├── .gitignore
├── .streamlit
├── config.toml
└── secrets.toml
├── .telemetry
├── LICENSE
├── README.md
├── conf
├── README.md
├── base
│ ├── catalog.yml
│ ├── logging.yml
│ └── parameters.yml
└── local
│ ├── .gitkeep
│ └── credentials.yml
├── data
├── crypto_candles_data.csv
├── dot_crypto_features_data.csv
├── dot_pipeline.json
├── dot_predictions.csv
├── ltc_crypto_features_data.csv
├── ltc_pipeline.json
├── ltc_predictions.csv
├── sol_crypto_features_data.csv
├── sol_pipeline.json
├── sol_predictions.csv
├── uni_crypto_features_data.csv
├── uni_pipeline.json
└── uni_predictions.csv
├── images
├── a12i_logo.png
├── kedro_viz.png
└── screenshots.png
├── kedro_run.cmd
├── kedro_viz.cmd
├── kedro_viz.sh
├── logs
└── .gitkeep
├── pyproject.toml
├── run.cmd
└── src
├── crypto_fc
├── __init__.py
├── __main__.py
├── constants.py
├── data.py
├── nodes.py
├── pipeline.py
├── pipeline_registry.py
└── settings.py
├── requirements.txt
├── setup.py
├── st_functions.py
├── streamlit_app.py
├── streamlit_debug.py
└── style.css
/.gitignore:
--------------------------------------------------------------------------------
1 | playground.ipynb
2 | .vscode
3 |
4 | # Byte-compiled / optimized / DLL files
5 | __pycache__/
6 | *.py[cod]
7 | *$py.class
8 |
9 | # C extensions
10 | *.so
11 |
12 | # Distribution / packaging
13 | .Python
14 | build/
15 | develop-eggs/
16 | dist/
17 | downloads/
18 | eggs/
19 | .eggs/
20 | lib/
21 | lib64/
22 | parts/
23 | sdist/
24 | var/
25 | wheels/
26 | pip-wheel-metadata/
27 | share/python-wheels/
28 | *.egg-info/
29 | .installed.cfg
30 | *.egg
31 | MANIFEST
32 |
33 | # PyInstaller
34 | # Usually these files are written by a python script from a template
35 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
36 | *.manifest
37 | *.spec
38 |
39 | # Installer logs
40 | pip-log.txt
41 | pip-delete-this-directory.txt
42 |
43 | # Unit test / coverage reports
44 | htmlcov/
45 | .tox/
46 | .nox/
47 | .coverage
48 | .coverage.*
49 | .cache
50 | nosetests.xml
51 | coverage.xml
52 | *.cover
53 | *.py,cover
54 | .hypothesis/
55 | .pytest_cache/
56 |
57 | # Translations
58 | *.mo
59 | *.pot
60 |
61 | # Django stuff:
62 | *.log
63 | local_settings.py
64 | db.sqlite3
65 | db.sqlite3-journal
66 |
67 | # Flask stuff:
68 | instance/
69 | .webassets-cache
70 |
71 | # Scrapy stuff:
72 | .scrapy
73 |
74 | # Sphinx documentation
75 | docs/_build/
76 |
77 | # PyBuilder
78 | target/
79 |
80 | # Jupyter Notebook
81 | .ipynb_checkpoints
82 |
83 | # IPython
84 | profile_default/
85 | ipython_config.py
86 |
87 | # pyenv
88 | .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
98 | __pypackages__/
99 |
100 | # Celery stuff
101 | celerybeat-schedule
102 | celerybeat.pid
103 |
104 | # SageMath parsed files
105 | *.sage.py
106 |
107 | # Environments
108 | .env
109 | .venv
110 | env/
111 | venv/
112 | ENV/
113 | env.bak/
114 | venv.bak/
115 |
116 | # Spyder project settings
117 | .spyderproject
118 | .spyproject
119 |
120 | # Rope project settings
121 | .ropeproject
122 |
123 | # mkdocs documentation
124 | /site
125 |
126 | # mypy
127 | .mypy_cache/
128 | .dmypy.json
129 | dmypy.json
130 |
131 | # Pyre type checker
132 | .pyre/
133 |
--------------------------------------------------------------------------------
/.streamlit/config.toml:
--------------------------------------------------------------------------------
1 | [theme]
2 | base = "light"
3 | font = "sans serif"
4 |
--------------------------------------------------------------------------------
/.streamlit/secrets.toml:
--------------------------------------------------------------------------------
1 | OS = 'windows' # 'unix', 'windows'
2 | IS_ST_CLOUD = false
3 |
--------------------------------------------------------------------------------
/.telemetry:
--------------------------------------------------------------------------------
1 | consent: false
2 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Arvindra
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Using ChatGPT to build a Kedro ML pipeline and Streamlit frontend
2 |
3 | 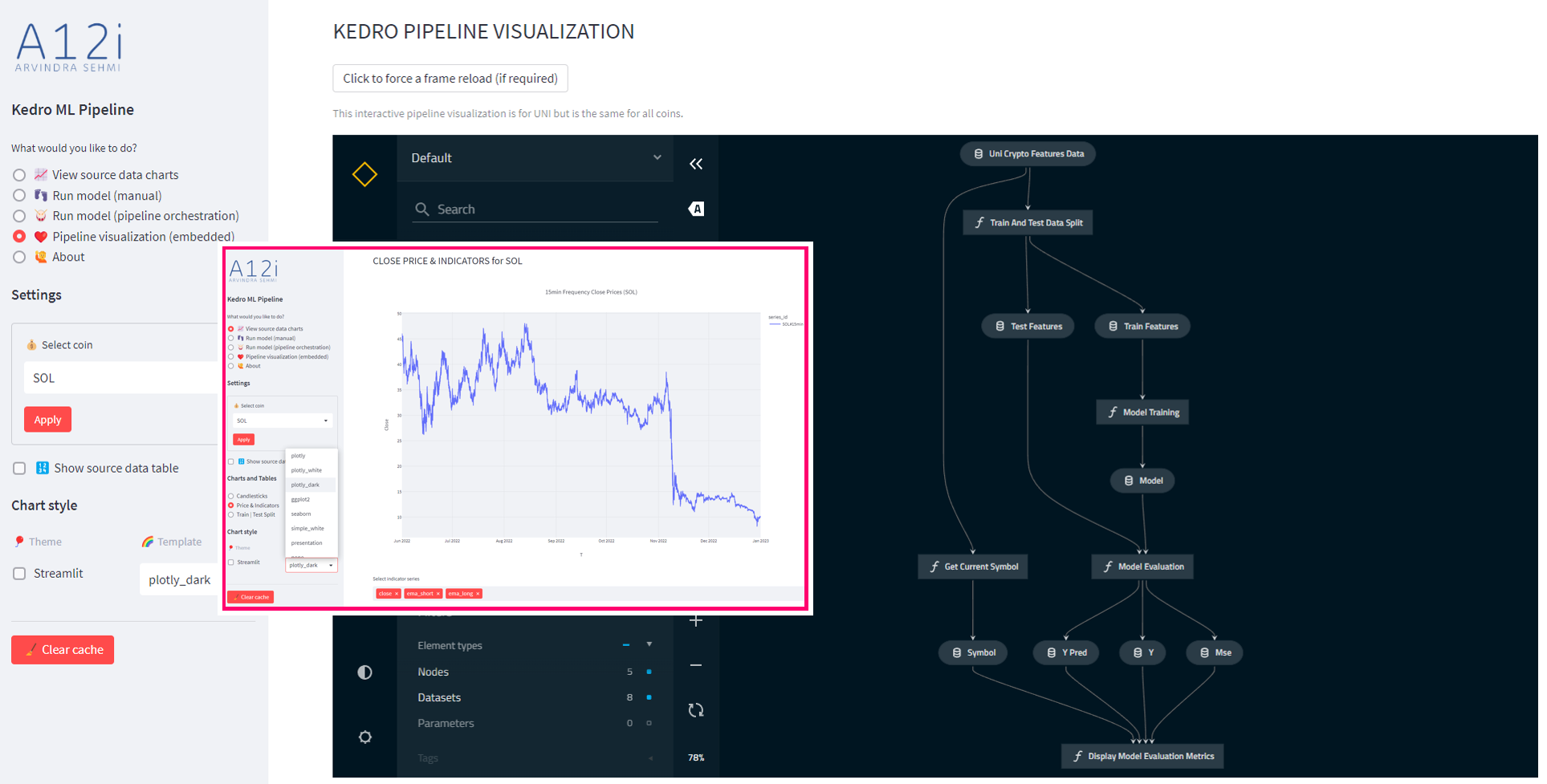
4 |
5 | date: "2023-02-07"
6 | author:
7 | name: "Arvindra Sehmi"
8 | url: "https://www.linkedin.com/in/asehmi/"
9 | mail: "vin [at] thesehmis.com"
10 | avatar: "https://twitter.com/asehmi/profile_image?size=original"
11 | related:
12 | https://blog.streamlit.io/using-chatgpt-to-build-a-kedro-ml-pipeline/
13 |
14 | ### Introduction
15 |
16 | I recently came across an open-source Python DevOps framework [Kedro](https://kedro.org/) and thought, “Why not have [ChatGPT](https://chat.openai.com/chat) teach me how to use it to build some ML/DevOps automation?” The idea was to:
17 | 1. Ask ChatGPT some basic questions about Kedro.
18 | 2. Ask it to use more advanced features in the Kedro framework.
19 | 3. Write my questions with hints and phrases that encouraged explanations of advanced Kedro features (to evolve incrementally as if I were taught by a teacher).
20 |
21 | Kedro has some pipeline visualization capabilities, so I wondered:
22 | - Could ChatGPT show me how to display pipeline graphs in Streamlit?
23 | - Could ChatGPT build me an example ML model and explicitly refer to it in the Kedro pipeline?
24 | - What does it take to scale the pipeline, and perform pipeline logging, monitoring, and error handling?
25 | - Could I connect Kedro logs to a cloud-based logging service?
26 | - Could ChatGPT contrast Kedro with similar (competing) products and services and show me how the pipeline it developed earlier could be implemented in one of them?
27 |
28 | I wrote a [blog post with annotated responses to the answers I got to my questions](https://blog.streamlit.io/using-chatgpt-to-build-a-kedro-ml-pipeline/). I was super impressed and decided to implement the Kedro pipeline and Streamlit application as planned from what I learned. This repository contains all the code for the application.
29 |
30 | > As you'll read in my blog post ChatGPT helps "understanding" and is why I found it useful for learning. The Kedro code ChatGPT generated was simplistic and in some cases wrong, but perfectly okay to get the gist of how it worked. This app is original, with small parts of it taken from Kedro's code template, so you're free to use it without any recourse under the MIT license.
31 |
32 | ### Try the Streamlit app yourself
33 |
34 | The application can be seen running in the Streamlit Cloud at the link below:
35 |
36 | [](https://kedro-ml-pipeline.streamlit.app//)
37 |
38 | - The source OCLH crypto currency data is supplied in a single CSV file, and was previously downloaded from the Bitfinex exchange
39 | - OCLH data is for 4 coins spanning the period June 1, 2022 to December 31, 2022
40 | - OCLH data is in 15min frequency
41 | - A Kedro data catalog of source and feature datasets is built for each coin and subsequently used in the Kedro ML pipeline
42 | - You can run the Kedro ML pipeline to train, test and evaluate a Linear Regression model to predict next period (t+1) close prices from several feature techical indicators derived from the close price and volume
43 | - You can visualize candlestick and line charts for the source and feature datasets, by coin
44 | - Run locally, you can visualize an interactive graph representation of the Kedro pipeline in the Streamlit application
45 | - You can run the pipeline nodes and the pipeline visualization from the command line too, using Kedro's CLI tools
46 |
47 | For Streamlit beginners, this aplication can be useful to learn how to:
48 | - Structure a multipage application
49 | - Use session state
50 | - Use widget callbacks
51 | - Use many different widgets
52 | - Launch sub-processes
53 | - Embed external GUIs
54 | - Cache data and clear caches
55 | - Plotly charting
56 | - (Check out my [gists](https://gist.github.com/asehmi) for more Streamlit goodies)
57 |
58 | ## Installation
59 |
60 | (_On Windows replace forward slashes with back slashes._)
61 |
62 | Clone this repository, then install package requirements:
63 |
64 | ```bash
65 | $ cd using_chatgpt_kedro_streamlit_app
66 | $ pip install -r src/requirements.txt
67 | ```
68 |
69 | ## Usage
70 |
71 | **Run the Streamlit app**:
72 |
73 | ```bash
74 | $ cd using_chatgpt_kedro_streamlit_app
75 | $ streamlit run --server.port=2023 src/streamlit_app.py
76 | ```
77 |
78 | **Run the Kedo pipeline from the command line**:
79 |
80 | ```bash
81 | $ cd using_chatgpt_kedro_streamlit_app
82 | $ kedro run
83 | ```
84 |
85 | You should see a trace similar to this:
86 |
87 |
88 | Kedro run output trace
89 |
90 | 🥁 Running from Kedro's CLI
91 | #### Pipeline execution order ####
92 | Inputs: uni_crypto_features_data
93 |
94 | Get-Current-Symbol
95 | Train-and-Test-Data-Split
96 | Model-Training
97 | Model-Evaluation
98 | Display-Model-Evaluation-Metrics
99 |
100 | Outputs: None
101 | ##################################
102 | [02/07/23 13:28:06] INFO Loading data from 'uni_crypto_features_data' (CSVDataSet)... data_catalog.py:343
103 | INFO Running node: Get-Current-Symbol: get_symbol([uni_crypto_features_data]) -> node.py:327
104 | [symbol]
105 | INFO Saving data to 'symbol' (MemoryDataSet)... data_catalog.py:382
106 | INFO Completed 1 out of 5 tasks sequential_runner.py:85
107 | INFO Loading data from 'uni_crypto_features_data' (CSVDataSet)... data_catalog.py:343
108 | INFO Running node: Train-and-Test-Data-Split: node.py:327
109 | train_test_split([uni_crypto_features_data]) -> [train_features,test_features]
110 | [02/07/23 13:28:08] INFO Saving data to 'train_features' (MemoryDataSet)... data_catalog.py:382
111 | INFO Saving data to 'test_features' (MemoryDataSet)... data_catalog.py:382
112 | INFO Completed 2 out of 5 tasks sequential_runner.py:85
113 | INFO Loading data from 'train_features' (MemoryDataSet)... data_catalog.py:343
114 | INFO Running node: Model-Training: train_model([train_features]) -> [model] node.py:327
115 | INFO Saving data to 'model' (MemoryDataSet)... data_catalog.py:382
116 | INFO Completed 3 out of 5 tasks sequential_runner.py:85
117 | INFO Loading data from 'model' (MemoryDataSet)... data_catalog.py:343
118 | INFO Loading data from 'test_features' (MemoryDataSet)... data_catalog.py:343
119 | INFO Running node: Model-Evaluation: evaluate_model([model,test_features]) -> node.py:327
120 | [y,y_pred,mse]
121 | INFO Saving data to 'y' (MemoryDataSet)... data_catalog.py:382
122 | INFO Saving data to 'y_pred' (MemoryDataSet)... data_catalog.py:382
123 | INFO Saving data to 'mse' (MemoryDataSet)... data_catalog.py:382
124 | INFO Completed 4 out of 5 tasks sequential_runner.py:85
125 | INFO Loading data from 'symbol' (MemoryDataSet)... data_catalog.py:343
126 | INFO Loading data from 'y' (MemoryDataSet)... data_catalog.py:343
127 | INFO Loading data from 'y_pred' (MemoryDataSet)... data_catalog.py:343
128 | INFO Loading data from 'mse' (MemoryDataSet)... data_catalog.py:343
129 | INFO Running node: Display-Model-Evaluation-Metrics: node.py:327
130 | plot_metric([symbol,y,y_pred,mse]) -> None
131 |
132 |
133 | 🤒 Mean Square Error (MSE) 0.109%
134 |
135 |
136 | close_t1 close_pred_t1
137 | Timestamp
138 | 2022-11-01 00:00:00 6.9463 6.948840
139 | 2022-11-01 00:15:00 6.9716 6.970235
140 | 2022-11-01 00:30:00 6.9570 6.957893
141 | 2022-11-01 00:45:00 6.9723 6.971893
142 | 2022-11-01 01:00:00 6.9933 6.991907
143 | ... ... ...
144 | 2022-12-31 22:45:00 5.1605 5.161068
145 | 2022-12-31 23:00:00 5.1687 5.169422
146 | 2022-12-31 23:15:00 5.1749 5.174875
147 | 2022-12-31 23:30:00 5.1660 5.166717
148 | 2022-12-31 23:45:00 5.1660 NaN
149 |
150 | [5554 rows x 2 columns]
151 | INFO Completed 5 out of 5 tasks sequential_runner.py:85
152 | INFO Pipeline execution completed successfully. runner.py:90
153 |
154 |
155 |
156 | **Run the Kedo pipeline visualization from the command line**:
157 |
158 | ```bash
159 | $ cd using_chatgpt_kedro_streamlit_app
160 | $ kedro viz
161 | ```
162 |
163 | You should see this displayed in a browser window:
164 |
165 | 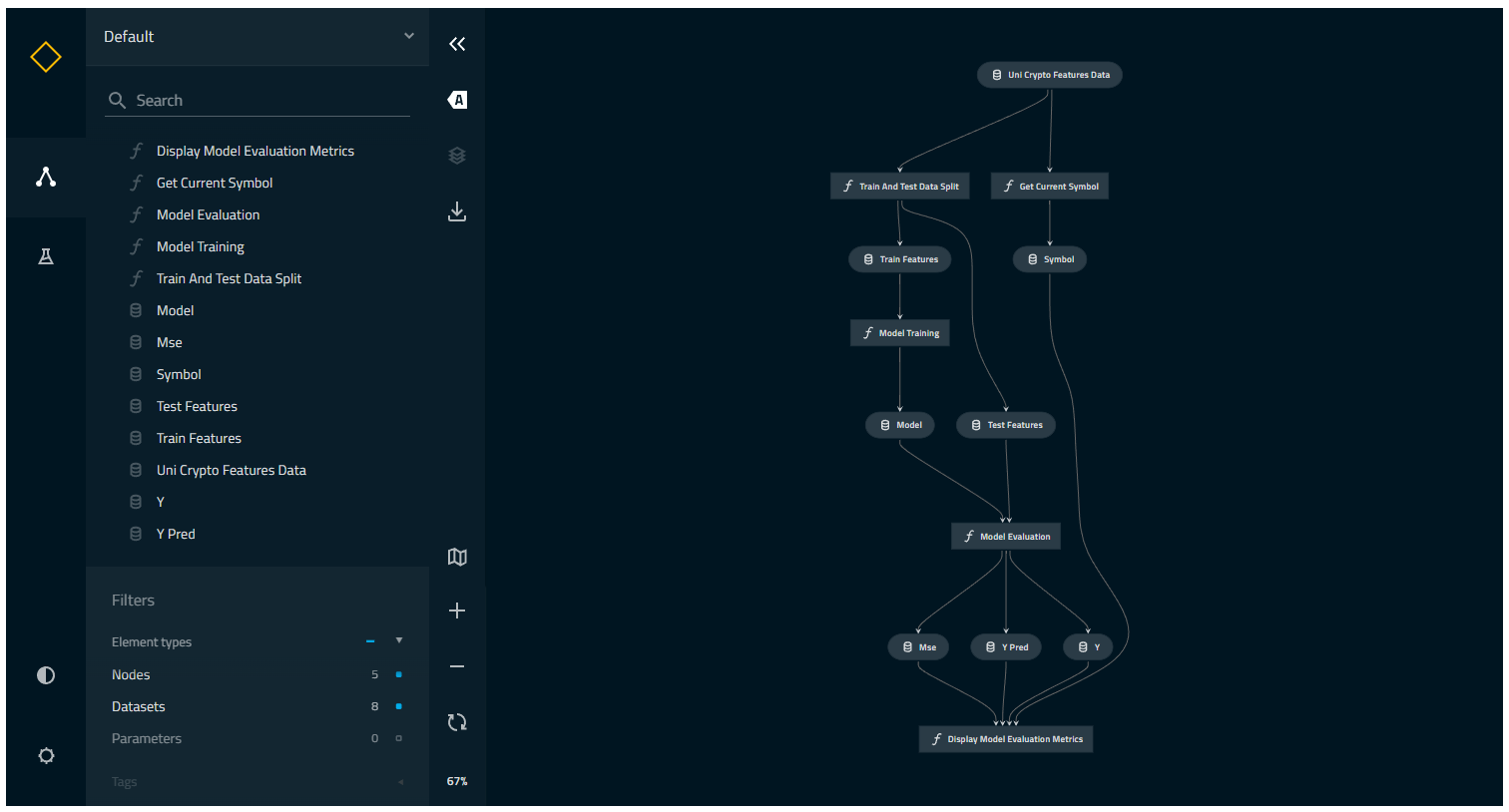
166 |
167 | ---
168 |
169 | ⭐ If you enjoyed this app and learned something, please consider starring its repository.
170 |
171 | Many thanks!
172 |
173 | Arvindra
174 |
175 | ---
176 |
177 | ## Disclaimer
178 |
179 | **_This application is a demo of Kedro and Streamlit concepts and the results should not be taken seriously! The Linear Regression model is highly simplistic._**
180 |
181 | - All investments involve risk, and the past performance of a crypto-currency, security, industry, sector, market, financial product, trading strategy, or individual’s trading does not guarantee future results or returns.
182 | - Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
183 | - The information you derive from the outputs of this application do not constitute investment advice. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from use of or reliance on such information.
184 |
185 | ---
--------------------------------------------------------------------------------
/conf/README.md:
--------------------------------------------------------------------------------
1 | # What is this for?
2 |
3 | This folder should be used to store configuration files used by Kedro or by separate tools.
4 |
5 | This file can be used to provide users with instructions for how to reproduce local configuration with their own credentials. You can edit the file however you like, but you may wish to retain the information below and add your own section in the [Instructions](#Instructions) section.
6 |
7 | ## Local configuration
8 |
9 | The `local` folder should be used for configuration that is either user-specific (e.g. IDE configuration) or protected (e.g. security keys).
10 |
11 | > *Note:* Please do not check in any local configuration to version control.
12 |
13 | ## Base configuration
14 |
15 | The `base` folder is for shared configuration, such as non-sensitive and project-related configuration that may be shared across team members.
16 |
17 | WARNING: Please do not put access credentials in the base configuration folder.
18 |
19 | ## Instructions
20 |
21 |
22 |
23 |
24 |
25 | ## Find out more
26 | You can find out more about configuration from the [user guide documentation](https://kedro.readthedocs.io/en/stable/user_guide/configuration.html).
27 |
--------------------------------------------------------------------------------
/conf/base/catalog.yml:
--------------------------------------------------------------------------------
1 | # Here you can define all your data sets by using simple YAML syntax.
2 | #
3 | # Documentation for this file format can be found in "The Data Catalog"
4 | # Link: https://kedro.readthedocs.io/en/stable/data/data_catalog.html
5 | #
6 | # We support interacting with a variety of data stores including local file systems, cloud, network and HDFS
7 | #
8 | # An example data set definition can look as follows:
9 | #
10 | #bikes:
11 | # type: pandas.CSVDataSet
12 | # filepath: "data/01_raw/bikes.csv"
13 | #
14 | #weather:
15 | # type: spark.SparkDataSet
16 | # filepath: s3a://your_bucket/data/01_raw/weather*
17 | # file_format: csv
18 | # credentials: dev_s3
19 | # load_args:
20 | # header: True
21 | # inferSchema: True
22 | # save_args:
23 | # sep: '|'
24 | # header: True
25 | #
26 | #scooters:
27 | # type: pandas.SQLTableDataSet
28 | # credentials: scooters_credentials
29 | # table_name: scooters
30 | # load_args:
31 | # index_col: ['name']
32 | # columns: ['name', 'gear']
33 | # save_args:
34 | # if_exists: 'replace'
35 | # # if_exists: 'fail'
36 | # # if_exists: 'append'
37 | #
38 | # The Data Catalog supports being able to reference the same file using two different DataSet implementations
39 | # (transcoding), templating and a way to reuse arguments that are frequently repeated. See more here:
40 | # https://kedro.readthedocs.io/en/stable/data/data_catalog.html
41 | #
42 | # This is a data set used by the "Hello World" example pipeline provided with the project
43 | # template. Please feel free to remove it once you remove the example pipeline.
44 |
45 | # example_iris_data:
46 | # type: pandas.CSVDataSet
47 | # filepath: data/01_raw/iris.csv
48 |
49 | # Configure primary exchange source data for all coins
50 | crypto_candles_data:
51 | type: pandas.CSVDataSet
52 | filepath: data/crypto_candles_data.csv
53 |
54 | # Configure dataset corresponding to SYMBOL_DEFUALT (which happens to be 'UNI')
55 | # You will have had to run the Streamlit app first to generate this source file!
56 | uni_crypto_features_data:
57 | type: pandas.CSVDataSet
58 | filepath: data/uni_crypto_features_data.csv
59 |
--------------------------------------------------------------------------------
/conf/base/logging.yml:
--------------------------------------------------------------------------------
1 | version: 1
2 |
3 | disable_existing_loggers: False
4 |
5 | formatters:
6 | simple:
7 | format: "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
8 |
9 | handlers:
10 | console:
11 | class: logging.StreamHandler
12 | level: INFO
13 | formatter: simple
14 | stream: ext://sys.stdout
15 |
16 | info_file_handler:
17 | class: logging.handlers.RotatingFileHandler
18 | level: INFO
19 | formatter: simple
20 | filename: logs/info.log
21 | maxBytes: 10485760 # 10MB
22 | backupCount: 20
23 | encoding: utf8
24 | delay: True
25 |
26 | error_file_handler:
27 | class: logging.handlers.RotatingFileHandler
28 | level: ERROR
29 | formatter: simple
30 | filename: logs/errors.log
31 | maxBytes: 10485760 # 10MB
32 | backupCount: 20
33 | encoding: utf8
34 | delay: True
35 |
36 | rich:
37 | class: rich.logging.RichHandler
38 |
39 | loggers:
40 | kedro:
41 | level: INFO
42 |
43 | iris:
44 | level: INFO
45 |
46 | crypto_fc:
47 | level: INFO
48 |
49 | root:
50 | handlers: [rich, info_file_handler, error_file_handler]
51 |
--------------------------------------------------------------------------------
/conf/base/parameters.yml:
--------------------------------------------------------------------------------
1 | # train_fraction: 0.8
2 | # random_state: 3
3 | # target_column: species
4 |
--------------------------------------------------------------------------------
/conf/local/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/asehmi/using_chatgpt_kedro_streamlit_app/8d4e9a8bdf16ffcd9103b402fb89335de3678da9/conf/local/.gitkeep
--------------------------------------------------------------------------------
/conf/local/credentials.yml:
--------------------------------------------------------------------------------
1 | # Here you can define credentials for different data sets and environment.
2 | #
3 | #
4 | # Example:
5 | #
6 | # dev_s3:
7 | # aws_access_key_id: token
8 | # aws_secret_access_key: key
9 | #
10 | # prod_s3:
11 | # aws_access_key_id: token
12 | # aws_secret_access_key: key
13 | #
14 | # dev_sql:
15 | # username: admin
16 | # password: admin
17 |
--------------------------------------------------------------------------------
/data/dot_pipeline.json:
--------------------------------------------------------------------------------
1 | {"kedro_version": "0.18.4", "pipeline": [{"name": "Get-Current-Symbol", "inputs": ["dot_crypto_features_data"], "outputs": ["symbol"], "tags": []}, {"name": "Train-and-Test-Data-Split", "inputs": ["dot_crypto_features_data"], "outputs": ["train_features", "test_features"], "tags": []}, {"name": "Model-Training", "inputs": ["train_features"], "outputs": ["model"], "tags": []}, {"name": "Model-Evaluation", "inputs": ["model", "test_features"], "outputs": ["y", "y_pred", "mse"], "tags": []}, {"name": "Display-Model-Evaluation-Metrics", "inputs": ["symbol", "y", "y_pred", "mse"], "outputs": [], "tags": []}]}
--------------------------------------------------------------------------------
/data/ltc_pipeline.json:
--------------------------------------------------------------------------------
1 | {"kedro_version": "0.18.4", "pipeline": [{"name": "Get-Current-Symbol", "inputs": ["ltc_crypto_features_data"], "outputs": ["symbol"], "tags": []}, {"name": "Train-and-Test-Data-Split", "inputs": ["ltc_crypto_features_data"], "outputs": ["train_features", "test_features"], "tags": []}, {"name": "Model-Training", "inputs": ["train_features"], "outputs": ["model"], "tags": []}, {"name": "Model-Evaluation", "inputs": ["model", "test_features"], "outputs": ["y", "y_pred", "mse"], "tags": []}, {"name": "Display-Model-Evaluation-Metrics", "inputs": ["symbol", "y", "y_pred", "mse"], "outputs": [], "tags": []}]}
--------------------------------------------------------------------------------
/data/sol_pipeline.json:
--------------------------------------------------------------------------------
1 | {"kedro_version": "0.18.4", "pipeline": [{"name": "Get-Current-Symbol", "inputs": ["sol_crypto_features_data"], "outputs": ["symbol"], "tags": []}, {"name": "Train-and-Test-Data-Split", "inputs": ["sol_crypto_features_data"], "outputs": ["train_features", "test_features"], "tags": []}, {"name": "Model-Training", "inputs": ["train_features"], "outputs": ["model"], "tags": []}, {"name": "Model-Evaluation", "inputs": ["model", "test_features"], "outputs": ["y", "y_pred", "mse"], "tags": []}, {"name": "Display-Model-Evaluation-Metrics", "inputs": ["symbol", "y", "y_pred", "mse"], "outputs": [], "tags": []}]}
--------------------------------------------------------------------------------
/data/uni_pipeline.json:
--------------------------------------------------------------------------------
1 | {"kedro_version": "0.18.4", "pipeline": [{"name": "Get-Current-Symbol", "inputs": ["uni_crypto_features_data"], "outputs": ["symbol"], "tags": []}, {"name": "Train-and-Test-Data-Split", "inputs": ["uni_crypto_features_data"], "outputs": ["train_features", "test_features"], "tags": []}, {"name": "Model-Training", "inputs": ["train_features"], "outputs": ["model"], "tags": []}, {"name": "Model-Evaluation", "inputs": ["model", "test_features"], "outputs": ["y", "y_pred", "mse"], "tags": []}, {"name": "Display-Model-Evaluation-Metrics", "inputs": ["symbol", "y", "y_pred", "mse"], "outputs": [], "tags": []}]}
--------------------------------------------------------------------------------
/images/a12i_logo.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/asehmi/using_chatgpt_kedro_streamlit_app/8d4e9a8bdf16ffcd9103b402fb89335de3678da9/images/a12i_logo.png
--------------------------------------------------------------------------------
/images/kedro_viz.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/asehmi/using_chatgpt_kedro_streamlit_app/8d4e9a8bdf16ffcd9103b402fb89335de3678da9/images/kedro_viz.png
--------------------------------------------------------------------------------
/images/screenshots.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/asehmi/using_chatgpt_kedro_streamlit_app/8d4e9a8bdf16ffcd9103b402fb89335de3678da9/images/screenshots.png
--------------------------------------------------------------------------------
/kedro_run.cmd:
--------------------------------------------------------------------------------
1 | kedro run
--------------------------------------------------------------------------------
/kedro_viz.cmd:
--------------------------------------------------------------------------------
1 | @echo off
2 | echo Visualization available at http://localhost:4141/
3 | kedro viz --no-browser
4 |
--------------------------------------------------------------------------------
/kedro_viz.sh:
--------------------------------------------------------------------------------
1 | sh kedro viz --no-browser
2 |
--------------------------------------------------------------------------------
/logs/.gitkeep:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/asehmi/using_chatgpt_kedro_streamlit_app/8d4e9a8bdf16ffcd9103b402fb89335de3678da9/logs/.gitkeep
--------------------------------------------------------------------------------
/pyproject.toml:
--------------------------------------------------------------------------------
1 | [tool.kedro]
2 | package_name = "crypto_fc"
3 | project_name = "Crypto Forecast"
4 | project_version = "0.18.4"
5 |
6 | [tool.isort]
7 | profile = "black"
8 |
9 | [tool.pytest.ini_options]
10 | addopts = """
11 | --cov-report term-missing \
12 | --cov src/crypto_fc -ra"""
13 |
14 | [tool.coverage.report]
15 | fail_under = 0
16 | show_missing = true
17 | exclude_lines = ["pragma: no cover", "raise NotImplementedError"]
18 |
--------------------------------------------------------------------------------
/run.cmd:
--------------------------------------------------------------------------------
1 | streamlit run --server.port=2023 src\streamlit_app.py
--------------------------------------------------------------------------------
/src/crypto_fc/__init__.py:
--------------------------------------------------------------------------------
1 | """Crypto Forecast
2 | """
3 |
4 | __version__ = "0.1"
5 |
--------------------------------------------------------------------------------
/src/crypto_fc/__main__.py:
--------------------------------------------------------------------------------
1 | """crypto_fc file for ensuring the package is executable
2 | as `crypto_fc` and `python -m crypto_fc`
3 | """
4 | import importlib
5 | from pathlib import Path
6 |
7 | from kedro.framework.cli.utils import KedroCliError, load_entry_points
8 | from kedro.framework.project import configure_project
9 |
10 |
11 | def _find_run_command(package_name):
12 | try:
13 | project_cli = importlib.import_module(f"{package_name}.cli")
14 | # fail gracefully if cli.py does not exist
15 | except ModuleNotFoundError as exc:
16 | if f"{package_name}.cli" not in str(exc):
17 | raise
18 | plugins = load_entry_points("project")
19 | run = _find_run_command_in_plugins(plugins) if plugins else None
20 | if run:
21 | # use run command from installed plugin if it exists
22 | return run
23 | # use run command from `kedro.framework.cli.project`
24 | from kedro.framework.cli.project import run
25 |
26 | return run
27 | # fail badly if cli.py exists, but has no `cli` in it
28 | if not hasattr(project_cli, "cli"):
29 | raise KedroCliError(f"Cannot load commands from {package_name}.cli")
30 | return project_cli.run
31 |
32 |
33 | def _find_run_command_in_plugins(plugins):
34 | for group in plugins:
35 | if "run" in group.commands:
36 | return group.commands["run"]
37 |
38 |
39 | def main(*args, **kwargs):
40 | package_name = Path(__file__).parent.name
41 | configure_project(package_name)
42 | run = _find_run_command(package_name)
43 | run(*args, **kwargs)
44 |
45 |
46 | if __name__ == "__main__":
47 | main()
48 |
--------------------------------------------------------------------------------
/src/crypto_fc/constants.py:
--------------------------------------------------------------------------------
1 | import datetime as dt
2 |
3 | SYMBOL_DEFAULT = 'UNI'
4 | START_DATE = dt.datetime(2022,6,1) # JUNE 1, 2022
5 | DATA_INDEX = lambda x: x.index >= START_DATE
6 |
7 | SPLIT_DATE = dt.datetime(2022,11,1) # NOVEMBER 1, 2022
8 | TRAIN_INDEX = lambda x: x.index < SPLIT_DATE
9 | TEST_INDEX = lambda x: x.index >= SPLIT_DATE
10 |
11 | OCLH_PERIOD = '15min'
12 | TIME_PERIOD = 6
13 | SHORT_PERIOD = TIME_PERIOD
14 | LONG_PERIOD = int(TIME_PERIOD * 2)
15 | FORECAST_HORIZON = 1
16 |
--------------------------------------------------------------------------------
/src/crypto_fc/data.py:
--------------------------------------------------------------------------------
1 | from typing import List
2 | import pandas as pd
3 | # https://github.com/twopirllc/pandas-ta
4 | import pandas_ta as ta
5 | import numpy as np
6 |
7 | from .constants import (
8 | OCLH_PERIOD,
9 | TIME_PERIOD,
10 | SHORT_PERIOD,
11 | LONG_PERIOD,
12 | FORECAST_HORIZON,
13 | )
14 |
15 | from kedro.io import DataCatalog
16 | from kedro.extras.datasets.pandas import CSVDataSet, GenericDataSet
17 |
18 | # -----------------------------------------------------------------------------
19 | # LOW LEVEL DATA CATALOG FUNCTIONS (not used)
20 |
21 | def __exists(var: str):
22 | return var in globals()
23 |
24 | if not __exists('__DATA_CATALOG__'):
25 | # Create a DataCatalog to manage the data for project
26 | global __DATA_CATALOG__
27 | __DATA_CATALOG__: DataCatalog = DataCatalog()
28 |
29 | def catalog_add_dataset(name, dataset):
30 | global __DATA_CATALOG__
31 | if not __DATA_CATALOG__:
32 | raise Exception('Data catalog has not been initialised.')
33 | else:
34 | __DATA_CATALOG__.add(name, dataset)
35 |
36 | def catalog_load_dataset_data(name):
37 | global __DATA_CATALOG__
38 | if not __DATA_CATALOG__:
39 | raise Exception('Data catalog has not been initialised.')
40 | else:
41 | # Load the data registered with catalog
42 | df_data = __DATA_CATALOG__.load(name)
43 | return df_data
44 |
45 | # -----------------------------------------------------------------------------
46 | # DATA CATALOG WRAPPER
47 |
48 | class MyDataCatalog(DataCatalog):
49 |
50 | def load_crypto_candles(self) -> pd.DataFrame:
51 | # COMMENT: Data loading code written by ChatGPT was incorrect
52 | crypto_ds = CSVDataSet(filepath="./data/crypto_candles_data.csv", load_args=None, save_args={'index': False})
53 | self.add('crypto_candles_data', crypto_ds)
54 | df_data: pd.DataFrame = self.load('crypto_candles_data')
55 | return df_data
56 |
57 | def filter_data_and_build_features(
58 | self,
59 | symbol, df_oclh,
60 | period=OCLH_PERIOD, timeperiod=TIME_PERIOD,
61 | ema_short_period=SHORT_PERIOD, ema_long_period=LONG_PERIOD,
62 | forecast_horizon=FORECAST_HORIZON,
63 | ) -> pd.DataFrame:
64 | if not isinstance(df_oclh, pd.DataFrame):
65 | raise Exception('ERROR: filter_data_and_build_features null data')
66 |
67 | # FILTER OCLH DATA FRAME
68 |
69 | # Key for the OCLH series data set. Each symbol's data set contains:
70 | # 'Timestamp', 'open', 'close', 'low', 'high', 'volume',
71 | df_oclh_filtered = df_oclh[
72 | df_oclh['symbol'] == symbol
73 | ].copy()
74 |
75 | # backfill OCLH dataframe for good measure
76 | df_oclh_filtered.fillna(method='bfill', inplace=True)
77 |
78 | # BUILD FILTERED FEATURE DATA SERIES
79 |
80 | # Price OCLH series
81 | open_price = df_oclh_filtered['open']
82 | close_price = df_oclh_filtered['close']
83 | low_price = df_oclh_filtered['low']
84 | high_price = df_oclh_filtered['high']
85 | # Volume series
86 | volume = df_oclh_filtered['volume']
87 |
88 | # CREATE NEW INDICATORS (using the above series)
89 |
90 | # SecurityPrice indicators
91 | close_price_pct_change = close_price.pct_change(periods=1, fill_method='bfill')
92 |
93 | rsi = ta.rsi(close_price, length=timeperiod)
94 |
95 | ema_short = ta.ema(close_price, length=ema_short_period)
96 | ema_long = ta.ema(close_price, length=ema_long_period)
97 |
98 | obv = ta.obv(close_price, volume)
99 |
100 | obv_ema_short = ta.ema(obv, length=ema_short_period)
101 | obv_ema_long = ta.ema(obv, length=ema_long_period)
102 |
103 | # Volatility measures
104 |
105 | close_off_high_temp = ( ((high_price - close_price) * 2)
106 | / (high_price - low_price - 1) )
107 | close_off_high = np.nan_to_num(close_off_high_temp, copy=True, posinf=0.0001, neginf=-0.0001)
108 |
109 | volat_zero_base_temp = (high_price - low_price) / open_price
110 | volat_zero_base = np.nan_to_num(volat_zero_base_temp, copy=True, posinf=0.0001, neginf=-0.0001)
111 |
112 | # BUILD INDICATORS DATA FRAME
113 |
114 | INDICATORS_DICT = {
115 | 'close_pct_change': close_price_pct_change,
116 | 'close_off_high': close_off_high,
117 |
118 | 'rsi': rsi,
119 | 'ema_short': ema_short,
120 | 'ema_long': ema_long,
121 | 'obv': obv,
122 | 'obv_ema_short': obv_ema_short,
123 | 'obv_ema_long': obv_ema_long,
124 |
125 | 'volat_zero_base': volat_zero_base,
126 | }
127 |
128 | # print([(k,len(v)) for k,v in INDICATORS_DICT.items()])
129 |
130 | indicators_df = pd.DataFrame(INDICATORS_DICT)
131 |
132 | # print('Indicators dataframe shape:', indicators_df.shape)
133 |
134 | # combine into final data frame
135 | df_features = df_oclh_filtered.join(indicators_df, how='inner')
136 |
137 | # add prediction target to final dataframe
138 |
139 | forecast_horizon_label = 'close' + f'_t{forecast_horizon}'
140 | df_features[forecast_horizon_label] = df_features['close'].shift(-forecast_horizon).fillna(method='ffill') # used as target prediction
141 |
142 | # FINALLY, LIMIT FULL FEATURE SET TO REQUIRED COLUMNS
143 |
144 | oclh_series_id = f'{symbol.upper()}#{period}'
145 | df_features['series_id'] = oclh_series_id
146 |
147 | # df_features_final is a copy not a view!
148 | df_features_final = df_features[['Timestamp', 'symbol', 'open' ,'close', 'low', 'high'] + list(INDICATORS_DICT.keys()) + ['series_id', forecast_horizon_label]].copy()
149 |
150 | # TAKE CARE TO DEAL PROPERLY WITH NANs PRODUCED FROM AVERAGING
151 |
152 | # The mean calc window is equivalent to 3 * longest averaging period (LONG_PERIOD)
153 | # We backfill with the mean of the head data so it is more reflective of the amplitude in that window only
154 | mean_calculation_window = (3 * LONG_PERIOD)
155 | for col in INDICATORS_DICT.keys():
156 | if ('short' in col) or ('long' in col) or ('rsi' in col):
157 | df_features_final[col].fillna(df_features_final[col].head(mean_calculation_window).mean(), inplace=True)
158 |
159 | df_features_final.replace([np.inf, -np.inf], np.nan, inplace=True)
160 | df_features_final.fillna(method='bfill', inplace=True)
161 |
162 | print(f'#### OCLH and Model Features Data | Series ID: {oclh_series_id} ####')
163 | print('Features shape:', df_features_final.shape)
164 | print('Features columns:', list(df_features_final.columns))
165 | # print('Features dtypes:', df_features_final.dtypes)
166 | # print(df_features_final.head(2))
167 | print(df_features_final.tail(2))
168 |
169 | features_ds = GenericDataSet(filepath=f'./data/{symbol.lower()}_crypto_features_data.csv', file_format='csv', load_args=None, save_args={'index': False})
170 | features_ds.save(df_features_final)
171 | self.add(f'{symbol.lower()}_crypto_features_data', features_ds)
172 | df_features_final_reloaded = self.load(f'{symbol.lower()}_crypto_features_data')
173 |
174 | return df_features_final_reloaded
175 |
176 | def build_data_catalog(self) -> List[str]:
177 | df_data = self.load_crypto_candles()
178 | symbols = df_data['symbol'].unique()
179 | for symbol in symbols:
180 | self.filter_data_and_build_features(symbol, df_data)
181 | catalog_datasets = self.list()
182 | print(catalog_datasets)
183 | return catalog_datasets
184 |
--------------------------------------------------------------------------------
/src/crypto_fc/nodes.py:
--------------------------------------------------------------------------------
1 | from typing import List
2 | import pandas as pd
3 | import numpy as np
4 |
5 | from sklearn.linear_model import LinearRegression
6 | from sklearn.metrics import mean_squared_error
7 |
8 | from .constants import (
9 | TRAIN_INDEX,
10 | TEST_INDEX,
11 | )
12 |
13 | # COMMENT:
14 | # ChatGPT doesn't suggest the argument to train_model() should be the training data split of the source data set.
15 | # My "target" column is the close price. You'd need to supply non-"target" columns. i.e. feature columns, in your dataset.
16 |
17 | def get_symbol(data) -> str:
18 | symbol = data['symbol'].unique()[0].upper()
19 | return symbol
20 |
21 | def train_model(data):
22 | # Split the data into features and targets
23 | X = data.drop(['symbol', 'open', 'close', 'low', 'high', 'close_t1', 'series_id'], axis=1)
24 | y = data['close_t1']
25 | # Create a LinearRegression model and fit it to the data
26 | model = LinearRegression()
27 | model.fit(X, y)
28 | return model
29 |
30 | def evaluate_model(model, data):
31 | X = data.drop(['symbol', 'open', 'close', 'low', 'high', 'close_t1', 'series_id'], axis=1)
32 | y = data['close_t1']
33 | # Make predictions using the model and calculate the mean squared error
34 | y_pred = model.predict(X)
35 | mse = mean_squared_error(y, y_pred)
36 | return y, y_pred, mse
37 |
38 |
39 | def plot_metric(symbol, y, y_pred, mse):
40 | result_df = pd.DataFrame(y)
41 | result_df['close_pred_t1'] = y_pred
42 | result_df['close_pred_t1'] = result_df['close_pred_t1'].shift(-1)
43 | result_df.dropna(inplace=True)
44 |
45 | print(f'Saving {symbol} predictions for display in Streamlit...')
46 | result_df.to_csv(f'./data/{symbol.lower()}_predictions.csv', index=False, encoding='utf-8')
47 |
48 | print('\n\n', '🤒 Mean Square Error (MSE)', f'{round(mse * 100, 3)}%', '\n\n')
49 | print(result_df)
50 |
51 | def train_test_split_2(data: pd.DataFrame) -> List[pd.DataFrame]:
52 | df_features = data.copy()
53 | df_features.drop('Timestamp', inplace=True)
54 | return np.array_split(df_features, 2)
55 |
56 | def train_test_split(data: pd.DataFrame, train_index=TRAIN_INDEX, test_index=TEST_INDEX) -> List[pd.DataFrame]:
57 | df_features = data.copy()
58 | df_features['Timestamp'] = pd.to_datetime(df_features['Timestamp'], dayfirst=True)
59 | df_features.set_index('Timestamp', inplace=True)
60 | return [df_features[train_index], df_features[test_index]]
--------------------------------------------------------------------------------
/src/crypto_fc/pipeline.py:
--------------------------------------------------------------------------------
1 | from kedro.pipeline import Pipeline, node, pipeline
2 | from kedro.runner import SequentialRunner
3 |
4 | from .constants import SYMBOL_DEFAULT
5 | from .nodes import (get_symbol, train_model, evaluate_model, plot_metric, train_test_split)
6 |
7 | # Create a pipeline to orchestrate the steps
8 | def create_pipeline(**kwargs) -> Pipeline:
9 | symbol = kwargs.get('symbol', SYMBOL_DEFAULT)
10 |
11 | pipeline_instance = pipeline([
12 | node(
13 | get_symbol,
14 | inputs=f'{symbol.lower()}_crypto_features_data',
15 | outputs='symbol',
16 | name='Get-Current-Symbol',
17 | ),
18 | node(
19 | train_test_split,
20 | inputs=f'{symbol.lower()}_crypto_features_data',
21 | outputs=['train_features', 'test_features'],
22 | name='Train-and-Test-Data-Split',
23 | ),
24 | node(
25 | train_model,
26 | inputs='train_features',
27 | outputs='model',
28 | name='Model-Training',
29 | ),
30 | node(
31 | evaluate_model,
32 | inputs=['model', 'test_features'],
33 | outputs=['y', 'y_pred', 'mse'],
34 | name='Model-Evaluation',
35 | ),
36 | node(
37 | plot_metric,
38 | inputs=['symbol', 'y', 'y_pred', 'mse'],
39 | outputs=None,
40 | name='Display-Model-Evaluation-Metrics',
41 | ),
42 | ])
43 |
44 | print(pipeline_instance.describe())
45 |
46 | return pipeline_instance
47 |
48 | # COMMENT: ChatGPT guessed that pipeline could be 'run' directly. In fact Pipeline doesn't have a run attribute.
49 | # One must create an executor and run the pipeline through that!
50 |
51 | # Execute the pipeline
52 | def run_pipeline(symbol, catalog):
53 | runner = SequentialRunner()
54 | pipeline_instance = create_pipeline(**{'symbol': symbol})
55 | runner.run(pipeline_instance, catalog)
56 |
--------------------------------------------------------------------------------
/src/crypto_fc/pipeline_registry.py:
--------------------------------------------------------------------------------
1 | """Project pipelines."""
2 | from typing import Dict
3 |
4 | from kedro.framework.project import find_pipelines
5 | from kedro.pipeline import Pipeline
6 |
7 |
8 | def register_pipelines() -> Dict[str, Pipeline]:
9 | """Register the project's pipelines.
10 |
11 | Returns:
12 | A mapping from pipeline names to ``Pipeline`` objects.
13 | """
14 | pipelines = find_pipelines()
15 | pipelines["__default__"] = sum(pipelines.values())
16 | return pipelines
17 |
--------------------------------------------------------------------------------
/src/crypto_fc/settings.py:
--------------------------------------------------------------------------------
1 | """Project settings. There is no need to edit this file unless you want to change values
2 | from the Kedro defaults. For further information, including these default values, see
3 | https://kedro.readthedocs.io/en/stable/kedro_project_setup/settings.html."""
4 |
5 | # Instantiated project hooks.
6 | # from iris.hooks import ProjectHooks
7 | # HOOKS = (ProjectHooks(),)
8 |
9 | # Installed plugins for which to disable hook auto-registration.
10 | # DISABLE_HOOKS_FOR_PLUGINS = ("kedro-viz",)
11 |
12 | # Class that manages storing KedroSession data.
13 | # from kedro.framework.session.store import ShelveStore
14 | # SESSION_STORE_CLASS = ShelveStore
15 | # Keyword arguments to pass to the `SESSION_STORE_CLASS` constructor.
16 | # SESSION_STORE_ARGS = {
17 | # "path": "./sessions"
18 | # }
19 |
20 | # Class that manages Kedro's library components.
21 | # from kedro.framework.context import KedroContext
22 | # CONTEXT_CLASS = KedroContext
23 |
24 | # Directory that holds configuration.
25 | # CONF_SOURCE = "conf"
26 |
27 | # Class that manages how configuration is loaded.
28 | # from kedro.config import TemplatedConfigLoader
29 | # CONFIG_LOADER_CLASS = TemplatedConfigLoader
30 | # Keyword arguments to pass to the `CONFIG_LOADER_CLASS` constructor.
31 | # CONFIG_LOADER_ARGS = {
32 | # "globals_pattern": "*globals.yml",
33 | # }
34 |
35 | # Class that manages the Data Catalog.
36 | # from kedro.io import DataCatalog
37 | # DATA_CATALOG_CLASS = DataCatalog
38 |
--------------------------------------------------------------------------------
/src/requirements.txt:
--------------------------------------------------------------------------------
1 | # My app requirements
2 | debugpy
3 | numpy
4 | pandas
5 | pandas_ta
6 | scikit-learn>=1.1.2
7 | streamlit>=1.18.0
8 | # Kedro requirements
9 | black~=22.0
10 | flake8>=3.7.9, <4.0
11 | ipython>=7.31.1, <8.0
12 | isort~=5.0
13 | jupyter~=1.0
14 | jupyterlab~=3.0
15 | kedro~=0.18.4
16 | kedro-viz
17 | kedro-datasets[pandas.CSVDataSet]~=1.0.0
18 | kedro-telemetry~=0.2.0
19 | nbstripout~=0.4
20 | pytest-cov~=3.0
21 | pytest-mock>=1.7.1, <2.0
22 | pytest~=6.2
23 |
--------------------------------------------------------------------------------
/src/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import find_packages, setup
2 |
3 | entry_point = (
4 | "crypto_fc = crypto_fc.__main__:main"
5 | )
6 |
7 |
8 | # get the dependencies and installs
9 | with open("requirements.txt", encoding="utf-8") as f:
10 | # Make sure we strip all comments and options (e.g "--extra-index-url")
11 | # that arise from a modified pip.conf file that configure global options
12 | # when running kedro build-reqs
13 | requires = []
14 | for line in f:
15 | req = line.split("#", 1)[0].strip()
16 | if req and not req.startswith("--"):
17 | requires.append(req)
18 |
19 | setup(
20 | name="crypto_fc",
21 | version="0.1",
22 | packages=find_packages(exclude=["tests"]),
23 | entry_points={"console_scripts": [entry_point]},
24 | install_requires=requires,
25 | extras_require={
26 | "docs": [
27 | "docutils<0.18.0",
28 | "sphinx~=3.4.3",
29 | "sphinx_rtd_theme==0.5.1",
30 | "nbsphinx==0.8.1",
31 | "nbstripout~=0.4",
32 | "myst-parser~=0.17.2",
33 | "sphinx-autodoc-typehints==1.11.1",
34 | "sphinx_copybutton==0.3.1",
35 | "ipykernel>=5.3, <7.0",
36 | "Jinja2<3.1.0",
37 | ]
38 | },
39 | )
40 |
--------------------------------------------------------------------------------
/src/st_functions.py:
--------------------------------------------------------------------------------
1 | # Gratefully copied from https://github.com/streamlit/links, by Chanin Nantasenamat.
2 | # See: https://chanin.streamlit.app/
3 | # @asehmi - Modified to add kedro button icon
4 |
5 | import streamlit as st
6 |
7 | style_css = """
8 | .appview-container {
9 | /* color: white; */
10 | /* background-color: black; */
11 | overflow: auto;
12 | }
13 | div[class="css-hxt7ib e1fqkh3o2"] {
14 | /* color: white; */
15 | /* background-color: black; */
16 | max-width: 100%;
17 | padding-top: 30px;
18 | overflow: auto;
19 | }
20 | div[class="block-container css-18e3th9 egzxvld2"] {
21 | max-width: 100%;
22 | padding-top: 30px;
23 | padding-right: 0px;
24 | padding-left: 30px;
25 | padding-bottom: 0px;
26 | }
27 | /*
28 | MainMenu {
29 | visibility: hidden;
30 | }
31 | */
32 | header {
33 | visibility: visible;
34 | height: 0%;
35 | }
36 | /*
37 | footer {
38 | visibility: hidden;
39 | }
40 | */
41 | """
42 |
43 | def load_css():
44 | try:
45 | # Can't find style.css is st cloud, so have a fallback (probably need to create a ./static folder for it)
46 | with open("style.css") as f:
47 | st.markdown(''.format(f.read()), unsafe_allow_html=True)
48 | except:
49 | st.markdown(''.format(style_css), unsafe_allow_html=True)
50 | st.markdown('', unsafe_allow_html=True)
51 |
52 | def st_button(icon, url, label, iconsize):
53 | if icon == 'kedro':
54 | button_code = f'''
55 |
56 |
57 |
76 | {label}
77 |
78 |
'''
79 | elif icon == 'youtube':
80 | button_code = f'''
81 |
82 |
83 |
86 | {label}
87 |
88 |
'''
89 | elif icon == 'twitter':
90 | button_code = f'''
91 |
92 |
93 |
96 | {label}
97 |
98 |
'''
99 | elif icon == 'linkedin':
100 | button_code = f'''
101 |
102 |
103 |
106 | {label}
107 |
108 |
'''
109 | elif icon == 'medium':
110 | button_code = f'''
111 |
112 |
113 |
116 | {label}
117 |
118 |
'''
119 | elif icon == 'newsletter':
120 | button_code = f'''
121 |
122 |
123 |
126 | {label}
127 |
128 |
'''
129 | elif icon == 'cup':
130 | button_code = f'''
131 |
132 |
133 |
136 | {label}
137 |
138 |
'''
139 | elif icon == '':
140 | button_code = f'''
141 |
142 |
143 | {label}
144 |
145 |
'''
146 | return st.markdown(button_code, unsafe_allow_html=True)
--------------------------------------------------------------------------------
/src/streamlit_app.py:
--------------------------------------------------------------------------------
1 | import time
2 | import pandas as pd
3 | import numpy as np
4 | import datetime as dt
5 | from PIL import Image
6 | import requests
7 |
8 | from sklearn.metrics import mean_squared_error
9 |
10 | import streamlit as st
11 | import streamlit.components.v1 as components
12 |
13 | from crypto_fc.constants import (
14 | SYMBOL_DEFAULT,
15 | OCLH_PERIOD,
16 | TRAIN_INDEX,
17 | TEST_INDEX,
18 | SPLIT_DATE,
19 | FORECAST_HORIZON
20 | )
21 |
22 | from crypto_fc.data import MyDataCatalog
23 | from crypto_fc.nodes import train_model, evaluate_model, plot_metric
24 | from crypto_fc.pipeline import create_pipeline, run_pipeline
25 |
26 | # https://plotly.com/python/plotly-express/#gallery
27 | # https://plotly.com/python/creating-and-updating-figures/
28 | # https://plotly.com/python/templates/
29 | import plotly.graph_objects as go
30 | import plotly.express as px
31 | px_templates = ['plotly', 'plotly_white', 'plotly_dark', 'ggplot2', 'seaborn', 'simple_white', 'presentation', 'none']
32 |
33 | st.set_page_config(page_title="Kedro Streamlit App!", page_icon='🤑', layout='wide')
34 |
35 | import st_functions
36 | st_functions.load_css()
37 |
38 | import streamlit_debug
39 | streamlit_debug.set(flag=True, wait_for_client=False, host='localhost', port=3210)
40 |
41 | #----------------------------------------------------------------------------
42 | # KEDRO CONFIG
43 |
44 | from pathlib import Path
45 | from kedro.framework.project import configure_project
46 |
47 | package_name = Path(__file__).parent.name
48 | configure_project(package_name)
49 |
50 | KEDRO_VIZ_SERVER_URL = 'http://127.0.0.1:4141/'
51 |
52 | #----------------------------------------------------------------------------
53 |
54 | state = st.session_state
55 |
56 | if 'kedro_viz_started' not in state:
57 | state['kedro_viz_started'] = False
58 |
59 | if 'chart_theme' not in state:
60 | state['chart_theme'] = None
61 | if 'chart_kwargs' not in state:
62 | state['chart_kwargs'] = {}
63 | if 'chart_template' not in state:
64 | state['chart_template'] = 'plotly_dark'
65 |
66 | if 'show_table' not in state:
67 | state['show_table'] = False
68 |
69 | if 'menu_choice' not in state:
70 | state['menu_choice'] = 0
71 |
72 | def _set_chart_theme_cb():
73 | if state['key_chart_theme']:
74 | state['chart_theme'] = 'streamlit'
75 | state['chart_kwargs'] = {}
76 | else:
77 | state['chart_theme'] = None
78 | state['chart_kwargs'] = {'template': state['chart_template']}
79 |
80 | def _charts_selectbox_cb(menu_map):
81 | state['menu_choice'] = list(menu_map.keys()).index(state['charts_selectbox'])
82 |
83 | def _set_chart_template_cb():
84 | state['chart_template'] = state['key_chart_template']
85 | state['chart_kwargs'] = {'template': state['chart_template']}
86 |
87 | def _show_table_checkbox_cb():
88 | state['show_table'] = state['show_table_checkbox']
89 |
90 | # -----------------------------------------------------------------------------
91 | # DATA WRAPPERS (uses latest Streamlit 1.18 @st.cache_data)
92 |
93 | @st.cache_data(ttl=dt.timedelta(hours=1), show_spinner="Building data catalog")
94 | def data_catalog() -> MyDataCatalog:
95 | catalog = MyDataCatalog()
96 | datasets = catalog.build_data_catalog()
97 | print('Available datasets:', datasets)
98 | return catalog
99 |
100 | @st.cache_data(ttl=dt.timedelta(hours=1), show_spinner="Loading crypto candles data")
101 | def load_data(symbol):
102 | data = data_catalog().load('crypto_candles_data')
103 | df_oclh = data.copy().query(f"symbol == '{symbol}' and period == '{OCLH_PERIOD}'")
104 | df_oclh['Timestamp'] = pd.to_datetime(df_oclh['Timestamp'], dayfirst=True)
105 | df_oclh.set_index('Timestamp', inplace=True)
106 | return df_oclh
107 |
108 | @st.cache_data(ttl=dt.timedelta(hours=1), show_spinner="Loading model features data")
109 | def load_features(symbol):
110 | data = data_catalog().load(f'{symbol.lower()}_crypto_features_data')
111 | df_features = data.copy()
112 | df_features['Timestamp'] = pd.to_datetime(df_features['Timestamp'], dayfirst=True)
113 | df_features.set_index('Timestamp', inplace=True)
114 | return df_features
115 |
116 | @st.cache_data(ttl=dt.timedelta(hours=1), show_spinner="Converting data to CSV")
117 | def _convert_df_to_csv(df: pd.DataFrame, index=False, name=None):
118 | return df.to_csv(index=index, encoding='utf-8')
119 |
120 | #----------------------------------------------------------------------------
121 | # KEDRO VIZ SERVER
122 |
123 | def launch_kedro_viz_server(reporter):
124 |
125 | if not state['kedro_viz_started']:
126 | import os
127 | import subprocess
128 | import threading
129 |
130 | def _run_job(job):
131 | print (f"\nRunning job: {job}\n")
132 | proc = subprocess.Popen(job)
133 | proc.wait()
134 | return proc
135 |
136 | if st.secrets['OS'] == 'windows':
137 | job = [os.path.join('.\\', 'kedro_viz.cmd')]
138 | else:
139 | job = [os.path.join('./', 'kedro_viz.sh')]
140 |
141 | reporter.warning('Starting visualization server...')
142 | time.sleep(3)
143 | # server thread will remain active as long as streamlit thread is running, or is manually shutdown
144 | thread = threading.Thread(name='Kedro-Viz', target=_run_job, args=(job,), daemon=True)
145 | thread.start()
146 | reporter.info('Waiting for server response...')
147 | time.sleep(3)
148 |
149 | retries = 5
150 | while True:
151 | reporter.info('Waiting for server response...')
152 | # give it time to start
153 | resp = None
154 | try:
155 | resp = requests.get(KEDRO_VIZ_SERVER_URL)
156 | except:
157 | pass
158 | if resp and resp.status_code == 200:
159 | state['kedro_viz_started'] = True
160 | reporter.empty()
161 | break
162 | else:
163 | time.sleep(1)
164 | retries -= 1
165 | if retries < 0:
166 | reporter.info('Right click on the empty iframe and select "Reload frame"')
167 | break
168 |
169 | #----------------------------------------------------------------------------
170 | #
171 | # PAGE DISPLAY FUNCTIONS
172 | #
173 | #----------------------------------------------------------------------------
174 | # CANDLESTICKS
175 |
176 | def page_candlesticks(symbol, df_oclh: pd.DataFrame):
177 | st.markdown(f'### CANDLESTICKS for {symbol}')
178 |
179 | layout = {
180 | 'title': f'{symbol} Price and Volume Chart',
181 | 'xaxis': {'title': 'T'},
182 | 'yaxis': {'title': 'Closing Price ($)'},
183 | 'xaxis_rangeslider_visible': True,
184 | 'width': 1200,
185 | 'height': 800,
186 | }
187 | if state['chart_kwargs']:
188 | layout['template'] = state['chart_kwargs']['template']
189 |
190 | fig = go.Figure(
191 | data = [
192 | go.Candlestick(
193 | x=df_oclh.index,
194 | open=df_oclh['open'],
195 | high=df_oclh['high'],
196 | low=df_oclh['low'],
197 | close=df_oclh['close'],
198 | increasing_line_color='green',
199 | decreasing_line_color='#FF4B4B',
200 | )
201 | ],
202 | layout = layout,
203 | )
204 | # fig.update_layout(xaxis_rangeslider_visible=True)
205 | st.plotly_chart(fig, theme=state['chart_theme'])
206 |
207 | df_oclh_copy = df_oclh.copy()
208 | df_oclh_copy['up_down'] = np.where(df_oclh_copy['close'] >= df_oclh_copy['open'], 'up', 'down')
209 | print(df_oclh_copy.head())
210 | fig = px.bar(
211 | df_oclh_copy,
212 | x=df_oclh_copy.index, y='volume',
213 | labels={df_oclh_copy.index.name: 'T', 'volume': 'Volume'},
214 | color='up_down',
215 | color_discrete_sequence=['green', '#FF4B4B'],
216 | opacity = 0.6,
217 | width=1200, height=250,
218 | **state['chart_kwargs']
219 | )
220 | st.plotly_chart(fig, theme=state['chart_theme'])
221 |
222 | #----------------------------------------------------------------------------
223 | # INDICATORS
224 |
225 | def page_price_indicators(symbol, df_features: pd.DataFrame):
226 | st.markdown(f'### CLOSE PRICE & INDICATORS for {symbol}')
227 |
228 | fig = px.line(
229 | df_features,
230 | x=df_features.index, y='close',
231 | labels={'Timestamp': 'T', 'close': 'Close'},
232 | color='series_id',
233 | title=f'{OCLH_PERIOD} Frequency Close Prices ({symbol})',
234 | width=1200, height=800,
235 | **state['chart_kwargs']
236 | )
237 | st.plotly_chart(fig, theme=state['chart_theme'])
238 |
239 | columns = [col for col in df_features.columns if not col in [
240 | 'Timestamp', 'symbol', 'period', 'series_id',
241 | 'open', 'low', 'high', f'close_t{FORECAST_HORIZON}'
242 | ]]
243 | indicators = st.multiselect('Select indicator series', options=columns, default=['close', 'ema_short', 'ema_long'], max_selections=5)
244 |
245 | fig = px.line(
246 | df_features[indicators],
247 | x=df_features.index, y=indicators,
248 | labels={'Timestamp': 'T'},
249 | # color=indicators,
250 | title=f'{OCLH_PERIOD} Frequency ({symbol})',
251 | width=1200, height=800,
252 | **state['chart_kwargs']
253 | )
254 | st.plotly_chart(fig, theme=state['chart_theme'])
255 |
256 | #----------------------------------------------------------------------------
257 | # TRAIN / TEST
258 |
259 | def page_train_test(symbol, df_oclh: pd.DataFrame):
260 | st.markdown(f'### TRAIN & TEST DATA SPLITS for {symbol}')
261 |
262 | train_df = df_oclh[TRAIN_INDEX].copy()
263 | if not train_df.empty:
264 | train_df['split_id'] = 'train'
265 | else:
266 | st.error(
267 | f'Training data set is not in display window. '
268 | f'Increase number of days data in window (split_date = {SPLIT_DATE}).'
269 | )
270 | test_df = df_oclh[TEST_INDEX].copy()
271 | test_df['split_id'] = 'test'
272 |
273 | train_test_df = pd.concat([train_df, test_df], axis=0)
274 |
275 | fig = px.line(
276 | train_test_df,
277 | x=train_test_df.index, y='close',
278 | labels={train_test_df.index.name: 'T', 'close': f'{symbol} Price ($)'},
279 | color='split_id',
280 | # color_discrete_sequence=['blue','green'],
281 | title=f'Train / Test Split: {symbol}',
282 | width=1200, height=800,
283 | **state['chart_kwargs']
284 | )
285 | st.plotly_chart(fig, theme=state['chart_theme'])
286 |
287 | # -----------------------------------------------------------------------------
288 | # PREDICTIONS
289 |
290 | def page_predictions(symbol):
291 | st.markdown(f'### PREDICTIONS for {symbol}')
292 | st.write('')
293 |
294 | reporter = st.empty()
295 |
296 | result_df = pd.read_csv(f'./data/{symbol.lower()}_predictions.csv', encoding='utf-8', keep_default_na=True)
297 |
298 | c1, c2, _ = st.columns([1,1,3])
299 | with c1:
300 | y, y_pred = result_df['close_t1'], result_df['close_pred_t1']
301 | mse = mean_squared_error(y, y_pred)
302 | st.markdown('##### 🤒 Mean Square Error (MSE)')
303 | st.metric('Mean Square Error (MSE)', f'{round(mse * 100, 3)}%' , f'{round((0.05 - mse) * 100, 3)}%', label_visibility='collapsed')
304 | with c2:
305 | # Launch button will only work locally
306 | if not st.secrets['IS_ST_CLOUD']:
307 | st.markdown('##### ⚙️ Pipeline visualization')
308 | launch_kedro_viz_server(reporter)
309 | if state['kedro_viz_started']:
310 | reporter.empty()
311 | st_functions.st_button('kedro', KEDRO_VIZ_SERVER_URL, 'Launch Kedro-Viz', 40)
312 | else:
313 | st.markdown('##### ⚙️ Pipeline specification')
314 | st.caption('_Please [clone the app](https://github.com/asehmi/using_chatgpt_kedro_streamlit_app) and run it locally to get an interactive pipeline visualization._')
315 |
316 | if st.checkbox('Show specification', False):
317 | with open(f'./data/{symbol.lower()}_pipeline.json', 'rt', encoding='utf-8') as fp:
318 | pipeline_json = fp.read()
319 | st.json(pipeline_json, expanded=True)
320 |
321 | if state['show_table']:
322 | st.markdown('---')
323 | st.subheader('Data')
324 | st.write(result_df)
325 |
326 | st.markdown('---')
327 | st.subheader('Chart')
328 | fig = px.line(
329 | result_df,
330 | x=result_df.index, y=['close_t1', 'close_pred_t1'],
331 | labels={result_df.index.name: 'T', 'close_t1': f'{symbol} Price ($)', 'close_pred_t1': f'{symbol} Price Prediction ($)'},
332 | title=f'Price Prediction: {symbol}',
333 | width=1200, height=800,
334 | **state['chart_kwargs']
335 | )
336 | st.plotly_chart(fig, theme=state['chart_theme'])
337 |
338 | # -----------------------------------------------------------------------------
339 | # SETTINGS and MENU
340 |
341 | def sidebar_menu():
342 | with st.sidebar:
343 | c1, _ = st.columns([1,1])
344 | with c1:
345 | st.image(Image.open('./images/a12i_logo.png'))
346 | st.header('Kedro ML Pipeline')
347 | menu_selection = st.radio('What would you like to do?', [
348 | '📈 View source data charts',
349 | '👣 Run model (manual)',
350 | '🥁 Run model (pipeline orchestration)',
351 | '❤️ Pipeline visualization (embedded)',
352 | '🙋 About',
353 | ], horizontal=False)
354 | return menu_selection
355 |
356 |
357 | def sidebar_settings():
358 | with st.sidebar:
359 | st.subheader('Settings')
360 | with st.form(key='settings_form'):
361 | options = ['LTC', 'SOL', 'UNI', 'DOT']
362 | symbol = st.selectbox('💰 Select coin', options=options, index=1)
363 | st.form_submit_button('Apply', type='primary')
364 | st.checkbox('🔢 Show source data table', state['show_table'], key='show_table_checkbox', on_change=_show_table_checkbox_cb)
365 | return symbol
366 |
367 |
368 | def sidebar_chart_style_and_other_settings():
369 | with st.sidebar:
370 | st.subheader('Chart style')
371 | c1, c2 = st.columns(2)
372 | with c1:
373 | st.caption('🎈 Theme')
374 | st.checkbox('Streamlit', value=state['chart_theme'], on_change=_set_chart_theme_cb, key='key_chart_theme')
375 | with c2:
376 | if not state['chart_theme']:
377 | st.caption('🌈 Template')
378 | st.selectbox(
379 | 'Label should not be visible', options=px_templates, index=px_templates.index(state['chart_template']),
380 | label_visibility='collapsed', on_change=_set_chart_template_cb, key='key_chart_template'
381 | )
382 |
383 | st.markdown('---')
384 | if st.button('🧹 Clear cache', type='primary', help='Refresh source data and data catalog for this application'):
385 | data_catalog.clear()
386 | load_data.clear()
387 | load_features.clear()
388 | _convert_df_to_csv.clear()
389 | st.experimental_rerun()
390 |
391 | # -----------------------------------------------------------------------------
392 | # TOP LEVEL MENU ACTIONS
393 |
394 | def view_source_data_charts(symbol):
395 |
396 | df_oclh = load_data(symbol)
397 | df_features = load_features(symbol)
398 | menu_map = {
399 | 'Candlesticks': (page_candlesticks, [symbol, df_oclh]),
400 | 'Price & Indicators': (page_price_indicators, [symbol, df_features]),
401 | 'Train | Test Split': (page_train_test, [symbol, df_oclh]),
402 | }
403 |
404 | with st.sidebar:
405 | st.subheader('Charts and Tables')
406 | menu_choice = st.radio(
407 | 'Charts',
408 | label_visibility='collapsed',
409 | options=menu_map.keys(),
410 | index=state['menu_choice'],
411 | key='charts_selectbox',
412 | on_change=_charts_selectbox_cb,
413 | args=(menu_map,)
414 | )
415 |
416 | if state['show_table']:
417 | with st.expander(f'Data Tables ({symbol})', expanded=True):
418 | tab1, tab2 = st.tabs(['OCLH Data', 'Features Data'])
419 |
420 | with tab1:
421 | st.markdown(f'### OCLH Data for {symbol}')
422 | c1, c2 = st.columns([3,1])
423 | with c1:
424 | st.write(df_oclh.sort_values(by=df_oclh.index.name, ascending=False))
425 | st.caption(f'Size {df_oclh.shape}')
426 | file_name=f'{symbol.lower()}_oclh.csv'
427 | st.download_button(
428 | label='📥 Download OCLH Data',
429 | help=file_name,
430 | data=_convert_df_to_csv(df_oclh, index=True, name=file_name),
431 | file_name=file_name,
432 | mime='text/csv',
433 | )
434 | with c2:
435 | st.write(df_oclh.shape)
436 | st.json(list(df_oclh.dtypes), expanded=False)
437 |
438 | with tab2:
439 | st.markdown(f'### Features Data for {symbol}')
440 | c1, c2 = st.columns([3,1])
441 | with c1:
442 | st.write(df_features.sort_values(by=df_features.index.name, ascending=False))
443 | st.caption(f'Size {df_features.shape}')
444 | file_name=f'{symbol.lower()}_features.csv'
445 | st.download_button(
446 | label='📥 Download Features Data',
447 | help=file_name,
448 | data=_convert_df_to_csv(df_features, index=True, name=file_name),
449 | file_name=file_name,
450 | mime='text/csv',
451 | )
452 | with c2:
453 | st.write(df_features.shape)
454 | st.json(list(df_features.dtypes), expanded=False)
455 |
456 | fn = menu_map[menu_choice][0]
457 | args = menu_map[menu_choice][1]
458 | fn(*args)
459 |
460 |
461 | def run_model_manual(symbol):
462 | df_features = load_features(symbol)
463 | model = train_model(df_features[TRAIN_INDEX])
464 | y, y_pred, mse = evaluate_model(model, df_features[TEST_INDEX])
465 | plot_metric(symbol, y, y_pred, mse)
466 | page_predictions(symbol)
467 |
468 |
469 | def run_model_pipeline(symbol):
470 | pipeline_json = create_pipeline(**{'symbol': symbol}).to_json()
471 | with open(f'./data/{symbol.lower()}_pipeline.json', 'wt', encoding='utf-8') as fp:
472 | fp.write(pipeline_json)
473 | run_pipeline(symbol, data_catalog())
474 | page_predictions(symbol)
475 |
476 |
477 | def show_pipeline_viz(symbol):
478 | # Render the pipeline graph (cool demo here: https://demo.kedro.org/)
479 | st.subheader('KEDRO PIPELINE VISUALIZATION')
480 |
481 | reporter = st.empty()
482 |
483 | if st.secrets['IS_ST_CLOUD']:
484 | st.markdown('**_The interactive pipeline visualization is only available when running this app on your local computer. Please [clone the app](https://github.com/asehmi/using_chatgpt_kedro_streamlit_app) and run it locally._**')
485 | st.write("Here's a preview image of what you will see:")
486 | st.image(Image.open('./images/kedro_viz.png'))
487 | return
488 |
489 | launch_kedro_viz_server(reporter)
490 |
491 | if state['kedro_viz_started']:
492 | st.caption(f'This interactive pipeline visualization is for {SYMBOL_DEFAULT} but is the same for all coins.')
493 | components.iframe(KEDRO_VIZ_SERVER_URL, width=1500, height=800)
494 |
495 |
496 | def show_about():
497 | c1, _ = st.columns([1,2])
498 | with c1:
499 | st.markdown("""
500 | ## Using ChatGPT to build a Kedro ML pipeline
501 |
502 | Hi community! 👋
503 |
504 | My name is Arvindra Sehmi, and I'm an active member of the Streamlit Creators group. I’m on a break from a 35-year-long career in tech
505 | (currently advising [Auth0.com](http://auth0.com/), [Macrometa.com](http://macrometa.com/), [Tangle.io](http://tangle.io/),
506 | [Crowdsense.ai](https://crowdsense.ai/), and [DNX ventures](https://www.dnx.vc/)) and am taking the opportunity to learn new software development tools.
507 |
508 | I recently came across an open-source Python DevOps framework [Kedro](https://kedro.org/) and thought, "Why not have [ChatGPT](https://chat.openai.com/chat)
509 | teach me how to use it to build some ML/DevOps automation?"
510 |
511 | The idea was to:
512 | 1. Ask ChatGPT some basic questions about Kedro.
513 | 2. Ask it to use more advanced features in the Kedro framework.
514 | 3. Write my questions with hints and phrases that encouraged explanations of advanced Kedro features (to evolve incrementally as if I were taught by a teacher).
515 |
516 | Kedro has some pipeline visualization capabilities, so I wondered:
517 | - Could ChatGPT show me how to display pipeline graphs in Streamlit?
518 | - Could ChatGPT build me an example ML model and explicitly refer to it in the Kedro pipeline?
519 | - What does it take to scale the pipeline, and perform pipeline logging, monitoring, and error handling?
520 | - Could I connect Kedro logs to a cloud-based logging service?
521 | - Could ChatGPT contrast Kedro with similar (competing) products and services and show me how the pipeline it developed earlier could be implemented in one of them?
522 |
523 | I wrote a [blog post with annotated responses to the answers I got to my questions](https://blog.streamlit.io/using-chatgpt-to-build-a-kedro-ml-pipeline/). I was
524 | super impressed and decided to implement the Kedro pipeline and Streamlit application as planned from what I learned. My [GitHub](https://github.com/asehmi/using_chatgpt_kedro_streamlit_app)
525 | repository contains the code for the application and details of installing and running it yourself.
526 |
527 | > As you'll read in my blog post ChatGPT helps "understanding" and is why I found it useful for learning. The Kedro code ChatGPT
528 | generated was simplistic and in some cases wrong, but perfectly okay to get the gist of how it worked. This app is original, with small parts of it
529 | taken from Kedro's code template, so you're free to use it without any recourse under the MIT license.
530 |
531 | Happy Streamlit-ing! 🎈
532 | """)
533 | c1, _ = st.columns([1,5])
534 | with c1:
535 | st_functions.st_button('twitter', 'https://twitter.com/asehmi/', 'Follow me on Twitter', 20)
536 | st_functions.st_button('linkedin', 'https://www.linkedin.com/in/asehmi/', 'Follow me on LinkedIn', 20)
537 | st_functions.st_button('cup', 'https://www.buymeacoffee.com/asehmi', 'Buy me a Coffee', 20)
538 |
539 | # -----------------------------------------------------------------------------
540 | # TOP LEVEL MENU ACTIONS DISPATCHER
541 |
542 | menu_selection = sidebar_menu()
543 | if menu_selection == '📈 View source data charts':
544 | symbol = sidebar_settings()
545 | view_source_data_charts(symbol)
546 | sidebar_chart_style_and_other_settings()
547 | if menu_selection == '👣 Run model (manual)':
548 | symbol = sidebar_settings()
549 | run_model_manual(symbol)
550 | sidebar_chart_style_and_other_settings()
551 | if menu_selection == '🥁 Run model (pipeline orchestration)':
552 | symbol = sidebar_settings()
553 | run_model_pipeline(symbol)
554 | sidebar_chart_style_and_other_settings()
555 | if menu_selection == '❤️ Pipeline visualization (embedded)':
556 | symbol = sidebar_settings()
557 | show_pipeline_viz(symbol)
558 | sidebar_chart_style_and_other_settings()
559 | if menu_selection == '🙋 About':
560 | show_about()
561 |
--------------------------------------------------------------------------------
/src/streamlit_debug.py:
--------------------------------------------------------------------------------
1 | # How to use:
2 | #
3 | # [1] Ensure you have `debugpy` installed:
4 | #
5 | # > pip install debugpy
6 | #
7 | # [2] In your main streamlit app:
8 | #
9 | # import streamlit_debug
10 | # streamlit_debug.set(flag=True, wait_for_client=True, host='localhost', port=8765)
11 | #
12 | # `flag=True` will initiate a debug session. `wait_for_client=True` will wait for a debug client to attach when
13 | # the streamlit app is run before hitting your next debug breakpoint. `wait_for_client=False` will not wait.
14 | #
15 | # If using VS Code, you need this config in your `.vscode/launch.json` file:
16 | #
17 | # {
18 | # // Use IntelliSense to learn about possible attributes.
19 | # // Hover to view descriptions of existing attributes.
20 | # // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
21 | # "version": "0.2.0",
22 | # "configurations": [
23 | # {
24 | # "name": "Python: Current File",
25 | # "type": "python",
26 | # "request": "launch",
27 | # "program": "${file}",
28 | # "console": "integratedTerminal",
29 | # "env": {"DEBUG": "true"}
30 | # },
31 | # {
32 | # "name": "Python: debugpy Remote Attach",
33 | # "type": "python",
34 | # "request": "attach",
35 | # "connect": {
36 | # "port": 8765,
37 | # "host": "127.0.0.1",
38 | # },
39 | # "justMyCode": false,
40 | # "redirectOutput": true,
41 | # "logToFile": true,
42 | # "pathMappings": [
43 | # {
44 | # "localRoot": "${workspaceFolder}",
45 | # "remoteRoot": "."
46 | # }
47 | # ]
48 | # // "debugAdapterPath": "${workspaceFolder}/src/debugpy/adapter",
49 | # },
50 | # ]
51 | # }
52 | #
53 | # The port numbers you use need to match - in `streamlit_debug.set()` and `launch.json`. It should NOT be the same port that
54 | # streamlit is started on.
55 | #
56 | # When `flag=True` and `wait_for_client=True`, you'll must activate the "Python: debugpy Remote Attach" debug session
57 | # from vs-code.
58 |
59 | import streamlit as st
60 | import logging
61 |
62 | _DEBUG = False
63 | def set(flag: bool=False, wait_for_client=False, host='localhost', port=8765):
64 | global _DEBUG
65 | _DEBUG = flag
66 | try:
67 | # To prevent debugpy loading again and again because of
68 | # Streamlit's execution model, we need to track debugging state
69 | if 'debugging' not in st.session_state:
70 | st.session_state.debugging = None
71 |
72 | if _DEBUG and not st.session_state.debugging:
73 | # https://code.visualstudio.com/docs/python/debugging
74 | import debugpy
75 | if not debugpy.is_client_connected():
76 | debugpy.listen((host, port))
77 | if wait_for_client:
78 | logging.info(f'>>> Waiting for debug client attach... <<<')
79 | debugpy.wait_for_client() # Only include this line if you always want to manually attach the debugger
80 | logging.info(f'>>> ...attached! <<<')
81 | # debugpy.breakpoint()
82 |
83 | if st.session_state.debugging == None:
84 | logging.info(f'>>> Remote debugging activated (host={host}, port={port}) <<<')
85 | st.session_state.debugging = True
86 |
87 | if not _DEBUG:
88 | if st.session_state.debugging == None:
89 | logging.info(f'>>> Remote debugging in NOT active <<<')
90 | st.session_state.debugging = False
91 | except:
92 | # Ignore... e.g. for cloud deployments
93 | pass
94 |
--------------------------------------------------------------------------------
/src/style.css:
--------------------------------------------------------------------------------
1 | .appview-container {
2 | /* color: white; */
3 | /* background-color: black; */
4 | overflow: auto;
5 | }
6 | div[class="css-hxt7ib e1fqkh3o2"] {
7 | /* color: white; */
8 | /* background-color: black; */
9 | max-width: 100%;
10 | padding-top: 30px;
11 | overflow: auto;
12 | }
13 | div[class="block-container css-18e3th9 egzxvld2"] {
14 | max-width: 100%;
15 | padding-top: 30px;
16 | padding-right: 0px;
17 | padding-left: 30px;
18 | padding-bottom: 0px;
19 | }
20 | /*
21 | MainMenu {
22 | visibility: hidden;
23 | }
24 | */
25 | header {
26 | visibility: visible;
27 | height: 0%;
28 | }
29 | /*
30 | footer {
31 | visibility: hidden;
32 | }
33 | */
34 |
--------------------------------------------------------------------------------