Cluster
93 | * Репликация и шардинг
94 | * Tarantool
95 | * Mongo
96 | * Брокеры сообщений
97 | * Rabbit
98 | * Kafka
99 | * Колоночные
100 | * ClickHouse
101 | * Vertica
102 | * Разное
103 | * Time-series
104 | * Blob-store
105 | * Сетевые
106 | * Графовые
107 |
108 | ## Архитектура
109 | * Основы ООП
110 | * Инкапсуляция
111 | * Полиморфзим
112 | * Наследование
113 | * Композиция/агрегация
114 | * Паттерны GoFБанда 4
115 | * Создающие
116 | * Поведенческие
117 | * Структурные
118 | * Принципы хорошей архитектуры
119 | * SOLID
120 | * GRASP
121 | * DRY
122 | * KISS
123 | * Архитектурные паттерны
124 | * Layer architecture
125 | * Onion architecture
126 | * Hexagonal architecture
127 | * CQRS
128 | * ES
129 | * Saga
130 | * DDD
131 | * Стратегические
132 | * Bounded context
133 | * Ubiquitous language
134 | * Subdomain
135 | * Тактические
136 | * Aggregate root
137 | * Entity
138 | * Value object
139 | * Api и Микросервисы
140 | * Rest
141 | * Rpc
142 | * JsonApi
143 | * GraphQL
144 | * gRpc
145 | * protobuf
146 |
147 | ## PHP
148 | * Фичи новых версий
149 | * PHP Internals
150 | * Zval
151 | * Union
152 | * CopyOnWrite
153 | * Стандартные функции
154 | * Фреймворки
155 | * Laravel
156 | * Symfony
157 | * Разное
158 |
159 | ## GoLang
160 | * scheduler
161 | * 3 сущности - горутина, поток, контекст привязанный к потоку
162 | * m : n (m задач на n потоках)
163 | * work stealing
164 | * указатели(передача по ссылке/значению)
165 | * arrays & slices
166 | * channels(небуферизированные/буферизированные) неблокирующее чтение
167 | * sync(mutex(r/w), atomic, once, pool, map, waitgrop)
168 | * рефлексия
169 | * unsafe
170 | * Error(), panic, deffer, recover
171 | * context.Context
172 |
173 | ## Информационная безопасность
174 | * SQL injection
175 | * XSS
176 | * CSRF
177 |
178 | ## Git
179 | * Rebase vs Merge
180 | * Checkout vs reset vs revert
181 |
182 | ## Основы сетей
183 | * Взаимодействие с веб-сервером
184 | * HTTP
185 | * SSL/TLS
186 | * DNS
187 | * Сетевые модели
188 | * realTime взаимодействие с сервером
189 | * Что происходит при нажатии на g
190 |
191 | ## Операционные системы
192 |
193 | - потоки и процессы
194 | - гринтреды
195 | - вытесняющая и кооперативная многозадачность
196 |
197 | ## Системное администрирование
198 | * Linux
199 | * Как убить процесс
200 | * Load Average
201 | * Docker
202 | * Теория виртуализации
203 | * Kubernetes
204 |
205 | ## Тестирование
206 | * Юнит тесты
207 | * Интеграционные тесты
208 | * Приемочные тесты
209 | * Системные
210 | * Мутационное тестирование
211 |
212 | ## Менеджмент и тимлидство
213 | * Обязанности тимлида
214 | * Resource Manager
215 | * Product Owner
216 | * Integrator
217 | * Technical Lead
218 | * Administrator
219 | * Методологии разработки
220 | * Водопад
221 | * Итеративные модели
222 | * Scrum
223 | * Kanban
224 | * Scrumban
--------------------------------------------------------------------------------
/src/db/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/db/.DS_Store
--------------------------------------------------------------------------------
/src/db/README.md:
--------------------------------------------------------------------------------
1 | # Базы данных
2 |
3 | В данном разделе рассказывается о классической теории баз данных + об особенностях работы и устройства конкретных реальных баз данных. Существующие базы данных, можно условно поделить на следующие группы - реляционные, документо-ориентированные, key=>value, временных рядов, колоночные, брокеры сообщений, blob-store, графовые, сетевые и т.д
4 |
5 | * [Теория Баз Данных](dBTheory/README.md)
6 | * [Реляционные БД](relational/README.MD)
7 | * [MySql](relational/mysql/README.MD)
8 | * [Архитектура MySql](relational/mysql/architecture.md)
9 | * [Конкурентный доступ](relational/mysql/concurency.md)
10 | * [Индексы](relational/mysql/indexes.md)
11 | * [Основы SQL](relational/mysql/sql.md)
12 | * [Explain](relational/mysql/explain.md)
13 | * [Разное](relational/mysql/unsorted.md)
14 | * [PostgreSql](relational/postgreSql/README.md)
15 | * [Колоночные](column/README.md)
16 | * [ClickHouse](column/clickhouse.md)
17 | * [Vertica](column/vertica.md)
18 | * [NoSql](noSql/README.md)
19 | * [Memcached](noSql/memcached.md)
20 | * [Redis](noSql/redis.md)
21 | * [Tarantool](noSql/tarantool.md)
22 | * [Mongo](noSql/mongo.md)
23 | * [Message brokers](messages/README.md)
24 | * [Rabbit](messages/rabbit.md)
25 | * [Kafka](messages/kafka.md)
26 | * [Nats](messages/nats.md)
27 |
--------------------------------------------------------------------------------
/src/db/column/README.md:
--------------------------------------------------------------------------------
1 | # Колоночные базы данных
2 |
3 | Колоночные базы данных (Columnar Databases) - это тип баз данных, где данные хранятся и организуются по колонкам, в отличие от традиционных реляционных баз данных, где данные хранятся по строкам. В колоночных базах данных каждая колонка содержит данные одного типа, и они компактно хранятся в сжатом формате.
4 |
5 | Преимущества колоночных баз данных включают более эффективное использование памяти, лучшую сжимаемость данных, быстрый доступ к определенным колонкам и поддержку агрегатных операций. Они обычно хорошо подходят для аналитических и OLAP (Online Analytical Processing) задач, где требуется обработка больших объемов данных.
6 |
7 | Некоторые известные колоночные базы данных: Apache Cassandra, Apache HBase, Google Bigtable и Vertica. Они широко используются в различных сценариях, включая аналитику, бизнес-интеллект и обработку больших данных.
--------------------------------------------------------------------------------
/src/db/column/vertica.md:
--------------------------------------------------------------------------------
1 | # Vertica
2 |
3 | Vertica - колоночная база данных, разработанная для обработки аналитических и OLAP-запросов на больших объемах данных. Вот некоторые особенности, отличительные черты, преимущества, недостатки и архитектура Vertica:
4 |
5 | Особенности и отличительные черты:
6 |
7 | 1. Колоночное хранение данных: Вертикальная организация данных по колонкам позволяет эффективно сжимать данные и ускоряет выполнение аналитических запросов, поскольку только необходимые колонки считываются с диска.
8 | 2. Распределенная архитектура: Vertica может работать в распределенном режиме на кластере серверов, где данные разделены и хранятся на разных узлах, обеспечивая высокую пропускную способность и масштабируемость.
9 | 3. Оптимизация для аналитических запросов: Vertica имеет множество встроенных функций и оптимизаций, таких как оптимизация запросов на основе статистики, параллельное выполнение запросов и сжатие данных, что позволяет обрабатывать сложные аналитические запросы быстро и эффективно.
10 |
11 | Преимущества:
12 |
13 | 1. Высокая производительность: Vertica обеспечивает быстрое выполнение аналитических запросов на больших объемах данных.
14 | 2. Горизонтальная масштабируемость: Vertica позволяет добавлять новые серверы в кластер для увеличения общей пропускной способности и хранения большего объема данных.
15 | 3. Встроенные аналитические функции: Vertica предлагает широкий набор встроенных функций для выполнения сложных аналитических операций и агрегирования данных.
16 |
17 | Недостатки:
18 |
19 | 1. Сложность установки и настройки: Установка и настройка Vertica может быть сложной и требует некоторых знаний и опыта в администрировании баз данных.
20 | 2. Высокие требования к аппаратному обеспечению: Vertica требует высокопроизводительного оборудования для достижения оптимальной производительности.
21 |
22 | Архитектура: Архитектура Vertica включает узлы хранения данных (Storage Nodes), узлы выполнения запросов (Query Nodes) и узлы управления (Management Nodes). Узлы хранения данных отвечают за хранение и управление данными, узлы выполнения запросов обрабатывают аналитические запросы, а узлы управления координируют работу кластера и управляют метаданными. Vertica также использует репликацию данных для обеспечения отказоустойчивости и доступности данных.
23 |
24 | Эта архитектура позволяет Vertica достигать высокой производительности и масштабируемости при обработке аналитических запросов на больших объемах данных.
--------------------------------------------------------------------------------
/src/db/dBTheory/README.md:
--------------------------------------------------------------------------------
1 | # Теория баз данных
2 |
3 | Классическая теория БД не привязанна к каким-либо конкретным системам хранения и обработки данных.
4 |
5 | База данных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины. Многие специалисты указывают на распространённую ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий.
6 |
7 |
--------------------------------------------------------------------------------
/src/db/dBTheory/distrubedDb/README.md:
--------------------------------------------------------------------------------
1 | # Распределенные системы
2 |
3 | - [Репликация](replication.md)
4 | - [Шардинг](sharding.md)
5 | - [Разное](unsorted.md)
--------------------------------------------------------------------------------
/src/db/messages/README.md:
--------------------------------------------------------------------------------
1 | # Брокеры сообщений
2 |
3 | ## Гарантии доставки
4 |
5 | - At-most-once delivery (“как максимум однократная доставка”). Это значит, что сообщение не может быть доставлено больше одного раза. При этом сообщение может быть потеряно.
6 | - At-least-once delivery (“как минимум однократная доставка”). Это значит, что сообщение никогда не будет потеряно. При этом сообщение может быть доставлено более одного раза.
7 | - Exactly-once delivery (“строго однократная доставка”). Святой грааль систем сообщений. Все сообщения доставляются строго единожды.
8 |
9 | * [Kafka](kafka.md)
10 | * [Rabbit](rabbit.md)
11 | * [Nats](nats.md)
--------------------------------------------------------------------------------
/src/db/messages/nats.md:
--------------------------------------------------------------------------------
1 | # Nats
2 |
3 |  4 |
5 | NATS — относительно молодой проект, созданный Derek Collison, за плечами которого более 20 лет работы над распределенными очередями сообщений.
6 |
7 | Нас покорила простота администрирования кластера NATS. Чтобы подключить новый узел, процессу NATS достаточно указать адрес любого другого узла кластера, и он мгновенно скачивает всю топологию и определяет живые/мертвые узлы. Сообщения в NATS группируются по темам, и каждый узел знает, какие узлы имеют живых подписчиков на какие темы. Все сообщения в кластере доставляются напрямую от отправителя получателю, без промежуточных шагов и с минимальной задержкой.
8 |
9 | По производительности NATS опережает все очереди с “гарантированной доставкой”. NATS написан на языке Go, но имеет клиентские библиотеки для всех популярных языков. Кроме того, клиенты NATS также знают топологию кластера и способны самостоятельно переподключаться в случае потери связи со своим узлом.
--------------------------------------------------------------------------------
/src/db/messages/rabbit.md:
--------------------------------------------------------------------------------
1 | # RabbitMQ
2 |
3 |
4 |
5 | NATS — относительно молодой проект, созданный Derek Collison, за плечами которого более 20 лет работы над распределенными очередями сообщений.
6 |
7 | Нас покорила простота администрирования кластера NATS. Чтобы подключить новый узел, процессу NATS достаточно указать адрес любого другого узла кластера, и он мгновенно скачивает всю топологию и определяет живые/мертвые узлы. Сообщения в NATS группируются по темам, и каждый узел знает, какие узлы имеют живых подписчиков на какие темы. Все сообщения в кластере доставляются напрямую от отправителя получателю, без промежуточных шагов и с минимальной задержкой.
8 |
9 | По производительности NATS опережает все очереди с “гарантированной доставкой”. NATS написан на языке Go, но имеет клиентские библиотеки для всех популярных языков. Кроме того, клиенты NATS также знают топологию кластера и способны самостоятельно переподключаться в случае потери связи со своим узлом.
--------------------------------------------------------------------------------
/src/db/messages/rabbit.md:
--------------------------------------------------------------------------------
1 | # RabbitMQ
2 |
3 |  4 |
5 | **RabbitMQ** — это распределенная система управления очередью сообщений. Распределенная, поскольку обычно работает как кластер узлов, где очереди распределяются по узлам и, опционально, реплицируются в целях устойчивости к ошибкам и высокой доступности. Штатно, она реализует AMQP 0.9.1 и предлагает другие протоколы, такие как STOMP, MQTT и HTTP через дополнительные модули.
6 |
7 | RabbitMQ использует как классический, так и новаторский подходы к обмену сообщениями. Классический в том смысле, что она ориентирована на очередь сообщений, а новаторский — в возможности гибкой маршрутизации. Именно эта возможность маршрутизации является ее уникальным преимуществом. Создание быстрой, масштабируемой и надежной распределенной системы сообщений само по себе является достижением, но функциональность маршрутизации сообщений делает ее действительно выдающейся среди множества технологий обмена сообщениями.
8 |
9 | ### Exchange'и и очереди
10 |
11 | Супер-упрощенный обзор:
12 |
13 | - Паблишеры (publishers) отправляют сообщения на exchange’и
14 | - Exchange’и отправляют сообщения в очереди и в другие exchange’и
15 | - RabbitMQ отправляет подтверждения паблишерам при получении сообщения
16 | - Получатели (consumers) поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь(-и) они получают
17 | - RabbitMQ проталкивает (push) сообщения получателям
18 | - Получатели отправляют подтверждения успеха/ошибки
19 | - После успешного получения, сообщения удаляются из очередей
20 |
21 | ### Гарантии доставки
22 |
23 | RabbitMQ предоставляет надёжные, долговременные гарантии обмена сообщениями, но есть много ситуаций, когда они не помогут. Вот список моментов, которые следует запомнить:
24 |
25 | - Следует применять зеркалирование очередей, надёжные очереди, устойчивые сообщения, подтверждения для отправителя, флаг подтверждения и принудительное уведомление от получателя, если требуются надёжные гарантии в стратегии “как минимум однократная доставка”.
26 | - Если отправка производится в рамках стратегии “как минимум однократная доставка”, может потребоваться добавить механизм дедубликации или идемпотентности при дублировании отправляемых данных.
27 | - Если вопрос потери сообщений не так важен, как вопрос скорости доставки и высокой масштабируемости, то подумайте о системах без резервирования, без устойчивых сообщений и без подтверждений на стороне источника. Я всё же предпочел бы оставить принудительные уведомления от получателя, чтобы контролировать поток принимаемых сообщений путем изменения ограничений предвыборки. При этом вам потребуется отправлять уведомления пакетами и использовать флаг “multiple”.
28 |
29 | *Дополнительно:*
30 |
31 | 1. https://habr.com/post/149694/
32 | 2. https://habr.com/post/150134/
33 | 3. https://habr.com/post/200870/
34 | 4. https://habr.com/post/201096/
35 | 5. https://habr.com/post/201178/
36 | 6. https://habr.com/post/236221/
--------------------------------------------------------------------------------
/src/db/noSql/README.md:
--------------------------------------------------------------------------------
1 | # noSql
2 |
3 | **NoSQL** (от [англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) not only SQL — *не только SQL*) — термин, обозначающий ряд подходов, направленных на реализацию хранилищ [баз данных](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B7%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85), имеющих существенные отличия от моделей, используемых в традиционных [реляционных СУБД](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94) с доступом к данным средствами языка [SQL](https://ru.wikipedia.org/wiki/SQL). Применяется к базам данных, в которых делается попытка решить проблемы [масштабируемости](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%81%D1%88%D1%82%D0%B0%D0%B1%D0%B8%D1%80%D1%83%D0%B5%D0%BC%D0%BE%D1%81%D1%82%D1%8C) и [доступности](https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D1%81%D1%82%D1%83%D0%BF%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8) за счёт [атомарности](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%BE%D1%81%D1%82%D1%8C) ([англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) atomicity) и [согласованности данных](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B3%D0%BB%D0%B0%D1%81%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85) ([англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) consistency).
--------------------------------------------------------------------------------
/src/db/noSql/memcached.md:
--------------------------------------------------------------------------------
1 | # Memcached
2 |
3 | [Memcached](http://code.google.com/p/memcached/) представляет собой сервер, хранящий в оперативной памяти некоторые данные с заданным временем жизни. Доступ к данным осуществляется по ключу (имени). Вы можете думать о Memcached, как о [хэш-таблице](https://eax.me/hash-tables/), хранящейся на сервере. Применяется он в основном для кэширования кода веб-страниц, результатов запросов к базе данных и тп.
4 |
5 | Также ничто не мешает использовать Memcached в качестве «не очень надежного» key-value хранилища. Например, в нем можно хранить сессии пользователей, коды капч или счетчик посетителей, находящихся в данный момент на сайте.
6 |
7 | Коротко о главном:
8 |
9 | - Умеет только key => value in memory
10 | - Вытеснение. Когда Memcache доходит до ограничения в памяти, он начинает удалять объекты по принципу [LRU](https://ruhighload.com/%d0%9a%d1%8d%d1%88%d0%b8%d1%80%d0%be%d0%b2%d0%b0%d0%bd%d0%b8%d0%b5+%d0%b4%d0%b0%d0%bd%d0%bd%d1%8b%d1%85#lru)(Least Recently Used). Memcache постарается удалить прежде всего те данные, которые запрашивались очень давно (т.е. менее популярные удалит, а более популярные оставит).
11 | - Шардинг из коробки(достаточно просто добавлять сервера, вся работа будет инкапсулирована в него)
12 | - Максимальная длина ключа по умолчанию составляет 250 байт, а длина значения — 1 Мб;
13 | - [Будьте осторожнее со спец-символами](https://eax.me/memcached/#comment-432394490);
14 | - Ключи можно «расширить», воспользовавшись каким-нибудь MD5 или SHA512 (в этом случае нехэшированный ключ будет разумно продублировать в значении);
15 | - Если хочется хранить очень длинные значения, можно сжимать их и/или разбивать на части;
16 | - Весь ввод-вывод осуществляется с помощью [libevent](https://eax.me/libevent/);
17 | - Для ускорения работы память выделяется при запуске демона и не освобождается до его остановки;
18 | - Для борьбы с фрагментацией памяти используется [slab allocator](http://ru.wikipedia.org/wiki/Slab);
19 | - Все операции являются атомарными, есть поддержка [compare-and-swap](http://ru.wikipedia.org/wiki/%D0%A1%D1%80%D0%B0%D0%B2%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81_%D0%BE%D0%B1%D0%BC%D0%B5%D0%BD%D0%BE%D0%BC);
20 | - С Memcached можно работать по UDP;
21 | - Помимо текстового протокола [также существует бинарный](http://code.google.com/p/memcached/wiki/BinaryProtocolRevamped);
22 |
23 |
24 |
25 | *Дополнительно:*
26 |
27 | - [Кэширование и Memcached](https://zinvapel.github.io/it/tools/2017/11/27/cache/)
28 |
29 |
--------------------------------------------------------------------------------
/src/db/noSql/mongo.md:
--------------------------------------------------------------------------------
1 | # MongoDb
2 |
3 | **MongoDB** — документоориентированная система управления базами данных (СУБД) с открытым исходным кодом, не требующая описания схемы таблиц. Классифицирована как NoSQL, использует JSON-подобные документы и схему базы данных. Написана на языке C++.
4 |
5 | ### Формат данных в MongoDB
6 |
7 | Одним из популярных стандартов обмена данными и их хранения является JSON (JavaScript Object Notation). JSON эффективно описывает сложные по структуре данные. Способ хранения данных в MongoDB в этом плане похож на JSON, хотя формально JSON не используется. Для хранения в MongoDB применяется формат, который называется **BSON** (БиСон) или сокращение от binary JSON.
8 |
9 | BSON позволяет работать с данными быстрее: быстрее выполняется поиск и обработка. Хотя надо отметить, что BSON в отличие от хранения данных в формате JSON имеет небольшой недостаток: в целом данные в JSON-формате занимают меньше места, чем в формате BSON, с другой стороны, данный недостаток с лихвой окупается скоростью.
10 |
11 | ### Документы вместо строк
12 |
13 | Если реляционные базы данных хранят строки, то MongoDB хранит документы. В отличие от строк документы могут хранить сложную по структуре информацию. Документ можно представить как хранилище ключей и значений.
14 |
15 | Ключ представляет простую метку, с которым ассоциировано определенный кусок данных.
16 |
17 | Однако при всех различиях есть одна особенность, которая сближает MongoDB и реляционные базы данных. В реляционных СУБД встречается такое понятие как первичный ключ. Это понятие описывает некий столбец, который имеет уникальные значения. В MongoDB для каждого документа имеется уникальный идентификатор, который называется `_id`. И если явным образом не указать его значение, то MongoDB автоматически сгенерирует для него значение.
18 |
19 | Каждому ключу сопоставляется определенное значение. Но здесь также надо учитывать одну особенность: если в реляционных базах есть четко очерченная структура, где есть поля, и если какое-то поле не имеет значение, ему (в зависимости от настроек конкретной бд) можно присвоить значение `NULL`. В MongoDB все иначе. Если какому-то ключу не сопоставлено значение, то этот ключ просто опускается в документе и не употребляется.
20 |
21 | ### Коллекции
22 |
23 | Если в традиционном мире SQL есть таблицы, то в мире MongoDB есть коллекции. И если в реляционных БД таблицы хранят однотипные жестко структурированные объекты, то в коллекции могут содержать самые разные объекты, имеющие различную структуру и различный набор свойств.
24 |
25 | ### Репликация
26 |
27 | Система хранения данных в MongoDB представляет набор реплик. В этом наборе есть основной узел, а также может быть набор вторичных узлов. Все вторичные узлы сохраняют целостность и автоматически обновляются вместе с обновлением главного узла. И если основной узел по каким-то причинам выходит из строя, то один из вторичных узлов становится главным.
28 |
29 | ### Простота в использовании
30 |
31 | Отсутствие жесткой схемы базы данных и в связи с этим потребности при малейшем изменении концепции хранения данных пересоздавать эту схему значительно облегчают работу с базами данных MongoDB и дальнейшим их масштабированием. Кроме того, экономится время разработчиков. Им больше не надо думать о пересоздании базы данных и тратить время на построение сложных запросов.
32 |
33 | ### GridFS
34 |
35 | Одной из проблем при работе с любыми системами баз данных является сохранение данных большого размера. Можно сохранять данные в файлах, используя различные языки программирования. Некоторые СУБД предлагают специальные типы данных для хранения бинарных данных в БД (например, BLOB в MySQL).
36 |
37 | В отличие от реляционных СУБД MongoDB позволяет сохранять различные документы с различным набором данных, однако при этом размер документа ограничивается 16 мб. Но MongoDB предлагает решение - специальную технологию **GridFS**, которая позволяет хранить данные по размеру больше, чем 16 мб.
38 |
39 | Система GridFS состоит из двух коллекций. В первой коллекции, которая называется `files`, хранятся имена файлов, а также их метаданные, например, размер. А в другой коллекции, которая называется `chunks`, в виде небольших сегментов хранятся данные файлов, обычно сегментами по 256 кб.
40 |
41 | Для тестирования GridFS можно использовать специальную утилиту **mongofiles**, которая идет в пакете mongodb.
42 |
43 | #
--------------------------------------------------------------------------------
/src/db/noSql/tarantool.md:
--------------------------------------------------------------------------------
1 | # Tarantool
2 |
3 | Tarantool представляет собой решение, совмещающее неблокирующий сервер приложений на Lua с NoSQL базой данных. Высокой производительности позволяет достичь стек технологий, который использует тарантул:
4 |
5 | - libev, libcoro и libeio для реализации event-loop'а, кооперативной многозадачности (coroutines/fibers) и асинхронной работы с сетью и другими задачами.
6 | - LuaJIT — Трассирующий JIT-компилятор для Lua (на стероидах).
7 |
8 | ### Особенности хранилища
9 |
10 | Базовым элементом хранения является кортеж. Кортеж имеет любую размерность, это просто произвольно длинный список полей, ассоциированный с уникальным ключом. Каждый кортеж принадлежит какому-то пространству (space). По полям кортежа можно определять индексы. Если проводить аналогии с реляционными СУБД, то "пространство" соответствует таблице, а "поля" соответствуют столбцам.
11 |
12 | 1. Несколько движков хранения данных:
13 | - Memtx — движок хранения данных полностью в памяти, с поддержкой нескольких видов индексов:
14 | - TREE (B+*-Дерево) — для быстрого поиска значений и возможности интегрирования.
15 | - HASH (Хеш-таблица) — для еще более быстрого поиска значений.
16 | - BITSET (Битовая маска) — возможность поиска по битовым маскам.
17 | - RTREE (многомерное R*-Дерево) — для быстрого поиска ближайших соседей (KNN) и точек в заданных многомерных параллелепипедах с заданными функциями расстояния между двумя точками.
18 | - Sophia — двухуровневый движок хранения информации на диске, который был разработан в ответ на "недостатки" в LSM-деревьях, B-Деревьях и других. Он прекрасно подходит для нагрузки типа "много записи данных среднего размера и немного чтений", но расчёт идёт также на то, что чтение не будет занимать много времени.
19 | 2. Возможность поддерживать "персистентность" с помощью xlog (также известный как Transaction Log), snap (который, в свою очередь, является полным снимком БД) и eventual-consistency (консистетность в конечном счёте) master-master репликации.
20 | 3. Поддержка вторичных ключей и составных ключей.
21 | 4. Аутентификация и привилегии для пользователей и ролей.
22 | 5. MessagePack в качестве протокола для связи клиента с сервером и хранения информации внутри самой базы. MessagePack обеспечивает упаковку некоторых данных, что позволяет снизить трафик, передаваемый по сети, и размер занимаемой памяти в самом хранилище.
23 | 6. Поддержка транзакций и мультиверсионности индексов.
24 |
25 | ### Характеристика сервера приложений
26 |
27 | Язык Lua прекрасно подходит для написания бизнес-логики вашего приложения и прост в освоении, а благодаря трассирующей JIT компиляции можно добиться существенной производительности. Также есть возможность писать модули приложения на языке C/C++.
28 |
29 | Из встроенных библиотек есть возможность работы с YAML, JSON и CSV; имеется возможность для работы с неблокирующим дисковым/сетевым вводом-выводом, работой с UUID, алгоритмами хешированиями, упаковкой-распаковкой данных с заданной схемой и другое.
30 |
31 | Имеется возможность связывать Tarantool'ы в кластера с помощью модуля 'net.box'. В качестве примера можно использовать модуль '[sharding](https://github.com/tarantool/shard)', который реализует шардинг на стороне сервера и '[connection-pool](https://github.com/tarantool/connection-pool)'.
--------------------------------------------------------------------------------
/src/db/relational/README.md:
--------------------------------------------------------------------------------
1 | # Реляционные базы данных
2 |
3 | Реляционные базы данных (РБД) представляют собой структурированные системы хранения данных, основанные на концепции таблиц и связей между ними. Они предоставляют эффективные механизмы для организации и манипуляции данными, обеспечивая целостность и надежность. РБД используют язык SQL (Structured Query Language) для выполнения запросов и управления данными. Они широко применяются в приложениях, требующих структурированного хранения данных, таких как учетная система, системы управления содержимым и бизнес-приложения.
--------------------------------------------------------------------------------
/src/db/relational/mysql/README.MD:
--------------------------------------------------------------------------------
1 | # MySql
2 |
3 | * [Архитектура MySql](architecture.md)
4 | * [Конкурентный доступ](concurency.md)
5 | * [Типы данных](dataTypes.md)
6 | * [Индексы](indexes.md)
7 | * [Оптимизация запросов](queryOptimization.md)
8 | * [Основы SQL](sql.md)
9 | * [Explain](explain.md)
10 | * [Разное](unsorted.md)
--------------------------------------------------------------------------------
/src/db/relational/mysql/architecture.md:
--------------------------------------------------------------------------------
1 | ## Логическая архитектура Mysql
2 |
3 | 
4 |
5 | На самом верхнем уровне содержатся службы, которые не являются уникальными для MySQL. Эти службы необходимы большинству сетевых клиент-серверных инструментов и серверов: они обеспечивают
6 | поддержку соединений, идентификацию, безопасность и т. п.
7 |
8 | Второй уровень представляет гораздо больший интерес. Здесь сосредоточена значительная часть интеллекта MySQL: синтаксический анализ запросов, оптимизация, кэширование и все встроенные функции (например, функции работы с датами и временем, математические функции, шифрование). На этом уровне реализуется любая независимая от подсистемы хранения данных функциональность, например хранимые
9 | процедуры, триггеры и представления.
10 |
11 | Третий уровень содержит подсистемы хранения данных. Они отвечают за сохранение и извлечение всех данных, хранимых в MySQL. Подобно различным файловым системам GNU/Linux, каждая подсистема хранения данных имеет свои сильные и слабые стороны. Сервер взаимодействует с ними с помощью API подсистемы хранения данных. Этот интерфейс скрывает различия между подсистемами хранения данных и делает их почти прозрачными на уровне запросов. Кроме того, данный интерфейс содержит пару десятков низкоуровневых функций, выполняющих операции типа «начать транзакцию» или «извлечь строку с таким первичным ключом». Подсистемы хранения не производят синтаксический анализ кода SQL и не взаимодействуют друг с другом, они просто отвечают на исходящие от сервера запросы.
12 |
13 | ## Управление соединениями и безопасность
14 |
15 | Для каждого клиентского соединения выделяется отдельный поток внутри процесса сервера. Запросы по данному соединению исполняются в пределах этого потока, который, в свою очередь, выполняется одним ядром или процессором. Сервер кэширует потоки, так что их не нужно создавать или уничтожать для каждого нового соединения. Когда клиенты (приложения) подключаются к серверу MySQL, сервер должен их идентифицировать. Идентификация основывается на имени пользователя, адресе хоста, с которого происходит соединение, и пароле. Также можно использовать сертификаты X.509 при соединении по протоколу Secure Sockets Layer (SSL). После того как клиент подключился, для каждого запроса сервер проверяет наличие необходимых привилегий (например, разрешено ли клиенту использовать команду SELECT применительно к таблице Country базы данных world).
16 |
--------------------------------------------------------------------------------
/src/db/relational/mysql/sql.md:
--------------------------------------------------------------------------------
1 | # Основы языка SQL
2 |
3 | SQL (structured query language — «язык структурированных запросов») — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных.
4 |
5 | ## Операторы
6 |
7 | Операторы SQL делятся на:
8 |
9 | - операторы определения данных (Data Definition Language, DDL):
10 | - CREATE создаёт объект БД (саму базу, таблицу, представление, пользователя и т. д.),
11 | - ALTER изменяет объект,
12 | - DROP удаляет объект;
13 | - операторы манипуляции данными (Data Manipulation Language, DML):
14 | - SELECT выбирает данные, удовлетворяющие заданным условиям,
15 | - INSERT добавляет новые данные,
16 | - UPDATE изменяет существующие данные,
17 | - DELETE удаляет данные;
18 | - операторы определения доступа к данным (Data Control Language, DCL):
19 | - GRANT предоставляет пользователю (группе) разрешения на определённые операции с объектом,
20 | - REVOKE отзывает ранее выданные разрешения,
21 | - DENY задаёт запрет, имеющий приоритет над разрешением;
22 | - операторы управления транзакциями (Transaction Control Language, TCL):
23 | - COMMIT применяет транзакцию,
24 | - ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции,
25 | - SAVEPOINT делит транзакцию на более мелкие участки.
26 |
27 | 
--------------------------------------------------------------------------------
/src/db/relational/postgreSql/README.md:
--------------------------------------------------------------------------------
1 | # Что такое PostgreSQL?
2 |
3 | PostgreSQL — это объектно-реляционная система управления базами данных (ОРСУБД, ORDBMS), основанная на [POSTGRES, Version 4.2](http://db.cs.berkeley.edu/postgres.html) — программе, разработанной на факультете компьютерных наук Калифорнийского университета в Беркли. В POSTGRES появилось множество новшеств, которые были реализованы в некоторых коммерческих СУБД гораздо позднее.
4 |
5 | PostgreSQL — СУБД с открытым исходным кодом, основой которого был код, написанный в Беркли. Она поддерживает большую часть стандарта SQL и предлагает множество современных функций:
6 |
7 | - сложные запросы
8 | - внешние ключи
9 | - триггеры
10 | - изменяемые представления
11 | - транзакционная целостность
12 | - многоверсионность
13 |
14 | Кроме того, пользователи могут всячески расширять возможности PostgreSQL, например создавая свои
15 |
16 | - типы данных
17 | - функции
18 | - операторы
19 | - агрегатные функции
20 | - методы индексирования
21 | - процедурные языки
22 |
--------------------------------------------------------------------------------
/src/db/relational/postgreSql/indexes.md:
--------------------------------------------------------------------------------
1 | # Индексы
2 |
3 | PostgreSQL поддерживает несколько типов индексов: B-дерево, хеш, GiST, SP-GiST, GIN и BRIN. Для разных типов индексов применяются разные алгоритмы, ориентированные на определённые типы запросов. По умолчанию команда `CREATE INDEX` создаёт индексы типа B-дерево, эффективные в большинстве случаев.
--------------------------------------------------------------------------------
/src/devmethods.md:
--------------------------------------------------------------------------------
1 | # Методологии разработки ПО
2 |
3 | ## Водопад или Каскадная модель
4 |
5 | **Каскадная модель** (waterfall model) - [*модель процесса разработки*](http://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D1%81%D0%BA%D0%B0%D0%B4%D0%BD%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C) программного обеспечения, в которой процесс разработки выглядит как поток, последовательно проходящий фазы анализа требований, проектирования, реализации, тестирования, интеграции и поддержки.
6 | Каскадная модель подходит для больших проектов с большими сроками, большими штатами, большим функционалом: сложные системы в банковской сфере, большие интернет-магазины, проекты с большим числом пользователей и так далее. ТЗ для таких проектов может занимать тысячи страниц, но для разработчиков такой процесс фактически идеален: все описано, всё завизировано и утверждено, сделано максимально всё, чтобы понять как должна работать система.
7 |
8 | Водопад даёт качественный результат в силу чёткого следования порядку работы, отсутствию смены требований.
9 |
10 | Минус системы: при необходимости изменений возникает большой объём "бюрократических" работ: согласование и утверждение со всеми заинтересованными лицами.
11 |
12 | ## Итеративный процесс
13 |
14 | **Итеративная разработка** - это выполнение работ параллельно с непрерывным анализом полученных результатов и корректировкой предыдущих этапов работы. Проект при этом [*подходе*](http://ru.wikipedia.org/wiki/%D0%98%D1%82%D0%B5%D1%80%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%B0%D1%8F_%D1%80%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0) в каждой фазе развития проходит повторяющийся цикл: Планирование — Реализация — Проверка — Оценка ( plan-do-check-act cycle).
15 |
16 | Предпочтителен в случаях когда система сложная и непонятно как она должна работать в конечном виде. Основной принцип: пошаговое приближение к конечной цели. То есть сделать от начала и до конца часть системы, внедрить, собрать фидбек, обсудить, скорректировать процесс и перейти к следующему шагу. Итерация может быть большой (2-3 месяца) или нет (2-3 недели).
17 |
18 | Метод очень эффективен в плане взаимодействия с клиентом. Особенно с тем, кто толком не представляет чего он хочет. Улучшается обратная связь с Заказчиком – он принимает каждый этап (итерацию). Выпуск проекта в стартовой, урезанной конфигурации позволяет Заказчику самому понять куда идти дальше. И он идёт дальше **вместе с вами**.
19 |
20 | Метод позволяет брать в работу приоритетные задачи и риски. Распределяется нагрузка равномерно по всему сроку, то есть проектировщики не сидят без дела, после выполнения проектирования, как было бы в методе "водопад", а после выполнения первого этапа, когда программисты только начали работу, переходят ко второму. В это время дизайнеры могут заниматься уже третьим этапом.
21 |
22 | Затраты на проект распределяются равномерно, а не в конце проекта. Это важно для Заказчика.
23 |
24 | Сложности метода:
25 |
26 | - Нужно внедрять, обучать людей;
27 | - Много ролей, требующих узкой специализации;
28 | - Требуется постоянный контроль, поддержание процесса.
29 |
30 | Итеративный процесс имеет несколько видов: Agile, XP, Kanban, RUP и другие.
31 |
32 | ### Agile/Scrum
33 |
34 | [***Agile***](http://www.agilemanifesto.org/iso/ru/) - серия подходов к разработке программного обеспечения, ориентированных на использование итеративной разработки, динамическое формирование требований и обеспечение их реализации в результате постоянного взаимодействия внутри самоорганизующихся рабочих групп, состоящих из специалистов различного профиля.
35 |
36 | **Scrum** - методология гибкой разработки программного обеспечения. Scrum чётко делает акцент на неотвратимости срока демонстрации готового функционала клиенту.
37 |
38 | 
39 |
40 | Работа организуется по следующему принципу:
41 |
42 | 1. Менеджер проекта (Product owner) собирает все потребности, "хотелки" по продукту, сценарии использования в списке задач (Product backlog).
43 | 2. На основе Product backlog на собрании перед циклом разработки (Sprint planning meeting) составляется круг задач (Sprint backlog) решаемых в этой итерации (Sprint'e)
44 | 3. Производится цикл с разработкой, тестированием, демонстрацией результата заказчику.
45 | 4. По результатам Sprint'а проводится публичный анализ (Sprint Retrospective) результатов работы.
46 | 5. Цикл повторяется нужное число раз до выхода готового продукта.
47 |
48 | **Плюсы и минусы технологии**
49 |
50 | **Плюсы:**
51 |
52 | - Просто внедрить
53 | - Разработчикам обычно нравится
54 | - Прозрачность проекта
55 | - Ориентация на результат
56 |
57 | **Минусы:**
58 |
59 | - Не все люди сработаются, сложности "человеческого фактора".
60 | - Издержки на «болтовню» 10-30%
61 | - Качество веб-системы может сильно пострадать, если неверно организован процесс и неверно заданы Definition of Done.
62 |
63 | ### Канбан
64 |
65 | **Kanban** - модель разработки, в условиях ограничения числа выполняемых задач каждым разработчиком.
66 |
67 | Модель подходит для веб-студий, работающих с большим количеством несложных заказов. Работа по этой модели - это работа без конечных сроков. Клиент платит за то, что студия потратила время. При доверии со стороны клиента, что программист работает эффективно и поставленную задачу реально можно было решить именно за то время, которое на неё потрачено.
68 |
69 | Канбан позволяет сократить время прохода задачи до состояния «готовности». Количество незавершённой работы разработчика должно быть ограничено. Новая задача может ставиться только тогда, когда какая-то из существующих передаётся следующему элементу производственного цикла. Kanban (или сигнальная карточка) подразумевает, что производится некое визуальное оповещение о том, что можно задавать новую работу, так как текущий объём работ не равен принятым лимитам.
70 |
71 | **Смысл системы с точки зрения разработчика**: максимально упростить бюрократию и дать человеку просто работать над небольшим числом задач.
72 |
73 | **Смысл системы с точки зрения компании**: снижение времени прохождения задачи через группу специалистов до её релиза. Система позволяет создать работнику такие комфортные условия работы, что бы задача проходила через все эти этапы быстро. При этом происходит визуализация задач, облегчающая контроль.
74 |
75 | 
76 |
--------------------------------------------------------------------------------
/src/devops/README.md:
--------------------------------------------------------------------------------
1 | # Системной администрирование
2 |
3 | Системное администрирование - обеспечение штатной работы парка компьютерной техники, сети и программного обеспечения. Зачастую системному администратору вменяется обеспечение информационной безопасности в организации. В контексте разработки нас больше интересует эксплуатация - всё что связано с нормальным развёртованием, функционированием и наблюдением за нашими приложениями на продакшн серверах.
4 |
5 | * [Linux](linux.md)
6 | * [Основы виртуализации](virtualization/README.md)
7 | * [Docker](virtualization/docker.md)
8 | * [Kubernetes](virtualization/kubernetes.md)
9 | * [Deployment](deployment.md)
10 | * [Observability](observability.md)
11 | * [Load Balancing](load_balancing.md)
--------------------------------------------------------------------------------
/src/devops/deployment.md:
--------------------------------------------------------------------------------
1 | # Deployment
2 |
3 | ## Green-Blue Deployment
4 |
5 | При этой стратегии создается полная копия инфраструктуры (Green) для
6 | новой версии приложения, а затем постепенно перенаправляется трафик на нее, оставляя предыдущую версию (Blue) работающей
7 | параллельно. Это обеспечивает возможность быстрого отката в случае проблем и минимизирует риски простоя системы.
8 |
9 | Одна из задач автоматизации деплоя — переход из одного состояния в другое внутри себя же, с переводом софта из финальной
10 | стадии тестирования в действующий продакшен. Обычно это нужно сделать быстро, чтобы минимизировать время простоя. При
11 | сине-зеленом подходе у вас есть два продакшена, насколько возможно идентичных. В любое время один из них, допустим
12 | синий, активен. При подготовке новой версии софта, вы делаете финальное тестирование в зелёном продакшене. Вы
13 | убеждаетесь, что программа в этом продакшене работает и настраиваете роутер так, чтобы все входящие запросы шли в
14 | зелёную операционную среду — синяя в режиме ожидания.
15 |
16 | Сине-зелёный деплой также даёт вам возможность быстро откатиться до старого состояния: если что-то пойдет не так,
17 | переключите роутер обратно на синий продакшен. Но вам всё ещё придётся справляться с пропущенными транзакциями, пока
18 | зелёный продакшен активен, и, в зависимости от структуры кода, вы сможете направлять транзакции в оба продакшена, чтобы
19 | сохранять синий как резервную копию, при активном зелёном. Или можете перевести приложение в read-only режим, перед
20 | синхронизацией, запустить его на время в этом режиме, а потом переключить в режим read-write. Этого может оказаться
21 | достаточно, чтобы избавиться от многих нерешенных проблем.
22 |
23 | ## Canary Deployment (канареечные релизы)
24 |
25 | При этой стратегии новая версия приложения запускается на ограниченной части инфраструктуры или для небольшого числа
26 | пользователей, чтобы проверить его работоспособность и сравнить с предыдущей
27 | версией. Если новая версия проходит проверку успешно, она постепенно внедряется на остальные серверы или для всех
28 | пользователей.
29 |
30 | Термин «канареечный релиз» придуман по аналогии с тем, как шахтеры в угольных шахтах брали с собой канареек в клетках,
31 | чтобы обнаруживать опасный уровень угарного газа. Если в шахте скапливалось много угарного газа, то он убивал канарейку
32 | до того, как становился опасным для шахтеров, и они успевали спастись.
33 |
34 | При использовании этого шаблона, когда мы делаем выпуск, то наблюдаем, как программное обеспечение работает в каждой
35 | среде. Когда что-то кажется неправильным, мы выполняем откат, в противном случае мы выполняем развертывание в следующей
36 | среде.
37 |
38 | ## Blue-Green-Canary Deployment
39 |
40 | Это комбинированная стратегия, объединяющая элементы Green-Blue и Canary деплоя. При этом создается новая версия (Blue),
41 | которая постепенно внедряется на ограниченный набор серверов или пользователей (Canary). После проверки и удовлетворения
42 | результатами, новая версия становится основной (Green), а предыдущая версия сохраняется в качестве резервной.
43 |
44 | ## Shadow Deployment (теневой)
45 |
46 | При данной стратегии новая версия приложения запускается параллельно с текущей активной версией, но не обрабатывает
47 | реальные запросы пользователей. Вместо этого, она получает копии запросов и используется для сбора данных о
48 | производительности и стабильности новой версии без риска негативного влияния на пользователей.
49 |
50 | ## Rolling Deployment (плавный деплоймент)
51 |
52 | Эта стратегия предусматривает постепенное обновление приложения или
53 | инфраструктуры путем замены старых компонентов новыми на протяжении определенного времени или количества этапов. Это
54 | позволяет распределить нагрузку и снизить риски, так как если что-то идет не так, можно быстро вернуться к предыдущей
55 | версии.
56 |
57 | ## A/B Testing (A/B тестирование)
58 |
59 | Эта стратегия предполагает разделение пользователей на две группы: одна получает новую
60 | версию приложения (группа A), а другая продолжает использовать предыдущую версию (группа B). Это позволяет сравнить
61 | производительность, стабильность и пользовательский опыт между версиями и принять решение о полном переходе на новую
62 | версию.
63 |
64 | ## Feature Toggles (фич-тоглы)
65 |
66 | Эта стратегия позволяет включать и отключать определенные функциональные возможности приложения в зависимости от
67 | конфигурации. Таким образом, можно поэтапно вводить новые функции или экспериментировать с разными вариантами, не влияя
68 | на работу основного приложения.
69 |
70 | ## Traffic Splitting (разделение трафика)
71 |
72 | При этой стратегии трафик распределяется между несколькими версиями приложения в определенных пропорциях. Это позволяет
73 | постепенно увеличивать нагрузку на новую версию и наблюдать ее работу в реальном времени, а также сравнивать ее с
74 | предыдущей версией.
75 |
76 | ## Immutable Infrastructure (неизменяемая инфраструктура)
77 |
78 | Эта стратегия предполагает создание инфраструктуры, которая не подвергается изменениям после развертывания. Вместо
79 | этого, для обновления приложения создается новая инфраструктура с новой версией приложения, что обеспечивает простоту
80 | отката и предотвращает проблемы, связанные с изменениями в рабочей инфраструктуре.
81 |
82 | ## Blue-Green-Red Deployment
83 |
84 | Это расширенная версия Blue-Green деплоя, в которой предусмотрено наличие третьей окружения (Red), используемого для
85 | разработки и тестирования новых функций. При этом Blue и Green окружения остаются стабильными и готовыми к
86 | использованию, а Red используется для экспериментов и разработки.
87 |
88 | ## Список стратегий деплоя
89 |
90 | * Green-Blue Deployment
91 | * Canary Deployment
92 | * Rolling Deployment
93 | * A/B Testing
94 | * Blue-Green-Canary Deployment
95 | * Shadow Deployment
96 | * Feature Toggles
97 | * Traffic Splitting
98 | * Immutable Infrastructure
99 | * Blue-Green-Red Deployment
100 | * Rolling Updates
101 | * Recreate Deployment
102 | * Traffic Mirroring
103 | * Dark Launching
104 | * Forking
105 | * Phased Rollout
106 | * Ring Deployment
107 | * Delta Deployment
108 | * Staged Rollout
109 | * Live Migration
110 | * Binary Delta Deployment
111 | * Hybrid Deployment
112 | * Multi-Armed Bandit
113 | * Traffic Shifting
114 | * Zero Downtime Deployment
115 | * Chaos Engineering
116 | * Parallel Deployment
117 | * Incremental Deployment
118 | * Strangler Pattern
119 | * Hot Patching
120 |
121 |
--------------------------------------------------------------------------------
/src/devops/observability.md:
--------------------------------------------------------------------------------
1 | # Observability
2 |
3 |
4 | Observability (**наблюдаемость**) - это концепция, которая означает, насколько легко и эффективно вы можете наблюдать, измерять и понимать, что происходит внутри вашей системы. Это очень важно так как позволяет быстро обнаруживать, диагностировать и устранять проблемы, а также улучшать производительность и безопасность системы.
5 |
6 | Можно выделить следующие направления:
7 |
8 | 1. **Логирование (Logging):**
9 | - Логирование - это процесс записи событий и данных о работе вашей системы в лог-файлы. Логи могут содержать информацию о действиях пользователя, ошибках, исключениях, запросах и других событиях.
10 | - Преимущества: Логи помогают выявлять и анализировать проблемы, воссоздавать сценарии ошибок и обеспечивать безопасность.
11 | - Популярные инструменты: Log4j, Logback, ELK Stack (Elasticsearch, Logstash, Kibana), Fluentd.
12 | 2. **Мониторинг (Monitoring):**
13 | - Мониторинг - это процесс наблюдения за состоянием системы в реальном времени. Он включает сбор и агрегацию метрик, таких как использование ресурсов, нагрузка на сервер и статус сервисов.
14 | - Преимущества: Мониторинг помогает оперативно обнаруживать и реагировать на проблемы, а также оптимизировать производительность системы.
15 | - Популярные инструменты: Prometheus, Grafana, Nagios, Zabbix.
16 | 3. **Алертинг(Alerting)**
17 | - Алертинг (Alerting) - это важная часть системы мониторинга и обеспечения надежности, которая позволяет оперативно реагировать на проблемы и уведомлять администраторов или инженеров о них.
18 | - Популярные инструменты: Prometheus Alertmanager, Grafana Alerting, Nagios, Zabbix и многие другие. Эти инструменты позволяют определять условия, при которых должно генерироваться уведомление.
19 | - **Триггеры и Условия (Triggers and Conditions):** Алерты создаются на основе заданных условий или триггеров. Например, условие может быть следующим: "Если использование процессора превышает 90% в течение 5 минут, сгенерировать алерт."
20 | - **Уровни Важности (Severity Levels):** Алерты могут иметь разные уровни важности, такие как информационные, предупреждающие, критические и т. д. Уровень важности определяет, насколько критична проблема.
21 | - **Уведомления (Notifications):** Системы алертинга интегрируются с различными каналами уведомления, такими как электронная почта, SMS, мессенджеры (Slack, Telegram), системы вызовов (PagerDuty) и другие. Когда алерт срабатывает, система отправляет уведомление на выбранный канал.
22 | 4. **Трейсинг (Tracing):**
23 | - Трейсинг - это метод изучения пути выполнения запроса через распределенную систему. Он позволяет отслеживать, какие компоненты обрабатывают запрос, и где возникают задержки.
24 | - Преимущества: Трейсинг упрощает обнаружение и устранение узких мест в производительности, а также улучшает отладку распределенных систем.
25 | - Популярные инструменты: Jaeger, Zipkin, OpenTelemetry.
26 | 5. **Профайлинг (Profiling):**
27 | - Профайлинг - это процесс анализа производительности приложения или системы, позволяющий выявить места, где приложение тратит больше всего времени.
28 | - Преимущества: Профайлинг позволяет оптимизировать производительность, выявлять "горячие" участки кода и улучшать архитектуру приложения.
29 | - Популярные инструменты: Go Profiler, pprof, Java Flight Recorder.
--------------------------------------------------------------------------------
/src/devops/virtualization/README.md:
--------------------------------------------------------------------------------
1 | # Виртуализация
2 |
3 | Для изоляции процессов, запущенных на одном хосте, запуска приложений, предназначенных для разных платформ, можно использовать виртуальные машины. Виртуальные машины делят между собой физические ресурсы хоста:
4 |
5 | - процессор,
6 | - память,
7 | - дисковое пространство,
8 | - сетевые интерфейсы.
9 |
10 |
11 | 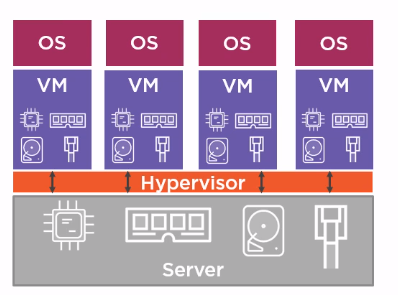
12 |
13 | На каждой ВМ устанавливаем нужную ОС и запускаем приложения. Недостатком такого подхода является то, что значительная часть ресурсов хоста расходуется не на полезную нагрузку(работа приложений), а на работу нескольких ОС.
14 |
15 |
16 |
17 | ### Контейнеры
18 |
19 | В отличие от аппаратной виртуализации, при которой эмулируется аппаратное окружение и может быть запущен широкий спектр гостевых операционных систем, в контейнере может быть запущен экземпляр операционной системы только с тем же ядром, что и у хостовой операционной системы (все контейнеры узла используют общее ядро). При этом при контейнеризации отсутствуют дополнительные ресурсные накладные расходы на эмуляцию виртуального оборудования и запуск полноценного экземпляра операционной системы, характерные при аппаратной виртуализации.
20 |
21 | Альтернативным подходом к изоляции приложений являются контейнеры. Само понятие контейнеров не ново и давно известно в Linux. Идея состоит в том, чтобы в рамках одной ОС выделить изолированную область и запускать в ней приложение. В этом случае говорим о виртуализации на уровне ОС. В отличие от ВМ контейнеры изолированно используют свой кусочек ОС:
22 |
23 | - файловая система
24 |
25 | - дерево процессов
26 |
27 | - сетевые интерфейсы
28 |
29 | - и др.
30 |
31 | 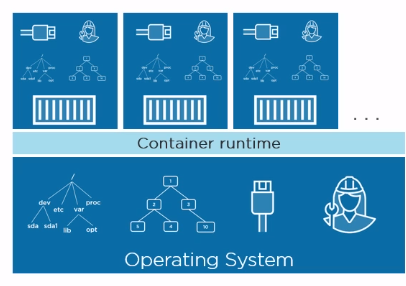
32 |
33 | Т.о. приложение, запущенное в контейнере думает, что оно одно во всей ОС. Изоляция достигается за счет использования таких Linux-механизмов, как **namespaces** и **control groups**. Если говорить просто, то namespaces обеспечивают изоляцию в рамках ОС, а control groups устанавливают лимиты на потребление контейнером ресурсов хоста, чтобы сбалансировать распределение ресурсов между запущенными контейнерами.
34 |
35 |
36 |
37 | Дополнительно:
38 |
39 | - [CGRoups](https://habr.com/ru/company/selectel/blog/303190/)
--------------------------------------------------------------------------------
/src/devops/virtualization/docker.md:
--------------------------------------------------------------------------------
1 | # Docker
2 |
3 | Docker — программное обеспечение для автоматизации развёртывания и управления приложениями в средах с поддержкой контейнеризации. Позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, который может быть перенесён на любую Linux-систему с поддержкой cgroups в ядре, а также предоставляет среду по управлению контейнерами. Изначально использовал возможности LXC, с 2015 года применял собственную библиотеку, абстрагирующую виртуализационные возможности ядра Linux — libcontainer. С появлением Open Container Initiative начался переход от монолитной к модульной архитектуре.
4 |
5 | ## Основные термины
6 |
7 | ### Image (образ)
8 |
9 | Образ в первом приближении можно рассматривать как набор файлов. В состав образа входит все необходимое для запуска и работы приложения на голой машине с докером: ОС, среда выполнения и приложение, готовое к развертыванию.
10 |
11 | - Образ — это набор файлов, необходимых для работы приложения на голой машине с установленным Docker.
12 | - Образ состоит из неизменяемых слоев, каждый из которых добавляет/удаляет/изменяет файлы из предыдущего слоя.
13 | - Неизменяемость слоев позволяет их использовать совместно в разных образах.
14 |
15 | ### Docker-контейнеры
16 |
17 | Контейнер - процесс, инициализированный на базе образа. То есть контейнер существует только когда запущен. Это как экземпляр класса, а образ это типа класс. Суть преобразования образа в контейнер состоит в добавлении верхнего слоя, для которого разрешена запись. Результаты работы приложения (файлы) пишутся именно в этом слое.
18 |
19 | 
20 |
21 |
22 |
23 | - **Host (хост)** – среда, в которой запускается докер т.е ваша локальная машина.
24 | - **Volume** – дисковое пространство между хостом и контейнером. Это папка на вашей локальной машине примонтированная внутрь контейнера. Меняете тут меняется там, и наоборот.
25 | - **Dockerfile** – файл с набором инструкций для создания образа будущего контейнера
26 | - **Service (сервис)** – по сути это запущенный образ (один или несколько контейнеров), дополнительно сконфигурированный такими опциями как открытие портов, маппинг папок (volume) и прочее. Обычно это делается при помощи docker-compose.yml файла.
27 | - **Docker-compose** – тулза, облегчающая сборку и запуск системы состоящей из нескольких контейнеров, связанных между собой.
28 | - **Build (билд, билдить)** – процесс создания образа из набора инструкций в докерфайле, или нескольких докерфайлов, если билд делается с помощью композера
29 |
30 |
31 | ## Популярные команды:
32 |
33 | - **RUN**
34 | - **CMD**
35 | - **ENTRYPOINT**
36 | - **ADD**
37 | - **COPY**
38 | - **FROM**
39 | - **ENV**
40 | - **WORKDIR**
41 | - **ARG**
42 | - **LABEL**
43 | - **EXPOSE**
44 |
45 | ## RUN vs CMD vs ENTRYPOINT
46 |
47 | Эти инструкции выполняются при сборке docker-образа из Dockerfile. `RUN` позволяет выполнять команды внутри вашего docker-образа — такие команды выполняются только **один раз во время сборки** и **создают новый слой** в итоговом docker-образе.
48 |
49 | Если вам необходимо установить пакет или создать каталог внутри вашего docker-образа, то инструкция `RUN` подойдет вам как нельзя лучше. Например:
50 |
51 | ```dockerfile
52 | RUN mkdir -p /var/www/test
53 | ```
54 |
55 | Инструкция `CMD` позволяет определить команду по умолчанию, которая будет выполняться при **запуске** вашего docker-контейнера (запущенный docker-образ называется контейнером). Эта инструкция **не выполняется во время сборки**!
56 |
57 | Например, в Dockerfile для веб-приложения вполне логично добавить инструкцию `CMD`, которая запустит веб-сервер при старте контейнера, например:
58 |
59 | ```dockerfile
60 | CMD ["php", "-S", "0.0.0.0:9095", "-t", "public", "public/index.php"]
61 | ```
62 |
63 | 1. Use RUN instructions to build your image by adding layers on top of initial image.
64 | 2. Prefer ENTRYPOINT to CMD when building executable Docker image, and you need a command always to be executed. Additionally, use CMD if you need to provide extra default arguments that could be overwritten from command line when docker container runs.
65 | 3. Choose CMD if you need to provide a default command and/or arguments that can be overwritten from command line when docker container runs.
66 |
67 |
68 |
69 | ## Docker-compose
70 |
71 | Пакетный менеджер Docker Compose, позволяющий описывать и запускать многоконтейнерные приложения. Конфигурационные файлы Compose описываются на языке YAML
72 |
73 |
74 |
75 | *Дополнительно:*
76 |
77 | - [Docker. Начало](https://habr.com/ru/post/353238/)
78 | - [Основы Docker за Х часов и Y дней](https://habr.com/ru/post/337306/)
79 | - [Изучаем Docker, часть 1: основы](https://habr.com/ru/company/ruvds/blog/438796/)
80 | - [Руководство по Docker Compose для начинающих](https://habr.com/ru/company/ruvds/blog/450312/)
--------------------------------------------------------------------------------
/src/devops/virtualization/kubernetes.md:
--------------------------------------------------------------------------------
1 | # Kubernetes
2 |
3 | **Kubernetes** (K8s) - это платформа управления контейнерами с открытым исходным кодом, разработанная Google. Она предоставляет средства для автоматизации развертывания, масштабирования и управления контейнеризированными приложениями.
4 |
5 | Kubernetes позволяет создавать и управлять группами контейнеров, которые объединяются в логические единицы, называемые "поды". Он обеспечивает автоматическую оркестрацию, балансировку нагрузки, масштабирование и высокую доступность приложений.
6 |
7 | Идея состоят в том, что ваш деплой строится на базе контейнеров (например, [Docker](https://eax.me/docker/)), а также описании того, сколько этих контейнеров нужно и какие ресурсы они используют. Kubernetes на базе этого описания и доступных физических машин разворачивает контейнеры и делает все возможное для поддержания требуемой конфигурации. В том числе, он перезапускает упавшие контейнеры, перемещает их для выделения ресурсов, необходимых новым контейнерам, и так далее.
8 |
9 | Зачем это нужно? Другими словами, используется декларативный подход — мы описываем, *что* требуется достичь, а а Kubernetes берет на себя задачи по достижению и поддержанию этого состояния. Из преимуществ данного подхода можно отметить следующие. Система сама себя восстанавливает в случае сбоев. У вас не болит голова о том, на какой физической машине запущен тот или иной контейнер, и куда его перенести, чтобы запустить новый тяжелый сервис. Система становится повторяемой. Если у вас все развернулось и работает в тестовом окружении, вы можете с хорошей долей уверенности сказать, что оно развернется в точно такую же систему и на продакшене. Наконец, система становится версионируемой. Если что-то пошло не так, вы можете достать из Git старую конфигурацию и развернуть все в точности, как было раньше.
10 |
11 | Kubernetes также предоставляет множество возможностей, таких как сервис-дискавери, маршрутизация трафика, хранение данных, мониторинг и многое другое, с помощью расширяемой архитектуры и плагинов.
12 |
13 |
14 |
15 | ## Основные компоненты платформы Kubernetes включают:
16 |
17 | ### Master Node
18 |
19 | Мастер-узел является главным управляющим компонентом Kubernetes. Он отвечает за принятие решений и координацию работы кластера. Компоненты мастер-узла включают API-сервер, контроллеры управления, планировщик (scheduler) и хранилище состояния кластера (etcd).
20 |
21 | ### Worker Nodes
22 |
23 | Рабочие узлы - это машины, на которых запускаются и работают контейнеры. Они получают команды от мастер-узла и выполняют их. Рабочие узлы включают в себя kubelet (агент Kubernetes), контейнерный рантайм (например, Docker или containerd) и kube-proxy (для управления сетевым взаимодействием).
24 |
25 | ### Pods
26 |
27 | Поды являются наименьшей развертываемой и масштабируемой единицей в Kubernetes. Они содержат один или несколько контейнеров, которые работают вместе и разделяют сеть и хранилище. Поды создаются, управляются и масштабируются Kubernetes.
28 |
29 | ### Services
30 |
31 | Сервисы предоставляют постоянный IP-адрес и стабильное DNS-имя для набора подов. Они позволяют установить коммуникацию между различными подами и внешними системами.
32 |
33 | ### Replication Controllers
34 |
35 | Репликационные контроллеры отвечают за поддержание заданного количества работающих экземпляров подов. Если какие-то поды выходят из строя, репликационный контроллер автоматически создает новые экземпляры, чтобы поддерживать желаемое состояние.
36 |
37 | ### Ingress
38 |
39 | Внешние объекты предоставляют маршрутизацию внешнего трафика к сервисам внутри кластера Kubernetes.
40 |
41 | ### ConfigMaps и Secrets
42 |
43 | ConfigMaps позволяют хранить конфигурационные данные, которые могут быть использованы в подах, а Secrets используются для хранения и управления конфиденциальной информацией, такой как пароли и ключи.
44 |
45 | ### Kubectl
46 |
47 | Kubectl - это клиентская утилита командной строки для взаимодействия с кластером Kubernetes. Она позволяет разработчикам и администраторам управлять и контролировать различные аспекты кластера, такие как создание, удаление и масштабирование ресурсов, просмотр логов и мониторинг состояния приложений.
48 |
49 | Kubectl позволяет выполнять следующие задачи:
50 |
51 | 1. Создание и управление ресурсами: Вы можете создавать и управлять различными ресурсами Kubernetes, такими как поды, сервисы, репликационные контроллеры, секреты и конфигурационные карты (ConfigMaps).
52 | 2. Масштабирование приложений: С помощью Kubectl вы можете масштабировать количество экземпляров подов или других ресурсов для обеспечения нужной производительности или отказоустойчивости.
53 | 3. Управление состоянием приложений: Kubectl предоставляет возможности для управления состоянием приложений, включая развертывание новых версий, обновление конфигураций и переключение между различными версиями.
54 | 4. Отладка и мониторинг: Вы можете получать доступ к логам и метрикам приложений, а также выполнять отладку и проверку состояния ресурсов Kubernetes с помощью Kubectl.
55 | 5. Работа с конфигурацией и контекстами: Kubectl позволяет управлять конфигурационными файлами Kubernetes и устанавливать контексты для работы с различными кластерами и окружениями.
56 |
57 | ### Minikube
58 |
59 | Minikube - это инструмент для локального развертывания единственной ноды Kubernetes. Он позволяет разработчикам запускать и тестировать приложения на своих локальных машинах без необходимости полноценного кластера Kubernetes. Minikube создает изолированную среду, в которой можно разрабатывать и отлаживать приложения в контейнерах.
60 |
61 | ### Kubelet
62 |
63 | Kubelet - это агент, который работает на каждом рабочем узле в кластере Kubernetes. Он отвечает за управление жизненным циклом подов на рабочем узле. Kubelet следит за состоянием подов, запускает и останавливает их, проверяет их здоровье, а также обеспечивает связь с мастер-узлом для получения инструкций и обновлений.
64 |
65 | Вместе Kubectl, Minikube и Kubelet предоставляют разработчикам и администраторам удобный способ взаимодействия с Kubernetes-кластерами и управления ими, позволяя разрабатывать, тестировать и развертывать приложения в контейнерах.
66 |
67 |
--------------------------------------------------------------------------------
/src/goLang/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/goLang/.DS_Store
--------------------------------------------------------------------------------
/src/goLang/README.md:
--------------------------------------------------------------------------------
1 | ## GoLang
2 |
3 | **Go** (Golang) — компилируемый многопоточный язык программирования.
4 |
5 | Язык Go разрабатывался как язык программирования для создания высокоэффективных программ, работающих на современных
6 | распределённых системах и многоядерных процессорах. Он может рассматриваться, как попытка создать замену языкам Си и C++.
7 |
8 | Компилируемый язык. Предполагается, что программы на Go будут транслироваться компилятором в объектный код целевой
9 | аппаратной платформы и в дальнейшем исполняться непосредственно, не требуя виртуальной машины. Архитектура языка
10 | изначально проектировалась так, чтобы обеспечить быструю компиляцию в эффективный объектный код.
11 |
12 | * [Типы данных](types/README.md)
13 |
14 | * [Скалярные](types/scalar.md)
15 | * [Массив и слайс](types/array_slice.md)
16 | * [Map](types/map.md)
17 | * [Структура](types/struct.md)
18 | * [Интерфейс](types/interface.md)
19 |
20 | * [Сoncurrency](concurrency/README.md)
21 |
22 | * [Каналы](concurrency/chanel.md)
23 | * [Планировщик](concurrency/scheduler.md)
24 | * [Горутины](concurrency/gouritine.md)
25 | * [Sync](concurrency/sync.md)
26 | * [Паттерны](concurrency/patterns.md)
27 |
28 | * [Управление памятью](memory.md)
29 |
30 | * [Экосистема](ecosystem.md)
31 |
32 | ## Вопросы
33 |
34 | - Как хранятся переменные в Golang?
35 |
36 | - Что представляет собой тип данных string в Go?
37 |
38 | - Что вернет функция len(), примененная к строке?
39 |
40 | - Что собой представляет тип данных rune?
41 |
42 | - Как устроен слайс и чем он отличается от массива?
43 |
44 | - Как работает функция append? Что происходит с capacity и базовым массивом?
45 |
46 | - Как создать многомерный массив в Golang
47 |
48 | - Нужно ли передавать slice по ссылке в функцию?
49 |
50 | - Что представляет собой map?
51 |
52 | - Чем является функция в Go?
53 |
54 | - Что такое метод структуры? Что такое получатель (receiver) метода? В чем разница между получателем по значению и
55 | указателем?
56 |
57 | - Значения-методы и выражения-методы - в чем отличие?
58 |
59 | - Что такое интерфейсы? Как устроен пустой интерфейс?
60 |
61 | - ООП в Golang
62 |
63 | - Как в golang освобождает память и можно ли отключить это поведение и зачем это делать?
64 |
65 | - Что такое каналы и каких видов они бывают?
66 |
67 | - В чем отличие буферизированного канала от небуферизированного?
68 | - Какой дефолтный размер буфера у канала?
69 | - Что вернет получение значения из закрытого канала?
70 | - Что произойдет при записи значения в закрытый канал?
71 | - Что будет если писать в
72 | неинициализированный канал?
73 |
74 | - Как огранить число потоков на системы при запуске Golang программы и возможно ли огранить их до 1 потока?
75 |
76 | - Каким способом происходит отмена работы других горутин?
77 |
78 | - Почему важно завершать горутины по окончании / прерывании работы главной программы?
79 |
80 | - Что такое гонка данных (race condition, состояние гонки)? Какие существуют способы избежать состояния гонки в Go?
81 |
82 | - Что такое семафор? Бинарный семафор? Что такое mutex? Какие бывают виды mutex в Go?
83 |
84 | - В чем различия goroutine от потока системы?
85 |
86 | *Дополнительно:*
87 |
88 | - [Исходный код](https://golang.org/src/runtime/chan.go)
89 | - [Каналы в спецификации Go](https://golang.org/ref/spec#Channel_types)
90 | - [Каналы Go на стероидах](https://docs.google.com/document/d/1yIAYmbvL3JxOKOjuCyon7JhW4cSv1wy5hC0ApeGMV9s/pub)
91 | - [Планировщик Go](https://habr.com/ru/company/ua-hosting/blog/269271/)
92 | - [Work-stealing планировщик в Go](https://habr.com/ru/post/333654/)
93 | - [Как не наступать на грабли в Go](https://habr.com/ru/post/325468)
94 | - [Go Traps](https://go-traps.appspot.com/)
95 | - [Хэш таблицы в Go. Детали реализации](https://habr.com/ru/post/457728)
96 | - [Algorithms to Go](https://yourbasic.org/)
97 | - [Практичный Go: советы по написанию поддерживаемых программ в реальном мире](https://habr.com/ru/post/441842/)
98 | - [50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков](https://habr.com/ru/company/mailru/blog/314804/)
--------------------------------------------------------------------------------
/src/goLang/concurrency/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/goLang/concurrency/.DS_Store
--------------------------------------------------------------------------------
/src/goLang/concurrency/README.md:
--------------------------------------------------------------------------------
1 | # Сoncurrency
2 |
3 | В данном разделе будут темы, относящиеся к параллелизму и конкурентности.
4 |
5 | - [Каналы](chanel.md)
6 | - [Планировщик](scheduler.md)
7 | - [Горутины](gouritine.md)
8 | - [Context](context.md)
9 | - [Sync](sync.md)
10 | - [Паттерны](patterns.md)
--------------------------------------------------------------------------------
/src/goLang/concurrency/gouritine.md:
--------------------------------------------------------------------------------
1 | # Goroutines
2 |
3 | Горутина — функция, которая может работать параллельно с другими функциями. Для создания горутины используется ключевое слово `go`, за которым следует вызов функции. Горутины очень легкие(примерно 4.5кб на горутину против нескольких мегабайт на поток POSIX).
4 |
5 | ## Отличия горутин от потоков
6 |
7 | ### Stack
8 |
9 | Каждый поток операционной системы имеет блок памяти фиксированного размера (зачастую до 2 Мбайт) для стека — рабочей области, в которой он хранит локальные переменные вызовов функций, находящиеся в работе или приостановленные на время вызова другой функции. В противоположность этому go-подпрограмма начинает работу с небольшим стеком, обычно около **2 Кбайт**. Стек go-подпрограммы, подобно стеку потока операционной системы, хранит локальные переменные активных и приостановленных функций, но, в отличие от потоков операционной системы, не является фиксированным; при необходимости он может расти и уменьшаться. Максимальный размер стека go-подпрограммы может быть около 1 Гбайта, на порядки больше типичного стека с фиксированным размером, хотя, конечно, такой большой стек могут использовать только несколько go-подпрограмм.
10 | Раньше использовался **Segmented Stacks** потом переделали на **Сontiguous Stacks**
11 |
12 | #### Segmented Stacks
13 |
14 | The 1.2 runtime uses segmented stacks, also known as split stacks.
15 |
16 | In this approach, stacks are discontiguous and grow incrementally.
17 |
18 | Each stack starts with a single segment. When the stack needs to grow, another segment is allocated and linked to the previous one, and so forth. Each stack is effectively a doubly linked list of one or more segments.
19 |
20 | #### Сontiguous Stacks
21 |
22 | The “hot split” were addressed in Go 1.3 by making the stacks contiguous.
23 |
24 | Now when a stack needs to grow, instead of allocating a new segment the runtime will:
25 |
26 | * create a new, somewhat larger stack
27 | * copy the contents of the old stack to the new stack
28 | * re-adjust every copied pointer to point to the new addresses
29 | * destroy the old stack
30 |
31 | ### Scheduler
32 |
33 | Потоки операционной системы планируются в ее ядре, а у go есть собственный **планировщик (m:n) мультиплексирующий(раскидывающий) горутинки(m) по потокам(n)**. Основной плюс = отсуствие оверхеда на переключение контекста. Т.к переключение тредов происходит **kernel space**, то переключение потока очень дорогое - нужно сохранить его стэк, сохранить регистры, файловы регистры и т.д Переключение горутин происходит в **user space** и гораздо быстрее и дешевле.
34 |
35 | ### Gomaxproc
36 |
37 | Планировщик Go использует параметр с именем **GOMAXPROCS** для определения, сколько потоков операционной системы могут одновременно активно выполнять код Go. Его значение по умолчанию равно количеству процессоров компьютера, так что на машине с 8 процессорами планировщик будет планировать код Go для выполнения на 8 потоках одновременно (**GOMAXPROCS** равно значению п в т:п-планировании).
38 | Спящие или заблокированные в процессе коммуникации go-подпрограммы потоков для себя не требуют. Go-подпрограммы, заблокированные в операции ввода-вывода или в других системных вызовах, или при вызове функций, не являющихся функциями Go, нуждаются в потоке операционной системы, но **GOMAXPROCS** их не учитывает.
39 |
40 | ### No identification
41 |
42 | В большинстве операционных систем и языков программирования, поддерживающих многопоточность, текущий поток имеет идентификацию, которая может быть легко получена как обычное значение (обычно — целое число или указатель). Это облегчает построение абстракции, именуемой локальной памятью потока, которая, по существу, является глобальным отображением, использующим в качестве ключа идентификатор потока, так что каждый поток может сохранять и извлекать значения независимо от других потоков. **У горутин нет идентификации, доступной программисту.** Так решено во время проектирования языка, поскольку локальной памятью потока программисты злоупотребляют.
43 |
44 | *Дополнительно:*
45 |
46 | - [Contiguous stacks in Go](https://agis.io/post/contiguous-stacks-golang/)
47 |
--------------------------------------------------------------------------------
/src/goLang/concurrency/patterns.md:
--------------------------------------------------------------------------------
1 | ## Concurrency patterns
2 |
3 | ## Pipeline(конвейер)
4 |
5 | Каналы могут использоваться для подключения go-подпрограмм так, чтобы выход одной из них был входом для другой. Это называется конвейером (pipeline).
6 |
7 | ```go
8 | func main() {
9 | naturals := make(chan int)
10 | squares := make(chan int)
11 | // Генерация
12 | go func() {
13 | for x := 0; ; x++ {
14 | naturals <-x
15 | }
16 | }()
17 | // Возведение в квадрат
18 | go func() {
19 | for {
20 | x := <-naturals
21 | squares <- x * x
22 | }
23 | }()
24 | // Вывод (в главной go-подпрограмме)
25 | for {
26 | fmt.Println(<-squares)
27 | }
28 | }
29 | ```
30 |
31 |
32 |
33 | ## Broadcasting
34 |
35 | В go нет возможности полноценной широковещательной рассылки нескольким получателям, однако есть лайфхак: при закрытии канала, все консюммеры, могут фиксировать это событие(закрытие канала)
36 |
37 | ## Cancelation
38 |
39 | Чтобы отменить выполнение горутины в определенный момент, можем использовать канал отмены:
40 |
41 | ```go
42 | func main() {
43 | var cancelChan chan bool
44 | cancelChan = make(chan bool)
45 |
46 | go func() {
47 | for {
48 | select {
49 | case <-cancelChan:
50 | fmt.Println("Получили сигнал, отмены, вышли")
51 | return
52 | default:
53 | fmt.Println("Делаем полезную работу")
54 | }
55 | time.Sleep(3)
56 |
57 | }
58 | }()
59 |
60 | time.Sleep(10)
61 | cancelChan <- true
62 | }
63 | ```
64 |
65 | ## Promises
66 |
67 | В информатике конструкции future, promise и delay в некоторых языках программирования формируют стратегию вычисления, применяемую для параллельных вычислений. С их помощью описывается объект, к которому можно обратиться за результатом, вычисление которого может быть не завершено на данный момент. Использование future может быть неявным (при любом обращении к future возвращается ссылка на значение) и явным (пользователь должен вызвать функцию, чтобы получить значение). Получение значения из явного future называют stinging или forcing. Явные future могут быть реализованы в качестве библиотеки, в то время, как неявные обычно реализуются как часть языка.
68 |
69 | ```go
70 | package main
71 |
72 | import (
73 | "fmt"
74 | "sync"
75 | "time"
76 | )
77 |
78 | type Promise struct {
79 | wg sync.WaitGroup
80 | res string
81 | err error
82 | }
83 |
84 | func NewPromise(f func() (string, error)) *Promise {
85 | p := &Promise{}
86 | p.wg.Add(1)
87 | go func() {
88 | p.res, p.err = f()
89 | p.wg.Done()
90 | }()
91 | return p
92 | }
93 |
94 | func (p *Promise) Then(r func(string), e func(error)) {
95 | go func() {
96 | p.wg.Wait()
97 | if p.err != nil {
98 | e(p.err)
99 | return
100 | }
101 | r(p.res)
102 | }()
103 | }
104 |
105 | func exampleTicker() (string, error) {
106 | <-time.Tick(time.Second * 1)
107 | return "hi", nil
108 | }
109 |
110 | func main() {
111 | doneChan := make(chan int)
112 | var p = NewPromise(exampleTicker)
113 | p.Then(func(result string) { fmt.Println(result); doneChan <- 1 }, func(err error) { fmt.Println(err) })
114 | <-doneChan
115 | }
116 |
117 | ```
118 |
119 | ### Generator aka Iterator
120 |
121 | ### Futures/Promises
122 |
123 | ### Fan-in, Fan-out
--------------------------------------------------------------------------------
/src/goLang/ecosystem.md:
--------------------------------------------------------------------------------
1 | ## Экосистема
2 |
3 | Пакетный менеджер, тестирование, линтеры, структура проектов и т.д
4 |
5 | ## Пакетный менеджер
6 |
7 | Go Modules (go mod) - это система управления зависимостями, встроенная в язык Go с версии 1.11 и выше. Go Modules
8 | упрощает управление зависимостями, обеспечивает версионирование и облегчает совместную работу над проектами.
9 | Он также обеспечивает возможность воспроизводимой сборки проекта и упрощает интеграцию с другими инструментами
10 | разработки. Вот основы использования Go Modules:
11 |
12 | * Инициализация модуля: Чтобы начать использовать Go Modules, нужно выполнить команду `go mod init` в корневом каталоге
13 | проекта. Это создаст файл `go.mod`, в котором будут записаны зависимости проекта.
14 | * Управление зависимостями: Go Modules использует явное указание версий зависимостей. Можно добавить новую зависимость с
15 | помощью команды `go get`, например `go get github.com/example/package@v1.2.3`. Go Modules автоматически загрузит
16 | указанную
17 | версию и запишет ее в файле go.mod.
18 | * Версионирование зависимостей: В файле `go.mod` указываются версии зависимостей, а также правила для выбора версий при
19 | разрешении зависимостей. Можно использовать конкретные версии, диапазоны версий или символ latest для самой новой
20 | версии.
21 | * Обновление зависимостей: Go Modules предоставляет команду `go get -u` для обновления зависимостей до последних версий.
22 | При обновлении зависимостей файл go.mod будет автоматически обновлен с учетом новых версий.
23 | * Версионирование модуля: В файле `go.mod` указывается версия самого модуля. При каждом изменении зависимостей или
24 | модуля,
25 | версия модуля будет автоматически обновляться.
26 |
27 | ### go mod tidy
28 |
29 | Команда `go mod tidy` является одной из команд Go Modules и используется для упорядочения и обновления файлов `go.mod`
30 | и `go.sum`, основанных на фактическом использовании зависимостей в проекте. Команда go mod tidy полезна при
31 | упорядочивании и обновлении файлов go.mod и go.sum для соответствия фактическому использованию зависимостей в проекте.
32 | Это помогает поддерживать эти файлы актуальными и устраняет неиспользуемые зависимости, упрощая управление зависимостями
33 | в проекте.
34 | Вот некоторая информация о команде `go mod tidy`:
35 |
36 | Удаление неиспользуемых зависимостей: Когда вы выполняете `go mod tidy`, Go Modules анализирует фактическое
37 | использование зависимостей в проекте и удаляет из файла `go.mod` записи о зависимостях, которые больше не используются.
38 | Это помогает очистить файл `go.mod` от лишних записей и упростить управление зависимостями.
39 |
40 | Обновление версий зависимостей: Команда `go mod tidy` также обновляет версии зависимостей в файле `go.mod` на основе
41 | фактического использования. Если в проекте используются новые версии зависимостей, команда `go mod tidy` автоматически
42 | обновит записи в файле go.mod, чтобы отразить актуальные версии.
43 |
44 | Обновление хэшей зависимостей: При выполнении `go mod tidy` также обновляется файл `go.sum`, который содержит хэши всех
45 | зависимостей проекта. Если версии зависимостей изменяются или обновляются, `go mod tidy` обновляет соответствующие хэши
46 | в файле `go.sum`.
47 |
48 | ## Тестирование
49 |
50 | Тесты в Go пишутся с использованием пакета `testing`. Тестовые функции должны начинаться с префикса "Test" и принимать
51 | аргумент типа `*testing.T`.
52 | Для запуска тестов можно использовать команду `go test` в директории проекта. Она автоматически находит и выполняет все
53 | тестовые функции.
54 | В тестовых функциях можно использовать функции `t.Errorf` и `t.Fail` для вывода ошибок и отметки теста как неудачного.
55 | Также популярные сторонние библиотеки **testify** и **gocheck**.
56 |
57 | ## Бенчмарки:
58 |
59 | Бенчмарки в Go пишутся с использованием пакета `testing` и префикса `Benchmark` для названия функций. Они принимают
60 | аргумент типа `*testing.B`.
61 | Бенчмарки позволяют измерить производительность кода и сравнить различные реализации. Они выполняются несколько раз,
62 | чтобы получить усредненные результаты.
63 | Для запуска бенчмарков можно использовать команду `go test` с флагом `-bench`, например: `go test -bench ..`
64 | Результаты бенчмарков выводятся в консоль и показывают среднее время выполнения и количество операций в секунду.
65 | Использование тестов и бенчмарков помогает обеспечить надежность и производительность вашего кода. Они позволяют
66 | автоматически проверить правильность работы кода и сравнить эффективность различных подходов.
67 |
68 | ## Библиотеки и фреймворки
69 |
70 | * Gin - минималистичный и быстрый фреймворк для веб-приложений.
71 | * Echo - легковесный и быстрый веб-фреймворк для Go.
72 | * Gorm - ORM для Go с поддержкой MySQL, PostgreSQL и SQLite.
73 | * Cobra - библиотека для создания мощных CLI-интерфейсов.
74 | * Viper - библиотека для работы с конфигурационными файлами различных форматов.
75 | * Logrus - популярный логгер с поддержкой различных уровней логирования.
76 | * testify - набор инструментов для модульного тестирования в Go.
77 | * gRPC - высокопроизводительный RPC-фреймворк.
78 | * govalidator - библиотека для валидации входных данных в Go.
79 | * Fiber - быстрый и экспрессивный веб-фреймворк для Go.
80 | * Mux - мощный HTTP-маршрутизатор и диспетчер запросов.
81 | * JWT-go - библиотека для работы с JSON Web Token (JWT).
82 | * sqlx - расширение для пакета database/sql для упрощения работы с SQL.
83 | * go-sqlmock - инструмент для создания мок-объектов базы данных для тестирования SQL запросов.
84 | * golang-migrate - инструмент для управления миграциями базы данных.
85 |
86 | *Дополнительно*:
87 |
88 | - [Статический анализ в Go](https://habr.com/ru/company/roistat/blog/413175/)
89 | - [Профилирование и оптимизация программ на Go](https://habr.com/ru/company/badoo/blog/301990/)
--------------------------------------------------------------------------------
/src/goLang/types/README.md:
--------------------------------------------------------------------------------
1 | # Типы данных GoLang
2 |
3 | * [Скалярные](scalar.md)
4 | * [Массив и слайс](array_slice.md)
5 | * [Map](map.md)
6 | * [Структура](struct.md)
7 | * [Интерфейс](interface.md)
8 |
9 |
10 |
11 | В Go, типы данных определяют характеристики и ограничения значений, которые могут быть присвоены переменным и использованы в программе. Вот некоторые основные типы данных в Go:
12 |
13 | - Целочисленные типы данных (`int`, `int8`, `int16`, `int32`, `int64`, `uint`, `uint8`, `uint16`, `uint32`, `uint64` и другие) представляют целые числа со знаком и без.
14 | - Типы данных с плавающей запятой (`float32`, `float64`) представляют числа с плавающей точкой.
15 | - Типы данных `bool` представляют логические значения `true` или `false`.
16 | - Строковый тип данных `string` представляет последовательность символов.
17 | - Тип данных `byte` представляет беззнаковый 8-битный целочисленный тип, который обычно используется для представления байтовых данных.
18 | - Типы данных `array` и `slice` представляют упорядоченные коллекции элементов одного типа. Они отличаются в том, что массив имеет фиксированную длину, а срез (slice) - динамическую длину.
19 | - Тип данных `struct` представляет составной тип, который позволяет объединять несколько значений разных типов в одну сущность.
20 | - Тип данных `map` представляет ассоциативный массив (отображение), который хранит пары ключ-значение.
21 | - Тип данных `interface` определяет набор методов, которые должны быть реализованы другими типами. Он позволяет создавать полиморфные объекты.
22 |
23 |
24 |
25 | В Golang переменные хранятся в оперативной памяти компьютера. Конкретный адрес в памяти зависит от архитектуры и операционной системы, а размер занимаемой памяти определяется типом данных переменной.
26 |
27 | В Go переменные могут быть объявлены как с фиксированным типом данных (например, int, float64, string) так и с динамическим типом (например, interface{}, которая может хранить любые значения).
28 |
29 | Для каждой переменной компилятор Go определяет оптимальный размер и располагает ее в памяти таким образом, чтобы она могла быть эффективно использована во время выполнения программы.
30 |
31 | Кроме того, в Go можно использовать указатели, которые хранят адрес в памяти переменной. Указатели позволяют получить доступ к значению переменной по ее адресу и изменять его.
32 |
33 | Также в Golang существует механизм сборки мусора, который автоматически освобождает память, занимаемую переменными, которые больше не используются. Это позволяет избежать утечек памяти и облегчает работу с переменными.
34 |
35 |
36 |
37 |
--------------------------------------------------------------------------------
/src/goLang/types/interface.md:
--------------------------------------------------------------------------------
1 | ## Интерфейсы
2 |
3 | ```go
4 | type iface struct {
5 | tab *itab
6 | data unsafe.Pointer
7 | }
8 |
9 | type itab struct {
10 | inter *interfacetype
11 | _type *_type
12 | hash uint32 // copy of _type.hash. Used for type switches.
13 | _ [4]byte
14 | fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
15 | }
16 |
17 | type interfacetype struct {
18 | typ _type
19 | pkgpath name
20 | mhdr []imethod
21 | }
22 |
23 | //пустой интерфейс interface{}
24 | type eface struct {
25 | _type *_type
26 | data unsafe.Pointer
27 | }
28 | ```
29 |
30 | Интерфейсы представляют абстракцию поведения других типов. Интерфейсы позволяют определять функции, которые не привязаны к конкретной реализации. То есть интерфейсы определяют некоторый функционал, но не реализуют его.
31 |
32 | Для определения интерфейса применяется ключевое слово `interface`:
33 |
34 | ```go
35 | type Car interface {
36 | move(x int, y int) err
37 | stop()
38 | }
39 | ```
40 |
41 | ### Nill interface vs nil pointer interface
42 |
43 | Тут важно понимать, что если переменная объявлена не под типо интерфейса, а под каким то конкретным типом, реализующим интерфейс - то при её сравнении с nil получим false, так как в структуре itab уже будет храниться значение конкретного типа в поле `type` и с точки зрения go это уже не будет **nil interface** a будет **nil pointer interface**
44 |
4 |
5 | **RabbitMQ** — это распределенная система управления очередью сообщений. Распределенная, поскольку обычно работает как кластер узлов, где очереди распределяются по узлам и, опционально, реплицируются в целях устойчивости к ошибкам и высокой доступности. Штатно, она реализует AMQP 0.9.1 и предлагает другие протоколы, такие как STOMP, MQTT и HTTP через дополнительные модули.
6 |
7 | RabbitMQ использует как классический, так и новаторский подходы к обмену сообщениями. Классический в том смысле, что она ориентирована на очередь сообщений, а новаторский — в возможности гибкой маршрутизации. Именно эта возможность маршрутизации является ее уникальным преимуществом. Создание быстрой, масштабируемой и надежной распределенной системы сообщений само по себе является достижением, но функциональность маршрутизации сообщений делает ее действительно выдающейся среди множества технологий обмена сообщениями.
8 |
9 | ### Exchange'и и очереди
10 |
11 | Супер-упрощенный обзор:
12 |
13 | - Паблишеры (publishers) отправляют сообщения на exchange’и
14 | - Exchange’и отправляют сообщения в очереди и в другие exchange’и
15 | - RabbitMQ отправляет подтверждения паблишерам при получении сообщения
16 | - Получатели (consumers) поддерживают постоянные TCP-соединения с RabbitMQ и объявляют, какую очередь(-и) они получают
17 | - RabbitMQ проталкивает (push) сообщения получателям
18 | - Получатели отправляют подтверждения успеха/ошибки
19 | - После успешного получения, сообщения удаляются из очередей
20 |
21 | ### Гарантии доставки
22 |
23 | RabbitMQ предоставляет надёжные, долговременные гарантии обмена сообщениями, но есть много ситуаций, когда они не помогут. Вот список моментов, которые следует запомнить:
24 |
25 | - Следует применять зеркалирование очередей, надёжные очереди, устойчивые сообщения, подтверждения для отправителя, флаг подтверждения и принудительное уведомление от получателя, если требуются надёжные гарантии в стратегии “как минимум однократная доставка”.
26 | - Если отправка производится в рамках стратегии “как минимум однократная доставка”, может потребоваться добавить механизм дедубликации или идемпотентности при дублировании отправляемых данных.
27 | - Если вопрос потери сообщений не так важен, как вопрос скорости доставки и высокой масштабируемости, то подумайте о системах без резервирования, без устойчивых сообщений и без подтверждений на стороне источника. Я всё же предпочел бы оставить принудительные уведомления от получателя, чтобы контролировать поток принимаемых сообщений путем изменения ограничений предвыборки. При этом вам потребуется отправлять уведомления пакетами и использовать флаг “multiple”.
28 |
29 | *Дополнительно:*
30 |
31 | 1. https://habr.com/post/149694/
32 | 2. https://habr.com/post/150134/
33 | 3. https://habr.com/post/200870/
34 | 4. https://habr.com/post/201096/
35 | 5. https://habr.com/post/201178/
36 | 6. https://habr.com/post/236221/
--------------------------------------------------------------------------------
/src/db/noSql/README.md:
--------------------------------------------------------------------------------
1 | # noSql
2 |
3 | **NoSQL** (от [англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) not only SQL — *не только SQL*) — термин, обозначающий ряд подходов, направленных на реализацию хранилищ [баз данных](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B7%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85), имеющих существенные отличия от моделей, используемых в традиционных [реляционных СУБД](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%BB%D1%8F%D1%86%D0%B8%D0%BE%D0%BD%D0%BD%D0%B0%D1%8F_%D0%A1%D0%A3%D0%91%D0%94) с доступом к данным средствами языка [SQL](https://ru.wikipedia.org/wiki/SQL). Применяется к базам данных, в которых делается попытка решить проблемы [масштабируемости](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%81%D1%88%D1%82%D0%B0%D0%B1%D0%B8%D1%80%D1%83%D0%B5%D0%BC%D0%BE%D1%81%D1%82%D1%8C) и [доступности](https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D1%81%D1%82%D1%83%D0%BF%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8) за счёт [атомарности](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%BE%D1%81%D1%82%D1%8C) ([англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) atomicity) и [согласованности данных](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%B3%D0%BB%D0%B0%D1%81%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85) ([англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) consistency).
--------------------------------------------------------------------------------
/src/db/noSql/memcached.md:
--------------------------------------------------------------------------------
1 | # Memcached
2 |
3 | [Memcached](http://code.google.com/p/memcached/) представляет собой сервер, хранящий в оперативной памяти некоторые данные с заданным временем жизни. Доступ к данным осуществляется по ключу (имени). Вы можете думать о Memcached, как о [хэш-таблице](https://eax.me/hash-tables/), хранящейся на сервере. Применяется он в основном для кэширования кода веб-страниц, результатов запросов к базе данных и тп.
4 |
5 | Также ничто не мешает использовать Memcached в качестве «не очень надежного» key-value хранилища. Например, в нем можно хранить сессии пользователей, коды капч или счетчик посетителей, находящихся в данный момент на сайте.
6 |
7 | Коротко о главном:
8 |
9 | - Умеет только key => value in memory
10 | - Вытеснение. Когда Memcache доходит до ограничения в памяти, он начинает удалять объекты по принципу [LRU](https://ruhighload.com/%d0%9a%d1%8d%d1%88%d0%b8%d1%80%d0%be%d0%b2%d0%b0%d0%bd%d0%b8%d0%b5+%d0%b4%d0%b0%d0%bd%d0%bd%d1%8b%d1%85#lru)(Least Recently Used). Memcache постарается удалить прежде всего те данные, которые запрашивались очень давно (т.е. менее популярные удалит, а более популярные оставит).
11 | - Шардинг из коробки(достаточно просто добавлять сервера, вся работа будет инкапсулирована в него)
12 | - Максимальная длина ключа по умолчанию составляет 250 байт, а длина значения — 1 Мб;
13 | - [Будьте осторожнее со спец-символами](https://eax.me/memcached/#comment-432394490);
14 | - Ключи можно «расширить», воспользовавшись каким-нибудь MD5 или SHA512 (в этом случае нехэшированный ключ будет разумно продублировать в значении);
15 | - Если хочется хранить очень длинные значения, можно сжимать их и/или разбивать на части;
16 | - Весь ввод-вывод осуществляется с помощью [libevent](https://eax.me/libevent/);
17 | - Для ускорения работы память выделяется при запуске демона и не освобождается до его остановки;
18 | - Для борьбы с фрагментацией памяти используется [slab allocator](http://ru.wikipedia.org/wiki/Slab);
19 | - Все операции являются атомарными, есть поддержка [compare-and-swap](http://ru.wikipedia.org/wiki/%D0%A1%D1%80%D0%B0%D0%B2%D0%BD%D0%B5%D0%BD%D0%B8%D0%B5_%D1%81_%D0%BE%D0%B1%D0%BC%D0%B5%D0%BD%D0%BE%D0%BC);
20 | - С Memcached можно работать по UDP;
21 | - Помимо текстового протокола [также существует бинарный](http://code.google.com/p/memcached/wiki/BinaryProtocolRevamped);
22 |
23 |
24 |
25 | *Дополнительно:*
26 |
27 | - [Кэширование и Memcached](https://zinvapel.github.io/it/tools/2017/11/27/cache/)
28 |
29 |
--------------------------------------------------------------------------------
/src/db/noSql/mongo.md:
--------------------------------------------------------------------------------
1 | # MongoDb
2 |
3 | **MongoDB** — документоориентированная система управления базами данных (СУБД) с открытым исходным кодом, не требующая описания схемы таблиц. Классифицирована как NoSQL, использует JSON-подобные документы и схему базы данных. Написана на языке C++.
4 |
5 | ### Формат данных в MongoDB
6 |
7 | Одним из популярных стандартов обмена данными и их хранения является JSON (JavaScript Object Notation). JSON эффективно описывает сложные по структуре данные. Способ хранения данных в MongoDB в этом плане похож на JSON, хотя формально JSON не используется. Для хранения в MongoDB применяется формат, который называется **BSON** (БиСон) или сокращение от binary JSON.
8 |
9 | BSON позволяет работать с данными быстрее: быстрее выполняется поиск и обработка. Хотя надо отметить, что BSON в отличие от хранения данных в формате JSON имеет небольшой недостаток: в целом данные в JSON-формате занимают меньше места, чем в формате BSON, с другой стороны, данный недостаток с лихвой окупается скоростью.
10 |
11 | ### Документы вместо строк
12 |
13 | Если реляционные базы данных хранят строки, то MongoDB хранит документы. В отличие от строк документы могут хранить сложную по структуре информацию. Документ можно представить как хранилище ключей и значений.
14 |
15 | Ключ представляет простую метку, с которым ассоциировано определенный кусок данных.
16 |
17 | Однако при всех различиях есть одна особенность, которая сближает MongoDB и реляционные базы данных. В реляционных СУБД встречается такое понятие как первичный ключ. Это понятие описывает некий столбец, который имеет уникальные значения. В MongoDB для каждого документа имеется уникальный идентификатор, который называется `_id`. И если явным образом не указать его значение, то MongoDB автоматически сгенерирует для него значение.
18 |
19 | Каждому ключу сопоставляется определенное значение. Но здесь также надо учитывать одну особенность: если в реляционных базах есть четко очерченная структура, где есть поля, и если какое-то поле не имеет значение, ему (в зависимости от настроек конкретной бд) можно присвоить значение `NULL`. В MongoDB все иначе. Если какому-то ключу не сопоставлено значение, то этот ключ просто опускается в документе и не употребляется.
20 |
21 | ### Коллекции
22 |
23 | Если в традиционном мире SQL есть таблицы, то в мире MongoDB есть коллекции. И если в реляционных БД таблицы хранят однотипные жестко структурированные объекты, то в коллекции могут содержать самые разные объекты, имеющие различную структуру и различный набор свойств.
24 |
25 | ### Репликация
26 |
27 | Система хранения данных в MongoDB представляет набор реплик. В этом наборе есть основной узел, а также может быть набор вторичных узлов. Все вторичные узлы сохраняют целостность и автоматически обновляются вместе с обновлением главного узла. И если основной узел по каким-то причинам выходит из строя, то один из вторичных узлов становится главным.
28 |
29 | ### Простота в использовании
30 |
31 | Отсутствие жесткой схемы базы данных и в связи с этим потребности при малейшем изменении концепции хранения данных пересоздавать эту схему значительно облегчают работу с базами данных MongoDB и дальнейшим их масштабированием. Кроме того, экономится время разработчиков. Им больше не надо думать о пересоздании базы данных и тратить время на построение сложных запросов.
32 |
33 | ### GridFS
34 |
35 | Одной из проблем при работе с любыми системами баз данных является сохранение данных большого размера. Можно сохранять данные в файлах, используя различные языки программирования. Некоторые СУБД предлагают специальные типы данных для хранения бинарных данных в БД (например, BLOB в MySQL).
36 |
37 | В отличие от реляционных СУБД MongoDB позволяет сохранять различные документы с различным набором данных, однако при этом размер документа ограничивается 16 мб. Но MongoDB предлагает решение - специальную технологию **GridFS**, которая позволяет хранить данные по размеру больше, чем 16 мб.
38 |
39 | Система GridFS состоит из двух коллекций. В первой коллекции, которая называется `files`, хранятся имена файлов, а также их метаданные, например, размер. А в другой коллекции, которая называется `chunks`, в виде небольших сегментов хранятся данные файлов, обычно сегментами по 256 кб.
40 |
41 | Для тестирования GridFS можно использовать специальную утилиту **mongofiles**, которая идет в пакете mongodb.
42 |
43 | #
--------------------------------------------------------------------------------
/src/db/noSql/tarantool.md:
--------------------------------------------------------------------------------
1 | # Tarantool
2 |
3 | Tarantool представляет собой решение, совмещающее неблокирующий сервер приложений на Lua с NoSQL базой данных. Высокой производительности позволяет достичь стек технологий, который использует тарантул:
4 |
5 | - libev, libcoro и libeio для реализации event-loop'а, кооперативной многозадачности (coroutines/fibers) и асинхронной работы с сетью и другими задачами.
6 | - LuaJIT — Трассирующий JIT-компилятор для Lua (на стероидах).
7 |
8 | ### Особенности хранилища
9 |
10 | Базовым элементом хранения является кортеж. Кортеж имеет любую размерность, это просто произвольно длинный список полей, ассоциированный с уникальным ключом. Каждый кортеж принадлежит какому-то пространству (space). По полям кортежа можно определять индексы. Если проводить аналогии с реляционными СУБД, то "пространство" соответствует таблице, а "поля" соответствуют столбцам.
11 |
12 | 1. Несколько движков хранения данных:
13 | - Memtx — движок хранения данных полностью в памяти, с поддержкой нескольких видов индексов:
14 | - TREE (B+*-Дерево) — для быстрого поиска значений и возможности интегрирования.
15 | - HASH (Хеш-таблица) — для еще более быстрого поиска значений.
16 | - BITSET (Битовая маска) — возможность поиска по битовым маскам.
17 | - RTREE (многомерное R*-Дерево) — для быстрого поиска ближайших соседей (KNN) и точек в заданных многомерных параллелепипедах с заданными функциями расстояния между двумя точками.
18 | - Sophia — двухуровневый движок хранения информации на диске, который был разработан в ответ на "недостатки" в LSM-деревьях, B-Деревьях и других. Он прекрасно подходит для нагрузки типа "много записи данных среднего размера и немного чтений", но расчёт идёт также на то, что чтение не будет занимать много времени.
19 | 2. Возможность поддерживать "персистентность" с помощью xlog (также известный как Transaction Log), snap (который, в свою очередь, является полным снимком БД) и eventual-consistency (консистетность в конечном счёте) master-master репликации.
20 | 3. Поддержка вторичных ключей и составных ключей.
21 | 4. Аутентификация и привилегии для пользователей и ролей.
22 | 5. MessagePack в качестве протокола для связи клиента с сервером и хранения информации внутри самой базы. MessagePack обеспечивает упаковку некоторых данных, что позволяет снизить трафик, передаваемый по сети, и размер занимаемой памяти в самом хранилище.
23 | 6. Поддержка транзакций и мультиверсионности индексов.
24 |
25 | ### Характеристика сервера приложений
26 |
27 | Язык Lua прекрасно подходит для написания бизнес-логики вашего приложения и прост в освоении, а благодаря трассирующей JIT компиляции можно добиться существенной производительности. Также есть возможность писать модули приложения на языке C/C++.
28 |
29 | Из встроенных библиотек есть возможность работы с YAML, JSON и CSV; имеется возможность для работы с неблокирующим дисковым/сетевым вводом-выводом, работой с UUID, алгоритмами хешированиями, упаковкой-распаковкой данных с заданной схемой и другое.
30 |
31 | Имеется возможность связывать Tarantool'ы в кластера с помощью модуля 'net.box'. В качестве примера можно использовать модуль '[sharding](https://github.com/tarantool/shard)', который реализует шардинг на стороне сервера и '[connection-pool](https://github.com/tarantool/connection-pool)'.
--------------------------------------------------------------------------------
/src/db/relational/README.md:
--------------------------------------------------------------------------------
1 | # Реляционные базы данных
2 |
3 | Реляционные базы данных (РБД) представляют собой структурированные системы хранения данных, основанные на концепции таблиц и связей между ними. Они предоставляют эффективные механизмы для организации и манипуляции данными, обеспечивая целостность и надежность. РБД используют язык SQL (Structured Query Language) для выполнения запросов и управления данными. Они широко применяются в приложениях, требующих структурированного хранения данных, таких как учетная система, системы управления содержимым и бизнес-приложения.
--------------------------------------------------------------------------------
/src/db/relational/mysql/README.MD:
--------------------------------------------------------------------------------
1 | # MySql
2 |
3 | * [Архитектура MySql](architecture.md)
4 | * [Конкурентный доступ](concurency.md)
5 | * [Типы данных](dataTypes.md)
6 | * [Индексы](indexes.md)
7 | * [Оптимизация запросов](queryOptimization.md)
8 | * [Основы SQL](sql.md)
9 | * [Explain](explain.md)
10 | * [Разное](unsorted.md)
--------------------------------------------------------------------------------
/src/db/relational/mysql/architecture.md:
--------------------------------------------------------------------------------
1 | ## Логическая архитектура Mysql
2 |
3 | 
4 |
5 | На самом верхнем уровне содержатся службы, которые не являются уникальными для MySQL. Эти службы необходимы большинству сетевых клиент-серверных инструментов и серверов: они обеспечивают
6 | поддержку соединений, идентификацию, безопасность и т. п.
7 |
8 | Второй уровень представляет гораздо больший интерес. Здесь сосредоточена значительная часть интеллекта MySQL: синтаксический анализ запросов, оптимизация, кэширование и все встроенные функции (например, функции работы с датами и временем, математические функции, шифрование). На этом уровне реализуется любая независимая от подсистемы хранения данных функциональность, например хранимые
9 | процедуры, триггеры и представления.
10 |
11 | Третий уровень содержит подсистемы хранения данных. Они отвечают за сохранение и извлечение всех данных, хранимых в MySQL. Подобно различным файловым системам GNU/Linux, каждая подсистема хранения данных имеет свои сильные и слабые стороны. Сервер взаимодействует с ними с помощью API подсистемы хранения данных. Этот интерфейс скрывает различия между подсистемами хранения данных и делает их почти прозрачными на уровне запросов. Кроме того, данный интерфейс содержит пару десятков низкоуровневых функций, выполняющих операции типа «начать транзакцию» или «извлечь строку с таким первичным ключом». Подсистемы хранения не производят синтаксический анализ кода SQL и не взаимодействуют друг с другом, они просто отвечают на исходящие от сервера запросы.
12 |
13 | ## Управление соединениями и безопасность
14 |
15 | Для каждого клиентского соединения выделяется отдельный поток внутри процесса сервера. Запросы по данному соединению исполняются в пределах этого потока, который, в свою очередь, выполняется одним ядром или процессором. Сервер кэширует потоки, так что их не нужно создавать или уничтожать для каждого нового соединения. Когда клиенты (приложения) подключаются к серверу MySQL, сервер должен их идентифицировать. Идентификация основывается на имени пользователя, адресе хоста, с которого происходит соединение, и пароле. Также можно использовать сертификаты X.509 при соединении по протоколу Secure Sockets Layer (SSL). После того как клиент подключился, для каждого запроса сервер проверяет наличие необходимых привилегий (например, разрешено ли клиенту использовать команду SELECT применительно к таблице Country базы данных world).
16 |
--------------------------------------------------------------------------------
/src/db/relational/mysql/sql.md:
--------------------------------------------------------------------------------
1 | # Основы языка SQL
2 |
3 | SQL (structured query language — «язык структурированных запросов») — декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных.
4 |
5 | ## Операторы
6 |
7 | Операторы SQL делятся на:
8 |
9 | - операторы определения данных (Data Definition Language, DDL):
10 | - CREATE создаёт объект БД (саму базу, таблицу, представление, пользователя и т. д.),
11 | - ALTER изменяет объект,
12 | - DROP удаляет объект;
13 | - операторы манипуляции данными (Data Manipulation Language, DML):
14 | - SELECT выбирает данные, удовлетворяющие заданным условиям,
15 | - INSERT добавляет новые данные,
16 | - UPDATE изменяет существующие данные,
17 | - DELETE удаляет данные;
18 | - операторы определения доступа к данным (Data Control Language, DCL):
19 | - GRANT предоставляет пользователю (группе) разрешения на определённые операции с объектом,
20 | - REVOKE отзывает ранее выданные разрешения,
21 | - DENY задаёт запрет, имеющий приоритет над разрешением;
22 | - операторы управления транзакциями (Transaction Control Language, TCL):
23 | - COMMIT применяет транзакцию,
24 | - ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции,
25 | - SAVEPOINT делит транзакцию на более мелкие участки.
26 |
27 | 
--------------------------------------------------------------------------------
/src/db/relational/postgreSql/README.md:
--------------------------------------------------------------------------------
1 | # Что такое PostgreSQL?
2 |
3 | PostgreSQL — это объектно-реляционная система управления базами данных (ОРСУБД, ORDBMS), основанная на [POSTGRES, Version 4.2](http://db.cs.berkeley.edu/postgres.html) — программе, разработанной на факультете компьютерных наук Калифорнийского университета в Беркли. В POSTGRES появилось множество новшеств, которые были реализованы в некоторых коммерческих СУБД гораздо позднее.
4 |
5 | PostgreSQL — СУБД с открытым исходным кодом, основой которого был код, написанный в Беркли. Она поддерживает большую часть стандарта SQL и предлагает множество современных функций:
6 |
7 | - сложные запросы
8 | - внешние ключи
9 | - триггеры
10 | - изменяемые представления
11 | - транзакционная целостность
12 | - многоверсионность
13 |
14 | Кроме того, пользователи могут всячески расширять возможности PostgreSQL, например создавая свои
15 |
16 | - типы данных
17 | - функции
18 | - операторы
19 | - агрегатные функции
20 | - методы индексирования
21 | - процедурные языки
22 |
--------------------------------------------------------------------------------
/src/db/relational/postgreSql/indexes.md:
--------------------------------------------------------------------------------
1 | # Индексы
2 |
3 | PostgreSQL поддерживает несколько типов индексов: B-дерево, хеш, GiST, SP-GiST, GIN и BRIN. Для разных типов индексов применяются разные алгоритмы, ориентированные на определённые типы запросов. По умолчанию команда `CREATE INDEX` создаёт индексы типа B-дерево, эффективные в большинстве случаев.
--------------------------------------------------------------------------------
/src/devmethods.md:
--------------------------------------------------------------------------------
1 | # Методологии разработки ПО
2 |
3 | ## Водопад или Каскадная модель
4 |
5 | **Каскадная модель** (waterfall model) - [*модель процесса разработки*](http://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D1%81%D0%BA%D0%B0%D0%B4%D0%BD%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C) программного обеспечения, в которой процесс разработки выглядит как поток, последовательно проходящий фазы анализа требований, проектирования, реализации, тестирования, интеграции и поддержки.
6 | Каскадная модель подходит для больших проектов с большими сроками, большими штатами, большим функционалом: сложные системы в банковской сфере, большие интернет-магазины, проекты с большим числом пользователей и так далее. ТЗ для таких проектов может занимать тысячи страниц, но для разработчиков такой процесс фактически идеален: все описано, всё завизировано и утверждено, сделано максимально всё, чтобы понять как должна работать система.
7 |
8 | Водопад даёт качественный результат в силу чёткого следования порядку работы, отсутствию смены требований.
9 |
10 | Минус системы: при необходимости изменений возникает большой объём "бюрократических" работ: согласование и утверждение со всеми заинтересованными лицами.
11 |
12 | ## Итеративный процесс
13 |
14 | **Итеративная разработка** - это выполнение работ параллельно с непрерывным анализом полученных результатов и корректировкой предыдущих этапов работы. Проект при этом [*подходе*](http://ru.wikipedia.org/wiki/%D0%98%D1%82%D0%B5%D1%80%D0%B0%D1%82%D0%B8%D0%B2%D0%BD%D0%B0%D1%8F_%D1%80%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B0) в каждой фазе развития проходит повторяющийся цикл: Планирование — Реализация — Проверка — Оценка ( plan-do-check-act cycle).
15 |
16 | Предпочтителен в случаях когда система сложная и непонятно как она должна работать в конечном виде. Основной принцип: пошаговое приближение к конечной цели. То есть сделать от начала и до конца часть системы, внедрить, собрать фидбек, обсудить, скорректировать процесс и перейти к следующему шагу. Итерация может быть большой (2-3 месяца) или нет (2-3 недели).
17 |
18 | Метод очень эффективен в плане взаимодействия с клиентом. Особенно с тем, кто толком не представляет чего он хочет. Улучшается обратная связь с Заказчиком – он принимает каждый этап (итерацию). Выпуск проекта в стартовой, урезанной конфигурации позволяет Заказчику самому понять куда идти дальше. И он идёт дальше **вместе с вами**.
19 |
20 | Метод позволяет брать в работу приоритетные задачи и риски. Распределяется нагрузка равномерно по всему сроку, то есть проектировщики не сидят без дела, после выполнения проектирования, как было бы в методе "водопад", а после выполнения первого этапа, когда программисты только начали работу, переходят ко второму. В это время дизайнеры могут заниматься уже третьим этапом.
21 |
22 | Затраты на проект распределяются равномерно, а не в конце проекта. Это важно для Заказчика.
23 |
24 | Сложности метода:
25 |
26 | - Нужно внедрять, обучать людей;
27 | - Много ролей, требующих узкой специализации;
28 | - Требуется постоянный контроль, поддержание процесса.
29 |
30 | Итеративный процесс имеет несколько видов: Agile, XP, Kanban, RUP и другие.
31 |
32 | ### Agile/Scrum
33 |
34 | [***Agile***](http://www.agilemanifesto.org/iso/ru/) - серия подходов к разработке программного обеспечения, ориентированных на использование итеративной разработки, динамическое формирование требований и обеспечение их реализации в результате постоянного взаимодействия внутри самоорганизующихся рабочих групп, состоящих из специалистов различного профиля.
35 |
36 | **Scrum** - методология гибкой разработки программного обеспечения. Scrum чётко делает акцент на неотвратимости срока демонстрации готового функционала клиенту.
37 |
38 | 
39 |
40 | Работа организуется по следующему принципу:
41 |
42 | 1. Менеджер проекта (Product owner) собирает все потребности, "хотелки" по продукту, сценарии использования в списке задач (Product backlog).
43 | 2. На основе Product backlog на собрании перед циклом разработки (Sprint planning meeting) составляется круг задач (Sprint backlog) решаемых в этой итерации (Sprint'e)
44 | 3. Производится цикл с разработкой, тестированием, демонстрацией результата заказчику.
45 | 4. По результатам Sprint'а проводится публичный анализ (Sprint Retrospective) результатов работы.
46 | 5. Цикл повторяется нужное число раз до выхода готового продукта.
47 |
48 | **Плюсы и минусы технологии**
49 |
50 | **Плюсы:**
51 |
52 | - Просто внедрить
53 | - Разработчикам обычно нравится
54 | - Прозрачность проекта
55 | - Ориентация на результат
56 |
57 | **Минусы:**
58 |
59 | - Не все люди сработаются, сложности "человеческого фактора".
60 | - Издержки на «болтовню» 10-30%
61 | - Качество веб-системы может сильно пострадать, если неверно организован процесс и неверно заданы Definition of Done.
62 |
63 | ### Канбан
64 |
65 | **Kanban** - модель разработки, в условиях ограничения числа выполняемых задач каждым разработчиком.
66 |
67 | Модель подходит для веб-студий, работающих с большим количеством несложных заказов. Работа по этой модели - это работа без конечных сроков. Клиент платит за то, что студия потратила время. При доверии со стороны клиента, что программист работает эффективно и поставленную задачу реально можно было решить именно за то время, которое на неё потрачено.
68 |
69 | Канбан позволяет сократить время прохода задачи до состояния «готовности». Количество незавершённой работы разработчика должно быть ограничено. Новая задача может ставиться только тогда, когда какая-то из существующих передаётся следующему элементу производственного цикла. Kanban (или сигнальная карточка) подразумевает, что производится некое визуальное оповещение о том, что можно задавать новую работу, так как текущий объём работ не равен принятым лимитам.
70 |
71 | **Смысл системы с точки зрения разработчика**: максимально упростить бюрократию и дать человеку просто работать над небольшим числом задач.
72 |
73 | **Смысл системы с точки зрения компании**: снижение времени прохождения задачи через группу специалистов до её релиза. Система позволяет создать работнику такие комфортные условия работы, что бы задача проходила через все эти этапы быстро. При этом происходит визуализация задач, облегчающая контроль.
74 |
75 | 
76 |
--------------------------------------------------------------------------------
/src/devops/README.md:
--------------------------------------------------------------------------------
1 | # Системной администрирование
2 |
3 | Системное администрирование - обеспечение штатной работы парка компьютерной техники, сети и программного обеспечения. Зачастую системному администратору вменяется обеспечение информационной безопасности в организации. В контексте разработки нас больше интересует эксплуатация - всё что связано с нормальным развёртованием, функционированием и наблюдением за нашими приложениями на продакшн серверах.
4 |
5 | * [Linux](linux.md)
6 | * [Основы виртуализации](virtualization/README.md)
7 | * [Docker](virtualization/docker.md)
8 | * [Kubernetes](virtualization/kubernetes.md)
9 | * [Deployment](deployment.md)
10 | * [Observability](observability.md)
11 | * [Load Balancing](load_balancing.md)
--------------------------------------------------------------------------------
/src/devops/deployment.md:
--------------------------------------------------------------------------------
1 | # Deployment
2 |
3 | ## Green-Blue Deployment
4 |
5 | При этой стратегии создается полная копия инфраструктуры (Green) для
6 | новой версии приложения, а затем постепенно перенаправляется трафик на нее, оставляя предыдущую версию (Blue) работающей
7 | параллельно. Это обеспечивает возможность быстрого отката в случае проблем и минимизирует риски простоя системы.
8 |
9 | Одна из задач автоматизации деплоя — переход из одного состояния в другое внутри себя же, с переводом софта из финальной
10 | стадии тестирования в действующий продакшен. Обычно это нужно сделать быстро, чтобы минимизировать время простоя. При
11 | сине-зеленом подходе у вас есть два продакшена, насколько возможно идентичных. В любое время один из них, допустим
12 | синий, активен. При подготовке новой версии софта, вы делаете финальное тестирование в зелёном продакшене. Вы
13 | убеждаетесь, что программа в этом продакшене работает и настраиваете роутер так, чтобы все входящие запросы шли в
14 | зелёную операционную среду — синяя в режиме ожидания.
15 |
16 | Сине-зелёный деплой также даёт вам возможность быстро откатиться до старого состояния: если что-то пойдет не так,
17 | переключите роутер обратно на синий продакшен. Но вам всё ещё придётся справляться с пропущенными транзакциями, пока
18 | зелёный продакшен активен, и, в зависимости от структуры кода, вы сможете направлять транзакции в оба продакшена, чтобы
19 | сохранять синий как резервную копию, при активном зелёном. Или можете перевести приложение в read-only режим, перед
20 | синхронизацией, запустить его на время в этом режиме, а потом переключить в режим read-write. Этого может оказаться
21 | достаточно, чтобы избавиться от многих нерешенных проблем.
22 |
23 | ## Canary Deployment (канареечные релизы)
24 |
25 | При этой стратегии новая версия приложения запускается на ограниченной части инфраструктуры или для небольшого числа
26 | пользователей, чтобы проверить его работоспособность и сравнить с предыдущей
27 | версией. Если новая версия проходит проверку успешно, она постепенно внедряется на остальные серверы или для всех
28 | пользователей.
29 |
30 | Термин «канареечный релиз» придуман по аналогии с тем, как шахтеры в угольных шахтах брали с собой канареек в клетках,
31 | чтобы обнаруживать опасный уровень угарного газа. Если в шахте скапливалось много угарного газа, то он убивал канарейку
32 | до того, как становился опасным для шахтеров, и они успевали спастись.
33 |
34 | При использовании этого шаблона, когда мы делаем выпуск, то наблюдаем, как программное обеспечение работает в каждой
35 | среде. Когда что-то кажется неправильным, мы выполняем откат, в противном случае мы выполняем развертывание в следующей
36 | среде.
37 |
38 | ## Blue-Green-Canary Deployment
39 |
40 | Это комбинированная стратегия, объединяющая элементы Green-Blue и Canary деплоя. При этом создается новая версия (Blue),
41 | которая постепенно внедряется на ограниченный набор серверов или пользователей (Canary). После проверки и удовлетворения
42 | результатами, новая версия становится основной (Green), а предыдущая версия сохраняется в качестве резервной.
43 |
44 | ## Shadow Deployment (теневой)
45 |
46 | При данной стратегии новая версия приложения запускается параллельно с текущей активной версией, но не обрабатывает
47 | реальные запросы пользователей. Вместо этого, она получает копии запросов и используется для сбора данных о
48 | производительности и стабильности новой версии без риска негативного влияния на пользователей.
49 |
50 | ## Rolling Deployment (плавный деплоймент)
51 |
52 | Эта стратегия предусматривает постепенное обновление приложения или
53 | инфраструктуры путем замены старых компонентов новыми на протяжении определенного времени или количества этапов. Это
54 | позволяет распределить нагрузку и снизить риски, так как если что-то идет не так, можно быстро вернуться к предыдущей
55 | версии.
56 |
57 | ## A/B Testing (A/B тестирование)
58 |
59 | Эта стратегия предполагает разделение пользователей на две группы: одна получает новую
60 | версию приложения (группа A), а другая продолжает использовать предыдущую версию (группа B). Это позволяет сравнить
61 | производительность, стабильность и пользовательский опыт между версиями и принять решение о полном переходе на новую
62 | версию.
63 |
64 | ## Feature Toggles (фич-тоглы)
65 |
66 | Эта стратегия позволяет включать и отключать определенные функциональные возможности приложения в зависимости от
67 | конфигурации. Таким образом, можно поэтапно вводить новые функции или экспериментировать с разными вариантами, не влияя
68 | на работу основного приложения.
69 |
70 | ## Traffic Splitting (разделение трафика)
71 |
72 | При этой стратегии трафик распределяется между несколькими версиями приложения в определенных пропорциях. Это позволяет
73 | постепенно увеличивать нагрузку на новую версию и наблюдать ее работу в реальном времени, а также сравнивать ее с
74 | предыдущей версией.
75 |
76 | ## Immutable Infrastructure (неизменяемая инфраструктура)
77 |
78 | Эта стратегия предполагает создание инфраструктуры, которая не подвергается изменениям после развертывания. Вместо
79 | этого, для обновления приложения создается новая инфраструктура с новой версией приложения, что обеспечивает простоту
80 | отката и предотвращает проблемы, связанные с изменениями в рабочей инфраструктуре.
81 |
82 | ## Blue-Green-Red Deployment
83 |
84 | Это расширенная версия Blue-Green деплоя, в которой предусмотрено наличие третьей окружения (Red), используемого для
85 | разработки и тестирования новых функций. При этом Blue и Green окружения остаются стабильными и готовыми к
86 | использованию, а Red используется для экспериментов и разработки.
87 |
88 | ## Список стратегий деплоя
89 |
90 | * Green-Blue Deployment
91 | * Canary Deployment
92 | * Rolling Deployment
93 | * A/B Testing
94 | * Blue-Green-Canary Deployment
95 | * Shadow Deployment
96 | * Feature Toggles
97 | * Traffic Splitting
98 | * Immutable Infrastructure
99 | * Blue-Green-Red Deployment
100 | * Rolling Updates
101 | * Recreate Deployment
102 | * Traffic Mirroring
103 | * Dark Launching
104 | * Forking
105 | * Phased Rollout
106 | * Ring Deployment
107 | * Delta Deployment
108 | * Staged Rollout
109 | * Live Migration
110 | * Binary Delta Deployment
111 | * Hybrid Deployment
112 | * Multi-Armed Bandit
113 | * Traffic Shifting
114 | * Zero Downtime Deployment
115 | * Chaos Engineering
116 | * Parallel Deployment
117 | * Incremental Deployment
118 | * Strangler Pattern
119 | * Hot Patching
120 |
121 |
--------------------------------------------------------------------------------
/src/devops/observability.md:
--------------------------------------------------------------------------------
1 | # Observability
2 |
3 |
4 | Observability (**наблюдаемость**) - это концепция, которая означает, насколько легко и эффективно вы можете наблюдать, измерять и понимать, что происходит внутри вашей системы. Это очень важно так как позволяет быстро обнаруживать, диагностировать и устранять проблемы, а также улучшать производительность и безопасность системы.
5 |
6 | Можно выделить следующие направления:
7 |
8 | 1. **Логирование (Logging):**
9 | - Логирование - это процесс записи событий и данных о работе вашей системы в лог-файлы. Логи могут содержать информацию о действиях пользователя, ошибках, исключениях, запросах и других событиях.
10 | - Преимущества: Логи помогают выявлять и анализировать проблемы, воссоздавать сценарии ошибок и обеспечивать безопасность.
11 | - Популярные инструменты: Log4j, Logback, ELK Stack (Elasticsearch, Logstash, Kibana), Fluentd.
12 | 2. **Мониторинг (Monitoring):**
13 | - Мониторинг - это процесс наблюдения за состоянием системы в реальном времени. Он включает сбор и агрегацию метрик, таких как использование ресурсов, нагрузка на сервер и статус сервисов.
14 | - Преимущества: Мониторинг помогает оперативно обнаруживать и реагировать на проблемы, а также оптимизировать производительность системы.
15 | - Популярные инструменты: Prometheus, Grafana, Nagios, Zabbix.
16 | 3. **Алертинг(Alerting)**
17 | - Алертинг (Alerting) - это важная часть системы мониторинга и обеспечения надежности, которая позволяет оперативно реагировать на проблемы и уведомлять администраторов или инженеров о них.
18 | - Популярные инструменты: Prometheus Alertmanager, Grafana Alerting, Nagios, Zabbix и многие другие. Эти инструменты позволяют определять условия, при которых должно генерироваться уведомление.
19 | - **Триггеры и Условия (Triggers and Conditions):** Алерты создаются на основе заданных условий или триггеров. Например, условие может быть следующим: "Если использование процессора превышает 90% в течение 5 минут, сгенерировать алерт."
20 | - **Уровни Важности (Severity Levels):** Алерты могут иметь разные уровни важности, такие как информационные, предупреждающие, критические и т. д. Уровень важности определяет, насколько критична проблема.
21 | - **Уведомления (Notifications):** Системы алертинга интегрируются с различными каналами уведомления, такими как электронная почта, SMS, мессенджеры (Slack, Telegram), системы вызовов (PagerDuty) и другие. Когда алерт срабатывает, система отправляет уведомление на выбранный канал.
22 | 4. **Трейсинг (Tracing):**
23 | - Трейсинг - это метод изучения пути выполнения запроса через распределенную систему. Он позволяет отслеживать, какие компоненты обрабатывают запрос, и где возникают задержки.
24 | - Преимущества: Трейсинг упрощает обнаружение и устранение узких мест в производительности, а также улучшает отладку распределенных систем.
25 | - Популярные инструменты: Jaeger, Zipkin, OpenTelemetry.
26 | 5. **Профайлинг (Profiling):**
27 | - Профайлинг - это процесс анализа производительности приложения или системы, позволяющий выявить места, где приложение тратит больше всего времени.
28 | - Преимущества: Профайлинг позволяет оптимизировать производительность, выявлять "горячие" участки кода и улучшать архитектуру приложения.
29 | - Популярные инструменты: Go Profiler, pprof, Java Flight Recorder.
--------------------------------------------------------------------------------
/src/devops/virtualization/README.md:
--------------------------------------------------------------------------------
1 | # Виртуализация
2 |
3 | Для изоляции процессов, запущенных на одном хосте, запуска приложений, предназначенных для разных платформ, можно использовать виртуальные машины. Виртуальные машины делят между собой физические ресурсы хоста:
4 |
5 | - процессор,
6 | - память,
7 | - дисковое пространство,
8 | - сетевые интерфейсы.
9 |
10 |
11 | 
12 |
13 | На каждой ВМ устанавливаем нужную ОС и запускаем приложения. Недостатком такого подхода является то, что значительная часть ресурсов хоста расходуется не на полезную нагрузку(работа приложений), а на работу нескольких ОС.
14 |
15 |
16 |
17 | ### Контейнеры
18 |
19 | В отличие от аппаратной виртуализации, при которой эмулируется аппаратное окружение и может быть запущен широкий спектр гостевых операционных систем, в контейнере может быть запущен экземпляр операционной системы только с тем же ядром, что и у хостовой операционной системы (все контейнеры узла используют общее ядро). При этом при контейнеризации отсутствуют дополнительные ресурсные накладные расходы на эмуляцию виртуального оборудования и запуск полноценного экземпляра операционной системы, характерные при аппаратной виртуализации.
20 |
21 | Альтернативным подходом к изоляции приложений являются контейнеры. Само понятие контейнеров не ново и давно известно в Linux. Идея состоит в том, чтобы в рамках одной ОС выделить изолированную область и запускать в ней приложение. В этом случае говорим о виртуализации на уровне ОС. В отличие от ВМ контейнеры изолированно используют свой кусочек ОС:
22 |
23 | - файловая система
24 |
25 | - дерево процессов
26 |
27 | - сетевые интерфейсы
28 |
29 | - и др.
30 |
31 | 
32 |
33 | Т.о. приложение, запущенное в контейнере думает, что оно одно во всей ОС. Изоляция достигается за счет использования таких Linux-механизмов, как **namespaces** и **control groups**. Если говорить просто, то namespaces обеспечивают изоляцию в рамках ОС, а control groups устанавливают лимиты на потребление контейнером ресурсов хоста, чтобы сбалансировать распределение ресурсов между запущенными контейнерами.
34 |
35 |
36 |
37 | Дополнительно:
38 |
39 | - [CGRoups](https://habr.com/ru/company/selectel/blog/303190/)
--------------------------------------------------------------------------------
/src/devops/virtualization/docker.md:
--------------------------------------------------------------------------------
1 | # Docker
2 |
3 | Docker — программное обеспечение для автоматизации развёртывания и управления приложениями в средах с поддержкой контейнеризации. Позволяет «упаковать» приложение со всем его окружением и зависимостями в контейнер, который может быть перенесён на любую Linux-систему с поддержкой cgroups в ядре, а также предоставляет среду по управлению контейнерами. Изначально использовал возможности LXC, с 2015 года применял собственную библиотеку, абстрагирующую виртуализационные возможности ядра Linux — libcontainer. С появлением Open Container Initiative начался переход от монолитной к модульной архитектуре.
4 |
5 | ## Основные термины
6 |
7 | ### Image (образ)
8 |
9 | Образ в первом приближении можно рассматривать как набор файлов. В состав образа входит все необходимое для запуска и работы приложения на голой машине с докером: ОС, среда выполнения и приложение, готовое к развертыванию.
10 |
11 | - Образ — это набор файлов, необходимых для работы приложения на голой машине с установленным Docker.
12 | - Образ состоит из неизменяемых слоев, каждый из которых добавляет/удаляет/изменяет файлы из предыдущего слоя.
13 | - Неизменяемость слоев позволяет их использовать совместно в разных образах.
14 |
15 | ### Docker-контейнеры
16 |
17 | Контейнер - процесс, инициализированный на базе образа. То есть контейнер существует только когда запущен. Это как экземпляр класса, а образ это типа класс. Суть преобразования образа в контейнер состоит в добавлении верхнего слоя, для которого разрешена запись. Результаты работы приложения (файлы) пишутся именно в этом слое.
18 |
19 | 
20 |
21 |
22 |
23 | - **Host (хост)** – среда, в которой запускается докер т.е ваша локальная машина.
24 | - **Volume** – дисковое пространство между хостом и контейнером. Это папка на вашей локальной машине примонтированная внутрь контейнера. Меняете тут меняется там, и наоборот.
25 | - **Dockerfile** – файл с набором инструкций для создания образа будущего контейнера
26 | - **Service (сервис)** – по сути это запущенный образ (один или несколько контейнеров), дополнительно сконфигурированный такими опциями как открытие портов, маппинг папок (volume) и прочее. Обычно это делается при помощи docker-compose.yml файла.
27 | - **Docker-compose** – тулза, облегчающая сборку и запуск системы состоящей из нескольких контейнеров, связанных между собой.
28 | - **Build (билд, билдить)** – процесс создания образа из набора инструкций в докерфайле, или нескольких докерфайлов, если билд делается с помощью композера
29 |
30 |
31 | ## Популярные команды:
32 |
33 | - **RUN**
34 | - **CMD**
35 | - **ENTRYPOINT**
36 | - **ADD**
37 | - **COPY**
38 | - **FROM**
39 | - **ENV**
40 | - **WORKDIR**
41 | - **ARG**
42 | - **LABEL**
43 | - **EXPOSE**
44 |
45 | ## RUN vs CMD vs ENTRYPOINT
46 |
47 | Эти инструкции выполняются при сборке docker-образа из Dockerfile. `RUN` позволяет выполнять команды внутри вашего docker-образа — такие команды выполняются только **один раз во время сборки** и **создают новый слой** в итоговом docker-образе.
48 |
49 | Если вам необходимо установить пакет или создать каталог внутри вашего docker-образа, то инструкция `RUN` подойдет вам как нельзя лучше. Например:
50 |
51 | ```dockerfile
52 | RUN mkdir -p /var/www/test
53 | ```
54 |
55 | Инструкция `CMD` позволяет определить команду по умолчанию, которая будет выполняться при **запуске** вашего docker-контейнера (запущенный docker-образ называется контейнером). Эта инструкция **не выполняется во время сборки**!
56 |
57 | Например, в Dockerfile для веб-приложения вполне логично добавить инструкцию `CMD`, которая запустит веб-сервер при старте контейнера, например:
58 |
59 | ```dockerfile
60 | CMD ["php", "-S", "0.0.0.0:9095", "-t", "public", "public/index.php"]
61 | ```
62 |
63 | 1. Use RUN instructions to build your image by adding layers on top of initial image.
64 | 2. Prefer ENTRYPOINT to CMD when building executable Docker image, and you need a command always to be executed. Additionally, use CMD if you need to provide extra default arguments that could be overwritten from command line when docker container runs.
65 | 3. Choose CMD if you need to provide a default command and/or arguments that can be overwritten from command line when docker container runs.
66 |
67 |
68 |
69 | ## Docker-compose
70 |
71 | Пакетный менеджер Docker Compose, позволяющий описывать и запускать многоконтейнерные приложения. Конфигурационные файлы Compose описываются на языке YAML
72 |
73 |
74 |
75 | *Дополнительно:*
76 |
77 | - [Docker. Начало](https://habr.com/ru/post/353238/)
78 | - [Основы Docker за Х часов и Y дней](https://habr.com/ru/post/337306/)
79 | - [Изучаем Docker, часть 1: основы](https://habr.com/ru/company/ruvds/blog/438796/)
80 | - [Руководство по Docker Compose для начинающих](https://habr.com/ru/company/ruvds/blog/450312/)
--------------------------------------------------------------------------------
/src/devops/virtualization/kubernetes.md:
--------------------------------------------------------------------------------
1 | # Kubernetes
2 |
3 | **Kubernetes** (K8s) - это платформа управления контейнерами с открытым исходным кодом, разработанная Google. Она предоставляет средства для автоматизации развертывания, масштабирования и управления контейнеризированными приложениями.
4 |
5 | Kubernetes позволяет создавать и управлять группами контейнеров, которые объединяются в логические единицы, называемые "поды". Он обеспечивает автоматическую оркестрацию, балансировку нагрузки, масштабирование и высокую доступность приложений.
6 |
7 | Идея состоят в том, что ваш деплой строится на базе контейнеров (например, [Docker](https://eax.me/docker/)), а также описании того, сколько этих контейнеров нужно и какие ресурсы они используют. Kubernetes на базе этого описания и доступных физических машин разворачивает контейнеры и делает все возможное для поддержания требуемой конфигурации. В том числе, он перезапускает упавшие контейнеры, перемещает их для выделения ресурсов, необходимых новым контейнерам, и так далее.
8 |
9 | Зачем это нужно? Другими словами, используется декларативный подход — мы описываем, *что* требуется достичь, а а Kubernetes берет на себя задачи по достижению и поддержанию этого состояния. Из преимуществ данного подхода можно отметить следующие. Система сама себя восстанавливает в случае сбоев. У вас не болит голова о том, на какой физической машине запущен тот или иной контейнер, и куда его перенести, чтобы запустить новый тяжелый сервис. Система становится повторяемой. Если у вас все развернулось и работает в тестовом окружении, вы можете с хорошей долей уверенности сказать, что оно развернется в точно такую же систему и на продакшене. Наконец, система становится версионируемой. Если что-то пошло не так, вы можете достать из Git старую конфигурацию и развернуть все в точности, как было раньше.
10 |
11 | Kubernetes также предоставляет множество возможностей, таких как сервис-дискавери, маршрутизация трафика, хранение данных, мониторинг и многое другое, с помощью расширяемой архитектуры и плагинов.
12 |
13 |
14 |
15 | ## Основные компоненты платформы Kubernetes включают:
16 |
17 | ### Master Node
18 |
19 | Мастер-узел является главным управляющим компонентом Kubernetes. Он отвечает за принятие решений и координацию работы кластера. Компоненты мастер-узла включают API-сервер, контроллеры управления, планировщик (scheduler) и хранилище состояния кластера (etcd).
20 |
21 | ### Worker Nodes
22 |
23 | Рабочие узлы - это машины, на которых запускаются и работают контейнеры. Они получают команды от мастер-узла и выполняют их. Рабочие узлы включают в себя kubelet (агент Kubernetes), контейнерный рантайм (например, Docker или containerd) и kube-proxy (для управления сетевым взаимодействием).
24 |
25 | ### Pods
26 |
27 | Поды являются наименьшей развертываемой и масштабируемой единицей в Kubernetes. Они содержат один или несколько контейнеров, которые работают вместе и разделяют сеть и хранилище. Поды создаются, управляются и масштабируются Kubernetes.
28 |
29 | ### Services
30 |
31 | Сервисы предоставляют постоянный IP-адрес и стабильное DNS-имя для набора подов. Они позволяют установить коммуникацию между различными подами и внешними системами.
32 |
33 | ### Replication Controllers
34 |
35 | Репликационные контроллеры отвечают за поддержание заданного количества работающих экземпляров подов. Если какие-то поды выходят из строя, репликационный контроллер автоматически создает новые экземпляры, чтобы поддерживать желаемое состояние.
36 |
37 | ### Ingress
38 |
39 | Внешние объекты предоставляют маршрутизацию внешнего трафика к сервисам внутри кластера Kubernetes.
40 |
41 | ### ConfigMaps и Secrets
42 |
43 | ConfigMaps позволяют хранить конфигурационные данные, которые могут быть использованы в подах, а Secrets используются для хранения и управления конфиденциальной информацией, такой как пароли и ключи.
44 |
45 | ### Kubectl
46 |
47 | Kubectl - это клиентская утилита командной строки для взаимодействия с кластером Kubernetes. Она позволяет разработчикам и администраторам управлять и контролировать различные аспекты кластера, такие как создание, удаление и масштабирование ресурсов, просмотр логов и мониторинг состояния приложений.
48 |
49 | Kubectl позволяет выполнять следующие задачи:
50 |
51 | 1. Создание и управление ресурсами: Вы можете создавать и управлять различными ресурсами Kubernetes, такими как поды, сервисы, репликационные контроллеры, секреты и конфигурационные карты (ConfigMaps).
52 | 2. Масштабирование приложений: С помощью Kubectl вы можете масштабировать количество экземпляров подов или других ресурсов для обеспечения нужной производительности или отказоустойчивости.
53 | 3. Управление состоянием приложений: Kubectl предоставляет возможности для управления состоянием приложений, включая развертывание новых версий, обновление конфигураций и переключение между различными версиями.
54 | 4. Отладка и мониторинг: Вы можете получать доступ к логам и метрикам приложений, а также выполнять отладку и проверку состояния ресурсов Kubernetes с помощью Kubectl.
55 | 5. Работа с конфигурацией и контекстами: Kubectl позволяет управлять конфигурационными файлами Kubernetes и устанавливать контексты для работы с различными кластерами и окружениями.
56 |
57 | ### Minikube
58 |
59 | Minikube - это инструмент для локального развертывания единственной ноды Kubernetes. Он позволяет разработчикам запускать и тестировать приложения на своих локальных машинах без необходимости полноценного кластера Kubernetes. Minikube создает изолированную среду, в которой можно разрабатывать и отлаживать приложения в контейнерах.
60 |
61 | ### Kubelet
62 |
63 | Kubelet - это агент, который работает на каждом рабочем узле в кластере Kubernetes. Он отвечает за управление жизненным циклом подов на рабочем узле. Kubelet следит за состоянием подов, запускает и останавливает их, проверяет их здоровье, а также обеспечивает связь с мастер-узлом для получения инструкций и обновлений.
64 |
65 | Вместе Kubectl, Minikube и Kubelet предоставляют разработчикам и администраторам удобный способ взаимодействия с Kubernetes-кластерами и управления ими, позволяя разрабатывать, тестировать и развертывать приложения в контейнерах.
66 |
67 |
--------------------------------------------------------------------------------
/src/goLang/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/goLang/.DS_Store
--------------------------------------------------------------------------------
/src/goLang/README.md:
--------------------------------------------------------------------------------
1 | ## GoLang
2 |
3 | **Go** (Golang) — компилируемый многопоточный язык программирования.
4 |
5 | Язык Go разрабатывался как язык программирования для создания высокоэффективных программ, работающих на современных
6 | распределённых системах и многоядерных процессорах. Он может рассматриваться, как попытка создать замену языкам Си и C++.
7 |
8 | Компилируемый язык. Предполагается, что программы на Go будут транслироваться компилятором в объектный код целевой
9 | аппаратной платформы и в дальнейшем исполняться непосредственно, не требуя виртуальной машины. Архитектура языка
10 | изначально проектировалась так, чтобы обеспечить быструю компиляцию в эффективный объектный код.
11 |
12 | * [Типы данных](types/README.md)
13 |
14 | * [Скалярные](types/scalar.md)
15 | * [Массив и слайс](types/array_slice.md)
16 | * [Map](types/map.md)
17 | * [Структура](types/struct.md)
18 | * [Интерфейс](types/interface.md)
19 |
20 | * [Сoncurrency](concurrency/README.md)
21 |
22 | * [Каналы](concurrency/chanel.md)
23 | * [Планировщик](concurrency/scheduler.md)
24 | * [Горутины](concurrency/gouritine.md)
25 | * [Sync](concurrency/sync.md)
26 | * [Паттерны](concurrency/patterns.md)
27 |
28 | * [Управление памятью](memory.md)
29 |
30 | * [Экосистема](ecosystem.md)
31 |
32 | ## Вопросы
33 |
34 | - Как хранятся переменные в Golang?
35 |
36 | - Что представляет собой тип данных string в Go?
37 |
38 | - Что вернет функция len(), примененная к строке?
39 |
40 | - Что собой представляет тип данных rune?
41 |
42 | - Как устроен слайс и чем он отличается от массива?
43 |
44 | - Как работает функция append? Что происходит с capacity и базовым массивом?
45 |
46 | - Как создать многомерный массив в Golang
47 |
48 | - Нужно ли передавать slice по ссылке в функцию?
49 |
50 | - Что представляет собой map?
51 |
52 | - Чем является функция в Go?
53 |
54 | - Что такое метод структуры? Что такое получатель (receiver) метода? В чем разница между получателем по значению и
55 | указателем?
56 |
57 | - Значения-методы и выражения-методы - в чем отличие?
58 |
59 | - Что такое интерфейсы? Как устроен пустой интерфейс?
60 |
61 | - ООП в Golang
62 |
63 | - Как в golang освобождает память и можно ли отключить это поведение и зачем это делать?
64 |
65 | - Что такое каналы и каких видов они бывают?
66 |
67 | - В чем отличие буферизированного канала от небуферизированного?
68 | - Какой дефолтный размер буфера у канала?
69 | - Что вернет получение значения из закрытого канала?
70 | - Что произойдет при записи значения в закрытый канал?
71 | - Что будет если писать в
72 | неинициализированный канал?
73 |
74 | - Как огранить число потоков на системы при запуске Golang программы и возможно ли огранить их до 1 потока?
75 |
76 | - Каким способом происходит отмена работы других горутин?
77 |
78 | - Почему важно завершать горутины по окончании / прерывании работы главной программы?
79 |
80 | - Что такое гонка данных (race condition, состояние гонки)? Какие существуют способы избежать состояния гонки в Go?
81 |
82 | - Что такое семафор? Бинарный семафор? Что такое mutex? Какие бывают виды mutex в Go?
83 |
84 | - В чем различия goroutine от потока системы?
85 |
86 | *Дополнительно:*
87 |
88 | - [Исходный код](https://golang.org/src/runtime/chan.go)
89 | - [Каналы в спецификации Go](https://golang.org/ref/spec#Channel_types)
90 | - [Каналы Go на стероидах](https://docs.google.com/document/d/1yIAYmbvL3JxOKOjuCyon7JhW4cSv1wy5hC0ApeGMV9s/pub)
91 | - [Планировщик Go](https://habr.com/ru/company/ua-hosting/blog/269271/)
92 | - [Work-stealing планировщик в Go](https://habr.com/ru/post/333654/)
93 | - [Как не наступать на грабли в Go](https://habr.com/ru/post/325468)
94 | - [Go Traps](https://go-traps.appspot.com/)
95 | - [Хэш таблицы в Go. Детали реализации](https://habr.com/ru/post/457728)
96 | - [Algorithms to Go](https://yourbasic.org/)
97 | - [Практичный Go: советы по написанию поддерживаемых программ в реальном мире](https://habr.com/ru/post/441842/)
98 | - [50 оттенков Go: ловушки, подводные камни и распространённые ошибки новичков](https://habr.com/ru/company/mailru/blog/314804/)
--------------------------------------------------------------------------------
/src/goLang/concurrency/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/goLang/concurrency/.DS_Store
--------------------------------------------------------------------------------
/src/goLang/concurrency/README.md:
--------------------------------------------------------------------------------
1 | # Сoncurrency
2 |
3 | В данном разделе будут темы, относящиеся к параллелизму и конкурентности.
4 |
5 | - [Каналы](chanel.md)
6 | - [Планировщик](scheduler.md)
7 | - [Горутины](gouritine.md)
8 | - [Context](context.md)
9 | - [Sync](sync.md)
10 | - [Паттерны](patterns.md)
--------------------------------------------------------------------------------
/src/goLang/concurrency/gouritine.md:
--------------------------------------------------------------------------------
1 | # Goroutines
2 |
3 | Горутина — функция, которая может работать параллельно с другими функциями. Для создания горутины используется ключевое слово `go`, за которым следует вызов функции. Горутины очень легкие(примерно 4.5кб на горутину против нескольких мегабайт на поток POSIX).
4 |
5 | ## Отличия горутин от потоков
6 |
7 | ### Stack
8 |
9 | Каждый поток операционной системы имеет блок памяти фиксированного размера (зачастую до 2 Мбайт) для стека — рабочей области, в которой он хранит локальные переменные вызовов функций, находящиеся в работе или приостановленные на время вызова другой функции. В противоположность этому go-подпрограмма начинает работу с небольшим стеком, обычно около **2 Кбайт**. Стек go-подпрограммы, подобно стеку потока операционной системы, хранит локальные переменные активных и приостановленных функций, но, в отличие от потоков операционной системы, не является фиксированным; при необходимости он может расти и уменьшаться. Максимальный размер стека go-подпрограммы может быть около 1 Гбайта, на порядки больше типичного стека с фиксированным размером, хотя, конечно, такой большой стек могут использовать только несколько go-подпрограмм.
10 | Раньше использовался **Segmented Stacks** потом переделали на **Сontiguous Stacks**
11 |
12 | #### Segmented Stacks
13 |
14 | The 1.2 runtime uses segmented stacks, also known as split stacks.
15 |
16 | In this approach, stacks are discontiguous and grow incrementally.
17 |
18 | Each stack starts with a single segment. When the stack needs to grow, another segment is allocated and linked to the previous one, and so forth. Each stack is effectively a doubly linked list of one or more segments.
19 |
20 | #### Сontiguous Stacks
21 |
22 | The “hot split” were addressed in Go 1.3 by making the stacks contiguous.
23 |
24 | Now when a stack needs to grow, instead of allocating a new segment the runtime will:
25 |
26 | * create a new, somewhat larger stack
27 | * copy the contents of the old stack to the new stack
28 | * re-adjust every copied pointer to point to the new addresses
29 | * destroy the old stack
30 |
31 | ### Scheduler
32 |
33 | Потоки операционной системы планируются в ее ядре, а у go есть собственный **планировщик (m:n) мультиплексирующий(раскидывающий) горутинки(m) по потокам(n)**. Основной плюс = отсуствие оверхеда на переключение контекста. Т.к переключение тредов происходит **kernel space**, то переключение потока очень дорогое - нужно сохранить его стэк, сохранить регистры, файловы регистры и т.д Переключение горутин происходит в **user space** и гораздо быстрее и дешевле.
34 |
35 | ### Gomaxproc
36 |
37 | Планировщик Go использует параметр с именем **GOMAXPROCS** для определения, сколько потоков операционной системы могут одновременно активно выполнять код Go. Его значение по умолчанию равно количеству процессоров компьютера, так что на машине с 8 процессорами планировщик будет планировать код Go для выполнения на 8 потоках одновременно (**GOMAXPROCS** равно значению п в т:п-планировании).
38 | Спящие или заблокированные в процессе коммуникации go-подпрограммы потоков для себя не требуют. Go-подпрограммы, заблокированные в операции ввода-вывода или в других системных вызовах, или при вызове функций, не являющихся функциями Go, нуждаются в потоке операционной системы, но **GOMAXPROCS** их не учитывает.
39 |
40 | ### No identification
41 |
42 | В большинстве операционных систем и языков программирования, поддерживающих многопоточность, текущий поток имеет идентификацию, которая может быть легко получена как обычное значение (обычно — целое число или указатель). Это облегчает построение абстракции, именуемой локальной памятью потока, которая, по существу, является глобальным отображением, использующим в качестве ключа идентификатор потока, так что каждый поток может сохранять и извлекать значения независимо от других потоков. **У горутин нет идентификации, доступной программисту.** Так решено во время проектирования языка, поскольку локальной памятью потока программисты злоупотребляют.
43 |
44 | *Дополнительно:*
45 |
46 | - [Contiguous stacks in Go](https://agis.io/post/contiguous-stacks-golang/)
47 |
--------------------------------------------------------------------------------
/src/goLang/concurrency/patterns.md:
--------------------------------------------------------------------------------
1 | ## Concurrency patterns
2 |
3 | ## Pipeline(конвейер)
4 |
5 | Каналы могут использоваться для подключения go-подпрограмм так, чтобы выход одной из них был входом для другой. Это называется конвейером (pipeline).
6 |
7 | ```go
8 | func main() {
9 | naturals := make(chan int)
10 | squares := make(chan int)
11 | // Генерация
12 | go func() {
13 | for x := 0; ; x++ {
14 | naturals <-x
15 | }
16 | }()
17 | // Возведение в квадрат
18 | go func() {
19 | for {
20 | x := <-naturals
21 | squares <- x * x
22 | }
23 | }()
24 | // Вывод (в главной go-подпрограмме)
25 | for {
26 | fmt.Println(<-squares)
27 | }
28 | }
29 | ```
30 |
31 |
32 |
33 | ## Broadcasting
34 |
35 | В go нет возможности полноценной широковещательной рассылки нескольким получателям, однако есть лайфхак: при закрытии канала, все консюммеры, могут фиксировать это событие(закрытие канала)
36 |
37 | ## Cancelation
38 |
39 | Чтобы отменить выполнение горутины в определенный момент, можем использовать канал отмены:
40 |
41 | ```go
42 | func main() {
43 | var cancelChan chan bool
44 | cancelChan = make(chan bool)
45 |
46 | go func() {
47 | for {
48 | select {
49 | case <-cancelChan:
50 | fmt.Println("Получили сигнал, отмены, вышли")
51 | return
52 | default:
53 | fmt.Println("Делаем полезную работу")
54 | }
55 | time.Sleep(3)
56 |
57 | }
58 | }()
59 |
60 | time.Sleep(10)
61 | cancelChan <- true
62 | }
63 | ```
64 |
65 | ## Promises
66 |
67 | В информатике конструкции future, promise и delay в некоторых языках программирования формируют стратегию вычисления, применяемую для параллельных вычислений. С их помощью описывается объект, к которому можно обратиться за результатом, вычисление которого может быть не завершено на данный момент. Использование future может быть неявным (при любом обращении к future возвращается ссылка на значение) и явным (пользователь должен вызвать функцию, чтобы получить значение). Получение значения из явного future называют stinging или forcing. Явные future могут быть реализованы в качестве библиотеки, в то время, как неявные обычно реализуются как часть языка.
68 |
69 | ```go
70 | package main
71 |
72 | import (
73 | "fmt"
74 | "sync"
75 | "time"
76 | )
77 |
78 | type Promise struct {
79 | wg sync.WaitGroup
80 | res string
81 | err error
82 | }
83 |
84 | func NewPromise(f func() (string, error)) *Promise {
85 | p := &Promise{}
86 | p.wg.Add(1)
87 | go func() {
88 | p.res, p.err = f()
89 | p.wg.Done()
90 | }()
91 | return p
92 | }
93 |
94 | func (p *Promise) Then(r func(string), e func(error)) {
95 | go func() {
96 | p.wg.Wait()
97 | if p.err != nil {
98 | e(p.err)
99 | return
100 | }
101 | r(p.res)
102 | }()
103 | }
104 |
105 | func exampleTicker() (string, error) {
106 | <-time.Tick(time.Second * 1)
107 | return "hi", nil
108 | }
109 |
110 | func main() {
111 | doneChan := make(chan int)
112 | var p = NewPromise(exampleTicker)
113 | p.Then(func(result string) { fmt.Println(result); doneChan <- 1 }, func(err error) { fmt.Println(err) })
114 | <-doneChan
115 | }
116 |
117 | ```
118 |
119 | ### Generator aka Iterator
120 |
121 | ### Futures/Promises
122 |
123 | ### Fan-in, Fan-out
--------------------------------------------------------------------------------
/src/goLang/ecosystem.md:
--------------------------------------------------------------------------------
1 | ## Экосистема
2 |
3 | Пакетный менеджер, тестирование, линтеры, структура проектов и т.д
4 |
5 | ## Пакетный менеджер
6 |
7 | Go Modules (go mod) - это система управления зависимостями, встроенная в язык Go с версии 1.11 и выше. Go Modules
8 | упрощает управление зависимостями, обеспечивает версионирование и облегчает совместную работу над проектами.
9 | Он также обеспечивает возможность воспроизводимой сборки проекта и упрощает интеграцию с другими инструментами
10 | разработки. Вот основы использования Go Modules:
11 |
12 | * Инициализация модуля: Чтобы начать использовать Go Modules, нужно выполнить команду `go mod init` в корневом каталоге
13 | проекта. Это создаст файл `go.mod`, в котором будут записаны зависимости проекта.
14 | * Управление зависимостями: Go Modules использует явное указание версий зависимостей. Можно добавить новую зависимость с
15 | помощью команды `go get`, например `go get github.com/example/package@v1.2.3`. Go Modules автоматически загрузит
16 | указанную
17 | версию и запишет ее в файле go.mod.
18 | * Версионирование зависимостей: В файле `go.mod` указываются версии зависимостей, а также правила для выбора версий при
19 | разрешении зависимостей. Можно использовать конкретные версии, диапазоны версий или символ latest для самой новой
20 | версии.
21 | * Обновление зависимостей: Go Modules предоставляет команду `go get -u` для обновления зависимостей до последних версий.
22 | При обновлении зависимостей файл go.mod будет автоматически обновлен с учетом новых версий.
23 | * Версионирование модуля: В файле `go.mod` указывается версия самого модуля. При каждом изменении зависимостей или
24 | модуля,
25 | версия модуля будет автоматически обновляться.
26 |
27 | ### go mod tidy
28 |
29 | Команда `go mod tidy` является одной из команд Go Modules и используется для упорядочения и обновления файлов `go.mod`
30 | и `go.sum`, основанных на фактическом использовании зависимостей в проекте. Команда go mod tidy полезна при
31 | упорядочивании и обновлении файлов go.mod и go.sum для соответствия фактическому использованию зависимостей в проекте.
32 | Это помогает поддерживать эти файлы актуальными и устраняет неиспользуемые зависимости, упрощая управление зависимостями
33 | в проекте.
34 | Вот некоторая информация о команде `go mod tidy`:
35 |
36 | Удаление неиспользуемых зависимостей: Когда вы выполняете `go mod tidy`, Go Modules анализирует фактическое
37 | использование зависимостей в проекте и удаляет из файла `go.mod` записи о зависимостях, которые больше не используются.
38 | Это помогает очистить файл `go.mod` от лишних записей и упростить управление зависимостями.
39 |
40 | Обновление версий зависимостей: Команда `go mod tidy` также обновляет версии зависимостей в файле `go.mod` на основе
41 | фактического использования. Если в проекте используются новые версии зависимостей, команда `go mod tidy` автоматически
42 | обновит записи в файле go.mod, чтобы отразить актуальные версии.
43 |
44 | Обновление хэшей зависимостей: При выполнении `go mod tidy` также обновляется файл `go.sum`, который содержит хэши всех
45 | зависимостей проекта. Если версии зависимостей изменяются или обновляются, `go mod tidy` обновляет соответствующие хэши
46 | в файле `go.sum`.
47 |
48 | ## Тестирование
49 |
50 | Тесты в Go пишутся с использованием пакета `testing`. Тестовые функции должны начинаться с префикса "Test" и принимать
51 | аргумент типа `*testing.T`.
52 | Для запуска тестов можно использовать команду `go test` в директории проекта. Она автоматически находит и выполняет все
53 | тестовые функции.
54 | В тестовых функциях можно использовать функции `t.Errorf` и `t.Fail` для вывода ошибок и отметки теста как неудачного.
55 | Также популярные сторонние библиотеки **testify** и **gocheck**.
56 |
57 | ## Бенчмарки:
58 |
59 | Бенчмарки в Go пишутся с использованием пакета `testing` и префикса `Benchmark` для названия функций. Они принимают
60 | аргумент типа `*testing.B`.
61 | Бенчмарки позволяют измерить производительность кода и сравнить различные реализации. Они выполняются несколько раз,
62 | чтобы получить усредненные результаты.
63 | Для запуска бенчмарков можно использовать команду `go test` с флагом `-bench`, например: `go test -bench ..`
64 | Результаты бенчмарков выводятся в консоль и показывают среднее время выполнения и количество операций в секунду.
65 | Использование тестов и бенчмарков помогает обеспечить надежность и производительность вашего кода. Они позволяют
66 | автоматически проверить правильность работы кода и сравнить эффективность различных подходов.
67 |
68 | ## Библиотеки и фреймворки
69 |
70 | * Gin - минималистичный и быстрый фреймворк для веб-приложений.
71 | * Echo - легковесный и быстрый веб-фреймворк для Go.
72 | * Gorm - ORM для Go с поддержкой MySQL, PostgreSQL и SQLite.
73 | * Cobra - библиотека для создания мощных CLI-интерфейсов.
74 | * Viper - библиотека для работы с конфигурационными файлами различных форматов.
75 | * Logrus - популярный логгер с поддержкой различных уровней логирования.
76 | * testify - набор инструментов для модульного тестирования в Go.
77 | * gRPC - высокопроизводительный RPC-фреймворк.
78 | * govalidator - библиотека для валидации входных данных в Go.
79 | * Fiber - быстрый и экспрессивный веб-фреймворк для Go.
80 | * Mux - мощный HTTP-маршрутизатор и диспетчер запросов.
81 | * JWT-go - библиотека для работы с JSON Web Token (JWT).
82 | * sqlx - расширение для пакета database/sql для упрощения работы с SQL.
83 | * go-sqlmock - инструмент для создания мок-объектов базы данных для тестирования SQL запросов.
84 | * golang-migrate - инструмент для управления миграциями базы данных.
85 |
86 | *Дополнительно*:
87 |
88 | - [Статический анализ в Go](https://habr.com/ru/company/roistat/blog/413175/)
89 | - [Профилирование и оптимизация программ на Go](https://habr.com/ru/company/badoo/blog/301990/)
--------------------------------------------------------------------------------
/src/goLang/types/README.md:
--------------------------------------------------------------------------------
1 | # Типы данных GoLang
2 |
3 | * [Скалярные](scalar.md)
4 | * [Массив и слайс](array_slice.md)
5 | * [Map](map.md)
6 | * [Структура](struct.md)
7 | * [Интерфейс](interface.md)
8 |
9 |
10 |
11 | В Go, типы данных определяют характеристики и ограничения значений, которые могут быть присвоены переменным и использованы в программе. Вот некоторые основные типы данных в Go:
12 |
13 | - Целочисленные типы данных (`int`, `int8`, `int16`, `int32`, `int64`, `uint`, `uint8`, `uint16`, `uint32`, `uint64` и другие) представляют целые числа со знаком и без.
14 | - Типы данных с плавающей запятой (`float32`, `float64`) представляют числа с плавающей точкой.
15 | - Типы данных `bool` представляют логические значения `true` или `false`.
16 | - Строковый тип данных `string` представляет последовательность символов.
17 | - Тип данных `byte` представляет беззнаковый 8-битный целочисленный тип, который обычно используется для представления байтовых данных.
18 | - Типы данных `array` и `slice` представляют упорядоченные коллекции элементов одного типа. Они отличаются в том, что массив имеет фиксированную длину, а срез (slice) - динамическую длину.
19 | - Тип данных `struct` представляет составной тип, который позволяет объединять несколько значений разных типов в одну сущность.
20 | - Тип данных `map` представляет ассоциативный массив (отображение), который хранит пары ключ-значение.
21 | - Тип данных `interface` определяет набор методов, которые должны быть реализованы другими типами. Он позволяет создавать полиморфные объекты.
22 |
23 |
24 |
25 | В Golang переменные хранятся в оперативной памяти компьютера. Конкретный адрес в памяти зависит от архитектуры и операционной системы, а размер занимаемой памяти определяется типом данных переменной.
26 |
27 | В Go переменные могут быть объявлены как с фиксированным типом данных (например, int, float64, string) так и с динамическим типом (например, interface{}, которая может хранить любые значения).
28 |
29 | Для каждой переменной компилятор Go определяет оптимальный размер и располагает ее в памяти таким образом, чтобы она могла быть эффективно использована во время выполнения программы.
30 |
31 | Кроме того, в Go можно использовать указатели, которые хранят адрес в памяти переменной. Указатели позволяют получить доступ к значению переменной по ее адресу и изменять его.
32 |
33 | Также в Golang существует механизм сборки мусора, который автоматически освобождает память, занимаемую переменными, которые больше не используются. Это позволяет избежать утечек памяти и облегчает работу с переменными.
34 |
35 |
36 |
37 |
--------------------------------------------------------------------------------
/src/goLang/types/interface.md:
--------------------------------------------------------------------------------
1 | ## Интерфейсы
2 |
3 | ```go
4 | type iface struct {
5 | tab *itab
6 | data unsafe.Pointer
7 | }
8 |
9 | type itab struct {
10 | inter *interfacetype
11 | _type *_type
12 | hash uint32 // copy of _type.hash. Used for type switches.
13 | _ [4]byte
14 | fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
15 | }
16 |
17 | type interfacetype struct {
18 | typ _type
19 | pkgpath name
20 | mhdr []imethod
21 | }
22 |
23 | //пустой интерфейс interface{}
24 | type eface struct {
25 | _type *_type
26 | data unsafe.Pointer
27 | }
28 | ```
29 |
30 | Интерфейсы представляют абстракцию поведения других типов. Интерфейсы позволяют определять функции, которые не привязаны к конкретной реализации. То есть интерфейсы определяют некоторый функционал, но не реализуют его.
31 |
32 | Для определения интерфейса применяется ключевое слово `interface`:
33 |
34 | ```go
35 | type Car interface {
36 | move(x int, y int) err
37 | stop()
38 | }
39 | ```
40 |
41 | ### Nill interface vs nil pointer interface
42 |
43 | Тут важно понимать, что если переменная объявлена не под типо интерфейса, а под каким то конкретным типом, реализующим интерфейс - то при её сравнении с nil получим false, так как в структуре itab уже будет храниться значение конкретного типа в поле `type` и с точки зрения go это уже не будет **nil interface** a будет **nil pointer interface**
44 |  45 |
46 |
47 |
48 | ## Type Assertion vs Type Conversoin
49 |
50 | | Выражение | Что делает? | Работает только с | Паника? |
51 | | --------------------- | ---------------------------- | --------------------------- | ---------------------------- |
52 | | `variable.(*MyType)` | Проверяет тип в интерфейсе | Интерфейс (`interface{}`) | Да, если тип не совпадает |
53 | | `(*MyType)(variable)` | Преобразует совместимые типы | Указатели, `unsafe.Pointer` | Нет (либо ошибка компиляции) |
54 |
55 |
56 |
--------------------------------------------------------------------------------
/src/goLang/types/map.md:
--------------------------------------------------------------------------------
1 | # Map
2 |
3 | В Go `map` — это встроенная хеш-таблица с открытой адресацией. Она обеспечивает быстрый доступ к данным с временной сложностью `O(1)` в среднем случае. Каждый элемент имеет уникальный ключ, по которому можно получить значение элемента. В `map[K]V`, `К` представляет тип ключа, а `V` - тип значения. Тип ключа K должен быть comparable(поддерживать операцию сравнения `==`)
4 |
5 | ```go
6 | // A header for a Go map.
7 | type hmap struct {
8 | // Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
9 | // Make sure this stays in sync with the compiler's definition.
10 | count int // # live cells == size of map. Must be first (used by len() builtin)
11 | flags uint8
12 | B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
13 | noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
14 | hash0 uint32 // hash seed
15 |
16 | buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
17 | oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
18 | nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
19 |
20 | extra *mapextra // optional fields
21 | }
22 | ```
23 |
24 | 
25 |
26 | Например, определение `map`, которое в качестве ключей имеет тип `string`, а в качестве значений - тип `int`:
27 |
28 | ```go
29 | var people map[string] int
30 | ```
31 |
32 | Для проверки наличия элемента по определенному ключу можно получать два значения, второе и будет показывать наличие:
33 |
34 | ```go
35 | var people = map[string]int{"Tom": 1, "Bob": 2, "Sam": 4, "Alice": 8}
36 |
37 | if val, ok := people["Tom"]; ok {
38 | fmt.Println(val)
39 | }
40 | ```
41 |
42 | Адрес элемента мапы получить невозможно(сделано из-за того что адрес может стать недействителен, после рехеширования)
43 |
44 | ```go
45 | _ = &ages["bob"] // ТАК НЕЛЬЗЯ!!!
46 | ```
47 |
48 | При чтении из nil мапы, ничего страшного не произойдёт, получим нулевое значение для типа. Но если писать в nil map то словим панику.
49 |
50 | ```go
51 | m1 := map[string]int{
52 | "key": 1,
53 | }
54 | m1 = nil
55 | fmt.Println(m1["key"]) // 0
56 | m1["key"] = 1 //panic: assignment to entry in nil map
57 | ```
58 |
59 |
60 |
61 | ## **Бакеты (buckets)**
62 |
63 | Данные в `map` хранятся в **бакетах**. Бакет содержит до 8 ключей и значений:
64 |
65 | ```go
66 | type bmap struct {
67 | tophash [8]uint8 // Первые 8 бит хеша ключей
68 | keys [8]K // Ключи
69 | values [8]V // Значения
70 | overflow *bmap // Указатель на следующий бакет (если есть переполнение)
71 | }
72 | ```
73 |
74 | - **`tophash`** хранит первые 8 бит хеша ключа.
75 | - **`keys`** и **`values`** — массивы ключей и значений.
76 |
77 | ## **Рехеширование (grow)**
78 |
79 | Когда элементов становится **слишком много**(больше 6.5 в среднем), `map` **удваивает** число бакетов:
80 |
81 | - Создаётся новый массив бакетов `2^(B+1)`.
82 | - Ключи перераспределяются.
83 | - Это происходит **постепенно** (incremental rehashing), чтобы избежать резкого скачка нагрузки.
84 |
85 | Когда рехеширование запускается:
86 |
87 | 1. `count > 6.5 * 2^B` → **увеличение размера (`grow`)**.
88 | 2. `overflow > определённого порога` → **перемещение (`evacuation`)**.
89 |
90 |
91 |
92 | ## **Итерация по `map`**
93 |
94 | ```go
95 | for k, v := range m {
96 | fmt.Println(k, v)
97 | }
98 | ```
99 |
100 | Итерация **не гарантирует порядок** — это связано с рандомизацией хеширования.
101 |
102 |
103 |
104 | ## Почему нельзя взять указатель на элемент `map`
105 |
106 | Go запрещает брать адрес элемента `map`:
107 |
108 | ```
109 | m := map[string]int{"Alice": 25}p := &m["Alice"] // Ошибка компиляции
110 | ```
111 |
112 | Причина в том, что Go **динамически перераспределяет память** для `map`. Когда в `map` добавляются новые элементы, он может **перераспределить бакеты** в памяти, и старые адреса станут невалидными. Это могло бы приводить к трудноотлавливаемым багам, поэтому Go запрещает такую возможность на уровне компилятора.
113 |
114 | ## Внутреннее устройство
115 |
116 | Map — это просто хеш-таблица. Данные организованы в массив бакетов. Каждый бакет содержит до 8 пар "ключ-значение". Младшие биты хеша используются для выбора бакета. Каждый бакет хранит несколько старших битов хеша, чтобы различать записи внутри одного бакета.
117 |
118 | Если в один бакет попадает более 8 ключей, создаются дополнительные (overflow) бакеты, образующие цепочку.
119 |
120 | Когда хеш-таблица увеличивается, создаётся новый массив бакетов в два раза больше. Бакеты постепенно (инкрементально) копируются из старого массива в новый.
121 |
122 | Итератор по map проходит по массиву бакетов и возвращает ключи в порядке обхода (сначала по номерам бакетов, затем по цепочкам overflow-бакетов, затем по индексам внутри бакета). Чтобы сохранить семантику итерации, ключи никогда не перемещаются внутри своего бакета (если бы они перемещались, один и тот же ключ мог бы быть возвращён 0 или 2 раза).
123 |
124 | Во время увеличения таблицы итераторы продолжают обход старого массива и должны проверять новый массив, если бакет, по которому они идут, был перемещён ("эвакуирован") в новую таблицу.
--------------------------------------------------------------------------------
/src/goLang/types/struct.md:
--------------------------------------------------------------------------------
1 | # Структура
2 |
3 | Тип данных `struct` в Go позволяет объединять несколько значений разных типов в одну составную сущность. `struct` представляет собой коллекцию полей, где каждое поле имеет имя и тип данных. Структура определяется с помощью ключевого слова `type` и указания имени структуры, а затем объявления полей с указанием имени и типа данных каждого поля:
4 |
5 | ```go
6 | Person struct {
7 | Name string
8 | Age int
9 | City string
10 | }
11 | ```
12 |
13 | Для создания экземпляра структуры используется оператор `var` вместе с именем структуры и фигурными скобками для инициализации полей:
14 |
15 | ```go
16 | var person Person
17 | person.Name = "John"
18 | person.Age = 30
19 | person.City = "New York"
20 | ```
21 |
22 | 1. Доступ к полям структуры: Доступ к полям структуры осуществляется с использованием оператора `.`. Например, `person.Name` обратится к полю `Name` в структуре `person`.
23 | 2. Вложенные структуры: Структуры могут быть вложенными, что позволяет создавать более сложные структуры данных. Пример:
24 |
25 | ```go
26 | type Address struct {
27 | Street string
28 | City string
29 | }
30 |
31 | type Person struct {
32 | Name string
33 | Age int
34 | Address Address
35 | }
36 | ```
37 |
38 | ## Struct embedding
39 |
40 | Структурное встраивание (struct embedding) в Go позволяет включать одну структуру в другую без явного объявления полей. Это создает отношение "является" (is-a) между структурами, где встроенная структура получает доступ к полям и методам внешней структуры.
41 |
42 |
43 |
44 | Выполняется путем включения имени структуры в определение другой структуры без указания имени поля.
45 |
46 | ```go
47 | type Person struct {
48 | Name string
49 | Age int
50 | }
51 |
52 | type Employee struct {
53 | Person
54 | EmployeeID int
55 | }
56 | ```
57 |
58 | Наследование полей и методов: В результате встраивания структуры `Person` в структуру `Employee`, поля и методы структуры `Person` автоматически становятся доступными в структуре `Employee`. Например, поле `Name` структуры `Person` может быть обращено как `Employee.Name` в структуре `Employee`.
59 |
60 | Если структуры, встраиваемые в одну структуру, содержат поле с одинаковым именем, то необходимо указать имя структуры перед полем для разрешения неоднозначности. Например:
61 |
62 | ```go
63 | type Person struct {
64 | Name string
65 | Age int
66 | }
67 |
68 | type Employee struct {
69 | Person
70 | Name string
71 | EmployeeID int
72 | }
73 | ```
74 |
75 | В данном примере поле `Name` из структуры `Person` может быть обращено как `Employee.Person.Name` для различения от поля `Name` в самой структуре `Employee`.
76 |
77 | Если во встроенной структуре имеется поле или метод с тем же именем, что и внешней структуре, то поле или метод внешней структуры будет переопределен. Переопределенное поле или метод будет доступно только через явное указание имени внешней структуры. Например:
78 |
79 | ```go
80 | type Person struct {
81 | Name string
82 | Age int
83 | }
84 |
85 | func (p Person) Greet() {
86 | fmt.Println("Hello, I'm", p.Name)
87 | }
88 |
89 | type Employee struct {
90 | Person
91 | Name string
92 | EmployeeID int
93 | }
94 |
95 | func (e Employee) Greet() {
96 | fmt.Println("Hello, I'm", e.Person.Name, "and I'm an employee")
97 | }
98 | ```
99 |
100 | В данном примере метод `Greet()` структуры `Employee` переопределяет метод с тем же именем в структуре `Person`.
--------------------------------------------------------------------------------
/src/javascript.md:
--------------------------------------------------------------------------------
1 | # JavaScript
2 |
3 | Джаваскрипт очень нужен, куда мы без него.
4 |
5 | ## Function Declaration vs Function Expression
6 |
7 | Давайте разберём ключевые отличия Function Declaration от Function Expression.
8 |
9 | Во-первых, синтаксис: как определить, что есть что в коде.
10 |
11 | - Function Declaration: функция объявляется отдельной конструкцией «function…» в основном потоке кода.
12 |
13 | ```javascript
14 | // Function Declaration
15 | function sum(a, b) {
16 | return a + b;
17 | }
18 | ```
19 |
20 | - Function Expression: функция, созданная внутри другого выражения или синтаксической конструкции. В данном случае функция создаётся в правой части «выражения присваивания» `=`:
21 |
22 | ```javascript
23 | // Function Expression
24 | let sum = function(a, b) {
25 | return a + b;
26 | };
27 | ```
28 |
29 | Более тонкое отличие состоит, в том, *когда* создаётся функция движком JavaScript.
30 |
31 | **Function Expression создаётся, когда выполнение доходит до него, и затем уже может использоваться.**
32 |
33 | После того, как поток выполнения достигнет правой части выражения присваивания `let sum = function…` – с этого момента, функция считается созданной и может быть использована (присвоена переменной, вызвана и т.д. ).
34 |
35 | С Function Declaration всё иначе.
36 |
37 | **Function Declaration можно использовать во всем скрипте (или блоке кода, если функция объявлена в блоке).**
38 |
39 | Другими словами, когда движок JavaScript *готовится* выполнять скрипт или блок кода, прежде всего он ищет в нём Function Declaration и создаёт все такие функции. Можно считать этот процесс «стадией инициализации».
40 |
41 | И только после того, как все объявления Function Declaration будут обработаны, продолжится выполнение.
42 |
43 | В результате функции, созданные, как Function Declaration могут быть вызваны раньше своих определений.
44 |
45 | ## Arrow Functions
46 |
47 |
48 |
49 | ## This
50 |
51 | Поведение ключевого слова `this` в JavaScript несколько отличается по сравнению с остальными языками. Имеются также различия при использовании `this` в [строгом](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Strict_mode) и нестрогом режиме.
52 |
53 | В большинстве случаев значение `this` определяется тем, каким образом вызвана функция. Значение `this` не может быть установлено путем присваивания во время исполнения кода и может иметь разное значение при каждом вызове функции. В ES5 представлен метод [`bind()`](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/bind), который используется для [`привязки значения ключевого слова this независимо от того, как вызвана функция`](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Operators/this#Метод_bind). Также в ES2015 представлены [`стрелочные функции`](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Functions/Arrow_functions), которые не создают собственные привязки к `this` (они сохраняют значение `this` лексического окружения, в котором были созданы).
54 |
55 |
56 |
57 | ## Use Strict
58 |
59 | **Преимущества:**
60 |
61 | - Не позволяет случайно создавать глобальные переменные.
62 | - Любое присваивание, которое в обычном режиме завершается неудачей, в строгом режиме выдаст исключение.
63 | - При попытке удалить неудаляемые свойства, выдаст исключение (в то время как в нестрогом режиме никакого действия бы не произошло).
64 | - Требует, чтобы имена параметров функции были уникальными.
65 | - `this` в глобальной области видимости равно undefined.
66 | - Перехватывает распространенные ошибки, выдавая исключения.
67 | - Исключает неочевидные особенности языка.
68 |
69 | **Недостатки:**
70 |
71 | - Нельзя использовать некоторые особенности языка, к которым привыкли некоторые разработчики.
72 | - Нет доступа к `function.caller` и `function.arguments`.
73 | - Объединение скриптов, написанных в строгом режиме может вызвать проблемы.
74 |
75 | ## Concurrency
76 |
77 | - Event Loop
78 | - Калбеки
79 | - промисы
80 | - async await
81 | - web workers
82 |
83 |
--------------------------------------------------------------------------------
/src/media/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/.DS_Store
--------------------------------------------------------------------------------
/src/media/algostruct/collision-resolving.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/collision-resolving.png
--------------------------------------------------------------------------------
/src/media/algostruct/collision_chain.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/collision_chain.png
--------------------------------------------------------------------------------
/src/media/algostruct/collision_open_hash.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/collision_open_hash.png
--------------------------------------------------------------------------------
/src/media/algostruct/hash-func.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/hash-func.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/accessRefreshJwt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/accessRefreshJwt.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/cookieSession.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/cookieSession.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/httpBasic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/httpBasic.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/httpDigest.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/httpDigest.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/jwt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/jwt.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/token.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/token.png
--------------------------------------------------------------------------------
/src/media/bAndB+.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/bAndB+.png
--------------------------------------------------------------------------------
/src/media/bTreeExample.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/bTreeExample.png
--------------------------------------------------------------------------------
/src/media/bTreeIndex.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/bTreeIndex.png
--------------------------------------------------------------------------------
/src/media/biHeap.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/biHeap.png
--------------------------------------------------------------------------------
/src/media/cgi.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/cgi.jpeg
--------------------------------------------------------------------------------
/src/media/db/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/.DS_Store
--------------------------------------------------------------------------------
/src/media/db/specific/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/.DS_Store
--------------------------------------------------------------------------------
/src/media/db/specific/messages/kaffka_prod_con.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/kaffka_prod_con.png
--------------------------------------------------------------------------------
/src/media/db/specific/messages/kafka.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/kafka.jpg
--------------------------------------------------------------------------------
/src/media/db/specific/messages/mcq.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/mcq.jpg
--------------------------------------------------------------------------------
/src/media/db/specific/messages/nats.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/nats.jpg
--------------------------------------------------------------------------------
/src/media/db/specific/messages/rabbit.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/rabbit.jpg
--------------------------------------------------------------------------------
/src/media/db/theory/sharding/consistent_hashing11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/theory/sharding/consistent_hashing11.png
--------------------------------------------------------------------------------
/src/media/db/theory/sharding/consistent_hashing4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/theory/sharding/consistent_hashing4.png
--------------------------------------------------------------------------------
/src/media/gitLifeCycle.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/gitLifeCycle.png
--------------------------------------------------------------------------------
/src/media/gitMergeRebase.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/gitMergeRebase.jpeg
--------------------------------------------------------------------------------
/src/media/gitRebaseOnTo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/gitRebaseOnTo.png
--------------------------------------------------------------------------------
/src/media/go/go_chan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/go_chan.png
--------------------------------------------------------------------------------
/src/media/go/go_hash.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/go_hash.png
--------------------------------------------------------------------------------
/src/media/go/nilIface.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/nilIface.png
--------------------------------------------------------------------------------
/src/media/go/scheduler_grq_lrq.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/scheduler_grq_lrq.png
--------------------------------------------------------------------------------
/src/media/go/scheduler_mpg.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/scheduler_mpg.jpeg
--------------------------------------------------------------------------------
/src/media/go/scheduler_mpg2.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/scheduler_mpg2.jpeg
--------------------------------------------------------------------------------
/src/media/go/slice-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/slice-1.png
--------------------------------------------------------------------------------
/src/media/go/slice-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/slice-2.png
--------------------------------------------------------------------------------
/src/media/go/slice-array.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/slice-array.png
--------------------------------------------------------------------------------
/src/media/go/stack_heap1.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/stack_heap1.jpeg
--------------------------------------------------------------------------------
/src/media/go/stack_heap2.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/stack_heap2.jpeg
--------------------------------------------------------------------------------
/src/media/image1.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image1.jpeg
--------------------------------------------------------------------------------
/src/media/image10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image10.png
--------------------------------------------------------------------------------
/src/media/image11.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image11.jpeg
--------------------------------------------------------------------------------
/src/media/image12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image12.png
--------------------------------------------------------------------------------
/src/media/image14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image14.png
--------------------------------------------------------------------------------
/src/media/image15.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image15.jpeg
--------------------------------------------------------------------------------
/src/media/image16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image16.png
--------------------------------------------------------------------------------
/src/media/image2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image2.png
--------------------------------------------------------------------------------
/src/media/image3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image3.png
--------------------------------------------------------------------------------
/src/media/image4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image4.png
--------------------------------------------------------------------------------
/src/media/image5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image5.png
--------------------------------------------------------------------------------
/src/media/image9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image9.png
--------------------------------------------------------------------------------
/src/media/joins.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/joins.png
--------------------------------------------------------------------------------
/src/media/kolka.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/kolka.png
--------------------------------------------------------------------------------
/src/media/masterSlaveReplication.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/masterSlaveReplication.png
--------------------------------------------------------------------------------
/src/media/multiColumnIndex.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/multiColumnIndex.png
--------------------------------------------------------------------------------
/src/media/multiSortIndex.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/multiSortIndex.png
--------------------------------------------------------------------------------
/src/media/mySqlArchitecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/mySqlArchitecture.png
--------------------------------------------------------------------------------
/src/media/network/htpp_v.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/htpp_v.png
--------------------------------------------------------------------------------
/src/media/network/tcp-vs-udp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tcp-vs-udp.png
--------------------------------------------------------------------------------
/src/media/network/tcp_udp_format.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tcp_udp_format.jpeg
--------------------------------------------------------------------------------
/src/media/network/tcp_udp_stack.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tcp_udp_stack.jpeg
--------------------------------------------------------------------------------
/src/media/network/tls-handshake.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tls-handshake.png
--------------------------------------------------------------------------------
/src/media/network/tls-internet.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tls-internet.png
--------------------------------------------------------------------------------
/src/media/osi-tcp-ip.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/osi-tcp-ip.png
--------------------------------------------------------------------------------
/src/media/phpCache.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/phpCache.png
--------------------------------------------------------------------------------
/src/media/redisTypes.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/redisTypes.jpg
--------------------------------------------------------------------------------
/src/media/replicationHl.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/replicationHl.jpg
--------------------------------------------------------------------------------
/src/media/replicationUpdate.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/replicationUpdate.jpg
--------------------------------------------------------------------------------
/src/media/rtree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/rtree.png
--------------------------------------------------------------------------------
/src/network/README.md:
--------------------------------------------------------------------------------
1 | # Основы сетей
2 |
3 | Базовая информация по сетевому взаимодействию и устройству сетевых протоколов.
4 |
5 | - [OSI](osi.md)
6 | - [TCP/IP](tcp_ip.md)
7 | - [HTTP](http.md)
8 | - [TLS](tls.md)
9 | - [DNS](dns.md)
10 | - [Что происходит при нажатии на g](whatHappenWhen.md)
11 | - [Real time с веб-сервером](realTime.md)
12 |
--------------------------------------------------------------------------------
/src/network/osi.md:
--------------------------------------------------------------------------------
1 | ## Сетевые модели(стеки протоколов)
2 |
3 | ## OSI
4 |
5 | **OSI** - формальная, теоретическая сетевая модель
6 |
7 | 1. Уровень приложений: **данные**; доступ к сетевым службам, (HTTP, FTP, SMTP, RDP, SNMP, DHCP)
8 | 2. Уровень представления данных: **данные**; представление и шифрование данных (ASCII, EBCDIC)
9 | 3. Сеансовый уровень: **данные**; управление сеансом связи (RPC, PAP)
10 | 4. Транспортный уровень: **сегменты / дейтаграммы**; прямая связь между конечными пунктами и надёжность (TCP, UDP, SCTP, PORTS)
11 | 5. Сетевой уровень: **пакеты**; определение маршрута и логическая адресация (IPv4, IPv6, IPsec, AppleTalk)
12 | 6. Канальный уровень: **биты / кадры**; физическая адресация (PPP, IEEE 802.22, Ethernet, DSL, ARP, L2TP, Network Cards)
13 | 7. Физический уровень: **биты**; Работа со средой передачи, сигналами и двоичными данными (USB, кабель ("витая пара", коаксиальный, оптоволоконный), радиоканал)
14 |
15 | ### 7 — протокол прикладного уровня (Application layer)
16 |
17 | - взаимодействие сети и пользователя
18 | - уровень разрешает приложениям пользователя иметь доступ к сетевым службам, таким, как обработчик запросов к базам данных, доступ к файлам, пересылке электронной почты
19 | - отвечает за передачу служебной информации, предоставляет приложениям информацию об ошибках и формирует запросы к уровню представления
20 |
21 | ### 6 — уровень представления (Presentation layer)
22 |
23 | - передаваемая информация не меняет содержания
24 | - преобразование данных
25 | - преобразование между различными наборами символов
26 | - сжатие данных для увеличения пропускной способности канала
27 | - шифрование и расшифрование
28 |
29 | ### 5 — сеансовый уровень (Session layer)
30 |
31 | - уровень управляет созданием/завершением сеанса, обменом информацией, синхронизацией задач, определением права на передачу данных и поддержанием сеанса в периоды неактивности приложений
32 | - синхронизация передачи обеспечивается помещением в поток данных контрольных точек, начиная с которых возобновляется процесс при нарушении взаимодействия
33 |
34 | ### 4 — транспортный уровень (Transport layer)
35 |
36 | - предоставляет сам механизм передачи
37 | - блоки данных он разделяет на фрагменты, размеры которых зависят от протокола: короткие объединяет в один, а длинные разбивает
38 | - протоколы этого уровня предназначены для взаимодействия типа точка-точка
39 | - протоколы транспортного уровня часто имеют функцию контроля доставки данных, заставляя принимающую данные систему отправлять подтверждения передающей стороне о приеме данных
40 | - отвечает за восстановление порядка данных при использовании **сетевых протоколов без установки соединения**
41 |
42 | ### 3 — сетевой уровень (Network layer)
43 |
44 | - предназначается для определения пути передачи данных
45 | - трансляцию логических адресов и имён в физические
46 | - определение кратчайших маршрутов, коммутацию и маршрутизацию, отслеживание неполадок и заторов в сети
47 | - На этом уровне работает такое сетевое устройство, как маршрутизатор.
48 | - типы:
49 | 1. **Протоколы с установкой соединения** начинают передачу данных с вызова или установки маршрута следования пакетов от источника к получателю. После чего начинают последовательную передачу данных и затем по окончании передачи разрывают связь.
50 | 2. **Протоколы без установки соединения** посылают данные, содержащие полную адресную информацию в каждом пакете. Каждый пакет содержит адрес отправителя и получателя. Далее каждое промежуточное сетевое устройство считывает адресную информацию и принимает решение о маршрутизации данных. Письмо или пакет данных передается от одного промежуточного устройства к другому до тех пор, пока не будет доставлено получателю. Протоколы без установки соединения не гарантируют поступление информации получателю в том порядке, в котором она была отправлена, так как разные пакеты могут пройти разными маршрутами.
51 |
52 | ### 2 — канальный уровень (Data Link layer)
53 |
54 | - получение доступа к среде передачи
55 | - выделение границ кадра (резервирование некоторой последовательности, обозначающей начало или конец кадра)
56 | - Аппаратная адресация (или адресация канального уровня). Требуется в том случае, когда кадр могут получить сразу несколько адресатов. В локальных сетях аппаратные адреса (MAC-адреса) применяются всегда.
57 | - обеспечение достоверности принимаемых данных. Во время передачи кадра есть вероятность, что данные исказятся. Важно это обнаружить и не пытаться обработать кадр, содержащий ошибку. Обычно на канальном уровне используются алгоритмы контрольных сумм, дающие высокую гарантию обнаружения ошибок.
58 | - в программировании доступ к этому уровню предоставляет драйвер сетевой платы
59 | - на этом уровне работают коммутаторы, мосты
60 | - 2 подуровня
61 | 1. **LLC (Logical Link Control)** обеспечивает обслуживание сетевого уровня
62 | 2. **MAC (Media Access Control)** регулирует доступ к разделяемой физической среде
63 | 1. выступает в качестве интерфейса между подуровнем LLC и физическим (первым) уровнем
64 | 2. обеспечивает адресацию и механизмы управления доступом к каналам, что позволяет нескольким терминалам или точкам доступа общаться между собой в многоточечной сети
65 | 3. эмулирует полнодуплексный логический канал связи в многоточечной сети
66 |
67 | ### 1 — физический слой (physical layer)
68 |
69 | - физическая и электрическая среда для передачи данных
70 | - способы передачи бит через физические среды линий связи, соединяющие сетевые устройства
71 | - описываются параметры сигналов, такие как амплитуда, частота, фаза, используемая модуляция, манипуляция
72 | - решаются вопросы связанные с синхронизацией, избавлением от помех, скорости передачи данных
73 |
74 | ## OSI vs TCP/IP
75 |
76 | 
77 |
78 |
--------------------------------------------------------------------------------
/src/network/realTime.md:
--------------------------------------------------------------------------------
1 | # COMET
2 |
3 | COMET – общий термин, описывающий различные техники получения данных по инициативе сервера. Можно сказать, что AJAX – это «отправил запрос – получил результат», а COMET – это «непрерывный канал, по которому приходят данные».
4 |
5 | Примеры COMET-приложений:
6 |
7 | - Чат – человек сидит и смотрит, что пишут другие. При этом новые сообщения приходят «сами по себе», он не должен нажимать на кнопку для обновления окна чата.
8 | - Аукцион – человек смотрит на экран и видит, как обновляется текущая ставка за товар.
9 | - Интерфейс редактирования – когда один редактор начинает изменять документ, другие видят информацию об этом. Возможно и совместное редактирование, когда редакторы видят изменения друг друга.
10 |
11 | Ниже рассмотрены разные варианты реализации.
12 |
13 | ## Частые опросы
14 |
15 | Первое решение, которое приходит в голову для непрерывного получения событий с сервера – это «частые опросы» (polling), т.е периодические запросы на сервер: «эй, я тут, изменилось ли что-нибудь?». Например, раз в 10 секунд.
16 |
17 | В ответ сервер, во-первых, помечает у себя, что клиент онлайн, а во-вторых посылает сообщение, в котором в специальном формате содержится весь пакет событий, накопившихся к данному моменту.
18 |
19 | При этом, однако, возможна задержка между появлением и получением данных, как раз в размере этих 10 секунд между запросами.
20 |
21 | Другой минус – лишний входящий трафик на сервер. При каждом запросе браузер передает множество заголовков и в ответ получает, кроме данных, также заголовки. Для некоторых приложений трафик заголовков может в 10 и более раз превосходить трафик реальных данных.
22 |
23 | ## Длинные опросы
24 |
25 | Длинные опросы – отличная альтернатива частым опросам. Они также удобны в реализации, и при этом сообщения доставляются без задержек.
26 |
27 | Схема:
28 |
29 | 1. Отправляется запрос на сервер.
30 | 2. Соединение не закрывается сервером, пока не появится сообщение.
31 | 3. Когда сообщение появилось – сервер отвечает на запрос, пересылая данные.
32 | 4. Браузер тут же делает новый запрос.
33 |
34 | Ситуация, когда браузер отправил запрос и держит соединение с сервером, ожидая ответа, является стандартной и прерывается только доставкой сообщений.
35 |
36 | Схема коммуникации:
37 |
38 | 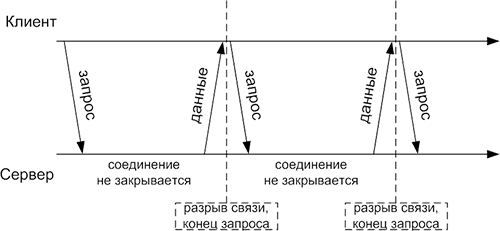
39 |
40 | При этом если соединение рвётся само, например, из-за ошибки в сети, то браузер тут же отсылает новый запрос.
41 |
42 | ## WebSocket
43 |
44 | Протокол связи поверх [TCP](https://ru.wikipedia.org/wiki/TCP)-соединения, предназначенный для асинхронного обмена сообщениями между браузером и веб-сервером в режиме реального времени.
45 |
46 | Протокол `WebSocket` работает *над* TCP. Это означает, что при соединении браузер отправляет по HTTP специальные заголовки, спрашивая: «поддерживает ли сервер WebSocket?». Если сервер в ответных заголовках отвечает «да, поддерживаю», то дальше HTTP прекращается и общение идёт на специальном протоколе WebSocket, который уже не имеет с HTTP ничего общего.
47 |
48 | ## Server Sent Events
49 |
50 | Современный стандарт [Server-Sent Events](https://html.spec.whatwg.org/multipage/comms.html#the-eventsource-interface) позволяет браузеру создавать специальный объект `EventSource`, который сам обеспечивает соединение с сервером, делает пересоединение в случае обрыва и генерирует события при поступлении данных.
51 |
52 | Он, по дизайну, может меньше, чем WebSocket’ы. С другой стороны, Server Side Events проще в реализации, работают по обычному протоколу HTTP и сразу поддерживают ряд возможностей, которые для WebSocket ещё надо реализовать. Поэтому в тех случаях, когда нужна преимущественно односторонняя передача данных от сервера к браузеру, они могут быть удачным выбором.
--------------------------------------------------------------------------------
/src/network/tcp_ip.md:
--------------------------------------------------------------------------------
1 | # TCP/IP
2 |
3 | Протокол **TCP/IP** - это набор сетевых протоколов, используемых для обмена данными в компьютерных сетях. **TCP/IP** — сетевая модель выведенная из практического использования(в отличии от OSI).
4 |
5 | 
6 |
7 | ## Network Interface Layer(канальные)
8 |
9 | Этот уровень отвечает за передачу данных через физическую сеть, такую как Ethernet или Wi-Fi. Он определяет способы кодирования, физические характеристики кабелей, методы доступа и другие аспекты, связанные с конкретной технологией передачи данных.
10 |
11 | - канальный уровень описывает среду передачи данных
12 | - описывает способ кодирования данных для передачи пакета данных на физическом уровне
13 | - канальный уровень иногда разделяют на 2 подуровня — LLC и MAC
14 | - на канальном уровне рассматривают помехоустойчивое кодирование — позволяющие обнаруживать и исправлять ошибки в данных вследствие воздействия шумов и помех на канал связи
15 |
16 | ## Internet Layer(межсетевой)
17 |
18 | Этот уровень обеспечивает маршрутизацию пакетов данных через различные сети. Он использует IP-адресацию для определения и доставки пакетов данных между узлами сети. Протокол IP (Internet Protocol) является ключевым протоколом этого уровня. Он также обрабатывает фрагментацию и сборку пакетов данных при передаче через сети с различными максимальными размерами пакетов.
19 |
20 | - изначально разработан для передачи данных из одной сети в другую
21 | - на этом уровне работают маршрутизаторы, которые перенаправляют пакеты в нужную сеть путем расчета адреса сети по маске сети
22 | - пакеты сетевого протокола IP могут содержать код, указывающий, какой именно протокол следующего уровня нужно использовать, чтобы извлечь данные из пакета. Это число — уникальный IP-номер протокола. ICMP и IGMP имеют номера, соответственно, 1 и 2
23 | - протоколы: DVMRP, ICMP, IGMP, MARS, PIM, RIP, RIP2, RSVP
24 |
25 | ## Transport Layer(транспортный)
26 |
27 | Этот уровень обеспечивает надежную доставку данных между хостами. В стеке TCP/IP транспортные протоколы определяют, для какого именно приложения предназначены эти данные. Два наиболее распространенных протокола на этом уровне - это TCP (Transmission Control Protocol) и UDP (User Datagram Protocol).
28 |
29 | ## Application Layer(прикладной)
30 |
31 | Этот уровень содержит различные протоколы, используемые приложениями для обмена данными. Некоторые из наиболее известных протоколов этого уровня включают HTTP (HyperText Transfer Protocol) для передачи веб-страниц, SMTP (Simple Mail Transfer Protocol) для отправки электронной почты, FTP (File Transfer Protocol) для передачи файлов и DNS (Domain Name System) для разрешения имен хостов в IP-адреса.
32 |
33 | - протоколы работают поверх **TCP** или **UDP** и привязаны к определённому порту
34 | - порты определены Агентством по выделению имен и уникальных параметров протоколов
35 | - протоколы: Echo, Finger, Gopher, HTTP, HTTPS, IMAP, IMAPS, IRC, NNTP, NTP, POP3, POPS, QOTD, RTSP, SNMP, SSH, Telnet, XDMCP.
36 |
37 | ## TCP/UDP
38 |
39 | Основные отличия **tcp** от **udp**.
40 |
41 | - `TCP гарантирует доставку пакетов данных в неизменных виде, последовательности и без потерь, UDP ничего не гарантирует.`
42 | - `TCP нумерует пакеты при передаче, а UDP нет`
43 | - `TCP работает в дуплексном режиме, в одном пакете можно отправлять информацию и подтверждать получение предыдущего пакета.`
44 | - `TCP требует заранее установленного соединения, UDP соединения не требует, у него это просто поток данных.`
45 | - `UDP обеспечивает более высокую скорость передачи данных.`
46 | - `TCP надежнее и осуществляет контроль над процессом обмена данными.`
47 | - `UDP предпочтительнее для программ, воспроизводящих потоковое видео, видеофонии и телефонии, сетевых игр.`
48 | - `UPD не содержит функций восстановления данных`
49 |
50 | Чтобы увидеть отличия, нужно посмотреть внутрь TCP- и UDP-пакета.
51 |
52 | 
53 |
54 | И там, и там есть порты. Но **в UDP есть только контрольная сумма** — длина пакета, этот протокол максимально простой. А
55 | в TCP — очень много данных, которые явно указывают окно, acknowledgement, sequence, пакеты и так далее. Очевидно, **TCP
56 | более сложный**. Если говорить очень грубо, то TCP — это протокол надежной доставки, а UDP — ненадежной.
57 |
58 | *Дополнительно*:
59 |
60 | - [Протокол TCP](https://networkguru.ru/protokol-transportnogo-urovnia-tcp-chto-nuzhno-znat/)
61 | - [TCP против UDP](https://habr.com/ru/company/oleg-bunin/blog/461829/)
62 |
63 |
--------------------------------------------------------------------------------
/src/network/tls.md:
--------------------------------------------------------------------------------
1 | ## TLS
2 |
3 | SSL и TLS представляют собой развитие одной и той же технологии. Аббревиатура TLS (Transport Layer Security) появилась в качестве замены обозначения SSL (Secure Sockets Layer) после того, как протокол окончательно стал интернет-стандартом. Такая замена вызвана юридическими аспектами, так как спецификация SSL изначально принадлежала компании Netscape. И сейчас нередко названия SSL и TLS продолжают использовать в качестве синонимов, но каноническим именем является TLS, а протоколы семейства SSL окончательно устарели и не должны использоваться.
4 |
5 |
6 |
7 | Конкретное место TLS (SSL) в стеке протоколов Интернета показано на схеме:
8 |
9 | 
10 |
11 | ##### **TLS Handshake**
12 |
13 | 
14 |
15 | Основные шаги процедуры создания защищённого сеанса связи:
16 |
17 | - клиент подключается к серверу, поддерживающему TLS, и запрашивает защищённое соединение;
18 | - клиент предоставляет список поддерживаемых [алгоритмов шифрования](https://ru.wikipedia.org/wiki/Шифрование) и [хеш-функций](https://ru.wikipedia.org/wiki/Хеширование);
19 | - сервер выбирает из списка, предоставленного клиентом, наиболее надёжные алгоритмы среди тех, которые поддерживаются сервером, и сообщает о своём выборе клиенту;
20 | - сервер отправляет клиенту цифровой сертификат для собственной аутентификации. Обычно цифровой сертификат содержит имя сервера, имя удостоверяющего центра сертификации и открытый ключ сервера;
21 | - клиент, до начала передачи данных, проверяет валидность (аутентичность) полученного серверного сертификата относительно имеющихся у клиента корневых сертификатов удостоверяющих центров (центров сертификации). Клиент также может проверить, не отозван ли серверный сертификат, связавшись с сервисом доверенного удостоверяющего центра;
22 | - для шифрования сессии используется [сеансовый ключ](https://ru.wikipedia.org/wiki/Сеансовый_ключ). Получение общего секретного сеансового ключа клиентом и сервером проводится по протоколу Диффи-Хеллмана. Существует исторический метод передачи сгенерированного клиентом секрета на сервер при помощи шифрования асимметричной криптосистемой RSA (используется ключ из сертификата сервера). Данный метод не рекомендован, но иногда продолжает встречаться на практике.
23 |
24 | На этом заканчивается процедура подтверждения связи. Между клиентом и сервером установлено безопасное соединение, данные, передаваемые по нему, шифруются и расшифровываются с использованием симметричной криптосистемы до тех пор, пока соединение не будет завершено.
25 |
26 |
27 |
28 | *Дополнительно:*
29 |
30 | - [TLS — Википедия](https://ru.wikipedia.org/wiki/TLS)
31 | - [Что такое TSL](https://habr.com/ru/post/258285/)
32 | - [Ключи, шифры, сообщения: как работает TLS](https://tls.dxdt.ru/tls.html)
33 | - [Руководство по выживанию — TLS/SSL и сертификаты SSL](https://www.opennet.ru/docs/RUS/ldap_apacheds/tech/ssl.html)
--------------------------------------------------------------------------------
/src/php/README.md:
--------------------------------------------------------------------------------
1 | # PHP
2 |
3 | **PHP** (PHP: Hypertext Preprocessor; первоначально Personal Home Page Tools) — скриптовый язык общего назначения, интенсивно применяемый для разработки веб-приложений. Является одним из лидеров среди языков, применяющихся для создания динамических веб-сайтов.
4 |
5 | - [Фичи новых версий](innovations.md)
6 | - [PHP Internals](internals.md)
7 | - [Взаимодействие с сервером](serverIteractions.md)
8 | - [Фреймворки](frameworks/README.md)
9 | - [Разное](uncategorized.md)
10 |
11 |
--------------------------------------------------------------------------------
/src/php/frameworks/README.md:
--------------------------------------------------------------------------------
1 | # Frameworks
2 |
3 | В этом разделе собрана разная фреймворкоспецифичная информация(Symfony и Laravel).
4 |
5 | - [Laravel](laravel.md)
6 | - [Symfony](symfony.md)
--------------------------------------------------------------------------------
/src/php/frameworks/laravel.md:
--------------------------------------------------------------------------------
1 | # Laravel
2 |
3 | Laravel — бесплатный веб-фреймворк с открытым кодом, предназначенный для **разработки** с использованием архитектурной модели MVC (англ. Model View Controller — модель-представление-контроллер). Laravel выпущен под лицензией MIT.
4 |
5 | Ключевые особенности, лежащие в основе архитектуры Laravel:
6 |
7 | - *Пакеты* (packages) — позволяют создавать и подключать модули в формате [Composer](https://ru.wikipedia.org/wiki/Composer) к приложению на Laravel. Многие дополнительные возможности уже доступны в виде таких модулей.
8 | - *Eloquent ORM* — реализация [шаблона проектирования](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F) [ActiveRecord](https://ru.wikipedia.org/wiki/ActiveRecord) на PHP. Позволяет строго определить отношения между объектами [базы данных](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B7%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85). Стандартный для Laravel построитель запросов Fluent поддерживается ядром Eloquent.
9 | - *Логика приложения* — часть разрабатываемого приложения, объявленная либо при помощи контроллеров, либо маршрутов ([функций-замыканий](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BC%D1%8B%D0%BA%D0%B0%D0%BD%D0%B8%D0%B5_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5))). Синтаксис объявлений похож на синтаксис, используемый в [каркасе](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D1%8B%D0%B9_%D0%BA%D0%B0%D1%80%D0%BA%D0%B0%D1%81) [Sinatra](https://ru.wikipedia.org/wiki/Sinatra).
10 | - *Обратная маршрутизация* связывает между собой генерируемые приложением ссылки и маршруты, позволяя изменять последние с автоматическим обновлением связанных ссылок. При создании ссылок с помощью именованных маршрутов Laravel автоматически генерирует конечные URL.
11 | - *REST-контроллеры* — дополнительный слой для разделения логики обработки GET- и POST-запросов HTTP.
12 | - *Автозагрузка классов* — механизм автоматической загрузки классов [PHP](https://ru.wikipedia.org/wiki/PHP) без необходимости подключать файлы их определений в *include*. Загрузка по требованию предотвращает загрузку ненужных компонентов; загружаются только те из них, которые действительно используются.
13 | - *Составители представлений* (view composers) — блоки кода, которые выполняются при генерации представления (шаблона).
14 | - *Инверсия управления* (Inversion of Control) — позволяет получать экземпляры объектов по принципу обратного управления. Также может использоваться для создания и получения [объектов-одиночек](https://ru.wikipedia.org/wiki/Singleton) ([англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) singleton).
15 | - *Миграции* — система управления версиями для баз данных. Позволяет связывать изменения в коде приложения с изменениями, которые требуется внести в структуру БД, что упрощает развёртывание и обновление приложения.
16 | - *Модульное тестирование* (*юнит-тесты*) — играет очень большую роль в Laravel, который сам по себе содержит большое число тестов для предотвращения [регрессий](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) (ошибок вследствие обновления кода или исправления других ошибок).
17 | - *Страничный вывод* (pagination) — упрощает генерацию страниц, заменяя различные способы решения этой задачи единым механизмом, встроенным в Laravel.
18 |
19 |
--------------------------------------------------------------------------------
/src/php/frameworks/symfony.md:
--------------------------------------------------------------------------------
1 | # Symfony
2 |
3 | ## Compiler Pass
4 |
5 | На этапе компиляции контейнер выполняет серию проходов для приведения своего содержимого в конечное состояние. Проходы являются реализацией интерфейса CompilerPassInterface и бывают 6 видов (в порядке исполнения):
6 |
7 | merge, beforeOptimization, optimization, beforeRemoving, removing, afterRemoving — по умолчанию конфигурация компилятора уже содержит набор проходов.
8 |
9 | - *before/after* — лишь «хуки» для пользовательских «проходов» и не используются стандартными (добавленными по умолчанию);
10 | - *merge* — обрабатывает *расширения (extensions)* контейнера;
11 | - *optimization* — оптимизируют контейнер, примерами могут служить: ResolveInterfaceInjectorsPass (преобразует [интерфейсные инъекции](http://martinfowler.com/articles/injection.html#InterfaceInjection)), CheckCircularReferencesPass (проверяет циклические ссылки в контейнере)
12 | - *removing* — удаляют неиспользуемые сервисы, например, RemoveUnusedDefinitionsPass (удаляет неиспользуемые приватные сервисы)
13 |
14 | В бандлах CompilerPass чаще всего используется для обработки тегов в контейнере
15 |
16 | Пример из стандартного TwigBundle:
17 |
18 | ```php
19 | $definition = $container->getDefinition('twig');
20 | $calls = $definition->getMethodCalls();
21 | $definition->setMethodCalls(array());
22 | foreach ($container->findTaggedServiceIds('twig.extension') as $id => $attributes) {
23 | $definition->addMethodCall('addExtension', array(new Reference($id)));
24 | }
25 | $definition->setMethodCalls(array_merge($definition->getMethodCalls(), $calls));
26 | ```
27 |
28 |
--------------------------------------------------------------------------------
/src/php/innovations.md:
--------------------------------------------------------------------------------
1 | ## Основные нововведения php
2 |
3 | ### [7.0](http://www.php.net/ChangeLog-7.php#7.0.0)
4 |
5 | 1. возможность обработки исключения, вместо фатальной ошибки
6 | 2. новые операторы сравнения ( <=>, ?? и другие)
7 | 3. анонимные классы
8 | 4. указание типа возвращаемого значения (return type declaration)
9 | 5. группировка для оператора use
10 | 6. работа с замыканиями (closure)
11 | 7. скалярные типы аргументов функции (scalar type hints)
12 | 8. опционально доступный "строгий режим" работы с типами (strict mode)
13 | 9. изменена трактовка переменных и выражений
14 | 10. улучшена работа с генераторами (ключевое слово yield from и другие изменения)
15 | 11. конструктор класса в стиле php4 (когда имя класса совпадает с именем метод) теперь генерирует E_DEPRECATED и будет удален в php8
16 | 12. изменено поведение побитовых операторов <<, >> и других
17 | 13. изменено поведение функций func_get_args и func_get_arg
18 | 14. функция языка unserialize принимает дополнительный аргумент
19 | 15. функция языка list изменила поведение
20 | 16. изменено поведение цикла foreach (например в работе с внутренним итератором)
21 | 17. новый синтаксис unicode последовательностей
22 |
23 | ## [7.1](http://php.net/ChangeLog-7.php#7.1.0)
24 |
25 | 1. возвращаемый тип void
26 | 2. псевдотип iterable
27 | 3. null в типизированных и возвращаемых параметрах
28 | 4. возможность использовать отрицательное значение для смещения в строках
29 | 5. разрешено использовать строковые ключи в конструкци
30 | 6. конвертация callable выражений в замыкание
31 | 7. Поддержка модификаторов видимости для констант класса
32 | 8. Ловить исключения можно объединяя несколько типов исключений в один блок
33 |
34 | ## [7.2](http://php.net/ChangeLog-7.php#7.2.0)
35 |
36 | 1. Добавлена возможность загружать расширения по имени
37 | 2. Добавлена возможность перегружать абстрактные функции(Liskov)
38 | 3. Запрещено number_format() возвращать -0
39 | 4. Добавлена возможность конвертировать нумерованные ключи при приведении типов object/array
40 | 5. Запрещено передавать null в качестве параметра для get_class()
41 | 6. Вызов Count с параметром, который нельзя посчитать
42 | 7. Возможность расширения типа параметра
43 | 8. Добавлена возможность указывать запятую в конце группированных неймспейсов
44 | 9. Реализовано семейство функций socket_getaddrinfo
45 | 10. Улучшены TLS-константы
46 | 11. Object typehint
47 | 12. LDAP EXOP
48 | 13. В ядро PHP добавлена Libsodium
49 | 14. Добавлен алгоритм Argon2 в хешировании пароля
50 | 15. HashContext as Object
51 | 16. Добавлен отладчик PDO Prepared statements
52 | 17. Добавлен отладчик PDO Prepared statements v2
53 | 18. Расширенные типы строк для PDO
54 | 19. Добавлены опции JSON_INVALID_UTF8_IGNORE и JSON_INVALID_UTF8_SUBSTITUTE
55 |
56 | ### [7.3](http://www.php.net/ChangeLog-7.php#7.3.0)
57 |
58 | 1. Смягчение требований к синтаксису Heredoc и Nowdoc
59 | 2. Поддержка конечных запятых в вызовах функций и методов
60 | 3. Ссылки в `list()`
61 | 4. Функция `image2wbmp()` объявлена устаревшей
62 | 5. Флаги `FILTER_FLAG_SCHEME_REQUIRED` и `FILTER_FLAG_HOST_REQUIRED` при использовании `FILTER_VALIDATE_URL` объявлены устаревшими
63 | 6. Регистро-независимые константы объявлены устаревшими
64 | 7. Опциональный выброс исключений при ошибках в функциях `json_encode` и `json_decode`
65 | 8. Добавление функции `is_countable()`
66 | 9. Добавление функций `array_key_first()` и `array_key_last()`
67 |
68 | ### 7.4
69 |
70 | - Типизированные свойства классов
71 | - Предзагрузка для улучшения производительности
72 | - Стрелочные функции для короткой записи анонимных функций
73 | - Присваивающий оператор объединения с null (??=)
74 | - Ковариантность/контравариантность в сигнатурах унаследованных методов
75 | - Интерфейс внешних функций, открывающий новые возможности для разработки расширений на PHP
76 | - Оператор распаковки в массивах
77 |
78 | ### [8](https://www.php.net/releases/8.0)
79 |
80 | 1. Именованные аргументы
81 | 2. Атрибуты
82 | 3. Объявление свойств в конструкторе
83 | 4. Union types
84 | 5. Выражение Match
85 | 6. Оператор Nullsafe
86 | 7. Улучшенное сравнение строк и чисел
87 | 8. Ошибки согласованности типов для встроенных функций
88 |
89 | ### 8.1
90 |
91 | - [Intersection Types](https://php.watch/versions/8.1/intersection-types)
92 | - [Enums](https://php.watch/versions/8.1/enums)
93 | - [`never` return type](https://php.watch/versions/8.1/never-return-type)
94 | - [Readonly Properties](https://php.watch/versions/8.1/readonly)
95 | - [Fibers](https://php.watch/versions/8.1/fibers)
96 | - [`final` class constants](https://php.watch/versions/8.1/final-class-const)
97 | - [New `fsync` and `fdatasync` functions](https://php.watch/versions/8.1/fsync-fdatasync)
98 | - [New `array_is_list` function](https://php.watch/versions/8.1/array_is_list)
99 | - [New Sodium `XChaCha20` functions](https://php.watch/versions/8.1/Sodium-XChaCha20-functions)
100 | - [`$_FILES`: New `full_path` value for directory-uploads](https://php.watch/versions/8.1/$_FILES-full-path)
101 | - [Intl: New `IntlDatePatternGenerator` class](https://php.watch/versions/8.1/IntlDatePatternGenerator)
102 | - [First-class Callable Syntax](https://php.watch/versions/8.1/first-class-callable-syntax)
103 | - [GD: AVIF image support](https://php.watch/versions/8.1/gd-avif)
104 | - [Phar: Added OpenSSL-256 and OpenSSL-512 signature algorithms](https://php.watch/versions/8.1/phar-openssl-256-openssl-512)
105 | - [GD: Lossless WebP encoding support](https://php.watch/versions/8.1/gd-webp-lossless)
106 | - [New `#[ReturnTypeWillChange\]` attribute](https://php.watch/versions/8.1/ReturnTypeWillChange)
107 | - [Array unpacking support for string-keyed arrays](https://php.watch/versions/8.1/spread-operator-string-array-keys)
108 | - [Explicit Octal numeral notation](https://php.watch/versions/8.1/explicit-octal-notation)
109 | - [Hash functions accept algorithm-specific `$options`](https://php.watch/versions/8.1/hash-options)
110 | - [MurmurHash3 hash algorithm support](https://php.watch/versions/8.1/MurmurHash3)
111 | - [xxHash hash algorithms support](https://php.watch/versions/8.1/xxHash)
112 | - [FPM: Configurable child-process spawn rate](https://php.watch/versions/8.1/fpm-pm-max_spawn_rate)
113 | - [Curl: DNS-over-HTTPS support](https://php.watch/versions/8.1/Curl-CURLOPT_DOH_URL)
114 | - [Curl: File uploads from strings with `CURLStringFile`](https://php.watch/versions/8.1/CURLStringFile)
115 | - [MySQLi: New `MYSQLI_REFRESH_REPLICA` constant](https://php.watch/versions/8.1/MYSQLI_REFRESH_REPLICA)
--------------------------------------------------------------------------------
/src/styles/website.css:
--------------------------------------------------------------------------------
1 | .book .book-summary ul.summary li a, .book .book-summary ul.summary li span {
2 | padding: 2px 5px;
3 | font-size: 0.85em;
4 | }
5 | .book .book-summary ul.summary li i.fa-check {
6 | right: 5px;
7 | top: 7px;
8 | }
9 |
10 | .markdown-section img {
11 | display: block;
12 | margin: 0 auto;
13 | }
--------------------------------------------------------------------------------
/src/unsorted/README.md:
--------------------------------------------------------------------------------
1 | # Неотсортированные темы
2 |
3 | Здесь будет различная инфа, которую сложно(на данный момент) отнести к какому-либо разделу книги.
4 |
5 | - [Побитовые операции](bits.md)
6 | - [Юникод](unicode.md)
7 | - [Типизация](types.md)
8 |
9 |
10 |
--------------------------------------------------------------------------------
/src/unsorted/bits.md:
--------------------------------------------------------------------------------
1 | # Побитовые операторы
2 |
3 | Побитовые операторы интерпретируют операнды как последовательность из 32 битов (нулей и единиц). Они производят операции, используя двоичное представление числа, и возвращают новую последовательность из 32 бит (число) в качестве результата.
4 |
5 | ## Формат 32-битного целого числа со знаком
6 | Что такое двоичная система счисления, вам, надеюсь, уже известно. При разборе побитовых операций мы будем обсуждать именно двоичное представление чисел, из 32 бит.
7 |
8 | Старший бит слева – это научное название для самого обычного порядка записи цифр (от большего разряда к меньшему). При этом, если больший разряд отсутствует, то соответствующий бит равен нулю.
9 |
10 | Примеры представления чисел в двоичной системе:
11 | ```
12 | a = 0; // 00000000000000000000000000000000
13 | a = 1; // 00000000000000000000000000000001
14 | a = 2; // 00000000000000000000000000000010
15 | a = 3; // 00000000000000000000000000000011
16 | a = 255;// 00000000000000000000000011111111
17 | ```
18 | Обратите внимание, каждое число состоит ровно из 32-битов.
19 |
20 | Дополнение до двойки – это название способа поддержки отрицательных чисел.
21 |
22 | Двоичный вид числа, обратного данному (например, 5 и -5) получается путём обращения всех битов с прибавлением 1.
23 |
24 | То есть, нули заменяются на единицы, единицы – на нули и к числу прибавляется 1. Получается внутреннее представление того же числа, но со знаком минус.
25 |
26 | Например, вот число 314:
27 |
28 | ```00000000000000000000000100111010```
29 |
30 | Чтобы получить -314, первый шаг – обратить биты числа: заменить 0 на 1, а 1 на 0:
31 |
32 | ```11111111111111111111111011000101```
33 |
34 | Второй шаг – к полученному двоичному числу прибавить единицу, обычным двоичным сложением: 11111111111111111111111011000101 + 1 = 11111111111111111111111011000110.
35 |
36 | Итак, мы получили:
37 |
38 | ```-314 = 11111111111111111111111011000110```
39 |
40 | Принцип дополнения до двойки делит все двоичные представления на два множества: если крайний-левый бит равен 0 – число положительное, если 1 – число отрицательное. Поэтому этот бит называется знаковым битом.
41 |
42 |
43 | *Дополнительно:*
44 | - [Основы JavaScript Побитовые операторы](https://learn.javascript.ru/bitwise-operators)
45 | - [Побитовые операторы](http://php.net/manual/ru/language.operators.bitwise.php)
46 |
--------------------------------------------------------------------------------
/src/unsorted/types.md:
--------------------------------------------------------------------------------
1 | # Типизация
2 |
3 | Языки программирования по типизации принято делить на два больших лагеря **типизированные** и **нетипизированные(бестиповые)**. К первому например относятся C, Python, Scala, PHP и Lua, а ко второму — язык ассемблера, Forth и Brainfuck.
4 |
5 | Так как «бестиповая типизация» по своей сути — проста как пробка, дальше она ни на какие другие виды не делится. А вот типизированные языки разделяются еще на несколько пересекающихся категорий:
6 |
7 | ***Статическая* / *динамическая*** типизация. Статическая определяется тем, что конечные типы переменных и функций устанавливаются на этапе компиляции. Т.е. уже компилятор на 100% уверен, какой тип где находится. В динамической типизации все типы выясняются уже во время выполнения программы.
8 |
9 | Примеры:
10 | Статическая: C, Java, C#;
11 | Динамическая: Python, JavaScript, Ruby.
12 |
13 | ***Сильная* / *слабая*** типизация (также иногда говорят строгая / нестрогая). Сильная типизация выделяется тем, что язык не позволяет смешивать в выражениях различные типы и не выполняет автоматические неявные преобразования, например нельзя вычесть из строки множество. Языки со слабой типизацией выполняют множество неявных преобразований автоматически, даже если может произойти потеря точности или преобразование неоднозначно.
14 |
15 | Примеры:
16 | Сильная: Java, Python, Haskell, Lisp;
17 | Слабая: C, JavaScript, Visual Basic, PHP.
18 |
19 | ***Явная* / *неявная*** типизация. Явно-типизированные языки отличаются тем, что тип новых переменных / функций / их аргументов нужно задавать явно. Соответственно языки с неявной типизацией перекладывают эту задачу на компилятор / интерпретатор.
20 |
21 | Примеры:
22 | Явная: C++, D, C#
23 | Неявная: PHP, Lua, JavaScript
24 |
25 | Также нужно заметить, что все эти категории пересекаются, например язык C имеет статическую слабую явную типизацию, а язык Python — динамическую сильную неявную.
26 |
27 |
28 |
29 | ***Номинативная/Структурная*** типизация. Номинативная, следит за названиями типов, структурная типизация принимает решение о совместимости типов на основе их содержимого. Т.е если тип А содержит все свойства/методы типа б, то он может быть использован как тип Б.
--------------------------------------------------------------------------------
/src/unsorted/unicode.md:
--------------------------------------------------------------------------------
1 | # О Юникоде
2 |
3 | До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
4 |
5 | - Всего 255 символов, да и то часть из них не графические;
6 | - Возможность открыть документ не с той кодировкой, в которой он был создан;
7 | - Шрифты необходимо создавать для каждой кодировки.
8 |
9 | Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
10 |
11 | ## О UTF-8
12 |
13 | Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
14 |
15 | UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
16 |
17 | ```
18 | 0 — 127: 0xxxxxxx
19 | 128 — 2047: 110xxxxx 10xxxxxx
20 | 2048 — 65535: 1110xxxx 10xxxxxx 10xxxxxx
21 | 655356 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
22 | ```
23 |
24 | ## Кодируем в UTF-8
25 |
26 | Порядок действий примерно такой:
27 |
28 | - Каждый символ превращаем в Юникод.
29 | - Проверяем из какого символ диапазона.
30 | - Если код символа меньше 128, то к результату добавляем его в неизменном виде.
31 | - Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
32 | - Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
33 |
34 | ## UTF-32
35 |
36 | UTF-32 — способ представления Юникода, при котором каждый символ занимает ровно 4 байта. Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод в ней непосредственно индексируемы, поэтому найти символ по номеру его позиции в файле можно чрезвычайно быстро, и получение любого символа *n*-й позиции при этом является операцией, занимающей всегда одинаковое время. Это также делает замену символов в строках UTF-32 очень простой. Напротив, кодировки с переменной длиной требуют последовательного доступа к символу *n*-й позиции, что может быть очень затратной по времени операцией. Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения любого символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства, редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства, зачастую не оправдано.
--------------------------------------------------------------------------------
45 |
46 |
47 |
48 | ## Type Assertion vs Type Conversoin
49 |
50 | | Выражение | Что делает? | Работает только с | Паника? |
51 | | --------------------- | ---------------------------- | --------------------------- | ---------------------------- |
52 | | `variable.(*MyType)` | Проверяет тип в интерфейсе | Интерфейс (`interface{}`) | Да, если тип не совпадает |
53 | | `(*MyType)(variable)` | Преобразует совместимые типы | Указатели, `unsafe.Pointer` | Нет (либо ошибка компиляции) |
54 |
55 |
56 |
--------------------------------------------------------------------------------
/src/goLang/types/map.md:
--------------------------------------------------------------------------------
1 | # Map
2 |
3 | В Go `map` — это встроенная хеш-таблица с открытой адресацией. Она обеспечивает быстрый доступ к данным с временной сложностью `O(1)` в среднем случае. Каждый элемент имеет уникальный ключ, по которому можно получить значение элемента. В `map[K]V`, `К` представляет тип ключа, а `V` - тип значения. Тип ключа K должен быть comparable(поддерживать операцию сравнения `==`)
4 |
5 | ```go
6 | // A header for a Go map.
7 | type hmap struct {
8 | // Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
9 | // Make sure this stays in sync with the compiler's definition.
10 | count int // # live cells == size of map. Must be first (used by len() builtin)
11 | flags uint8
12 | B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
13 | noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
14 | hash0 uint32 // hash seed
15 |
16 | buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
17 | oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
18 | nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
19 |
20 | extra *mapextra // optional fields
21 | }
22 | ```
23 |
24 | 
25 |
26 | Например, определение `map`, которое в качестве ключей имеет тип `string`, а в качестве значений - тип `int`:
27 |
28 | ```go
29 | var people map[string] int
30 | ```
31 |
32 | Для проверки наличия элемента по определенному ключу можно получать два значения, второе и будет показывать наличие:
33 |
34 | ```go
35 | var people = map[string]int{"Tom": 1, "Bob": 2, "Sam": 4, "Alice": 8}
36 |
37 | if val, ok := people["Tom"]; ok {
38 | fmt.Println(val)
39 | }
40 | ```
41 |
42 | Адрес элемента мапы получить невозможно(сделано из-за того что адрес может стать недействителен, после рехеширования)
43 |
44 | ```go
45 | _ = &ages["bob"] // ТАК НЕЛЬЗЯ!!!
46 | ```
47 |
48 | При чтении из nil мапы, ничего страшного не произойдёт, получим нулевое значение для типа. Но если писать в nil map то словим панику.
49 |
50 | ```go
51 | m1 := map[string]int{
52 | "key": 1,
53 | }
54 | m1 = nil
55 | fmt.Println(m1["key"]) // 0
56 | m1["key"] = 1 //panic: assignment to entry in nil map
57 | ```
58 |
59 |
60 |
61 | ## **Бакеты (buckets)**
62 |
63 | Данные в `map` хранятся в **бакетах**. Бакет содержит до 8 ключей и значений:
64 |
65 | ```go
66 | type bmap struct {
67 | tophash [8]uint8 // Первые 8 бит хеша ключей
68 | keys [8]K // Ключи
69 | values [8]V // Значения
70 | overflow *bmap // Указатель на следующий бакет (если есть переполнение)
71 | }
72 | ```
73 |
74 | - **`tophash`** хранит первые 8 бит хеша ключа.
75 | - **`keys`** и **`values`** — массивы ключей и значений.
76 |
77 | ## **Рехеширование (grow)**
78 |
79 | Когда элементов становится **слишком много**(больше 6.5 в среднем), `map` **удваивает** число бакетов:
80 |
81 | - Создаётся новый массив бакетов `2^(B+1)`.
82 | - Ключи перераспределяются.
83 | - Это происходит **постепенно** (incremental rehashing), чтобы избежать резкого скачка нагрузки.
84 |
85 | Когда рехеширование запускается:
86 |
87 | 1. `count > 6.5 * 2^B` → **увеличение размера (`grow`)**.
88 | 2. `overflow > определённого порога` → **перемещение (`evacuation`)**.
89 |
90 |
91 |
92 | ## **Итерация по `map`**
93 |
94 | ```go
95 | for k, v := range m {
96 | fmt.Println(k, v)
97 | }
98 | ```
99 |
100 | Итерация **не гарантирует порядок** — это связано с рандомизацией хеширования.
101 |
102 |
103 |
104 | ## Почему нельзя взять указатель на элемент `map`
105 |
106 | Go запрещает брать адрес элемента `map`:
107 |
108 | ```
109 | m := map[string]int{"Alice": 25}p := &m["Alice"] // Ошибка компиляции
110 | ```
111 |
112 | Причина в том, что Go **динамически перераспределяет память** для `map`. Когда в `map` добавляются новые элементы, он может **перераспределить бакеты** в памяти, и старые адреса станут невалидными. Это могло бы приводить к трудноотлавливаемым багам, поэтому Go запрещает такую возможность на уровне компилятора.
113 |
114 | ## Внутреннее устройство
115 |
116 | Map — это просто хеш-таблица. Данные организованы в массив бакетов. Каждый бакет содержит до 8 пар "ключ-значение". Младшие биты хеша используются для выбора бакета. Каждый бакет хранит несколько старших битов хеша, чтобы различать записи внутри одного бакета.
117 |
118 | Если в один бакет попадает более 8 ключей, создаются дополнительные (overflow) бакеты, образующие цепочку.
119 |
120 | Когда хеш-таблица увеличивается, создаётся новый массив бакетов в два раза больше. Бакеты постепенно (инкрементально) копируются из старого массива в новый.
121 |
122 | Итератор по map проходит по массиву бакетов и возвращает ключи в порядке обхода (сначала по номерам бакетов, затем по цепочкам overflow-бакетов, затем по индексам внутри бакета). Чтобы сохранить семантику итерации, ключи никогда не перемещаются внутри своего бакета (если бы они перемещались, один и тот же ключ мог бы быть возвращён 0 или 2 раза).
123 |
124 | Во время увеличения таблицы итераторы продолжают обход старого массива и должны проверять новый массив, если бакет, по которому они идут, был перемещён ("эвакуирован") в новую таблицу.
--------------------------------------------------------------------------------
/src/goLang/types/struct.md:
--------------------------------------------------------------------------------
1 | # Структура
2 |
3 | Тип данных `struct` в Go позволяет объединять несколько значений разных типов в одну составную сущность. `struct` представляет собой коллекцию полей, где каждое поле имеет имя и тип данных. Структура определяется с помощью ключевого слова `type` и указания имени структуры, а затем объявления полей с указанием имени и типа данных каждого поля:
4 |
5 | ```go
6 | Person struct {
7 | Name string
8 | Age int
9 | City string
10 | }
11 | ```
12 |
13 | Для создания экземпляра структуры используется оператор `var` вместе с именем структуры и фигурными скобками для инициализации полей:
14 |
15 | ```go
16 | var person Person
17 | person.Name = "John"
18 | person.Age = 30
19 | person.City = "New York"
20 | ```
21 |
22 | 1. Доступ к полям структуры: Доступ к полям структуры осуществляется с использованием оператора `.`. Например, `person.Name` обратится к полю `Name` в структуре `person`.
23 | 2. Вложенные структуры: Структуры могут быть вложенными, что позволяет создавать более сложные структуры данных. Пример:
24 |
25 | ```go
26 | type Address struct {
27 | Street string
28 | City string
29 | }
30 |
31 | type Person struct {
32 | Name string
33 | Age int
34 | Address Address
35 | }
36 | ```
37 |
38 | ## Struct embedding
39 |
40 | Структурное встраивание (struct embedding) в Go позволяет включать одну структуру в другую без явного объявления полей. Это создает отношение "является" (is-a) между структурами, где встроенная структура получает доступ к полям и методам внешней структуры.
41 |
42 |
43 |
44 | Выполняется путем включения имени структуры в определение другой структуры без указания имени поля.
45 |
46 | ```go
47 | type Person struct {
48 | Name string
49 | Age int
50 | }
51 |
52 | type Employee struct {
53 | Person
54 | EmployeeID int
55 | }
56 | ```
57 |
58 | Наследование полей и методов: В результате встраивания структуры `Person` в структуру `Employee`, поля и методы структуры `Person` автоматически становятся доступными в структуре `Employee`. Например, поле `Name` структуры `Person` может быть обращено как `Employee.Name` в структуре `Employee`.
59 |
60 | Если структуры, встраиваемые в одну структуру, содержат поле с одинаковым именем, то необходимо указать имя структуры перед полем для разрешения неоднозначности. Например:
61 |
62 | ```go
63 | type Person struct {
64 | Name string
65 | Age int
66 | }
67 |
68 | type Employee struct {
69 | Person
70 | Name string
71 | EmployeeID int
72 | }
73 | ```
74 |
75 | В данном примере поле `Name` из структуры `Person` может быть обращено как `Employee.Person.Name` для различения от поля `Name` в самой структуре `Employee`.
76 |
77 | Если во встроенной структуре имеется поле или метод с тем же именем, что и внешней структуре, то поле или метод внешней структуры будет переопределен. Переопределенное поле или метод будет доступно только через явное указание имени внешней структуры. Например:
78 |
79 | ```go
80 | type Person struct {
81 | Name string
82 | Age int
83 | }
84 |
85 | func (p Person) Greet() {
86 | fmt.Println("Hello, I'm", p.Name)
87 | }
88 |
89 | type Employee struct {
90 | Person
91 | Name string
92 | EmployeeID int
93 | }
94 |
95 | func (e Employee) Greet() {
96 | fmt.Println("Hello, I'm", e.Person.Name, "and I'm an employee")
97 | }
98 | ```
99 |
100 | В данном примере метод `Greet()` структуры `Employee` переопределяет метод с тем же именем в структуре `Person`.
--------------------------------------------------------------------------------
/src/javascript.md:
--------------------------------------------------------------------------------
1 | # JavaScript
2 |
3 | Джаваскрипт очень нужен, куда мы без него.
4 |
5 | ## Function Declaration vs Function Expression
6 |
7 | Давайте разберём ключевые отличия Function Declaration от Function Expression.
8 |
9 | Во-первых, синтаксис: как определить, что есть что в коде.
10 |
11 | - Function Declaration: функция объявляется отдельной конструкцией «function…» в основном потоке кода.
12 |
13 | ```javascript
14 | // Function Declaration
15 | function sum(a, b) {
16 | return a + b;
17 | }
18 | ```
19 |
20 | - Function Expression: функция, созданная внутри другого выражения или синтаксической конструкции. В данном случае функция создаётся в правой части «выражения присваивания» `=`:
21 |
22 | ```javascript
23 | // Function Expression
24 | let sum = function(a, b) {
25 | return a + b;
26 | };
27 | ```
28 |
29 | Более тонкое отличие состоит, в том, *когда* создаётся функция движком JavaScript.
30 |
31 | **Function Expression создаётся, когда выполнение доходит до него, и затем уже может использоваться.**
32 |
33 | После того, как поток выполнения достигнет правой части выражения присваивания `let sum = function…` – с этого момента, функция считается созданной и может быть использована (присвоена переменной, вызвана и т.д. ).
34 |
35 | С Function Declaration всё иначе.
36 |
37 | **Function Declaration можно использовать во всем скрипте (или блоке кода, если функция объявлена в блоке).**
38 |
39 | Другими словами, когда движок JavaScript *готовится* выполнять скрипт или блок кода, прежде всего он ищет в нём Function Declaration и создаёт все такие функции. Можно считать этот процесс «стадией инициализации».
40 |
41 | И только после того, как все объявления Function Declaration будут обработаны, продолжится выполнение.
42 |
43 | В результате функции, созданные, как Function Declaration могут быть вызваны раньше своих определений.
44 |
45 | ## Arrow Functions
46 |
47 |
48 |
49 | ## This
50 |
51 | Поведение ключевого слова `this` в JavaScript несколько отличается по сравнению с остальными языками. Имеются также различия при использовании `this` в [строгом](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Strict_mode) и нестрогом режиме.
52 |
53 | В большинстве случаев значение `this` определяется тем, каким образом вызвана функция. Значение `this` не может быть установлено путем присваивания во время исполнения кода и может иметь разное значение при каждом вызове функции. В ES5 представлен метод [`bind()`](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/Function/bind), который используется для [`привязки значения ключевого слова this независимо от того, как вызвана функция`](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Operators/this#Метод_bind). Также в ES2015 представлены [`стрелочные функции`](https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Functions/Arrow_functions), которые не создают собственные привязки к `this` (они сохраняют значение `this` лексического окружения, в котором были созданы).
54 |
55 |
56 |
57 | ## Use Strict
58 |
59 | **Преимущества:**
60 |
61 | - Не позволяет случайно создавать глобальные переменные.
62 | - Любое присваивание, которое в обычном режиме завершается неудачей, в строгом режиме выдаст исключение.
63 | - При попытке удалить неудаляемые свойства, выдаст исключение (в то время как в нестрогом режиме никакого действия бы не произошло).
64 | - Требует, чтобы имена параметров функции были уникальными.
65 | - `this` в глобальной области видимости равно undefined.
66 | - Перехватывает распространенные ошибки, выдавая исключения.
67 | - Исключает неочевидные особенности языка.
68 |
69 | **Недостатки:**
70 |
71 | - Нельзя использовать некоторые особенности языка, к которым привыкли некоторые разработчики.
72 | - Нет доступа к `function.caller` и `function.arguments`.
73 | - Объединение скриптов, написанных в строгом режиме может вызвать проблемы.
74 |
75 | ## Concurrency
76 |
77 | - Event Loop
78 | - Калбеки
79 | - промисы
80 | - async await
81 | - web workers
82 |
83 |
--------------------------------------------------------------------------------
/src/media/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/.DS_Store
--------------------------------------------------------------------------------
/src/media/algostruct/collision-resolving.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/collision-resolving.png
--------------------------------------------------------------------------------
/src/media/algostruct/collision_chain.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/collision_chain.png
--------------------------------------------------------------------------------
/src/media/algostruct/collision_open_hash.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/collision_open_hash.png
--------------------------------------------------------------------------------
/src/media/algostruct/hash-func.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/algostruct/hash-func.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/accessRefreshJwt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/accessRefreshJwt.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/cookieSession.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/cookieSession.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/httpBasic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/httpBasic.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/httpDigest.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/httpDigest.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/jwt.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/jwt.png
--------------------------------------------------------------------------------
/src/media/auth/webAuth/token.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/auth/webAuth/token.png
--------------------------------------------------------------------------------
/src/media/bAndB+.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/bAndB+.png
--------------------------------------------------------------------------------
/src/media/bTreeExample.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/bTreeExample.png
--------------------------------------------------------------------------------
/src/media/bTreeIndex.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/bTreeIndex.png
--------------------------------------------------------------------------------
/src/media/biHeap.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/biHeap.png
--------------------------------------------------------------------------------
/src/media/cgi.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/cgi.jpeg
--------------------------------------------------------------------------------
/src/media/db/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/.DS_Store
--------------------------------------------------------------------------------
/src/media/db/specific/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/.DS_Store
--------------------------------------------------------------------------------
/src/media/db/specific/messages/kaffka_prod_con.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/kaffka_prod_con.png
--------------------------------------------------------------------------------
/src/media/db/specific/messages/kafka.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/kafka.jpg
--------------------------------------------------------------------------------
/src/media/db/specific/messages/mcq.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/mcq.jpg
--------------------------------------------------------------------------------
/src/media/db/specific/messages/nats.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/nats.jpg
--------------------------------------------------------------------------------
/src/media/db/specific/messages/rabbit.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/specific/messages/rabbit.jpg
--------------------------------------------------------------------------------
/src/media/db/theory/sharding/consistent_hashing11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/theory/sharding/consistent_hashing11.png
--------------------------------------------------------------------------------
/src/media/db/theory/sharding/consistent_hashing4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/db/theory/sharding/consistent_hashing4.png
--------------------------------------------------------------------------------
/src/media/gitLifeCycle.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/gitLifeCycle.png
--------------------------------------------------------------------------------
/src/media/gitMergeRebase.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/gitMergeRebase.jpeg
--------------------------------------------------------------------------------
/src/media/gitRebaseOnTo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/gitRebaseOnTo.png
--------------------------------------------------------------------------------
/src/media/go/go_chan.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/go_chan.png
--------------------------------------------------------------------------------
/src/media/go/go_hash.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/go_hash.png
--------------------------------------------------------------------------------
/src/media/go/nilIface.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/nilIface.png
--------------------------------------------------------------------------------
/src/media/go/scheduler_grq_lrq.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/scheduler_grq_lrq.png
--------------------------------------------------------------------------------
/src/media/go/scheduler_mpg.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/scheduler_mpg.jpeg
--------------------------------------------------------------------------------
/src/media/go/scheduler_mpg2.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/scheduler_mpg2.jpeg
--------------------------------------------------------------------------------
/src/media/go/slice-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/slice-1.png
--------------------------------------------------------------------------------
/src/media/go/slice-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/slice-2.png
--------------------------------------------------------------------------------
/src/media/go/slice-array.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/slice-array.png
--------------------------------------------------------------------------------
/src/media/go/stack_heap1.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/stack_heap1.jpeg
--------------------------------------------------------------------------------
/src/media/go/stack_heap2.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/go/stack_heap2.jpeg
--------------------------------------------------------------------------------
/src/media/image1.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image1.jpeg
--------------------------------------------------------------------------------
/src/media/image10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image10.png
--------------------------------------------------------------------------------
/src/media/image11.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image11.jpeg
--------------------------------------------------------------------------------
/src/media/image12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image12.png
--------------------------------------------------------------------------------
/src/media/image14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image14.png
--------------------------------------------------------------------------------
/src/media/image15.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image15.jpeg
--------------------------------------------------------------------------------
/src/media/image16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image16.png
--------------------------------------------------------------------------------
/src/media/image2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image2.png
--------------------------------------------------------------------------------
/src/media/image3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image3.png
--------------------------------------------------------------------------------
/src/media/image4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image4.png
--------------------------------------------------------------------------------
/src/media/image5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image5.png
--------------------------------------------------------------------------------
/src/media/image9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/image9.png
--------------------------------------------------------------------------------
/src/media/joins.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/joins.png
--------------------------------------------------------------------------------
/src/media/kolka.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/kolka.png
--------------------------------------------------------------------------------
/src/media/masterSlaveReplication.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/masterSlaveReplication.png
--------------------------------------------------------------------------------
/src/media/multiColumnIndex.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/multiColumnIndex.png
--------------------------------------------------------------------------------
/src/media/multiSortIndex.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/multiSortIndex.png
--------------------------------------------------------------------------------
/src/media/mySqlArchitecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/mySqlArchitecture.png
--------------------------------------------------------------------------------
/src/media/network/htpp_v.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/htpp_v.png
--------------------------------------------------------------------------------
/src/media/network/tcp-vs-udp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tcp-vs-udp.png
--------------------------------------------------------------------------------
/src/media/network/tcp_udp_format.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tcp_udp_format.jpeg
--------------------------------------------------------------------------------
/src/media/network/tcp_udp_stack.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tcp_udp_stack.jpeg
--------------------------------------------------------------------------------
/src/media/network/tls-handshake.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tls-handshake.png
--------------------------------------------------------------------------------
/src/media/network/tls-internet.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/network/tls-internet.png
--------------------------------------------------------------------------------
/src/media/osi-tcp-ip.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/osi-tcp-ip.png
--------------------------------------------------------------------------------
/src/media/phpCache.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/phpCache.png
--------------------------------------------------------------------------------
/src/media/redisTypes.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/redisTypes.jpg
--------------------------------------------------------------------------------
/src/media/replicationHl.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/replicationHl.jpg
--------------------------------------------------------------------------------
/src/media/replicationUpdate.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/replicationUpdate.jpg
--------------------------------------------------------------------------------
/src/media/rtree.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/arturpanteleev/backendinterview/420b8f695c0020a5aebd6cffa5fbe5242b50c4f6/src/media/rtree.png
--------------------------------------------------------------------------------
/src/network/README.md:
--------------------------------------------------------------------------------
1 | # Основы сетей
2 |
3 | Базовая информация по сетевому взаимодействию и устройству сетевых протоколов.
4 |
5 | - [OSI](osi.md)
6 | - [TCP/IP](tcp_ip.md)
7 | - [HTTP](http.md)
8 | - [TLS](tls.md)
9 | - [DNS](dns.md)
10 | - [Что происходит при нажатии на g](whatHappenWhen.md)
11 | - [Real time с веб-сервером](realTime.md)
12 |
--------------------------------------------------------------------------------
/src/network/osi.md:
--------------------------------------------------------------------------------
1 | ## Сетевые модели(стеки протоколов)
2 |
3 | ## OSI
4 |
5 | **OSI** - формальная, теоретическая сетевая модель
6 |
7 | 1. Уровень приложений: **данные**; доступ к сетевым службам, (HTTP, FTP, SMTP, RDP, SNMP, DHCP)
8 | 2. Уровень представления данных: **данные**; представление и шифрование данных (ASCII, EBCDIC)
9 | 3. Сеансовый уровень: **данные**; управление сеансом связи (RPC, PAP)
10 | 4. Транспортный уровень: **сегменты / дейтаграммы**; прямая связь между конечными пунктами и надёжность (TCP, UDP, SCTP, PORTS)
11 | 5. Сетевой уровень: **пакеты**; определение маршрута и логическая адресация (IPv4, IPv6, IPsec, AppleTalk)
12 | 6. Канальный уровень: **биты / кадры**; физическая адресация (PPP, IEEE 802.22, Ethernet, DSL, ARP, L2TP, Network Cards)
13 | 7. Физический уровень: **биты**; Работа со средой передачи, сигналами и двоичными данными (USB, кабель ("витая пара", коаксиальный, оптоволоконный), радиоканал)
14 |
15 | ### 7 — протокол прикладного уровня (Application layer)
16 |
17 | - взаимодействие сети и пользователя
18 | - уровень разрешает приложениям пользователя иметь доступ к сетевым службам, таким, как обработчик запросов к базам данных, доступ к файлам, пересылке электронной почты
19 | - отвечает за передачу служебной информации, предоставляет приложениям информацию об ошибках и формирует запросы к уровню представления
20 |
21 | ### 6 — уровень представления (Presentation layer)
22 |
23 | - передаваемая информация не меняет содержания
24 | - преобразование данных
25 | - преобразование между различными наборами символов
26 | - сжатие данных для увеличения пропускной способности канала
27 | - шифрование и расшифрование
28 |
29 | ### 5 — сеансовый уровень (Session layer)
30 |
31 | - уровень управляет созданием/завершением сеанса, обменом информацией, синхронизацией задач, определением права на передачу данных и поддержанием сеанса в периоды неактивности приложений
32 | - синхронизация передачи обеспечивается помещением в поток данных контрольных точек, начиная с которых возобновляется процесс при нарушении взаимодействия
33 |
34 | ### 4 — транспортный уровень (Transport layer)
35 |
36 | - предоставляет сам механизм передачи
37 | - блоки данных он разделяет на фрагменты, размеры которых зависят от протокола: короткие объединяет в один, а длинные разбивает
38 | - протоколы этого уровня предназначены для взаимодействия типа точка-точка
39 | - протоколы транспортного уровня часто имеют функцию контроля доставки данных, заставляя принимающую данные систему отправлять подтверждения передающей стороне о приеме данных
40 | - отвечает за восстановление порядка данных при использовании **сетевых протоколов без установки соединения**
41 |
42 | ### 3 — сетевой уровень (Network layer)
43 |
44 | - предназначается для определения пути передачи данных
45 | - трансляцию логических адресов и имён в физические
46 | - определение кратчайших маршрутов, коммутацию и маршрутизацию, отслеживание неполадок и заторов в сети
47 | - На этом уровне работает такое сетевое устройство, как маршрутизатор.
48 | - типы:
49 | 1. **Протоколы с установкой соединения** начинают передачу данных с вызова или установки маршрута следования пакетов от источника к получателю. После чего начинают последовательную передачу данных и затем по окончании передачи разрывают связь.
50 | 2. **Протоколы без установки соединения** посылают данные, содержащие полную адресную информацию в каждом пакете. Каждый пакет содержит адрес отправителя и получателя. Далее каждое промежуточное сетевое устройство считывает адресную информацию и принимает решение о маршрутизации данных. Письмо или пакет данных передается от одного промежуточного устройства к другому до тех пор, пока не будет доставлено получателю. Протоколы без установки соединения не гарантируют поступление информации получателю в том порядке, в котором она была отправлена, так как разные пакеты могут пройти разными маршрутами.
51 |
52 | ### 2 — канальный уровень (Data Link layer)
53 |
54 | - получение доступа к среде передачи
55 | - выделение границ кадра (резервирование некоторой последовательности, обозначающей начало или конец кадра)
56 | - Аппаратная адресация (или адресация канального уровня). Требуется в том случае, когда кадр могут получить сразу несколько адресатов. В локальных сетях аппаратные адреса (MAC-адреса) применяются всегда.
57 | - обеспечение достоверности принимаемых данных. Во время передачи кадра есть вероятность, что данные исказятся. Важно это обнаружить и не пытаться обработать кадр, содержащий ошибку. Обычно на канальном уровне используются алгоритмы контрольных сумм, дающие высокую гарантию обнаружения ошибок.
58 | - в программировании доступ к этому уровню предоставляет драйвер сетевой платы
59 | - на этом уровне работают коммутаторы, мосты
60 | - 2 подуровня
61 | 1. **LLC (Logical Link Control)** обеспечивает обслуживание сетевого уровня
62 | 2. **MAC (Media Access Control)** регулирует доступ к разделяемой физической среде
63 | 1. выступает в качестве интерфейса между подуровнем LLC и физическим (первым) уровнем
64 | 2. обеспечивает адресацию и механизмы управления доступом к каналам, что позволяет нескольким терминалам или точкам доступа общаться между собой в многоточечной сети
65 | 3. эмулирует полнодуплексный логический канал связи в многоточечной сети
66 |
67 | ### 1 — физический слой (physical layer)
68 |
69 | - физическая и электрическая среда для передачи данных
70 | - способы передачи бит через физические среды линий связи, соединяющие сетевые устройства
71 | - описываются параметры сигналов, такие как амплитуда, частота, фаза, используемая модуляция, манипуляция
72 | - решаются вопросы связанные с синхронизацией, избавлением от помех, скорости передачи данных
73 |
74 | ## OSI vs TCP/IP
75 |
76 | 
77 |
78 |
--------------------------------------------------------------------------------
/src/network/realTime.md:
--------------------------------------------------------------------------------
1 | # COMET
2 |
3 | COMET – общий термин, описывающий различные техники получения данных по инициативе сервера. Можно сказать, что AJAX – это «отправил запрос – получил результат», а COMET – это «непрерывный канал, по которому приходят данные».
4 |
5 | Примеры COMET-приложений:
6 |
7 | - Чат – человек сидит и смотрит, что пишут другие. При этом новые сообщения приходят «сами по себе», он не должен нажимать на кнопку для обновления окна чата.
8 | - Аукцион – человек смотрит на экран и видит, как обновляется текущая ставка за товар.
9 | - Интерфейс редактирования – когда один редактор начинает изменять документ, другие видят информацию об этом. Возможно и совместное редактирование, когда редакторы видят изменения друг друга.
10 |
11 | Ниже рассмотрены разные варианты реализации.
12 |
13 | ## Частые опросы
14 |
15 | Первое решение, которое приходит в голову для непрерывного получения событий с сервера – это «частые опросы» (polling), т.е периодические запросы на сервер: «эй, я тут, изменилось ли что-нибудь?». Например, раз в 10 секунд.
16 |
17 | В ответ сервер, во-первых, помечает у себя, что клиент онлайн, а во-вторых посылает сообщение, в котором в специальном формате содержится весь пакет событий, накопившихся к данному моменту.
18 |
19 | При этом, однако, возможна задержка между появлением и получением данных, как раз в размере этих 10 секунд между запросами.
20 |
21 | Другой минус – лишний входящий трафик на сервер. При каждом запросе браузер передает множество заголовков и в ответ получает, кроме данных, также заголовки. Для некоторых приложений трафик заголовков может в 10 и более раз превосходить трафик реальных данных.
22 |
23 | ## Длинные опросы
24 |
25 | Длинные опросы – отличная альтернатива частым опросам. Они также удобны в реализации, и при этом сообщения доставляются без задержек.
26 |
27 | Схема:
28 |
29 | 1. Отправляется запрос на сервер.
30 | 2. Соединение не закрывается сервером, пока не появится сообщение.
31 | 3. Когда сообщение появилось – сервер отвечает на запрос, пересылая данные.
32 | 4. Браузер тут же делает новый запрос.
33 |
34 | Ситуация, когда браузер отправил запрос и держит соединение с сервером, ожидая ответа, является стандартной и прерывается только доставкой сообщений.
35 |
36 | Схема коммуникации:
37 |
38 | 
39 |
40 | При этом если соединение рвётся само, например, из-за ошибки в сети, то браузер тут же отсылает новый запрос.
41 |
42 | ## WebSocket
43 |
44 | Протокол связи поверх [TCP](https://ru.wikipedia.org/wiki/TCP)-соединения, предназначенный для асинхронного обмена сообщениями между браузером и веб-сервером в режиме реального времени.
45 |
46 | Протокол `WebSocket` работает *над* TCP. Это означает, что при соединении браузер отправляет по HTTP специальные заголовки, спрашивая: «поддерживает ли сервер WebSocket?». Если сервер в ответных заголовках отвечает «да, поддерживаю», то дальше HTTP прекращается и общение идёт на специальном протоколе WebSocket, который уже не имеет с HTTP ничего общего.
47 |
48 | ## Server Sent Events
49 |
50 | Современный стандарт [Server-Sent Events](https://html.spec.whatwg.org/multipage/comms.html#the-eventsource-interface) позволяет браузеру создавать специальный объект `EventSource`, который сам обеспечивает соединение с сервером, делает пересоединение в случае обрыва и генерирует события при поступлении данных.
51 |
52 | Он, по дизайну, может меньше, чем WebSocket’ы. С другой стороны, Server Side Events проще в реализации, работают по обычному протоколу HTTP и сразу поддерживают ряд возможностей, которые для WebSocket ещё надо реализовать. Поэтому в тех случаях, когда нужна преимущественно односторонняя передача данных от сервера к браузеру, они могут быть удачным выбором.
--------------------------------------------------------------------------------
/src/network/tcp_ip.md:
--------------------------------------------------------------------------------
1 | # TCP/IP
2 |
3 | Протокол **TCP/IP** - это набор сетевых протоколов, используемых для обмена данными в компьютерных сетях. **TCP/IP** — сетевая модель выведенная из практического использования(в отличии от OSI).
4 |
5 | 
6 |
7 | ## Network Interface Layer(канальные)
8 |
9 | Этот уровень отвечает за передачу данных через физическую сеть, такую как Ethernet или Wi-Fi. Он определяет способы кодирования, физические характеристики кабелей, методы доступа и другие аспекты, связанные с конкретной технологией передачи данных.
10 |
11 | - канальный уровень описывает среду передачи данных
12 | - описывает способ кодирования данных для передачи пакета данных на физическом уровне
13 | - канальный уровень иногда разделяют на 2 подуровня — LLC и MAC
14 | - на канальном уровне рассматривают помехоустойчивое кодирование — позволяющие обнаруживать и исправлять ошибки в данных вследствие воздействия шумов и помех на канал связи
15 |
16 | ## Internet Layer(межсетевой)
17 |
18 | Этот уровень обеспечивает маршрутизацию пакетов данных через различные сети. Он использует IP-адресацию для определения и доставки пакетов данных между узлами сети. Протокол IP (Internet Protocol) является ключевым протоколом этого уровня. Он также обрабатывает фрагментацию и сборку пакетов данных при передаче через сети с различными максимальными размерами пакетов.
19 |
20 | - изначально разработан для передачи данных из одной сети в другую
21 | - на этом уровне работают маршрутизаторы, которые перенаправляют пакеты в нужную сеть путем расчета адреса сети по маске сети
22 | - пакеты сетевого протокола IP могут содержать код, указывающий, какой именно протокол следующего уровня нужно использовать, чтобы извлечь данные из пакета. Это число — уникальный IP-номер протокола. ICMP и IGMP имеют номера, соответственно, 1 и 2
23 | - протоколы: DVMRP, ICMP, IGMP, MARS, PIM, RIP, RIP2, RSVP
24 |
25 | ## Transport Layer(транспортный)
26 |
27 | Этот уровень обеспечивает надежную доставку данных между хостами. В стеке TCP/IP транспортные протоколы определяют, для какого именно приложения предназначены эти данные. Два наиболее распространенных протокола на этом уровне - это TCP (Transmission Control Protocol) и UDP (User Datagram Protocol).
28 |
29 | ## Application Layer(прикладной)
30 |
31 | Этот уровень содержит различные протоколы, используемые приложениями для обмена данными. Некоторые из наиболее известных протоколов этого уровня включают HTTP (HyperText Transfer Protocol) для передачи веб-страниц, SMTP (Simple Mail Transfer Protocol) для отправки электронной почты, FTP (File Transfer Protocol) для передачи файлов и DNS (Domain Name System) для разрешения имен хостов в IP-адреса.
32 |
33 | - протоколы работают поверх **TCP** или **UDP** и привязаны к определённому порту
34 | - порты определены Агентством по выделению имен и уникальных параметров протоколов
35 | - протоколы: Echo, Finger, Gopher, HTTP, HTTPS, IMAP, IMAPS, IRC, NNTP, NTP, POP3, POPS, QOTD, RTSP, SNMP, SSH, Telnet, XDMCP.
36 |
37 | ## TCP/UDP
38 |
39 | Основные отличия **tcp** от **udp**.
40 |
41 | - `TCP гарантирует доставку пакетов данных в неизменных виде, последовательности и без потерь, UDP ничего не гарантирует.`
42 | - `TCP нумерует пакеты при передаче, а UDP нет`
43 | - `TCP работает в дуплексном режиме, в одном пакете можно отправлять информацию и подтверждать получение предыдущего пакета.`
44 | - `TCP требует заранее установленного соединения, UDP соединения не требует, у него это просто поток данных.`
45 | - `UDP обеспечивает более высокую скорость передачи данных.`
46 | - `TCP надежнее и осуществляет контроль над процессом обмена данными.`
47 | - `UDP предпочтительнее для программ, воспроизводящих потоковое видео, видеофонии и телефонии, сетевых игр.`
48 | - `UPD не содержит функций восстановления данных`
49 |
50 | Чтобы увидеть отличия, нужно посмотреть внутрь TCP- и UDP-пакета.
51 |
52 | 
53 |
54 | И там, и там есть порты. Но **в UDP есть только контрольная сумма** — длина пакета, этот протокол максимально простой. А
55 | в TCP — очень много данных, которые явно указывают окно, acknowledgement, sequence, пакеты и так далее. Очевидно, **TCP
56 | более сложный**. Если говорить очень грубо, то TCP — это протокол надежной доставки, а UDP — ненадежной.
57 |
58 | *Дополнительно*:
59 |
60 | - [Протокол TCP](https://networkguru.ru/protokol-transportnogo-urovnia-tcp-chto-nuzhno-znat/)
61 | - [TCP против UDP](https://habr.com/ru/company/oleg-bunin/blog/461829/)
62 |
63 |
--------------------------------------------------------------------------------
/src/network/tls.md:
--------------------------------------------------------------------------------
1 | ## TLS
2 |
3 | SSL и TLS представляют собой развитие одной и той же технологии. Аббревиатура TLS (Transport Layer Security) появилась в качестве замены обозначения SSL (Secure Sockets Layer) после того, как протокол окончательно стал интернет-стандартом. Такая замена вызвана юридическими аспектами, так как спецификация SSL изначально принадлежала компании Netscape. И сейчас нередко названия SSL и TLS продолжают использовать в качестве синонимов, но каноническим именем является TLS, а протоколы семейства SSL окончательно устарели и не должны использоваться.
4 |
5 |
6 |
7 | Конкретное место TLS (SSL) в стеке протоколов Интернета показано на схеме:
8 |
9 | 
10 |
11 | ##### **TLS Handshake**
12 |
13 | 
14 |
15 | Основные шаги процедуры создания защищённого сеанса связи:
16 |
17 | - клиент подключается к серверу, поддерживающему TLS, и запрашивает защищённое соединение;
18 | - клиент предоставляет список поддерживаемых [алгоритмов шифрования](https://ru.wikipedia.org/wiki/Шифрование) и [хеш-функций](https://ru.wikipedia.org/wiki/Хеширование);
19 | - сервер выбирает из списка, предоставленного клиентом, наиболее надёжные алгоритмы среди тех, которые поддерживаются сервером, и сообщает о своём выборе клиенту;
20 | - сервер отправляет клиенту цифровой сертификат для собственной аутентификации. Обычно цифровой сертификат содержит имя сервера, имя удостоверяющего центра сертификации и открытый ключ сервера;
21 | - клиент, до начала передачи данных, проверяет валидность (аутентичность) полученного серверного сертификата относительно имеющихся у клиента корневых сертификатов удостоверяющих центров (центров сертификации). Клиент также может проверить, не отозван ли серверный сертификат, связавшись с сервисом доверенного удостоверяющего центра;
22 | - для шифрования сессии используется [сеансовый ключ](https://ru.wikipedia.org/wiki/Сеансовый_ключ). Получение общего секретного сеансового ключа клиентом и сервером проводится по протоколу Диффи-Хеллмана. Существует исторический метод передачи сгенерированного клиентом секрета на сервер при помощи шифрования асимметричной криптосистемой RSA (используется ключ из сертификата сервера). Данный метод не рекомендован, но иногда продолжает встречаться на практике.
23 |
24 | На этом заканчивается процедура подтверждения связи. Между клиентом и сервером установлено безопасное соединение, данные, передаваемые по нему, шифруются и расшифровываются с использованием симметричной криптосистемы до тех пор, пока соединение не будет завершено.
25 |
26 |
27 |
28 | *Дополнительно:*
29 |
30 | - [TLS — Википедия](https://ru.wikipedia.org/wiki/TLS)
31 | - [Что такое TSL](https://habr.com/ru/post/258285/)
32 | - [Ключи, шифры, сообщения: как работает TLS](https://tls.dxdt.ru/tls.html)
33 | - [Руководство по выживанию — TLS/SSL и сертификаты SSL](https://www.opennet.ru/docs/RUS/ldap_apacheds/tech/ssl.html)
--------------------------------------------------------------------------------
/src/php/README.md:
--------------------------------------------------------------------------------
1 | # PHP
2 |
3 | **PHP** (PHP: Hypertext Preprocessor; первоначально Personal Home Page Tools) — скриптовый язык общего назначения, интенсивно применяемый для разработки веб-приложений. Является одним из лидеров среди языков, применяющихся для создания динамических веб-сайтов.
4 |
5 | - [Фичи новых версий](innovations.md)
6 | - [PHP Internals](internals.md)
7 | - [Взаимодействие с сервером](serverIteractions.md)
8 | - [Фреймворки](frameworks/README.md)
9 | - [Разное](uncategorized.md)
10 |
11 |
--------------------------------------------------------------------------------
/src/php/frameworks/README.md:
--------------------------------------------------------------------------------
1 | # Frameworks
2 |
3 | В этом разделе собрана разная фреймворкоспецифичная информация(Symfony и Laravel).
4 |
5 | - [Laravel](laravel.md)
6 | - [Symfony](symfony.md)
--------------------------------------------------------------------------------
/src/php/frameworks/laravel.md:
--------------------------------------------------------------------------------
1 | # Laravel
2 |
3 | Laravel — бесплатный веб-фреймворк с открытым кодом, предназначенный для **разработки** с использованием архитектурной модели MVC (англ. Model View Controller — модель-представление-контроллер). Laravel выпущен под лицензией MIT.
4 |
5 | Ключевые особенности, лежащие в основе архитектуры Laravel:
6 |
7 | - *Пакеты* (packages) — позволяют создавать и подключать модули в формате [Composer](https://ru.wikipedia.org/wiki/Composer) к приложению на Laravel. Многие дополнительные возможности уже доступны в виде таких модулей.
8 | - *Eloquent ORM* — реализация [шаблона проектирования](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D0%B1%D0%BB%D0%BE%D0%BD_%D0%BF%D1%80%D0%BE%D0%B5%D0%BA%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F) [ActiveRecord](https://ru.wikipedia.org/wiki/ActiveRecord) на PHP. Позволяет строго определить отношения между объектами [базы данных](https://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B7%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85). Стандартный для Laravel построитель запросов Fluent поддерживается ядром Eloquent.
9 | - *Логика приложения* — часть разрабатываемого приложения, объявленная либо при помощи контроллеров, либо маршрутов ([функций-замыканий](https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%BC%D1%8B%D0%BA%D0%B0%D0%BD%D0%B8%D0%B5_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5))). Синтаксис объявлений похож на синтаксис, используемый в [каркасе](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%BD%D1%8B%D0%B9_%D0%BA%D0%B0%D1%80%D0%BA%D0%B0%D1%81) [Sinatra](https://ru.wikipedia.org/wiki/Sinatra).
10 | - *Обратная маршрутизация* связывает между собой генерируемые приложением ссылки и маршруты, позволяя изменять последние с автоматическим обновлением связанных ссылок. При создании ссылок с помощью именованных маршрутов Laravel автоматически генерирует конечные URL.
11 | - *REST-контроллеры* — дополнительный слой для разделения логики обработки GET- и POST-запросов HTTP.
12 | - *Автозагрузка классов* — механизм автоматической загрузки классов [PHP](https://ru.wikipedia.org/wiki/PHP) без необходимости подключать файлы их определений в *include*. Загрузка по требованию предотвращает загрузку ненужных компонентов; загружаются только те из них, которые действительно используются.
13 | - *Составители представлений* (view composers) — блоки кода, которые выполняются при генерации представления (шаблона).
14 | - *Инверсия управления* (Inversion of Control) — позволяет получать экземпляры объектов по принципу обратного управления. Также может использоваться для создания и получения [объектов-одиночек](https://ru.wikipedia.org/wiki/Singleton) ([англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) singleton).
15 | - *Миграции* — система управления версиями для баз данных. Позволяет связывать изменения в коде приложения с изменениями, которые требуется внести в структуру БД, что упрощает развёртывание и обновление приложения.
16 | - *Модульное тестирование* (*юнит-тесты*) — играет очень большую роль в Laravel, который сам по себе содержит большое число тестов для предотвращения [регрессий](https://ru.wikipedia.org/wiki/%D0%A0%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) (ошибок вследствие обновления кода или исправления других ошибок).
17 | - *Страничный вывод* (pagination) — упрощает генерацию страниц, заменяя различные способы решения этой задачи единым механизмом, встроенным в Laravel.
18 |
19 |
--------------------------------------------------------------------------------
/src/php/frameworks/symfony.md:
--------------------------------------------------------------------------------
1 | # Symfony
2 |
3 | ## Compiler Pass
4 |
5 | На этапе компиляции контейнер выполняет серию проходов для приведения своего содержимого в конечное состояние. Проходы являются реализацией интерфейса CompilerPassInterface и бывают 6 видов (в порядке исполнения):
6 |
7 | merge, beforeOptimization, optimization, beforeRemoving, removing, afterRemoving — по умолчанию конфигурация компилятора уже содержит набор проходов.
8 |
9 | - *before/after* — лишь «хуки» для пользовательских «проходов» и не используются стандартными (добавленными по умолчанию);
10 | - *merge* — обрабатывает *расширения (extensions)* контейнера;
11 | - *optimization* — оптимизируют контейнер, примерами могут служить: ResolveInterfaceInjectorsPass (преобразует [интерфейсные инъекции](http://martinfowler.com/articles/injection.html#InterfaceInjection)), CheckCircularReferencesPass (проверяет циклические ссылки в контейнере)
12 | - *removing* — удаляют неиспользуемые сервисы, например, RemoveUnusedDefinitionsPass (удаляет неиспользуемые приватные сервисы)
13 |
14 | В бандлах CompilerPass чаще всего используется для обработки тегов в контейнере
15 |
16 | Пример из стандартного TwigBundle:
17 |
18 | ```php
19 | $definition = $container->getDefinition('twig');
20 | $calls = $definition->getMethodCalls();
21 | $definition->setMethodCalls(array());
22 | foreach ($container->findTaggedServiceIds('twig.extension') as $id => $attributes) {
23 | $definition->addMethodCall('addExtension', array(new Reference($id)));
24 | }
25 | $definition->setMethodCalls(array_merge($definition->getMethodCalls(), $calls));
26 | ```
27 |
28 |
--------------------------------------------------------------------------------
/src/php/innovations.md:
--------------------------------------------------------------------------------
1 | ## Основные нововведения php
2 |
3 | ### [7.0](http://www.php.net/ChangeLog-7.php#7.0.0)
4 |
5 | 1. возможность обработки исключения, вместо фатальной ошибки
6 | 2. новые операторы сравнения ( <=>, ?? и другие)
7 | 3. анонимные классы
8 | 4. указание типа возвращаемого значения (return type declaration)
9 | 5. группировка для оператора use
10 | 6. работа с замыканиями (closure)
11 | 7. скалярные типы аргументов функции (scalar type hints)
12 | 8. опционально доступный "строгий режим" работы с типами (strict mode)
13 | 9. изменена трактовка переменных и выражений
14 | 10. улучшена работа с генераторами (ключевое слово yield from и другие изменения)
15 | 11. конструктор класса в стиле php4 (когда имя класса совпадает с именем метод) теперь генерирует E_DEPRECATED и будет удален в php8
16 | 12. изменено поведение побитовых операторов <<, >> и других
17 | 13. изменено поведение функций func_get_args и func_get_arg
18 | 14. функция языка unserialize принимает дополнительный аргумент
19 | 15. функция языка list изменила поведение
20 | 16. изменено поведение цикла foreach (например в работе с внутренним итератором)
21 | 17. новый синтаксис unicode последовательностей
22 |
23 | ## [7.1](http://php.net/ChangeLog-7.php#7.1.0)
24 |
25 | 1. возвращаемый тип void
26 | 2. псевдотип iterable
27 | 3. null в типизированных и возвращаемых параметрах
28 | 4. возможность использовать отрицательное значение для смещения в строках
29 | 5. разрешено использовать строковые ключи в конструкци
30 | 6. конвертация callable выражений в замыкание
31 | 7. Поддержка модификаторов видимости для констант класса
32 | 8. Ловить исключения можно объединяя несколько типов исключений в один блок
33 |
34 | ## [7.2](http://php.net/ChangeLog-7.php#7.2.0)
35 |
36 | 1. Добавлена возможность загружать расширения по имени
37 | 2. Добавлена возможность перегружать абстрактные функции(Liskov)
38 | 3. Запрещено number_format() возвращать -0
39 | 4. Добавлена возможность конвертировать нумерованные ключи при приведении типов object/array
40 | 5. Запрещено передавать null в качестве параметра для get_class()
41 | 6. Вызов Count с параметром, который нельзя посчитать
42 | 7. Возможность расширения типа параметра
43 | 8. Добавлена возможность указывать запятую в конце группированных неймспейсов
44 | 9. Реализовано семейство функций socket_getaddrinfo
45 | 10. Улучшены TLS-константы
46 | 11. Object typehint
47 | 12. LDAP EXOP
48 | 13. В ядро PHP добавлена Libsodium
49 | 14. Добавлен алгоритм Argon2 в хешировании пароля
50 | 15. HashContext as Object
51 | 16. Добавлен отладчик PDO Prepared statements
52 | 17. Добавлен отладчик PDO Prepared statements v2
53 | 18. Расширенные типы строк для PDO
54 | 19. Добавлены опции JSON_INVALID_UTF8_IGNORE и JSON_INVALID_UTF8_SUBSTITUTE
55 |
56 | ### [7.3](http://www.php.net/ChangeLog-7.php#7.3.0)
57 |
58 | 1. Смягчение требований к синтаксису Heredoc и Nowdoc
59 | 2. Поддержка конечных запятых в вызовах функций и методов
60 | 3. Ссылки в `list()`
61 | 4. Функция `image2wbmp()` объявлена устаревшей
62 | 5. Флаги `FILTER_FLAG_SCHEME_REQUIRED` и `FILTER_FLAG_HOST_REQUIRED` при использовании `FILTER_VALIDATE_URL` объявлены устаревшими
63 | 6. Регистро-независимые константы объявлены устаревшими
64 | 7. Опциональный выброс исключений при ошибках в функциях `json_encode` и `json_decode`
65 | 8. Добавление функции `is_countable()`
66 | 9. Добавление функций `array_key_first()` и `array_key_last()`
67 |
68 | ### 7.4
69 |
70 | - Типизированные свойства классов
71 | - Предзагрузка для улучшения производительности
72 | - Стрелочные функции для короткой записи анонимных функций
73 | - Присваивающий оператор объединения с null (??=)
74 | - Ковариантность/контравариантность в сигнатурах унаследованных методов
75 | - Интерфейс внешних функций, открывающий новые возможности для разработки расширений на PHP
76 | - Оператор распаковки в массивах
77 |
78 | ### [8](https://www.php.net/releases/8.0)
79 |
80 | 1. Именованные аргументы
81 | 2. Атрибуты
82 | 3. Объявление свойств в конструкторе
83 | 4. Union types
84 | 5. Выражение Match
85 | 6. Оператор Nullsafe
86 | 7. Улучшенное сравнение строк и чисел
87 | 8. Ошибки согласованности типов для встроенных функций
88 |
89 | ### 8.1
90 |
91 | - [Intersection Types](https://php.watch/versions/8.1/intersection-types)
92 | - [Enums](https://php.watch/versions/8.1/enums)
93 | - [`never` return type](https://php.watch/versions/8.1/never-return-type)
94 | - [Readonly Properties](https://php.watch/versions/8.1/readonly)
95 | - [Fibers](https://php.watch/versions/8.1/fibers)
96 | - [`final` class constants](https://php.watch/versions/8.1/final-class-const)
97 | - [New `fsync` and `fdatasync` functions](https://php.watch/versions/8.1/fsync-fdatasync)
98 | - [New `array_is_list` function](https://php.watch/versions/8.1/array_is_list)
99 | - [New Sodium `XChaCha20` functions](https://php.watch/versions/8.1/Sodium-XChaCha20-functions)
100 | - [`$_FILES`: New `full_path` value for directory-uploads](https://php.watch/versions/8.1/$_FILES-full-path)
101 | - [Intl: New `IntlDatePatternGenerator` class](https://php.watch/versions/8.1/IntlDatePatternGenerator)
102 | - [First-class Callable Syntax](https://php.watch/versions/8.1/first-class-callable-syntax)
103 | - [GD: AVIF image support](https://php.watch/versions/8.1/gd-avif)
104 | - [Phar: Added OpenSSL-256 and OpenSSL-512 signature algorithms](https://php.watch/versions/8.1/phar-openssl-256-openssl-512)
105 | - [GD: Lossless WebP encoding support](https://php.watch/versions/8.1/gd-webp-lossless)
106 | - [New `#[ReturnTypeWillChange\]` attribute](https://php.watch/versions/8.1/ReturnTypeWillChange)
107 | - [Array unpacking support for string-keyed arrays](https://php.watch/versions/8.1/spread-operator-string-array-keys)
108 | - [Explicit Octal numeral notation](https://php.watch/versions/8.1/explicit-octal-notation)
109 | - [Hash functions accept algorithm-specific `$options`](https://php.watch/versions/8.1/hash-options)
110 | - [MurmurHash3 hash algorithm support](https://php.watch/versions/8.1/MurmurHash3)
111 | - [xxHash hash algorithms support](https://php.watch/versions/8.1/xxHash)
112 | - [FPM: Configurable child-process spawn rate](https://php.watch/versions/8.1/fpm-pm-max_spawn_rate)
113 | - [Curl: DNS-over-HTTPS support](https://php.watch/versions/8.1/Curl-CURLOPT_DOH_URL)
114 | - [Curl: File uploads from strings with `CURLStringFile`](https://php.watch/versions/8.1/CURLStringFile)
115 | - [MySQLi: New `MYSQLI_REFRESH_REPLICA` constant](https://php.watch/versions/8.1/MYSQLI_REFRESH_REPLICA)
--------------------------------------------------------------------------------
/src/styles/website.css:
--------------------------------------------------------------------------------
1 | .book .book-summary ul.summary li a, .book .book-summary ul.summary li span {
2 | padding: 2px 5px;
3 | font-size: 0.85em;
4 | }
5 | .book .book-summary ul.summary li i.fa-check {
6 | right: 5px;
7 | top: 7px;
8 | }
9 |
10 | .markdown-section img {
11 | display: block;
12 | margin: 0 auto;
13 | }
--------------------------------------------------------------------------------
/src/unsorted/README.md:
--------------------------------------------------------------------------------
1 | # Неотсортированные темы
2 |
3 | Здесь будет различная инфа, которую сложно(на данный момент) отнести к какому-либо разделу книги.
4 |
5 | - [Побитовые операции](bits.md)
6 | - [Юникод](unicode.md)
7 | - [Типизация](types.md)
8 |
9 |
10 |
--------------------------------------------------------------------------------
/src/unsorted/bits.md:
--------------------------------------------------------------------------------
1 | # Побитовые операторы
2 |
3 | Побитовые операторы интерпретируют операнды как последовательность из 32 битов (нулей и единиц). Они производят операции, используя двоичное представление числа, и возвращают новую последовательность из 32 бит (число) в качестве результата.
4 |
5 | ## Формат 32-битного целого числа со знаком
6 | Что такое двоичная система счисления, вам, надеюсь, уже известно. При разборе побитовых операций мы будем обсуждать именно двоичное представление чисел, из 32 бит.
7 |
8 | Старший бит слева – это научное название для самого обычного порядка записи цифр (от большего разряда к меньшему). При этом, если больший разряд отсутствует, то соответствующий бит равен нулю.
9 |
10 | Примеры представления чисел в двоичной системе:
11 | ```
12 | a = 0; // 00000000000000000000000000000000
13 | a = 1; // 00000000000000000000000000000001
14 | a = 2; // 00000000000000000000000000000010
15 | a = 3; // 00000000000000000000000000000011
16 | a = 255;// 00000000000000000000000011111111
17 | ```
18 | Обратите внимание, каждое число состоит ровно из 32-битов.
19 |
20 | Дополнение до двойки – это название способа поддержки отрицательных чисел.
21 |
22 | Двоичный вид числа, обратного данному (например, 5 и -5) получается путём обращения всех битов с прибавлением 1.
23 |
24 | То есть, нули заменяются на единицы, единицы – на нули и к числу прибавляется 1. Получается внутреннее представление того же числа, но со знаком минус.
25 |
26 | Например, вот число 314:
27 |
28 | ```00000000000000000000000100111010```
29 |
30 | Чтобы получить -314, первый шаг – обратить биты числа: заменить 0 на 1, а 1 на 0:
31 |
32 | ```11111111111111111111111011000101```
33 |
34 | Второй шаг – к полученному двоичному числу прибавить единицу, обычным двоичным сложением: 11111111111111111111111011000101 + 1 = 11111111111111111111111011000110.
35 |
36 | Итак, мы получили:
37 |
38 | ```-314 = 11111111111111111111111011000110```
39 |
40 | Принцип дополнения до двойки делит все двоичные представления на два множества: если крайний-левый бит равен 0 – число положительное, если 1 – число отрицательное. Поэтому этот бит называется знаковым битом.
41 |
42 |
43 | *Дополнительно:*
44 | - [Основы JavaScript Побитовые операторы](https://learn.javascript.ru/bitwise-operators)
45 | - [Побитовые операторы](http://php.net/manual/ru/language.operators.bitwise.php)
46 |
--------------------------------------------------------------------------------
/src/unsorted/types.md:
--------------------------------------------------------------------------------
1 | # Типизация
2 |
3 | Языки программирования по типизации принято делить на два больших лагеря **типизированные** и **нетипизированные(бестиповые)**. К первому например относятся C, Python, Scala, PHP и Lua, а ко второму — язык ассемблера, Forth и Brainfuck.
4 |
5 | Так как «бестиповая типизация» по своей сути — проста как пробка, дальше она ни на какие другие виды не делится. А вот типизированные языки разделяются еще на несколько пересекающихся категорий:
6 |
7 | ***Статическая* / *динамическая*** типизация. Статическая определяется тем, что конечные типы переменных и функций устанавливаются на этапе компиляции. Т.е. уже компилятор на 100% уверен, какой тип где находится. В динамической типизации все типы выясняются уже во время выполнения программы.
8 |
9 | Примеры:
10 | Статическая: C, Java, C#;
11 | Динамическая: Python, JavaScript, Ruby.
12 |
13 | ***Сильная* / *слабая*** типизация (также иногда говорят строгая / нестрогая). Сильная типизация выделяется тем, что язык не позволяет смешивать в выражениях различные типы и не выполняет автоматические неявные преобразования, например нельзя вычесть из строки множество. Языки со слабой типизацией выполняют множество неявных преобразований автоматически, даже если может произойти потеря точности или преобразование неоднозначно.
14 |
15 | Примеры:
16 | Сильная: Java, Python, Haskell, Lisp;
17 | Слабая: C, JavaScript, Visual Basic, PHP.
18 |
19 | ***Явная* / *неявная*** типизация. Явно-типизированные языки отличаются тем, что тип новых переменных / функций / их аргументов нужно задавать явно. Соответственно языки с неявной типизацией перекладывают эту задачу на компилятор / интерпретатор.
20 |
21 | Примеры:
22 | Явная: C++, D, C#
23 | Неявная: PHP, Lua, JavaScript
24 |
25 | Также нужно заметить, что все эти категории пересекаются, например язык C имеет статическую слабую явную типизацию, а язык Python — динамическую сильную неявную.
26 |
27 |
28 |
29 | ***Номинативная/Структурная*** типизация. Номинативная, следит за названиями типов, структурная типизация принимает решение о совместимости типов на основе их содержимого. Т.е если тип А содержит все свойства/методы типа б, то он может быть использован как тип Б.
--------------------------------------------------------------------------------
/src/unsorted/unicode.md:
--------------------------------------------------------------------------------
1 | # О Юникоде
2 |
3 | До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
4 |
5 | - Всего 255 символов, да и то часть из них не графические;
6 | - Возможность открыть документ не с той кодировкой, в которой он был создан;
7 | - Шрифты необходимо создавать для каждой кодировки.
8 |
9 | Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
10 |
11 | ## О UTF-8
12 |
13 | Когда-то я думал что есть Юникод, а есть UTF-8. Позже я узнал, что ошибался.
14 |
15 | UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
16 |
17 | ```
18 | 0 — 127: 0xxxxxxx
19 | 128 — 2047: 110xxxxx 10xxxxxx
20 | 2048 — 65535: 1110xxxx 10xxxxxx 10xxxxxx
21 | 655356 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
22 | ```
23 |
24 | ## Кодируем в UTF-8
25 |
26 | Порядок действий примерно такой:
27 |
28 | - Каждый символ превращаем в Юникод.
29 | - Проверяем из какого символ диапазона.
30 | - Если код символа меньше 128, то к результату добавляем его в неизменном виде.
31 | - Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
32 | - Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
33 |
34 | ## UTF-32
35 |
36 | UTF-32 — способ представления Юникода, при котором каждый символ занимает ровно 4 байта. Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод в ней непосредственно индексируемы, поэтому найти символ по номеру его позиции в файле можно чрезвычайно быстро, и получение любого символа *n*-й позиции при этом является операцией, занимающей всегда одинаковое время. Это также делает замену символов в строках UTF-32 очень простой. Напротив, кодировки с переменной длиной требуют последовательного доступа к символу *n*-й позиции, что может быть очень затратной по времени операцией. Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения любого символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства, редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства, зачастую не оправдано.
--------------------------------------------------------------------------------