├── .gitignore
├── .travis.yml
├── LICENSE
├── MANIFEST.in
├── README.rst
├── Readme.md
├── conf.py
├── docs
├── Makefile
├── conf.py
├── index.md
├── index.rst
└── make.bat
├── others
├── algorithm.png
├── backtracking.png
├── fig13_col-wise_seamseq.gif
├── fig4_col-wise_seamseq.gif
├── logo.jpg
└── papers
│ ├── 1506.02640.pdf
│ ├── 1612.08242.pdf
│ ├── YOLOv3.pdf
│ └── imret.pdf
├── pyCAIR
├── __init__.py
├── helpers.py
├── images
│ ├── fig1.jpg
│ ├── fig10.jpg
│ ├── fig11.jpg
│ ├── fig12.jpg
│ ├── fig13.jpg
│ ├── fig14.jpg
│ ├── fig2.jpg
│ ├── fig3.jpg
│ ├── fig4.png
│ ├── fig5.png
│ ├── fig6.jpg
│ ├── fig7.png
│ ├── fig8.png
│ └── fig9.jpg
├── imgtovideos.py
├── notdoneyet.py
├── notes
│ ├── notes1.png
│ ├── notes2.png
│ ├── notes3.png
│ └── notes4.png
├── opencv_generators.py
├── researchpaper.pdf
├── results
│ ├── fig13
│ │ ├── colormap1.jpg
│ │ ├── colormap2.jpg
│ │ ├── column_cropped.jpg
│ │ ├── column_seams.jpg
│ │ ├── energy.jpg
│ │ ├── gray.jpg
│ │ ├── row_cropped.jpg
│ │ └── row_seams.jpg
│ ├── fig2
│ │ ├── colormap1.jpg
│ │ ├── colormap2.jpg
│ │ ├── column_cropped.jpg
│ │ ├── column_seams.jpg
│ │ ├── energy.jpg
│ │ ├── gray.jpg
│ │ ├── row_cropped.jpg
│ │ └── row_seams.jpg
│ ├── fig4
│ │ ├── colormap1.png
│ │ ├── colormap2.png
│ │ ├── column_cropped.png
│ │ ├── column_seams.png
│ │ ├── energy.png
│ │ ├── gray.png
│ │ ├── row_cropped.png
│ │ └── row_seams.png
│ └── fig9
│ │ ├── colormap1.jpg
│ │ ├── colormap2.jpg
│ │ ├── column_cropped.jpg
│ │ ├── column_seams.jpg
│ │ ├── energy.jpg
│ │ ├── gray.jpg
│ │ ├── row_cropped.jpg
│ │ └── row_seams.jpg
├── seam_carve.py
├── sequences.7z
├── videos
│ ├── fig13_col-wise_cropseq.avi
│ ├── fig13_col-wise_seamseq.avi
│ ├── fig13_row-wise_cropseq.avi
│ ├── fig13_row-wise_seamseq.avi
│ ├── fig2_col-wise_cropseq.avi
│ ├── fig2_col-wise_seamseq.avi
│ ├── fig2_row-wise_cropseq.avi
│ ├── fig2_row-wise_seamseq.avi
│ ├── fig4_col-wise_cropseq.avi
│ ├── fig4_col-wise_seamseq.avi
│ ├── fig4_row-wise_cropseq.avi
│ └── fig4_row-wise_seamseq.avi
└── yoloV3
│ ├── bbox.py
│ ├── cam_demo.py
│ ├── cfg
│ ├── tiny-yolo-voc.cfg
│ ├── yolo-voc.cfg
│ ├── yolo.cfg
│ └── yolov3.cfg
│ ├── darknet.py
│ ├── data
│ ├── coco.names
│ └── voc.names
│ ├── detect.py
│ ├── images
│ ├── fig1.jpg
│ ├── fig10.jpg
│ ├── fig11.jpg
│ ├── fig12.jpg
│ ├── fig13.jpg
│ ├── fig14.jpg
│ ├── fig2.jpg
│ ├── fig3.jpg
│ ├── fig4.png
│ ├── fig5.png
│ ├── fig6.jpg
│ ├── fig7.png
│ ├── fig8.png
│ └── fig9.jpg
│ ├── pallete
│ ├── preprocess.py
│ ├── util.py
│ ├── video_demo.py
│ └── video_demo_half.py
├── requirements.txt
├── setup.cfg
└── setup.py
/.gitignore:
--------------------------------------------------------------------------------
1 | pyCAIR/sequences/
2 | build/
3 | pyCAIR.egg-info/
4 | Readme.txt
5 | dist/
6 | pyCAIR/__pycache__
7 | .travis.yml
8 | docs/_build
9 | docs/_static
10 | docs/_templates
11 |
12 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | language: python
2 |
3 | python:
4 | - "3.4"
5 |
6 | script: python -m unittest -v pyCAIR/tests/__tests.py
7 |
8 | notifications:
9 | email:
10 | on_success: never
11 | on_failure: never
--------------------------------------------------------------------------------
/MANIFEST.in:
--------------------------------------------------------------------------------
1 | include README.md
2 | include README.rst
3 | include LICENSE
--------------------------------------------------------------------------------
/Readme.md:
--------------------------------------------------------------------------------
1 | 
2 |
3 | pyCAIR is a content-aware image resizing(CAIR) [library](https://pypi.org/project/pyCAIR/) based on [Seam Carving for Content-Aware Image Resizing](http://http://graphics.cs.cmu.edu/courses/15-463/2012_fall/hw/proj3-seamcarving/imret.pdf "Seam Carving for Content-Aware Image Resizing") paper.
4 |
5 | ------------
6 |
7 | [](https://badge.fury.io/py/pyCAIR)
8 | [](https://www.gnu.org/licenses/gpl-3.0)
9 | [](https://pycair.readthedocs.io/en/latest/?badge=latest)
10 | [](https://github.com/avidLearnerInProgress/pyCAIR)
11 | [](https://landscape.io/github/avidLearnerInProgress/pyCAIR/master)
12 |
13 |
14 | -----------
15 |
16 |
17 |
18 | ## Table of Contents
19 |
20 | 1. [How CAIR works](#how-does-it-work)
21 | 2. [Understanding the research paper](#intutive-explanation-of-research-paper)
22 | 3. [Project structure and explanation](#project-structure-and-explanation)
23 | 4. [Installation](#installation)
24 | 5. [Usage](#usage)
25 | 6. [Demo](#in-action)
26 | 7. [Screenshots](#screenshots)
27 | 8. [Todo](#todo)
28 |
29 |
30 | ## How does it work
31 |
32 | - An energy map and a grayscale format of image is generated from the provided image.
33 |
34 | - Seam Carving algorithm tries to find the not so useful regions in image by picking up the lowest energy values from energy map.
35 |
36 | - With the help of Dynamic Programming coupled with backtracking, seam carving algorithm generates individual seams over the image using top-down approach or left-right approach.(depending on vertical or horizontal resizing)
37 |
38 | - By traversing the image matrix row-wise, the cumulative minimum energy is computed for all possible connected seams for each entry. The minimum energy level is calculated by summing up the current pixel with the lowest value of the neighboring pixels from the previous row.
39 |
40 | - Find the lowest cost seam from the energy matrix starting from the last row and remove it.
41 |
42 | - Repeat the process iteratively until the image is resized depending on user specified ratio.
43 |
44 | | 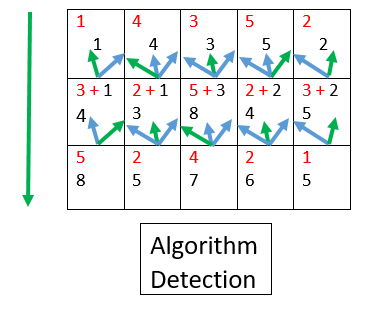 | 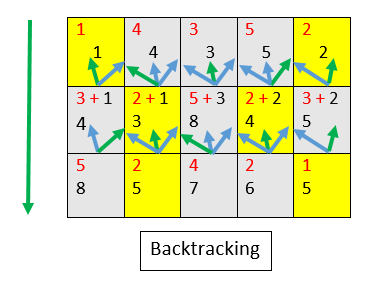 |
45 | |:---:|:---:|
46 | | DP Matrix | Backtracking with minimum energy |
47 |
48 | ## Intutive explanation of research paper
49 |
50 | > 
51 |
52 | > 
53 |
54 | > 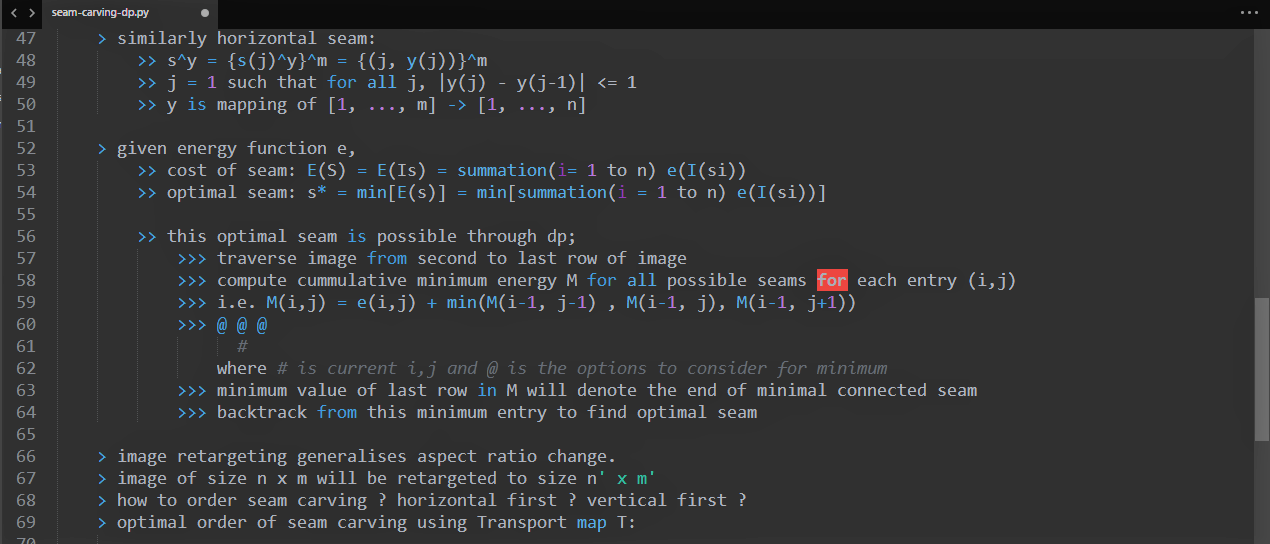
55 |
56 | > 
57 |
58 |
59 | ## Project structure and explanation
60 |
61 | **Directory structure:**
62 |
63 | **pyCAIR** (root directory)
64 | | - images/
65 | | - results /
66 | | - sequences/ (zipped in repository)
67 | | - videos/
68 | | - [notdoneyet.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/notdoneyet.py)
69 | | - [imgtovideos.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/imgtovideos.py)
70 | | - [opencv_generators.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/opencv_generators.py)
71 | | - [seam_carve.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/seam_carve.py)
72 | | - [helpers.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/helpers.py)
73 |
74 | **File:** [notdoneyet.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/notdoneyet.py)
75 |
76 | - **user_input()** -
77 | Parameters:
78 | - Alignment: Specify on which axis the resizing operation has to be performed.
79 | - Scale Ratio: Floating point operation between 0 and 1 to scale the output image.
80 | - Display Seam: If this option isn't selected, the image is only seamed in background.
81 | - Input Image
82 | - Generate Sequences: Generate intermediate sequences to form a video after all the operations are performed.
83 |
84 | **File:** [imgtovideos.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/imgtovideos.py)
85 |
86 | - **generateVideo()** - pass each image path to **vid()** for video generation.
87 |
88 | - **vid()**- writes each input image to video buffer for creating a complete video.
89 |
90 | **File:** [opencv_generators.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/opencv_generators.py)
91 |
92 | - **generateEnergyMap()** - utilised OpenCV inbuilt functions for obtaining energies and converting image to grayscale.
93 |
94 | - **generateColorMap()** - utilised OpenCV inbuilt functions to superimpose heatmaps on the given image.
95 |
96 | **File:** [seam_carve.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/seam_carve.py)
97 |
98 | - **getEnergy()** - generated energy map using sobel operators and convolve function.
99 |
100 | - **getMaps()** - implemented the function to get seams using Dynamic Programming. Also, stored results of minimum seam in seperate list for backtracking.
101 |
102 | - **drawSeam()** - Plot seams(vertical and horizontal) using red color on image.
103 |
104 | - **carve()** - reshape and crop image.
105 |
106 | - **cropByColumn()** - Implements cropping on both axes, i.e. vertical and horizontal.
107 |
108 | - **cropByRow()** - Rotate image to ignore repeated computations and provide the rotated image as an input to *cropByColumn* function.
109 |
110 | **File:** [helpers.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/helpers.py)
111 |
112 | - **writeImage()** - stores the images in results directory.
113 |
114 | - **writeImageG()** - stores intermediate generated sequence of images in sequences directory.
115 |
116 | - **createFolder()** - self explanatory
117 |
118 | - **getFileExtension()** - self explanatory
119 |
120 | **Other folders:**
121 |
122 | - **images/** - stores the input images for testing.
123 |
124 | - **videos/** - stores the videos generated from the intermediate sequences.
125 |
126 | - **results/** - stores the final results.
127 |
128 | - **sequences/** - stores the intermediate sequences generated.
129 |
130 |
131 |
132 | ## Installation
133 |
134 | - Simply run `pip install pyCAIR`
135 |
136 | - [Direct download option](https://github.com/avidLearnerInProgress/pyCAIR/archive/0.1.tar.gz)
137 |
138 | ## Usage
139 |
140 | ```python
141 | '''
142 | It runs the entire code and returns final results
143 | '''
144 | from pyCAIR import user_input
145 | user_input(alignment, scale, seam, input_image, generate_sequences)
146 |
147 | '''
148 | It generates the energy map
149 | '''
150 | from pyCAIR import generateEnergyMap
151 | generateEnergyMap(image_name, file_extension, file_name)
152 |
153 | '''
154 | It generates color maps
155 | '''
156 | from pyCAIR import generateColorMap
157 | generateColorMap(image_name, file_extension, file_name)
158 |
159 | '''
160 | It converts sequence of images generated to video
161 | '''
162 | from pyCAIR import generateVideo
163 | generateVideo()
164 |
165 | '''
166 | It returns all the paths where images are present for generating video
167 | '''
168 | from pyCAIR import getToProcessPaths
169 | getToProcessPaths()
170 |
171 | '''
172 | It returns seams, cropped image for an image
173 | '''
174 | from pyCAIR import cropByColumn
175 | seam_img, crop_img = cropByColumn(image, display_seams, generate, lsit, scale_c, fromRow)
176 |
177 | '''
178 | It returns seams, cropped image for an image
179 | '''
180 | from pyCAIR import cropByRow
181 | seam_img, crop_img = cropByRow(image, display_seams, generate, lsit, scale_c)
182 |
183 | '''
184 | It returns created folder
185 | '''
186 | from pyCAIR import createFolder
187 | f = createFolder(folder_name)
188 |
189 | '''
190 | It returns extension of file
191 | '''
192 | from pyCAIR import getFileExtension
193 | f = getFileExtension(file_name)
194 |
195 | '''
196 | It writes image to specified folder
197 | '''
198 | from pyCAIR import writeImage
199 | f = writeImage(image, args)
200 | ```
201 |
202 | ## In Action
203 |
204 | > 
205 |
206 | > 
207 |
208 | > [Video Playlist](https://www.youtube.com/playlist?list=PL7k5xCepzh7o2kF_FMh4P9tZgALoAx48N)
209 |
210 | ## Screenshots
211 |
212 | #### Results for Image 1:
213 |
214 | |  |  |  |
215 | |:---:|:---:|:---:|
216 | | Original Image | Grayscale | Energy Map |
217 |
218 | |  |  |
219 | |:---:|:---:|
220 | | Color Map Winter | Color Map Hot |
221 |
222 | |  |  |
223 | |:---:|:---:|
224 | | Seams for Columns | Columns Cropped |
225 |
226 | |  |  |
227 | |:---:|:---:|
228 | | Seams for Rows | Rows Cropped |
229 |
230 | #### Results for Image 2:
231 |
232 | |  |  |  |
233 | |:---:|:---:|:---:|
234 | | Original Image | Grayscale | Energy Map |
235 |
236 | |  |  |
237 | |:---:|:---:|
238 | | Color Map Winter | Color Map Hot |
239 |
240 | |  | |
241 | |:---:|:---:|
242 | | Seams for Columns | Columns Cropped |
243 |
244 | |  |  |
245 | |:---:|:---:|
246 | | Seams for Rows | Rows Cropped |
247 |
248 | ## Todo
249 |
250 | - [x] Implement Seam Algorithm
251 | - [x] Generate energy maps and color maps for image
252 | - [x] Display Vertical Seams
253 | - [x] Display Horizontal Seams
254 | - [x] Crop Columns
255 | - [x] Crop Rows
256 | - [x] Use argparse for Command Line Application
257 | - [x] Store subsamples in different directories for crop and seam respectively
258 | - [x] Generate video/gif from sub-samples
259 | - [x] Provide a better Readme
260 | - [x] Provide examples for usage
261 | - [x] Add badges
262 | - [x] Provide better project description on PyPI
263 | - [x] Documentation
264 | - [ ] Integrate object detection using YOLOv2 (work in progress.)
265 | - [ ] Identify most important object (using probability of predicted object)
266 | - [ ] Invert energy values of most important object
267 | - [ ] Re-apply Seam Carve and compare results
268 |
269 | ## License
270 |
271 | This software is licensed under the [GNU General Public License v3.0](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/LICENSE) © [Chirag Shah](https://github.com/avidLearnerInProgress)
272 |
--------------------------------------------------------------------------------
/conf.py:
--------------------------------------------------------------------------------
1 | from recommonmark.parser import CommonMarkParser
2 |
3 | source_parsers = {
4 | '.md': CommonMarkParser,
5 | }
6 |
7 | source_suffix = ['.rst', '.md']
8 |
9 |
--------------------------------------------------------------------------------
/docs/Makefile:
--------------------------------------------------------------------------------
1 | # Makefile for Sphinx documentation
2 | #
3 |
4 | # You can set these variables from the command line.
5 | SPHINXOPTS =
6 | SPHINXBUILD = sphinx-build
7 | PAPER =
8 | BUILDDIR = _build
9 |
10 | # Internal variables.
11 | PAPEROPT_a4 = -D latex_paper_size=a4
12 | PAPEROPT_letter = -D latex_paper_size=letter
13 | ALLSPHINXOPTS = -d $(BUILDDIR)/doctrees $(PAPEROPT_$(PAPER)) $(SPHINXOPTS) .
14 | # the i18n builder cannot share the environment and doctrees with the others
15 | I18NSPHINXOPTS = $(PAPEROPT_$(PAPER)) $(SPHINXOPTS) .
16 |
17 | .PHONY: help
18 | help:
19 | @echo "Please use \`make ' where is one of"
20 | @echo " html to make standalone HTML files"
21 | @echo " dirhtml to make HTML files named index.html in directories"
22 | @echo " singlehtml to make a single large HTML file"
23 | @echo " pickle to make pickle files"
24 | @echo " json to make JSON files"
25 | @echo " htmlhelp to make HTML files and a HTML help project"
26 | @echo " qthelp to make HTML files and a qthelp project"
27 | @echo " applehelp to make an Apple Help Book"
28 | @echo " devhelp to make HTML files and a Devhelp project"
29 | @echo " epub to make an epub"
30 | @echo " epub3 to make an epub3"
31 | @echo " latex to make LaTeX files, you can set PAPER=a4 or PAPER=letter"
32 | @echo " latexpdf to make LaTeX files and run them through pdflatex"
33 | @echo " latexpdfja to make LaTeX files and run them through platex/dvipdfmx"
34 | @echo " text to make text files"
35 | @echo " man to make manual pages"
36 | @echo " texinfo to make Texinfo files"
37 | @echo " info to make Texinfo files and run them through makeinfo"
38 | @echo " gettext to make PO message catalogs"
39 | @echo " changes to make an overview of all changed/added/deprecated items"
40 | @echo " xml to make Docutils-native XML files"
41 | @echo " pseudoxml to make pseudoxml-XML files for display purposes"
42 | @echo " linkcheck to check all external links for integrity"
43 | @echo " doctest to run all doctests embedded in the documentation (if enabled)"
44 | @echo " coverage to run coverage check of the documentation (if enabled)"
45 | @echo " dummy to check syntax errors of document sources"
46 |
47 | .PHONY: clean
48 | clean:
49 | rm -rf $(BUILDDIR)/*
50 |
51 | .PHONY: html
52 | html:
53 | $(SPHINXBUILD) -b html $(ALLSPHINXOPTS) $(BUILDDIR)/html
54 | @echo
55 | @echo "Build finished. The HTML pages are in $(BUILDDIR)/html."
56 |
57 | .PHONY: dirhtml
58 | dirhtml:
59 | $(SPHINXBUILD) -b dirhtml $(ALLSPHINXOPTS) $(BUILDDIR)/dirhtml
60 | @echo
61 | @echo "Build finished. The HTML pages are in $(BUILDDIR)/dirhtml."
62 |
63 | .PHONY: singlehtml
64 | singlehtml:
65 | $(SPHINXBUILD) -b singlehtml $(ALLSPHINXOPTS) $(BUILDDIR)/singlehtml
66 | @echo
67 | @echo "Build finished. The HTML page is in $(BUILDDIR)/singlehtml."
68 |
69 | .PHONY: pickle
70 | pickle:
71 | $(SPHINXBUILD) -b pickle $(ALLSPHINXOPTS) $(BUILDDIR)/pickle
72 | @echo
73 | @echo "Build finished; now you can process the pickle files."
74 |
75 | .PHONY: json
76 | json:
77 | $(SPHINXBUILD) -b json $(ALLSPHINXOPTS) $(BUILDDIR)/json
78 | @echo
79 | @echo "Build finished; now you can process the JSON files."
80 |
81 | .PHONY: htmlhelp
82 | htmlhelp:
83 | $(SPHINXBUILD) -b htmlhelp $(ALLSPHINXOPTS) $(BUILDDIR)/htmlhelp
84 | @echo
85 | @echo "Build finished; now you can run HTML Help Workshop with the" \
86 | ".hhp project file in $(BUILDDIR)/htmlhelp."
87 |
88 | .PHONY: qthelp
89 | qthelp:
90 | $(SPHINXBUILD) -b qthelp $(ALLSPHINXOPTS) $(BUILDDIR)/qthelp
91 | @echo
92 | @echo "Build finished; now you can run "qcollectiongenerator" with the" \
93 | ".qhcp project file in $(BUILDDIR)/qthelp, like this:"
94 | @echo "# qcollectiongenerator $(BUILDDIR)/qthelp/pyCAIR.qhcp"
95 | @echo "To view the help file:"
96 | @echo "# assistant -collectionFile $(BUILDDIR)/qthelp/pyCAIR.qhc"
97 |
98 | .PHONY: applehelp
99 | applehelp:
100 | $(SPHINXBUILD) -b applehelp $(ALLSPHINXOPTS) $(BUILDDIR)/applehelp
101 | @echo
102 | @echo "Build finished. The help book is in $(BUILDDIR)/applehelp."
103 | @echo "N.B. You won't be able to view it unless you put it in" \
104 | "~/Library/Documentation/Help or install it in your application" \
105 | "bundle."
106 |
107 | .PHONY: devhelp
108 | devhelp:
109 | $(SPHINXBUILD) -b devhelp $(ALLSPHINXOPTS) $(BUILDDIR)/devhelp
110 | @echo
111 | @echo "Build finished."
112 | @echo "To view the help file:"
113 | @echo "# mkdir -p $$HOME/.local/share/devhelp/pyCAIR"
114 | @echo "# ln -s $(BUILDDIR)/devhelp $$HOME/.local/share/devhelp/pyCAIR"
115 | @echo "# devhelp"
116 |
117 | .PHONY: epub
118 | epub:
119 | $(SPHINXBUILD) -b epub $(ALLSPHINXOPTS) $(BUILDDIR)/epub
120 | @echo
121 | @echo "Build finished. The epub file is in $(BUILDDIR)/epub."
122 |
123 | .PHONY: epub3
124 | epub3:
125 | $(SPHINXBUILD) -b epub3 $(ALLSPHINXOPTS) $(BUILDDIR)/epub3
126 | @echo
127 | @echo "Build finished. The epub3 file is in $(BUILDDIR)/epub3."
128 |
129 | .PHONY: latex
130 | latex:
131 | $(SPHINXBUILD) -b latex $(ALLSPHINXOPTS) $(BUILDDIR)/latex
132 | @echo
133 | @echo "Build finished; the LaTeX files are in $(BUILDDIR)/latex."
134 | @echo "Run \`make' in that directory to run these through (pdf)latex" \
135 | "(use \`make latexpdf' here to do that automatically)."
136 |
137 | .PHONY: latexpdf
138 | latexpdf:
139 | $(SPHINXBUILD) -b latex $(ALLSPHINXOPTS) $(BUILDDIR)/latex
140 | @echo "Running LaTeX files through pdflatex..."
141 | $(MAKE) -C $(BUILDDIR)/latex all-pdf
142 | @echo "pdflatex finished; the PDF files are in $(BUILDDIR)/latex."
143 |
144 | .PHONY: latexpdfja
145 | latexpdfja:
146 | $(SPHINXBUILD) -b latex $(ALLSPHINXOPTS) $(BUILDDIR)/latex
147 | @echo "Running LaTeX files through platex and dvipdfmx..."
148 | $(MAKE) -C $(BUILDDIR)/latex all-pdf-ja
149 | @echo "pdflatex finished; the PDF files are in $(BUILDDIR)/latex."
150 |
151 | .PHONY: text
152 | text:
153 | $(SPHINXBUILD) -b text $(ALLSPHINXOPTS) $(BUILDDIR)/text
154 | @echo
155 | @echo "Build finished. The text files are in $(BUILDDIR)/text."
156 |
157 | .PHONY: man
158 | man:
159 | $(SPHINXBUILD) -b man $(ALLSPHINXOPTS) $(BUILDDIR)/man
160 | @echo
161 | @echo "Build finished. The manual pages are in $(BUILDDIR)/man."
162 |
163 | .PHONY: texinfo
164 | texinfo:
165 | $(SPHINXBUILD) -b texinfo $(ALLSPHINXOPTS) $(BUILDDIR)/texinfo
166 | @echo
167 | @echo "Build finished. The Texinfo files are in $(BUILDDIR)/texinfo."
168 | @echo "Run \`make' in that directory to run these through makeinfo" \
169 | "(use \`make info' here to do that automatically)."
170 |
171 | .PHONY: info
172 | info:
173 | $(SPHINXBUILD) -b texinfo $(ALLSPHINXOPTS) $(BUILDDIR)/texinfo
174 | @echo "Running Texinfo files through makeinfo..."
175 | make -C $(BUILDDIR)/texinfo info
176 | @echo "makeinfo finished; the Info files are in $(BUILDDIR)/texinfo."
177 |
178 | .PHONY: gettext
179 | gettext:
180 | $(SPHINXBUILD) -b gettext $(I18NSPHINXOPTS) $(BUILDDIR)/locale
181 | @echo
182 | @echo "Build finished. The message catalogs are in $(BUILDDIR)/locale."
183 |
184 | .PHONY: changes
185 | changes:
186 | $(SPHINXBUILD) -b changes $(ALLSPHINXOPTS) $(BUILDDIR)/changes
187 | @echo
188 | @echo "The overview file is in $(BUILDDIR)/changes."
189 |
190 | .PHONY: linkcheck
191 | linkcheck:
192 | $(SPHINXBUILD) -b linkcheck $(ALLSPHINXOPTS) $(BUILDDIR)/linkcheck
193 | @echo
194 | @echo "Link check complete; look for any errors in the above output " \
195 | "or in $(BUILDDIR)/linkcheck/output.txt."
196 |
197 | .PHONY: doctest
198 | doctest:
199 | $(SPHINXBUILD) -b doctest $(ALLSPHINXOPTS) $(BUILDDIR)/doctest
200 | @echo "Testing of doctests in the sources finished, look at the " \
201 | "results in $(BUILDDIR)/doctest/output.txt."
202 |
203 | .PHONY: coverage
204 | coverage:
205 | $(SPHINXBUILD) -b coverage $(ALLSPHINXOPTS) $(BUILDDIR)/coverage
206 | @echo "Testing of coverage in the sources finished, look at the " \
207 | "results in $(BUILDDIR)/coverage/python.txt."
208 |
209 | .PHONY: xml
210 | xml:
211 | $(SPHINXBUILD) -b xml $(ALLSPHINXOPTS) $(BUILDDIR)/xml
212 | @echo
213 | @echo "Build finished. The XML files are in $(BUILDDIR)/xml."
214 |
215 | .PHONY: pseudoxml
216 | pseudoxml:
217 | $(SPHINXBUILD) -b pseudoxml $(ALLSPHINXOPTS) $(BUILDDIR)/pseudoxml
218 | @echo
219 | @echo "Build finished. The pseudo-XML files are in $(BUILDDIR)/pseudoxml."
220 |
221 | .PHONY: dummy
222 | dummy:
223 | $(SPHINXBUILD) -b dummy $(ALLSPHINXOPTS) $(BUILDDIR)/dummy
224 | @echo
225 | @echo "Build finished. Dummy builder generates no files."
226 |
--------------------------------------------------------------------------------
/docs/conf.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | # -*- coding: utf-8 -*-
3 | #
4 | # pyCAIR documentation build configuration file, created by
5 | # sphinx-quickstart on Mon Jun 25 06:57:12 2018.
6 | #
7 | # This file is execfile()d with the current directory set to its
8 | # containing dir.
9 | #
10 | # Note that not all possible configuration values are present in this
11 | # autogenerated file.
12 | #
13 | # All configuration values have a default; values that are commented out
14 | # serve to show the default.
15 |
16 | # If extensions (or modules to document with autodoc) are in another directory,
17 | # add these directories to sys.path here. If the directory is relative to the
18 | # documentation root, use os.path.abspath to make it absolute, like shown here.
19 | #
20 | # import os
21 | # import sys
22 | # sys.path.insert(0, os.path.abspath('.'))
23 |
24 | # -- General configuration ------------------------------------------------
25 |
26 | # If your documentation needs a minimal Sphinx version, state it here.
27 | #
28 | # needs_sphinx = '1.0'
29 |
30 | # Add any Sphinx extension module names here, as strings. They can be
31 | # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
32 | # ones.
33 | extensions = []
34 |
35 | # Add any paths that contain templates here, relative to this directory.
36 | templates_path = ['_templates']
37 |
38 | # The suffix(es) of source filenames.
39 | # You can specify multiple suffix as a list of string:
40 | #
41 | # source_suffix = ['.rst', '.md']
42 | source_suffix = '.rst'
43 |
44 | # The encoding of source files.
45 | #
46 | # source_encoding = 'utf-8-sig'
47 |
48 | # The master toctree document.
49 | master_doc = 'index'
50 |
51 | # General information about the project.
52 | project = 'pyCAIR'
53 | copyright = '2018, Chirag Shah'
54 | author = 'Chirag Shah'
55 |
56 | # The version info for the project you're documenting, acts as replacement for
57 | # |version| and |release|, also used in various other places throughout the
58 | # built documents.
59 | #
60 | # The short X.Y version.
61 | version = '0.1.13'
62 | # The full version, including alpha/beta/rc tags.
63 | release = 'beta�[D�[D�[B�[F'
64 |
65 | # The language for content autogenerated by Sphinx. Refer to documentation
66 | # for a list of supported languages.
67 | #
68 | # This is also used if you do content translation via gettext catalogs.
69 | # Usually you set "language" from the command line for these cases.
70 | language = None
71 |
72 | # There are two options for replacing |today|: either, you set today to some
73 | # non-false value, then it is used:
74 | #
75 | # today = ''
76 | #
77 | # Else, today_fmt is used as the format for a strftime call.
78 | #
79 | # today_fmt = '%B %d, %Y'
80 |
81 | # List of patterns, relative to source directory, that match files and
82 | # directories to ignore when looking for source files.
83 | # This patterns also effect to html_static_path and html_extra_path
84 | exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
85 |
86 | # The reST default role (used for this markup: `text`) to use for all
87 | # documents.
88 | #
89 | # default_role = None
90 |
91 | # If true, '()' will be appended to :func: etc. cross-reference text.
92 | #
93 | # add_function_parentheses = True
94 |
95 | # If true, the current module name will be prepended to all description
96 | # unit titles (such as .. function::).
97 | #
98 | # add_module_names = True
99 |
100 | # If true, sectionauthor and moduleauthor directives will be shown in the
101 | # output. They are ignored by default.
102 | #
103 | # show_authors = False
104 |
105 | # The name of the Pygments (syntax highlighting) style to use.
106 | pygments_style = 'sphinx'
107 |
108 | # A list of ignored prefixes for module index sorting.
109 | # modindex_common_prefix = []
110 |
111 | # If true, keep warnings as "system message" paragraphs in the built documents.
112 | # keep_warnings = False
113 |
114 | # If true, `todo` and `todoList` produce output, else they produce nothing.
115 | todo_include_todos = False
116 |
117 |
118 | # -- Options for HTML output ----------------------------------------------
119 |
120 | # The theme to use for HTML and HTML Help pages. See the documentation for
121 | # a list of builtin themes.
122 | #
123 | html_theme = 'alabaster'
124 |
125 | # Theme options are theme-specific and customize the look and feel of a theme
126 | # further. For a list of options available for each theme, see the
127 | # documentation.
128 | #
129 | # html_theme_options = {}
130 |
131 | # Add any paths that contain custom themes here, relative to this directory.
132 | # html_theme_path = []
133 |
134 | # The name for this set of Sphinx documents.
135 | # " v documentation" by default.
136 | #
137 | # html_title = 'pyCAIR vbeta�[D�[D�[B�[F'
138 |
139 | # A shorter title for the navigation bar. Default is the same as html_title.
140 | #
141 | # html_short_title = None
142 |
143 | # The name of an image file (relative to this directory) to place at the top
144 | # of the sidebar.
145 | #
146 | # html_logo = None
147 |
148 | # The name of an image file (relative to this directory) to use as a favicon of
149 | # the docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
150 | # pixels large.
151 | #
152 | # html_favicon = None
153 |
154 | # Add any paths that contain custom static files (such as style sheets) here,
155 | # relative to this directory. They are copied after the builtin static files,
156 | # so a file named "default.css" will overwrite the builtin "default.css".
157 | html_static_path = ['_static']
158 |
159 | # Add any extra paths that contain custom files (such as robots.txt or
160 | # .htaccess) here, relative to this directory. These files are copied
161 | # directly to the root of the documentation.
162 | #
163 | # html_extra_path = []
164 |
165 | # If not None, a 'Last updated on:' timestamp is inserted at every page
166 | # bottom, using the given strftime format.
167 | # The empty string is equivalent to '%b %d, %Y'.
168 | #
169 | # html_last_updated_fmt = None
170 |
171 | # If true, SmartyPants will be used to convert quotes and dashes to
172 | # typographically correct entities.
173 | #
174 | # html_use_smartypants = True
175 |
176 | # Custom sidebar templates, maps document names to template names.
177 | #
178 | # html_sidebars = {}
179 |
180 | # Additional templates that should be rendered to pages, maps page names to
181 | # template names.
182 | #
183 | # html_additional_pages = {}
184 |
185 | # If false, no module index is generated.
186 | #
187 | # html_domain_indices = True
188 |
189 | # If false, no index is generated.
190 | #
191 | # html_use_index = True
192 |
193 | # If true, the index is split into individual pages for each letter.
194 | #
195 | # html_split_index = False
196 |
197 | # If true, links to the reST sources are added to the pages.
198 | #
199 | # html_show_sourcelink = True
200 |
201 | # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
202 | #
203 | # html_show_sphinx = True
204 |
205 | # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
206 | #
207 | # html_show_copyright = True
208 |
209 | # If true, an OpenSearch description file will be output, and all pages will
210 | # contain a tag referring to it. The value of this option must be the
211 | # base URL from which the finished HTML is served.
212 | #
213 | # html_use_opensearch = ''
214 |
215 | # This is the file name suffix for HTML files (e.g. ".xhtml").
216 | # html_file_suffix = None
217 |
218 | # Language to be used for generating the HTML full-text search index.
219 | # Sphinx supports the following languages:
220 | # 'da', 'de', 'en', 'es', 'fi', 'fr', 'h', 'it', 'ja'
221 | # 'nl', 'no', 'pt', 'ro', 'r', 'sv', 'tr', 'zh'
222 | #
223 | # html_search_language = 'en'
224 |
225 | # A dictionary with options for the search language support, empty by default.
226 | # 'ja' uses this config value.
227 | # 'zh' user can custom change `jieba` dictionary path.
228 | #
229 | # html_search_options = {'type': 'default'}
230 |
231 | # The name of a javascript file (relative to the configuration directory) that
232 | # implements a search results scorer. If empty, the default will be used.
233 | #
234 | # html_search_scorer = 'scorer.js'
235 |
236 | # Output file base name for HTML help builder.
237 | htmlhelp_basename = 'pyCAIRdoc'
238 |
239 | # -- Options for LaTeX output ---------------------------------------------
240 |
241 | latex_elements = {
242 | # The paper size ('letterpaper' or 'a4paper').
243 | #
244 | # 'papersize': 'letterpaper',
245 |
246 | # The font size ('10pt', '11pt' or '12pt').
247 | #
248 | # 'pointsize': '10pt',
249 |
250 | # Additional stuff for the LaTeX preamble.
251 | #
252 | # 'preamble': '',
253 |
254 | # Latex figure (float) alignment
255 | #
256 | # 'figure_align': 'htbp',
257 | }
258 |
259 | # Grouping the document tree into LaTeX files. List of tuples
260 | # (source start file, target name, title,
261 | # author, documentclass [howto, manual, or own class]).
262 | latex_documents = [
263 | (master_doc, 'pyCAIR.tex', 'pyCAIR Documentation',
264 | 'Chirag Shah', 'manual'),
265 | ]
266 |
267 | # The name of an image file (relative to this directory) to place at the top of
268 | # the title page.
269 | #
270 | # latex_logo = None
271 |
272 | # For "manual" documents, if this is true, then toplevel headings are parts,
273 | # not chapters.
274 | #
275 | # latex_use_parts = False
276 |
277 | # If true, show page references after internal links.
278 | #
279 | # latex_show_pagerefs = False
280 |
281 | # If true, show URL addresses after external links.
282 | #
283 | # latex_show_urls = False
284 |
285 | # Documents to append as an appendix to all manuals.
286 | #
287 | # latex_appendices = []
288 |
289 | # It false, will not define \strong, \code, itleref, \crossref ... but only
290 | # \sphinxstrong, ..., \sphinxtitleref, ... To help avoid clash with user added
291 | # packages.
292 | #
293 | # latex_keep_old_macro_names = True
294 |
295 | # If false, no module index is generated.
296 | #
297 | # latex_domain_indices = True
298 |
299 |
300 | # -- Options for manual page output ---------------------------------------
301 |
302 | # One entry per manual page. List of tuples
303 | # (source start file, name, description, authors, manual section).
304 | man_pages = [
305 | (master_doc, 'pycair', 'pyCAIR Documentation',
306 | [author], 1)
307 | ]
308 |
309 | # If true, show URL addresses after external links.
310 | #
311 | # man_show_urls = False
312 |
313 |
314 | # -- Options for Texinfo output -------------------------------------------
315 |
316 | # Grouping the document tree into Texinfo files. List of tuples
317 | # (source start file, target name, title, author,
318 | # dir menu entry, description, category)
319 | texinfo_documents = [
320 | (master_doc, 'pyCAIR', 'pyCAIR Documentation',
321 | author, 'pyCAIR', 'One line description of project.',
322 | 'Miscellaneous'),
323 | ]
324 |
325 | # Documents to append as an appendix to all manuals.
326 | #
327 | # texinfo_appendices = []
328 |
329 | # If false, no module index is generated.
330 | #
331 | # texinfo_domain_indices = True
332 |
333 | # How to display URL addresses: 'footnote', 'no', or 'inline'.
334 | #
335 | # texinfo_show_urls = 'footnote'
336 |
337 | # If true, do not generate a @detailmenu in the "Top" node's menu.
338 | #
339 | # texinfo_no_detailmenu = False
340 |
--------------------------------------------------------------------------------
/docs/index.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | pyCAIR is a content-aware image resizing(CAIR) [library](https://pypi.org/project/pyCAIR/) based on [Seam Carving for Content-Aware Image Resizing](http://http://graphics.cs.cmu.edu/courses/15-463/2012_fall/hw/proj3-seamcarving/imret.pdf "Seam Carving for Content-Aware Image Resizing") paper.
4 |
5 | ------------
6 |
7 | [](https://badge.fury.io/py/pyCAIR)
8 | [](https://www.gnu.org/licenses/gpl-3.0)
9 | [](https://pycair.readthedocs.io/en/latest/?badge=latest)
10 | [](https://github.com/avidLearnerInProgress/pyCAIR)
11 | [](https://landscape.io/github/avidLearnerInProgress/pyCAIR/master)
12 |
13 |
14 | -----------
15 |
16 |
17 | ## Table of Contents
18 |
19 | 1. [How CAIR works](#how-does-it-work)
20 | 2. [Understanding the research paper](#intutive-explanation-of-research-paper)
21 | 3. [Project structure and explanation](#project-structure-and-explanation)
22 | 4. [Installation](#installation)
23 | 5. [Usage](#usage)
24 | 6. [Demo](#in-action)
25 | 7. [Screenshots](#screenshots)
26 | 8. [Todo](#todo)
27 |
28 |
29 | ## How does it work
30 |
31 | - An energy map and a grayscale format of image is generated from the provided image.
32 |
33 | - Seam Carving algorithm tries to find the not so useful regions in image by picking up the lowest energy values from energy map.
34 |
35 | - With the help of Dynamic Programming coupled with backtracking, seam carving algorithm generates individual seams over the image using top-down approach or left-right approach.(depending on vertical or horizontal resizing)
36 |
37 | - By traversing the image matrix row-wise, the cumulative minimum energy is computed for all possible connected seams for each entry. The minimum energy level is calculated by summing up the current pixel with the lowest value of the neighboring pixels from the previous row.
38 |
39 | - Find the lowest cost seam from the energy matrix starting from the last row and remove it.
40 |
41 | - Repeat the process iteratively until the image is resized depending on user specified ratio.
42 |
43 | |  |  |
44 | |:---:|:---:|
45 | | DP Matrix | Backtracking with minimum energy |
46 |
47 | ## Intutive explanation of research paper
48 |
49 | > 
50 |
51 | > 
52 |
53 | > 
54 |
55 | > 
56 |
57 |
58 | ## Project structure and explanation
59 |
60 | **Directory structure:**
61 |
62 | **pyCAIR** (root directory)
63 | | - images/
64 | | - results /
65 | | - sequences/ (zipped in repository)
66 | | - videos/
67 | | - [notdoneyet.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/notdoneyet.py)
68 | | - [imgtovideos.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/imgtovideos.py)
69 | | - [opencv_generators.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/opencv_generators.py)
70 | | - [seam_carve.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/seam_carve.py)
71 | | - [helpers.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/helpers.py)
72 |
73 | **File:** [notdoneyet.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/notdoneyet.py)
74 |
75 | - **user_input()** -
76 | Parameters:
77 | - Alignment: Specify on which axis the resizing operation has to be performed.
78 | - Scale Ratio: Floating point operation between 0 and 1 to scale the output image.
79 | - Display Seam: If this option isn't selected, the image is only seamed in background.
80 | - Input Image
81 | - Generate Sequences: Generate intermediate sequences to form a video after all the operations are performed.
82 |
83 | **File:** [imgtovideos.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/imgtovideos.py)
84 |
85 | - **generateVideo()** - pass each image path to **vid()** for video generation.
86 |
87 | - **vid()**- writes each input image to video buffer for creating a complete video.
88 |
89 | **File:** [opencv_generators.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/opencv_generators.py)
90 |
91 | - **generateEnergyMap()** - utilised OpenCV inbuilt functions for obtaining energies and converting image to grayscale.
92 |
93 | - **generateColorMap()** - utilised OpenCV inbuilt functions to superimpose heatmaps on the given image.
94 |
95 | **File:** [seam_carve.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/pyCAIR/seam_carve.py)
96 |
97 | - **getEnergy()** - generated energy map using sobel operators and convolve function.
98 |
99 | - **getMaps()** - implemented the function to get seams using Dynamic Programming. Also, stored results of minimum seam in seperate list for backtracking.
100 |
101 | - **drawSeam()** - Plot seams(vertical and horizontal) using red color on image.
102 |
103 | - **carve()** - reshape and crop image.
104 |
105 | - **cropByColumn()** - Implements cropping on both axes, i.e. vertical and horizontal.
106 |
107 | - **cropByRow()** - Rotate image to ignore repeated computations and provide the rotated image as an input to *cropByColumn* function.
108 |
109 | **File:** [helpers.py](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/helpers.py)
110 |
111 | - **writeImage()** - stores the images in results directory.
112 |
113 | - **writeImageG()** - stores intermediate generated sequence of images in sequences directory.
114 |
115 | - **createFolder()** - self explanatory
116 |
117 | - **getFileExtension()** - self explanatory
118 |
119 | **Other folders:**
120 |
121 | - **images/** - stores the input images for testing.
122 |
123 | - **videos/** - stores the videos generated from the intermediate sequences.
124 |
125 | - **results/** - stores the final results.
126 |
127 | - **sequences/** - stores the intermediate sequences generated.
128 |
129 |
130 |
131 | ## Installation
132 |
133 | - Simply run `pip install pyCAIR`
134 |
135 | - [Direct download option](https://github.com/avidLearnerInProgress/pyCAIR/archive/0.1.tar.gz)
136 |
137 | ## Usage
138 |
139 | ```python
140 | '''
141 | It runs the entire code and returns final results
142 | '''
143 | from pyCAIR import user_input
144 | user_input(alignment, scale, seam, input_image, generate_sequences)
145 |
146 | '''
147 | It generates the energy map
148 | '''
149 | from pyCAIR import generateEnergyMap
150 | generateEnergyMap(image_name, file_extension, file_name)
151 |
152 | '''
153 | It generates color maps
154 | '''
155 | from pyCAIR import generateColorMap
156 | generateColorMap(image_name, file_extension, file_name)
157 |
158 | '''
159 | It converts sequence of images generated to video
160 | '''
161 | from pyCAIR import generateVideo
162 | generateVideo()
163 |
164 | '''
165 | It returns all the paths where images are present for generating video
166 | '''
167 | from pyCAIR import getToProcessPaths
168 | getToProcessPaths()
169 |
170 | '''
171 | It returns seams, cropped image for an image
172 | '''
173 | from pyCAIR import cropByColumn
174 | seam_img, crop_img = cropByColumn(image, display_seams, generate, lsit, scale_c, fromRow)
175 |
176 | '''
177 | It returns seams, cropped image for an image
178 | '''
179 | from pyCAIR import cropByRow
180 | seam_img, crop_img = cropByRow(image, display_seams, generate, lsit, scale_c)
181 |
182 | '''
183 | It returns created folder
184 | '''
185 | from pyCAIR import createFolder
186 | f = createFolder(folder_name)
187 |
188 | '''
189 | It returns extension of file
190 | '''
191 | from pyCAIR import getFileExtension
192 | f = getFileExtension(file_name)
193 |
194 | '''
195 | It writes image to specified folder
196 | '''
197 | from pyCAIR import writeImage
198 | f = writeImage(image, args)
199 | ```
200 |
201 | ## In Action
202 |
203 | > 
204 |
205 | > 
206 |
207 | > [Video Playlist](https://www.youtube.com/playlist?list=PL7k5xCepzh7o2kF_FMh4P9tZgALoAx48N)
208 |
209 | ## Screenshots
210 |
211 | #### Results for Image 1:
212 |
213 | |  |  |  |
214 | |:---:|:---:|:---:|
215 | | Original Image | Grayscale | Energy Map |
216 |
217 | |  |  |
218 | |:---:|:---:|
219 | | Color Map Winter | Color Map Hot |
220 |
221 | |  |  |
222 | |:---:|:---:|
223 | | Seams for Columns | Columns Cropped |
224 |
225 | |  |  |
226 | |:---:|:---:|
227 | | Seams for Rows | Rows Cropped |
228 |
229 | #### Results for Image 2:
230 |
231 | |  |  |  |
232 | |:---:|:---:|:---:|
233 | | Original Image | Grayscale | Energy Map |
234 |
235 | |  |  |
236 | |:---:|:---:|
237 | | Color Map Winter | Color Map Hot |
238 |
239 | |  | |
240 | |:---:|:---:|
241 | | Seams for Columns | Columns Cropped |
242 |
243 | |  |  |
244 | |:---:|:---:|
245 | | Seams for Rows | Rows Cropped |
246 |
247 |
248 | ## License
249 |
250 | This software is licensed under the [GNU General Public License v3.0](https://github.com/avidLearnerInProgress/pyCAIR/blob/master/LICENSE) © [Chirag Shah](https://github.com/avidLearnerInProgress)
251 |
--------------------------------------------------------------------------------
/docs/index.rst:
--------------------------------------------------------------------------------
1 | .. pyCAIR documentation master file, created by
2 | sphinx-quickstart on Mon Jun 25 06:57:12 2018.
3 | You can adapt this file completely to your liking, but it should at least
4 | contain the root `toctree` directive.
5 |
6 | Welcome to pyCAIR's documentation!
7 | ==================================
8 |
9 | Contents:
10 |
11 | .. toctree::
12 | :maxdepth: 2
13 |
14 |
15 |
16 | .. raw:: html
17 |
18 |
19 |
20 | .. raw:: html
21 |
22 |
23 |
24 | pyCAIR is a content-aware image resizing(CAIR)
25 | `library `__ based on `Seam Carving
26 | for Content-Aware Image
27 | Resizing `__
28 | paper.
29 |
30 | |PyPI version| |License: GPL v3|
31 |
32 | Table of Contents
33 | =================
34 |
35 | 1. `How CAIR works <#how-does-it-work>`__
36 | 2. `Understanding the research
37 | paper <#intutive-explanation-of-research-paper>`__
38 | 3. `Project structure and
39 | explanation <#project-structure-and-explanation>`__
40 | 4. `Installation <#installation>`__
41 | 5. `Usage <#usage>`__
42 | 6. `Demo <#in-action>`__
43 | 7. `Screenshots <#screenshots>`__
44 | 8. `Todo <#todo>`__
45 |
46 | How does it work
47 | ================
48 |
49 | - An energy map and a grayscale format of image is generated from the
50 | provided image.
51 |
52 | - Seam Carving algorithm tries to find the not so useful regions in
53 | image by picking up the lowest energy values from energy map.
54 |
55 | - With the help of Dynamic Programming coupled with backtracking, seam
56 | carving algorithm generates individual seams over the image using
57 | top-down approach or left-right approach.(depending on vertical or
58 | horizontal resizing)
59 |
60 | - By traversing the image matrix row-wise, the cumulative minimum
61 | energy is computed for all possible connected seams for each entry.
62 | The minimum energy level is calculated by summing up the current
63 | pixel with the lowest value of the neighboring pixels from the
64 | previous row.
65 |
66 | - Find the lowest cost seam from the energy matrix starting from the
67 | last row and remove it.
68 |
69 | - Repeat the process iteratively until the image is resized depending
70 | on user specified ratio.
71 |
72 | +-----------+----------------------------------+
73 | | |Result7| | |Result8| |
74 | +===========+==================================+
75 | | DP Matrix | Backtracking with minimum energy |
76 | +-----------+----------------------------------+
77 |
78 | Intutive explanation of research paper
79 | ======================================
80 |
81 | .. figure:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/06ce7c6e/notes/notes1.png
82 | :alt: Notes1
83 |
84 | Notes1
85 |
86 | ..
87 |
88 | .. figure:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/06ce7c6e/notes/notes2.png
89 | :alt: Notes2
90 |
91 | Notes2
92 |
93 | ..
94 |
95 | .. figure:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/06ce7c6e/notes/notes3.png
96 | :alt: Notes3
97 |
98 | Notes3
99 |
100 | ..
101 |
102 | .. figure:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/06ce7c6e/notes/notes4.png
103 | :alt: Notes4
104 |
105 | Notes4
106 |
107 | Project structure and explanation
108 | =================================
109 |
110 | **Directory structure:**
111 |
112 | | **pyCAIR** (root directory)
113 | | \| - images/
114 | | \| - results /
115 | | \| - sequences/ (zipped in repository)
116 | | \| - videos/
117 | | \| -
118 | `notdoneyet.py `__
119 | | \| -
120 | `imgtovideos.py `__
121 | | \| -
122 | `opencv_generators.py `__
123 | | \| -
124 | `seam_carve.py `__
125 | | \| -
126 | `helpers.py `__
127 |
128 | **File:**
129 | `notdoneyet.py `__
130 |
131 | - **user_input()** -
132 | Parameters:
133 |
134 | - Alignment: Specify on which axis the resizing operation has to be
135 | performed.
136 | - Scale Ratio: Floating point operation between 0 and 1 to scale the
137 | output image.
138 | - Display Seam: If this option isn’t selected, the image is only
139 | seamed in background.
140 | - Input Image
141 | - Generate Sequences: Generate intermediate sequences to form a
142 | video after all the operations are performed.
143 |
144 | **File:**
145 | `imgtovideos.py `__
146 |
147 | - **generateVideo()** - pass each image path to **vid()** for video
148 | generation.
149 |
150 | - **vid()**- writes each input image to video buffer for creating a
151 | complete video.
152 |
153 | **File:**
154 | `opencv_generators.py `__
155 |
156 | - **generateEnergyMap()** - utilised OpenCV inbuilt functions for
157 | obtaining energies and converting image to grayscale.
158 |
159 | - **generateColorMap()** - utilised OpenCV inbuilt functions to
160 | superimpose heatmaps on the given image.
161 |
162 | **File:**
163 | `seam_carve.py `__
164 |
165 | - **getEnergy()** - generated energy map using sobel operators and
166 | convolve function.
167 |
168 | - **getMaps()** - implemented the function to get seams using Dynamic
169 | Programming. Also, stored results of minimum seam in seperate list
170 | for backtracking.
171 |
172 | - **drawSeam()** - Plot seams(vertical and horizontal) using red color
173 | on image.
174 |
175 | - **carve()** - reshape and crop image.
176 |
177 | - **cropByColumn()** - Implements cropping on both axes, i.e. vertical
178 | and horizontal.
179 |
180 | - **cropByRow()** - Rotate image to ignore repeated computations and
181 | provide the rotated image as an input to *cropByColumn* function.
182 |
183 | **File:**
184 | `helpers.py `__
185 |
186 | - **writeImage()** - stores the images in results directory.
187 |
188 | - **writeImageG()** - stores intermediate generated sequence of images
189 | in sequences directory.
190 |
191 | - **createFolder()** - self explanatory
192 |
193 | - **getFileExtension()** - self explanatory
194 |
195 | **Other folders:**
196 |
197 | - **images/** - stores the input images for testing.
198 |
199 | - **videos/** - stores the videos generated from the intermediate
200 | sequences.
201 |
202 | - **results/** - stores the final results.
203 |
204 | - **sequences/** - stores the intermediate sequences generated.
205 |
206 | Installation
207 | ============
208 |
209 | - Simply run ``pip install pyCAIR``
210 |
211 | - `Direct download
212 | option `__
213 |
214 | Usage
215 | =====
216 |
217 | .. code:: python
218 |
219 | '''
220 | It runs the entire code and returns final results
221 | '''
222 | from pyCAIR import user_input
223 | user_input(alignment, scale, seam, input_image, generate_sequences)
224 |
225 | '''
226 | It generates the energy map
227 | '''
228 | from pyCAIR import generateEnergyMap
229 | generateEnergyMap(image_name, file_extension, file_name)
230 |
231 | '''
232 | It generates color maps
233 | '''
234 | from pyCAIR import generateColorMap
235 | generateColorMap(image_name, file_extension, file_name)
236 |
237 | '''
238 | It converts sequence of images generated to video
239 | '''
240 | from pyCAIR import generateVideo
241 | generateVideo()
242 |
243 | '''
244 | It returns all the paths where images are present for generating video
245 | '''
246 | from pyCAIR import getToProcessPaths
247 | getToProcessPaths()
248 |
249 | '''
250 | It returns seams, cropped image for an image
251 | '''
252 | from pyCAIR import cropByColumn
253 | seam_img, crop_img = cropByColumn(image, display_seams, generate, lsit, scale_c, fromRow)
254 |
255 | '''
256 | It returns seams, cropped image for an image
257 | '''
258 | from pyCAIR import cropByRow
259 | seam_img, crop_img = cropByRow(image, display_seams, generate, lsit, scale_c)
260 |
261 | '''
262 | It returns created folder
263 | '''
264 | from pyCAIR import createFolder
265 | f = createFolder(folder_name)
266 |
267 | '''
268 | It returns extension of file
269 | '''
270 | from pyCAIR import getFileExtension
271 | f = getFileExtension(file_name)
272 |
273 | '''
274 | It writes image to specified folder
275 | '''
276 | from pyCAIR import writeImage
277 | f = writeImage(image, args)
278 |
279 | In Action
280 | =========
281 |
282 | .. figure:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/5eb764fd/others/fig13_col-wise_seamseq.gif
283 | :alt: Gif1
284 |
285 | Gif1
286 |
287 | ..
288 |
289 | .. figure:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/5eb764fd/others/fig4_col-wise_seamseq.gif
290 | :alt: Gif2
291 |
292 | Gif2
293 |
294 | ..
295 |
296 | `Video
297 | Playlist `__
298 |
299 | Screenshots
300 | ===========
301 |
302 | Results for Image 1:
303 | --------------------
304 |
305 | +----------------+-----------+------------+
306 | | |Result0| | |Result1| | |Result2| |
307 | +================+===========+============+
308 | | Original Image | Grayscale | Energy Map |
309 | +----------------+-----------+------------+
310 |
311 | +------------------+---------------+
312 | | |Result3| | |Result4| |
313 | +==================+===============+
314 | | Color Map Winter | Color Map Hot |
315 | +------------------+---------------+
316 |
317 | +-------------------+-----------------+
318 | | |Result5| | |Result6| |
319 | +===================+=================+
320 | | Seams for Columns | Columns Cropped |
321 | +-------------------+-----------------+
322 |
323 | +----------------+--------------+
324 | | |Result7| | |Result8| |
325 | +================+==============+
326 | | Seams for Rows | Rows Cropped |
327 | +----------------+--------------+
328 |
329 | Results for Image 2:
330 | --------------------
331 |
332 | +----------------+-----------+------------+
333 | | |Result0| | |Result1| | |Result2| |
334 | +================+===========+============+
335 | | Original Image | Grayscale | Energy Map |
336 | +----------------+-----------+------------+
337 |
338 | +------------------+---------------+
339 | | |Result3| | |Result4| |
340 | +==================+===============+
341 | | Color Map Winter | Color Map Hot |
342 | +------------------+---------------+
343 |
344 | +-------------------+-----------------+
345 | | |Result5| | |Result6| |
346 | +===================+=================+
347 | | Seams for Columns | Columns Cropped |
348 | +-------------------+-----------------+
349 |
350 | +----------------+--------------+
351 | | |Result7| | |Result8| |
352 | +================+==============+
353 | | Seams for Rows | Rows Cropped |
354 | +----------------+--------------+
355 |
356 |
357 | License
358 | =======
359 |
360 | This software is licensed under the `GNU General Public License
361 | v3.0 `__
362 | © `Chirag Shah `__
363 |
364 | .. |PyPI version| image:: https://badge.fury.io/py/pyCAIR.svg
365 | :target: https://badge.fury.io/py/pyCAIR
366 | .. |License: GPL v3| image:: https://img.shields.io/badge/License-GPL%20v3-blue.svg
367 | :target: https://www.gnu.org/licenses/gpl-3.0
368 | .. |Result7| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/c4692303/others/algorithm.png
369 | .. |Result8| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/c4692303/others/backtracking.png
370 | .. |Result0| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/images/fig4.png
371 | .. |Result1| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/gray.png
372 | .. |Result2| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/energy.png
373 | .. |Result3| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/colormap1.png
374 | .. |Result4| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/colormap2.png
375 | .. |Result5| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/column_seams.png
376 | .. |Result6| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/column_cropped.png
377 | .. |Result7| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/row_seams.png
378 | .. |Result8| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig4/row_cropped.png
379 | .. |Result0| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/images/fig13.jpg
380 | .. |Result1| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/gray.jpg
381 | .. |Result2| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/energy.jpg
382 | .. |Result3| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/colormap1.jpg
383 | .. |Result4| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/colormap2.jpg
384 | .. |Result5| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/column_seams.jpg
385 | .. |Result6| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/column_cropped.jpg
386 | .. |Result7| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/row_seams.jpg
387 | .. |Result8| image:: https://cdn.rawgit.com/avidLearnerInProgress/pyCAIR/0fc66d01/results/fig13/row_cropped.jpg
388 |
--------------------------------------------------------------------------------
/docs/make.bat:
--------------------------------------------------------------------------------
1 | @ECHO OFF
2 |
3 | REM Command file for Sphinx documentation
4 |
5 | if "%SPHINXBUILD%" == "" (
6 | set SPHINXBUILD=sphinx-build
7 | )
8 | set BUILDDIR=_build
9 | set ALLSPHINXOPTS=-d %BUILDDIR%/doctrees %SPHINXOPTS% .
10 | set I18NSPHINXOPTS=%SPHINXOPTS% .
11 | if NOT "%PAPER%" == "" (
12 | set ALLSPHINXOPTS=-D latex_paper_size=%PAPER% %ALLSPHINXOPTS%
13 | set I18NSPHINXOPTS=-D latex_paper_size=%PAPER% %I18NSPHINXOPTS%
14 | )
15 |
16 | if "%1" == "" goto help
17 |
18 | if "%1" == "help" (
19 | :help
20 | echo.Please use `make ^` where ^ is one of
21 | echo. html to make standalone HTML files
22 | echo. dirhtml to make HTML files named index.html in directories
23 | echo. singlehtml to make a single large HTML file
24 | echo. pickle to make pickle files
25 | echo. json to make JSON files
26 | echo. htmlhelp to make HTML files and a HTML help project
27 | echo. qthelp to make HTML files and a qthelp project
28 | echo. devhelp to make HTML files and a Devhelp project
29 | echo. epub to make an epub
30 | echo. epub3 to make an epub3
31 | echo. latex to make LaTeX files, you can set PAPER=a4 or PAPER=letter
32 | echo. text to make text files
33 | echo. man to make manual pages
34 | echo. texinfo to make Texinfo files
35 | echo. gettext to make PO message catalogs
36 | echo. changes to make an overview over all changed/added/deprecated items
37 | echo. xml to make Docutils-native XML files
38 | echo. pseudoxml to make pseudoxml-XML files for display purposes
39 | echo. linkcheck to check all external links for integrity
40 | echo. doctest to run all doctests embedded in the documentation if enabled
41 | echo. coverage to run coverage check of the documentation if enabled
42 | echo. dummy to check syntax errors of document sources
43 | goto end
44 | )
45 |
46 | if "%1" == "clean" (
47 | for /d %%i in (%BUILDDIR%\*) do rmdir /q /s %%i
48 | del /q /s %BUILDDIR%\*
49 | goto end
50 | )
51 |
52 |
53 | REM Check if sphinx-build is available and fallback to Python version if any
54 | %SPHINXBUILD% 1>NUL 2>NUL
55 | if errorlevel 9009 goto sphinx_python
56 | goto sphinx_ok
57 |
58 | :sphinx_python
59 |
60 | set SPHINXBUILD=python -m sphinx.__init__
61 | %SPHINXBUILD% 2> nul
62 | if errorlevel 9009 (
63 | echo.
64 | echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
65 | echo.installed, then set the SPHINXBUILD environment variable to point
66 | echo.to the full path of the 'sphinx-build' executable. Alternatively you
67 | echo.may add the Sphinx directory to PATH.
68 | echo.
69 | echo.If you don't have Sphinx installed, grab it from
70 | echo.http://sphinx-doc.org/
71 | exit /b 1
72 | )
73 |
74 | :sphinx_ok
75 |
76 |
77 | if "%1" == "html" (
78 | %SPHINXBUILD% -b html %ALLSPHINXOPTS% %BUILDDIR%/html
79 | if errorlevel 1 exit /b 1
80 | echo.
81 | echo.Build finished. The HTML pages are in %BUILDDIR%/html.
82 | goto end
83 | )
84 |
85 | if "%1" == "dirhtml" (
86 | %SPHINXBUILD% -b dirhtml %ALLSPHINXOPTS% %BUILDDIR%/dirhtml
87 | if errorlevel 1 exit /b 1
88 | echo.
89 | echo.Build finished. The HTML pages are in %BUILDDIR%/dirhtml.
90 | goto end
91 | )
92 |
93 | if "%1" == "singlehtml" (
94 | %SPHINXBUILD% -b singlehtml %ALLSPHINXOPTS% %BUILDDIR%/singlehtml
95 | if errorlevel 1 exit /b 1
96 | echo.
97 | echo.Build finished. The HTML pages are in %BUILDDIR%/singlehtml.
98 | goto end
99 | )
100 |
101 | if "%1" == "pickle" (
102 | %SPHINXBUILD% -b pickle %ALLSPHINXOPTS% %BUILDDIR%/pickle
103 | if errorlevel 1 exit /b 1
104 | echo.
105 | echo.Build finished; now you can process the pickle files.
106 | goto end
107 | )
108 |
109 | if "%1" == "json" (
110 | %SPHINXBUILD% -b json %ALLSPHINXOPTS% %BUILDDIR%/json
111 | if errorlevel 1 exit /b 1
112 | echo.
113 | echo.Build finished; now you can process the JSON files.
114 | goto end
115 | )
116 |
117 | if "%1" == "htmlhelp" (
118 | %SPHINXBUILD% -b htmlhelp %ALLSPHINXOPTS% %BUILDDIR%/htmlhelp
119 | if errorlevel 1 exit /b 1
120 | echo.
121 | echo.Build finished; now you can run HTML Help Workshop with the ^
122 | .hhp project file in %BUILDDIR%/htmlhelp.
123 | goto end
124 | )
125 |
126 | if "%1" == "qthelp" (
127 | %SPHINXBUILD% -b qthelp %ALLSPHINXOPTS% %BUILDDIR%/qthelp
128 | if errorlevel 1 exit /b 1
129 | echo.
130 | echo.Build finished; now you can run "qcollectiongenerator" with the ^
131 | .qhcp project file in %BUILDDIR%/qthelp, like this:
132 | echo.^> qcollectiongenerator %BUILDDIR%\qthelp\pyCAIR.qhcp
133 | echo.To view the help file:
134 | echo.^> assistant -collectionFile %BUILDDIR%\qthelp\pyCAIR.ghc
135 | goto end
136 | )
137 |
138 | if "%1" == "devhelp" (
139 | %SPHINXBUILD% -b devhelp %ALLSPHINXOPTS% %BUILDDIR%/devhelp
140 | if errorlevel 1 exit /b 1
141 | echo.
142 | echo.Build finished.
143 | goto end
144 | )
145 |
146 | if "%1" == "epub" (
147 | %SPHINXBUILD% -b epub %ALLSPHINXOPTS% %BUILDDIR%/epub
148 | if errorlevel 1 exit /b 1
149 | echo.
150 | echo.Build finished. The epub file is in %BUILDDIR%/epub.
151 | goto end
152 | )
153 |
154 | if "%1" == "epub3" (
155 | %SPHINXBUILD% -b epub3 %ALLSPHINXOPTS% %BUILDDIR%/epub3
156 | if errorlevel 1 exit /b 1
157 | echo.
158 | echo.Build finished. The epub3 file is in %BUILDDIR%/epub3.
159 | goto end
160 | )
161 |
162 | if "%1" == "latex" (
163 | %SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex
164 | if errorlevel 1 exit /b 1
165 | echo.
166 | echo.Build finished; the LaTeX files are in %BUILDDIR%/latex.
167 | goto end
168 | )
169 |
170 | if "%1" == "latexpdf" (
171 | %SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex
172 | cd %BUILDDIR%/latex
173 | make all-pdf
174 | cd %~dp0
175 | echo.
176 | echo.Build finished; the PDF files are in %BUILDDIR%/latex.
177 | goto end
178 | )
179 |
180 | if "%1" == "latexpdfja" (
181 | %SPHINXBUILD% -b latex %ALLSPHINXOPTS% %BUILDDIR%/latex
182 | cd %BUILDDIR%/latex
183 | make all-pdf-ja
184 | cd %~dp0
185 | echo.
186 | echo.Build finished; the PDF files are in %BUILDDIR%/latex.
187 | goto end
188 | )
189 |
190 | if "%1" == "text" (
191 | %SPHINXBUILD% -b text %ALLSPHINXOPTS% %BUILDDIR%/text
192 | if errorlevel 1 exit /b 1
193 | echo.
194 | echo.Build finished. The text files are in %BUILDDIR%/text.
195 | goto end
196 | )
197 |
198 | if "%1" == "man" (
199 | %SPHINXBUILD% -b man %ALLSPHINXOPTS% %BUILDDIR%/man
200 | if errorlevel 1 exit /b 1
201 | echo.
202 | echo.Build finished. The manual pages are in %BUILDDIR%/man.
203 | goto end
204 | )
205 |
206 | if "%1" == "texinfo" (
207 | %SPHINXBUILD% -b texinfo %ALLSPHINXOPTS% %BUILDDIR%/texinfo
208 | if errorlevel 1 exit /b 1
209 | echo.
210 | echo.Build finished. The Texinfo files are in %BUILDDIR%/texinfo.
211 | goto end
212 | )
213 |
214 | if "%1" == "gettext" (
215 | %SPHINXBUILD% -b gettext %I18NSPHINXOPTS% %BUILDDIR%/locale
216 | if errorlevel 1 exit /b 1
217 | echo.
218 | echo.Build finished. The message catalogs are in %BUILDDIR%/locale.
219 | goto end
220 | )
221 |
222 | if "%1" == "changes" (
223 | %SPHINXBUILD% -b changes %ALLSPHINXOPTS% %BUILDDIR%/changes
224 | if errorlevel 1 exit /b 1
225 | echo.
226 | echo.The overview file is in %BUILDDIR%/changes.
227 | goto end
228 | )
229 |
230 | if "%1" == "linkcheck" (
231 | %SPHINXBUILD% -b linkcheck %ALLSPHINXOPTS% %BUILDDIR%/linkcheck
232 | if errorlevel 1 exit /b 1
233 | echo.
234 | echo.Link check complete; look for any errors in the above output ^
235 | or in %BUILDDIR%/linkcheck/output.txt.
236 | goto end
237 | )
238 |
239 | if "%1" == "doctest" (
240 | %SPHINXBUILD% -b doctest %ALLSPHINXOPTS% %BUILDDIR%/doctest
241 | if errorlevel 1 exit /b 1
242 | echo.
243 | echo.Testing of doctests in the sources finished, look at the ^
244 | results in %BUILDDIR%/doctest/output.txt.
245 | goto end
246 | )
247 |
248 | if "%1" == "coverage" (
249 | %SPHINXBUILD% -b coverage %ALLSPHINXOPTS% %BUILDDIR%/coverage
250 | if errorlevel 1 exit /b 1
251 | echo.
252 | echo.Testing of coverage in the sources finished, look at the ^
253 | results in %BUILDDIR%/coverage/python.txt.
254 | goto end
255 | )
256 |
257 | if "%1" == "xml" (
258 | %SPHINXBUILD% -b xml %ALLSPHINXOPTS% %BUILDDIR%/xml
259 | if errorlevel 1 exit /b 1
260 | echo.
261 | echo.Build finished. The XML files are in %BUILDDIR%/xml.
262 | goto end
263 | )
264 |
265 | if "%1" == "pseudoxml" (
266 | %SPHINXBUILD% -b pseudoxml %ALLSPHINXOPTS% %BUILDDIR%/pseudoxml
267 | if errorlevel 1 exit /b 1
268 | echo.
269 | echo.Build finished. The pseudo-XML files are in %BUILDDIR%/pseudoxml.
270 | goto end
271 | )
272 |
273 | if "%1" == "dummy" (
274 | %SPHINXBUILD% -b dummy %ALLSPHINXOPTS% %BUILDDIR%/dummy
275 | if errorlevel 1 exit /b 1
276 | echo.
277 | echo.Build finished. Dummy builder generates no files.
278 | goto end
279 | )
280 |
281 | :end
282 |
--------------------------------------------------------------------------------
/others/algorithm.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/algorithm.png
--------------------------------------------------------------------------------
/others/backtracking.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/backtracking.png
--------------------------------------------------------------------------------
/others/fig13_col-wise_seamseq.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/fig13_col-wise_seamseq.gif
--------------------------------------------------------------------------------
/others/fig4_col-wise_seamseq.gif:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/fig4_col-wise_seamseq.gif
--------------------------------------------------------------------------------
/others/logo.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/logo.jpg
--------------------------------------------------------------------------------
/others/papers/1506.02640.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/papers/1506.02640.pdf
--------------------------------------------------------------------------------
/others/papers/1612.08242.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/papers/1612.08242.pdf
--------------------------------------------------------------------------------
/others/papers/YOLOv3.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/papers/YOLOv3.pdf
--------------------------------------------------------------------------------
/others/papers/imret.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/others/papers/imret.pdf
--------------------------------------------------------------------------------
/pyCAIR/__init__.py:
--------------------------------------------------------------------------------
1 | from .notdoneyet import user_input
2 |
3 | from .opencv_generators import generateEnergyMap
4 | from .opencv_generators import generateColorMap
5 |
6 | from .imgtovideos import generateVideo
7 | from .imgtovideos import getToProcessPaths
8 |
9 | from .helpers import createFolder
10 | from .helpers import getFileExtension
11 | from .helpers import writeImage
12 |
13 | from .seam_carve import cropByColumn
14 | from .seam_carve import cropByRow
--------------------------------------------------------------------------------
/pyCAIR/helpers.py:
--------------------------------------------------------------------------------
1 | import os, cv2
2 |
3 | def createFolder(directory):
4 | if not os.path.exists(directory):
5 | os.makedirs(directory)
6 |
7 | def getFileExtension(ip):
8 | front, back = ip.split('.')
9 | _, name = front.split('/')
10 | return back, name
11 |
12 | def writeImage(image, args):
13 | name = 'results/' + str(args[2]) + '/' + str(args[0]) + '.' + str(args[1])
14 | cv2.imwrite(name, image)
15 | cv2.destroyAllWindows()
16 |
17 | def writeImageG(image, cname, extension, filename, switch, _path = 'col-wise'):
18 | if switch == 0:
19 | insert = 'cropseq'
20 | else:
21 | insert = 'seamseq'
22 |
23 | name = 'sequences/' + filename + '/' + _path + '/' + insert + '/' + cname + '.' + extension
24 | cv2.imwrite(name, image)
--------------------------------------------------------------------------------
/pyCAIR/images/fig1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig1.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig10.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig11.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig12.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig13.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig14.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig2.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig3.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig4.png
--------------------------------------------------------------------------------
/pyCAIR/images/fig5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig5.png
--------------------------------------------------------------------------------
/pyCAIR/images/fig6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig6.jpg
--------------------------------------------------------------------------------
/pyCAIR/images/fig7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig7.png
--------------------------------------------------------------------------------
/pyCAIR/images/fig8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig8.png
--------------------------------------------------------------------------------
/pyCAIR/images/fig9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/images/fig9.jpg
--------------------------------------------------------------------------------
/pyCAIR/imgtovideos.py:
--------------------------------------------------------------------------------
1 | from natsort import natsorted
2 | import os,cv2
3 | from pathlib import Path
4 |
5 | from pyCAIR.helpers import createFolder as cF
6 |
7 | def vid(path):
8 |
9 | dir_path = path
10 | ext1, ext2 = '.png', '.jpg'
11 | opath = str(Path(__file__).resolve().parents[0]) + '\\videos'
12 | cF(opath)
13 | a, b = dir_path.rsplit('\\', 1)[0], dir_path.rsplit('\\', 1)[1]
14 | c, d = a.rsplit('\\', 1)[0], a.rsplit('\\', 1)[1]
15 | _, f = c.rsplit('\\', 1)[0], c.rsplit('\\', 1)[1]
16 | vid_name = f + '_' + d + '_' + b + '.avi'
17 | print(vid_name)
18 | op = os.path.join(opath, vid_name)
19 |
20 | #exit()
21 | shape = 640, 540
22 | fps = 5
23 |
24 | #images = [f for f in os.listdir(dir_path) if f.endswith(ext)]
25 | images = []
26 | for f in os.listdir(dir_path):
27 | if f.endswith(ext1) or f.endswith(ext2):
28 | images.append(f)
29 |
30 | images = natsorted(images)
31 | print(images[0])
32 |
33 | fourcc = cv2.VideoWriter_fourcc(*'DIVX')
34 | video = cv2.VideoWriter(op, fourcc, fps, shape)
35 |
36 | for image in images:
37 | image_path = os.path.join(dir_path, image)
38 | image = cv2.imread(image_path)
39 | resized=cv2.resize(image,shape)
40 | video.write(resized)
41 | video.release()
42 |
43 | def getToProcessPaths(directory):
44 |
45 | all_subdirs = [x[0] for x in os.walk(directory)]
46 | get = []
47 | for i in range(len(all_subdirs)):
48 | if all_subdirs[i].endswith('cropseq') or all_subdirs[i].endswith('seamseq'):
49 | if all_subdirs[i] not in get:
50 | get.append(all_subdirs[i])
51 |
52 | return get
53 |
54 | def generateVideo():
55 | base_path = str(Path(__file__).resolve().parents[0])
56 | base_path += "\sequences\\"
57 | allpaths = getToProcessPaths(base_path)
58 |
59 | for i in range(len(allpaths)):
60 | cpath = allpaths[i]
61 | vid(cpath)
--------------------------------------------------------------------------------
/pyCAIR/notdoneyet.py:
--------------------------------------------------------------------------------
1 | import os, cv2
2 |
3 | #Local imports
4 | from pyCAIR.imgtovideos import generateVideo as gV
5 | from pyCAIR.helpers import getFileExtension as gFE
6 | from pyCAIR.helpers import createFolder as cF
7 | from pyCAIR.helpers import writeImage as wI
8 | from pyCAIR.opencv_generators import generateEnergyMap as gEM
9 | from pyCAIR.opencv_generators import generateColorMap as gCM
10 | from pyCAIR.seam_carve import cropByColumn as cBC
11 | from pyCAIR.seam_carve import cropByRow as cBR
12 |
13 | def main(argsip):
14 | #usr inpt
15 | toggle = argsip[0]
16 | scale = argsip[1]
17 | display_seams = argsip[2]
18 | _in = argsip[3]
19 | g = argsip[4]
20 |
21 | image = cv2.imread(_in)
22 | file_extension, file_name = gFE(_in)
23 | #print(file_extension + " " + file_name)
24 | root = os.getcwd() + str('\\results\\')
25 | cF(root + file_name)
26 | gEM(image, file_extension, file_name)
27 | gCM(image, file_extension, file_name)
28 | image_ = image.copy()
29 | lsit = [file_name, file_extension]
30 |
31 | if toggle == 0:
32 | #cropbycol
33 | if display_seams == 1:
34 | seam_image, crop_image = cBC(image, display_seams, g, lsit, scale)
35 | wI(seam_image, ['column_seams', file_extension, file_name])
36 | wI(crop_image, ['column_cropped', file_extension, file_name])
37 |
38 | else:
39 | crop_image = cBC(image, display_seams, g, lsit, scale)
40 | wI(crop_image, ['column_cropped', file_extension, file_name])
41 |
42 | elif toggle == 1:
43 | #cropbyrow
44 | if display_seams == 1:
45 | seam_image, crop_image = cBR(image, display_seams, g, lsit, scale)
46 | wI(seam_image, ['row_seams', file_extension, file_name])
47 | wI(crop_image, ['row_cropped', file_extension, file_name])
48 |
49 | else:
50 | crop_image = cBR(image, display_seams, g, lsit, scale)
51 | wI(crop_image, ['row_cropped', file_extension, file_name])
52 |
53 | elif toggle == 2:
54 | #cropbyrow&column
55 | if display_seams == 1:
56 | seam_col, crop_col = cBC(image, display_seams, g, lsit, scale)
57 | seam_row, crop_row = cBR(image_, display_seams, g, lsit, scale)
58 | wI(seam_col, ['column_seams', file_extension, file_name])
59 | wI(seam_row, ['row_seams', file_extension, file_name])
60 | wI(crop_col, ['column_cropped', file_extension, file_name])
61 | wI(crop_row, ['row_cropped', file_extension, file_name])
62 |
63 | else:
64 | crop_col = cBC(image, display_seams, g, scale)
65 | crop_row = cBR(image, display_seams, g, scale)
66 | wI(crop_row, ['row_cropped', file_extension, file_name])
67 | wI(crop_col, ['column_cropped', file_extension, file_name])
68 | else:
69 | print('Invalid input!')
70 | exit()
71 |
72 | gV()
73 |
74 | def user_input(alignment = 0, scale = 0.5, display_seam = 1, image = 'images/fig4.png', generate = 1):
75 | argsip = []
76 | argsip.append(alignment)
77 | argsip.append(scale)
78 | argsip.append(display_seam)
79 | argsip.append(image)
80 | argsip.append(generate)
81 | main(argsip)
--------------------------------------------------------------------------------
/pyCAIR/notes/notes1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/notes/notes1.png
--------------------------------------------------------------------------------
/pyCAIR/notes/notes2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/notes/notes2.png
--------------------------------------------------------------------------------
/pyCAIR/notes/notes3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/notes/notes3.png
--------------------------------------------------------------------------------
/pyCAIR/notes/notes4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/notes/notes4.png
--------------------------------------------------------------------------------
/pyCAIR/opencv_generators.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | import numpy as np
3 |
4 | from pyCAIR.helpers import writeImage as wI
5 |
6 | def generateEnergyMap(image, file_extension, file_name):
7 | image = cv2.cvtColor(image.astype(np.uint8), cv2.COLOR_BGR2GRAY)
8 | wI(image, ['gray', file_extension, file_name])
9 | dx = cv2.Sobel(image, cv2.CV_16S, 1, 0, ksize=3)
10 | abs_x = cv2.convertScaleAbs(dx)
11 | dy = cv2.Sobel(image, cv2.CV_16S, 0, 1, ksize=3)
12 | abs_y = cv2.convertScaleAbs(dy)
13 | output = cv2.addWeighted(abs_x, 0.5, abs_y, 0.5, 0)
14 | wI(output, ['energy', file_extension, file_name])
15 |
16 | def generateColorMap(image, file_extension, file_name):
17 | img = image
18 | gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
19 | heatmap1_img = cv2.applyColorMap(gray_img, 3)
20 | heatmap2_img = cv2.applyColorMap(gray_img, 11)
21 | superimpose1 = cv2.addWeighted(heatmap1_img, 0.7, img, 0.3, 0)
22 | superimpose2 = cv2.addWeighted(heatmap2_img, 0.7, img, 0.3, 0)
23 | wI(superimpose1, ['colormap1', file_extension, file_name])
24 | wI(superimpose2, ['colormap2', file_extension, file_name])
--------------------------------------------------------------------------------
/pyCAIR/researchpaper.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/researchpaper.pdf
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/colormap1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/colormap1.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/colormap2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/colormap2.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/column_cropped.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/column_cropped.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/column_seams.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/column_seams.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/energy.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/energy.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/gray.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/gray.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/row_cropped.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/row_cropped.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig13/row_seams.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig13/row_seams.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/colormap1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/colormap1.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/colormap2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/colormap2.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/column_cropped.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/column_cropped.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/column_seams.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/column_seams.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/energy.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/energy.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/gray.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/gray.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/row_cropped.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/row_cropped.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig2/row_seams.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig2/row_seams.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/colormap1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/colormap1.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/colormap2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/colormap2.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/column_cropped.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/column_cropped.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/column_seams.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/column_seams.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/energy.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/energy.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/gray.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/gray.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/row_cropped.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/row_cropped.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig4/row_seams.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig4/row_seams.png
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/colormap1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/colormap1.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/colormap2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/colormap2.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/column_cropped.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/column_cropped.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/column_seams.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/column_seams.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/energy.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/energy.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/gray.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/gray.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/row_cropped.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/row_cropped.jpg
--------------------------------------------------------------------------------
/pyCAIR/results/fig9/row_seams.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/results/fig9/row_seams.jpg
--------------------------------------------------------------------------------
/pyCAIR/seam_carve.py:
--------------------------------------------------------------------------------
1 | import os
2 | import numpy as np
3 | from scipy.ndimage import rotate
4 | from scipy.ndimage.filters import convolve
5 | from tqdm import trange
6 |
7 | from pyCAIR.helpers import createFolder as cF
8 | from pyCAIR.helpers import writeImageG as wIG
9 |
10 | def getEnergy(image):
11 |
12 | filter_x = np.array([
13 | [1.0, 2.0, 1.0],
14 | [0.0, 0.0, 0.0],
15 | [-1.0, -2.0, -1.0],
16 | ])
17 |
18 | filter_x = np.stack([filter_x] * 3, axis = 2)
19 |
20 | filter_y = np.array([
21 | [1.0, 0.0, -1.0],
22 | [2.0, 0.0, -2.0],
23 | [1.0, 0.0, -1.0],
24 | ])
25 |
26 | filter_y = np.stack([filter_y] * 3, axis = 2)
27 |
28 | image = image.astype('float32')
29 |
30 | convoluted = np.absolute(convolve(image, filter_x)) + np.absolute(convolve(image, filter_y))
31 |
32 | energy_map = convoluted.sum(axis = 2)
33 |
34 | return energy_map
35 |
36 | def getMaps(image):
37 | rows, columns, _ = image.shape
38 | energy_map = getEnergy(image)
39 |
40 | current_map = energy_map.copy()
41 | goback = np.zeros_like(current_map, dtype = int)
42 |
43 | for i in range(1, rows):
44 | for j in range(0, columns):
45 | if j == 0:
46 | min_index = np.argmin(current_map[i - 1, j : j + 2])
47 | goback[i, j] = min_index + j
48 | min_energy = current_map[i - 1, min_index + j]
49 |
50 | else:
51 | min_index = np.argmin(current_map[i - 1, j - 1 : j + 2])
52 | goback[i, j] = min_index + j -1
53 | min_energy = current_map[i - 1, min_index + j - 1]
54 |
55 | current_map[i, j] += min_energy
56 |
57 | return current_map, goback
58 |
59 | def drawSeam(image):
60 |
61 | rows, columns, _ = image.shape
62 | cMap, goback = getMaps(image)
63 |
64 | mask = np.ones((rows, columns), dtype = bool)
65 |
66 | j = np.argmin(cMap[-1])
67 |
68 | for i in reversed(range(rows)):
69 | mask[i, j] = False
70 | j = goback[i, j]
71 |
72 | mask = np.logical_not(mask)
73 | image[...,0][mask] = 0
74 | image[...,1][mask] = 0
75 | image[...,2][mask] = 255
76 |
77 | return image
78 |
79 | def carve(image):
80 |
81 | rows, columns, _ = image.shape
82 | cMap, goback = getMaps(image)
83 |
84 | mask = np.ones((rows, columns), dtype = bool)
85 |
86 | j = np.argmin(cMap[-1])
87 |
88 | for i in reversed(range(rows)):
89 | mask[i, j] = False
90 | j = goback[i, j]
91 |
92 | mask = np.stack([mask] * 3, axis = 2)
93 | image = image[mask].reshape((rows, columns - 1, 3))
94 |
95 | return image
96 |
97 | def cropByColumn(image, display_seams, generate = 0, lsit = ['my_image', 'jpg'], scale_c = 0.5, fromRow = 0):
98 | '''
99 | Parameters:
100 | image: numpy array of image
101 | display_seams: 0 or 1
102 | generate: 0 or 1
103 | lsit: list of image name and extension - ['my_image', '.jpg']
104 | scale_c: scale factor for columns
105 | fromRow: 0 or 1
106 |
107 | Returns:
108 | image: numpy array of image
109 | crop: numpy array of cropped image
110 | '''
111 | rows, columns, _ = image.shape
112 |
113 | newcolumns = int(columns * scale_c)
114 | crop = image.copy()
115 |
116 | if fromRow == 1:
117 | _path = 'row-wise'
118 | else:
119 | _path = 'col-wise'
120 |
121 | if display_seams == 0:
122 | a = 0
123 | gc = 0
124 | cF(os.getcwd() + str('/sequences/' + lsit[0] + '/' + _path + '/cropseq/'))
125 | for i in trange(columns - newcolumns):
126 | if generate == 1:
127 | crop = carve(crop)
128 | if i % 5 == 0:
129 | if fromRow == 1:
130 | _rotate = crop.copy()
131 | _rotate = np.rot90(_rotate, 3, (0, 1))
132 | wIG(_rotate, str(gc)+'. cropped_'+str(i), lsit[1], lsit[0], a, _path)
133 | gc += 1
134 | else:
135 | wIG(crop, str(gc)+'. cropped_'+str(i), lsit[1], lsit[0], a)
136 | gc += 1
137 | else:
138 | pass
139 | else:
140 | crop = carve(crop)
141 |
142 | return crop
143 |
144 | else:
145 | a = 0
146 | b = 1
147 | gc_img = 0
148 | gc_crop = 0
149 | cF(os.getcwd() + str('/sequences/' + lsit[0] + '/' + _path + '/cropseq/'))
150 | cF(os.getcwd() + str('/sequences/' + lsit[0] + '/' + _path + '/seamseq/'))
151 | for i in trange(columns - newcolumns):
152 | if generate == 1:
153 | #give me a way to parallelize this portion of code :|
154 | image = drawSeam(image)
155 | crop = carve(crop)
156 | if i % 5 == 0:
157 | if fromRow == 1:
158 | _rotate1 = image.copy()
159 | _rotate2 = crop.copy()
160 | _rotate1 = np.rot90(_rotate1, 3, (0, 1))
161 | _rotate2 = np.rot90(_rotate2, 3, (0, 1))
162 | wIG(_rotate1, str(gc_img)+'. seamed_'+str(i), lsit[1], lsit[0], b, _path)
163 | wIG(_rotate2, str(gc_crop)+'. cropped_'+str(i), lsit[1], lsit[0], a, _path)
164 | gc_img += 1
165 | gc_crop += 1
166 | else:
167 | wIG(image,str(gc_img)+'. seamed_'+str(i), lsit[1], lsit[0], b)
168 | wIG(crop,str(gc_crop)+'. cropped_'+str(i), lsit[1], lsit[0], a)
169 | gc_img += 1
170 | gc_crop += 1
171 | else:
172 | pass
173 | else:
174 | image = drawSeam(image)
175 | crop = carve(crop)
176 |
177 | return image, crop
178 |
179 | def cropByRow(image, display_seams, generate = 0, lsit = None, scale_r = 0.5):
180 |
181 | fromRow = 1
182 | image = np.rot90(image, 1, (0, 1))
183 | seam_image, crop_image = cropByColumn(image, display_seams, generate, lsit, scale_r, fromRow)
184 | crop_image = np.rot90(crop_image, 3, (0, 1))
185 | seam_image = np.rot90(seam_image, 3, (0, 1))
186 |
187 | return seam_image, crop_image
188 |
--------------------------------------------------------------------------------
/pyCAIR/sequences.7z:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/sequences.7z
--------------------------------------------------------------------------------
/pyCAIR/videos/fig13_col-wise_cropseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig13_col-wise_cropseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig13_col-wise_seamseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig13_col-wise_seamseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig13_row-wise_cropseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig13_row-wise_cropseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig13_row-wise_seamseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig13_row-wise_seamseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig2_col-wise_cropseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig2_col-wise_cropseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig2_col-wise_seamseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig2_col-wise_seamseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig2_row-wise_cropseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig2_row-wise_cropseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig2_row-wise_seamseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig2_row-wise_seamseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig4_col-wise_cropseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig4_col-wise_cropseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig4_col-wise_seamseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig4_col-wise_seamseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig4_row-wise_cropseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig4_row-wise_cropseq.avi
--------------------------------------------------------------------------------
/pyCAIR/videos/fig4_row-wise_seamseq.avi:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/videos/fig4_row-wise_seamseq.avi
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/bbox.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 |
3 | import torch
4 | import random
5 |
6 | import numpy as np
7 | import cv2
8 |
9 | def confidence_filter(result, confidence):
10 | conf_mask = (result[:,:,4] > confidence).float().unsqueeze(2)
11 | result = result*conf_mask
12 |
13 | return result
14 |
15 | def confidence_filter_cls(result, confidence):
16 | max_scores = torch.max(result[:,:,5:25], 2)[0]
17 | res = torch.cat((result, max_scores),2)
18 | print(res.shape)
19 |
20 |
21 | cond_1 = (res[:,:,4] > confidence).float()
22 | cond_2 = (res[:,:,25] > 0.995).float()
23 |
24 | conf = cond_1 + cond_2
25 | conf = torch.clamp(conf, 0.0, 1.0)
26 | conf = conf.unsqueeze(2)
27 | result = result*conf
28 | return result
29 |
30 |
31 |
32 | def get_abs_coord(box):
33 | box[2], box[3] = abs(box[2]), abs(box[3])
34 | x1 = (box[0] - box[2]/2) - 1
35 | y1 = (box[1] - box[3]/2) - 1
36 | x2 = (box[0] + box[2]/2) - 1
37 | y2 = (box[1] + box[3]/2) - 1
38 | return x1, y1, x2, y2
39 |
40 |
41 |
42 | def sanity_fix(box):
43 | if (box[0] > box[2]):
44 | box[0], box[2] = box[2], box[0]
45 |
46 | if (box[1] > box[3]):
47 | box[1], box[3] = box[3], box[1]
48 |
49 | return box
50 |
51 | def bbox_iou(box1, box2):
52 | """
53 | Returns the IoU of two bounding boxes
54 |
55 |
56 | """
57 | #Get the coordinates of bounding boxes
58 | b1_x1, b1_y1, b1_x2, b1_y2 = box1[:,0], box1[:,1], box1[:,2], box1[:,3]
59 | b2_x1, b2_y1, b2_x2, b2_y2 = box2[:,0], box2[:,1], box2[:,2], box2[:,3]
60 |
61 | #get the corrdinates of the intersection rectangle
62 | inter_rect_x1 = torch.max(b1_x1, b2_x1)
63 | inter_rect_y1 = torch.max(b1_y1, b2_y1)
64 | inter_rect_x2 = torch.min(b1_x2, b2_x2)
65 | inter_rect_y2 = torch.min(b1_y2, b2_y2)
66 |
67 | #Intersection area
68 | if torch.cuda.is_available():
69 | inter_area = torch.max(inter_rect_x2 - inter_rect_x1 + 1,torch.zeros(inter_rect_x2.shape).cuda())*torch.max(inter_rect_y2 - inter_rect_y1 + 1, torch.zeros(inter_rect_x2.shape).cuda())
70 | else:
71 | inter_area = torch.max(inter_rect_x2 - inter_rect_x1 + 1,torch.zeros(inter_rect_x2.shape))*torch.max(inter_rect_y2 - inter_rect_y1 + 1, torch.zeros(inter_rect_x2.shape))
72 |
73 | #Union Area
74 | b1_area = (b1_x2 - b1_x1 + 1)*(b1_y2 - b1_y1 + 1)
75 | b2_area = (b2_x2 - b2_x1 + 1)*(b2_y2 - b2_y1 + 1)
76 |
77 | iou = inter_area / (b1_area + b2_area - inter_area)
78 |
79 | return iou
80 |
81 |
82 | def pred_corner_coord(prediction):
83 | #Get indices of non-zero confidence bboxes
84 | ind_nz = torch.nonzero(prediction[:,:,4]).transpose(0,1).contiguous()
85 |
86 | box = prediction[ind_nz[0], ind_nz[1]]
87 |
88 |
89 | box_a = box.new(box.shape)
90 | box_a[:,0] = (box[:,0] - box[:,2]/2)
91 | box_a[:,1] = (box[:,1] - box[:,3]/2)
92 | box_a[:,2] = (box[:,0] + box[:,2]/2)
93 | box_a[:,3] = (box[:,1] + box[:,3]/2)
94 | box[:,:4] = box_a[:,:4]
95 |
96 | prediction[ind_nz[0], ind_nz[1]] = box
97 |
98 | return prediction
99 |
100 |
101 |
102 |
103 | def write(x, batches, results, colors, classes):
104 | c1 = tuple(x[1:3].int())
105 | c2 = tuple(x[3:5].int())
106 | img = results[int(x[0])]
107 | cls = int(x[-1])
108 | label = "{0}".format(classes[cls])
109 | color = random.choice(colors)
110 | cv2.rectangle(img, c1, c2,color, 1)
111 | t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0]
112 | c2 = c1[0] + t_size[0] + 3, c1[1] + t_size[1] + 4
113 | cv2.rectangle(img, c1, c2,color, -1)
114 | cv2.putText(img, label, (c1[0], c1[1] + t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 1, [225,255,255], 1);
115 | return img
116 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/cam_demo.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 | import time
3 | import torch
4 | import torch.nn as nn
5 | from torch.autograd import Variable
6 | import numpy as np
7 | import cv2
8 | from util import *
9 | from darknet import Darknet
10 | from preprocess import prep_image, inp_to_image
11 | import pandas as pd
12 | import random
13 | import argparse
14 | import pickle as pkl
15 |
16 | def get_test_input(input_dim, CUDA):
17 | img = cv2.imread("imgs/messi.jpg")
18 | img = cv2.resize(img, (input_dim, input_dim))
19 | img_ = img[:,:,::-1].transpose((2,0,1))
20 | img_ = img_[np.newaxis,:,:,:]/255.0
21 | img_ = torch.from_numpy(img_).float()
22 | img_ = Variable(img_)
23 |
24 | if CUDA:
25 | img_ = img_.cuda()
26 |
27 | return img_
28 |
29 | def prep_image(img, inp_dim):
30 | """
31 | Prepare image for inputting to the neural network.
32 |
33 | Returns a Variable
34 | """
35 |
36 | orig_im = img
37 | dim = orig_im.shape[1], orig_im.shape[0]
38 | img = cv2.resize(orig_im, (inp_dim, inp_dim))
39 | img_ = img[:,:,::-1].transpose((2,0,1)).copy()
40 | img_ = torch.from_numpy(img_).float().div(255.0).unsqueeze(0)
41 | return img_, orig_im, dim
42 |
43 | def write(x, img):
44 | c1 = tuple(x[1:3].int())
45 | c2 = tuple(x[3:5].int())
46 | cls = int(x[-1])
47 | label = "{0}".format(classes[cls])
48 | color = random.choice(colors)
49 | cv2.rectangle(img, c1, c2,color, 1)
50 | t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0]
51 | c2 = c1[0] + t_size[0] + 3, c1[1] + t_size[1] + 4
52 | cv2.rectangle(img, c1, c2,color, -1)
53 | cv2.putText(img, label, (c1[0], c1[1] + t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 1, [225,255,255], 1);
54 | return img
55 |
56 | def arg_parse():
57 | """
58 | Parse arguements to the detect module
59 |
60 | """
61 |
62 |
63 | parser = argparse.ArgumentParser(description='YOLO v3 Cam Demo')
64 | parser.add_argument("--confidence", dest = "confidence", help = "Object Confidence to filter predictions", default = 0.25)
65 | parser.add_argument("--nms_thresh", dest = "nms_thresh", help = "NMS Threshhold", default = 0.4)
66 | parser.add_argument("--reso", dest = 'reso', help =
67 | "Input resolution of the network. Increase to increase accuracy. Decrease to increase speed",
68 | default = "160", type = str)
69 | return parser.parse_args()
70 |
71 |
72 |
73 | if __name__ == '__main__':
74 | cfgfile = "cfg/yolov3.cfg"
75 | weightsfile = "yolov3.weights"
76 | num_classes = 80
77 |
78 | args = arg_parse()
79 | confidence = float(args.confidence)
80 | nms_thesh = float(args.nms_thresh)
81 | start = 0
82 | CUDA = torch.cuda.is_available()
83 |
84 |
85 |
86 |
87 | num_classes = 80
88 | bbox_attrs = 5 + num_classes
89 |
90 | model = Darknet(cfgfile)
91 | model.load_weights(weightsfile)
92 |
93 | model.net_info["height"] = args.reso
94 | inp_dim = int(model.net_info["height"])
95 |
96 | assert inp_dim % 32 == 0
97 | assert inp_dim > 32
98 |
99 | if CUDA:
100 | model.cuda()
101 |
102 | model.eval()
103 |
104 | videofile = 'video.avi'
105 |
106 | cap = cv2.VideoCapture(0)
107 |
108 | assert cap.isOpened(), 'Cannot capture source'
109 |
110 | frames = 0
111 | start = time.time()
112 | while cap.isOpened():
113 |
114 | ret, frame = cap.read()
115 | if ret:
116 |
117 | img, orig_im, dim = prep_image(frame, inp_dim)
118 |
119 | # im_dim = torch.FloatTensor(dim).repeat(1,2)
120 |
121 |
122 | if CUDA:
123 | im_dim = im_dim.cuda()
124 | img = img.cuda()
125 |
126 |
127 | output = model(Variable(img), CUDA)
128 | output = write_results(output, confidence, num_classes, nms = True, nms_conf = nms_thesh)
129 |
130 | if type(output) == int:
131 | frames += 1
132 | print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
133 | cv2.imshow("frame", orig_im)
134 | key = cv2.waitKey(1)
135 | if key & 0xFF == ord('q'):
136 | break
137 | continue
138 |
139 |
140 |
141 | output[:,1:5] = torch.clamp(output[:,1:5], 0.0, float(inp_dim))/inp_dim
142 |
143 | # im_dim = im_dim.repeat(output.size(0), 1)
144 | output[:,[1,3]] *= frame.shape[1]
145 | output[:,[2,4]] *= frame.shape[0]
146 |
147 |
148 | classes = load_classes('data/coco.names')
149 | colors = pkl.load(open("pallete", "rb"))
150 |
151 | list(map(lambda x: write(x, orig_im), output))
152 |
153 |
154 | cv2.imshow("frame", orig_im)
155 | key = cv2.waitKey(1)
156 | if key & 0xFF == ord('q'):
157 | break
158 | frames += 1
159 | print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
160 |
161 |
162 | else:
163 | break
164 |
165 |
166 |
167 |
168 |
169 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/cfg/tiny-yolo-voc.cfg:
--------------------------------------------------------------------------------
1 | [net]
2 | batch=64
3 | subdivisions=8
4 | width=416
5 | height=416
6 | channels=3
7 | momentum=0.9
8 | decay=0.0005
9 | angle=0
10 | saturation = 1.5
11 | exposure = 1.5
12 | hue=.1
13 |
14 | learning_rate=0.001
15 | max_batches = 40200
16 | policy=steps
17 | steps=-1,100,20000,30000
18 | scales=.1,10,.1,.1
19 |
20 | [convolutional]
21 | batch_normalize=1
22 | filters=16
23 | size=3
24 | stride=1
25 | pad=1
26 | activation=leaky
27 |
28 | [maxpool]
29 | size=2
30 | stride=2
31 |
32 | [convolutional]
33 | batch_normalize=1
34 | filters=32
35 | size=3
36 | stride=1
37 | pad=1
38 | activation=leaky
39 |
40 | [maxpool]
41 | size=2
42 | stride=2
43 |
44 | [convolutional]
45 | batch_normalize=1
46 | filters=64
47 | size=3
48 | stride=1
49 | pad=1
50 | activation=leaky
51 |
52 | [maxpool]
53 | size=2
54 | stride=2
55 |
56 | [convolutional]
57 | batch_normalize=1
58 | filters=128
59 | size=3
60 | stride=1
61 | pad=1
62 | activation=leaky
63 |
64 | [maxpool]
65 | size=2
66 | stride=2
67 |
68 | [convolutional]
69 | batch_normalize=1
70 | filters=256
71 | size=3
72 | stride=1
73 | pad=1
74 | activation=leaky
75 |
76 | [maxpool]
77 | size=2
78 | stride=2
79 |
80 | [convolutional]
81 | batch_normalize=1
82 | filters=512
83 | size=3
84 | stride=1
85 | pad=1
86 | activation=leaky
87 |
88 | [maxpool]
89 | size=2
90 | stride=1
91 |
92 | [convolutional]
93 | batch_normalize=1
94 | filters=1024
95 | size=3
96 | stride=1
97 | pad=1
98 | activation=leaky
99 |
100 | ###########
101 |
102 | [convolutional]
103 | batch_normalize=1
104 | size=3
105 | stride=1
106 | pad=1
107 | filters=1024
108 | activation=leaky
109 |
110 | [convolutional]
111 | size=1
112 | stride=1
113 | pad=1
114 | filters=125
115 | activation=linear
116 |
117 | [region]
118 | anchors = 1.08,1.19, 3.42,4.41, 6.63,11.38, 9.42,5.11, 16.62,10.52
119 | bias_match=1
120 | classes=20
121 | coords=4
122 | num=5
123 | softmax=1
124 | jitter=.2
125 | rescore=1
126 |
127 | object_scale=5
128 | noobject_scale=1
129 | class_scale=1
130 | coord_scale=1
131 |
132 | absolute=1
133 | thresh = .6
134 | random=1
135 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/cfg/yolo-voc.cfg:
--------------------------------------------------------------------------------
1 | [net]
2 | # Testing
3 | batch=64
4 | subdivisions=8
5 | # Training
6 | # batch=64
7 | # subdivisions=8
8 | height=416
9 | width=416
10 | channels=3
11 | momentum=0.9
12 | decay=0.0005
13 | angle=0
14 | saturation = 1.5
15 | exposure = 1.5
16 | hue=.1
17 |
18 | learning_rate=0.001
19 | burn_in=1000
20 | max_batches = 80200
21 | policy=steps
22 | steps=-1,500,40000,60000
23 | scales=0.1,10,.1,.1
24 |
25 | [convolutional]
26 | batch_normalize=1
27 | filters=32
28 | size=3
29 | stride=1
30 | pad=1
31 | activation=leaky
32 |
33 | [maxpool]
34 | size=2
35 | stride=2
36 |
37 | [convolutional]
38 | batch_normalize=1
39 | filters=64
40 | size=3
41 | stride=1
42 | pad=1
43 | activation=leaky
44 |
45 | [maxpool]
46 | size=2
47 | stride=2
48 |
49 | [convolutional]
50 | batch_normalize=1
51 | filters=128
52 | size=3
53 | stride=1
54 | pad=1
55 | activation=leaky
56 |
57 | [convolutional]
58 | batch_normalize=1
59 | filters=64
60 | size=1
61 | stride=1
62 | pad=1
63 | activation=leaky
64 |
65 | [convolutional]
66 | batch_normalize=1
67 | filters=128
68 | size=3
69 | stride=1
70 | pad=1
71 | activation=leaky
72 |
73 | [maxpool]
74 | size=2
75 | stride=2
76 |
77 | [convolutional]
78 | batch_normalize=1
79 | filters=256
80 | size=3
81 | stride=1
82 | pad=1
83 | activation=leaky
84 |
85 | [convolutional]
86 | batch_normalize=1
87 | filters=128
88 | size=1
89 | stride=1
90 | pad=1
91 | activation=leaky
92 |
93 | [convolutional]
94 | batch_normalize=1
95 | filters=256
96 | size=3
97 | stride=1
98 | pad=1
99 | activation=leaky
100 |
101 | [maxpool]
102 | size=2
103 | stride=2
104 |
105 | [convolutional]
106 | batch_normalize=1
107 | filters=512
108 | size=3
109 | stride=1
110 | pad=1
111 | activation=leaky
112 |
113 | [convolutional]
114 | batch_normalize=1
115 | filters=256
116 | size=1
117 | stride=1
118 | pad=1
119 | activation=leaky
120 |
121 | [convolutional]
122 | batch_normalize=1
123 | filters=512
124 | size=3
125 | stride=1
126 | pad=1
127 | activation=leaky
128 |
129 | [convolutional]
130 | batch_normalize=1
131 | filters=256
132 | size=1
133 | stride=1
134 | pad=1
135 | activation=leaky
136 |
137 | [convolutional]
138 | batch_normalize=1
139 | filters=512
140 | size=3
141 | stride=1
142 | pad=1
143 | activation=leaky
144 |
145 | [maxpool]
146 | size=2
147 | stride=2
148 |
149 | [convolutional]
150 | batch_normalize=1
151 | filters=1024
152 | size=3
153 | stride=1
154 | pad=1
155 | activation=leaky
156 |
157 | [convolutional]
158 | batch_normalize=1
159 | filters=512
160 | size=1
161 | stride=1
162 | pad=1
163 | activation=leaky
164 |
165 | [convolutional]
166 | batch_normalize=1
167 | filters=1024
168 | size=3
169 | stride=1
170 | pad=1
171 | activation=leaky
172 |
173 | [convolutional]
174 | batch_normalize=1
175 | filters=512
176 | size=1
177 | stride=1
178 | pad=1
179 | activation=leaky
180 |
181 | [convolutional]
182 | batch_normalize=1
183 | filters=1024
184 | size=3
185 | stride=1
186 | pad=1
187 | activation=leaky
188 |
189 |
190 | #######
191 |
192 | [convolutional]
193 | batch_normalize=1
194 | size=3
195 | stride=1
196 | pad=1
197 | filters=1024
198 | activation=leaky
199 |
200 | [convolutional]
201 | batch_normalize=1
202 | size=3
203 | stride=1
204 | pad=1
205 | filters=1024
206 | activation=leaky
207 |
208 | [route]
209 | layers=-9
210 |
211 | [convolutional]
212 | batch_normalize=1
213 | size=1
214 | stride=1
215 | pad=1
216 | filters=64
217 | activation=leaky
218 |
219 | [reorg]
220 | stride=2
221 |
222 | [route]
223 | layers=-1,-4
224 |
225 | [convolutional]
226 | batch_normalize=1
227 | size=3
228 | stride=1
229 | pad=1
230 | filters=1024
231 | activation=leaky
232 |
233 | [convolutional]
234 | size=1
235 | stride=1
236 | pad=1
237 | filters=125
238 | activation=linear
239 |
240 |
241 | [region]
242 | anchors = 1.3221, 1.73145, 3.19275, 4.00944, 5.05587, 8.09892, 9.47112, 4.84053, 11.2364, 10.0071
243 | bias_match=1
244 | classes=20
245 | coords=4
246 | num=5
247 | softmax=1
248 | jitter=.3
249 | rescore=1
250 |
251 | object_scale=5
252 | noobject_scale=1
253 | class_scale=1
254 | coord_scale=1
255 |
256 | absolute=1
257 | thresh = .6
258 | random=1
259 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/cfg/yolo.cfg:
--------------------------------------------------------------------------------
1 | [net]
2 | # Testing
3 | batch=1
4 | subdivisions=1
5 | # Training
6 | # batch=64
7 | # subdivisions=8
8 | width=416
9 | height=416
10 | channels=3
11 | momentum=0.9
12 | decay=0.0005
13 | angle=0
14 | saturation = 1.5
15 | exposure = 1.5
16 | hue=.1
17 |
18 | learning_rate=0.001
19 | burn_in=1000
20 | max_batches = 500200
21 | policy=steps
22 | steps=400000,450000
23 | scales=.1,.1
24 |
25 | [convolutional]
26 | batch_normalize=1
27 | filters=32
28 | size=3
29 | stride=1
30 | pad=1
31 | activation=leaky
32 |
33 | [maxpool]
34 | size=2
35 | stride=2
36 |
37 | [convolutional]
38 | batch_normalize=1
39 | filters=64
40 | size=3
41 | stride=1
42 | pad=1
43 | activation=leaky
44 |
45 | [maxpool]
46 | size=2
47 | stride=2
48 |
49 | [convolutional]
50 | batch_normalize=1
51 | filters=128
52 | size=3
53 | stride=1
54 | pad=1
55 | activation=leaky
56 |
57 | [convolutional]
58 | batch_normalize=1
59 | filters=64
60 | size=1
61 | stride=1
62 | pad=1
63 | activation=leaky
64 |
65 | [convolutional]
66 | batch_normalize=1
67 | filters=128
68 | size=3
69 | stride=1
70 | pad=1
71 | activation=leaky
72 |
73 | [maxpool]
74 | size=2
75 | stride=2
76 |
77 | [convolutional]
78 | batch_normalize=1
79 | filters=256
80 | size=3
81 | stride=1
82 | pad=1
83 | activation=leaky
84 |
85 | [convolutional]
86 | batch_normalize=1
87 | filters=128
88 | size=1
89 | stride=1
90 | pad=1
91 | activation=leaky
92 |
93 | [convolutional]
94 | batch_normalize=1
95 | filters=256
96 | size=3
97 | stride=1
98 | pad=1
99 | activation=leaky
100 |
101 | [maxpool]
102 | size=2
103 | stride=2
104 |
105 | [convolutional]
106 | batch_normalize=1
107 | filters=512
108 | size=3
109 | stride=1
110 | pad=1
111 | activation=leaky
112 |
113 | [convolutional]
114 | batch_normalize=1
115 | filters=256
116 | size=1
117 | stride=1
118 | pad=1
119 | activation=leaky
120 |
121 | [convolutional]
122 | batch_normalize=1
123 | filters=512
124 | size=3
125 | stride=1
126 | pad=1
127 | activation=leaky
128 |
129 | [convolutional]
130 | batch_normalize=1
131 | filters=256
132 | size=1
133 | stride=1
134 | pad=1
135 | activation=leaky
136 |
137 | [convolutional]
138 | batch_normalize=1
139 | filters=512
140 | size=3
141 | stride=1
142 | pad=1
143 | activation=leaky
144 |
145 | [maxpool]
146 | size=2
147 | stride=2
148 |
149 | [convolutional]
150 | batch_normalize=1
151 | filters=1024
152 | size=3
153 | stride=1
154 | pad=1
155 | activation=leaky
156 |
157 | [convolutional]
158 | batch_normalize=1
159 | filters=512
160 | size=1
161 | stride=1
162 | pad=1
163 | activation=leaky
164 |
165 | [convolutional]
166 | batch_normalize=1
167 | filters=1024
168 | size=3
169 | stride=1
170 | pad=1
171 | activation=leaky
172 |
173 | [convolutional]
174 | batch_normalize=1
175 | filters=512
176 | size=1
177 | stride=1
178 | pad=1
179 | activation=leaky
180 |
181 | [convolutional]
182 | batch_normalize=1
183 | filters=1024
184 | size=3
185 | stride=1
186 | pad=1
187 | activation=leaky
188 |
189 |
190 | #######
191 |
192 | [convolutional]
193 | batch_normalize=1
194 | size=3
195 | stride=1
196 | pad=1
197 | filters=1024
198 | activation=leaky
199 |
200 | [convolutional]
201 | batch_normalize=1
202 | size=3
203 | stride=1
204 | pad=1
205 | filters=1024
206 | activation=leaky
207 |
208 | [route]
209 | layers=-9
210 |
211 | [convolutional]
212 | batch_normalize=1
213 | size=1
214 | stride=1
215 | pad=1
216 | filters=64
217 | activation=leaky
218 |
219 | [reorg]
220 | stride=2
221 |
222 | [route]
223 | layers=-1,-4
224 |
225 | [convolutional]
226 | batch_normalize=1
227 | size=3
228 | stride=1
229 | pad=1
230 | filters=1024
231 | activation=leaky
232 |
233 | [convolutional]
234 | size=1
235 | stride=1
236 | pad=1
237 | filters=425
238 | activation=linear
239 |
240 |
241 | [region]
242 | anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828
243 | bias_match=1
244 | classes=80
245 | coords=4
246 | num=5
247 | softmax=1
248 | jitter=.3
249 | rescore=1
250 |
251 | object_scale=5
252 | noobject_scale=1
253 | class_scale=1
254 | coord_scale=1
255 |
256 | absolute=1
257 | thresh = .6
258 | random=1
259 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/cfg/yolov3.cfg:
--------------------------------------------------------------------------------
1 | [net]
2 | # Testing
3 | batch=1
4 | subdivisions=1
5 | # Training
6 | # batch=64
7 | # subdivisions=16
8 | width= 320
9 | height = 320
10 | channels=3
11 | momentum=0.9
12 | decay=0.0005
13 | angle=0
14 | saturation = 1.5
15 | exposure = 1.5
16 | hue=.1
17 |
18 | learning_rate=0.001
19 | burn_in=1000
20 | max_batches = 500200
21 | policy=steps
22 | steps=400000,450000
23 | scales=.1,.1
24 |
25 | [convolutional]
26 | batch_normalize=1
27 | filters=32
28 | size=3
29 | stride=1
30 | pad=1
31 | activation=leaky
32 |
33 | # Downsample
34 |
35 | [convolutional]
36 | batch_normalize=1
37 | filters=64
38 | size=3
39 | stride=2
40 | pad=1
41 | activation=leaky
42 |
43 | [convolutional]
44 | batch_normalize=1
45 | filters=32
46 | size=1
47 | stride=1
48 | pad=1
49 | activation=leaky
50 |
51 | [convolutional]
52 | batch_normalize=1
53 | filters=64
54 | size=3
55 | stride=1
56 | pad=1
57 | activation=leaky
58 |
59 | [shortcut]
60 | from=-3
61 | activation=linear
62 |
63 | # Downsample
64 |
65 | [convolutional]
66 | batch_normalize=1
67 | filters=128
68 | size=3
69 | stride=2
70 | pad=1
71 | activation=leaky
72 |
73 | [convolutional]
74 | batch_normalize=1
75 | filters=64
76 | size=1
77 | stride=1
78 | pad=1
79 | activation=leaky
80 |
81 | [convolutional]
82 | batch_normalize=1
83 | filters=128
84 | size=3
85 | stride=1
86 | pad=1
87 | activation=leaky
88 |
89 | [shortcut]
90 | from=-3
91 | activation=linear
92 |
93 | [convolutional]
94 | batch_normalize=1
95 | filters=64
96 | size=1
97 | stride=1
98 | pad=1
99 | activation=leaky
100 |
101 | [convolutional]
102 | batch_normalize=1
103 | filters=128
104 | size=3
105 | stride=1
106 | pad=1
107 | activation=leaky
108 |
109 | [shortcut]
110 | from=-3
111 | activation=linear
112 |
113 | # Downsample
114 |
115 | [convolutional]
116 | batch_normalize=1
117 | filters=256
118 | size=3
119 | stride=2
120 | pad=1
121 | activation=leaky
122 |
123 | [convolutional]
124 | batch_normalize=1
125 | filters=128
126 | size=1
127 | stride=1
128 | pad=1
129 | activation=leaky
130 |
131 | [convolutional]
132 | batch_normalize=1
133 | filters=256
134 | size=3
135 | stride=1
136 | pad=1
137 | activation=leaky
138 |
139 | [shortcut]
140 | from=-3
141 | activation=linear
142 |
143 | [convolutional]
144 | batch_normalize=1
145 | filters=128
146 | size=1
147 | stride=1
148 | pad=1
149 | activation=leaky
150 |
151 | [convolutional]
152 | batch_normalize=1
153 | filters=256
154 | size=3
155 | stride=1
156 | pad=1
157 | activation=leaky
158 |
159 | [shortcut]
160 | from=-3
161 | activation=linear
162 |
163 | [convolutional]
164 | batch_normalize=1
165 | filters=128
166 | size=1
167 | stride=1
168 | pad=1
169 | activation=leaky
170 |
171 | [convolutional]
172 | batch_normalize=1
173 | filters=256
174 | size=3
175 | stride=1
176 | pad=1
177 | activation=leaky
178 |
179 | [shortcut]
180 | from=-3
181 | activation=linear
182 |
183 | [convolutional]
184 | batch_normalize=1
185 | filters=128
186 | size=1
187 | stride=1
188 | pad=1
189 | activation=leaky
190 |
191 | [convolutional]
192 | batch_normalize=1
193 | filters=256
194 | size=3
195 | stride=1
196 | pad=1
197 | activation=leaky
198 |
199 | [shortcut]
200 | from=-3
201 | activation=linear
202 |
203 |
204 | [convolutional]
205 | batch_normalize=1
206 | filters=128
207 | size=1
208 | stride=1
209 | pad=1
210 | activation=leaky
211 |
212 | [convolutional]
213 | batch_normalize=1
214 | filters=256
215 | size=3
216 | stride=1
217 | pad=1
218 | activation=leaky
219 |
220 | [shortcut]
221 | from=-3
222 | activation=linear
223 |
224 | [convolutional]
225 | batch_normalize=1
226 | filters=128
227 | size=1
228 | stride=1
229 | pad=1
230 | activation=leaky
231 |
232 | [convolutional]
233 | batch_normalize=1
234 | filters=256
235 | size=3
236 | stride=1
237 | pad=1
238 | activation=leaky
239 |
240 | [shortcut]
241 | from=-3
242 | activation=linear
243 |
244 | [convolutional]
245 | batch_normalize=1
246 | filters=128
247 | size=1
248 | stride=1
249 | pad=1
250 | activation=leaky
251 |
252 | [convolutional]
253 | batch_normalize=1
254 | filters=256
255 | size=3
256 | stride=1
257 | pad=1
258 | activation=leaky
259 |
260 | [shortcut]
261 | from=-3
262 | activation=linear
263 |
264 | [convolutional]
265 | batch_normalize=1
266 | filters=128
267 | size=1
268 | stride=1
269 | pad=1
270 | activation=leaky
271 |
272 | [convolutional]
273 | batch_normalize=1
274 | filters=256
275 | size=3
276 | stride=1
277 | pad=1
278 | activation=leaky
279 |
280 | [shortcut]
281 | from=-3
282 | activation=linear
283 |
284 | # Downsample
285 |
286 | [convolutional]
287 | batch_normalize=1
288 | filters=512
289 | size=3
290 | stride=2
291 | pad=1
292 | activation=leaky
293 |
294 | [convolutional]
295 | batch_normalize=1
296 | filters=256
297 | size=1
298 | stride=1
299 | pad=1
300 | activation=leaky
301 |
302 | [convolutional]
303 | batch_normalize=1
304 | filters=512
305 | size=3
306 | stride=1
307 | pad=1
308 | activation=leaky
309 |
310 | [shortcut]
311 | from=-3
312 | activation=linear
313 |
314 |
315 | [convolutional]
316 | batch_normalize=1
317 | filters=256
318 | size=1
319 | stride=1
320 | pad=1
321 | activation=leaky
322 |
323 | [convolutional]
324 | batch_normalize=1
325 | filters=512
326 | size=3
327 | stride=1
328 | pad=1
329 | activation=leaky
330 |
331 | [shortcut]
332 | from=-3
333 | activation=linear
334 |
335 |
336 | [convolutional]
337 | batch_normalize=1
338 | filters=256
339 | size=1
340 | stride=1
341 | pad=1
342 | activation=leaky
343 |
344 | [convolutional]
345 | batch_normalize=1
346 | filters=512
347 | size=3
348 | stride=1
349 | pad=1
350 | activation=leaky
351 |
352 | [shortcut]
353 | from=-3
354 | activation=linear
355 |
356 |
357 | [convolutional]
358 | batch_normalize=1
359 | filters=256
360 | size=1
361 | stride=1
362 | pad=1
363 | activation=leaky
364 |
365 | [convolutional]
366 | batch_normalize=1
367 | filters=512
368 | size=3
369 | stride=1
370 | pad=1
371 | activation=leaky
372 |
373 | [shortcut]
374 | from=-3
375 | activation=linear
376 |
377 | [convolutional]
378 | batch_normalize=1
379 | filters=256
380 | size=1
381 | stride=1
382 | pad=1
383 | activation=leaky
384 |
385 | [convolutional]
386 | batch_normalize=1
387 | filters=512
388 | size=3
389 | stride=1
390 | pad=1
391 | activation=leaky
392 |
393 | [shortcut]
394 | from=-3
395 | activation=linear
396 |
397 |
398 | [convolutional]
399 | batch_normalize=1
400 | filters=256
401 | size=1
402 | stride=1
403 | pad=1
404 | activation=leaky
405 |
406 | [convolutional]
407 | batch_normalize=1
408 | filters=512
409 | size=3
410 | stride=1
411 | pad=1
412 | activation=leaky
413 |
414 | [shortcut]
415 | from=-3
416 | activation=linear
417 |
418 |
419 | [convolutional]
420 | batch_normalize=1
421 | filters=256
422 | size=1
423 | stride=1
424 | pad=1
425 | activation=leaky
426 |
427 | [convolutional]
428 | batch_normalize=1
429 | filters=512
430 | size=3
431 | stride=1
432 | pad=1
433 | activation=leaky
434 |
435 | [shortcut]
436 | from=-3
437 | activation=linear
438 |
439 | [convolutional]
440 | batch_normalize=1
441 | filters=256
442 | size=1
443 | stride=1
444 | pad=1
445 | activation=leaky
446 |
447 | [convolutional]
448 | batch_normalize=1
449 | filters=512
450 | size=3
451 | stride=1
452 | pad=1
453 | activation=leaky
454 |
455 | [shortcut]
456 | from=-3
457 | activation=linear
458 |
459 | # Downsample
460 |
461 | [convolutional]
462 | batch_normalize=1
463 | filters=1024
464 | size=3
465 | stride=2
466 | pad=1
467 | activation=leaky
468 |
469 | [convolutional]
470 | batch_normalize=1
471 | filters=512
472 | size=1
473 | stride=1
474 | pad=1
475 | activation=leaky
476 |
477 | [convolutional]
478 | batch_normalize=1
479 | filters=1024
480 | size=3
481 | stride=1
482 | pad=1
483 | activation=leaky
484 |
485 | [shortcut]
486 | from=-3
487 | activation=linear
488 |
489 | [convolutional]
490 | batch_normalize=1
491 | filters=512
492 | size=1
493 | stride=1
494 | pad=1
495 | activation=leaky
496 |
497 | [convolutional]
498 | batch_normalize=1
499 | filters=1024
500 | size=3
501 | stride=1
502 | pad=1
503 | activation=leaky
504 |
505 | [shortcut]
506 | from=-3
507 | activation=linear
508 |
509 | [convolutional]
510 | batch_normalize=1
511 | filters=512
512 | size=1
513 | stride=1
514 | pad=1
515 | activation=leaky
516 |
517 | [convolutional]
518 | batch_normalize=1
519 | filters=1024
520 | size=3
521 | stride=1
522 | pad=1
523 | activation=leaky
524 |
525 | [shortcut]
526 | from=-3
527 | activation=linear
528 |
529 | [convolutional]
530 | batch_normalize=1
531 | filters=512
532 | size=1
533 | stride=1
534 | pad=1
535 | activation=leaky
536 |
537 | [convolutional]
538 | batch_normalize=1
539 | filters=1024
540 | size=3
541 | stride=1
542 | pad=1
543 | activation=leaky
544 |
545 | [shortcut]
546 | from=-3
547 | activation=linear
548 |
549 | ######################
550 |
551 | [convolutional]
552 | batch_normalize=1
553 | filters=512
554 | size=1
555 | stride=1
556 | pad=1
557 | activation=leaky
558 |
559 | [convolutional]
560 | batch_normalize=1
561 | size=3
562 | stride=1
563 | pad=1
564 | filters=1024
565 | activation=leaky
566 |
567 | [convolutional]
568 | batch_normalize=1
569 | filters=512
570 | size=1
571 | stride=1
572 | pad=1
573 | activation=leaky
574 |
575 | [convolutional]
576 | batch_normalize=1
577 | size=3
578 | stride=1
579 | pad=1
580 | filters=1024
581 | activation=leaky
582 |
583 | [convolutional]
584 | batch_normalize=1
585 | filters=512
586 | size=1
587 | stride=1
588 | pad=1
589 | activation=leaky
590 |
591 | [convolutional]
592 | batch_normalize=1
593 | size=3
594 | stride=1
595 | pad=1
596 | filters=1024
597 | activation=leaky
598 |
599 | [convolutional]
600 | size=1
601 | stride=1
602 | pad=1
603 | filters=255
604 | activation=linear
605 |
606 |
607 | [yolo]
608 | mask = 6,7,8
609 | anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
610 | classes=80
611 | num=9
612 | jitter=.3
613 | ignore_thresh = .5
614 | truth_thresh = 1
615 | random=1
616 |
617 |
618 | [route]
619 | layers = -4
620 |
621 | [convolutional]
622 | batch_normalize=1
623 | filters=256
624 | size=1
625 | stride=1
626 | pad=1
627 | activation=leaky
628 |
629 | [upsample]
630 | stride=2
631 |
632 | [route]
633 | layers = -1, 61
634 |
635 |
636 |
637 | [convolutional]
638 | batch_normalize=1
639 | filters=256
640 | size=1
641 | stride=1
642 | pad=1
643 | activation=leaky
644 |
645 | [convolutional]
646 | batch_normalize=1
647 | size=3
648 | stride=1
649 | pad=1
650 | filters=512
651 | activation=leaky
652 |
653 | [convolutional]
654 | batch_normalize=1
655 | filters=256
656 | size=1
657 | stride=1
658 | pad=1
659 | activation=leaky
660 |
661 | [convolutional]
662 | batch_normalize=1
663 | size=3
664 | stride=1
665 | pad=1
666 | filters=512
667 | activation=leaky
668 |
669 | [convolutional]
670 | batch_normalize=1
671 | filters=256
672 | size=1
673 | stride=1
674 | pad=1
675 | activation=leaky
676 |
677 | [convolutional]
678 | batch_normalize=1
679 | size=3
680 | stride=1
681 | pad=1
682 | filters=512
683 | activation=leaky
684 |
685 | [convolutional]
686 | size=1
687 | stride=1
688 | pad=1
689 | filters=255
690 | activation=linear
691 |
692 |
693 | [yolo]
694 | mask = 3,4,5
695 | anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
696 | classes=80
697 | num=9
698 | jitter=.3
699 | ignore_thresh = .5
700 | truth_thresh = 1
701 | random=1
702 |
703 |
704 |
705 | [route]
706 | layers = -4
707 |
708 | [convolutional]
709 | batch_normalize=1
710 | filters=128
711 | size=1
712 | stride=1
713 | pad=1
714 | activation=leaky
715 |
716 | [upsample]
717 | stride=2
718 |
719 | [route]
720 | layers = -1, 36
721 |
722 |
723 |
724 | [convolutional]
725 | batch_normalize=1
726 | filters=128
727 | size=1
728 | stride=1
729 | pad=1
730 | activation=leaky
731 |
732 | [convolutional]
733 | batch_normalize=1
734 | size=3
735 | stride=1
736 | pad=1
737 | filters=256
738 | activation=leaky
739 |
740 | [convolutional]
741 | batch_normalize=1
742 | filters=128
743 | size=1
744 | stride=1
745 | pad=1
746 | activation=leaky
747 |
748 | [convolutional]
749 | batch_normalize=1
750 | size=3
751 | stride=1
752 | pad=1
753 | filters=256
754 | activation=leaky
755 |
756 | [convolutional]
757 | batch_normalize=1
758 | filters=128
759 | size=1
760 | stride=1
761 | pad=1
762 | activation=leaky
763 |
764 | [convolutional]
765 | batch_normalize=1
766 | size=3
767 | stride=1
768 | pad=1
769 | filters=256
770 | activation=leaky
771 |
772 | [convolutional]
773 | size=1
774 | stride=1
775 | pad=1
776 | filters=255
777 | activation=linear
778 |
779 |
780 | [yolo]
781 | mask = 0,1,2
782 | anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
783 | classes=80
784 | num=9
785 | jitter=.3
786 | ignore_thresh = .5
787 | truth_thresh = 1
788 | random=1
789 |
790 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/darknet.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 | from torch.autograd import Variable
7 | import numpy as np
8 | import cv2
9 | import matplotlib.pyplot as plt
10 | from util import count_parameters as count
11 | from util import convert2cpu as cpu
12 | from util import predict_transform
13 |
14 | class test_net(nn.Module):
15 | def __init__(self, num_layers, input_size):
16 | super(test_net, self).__init__()
17 | self.num_layers= num_layers
18 | self.linear_1 = nn.Linear(input_size, 5)
19 | self.middle = nn.ModuleList([nn.Linear(5,5) for x in range(num_layers)])
20 | self.output = nn.Linear(5,2)
21 |
22 | def forward(self, x):
23 | x = x.view(-1)
24 | fwd = nn.Sequential(self.linear_1, *self.middle, self.output)
25 | return fwd(x)
26 |
27 | def get_test_input():
28 | img = cv2.imread("dog-cycle-car.png")
29 | img = cv2.resize(img, (416,416))
30 | img_ = img[:,:,::-1].transpose((2,0,1))
31 | img_ = img_[np.newaxis,:,:,:]/255.0
32 | img_ = torch.from_numpy(img_).float()
33 | img_ = Variable(img_)
34 | return img_
35 |
36 |
37 | def parse_cfg(cfgfile):
38 | """
39 | Takes a configuration file
40 |
41 | Returns a list of blocks. Each blocks describes a block in the neural
42 | network to be built. Block is represented as a dictionary in the list
43 |
44 | """
45 | file = open(cfgfile, 'r')
46 | lines = file.read().split('\n') #store the lines in a list
47 | lines = [x for x in lines if len(x) > 0] #get read of the empty lines
48 | lines = [x for x in lines if x[0] != '#']
49 | lines = [x.rstrip().lstrip() for x in lines]
50 |
51 |
52 | block = {}
53 | blocks = []
54 |
55 | for line in lines:
56 | if line[0] == "[": #This marks the start of a new block
57 | if len(block) != 0:
58 | blocks.append(block)
59 | block = {}
60 | block["type"] = line[1:-1].rstrip()
61 | else:
62 | key,value = line.split("=")
63 | block[key.rstrip()] = value.lstrip()
64 | blocks.append(block)
65 |
66 | return blocks
67 | # print('\n\n'.join([repr(x) for x in blocks]))
68 |
69 | import pickle as pkl
70 |
71 | class MaxPoolStride1(nn.Module):
72 | def __init__(self, kernel_size):
73 | super(MaxPoolStride1, self).__init__()
74 | self.kernel_size = kernel_size
75 | self.pad = kernel_size - 1
76 |
77 | def forward(self, x):
78 | padded_x = F.pad(x, (0,self.pad,0,self.pad), mode="replicate")
79 | pooled_x = nn.MaxPool2d(self.kernel_size, self.pad)(padded_x)
80 | return pooled_x
81 |
82 |
83 | class EmptyLayer(nn.Module):
84 | def __init__(self):
85 | super(EmptyLayer, self).__init__()
86 |
87 |
88 | class DetectionLayer(nn.Module):
89 | def __init__(self, anchors):
90 | super(DetectionLayer, self).__init__()
91 | self.anchors = anchors
92 |
93 | def forward(self, x, inp_dim, num_classes, confidence):
94 | x = x.data
95 | global CUDA
96 | prediction = x
97 | prediction = predict_transform(prediction, inp_dim, self.anchors, num_classes, confidence, CUDA)
98 | return prediction
99 |
100 |
101 |
102 |
103 |
104 | class Upsample(nn.Module):
105 | def __init__(self, stride=2):
106 | super(Upsample, self).__init__()
107 | self.stride = stride
108 |
109 | def forward(self, x):
110 | stride = self.stride
111 | assert(x.data.dim() == 4)
112 | B = x.data.size(0)
113 | C = x.data.size(1)
114 | H = x.data.size(2)
115 | W = x.data.size(3)
116 | ws = stride
117 | hs = stride
118 | x = x.view(B, C, H, 1, W, 1).expand(B, C, H, stride, W, stride).contiguous().view(B, C, H*stride, W*stride)
119 | return x
120 | #
121 |
122 | class ReOrgLayer(nn.Module):
123 | def __init__(self, stride = 2):
124 | super(ReOrgLayer, self).__init__()
125 | self.stride= stride
126 |
127 | def forward(self,x):
128 | assert(x.data.dim() == 4)
129 | B,C,H,W = x.data.shape
130 | hs = self.stride
131 | ws = self.stride
132 | assert(H % hs == 0), "The stride " + str(self.stride) + " is not a proper divisor of height " + str(H)
133 | assert(W % ws == 0), "The stride " + str(self.stride) + " is not a proper divisor of height " + str(W)
134 | x = x.view(B,C, H // hs, hs, W // ws, ws).transpose(-2,-3).contiguous()
135 | x = x.view(B,C, H // hs * W // ws, hs, ws)
136 | x = x.view(B,C, H // hs * W // ws, hs*ws).transpose(-1,-2).contiguous()
137 | x = x.view(B, C, ws*hs, H // ws, W // ws).transpose(1,2).contiguous()
138 | x = x.view(B, C*ws*hs, H // ws, W // ws)
139 | return x
140 |
141 |
142 | def create_modules(blocks):
143 | net_info = blocks[0] #Captures the information about the input and pre-processing
144 |
145 | module_list = nn.ModuleList()
146 |
147 | index = 0 #indexing blocks helps with implementing route layers (skip connections)
148 |
149 |
150 | prev_filters = 3
151 |
152 | output_filters = []
153 |
154 | for x in blocks:
155 | module = nn.Sequential()
156 |
157 | if (x["type"] == "net"):
158 | continue
159 |
160 | #If it's a convolutional layer
161 | if (x["type"] == "convolutional"):
162 | #Get the info about the layer
163 | activation = x["activation"]
164 | try:
165 | batch_normalize = int(x["batch_normalize"])
166 | bias = False
167 | except:
168 | batch_normalize = 0
169 | bias = True
170 |
171 | filters= int(x["filters"])
172 | padding = int(x["pad"])
173 | kernel_size = int(x["size"])
174 | stride = int(x["stride"])
175 |
176 | if padding:
177 | pad = (kernel_size - 1) // 2
178 | else:
179 | pad = 0
180 |
181 | #Add the convolutional layer
182 | conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias = bias)
183 | module.add_module("conv_{0}".format(index), conv)
184 |
185 | #Add the Batch Norm Layer
186 | if batch_normalize:
187 | bn = nn.BatchNorm2d(filters)
188 | module.add_module("batch_norm_{0}".format(index), bn)
189 |
190 | #Check the activation.
191 | #It is either Linear or a Leaky ReLU for YOLO
192 | if activation == "leaky":
193 | activn = nn.LeakyReLU(0.1, inplace = True)
194 | module.add_module("leaky_{0}".format(index), activn)
195 |
196 |
197 |
198 | #If it's an upsampling layer
199 | #We use Bilinear2dUpsampling
200 |
201 | elif (x["type"] == "upsample"):
202 | stride = int(x["stride"])
203 | # upsample = Upsample(stride)
204 | upsample = nn.Upsample(scale_factor = 2, mode = "nearest")
205 | module.add_module("upsample_{}".format(index), upsample)
206 |
207 | #If it is a route layer
208 | elif (x["type"] == "route"):
209 | x["layers"] = x["layers"].split(',')
210 |
211 | #Start of a route
212 | start = int(x["layers"][0])
213 |
214 | #end, if there exists one.
215 | try:
216 | end = int(x["layers"][1])
217 | except:
218 | end = 0
219 |
220 |
221 |
222 | #Positive anotation
223 | if start > 0:
224 | start = start - index
225 |
226 | if end > 0:
227 | end = end - index
228 |
229 |
230 | route = EmptyLayer()
231 | module.add_module("route_{0}".format(index), route)
232 |
233 |
234 |
235 | if end < 0:
236 | filters = output_filters[index + start] + output_filters[index + end]
237 | else:
238 | filters= output_filters[index + start]
239 |
240 |
241 |
242 | #shortcut corresponds to skip connection
243 | elif x["type"] == "shortcut":
244 | from_ = int(x["from"])
245 | shortcut = EmptyLayer()
246 | module.add_module("shortcut_{}".format(index), shortcut)
247 |
248 |
249 | elif x["type"] == "maxpool":
250 | stride = int(x["stride"])
251 | size = int(x["size"])
252 | if stride != 1:
253 | maxpool = nn.MaxPool2d(size, stride)
254 | else:
255 | maxpool = MaxPoolStride1(size)
256 |
257 | module.add_module("maxpool_{}".format(index), maxpool)
258 |
259 | #Yolo is the detection layer
260 | elif x["type"] == "yolo":
261 | mask = x["mask"].split(",")
262 | mask = [int(x) for x in mask]
263 |
264 |
265 | anchors = x["anchors"].split(",")
266 | anchors = [int(a) for a in anchors]
267 | anchors = [(anchors[i], anchors[i+1]) for i in range(0, len(anchors),2)]
268 | anchors = [anchors[i] for i in mask]
269 |
270 | detection = DetectionLayer(anchors)
271 | module.add_module("Detection_{}".format(index), detection)
272 |
273 |
274 |
275 | else:
276 | print("Something I dunno")
277 | assert False
278 |
279 |
280 | module_list.append(module)
281 | prev_filters = filters
282 | output_filters.append(filters)
283 | index += 1
284 |
285 |
286 | return (net_info, module_list)
287 |
288 |
289 |
290 | class Darknet(nn.Module):
291 | def __init__(self, cfgfile):
292 | super(Darknet, self).__init__()
293 | self.blocks = parse_cfg(cfgfile)
294 | self.net_info, self.module_list = create_modules(self.blocks)
295 | self.header = torch.IntTensor([0,0,0,0])
296 | self.seen = 0
297 |
298 |
299 |
300 | def get_blocks(self):
301 | return self.blocks
302 |
303 | def get_module_list(self):
304 | return self.module_list
305 |
306 |
307 | def forward(self, x, CUDA):
308 | detections = []
309 | modules = self.blocks[1:]
310 | outputs = {} #We cache the outputs for the route layer
311 |
312 |
313 | write = 0
314 | for i in range(len(modules)):
315 |
316 | module_type = (modules[i]["type"])
317 | if module_type == "convolutional" or module_type == "upsample" or module_type == "maxpool":
318 |
319 | x = self.module_list[i](x)
320 | outputs[i] = x
321 |
322 |
323 | elif module_type == "route":
324 | layers = modules[i]["layers"]
325 | layers = [int(a) for a in layers]
326 |
327 | if (layers[0]) > 0:
328 | layers[0] = layers[0] - i
329 |
330 | if len(layers) == 1:
331 | x = outputs[i + (layers[0])]
332 |
333 | else:
334 | if (layers[1]) > 0:
335 | layers[1] = layers[1] - i
336 |
337 | map1 = outputs[i + layers[0]]
338 | map2 = outputs[i + layers[1]]
339 |
340 |
341 | x = torch.cat((map1, map2), 1)
342 | outputs[i] = x
343 |
344 | elif module_type == "shortcut":
345 | from_ = int(modules[i]["from"])
346 | x = outputs[i-1] + outputs[i+from_]
347 | outputs[i] = x
348 |
349 |
350 |
351 | elif module_type == 'yolo':
352 |
353 | anchors = self.module_list[i][0].anchors
354 | #Get the input dimensions
355 | inp_dim = int (self.net_info["height"])
356 |
357 | #Get the number of classes
358 | num_classes = int (modules[i]["classes"])
359 |
360 | #Output the result
361 | x = x.data
362 | x = predict_transform(x, inp_dim, anchors, num_classes, CUDA)
363 |
364 | if type(x) == int:
365 | continue
366 |
367 |
368 | if not write:
369 | detections = x
370 | write = 1
371 |
372 | else:
373 | detections = torch.cat((detections, x), 1)
374 |
375 | outputs[i] = outputs[i-1]
376 |
377 |
378 |
379 | try:
380 | return detections
381 | except:
382 | return 0
383 |
384 |
385 | def load_weights(self, weightfile):
386 |
387 | #Open the weights file
388 | fp = open(weightfile, "rb")
389 |
390 | #The first 4 values are header information
391 | # 1. Major version number
392 | # 2. Minor Version Number
393 | # 3. Subversion number
394 | # 4. IMages seen
395 | header = np.fromfile(fp, dtype = np.int32, count = 5)
396 | self.header = torch.from_numpy(header)
397 | self.seen = self.header[3]
398 |
399 | #The rest of the values are the weights
400 | # Let's load them up
401 | weights = np.fromfile(fp, dtype = np.float32)
402 |
403 | ptr = 0
404 | for i in range(len(self.module_list)):
405 | module_type = self.blocks[i + 1]["type"]
406 |
407 | if module_type == "convolutional":
408 | model = self.module_list[i]
409 | try:
410 | batch_normalize = int(self.blocks[i+1]["batch_normalize"])
411 | except:
412 | batch_normalize = 0
413 |
414 | conv = model[0]
415 |
416 | if (batch_normalize):
417 | bn = model[1]
418 |
419 | #Get the number of weights of Batch Norm Layer
420 | num_bn_biases = bn.bias.numel()
421 |
422 | #Load the weights
423 | bn_biases = torch.from_numpy(weights[ptr:ptr + num_bn_biases])
424 | ptr += num_bn_biases
425 |
426 | bn_weights = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
427 | ptr += num_bn_biases
428 |
429 | bn_running_mean = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
430 | ptr += num_bn_biases
431 |
432 | bn_running_var = torch.from_numpy(weights[ptr: ptr + num_bn_biases])
433 | ptr += num_bn_biases
434 |
435 | #Cast the loaded weights into dims of model weights.
436 | bn_biases = bn_biases.view_as(bn.bias.data)
437 | bn_weights = bn_weights.view_as(bn.weight.data)
438 | bn_running_mean = bn_running_mean.view_as(bn.running_mean)
439 | bn_running_var = bn_running_var.view_as(bn.running_var)
440 |
441 | #Copy the data to model
442 | bn.bias.data.copy_(bn_biases)
443 | bn.weight.data.copy_(bn_weights)
444 | bn.running_mean.copy_(bn_running_mean)
445 | bn.running_var.copy_(bn_running_var)
446 |
447 | else:
448 | #Number of biases
449 | num_biases = conv.bias.numel()
450 |
451 | #Load the weights
452 | conv_biases = torch.from_numpy(weights[ptr: ptr + num_biases])
453 | ptr = ptr + num_biases
454 |
455 | #reshape the loaded weights according to the dims of the model weights
456 | conv_biases = conv_biases.view_as(conv.bias.data)
457 |
458 | #Finally copy the data
459 | conv.bias.data.copy_(conv_biases)
460 |
461 |
462 | #Let us load the weights for the Convolutional layers
463 | num_weights = conv.weight.numel()
464 |
465 | #Do the same as above for weights
466 | conv_weights = torch.from_numpy(weights[ptr:ptr+num_weights])
467 | ptr = ptr + num_weights
468 |
469 | conv_weights = conv_weights.view_as(conv.weight.data)
470 | conv.weight.data.copy_(conv_weights)
471 |
472 | def save_weights(self, savedfile, cutoff = 0):
473 |
474 | if cutoff <= 0:
475 | cutoff = len(self.blocks) - 1
476 |
477 | fp = open(savedfile, 'wb')
478 |
479 | # Attach the header at the top of the file
480 | self.header[3] = self.seen
481 | header = self.header
482 |
483 | header = header.numpy()
484 | header.tofile(fp)
485 |
486 | # Now, let us save the weights
487 | for i in range(len(self.module_list)):
488 | module_type = self.blocks[i+1]["type"]
489 |
490 | if (module_type) == "convolutional":
491 | model = self.module_list[i]
492 | try:
493 | batch_normalize = int(self.blocks[i+1]["batch_normalize"])
494 | except:
495 | batch_normalize = 0
496 |
497 | conv = model[0]
498 |
499 | if (batch_normalize):
500 | bn = model[1]
501 |
502 | #If the parameters are on GPU, convert them back to CPU
503 | #We don't convert the parameter to GPU
504 | #Instead. we copy the parameter and then convert it to CPU
505 | #This is done as weight are need to be saved during training
506 | cpu(bn.bias.data).numpy().tofile(fp)
507 | cpu(bn.weight.data).numpy().tofile(fp)
508 | cpu(bn.running_mean).numpy().tofile(fp)
509 | cpu(bn.running_var).numpy().tofile(fp)
510 |
511 |
512 | else:
513 | cpu(conv.bias.data).numpy().tofile(fp)
514 |
515 |
516 | #Let us save the weights for the Convolutional layers
517 | cpu(conv.weight.data).numpy().tofile(fp)
518 |
519 |
520 |
521 |
522 |
523 | #
524 | #dn = Darknet('cfg/yolov3.cfg')
525 | #dn.load_weights("yolov3.weights")
526 | #inp = get_test_input()
527 | #a, interms = dn(inp)
528 | #dn.eval()
529 | #a_i, interms_i = dn(inp)
530 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/data/coco.names:
--------------------------------------------------------------------------------
1 | person
2 | bicycle
3 | car
4 | motorbike
5 | aeroplane
6 | bus
7 | train
8 | truck
9 | boat
10 | traffic light
11 | fire hydrant
12 | stop sign
13 | parking meter
14 | bench
15 | bird
16 | cat
17 | dog
18 | horse
19 | sheep
20 | cow
21 | elephant
22 | bear
23 | zebra
24 | giraffe
25 | backpack
26 | umbrella
27 | handbag
28 | tie
29 | suitcase
30 | frisbee
31 | skis
32 | snowboard
33 | sports ball
34 | kite
35 | baseball bat
36 | baseball glove
37 | skateboard
38 | surfboard
39 | tennis racket
40 | bottle
41 | wine glass
42 | cup
43 | fork
44 | knife
45 | spoon
46 | bowl
47 | banana
48 | apple
49 | sandwich
50 | orange
51 | broccoli
52 | carrot
53 | hot dog
54 | pizza
55 | donut
56 | cake
57 | chair
58 | sofa
59 | pottedplant
60 | bed
61 | diningtable
62 | toilet
63 | tvmonitor
64 | laptop
65 | mouse
66 | remote
67 | keyboard
68 | cell phone
69 | microwave
70 | oven
71 | toaster
72 | sink
73 | refrigerator
74 | book
75 | clock
76 | vase
77 | scissors
78 | teddy bear
79 | hair drier
80 | toothbrush
81 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/data/voc.names:
--------------------------------------------------------------------------------
1 | aeroplane
2 | bicycle
3 | bird
4 | boat
5 | bottle
6 | bus
7 | car
8 | cat
9 | chair
10 | cow
11 | diningtable
12 | dog
13 | horse
14 | motorbike
15 | person
16 | pottedplant
17 | sheep
18 | sofa
19 | train
20 | tvmonitor
21 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/detect.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 | import time
3 | import torch
4 | import torch.nn as nn
5 | from torch.autograd import Variable
6 | import numpy as np
7 | import cv2
8 | from util import *
9 | import argparse
10 | import os
11 | import os.path as osp
12 | from darknet import Darknet
13 | from preprocess import prep_image, inp_to_image
14 | import pandas as pd
15 | import random
16 | import pickle as pkl
17 | import itertools
18 |
19 | class test_net(nn.Module):
20 | def __init__(self, num_layers, input_size):
21 | super(test_net, self).__init__()
22 | self.num_layers= num_layers
23 | self.linear_1 = nn.Linear(input_size, 5)
24 | self.middle = nn.ModuleList([nn.Linear(5,5) for x in range(num_layers)])
25 | self.output = nn.Linear(5,2)
26 |
27 | def forward(self, x):
28 | x = x.view(-1)
29 | fwd = nn.Sequential(self.linear_1, *self.middle, self.output)
30 | return fwd(x)
31 |
32 | def get_test_input(input_dim, CUDA):
33 | img = cv2.imread("dog-cycle-car.png")
34 | img = cv2.resize(img, (input_dim, input_dim))
35 | img_ = img[:,:,::-1].transpose((2,0,1))
36 | img_ = img_[np.newaxis,:,:,:]/255.0
37 | img_ = torch.from_numpy(img_).float()
38 | img_ = Variable(img_)
39 |
40 | if CUDA:
41 | img_ = img_.cuda()
42 | num_classes
43 | return img_
44 |
45 |
46 |
47 | def arg_parse():
48 | """
49 | Parse arguements to the detect module
50 |
51 | """
52 |
53 |
54 | parser = argparse.ArgumentParser(description='YOLO v3 Detection Module')
55 |
56 | parser.add_argument("--images", dest = 'images', help =
57 | "Image / Directory containing images to perform detection upon",
58 | default = "imgs", type = str)
59 | parser.add_argument("--det", dest = 'det', help =
60 | "Image / Directory to store detections to",
61 | default = "det", type = str)
62 | parser.add_argument("--bs", dest = "bs", help = "Batch size", default = 1)
63 | parser.add_argument("--confidence", dest = "confidence", help = "Object Confidence to filter predictions", default = 0.5)
64 | parser.add_argument("--nms_thresh", dest = "nms_thresh", help = "NMS Threshhold", default = 0.4)
65 | parser.add_argument("--cfg", dest = 'cfgfile', help =
66 | "Config file",
67 | default = "cfg/yolov3.cfg", type = str)
68 | parser.add_argument("--weights", dest = 'weightsfile', help =
69 | "weightsfile",
70 | default = "yolov3.weights", type = str)
71 | parser.add_argument("--reso", dest = 'reso', help =
72 | "Input resolution of the network. Increase to increase accuracy. Decrease to increase speed",
73 | default = "416", type = str)
74 | parser.add_argument("--scales", dest = "scales", help = "Scales to use for detection",
75 | default = "1,2,3", type = str)
76 |
77 | return parser.parse_args()
78 |
79 | if __name__ == '__main__':
80 | args = arg_parse()
81 |
82 | scales = args.scales
83 |
84 |
85 | # scales = [int(x) for x in scales.split(',')]
86 | #
87 | #
88 | #
89 | # args.reso = int(args.reso)
90 | #
91 | # num_boxes = [args.reso//32, args.reso//16, args.reso//8]
92 | # scale_indices = [3*(x**2) for x in num_boxes]
93 | # scale_indices = list(itertools.accumulate(scale_indices, lambda x,y : x+y))
94 | #
95 | #
96 | # li = []
97 | # i = 0
98 | # for scale in scale_indices:
99 | # li.extend(list(range(i, scale)))
100 | # i = scale
101 | #
102 | # scale_indices = li
103 |
104 | images = args.images
105 | batch_size = int(args.bs)
106 | confidence = float(args.confidence)
107 | nms_thesh = float(args.nms_thresh)
108 | start = 0
109 |
110 | CUDA = torch.cuda.is_available()
111 |
112 | num_classes = 80
113 | classes = load_classes('data/coco.names')
114 |
115 | #Set up the neural network
116 | print("Loading network.....")
117 | model = Darknet(args.cfgfile)
118 | model.load_weights(args.weightsfile)
119 | print("Network successfully loaded")
120 |
121 | model.net_info["height"] = args.reso
122 | inp_dim = int(model.net_info["height"])
123 | assert inp_dim % 32 == 0
124 | assert inp_dim > 32
125 |
126 | #If there's a GPU availible, put the model on GPU
127 | if CUDA:
128 | model.cuda()
129 |
130 |
131 | #Set the model in evaluation mode
132 | model.eval()
133 |
134 | read_dir = time.time()
135 | #Detection phase
136 | try:
137 | imlist = [osp.join(osp.realpath('.'), images, img) for img in os.listdir(images) if os.path.splitext(img)[1] == '.png' or os.path.splitext(img)[1] =='.jpeg' or os.path.splitext(img)[1] =='.jpg']
138 | except NotADirectoryError:
139 | imlist = []
140 | imlist.append(osp.join(osp.realpath('.'), images))
141 | except FileNotFoundError:
142 | print ("No file or directory with the name {}".format(images))
143 | exit()
144 |
145 | if not os.path.exists(args.det):
146 | os.makedirs(args.det)
147 |
148 | load_batch = time.time()
149 |
150 | batches = list(map(prep_image, imlist, [inp_dim for x in range(len(imlist))]))
151 | im_batches = [x[0] for x in batches]
152 | orig_ims = [x[1] for x in batches]
153 | im_dim_list = [x[2] for x in batches]
154 | im_dim_list = torch.FloatTensor(im_dim_list).repeat(1,2)
155 |
156 |
157 |
158 | if CUDA:
159 | im_dim_list = im_dim_list.cuda()
160 |
161 | leftover = 0
162 |
163 | if (len(im_dim_list) % batch_size):
164 | leftover = 1
165 |
166 |
167 | if batch_size != 1:
168 | num_batches = len(imlist) // batch_size + leftover
169 | im_batches = [torch.cat((im_batches[i*batch_size : min((i + 1)*batch_size,
170 | len(im_batches))])) for i in range(num_batches)]
171 |
172 |
173 | i = 0
174 |
175 |
176 | write = False
177 | model(get_test_input(inp_dim, CUDA), CUDA)
178 |
179 | start_det_loop = time.time()
180 |
181 | objs = {}
182 |
183 |
184 |
185 | for batch in im_batches:
186 | #load the image
187 | start = time.time()
188 | if CUDA:
189 | batch = batch.cuda()
190 |
191 |
192 | #Apply offsets to the result predictions
193 | #Tranform the predictions as described in the YOLO paper
194 | #flatten the prediction vector
195 | # B x (bbox cord x no. of anchors) x grid_w x grid_h --> B x bbox x (all the boxes)
196 | # Put every proposed box as a row.
197 | with torch.no_grad():
198 | prediction = model(Variable(batch), CUDA)
199 |
200 | # prediction = prediction[:,scale_indices]
201 |
202 |
203 | #get the boxes with object confidence > threshold
204 | #Convert the cordinates to absolute coordinates
205 | #perform NMS on these boxes, and save the results
206 | #I could have done NMS and saving seperately to have a better abstraction
207 | #But both these operations require looping, hence
208 | #clubbing these ops in one loop instead of two.
209 | #loops are slower than vectorised operations.
210 |
211 | prediction = write_results(prediction, confidence, num_classes, nms = True, nms_conf = nms_thesh)
212 |
213 |
214 | if type(prediction) == int:
215 | i += 1
216 | continue
217 |
218 | end = time.time()
219 |
220 |
221 | # print(end - start)
222 |
223 |
224 |
225 | prediction[:,0] += i*batch_size
226 |
227 |
228 |
229 |
230 | if not write:
231 | output = prediction
232 | write = 1
233 | else:
234 | output = torch.cat((output,prediction))
235 |
236 |
237 |
238 |
239 | for im_num, image in enumerate(imlist[i*batch_size: min((i + 1)*batch_size, len(imlist))]):
240 | im_id = i*batch_size + im_num
241 | objs = [classes[int(x[-1])] for x in output if int(x[0]) == im_id]
242 | print("{0:20s} predicted in {1:6.3f} seconds".format(image.split("/")[-1], (end - start)/batch_size))
243 | print("{0:20s} {1:s}".format("Objects Detected:", " ".join(objs)))
244 | print("----------------------------------------------------------")
245 | i += 1
246 |
247 |
248 | if CUDA:
249 | torch.cuda.synchronize()
250 |
251 | try:
252 | output
253 | except NameError:
254 | print("No detections were made")
255 | exit()
256 |
257 | im_dim_list = torch.index_select(im_dim_list, 0, output[:,0].long())
258 |
259 | scaling_factor = torch.min(inp_dim/im_dim_list,1)[0].view(-1,1)
260 |
261 |
262 | output[:,[1,3]] -= (inp_dim - scaling_factor*im_dim_list[:,0].view(-1,1))/2
263 | output[:,[2,4]] -= (inp_dim - scaling_factor*im_dim_list[:,1].view(-1,1))/2
264 |
265 |
266 |
267 | output[:,1:5] /= scaling_factor
268 |
269 | for i in range(output.shape[0]):
270 | output[i, [1,3]] = torch.clamp(output[i, [1,3]], 0.0, im_dim_list[i,0])
271 | output[i, [2,4]] = torch.clamp(output[i, [2,4]], 0.0, im_dim_list[i,1])
272 |
273 |
274 | output_recast = time.time()
275 |
276 |
277 | class_load = time.time()
278 |
279 | colors = pkl.load(open("pallete", "rb"))
280 |
281 |
282 | draw = time.time()
283 |
284 |
285 | def write(x, batches, results):
286 | c1 = tuple(x[1:3].int())
287 | c2 = tuple(x[3:5].int())
288 | img = results[int(x[0])]
289 | cls = int(x[-1])
290 | label = "{0}".format(classes[cls])
291 | color = random.choice(colors)
292 | cv2.rectangle(img, c1, c2,color, 1)
293 | t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0]
294 | c2 = c1[0] + t_size[0] + 3, c1[1] + t_size[1] + 4
295 |
296 | cv2.rectangle(img, c1, c2,color, -1)
297 | cv2.putText(img, label, (c1[0], c1[1] + t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 1, [225,255,255], 1)
298 | cv2.imshow("res", img)
299 | cv2.waitKey(0)
300 | #cv2.imwrite("",cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
301 | return img
302 |
303 |
304 | list(map(lambda x: write(x, im_batches, orig_ims), output))
305 |
306 | det_names = pd.Series(imlist).apply(lambda x: "{}/det_{}".format(args.det,x.split("/")[-1]))
307 |
308 | list(map(cv2.imwrite, det_names, orig_ims))
309 |
310 | end = time.time()
311 |
312 | print()
313 | print("SUMMARY")
314 | print("----------------------------------------------------------")
315 | print("{:25s}: {}".format("Task", "Time Taken (in seconds)"))
316 | print()
317 | print("{:25s}: {:2.3f}".format("Reading addresses", load_batch - read_dir))
318 | print("{:25s}: {:2.3f}".format("Loading batch", start_det_loop - load_batch))
319 | print("{:25s}: {:2.3f}".format("Detection (" + str(len(imlist)) + " images)", output_recast - start_det_loop))
320 | print("{:25s}: {:2.3f}".format("Output Processing", class_load - output_recast))
321 | print("{:25s}: {:2.3f}".format("Drawing Boxes", end - draw))
322 | print("{:25s}: {:2.3f}".format("Average time_per_img", (end - load_batch)/len(imlist)))
323 | print("----------------------------------------------------------")
324 |
325 |
326 | torch.cuda.empty_cache()
327 |
328 |
329 |
330 |
331 |
332 |
333 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig1.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig10.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig10.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig11.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig11.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig12.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig12.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig13.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig13.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig14.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig14.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig2.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig3.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig4.png
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig5.png
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig6.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig7.png
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig8.png
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/images/fig9.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/images/fig9.jpg
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/pallete:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/avidLearnerInProgress/pyCAIR/22246864861709102813d6c6e85394d5d0bf8a31/pyCAIR/yoloV3/pallete
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/preprocess.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 |
3 | import torch
4 | import torch.nn as nn
5 | import torch.nn.functional as F
6 | from torch.autograd import Variable
7 | import numpy as np
8 | import cv2
9 | import matplotlib.pyplot as plt
10 | from util import count_parameters as count
11 | from util import convert2cpu as cpu
12 | from PIL import Image, ImageDraw
13 |
14 |
15 | def letterbox_image(img, inp_dim):
16 | '''resize image with unchanged aspect ratio using padding'''
17 | img_w, img_h = img.shape[1], img.shape[0]
18 | w, h = inp_dim
19 | new_w = int(img_w * min(w/img_w, h/img_h))
20 | new_h = int(img_h * min(w/img_w, h/img_h))
21 | resized_image = cv2.resize(img, (new_w,new_h), interpolation = cv2.INTER_CUBIC)
22 |
23 | canvas = np.full((inp_dim[1], inp_dim[0], 3), 128)
24 |
25 | canvas[(h-new_h)//2:(h-new_h)//2 + new_h,(w-new_w)//2:(w-new_w)//2 + new_w, :] = resized_image
26 |
27 | return canvas
28 |
29 |
30 |
31 | def prep_image(img, inp_dim):
32 | """
33 | Prepare image for inputting to the neural network.
34 |
35 | Returns a Variable
36 | """
37 |
38 | orig_im = cv2.imread(img)
39 | dim = orig_im.shape[1], orig_im.shape[0]
40 | img = (letterbox_image(orig_im, (inp_dim, inp_dim)))
41 | img_ = img[:,:,::-1].transpose((2,0,1)).copy()
42 | img_ = torch.from_numpy(img_).float().div(255.0).unsqueeze(0)
43 | return img_, orig_im, dim
44 |
45 | def prep_image_pil(img, network_dim):
46 | orig_im = Image.open(img)
47 | img = orig_im.convert('RGB')
48 | dim = img.size
49 | img = img.resize(network_dim)
50 | img = torch.ByteTensor(torch.ByteStorage.from_buffer(img.tobytes()))
51 | img = img.view(*network_dim, 3).transpose(0,1).transpose(0,2).contiguous()
52 | img = img.view(1, 3,*network_dim)
53 | img = img.float().div(255.0)
54 | return (img, orig_im, dim)
55 |
56 | def inp_to_image(inp):
57 | inp = inp.cpu().squeeze()
58 | inp = inp*255
59 | try:
60 | inp = inp.data.numpy()
61 | except RuntimeError:
62 | inp = inp.numpy()
63 | inp = inp.transpose(1,2,0)
64 |
65 | inp = inp[:,:,::-1]
66 | return inp
67 |
68 |
69 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/util.py:
--------------------------------------------------------------------------------
1 |
2 | from __future__ import division
3 |
4 | import torch
5 | import torch.nn as nn
6 | import torch.nn.functional as F
7 | from torch.autograd import Variable
8 | import numpy as np
9 | import cv2
10 | import matplotlib.pyplot as plt
11 | from bbox import bbox_iou
12 |
13 | def count_parameters(model):
14 | return sum(p.numel() for p in model.parameters())
15 |
16 | def count_learnable_parameters(model):
17 | return sum(p.numel() for p in model.parameters() if p.requires_grad)
18 |
19 | def convert2cpu(matrix):
20 | if matrix.is_cuda:
21 | return torch.FloatTensor(matrix.size()).copy_(matrix)
22 | else:
23 | return matrix
24 |
25 | def predict_transform(prediction, inp_dim, anchors, num_classes, CUDA = True):
26 | batch_size = prediction.size(0)
27 | stride = inp_dim // prediction.size(2)
28 | grid_size = inp_dim // stride
29 | bbox_attrs = 5 + num_classes
30 | num_anchors = len(anchors)
31 |
32 | anchors = [(a[0]/stride, a[1]/stride) for a in anchors]
33 |
34 |
35 |
36 | prediction = prediction.view(batch_size, bbox_attrs*num_anchors, grid_size*grid_size)
37 | prediction = prediction.transpose(1,2).contiguous()
38 | prediction = prediction.view(batch_size, grid_size*grid_size*num_anchors, bbox_attrs)
39 |
40 |
41 | #Sigmoid the centre_X, centre_Y. and object confidencce
42 | prediction[:,:,0] = torch.sigmoid(prediction[:,:,0])
43 | prediction[:,:,1] = torch.sigmoid(prediction[:,:,1])
44 | prediction[:,:,4] = torch.sigmoid(prediction[:,:,4])
45 |
46 |
47 |
48 | #Add the center offsets
49 | grid_len = np.arange(grid_size)
50 | a,b = np.meshgrid(grid_len, grid_len)
51 |
52 | x_offset = torch.FloatTensor(a).view(-1,1)
53 | y_offset = torch.FloatTensor(b).view(-1,1)
54 |
55 | if CUDA:
56 | x_offset = x_offset.cuda()
57 | y_offset = y_offset.cuda()
58 |
59 | x_y_offset = torch.cat((x_offset, y_offset), 1).repeat(1,num_anchors).view(-1,2).unsqueeze(0)
60 |
61 | prediction[:,:,:2] += x_y_offset
62 |
63 | #log space transform height and the width
64 | anchors = torch.FloatTensor(anchors)
65 |
66 | if CUDA:
67 | anchors = anchors.cuda()
68 |
69 | anchors = anchors.repeat(grid_size*grid_size, 1).unsqueeze(0)
70 | prediction[:,:,2:4] = torch.exp(prediction[:,:,2:4])*anchors
71 |
72 | #Softmax the class scores
73 | prediction[:,:,5: 5 + num_classes] = torch.sigmoid((prediction[:,:, 5 : 5 + num_classes]))
74 |
75 | prediction[:,:,:4] *= stride
76 |
77 |
78 | return prediction
79 |
80 | def load_classes(namesfile):
81 | fp = open(namesfile, "r")
82 | names = fp.read().split("\n")[:-1]
83 | return names
84 |
85 | def get_im_dim(im):
86 | im = cv2.imread(im)
87 | w,h = im.shape[1], im.shape[0]
88 | return w,h
89 |
90 | def unique(tensor):
91 | tensor_np = tensor.cpu().numpy()
92 | unique_np = np.unique(tensor_np)
93 | unique_tensor = torch.from_numpy(unique_np)
94 |
95 | tensor_res = tensor.new(unique_tensor.shape)
96 | tensor_res.copy_(unique_tensor)
97 | return tensor_res
98 |
99 | def write_results(prediction, confidence, num_classes, nms = True, nms_conf = 0.4):
100 | conf_mask = (prediction[:,:,4] > confidence).float().unsqueeze(2)
101 | prediction = prediction*conf_mask
102 |
103 |
104 | try:
105 | ind_nz = torch.nonzero(prediction[:,:,4]).transpose(0,1).contiguous()
106 | except:
107 | return 0
108 |
109 |
110 | box_a = prediction.new(prediction.shape)
111 | box_a[:,:,0] = (prediction[:,:,0] - prediction[:,:,2]/2)
112 | box_a[:,:,1] = (prediction[:,:,1] - prediction[:,:,3]/2)
113 | box_a[:,:,2] = (prediction[:,:,0] + prediction[:,:,2]/2)
114 | box_a[:,:,3] = (prediction[:,:,1] + prediction[:,:,3]/2)
115 | prediction[:,:,:4] = box_a[:,:,:4]
116 |
117 |
118 |
119 | batch_size = prediction.size(0)
120 |
121 | output = prediction.new(1, prediction.size(2) + 1)
122 | write = False
123 |
124 |
125 | for ind in range(batch_size):
126 | #select the image from the batch
127 | image_pred = prediction[ind]
128 |
129 |
130 |
131 | #Get the class having maximum score, and the index of that class
132 | #Get rid of num_classes softmax scores
133 | #Add the class index and the class score of class having maximum score
134 | max_conf, max_conf_score = torch.max(image_pred[:,5:5+ num_classes], 1)
135 | max_conf = max_conf.float().unsqueeze(1)
136 | max_conf_score = max_conf_score.float().unsqueeze(1)
137 | seq = (image_pred[:,:5], max_conf, max_conf_score)
138 | image_pred = torch.cat(seq, 1)
139 |
140 |
141 |
142 | #Get rid of the zero entries
143 | non_zero_ind = (torch.nonzero(image_pred[:,4]))
144 |
145 |
146 | image_pred_ = image_pred[non_zero_ind.squeeze(),:].view(-1,7)
147 |
148 | #Get the various classes detected in the image
149 | try:
150 | img_classes = unique(image_pred_[:,-1])
151 | except:
152 | continue
153 | #WE will do NMS classwise
154 | for cls in img_classes:
155 | #get the detections with one particular class
156 | cls_mask = image_pred_*(image_pred_[:,-1] == cls).float().unsqueeze(1)
157 | class_mask_ind = torch.nonzero(cls_mask[:,-2]).squeeze()
158 |
159 |
160 | image_pred_class = image_pred_[class_mask_ind].view(-1,7)
161 |
162 |
163 |
164 | #sort the detections such that the entry with the maximum objectness
165 | #confidence is at the top
166 | conf_sort_index = torch.sort(image_pred_class[:,4], descending = True )[1]
167 | image_pred_class = image_pred_class[conf_sort_index]
168 | idx = image_pred_class.size(0)
169 |
170 | #if nms has to be done
171 | if nms:
172 | #For each detection
173 | for i in range(idx):
174 | #Get the IOUs of all boxes that come after the one we are looking at
175 | #in the loop
176 | try:
177 | ious = bbox_iou(image_pred_class[i].unsqueeze(0), image_pred_class[i+1:])
178 | except ValueError:
179 | break
180 |
181 | except IndexError:
182 | break
183 |
184 | #Zero out all the detections that have IoU > treshhold
185 | iou_mask = (ious < nms_conf).float().unsqueeze(1)
186 | image_pred_class[i+1:] *= iou_mask
187 |
188 | #Remove the non-zero entries
189 | non_zero_ind = torch.nonzero(image_pred_class[:,4]).squeeze()
190 | image_pred_class = image_pred_class[non_zero_ind].view(-1,7)
191 |
192 |
193 |
194 | #Concatenate the batch_id of the image to the detection
195 | #this helps us identify which image does the detection correspond to
196 | #We use a linear straucture to hold ALL the detections from the batch
197 | #the batch_dim is flattened
198 | #batch is identified by extra batch column
199 |
200 |
201 | batch_ind = image_pred_class.new(image_pred_class.size(0), 1).fill_(ind)
202 | seq = batch_ind, image_pred_class
203 | if not write:
204 | output = torch.cat(seq,1)
205 | write = True
206 | else:
207 | out = torch.cat(seq,1)
208 | output = torch.cat((output,out))
209 |
210 | return output
211 |
212 | #!/usr/bin/env python3
213 | # -*- coding: utf-8 -*-
214 | """
215 | Created on Sat Mar 24 00:12:16 2018
216 |
217 | @author: ayooshmac
218 | """
219 |
220 | def predict_transform_half(prediction, inp_dim, anchors, num_classes, CUDA = True):
221 | batch_size = prediction.size(0)
222 | stride = inp_dim // prediction.size(2)
223 |
224 | bbox_attrs = 5 + num_classes
225 | num_anchors = len(anchors)
226 | grid_size = inp_dim // stride
227 |
228 |
229 | prediction = prediction.view(batch_size, bbox_attrs*num_anchors, grid_size*grid_size)
230 | prediction = prediction.transpose(1,2).contiguous()
231 | prediction = prediction.view(batch_size, grid_size*grid_size*num_anchors, bbox_attrs)
232 |
233 |
234 | #Sigmoid the centre_X, centre_Y. and object confidencce
235 | prediction[:,:,0] = torch.sigmoid(prediction[:,:,0])
236 | prediction[:,:,1] = torch.sigmoid(prediction[:,:,1])
237 | prediction[:,:,4] = torch.sigmoid(prediction[:,:,4])
238 |
239 |
240 | #Add the center offsets
241 | grid_len = np.arange(grid_size)
242 | a,b = np.meshgrid(grid_len, grid_len)
243 |
244 | x_offset = torch.FloatTensor(a).view(-1,1)
245 | y_offset = torch.FloatTensor(b).view(-1,1)
246 |
247 | if CUDA:
248 | x_offset = x_offset.cuda().half()
249 | y_offset = y_offset.cuda().half()
250 |
251 | x_y_offset = torch.cat((x_offset, y_offset), 1).repeat(1,num_anchors).view(-1,2).unsqueeze(0)
252 |
253 | prediction[:,:,:2] += x_y_offset
254 |
255 | #log space transform height and the width
256 | anchors = torch.HalfTensor(anchors)
257 |
258 | if CUDA:
259 | anchors = anchors.cuda()
260 |
261 | anchors = anchors.repeat(grid_size*grid_size, 1).unsqueeze(0)
262 | prediction[:,:,2:4] = torch.exp(prediction[:,:,2:4])*anchors
263 |
264 | #Softmax the class scores
265 | prediction[:,:,5: 5 + num_classes] = nn.Softmax(-1)(Variable(prediction[:,:, 5 : 5 + num_classes])).data
266 |
267 | prediction[:,:,:4] *= stride
268 |
269 |
270 | return prediction
271 |
272 |
273 | def write_results_half(prediction, confidence, num_classes, nms = True, nms_conf = 0.4):
274 | conf_mask = (prediction[:,:,4] > confidence).half().unsqueeze(2)
275 | prediction = prediction*conf_mask
276 |
277 | try:
278 | ind_nz = torch.nonzero(prediction[:,:,4]).transpose(0,1).contiguous()
279 | except:
280 | return 0
281 |
282 |
283 |
284 | box_a = prediction.new(prediction.shape)
285 | box_a[:,:,0] = (prediction[:,:,0] - prediction[:,:,2]/2)
286 | box_a[:,:,1] = (prediction[:,:,1] - prediction[:,:,3]/2)
287 | box_a[:,:,2] = (prediction[:,:,0] + prediction[:,:,2]/2)
288 | box_a[:,:,3] = (prediction[:,:,1] + prediction[:,:,3]/2)
289 | prediction[:,:,:4] = box_a[:,:,:4]
290 |
291 |
292 |
293 | batch_size = prediction.size(0)
294 |
295 | output = prediction.new(1, prediction.size(2) + 1)
296 | write = False
297 |
298 | for ind in range(batch_size):
299 | #select the image from the batch
300 | image_pred = prediction[ind]
301 |
302 |
303 | #Get the class having maximum score, and the index of that class
304 | #Get rid of num_classes softmax scores
305 | #Add the class index and the class score of class having maximum score
306 | max_conf, max_conf_score = torch.max(image_pred[:,5:5+ num_classes], 1)
307 | max_conf = max_conf.half().unsqueeze(1)
308 | max_conf_score = max_conf_score.half().unsqueeze(1)
309 | seq = (image_pred[:,:5], max_conf, max_conf_score)
310 | image_pred = torch.cat(seq, 1)
311 |
312 |
313 | #Get rid of the zero entries
314 | non_zero_ind = (torch.nonzero(image_pred[:,4]))
315 | try:
316 | image_pred_ = image_pred[non_zero_ind.squeeze(),:]
317 | except:
318 | continue
319 |
320 | #Get the various classes detected in the image
321 | img_classes = unique(image_pred_[:,-1].long()).half()
322 |
323 |
324 |
325 |
326 | #WE will do NMS classwise
327 | for cls in img_classes:
328 | #get the detections with one particular class
329 | cls_mask = image_pred_*(image_pred_[:,-1] == cls).half().unsqueeze(1)
330 | class_mask_ind = torch.nonzero(cls_mask[:,-2]).squeeze()
331 |
332 |
333 | image_pred_class = image_pred_[class_mask_ind]
334 |
335 |
336 | #sort the detections such that the entry with the maximum objectness
337 | #confidence is at the top
338 | conf_sort_index = torch.sort(image_pred_class[:,4], descending = True )[1]
339 | image_pred_class = image_pred_class[conf_sort_index]
340 | idx = image_pred_class.size(0)
341 |
342 | #if nms has to be done
343 | if nms:
344 | #For each detection
345 | for i in range(idx):
346 | #Get the IOUs of all boxes that come after the one we are looking at
347 | #in the loop
348 | try:
349 | ious = bbox_iou(image_pred_class[i].unsqueeze(0), image_pred_class[i+1:])
350 | except ValueError:
351 | break
352 |
353 | except IndexError:
354 | break
355 |
356 | #Zero out all the detections that have IoU > treshhold
357 | iou_mask = (ious < nms_conf).half().unsqueeze(1)
358 | image_pred_class[i+1:] *= iou_mask
359 |
360 | #Remove the non-zero entries
361 | non_zero_ind = torch.nonzero(image_pred_class[:,4]).squeeze()
362 | image_pred_class = image_pred_class[non_zero_ind]
363 |
364 |
365 |
366 | #Concatenate the batch_id of the image to the detection
367 | #this helps us identify which image does the detection correspond to
368 | #We use a linear straucture to hold ALL the detections from the batch
369 | #the batch_dim is flattened
370 | #batch is identified by extra batch column
371 | batch_ind = image_pred_class.new(image_pred_class.size(0), 1).fill_(ind)
372 | seq = batch_ind, image_pred_class
373 |
374 | if not write:
375 | output = torch.cat(seq,1)
376 | write = True
377 | else:
378 | out = torch.cat(seq,1)
379 | output = torch.cat((output,out))
380 |
381 | return output
382 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/video_demo.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 | import time
3 | import torch
4 | import torch.nn as nn
5 | from torch.autograd import Variable
6 | import numpy as np
7 | import cv2
8 | from util import *
9 | from darknet import Darknet
10 | from preprocess import prep_image, inp_to_image, letterbox_image
11 | import pandas as pd
12 | import random
13 | import pickle as pkl
14 | import argparse
15 |
16 |
17 | def get_test_input(input_dim, CUDA):
18 | img = cv2.imread("dog-cycle-car.png")
19 | img = cv2.resize(img, (input_dim, input_dim))
20 | img_ = img[:,:,::-1].transpose((2,0,1))
21 | img_ = img_[np.newaxis,:,:,:]/255.0
22 | img_ = torch.from_numpy(img_).float()
23 | img_ = Variable(img_)
24 |
25 | if CUDA:
26 | img_ = img_.cuda()
27 |
28 | return img_
29 |
30 | def prep_image(img, inp_dim):
31 | """
32 | Prepare image for inputting to the neural network.
33 |
34 | Returns a Variable
35 | """
36 |
37 | orig_im = img
38 | dim = orig_im.shape[1], orig_im.shape[0]
39 | img = (letterbox_image(orig_im, (inp_dim, inp_dim)))
40 | img_ = img[:,:,::-1].transpose((2,0,1)).copy()
41 | img_ = torch.from_numpy(img_).float().div(255.0).unsqueeze(0)
42 | return img_, orig_im, dim
43 |
44 | def write(x, img):
45 | c1 = tuple(x[1:3].int())
46 | c2 = tuple(x[3:5].int())
47 | cls = int(x[-1])
48 | label = "{0}".format(classes[cls])
49 | color = random.choice(colors)
50 | cv2.rectangle(img, c1, c2,color, 1)
51 | t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0]
52 | c2 = c1[0] + t_size[0] + 3, c1[1] + t_size[1] + 4
53 | cv2.rectangle(img, c1, c2,color, -1)
54 | cv2.putText(img, label, (c1[0], c1[1] + t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 1, [225,255,255], 1);
55 | return img
56 |
57 | def arg_parse():
58 | """
59 | Parse arguements to the detect module
60 |
61 | """
62 |
63 |
64 | parser = argparse.ArgumentParser(description='YOLO v3 Video Detection Module')
65 |
66 | parser.add_argument("--video", dest = 'video', help =
67 | "Video to run detection upon",
68 | default = "video.avi", type = str)
69 | parser.add_argument("--dataset", dest = "dataset", help = "Dataset on which the network has been trained", default = "pascal")
70 | parser.add_argument("--confidence", dest = "confidence", help = "Object Confidence to filter predictions", default = 0.5)
71 | parser.add_argument("--nms_thresh", dest = "nms_thresh", help = "NMS Threshhold", default = 0.4)
72 | parser.add_argument("--cfg", dest = 'cfgfile', help =
73 | "Config file",
74 | default = "cfg/yolov3.cfg", type = str)
75 | parser.add_argument("--weights", dest = 'weightsfile', help =
76 | "weightsfile",
77 | default = "yolov3.weights", type = str)
78 | parser.add_argument("--reso", dest = 'reso', help =
79 | "Input resolution of the network. Increase to increase accuracy. Decrease to increase speed",
80 | default = "416", type = str)
81 | return parser.parse_args()
82 |
83 |
84 | if __name__ == '__main__':
85 | args = arg_parse()
86 | confidence = float(args.confidence)
87 | nms_thesh = float(args.nms_thresh)
88 | start = 0
89 |
90 | CUDA = torch.cuda.is_available()
91 |
92 | num_classes = 80
93 |
94 | CUDA = torch.cuda.is_available()
95 |
96 | bbox_attrs = 5 + num_classes
97 |
98 | print("Loading network.....")
99 | model = Darknet(args.cfgfile)
100 | model.load_weights(args.weightsfile)
101 | print("Network successfully loaded")
102 |
103 | model.net_info["height"] = args.reso
104 | inp_dim = int(model.net_info["height"])
105 | assert inp_dim % 32 == 0
106 | assert inp_dim > 32
107 |
108 | if CUDA:
109 | model.cuda()
110 |
111 | model(get_test_input(inp_dim, CUDA), CUDA)
112 |
113 | model.eval()
114 |
115 | videofile = args.video
116 |
117 | cap = cv2.VideoCapture(videofile)
118 |
119 | assert cap.isOpened(), 'Cannot capture source'
120 |
121 | frames = 0
122 | start = time.time()
123 | while cap.isOpened():
124 |
125 | ret, frame = cap.read()
126 | if ret:
127 |
128 |
129 | img, orig_im, dim = prep_image(frame, inp_dim)
130 |
131 | im_dim = torch.FloatTensor(dim).repeat(1,2)
132 |
133 |
134 | if CUDA:
135 | im_dim = im_dim.cuda()
136 | img = img.cuda()
137 |
138 | with torch.no_grad():
139 | output = model(Variable(img), CUDA)
140 | output = write_results(output, confidence, num_classes, nms = True, nms_conf = nms_thesh)
141 |
142 | if type(output) == int:
143 | frames += 1
144 | print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
145 | cv2.imshow("frame", orig_im)
146 | key = cv2.waitKey(1)
147 | if key & 0xFF == ord('q'):
148 | break
149 | continue
150 |
151 |
152 |
153 |
154 | im_dim = im_dim.repeat(output.size(0), 1)
155 | scaling_factor = torch.min(inp_dim/im_dim,1)[0].view(-1,1)
156 |
157 | output[:,[1,3]] -= (inp_dim - scaling_factor*im_dim[:,0].view(-1,1))/2
158 | output[:,[2,4]] -= (inp_dim - scaling_factor*im_dim[:,1].view(-1,1))/2
159 |
160 | output[:,1:5] /= scaling_factor
161 |
162 | for i in range(output.shape[0]):
163 | output[i, [1,3]] = torch.clamp(output[i, [1,3]], 0.0, im_dim[i,0])
164 | output[i, [2,4]] = torch.clamp(output[i, [2,4]], 0.0, im_dim[i,1])
165 |
166 | classes = load_classes('data/coco.names')
167 | colors = pkl.load(open("pallete", "rb"))
168 |
169 | list(map(lambda x: write(x, orig_im), output))
170 |
171 |
172 | cv2.imshow("frame", orig_im)
173 | key = cv2.waitKey(1)
174 | if key & 0xFF == ord('q'):
175 | break
176 | frames += 1
177 | print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
178 |
179 |
180 | else:
181 | break
182 |
183 |
184 |
185 |
186 |
187 |
--------------------------------------------------------------------------------
/pyCAIR/yoloV3/video_demo_half.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 | import time
3 | import torch
4 | import torch.nn as nn
5 | from torch.autograd import Variable
6 | import numpy as np
7 | import cv2
8 | from util import *
9 | from darknet import Darknet
10 | from preprocess import prep_image, inp_to_image, letterbox_image
11 | import pandas as pd
12 | import random
13 | import pickle as pkl
14 | import argparse
15 |
16 |
17 | def get_test_input(input_dim, CUDA):
18 | img = cv2.imread("dog-cycle-car.png")
19 | img = cv2.resize(img, (input_dim, input_dim))
20 | img_ = img[:,:,::-1].transpose((2,0,1))
21 | img_ = img_[np.newaxis,:,:,:]/255.0
22 | img_ = torch.from_numpy(img_).float()
23 | img_ = Variable(img_)
24 |
25 | if CUDA:
26 | img_ = img_.cuda()
27 |
28 | return img_
29 |
30 | def prep_image(img, inp_dim):
31 | """
32 | Prepare image for inputting to the neural network.
33 |
34 | Returns a Variable
35 | """
36 |
37 | orig_im = img
38 | dim = orig_im.shape[1], orig_im.shape[0]
39 | img = (letterbox_image(orig_im, (inp_dim, inp_dim)))
40 | img_ = img[:,:,::-1].transpose((2,0,1)).copy()
41 | img_ = torch.from_numpy(img_).float().div(255.0).unsqueeze(0)
42 | return img_, orig_im, dim
43 |
44 | def write(x, img):
45 | c1 = tuple(x[1:3].int())
46 | c2 = tuple(x[3:5].int())
47 | cls = int(x[-1])
48 | label = "{0}".format(classes[cls])
49 | color = random.choice(colors)
50 | cv2.rectangle(img, c1, c2,color, 1)
51 | t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0]
52 | c2 = c1[0] + t_size[0] + 3, c1[1] + t_size[1] + 4
53 | cv2.rectangle(img, c1, c2,color, -1)
54 | cv2.putText(img, label, (c1[0], c1[1] + t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 1, [225,255,255], 1);
55 | return img
56 |
57 | def arg_parse():
58 | """
59 | Parse arguements to the detect module
60 |
61 | """
62 |
63 |
64 | parser = argparse.ArgumentParser(description='YOLO v2 Video Detection Module')
65 |
66 | parser.add_argument("--video", dest = 'video', help =
67 | "Video to run detection upon",
68 | default = "video.avi", type = str)
69 | parser.add_argument("--dataset", dest = "dataset", help = "Dataset on which the network has been trained", default = "pascal")
70 | parser.add_argument("--confidence", dest = "confidence", help = "Object Confidence to filter predictions", default = 0.5)
71 | parser.add_argument("--nms_thresh", dest = "nms_thresh", help = "NMS Threshhold", default = 0.4)
72 | parser.add_argument("--cfg", dest = 'cfgfile', help =
73 | "Config file",
74 | default = "cfg/yolov3.cfg", type = str)
75 | parser.add_argument("--weights", dest = 'weightsfile', help =
76 | "weightsfile",
77 | default = "yolov3.weights", type = str)
78 | parser.add_argument("--reso", dest = 'reso', help =
79 | "Input resolution of the network. Increase to increase accuracy. Decrease to increase speed",
80 | default = "416", type = str)
81 | return parser.parse_args()
82 |
83 |
84 | if __name__ == '__main__':
85 | args = arg_parse()
86 | confidence = float(args.confidence)
87 | nms_thesh = float(args.nms_thresh)
88 | start = 0
89 |
90 | CUDA = torch.cuda.is_available()
91 |
92 |
93 |
94 | CUDA = torch.cuda.is_available()
95 | num_classes = 80
96 | bbox_attrs = 5 + num_classes
97 |
98 | print("Loading network.....")
99 | model = Darknet(args.cfgfile)
100 | model.load_weights(args.weightsfile)
101 | print("Network successfully loaded")
102 |
103 | model.net_info["height"] = args.reso
104 | inp_dim = int(model.net_info["height"])
105 | assert inp_dim % 32 == 0
106 | assert inp_dim > 32
107 |
108 |
109 | if CUDA:
110 | model.cuda().half()
111 |
112 | model(get_test_input(inp_dim, CUDA), CUDA)
113 |
114 | model.eval()
115 |
116 | videofile = 'video.avi'
117 |
118 | cap = cv2.VideoCapture(videofile)
119 |
120 | assert cap.isOpened(), 'Cannot capture source'
121 |
122 | frames = 0
123 | start = time.time()
124 | while cap.isOpened():
125 |
126 | ret, frame = cap.read()
127 | if ret:
128 |
129 |
130 | img, orig_im, dim = prep_image(frame, inp_dim)
131 |
132 | im_dim = torch.FloatTensor(dim).repeat(1,2)
133 |
134 |
135 | if CUDA:
136 | img = img.cuda().half()
137 | im_dim = im_dim.half().cuda()
138 | write_results = write_results_half
139 | predict_transform = predict_transform_half
140 |
141 |
142 | output = model(Variable(img, volatile = True), CUDA)
143 | output = write_results(output, confidence, num_classes, nms = True, nms_conf = nms_thesh)
144 |
145 |
146 | if type(output) == int:
147 | frames += 1
148 | print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
149 | cv2.imshow("frame", orig_im)
150 | key = cv2.waitKey(1)
151 | if key & 0xFF == ord('q'):
152 | break
153 | continue
154 |
155 |
156 | im_dim = im_dim.repeat(output.size(0), 1)
157 | scaling_factor = torch.min(inp_dim/im_dim,1)[0].view(-1,1)
158 |
159 | output[:,[1,3]] -= (inp_dim - scaling_factor*im_dim[:,0].view(-1,1))/2
160 | output[:,[2,4]] -= (inp_dim - scaling_factor*im_dim[:,1].view(-1,1))/2
161 |
162 | output[:,1:5] /= scaling_factor
163 |
164 | for i in range(output.shape[0]):
165 | output[i, [1,3]] = torch.clamp(output[i, [1,3]], 0.0, im_dim[i,0])
166 | output[i, [2,4]] = torch.clamp(output[i, [2,4]], 0.0, im_dim[i,1])
167 |
168 |
169 | classes = load_classes('data/coco.names')
170 | colors = pkl.load(open("pallete", "rb"))
171 |
172 | list(map(lambda x: write(x, orig_im), output))
173 |
174 |
175 | cv2.imshow("frame", orig_im)
176 | key = cv2.waitKey(1)
177 | if key & 0xFF == ord('q'):
178 | break
179 | frames += 1
180 | print("FPS of the video is {:5.2f}".format( frames / (time.time() - start)))
181 |
182 |
183 | else:
184 | break
185 |
186 |
187 |
188 |
189 |
190 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | natsort==8.4.0
2 | numpy==1.24.4
3 | opencv-python==4.8.1.78
4 | Pillow==10.1.0
5 | pyCAIR==0.1.13
6 | scipy==1.10.1
7 | tqdm==4.66.1
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | description-file = README.md
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup
2 | from os import path
3 |
4 | this_directory = path.abspath(path.dirname(__file__))
5 | with open(path.join(this_directory, 'README.md'), encoding='utf-8') as f:
6 | long_description = f.read()
7 |
8 | with open(path.join(this_directory, 'requirements.txt'), encoding='utf-8') as f:
9 | requirements = f.read().splitlines()
10 |
11 | python_requires = '>3.4'
12 |
13 | setup(
14 | name='pyCAIR',
15 | packages=['pyCAIR'],
16 | version='0.1.13',
17 | description='This module provides a simple yet powerful mechanism to resize images using Seam Carving Algorithm.',
18 | long_description=long_description,
19 | long_description_content_type='text/markdown',
20 | author='Chirag Shah',
21 | author_email='chiragshah9696@gmail.com',
22 | url='https://github.com/avidLearnerInProgress/pyCAIR',
23 | download_url='https://github.com/avidLearnerInProgress/pyCAIR/archive/0.1.tar.gz',
24 | license='GPL-3.0',
25 | keywords=['python', 'openCV', 'image-processing', 'dynamic-programming', 'seam-carving'],
26 | classifiers=[],
27 | install_requires=requirements,
28 | python_requires=python_requires
29 | )
--------------------------------------------------------------------------------