├── .gitignore
├── 01-fine-tune-sam-geospatial.ipynb
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── assets
├── .$SAM-finetuning-architecture.drawio.bkp
├── SAM-finetuning-architecture.png
├── prediction_results.png
└── raw_data.png
└── src
├── requirements.txt
└── train_distributed.py
/.gitignore:
--------------------------------------------------------------------------------
1 | .DS_Store
2 |
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | ## Code of Conduct
2 | This project has adopted the [Amazon Open Source Code of Conduct](https://aws.github.io/code-of-conduct).
3 | For more information see the [Code of Conduct FAQ](https://aws.github.io/code-of-conduct-faq) or contact
4 | opensource-codeofconduct@amazon.com with any additional questions or comments.
5 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing Guidelines
2 |
3 | Thank you for your interest in contributing to our project. Whether it's a bug report, new feature, correction, or additional
4 | documentation, we greatly value feedback and contributions from our community.
5 |
6 | Please read through this document before submitting any issues or pull requests to ensure we have all the necessary
7 | information to effectively respond to your bug report or contribution.
8 |
9 |
10 | ## Reporting Bugs/Feature Requests
11 |
12 | We welcome you to use the GitHub issue tracker to report bugs or suggest features.
13 |
14 | When filing an issue, please check existing open, or recently closed, issues to make sure somebody else hasn't already
15 | reported the issue. Please try to include as much information as you can. Details like these are incredibly useful:
16 |
17 | * A reproducible test case or series of steps
18 | * The version of our code being used
19 | * Any modifications you've made relevant to the bug
20 | * Anything unusual about your environment or deployment
21 |
22 |
23 | ## Contributing via Pull Requests
24 | Contributions via pull requests are much appreciated. Before sending us a pull request, please ensure that:
25 |
26 | 1. You are working against the latest source on the *main* branch.
27 | 2. You check existing open, and recently merged, pull requests to make sure someone else hasn't addressed the problem already.
28 | 3. You open an issue to discuss any significant work - we would hate for your time to be wasted.
29 |
30 | To send us a pull request, please:
31 |
32 | 1. Fork the repository.
33 | 2. Modify the source; please focus on the specific change you are contributing. If you also reformat all the code, it will be hard for us to focus on your change.
34 | 3. Ensure local tests pass.
35 | 4. Commit to your fork using clear commit messages.
36 | 5. Send us a pull request, answering any default questions in the pull request interface.
37 | 6. Pay attention to any automated CI failures reported in the pull request, and stay involved in the conversation.
38 |
39 | GitHub provides additional document on [forking a repository](https://help.github.com/articles/fork-a-repo/) and
40 | [creating a pull request](https://help.github.com/articles/creating-a-pull-request/).
41 |
42 |
43 | ## Finding contributions to work on
44 | Looking at the existing issues is a great way to find something to contribute on. As our projects, by default, use the default GitHub issue labels (enhancement/bug/duplicate/help wanted/invalid/question/wontfix), looking at any 'help wanted' issues is a great place to start.
45 |
46 |
47 | ## Code of Conduct
48 | This project has adopted the [Amazon Open Source Code of Conduct](https://aws.github.io/code-of-conduct).
49 | For more information see the [Code of Conduct FAQ](https://aws.github.io/code-of-conduct-faq) or contact
50 | opensource-codeofconduct@amazon.com with any additional questions or comments.
51 |
52 |
53 | ## Security issue notifications
54 | If you discover a potential security issue in this project we ask that you notify AWS/Amazon Security via our [vulnerability reporting page](http://aws.amazon.com/security/vulnerability-reporting/). Please do **not** create a public github issue.
55 |
56 |
57 | ## Licensing
58 |
59 | See the [LICENSE](LICENSE) file for our project's licensing. We will ask you to confirm the licensing of your contribution.
60 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT No Attribution
2 |
3 | Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy of
6 | this software and associated documentation files (the "Software"), to deal in
7 | the Software without restriction, including without limitation the rights to
8 | use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
9 | the Software, and to permit persons to whom the Software is furnished to do so.
10 |
11 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
12 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
13 | FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
14 | COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
15 | IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
16 | CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
17 |
18 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Fine-tune SAM (Segment Anything Model) using Distributed Training on Amazon SageMaker
2 |
3 | This code sampes explores how to fine-tune [Segment Anything Model (SAM)](https://segment-anything.com/), a state-of-the-art promptable vision model for your specialized image segmemtation use case. SAM is an open-source transformer-based vision model which excells in zero-shot object segmentation from images. It is available in three different sizes (base, large, huge) on the HuggingFace Hub. We demonstrate how you can leverage SAM's general notion of what objects are in an image for your own specialized object segmentation use cases. Specifically, this tutorial guides you through the process of fine-tuning the SAM base architecture on labeled satellite imagery to segment building footprints. Scripts have been optimized for distributed training using Amazon SageMaker Training Jobs (using the `PyTorch()` estimator class) and the PyTorch distributed data parallel (DDP) wrapper.
4 |
5 | ## Background
6 |
7 | ### Why fine-tune a pre-trained vision foundation model?
8 |
9 | Vision Transformer (ViT)-based foundation models (FMs) are large, general-purpose computer vision models that have been pre-trained on vast amounts of image data in a porcess called [self-supervised learning](https://en.wikipedia.org/wiki/Self-supervised_learning). During the training process, input images are divided into equally sized patches and a certain portion of patches is masked (i.e., withheld) from the model. The core training objective is for the ViT to fill in the missing patches, effectively re-creating the original image. Note that this process does not typically required labelled data.
10 |
11 | The key component of interest resulting from this pre-training process is the Vision Encoder which has learned to produce embeddings that represent any given input image in lower dimensional space without significant loss of information. Fine-tuning leverages this capability by training (or adapting) a specialized decoder that sits on top of the pre-trained ViT and takes the embeddings generated by the encoder as input. This has several advantages, compared to training a dedicated model from scratch. First, the process usually requires less labeled data. Second, the decoder is typically lightweight and can often be trained on a single GPU. Third, the new model takes advantage of the representation capabilities of the pre-trained image encoder, re-using it for multiple downstream tasks.
12 |
13 | ### SAM Model Architecture
14 | The Segment Anayting Model (SAM) is made up of 3 main modules:
15 | * The VisionEncoder: a VIT based image encoder. It computes the image embeddings using attention on patches of the image. Relative Positional Embedding is used. SAM leverages a pre-trained vision encoder trained using masked auto-encoding (MAE).
16 | * The PromptEncoder: generates embeddings for points, bounding boxes, and/or text prompts. Here we will use only bounding boxes as prompts.
17 | * The MaskDecoder: a two-ways transformer which performs cross attention between the image embedding and the prompt embeddings (->) and between the prompt embeddings and the image embeddings.
18 |
19 | Fine-tuning focuses on the __MaskDecoder__. All other weights are frozen.
20 |
21 |
22 | 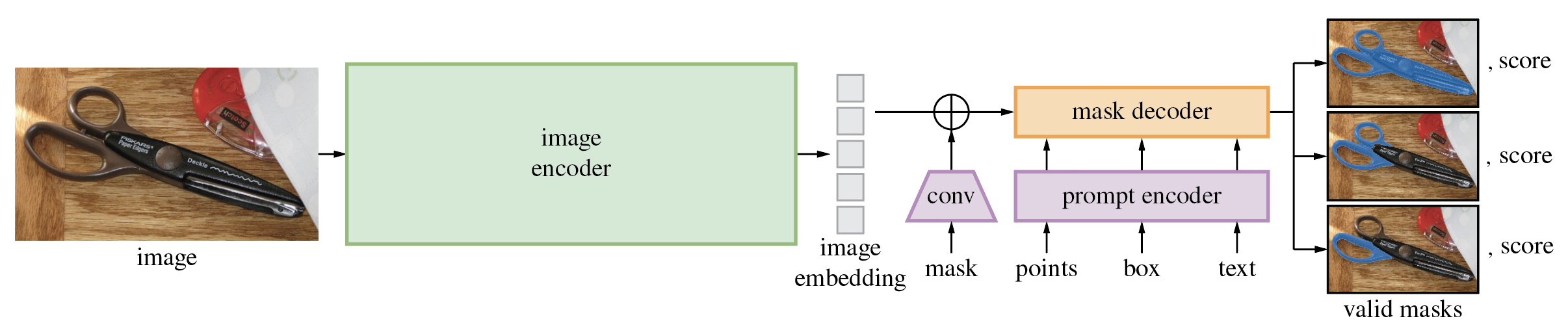 23 | Detailed architecture of Segment Anything Model (SAM).
24 |
23 | Detailed architecture of Segment Anything Model (SAM).
24 |
25 |
26 | There is also a fourth component (sometimes called the neck), which is represented as a convolutional layer taking a segmentation mask as input. This component can be optionally used to submit a previously generated mask as context whenever users interact with SAM over multiple iterations (e.g., re-drawing bounding boxes, etc.). We will not use this option here.
27 |
28 | ## Architecture & Solution Overview
29 |
30 | Fine-tuning SAM on a custom dataset comprises the following steps:
31 | 1. Use a SageMaker Studio Notebook to retrieve and prepare custom data for fine-tuning and save to S3
32 | 2. Download SAM model weights from the HuggingFace Hub
33 | 3. Run distributed training using a SageMaker Training Job
34 | 4. Retrieve fine-tuned model weights and run exemplary inferences on a SageMaker Studio Notebook
35 |
36 | 
37 |
38 | ### SpaceNet Satellite Imagery as Custom Dataset
39 | SAM was trained on >1bn annotated images (SA-1B Dataset). You can explore the SA-1B Dataset [here](https://segment-anything.com/dataset/index.html). To illustrate the power of fine-tuning we will focus on the case of satellite image segmentation, a class of images that is not represented widely in SA-1B. Specialized image data like satellite imagery represents a good out-of-domain test case to demonstrate the power of fine-tuning a general-purpose vision foundation model like SAM for highly specialized applications and domains.
40 |
41 | Specifically, this tutorial uses [SpaceNet data](https://registry.opendata.aws/spacenet/), available on the Amazon Registry of Open Data. This dataset consists of 200mx200m satellite images/labels.
42 |
43 | We will use pre-extracted ~0.3m resolution pan-sharpened RGB (`PS-RGB`) 3-channel satellite images from the city of Las Vegas that have been white-balanced. We have also extracted ground truth masks of buildings as GeoJSON files (`geojson_buildings/` directory). The pre-processed data sample is hosted on a public Amazon S3 bucket: `s3://aws-satellite-lidar-tutorial/data/`. See below for an example of the ground truth data used here:
44 |
45 | 
46 |
47 | ### Model Weights on the HuggingFace Hub
48 |
49 | The SAM foundation model is available as an open-source implementation under the [Apache 2.0 license](https://choosealicense.com/licenses/apache-2.0/) via the HuggingFace Hub. There are three different versions of SAM available:
50 | * [`sam-vit-base`](https://huggingface.co/facebook/sam-vit-base) (~94M params, 0.3 GB)
51 | * [`sam-vit-large`](https://huggingface.co/facebook/sam-vit-large) (~312M params, 1.25 GB)
52 | * [`sam-vit-huge`](https://huggingface.co/facebook/sam-vit-huge) (~641M params, 2.56 GB)
53 |
54 | For illustrative purposes, this example focuses on fine-tuning `sam-vit-large`, although the model type is a parameter that is configurable and you can opt for the smaller (or larger) versions depending on your preferences.
55 |
56 | ### Distributed Training using an Amazon SageMaker Training Job
57 | Training is fascilitated via a [SageMaker Training Job](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-training.html) and is implemented on top of a managed [PyTorch Estimator](https://sagemaker.readthedocs.io/en/stable/frameworks/pytorch/using_pytorch.html#train-a-model-with-pytorch) that leverages AWS-managed pre-built training Docker image optimized for PyTorch environments.
58 |
59 | Note that the SAM model family consist of onyl moderately large model which can fit a single modern GPU's vRAM, provided batch size is not too large. Yet, to speed up training times, especially when training on large datasets, distributing the training load across multiple GPUs may be advisable. In this example we have implemented a Data Parallel strategy using PyTorch's Distributed Data Parallel framework. Adapting a PyTorch training script for DDP is straight forward and detailed [here]().
60 |
61 | In addition to distributed training, we have made several additional optimizations. These include:
62 |
63 | * **Gradient Accumulation**: Gradient Accumulation helps reduce the memory footprint by achieving the same effective batch size at significantly smaller actual batch sizes. In others words: with a gradient accumulation frequency of 2, you can reduce batch size by a factor of 2 for the same result, hence reducing memory footprint associated with 1/ storing large batches on GPU and 2/ persisting the activations associated with passing larger batches through the network. Note that this can come at a small speed penalty due to more forward and backward passes through the network.
64 | * **Mixed Precision Training (Pytorch AMP)**: Mixed precision training reduces compute and usually memory requirements. It does so by representing some matrices in lower precision (i.e., FP16 at 2 bytes/element, vs. FP32 full precision at 4 bytes/element). The memory savings exclusively originate from reducing the activation footprint. Weights are saved in both full and half precision, optimizer states retain full precision and gradients are re-cast to full precision for the optimization. Mixed Precision will be most effective if the share of activations in the total memory footprint is large (as is the case with large minibatch sizes).
65 |
66 | To further reduce memory footprint users may also consider [Gradient Checkpointing](https://github.com/prigoyal/pytorch_memonger/blob/master/tutorial/Checkpointing_for_PyTorch_models.ipynb), which trades memory for compute. Also refer to [this](https://huggingface.co/docs/transformers/v4.20.1/en/perf_train_gpu_one) post for additional details.
67 |
68 | To improve cost performance this sample also implements [managed spot training](https://docs.aws.amazon.com/sagemaker/latest/dg/model-managed-spot-training.html) that makes it easy to train machine learning models using managed Amazon EC2 Spot instances.
69 |
70 | ### Run Inferences
71 | Below is an example of the fine-tuned model output. The left pane shows the ground truth building masks overlaid on the raw satellite image. The middel pane shows the post processed output from the fine-tuned model (after applying a sigmoid function), the right pane shows the "hard" (i.e., binary) building maks derived from the probability mask (middle pane) by applying simple threshholding (p=0.6 in this case):
72 |
73 | 
74 |
75 | ## Prerequisites & Deployment
76 |
77 | To get started clone this repository to your SageMaker Studio JupyterLab Space and follow the instructions laid out in `01-fine-tune-sam-geospatial.ipynb`. It is recommended to run this notebook on a `ml.g5s.2xlarge` instance. The training job can be run on a `ml.g5.12xlarge` or larger.
78 |
79 | ## Security
80 |
81 | See [CONTRIBUTING](CONTRIBUTING.md#security-issue-notifications) for more information.
82 |
83 | ## License
84 |
85 | This library is licensed under the MIT-0 License. See the LICENSE file.
86 |
87 |
--------------------------------------------------------------------------------
/assets/SAM-finetuning-architecture.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/fine-tune-segment-anything-sagemaker/99f1ff29817a12dcee6b20a0037deb9ee37d87a0/assets/SAM-finetuning-architecture.png
--------------------------------------------------------------------------------
/assets/prediction_results.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/fine-tune-segment-anything-sagemaker/99f1ff29817a12dcee6b20a0037deb9ee37d87a0/assets/prediction_results.png
--------------------------------------------------------------------------------
/assets/raw_data.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/fine-tune-segment-anything-sagemaker/99f1ff29817a12dcee6b20a0037deb9ee37d87a0/assets/raw_data.png
--------------------------------------------------------------------------------
/src/requirements.txt:
--------------------------------------------------------------------------------
1 | sagemaker-training
2 | transformers~=4.38.2
3 | datasets~=2.18.0
4 | monai
--------------------------------------------------------------------------------
/src/train_distributed.py:
--------------------------------------------------------------------------------
1 | #Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 | #SPDX-License-Identifier: MIT-0
3 |
4 | #system
5 | import sys
6 | import os
7 | import random
8 | import logging
9 | import argparse
10 | import time
11 | #general
12 | import numpy as np
13 | from statistics import mean
14 | from tqdm import tqdm
15 | #torch
16 | from sagemaker_training import environment
17 | import torch
18 | from torch.utils.data import Dataset
19 | from torch.utils.data import DataLoader
20 | from torch.optim import Adam
21 | from torch.nn.functional import threshold, normalize
22 | import torch.cuda.amp as amp #automatic mixed precision
23 | import torch.multiprocessing as mp
24 | import torch.distributed as dist
25 | from torch.nn.parallel import DistributedDataParallel as DDP
26 | #HF transformer modules
27 | from transformers import SamModel
28 | from transformers import SamProcessor
29 | from datasets import load_from_disk
30 | #custom loss
31 | import monai # for custome DiceCELoss
32 |
33 | if __name__ == '__main__':
34 | # Set up logging
35 | logger = logging.getLogger(__name__)
36 |
37 | logging.basicConfig(
38 | level=logging.getLevelName("INFO"),
39 | handlers=[logging.StreamHandler(sys.stdout)],
40 | format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
41 | )
42 |
43 | parser = argparse.ArgumentParser()
44 | # hyperparameters sent by the client are passed as arguments to the script.
45 | parser.add_argument("--num_epochs", type=int, default=50)
46 | parser.add_argument("--train_batch_size", type=int, default=8)
47 | parser.add_argument("--gradient_accum_freq", type=int, default=4)
48 | parser.add_argument("--learning_rate", type=float, default=1e-5)
49 | parser.add_argument("--weight_decay", type=int, default=0)
50 | parser.add_argument("--model_id", type=str, default="facebook/sam-vit-base", help='the HF hub model ID, choose between [facebook/sam-vit-base, facebook/sam-vit-large, facebook/sam-vit-huge]')
51 | #parameters for DDP
52 | parser.add_argument("--dist_backend", type=str, default="nccl", help='backend to use for dist. training (default: NVIDIA Collective Communications Library (NCCL))')
53 | parser.add_argument('--workers', type=int, default=int(os.environ["SM_NUM_GPUS"]), help='number of data loading workers (default: )')
54 | parser.add_argument("--num_cpu", type=int, default=int(os.environ["SM_NUM_CPUS"]))
55 | parser.add_argument("--num_gpu", type=int, default=int(os.environ["SM_NUM_GPUS"]))
56 | # data, model, and output directories (defaults are stored in SM environment variables)
57 | # see here for envrionment vars: https://sagemaker.readthedocs.io/en/stable/overview.html#prepare-a-training-script
58 | parser.add_argument("--train_dir", type=str, default=os.environ["SM_CHANNEL_TRAIN"])
59 | parser.add_argument("--valid_dir", type=str, default=os.environ["SM_CHANNEL_VALID"])
60 | parser.add_argument("--model_dir", type=str, default=os.environ["SM_MODEL_DIR"])
61 | parser.add_argument("--output_data_dir", type=str, default=os.environ["SM_OUTPUT_DATA_DIR"])
62 | #set some env variables
63 | os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:256' #avoid memory fragmentation
64 | os.environ['TORCH_DISTRIBUTED_DEBUG'] = 'INFO' #get detailed output for debugging
65 | os.environ['NCCL_IGNORE_DISABLED_P2P'] = '1'
66 |
67 | args = parser.parse_args()
68 |
69 | #initialize process group https://sagemaker.readthedocs.io/en/stable/frameworks/pytorch/using_pytorch.html#distributed-pytorch-training
70 | training_env = environment.Environment()
71 | smdataparallel_enabled = training_env.additional_framework_parameters.get('sagemaker_distributed_dataparallel_enabled', False)
72 | if smdataparallel_enabled:
73 | try:
74 | import smdistributed.dataparallel.torch.torch_smddp
75 | import smdistributed.dataparallel.torch.distributed as dist
76 | from smdistributed.dataparallel.torch.parallel.distributed import DistributedDataParallel as DDP
77 | args.dist_backend = 'smddp'
78 | except ImportError:
79 | print('smdistributed module not available, falling back to NCCL collectives.')
80 |
81 | #initialize process group
82 | dist.init_process_group(backend=args.dist_backend,init_method="env://") #use environment variables to get world size and local rank
83 |
84 | world_size = dist.get_world_size()
85 | rank = dist.get_rank()
86 | logger.info(f"Num CPU: {args.num_cpu}")
87 | logger.info(f"Num GPU: {args.num_gpu}")
88 | logger.info(f"Rank {rank} in world size of {world_size}...")
89 | logger.info(f"Distributed process group initiated with {args.dist_backend} backend...(Rank: {rank})")
90 |
91 | # LOAD DATA & INITIALIZE DATALOADER
92 | def get_bounding_box(ground_truth_map):
93 | # get bounding box from mask
94 | y_indices, x_indices = np.where(ground_truth_map > 0)
95 | x_min, x_max = np.min(x_indices), np.max(x_indices)
96 | y_min, y_max = np.min(y_indices), np.max(y_indices)
97 | # add perturbation to bounding box coordinates
98 | H, W = ground_truth_map.shape
99 | x_min = max(0, x_min - np.random.randint(0, 20))
100 | x_max = min(W, x_max + np.random.randint(0, 20))
101 | y_min = max(0, y_min - np.random.randint(0, 20))
102 | y_max = min(H, y_max + np.random.randint(0, 20))
103 | bbox = [x_min, y_min, x_max, y_max]
104 | return bbox
105 |
106 | class CustomSAMDataset(Dataset):
107 | def __init__(self, dataset, processor):
108 | self.dataset = dataset
109 | self.processor = processor
110 |
111 | def __len__(self):
112 | return len(self.dataset)
113 |
114 | def __getitem__(self, idx):
115 | item = self.dataset[idx]
116 | image = item["image"]
117 | ground_truth_mask = np.array(item["label"])
118 | # get bounding box prompt
119 | prompt = get_bounding_box(ground_truth_mask)
120 | # prepare image and prompt for the model
121 | inputs = self.processor(image, input_boxes=[[prompt]], return_tensors="pt")
122 | # remove batch dimension which the processor adds by default
123 | inputs = {k:v.squeeze(0) for k,v in inputs.items()}
124 | # add ground truth segmentation
125 | inputs["ground_truth_mask"] = ground_truth_mask
126 | return inputs
127 |
128 | #instantiate processor, dataset and dataloader
129 | data_train = load_from_disk(args.train_dir)
130 | data_valid = load_from_disk(args.valid_dir)
131 | processor = SamProcessor.from_pretrained(args.model_id) #instantiate the processor associated with SAM
132 | train_dataset = CustomSAMDataset(dataset=data_train, processor=processor) #instantiate dataset
133 | valid_dataset = CustomSAMDataset(dataset=data_valid, processor=processor) #instantiate dataset
134 |
135 | train_sampler = torch.utils.data.distributed.DistributedSampler(
136 | train_dataset, num_replicas=world_size, rank=rank
137 | )
138 |
139 | valid_sampler = torch.utils.data.distributed.DistributedSampler(
140 | valid_dataset, num_replicas=world_size, rank=rank
141 | )
142 |
143 | train_dataloader = torch.utils.data.DataLoader(
144 | train_dataset,
145 | batch_size=args.train_batch_size,
146 | #shuffle=True,
147 | num_workers=int(args.num_gpu), # one worker per GPU
148 | pin_memory=True,
149 | sampler=train_sampler,
150 | )
151 |
152 | valid_dataloader = torch.utils.data.DataLoader(
153 | valid_dataset,
154 | batch_size=args.train_batch_size,
155 | #shuffle=False,
156 | num_workers=int(args.num_gpu), # one worker per GPU
157 | pin_memory=True,
158 | sampler=valid_sampler,
159 | )
160 |
161 | def l(lstring):
162 | """
163 | Log info on main process only.
164 | """
165 | if dist.get_rank() == 0:
166 | logger.info(lstring)
167 |
168 | l("distributed dataloaders initialized")
169 |
170 | #download model config and weights from HF hub and initialize model class
171 | model = SamModel.from_pretrained(args.model_id)
172 | #freeze vision and prompt encoder weights, i.e., make sure we only compute gradients for the maks decoder
173 | for name, param in model.named_parameters():
174 | if name.startswith("vision_encoder") or name.startswith("prompt_encoder"):
175 | param.requires_grad_(False)
176 | l(f"model {args.model_id} downloaded from HF hub...")
177 |
178 | #define optimizer and loss
179 | optimizer = Adam(model.mask_decoder.parameters(), lr=args.learning_rate, weight_decay=args.weight_decay)
180 | # DiceCE returns weighted sum of Dice and Cross Entropy losses. see here: https://docs.monai.io/en/stable/losses.html#diceceloss
181 | seg_loss = monai.losses.DiceCELoss(sigmoid=True, squared_pred=True, reduction='mean')
182 | l("optimizer and loss initialized...")
183 |
184 | device = torch.device(f'cuda:{rank}')
185 | model.to(device)
186 | model = DDP(model, device_ids=[rank],find_unused_parameters=True) # set find_unused_parameters=True to ensure only mask decoder weights are updated
187 | l("distributed model initialized...")
188 |
189 | #run training
190 | training_start_time = time.time()
191 | l('training started')
192 | # create a GradScaler object for mixed precision training
193 | scaler = amp.GradScaler()
194 | #set model to training mode
195 | model.train()
196 |
197 | #Training loop
198 | for epoch in range(args.num_epochs):
199 | epoch_start_time = time.time() # record the start time of the epoch
200 | epoch_losses = []
201 | batch_idx=0
202 | for batch in train_dataloader:
203 | # forward pass is run in mixed precision, this reduces activation memory
204 | with amp.autocast():
205 | outputs = model(pixel_values=batch["pixel_values"].to(device),
206 | input_boxes=batch["input_boxes"].to(device),
207 | multimask_output=False)
208 | # compute loss
209 | predicted_masks = outputs.pred_masks.squeeze(1)
210 | ground_truth_masks = batch["ground_truth_mask"].float().to(device)
211 | loss = seg_loss(predicted_masks, ground_truth_masks.unsqueeze(1))
212 | epoch_losses.append(loss.item()) #collect losses (for comparability during validation)
213 |
214 | #scale loss by gradient_accum_freq to account for accumulation of gradients
215 | #see here: https://stackoverflow.com/questions/65842691/final-step-of-pytorch-gradient-accumulation-for-small-datasets/65913698#65913698
216 | loss_norm = loss / args.gradient_accum_freq
217 | #accumulate gradients
218 | scaler.scale(loss_norm).backward() # scales the loss and computes the gradients in mixed precision
219 |
220 | # optimize once gradients have accumulated over n=gradient_accum_freq batches or if end of data
221 | if ((batch_idx + 1) % args.gradient_accum_freq == 0) or (batch_idx + 1 == len(train_dataloader)):
222 | scaler.step(optimizer) # update the weights using the scaled gradients
223 | scaler.update() # update the GradScaler object for the next iteration
224 | optimizer.zero_grad() # re-set gradients to zero for next n=gradient_accum_freq iteration over minibatches
225 | batch_idx+=1
226 |
227 | #validation loop
228 | model.eval() # Set the model to evaluation mode
229 | val_loss = []
230 | with amp.autocast(): #enable autocast during forward pass (minimal impact as there is no .backward() pass)
231 | with torch.no_grad(): #disable grad calculation to save memory
232 | for item in valid_dataloader:
233 | outputs = model(pixel_values=item["pixel_values"].to(device),
234 | input_boxes=item["input_boxes"].to(device),
235 | multimask_output=False)
236 | predicted_masks = outputs.pred_masks.squeeze(1)
237 | ground_truth_masks = item["ground_truth_mask"].float().to(device)
238 | val_loss_item = seg_loss(predicted_masks, ground_truth_masks.unsqueeze(1))
239 | val_loss.append(val_loss_item.item())
240 |
241 | epoch_end_time = time.time() # Record the end time of the epoch
242 | epoch_duration = epoch_end_time - epoch_start_time # Calculate the duration of the epoch
243 |
244 | l(f'epoch {epoch + 1} completed...')
245 | l(f'Loss: training loss: {mean(epoch_losses)}; validation loss: {mean(val_loss)};')
246 | l(f'Perf: duration: {round(epoch_duration, 2)}; throughput: {round(len(train_dataset)/epoch_duration, 2)};')
247 |
248 |
249 | training_end_time = time.time()
250 | training_duration = training_end_time-training_start_time
251 | l(f'full training completed')
252 | l(f'total training duration [sec]: {round(training_duration, 2)}')
253 | l(f'avg training throughput [samples/sec]: {round((args.num_epochs * len(train_dataset))/training_duration, 2)}')
254 |
255 | #save pytorch.bin and config.json such that model can be loaded
256 | #save trained model
257 | if dist.get_rank() == 0:
258 | l('training completed')
259 | model.module.save_pretrained(args.model_dir)
260 | #model.module.save_model(args.model_dir)
261 | l('model saved')
262 | dist.destroy_process_group()
--------------------------------------------------------------------------------