 34 |
35 |
34 |
35 | 2 |
4 | Haofei Xu
5 | ·
6 | Anpei Chen
7 | ·
8 | Yuedong Chen
9 | ·
10 | Christos Sakaridis
11 | ·
12 | Yulun Zhang
13 | Marc Pollefeys
14 | ·
15 | Andreas Geiger
16 | ·
17 | Fisher Yu
18 |
29 | MuRF supports multiple different baseline settings. 30 |
31 |
32 |
33 |
34 |
35 |
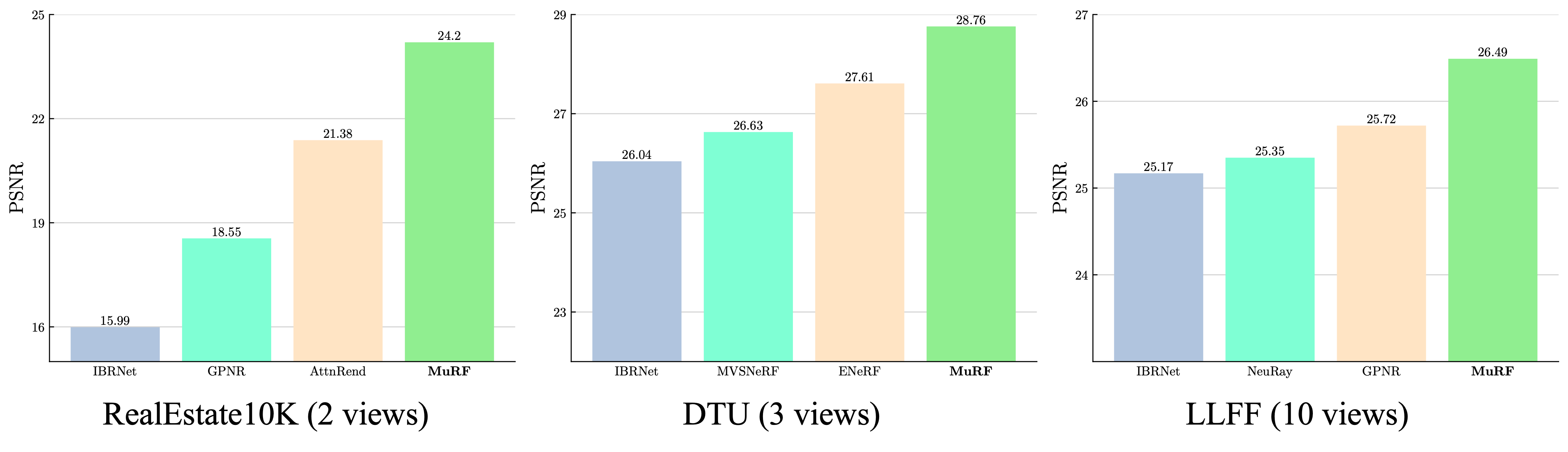
38 | MuRF achieves state-of-the-art performance under various evaluation settings. 39 |
40 | 41 | ## Installation 42 | 43 | Our code is developed based on pytorch 1.10.1, CUDA 11.3 and python 3.8. 44 | 45 | We recommend using [conda](https://www.anaconda.com/distribution/) for installation: 46 | 47 | ``` 48 | conda create -n murf python=3.8 49 | conda activate murf 50 | pip install -r requirements.txt 51 | ``` 52 | 53 | 54 | 55 | ## Model Zoo 56 | 57 | The models are hosted on Hugging Face 🤗 : https://huggingface.co/haofeixu/murf 58 | 59 | Model details can be found at [MODEL_ZOO.md](MODEL_ZOO.md). 60 | 61 | 62 | 63 | ## Datasets 64 | 65 | The datasets used to train and evaluate our models are detailed in [DATASETS.md](DATASETS.md) 66 | 67 | 68 | 69 | ## Evaluation 70 | 71 | The evaluation scripts used to reproduce the numbers in our paper are detailed in [scripts/*_evaluate.sh](scripts). 72 | 73 | 74 | 75 | ## Rendering 76 | 77 | The rendering scripts are detailed in [scripts/*_render.sh](scripts). 78 | 79 | 80 | ## Training 81 | 82 | The training scripts are detailed in [scripts/*_train.sh](scripts). 83 | 84 | 85 | 86 | ## Citation 87 | 88 | ``` 89 | @inproceedings{xu2024murf, 90 | title={MuRF: Multi-Baseline Radiance Fields}, 91 | author={Xu, Haofei and Chen, Anpei and Chen, Yuedong and Sakaridis, Christos and Zhang, Yulun and Pollefeys, Marc and Geiger, Andreas and Yu, Fisher}, 92 | booktitle={CVPR}, 93 | year={2024} 94 | } 95 | ``` 96 | 97 | 98 | 99 | ## Acknowledgements 100 | 101 | This repo is heavily based on [MatchNeRF](https://github.com/donydchen/matchnerf), thanks [Yuedong Chen](https://donydchen.github.io/) for this fantastic work. This project also borrows code from several other repos: [GMFlow](https://github.com/haofeixu/gmflow), [UniMatch](https://github.com/autonomousvision/unimatch), [latent-diffusion](https://github.com/CompVis/latent-diffusion), [MVSNeRF](https://github.com/apchenstu/mvsnerf), [IBRNet](https://github.com/googleinterns/IBRNet), [ENeRF](https://github.com/zju3dv/ENeRF) and [cross_attention_renderer](https://github.com/yilundu/cross_attention_renderer). We thank the original authors for their excellent work. 102 | 103 | 104 | 105 | 106 | 107 | 108 | 109 | -------------------------------------------------------------------------------- /configs/base.yaml: -------------------------------------------------------------------------------- 1 | # default 2 | 3 | name: # name of experiment run 4 | yaml: # config file (must be specified from command line) 5 | model: murf # type of model 6 | seed: 0 # seed number (for both numpy and pytorch) 7 | gpu_ids: [0] # GPU id list 8 | cpu: false # run only on CPU (not supported now) 9 | load: # load checkpoint from filename 10 | n_src_views: 3 # number of source views 11 | batch_size: 1 # batch size 12 | max_epoch: 20 # train to maximum number of epochs 13 | resume: false # resume training (true for latest checkpoint, or number for specific epoch number) 14 | output_path: outputs 15 | 16 | encoder: 17 | attn_splits_list: [2] 18 | cos_n_group: [8,8,6,4] 19 | pretrain_weight: pretrained/gmflow_sintel-0c07dcb3.pth 20 | num_transformer_layers: 6 21 | use_multiview_gmflow: true 22 | add_per_view_attn: false # multiview version of gmflow 23 | wo_self_attn: false 24 | feature_sample_local_radius: 0 25 | feature_sample_local_dilation: 1 26 | 27 | with_cnn_feature: true 28 | radiance_subsample_factor: 8 29 | sample_color_window_radius: 4 30 | decoder_input_feature: true 31 | input_viewdir_diff: true 32 | decoder_num_resblocks: 12 33 | conv_2plus1d: true 34 | residual_color_cosine: true 35 | upconv_channel_list: [128,64,16] 36 | 37 | decoder: # architectural options 38 | net_width: 128 39 | net_depth: 6 40 | skip: [4] # skip connections 41 | posenc: # positional encoding 42 | L_3D: 10 # number of bases (3D point) 43 | L_view: 0 # number of bases (viewpoint) 44 | 45 | nerf: # NeRF-specific options 46 | legacy_coord: true # legacy coordinate adopted from the original codebase, to match the pretrain_weight 47 | wo_render_interval: true 48 | view_dep: true # condition MLP on viewpoint 49 | depth: # depth-related options 50 | param: metric # depth parametrization (for sampling along the ray) 51 | sample_intvs: 64 # number of samples 52 | sample_stratified: true # stratified sampling, only used for training mode 53 | fine_sampling: false # hierarchical sampling with another NeRF 54 | sample_intvs_fine: # number of samples for the fine NeRF 55 | density_noise_reg: # Gaussian noise on density output as regularization 56 | render_video: false 57 | 58 | loss_weight: 59 | render: 1. 60 | ssim: 1. 61 | lpips: 1. 62 | 63 | no_val: true 64 | 65 | tb: # TensorBoard options 66 | -------------------------------------------------------------------------------- /configs/dtu_meta/regnerf_test.txt: -------------------------------------------------------------------------------- 1 | scan8 2 | scan21 3 | scan30 4 | scan31 5 | scan34 6 | scan38 7 | scan40 8 | scan41 9 | scan45 10 | scan55 11 | scan63 12 | scan82 13 | scan103 14 | scan110 15 | scan114 -------------------------------------------------------------------------------- /configs/dtu_meta/regnerf_train.txt: -------------------------------------------------------------------------------- 1 | scan1 2 | scan2 3 | scan3 4 | scan4 5 | scan5 6 | scan6 7 | scan7 8 | scan9 9 | scan10 10 | scan11 11 | scan12 12 | scan13 13 | scan14 14 | scan15 15 | scan16 16 | scan17 17 | scan18 18 | scan19 19 | scan20 20 | scan22 21 | scan23 22 | scan24 23 | scan25 24 | scan26 25 | scan27 26 | scan28 27 | scan29 28 | scan32 29 | scan33 30 | scan35 31 | scan36 32 | scan37 33 | scan39 34 | scan42 35 | scan43 36 | scan44 37 | scan46 38 | scan47 39 | scan48 40 | scan49 41 | scan50 42 | scan51 43 | scan52 44 | scan53 45 | scan54 46 | scan56 47 | scan57 48 | scan58 49 | scan59 50 | scan60 51 | scan61 52 | scan62 53 | scan64 54 | scan65 55 | scan66 56 | scan67 57 | scan68 58 | scan69 59 | scan70 60 | scan71 61 | scan72 62 | scan73 63 | scan74 64 | scan75 65 | scan76 66 | scan77 67 | scan83 68 | scan84 69 | scan85 70 | scan86 71 | scan87 72 | scan88 73 | scan89 74 | scan90 75 | scan91 76 | scan92 77 | scan93 78 | scan94 79 | scan95 80 | scan96 81 | scan97 82 | scan98 83 | scan99 84 | scan100 85 | scan101 86 | scan102 87 | scan104 88 | scan105 89 | scan106 90 | scan107 91 | scan108 92 | scan109 93 | scan111 94 | scan112 95 | scan113 96 | scan115 97 | scan116 98 | scan117 99 | scan118 100 | scan119 101 | scan120 102 | scan121 103 | scan122 104 | scan123 105 | scan124 106 | scan125 107 | scan126 108 | scan127 109 | scan128 -------------------------------------------------------------------------------- /configs/dtu_meta/test_all.txt: -------------------------------------------------------------------------------- 1 | scan29 2 | scan1 3 | scan2 4 | scan7 5 | scan8 6 | scan21 7 | scan30 8 | scan31 9 | scan34 10 | scan38 11 | scan39 12 | scan40 13 | scan41 14 | scan45 15 | scan51 16 | scan55 17 | scan56 18 | scan57 19 | scan58 20 | scan63 21 | scan82 22 | scan83 23 | scan103 24 | scan110 25 | scan111 26 | scan112 27 | scan113 28 | scan114 29 | scan115 30 | scan116 31 | scan117 -------------------------------------------------------------------------------- /configs/dtu_meta/train_all.txt: -------------------------------------------------------------------------------- 1 | scan3 2 | scan4 3 | scan5 4 | scan6 5 | scan9 6 | scan10 7 | scan11 8 | scan12 9 | scan13 10 | scan14 11 | scan15 12 | scan16 13 | scan17 14 | scan18 15 | scan19 16 | scan20 17 | scan22 18 | scan23 19 | scan24 20 | scan28 21 | scan32 22 | scan33 23 | scan35 24 | scan36 25 | scan37 26 | scan42 27 | scan43 28 | scan44 29 | scan46 30 | scan47 31 | scan48 32 | scan49 33 | scan50 34 | scan52 35 | scan53 36 | scan59 37 | scan60 38 | scan61 39 | scan62 40 | scan64 41 | scan65 42 | scan66 43 | scan67 44 | scan68 45 | scan69 46 | scan70 47 | scan71 48 | scan72 49 | scan74 50 | scan75 51 | scan76 52 | scan77 53 | scan84 54 | scan85 55 | scan86 56 | scan87 57 | scan88 58 | scan89 59 | scan90 60 | scan91 61 | scan92 62 | scan93 63 | scan94 64 | scan95 65 | scan96 66 | scan97 67 | scan98 68 | scan99 69 | scan100 70 | scan101 71 | scan102 72 | scan104 73 | scan105 74 | scan106 75 | scan107 76 | scan108 77 | scan109 78 | scan118 79 | scan119 80 | scan120 81 | scan121 82 | scan122 83 | scan123 84 | scan124 85 | scan125 86 | scan126 87 | scan127 88 | scan128 -------------------------------------------------------------------------------- /configs/dtu_meta/val_all.txt: -------------------------------------------------------------------------------- 1 | scan1 2 | scan8 3 | scan21 4 | scan30 5 | scan31 6 | scan34 7 | scan38 8 | scan40 9 | scan41 10 | scan45 11 | scan55 12 | scan63 13 | scan82 14 | scan103 15 | scan110 16 | scan114 -------------------------------------------------------------------------------- /configs/dtu_meta/view_pairs.txt: -------------------------------------------------------------------------------- 1 | 49 2 | 0 3 | 10 10 2346.41 1 2036.53 9 1243.89 12 1052.87 11 1000.84 13 703.583 2 604.456 8 439.759 14 327.419 27 249.278 4 | 1 5 | 10 9 2850.87 10 2583.94 2 2105.59 0 2052.84 8 1868.24 13 1184.23 14 1017.51 12 961.966 7 670.208 15 657.218 6 | 2 7 | 10 8 2501.24 1 2106.88 7 1856.5 9 1782.34 3 1141.77 15 1061.76 14 815.457 16 762.153 6 709.789 10 699.921 8 | 3 9 | 10 7 1294.39 6 1159.13 2 1134.27 4 905.717 8 687.32 5 600.015 17 496.958 16 481.969 1 379.011 15 307.45 10 | 4 11 | 10 5 1333.74 6 1145.15 3 895.254 7 486.504 18 446.42 2 418.517 17 326.528 8 161.115 16 149.154 1 103.626 12 | 5 13 | 10 6 1676.06 18 1555.06 4 1335.55 17 868.416 3 593.755 7 467.816 20 440.579 19 428.255 16 242.327 21 210.253 14 | 6 15 | 10 17 2332.35 7 1848.24 18 1812.74 5 1696.07 16 1273 3 1157.99 4 1155.41 20 771.624 21 744.945 2 700.368 16 | 7 17 | 10 16 2709.46 8 2439.7 15 2078.21 6 1864.16 2 1846.6 17 1791.71 3 1296.86 22 957.793 9 879.088 21 782.277 18 | 8 19 | 10 15 3124.01 9 3099.92 14 2756.29 2 2501.22 7 2449.32 1 1875.94 16 1726.04 13 1325.76 23 1177.09 24 1108.82 20 | 9 21 | 10 13 3355.62 14 3226.07 8 3098.8 10 3097.07 1 2861.42 12 1873.63 2 1785.98 15 1753.32 25 1365.45 0 1261.59 22 | 10 23 | 10 12 3750.7 9 3085.87 13 3028.39 1 2590.55 0 2369.79 11 2266.67 14 1524.16 26 1448.15 27 1293.6 8 1041.84 24 | 11 25 | 10 12 3543.76 27 3056.05 10 2248.07 26 1524.28 28 1273.33 13 1265.9 29 1129.55 0 998.164 9 591.176 30 572.919 26 | 12 27 | 10 27 3889.87 10 3754.54 13 3745.21 11 3584.26 26 3574.56 25 1877.11 9 1866.34 29 1482.72 30 1418.51 14 1341.86 28 | 13 29 | 10 12 3773.14 26 3699.28 25 3657.17 14 3652.04 9 3356.29 10 3049.27 24 2098.91 27 1900.96 31 1460.96 30 1349.62 30 | 14 31 | 10 13 3663.52 24 3610.69 9 3232.55 25 3216.4 15 3128.84 8 2758.04 23 2219.91 26 1567.45 10 1536.6 32 1419.33 32 | 15 33 | 10 23 3194.92 14 3126 8 3120.43 16 2897.02 24 2562.49 7 2084.05 22 2041.63 9 1752.08 33 1232.29 13 1137.55 34 | 16 35 | 10 15 2884.14 7 2713.88 22 2708.57 17 2448.5 21 2173.3 23 1908.03 8 1718.79 6 1281.96 35 1047.38 34 980.064 36 | 17 37 | 10 21 2632.48 16 2428 6 2343.57 18 2250.23 20 2149.75 7 1779.42 22 1380.25 36 957.046 5 878.398 15 789.068 38 | 18 39 | 10 17 2219.15 20 2173.02 6 1802.39 19 1575.77 5 1564.81 21 1160.13 37 827.951 16 660.317 7 589.484 36 559.983 40 | 19 41 | 10 20 1828.97 18 1564.63 37 1474.35 17 685.249 38 620.304 36 613.42 21 572.77 39 499.123 5 427.597 6 368.651 42 | 20 43 | 10 37 2569.8 21 2569.79 36 2258.33 18 2186.71 17 2130.67 19 1865.06 39 1049.03 35 996.122 16 799.808 40 778.721 44 | 21 45 | 10 36 2704.59 35 2639.69 17 2638.19 20 2605.43 22 2604.26 16 2158.25 37 1446.49 34 1239.25 18 1178.24 40 1128.57 46 | 22 47 | 10 23 3232.68 34 3175.15 35 2831.09 16 2712.51 21 2632.19 15 2033.39 33 1712.67 17 1393.86 36 1290.96 24 1195.33 48 | 23 49 | 10 24 3710.9 33 3603.07 22 3244.2 15 3190.62 34 3086.49 14 2220.11 32 2100 16 1917.1 35 1359.79 25 1356.71 50 | 24 51 | 10 25 3844.6 32 3750.75 23 3710.6 14 3609.09 33 3091.04 15 2559.24 31 2423.71 13 2109.36 26 1440.58 34 1410.03 52 | 25 53 | 10 26 3951.74 31 3888.57 24 3833.07 13 3667.35 14 3208.21 32 2993.46 30 2681.52 12 1900.23 45 1484.03 27 1462.88 54 | 26 55 | 10 30 4033.35 27 3970.47 25 3925.25 13 3686.34 12 3595.59 29 2943.87 31 2917 14 1556.34 11 1554.75 46 1503.84 56 | 27 57 | 10 29 4027.84 26 3929.94 12 3875.58 11 3085.03 28 2908.6 30 2792.67 13 1878.42 25 1438.55 47 1425.2 10 1290.25 58 | 28 59 | 10 29 3687.02 48 3209.13 27 2872.86 47 2014.53 30 1361.95 11 1273.6 26 1062.85 12 840.841 46 672.985 31 271.952 60 | 29 61 | 10 27 4029.43 30 3909.55 28 3739.93 47 3695.23 48 3135.87 26 2910.97 46 2229.55 12 1479.16 31 1430.26 11 1144.56 62 | 30 63 | 10 26 4029.86 29 3953.72 31 3811.12 46 3630.46 47 3105.96 27 2824.43 25 2657.89 45 2347.75 32 1459.11 12 1429.62 64 | 31 65 | 10 25 3882.21 30 3841.88 32 3808.5 45 3649.82 46 3000.67 26 2939.94 24 2409.93 44 2381.3 13 1467.59 29 1459.56 66 | 32 67 | 10 31 3826.5 24 3744.14 33 3613.24 44 3552.04 25 3004.6 45 2884.59 43 2393.34 23 2095.27 30 1478.6 14 1420.78 68 | 33 69 | 10 32 3618.11 23 3598.1 34 3530.53 43 3462.37 24 3091.53 44 2608.08 42 2426 22 1717.94 31 1407.65 25 1324.78 70 | 34 71 | 10 33 3523.37 42 3356.55 35 3210.34 22 3178.85 23 3079.03 43 2396.45 41 2386.86 24 1408.02 32 1301.34 21 1256.45 72 | 35 73 | 10 34 3187.88 41 3106.44 36 2866.04 22 2817.74 21 2654.87 40 2416.98 42 2137.81 23 1346.86 33 1150.33 16 1044.66 74 | 36 75 | 10 40 2910.7 35 2832.66 21 2689.96 37 2641.43 39 2349.53 20 2280.46 41 1787.97 22 1268.49 34 981.636 17 954.229 76 | 37 77 | 10 39 2678.55 36 2602.5 20 2558.22 38 1854.56 40 1611.7 19 1498.88 21 1419.51 35 902.641 18 826.803 17 680.253 78 | 38 79 | 10 39 2189.15 37 1834.05 40 824.669 36 771.589 19 622.648 20 590.632 21 190.621 41 157.673 35 155.716 18 134.943 80 | 39 81 | 10 40 2741.73 37 2690.66 36 2322.38 38 2228 20 1046.1 41 983.275 35 883.261 21 693.084 19 509.504 42 193.016 82 | 40 83 | 10 36 2918.14 41 2852.62 39 2782.6 35 2392.96 37 1641.45 21 1124.3 42 1056.48 34 877.946 38 853.944 20 788.701 84 | 41 85 | 10 35 3111.05 42 3049.71 40 2885.36 34 2371.02 36 1813.69 43 1164.71 22 1126.9 39 1011.26 21 906.536 33 903.238 86 | 42 87 | 10 34 3356.98 43 3183 41 3070.54 33 2421.77 35 2155.08 44 1278.41 23 1183.52 22 1147.07 40 1077.08 32 899.646 88 | 43 89 | 10 33 3461.24 44 3380.74 42 3188.7 34 2400.6 32 2399.09 45 1359.37 23 1314.08 41 1176.12 24 1159.62 31 901.556 90 | 44 91 | 10 32 3550.81 45 3510.16 43 3373.11 33 2602.33 31 2395.93 24 1410.43 46 1386.31 42 1279 25 1095.24 34 968.44 92 | 45 93 | 10 31 3650.09 46 3555.09 44 3491.15 32 2868.39 30 2373.59 25 1485.37 47 1405.28 43 1349.54 33 1104.77 26 1046.81 94 | 46 95 | 10 30 3635.64 47 3562.17 45 3524.17 31 2976.82 29 2264.04 26 1508.87 44 1367.41 48 1352.1 32 1211.24 25 1102.17 96 | 47 97 | 10 29 3705.31 46 3519.76 48 3450.48 30 3074.77 28 2054.63 27 1434.57 45 1377.34 31 1268.23 26 1223.83 25 471.111 98 | 48 99 | 10 47 3401.95 28 3224.84 29 3101.16 46 1317.1 30 1306.7 27 1235.07 26 537.731 31 291.919 45 276.869 11 258.856 100 | -------------------------------------------------------------------------------- /configs/pairs.th: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/autonomousvision/murf/57d564203820815feced49045af0ea3fced04463/configs/pairs.th -------------------------------------------------------------------------------- /configs/test_dtu.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/base.yaml 2 | 3 | tb: false 4 | batch_size: 1 5 | 6 | data_test: 7 | dtu: 8 | root_dir: data/DTU 9 | dataset_name: dtu 10 | img_wh: [640, 512] 11 | num_workers: 0 12 | max_len: -1 13 | test_views_method: nearest 14 | -------------------------------------------------------------------------------- /configs/test_dtu_regnerf.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/base.yaml 2 | 3 | tb: false 4 | batch_size: 1 5 | 6 | data_test: 7 | dtu_regnerf: 8 | root_dir: data/DTU 9 | dataset_name: dtu_regnerf 10 | img_wh: [400, 304] 11 | downSample: 1.0 12 | num_workers: 0 13 | max_len: -1 14 | test_views_method: fixed 15 | -------------------------------------------------------------------------------- /configs/test_ibrnet_llff_test.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/base.yaml 2 | 3 | tb: false 4 | batch_size: 1 5 | 6 | log_sampler: true 7 | 8 | data_test: 9 | ibrnet_llff_test: 10 | root_dir: data/llff 11 | dataset_name: ibrnet_llff_test 12 | img_wh: 13 | num_workers: 0 14 | max_len: -1 15 | scene_list: 16 | test_views_method: nearest 17 | -------------------------------------------------------------------------------- /configs/test_mipnerf360.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/base.yaml 2 | 3 | tb: false 4 | batch_size: 1 5 | 6 | log_sampler: true 7 | 8 | data_test: 9 | mipnerf360: 10 | root_dir: data/mipnerf360 11 | dataset_name: mipnerf360 12 | img_wh: 13 | num_workers: 0 14 | max_len: -1 15 | scene_list: 16 | 17 | -------------------------------------------------------------------------------- /configs/test_realestate.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/base.yaml 2 | 3 | tb: false 4 | batch_size: 1 5 | 6 | log_sampler: true 7 | 8 | data_test: 9 | realestate_test: 10 | root_dir: data/realestate 11 | dataset_name: realestate_test 12 | img_wh: [256, 256] 13 | num_workers: 0 14 | max_len: -1 15 | test_views_method: fixed 16 | 17 | -------------------------------------------------------------------------------- /configs/test_video_dtu.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/test_dtu.yaml 2 | 3 | nerf: 4 | rand_rays_test: 20480 # number of random rays for each step 5 | render_video: true 6 | video_n_frames: 60 7 | video_rads_scale: 0.3 8 | -------------------------------------------------------------------------------- /configs/test_video_mipnerf360.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/test_mipnerf360.yaml 2 | 3 | nerf: 4 | rand_rays_test: 20480 5 | render_video: true 6 | video_n_frames: 60 7 | video_rads_scale: 0.3 8 | -------------------------------------------------------------------------------- /configs/test_video_realestate.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/test_realestate.yaml 2 | 3 | nerf: 4 | rand_rays_test: 20480 5 | render_video: true 6 | video_n_frames: 60 7 | video_rads_scale: 0.3 8 | -------------------------------------------------------------------------------- /configs/train_dtu.yaml: -------------------------------------------------------------------------------- 1 | _parent_: configs/base.yaml 2 | 3 | tb: true 4 | batch_size: 1 # batch size (not used for NeRF/BARF) 5 | max_epoch: 20 # train to maximum number of epochs (not used for NeRF/BARF) 6 | sanity_check: false 7 | 8 | data_train: # data options 9 | root_dir: data/DTU 10 | dataset_name: dtu # dataset name 11 | img_wh: [640, 512] # input image sizes [width, height] 12 | num_workers: 4 # number of parallel workers for data loading 13 | max_len: -1 14 | 15 | data_test: 16 | dtu: 17 | root_dir: data/DTU 18 | dataset_name: dtu # dataset name 19 | img_wh: [640, 512] # input image sizes [width, height] 20 | num_workers: 0 # number of parallel workers for data loading 21 | max_len: -1 22 | 23 | loss_weight: # loss weights (in log scale) 24 | render: 1 # RGB rendering loss 25 | render_fine: # RGB rendering loss (for fine NeRF) 26 | 27 | optim: # optimization options 28 | lr_enc: 5.e-5 29 | lr_dec: 5.e-4 30 | clip_enc: 1. 31 | algo: 32 | type: AdamW 33 | weight_decay: 1.e-4 34 | sched: # learning rate scheduling options 35 | type: OneCycleLR # scheduler (see PyTorch doc) 36 | pct_start: 0.05 37 | cycle_momentum: false 38 | anneal_strategy: cos 39 | 40 | freq: # periodic actions during training 41 | scalar: 20 # log losses and scalar states (every N iterations) 42 | ckpt_ep: 1 # save checkpoint (every N epochs) 43 | ckpt_it: 0.1 # save latest checkpoint (every ckpt_it * len(loader) iterations) 44 | val_it: 0.5 # validate model (every val_it * len(loader) iterations) 45 | test_ep: 1 # test model (every N epochs) 46 | -------------------------------------------------------------------------------- /datasets/__init__.py: -------------------------------------------------------------------------------- 1 | from .dtu import MVSDatasetDTU 2 | from .dtu_regnerf import MVSDatasetDTURegNeRF 3 | from .realestate10k import RealEstate10k, RealEstate10kTest 4 | from .realestate10k_subset import RealEstate10kSubset, RealEstate10kSubsetTest 5 | from .ibrnet_mix.google_scanned_objects import GoogleScannedDataset 6 | from .ibrnet_mix.llff import LLFFDataset 7 | from .ibrnet_mix.llff_test import LLFFTestDataset 8 | from .ibrnet_mix.ibrnet_collected import IBRNetCollectedDataset 9 | from .ibrnet_mix.realestate import RealEstateDataset 10 | from .ibrnet_mix.spaces_dataset import SpacesFreeDataset 11 | from .mipnerf360 import MipNeRF360Dataset 12 | 13 | datas_dict = { 14 | 'dtu': MVSDatasetDTU, 15 | 'google_scanned': GoogleScannedDataset, 16 | 'dtu_regnerf': MVSDatasetDTURegNeRF, 17 | 'realestate': RealEstate10k, 18 | 'realestate_test': RealEstate10kTest, 19 | 'realestate_subset': RealEstate10kSubset, 20 | 'realestate_subset_test': RealEstate10kSubsetTest, 21 | 'ibrnet_llff': LLFFDataset, 22 | 'ibrnet_llff_test': LLFFTestDataset, 23 | 'ibrnet_collected': IBRNetCollectedDataset, 24 | 'ibrnet_realestate': RealEstateDataset, 25 | 'spaces': SpacesFreeDataset, 26 | 'mipnerf360': MipNeRF360Dataset, 27 | } 28 | -------------------------------------------------------------------------------- /datasets/ibrnet_mix/__init__.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | 16 | from .google_scanned_objects import GoogleScannedDataset 17 | from .realestate import RealEstateDataset 18 | from .llff import LLFFDataset 19 | from .ibrnet_collected import IBRNetCollectedDataset 20 | from .spaces_dataset import SpacesFreeDataset 21 | 22 | dataset_dict = { 23 | 'spaces': SpacesFreeDataset, 24 | 'google_scanned': GoogleScannedDataset, 25 | 'realestate': RealEstateDataset, 26 | 'llff': LLFFDataset, 27 | 'ibrnet_collected': IBRNetCollectedDataset, 28 | } 29 | -------------------------------------------------------------------------------- /datasets/ibrnet_mix/create_training_dataset.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | 16 | import numpy as np 17 | from . import dataset_dict 18 | from torch.utils.data import Dataset, Sampler 19 | from torch.utils.data import DistributedSampler, WeightedRandomSampler 20 | from typing import Optional 21 | from operator import itemgetter 22 | import torch 23 | import os 24 | 25 | 26 | class DatasetFromSampler(Dataset): 27 | """Dataset to create indexes from `Sampler`. 28 | Args: 29 | sampler: PyTorch sampler 30 | """ 31 | 32 | def __init__(self, sampler: Sampler): 33 | """Initialisation for DatasetFromSampler.""" 34 | self.sampler = sampler 35 | self.sampler_list = None 36 | 37 | def __getitem__(self, index: int): 38 | """Gets element of the dataset. 39 | Args: 40 | index: index of the element in the dataset 41 | Returns: 42 | Single element by index 43 | """ 44 | if self.sampler_list is None: 45 | self.sampler_list = list(self.sampler) 46 | return self.sampler_list[index] 47 | 48 | def __len__(self) -> int: 49 | """ 50 | Returns: 51 | int: length of the dataset 52 | """ 53 | return len(self.sampler) 54 | 55 | 56 | class DistributedSamplerWrapper(DistributedSampler): 57 | """ 58 | Wrapper over `Sampler` for distributed training. 59 | Allows you to use any sampler in distributed mode. 60 | It is especially useful in conjunction with 61 | `torch.nn.parallel.DistributedDataParallel`. In such case, each 62 | process can pass a DistributedSamplerWrapper instance as a DataLoader 63 | sampler, and load a subset of subsampled data of the original dataset 64 | that is exclusive to it. 65 | .. note:: 66 | Sampler is assumed to be of constant size. 67 | """ 68 | 69 | def __init__( 70 | self, 71 | sampler, 72 | num_replicas: Optional[int] = None, 73 | rank: Optional[int] = None, 74 | shuffle: bool = True, 75 | ): 76 | """ 77 | Args: 78 | sampler: Sampler used for subsampling 79 | num_replicas (int, optional): Number of processes participating in 80 | distributed training 81 | rank (int, optional): Rank of the current process 82 | within ``num_replicas`` 83 | shuffle (bool, optional): If true (default), 84 | sampler will shuffle the indices 85 | """ 86 | super(DistributedSamplerWrapper, self).__init__( 87 | DatasetFromSampler(sampler), 88 | num_replicas=num_replicas, 89 | rank=rank, 90 | shuffle=shuffle, 91 | ) 92 | self.sampler = sampler 93 | 94 | def __iter__(self): 95 | self.dataset = DatasetFromSampler(self.sampler) 96 | indexes_of_indexes = super().__iter__() 97 | subsampler_indexes = self.dataset 98 | return iter(itemgetter(*indexes_of_indexes)(subsampler_indexes)) 99 | 100 | 101 | def create_training_dataset(root_dir, 102 | n_views=5, 103 | train_dataset="llff+spaces+ibrnet_collected+realestate+google_scanned", 104 | dataset_weights=[0.3, 0.15, 0.35, 0.15, 0.05], 105 | distributed=False, 106 | num_replicas=None, 107 | rank=None, 108 | mixall=False, 109 | no_random_view=False, 110 | dataset_replicas=None, 111 | realestate_full_set=False, 112 | realestate_frame_dir=None, 113 | mixall_random_view=False, 114 | realestate_use_all_scenes=False, 115 | ): 116 | # parse args.train_dataset, "+" indicates that multiple datasets are used, for example "ibrnet_collect+llff+spaces" 117 | # otherwise only one dataset is used 118 | # args.dataset_weights should be a list representing the resampling rate for each dataset, and should sum up to 1 119 | 120 | print('training dataset: {}'.format(train_dataset)) 121 | mode = 'train' 122 | train_dataset_names = train_dataset.split('+') 123 | weights = dataset_weights 124 | 125 | if dataset_replicas is not None: 126 | # increase the number of samples per epoch for better training efficiency 127 | train_dataset_names = train_dataset_names * dataset_replicas 128 | weights = weights * dataset_replicas 129 | weights = [x / dataset_replicas for x in weights] 130 | 131 | assert len(train_dataset_names) == len(weights) 132 | assert np.abs(np.sum(weights) - 1.) < 1e-6 133 | print(train_dataset_names) 134 | print('weights:{}'.format(weights)) 135 | train_datasets = [] 136 | train_weights_samples = [] 137 | 138 | for training_dataset_name, weight in zip(train_dataset_names, weights): 139 | if mixall: 140 | train_dataset = dataset_dict[training_dataset_name](root_dir, split=mode, n_views=n_views, 141 | no_random_view=not mixall_random_view, 142 | large_subsample=True, 143 | include_more_scenes=True, # ibrnet_collected_more 144 | full_set=realestate_full_set, 145 | frame_dir=realestate_frame_dir, 146 | use_all_scenes=realestate_use_all_scenes, 147 | ) 148 | else: 149 | train_dataset = dataset_dict[training_dataset_name](root_dir, split=mode, n_views=n_views, 150 | no_random_view=no_random_view, 151 | full_set=realestate_full_set, 152 | frame_dir=realestate_frame_dir, 153 | ) 154 | print(training_dataset_name, len(train_dataset)) 155 | train_datasets.append(train_dataset) 156 | num_samples = len(train_dataset) 157 | weight_each_sample = weight / num_samples 158 | train_weights_samples.extend([weight_each_sample]*num_samples) 159 | 160 | train_dataset = torch.utils.data.ConcatDataset(train_datasets) 161 | train_weights = torch.from_numpy(np.array(train_weights_samples)) 162 | sampler = WeightedRandomSampler(train_weights, len(train_weights)) 163 | train_sampler = DistributedSamplerWrapper( 164 | sampler, num_replicas=num_replicas, rank=rank) if distributed else sampler 165 | 166 | return train_dataset, train_sampler 167 | -------------------------------------------------------------------------------- /datasets/ibrnet_mix/google_scanned_objects.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | 16 | from torchvision import transforms as T 17 | from .data_utils import rectify_inplane_rotation, get_nearest_pose_ids 18 | import os 19 | import numpy as np 20 | import imageio 21 | import torch 22 | from torch.utils.data import Dataset 23 | import glob 24 | import sys 25 | sys.path.append('../') 26 | 27 | 28 | class GoogleScannedDataset(Dataset): 29 | def __init__(self, root_dir, split='train', n_views=3, **kwargs): 30 | self.folder_path = os.path.join(root_dir, 'google_scanned_objects/') 31 | self.num_source_views = n_views 32 | self.rectify_inplane_rotation = False 33 | self.scene_path_list = glob.glob(os.path.join(self.folder_path, '*')) 34 | self.transform = self.define_transforms() 35 | 36 | all_rgb_files = [] 37 | all_pose_files = [] 38 | all_intrinsics_files = [] 39 | num_files = 250 40 | for i, scene_path in enumerate(self.scene_path_list): 41 | rgb_files = [os.path.join(scene_path, 'rgb', f) 42 | for f in sorted(os.listdir(os.path.join(scene_path, 'rgb')))] 43 | pose_files = [f.replace('rgb', 'pose').replace( 44 | 'png', 'txt') for f in rgb_files] 45 | intrinsics_files = [f.replace('rgb', 'intrinsics').replace( 46 | 'png', 'txt') for f in rgb_files] 47 | 48 | if np.min([len(rgb_files), len(pose_files), len(intrinsics_files)]) \ 49 | < num_files: 50 | print(scene_path) 51 | continue 52 | 53 | all_rgb_files.append(rgb_files) 54 | all_pose_files.append(pose_files) 55 | all_intrinsics_files.append(intrinsics_files) 56 | 57 | index = np.arange(len(all_rgb_files)) 58 | self.all_rgb_files = np.array(all_rgb_files)[index] 59 | self.all_pose_files = np.array(all_pose_files)[index] 60 | self.all_intrinsics_files = np.array(all_intrinsics_files)[index] 61 | 62 | def get_name(self): 63 | dataname = 'google_scanned' 64 | return dataname 65 | 66 | def define_transforms(self): 67 | transform = T.Compose([T.ToTensor(),]) # (3, h, w) 68 | # T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) 69 | return transform 70 | 71 | def __len__(self): 72 | return len(self.all_rgb_files) 73 | 74 | def __getitem__(self, idx): 75 | sample = {} 76 | rgb_files = self.all_rgb_files[idx] 77 | 78 | pose_files = self.all_pose_files[idx] 79 | intrinsics_files = self.all_intrinsics_files[idx] 80 | 81 | id_render = np.random.choice(np.arange(len(rgb_files))) 82 | train_poses = np.stack([np.loadtxt(file).reshape(4, 4) 83 | for file in pose_files], axis=0) 84 | render_pose = train_poses[id_render] 85 | subsample_factor = np.random.choice( 86 | np.arange(1, 6), p=[0.3, 0.25, 0.2, 0.2, 0.05]) 87 | 88 | id_feat_pool = get_nearest_pose_ids(render_pose, 89 | train_poses, 90 | self.num_source_views*subsample_factor, 91 | tar_id=id_render, 92 | angular_dist_method='vector') 93 | id_feat = np.random.choice( 94 | id_feat_pool, self.num_source_views, replace=False) 95 | 96 | assert id_render not in id_feat 97 | # occasionally include input image 98 | if np.random.choice([0, 1], p=[0.995, 0.005]): 99 | id_feat[np.random.choice(len(id_feat))] = id_render 100 | 101 | rgb = imageio.imread(rgb_files[id_render]).astype(np.float32) / 255. 102 | 103 | render_intrinsics = np.loadtxt(intrinsics_files[id_render]) 104 | img_size = rgb.shape[:2] 105 | camera = np.concatenate( 106 | (list(img_size), render_intrinsics, render_pose.flatten())).astype(np.float32) 107 | 108 | # get depth range 109 | min_ratio = 0.1 110 | origin_depth = np.linalg.inv(render_pose)[2, 3] 111 | max_radius = 0.5 * np.sqrt(2) * 1.1 112 | near_depth = max(origin_depth - max_radius, min_ratio * origin_depth) 113 | far_depth = origin_depth + max_radius 114 | 115 | src_rgbs = [] 116 | src_intrs = [] 117 | src_poses = [] 118 | for id in id_feat: 119 | src_rgb = imageio.imread(rgb_files[id]).astype(np.float32) / 255. 120 | pose = np.loadtxt(pose_files[id]) 121 | if self.rectify_inplane_rotation: 122 | pose, src_rgb = rectify_inplane_rotation( 123 | pose.reshape(4, 4), render_pose, src_rgb) 124 | 125 | src_rgbs.append(src_rgb) 126 | intrinsics = np.loadtxt(intrinsics_files[id]) 127 | src_intrs.append(intrinsics) 128 | src_poses.append(pose) 129 | 130 | sample['images'] = torch.stack( 131 | [self.transform(img) for img in [*src_rgbs, rgb]]).float() # (V, C, H, W) 132 | sample['extrinsics'] = np.stack([np.linalg.inv(x.reshape(4, 4)) for x in [ 133 | *src_poses, render_pose]]).astype(np.float32) # (V, 4, 4) 134 | sample['intrinsics'] = np.stack([x.reshape(4, 4)[:3, :3] for x in [ 135 | *src_intrs, render_intrinsics]]).astype(np.float32) # (V, 3, 3) 136 | sample['view_ids'] = np.array([*id_feat, id_render]) 137 | sample['scene'] = f"{self.get_name()}_{rgb_files[0].split('/')[-3]}" 138 | sample['img_wh'] = np.array([img_size[1], img_size[0]]).astype('int') 139 | sample['near_fars'] = np.expand_dims(np.array([near_depth, far_depth]), axis=0).repeat( 140 | sample['view_ids'].shape[0], axis=0).astype(np.float32) 141 | 142 | return sample 143 | -------------------------------------------------------------------------------- /datasets/ibrnet_mix/ibrnet_collected.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | from torchvision import transforms as T 16 | from .llff_data_utils import load_llff_data, batch_parse_llff_poses 17 | from .data_utils import rectify_inplane_rotation, random_crop, random_flip, get_nearest_pose_ids 18 | import os 19 | import numpy as np 20 | import imageio 21 | import torch 22 | from torch.utils.data import Dataset 23 | import glob 24 | import sys 25 | sys.path.append('../') 26 | 27 | 28 | class IBRNetCollectedDataset(Dataset): 29 | def __init__(self, root_dir, split='train', n_views=3, random_crop=True, 30 | no_random_view=False, 31 | large_subsample=False, 32 | include_more_scenes=False, 33 | **kwargs): 34 | rootdir = root_dir 35 | mode = split 36 | num_source_views = n_views 37 | llffhold = 8 38 | 39 | self.folder_path1 = os.path.join(rootdir, 'ibrnet_collected_1/') 40 | self.folder_path2 = os.path.join(rootdir, 'ibrnet_collected_2/') 41 | self.rectify_inplane_rotation = False 42 | self.mode = mode # train / test / validation 43 | self.num_source_views = num_source_views 44 | self.random_crop = random_crop 45 | self.no_random_view = no_random_view 46 | self.large_subsample = large_subsample 47 | 48 | all_scenes = glob.glob(self.folder_path1 + '*') + \ 49 | glob.glob(self.folder_path2 + '*') 50 | 51 | if include_more_scenes: 52 | self.folder_path3 = os.path.join(rootdir, 'ibrnet_collected_more/') 53 | all_scenes = all_scenes + \ 54 | sorted(glob.glob(self.folder_path3 + '*')) 55 | 56 | self.render_rgb_files = [] 57 | self.render_intrinsics = [] 58 | self.render_poses = [] 59 | self.render_train_set_ids = [] 60 | self.render_depth_range = [] 61 | 62 | self.train_intrinsics = [] 63 | self.train_poses = [] 64 | self.train_rgb_files = [] 65 | self.transform = self.define_transforms() 66 | 67 | for i, scene in enumerate(all_scenes): 68 | if 'ibrnet_collected_2' in scene or 'ibrnet_collected_more' in scene: 69 | factor = 8 70 | else: 71 | factor = 2 72 | _, poses, bds, render_poses, i_test, rgb_files = load_llff_data( 73 | scene, load_imgs=False, factor=factor) 74 | near_depth = np.min(bds) 75 | far_depth = np.max(bds) 76 | intrinsics, c2w_mats = batch_parse_llff_poses(poses) 77 | if mode == 'train': 78 | i_train = np.array(np.arange(int(poses.shape[0]))) 79 | i_render = i_train 80 | else: 81 | i_test = np.arange(poses.shape[0])[::llffhold] 82 | i_train = np.array([j for j in np.arange(int(poses.shape[0])) if 83 | (j not in i_test and j not in i_test)]) 84 | i_render = i_test 85 | 86 | self.train_intrinsics.append(intrinsics[i_train]) 87 | self.train_poses.append(c2w_mats[i_train]) 88 | self.train_rgb_files.append(np.array(rgb_files)[i_train].tolist()) 89 | num_render = len(i_render) 90 | self.render_rgb_files.extend( 91 | np.array(rgb_files)[i_render].tolist()) 92 | self.render_intrinsics.extend( 93 | [intrinsics_ for intrinsics_ in intrinsics[i_render]]) 94 | self.render_poses.extend( 95 | [c2w_mat for c2w_mat in c2w_mats[i_render]]) 96 | self.render_depth_range.extend( 97 | [[near_depth, far_depth]]*num_render) 98 | self.render_train_set_ids.extend([i]*num_render) 99 | 100 | def get_name(self): 101 | dataname = 'ibrnet_collected' 102 | return dataname 103 | 104 | def define_transforms(self): 105 | transform = T.Compose([T.ToTensor(),]) # (3, h, w) 106 | return transform 107 | 108 | def __len__(self): 109 | return len(self.render_rgb_files) 110 | 111 | def __getitem__(self, idx): 112 | sample = {} 113 | rgb_file = self.render_rgb_files[idx] 114 | rgb = imageio.imread(rgb_file).astype(np.float32) / 255. 115 | render_pose = self.render_poses[idx] 116 | intrinsics = self.render_intrinsics[idx] 117 | depth_range = self.render_depth_range[idx] 118 | mean_depth = np.mean(depth_range) 119 | world_center = (render_pose.dot( 120 | np.array([[0, 0, mean_depth, 1]]).T)).flatten()[:3] 121 | 122 | train_set_id = self.render_train_set_ids[idx] 123 | train_rgb_files = self.train_rgb_files[train_set_id] 124 | train_poses = self.train_poses[train_set_id] 125 | train_intrinsics = self.train_intrinsics[train_set_id] 126 | 127 | img_size = rgb.shape[:2] 128 | camera = np.concatenate((list(img_size), intrinsics.flatten(), 129 | render_pose.flatten())).astype(np.float32) 130 | 131 | if self.mode == 'train': 132 | id_render = train_rgb_files.index(rgb_file) 133 | 134 | if self.large_subsample: 135 | subsample_factor = np.random.choice(np.arange(5, 11)) 136 | else: 137 | subsample_factor = np.random.choice( 138 | np.arange(1, 4), p=[0.2, 0.45, 0.35]) 139 | 140 | if self.no_random_view: 141 | num_select = self.num_source_views 142 | else: 143 | num_select = self.num_source_views + \ 144 | np.random.randint(low=-2, high=3) 145 | else: 146 | id_render = -1 147 | subsample_factor = 1 148 | num_select = self.num_source_views 149 | 150 | nearest_pose_ids = get_nearest_pose_ids(render_pose, 151 | train_poses, 152 | min(self.num_source_views * 153 | subsample_factor, 22), 154 | tar_id=id_render, 155 | angular_dist_method='dist', 156 | scene_center=world_center) 157 | nearest_pose_ids = np.random.choice(nearest_pose_ids, min( 158 | num_select, len(nearest_pose_ids)), replace=False) 159 | 160 | assert id_render not in nearest_pose_ids 161 | # occasionally include input image 162 | if np.random.choice([0, 1], p=[0.995, 0.005]) and self.mode == 'train': 163 | nearest_pose_ids[np.random.choice( 164 | len(nearest_pose_ids))] = id_render 165 | 166 | src_rgbs = [] 167 | src_cameras = [] 168 | for id in nearest_pose_ids: 169 | src_rgb = imageio.imread( 170 | train_rgb_files[id]).astype(np.float32) / 255. 171 | train_pose = train_poses[id] 172 | train_intrinsics_ = train_intrinsics[id] 173 | if self.rectify_inplane_rotation: 174 | train_pose, src_rgb = rectify_inplane_rotation( 175 | train_pose, render_pose, src_rgb) 176 | 177 | src_rgbs.append(src_rgb) 178 | img_size = src_rgb.shape[:2] 179 | src_camera = np.concatenate((list(img_size), train_intrinsics_.flatten(), 180 | train_pose.flatten())).astype(np.float32) 181 | src_cameras.append(src_camera) 182 | 183 | src_rgbs = np.stack(src_rgbs, axis=0) 184 | src_cameras = np.stack(src_cameras, axis=0) 185 | 186 | if self.mode == 'train' and self.random_crop: 187 | rgb, camera, src_rgbs, src_cameras = random_crop( 188 | rgb, camera, src_rgbs, src_cameras) 189 | 190 | if self.mode == 'train' and np.random.choice([0, 1], p=[0.5, 0.5]): 191 | rgb, camera, src_rgbs, src_cameras = random_flip( 192 | rgb, camera, src_rgbs, src_cameras) 193 | 194 | depth_range = torch.tensor( 195 | [depth_range[0] * 0.9, depth_range[1] * 1.5]) 196 | 197 | sample['images'] = torch.stack( 198 | [self.transform(img) for img in [*src_rgbs, rgb]]).float() # (V, C, H, W) 199 | # ibrnet camera format: [(h, w, intr(16), extr(16))] 200 | sample['extrinsics'] = np.stack([np.linalg.inv( 201 | x[-16:].reshape(4, 4)) for x in [*src_cameras, camera]]).astype(np.float32) # (V, 4, 4) 202 | sample['intrinsics'] = np.stack([x[2:-16].reshape(4, 4)[:3, :3] 203 | for x in [*src_cameras, camera]]).astype(np.float32) # (V, 3, 3) 204 | sample['view_ids'] = np.array([*nearest_pose_ids, id_render]) 205 | sample['scene'] = f"{self.get_name()}_{rgb_file.split('/')[-3]}" 206 | sample['img_wh'] = np.array([camera[1], camera[0]]).astype('int') 207 | sample['near_fars'] = np.expand_dims(np.array([depth_range[0].item(), depth_range[1].item( 208 | )]), axis=0).repeat(sample['view_ids'].shape[0], axis=0).astype(np.float32) 209 | 210 | return sample 211 | -------------------------------------------------------------------------------- /datasets/ibrnet_mix/llff.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | from torchvision import transforms as T 16 | from .llff_data_utils import load_llff_data, batch_parse_llff_poses 17 | from .data_utils import random_crop, random_flip, get_nearest_pose_ids 18 | import os 19 | import numpy as np 20 | import imageio 21 | import torch 22 | from torch.utils.data import Dataset 23 | import sys 24 | sys.path.append('../') 25 | 26 | 27 | class LLFFDataset(Dataset): 28 | def __init__(self, root_dir, split='train', n_views=3, 29 | no_random_view=False, 30 | large_subsample=False, 31 | **kwargs): 32 | rootdir = root_dir 33 | num_source_views = n_views 34 | mode = split 35 | llffhold = 8 36 | 37 | base_dir = os.path.join(rootdir, 'real_iconic_noface/') 38 | self.mode = mode # train / test / validation 39 | self.num_source_views = num_source_views 40 | self.render_rgb_files = [] 41 | self.render_intrinsics = [] 42 | self.render_poses = [] 43 | self.render_train_set_ids = [] 44 | self.render_depth_range = [] 45 | 46 | self.train_intrinsics = [] 47 | self.train_poses = [] 48 | self.train_rgb_files = [] 49 | self.transform = self.define_transforms() 50 | 51 | self.no_random_view = no_random_view 52 | self.large_subsample = large_subsample 53 | 54 | scenes = os.listdir(base_dir) 55 | for i, scene in enumerate(scenes): 56 | scene_path = os.path.join(base_dir, scene) 57 | _, poses, bds, render_poses, i_test, rgb_files = load_llff_data( 58 | scene_path, load_imgs=False, factor=4) 59 | near_depth = np.min(bds) 60 | far_depth = np.max(bds) 61 | intrinsics, c2w_mats = batch_parse_llff_poses(poses) 62 | 63 | if mode == 'train': 64 | i_train = np.array(np.arange(int(poses.shape[0]))) 65 | i_render = i_train 66 | else: 67 | i_test = np.arange(poses.shape[0])[::llffhold] 68 | i_train = np.array([j for j in np.arange(int(poses.shape[0])) if 69 | (j not in i_test and j not in i_test)]) 70 | i_render = i_test 71 | 72 | self.train_intrinsics.append(intrinsics[i_train]) 73 | self.train_poses.append(c2w_mats[i_train]) 74 | self.train_rgb_files.append(np.array(rgb_files)[i_train].tolist()) 75 | num_render = len(i_render) 76 | self.render_rgb_files.extend( 77 | np.array(rgb_files)[i_render].tolist()) 78 | self.render_intrinsics.extend( 79 | [intrinsics_ for intrinsics_ in intrinsics[i_render]]) 80 | self.render_poses.extend( 81 | [c2w_mat for c2w_mat in c2w_mats[i_render]]) 82 | self.render_depth_range.extend( 83 | [[near_depth, far_depth]]*num_render) 84 | self.render_train_set_ids.extend([i]*num_render) 85 | 86 | def get_name(self): 87 | dataname = 'ibrnet_llff' 88 | return dataname 89 | 90 | def define_transforms(self): 91 | transform = T.Compose([T.ToTensor(),]) # (3, h, w) 92 | # T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) 93 | return transform 94 | 95 | def __len__(self): 96 | return len(self.render_rgb_files) 97 | 98 | def __getitem__(self, idx): 99 | sample = {} 100 | rgb_file = self.render_rgb_files[idx] 101 | rgb = imageio.imread(rgb_file).astype(np.float32) / 255. 102 | render_pose = self.render_poses[idx] 103 | intrinsics = self.render_intrinsics[idx] 104 | depth_range = self.render_depth_range[idx] 105 | 106 | train_set_id = self.render_train_set_ids[idx] 107 | train_rgb_files = self.train_rgb_files[train_set_id] 108 | train_poses = self.train_poses[train_set_id] 109 | train_intrinsics = self.train_intrinsics[train_set_id] 110 | 111 | img_size = rgb.shape[:2] 112 | camera = np.concatenate((list(img_size), intrinsics.flatten(), 113 | render_pose.flatten())).astype(np.float32) 114 | 115 | if self.mode == 'train': 116 | id_render = train_rgb_files.index(rgb_file) 117 | if self.large_subsample: 118 | subsample_factor = np.random.choice(np.arange(5, 11)) 119 | else: 120 | subsample_factor = np.random.choice( 121 | np.arange(1, 4), p=[0.2, 0.45, 0.35]) 122 | 123 | if self.no_random_view: 124 | num_select = self.num_source_views 125 | else: 126 | num_select = self.num_source_views + \ 127 | np.random.randint(low=-2, high=3) 128 | else: 129 | id_render = -1 130 | subsample_factor = 1 131 | num_select = self.num_source_views 132 | 133 | nearest_pose_ids = get_nearest_pose_ids(render_pose, 134 | train_poses, 135 | min(self.num_source_views * 136 | subsample_factor, 20), 137 | tar_id=id_render, 138 | angular_dist_method='dist') 139 | nearest_pose_ids = np.random.choice(nearest_pose_ids, min( 140 | num_select, len(nearest_pose_ids)), replace=False) 141 | 142 | assert id_render not in nearest_pose_ids 143 | # occasionally include input image 144 | if np.random.choice([0, 1], p=[0.995, 0.005]) and self.mode == 'train': 145 | nearest_pose_ids[np.random.choice( 146 | len(nearest_pose_ids))] = id_render 147 | 148 | src_rgbs = [] 149 | src_cameras = [] 150 | for id in nearest_pose_ids: 151 | src_rgb = imageio.imread( 152 | train_rgb_files[id]).astype(np.float32) / 255. 153 | train_pose = train_poses[id] 154 | train_intrinsics_ = train_intrinsics[id] 155 | src_rgbs.append(src_rgb) 156 | img_size = src_rgb.shape[:2] 157 | src_camera = np.concatenate((list(img_size), train_intrinsics_.flatten(), 158 | train_pose.flatten())).astype(np.float32) 159 | src_cameras.append(src_camera) 160 | 161 | src_rgbs = np.stack(src_rgbs, axis=0) 162 | src_cameras = np.stack(src_cameras, axis=0) 163 | if self.mode == 'train': 164 | crop_h = np.random.randint(low=250, high=750) 165 | crop_h = crop_h + 1 if crop_h % 2 == 1 else crop_h 166 | crop_w = int(400 * 600 / crop_h) 167 | crop_w = crop_w + 1 if crop_w % 2 == 1 else crop_w 168 | rgb, camera, src_rgbs, src_cameras = random_crop(rgb, camera, src_rgbs, src_cameras, 169 | (crop_h, crop_w)) 170 | 171 | if self.mode == 'train' and np.random.choice([0, 1]): 172 | rgb, camera, src_rgbs, src_cameras = random_flip( 173 | rgb, camera, src_rgbs, src_cameras) 174 | 175 | depth_range = torch.tensor( 176 | [depth_range[0] * 0.9, depth_range[1] * 1.6]) 177 | 178 | sample['images'] = torch.stack( 179 | [self.transform(img) for img in [*src_rgbs, rgb]]).float() # (V, C, H, W) 180 | # ibrnet camera format: [(h, w, intr(16), extr(16))] 181 | sample['extrinsics'] = np.stack([np.linalg.inv( 182 | x[-16:].reshape(4, 4)) for x in [*src_cameras, camera]]).astype(np.float32) # (V, 4, 4) 183 | sample['intrinsics'] = np.stack([x[2:-16].reshape(4, 4)[:3, :3] 184 | for x in [*src_cameras, camera]]).astype(np.float32) # (V, 3, 3) 185 | sample['view_ids'] = np.array([*nearest_pose_ids, id_render]) 186 | sample['scene'] = f"{self.get_name()}_{rgb_file.split('/')[-3]}" 187 | sample['img_wh'] = np.array([camera[1], camera[0]]).astype('int') 188 | sample['near_fars'] = np.expand_dims(np.array([depth_range[0].item(), depth_range[1].item( 189 | )]), axis=0).repeat(sample['view_ids'].shape[0], axis=0).astype(np.float32) 190 | 191 | return sample 192 | -------------------------------------------------------------------------------- /datasets/ibrnet_mix/llff_test.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | from torchvision import transforms as T 16 | from .llff_data_utils import load_llff_data, batch_parse_llff_poses 17 | from .data_utils import random_crop, get_nearest_pose_ids 18 | from torch.utils.data import Dataset 19 | import os 20 | import numpy as np 21 | import imageio 22 | import torch 23 | import sys 24 | sys.path.append('../') 25 | 26 | 27 | class LLFFTestDataset(Dataset): 28 | def __init__(self, root_dir, split='test', scenes=(), n_views=3, random_crop=True, 29 | img_scale_factor=4, 30 | max_len=-1, 31 | **kwargs): 32 | rootdir = root_dir 33 | num_source_views = n_views 34 | mode = split 35 | llffhold = 8 36 | 37 | self.folder_path = os.path.join(root_dir, 'nerf_llff_data/') 38 | # self.args = args 39 | self.mode = mode # train / test / validation 40 | self.num_source_views = num_source_views 41 | self.random_crop = random_crop 42 | self.render_rgb_files = [] 43 | self.render_intrinsics = [] 44 | self.render_poses = [] 45 | self.render_train_set_ids = [] 46 | self.render_depth_range = [] 47 | self.max_len = max_len 48 | 49 | self.train_intrinsics = [] 50 | self.train_poses = [] 51 | self.train_rgb_files = [] 52 | self.transform = self.define_transforms() 53 | 54 | all_scenes = os.listdir(self.folder_path) 55 | if len(scenes) > 0: 56 | if isinstance(scenes, str): 57 | scenes = [scenes] 58 | else: 59 | scenes = all_scenes 60 | 61 | print("loading {} for {}".format(scenes, mode)) 62 | for i, scene in enumerate(scenes): 63 | scene_path = os.path.join(self.folder_path, scene) 64 | _, poses, bds, render_poses, i_test, rgb_files = load_llff_data( 65 | scene_path, load_imgs=False, factor=img_scale_factor) 66 | near_depth = np.min(bds) 67 | far_depth = np.max(bds) 68 | intrinsics, c2w_mats = batch_parse_llff_poses(poses) 69 | 70 | i_test = np.arange(poses.shape[0])[::llffhold] 71 | i_train = np.array([j for j in np.arange(int(poses.shape[0])) if 72 | (j not in i_test and j not in i_test)]) 73 | 74 | if mode == 'train': 75 | i_render = i_train 76 | else: 77 | i_render = i_test 78 | 79 | self.train_intrinsics.append(intrinsics[i_train]) 80 | self.train_poses.append(c2w_mats[i_train]) 81 | self.train_rgb_files.append(np.array(rgb_files)[i_train].tolist()) 82 | num_render = len(i_render) 83 | self.render_rgb_files.extend( 84 | np.array(rgb_files)[i_render].tolist()) 85 | self.render_intrinsics.extend( 86 | [intrinsics_ for intrinsics_ in intrinsics[i_render]]) 87 | self.render_poses.extend( 88 | [c2w_mat for c2w_mat in c2w_mats[i_render]]) 89 | self.render_depth_range.extend( 90 | [[near_depth, far_depth]]*num_render) 91 | self.render_train_set_ids.extend([i]*num_render) 92 | 93 | def get_name(self): 94 | dataname = 'ibrnet_llff_test' 95 | return dataname 96 | 97 | def define_transforms(self): 98 | transform = T.Compose([T.ToTensor(),]) # (3, h, w) 99 | # T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]) 100 | return transform 101 | 102 | def __len__(self): 103 | return len(self.render_rgb_files) if self.max_len <= 0 else self.max_len 104 | 105 | def __getitem__(self, idx): 106 | sample = {} 107 | 108 | rgb_file = self.render_rgb_files[idx] 109 | rgb = imageio.imread(rgb_file).astype(np.float32) / 255. 110 | render_pose = self.render_poses[idx] 111 | intrinsics = self.render_intrinsics[idx] 112 | depth_range = self.render_depth_range[idx] 113 | 114 | train_set_id = self.render_train_set_ids[idx] 115 | train_rgb_files = self.train_rgb_files[train_set_id] 116 | train_poses = self.train_poses[train_set_id] 117 | train_intrinsics = self.train_intrinsics[train_set_id] 118 | 119 | img_size = rgb.shape[:2] 120 | camera = np.concatenate((list(img_size), intrinsics.flatten(), 121 | render_pose.flatten())).astype(np.float32) 122 | 123 | if self.mode == 'train': 124 | if rgb_file in train_rgb_files: 125 | id_render = train_rgb_files.index(rgb_file) 126 | else: 127 | id_render = -1 128 | subsample_factor = np.random.choice( 129 | np.arange(1, 4), p=[0.2, 0.45, 0.35]) 130 | num_select = self.num_source_views + \ 131 | np.random.randint(low=-2, high=2) 132 | else: 133 | id_render = -1 134 | subsample_factor = 1 135 | num_select = self.num_source_views 136 | 137 | nearest_pose_ids = get_nearest_pose_ids(render_pose, 138 | train_poses, 139 | min(self.num_source_views * 140 | subsample_factor, 28), 141 | tar_id=id_render, 142 | angular_dist_method='dist') 143 | nearest_pose_ids = np.random.choice(nearest_pose_ids, min( 144 | num_select, len(nearest_pose_ids)), replace=False) 145 | 146 | assert id_render not in nearest_pose_ids 147 | # occasionally include input image 148 | if np.random.choice([0, 1], p=[0.995, 0.005]) and self.mode == 'train': 149 | nearest_pose_ids[np.random.choice( 150 | len(nearest_pose_ids))] = id_render 151 | 152 | src_rgbs = [] 153 | src_cameras = [] 154 | for id in nearest_pose_ids: 155 | src_rgb = imageio.imread( 156 | train_rgb_files[id]).astype(np.float32) / 255. 157 | train_pose = train_poses[id] 158 | train_intrinsics_ = train_intrinsics[id] 159 | 160 | src_rgbs.append(src_rgb) 161 | img_size = src_rgb.shape[:2] 162 | src_camera = np.concatenate((list(img_size), train_intrinsics_.flatten(), 163 | train_pose.flatten())).astype(np.float32) 164 | src_cameras.append(src_camera) 165 | 166 | src_rgbs = np.stack(src_rgbs, axis=0) 167 | src_cameras = np.stack(src_cameras, axis=0) 168 | if self.mode == 'train' and self.random_crop: 169 | crop_h = np.random.randint(low=250, high=750) 170 | crop_h = crop_h + 1 if crop_h % 2 == 1 else crop_h 171 | crop_w = int(400 * 600 / crop_h) 172 | crop_w = crop_w + 1 if crop_w % 2 == 1 else crop_w 173 | rgb, camera, src_rgbs, src_cameras = random_crop(rgb, camera, src_rgbs, src_cameras, 174 | (crop_h, crop_w)) 175 | 176 | depth_range = torch.tensor( 177 | [depth_range[0] * 0.9, depth_range[1] * 1.6]) 178 | 179 | sample['images'] = torch.stack( 180 | [self.transform(img) for img in [*src_rgbs, rgb]]).float() # (V, C, H, W) 181 | # ibrnet camera format: [(h, w, intr(16), extr(16))] 182 | sample['extrinsics'] = np.stack([np.linalg.inv( 183 | x[-16:].reshape(4, 4)) for x in [*src_cameras, camera]]).astype(np.float32) # (V, 4, 4) 184 | sample['intrinsics'] = np.stack([x[2:-16].reshape(4, 4)[:3, :3] 185 | for x in [*src_cameras, camera]]).astype(np.float32) # (V, 3, 3) 186 | sample['view_ids'] = np.array([*nearest_pose_ids, id_render]) 187 | sample['scene'] = f"{self.get_name()}_{rgb_file.split('/')[-3]}" 188 | sample['img_wh'] = np.array([camera[1], camera[0]]).astype('int') 189 | sample['near_fars'] = np.expand_dims(np.array([depth_range[0].item(), depth_range[1].item( 190 | )]), axis=0).repeat(sample['view_ids'].shape[0], axis=0).astype(np.float32) 191 | 192 | # c2ws for all train views, required for rendering videos 193 | c2ws_all = [x[-16:].reshape(4, 4) for x in train_poses] 194 | sample['c2ws_all'] = np.stack(c2ws_all).astype(np.float32) 195 | 196 | return sample 197 | -------------------------------------------------------------------------------- /datasets/ibrnet_mix/realestate.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | 16 | import os 17 | import numpy as np 18 | import imageio 19 | import torch 20 | from torch.utils.data import Dataset 21 | import glob 22 | import cv2 23 | from torchvision import transforms as T 24 | 25 | 26 | class Camera(object): 27 | def __init__(self, entry): 28 | fx, fy, cx, cy = entry[1:5] 29 | self.intrinsics = np.array([[fx, 0, cx, 0], 30 | [0, fy, cy, 0], 31 | [0, 0, 1, 0], 32 | [0, 0, 0, 1]]) 33 | w2c_mat = np.array(entry[7:]).reshape(3, 4) 34 | w2c_mat_4x4 = np.eye(4) 35 | w2c_mat_4x4[:3, :] = w2c_mat 36 | self.w2c_mat = w2c_mat_4x4 37 | self.c2w_mat = np.linalg.inv(w2c_mat_4x4) 38 | 39 | 40 | def unnormalize_intrinsics(intrinsics, h, w): 41 | intrinsics[0] *= w 42 | intrinsics[1] *= h 43 | return intrinsics 44 | 45 | 46 | def parse_pose_file(file): 47 | f = open(file, 'r') 48 | cam_params = {} 49 | for i, line in enumerate(f): 50 | if i == 0: 51 | continue 52 | entry = [float(x) for x in line.split()] 53 | id = int(entry[0]) 54 | cam_params[id] = Camera(entry) 55 | return cam_params 56 | 57 | 58 | class RealEstateDataset(Dataset): 59 | def __init__(self, root_dir, split='train', n_views=3, 60 | no_random_view=False, 61 | large_subsample=False, 62 | full_set=False, 63 | frame_dir=None, 64 | use_all_scenes=False, 65 | **kwargs): 66 | self.use_all_scenes = use_all_scenes 67 | 68 | if full_set: 69 | self.folder_path = os.path.join(os.path.dirname( 70 | root_dir), 'RealEstate10KFull720p/data/') 71 | else: 72 | self.folder_path = os.path.join(root_dir, 'RealEstate10K-subset/') 73 | 74 | self.mode = split # train / test / validation 75 | self.num_source_views = n_views 76 | self.target_h, self.target_w = 450, 800 77 | assert split in ['train'], "real estate only for training" 78 | self.frame_dir = frame_dir if frame_dir is not None else 'frames' 79 | if use_all_scenes: 80 | self.scene_path_list = glob.glob(os.path.join( 81 | self.folder_path, 'frames_camera_*', split, '*')) 82 | elif full_set: 83 | self.scene_path_list = glob.glob(os.path.join( 84 | self.folder_path, self.frame_dir, split, '*')) 85 | else: 86 | self.scene_path_list = glob.glob(os.path.join( 87 | self.folder_path, split, self.frame_dir, '*')) 88 | self.transform = self.define_transforms() 89 | 90 | self.no_random_view = no_random_view 91 | self.large_subsample = large_subsample 92 | 93 | all_rgb_files = [] 94 | all_timestamps = [] 95 | for i, scene_path in enumerate(self.scene_path_list): 96 | rgb_files = [os.path.join(scene_path, f) 97 | for f in sorted(os.listdir(scene_path))] 98 | if len(rgb_files) < 10: 99 | # print('omitting {}, too few images'.format(os.path.basename(scene_path))) 100 | continue 101 | timestamps = [int(os.path.basename(rgb_file).split('.')[0]) 102 | for rgb_file in rgb_files] 103 | sorted_ids = np.argsort(timestamps) 104 | all_rgb_files.append(np.array(rgb_files)[sorted_ids]) 105 | all_timestamps.append(np.array(timestamps)[sorted_ids]) 106 | 107 | index = np.arange(len(all_rgb_files)) 108 | self.all_rgb_files = np.array(all_rgb_files)[index] 109 | self.all_timestamps = np.array(all_timestamps)[index] 110 | 111 | def get_name(self): 112 | dataname = 'ibrnet_realestate' 113 | return dataname 114 | 115 | def define_transforms(self): 116 | transform = T.Compose([T.ToTensor()]) # (3, h, w) 117 | return transform 118 | 119 | def __len__(self): 120 | return len(self.all_rgb_files) 121 | 122 | def __getitem__(self, idx): 123 | sample = {} 124 | rgb_files = self.all_rgb_files[idx] 125 | timestamps = self.all_timestamps[idx] 126 | 127 | assert (timestamps == sorted(timestamps)).all() 128 | num_frames = len(rgb_files) 129 | 130 | if self.large_subsample: 131 | window_size = np.random.randint(32, 96) 132 | else: 133 | window_size = 32 134 | shift = np.random.randint(low=-1, high=2) 135 | id_render = np.random.randint(low=4, high=num_frames-4-1) 136 | 137 | right_bound = min(id_render + window_size + shift, num_frames-1) 138 | left_bound = max(0, right_bound - 2 * window_size) 139 | candidate_ids = np.arange(left_bound, right_bound) 140 | # remove the query frame itself with high probability 141 | if np.random.choice([0, 1], p=[0.01, 0.99]): 142 | candidate_ids = candidate_ids[candidate_ids != id_render] 143 | 144 | id_feat = np.random.choice(candidate_ids, size=min(self.num_source_views, len(candidate_ids)), 145 | replace=False) 146 | 147 | if len(id_feat) < self.num_source_views: 148 | return self.__getitem__(np.random.randint(0, len(self.all_rgb_files))) 149 | 150 | rgb_file = rgb_files[id_render] 151 | rgb = imageio.imread(rgb_files[id_render]) 152 | # resize the image to target size 153 | rgb = cv2.resize(rgb, dsize=(self.target_w, self.target_h), 154 | interpolation=cv2.INTER_AREA) 155 | rgb = rgb.astype(np.float32) / 255. 156 | 157 | if self.use_all_scenes: 158 | camera_file = os.path.dirname(rgb_file).replace(os.path.basename( 159 | os.path.dirname(os.path.dirname(os.path.dirname(rgb_file)))), 'cameras') + '.txt' 160 | else: 161 | camera_file = os.path.dirname(rgb_file).replace( 162 | self.frame_dir, 'cameras') + '.txt' 163 | cam_params = parse_pose_file(camera_file) 164 | cam_param = cam_params[timestamps[id_render]] 165 | 166 | img_size = rgb.shape[:2] 167 | camera = np.concatenate((list(img_size), 168 | unnormalize_intrinsics( 169 | cam_param.intrinsics, self.target_h, self.target_w).flatten(), 170 | cam_param.c2w_mat.flatten())).astype(np.float32) 171 | 172 | depth_range = torch.tensor([1., 100.]) 173 | 174 | src_rgbs = [] 175 | src_cameras = [] 176 | for id in id_feat: 177 | src_rgb = imageio.imread(rgb_files[id]) 178 | # resize the image to target size 179 | src_rgb = cv2.resize(src_rgb, dsize=( 180 | self.target_w, self.target_h), interpolation=cv2.INTER_AREA) 181 | src_rgb = src_rgb.astype(np.float32) / 255. 182 | src_rgbs.append(src_rgb) 183 | 184 | img_size = src_rgb.shape[:2] 185 | cam_param = cam_params[timestamps[id]] 186 | src_camera = np.concatenate((list(img_size), 187 | unnormalize_intrinsics(cam_param.intrinsics, 188 | self.target_h, self.target_w).flatten(), 189 | cam_param.c2w_mat.flatten())).astype(np.float32) 190 | src_cameras.append(src_camera) 191 | 192 | sample['images'] = torch.stack( 193 | [self.transform(img) for img in [*src_rgbs, rgb]]).float() # (V, C, H, W) 194 | # ibrnet camera format: [(h, w, intr(16), extr(16))] 195 | sample['extrinsics'] = np.stack([np.linalg.inv( 196 | x[-16:].reshape(4, 4)) for x in [*src_cameras, camera]]).astype(np.float32) # (V, 4, 4) 197 | sample['intrinsics'] = np.stack([x[2:-16].reshape(4, 4)[:3, :3] 198 | for x in [*src_cameras, camera]]).astype(np.float32) # (V, 3, 3) 199 | sample['view_ids'] = np.array([*id_feat, id_render]) 200 | sample['scene'] = f"{self.get_name()}_{rgb_file.split('/')[-2]}" 201 | sample['img_wh'] = np.array([camera[1], camera[0]]).astype('int') 202 | sample['near_fars'] = np.expand_dims(np.array([depth_range[0].item(), depth_range[1].item( 203 | )]), axis=0).repeat(sample['view_ids'].shape[0], axis=0).astype(np.float32) 204 | 205 | return sample 206 | -------------------------------------------------------------------------------- /datasets/mipnerf360.py: -------------------------------------------------------------------------------- 1 | # Copyright 2020 Google LLC 2 | # 3 | # Licensed under the Apache License, Version 2.0 (the "License"); 4 | # you may not use this file except in compliance with the License. 5 | # You may obtain a copy of the License at 6 | # 7 | # https://www.apache.org/licenses/LICENSE-2.0 8 | # 9 | # Unless required by applicable law or agreed to in writing, software 10 | # distributed under the License is distributed on an "AS IS" BASIS, 11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 | # See the License for the specific language governing permissions and 13 | # limitations under the License. 14 | 15 | import os 16 | import numpy as np 17 | import imageio 18 | import torch 19 | from torch.utils.data import Dataset 20 | from .ibrnet_mix.data_utils import random_crop, random_flip, get_nearest_pose_ids 21 | from .ibrnet_mix.llff_data_utils import load_llff_data, batch_parse_llff_poses 22 | from torchvision import transforms as T 23 | 24 | 25 | class MipNeRF360Dataset(Dataset): 26 | def __init__(self, root_dir, split='test', n_views=3, 27 | downsample_factor=8, 28 | test_views_method='nearest', 29 | view_selection_stride=1, 30 | test_scene_name=None, 31 | max_len=-1, 32 | **kwargs): 33 | num_source_views = n_views 34 | llffhold = 8 35 | 36 | self.mode = split # train / test / validation 37 | self.num_source_views = num_source_views 38 | self.render_rgb_files = [] 39 | self.render_intrinsics = [] 40 | self.render_poses = [] 41 | self.render_train_set_ids = [] 42 | self.render_depth_range = [] 43 | 44 | self.train_intrinsics = [] 45 | self.train_poses = [] 46 | self.train_rgb_files = [] 47 | self.transform = self.define_transforms() 48 | self.test_views_method = test_views_method 49 | self.view_selection_stride = view_selection_stride 50 | self.max_len = max_len 51 | 52 | scenes = sorted(os.listdir(root_dir)) 53 | # some scenes are not available, as .txt files 54 | scenes = [scene for scene in scenes if os.path.isdir( 55 | os.path.join(root_dir, scene))] 56 | # ['bicycle', 'bonsai', 'counter', 'garden', 'kitchen', 'room', 'stump'] 57 | 58 | self.test_scene_name = test_scene_name 59 | 60 | if self.test_scene_name is not None: 61 | scenes = [self.test_scene_name] 62 | print(scenes[0]) 63 | 64 | for i, scene in enumerate(scenes): 65 | if scene == 'stump': 66 | continue 67 | 68 | scene_path = os.path.join(root_dir, scene) 69 | 70 | if scene in ['bicycle']: 71 | _, poses, bds, render_poses, i_test, rgb_files = load_llff_data(scene_path, load_imgs=False, factor=downsample_factor, 72 | subsample_factor=2 73 | ) 74 | else: 75 | _, poses, bds, render_poses, i_test, rgb_files = load_llff_data( 76 | scene_path, load_imgs=False, factor=downsample_factor) 77 | 78 | near_depth = np.min(bds) 79 | far_depth = np.max(bds) 80 | intrinsics, c2w_mats = batch_parse_llff_poses(poses) 81 | 82 | if self.mode == 'train': 83 | i_train = np.array(np.arange(int(poses.shape[0]))) 84 | i_render = i_train 85 | else: 86 | i_test = np.arange(poses.shape[0])[::llffhold] 87 | 88 | i_train = np.array([j for j in np.arange(int(poses.shape[0])) if 89 | (j not in i_test and j not in i_test)]) 90 | i_render = i_test 91 | 92 | self.train_intrinsics.append(intrinsics[i_train]) 93 | self.train_poses.append(c2w_mats[i_train]) 94 | self.train_rgb_files.append(np.array(rgb_files)[i_train].tolist()) 95 | num_render = len(i_render) 96 | self.render_rgb_files.extend( 97 | np.array(rgb_files)[i_render].tolist()) 98 | self.render_intrinsics.extend( 99 | [intrinsics_ for intrinsics_ in intrinsics[i_render]]) 100 | self.render_poses.extend( 101 | [c2w_mat for c2w_mat in c2w_mats[i_render]]) 102 | self.render_depth_range.extend( 103 | [[near_depth, far_depth]]*num_render) 104 | self.render_train_set_ids.extend([i]*num_render) 105 | 106 | def get_name(self): 107 | dataname = 'mipnerf360' 108 | return dataname 109 | 110 | def define_transforms(self): 111 | transform = T.Compose([T.ToTensor(),]) # (3, h, w) 112 | return transform 113 | 114 | def __len__(self): 115 | return len(self.render_rgb_files) if self.max_len <= 0 else self.max_len 116 | 117 | def __getitem__(self, idx): 118 | sample = {} 119 | rgb_file = self.render_rgb_files[idx] 120 | rgb = imageio.imread(rgb_file).astype(np.float32) / 255. 121 | render_pose = self.render_poses[idx] 122 | intrinsics = self.render_intrinsics[idx] 123 | depth_range = self.render_depth_range[idx] 124 | 125 | train_set_id = self.render_train_set_ids[idx] 126 | train_rgb_files = self.train_rgb_files[train_set_id] 127 | train_poses = self.train_poses[train_set_id] 128 | train_intrinsics = self.train_intrinsics[train_set_id] 129 | 130 | img_size = rgb.shape[:2] 131 | camera = np.concatenate((list(img_size), intrinsics.flatten(), 132 | render_pose.flatten())).astype(np.float32) 133 | 134 | if self.mode == 'train': 135 | id_render = train_rgb_files.index(rgb_file) 136 | subsample_factor = np.random.choice( 137 | np.arange(1, 4), p=[0.2, 0.45, 0.35]) 138 | num_select = self.num_source_views + \ 139 | np.random.randint(low=-2, high=3) 140 | else: 141 | id_render = -1 142 | subsample_factor = 1 143 | num_select = self.num_source_views 144 | 145 | nearest_pose_ids = get_nearest_pose_ids(render_pose, 146 | train_poses, 147 | min(self.num_source_views * 148 | subsample_factor, 20), 149 | tar_id=id_render, 150 | angular_dist_method='dist', 151 | view_selection_method=self.test_views_method, 152 | view_selection_stride=self.view_selection_stride, 153 | ) 154 | nearest_pose_ids = np.random.choice(nearest_pose_ids, min( 155 | num_select, len(nearest_pose_ids)), replace=False) 156 | 157 | assert id_render not in nearest_pose_ids 158 | # occasionally include input image 159 | if np.random.choice([0, 1], p=[0.995, 0.005]) and self.mode == 'train': 160 | nearest_pose_ids[np.random.choice( 161 | len(nearest_pose_ids))] = id_render 162 | 163 | src_rgbs = [] 164 | src_cameras = [] 165 | for id in nearest_pose_ids: 166 | src_rgb = imageio.imread( 167 | train_rgb_files[id]).astype(np.float32) / 255. 168 | train_pose = train_poses[id] 169 | train_intrinsics_ = train_intrinsics[id] 170 | src_rgbs.append(src_rgb) 171 | img_size = src_rgb.shape[:2] 172 | src_camera = np.concatenate((list(img_size), train_intrinsics_.flatten(), 173 | train_pose.flatten())).astype(np.float32) 174 | src_cameras.append(src_camera) 175 | 176 | src_rgbs = np.stack(src_rgbs, axis=0) 177 | src_cameras = np.stack(src_cameras, axis=0) 178 | if self.mode == 'train': 179 | crop_h = np.random.randint(low=250, high=750) 180 | crop_h = crop_h + 1 if crop_h % 2 == 1 else crop_h 181 | crop_w = int(400 * 600 / crop_h) 182 | crop_w = crop_w + 1 if crop_w % 2 == 1 else crop_w 183 | rgb, camera, src_rgbs, src_cameras = random_crop(rgb, camera, src_rgbs, src_cameras, 184 | (crop_h, crop_w)) 185 | 186 | if self.mode == 'train' and np.random.choice([0, 1]): 187 | rgb, camera, src_rgbs, src_cameras = random_flip( 188 | rgb, camera, src_rgbs, src_cameras) 189 | 190 | depth_range = torch.tensor( 191 | [depth_range[0] * 0.9, depth_range[1] * 1.6]) 192 | 193 | sample['images'] = torch.stack( 194 | [self.transform(img) for img in [*src_rgbs, rgb]]).float() # (V, C, H, W) 195 | # ibrnet camera format: [(h, w, intr(16), extr(16))] 196 | sample['extrinsics'] = np.stack([np.linalg.inv( 197 | x[-16:].reshape(4, 4)) for x in [*src_cameras, camera]]).astype(np.float32) # (V, 4, 4) 198 | sample['intrinsics'] = np.stack([x[2:-16].reshape(4, 4)[:3, :3] 199 | for x in [*src_cameras, camera]]).astype(np.float32) # (V, 3, 3) 200 | sample['view_ids'] = np.array([*nearest_pose_ids, id_render]) 201 | sample['scene'] = f"{self.get_name()}_{rgb_file.split('/')[-3]}" 202 | sample['img_wh'] = np.array([camera[1], camera[0]]).astype('int') 203 | sample['near_fars'] = np.expand_dims(np.array([depth_range[0].item(), depth_range[1].item( 204 | )]), axis=0).repeat(sample['view_ids'].shape[0], axis=0).astype(np.float32) 205 | 206 | return sample 207 | -------------------------------------------------------------------------------- /datasets/transforms.py: -------------------------------------------------------------------------------- 1 | import numpy as np 2 | 3 | import torch 4 | import torchvision 5 | import torchvision.transforms as T 6 | import torch.nn.functional as F 7 | 8 | 9 | class RandomCrop(object): 10 | def __init__(self, crop_height, crop_width, fixed_crop=False, 11 | with_batch_dim=False, 12 | ): 13 | self.crop_height = crop_height 14 | self.crop_width = crop_width 15 | self.with_batch_dim = with_batch_dim 16 | 17 | # center crop, debug purpose 18 | self.fixed_crop = fixed_crop 19 | 20 | def __call__(self, sample): 21 | # [V, 3, H, W] or [B, V, 3, H, W] 22 | size_index = 3 if self.with_batch_dim else 2 23 | ori_height, ori_width = sample['images'].shape[size_index:] 24 | assert self.crop_height <= ori_height and self.crop_width <= ori_width 25 | 26 | if self.fixed_crop: 27 | offset_x = (ori_width - self.crop_width) // 2 28 | offset_y = (ori_height - self.crop_height) // 2 29 | else: 30 | # random crop 31 | offset_x = np.random.randint(ori_width - self.crop_width + 1) 32 | offset_y = np.random.randint(ori_height - self.crop_height + 1) 33 | 34 | # crop images 35 | if self.with_batch_dim: 36 | sample['images'] = sample['images'][:, :, :, offset_y:offset_y + self.crop_height, 37 | offset_x:offset_x + self.crop_width] 38 | else: 39 | sample['images'] = sample['images'][:, :, offset_y:offset_y + self.crop_height, 40 | offset_x:offset_x + self.crop_width] 41 | 42 | # update intrinsics 43 | if isinstance(sample['intrinsics'], torch.Tensor): 44 | intrinsics = sample['intrinsics'].clone() # [V, 3, 3] 45 | else: 46 | intrinsics = sample['intrinsics'].copy() # [V, 3, 3] 47 | 48 | if self.with_batch_dim: 49 | intrinsics[:, :, 0, 2] = intrinsics[:, :, 0, 2] - offset_x 50 | intrinsics[:, :, 1, 2] = intrinsics[:, :, 1, 2] - offset_y 51 | else: 52 | intrinsics[:, 0, 2] = intrinsics[:, 0, 2] - offset_x 53 | intrinsics[:, 1, 2] = intrinsics[:, 1, 2] - offset_y 54 | 55 | sample['intrinsics'] = intrinsics 56 | 57 | # update size 58 | if isinstance(sample['img_wh'], torch.Tensor): 59 | img_wh = sample['img_wh'].clone() 60 | else: 61 | img_wh = sample['img_wh'].copy() 62 | 63 | if self.with_batch_dim: 64 | img_wh[:, 0] = self.crop_width 65 | img_wh[:, 1] = self.crop_height 66 | else: 67 | img_wh[0] = self.crop_width 68 | img_wh[1] = self.crop_height 69 | 70 | sample['img_wh'] = img_wh 71 | 72 | # crop depth 73 | if 'depth' in sample: 74 | sample['depth'] = sample['depth'][offset_y:offset_y + 75 | self.crop_height, offset_x:offset_x + self.crop_width] 76 | 77 | if 'depth_gt' in sample: 78 | sample['depth_gt'] = sample['depth_gt'][offset_y:offset_y + 79 | self.crop_height, offset_x:offset_x + self.crop_width] 80 | 81 | return sample 82 | 83 | 84 | class RandomResize(object): 85 | def __init__(self, prob=0.5, 86 | crop_height=256, 87 | crop_width=384, 88 | max_crop_height=None, 89 | max_crop_width=None, 90 | min_scale=0.8, 91 | max_scale=1.2, 92 | min_crop_height=None, 93 | min_crop_width=None, 94 | ): 95 | self.prob = prob 96 | self.crop_height = crop_height 97 | self.crop_width = crop_width 98 | self.min_scale = min_scale 99 | self.max_scale = max_scale 100 | self.max_crop_height = max_crop_height 101 | self.max_crop_width = max_crop_width 102 | self.min_crop_height = min_crop_height 103 | self.min_crop_width = min_crop_width 104 | 105 | def __call__(self, sample): 106 | if np.random.rand() < self.prob: 107 | ori_height, ori_width = sample['images'].shape[2:] 108 | # print(ori_height, ori_width) 109 | 110 | if self.max_crop_height is not None and self.max_crop_width is not None: 111 | # recompute min_scale and max_scale, used for mvimgnet dataset 112 | if ori_height < ori_width: 113 | min_scale = max((self.max_crop_height + 64) / 114 | ori_height, (self.max_crop_width + 64) / ori_width) 115 | max_scale = max(min((self.max_crop_height + 128) / ori_height, 116 | (self.max_crop_width + 128) / ori_width), min_scale + 0.01) 117 | else: 118 | min_scale = max((self.max_crop_width + 64) / ori_height, 119 | (self.max_crop_height + 64) / ori_width) 120 | max_scale = max(min((self.max_crop_width + 128) / ori_height, 121 | (self.max_crop_height + 128) / ori_width), min_scale + 0.01) 122 | # print(min_scale, max_scale) 123 | 124 | scale_factor = np.random.uniform(min_scale, max_scale) 125 | elif self.min_crop_height is not None and self.min_crop_width is not None: 126 | # recompute min_scale and max_scale, used for mvimgnet dataset 127 | if ori_height < ori_width: 128 | min_scale = max((self.min_crop_height + 64) / 129 | ori_height, (self.min_crop_width + 64) / ori_width) 130 | max_scale = max(min((self.min_crop_height + 128) / ori_height, 131 | (self.min_crop_width + 128) / ori_width), min_scale + 0.05) 132 | else: 133 | min_scale = max((self.min_crop_width + 64) / ori_height, 134 | (self.min_crop_height + 64) / ori_width) 135 | max_scale = max(min((self.min_crop_width + 128) / ori_height, 136 | (self.min_crop_height + 128) / ori_width), min_scale + 0.05) 137 | 138 | scale_factor = np.random.uniform(min_scale, max_scale) 139 | else: 140 | min_scale_factor = np.maximum( 141 | self.crop_height / ori_height, self.crop_width / ori_width) 142 | scale_factor = np.random.uniform( 143 | self.min_scale, self.max_scale) 144 | scale_factor = np.maximum(min_scale_factor, scale_factor) 145 | 146 | new_height = int(ori_height * scale_factor) 147 | new_width = int(ori_width * scale_factor) 148 | 149 | sample['images'] = F.interpolate(sample['images'], size=( 150 | new_height, new_width), mode='bilinear', align_corners=True) 151 | 152 | if 'depth' in sample: 153 | sample['depth'] = F.interpolate(sample['depth'].unsqueeze(0).unsqueeze(0), size=( 154 | new_height, new_width), mode='nearest', align_corners=True).suqeeze(0).squeeze(0) # [H, W] 155 | 156 | if 'depth_gt' in sample: 157 | sample['depth_gt'] = F.interpolate(sample['depth_gt'].unsqueeze(0).unsqueeze(0), size=( 158 | new_height, new_width), mode='nearest', align_corners=True).suqeeze(0).squeeze(0) # [H, W] 159 | 160 | # update intrinsics 161 | intrinsics = sample['intrinsics'].copy() # [V, 3, 3] 162 | intrinsics[:, 0, :] * scale_factor 163 | intrinsics[:, 1, :] * scale_factor 164 | 165 | sample['intrinsics'] = intrinsics 166 | 167 | # update size 168 | sample['img_wh'] = np.array([new_width, new_height]).astype('int') 169 | 170 | return sample 171 | 172 | else: 173 | return sample 174 | -------------------------------------------------------------------------------- /loss.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.nn as nn 3 | 4 | import lpips 5 | 6 | 7 | # https://github.com/nianticlabs/monodepth2/blob/master/layers.py 8 | class SSIM(nn.Module): 9 | """Layer to compute the SSIM loss between a pair of images 10 | """ 11 | 12 | def __init__(self, patch_size=3): 13 | super(SSIM, self).__init__() 14 | self.mu_x_pool = nn.AvgPool2d(patch_size, 1) 15 | self.mu_y_pool = nn.AvgPool2d(patch_size, 1) 16 | self.sig_x_pool = nn.AvgPool2d(patch_size, 1) 17 | self.sig_y_pool = nn.AvgPool2d(patch_size, 1) 18 | self.sig_xy_pool = nn.AvgPool2d(patch_size, 1) 19 | 20 | self.refl = nn.ReflectionPad2d(patch_size // 2) 21 | 22 | self.C1 = 0.01 ** 2 23 | self.C2 = 0.03 ** 2 24 | 25 | def forward(self, x, y): 26 | x = self.refl(x) 27 | y = self.refl(y) 28 | 29 | mu_x = self.mu_x_pool(x) 30 | mu_y = self.mu_y_pool(y) 31 | 32 | sigma_x = self.sig_x_pool(x ** 2) - mu_x ** 2 33 | sigma_y = self.sig_y_pool(y ** 2) - mu_y ** 2 34 | sigma_xy = self.sig_xy_pool(x * y) - mu_x * mu_y 35 | 36 | SSIM_n = (2 * mu_x * mu_y + self.C1) * (2 * sigma_xy + self.C2) 37 | SSIM_d = (mu_x ** 2 + mu_y ** 2 + self.C1) * \ 38 | (sigma_x + sigma_y + self.C2) 39 | 40 | return torch.clamp((1 - SSIM_n / SSIM_d) / 2, 0, 1) 41 | 42 | 43 | def lpips_loss_func(pred, gt): 44 | # image should be RGB, IMPORTANT: normalized to [-1,1] 45 | assert pred.dim() == 4 and pred.size() == gt.size() # [B, 3, H, W] 46 | assert pred.min() >= -1 and pred.max() <= 1 and gt.min() >= -1 and gt.max() <= 1 47 | 48 | loss_func = lpips.LPIPS(net='vgg').to(pred.device) 49 | for param in loss_func.parameters(): 50 | param.requires_grad = False 51 | 52 | loss = loss_func(pred, gt) 53 | 54 | return loss 55 | -------------------------------------------------------------------------------- /misc/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/autonomousvision/murf/57d564203820815feced49045af0ea3fced04463/misc/__init__.py -------------------------------------------------------------------------------- /misc/depth_viz.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.utils.data 3 | import numpy as np 4 | import torchvision.utils as vutils 5 | import cv2 6 | from matplotlib.cm import get_cmap 7 | import matplotlib as mpl 8 | import matplotlib.cm as cm 9 | 10 | 11 | def viz_depth_tensor(disp, return_numpy=False, colormap='plasma'): 12 | # visualize inverse depth 13 | assert isinstance(disp, torch.Tensor) 14 | 15 | disp = disp.numpy() 16 | vmax = np.percentile(disp, 95) 17 | normalizer = mpl.colors.Normalize(vmin=disp.min(), vmax=vmax) 18 | mapper = cm.ScalarMappable(norm=normalizer, cmap=colormap) 19 | colormapped_im = (mapper.to_rgba(disp)[:, :, :3] * 255).astype(np.uint8) # [H, W, 3] 20 | 21 | if return_numpy: 22 | return colormapped_im 23 | 24 | viz = torch.from_numpy(colormapped_im).permute(2, 0, 1) # [3, H, W] 25 | 26 | return viz 27 | 28 | -------------------------------------------------------------------------------- /misc/dist_utils.py: -------------------------------------------------------------------------------- 1 | # Copyright (c) OpenMMLab. All rights reserved. 2 | # https://github.com/open-mmlab/mmcv/blob/7540cf73ac7e5d1e14d0ffbd9b6759e83929ecfc/mmcv/runner/dist_utils.py 3 | 4 | import os 5 | import subprocess 6 | 7 | import torch 8 | import torch.multiprocessing as mp 9 | from torch import distributed as dist 10 | 11 | 12 | def init_dist(launcher, backend='nccl', **kwargs): 13 | if mp.get_start_method(allow_none=True) is None: 14 | mp.set_start_method('spawn') 15 | if launcher == 'pytorch': 16 | _init_dist_pytorch(backend, **kwargs) 17 | elif launcher == 'mpi': 18 | _init_dist_mpi(backend, **kwargs) 19 | elif launcher == 'slurm': 20 | _init_dist_slurm(backend, **kwargs) 21 | else: 22 | raise ValueError(f'Invalid launcher type: {launcher}') 23 | 24 | 25 | def _init_dist_pytorch(backend, **kwargs): 26 | # TODO: use local_rank instead of rank % num_gpus 27 | rank = int(os.environ['RANK']) 28 | num_gpus = torch.cuda.device_count() 29 | torch.cuda.set_device(rank % num_gpus) 30 | dist.init_process_group(backend=backend, **kwargs) 31 | 32 | 33 | def _init_dist_mpi(backend, **kwargs): 34 | # TODO: use local_rank instead of rank % num_gpus 35 | rank = int(os.environ['OMPI_COMM_WORLD_RANK']) 36 | num_gpus = torch.cuda.device_count() 37 | torch.cuda.set_device(rank % num_gpus) 38 | dist.init_process_group(backend=backend, **kwargs) 39 | 40 | 41 | def _init_dist_slurm(backend, port=None): 42 | """Initialize slurm distributed training environment. 43 | If argument ``port`` is not specified, then the master port will be system 44 | environment variable ``MASTER_PORT``. If ``MASTER_PORT`` is not in system 45 | environment variable, then a default port ``29500`` will be used. 46 | Args: 47 | backend (str): Backend of torch.distributed. 48 | port (int, optional): Master port. Defaults to None. 49 | """ 50 | proc_id = int(os.environ['SLURM_PROCID']) 51 | ntasks = int(os.environ['SLURM_NTASKS']) 52 | node_list = os.environ['SLURM_NODELIST'] 53 | num_gpus = torch.cuda.device_count() 54 | torch.cuda.set_device(proc_id % num_gpus) 55 | addr = subprocess.getoutput( 56 | f'scontrol show hostname {node_list} | head -n1') 57 | # specify master port 58 | if port is not None: 59 | os.environ['MASTER_PORT'] = str(port) 60 | elif 'MASTER_PORT' in os.environ: 61 | pass # use MASTER_PORT in the environment variable 62 | else: 63 | # 29500 is torch.distributed default port 64 | os.environ['MASTER_PORT'] = '29500' 65 | # use MASTER_ADDR in the environment variable if it already exists 66 | if 'MASTER_ADDR' not in os.environ: 67 | os.environ['MASTER_ADDR'] = addr 68 | os.environ['WORLD_SIZE'] = str(ntasks) 69 | os.environ['LOCAL_RANK'] = str(proc_id % num_gpus) 70 | os.environ['RANK'] = str(proc_id) 71 | dist.init_process_group(backend=backend) 72 | 73 | 74 | def get_dist_info(): 75 | # if (TORCH_VERSION != 'parrots' 76 | # and digit_version(TORCH_VERSION) < digit_version('1.0')): 77 | # initialized = dist._initialized 78 | # else: 79 | if dist.is_available(): 80 | initialized = dist.is_initialized() 81 | else: 82 | initialized = False 83 | if initialized: 84 | rank = dist.get_rank() 85 | world_size = dist.get_world_size() 86 | else: 87 | rank = 0 88 | world_size = 1 89 | return rank, world_size 90 | 91 | 92 | # from DETR repo 93 | def setup_for_distributed(is_master): 94 | """ 95 | This function disables printing when not in master process 96 | """ 97 | import builtins as __builtin__ 98 | builtin_print = __builtin__.print 99 | 100 | def print(*args, **kwargs): 101 | force = kwargs.pop('force', False) 102 | if is_master or force: 103 | builtin_print(*args, **kwargs) 104 | 105 | __builtin__.print = print 106 | -------------------------------------------------------------------------------- /misc/flow_io.py: -------------------------------------------------------------------------------- 1 | from __future__ import absolute_import 2 | from __future__ import division 3 | from __future__ import print_function 4 | 5 | import numpy as np 6 | import re 7 | from PIL import Image 8 | import sys 9 | import cv2 10 | import json 11 | import os 12 | 13 | 14 | def read_img(filename): 15 | # convert to RGB for scene flow finalpass data 16 | img = np.array(Image.open(filename).convert('RGB')).astype(np.float32) 17 | return img 18 | 19 | 20 | def read_disp(filename, subset=False, vkitti2=False, sintel=False, 21 | tartanair=False, instereo2k=False, crestereo=False, 22 | fallingthings=False, 23 | argoverse=False, 24 | raw_disp_png=False, 25 | ): 26 | # Scene Flow dataset 27 | if filename.endswith('pfm'): 28 | # For finalpass and cleanpass, gt disparity is positive, subset is negative 29 | disp = np.ascontiguousarray(_read_pfm(filename)[0]) 30 | if subset: 31 | disp = -disp 32 | # VKITTI2 dataset 33 | elif vkitti2: 34 | disp = _read_vkitti2_disp(filename) 35 | # Sintel 36 | elif sintel: 37 | disp = _read_sintel_disparity(filename) 38 | elif tartanair: 39 | disp = _read_tartanair_disp(filename) 40 | elif instereo2k: 41 | disp = _read_instereo2k_disp(filename) 42 | elif crestereo: 43 | disp = _read_crestereo_disp(filename) 44 | elif fallingthings: 45 | disp = _read_fallingthings_disp(filename) 46 | elif argoverse: 47 | disp = _read_argoverse_disp(filename) 48 | elif raw_disp_png: 49 | disp = np.array(Image.open(filename)).astype(np.float32) 50 | # KITTI 51 | elif filename.endswith('png'): 52 | disp = _read_kitti_disp(filename) 53 | elif filename.endswith('npy'): 54 | disp = np.load(filename) 55 | else: 56 | raise Exception('Invalid disparity file format!') 57 | return disp # [H, W] 58 | 59 | 60 | def _read_pfm(file): 61 | file = open(file, 'rb') 62 | 63 | color = None 64 | width = None 65 | height = None 66 | scale = None 67 | endian = None 68 | 69 | header = file.readline().rstrip() 70 | if header.decode("ascii") == 'PF': 71 | color = True 72 | elif header.decode("ascii") == 'Pf': 73 | color = False 74 | else: 75 | raise Exception('Not a PFM file.') 76 | 77 | dim_match = re.match(r'^(\d+)\s(\d+)\s$', file.readline().decode("ascii")) 78 | if dim_match: 79 | width, height = list(map(int, dim_match.groups())) 80 | else: 81 | raise Exception('Malformed PFM header.') 82 | 83 | scale = float(file.readline().decode("ascii").rstrip()) 84 | if scale < 0: # little-endian 85 | endian = '<' 86 | scale = -scale 87 | else: 88 | endian = '>' # big-endian 89 | 90 | data = np.fromfile(file, endian + 'f') 91 | shape = (height, width, 3) if color else (height, width) 92 | 93 | data = np.reshape(data, shape) 94 | data = np.flipud(data) 95 | return data, scale 96 | 97 | 98 | def write_pfm(file, image, scale=1): 99 | file = open(file, 'wb') 100 | 101 | color = None 102 | 103 | if image.dtype.name != 'float32': 104 | raise Exception('Image dtype must be float32.') 105 | 106 | image = np.flipud(image) 107 | 108 | if len(image.shape) == 3 and image.shape[2] == 3: # color image 109 | color = True 110 | elif len(image.shape) == 2 or len( 111 | image.shape) == 3 and image.shape[2] == 1: # greyscale 112 | color = False 113 | else: 114 | raise Exception( 115 | 'Image must have H x W x 3, H x W x 1 or H x W dimensions.') 116 | 117 | file.write(b'PF\n' if color else b'Pf\n') 118 | file.write(b'%d %d\n' % (image.shape[1], image.shape[0])) 119 | 120 | endian = image.dtype.byteorder 121 | 122 | if endian == '<' or endian == '=' and sys.byteorder == 'little': 123 | scale = -scale 124 | 125 | file.write(b'%f\n' % scale) 126 | 127 | image.tofile(file) 128 | 129 | 130 | def _read_kitti_disp(filename): 131 | depth = np.array(Image.open(filename)) 132 | depth = depth.astype(np.float32) / 256. 133 | return depth 134 | 135 | 136 | def _read_vkitti2_disp(filename): 137 | # read depth 138 | depth = cv2.imread(filename, cv2.IMREAD_ANYCOLOR | cv2.IMREAD_ANYDEPTH) # in cm 139 | depth = (depth / 100).astype(np.float32) # depth clipped to 655.35m for sky 140 | 141 | valid = (depth > 0) & (depth < 655) # depth clipped to 655.35m for sky 142 | 143 | # convert to disparity 144 | focal_length = 725.0087 # in pixels 145 | baseline = 0.532725 # meter 146 | 147 | disp = baseline * focal_length / depth 148 | 149 | disp[~valid] = 0.000001 # invalid as very small value 150 | 151 | return disp 152 | 153 | 154 | def _read_sintel_disparity(filename): 155 | """ Return disparity read from filename. """ 156 | f_in = np.array(Image.open(filename)) 157 | 158 | d_r = f_in[:, :, 0].astype('float32') 159 | d_g = f_in[:, :, 1].astype('float32') 160 | d_b = f_in[:, :, 2].astype('float32') 161 | 162 | depth = d_r * 4 + d_g / (2 ** 6) + d_b / (2 ** 14) 163 | return depth 164 | 165 | 166 | def _read_tartanair_disp(filename): 167 | # the infinite distant object such as the sky has a large depth value (e.g. 10000) 168 | depth = np.load(filename) 169 | 170 | # change to disparity image 171 | disparity = 80.0 / depth 172 | 173 | return disparity 174 | 175 | 176 | def _read_instereo2k_disp(filename): 177 | disp = np.array(Image.open(filename)) 178 | disp = disp.astype(np.float32) / 100. 179 | return disp 180 | 181 | 182 | def _read_crestereo_disp(filename): 183 | disp = np.array(Image.open(filename)) 184 | return disp.astype(np.float32) / 32. 185 | 186 | 187 | def _read_fallingthings_disp(filename): 188 | depth = np.array(Image.open(filename)) 189 | camera_file = os.path.join(os.path.dirname(filename), '_camera_settings.json') 190 | with open(camera_file, 'r') as f: 191 | intrinsics = json.load(f) 192 | fx = intrinsics['camera_settings'][0]['intrinsic_settings']['fx'] 193 | disp = (fx * 6.0 * 100) / depth.astype(np.float32) 194 | 195 | return disp 196 | 197 | 198 | def _read_argoverse_disp(filename): 199 | disparity_map = cv2.imread(filename, cv2.IMREAD_ANYCOLOR | cv2.IMREAD_ANYDEPTH) 200 | return np.float32(disparity_map) / 256. 201 | 202 | 203 | def extract_video(video_name): 204 | cap = cv2.VideoCapture(video_name) 205 | assert cap.isOpened(), f'Failed to load video file {video_name}' 206 | # get video info 207 | size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), 208 | int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))) 209 | fps = cap.get(cv2.CAP_PROP_FPS) 210 | 211 | print('video size (hxw): %dx%d' % (size[1], size[0])) 212 | print('fps: %d' % fps) 213 | 214 | imgs = [] 215 | while cap.isOpened(): 216 | # get frames 217 | flag, img = cap.read() 218 | if not flag: 219 | break 220 | # to rgb format 221 | img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) 222 | imgs.append(img) 223 | 224 | return imgs, fps -------------------------------------------------------------------------------- /misc/flow_viz.py: -------------------------------------------------------------------------------- 1 | # MIT License 2 | # 3 | # Copyright (c) 2018 Tom Runia 4 | # 5 | # Permission is hereby granted, free of charge, to any person obtaining a copy 6 | # of this software and associated documentation files (the "Software"), to deal 7 | # in the Software without restriction, including without limitation the rights 8 | # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell 9 | # copies of the Software, and to permit persons to whom the Software is 10 | # furnished to do so, subject to conditions. 11 | # 12 | # Author: Tom Runia 13 | # Date Created: 2018-08-03 14 | 15 | from __future__ import absolute_import 16 | from __future__ import division 17 | from __future__ import print_function 18 | 19 | import numpy as np 20 | from PIL import Image 21 | 22 | 23 | def make_colorwheel(): 24 | ''' 25 | Generates a color wheel for optical flow visualization as presented in: 26 | Baker et al. "A Database and Evaluation Methodology for Optical Flow" (ICCV, 2007) 27 | URL: http://vision.middlebury.edu/flow/flowEval-iccv07.pdf 28 | According to the C++ source code of Daniel Scharstein 29 | According to the Matlab source code of Deqing Sun 30 | ''' 31 | 32 | RY = 15 33 | YG = 6 34 | GC = 4 35 | CB = 11 36 | BM = 13 37 | MR = 6 38 | 39 | ncols = RY + YG + GC + CB + BM + MR 40 | colorwheel = np.zeros((ncols, 3)) 41 | col = 0 42 | 43 | # RY 44 | colorwheel[0:RY, 0] = 255 45 | colorwheel[0:RY, 1] = np.floor(255 * np.arange(0, RY) / RY) 46 | col = col + RY 47 | # YG 48 | colorwheel[col:col + YG, 0] = 255 - np.floor(255 * np.arange(0, YG) / YG) 49 | colorwheel[col:col + YG, 1] = 255 50 | col = col + YG 51 | # GC 52 | colorwheel[col:col + GC, 1] = 255 53 | colorwheel[col:col + GC, 2] = np.floor(255 * np.arange(0, GC) / GC) 54 | col = col + GC 55 | # CB 56 | colorwheel[col:col + CB, 1] = 255 - np.floor(255 * np.arange(CB) / CB) 57 | colorwheel[col:col + CB, 2] = 255 58 | col = col + CB 59 | # BM 60 | colorwheel[col:col + BM, 2] = 255 61 | colorwheel[col:col + BM, 0] = np.floor(255 * np.arange(0, BM) / BM) 62 | col = col + BM 63 | # MR 64 | colorwheel[col:col + MR, 2] = 255 - np.floor(255 * np.arange(MR) / MR) 65 | colorwheel[col:col + MR, 0] = 255 66 | return colorwheel 67 | 68 | 69 | def flow_compute_color(u, v, convert_to_bgr=False): 70 | ''' 71 | Applies the flow color wheel to (possibly clipped) flow components u and v. 72 | According to the C++ source code of Daniel Scharstein 73 | According to the Matlab source code of Deqing Sun 74 | :param u: np.ndarray, input horizontal flow 75 | :param v: np.ndarray, input vertical flow 76 | :param convert_to_bgr: bool, whether to change ordering and output BGR instead of RGB 77 | :return: 78 | ''' 79 | 80 | flow_image = np.zeros((u.shape[0], u.shape[1], 3), np.uint8) 81 | 82 | colorwheel = make_colorwheel() # shape [55x3] 83 | ncols = colorwheel.shape[0] 84 | 85 | rad = np.sqrt(np.square(u) + np.square(v)) 86 | a = np.arctan2(-v, -u) / np.pi 87 | 88 | fk = (a + 1) / 2 * (ncols - 1) + 1 89 | k0 = np.floor(fk).astype(np.int32) 90 | k1 = k0 + 1 91 | k1[k1 == ncols] = 1 92 | f = fk - k0 93 | 94 | for i in range(colorwheel.shape[1]): 95 | tmp = colorwheel[:, i] 96 | col0 = tmp[k0] / 255.0 97 | col1 = tmp[k1] / 255.0 98 | col = (1 - f) * col0 + f * col1 99 | 100 | idx = (rad <= 1) 101 | col[idx] = 1 - rad[idx] * (1 - col[idx]) 102 | col[~idx] = col[~idx] * 0.75 # out of range? 103 | 104 | # Note the 2-i => BGR instead of RGB 105 | ch_idx = 2 - i if convert_to_bgr else i 106 | flow_image[:, :, ch_idx] = np.floor(255 * col) 107 | 108 | return flow_image 109 | 110 | 111 | def flow_to_color(flow_uv, clip_flow=None, convert_to_bgr=False): 112 | ''' 113 | Expects a two dimensional flow image of shape [H,W,2] 114 | According to the C++ source code of Daniel Scharstein 115 | According to the Matlab source code of Deqing Sun 116 | :param flow_uv: np.ndarray of shape [H,W,2] 117 | :param clip_flow: float, maximum clipping value for flow 118 | :return: 119 | ''' 120 | 121 | assert flow_uv.ndim == 3, 'input flow must have three dimensions' 122 | assert flow_uv.shape[2] == 2, 'input flow must have shape [H,W,2]' 123 | 124 | if clip_flow is not None: 125 | flow_uv = np.clip(flow_uv, 0, clip_flow) 126 | 127 | u = flow_uv[:, :, 0] 128 | v = flow_uv[:, :, 1] 129 | 130 | rad = np.sqrt(np.square(u) + np.square(v)) 131 | rad_max = np.max(rad) 132 | 133 | epsilon = 1e-5 134 | u = u / (rad_max + epsilon) 135 | v = v / (rad_max + epsilon) 136 | 137 | return flow_compute_color(u, v, convert_to_bgr) 138 | 139 | 140 | UNKNOWN_FLOW_THRESH = 1e7 141 | SMALLFLOW = 0.0 142 | LARGEFLOW = 1e8 143 | 144 | 145 | def make_color_wheel(): 146 | """ 147 | Generate color wheel according Middlebury color code 148 | :return: Color wheel 149 | """ 150 | RY = 15 151 | YG = 6 152 | GC = 4 153 | CB = 11 154 | BM = 13 155 | MR = 6 156 | 157 | ncols = RY + YG + GC + CB + BM + MR 158 | 159 | colorwheel = np.zeros([ncols, 3]) 160 | 161 | col = 0 162 | 163 | # RY 164 | colorwheel[0:RY, 0] = 255 165 | colorwheel[0:RY, 1] = np.transpose(np.floor(255 * np.arange(0, RY) / RY)) 166 | col += RY 167 | 168 | # YG 169 | colorwheel[col:col + YG, 0] = 255 - np.transpose(np.floor(255 * np.arange(0, YG) / YG)) 170 | colorwheel[col:col + YG, 1] = 255 171 | col += YG 172 | 173 | # GC 174 | colorwheel[col:col + GC, 1] = 255 175 | colorwheel[col:col + GC, 2] = np.transpose(np.floor(255 * np.arange(0, GC) / GC)) 176 | col += GC 177 | 178 | # CB 179 | colorwheel[col:col + CB, 1] = 255 - np.transpose(np.floor(255 * np.arange(0, CB) / CB)) 180 | colorwheel[col:col + CB, 2] = 255 181 | col += CB 182 | 183 | # BM 184 | colorwheel[col:col + BM, 2] = 255 185 | colorwheel[col:col + BM, 0] = np.transpose(np.floor(255 * np.arange(0, BM) / BM)) 186 | col += + BM 187 | 188 | # MR 189 | colorwheel[col:col + MR, 2] = 255 - np.transpose(np.floor(255 * np.arange(0, MR) / MR)) 190 | colorwheel[col:col + MR, 0] = 255 191 | 192 | return colorwheel 193 | 194 | 195 | def compute_color(u, v): 196 | """ 197 | compute optical flow color map 198 | :param u: optical flow horizontal map 199 | :param v: optical flow vertical map 200 | :return: optical flow in color code 201 | """ 202 | [h, w] = u.shape 203 | img = np.zeros([h, w, 3]) 204 | nanIdx = np.isnan(u) | np.isnan(v) 205 | u[nanIdx] = 0 206 | v[nanIdx] = 0 207 | 208 | colorwheel = make_color_wheel() 209 | ncols = np.size(colorwheel, 0) 210 | 211 | rad = np.sqrt(u ** 2 + v ** 2) 212 | 213 | a = np.arctan2(-v, -u) / np.pi 214 | 215 | fk = (a + 1) / 2 * (ncols - 1) + 1 216 | 217 | k0 = np.floor(fk).astype(int) 218 | 219 | k1 = k0 + 1 220 | k1[k1 == ncols + 1] = 1 221 | f = fk - k0 222 | 223 | for i in range(0, np.size(colorwheel, 1)): 224 | tmp = colorwheel[:, i] 225 | col0 = tmp[k0 - 1] / 255 226 | col1 = tmp[k1 - 1] / 255 227 | col = (1 - f) * col0 + f * col1 228 | 229 | idx = rad <= 1 230 | col[idx] = 1 - rad[idx] * (1 - col[idx]) 231 | notidx = np.logical_not(idx) 232 | 233 | col[notidx] *= 0.75 234 | img[:, :, i] = np.uint8(np.floor(255 * col * (1 - nanIdx))) 235 | 236 | return img 237 | 238 | 239 | # from https://github.com/gengshan-y/VCN 240 | def flow_to_image(flow): 241 | """ 242 | Convert flow into middlebury color code image 243 | :param flow: optical flow map 244 | :return: optical flow image in middlebury color 245 | """ 246 | u = flow[:, :, 0] 247 | v = flow[:, :, 1] 248 | 249 | maxu = -999. 250 | maxv = -999. 251 | minu = 999. 252 | minv = 999. 253 | 254 | idxUnknow = (abs(u) > UNKNOWN_FLOW_THRESH) | (abs(v) > UNKNOWN_FLOW_THRESH) 255 | u[idxUnknow] = 0 256 | v[idxUnknow] = 0 257 | 258 | maxu = max(maxu, np.max(u)) 259 | minu = min(minu, np.min(u)) 260 | 261 | maxv = max(maxv, np.max(v)) 262 | minv = min(minv, np.min(v)) 263 | 264 | rad = np.sqrt(u ** 2 + v ** 2) 265 | maxrad = max(-1, np.max(rad)) 266 | 267 | u = u / (maxrad + np.finfo(float).eps) 268 | v = v / (maxrad + np.finfo(float).eps) 269 | 270 | img = compute_color(u, v) 271 | 272 | idx = np.repeat(idxUnknow[:, :, np.newaxis], 3, axis=2) 273 | img[idx] = 0 274 | 275 | return np.uint8(img) 276 | 277 | 278 | def save_vis_flow_tofile(flow, output_path): 279 | vis_flow = flow_to_image(flow) 280 | Image.fromarray(vis_flow).save(output_path) 281 | 282 | 283 | def flow_tensor_to_image(flow): 284 | """Used for tensorboard visualization""" 285 | flow = flow.permute(1, 2, 0) # [H, W, 2] 286 | flow = flow.detach().cpu().numpy() 287 | flow = flow_to_image(flow) # [H, W, 3] 288 | flow = np.transpose(flow, (2, 0, 1)) # [3, H, W] 289 | 290 | return flow -------------------------------------------------------------------------------- /misc/frame_utils.py: -------------------------------------------------------------------------------- 1 | import numpy as np 2 | from PIL import Image 3 | from os.path import * 4 | import re 5 | import cv2 6 | 7 | TAG_CHAR = np.array([202021.25], np.float32) 8 | 9 | 10 | def readFlow(fn): 11 | """ Read .flo file in Middlebury format""" 12 | # Code adapted from: 13 | # http://stackoverflow.com/questions/28013200/reading-middlebury-flow-files-with-python-bytes-array-numpy 14 | 15 | # WARNING: this will work on little-endian architectures (eg Intel x86) only! 16 | # print 'fn = %s'%(fn) 17 | with open(fn, 'rb') as f: 18 | magic = np.fromfile(f, np.float32, count=1) 19 | if 202021.25 != magic: 20 | print('Magic number incorrect. Invalid .flo file') 21 | return None 22 | else: 23 | w = np.fromfile(f, np.int32, count=1) 24 | h = np.fromfile(f, np.int32, count=1) 25 | # print 'Reading %d x %d flo file\n' % (w, h) 26 | data = np.fromfile(f, np.float32, count=2 * int(w) * int(h)) 27 | # Reshape testdata into 3D array (columns, rows, bands) 28 | # The reshape here is for visualization, the original code is (w,h,2) 29 | return np.resize(data, (int(h), int(w), 2)) 30 | 31 | 32 | def readPFM(file): 33 | file = open(file, 'rb') 34 | 35 | color = None 36 | width = None 37 | height = None 38 | scale = None 39 | endian = None 40 | 41 | header = file.readline().rstrip() 42 | if header == b'PF': 43 | color = True 44 | elif header == b'Pf': 45 | color = False 46 | else: 47 | raise Exception('Not a PFM file.') 48 | 49 | dim_match = re.match(rb'^(\d+)\s(\d+)\s$', file.readline()) 50 | if dim_match: 51 | width, height = map(int, dim_match.groups()) 52 | else: 53 | raise Exception('Malformed PFM header.') 54 | 55 | scale = float(file.readline().rstrip()) 56 | if scale < 0: # little-endian 57 | endian = '<' 58 | scale = -scale 59 | else: 60 | endian = '>' # big-endian 61 | 62 | data = np.fromfile(file, endian + 'f') 63 | shape = (height, width, 3) if color else (height, width) 64 | 65 | data = np.reshape(data, shape) 66 | data = np.flipud(data) 67 | return data 68 | 69 | 70 | def writeFlow(filename, uv, v=None): 71 | """ Write optical flow to file. 72 | 73 | If v is None, uv is assumed to contain both u and v channels, 74 | stacked in depth. 75 | Original code by Deqing Sun, adapted from Daniel Scharstein. 76 | """ 77 | nBands = 2 78 | 79 | if v is None: 80 | assert (uv.ndim == 3) 81 | assert (uv.shape[2] == 2) 82 | u = uv[:, :, 0] 83 | v = uv[:, :, 1] 84 | else: 85 | u = uv 86 | 87 | assert (u.shape == v.shape) 88 | height, width = u.shape 89 | f = open(filename, 'wb') 90 | # write the header 91 | f.write(TAG_CHAR) 92 | np.array(width).astype(np.int32).tofile(f) 93 | np.array(height).astype(np.int32).tofile(f) 94 | # arrange into matrix form 95 | tmp = np.zeros((height, width * nBands)) 96 | tmp[:, np.arange(width) * 2] = u 97 | tmp[:, np.arange(width) * 2 + 1] = v 98 | tmp.astype(np.float32).tofile(f) 99 | f.close() 100 | 101 | 102 | def readFlowKITTI(filename): 103 | flow = cv2.imread(filename, cv2.IMREAD_ANYDEPTH | cv2.IMREAD_COLOR) 104 | flow = flow[:, :, ::-1].astype(np.float32) 105 | flow, valid = flow[:, :, :2], flow[:, :, 2] 106 | flow = (flow - 2 ** 15) / 64.0 107 | return flow, valid 108 | 109 | 110 | def readDispKITTI(filename): 111 | disp = cv2.imread(filename, cv2.IMREAD_ANYDEPTH) / 256.0 112 | valid = disp > 0.0 113 | flow = np.stack([-disp, np.zeros_like(disp)], -1) 114 | return flow, valid 115 | 116 | 117 | def writeFlowKITTI(filename, uv): 118 | uv = 64.0 * uv + 2 ** 15 119 | valid = np.ones([uv.shape[0], uv.shape[1], 1]) 120 | uv = np.concatenate([uv, valid], axis=-1).astype(np.uint16) 121 | cv2.imwrite(filename, uv[..., ::-1]) 122 | 123 | 124 | def read_gen(file_name, pil=False): 125 | ext = splitext(file_name)[-1] 126 | if ext == '.png' or ext == '.jpeg' or ext == '.ppm' or ext == '.jpg': 127 | return Image.open(file_name) 128 | elif ext == '.bin' or ext == '.raw': 129 | return np.load(file_name) 130 | elif ext == '.flo': 131 | return readFlow(file_name).astype(np.float32) 132 | elif ext == '.pfm': 133 | flow = readPFM(file_name).astype(np.float32) 134 | if len(flow.shape) == 2: 135 | return flow 136 | else: 137 | return flow[:, :, :-1] 138 | return [] 139 | 140 | 141 | def read_vkitti2_flow(filename): 142 | # In R, flow along x-axis normalized by image width and quantized to [0;2^16 – 1] 143 | # In G, flow along x-axis normalized by image width and quantized to [0;2^16 – 1] 144 | # B = 0 for invalid flow (e.g., sky pixels) 145 | bgr = cv2.imread(filename, cv2.IMREAD_ANYCOLOR | cv2.IMREAD_ANYDEPTH) 146 | h, w, _c = bgr.shape 147 | assert bgr.dtype == np.uint16 and _c == 3 148 | # b == invalid flow flag == 0 for sky or other invalid flow 149 | invalid = bgr[:, :, 0] == 0 150 | # g,r == flow_y,x normalized by height,width and scaled to [0;2**16 – 1] 151 | out_flow = 2.0 / (2 ** 16 - 1.0) * bgr[:, :, 2:0:-1].astype('f4') - 1 # [H, W, 2] 152 | out_flow[..., 0] *= (w - 1) 153 | out_flow[..., 1] *= (h - 1) 154 | 155 | out_flow[invalid] = 0.000001 # invalid as very small value to add supervison on the sky 156 | valid = (np.logical_or(invalid, ~invalid)).astype(np.float32) 157 | 158 | return out_flow, valid 159 | -------------------------------------------------------------------------------- /misc/metrics.py: -------------------------------------------------------------------------------- 1 | import numpy as np 2 | from collections import OrderedDict 3 | from skimage.metrics import structural_similarity 4 | import torch 5 | import lpips 6 | 7 | from misc.utils import suppress 8 | 9 | 10 | class EvalTools(object): 11 | """docstring for EvalTools.""" 12 | def __init__(self, device): 13 | super(EvalTools, self).__init__() 14 | self.support_metrics = ['PSNR', 'SSIM', 'LPIPS', 'depth_abs', 'thres005', 'thres001'] 15 | self.device = device 16 | with torch.no_grad(), suppress(stdout=True, stderr=True): 17 | self.lpips_metric = lpips.LPIPS(net='vgg').to(device) 18 | 19 | def set_inputs(self, pred_img, gt_img, img_mask=None, full_img_eval=False, 20 | pred_depth=None, 21 | gt_depth=None, 22 | ): 23 | self.full_pred = pred_img 24 | self.full_gt = gt_img 25 | 26 | if full_img_eval: 27 | # print('full image eval') 28 | self.img_mask = None 29 | self.proc_pred = pred_img 30 | self.proc_gt = gt_img 31 | else: 32 | if img_mask is not None: 33 | # print('evaluation with depth mask: ', np.mean(img_mask)) # ~30% mask 34 | self.img_mask = img_mask 35 | self.proc_pred = pred_img.copy() 36 | self.proc_gt = gt_img.copy() 37 | self.proc_pred[img_mask] = 0. 38 | self.proc_gt[img_mask] = 0. 39 | else: # center crop to 80% 40 | # print('center crop evaluation') 41 | # TODO: use full image evaluation 42 | # print('center crop eval') 43 | self.img_mask = None 44 | H_crop, W_crop = np.array(pred_img.shape[:2]) // 10 45 | self.proc_pred = pred_img[H_crop:-H_crop, W_crop:-W_crop] 46 | self.proc_gt = gt_img[H_crop:-H_crop, W_crop:-W_crop] 47 | 48 | if pred_depth is not None: 49 | self.pred_depth = pred_depth 50 | self.gt_depth = gt_depth 51 | else: 52 | self.pred_depth = None 53 | self.gt_depth = None 54 | 55 | def get_psnr(self, pred_img, gt_img, use_mask): 56 | if use_mask: 57 | mse = np.mean((pred_img[~self.img_mask] - gt_img[~self.img_mask]) ** 2) 58 | else: 59 | mse = np.mean((pred_img - gt_img) ** 2) 60 | psnr = -10. * np.log(mse) / np.log(10.) 61 | return psnr 62 | 63 | def get_ssim(self, pred_img, gt_img, **kwargs): 64 | ssim = structural_similarity(pred_img, gt_img, channel_axis=-1) 65 | return ssim 66 | 67 | @torch.no_grad() 68 | def get_lpips(self, pred_img, gt_img, **kwargs): 69 | pred_tensor = torch.from_numpy(pred_img)[None].permute(0,3,1,2).float() * 2 - 1.0 # image should be RGB, IMPORTANT: normalized to [-1,1] 70 | gt_tensor = torch.from_numpy(gt_img)[None].permute(0,3,1,2).float() * 2 - 1.0 71 | lpips = self.lpips_metric(pred_tensor.to(self.device), gt_tensor.to(self.device)) 72 | return lpips.item() 73 | 74 | def get_metrics(self, metrics=None, return_full=False): 75 | out_dict = OrderedDict() 76 | if metrics is None: 77 | metrics = self.support_metrics 78 | for metric in metrics: 79 | assert metric in self.support_metrics, f"only support metrics: [{','.join(self.support_metrics)}]" 80 | if metric == 'depth_abs' or metric == 'thres005' or metric == 'thres001': 81 | continue 82 | 83 | eval_func = getattr(self, f'get_{metric.lower()}') 84 | out_dict[metric] = eval_func(self.proc_pred, self.proc_gt, use_mask=(self.img_mask is not None)) 85 | if return_full: 86 | out_dict[f'{metric}_Full'] = eval_func(self.full_pred, self.full_gt, use_mask=False) 87 | 88 | # additional depth error 89 | if self.pred_depth is not None and self.gt_depth is not None: 90 | valid_mask = self.gt_depth != 0. 91 | depth_abs_error = np.mean(np.abs((self.pred_depth[valid_mask] - self.gt_depth[valid_mask]))) 92 | out_dict['depth_abs'] = depth_abs_error 93 | 94 | out_dict['thres005'] = acc_threshold(self.pred_depth, self.gt_depth, valid_mask, threshold=0.05) 95 | 96 | out_dict['thres001'] = acc_threshold(self.pred_depth, self.gt_depth, valid_mask, threshold=0.01) 97 | 98 | return out_dict 99 | 100 | 101 | def acc_threshold(depth_pred, depth_gt, mask, threshold): 102 | """ 103 | computes the percentage of pixels whose depth error is less than @threshold 104 | """ 105 | errors = np.abs((depth_pred[mask] - depth_gt[mask])) 106 | acc_mask = errors < threshold 107 | return acc_mask.astype('float').mean() 108 | -------------------------------------------------------------------------------- /misc/train_helpers.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import os 3 | import numpy as np 4 | import telepot 5 | from collections import OrderedDict 6 | 7 | 8 | @torch.no_grad() 9 | def summarize_metrics(metrics, out_dir, it=None, ep=None): 10 | head_info = "" 11 | if it is not None: 12 | head_info = f" at Iteration [{it}]" 13 | if ep is not None: 14 | head_info = f" at Epoch [{ep}]" 15 | 16 | dataset_metrics = {} 17 | for dataname, raw_metrics in metrics.items(): 18 | dataset_metrics[dataname] = {} 19 | header = f"------------ {dataname.upper()} Nearest 3{head_info} ------------" 20 | all_msgs = [header] 21 | cur_scene = "" 22 | for view_id, view_metrics in raw_metrics.items(): 23 | if view_id.split('_')[0] != cur_scene: 24 | if cur_scene != "": # summarise scene buffer and log 25 | scene_info = f"====> scene: {cur_scene}," 26 | for k, v in scene_metrics.items(): 27 | scene_info = scene_info + f" {k}: {float(np.array(v).mean())}," 28 | all_msgs.append(scene_info) 29 | else: # init dataset 30 | dataset_metrics[dataname] = OrderedDict({k:[] for k in view_metrics.keys()}) 31 | # reset scene buffer 32 | cur_scene = view_id.split('_')[0] 33 | scene_metrics = {k:[] for k in view_metrics.keys()} 34 | # log view 35 | view_info = f"==> view: {view_id}," 36 | for k, v in view_metrics.items(): 37 | view_info = view_info + f" {k}: {float(v)}," 38 | scene_metrics[k].append(v) 39 | dataset_metrics[dataname][k].append(v) 40 | all_msgs.append(view_info) 41 | # summarise dataset 42 | data_info = f"======> {dataname.upper()}{head_info}," 43 | for k, v in dataset_metrics[dataname].items(): 44 | data_info = data_info + f" {k}: {float(np.array(v).mean())}," 45 | all_msgs.append(data_info) 46 | with open(os.path.join(out_dir, f"0results_{dataname}.txt"), "a+") as f: 47 | f.write('\n'.join(all_msgs)) 48 | f.write('\n') 49 | 50 | # a single file only log mean metrics for simplicity 51 | with open(os.path.join(out_dir, f"0results_{dataname}_mean.txt"), "a+") as f: 52 | f.write(data_info) 53 | f.write('\n') 54 | 55 | return dataset_metrics 56 | 57 | 58 | @torch.no_grad() 59 | def summarize_metrics_list(metrics, out_dir, it=None, ep=None): 60 | # metrics: dict of dataname: list 61 | head_info = "" 62 | if it is not None: 63 | head_info = f"Iteration [{it}]" 64 | if ep is not None: 65 | head_info = f"Epoch [{ep}]" 66 | 67 | dataset_metrics = {} 68 | for dataname, raw_metrics in metrics.items(): 69 | dataset_metrics[dataname] = {} 70 | 71 | all_msgs = [head_info] 72 | 73 | all_metrics = OrderedDict({k:[] for k in raw_metrics[0].keys()}) 74 | for i, single_metric in enumerate(raw_metrics): 75 | for k, v in single_metric.items(): 76 | all_metrics[k].append(v) 77 | 78 | data_info = "" 79 | for k, v in all_metrics.items(): 80 | dataset_metrics[dataname][k] = float(np.array(v).mean()) 81 | data_info = data_info + f"{k}: {dataset_metrics[dataname][k]}, " 82 | 83 | all_msgs.append(data_info) 84 | 85 | with open(os.path.join(out_dir, f"0results_{dataname}_mean.txt"), "a+") as f: 86 | f.write(data_info) 87 | f.write('\n') 88 | 89 | return dataset_metrics 90 | 91 | 92 | def summarize_loss(loss, loss_weight): 93 | loss_all = 0. 94 | assert("all" not in loss) 95 | # weigh losses 96 | for key in loss: 97 | assert(key in loss_weight) 98 | assert(loss[key].shape==()) 99 | if loss_weight[key] is not None: 100 | # skip nan loss 101 | if torch.isinf(loss[key]): 102 | print("loss {} is Inf".format(key)) 103 | continue 104 | 105 | if torch.isnan(loss[key]): 106 | print("loss {} is NaN".format(key)) 107 | continue 108 | 109 | # assert not torch.isinf(loss[key]),"loss {} is Inf".format(key) 110 | # assert not torch.isnan(loss[key]),"loss {} is NaN".format(key) 111 | loss_all = loss_all + float(loss_weight[key]) * loss[key] 112 | loss.update(all=loss_all) 113 | return loss 114 | 115 | 116 | class TGDebugMessager(object): 117 | """Tools to send and update logs to the telegram bot.""" 118 | def __init__(self, tg_token, tg_chat_id): 119 | super(TGDebugMessager, self).__init__() 120 | self.tg_bot = telepot.Bot(token=tg_token) 121 | self.tg_chat_id = tg_chat_id 122 | self.reset_msg() 123 | 124 | def send_msg(self, msg, parse_mode): 125 | full_msg = self.update_full_msg(msg) 126 | sent_msg = self.tg_bot.sendMessage(chat_id=self.tg_chat_id, text=full_msg, parse_mode=parse_mode) 127 | self.msg_id = telepot.message_identifier(sent_msg) 128 | 129 | def reset_msg(self): 130 | self.msg_id = None 131 | self.msg_text = [] 132 | 133 | def update_full_msg(self, msg): 134 | self.msg_text.append(msg) 135 | out_text = '\n'.join(self.msg_text) 136 | return out_text 137 | 138 | def edit_msg(self, msg, parse_mode): 139 | assert self.msg_id is not None, "Cannot find the original message." 140 | 141 | full_msg = self.update_full_msg(msg) 142 | self.tg_bot.editMessageText(self.msg_id, full_msg, parse_mode=parse_mode) 143 | 144 | def __call__(self, msg, parse_mode="HTML", **kwds): 145 | try: 146 | if self.msg_id is None: 147 | self.send_msg(msg, parse_mode) 148 | else: 149 | self.edit_msg(msg, parse_mode) 150 | except: 151 | print("[WARNING] Telegram bot fails to send message, continue.") 152 | -------------------------------------------------------------------------------- /models/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/autonomousvision/murf/57d564203820815feced49045af0ea3fced04463/models/__init__.py -------------------------------------------------------------------------------- /models/gmflow/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/autonomousvision/murf/57d564203820815feced49045af0ea3fced04463/models/gmflow/__init__.py -------------------------------------------------------------------------------- /models/gmflow/backbone.py: -------------------------------------------------------------------------------- 1 | import torch.nn as nn 2 | 3 | 4 | class ResidualBlock(nn.Module): 5 | def __init__(self, in_planes, planes, norm_layer=nn.InstanceNorm2d, stride=1, dilation=1, 6 | ): 7 | super(ResidualBlock, self).__init__() 8 | 9 | self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, 10 | dilation=dilation, padding=dilation, stride=stride, bias=False) 11 | self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, 12 | dilation=dilation, padding=dilation, bias=False) 13 | self.relu = nn.ReLU(inplace=True) 14 | 15 | self.norm1 = norm_layer(planes) 16 | self.norm2 = norm_layer(planes) 17 | if not stride == 1 or in_planes != planes: 18 | self.norm3 = norm_layer(planes) 19 | 20 | if stride == 1 and in_planes == planes: 21 | self.downsample = None 22 | else: 23 | self.downsample = nn.Sequential( 24 | nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride), self.norm3) 25 | 26 | def forward(self, x): 27 | y = x 28 | y = self.relu(self.norm1(self.conv1(y))) 29 | y = self.relu(self.norm2(self.conv2(y))) 30 | 31 | if self.downsample is not None: 32 | x = self.downsample(x) 33 | 34 | return self.relu(x + y) 35 | 36 | 37 | class CNNEncoder(nn.Module): 38 | def __init__(self, output_dim=128, 39 | norm_layer=nn.InstanceNorm2d, 40 | num_output_scales=1, 41 | with_cnn_features=False, 42 | **kwargs, 43 | ): 44 | super(CNNEncoder, self).__init__() 45 | self.num_branch = num_output_scales 46 | self.with_cnn_features = with_cnn_features 47 | 48 | feature_dims = [64, 96, 128] 49 | 50 | self.conv1 = nn.Conv2d( 51 | 3, feature_dims[0], kernel_size=7, stride=2, padding=3, bias=False) # 1/2 52 | self.norm1 = norm_layer(feature_dims[0]) 53 | self.relu1 = nn.ReLU(inplace=True) 54 | 55 | self.in_planes = feature_dims[0] 56 | self.layer1 = self._make_layer( 57 | feature_dims[0], stride=1, norm_layer=norm_layer) # 1/2 58 | self.layer2 = self._make_layer( 59 | feature_dims[1], stride=2, norm_layer=norm_layer) # 1/4 60 | 61 | # highest resolution 1/4 or 1/8 62 | stride = 2 if num_output_scales == 1 else 1 63 | 64 | self.layer3 = self._make_layer(feature_dims[2], stride=stride, 65 | norm_layer=norm_layer, 66 | ) # 1/4 or 1/8 67 | 68 | self.conv2 = nn.Conv2d(feature_dims[2], output_dim, 1, 1, 0) 69 | 70 | for m in self.modules(): 71 | if isinstance(m, nn.Conv2d): 72 | nn.init.kaiming_normal_( 73 | m.weight, mode='fan_out', nonlinearity='relu') 74 | elif isinstance(m, (nn.BatchNorm2d, nn.InstanceNorm2d, nn.GroupNorm)): 75 | if m.weight is not None: 76 | nn.init.constant_(m.weight, 1) 77 | if m.bias is not None: 78 | nn.init.constant_(m.bias, 0) 79 | 80 | def _make_layer(self, dim, stride=1, dilation=1, norm_layer=nn.InstanceNorm2d): 81 | layer1 = ResidualBlock( 82 | self.in_planes, dim, norm_layer=norm_layer, stride=stride, dilation=dilation) 83 | layer2 = ResidualBlock( 84 | dim, dim, norm_layer=norm_layer, stride=1, dilation=dilation) 85 | 86 | layers = (layer1, layer2) 87 | 88 | self.in_planes = dim 89 | return nn.Sequential(*layers) 90 | 91 | def forward(self, x, keep_midfeat=False): 92 | out = [] 93 | 94 | x = self.conv1(x) 95 | x = self.norm1(x) 96 | x = self.relu1(x) 97 | 98 | x = self.layer1(x) # 1/2 99 | 100 | if self.with_cnn_features: 101 | out.append(x) 102 | 103 | x = self.layer2(x) # 1/4 104 | 105 | if self.with_cnn_features: 106 | out.append(x) 107 | 108 | x = self.layer3(x) # 1/8 or 1/4 109 | 110 | x = self.conv2(x) 111 | out.append(x) 112 | 113 | return out 114 | -------------------------------------------------------------------------------- /models/gmflow/geometry.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.nn.functional as F 3 | 4 | 5 | def coords_grid(b, h, w, homogeneous=False, device=None): 6 | y, x = torch.meshgrid(torch.arange( 7 | h), torch.arange(w), indexing='ij') # [H, W] 8 | 9 | stacks = [x, y] 10 | 11 | if homogeneous: 12 | ones = torch.ones_like(x) # [H, W] 13 | stacks.append(ones) 14 | 15 | grid = torch.stack(stacks, dim=0).float() # [2, H, W] or [3, H, W] 16 | 17 | grid = grid[None].repeat(b, 1, 1, 1) # [B, 2, H, W] or [B, 3, H, W] 18 | 19 | if device is not None: 20 | grid = grid.to(device) 21 | 22 | return grid 23 | 24 | 25 | def generate_window_grid(h_min, h_max, w_min, w_max, len_h, len_w, device=None): 26 | assert device is not None 27 | 28 | x, y = torch.meshgrid([torch.linspace(w_min, w_max, len_w, device=device), 29 | torch.linspace(h_min, h_max, len_h, device=device)], 30 | indexing='ij') 31 | grid = torch.stack((x, y), -1).transpose(0, 1).float() # [H, W, 2] 32 | 33 | return grid 34 | 35 | 36 | def normalize_coords(coords, h, w): 37 | # coords: [B, H, W, 2] 38 | c = torch.Tensor([(w - 1) / 2., (h - 1) / 2.]).float().to(coords.device) 39 | return (coords - c) / c # [-1, 1] 40 | 41 | 42 | def bilinear_sample(img, sample_coords, mode='bilinear', padding_mode='zeros', return_mask=False): 43 | # img: [B, C, H, W] 44 | # sample_coords: [B, 2, H, W] in image scale 45 | if sample_coords.size(1) != 2: # [B, H, W, 2] 46 | sample_coords = sample_coords.permute(0, 3, 1, 2) 47 | 48 | b, _, h, w = sample_coords.shape 49 | 50 | # Normalize to [-1, 1] 51 | x_grid = 2 * sample_coords[:, 0] / (w - 1) - 1 52 | y_grid = 2 * sample_coords[:, 1] / (h - 1) - 1 53 | 54 | grid = torch.stack([x_grid, y_grid], dim=-1) # [B, H, W, 2] 55 | 56 | img = F.grid_sample(img, grid, mode=mode, 57 | padding_mode=padding_mode, align_corners=True) 58 | 59 | if return_mask: 60 | mask = (x_grid >= -1) & (y_grid >= -1) & (x_grid <= 61 | 1) & (y_grid <= 1) # [B, H, W] 62 | 63 | return img, mask 64 | 65 | return img 66 | 67 | -------------------------------------------------------------------------------- /models/gmflow/multiview_gmflow.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.nn as nn 3 | import torch.nn.functional as F 4 | 5 | from .backbone import CNNEncoder 6 | from .utils import feature_add_position_list 7 | from .multiview_transformer import MultiViewFeatureTransformer 8 | 9 | 10 | class MultiViewGMFlow(nn.Module): 11 | def __init__(self, 12 | num_scales=1, 13 | with_cnn_features=True, 14 | upsample_factor=8, 15 | feature_channels=128, 16 | attention_type='swin', 17 | num_transformer_layers=6, 18 | ffn_dim_expansion=4, 19 | num_head=1, 20 | feature_upsampler='none', 21 | add_per_view_attn=False, 22 | no_cross_attn=False, 23 | **kwargs, 24 | ): 25 | super(MultiViewGMFlow, self).__init__() 26 | 27 | self.num_scales = num_scales 28 | self.with_cnn_features = with_cnn_features 29 | self.feature_channels = feature_channels 30 | self.upsample_factor = upsample_factor 31 | self.attention_type = attention_type 32 | self.num_transformer_layers = num_transformer_layers 33 | self.feature_upsampler = feature_upsampler 34 | 35 | # CNN 36 | self.backbone = CNNEncoder(output_dim=feature_channels, num_output_scales=num_scales, 37 | with_cnn_features=with_cnn_features, 38 | ) 39 | 40 | # Transformer 41 | self.transformer = MultiViewFeatureTransformer(num_layers=num_transformer_layers, 42 | d_model=feature_channels, 43 | nhead=num_head, 44 | attention_type=attention_type, 45 | ffn_dim_expansion=ffn_dim_expansion, 46 | add_per_view_attn=add_per_view_attn, 47 | no_cross_attn=no_cross_attn, 48 | ) 49 | 50 | def extract_feature(self, images): 51 | batch_size, n_img, c, h, w = images.shape 52 | concat = images.reshape(batch_size*n_img, c, h, w) # [nB, C, H, W] 53 | # list of [nB, C, H, W], resolution from high to low 54 | features = self.backbone(concat) 55 | 56 | if not isinstance(features, list): 57 | features = [features] 58 | 59 | # reverse: resolution from low to high 60 | features = features[::-1] 61 | 62 | features_list = [[] for _ in range(n_img)] 63 | 64 | if self.with_cnn_features: 65 | final_features_list = [[] for _ in range(n_img)] 66 | 67 | for i in range(len(features)): 68 | feature = features[i] 69 | chunks = torch.chunk(feature, n_img, 0) # tuple 70 | for idx, chunk in enumerate(chunks): 71 | features_list[idx].append(chunk) 72 | 73 | # only the final cnn features 74 | if self.with_cnn_features and i == 0: 75 | for idx, chunk in enumerate(chunks): 76 | final_features_list[idx].append(chunk) 77 | 78 | if self.with_cnn_features: 79 | return features_list, final_features_list 80 | 81 | return features_list 82 | 83 | def normalize_images(self, images): 84 | '''Normalize image to match the pretrained GMFlow backbone. 85 | images: (B, N_Views, C, H, W) 86 | ''' 87 | shape = [*[1]*(images.dim() - 3), 3, 1, 1] 88 | mean = torch.tensor([0.485, 0.456, 0.406]).reshape( 89 | *shape).to(images.device) 90 | std = torch.tensor([0.229, 0.224, 0.225]).reshape( 91 | *shape).to(images.device) 92 | 93 | return (images - mean) / std 94 | 95 | def forward(self, images, attn_splits_list=None, **kwargs): 96 | ''' images: (B, N_Views, C, H, W), range [0, 1] ''' 97 | results_dict = {} 98 | aug_features_list = [] 99 | 100 | # resolution low to high 101 | features_list = self.extract_feature( 102 | self.normalize_images(images)) # list of features 103 | 104 | if self.with_cnn_features: 105 | full_features_list, features_list = features_list 106 | 107 | for scale_idx in range(3): 108 | cur_features_list = [x[scale_idx] for x in full_features_list] 109 | ls_feats = torch.stack( 110 | cur_features_list, dim=1) # [B, V, C, H, W] 111 | 112 | aug_features_list.append(ls_feats) 113 | 114 | assert len(attn_splits_list) == self.num_scales 115 | 116 | for scale_idx in range(self.num_scales): 117 | cur_features_list = [x[scale_idx] for x in features_list] 118 | 119 | attn_splits = attn_splits_list[scale_idx] 120 | 121 | # add position to features 122 | cur_features_list = feature_add_position_list( 123 | cur_features_list, attn_splits, self.feature_channels) 124 | 125 | # Transformer 126 | cur_features_list = self.transformer( 127 | cur_features_list, attn_num_splits=attn_splits) 128 | 129 | up_features = torch.stack( 130 | cur_features_list, dim=1) # [B, V, C, H, W] 131 | 132 | if self.with_cnn_features: 133 | # 1/8, 1/8, 1/4, 1/2 134 | aug_features_list.insert(0, up_features) 135 | else: 136 | aug_features_list.append(up_features) # BxVxCxHxW 137 | 138 | results_dict.update({ 139 | 'aug_feats_list': aug_features_list 140 | }) 141 | 142 | return results_dict 143 | -------------------------------------------------------------------------------- /models/gmflow/position.py: -------------------------------------------------------------------------------- 1 | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved 2 | # https://github.com/facebookresearch/detr/blob/main/models/position_encoding.py 3 | 4 | import torch 5 | import torch.nn as nn 6 | import math 7 | 8 | 9 | class PositionEmbeddingSine(nn.Module): 10 | """ 11 | This is a more standard version of the position embedding, very similar to the one 12 | used by the Attention is all you need paper, generalized to work on images. 13 | """ 14 | 15 | def __init__(self, num_pos_feats=64, temperature=10000, normalize=True, scale=None): 16 | super().__init__() 17 | self.num_pos_feats = num_pos_feats 18 | self.temperature = temperature 19 | self.normalize = normalize 20 | if scale is not None and normalize is False: 21 | raise ValueError("normalize should be True if scale is passed") 22 | if scale is None: 23 | scale = 2 * math.pi 24 | self.scale = scale 25 | 26 | def forward(self, x): 27 | # x = tensor_list.tensors # [B, C, H, W] 28 | # mask = tensor_list.mask # [B, H, W], input with padding, valid as 0 29 | b, c, h, w = x.size() 30 | mask = torch.ones((b, h, w), device=x.device) # [B, H, W] 31 | y_embed = mask.cumsum(1, dtype=torch.float32) 32 | x_embed = mask.cumsum(2, dtype=torch.float32) 33 | if self.normalize: 34 | eps = 1e-6 35 | y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale 36 | x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale 37 | 38 | dim_t = torch.arange(self.num_pos_feats, 39 | dtype=torch.float32, device=x.device) 40 | # dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) 41 | dim_t = self.temperature ** (2 * torch.div(dim_t, 42 | 2, rounding_mode='trunc') / self.num_pos_feats) 43 | 44 | pos_x = x_embed[:, :, :, None] / dim_t 45 | pos_y = y_embed[:, :, :, None] / dim_t 46 | pos_x = torch.stack( 47 | (pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3) 48 | pos_y = torch.stack( 49 | (pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3) 50 | pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2) 51 | return pos 52 | -------------------------------------------------------------------------------- /models/gmflow/utils.py: -------------------------------------------------------------------------------- 1 | import torch 2 | from .position import PositionEmbeddingSine 3 | import torch.nn.functional as F 4 | from .geometry import generate_window_grid 5 | 6 | 7 | def split_feature(feature, 8 | num_splits=2, 9 | channel_last=False, 10 | ): 11 | if channel_last: # [B, H, W, C] 12 | b, h, w, c = feature.size() 13 | assert h % num_splits == 0 and w % num_splits == 0 14 | 15 | b_new = b * num_splits * num_splits 16 | h_new = h // num_splits 17 | w_new = w // num_splits 18 | 19 | feature = feature.view(b, num_splits, h // num_splits, num_splits, w // num_splits, c 20 | ).permute(0, 1, 3, 2, 4, 5).reshape(b_new, h_new, w_new, c) # [B*K*K, H/K, W/K, C] 21 | else: # [B, C, H, W] 22 | b, c, h, w = feature.size() 23 | assert h % num_splits == 0 and w % num_splits == 0 24 | 25 | b_new = b * num_splits * num_splits 26 | h_new = h // num_splits 27 | w_new = w // num_splits 28 | 29 | feature = feature.view(b, c, num_splits, h // num_splits, num_splits, w // num_splits 30 | ).permute(0, 2, 4, 1, 3, 5).reshape(b_new, c, h_new, w_new) # [B*K*K, C, H/K, W/K] 31 | 32 | return feature 33 | 34 | 35 | def merge_splits(splits, 36 | num_splits=2, 37 | channel_last=False, 38 | ): 39 | if channel_last: # [B*K*K, H/K, W/K, C] 40 | b, h, w, c = splits.size() 41 | new_b = b // num_splits // num_splits 42 | 43 | splits = splits.view(new_b, num_splits, num_splits, h, w, c) 44 | merge = splits.permute(0, 1, 3, 2, 4, 5).contiguous().view( 45 | new_b, num_splits * h, num_splits * w, c) # [B, H, W, C] 46 | else: # [B*K*K, C, H/K, W/K] 47 | b, c, h, w = splits.size() 48 | new_b = b // num_splits // num_splits 49 | 50 | splits = splits.view(new_b, num_splits, num_splits, c, h, w) 51 | merge = splits.permute(0, 3, 1, 4, 2, 5).contiguous().view( 52 | new_b, c, num_splits * h, num_splits * w) # [B, C, H, W] 53 | 54 | return merge 55 | 56 | 57 | def normalize_img(img0, img1): 58 | # loaded images are in [0, 255] 59 | # normalize by ImageNet mean and std 60 | mean = torch.tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1).to(img1.device) 61 | std = torch.tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1).to(img1.device) 62 | img0 = (img0 / 255. - mean) / std 63 | img1 = (img1 / 255. - mean) / std 64 | 65 | return img0, img1 66 | 67 | 68 | def feature_add_position(feature0, feature1, attn_splits, feature_channels): 69 | pos_enc = PositionEmbeddingSine(num_pos_feats=feature_channels // 2) 70 | 71 | if attn_splits > 1: # add position in splited window 72 | feature0_splits = split_feature(feature0, num_splits=attn_splits) 73 | feature1_splits = split_feature(feature1, num_splits=attn_splits) 74 | 75 | position = pos_enc(feature0_splits) 76 | 77 | feature0_splits = feature0_splits + position 78 | feature1_splits = feature1_splits + position 79 | 80 | feature0 = merge_splits(feature0_splits, num_splits=attn_splits) 81 | feature1 = merge_splits(feature1_splits, num_splits=attn_splits) 82 | else: 83 | position = pos_enc(feature0) 84 | 85 | feature0 = feature0 + position 86 | feature1 = feature1 + position 87 | 88 | return feature0, feature1 89 | 90 | 91 | def feature_add_position_list(features_list, attn_splits, feature_channels): 92 | pos_enc = PositionEmbeddingSine(num_pos_feats=feature_channels // 2) 93 | 94 | if attn_splits > 1: # add position in splited window 95 | features_splits = [split_feature(x, num_splits=attn_splits) for x in features_list] 96 | 97 | position = pos_enc(features_splits[0]) 98 | features_splits = [x + position for x in features_splits] 99 | 100 | out_features_list = [merge_splits(x, num_splits=attn_splits) for x in features_splits] 101 | 102 | else: 103 | position = pos_enc(features_list[0]) 104 | 105 | out_features_list = [x + position for x in features_list] 106 | 107 | return out_features_list 108 | 109 | 110 | class InputPadder: 111 | """ Pads images such that dimensions are divisible by 8 """ 112 | 113 | def __init__(self, dims, mode='sintel', padding_factor=8): 114 | self.ht, self.wd = dims[-2:] 115 | pad_ht = (((self.ht // padding_factor) + 1) * padding_factor - self.ht) % padding_factor 116 | pad_wd = (((self.wd // padding_factor) + 1) * padding_factor - self.wd) % padding_factor 117 | if mode == 'sintel': 118 | self._pad = [pad_wd // 2, pad_wd - pad_wd // 2, pad_ht // 2, pad_ht - pad_ht // 2] 119 | else: 120 | self._pad = [pad_wd // 2, pad_wd - pad_wd // 2, 0, pad_ht] 121 | 122 | def pad(self, *inputs): 123 | return [F.pad(x, self._pad, mode='replicate') for x in inputs] 124 | 125 | def unpad(self, x): 126 | ht, wd = x.shape[-2:] 127 | c = [self._pad[2], ht - self._pad[3], self._pad[0], wd - self._pad[1]] 128 | return x[..., c[0]:c[1], c[2]:c[3]] 129 | 130 | 131 | def sample_features_by_grid(raw_whole_feats, grid, align_corners=True, mode='bilinear', padding_mode='border', 132 | local_radius=0, local_dilation=1, average_cosine=False, concat_cosine=False): 133 | if local_radius <= 0: 134 | return F.grid_sample(raw_whole_feats, grid, align_corners=align_corners, mode=mode, padding_mode=padding_mode) 135 | 136 | # --- sample on a local grid 137 | # unnomarlize original gird 138 | h, w = raw_whole_feats.shape[-2:] 139 | c = torch.Tensor([(w - 1) / 2., (h - 1) / 2.]).float().to(grid.device) # inverse scale 140 | unnorm_grid = (grid * c + c).reshape(grid.shape[0], -1, 2) # [B, n_rays*n_pts, 2] 141 | # build local grid 142 | local_h = 2 * local_radius + 1 143 | local_w = 2 * local_radius + 1 144 | window_grid = generate_window_grid(-local_radius, local_radius, 145 | -local_radius, local_radius, 146 | local_h, local_w, device=raw_whole_feats.device) # [2R+1, 2R+1, 2] 147 | window_grid = window_grid.reshape(1, -1, 2).repeat(grid.shape[0], 1, 1) * local_dilation # [B, (2R+1)^2, 2] 148 | # merge grid and normalize 149 | sample_grid = unnorm_grid.unsqueeze(2) + window_grid.unsqueeze(1) # [B, n_rays*n_pts, (2R+1)^2, 2] 150 | # bug before 151 | # c = torch.Tensor([(w + local_w * local_dilation - 1) / 2., 152 | # (h + local_h * local_dilation - 1) / 2.]).float().to(sample_grid.device) # inverse scale 153 | norm_sample_grid = (sample_grid - c) / c # range (-1, 1) 154 | # sample features 155 | sampled_feats = F.grid_sample(raw_whole_feats, norm_sample_grid, 156 | align_corners=align_corners, mode=mode, padding_mode=padding_mode) # [B, C, n_rays*n_pts, (2R+1)^2] 157 | # merge features of local grid 158 | b, c, n = sampled_feats.shape[:3] 159 | n_rays, n_pts = grid.shape[1:3] 160 | 161 | if average_cosine or concat_cosine: 162 | # concat on the batch dim for further processing after computing cosine 163 | sampled_feats = sampled_feats.permute(0, 3, 1, 2).reshape(b * local_h * local_w, c, n_rays, n_pts) # [B*(2R+1)^2, C, N, D] 164 | else: 165 | sampled_feats = sampled_feats.reshape(b, c*n, local_h, local_w) # [B, C*n_rays*n_pts, 2R+1, 2R+1] 166 | # TODO: may need to compare with average per-pixel cosine, instead of average feature first and then compute cosine 167 | avg_feats = F.adaptive_avg_pool2d(sampled_feats, (1, 1)) # [B, C*n_rays*n_pts, 1, 1] 168 | sampled_feats = avg_feats.reshape(b, c, n_rays, n_pts) 169 | 170 | return sampled_feats 171 | 172 | 173 | 174 | def merge_patches_to_channel(feature, 175 | patch_size=2, 176 | ): 177 | 178 | # feature: [B, C, H, W, D] 179 | b, c, h, w, d = feature.size() 180 | assert h % patch_size == 0 and w % patch_size == 0 181 | feature = feature.view(b, c, patch_size, h // patch_size, patch_size, w // patch_size, d 182 | ).permute(0, 1, 2, 4, 3, 5, 6).reshape( 183 | b, c * patch_size * patch_size, h // patch_size, w // patch_size, d) # [B, C*P*P, H/P, W/P, D] 184 | return feature 185 | 186 | 187 | 188 | def reverse_channel_patches(feature, 189 | patch_size=2): 190 | # feature: [B, C*P*P, H/P, W/P, D] 191 | b, c, h, w, d = feature.size() 192 | assert c % (patch_size ** 2) == 0 193 | 194 | feature = feature.view(b, c // (patch_size ** 2), patch_size, patch_size, h, w, d 195 | ).permute(0, 1, 2, 4, 3, 5, 6 196 | ).reshape(b, c // (patch_size ** 2), patch_size * h, patch_size * w, d) # [B, C, H, W, D] 197 | 198 | return feature 199 | 200 | 201 | 202 | -------------------------------------------------------------------------------- /models/rfdecoder/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/autonomousvision/murf/57d564203820815feced49045af0ea3fced04463/models/rfdecoder/__init__.py -------------------------------------------------------------------------------- /models/rfdecoder/cond_nerf.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import os 3 | import torch.nn.functional as F 4 | import torch.nn as nn 5 | from math import log2 6 | from .nerf import NeRF 7 | from .resblock import BasicBlock 8 | from .utils import MultiViewAgg 9 | 10 | 11 | class CondNeRF(NeRF): 12 | def __init__(self, opt, 13 | ): 14 | super(CondNeRF, self).__init__(opt) 15 | 16 | def define_network(self, opt): 17 | 18 | W = opt.decoder.net_width 19 | 20 | if getattr(opt, 'weighted_cosine', False): 21 | self.vis = nn.Sequential( 22 | nn.Conv2d(1, 8, 3, 1, 1), 23 | nn.GELU(), 24 | nn.Conv2d(8, 8, 3, 1, 1), 25 | nn.GELU(), 26 | nn.Conv2d(8, 1, 3, 1, 1), 27 | nn.Sigmoid(), 28 | ) 29 | 30 | # merge multi-view feature, color and view dir diff information with predicted weights 31 | sampled_feature_channels = 64 + 96 + 2 * 128 # cnn and transformer features 32 | input_channels = sampled_feature_channels + 3 * \ 33 | (2 * getattr(opt, 'sample_color_window_radius', 0) + 1) ** 2 34 | 35 | opt.feature_agg_channel = opt.decoder.net_width 36 | self.mvagg = MultiViewAgg(feat_ch=opt.feature_agg_channel, 37 | input_feat_channels=input_channels, 38 | ) 39 | 40 | input_ch_feat = opt.feature_agg_channel + sum(opt.encoder.cos_n_group) 41 | 42 | # residual connection 43 | self.residual = nn.Conv3d(input_ch_feat, W, 1, 1, 0) 44 | 45 | # decoder 46 | modules = [nn.Conv3d(input_ch_feat, W, (3, 3, 1), 1, (1, 1, 0)), 47 | nn.LeakyReLU(0.1), 48 | nn.Conv3d(W, W, (1, 1, 3), 1, (0, 0, 1)), 49 | nn.GroupNorm(8, W), 50 | nn.LeakyReLU(0.1), 51 | ] 52 | 53 | decoder_num_resblocks = opt.decoder_num_resblocks 54 | 55 | for i in range(decoder_num_resblocks): 56 | modules.append(BasicBlock(W, W, kernel=3, 57 | conv_2plus1d=True, 58 | ) 59 | ) 60 | 61 | self.regressor = nn.Sequential(*modules) 62 | 63 | # output head 64 | channels = opt.upconv_channel_list[-1] 65 | 66 | self.density_head = nn.Sequential(nn.Linear(channels, channels), 67 | nn.GELU(), 68 | nn.Linear(channels, 1), 69 | nn.Softplus() 70 | ) 71 | 72 | self.rgb_head = nn.Sequential(nn.Linear(channels, channels), 73 | nn.GELU(), 74 | nn.Linear(channels, 3), 75 | nn.Sigmoid(), 76 | ) 77 | 78 | # upsample 79 | upsample_factor = opt.radiance_subsample_factor 80 | channels = W 81 | 82 | # upsampler 83 | num_upsamples = int(log2(upsample_factor)) 84 | self.up_convs = nn.ModuleList() 85 | for i in range(num_upsamples): 86 | channel_expansion = 4 87 | 88 | # specify the upsampling conv channels in list 89 | upconv_channel_list = opt.upconv_channel_list 90 | assert len(upconv_channel_list) == num_upsamples 91 | 92 | self.up_convs.append(nn.Conv3d( 93 | upconv_channel_list[i], upconv_channel_list[i + 1 if i < num_upsamples - 1 else i] * channel_expansion, 3, 1, 1)) 94 | 95 | self.pixel_shuffle = nn.PixelShuffle(2) 96 | # conv after the final pixelshuffle layer 97 | self.conv = nn.Conv3d( 98 | upconv_channel_list[-1], upconv_channel_list[-1], 3, 1, 1) 99 | 100 | def forward(self, opt, cond_info=None, 101 | img_hw=None, 102 | num_views=None, 103 | **kwargs, 104 | ): 105 | 106 | opt.n_src_views = num_views 107 | 108 | assert img_hw is not None 109 | curr_h, curr_w = img_hw 110 | 111 | if self.training and getattr(opt, 'random_crop', False): 112 | curr_h, curr_w = opt.crop_height, opt.crop_width 113 | 114 | if getattr(opt, 'radiance_subsample_factor', False): 115 | curr_h = curr_h // opt.radiance_subsample_factor 116 | curr_w = curr_w // opt.radiance_subsample_factor 117 | 118 | if getattr(opt, 'weighted_cosine', False): 119 | cosine = cond_info['feat_info'] # [B, V, D, H*W, C] 120 | # predict the visibility based on entropy 121 | cosine_sum = cosine.sum(dim=-1) # [B, V, D, H*W] 122 | cosine_sum_norm = F.softmax( 123 | cosine_sum.detach(), dim=2) # [B, V, D, H*W] 124 | entropy = (-cosine_sum_norm * torch.log(cosine_sum_norm + 125 | 1e-6)).sum(dim=2, keepdim=True) # [B, V, 1, H*W] 126 | 127 | b_, v_ = entropy.shape[:2] 128 | 129 | vis_weight = self.vis(entropy.view( 130 | b_ * v_, 1, curr_h, curr_w)).view(b_, v_, 1, -1, 1) # [B, V, 1, H*W, 1] 131 | 132 | merged_cosine = (cosine * vis_weight).sum(dim=1) / \ 133 | (vis_weight.sum(1) + 1e-6) # [B, D, H*W, C] 134 | 135 | cond_info['feat_info'] = merged_cosine.permute( 136 | 0, 2, 1, 3) # [B, H*W, D, C] 137 | 138 | # multi-view aggregation of features and colors 139 | features = cond_info['sampled_feature_info'] # [B, V, C, H*W, D] 140 | b_, v_, _, l_, d_ = features.shape 141 | features = features.permute( 142 | 0, 3, 4, 1, 2).contiguous() # [B, H*W, D, V, C] 143 | 144 | colors = cond_info['color_info'].permute( 145 | 0, 1, 2, 4, 3).contiguous() # [B, H*W, D, V, (2R+1)^2 * 3] 146 | v_ = colors.size(-2) 147 | 148 | viewdir_diff = cond_info['viewdir_diff'] # [B, V, H*W, D, 4] 149 | 150 | viewdir_diff = viewdir_diff.permute(0, 2, 3, 1, 4) # [B, H*W, D, V, 4] 151 | 152 | # 128+128+96+64, (2*8+1)**2 * 3, 4 153 | concat = torch.cat((features, colors, viewdir_diff), 154 | dim=-1).view(b_, l_ * d_, v_, -1) # [B, H*W*D, V, C] 155 | agg = self.mvagg(concat) # [B, H*W*D, C] 156 | 157 | agg = agg.view(b_, l_, d_, -1) # [B, H*W, D, C] 158 | 159 | # decoder input 160 | conv_input = torch.cat( 161 | (cond_info['feat_info'], agg), dim=-1) # [B, H*W, D, C] 162 | 163 | batch_size, _, n_samples, _ = conv_input.shape 164 | 165 | conv_input = conv_input.reshape( 166 | batch_size, curr_h, curr_w, n_samples, -1).permute(0, 4, 1, 2, 3).contiguous() # [B, C, H, W, D] 167 | 168 | # add residual connection from input to the head 169 | residual_color_cosine = self.residual( 170 | conv_input) # [B, 64, H, W, D] 171 | 172 | out = self.regressor(conv_input) # [B, C, H, W, D] 173 | 174 | # add residual connection from input to the head 175 | out = out + residual_color_cosine 176 | 177 | # upsample 178 | for i in range(len(self.up_convs)): 179 | 180 | # out: [B, C, H, W, D] 181 | out = self.up_convs[i](out) 182 | 183 | # pixel shuffle upsampling 184 | # [B, D, C, H, W] 185 | out = out.permute(0, 4, 1, 2, 3) 186 | out = self.pixel_shuffle(out) 187 | out = F.leaky_relu(out, 0.1, inplace=True) 188 | # [B, C, H, W, D] 189 | out = out.permute(0, 2, 3, 4, 1) 190 | 191 | if i + 1 == len(self.up_convs): 192 | # conv at the final resolution 193 | out = self.conv(out) 194 | 195 | upsample_factor = opt.radiance_subsample_factor 196 | 197 | h = out.reshape(batch_size, -1, curr_h * curr_w * (upsample_factor ** 2), 198 | n_samples).permute(0, 2, 3, 1) # [B, H*W, D, C] 199 | 200 | # output head 201 | density = self.density_head(h).squeeze(-1) # [B, H*W, D] 202 | rgb = self.rgb_head(h) # [B, H*W, D, 3] 203 | 204 | return rgb, density 205 | -------------------------------------------------------------------------------- /models/rfdecoder/cond_nerf_fine.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import os 3 | import torch.nn.functional as F 4 | import torch.nn as nn 5 | import numpy as np 6 | from .ldm_unet.unet import UNetModel 7 | from .nerf import NeRF 8 | from .utils import MultiViewAgg 9 | 10 | 11 | class CondNeRFFine(NeRF): 12 | def __init__(self, 13 | net_width=16, 14 | num_samples=16, 15 | unet_num_res_blocks=1, 16 | device='cuda', 17 | **kwargs, 18 | ): 19 | 20 | self.device = device 21 | 22 | self.net_width = net_width 23 | self.num_samples = num_samples 24 | self.unet_num_res_blocks = unet_num_res_blocks 25 | 26 | self.cos_n_group = [1, 1, 1, 1] 27 | 28 | super(CondNeRFFine, self).__init__(None) 29 | 30 | def define_network(self, opt): 31 | 32 | W = self.net_width 33 | color_channels = 3 34 | 35 | proj_channels = 8 36 | # project features to lower dim 37 | self.feature_proj = nn.ModuleList([ 38 | nn.Sequential(nn.Conv2d(128, 128, 1), nn.GELU(), 39 | nn.Conv2d(128, proj_channels, 1)), 40 | nn.Sequential(nn.Conv2d(128, 128, 1), nn.GELU(), 41 | nn.Conv2d(128, proj_channels, 1)), 42 | nn.Sequential(nn.Conv2d(96, 96, 1), nn.GELU(), 43 | nn.Conv2d(96, proj_channels, 1)), 44 | nn.Sequential(nn.Conv2d(64, 64, 1), nn.GELU(), 45 | nn.Conv2d(64, proj_channels, 1)) 46 | ]) 47 | sampled_feature_channels = proj_channels * 4 48 | input_channels = sampled_feature_channels + 3 # feature and color 49 | 50 | # multi-view color and feature aggregation 51 | self.mvagg = MultiViewAgg(feat_ch=self.net_width, 52 | input_feat_channels=input_channels 53 | ) 54 | 55 | input_ch_feat = sum(self.cos_n_group) 56 | 57 | input_ch_feat += color_channels 58 | 59 | # (cosine, feature, color) 60 | input_ch_feat = self.net_width + sum(self.cos_n_group) 61 | 62 | # residual_color_cosine 63 | self.residual = nn.Conv3d(input_ch_feat, W, 1, 1, 0) 64 | 65 | self.regressor = UNetModel(image_size=None, 66 | in_channels=input_ch_feat, 67 | model_channels=W, 68 | out_channels=W, 69 | num_res_blocks=self.unet_num_res_blocks, 70 | attention_resolutions=[], 71 | channel_mult=[1, 1, 2, 4], 72 | num_head_channels=8, 73 | dims=3, 74 | postnorm=True, 75 | channels_per_group=4, 76 | condition_channels=input_ch_feat, 77 | ) 78 | 79 | channels = W 80 | self.density_head = nn.Sequential(nn.Linear(channels, channels), 81 | nn.GELU(), 82 | nn.Linear(channels, 1), 83 | nn.Softplus() 84 | ) 85 | 86 | self.rgb_head = nn.Sequential(nn.Linear(channels, channels), 87 | nn.GELU(), 88 | nn.Linear(channels, 3), 89 | nn.Sigmoid(), 90 | ) 91 | 92 | def forward(self, cond_info=None, img_hw=None, 93 | **kwargs, 94 | ): 95 | 96 | assert img_hw is not None 97 | curr_h, curr_w = img_hw 98 | 99 | # construct input to the decoder 100 | b_, l_, d_ = cond_info['color_info'].shape[:3] 101 | 102 | colors = cond_info['color_info'].permute( 103 | 0, 1, 2, 4, 3).contiguous() # [B, H*W, D, V, (2R+1)^2 * 3] 104 | v_colors = colors.size(-2) 105 | 106 | viewdir_diff = cond_info['viewdir_diff'] # [B, V, H*W, D, 4] 107 | 108 | viewdir_diff = viewdir_diff.permute(0, 2, 3, 1, 4) # [B, H*W, D, V, 4] 109 | 110 | features = cond_info['sampled_feature_info'] # [B, V, C, H*W, D] 111 | b_, v_features, _, l_, d_ = features.shape 112 | features = features.permute( 113 | 0, 3, 4, 1, 2).contiguous() # [B, H*W, D, V, C] 114 | 115 | concat = torch.cat((features, colors, viewdir_diff), 116 | dim=-1).view(b_, l_ * d_, v_colors, -1) # [B, H*W*D, V, C] 117 | 118 | agg = self.mvagg(concat) # [B, H*W*D, C] 119 | 120 | agg = agg.view(b_, l_, d_, -1) # [B, H*W, D, C] 121 | 122 | agg_input = torch.cat( 123 | (cond_info['feat_info'], agg), dim=-1) # [B, H*W, D, C] 124 | 125 | # decoder 126 | batch_size, _, n_samples, _ = agg_input.shape 127 | 128 | conv_input = agg_input # [B, H*W, D, C] 129 | 130 | conv_input = conv_input.reshape( 131 | batch_size, curr_h, curr_w, n_samples, -1).permute(0, 4, 1, 2, 3).contiguous() # [B, C, H, W, D] 132 | 133 | # add residual connection from input to the head 134 | residual_color_cosine = self.residual( 135 | conv_input) # [B, 64, H, W, D] 136 | 137 | # [B, C, D, H, W] for ldmunet, since downsampling is only performed in H, W dims 138 | x_ = conv_input.permute(0, 1, 4, 2, 3) 139 | x_ = self.regressor(x_) 140 | out = x_.permute(0, 1, 3, 4, 2) # [B, C, H, W, D] 141 | 142 | # add residual connection from input to the head 143 | out = out + residual_color_cosine 144 | 145 | h = out.reshape(batch_size, -1, curr_h * curr_w, 146 | n_samples).permute(0, 2, 3, 1) # [B, H*W, D, C] 147 | 148 | # output head 149 | density = self.density_head(h).squeeze(-1) # [B, H*W, D] 150 | rgb = self.rgb_head(h) # [B, H*W, D, 3] 151 | 152 | return rgb, density 153 | -------------------------------------------------------------------------------- /models/rfdecoder/ldm_unet/__init__.py: -------------------------------------------------------------------------------- https://raw.githubusercontent.com/autonomousvision/murf/57d564203820815feced49045af0ea3fced04463/models/rfdecoder/ldm_unet/__init__.py -------------------------------------------------------------------------------- /models/rfdecoder/ldm_unet/attention.py: -------------------------------------------------------------------------------- 1 | from inspect import isfunction 2 | import math 3 | import torch 4 | import torch.nn.functional as F 5 | from torch import nn, einsum 6 | from einops import rearrange, repeat 7 | 8 | 9 | def exists(val): 10 | return val is not None 11 | 12 | 13 | def uniq(arr): 14 | return{el: True for el in arr}.keys() 15 | 16 | 17 | def default(val, d): 18 | if exists(val): 19 | return val 20 | return d() if isfunction(d) else d 21 | 22 | 23 | def max_neg_value(t): 24 | return -torch.finfo(t.dtype).max 25 | 26 | 27 | def init_(tensor): 28 | dim = tensor.shape[-1] 29 | std = 1 / math.sqrt(dim) 30 | tensor.uniform_(-std, std) 31 | return tensor 32 | 33 | 34 | # feedforward 35 | class GEGLU(nn.Module): 36 | def __init__(self, dim_in, dim_out): 37 | super().__init__() 38 | self.proj = nn.Linear(dim_in, dim_out * 2) 39 | 40 | def forward(self, x): 41 | x, gate = self.proj(x).chunk(2, dim=-1) 42 | return x * F.gelu(gate) 43 | 44 | 45 | class FeedForward(nn.Module): 46 | def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.): 47 | super().__init__() 48 | inner_dim = int(dim * mult) 49 | dim_out = default(dim_out, dim) 50 | project_in = nn.Sequential( 51 | nn.Linear(dim, inner_dim), 52 | nn.GELU() 53 | ) if not glu else GEGLU(dim, inner_dim) 54 | 55 | self.net = nn.Sequential( 56 | project_in, 57 | nn.Dropout(dropout), 58 | nn.Linear(inner_dim, dim_out) 59 | ) 60 | 61 | def forward(self, x): 62 | return self.net(x) 63 | 64 | 65 | def zero_module(module): 66 | """ 67 | Zero out the parameters of a module and return it. 68 | """ 69 | for p in module.parameters(): 70 | p.detach().zero_() 71 | return module 72 | 73 | 74 | def Normalize(in_channels): 75 | return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True) 76 | 77 | 78 | class LinearAttention(nn.Module): 79 | def __init__(self, dim, heads=4, dim_head=32): 80 | super().__init__() 81 | self.heads = heads 82 | hidden_dim = dim_head * heads 83 | self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False) 84 | self.to_out = nn.Conv2d(hidden_dim, dim, 1) 85 | 86 | def forward(self, x): 87 | b, c, h, w = x.shape 88 | qkv = self.to_qkv(x) 89 | q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)', heads = self.heads, qkv=3) 90 | k = k.softmax(dim=-1) 91 | context = torch.einsum('bhdn,bhen->bhde', k, v) 92 | out = torch.einsum('bhde,bhdn->bhen', context, q) 93 | out = rearrange(out, 'b heads c (h w) -> b (heads c) h w', heads=self.heads, h=h, w=w) 94 | return self.to_out(out) 95 | 96 | 97 | class SpatialSelfAttention(nn.Module): 98 | def __init__(self, in_channels): 99 | super().__init__() 100 | self.in_channels = in_channels 101 | 102 | self.norm = Normalize(in_channels) 103 | self.q = torch.nn.Conv2d(in_channels, 104 | in_channels, 105 | kernel_size=1, 106 | stride=1, 107 | padding=0) 108 | self.k = torch.nn.Conv2d(in_channels, 109 | in_channels, 110 | kernel_size=1, 111 | stride=1, 112 | padding=0) 113 | self.v = torch.nn.Conv2d(in_channels, 114 | in_channels, 115 | kernel_size=1, 116 | stride=1, 117 | padding=0) 118 | self.proj_out = torch.nn.Conv2d(in_channels, 119 | in_channels, 120 | kernel_size=1, 121 | stride=1, 122 | padding=0) 123 | 124 | def forward(self, x): 125 | h_ = x 126 | h_ = self.norm(h_) 127 | q = self.q(h_) 128 | k = self.k(h_) 129 | v = self.v(h_) 130 | 131 | # compute attention 132 | b,c,h,w = q.shape 133 | q = rearrange(q, 'b c h w -> b (h w) c') 134 | k = rearrange(k, 'b c h w -> b c (h w)') 135 | w_ = torch.einsum('bij,bjk->bik', q, k) 136 | 137 | w_ = w_ * (int(c)**(-0.5)) 138 | w_ = torch.nn.functional.softmax(w_, dim=2) 139 | 140 | # attend to values 141 | v = rearrange(v, 'b c h w -> b c (h w)') 142 | w_ = rearrange(w_, 'b i j -> b j i') 143 | h_ = torch.einsum('bij,bjk->bik', v, w_) 144 | h_ = rearrange(h_, 'b c (h w) -> b c h w', h=h) 145 | h_ = self.proj_out(h_) 146 | 147 | return x+h_ 148 | 149 | 150 | class CrossAttention(nn.Module): 151 | def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.): 152 | super().__init__() 153 | inner_dim = dim_head * heads 154 | context_dim = default(context_dim, query_dim) 155 | 156 | self.scale = dim_head ** -0.5 157 | self.heads = heads 158 | 159 | self.to_q = nn.Linear(query_dim, inner_dim, bias=False) 160 | self.to_k = nn.Linear(context_dim, inner_dim, bias=False) 161 | self.to_v = nn.Linear(context_dim, inner_dim, bias=False) 162 | 163 | self.to_out = nn.Sequential( 164 | nn.Linear(inner_dim, query_dim), 165 | nn.Dropout(dropout) 166 | ) 167 | 168 | def forward(self, x, context=None, mask=None): 169 | h = self.heads 170 | 171 | q = self.to_q(x) 172 | context = default(context, x) 173 | k = self.to_k(context) 174 | v = self.to_v(context) 175 | 176 | q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v)) 177 | 178 | sim = einsum('b i d, b j d -> b i j', q, k) * self.scale 179 | 180 | if exists(mask): 181 | mask = rearrange(mask, 'b ... -> b (...)') 182 | max_neg_value = -torch.finfo(sim.dtype).max 183 | mask = repeat(mask, 'b j -> (b h) () j', h=h) 184 | sim.masked_fill_(~mask, max_neg_value) 185 | 186 | # attention, what we cannot get enough of 187 | attn = sim.softmax(dim=-1) 188 | 189 | out = einsum('b i j, b j d -> b i d', attn, v) 190 | out = rearrange(out, '(b h) n d -> b n (h d)', h=h) 191 | return self.to_out(out) 192 | 193 | 194 | class BasicTransformerBlock(nn.Module): 195 | def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=False): 196 | super().__init__() 197 | self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention 198 | self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff) 199 | self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim, 200 | heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none 201 | self.norm1 = nn.LayerNorm(dim) 202 | self.norm2 = nn.LayerNorm(dim) 203 | self.norm3 = nn.LayerNorm(dim) 204 | # self.checkpoint = checkpoint 205 | 206 | def forward(self, x, context=None): 207 | # return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint) 208 | 209 | return _forward(x, context) 210 | 211 | def _forward(self, x, context=None): 212 | x = self.attn1(self.norm1(x)) + x 213 | x = self.attn2(self.norm2(x), context=context) + x 214 | x = self.ff(self.norm3(x)) + x 215 | return x 216 | 217 | 218 | class SpatialTransformer(nn.Module): 219 | """ 220 | Transformer block for image-like data. 221 | First, project the input (aka embedding) 222 | and reshape to b, t, d. 223 | Then apply standard transformer action. 224 | Finally, reshape to image 225 | """ 226 | def __init__(self, in_channels, n_heads, d_head, 227 | depth=1, dropout=0., context_dim=None): 228 | super().__init__() 229 | self.in_channels = in_channels 230 | inner_dim = n_heads * d_head 231 | self.norm = Normalize(in_channels) 232 | 233 | self.proj_in = nn.Conv2d(in_channels, 234 | inner_dim, 235 | kernel_size=1, 236 | stride=1, 237 | padding=0) 238 | 239 | self.transformer_blocks = nn.ModuleList( 240 | [BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim) 241 | for d in range(depth)] 242 | ) 243 | 244 | self.proj_out = zero_module(nn.Conv2d(inner_dim, 245 | in_channels, 246 | kernel_size=1, 247 | stride=1, 248 | padding=0)) 249 | 250 | def forward(self, x, context=None): 251 | # note: if no context is given, cross-attention defaults to self-attention 252 | b, c, h, w = x.shape 253 | x_in = x 254 | x = self.norm(x) 255 | x = self.proj_in(x) 256 | x = rearrange(x, 'b c h w -> b (h w) c') 257 | for block in self.transformer_blocks: 258 | x = block(x, context=context) 259 | x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w) 260 | x = self.proj_out(x) 261 | return x + x_in -------------------------------------------------------------------------------- /models/rfdecoder/nerf.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.nn.functional as torch_F 3 | from misc import camera, utils 4 | import numpy as np 5 | 6 | 7 | class NeRF(torch.nn.Module): 8 | 9 | def __init__(self, opt): 10 | super().__init__() 11 | self.define_network(opt) 12 | 13 | def define_network(self, opt): 14 | input_3D_dim = 3+6*opt.decoder.posenc.L_3D if opt.decoder.posenc else 3 15 | if opt.nerf.view_dep: 16 | input_view_dim = 3+6*opt.decoder.posenc.L_view if opt.decoder.posenc else 3 17 | # point-wise feature 18 | self.mlp_feat = torch.nn.ModuleList() 19 | L = utils.get_layer_dims(opt.decoder.layers_feat) 20 | for li, (k_in, k_out) in enumerate(L): 21 | if li == 0: 22 | k_in = input_3D_dim 23 | if li in opt.decoder.skip: 24 | k_in += input_3D_dim 25 | if li == len(L)-1: 26 | k_out += 1 27 | linear = torch.nn.Linear(k_in, k_out) 28 | if opt.decoder.tf_init: 29 | self.tensorflow_init_weights( 30 | opt, linear, out="first" if li == len(L)-1 else None) 31 | self.mlp_feat.append(linear) 32 | # RGB prediction 33 | self.mlp_rgb = torch.nn.ModuleList() 34 | L = utils.get_layer_dims(opt.decoder.layers_rgb) 35 | feat_dim = opt.decoder.layers_feat[-1] 36 | for li, (k_in, k_out) in enumerate(L): 37 | if li == 0: 38 | k_in = feat_dim+(input_view_dim if opt.nerf.view_dep else 0) 39 | linear = torch.nn.Linear(k_in, k_out) 40 | if opt.decoder.tf_init: 41 | self.tensorflow_init_weights( 42 | opt, linear, out="all" if li == len(L)-1 else None) 43 | self.mlp_rgb.append(linear) 44 | 45 | def tensorflow_init_weights(self, opt, linear, out=None): 46 | # use Xavier init instead of Kaiming init 47 | relu_gain = torch.nn.init.calculate_gain("relu") # sqrt(2) 48 | if out == "all": 49 | torch.nn.init.xavier_uniform_(linear.weight) 50 | elif out == "first": 51 | torch.nn.init.xavier_uniform_(linear.weight[:1]) 52 | torch.nn.init.xavier_uniform_(linear.weight[1:], gain=relu_gain) 53 | else: 54 | torch.nn.init.xavier_uniform_(linear.weight, gain=relu_gain) 55 | torch.nn.init.zeros_(linear.bias) 56 | 57 | # [B,...,3] 58 | def forward(self, opt, points_3D, ray_unit=None, mode=None, **kwargs): 59 | if opt.decoder.posenc: 60 | points_enc = self.positional_encoding( 61 | opt, points_3D, L=opt.decoder.posenc.L_3D) 62 | points_enc = torch.cat( 63 | [points_3D, points_enc], dim=-1) # [B,...,6L+3] 64 | else: 65 | points_enc = points_3D 66 | feat = points_enc 67 | # extract coordinate-based features 68 | for li, layer in enumerate(self.mlp_feat): 69 | if li in opt.decoder.skip: 70 | feat = torch.cat([feat, points_enc], dim=-1) 71 | feat = layer(feat) 72 | if li == len(self.mlp_feat)-1: 73 | density = feat[..., 0] 74 | if opt.nerf.density_noise_reg and mode == "train": 75 | density += torch.randn_like(density) * \ 76 | opt.nerf.density_noise_reg 77 | # relu_,abs_,sigmoid_,exp_.... 78 | density_activ = getattr(torch_F, opt.decoder.density_activ) 79 | density = density_activ(density) 80 | feat = feat[..., 1:] 81 | feat = torch_F.relu(feat) 82 | # predict RGB values 83 | if opt.nerf.view_dep: 84 | assert (ray_unit is not None) 85 | if opt.decoder.posenc: 86 | ray_enc = self.positional_encoding( 87 | opt, ray_unit, L=opt.decoder.posenc.L_view) 88 | ray_enc = torch.cat([ray_unit, ray_enc], 89 | dim=-1) # [B,...,6L+3] 90 | else: 91 | ray_enc = ray_unit 92 | feat = torch.cat([feat, ray_enc], dim=-1) 93 | for li, layer in enumerate(self.mlp_rgb): 94 | feat = layer(feat) 95 | if li != len(self.mlp_rgb)-1: 96 | feat = torch_F.relu(feat) 97 | rgb = feat.sigmoid_() # [B,...,3] 98 | return rgb, density 99 | 100 | def forward_samples(self, opt, center, ray, depth_samples, mode=None): 101 | points_3D_samples = camera.get_3D_points_from_depth( 102 | opt, center, ray, depth_samples, multi_samples=True) # [B,HW,N,3] 103 | if opt.nerf.view_dep: 104 | ray_unit = torch_F.normalize(ray, dim=-1) # [B,HW,3] 105 | ray_unit_samples = ray_unit[..., None, :].expand_as( 106 | points_3D_samples) # [B,HW,N,3] 107 | else: 108 | ray_unit_samples = None 109 | rgb_samples, density_samples = self.forward( 110 | opt, points_3D_samples, ray_unit=ray_unit_samples, mode=mode) # [B,HW,N],[B,HW,N,3] 111 | return rgb_samples, density_samples 112 | 113 | def composite(self, opt, ray, rgb_samples, density_samples, depth_samples, setbg_opaque, 114 | render_depth_no_boundary=None, 115 | ): 116 | ray_length = ray.norm(dim=-1, keepdim=True) # [B,HW,1] 117 | # volume rendering: compute probability (using quadrature) 118 | depth_intv_samples = depth_samples[..., 1:, 119 | 0]-depth_samples[..., :-1, 0] # [B,HW,N-1] 120 | depth_intv_samples = torch.cat([depth_intv_samples, torch.empty_like( 121 | depth_intv_samples[..., :1]).fill_(1e10)], dim=2) # [B,HW,N] 122 | dist_samples = depth_intv_samples*ray_length # [B,HW,N] 123 | if opt.nerf.wo_render_interval: 124 | # note: we did not use the intervals here, because in practice different scenes from COLMAP can have 125 | # very different scales, and using interval can affect the model's generalization ability. 126 | # Therefore we don't use the intervals for both training and evaluation. [IBRNet] 127 | sigma_delta = density_samples 128 | else: 129 | sigma_delta = density_samples*dist_samples # [B,HW,N] 130 | 131 | alpha = 1-(-sigma_delta).exp_() # [B,HW,N] 132 | T = (-torch.cat([torch.zeros_like(sigma_delta[..., :1]), 133 | sigma_delta[..., :-1]], dim=2).cumsum(dim=2)).exp_() # [B,HW,N] 134 | prob = (T*alpha)[..., None] # [B,HW,N,1] 135 | # integrate RGB and depth weighted by probability 136 | if render_depth_no_boundary is not None: 137 | remove = render_depth_no_boundary 138 | depth_prob = (prob[:, :, remove:-remove]) / ( 139 | torch.sum(prob[:, :, remove:-remove], dim=2, keepdim=True) + 1e-8) 140 | depth = (depth_samples[:, :, remove:-remove] 141 | * depth_prob).sum(dim=2) # [B,HW,1] 142 | else: 143 | depth_prob = prob / (torch.sum(prob, dim=2, keepdim=True) + 1e-8) 144 | depth = (depth_samples*depth_prob).sum(dim=2) # [B,HW,1] 145 | 146 | rgb = (rgb_samples*prob).sum(dim=2) # [B,HW,3] 147 | opacity = prob.sum(dim=2) # [B,HW,1] 148 | if setbg_opaque: 149 | rgb = rgb + 1 * (1 - opacity) 150 | return rgb, depth, opacity, prob # [B,HW,K] 151 | 152 | def positional_encoding(self, opt, input, L): # [B,...,N] 153 | shape = input.shape 154 | freq = 2**torch.arange(L, dtype=torch.float32, 155 | device=opt.device) * np.pi # [L] 156 | spectrum = input[..., None]*freq # [B,...,N,L] 157 | sin, cos = spectrum.sin(), spectrum.cos() # [B,...,N,L] 158 | input_enc = torch.stack([sin, cos], dim=-2) # [B,...,N,2,L] 159 | input_enc = input_enc.view(*shape[:-1], -1) # [B,...,2NL] 160 | return input_enc 161 | -------------------------------------------------------------------------------- /models/rfdecoder/resblock.py: -------------------------------------------------------------------------------- 1 | import torch 2 | from torch import nn 3 | import torch.nn.functional as F 4 | 5 | 6 | def conv3x3x3(in_planes, out_planes, stride=1, kernel=3): 7 | return nn.Conv3d(in_planes, 8 | out_planes, 9 | kernel_size=kernel, 10 | stride=stride, 11 | padding=(kernel - 1) // 2 if isinstance(kernel, 12 | int) else (i // 2 for i in kernel), 13 | bias=False) 14 | 15 | 16 | def conv1x1x1(in_planes, out_planes, stride=1): 17 | return nn.Conv3d(in_planes, 18 | out_planes, 19 | kernel_size=1, 20 | stride=stride, 21 | bias=False) 22 | 23 | 24 | class BasicBlock(nn.Module): 25 | expansion = 1 26 | 27 | def __init__(self, in_planes, planes, stride=1, downsample=None, kernel=3, no_norm=False, gelu_act=False, 28 | conv_2plus1d=False, 29 | zero_init_last_layer=False, 30 | ): 31 | super().__init__() 32 | 33 | self.no_norm = no_norm 34 | 35 | if conv_2plus1d: 36 | self.conv1 = nn.Sequential( 37 | conv3x3x3(in_planes, planes, stride, 38 | kernel=(3, 3, 1)), # spatial 39 | nn.GroupNorm(8, planes), 40 | nn.ReLU(inplace=True), 41 | conv3x3x3(planes, planes, stride, kernel=(1, 1, 3), # depth 42 | )) 43 | else: 44 | self.conv1 = conv3x3x3(in_planes, planes, stride, kernel=kernel) 45 | if not no_norm: 46 | self.bn1 = nn.GroupNorm(8, planes) 47 | if gelu_act: 48 | self.act = nn.GELU() 49 | else: 50 | self.act = nn.ReLU(inplace=True) 51 | 52 | if conv_2plus1d: 53 | self.conv2 = nn.Sequential( 54 | conv3x3x3(planes, planes, stride, kernel=(3, 3, 1)), # spatial 55 | nn.GroupNorm(8, planes), 56 | nn.ReLU(inplace=True), 57 | conv3x3x3(planes, planes, stride, kernel=(1, 1, 3), # depth 58 | )) 59 | else: 60 | self.conv2 = conv3x3x3(planes, planes, kernel=kernel) 61 | if not no_norm: 62 | self.bn2 = nn.GroupNorm(8, planes) 63 | self.downsample = downsample 64 | self.stride = stride 65 | 66 | if zero_init_last_layer: 67 | # resume from a pretrained small model, maintain the initial behavior 68 | self.bn2.weight.data.zero_() 69 | self.bn2.bias.data.zero_() 70 | 71 | def forward(self, x): 72 | residual = x 73 | 74 | out = self.conv1(x) 75 | if not self.no_norm: 76 | out = self.bn1(out) 77 | out = self.act(out) 78 | 79 | out = self.conv2(out) 80 | if not self.no_norm: 81 | out = self.bn2(out) 82 | 83 | if self.downsample is not None: 84 | residual = self.downsample(x) 85 | 86 | out += residual 87 | out = self.act(out) 88 | 89 | return out 90 | -------------------------------------------------------------------------------- /models/rfdecoder/utils.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import torch.nn as nn 3 | import torch.nn.functional as F 4 | 5 | 6 | class MultiViewAgg(nn.Module): 7 | def __init__(self, feat_ch=128, 8 | input_feat_channels=371, 9 | ): 10 | super(MultiViewAgg, self).__init__() 11 | self.feat_ch = feat_ch 12 | self.proj = nn.Linear(input_feat_channels, feat_ch) 13 | self.view_fc = nn.Linear(4, feat_ch) 14 | in_channels = feat_ch * 3 15 | self.global_fc = nn.Linear(in_channels, feat_ch) 16 | 17 | self.agg_w_fc = nn.Linear(feat_ch, 1) 18 | self.fc = nn.Linear(feat_ch, feat_ch) 19 | 20 | def forward(self, img_feat_rgb_dir): 21 | B, S = len(img_feat_rgb_dir), img_feat_rgb_dir.shape[-2] 22 | 23 | view_feat = self.view_fc(img_feat_rgb_dir[..., -4:]) 24 | img_feat_rgb = self.proj(img_feat_rgb_dir[..., :-4]) + view_feat 25 | 26 | var_feat = torch.var(img_feat_rgb, dim=-2).view(B, -1, 27 | 1, self.feat_ch).repeat(1, 1, S, 1) 28 | avg_feat = torch.mean(img_feat_rgb, dim=-2).view(B, -1, 29 | 1, self.feat_ch).repeat(1, 1, S, 1) 30 | 31 | feat = torch.cat([img_feat_rgb, var_feat, avg_feat], dim=-1) 32 | 33 | global_feat = self.global_fc(feat) 34 | agg_w = F.softmax(self.agg_w_fc(global_feat), dim=-2) 35 | im_feat = (global_feat * agg_w).sum(dim=-2) 36 | return self.fc(im_feat) 37 | -------------------------------------------------------------------------------- /models/utils.py: -------------------------------------------------------------------------------- 1 | import numpy as np 2 | import math 3 | import torch 4 | 5 | 6 | def compute_grid_indices(image_shape, patch_size, min_overlap=20): 7 | if min_overlap >= patch_size[0] or min_overlap >= patch_size[1]: 8 | raise ValueError("!!") 9 | hs = list(range(0, image_shape[0], patch_size[0] - min_overlap)) 10 | ws = list(range(0, image_shape[1], patch_size[1] - min_overlap)) 11 | # Make sure the final patch is flush with the image boundary 12 | hs[-1] = image_shape[0] - patch_size[0] 13 | ws[-1] = image_shape[1] - patch_size[1] 14 | return [(h, w) for h in hs for w in ws] 15 | 16 | 17 | def compute_view_dir_diff(xyz, tgt_extrinsics, src_extrinsics): 18 | # xyz: [B, N, D, 3] 19 | # tgt_extrinsics: [B, 3, 4] 20 | # src_extrinsics: [B, V, 3, 4] 21 | 22 | b, n, d = xyz.shape[:3] 23 | num_views = src_extrinsics.size(1) 24 | tgt_camera_pos = - \ 25 | torch.bmm(tgt_extrinsics[:, :, :3].inverse(), 26 | tgt_extrinsics[:, :, 3:])[:, :, -1] # [B, 3] 27 | src_camera_pos = [-torch.bmm(src_extrinsics[:, i, :, :3].inverse(), src_extrinsics[:, i, :, 3:])[ 28 | :, :, -1] for i in range(num_views)] # list of [B, 3] 29 | tgt_diff = xyz - tgt_camera_pos[:, None, None] # [B, N, D, 3] 30 | src_diff = [xyz - src_camera_pos[i][:, None, None] 31 | for i in range(num_views)] # list of [B, N, D, 3] 32 | 33 | tgt_diff = tgt_diff / (torch.norm(tgt_diff, dim=-1, keepdim=True) + 1e-6) 34 | src_diff = [src_diff[i] / (torch.norm(src_diff[i], dim=-1, keepdim=True)) 35 | for i in range(num_views)] 36 | 37 | ray_diff_dot = [torch.sum(tgt_diff * src_diff[i], 38 | dim=-1, keepdim=True) for i in range(num_views)] 39 | 40 | ray_diff_dot = torch.stack(ray_diff_dot, dim=1) # [B, V, N, D, 1] 41 | 42 | ray_diff = [tgt_diff - src_diff[i] for i in range(num_views)] 43 | ray_diff_norm = [torch.norm(ray_diff[i], dim=-1, keepdim=True) 44 | for i in range(num_views)] # list of [B, N, D, 1] 45 | ray_diff_dir = [ray_diff[i] / (ray_diff_norm[i] + 1e-6) 46 | for i in range(num_views)] 47 | 48 | ray_diff_dir = torch.stack(ray_diff_dir, dim=1) # [B, V, N, D, 3] 49 | 50 | ray_diff = torch.cat((ray_diff_dir, ray_diff_dot), 51 | dim=-1) # [B, V, N, D, 4] 52 | 53 | return ray_diff 54 | 55 | -------------------------------------------------------------------------------- /options.py: -------------------------------------------------------------------------------- 1 | import numpy as np 2 | import os 3 | import torch 4 | import random 5 | import string 6 | import yaml 7 | from easydict import EasyDict as edict 8 | import time 9 | import sys 10 | 11 | from misc import utils 12 | from misc.utils import log 13 | 14 | 15 | def parse_arguments(args): 16 | """ 17 | Parse arguments from command line. 18 | Syntax: --key1.key2.key3=value --> value 19 | --key1.key2.key3= --> None 20 | --key1.key2.key3 --> True 21 | --key1.key2.key3! --> False 22 | """ 23 | opt_cmd = {} 24 | for arg in args: 25 | assert(arg.startswith("--")) 26 | if "=" not in arg[2:]: 27 | key_str,value = (arg[2:-1],"false") if arg[-1]=="!" else (arg[2:],"true") 28 | else: 29 | key_str,value = arg[2:].split("=") 30 | keys_sub = key_str.split(".") 31 | opt_sub = opt_cmd 32 | for k in keys_sub[:-1]: 33 | if k not in opt_sub: opt_sub[k] = {} 34 | opt_sub = opt_sub[k] 35 | assert keys_sub[-1] not in opt_sub,keys_sub[-1] 36 | opt_sub[keys_sub[-1]] = yaml.safe_load(value) 37 | opt_cmd = edict(opt_cmd) 38 | return opt_cmd 39 | 40 | 41 | def set(opt_cmd={}, load_confd=True): 42 | log.info("setting configurations...") 43 | # assert("model" in opt_cmd) 44 | # load config from yaml file 45 | assert("yaml" in opt_cmd) 46 | fname = "configs/{}.yaml".format(opt_cmd.yaml) 47 | opt_base = load_options(fname) 48 | if load_confd and os.path.isfile("configs/confidentiality.yaml"): 49 | opt_conf = load_options("configs/confidentiality.yaml") 50 | opt_base = override_options(opt_base, opt_conf, key_stack=[], safe_check=False) 51 | # override with command line arguments 52 | # opt = override_options(opt_base,opt_cmd,key_stack=[],safe_check=True) 53 | # no safe check 54 | opt = override_options(opt_base,opt_cmd,key_stack=[],safe_check=False) 55 | process_options(opt) 56 | log.options(opt) 57 | return opt 58 | 59 | 60 | def load_options(fname): 61 | with open(fname) as file: 62 | opt = edict(yaml.safe_load(file)) 63 | if "_parent_" in opt: 64 | # load parent yaml file(s) as base options 65 | parent_fnames = opt.pop("_parent_") 66 | if type(parent_fnames) is str: 67 | parent_fnames = [parent_fnames] 68 | for parent_fname in parent_fnames: 69 | opt_parent = load_options(parent_fname) 70 | opt_parent = override_options(opt_parent,opt,key_stack=[]) 71 | opt = opt_parent 72 | print("loading {}...".format(fname)) 73 | return opt 74 | 75 | 76 | def override_options(opt,opt_over,key_stack=None,safe_check=False): 77 | for key,value in opt_over.items(): 78 | if isinstance(value,dict): 79 | # parse child options (until leaf nodes are reached) 80 | opt[key] = override_options(opt.get(key,dict()),value,key_stack=key_stack+[key],safe_check=safe_check) 81 | else: 82 | # ensure command line argument to override is also in yaml file 83 | if safe_check and key not in opt: 84 | add_new = None 85 | while add_new not in ["y","n"]: 86 | key_str = ".".join(key_stack+[key]) 87 | add_new = input("\"{}\" not found in original opt, add? (y/n) ".format(key_str)) 88 | if add_new=="n": 89 | print("safe exiting...") 90 | exit() 91 | opt[key] = value 92 | return opt 93 | 94 | 95 | def process_options(opt): 96 | # if opt.name is None: 97 | # opt.name = time.strftime("%b%d_%H%M%S").lower() 98 | 99 | # update scene_list 100 | if hasattr(opt, "data_test"): 101 | for k, v in getattr(opt, "data_test").items(): 102 | if v is None: 103 | continue 104 | if getattr(v, "scene_list", None) is not None and isinstance(getattr(v, "scene_list", None), str): 105 | attr_str = getattr(v, "scene_list") 106 | setattr(v, "scene_list", attr_str.split(',')) 107 | 108 | # update gpu_ids list 109 | if isinstance(getattr(opt, "gpu_ids"), str): 110 | gpu_ids = getattr(opt, "gpu_ids") 111 | setattr(opt, "gpu_ids", [int(x) for x in gpu_ids.split(',') if x.strip()]) 112 | if isinstance(getattr(opt, "gpu_ids"), int): 113 | opt.gpu_ids = [opt.gpu_ids] 114 | 115 | # set seed 116 | if opt.seed is not None: 117 | random.seed(opt.seed) 118 | np.random.seed(opt.seed) 119 | torch.manual_seed(opt.seed) 120 | torch.cuda.manual_seed_all(opt.seed) 121 | # if opt.seed!=0: 122 | # opt.name = str(opt.name)+"_seed{}".format(opt.seed) 123 | else: 124 | # create random string as run ID 125 | randkey = "".join(random.choice(string.ascii_uppercase) for _ in range(4)) 126 | # opt.name = str(opt.name)+"_{}".format(randkey) 127 | # other default options 128 | # opt.output_path = os.path.join(opt.output_root, opt.name) 129 | os.makedirs(opt.output_path, exist_ok=True) 130 | # save run commands 131 | with open(os.path.join(opt.output_path, 'run.bash'), 'a+') as f: 132 | command = 'python %s\n' % (' '.join(sys.argv)) 133 | f.write(command) 134 | opt.device = "cpu" if opt.cpu or not torch.cuda.is_available() else "cuda:{}".format(opt.gpu_ids[0]) 135 | 136 | 137 | def save_options_file(opt): 138 | opt_fname = "{}/options.yaml".format(opt.output_path) 139 | if os.path.isfile(opt_fname): 140 | with open(opt_fname) as file: 141 | opt_old = yaml.safe_load(file) 142 | if opt!=opt_old: 143 | # prompt if options are not identical 144 | opt_new_fname = "{}/options_temp.yaml".format(opt.output_path) 145 | with open(opt_new_fname,"w") as file: 146 | yaml.safe_dump(utils.to_dict(opt),file,default_flow_style=False,indent=4) 147 | print("existing options file found (different from current one)...") 148 | os.system("diff {} {}".format(opt_fname,opt_new_fname)) 149 | os.system("rm {}".format(opt_new_fname)) 150 | else: 151 | print("existing options file found (identical)") 152 | else: print("(creating new options file...)") 153 | with open(opt_fname,"w") as file: 154 | yaml.safe_dump(utils.to_dict(opt),file,default_flow_style=False,indent=4) 155 | -------------------------------------------------------------------------------- /requirements.txt: -------------------------------------------------------------------------------- 1 | -f https://download.pytorch.org/whl/cu113/torch_stable.html 2 | torch==1.10.1+cu113 3 | torchvision==0.11.2+cu113 4 | easydict==1.10 5 | imageio==2.16.2 6 | ipdb==0.13.11 7 | lpips==0.1.4 8 | numpy==1.22.3 9 | opencv_python==4.5.5.64 10 | Pillow==9.4.0 11 | PyYAML==6.0 12 | scikit_image==0.19.2 13 | sk-video==1.1.10 14 | telepot==12.7 15 | termcolor==2.1.1 16 | tqdm==4.64.0 17 | tensorboard==2.10.0 18 | setuptools==59.5.0 19 | matplotlib==3.5.1 20 | einops==0.4.1 21 | -------------------------------------------------------------------------------- /scripts/murf_dtu_large_baseline_evaluate.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # reproduce the numbers in Table 3 of our paper 5 | 6 | 7 | # evaluate on dtu_regnerf test set, 3 input views 8 | # 21.31, 0.885, 0.127 9 | CHECKPOINT_DIR=checkpoints/tmp && \ 10 | mkdir -p ${CHECKPOINT_DIR} && \ 11 | CUDA_VISIBLE_DEVICES=0 python test.py \ 12 | --output_path=${CHECKPOINT_DIR} \ 13 | --load=pretrained/murf-dtu-large-baseline-6view-c52d3b16.pth \ 14 | --yaml=test_dtu_regnerf \ 15 | --n_src_views=3 \ 16 | --weighted_cosine \ 17 | --with_fine_nerf \ 18 | --data_test.dtu_regnerf.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 19 | --data_test.dtu_regnerf.img_wh=[400,300] \ 20 | --inference_size=[304,400] 21 | 22 | # to save the results, use additional 23 | --save_imgs \ 24 | --save_source_target_images 25 | 26 | 27 | # for less memory consumption, use additional 28 | --inference_splits=2 \ 29 | --fine_inference_splits=2 30 | 31 | 32 | # evaluate on dtu_regnerf test set, 6 input views 33 | # 23.74, 0.921, 0.095 34 | CHECKPOINT_DIR=checkpoints/tmp && \ 35 | mkdir -p ${CHECKPOINT_DIR} && \ 36 | CUDA_VISIBLE_DEVICES=0 python test.py \ 37 | --output_path=${CHECKPOINT_DIR} \ 38 | --load=pretrained/murf-dtu-large-baseline-9view-6754a597.pth \ 39 | --yaml=test_dtu_regnerf \ 40 | --n_src_views=6 \ 41 | --weighted_cosine \ 42 | --with_fine_nerf \ 43 | --data_test.dtu_regnerf.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 44 | --data_test.dtu_regnerf.img_wh=[400,300] \ 45 | --inference_size=[304,400] 46 | 47 | 48 | # evaluate on dtu_regnerf test set, 9 input views 49 | # 25.28, 0.936, 0.084 50 | CHECKPOINT_DIR=checkpoints/tmp && \ 51 | mkdir -p ${CHECKPOINT_DIR} && \ 52 | CUDA_VISIBLE_DEVICES=0 python test.py \ 53 | --output_path=${CHECKPOINT_DIR} \ 54 | --load=pretrained/murf-dtu-large-baseline-9view-6754a597.pth \ 55 | --yaml=test_dtu_regnerf \ 56 | --n_src_views=9 \ 57 | --weighted_cosine \ 58 | --with_fine_nerf \ 59 | --data_test.dtu_regnerf.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 60 | --data_test.dtu_regnerf.img_wh=[400,300] \ 61 | --inference_size=[304,400] 62 | 63 | -------------------------------------------------------------------------------- /scripts/murf_dtu_small_baseline_evaluate.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # reproduce the numbers in Table 1 of our paper 5 | 6 | 7 | # evaluate on dtu test set, 3 input views 8 | # 28.76, 0.961, 0.077 9 | CHECKPOINT_DIR=checkpoints/tmp && \ 10 | mkdir -p ${CHECKPOINT_DIR} && \ 11 | CUDA_VISIBLE_DEVICES=0 python test.py \ 12 | --output_path=${CHECKPOINT_DIR} \ 13 | --load=pretrained/murf-dtu-small-baseline-3view-ecc90367.pth \ 14 | --yaml=test_dtu \ 15 | --n_src_views=3 \ 16 | --weighted_cosine \ 17 | --with_fine_nerf \ 18 | --data_test.dtu.root_dir=UPDATE_WITH_YOUR_DATA_PATH 19 | 20 | 21 | # to save the results, use additional 22 | --save_imgs \ 23 | --save_source_target_images 24 | 25 | 26 | # for less memory consumption, use additional 27 | --inference_splits=2 \ 28 | --fine_inference_splits=2 29 | 30 | 31 | # evaluate on dtu test set, 2 input views 32 | # 27.02, 0.949, 0.088 33 | CHECKPOINT_DIR=checkpoints/tmp && \ 34 | mkdir -p ${CHECKPOINT_DIR} && \ 35 | CUDA_VISIBLE_DEVICES=0 python test.py \ 36 | --output_path=${CHECKPOINT_DIR} \ 37 | --load=pretrained/murf-dtu-small-baseline-2view-21d62708.pth \ 38 | --yaml=test_dtu \ 39 | --n_src_views=2 \ 40 | --with_fine_nerf \ 41 | --data_test.dtu.root_dir=UPDATE_WITH_YOUR_DATA_PATH 42 | 43 | -------------------------------------------------------------------------------- /scripts/murf_dtu_small_baseline_render.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # NOTE: to render videos, you should have `ffmpeg` installed 5 | 6 | 7 | # render videos from 2 input views 8 | CHECKPOINT_DIR=checkpoints/tmp && \ 9 | mkdir -p ${CHECKPOINT_DIR} && \ 10 | CUDA_VISIBLE_DEVICES=0 python test.py \ 11 | --output_path=${CHECKPOINT_DIR} \ 12 | --load=pretrained/murf-dtu-small-baseline-2view-21d62708.pth \ 13 | --yaml=test_video_dtu \ 14 | --n_src_views=2 \ 15 | --with_fine_nerf \ 16 | --data_test.dtu.root_dir=UPDATE_WITH_YOUR_DATA_PATH 17 | 18 | # for less memory consumption, use additional 19 | --inference_splits=2 \ 20 | --fine_inference_splits=2 21 | 22 | 23 | # render videos from 3 input views 24 | CHECKPOINT_DIR=checkpoints/tmp && \ 25 | mkdir -p ${CHECKPOINT_DIR} && \ 26 | CUDA_VISIBLE_DEVICES=0 python test.py \ 27 | --output_path=${CHECKPOINT_DIR} \ 28 | --load=pretrained/murf-dtu-small-baseline-3view-ecc90367.pth \ 29 | --yaml=test_video_dtu \ 30 | --n_src_views=3 \ 31 | --weighted_cosine \ 32 | --with_fine_nerf \ 33 | --data_test.dtu.root_dir=UPDATE_WITH_YOUR_DATA_PATH 34 | 35 | -------------------------------------------------------------------------------- /scripts/murf_dtu_small_baseline_train.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # before training, first download gmflow pretrained weight: 5 | # wget https://huggingface.co/haofeixu/murf/resolve/main/gmflow_sintel-0c07dcb3.pth -P pretrained 6 | 7 | 8 | # train on dtu for 3 input views 9 | CHECKPOINT_DIR=checkpoints/tmp && \ 10 | mkdir -p ${CHECKPOINT_DIR} && \ 11 | python -m torch.distributed.launch --nproc_per_node=8 --master_port=9021 train.py \ 12 | --dist \ 13 | --yaml=train_dtu \ 14 | --max_epoch=20 \ 15 | --batch_size=1 \ 16 | --n_src_views=3 \ 17 | --random_crop \ 18 | --crop_height=384 \ 19 | --crop_width=512 \ 20 | --output_path=${CHECKPOINT_DIR} \ 21 | --data_train.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 22 | --data_test.dtu.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 23 | 2>&1 | tee -a ${CHECKPOINT_DIR}/train.log 24 | 25 | -------------------------------------------------------------------------------- /scripts/murf_llff_evaluate.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # reproduce the numbers in Table 4 of our paper 5 | 6 | 7 | # evaluate on llff test set, 4 input views 8 | # 25.95, 0.897, 0.149 9 | CHECKPOINT_DIR=checkpoints/tmp && \ 10 | mkdir -p ${CHECKPOINT_DIR} && \ 11 | CUDA_VISIBLE_DEVICES=0 python test.py \ 12 | --output_path=${CHECKPOINT_DIR} \ 13 | --yaml=test_ibrnet_llff_test \ 14 | --load=pretrained/murf-llff-6view-15d3646e.pth \ 15 | --n_src_views=4 \ 16 | --encoder.attn_splits_list=[4] \ 17 | --resize_factor=32 \ 18 | --weighted_cosine \ 19 | --with_fine_nerf \ 20 | --data_test.ibrnet_llff_test.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 21 | --inference_size=[768,1024] \ 22 | --inference_splits=4 \ 23 | --fine_inference_splits=4 24 | 25 | 26 | # evaluate on llff test set, 6 input views 27 | # 26.04, 0.900, 0.153 28 | CHECKPOINT_DIR=checkpoints/tmp && \ 29 | mkdir -p ${CHECKPOINT_DIR} && \ 30 | CUDA_VISIBLE_DEVICES=0 python test.py \ 31 | --output_path=${CHECKPOINT_DIR} \ 32 | --yaml=test_ibrnet_llff_test \ 33 | --load=pretrained/murf-llff-6view-15d3646e.pth \ 34 | --n_src_views=6 \ 35 | --encoder.attn_splits_list=[4] \ 36 | --resize_factor=32 \ 37 | --weighted_cosine \ 38 | --with_fine_nerf \ 39 | --data_test.ibrnet_llff_test.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 40 | --inference_size=[768,1024] \ 41 | --inference_splits=4 \ 42 | --fine_inference_splits=4 43 | 44 | 45 | # evaluate on llff test set, 10 input views 46 | # 26.49, 0.909, 0.143 47 | CHECKPOINT_DIR=checkpoints/tmp && \ 48 | mkdir -p ${CHECKPOINT_DIR} && \ 49 | CUDA_VISIBLE_DEVICES=0 python test.py \ 50 | --output_path=${CHECKPOINT_DIR} \ 51 | --yaml=test_ibrnet_llff_test \ 52 | --load=pretrained/murf-llff-10view-d74cff18.pth \ 53 | --n_src_views=10 \ 54 | --encoder.attn_splits_list=[4] \ 55 | --resize_factor=32 \ 56 | --weighted_cosine \ 57 | --with_fine_nerf \ 58 | --data_test.ibrnet_llff_test.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 59 | --inference_size=[768,1024] \ 60 | --inference_splits=4 \ 61 | --fine_inference_splits=4 62 | -------------------------------------------------------------------------------- /scripts/murf_mipnerf360_evaluate.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # reproduce the numbers in Table 5 of our paper 5 | 6 | 7 | # evaluate on mipnerf360 test set, 2 input views, with the model trained realestate10k 8 | # 23.98, 0.800, 0.293 9 | CHECKPOINT_DIR=checkpoints/tmp && \ 10 | mkdir -p ${CHECKPOINT_DIR} && \ 11 | CUDA_VISIBLE_DEVICES=0 python test.py \ 12 | --output_path=${CHECKPOINT_DIR} \ 13 | --load=pretrained/murf-realestate10k-2view-74b3217d.pth \ 14 | --yaml=test_mipnerf360 \ 15 | --n_src_views=2 \ 16 | --radiance_subsample_factor=4 \ 17 | --sample_color_window_radius=2 \ 18 | --decoder.net_width=64 \ 19 | --upconv_channel_list=[64,16] \ 20 | --data_test.mipnerf360.root_dir=UPDATE_WITH_YOUR_DATA_PATH 21 | 22 | 23 | # evaluate on mipnerf360 test set, 2 input views, with the model further finetuned on the mixed datasets 24 | # 25.30, 0.850, 0.192 25 | CHECKPOINT_DIR=checkpoints/tmp && \ 26 | mkdir -p ${CHECKPOINT_DIR} && \ 27 | CUDA_VISIBLE_DEVICES=0 python test.py \ 28 | --output_path=${CHECKPOINT_DIR} \ 29 | --load=pretrained/murf-mipnerf360-2view-42df3b73.pth \ 30 | --yaml=test_mipnerf360 \ 31 | --n_src_views=2 \ 32 | --radiance_subsample_factor=4 \ 33 | --sample_color_window_radius=2 \ 34 | --decoder.net_width=64 \ 35 | --upconv_channel_list=[64,16] \ 36 | --with_fine_nerf \ 37 | --fine_inference_splits=2 \ 38 | --data_test.mipnerf360.root_dir=UPDATE_WITH_YOUR_DATA_PATH 39 | 40 | -------------------------------------------------------------------------------- /scripts/murf_mipnerf360_render.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # NOTE: to render videos, you should have `ffmpeg` installed 5 | 6 | 7 | # render videos from 2 input views 8 | CHECKPOINT_DIR=checkpoints/tmp && \ 9 | mkdir -p ${CHECKPOINT_DIR} && \ 10 | CUDA_VISIBLE_DEVICES=0 python test.py \ 11 | --output_path=${CHECKPOINT_DIR} \ 12 | --load=pretrained/murf-mipnerf360-2view-42df3b73.pth \ 13 | --yaml=test_video_mipnerf360 \ 14 | --n_src_views=2 \ 15 | --radiance_subsample_factor=4 \ 16 | --sample_color_window_radius=2 \ 17 | --decoder.net_width=64 \ 18 | --upconv_channel_list=[64,16] \ 19 | --with_fine_nerf \ 20 | --fine_inference_splits=2 \ 21 | --data_test.mipnerf360.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 22 | --no_resize_back 23 | -------------------------------------------------------------------------------- /scripts/murf_realestate10k_evaluate.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # reproduce the numbers in Table 2 of our paper 5 | 6 | 7 | # evaluate on realestate10k test set, 2 input views 8 | # R: 24.20, 0.865, 0.170 9 | CHECKPOINT_DIR=checkpoints/tmp && \ 10 | mkdir -p ${CHECKPOINT_DIR} && \ 11 | CUDA_VISIBLE_DEVICES=0 python test.py \ 12 | --output_path=${CHECKPOINT_DIR} \ 13 | --load=pretrained/murf-realestate10k-2view-74b3217d.pth \ 14 | --yaml=test_realestate \ 15 | --n_src_views=2 \ 16 | --radiance_subsample_factor=4 \ 17 | --sample_color_window_radius=2 \ 18 | --decoder.net_width=64 \ 19 | --upconv_channel_list=[64,16] \ 20 | --data_test.realestate_test.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 21 | --data_test.realestate_test.pose_dir=UPDATE_WITH_YOUR_DATA_PATH 22 | -------------------------------------------------------------------------------- /scripts/murf_realestate10k_render.sh: -------------------------------------------------------------------------------- 1 | #!/usr/bin/env bash 2 | 3 | 4 | # NOTE: to render videos, you should have `ffmpeg` installed 5 | 6 | 7 | # render videos from 2 input views 8 | CHECKPOINT_DIR=checkpoints/tmp && \ 9 | mkdir -p ${CHECKPOINT_DIR} && \ 10 | CUDA_VISIBLE_DEVICES=0 python test.py \ 11 | --output_path=${CHECKPOINT_DIR} \ 12 | --load=pretrained/murf-realestate10k-2view-74b3217d.pth \ 13 | --yaml=test_video_realestate \ 14 | --n_src_views=2 \ 15 | --radiance_subsample_factor=4 \ 16 | --sample_color_window_radius=2 \ 17 | --decoder.net_width=64 \ 18 | --upconv_channel_list=[64,16] \ 19 | --data_test.realestate_test.root_dir=UPDATE_WITH_YOUR_DATA_PATH \ 20 | --data_test.realestate_test.pose_dir=UPDATE_WITH_YOUR_DATA_PATH \ 21 | --fixed_realestate_test_set 22 | -------------------------------------------------------------------------------- /test.py: -------------------------------------------------------------------------------- 1 | import os 2 | import options 3 | import sys 4 | import torch 5 | 6 | from engine import Engine 7 | from misc.utils import log 8 | 9 | 10 | def main(): 11 | log.process(os.getpid()) 12 | log.title("[{}] (PyTorch code for testing MuRF)".format(sys.argv[0])) 13 | 14 | opt_cmd = options.parse_arguments(sys.argv[1:]) 15 | opt = options.set(opt_cmd=opt_cmd, load_confd=False) 16 | options.save_options_file(opt) 17 | 18 | opt.dist = False 19 | opt.local_rank = 0 20 | 21 | with torch.cuda.device(opt.device): 22 | m = Engine(opt) 23 | 24 | m.build_networks() 25 | m.restore_checkpoint() 26 | 27 | split = 'val' if getattr(opt, 'test_on_val_set', False) else 'test' 28 | 29 | m.load_dataset(splits=[split]) 30 | 31 | if opt.nerf.render_video: 32 | m.test_model_video(leave_tqdm=True, 33 | save_depth_video=getattr(opt, 'save_depth_video', False), 34 | save_depth_np=getattr(opt, 'save_depth_np', False), 35 | ) 36 | else: 37 | m.test_model(leave_tqdm=True, save_depth=getattr(opt, 'save_depth', False), 38 | save_gt_depth=getattr(opt, 'save_gt_depth', False), 39 | with_depth_metric=getattr(opt, 'with_depth_metric', False), 40 | save_images=getattr(opt, 'save_imgs', False), 41 | save_depth_np=getattr(opt, 'save_depth_np', False), 42 | save_gt_depth_np=getattr(opt, 'save_gt_depth_np', False), 43 | ) 44 | 45 | 46 | if __name__ == "__main__": 47 | main() 48 | -------------------------------------------------------------------------------- /train.py: -------------------------------------------------------------------------------- 1 | import torch 2 | import sys 3 | import os 4 | 5 | from engine import Engine 6 | from misc.utils import log 7 | import options 8 | 9 | import argparse 10 | 11 | from misc.dist_utils import get_dist_info, init_dist, setup_for_distributed 12 | 13 | 14 | def main(): 15 | log.process(os.getpid()) 16 | log.title("[{}] (PyTorch code for training MuRF)".format(sys.argv[0])) 17 | 18 | opt_cmd = options.parse_arguments(sys.argv[1:]) 19 | opt = options.set(opt_cmd=opt_cmd, load_confd=True) 20 | options.save_options_file(opt) 21 | 22 | # distributed training 23 | if getattr(opt, 'dist', False): 24 | print('distributed training') 25 | dist_params = dict(backend='nccl') 26 | launcher = getattr(opt, 'launcher', 'pytorch') 27 | init_dist(launcher, **dist_params) 28 | # re-set gpu_ids with distributed training mode 29 | _, world_size = get_dist_info() 30 | opt.gpu_ids = range(world_size) 31 | opt.local_rank = int(os.environ['LOCAL_RANK']) 32 | opt.device = torch.device('cuda:{}'.format(opt.local_rank)) 33 | 34 | setup_for_distributed(opt.local_rank == 0) 35 | 36 | else: 37 | opt.local_rank = 0 38 | opt.dist = False 39 | 40 | m = Engine(opt) 41 | 42 | # setup model 43 | m.build_networks() 44 | 45 | # setup dataset 46 | if getattr(opt, 'no_val', False): 47 | m.load_dataset(splits=['train', 'test']) 48 | else: 49 | m.load_dataset(splits=['train', 'val', 'test']) 50 | 51 | # setup trianing utils 52 | m.setup_visualizer() 53 | m.setup_optimizer() 54 | 55 | if opt.resume or opt.load: 56 | m.restore_checkpoint() 57 | 58 | m.train_model() 59 | 60 | 61 | if __name__=="__main__": 62 | main() 63 | --------------------------------------------------------------------------------