├── .gitignore
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── app.py
├── athena_query.png
├── cdk.json
├── create_lake.sh
├── glue-crawler.png
├── glue-table.png
├── glue-workflow.png
├── requirements-dev.txt
├── requirements.txt
├── serverless-datalake.drawio.png
├── serverless_datalake.zip
├── serverless_datalake
├── __init__.py
├── infrastructure
│ ├── etl_stack.py
│ ├── glue_job
│ │ └── event-bridge-dev-etl.py
│ ├── ingestion_stack.py
│ ├── lambda_tester
│ │ └── event_simulator.py
│ └── test_stack.py
└── serverless_datalake_stack.py
└── source.bat
/.gitignore:
--------------------------------------------------------------------------------
1 |
2 | .venv
3 | cdk.out/
4 | *.pyc
--------------------------------------------------------------------------------
/CODE_OF_CONDUCT.md:
--------------------------------------------------------------------------------
1 | ## Code of Conduct
2 | This project has adopted the [Amazon Open Source Code of Conduct](https://aws.github.io/code-of-conduct).
3 | For more information see the [Code of Conduct FAQ](https://aws.github.io/code-of-conduct-faq) or contact
4 | opensource-codeofconduct@amazon.com with any additional questions or comments.
5 |
--------------------------------------------------------------------------------
/CONTRIBUTING.md:
--------------------------------------------------------------------------------
1 | # Contributing Guidelines
2 |
3 | Thank you for your interest in contributing to our project. Whether it's a bug report, new feature, correction, or additional
4 | documentation, we greatly value feedback and contributions from our community.
5 |
6 | Please read through this document before submitting any issues or pull requests to ensure we have all the necessary
7 | information to effectively respond to your bug report or contribution.
8 |
9 |
10 | ## Reporting Bugs/Feature Requests
11 |
12 | We welcome you to use the GitHub issue tracker to report bugs or suggest features.
13 |
14 | When filing an issue, please check existing open, or recently closed, issues to make sure somebody else hasn't already
15 | reported the issue. Please try to include as much information as you can. Details like these are incredibly useful:
16 |
17 | * A reproducible test case or series of steps
18 | * The version of our code being used
19 | * Any modifications you've made relevant to the bug
20 | * Anything unusual about your environment or deployment
21 |
22 |
23 | ## Contributing via Pull Requests
24 | Contributions via pull requests are much appreciated. Before sending us a pull request, please ensure that:
25 |
26 | 1. You are working against the latest source on the *main* branch.
27 | 2. You check existing open, and recently merged, pull requests to make sure someone else hasn't addressed the problem already.
28 | 3. You open an issue to discuss any significant work - we would hate for your time to be wasted.
29 |
30 | To send us a pull request, please:
31 |
32 | 1. Fork the repository.
33 | 2. Modify the source; please focus on the specific change you are contributing. If you also reformat all the code, it will be hard for us to focus on your change.
34 | 3. Ensure local tests pass.
35 | 4. Commit to your fork using clear commit messages.
36 | 5. Send us a pull request, answering any default questions in the pull request interface.
37 | 6. Pay attention to any automated CI failures reported in the pull request, and stay involved in the conversation.
38 |
39 | GitHub provides additional document on [forking a repository](https://help.github.com/articles/fork-a-repo/) and
40 | [creating a pull request](https://help.github.com/articles/creating-a-pull-request/).
41 |
42 |
43 | ## Finding contributions to work on
44 | Looking at the existing issues is a great way to find something to contribute on. As our projects, by default, use the default GitHub issue labels (enhancement/bug/duplicate/help wanted/invalid/question/wontfix), looking at any 'help wanted' issues is a great place to start.
45 |
46 |
47 | ## Code of Conduct
48 | This project has adopted the [Amazon Open Source Code of Conduct](https://aws.github.io/code-of-conduct).
49 | For more information see the [Code of Conduct FAQ](https://aws.github.io/code-of-conduct-faq) or contact
50 | opensource-codeofconduct@amazon.com with any additional questions or comments.
51 |
52 |
53 | ## Security issue notifications
54 | If you discover a potential security issue in this project we ask that you notify AWS/Amazon Security via our [vulnerability reporting page](http://aws.amazon.com/security/vulnerability-reporting/). Please do **not** create a public github issue.
55 |
56 |
57 | ## Licensing
58 |
59 | See the [LICENSE](LICENSE) file for our project's licensing. We will ask you to confirm the licensing of your contribution.
60 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 |
3 | Permission is hereby granted, free of charge, to any person obtaining a copy of
4 | this software and associated documentation files (the "Software"), to deal in
5 | the Software without restriction, including without limitation the rights to
6 | use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
7 | the Software, and to permit persons to whom the Software is furnished to do so.
8 |
9 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
10 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
11 | FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
12 | COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
13 | IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
14 | CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
15 |
16 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | # Serverless Datalake with Amazon EventBridge
3 |
4 | ### Architecture
5 | 
6 |
7 |
8 |
9 |
10 | ### Overview
11 | This solution demonstrates how we could build a serverless ETL solution with Amazon Eventbridge, Kinesis Firehose, AWS Glue.
12 |
13 | * Amazon Eventbridge is a high throughput serverless event router used for ingesting data, it provides out-of-the-box integration with multiple AWS services. We could generate custom events from multiple hetrogenous sources and route it to any of the AWS services without the need to write any integration logic. With content based routing , a single event bus can route events to different services based on the match/un-matched event content.
14 |
15 | * Kinesis Firehose is used to buffer the events and store them as json files in S3.
16 |
17 | * AWS Glue is a serverless data integration service. We've used Glue to transform the raw event data and also to generate a
18 | schema using AWS Glue crawler. AWS Glue Jobs run some basic transformations on the incoming raw data. It then compresses, partitions the data and stores it in parquet(columnar) storage. AWS Glue job is configured to run every hour. A successful AWS Glue job completion would trigger the AWS Glue Crawler that in turn would either create a schema on the S3 data or update the schema and other metadata such as newly added/deleted table partitions.
19 |
20 | * Glue Workflow
21 |  22 |
23 | * Glue Crawler
24 |
22 |
23 | * Glue Crawler
24 |  25 |
26 | * Datalake Table
27 |
25 |
26 | * Datalake Table
27 |  28 |
29 | * Once the table is created we could query it through Athena and visualize it using Quicksight.
28 |
29 | * Once the table is created we could query it through Athena and visualize it using Quicksight.
30 | Athena Query
31 |  32 |
33 | * This solution also provides a test lambda that generates 500 random events to push to the bus. The lambda is part of the **test_stack.py** nested stack. The lambda should be invoked on demand.
34 | Test lambda name: **serverless-event-simulator-dev**
35 |
36 |
37 |
38 | This solution could be used to build a datalake for API usage tracking, State Change Notifications, Content based routing and much more.
39 |
40 |
41 | ### Setup to execute on AWS Cloudshell
42 |
43 | 1. Create an new IAM user(username = LakeAdmin) with Administrator access.Enable Console access too
44 |
45 |
32 |
33 | * This solution also provides a test lambda that generates 500 random events to push to the bus. The lambda is part of the **test_stack.py** nested stack. The lambda should be invoked on demand.
34 | Test lambda name: **serverless-event-simulator-dev**
35 |
36 |
37 |
38 | This solution could be used to build a datalake for API usage tracking, State Change Notifications, Content based routing and much more.
39 |
40 |
41 | ### Setup to execute on AWS Cloudshell
42 |
43 | 1. Create an new IAM user(username = LakeAdmin) with Administrator access.Enable Console access too
44 |
45 | 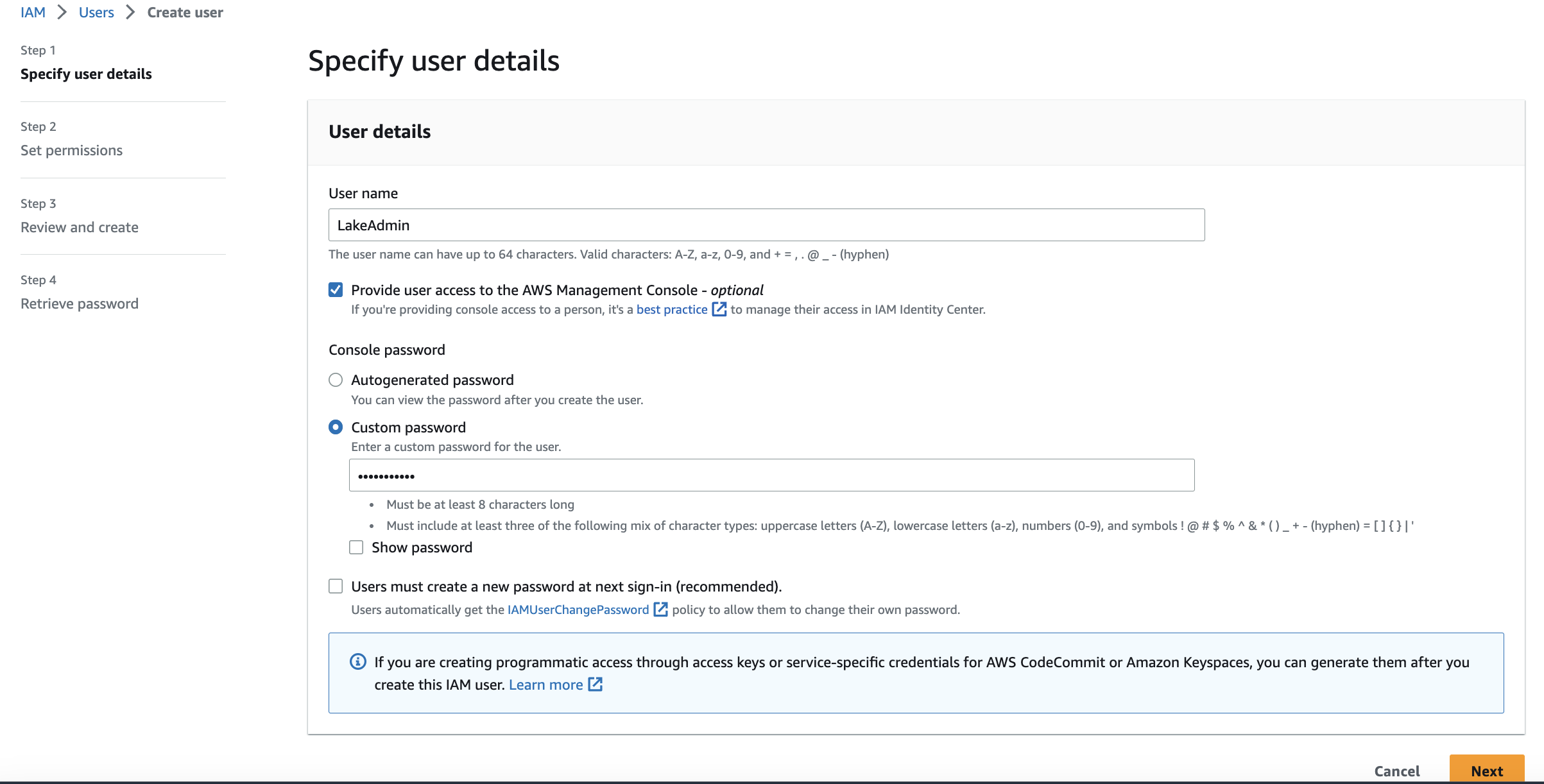 46 |
47 |
48 | 2. Once the user is created. Head to Security Credentials Tab and generate access/secret key for the new IAM user.
49 |
50 |
46 |
47 |
48 | 2. Once the user is created. Head to Security Credentials Tab and generate access/secret key for the new IAM user.
49 |
50 |  51 |
52 | 2. Copy access/secret keys for the newly created IAM User on your local machine.
53 |
54 |
51 |
52 | 2. Copy access/secret keys for the newly created IAM User on your local machine.
53 |
54 |  55 |
56 |
57 | 3. Search for AWS Cloudshell. Configure your aws cli environment with the access/secret keys of the new admin user using the below command on AWS Cloudshell
58 | ```
59 | aws configure
60 | ```
61 |
55 |
56 |
57 | 3. Search for AWS Cloudshell. Configure your aws cli environment with the access/secret keys of the new admin user using the below command on AWS Cloudshell
58 | ```
59 | aws configure
60 | ```
61 |  62 |
63 |
64 | 4. Git Clone the serverless-datalake repository from aws-samples
65 | ```
66 | git clone https://github.com/aws-samples/serverless-datalake.git
67 | ```
68 |
69 | 8. cd serverless-datalake
70 | ```
71 | cd serverless-datalake
72 |
73 | ```
74 |
75 | 9. Fire the bash script that automates the lake creation process.
76 | ```
77 | sh create_lake.sh
78 | ```
79 |
80 | 10. After you've successfully deployed this stack on your account, you could test it out by executing the test lambda thats deployed as part of this stack.
81 | Test lambda name: **serverless-event-simulator-dev** . This lambda will push 1K random transaction events to the event-bus.
82 |
83 | 11. Verify if raw data is available in the s3 bucket under prefix 'raw-data/....'
84 |
85 | 12. Verify if the Glue job is running
86 |
87 | 13. Once the Glue job succeeds, it would trigger a glue crawler that creates a table in our datalake
88 |
89 | 14. Head to Athena after the table is created and query the table
90 |
91 | 15. Create 3 roles in IAM with Administrator access -> cloud-developer / cloud-analyst / cloud-data-engineer
92 |
93 | 16. Add inline Permissions to IAM user(LakeAdmin) so that we can switch roles
94 | ```
95 | {
96 | "Version": "2012-10-17",
97 | "Statement": {
98 | "Effect": "Allow",
99 | "Action": "sts:AssumeRole",
100 | "Resource": "arn:aws:iam::account-id:role/cloud-*"
101 | }
102 | }
103 | ```
104 |
105 | 16. Head to Amazon Lake formation and under Tables, select our table -> Actions -> Grant privileges to cloud-developer role
106 | 16.a: Add column level security
107 |
108 |
62 |
63 |
64 | 4. Git Clone the serverless-datalake repository from aws-samples
65 | ```
66 | git clone https://github.com/aws-samples/serverless-datalake.git
67 | ```
68 |
69 | 8. cd serverless-datalake
70 | ```
71 | cd serverless-datalake
72 |
73 | ```
74 |
75 | 9. Fire the bash script that automates the lake creation process.
76 | ```
77 | sh create_lake.sh
78 | ```
79 |
80 | 10. After you've successfully deployed this stack on your account, you could test it out by executing the test lambda thats deployed as part of this stack.
81 | Test lambda name: **serverless-event-simulator-dev** . This lambda will push 1K random transaction events to the event-bus.
82 |
83 | 11. Verify if raw data is available in the s3 bucket under prefix 'raw-data/....'
84 |
85 | 12. Verify if the Glue job is running
86 |
87 | 13. Once the Glue job succeeds, it would trigger a glue crawler that creates a table in our datalake
88 |
89 | 14. Head to Athena after the table is created and query the table
90 |
91 | 15. Create 3 roles in IAM with Administrator access -> cloud-developer / cloud-analyst / cloud-data-engineer
92 |
93 | 16. Add inline Permissions to IAM user(LakeAdmin) so that we can switch roles
94 | ```
95 | {
96 | "Version": "2012-10-17",
97 | "Statement": {
98 | "Effect": "Allow",
99 | "Action": "sts:AssumeRole",
100 | "Resource": "arn:aws:iam::account-id:role/cloud-*"
101 | }
102 | }
103 | ```
104 |
105 | 16. Head to Amazon Lake formation and under Tables, select our table -> Actions -> Grant privileges to cloud-developer role
106 | 16.a: Add column level security
107 |
108 |  109 |
110 | 17. View Permissions for the table and revoke IAMAllowedPrincipals. https://docs.aws.amazon.com/lake-formation/latest/dg/upgrade-glue-lake-formation-background.html
111 |
112 |
109 |
110 | 17. View Permissions for the table and revoke IAMAllowedPrincipals. https://docs.aws.amazon.com/lake-formation/latest/dg/upgrade-glue-lake-formation-background.html
111 |
112 |  113 |
114 | 18. In an incognito window, login as LakeAdmin user.
115 |
116 | 19. Switch roles and head to Athena and test Column level security.
117 |
118 | 20. Now in Amazon Lake Formation (Back to our main window), create a Data Filter and add the below
119 | a. Under Row Filter expression add -> country='IN'
120 | a.1 https://docs.aws.amazon.com/lake-formation/latest/dg/data-filters-about.html
121 | b. Include columns you wish to view for that role.
122 |
123 |
113 |
114 | 18. In an incognito window, login as LakeAdmin user.
115 |
116 | 19. Switch roles and head to Athena and test Column level security.
117 |
118 | 20. Now in Amazon Lake Formation (Back to our main window), create a Data Filter and add the below
119 | a. Under Row Filter expression add -> country='IN'
120 | a.1 https://docs.aws.amazon.com/lake-formation/latest/dg/data-filters-about.html
121 | b. Include columns you wish to view for that role.
122 |
123 |  124 |
125 |
126 |
127 | 21. Head back to the incognito window and fire the select command. Confirm if RLS and CLS are correctly working for that role.
128 | 22. Configurations for dev environment are defined in cdk.json. S3 bucket name is created on the fly based on account_id and region in which the cdk is deployed
129 |
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | import os
3 |
4 | import aws_cdk as cdk
5 |
6 | from serverless_datalake.serverless_datalake_stack import ServerlessDatalakeStack
7 |
8 | account_id = os.getenv('CDK_DEFAULT_ACCOUNT')
9 | region = os.getenv('CDK_DEFAULT_REGION')
10 |
11 | app = cdk.App()
12 | env=cdk.Environment(account=account_id, region=region)
13 | # Set Context Bucket_name
14 | env_name = app.node.try_get_context('environment_name')
15 | bucket_name = f"lake-store-{env_name}-{region}-{account_id}"
16 | ServerlessDatalakeStack(app, "ServerlessDatalakeStack", bucket_name=bucket_name,
17 | # If you don't specify 'env', this stack will be environment-agnostic.
18 | # Account/Region-dependent features and context lookups will not work,
19 | # but a single synthesized template can be deployed anywhere.
20 |
21 | # Uncomment the next line to specialize this stack for the AWS Account
22 | # and Region that are implied by the current CLI configuration.
23 | env=env
24 |
25 | # Uncomment the next line if you know exactly what Account and Region you
26 | # want to deploy the stack to. */
27 |
28 | #env=cdk.Environment(account='123456789012', region='us-east-1'),
29 |
30 | # For more information, see https://docs.aws.amazon.com/cdk/latest/guide/environments.html
31 | )
32 |
33 | app.synth()
34 |
--------------------------------------------------------------------------------
/athena_query.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/athena_query.png
--------------------------------------------------------------------------------
/cdk.json:
--------------------------------------------------------------------------------
1 | {
2 | "app": "python3 app.py",
3 | "watch": {
4 | "include": [
5 | "**"
6 | ],
7 | "exclude": [
8 | "README.md",
9 | "cdk*.json",
10 | "requirements*.txt",
11 | "source.bat",
12 | "**/__init__.py",
13 | "python/__pycache__",
14 | "tests"
15 | ]
16 | },
17 | "context": {
18 | "@aws-cdk/aws-apigateway:usagePlanKeyOrderInsensitiveId": true,
19 | "@aws-cdk/core:stackRelativeExports": true,
20 | "@aws-cdk/aws-rds:lowercaseDbIdentifier": true,
21 | "@aws-cdk/aws-lambda:recognizeVersionProps": true,
22 | "@aws-cdk/aws-lambda:recognizeLayerVersion": true,
23 | "@aws-cdk/aws-cloudfront:defaultSecurityPolicyTLSv1.2_2021": true,
24 | "@aws-cdk-containers/ecs-service-extensions:enableDefaultLogDriver": true,
25 | "@aws-cdk/aws-ec2:uniqueImdsv2TemplateName": true,
26 | "@aws-cdk/core:checkSecretUsage": true,
27 | "@aws-cdk/aws-iam:minimizePolicies": true,
28 | "@aws-cdk/aws-ecs:arnFormatIncludesClusterName": true,
29 | "@aws-cdk/core:validateSnapshotRemovalPolicy": true,
30 | "@aws-cdk/aws-codepipeline:crossAccountKeyAliasStackSafeResourceName": true,
31 | "@aws-cdk/aws-s3:createDefaultLoggingPolicy": true,
32 | "@aws-cdk/aws-sns-subscriptions:restrictSqsDescryption": true,
33 | "@aws-cdk/aws-apigateway:disableCloudWatchRole": true,
34 | "@aws-cdk/core:enablePartitionLiterals": true,
35 | "@aws-cdk/core:target-partitions": [
36 | "aws",
37 | "aws-cn"
38 | ],
39 | "dev": {
40 | "bus-name": "serverless-bus-dev",
41 | "rule-name": "custom-event-rule-dev",
42 | "event-pattern": "custom-event-pattern-dev",
43 | "firehose-name": "sample-stream-dev",
44 | "buffering-interval-in-seconds": 120,
45 | "buffering-size-in-mb": 128,
46 | "firehose-s3-rolename": "firehoses3dev",
47 | "eventbus-firehose-rolename": "eventbusfirehosedev",
48 | "glue-job-name": "serverless-etl-job-dev",
49 | "workers": 7,
50 | "worker-type": "G.1X",
51 | "glue-script-location": "glue/scripts/",
52 | "glue-script-uri": "/glue/scripts/event-bridge-dev-etl.py",
53 | "temp-location": "/glue/etl/temp/",
54 | "glue-database-location": "/glue/etl/database/",
55 | "glue-database-name": "serverless-lake",
56 | "glue-table-name": "processed-table",
57 | "glue-crawler": "serverless-lake-crawler",
58 | "glue-output": "/glue/output/",
59 | "glue-job-trigger-name": "scheduled-etl-job-trigger-dev",
60 | "glue-job-cron": "cron(0/15 * * * ? *)",
61 | "glue-crawler-trigger-name": "crawler-trigger-dev",
62 | "glue-script-local-machine": ""
63 | }
64 | }
65 | }
66 |
--------------------------------------------------------------------------------
/create_lake.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # Assuming we are in Serverless-datalake folder
3 | cd ..
4 | echo "--- Upgrading npm ---"
5 | sudo npm install n stable -g
6 | echo "--- Installing cdk ---"
7 | sudo npm install -g aws-cdk@2.55.1
8 | echo "--- Bootstrapping CDK on account ---"
9 | cdk bootstrap aws://$(aws sts get-caller-identity --query "Account" --output text)/us-east-1
10 | echo "--- Cloning serverless-datalake project from aws-samples ---"
11 | # assuming we have already cloned.
12 | # git clone https://github.com/aws-samples/serverless-datalake.git
13 | cd serverless-datalake
14 | echo "--- Set python virtual environment ---"
15 | python3 -m venv .venv
16 | echo "--- Activate virtual environment ---"
17 | source .venv/bin/activate
18 | echo "--- Install Requirements ---"
19 | pip install -r requirements.txt
20 | echo "--- CDK synthesize ---"
21 | cdk synth -c environment_name=dev
22 | echo "--- CDK deploy ---"
23 | # read -p "Press any key to deploy the Serverless Datalake ..."
24 | cdk deploy -c environment_name=dev ServerlessDatalakeStack
25 | echo "Lake deployed successfully"
26 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
27 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
28 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
29 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
30 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
31 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
32 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
33 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
34 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
35 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
--------------------------------------------------------------------------------
/glue-crawler.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/glue-crawler.png
--------------------------------------------------------------------------------
/glue-table.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/glue-table.png
--------------------------------------------------------------------------------
/glue-workflow.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/glue-workflow.png
--------------------------------------------------------------------------------
/requirements-dev.txt:
--------------------------------------------------------------------------------
1 | pytest==6.2.5
2 | aws-cdk-lib==2.55.1
3 | aws-cdk.aws-glue-alpha==2.55.1a0
4 | constructs>=10.0.0,<11.0.0
5 |
6 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | aws-cdk-lib==2.55.1
2 | aws-cdk.aws-glue-alpha==2.55.1a0
3 | constructs>=10.0.0,<11.0.0
4 |
--------------------------------------------------------------------------------
/serverless-datalake.drawio.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/serverless-datalake.drawio.png
--------------------------------------------------------------------------------
/serverless_datalake.zip:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/serverless_datalake.zip
--------------------------------------------------------------------------------
/serverless_datalake/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/serverless_datalake/__init__.py
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/etl_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack,
4 | NestedStack,
5 | aws_glue_alpha as _glue_alpha
6 | # aws_sqs as sqs,
7 | )
8 | import aws_cdk as _cdk
9 | from constructs import Construct
10 | import os
11 |
12 |
13 | class EtlStack(NestedStack):
14 |
15 | def __init__(self, scope: Construct, construct_id: str, bucket_name, **kwargs) -> None:
16 | super().__init__(scope, construct_id, **kwargs)
17 | env = self.node.try_get_context('environment_name')
18 | if env is None:
19 | print('Setting environment as Dev')
20 | print('Fetching Dev Properties')
21 | env = 'dev'
22 | # fetching details from cdk.json
23 | config_details = self.node.try_get_context(env)
24 | # Create a Glue Role
25 | glue_role = _cdk.aws_iam.Role(self, f'etl-role-{env}', assumed_by=_cdk.aws_iam.ServicePrincipal(service='glue.amazonaws.com'),
26 | role_name=f'etlrole{env}', managed_policies=[
27 | _cdk.aws_iam.ManagedPolicy.from_managed_policy_arn(self, 's3-full-access-etl',
28 | managed_policy_arn='arn:aws:iam::aws:policy/AmazonS3FullAccess'),
29 | _cdk.aws_iam.ManagedPolicy.from_managed_policy_arn(self, 'comprehend-full-access-etl',
30 | managed_policy_arn='arn:aws:iam::aws:policy/ComprehendFullAccess'),
31 | _cdk.aws_iam.ManagedPolicy.from_aws_managed_policy_name(
32 | "service-role/AWSGlueServiceRole")
33 | ]
34 | )
35 |
36 | s3_bucket = _cdk.aws_s3.Bucket.from_bucket_name(
37 | self, f's3_lake_{env}', bucket_name=bucket_name)
38 |
39 | # Upload Glue Script on S3
40 | _cdk.aws_s3_deployment.BucketDeployment(self, f"glue_scripts_deploy_{env}",
41 | sources=[_cdk.aws_s3_deployment.Source
42 | .asset(os.path.join(os.getcwd(), 'serverless_datalake/infrastructure/glue_job/'))],
43 | destination_bucket=s3_bucket,
44 | destination_key_prefix=config_details[
45 | "glue-script-location"]
46 | )
47 | workflow = _cdk.aws_glue.CfnWorkflow(self, f'workflow-{env}', name=f'serverless-etl-{env}',
48 | description='sample etl with eventbridge ingestion', max_concurrent_runs=1)
49 |
50 | # Create a Glue job and run on schedule
51 | glue_job = _cdk.aws_glue.CfnJob(
52 | self, f'serverless-etl-{env}',
53 | name=config_details['glue-job-name'],
54 | number_of_workers=config_details['workers'],
55 | worker_type=config_details['worker-type'],
56 | command=_cdk.aws_glue.CfnJob.JobCommandProperty(name='glueetl',
57 | script_location=f"s3://{bucket_name}{config_details['glue-script-uri']}",
58 | ),
59 | role=glue_role.role_arn,
60 | glue_version='3.0',
61 | execution_property=_cdk.aws_glue.CfnJob.ExecutionPropertyProperty(
62 | max_concurrent_runs=1),
63 | description='Serverless etl processing raw data from event-bus',
64 | default_arguments={
65 | "--enable-metrics": "",
66 | "--enable-job-insights": "true",
67 | '--TempDir': f"s3://{bucket_name}{config_details['temp-location']}",
68 | '--job-bookmark-option': 'job-bookmark-enable',
69 | '--s3_input_location': f's3://{bucket_name}/raw-data/',
70 | '--s3_output_location': f"s3://{bucket_name}{config_details['glue-output']}"
71 | }
72 | )
73 |
74 |
75 | # Create a Glue Database
76 | glue_database = _cdk.aws_glue.CfnDatabase(self, f'glue-database-{env}',
77 | catalog_id=self.account, database_input=_cdk.aws_glue.CfnDatabase
78 | .DatabaseInputProperty(
79 | location_uri=f"s3://{bucket_name}{config_details['glue-database-location']}",
80 | description='store processed data', name=config_details['glue-database-name']))
81 |
82 | # Create a Glue Crawler
83 | glue_crawler = _cdk.aws_glue.CfnCrawler(self, f'glue-crawler-{env}',
84 | role=glue_role.role_arn, name=config_details['glue-crawler'],
85 | database_name=config_details['glue-database-name'],
86 | targets=_cdk.aws_glue.CfnCrawler.TargetsProperty(s3_targets=[
87 | _cdk.aws_glue.CfnCrawler.S3TargetProperty(
88 | path=f"s3://{bucket_name}{config_details['glue-output']}")
89 | ]), table_prefix=config_details['glue-table-name'],
90 | description='Crawl over processed parquet data. This optimizes query cost'
91 | )
92 |
93 | # Create a Glue cron Trigger ̰
94 | job_trigger = _cdk.aws_glue.CfnTrigger(self, f'glue-job-trigger-{env}',
95 | name=config_details['glue-job-trigger-name'],
96 | actions=[_cdk.aws_glue.CfnTrigger.ActionProperty(job_name=glue_job.name)],
97 | workflow_name=workflow.name,
98 | type='SCHEDULED',
99 | start_on_creation=True,
100 | schedule=config_details['glue-job-cron'])
101 |
102 | job_trigger.add_depends_on(glue_job)
103 | job_trigger.add_depends_on(glue_crawler)
104 | job_trigger.add_depends_on(glue_database)
105 |
106 | # Create a Glue conditional trigger that triggers the crawler on successful job completion
107 | crawler_trigger = _cdk.aws_glue.CfnTrigger(self, f'glue-crawler-trigger-{env}',
108 | name=config_details['glue-crawler-trigger-name'],
109 | actions=[_cdk.aws_glue.CfnTrigger.ActionProperty(
110 | crawler_name=glue_crawler.name)],
111 | workflow_name=workflow.name,
112 | type='CONDITIONAL',
113 | predicate=_cdk.aws_glue.CfnTrigger.PredicateProperty(
114 | conditions=[_cdk.aws_glue.CfnTrigger.ConditionProperty(
115 | job_name=glue_job.name,
116 | logical_operator='EQUALS',
117 | state="SUCCEEDED"
118 | )]
119 | ),
120 | start_on_creation=True
121 | )
122 |
123 | crawler_trigger.add_depends_on(glue_job)
124 | crawler_trigger.add_depends_on(glue_crawler)
125 | crawler_trigger.add_depends_on(glue_database)
126 |
127 |
128 |
129 |
130 | #TODO: Create an Athena Workgroup
131 |
132 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/glue_job/event-bridge-dev-etl.py:
--------------------------------------------------------------------------------
1 | import boto3
2 | import sys
3 | from awsglue.transforms import *
4 | from awsglue.utils import getResolvedOptions
5 | from pyspark.context import SparkContext
6 | from awsglue.context import GlueContext
7 | from awsglue.job import Job
8 | from awsglue.dynamicframe import DynamicFrame
9 | from datetime import datetime, timedelta
10 | from pyspark.sql.functions import to_json, struct, substring, from_json, lit, col, when, concat, concat_ws
11 | from pyspark.sql.types import StringType
12 | import hashlib, uuid
13 |
14 |
15 | def get_masked_entities():
16 | """
17 | return a list of entities to be masked.
18 | If unstructured, use comprehend to determine entities to be masked
19 | """
20 | return ["name", "credit_card", "account", "city"]
21 |
22 | def get_encrypted_entities():
23 | """
24 | return a list of entities to be masked.
25 | """
26 | return ["name", "credit_card"]
27 |
28 |
29 | def get_region_name():
30 | global my_region
31 | my_session = boto3.session.Session()
32 | return my_session.region_name
33 |
34 |
35 | def detect_sensitive_info(r):
36 | """
37 | return a tuple after masking is complete.
38 | If unstructured, use comprehend to determine entities to be masked
39 | """
40 |
41 | metadata = r['trnx_msg']
42 | try:
43 | for entity in get_masked_entities():
44 | entity_masked = entity + "_masked"
45 | r[entity_masked] = "#######################"
46 | except:
47 | print ("DEBUG:",sys.exc_info())
48 |
49 | ''' Uncomment to mask unstructured text through Amazon Comprehend '''
50 | ''' Can result in extendend Glue Job times'''
51 | # client_pii = boto3.client('comprehend', region_name=get_region_name())
52 |
53 | # try:
54 | # response = client_pii.detect_pii_entities(
55 | # Text = metadata,
56 | # LanguageCode = 'en'
57 | # )
58 | # clean_text = metadata
59 | # # reversed to not modify the offsets of other entities when substituting
60 | # for NER in reversed(response['Entities']):
61 | # clean_text = clean_text[:NER['BeginOffset']] + NER['Type'] + clean_text[NER['EndOffset']:]
62 | # print(clean_text)
63 | # r['trnx_msg_masked'] = clean_text
64 | # except:
65 | # print ("DEBUG:",sys.exc_info())
66 |
67 | return r
68 |
69 |
70 | def encrypt_rows(r):
71 | """
72 | return tuple with encrypted string
73 | Hardcoding salted string. PLease feel free to use SSM and KMS.
74 | """
75 | salted_string = 'glue_crypt'
76 | encrypted_entities = get_encrypted_entities()
77 | print ("encrypt_rows", salted_string, encrypted_entities)
78 | try:
79 | for entity in encrypted_entities:
80 | salted_entity = r[entity] + salted_string
81 | hashkey = hashlib.sha3_256(salted_entity.encode()).hexdigest()
82 | r[entity + '_encrypted'] = hashkey
83 | except:
84 | print ("DEBUG:",sys.exc_info())
85 | return r
86 |
87 |
88 | args = getResolvedOptions(sys.argv, ['JOB_NAME', 's3_output_location', 's3_input_location'])
89 | sc = SparkContext()
90 | glueContext = GlueContext(sc)
91 | spark = glueContext.spark_session
92 | job = Job(glueContext)
93 | job.init(args['JOB_NAME'], args)
94 | logger = glueContext.get_logger()
95 |
96 | logger.info('\n -- Glue ETL Job begins -- ')
97 |
98 | s3_input_path = args["s3_input_location"]
99 | s3_output_path = args["s3_output_location"]
100 |
101 | now = datetime.utcnow()
102 | current_date = now.date()
103 | # Go back 5 days in the past. With Glue Bookmarking enabled only newer files are processed
104 | from_date = current_date - timedelta(days=5)
105 | delta = timedelta(days=1)
106 | bucket_path = []
107 | while from_date <= current_date:
108 | # S3 Paths to process.
109 | if len(bucket_path) >= 10:
110 | logger.info(f'\n Backtrack complete: Found all paths up to {from_date} ')
111 | break
112 | lastprocessedtimestamp = str(from_date)
113 | path = s3_input_path + 'year=' + str(from_date.year) + '/month=' + str(from_date.month).zfill(
114 | 2) + '/day=' + str(from_date.day).zfill(2)
115 | logger.info(f'\n AWS Glue will check for newer unprocessed files in path : {path}')
116 | bucket_path.append(path)
117 | from_date += delta
118 |
119 |
120 |
121 | if len(bucket_path) > 0:
122 | # Read S3 data as a Glue Dynamic Frame
123 | datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3",
124 | connection_options={'paths': bucket_path,
125 | 'groupFiles': 'inPartition'},
126 | format="json", transformation_ctx="dtx")
127 | if datasource0 and datasource0.count() > 0:
128 |
129 | logger.info('\n -- Printing datasource schema --')
130 | logger.info(datasource0.printSchema())
131 |
132 | # Unnests json data into a flat dataframe.
133 | # This glue transform converts a nested json into a flattened Glue DynamicFrame
134 | logger.info('\n -- Unnest dynamic frame --')
135 | unnested_dyf = UnnestFrame.apply(frame=datasource0, transformation_ctx='unnest')
136 |
137 | # Convert to a Spark DataFrame
138 | sparkDF = unnested_dyf.toDF()
139 |
140 | logger.info('\n -- Add new Columns to Spark data frame --')
141 | # Generate Year/Month/day columns from the time field
142 | sparkDF = sparkDF.withColumn('year', substring('time', 1, 4))
143 | sparkDF = sparkDF.withColumn('month', substring('time', 6, 2))
144 | sparkDF = sparkDF.withColumn('day', substring('time', 9, 2))
145 |
146 | # Rename fields
147 | sparkDF = sparkDF.withColumnRenamed("detail.amount.value", "amount")
148 | sparkDF = sparkDF.withColumnRenamed("detail.amount.currency", "currency")
149 | sparkDF = sparkDF.withColumnRenamed("detail.location.country", "country")
150 | sparkDF = sparkDF.withColumnRenamed("detail.location.state", "state")
151 | sparkDF = sparkDF.withColumnRenamed("detail.location.city", "city")
152 | sparkDF = sparkDF.withColumnRenamed("detail.credit_card", "credit_card_number")
153 | sparkDF = sparkDF.withColumnRenamed("detail.transaction_message", "trnx_msg")
154 |
155 | # Concat firstName and LastName columns
156 | sparkDF = sparkDF.withColumn('name', concat_ws(' ', sparkDF["`detail.firstName`"], sparkDF["`detail.lastName`"]))
157 |
158 | dt_cols = sparkDF.columns
159 | # Drop detail.* columns
160 | for col_dt in dt_cols:
161 | if '.' in col_dt:
162 | logger.info(f'Dropping Column {col_dt}')
163 | sparkDF = sparkDF.drop(col_dt)
164 |
165 |
166 | transformed_dyf = DynamicFrame.fromDF(sparkDF, glueContext, "trnx")
167 |
168 | # Secure the lake through masking and encryption
169 | # Approach 1: Mask PII data
170 | masked_dyf = Map.apply(frame = transformed_dyf, f = detect_sensitive_info)
171 | masked_dyf.show()
172 |
173 | # Approach 2: Encrypting PII data
174 | # Apply encryption to the identified fields
175 | encrypted_dyf = Map.apply(frame = masked_dyf, f = encrypt_rows)
176 |
177 |
178 | # This Glue Transform drops null fields/columns if present in the dataset
179 | dropnullfields = DropNullFields.apply(frame=encrypted_dyf, transformation_ctx="dropnullfields")
180 | # This function repartitions the dataset into exactly two files however Coalesce is preferred
181 | # dropnullfields = dropnullfields.repartition(2)
182 |
183 | # logger.info('\n -- Printing schema after ETL --')
184 | # logger.info(dropnullfields.printSchema())
185 |
186 | logger.info('\n -- Storing data in snappy compressed, partitioned, parquet format for optimal query performance --')
187 | # Partition the DynamicFrame by Year/Month/Day. Compression type is snappy. Format is Parquet
188 | datasink4 = glueContext.write_dynamic_frame.from_options(frame=dropnullfields, connection_type="s3",
189 | connection_options={"path": s3_output_path,
190 | "partitionKeys": ['year', 'month',
191 | 'day']},
192 | format="parquet", transformation_ctx="s3sink")
193 |
194 |
195 | logger.info('Sample Glue Job complete')
196 | # Necessary for Glue Job Bookmarking
197 | job.commit()
198 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/ingestion_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack,
4 | NestedStack,
5 | aws_glue_alpha as _glue_alpha
6 | # aws_sqs as sqs,
7 | )
8 | import aws_cdk as _cdk
9 | from constructs import Construct
10 | import os
11 | from .etl_stack import EtlStack
12 |
13 |
14 | class IngestionStack(NestedStack):
15 |
16 | def __init__(self, scope: Construct, construct_id: str, bucket_name, **kwargs) -> None:
17 | super().__init__(scope, construct_id, **kwargs)
18 | env = self.node.try_get_context('environment_name')
19 | if env is None:
20 | print('Setting environment as Dev')
21 | print('Fetching Dev Properties')
22 | env = 'dev'
23 | # fetching details from cdk.json
24 | config_details = self.node.try_get_context(env)
25 | # Create an EventBus
26 | evt_bus = _cdk.aws_events.EventBus(
27 | self, f'bus-{env}', event_bus_name=config_details['bus-name'])
28 |
29 | # Create a rule that triggers on a Custom Bus event and sends data to Firehose
30 | # Define a rule that captures only card-events as an example
31 | custom_rule = _cdk.aws_events.Rule(self, f'bus-rule-{env}', rule_name=config_details['rule-name'],
32 | description="Match a custom-event type", event_bus=evt_bus,
33 | event_pattern=_cdk.aws_events.EventPattern(source=['transactions'], detail_type=['card-event']))
34 |
35 | # Create Kinesis Firehose as an Event Target
36 | # Step 1: Create a Firehose role
37 | firehose_to_s3_role = _cdk.aws_iam.Role(self, f'firehose_s3_role_{env}', assumed_by=_cdk.aws_iam.ServicePrincipal(
38 | 'firehose.amazonaws.com'), role_name=config_details['firehose-s3-rolename'])
39 |
40 | # Step 2: Create an S3 bucket as a Firehose target
41 | s3_bucket = _cdk.aws_s3.Bucket(
42 | self, f'evtbus_s3_{env}', bucket_name=bucket_name)
43 | s3_bucket.grant_read_write(firehose_to_s3_role)
44 |
45 | # Step 3: Create a Firehose Delivery Stream
46 | firehose_stream = _cdk.aws_kinesisfirehose.CfnDeliveryStream(self, f'firehose_stream_{env}',
47 | delivery_stream_name=config_details['firehose-name'],
48 | delivery_stream_type='DirectPut',
49 | s3_destination_configuration=_cdk.aws_kinesisfirehose
50 | .CfnDeliveryStream.S3DestinationConfigurationProperty(
51 | bucket_arn=s3_bucket.bucket_arn,
52 | compression_format='GZIP',
53 | role_arn=firehose_to_s3_role.role_arn,
54 | buffering_hints=_cdk.aws_kinesisfirehose.CfnDeliveryStream.BufferingHintsProperty(
55 | interval_in_seconds=config_details['buffering-interval-in-seconds'],
56 | size_in_m_bs=config_details['buffering-size-in-mb']
57 | ),
58 | prefix='raw-data/year=!{timestamp:YYYY}/month=!{timestamp:MM}/day=!{timestamp:dd}/',
59 | error_output_prefix='error/!{firehose:random-string}/!{firehose:error-output-type}/year=!{timestamp:YYYY}/month=!{timestamp:MM}/day=!{timestamp:dd}/'
60 | )
61 | )
62 |
63 | # Create an IAM role that allows EventBus to communicate with Kinesis Firehose
64 | evt_firehose_role = _cdk.aws_iam.Role(self, f'evt_bus_to_firehose_{env}',
65 | assumed_by=_cdk.aws_iam.ServicePrincipal('events.amazonaws.com'),
66 | role_name=config_details['eventbus-firehose-rolename'])
67 |
68 | evt_firehose_role.add_to_policy(_cdk.aws_iam.PolicyStatement(
69 | resources=[firehose_stream.attr_arn],
70 | actions=['firehose:PutRecord', 'firehose:PutRecordBatch']
71 | ))
72 |
73 | # Link EventBus/ EventRule/ Firehose Target
74 | custom_rule.add_target(_cdk.aws_events_targets.KinesisFirehoseStream(firehose_stream))
75 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/lambda_tester/event_simulator.py:
--------------------------------------------------------------------------------
1 | import boto3
2 | import json
3 | import datetime
4 | import random
5 |
6 | client = boto3.client('events')
7 |
8 |
9 | def handler(event, context):
10 |
11 | print(f'Event Emitter Sample')
12 |
13 | currencies = ['dollar', 'rupee', 'pound', 'rial']
14 | locations = ['US-TX-alto road, T4 serein', 'US-FL-palo road, lake view', 'IN-MH-cira street, Sector 17 Vashi', 'IN-GA-MG Road, Sector 25 Navi', 'IN-AP-SB Road, Sector 10 Mokl']
15 | # First name , Last name, Credit card number
16 | names = ['Adam-Oldham-4024007175687564', 'William-Wong-4250653376577248', 'Karma-Chako-4532695203170069', 'Fraser-Sequeira-376442558724183', 'Prasad-Vedhantham-340657673453698', 'Preeti-Mathias-5247358584639920', 'David-Valles-5409458579753902', 'Nathan-S-374420227894977', 'Sanjay-C-374549020453175', 'Vikas-K-3661894701348823']
17 | sample_json = {
18 | "amount": {
19 | "value": 50,
20 | "currency": "dollar"
21 | },
22 | "location": {
23 | "country": "US",
24 | "state": "TX",
25 | },
26 | "timestamp": "2022-12-31T00:00:00.000Z",
27 | "firstName": "Rav",
28 | "lastName": "G"
29 | }
30 |
31 | for i in range(0, 1000):
32 | sample_json["amount"]["value"] = random.randint(10, 5000)
33 | sample_json["amount"]["currency"] = random.choice(currencies)
34 | location = random.choice(locations).split('-')
35 | sample_json["location"]["country"] = location[0]
36 | sample_json["location"]["state"] = location[1]
37 | sample_json["location"]["city"] = location[2]
38 | name = random.choice(names).split('-')
39 | sample_json["firstName"] = name[0]
40 | sample_json["lastName"] = name[1]
41 | sample_json["credit_card"] = name[2]
42 | sample_json["transaction_message"] = name[0] + ' with credit card number ' + name[2] + ' made a purchase of ' + sample_json["amount"]["currency"] + '. Residing at ' + location[2] + ',' + location[1] + ', ' + location[0] + '.'
43 | sample_json["timestamp"] = datetime.datetime.utcnow().isoformat()[
44 | :-3] + 'Z'
45 |
46 | response = client.put_events(
47 | Entries=[
48 | {
49 | 'Time': datetime.datetime.now(),
50 | 'Source': 'transactions',
51 | 'DetailType': 'card-event',
52 | 'Detail': json.dumps(sample_json),
53 | 'EventBusName': 'serverless-bus-dev'
54 | },
55 | ]
56 | )
57 |
58 | #print(response)
59 | print('Simulation Complete. Events should be visible in S3 after 2(configured Firehose Buffer time) minutes')
60 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/test_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack,
4 | NestedStack
5 | # aws_sqs as sqs,
6 | )
7 | import aws_cdk as _cdk
8 | from constructs import Construct
9 | import os
10 |
11 |
12 | class TestStack(NestedStack):
13 |
14 | def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
15 | super().__init__(scope, construct_id, **kwargs)
16 | env = self.node.try_get_context('environment_name')
17 |
18 | # Define an On-demand Lambda function to randomly push data to the event bus
19 | function = _cdk.aws_lambda.Function(self, f'test_function_{env}', function_name=f'serverless-event-simulator-{env}',
20 | runtime=_cdk.aws_lambda.Runtime.PYTHON_3_9, memory_size=512, handler='event_simulator.handler',
21 | timeout= _cdk.Duration.minutes(10),
22 | code= _cdk.aws_lambda.Code.from_asset(os.path.join(os.getcwd(), 'serverless_datalake/infrastructure/lambda_tester/') ))
23 |
24 | lambda_policy = _cdk.aws_iam.PolicyStatement(actions=[
25 | "events:*",
26 | ], resources=["*"])
27 |
28 | function.add_to_role_policy(lambda_policy)
29 |
30 |
--------------------------------------------------------------------------------
/serverless_datalake/serverless_datalake_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack
4 | # aws_sqs as sqs,
5 | )
6 | import aws_cdk as _cdk
7 | import os
8 | from constructs import Construct
9 | from .infrastructure.ingestion_stack import IngestionStack
10 | from .infrastructure.etl_stack import EtlStack
11 | from .infrastructure.test_stack import TestStack
12 |
13 |
14 | class ServerlessDatalakeStack(Stack):
15 |
16 | def tag_my_stack(self, stack):
17 | tags = _cdk.Tags.of(stack)
18 | tags.add("project", "serverless-streaming-etl-sample")
19 |
20 | def __init__(self, scope: Construct, construct_id: str, bucket_name, **kwargs) -> None:
21 | super().__init__(scope, construct_id, **kwargs)
22 | env_name = self.node.try_get_context('environment_name')
23 | if env_name is None:
24 | print('Setting environment to dev as environment_name is not passed during synthesis')
25 | env_name = 'dev'
26 | account_id = os.getenv('CDK_DEFAULT_ACCOUNT')
27 | region = os.getenv('CDK_DEFAULT_REGION')
28 | env = _cdk.Environment(account=account_id, region=region)
29 | ingestion_bus_stack = IngestionStack(self, f'ingestion-bus-stack-{env_name}', bucket_name=bucket_name)
30 | etl_serverless_stack = EtlStack(self, f'etl-serverless-stack-{env}', bucket_name=bucket_name)
31 | test_stack = TestStack(self, f'test_serverless_datalake-{env}')
32 | self.tag_my_stack(ingestion_bus_stack)
33 | self.tag_my_stack(etl_serverless_stack)
34 | self.tag_my_stack(test_stack)
35 | etl_serverless_stack.add_dependency(ingestion_bus_stack)
36 | test_stack.add_dependency(etl_serverless_stack)
37 |
--------------------------------------------------------------------------------
/source.bat:
--------------------------------------------------------------------------------
1 | @echo off
2 |
3 | rem The sole purpose of this script is to make the command
4 | rem
5 | rem source .venv/bin/activate
6 | rem
7 | rem (which activates a Python virtualenv on Linux or Mac OS X) work on Windows.
8 | rem On Windows, this command just runs this batch file (the argument is ignored).
9 | rem
10 | rem Now we don't need to document a Windows command for activating a virtualenv.
11 |
12 | echo Executing .venv\Scripts\activate.bat for you
13 | .venv\Scripts\activate.bat
14 |
--------------------------------------------------------------------------------
124 |
125 |
126 |
127 | 21. Head back to the incognito window and fire the select command. Confirm if RLS and CLS are correctly working for that role.
128 | 22. Configurations for dev environment are defined in cdk.json. S3 bucket name is created on the fly based on account_id and region in which the cdk is deployed
129 |
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python3
2 | import os
3 |
4 | import aws_cdk as cdk
5 |
6 | from serverless_datalake.serverless_datalake_stack import ServerlessDatalakeStack
7 |
8 | account_id = os.getenv('CDK_DEFAULT_ACCOUNT')
9 | region = os.getenv('CDK_DEFAULT_REGION')
10 |
11 | app = cdk.App()
12 | env=cdk.Environment(account=account_id, region=region)
13 | # Set Context Bucket_name
14 | env_name = app.node.try_get_context('environment_name')
15 | bucket_name = f"lake-store-{env_name}-{region}-{account_id}"
16 | ServerlessDatalakeStack(app, "ServerlessDatalakeStack", bucket_name=bucket_name,
17 | # If you don't specify 'env', this stack will be environment-agnostic.
18 | # Account/Region-dependent features and context lookups will not work,
19 | # but a single synthesized template can be deployed anywhere.
20 |
21 | # Uncomment the next line to specialize this stack for the AWS Account
22 | # and Region that are implied by the current CLI configuration.
23 | env=env
24 |
25 | # Uncomment the next line if you know exactly what Account and Region you
26 | # want to deploy the stack to. */
27 |
28 | #env=cdk.Environment(account='123456789012', region='us-east-1'),
29 |
30 | # For more information, see https://docs.aws.amazon.com/cdk/latest/guide/environments.html
31 | )
32 |
33 | app.synth()
34 |
--------------------------------------------------------------------------------
/athena_query.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/athena_query.png
--------------------------------------------------------------------------------
/cdk.json:
--------------------------------------------------------------------------------
1 | {
2 | "app": "python3 app.py",
3 | "watch": {
4 | "include": [
5 | "**"
6 | ],
7 | "exclude": [
8 | "README.md",
9 | "cdk*.json",
10 | "requirements*.txt",
11 | "source.bat",
12 | "**/__init__.py",
13 | "python/__pycache__",
14 | "tests"
15 | ]
16 | },
17 | "context": {
18 | "@aws-cdk/aws-apigateway:usagePlanKeyOrderInsensitiveId": true,
19 | "@aws-cdk/core:stackRelativeExports": true,
20 | "@aws-cdk/aws-rds:lowercaseDbIdentifier": true,
21 | "@aws-cdk/aws-lambda:recognizeVersionProps": true,
22 | "@aws-cdk/aws-lambda:recognizeLayerVersion": true,
23 | "@aws-cdk/aws-cloudfront:defaultSecurityPolicyTLSv1.2_2021": true,
24 | "@aws-cdk-containers/ecs-service-extensions:enableDefaultLogDriver": true,
25 | "@aws-cdk/aws-ec2:uniqueImdsv2TemplateName": true,
26 | "@aws-cdk/core:checkSecretUsage": true,
27 | "@aws-cdk/aws-iam:minimizePolicies": true,
28 | "@aws-cdk/aws-ecs:arnFormatIncludesClusterName": true,
29 | "@aws-cdk/core:validateSnapshotRemovalPolicy": true,
30 | "@aws-cdk/aws-codepipeline:crossAccountKeyAliasStackSafeResourceName": true,
31 | "@aws-cdk/aws-s3:createDefaultLoggingPolicy": true,
32 | "@aws-cdk/aws-sns-subscriptions:restrictSqsDescryption": true,
33 | "@aws-cdk/aws-apigateway:disableCloudWatchRole": true,
34 | "@aws-cdk/core:enablePartitionLiterals": true,
35 | "@aws-cdk/core:target-partitions": [
36 | "aws",
37 | "aws-cn"
38 | ],
39 | "dev": {
40 | "bus-name": "serverless-bus-dev",
41 | "rule-name": "custom-event-rule-dev",
42 | "event-pattern": "custom-event-pattern-dev",
43 | "firehose-name": "sample-stream-dev",
44 | "buffering-interval-in-seconds": 120,
45 | "buffering-size-in-mb": 128,
46 | "firehose-s3-rolename": "firehoses3dev",
47 | "eventbus-firehose-rolename": "eventbusfirehosedev",
48 | "glue-job-name": "serverless-etl-job-dev",
49 | "workers": 7,
50 | "worker-type": "G.1X",
51 | "glue-script-location": "glue/scripts/",
52 | "glue-script-uri": "/glue/scripts/event-bridge-dev-etl.py",
53 | "temp-location": "/glue/etl/temp/",
54 | "glue-database-location": "/glue/etl/database/",
55 | "glue-database-name": "serverless-lake",
56 | "glue-table-name": "processed-table",
57 | "glue-crawler": "serverless-lake-crawler",
58 | "glue-output": "/glue/output/",
59 | "glue-job-trigger-name": "scheduled-etl-job-trigger-dev",
60 | "glue-job-cron": "cron(0/15 * * * ? *)",
61 | "glue-crawler-trigger-name": "crawler-trigger-dev",
62 | "glue-script-local-machine": ""
63 | }
64 | }
65 | }
66 |
--------------------------------------------------------------------------------
/create_lake.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 | # Assuming we are in Serverless-datalake folder
3 | cd ..
4 | echo "--- Upgrading npm ---"
5 | sudo npm install n stable -g
6 | echo "--- Installing cdk ---"
7 | sudo npm install -g aws-cdk@2.55.1
8 | echo "--- Bootstrapping CDK on account ---"
9 | cdk bootstrap aws://$(aws sts get-caller-identity --query "Account" --output text)/us-east-1
10 | echo "--- Cloning serverless-datalake project from aws-samples ---"
11 | # assuming we have already cloned.
12 | # git clone https://github.com/aws-samples/serverless-datalake.git
13 | cd serverless-datalake
14 | echo "--- Set python virtual environment ---"
15 | python3 -m venv .venv
16 | echo "--- Activate virtual environment ---"
17 | source .venv/bin/activate
18 | echo "--- Install Requirements ---"
19 | pip install -r requirements.txt
20 | echo "--- CDK synthesize ---"
21 | cdk synth -c environment_name=dev
22 | echo "--- CDK deploy ---"
23 | # read -p "Press any key to deploy the Serverless Datalake ..."
24 | cdk deploy -c environment_name=dev ServerlessDatalakeStack
25 | echo "Lake deployed successfully"
26 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
27 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
28 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
29 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
30 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
31 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
32 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
33 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
34 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
35 | aws lambda invoke --function-name serverless-event-simulator-dev --invocation-type Event --cli-binary-format raw-in-base64-out --payload '{ "name": "sample" }' response.json
--------------------------------------------------------------------------------
/glue-crawler.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/glue-crawler.png
--------------------------------------------------------------------------------
/glue-table.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/glue-table.png
--------------------------------------------------------------------------------
/glue-workflow.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/glue-workflow.png
--------------------------------------------------------------------------------
/requirements-dev.txt:
--------------------------------------------------------------------------------
1 | pytest==6.2.5
2 | aws-cdk-lib==2.55.1
3 | aws-cdk.aws-glue-alpha==2.55.1a0
4 | constructs>=10.0.0,<11.0.0
5 |
6 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | aws-cdk-lib==2.55.1
2 | aws-cdk.aws-glue-alpha==2.55.1a0
3 | constructs>=10.0.0,<11.0.0
4 |
--------------------------------------------------------------------------------
/serverless-datalake.drawio.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/serverless-datalake.drawio.png
--------------------------------------------------------------------------------
/serverless_datalake.zip:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/serverless_datalake.zip
--------------------------------------------------------------------------------
/serverless_datalake/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/aws-samples/serverless-datalake/3569b8c035a36e63356fe6423c2490cf442644b1/serverless_datalake/__init__.py
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/etl_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack,
4 | NestedStack,
5 | aws_glue_alpha as _glue_alpha
6 | # aws_sqs as sqs,
7 | )
8 | import aws_cdk as _cdk
9 | from constructs import Construct
10 | import os
11 |
12 |
13 | class EtlStack(NestedStack):
14 |
15 | def __init__(self, scope: Construct, construct_id: str, bucket_name, **kwargs) -> None:
16 | super().__init__(scope, construct_id, **kwargs)
17 | env = self.node.try_get_context('environment_name')
18 | if env is None:
19 | print('Setting environment as Dev')
20 | print('Fetching Dev Properties')
21 | env = 'dev'
22 | # fetching details from cdk.json
23 | config_details = self.node.try_get_context(env)
24 | # Create a Glue Role
25 | glue_role = _cdk.aws_iam.Role(self, f'etl-role-{env}', assumed_by=_cdk.aws_iam.ServicePrincipal(service='glue.amazonaws.com'),
26 | role_name=f'etlrole{env}', managed_policies=[
27 | _cdk.aws_iam.ManagedPolicy.from_managed_policy_arn(self, 's3-full-access-etl',
28 | managed_policy_arn='arn:aws:iam::aws:policy/AmazonS3FullAccess'),
29 | _cdk.aws_iam.ManagedPolicy.from_managed_policy_arn(self, 'comprehend-full-access-etl',
30 | managed_policy_arn='arn:aws:iam::aws:policy/ComprehendFullAccess'),
31 | _cdk.aws_iam.ManagedPolicy.from_aws_managed_policy_name(
32 | "service-role/AWSGlueServiceRole")
33 | ]
34 | )
35 |
36 | s3_bucket = _cdk.aws_s3.Bucket.from_bucket_name(
37 | self, f's3_lake_{env}', bucket_name=bucket_name)
38 |
39 | # Upload Glue Script on S3
40 | _cdk.aws_s3_deployment.BucketDeployment(self, f"glue_scripts_deploy_{env}",
41 | sources=[_cdk.aws_s3_deployment.Source
42 | .asset(os.path.join(os.getcwd(), 'serverless_datalake/infrastructure/glue_job/'))],
43 | destination_bucket=s3_bucket,
44 | destination_key_prefix=config_details[
45 | "glue-script-location"]
46 | )
47 | workflow = _cdk.aws_glue.CfnWorkflow(self, f'workflow-{env}', name=f'serverless-etl-{env}',
48 | description='sample etl with eventbridge ingestion', max_concurrent_runs=1)
49 |
50 | # Create a Glue job and run on schedule
51 | glue_job = _cdk.aws_glue.CfnJob(
52 | self, f'serverless-etl-{env}',
53 | name=config_details['glue-job-name'],
54 | number_of_workers=config_details['workers'],
55 | worker_type=config_details['worker-type'],
56 | command=_cdk.aws_glue.CfnJob.JobCommandProperty(name='glueetl',
57 | script_location=f"s3://{bucket_name}{config_details['glue-script-uri']}",
58 | ),
59 | role=glue_role.role_arn,
60 | glue_version='3.0',
61 | execution_property=_cdk.aws_glue.CfnJob.ExecutionPropertyProperty(
62 | max_concurrent_runs=1),
63 | description='Serverless etl processing raw data from event-bus',
64 | default_arguments={
65 | "--enable-metrics": "",
66 | "--enable-job-insights": "true",
67 | '--TempDir': f"s3://{bucket_name}{config_details['temp-location']}",
68 | '--job-bookmark-option': 'job-bookmark-enable',
69 | '--s3_input_location': f's3://{bucket_name}/raw-data/',
70 | '--s3_output_location': f"s3://{bucket_name}{config_details['glue-output']}"
71 | }
72 | )
73 |
74 |
75 | # Create a Glue Database
76 | glue_database = _cdk.aws_glue.CfnDatabase(self, f'glue-database-{env}',
77 | catalog_id=self.account, database_input=_cdk.aws_glue.CfnDatabase
78 | .DatabaseInputProperty(
79 | location_uri=f"s3://{bucket_name}{config_details['glue-database-location']}",
80 | description='store processed data', name=config_details['glue-database-name']))
81 |
82 | # Create a Glue Crawler
83 | glue_crawler = _cdk.aws_glue.CfnCrawler(self, f'glue-crawler-{env}',
84 | role=glue_role.role_arn, name=config_details['glue-crawler'],
85 | database_name=config_details['glue-database-name'],
86 | targets=_cdk.aws_glue.CfnCrawler.TargetsProperty(s3_targets=[
87 | _cdk.aws_glue.CfnCrawler.S3TargetProperty(
88 | path=f"s3://{bucket_name}{config_details['glue-output']}")
89 | ]), table_prefix=config_details['glue-table-name'],
90 | description='Crawl over processed parquet data. This optimizes query cost'
91 | )
92 |
93 | # Create a Glue cron Trigger ̰
94 | job_trigger = _cdk.aws_glue.CfnTrigger(self, f'glue-job-trigger-{env}',
95 | name=config_details['glue-job-trigger-name'],
96 | actions=[_cdk.aws_glue.CfnTrigger.ActionProperty(job_name=glue_job.name)],
97 | workflow_name=workflow.name,
98 | type='SCHEDULED',
99 | start_on_creation=True,
100 | schedule=config_details['glue-job-cron'])
101 |
102 | job_trigger.add_depends_on(glue_job)
103 | job_trigger.add_depends_on(glue_crawler)
104 | job_trigger.add_depends_on(glue_database)
105 |
106 | # Create a Glue conditional trigger that triggers the crawler on successful job completion
107 | crawler_trigger = _cdk.aws_glue.CfnTrigger(self, f'glue-crawler-trigger-{env}',
108 | name=config_details['glue-crawler-trigger-name'],
109 | actions=[_cdk.aws_glue.CfnTrigger.ActionProperty(
110 | crawler_name=glue_crawler.name)],
111 | workflow_name=workflow.name,
112 | type='CONDITIONAL',
113 | predicate=_cdk.aws_glue.CfnTrigger.PredicateProperty(
114 | conditions=[_cdk.aws_glue.CfnTrigger.ConditionProperty(
115 | job_name=glue_job.name,
116 | logical_operator='EQUALS',
117 | state="SUCCEEDED"
118 | )]
119 | ),
120 | start_on_creation=True
121 | )
122 |
123 | crawler_trigger.add_depends_on(glue_job)
124 | crawler_trigger.add_depends_on(glue_crawler)
125 | crawler_trigger.add_depends_on(glue_database)
126 |
127 |
128 |
129 |
130 | #TODO: Create an Athena Workgroup
131 |
132 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/glue_job/event-bridge-dev-etl.py:
--------------------------------------------------------------------------------
1 | import boto3
2 | import sys
3 | from awsglue.transforms import *
4 | from awsglue.utils import getResolvedOptions
5 | from pyspark.context import SparkContext
6 | from awsglue.context import GlueContext
7 | from awsglue.job import Job
8 | from awsglue.dynamicframe import DynamicFrame
9 | from datetime import datetime, timedelta
10 | from pyspark.sql.functions import to_json, struct, substring, from_json, lit, col, when, concat, concat_ws
11 | from pyspark.sql.types import StringType
12 | import hashlib, uuid
13 |
14 |
15 | def get_masked_entities():
16 | """
17 | return a list of entities to be masked.
18 | If unstructured, use comprehend to determine entities to be masked
19 | """
20 | return ["name", "credit_card", "account", "city"]
21 |
22 | def get_encrypted_entities():
23 | """
24 | return a list of entities to be masked.
25 | """
26 | return ["name", "credit_card"]
27 |
28 |
29 | def get_region_name():
30 | global my_region
31 | my_session = boto3.session.Session()
32 | return my_session.region_name
33 |
34 |
35 | def detect_sensitive_info(r):
36 | """
37 | return a tuple after masking is complete.
38 | If unstructured, use comprehend to determine entities to be masked
39 | """
40 |
41 | metadata = r['trnx_msg']
42 | try:
43 | for entity in get_masked_entities():
44 | entity_masked = entity + "_masked"
45 | r[entity_masked] = "#######################"
46 | except:
47 | print ("DEBUG:",sys.exc_info())
48 |
49 | ''' Uncomment to mask unstructured text through Amazon Comprehend '''
50 | ''' Can result in extendend Glue Job times'''
51 | # client_pii = boto3.client('comprehend', region_name=get_region_name())
52 |
53 | # try:
54 | # response = client_pii.detect_pii_entities(
55 | # Text = metadata,
56 | # LanguageCode = 'en'
57 | # )
58 | # clean_text = metadata
59 | # # reversed to not modify the offsets of other entities when substituting
60 | # for NER in reversed(response['Entities']):
61 | # clean_text = clean_text[:NER['BeginOffset']] + NER['Type'] + clean_text[NER['EndOffset']:]
62 | # print(clean_text)
63 | # r['trnx_msg_masked'] = clean_text
64 | # except:
65 | # print ("DEBUG:",sys.exc_info())
66 |
67 | return r
68 |
69 |
70 | def encrypt_rows(r):
71 | """
72 | return tuple with encrypted string
73 | Hardcoding salted string. PLease feel free to use SSM and KMS.
74 | """
75 | salted_string = 'glue_crypt'
76 | encrypted_entities = get_encrypted_entities()
77 | print ("encrypt_rows", salted_string, encrypted_entities)
78 | try:
79 | for entity in encrypted_entities:
80 | salted_entity = r[entity] + salted_string
81 | hashkey = hashlib.sha3_256(salted_entity.encode()).hexdigest()
82 | r[entity + '_encrypted'] = hashkey
83 | except:
84 | print ("DEBUG:",sys.exc_info())
85 | return r
86 |
87 |
88 | args = getResolvedOptions(sys.argv, ['JOB_NAME', 's3_output_location', 's3_input_location'])
89 | sc = SparkContext()
90 | glueContext = GlueContext(sc)
91 | spark = glueContext.spark_session
92 | job = Job(glueContext)
93 | job.init(args['JOB_NAME'], args)
94 | logger = glueContext.get_logger()
95 |
96 | logger.info('\n -- Glue ETL Job begins -- ')
97 |
98 | s3_input_path = args["s3_input_location"]
99 | s3_output_path = args["s3_output_location"]
100 |
101 | now = datetime.utcnow()
102 | current_date = now.date()
103 | # Go back 5 days in the past. With Glue Bookmarking enabled only newer files are processed
104 | from_date = current_date - timedelta(days=5)
105 | delta = timedelta(days=1)
106 | bucket_path = []
107 | while from_date <= current_date:
108 | # S3 Paths to process.
109 | if len(bucket_path) >= 10:
110 | logger.info(f'\n Backtrack complete: Found all paths up to {from_date} ')
111 | break
112 | lastprocessedtimestamp = str(from_date)
113 | path = s3_input_path + 'year=' + str(from_date.year) + '/month=' + str(from_date.month).zfill(
114 | 2) + '/day=' + str(from_date.day).zfill(2)
115 | logger.info(f'\n AWS Glue will check for newer unprocessed files in path : {path}')
116 | bucket_path.append(path)
117 | from_date += delta
118 |
119 |
120 |
121 | if len(bucket_path) > 0:
122 | # Read S3 data as a Glue Dynamic Frame
123 | datasource0 = glueContext.create_dynamic_frame.from_options(connection_type="s3",
124 | connection_options={'paths': bucket_path,
125 | 'groupFiles': 'inPartition'},
126 | format="json", transformation_ctx="dtx")
127 | if datasource0 and datasource0.count() > 0:
128 |
129 | logger.info('\n -- Printing datasource schema --')
130 | logger.info(datasource0.printSchema())
131 |
132 | # Unnests json data into a flat dataframe.
133 | # This glue transform converts a nested json into a flattened Glue DynamicFrame
134 | logger.info('\n -- Unnest dynamic frame --')
135 | unnested_dyf = UnnestFrame.apply(frame=datasource0, transformation_ctx='unnest')
136 |
137 | # Convert to a Spark DataFrame
138 | sparkDF = unnested_dyf.toDF()
139 |
140 | logger.info('\n -- Add new Columns to Spark data frame --')
141 | # Generate Year/Month/day columns from the time field
142 | sparkDF = sparkDF.withColumn('year', substring('time', 1, 4))
143 | sparkDF = sparkDF.withColumn('month', substring('time', 6, 2))
144 | sparkDF = sparkDF.withColumn('day', substring('time', 9, 2))
145 |
146 | # Rename fields
147 | sparkDF = sparkDF.withColumnRenamed("detail.amount.value", "amount")
148 | sparkDF = sparkDF.withColumnRenamed("detail.amount.currency", "currency")
149 | sparkDF = sparkDF.withColumnRenamed("detail.location.country", "country")
150 | sparkDF = sparkDF.withColumnRenamed("detail.location.state", "state")
151 | sparkDF = sparkDF.withColumnRenamed("detail.location.city", "city")
152 | sparkDF = sparkDF.withColumnRenamed("detail.credit_card", "credit_card_number")
153 | sparkDF = sparkDF.withColumnRenamed("detail.transaction_message", "trnx_msg")
154 |
155 | # Concat firstName and LastName columns
156 | sparkDF = sparkDF.withColumn('name', concat_ws(' ', sparkDF["`detail.firstName`"], sparkDF["`detail.lastName`"]))
157 |
158 | dt_cols = sparkDF.columns
159 | # Drop detail.* columns
160 | for col_dt in dt_cols:
161 | if '.' in col_dt:
162 | logger.info(f'Dropping Column {col_dt}')
163 | sparkDF = sparkDF.drop(col_dt)
164 |
165 |
166 | transformed_dyf = DynamicFrame.fromDF(sparkDF, glueContext, "trnx")
167 |
168 | # Secure the lake through masking and encryption
169 | # Approach 1: Mask PII data
170 | masked_dyf = Map.apply(frame = transformed_dyf, f = detect_sensitive_info)
171 | masked_dyf.show()
172 |
173 | # Approach 2: Encrypting PII data
174 | # Apply encryption to the identified fields
175 | encrypted_dyf = Map.apply(frame = masked_dyf, f = encrypt_rows)
176 |
177 |
178 | # This Glue Transform drops null fields/columns if present in the dataset
179 | dropnullfields = DropNullFields.apply(frame=encrypted_dyf, transformation_ctx="dropnullfields")
180 | # This function repartitions the dataset into exactly two files however Coalesce is preferred
181 | # dropnullfields = dropnullfields.repartition(2)
182 |
183 | # logger.info('\n -- Printing schema after ETL --')
184 | # logger.info(dropnullfields.printSchema())
185 |
186 | logger.info('\n -- Storing data in snappy compressed, partitioned, parquet format for optimal query performance --')
187 | # Partition the DynamicFrame by Year/Month/Day. Compression type is snappy. Format is Parquet
188 | datasink4 = glueContext.write_dynamic_frame.from_options(frame=dropnullfields, connection_type="s3",
189 | connection_options={"path": s3_output_path,
190 | "partitionKeys": ['year', 'month',
191 | 'day']},
192 | format="parquet", transformation_ctx="s3sink")
193 |
194 |
195 | logger.info('Sample Glue Job complete')
196 | # Necessary for Glue Job Bookmarking
197 | job.commit()
198 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/ingestion_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack,
4 | NestedStack,
5 | aws_glue_alpha as _glue_alpha
6 | # aws_sqs as sqs,
7 | )
8 | import aws_cdk as _cdk
9 | from constructs import Construct
10 | import os
11 | from .etl_stack import EtlStack
12 |
13 |
14 | class IngestionStack(NestedStack):
15 |
16 | def __init__(self, scope: Construct, construct_id: str, bucket_name, **kwargs) -> None:
17 | super().__init__(scope, construct_id, **kwargs)
18 | env = self.node.try_get_context('environment_name')
19 | if env is None:
20 | print('Setting environment as Dev')
21 | print('Fetching Dev Properties')
22 | env = 'dev'
23 | # fetching details from cdk.json
24 | config_details = self.node.try_get_context(env)
25 | # Create an EventBus
26 | evt_bus = _cdk.aws_events.EventBus(
27 | self, f'bus-{env}', event_bus_name=config_details['bus-name'])
28 |
29 | # Create a rule that triggers on a Custom Bus event and sends data to Firehose
30 | # Define a rule that captures only card-events as an example
31 | custom_rule = _cdk.aws_events.Rule(self, f'bus-rule-{env}', rule_name=config_details['rule-name'],
32 | description="Match a custom-event type", event_bus=evt_bus,
33 | event_pattern=_cdk.aws_events.EventPattern(source=['transactions'], detail_type=['card-event']))
34 |
35 | # Create Kinesis Firehose as an Event Target
36 | # Step 1: Create a Firehose role
37 | firehose_to_s3_role = _cdk.aws_iam.Role(self, f'firehose_s3_role_{env}', assumed_by=_cdk.aws_iam.ServicePrincipal(
38 | 'firehose.amazonaws.com'), role_name=config_details['firehose-s3-rolename'])
39 |
40 | # Step 2: Create an S3 bucket as a Firehose target
41 | s3_bucket = _cdk.aws_s3.Bucket(
42 | self, f'evtbus_s3_{env}', bucket_name=bucket_name)
43 | s3_bucket.grant_read_write(firehose_to_s3_role)
44 |
45 | # Step 3: Create a Firehose Delivery Stream
46 | firehose_stream = _cdk.aws_kinesisfirehose.CfnDeliveryStream(self, f'firehose_stream_{env}',
47 | delivery_stream_name=config_details['firehose-name'],
48 | delivery_stream_type='DirectPut',
49 | s3_destination_configuration=_cdk.aws_kinesisfirehose
50 | .CfnDeliveryStream.S3DestinationConfigurationProperty(
51 | bucket_arn=s3_bucket.bucket_arn,
52 | compression_format='GZIP',
53 | role_arn=firehose_to_s3_role.role_arn,
54 | buffering_hints=_cdk.aws_kinesisfirehose.CfnDeliveryStream.BufferingHintsProperty(
55 | interval_in_seconds=config_details['buffering-interval-in-seconds'],
56 | size_in_m_bs=config_details['buffering-size-in-mb']
57 | ),
58 | prefix='raw-data/year=!{timestamp:YYYY}/month=!{timestamp:MM}/day=!{timestamp:dd}/',
59 | error_output_prefix='error/!{firehose:random-string}/!{firehose:error-output-type}/year=!{timestamp:YYYY}/month=!{timestamp:MM}/day=!{timestamp:dd}/'
60 | )
61 | )
62 |
63 | # Create an IAM role that allows EventBus to communicate with Kinesis Firehose
64 | evt_firehose_role = _cdk.aws_iam.Role(self, f'evt_bus_to_firehose_{env}',
65 | assumed_by=_cdk.aws_iam.ServicePrincipal('events.amazonaws.com'),
66 | role_name=config_details['eventbus-firehose-rolename'])
67 |
68 | evt_firehose_role.add_to_policy(_cdk.aws_iam.PolicyStatement(
69 | resources=[firehose_stream.attr_arn],
70 | actions=['firehose:PutRecord', 'firehose:PutRecordBatch']
71 | ))
72 |
73 | # Link EventBus/ EventRule/ Firehose Target
74 | custom_rule.add_target(_cdk.aws_events_targets.KinesisFirehoseStream(firehose_stream))
75 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/lambda_tester/event_simulator.py:
--------------------------------------------------------------------------------
1 | import boto3
2 | import json
3 | import datetime
4 | import random
5 |
6 | client = boto3.client('events')
7 |
8 |
9 | def handler(event, context):
10 |
11 | print(f'Event Emitter Sample')
12 |
13 | currencies = ['dollar', 'rupee', 'pound', 'rial']
14 | locations = ['US-TX-alto road, T4 serein', 'US-FL-palo road, lake view', 'IN-MH-cira street, Sector 17 Vashi', 'IN-GA-MG Road, Sector 25 Navi', 'IN-AP-SB Road, Sector 10 Mokl']
15 | # First name , Last name, Credit card number
16 | names = ['Adam-Oldham-4024007175687564', 'William-Wong-4250653376577248', 'Karma-Chako-4532695203170069', 'Fraser-Sequeira-376442558724183', 'Prasad-Vedhantham-340657673453698', 'Preeti-Mathias-5247358584639920', 'David-Valles-5409458579753902', 'Nathan-S-374420227894977', 'Sanjay-C-374549020453175', 'Vikas-K-3661894701348823']
17 | sample_json = {
18 | "amount": {
19 | "value": 50,
20 | "currency": "dollar"
21 | },
22 | "location": {
23 | "country": "US",
24 | "state": "TX",
25 | },
26 | "timestamp": "2022-12-31T00:00:00.000Z",
27 | "firstName": "Rav",
28 | "lastName": "G"
29 | }
30 |
31 | for i in range(0, 1000):
32 | sample_json["amount"]["value"] = random.randint(10, 5000)
33 | sample_json["amount"]["currency"] = random.choice(currencies)
34 | location = random.choice(locations).split('-')
35 | sample_json["location"]["country"] = location[0]
36 | sample_json["location"]["state"] = location[1]
37 | sample_json["location"]["city"] = location[2]
38 | name = random.choice(names).split('-')
39 | sample_json["firstName"] = name[0]
40 | sample_json["lastName"] = name[1]
41 | sample_json["credit_card"] = name[2]
42 | sample_json["transaction_message"] = name[0] + ' with credit card number ' + name[2] + ' made a purchase of ' + sample_json["amount"]["currency"] + '. Residing at ' + location[2] + ',' + location[1] + ', ' + location[0] + '.'
43 | sample_json["timestamp"] = datetime.datetime.utcnow().isoformat()[
44 | :-3] + 'Z'
45 |
46 | response = client.put_events(
47 | Entries=[
48 | {
49 | 'Time': datetime.datetime.now(),
50 | 'Source': 'transactions',
51 | 'DetailType': 'card-event',
52 | 'Detail': json.dumps(sample_json),
53 | 'EventBusName': 'serverless-bus-dev'
54 | },
55 | ]
56 | )
57 |
58 | #print(response)
59 | print('Simulation Complete. Events should be visible in S3 after 2(configured Firehose Buffer time) minutes')
60 |
--------------------------------------------------------------------------------
/serverless_datalake/infrastructure/test_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack,
4 | NestedStack
5 | # aws_sqs as sqs,
6 | )
7 | import aws_cdk as _cdk
8 | from constructs import Construct
9 | import os
10 |
11 |
12 | class TestStack(NestedStack):
13 |
14 | def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
15 | super().__init__(scope, construct_id, **kwargs)
16 | env = self.node.try_get_context('environment_name')
17 |
18 | # Define an On-demand Lambda function to randomly push data to the event bus
19 | function = _cdk.aws_lambda.Function(self, f'test_function_{env}', function_name=f'serverless-event-simulator-{env}',
20 | runtime=_cdk.aws_lambda.Runtime.PYTHON_3_9, memory_size=512, handler='event_simulator.handler',
21 | timeout= _cdk.Duration.minutes(10),
22 | code= _cdk.aws_lambda.Code.from_asset(os.path.join(os.getcwd(), 'serverless_datalake/infrastructure/lambda_tester/') ))
23 |
24 | lambda_policy = _cdk.aws_iam.PolicyStatement(actions=[
25 | "events:*",
26 | ], resources=["*"])
27 |
28 | function.add_to_role_policy(lambda_policy)
29 |
30 |
--------------------------------------------------------------------------------
/serverless_datalake/serverless_datalake_stack.py:
--------------------------------------------------------------------------------
1 | from aws_cdk import (
2 | # Duration,
3 | Stack
4 | # aws_sqs as sqs,
5 | )
6 | import aws_cdk as _cdk
7 | import os
8 | from constructs import Construct
9 | from .infrastructure.ingestion_stack import IngestionStack
10 | from .infrastructure.etl_stack import EtlStack
11 | from .infrastructure.test_stack import TestStack
12 |
13 |
14 | class ServerlessDatalakeStack(Stack):
15 |
16 | def tag_my_stack(self, stack):
17 | tags = _cdk.Tags.of(stack)
18 | tags.add("project", "serverless-streaming-etl-sample")
19 |
20 | def __init__(self, scope: Construct, construct_id: str, bucket_name, **kwargs) -> None:
21 | super().__init__(scope, construct_id, **kwargs)
22 | env_name = self.node.try_get_context('environment_name')
23 | if env_name is None:
24 | print('Setting environment to dev as environment_name is not passed during synthesis')
25 | env_name = 'dev'
26 | account_id = os.getenv('CDK_DEFAULT_ACCOUNT')
27 | region = os.getenv('CDK_DEFAULT_REGION')
28 | env = _cdk.Environment(account=account_id, region=region)
29 | ingestion_bus_stack = IngestionStack(self, f'ingestion-bus-stack-{env_name}', bucket_name=bucket_name)
30 | etl_serverless_stack = EtlStack(self, f'etl-serverless-stack-{env}', bucket_name=bucket_name)
31 | test_stack = TestStack(self, f'test_serverless_datalake-{env}')
32 | self.tag_my_stack(ingestion_bus_stack)
33 | self.tag_my_stack(etl_serverless_stack)
34 | self.tag_my_stack(test_stack)
35 | etl_serverless_stack.add_dependency(ingestion_bus_stack)
36 | test_stack.add_dependency(etl_serverless_stack)
37 |
--------------------------------------------------------------------------------
/source.bat:
--------------------------------------------------------------------------------
1 | @echo off
2 |
3 | rem The sole purpose of this script is to make the command
4 | rem
5 | rem source .venv/bin/activate
6 | rem
7 | rem (which activates a Python virtualenv on Linux or Mac OS X) work on Windows.
8 | rem On Windows, this command just runs this batch file (the argument is ignored).
9 | rem
10 | rem Now we don't need to document a Windows command for activating a virtualenv.
11 |
12 | echo Executing .venv\Scripts\activate.bat for you
13 | .venv\Scripts\activate.bat
14 |
--------------------------------------------------------------------------------