├── .gitignore
├── README.md
├── config.py
├── demonstration.jpg
├── frameworks
├── __init__.py
├── evaluating
│ ├── __init__.py
│ ├── base.py
│ ├── evaluator_manager.py
│ └── frame_evaluator.py
├── models
│ ├── __init__.py
│ ├── backbone
│ │ ├── __init__.py
│ │ └── resnet_backbone.py
│ ├── model_arch.py
│ └── weight_utils.py
└── training
│ ├── __init__.py
│ ├── base.py
│ ├── data_parallel.py
│ ├── optimizers.py
│ └── trainer.py
├── io_stream
├── __init__.py
├── data_manager.py
├── data_utils.py
├── datasets
│ ├── duke.py
│ ├── market.py
│ └── msmt.py
└── samplers.py
├── requirements.txt
├── run_demo.sh
├── test_model.py
├── train_model.py
└── utils
├── __init__.py
├── meters.py
├── serialization.py
└── transforms.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # IDE and others
2 | .idea
3 | *DS_Store
4 | # folders
5 | data
6 | pytorch-ckpt
7 | # others
8 | *.h5
9 | *.pkl
10 | *.npy
11 | *.pdf
12 | *.pickle
13 | __pycache__
14 | *.pyc
15 |
16 | # Byte-compiled / optimized / DLL files
17 | __pycache__/
18 | *.py[cod]
19 | *$py.class
20 |
21 | # C extensions
22 | *.so
23 |
24 | # Distribution / packaging
25 | .Python
26 | build/
27 | develop-eggs/
28 | dist/
29 | downloads/
30 | eggs/
31 | .eggs/
32 | lib/
33 | lib64/
34 | parts/
35 | sdist/
36 | var/
37 | wheels/
38 | *.egg-info/
39 | .installed.cfg
40 | *.egg
41 | MANIFEST
42 |
43 | # PyInstaller
44 | # Usually these files are written by a python script from a template
45 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
46 | *.manifest
47 | *.spec
48 |
49 | # Installer logs
50 | pip-log.txt
51 | pip-delete-this-directory.txt
52 |
53 | # Unit test / coverage reports
54 | htmlcov/
55 | .tox/
56 | .coverage
57 | .coverage.*
58 | .cache
59 | nosetests.xml
60 | coverage.xml
61 | *.cover
62 | .hypothesis/
63 | .pytest_cache/
64 |
65 | # Translations
66 | *.mo
67 | *.pot
68 |
69 | # Django stuff:
70 | *.log
71 | local_settings.py
72 | db.sqlite3
73 |
74 | # Flask stuff:
75 | instance/
76 | .webassets-cache
77 |
78 | # Scrapy stuff:
79 | .scrapy
80 |
81 | # Sphinx documentation
82 | docs/_build/
83 |
84 | # PyBuilder
85 | target/
86 |
87 | # Jupyter Notebook
88 | .ipynb_checkpoints
89 |
90 | # pyenv
91 | .python-version
92 |
93 | # celery beat schedule file
94 | celerybeat-schedule
95 |
96 | # SageMath parsed files
97 | *.sage.py
98 |
99 | # Environments
100 | .env
101 | .venv
102 | env/
103 | venv/
104 | ENV/
105 | env.bak/
106 | venv.bak/
107 |
108 | # Spyder project settings
109 | .spyderproject
110 | .spyproject
111 |
112 | # Rope project settings
113 | .ropeproject
114 |
115 | # mkdocs documentation
116 | /site
117 |
118 | # mypy
119 | .mypy_cache/
120 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Camera-based Person Re-identification
2 | The official code for [Rethinking the Distribution Gap of Person Re-identification with Camera-based Batch Normalization](https://arxiv.org/abs/2001.08680).
3 | It implements the fundamental idea of our paper: aligning all training and testing cameras.
4 | This code is based on an early version of [Cysu/open-reid](https://github.com/Cysu/open-reid).
5 |
6 | ## Demonstration
7 |
8 | 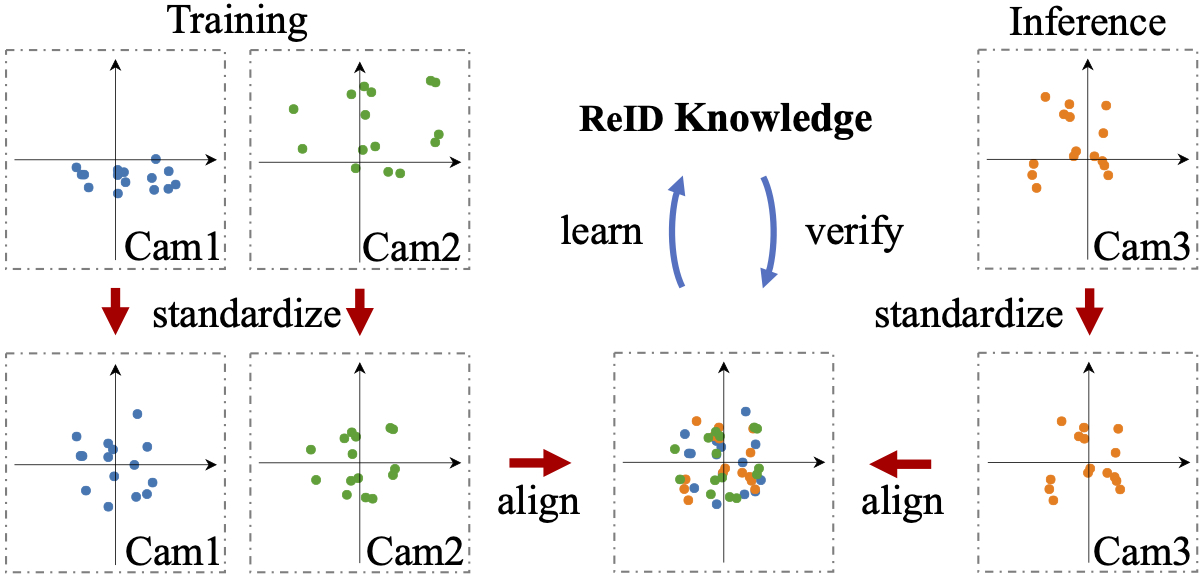 9 |
10 | ## Details
11 |
12 | The goal of our code is to provide a generic camera-aligned framework for future researches.
13 | Thus, the fundamental principle is to make the entire camera alignment process transparent to the neural network and loss functions.
14 | To this end, we make two major changes.
15 |
16 | **First:** we avoid customizing the BatchNorm layer. Otherwise, the forward process will require additional input for identifying camera IDs.
17 | Given that the **nn.Sequential** module is widely used in PyTorch, a customized BatchNorm layer will lead to massive changes in the network definition.
18 | Instead, we turn to use the official BatchNorm layer.
19 | For the training process, we can simply use the official BatchNorm implementation and feed the network with images from the same camera.
20 | In this stage, the collected *running_mean* and *running_var* are directly ignored since they will always be overridden in the testing stage.
21 | Thus, the BN parameter *momentum* can be set to any value.
22 | For the testing process, we change the default definition of BatchNorm layers from:
23 | ```python
24 | nn.BatchNorm2d(planes, momentum=0.1)
25 | ```
26 | to:
27 | ```python
28 | nn.BatchNorm2d(planes, momentum=None)
29 | ```
30 |
31 | **Note:**
32 |
33 | **In PyTorch,**
34 | **Momentum=None is not equivalent to Momentum=0.0.
35 | It calculates the cumulative moving average.
36 | Please check https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html for more details.**
37 |
38 |
39 | Then, given several mini-batches from a specific camera, we simply set the network to the **Train** mode and forward all these mini-batches.
40 | After forwarding all these batches, the *running_mean* and *running_var* in each BatchNorm layer are the statistics for this exact camera.
41 | Then, we simply set the network to the **Eval** mode and process images from this specific camera.
42 |
43 |
44 | **Second:** during training, we need a process of re-organizing mini-batches.
45 | With a tensor sampled by an arbitrary sampler, we split this tensor by the corresponding camera IDs and re-organize them as a list of tensors.
46 | It is achieved by our customized [Trainer](https://github.com/automan000/Camera-based-Person-ReID/blob/master/frameworks/training/trainer.py).
47 | Then, our [DataParallel](https://github.com/automan000/Camera-based-Person-ReID/blob/master/frameworks/training/data_parallel.py) forwards these tensors one by one, assembles all outputs, and then feeds them to the loss function in the same way of the conventional DataParallel.
48 |
49 |
50 |
51 | ## Preparation
52 |
53 | **1. Download Market-1501, DukeMTMC-reID, and MSMT17 and organize them as follows:**
54 |
9 |
10 | ## Details
11 |
12 | The goal of our code is to provide a generic camera-aligned framework for future researches.
13 | Thus, the fundamental principle is to make the entire camera alignment process transparent to the neural network and loss functions.
14 | To this end, we make two major changes.
15 |
16 | **First:** we avoid customizing the BatchNorm layer. Otherwise, the forward process will require additional input for identifying camera IDs.
17 | Given that the **nn.Sequential** module is widely used in PyTorch, a customized BatchNorm layer will lead to massive changes in the network definition.
18 | Instead, we turn to use the official BatchNorm layer.
19 | For the training process, we can simply use the official BatchNorm implementation and feed the network with images from the same camera.
20 | In this stage, the collected *running_mean* and *running_var* are directly ignored since they will always be overridden in the testing stage.
21 | Thus, the BN parameter *momentum* can be set to any value.
22 | For the testing process, we change the default definition of BatchNorm layers from:
23 | ```python
24 | nn.BatchNorm2d(planes, momentum=0.1)
25 | ```
26 | to:
27 | ```python
28 | nn.BatchNorm2d(planes, momentum=None)
29 | ```
30 |
31 | **Note:**
32 |
33 | **In PyTorch,**
34 | **Momentum=None is not equivalent to Momentum=0.0.
35 | It calculates the cumulative moving average.
36 | Please check https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html for more details.**
37 |
38 |
39 | Then, given several mini-batches from a specific camera, we simply set the network to the **Train** mode and forward all these mini-batches.
40 | After forwarding all these batches, the *running_mean* and *running_var* in each BatchNorm layer are the statistics for this exact camera.
41 | Then, we simply set the network to the **Eval** mode and process images from this specific camera.
42 |
43 |
44 | **Second:** during training, we need a process of re-organizing mini-batches.
45 | With a tensor sampled by an arbitrary sampler, we split this tensor by the corresponding camera IDs and re-organize them as a list of tensors.
46 | It is achieved by our customized [Trainer](https://github.com/automan000/Camera-based-Person-ReID/blob/master/frameworks/training/trainer.py).
47 | Then, our [DataParallel](https://github.com/automan000/Camera-based-Person-ReID/blob/master/frameworks/training/data_parallel.py) forwards these tensors one by one, assembles all outputs, and then feeds them to the loss function in the same way of the conventional DataParallel.
48 |
49 |
50 |
51 | ## Preparation
52 |
53 | **1. Download Market-1501, DukeMTMC-reID, and MSMT17 and organize them as follows:**
54 |
55 | .
56 | +-- data
57 | | +-- market
58 | | +-- bounding_box_train
59 | | +-- query
60 | | +-- bounding_box_test
61 | | +-- duke
62 | | +-- bounding_box_train
63 | | +-- query
64 | | +-- bounding_box_test
65 | | +-- msmt17
66 | | +-- train
67 | | +-- test
68 | | +-- list_train.txt
69 | | +-- list_val.txt
70 | | +-- list_query.txt
71 | | +-- list_gallery.txt
72 | + -- other files in this repo
73 |
74 |
75 | **Note:**
76 | For MSMT17, we highly recommend the V1 version.
77 | Our experiments show that the noises introduced in the V2 version affect the performance of both the fully supervised learning and direct transfer tasks.
78 |
79 |
80 | **2. Install the required packages**
81 | ```console
82 | pip install -r requirements.txt
83 | ```
84 | **Note:**
85 | Our code is only tested with Python3.
86 |
87 |
88 | **3. Put the official PyTorch [ResNet-50](https://download.pytorch.org/models/resnet50-19c8e357.pth) pretrained model to your home folder:
89 | '~/.torch/models/'**
90 |
91 | ## Usage
92 | **1. Train a ReID model**
93 |
94 | Reproduce the results in our paper
95 |
96 | ```console
97 | CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0 \
98 | python train_model.py train --trainset_name market --save_dir='market_demo'
99 | ```
100 |
101 | Note that our training code also supports an arbitrary number of GPUs.
102 |
103 | ```console
104 | CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0,1,2,3 \
105 | python train_model.py train --trainset_name market --save_dir='market_demo'
106 | ```
107 |
108 | However, since the current implementation is immature, the ratio of speedup is not good.
109 | Any advice about the parallel acceleration is welcomed.
110 |
111 |
112 | **2. Evaluate a trained model**
113 | ```console
114 | CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0 \
115 | python test_model.py test --testset_name market --save_dir='market_demo'
116 | ```
117 |
118 | To reproduce our reported performance, each experiment should be conducted 10 times.
119 |
120 |
121 | ## Trained Models
122 |
123 | You can download our trained models via [Google Drive](https://drive.google.com/drive/folders/1oxO6W9VAReKx2QrJNesN2X-O6mNOVsEd?usp=sharing).
124 |
125 |
126 | ## Cite our paper
127 |
128 | If you use our code in your paper, please kindly use the following BibTeX entry.
129 |
130 | ```console
131 | @inproceedings{zhuang2020rethinking,
132 | title={Rethinking the Distribution Gap of Person Re-identification with Camera-Based Batch Normalization},
133 | author={Zhuang, Zijie and Wei, Longhui and Xie, Lingxi and Zhang, Tianyu and Zhang, Hengheng and Wu, Haozhe and Ai, Haizhou and Tian, Qi},
134 | booktitle={European Conference on Computer Vision},
135 | pages={140--157},
136 | year={2020},
137 | organization={Springer}
138 | }
139 | ```
--------------------------------------------------------------------------------
/config.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 | import warnings
6 |
7 |
8 | class DefaultConfig(object):
9 | seed = 0
10 | # dataset options
11 | trainset_name = 'market'
12 | testset_name = 'duke'
13 | height = 256
14 | width = 128
15 | # sampler
16 | workers = 8
17 | num_instances = 4
18 | # default optimization params
19 | train_batch = 64
20 | test_batch = 64
21 | max_epoch = 60
22 | decay_epoch = 40
23 | # estimate bn statistics
24 | batch_num_bn_estimatation = 50
25 | # io
26 | print_freq = 50
27 | save_dir = './pytorch-ckpt/market'
28 |
29 | def _parse(self, kwargs):
30 | for k, v in kwargs.items():
31 | if not hasattr(self, k):
32 | warnings.warn("Warning: opt has not attribut %s" % k)
33 | setattr(self, k, v)
34 |
35 | def _state_dict(self):
36 | return {k: getattr(self, k) for k, _ in DefaultConfig.__dict__.items()
37 | if not k.startswith('_')}
38 |
39 |
40 | opt = DefaultConfig()
41 |
--------------------------------------------------------------------------------
/demonstration.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/automan000/Camera-based-Person-ReID/5cade2a02296d424f5e4a437ebb2f5cc05c40e41/demonstration.jpg
--------------------------------------------------------------------------------
/frameworks/__init__.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
--------------------------------------------------------------------------------
/frameworks/evaluating/__init__.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | __all__ = [
7 | 'init_evaluator'
8 | ]
9 |
10 | from .evaluator_manager import init_evaluator
11 |
--------------------------------------------------------------------------------
/frameworks/evaluating/base.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import matplotlib
7 |
8 | matplotlib.use('Agg')
9 |
10 | import numpy as np
11 | from multiprocessing import cpu_count
12 | from multiprocessing import Pool
13 |
14 |
15 | def mt_eval_func(query_id, query_cam, gallery_ids, gallery_cams, order, matches, max_rank):
16 | remove = (gallery_ids[order] == query_id) & (gallery_cams[order] == query_cam)
17 | keep = np.invert(remove)
18 | orig_cmc = matches[keep]
19 | if not np.any(orig_cmc):
20 | return -1, -1
21 |
22 | cmc = orig_cmc.cumsum()
23 | cmc[cmc > 1] = 1
24 | single_cmc = cmc[:max_rank]
25 |
26 | num_rel = orig_cmc.sum()
27 | tmp_cmc = orig_cmc.cumsum()
28 | tmp_cmc = [x / (i + 1.) for i, x in enumerate(tmp_cmc)]
29 | tmp_cmc = np.asarray(tmp_cmc) * orig_cmc
30 | single_ap = tmp_cmc.sum() / num_rel
31 | return single_ap, single_cmc, orig_cmc[:max_rank]
32 |
33 |
34 | class BaseEvaluator(object):
35 | def __init__(self, model):
36 | self.model = model
37 |
38 | def _parse_data(self, inputs):
39 | raise NotImplementedError
40 |
41 | def _forward(self, inputs):
42 | raise NotImplementedError
43 |
44 | def evaluate(self, queryloader, galleryloader, ranks):
45 | raise NotImplementedError
46 |
47 | def eval_func(self, distmat, q_pids, g_pids, q_camids, g_camids, max_rank=50):
48 | num_q, num_g = distmat.shape
49 | if num_g < max_rank:
50 | max_rank = num_g
51 | print("Note: number of gallery samples is quite small, got {}".format(num_g))
52 | indices = np.argsort(distmat, axis=1)
53 | matches = (g_pids[indices] == q_pids[:, np.newaxis]).astype(np.int32)
54 |
55 | mt_pool = Pool(cpu_count())
56 | results = []
57 | for q_idx in range(num_q):
58 | params = (q_pids[q_idx], q_camids[q_idx], g_pids, g_camids, indices[q_idx], matches[q_idx], max_rank)
59 | results.append(mt_pool.apply_async(mt_eval_func, params))
60 |
61 | mt_pool.close()
62 | mt_pool.join()
63 |
64 | results = [x.get() for x in results]
65 | all_AP = np.array([x[0] for x in results])
66 | valid_index = all_AP > -1
67 | all_AP = all_AP[valid_index]
68 | all_cmc = np.array([x[1] for x in results])
69 | all_cmc = all_cmc[valid_index, ...]
70 | num_valid_q = len(all_AP)
71 |
72 | all_ranks = np.array([x[2] for x in results])
73 |
74 | all_cmc = np.asarray(all_cmc).astype(np.float32)
75 | all_cmc = all_cmc.sum(0) / num_valid_q
76 | mAP = np.mean(all_AP)
77 |
78 | return all_cmc, mAP, all_ranks
79 |
--------------------------------------------------------------------------------
/frameworks/evaluating/evaluator_manager.py:
--------------------------------------------------------------------------------
1 | from frameworks.evaluating.frame_evaluator import FrameEvaluator
2 |
3 | __data_factory = {
4 | 'market': FrameEvaluator,
5 | 'msmt': FrameEvaluator,
6 | 'duke': FrameEvaluator,
7 | }
8 |
9 |
10 | def init_evaluator(name, model, flip):
11 | if name not in __data_factory.keys():
12 | raise KeyError("Unknown data_components: {}".format(name))
13 | return __data_factory[name](model, flip)
14 |
--------------------------------------------------------------------------------
/frameworks/evaluating/frame_evaluator.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import numpy as np
7 | import torch
8 |
9 | from frameworks.evaluating.base import BaseEvaluator
10 |
11 |
12 | class FrameEvaluator(BaseEvaluator):
13 | def __init__(self, model, flip=True):
14 | super().__init__(model)
15 | self.loop = 2 if flip else 1
16 | self.evaluator_prints = []
17 |
18 | def _parse_data(self, inputs):
19 | imgs, pids, camids = inputs
20 | return imgs.cuda(), pids, camids
21 |
22 | def flip_tensor_lr(self, img):
23 | inv_idx = torch.arange(img.size(3) - 1, -1, -1).long().cuda()
24 | img_flip = img.index_select(3, inv_idx)
25 | return img_flip
26 |
27 | def _forward(self, inputs):
28 | with torch.no_grad():
29 | feature = self.model(inputs)
30 | if isinstance(feature, tuple) or isinstance(feature, list):
31 | output = []
32 | for x in feature:
33 | if isinstance(x, tuple) or isinstance(x, list):
34 | output.append([item.cpu() for item in x])
35 | else:
36 | output.append(x.cpu())
37 | return output
38 | else:
39 | return feature.cpu()
40 |
41 | def produce_features(self, dataloader, normalize=True):
42 | self.model.eval()
43 | all_feature_norm = []
44 | qf, q_pids, q_camids = [], [], []
45 | for batch_idx, inputs in enumerate(dataloader):
46 | inputs, pids, camids = self._parse_data(inputs)
47 | feature = None
48 | for i in range(self.loop):
49 | if i == 1:
50 | inputs = self.flip_tensor_lr(inputs)
51 | global_f = self._forward(inputs)
52 |
53 | if feature is None:
54 | feature = global_f
55 | else:
56 | feature += global_f
57 | if normalize:
58 | fnorm = torch.norm(feature, p=2, dim=1, keepdim=True)
59 | all_feature_norm.extend(list(fnorm.cpu().numpy()[:, 0]))
60 | feature = feature.div(fnorm.expand_as(feature))
61 | else:
62 | feature = feature / 2
63 | qf.append(feature)
64 | q_pids.extend(pids)
65 | q_camids.extend(camids)
66 |
67 | qf = torch.cat(qf, 0)
68 | q_pids = np.asarray(q_pids)
69 | q_camids = np.asarray(q_camids)
70 |
71 | return qf, q_pids, q_camids
72 |
73 | def get_final_results_with_features(self, qf, q_pids, q_camids, gf, g_pids, g_camids, target_ranks=[1, 5, 10, 20]):
74 | m, n = qf.size(0), gf.size(0)
75 | distmat = torch.pow(qf, 2).sum(dim=1, keepdim=True).expand(m, n) + \
76 | torch.pow(gf, 2).sum(dim=1, keepdim=True).expand(n, m).t()
77 | distmat.addmm_(1, -2, qf, gf.t())
78 | distmat = distmat.numpy()
79 | cmc, mAP, ranks = self.eval_func(distmat, q_pids, g_pids, q_camids, g_camids)
80 | print("Results ----------")
81 | print("mAP: {:.1%}".format(mAP))
82 | self.evaluator_prints.append("mAP: {:.1%}".format(mAP))
83 | print("CMC curve")
84 | self.evaluator_prints.append("CMC curve")
85 | for r in target_ranks:
86 | print("Rank-{:<3}: {:.1%}".format(r, cmc[r - 1]))
87 | self.evaluator_prints.append("Rank-{:<3}: {:.1%}".format(r, cmc[r - 1]))
88 | print("------------------")
89 | return cmc[0]
90 |
91 | def collect_sim_bn_info(self, dataloader):
92 | network_bns = [x for x in list(self.model.modules()) if
93 | isinstance(x, torch.nn.BatchNorm2d) or isinstance(x, torch.nn.BatchNorm1d)]
94 | for bn in network_bns:
95 | bn.running_mean = torch.zeros(bn.running_mean.size()).float().cuda()
96 | bn.running_var = torch.ones(bn.running_var.size()).float().cuda()
97 | bn.num_batches_tracked = torch.tensor(0).cuda().long()
98 |
99 | self.model.train()
100 | for batch_idx, inputs in enumerate(dataloader):
101 | # each camera should has at least 2 images for estimating BN statistics
102 | assert len(inputs[0].size()) == 4 and inputs[0].size(
103 | 0) > 1, 'Cannot estimate BN statistics. Each camera should have at least 2 images'
104 | inputs, pids, camids = self._parse_data(inputs)
105 | for i in range(self.loop):
106 | if i == 1:
107 | inputs = self.flip_tensor_lr(inputs)
108 | self._forward(inputs)
109 | self.model.eval()
110 |
--------------------------------------------------------------------------------
/frameworks/models/__init__.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | __all__ = [
7 | 'ResNetBuilder',
8 | ]
9 |
10 | from .model_arch import ResNetBuilder
11 |
12 |
--------------------------------------------------------------------------------
/frameworks/models/backbone/__init__.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | __all__ = [
7 | 'ResNet_Backbone',
8 | ]
9 |
10 | from .resnet_backbone import ResNet as ResNet_Backbone
11 |
--------------------------------------------------------------------------------
/frameworks/models/backbone/resnet_backbone.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import math
7 |
8 | import torch as th
9 | from torch import nn
10 |
11 |
12 | class Bottleneck(nn.Module):
13 | expansion = 4
14 |
15 | def __init__(self, inplanes, planes, stride=1, downsample=None):
16 | super(Bottleneck, self).__init__()
17 | self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
18 | self.bn1 = nn.BatchNorm2d(planes, momentum=None)
19 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
20 | padding=1, bias=False)
21 | self.bn2 = nn.BatchNorm2d(planes, momentum=None)
22 | self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
23 | self.bn3 = nn.BatchNorm2d(planes * 4, momentum=None)
24 | self.relu = nn.ReLU(inplace=True)
25 | self.downsample = downsample
26 | self.stride = stride
27 |
28 | def forward(self, x):
29 | residual = x
30 | out = self.conv1(x)
31 | out = self.bn1(out)
32 | out = self.relu(out)
33 |
34 | out = self.conv2(out)
35 | out = self.bn2(out)
36 | out = self.relu(out)
37 |
38 | out = self.conv3(out)
39 | out = self.bn3(out)
40 |
41 | if self.downsample is not None:
42 | residual = self.downsample(x)
43 |
44 | out += residual
45 | out = self.relu(out)
46 |
47 | return out
48 |
49 |
50 | class ResNet(nn.Module):
51 | def __init__(self, last_stride=2, block=Bottleneck, layers=[3, 4, 6, 3]):
52 | self.inplanes = 64
53 | super().__init__()
54 | self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
55 | bias=False)
56 | self.bn1 = nn.BatchNorm2d(64, momentum=None)
57 | self.relu = nn.ReLU(inplace=True)
58 | self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
59 | self.layer1 = self._make_layer(block, 64, layers[0], stride=1)
60 | self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
61 | self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
62 | self.layer4 = self._make_layer(
63 | block, 512, layers[3], stride=last_stride)
64 |
65 | def _make_layer(self, block, planes, blocks, stride):
66 | downsample = None
67 | if stride != 1 or self.inplanes != planes * block.expansion:
68 | downsample = nn.Sequential(
69 | nn.Conv2d(self.inplanes, planes * block.expansion,
70 | kernel_size=1, stride=stride, bias=False),
71 | nn.BatchNorm2d(planes * block.expansion, momentum=None)
72 | )
73 |
74 | layers = []
75 | layers.append(block(self.inplanes, planes, stride, downsample))
76 | self.inplanes = planes * block.expansion
77 | for i in range(1, blocks):
78 | layers.append(block(self.inplanes, planes))
79 |
80 | return nn.Sequential(*layers)
81 |
82 | def forward(self, x):
83 | x = self.conv1(x)
84 | x = self.bn1(x)
85 | x = self.relu(x)
86 | x = self.maxpool(x)
87 | x = self.layer1(x)
88 | x = self.layer2(x)
89 | x = self.layer3(x)
90 | x = self.layer4(x)
91 | return x
92 |
93 | def load_param(self, model_path, ):
94 | param_dict = th.load(model_path)
95 | for param_name in param_dict:
96 | if 'fc' in param_name:
97 | continue
98 | if param_name in self.state_dict():
99 | self.state_dict()[param_name].copy_(param_dict[param_name])
100 |
101 | def random_init(self):
102 | for m in self.modules():
103 | if isinstance(m, nn.Conv2d):
104 | n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
105 | m.weight.data.normal_(0, math.sqrt(2. / n))
106 | elif isinstance(m, nn.BatchNorm2d):
107 | m.weight.data.fill_(1)
108 | m.bias.data.zero_()
109 |
--------------------------------------------------------------------------------
/frameworks/models/model_arch.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | from getpass import getuser
7 |
8 | from torch import nn
9 | import torch.nn.functional as F
10 |
11 | from frameworks.models.backbone import ResNet_Backbone
12 | from frameworks.models.weight_utils import weights_init_kaiming
13 |
14 |
15 | def weights_init_classifier(m):
16 | classname = m.__class__.__name__
17 | if classname.find('Linear') != -1:
18 | nn.init.normal_(m.weight, std=0.001)
19 | if m.bias is not None:
20 | nn.init.constant_(m.bias, 0.0)
21 |
22 |
23 | class ResNetBuilder(nn.Module):
24 | in_planes = 2048
25 |
26 | def __init__(self, num_pids=None, last_stride=1):
27 | super().__init__()
28 | self.num_pids = num_pids
29 | self.base = ResNet_Backbone(last_stride)
30 | model_path = '/home/' + getuser() + '/.torch/models/resnet50-19c8e357.pth'
31 | self.base.load_param(model_path)
32 | bn_neck = nn.BatchNorm1d(2048, momentum=None)
33 | bn_neck.bias.requires_grad_(False)
34 | self.bottleneck = nn.Sequential(bn_neck)
35 | self.bottleneck.apply(weights_init_kaiming)
36 | if self.num_pids is not None:
37 | self.classifier = nn.Linear(2048, self.num_pids, bias=False)
38 | self.classifier.apply(weights_init_classifier)
39 |
40 | def forward(self, x):
41 | feat_before_bn = self.base(x)
42 | feat_before_bn = F.avg_pool2d(feat_before_bn, feat_before_bn.shape[2:])
43 | feat_before_bn = feat_before_bn.view(feat_before_bn.shape[0], -1)
44 | feat_after_bn = self.bottleneck(feat_before_bn)
45 | if self.num_pids is not None:
46 | classification_results = self.classifier(feat_after_bn)
47 | return feat_after_bn, classification_results
48 | else:
49 | return feat_after_bn
50 |
51 | def get_optim_policy(self):
52 | base_param_group = filter(lambda p: p.requires_grad, self.base.parameters())
53 | add_param_group = filter(lambda p: p.requires_grad, self.bottleneck.parameters())
54 | cls_param_group = filter(lambda p: p.requires_grad, self.classifier.parameters())
55 |
56 | all_param_groups = []
57 | all_param_groups.append({'params': base_param_group, "weight_decay": 0.0005})
58 | all_param_groups.append({'params': add_param_group, "weight_decay": 0.0005})
59 | all_param_groups.append({'params': cls_param_group, "weight_decay": 0.0005})
60 | return all_param_groups
61 |
--------------------------------------------------------------------------------
/frameworks/models/weight_utils.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 |
3 |
4 | def weights_init_kaiming(m):
5 | classname = m.__class__.__name__
6 | if classname.find('Linear') != -1:
7 | nn.init.kaiming_normal_(m.weight, a=0, mode='fan_out')
8 | if m.bias is not None:
9 | nn.init.constant_(m.bias, 0.0)
10 | elif classname.find('Conv') != -1:
11 | nn.init.kaiming_normal_(m.weight, a=0, mode='fan_in')
12 | if m.bias is not None:
13 | nn.init.constant_(m.bias, 0.0)
14 | elif classname.find('BatchNorm') != -1:
15 | if m.affine:
16 | nn.init.normal_(m.weight, 1.0, 0.02)
17 | nn.init.constant_(m.bias, 0.0)
18 |
19 |
20 | def weights_init_classifier(m):
21 | classname = m.__class__.__name__
22 | if classname.find('Linear') != -1:
23 | nn.init.normal_(m.weight, std=0.001)
24 | if m.bias is not None:
25 | nn.init.constant_(m.bias, 0.0)
26 |
--------------------------------------------------------------------------------
/frameworks/training/__init__.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | __all__ = [
7 | 'get_optimizer_strategy',
8 | 'CameraClsTrainer',
9 | 'CameraClsTrainer',
10 | 'CamDataParallel'
11 | ]
12 |
13 | from .optimizers import get_optimizer_strategy
14 | from .trainer import CameraClsTrainer, CameraClsTrainer
15 | from .data_parallel import CamDataParallel
--------------------------------------------------------------------------------
/frameworks/training/base.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import time
7 | from utils.meters import AverageMeter
8 |
9 |
10 | class BaseTrainer(object):
11 | def __init__(self, opt, model, optimzier, criterion, summary_writer):
12 | self.opt = opt
13 | self.model = model
14 | self.optimizer = optimzier
15 | self.criterion = criterion
16 | self.summary_writer = summary_writer
17 | self.global_step = 0
18 |
19 | def train(self, epoch, data_loader):
20 | self.model.train()
21 |
22 | batch_time = AverageMeter()
23 | data_time = AverageMeter()
24 | losses = AverageMeter()
25 |
26 | start = time.time()
27 | for i, inputs in enumerate(data_loader):
28 |
29 | data_time.update(time.time() - start)
30 | # model optimizer
31 | self._parse_data(inputs)
32 | self._forward(epoch)
33 |
34 | self.optimizer.zero_grad()
35 | self._backward()
36 | self.optimizer.step()
37 |
38 | batch_time.update(time.time() - start)
39 | losses.update(self.loss.item())
40 |
41 | # tensorboard
42 | self.global_step = epoch * len(data_loader) + i
43 | self.summary_writer.add_scalar('loss', self.loss.item(), self.global_step)
44 | self.summary_writer.add_scalar('lr', self.optimizer.param_groups[0]['lr'], self.global_step)
45 |
46 | start = time.time()
47 |
48 | if (i + 1) % self.opt.print_freq == 0:
49 | print('Epoch: [{}][{}/{}]\t'
50 | 'Batch Time {:.3f} ({:.3f})\t'
51 | 'Data Time {:.3f} ({:.3f})\t'
52 | 'Loss {:.3f} ({:.3f})\t'
53 | .format(epoch, i + 1, len(data_loader),
54 | batch_time.mean, batch_time.val,
55 | data_time.mean, data_time.val,
56 | losses.mean, losses.val))
57 |
58 | param_group = self.optimizer.param_groups
59 | print('Epoch: [{}]\tEpoch Time {:.3f} s\tLoss {:.3f}\t'
60 | 'Lr {:.2e}'
61 | .format(epoch, batch_time.sum, losses.mean, param_group[0]['lr']))
62 |
63 | def _parse_data(self, inputs):
64 | raise NotImplementedError
65 |
66 | def _forward(self):
67 | raise NotImplementedError
68 |
69 | def _backward(self):
70 | raise NotImplementedError
71 |
--------------------------------------------------------------------------------
/frameworks/training/data_parallel.py:
--------------------------------------------------------------------------------
1 | from itertools import chain
2 |
3 | from torch.nn import DataParallel
4 | from torch.nn.parallel.scatter_gather import scatter, gather
5 | from torch.nn.parallel.replicate import replicate
6 | from torch.nn.parallel.parallel_apply import parallel_apply
7 |
8 |
9 | class CamDataParallel(DataParallel):
10 | def forward(self, *inputs, **kwargs):
11 | if not self.device_ids:
12 | return self.module(*inputs, **kwargs)
13 |
14 | for t in chain(self.module.parameters(), self.module.buffers()):
15 | if t.device != self.src_device_obj:
16 | raise RuntimeError("module must have its parameters and buffers "
17 | "on device {} (device_ids[0]) but found one of "
18 | "them on device: {}".format(self.src_device_obj, t.device))
19 |
20 | all_inputs = inputs[0]
21 | all_kwargs = kwargs
22 | all_outputs = []
23 |
24 | while len(all_inputs) > 0:
25 | num_required_gpu = min(len(all_inputs), len(self.device_ids))
26 | actual_inputs = [all_inputs.pop(0) for _ in range(num_required_gpu)]
27 | inputs, kwargs = self.scatter(actual_inputs, all_kwargs, self.device_ids[:num_required_gpu])
28 | replicas = self.replicate(self.module, self.device_ids[:num_required_gpu])
29 | all_outputs.extend(self.parallel_apply(replicas, inputs, kwargs))
30 |
31 | return self.gather(all_outputs, self.output_device)
32 |
33 | def replicate(self, module, device_ids):
34 | return replicate(module, device_ids)
35 |
36 | def scatter(self, input_list, kwargs, device_ids):
37 | inputs = []
38 | for input, gpu in zip(input_list, device_ids):
39 | inputs.extend(scatter(input, [gpu], dim=0))
40 | kwargs = scatter(kwargs, device_ids, dim=0) if kwargs else []
41 | if len(inputs) < len(kwargs):
42 | inputs.extend([() for _ in range(len(kwargs) - len(inputs))])
43 | elif len(kwargs) < len(inputs):
44 | kwargs.extend([{} for _ in range(len(inputs) - len(kwargs))])
45 | inputs = tuple(inputs)
46 | kwargs = tuple(kwargs)
47 | return inputs, kwargs
48 |
49 | def parallel_apply(self, replicas, inputs, kwargs):
50 | return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
51 |
52 | def gather(self, outputs, output_device):
53 | return gather(outputs, output_device, dim=self.dim)
54 |
--------------------------------------------------------------------------------
/frameworks/training/optimizers.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import torch
7 |
8 |
9 | def get_optimizer_strategy(opt, optim_policy=None):
10 | optimizer = torch.optim.SGD(
11 | optim_policy, lr=1e-2, weight_decay=5e-4, momentum=0.9
12 | )
13 |
14 | def adjust_lr(optimizer, ep):
15 | if ep < opt.decay_epoch:
16 | lr = 1e-2
17 | else:
18 | lr = 1e-3
19 | for i, p in enumerate(optimizer.param_groups):
20 | p['lr'] = lr
21 | return lr
22 |
23 | return optimizer, adjust_lr
24 |
--------------------------------------------------------------------------------
/frameworks/training/trainer.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 | import collections
6 | import torch
7 | from frameworks.training.base import BaseTrainer
8 | from utils.meters import AverageMeter
9 | import time
10 |
11 |
12 | class CameraClsTrainer(BaseTrainer):
13 | def __init__(self, opt, model, optimizer, criterion, summary_writer):
14 | super().__init__(opt, model, optimizer, criterion, summary_writer)
15 |
16 | def _parse_data(self, inputs):
17 | imgs, pids, camids = inputs
18 | self.data = imgs.cuda()
19 | self.pids = pids.cuda()
20 | self.camids = camids.cuda()
21 |
22 | def _ogranize_data(self):
23 | unique_camids = torch.unique(self.camids).cpu().numpy()
24 | reorg_data = []
25 | reorg_pids = []
26 | for current_camid in unique_camids:
27 | current_camid = (self.camids == current_camid).nonzero().view(-1)
28 | if current_camid.size(0) > 1:
29 | data = torch.index_select(self.data, index=current_camid, dim=0)
30 | pids = torch.index_select(self.pids, index=current_camid, dim=0)
31 | reorg_data.append(data)
32 | reorg_pids.append(pids)
33 |
34 | # Sort the list for our modified data-parallel
35 | # This process helps to increase efficiency when utilizing multiple GPUs
36 | # However, our experiments show that this process slightly decreases the final performance
37 | # You can enable the following process if you prefer
38 | # sort_index = [x.size(0) for x in reorg_pids]
39 | # sort_index = [i[0] for i in sorted(enumerate(sort_index), key=lambda x: x[1], reverse=True)]
40 | # reorg_data = [reorg_data[i] for i in sort_index]
41 | # reorg_pids = [reorg_pids[i] for i in sort_index]
42 | # ===== The end of the sort process ==== #
43 | self.data = reorg_data
44 | self.pids = reorg_pids
45 |
46 | def _forward(self, data):
47 | feat, id_scores = self.model(data)
48 | return feat, id_scores
49 |
50 | def _backward(self):
51 | self.loss.backward()
52 |
53 | def train(self, epoch, data_loader):
54 | self.model.train()
55 | batch_time = AverageMeter()
56 | losses = AverageMeter()
57 | for i, inputs in enumerate(data_loader):
58 | self._parse_data(inputs)
59 | self._ogranize_data()
60 |
61 | torch.cuda.synchronize()
62 | tic = time.time()
63 |
64 | feat, id_scores = self._forward(self.data)
65 | pids = torch.cat(self.pids, dim=0)
66 | self.loss = self.criterion(id_scores, pids, self.global_step,
67 | self.summary_writer)
68 | self.optimizer.zero_grad()
69 | self._backward()
70 | self.optimizer.step()
71 |
72 | torch.cuda.synchronize()
73 | batch_time.update(time.time() - tic)
74 | losses.update(self.loss.item())
75 | # tensorboard
76 | self.global_step = epoch * len(data_loader) + i
77 | self.summary_writer.add_scalar('loss', self.loss.item(), self.global_step)
78 | self.summary_writer.add_scalar('lr', self.optimizer.param_groups[0]['lr'], self.global_step)
79 | if (i + 1) % self.opt.print_freq == 0:
80 | print('Epoch: [{}][{}/{}]\t'
81 | 'Batch Time {:.3f} ({:.3f})\t'
82 | 'Loss {:.3f} ({:.3f})\t'
83 | .format(epoch, i + 1, len(data_loader),
84 | batch_time.mean, batch_time.val,
85 | losses.mean, losses.val))
86 |
87 | param_group = self.optimizer.param_groups
88 | print('Epoch: [{}]\tEpoch Time {:.3f} s\tLoss {:.3f}\t'
89 | 'Lr {:.2e}'
90 | .format(epoch, batch_time.sum, losses.mean, param_group[0]['lr']))
91 |
--------------------------------------------------------------------------------
/io_stream/__init__.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | __all__ = [
7 | 'data_manager',
8 | 'NormalCollateFn',
9 | 'IdentitySampler',
10 | ]
11 |
12 | from . import data_manager
13 | from .samplers import NormalCollateFn, IdentitySampler
14 |
--------------------------------------------------------------------------------
/io_stream/data_manager.py:
--------------------------------------------------------------------------------
1 | from __future__ import print_function, absolute_import
2 |
3 | from PIL import Image
4 | from torch.utils.data import Dataset
5 |
6 | from io_stream.datasets.market import Market1501
7 | from io_stream.datasets.msmt import MSMT17
8 | from io_stream.datasets.duke import Duke
9 |
10 |
11 | class ReID_Data(Dataset):
12 | def __init__(self, dataset, transform):
13 | self.dataset = dataset
14 | self.transform = transform
15 |
16 | def __getitem__(self, item):
17 | img_path, pid, camid = self.dataset[item]
18 | img = Image.open(img_path).convert('RGB')
19 | if self.transform is not None:
20 | img = self.transform(img)
21 | return img, pid, camid
22 |
23 | def __len__(self):
24 | return len(self.dataset)
25 |
26 |
27 | """Create datasets"""
28 |
29 | __data_factory = {
30 | 'market': Market1501,
31 | 'duke': Duke,
32 | 'msmt': MSMT17,
33 | }
34 |
35 | __folder_factory = {
36 | 'market': ReID_Data,
37 | 'duke': ReID_Data,
38 | 'msmt': ReID_Data,
39 | }
40 |
41 |
42 | def init_dataset(name, *args, **kwargs):
43 | if name not in __data_factory.keys():
44 | raise KeyError("Unknown datasets: {}".format(name))
45 | return __data_factory[name](*args, **kwargs)
46 |
47 |
48 | def init_datafolder(name, data_list, transforms):
49 | if name not in __folder_factory.keys():
50 | raise KeyError("Unknown datasets: {}".format(name))
51 | return __folder_factory[name](data_list, transforms)
52 |
--------------------------------------------------------------------------------
/io_stream/data_utils.py:
--------------------------------------------------------------------------------
1 | import random
2 | from collections import defaultdict
3 | import numpy as np
4 |
5 |
6 | def reorganize_images_by_camera(data, sample_per_camera):
7 | cams = np.unique([x[2] for x in data])
8 | images_per_cam = defaultdict(list)
9 | images_per_cam_sampled = defaultdict(list)
10 | for cam_id in cams:
11 | all_file_info = [x for x in data if x[2] == cam_id]
12 | all_file_info = sorted(all_file_info, key=lambda x: x[0])
13 | random.shuffle(all_file_info)
14 | images_per_cam[cam_id] = all_file_info
15 | images_per_cam_sampled[cam_id] = all_file_info[:sample_per_camera]
16 |
17 | return images_per_cam, images_per_cam_sampled
18 |
--------------------------------------------------------------------------------
/io_stream/datasets/duke.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import re
3 | from os import path as osp
4 | from io_stream.data_utils import reorganize_images_by_camera
5 |
6 |
7 | class Duke(object):
8 | """
9 | Market1501
10 | Reference:
11 | Zheng et al. Scalable Person Re-identification: A Benchmark. ICCV 2015.
12 | URL: http://www.liangzheng.org/Project/project_reid.html
13 |
14 | Dataset statistics:
15 | # identities: 1501 (+1 for background)
16 | # images: 12936 (train) + 3368 (query) + 15913 (gallery)
17 | """
18 | dataset_dir = 'duke'
19 |
20 | def __init__(self, root='data', **kwargs):
21 | self.name = 'duke'
22 | self.dataset_dir = osp.join(root, self.dataset_dir)
23 | self.train_dir = osp.join(self.dataset_dir, 'bounding_box_train')
24 | self.query_dir = osp.join(self.dataset_dir, 'query')
25 | self.gallery_dir = osp.join(self.dataset_dir, 'bounding_box_test')
26 | self._check_before_run()
27 |
28 | train, num_train_pids, num_train_imgs = self._process_dir(self.train_dir, relabel=True)
29 | query, num_query_pids, num_query_imgs = self._process_dir(self.query_dir, relabel=False)
30 | gallery, num_gallery_pids, num_gallery_imgs = self._process_dir(self.gallery_dir, relabel=False)
31 |
32 | num_total_pids = num_train_pids + num_query_pids
33 | num_total_imgs = num_train_imgs + num_query_imgs + num_gallery_imgs
34 |
35 | print("=> DukeMTMC-reID loaded")
36 | print("Dataset statistics:")
37 | print(" ------------------------------")
38 | print(" subset | # ids | # images")
39 | print(" ------------------------------")
40 | print(" train | {:5d} | {:8d}".format(num_train_pids, num_train_imgs))
41 | print(" query | {:5d} | {:8d}".format(num_query_pids, num_query_imgs))
42 | print(" gallery | {:5d} | {:8d}".format(num_gallery_pids, num_gallery_imgs))
43 | print(" ------------------------------")
44 | print(" total | {:5d} | {:8d}".format(num_total_pids, num_total_imgs))
45 | print(" ------------------------------")
46 |
47 | self.train = train
48 | self.query = query
49 | self.gallery = gallery
50 |
51 | self.num_train_pids = num_train_pids
52 | self.num_query_pids = num_query_pids
53 | self.num_gallery_pids = num_gallery_pids
54 | self.train_per_cam, self.train_per_cam_sampled = reorganize_images_by_camera(self.train,
55 | kwargs['num_bn_sample'])
56 | self.query_per_cam, self.query_per_cam_sampled = reorganize_images_by_camera(self.query,
57 | kwargs['num_bn_sample'])
58 | self.gallery_per_cam, self.gallery_per_cam_sampled = reorganize_images_by_camera(self.gallery,
59 | kwargs['num_bn_sample'])
60 |
61 | def _check_before_run(self):
62 | """Check if all files are available before going deeper"""
63 | if not osp.exists(self.dataset_dir):
64 | raise RuntimeError("'{}' is not available".format(self.dataset_dir))
65 | if not osp.exists(self.train_dir):
66 | raise RuntimeError("'{}' is not available".format(self.train_dir))
67 | if not osp.exists(self.query_dir):
68 | raise RuntimeError("'{}' is not available".format(self.query_dir))
69 | if not osp.exists(self.gallery_dir):
70 | raise RuntimeError("'{}' is not available".format(self.gallery_dir))
71 |
72 | def _process_dir(self, dir_path, relabel=False):
73 | img_paths = glob.glob(osp.join(dir_path, '*.jpg'))
74 | pattern = re.compile(r'([-\d]+)_c(\d)')
75 |
76 | pid_container = set()
77 | for img_path in img_paths:
78 | pid, _ = map(int, pattern.search(img_path).groups())
79 | if pid == -1: continue # junk images are just ignored
80 | pid_container.add(pid)
81 | pid2label = {pid: label for label, pid in enumerate(pid_container)}
82 |
83 | dataset = []
84 | for img_path in img_paths:
85 | pid, camid = map(int, pattern.search(img_path).groups())
86 | if pid == -1:
87 | continue
88 | camid -= 1 # index starts from 0
89 | if relabel: pid = pid2label[pid]
90 | dataset.append((img_path, pid, camid))
91 | if relabel:
92 | self.pid2label = pid2label
93 | num_pids = len(pid_container)
94 | num_imgs = len(dataset)
95 |
96 | dataset = sorted(dataset, key=lambda k: k[2])
97 | return dataset, num_pids, num_imgs
98 |
--------------------------------------------------------------------------------
/io_stream/datasets/market.py:
--------------------------------------------------------------------------------
1 | import glob
2 | import re
3 | import numpy as np
4 | import random
5 | from os import path as osp
6 | from collections import defaultdict
7 | from io_stream.data_utils import reorganize_images_by_camera
8 |
9 |
10 | class Market1501(object):
11 | """
12 | Market1501
13 | Reference:
14 | Zheng et al. Scalable Person Re-identification: A Benchmark. ICCV 2015.
15 | URL: http://www.liangzheng.org/Project/project_reid.html
16 |
17 | Dataset statistics:
18 | # identities: 1501 (+1 for background)
19 | # images: 12936 (train) + 3368 (query) + 15913 (gallery)
20 | """
21 | dataset_dir = 'market'
22 |
23 | def __init__(self, root='data', **kwargs):
24 | self.name = 'market'
25 | self.dataset_dir = osp.join(root, self.dataset_dir)
26 | self.train_dir = osp.join(self.dataset_dir, 'bounding_box_train')
27 | self.query_dir = osp.join(self.dataset_dir, 'query')
28 | self.gallery_dir = osp.join(self.dataset_dir, 'bounding_box_test')
29 | self._check_before_run()
30 |
31 | train, num_train_pids, num_train_imgs = self._process_dir(self.train_dir, relabel=True)
32 | query, num_query_pids, num_query_imgs = self._process_dir(self.query_dir, relabel=False)
33 | gallery, num_gallery_pids, num_gallery_imgs = self._process_dir(self.gallery_dir, relabel=False)
34 |
35 | num_total_pids = num_train_pids + num_query_pids
36 | num_total_imgs = num_train_imgs + num_query_imgs + num_gallery_imgs
37 |
38 | print("=> Market1501 loaded")
39 | print("Dataset statistics:")
40 | print(" ------------------------------")
41 | print(" subset | # ids | # images")
42 | print(" ------------------------------")
43 | print(" train | {:5d} | {:8d}".format(num_train_pids, num_train_imgs))
44 | print(" query | {:5d} | {:8d}".format(num_query_pids, num_query_imgs))
45 | print(" gallery | {:5d} | {:8d}".format(num_gallery_pids, num_gallery_imgs))
46 | print(" ------------------------------")
47 | print(" total | {:5d} | {:8d}".format(num_total_pids, num_total_imgs))
48 | print(" ------------------------------")
49 |
50 | self.train = train
51 | self.query = query
52 | self.gallery = gallery
53 |
54 | self.num_train_pids = num_train_pids
55 | self.num_query_pids = num_query_pids
56 | self.num_gallery_pids = num_gallery_pids
57 | self.train_per_cam, self.train_per_cam_sampled = reorganize_images_by_camera(self.train,
58 | kwargs['num_bn_sample'])
59 | self.query_per_cam, self.query_per_cam_sampled = reorganize_images_by_camera(self.query,
60 | kwargs['num_bn_sample'])
61 | self.gallery_per_cam, self.gallery_per_cam_sampled = reorganize_images_by_camera(self.gallery,
62 | kwargs['num_bn_sample'])
63 |
64 | def _check_before_run(self):
65 | """Check if all files are available before going deeper"""
66 | if not osp.exists(self.dataset_dir):
67 | raise RuntimeError("'{}' is not available".format(self.dataset_dir))
68 | if not osp.exists(self.train_dir):
69 | raise RuntimeError("'{}' is not available".format(self.train_dir))
70 | if not osp.exists(self.query_dir):
71 | raise RuntimeError("'{}' is not available".format(self.query_dir))
72 | if not osp.exists(self.gallery_dir):
73 | raise RuntimeError("'{}' is not available".format(self.gallery_dir))
74 |
75 | def _process_dir(self, dir_path, relabel=False):
76 | img_paths = glob.glob(osp.join(dir_path, '*.jpg'))
77 | pattern = re.compile(r'([-\d]+)_c(\d)')
78 |
79 | pid_container = set()
80 | for img_path in img_paths:
81 | pid, _ = map(int, pattern.search(img_path).groups())
82 | if pid == -1: continue # junk images are just ignored
83 | pid_container.add(pid)
84 |
85 | pid2label = {pid: label for label, pid in enumerate(pid_container)}
86 | if relabel == True:
87 | self.pid2label = pid2label
88 |
89 | dataset = []
90 | for img_path in img_paths:
91 | pid, camid = map(int, pattern.search(img_path).groups())
92 | if pid == -1:
93 | continue
94 | camid -= 1 # index starts from 0
95 | if relabel: pid = pid2label[pid]
96 | dataset.append((img_path, pid, camid))
97 |
98 | if relabel:
99 | self.pid2label = pid2label
100 | num_pids = len(pid_container)
101 | num_imgs = len(dataset)
102 | return dataset, num_pids, num_imgs
103 |
--------------------------------------------------------------------------------
/io_stream/datasets/msmt.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 |
5 | import os.path as osp
6 | from io_stream.data_utils import reorganize_images_by_camera
7 |
8 |
9 | class MSMT17(object):
10 | """
11 | MSMT17
12 |
13 | Reference:
14 | Wei et al. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. CVPR 2018.
15 |
16 | URL: http://www.pkuvmc.com/publications/msmt17.html
17 |
18 | Dataset statistics:
19 | # identities: 4101
20 | # images: 32621 (train) + 11659 (query) + 82161 (gallery)
21 | # cameras: 15
22 | """
23 | dataset_dir = 'msmt17'
24 |
25 | def __init__(self, root='data', **kwargs):
26 | self.name = "msmt"
27 | self.dataset_dir = osp.join(root, self.dataset_dir)
28 | self.train_dir = osp.join(self.dataset_dir, 'train')
29 | self.test_dir = osp.join(self.dataset_dir, 'test')
30 | self.list_train_path = osp.join(self.dataset_dir, 'list_train.txt')
31 | self.list_val_path = osp.join(self.dataset_dir, 'list_val.txt')
32 | self.list_query_path = osp.join(self.dataset_dir, 'list_query.txt')
33 | self.list_gallery_path = osp.join(self.dataset_dir, 'list_gallery.txt')
34 |
35 | self._check_before_run()
36 | train = self._process_dir(self.train_dir, self.list_train_path)
37 | query = self._process_dir(self.test_dir, self.list_query_path)
38 | gallery = self._process_dir(self.test_dir, self.list_gallery_path)
39 |
40 | self.train = train
41 | self.query = query
42 | self.gallery = gallery
43 |
44 | self.num_train_pids, self.num_train_imgs, self.num_train_cams = self.get_imagedata_info(self.train)
45 | self.num_query_pids, self.num_query_imgs, self.num_query_cams = self.get_imagedata_info(self.query)
46 | self.num_gallery_pids, self.num_gallery_imgs, self.num_gallery_cams = self.get_imagedata_info(self.gallery)
47 |
48 | self.num_total_pids = self.num_train_pids + self.num_query_pids
49 | self.num_total_imgs = self.num_train_imgs + self.num_query_imgs + self.num_gallery_imgs
50 |
51 | print("=> MSMT17 loaded")
52 | print("Dataset statistics:")
53 | print(" ------------------------------")
54 | print(" subset | # ids | # images")
55 | print(" ------------------------------")
56 | print(" train | {:5d} | {:8d}".format(self.num_train_pids, self.num_train_imgs))
57 | print(" query | {:5d} | {:8d}".format(self.num_query_pids, self.num_query_imgs))
58 | print(" gallery | {:5d} | {:8d}".format(self.num_gallery_pids, self.num_gallery_imgs))
59 | print(" ------------------------------")
60 | print(" total | {:5d} | {:8d}".format(self.num_total_pids, self.num_total_imgs))
61 | print(" ------------------------------")
62 | self.train_per_cam, self.train_per_cam_sampled = reorganize_images_by_camera(self.train,
63 | kwargs['num_bn_sample'])
64 | self.query_per_cam, self.query_per_cam_sampled = reorganize_images_by_camera(self.query,
65 | kwargs['num_bn_sample'])
66 | self.gallery_per_cam, self.gallery_per_cam_sampled = reorganize_images_by_camera(self.gallery,
67 | kwargs['num_bn_sample'])
68 |
69 | def get_imagedata_info(self, data):
70 | pids, cams = [], []
71 | for _, pid, camid in data:
72 | pids += [pid]
73 | cams += [camid]
74 | pids = set(pids)
75 | cams = set(cams)
76 | num_pids = len(pids)
77 | num_cams = len(cams)
78 | num_imgs = len(data)
79 | return num_pids, num_imgs, num_cams
80 |
81 | def _check_before_run(self):
82 | """Check if all files are available before going deeper"""
83 | if not osp.exists(self.dataset_dir):
84 | raise RuntimeError("'{}' is not available".format(self.dataset_dir))
85 | if not osp.exists(self.train_dir):
86 | raise RuntimeError("'{}' is not available".format(self.train_dir))
87 | if not osp.exists(self.test_dir):
88 | raise RuntimeError("'{}' is not available".format(self.test_dir))
89 |
90 | def _process_dir(self, dir_path, list_path):
91 | with open(list_path, 'r') as txt:
92 | lines = txt.readlines()
93 | dataset = []
94 | pid_container = set()
95 | for img_idx, img_info in enumerate(lines):
96 | img_path, pid = img_info.split(' ')
97 | pid = int(pid) # no need to relabel
98 | camid = int(img_path.split('_')[2]) - 1 # index starts from 0
99 | img_path = osp.join(dir_path, img_path)
100 | dataset.append((img_path, pid, camid))
101 | pid_container.add(pid)
102 |
103 | # check if pid starts from 0 and increments with 1
104 | for idx, pid in enumerate(pid_container):
105 | assert idx == pid, "See code comment for explanation"
106 | return dataset
107 |
--------------------------------------------------------------------------------
/io_stream/samplers.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 |
3 | from collections import defaultdict
4 | import random
5 | import numpy as np
6 | import torch
7 | import copy
8 | from torch.utils.data.sampler import Sampler
9 |
10 |
11 | class IdentitySampler(Sampler):
12 | def __init__(self, data_source, batch_size, num_instances):
13 | if batch_size < num_instances:
14 | raise ValueError('batch_size={} must be no less '
15 | 'than num_instances={}'.format(batch_size, num_instances))
16 | self.data_source = data_source
17 | self.batch_size = batch_size
18 | self.num_instances = num_instances
19 | self.num_pids_per_batch = self.batch_size // self.num_instances # approximate
20 | self.index_dic = defaultdict(list)
21 | for index, (_, pid, camid) in enumerate(self.data_source):
22 | self.index_dic[pid].append(index)
23 | self.pids = list(self.index_dic.keys())
24 |
25 | def __iter__(self):
26 | batch_idxs_dict = defaultdict(list)
27 | for pid in self.pids:
28 | idxs = copy.deepcopy(self.index_dic[pid])
29 | if len(idxs) < self.num_instances:
30 | idxs = np.random.choice(idxs, size=self.num_instances, replace=True)
31 | random.shuffle(idxs)
32 | batch_idxs = []
33 | for idx in idxs:
34 | batch_idxs.append(idx)
35 | if len(batch_idxs) == self.num_instances:
36 | batch_idxs_dict[pid].append(batch_idxs)
37 | batch_idxs = []
38 |
39 | avai_pids = copy.deepcopy(self.pids)
40 | final_idxs = []
41 | while len(avai_pids) >= self.num_pids_per_batch:
42 | selected_pids = random.sample(avai_pids, self.num_pids_per_batch)
43 | for pid in selected_pids:
44 | batch_idxs = batch_idxs_dict[pid].pop(0)
45 | final_idxs.extend(batch_idxs)
46 | if len(batch_idxs_dict[pid]) == 0:
47 | avai_pids.remove(pid)
48 | self.length = len(final_idxs)
49 | return iter(final_idxs)
50 |
51 | def __len__(self):
52 | return self.length
53 |
54 |
55 | class NormalCollateFn:
56 | def __call__(self, batch):
57 | img_tensor = [x[0] for x in batch]
58 | pids = np.array([x[1] for x in batch])
59 | camids = np.array([x[2] for x in batch])
60 | return torch.stack(img_tensor, dim=0), torch.from_numpy(pids), torch.from_numpy(np.array(camids))
61 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | torch==1.3.1
2 | torchvision==0.4.2
3 | tensorboard
4 | future
5 | fire
6 | tqdm
--------------------------------------------------------------------------------
/run_demo.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | # train
3 | CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0 python train_model.py train --trainset_name market --save_dir='market_demo'
4 | CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0 python test_model.py test --testset_name market --save_dir='market_demo'
5 | CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0 python test_model.py test --testset_name duke --save_dir='market_demo'
6 |
--------------------------------------------------------------------------------
/test_model.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import os
7 | import sys
8 | import random
9 | import tqdm
10 | import time
11 | import numpy as np
12 | import torch
13 | from torch.utils.data import DataLoader
14 |
15 | from config import opt
16 | from io_stream import data_manager
17 |
18 | from frameworks.models import ResNetBuilder
19 | from frameworks.evaluating import evaluator_manager
20 |
21 | from utils.serialization import Logger, load_previous_model
22 | from utils.transforms import TestTransform
23 |
24 |
25 | def test(**kwargs):
26 | opt._parse(kwargs)
27 | sys.stdout = Logger(
28 | os.path.join("./pytorch-ckpt/current", opt.save_dir, 'log_test_{}.txt'.format(opt.testset_name)))
29 | torch.manual_seed(opt.seed)
30 | random.seed(opt.seed)
31 | np.random.seed(opt.seed)
32 |
33 | use_gpu = torch.cuda.is_available()
34 | print('initializing dataset {}'.format(opt.testset_name))
35 | dataset = data_manager.init_dataset(name=opt.testset_name,
36 | num_bn_sample=opt.batch_num_bn_estimatation * opt.test_batch)
37 |
38 | pin_memory = True if use_gpu else False
39 |
40 | print('loading model from {} ...'.format(opt.save_dir))
41 | model = ResNetBuilder()
42 | model_path = os.path.join("./pytorch-ckpt/current", opt.save_dir,
43 | 'model_best.pth.tar')
44 | model = load_previous_model(model, model_path, load_fc_layers=False)
45 | model.eval()
46 |
47 | if use_gpu:
48 | model = torch.nn.DataParallel(model).cuda()
49 | reid_evaluator = evaluator_manager.init_evaluator(opt.testset_name, model, flip=True)
50 |
51 | def _calculate_bn_and_features(all_data, sampled_data):
52 | time.sleep(1)
53 | all_features, all_ids, all_cams = [], [], []
54 | available_cams = list(sampled_data)
55 |
56 | for current_cam in tqdm.tqdm(available_cams):
57 | camera_samples = sampled_data[current_cam]
58 | data_for_camera_loader = DataLoader(
59 | data_manager.init_datafolder(opt.testset_name, camera_samples, TestTransform(opt.height, opt.width)),
60 | batch_size=opt.test_batch, num_workers=opt.workers,
61 | pin_memory=False, drop_last=True
62 | )
63 | reid_evaluator.collect_sim_bn_info(data_for_camera_loader)
64 |
65 | camera_data = all_data[current_cam]
66 | data_loader = DataLoader(
67 | data_manager.init_datafolder(opt.testset_name, camera_data, TestTransform(opt.height, opt.width)),
68 | batch_size=opt.test_batch, num_workers=opt.workers,
69 | pin_memory=pin_memory, shuffle=False
70 | )
71 | fs, pids, camids = reid_evaluator.produce_features(data_loader, normalize=True)
72 | all_features.append(fs)
73 | all_ids.append(pids)
74 | all_cams.append(camids)
75 |
76 | all_features = torch.cat(all_features, 0)
77 | all_ids = np.concatenate(all_ids, axis=0)
78 | all_cams = np.concatenate(all_cams, axis=0)
79 | time.sleep(1)
80 | return all_features, all_ids, all_cams
81 |
82 | print('Processing query features...')
83 | qf, q_pids, q_camids = _calculate_bn_and_features(dataset.query_per_cam, dataset.query_per_cam_sampled)
84 | print('Processing gallery features...')
85 | gf, g_pids, g_camids = _calculate_bn_and_features(dataset.gallery_per_cam,
86 | dataset.gallery_per_cam_sampled)
87 | print('Computing CMC and mAP...')
88 | reid_evaluator.get_final_results_with_features(qf, q_pids, q_camids, gf, g_pids, g_camids)
89 |
90 |
91 | if __name__ == '__main__':
92 | import fire
93 |
94 | fire.Fire()
95 |
--------------------------------------------------------------------------------
/train_model.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import sys
7 | import os
8 | import random
9 | import numpy as np
10 |
11 | import torch
12 | from torch import nn
13 | from torch.backends import cudnn
14 | from torch.utils.data import DataLoader
15 | from torch.utils.tensorboard import SummaryWriter
16 |
17 | from config import opt
18 |
19 | from io_stream import data_manager, NormalCollateFn, IdentitySampler
20 |
21 | from frameworks.models import ResNetBuilder
22 | from frameworks.training import CameraClsTrainer, get_optimizer_strategy, CamDataParallel
23 |
24 | from utils.serialization import Logger, save_checkpoint
25 | from utils.transforms import TrainTransform
26 |
27 |
28 | def train(**kwargs):
29 | opt._parse(kwargs)
30 | # torch.backends.cudnn.deterministic = True # I think this line may slow down the training process
31 | # set random seed and cudnn benchmark
32 | torch.manual_seed(opt.seed)
33 | random.seed(opt.seed)
34 | np.random.seed(opt.seed)
35 |
36 | use_gpu = torch.cuda.is_available()
37 | sys.stdout = Logger(os.path.join('./pytorch-ckpt/current', opt.save_dir, 'log_train.txt'))
38 |
39 | if use_gpu:
40 | print('currently using GPU')
41 | cudnn.benchmark = True
42 | else:
43 | print('currently using cpu')
44 |
45 | print('initializing dataset {}'.format(opt.trainset_name))
46 | train_dataset = data_manager.init_dataset(name=opt.trainset_name,
47 | num_bn_sample=opt.batch_num_bn_estimatation * opt.test_batch)
48 | pin_memory = True if use_gpu else False
49 | summary_writer = SummaryWriter(os.path.join('./pytorch-ckpt/current', opt.save_dir, 'tensorboard_log'))
50 |
51 | trainloader = DataLoader(
52 | data_manager.init_datafolder(opt.trainset_name, train_dataset.train, TrainTransform(opt.height, opt.width)),
53 | sampler=IdentitySampler(train_dataset.train, opt.train_batch, opt.num_instances),
54 | batch_size=opt.train_batch, num_workers=opt.workers,
55 | pin_memory=pin_memory, drop_last=True, collate_fn=NormalCollateFn()
56 | )
57 | print('initializing model ...')
58 | model = ResNetBuilder(train_dataset.num_train_pids)
59 | optim_policy = model.get_optim_policy()
60 | print('model size: {:.5f}M'.format(sum(p.numel()
61 | for p in model.parameters()) / 1e6))
62 |
63 | if use_gpu:
64 | model = CamDataParallel(model).cuda()
65 |
66 | xent = nn.CrossEntropyLoss()
67 |
68 | def standard_cls_criterion(preditions,
69 | targets,
70 | global_step,
71 | summary_writer):
72 | identity_loss = xent(preditions, targets)
73 | identity_accuracy = torch.mean((torch.argmax(preditions, dim=1) == targets).float())
74 | summary_writer.add_scalar('cls_loss', identity_loss.item(), global_step)
75 | summary_writer.add_scalar('cls_accuracy', identity_accuracy.item(), global_step)
76 | return identity_loss
77 |
78 | # get trainer and evaluator
79 | optimizer, adjust_lr = get_optimizer_strategy(opt, optim_policy)
80 | reid_trainer = CameraClsTrainer(opt, model, optimizer, standard_cls_criterion, summary_writer)
81 |
82 | print('Start training')
83 | for epoch in range(opt.max_epoch):
84 | adjust_lr(optimizer, epoch)
85 | reid_trainer.train(epoch, trainloader)
86 |
87 | if use_gpu:
88 | state_dict = model.module.state_dict()
89 | else:
90 | state_dict = model.state_dict()
91 |
92 | save_checkpoint({
93 | 'state_dict': state_dict,
94 | 'epoch': epoch + 1,
95 | }, save_dir=os.path.join('./pytorch-ckpt/current', opt.save_dir))
96 |
97 |
98 | if __name__ == '__main__':
99 | import fire
100 | fire.Fire()
101 |
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 |
--------------------------------------------------------------------------------
/utils/meters.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import math
7 | import numpy as np
8 |
9 |
10 | class AverageMeter(object):
11 | def __init__(self):
12 | self.n = 0
13 | self.sum = 0.0
14 | self.var = 0.0
15 | self.val = 0.0
16 | self.mean = np.nan
17 | self.std = np.nan
18 |
19 | def update(self, value, n=1):
20 | self.val = value
21 | self.sum += value
22 | self.var += value * value
23 | self.n += n
24 |
25 | if self.n == 0:
26 | self.mean, self.std = np.nan, np.nan
27 | elif self.n == 1:
28 | self.mean, self.std = self.sum, np.inf
29 | else:
30 | self.mean = self.sum / self.n
31 | self.std = math.sqrt(
32 | (self.var - self.n * self.mean * self.mean) / (self.n - 1.0))
33 |
34 | def value(self):
35 | return self.mean, self.std
36 |
37 | def reset(self):
38 | self.n = 0
39 | self.sum = 0.0
40 | self.var = 0.0
41 | self.val = 0.0
42 | self.mean = np.nan
43 | self.std = np.nan
44 |
--------------------------------------------------------------------------------
/utils/serialization.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | import errno
7 | import os
8 | import sys
9 |
10 | import os.path as osp
11 | import torch
12 |
13 |
14 | class Logger(object):
15 | """
16 | Write console output to external text file.
17 | Code imported from https://github.com/Cysu/open-reid/blob/master/reid/utils/logging.py.
18 | """
19 |
20 | def __init__(self, fpath=None):
21 | self.console = sys.stdout
22 | self.file = None
23 | if fpath is not None:
24 | mkdir_if_missing(os.path.dirname(fpath))
25 | self.file = open(fpath, 'w')
26 |
27 | def __del__(self):
28 | self.close()
29 |
30 | def __enter__(self):
31 | pass
32 |
33 | def __exit__(self, *args):
34 | self.close()
35 |
36 | def write(self, msg):
37 | self.console.write(msg)
38 | if self.file is not None:
39 | self.file.write(msg)
40 |
41 | def flush(self):
42 | self.console.flush()
43 | if self.file is not None:
44 | self.file.flush()
45 | os.fsync(self.file.fileno())
46 |
47 | def close(self):
48 | self.console.close()
49 | if self.file is not None:
50 | self.file.close()
51 |
52 |
53 | def mkdir_if_missing(dir_path):
54 | try:
55 | os.makedirs(dir_path)
56 | except OSError as e:
57 | if e.errno != errno.EEXIST:
58 | raise
59 |
60 |
61 | def save_checkpoint(state, save_dir):
62 | mkdir_if_missing(save_dir)
63 | fpath = osp.join(save_dir, 'model_best.pth.tar')
64 | torch.save(state, fpath)
65 |
66 |
67 | def load_previous_model(model, file_path=None, load_fc_layers=True):
68 | assert file_path is not None, 'Must define the path of the saved model'
69 | ckpt = torch.load(file_path)
70 | if load_fc_layers:
71 | state_dict = ckpt['state_dict']
72 | else:
73 | state_dict = dict()
74 | for k, v in ckpt['state_dict'].items():
75 | if 'classifer' not in k:
76 | state_dict[k] = v
77 |
78 | model.load_state_dict(state_dict, strict=False)
79 | print('model size: {:.5f}M'.format(sum(p.numel() for p in model.parameters()) / 1e6))
80 | return model
81 |
--------------------------------------------------------------------------------
/utils/transforms.py:
--------------------------------------------------------------------------------
1 | from __future__ import absolute_import
2 | from __future__ import division
3 | from __future__ import print_function
4 | from __future__ import unicode_literals
5 |
6 | from torchvision import transforms as T
7 |
8 |
9 | class TrainTransform(object):
10 | def __init__(self, h, w):
11 | self.h = h
12 | self.w = w
13 |
14 | def __call__(self, x):
15 | x = T.Resize((self.h, self.w))(x)
16 | x = T.RandomHorizontalFlip()(x)
17 | x = T.Pad(10)(x)
18 | x = T.RandomCrop(size=(self.h, self.w))(x)
19 | x = T.ToTensor()(x)
20 | x = T.Normalize(mean=[0.485, 0.456, 0.406],
21 | std=[0.229, 0.224, 0.225])(x)
22 | return x
23 |
24 |
25 | class TestTransform(object):
26 | def __init__(self, h, w):
27 | self.h = h
28 | self.w = w
29 |
30 | def __call__(self, x=None):
31 | x = T.Resize((self.h, self.w))(x)
32 | x = T.ToTensor()(x)
33 | x = T.Normalize(mean=[0.485, 0.456, 0.406],
34 | std=[0.229, 0.224, 0.225])(x)
35 | return x
36 |
--------------------------------------------------------------------------------