├── .claude
├── commands
│ ├── INDEX.md
│ ├── README.md
│ ├── architecture-design.md
│ ├── context-compact.md
│ ├── crawl-docs.md
│ ├── daily-check.md
│ ├── firecrawl-api-research.md
│ ├── generate-tests.md
│ ├── knowledge-extract.md
│ ├── linear-continue-debugging.md
│ ├── linear-continue-testing.md
│ ├── linear-continue-work.md
│ ├── linear-debug-systematic.md
│ ├── linear-feature.md
│ ├── linear-plan-implementation.md
│ ├── linear-retroactive-git.md
│ ├── mcp-context-build.md
│ ├── mcp-doc-extract.md
│ ├── mcp-repo-analyze.md
│ ├── pr-complete.md
│ ├── pre-commit-fix.md
│ ├── standards-check.md
│ └── validate-docs.md
├── debugging
│ ├── cfos-41-lance-issues
│ │ ├── COMPLETION_SUMMARY.md
│ │ ├── COMPREHENSIVE_SOLUTIONS_ANALYSIS.md
│ │ ├── FINAL_IMPLEMENTATION_PLAN.md
│ │ ├── LANCE_BLOB_FILTER_BUG_ANALYSIS.md
│ │ ├── LANCE_ISSUE_SOLUTION.md
│ │ ├── LONG_TERM_IMPLEMENTATION_PLAN.md
│ │ ├── README.md
│ │ └── SOLUTION_SUMMARY.md
│ └── lance-map-type-issue.md
├── development-workflow.md
├── documentation
│ ├── docling
│ │ ├── docling-project.github.io_docling_.md
│ │ ├── docling-project.github.io_docling_concepts_.md
│ │ ├── docling-project.github.io_docling_concepts_architecture_.md
│ │ ├── docling-project.github.io_docling_concepts_chunking_.md
│ │ ├── docling-project.github.io_docling_concepts_docling_document_.md
│ │ ├── docling-project.github.io_docling_concepts_plugins_.md
│ │ ├── docling-project.github.io_docling_concepts_serialization_.md
│ │ ├── docling-project.github.io_docling_examples_.md
│ │ ├── docling-project.github.io_docling_examples_advanced_chunking_and_serialization_.md
│ │ ├── docling-project.github.io_docling_examples_backend_csv_.md
│ │ ├── docling-project.github.io_docling_examples_backend_xml_rag_.md
│ │ ├── docling-project.github.io_docling_examples_batch_convert_.md
│ │ ├── docling-project.github.io_docling_examples_compare_vlm_models_.md
│ │ ├── docling-project.github.io_docling_examples_custom_convert_.md
│ │ ├── docling-project.github.io_docling_examples_develop_formula_understanding_.md
│ │ ├── docling-project.github.io_docling_examples_develop_picture_enrichment_.md
│ │ ├── docling-project.github.io_docling_examples_export_figures_.md
│ │ ├── docling-project.github.io_docling_examples_export_multimodal_.md
│ │ ├── docling-project.github.io_docling_examples_export_tables_.md
│ │ ├── docling-project.github.io_docling_examples_full_page_ocr_.md
│ │ ├── docling-project.github.io_docling_examples_hybrid_chunking_.md
│ │ ├── docling-project.github.io_docling_examples_inspect_picture_content_.md
│ │ ├── docling-project.github.io_docling_examples_minimal_.md
│ │ ├── docling-project.github.io_docling_examples_minimal_vlm_pipeline_.md
│ │ ├── docling-project.github.io_docling_examples_pictures_description_.md
│ │ ├── docling-project.github.io_docling_examples_pictures_description_api_.md
│ │ ├── docling-project.github.io_docling_examples_rag_azuresearch_.md
│ │ ├── docling-project.github.io_docling_examples_rag_haystack_.md
│ │ ├── docling-project.github.io_docling_examples_rag_langchain_.md
│ │ ├── docling-project.github.io_docling_examples_rag_llamaindex_.md
│ │ ├── docling-project.github.io_docling_examples_rag_milvus_.md
│ │ ├── docling-project.github.io_docling_examples_rag_weaviate_.md
│ │ ├── docling-project.github.io_docling_examples_rapidocr_with_custom_models_.md
│ │ ├── docling-project.github.io_docling_examples_retrieval_qdrant_.md
│ │ ├── docling-project.github.io_docling_examples_run_md_.md
│ │ ├── docling-project.github.io_docling_examples_run_with_accelerator_.md
│ │ ├── docling-project.github.io_docling_examples_run_with_formats_.md
│ │ ├── docling-project.github.io_docling_examples_serialization_.md
│ │ ├── docling-project.github.io_docling_examples_tesseract_lang_detection_.md
│ │ ├── docling-project.github.io_docling_examples_translate_.md
│ │ ├── docling-project.github.io_docling_examples_visual_grounding_.md
│ │ ├── docling-project.github.io_docling_examples_vlm_pipeline_api_model_.md
│ │ ├── docling-project.github.io_docling_faq_.md
│ │ ├── docling-project.github.io_docling_installation_.md
│ │ ├── docling-project.github.io_docling_integrations_.md
│ │ ├── docling-project.github.io_docling_integrations_apify_.md
│ │ ├── docling-project.github.io_docling_integrations_bee_.md
│ │ ├── docling-project.github.io_docling_integrations_cloudera_.md
│ │ ├── docling-project.github.io_docling_integrations_crewai_.md
│ │ ├── docling-project.github.io_docling_integrations_data_prep_kit_.md
│ │ ├── docling-project.github.io_docling_integrations_docetl_.md
│ │ ├── docling-project.github.io_docling_integrations_haystack_.md
│ │ ├── docling-project.github.io_docling_integrations_instructlab_.md
│ │ ├── docling-project.github.io_docling_integrations_kotaemon_.md
│ │ ├── docling-project.github.io_docling_integrations_langchain_.md
│ │ ├── docling-project.github.io_docling_integrations_llamaindex_.md
│ │ ├── docling-project.github.io_docling_integrations_nvidia_.md
│ │ ├── docling-project.github.io_docling_integrations_opencontracts_.md
│ │ ├── docling-project.github.io_docling_integrations_openwebui_.md
│ │ ├── docling-project.github.io_docling_integrations_prodigy_.md
│ │ ├── docling-project.github.io_docling_integrations_rhel_ai_.md
│ │ ├── docling-project.github.io_docling_integrations_spacy_.md
│ │ ├── docling-project.github.io_docling_integrations_txtai_.md
│ │ ├── docling-project.github.io_docling_integrations_vectara_.md
│ │ ├── docling-project.github.io_docling_reference_cli_.md
│ │ ├── docling-project.github.io_docling_reference_docling_document_.md
│ │ ├── docling-project.github.io_docling_reference_document_converter_.md
│ │ ├── docling-project.github.io_docling_reference_pipeline_options_.md
│ │ ├── docling-project.github.io_docling_usage_.md
│ │ ├── docling-project.github.io_docling_usage_enrichments_.md
│ │ ├── docling-project.github.io_docling_usage_supported_formats_.md
│ │ ├── docling-project.github.io_docling_usage_vision_models_.md
│ │ └── docling-project.github.io_docling_v2_.md
│ ├── lance
│ │ ├── lancedb.github.io_lance_.md
│ │ ├── lancedb.github.io_lance_api_api.html.md
│ │ ├── lancedb.github.io_lance_api_py_modules.html.md
│ │ ├── lancedb.github.io_lance_api_python.html.md
│ │ ├── lancedb.github.io_lance_arrays.html.md
│ │ ├── lancedb.github.io_lance_blob.html.md
│ │ ├── lancedb.github.io_lance_contributing.html.md
│ │ ├── lancedb.github.io_lance_distributed_write.html.md
│ │ ├── lancedb.github.io_lance_examples_examples.html.md
│ │ ├── lancedb.github.io_lance_format.html.md
│ │ ├── lancedb.github.io_lance_format.rst.md
│ │ ├── lancedb.github.io_lance_genindex.html.md
│ │ ├── lancedb.github.io_lance_integrations_huggingface.html.md
│ │ ├── lancedb.github.io_lance_integrations_pytorch.html.md
│ │ ├── lancedb.github.io_lance_integrations_ray.html.md
│ │ ├── lancedb.github.io_lance_integrations_spark.html.md
│ │ ├── lancedb.github.io_lance_integrations_tensorflow.html.md
│ │ ├── lancedb.github.io_lance_introduction_read_and_write.html.md
│ │ ├── lancedb.github.io_lance_introduction_schema_evolution.html.md
│ │ ├── lancedb.github.io_lance_notebooks_quickstart.html.md
│ │ ├── lancedb.github.io_lance_object_store.html.md
│ │ ├── lancedb.github.io_lance_performance.html.md
│ │ ├── lancedb.github.io_lance_py-modindex.html.md
│ │ ├── lancedb.github.io_lance_search.html.md
│ │ ├── lancedb.github.io_lance_tags.html.md
│ │ └── lancedb.github.io_lance_tokenizer.html.md
│ ├── litellm
│ │ ├── docs.litellm.ai_docs_.md
│ │ ├── docs.litellm.ai_docs_anthropic_unified.md
│ │ ├── docs.litellm.ai_docs_apply_guardrail.md
│ │ ├── docs.litellm.ai_docs_assistants.md
│ │ ├── docs.litellm.ai_docs_audio_transcription.md
│ │ ├── docs.litellm.ai_docs_batches.md
│ │ ├── docs.litellm.ai_docs_budget_manager.md
│ │ ├── docs.litellm.ai_docs_completion.md
│ │ ├── docs.litellm.ai_docs_contributing.md
│ │ ├── docs.litellm.ai_docs_data_retention.md
│ │ ├── docs.litellm.ai_docs_data_security.md
│ │ ├── docs.litellm.ai_docs_enterprise.md
│ │ ├── docs.litellm.ai_docs_exception_mapping.md
│ │ ├── docs.litellm.ai_docs_files_endpoints.md
│ │ ├── docs.litellm.ai_docs_fine_tuning.md
│ │ ├── docs.litellm.ai_docs_hosted.md
│ │ ├── docs.litellm.ai_docs_image_edits.md
│ │ ├── docs.litellm.ai_docs_image_generation.md
│ │ ├── docs.litellm.ai_docs_image_variations.md
│ │ ├── docs.litellm.ai_docs_langchain_.md
│ │ ├── docs.litellm.ai_docs_mcp.md
│ │ ├── docs.litellm.ai_docs_migration.md
│ │ ├── docs.litellm.ai_docs_migration_policy.md
│ │ ├── docs.litellm.ai_docs_moderation.md
│ │ ├── docs.litellm.ai_docs_oidc.md
│ │ ├── docs.litellm.ai_docs_project.md
│ │ ├── docs.litellm.ai_docs_providers.md
│ │ ├── docs.litellm.ai_docs_proxy_server.md
│ │ ├── docs.litellm.ai_docs_realtime.md
│ │ ├── docs.litellm.ai_docs_reasoning_content.md
│ │ ├── docs.litellm.ai_docs_rerank.md
│ │ ├── docs.litellm.ai_docs_response_api.md
│ │ ├── docs.litellm.ai_docs_routing-load-balancing.md
│ │ ├── docs.litellm.ai_docs_routing.md
│ │ ├── docs.litellm.ai_docs_rules.md
│ │ ├── docs.litellm.ai_docs_scheduler.md
│ │ ├── docs.litellm.ai_docs_sdk_custom_pricing.md
│ │ ├── docs.litellm.ai_docs_secret.md
│ │ ├── docs.litellm.ai_docs_set_keys.md
│ │ ├── docs.litellm.ai_docs_simple_proxy.md
│ │ ├── docs.litellm.ai_docs_supported_endpoints.md
│ │ ├── docs.litellm.ai_docs_text_completion.md
│ │ ├── docs.litellm.ai_docs_text_to_speech.md
│ │ ├── docs.litellm.ai_docs_troubleshoot.md
│ │ └── docs.litellm.ai_docs_wildcard_routing.md
│ ├── mirascope
│ │ ├── mirascope.com_docs_mirascope.md
│ │ ├── mirascope.com_docs_mirascope_api.md
│ │ ├── mirascope.com_docs_mirascope_api_core_anthropic_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_anthropic_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_anthropic_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_anthropic_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_anthropic_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_anthropic_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_anthropic_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_azure_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_azure_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_azure_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_azure_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_azure_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_azure_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_azure_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_call_factory.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_merge_decorators.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_message_param.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_metadata.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_prompt.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_structured_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_toolkit.md
│ │ ├── mirascope.com_docs_mirascope_api_core_base_types.md
│ │ ├── mirascope.com_docs_mirascope_api_core_bedrock_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_bedrock_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_bedrock_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_bedrock_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_bedrock_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_bedrock_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_bedrock_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_cohere_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_cohere_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_cohere_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_cohere_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_cohere_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_cohere_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_cohere_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_costs_calculate_cost.md
│ │ ├── mirascope.com_docs_mirascope_api_core_google_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_google_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_google_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_google_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_google_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_google_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_google_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_groq_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_groq_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_groq_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_groq_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_groq_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_groq_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_groq_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_litellm_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_litellm_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_litellm_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_litellm_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_litellm_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_litellm_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_litellm_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_mistral_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_mistral_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_mistral_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_mistral_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_mistral_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_mistral_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_mistral_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_openai_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_openai_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_openai_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_openai_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_openai_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_openai_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_openai_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_core_xai_call.md
│ │ ├── mirascope.com_docs_mirascope_api_core_xai_call_params.md
│ │ ├── mirascope.com_docs_mirascope_api_core_xai_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_core_xai_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_core_xai_dynamic_config.md
│ │ ├── mirascope.com_docs_mirascope_api_core_xai_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_core_xai_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_llm_call.md
│ │ ├── mirascope.com_docs_mirascope_api_llm_call_response.md
│ │ ├── mirascope.com_docs_mirascope_api_llm_call_response_chunk.md
│ │ ├── mirascope.com_docs_mirascope_api_llm_context.md
│ │ ├── mirascope.com_docs_mirascope_api_llm_override.md
│ │ ├── mirascope.com_docs_mirascope_api_llm_stream.md
│ │ ├── mirascope.com_docs_mirascope_api_llm_tool.md
│ │ ├── mirascope.com_docs_mirascope_api_mcp_client.md
│ │ ├── mirascope.com_docs_mirascope_api_retries_fallback.md
│ │ ├── mirascope.com_docs_mirascope_api_retries_tenacity.md
│ │ ├── mirascope.com_docs_mirascope_api_tools_system_docker_operation.md
│ │ ├── mirascope.com_docs_mirascope_api_tools_system_file_system.md
│ │ ├── mirascope.com_docs_mirascope_api_tools_web_duckduckgo.md
│ │ ├── mirascope.com_docs_mirascope_api_tools_web_httpx.md
│ │ ├── mirascope.com_docs_mirascope_api_tools_web_parse_url_content.md
│ │ ├── mirascope.com_docs_mirascope_api_tools_web_requests.md
│ │ ├── mirascope.com_docs_mirascope_getting-started_contributing.md
│ │ ├── mirascope.com_docs_mirascope_getting-started_help.md
│ │ ├── mirascope.com_docs_mirascope_getting-started_migration.md
│ │ ├── mirascope.com_docs_mirascope_getting-started_why.md
│ │ ├── mirascope.com_docs_mirascope_guides.md
│ │ ├── mirascope.com_docs_mirascope_guides_agents_blog-writing-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_agents_documentation-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_agents_local-chat-with-codebase.md
│ │ ├── mirascope.com_docs_mirascope_guides_agents_localized-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_agents_qwant-search-agent-with-sources.md
│ │ ├── mirascope.com_docs_mirascope_guides_agents_sql-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_agents_web-search-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_evals_evaluating-documentation-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_evals_evaluating-sql-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_evals_evaluating-web-search-agent.md
│ │ ├── mirascope.com_docs_mirascope_guides_getting-started_dynamic-configuration-and-chaining.md
│ │ ├── mirascope.com_docs_mirascope_guides_getting-started_quickstart.md
│ │ ├── mirascope.com_docs_mirascope_guides_getting-started_structured-outputs.md
│ │ ├── mirascope.com_docs_mirascope_guides_getting-started_tools-and-agents.md
│ │ ├── mirascope.com_docs_mirascope_guides_langgraph-vs-mirascope_quickstart.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_code-generation-and-execution.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_document-segmentation.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_extract-from-pdf.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_extraction-using-vision.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_generating-captions.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_generating-synthetic-data.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_knowledge-graph.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_llm-validation-with-retries.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_named-entity-recognition.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_o1-style-thinking.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_pii-scrubbing.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_query-plan.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_removing-semantic-duplicates.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_search-with-sources.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_speech-transcription.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_support-ticket-routing.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_text-classification.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_text-summarization.md
│ │ ├── mirascope.com_docs_mirascope_guides_more-advanced_text-translation.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_chain-of-verification.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_decomposed-prompting.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_demonstration-ensembling.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_diverse.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_least-to-most.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_mixture-of-reasoning.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_prompt-paraphrasing.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_reverse-chain-of-thought.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_self-consistency.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_self-refine.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_sim-to-m.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_skeleton-of-thought.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_step-back.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_chaining-based_system-to-attention.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_chain-of-thought.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_common-phrases.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_contrastive-chain-of-thought.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_emotion-prompting.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_plan-and-solve.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_rephrase-and-respond.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_rereading.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_role-prompting.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_self-ask.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_tabular-chain-of-thought.md
│ │ ├── mirascope.com_docs_mirascope_guides_prompt-engineering_text-based_thread-of-thought.md
│ │ ├── mirascope.com_docs_mirascope_learn.md
│ │ ├── mirascope.com_docs_mirascope_learn_agents.md
│ │ ├── mirascope.com_docs_mirascope_learn_async.md
│ │ ├── mirascope.com_docs_mirascope_learn_calls.md
│ │ ├── mirascope.com_docs_mirascope_learn_chaining.md
│ │ ├── mirascope.com_docs_mirascope_learn_evals.md
│ │ ├── mirascope.com_docs_mirascope_learn_extensions_custom_provider.md
│ │ ├── mirascope.com_docs_mirascope_learn_extensions_middleware.md
│ │ ├── mirascope.com_docs_mirascope_learn_json_mode.md
│ │ ├── mirascope.com_docs_mirascope_learn_local_models.md
│ │ ├── mirascope.com_docs_mirascope_learn_mcp_client.md
│ │ ├── mirascope.com_docs_mirascope_learn_output_parsers.md
│ │ ├── mirascope.com_docs_mirascope_learn_prompts.md
│ │ ├── mirascope.com_docs_mirascope_learn_provider-specific_anthropic.md
│ │ ├── mirascope.com_docs_mirascope_learn_provider-specific_openai.md
│ │ ├── mirascope.com_docs_mirascope_learn_response_models.md
│ │ ├── mirascope.com_docs_mirascope_learn_retries.md
│ │ ├── mirascope.com_docs_mirascope_learn_streams.md
│ │ ├── mirascope.com_docs_mirascope_learn_tools.md
│ │ ├── mirascope.com_docs_mirascope_llms-full.md
│ │ └── mirascope.com_docs_mirascope_llms-full.txt.md
│ └── modelcontextprotocol
│ │ ├── 01_overview
│ │ └── index.md
│ │ ├── 02_architecture
│ │ └── architecture.md
│ │ ├── 03_base_protocol
│ │ ├── 01_overview.md
│ │ ├── 02_lifecycle.md
│ │ ├── 03_transports.md
│ │ └── 04_authorization.md
│ │ ├── 04_server_features
│ │ ├── 01_overview.md
│ │ ├── 02_prompts.md
│ │ ├── 03_resources.md
│ │ └── 04_tools.md
│ │ ├── 05_client_features
│ │ ├── 01_roots.md
│ │ └── 02_sampling.md
│ │ └── README.md
├── implementations
│ ├── collection_metadata_fix.md
│ ├── collection_metadata_lance_filtering_analysis.md
│ ├── elasticsearch_migration_guide.md
│ ├── http_primary_transport.md
│ ├── mcp_architecture_analysis.md
│ ├── mcp_documentation_summary.md
│ ├── mcp_integration_patterns.md
│ ├── mcp_monitoring_analysis.md
│ ├── mcp_protocol_research.md
│ ├── mcp_security_analysis.md
│ ├── mcp_tools_analysis.md
│ ├── mcp_transport_analysis.md
│ ├── mongodb_atlas_vector_search_research.md
│ ├── phase2_mcp_server.md
│ ├── phase3.2_batch_operations.md
│ ├── phase3.3_collection_management.md
│ ├── phase3.3_collection_management_complete.md
│ ├── phase3.4_subscription_system.md
│ ├── phase3.5_http_transport.md
│ ├── phase3.6_analytics_performance.md
│ ├── phase3_mcp_server.md
│ ├── phase4.1_monitoring.md
│ └── weaviate_export_research.md
├── pre-commit-quick-fixes.md
├── standards
│ ├── claude-code-meta-standards.md
│ ├── code-standards.md
│ ├── meta-prompts-library.md
│ ├── mirascope-lilypad-best-practice-standards.md
│ ├── quick-reference.md
│ └── testing-standards.md
└── temp
│ ├── claude-code-advanced-temp.md
│ ├── claude-prompting-temp.md
│ ├── firecrawl-tools-temp.md
│ ├── lance-quickstart-temp.md
│ ├── memvid-analysis-temp.md
│ └── semantic-splitter-temp.mc
├── .cursor
└── rules
│ ├── MDC-file to-help-generate-MDC-files.mdc
│ ├── contextframe-concepts.mdc
│ └── python_package_best_practices.mdc
├── .github
└── workflows
│ └── claude.yml
├── .gitignore
├── .mypy.ini
├── .pre-commit-config.yaml
├── .vscode
├── extensions.json
├── launch.json
└── settings.json
├── CHANGELOG.md
├── CLAUDE.md
├── CODE_OF_CONDUCT.md
├── LICENSE
├── MANIFEST.in
├── README.md
├── contextframe
├── __init__.py
├── __main__.py
├── builders
│ ├── __init__.py
│ ├── embed.py
│ ├── encode.py
│ ├── enhance.py
│ └── serve.py
├── cli.py
├── connectors
│ ├── __init__.py
│ ├── base.py
│ ├── discord.py
│ ├── github.py
│ ├── google_drive.py
│ ├── linear.py
│ ├── notion.py
│ ├── obsidian.py
│ └── slack.py
├── embed
│ ├── __init__.py
│ ├── base.py
│ ├── batch.py
│ ├── integration.py
│ └── litellm_provider.py
├── enhance
│ ├── __init__.py
│ ├── base.py
│ ├── prompts.py
│ └── tools.py
├── examples
│ └── __init__.py
├── exceptions.py
├── extract
│ ├── __init__.py
│ ├── base.py
│ ├── batch.py
│ ├── chunking.py
│ └── extractors.py
├── frame.py
├── helpers
│ ├── __init__.py
│ └── metadata_utils.py
├── io
│ ├── __init__.py
│ ├── exporter.py
│ ├── formats.py
│ └── importer.py
├── mcp
│ ├── README.md
│ ├── TRANSPORT_GUIDE.md
│ ├── __init__.py
│ ├── __main__.py
│ ├── analytics
│ │ ├── __init__.py
│ │ ├── analyzer.py
│ │ ├── optimizer.py
│ │ ├── stats.py
│ │ └── tools.py
│ ├── batch
│ │ ├── __init__.py
│ │ ├── handler.py
│ │ ├── tools.py
│ │ └── transaction.py
│ ├── collections
│ │ ├── __init__.py
│ │ ├── templates.py
│ │ └── tools.py
│ ├── core
│ │ ├── __init__.py
│ │ ├── streaming.py
│ │ └── transport.py
│ ├── enhancement_tools.py
│ ├── errors.py
│ ├── example_client.py
│ ├── handlers.py
│ ├── http_client_example.py
│ ├── monitoring
│ │ ├── __init__.py
│ │ ├── collector.py
│ │ ├── cost.py
│ │ ├── integration.py
│ │ ├── performance.py
│ │ ├── tools.py
│ │ └── usage.py
│ ├── resources.py
│ ├── schemas.py
│ ├── security
│ │ ├── __init__.py
│ │ ├── audit.py
│ │ ├── auth.py
│ │ ├── authorization.py
│ │ ├── integration.py
│ │ ├── jwt.py
│ │ ├── oauth.py
│ │ └── rate_limiting.py
│ ├── server.py
│ ├── subscriptions
│ │ ├── __init__.py
│ │ ├── manager.py
│ │ └── tools.py
│ ├── tools.py
│ ├── transport.py
│ └── transports
│ │ ├── __init__.py
│ │ ├── http
│ │ ├── __init__.py
│ │ ├── adapter.py
│ │ ├── auth.py
│ │ ├── config.py
│ │ ├── security.py
│ │ ├── server.py
│ │ └── sse.py
│ │ └── stdio.py
├── schema
│ ├── __init__.py
│ ├── contextframe_schema.json
│ ├── contextframe_schema.py
│ └── validation.py
├── scripts
│ ├── README.md
│ ├── __init__.py
│ ├── add_impl.py
│ ├── contextframe-add
│ ├── contextframe-get
│ ├── contextframe-list
│ ├── contextframe-search
│ ├── create_dataset.py
│ ├── get_impl.py
│ ├── list_impl.py
│ └── search_impl.py
├── templates
│ ├── __init__.py
│ ├── base.py
│ ├── business.py
│ ├── examples
│ │ └── __init__.py
│ ├── registry.py
│ ├── research.py
│ └── software.py
└── tests
│ ├── test_all_connectors.py
│ ├── test_connectors.py
│ └── test_mcp
│ ├── __init__.py
│ ├── test_analytics.py
│ ├── test_batch_handler.py
│ ├── test_batch_tools.py
│ ├── test_batch_tools_integration.py
│ ├── test_collection_tools.py
│ ├── test_http_first_approach.py
│ ├── test_http_primary.py
│ ├── test_monitoring.py
│ ├── test_protocol.py
│ ├── test_security.py
│ ├── test_subscription_tools.py
│ ├── test_transport_migration.py
│ └── test_transports
│ ├── __init__.py
│ └── test_http.py
├── docs
├── CNAME
├── api
│ ├── connectors.md
│ ├── frame-dataset.md
│ ├── frame-record.md
│ ├── overview.md
│ ├── schema.md
│ └── utilities.md
├── blog
│ └── index.md
├── cli
│ ├── commands.md
│ ├── configuration.md
│ ├── overview.md
│ └── versioning.md
├── community
│ ├── code-of-conduct.md
│ ├── contributing.md
│ ├── index.md
│ └── support.md
├── concepts
│ ├── dataset_layout.md
│ ├── frame_storage.md
│ └── schema_cheatsheet.md
├── cookbook
│ ├── api-docs.md
│ ├── changelog-tracking.md
│ ├── course-materials.md
│ ├── customer-support-analytics.md
│ ├── document-pipeline.md
│ ├── email-archive.md
│ ├── extraction_patterns.md
│ ├── financial-analysis.md
│ ├── github-knowledge-base.md
│ ├── index.md
│ ├── legal-repository.md
│ ├── meeting-notes.md
│ ├── multi-language.md
│ ├── multi-source-search.md
│ ├── news-clustering.md
│ ├── patent-search.md
│ ├── podcast-index.md
│ ├── rag-system.md
│ ├── research-papers.md
│ ├── scientific-catalog.md
│ ├── slack-knowledge.md
│ └── video-transcripts.md
├── core-concepts
│ ├── architecture.md
│ ├── collections-relationships.md
│ ├── data-model.md
│ ├── record-types.md
│ ├── schema-system.md
│ └── storage-layer.md
├── faq.md
├── getting-started
│ ├── basic-examples.md
│ ├── first-steps.md
│ └── installation.md
├── index.md
├── integration
│ ├── blobs.md
│ ├── connectors
│ │ ├── index.md
│ │ └── introduction.md
│ ├── custom.md
│ ├── discord.md
│ ├── docling_integration_analysis.md
│ ├── embedding_providers.md
│ ├── external-connectors.md
│ ├── external_extraction_tools.md
│ ├── github.md
│ ├── google-drive.md
│ ├── installation.md
│ ├── linear.md
│ ├── notion.md
│ ├── object_storage.md
│ ├── obsidian.md
│ ├── overview.md
│ ├── python_api.md
│ ├── slack.md
│ └── validation.md
├── mcp
│ ├── api
│ │ └── tools.md
│ ├── concepts
│ │ ├── overview.md
│ │ ├── tools.md
│ │ └── transport.md
│ ├── configuration
│ │ ├── index.md
│ │ ├── monitoring.md
│ │ └── security.md
│ ├── cookbook
│ │ └── index.md
│ ├── getting-started
│ │ ├── installation.md
│ │ └── quickstart.md
│ ├── guides
│ │ ├── agent-integration.md
│ │ └── cli-tools.md
│ ├── index.md
│ └── mcp_implementation_plan.md
├── migration
│ ├── data-import-export.md
│ ├── from-document-stores.md
│ ├── from-vector-databases.md
│ ├── overview.md
│ └── pgvector_export_guide.md
├── modules
│ ├── embeddings.md
│ ├── enrichment.md
│ ├── frame-dataset.md
│ ├── frame-record.md
│ ├── import-export.md
│ └── search-query.md
├── quickstart.md
├── recipes
│ ├── bulk_ingest_embedding.md
│ ├── collections_relationships.md
│ ├── fastapi_vector_search.md
│ ├── frameset_export_import.md
│ ├── s3_roundtrip.md
│ └── store_images_blobs.md
├── reference
│ ├── error-codes.md
│ ├── index.md
│ └── schema.md
├── troubleshooting.md
└── tutorials
│ └── basics_tutorial.md
├── examples
├── all_connectors_usage.py
├── connector_usage.py
├── embedding_providers_demo.py
├── enrichment_demo.py
├── external_tools
│ ├── chunkr_pipeline.py
│ ├── docling_pdf_pipeline.py
│ ├── ollama_local_embedding.py
│ ├── reducto_pipeline.py
│ └── unstructured_io_pipeline.py
└── semantic_chunking_demo.py
├── mkdocs.yml
├── pyproject.toml
├── schema_discrepancy_report.md
└── tests
├── test_embed.py
├── test_enhance.py
├── test_extract.py
├── test_extract_integration.py
├── test_frameset.py
├── test_io.py
├── test_lazy_loading.py
├── test_litellm_provider.py
└── test_templates.py
/.claude/commands/INDEX.md:
--------------------------------------------------------------------------------
1 | CLAUDE COMMANDS - QUICK INDEX
2 |
3 | ## Core Workflow Commands
4 |
5 | - `/project:plan-implementation` - Create Linear implementation plans with project organization
6 | - `/project:linear-feature` - Complete feature workflow (Linear → Branch → Commits → PR)
7 | - `/project:daily-check` - Daily development status check
8 | - `/project:debug-systematic` - Scientific debugging with root cause analysis
9 | - `/project:pr-complete` - Create professional pull requests
10 |
11 | ## Quality & Testing Commands
12 |
13 | - `/project:standards-check` - Check and auto-fix code standards
14 | - `/project:generate-tests` - Generate comprehensive test suites (80/20 rule)
15 |
16 | ## Architecture & Documentation Commands
17 |
18 | - `/project:architecture-design` - Design system architecture with ADRs
19 | - `/project:knowledge-extract` - Extract and document code knowledge
20 | - `/project:crawl-docs` - Extract web documentation to local files
21 | - `/project:validate-docs` - Validate documentation against codebase implementation
22 |
23 | ## MCP-Powered Commands
24 |
25 | - `/project:mcp-doc-extract` - Extract docs using Firecrawl MCP
26 | - `/project:mcp-repo-analyze` - Analyze GitHub repos using DeepWiki MCP
27 | - `/project:mcp-api-research` - Research APIs using Firecrawl deep research
28 | - `/project:mcp-context-build` - Build context using both MCPs
29 |
30 | ---
31 |
32 | **Usage**: `/project:[command-name] [arguments]`
33 |
34 | **Example**: `/project:plan-implementation User authentication system`
35 |
36 | **Details**: See individual command files or `README.md` for full documentation.
37 |
--------------------------------------------------------------------------------
/.claude/commands/architecture-design.md:
--------------------------------------------------------------------------------
1 | Design comprehensive architecture for: $ARGUMENTS
2 |
3 |
4 | Think deeply. Consider everything. This design guides months of development.
5 |
6 |
7 |
8 | The assistant should create production-grade architecture covering scalability, maintainability, security, performance. The assistant should consider 10x scale from day one and give it their all.
9 |
10 |
11 |
12 | Building foundation for: $ARGUMENTS
13 | Need complete technical blueprint with all decisions documented
14 |
15 |
16 |
17 | - High-level architecture with ASCII diagrams
18 | - Component design with clear boundaries
19 | - Data architecture (entities, flow, consistency)
20 | - Security architecture (auth, encryption, audit)
21 | - Performance strategy (caching, async, monitoring)
22 | - Architecture Decision Records (ADRs) for key choices
23 | - Risk assessment with mitigations
24 | - Implementation roadmap with Linear phases
25 |
26 |
27 |
28 | 1. Analyze requirements (functional, non-functional, constraints, growth)
29 | 2. Design system architecture with clear service boundaries
30 | 3. Create component specifications (responsibilities, interfaces, scaling)
31 | 4. Document all technical decisions with ADRs
32 | 5. Build security layer (authentication, authorization, compliance)
33 | 6. Design performance optimization strategy
34 | 7. Create Linear epic with phased implementation plan
35 | 8. Save to `.claude/architecture/$ARGUMENTS/` with all artifacts
36 |
37 |
38 | The assistant should generate comprehensive architecture that future developers will thank them for. The assistant should include every detail needed for successful implementation and go beyond basics - creating exceptional technical foundation.
39 |
40 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
--------------------------------------------------------------------------------
/.claude/commands/crawl-docs.md:
--------------------------------------------------------------------------------
1 | Extract comprehensive documentation from: $ARGUMENTS
2 |
3 |
4 | Capture every useful detail, example, pattern. Make this our definitive knowledge source.
5 |
6 |
7 |
8 | The assistant should use WebFetch for intelligent content extraction, follow links, find hidden gems, and organize systematically.
9 |
10 |
11 |
12 | Need complete documentation extraction from: $ARGUMENTS
13 | Will become our source of truth for development
14 |
15 |
16 |
17 | - Deep content analysis with link following
18 | - Logical organization (concepts, API, examples, troubleshooting)
19 | - Code snippet extraction with context
20 | - Configuration examples and patterns
21 | - Version-specific information
22 | - Quality verification
23 |
24 |
25 |
26 | 1. WebFetch main page → identify structure and navigation
27 | 2. Extract linked pages, subpages, related docs
28 | 3. Organize by categories: Getting Started, Core Concepts, API Reference, Examples, Best Practices, Configuration, Troubleshooting, Advanced
29 | 4. Extract all code snippets with descriptions
30 | 5. Capture error messages, solutions, patterns, anti-patterns
31 | 6. Save to `.claude/documentation/[source-name]/` with metadata
32 | 7. Generate quick reference guide and cheatsheet
33 | 8. Flag outdated or conflicting information
34 |
35 |
36 | The assistant should create comprehensive, well-organized documentation package that accelerates development and makes it immediately useful.
37 |
38 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
39 |
--------------------------------------------------------------------------------
/.claude/commands/daily-check.md:
--------------------------------------------------------------------------------
1 | Perform comprehensive daily development check: $ARGUMENTS
2 |
3 |
4 | What needs attention? What's blocked? What moves the project forward today?
5 |
6 |
7 |
8 | The assistant should analyze Linear issues, git state, code quality and create focused action plan optimizing for flow and impact.
9 |
10 |
11 |
12 | Daily standup replacement - comprehensive development status and prioritization
13 | Need clear picture of work state and optimal task order
14 |
15 |
16 |
17 | - Linear status (in progress, todo, blocked, in review)
18 | - Git repository state (branch, changes, pending PRs)
19 | - Code quality indicators (tests, linting, coverage)
20 | - Priority matrix (urgent/important, quick wins)
21 | - Health indicators (tech debt, blockers, days since deploy)
22 |
23 |
24 |
25 | 1. mcp_linear.list_my_issues() → categorize by status
26 | 2. git status && git diff --stat && git log --oneline -10
27 | 3. gh pr list --author @me
28 | 4. pytest -x && ruff check --select E,F
29 | 5. Generate priority matrix: 🔴 Urgent (blocked PRs, critical bugs) 🟡 Important (features, reviews) 🟢 Quick wins
30 | 6. Create focused action items with specific Linear issue numbers
31 | 7. Identify blockers, risks, coordination needs
32 | 8. Generate end-of-day checklist
33 |
34 |
35 | The assistant should cut through noise, highlight what truly needs attention, make today productive and move the project forward meaningfully.
36 |
37 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
38 |
--------------------------------------------------------------------------------
/.claude/commands/firecrawl-api-research.md:
--------------------------------------------------------------------------------
1 | Deep API research using Firecrawl MCP for: $ARGUMENTS
2 |
3 |
4 | Extract everything needed for robust integration. Authentication, endpoints, rate limits, examples, edge cases.
5 |
6 |
7 |
8 | The assistant should use Firecrawl's AI-powered extraction and build complete API understanding for production integration.
9 |
10 |
11 |
12 | Researching API: $ARGUMENTS
13 | Need comprehensive documentation for integration
14 |
15 |
16 |
17 | - Complete API specification extraction
18 | - Authentication methods and setup
19 | - All endpoints with parameters/responses
20 | - Rate limits and error codes
21 | - Real-world usage examples
22 | - SDK/library documentation
23 | - Common issues and solutions
24 |
25 |
26 |
27 | 1. mcp_firecrawl.firecrawl_scrape(url="$ARGUMENTS", formats=["markdown", "links"])
28 | 2. mcp_firecrawl.firecrawl_deep_research(query="$ARGUMENTS API authentication endpoints rate limits error codes examples", maxDepth=3, maxUrls=75)
29 | 3. mcp_firecrawl.firecrawl_extract(urls=["$ARGUMENTS/reference", "$ARGUMENTS/auth", "$ARGUMENTS/endpoints"], schema={endpoints, authentication, rateLimits, errorCodes})
30 | 4. mcp_firecrawl.firecrawl_search(query="$ARGUMENTS API integration example Python JavaScript", limit=20)
31 | 5. mcp_firecrawl.firecrawl_batch_scrape(urls=[SDKs, libraries, quickstart])
32 | 6. Research common issues: timeout, rate limit, 401, 403 errors
33 | 7. Extract all code examples with full implementation
34 | 8. Generate API client template with retry logic, rate limiting, error handling
35 | 9. Create integration guide with checklist
36 | 10. Monitor API changes via changelog
37 |
38 |
39 | The assistant should build complete API understanding enabling smooth, robust integration and generate production-ready client implementation.
40 |
41 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
42 |
--------------------------------------------------------------------------------
/.claude/commands/generate-tests.md:
--------------------------------------------------------------------------------
1 | Generate comprehensive test suite for: $ARGUMENTS
2 |
3 |
4 | Strategic coverage. Focus effort where it matters. Prevent real bugs.
5 |
6 |
7 |
8 | The assistant should apply 80/20 rule and test critical paths thoroughly, common cases well, edge cases smartly.
9 |
10 |
11 |
12 | Creating test suite for: $ARGUMENTS
13 | Need meaningful protection against regressions
14 |
15 |
16 |
17 | - Map all functions, dependencies, critical paths
18 | - Priority 1: Core business logic (50% effort)
19 | - Priority 2: Happy paths (30% effort)
20 | - Priority 3: Edge cases (20% effort)
21 | - Performance benchmarks for critical operations
22 | - Test utilities (factories, mocks, fixtures)
23 | - 80% overall coverage, 90%+ for business logic
24 |
25 |
26 |
27 | 1. Analyze code structure → identify test targets
28 | 2. Generate test file structure with proper fixtures
29 | 3. Write comprehensive happy path tests first
30 | 4. Add error handling tests with specific assertions
31 | 5. Create parametrized edge case tests
32 | 6. Add performance benchmarks: assert benchmark.stats['median'] < 0.1
33 | 7. Generate test data factories and mock helpers
34 | 8. Run coverage: pytest --cov=$ARGUMENTS --cov-report=term-missing
35 | 9. Document test intentions (what, why, failure meaning)
36 |
37 |
38 | Every test should prevent a real bug. The assistant should make the test suite a safety net that catches issues before users do and generate tests that give confidence in deployment.
39 |
40 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
41 |
--------------------------------------------------------------------------------
/.claude/commands/knowledge-extract.md:
--------------------------------------------------------------------------------
1 | Extract deep knowledge about: $ARGUMENTS
2 |
3 |
4 | Investigative journalism mode. Uncover the complete story - WHY it exists, HOW it evolved, WHAT it teaches.
5 |
6 |
7 |
8 | The assistant should dig into history, design decisions, trade-offs, document the undocumented, and capture tribal knowledge.
9 |
10 |
11 |
12 | Knowledge extraction for: $ARGUMENTS
13 | Create organizational memory that makes future work easier
14 |
15 |
16 |
17 | - Code archaeology (git history, evolution, major changes)
18 | - Design rationale (why this approach, alternatives considered)
19 | - Dependency mapping (uses, used by, breaking impacts)
20 | - Usage patterns (common, advanced, mistakes to avoid)
21 | - Tribal knowledge (gotchas, tricks, workarounds)
22 | - Performance characteristics
23 | - Future roadmap ideas
24 |
25 |
26 |
27 | 1. git log --follow -- $ARGUMENTS && git blame $ARGUMENTS
28 | 2. rg -l "$ARGUMENTS" → find all usages
29 | 3. rg -B2 -A2 "$ARGUMENTS" → understand contexts
30 | 4. Ask as if interviewing creator: Why created? Alternatives? Do differently? Most important? Breaks often? Bottlenecks?
31 | 5. Document undocumented: deployment gotchas, config secrets, debugging tricks, tuning, known issues
32 | 6. Create `.claude/knowledge/$ARGUMENTS/` structure:
33 | - Executive Summary
34 | - Core Concepts
35 | - Architecture & Design
36 | - Usage Guide (basic, advanced, troubleshooting)
37 | - Implementation Details
38 | - Performance Characteristics
39 | - Evolution History
40 | - Lessons Learned
41 | 7. Generate one-page quick reference
42 | 8. Create FAQ from issues and comments
43 |
44 |
45 | The assistant should create time capsule for future developers so they understand the full story - not just WHAT but WHY and HOW to work with it effectively.
46 |
47 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
48 |
--------------------------------------------------------------------------------
/.claude/commands/linear-debug-systematic.md:
--------------------------------------------------------------------------------
1 | Debug systematically: $ARGUMENTS
2 |
3 |
4 | Think harder. Dig deeper. Find root cause, not symptoms.
5 |
6 |
7 |
8 | The assistant should use scientific method, generate hypotheses, design tests, prove/disprove, and extract maximum learning.
9 |
10 |
11 |
12 | Debugging issue: $ARGUMENTS
13 | Need root cause analysis and comprehensive fix
14 |
15 |
16 |
17 | - Minimal reproduction case
18 | - Complete error capture (messages, logs, stack traces, environment)
19 | - Multiple hypotheses (most likely, most dangerous, most subtle)
20 | - Scientific testing approach
21 | - Root cause fix (not symptom patch)
22 | - Regression prevention
23 | - Knowledge capture
24 |
25 |
26 |
27 | 1. Create Linear tracking:
28 | - For simple bugs: mcp_linear.create_issue(title="[Bug] $ARGUMENTS", description="Systematic debugging with RCA")
29 | - For complex bugs: Create project with issues for investigation, fix, tests, and prevention
30 | 2. Reproduce → document exact steps, intermittency patterns
31 | 3. Generate ranked hypotheses → think harder about causes
32 | 4. Design specific tests for each hypothesis
33 | 5. Add targeted logging: logger.debug(f"State: {state}, Inputs: {inputs}, Conditions: {conditions}")
34 | 6. Fix root cause → handle all discovered edge cases
35 | 7. Write failing test → add integration test → document pattern
36 | 8. Create `.claude/debugging/[issue-type].md` with full learnings
37 | 9. If using project: Update all related issues with findings
38 |
39 |
40 | This bug teaches us about our system. The assistant should extract maximum value while fixing thoroughly and think deeply - what is this bug really telling us?
41 |
42 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
43 |
--------------------------------------------------------------------------------
/.claude/commands/linear-feature.md:
--------------------------------------------------------------------------------
1 | Execute complete feature workflow for: $ARGUMENTS
2 |
3 |
4 | Step-by-step through entire lifecycle. Meticulous. Thorough. Zero technical debt.
5 |
6 |
7 |
8 | The assistant should use Linear integration for structured development with project-based organization where each issue = one branch/PR, maintaining clean history and production-ready code.
9 |
10 |
11 |
12 | Implementing feature: $ARGUMENTS
13 | Need complete workflow from Linear issue to merged PR
14 |
15 |
16 |
17 | - Linear project for feature organization
18 | - Separate issues for each major component
19 | - One branch/PR per issue
20 | - Full error handling and tests
21 | - Quality checks at each step
22 | - Comprehensive PRs with Linear links
23 |
24 |
25 |
26 | 1. Check/Create Linear project:
27 | - Check existing: mcp_linear.list_projects(teamId, includeArchived=false)
28 | - Find or create: project = mcp_linear.create_project(name="[Feature] $ARGUMENTS", teamId)
29 | 2. Create focused issues within project:
30 | - Design Issue: Architecture and data models
31 | - Implementation Issue: Core business logic
32 | - API Issue: Endpoints and contracts
33 | - Frontend Issue: UI components (if applicable)
34 | - Testing Issue: Test suite implementation
35 | - Documentation Issue: User and API docs
36 | 3. For each issue:
37 | - Get branch: mcp_linear.get_issue_git_branch_name(issueId)
38 | - git checkout -b {branch}
39 | - Mark "In Progress" in Linear
40 | - Implement with full error handling
41 | - Write comprehensive tests
42 | - Commit with issue reference
43 | - Push and create PR
44 | - Link PR to Linear issue
45 | - Update to "Done" when merged
46 | 4. Quality gates per PR: tests pass, linting clean, docs updated
47 | 5. Track progress via project view in Linear
48 |
49 |
50 | The assistant should execute workflow completely where each step builds on previous with the goal of production-ready feature with zero technical debt.
51 |
52 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
53 |
--------------------------------------------------------------------------------
/.claude/commands/mcp-context-build.md:
--------------------------------------------------------------------------------
1 | Build comprehensive development context: $ARGUMENTS
2 |
3 |
4 | Combine DeepWiki repository analysis + Firecrawl web research. Maximum context for informed decisions.
5 |
6 |
7 |
8 | The assistant should perform multi-source intelligence gathering including internal patterns, external best practices, and implementation examples.
9 |
10 |
11 |
12 | Building context for: $ARGUMENTS
13 | Could be new tech, feature, problem, or architecture decision
14 |
15 |
16 |
17 | - Internal codebase analysis (our patterns, similar solutions)
18 | - External documentation research (official docs, best practices)
19 | - Open source implementation examples
20 | - Technical specifications and constraints
21 | - Problem domain understanding
22 | - Decision matrix with trade-offs
23 | - Implementation guidance
24 |
25 |
26 |
27 | Internal Analysis:
28 | 1. mcp_deepwiki.ask_question(repo="[our-repo]", question="How is $ARGUMENTS implemented/used? Include patterns.")
29 | 2. mcp_deepwiki.ask_question(repo="[our-repo]", question="What similar solutions exist?")
30 |
31 | External Research:
32 | 3. mcp_firecrawl.firecrawl_deep_research(query="$ARGUMENTS best practices implementation guide", maxDepth=3, maxUrls=100)
33 | 4. mcp_firecrawl.firecrawl_search(query="$ARGUMENTS implementation example github production", limit=20)
34 | 5. For found repos: mcp_deepwiki.ask_question(repo="[found-repo]", question="How is $ARGUMENTS implemented? Patterns? Best practices?")
35 | 6. mcp_firecrawl.firecrawl_extract(urls=["[docs-url]"], prompt="Extract specifications, requirements, constraints, best practices")
36 |
37 | Synthesis:
38 | 7. Research problem domain and alternatives
39 | 8. Build decision matrix from findings
40 | 9. Create implementation guide based on context
41 | 10. Extract lessons learned from others
42 | 11. Generate `.claude/context/$ARGUMENTS/` package
43 | 12. Create LLM-friendly reference: mcp_firecrawl.firecrawl_generate_llmstxt()
44 | 13. Output to `.claude/context/$ARGUMENTS/` directory as a markdown file
45 |
46 |
47 | The assistant should combine repository wisdom with web intelligence and build context that accelerates development and improves decisions.
48 |
49 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
50 |
--------------------------------------------------------------------------------
/.claude/commands/mcp-doc-extract.md:
--------------------------------------------------------------------------------
1 | Extract comprehensive documentation using Firecrawl: $ARGUMENTS
2 |
3 |
4 | Intelligent crawling. Structure extraction. Practical artifacts for development.
5 |
6 |
7 |
8 | The assistant should demonstrate Firecrawl MCP mastery, perform deep crawl, extract patterns, and generate actionable docs.
9 |
10 |
11 |
12 | Documentation source: $ARGUMENTS
13 | Transform into practical development resource
14 |
15 |
16 |
17 | - Site structure analysis and navigation mapping
18 | - Deep crawl with deduplication
19 | - Structured information extraction
20 | - Code examples with context
21 | - Configuration and error handling
22 | - LLM-friendly output generation
23 |
24 |
25 |
26 | 1. mcp_firecrawl.firecrawl_scrape(url="$ARGUMENTS", formats=["markdown", "links"]) → analyze structure
27 | 2. mcp_firecrawl.firecrawl_crawl(url="$ARGUMENTS", maxDepth=3, limit=100, deduplicateSimilarURLs=true)
28 | 3. mcp_firecrawl.firecrawl_extract(urls=[key sections], schema={endpoints, auth, examples, config, errors})
29 | 4. mcp_firecrawl.firecrawl_batch_scrape(urls=[essential pages], options={onlyMainContent: true})
30 | 5. mcp_firecrawl.firecrawl_search(query="$ARGUMENTS authentication OAuth JWT", limit=10)
31 | 6. mcp_firecrawl.firecrawl_generate_llmstxt(url="$ARGUMENTS", maxUrls=50, showFullText=true)
32 | 7. Organize in `.claude/docs/[source]/`: index, quick-start, api/, examples/, config, troubleshooting
33 | 8. Extract all code examples with use cases
34 | 9. Create integration guide tailored to our stack
35 | 10. Set up monitoring for updates
36 | 11. Output to `.claude/docs/$ARGUMENTS/` directory as a markdown file
37 |
38 |
39 | The assistant should create comprehensive, practical documentation package that accelerates development and makes it immediately useful.
40 |
41 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
42 |
43 |
--------------------------------------------------------------------------------
/.claude/commands/mcp-repo-analyze.md:
--------------------------------------------------------------------------------
1 | Analyze repository using DeepWiki: $ARGUMENTS
2 |
3 |
4 | Extract patterns, solutions, wisdom. Learn from their code to improve ours.
5 |
6 |
7 |
8 | The assistant should perform DeepWiki AI-powered analysis, understand architecture, patterns, decisions, and extract reusable wisdom.
9 |
10 |
11 |
12 | Repository to analyze: $ARGUMENTS
13 | Extract actionable insights for our development
14 |
15 |
16 |
17 | - Documentation structure and core concepts
18 | - Architectural patterns and design decisions
19 | - Code conventions and best practices
20 | - Problem solutions and approaches
21 | - Testing and quality strategies
22 | - Reusable components and utilities
23 | - Security measures and performance tactics
24 |
25 |
26 |
27 | 1. mcp_deepwiki.read_wiki_structure(repo="$ARGUMENTS") → map available docs
28 | 2. Read core docs: architecture, API, contributing
29 | 3. Ask targeted questions:
30 | - "Main architectural patterns? Service boundaries, data flow, key decisions?"
31 | - "Coding patterns? Error handling, testing strategies, utilities?"
32 | - "Performance optimization? Caching, database, scaling?"
33 | - "Interesting problem solutions? Auth, validation, API design?"
34 | - "Testing strategy? Structure, mocking, coverage, CI/CD?"
35 | - "Reusable components? Purpose and implementation?"
36 | - "Development workflow? Branches, reviews, deployment?"
37 | - "Security practices? Auth, data protection, validation?"
38 | 4. Extract specific pattern implementations with file paths
39 | 5. Compare approaches with common practices
40 | 6. Create `.claude/learning/[repo]/` with insights
41 | 7. Generate adoption plan: immediate wins, architecture ideas, code to extract
42 | 8. Output to `.claude/learning/$ARGUMENTS/` directory as a markdown file
43 |
44 |
45 | The assistant should extract maximum learning value and focus on patterns we can apply immediately to improve our codebase.
46 |
47 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
48 |
--------------------------------------------------------------------------------
/.claude/commands/pr-complete.md:
--------------------------------------------------------------------------------
1 | Create exemplary pull request for current changes: $ARGUMENTS
2 |
3 |
4 | Professional. Complete. Everything reviewers need to understand, verify, merge confidently.
5 |
6 |
7 |
8 | The assistant should create PRs that reviewers appreciate with clear context, comprehensive testing, and zero friction to merge.
9 |
10 |
11 |
12 | Creating PR for current branch changes
13 | Make review process smooth and efficient
14 |
15 |
16 |
17 | - Pre-flight quality checks
18 | - Complete change analysis
19 | - Linear issue context
20 | - Professional PR description
21 | - Testing documentation
22 | - Performance impact
23 | - Breaking change assessment
24 | - Post-PR monitoring
25 |
26 |
27 |
28 | 1. Pre-flight: git status && pytest && ruff check && ruff format && pre-commit run --all-files
29 | 2. Analyze changes: git diff --stat && git diff main...HEAD && git log main..HEAD --oneline
30 | 3. Extract Linear context from commits → get issue titles and scope
31 | 4. Create PR with comprehensive body:
32 | ```
33 | gh pr create --title "[Type] Description #FUN-XXX" --body "$(cat <<'EOF'
34 | ## Summary
35 | [What and why]
36 |
37 | ## Changes
38 |
39 | - Feature: [additions]
40 | - Fix: [corrections]
41 | - Refactor: [improvements]
42 | - Docs: [documentation]
43 | - Tests: [test coverage]
44 |
45 | ## Linear Issues
46 |
47 | Resolves: #FUN-XXX, #FUN-YYY
48 |
49 | ## Testing
50 |
51 | - How to test: [steps]
52 | - Coverage: X% → Y%
53 | - Critical paths: [steps]
54 |
55 | ## Performance
56 |
57 | - Benchmarks: [results]
58 | - Impact: [assessment]
59 |
60 | ## Breaking Changes
61 |
62 | - [ ] None / [migration path]
63 |
64 | ## Checklist
65 |
66 | - [x] Tests pass
67 | - [x] Standards met
68 | - [x] Docs updated
69 | - [x] Ready for review
70 | EOF)"
71 |
72 | ```
73 |
74 | 5. Update Linear: link PR, set "In Review", add PR link to issues
75 | 6. Set up success: request reviews, add labels, enable auto-merge
76 | 7. Monitor CI/CD → respond to feedback → keep updated with main
77 |
78 |
79 | The assistant should create PR that makes review a pleasure - complete, clear, ready to merge. This is work's presentation layer - the assistant should make it shine.
80 |
81 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
82 |
--------------------------------------------------------------------------------
/.claude/commands/standards-check.md:
--------------------------------------------------------------------------------
1 | Comprehensive standards compliance check: $ARGUMENTS
2 |
3 |
4 | The assistant should not just check - but actively fix and elevate code to excellence.
5 |
6 |
7 |
8 | The assistant should enforce meticulous standards, auto-fix everything possible, and make code exemplary.
9 |
10 |
11 |
12 | Checking standards compliance for: $ARGUMENTS
13 | Need to meet all project standards automatically
14 |
15 |
16 |
17 | - Code standards (line length, imports, types, docstrings)
18 | - Testing standards (coverage, structure, naming)
19 | - Mirascope/Lilypad patterns
20 | - Pre-commit compliance
21 | - Documentation completeness
22 | - Security and performance
23 |
24 |
25 |
26 | 1. Code Standards (`.claude/standards/code-standards.md`):
27 | - Fix line length ≤ 130
28 | - Organize imports: stdlib → third-party → local
29 | - Add missing type hints
30 | - Ensure Google-style docstrings
31 | - Remove debug statements
32 | - Fix naming conventions
33 |
34 | 2. Testing Standards (`.claude/standards/testing-standards.md`):
35 | - Check coverage: 80% overall, 90%+ business logic
36 | - Generate missing tests
37 | - Fix test structure and naming
38 |
39 | 3. Framework Patterns:
40 | - Proper @llm.call, @prompt_template usage
41 | - Async patterns for LLM calls
42 | - Response model definitions
43 | - Error handling with retries
44 |
45 | 4. Auto-fix with tools:
46 | ```bash
47 | ruff check --fix && ruff format
48 | pre-commit run --all-files
49 | ```
50 |
51 | 5. Documentation: verify all public functions documented
52 | 6. Security: no hardcoded secrets, input validation, SQL safety
53 | 7. Generate report:
54 | ```markdown
55 | ## Compliance Report
56 | - Score: X/10
57 | - Auto-fixed: X issues
58 | - Manual needed: X items
59 | - [Detailed findings]
60 | - [Applied fixes]
61 | - [Remaining actions]
62 | ```
63 |
64 |
65 | The assistant should not just report issues - but fix everything possible automatically, make this code exemplary, and elevate quality to highest standards.
66 |
67 | Take a deep breath in, count 1... 2... 3... and breathe out. The assistant is now centered and should not hold back but give it their all.
68 |
--------------------------------------------------------------------------------
/.claude/debugging/cfos-41-lance-issues/COMPLETION_SUMMARY.md:
--------------------------------------------------------------------------------
1 | # CFOS-41 Completion Summary
2 |
3 | ## Issue Resolution
4 | The issue has been successfully resolved. What initially appeared to be a Map type incompatibility issue with custom_metadata turned out to be a more fundamental limitation in Lance: it cannot scan/filter blob-encoded columns.
5 |
6 | ## Changes Made
7 |
8 | ### 1. Schema Updates
9 | - Changed `custom_metadata` from `pa.map_` to `pa.list_(pa.struct([...]))` for Lance compatibility
10 | - Added `custom_metadata` field to JSON validation schema
11 |
12 | ### 2. Code Changes in frame.py
13 | - Added `_get_non_blob_columns()` helper method to identify non-blob columns
14 | - Modified `scanner()` method to automatically exclude blob columns when filters are used
15 | - Updated `get_by_uuid()` to use the filtered scanner
16 | - Fixed `from_arrow()` to handle missing fields gracefully (for when raw_data is excluded)
17 | - Fixed `delete_record()` to handle Lance's delete method returning None
18 | - Added missing return statement in `find_related_to()`
19 |
20 | ### 3. Documentation
21 | - Created comprehensive documentation in `.claude/debugging/cfos-41-lance-issues/`
22 | - Updated the original lance-map-type-issue.md to reference the resolved status
23 | - Organized all findings and analysis in a structured directory
24 |
25 | ## Current Status
26 | - All tests pass ✅
27 | - Code has been formatted with ruff ✅
28 | - Type checking shows only expected errors (missing stubs for pyarrow/lance) ✅
29 | - Documentation is complete and organized ✅
30 |
31 | ## Key Learnings
32 | 1. Lance doesn't support Map type - must use list instead
33 | 2. Lance cannot scan blob-encoded columns - this is documented behavior, not a bug
34 | 3. The solution is to exclude blob columns from scanner projections when filtering
35 | 4. The Lance Blob API (take_blobs) should be used for retrieving blob data separately
36 |
37 | ## Trade-offs
38 | - When records are retrieved via filtering, the `raw_data` field will be None
39 | - This is acceptable since raw_data is typically not needed during search/filter operations
40 | - If blob data is needed, it can be retrieved separately using the take_blobs API (future enhancement)
41 |
42 | ## Next Steps
43 | The branch is ready for PR creation and merging. All changes are minimal, backward-compatible, and solve the issue effectively.
--------------------------------------------------------------------------------
/.claude/debugging/cfos-41-lance-issues/LANCE_ISSUE_SOLUTION.md:
--------------------------------------------------------------------------------
1 | # Lance Filtering Issue - Root Cause and Solution
2 |
3 | ## Summary
4 |
5 | We've identified and solved the Lance filtering panic issue that was blocking CFOS-41 and CFOS-20.
6 |
7 | ## Root Cause
8 |
9 | The issue was **NOT** caused by the `custom_metadata` field's `list` type as initially suspected. Instead, it was caused by a combination of:
10 |
11 | 1. The `raw_data` field being `pa.large_binary()` with `lance-encoding:blob` metadata
12 | 2. Having null values in this blob-encoded field
13 | 3. Using any filter operation on the dataset
14 |
15 | This appears to be a bug in Lance where filtering operations cause a panic when blob-encoded fields contain null values.
16 |
17 | ## Solution
18 |
19 | We need to make two changes to fix the issue:
20 |
21 | ### 1. Remove blob encoding from raw_data field
22 |
23 | Change from:
24 | ```python
25 | pa.field("raw_data", pa.large_binary(), metadata={"lance-encoding:blob": "true"})
26 | ```
27 |
28 | To:
29 | ```python
30 | pa.field("raw_data", pa.large_binary())
31 | ```
32 |
33 | ### 2. Change custom_metadata to JSON string (optional but recommended)
34 |
35 | While the `list` approach works, using a JSON string is simpler and more flexible:
36 |
37 | Change from:
38 | ```python
39 | pa.field("custom_metadata", pa.list_(pa.struct([
40 | pa.field("key", pa.string()),
41 | pa.field("value", pa.string())
42 | ])))
43 | ```
44 |
45 | To:
46 | ```python
47 | pa.field("custom_metadata", pa.string()) # Store as JSON string
48 | ```
49 |
50 | ## Data Conversion
51 |
52 | For the custom_metadata field, use these helper functions:
53 |
54 | ```python
55 | import json
56 |
57 | # When writing to Lance
58 | def dict_to_lance(metadata_dict):
59 | return json.dumps(metadata_dict) if metadata_dict else None
60 |
61 | # When reading from Lance
62 | def lance_to_dict(metadata_json):
63 | return json.loads(metadata_json) if metadata_json else {}
64 | ```
65 |
66 | ## Testing Results
67 |
68 | With these changes:
69 | - ✅ All write operations work
70 | - ✅ All read operations work
71 | - ✅ All filter operations work (uuid, IS NOT NULL, compound filters, etc.)
72 | - ✅ No Lance panics occur
73 |
74 | ## Next Steps
75 |
76 | 1. Update `contextframe_schema.py` to implement these changes
77 | 2. Update `frame.py` to handle JSON conversion for custom_metadata
78 | 3. Run all tests to ensure compatibility
79 | 4. Consider filing a bug report with Lance about the blob+null+filter issue
--------------------------------------------------------------------------------
/.claude/debugging/cfos-41-lance-issues/README.md:
--------------------------------------------------------------------------------
1 | # CFOS-41: Lance Map Type and Blob Filter Issues
2 |
3 | This directory contains the investigation and solution documentation for CFOS-41, which initially appeared to be a Lance Map type incompatibility issue but turned out to be a more fundamental limitation with Lance's blob column scanning.
4 |
5 | ## Files in This Directory
6 |
7 | 1. **SOLUTION_SUMMARY.md** - Final summary of the implemented solution
8 | 2. **LANCE_ISSUE_SOLUTION.md** - Initial solution thoughts
9 | 3. **COMPREHENSIVE_SOLUTIONS_ANALYSIS.md** - Detailed analysis of different approaches
10 | 4. **LANCE_BLOB_FILTER_BUG_ANALYSIS.md** - Deep dive into the Lance blob filtering issue
11 | 5. **LONG_TERM_IMPLEMENTATION_PLAN.md** - Long-term strategy for handling Lance limitations
12 | 6. **FINAL_IMPLEMENTATION_PLAN.md** - The final implementation approach
13 |
14 | ## Key Findings
15 |
16 | 1. **Lance doesn't support Map type** - We must use `list` instead
17 | 2. **Lance can't scan blob-encoded columns** - This is the root cause of the panics
18 | 3. **Solution**: Automatically exclude blob columns from scanner projections when filters are used
19 |
20 | ## Implementation
21 |
22 | The solution was implemented in `contextframe/frame.py`:
23 | - Added `_get_non_blob_columns()` helper
24 | - Modified `scanner()` to exclude blob columns when filtering
25 | - Updated `from_arrow()` to handle missing fields gracefully
26 |
27 | ## Test Files
28 |
29 | All tests were implemented in the standard location:
30 | - `contextframe/tests/test_frameset.py` - Contains tests for frameset functionality
31 |
32 | ## Related Linear Issue
33 |
34 | - **CFOS-41**: Fix Lance Map type incompatibility for custom_metadata field
35 | - Status: Resolved with the blob column exclusion approach
--------------------------------------------------------------------------------
/.claude/debugging/cfos-41-lance-issues/SOLUTION_SUMMARY.md:
--------------------------------------------------------------------------------
1 | # Solution Summary for CFOS-41
2 |
3 | ## Problem
4 | Lance was causing panics when filtering datasets that contained blob-encoded fields with null values. Initially thought to be a Map type incompatibility issue with custom_metadata.
5 |
6 | ## Root Cause Discovery
7 | Through extensive testing and research:
8 |
9 | 1. **Lance doesn't support Map type** - Confirmed this is still the case
10 | 2. **The real issue**: Lance doesn't support scanning/filtering blob-encoded columns at all
11 | 3. **Lance documentation confirms**: You must exclude blob columns from scanner projections and use `take_blobs` API separately
12 |
13 | ## Solution Implemented
14 |
15 | ### 1. Schema Changes
16 | - Changed `custom_metadata` from `pa.map_` to `pa.list_(pa.struct([...]))` for Lance compatibility
17 | - Added `custom_metadata` to JSON validation schema
18 |
19 | ### 2. Frame.py Changes
20 | - Added `_get_non_blob_columns()` helper to identify non-blob columns
21 | - Modified `scanner()` to automatically exclude blob columns when filters are used
22 | - Updated `get_by_uuid()` to use the filtered scanner
23 | - Fixed `from_arrow()` to handle missing fields gracefully
24 | - Fixed `delete_record()` to handle Lance's delete method returning None
25 | - Added missing return statement in `find_related_to()`
26 |
27 | ### 3. Key Code Changes
28 |
29 | ```python
30 | # Automatically exclude blob columns from filtered scans
31 | def scanner(self, **scan_kwargs):
32 | if 'filter' in scan_kwargs and self._non_blob_columns is not None:
33 | if 'columns' not in scan_kwargs:
34 | scan_kwargs['columns'] = self._non_blob_columns
35 | return self._dataset.scanner(**scan_kwargs)
36 | ```
37 |
38 | ## Benefits
39 | 1. **No more panics** - Lance can't scan blob columns, so we don't let it try
40 | 2. **Transparent to users** - Filtering still works as expected
41 | 3. **Minimal changes** - No complex workarounds or post-filtering needed
42 | 4. **Future-proof** - When Lance adds blob scanning support, we can easily remove this
43 |
44 | ## Trade-offs
45 | 1. `raw_data` field will be None when records are retrieved via filtering
46 | 2. If blob data is needed, must use `take_blobs` API separately (not implemented yet)
47 |
48 | ## Testing
49 | All frameset tests now pass, confirming the solution works correctly.
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_concepts_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/concepts/"
3 | title: "Concepts - Docling"
4 | ---
5 |
6 | # Concepts
7 |
8 | Use the navigation on the left to browse through some core Docling concepts.
9 |
10 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_concepts_architecture_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/concepts/architecture/"
3 | title: "Architecture - Docling"
4 | ---
5 |
6 | # Architecture
7 |
8 | 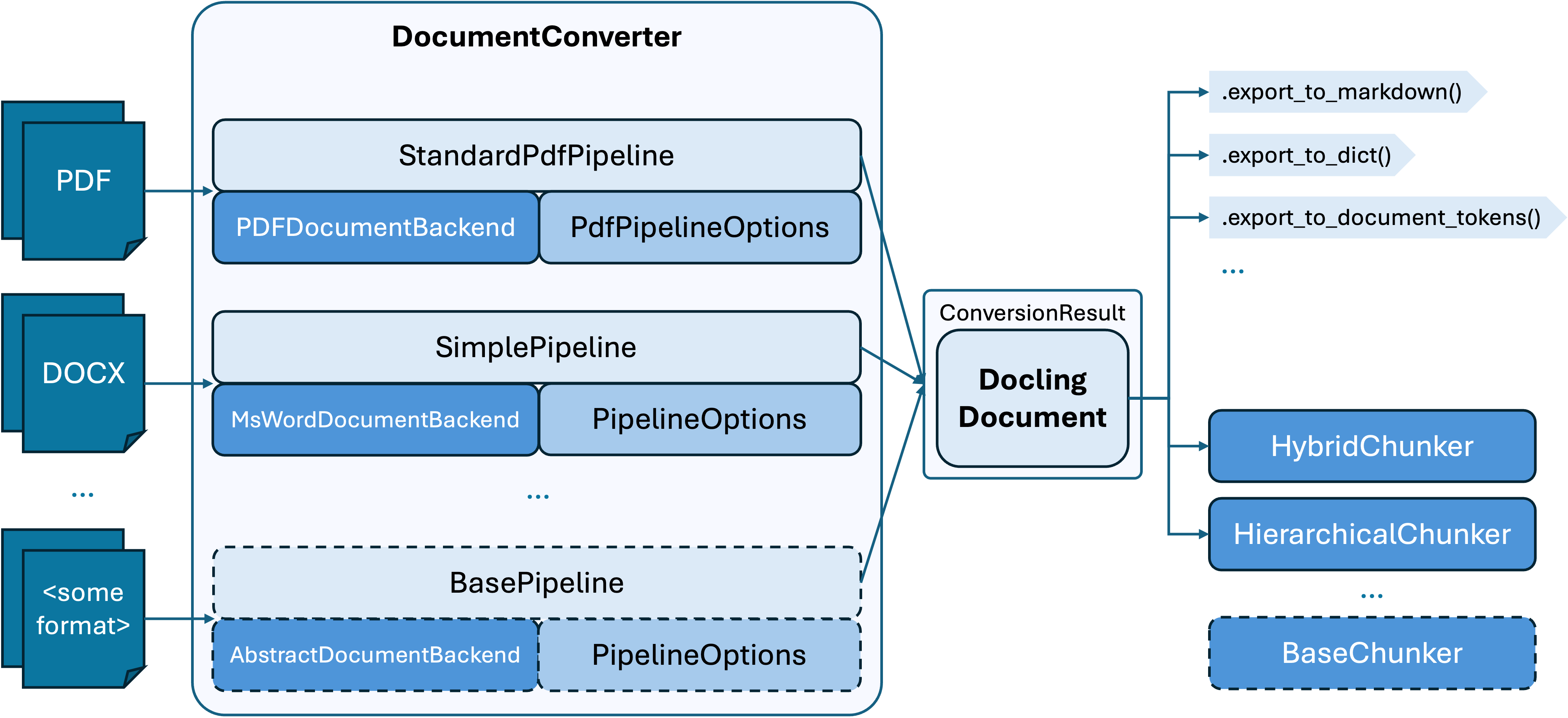
9 |
10 | In a nutshell, Docling's architecture is outlined in the diagram above.
11 |
12 | For each document format, the _document converter_ knows which format-specific _backend_ to employ for parsing the document and which _pipeline_ to use for orchestrating the execution, along with any relevant _options_.
13 |
14 | Tip
15 |
16 | While the document converter holds a default mapping, this configuration is parametrizable, so e.g. for the PDF format, different backends and different pipeline options can be used — see [Usage](https://docling-project.github.io/docling/usage/#adjust-pipeline-features).
17 |
18 | The _conversion result_ contains the [_Docling document_](https://docling-project.github.io/docling/concepts/docling_document/), Docling's fundamental document representation.
19 |
20 | Some typical scenarios for using a Docling document include directly calling its _export methods_, such as for markdown, dictionary etc., or having it serialized by a
21 | [_serializer_](https://docling-project.github.io/docling/concepts/serialization/) or chunked by a [_chunker_](https://docling-project.github.io/docling/concepts/chunking/).
22 |
23 | For more details on Docling's architecture, check out the [Docling Technical Report](https://arxiv.org/abs/2408.09869).
24 |
25 | Note
26 |
27 | The components illustrated with dashed outline indicate base classes that can be subclassed for specialized implementations.
28 |
29 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_concepts_serialization_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/concepts/serialization/"
3 | title: "Serialization - Docling"
4 | ---
5 |
6 | [Skip to content](https://docling-project.github.io/docling/concepts/serialization/#introduction)
7 |
8 | # Serialization
9 |
10 | ## Introduction
11 |
12 | A _document serializer_ (AKA simply _serializer_) is a Docling abstraction that is
13 | initialized with a given [`DoclingDocument`](https://docling-project.github.io/docling/concepts/docling_document/) and returns a
14 | textual representation for that document.
15 |
16 | Besides the document serializer, Docling defines similar abstractions for several
17 | document subcomponents, for example: _text serializer_, _table serializer_,
18 | _picture serializer_, _list serializer_, _inline serializer_, and more.
19 |
20 | Last but not least, a _serializer provider_ is a wrapper that abstracts the
21 | document serialization strategy from the document instance.
22 |
23 | ## Base classes
24 |
25 | To enable both flexibility for downstream applications and out-of-the-box utility,
26 | Docling defines a serialization class hierarchy, providing:
27 |
28 | - base types for the above abstractions: `BaseDocSerializer`, as well as
29 | `BaseTextSerializer`, `BaseTableSerializer` etc, and `BaseSerializerProvider`, and
30 | - specific subclasses for the above-mentioned base types, e.g. `MarkdownDocSerializer`.
31 |
32 | You can review all methods required to define the above base classes [here](https://github.com/docling-project/docling-core/blob/main/docling_core/transforms/serializer/base.py).
33 |
34 | From a client perspective, the most relevant is `BaseDocSerializer.serialize()`, which
35 | returns the textual representation, as well as relevant metadata on which document
36 | components contributed to that serialization.
37 |
38 | ## Use in `DoclingDocument` export methods
39 |
40 | Docling provides predefined serializers for Markdown, HTML, and DocTags.
41 |
42 | The respective `DoclingDocument` export methods (e.g. `export_to_markdown()`) are
43 | provided as user shorthands — internally directly instantiating and delegating to
44 | respective serializers.
45 |
46 | ## Examples
47 |
48 | For an example showcasing how to use serializers, see
49 | [here](https://docling-project.github.io/docling/examples/serialization/).
50 |
51 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_examples_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/examples/"
3 | title: "Examples - Docling"
4 | ---
5 |
6 | # Examples
7 |
8 | Use the navigation on the left to browse through examples covering a range of possible workflows and use cases.
9 |
10 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_examples_minimal_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/examples/minimal/"
3 | title: "Simple conversion - Docling"
4 | ---
5 |
6 | # Simple conversion
7 |
8 | In \[ \]:
9 |
10 | Copied!
11 |
12 | ```
13 | from docling.document_converter import DocumentConverter
14 |
15 | ```
16 |
17 | from docling.document\_converter import DocumentConverter
18 |
19 | In \[ \]:
20 |
21 | Copied!
22 |
23 | ```
24 | source = "https://arxiv.org/pdf/2408.09869" # document per local path or URL
25 |
26 | ```
27 |
28 | source = "https://arxiv.org/pdf/2408.09869" # document per local path or URL
29 |
30 | In \[ \]:
31 |
32 | Copied!
33 |
34 | ```
35 | converter = DocumentConverter()
36 | doc = converter.convert(source).document
37 |
38 | ```
39 |
40 | converter = DocumentConverter()
41 | doc = converter.convert(source).document
42 |
43 | In \[ \]:
44 |
45 | Copied!
46 |
47 | ```
48 | print(doc.export_to_markdown())
49 | # output: ## Docling Technical Report [...]"
50 |
51 | ```
52 |
53 | print(doc.export\_to\_markdown())
54 | \# output: ## Docling Technical Report \[...\]"
55 |
56 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/"
3 | title: "Integrations - Docling"
4 | ---
5 |
6 | # Integrations
7 |
8 | Use the navigation on the left to browse through Docling integrations with popular frameworks and tools.
9 |
10 | 
11 |
12 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_apify_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/apify/"
3 | title: "Apify - Docling"
4 | ---
5 |
6 | # Apify
7 |
8 | You can run Docling in the cloud without installation using the [Docling Actor](https://apify.com/vancura/docling?fpr=docling) on Apify platform. Simply provide a document URL and get the processed result:
9 |
10 | [](https://apify.com/vancura/docling?fpr=docling)
11 |
12 | ```
13 | apify call vancura/docling -i '{
14 | "options": {
15 | "to_formats": ["md", "json", "html", "text", "doctags"]
16 | },
17 | "http_sources": [\
18 | {"url": "https://vancura.dev/assets/actor-test/facial-hairstyles-and-filtering-facepiece-respirators.pdf"},\
19 | {"url": "https://arxiv.org/pdf/2408.09869"}\
20 | ]
21 | }'
22 |
23 | ```
24 |
25 | The Actor stores results in:
26 |
27 | - Processed document in key-value store ( `OUTPUT_RESULT`)
28 | - Processing logs ( `DOCLING_LOG`)
29 | - Dataset record with result URL and status
30 |
31 | Read more about the [Docling Actor](https://docling-project.github.io/docling/integrations/apify/.actor/README.md), including how to use it via the Apify API and CLI.
32 |
33 | - 💻 [GitHub](https://github.com/docling-project/docling/tree/main/.actor/)
34 | - 📖 [Docs](https://github.com/docling-project/docling/tree/main/.actor/README.md)
35 | - 📦 [Docling Actor](https://apify.com/vancura/docling?fpr=docling)
36 |
37 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_bee_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/bee/"
3 | title: "Bee Agent Framework - Docling"
4 | ---
5 |
6 | # Bee Agent Framework
7 |
8 | Docling is available as an extraction backend in the [Bee](https://github.com/i-am-bee) framework.
9 |
10 | - 💻 [Bee GitHub](https://github.com/i-am-bee)
11 | - 📖 [Bee docs](https://i-am-bee.github.io/bee-agent-framework/)
12 | - 📦 [Bee NPM](https://www.npmjs.com/package/bee-agent-framework)
13 |
14 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_cloudera_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/cloudera/"
3 | title: "Cloudera - Docling"
4 | ---
5 |
6 | # Cloudera
7 |
8 | Docling is available in [Cloudera](https://www.cloudera.com/) through the _RAG Studio_
9 | Accelerator for Machine Learning Projects (AMP).
10 |
11 | - 💻 [RAG Studio AMP GitHub](https://github.com/cloudera/CML_AMP_RAG_Studio)
12 |
13 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_crewai_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/crewai/"
3 | title: "Crew AI - Docling"
4 | ---
5 |
6 | # Crew AI
7 |
8 | Docling is available in [CrewAI](https://www.crewai.com/) as the `CrewDoclingSource`
9 | knowledge source.
10 |
11 | - 💻 [Crew AI GitHub](https://github.com/crewAIInc/crewAI/)
12 | - 📖 [Crew AI knowledge docs](https://docs.crewai.com/concepts/knowledge)
13 | - 📦 [Crew AI PyPI](https://pypi.org/project/crewai/)
14 |
15 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_data_prep_kit_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/data_prep_kit/"
3 | title: "Data Prep Kit - Docling"
4 | ---
5 |
6 | [Skip to content](https://docling-project.github.io/docling/integrations/data_prep_kit/#components)
7 |
8 | # Data Prep Kit
9 |
10 | Docling is used by the [Data Prep Kit](https://data-prep-kit.github.io/data-prep-kit/) open-source toolkit for preparing unstructured data for LLM application development ranging from laptop scale to datacenter scale.
11 |
12 | ## Components
13 |
14 | ### PDF ingestion to Parquet
15 |
16 | - 💻 [Docling2Parquet source](https://github.com/data-prep-kit/data-prep-kit/tree/dev/transforms/language/docling2parquet)
17 | - 📖 [Docling2Parquet docs](https://data-prep-kit.github.io/data-prep-kit/transforms/language/pdf2parquet/)
18 |
19 | ### Document chunking
20 |
21 | - 💻 [Doc Chunking source](https://github.com/data-prep-kit/data-prep-kit/tree/dev/transforms/language/doc_chunk)
22 | - 📖 [Doc Chunking docs](https://data-prep-kit.github.io/data-prep-kit/transforms/language/doc_chunk/)
23 |
24 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_docetl_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/docetl/"
3 | title: "DocETL - Docling"
4 | ---
5 |
6 | # DocETL
7 |
8 | Docling is available as a file conversion method in [DocETL](https://github.com/ucbepic/docetl):
9 |
10 | - 💻 [DocETL GitHub](https://github.com/ucbepic/docetl)
11 | - 📖 [DocETL docs](https://ucbepic.github.io/docetl/)
12 | - 📦 [DocETL PyPI](https://pypi.org/project/docetl/)
13 |
14 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_haystack_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/haystack/"
3 | title: "Haystack - Docling"
4 | ---
5 |
6 | # Haystack
7 |
8 | Docling is available as a converter in [Haystack](https://haystack.deepset.ai/):
9 |
10 | - 📖 [Docling Haystack integration docs](https://haystack.deepset.ai/integrations/docling)
11 | - 💻 [Docling Haystack integration GitHub](https://github.com/docling-project/docling-haystack)
12 | - 🧑🏽🍳 [Docling Haystack integration example](https://docling-project.github.io/docling/examples/rag_haystack/)
13 | - 📦 [Docling Haystack integration PyPI](https://pypi.org/project/docling-haystack)
14 |
15 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_instructlab_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/instructlab/"
3 | title: "InstructLab - Docling"
4 | ---
5 |
6 | # InstructLab
7 |
8 | Docling is powering document processing in [InstructLab](https://instructlab.ai/),
9 | enabling users to unlock the knowledge hidden in documents and present it to
10 | InstructLab's fine-tuning for aligning AI models to the user's specific data.
11 |
12 | More details can be found in this [blog post](https://www.redhat.com/en/blog/docling-missing-document-processing-companion-generative-ai).
13 |
14 | - 🏠 [InstructLab home](https://instructlab.ai/)
15 | - 💻 [InstructLab GitHub](https://github.com/instructlab)
16 | - 🧑🏻💻 [InstructLab UI](https://ui.instructlab.ai/)
17 | - 📖 [InstructLab docs](https://docs.instructlab.ai/)
18 |
19 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_kotaemon_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/kotaemon/"
3 | title: "Kotaemon - Docling"
4 | ---
5 |
6 | # Kotaemon
7 |
8 | Docling is available in [Kotaemon](https://cinnamon.github.io/kotaemon/) as the `DoclingReader` loader:
9 |
10 | - 💻 [Kotaemon GitHub](https://github.com/Cinnamon/kotaemon)
11 | - 📖 [DoclingReader docs](https://cinnamon.github.io/kotaemon/reference/loaders/docling_loader/)
12 | - ⚙️ [Docling setup in Kotaemon](https://cinnamon.github.io/kotaemon/development/?h=docling#setup-multimodal-document-parsing-ocr-table-parsing-figure-extraction)
13 |
14 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_langchain_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/langchain/"
3 | title: "LangChain - Docling"
4 | ---
5 |
6 | # LangChain
7 |
8 | Docling is available as an official [LangChain](https://python.langchain.com/) extension.
9 |
10 | To get started, check out the [step-by-step guide in LangChain](https://python.langchain.com/docs/integrations/document_loaders/docling/).
11 |
12 | - 📖 [LangChain Docling integration docs](https://python.langchain.com/docs/integrations/providers/docling/)
13 | - 💻 [LangChain Docling integration GitHub](https://github.com/docling-project/docling-langchain)
14 | - 🧑🏽🍳 [LangChain Docling integration example](https://docling-project.github.io/docling/examples/rag_langchain/)
15 | - 📦 [LangChain Docling integration PyPI](https://pypi.org/project/langchain-docling/)
16 |
17 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_llamaindex_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/llamaindex/"
3 | title: "LlamaIndex - Docling"
4 | ---
5 |
6 | [Skip to content](https://docling-project.github.io/docling/integrations/llamaindex/#components)
7 |
8 | # LlamaIndex
9 |
10 | Docling is available as an official [LlamaIndex](https://docs.llamaindex.ai/) extension.
11 |
12 | To get started, check out the [step-by-step guide in LlamaIndex](https://docs.llamaindex.ai/en/stable/examples/data_connectors/DoclingReaderDemo/).
13 |
14 | ## Components
15 |
16 | ### Docling Reader
17 |
18 | Reads document files and uses Docling to populate LlamaIndex `Document` objects — either serializing Docling's data model (losslessly, e.g. as JSON) or exporting to a simplified format (lossily, e.g. as Markdown).
19 |
20 | - 💻 [Docling Reader GitHub](https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/readers/llama-index-readers-docling)
21 | - 📖 [Docling Reader docs](https://docs.llamaindex.ai/en/stable/api_reference/readers/docling/)
22 | - 📦 [Docling Reader PyPI](https://pypi.org/project/llama-index-readers-docling/)
23 |
24 | ### Docling Node Parser
25 |
26 | Reads LlamaIndex `Document` objects populated in Docling's format by Docling Reader and, using its knowledge of the Docling format, parses them to LlamaIndex `Node` objects for downstream usage in LlamaIndex applications, e.g. as chunks for embedding.
27 |
28 | - 💻 [Docling Node Parser GitHub](https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/node_parser/llama-index-node-parser-docling)
29 | - 📖 [Docling Node Parser docs](https://docs.llamaindex.ai/en/stable/api_reference/node_parser/docling/)
30 | - 📦 [Docling Node Parser PyPI](https://pypi.org/project/llama-index-node-parser-docling/)
31 |
32 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_nvidia_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/nvidia/"
3 | title: "NVIDIA - Docling"
4 | ---
5 |
6 | # NVIDIA
7 |
8 | Docling is powering the NVIDIA _PDF to Podcast_ agentic AI blueprint:
9 |
10 | - [🏠 PDF to Podcast home](https://build.nvidia.com/nvidia/pdf-to-podcast)
11 | - [💻 PDF to Podcast GitHub](https://github.com/NVIDIA-AI-Blueprints/pdf-to-podcast)
12 | - [📣 PDF to Podcast announcement](https://nvidianews.nvidia.com/news/nvidia-launches-ai-foundation-models-for-rtx-ai-pcs)
13 | - [✍️ PDF to Podcast blog post](https://blogs.nvidia.com/blog/agentic-ai-blueprints/)
14 |
15 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_opencontracts_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/opencontracts/"
3 | title: "OpenContracts - Docling"
4 | ---
5 |
6 | # OpenContracts
7 |
8 | Docling is available an ingestion engine for [OpenContracts](https://github.com/JSv4/OpenContracts), allowing you to use Docling's OCR engine(s), chunker(s), labels, etc. and load them into a platform supporting bulk data extraction, text annotating, and question-answering:
9 |
10 | - 💻 [OpenContracts GitHub](https://github.com/JSv4/OpenContracts)
11 | - 📖 [OpenContracts Docs](https://jsv4.github.io/OpenContracts/)
12 | - ▶️ [OpenContracts x Docling PDF annotation screen capture](https://github.com/JSv4/OpenContracts/blob/main/docs/assets/images/gifs/PDF%20Annotation%20Flow.gif)
13 |
14 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_openwebui_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/openwebui/"
3 | title: "Open WebUI - Docling"
4 | ---
5 |
6 | # Open WebUI
7 |
8 | Docling is available as a plugin for [Open WebUI](https://github.com/open-webui/open-webui).
9 |
10 | - 📖 [Docs](https://docs.openwebui.com/features/document-extraction/docling)
11 | - 💻 [GitHub](https://github.com/open-webui/open-webui)
12 |
13 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_prodigy_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/prodigy/"
3 | title: "Prodigy - Docling"
4 | ---
5 |
6 | # Prodigy
7 |
8 | Docling is available in [Prodigy](https://prodi.gy/) as a [Prodigy-PDF plugin](https://prodi.gy/docs/plugins#pdf) recipe.
9 |
10 | More details can be found in this [blog post](https://explosion.ai/blog/pdfs-nlp-structured-data).
11 |
12 | - 🌐 [Prodigy home](https://prodi.gy/)
13 | - 🔌 [Prodigy-PDF plugin](https://prodi.gy/docs/plugins#pdf)
14 | - 🧑🏽🍳 [pdf-spans.manual recipe](https://prodi.gy/docs/plugins#pdf-spans.manual)
15 |
16 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_rhel_ai_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/rhel_ai/"
3 | title: "RHEL AI - Docling"
4 | ---
5 |
6 | # RHEL AI
7 |
8 | Docling is powering document processing in [Red Hat Enterprise Linux AI (RHEL AI)](https://rhel.ai/),
9 | enabling users to unlock the knowledge hidden in documents and present it to
10 | InstructLab's fine-tuning for aligning AI models to the user's specific data.
11 |
12 | - 📣 [RHEL AI 1.3 announcement](https://www.redhat.com/en/about/press-releases/red-hat-delivers-next-wave-gen-ai-innovation-new-red-hat-enterprise-linux-ai-capabilities)
13 | - ✍️ RHEL blog posts:
14 | - [RHEL AI 1.3 Docling context aware chunking: What you need to know](https://www.redhat.com/en/blog/rhel-13-docling-context-aware-chunking-what-you-need-know)
15 | - [Docling: The missing document processing companion for generative AI](https://www.redhat.com/en/blog/docling-missing-document-processing-companion-generative-ai)
16 |
17 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_spacy_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/spacy/"
3 | title: "spaCy - Docling"
4 | ---
5 |
6 | # spaCy
7 |
8 | Docling is available in [spaCy](https://spacy.io/) as the _spaCy Layout_ plugin.
9 |
10 | More details can be found in this [blog post](https://explosion.ai/blog/pdfs-nlp-structured-data).
11 |
12 | - 💻 [SpacyLayout GitHub](https://github.com/explosion/spacy-layout)
13 | - 📖 [SpacyLayout docs](https://github.com/explosion/spacy-layout?tab=readme-ov-file#readme)
14 | - 📦 [SpacyLayout PyPI](https://pypi.org/project/spacy-layout/)
15 |
16 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_txtai_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/txtai/"
3 | title: "txtai - Docling"
4 | ---
5 |
6 | # txtai
7 |
8 | Docling is available as a text extraction backend for [txtai](https://neuml.github.io/txtai/).
9 |
10 | - 💻 [txtai GitHub](https://github.com/neuml/txtai)
11 | - 📖 [txtai docs](https://neuml.github.io/txtai)
12 | - 📖 [txtai Docling backend](https://neuml.github.io/txtai/pipeline/data/filetohtml/#docling)
13 |
14 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_integrations_vectara_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/integrations/vectara/"
3 | title: "Vectara - Docling"
4 | ---
5 |
6 | # Vectara
7 |
8 | Docling is available as a document parser in [Vectara](https://www.vectara.com/).
9 |
10 | - 💻 [Vectara GitHub org](https://github.com/vectara)
11 | - [vectara-ingest GitHub repo](https://github.com/vectara/vectara-ingest)
12 | - 📖 [Vectara docs](https://docs.vectara.com/)
13 |
14 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/docling/docling-project.github.io_docling_usage_supported_formats_.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docling-project.github.io/docling/usage/supported_formats/"
3 | title: "Supported formats - Docling"
4 | ---
5 |
6 | [Skip to content](https://docling-project.github.io/docling/usage/supported_formats/#supported-input-formats)
7 |
8 | # Supported formats
9 |
10 | Docling can parse various documents formats into a unified representation (Docling
11 | Document), which it can export to different formats too — check out
12 | [Architecture](https://docling-project.github.io/docling/concepts/architecture/) for more details.
13 |
14 | Below you can find a listing of all supported input and output formats.
15 |
16 | ## Supported input formats
17 |
18 | | Format | Description |
19 | | --- | --- |
20 | | PDF | |
21 | | DOCX, XLSX, PPTX | Default formats in MS Office 2007+, based on Office Open XML |
22 | | Markdown | |
23 | | AsciiDoc | |
24 | | HTML, XHTML | |
25 | | CSV | |
26 | | PNG, JPEG, TIFF, BMP, WEBP | Image formats |
27 |
28 | Schema-specific support:
29 |
30 | | Format | Description |
31 | | --- | --- |
32 | | USPTO XML | XML format followed by [USPTO](https://www.uspto.gov/patents) patents |
33 | | JATS XML | XML format followed by [JATS](https://jats.nlm.nih.gov/) articles |
34 | | Docling JSON | JSON-serialized [Docling Document](https://docling-project.github.io/docling/concepts/docling_document/) |
35 |
36 | ## Supported output formats
37 |
38 | | Format | Description |
39 | | --- | --- |
40 | | HTML | Both image embedding and referencing are supported |
41 | | Markdown | |
42 | | JSON | Lossless serialization of Docling Document |
43 | | Text | Plain text, i.e. without Markdown markers |
44 | | Doctags | |
45 |
46 | Back to top
--------------------------------------------------------------------------------
/.claude/documentation/lance/lancedb.github.io_lance_api_api.html.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://lancedb.github.io/lance/api/api.html"
3 | title: "APIs - Lance documentation"
4 | ---
5 |
6 | # APIs [¶](https://lancedb.github.io/lance/api/api.html\#apis "Link to this heading")
7 |
8 | - [Rust](https://docs.rs/crate/lance/latest)
9 | - [Python](https://lancedb.github.io/lance/api/python.html)
--------------------------------------------------------------------------------
/.claude/documentation/lance/lancedb.github.io_lance_blob.html.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://lancedb.github.io/lance/blob.html"
3 | title: "Blob As Files - Lance documentation"
4 | ---
5 |
6 | # Blob As Files [¶](https://lancedb.github.io/lance/blob.html\#blob-as-files "Link to this heading")
7 |
8 | Unlike other data formats, large multimodal data is a first-class citizen in the Lance columnar format.
9 | Lance provides a high-level API to store and retrieve large binary objects (blobs) in Lance datasets.
10 |
11 | [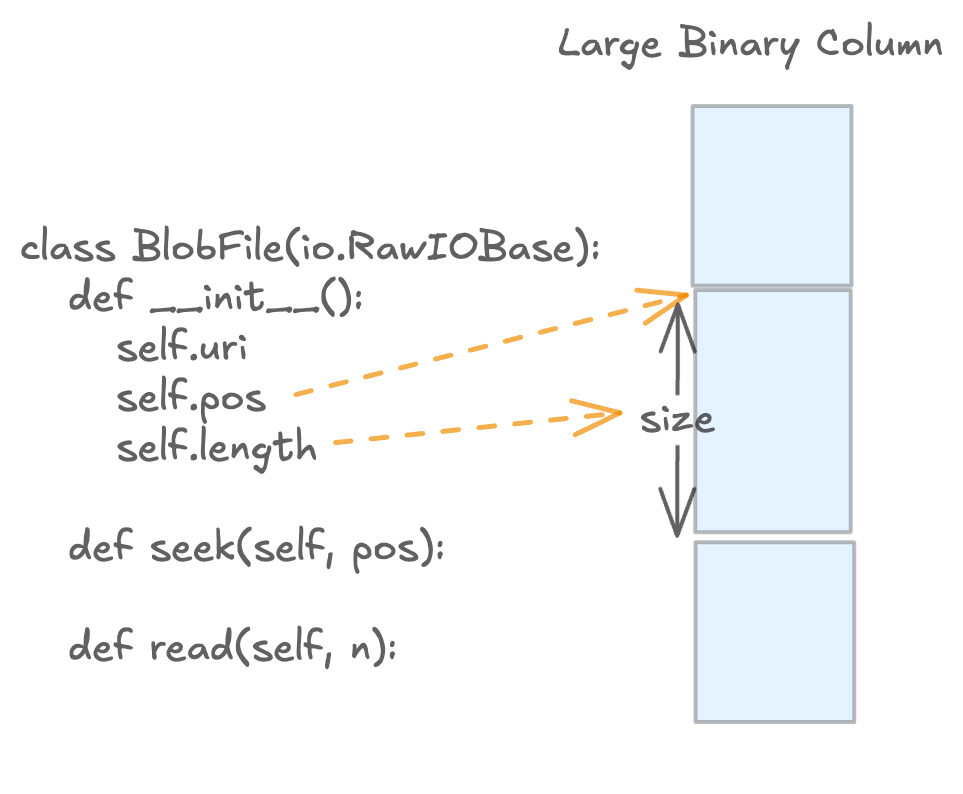](https://lancedb.github.io/lance/_images/blob.png)
12 |
13 | Lance serves large binary data using [`lance.BlobFile`](https://lancedb.github.io/lance/api/python/BlobFile.html "lance.BlobFile — Represents a blob in a Lance dataset as a file-like object."), which
14 | is a file-like object that lazily reads large binary objects.
15 |
16 | To create a Lance dataset with large blob data, you can mark a large binary column as a blob column by
17 | adding the metadata `lance-encoding:blob` to `true`.
18 |
19 | ```
20 | import pyarrow as pa
21 |
22 | schema = pa.schema(
23 | [\
24 | pa.field("id", pa.int64()),\
25 | pa.field("video",\
26 | pa.large_binary(),\
27 | metadata={"lance-encoding:blob": "true"}\
28 | ),\
29 | ]
30 | )
31 |
32 | ```
33 |
34 | To fetch blobs from a Lance dataset, you can use [`lance.dataset.LanceDataset.take_blobs()`](https://lancedb.github.io/lance/api/py_modules.html#lance.dataset.LanceDataset.take_blobs "lance.dataset.LanceDataset.take_blobs — Select blobs by row IDs.").
35 |
36 | For example, it’s easy to use BlobFile to extract frames from a video file without
37 | loading the entire video into memory.
38 |
39 | ```
40 | # pip install av pylance
41 |
42 | import av
43 | import lance
44 |
45 | ds = lance.dataset("./youtube.lance")
46 | start_time, end_time = 500, 1000
47 | blobs = ds.take_blobs([5], "video")
48 | with av.open(blobs[0]) as container:
49 | stream = container.streams.video[0]
50 | stream.codec_context.skip_frame = "NONKEY"
51 |
52 | start_time = start_time / stream.time_base
53 | start_time = start_time.as_integer_ratio()[0]
54 | end_time = end_time / stream.time_base
55 | container.seek(start_time, stream=stream)
56 |
57 | for frame in container.decode(stream):
58 | if frame.time > end_time:
59 | break
60 | display(frame.to_image())
61 | clear_output(wait=True)
62 |
63 | ```
--------------------------------------------------------------------------------
/.claude/documentation/lance/lancedb.github.io_lance_examples_examples.html.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://lancedb.github.io/lance/examples/examples.html"
3 | title: "Examples - Lance documentation"
4 | ---
5 |
6 | [Skip to content](https://lancedb.github.io/lance/examples/examples.html#python-examples)
7 |
8 | # Examples [¶](https://lancedb.github.io/lance/examples/examples.html\#examples "Link to this heading")
9 |
10 | ## Python Examples [¶](https://lancedb.github.io/lance/examples/examples.html\#python-examples "Link to this heading")
11 |
12 | - [Creating text dataset for LLM training using Lance](https://lancedb.github.io/lance/examples/Python/llm_dataset_creation.html)
13 | - [Training LLMs using a Lance text dataset](https://lancedb.github.io/lance/examples/Python/llm_training.html)
14 | - [Creating Multi-Modal datasets using Lance](https://lancedb.github.io/lance/examples/Python/flickr8k_dataset_creation.html)
15 | - [Training Multi-Modal models using a Lance dataset](https://lancedb.github.io/lance/examples/Python/clip_training.html)
16 | - [Deep Learning Artefact Management using Lance](https://lancedb.github.io/lance/examples/Python/artefact_management.html)
17 | - [Writing and Reading a Dataset Using Spark](https://lancedb.github.io/lance/examples/Python/spark_datasource_example.html)
18 |
19 | ## Rust Examples [¶](https://lancedb.github.io/lance/examples/examples.html\#rust-examples "Link to this heading")
20 |
21 | - [Writing and reading a dataset using Lance](https://lancedb.github.io/lance/examples/Rust/write_read_dataset.html)
22 | - [Creating text dataset for LLM training using Lance in Rust](https://lancedb.github.io/lance/examples/Rust/llm_dataset_creation.html)
23 | - [Indexing a dataset with HNSW(Hierarchical Navigable Small World)](https://lancedb.github.io/lance/examples/Rust/hnsw.html)
--------------------------------------------------------------------------------
/.claude/documentation/lance/lancedb.github.io_lance_format.rst.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://lancedb.github.io/lance/format.rst"
3 | title: "Page not found · GitHub Pages"
4 | ---
5 |
6 | # 404
7 |
8 | **File not found**
9 |
10 | The site configured at this address does not
11 | contain the requested file.
12 |
13 |
14 | If this is your site, make sure that the filename case matches the URL
15 | as well as any file permissions.
16 |
17 | For root URLs (like `http://example.com/`) you must provide an
18 | `index.html` file.
19 |
20 |
21 | [Read the full documentation](https://help.github.com/pages/)
22 | for more information about using **GitHub Pages**.
23 |
24 |
25 | [GitHub Status](https://githubstatus.com/) —
26 | [@githubstatus](https://twitter.com/githubstatus)
27 |
28 | [![]()](https://lancedb.github.io/)[![]()](https://lancedb.github.io/)
--------------------------------------------------------------------------------
/.claude/documentation/lance/lancedb.github.io_lance_integrations_huggingface.html.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://lancedb.github.io/lance/integrations/huggingface.html"
3 | title: "Lance ❤️ HuggingFace - Lance documentation"
4 | ---
5 |
6 | # Lance ❤️ HuggingFace [¶](https://lancedb.github.io/lance/integrations/huggingface.html\#lance-huggingface "Link to this heading")
7 |
8 | The HuggingFace Hub has become the go to place for ML practitioners to find pre-trained models and useful datasets.
9 |
10 | HuggingFace datasets can be written directly into Lance format by using the
11 | [`lance.write_dataset()`](https://lancedb.github.io/lance/api/python/write_dataset.html "lance.write_dataset — Write a given data_obj to the given uri") method. You can write the entire dataset or a particular split. For example:
12 |
13 | ```
14 | # Huggingface datasets
15 | import datasets
16 | import lance
17 |
18 | lance.write_dataset(datasets.load_dataset(
19 | "poloclub/diffusiondb", split="train[:10]",
20 | ), "diffusiondb_train.lance")
21 |
22 | ```
--------------------------------------------------------------------------------
/.claude/documentation/lance/lancedb.github.io_lance_py-modindex.html.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://lancedb.github.io/lance/py-modindex.html"
3 | title: "Python Module Index - Lance documentation"
4 | ---
5 |
6 | # Python Module Index
7 |
8 | [**l**](https://lancedb.github.io/lance/py-modindex.html#cap-l)
9 |
10 | | | | |
11 | | --- | --- | --- |
12 | | | | |
13 | | | **l** | |
14 | |  | [`lance`](https://lancedb.github.io/lance/api/py_modules.html#module-lance) | |
15 | | | [`lance.dataset`](https://lancedb.github.io/lance/api/py_modules.html#module-lance.dataset) | |
16 | | | [`lance.fragment`](https://lancedb.github.io/lance/api/py_modules.html#module-lance.fragment) | |
--------------------------------------------------------------------------------
/.claude/documentation/lance/lancedb.github.io_lance_search.html.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://lancedb.github.io/lance/search.html"
3 | title: "Page not found · GitHub Pages"
4 | ---
5 |
6 | # 404
7 |
8 | **File not found**
9 |
10 | The site configured at this address does not
11 | contain the requested file.
12 |
13 |
14 | If this is your site, make sure that the filename case matches the URL
15 | as well as any file permissions.
16 |
17 | For root URLs (like `http://example.com/`) you must provide an
18 | `index.html` file.
19 |
20 |
21 | [Read the full documentation](https://help.github.com/pages/)
22 | for more information about using **GitHub Pages**.
23 |
24 |
25 | [GitHub Status](https://githubstatus.com/) —
26 | [@githubstatus](https://twitter.com/githubstatus)
27 |
28 | [![]()](https://lancedb.github.io/)[![]()](https://lancedb.github.io/)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_completion.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/completion"
3 | title: "Chat Completions | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/completion#__docusaurus_skipToContent_fallback)
7 |
8 | [**📄️Input Params** \\
9 | Common Params](https://docs.litellm.ai/docs/completion/input)[**📄️Output** \\
10 | Format](https://docs.litellm.ai/docs/completion/output)[**📄️Usage** \\
11 | LiteLLM returns the OpenAI compatible usage object across all providers.](https://docs.litellm.ai/docs/completion/usage)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_contributing.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/contributing"
3 | title: "Contributing - UI | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/contributing#__docusaurus_skipToContent_fallback)
7 |
8 | On this page
9 |
10 | # Contributing - UI
11 |
12 | Here's how to run the LiteLLM UI locally for making changes:
13 |
14 | ## 1\. Clone the repo [](https://docs.litellm.ai/docs/contributing\#1-clone-the-repo "Direct link to 1. Clone the repo")
15 |
16 | ```codeBlockLines_e6Vv
17 | git clone https://github.com/BerriAI/litellm.git
18 |
19 | ```
20 |
21 | ## 2\. Start the UI + Proxy [](https://docs.litellm.ai/docs/contributing\#2-start-the-ui--proxy "Direct link to 2. Start the UI + Proxy")
22 |
23 | **2.1 Start the proxy on port 4000**
24 |
25 | Tell the proxy where the UI is located
26 |
27 | ```codeBlockLines_e6Vv
28 | export PROXY_BASE_URL="http://localhost:3000/"
29 |
30 | ```
31 |
32 | ```codeBlockLines_e6Vv
33 | cd litellm/litellm/proxy
34 | python3 proxy_cli.py --config /path/to/config.yaml --port 4000
35 |
36 | ```
37 |
38 | **2.2 Start the UI**
39 |
40 | Set the mode as development (this will assume the proxy is running on localhost:4000)
41 |
42 | ```codeBlockLines_e6Vv
43 | export NODE_ENV="development"
44 |
45 | ```
46 |
47 | ```codeBlockLines_e6Vv
48 | cd litellm/ui/litellm-dashboard
49 |
50 | npm run dev
51 |
52 | # starts on http://0.0.0.0:3000
53 |
54 | ```
55 |
56 | ## 3\. Go to local UI [](https://docs.litellm.ai/docs/contributing\#3-go-to-local-ui "Direct link to 3. Go to local UI")
57 |
58 | ```codeBlockLines_e6Vv
59 | http://0.0.0.0:3000
60 |
61 | ```
62 |
63 | - [1\. Clone the repo](https://docs.litellm.ai/docs/contributing#1-clone-the-repo)
64 | - [2\. Start the UI + Proxy](https://docs.litellm.ai/docs/contributing#2-start-the-ui--proxy)
65 | - [3\. Go to local UI](https://docs.litellm.ai/docs/contributing#3-go-to-local-ui)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_image_variations.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/image_variations"
3 | title: "[BETA] Image Variations | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/image_variations#__docusaurus_skipToContent_fallback)
7 |
8 | On this page
9 |
10 | # \[BETA\] Image Variations
11 |
12 | OpenAI's `/image/variations` endpoint is now supported.
13 |
14 | ## Quick Start [](https://docs.litellm.ai/docs/image_variations\#quick-start "Direct link to Quick Start")
15 |
16 | ```codeBlockLines_e6Vv
17 | from litellm import image_variation
18 | import os
19 |
20 | # set env vars
21 | os.environ["OPENAI_API_KEY"] = ""
22 | os.environ["TOPAZ_API_KEY"] = ""
23 |
24 | # openai call
25 | response = image_variation(
26 | model="dall-e-2", image=image_url
27 | )
28 |
29 | # topaz call
30 | response = image_variation(
31 | model="topaz/Standard V2", image=image_url
32 | )
33 |
34 | print(response)
35 |
36 | ```
37 |
38 | ## Supported Providers [](https://docs.litellm.ai/docs/image_variations\#supported-providers "Direct link to Supported Providers")
39 |
40 | - OpenAI
41 | - Topaz
42 |
43 | - [Quick Start](https://docs.litellm.ai/docs/image_variations#quick-start)
44 | - [Supported Providers](https://docs.litellm.ai/docs/image_variations#supported-providers)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_migration.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/migration"
3 | title: "Migration Guide - LiteLLM v1.0.0+ | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/migration#__docusaurus_skipToContent_fallback)
7 |
8 | On this page
9 |
10 | # Migration Guide - LiteLLM v1.0.0+
11 |
12 | When we have breaking changes (i.e. going from 1.x.x to 2.x.x), we will document those changes here.
13 |
14 | ## `1.0.0` [](https://docs.litellm.ai/docs/migration\#100 "Direct link to 100")
15 |
16 | **Last Release before breaking change**: 0.14.0
17 |
18 | **What changed?**
19 |
20 | - Requires `openai>=1.0.0`
21 | - `openai.InvalidRequestError` → `openai.BadRequestError`
22 | - `openai.ServiceUnavailableError` → `openai.APIStatusError`
23 | - _NEW_ litellm client, allow users to pass api\_key
24 | - `litellm.Litellm(api_key="sk-123")`
25 | - response objects now inherit from `BaseModel` (prev. `OpenAIObject`)
26 | - _NEW_ default exception - `APIConnectionError` (prev. `APIError`)
27 | - litellm.get\_max\_tokens() now returns an int not a dict
28 |
29 |
30 |
31 |
32 | ```codeBlockLines_e6Vv
33 | max_tokens = litellm.get_max_tokens("gpt-3.5-turbo") # returns an int not a dict
34 | assert max_tokens==4097
35 |
36 | ```
37 |
38 | - Streaming - OpenAI Chunks now return `None` for empty stream chunks. This is how to process stream chunks with content
39 |
40 |
41 |
42 |
43 | ```codeBlockLines_e6Vv
44 | response = litellm.completion(model="gpt-3.5-turbo", messages=messages, stream=True)
45 | for part in response:
46 | print(part.choices[0].delta.content or "")
47 |
48 | ```
49 |
50 |
51 | **How can we communicate changes better?**
52 | Tell us
53 |
54 | - [Discord](https://discord.com/invite/wuPM9dRgDw)
55 | - Email ( [krrish@berri.ai](mailto:krrish@berri.ai)/ [ishaan@berri.ai](mailto:ishaan@berri.ai))
56 | - Text us (+17708783106)
57 |
58 | - [`1.0.0`](https://docs.litellm.ai/docs/migration#100)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_migration_policy.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/migration_policy"
3 | title: "Migration Policy | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/migration_policy#__docusaurus_skipToContent_fallback)
7 |
8 | On this page
9 |
10 | # Migration Policy
11 |
12 | ## New Beta Feature Introduction [](https://docs.litellm.ai/docs/migration_policy\#new-beta-feature-introduction "Direct link to New Beta Feature Introduction")
13 |
14 | - If we introduce a new feature that may move to the Enterprise Tier it will be clearly labeled as **Beta**. With the following example disclaimer
15 | **Example Disclaimer**
16 |
17 | info
18 |
19 | Beta Feature - This feature might move to LiteLLM Enterprise
20 |
21 | ## Policy if a Beta Feature moves to Enterprise [](https://docs.litellm.ai/docs/migration_policy\#policy-if-a-beta-feature-moves-to-enterprise "Direct link to Policy if a Beta Feature moves to Enterprise")
22 |
23 | If we decide to move a beta feature to the paid Enterprise version we will:
24 |
25 | - Provide **at least 30 days** notice to all users of the beta feature
26 | - Provide **a free 3 month License to prevent any disruptions to production**
27 | - Provide a **dedicated slack, discord, microsoft teams support channel** to help your team during this transition
28 |
29 | - [New Beta Feature Introduction](https://docs.litellm.ai/docs/migration_policy#new-beta-feature-introduction)
30 | - [Policy if a Beta Feature moves to Enterprise](https://docs.litellm.ai/docs/migration_policy#policy-if-a-beta-feature-moves-to-enterprise)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_routing-load-balancing.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/routing-load-balancing"
3 | title: "Routing, Loadbalancing & Fallbacks | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/routing-load-balancing#__docusaurus_skipToContent_fallback)
7 |
8 | [**📄️Router - Load Balancing** \\
9 | LiteLLM manages:](https://docs.litellm.ai/docs/routing)[**📄️\[BETA\] Request Prioritization** \\
10 | Beta feature. Use for testing only.](https://docs.litellm.ai/docs/scheduler)[**📄️Proxy - Load Balancing** \\
11 | Load balance multiple instances of the same model](https://docs.litellm.ai/docs/proxy/load_balancing)[**📄️Fallbacks** \\
12 | If a call fails after num\_retries, fallback to another model group.](https://docs.litellm.ai/docs/proxy/reliability)[**📄️Timeouts** \\
13 | The timeout set in router is for the entire length of the call, and is passed down to the completion() call level as well.](https://docs.litellm.ai/docs/proxy/timeout)[**📄️Tag Based Routing** \\
14 | Route requests based on tags.](https://docs.litellm.ai/docs/proxy/tag_routing)[**📄️Budget Routing** \\
15 | LiteLLM Supports setting the following budgets:](https://docs.litellm.ai/docs/proxy/provider_budget_routing)[**📄️Provider specific Wildcard routing** \\
16 | Proxy all models from a provider](https://docs.litellm.ai/docs/wildcard_routing)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_simple_proxy.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/simple_proxy"
3 | title: "LiteLLM Proxy Server (LLM Gateway) | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/simple_proxy#__docusaurus_skipToContent_fallback)
7 |
8 | [**📄️Getting Started - E2E Tutorial** \\
9 | End-to-End tutorial for LiteLLM Proxy to:](https://docs.litellm.ai/docs/proxy/docker_quick_start)[**🗃️Config.yaml** \\
10 | 3 items](https://docs.litellm.ai/docs/proxy/configs)[**🗃️Setup & Deployment** \\
11 | 9 items](https://docs.litellm.ai/docs/proxy/deploy)[**📄️Demo App** \\
12 | Here is a demo of the proxy. To log in pass in:](https://docs.litellm.ai/docs/proxy/demo)[**🗃️Architecture** \\
13 | 8 items](https://docs.litellm.ai/docs/proxy/architecture)[**🔗All Endpoints (Swagger)**](https://litellm-api.up.railway.app/)[**📄️✨ Enterprise Features** \\
14 | To get a license, get in touch with us here](https://docs.litellm.ai/docs/proxy/enterprise)[**📄️LiteLLM Proxy CLI** \\
15 | The litellm-proxy CLI is a command-line tool for managing your LiteLLM proxy](https://docs.litellm.ai/docs/proxy/management_cli)[**🗃️Making LLM Requests** \\
16 | 5 items](https://docs.litellm.ai/docs/proxy/user_keys)[**🗃️Authentication** \\
17 | 8 items](https://docs.litellm.ai/docs/proxy/virtual_keys)[**🗃️Model Access** \\
18 | 2 items](https://docs.litellm.ai/docs/proxy/model_access)[**🗃️Admin UI** \\
19 | 9 items](https://docs.litellm.ai/docs/proxy/ui)[**🗃️Spend Tracking** \\
20 | 3 items](https://docs.litellm.ai/docs/proxy/cost_tracking)[**🗃️Budgets + Rate Limits** \\
21 | 5 items](https://docs.litellm.ai/docs/proxy/users)[**🔗Load Balancing, Routing, Fallbacks**](https://docs.litellm.ai/docs/routing-load-balancing)[**🗃️Logging, Alerting, Metrics** \\
22 | 6 items](https://docs.litellm.ai/docs/proxy/logging)[**🗃️\[Beta\] Guardrails** \\
23 | 12 items](https://docs.litellm.ai/docs/proxy/guardrails/quick_start)[**🗃️Secret Managers** \\
24 | 2 items](https://docs.litellm.ai/docs/secret)[**🗃️Create Custom Plugins** \\
25 | Modify requests, responses, and more](https://docs.litellm.ai/docs/proxy/call_hooks)[**📄️Caching** \\
26 | For OpenAI/Anthropic Prompt Caching, go here](https://docs.litellm.ai/docs/proxy/caching)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_supported_endpoints.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/supported_endpoints"
3 | title: "Supported Endpoints | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/supported_endpoints#__docusaurus_skipToContent_fallback)
7 |
8 | [**🗃️/chat/completions** \\
9 | 3 items](https://docs.litellm.ai/docs/completion)[**📄️/responses \[Beta\]** \\
10 | LiteLLM provides a BETA endpoint in the spec of OpenAI's /responses API](https://docs.litellm.ai/docs/response_api)[**📄️/completions** \\
11 | Usage](https://docs.litellm.ai/docs/text_completion)[**📄️/embeddings** \\
12 | Quick Start](https://docs.litellm.ai/docs/embedding/supported_embedding)[**📄️/v1/messages \[BETA\]** \\
13 | Use LiteLLM to call all your LLM APIs in the Anthropic v1/messages format.](https://docs.litellm.ai/docs/anthropic_unified)[**📄️/mcp \[BETA\] - Model Context Protocol** \\
14 | Expose MCP tools on LiteLLM Proxy Server](https://docs.litellm.ai/docs/mcp)[**🗃️/images** \\
15 | 3 items](https://docs.litellm.ai/docs/image_generation)[**🗃️/audio** \\
16 | 2 items](https://docs.litellm.ai/docs/audio_transcription)[**🗃️Pass-through Endpoints (Anthropic SDK, etc.)** \\
17 | 12 items](https://docs.litellm.ai/docs/pass_through/intro)[**📄️/rerank** \\
18 | LiteLLM Follows the cohere api request / response for the rerank api](https://docs.litellm.ai/docs/rerank)[**📄️/assistants** \\
19 | Covers Threads, Messages, Assistants.](https://docs.litellm.ai/docs/assistants)[**🗃️/files** \\
20 | 2 items](https://docs.litellm.ai/docs/files_endpoints)[**🗃️/batches** \\
21 | 2 items](https://docs.litellm.ai/docs/batches)[**📄️/realtime** \\
22 | Use this to loadbalance across Azure + OpenAI.](https://docs.litellm.ai/docs/realtime)[**🗃️/fine\_tuning** \\
23 | 2 items](https://docs.litellm.ai/docs/fine_tuning)[**📄️/moderations** \\
24 | Usage](https://docs.litellm.ai/docs/moderation)[**📄️/guardrails/apply\_guardrail** \\
25 | Use this endpoint to directly call a guardrail configured on your LiteLLM instance. This is useful when you have services that need to directly call a guardrail.](https://docs.litellm.ai/docs/apply_guardrail)
--------------------------------------------------------------------------------
/.claude/documentation/litellm/docs.litellm.ai_docs_troubleshoot.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://docs.litellm.ai/docs/troubleshoot"
3 | title: "Support & Talk with founders | liteLLM"
4 | ---
5 |
6 | [Skip to main content](https://docs.litellm.ai/docs/troubleshoot#__docusaurus_skipToContent_fallback)
7 |
8 | # Support & Talk with founders
9 |
10 | [Schedule Demo 👋](https://calendly.com/d/4mp-gd3-k5k/berriai-1-1-onboarding-litellm-hosted-version)
11 |
12 | [Community Discord 💭](https://discord.gg/wuPM9dRgDw)
13 |
14 | Our numbers 📞 +1 (770) 8783-106 / +1 (412) 618-6238
15 |
16 | Our emails ✉️ [ishaan@berri.ai](mailto:ishaan@berri.ai) / [krrish@berri.ai](mailto:krrish@berri.ai)
17 |
18 | [](https://wa.link/huol9n)[](https://discord.gg/wuPM9dRgDw)
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api"
3 | title: "Mirascope API Reference | Mirascope"
4 | ---
5 |
6 | # Mirascope API Reference [Link to this heading](https://mirascope.com/docs/mirascope/api\#mirascope-api-reference)
7 |
8 | Welcome to the Mirascope API reference documentation. This section provides detailed information about the classes, methods, and interfaces that make up the Mirascope library.
9 |
10 | Use the sidebar to navigate through the different API components.
11 |
12 | Copy as Markdown
13 |
14 | #### Provider
15 |
16 | OpenAI
17 |
18 | #### On this page
19 |
20 | Copy as Markdown
21 |
22 | #### Provider
23 |
24 | OpenAI
25 |
26 | #### On this page
27 |
28 | ## Cookie Consent
29 |
30 | We use cookies to track usage and improve the site.
31 |
32 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_azure_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/azure/dynamic_config"
3 | title: "mirascope.core.azure.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.azure.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/azure/dynamic_config\#mirascope-core-azure-dynamic-config)
7 |
8 | ## Module dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/azure/dynamic_config\#dynamic-config)
9 |
10 | This module defines the function return type for functions as LLM calls.
11 |
12 | ## Attribute AsyncAzureDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/azure/dynamic_config\#asyncazuredynamicconfig)
13 |
14 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatRequestMessage \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [AzureCallParams](https://mirascope.com/docs/mirascope/api/core/azure/call_params#azurecallparams), AsyncChatCompletionsClient\]
15 |
16 | ## Attribute AzureDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/azure/dynamic_config\#azuredynamicconfig)
17 |
18 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatRequestMessage \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [AzureCallParams](https://mirascope.com/docs/mirascope/api/core/azure/call_params#azurecallparams), ChatCompletionsClient\]
19 |
20 | The function return type for functions wrapped with the `azure_call` decorator.
21 |
22 | Example:
23 |
24 | ```
25 | from mirascope.core import prompt_template
26 | from mirascope.core.azure import AzureDynamicConfig, azure_call
27 |
28 | @azure_call("gpt-4o-mini")
29 | @prompt_template("Recommend a {capitalized_genre} book")
30 | def recommend_book(genre: str) -> AzureDynamicConfig:
31 | return {"computed_fields": {"capitalized_genre": genre.capitalize()}}
32 | ```
33 |
34 | Copy as Markdown
35 |
36 | #### Provider
37 |
38 | OpenAI
39 |
40 | #### On this page
41 |
42 | Copy as Markdown
43 |
44 | #### Provider
45 |
46 | OpenAI
47 |
48 | #### On this page
49 |
50 | ## Cookie Consent
51 |
52 | We use cookies to track usage and improve the site.
53 |
54 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_base_call_params.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/base/call_params"
3 | title: "mirascope.core.base.call_params | Mirascope"
4 | ---
5 |
6 | # mirascope.core.base.call\_params [Link to this heading](https://mirascope.com/docs/mirascope/api/core/base/call_params\#mirascope-core-base-call-params)
7 |
8 | ## `BaseCallParams` [Link to this heading](https://mirascope.com/docs/mirascope/api/core/base/call_params\#basecallparams)
9 |
10 | Base Class Definition
11 |
12 | This class is simply a means of binding type variables to ensure they are call params, but the class itself is empty. We do this because you cannot bind a type variable to a base `TypedDict` type and must create your own subclass to do so.
13 |
14 | ## Class BaseCallParams [Link to this heading](https://mirascope.com/docs/mirascope/api/core/base/call_params\#basecallparams)
15 |
16 | **Bases:**
17 |
18 | [TypedDict](https://docs.python.org/3/library/typing.html#typing.TypedDict)
19 |
20 | Copy as Markdown
21 |
22 | #### Provider
23 |
24 | OpenAI
25 |
26 | #### On this page
27 |
28 | Copy as Markdown
29 |
30 | #### Provider
31 |
32 | OpenAI
33 |
34 | #### On this page
35 |
36 | ## Cookie Consent
37 |
38 | We use cookies to track usage and improve the site.
39 |
40 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_base_merge_decorators.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/base/merge_decorators"
3 | title: "mirascope.core.base.merge_decorators | Mirascope"
4 | ---
5 |
6 | # mirascope.core.base.merge\_decorators [Link to this heading](https://mirascope.com/docs/mirascope/api/core/base/merge_decorators\#mirascope-core-base-merge-decorators)
7 |
8 | ## Function merge\_decorators [Link to this heading](https://mirascope.com/docs/mirascope/api/core/base/merge_decorators\#merge-decorators)
9 |
10 | Combines multiple decorators into a single decorator factory.
11 |
12 | This function allows you to merge multiple decorators into a single decorator factory.
13 | The decorators are applied in the order they are passed to the function.
14 | All function metadata (e.g. docstrings, function name) is preserved through the decoration chain.
15 |
16 | ### Parameters
17 |
18 | | Name | Type | Description |
19 | | --- | --- | --- |
20 | | decorator | (() =\> \_R) =\> () =\> \_WR | The base decorator that determines the type signature of the decorated function. |
21 | | additional\_decorators= () | ([Callable](https://docs.python.org/3/library/typing.html#typing.Callable)) =\> [Callable](https://docs.python.org/3/library/typing.html#typing.Callable) | - |
22 |
23 | ### Returns
24 |
25 | | Type | Description |
26 | | --- | --- |
27 | | () =\> (() =\> \_R) =\> () =\> \_WR | A decorator factory function that applies all decorators in the specified order. |
28 |
29 | Copy as Markdown
30 |
31 | #### Provider
32 |
33 | OpenAI
34 |
35 | #### On this page
36 |
37 | Copy as Markdown
38 |
39 | #### Provider
40 |
41 | OpenAI
42 |
43 | #### On this page
44 |
45 | ## Cookie Consent
46 |
47 | We use cookies to track usage and improve the site.
48 |
49 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_base_metadata.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/base/metadata"
3 | title: "mirascope.core.base.metadata | Mirascope"
4 | ---
5 |
6 | # mirascope.core.base.metadata [Link to this heading](https://mirascope.com/docs/mirascope/api/core/base/metadata\#mirascope-core-base-metadata)
7 |
8 | The `Metadata` typed dictionary for including general metadata.
9 |
10 | ## Class Metadata [Link to this heading](https://mirascope.com/docs/mirascope/api/core/base/metadata\#metadata)
11 |
12 | The `Metadata` typed dictionary for including general metadata.
13 |
14 | **Bases:**
15 |
16 | [TypedDict](https://docs.python.org/3/library/typing.html#typing.TypedDict)
17 |
18 | ### Attributes
19 |
20 | | Name | Type | Description |
21 | | --- | --- | --- |
22 | | tags | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[[set](https://docs.python.org/3/library/stdtypes.html#set)\[[str](https://docs.python.org/3/library/stdtypes.html#str)\]\] | - |
23 |
24 | Copy as Markdown
25 |
26 | #### Provider
27 |
28 | OpenAI
29 |
30 | #### On this page
31 |
32 | Copy as Markdown
33 |
34 | #### Provider
35 |
36 | OpenAI
37 |
38 | #### On this page
39 |
40 | ## Cookie Consent
41 |
42 | We use cookies to track usage and improve the site.
43 |
44 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_bedrock_call_params.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/bedrock/call_params"
3 | title: "mirascope.core.bedrock.call_params | Mirascope"
4 | ---
5 |
6 | # mirascope.core.bedrock.call\_params [Link to this heading](https://mirascope.com/docs/mirascope/api/core/bedrock/call_params\#mirascope-core-bedrock-call-params)
7 |
8 | Usage
9 |
10 | [Calls](https://mirascope.com/docs/mirascope/learn/calls#provider-specific-parameters)
11 |
12 | ## Class BedrockCallParams [Link to this heading](https://mirascope.com/docs/mirascope/api/core/bedrock/call_params\#bedrockcallparams)
13 |
14 | The parameters to use when calling the Bedrock API.
15 |
16 | [Bedrock converse API Reference](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/bedrock-runtime/client/converse.html)
17 |
18 | **Bases:**
19 |
20 | [BaseCallParams](https://mirascope.com/docs/mirascope/api/core/base/call_params#basecallparams)
21 |
22 | ### Attributes
23 |
24 | | Name | Type | Description |
25 | | --- | --- | --- |
26 | | system | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[[list](https://docs.python.org/3/library/stdtypes.html#list)\[SystemContentBlockTypeDef\]\] | - |
27 | | inferenceConfig | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[InferenceConfigurationTypeDef\] | - |
28 | | toolConfig | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[ToolConfigurationTypeDef\] | - |
29 | | guardrailConfig | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[GuardrailConfigurationTypeDef\] | - |
30 | | additionalModelRequestFields | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[Mapping\[[str](https://docs.python.org/3/library/stdtypes.html#str), [Any](https://docs.python.org/3/library/typing.html#typing.Any)\]\] | - |
31 | | additionalModelResponseFieldPaths | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[[list](https://docs.python.org/3/library/stdtypes.html#list)\[[str](https://docs.python.org/3/library/stdtypes.html#str)\]\] | - |
32 |
33 | Copy as Markdown
34 |
35 | #### Provider
36 |
37 | OpenAI
38 |
39 | #### On this page
40 |
41 | Copy as Markdown
42 |
43 | #### Provider
44 |
45 | OpenAI
46 |
47 | #### On this page
48 |
49 | ## Cookie Consent
50 |
51 | We use cookies to track usage and improve the site.
52 |
53 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_cohere_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/cohere/dynamic_config"
3 | title: "mirascope.core.cohere.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.cohere.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/cohere/dynamic_config\#mirascope-core-cohere-dynamic-config)
7 |
8 | ## Module dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/cohere/dynamic_config\#dynamic-config)
9 |
10 | This module defines the function return type for functions as LLM calls.
11 |
12 | ## Attribute AsyncCohereDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/cohere/dynamic_config\#asynccoheredynamicconfig)
13 |
14 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatMessage \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [CohereCallParams](https://mirascope.com/docs/mirascope/api/core/cohere/call_params#coherecallparams), AsyncClient\]
15 |
16 | ## Attribute CohereDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/cohere/dynamic_config\#coheredynamicconfig)
17 |
18 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatMessage \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [CohereCallParams](https://mirascope.com/docs/mirascope/api/core/cohere/call_params#coherecallparams), Client\]
19 |
20 | The function return type for functions wrapped with the `cohere_call` decorator.
21 |
22 | Example:
23 |
24 | ```
25 | from mirascope.core import prompt_template
26 | from mirascope.core.cohere import CohereDynamicConfig, cohere_call
27 |
28 | @cohere_call("command-r-plus")
29 | @prompt_template("Recommend a {capitalized_genre} book")
30 | def recommend_book(genre: str) -> CohereDynamicConfig:
31 | return {"computed_fields": {"capitalized_genre": genre.capitalize()}}
32 | ```
33 |
34 | Copy as Markdown
35 |
36 | #### Provider
37 |
38 | OpenAI
39 |
40 | #### On this page
41 |
42 | Copy as Markdown
43 |
44 | #### Provider
45 |
46 | OpenAI
47 |
48 | #### On this page
49 |
50 | ## Cookie Consent
51 |
52 | We use cookies to track usage and improve the site.
53 |
54 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_costs_calculate_cost.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/costs/calculate_cost"
3 | title: "mirascope.core.costs.calculate_cost | Mirascope"
4 | ---
5 |
6 | # mirascope.core.costs.calculate\_cost [Link to this heading](https://mirascope.com/docs/mirascope/api/core/costs/calculate_cost\#mirascope-core-costs-calculate-cost)
7 |
8 | Cost calculation utilities for LLM API calls.
9 |
10 | ## Function calculate\_cost [Link to this heading](https://mirascope.com/docs/mirascope/api/core/costs/calculate_cost\#calculate-cost)
11 |
12 | Calculate the cost for an LLM API call.
13 |
14 | This function routes to the appropriate provider-specific cost calculation function,
15 | preserving existing behavior while providing a unified interface.
16 |
17 | ### Parameters
18 |
19 | | Name | Type | Description |
20 | | --- | --- | --- |
21 | | provider | [Provider](https://mirascope.com/docs/mirascope/api/core/base/types#provider) | The LLM provider (e.g., "openai", "anthropic") |
22 | | model | [str](https://docs.python.org/3/library/stdtypes.html#str) | The model name (e.g., "gpt-4", "claude-3-opus") |
23 | | metadata= None | [CostMetadata](https://mirascope.com/docs/mirascope/api/core/base/types#costmetadata) \| [None](https://docs.python.org/3/library/constants.html#None) | Additional metadata required for cost calculation |
24 |
25 | ### Returns
26 |
27 | | Type | Description |
28 | | --- | --- |
29 | | [float](https://docs.python.org/3/library/functions.html#float) \| [None](https://docs.python.org/3/library/constants.html#None) | The calculated cost in USD or None if unable to calculate |
30 |
31 | Copy as Markdown
32 |
33 | #### Provider
34 |
35 | OpenAI
36 |
37 | #### On this page
38 |
39 | Copy as Markdown
40 |
41 | #### Provider
42 |
43 | OpenAI
44 |
45 | #### On this page
46 |
47 | ## Cookie Consent
48 |
49 | We use cookies to track usage and improve the site.
50 |
51 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_google_call_params.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/google/call_params"
3 | title: "mirascope.core.google.call_params | Mirascope"
4 | ---
5 |
6 | # mirascope.core.google.call\_params [Link to this heading](https://mirascope.com/docs/mirascope/api/core/google/call_params\#mirascope-core-google-call-params)
7 |
8 | Usage
9 |
10 | [Calls](https://mirascope.com/docs/mirascope/learn/calls#provider-specific-parameters)
11 |
12 | ## Class GoogleCallParams [Link to this heading](https://mirascope.com/docs/mirascope/api/core/google/call_params\#googlecallparams)
13 |
14 | The parameters to use when calling the Google API.
15 |
16 | [Google API Reference](https://ai.google.dev/google-api/docs/text-generation?lang=python)
17 |
18 | **Bases:**
19 |
20 | [BaseCallParams](https://mirascope.com/docs/mirascope/api/core/base/call_params#basecallparams)
21 |
22 | ### Attributes
23 |
24 | | Name | Type | Description |
25 | | --- | --- | --- |
26 | | config | [NotRequired](https://docs.python.org/3/library/typing.html#typing.NotRequired)\[GenerateContentConfigOrDict\] | - |
27 |
28 | Copy as Markdown
29 |
30 | #### Provider
31 |
32 | OpenAI
33 |
34 | #### On this page
35 |
36 | Copy as Markdown
37 |
38 | #### Provider
39 |
40 | OpenAI
41 |
42 | #### On this page
43 |
44 | ## Cookie Consent
45 |
46 | We use cookies to track usage and improve the site.
47 |
48 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_google_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/google/dynamic_config"
3 | title: "mirascope.core.google.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.google.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/google/dynamic_config\#mirascope-core-google-dynamic-config)
7 |
8 | This module defines the function return type for functions as LLM calls.
9 |
10 | ## Attribute GoogleDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/google/dynamic_config\#googledynamicconfig)
11 |
12 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ContentListUnion \| ContentListUnionDict \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [GoogleCallParams](https://mirascope.com/docs/mirascope/api/core/google/call_params#googlecallparams), Client\]
13 |
14 | The function return type for functions wrapped with the `google_call` decorator.
15 |
16 | Example:
17 |
18 | ```
19 | from mirascope.core import prompt_template
20 | from mirascope.core.google import GoogleDynamicConfig, google_call
21 |
22 | @google_call("google-1.5-flash")
23 | @prompt_template("Recommend a {capitalized_genre} book")
24 | def recommend_book(genre: str) -> GoogleDynamicConfig:
25 | return {"computed_fields": {"capitalized_genre": genre.capitalize()}}
26 | ```
27 |
28 | Copy as Markdown
29 |
30 | #### Provider
31 |
32 | OpenAI
33 |
34 | #### On this page
35 |
36 | Copy as Markdown
37 |
38 | #### Provider
39 |
40 | OpenAI
41 |
42 | #### On this page
43 |
44 | ## Cookie Consent
45 |
46 | We use cookies to track usage and improve the site.
47 |
48 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_groq_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/groq/dynamic_config"
3 | title: "mirascope.core.groq.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.groq.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/groq/dynamic_config\#mirascope-core-groq-dynamic-config)
7 |
8 | ## Module dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/groq/dynamic_config\#dynamic-config)
9 |
10 | This module defines the function return type for functions as LLM calls.
11 |
12 | ## Attribute AsyncGroqDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/groq/dynamic_config\#asyncgroqdynamicconfig)
13 |
14 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatCompletionMessageParam \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [GroqCallParams](https://mirascope.com/docs/mirascope/api/core/groq/call_params#groqcallparams), AsyncGroq\]
15 |
16 | ## Attribute GroqDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/groq/dynamic_config\#groqdynamicconfig)
17 |
18 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatCompletionMessageParam \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [GroqCallParams](https://mirascope.com/docs/mirascope/api/core/groq/call_params#groqcallparams), Groq\]
19 |
20 | The function return type for functions wrapped with the `groq_call` decorator.
21 |
22 | Example:
23 |
24 | ```
25 | from mirascope.core import prompt_template
26 | from mirascope.core.groq import GroqDynamicConfig, groq_call
27 |
28 | @groq_call("llama-3.1-8b-instant")
29 | @prompt_template("Recommend a {capitalized_genre} book")
30 | def recommend_book(genre: str) -> GroqDynamicConfig:
31 | return {"computed_fields": {"capitalized_genre": genre.capitalize()}}
32 | ```
33 |
34 | Copy as Markdown
35 |
36 | #### Provider
37 |
38 | OpenAI
39 |
40 | #### On this page
41 |
42 | Copy as Markdown
43 |
44 | #### Provider
45 |
46 | OpenAI
47 |
48 | #### On this page
49 |
50 | ## Cookie Consent
51 |
52 | We use cookies to track usage and improve the site.
53 |
54 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_litellm_call_params.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/litellm/call_params"
3 | title: "mirascope.core.litellm.call_params | Mirascope"
4 | ---
5 |
6 | # mirascope.core.litellm.call\_params [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/call_params\#mirascope-core-litellm-call-params)
7 |
8 | Usage
9 |
10 | [Calls](https://mirascope.com/docs/mirascope/learn/calls#provider-specific-parameters)
11 |
12 | ## Class LiteLLMCallParams [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/call_params\#litellmcallparams)
13 |
14 | A simple wrapper around `OpenAICallParams.`
15 |
16 | Since LiteLLM uses the OpenAI spec, we change nothing here.
17 |
18 | **Bases:**
19 |
20 | [OpenAICallParams](https://mirascope.com/docs/mirascope/api/core/openai/call_params#openaicallparams)
21 |
22 | Copy as Markdown
23 |
24 | #### Provider
25 |
26 | OpenAI
27 |
28 | #### On this page
29 |
30 | Copy as Markdown
31 |
32 | #### Provider
33 |
34 | OpenAI
35 |
36 | #### On this page
37 |
38 | ## Cookie Consent
39 |
40 | We use cookies to track usage and improve the site.
41 |
42 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_litellm_call_response.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/litellm/call_response"
3 | title: "mirascope.core.litellm.call_response | Mirascope"
4 | ---
5 |
6 | # mirascope.core.litellm.call\_response [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/call_response\#mirascope-core-litellm-call-response)
7 |
8 | This module contains the `LiteLLMCallResponse` class.
9 |
10 | Usage
11 |
12 | [Calls](https://mirascope.com/docs/mirascope/learn/calls#handling-responses)
13 |
14 | ## Class LiteLLMCallResponse [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/call_response\#litellmcallresponse)
15 |
16 | A simpler wrapper around `OpenAICallResponse`.
17 |
18 | Everything is the same except the `cost` property, which has been updated to use
19 | LiteLLM's cost calculations so that cost tracking works for non-OpenAI models.
20 |
21 | **Bases:**
22 |
23 | [OpenAICallResponse](https://mirascope.com/docs/mirascope/api/core/openai/call_response#openaicallresponse)
24 |
25 | ### Attributes
26 |
27 | | Name | Type | Description |
28 | | --- | --- | --- |
29 | | cost\_metadata | [CostMetadata](https://mirascope.com/docs/mirascope/api/core/base/types#costmetadata) | - |
30 |
31 | Copy as Markdown
32 |
33 | #### Provider
34 |
35 | OpenAI
36 |
37 | #### On this page
38 |
39 | Copy as Markdown
40 |
41 | #### Provider
42 |
43 | OpenAI
44 |
45 | #### On this page
46 |
47 | ## Cookie Consent
48 |
49 | We use cookies to track usage and improve the site.
50 |
51 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_litellm_call_response_chunk.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/litellm/call_response_chunk"
3 | title: "mirascope.core.litellm.call_response_chunk | Mirascope"
4 | ---
5 |
6 | # mirascope.core.litellm.call\_response\_chunk [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/call_response_chunk\#mirascope-core-litellm-call-response-chunk)
7 |
8 | This module contains the `LiteLLMCallResponseChunk` class.
9 |
10 | Usage
11 |
12 | [Streams](https://mirascope.com/docs/mirascope/learn/streams#handling-streamed-responses)
13 |
14 | ## Class LiteLLMCallResponseChunk [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/call_response_chunk\#litellmcallresponsechunk)
15 |
16 | A simpler wrapper around `OpenAICallResponse`.
17 |
18 | Everything is the same except the `cost` property, which has been updated to use
19 | LiteLLM's cost calculations so that cost tracking works for non-OpenAI models.
20 |
21 | **Bases:**
22 |
23 | [OpenAICallResponseChunk](https://mirascope.com/docs/mirascope/api/core/openai/call_response_chunk#openaicallresponsechunk)
24 |
25 | Copy as Markdown
26 |
27 | #### Provider
28 |
29 | OpenAI
30 |
31 | #### On this page
32 |
33 | Copy as Markdown
34 |
35 | #### Provider
36 |
37 | OpenAI
38 |
39 | #### On this page
40 |
41 | ## Cookie Consent
42 |
43 | We use cookies to track usage and improve the site.
44 |
45 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_litellm_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/litellm/dynamic_config"
3 | title: "mirascope.core.litellm.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.litellm.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/dynamic_config\#mirascope-core-litellm-dynamic-config)
7 |
8 | ## Module dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/dynamic_config\#dynamic-config)
9 |
10 | This module defines the function return type for functions as LLM calls.
11 |
12 | ## Attribute AsyncLiteLLMDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/dynamic_config\#asynclitellmdynamicconfig)
13 |
14 | **Type:** TypeAlias
15 |
16 | ## Attribute LiteLLMDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/dynamic_config\#litellmdynamicconfig)
17 |
18 | **Type:** TypeAlias
19 |
20 | Copy as Markdown
21 |
22 | #### Provider
23 |
24 | OpenAI
25 |
26 | #### On this page
27 |
28 | Copy as Markdown
29 |
30 | #### Provider
31 |
32 | OpenAI
33 |
34 | #### On this page
35 |
36 | ## Cookie Consent
37 |
38 | We use cookies to track usage and improve the site.
39 |
40 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_litellm_stream.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/litellm/stream"
3 | title: "mirascope.core.litellm.stream | Mirascope"
4 | ---
5 |
6 | # mirascope.core.litellm.stream [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/stream\#mirascope-core-litellm-stream)
7 |
8 | The `LiteLLMStream` class for convenience around streaming LLM calls.
9 |
10 | Usage
11 |
12 | [Streams](https://mirascope.com/docs/mirascope/learn/streams)
13 |
14 | ## Class LiteLLMStream [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/stream\#litellmstream)
15 |
16 | A simple wrapper around `OpenAIStream`.
17 |
18 | Everything is the same except updates to the `construct_call_response` method and
19 | the `cost` property so that cost is properly calculated using LiteLLM's cost
20 | calculation method. This ensures cost calculation works for non-OpenAI models.
21 |
22 | **Bases:**
23 |
24 | [OpenAIStream](https://mirascope.com/docs/mirascope/api/core/openai/stream#openaistream)
25 |
26 | ### Attributes
27 |
28 | | Name | Type | Description |
29 | | --- | --- | --- |
30 | | cost\_metadata | [CostMetadata](https://mirascope.com/docs/mirascope/api/core/base/types#costmetadata) | Returns metadata needed for cost calculation. |
31 |
32 | ## Function construct\_call\_response [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/stream\#construct-call-response)
33 |
34 | ### Parameters
35 |
36 | | Name | Type | Description |
37 | | --- | --- | --- |
38 | | self | Any | - |
39 |
40 | ### Returns
41 |
42 | | Type | Description |
43 | | --- | --- |
44 | | [LiteLLMCallResponse](https://mirascope.com/docs/mirascope/api/core/litellm/call_response#litellmcallresponse) | - |
45 |
46 | Copy as Markdown
47 |
48 | #### Provider
49 |
50 | OpenAI
51 |
52 | #### On this page
53 |
54 | Copy as Markdown
55 |
56 | #### Provider
57 |
58 | OpenAI
59 |
60 | #### On this page
61 |
62 | ## Cookie Consent
63 |
64 | We use cookies to track usage and improve the site.
65 |
66 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_litellm_tool.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/litellm/tool"
3 | title: "mirascope.core.litellm.tool | Mirascope"
4 | ---
5 |
6 | # mirascope.core.litellm.tool [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/tool\#mirascope-core-litellm-tool)
7 |
8 | The `LiteLLMTool` class for easy tool usage with LiteLLM LLM calls.
9 |
10 | Usage
11 |
12 | [Tools](https://mirascope.com/docs/mirascope/learn/tools)
13 |
14 | ## Class LiteLLMTool [Link to this heading](https://mirascope.com/docs/mirascope/api/core/litellm/tool\#litellmtool)
15 |
16 | A simple wrapper around `OpenAITool`.
17 |
18 | Since LiteLLM uses the OpenAI spec, we change nothing here.
19 |
20 | **Bases:**
21 |
22 | [OpenAITool](https://mirascope.com/docs/mirascope/api/core/openai/tool#openaitool)
23 |
24 | Copy as Markdown
25 |
26 | #### Provider
27 |
28 | OpenAI
29 |
30 | #### On this page
31 |
32 | Copy as Markdown
33 |
34 | #### Provider
35 |
36 | OpenAI
37 |
38 | #### On this page
39 |
40 | ## Cookie Consent
41 |
42 | We use cookies to track usage and improve the site.
43 |
44 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_mistral_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/mistral/dynamic_config"
3 | title: "mirascope.core.mistral.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.mistral.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/mistral/dynamic_config\#mirascope-core-mistral-dynamic-config)
7 |
8 | This module defines the function return type for functions as LLM calls.
9 |
10 | ## Attribute MistralDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/mistral/dynamic_config\#mistraldynamicconfig)
11 |
12 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[AssistantMessage \| SystemMessage \| ToolMessage \| UserMessage \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [MistralCallParams](https://mirascope.com/docs/mirascope/api/core/mistral/call_params#mistralcallparams), Mistral\]
13 |
14 | The function return type for functions wrapped with the `mistral_call` decorator.
15 |
16 | Example:
17 |
18 | ```
19 | from mirascope.core import prompt_template
20 | from mirascope.core.mistral import MistralDynamicConfig, mistral_call
21 |
22 | @mistral_call("mistral-large-latest")
23 | @prompt_template("Recommend a {capitalized_genre} book")
24 | def recommend_book(genre: str) -> MistralDynamicConfig:
25 | return {"computed_fields": {"capitalized_genre": genre.capitalize()}}
26 | ```
27 |
28 | Copy as Markdown
29 |
30 | #### Provider
31 |
32 | OpenAI
33 |
34 | #### On this page
35 |
36 | Copy as Markdown
37 |
38 | #### Provider
39 |
40 | OpenAI
41 |
42 | #### On this page
43 |
44 | ## Cookie Consent
45 |
46 | We use cookies to track usage and improve the site.
47 |
48 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_openai_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/openai/dynamic_config"
3 | title: "mirascope.core.openai.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.openai.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/openai/dynamic_config\#mirascope-core-openai-dynamic-config)
7 |
8 | ## Module dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/openai/dynamic_config\#dynamic-config)
9 |
10 | This module defines the function return type for functions as LLM calls.
11 |
12 | ## Attribute AsyncOpenAIDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/openai/dynamic_config\#asyncopenaidynamicconfig)
13 |
14 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatCompletionMessageParam \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [OpenAICallParams](https://mirascope.com/docs/mirascope/api/core/openai/call_params#openaicallparams), AsyncOpenAI \| AsyncAzureOpenAI\]
15 |
16 | ## Attribute OpenAIDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/openai/dynamic_config\#openaidynamicconfig)
17 |
18 | **Type:** [BaseDynamicConfig](https://mirascope.com/docs/mirascope/api/core/base/dynamic_config#basedynamicconfig)\[ChatCompletionMessageParam \| [BaseMessageParam](https://mirascope.com/docs/mirascope/api/core/base/message_param#basemessageparam), [OpenAICallParams](https://mirascope.com/docs/mirascope/api/core/openai/call_params#openaicallparams), OpenAI \| AzureOpenAI\]
19 |
20 | The function return type for functions wrapped with the `openai_call` decorator.
21 |
22 | Example:
23 |
24 | ```
25 | from mirascope.core import prompt_template
26 | from mirascope.core.openai import OpenAIDynamicConfig, openai_call
27 |
28 | @openai_call("gpt-4o-mini")
29 | @prompt_template("Recommend a {capitalized_genre} book")
30 | def recommend_book(genre: str) -> OpenAIDynamicConfig:
31 | return {"computed_fields": {"capitalized_genre": genre.capitalize()}}
32 | ```
33 |
34 | Copy as Markdown
35 |
36 | #### Provider
37 |
38 | OpenAI
39 |
40 | #### On this page
41 |
42 | Copy as Markdown
43 |
44 | #### Provider
45 |
46 | OpenAI
47 |
48 | #### On this page
49 |
50 | ## Cookie Consent
51 |
52 | We use cookies to track usage and improve the site.
53 |
54 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_xai_call_params.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/xai/call_params"
3 | title: "mirascope.core.xai.call_params | Mirascope"
4 | ---
5 |
6 | # mirascope.core.xai.call\_params [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/call_params\#mirascope-core-xai-call-params)
7 |
8 | Usage
9 |
10 | [Calls](https://mirascope.com/docs/mirascope/learn/calls#provider-specific-parameters)
11 |
12 | ## Class XAICallParams [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/call_params\#xaicallparams)
13 |
14 | A simple wrapper around `OpenAICallParams.`
15 |
16 | Since xAI supports the OpenAI spec, we change nothing here.
17 |
18 | **Bases:**
19 |
20 | [OpenAICallParams](https://mirascope.com/docs/mirascope/api/core/openai/call_params#openaicallparams)
21 |
22 | Copy as Markdown
23 |
24 | #### Provider
25 |
26 | OpenAI
27 |
28 | #### On this page
29 |
30 | Copy as Markdown
31 |
32 | #### Provider
33 |
34 | OpenAI
35 |
36 | #### On this page
37 |
38 | ## Cookie Consent
39 |
40 | We use cookies to track usage and improve the site.
41 |
42 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_xai_call_response.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/xai/call_response"
3 | title: "mirascope.core.xai.call_response | Mirascope"
4 | ---
5 |
6 | # mirascope.core.xai.call\_response [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/call_response\#mirascope-core-xai-call-response)
7 |
8 | This module contains the `XAICallResponse` class.
9 |
10 | Usage
11 |
12 | [Calls](https://mirascope.com/docs/mirascope/learn/calls#handling-responses)
13 |
14 | ## Class XAICallResponse [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/call_response\#xaicallresponse)
15 |
16 | A simpler wrapper around `OpenAICallResponse`.
17 |
18 | Everything is the same except the `cost` property, which has been updated to use
19 | xAI's cost calculations so that cost tracking works for non-OpenAI models.
20 |
21 | **Bases:**
22 |
23 | [OpenAICallResponse](https://mirascope.com/docs/mirascope/api/core/openai/call_response#openaicallresponse)
24 |
25 | Copy as Markdown
26 |
27 | #### Provider
28 |
29 | OpenAI
30 |
31 | #### On this page
32 |
33 | Copy as Markdown
34 |
35 | #### Provider
36 |
37 | OpenAI
38 |
39 | #### On this page
40 |
41 | ## Cookie Consent
42 |
43 | We use cookies to track usage and improve the site.
44 |
45 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_xai_call_response_chunk.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/xai/call_response_chunk"
3 | title: "mirascope.core.xai.call_response_chunk | Mirascope"
4 | ---
5 |
6 | # mirascope.core.xai.call\_response\_chunk [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/call_response_chunk\#mirascope-core-xai-call-response-chunk)
7 |
8 | This module contains the `XAICallResponseChunk` class.
9 |
10 | Usage
11 |
12 | [Streams](https://mirascope.com/docs/mirascope/learn/streams#handling-streamed-responses)
13 |
14 | ## Class XAICallResponseChunk [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/call_response_chunk\#xaicallresponsechunk)
15 |
16 | A simpler wrapper around `OpenAICallResponse`.
17 |
18 | Everything is the same except the `cost` property, which has been updated to use
19 | xAI's cost calculations so that cost tracking works for non-OpenAI models.
20 |
21 | **Bases:**
22 |
23 | [OpenAICallResponseChunk](https://mirascope.com/docs/mirascope/api/core/openai/call_response_chunk#openaicallresponsechunk)
24 |
25 | Copy as Markdown
26 |
27 | #### Provider
28 |
29 | OpenAI
30 |
31 | #### On this page
32 |
33 | Copy as Markdown
34 |
35 | #### Provider
36 |
37 | OpenAI
38 |
39 | #### On this page
40 |
41 | ## Cookie Consent
42 |
43 | We use cookies to track usage and improve the site.
44 |
45 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_xai_dynamic_config.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/xai/dynamic_config"
3 | title: "mirascope.core.xai.dynamic_config | Mirascope"
4 | ---
5 |
6 | # mirascope.core.xai.dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/dynamic_config\#mirascope-core-xai-dynamic-config)
7 |
8 | ## Module dynamic\_config [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/dynamic_config\#dynamic-config)
9 |
10 | This module defines the function return type for functions as LLM calls.
11 |
12 | ## Attribute AsyncXAIDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/dynamic_config\#asyncxaidynamicconfig)
13 |
14 | **Type:** TypeAlias
15 |
16 | ## Attribute XAIDynamicConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/dynamic_config\#xaidynamicconfig)
17 |
18 | **Type:** TypeAlias
19 |
20 | Copy as Markdown
21 |
22 | #### Provider
23 |
24 | OpenAI
25 |
26 | #### On this page
27 |
28 | Copy as Markdown
29 |
30 | #### Provider
31 |
32 | OpenAI
33 |
34 | #### On this page
35 |
36 | ## Cookie Consent
37 |
38 | We use cookies to track usage and improve the site.
39 |
40 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_xai_stream.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/xai/stream"
3 | title: "mirascope.core.xai.stream | Mirascope"
4 | ---
5 |
6 | # mirascope.core.xai.stream [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/stream\#mirascope-core-xai-stream)
7 |
8 | The `XAIStream` class for convenience around streaming xAI LLM calls.
9 |
10 | Usage
11 |
12 | [Streams](https://mirascope.com/docs/mirascope/learn/streams)
13 |
14 | ## Class XAIStream [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/stream\#xaistream)
15 |
16 | A simple wrapper around `OpenAIStream`.
17 |
18 | Everything is the same except updates to the `construct_call_response` method and
19 | the `cost` property so that cost is properly calculated using xAI's cost
20 | calculation method. This ensures cost calculation works for non-OpenAI models.
21 |
22 | **Bases:**
23 |
24 | [OpenAIStream](https://mirascope.com/docs/mirascope/api/core/openai/stream#openaistream)
25 |
26 | ### Attributes
27 |
28 | | Name | Type | Description |
29 | | --- | --- | --- |
30 | | cost | [float](https://docs.python.org/3/library/functions.html#float) \| [None](https://docs.python.org/3/library/constants.html#None) | Returns the cost of the call. |
31 |
32 | ## Function construct\_call\_response [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/stream\#construct-call-response)
33 |
34 | ### Parameters
35 |
36 | | Name | Type | Description |
37 | | --- | --- | --- |
38 | | self | Any | - |
39 |
40 | ### Returns
41 |
42 | | Type | Description |
43 | | --- | --- |
44 | | [XAICallResponse](https://mirascope.com/docs/mirascope/api/core/xai/call_response#xaicallresponse) | - |
45 |
46 | Copy as Markdown
47 |
48 | #### Provider
49 |
50 | OpenAI
51 |
52 | #### On this page
53 |
54 | Copy as Markdown
55 |
56 | #### Provider
57 |
58 | OpenAI
59 |
60 | #### On this page
61 |
62 | ## Cookie Consent
63 |
64 | We use cookies to track usage and improve the site.
65 |
66 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_core_xai_tool.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/core/xai/tool"
3 | title: "mirascope.core.xai.tool | Mirascope"
4 | ---
5 |
6 | # mirascope.core.xai.tool [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/tool\#mirascope-core-xai-tool)
7 |
8 | The `XAITool` class for easy tool usage with xAI LLM calls.
9 |
10 | Usage
11 |
12 | [Tools](https://mirascope.com/docs/mirascope/learn/tools)
13 |
14 | ## Class XAITool [Link to this heading](https://mirascope.com/docs/mirascope/api/core/xai/tool\#xaitool)
15 |
16 | A simple wrapper around `OpenAITool`.
17 |
18 | Since xAI supports the OpenAI spec, we change nothing here.
19 |
20 | **Bases:**
21 |
22 | [OpenAITool](https://mirascope.com/docs/mirascope/api/core/openai/tool#openaitool)
23 |
24 | Copy as Markdown
25 |
26 | #### Provider
27 |
28 | OpenAI
29 |
30 | #### On this page
31 |
32 | Copy as Markdown
33 |
34 | #### Provider
35 |
36 | OpenAI
37 |
38 | #### On this page
39 |
40 | ## Cookie Consent
41 |
42 | We use cookies to track usage and improve the site.
43 |
44 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_llm_call_response_chunk.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/llm/call_response_chunk"
3 | title: "mirascope.llm.call_response_chunk | Mirascope"
4 | ---
5 |
6 | # mirascope.llm.call\_response\_chunk [Link to this heading](https://mirascope.com/docs/mirascope/api/llm/call_response_chunk\#mirascope-llm-call-response-chunk)
7 |
8 | Call response chunk module.
9 |
10 | ## Class CallResponseChunk [Link to this heading](https://mirascope.com/docs/mirascope/api/llm/call_response_chunk\#callresponsechunk)
11 |
12 | **Bases:**
13 |
14 | [BaseCallResponseChunk](https://mirascope.com/docs/mirascope/api/core/base/call_response_chunk#basecallresponsechunk)\[[Any](https://docs.python.org/3/library/typing.html#typing.Any), [FinishReason](https://mirascope.com/docs/mirascope/api/core/openai/call_response_chunk#finishreason)\]
15 |
16 | ### Attributes
17 |
18 | | Name | Type | Description |
19 | | --- | --- | --- |
20 | | finish\_reasons | [list](https://docs.python.org/3/library/stdtypes.html#list)\[[FinishReason](https://mirascope.com/docs/mirascope/api/core/openai/call_response_chunk#finishreason)\] \| [None](https://docs.python.org/3/library/constants.html#None) | - |
21 | | usage | [Usage](https://mirascope.com/docs/mirascope/api/core/base/types#usage) \| [None](https://docs.python.org/3/library/constants.html#None) | - |
22 | | cost\_metadata | [CostMetadata](https://mirascope.com/docs/mirascope/api/core/base/types#costmetadata) | Get metadata required for cost calculation. |
23 |
24 | Copy as Markdown
25 |
26 | #### Provider
27 |
28 | OpenAI
29 |
30 | #### On this page
31 |
32 | Copy as Markdown
33 |
34 | #### Provider
35 |
36 | OpenAI
37 |
38 | #### On this page
39 |
40 | ## Cookie Consent
41 |
42 | We use cookies to track usage and improve the site.
43 |
44 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_llm_context.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/llm/context"
3 | title: "mirascope.llm.context | Mirascope"
4 | ---
5 |
6 | # mirascope.llm.context [Link to this heading](https://mirascope.com/docs/mirascope/api/llm/context\#mirascope-llm-context)
7 |
8 | ## Alias context [Link to this heading](https://mirascope.com/docs/mirascope/api/llm/context\#context)
9 |
10 | Context manager for LLM API calls.
11 |
12 | This method only allows setting overrides (provider, model, client, call\_params)
13 | and does not allow structural overrides (stream, tools, response\_model, etc.).
14 |
15 | ### Parameters
16 |
17 | | Name | Type | Description |
18 | | --- | --- | --- |
19 | | provider | [Provider](https://mirascope.com/docs/mirascope/api/core/base/types#provider) \| [LocalProvider](https://mirascope.com/docs/mirascope/api/core/base/types#localprovider) | The provider to use for the LLM API call. |
20 | | model | [str](https://docs.python.org/3/library/stdtypes.html#str) | The model to use for the LLM API call. |
21 | | client= None | [Any](https://docs.python.org/3/library/typing.html#typing.Any) \| [None](https://docs.python.org/3/library/constants.html#None) | The client to use for the LLM API call. |
22 | | call\_params= None | CommonCallParams \| [Any](https://docs.python.org/3/library/typing.html#typing.Any) \| [None](https://docs.python.org/3/library/constants.html#None) | The call parameters for the LLM API call. |
23 |
24 | ### Returns
25 |
26 | | Type | Description |
27 | | --- | --- |
28 | | LLMContext | - |
29 |
30 | **Alias to:** `mirascope.llm._context.context`
31 |
32 | Copy as Markdown
33 |
34 | #### Provider
35 |
36 | OpenAI
37 |
38 | #### On this page
39 |
40 | Copy as Markdown
41 |
42 | #### Provider
43 |
44 | OpenAI
45 |
46 | #### On this page
47 |
48 | ## Cookie Consent
49 |
50 | We use cookies to track usage and improve the site.
51 |
52 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_llm_tool.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/llm/tool"
3 | title: "mirascope.llm.tool | Mirascope"
4 | ---
5 |
6 | # mirascope.llm.tool [Link to this heading](https://mirascope.com/docs/mirascope/api/llm/tool\#mirascope-llm-tool)
7 |
8 | Tool class for the provider-agnostic tool.
9 |
10 | ## Class Tool [Link to this heading](https://mirascope.com/docs/mirascope/api/llm/tool\#tool)
11 |
12 | A provider-agnostic Tool class.
13 |
14 | - No BaseProviderConverter
15 | - Relies on \_response having `common_` methods/properties if needed.
16 |
17 | **Bases:**
18 |
19 | [BaseTool](https://mirascope.com/docs/mirascope/api/core/base/tool#basetool)
20 |
21 | Copy as Markdown
22 |
23 | #### Provider
24 |
25 | OpenAI
26 |
27 | #### On this page
28 |
29 | Copy as Markdown
30 |
31 | #### Provider
32 |
33 | OpenAI
34 |
35 | #### On this page
36 |
37 | ## Cookie Consent
38 |
39 | We use cookies to track usage and improve the site.
40 |
41 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_retries_tenacity.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/retries/tenacity"
3 | title: "mirascope.retries.tenacity | Mirascope"
4 | ---
5 |
6 | # mirascope.retries.tenacity [Link to this heading](https://mirascope.com/docs/mirascope/api/retries/tenacity\#mirascope-retries-tenacity)
7 |
8 | Utitlies for more easily using Tenacity to reinsert errors on failed API calls.
9 |
10 | ## Function collect\_errors [Link to this heading](https://mirascope.com/docs/mirascope/api/retries/tenacity\#collect-errors)
11 |
12 | Collects specified errors into an `errors` keyword argument.
13 |
14 | Example:
15 |
16 | ```
17 | from mirascope.integrations.tenacity import collect_errors
18 | from tenacity import retry, stop_after_attempt
19 |
20 | @retry(stop=stop_after_attempt(3), after=collect_errors(ValueError))
21 | def throw_value_error(*, errors: list[ValueError] | None = None):
22 | if errors:
23 | print(errors[-1])
24 | raise ValueError("Throwing Error")
25 |
26 | try:
27 | throw_value_error()
28 | # > Throwing Error
29 | # > Throwing Error
30 | except RetryError:
31 | ...
32 | ```
33 |
34 | ### Parameters
35 |
36 | | Name | Type | Description |
37 | | --- | --- | --- |
38 | | args= () | [type](https://docs.python.org/3/library/functions.html#type)\[Exception\] | - |
39 |
40 | ### Returns
41 |
42 | | Type | Description |
43 | | --- | --- |
44 | | (RetryCallState) =\> [None](https://docs.python.org/3/library/constants.html#None) | - |
45 |
46 | Copy as Markdown
47 |
48 | #### Provider
49 |
50 | OpenAI
51 |
52 | #### On this page
53 |
54 | Copy as Markdown
55 |
56 | #### Provider
57 |
58 | OpenAI
59 |
60 | #### On this page
61 |
62 | ## Cookie Consent
63 |
64 | We use cookies to track usage and improve the site.
65 |
66 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_tools_web_httpx.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/tools/web/httpx"
3 | title: "mirascope.tools.web._httpx | Mirascope"
4 | ---
5 |
6 | # mirascope.tools.web.\_httpx [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/httpx\#mirascope-tools-web-httpx)
7 |
8 | ## Module \_httpx [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/httpx\#httpx)
9 |
10 | ## Class HTTPXConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/httpx\#httpxconfig)
11 |
12 | Configuration for HTTPX requests
13 |
14 | **Bases:**
15 |
16 | \_ConfigurableToolConfig
17 |
18 | ### Attributes
19 |
20 | | Name | Type | Description |
21 | | --- | --- | --- |
22 | | timeout | [int](https://docs.python.org/3/library/functions.html#int) | - |
23 |
24 | ## Class HTTPX [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/httpx\#httpx)
25 |
26 | **Bases:**
27 |
28 | \_BaseHTTPX
29 |
30 | ## Function call [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/httpx\#call)
31 |
32 | Make an HTTP request to the given URL using HTTPX.
33 |
34 | ### Parameters
35 |
36 | | Name | Type | Description |
37 | | --- | --- | --- |
38 | | self | Any | - |
39 |
40 | ### Returns
41 |
42 | | Type | Description |
43 | | --- | --- |
44 | | [str](https://docs.python.org/3/library/stdtypes.html#str) | Response text if successful, error message if request fails |
45 |
46 | ## Class AsyncHTTPX [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/httpx\#asynchttpx)
47 |
48 | **Bases:**
49 |
50 | \_BaseHTTPX
51 |
52 | ## Function call [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/httpx\#call)
53 |
54 | Make an asynchronous HTTP request to the given URL using HTTPX.
55 |
56 | ### Parameters
57 |
58 | | Name | Type | Description |
59 | | --- | --- | --- |
60 | | self | Any | - |
61 |
62 | ### Returns
63 |
64 | | Type | Description |
65 | | --- | --- |
66 | | [str](https://docs.python.org/3/library/stdtypes.html#str) | Response text if successful, error message if request fails |
67 |
68 | Copy as Markdown
69 |
70 | #### Provider
71 |
72 | OpenAI
73 |
74 | #### On this page
75 |
76 | Copy as Markdown
77 |
78 | #### Provider
79 |
80 | OpenAI
81 |
82 | #### On this page
83 |
84 | ## Cookie Consent
85 |
86 | We use cookies to track usage and improve the site.
87 |
88 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_api_tools_web_requests.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/api/tools/web/requests"
3 | title: "mirascope.tools.web._requests | Mirascope"
4 | ---
5 |
6 | # mirascope.tools.web.\_requests [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/requests\#mirascope-tools-web-requests)
7 |
8 | ## Module \_requests [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/requests\#requests)
9 |
10 | ## Class RequestsConfig [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/requests\#requestsconfig)
11 |
12 | Configuration for HTTP requests
13 |
14 | **Bases:**
15 |
16 | \_ConfigurableToolConfig
17 |
18 | ### Attributes
19 |
20 | | Name | Type | Description |
21 | | --- | --- | --- |
22 | | timeout | [int](https://docs.python.org/3/library/functions.html#int) | - |
23 |
24 | ## Class Requests [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/requests\#requests)
25 |
26 | Tool for making HTTP requests with built-in requests library.
27 |
28 | **Bases:**
29 |
30 | ConfigurableTool
31 |
32 | ### Attributes
33 |
34 | | Name | Type | Description |
35 | | --- | --- | --- |
36 | | url | [str](https://docs.python.org/3/library/stdtypes.html#str) | - |
37 | | method | [Literal](https://docs.python.org/3/library/typing.html#typing.Literal)\['GET', 'POST', 'PUT', 'DELETE'\] | - |
38 | | data | [dict](https://docs.python.org/3/library/stdtypes.html#dict) \| [None](https://docs.python.org/3/library/constants.html#None) | - |
39 | | headers | [dict](https://docs.python.org/3/library/stdtypes.html#dict) \| [None](https://docs.python.org/3/library/constants.html#None) | - |
40 |
41 | ## Function call [Link to this heading](https://mirascope.com/docs/mirascope/api/tools/web/requests\#call)
42 |
43 | Make an HTTP request to the given URL.
44 |
45 | ### Parameters
46 |
47 | | Name | Type | Description |
48 | | --- | --- | --- |
49 | | self | Any | - |
50 |
51 | ### Returns
52 |
53 | | Type | Description |
54 | | --- | --- |
55 | | [str](https://docs.python.org/3/library/stdtypes.html#str) | Response text content if successful, error message if request fails |
56 |
57 | Copy as Markdown
58 |
59 | #### Provider
60 |
61 | OpenAI
62 |
63 | #### On this page
64 |
65 | Copy as Markdown
66 |
67 | #### Provider
68 |
69 | OpenAI
70 |
71 | #### On this page
72 |
73 | ## Cookie Consent
74 |
75 | We use cookies to track usage and improve the site.
76 |
77 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/mirascope/mirascope.com_docs_mirascope_guides.md:
--------------------------------------------------------------------------------
1 | ---
2 | url: "https://mirascope.com/docs/mirascope/guides"
3 | title: "Mirascope Guides | Mirascope"
4 | ---
5 |
6 | # Mirascope Guides [Link to this heading](https://mirascope.com/docs/mirascope/guides\#mirascope-guides)
7 |
8 | Welcome to Mirascope guides! Here you'll find practical examples and tutorials to help you build powerful AI applications with Mirascope.
9 |
10 | These guides showcase how to use Mirascope's features to solve real-world problems and implement common patterns in AI application development.
11 |
12 | Choose a guide category from the sidebar to get started.
13 |
14 | Copy as Markdown
15 |
16 | #### Provider
17 |
18 | OpenAI
19 |
20 | #### On this page
21 |
22 | Copy as Markdown
23 |
24 | #### Provider
25 |
26 | OpenAI
27 |
28 | #### On this page
29 |
30 | ## Cookie Consent
31 |
32 | We use cookies to track usage and improve the site.
33 |
34 | RejectAccept
--------------------------------------------------------------------------------
/.claude/documentation/modelcontextprotocol/04_server_features/01_overview.md:
--------------------------------------------------------------------------------
1 | # Server Features Overview
2 |
3 | **Protocol Revision**: 2025-03-26
4 |
5 | Servers provide the fundamental building blocks for adding context to language models via
6 | MCP. These primitives enable rich interactions between clients, servers, and language
7 | models:
8 |
9 | - **Prompts**: Pre-defined templates or instructions that guide language model
10 | interactions
11 | - **Resources**: Structured data or content that provides additional context to the model
12 | - **Tools**: Executable functions that allow models to perform actions or retrieve
13 | information
14 |
15 | Each primitive can be summarized in the following control hierarchy:
16 |
17 | | Primitive | Control | Description | Example |
18 | | --- | --- | --- | --- |
19 | | Prompts | User-controlled | Interactive templates invoked by user choice | Slash commands, menu options |
20 | | Resources | Application-controlled | Contextual data attached and managed by the client | File contents, git history |
21 | | Tools | Model-controlled | Functions exposed to the LLM to take actions | API POST requests, file writing |
22 |
23 | Explore these key primitives in more detail below:
24 |
25 | - **Prompts**
26 | - **Resources**
27 | - **Tools**
--------------------------------------------------------------------------------
/.claude/documentation/modelcontextprotocol/README.md:
--------------------------------------------------------------------------------
1 | # Model Context Protocol Documentation
2 |
3 | This directory contains the scraped documentation from the Model Context Protocol (MCP) specification (version 2025-03-26).
4 |
5 | ## Structure
6 |
7 | - **01_overview/** - Main specification overview and introduction
8 | - **02_architecture/** - MCP architecture and design principles
9 | - **03_base_protocol/** - Core protocol details including lifecycle, transports, and authorization
10 | - **04_server_features/** - Server-side features: prompts, resources, and tools
11 | - **05_client_features/** - Client-side features: roots and sampling
12 |
13 | ## About MCP
14 |
15 | The Model Context Protocol (MCP) is an open protocol that enables seamless integration between LLM applications and external data sources and tools. It provides a standardized way to connect LLMs with the context they need through:
16 |
17 | - **Resources**: Context and data for the AI model to use
18 | - **Prompts**: Templated messages and workflows
19 | - **Tools**: Functions for the AI model to execute
20 | - **Sampling**: Server-initiated LLM interactions
21 |
22 | The protocol uses JSON-RPC 2.0 for communication and supports multiple transport mechanisms including stdio and HTTP.
23 |
24 | For the latest documentation and implementation details, visit [modelcontextprotocol.io](https://modelcontextprotocol.io/).
--------------------------------------------------------------------------------
/.github/workflows/claude.yml:
--------------------------------------------------------------------------------
1 | name: Claude Code
2 |
3 | on:
4 | issue_comment:
5 | types: [created]
6 | pull_request_review_comment:
7 | types: [created]
8 | issues:
9 | types: [opened, assigned]
10 | pull_request_review:
11 | types: [submitted]
12 |
13 | jobs:
14 | claude:
15 | if: |
16 | (github.event_name == 'issue_comment' && contains(github.event.comment.body, '@claude')) ||
17 | (github.event_name == 'pull_request_review_comment' && contains(github.event.comment.body, '@claude')) ||
18 | (github.event_name == 'pull_request_review' && contains(github.event.review.body, '@claude')) ||
19 | (github.event_name == 'issues' && (contains(github.event.issue.body, '@claude') || contains(github.event.issue.title, '@claude')))
20 | runs-on: ubuntu-latest
21 | permissions:
22 | contents: read
23 | pull-requests: read
24 | issues: read
25 | id-token: write
26 | steps:
27 | - name: Checkout repository
28 | uses: actions/checkout@v4
29 | with:
30 | fetch-depth: 1
31 |
32 | - name: Run Claude Code
33 | id: claude
34 | uses: anthropics/claude-code-action@beta
35 | with:
36 | anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
37 |
38 |
--------------------------------------------------------------------------------
/.mypy.ini:
--------------------------------------------------------------------------------
1 | # Reference:
2 | # https://github.com/openai/openai-python/blob/main/mypy.ini
3 | # https://github.com/pytorch/pytorch/blob/main/mypy.ini
4 | [mypy]
5 | pretty=True
6 | show_error_codes=True
7 | python_version=3.11
8 |
9 | strict_equality=True
10 | implicit_reexport=True
11 | check_untyped_defs=True
12 | no_implicit_optional=True
13 |
14 | warn_return_any=False
15 | warn_unreachable=True
16 | warn_unused_configs=True
17 |
18 | # Turn these options off as it could cause conflicts
19 | # with the Pyright options.
20 | warn_unused_ignores=False
21 | warn_redundant_casts=False
22 |
23 | disallow_any_generics=True
24 | disallow_untyped_defs=True
25 | disallow_untyped_calls=True
26 | disallow_subclassing_any=True
27 | disallow_incomplete_defs=True
28 | disallow_untyped_decorators=True
29 | cache_fine_grained=True
--------------------------------------------------------------------------------
/.pre-commit-config.yaml:
--------------------------------------------------------------------------------
1 | repos:
2 | - repo: https://github.com/astral-sh/ruff-pre-commit
3 | rev: v0.3.0 # Updated Ruff version
4 | hooks:
5 | - id: ruff # Run the linter.
6 | name: Run Linter Check (Ruff)
7 | args: [ --fix ]
8 | files: ^(contextframe|tests|examples)/
9 | types_or: [ python, pyi ]
10 | - id: ruff-format # Run the formatter.
11 | name: Run Formatter (Ruff)
12 | types_or: [ python, pyi ]
13 | - repo: local
14 | hooks:
15 | - id: ci_type_mypy
16 | name: Run Type Check (Mypy)
17 | entry: mypy --config-file .mypy.ini
18 | language: system
19 | types: [python]
20 | pass_filenames: false
21 |
--------------------------------------------------------------------------------
/.vscode/extensions.json:
--------------------------------------------------------------------------------
1 | {
2 | "recommendations": [
3 | "aaron-bond.better-comments",
4 | "charliermarsh.ruff",
5 | "codezombiech.gitignore",
6 | "doppler.doppler-vscode",
7 | "EditorConfig.EditorConfig",
8 | "mechatroner.rainbow-csv",
9 | "ms-azuretools.vscode-docker",
10 | "ms-python.python",
11 | "redhat.vscode-yaml",
12 | "ryu1kn.partial-diff",
13 | ]
14 | }
15 |
--------------------------------------------------------------------------------
/.vscode/launch.json:
--------------------------------------------------------------------------------
1 | {
2 | // Use IntelliSense to learn about possible attributes.
3 | // Hover to view descriptions of existing attributes.
4 | // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
5 | // pytest: https://stackoverflow.com/questions/70259564/how-to-debug-the-current-python-test-file-with-pytest-in-vs-code
6 | "version": "0.2.0",
7 | "configurations": [
8 | {
9 | "name": "Python: Current File",
10 | "type": "debugpy",
11 | "request": "launch",
12 | "program": "${file}",
13 | "console": "integratedTerminal",
14 | "cwd": "${fileDirname}",
15 | "pythonArgs": [
16 | "-Xfrozen_modules=off"
17 | ],
18 | "env": {
19 | "PYDEVD_DISABLE_FILE_VALIDATION": "1",
20 | "DOPPLER_ENV": "1"
21 | }
22 | // "args": ["-i", "response.xml", "-o", "response.csv"],
23 | },
24 | {
25 | "name": "Python: FastAPI",
26 | "type": "debugpy",
27 | "request": "launch",
28 | "module": "uvicorn",
29 | "args": [
30 | "app.main:app",
31 | "--reload",
32 | "--port",
33 | "8000"
34 | ],
35 | "console": "integratedTerminal",
36 | "cwd": "${workspaceFolder}",
37 | "pythonArgs": [
38 | "-Xfrozen_modules=off"
39 | ],
40 | "env": {
41 | "PYDEVD_DISABLE_FILE_VALIDATION": "1",
42 | "DOPPLER_ENV": "1"
43 | }
44 | }
45 | ]
46 | }
47 |
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "[python]": {
3 | "editor.insertSpaces": true,
4 | "editor.tabSize": 4,
5 | "editor.codeActionsOnSave": {
6 | "source.organizeImports": "explicit",
7 | "source.fixAll": "explicit"
8 | }
9 | },
10 | "python.testing.pytestArgs": [
11 | "tests"
12 | ],
13 | "python.testing.unittestEnabled": false,
14 | "python.testing.pytestEnabled": true,
15 | // https://github.com/astral-sh/ruff-vscode
16 | "python.analysis.ignore": [
17 | "*"
18 | ]
19 | }
20 |
--------------------------------------------------------------------------------
/CHANGELOG.md:
--------------------------------------------------------------------------------
1 | # Changelog
2 |
3 | All notable changes to this project will be documented in this file.
4 |
5 | The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
6 | and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
7 |
8 | ## [Unreleased]
9 |
10 | ### Changed
11 |
12 | - **BREAKING**: Replaced LlamaIndex text splitter with lightweight `semantic-text-splitter` (Rust-based)
13 | - Removed `llama_index_splitter` function from `contextframe.extract.chunking`
14 | - Renamed to `semantic_splitter` with updated parameters
15 | - Significantly reduced dependency footprint (no PyTorch required)
16 | - All tree-sitter language packages now included in base `extract` dependencies
17 |
18 | ### Added
19 |
20 | - Comprehensive embedding provider documentation (`docs/embedding_providers.md`)
21 | - Example demonstrating all embedding provider options (`examples/embedding_providers_demo.py`)
22 | - External extraction tool examples:
23 | - `examples/external_tools/docling_pdf_pipeline.py` - Docling integration pattern
24 | - `examples/external_tools/unstructured_io_pipeline.py` - Unstructured.io API and local usage
25 | - `examples/external_tools/chunkr_pipeline.py` - Intelligent chunking service
26 | - `examples/external_tools/reducto_pipeline.py` - Scientific document processing
27 | - Documentation for external extraction tools (`docs/external_extraction_tools.md`)
28 | - Documentation for extraction patterns (`docs/extraction_patterns.md`)
29 |
30 | ## [0.1.0] - 2025-05-05
31 |
32 | Initial release of ContextFrame.
33 |
34 | ### Added
35 |
36 | - Core functionality for managing LLM context with Lance files
37 | - Schema validation and standardized metadata
38 | - Document extraction and chunking capabilities
39 | - Embedding generation with multiple providers
40 | - Example pipelines and documentation
41 |
42 | ### Fixed
43 |
44 | - N/A (initial release)
45 |
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | # Code of Conduct
2 |
3 | ## Our Pledge
4 |
5 | We as members, contributors, and leaders pledge to make participation in our community a respectful and professional experience for everyone.
6 |
7 | ## Our Standards
8 |
9 | Examples of behavior that contributes to a positive environment:
10 |
11 | * Using welcoming and inclusive language
12 | * Being respectful of differing viewpoints and experiences
13 | * Gracefully accepting constructive criticism
14 | * Focusing on what is best for the community
15 | * Showing empathy towards other community members
16 |
17 | Examples of unacceptable behavior:
18 |
19 | * The use of inappropriate language or imagery
20 | * Trolling or insulting/derogatory comments
21 | * Public or private harassment
22 | * Publishing others' private information without permission
23 | * Other conduct which could reasonably be considered inappropriate in a professional setting
24 |
25 | ## Our Responsibilities
26 |
27 | Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
28 |
29 | ## Scope
30 |
31 | This Code of Conduct applies within all project spaces, and it also applies when an individual is representing the project or its community in public spaces.
32 |
33 | ## Enforcement
34 |
35 | Instances of unacceptable behavior may be reported by contacting the project team. All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances.
36 |
37 | ## Attribution
38 |
39 | This Code of Conduct is adapted from the Contributor Covenant, version 2.0.
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2025 Grey Haven, LLC
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include contextframe/examples/*.lance
--------------------------------------------------------------------------------
/contextframe/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Context Frame is a file format and toolkit for working with
3 | documents with structured metadata for AI workflows.
4 | """
5 |
6 | # Direct imports for convenience
7 | from .exceptions import (
8 | ConflictError,
9 | ContextFrameError,
10 | FormatError,
11 | RelationshipError,
12 | ValidationError,
13 | VersioningError,
14 | )
15 | from .frame import FrameDataset, FrameRecord
16 |
17 | # Collection helpers are still applicable (operate via FrameDataset internally)
18 | # from .collection import Collection # type: ignore # noqa: E402
19 | # Convenience exports
20 | from .helpers.metadata_utils import (
21 | add_relationship_to_metadata,
22 | compare_semantic_versions,
23 | create_metadata,
24 | create_relationship,
25 | generate_uuid,
26 | get_standard_fields,
27 | is_semantic_version,
28 | is_valid_uuid,
29 | next_version,
30 | validate_relationships,
31 | ) # noqa: E402
32 |
33 | # I/O functionality
34 | from .io import ExportFormat, FrameSetExporter, FrameSetImporter # noqa: E402
35 | from .schema import MimeTypes, RecordType, get_schema # noqa: E402
36 |
37 | # Define version
38 | __version__ = "0.1.0"
39 |
40 |
41 | # CLI entry point
42 | def cli():
43 | """Command-line interface entry point."""
44 | from .cli import main
45 |
46 | main()
47 |
48 |
49 | # Public re-exports
50 | __all__ = [
51 | # Public API for the library
52 | "FrameRecord",
53 | "FrameDataset",
54 | # Metadata helpers re-exported for convenience
55 | "create_metadata",
56 | "create_relationship",
57 | "add_relationship_to_metadata",
58 | "validate_relationships",
59 | "is_semantic_version",
60 | "compare_semantic_versions",
61 | "next_version",
62 | "get_standard_fields",
63 | "generate_uuid",
64 | "is_valid_uuid",
65 | # Schema access
66 | "get_schema",
67 | "RecordType",
68 | "MimeTypes",
69 | # I/O functionality
70 | "FrameSetExporter",
71 | "FrameSetImporter",
72 | "ExportFormat",
73 | # Exceptions
74 | "ContextFrameError",
75 | "ValidationError",
76 | "RelationshipError",
77 | "VersioningError",
78 | "ConflictError",
79 | "FormatError",
80 | # CLI entry point
81 | "cli",
82 | ]
83 |
--------------------------------------------------------------------------------
/contextframe/__main__.py:
--------------------------------------------------------------------------------
1 | """
2 | Command-line entry point for the contextframe package.
3 |
4 | This module allows the package to be run directly as a command-line script:
5 | python -m contextframe
6 | """
7 |
8 | import sys
9 | from .cli import main
10 |
11 |
12 | def main_entry():
13 | """Main entry point for the CLI."""
14 | # Extract arguments (excluding the script name)
15 | args = sys.argv[1:] if len(sys.argv) > 1 else []
16 |
17 | try:
18 | # Call the main CLI function
19 | return_code = main(args)
20 |
21 | # Exit with the appropriate return code
22 | sys.exit(return_code)
23 | except Exception as e:
24 | # In case of unexpected errors, print and exit with error code
25 | print(f"Error: {str(e)}", file=sys.stderr)
26 | sys.exit(1)
27 |
28 |
29 | if __name__ == "__main__":
30 | main_entry()
31 |
--------------------------------------------------------------------------------
/contextframe/builders/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ContextFrame Builders Module
3 |
4 | Provides optional functionality for document extraction, enrichment, analysis,
5 | templates, and serving. Each sub-module is lazily loaded to minimize dependencies.
6 | """
7 |
8 | import importlib
9 | from typing import Any, Dict, Optional
10 |
11 |
12 | class LazyLoader:
13 | """Lazy loader for optional modules with clear error messages."""
14 |
15 | def __init__(self, module_name: str, package: str, extras_name: str):
16 | self.module_name = module_name
17 | self.package = package
18 | self.extras_name = extras_name
19 | self._module: Any | None = None
20 |
21 | def __getattr__(self, name: str) -> Any:
22 | if self._module is None:
23 | try:
24 | self._module = importlib.import_module(
25 | f".{self.module_name}", package=self.package
26 | )
27 | except ImportError as e:
28 | raise ImportError(
29 | f"\nThe '{self.module_name}' module requires additional dependencies.\n"
30 | f"Please install with: pip install \"contextframe[{self.extras_name}]\"\n"
31 | f"Or for all optional features: pip install \"contextframe[all]\"\n"
32 | f"\nOriginal error: {e}"
33 | )
34 | return getattr(self._module, name)
35 |
36 |
37 | # Lazy loading of optional modules
38 | extract = LazyLoader("extract", __package__, "extract")
39 | embed = LazyLoader("embed", __package__, "embed")
40 | enhance = LazyLoader("enhance", __package__, "enhance")
41 | encode = LazyLoader("encode", __package__, "encode")
42 | serve = LazyLoader("serve", __package__, "serve")
43 |
44 |
45 | __all__ = ["extract", "embed", "enhance", "encode", "serve"]
46 |
--------------------------------------------------------------------------------
/contextframe/builders/embed.py:
--------------------------------------------------------------------------------
1 | """
2 | Embedding module for ContextFrame.
3 |
4 | Provides utilities for generating embeddings from text using various
5 | embedding models and services.
6 | """
7 |
8 | import numpy as np
9 | import os
10 | from typing import List, Optional, Union
11 |
12 |
13 | def generate_sentence_transformer_embeddings(
14 | text: str, model: str = "sentence-transformers/all-MiniLM-L6-v2"
15 | ) -> np.ndarray:
16 | """
17 | Generate embeddings using sentence transformers.
18 |
19 | Args:
20 | text: Text to embed
21 | model: Model name to use
22 |
23 | Returns:
24 | Numpy array of embeddings
25 | """
26 | from sentence_transformers import SentenceTransformer
27 |
28 | # Implementation placeholder
29 | raise NotImplementedError("Sentence transformer embeddings coming soon")
30 |
31 |
32 | def generate_openai_embeddings(
33 | text: str, model: str = "text-embedding-ada-002", api_key: str | None = None
34 | ) -> np.ndarray:
35 | """
36 | Generate embeddings using OpenAI API.
37 |
38 | Args:
39 | text: Text to embed
40 | model: OpenAI model to use
41 | api_key: API key (optional, uses env var if not provided)
42 |
43 | Returns:
44 | Numpy array of embeddings
45 | """
46 | import openai
47 |
48 | # Implementation placeholder
49 | raise NotImplementedError("OpenAI embeddings coming soon")
50 |
51 |
52 | def generate_cohere_embeddings(
53 | text: str, model: str = "embed-english-v3.0", api_key: str | None = None
54 | ) -> np.ndarray:
55 | """
56 | Generate embeddings using Cohere API.
57 |
58 | Args:
59 | text: Text to embed
60 | model: Cohere model to use
61 | api_key: API key (optional, uses env var if not provided)
62 |
63 | Returns:
64 | Numpy array of embeddings
65 | """
66 | import cohere
67 |
68 | # Implementation placeholder
69 | raise NotImplementedError("Cohere embeddings coming soon")
70 |
71 |
72 | __all__ = [
73 | "generate_sentence_transformer_embeddings",
74 | "generate_openai_embeddings",
75 | "generate_cohere_embeddings",
76 | ]
77 |
--------------------------------------------------------------------------------
/contextframe/builders/serve.py:
--------------------------------------------------------------------------------
1 | """
2 | Serving module for ContextFrame.
3 |
4 | Provides MCP (Model Context Protocol) server capabilities for ContextFrame datasets,
5 | allowing LLMs and agents to interact with context data.
6 | """
7 |
8 | from pathlib import Path
9 | from typing import Any
10 |
11 |
12 | def create_mcp_server(
13 | dataset_path: str | Path, server_name: str = "contextframe"
14 | ) -> Any:
15 | """
16 | Create an MCP server for a ContextFrame dataset.
17 |
18 | Args:
19 | dataset_path: Path to the Lance dataset
20 | server_name: Name for the MCP server
21 |
22 | Returns:
23 | MCP server instance
24 | """
25 | import mcp
26 |
27 | # Implementation placeholder
28 | raise NotImplementedError("MCP server creation coming soon")
29 |
30 |
31 | def create_mcp_tools(dataset) -> list[dict[str, Any]]:
32 | """
33 | Create MCP tool definitions for ContextFrame operations.
34 |
35 | Args:
36 | dataset: ContextFrame dataset instance
37 |
38 | Returns:
39 | List of MCP tool definitions
40 | """
41 | import mcp
42 |
43 | # Implementation placeholder
44 | raise NotImplementedError("MCP tools creation coming soon")
45 |
46 |
47 | def create_rest_api(dataset_path: str | Path, include_mcp_bridge: bool = True) -> Any:
48 | """
49 | Create a REST API for ContextFrame dataset with optional MCP bridge.
50 |
51 | Args:
52 | dataset_path: Path to the Lance dataset
53 | include_mcp_bridge: Include MCP-compatible endpoints
54 |
55 | Returns:
56 | FastAPI application instance
57 | """
58 | import uvicorn
59 | from fastapi import FastAPI
60 |
61 | # Implementation placeholder
62 | raise NotImplementedError("REST API creation coming soon")
63 |
64 |
65 | def serve_dataset(
66 | dataset_path: str | Path,
67 | host: str = "0.0.0.0",
68 | port: int = 8000,
69 | server_type: str = "mcp",
70 | ) -> None:
71 | """
72 | Serve a ContextFrame dataset via MCP or REST API.
73 |
74 | Args:
75 | dataset_path: Path to the Lance dataset
76 | host: Host to bind to
77 | port: Port to bind to
78 | server_type: Type of server ("mcp" or "rest")
79 | """
80 | import uvicorn
81 |
82 | # Implementation placeholder
83 | raise NotImplementedError("Dataset serving coming soon")
84 |
85 |
86 | __all__ = ["create_mcp_server", "create_mcp_tools", "create_rest_api", "serve_dataset"]
87 |
--------------------------------------------------------------------------------
/contextframe/connectors/__init__.py:
--------------------------------------------------------------------------------
1 | """External system connectors for importing data into ContextFrame.
2 |
3 | This module provides connectors to import data from various external systems
4 | like GitHub, Linear, Google Drive, etc. into ContextFrame datasets.
5 | """
6 |
7 | from contextframe.connectors.base import (
8 | AuthType,
9 | ConnectorConfig,
10 | SourceConnector,
11 | SyncResult,
12 | )
13 | from contextframe.connectors.discord import DiscordConnector
14 | from contextframe.connectors.github import GitHubConnector
15 | from contextframe.connectors.google_drive import GoogleDriveConnector
16 | from contextframe.connectors.linear import LinearConnector
17 | from contextframe.connectors.notion import NotionConnector
18 | from contextframe.connectors.obsidian import ObsidianConnector
19 | from contextframe.connectors.slack import SlackConnector
20 |
21 | __all__ = [
22 | "SourceConnector",
23 | "ConnectorConfig",
24 | "SyncResult",
25 | "AuthType",
26 | "GitHubConnector",
27 | "LinearConnector",
28 | "GoogleDriveConnector",
29 | "NotionConnector",
30 | "SlackConnector",
31 | "DiscordConnector",
32 | "ObsidianConnector",
33 | ]
34 |
--------------------------------------------------------------------------------
/contextframe/embed/__init__.py:
--------------------------------------------------------------------------------
1 | """Embedding generation module for ContextFrame."""
2 |
3 | from .base import EmbeddingProvider, EmbeddingResult
4 | from .batch import BatchEmbedder, create_embedder
5 | from .integration import create_frame_records_with_embeddings, embed_extraction_results
6 | from .litellm_provider import LiteLLMProvider
7 |
8 | __all__ = [
9 | "EmbeddingProvider",
10 | "EmbeddingResult",
11 | "LiteLLMProvider",
12 | "BatchEmbedder",
13 | "create_embedder",
14 | "embed_extraction_results",
15 | "create_frame_records_with_embeddings",
16 | ]
17 |
--------------------------------------------------------------------------------
/contextframe/enhance/__init__.py:
--------------------------------------------------------------------------------
1 | """Context enhancement module for ContextFrame.
2 |
3 | This module provides LLM-powered enhancement capabilities for documents,
4 | allowing AI agents and users to automatically populate ContextFrame
5 | schema fields with meaningful metadata, relationships, and context.
6 |
7 | Key Features:
8 | - User-driven enhancement through custom prompts
9 | - MCP-compatible tool interface for agent integration
10 | - Direct schema field population (context, tags, relationships, etc.)
11 | - Example prompts for common enhancement patterns
12 | - Batch processing with progress tracking
13 | """
14 |
15 | from contextframe.enhance.base import (
16 | ContextEnhancer,
17 | EnhancementResult,
18 | )
19 | from contextframe.enhance.prompts import (
20 | build_enhancement_prompt,
21 | get_prompt_template,
22 | list_available_prompts,
23 | )
24 | from contextframe.enhance.tools import (
25 | ENHANCEMENT_TOOLS,
26 | EnhancementTools,
27 | create_enhancement_tool,
28 | get_tool_schema,
29 | list_available_tools,
30 | )
31 |
32 | __all__ = [
33 | # Core enhancer
34 | "ContextEnhancer",
35 | "EnhancementResult",
36 | # MCP tools
37 | "EnhancementTools",
38 | "create_enhancement_tool",
39 | "get_tool_schema",
40 | "list_available_tools",
41 | "ENHANCEMENT_TOOLS",
42 | # Prompt templates
43 | "get_prompt_template",
44 | "list_available_prompts",
45 | "build_enhancement_prompt",
46 | ]
47 |
--------------------------------------------------------------------------------
/contextframe/examples/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Example context frame files and usage patterns.
3 |
4 | This package contains example context frame files and usage patterns.
5 | """
6 |
--------------------------------------------------------------------------------
/contextframe/exceptions.py:
--------------------------------------------------------------------------------
1 | """
2 | Exceptions used throughout the ContextFrame package.
3 |
4 | This module defines custom exceptions that are raised by various components
5 | of the ContextFrame package.
6 | """
7 |
8 |
9 | class ContextFrameError(Exception):
10 | """Base exception for all ContextFrame-related errors."""
11 |
12 | pass
13 |
14 |
15 | class ValidationError(ContextFrameError):
16 | """Raised when validation of ContextFrame metadata or content fails."""
17 |
18 | pass
19 |
20 |
21 | class RelationshipError(ContextFrameError):
22 | """Raised when there's an issue with ContextFrame relationships."""
23 |
24 | pass
25 |
26 |
27 | class VersioningError(ContextFrameError):
28 | """Raised when there's an issue with ContextFrame versioning."""
29 |
30 | pass
31 |
32 |
33 | class ConflictError(ContextFrameError):
34 | """Raised when there's a conflict during ContextFrame operations."""
35 |
36 | pass
37 |
38 |
39 | class FormatError(ContextFrameError):
40 | """Raised when there's an issue with ContextFrame formatting."""
41 |
42 | pass
43 |
--------------------------------------------------------------------------------
/contextframe/extract/__init__.py:
--------------------------------------------------------------------------------
1 | """Lightweight document extraction module for ContextFrame.
2 |
3 | This module provides utilities for extracting content and metadata from
4 | lightweight text-based formats. For heavy document processing (PDFs, images),
5 | see the documentation for recommended external tools and integration patterns.
6 | """
7 |
8 | from .base import ExtractionResult, TextExtractor
9 | from .batch import BatchExtractor
10 | from .extractors import (
11 | CSVExtractor,
12 | JSONExtractor,
13 | MarkdownExtractor,
14 | TextFileExtractor,
15 | YAMLExtractor,
16 | )
17 |
18 | __all__ = [
19 | "TextExtractor",
20 | "ExtractionResult",
21 | "BatchExtractor",
22 | "MarkdownExtractor",
23 | "JSONExtractor",
24 | "TextFileExtractor",
25 | "YAMLExtractor",
26 | "CSVExtractor",
27 | ]
28 |
--------------------------------------------------------------------------------
/contextframe/helpers/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Helper utilities for the contextframe package.
3 | """
4 |
5 | from .metadata_utils import (
6 | add_relationship_to_metadata,
7 | compare_semantic_versions,
8 | create_metadata,
9 | create_relationship,
10 | generate_uuid,
11 | get_standard_fields,
12 | is_semantic_version,
13 | is_valid_uuid,
14 | next_version,
15 | validate_relationships,
16 | )
17 |
18 | __all__ = [
19 | "add_relationship_to_metadata",
20 | "compare_semantic_versions",
21 | "create_metadata",
22 | "create_relationship",
23 | "generate_uuid",
24 | "get_standard_fields",
25 | "is_semantic_version",
26 | "is_valid_uuid",
27 | "next_version",
28 | "validate_relationships",
29 | ]
30 |
--------------------------------------------------------------------------------
/contextframe/io/__init__.py:
--------------------------------------------------------------------------------
1 | """FrameSet I/O functionality for ContextFrame.
2 |
3 | This module provides tools for importing and exporting FrameSets
4 | to/from various formats, with a focus on portable Markdown files.
5 | """
6 |
7 | from .exporter import FrameSetExporter
8 | from .formats import ExportFormat
9 | from .importer import FrameSetImporter
10 |
11 | __all__ = ["FrameSetExporter", "FrameSetImporter", "ExportFormat"]
12 |
--------------------------------------------------------------------------------
/contextframe/io/formats.py:
--------------------------------------------------------------------------------
1 | """Export format definitions and constants."""
2 |
3 | from enum import Enum
4 |
5 |
6 | class ExportFormat(Enum):
7 | """Supported export formats for FrameSets."""
8 |
9 | MARKDOWN = "markdown" # .md - Human-readable with YAML frontmatter
10 | TEXT = "text" # .txt - Plain text, simple format
11 | JSON = "json" # .json - Structured data interchange
12 | JSONL = "jsonl" # .jsonl - Newline-delimited JSON for streaming
13 | PARQUET = "parquet" # .parquet - Columnar format for data analysis
14 | CSV = "csv" # .csv - Tabular data for spreadsheets/analysis
15 |
16 | @classmethod
17 | def choices(cls) -> list[str]:
18 | """Return list of format choices."""
19 | return [fmt.value for fmt in cls]
20 |
--------------------------------------------------------------------------------
/contextframe/mcp/__init__.py:
--------------------------------------------------------------------------------
1 | """MCP (Model Context Protocol) server implementation for ContextFrame.
2 |
3 | This module provides a standardized way to expose ContextFrame datasets
4 | to LLMs and AI agents through the Model Context Protocol.
5 | """
6 |
7 | from contextframe.mcp.server import ContextFrameMCPServer
8 |
9 | __all__ = ["ContextFrameMCPServer"]
10 |
--------------------------------------------------------------------------------
/contextframe/mcp/__main__.py:
--------------------------------------------------------------------------------
1 | """Entry point for running MCP server as a module.
2 |
3 | Usage:
4 | python -m contextframe.mcp /path/to/dataset.lance
5 | """
6 |
7 | import asyncio
8 | from contextframe.mcp.server import main
9 |
10 | if __name__ == "__main__":
11 | asyncio.run(main())
12 |
--------------------------------------------------------------------------------
/contextframe/mcp/analytics/__init__.py:
--------------------------------------------------------------------------------
1 | """Analytics and performance tools for ContextFrame MCP server.
2 |
3 | This module provides tools for:
4 | - Dataset statistics and metrics
5 | - Usage pattern analysis
6 | - Query performance monitoring
7 | - Relationship graph analysis
8 | - Storage optimization
9 | - Index recommendations
10 | - Operation benchmarking
11 | - Metrics export for monitoring
12 | """
13 |
14 | from .analyzer import QueryAnalyzer, RelationshipAnalyzer, UsageAnalyzer
15 | from .optimizer import IndexAdvisor, PerformanceBenchmark, StorageOptimizer
16 | from .stats import DatasetStats, StatsCollector
17 | from .tools import (
18 | AnalyzeUsageHandler,
19 | BenchmarkOperationsHandler,
20 | ExportMetricsHandler,
21 | GetDatasetStatsHandler,
22 | IndexRecommendationsHandler,
23 | OptimizeStorageHandler,
24 | QueryPerformanceHandler,
25 | RelationshipAnalysisHandler,
26 | )
27 |
28 | __all__ = [
29 | # Core classes
30 | "StatsCollector",
31 | "DatasetStats",
32 | "QueryAnalyzer",
33 | "UsageAnalyzer",
34 | "RelationshipAnalyzer",
35 | "StorageOptimizer",
36 | "IndexAdvisor",
37 | "PerformanceBenchmark",
38 | # Tool handlers
39 | "GetDatasetStatsHandler",
40 | "AnalyzeUsageHandler",
41 | "QueryPerformanceHandler",
42 | "RelationshipAnalysisHandler",
43 | "OptimizeStorageHandler",
44 | "IndexRecommendationsHandler",
45 | "BenchmarkOperationsHandler",
46 | "ExportMetricsHandler",
47 | ]
48 |
--------------------------------------------------------------------------------
/contextframe/mcp/batch/__init__.py:
--------------------------------------------------------------------------------
1 | """Batch operations for MCP server."""
2 |
3 | from .handler import BatchOperationHandler
4 | from .tools import BatchTools
5 |
6 | __all__ = ["BatchOperationHandler", "BatchTools"]
7 |
--------------------------------------------------------------------------------
/contextframe/mcp/collections/__init__.py:
--------------------------------------------------------------------------------
1 | """Collection management tools for MCP server."""
2 |
3 | from .tools import CollectionTools
4 |
5 | __all__ = ["CollectionTools"]
6 |
--------------------------------------------------------------------------------
/contextframe/mcp/core/__init__.py:
--------------------------------------------------------------------------------
1 | """Core abstractions for transport-agnostic MCP implementation."""
2 |
3 | from contextframe.mcp.core.streaming import StreamingAdapter
4 | from contextframe.mcp.core.transport import Progress, TransportAdapter
5 |
6 | __all__ = ["TransportAdapter", "Progress", "StreamingAdapter"]
7 |
--------------------------------------------------------------------------------
/contextframe/mcp/monitoring/__init__.py:
--------------------------------------------------------------------------------
1 | """Monitoring module for MCP server.
2 |
3 | Provides comprehensive monitoring capabilities including:
4 | - Context usage metrics
5 | - Agent performance tracking
6 | - Cost attribution
7 | - Metrics export
8 | """
9 |
10 | from .collector import MetricsCollector
11 | from .cost import CostCalculator, PricingConfig
12 | from .performance import OperationContext, PerformanceMonitor
13 | from .usage import UsageStats, UsageTracker
14 |
15 | __all__ = [
16 | "MetricsCollector",
17 | "UsageTracker",
18 | "UsageStats",
19 | "PerformanceMonitor",
20 | "OperationContext",
21 | "CostCalculator",
22 | "PricingConfig",
23 | ]
--------------------------------------------------------------------------------
/contextframe/mcp/security/__init__.py:
--------------------------------------------------------------------------------
1 | """Security components for MCP server.
2 |
3 | Provides authentication, authorization, rate limiting, and audit logging
4 | for the MCP server to ensure secure access to ContextFrame datasets.
5 | """
6 |
7 | from .audit import AuditLogger, AuditEvent
8 | from .auth import (
9 | AuthenticationError,
10 | AuthProvider,
11 | APIKeyAuth,
12 | SecurityContext,
13 | )
14 | from .authorization import (
15 | AuthorizationError,
16 | Permission,
17 | Role,
18 | AccessControl,
19 | )
20 | from .integration import SecurityMiddleware, SecuredMessageHandler
21 | from .jwt import JWTHandler, JWTConfig
22 | from .oauth import OAuth2Provider, OAuth2Config
23 | from .rate_limiting import (
24 | RateLimiter,
25 | RateLimitExceeded,
26 | RateLimitConfig,
27 | )
28 |
29 | __all__ = [
30 | # Authentication
31 | "AuthenticationError",
32 | "AuthProvider",
33 | "APIKeyAuth",
34 | "SecurityContext",
35 | # Authorization
36 | "AuthorizationError",
37 | "Permission",
38 | "Role",
39 | "AccessControl",
40 | # OAuth 2.1
41 | "OAuth2Provider",
42 | "OAuth2Config",
43 | # JWT
44 | "JWTHandler",
45 | "JWTConfig",
46 | # Rate Limiting
47 | "RateLimiter",
48 | "RateLimitExceeded",
49 | "RateLimitConfig",
50 | # Audit
51 | "AuditLogger",
52 | "AuditEvent",
53 | # Integration
54 | "SecurityMiddleware",
55 | "SecuredMessageHandler",
56 | ]
--------------------------------------------------------------------------------
/contextframe/mcp/subscriptions/__init__.py:
--------------------------------------------------------------------------------
1 | """Subscription system for monitoring dataset changes."""
2 |
3 | from .manager import SubscriptionManager
4 | from .tools import get_subscriptions, poll_changes, subscribe_changes, unsubscribe
5 |
6 | __all__ = [
7 | "SubscriptionManager",
8 | "subscribe_changes",
9 | "poll_changes",
10 | "unsubscribe",
11 | "get_subscriptions",
12 | ]
13 |
--------------------------------------------------------------------------------
/contextframe/mcp/transports/__init__.py:
--------------------------------------------------------------------------------
1 | """Transport implementations for MCP server."""
2 |
3 | from contextframe.mcp.transports.stdio import StdioAdapter
4 |
5 | __all__ = ["StdioAdapter"]
6 |
--------------------------------------------------------------------------------
/contextframe/mcp/transports/http/__init__.py:
--------------------------------------------------------------------------------
1 | """HTTP transport implementation for MCP server."""
2 |
3 | from .adapter import HttpAdapter
4 | from .server import create_http_server
5 | from .sse import SSEStream
6 |
7 | __all__ = ["HttpAdapter", "create_http_server", "SSEStream"]
8 |
--------------------------------------------------------------------------------
/contextframe/schema/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | Schema module for ContextFrame.
3 |
4 | This module provides schema validation and definition functionality for ContextFrame.
5 | """
6 |
7 | # Public re-exports for convenience
8 | from .contextframe_schema import MimeTypes, RecordType, get_schema # noqa: F401
9 |
10 | __all__ = [
11 | "get_schema",
12 | "RecordType",
13 | "MimeTypes",
14 | ]
15 |
--------------------------------------------------------------------------------
/contextframe/scripts/__init__.py:
--------------------------------------------------------------------------------
1 | """
2 | ContextFrame CLI scripts for common operations.
3 |
4 | These scripts provide bash-friendly wrappers around ContextFrame operations,
5 | designed for use with AI agents like Claude Code and manual CLI usage.
6 | """
7 |
--------------------------------------------------------------------------------
/contextframe/scripts/contextframe-get:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | # Get a specific document from a ContextFrame dataset
3 | # Usage: contextframe-get [--format json|text|markdown]
4 |
5 | set -euo pipefail
6 |
7 | # Default values
8 | FORMAT="text"
9 |
10 | # Parse arguments
11 | if [ $# -lt 2 ]; then
12 | echo "Usage: contextframe-get [options]"
13 | echo ""
14 | echo "Options:"
15 | echo " --format FORMAT Output format: json, text, or markdown (default: text)"
16 | echo ""
17 | echo "Examples:"
18 | echo " contextframe-get data.lance doc-123"
19 | echo " contextframe-get data.lance doc-123 --format json"
20 | exit 1
21 | fi
22 |
23 | DATASET="$1"
24 | IDENTIFIER="$2"
25 | shift 2
26 |
27 | # Parse optional arguments
28 | while [[ $# -gt 0 ]]; do
29 | case $1 in
30 | --format)
31 | FORMAT="$2"
32 | shift 2
33 | ;;
34 | *)
35 | echo "Unknown option: $1"
36 | exit 1
37 | ;;
38 | esac
39 | done
40 |
41 | # Validate format
42 | if [[ ! "$FORMAT" =~ ^(json|text|markdown)$ ]]; then
43 | echo "Error: Invalid format. Must be 'json', 'text', or 'markdown'"
44 | exit 1
45 | fi
46 |
47 | # Check if dataset exists
48 | if [ ! -d "$DATASET" ]; then
49 | echo "Error: Dataset not found: $DATASET"
50 | exit 1
51 | fi
52 |
53 | # Execute get operation using Python
54 | python -m contextframe.scripts.get_impl \
55 | "$DATASET" \
56 | "$IDENTIFIER" \
57 | --format "$FORMAT"
--------------------------------------------------------------------------------
/contextframe/scripts/create_dataset.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | """Helper script to create a new ContextFrame dataset."""
3 |
4 | import sys
5 | from contextframe.frame import FrameDataset
6 | from pathlib import Path
7 |
8 |
9 | def main():
10 | if len(sys.argv) != 2:
11 | print("Usage: python -m contextframe.scripts.create_dataset ")
12 | sys.exit(1)
13 |
14 | dataset_path = Path(sys.argv[1])
15 |
16 | try:
17 | # Create the dataset
18 | dataset = FrameDataset.create(dataset_path)
19 | print(f"Created dataset at: {dataset_path}")
20 | except Exception as e:
21 | print(f"Error creating dataset: {e}", file=sys.stderr)
22 | sys.exit(1)
23 |
24 |
25 | if __name__ == '__main__':
26 | main()
27 |
--------------------------------------------------------------------------------
/contextframe/templates/__init__.py:
--------------------------------------------------------------------------------
1 | """Context Templates for common document organization patterns.
2 |
3 | Templates provide pre-configured patterns for importing and structuring
4 | documents into ContextFrame datasets. They handle:
5 |
6 | - Document discovery and categorization
7 | - Automatic relationship creation
8 | - Collection organization
9 | - Domain-specific metadata
10 | - Enrichment suggestions
11 |
12 | Example:
13 | >>> from contextframe import FrameDataset
14 | >>> from contextframe.templates import SoftwareProjectTemplate
15 | >>>
16 | >>> template = SoftwareProjectTemplate()
17 | >>> dataset = FrameDataset.create("my-project.lance")
18 | >>>
19 | >>> # Apply template to import project
20 | >>> results = template.apply(
21 | ... source_path="~/my-project",
22 | ... dataset=dataset,
23 | ... auto_enhance=True
24 | ... )
25 | """
26 |
27 | from .base import ContextTemplate, TemplateResult
28 | from .business import BusinessTemplate
29 | from .registry import TemplateRegistry, get_template, list_templates
30 | from .research import ResearchTemplate
31 | from .software import SoftwareProjectTemplate
32 |
33 | __all__ = [
34 | "ContextTemplate",
35 | "TemplateResult",
36 | "TemplateRegistry",
37 | "get_template",
38 | "list_templates",
39 | "SoftwareProjectTemplate",
40 | "ResearchTemplate",
41 | "BusinessTemplate",
42 | ]
43 |
--------------------------------------------------------------------------------
/contextframe/templates/examples/__init__.py:
--------------------------------------------------------------------------------
1 | """Example Context Templates for custom use cases."""
2 |
--------------------------------------------------------------------------------
/contextframe/tests/test_mcp/__init__.py:
--------------------------------------------------------------------------------
1 | """Tests for MCP server implementation."""
2 |
--------------------------------------------------------------------------------
/contextframe/tests/test_mcp/test_transports/__init__.py:
--------------------------------------------------------------------------------
1 | """Tests for MCP transport implementations."""
2 |
--------------------------------------------------------------------------------
/docs/CNAME:
--------------------------------------------------------------------------------
1 | www.contextframe.org
--------------------------------------------------------------------------------
/docs/blog/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "ContextFrame Blog"
3 | author: "ContextFrame Team"
4 | ---
5 |
6 | # ContextFrame Blog
7 |
8 | Welcome to the ContextFrame Blog, where we share updates, announcements, and articles about the ContextFrame specification and ecosystem.
9 |
10 | Stay tuned for upcoming posts about:
11 |
12 | - ContextFrame development updates
13 | - Use cases and implementation examples
14 | - Community contributions
15 | - Integration with LLMs and AI systems
16 | - Best practices for document management with ContextFrame
17 |
18 | ## Latest Posts
19 |
20 | ### [Solving the Document Context Problem for AI with ContextFrame](solving-context-problem.md)
21 |
22 | *February 28, 2024*
23 |
24 | In today's AI ecosystem, one of the most significant challenges is maintaining document context and relationships. When documents are processed by Large Language Models (LLMs), crucial information about their purpose, origin, and relationships to other documents is often lost. This leads to inefficient use of documents and duplicative processing work.
25 |
26 | ContextFrame addresses this problem by providing a unified format that keeps metadata and content together, while explicitly modeling relationships between documents. This post explores how ContextFrame's approach to document context and relationships makes it an ideal format for AI-driven document processing systems.
27 |
28 | [Read more →](solving-context-problem.md)
29 |
30 | ### [Integrating ContextFrame with Modern LLM Applications](llm-integration.md)
31 |
32 | *Coming soon*
33 |
34 | How to leverage ContextFrame's structured metadata and relationships in your LLM applications for improved context awareness and document processing efficiency.
35 |
36 | ### [The ContextFrame Collection: Managing Document Sets with Context](collections.md)
37 |
38 | *Coming soon*
39 |
40 | An in-depth guide to using ContextFrame Collections to manage groups of related documents while preserving relationships and context.
--------------------------------------------------------------------------------
/docs/cli/overview.md:
--------------------------------------------------------------------------------
1 | # CLI Reference Overview
2 |
3 | The ContextFrame CLI provides command-line tools for managing and interacting with ContextFrame datasets. It offers a convenient interface for common operations without writing Python code.
4 |
5 | ## Installation
6 |
7 | The CLI is included when you install ContextFrame:
8 |
9 | ```bash
10 | pip install contextframe
11 | ```
12 |
13 | After installation, the `contextframe` command will be available in your terminal.
14 |
15 | ## Core Commands
16 |
17 | The ContextFrame CLI is organized into command groups:
18 |
19 | - **`dataset`** - Create, inspect, and manage datasets
20 | - **`record`** - Add, update, and query records
21 | - **`search`** - Perform vector and text searches
22 | - **`export`** - Export data in various formats
23 | - **`import`** - Import data from different sources
24 | - **`version`** - Manage dataset versions
25 |
26 | ## Quick Examples
27 |
28 | ### Create a new dataset
29 | ```bash
30 | contextframe dataset create my_docs.lance
31 | ```
32 |
33 | ### Add a document
34 | ```bash
35 | contextframe record add my_docs.lance --file document.txt --title "My Document"
36 | ```
37 |
38 | ### Search for similar documents
39 | ```bash
40 | contextframe search vector my_docs.lance --query "machine learning concepts" --limit 5
41 | ```
42 |
43 | ### Export to JSON
44 | ```bash
45 | contextframe export json my_docs.lance output.json
46 | ```
47 |
48 | ## Global Options
49 |
50 | All commands support these global options:
51 |
52 | - `--help` - Show help for any command
53 | - `--version` - Display ContextFrame version
54 | - `--verbose` - Enable detailed output
55 | - `--quiet` - Suppress non-essential output
56 | - `--config` - Specify configuration file
57 |
58 | ## Configuration
59 |
60 | The CLI can be configured using:
61 |
62 | 1. **Configuration file** (`~/.contextframe/config.yaml`)
63 | 2. **Environment variables** (prefixed with `CONTEXTFRAME_`)
64 | 3. **Command-line options** (highest priority)
65 |
66 | Example configuration file:
67 | ```yaml
68 | # ~/.contextframe/config.yaml
69 | default_embedding_model: "openai/text-embedding-3-small"
70 | openai_api_key: "your-key-here"
71 | default_chunk_size: 1000
72 | verbose: false
73 | ```
74 |
75 | ## Next Steps
76 |
77 | - See [Commands](commands.md) for detailed command reference
78 | - Learn about [Configuration](configuration.md) options
79 | - Check out usage examples in the [Cookbook](../cookbook/index.md)
--------------------------------------------------------------------------------
/docs/cli/versioning.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "CLI – Working With Versions"
3 | summary: "Every mutating command writes a new dataset version; learn the implications and tooling."
4 | ---
5 |
6 | ContextFrame's command-line interface (`contextframe …`) wraps the same
7 | high-level Python API that powers your scripts. **All commands that change a
8 | `.lance` dataset automatically create a new manifest version.**
9 |
10 | | Command | Resulting operation | Version written? |
11 | |-------------------------------------------|---------------------|------------------|
12 | | `contextframe create` | New dataset / row | **Yes** |
13 | | `contextframe version create` | Snapshot of current file | **Yes** |
14 | | `contextframe version rollback` | Overwrite working copy with older snapshot | **Yes** (rollback itself) |
15 | | `contextframe conflicts merge` | 3-way merge + write | **Yes** |
16 | | `contextframe conflicts apply-resolution` | Apply manual resolution | **Yes** |
17 |
18 | ### Inspecting versions
19 |
20 | ```bash
21 | contextframe version list mydoc.lance
22 | contextframe version show mydoc.lance 42
23 | ```
24 |
25 | ### Time-travel in Python
26 |
27 | ```python
28 | from contextframe import FrameDataset
29 |
30 | # Latest
31 | ds = FrameDataset.open("mydoc.lance")
32 | print(ds.versions()) # -> [0, 1, 2, 3]
33 |
34 | # Historical view (read-only)
35 | historical = ds.checkout(1)
36 | print(historical.count_by_filter("True"))
37 | ```
38 |
39 | ### Garbage collection
40 |
41 | Versions are cheap because Lance uses *zero-copy* manifests, but they are **not
42 | free**. If you keep thousands of versions you will eventually accumulate
43 | obsolete fragments. Run:
44 |
45 | ```python
46 | FrameDataset.open("mydoc.lance")._native.cleanup_old_versions(keep=10)
47 | ```
48 |
49 | to keep only the last 10 versions (**irreversible**).
50 |
51 | > **Best practice** — Keep enough history for debugging / reproducibility, then
52 | > schedule periodic clean-ups.
53 |
--------------------------------------------------------------------------------
/docs/community/code-of-conduct.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Code of Conduct"
3 | ---
4 |
5 | # Code of Conduct
6 |
7 | ## Our Pledge
8 |
9 | We as members, contributors, and leaders pledge to make participation in our community a respectful and professional experience for everyone.
10 |
11 | ## Our Standards
12 |
13 | Examples of behavior that contributes to a positive environment:
14 |
15 | * Using welcoming and inclusive language
16 | * Being respectful of differing viewpoints and experiences
17 | * Gracefully accepting constructive criticism
18 | * Focusing on what is best for the community
19 | * Showing empathy towards other community members
20 |
21 | Examples of unacceptable behavior:
22 |
23 | * The use of inappropriate language or imagery
24 | * Trolling or insulting/derogatory comments
25 | * Public or private harassment
26 | * Publishing others' private information without permission
27 | * Other conduct which could reasonably be considered inappropriate in a professional setting
28 |
29 | ## Our Responsibilities
30 |
31 | Project maintainers are responsible for clarifying the standards of acceptable behavior and are expected to take appropriate and fair corrective action in response to any instances of unacceptable behavior.
32 |
33 | ## Scope
34 |
35 | This Code of Conduct applies within all project spaces, and it also applies when an individual is representing the project or its community in public spaces.
36 |
37 | ## Enforcement
38 |
39 | Instances of unacceptable behavior may be reported by contacting the project team. All complaints will be reviewed and investigated and will result in a response that is deemed necessary and appropriate to the circumstances.
40 |
41 | ## Attribution
42 |
43 | This Code of Conduct is adapted from the Contributor Covenant, version 2.0.
--------------------------------------------------------------------------------
/docs/community/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "ContextFrame Community Resources"
3 | version: "1.0.0"
4 | author: "ContextFrame Team"
5 | published_date: "2024-10-18"
6 | status: "Active"
7 | uuid: "c93a7f6d-1e45-4a8b-b567-0e02b2c3d480"
8 | ---
9 |
10 | # ContextFrame Community
11 |
12 | Welcome to the ContextFrame community section! This area contains resources for becoming part of the ContextFrame open-source community.
13 |
14 | ## Resources
15 |
16 | - [Contributing Guidelines](contributing.md): Detailed instructions on how to contribute to the ContextFrame project, including development setup, workflow, and best practices.
17 |
18 | - [Community Support](support.md): How to get help, report issues, and contribute to community support.
19 |
20 | - [Code of Conduct](code-of-conduct.md): Community standards and expectations for respectful collaboration.
21 |
22 | - [GitHub Repository](https://github.com/greyhaven-ai/contextframe): Source code, issue tracking, and project management.
23 |
24 | - [Discussion Forum](https://github.com/greyhaven-ai/contextframe/discussions): Community discussions, support, and announcements.
25 |
26 | ## Get Involved
27 |
28 | We welcome contributions from developers, writers, designers, and users at all experience levels. There are many ways to contribute:
29 |
30 | - **Code**: Help with the implementation in various languages
31 | - **Documentation**: Improve guides, examples, and references
32 | - **Testing**: Create test cases and report bugs
33 | - **Ideas**: Suggest improvements to the specification
34 | - **Community**: Help answer questions and support other users
35 |
36 | ## Community Events
37 |
38 | Stay tuned for upcoming community events, including:
39 |
40 | - Online meetups
41 | - Development sprints
42 | - Conference presentations
43 | - Workshops and training sessions
44 |
45 | ## Code of Conduct
46 |
47 | Our community adheres to a [Code of Conduct](code-of-conduct.md) that promotes respect, inclusivity, and collaboration. All participants are expected to uphold these values in all community spaces.
48 |
49 | ## Contact
50 |
51 | Have questions about getting involved? Reach out to the MDP team:
52 |
53 | - Through [GitHub Discussions](https://github.com/greyhaven-ai/contextframe/discussions)
54 | - By opening an issue in the [repository](https://github.com/greyhaven-ai/contextframe/issues)
55 |
--------------------------------------------------------------------------------
/docs/concepts/schema_cheatsheet.md:
--------------------------------------------------------------------------------
1 | # Schema Cheatsheet
2 |
3 | The table below is your **one-stop reference** for how `FrameRecord` properties and metadata keys map to physical columns inside a `.lance` dataset.
4 |
5 | | API attribute / Metadata key | Lance column | Arrow type |
6 | |------------------------------|--------------|------------|
7 | | `uuid` | `uuid` | `string` |
8 | | `content / text_content` | `text_content` | `string` |
9 | | `vector` | `vector` | `fixed_size_list[1536]` |
10 | | `metadata['title']` | `title` | `string` |
11 | | `metadata['version']` | `version` | `string` |
12 | | `metadata['author']` | `author` | `string` |
13 | | `metadata['tags']` | `tags` | `list` |
14 | | `metadata['created_at']` | `created_at` | `string` (YYYY-MM-DD) |
15 | | `metadata['updated_at']` | `updated_at` | `string` |
16 | | `raw_data_type` (param) | `raw_data_type` | `string` |
17 | | `raw_data` (param) | `raw_data` | `large_binary` (blob) |
18 | | `metadata['relationships']` | `relationships` | `list` |
19 | | `metadata['custom_metadata']`| `custom_metadata` | `map` |
20 |
21 | > Need a field that's not listed? Store it under `custom_metadata` or extend the dataset schema via `FrameDataset._native.replace_schema()`.
22 |
23 | For deeper background on how Lance stores these columns on disk see the full **Frame Storage** concept page.
24 |
--------------------------------------------------------------------------------
/docs/faq.md:
--------------------------------------------------------------------------------
1 | # Frequently Asked Questions
2 |
3 | ## “ImportError: No module named _lance”
4 |
5 | Install the Lance engine extras:
6 |
7 | ```bash
8 | pip install contextframe
9 | ```
10 |
11 | ---
12 |
13 | ## “ValueError: Vector length X != embedding dimension 1536”
14 |
15 | Your query or record vector must have the exact dimension configured for the dataset (default 1536). Re-encode or pad/truncate the array.
16 |
17 | ---
18 |
19 | ## “Why is my `.lance` directory empty?”
20 |
21 | You created a dataset but never inserted a record. Call `record.save(path)` or `dataset.add(record)` after `FrameDataset.create()`.
22 |
23 | ---
24 |
25 | ## “How big can a blob be?”
26 |
27 | Lance streams blobs in chunks. Individual objects of **GBs** are fine; very large collections may benefit from object storage (S3/GCS/etc.).
28 |
29 | ---
30 |
31 | ## “How do I store datasets on S3?”
32 |
33 | Just pass an `s3://…` URI to `FrameDataset.create()` / `FrameRecord.save()` and, if needed, a `storage_options` dict with your region or custom endpoint.
34 |
35 | ```python
36 | FrameDataset.create("s3://my-bucket/cf.lance", storage_options={"region": "us-east-1"})
37 | ```
38 |
39 | ---
40 |
41 | ## “How do I clean up old versions?”
42 |
43 | ```python
44 | FrameDataset.open("docs.lance")._native.cleanup_old_versions(keep=10)
45 | ```
46 |
47 | This rewrites manifests to retain only the last 10 versions (irreversible).
48 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "ContextFrame: A Global Standard for LLM Context Management"
3 | version: "1.0.0"
4 | author: "ContextFrame Team"
5 | status: "Draft"
6 | ---
7 |
8 | ## ContextFrame
9 |
10 | **A global standard file specification for document management with context and relationships.**
11 |
12 | ## The Problem
13 |
14 | In today's AI ecosystem, document management faces critical challenges:
15 |
16 | - **Context Loss**: Documents lose their context when processed by LLMs
17 | - **Relationship Blindness**: Connections between related documents are not easily accessible
18 | - **Duplication Waste**: Systems repeatedly parse the same documents to understand their structure
19 | - **Split Formats**: Either human-readable OR machine-processable, rarely both
20 | - **Metadata Isolation**: Important metadata is often separated from content
21 |
22 | Current document formats force a trade-off between human-friendliness and machine-processability, leading to inefficient document usage by LLMs and forcing systems to duplicate work.
23 |
24 | ## The Solution: ContextFrame
25 |
26 | ContextFrame is a simple yet powerful file format that combines:
27 |
28 | - **Context Preservation**: Keep important context with the content
29 |
30 | ## Key Benefits
31 |
32 | - **Efficiency**: LLMs process documents more effectively with embedded context
33 | - **Relationships**: Documents explicitly reference related information
34 | - **Simplicity**: Single `.lance` file format instead of multiple files
35 | - **Compatibility**: Works with .lance compatible tools
36 | - **Extensibility**: Custom metadata fields for specialized use cases
37 |
38 | ## Quick Example
39 |
40 | ## Project Requirements
41 |
42 | This document outlines the requirements for the project.
43 |
44 | ## Functional Requirements
45 |
46 | 1. The system shall provide user authentication
47 | 2. The system shall allow document uploading
48 | 3. The system shall support search functionality
49 |
50 | ## Getting Started
51 |
52 | Visit the [Specification](specification/contextframe_specification.md) section to learn more about the ContextFrame format, or check out the [Integration](integration/installation.md) guide to start using ContextFrame in your projects.
53 |
--------------------------------------------------------------------------------
/docs/integration/connectors/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Connectors"
3 | ---
4 |
5 | # ContextFrame Connectors
6 |
7 | ContextFrame connectors enable seamless integration with external platforms and services.
8 |
9 | ## Getting Started
10 |
11 | - **[Introduction to Connectors](introduction.md)** - Learn about connector concepts and capabilities
12 | - **[Installation Guide](../installation.md)** - Set up connectors and dependencies
13 |
14 | ## Available Connectors
15 |
16 | ### Productivity & Collaboration
17 | - **[Slack](../slack.md)** - Import Slack conversations and files
18 | - **[Discord](../discord.md)** - Import Discord messages and attachments
19 | - **[Notion](../notion.md)** - Import Notion pages and databases
20 | - **[Linear](../linear.md)** - Import Linear issues and projects
21 |
22 | ### Cloud Storage
23 | - **[Google Drive](../google-drive.md)** - Import Google Docs, Sheets, and Slides
24 | - **[Object Storage](../object_storage.md)** - Import from S3, GCS, and Azure
25 |
26 | ### Development
27 | - **[GitHub](../github.md)** - Import repositories, issues, and PRs
28 | - **[Obsidian](../obsidian.md)** - Import Obsidian vaults
29 |
30 | ## Building Custom Connectors
31 |
32 | - **[Custom Connector Guide](../custom.md)** - Create your own connectors
33 | - **[Validation](../validation.md)** - Validate connector output
34 |
35 | ## Integration Examples
36 |
37 | See the [Cookbook](../../cookbook/index.md) for real-world integration examples.
--------------------------------------------------------------------------------
/docs/integration/installation.md:
--------------------------------------------------------------------------------
1 | # Installing and Setting Up ContextFrame
2 |
3 | This guide covers installing the ContextFrame Python package and getting started with basic usage.
4 |
5 | ## Prerequisites
6 |
7 | Before installing ContextFrame, ensure you have:
8 |
9 | - Python 3.10 or newer
10 | - pip (Python package installer)
11 |
12 | ## Installation Methods
13 |
14 | ### Standard Installation
15 |
16 | The simplest way to install ContextFrame is via pip:
17 |
18 | ```bash
19 | pip install contextframe
20 | ```
21 |
22 | ### Development Installation
23 |
24 | For development or to contribute to the ContextFrame project, clone the repository and install in development mode:
25 |
26 | ```bash
27 | git clone https://github.com/greyhaven-ai/contextframe.git
28 | cd contextframe
29 | pip install -e .
30 | ```
31 |
32 | ### Optional Dependencies
33 |
34 | ## Verifying Installation
35 |
36 | To verify that ContextFrame is installed correctly, run the following command:
37 |
38 | ```bash
39 | python -c "import contextframe; print(contextframe.__version__)"
40 | ```
41 |
42 | You should see the current version number of the ContextFrame package.
43 |
44 | ## Setting Up Your Environment
45 |
46 | ### Environment Variables
47 |
48 | ### Configuration File
49 |
50 | ## Command Line Interface
51 |
52 | ContextFrame includes a command-line interface for working with ContextFrame files. After installation, the `contextframe` command will be available:
53 |
54 | ## Next Steps
55 |
56 | After installation, you may want to:
57 |
58 | ## Troubleshooting
59 |
60 | ### Common Issues
61 |
62 | ### Getting Help
63 |
64 | If you encounter issues:
65 |
66 | - Check the [GitHub issues](https://github.com/greyhaven-ai/contextframe/issues)
67 | - Join the [discussion forum](https://github.com/greyhaven-ai/contextframe/discussions)
68 | - Read the [full documentation](https://greyhaven-ai.github.io/contextframe/)
69 |
--------------------------------------------------------------------------------
/docs/integration/validation.md:
--------------------------------------------------------------------------------
1 | # ContextFrame Validation Guide
2 |
3 | This guide explains how to validate ContextFrame documents and ensure they conform to the specification.
4 |
5 |
6 |
--------------------------------------------------------------------------------
/docs/quickstart.md:
--------------------------------------------------------------------------------
1 | # ContextFrame Quick Start
2 |
3 | This page takes you from **zero to query** in less than five minutes.
4 |
5 | ## 1 – Install the library
6 |
7 | ```bash
8 | pip install contextframe
9 | ```
10 |
11 | ## 2 – Create an in-memory record
12 |
13 | ```python
14 | from contextframe import FrameRecord
15 |
16 | record = FrameRecord.create(
17 | title="Hello ContextFrame",
18 | content="Just a tiny example document…",
19 | author="Alice",
20 | tags=["example", "quickstart"],
21 | )
22 | ```
23 |
24 | ## 3 – Persist it to a dataset
25 |
26 | ```python
27 | from pathlib import Path
28 | from contextframe import FrameDataset
29 |
30 | DATASET = Path("demo.lance")
31 |
32 | # Create an *empty* dataset (overwrites if it already exists)
33 | FrameDataset.create(DATASET, overwrite=True)
34 |
35 | # Append the record
36 | record.save(DATASET)
37 | ```
38 |
39 | At this point you have a self-contained **`demo.lance/`** directory on disk (or S3/GCS/Azure if you passed a cloud URI).
40 |
41 | ## 4 – Run a vector search
42 |
43 | ```python
44 | import numpy as np
45 | from contextframe import FrameDataset
46 |
47 | query_vec = np.zeros(1536, dtype=np.float32) # substitute a real embedding
48 | results = FrameDataset.open(DATASET).nearest(query_vec, k=3)
49 |
50 | for r in results:
51 | print(r.uuid, r.title)
52 | ```
53 |
54 | ## 5 – Inspect from the CLI
55 |
56 | ```bash
57 | contextframe info demo.lance
58 | ```
59 |
60 | Output:
61 |
62 | ```text
63 | Title: Hello ContextFrame
64 | Created: 2025-05-08
65 | Metadata: 8 fields
66 | Content: 1 lines, 5 words
67 | ```
68 |
69 | That's it! Head over to the **Basics Tutorial** next for a deeper walk-through.
70 |
--------------------------------------------------------------------------------
/docs/recipes/bulk_ingest_embedding.md:
--------------------------------------------------------------------------------
1 | # Recipe – Bulk Ingest With Embeddings
2 |
3 | This example ingests a folder of Markdown files, generates embeddings with a Hugging Face model, and stores everything in a single `.lance` dataset.
4 |
5 | > Tested with `sentence-transformers==2.6.1` and `contextframe`.
6 |
7 | ---
8 |
9 | ## 1. Install deps
10 |
11 | ```bash
12 | pip install contextframe sentence-transformers tqdm
13 | ```
14 |
15 | ## 2. Script `ingest_md.py`
16 |
17 | ```python
18 | from pathlib import Path
19 | from typing import List
20 |
21 | from sentence_transformers import SentenceTransformer
22 | from tqdm import tqdm
23 |
24 | from contextframe import FrameRecord, FrameDataset
25 |
26 | SOURCE_DIR = Path("docs_markdown") # folder with .md files
27 | DATASET = Path("markdown_corpus.lance") # output dataset
28 | MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2"
29 |
30 | # 1️⃣ Create (or overwrite) the dataset
31 | FrameDataset.create(DATASET, overwrite=True)
32 |
33 | ds = FrameDataset.open(DATASET)
34 | model = SentenceTransformer(MODEL_NAME)
35 |
36 | records: List[FrameRecord] = []
37 | for md_file in tqdm(sorted(SOURCE_DIR.glob("*.md"))):
38 | text = md_file.read_text(encoding="utf-8")
39 | embedding = model.encode(text, convert_to_numpy=True) # float32, 384-dim
40 |
41 | rec = FrameRecord.create(
42 | title=md_file.stem,
43 | content=text,
44 | vector=embedding,
45 | source_file=str(md_file),
46 | )
47 | records.append(rec)
48 |
49 | # 2️⃣ Bulk insert
50 | print(f"Ingesting {len(records)} records …")
51 | ds.add_many(records)
52 |
53 | # 3️⃣ Build vector index for fast search
54 | print("Creating IVF_PQ index …")
55 | ds.create_vector_index(index_type="IVF_PQ")
56 | print("Done ✔")
57 | ```
58 |
59 | Run it:
60 |
61 | ```bash
62 | python ingest_md.py
63 | ```
64 |
65 | Your dataset `markdown_corpus.lance/` is now ready for similarity search and full-text queries.
66 |
--------------------------------------------------------------------------------
/docs/recipes/collections_relationships.md:
--------------------------------------------------------------------------------
1 | # Recipe – Collections & Relationships
2 |
3 | Group several documents under a logical *collection* and keep the structure queryable via relationships.
4 |
5 | ---
6 |
7 | ## 1. Create a **collection header**
8 |
9 | ```python
10 | from contextframe import FrameRecord, FrameDataset
11 |
12 | header = FrameRecord.create(
13 | title="🗂️ Project Alpha",
14 | content="This is the header describing Project Alpha.",
15 | collection="project-alpha",
16 | record_type="collection_header",
17 | )
18 |
19 | DATASET = "projects.lance"
20 | FrameDataset.create(DATASET, overwrite=True)
21 | header.save(DATASET)
22 | print("Header UUID:", header.uuid)
23 | ```
24 |
25 | ## 2. Add member documents
26 |
27 | ```python
28 | members = [
29 | FrameRecord.create(title="Spec", content="…", collection="project-alpha"),
30 | FrameRecord.create(title="Meeting notes", content="…", collection="project-alpha"),
31 | ]
32 | for m in members:
33 | # Link back to header (type = `member_of`)
34 | m.add_relationship(header, relationship_type="member_of")
35 | m.save(DATASET)
36 | ```
37 |
38 | ## 3. Query the collection
39 |
40 | ```python
41 | from contextframe import FrameDataset
42 |
43 | ds = FrameDataset.open(DATASET)
44 |
45 | header_doc = ds.get_collection_header("project-alpha")
46 | print("Header title:", header_doc.title)
47 |
48 | member_docs = ds.get_members_linked_to_header(header_doc.uuid)
49 | print("Members:", [d.title for d in member_docs])
50 | ```
51 |
52 | ---
53 |
54 | Diagram of the relationship:
55 |
56 | ```mermaid
57 | flowchart LR
58 | H(Header) -->|member_of| S(Spec)
59 | H -->|member_of| M(Meeting notes)
60 | ```
61 |
--------------------------------------------------------------------------------
/docs/recipes/fastapi_vector_search.md:
--------------------------------------------------------------------------------
1 | # Recipe – FastAPI Vector Search Endpoint
2 |
3 | This snippet shows how to wrap the `FrameDataset.nearest()` helper in a **FastAPI** micro-service.
4 |
5 | > **Why?** Turn your ContextFrame dataset into a low-latency similarity-search API that any web or mobile client can call.
6 |
7 | ---
8 |
9 | ## 1. Install dependencies
10 |
11 | ```bash
12 | pip install contextframe fastapi uvicorn[standard] numpy
13 | ```
14 |
15 | ## 2. Save `app.py`
16 |
17 | ```python
18 | from pathlib import Path
19 | from typing import List
20 |
21 | import numpy as np
22 | from fastapi import FastAPI, HTTPException
23 | from pydantic import BaseModel, validator
24 |
25 | from contextframe import FrameDataset
26 |
27 | DATASET_PATH = Path("my_docs.lance") # change to your dataset
28 |
29 | # Load dataset once at start-up
30 | DS = FrameDataset.open(DATASET_PATH)
31 | VECTOR_DIM = DS._native.schema.field("vector").type.list_size
32 |
33 | app = FastAPI(title="ContextFrame Vector Search")
34 |
35 | class Query(BaseModel):
36 | vector: List[float]
37 | k: int = 5
38 |
39 | @validator("vector")
40 | def _check_dim(cls, v): # noqa: N805 – Pydantic wants "cls"
41 | if len(v) != VECTOR_DIM:
42 | raise ValueError(f"Expected vector of length {VECTOR_DIM}")
43 | return v
44 |
45 | @app.post("/search")
46 | def search(q: Query):
47 | vec = np.array(q.vector, dtype=np.float32)
48 | try:
49 | neighbours = DS.nearest(vec, k=q.k)
50 | except Exception as exc: # pragma: no cover – guard against runtime issues
51 | raise HTTPException(status_code=500, detail=str(exc)) from exc
52 |
53 | return [
54 | {
55 | "uuid": r.uuid,
56 | "title": r.title,
57 | "score": float(r.metadata.get("_distance", 0)),
58 | }
59 | for r in neighbours
60 | ]
61 | ```
62 |
63 | ## 3. Run the server
64 |
65 | ```bash
66 | uvicorn app:app --reload
67 | ```
68 |
69 | Then `POST /search` with JSON like
70 |
71 | ```json
72 | {
73 | "vector": [0.0, 0.1, 0.2, …],
74 | "k": 3
75 | }
76 | ```
77 |
78 | to receive the top-k nearest documents.
79 |
80 | ---
81 |
82 | ### Production notes
83 |
84 | * Consider creating a **vector index** (`FrameDataset.create_vector_index`) beforehand.
85 | * Mount the dataset directory on a fast SSD or use a read-through cache for S3.
86 | * Add auth & rate-limiting (fastapi-limiter, auth headers, etc.) as needed.
87 |
--------------------------------------------------------------------------------
/docs/recipes/s3_roundtrip.md:
--------------------------------------------------------------------------------
1 | # Recipe – S3 Round-Trip
2 |
3 | Store and read a dataset on Amazon S3 (or any S3-compatible service) with **zero code changes** beyond the URI.
4 |
5 | ---
6 |
7 | ## 1. Environment & packages
8 |
9 | ```bash
10 | export AWS_ACCESS_KEY_ID=""
11 | export AWS_SECRET_ACCESS_KEY=""
12 | export AWS_REGION="us-east-1"
13 |
14 | pip install contextframe
15 | ```
16 |
17 | ## 2. Write a dataset directly to S3
18 |
19 | ```python
20 | from contextframe import FrameRecord
21 |
22 | rec = FrameRecord.create(title="S3 Example", content="Stored on S3!")
23 |
24 | S3_URI = "s3://my-bucket/cf_demo.lance"
25 | rec.save(S3_URI, storage_options={"region": "us-east-1"})
26 | ```
27 |
28 | ## 3. Append from another process / machine
29 |
30 | ```python
31 | from contextframe import FrameDataset, FrameRecord
32 |
33 | new_doc = FrameRecord.create(title="Another doc", content="Hello from EC2")
34 | FrameDataset.open(S3_URI, storage_options={"region": "us-east-1"}).add(new_doc)
35 | ```
36 |
37 | ## 4. List versions & cleanup
38 |
39 | ```bash
40 | contextframe version list $S3_URI --json | jq
41 | ```
42 |
43 | ```python
44 | from contextframe import FrameDataset
45 | FrameDataset.open(S3_URI, storage_options={"region": "us-east-1"})._native.cleanup_old_versions(keep=5)
46 | ```
47 |
48 | ### Concurrency note
49 |
50 | S3 lacks atomic renames. For **multiple writers** use a DynamoDB manifest store (switch URI to `s3+ddb://…`) **or** pass an external `commit_lock`.
51 |
--------------------------------------------------------------------------------
/docs/recipes/store_images_blobs.md:
--------------------------------------------------------------------------------
1 | # Recipe – Store & Retrieve Images as Blobs
2 |
3 | Attach raw binary data (e.g. JPEGs) to a `FrameRecord` and stream it back without loading the whole file into memory.
4 |
5 | ---
6 |
7 | ## 1. Install deps
8 |
9 | ```bash
10 | pip install contextframe pillow
11 | ```
12 |
13 | ## 2. Save an image
14 |
15 | ```python
16 | from pathlib import Path
17 | from contextframe import FrameRecord, FrameDataset, MimeTypes
18 |
19 | img_path = Path("cat.jpg")
20 | bytes_data = img_path.read_bytes()
21 |
22 | rec = FrameRecord.create(
23 | title="Cute Cat",
24 | content="An image of a cute cat.",
25 | raw_data=bytes_data,
26 | raw_data_type=MimeTypes.IMAGE_JPEG,
27 | )
28 |
29 | DATASET = Path("images.lance")
30 | FrameDataset.create(DATASET, overwrite=True)
31 | rec.save(DATASET)
32 | ```
33 |
34 | ## 3. Retrieve & display lazily
35 |
36 | ```python
37 | from PIL import Image
38 | from contextframe import FrameDataset
39 |
40 | ds = FrameDataset.open("images.lance")
41 | row_idx = 0 # only one row in this toy example
42 | blob_files = ds._native.take_blobs([row_idx], column="raw_data")
43 | with Image.open(blob_files[0]) as img:
44 | img.show()
45 | ```
46 |
47 | The image bytes are streamed directly from disk (or S3) only when `Image.open` reads them.
48 |
49 | ---
50 |
51 | **Tip** – store metadata like *resolution*, *format*, or *camera* in normal scalar fields so you can filter quickly without touching the blob column.
52 |
--------------------------------------------------------------------------------
/docs/reference/index.md:
--------------------------------------------------------------------------------
1 | ---
2 | title: "Reference Documentation"
3 | ---
4 |
5 | # Reference Documentation
6 |
7 | This section contains detailed reference materials for ContextFrame.
8 |
9 | ## Available References
10 |
11 | ### [Schema Reference](schema.md)
12 | Comprehensive documentation of the ContextFrame schema, including:
13 | - Core schema fields
14 | - Record types
15 | - Validation rules
16 | - Best practices
17 | - Complete examples
18 |
19 | ### [Error Codes](error-codes.md)
20 | Complete list of error codes you may encounter when using ContextFrame:
21 | - Schema validation errors (CF-1xxx)
22 | - Data operation errors (CF-2xxx)
23 | - Relationship errors (CF-3xxx)
24 | - Embedding errors (CF-4xxx)
25 | - Connector errors (CF-5xxx)
26 | - Import/Export errors (CF-6xxx)
27 | - MCP server errors (CF-7xxx)
28 |
29 | ## Related Documentation
30 |
31 | - [API Reference](../api/overview.md) - Detailed API documentation
32 | - [CLI Reference](../cli/commands.md) - Command-line interface reference
33 | - [Troubleshooting Guide](../troubleshooting.md) - Common issues and solutions
--------------------------------------------------------------------------------
/docs/troubleshooting.md:
--------------------------------------------------------------------------------
1 | # Troubleshooting
2 |
3 | | Symptom | Likely Cause | Quick Fix |
4 | |---------|--------------|-----------|
5 | | Inserts are slow | No vector index, small batch inserts | Use `FrameDataset.create_vector_index()` and batch `add_many()` |
6 | | "Dataset not found" when opening | Path typo or `.lance` directory missing | Verify path, run `FrameDataset.create()` first |
7 | | "Concurrent write detected" on S3 | Multiple writers, no commit lock | Use DynamoDB manifest store or external `commit_lock` |
8 | | "Arrow version mismatch" | Mixed binary wheels of Arrow | `pip uninstall pyarrow` then reinstall all deps with same Arrow version |
9 | | Windows shows `PathTooLongError` | Long dataset paths exceed 260 char | Enable long-path support or shorten path |
10 |
11 | If the table doesn't cover your issue, search the FAQ or open an issue on GitHub.
12 |
--------------------------------------------------------------------------------
/docs/tutorials/basics_tutorial.md:
--------------------------------------------------------------------------------
1 | # Basics Tutorial
2 |
3 | A hands-on walk-through of the core ContextFrame workflow. Follow along in a fresh Python session.
4 |
5 | > **Prerequisites** – `pip install contextframe` and make sure you ran the Quick Start.
6 |
7 | ---
8 |
9 | ## 1. Set-up a working dataset
10 |
11 | ```python
12 | from pathlib import Path
13 | from contextframe import FrameRecord, FrameDataset
14 |
15 | dataset = Path("my_docs.lance")
16 | FrameDataset.create(dataset, overwrite=True)
17 | ```
18 |
19 | ## 2. Create your first record
20 |
21 | ```python
22 | first = FrameRecord.create(
23 | title="ContextFrame Tutorial",
24 | content=(
25 | "ContextFrame stores documents as *frames* backed by the Lance\n"
26 | "columnar format. This is the first one."
27 | ),
28 | author="You",
29 | tags=["docs", "tutorial"],
30 | )
31 | first.save(dataset)
32 | ```
33 |
34 | ## 3. Bulk-append more records
35 |
36 | ```python
37 | records = [
38 | FrameRecord.create(title=f"Doc {i}", content=f"Content {i}") for i in range(3)
39 | ]
40 | FrameDataset.open(dataset).add_many(records)
41 | ```
42 |
43 | ## 4. Similarity search
44 |
45 | ```python
46 | import numpy as np
47 | from contextframe import FrameDataset
48 |
49 | ds = FrameDataset.open(dataset)
50 | query_vec = np.zeros(1536, dtype=np.float32) # Replace with a real embedding
51 | nearest = ds.nearest(query_vec, k=2)
52 | for r in nearest:
53 | print(r.title, r.uuid)
54 | ```
55 |
56 | ## 5. Full-text search
57 |
58 | ```python
59 | hits = ds.full_text_search("ContextFrame", k=10)
60 | print([h.title for h in hits])
61 | ```
62 |
63 | ## 6. Update a record in-place
64 |
65 | ```python
66 | first.tags.append("updated")
67 | first.content += "\nUpdated content." # mutate in memory
68 | FrameDataset.open(dataset).update_record(first)
69 | ```
70 |
71 | ## 7. Basic versioning via CLI
72 |
73 | ```bash
74 | # Create a snapshot
75 | contextframe version create my_docs.lance -d "Added three docs" -a "You"
76 |
77 | # List versions
78 | contextframe version list my_docs.lance
79 |
80 | # Roll back to version 0
81 | contextframe version rollback my_docs.lance 0
82 | ```
83 |
84 | ---
85 |
86 | Next steps:
87 | • See the **Schema Cheatsheet** for column-level mapping.
88 | • Checkout the **FastAPI Vector Search** recipe for a web-ready endpoint.
--------------------------------------------------------------------------------