├── img
├── feature-engineering.pdf
├── feature-engineering.png
└── feature-engineering.drawio
├── .gitignore
├── tmall
├── graph_embedding
│ ├── train_node2vec.py
│ └── create_graph_embedding_data.py
├── filter_features.py
├── build_value_counts.py
├── calc_similarity_offline.py
├── utils.py
├── stat_feat
│ ├── preprocessing.py
│ ├── fesys_pyspark.py
│ └── build_feat_pyspark.py
└── bagging.py
├── train_lgbm.py
└── README.md
/img/feature-engineering.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/auto-flow/tmall-repeat/HEAD/img/feature-engineering.pdf
--------------------------------------------------------------------------------
/img/feature-engineering.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/auto-flow/tmall-repeat/HEAD/img/feature-engineering.png
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | __pycache__
3 | *.pyc
4 | *.csv
5 | venv
6 | *.json
7 | *.pkl
8 | .pytest_cache
9 | *.log
10 | .virtual_documents
11 | .ipynb_checkpoints
12 | build
13 | dist
14 | *.egg-info
15 | toy.ipynb
16 | *.bak
17 | dask-worker-space
18 | *.lock
19 | *.dirlock
20 | _tutorials
21 | _module
22 | !favicon.png
23 | !logo.png
24 | smac3-output_*
25 | .coverage*
26 |
--------------------------------------------------------------------------------
/tmall/graph_embedding/train_node2vec.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-24
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | import csrgraph as cg
7 | from joblib import dump
8 | from nodevectors import Node2Vec
9 |
10 | G = cg.read_edgelist("data/graph_data.csv", directed=False, sep=',')
11 | node2vec = Node2Vec(threads=6, n_components=100, w2vparams=dict(workers=12))
12 | node2vec.fit(G)
13 | print(node2vec)
14 | dump(node2vec, "data/node2vec.pkl")
15 |
--------------------------------------------------------------------------------
/tmall/filter_features.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-24
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | import numpy as np
7 | import pandas as pd
8 | from boruta import BorutaPy
9 | from sklearn.ensemble import ExtraTreesClassifier
10 | from joblib import dump
11 | from joblib import load
12 | import os
13 |
14 | boruta = BorutaPy(
15 | ExtraTreesClassifier(max_depth=5, n_jobs=4),
16 | n_estimators='auto', max_iter=1000, random_state=0, verbose=2)
17 |
18 | train = load('data/train2.pkl')
19 | train.fillna(0, inplace=True)
20 | train[np.isinf(train)] = 0
21 | y = train.pop('label')
22 | boruta.fit(train, y)
23 | dump(boruta, 'data/boruta3.pkl')
24 | os.system('google-chrome https://ssl.gstatic.com/dictionary/static/sounds/oxford/ok--_gb_1.mp3')
25 | print(boruta)
26 |
--------------------------------------------------------------------------------
/tmall/build_value_counts.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-25
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | from collections import Counter
7 |
8 | import gc
9 | import pandas as pd
10 |
11 | user_log: pd.DataFrame = pd.read_pickle('data/user_log.pkl')
12 | print(user_log)
13 | core_ids = ['user_id', 'merchant_id']
14 | item_ids = ['brand_id', 'item_id', 'cat_id']
15 |
16 |
17 | def value_counts_ratio(seq):
18 | n_seq = len(seq)
19 | count = Counter(seq)
20 | return {k: v / n_seq for k, v in count.items()}
21 |
22 |
23 | for pk in core_ids:
24 | df = user_log.groupby(pk).agg(
25 | dict(zip(item_ids, [value_counts_ratio] * len(item_ids)))).\
26 | reset_index()
27 | df.to_pickle(f'data/{pk}_value_counts_ratio.pkl')
28 | del df
29 | gc.collect()
30 |
--------------------------------------------------------------------------------
/tmall/graph_embedding/create_graph_embedding_data.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-23
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | from collections import defaultdict
7 | from functools import partial
8 |
9 | import pandas as pd
10 | from joblib import dump
11 |
12 | user_log: pd.DataFrame = pd.read_pickle("user_log.pkl")[['user_id', 'merchant_id', 'action_type']]
13 |
14 | G = defaultdict(lambda: defaultdict(int))
15 | entity2id = {}
16 |
17 |
18 | def get_id_of_entity(id, prefix):
19 | id = f"{prefix}{id}"
20 | if id not in entity2id:
21 | entity2id[id] = len(entity2id)
22 | return entity2id[id]
23 |
24 |
25 | uid = partial(get_id_of_entity, prefix="u")
26 | mid = partial(get_id_of_entity, prefix="m")
27 |
28 | # 遍历
29 | for i, (user_id, merchant_id, action_type) in user_log.iterrows():
30 | G[uid(user_id)][mid(merchant_id)] += 1
31 |
32 | # 输出
33 | data = []
34 | for u in G.keys():
35 | Gu = G[u]
36 | for v, Guv in Gu.items():
37 | data.append([u, v, Guv])
38 |
39 | pd.DataFrame(data).to_csv('data/graph_data.csv', header=False, index=False)
40 | # 对字典进行序列化
41 | dump(entity2id, "data/entity2id.pkl")
42 | # 因为含有lambda,所以无法直接序列化
43 | # 结点规模是40w
44 | dump(dict(G), "data/graph_data.pkl")
45 |
--------------------------------------------------------------------------------
/tmall/calc_similarity_offline.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-25
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | '''离线计算相似度特征'''
7 | import os
8 |
9 | import numpy as np
10 | import pandas as pd
11 | from joblib import load
12 |
13 | train = pd.read_csv('data_format1/train_format1.csv')
14 | test = pd.read_csv('data_format1/test_format1.csv')
15 | train.pop('label')
16 | test.pop('prob')
17 | N = train.shape[0]
18 | all_data = pd.concat([train, test], axis=0)
19 | res = all_data.copy()
20 | pk2vcr = load("data/pk2vcr2.pkl")
21 | core_ids = ['user_id', 'merchant_id']
22 | item_ids = ['brand_id', 'item_id', 'cat_id']
23 | for pk in core_ids:
24 | columns = pk2vcr[pk].columns[1:]
25 | all_data = all_data.merge(pk2vcr[pk], "left", pk)
26 | all_data.rename(columns=dict(zip(
27 | [f"{x}_vectors" for x in item_ids],
28 | [f"{pk}_{x}_vectors" for x in item_ids],
29 | )), inplace=True)
30 | for id_ in item_ids:
31 | A = np.array(all_data[f"user_id_{id_}_vectors"].tolist())
32 | B = np.array(all_data[f"merchant_id_{id_}_vectors"].tolist())
33 | res[f"{id_}_similarity"] = np.sum(A * B, axis=1) / \
34 | (np.linalg.norm(A, axis=1) * np.linalg.norm(B, axis=1))
35 | all_data.to_pickle("data/items_vectors2.pkl")
36 | res.to_pickle("data/similarity_features2.pkl")
37 | os.system('google-chrome https://ssl.gstatic.com/dictionary/static/sounds/oxford/ok--_gb_1.mp3')
38 |
--------------------------------------------------------------------------------
/tmall/utils.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-22
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | import warnings
7 | from pathlib import Path
8 |
9 | import numpy as np
10 |
11 | warnings.filterwarnings("ignore")
12 |
13 |
14 | def get_data_path() -> str:
15 | return (Path(__file__).parent.parent / 'data').as_posix()
16 |
17 |
18 | def reduce_mem_usage(df, verbose=True):
19 | start_mem = df.memory_usage().sum() / 1024 ** 2
20 | numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
21 |
22 | for col in df.columns:
23 | col_type = df[col].dtypes
24 | if col_type in numerics:
25 | c_min = df[col].min()
26 | c_max = df[col].max()
27 | if str(col_type)[:3] == 'int':
28 | if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
29 | df[col] = df[col].astype(np.int8)
30 | elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
31 | df[col] = df[col].astype(np.int16)
32 | elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
33 | df[col] = df[col].astype(np.int32)
34 | elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
35 | df[col] = df[col].astype(np.int64)
36 | else:
37 | if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
38 | df[col] = df[col].astype(np.float16)
39 | elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
40 | df[col] = df[col].astype(np.float32)
41 | else:
42 | df[col] = df[col].astype(np.float64)
43 |
44 | end_mem = df.memory_usage().sum() / 1024 ** 2
45 | if verbose:
46 | print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
47 | print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
48 | return df
49 |
50 | import pandas as pd
51 |
52 | def _map_to_pandas(rdds):
53 | """ Needs to be here due to pickling issues """
54 | return [pd.DataFrame(list(rdds))]
55 |
56 | def spark_to_pandas(df, n_partitions=None):
57 | """
58 | Returns the contents of `df` as a local `pandas.DataFrame` in a speedy fashion. The DataFrame is
59 | repartitioned if `n_partitions` is passed.
60 | :param df: pyspark.sql.DataFrame
61 | :param n_partitions: int or None
62 | :return: pandas.DataFrame
63 | """
64 | if n_partitions is not None: df = df.repartition(n_partitions)
65 | df_pand = df.rdd.mapPartitions(_map_to_pandas).collect()
66 | df_pand = pd.concat(df_pand)
67 | df_pand.columns = df.columns
68 | return df_pand
69 |
--------------------------------------------------------------------------------
/tmall/stat_feat/preprocessing.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-03-02
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | import datetime
7 | import warnings
8 |
9 | import gc
10 | import pandas as pd
11 |
12 | from tmall.utils import reduce_mem_usage, get_data_path
13 |
14 | warnings.filterwarnings("ignore")
15 |
16 |
17 | def read_csv(file_name, num_rows):
18 | return pd.read_csv(file_name, nrows=num_rows)
19 |
20 | data_path=get_data_path()
21 |
22 | # num_rows = 200 * 10000 # 1000条测试代码使用
23 | num_rows = None
24 |
25 | # 读入数据,内存压缩
26 | train_file = f'{data_path}/data_format1/train_format1.csv'
27 | test_file = f'{data_path}/data_format1/test_format1.csv'
28 |
29 | user_info_file = f'{data_path}/data_format1/user_info_format1.csv'
30 | user_log_file = f'{data_path}/data_format1/user_log_format1.csv'
31 |
32 | train_data = reduce_mem_usage(read_csv(train_file, num_rows))
33 | test_data = reduce_mem_usage(read_csv(test_file, num_rows))
34 | user_info = reduce_mem_usage(read_csv(user_info_file, num_rows))
35 | # 处理缺失值
36 | user_info['age_range'][pd.isna(user_info['age_range'])] = 0
37 | user_info['gender'][pd.isna(user_info['gender'])] = 2
38 | user_info[['age_range', 'gender']] = user_info[['age_range', 'gender']].astype('int8')
39 | user_info.to_pickle('user_info.pkl')
40 | user_log = reduce_mem_usage(read_csv(user_log_file, num_rows))
41 | user_log.rename(columns={'seller': 'merchant_id'})
42 |
43 | del test_data['prob']
44 | all_data = train_data.append(test_data)
45 | all_data = all_data.merge(user_info, 'left', on=['user_id'], how='left')
46 | gc.collect()
47 | # seller_id 与 训练测试集不匹配
48 | user_log.rename(columns={'seller_id': 'merchant_id'}, inplace=True)
49 | # user_log 的 brand_id存在空值,用0填充
50 | user_log['brand_id'][pd.isna(user_log['brand_id'])] = 0
51 | user_log['brand_id'] = user_log['brand_id'].astype('int16')
52 | # 引入用户画像信息到用户日志中
53 | user_log = pd.merge(user_info, 'left', user_log, on='user_id')
54 | # 把月和天的信息抽取出来
55 | # pandas做这件事特别慢
56 | # user_log['month'] = user_log['time_stamp'].apply(lambda x: int(f"{x:04d}"[:2])).astype('int8')
57 | # user_log['day'] = user_log['time_stamp'].apply(lambda x: int(f"{x:04d}"[2:])).astype('int8')
58 | user_log['month'] = (user_log['time_stamp'] // 100).astype('int8')
59 | user_log['day'] = (user_log['time_stamp'] % 100).astype('int8')
60 | # 查一下是星期几的
61 | user_log['time_stamp'] = user_log['time_stamp'].apply(lambda x: datetime.datetime.strptime(f'2016{x:04d}', '%Y%m%d'))
62 | user_log['weekday'] = user_log['time_stamp'].apply(lambda x: x.weekday()).astype('int8')
63 | # 加入标签特征
64 | train = pd.read_csv('data_format1/train_format1.csv')
65 | user_log = user_log.merge(train, 'left', ['user_id', 'merchant_id'])
66 | user_log['label'].fillna(-1, inplace=True)
67 | user_log['time_stamp_int']=(user_log['month']*100+user_log['day']).astype('int16')
68 | # 保存
69 | user_log.to_pickle(f'{data_path}/user_log.pkl')
70 |
--------------------------------------------------------------------------------
/train_lgbm.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-22
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | import os
7 |
8 | import pandas as pd
9 | # from imblearn.ensemble import BalancedBaggingClassifier
10 | from joblib import load
11 | from lightgbm import LGBMClassifier
12 |
13 | from tmall.bagging import BalancedBaggingClassifier
14 |
15 | train, y, test = load('data/all_data.pkl')
16 | # merchant_w2v: pd.DataFrame = load('data/merchant_w2v.pkl')
17 | # train = pd.merge(train, merchant_w2v, 'left', 'merchant_id')
18 | # test = pd.merge(test, merchant_w2v, 'left', 'merchant_id')
19 | highR_cols = [
20 | 'purchase-merchant_id-user_id-mostlike',
21 | 'merchant_id-user_id-mostlike',
22 | 'merchant_id-item_id-mostlike',
23 | 'user_id'
24 | ]
25 | # cat_encoder = CatBoostEncoder(random_state=0, cols=highR_cols).fit(train, y)
26 | # train = cat_encoder.transform(train)
27 | # test = cat_encoder.transform(test)
28 | # train.drop(highR_cols, axis=1, inplace=True)
29 | # test.drop(highR_cols, axis=1, inplace=True)
30 | train.fillna(0, inplace=True)
31 | test.fillna(0, inplace=True)
32 | categorical_feature = [
33 | c for i, c in enumerate(train.columns)
34 | if c.endswith('merchant_id') or c.endswith('mostlike') and c.split('-')[-2] != 'user_id'
35 | ]
36 | feature_name = train.columns.tolist()
37 |
38 | # train[cat_features] = train[cat_features].astype(int)
39 | # test[cat_features] = test[cat_features].astype(int)
40 |
41 | sample_weight = load('data/sample_weights.pkl').mean(1)[:train.shape[0]]
42 | # train_hid, test_hid = load('data/hidden_features.pkl')
43 | # hid_cols = [f"hidden_{i}" for i in range(20)]
44 | # train[hid_cols] = train_hid
45 | # test[hid_cols] = test_hid
46 | # merchant_w2v = pd.read_pickle('data/merchant_n2v.pkl')
47 | # user_w2v = pd.read_pickle('data/user_n2v.pkl')
48 | # merchant_w2v_col = merchant_w2v.columns.tolist()[1:]
49 | # user_w2v_col = user_w2v.columns.tolist()[1:]
50 | # train.drop(user_w2v_col + merchant_w2v_col, axis=1, inplace=True)
51 | # test.drop(user_w2v_col + merchant_w2v_col, axis=1, inplace=True)
52 | print(train.shape)
53 |
54 |
55 | class MyLGBMClassifier(LGBMClassifier):
56 | def fit(self, X, y,
57 | sample_weight=None):
58 | super(MyLGBMClassifier, self).fit(
59 | X, y, feature_name=feature_name, categorical_feature=categorical_feature)
60 |
61 |
62 | gbm = LGBMClassifier(random_state=None, silent=False, learning_rate=0.04, n_estimators=1000) # n_estimators=100
63 | bc = BalancedBaggingClassifier(
64 | gbm, random_state=0, n_estimators=50, n_jobs=1,
65 | oob_score=True, # warm_start=True
66 | )
67 |
68 | prediction = pd.read_csv('data_format1/test_format1.csv')
69 | prediction.pop('prob')
70 |
71 | model = bc.fit(train, y, sample_weight=sample_weight)
72 | # dump(model, "data/catboost.pkl")
73 | y_pred = bc.predict_proba(test)
74 | prediction['prob'] = y_pred[:, 1]
75 | prediction.to_csv('predictions/prediction3.csv', index=False)
76 | os.system('google-chrome https://ssl.gstatic.com/dictionary/static/sounds/oxford/ok--_gb_1.mp3')
77 | print(bc)
78 |
--------------------------------------------------------------------------------
/img/feature-engineering.drawio:
--------------------------------------------------------------------------------
1 | 7V1Zc9u2Fv41fIyH4M5H0ZbbO006vk17mzx1aImx2FCiSlGJ3V9/ARDgBpAiLYJLjLQzFimIC86H7yw4OFD02/3zT4l/3H2It0GkaOr2WdHvFE0DhqbCP+jMCzmjquTMUxJuybnixMfw34A2JGfP4TY4VRqmcRyl4bF6chMfDsEmrZzzkyT+Xm32JY6qdz36TwFz4uPGj9izf4bbdEfOWqZRfPFzED7t6K2B5Wbf7H3amrzKaedv4++lU/pa0W+TOE6zT/vn2yBC3Uc7JvvdfcO3+ZMlwSHt8oO7z/tffr775b/3n/9wPp4fnE//bFfvbJs8XPpCXznYwh4gh3GS7uKn+OBH6+Kstzkn3wJ0VQAPkvh82OIjFR4VP3gfx0fS5O8gTV+IbP1zGsNTu3QfkW/h4ycvn9Dvb0x6+JlcDh/cPVeOXsjR1j/t8qc4pUn8NbiNozjBb6Hf36uqg5p9iQ8puTfQyDGvHdudpIdP8TnZBC19aJoEmH7yFKRtna1nDVEPl25BxPVTEO8D+IKwQRJEfhp+q2LQJ1B+ytuRn66SxH8pNTjG4SE9la78gE7ABmRY6hSRZFDaNdzUmltWW3P4Ibs/PSq9SHEKQ7EHLIHxClhej8TnMP1EsQY/fy59LkCIDigGGdjd3sLuug5OAAhBCSNX26nK1TTtG6v0z65eMEM3uUZF/oNI3HSy233zozN5oz9OQfI+fmKQcPoe7iP/ENDBTb5Bvb7ZhdH2vf8Sn1Gnn1J/85Ueebs4Cf+F7X0qbvh1QqlBs9DVwiiisjzE+AbFjz6ii5HbJMEJ/uyBChfUTn3wnysN3/unlD5gHEX+8RQ+4kdGP9zDfg0PXpym8b4JVSr+14aqb0GSBs+tcCHfGrXR75LD7yX1ZpBzu5Jm01TnIsJ+gyrYPzzBdytuV2OP/Nql+5m821nVu/lRGiQHPw08NMpPQiDoMhA8Qwj+BX9UhyDs65QRFIEMB0V+FD4d4GEUfEE/Q8IKoY2xIqdTxE/e6ehvwsPTe9zmzijO/EZ6BZ2K4W+/RNiM2IXbbXDAvJf6qf+YDwLC//BBTQ/+Dzv3FqlWEz74LTwGxTH8HzVPoEI8wHfxQ4yqAML1e4Agy8Fb++C9jMKXqngvos5qBl1F/n2FTWFZEnaYBnspbAHCNrWphQ0YYW/8VMpagKxtZ2pZ64ys90Gy2fkHKXARAgeqMbXEDUbij4l/2EpxixC33tVeFCZukxF3Gu6Dv6A5vz9KgQ8ucHNyU81iBO5v0jA+/JW+HAMp8cEl7oxor31b/Rw8Bqr9z87axx82n142H/7zDmgmI9axw5KvDC/mMaQbwyyFkWh4iR9GQgcPQQJZDDq5SinYyQmL5iHThrAoC4vOcUxiOZXjmFzxUEYQHaFyzGrswHFrl2iISfUOiNLQBr2P3h4RdRy7rb2YkKjJ2rXK2lZcQ1k5ytpSHEfxbHxmpTgGOuOZinOvrB1lZaNv16birfAZEx26bOS/Oma+76BD/BHSHPr2e+Ifq+NDaJBKo/Mr1KsAHKtD41ASdesFUJK+fErqwUjjs4/RkX10YyT2qUUuTbeGraHYB1Sxbjr92KfWXhD7sD4Wj30MxXMUZ40oxoUsYylrV3F1xDsFMRmYhm7RV46Ofw4be4q3XhAfGZwo9rh8pE8/cVvnmWZGqhDXFRRhjjPytZrdYRtiRn6e5ZAb3u0jv96ePpfYkc+624pmRcgDOVbwZ/1zRqkMXhQegnd0DKxgE/xaZtEAfnrCfzsRiIkIxAGEN1aUQFytYutAa2ZlYhPnHn1GZ+BnFV/5Tlmt6SPDLjjm958x39RnzcwR+YbvhLOTYywBHbYrlHMDjzaRfzqFmwtdlhNE2Wuihgk2N25UYA/mOl3KKOlJoAOz2sX0EbOr4XNhapWeu5IlLbuKUUOtYS97c4Yl2USE2oy0bnaj21cwHN+016c37UuQtVS7YnHfqJZ+CbjoqD4KXuktvB7Idtf4AdA1IYq8r/6tZzbparv+BZqrt/1AjAK2OY7/MApYxwrzVlmpSJc6ruK5+Mwa61tHWQGknJelOS11bprT5rhOpE/R2OOKEH3x7oRHJRagdnyGf3APqax43bp41U3eucVJHWWmoVg6a4dZCAJI+NRa6mJRoa/gB41Yb/Ah2ly7HETZOzfgiMTuG8FyOYy/gdBBFMgE8vfhdouJm4fOKn4ZxyaL9cNDvTj6HTM7ah75j0Hk+ZuvT/gytQfLvo2TbZDU36JvJmr3UVBP8dQ5/qrTYhoMPwjEeRHVsdQb+RCujksA72UBC/gBOxXQD0FuRiluWgc868Dwwq51Tyb3W9iIbMMw6UDBcugM5XpVQz2WxlEgYNSxw85/MtI/7fwj+git0ujFS2CPIgvskiYuZAcuCqNZa1+dYd9dOLZWjX0CjnB4yj1vN7xw2Lzli9q9UYMTDc/V/q/X7oSkHl4gEJKvmKvuMXthonIt1MLzFDcjrTUy+zjm4D2yFJFur7NgXytSGgAjsJhVMwC0yQPWbAomTq7+EvjpOWGzOIQl+U+S0c+As7PX3YMb6+s5OBK3OBJ3NUES1/gS52TlUe0F3z8N/ahYRqB7aTHKsuQbLATy9OjzI+1noFxM5skpgMMf1RQffR45PtskPv5OwylqbSyYnXDUOhivytfngUkXRR9sEOThl6tx9Fgeo/1zw3I4CUoPu4QO9JoKfy6uIw60BhzkC2rJsynlJatNsWZ9TDywNjFe7Asfc60pkAlXVvFBCN2ol/GR5Q4um2tG4BZegimPW4SlG9rd/auRmEVo1ql4WrEaIDAYrYjLPGWXhUn6mDd98LKVefQBhHk2rGsj+eMq/shHoTACEQcG1uvJl59JX1eUr8tdsjCqswv6LTuUHu/YHm+TqzNflxewE8fS5x1AuegNSJi/0wvYWVTp9c7EbO3NL5O7vaDHvKK0WzuBwGwAwfwdX02AEyMZRCyDTO75UoxIBhksIN/kCs3f89VYDwjP90n3d3D3162l3gPAVt3ReDlK4uZ6WV8ln+yFV1SlLzwjX1hr8oD6+MJcfAnzfDTW85G+8ADqxmhAwvx9YU3OAM/Vku3PLxxfmMsv4twfOQc8NLUsdxKYLk+TvvByGITjC3MZRJj7o/OW6UkGuYJB8mG4PF9Yb17zN0rRBLbqCl2IhzLzTZLH75hkiZ+rKi7Aq/ZstCRgWSs+ndqakBnUZuEtdqv1H1oqcOz+9t0h31DmXbfYXtHp7h8VrVovdjLYUhlOhJkFM0R+C9bAK7Dm4f960E5TEL+VXnirKYX1JMc+4fUki7rZ9mR1b5HJOrZTjT1N/XVxHaupE/csr34Yo64WNfjpelFaSHGqnuUoG17PLogM6j07E3LgTJfzOnpB5NDQ0ZOTRYdgTKnWFN2qh93IqVxKqqh+eanipVIuGVVUkGqovdNnC6hWeV3eGCprd7FO1LzKRNWL6dUDwl2rROm1wi7v6ku6BW9QxVvnLTHJKfm0AEy6w0Cyfp2REdmvIh8Hka9E12uQPB4itY6I7FrDfBxEOu1I6k6S9o1a+qe14lwwPnnrYi5Pzc2jAgSOfYYx+pX7CpT2qNTkVkQEzJZd9q6LvvB8WymNmjQMdXhxtO6hICZC7AFU0SUrK7XCH1yNBH3zGlSOi8/kEWLY8h6VdvvxI8S2qt0QaEwWI7Y5Mbx6D4qOEes1+8VyWL/P4E6iGaYgltI43dItSEzn1s77aLVJ4zLjvEcVeB7iU0g4hE6rNRXugfD7gv81zqmVkBufUzQ0b/MNyLnmTl8nPodHjwgfIzvelJewMpdXTHr064HeMOfMfPCiGQJB3aFrhMWI2oV19RwHGGIOld9rHA15q2XDn6Pj5mm5DC8P6nvWHAZWn/E3cRYlLE7IrhAWY3W8bWFZUwuLE8tiy5TylOzbkhOYelTpHVboTaNTQcfJGHFKVe8wSTCyUm3KeJyRUtU5Q/+HVard5TFPpapzIrw/rFK9VlhTK1V6s0tKlWWptyWnyZWq0WGl8zRKVefsrT2uUjU6RKXGVapG92jfZErV4ITWf1Sl2kMe81SqBicT7UdVqlcLa3Kl2prcVihVNufqbclpTKXKV4Iz2EKN7iGolNISlLakhMF2SGu1Cy5mLBjEk72YskBd3uG2TbtucHI88AXOKIOGPReunZdpSBISNqPodMgHEj2jWC9MoXPCRHl2aYWYwAAmLbdbupj7y9w9px0FnScOOculhG2hw5cQ63Tg2iHB/jHYbtG+K4y83nrFmGtF/9wo+nGrpnI8J7lHyEyqxOTDcjkVUzm+nawSc/1CbGO5FVM5DqSsEjOPGg/9+WXyiqmGrJg6NLUst2Iqz/2VDDJvBpm8YqrRYRmZZJBeILAbQDD/KjEGG7HJ62RK53cs5zcPoesTO8N0KZncQmSmDnHv0NrkDrHJBj+lQ3y9zslH6vIcYpMNtkqHeCbmbG9+mdwhNmXRw6Gppcmnmb9DbPKKHkoGmTWDTO4Qmx3WxkkG6cUgwmu6CwODy3pADBjGTmGwdN5i8ZGTGMwescYfIInBbbKv55vEYLKBvY0vwzh9yauH5OeSw2CyUTwkeRmxmT5ikw/K5URsLFYFyojNAEZRk2U8/4iNxcbwZMRmHv5Wf36ZPGJjsfG/qdll4f6Wdb3rMVXExhIQvpMMIpZBJo/YWALCfG+cQYTnV4oDAxu+e0z8w1Y6vj0x8HrHdzb5CxabHZlhQbrC07vCVvdiSLNxhdmgp3SFB9A2wjdmFIcINsgqXeF5GLL9+WV6V7jDgllpyPYCQZM3M39X2GbjrpJBZs4gk7vCdo+15ZJBuoDAbnKD5u8Ku6+vKzZY8gLQmOyFyQswUH/zreQudK/lM5fcBbdhFX4ew+EITAZxrpP9XLIXXDaaKyswzCRm4zbFhecbs3HZeLCM2VxvFrnCczrFIYKNCsuYzTw8rv78MnnMxhWw6P5te1yu8HCwODAIWEwvGUQsg0wes3Fl1HdoBhEe9RUGBkBDIa0lGKT7K9r9nU0OA1DZKJ4swjAjn7gYsctxigHd9EN6xYMqnmKwLs8tBiobdJV+8Tys2ldwzOSOMVBlWu7g9CI8L1cgHASsq5csIphFJneOgSornA7OIsJLnAqEAy/cakW4ZyqgsP45x+gs2gr9HX22FWyCNwo1iwbw0xP5iy+DehX3BJ1wLxrqlqWqKFuV+e3aUlaq4rl4R/g7ZbXm7BGPdgfS0A5OxX5BLtovyFuhM6t7/HNmb67Kr6o7QaFbrBTHQLdw7xRHRxd0bPQAa3i1W9omewx4wRV6yKKxie7o4Q/ojI0awyd38aPCQ/RgsLGlQPZaG4rnINsPPaGHb9rrBfNHhTc1SRsHvrWJG6sK9NTJw99TQUCAZLKoygeePhbnakxw/V4ul3yTyzu51IcloQWkT4qj3wteas0Syb6Nk22Q1N+hc1ZI7yAIAE41DGJ13rFe3MBno6SYHpF7Aq+sqSniRxkWu1r29RAYbw/IkUNgVJ3wUkLgJVUZD5tVPGx5VUkBkGVJhZiaoMnjWEA8DLAxUhkPm4snu7zKpADI0qSD04vWAIMFxMOALE66PBaZPh4GZHnSwVlkufVJgXZ9PMwZPh72a7wNtP8FGxw/WuO4j4sNpWxDc0/x1vOPBA2xq+/yY0FmfQN2lRMOMDmYN8VhnpdlOTnm/4SCacK8g8K7KCwrMb9EzDsGW295ZMxTrTLldvYH+Cb5fvboAG9of2PSw2JPe3w0+Kb2RI7l7etbN9gub1/fHp4Yf//6BimDyaU8urRoxvZwMiA/fUB2ZCmwrddGtVEPHWV4IT+riTJ/jmuka7496cJe7zoYqTc2m8HIxv/I3CuaqDWRDZvNxq7ukEmbaXvHJSrdWZcmPfGcqXuPDYG1sgKc69SRURX1hXXnzWvJB9CGQKsNnFz1ldUhb4G4JU4dNrs9/Wy3LtYifn+etZiJHMoYytW7R/abpv4dZ3OSBAUGmTlfZXPpJp5Lz3MEHISFbAqdYzKuEbLIfLtOZ+DXqM1KI9P+yJr0OFduMiKlwShowtxt0C0TDpFmL2n4IdKYVJNniWgqFMo59UtJJhZKPkHrs1UygBCL4iGRJa5cZFrN8vcITofH07HqI0nUj4B6t5Ylwqsd4XIwb/fHPDxMYoSswiCDfbr7EG8D1OL/
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | 最近尝试了一个数据比赛,截止2021年2月,成绩是 rank 7 / 4313
2 | 
3 |
4 | @[toc]
5 | # 1. 特征工程
6 |
7 | ## 1.1 特征工程总览
8 |
9 | 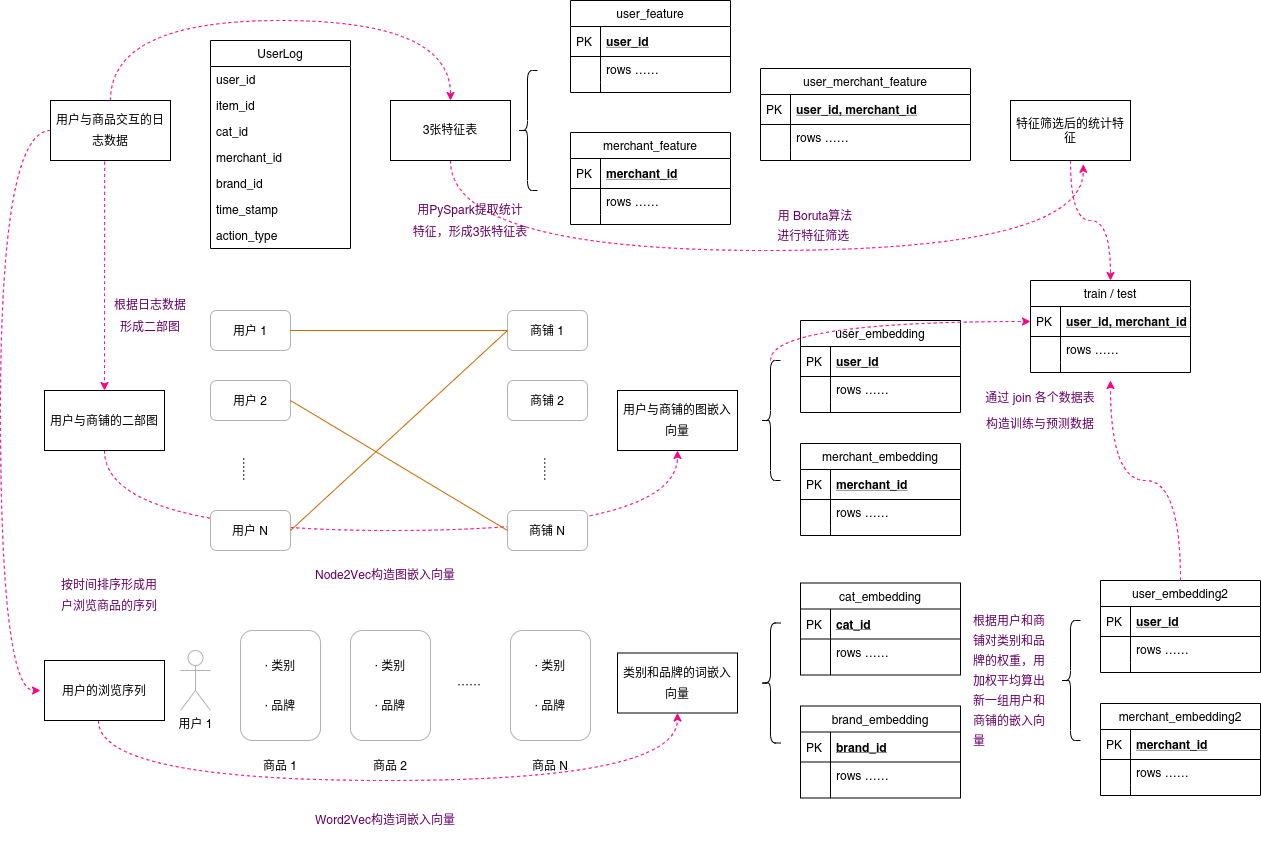
10 |
11 |
12 | 图1. 本项目特征工程总览
13 |
14 | 上图为本项目用到的特征工程,主要分为`统计特征`,`图嵌入特征`,`词嵌入特征`,最后通过`join`操作将各个特征join到主键为`user_id, merchant_id`的训练数据上。
15 |
16 | 如果您觉得图片过于模糊,可前往 [Github](https://github.com/auto-flow/tmall-repeat/blob/master/img/feature-engineering.pdf) 下载PDF。
17 |
18 |
19 | ## 1.2 通过PySpark构造统计特征
20 |
21 | - 特征构造器:[build_feat_pyspark.py](https://github.com/auto-flow/tmall-repeat/blob/master/build_feat_pyspark.py)
22 | - 调用特征构造器:[fesys_pyspark.py](https://github.com/auto-flow/tmall-repeat/blob/master/fesys_pyspark.py)
23 |
24 | ### 1.2.1 特征构造器的特点
25 |
26 | 本项目的一大创新点就是开发了一个 **特征构造器** `FeatureBuilder` 。该构造器专门用于构造日志数据中的统计特征,其特点有:
27 |
28 | 1. 以主键为核心构建特征表
29 | 2. 支持通过where语句来丰富特征库
30 | 3. 支持dummy计数、用户自定义聚集函数等操作获取统计特征
31 | 4. 采用PySpark计算,可在集群中并行
32 |
33 | 该构造器的设计哲学是以**主键**为核心构建**与主键相关的特征列**。如本赛题中,训练数据的主键为`user_id, merchant_id`,那么我们就可以构造出`user_id`, `merchant_id`, `user_id, merchant_id` 这三个特征表。
34 |
35 | 例如,在`user_id`特征表中构造**用户最喜欢的商品、店铺**等统计特征,在`merchant_id`特征表中构造**商铺历史中各个年龄阶段的占比**等统计特征,在`user_id, merchant_id`特征表中构造**用户,商铺的交互次数**等统计特征。
36 |
37 | 同时,我们还可以通过加上`where`语句让特征成倍地增加。例如,除了计算全局的(即不加where的)统计特征外,还可以计算双十一期间的统计特征,有购买行为限定的统计特征等等。
38 |
39 |
40 | 我们用一个例子讲讲`dummy计数、用户自定义聚集函数`这些特性。例如我们获取【商铺在各个年龄段的计数和占比】这些特征时,可以用这个代码:
41 |
42 | ```python
43 | feat_builder.buildCountFeatures('merchant_id', ['age_range'], dummy=True, ratio=True)
44 | # agg_funcs=['mean', 'max', 'min', 'median', 'std', 'var', unique_udf]
45 | ```
46 |
47 | 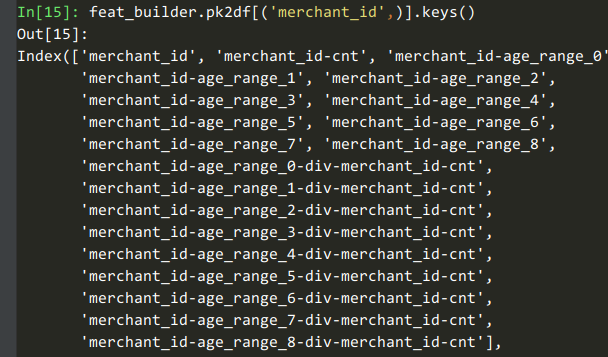
48 | 
49 | 可以看到这8列是对【商铺在8个年龄段的计数】的统计。
50 |
51 | 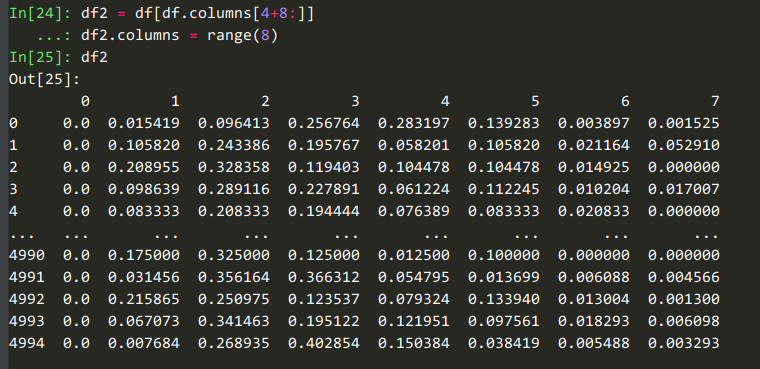
52 |
53 | 这8列是对【商铺在8个年龄段的占比】的统计。
54 |
55 |
56 | 如果我们要获取【商铺购买记录中年龄段的最小值、最大值、平均值等统计量】这些特征时,可以用这个代码:
57 |
58 | ```python
59 | feat_builder.buildCountFeatures('merchant_id', ['age_range'], dummy=False, ratio=False,
60 | agg_funcs=['mean', 'max', 'min', 'median', 'std', 'var', unique_udf] )
61 | ```
62 |
63 | 
64 | 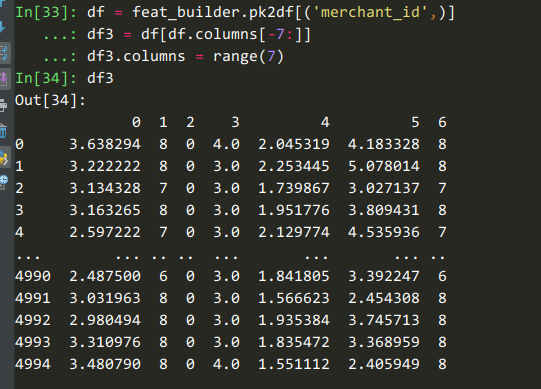
65 |
66 | 最后,**特征构造器** 支持持久化序列化等操作,在构建训练数据与测试数据时只需要依次将各个特征表join到主表即可,使各个特征解耦和。
67 |
68 | ### 1.2.2 可以构造哪些统计特征
69 |
70 | - 计算用户和商铺的复购次数(复购率用`rebuy_udf`算)
71 | - 【商家】与用户的【年龄,性别】两个特征的交互
72 | - 【商家,商品,品牌,类别】与多少【用户】交互过
73 | - 【用户】与多少【商家,商品,品牌,类别】交互过(去重)
74 | - `※ `【商家】,【用户,商品】与多少【商品,品牌,类别】交互过(去重)
75 | - `※`【用户,商家,商品,品牌,类别】的【action_type】统计 (行为比例)
76 | - 【用户,商家,【用户,商家】】每个【月,星期】的互动次数, 持续时间跨度,用户与商铺开始、终止时间统计
77 | - “最喜欢”特征,如用户最喜欢的商家、商品,主宾都可以互换
78 | - `※` 用户在商铺的出现比例, 以及相反
79 | - `※` 用户和商铺的复购率
80 | - 对各种频率分布进行统计。如:商铺的用户序列是 [user1, user1, user2], 那么频率分布就是[2,1],计算这个分布的统计特征,如方差。
81 |
82 | 然后,取`action_type=purchase`的where条件,再把上述特征计算一遍。
83 |
84 | 最后,取`交互日期为双十一`的where条件,把上述星号`※`的特征计算一遍。
85 |
86 |
87 | ## 1.3 通过Node2Vec构造图嵌入特征
88 |
89 | - 生成二部图数据: [create_graph_embedding_data.py](https://github.com/auto-flow/tmall-repeat/blob/master/create_graph_embedding_data.py)
90 | - 训练`Node2Vec`: [train_node2vec.py](https://github.com/auto-flow/tmall-repeat/blob/master/train_node2vec.py)
91 |
92 | ### 1.3.1 为什么用graph-embedding获取隐向量
93 |
94 | 为什么要用对二部图做graph-embedding的方法获取**用户和商铺的向量**呢?
95 |
96 | 我们知道,在推荐系统中有一个`user-item`共现矩阵,如下图:
97 |
98 | 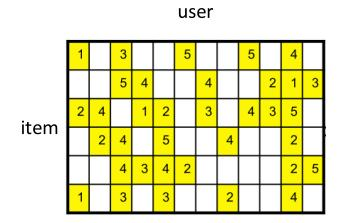
99 | 图2. user-item共现矩阵
100 |
101 |
102 | 如果我们要通过`user-item`共现矩阵得到`user-embedding`和`item-embedding`,一般有两种做法:
103 |
104 | 1. 对这个矩阵进行矩阵分解,如SVD或神经网络的方法,得到隐向量。
105 | 2. 将矩阵视为词袋,用TF-IDF再加上LSA、LDA等方法得到主题向量。
106 | 3. 按照时间顺序整理用户看过的物品序列,用Word2Vec学习这个序列中上下文的相关性,得到物品隐向量。反之得到用户隐向量。
107 | 4. 将`user-item`共现矩阵转换为二部图的邻接矩阵(图3)后,可以在这个图上使用`deep-walk`,`node2vec`等`graph-embedding`的方法得到图嵌入向量。
108 |
109 | ·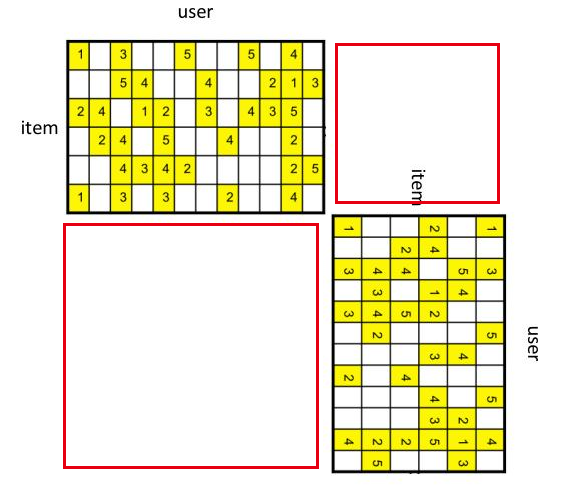
110 | 图3. user-item二部图邻接矩阵
111 |
112 | 本项目经过综合考虑,选择了方案4,即图嵌入的方案,理由如下:
113 |
114 | 1. `graph-embedding`得到的**用户向量**与**店铺向量**之间的**内积**可以表示**用户对商铺的喜欢程度**,与矩阵分解的性质相似。方案2和方案3没有这个性质。
115 | 2. `graph-embedding`可以考虑到一些隐含信息,如用户1和用户2都喜欢店铺A,而用户1还喜欢店铺B,这样用户2也有可能喜欢店铺B。这样的隐含信息是矩阵分解学不到的。
116 |
117 |
118 | ### 1.3.2 什么是Node2Vec
119 |
120 | 图嵌入算法中最常见的是Deep Walk,它的主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入 Word2vec 进行训练,最终得到物品的 Embedding。因此,DeepWalk 可以被看作连接序列 Embedding 和 Graph Embedding 的一种过渡方法。图 4 展示了 DeepWalk 方法的执行过程。
121 |
122 | 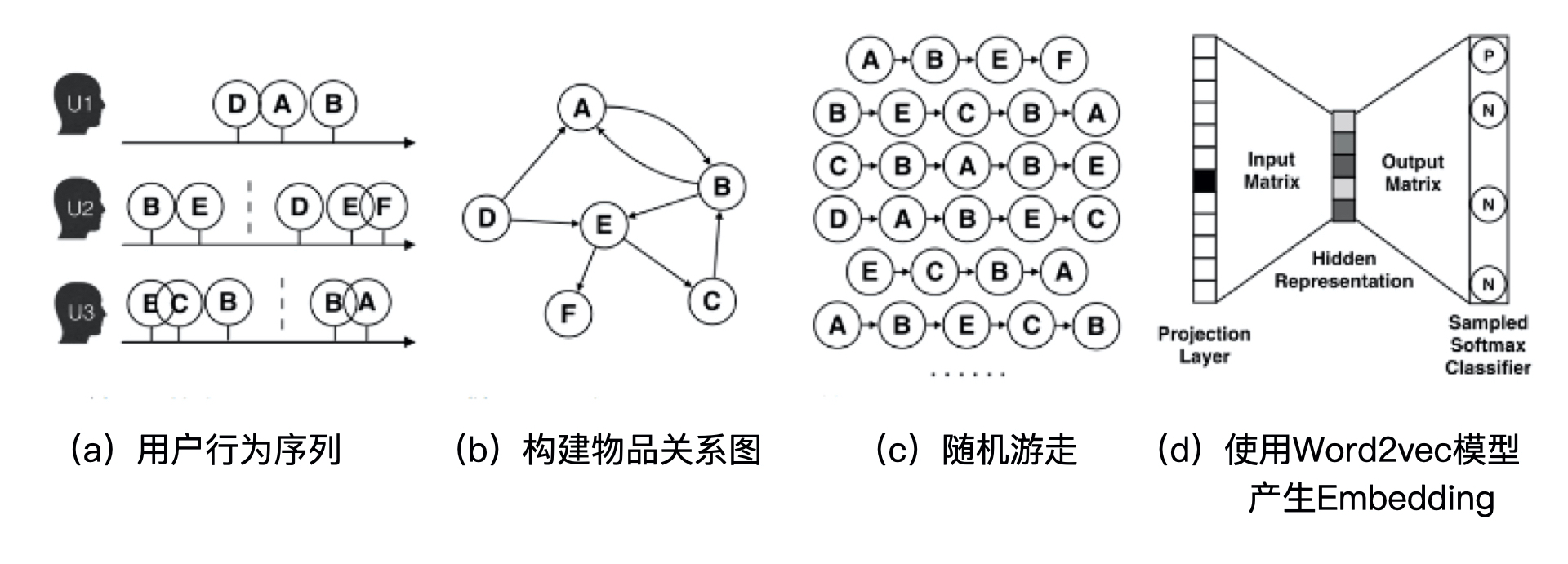图4 DeepWalk方法的过程
123 |
124 | Node2Vec在DeepWalk的基础上,通过调整游走权重的方法试Graph Embedding的结果更倾向与体现网络的**同质性**(homophily)或**结构性**(structural equivalence)。其中“**同质性**”指的是距离相近节点的 Embedding 应该尽量近似,“**结构性**”指的是结构上相似的节点的 Embedding 应该尽量接近。
125 |
126 |
127 |
128 | 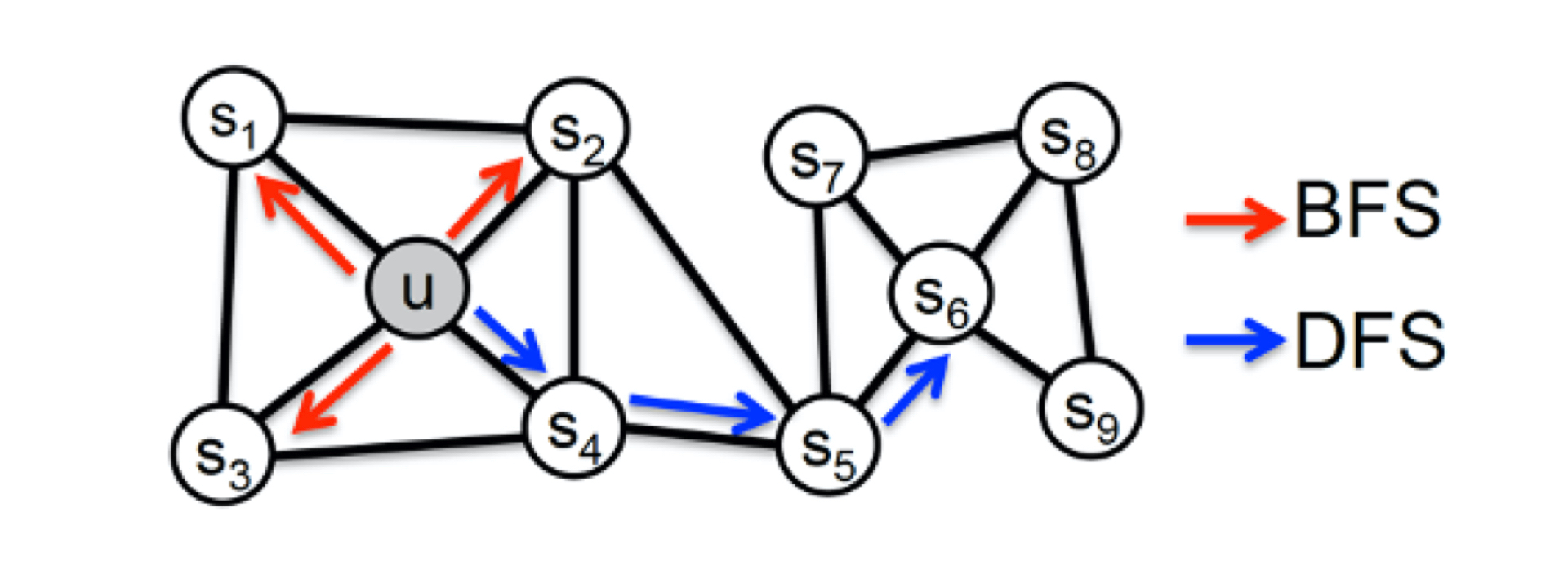图5 网络的BFS和 DFS示意图
129 |
130 |
131 | 为了使 Graph Embedding 的结果能够表达网络的“**结构性**”,在随机游走的过程中,我们需要让游走的过程更倾向于 **BFS(Breadth First Search,宽度优先搜索)**,因为 BFS 会更多地在当前节点的邻域中进行游走遍历,相当于对当前节点周边的网络结构进行一次“微观扫描”。当前节点是“局部中心节点”,还是“边缘节点”,亦或是“连接性节点”,其生成的序列包含的节点数量和顺序必然是不同的,从而让最终的 Embedding 抓取到更多结构性信息。
132 |
133 | 而为了表达“**同质性**”,随机游走要更倾向于 **DFS(Depth First Search,深度优先搜索)**才行,因为 DFS 更有可能通过多次跳转,游走到远方的节点上。但无论怎样,DFS 的游走更大概率会在一个大的集团内部进行,这就使得一个集团或者社区内部节点的 Embedding 更为相似,从而更多地表达网络的“同质性”。
134 |
135 | Node2Vec主要是通过**节点间的跳转概率**来控制跳转的倾向性。图 6 所示为 Node2vec 算法从节点 $t$ 跳转到节点 $v$ 后,再从节点 $v$ 跳转到周围各点的跳转概率。这里,你要注意这几个节点的特点。比如,节点 $t$ 是随机游走上一步访问的节点,节点 $v$ 是当前访问的节点,节点 $x_1$、$x_2$、$x_3$是与 $v$ 相连的非 $t$ 节点,但节点 $x_1$还与节点 $t$ 相连,这些不同的特点决定了随机游走时下一次跳转的概率。
136 |
137 | 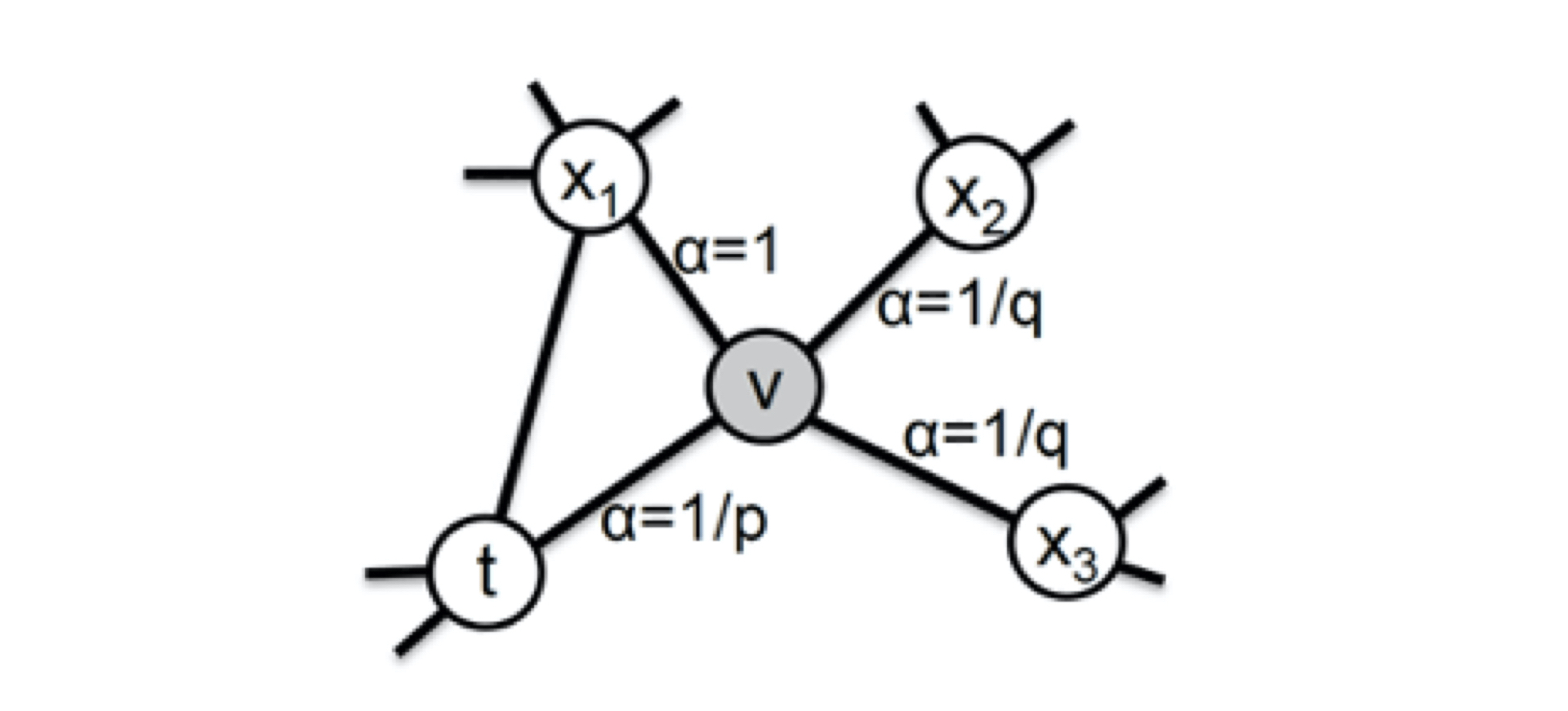图6 Node2vec的跳转概率
138 |
139 | 这些概率我们还可以用具体的公式来表示,从当前节点 $v$ 跳转到下一个节点 $x$ 的概率 $\pi vx=\alpha _{pq}(t,x)\cdot \omega _{vx}$ ,其中 $\omega _{vx}$ 是边 $vx$ 的原始权重,$\alpha _{pq}(t,x)$ 是 Node2vec 定义的一个跳转权重。到底是倾向于 DFS 还是 BFS,主要就与这个跳转权重$\alpha _{pq}(t,x)$的定义有关了:
140 |
141 | $\alpha_{p q(t, x)=}\left\{\begin{array}{cc}\frac{1}{p} & \text { 如果 } d_{t x}=0 \\ 1 & \text { 如果 } d_{t x}=1 \\ \frac{1}{q} & \text { 如果 } d_{t x}=2\end{array}\right.$
142 |
143 | $\alpha _{pq}(t,x)$ 中的参数 $p$ 和 $q$ 共同控制着随机游走的倾向性。参数 $p$ 被称为**返回参数(Return Parameter)**,$p$ 越小,随机游走回节点 $t$ 的可能性越大,Node2vec 就更注重表达网络的结构性。参数 $q$ 被称为**进出参数(In-out Parameter)**,$q$ 越小,随机游走到远方节点的可能性越大,Node2vec 更注重表达网络的同质性。反之,当前节点更可能在附近节点游走。
144 |
145 |
146 | ## 1.4 通过Word2Vec构造词嵌入向量
147 |
148 | 用户在浏览商品时,存在浏览相似商品的行为,我们可以利用这一特性对不同商品间的相似性进行建模。而Word2Vec可以对序列数据进行无监督学习,可以满足我们的需求。
149 |
150 | 在当前场景下,商品有`brand_id`和`cat_id`两个特征,即品牌ID和类别ID。我们可以用Word2Vec将这两个**类别变量**转化为低维连续变量,并根据用户历史记录中**用户**或**商铺**对`brand_id`和`cat_id`的权重对其进行加权平均,得到新的**用户隐向量**和**商铺隐向量**,丰富了特征信息。
151 |
152 | 举例,用户按时间顺序访问了以下5个商品:
153 |
154 | |item_id|cat_id|brand_id|
155 | |-|-|-|
156 | |1|A|a|
157 | |2|B|b|
158 | |3|B|c|
159 | |4|A|a|
160 | |5|A|a|
161 |
162 | 对于这些商品的`cat_id`,我们可以得到一个序列:
163 |
164 | `[A, B, B, A, A]`
165 |
166 | 假设我们用Word2Vec对`cat_id`序列了3维的隐向量(词嵌入向量),如下:
167 |
168 | |cat_id|dim-1|dim-2|dim-3|
169 | |-|-|-|-|
170 | |A|0|1|0.5|
171 | |B|1|0|0.5|
172 |
173 | 假如用户U1曾访问过75次`cat_id = A`的商品,访问过25次`cat_id = B`的商品,那么可以用加权平均算得U1的隐向量如下:
174 |
175 |
176 | |user_id|dim-1|dim-2|dim-3|
177 | |-|-|-|-|
178 | |U1|0.25|0.75|0.5|
179 |
180 |
181 | 同理可以计算商铺的隐向量。
182 |
183 | 通过以上方式,我们从新的角度对**用户**和**商铺**进行了编码,引入了新的特征。
184 |
185 |
186 |
187 | ## 1.5 boruta特征筛选
188 |
189 |
190 |
191 |
192 | # 2. 模型训练与模型融合
193 |
194 |
195 |
196 | # 参考资料
197 |
198 | [【Graph Embedding】node2vec:算法原理,实现和应用](https://zhuanlan.zhihu.com/p/56542707)
199 |
200 | [Alias Method:时间复杂度O(1)的离散采样方法](https://zhuanlan.zhihu.com/p/54867139)
201 |
202 | [【数学】时间复杂度O(1)的离散采样算法—— Alias method/别名采样方法](https://blog.csdn.net/haolexiao/article/details/65157026)
203 |
204 | [07 | Embedding进阶:如何利用图结构数据生成Graph Embedding?](https://time.geekbang.org/column/article/296672)
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 |
213 |
214 |
215 |
216 |
217 |
218 |
--------------------------------------------------------------------------------
/tmall/stat_feat/fesys_pyspark.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-21
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | import warnings
7 | from typing import List, Dict, Union, Tuple, Callable, Optional
8 |
9 | import pandas as pd
10 | import pyspark.sql.functions as F
11 | from pyspark.sql.dataframe import DataFrame
12 |
13 |
14 | def get_dummies(df, columns, prefix=None):
15 | if not isinstance(columns, list):
16 | columns = [columns]
17 | for column in columns:
18 | dst_df = df.select(column).distinct().toPandas()
19 | dst_df = dst_df.sort_values(by=column)
20 | for dst in dst_df[column]:
21 | if prefix is None:
22 | col_name = f"{column}_{dst}"
23 | else:
24 | col_name = f"{prefix}_{dst}"
25 | df = df.withColumn(col_name, F.when(df[column] == dst, 1).otherwise(0))
26 | return df
27 |
28 |
29 | # 尽量能和pandas的规则对应上
30 | window_func = {
31 | "max": F.max,
32 | "min": F.min,
33 | "mean": F.avg,
34 | "avg": F.avg,
35 | "count": F.count,
36 | "nunique": F.countDistinct,
37 | "var": F.var_samp,
38 | "std": F.stddev,
39 | }
40 |
41 | from tmall.utils import reduce_mem_usage, spark_to_pandas
42 |
43 | warnings.filterwarnings("ignore")
44 |
45 |
46 | class FeaturesBuilder():
47 | def __init__(self, core_df):
48 | self.core_df: DataFrame = core_df
49 | self.pk2df: Dict[str, DataFrame] = {} # primaryKeyToDataFrame
50 | self.op_feats: List[Tuple[str, Callable]] = []
51 |
52 | @property
53 | def n_features(self):
54 | # todo
55 | res = 0
56 | for pk, df in self.pk2df.items():
57 | res += df.shape[1] - len(pk)
58 | res += len(self.op_feats)
59 | return res
60 |
61 | def convert_to_pandas(self):
62 | for pk, df in self.pk2df.items():
63 | self.pk2df[pk] = df if isinstance(df, pd.DataFrame) else spark_to_pandas(df, 12)
64 |
65 | def reduce_mem_usage(self):
66 | self.convert_to_pandas()
67 | for pk in self.pk2df:
68 | self.pk2df[pk] = reduce_mem_usage(self.pk2df[pk])
69 |
70 | def buildCountFeatures(
71 | self,
72 | primaryKey: Union[List[str], str],
73 | countValues: Union[List[str], str, None],
74 | countPK=True,
75 | dummy=True,
76 | ratio=True,
77 | agg_funcs=None, # 注意, 如果countValues为离散特征或计数特征请谨慎使用,所以默认为None
78 | multi_out_agg_funcs: Optional[List[Tuple[List[str], Callable]]] = None,
79 | prefix=None
80 | # descriptions=None # 如果不为空,长度需要与countValues一致
81 | ):
82 | if isinstance(primaryKey, str):
83 | primaryKey = [primaryKey]
84 | if isinstance(countValues, str):
85 | countValues = [countValues]
86 | # 如果不存在主键对应的DF,创建新的
87 | t_pk = tuple(primaryKey)
88 | if t_pk not in self.pk2df:
89 | df = self.core_df[primaryKey].drop_duplicates().sort(primaryKey)
90 | self.pk2df[t_pk] = df
91 | # 主键列名
92 | pk_col = "-".join(primaryKey)
93 | if prefix:
94 | pk_col = f"{prefix}-{pk_col}"
95 | # 根据规则对参数进行校验
96 | if not countValues:
97 | dummy = False
98 | agg_funcs = None
99 | if dummy == False or countPK == False:
100 | ratio = False
101 | # 先对主键进行统计
102 | pk_cnt_col = f"{pk_col}-cnt"
103 | if countPK and pk_cnt_col not in self.pk2df[t_pk].columns:
104 | pk_cnt_df = self.core_df.groupby(primaryKey).count().withColumnRenamed("count", pk_cnt_col)
105 | self.pk2df[t_pk] = self.pk2df[t_pk].join(pk_cnt_df, how='left', on=primaryKey)
106 | # 对countValues进行处理
107 | if not countValues:
108 | countValues = []
109 | # for循环,对每个要计算的列进行统计
110 | for countValue in countValues:
111 | # 共现列名(fixme: 在dummy中会被删除)
112 | pk_val_col = f"{pk_col}-{countValue}"
113 | # 对聚集函数进行处理
114 | agg_args = []
115 | if agg_funcs is not None:
116 | for agg_func in agg_funcs:
117 | if isinstance(agg_func, str):
118 | agg_func_ = (window_func[agg_func])
119 | agg_col_ = (agg_func)
120 | agg_obj_ = (countValue)
121 | else:
122 | agg_func_ = (agg_func)
123 | agg_col_ = (agg_func.__name__)
124 | agg_obj_ = (F.collect_list(countValue))
125 | new_name = f"{pk_val_col}-{agg_col_}"
126 | agg_args.append(agg_func_(agg_obj_).alias(new_name))
127 |
128 | if agg_args:
129 | df_agg = self.core_df.groupby(primaryKey).agg(*agg_args)
130 | # 将除0产生的nan替换为0
131 | df_agg = df_agg.fillna(0)
132 | self.pk2df[t_pk] = self.pk2df[t_pk].join(df_agg, how='left', on=primaryKey)
133 | # 对频率分布进行统计
134 | if multi_out_agg_funcs:
135 | for names, func in multi_out_agg_funcs:
136 | df_mo_agg = self.core_df.groupby(primaryKey).agg(
137 | func(F.collect_list(countValue)).alias("multi_output"))
138 | for i, name in enumerate(names):
139 | df_mo_agg = df_mo_agg.withColumn(f"{pk_val_col}-{name}", df_mo_agg['multi_output'][i])
140 | df_mo_agg = df_mo_agg.drop('multi_output')
141 | self.pk2df[t_pk] = self.pk2df[t_pk].join(df_mo_agg, how='left', on=primaryKey)
142 | dummy_columns = []
143 | if dummy:
144 | # todo
145 | # 对values计数,得到dummy特征
146 | pk_val_cnt_df = self.core_df.groupby(primaryKey + [countValue]).count(). \
147 | withColumnRenamed("count", pk_val_col)
148 | pk_cnt_df_dummy = get_dummies(pk_val_cnt_df, columns=[countValue], prefix=pk_val_col)
149 | dummy_columns = pk_cnt_df_dummy.columns[len(primaryKey) + 2:] # pk , countValue , pk_val_col
150 | for column in dummy_columns:
151 | pk_cnt_df_dummy = pk_cnt_df_dummy.withColumn(
152 | column,
153 | pk_cnt_df_dummy[column] * pk_cnt_df_dummy[pk_val_col]
154 | )
155 | pk_cnt_df_dummy = pk_cnt_df_dummy.drop(countValue)
156 | pk_cnt_df_dummy = pk_cnt_df_dummy.drop(pk_val_col)
157 | columns = pk_cnt_df_dummy.columns
158 | pk_cnt_df_dummy = pk_cnt_df_dummy.groupby(primaryKey).sum()
159 | for pk in primaryKey: # 删掉原主键(新增了sum(pk)),呆的一笔
160 | pk_cnt_df_dummy = pk_cnt_df_dummy.drop(pk)
161 | cur_cols = pk_cnt_df_dummy.columns
162 | # todo: 更好的重命名方法
163 | for cur, new in zip(cur_cols, columns):
164 | pk_cnt_df_dummy = pk_cnt_df_dummy.withColumnRenamed(cur, new)
165 | self.pk2df[t_pk] = self.pk2df[t_pk].join(pk_cnt_df_dummy, how='left', on=primaryKey)
166 | if ratio and dummy_columns:
167 | df = self.pk2df[t_pk]
168 | ratio_columns = [f"{dummy_column}-ratio" for dummy_column in dummy_columns]
169 | for ratio_column, dummy_column in zip(ratio_columns, dummy_columns):
170 | # 新建一个ratio columns
171 | df = df.withColumn(
172 | ratio_column,
173 | df[dummy_column] / df[pk_cnt_col]
174 | )
175 | # 将除0产生的nan替换为0
176 | self.pk2df[t_pk] = df
177 | self.pk2df[t_pk] = self.pk2df[t_pk].fillna(0)
178 | self.pk2df[t_pk].cache() # 先缓存再transform
179 | self.pk2df[t_pk].take(1) # dummy transform
180 |
181 | def addOperateFeatures(
182 | self,
183 | new_feature_name: str,
184 | df_apply_func: Union[Callable, str]
185 | ):
186 | # 记得处理nan
187 | self.op_feats.append([new_feature_name, df_apply_func])
188 |
189 | def outputFeatures(self, base_df: pd.DataFrame, apply_op=True):
190 | # todo
191 | df = base_df
192 | pk_list = list(self.pk2df.keys())
193 | pk_list.sort()
194 | for pk in pk_list:
195 | df = df.merge(self.pk2df[pk], 'left', on=pk)
196 | if apply_op:
197 | self.applyOperateFeatures(df)
198 | return df
199 |
200 | def applyOperateFeatures(self, base_df: pd.DataFrame):
201 | for name, func in self.op_feats:
202 | if isinstance(func, str):
203 | func = eval(func)
204 | base_df[name] = func(base_df)
205 | return base_df
206 |
--------------------------------------------------------------------------------
/tmall/bagging.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-31
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | """Bagging classifier trained on balanced bootstrap samples."""
7 |
8 | # Authors: Guillaume Lemaitre
9 | # Christos Aridas
10 | # License: MIT
11 | import itertools
12 | import numbers
13 | from warnings import warn
14 |
15 | import numpy as np
16 | from imblearn.under_sampling import RandomUnderSampler
17 | from joblib import Parallel, delayed
18 | from sklearn.ensemble import BaggingClassifier
19 | from sklearn.ensemble._bagging import MAX_INT, _generate_bagging_indices
20 | from sklearn.ensemble._base import _partition_estimators
21 | from sklearn.utils import check_random_state, check_X_y
22 | from sklearn.utils.validation import _check_sample_weight
23 |
24 |
25 | # from ..pipeline import Pipeline
26 | # from ..under_sampling import RandomUnderSampler
27 | # from ..under_sampling.base import BaseUnderSampler
28 | # from ..utils import Substitution, check_target_type
29 | # from ..utils._docstring import _n_jobs_docstring
30 | # from ..utils._docstring import _random_state_docstring
31 |
32 |
33 | def _parallel_build_estimators(n_estimators, ensemble, X, y, sample_weight,
34 | seeds, total_n_estimators, verbose):
35 | """Private function used to build a batch of estimators within a job."""
36 | # Retrieve settings
37 | n_samples, n_features = X.shape
38 | max_features = ensemble._max_features
39 | max_samples = ensemble._max_samples
40 | bootstrap = ensemble.bootstrap
41 | bootstrap_features = ensemble.bootstrap_features
42 | # fixme 自己改的, 防止 'fit_params' 导致检测失败
43 | support_sample_weight = sample_weight is not None
44 | # support_sample_weight = has_fit_parameter(ensemble.base_estimator_,
45 | # "sample_weight")
46 | # if not support_sample_weight and sample_weight is not None:
47 | # raise ValueError("The base estimator doesn't support sample weight")
48 |
49 | # Build estimators
50 | estimators = []
51 | estimators_features = []
52 |
53 | for i in range(n_estimators):
54 | if verbose > 1:
55 | print("Building estimator %d of %d for this parallel run "
56 | "(total %d)..." % (i + 1, n_estimators, total_n_estimators))
57 |
58 | random_state = np.random.RandomState(seeds[i])
59 | estimator = ensemble._make_estimator(append=False,
60 | random_state=random_state)
61 | print(estimator)
62 | # Draw random feature, sample indices
63 | features, indices = _generate_bagging_indices(random_state,
64 | bootstrap_features,
65 | bootstrap, n_features,
66 | n_samples, max_features,
67 | max_samples)
68 | # 先bagging, 再下采样
69 | X_ = X[indices]
70 | y_ = y[indices]
71 | sampler = RandomUnderSampler(random_state=seeds[i]) # todo 参数化
72 | X_, y_ = sampler.fit_resample(X_, y_)
73 | sample_weight_ = None
74 | if sample_weight is not None:
75 | sample_weight_ = sample_weight[indices].copy()
76 | sample_weight_ = sample_weight_[sampler.sample_indices_]
77 | # todo: 重构样本分布
78 | # sample_weight_ -= np.min(sample_weight_)
79 | # sample_weight_ /= np.max(sample_weight_)
80 | # alpha = 0.1 # todo: 参数化
81 | # sample_weight_ *= (1 - alpha)
82 | # sample_weight_ += alpha
83 |
84 | # Draw samples, using sample weights, and then fit
85 | if support_sample_weight:
86 | estimator.fit(X_[:, features], y_, sample_weight=sample_weight_)
87 | else:
88 | estimator.fit(X_[:, features], y_)
89 |
90 | estimators.append(estimator)
91 | estimators_features.append(features)
92 |
93 | return estimators, estimators_features
94 |
95 |
96 | class BalancedBaggingClassifier(BaggingClassifier):
97 | def __init__(
98 | self,
99 | base_estimator=None,
100 | n_estimators=10,
101 | max_samples=1.0,
102 | max_features=1.0,
103 | bootstrap=True,
104 | bootstrap_features=False,
105 | oob_score=False,
106 | warm_start=False,
107 | n_jobs=None,
108 | random_state=None,
109 | verbose=0,
110 | sampling_strategy="auto",
111 | replacement=False,
112 | ):
113 |
114 | super().__init__(
115 | base_estimator,
116 | n_estimators=n_estimators,
117 | max_samples=max_samples,
118 | max_features=max_features,
119 | bootstrap=bootstrap,
120 | bootstrap_features=bootstrap_features,
121 | oob_score=oob_score,
122 | warm_start=warm_start,
123 | n_jobs=n_jobs,
124 | random_state=random_state,
125 | verbose=verbose,
126 | )
127 | self.sampling_strategy = sampling_strategy
128 | self.replacement = replacement
129 |
130 | def fit(self, X, y, sample_weight=None):
131 | random_state = check_random_state(self.random_state)
132 | self._max_samples = int(self.max_samples * X.shape[0])
133 | # Convert data (X is required to be 2d and indexable)
134 | X, y = check_X_y(
135 | X, y, ['csr', 'csc'], dtype=None, force_all_finite=False,
136 | multi_output=True
137 | )
138 | if sample_weight is not None:
139 | sample_weight = _check_sample_weight(sample_weight, X, dtype=None)
140 |
141 | # Remap output
142 | n_samples, self.n_features_ = X.shape
143 | self._n_samples = n_samples
144 | y = self._validate_y(y)
145 |
146 | # Check parameters
147 | self._validate_estimator()
148 |
149 | # Validate max_features
150 | if isinstance(self.max_features, numbers.Integral):
151 | max_features = self.max_features
152 | elif isinstance(self.max_features, np.float):
153 | max_features = self.max_features * self.n_features_
154 | else:
155 | raise ValueError("max_features must be int or float")
156 |
157 | if not (0 < max_features <= self.n_features_):
158 | raise ValueError("max_features must be in (0, n_features]")
159 |
160 | max_features = max(1, int(max_features))
161 |
162 | # Store validated integer feature sampling value
163 | self._max_features = max_features
164 |
165 | # Other checks
166 | if not self.bootstrap and self.oob_score:
167 | raise ValueError("Out of bag estimation only available"
168 | " if bootstrap=True")
169 |
170 | if self.warm_start and self.oob_score:
171 | raise ValueError("Out of bag estimate only available"
172 | " if warm_start=False")
173 |
174 | if hasattr(self, "oob_score_") and self.warm_start:
175 | del self.oob_score_
176 |
177 | if not self.warm_start or not hasattr(self, 'estimators_'):
178 | # Free allocated memory, if any
179 | self.estimators_ = []
180 | self.estimators_features_ = []
181 |
182 | n_more_estimators = self.n_estimators - len(self.estimators_)
183 |
184 | if n_more_estimators < 0:
185 | raise ValueError('n_estimators=%d must be larger or equal to '
186 | 'len(estimators_)=%d when warm_start==True'
187 | % (self.n_estimators, len(self.estimators_)))
188 |
189 | elif n_more_estimators == 0:
190 | warn("Warm-start fitting without increasing n_estimators does not "
191 | "fit new trees.")
192 | return self
193 |
194 | # Parallel loop
195 | n_jobs, n_estimators, starts = _partition_estimators(n_more_estimators,
196 | self.n_jobs)
197 | total_n_estimators = sum(n_estimators)
198 |
199 | # Advance random state to state after training
200 | # the first n_estimators
201 | if self.warm_start and len(self.estimators_) > 0:
202 | random_state.randint(MAX_INT, size=len(self.estimators_))
203 |
204 | seeds = random_state.randint(MAX_INT, size=n_more_estimators)
205 | self._seeds = seeds
206 |
207 | all_results = Parallel(n_jobs=n_jobs, verbose=self.verbose,
208 | **self._parallel_args())(
209 | delayed(_parallel_build_estimators)(
210 | n_estimators[i],
211 | self,
212 | X,
213 | y,
214 | sample_weight,
215 | seeds[starts[i]:starts[i + 1]],
216 | total_n_estimators,
217 | verbose=self.verbose)
218 | for i in range(n_jobs))
219 |
220 | # Reduce
221 | self.estimators_ += list(itertools.chain.from_iterable(
222 | t[0] for t in all_results))
223 | self.estimators_features_ += list(itertools.chain.from_iterable(
224 | t[1] for t in all_results))
225 |
226 | if self.oob_score:
227 | self._set_oob_score(X, y)
228 |
229 | return self
230 |
--------------------------------------------------------------------------------
/tmall/stat_feat/build_feat_pyspark.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | # @Author : qichun tang
4 | # @Date : 2021-01-22
5 | # @Contact : qichun.tang@bupt.edu.cn
6 | import warnings
7 | from collections import Counter
8 |
9 | import gc
10 | import numpy as np
11 | import pandas as pd
12 | from joblib import dump
13 | from pyspark.sql import SQLContext
14 | from pyspark.sql import SparkSession
15 | from pyspark.sql.functions import udf
16 | # spark 变量类型:https://spark.apache.org/docs/latest/sql-ref-datatypes.html
17 | from pyspark.sql.types import ByteType, ShortType, IntegerType, LongType, ArrayType
18 | from pyspark.sql.types import FloatType, DoubleType
19 | from pyspark.sql.types import StructType, StructField
20 | from pyspark.sql.types import TimestampType
21 |
22 | from tmall.stat_feat.fesys_pyspark import FeaturesBuilder
23 | from tmall.utils import get_data_path
24 |
25 |
26 | def get_schema_from_df(df: pd.DataFrame):
27 | convert = {
28 | "int32": IntegerType(),
29 | "int64": LongType(),
30 | "int16": ShortType(),
31 | "int8": ByteType(),
32 | "float8": FloatType(),
33 | "float16": FloatType(),
34 | "float32": FloatType(),
35 | "float64": DoubleType(),
36 | }
37 | fields = []
38 | for col_name, dtype in zip(df.columns, df.dtypes):
39 | dtype_name = dtype.name
40 | spark_type = convert.get(dtype_name, TimestampType())
41 | fields.append(StructField(col_name, spark_type, True))
42 | return StructType(fields)
43 |
44 |
45 | # from fesys2 import FeaturesBuilder
46 | data_path = get_data_path()
47 | warnings.filterwarnings("ignore")
48 |
49 | user_log = pd.read_pickle(f'{data_path}/user_log.pkl')
50 | user_log['label'] = user_log['label'].astype('int8') # 之前的操作忘了这步
51 |
52 | spark = SparkSession.builder \
53 | .appName("tmall") \
54 | .config("master", "local[*]") \
55 | .enableHiveSupport() \
56 | .getOrCreate()
57 | sc = spark.sparkContext
58 | sqlContest = SQLContext(sc)
59 | print('loading data to spark dataframe ...')
60 | schema = get_schema_from_df(user_log)
61 | # user_log = sqlContest.createDataFrame(user_log.iloc[:10000, :], schema=schema) # 采样
62 | user_log = sqlContest.createDataFrame(user_log, schema=schema) # fixme
63 | user_log.repartition(12) # 切片
64 | gc.collect()
65 | print('done')
66 |
67 | feat_builder = FeaturesBuilder(user_log)
68 | # udf
69 | median_udf = udf(lambda values: float(np.median(values)), FloatType())
70 | median_udf.__name__ = "median"
71 | timediff_udf = udf(lambda x: (max(x) - min(x)).days, IntegerType())
72 | timediff_udf.__name__ = 'timediff'
73 | mostlike_udf = udf(lambda x: Counter(x).most_common(1)[0][0] if len(x) else 0, IntegerType())
74 | mostlike_udf.__name__ = 'mostlike'
75 |
76 |
77 | def freq_stat_info(seq):
78 | cnt = Counter(seq)
79 | size = len(seq)
80 | freq = [v / size for v in cnt.values()]
81 | return [float(i) for i in (np.min(freq), np.mean(freq), np.max(freq), np.std(freq))]
82 |
83 |
84 | freq_stat_info_udf = udf(freq_stat_info, ArrayType(FloatType()))
85 | freq_stat_info_names = ["freq_min", "freq_mean", "freq_max", "freq_std"]
86 | rebuy_ranges = list(range(1, 11, 1)) # fixme
87 | # rebuy_ranges = list(range(1, 2, 1))
88 | rebuy_udf1 = udf(lambda x: sum([cnt for cnt in Counter(x).values() if cnt > 1]),
89 | IntegerType())
90 | rebuy_udf1.__name__ = f"rebuy{1}"
91 | merchant_item_ids = ['merchant_id', 'item_id', 'brand_id', 'cat_id']
92 | item_ids = ['item_id', 'brand_id', 'cat_id']
93 | user_feats = ['age_range', 'gender']
94 | # cross_feats = [['user_id', 'merchant_id']]
95 | core_ids = ['user_id', 'merchant_id']
96 | indicator2action_type = {
97 | 'click': 0,
98 | 'add_car': 1,
99 | 'purchase': 2,
100 | 'favorite': 3,
101 | }
102 |
103 |
104 | # 统计双11 3天时间内的一些重要特征 (记录数占24%)
105 | d11_user_log = user_log.filter(user_log['time_stamp_int'].isin([1110, 1111, 1112]))
106 | feat_builder.core_df = d11_user_log
107 | core_df = d11_user_log
108 | for indicator in ["purchase", None]: # fixme
109 | # for indicator in ["purchase"]:
110 | # where action_type = 'purchase'
111 | if indicator is not None:
112 | action_type = indicator2action_type[indicator]
113 | feat_builder.core_df = user_log.filter(user_log['action_type'] == action_type)
114 | else:
115 | feat_builder.core_df = user_log
116 | # 改indicator名
117 | if indicator is None:
118 | indicator = "d11"
119 | else:
120 | indicator = f"d11-{indicator}"
121 | # 预判前缀
122 | prefix = f"{indicator}-"
123 | print('以【用户,商铺,【用户 商铺】】为主键,对【items】等算nunique计数')
124 | for pk in core_ids:
125 | target = [id_ for id_ in core_ids + item_ids if id_ != pk]
126 | feat_builder.buildCountFeatures(
127 | pk, target, dummy=False,
128 | agg_funcs=['nunique'],
129 | prefix=indicator)
130 | feat_builder.buildCountFeatures(core_ids, item_ids, dummy=False, agg_funcs=['nunique'], prefix=indicator)
131 | print('用户,商铺,用户商铺的行为比例')
132 | if indicator == "d11":
133 | for pk in core_ids + [core_ids]:
134 | feat_builder.buildCountFeatures(pk, 'action_type', prefix=indicator) # , agg_funcs=[unique_udf] 感觉没必要
135 | print('双11期间的复购 (不计算多重复购的统计信息了)')
136 | if indicator != "d11":
137 | feat_builder.buildCountFeatures('user_id', 'merchant_id', dummy=False,
138 | agg_funcs=[rebuy_udf1], prefix=indicator)
139 | feat_builder.buildCountFeatures('merchant_id', 'user_id', dummy=False,
140 | agg_funcs=[rebuy_udf1], prefix=indicator)
141 | feat_builder.addOperateFeatures(f'{prefix}user_rebuy_ratio',
142 | f"lambda x: x['{prefix}user_id-merchant_id-rebuy'] / x['{prefix}user_id-cnt']")
143 | feat_builder.addOperateFeatures(f'{prefix}merchant_rebuy_ratio',
144 | f"lambda x: x['{prefix}merchant_id-user_id-rebuy'] / x['{prefix}merchant_id-cnt']")
145 | print('双11期间的用户、商铺比例特征')
146 | feat_builder.addOperateFeatures(f'{prefix}users_div_merchants',
147 | f"lambda x: x['{prefix}user_id-cnt'] / x['{prefix}merchant_id-cnt']")
148 | feat_builder.addOperateFeatures(f'{prefix}merchants_div_users',
149 | f"lambda x: x['{prefix}user_id-cnt'] / x['{prefix}merchant_id-cnt']")
150 |
151 | for indicator in ["purchase", None]: # fixme
152 | # for indicator in ["purchase"]:
153 | if indicator is not None:
154 | action_type = indicator2action_type[indicator]
155 | feat_builder.core_df = user_log.filter(user_log['action_type'] == action_type)
156 | else:
157 | feat_builder.core_df = user_log
158 | # =============================================
159 | print('对频率分布的统计特征')
160 | for pk in core_ids:
161 | target = [id_ for id_ in core_ids + item_ids if id_ != pk]
162 | feat_builder.buildCountFeatures(
163 | pk, target, dummy=False,
164 | multi_out_agg_funcs=[(freq_stat_info_names, freq_stat_info_udf)],
165 | prefix=indicator)
166 | feat_builder.buildCountFeatures(
167 | core_ids, item_ids, dummy=False,
168 | multi_out_agg_funcs=[(freq_stat_info_names, freq_stat_info_udf)],
169 | prefix=indicator)
170 | # ==============================================
171 | print('计算用户和商铺的复购次数(复购率用UDF算)')
172 | if indicator is not None:
173 | for rebuy_times in rebuy_ranges:
174 | rebuy_udf = udf(lambda x: sum([cnt for cnt in Counter(x).values() if cnt > rebuy_times]),
175 | IntegerType())
176 | rebuy_udf.__name__ = f"rebuy{rebuy_times}"
177 | feat_builder.buildCountFeatures('user_id', 'merchant_id', dummy=False,
178 | agg_funcs=[rebuy_udf], prefix=indicator)
179 | feat_builder.buildCountFeatures('merchant_id', 'user_id', dummy=False,
180 | agg_funcs=[rebuy_udf], prefix=indicator)
181 | # =============================================
182 | print('【商家】与用户的【年龄,性别】两个特征的交互')
183 | for pk in merchant_item_ids:
184 | feat_builder.buildCountFeatures(pk, user_feats, prefix=indicator,
185 | agg_funcs=['mean', 'max', 'min', median_udf, 'std', 'var', 'nunique'])
186 | # =============================================
187 | print('构造开始终止时间特征')
188 | for pk in core_ids + [core_ids]:
189 | feat_builder.buildCountFeatures(pk, "time_stamp_int", dummy=False, agg_funcs=["min", "max"],
190 | prefix=indicator)
191 | # =============================================
192 | print('【商家,商品,品牌,类别】与多少【用户】交互过(去重)')
193 | for pk in merchant_item_ids:
194 | feat_builder.buildCountFeatures(pk, 'user_id', dummy=False, agg_funcs=['nunique'], prefix=indicator)
195 | # =============================================
196 | print('【用户】与多少【商家,商品,品牌,类别】交互过(去重)')
197 | feat_builder.buildCountFeatures('user_id', merchant_item_ids, dummy=False, agg_funcs=['nunique'], prefix=indicator)
198 | print('【商家】,【用户,商品】与多少【商品,品牌,类别】交互过(去重)')
199 | for pk in ['merchant_id'] + [core_ids]:
200 | feat_builder.buildCountFeatures(pk, item_ids, dummy=False, agg_funcs=['nunique'],
201 | prefix=indicator)
202 | # =============================================
203 | if indicator is None:
204 | print('【用户,商家,商品,品牌,类别, 。。。】的【action_type】统计 (行为比例)')
205 | for pk in ['user_id', 'merchant_id'] + [core_ids]:
206 | feat_builder.buildCountFeatures(pk, 'action_type', agg_funcs=['nunique'], prefix=indicator)
207 | # =============================================
208 | print('【用户,商家,【用户,商家】】每个【月,星期】的互动次数, 持续时间跨度')
209 | for pk in ['user_id', 'merchant_id'] + [core_ids]:
210 | feat_builder.buildCountFeatures(pk, ['month', 'weekday'], agg_funcs=['nunique'], prefix=indicator)
211 | feat_builder.buildCountFeatures(pk, ['time_stamp'], dummy=False, agg_funcs=[timediff_udf], prefix=indicator)
212 | # =============================================
213 | print('最喜欢特征')
214 | all_features = ['user_id'] + ['month', 'weekday'] + merchant_item_ids
215 | if indicator is None:
216 | all_features.append('action_type')
217 | for feat_a in ['user_id', 'merchant_id']:
218 | targets = [feat_b for feat_b in all_features if feat_b != feat_a]
219 | feat_builder.buildCountFeatures(feat_a, targets, dummy=False, agg_funcs=[mostlike_udf], prefix=indicator)
220 | prefix = ""
221 | if indicator is not None:
222 | prefix = f"{indicator}-"
223 | print('用户在商铺的出现比例, 以及相反')
224 | feat_builder.addOperateFeatures(f'{prefix}users_div_merchants',
225 | f"lambda x: x['{prefix}user_id-cnt'] / x['{prefix}merchant_id-cnt']")
226 | feat_builder.addOperateFeatures(f'{prefix}merchants_div_users',
227 | f"lambda x: x['{prefix}user_id-cnt'] / x['{prefix}merchant_id-cnt']")
228 | print('用户和商铺的复购率')
229 | if indicator:
230 | for rebuy_times in rebuy_ranges:
231 | feat_builder.addOperateFeatures(f'{prefix}user_rebuy{rebuy_times}_ratio',
232 | f"lambda x: x['{prefix}user_id-merchant_id-rebuy{rebuy_times}'] / x['{prefix}user_id-cnt']")
233 | feat_builder.addOperateFeatures(f'{prefix}merchant_rebuy{rebuy_times}_ratio',
234 | f"lambda x: x['{prefix}merchant_id-user_id-rebuy{rebuy_times}'] / x['{prefix}merchant_id-cnt']")
235 | print('finish', indicator)
236 |
237 |
238 |
239 | feat_builder.reduce_mem_usage()
240 | del feat_builder.core_df
241 | dump(feat_builder, f"{data_path}/feat_builder.pkl")
242 | # 打印出来的总特征数不准,因为有些主键对应的表用不上
243 | print("总特征数:", feat_builder.n_features)
244 |
--------------------------------------------------------------------------------