├── .gitignore
├── 2. 네트워크(1)
├── 박상욱.md
├── 김대현
│ ├── attachments
│ │ ├── Pasted image 20230131200125.png
│ │ ├── Pasted image 20230131200354.png
│ │ ├── Pasted image 20230131200544.png
│ │ ├── Pasted image 20230131200953.png
│ │ ├── Pasted image 20230131201009.png
│ │ ├── Pasted image 20230131201819.png
│ │ ├── Pasted image 20230131201826.png
│ │ ├── Pasted image 20230131204315.png
│ │ ├── Pasted image 20230131212433.png
│ │ ├── Pasted image 20230131215423.png
│ │ └── Pasted image 20230131220505.png
│ ├── 2.1 네트워크의 기초.md
│ └── 2.2 TCP-IP 4계층 모델.md
├── README.md
├── 네트워크의 기초(1)_송민진.md
├── 네트워크(1)_이홍섭.md
└── OSI 7계층 모델(2)_송민진.md
├── 3. 운영체제(1)
├── 운영체제(1)_박상욱.md
├── 운영체제(1)_김대현
│ ├── attachments
│ │ ├── Pasted image 20230216232448.png
│ │ ├── Pasted image 20230216233311.png
│ │ └── Pasted image 20230216233547.png
│ ├── 3.1 운영체제와 컴퓨터.md
│ └── 3.2 메모리.md
├── README.md
├── 운영체제(1)_이홍섭.md
└── 운영체제(1)_송민진.md
├── 3. 운영체제(2)
├── 운영체제(2)_박상욱.md
├── 운영체제(2)_김대현
│ ├── attachments
│ │ ├── Pasted image 20230224000610.png
│ │ ├── Pasted image 20230224001217.png
│ │ ├── Pasted image 20230224005331.png
│ │ └── Pasted image 20230224010005.png
│ ├── 3.4 CPU 스케쥴링 알고리즘.md
│ └── 3.3 프로세스와 스레드.md
├── 운영체제(2)_송민진
│ ├── attachments
│ │ ├── Pasted image 20230224001244.png
│ │ ├── Pasted image 20230224004257.png
│ │ ├── Pasted image 20230224172321.png
│ │ ├── Pasted image 20230224174152.png
│ │ ├── Pasted image 20230306001212.png
│ │ ├── Pasted image 20230306001403.png
│ │ ├── Pasted image 20230306001649.png
│ │ ├── Pasted image 20230306001757.png
│ │ ├── Pasted image 20230306003458.png
│ │ └── Pasted image 20230306004212.png
│ └── 운영체제(2)_송민진.md
├── README.md
└── 운영체제(2)_이홍섭.md
├── 2. 네트워크(2)
├── 박상욱.md
├── 김대현
│ ├── attachments
│ │ ├── Pasted image 20230210110801.png
│ │ ├── Pasted image 20230210111157.png
│ │ ├── Pasted image 20230210111617.png
│ │ ├── Pasted image 20230210114522.png
│ │ ├── Pasted image 20230210134250.png
│ │ ├── Pasted image 20230210134336.png
│ │ ├── Pasted image 20230210134518.png
│ │ ├── Pasted image 20230210134957.png
│ │ ├── Pasted image 20230210140125.png
│ │ ├── Pasted image 20230210140348.png
│ │ ├── Pasted image 20230210140817.png
│ │ ├── Pasted image 20230210142830.png
│ │ ├── Pasted image 20230210143300.png
│ │ ├── Pasted image 20230210143409.png
│ │ ├── Pasted image 20230210143644.png
│ │ └── Pasted image 20230210143927.png
│ ├── 2.4 IP 주소.md
│ └── 2.5 HTTP.md
├── README.md
└── 네트워크(2)_이홍섭.md
├── 4. 데이터베이스(1)
├── 데이터베이스(1)_김대현
│ ├── attachments
│ │ ├── Pasted image 20230303140028.png
│ │ ├── Pasted image 20230303140043.png
│ │ ├── Pasted image 20230303140124.png
│ │ ├── Pasted image 20230303140239.png
│ │ ├── Pasted image 20230303141546.png
│ │ ├── Pasted image 20230303141659.png
│ │ ├── Pasted image 20230303141847.png
│ │ ├── Pasted image 20230303142532.png
│ │ ├── Pasted image 20230303145133.png
│ │ ├── Pasted image 20230303145213.png
│ │ ├── Pasted image 20230303145239.png
│ │ ├── Pasted image 20230303145433.png
│ │ └── Pasted image 20230303145558.png
│ ├── 4.2 ERD와 정규화 과정.md
│ └── 4.3 트랜잭션과 무결성.md
├── 데이터베이스(1)_송민진
│ ├── attachments
│ │ ├── Pasted image 20230303025149.png
│ │ ├── Pasted image 20230303025232.png
│ │ ├── Pasted image 20230303025541.png
│ │ ├── Pasted image 20230303030049.png
│ │ ├── Pasted image 20230303030852.png
│ │ ├── Pasted image 20230303031321.png
│ │ ├── Pasted image 20230303031348.png
│ │ ├── Pasted image 20230303032130.png
│ │ ├── Pasted image 20230303032307.png
│ │ └── Pasted image 20230303040223.png
│ └── 데이터베이스(1)_송민진.md
├── README.md
└── 데이터베이스(1)_이홍섭.md
├── 4. 데이터베이스(2)
├── 데이터베이스(2)_송민진
│ ├── attachments
│ │ ├── Pasted image 20230312001535.png
│ │ ├── Pasted image 20230312001857.png
│ │ ├── Pasted image 20230312005143.png
│ │ ├── Pasted image 20230312011124.png
│ │ └── Pasted image 20230312195337.png
│ ├── 4.6 조인의 종류.md
│ ├── 4.7 조인의 원리.md
│ ├── 4.4 데이터베이스의 종류.md
│ └── 4.5 인덱스.md
├── README.md
├── 데이터베이스(2)_이홍섭.md
└── 데이터베이스(2)_박상욱.md
├── 1. 디자인 패턴과 프로그래밍 패러다임(1)
├── README.md
├── 디자인 패턴과 프로그래밍 패러다임(1)_김대현.md
├── 디자인 패턴과 프로그래밍 패러다임(2)_김대현.md
├── 1. 디자인 패턴과 프로그래밍 패러다임(1)_송민진.md
└── 디자인 패턴과 프로그래밍 패러다임(1)_이홍섭.md
└── README.md
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | .obsidian
3 |
--------------------------------------------------------------------------------
/2. 네트워크(1)/박상욱.md:
--------------------------------------------------------------------------------
1 | [네트워크의 기초](https://rio0205.tistory.com/31)
2 | [TCP/IP 4계층 모델](https://rio0205.tistory.com/32)
3 |
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_박상욱.md:
--------------------------------------------------------------------------------
1 | [운영체제와 컴퓨터](https://rio0205.tistory.com/36)
2 | [메모리](https://rio0205.tistory.com/37)
3 |
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_박상욱.md:
--------------------------------------------------------------------------------
1 | [프로세스와 스레드](https://rio0205.tistory.com/38)
2 | [CPU 스케줄링](https://rio0205.tistory.com/39)
3 |
--------------------------------------------------------------------------------
/2. 네트워크(2)/박상욱.md:
--------------------------------------------------------------------------------
1 | [네트워크 기기의 범위](https://rio0205.tistory.com/33)
2 | [IP 주소](https://rio0205.tistory.com/34)
3 | [HTTP](https://rio0205.tistory.com/35)
4 |
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200125.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200125.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200354.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200354.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200544.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200544.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200953.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131200953.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131201009.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131201009.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131201819.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131201819.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131201826.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131201826.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131204315.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131204315.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131212433.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131212433.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131215423.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131215423.png
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/attachments/Pasted image 20230131220505.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(1)/김대현/attachments/Pasted image 20230131220505.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210110801.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210110801.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210111157.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210111157.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210111617.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210111617.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210114522.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210114522.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134250.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134250.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134336.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134336.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134518.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134518.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134957.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210134957.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210140125.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210140125.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210140348.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210140348.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210140817.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210140817.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210142830.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210142830.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143300.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143300.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143409.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143409.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143644.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143644.png
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143927.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/2. 네트워크(2)/김대현/attachments/Pasted image 20230210143927.png
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_김대현/attachments/Pasted image 20230216232448.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(1)/운영체제(1)_김대현/attachments/Pasted image 20230216232448.png
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_김대현/attachments/Pasted image 20230216233311.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(1)/운영체제(1)_김대현/attachments/Pasted image 20230216233311.png
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_김대현/attachments/Pasted image 20230216233547.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(1)/운영체제(1)_김대현/attachments/Pasted image 20230216233547.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224000610.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224000610.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224001217.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224001217.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224005331.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224005331.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224010005.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_김대현/attachments/Pasted image 20230224010005.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224001244.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224001244.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224004257.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224004257.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224172321.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224172321.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224174152.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230224174152.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001212.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001212.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001403.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001403.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001649.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001649.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001757.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306001757.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306003458.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306003458.png
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306004212.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/3. 운영체제(2)/운영체제(2)_송민진/attachments/Pasted image 20230306004212.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140028.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140028.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140043.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140043.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140124.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140124.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140239.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303140239.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303141546.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303141546.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303141659.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303141659.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303141847.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303141847.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303142532.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303142532.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145133.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145133.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145213.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145213.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145239.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145239.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145433.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145433.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145558.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_김대현/attachments/Pasted image 20230303145558.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303025149.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303025149.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303025232.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303025232.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303025541.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303025541.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303030049.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303030049.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303030852.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303030852.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303031321.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303031321.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303031348.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303031348.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303032130.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303032130.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303032307.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303032307.png
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303040223.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(1)/데이터베이스(1)_송민진/attachments/Pasted image 20230303040223.png
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312001535.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312001535.png
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312001857.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312001857.png
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312005143.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312005143.png
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312011124.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312011124.png
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312195337.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/backend-deep-dive/CS-Study/HEAD/4. 데이터베이스(2)/데이터베이스(2)_송민진/attachments/Pasted image 20230312195337.png
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/README.md:
--------------------------------------------------------------------------------
1 | # 4. 데이터베이스(1)
2 |
3 | ## 범위
4 |
5 | - 4.4 데이터베이스의 종류 (선택)
6 | - 4.5 인덱스
7 | - 4.6 조인의 종류 (선택)
8 | - 4.7 조인의 원리
9 |
10 | ## 발표자
11 |
12 | - 미정
13 |
14 | ## 진행 날짜
15 |
16 | - 2023년 3월 12일 (일요일)
17 |
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_김대현/3.4 CPU 스케쥴링 알고리즘.md:
--------------------------------------------------------------------------------
1 |
2 | ### 3.4.1 비선점형 방식
3 |
4 | non-preemptive
5 |
6 | 스스로 CPU 소유권을 포기하는 방식
7 |
8 | #### FCFS
9 |
10 | First Come, First Serve
11 |
12 | #### SJF
13 |
14 | Shortest Job First
15 |
16 | #### 우선순위
17 |
18 | aging
19 |
20 | ### 3.4.2 선점형 방식
21 |
22 | 지금 사용하고 있는 프로세스를 강제 중단하고 다른 프로세스에 CPU를 할당
23 |
24 | #### 라운드 로빈
25 |
26 | #### SRF
27 |
28 | Shortest Remaining Time First
29 |
30 | #### 다단계 큐
31 |
32 | Multiple Priority Queue
33 |
34 |
35 |
--------------------------------------------------------------------------------
/3. 운영체제(1)/README.md:
--------------------------------------------------------------------------------
1 | # 3. 운영체제(1)
2 |
3 | ## 범위
4 |
5 | - 3.1 운영체제와 컴퓨터
6 | - 3.2 메모리
7 |
8 |
9 | ## 발표자
10 |
11 | - 3.1 운영체제와 컴퓨터 : [박상욱](https://github.com/hongxeob/CS-Study/blob/main/3.%20%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(1)/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(1)_%EB%B0%95%EC%83%81%EC%9A%B1.md)
12 | - 3.2 메모리 : [송민진](https://github.com/hongxeob/CS-Study/blob/main/3.%20%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(1)/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(1)_%EC%86%A1%EB%AF%BC%EC%A7%84.md)
13 |
14 | ## 진행 날짜
15 |
16 | - 2023년 2월 17일 (금요일)
17 |
--------------------------------------------------------------------------------
/2. 네트워크(1)/README.md:
--------------------------------------------------------------------------------
1 | # 2. 네트워크(1)
2 |
3 | ## 범위
4 |
5 | - 2.1 네트워크의 기초
6 | - 2.2 TCP/IP 4계층 모델
7 |
8 | ## 발표자
9 |
10 | - 네트워크의 기초 : [송민진](https://github.com/Dev-CS-Study/CS-Study/blob/main/2.%20%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC(1)/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC%EC%9D%98%20%EA%B8%B0%EC%B4%88(1)_%EC%86%A1%EB%AF%BC%EC%A7%84.md)
11 | - TCP/IP 4계층 모델 : [김대현](https://github.com/Dev-CS-Study/CS-Study/blob/main/2.%20%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC(1)/%EA%B9%80%EB%8C%80%ED%98%84/2.2%20TCP-IP%204%EA%B3%84%EC%B8%B5%20%EB%AA%A8%EB%8D%B8.md)
12 |
13 | ## 진행 날짜
14 |
15 | - 2023년 2월 3일 (금요일)
16 |
--------------------------------------------------------------------------------
/2. 네트워크(2)/README.md:
--------------------------------------------------------------------------------
1 | # 2. 네트워크(2)
2 |
3 | ## 범위
4 |
5 | - 2.3 네트워크 기기
6 | - 2.4 IP 주소
7 | - 2.5 HTTP
8 |
9 | ## 발표자
10 |
11 | - 2.3 네트워크 기기 : [이홍섭](https://github.com/hongxeob/CS-Study/blob/main/2.%20%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC(2)/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC(2)_%EC%9D%B4%ED%99%8D%EC%84%AD.md)
12 | - 2.4 IP 주소 : [김대현](https://github.com/hongxeob/CS-Study/blob/main/2.%20%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC(2)/%EA%B9%80%EB%8C%80%ED%98%84/2.4%20IP%20%EC%A3%BC%EC%86%8C.md)
13 | - 2.5 HTTP : [박상욱](https://github.com/hongxeob/CS-Study/blob/main/2.%20%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC(2)/%EB%B0%95%EC%83%81%EC%9A%B1.md)
14 |
15 | ## 진행 날짜
16 |
17 | - 2023년 2월 10일 (금요일)
18 |
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/README.md:
--------------------------------------------------------------------------------
1 | # 4. 데이터베이스(1)
2 |
3 | ## 범위
4 |
5 | - ~~4.1 개인 공부~~
6 | - 4.2 ERD와 정규화 과정
7 | - 4.3 트랜잭션과 무결성
8 |
9 | ## 발표자
10 |
11 | - 4.2 ERD와 정규화 과 트랜잭션과 무결성 : [김대현](https://github.com/Dev-CS-Study/CS-Study/blob/main/4.%20%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4(1)/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4(1)_%EA%B9%80%EB%8C%80%ED%98%84/4.2%20ERD%EC%99%80%20%EC%A0%95%EA%B7%9C%ED%99%94%20%EA%B3%BC%EC%A0%95.md)
12 | - 4.3 트랜잭션과 무결성 : [송민진](https://github.com/Dev-CS-Study/CS-Study/blob/main/4.%20%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4(1)/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4(1)_%EC%86%A1%EB%AF%BC%EC%A7%84/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4(1)_%EC%86%A1%EB%AF%BC%EC%A7%84.md)
13 |
14 | ## 진행 날짜
15 |
16 | - 2023년 3월 3일 (금요일)
17 |
--------------------------------------------------------------------------------
/3. 운영체제(2)/README.md:
--------------------------------------------------------------------------------
1 | # 3. 운영체제(2)
2 |
3 | ## 범위
4 |
5 | - 3.3 프로세스와 스레드
6 | - 3.4 CPU 스케줄링 알고리즘
7 |
8 | ## 발표자
9 |
10 | - 3.3 (1) 프로세스와 스레드 : [송민진](https://github.com/Dev-CS-Study/CS-Study/blob/main/3.%20%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(2)/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(2)_%EC%86%A1%EB%AF%BC%EC%A7%84/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(2)_%EC%86%A1%EB%AF%BC%EC%A7%84.md)
11 | - 3.3 (2) 프로세스와 스레드 : [박상욱](https://github.com/Dev-CS-Study/CS-Study/blob/main/3.%20%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(2)/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(2)_%EB%B0%95%EC%83%81%EC%9A%B1.md)
12 | - 3.4 CPU 스케줄링 알고리즘 : [이홍섭](https://github.com/Dev-CS-Study/CS-Study/blob/main/3.%20%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(2)/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C(2)_%EC%9D%B4%ED%99%8D%EC%84%AD.md)
13 | ## 진행 날짜
14 |
15 | - 2023년 2월 24일 (금요일)
16 |
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/4.6 조인의 종류.md:
--------------------------------------------------------------------------------
1 |
2 | ### Join
3 |
4 | : 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서 하나의 결과물을 만드는 것
5 |
6 | - MySQL - JOIN
7 | - MongoDB - lookup
8 |
9 | > 참고!
10 | > MongoDB에서 lookup은 되도록 사용하지 말아야 함!
11 | > - MongoDB는 조인 연산(lookup)에 대해 RDB보다 성능이 떨어진다고 알려져 있음
12 | > - 여러 테이블 조인 작업이 많을 경우, MongoDB보다는 RDB를 써야 함
13 |
14 |
15 |
16 | ### Inner Join
17 | : 왼쪽 테이블과 오른쪽 테이블의 두 행이 모두 일치하는 행이 있는 부분만 표기함
18 | - 즉, 교집합
19 | ```sql
20 | SELECT * FROM TableA A
21 | INNER JOIN TableB B ON
22 | A.key = B.key
23 | ```
24 |
25 | ### Left Outer Join
26 | : 왼쪽 테이블의 모든 행이 결과 테이블에 표시됨
27 | - 만약 테이블B에 일치하는 항목이 없으면, 해당값은 null이 됨
28 | ```sql
29 | SELECT * FROM TableA A
30 | LEFT JOIN TableB B ON
31 | A.key = B.key
32 | ```
33 |
34 | ### Right Outer Join
35 | : 오른쪽 테이블의 모든 행이 결과 테이블에 표시됨
36 | ```sql
37 | SELECT * FROM TableA A
38 | RIGHT JOIN TableB B ON
39 | A.key = B.key
40 | ```
41 |
42 | ### Full Outer Join
43 | : 두 개의 테이블을 기반으로, 조인 조건에 만족하지 않는 행까지 모두 표기
44 | ```sql
45 | FULL OUTER JOIN TableB B ON
46 | A.key = B.key
47 | ```
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_김대현/3.1 운영체제와 컴퓨터.md:
--------------------------------------------------------------------------------
1 | ### 3.1.1 운영체제의 역할과 구조
2 |
3 | 
4 |
5 | #### 시스템콜
6 |
7 | 시스템콜이란 운영체제가 커널에 접근하기 위한 인터페이스이며 유저 프로그램이 운영체제의 서비스를 받기 위해 커널 함수를 호출할 때 사용한다.
8 |
9 | #### modebit
10 |
11 | 0은 커널 모드, 1은 유저 모드로 설정되어 있음.
12 |
13 | #### 커널
14 |
15 | 운영체제의 핵심 부분이자 시스템콜 인터페이스를 제공하며
16 |
17 | - 보안
18 | - 메모리
19 | - 프로세스
20 | - 파일 시스템
21 | - I/O 디바이스
22 | - I/O 요청관리
23 |
24 | 등의 중추적인 역할을 한다.
25 |
26 | #### 커널 모드
27 |
28 | 운영체제의 모든 자원에 접근할 수 있는 모드
29 |
30 | ---
31 |
32 | ### 3.1.2 컴퓨터의 요소
33 |
34 | #### 인터럽트
35 |
36 | 어떤 신호가 들어왔을 때 CPU를 잠시 정지시키는 것을 말합니다.
37 |
38 | - IO 인터럽트
39 | - 산술 연산 인터럽트
40 | - 프로세스 오류 인터럽트
41 |
42 | ###### 프로세스 오류 인터럽트는 어떤 종류가 있을까? #question
43 |
44 | ##### 인터럽트가 발생되면 어떤 과정을 거치는가?
45 |
46 | 인터럽트 핸들러 함수가 모여 있는 인터럽트 벡터로 가서, 함수를 찾고 해당 함수가 실행됩니다.
47 |
48 | IRQ? #question
49 |
50 | 우선순위가 있고 우선순위에 따라 실행된다.
51 |
52 | ##### 하드웨어 인터럽트
53 |
54 | ##### 소프트웨어 인터럽트
55 |
56 | 트랩, 익셉션의 차이는 무엇인가? #question
57 |
58 | #### DMA 컨트롤러
59 |
60 | Direct Memory Access, 즉 메모리에 직접 접근하는 하드웨어 장치이다.
61 |
62 | ---
63 |
64 |
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/4.7 조인의 원리.md:
--------------------------------------------------------------------------------
1 |
2 | ### Nested Loop Join
3 | : NLJ, 중첩 루프 조인
4 |
5 | - 중첩 for문과 같은 원리로 조건에 맞는 조인을 하는 방법
6 | - 랜덤 접근에 대한 비용이 많이 증가하므로, 대용량의 테이블에서는 사용하지 않음
7 |
8 | - Block Nested Loop(BNL) : 중첩 루프 조인의 발전된 형태. 조인할 테이블을 작은 블록으로 나눠서, 블록 하나씩 조인한다.
9 |
10 |
11 | ### Sort Merge Join
12 | : SMJ, 정렬 병합 조인
13 |
14 | - 각각의 테이블을 조인할 필드 기준으로 정렬하고, 정렬이 끝난 이후에 조인 작업을 수행하는 조인
15 | - 조인할 때 쓸 적절한 인덱스가 없고, 대용량의 테이블을 조인해야 하며, 조인 조건으로 `<`, `>` 등의 범위 비교 연산자가 있을 때 사용함
16 |
17 |
18 | ### Hash Join
19 | : 해시 조인
20 |
21 | - 해시 테이블을 기반으로 조인하는 방법
22 | - 두 개의 테이블을 조인한다고 했을 때, 하나의 테이블이 메모리에 온전히 들어간다면 보통 중첩 루프 조인보다 더 효율적임
23 | > 단, 메모리에 올릴 수 없을 정도로 크다면 디스크 사용 비용 따로 발생
24 | - 동등(=) 조인에서만 사용 가능
25 |
26 | #### MySQL과 Hash Join
27 | - MySQL8.0.18 릴리스와 함께 이 기능이 추가됨
28 | - 빌드 단계, 프로브 단계로 나뉨
29 |
30 | **빌드 단계**
31 | - 입력 테이블 중 하나를 기반으로, 메모리 내 해시 테이블을 빌드하는 단계
32 | - 두 테이블 중 바이트가 더 작은 테이블을 기반으로 해서 해시 테이블 빌드
33 | - 조인에 사용되는 필드가 해시 테이블의 키로 사용됨 ![[Pasted image 20230312195337.png]]
34 |
35 | **프로브 단계**
36 | - 레코드 읽기를 시작하며, 각 레코드에서 key에 일치하는 레코드를 찾아서 결과값으로 반환함
37 | - 이를 통해 각 테이블은 한 번씩만 읽게 되어, 중첩 루프 조인보다는 성능이 보통 더 좋음
38 |
39 | > 사용 가능한 메모리 양 : 시스템 변수 `join_buffer_size`에 의해 제어됨. 런타임시 조정 가능
--------------------------------------------------------------------------------
/1. 디자인 패턴과 프로그래밍 패러다임(1)/README.md:
--------------------------------------------------------------------------------
1 | # 디자인 패턴과 프로그래밍 패러다임(1)
2 |
3 | ## 범위
4 |
5 | - 1.1.1 싱글톤 팩턴
6 | - 1.1.2 팩토리 패턴
7 | - 1.1.3 전략 패턴
8 | - 1.1.4 옵저버 패턴
9 | - 1.1.5 프록시 패턴과 프록시 서버
10 | - 1.1.6 이터레이터 패턴
11 | - 1.1.7 노출모듈 패턴
12 | - 1.1.8 MVC 패턴
13 | - 1.1.9 MVP 패턴
14 | - 1.1.10 MVVM 패턴
15 | ---
16 | - 1.2.1 선언형과 함수형 프로다이밍
17 | - 1.2.2 객체지향 프로그래밍
18 | - 1.2.3 절차형 프로그래밍
19 | - 1.2.4 패러다임의 혼합
20 |
21 | ## 발표자
22 |
23 | - 디자인 패턴 : [김대현](https://github.com/Dev-CS-Study/CS-Study/blob/main/1.%20%EB%94%94%EC%9E%90%EC%9D%B8%20%ED%8C%A8%ED%84%B4%EA%B3%BC%20%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D%20%ED%8C%A8%EB%9F%AC%EB%8B%A4%EC%9E%84(1)/%EB%94%94%EC%9E%90%EC%9D%B8%20%ED%8C%A8%ED%84%B4%EA%B3%BC%20%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D%20%ED%8C%A8%EB%9F%AC%EB%8B%A4%EC%9E%84(1)_%EA%B9%80%EB%8C%80%ED%98%84.md)
24 | - 프로그래밍 패러다임 : [이홍섭](https://github.com/Dev-CS-Study/CS-Study/blob/main/1.%20%EB%94%94%EC%9E%90%EC%9D%B8%20%ED%8C%A8%ED%84%B4%EA%B3%BC%20%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D%20%ED%8C%A8%EB%9F%AC%EB%8B%A4%EC%9E%84(1)/%EB%94%94%EC%9E%90%EC%9D%B8%20%ED%8C%A8%ED%84%B4%EA%B3%BC%20%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D%20%ED%8C%A8%EB%9F%AC%EB%8B%A4%EC%9E%84(1)_%EC%9D%B4%ED%99%8D%EC%84%AD.md)
25 |
26 | ## 진행 날짜
27 |
28 | - 2023년 1월 27일 (금요일)
29 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # [면접을 위한 CS 전공지식 노트](http://www.yes24.com/Product/Goods/108887922) CS 스터디
2 |
3 | 현 저장소는 CS 전공지식에 관한 스터디 내용을 담은 저장소입니다.
4 |
5 | ## 스터디 사용 책
6 |
7 | [[면접을 위한 CS 전공지식 노트, 주홍철 저]](http://www.yes24.com/Product/Goods/108887922) 책을 기준으로 진행됩니다.
8 |
9 | ## 진행 방식
10 |
11 | - 주 1회 금요일, 오프라인으로 만나 약 1시간의 스터디 시간(17:00~18:00)을 가집니다.
12 | - 책 1~5장의 내용을, 각 장을 1주에 걸쳐 학습합니다 __(섹션의 내용이 방대해질 경우, 유동적으로 섹션 분리)__
13 | - 스터디 모임 전, 각 스터디원은 해당 주에 학습하는 내용에 대해 아래 내용을 준비해 와야 합니다.
14 | - 스터디 범위 공부 및 내용 정리
15 | - 공부하면서 모르는 내용 정리 (스터디 시간에 다른 구성원이 답변)
16 | - 다른 구성원(발표자)에게 낼 **질문** 정리 -> [issues](https://github.com/Dev-CS-Study/CS-Study/issues) 기능 이용 (최소 2가지 이상, 답변 내용이 미흡한 경우 스터디원들이 함께 추가 설명 및 토의)
17 | - 스터디 모임시 발표 인원은 파트의 섹션별 **최소 한 명**입니다. (유기적으로 변할 수 있습니다)
18 | - 매 스터디 모임마다 발표할 사람은 랜덤으로 정해집니다 (예: 사다리 타기).
19 | - 매 스터디 모임마다 한 사람이 발표한 후, 다른 사람들이 발표자에게 질문하는 식으로 진행됩니다.
20 | - 스터디 진행 내용을 본 저장소에 기록하여 저장합니다. 기록하는 내용은 아래와 같습니다.
21 | - 발표자 및 발표 내용 체크
22 | - 스터디 중 발생한 질문 및 답변 (당일 발표자가 해당 [issues](https://github.com/Dev-CS-Study/CS-Study/issues) 에 기록한다)
23 | - 발표한 내용에 추가 혹은 보완할 내용
24 | - 기본적으로 모든 내용은 책을 바탕으로 합니다.
25 | - 책에 나오는 내용 외에 추가적인 내용을 다루는 경우, 명확한 출처와 근거 자료를 제시해야 합니다. (잘못된 내용을 학습하는 것을 막기 위함)
26 |
27 | ## 저장소의 네이밍 컨벤션
28 |
29 | - 주차별 디렉토리
30 | - `목차. 목차명(섹션 분리 넘버)`
31 | - ex) 1. 디자인 패턴과 프로그래밍 패러다임(1)
32 | - ex) 4. 데이터베이스(1)
33 | - ex) 4. 데이터베이스(2)
34 | - 개인의 발표자료
35 | - `목차명(섹션 분리 넘버)_이름`
36 | - ex) 디자인 패턴과 프로그래밍 패러다임(1)_홍길동.md
37 | - ex) 네트워크(2)_홍길동.md
38 |
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/4.2 ERD와 정규화 과정.md:
--------------------------------------------------------------------------------
1 |
2 | ### 4.2.1 ERD의 중요성
3 |
4 | ### 4.2.2 예제로 배우는 ERD
5 |
6 | ### 4.2.3 정규화 과정
7 |
8 | #### 정규형 원칙
9 |
10 | https://rebro.kr/160
11 |
12 | https://namu.wiki/w/SQL/%EC%A0%95%EA%B7%9C%ED%99%94#s-4.1
13 |
14 | 책보다 나무위키의 설명이 더 직관적이고, 장단이 잘 서술되어 있습니다.
15 |
16 | ### 제 1정규형
17 |
18 | 릴레이션의 모든 도메인이 더 이상 분해될 수 없는 원자 값(atomic value)만으로 구성되어야 합니다.
19 |
20 | 한 개의 기본키에 대해 두 개 이상의 값을 가지는 반복 집합이 있어서는 안 됩니다.
21 |
22 | 
23 |
24 | 해야 하는 이유:
25 |
26 | 
27 |
28 | ---
29 | #### 제 2정규형
30 |
31 | 릴레이션이 제1정규형이며 부분 함수의 종속성을 제거한 형태를 말합니다.
32 |
33 | 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속적인 것을 뜻합니다.
34 |
35 | 
36 |
37 |
38 | 
39 |
40 | #### 함수적 종속
41 |
42 | Functional Dependency
43 |
44 | X의 값을 알면 Y의 값을 바로 식별할 수 있고, X의 값에 따라 Y의 값이 달라질 때
45 | Y는 X에 **함수적 종속**이라고 합니다.
46 |
47 | #### 완전 함수적 종속
48 |
49 | Full Functional Dependency
50 |
51 | 종속자가 기본키에만 종속되며, 기본키가 여러 속성으로 구성되어 있을 경우 기본키를 구성하는 모든 속성이 포함된 기본키의 부분집합에 종속된 경우.
52 |
53 | 
54 |
55 | ---
56 |
57 | ### 제3 정규형
58 |
59 | 제2 정규형에서 기본키가 아닌 모든 속성이 이행적 함수 종속을 만족하지 않는 상태를 뜻합니다.
60 |
61 | 이행적 함수 종속이란, A->B, B->C가 존재하면 논리적으로 A->C인데, 이때 집합 C가 집합 A에 이행적으로 함수 종속이 되었다고 합니다.
62 |
63 | 
64 |
65 | > 학번이 주어졌을 때 바로 학과를 알고 싶은 경우가 많다. 지도교수 테이블로 join을 해서 알아내야만 한다는 사실이 조금 비직관적이다. 이렇게까지 해야 하나 싶기도 하다.
66 |
67 | 
68 | 여전히 이런 이상 현상들이 발생합니다.
69 |
70 | ---
71 |
72 | #### 보이스 코드 정규형
73 |
74 | BCNF
75 |
76 | 강한 제3 정규형
77 |
78 | 결정자가 후보키가 아닌 함수 종속 관계를 제거하여 릴레이션의 함수 종속 관계에서 모든 결정자가 후보키인 상태를 말합니다.
79 |
80 |
81 | 
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_김대현/4.3 트랜잭션과 무결성.md:
--------------------------------------------------------------------------------
1 | ### 4.3.1 트랜잭션
2 |
3 | 트랜잭션은 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위를 말하며 데이터베이스에 접근하는 방법은 쿼리이므로, 즉 여러 개의 쿼리들을 하나로 묶는 단위를 말합니다.
4 |
5 | ACID
6 |
7 | - Atomicity
8 | - Consistency
9 | - Isolation
10 | - Durability
11 |
12 | ---
13 |
14 | https://www.youtube.com/watch?v=e9PC0sroCzc&ab_channel=%EC%9A%B0%EC%95%84%ED%95%9C%ED%85%8C%ED%81%AC
15 |
16 | #### Atomicity
17 |
18 | 트랜잭션은 DB에 모두 반영되거나, 전혀 반영되지 않아야 한다.
19 |
20 | commit 과 rollback으로 관리한다.
21 |
22 | ##### 트랜잭션 전파
23 |
24 | 
25 |
26 | ---
27 |
28 | #### Consistency
29 |
30 | 트랜잭션의 작업처리결과는 항상 일관성 있어야 한다.
31 | 데이터베이스는 항상 일관된 상태로 유지되어야 한다.
32 |
33 | 무슨 뜻일까?
34 |
35 | 허용된 방식으로만 데이터를 변경해야 하는 것을 의미한다.
36 | 여러 가지 조건, 규칙에 따라 유효함을 가져야 합니다.
37 |
38 | ---
39 |
40 | #### Isolation
41 |
42 | 둘 이상의 트랜잭션이 동시 실행되고 있을 때, 어떤 트랜잭션도 다른 트랜잭션 연산에 개입할 수 없다.
43 | (= 각각의 트랜잭션은 서로 간섭 없이 독립적으로 이루어져야 한다.)
44 |
45 | ##### READ_UNCOMMITED
46 |
47 | 커밋 전의 트랜잭션의 데이터 변경 내용을 다른 트랜잭션이 읽는 것을 허용한다.
48 |
49 | 
50 |
51 | ##### READ_COMMITED
52 |
53 | 커밋이 완료된 트랜잭션의 변경사항만 다른 트랜잭션에서 조회 가능
54 |
55 | 
56 |
57 | ##### REPEATABLE_READ
58 |
59 | 
60 |
61 | Non-repeatable read 와 Phantom read의 차이는 무엇인가?
62 |
63 | 팬텀 리드: 조회해온 결과의 행이 새로 생기거나 없어지는 현상
64 |
65 | ##### SERIALIZABLE
66 |
67 | 한 트랜잭션에서 사용하는 데이터를 다른 트랜잭션에서 접근 불가
68 |
69 | 
70 |
71 | ---
72 |
73 | #### Durability
74 |
75 | 트랜잭션이 성공하면 결과는 영구히 반영되어야 한다.
76 |
77 | 시스템 장애가 발생해도 원래 상태로 복구하는 회복 기능이 있어야 합니다. 체크섬, 저널링, 롤백 등의 기능을 제공합니다.
78 |
79 | #### 저널링
80 |
81 | 파일 시스템 또는 데이터베이스 시스템에 변경 사항을 반영하기 전에 로깅하는 것. 트랜잭션 등 변경 사항에 대한 로그를 남기는 것.
82 |
83 | ---
84 |
85 | ### 4.3.2 무결성
86 |
87 | 데이터의 정확성, 일관성, 유효성을 유지하는 것을 말한다.
88 |
89 | - 개체 무결성: 기본키로 선택된 필드는 빈 값을 허용하지 않는다.
90 | - 참조 무결성: 서로 참조 관계에 있는 두 테이블의 데이터는 항상 일관된 값을 유지한다.
91 | - 고유 무결성: 특정 속성에 대해 고유한 값을 가지도록 조건이 주어지면 그렇게 한다.
92 | - NULL 무결성: 특정 속성 값이 NULL이 올 수 없다는 제약 조건.
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_김대현/3.3 프로세스와 스레드.md:
--------------------------------------------------------------------------------
1 |
2 | ### 3.3.1 프로세스와 컴파일 과정
3 |
4 | ### 3.3.2 프로세스의 상태
5 |
6 | 
7 |
8 | - fork
9 | - exec
10 |
11 | 앞 부분은
12 |
13 | https://github.com/Metacognition-Polymath/operating-system-concepts/tree/main/03_%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4/Dk
14 |
15 | 참고
16 |
17 |
18 | ---
19 |
20 | ### 3.3.6 스레드와 멀티스레딩
21 |
22 | 코드, 데이터, 힙은 스레드끼리 서로 공유. 그 외 영역은 각각 생성된다.
23 |
24 | #### 멀티스레딩
25 |
26 | 멀티스레딩을 통해 서로 자원을 공유하기 때문에 효율성이 높다.
27 |
28 | 
29 | ### 3.3.7 공유 자원과 임계 영역
30 |
31 | #### 공유 자원 (shared resource)
32 |
33 | 공유 자원: 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 모니터, 프린터, 메모리, 파일, 데이터 드으이 자원이나 변수 등을 의미합니다.
34 |
35 | 이 공유 자원을 두 개 이상의 프로세스가 동시에 읽거나 쓰는 상황을 경쟁 상태라고 합니다.
36 |
37 | 
38 |
39 |
40 | #### 임계 영역
41 |
42 | 임계 영역(critical section)은 둘 이상의 프로세스, 스레드가 공유 자원에 접근할 때 순서 등의 이유로 결과가 달라지는 코드 영역을 말합니다.
43 |
44 | 뮤텍스, 세마포어, 모니터 등의 해결책이 있습니다.
45 |
46 | 이는
47 |
48 | - 상호 배제: 한 프로세스가 임계 영역에 들어갔을 때 다른 프로세스는 들어갈 수 없다.
49 | - 한정 대기: 특정 프로세스가 영원히 임계 영역에 들어가지 못하면 안된다.
50 | - 융통성: 한 프로세스가 다른 프로세스의 일을 방해해서는 안된다.
51 |
52 | 의 조건을 만족합니다.
53 |
54 | ##### 뮤텍스
55 |
56 | lock을 통해 잠금 설정하고 사용한 후에는 unlock을 통해 잠금 해제하는 객체입니다.
57 |
58 | ##### 세마포어
59 |
60 | semaphore
61 |
62 | 일반화된 뮤텍스입니다. 간단한 정수 값과 두 가지 함수 wait 및 signal로 공유 자원에 대한 접근을 처리합니다.
63 |
64 | wait()은 자신의 차례를 기다립니다.
65 | signal은 다음 프로세스로 순서를 넘겨줍니다.
66 |
67 | ###### 바이너리 세마포어
68 |
69 | 0과 1의 두 가지 값만 가질 수 있는 세마포어.
70 | 뮤텍스와 햇갈릴 수 있으나, 뮤텍스는 잠금 메커니즘이고, 세마포어는 신호 메커니즘입니다.
71 |
72 | ###### 카운팅 세마포어
73 |
74 | 여러 값을 가질 수 있으며, 여러 자원에 대한 접근을 제어합니다.
75 |
76 | ##### 모니터
77 |
78 | 둘 이상의 스레드나 프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유 자원을 숨기고 해당 접근에 대해 인터페이스만 제공합니다.
79 |
80 | 모니터큐를 통해 공유 자원에 대한 작업을 순차적으로 처리합니다.
81 |
82 | 
83 |
84 | ### 교착 상태
85 |
86 | deadlock
87 |
88 | 두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태
89 |
90 |
91 | #### 해결책
92 |
93 | 1. 애초에 데드락이 발생하지 않도록 설계
94 | 2. 교착 상태 가능성이 없을때만 자원 할당, 은행원 알고리즘을 사용
95 | 3. 사이클을 찾고 하나씩 지우기
96 | 4. 그냥 시스템 종료
97 |
98 |
99 |
100 |
101 |
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/2.4 IP 주소.md:
--------------------------------------------------------------------------------
1 |
2 | ## 2.4.1 ARP
3 |
4 | ### ARP: Address Resolution Protocol.
5 |
6 | 결국 실제로 통신하려면 IP주소가 아닌 MAC 주소가 필요하다.
7 | IP주소를 MAC 주소로 바꿔주는 프로토콜이 ARP.
8 |
9 | - IP: 가상 주소
10 | - ARP: 실제 주소
11 | - RARP(Reverse Address Resolution Protocol): MAC -> IP
12 |
13 | 
14 |
15 | ---
16 |
17 | 브로드캐스트: 방송하다. 연결된 모든 호스트에게 전송
18 |
19 | 유니캐스트: 하나의 특정 호스트에게만 전송
20 |
21 | ---
22 |
23 | ## 2.4.2 홉바이홉 통신
24 |
25 | 홉바이홉 통신이란? IP 주소를 통해 통신하는 과정. 각 패킷이 여러 개의 라우터를 건너가는 모습을 껑충껑충 뛰어가는 모양새와 비유한 것.
26 |
27 | 
28 |
29 | ---
30 |
31 | - 라우팅이란? IP 주소를 찾아가는 과정
32 |
33 | ### 라우팅 테이블
34 |
35 | 목적지 정보들과, 목적지로 가기 위한 방법이 들어있는 리스트. 다음 라우터의 정보를 가지고 있다.
36 |
37 | ### 게이트웨이
38 |
39 | 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 관문 역할을 하는 컴퓨터나 소프트웨어
40 |
41 | - 통신 프로토콜의 변환
42 |
43 | netstat -r 명령어를 통해
44 |
45 | 
46 |
47 | ---
48 |
49 | https://blog.naver.com/PostView.naver?blogId=kilokilo77&logNo=40016020790&redirect=Dlog&widgetTypeCall=true&directAccess=false
50 |
51 | ### 라우팅 테이블 해석하는 법
52 |
53 | 목적지 경로와 네트워크 마스크를 비트 AND 연산을 수행하여, 네트워크 대상과 일치하면 그쪽으로 이동한다.
54 |
55 | 
56 |
57 | ---
58 |
59 | ## 2.4.3 IP 주소 체계
60 |
61 | Classful Network Addressing
62 |
63 | #### 클래스 기반 할당 방식
64 |
65 | 
66 |
67 | ---
68 |
69 | 
70 |
71 | 
72 |
73 | - 12.0.0.1 - 12.255.255.254 는 호스트 주소
74 | - 가장 마지막 주소는 브로드캐스트용 주소
75 | - 가장 첫 주소는 네트워크 구별 주소
76 |
77 | 단점
78 |
79 | - 버리는 주소가 더 많다.
80 | - 이를 해소하기 위해 나온 것이 DHCP, NAT, IPv6
81 |
82 | ---
83 |
84 | ### DHCP
85 |
86 | Dynamic Host Configuration Protocol
87 |
88 | IP주소와 기타 변수들을 자동으로 할당하고 관리하는 프로토콜
89 |
90 | 대부분 가정용 네트워크에서 IP를 할당
91 |
92 | ---
93 |
94 | ### NAT
95 |
96 | Network Address Translation
97 |
98 | 패킷이 라우팅 장치를 통해 전송되는 동안 패킷의 IP주소를 수정하여 다른 주소로 매핑하는 방법.
99 |
100 | Public IP, private IP로 나눠 많은 주소들을 처리한다.
101 |
102 | 
103 |
104 |
105 | - ICS
106 | - RRAS
107 | - Net filter
108 |
109 | 등이 있다.
110 |
111 | ---
112 |
113 |
114 | ### NAT을 쓰는 이유?
115 |
116 | 주로 여러 대의 호스트가 하나의 공인 IP 주소를 사용하여 인터넷에 접속하기 위함. 공유기에 NAT 기능이 있음.
117 |
118 | ### 보안
119 |
120 | 외부에 드러나는 IP 주소를 다르게 유지할 수 있기 때문에 내부 네트워크에 대한 보안이 가능해집니다.
121 |
122 | ### 단점
123 |
124 | 여러 명이 접속하면 속도가 느려질 수 있습니다.
125 |
126 | ---
127 |
128 | ## 2.4.4 IP 주소를 이용한 위치 추적
129 |
130 | 동 위치까지 가능합니다~
131 |
132 | ---
133 |
134 | ## 궁금증
135 |
136 | ### CIDR 에 대한 설명은 없는가?
137 |
138 | ### 라우팅 알고리즘은?
139 |
140 | ### 같은 풀?
--------------------------------------------------------------------------------
/1. 디자인 패턴과 프로그래밍 패러다임(1)/디자인 패턴과 프로그래밍 패러다임(1)_김대현.md:
--------------------------------------------------------------------------------
1 | # Section 1.1 디자인 패턴
2 |
3 | ---
4 |
5 |
6 | [0. 면접을 위한 CS 전공지식 노트 목차](0.%20면접을%20위한%20CS%20전공지식%20노트%20목차.md)
7 | 싱글톤 패턴
8 |
9 | 하나의 인스턴스를 만들어 놓고 해당 인스턴스를 다른 모듈들이 모두 공유하며 사용합니다.
10 | 의존성이 높아지는 단점이 있습니다.
11 |
12 | ---
13 |
14 |
15 | 싱글톤 패턴의 단점
16 |
17 | TDD의 걸림돌이 됩니다. 단위 테스트는 서로 독립적이어야 하며 어떤 순서로든 실행할 수 있어야 하는데, 싱글톤 패턴은 각각의 테스트에 독립적인 인스턴스를 만들기 어렵습니다.
18 |
19 | ---
20 |
21 | 모듈 간의 결합을 강하게 만들기 때문에 Dependency Inversion이 필요하다. ^6cbb84
22 |
23 | ![[../attachments/Pasted image 20230120144020.png]]
24 |
25 | ---
26 |
27 | 의존성 주입의 장점
28 |
29 | - 테스팅이 쉽다.
30 | - 마이그래이션이 쉽다.
31 |
32 | ---
33 |
34 | 의존성 주입의 단점
35 |
36 | - 복잡성 증가, 약간의 런타임 패널티
37 |
38 | ---
39 |
40 | 의존성 주입 원칙
41 |
42 | - 상위 모듈은 하위 모듈에서 어떠한 것도 가져와서는 안된다.
43 | - 추상화는 세부 사항에 의존하지 말아야 한다.
44 |
45 | ---
46 |
47 | 팩토리 패턴
48 |
49 | **객체 생성 부분을 때어내어 추상화**
50 |
51 | ---
52 |
53 | 커피라는 상위클래스와, 라떼, 아메리카노라는 하위 클래스가 있을때,
54 | 커피팩토리 클래스에서 파라미터에 따라 하위 클래스를 생산
55 |
56 | ---
57 |
58 | 이는 의존성 주입이라고 볼 수도 있다. <- ?
59 | 책에서의 JS와 JAVA의 예제가 다르다...
60 |
61 | ---
62 |
63 | 전략 패턴 혹은 정책 패턴
64 |
65 | Strategy, policy pattern
66 |
67 | 객체의 행위를 바꿔주고 싶은 경우, '직접' 수정하지 않고 전략이라고 부르는 '알고리즘'을 바꿔주면서 상호 교체가 가능하게 만드는 패턴.
68 |
69 | ---
70 |
71 | 전략 패턴의 예시
72 |
73 | 결제를 위해 카카오페이, 라인페이, 네이버페이 등, 다양한 전략을 사용할 수 있음.
74 |
75 | 소팅을 위해 버블 소팅, 퀵 소팅, 머지 소팅 등 다양한 소팅 방법을 사용할 수 있음.
76 |
77 | ---
78 |
79 | 나의 궁금증: stategy pattern과 command pattern의 차이는 무엇인가?
80 |
81 | ---
82 |
83 | Observer pattern
84 |
85 | 어떤 객체의 상태변화를 관찰하다가 상태 변화가 있을 때마다 미리 등록한 옵저버들에게 변화를 알려주는 패턴
86 |
87 | Pull based 가 아닌 push based 를 구현하기 위함이라고 생각하면 편하다.
88 |
89 | ---
90 |
91 | MVC패턴에서의 옵저버 패턴
92 |
93 | Model에 변경사항이 생기면 update를 통해 View에 알려준다.
94 |
95 | ---
96 |
97 | Proxy Pattern
98 |
99 | 대상 객체에 접근하기 전에 그 접근에 대한 흐름을 가로채 대상 앞단의 인터페이스 역할을 하는 디자인 패턴
100 |
101 | 즉, 무언가를 하기 전에 거쳐야 하는 관문, Layer의 역할을 한다.
102 |
103 | ---
104 |
105 | Iterator Pattern
106 |
107 | 자료구조와는 상관없이 전체 자료 순회 인터페이스를 지원하는 디자인패턴
108 |
109 | ---
110 |
111 | 이터레이터, 이터러블의 차이점은 무엇인가?
112 |
113 | ---
114 |
115 | revealing module 패턴, 노출모듈 패턴
116 |
117 | 접근 제어자가 없는 자바스크립트 등의 언어에 한정.
118 |
119 | 찾아보니 파이썬 등에서도 사용 가능하나 그 쪽 진영은 ```__XXX___``` 형태를 더 선호
120 |
121 | ---
122 |
123 | MVC 패턴
124 |
125 | Model, View, Controller 로 이루어진 디자인 패턴
126 |
127 | 모델: 비즈니스 로직을 다룸
128 | 뷰: 보여지는 사용자 인터페이스 요소에 집중함.
129 | 컨트롤러: 모델과 뷰 사이에서 서로의 상호작용을 잇는 다리 역할
130 |
131 | ---
132 |
133 | MVP 패턴
134 |
135 | C가 Presenter로 교체된 패턴
136 |
137 | 다대다 연결이 가능했던 MVC와 달리, V와 C 사이의 관계는 항상 1대1이므로 더 강한 결합을 가진 디자인 패턴.
138 |
139 | ---
140 |
141 | MVVM 패턴
142 |
143 | C가 VM으로 교체된 패턴
144 |
145 | 커맨드와 데이터바인딩을 가지는 것이 특징
146 | 양방향 데이터 바인딩을 가진다
147 | UI를 별도의 코드 수정 없이 재사용할 수 있고 단위 테스팅하는 것이 쉽다.
148 |
149 | ---
150 |
151 | MVP와 MVVM의 차이점은 무엇인가? (geeksforgeeks)
152 |
153 | - 일대일인 MVP와는 다르게, 하나의 VM에 여러개의 V가 매핑될 수 있다.
154 | - VM은 V에 대해 모른다.
155 | - MVP에서는 M에 변화가 있으면 P에 전달된 다음, P가 V로 전달하지만, MVVM에서는 M이 직접 V로 전달한다.
156 | - MVVM, MVP, MVC 순으로 유닛 테스트가 용이하다.
157 | - MVVM은 작은 규모의 프로젝트에는 적합하지 않다? ^aaf8c7
158 |
159 | ---
160 |
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/2.1 네트워크의 기초.md:
--------------------------------------------------------------------------------
1 | ### 네트워크란?
2 | 노드와 링크가 서로 연결되어 있거나 연결되어 있지 않은 집합체를 의미합니다.
3 |
4 | ---
5 | ### 노드란?
6 | 서버, 라우터, 스위치 등 네트워크 장치를 의미한다
7 |
8 | ---
9 | ### 링크란?
10 | 유선 또는 무선을 의미합니다.
11 |
12 | ---
13 |
14 | ### 처리량 (throughput)
15 |
16 | 링크를 통해 전달되는 단위 시간 당 데이터 양
17 |
18 | 단위로는 bps를 많이 쓴다.
19 |
20 |
21 |
22 | 처리량은 트래픽, 네트워크 장치 간의 대역폭, 에러, 하드웨어 스펙에 따라 달라진다.
23 |
24 | ---
25 |
26 | ### 대역폭 (bandwidth)
27 |
28 | 주어진 시간동안 네트워크 연결을 통해 흐를 수 있는 최대 비트 수
29 |
30 | ---
31 |
32 | ### 처리량과 대역폭의 차이점
33 |
34 | 대역폭은 최대값이다. 일정한 값으로 고정.
35 |
36 | ---
37 |
38 | ### 지연 시간 (Latency)
39 |
40 | 요청이 처리되는 시간을 말한다.
41 | 어떤 메세지가 두 장치 사이를 왕복하는 데 걸린 시간을 말한다.
42 |
43 | 영향을 주는 것들:
44 | - 무선 / 유선
45 | - 패킷 크기
46 | - 라우터의 패킷 처리 시간
47 |
48 | ---
49 |
50 | ### 네트워크 토폴로지
51 |
52 | 노드와 링크가 배치되어 있는 방식이자 연결 형태
53 |
54 | ---
55 |
56 | ### 트리 토폴로지
57 |
58 | 장점:
59 | - 노드의 추가, 삭제가 쉽다.
60 |
61 | 단점:
62 | - 트래픽이 집중될 때 하위 노드가 모두 느려진다.
63 |
64 | ---
65 |
66 | ### 버스 토폴로지
67 |
68 | 중앙 통신 회선 하나에 여러 개의 노드가 연결되어 공유하는 네트워크 구성을 말한다.
69 | 
70 |
71 | - 설치 비용이 적다.
72 | - 중앙 통신 회선에 노드를 추가하거나 삭제하기 쉽다.
73 | - 하지만 스푸핑이 가능하다.
74 |
75 | ---
76 |
77 | ### 스푸핑
78 |
79 | 스위칭 기능을 마비시키거나 특정 노드에 해당 패킷이 (잘못) 오도록 처리하는 것을 말합니다.
80 |
81 | ---
82 |
83 | ### 스타 토폴로지
84 |
85 | 중앙에 있는 노드에 모두 연결된 네트워크 구성
86 | 
87 |
88 | ---
89 |
90 | ### 스타 토폴로지
91 |
92 | - 노드를 추가하기 쉽다.
93 | - 에러를 탐지하기 쉽다.
94 | - 패킷의 충돌 가능성이 적다.
95 | - 중앙 노드에 장애가 발생하면 전체 네트워크를 사용할 수 없다.
96 | ---
97 |
98 | ### 링형 토폴로지
99 |
100 | 
101 |
102 | ---
103 |
104 | - 노드 수가 증가해도 네트워크 상의 손실이 거의 없다.
105 | - 충돌 가능성이 적다.
106 | - 노드 고장을 쉽게 찾는다.
107 | - 네트워크 구성 변경이 어렵다.
108 | - 회선에 장애가 발생하면 전체 네트워크에 영향을 크게 끼친다.
109 |
110 | ---
111 |
112 | ### 메시 토폴로지
113 |
114 | 
115 |
116 | ---
117 |
118 | - 장애 발생에 강하다.
119 | - 트래픽 분산 처리 가능
120 | - 노드의 추가가 어렵다
121 | - 구축, 운용 비용이 고가이다.
122 |
123 | ---
124 |
125 | 병목 현상 (bottleneck)
126 |
127 | 전체 시스템이 하나의 구성 요소로 인해 제한을 받는 현상.
128 |
129 | ---
130 |
131 | LAN
132 |
133 | 근거리 통신망.
134 | 같은 건물이나 캠퍼스같은 좁은 공간.
135 |
136 | ---
137 |
138 | MAN
139 |
140 | Metropolitan Area Network
141 |
142 | 대도시 지역 네트워크. 전송 속도는 평균이다.
143 |
144 | ---
145 |
146 | WAN
147 |
148 | 광역 네트워크를 의미하며, 국가 또는 대륙같은 더 넓은 지역에서 운영.
149 |
150 | ---
151 |
152 | 성능 분석 툴
153 |
154 | ---
155 |
156 | ping
157 |
158 | ```
159 | ping www.google.com -n 12
160 | ```
161 |
162 | 12번의 패킷을 보내고 12번의 패킷을 받는다.
163 |
164 | ---
165 |
166 | ping
167 |
168 | 패킷 수신 상태와, 도달하기까지 걸리는 시간 등을 알 수 있다.
169 |
170 | IMCP, traceroute를 차단하는 대상의 경우 ping 테스팅이 불가능하다.
171 |
172 | ---
173 |
174 | Netstat
175 |
176 | 두 가지 대표적인 기능이 있음.
177 |
178 | - 라우팅 테이블 확인
179 | - 프로토콜 리스트
180 | - 서비스 포트 열려 있는지 확인
181 |
182 | ---
183 |
184 | nslookup
185 |
186 | name server lookup
187 |
188 | 특정 도메인에 매핑된 IP를 확인하기 위해 사용합니다.
189 |
190 | ---
191 |
192 | tracert / traceroute (linux)
193 |
194 | 목적지 노드까지의 네트워크 경로를 확인할 때 사용합니다.
195 |
196 | 어느 구간에서 응답 시간이 느려지는지 등을 확인 가능합니다.
197 |
198 | ---
199 |
200 | 그 외의 툴들
201 |
202 | - ftpdump
203 | - wireshark
204 | - netmon
205 |
206 | ---
207 |
208 | 표준화된 프로토콜
209 |
210 | IEEE, IETF 에서 정한다.
211 |
212 | ---
213 |
214 |
215 |
--------------------------------------------------------------------------------
/1. 디자인 패턴과 프로그래밍 패러다임(1)/디자인 패턴과 프로그래밍 패러다임(2)_김대현.md:
--------------------------------------------------------------------------------
1 | # 1.2 프로그래밍 패러다임
2 |
3 | ---
4 |
5 | ### 1.2.1 선언형과 함수형 프로그래밍
6 | map, filter, reduce 를 사용하자!
7 |
8 | https://www.youtube.com/watch?v=e-5obm1G_FY&ab_channel=JSConf
9 |
10 | ---
11 |
12 | 함수가 일급객체이다.
13 |
14 | 일급객체란(First Class Citizen)?
15 | 변수에 할당될 수 있다. 함수에 인자로 넘어갈 수 있고, return 값으로 사용될 수도 있다.
16 |
17 | ---
18 |
19 | 순수함수(Pure Function):
20 | Input이 같다면 Output이 항상 같고, 다른 전역 변수 등에 전혀 영향을 받지도 주지도 않는 함수
21 |
22 | 디버깅과 유닛테스팅에 용이합니다.
23 |
24 | ---
25 |
26 | ### 1.2.2 객체지향 프로그래밍
27 |
28 | 특징
29 | - Abstraction: 복잡한 시스템으로부터 핵심 기능을 간추려내는 것.
30 | - Encapsulation: 객체의 속성과 메서드를 하나로 묶고 일부를 외부에 감추어 은닉하는 것
31 |
32 | ---
33 |
34 | - Inheritance: 상위 클래스의 특성을 하위 클래스가 이어받아 중복을 제거하고 코드 재사용성을 높이는 것.
35 | - Polymorphism: 하나의 메서드나 클래스가 다양한 방법으로 동작하는 것. 오버로딩, 오버라이딩
36 |
37 | ---
38 |
39 | #### 오버로딩과 오버라이딩의 차이
40 |
41 | - 오버로딩: 이름은 같지만 함수 **시그니처(파라미터 수, 타입)** 이 다른 메소드를 새롭게 정의
42 |
43 | - 오버라이딩: 상속받은 메서드의 내용을 변경
44 |
45 | ---
46 |
47 | #### 설계 원칙
48 |
49 | SOLID
50 |
51 | - Single Responsibility Principle
52 | - Open Closed Principle
53 | - Liskov Substitution Principle
54 | - Interface Segregation Principle
55 | - Dependency Inversion Principle
56 |
57 | ---
58 |
59 | - Single Responsibility Principle
60 | 모든 클래스는 하나의 책임만을 가져야 한다. 하나의 역할만 해야 한다.
61 |
62 | There should never be more than one reason for a class to change. In other words, every class should have only one responsibility.
63 |
64 | ---
65 |
66 | - Open Closed Principle
67 | 수정에는 닫여 있어야 하고, 확장에는 열려있어야 한다.
68 | 새로운 기능을 추가할 때는 가급적 기존 코드를 수정하지 말고, 새로운 코드를 추가하는 형식으로 설계되어야 한다.
69 |
70 | Software entities, should be open for extension, but closed for modification.
71 |
72 | ---
73 |
74 | - Liskov Substitution Principle
75 | 자식 객체는 부모를 대신할 수 있지만 부모는 자식을 대신할 수 없다.
76 | 예시: 사람을 상속받은 학생은 .breathe() 를 사용할 수 있지만, 학생의 부모객체인 사람은 .useIntelliJUltimateForFree() 를 사용할 수 없다.
77 |
78 | Functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.
79 |
80 | ---
81 |
82 | - Interface Segregation Principle
83 | 하나의 일반적인 인터페이스보다는 구체적으로 여러개의 인터페이스를 만들어야 한다.
84 |
85 | Clients should not be forced to depend upon interfaces that they do not use.
86 |
87 | ---
88 |
89 | - Dependency Inversion Principle
90 |
91 | 상위 계층은 하위 계층의 변화에 대한 구현으로부터 독립적이어야 한다.
92 | 자신보다 변하기 쉬운 하위 계층에 의존한다면, 그 사이에 인터페이스와 같은 layer를 두어 변화로부터 스스로를 보호해야 한다.
93 |
94 | Depend upon abstractions, not concretions.
95 |
96 | ---
97 |
98 | ### 1.2.3 Procedural programming
99 |
100 | 가장 원시적인 프로그래밍 접근
101 |
102 | ---
103 |
104 | Q. Proxy server 를 설명하세요.
105 |
106 | 서버 앞단에 layer를 하나 더 추가하여 caching, logging, data analysis 등의 분석을 먼저하는 서버를 뜻합니다. DDOS를 차단하거나, 접근을 막거나, CDN을 프록시 서버로 달아서 캐싱을 용이하게 한다. nginx로 버퍼 오버플로우를 예방하거나, CloudFlare로 캐싱, 로그 분석을 하는 사례가 있습니다.
107 |
108 | ---
109 |
110 | Q. MVC, MVVM의 차이점은 무엇인가?
111 |
112 | Model, View, Controller 로 나눈 디자인 패턴입니다. View는 보여지는 것에 집중하고, Model은 비즈니스의 핵심 기능에 집중하며, Controller는 그 사이에서 View와 Model의 상호작용을 조정합니다.
113 |
114 | ---
115 |
116 | MVVM은 C가 더 고도화되어 VM, View model로 바뀐 패턴입니다.
117 | 왜?
118 | - 커맨드와 데이터 바인딩을 가집니다(?).
119 | - 뷰와 뷰모델 사이 양방향 데이터 바인딩을 지원합니다?
120 | - UI를 별도의 코드 수정 없이 재사용 가능합니다?
121 | - 단위 테스팅이 쉽습니다?
122 | ---
123 |
124 | Obsidian .obsidian 함부로 symbolic link 로 setting sync하거나 하면 안됨. workspace 문제도 있고 여러가지 버그도 있음.
125 |
126 | 대표적 버그: vault 내부에 새로운 폴더 만들고 그걸 inner vault 로 썼다가 모든 게 사라져버리는 상
127 |
128 | ---
129 |
130 | https://www.acmicpc.net/problem/15649
131 | https://www.acmicpc.net/problem/10974
132 |
133 | 차이점 생각해보기
134 |
135 | ---
136 |
137 | https://stackoverflow.com/questions/58293514/should-developers-share-git-branches
138 |
139 | 브랜치는 share 되어야 하는가? 아니면 각자의 브랜치로 일해야 하는가?
140 |
141 | branch access restriction
142 |
143 | ---
144 |
145 | ``` python
146 | print ("hello world")
147 | ```
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/4.4 데이터베이스의 종류.md:
--------------------------------------------------------------------------------
1 |
2 | ## RDB vs NoSQL
3 |
4 | >SQL = Structured Query Language
5 |
6 | ##### RDBMS
7 | - SQL 쿼리 언어를 사용한다.
8 | - 테이블마다 스키마(Schema)를 정의해야한다.
9 | - 데이터 타입과 제약으로 데이터의 정확성이 보장된다.
10 | - 속도보다 트랜잭션 시의 ACID가 중요하다.
11 | - 수직적 확장(Scale up)에 적합하다.
12 | - 데이터 중복이 없어 쓰기 속도가 빠르다.
13 | - MySQL, Oracle, MariaDB, SQL Server 등이 있다.
14 |
15 | ##### NoSQL
16 | : Not Only SQL
17 | - SQL 쿼리 언어를 사용하지 않는다.
18 | - 스키마를 반드시 정의하지 않아도 된다.(Schema-less)
19 | - 사용 목적에 따라 ACID가 중요하지 않을 수 있다.
20 | - RDB의 확장성 이슈를 해결하기 위해 나온 데이터베이스 모델이다.
21 | - key-value방식으로 데이터를 관리한다.
22 | - 수평적 확장(Scale out)에 적합하다.
23 | - 데이터 중복이 가능해 읽기 속도가 빠르다.
24 | - Undo와 Redo를 제공하지 않는다.
25 | - 트렌잭션 관리가 안된다.
26 | - MongoDB, Redis 등이 있다.
27 |
28 |
29 |
30 | ## Storae Engine
31 |
32 | : 스토리지 엔진 (=Database Engine)
33 |
34 | - 데이터베이스의 심장과도 같은 역할
35 | - DBMS가 데이터베이스에 대해 데이터 CRUD를 하는 데에 사용하는 기본 소프트웨어 컴포넌트
36 | - DB에서 데이터를 어떠한 방식으로 저장하고 접근할 것인지에 대한 기능을 제공함
37 | - 스토리지엔진의 특성에 따라 데이터 접근이 얼마나 빠른지, 얼마나 안정적인지, 트랜잭션 등의 기능을 제공하는지 등의 차이점 발생
38 |
39 |
40 |
41 | ## 1. MySQL
42 |
43 | : 대부분의 운영체제와 호환되며, 현재 가장 많이 사용되는 데이터베이스
44 |
45 | - C, C++로 만들어짐
46 | - MyISAM 인덱스 압축 기술
47 | - B-tree 기반의 인덱스
48 | - 스레드 기반의 메모리 할당 시스템
49 | - 매우 빠른 조인
50 | - 최대 64개의 인덱스
51 | - 대용량 데이터베이스를 위해 설계되어 있음
52 | - 롤백, 커밋, 이중 암호 지원 보안 등의 기능을 제공함
53 |
54 | #### MySQL Storage Engine
55 |
56 | ![[Pasted image 20230312001535.png]]
57 | - MySQL 스토리지 엔진은 모듈식 아키텍처로, 쉽게 스토리지 엔진을 바꿀 수 있으며 데이터 웨어하우징, 트랜잭션 처리, 고가용성 처리에 강점을 두고 있다.
58 | - 스토리지 엔진 위에는 커넥터 API 및 서비스 계층을 통해 MySQL 데이터베이스와 쉽게 상호 작용할 수 있다.
59 |
60 | **종류**
61 | - **MyISAM**
62 | - MySQL5.5 버전 이전의 기본 스토리지 엔진
63 | - 기본적인 기능을 제공하여 상대적으로 가벼움
64 | - 더 이상 사용할 수 없는 구형 ISAM스토리지 엔진을 기반으로 하지만 유용한 확장 기능이 있음
65 | - **트랜잭션 처리가 필요 없음
66 | - **Read only 기능이 많은 서비스일수록 효율적**. 대신 write가 많은 서비스에서 불리함
67 | - 테이블과 인덱스를 별도의 파일로 저장
68 |
69 | - **InnoDB**
70 | - 많은 기능을 제공하여 상대적으로 무거움
71 | - Row level locking 지원으로 INSERT,UPDATE,DELETE에 유리함. 특히, write가 많은 서비스에서 유리함
72 | - 테이블과 인덱스를 테이블 스페이스에 저장
73 | - **트랜잭션 처리가 필요**함
74 | - **대용량의 데이터를 다루는 부분에서** 효율적임
75 |
76 | - **Cluster** (NDB)
77 | - 트랜잭션을 지원
78 | - 모든 데이터와 인덱스가 메모리에 존재하여 매우 빠른 데이터 로드 속도를 자랑함
79 | - PK 사용시 최상의 속도를 냄
80 |
81 | - **Archive**
82 | - MySQL 5.0부터 새롭게 도입된 엔진
83 | - 작은 풋 프린트에서 인덱싱되지 않은 많은 양의 데이터를 저장함
84 | - 자동적으로 데이터 압축을 지원하며 다른 엔진에 비해 80% 저장공간 절약 효과가 있음
85 | - 가장 빠른 데이터 로드 속도가 장점
86 | - 단, INSERT와 SELECT만이 가능함
87 |
88 | - **Federated**
89 | - MySQL 5.0부터 새롭게 도입된 엔진
90 | - 물리적 데이터베이스에 대한 논리적 데이터베이스를 생성하여 원격 데이터를 컨트롤 할 수 있음
91 | - 실행속도는 네트워크 요소에 따라 좌우되며, 테이블 정의를 통한 SSL 보안 처리를 함
92 | - 분산 데이터베이스 환경에 사용함
93 |
94 |
95 |
96 | ## 2. PostgreSQL
97 |
98 | **특징**
99 | - MySQL 다음으로 개발자들이 선호하는 데이터베이스 기술
100 | - VACUUM : 디스크 조각이 차지하는 영역을 회수할 수 있는 장치
101 | - 최대 테이블의 크기는 32TB
102 | - ORDBMS (객체-관계형 데이터베이스 시스템) : SQL 뿐만 아니라 JSON을 이용해서 데이터에 접근할 수 있음
103 | - 지정 시간에 복구하는 기능, 로깅, 접근 제어, 중첩된 트랜잭션, 백업 등을 할 수 있음
104 |
105 |
106 |
107 | ## 3. MongoDB
108 |
109 | - JSON을 통해 데이터에 접근할 수 있고, Binary JSON 형태(BSON)로 데이터가 저장됨
110 | - 와이어드 타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐먼트 기반의 데이터베이스
111 | - 확장성이 뛰어남
112 | - 빅데이터를 저장할 때 성능이 좋음
113 | - 고가용성, 샤딩*, 레플리카셋을 지원함
114 | - 스키마를 정해놓지 않고 데이터 삽입 가능 - 다양한 도메인의 데이터베이스를 기반으로 분석하거나, 로깅 등을 구현할 때 강점을 보임
115 | - 도큐먼트를 생성할 때마다 ObjectID가 생성됨
116 | > ObjectID : 다른 컬렉션에서 중복된 값을 지니기 힘든 유니크한 값
117 | > ![[Pasted image 20230312005143.png]]
118 | > - 기본키
119 | > - 유닉스 시간 기반의 타임스탬프(4바이트), 랜덤 값(5바이트), 카운터(3바이트)로 이루어져 있음
120 |
121 |
122 |
123 | ## 4. Redis
124 |
125 | : 인메모리 데이터베이스, 키-값 데이터 모델 기반의 데이터베이스
126 |
127 | - 기본 데이터 타입 : String
128 | - 최대 512MB까지 저장 가능
129 | - set, hash 등을 지원함
130 | - pub/sub 기능을 통해 채팅 시스템, 다른 데이터베이스 앞단에 두어 사용하는 캐싱 계층, 단순히 키-값이 필요한 세션 정보 관리, sorted set 자료 구조를 이용한 실시간 순위표 서비스에 사용함
--------------------------------------------------------------------------------
/2. 네트워크(1)/김대현/2.2 TCP-IP 4계층 모델.md:
--------------------------------------------------------------------------------
1 |
2 | - OSI 7계층 모델
3 |
4 | 밑에서부터
5 |
6 | - 물리
7 | - 데이터링크
8 | - 네트워크
9 | - 트랜스포트
10 | - 세션
11 | - 프레젠테이션
12 | - 애플리케이션
13 |
14 | ---
15 |
16 | 위에서부터
17 |
18 | - 애플리케이션
19 | - 프레젠테이션
20 | - 세션
21 | - 트랜스포트
22 | - 네트워크
23 | - 데이터링크
24 | - 물리
25 |
26 | ---
27 |
28 | OSI 7계층에서 4개를 뽑아내면 TCP/IP 4계층
29 |
30 | ---
31 |
32 | ### 대표적인 애플리케이션 계층 프로토콜
33 |
34 | - FTP: 장치와 장치 간 파일 전송
35 | - HTTP: WWW를 위한 데이터 통신
36 | - SMTP: 전자 메일 전송
37 | - DNS: 도메인과 IP 주소를 매핑
38 |
39 | ---
40 |
41 | 전송 계층 (Transport Layer)
42 |
43 | - 송신자와 수신자를 연결하는 서비스를 제공
44 | - 연결 지향 데이터 스트림 지원
45 | - 신뢰성 제공
46 | - 흐름 제어 제공
47 |
48 | ---
49 |
50 | 대표적인 트랜스포트 계층 프로토콜
51 |
52 | - TCP: 패킷 사이의 순서 보장, 연결 지향, 신뢰성 구축, 수신 여부 확인, '가상회선 패킷 교환 방식(?)' 사용 #todo
53 | - UDP: 순서 보장 x, 수신 여부 확인 x, 데이터그램 패킷 교환 방식 사용
54 | - [QUIC](../../wiki/QUIC.md): 구글이 만듬. TCP 대체 예
55 |
56 | ---
57 |
58 | 가상 회선 패킷 교환 방식
59 |
60 | Packet switching (virtual circuit approach)
61 |
62 | 각 패킷이 가상 회선 식별자를 포함하고, 모든 패킷이 전송 완료되면 '순서대로' 도착 (?)
63 |
64 | ---
65 |
66 | Datagram approach
67 |
68 | 각자도생
69 |
70 | ---
71 |
72 | TCP의 3-way handshake 연결
73 |
74 | 1. Syn
75 | 2. Ack + Syn
76 | 3. Ack
77 |
78 | ---
79 |
80 | SYN: synchronization
81 |
82 | ACK: Acknowledgement
83 |
84 | ISN: Initial Sequence Numbers, 32비트 고유 시퀀스 번호
85 |
86 | ---
87 |
88 | TCP의 4-way handshake 연결 해제
89 |
90 | 1. Fin
91 | 2. Ack
92 | 3. Fin
93 | 4. Ack
94 |
95 | ---
96 | 사진:
97 |
98 | 
99 |
100 | ---
101 |
102 | TIME_WAIT
103 |
104 | 지연 패킷 문제를 해결할 때 쓰인다.
105 |
106 | ---
107 |
108 | 인터넷 / 네트워크 계층
109 |
110 | 장치로부터 받은 패킷을 IP 주소로 지정된 목적지로 전송하는 계층.
111 |
112 | 수신 여부를 보장하지 않음.
113 |
114 | ---
115 |
116 | 대표적인 인터넷 / 네트워크 계층
117 |
118 | - IP
119 | - ARP
120 | - ICMP
121 |
122 | ---
123 |
124 | 링크 계층
125 |
126 | 장치 간에 신호를 주고받는 규칙을 정하는 계층.
127 |
128 | 데이터 링크 계층 / 물리 계층으로 나뉨
129 |
130 | 물리: 0과 1로 이루어진 데이터를 보내는 계층
131 |
132 | ---
133 |
134 | 데이터 링크: [이더넷 프레임](#이더넷%20프레임)을 통해
135 | - 에러 확인
136 | - 흐름 제어
137 | - 접근 제어
138 |
139 | ---
140 |
141 | 유선 LAN (IEEE802.3)
142 |
143 | 이더넷이며, 전이중화 통신 사용
144 |
145 | ---
146 |
147 | 전 이중화 통신 (full duplex)
148 |
149 | 양쪽 장치가 동시에 송수신. 현대의 이더넷
150 |
151 | ---
152 |
153 | CSMA/CD
154 |
155 | 전 이중화 통신 이전에는 반 이중화 통신 중 하나인 이것을 썼다.
156 |
157 | ---
158 |
159 | 무선 랜 (IEEE802.11)
160 |
161 | 반 이중화 통신 사용
162 |
163 | ---
164 |
165 | 반 이중화 통신 (half duplex)
166 |
167 | 한번에 한쪽 방향만 통신할 수 있다. 기다려야 한다. 충돌 방지 시스템이 필요하다.
168 |
169 | ---
170 |
171 | CSMA/CA
172 |
173 | 반 이중화 통신 중 하나
174 |
175 | 캐리어 감지: 회선이 비어 있는지를 판단합니다.
176 |
177 | 랜덤 값을 기반으로 정해진 시간만큼 기다리며, 무선 매체가 사용 중이면 점점 그 간격을 늘려간다.
178 |
179 | ---
180 |
181 | 무선 LAN을 이루는 주파수
182 |
183 | WLAN은 비유도 매체인 공기에 주파수를 쏘아 무선 통신망을 구축한다.
184 |
185 | ---
186 |
187 | wifi는 Access Point, 즉 공유기가 있어야 한다. 유선 LAN을 무선 LAN으로 바꿔준다. 지그비, 블루투스도 무선 LAN
188 |
189 | ---
190 |
191 | BSS (Basic Service Set)
192 |
193 | 동일 BSS에 있는 AP들과 장치들이 서로 통신이 가능한 구조
194 |
195 | ---
196 |
197 | ESS (Extended Service Set)
198 |
199 | 하나 이상의 연결된 BSS 그룹. 사용자는 한 장소에서 다른 장소로 이동하며 중단 없이 네트워크를 사용 가능.
200 |
201 | ---
202 |
203 | ### 이더넷 프레임
204 |
205 | 
206 |
207 | - 에러 검출
208 | - 캡슐화
209 |
210 | ---
211 |
212 | - Preamable: 이더넷 프레임 시작
213 | - SFD: 다음 바이트부터 MAC
214 | - DMAC, SMAC: 수신 송신 MAC
215 | - EtherType: IP 프로토콜 정의, IPv4, IPv6
216 | - Payload: 데이터
217 | - CRC: 에러 확인 비트
218 |
219 | > MAC: 6바이트 LAN 카드 (Network Interface Controller) 고유 식별 주소
220 | >
221 | > Media Access Control Address
222 |
223 | ---
224 |
225 | ### 캡슐화
226 |
227 | 
228 |
229 | ---
230 |
231 | ### PDU
232 |
233 | Protocol Data Unit.
234 | 각 계층마다 부르는 명칭이 다르다.
235 |
236 | - 애플: 메시지
237 | - 전송: 세그먼트, 데이터그램
238 | - 인터넷: 패킷
239 | - 링크: 프레임, 비트
240 |
241 | ---
242 |
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_송민진/데이터베이스(1)_송민진.md:
--------------------------------------------------------------------------------
1 |
2 | ### ERD (Entity Relation Diagram)
3 | - 데이터베이스 구축할 때 가장 기초적인 뼈대 역할을 함
4 | - 릴레이션 간의 관계들을 정의한 것
5 | - 비정형 데이터를 충분히 표현할 수 없다는 단점이 있음
6 |
7 |
8 |
9 | ### 정규화 (Normalization)
10 |
11 | 이상현상이 있는 릴레이션을 분해하여 이상현상(Anomaly)을 없애는 과정
12 | 즉, 중복을 최소화하게 데이터를 구조화하는 프로세스
13 |
14 | >**정규화의 기본 목표**
15 | >관련이 없는 함수 종속성은 별개의 릴레이션으로 표현하는 것
16 |
17 | **장점**
18 | - 데이터베이스 변경 시 이상 현상(Anomaly)을 제거할 수 있다.
19 |
20 | **단점**
21 | - 릴레이션의 분해로 인해 릴레이션 간의 JOIN연산이 많아진다. -> 연산 시간이 증가한다. -> 반정규화가 해답이 될 수도 있음
22 |
23 | ![[Pasted image 20230303030049.png]]
24 |
25 |
26 | #### **제1정규형 (1NF)**
27 | - 각 컬럼이 하나의 속성만을 가져야 한다.
28 | - 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다.
29 | - 각 컬럼이 유일한(unique) 이름을 가져야 한다.
30 | - 칼럼의 순서가 상관없어야 한다.
31 |
32 | ![[Pasted image 20230303025149.png]]
33 |
34 |
35 |
36 | #### **제2정규형(2NF)**
37 | - 1정규형을 만족해야 한다.
38 | - 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. == 모든 칼럼이 완전 함수 종속을 만족해야 한다.
39 | - 즉, 부분 함수의 종속성을 제거한 형태
40 |
41 | > **부분 함수의 종속성 제거란?**
42 | > 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속적인 것을 말함
43 |
44 | ![[Pasted image 20230303025541.png]]
45 |
46 |
47 |
48 | #### **제3정규형(3NF)**
49 |
50 | - 제2정규형을 만족해야 한다.
51 | - 기본키를 제외한 속성들 간의 이행적 함수 종속이 없어야 한다.
52 |
53 | > **이행적 함수 종속 (Transitive Function Dependency)**
54 | > A → B와 B → C가 존재하면 논리적으로 A → C가 성립하는데, 이때 집합 C가 집합 A에 *이행적으로 함수 종속*이 되었다고 함
55 |
56 | ![[Pasted image 20230303030852.png]]
57 |
58 |
59 |
60 | #### 보이스/코드 정규형 (BCNF)
61 |
62 | - 3정규형을 만족해야 한다.
63 | - 모든 결정자가 후보키 집합에 속해야 한다.
64 |
65 | >**결정자**
66 | >함수 종속 관계에서 특정 종속자를 결정짓는 요소
67 | >X → Y일 때, X는 결정자, Y는 종속자이다.
68 |
69 | ![[Pasted image 20230303031348.png]]
70 | ![[Pasted image 20230303032130.png]]
71 | >강사 속성이 결정자이지만 후보키가 아니므로 이 강사 속성을 분리해야 한다.
72 |
73 |
74 | ![[Pasted image 20230303032307.png]]
75 |
76 |
77 |
78 | ---
79 |
80 |
81 | ## 트랜잭션과 무결성
82 |
83 | #### 트랜잭션
84 | : 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 작업의 단위
85 |
86 | - 즉, 여러 개의 쿼리들을 하나로 묶는 단위
87 | - ACID : 원자성, 일관성, 독립성, 지속성이 있음
88 |
89 | **Atomicity (원자성)**
90 | : 트랜잭션과 관련된 일이 모두 수행되었거나 되지 않았거나를 보장하는 특징
91 | - all or nothing
92 | - 트랜잭션을 커밋했는데, 문제가 발생하는 경우 그 이후에 모두 수행되지 않음을 보장하는 것
93 |
94 | >**스프링에서 `@Transactional`을 이용한 트랜잭션 전파**
95 | >여러 쿼리 관련 코드들을 하나의 트랜잭션으로 처리함
96 |
97 |
98 | **Consistency (일관성)**
99 | : 허용된 방식으로만 데이터를 변경해야 하는 것. 데이터베이스의 상태가 일관되어야 한다는 성질
100 | - 하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 한다.
101 |
102 |
103 | **Isolation (격리성, 고립성)**
104 | : 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다.
105 | - 실제로 동시에 여러 개의 트랜잭션들이 수행될 때, 각 트랜잭션은 고립/격리되어 있어 연속으로 실행된 것과 동일한 결과를 나타냄
106 |
107 | ![[Pasted image 20230303040223.png]]
108 |
109 | - 격리 수준에 따라 발생하는 현상
110 | - Phantom Read (팬텀 리드) : 한 트랜잭션 내에서 동일한 쿼리를 보냈을 때 해당 조회 결과가 다른 경우
111 | - Non-repeatable Readd (반복 가능하지 않은 조회) : 한 트랜잭션 내의 같은 행에 두 번 이상 조회가 발생하였는데, 그 값이 다른 경우. 팬텀리드와 다른 점 : 팬텀 리드는 다른 행이 선택될 수도 있는 반면, 이 때는 다른 행이 선택될 수도 있음
112 | - Dirty Read (더티 리드) : 한 트랜잭션이 실행 중일 때 다른 트랜잭션에 의해 수정되었지만 아직 커밋되지 않은 행의 데이터를 읽는 것
113 |
114 | - 격리 수준
115 | - Serializable : 트랜잭션을 순차적으로 진행시키는 것. 여러 트랜잭션이 동시에 같은 행에 접근할 수 없음. 따라서 교착 상태가 일어날 확률도 많고, 가장 성능이 떨어지는 격리 수준임
116 | - Repeatable Read : 하나의 트랜잭션이 수정한 행을 다른 트랜잭션이 수정할 수 없도록 막아주지만, 새로운 행을 추가하는 것은 막지 않음
117 | - Read Committed : 가장 많이 사용되는 격리 수준. MySQL, PostgreSQL, SQL Server, Oracle에서 기본값으로 설정되어 있음. 다른 트랜잭션이 커밋하지 않은 정보는 읽을 수 없다. 즉, 커밋 완료된 데이터에 대해서만 조회를 허용한다.
118 | - Read Unommitted : 가장 낮은 격리 수준. 데이터 무결성을 위해 되도록 사용하지 않는 것이 이상적이나, 대량의 데이터를 어림잡아 집계하는 데에는 사용하면 좋음
119 |
120 |
121 | **Durability (지속성)**
122 | : 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야 하는 성질
123 |
124 | - 성공된 트랜잭션은 영원히 반영되어야 함
125 | - 즉, 데이터베이스에 시스템 장애가 발생해도 원래 상태로 복구하는 회복 기능이 있어야 함. 이를 위해 데이터베이스는 체크섬, 저널링, 롤백 등의 기능 제공
126 |
127 |
128 | > 체크섬 : 중복 검사의 한 형태. 오류 정정을 통해 송신된 자료의 무결성을 보호함
129 |
130 | > 저널링 : 파일 시스템 또는 데이터베이스 시스템에 변경 사항을 반영하기 전에 로깅하는 것. 트랜잭션 등 변경 사항에 대한 로그를 남기는 것
131 |
132 |
133 | #### **Integerity(무결성)**
134 |
135 | : 데이터의 정확성, 일관성, 유효성을 유지하는 것
136 |
137 | - 데이터베이스에 저장된 데이터 값과 그 값에 해당하는 현실 세계의 실제 값이 일치하는지 여부
138 |
139 | **종류**
140 | - 개체 무결성
141 | - 참조 무결성
142 | - 고유 무결성
143 | - NULL 무결성
144 |
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_김대현/3.2 메모리.md:
--------------------------------------------------------------------------------
1 | ### 3.2.1 메모리 계층
2 |
3 | 
4 |
5 | #### 캐시
6 |
7 | 데이터를 미리 복사해두는 임시 저장소, 병목 현상을 줄이기 위함.
8 |
9 | ##### 지역성의 원리
10 |
11 | 로컬리티 locality
12 |
13 | ###### 시간 지역성
14 |
15 | 최근 사용한 데이터에 다시 접근하려는 특성을 말합니다.
16 |
17 | ###### 공간 지역성
18 |
19 | 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성을 말합니다.
20 |
21 | #### 캐시히트와 캐시미스
22 |
23 | 
24 | 캐시미스가 발생하면 메모리에 직접 접근해서 데이터를 가져와야 하는데, 시스템 버스를 기반으로 하기 때문에 캐시에 비해 느리다.
25 |
26 | ##### 캐시매핑
27 |
28 | !!! 매우 중요
29 |
30 | ###### 직접 매핑
31 |
32 | Directed mapping
33 |
34 | 메모리가 1-100까지, 캐시가 1-10까지 있다면, 즉 캐시가 메모리의 10분의 1이라면, 메모리를 10조각으로 잘게 나눠서 할당하는 것을 뜻함.
35 |
36 | 즉 1-10 사이의 메모리 접근은 1번째 캐시에 저장해둔다.
37 |
38 | 단점: 지역적 로컬리티를 전혀 고려하지 않고, 캐시 미스가 잦다.
39 |
40 | ###### 연관 매핑
41 |
42 | Associative mapping
43 |
44 | 순서 없이 관련 있는 캐시와 메모리를 매핑합니다. 충돌이 적지만 모든 캐시 블록을 탐색해야 해서 속도가 느립니다.
45 |
46 | Q. 연관매핑의 예시 #question
47 |
48 | ###### 집합 연관 매핑
49 |
50 | Set associative mapping
51 |
52 | 직접 매핑과 연관 매핑을 합쳐 놓은 것이다. 순서는 일치시키지만 집합을 둬서 저장한다. 검색은 조금 더 효율적이다.
53 |
54 | Q. 책 예시가 부실. 집합 연관 매핑의 예시 #question
55 |
56 | ##### 웹 브라우저의 캐시
57 |
58 | ###### 쿠키
59 |
60 | 만료기한이 있는 키-값 저장소. 4KB까지 정할 수 있습니다.
61 | httponly 옵션이 중요하다. 주로 서버에서 만료기한을 정한다.
62 |
63 | ###### 로컬 스토리지
64 |
65 | 만료기한이 없는 키-값 저장소. 10MB까지 저장할 수 있으며 웹 브라우저를 닫아도 유지된다. HMTL5가 지원되어야만 사용할 수 있다.
66 |
67 | Q. 도메인 단위로 저장된다는 게 무슨 의미인가? #question
68 |
69 | ###### 세션 스토리지
70 |
71 | 만료기한이 없는 키-값 저장소. 탭 단위로 세션 스토리지를 생성하며, 탭을 닫을 때 해당 데이터가 삭제됩니다. 5MB까지 지원 가능. HTML5에서만 가능.
72 |
73 | ##### 디비의 캐싱 계층
74 |
75 | 레디스 등의 주메모리 기반 캐싱 계층을 둬서 디비 성능을 향상시킵니다.
76 |
77 | ---
78 |
79 | ### 3.2.2 메모리 관리
80 |
81 | #### 가상 메모리
82 |
83 | 메모리 관리 기법의 하나로 컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 이를 사용하는 사용자들에게 매우 큰 메모리로 보이게 만드는 것
84 |
85 | ##### TLB
86 |
87 | 메모리와 CPU 사이에 있는 주소 변환을 위한 캐시. 페이지 테이블에 있는 리스트를 보관하며 CPU가 페이지 테이블까지 가지 않도록 해 속도를 향상시킬 수 있다.
88 |
89 | #### 스와핑
90 |
91 | 생략
92 |
93 | #### 페이지 폴트
94 |
95 | page fault
96 |
97 | 프로세스 주소 공간에는 존재하지만 지금 이 컴퓨터의 RAM에는 없는 데이터에 접근했을 때 발생한다.
98 |
99 | 1. 물리 메모리를 확인하여 없으면 트랩을 발생시킨다.
100 | 2. CPU 정지
101 | 3. 페이지 테이블을 확인하여 가상 메모리에 페이지가 존재하는지 확인하고, 없으면 프로세스를 중단하고 현재 물리 메모리에 비어 있는 프레임이 있는지 찾습니다.
102 | 4. 비어 있는 프레임에 해당 페이지를 로드하고, 페이지 테이블을 최신화합니다.
103 | 5. CPU 재시작
104 |
105 | ##### 페이지
106 |
107 | 가상 메모리 최소 단위
108 |
109 | ##### 프레임
110 |
111 | 물리 메모리 최소 단위
112 |
113 | #### 스레싱
114 |
115 | thrashing
116 |
117 | 메모리의 페이지 폴트율이 높은 것을 의미하며, 심각한 성능 저하를 초래한다.
118 |
119 | 메모리에 너무 많은 프로세스가 동시에 올라가면, 스와핑이 많이 발생한다. 그러면 CPU 이용률이 낮아지고, 이용률이 낮아지면 더 많은 프로세스가 메모리에 올라가는 악순환이 벌어진다.
120 |
121 | 해결책:
122 |
123 | ##### 작업 세트
124 |
125 | working set
126 |
127 | 로컬리티를 이용해서 비슷한 페이지 집합들을 미리 로딩해두는 것이다.
128 |
129 | ##### PFF
130 |
131 | Page Fault Frequency
132 |
133 | 페이지 폴트 빈도를 조절하는 방법. 상한과 하한을 만든다. 상한에 도달하면 프레임을 늘리고, 하한에 도달하면 프레임을 줄인다.
134 |
135 | Q. 하한에 도달하면 프레임을 줄인다는 게 무슨 의미인가? #question
136 |
137 | #### 메모리 할당
138 |
139 | ##### 연속 할당
140 |
141 | 연속적으로 공간을 할당하는 것
142 |
143 | ###### 고정 분할 방식
144 |
145 | fixed partition allocation
146 |
147 | 메모리를 미리 나누어 관리하는 방식. 내부 단편화가 발생한다.
148 |
149 | ###### 가변 분할 방식
150 |
151 | variable partition allocation
152 |
153 | 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용합니다. 외부 단편화가 발생합니다.
154 |
155 | - first fit: 위에서부터 홀을 찾으면 바로 할당한다.
156 | - best fit: 맞는 메모리 공간 중 가장 작은 공간을 찾는다.
157 | - worst fit: 크기가 가장 많이 차이나는 홀에 할당한다.
158 |
159 | 등의 방법이 있다.
160 |
161 | ##### 내부 단편화
162 |
163 | 메모리를 나눈 크기보다 프로그램이 작아서 들어가지 못하는 공간이 많이 발생하는 상황
164 |
165 | ##### 외부 단편화
166 |
167 | 메모리를 나눈 크기보다 프로그램이 커서 들어가지 못하는 공간이 많이 발생하는 현상
168 |
169 | Q. 좀 더 자세히 설명해보아라. #question
170 |
171 | ---
172 |
173 | ##### 불연속 할당
174 |
175 | 메모리를 동일한 크기의 페이지 (4kb)로 나누고 페이지 테이블을 두어 이를 통해 메모리에 프로그램을 할당하는 방식.
176 |
177 | ###### 페이징
178 |
179 | 동일한 크기의 페이지 단위로 나누어 메모리의 서로 다른 위치에 프로세스를 할당합니다. 주소 변환이 복잡하다.
180 |
181 | ###### 세그멘테이션
182 |
183 | segmentation
184 |
185 | ???
186 |
187 | ###### 페이지드 세그멘테이션
188 |
189 | ???
190 |
191 | #### 페이지 교체 알고리즘
192 |
193 | offline algorithm: 미래를 알고 있는 방법
194 |
195 | ##### FIFO
196 |
197 | 가장 먼저 온 페이지를 교체해버리는 것
198 |
199 | ##### LRU
200 |
201 | 가장 오래된 페이지를 교체
202 |
203 | 계수기와 스택을 두어야 한다.
204 |
205 | 두 개의 자료 구조로 구현한다.
206 |
207 | 해시 테이블을 통해 빨리 찾을 수 있도록 하고,
208 |
209 | 이중 연결 리스트에서 뺀다.
210 |
211 | ##### NUR
212 |
213 | Not Used Recently
214 |
215 | 시계 방향으로 돌면서 1이면 0으로 바꾸고, 0이면 바꾸는 알고리즘입니다.
216 |
217 | 굉장히 간단하고 빠르고 쉽다.
218 |
219 | ### LFU
220 |
221 | Least Frequently Used
222 |
223 | 가장 참조 횟수가 적은 페이지를 교체한다.
224 |
225 | 단점: 한번에 엄청 많이 쓰이고 더 이상 쓰이지 않는 페이지는 계속 남아있는다.
226 |
227 | Frecency가 중요할듯?
228 |
229 |
230 |
--------------------------------------------------------------------------------
/2. 네트워크(2)/김대현/2.5 HTTP.md:
--------------------------------------------------------------------------------
1 | ## 2.5.1 HTTP/1.0
2 |
3 | 한 연결 당 하나의 요청을 처리
4 |
5 | ### RTT 증가
6 |
7 | ### 해결책
8 |
9 | - 이미지 스플리팅
10 | - 코드 압축
11 | - 이미지 Base64 인코딩
12 |
13 | ---
14 |
15 | ## 2.5.2 HTTP/1.1
16 |
17 | 
18 |
19 | keep-alive 설정을 통해 한 번의 TCP handshake 이후 여러 파일을 송수신할 수 있다.
20 |
21 | 하지만 여전히 리소스 개수에 비례해서 대기 시간이 길어지는 단점이 있다.
22 |
23 | ---
24 |
25 | ### HOL Blocking
26 |
27 | Head of line blocking
28 |
29 | 같은 큐에 있는 패킷이 앞쪽 패킷 때문에 지연되어 발생하는 성능 저하 현상
30 |
31 | 
32 |
33 | 정확하게 일어나는 원인은?
34 |
35 | ---
36 |
37 | ### 무거운 헤더 구조
38 |
39 | HTTP/1.1의 헤더에는 쿠키 등 많은 메타데이터가 들어가 있어 무겁다.
40 |
41 | ---
42 |
43 | ## 2.5.3 HTTP/2
44 |
45 | 구글이 만든 SPDY 프로코톨에서 파생됨.
46 |
47 | 지연 시간을 줄이고 응답 시간을 더 빠르게 할 수 있다.
48 |
49 | - 멀티플렉싱
50 | - 헤더 압축
51 | - 서버 푸시
52 | - 요청의 우선순위 처리
53 |
54 | 등을 지원한다.
55 |
56 | ---
57 |
58 | ### 멀티플렉싱
59 |
60 | 여러 개의 스트림을 사용하여 송수신. 특정 패킷이 손실되었다 하더라도 해당 스트림에만 영향을 미치고 나머지 스트림은 동작함.
61 |
62 | 
63 |
64 | HOL Blocking 해결
65 |
66 | ---
67 |
68 | ### 헤더 압축
69 |
70 | 허프만 코딩 압축 알고리즘을 사용해 HPACK 압축 형식을 가진다.
71 |
72 | ---
73 |
74 | ### 서버 푸시
75 |
76 | 클라이언트의 요청 없이 바로 리소스를 보내버리는 것.
77 |
78 | html 을 요청했다면 어차피 js, css 파일이 포함되어야 하므로 클라이언트에서 알아서 한꺼번에 다 보내버리는 기술
79 |
80 | ---
81 |
82 | ## 2.5.4 HTTPS
83 |
84 | HTTP/2는 HTTPS 위에서 동작.
85 |
86 | 애플리케이션 계층과 전송 계층 사이에 신뢰 계층인 SSL/TLS 계층을 넣은 신뢰할 수 있는 HTTP 요청을 뜻한다.
87 |
88 | 통신 암호화
89 |
90 | ### SSL/TLS
91 |
92 | Secure Socket Layer
93 | Transport Layer Security Protocol
94 |
95 | 전송 계층에서 보안을 제공하는 프로토콜. 제 3자의 도청과 변조를 막는다.
96 |
97 | - 인증 메커니즘
98 | - 키 교환
99 | - 해싱
100 |
101 | ---
102 |
103 | ### 보안 세션
104 |
105 | 보안이 시작되고 끝나는 동안 유지되는 세션을 말하고, SSL/TLS는 핸드셰이크를 통해 보안 세션을 생성하고 이를 기반으로 상태 정보 등을 공유
106 |
107 | - 세션: 운영체제가 어떤 사용자로부터 자신의 자산 이용을 허락하는 일정한 기간을 뜻한다. 즉 사용자는 일정 시간 동안 응용 프로그램, 자원 등을 사용할 수 있다.
108 |
109 | 
110 |
111 | 잘 몰라서 추가로 공부해야 함.
112 |
113 | ---
114 |
115 | 1-RTT를 소모하여 인증, 인증 확인하는 작업 이후 데이터 송수신한다. 이때 사이퍼 슈트를 클라에서 서버로 보낸다.
116 |
117 | ### 사이퍼 슈트
118 |
119 | Cyper suites
120 |
121 | 프로토콜, AEAD 사이퍼 모드, 해싱 알고리즘이 나열된 규약을 말한다.
122 |
123 | ---
124 |
125 | ### AEAD 사이퍼 모드
126 |
127 | Authenticated Encryption with Associated Data
128 |
129 | 데이터 암호화 알고리즘.
130 |
131 | AES_128_GCM은 128비트의 키를 사용하는 표준 블록 암호화 기술과 병렬 계산에 용이한 암호화 알고리즘 GCM이 결합됨.
132 |
133 | ---
134 |
135 | ### 인증 메커니즘
136 |
137 | CA(Certificate Authorities)에서 발급한 인증서를 기반으로 이루어진다.
138 |
139 | 안전한 연결을 시작하는 데에 있어 필요한 '공개키'를 클라이언트에 제공하고 사용자가 접속한 '서버가 신뢰'할 수 있는 서버임을 보장한다.
140 |
141 | - 서비스 정보
142 | - 공개키
143 | - 지문
144 | - 디지털 서명
145 |
146 | 등으로 이루어져 있다.
147 |
148 | CA는 신뢰성이 엄격하게 공인된 기업들만 참여할 수 있다.
149 |
150 | - Comodo
151 | - GoDaddy
152 | - GlobalSign
153 | - Amazon
154 |
155 | 등이 있다.
156 |
157 | ---
158 |
159 | CA 인증서를 발급 받으려면 자신의 사이트 정보와 공개키를 CA에 제출해야 한다. 이후 CA는 공개키를 해시한 값이 지문 (finger print)를 사용하는 CA의 비밀키 등을 기반으로 CA 인증서를 발급한다.
160 |
161 | ---
162 |
163 | ### 암호화 알고리즘
164 |
165 | - ECDHE (Elliptic Curve Diffie-Hellman Ephemeral): 대수곡선 기반의 알고리즘
166 | - DHE (Diffie-Hellman Ephemeral): 모듈식 기반
167 |
168 | ---
169 |
170 | ### Diffie Hellman
171 |
172 | 각자의 비밀키는 혼자만 (절대 네트워크로 통신 금지)
173 | 공개키는 공유
174 |
175 | 공개키와 비밀키를 혼합한 값은 공유
176 |
177 | 그 값을 각자의 비밀키와 혼합하면 공통의 암호키 생성 (PSK, pre-shared key)
178 |
179 | ---
180 |
181 | TLS 1.3 은 사용자가 이전에 방문한 사이트로 다시 재방문할때 SSL/TLS 보안 세션 통신을 다시 하지 않아도 괜찮다. 0-RTT
182 |
183 | ---
184 |
185 | ### SEO
186 |
187 | - 캐노니컬 설정
188 | - 메타 설정 
189 |
190 | ---
191 |
192 | ### 페이지 속도 개선
193 |
194 | 구글의 PaegSpeedInsights 로 가서 자신의 서비스에 대한 리포팅을 받을 수 있다.
195 |
196 | 
197 |
198 | ---
199 |
200 | ### 사이트맵 관리
201 |
202 | 사이트맵 제너레이터를 사용한다.
203 |
204 | ---
205 |
206 |
207 | ### HTTPS 구축 방법
208 |
209 | - 직접 CA에서 구매한 인증키를 기반으로 HTTPS 서비스를 구축
210 | - 서버 앞단의 HTTPS를 제공하는 로드밸런서를 둔다.
211 | - 서버 앞단에 HTTPS를 제공하는 CDN을 둔다.
212 |
213 | ---
214 |
215 | ## 2.5.5 HTTP/3
216 |
217 | HTTP/2와 다르게, 3는 QUIC 기반으로 돌아가며, UDP를 주로 사용합니다.
218 |
219 | 
220 |
221 | ---
222 |
223 | ### 초기 연결 설정 시 지연 시간 감소
224 |
225 | 3 way handshaking 을 하지 않고 1-RTT 만에 연결할 수 있다. 클라이언트가 서버에 신호를 주고, 서버도 응답하기만 하면 바로 본 통신을 시작할 수 있다.
226 |
227 | 
228 |
229 | 이 사진은 무슨 의미일까...?
230 |
231 | ### 순방향 오류 수정 메커니즘
232 |
233 | FEC
234 |
235 | Forward Error Correction
236 |
237 | 전송한 패킷이 손실되었다면 수신 측에서 에러를 검출하고 수정하는 방식. 열악한 네트워크에서도 낮은 패킷 손실률을 자랑한다.
238 |
239 | ---
240 |
241 | ### 예상 질문
242 |
243 | #### HTTP의 발전을 주욱 설명하고 각각의 단계마다 추가된 장점을 말하시오.
244 |
245 | ###
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_송민진/4.5 인덱스.md:
--------------------------------------------------------------------------------
1 |
2 | # 인덱스
3 |
4 | - 데이터를 빠르게 찾을 수 있는 하나의 장치. 일종의 목차
5 | - DBMS는 B-tree의 인덱싱을 활용해 특정 데이터를 찾기 위한 읽기 작업의 빈도를 낮춤
6 | - B-tree의 각각의 노드는 메모리에서 하나의 페이지를 담당하여, 각 노드가 최소한 절반을 채워두도록 하여 읽기 접근의 횟수를 줄입니다.
7 |
8 |
9 |
10 | ## B-tree
11 |
12 | > 💡 **B-Tree는 무슨 줄임말인가?**
13 | > B-트리의 창시자인 루돌프 바이어는 ‘B’가 무엇을 의미하는지 따로 언급하지는 않았다. 가장 가능성 있는 대답은 리프 노드를 같은 높이에서 유지시켜주므로 균형잡혀있다(balanced)는 뜻에서의 ‘B’라는 것이다. ‘바이어(Bayer)’의 ‘B’를 나타낸다는 의견도, 혹은 그가 일했던 보잉 과학 연구소(Boeing Scientific Research Labs)에서의 ‘B’를 나타낸다는 의견도 있다.
14 |
15 | > 💡 **Btree는 정렬된 순서를 보장하고, 멀티레벨 인덱싱을 통한 빠른 검색을 할 수 있기 때문에 DB에 사용한다.**
16 |
17 | B트리는 이진트리와 다르게 하나의 노드에 많은 수의 정보를 가지고 있을 수 있다. **최대 m개의 자식**을 가질 수 있는 B트리를 **m차 B트리**라고 하며 다음과 같은 특징을 가진다.
18 |
19 |
20 | **특징**
21 | - **모든 리프 노드**는 **같은 레벨**에 있다 (**perfectly balanced**)
22 | - **루트 노드**는 **리프 노드**이거나 **최소 2개의 자식 노드**가 있다.
23 | - 루트 노드와 리프 노드가 아닌 **노드**는 **_m_/2개**부터 **최대 _m_개**까지의 **자식**을 가질 수 있다.
24 | - 노드에는 **최대 _m_−1개 부터 [_m_/2]−1개의 key**가 포함될 수 있다.
25 | - 노드의 **key가 _x_개**라면 **자식의 수는 _x_+1개**이다.
26 | - **최소차수**는 **자식수의 하한값**을 의미하며, **최소차수가 t**라고 하면 **m=2t−1**을 만족한다. (최소차수 t가 2라면 3차 B트리이며, key의 하한은 1개)
27 |
28 |
29 | ![[Pasted image 20230312011124.png]]
30 |
31 |
32 | ## **B+tree**
33 | : B-tree의 변형 구조
34 |
35 | - **index 부분**과 **리프 노드로 구성된 순차 데이터 부분**으로 이루어짐
36 | - 즉, B-tree의 그림에서는 편의상 data를 생략해서 그렸지만 각 key값이 data를 가지고 있었고, B+tree의 경우에는 인덱스 부분의 key 값은 리프 노드에 있는 key 값을 직접 찾아가는데 사용한다고 생각하면 됨
37 |
38 | - 동작 방식의 다른점이라고 하면 **리프 노드가 연결리스트의 형태**를 띄어 **선형 검색이 가능하다**. 이러한 특징점 때문에 **굉장히 작은 시간복잡도**에 **검색**을 수행할 수 있다.
39 |
40 | - 이런 장점들 때문에 모든 RDBMS에서 B+ Tree를 지원하고 있으며, 거의 모든 file system에서도 B+Tree를 사용한다.
41 |
42 | > 💡 실제 **DB의 인덱싱은 B+트리**로 이루어져있다고 한다. 다음 그림은 인덱싱을 나타낸 것이다. 인덱싱은 어떠한 자료를 찾는데 key값을 이용해 효과적으로 찾을 수 있는 기능이다.
43 | > 
44 | >
45 | > 다음과 같은 인덱싱을 **B+트리**로 나타내면 아래 그림과 같습니다.
46 | > 
47 |
48 |
49 | ### B+tree가 B-tree와 다른 점
50 |
51 | 1. **모든 key, data가 리프노드에 모여있다.**
52 | B트리는 리프노드가 아닌 각자 key마다 data를 가진다면, B+트리는 리프 노드에 모든 data를 가진다.
53 |
54 | 1. **모든 리프노드가 연결리스트의 형태를 띄고 있다.**
55 | B트리는 옆에있는 리프노드를 검사할 때, 다시 루트노드부터 검사해야 한다면, B+트리는 리프노드에서 선형검사를 수행할 수 있어 시간복잡도가 굉장히 줄어든다.
56 |
57 | 3. **데이터의 빠른 접근을 위한 인덱스 역할만 하는 비단말 노드(Non-Leaf)가 있다.**
58 | 기존의 B-Tree와 데이터의 연결리스트로 구현된 색인구조. 데이터의 빠른 접근을 위한 인덱스 역할만 한다.
59 |
60 | 4. key 값을 기준으로 **왼쪽 pointer**는 key 값보다 **작은** key 값의 노드를, key 값을 기준으로 **오른쪽 pointer**는 key 값보다 **크거나 같은** key 값의 노드를 가리킨다.
61 |
62 |
63 | #### **장점**
64 | - **블록 사이즈를 더 많이 이용할 수 있음**
65 | - key 값에 대한 하드디스크 액세스 주소가 없기 때문이다.
66 | - 리프 노드를 제외하고 데이터를 담아두지 않기 때문에 메모리를 더 확보함으로써 더 많은 key들을 수용할 수 있다.
67 | - 하나의 노드에 더 많은 key들을 담을 수 있기에 트리의 높이는 더 낮아진다.
68 | - cache hit를 높일 수 있다.
69 |
70 | - **리프 노드끼리 연결 리스트로 연결되어 있어서 범위 탐색에 매우 유리**
71 | ex : Full scan시 선형탐색 1번이면 된다.
72 |
73 |
74 | ##### 단점
75 | - B-tree의 경우 최상 케이스에서는 루트에서 끝날 수 있지만, B+tree는 무조건 리프 노드까지 내려가봐야 함
76 |
77 |
78 |
79 | ## 인덱스와 대수 확장성
80 |
81 | - 인덱스가 효율적인 이유 : 효율적인 단계를 거쳐, 모든 요소에 접근할 수 있는 균형 잡힌 트리 구조를 사용하기 때문! 트리 깊이의 대수확장성과 관련이 있다.
82 |
83 | ##### 대수 확장성
84 | - 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 성질
85 | - 기본적으로 인덱스가 한 깊이씩 증가할 때마다, 최대 인덱스 항목의 수는 4배씩 증가함
86 |
87 |
88 |
89 | ## DBMS와 인덱스
90 |
91 | ### MySQL의 인덱스
92 |
93 | #### **종류**
94 | - 클러스터형 인덱스
95 | - 세컨더리 인덱스
96 |
97 | #### **생성 방법**
98 |
99 | **클러스터형 인덱스**
100 | - 테이블당 하나 설정 가능
101 | - primary key 옵션으로 기본키를 만들면 인덱스 생성됨
102 | - unique not null 옵션 붙이면 인덱스 생성 가능
103 |
104 | **세컨더리 인덱스**
105 | - create index ... 명령어를 기반으로 만들면 생성 가능
106 | - 보조인덱스. 여러 개의 필드 값을 기반으로 쿼리를 많이 보낼 때 생성해야 함
107 | > 하나의 인덱스만 생성할 것이라면 클러스터형 인덱스를 만드는 것이 세컨더리 인덱스를 만드는 것보다 성능이 좋음
108 |
109 |
110 | ### MongoDB의 인덱스
111 |
112 | - 도큐먼트를 만들면 자동으로 ObjectID가 형성되며, 해당 키가 기본키로 설정됨
113 | - 세컨더리키도 부가적으로 설정 가능
114 | - 기본키, 세컨더리키를 같이 쓰는 복합 인덱스를 설정할 수 있음
115 |
116 |
117 |
118 | ## 인덱스 최적화 기법
119 |
120 | > 데이터베이스마다 조금씩 다르지만, 기본적인 골조는 똑같음.
121 | > 아래는 MongoDB를 기반으로 한 인덱스 최적화 기법을 설명함
122 |
123 |
124 | #### 1. 인덱스도 결국 비용이 든다.
125 | - 인덱스 리스트, 그 다음 컬렉션 순으로 탐색한다. 관련 읽기 비용이 발생한다.
126 | - 컬렉션이 수정되었을 때, 인덱스도 수정되어야 한다. B-tree 높이를 균형 있게 조정하는 비용도 들고, 데이터를 효율적으로 조회할 수 있도록 분산시키는 비용도 들음
127 | >👉🏻 쿼리의 모든 필드에 인덱스를 무작정 다 설정하는 것은 답이 아님. 또, 컬렉션에서 가져와야 하는 양이 많을수록, 인덱스 사용이 비효율적일 수도 있음
128 |
129 |
130 |
131 | #### 2. 항상 테스팅하라.
132 |
133 | - 서비스에 따라 인덱스 최적화 기법이 다르기 때문에, 결국 항상 직접 테스팅하는 것이 가장 중요!
134 | - `explain()` 함수를 통해 인덱스를 만들고, 쿼리를 보낸 후에 테스팅을 하며 걸리는 시간을 최소화하기
135 | - MySQL 코드 최적화 테스팅 방법
136 | ```sql
137 | EXPLAIN
138 | SELECT * FROM t1
139 | JOIN t2 ON t1.c1 = t2.c1
140 | ```
141 |
142 |
143 | ### 3. 복합 인덱스는 같음 → 정렬 → 다중값 → 카디널리티 순
144 | - 여러 필드를 기반으로 조회할 때 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고, 순서에 따라 인덱스 성능이 달라진다.
145 | - 바람직한 순서는 같음, 정렬, 다중값, 카디널리티 순이다.
146 | > 카디널리티 : 유니크한 값의 정도
147 |
148 | 1. `==`, `equal`
149 | 2. 정렬에 쓰이는 필드
150 | 3. 다중 값을 출력해야 하는 필드. 즉, 쿼리 자체가 > 이거나 < 등 많은 값을 출력해야 하는 쿼리에 쓰는 필드라면, 나중에 인덱스를 설정하기
151 | 4. 카디널리티가 높은 순서를 기반으로 인덱스 생성
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_이홍섭.md:
--------------------------------------------------------------------------------
1 | # 4. 데이터베이스(2)
2 |
3 | ## 목차
4 | ### 4.4 데이터베이스의 종류 (선택)
5 | - 4.4.1 관계형 데이터베이스
6 | - 4.4.2 NoSQL 데이터베이스
7 | ### 4.5 인덱스
8 | - 4.5.1 인덱스의 필요성
9 | - 4.5.2 B-트리
10 | - 4.5.3 인덱스 만드는 방법
11 | - 4.5.4 인덱스 최적화 기법
12 | ### 4.6 조인의 종류 (선택)
13 | - 4.6.1 내부 조인
14 | - 4.6.2 왼쪽 조인
15 | - 4.6.3 오른쪽 조인
16 | - 4.6.4 합집합 조인
17 | ### 4.7 조인의 원리
18 | - 4.7.1 중첩 루프 조인
19 | - 4.7.2 정렬 병합 조인
20 | - 4.7.3 해시 조인
21 | ---
22 | # 4.4 데이터베이스의 종류
23 | ## 1. 관계형 데이터베이스
24 | - 행과 열을 가지는 표 형식 데이터를 저장하는 형태의 DB를 가리킨다
25 | - SQL이라는 언어를 써서 조작한다
26 | - 대표적으로 MySQL, PostgreSQL 등이 있다.
27 | ## 2. NoSQL 데이터베이스
28 | - Not only SQL 이라는 슬로건에서 생겨난 DB이다
29 | - SQL을 사용하지 않는 데이터베이스를 말한다
30 | - 대표적으로 몽고DB, redis 등이 있다.
31 | # 4.5 인덱스
32 | ## 1. 인덱스의 필요성
33 | - 인덱스는 데이터를 빠르게 찾을 수 있는 하나의 장치이다
34 | - 예를 들어 책의 마지막 장에 있는 찾아보기를 생각하면 된다
35 | - 책의 본문 안의 특정한 개념이나 단어를 빠르게 찾을 수 있듯이, 인덱스도 DB에서 원하는 데이터를 빠르게 찾을 수 있도록 한다.
36 | ## 2. B-트리
37 |  38 |
39 | MySQL,PostgreSQL등 대부분의 DB 시트템에서 인덳느는 보통 `B-tree` 라고하는 자료구조로 이루어져 있다.
38 |
39 | MySQL,PostgreSQL등 대부분의 DB 시트템에서 인덳느는 보통 `B-tree` 라고하는 자료구조로 이루어져 있다.
40 | B-tree는 `Root노드`, `Leaf노드`, 그 사이의 `Branch노드`로 나뉜다
41 | - 특성으로는
42 | - 루트에서 리프 노드까지의 경로의 길이는 모두 같다
43 | - 루트나 리프가 아닌 노드의 자식 노드의 수는 [n/2, n]개로 한정된다
44 | - 리프 노드의 값은 [(n-1)/2, n-1]로 한정된다
45 | - B-tree는 Binary search tree와 유사하지만, 한 노드 당 자식 노드가 2개 이상 가능하다.
46 | - key 값을 이용해 찾고자 하는 데이터를 트리 구조를 이용해 찾는 것이다.
47 | - 효율적인 단계를 거쳐 모든 요소에 접근할 수 있는 균형잡힌 트리 구조와 트리 깊이의 **대수확장성** 때문에 인덱스가 효율적이다.
48 |
49 | >**대수확장성이란?**
50 | 트리 깊이가 리프 노두 수에 비해 매우 느리게 성장하는 것을 의미한다.
51 | 기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가한다.
52 |
53 | ## 3. 인덱스 만드는 방법
54 | 인덱스를 생성하는 방법은 DB마다 다르며 이에 따른 인덱싱의 방식에도 약간 차이가 있다
55 | ### 1) MySQL
56 | - 클러스터형 인덱스와 세컨더리 인덱스가 있다.
57 | - `클러스터형 인덱스`
58 | - 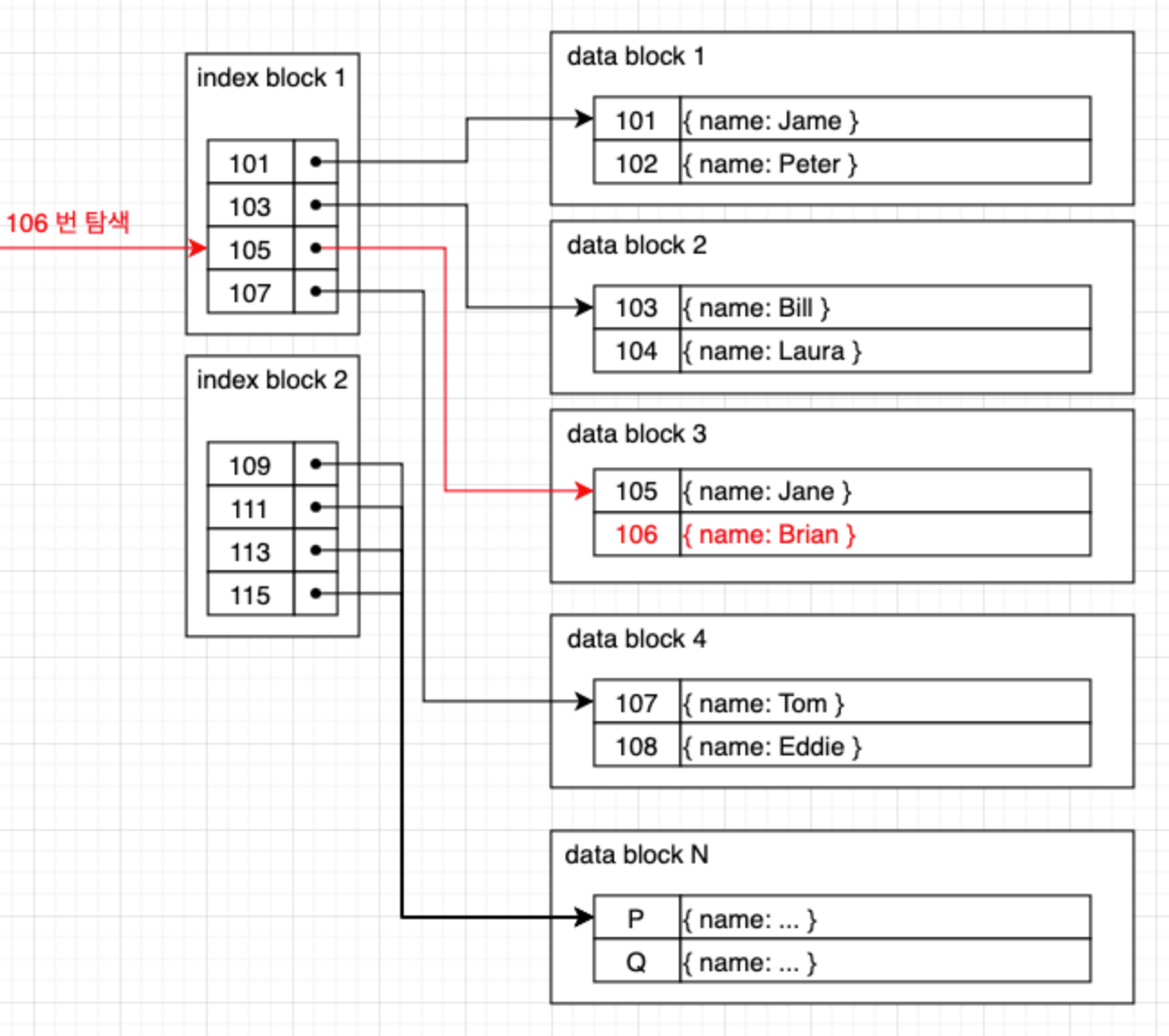
59 | - **테이블 전체가 정렬된 인덱스가 되는 방식**의 종류이다
60 | - 실제 데이터와 무리(cluster)를 지어 인덱싱 되므로 클러스터형 인덱스라 부른다
61 | - 영어 사전과 비슷하다. 영어 사전은 영어 단어가 사전순으로 정렬되어 있으면서, 영어 단어의 뜻도 함께 존재하기 때문이다
62 | - 테이블당 하나를 설정할 수 있다.
63 | - PK 옵션으로 기본키로 만들면 생성할 수 있다.
64 | - PK로 만들지 않고 unique not null 옵션을 붙이면 클러스터형 인덱스로 만들 수 있다.
65 | - `세컨더리 인덱스`
66 | - 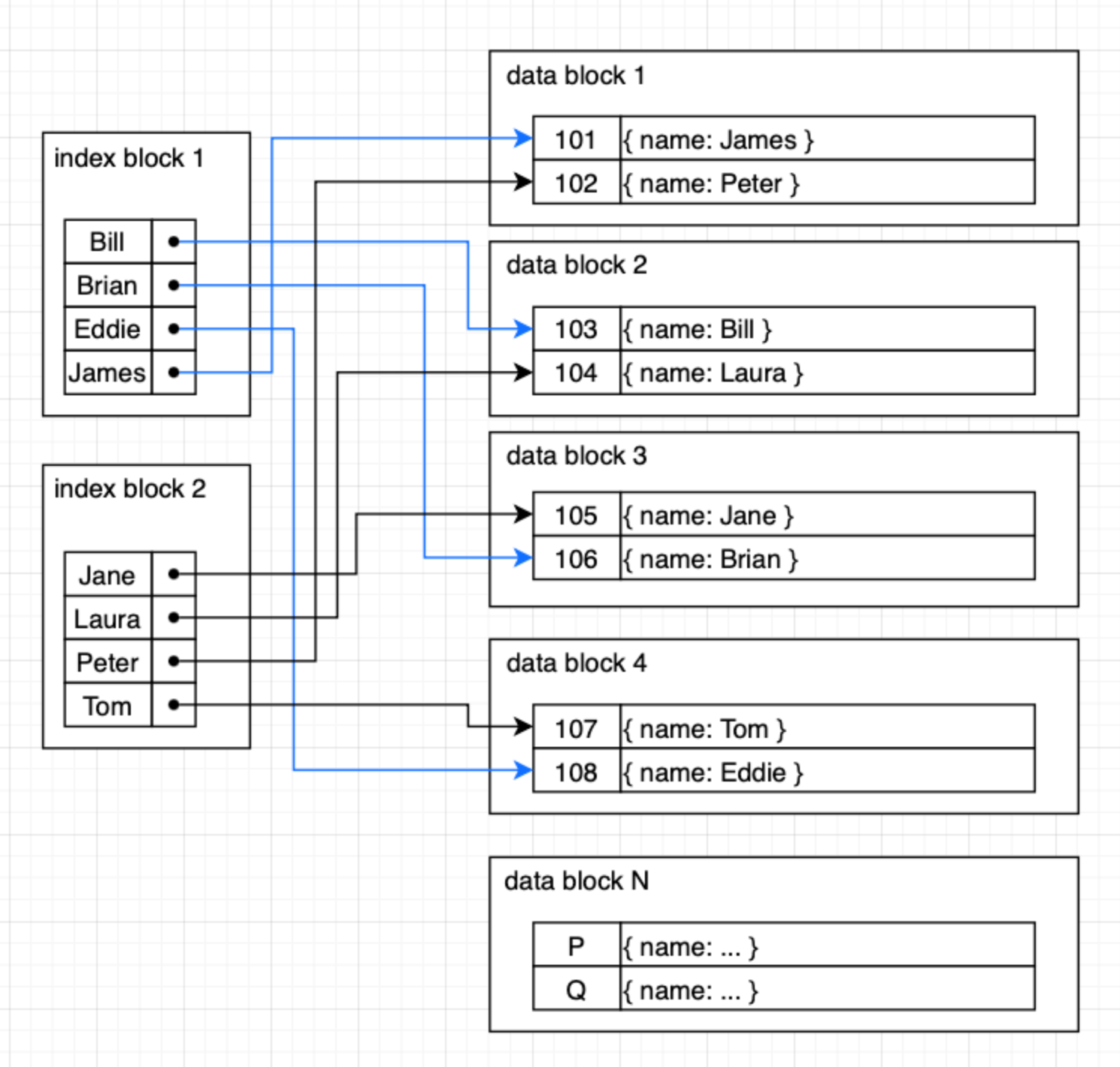 67 |
68 | - create index…. 명령어를 기반으로 만들면 만들 수 있다
69 | - 하나의 인덱스만 생성할 것이라면 성능상 클러스터형 > 세컨더리 인덱스
70 | - 보조 인덱스로 **여러 개의 필드 값**을 기반으로 쿼리를 많이 보낼 때 생성하는 인덱스 이다.
71 |
72 | ### 2) MongoDB
73 |
74 | - 도큐먼트를 만들면 자동으로 ObjectID가 형성되며, 해당 key가 기본키로 설정된다
75 | - 세컨더리 key도 부가적으로 설정해서 기본키와 세컨더리key를 같이 쓰는 복합 인덱스 설정 가능
76 |
77 | ## 4. 인덱스 최적화 기법
78 |
79 | ### 1) 인덱스와 비용
80 |
81 | - 인덱스의 구조에서 보았듯이 익덱스를 탐색하는데 필요한 일정 비용이 있다
82 | - 두 번 탐색하도록 강요된다. 인덱스 리스트 → 컬렉션
83 | - 또한 인덱스 삽입과 삭제 연산과 관련해서도 균형을 유지하기 위한 유지보수 비용이 소모된다
84 | - **때문에 뭐리에 있는 필드에 인덱스를 무작정 다 설정하는 것은 비효율적이다.** 이러한 점을 고려하여 인덱스를 설정해야 한다
85 |
86 | ### 2) 테스팅
87 | - 인덱스 최적화 기법은 서비스 특징에 따라 달라진다
88 | - 서비스에서 사용하는 객체의 깊이,테이블의 양 등이 다르기 때문에
89 | - **때문에 항상 테스팅하는 것이 중요하다!**
90 | - MySQL에서는 EXPLAIN같은 함수를 통해 테스팅을 수행할 수 있다
91 |
92 | ### 3) 복합 인덱스의 순서
93 |
94 | >대개 여러 필드를 기반으로 조회할 때 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다.
67 |
68 | - create index…. 명령어를 기반으로 만들면 만들 수 있다
69 | - 하나의 인덱스만 생성할 것이라면 성능상 클러스터형 > 세컨더리 인덱스
70 | - 보조 인덱스로 **여러 개의 필드 값**을 기반으로 쿼리를 많이 보낼 때 생성하는 인덱스 이다.
71 |
72 | ### 2) MongoDB
73 |
74 | - 도큐먼트를 만들면 자동으로 ObjectID가 형성되며, 해당 key가 기본키로 설정된다
75 | - 세컨더리 key도 부가적으로 설정해서 기본키와 세컨더리key를 같이 쓰는 복합 인덱스 설정 가능
76 |
77 | ## 4. 인덱스 최적화 기법
78 |
79 | ### 1) 인덱스와 비용
80 |
81 | - 인덱스의 구조에서 보았듯이 익덱스를 탐색하는데 필요한 일정 비용이 있다
82 | - 두 번 탐색하도록 강요된다. 인덱스 리스트 → 컬렉션
83 | - 또한 인덱스 삽입과 삭제 연산과 관련해서도 균형을 유지하기 위한 유지보수 비용이 소모된다
84 | - **때문에 뭐리에 있는 필드에 인덱스를 무작정 다 설정하는 것은 비효율적이다.** 이러한 점을 고려하여 인덱스를 설정해야 한다
85 |
86 | ### 2) 테스팅
87 | - 인덱스 최적화 기법은 서비스 특징에 따라 달라진다
88 | - 서비스에서 사용하는 객체의 깊이,테이블의 양 등이 다르기 때문에
89 | - **때문에 항상 테스팅하는 것이 중요하다!**
90 | - MySQL에서는 EXPLAIN같은 함수를 통해 테스팅을 수행할 수 있다
91 |
92 | ### 3) 복합 인덱스의 순서
93 |
94 | >대개 여러 필드를 기반으로 조회할 때 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다.
95 | 같음, 정렬, 다중 값 , 카디널리티 순으로 생성해야 한다
96 |
97 | 1. 값을 비교하는 `==` 이나 `equal`이라는 쿼리가 있다면 제일 먼저 인덱스로 설정한다
98 | 2. `정렬`에 사용되는 필드를 인덱스로 설정
99 | 3. 쿼리 자체가 부등호< , >와 같은 연산이 있어 `다중 값`을 출력 해야한다면 인덱스로 설정함
100 | 4. `카디널리티`(유니크한 값의 정도)가 높은 순서를 기반으로 인덱스를 생성한다
101 | 1. ex) age와 email중 카디널리티는 email이 더 높으므로 email 필드에 대한 인덱스를 먼저 생성해야 한다
102 | # 4.6 조인의 종류
103 | >**조인**이란 하나의 테이블이 아닌 두 개 이상의 테이블을 묶어서 하나의 결과물을 만드는 것을 말한다
104 |
보통 NoSQL보단, 관계형 데이터베이스에서 많이 사용된다 (성능상)
105 |
106 | ## 1. 내부 조인
107 | ```sql
108 | SELECT * FROM TableA A
109 | INNER JOIN TableB B ON
110 | A.key = B.key
111 | ```
112 | - 두 테이블 간에 **교집합**을 나타낸다
113 | ## 2. 왼쪽 조인
114 | ```sql
115 | SELECT * FROM TableA A
116 | LEFT JOIN TableB B ON
117 | A.key = B.key
118 | ```
119 | - 테이블B의 일치하는 부분의 레코드와 함께 **테이블A를 기준**으로 완전한 레코드 집합을 생성
120 | - 만약 B테이블에 일치하는 항목이 없다면 해당 값은 null값이 된다
121 | ## 3. 합집합 조인
122 | ```sql
123 | SELECT * FROM TableA A
124 | FULL OUTER JOIN TableB B ON
125 | A.key = B.key
126 | ```
127 | - 양쪽 테이블에서 일치하는 레코드와 함께 테이블 A와 테이블 B의 **모든 레코드 집합을 생성**한다
128 | - 이때 일치하는 항목이 없으면 누락된 쪽에 null값이 포함되어 출력된다
129 |
130 | # 4.7 조인의 원리
131 |
132 | >앞서 나온 조인들은 조인의 원리를 기반으로 조인 작업이 이루어진다
133 | 각 조인의 방법바다 장단점이 있고, 조인의 성격과 조인의 원리의 디스크 I/O 복잡도에 따라 성능이 상이하다
134 |
135 | ## 1. 중첩 루프 조인 (NLJ)
136 |
137 | - **2중 for문과 같은 원리로 조인하는 방법**
138 | - ex) A1,A2 테이블을 조인한다면, 첫 번째 테이블에서 행을 한 번에 하나씩 읽고 그 다음 테이블에서도 행을 하나씩 읽어 조건에 맞는 레코드를 찾아 결과값 반환
139 | - 랜덤 접근에 대한 비용이 많이 증가하므로 대용량의 테이블에서 사용X
140 | - 중첩 루프 조인에서 발전한 조인할 테이블을 작은 블록으로 나누어서 블록 하나씩 조인하는 `블록 중첩 루프 조인` 방식도 있다
141 |
142 | ## 2. 정렬 병합 조인
143 |
144 | - 각각의 테이블을 **조인할 필드 기준으로 정렬**하고, 정렬이 끝난 이후에 조인 작업을 수행하는 조인
145 | - 조인할 때 적절한 인덱스가 없고 대용량의 테이블들을 조인하고, 조인 조건으로 <,>등 범위 비교 연산자가 있을 때 쓴다
146 |
147 | ## 3. 해시 조인
148 |
149 | - **해시 테이블을 기반**으로 조인하는 방법
150 | - 해시 조인은 우선 두 테이블 중 크기가 작은 테이블을 기준으로 조인에서 사용되는 필드의 데이터를 해싱된 키가 매핑된다
151 | - 두 개의 테이블을 조인한다고 했을 때 하나의 테이블이 메모리에 온전히 들어간다면, 보통 중첩 루프 조인(NLJ)보다 더 효율적이다
152 | - 동등(==)조건에서만 사용할 수 있다
153 |
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_이홍섭.md:
--------------------------------------------------------------------------------
1 | # 3. 운영체제(1)
2 |
3 | ## 목차
4 |
5 | ### 3.1 운영체제와 컴퓨터
6 | - 3.1.1 운영체제의 역할과 구조
7 | - 3.1.2 컴퓨터의 요소
8 | ### 3.2 메모리
9 | - 3.2.1 메모리 계층
10 | - 3.2.2 메모리 관리
11 | ---
12 | # 1. 운영체제와 컴퓨터
13 |
14 | ## 1.1 운영체제의 역할과 구조
15 | **운영체제의 역할**
16 | - CPU 스케줄링과 프로세스 관리
17 | - CPU를 할당 받을 프로스세를 관리하고,프로세스의 생성,삭제,자원 할당 및 반환을 관리한다
18 | - 메모리 관리
19 | - 각 프로세스가 할당받는 메모리를 관리하고, 한정된 메모리를 어떤 프로세스에 얼만큼 할당해야 하는지 관리
20 | - 디스크 파일 관리
21 | - 파일을 저장하고 관리한다
22 | - I/O 디바이스 관리
23 | - 입력장치(마우스,프린터,키보드 등)와 컴퓨터 간에 신호를 주고 받으며,데이터를 주고 받은 것을 적당한 프로세스에 전달한다
24 |
25 | [운영체제의 구조는 어떻게 생겼을까?](https://math-coding.tistory.com/80)
26 | - 시스템 콜
27 | - OS가 커널에 접근하기 위한 인터페이스
28 | - 유저 프로그램이 OS의 서비스를 받기 위해 커널 함수를 호출할 때 사용한다
29 | - 단,유저 프로그램은 커널에 바로 접근할 수 없으며 시스템 콜이라는 인터페이스와 커널을 거쳐 OS에 전달된다
30 | - 장점으로는, 시스템 콜은 하나의 추상화 계층이다
31 | - 때문에 네트워크 통신이나 DB같은 낮은 단계의 영역 처리에 대한 부분을 많이 신경 쓰지 않고 프로그램을 구현할 수 있다
32 | - modebit
33 | - 시스템콜이 작동될 때 modebit을 참고해서 유저 모드 or 커널 모드를 구분한다
34 | - 1(유저 모드)또는 0(커널 모드)의 값을 가지는 플래그 변수
35 | - 유저모드일 때 실행되면 안되는 동작과,커널 모드일 때 사용하면 안되는 동작을 구분하여 실행하도록 해준다
36 |
37 | ## 1.2 컴퓨터의 요소
38 | >컴퓨터는 CPU,DMA,컨트롤러,메모리,타이머,디바이스 컨트롤러 등으로 구성되었다
39 | >
40 | ### 1.CPU (Central Processing Unit)
41 | - **ALU(산술논리연산장치),제어장치,레지스터**로 구성되어 있는 컴퓨터 장치
42 | - 인터럽트에 의해 단순히 메모리에 존재하는 명령어를 해석해서 실행한다
43 | - **ALU (산술논리연산장치)**
44 | - 덧셈,뺄셈,논리합,논리곱 등 연산을 계산하는 장치
45 | - **제어장치**
46 | - 프로세스 조작을 지시하는 CPU의 부품
47 | - 입출력장치 간 통신을 제어/명령어 해석/데이터 처리를 위한 순서를 결정한다
48 | - CPU가 해석해야 할 명령어는 '명령어 레지스터'라는 특별 레지스터에 저장됨
49 | - **레지스터**
50 | - CPU안에 있는 매우 빠른 임시기억장치
51 | - CPU와 직접 연결되어 있어, 연산 속도가 메모리보다 수십~수백 배 빠르다
52 | - >Tip : ALU에서 결과값을 레지스터로 저장하는데, 이유는 CPU가 메모리에 접근하는 것보다 훨씬 빠르기 때문이다.
53 | - CPU는 직접 데이터를 전달할 수 없으므로, 레지스터를 통해 전달한다
54 |
55 | >#### CPU의 연산 처리
56 | >- 인터럽트
57 | > - 인터럽트는 어떤 신호가 들어왔을 때 CPU를 잠깐 정지시키는 것
58 | >- 하드웨어 인터럽트
59 | > - 하드웨어 장비를 연결하는 일 등 IO 디바이스에서 발생하는 인터럽트
60 | >- 소프트웨어 인터럽트
61 | > - 트랩(trap)이라고도 한다
62 | > - 프로세스 오류등으로 프로세스가 시스템 콜을 호출할 때 발동한다
63 | ### 2.DMA 컨트롤러
64 | - I/O 장치가 메로리에 접근할 수 있도록 한다
65 | - CPU에만 몰리는 인터럽트 요청을 분산 시켜 받아준다 (CPU의 보조 일꾼?)
66 | - 한 작업을 CPU와 DMA 컨트롤러가 동시에 하는것을 방지한다
67 | ### 3.메모리
68 | - 전자회로에서 데이터나 상태,명령어 등을 기록하는 장치
69 | - CPU로부터 이루어진 계산의 결과를,메모리는 기억하는 담당을 한다
70 | ### 4.타이머
71 | - 특정 프로세스에 시간 제한을 거는 역할을 한다
72 | ### 5.디바이스 컨트롤러
73 | - 컴퓨터와 연결되어 있는 IO 디바이스들의 작은 CPU를 말한다
74 | - 옆에 붙어 있는 로컬 버퍼는 각 디바이스에서 데이터를 임시로 저장하기 위한 작은 메모리를 뜻한다
75 |
76 | # 2. 메모리
77 | ## 2.1 메모리 계층
78 | [메모리는 다음과 같은 계층을 가진다](https://velog.io/@yu-jin-song/CS-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B3%84%EC%B8%B5-%EA%B5%AC%EC%A1%B0)
79 | - **레지스터** : CPU 안에 있는 작은 메모리, 휘발성, 속도 가장 빠르지만 기억 용량이 가장 적다
80 | - **캐시 (L1,L2 캐시)** : 휘발성, 속도 빠름, 기억 용량이 적다. L3 캐시도 존재한다
81 | - **주기억장치(메모리/RAM)** : 휘발성, 속도 보통, 기억 용량 보통
82 | - **보조기억장치(스토리지/HDD,SDD)** : 비휘발성, 속도 낮음, 기억 용량이 크다
83 | > 데이터들은 보조기억장치(스토리지)부터 메모리(RAM)에 불려와 지며, 메모리(RAM)에 올라온 데이터 일부는 빠른 연산을 위해 캐시에 할당되고, CPU가 즉시 손대는 데이터는 레지스터에 존재한다
84 |
85 | ### 캐시 (캐시 히트와 미스)
86 | - 데이터를 미리 복사해 놓는 임시 저장소이자, 빠른 장치와 느린 장치사이에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리
87 | - ex) 메모리 <-> CPU 사이 속도 차이가 크기에, 중간에 레지스터 계층을 둬 속도 차이를 해결
88 | - 캐시를 직접 설정할 때는, 자주 사용하는 데이터를 기반으로 설정해야 한다
89 | - 이의 근거가 되는 개념을 **지역성**이라고 부른다
90 | - 지역성에는 시간 지역성 (temporal locality)과 공간 지역성 (spatial locality)로 나뉜다
91 | - 시간 지역성
92 | - 가장 최근에 사용한 데이터에 다시 접근하려는 특성
93 | - ex) for문 안의 변수 i에 계속 접근한다
94 | - 공간 지역성
95 | - 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성
96 | - ex) for문을 통하여 배열 arr의 원소에 접근한다
97 |
98 | >캐시에서 원하는 값을 찾았다면 **캐시히트**라고 하며, 해당 값이 캐시에 없다면 주 메모리로 가서 값을 찾아오는데, 이것은 **캐시미스**라고 한다
99 |
100 | #### 웹 브라우저의 캐시
101 | - 쿠키
102 | - 만료기한이 있는 key-value 형태 저장소
103 | - 서버단에서 만료 기한을 정한다
104 | - 로컬 스토리지
105 | - 만료기한이 없는 key-value 형태 저장소
106 | - 웹 브라우저를 닫아도 유지되며 도메인 단위로 저장,생성된다
107 | - 클라이언트단에서만 수정 가능
108 | - 세션 스토리지
109 | - 만료기한이 없는 key-value 형태 저장소
110 | - 탭 단위로 세션 스토리지 생성하며 탭을 닫을 때 해당 데이터가 삭제된다
111 | - 클라이언트단에서만 수정 가능
112 |
113 | ## 2.2 메모리 관리
114 | >운영체제의 대표적인 역할중 하나가 **메모리 관리**이다
115 | > 컴퓨터에 주어진 한정된 메모리를 극한으로 활용해야 한다
116 |
117 | ### 가상 메모리
118 | - 실제로 이용 가능한 메모리 자원을 추상화하여 이를 매우 큰 메모리로 보이게 만드는 메모리 관리 기법
119 | - 클라이언트는 가상 주소를 통하여 메모리에 접근하고, 해당 주소는 실제 메모리 주소로 변환되어 사용 된다
120 | - 가상 주소 <-> 실제 주소간의 주소 변환은 '페이지 테이블'로 관리된다
121 | #### 스와핑
122 | - 가상 메모리에는 존재하지만, 실제 메모리인 RAM에는 현재 없는 데이터나 코드에 접근할 경우 페이지 폴트가 발생
123 | - 이를 방지하기 위해 메모리에서 당장 사용하지 않는 영역을 하드디스크로 옮겨 놓고, 필요하다면 다시 RAM으로 올리는 작업을 **스와핑** 이라고 한다
124 | #### 페이지폴트
125 | - 프로세스의 주소 공간에는 존재하지만 실제 메모리(RAM)에는 없는 데이터에 접근하는 경우 발생한다 (캐시 미스와 비슷)
126 | ### 스레싱
127 | - 메모리의 페이지 폴트율이 높은 현상 -> 컴퓨터의 심각한 성능 저하를 초래한다
128 | - 즉 메모리에 너무 많은 프로세스가 동시에 올라가게 되면 스와핑이 많이 일어나서 발생한다
129 | - 위와 같은 현상으로 페이지 폴트가 일어나면 CPU 이용률이 낮아지며, 더 많은 프로세스를 메모리에 올리는 불상사가 생긴다
130 | ### 메모리 할당
131 | 메모리에 프로그램을 할당할 때는 시작 메모리 위치, 메모리의 할당 크기를 기반으로 할당하는데, 연속 할당/불연속 할당으로 나뉜다
132 | - 연속 할당 : 메모리에 연속적으로 공간을 할당 하는 것
133 | - 고정 분할 방식 : 메모리를 미리 나누어 관리하는 방식, *내부 단편화 발생
134 | - 가변 분할 방식 : 매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용.내부 단편화 발생X / *외부 단편화가 발생 할수 있따
135 | - > *내부 단편화 : 메모리를 나눈 크기보다 프로그램이 작아서 들어가지 못하는 공간이 많이 발생하는 현상
136 | > *외부 단편화 : 메모리를 나눈 크기보다 프로그램이 커서 들어가지 못하는 공간이 많이 발생하는 현상
137 | > 홀(hole) : 할당할 수 있는 비어 있는 메모리 공간
138 | - 불연속 할당
139 | - 페이징 : 동일한 크기의 페이지 단위로 나누어 할당. 크기가 균일해지지만 주소 변환이 복잡하다
140 | - 세그멘테이션 : 의미 단위인 세그먼트로 나누는 방식. 공유와 보안 측면에서 장점을 가진다 / 홀 크기가 균일하지 않은 단점이 있다
141 | - 페이지드 세그멘테이션 : 프로그램을 의미 단위인 세그먼트로 나눠 공유나 보안 측면에 강점을 두고, 동일한 크기의 페이지 단위로 나누는 것
142 | ### 페이지 교체 알고리즘
143 | 메모리 스와핑을 가장 덜 일어나도록 하는 다양한 알고리즘이 존재한다
144 | #### 오프라인 알고리즘
145 | - 먼 미래에 사용되는 페이지와 현재 할당하는 페이지를 바꾸는 방법
146 | - 미래에 사용되는 프로세스를 모르기에 현실성이 떨어진다
147 | - 사용할 수 없는 알고리즘이지만 가장 좋은 알고리즘 이기에 주로 다른 알고리즘과의 성능 비교의 기준점을 제공한다
148 | #### FIFO (First-In First-Out)
149 | - 가장 먼저 들어온 페이지를 먼저 내보낸다
150 | #### LRU (Least Recently Used)
151 | - 사용하지 않은지 제일 오래된 페이지를 먼저 내보내는 방법. 오래된 것을 파악하기 위해 각 페이지마다 계수기, 스택을 두어야 하는 문제점이 있다
152 |
153 | 그밖에 NUR(Not Used Recently), 가장 참조 횟수가 적은 페이지를 내보내는 LFU(Least Frequently Used)가 있다
154 |
155 |
156 |
157 |
--------------------------------------------------------------------------------
/4. 데이터베이스(2)/데이터베이스(2)_박상욱.md:
--------------------------------------------------------------------------------
1 |
2 | # 인덱스의 필요성
3 |
4 | 인덱스는 데이터를 빠르게 찾을 수 있는 하나의 장치이다.
5 |
6 |
7 | # B-트리
8 |
9 | 인덱스는 보통 B-트리라는 자료 구조로 이루어져 있다.
10 | 이는 **루트 노트**, **리프 노트** 그리고 루트 노드와 리프 노드 사이에 있는 브랜치 노드로 나뉜다.
11 |
12 | B-트리는 탐색 성능을 높이기 위해 균형 있게 높이를 유지하는 Balanced Tree 의 일종이다.
13 |
14 | 자식 node의 개수가 2개 이상이며, node 내의 key가 1개 이상일 수도 있다.
15 | node의 자식 수 중 최댓값이 K(만약 3)라고 하면, 해당 B-Tree를 K(3)차 B-트리이다.
16 |
17 | ### B-트리의 조건
18 |
19 | - 노드가 자식을 K개 가졌다면, key는 K-1개를 가진다.
20 | - 노드의 key는 반드시 오름차순으로 정렬된 상태여야 한다.
21 | - 루트 노드는 항상 2개 이상의 자식 노드를 가진다. (루트 노드가 리프 노드인 경우는 제외)
22 | - K차 트리일 떄, 루트 노드와 리프 노드를 제외하고 각 노드의 최소 자식 노드 수는 [M/2]
23 | 각 노드의 최소 key 수는 [m/2]-1 이 된다.
24 |
25 |
26 | ### B-트리 검색
27 | 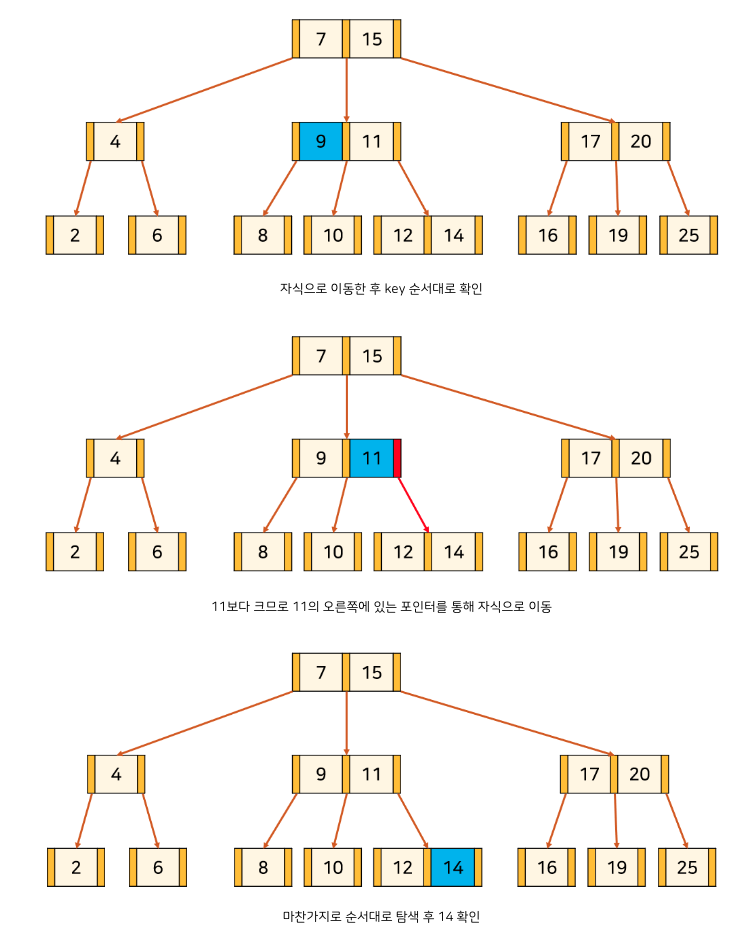
28 |
29 |
30 | ### DB에서 B-Tree를 인덱스로 사용하는 이유
31 |
32 | 일반적인 Tree의 경우 탐색하는데 평균적인 시간 복잡도로 O(logN)을 갖지만,
33 | 트리가 편향된 경우 최악의 시간복잡도로 O(N)을 가지게 된다.
34 |
35 | B-Tree는 편향적이지 않고 밸런스를 유지하는 트리이기에 자식들의 밸런스를 잘 유지하면
36 | 최악의 경우에도 O(logN)의 시간을 가지게 된다.
37 |
38 | 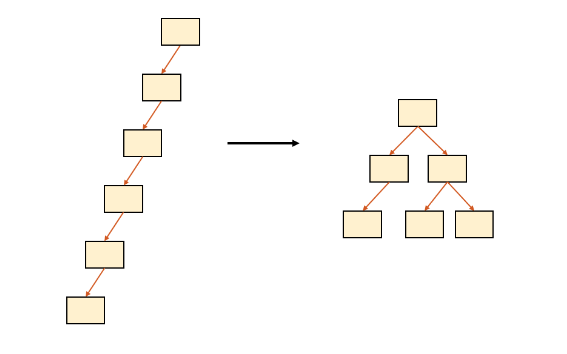
39 |
40 |
41 |
42 | DB는 기본적으로 secondary storage(SSD or HDD)에 저장된다.
43 |
44 | 평균적인 경우에 B-트리는 **네 개의 level만으로도 수백 만, 수 천만 개의 데이터를 저장할 수 있다.**
45 | **루트 노드에서 가장 멀리 있는 데이터도 3번의 이동만으로 접근할 수 있다.**
46 |
47 | 따라서 데이터를 찾기위해 secondary storage에 접근을 적게한다.
48 | 또한 block 단위의 저장 공간을 알차게 사용할 수 있다.
49 |
50 |
51 | ---
52 |
53 | # 인덱스 만드는 방법
54 |
55 | 인덱스는 크게 Cluster index 와 Non-Clustered index가 있다.
56 |
57 | ### Cluster index
58 |
59 | - 각 테이블 / 뷰가 하나의 Cluster index만 가질 수 있다.
60 | - Cluster index는 작업에 필요한 메모리가 적기 때문에 더 빠르다. (검색에 빠르다.)
61 | 이는 Cluster index의 리프 노드가 행 식별자(pointer의 개념)가 아닌 실제 데이터를 저장하기 때문이다.
62 | - 어느 열에 Cluster index를 생성하느냐에 따라서 시스템의 성능이 달라질 수 있다.
63 | - Cluster index가 지정되어 있지 않는 테이블에 이미 대용량의 데이터가 입력된 상태라면
64 | Cluster index를 생성하는 것은 시스템에 큰 부하를 가져다 줄 수 있다.
65 | - 테이블 생성 시 Primary Key를 사용하면 Cluster index가 생성된다.
66 |
67 | 
68 |
69 |
70 |
71 | ### Non-Clustered index
72 |
73 | - Non-Clustered index는 논리적 인덱스이며 인덱스가 작성된 열에 따라 테이블 / 뷰의 데이터를
74 | 정렬하지 않는다.
75 | - 입력 / 수정/ 삭제 등에 Cluster index 보다 쿼리의 성능을 향상 시킬 수 있다.
76 | - Non-Clustered index는 하나가 아니라 여러 개 생성할 수 있지만 남용할 경우 성능 저하를 가져올 수 있다.
77 | - UNIQUE 제약 조건을 생성하면 기본적으로 Non-Clustered index 가 생성된다.
78 |
79 | 
80 |
81 |
82 |
83 | ---
84 |
85 | ## 인덱스 최적화 기법
86 |
87 | ### 인덱스는 비용이다.
88 |
89 | 먼저 인덱스는 두 번 탐색하도록 강요한다.
90 | 인덱스 리스트, 그 다음 컬렉션 순으로 탐색하기 때문이며, 관련 읽기 비용(처리 소요시간, 자원량 등)도 들게 된다.
91 | 또한, 컬렉션이 수정되었을 때 인덱스도 수정되어야 한다.
92 | 그렇게 때문에 쿼리에 있는 필드에 무작정 다 인덱스를 설정하는 것이 답은 아니다.
93 | 한, 컬렉션에서 가져와야 하는 양이 많을수록 인덱스를 사용하는 것은 비효율적이다.
94 |
95 | ### 항상 테스팅하라.
96 |
97 | expain() 함수를 통해 인덱스를 만들고 쿼리를 보낸 이후에 테스팅을 하며 걸리는 시간을 최소화하자.
98 |
99 | ### 복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순이다.
100 |
101 | 보통 여러 필드를 기반으로 조회를 할 떄 복합 인덱스를 생성하는데, 이 인덱스를 생성할 때는
102 | 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다.
103 |
104 | 같음, 정렬, 다중 값, 다키널리티 순으로 생성해야 한다.
105 |
106 | - 어떠한 값곽 같음을 비교하는 == 이나 equal 이라는 쿼리가 있다면 제일 먼저 인덱스로 설정한다.
107 | - 정렬에 쓰는 필드라면 그 다음 인덱스로 설정한다.
108 | - 다중 값을 출력해야 하는 필드, 즉 쿼리 자체가 >, < 등 많은 값을 출력해야 하는 쿼리에 쓰는 필드라면
109 | 나중에 인덱스를 설정한다.
110 | - 카디널리티(고유성)을 바탕으로 카디널리티가 높은 (중복되는게 적은) 순서를 기반으로 인덱스를 생성해야 한다.
111 |
112 |
113 | ---
114 | ---
115 | ---
116 |
117 |
118 | 조인의 원리인 중첩 루프 조인, 정렬 병합 조인, 해시 조인에 대해 알아보자
119 |
120 | https://sql-joins.leopard.in.ua/
121 |
122 | ## 중첩 루프 조인
123 |
124 | 중첩 루프 조인은 (NJL, Nested Loop Join)은 for 문과 같은 원리로 조건에 맞는 조인을 하는 방법이다.
125 | 랜덤 접근에 대한 비용이 많이 증가하므로 대용량의 테이블에서는 사용하지 않는다.
126 |
127 | 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 행을 결합하여 원하는 결과를 조합하는 조인방식으로, 선정된 한 테이블로부터 where 절에 정의된 검색 조건을 만족하는 데이터들을 걸러낸 후,
128 | 이 값을 가지고 조인 대상 테이블을 반복적으로 검색하면서 조인 조건에 만족하는 최종 결과값을 얻어낸다.
129 |
130 | 
131 |
132 | 1. 선행 테이블에서 조건을 만족하는 첫 번째 행을 찾는다. -> 이떄 선행 테이블에 주어진 조건을 만족하지 않는 경우 해당 데이터는 필터링 된다.
133 | 2. 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾으러 간다. -> 조인 시도
134 | 3. 후행 테이블의 인덱스에서 선행 테이블의 조인 키가 존재하는지 확인 -> 선행 테이블의 조인 키 값이 후행 테이블에 존재하지 않으면 데이터는 필터링 됨 (조인 작업을 진행할 필요가 없음)
135 | 4. 모두 만족한 해당 행을 추출 버퍼에 넣음
136 | 5. 반복
137 |
138 |
139 | ### 중첩 루프 조인 장단점
140 |
141 | - 인덱스에 의한 랜덤 엑세스에 기반하고 있기 때문에 대량의 데이터 처리 시 적합하지 않다.
142 | - 선정된 테이블은 데이터가 적거나 where 절 조건으로 행의 숫자를 줄일 수 있는 테이블이어야 한다.
143 | - 비선정된 테이블은 조인을 위한 적절한 인덱스가 생성되어 있어야 한다.
144 | - 선행 테이블의 결과를 통해 후행 테이블을 액세스 할 떄 랜덤 I/O이 발생한다.
145 |
146 |
147 |
148 |
149 |
150 | ## 정렬 병합 조인
151 |
152 | 정렬 병합 조인(Sort Merge Join)이란 각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후에 조인 작업을 수행하는 조인이다.
153 |
154 | 조인할 때 쓸 적절한 인덱스가 없고 대용량의 테이블들을 조인하고 조인 조건으로 < , > 등 범위 연산자가 있을 때 사용한다.
155 |
156 | 
157 |
158 | 1. 선행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
159 | 2. 해당 행들에 대해서, 선행 테이블의 조인 키(컬럼)을 기준으로 데이터를 정렬
160 | 3. 후행 테이블에서 주어진 조건을 만족하는 행을 찾는다.
161 | 4. 해당 행들에 대해서, 후행 테이블의 조인 키(컬럼)을 기준으로 데이터를 정렬
162 | 5. JOIN을 수행
163 | 6. 조인에 성공하면 추출버퍼에 넣는다.
164 |
165 |
166 |
167 |
168 | ## 해시 조인
169 |
170 | 해시 조인은 해시 테이블을 기반으로 조인하는 방버이다. 두 개의 테이블을 조인한다고 했을 때
171 | 하나의 테이블이 메모리에 온전히 들어간다면 보통 중첩 루프 조인보다 더 효율적이다.
172 | 하지만, 동등 (=) 조인에서만 사용가능하고, 데이터가 크다면 디스크를 사용하는 비용이 발생한다.
173 |
174 | 해쉬 함수를 적용한 실제 값은 어떤 값으로 Hashing 될 지 예측할 수 없다.
175 | 하지만 해쉬 함수가 적용될 때 동일한 값은 항상 같은 값으로 Hashing 됨이 보장된다.
176 | 따라서 해쉬 조인은 동등 조인 (=) 에서만 사용할 수 있는 것이다.
177 |
178 |
179 | ### 빌드 단계
180 |
181 | 해쉬 조인은 조인 작업을 수행하기 위해 '해쉬 테이블'을 메모리에 생성한다.
182 | 해쉬 테이블의 크기가 메모리에 적재할 수 있는 크기보다 커지면 디스크에 해쉬 테이블을 지정하기에
183 | 해쉬 조인을 할 때는 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.
184 |
185 |
186 | ### 프로브 단계
187 |
188 | 후행 테이블은 만들어진 해쉬 테이블에 대해 해쉬 값 존재여부를 검사한다.
189 | 이를 Prove Input 이라고 한다.
190 |
191 | 
192 |
193 |
194 | 1. 선행 테이블에 주어진 조건을 만족하는 행을 찾는다.
195 | 2. 해당 행들에 대해서, 선행 테이블의 조인 키(컬럼)를 기준으로 Hash 함수를 적용하여 해쉬 테이블을 생성한다
196 | 3. 후행 테이블에서 주어진 조건에 맞는 행을 찾는다.
197 | 4. 해당 행들에 대해서, 후행 테이블에 Hash 함수를 적용하여 선행 테이블의 해쉬 테이블에 맞는 버킷을 찾는다.
198 | 5. JOIN 수행이 성공하면 추출 버퍼에 넣는다.
199 | 6. 후행 테이블의 조건을 만족하는 모든 행에 대해서 3~5번을 반복한다.
200 |
201 |
202 |
203 |
--------------------------------------------------------------------------------
/2. 네트워크(2)/네트워크(2)_이홍섭.md:
--------------------------------------------------------------------------------
1 | # 2. 네트워크(2)
2 |
3 | ## 목차
4 |
5 | ### 2.3 네트워크의 기초
6 | - 2.3.1 네트워크 기기의 처리 범위
7 | - 2.3.2 애플리케이션 계층을 처리하는 기기
8 | - 2.3.3 인터넷 계층을 처리하는 기기
9 | - 2.3.4 데이터 링크 계층을 처리하는 기기
10 | - 2.3.5 물리 계층을 처리하는 기기
11 | ### 2.4 IP 주소
12 | - 2.4.1 ARP
13 | - 2.4.2 홉바이홉 통신
14 | - 2.4.3 IP 주소 체계
15 | - 2.4.4 IP 주소를 이용한 위치정보
16 | ### 2.5 HTTP
17 | - 2.5.1 HTTP/1.0
18 | - 2.5.2 HTTP/1.1
19 | - 2.5.3 HTTP/2
20 | - 2.5.4 HTTPS
21 | - 2.5.5 HTTP/3
22 | ---
23 | # 2.3 네트워크의 기초
24 | ## 2.3.1 네트워크 기기
25 |
26 | 네트워크는 여러 개의 네트워크 기기를 기반으로 구축된다
27 | 네트워크 기기는 계층별로 처리 범위를 나눌 수 있다
28 | - 애플리케이션 계층 : L7 스위치
29 | - 인터넷 계층 : 라우터, L3 스위치
30 | - 데이터 링크 계층 : 브리지, L2 스위치
31 | - 물리 계층 : NIC, 리피터, AP
32 | > 상위 계층을 처리하는 기기는 하위 계층을 처리할 수 있지만 그 반대는 불가
33 |
34 | ## 2.3.2 애플리케이션 계층을 처리하는 기기
35 |
36 | ### L7 스위치
37 | > 스위치는 기본적으로 여러 장비를 연결하고 데이터 통신을 중재한다 목적지가 연견될 포트로만 전기 신호를 보내 통신을 한다
38 |
39 | - L7 스위치는 **로드밸런서** 라고도 한다
40 | - 서버의 부하를 분산하는 기기이다
41 | - 클라이언트로부터 오는 요청들을 뒤쪽의 여러 서버로 나누는 역할을 한다
42 | - 클라이언트 -> (---) -> 로드밸런서 -> 여러대의 서버
43 | - 시스템이 처리할 수 있는 **트래픽 증가**를 목표로 한다
44 | - URL,서버,캐시,쿠키들을 기반으로 트래픽을 분산한다
45 | - 바이러스,불필요한 외부 데이터 등을 걸러내는 필터링 기능을 가진다
46 | - 로드밸런서는 L7과 L4 또한 가지는데,
47 | - **L4 스위치는 인터넷 계층**을 처리하는 기기이다
48 | - L4 스위치는 IP와 포트를 기반으로 트래픽을 분산한다
49 | - L7 로드밸런서는 IP,포트 외에도 URL,HTTP 헤더,쿠키 등을 기반으로 트래픽을 분산한다
50 | - 두 스위치 모두 헬스 체크를 통해 정상,비정상적인 서버를 판별한다
51 | - > 헬스 체크 : 전송 주기와 재전송 횟수 등을 설정한 이후 반복적으로 서버에 요청을 보내는 것
52 | - 로드밸런서의 대표적인 기능에는 **서버 이중화**가 있다
53 | - 로드밸런서는 2대 이상의 서버를 기반으로 가상 IP를 제공하고 이를 기반으로 안정적인 서비스를 제공한다
54 |
55 | ## 2.3.3 인터넷 계층을 처리하는 기기
56 |
57 | ### 라우터
58 | - 여러개의 네트워크를 연결,분할,구분 시켜주는 역할
59 | - 소프트웨어 기반, 하드웨어 기반의 라우팅하는것으로 나뉘어 진다
60 | - 다른 네트워크에 존재하는 장치끼리 서로 데이터를 주고받을 때 패킷 소모를 최소화한다
61 | - 경로를 최적화하여 최소 경로로 패킷을 포워딩한다
62 | - 공유기가 여기에 속한다
63 |
64 | ### L3 스위치
65 | - L2 스위치의 기능과 라우팅 기능을 갖춘 장비
66 | - L3 == 라우터
67 | - L3는 하드웨어 기반의 라우팅을 담당하는 스위치
68 |
69 | | 구분 | L2 스위치 | L3 스위치 |
70 | | ----------- | --------------- | ------------- |
71 | | 참조 테이블 | MAC 주소 테이블 | 라우팅 테이블 |
72 | | 참조 PDU | 이더넷 프레임 | IP 패킷 |
73 | | 참조 주소 | MAC 주소 | IP 주소 |
74 |
75 | ## 2.3.4 데이터 링크 계층을 처리하는 기기
76 |
77 | ### L2 스위치
78 | - 장치들의 •MAC 주소를 기반으로 장치를 관리한다
79 | - 연결된 장치로부터 패킷이 왔을 때 패킷 전송을 담당한다
80 | - 이를 위해 MAC 주소 테이블을 사용함 (IP주소 이해 불가)
81 | - 목적지가 MAC 주소 테이블에 없다면 전체 포트 전달
82 | - 주소는 일정 시간 이후 삭제하는 기능도 있다
83 | > MAC (Media Access Control Address)
84 | > - MAC 주소는 간단히 말해 인터넷을 할 수 있는 이더넷 기반 기기에는 모두 다 하나씩 할당되어 있는 고유한 ID이다
85 |
86 | ### 브릿지
87 | - 두 개의 근거리 통신망(LAN)을 상호 접속할 수 있도록 하는 통신망 연결 장치
88 | - 포트와 포트 사이의 다리 역할을 한다
89 | - 장치에서 받아온 MAC 주소-> MAC 주소 테이블로 관리
90 | - **즉 통신망 범위를 확장하고 서로 다른 LAN 등으로 이루어진 '하나의' 통신망을 구축할 때 쓰인다**
91 |
92 | ## 2.3.5 물리 계층을 처리하는 기기
93 |
94 | ### NIC
95 | - LAN 카드라고 하는 네트워크 인터페이스 카드(NIC, Network Interface Card)
96 | - 2대 이상의 컴퓨터 네트워크를 구성하는데 사용한다
97 | - 빠른 속도로 데이터를 송수신할 수 있게 컴퓨터에 설치하는 확장 카드
98 | - 각 LAN 카드에는 주민등록번호처럼 각각을 구분하기 위한 고유의 식별번호인 MAC 주소가 있다
99 |
100 | ### 리피터
101 | - 들어오는 약해진 신호 정도를 증폭하여 다른 쪽으로 전달하는 장치
102 | - 이를 통해 패킷이 더 멀리 갈 수 있다
103 | - 하지만 요즘에는 잘 쓰이지 않는다 (광케이블 보급)
104 |
105 | ### AP (Access Point)
106 | - AP에 유선 LAN을 연결한 후 다른 장치에서 무선 LAN 기술(와이파이)을 사용하여 무선 네트워크 연결 가능
107 |
108 | # 2.4 IP
109 | ## 2.4.1 ARP (Address Resolution Protocol)
110 | >IP 주소를 통한 인터넷 계층의 통신이란, IP 주소를 기반으로 MAC 주소를 찾아 통신을 진행하는 과정
111 | - ARP는 가상 주소인 IP 주소를 실제 주소 MAC주소로 변환할 때 다리 역할을 하는 프로토콜
112 | - IP(가상 주소) -> (ARP) -> MAC(실제 주소)
113 | - RARP는 반대로 실제 주소인 MAC 주소를 가상 주소인 IP 주소로 변환
114 | - MAC(실제 주소) -> (ARP) -> IP(가상 주소)
115 | - 가상 주소 (IP)를 실제 주소 (MAC)으로 변환하는 과정이 필요하다.
116 |
117 | ## 2.4.2 홉 바이 홉 통신
118 | - 홉(Hop)이란 영어 뜻 자체로는 건너뛰는 모습을 의미한다
119 | - 통신망에서 각 패킷이 여러 개의 라우터를 건너가는 모습을 비유적으로 표현
120 | - 라우팅을 통해 라우팅 테이블을 만들고, 실제로 패킷이 라우팅 테이블을 타고 최종 목적지까지 도달하는 통신을 말한다
121 | - **라우팅 테이블** :
122 | - 송신지에서 수신지까지 도달하기 위해 사용된다
123 | - 라우터에 들어가 있는 목적지 정보들과 그 목적지로 가기 위한 방법이 들어있는 리스트
124 | - 게이트웨이와 모든 목적이데 대해 해당 목적지에 도달하기 위해 거쳐야 할 다음 라우터의 정보를 갖고 있다
125 | - **게이트 웨이** :
126 | - 서로 다른 네트워크, 프로토콜 간 통신을 중간에서 가능하도록 하는 매개체(컴퓨타,소프트웨어..등등)
127 |
128 | ## 2.4.3 IP 주소 체계
129 |
130 | - IPv4 :
131 | - 32비트를 8비트 단위로 점을 찍어 표기 (ex- 255.255.255.0)
132 | - IPv6 :
133 | - 128비트를 16비트 단위로 점을 찍어 표기 (ex- 2001:db8::ff00:42:8329)
134 | - IPv4의 한계를 극복하기 위해 나타난 방식이지만, IPv4에 비해 보급이 더디다
135 |
136 | ### 클래스 기반 할당 방식
137 | - IP주소 체계는 처음에 A,B,C,D,E 다섯개의 클래스로 구분하는 클래스 기반 할당 방식(Classful Addressing)을 사용하였다
138 | - 클래스 A,B,C는 일대일 통신, 클래스 D는 멀티캐스트 통신, 클래스 E는 예비용으로 선점된다
139 | - 클래스 A: 0.0.0.0 ~ 127.255.255.255
140 | - 클래스 B: 128.0.0.0 ~ 191.255.255.255
141 | - 클래스 C: 192.0.0.0 ~ 223.255.255.255
142 | - 맨 왼쪽에 있는 비트를 '구분 비트'라고 한다
143 | - 하지만 이 방식은 사용하는 주소보다 버리는 주소가 많은 단점이 있다
144 | - 해소하기 위해 DHCP와 IPv6, NAT등장
145 |
146 | ### DHCP (Dynamic Host Configuration Protocol)
147 | - IP 주소 및 기타 통신 매개변수를 자동으로 할당하기 위한 네트워크 관리 프로토콜
148 | - 네트워크 장치의 IP 주소를 수동으로 설정할 필요 없이 인터넷에 접속할 때 마다 자동으로 IP주소 할당 가능
149 | - 많은 라우터,게이트웨이 장비에 이 기능이 있고, 이를 통해 대부분의 가정용 네트워크에서 IP 주소를 할당한다
150 |
151 | ### NAT (Network Address Translation)
152 | - IPv4 주소 체계만으로는 많은 주소들을 감당하지 못해, 이를 해결하기 위해 공인 IP, 사설 IP로 나눈다
153 | - 패킷이 라우팅 장치를 통해 전송되는 동안 IP 주소 정보를 수정하여 다른 주소로 매핑하는 방법
154 | - 기업체 등에서 여러 개의 호스트는 사설 IP를 통해 내부적으로 구분되고, 하나의 공인 IP 주소를 사용(로 변환)하여, 여러 명이 동시에 인터넷에 접속할 수 있다
155 | - 장점 :
156 | - 내부 네트워크에서 사용하는 IP 주소와 외부에 드러나는 주소를 다르게 유지할 수 있기 때문에 내부 네트워크에 대한 어느 정도의 **보안** 기능을 한다
157 | - 단점 :
158 | - 여러 명이 동시에 인터넷을 접속하게 되므로, 실제로 접속하는 호스트 숫자에 따라서 **접속 속도**가 느려질 수 있다
159 |
160 | ## 2.4.4 IP 주소를 이용한 위치 정보
161 | - IP 주소는 **인터넷에서 사용하는 네트워크 주소**이기 때문에 이를 통해 동 또는 구까지 위치 추적이 가능하다
162 |
163 | # 2.5 HTTP
164 | ### 2.5.1 HTTP/1.0
165 | - 한 연결당 하나의 요청을 처리한다 -> RTT(패킷 왕복 시간) 증가
166 | - 그래서 요청 하나당 3 Way-Handshake등의 과정을 거쳐야 한다 -> RTT(패킷 왕복 시간) 증가
167 | - 이를 해결하기 위해 이미지 스플리팅, 코드 압축, 이미지 Base64 인코딩을 사용하곤 하였다
168 |
169 | ### 2.5.2 HTTP/1.1
170 | - HTTP/1.0에서 발전한 것
171 | - 매번 TCP 연결을 하는 것이 아니라, 한번 TCP를 초기화 한 후 Keep-alive 옵션으로 여러개의 파일을 송수신 하게 바뀌었다
172 | - HTTP/1.0에서도 keep-alive가 있었지만 표준화가 되어 있지 않았고 HTTP/1.1부터 표준화가 되어 기본 옵션으로 설정되었다
173 | > **HOL Blocking**
174 | > - HTTP/1.x 버전에서 발생하는 문제로 같은 큐에 있는 패킷이 그 첫 번째 패킷에 의해 지연될 때 발생하는 성능 저하 현상을 말한다
175 |
176 | ### 2.5.3 HTTP/2
177 | - SPDY 프로토콜에서 파생된 HTTP/1.x 보다 지연 시간을 줄이고 응답을 더 빠르게 할수 있다
178 | - _멀티플렉싱, 헤더 압축, 서버 푸시_, 요청의 우선순위 처리를 지원한다
179 | - 멀티 플렉싱 :
180 | - 여러 개의 스트림을 사용하여 송수신한다
181 | - 특정 스트림의 패킷이 손실되었다고 해도 해당 스트림에만 영향을 미친다 (나머지는 멀쩡)
182 | - 헤더 압축 :
183 | - HTTP/1.x 에는 크기가 큰 헤더라는 문제가 있었다
184 | - huffman coding 알고리즘을 이용하여, 문자열을 문자 단위로 쪼개, 전체 데이터의 표현에 필요한 비트양을 줄이게 되었다
185 | - 서버 푸시 :
186 | - 기존에는 클라이언트가 서버에 요청을 해야 파일을 다운로드 받을 수 있었지만, HTTP/2에서는 서버가 클라이언트로부터의 요청 없이 리소스를 바로 푸시할 수 있다
187 |
188 | ### 2.5.4 HTTPS
189 | - HTTPS는 애플리케이션 계층과 전송 계층 사이에 신뢰 계층인 SSL/TLS 계층을 넣어 신뢰할 수 있는 HTTP 요청을 말한다
190 | - HTTP/2는 HTTPS 위에서 동작
191 | #### SSL/TLS
192 | - 전송 계층에서 보안을 제공하는 프로토콜
193 | - 클라이언트와 서버가 통신할 때 SSL/TLS를 통해 제3자가 메시지를 도청하거나 변조하지 못하도록 한다 -> 인터셉터 방지
194 | - *보안 세션*을 기반으로 데이터를 암호화하며, 보안 세션이 만들어질 때 인증 메커니즘, 키 교환 암호화 알고리즘, 해싱 알고리즘이 사용된다
195 | > 보안 세션
196 | > - 보안이 시작되고 끝나는 동안 유지되는 세션
197 | > - SSL/TLS는 HandShake를 통해 보안 세션을 생성하고, 이를 통해 상태 정보 등을 공유
198 |
199 | ### 2.5.5 HTTP/3
200 | - TCP가 아닌 UDP 기반
201 | - TCP 위에서 돌아가는 HTTP/2와는 달리 HTTP/3은 QUIC이라는 계층 위에서 돌아간다
202 | - QUIC는 TCP를 사용하지 않기에 통신을 시작할 때 3 Way-Handshake같은 과정을 거치지 않는다 -> **지연 시간을 감소**하는 장점이 있다
--------------------------------------------------------------------------------
/2. 네트워크(1)/네트워크의 기초(1)_송민진.md:
--------------------------------------------------------------------------------
1 | # 네트워크란?
2 |
3 |
4 | : 컴퓨터 등의 장치들이 통신 기술을 이용하여 구축하는 연결망
5 |
6 | - Net + Work
7 |
8 | - 두 대 이상의 컴퓨터들을 연결하고 서로 통신할 수 있는 것
9 |
10 | - 어떤 연결을 통해 컴퓨터의 자원을 공유하는 것
11 |
12 |
13 |
14 | ## 네트워크의 기초
15 |
16 | **네트워크** : 노드와 링크가 서로 연결되어 있거나, 연결되어 있으며 리소스를 공유하는 집합
17 |
18 | - Node : 서버, 라우터, 스위치 등 네트워크 장치
19 |
20 | - Link : 유선 또는 무선
21 |
22 |
23 | **처리량 (Throughput)** : 링크를 통해 전달되는 단위 시간당 데이터양
24 |
25 | - "얼마나 많은 데이터가 단위시간 내에 목적지에 전달될 수 있는가?"
26 |
27 | - 사용자들이 많이 접속할 때마다 커지는 트래픽, 네트워크 장치 간의 대역폭, 네트워크 중간에 발생하는 에러, 장치의 하드웨어 스펙에 영향을 받음
28 |
29 | - 시스템의 출력률을 명시할 땐 평균 출력(Average Throughput) 값을 사용함
30 |
31 | > 📌**처리량의 단위**
32 | > 가장 많이 사용되는 것은 bps, 더 큰 출력을 가진 시스템은 Mbps, Gbps 사용
33 | > - bps(bits per second) - 초당 전송 또는 수신되는 비트 수
34 | > - megabits per second (Mbps)
35 | > - gigabits per second (Gbps)
36 |
37 |
38 | **대역폭(bandwidth)** : 단위 시간 내 전달할 수 있는 최대 크기의 전달 용량
39 |
40 | - 주어진 시간 동안 네트워크 연결을 통해 흐를 수 있는 최대 비트 수
41 |
42 | - 대역폭 자체는 전달 속도와는 관계가 없으며 오히려 용량(capacity)과 관계가 있음
43 |
44 | - 대역폭이 곧 인터넷 속도를 의미하는 경우가 꽤 많음
45 |
46 | 
47 |
48 | > - 일반적으로 대역폭은 고정되어 있다. (cf. 가변 대역폭을 사용하는 경우도 종종 있음)
49 | > - 출력을 시간별로 검사하면, 시스템을 시작하기 전에는 0, 사용자의 요청의 양에 따라 전달하는 bit 수가 점차 변하게 됨
50 |
51 |
52 | **네트워크 지연 (network latency)** : 예상하지 못한 시간(time)이 데이터 전달에 소요되는 현상
53 |
54 | - 지연 시간 : 요청이 처리되는 시간. 어떤 메시지가 두 장치 사이를 왕복하는 데에 걸린 시간
55 |
56 | - 매체 타입(무선, 유선), 패킷 크기, 라우터의 패킷 처리 시간에 영향을 받음
57 |
58 | **네트워크 혼잡 (network congestion)** : 전달해야 하는 데이터의 양이 네트워크에 몰리는 현상
59 |
60 | **패킷 손실 (packet loss)** : 패킷이 전달되는 동안 예상치 못하게 손실되는 현상
61 |
62 | > 💡 **요약**
63 | > - 출력은 높고 대역폭은 작다면 ➡ 네트워크 출구에서 대기하는 데이터가 많음 ➡ 시스템의 성능(performance)에 안 좋은 영향
64 | >
65 | > - 출력은 낮은데 대역폭은 크다면 ➡ 대역폭, 비용의 낭비
66 |
67 |
68 |
69 | ## 네트워크 토폴로지
70 |
71 | > 네트워크 설계시 토폴로지를 고려해야 함
72 |
73 | **네트워크 토폴로지 (network topology)** : 노드와 링크가 어떻게 배치되어 있는지에 대한 방식이자 연결 형태
74 |
75 | **tree topology**
76 | - 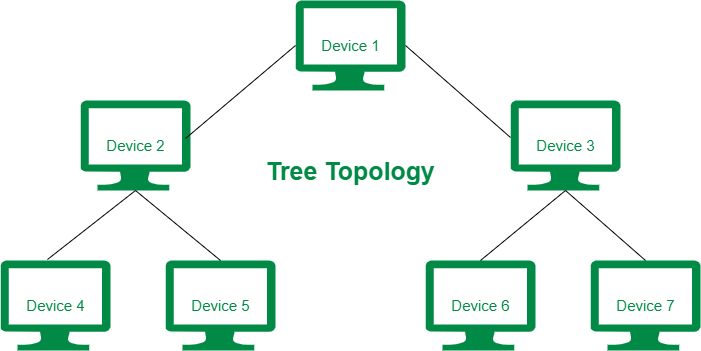
77 | - (= 계층형 토폴로지)
78 | - 트리 형태로 배치한 네트워크 구성
79 | - 노드의 추가/삭제가 쉬우며, 특정 노드에 트래픽이 집중될 때 하위 노드에 영향을 끼침
80 |
81 | **bus topology**
82 | - 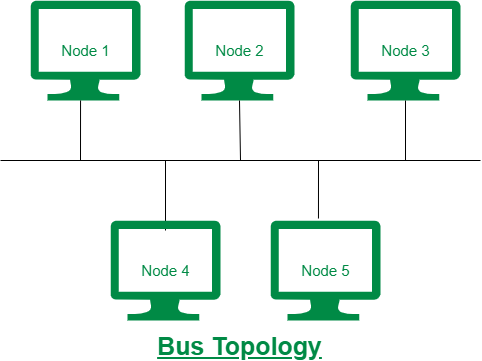
83 | - 중앙 통신 회선 하나에 여러 개의 노드가 연결되어 공유하는 네트워크 구성
84 | - 근거리 통신망(LAN)에 사용됨
85 | - 설치 비용이 적고 신뢰성이 우수함
86 | - 중앙 통신 회선에 노드 추가/삭제가 쉬움
87 | - 스푸핑이 가능한 문제점 있음
88 | > 📌 **스푸핑 (Spoofing)** : LAN상에서 송신부의 패킷을 송신과 관련 없는 다른 호스트에 가지 않도록 하는 스위칭 기능을 마비시키거나 속여 특정 노드에 해당 패킷이 오도록 처리하는 것
89 | > 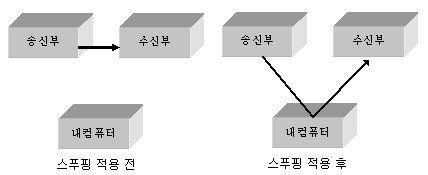
90 |
91 | **star topology**
92 | - 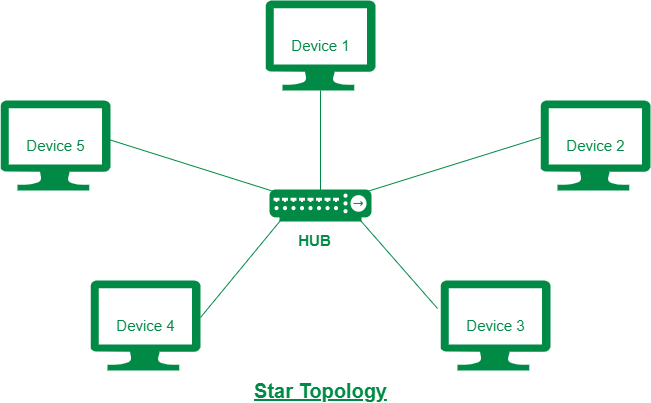
93 | - 성형 토폴로지. 중앙에 있는 노드에 모두 연결된 네트워크 구성
94 | - 노드 추가가 쉬우며, 에러 탐지도 쉬움
95 | - 패킷의 충돌 가능성이 적음
96 | - 장애 노드가 중앙 노드가 아닐 경우, 다른 노드에 영향을 끼치는 것이 적음
97 | - 중앙 노드에 장애가 발생할 경우, 전체 네트워크를 사용할 수 없음
98 | - 설치 비용이 고가임
99 |
100 | **ring topology**
101 | - 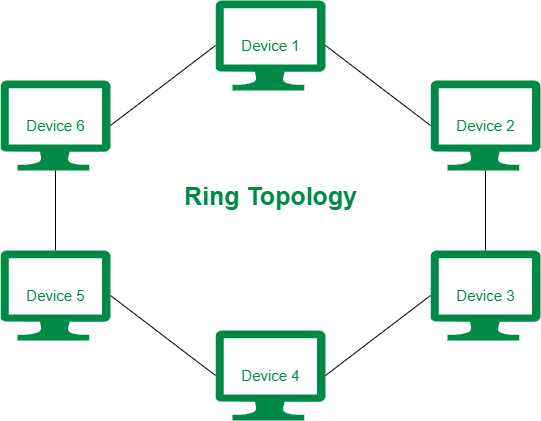
102 | - 각각의 노드가 양 옆의 두 노드와 연결하여 전체적으로 고리처럼 하나의 연속된 길을 통해 통신함
103 | - 데이터는 노드에서 노드로 이동하며, 각각의 노드는 고리 모양의 길을 통해 패킷 처리
104 | - 노드 수가 증가되어도 네트워크 상의 손실이 거의 없음
105 | - 충돌 발생 가능성이 낮으며, 노드의 고장 발견을 쉽게 찾을 수 있음
106 | - 네트워크 구성 변경이 어렵고, 회선에 장애가 발생하면 전체 네트워크에 영향을 크게 끼치는 단점이 있음
107 |
108 | **mesh topology**
109 | - 
110 | - 메시 토폴로지 = 망형 토폴로지. 그물망처럼 연결되어 있는 구조
111 | - 한 단말 장치에 장애가 발생해도, 여러 개의 경로가 존재하므로 네트워크를 계속 사용할 수 있음
112 | - 트래픽 분산 처리도 가능
113 | - 노드의 추가가 어렵고, 구축/운용 비용이 고가임
114 |
115 | > 토폴로지는 병목 현상을 찾을 때 중요한 기준이 되기 때문에 중요하다.
116 |
117 |
118 |
119 | ## 병목 현상
120 |
121 | : 전체 시스템의 성능이나 용량이 하나의 구성 요소로 인해 제한을 받는 현상
122 |
123 | - 병의 몸통보다 병의 목 부분 내부 지름이 좁아서 물이 상대적으로 천천히 쏟아지는 것과 같은 현상
124 | - 서비스에서 이벤트 개최시 트래픽이 많이 생기고, 그를 잘 관리하지 못하면 병목현상 발생 ➡ 해당 사이트 접근 불가
125 |
126 | ### **병목 현상의 주된 원인**
127 | - 네트워크 대역폭
128 | - 네트워크 토폴로지
129 | - 서버 CPU, 메모리 사용량
130 | - 비효율적인 네트워크 구성
131 |
132 |
133 |
134 |
135 | ## 네트워크의 종류
136 |
137 | 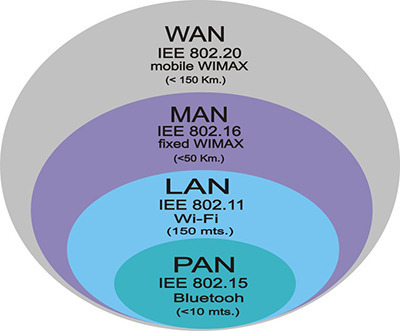
138 |
139 | - **PAN (Personal Area Network)** : 가장 작은 규모의 네트워크
140 | - **LAN (Local Area Network)** : 근거리 영역 네트워크. 근거리 통신망. 건물이나 캠퍼스 등의 좁은 공간에서 운영됨. 전송 속도가 빠르고 혼잡하지 않음
141 | - **MAN (Metropolitan Area Network)** : 대도시 영역 네트워크. 전송 속도는 평균이며, LAN보다는 더 혼잡함
142 | - **WAN (Wide Ares Network)** : 광대역 네트워크. 국가 또는 대륙 같은 넓은 지역에서 운영됨. 전송 속도는 낮으며, MAN보다 더 혼잡함
143 | - **VAN (Value Added Network)** : 부가가치 통신망 정보의 축적과 제공, 통신속도와 형식의 변화, 통신경로의 선택 등 여러 종류의 정보서비스가 부가된 통신망.
144 | - **ISDN (Integrated Services Digital Network)** : 종합정보 통신망(=BISDN) 전화, 팩스, 데이터 통신, 비디오텍스 등 통신관련 서비스를 종합하여 다루는 통합서비스 디지털 통신망. 디지털 전송방식과 광섬유 케이블 사용. 꿈의 통신망이라 불립니다.
145 |
146 |
147 |
148 | ## 네트워크 성능 분석 명령어
149 |
150 | > 애플리케이션 코드 상에는 전혀 문제가 없는데 사용자가 서비스로부터 데이터를 가져오지 못하는 상황 ➡ 네트워크 병목현상일 가능성도 있음!
151 |
152 | **`ping`**
153 | _Packet INternet Groper_
154 | : 네트워크 상태를 확인하려는 대상 노드를 향해, 일정 크기의 패킷을 전송하는 명령어
155 | - 해당 노드의 패킷 수신 상태와, 도달하기까지 시간 등을 알 수 있음
156 | - 해당 노드까지 네트워크가 잘 연결되어 있는지 확인할 수 있음
157 | - TCP/IP 프로토콜 중 ICMP 프로토콜을 통해 동작함
158 | > 👉 **ping 테스팅 불가능한 경우**
159 | > - ICMP 프로토콜을 지원하지 않는 기기를 대상으로 테스트할 경우
160 | > - 네트워크 정책상 ICMP나 traceroute를 차단하는 대상의 경우
161 | - 활용
162 | ```shell
163 | # ping [IP주소 또는 도메인 주소]
164 | ping www.google.com -n 12
165 | ```
166 | : `-n 12` : 12번의 패킷을 보내고 12번의 패킷을 받음
167 |
168 |
169 |
170 | **`netstat`**
171 | _network statistics_
172 | : 접속되어 있는 서비스들의 네트워크 상태를 표시하기
173 |
174 | - 네트워크 접속, 라우팅 테이블, 네트워크 프로토콜 등 리스트를 보여줌
175 | - 주로 서비스의 포트가 열려 있는지 확인할 때 씀
176 | - 활용
177 | ```shell
178 | netstat
179 | ```
180 | : 현재 내가 접속하고 있는 사이트 등에 관한 네트워크 상태 리스트 확인 가능
181 | ```shell
182 | netstat -ano
183 | ```
184 | : 내 PC에서 사용중인 포트 확인하기
185 |
186 |
187 |
188 | **`nslookup`**
189 | _name server lookup_
190 | : DNS 서버로부터 여러 가지 정보를 얻을 수 있는 명령어
191 | - 특정 도메인에 매핑된 IP를 확인하기 위해 사용함
192 | - 활용
193 | ```shell
194 | nslookup
195 | # 아래에, 특정 도메인 입력. 예를 들면, google.com
196 | # 그럼 해당 도메인에 대한 DNS 확인 가능
197 | ```
198 |
199 |
200 |
201 | **`tracert`**
202 | __Trace Route__
203 | : 지정된 호스트에 도달할 때까지 통과하는 경로의 정보와 각 경로에서의 지연 시간을 추적하는 네트워크 명령어
204 | - 목적지 노드까지 네트워크 경로를 확인할 때 사용
205 | - 특정 사이트에 접속이 되지 않거나 지연이 있는 경우 어디에서 병목이 발생하는지를 알아보는데 유용함
206 | - 활용
207 | ```shell
208 | tracert www.google.com
209 | ```
210 | : google 사이트에 도달하기까지의 경로 추적
211 |
212 |
213 |
214 | **`ftp`** : 대형 파일 전송하여 테스팅
215 |
216 |
217 | **`tcpdump`** : 노드로 오고 가는 패킷 캡처
218 |
219 |
220 |
221 | > 📌 **네트워크 분석 프로그램**
222 | > - wireshark
223 | > - netmon
224 |
225 |
226 |
227 | ## 네트워크 프로토콜 표준화
228 |
229 | ### 네트워크 프로토콜이란?
230 |
231 |
232 | : 다른 장치들끼리 데이터를 주고받기 위해 설정된 공통된 인터페이스
233 |
234 | - 기업이나 개인이 발표해서 정하는 것이 아니라, IEEE 또는 IETF라는 표준어 단체가 이를 정함
235 |
236 | **`IEEE802.3`**
237 | : 유선 LAN 프로토콜. 유선으로 LAN을 구축할 때 쓰임
238 |
239 |
240 |
241 |
242 | ---
243 |
244 | **참고자료**
245 |
246 | - [네트워크 출력(throughput)와 대역폭(bandwidth)을 이해하자 - 네이버 블로그](https://blog.naver.com/PostView.naver?blogId=techtrip&logNo=221719292177&redirect=Dlog&widgetTypeCall=true&topReferer=https%3A%2F%2Fwww.google.com%2F&directAccess=false)
--------------------------------------------------------------------------------
/1. 디자인 패턴과 프로그래밍 패러다임(1)/1. 디자인 패턴과 프로그래밍 패러다임(1)_송민진.md:
--------------------------------------------------------------------------------
1 | # 디자인 패턴이란?
2 |
3 | : 기존 환경 내에서 반복적으로 일어나는 문제들을 어떻게 풀어나갈 것인가에 대한 일종의 솔루션
4 |
5 | - 설계할 때 발생했던 문제점들을 객체 간의 상호관계 등을 이용하여 해결할 수 있도록 하나의 '규약' 형태로 만들어놓은 것
6 |
7 | - GoF의 디자인 패턴(디자인 패턴계의 교과서)에서는 객체지향적 디자인 패턴의 카테고리를 3가지로 분류
8 | - 생성 패턴 (Creational Pattern)
9 | - 구조 패턴 (Structural Pattern)
10 | - 행동 패턴 (Behavioral Pattern)
11 |
12 |
13 | 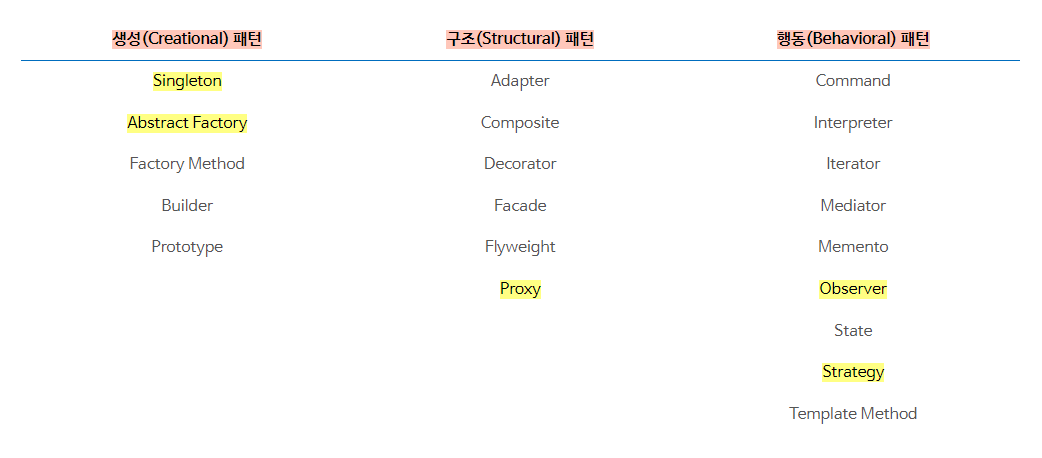
14 |
15 |
16 | # 1. 생성 패턴
17 |
18 | : 객체의 생성에 관련된 패턴으로, 객체의 생성절차를 추상화하는 패턴
19 |
20 | - 인스턴스를 만드는 절차를 추상화하는 패턴
21 |
22 | - 시스템으로부터 객체의 생성/합성 방법을 분리해내기 위함
23 |
24 | ### 생성패턴의 특징
25 |
26 | - 시스템이 어떤 구체 클래스를 사용하는지, 인스턴스들이 어떻게 만들어지고 어떻게 합성되는지에 대한 정보를 완전히 가려줌(캡슐화)
27 |
28 | - `무엇`이 생성되나요? → 알 수 없음
29 | - `어떻게` 생성되나요? → 알 수 없음
30 | - `언제` 생성되나요? → 알 수 없음
31 | - `누가` 이걸 생성하나요? → 알 수 없음
32 |
33 |
34 |
35 | ## 1-1. 싱글톤 패턴(Singleton Pattern)
36 |
37 |
38 | : 하나의 클래스에 오직 하나의 인스턴스만 가지는 패턴
39 |
40 | - 하나의 클래스를 기반으로 단 하나의 인스턴스를 만들어, 이를 기반으로 로직을 만드는 데에 쓰임
41 |
42 | - 생성자가 여러 차례 호출되더라도 실제로 생성되는 객체는 하나이고 최초 생성 이후에 호출된 생성자는 최초의 생성자가 생성한 객체를 리턴함
43 |
44 | - 하나의 인스턴스를 만들어놓고, 해당 인스턴스를 다른 모듈들이 공유하여 사용하기 때문에 인스턴스 생성 비용이 감소됨
45 |
46 | - 모듈 간의 결합을 강하게 만든다는 단점이 있음
47 |
48 | > 💡 이러한 모듈 간의 결합을 조금 느슨하게 하기 위해 의존성 주입(Dependency Injection)이라는 개념을 사용할 수 있다.
49 |
50 | ### 사용 예시
51 |
52 | - 보통 데이터베이스 연결 모듈(DBCP, DataBase Connection Pool)에 많이 사용함
53 | (DB 연결 과정이 부하가 크고, 한 번 연결된 객체를 계속 사용해야 하기 때문)
54 |
55 | - 스프링 컨테이너도 객체를 싱글톤으로 관리함
56 |
57 |
58 | ### 구현
59 |
60 | **Java에서의 싱글톤 구현**
61 | ```java
62 | class Singleton {
63 | private static class singleInstanceHolder {
64 | private static final Singleton INSTANCE = new Singleton();
65 | }
66 | public static Singleton getInstance() {
67 | return singleInstanceHolder.INSTANCE;
68 | }
69 | }
70 |
71 | public class HelloWorld {
72 | public static void main(String[] args) {
73 | Singleton a = Singleton.getInstance();
74 | Singleton b = Singleton.getInstance();
75 | System.out.println(a.hashCode());
76 | System.out.println(b.hashCode());
77 | if (a == b) {
78 | System.out.println(true);
79 | }
80 | }
81 | }
82 | ```
83 |
84 |
85 | **JDBC에서 싱글톤을 활용하여 DB 연결하기**
86 |
87 | ```java
88 | // 데이터베이스와 연결과 끊어주기위한 클래스
89 |
90 | import java.sql.Connection;
91 | import java.sql.DriverManager;
92 | import java.sql.SQLException;
93 |
94 |
95 | public class DBConn {
96 |
97 | private static Connection dbConn;
98 | public static Connection getConnection() throws SQLException, ClassNotFoundException{
99 | if (dbConn == null){
100 | //dbConn이 null이면, 연결된 것이 없으니 연결해야한다.
101 | String url = "jdbc:oracle:thin:@127.0.0.1:1521:xe" ;
102 | String user = "hr";
103 | String pass = "12345";
104 | Class. forName("oracle.jdbc.driver.OracleDriver");
105 | dbConn = DriverManager.getConnection(url, user, pass);
106 | }
107 | return dbConn ;
108 | }
109 | //db와의 연결을 맺어주기 위한 메소드.
110 |
111 | public static void close() throws SQLException {
112 | if (dbConn != null){
113 | if(!dbConn .isClosed()){
114 | dbConn.close();
115 | }
116 | }
117 | }
118 | //db와의 연결을 끊어주는 메소드
119 | }
120 | ```
121 | ```java
122 | // ex) 연결하기 예제
123 |
124 | import java.sql.Connection;
125 |
126 |
127 | public class jdbcTest {
128 |
129 | public static void main(String[] args) {
130 |
131 | try{
132 | Connection conn = DBConn.getConnection ();
133 | //정의한 DBConn 클래스로 손쉽게 연결.
134 | System. out.println("오라클에 연결되었습니다." );
135 | } catch(Exception e){
136 | System. out.println(e.toString());
137 | }
138 | }
139 |
140 | }
141 | ```
142 |
143 |
144 |
145 | ### 문제점
146 |
147 | - 객체지향 프로그래밍의 핵심인 **상속**과 **다형성**을 해친다.
148 |
149 | - 객체지향 프로그래밍의 또 다른 핵심인 **정보 은닉**을 해친다. 공유의 목적으로 생성된 클래스이기 때문에, 객체를 요청하는 메소드를 public으로 강제할 수밖에 없다.
150 |
151 | - Java의 고정적 싱글턴 패턴은 객체가 하나인 것을 보장할 수 없다.
152 |
153 | > 💡 **싱글턴 패턴을 사용할 땐 조심하자!**
154 | >
155 | > 즉, 싱글턴 패턴은 굉장히 많이 활용되는 패턴이나, 앞서 말한 객체지향 프로그래밍의 기본 사상들을 많이 침해하기 때문에 굉장히 비판을 많이 받는 디자인 패턴이다.
156 | >
157 | > 따라서 싱글턴 패턴은 사용 시 매우 조심해서 사용해야 한다.
158 | >
159 | > 그것이 아니라면 위의 고전적인 싱글턴 패턴이 아닌 개선된 방식으로 객체의 싱글턴 방식을 구현하여 사용해야 한다.
160 |
161 |
162 |
163 |
164 | ## 1-2. 팩토리 패턴 (Factory Pattern)
165 |
166 |
167 | : 객체를 사용하는 코드에서 객체 생성 부분을 떼어내 추상화한 패턴
168 |
169 | - 상속 관계에 있는 두 클래스에서, 상위 클래스가 중요한 뼈대를 결정하고, 하위 클래스에서 객체 생성에 관한 구체적인 내용을 결정함
170 |
171 | - 상위 클래스와 하위 클래스가 분리되기 때문에 느슨한 결합을 가짐
172 |
173 | - 상위 클래스에서는 인스턴스 생성 방식에 대해 전혀 알 필요가 없기 때문에, 더 많은 유연성을 가지게 됨
174 |
175 | - 객체 생성 로직이 따로 떼어져 있기 때문에, 코드를 리팩터링하더라도 한 곳만 고칠 수 있게 됨 → 유지 보수성 증가
176 |
177 | ### 종류
178 |
179 | - **팩토리 메소드 패턴** : 객체를 생성하기 위한 인터페이스를 정의하는데, 어떤 클래스의 인스턴스를 만들지는 서브클래스에서 결정하게 만든다. 즉 팩토리 메소드 패턴을 이용하면 클래스의 인스턴스를 만드는 일을 서브클래스에게 맡기는 것.
180 |
181 | - **추상 팩토리 패턴** : 인터페이스를 이용하여 서로 연관된, 또는 의존하는 객체를 구상 클래스를 지정하지 않고도 생성.
182 |
183 | ### 구현
184 |
185 | **Java에서의 팩토리 패턴 구현**
186 |
187 | ```java
188 | 추후 작성 예정
189 | ```
190 |
191 | > 💡 **Enum 타입**
192 | > - 상수의 집합을 정의할 때 사용되는 타입
193 | > - 코드를 리팩터링할 때 해당 집합에 관한 로직 수정 시 이 부분만 수정하면 됨 : 큰 강점
194 |
195 |
196 |
197 | # 2. 구조 패턴
198 |
199 | ## 2-1. 프록시 패턴 (Proxy Pattern)
200 |
201 | : 대상 객체(subject)에 접근하기 전, 그 접근에 대한 흐름을 가로채 대상 객체 앞단의 인터페이스 역할을 하는 디자인 패턴
202 |
203 | - 이를 통해 객체의 속성, 변환 등을 보안 / 데이터 검증 / 캐싱 / 로깅에 사용함
204 |
205 | - 프록시 객체로 쓰이기도 하지만, 프록시 서버로도 활용함
206 |
207 | ### 프록시 객체
208 |
209 | : 어떠한 대상의 기본적인 동작(속성 접근, 할당, 순회, 열거, 함수 호출 등)의 작업을 가로챌 수 있는 객체를 뜻함
210 |
211 | - 자바스크립트에서 프록시 객체는 2개의 매개변수를 가짐
212 |
213 | - 프록시 패턴이 녹아들어 있는 객체
214 |
215 | - **`target`** : 프록시할 대상
216 |
217 | - **`handler`** : 프록시 객체의 target 동작을 가로채서 정의할 동작들이 정해져 있는 함수
218 |
219 | ### 프록시 서버
220 |
221 | : 서버와 클라이언트 사이에서 클라이언트가 자신을 통해 다른 네트워크 서비스에 간접적으로 접속할 수 있게 해주는 컴퓨터 시스템이나 응용프로그램
222 |
223 | ### 사례
224 |
225 | - **nginx** : 비동기 이벤트 기반의 구조와 다수의 연결을 효과적으로 처리 가능한 웹 서버. nginx를 프록시 서버로 둬서 실제 포트를 숨길 수도 있고, 정적 자원을 gzip 압축하거나, 메인 서버 앞단에서의 로딩을 할 수도 있다.
226 |
227 | > 프록시 서버를 통해, 익명 사용자의 직접적인 서버로의 접근을 차단하고, 간접적으로 한 단계를 더 거침으로써 보안성을 더욱 강화할 수 있다.
228 |
229 |
230 |
231 |
232 | # 3. 행동 패턴
233 |
234 | ## 3-1.전략 패턴 (Strategy Pattern)
235 |
236 | : 객체의 행위를 바꾸고 싶은 경우 '직접' 수정하지 않고 전략이라고 부르는 '캡슐화한 알고리즘'을 컨텍스트 안에서 바꿔주면서 상호 교체가 가능하게 만드는 패턴. = 정책 패턴(Policy Pattern)
237 |
238 | 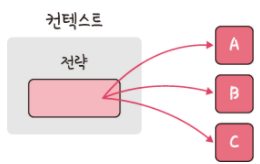
239 |
240 | -
241 |
242 | > 💡 **컨텍스트**
243 | > 프로그래밍에서의 컨텍스트 : 상황, 맥락, 문맥을 의미하며, 개발자가 어떠한 작업을 완료하는 데 필요한 모든 관련 정보
244 |
245 |
246 |
247 | ## 3-2. 옵저버 패턴 (Observer Pattern)
248 |
249 | : 주체가 어떤 객체의 상태 변화를 관찰하다가 상태 변화가 있을 때마다 메서드 등을 통해 옵저버 목록에 있는 옵저버들에게 변화를 알려주는 디자인 패턴
250 |
251 |
252 | - 주체 : 객체의 상태 변화를 보고 있는 관찰자
253 | - 옵저버 : 이 객체의 상태 변화에 따라 전달되는 메서드 등을 기반으로 '추가 변화 사항'이 생기는 객체들
254 |
255 | ### 사례
256 |
257 | - **Twitter(트위터)** : 주체가 포스팅을 올리게 되면 알림이 팔로워에게 감
258 |
259 | - **Event-Driven System**
260 |
261 | - **MVC 패턴** : Model(=주체)에서 변경 사항이 생겨 update() 메서드로 View(=옵저버)에 알려주고, 이를 기반으로 Controller가 작동함
262 |
263 |
264 |
265 |
266 | # 아키텍처 패턴
267 |
268 |
--------------------------------------------------------------------------------
/4. 데이터베이스(1)/데이터베이스(1)_이홍섭.md:
--------------------------------------------------------------------------------
1 | # 4. 데이터베이스(1)
2 |
3 | ## 목차
4 |
5 |
6 | ### ~~4.1 데이터베이스의 기본~~
7 | ### 4.2 ERD와 정규화 과정
8 | - 4.2.1 ERD의 중요성
9 | - 4.2.2 예제로 배우는 ERD
10 | - 4.2.3 정규화 과정
11 | ### 4.3 트랜잭션과 무결성
12 | - 4.3.1 트랜잭션
13 | - 4.3.2 무결성
14 | ---
15 | # 4.2 ERD와 정규화 과정
16 | ## 1. ERD
17 | >ERD(Entity Relationship Diagram)는 DB를 구축할 때 가장 기초적인 뼈대 역할을 하며, **릴레이션 간의 관계들을 정의**한 것이다. 서비스를 구축할 때 가장 먼저 신경 써야 할 부분이다
18 | - 관계형 DB를 표현하기에 유리하다
19 | - 비정형 DB(NoSQL)에는 적합하지 않다
20 | ## 2. 정규화
21 | > 정규화 과정은 릴레이션 간 잘못된 종속 관계를 바로 잡아 중복 데이터를 제거하고, 데이터 정합성(integrity)을 만족하도록 릴레이션을 여러개로 분리하는 과정을 말한다
22 | > 예를 들어, 유저 정보 테이블도 닉네임을 갖고, 게시물 테이블, 댓글 테이블도 각자 사용자 닉네임을 가지고 있는데, 사용자 닉네임이 변경 될때, 정규화가 제대로 되어 있지 않은 상태에서는 모든 테이블에 기록된 닉네임을 일일이 수정해야 한다
23 | ### 정규형 원칙
24 | - 같은 의미를 표현하는 릴레이션이지만 좀 더 좋은 구조로 만들어야 한다
25 | - 자료의 중복성은 감소하고, 독립적인 관계는 별개의 릴레이션으로 표현해야 한다
26 | - 정규형(정규화된 정도)은 제1정규형~제3정규형, 보이스/코드 정규형이 있다
27 | - 고급 정규형인 제4정구형,제5정규형 등도 있다
28 | ### 1) 제1정규형
29 | - 모든 도메인이 더 이상 분해될 수 없는 원자값(atomic)으로만 구성되어 있는 상태를 제1정규형이라고 한다
30 | - 릴레이션 속성 값 중 한 개의 PK에 두 개 이상의 값 가지는 반복 집합이 있어서는 안되
31 | - 반복 집합이 있다면 제거해야 한다
32 |
33 | | boardId | userName | content |
34 | |---------|----------|-------------|
35 | | 1 | hongseob | {안녕}, {공부중} |
36 |
37 | 위와 같은 테이블은 제1정규화가 되어있지 않다. content 속성에 값이 2개가 존재하는 경우가 있다
38 | 이것을 나눠서 반복 집합을 제거 해주면 아래처럼 제1정규화를 진행할 수 있다
39 |
40 | | boardId | userName | content |
41 | |---------|----------|-----|
42 | | 1 | hongseob | 안녕 |
43 | | 2 | hongseob | 공부중 |
44 | #### 이상현상
45 | 대부분 정규형에는 이상현상이 존재한다
46 | 제 1정규형에는 아래와 같은 이상 현상이 존재한다
47 | - 삽입 이상 : 불필요한 정보가 필요함
48 | - 삭제 이상 : 불필요한 정보까지 삭제됨
49 | - 갱신 이상 : 불필요한 정보까지 갱신 필요
50 | ### 2) 제2정규형
51 | - 릴레이션이 제1정규형이며 부분 함수의 종속성을 제거한 형태를 말한다
52 | - 부분 함수의 종속성 제거란 PK가 아닌 모든 속성이 PK에 완전 함수 종속적인 것을 말한다
53 | - 즉 제1정규형 이며, PK에 속하지 않은 속성 모두가 PK에 완전 함수 종속인 정규형
54 |
55 | | boardId | creatorId | contents | commentId | commentViews |
56 | |---------|-----------|----------| --------- |--------------|
57 | | 1 | USER1 | 안녕 | 1 | 20 |
58 | | 2 | USER2 | 등업좀요 | 2 | 10 |
59 | | 3 | USER3 | 공부하자 | 3 | 37 |
60 | | 4 | USER4 | 취업성공 | 4 | 132 |
61 |
62 | 위의 테이블은 PK는 `boardId` 이다
63 | 각 게시물은 하나의 작성자, 하나의 내용, 여러 개의 댓글을 가진다. 한 댓글은 하나의 조회수를 가진다
64 | `creatorId`,`contents`는 `boardId`에 의존하지만 `commentViews`는 `commentId`에 의존한다
65 | 따라서 위의 릴레이션은 부분 함수의 종속성이 존재하므로, 제2정규화를 통해 아래와 같이 분리할 수 있다
66 |
67 | | boardId | creatorId | contents |
68 | |------------| ---------- | --------------------- |
69 | | 1 | KAKAO00001 | 안녕 |
70 | | 2 | GOOGL00001 | 등업좀요 |
71 | | 3 | KAKAO00002 | 히어로즈 오브 더 스톰 |
72 | | 4 | NAVER00001 | 네카라쿠배 |
73 |
74 | | commentId | boardId | commentViews|
75 | | --------- | ---|-------------|
76 | | 1 | 1 | 23 |
77 | | 2 | 2 | 21 |
78 | | 3 | 3 | 37 |
79 | | 4 | 4 | 132 |
80 |
81 | 기본키인 {이름, 수강명}과 같은 완전 종속된 유저번호 릴레이션과 {이름, 수강명}에 따른 성취도 릴레이션으로 분리하였다
82 | #### 이상현상
83 | 제 2정규형에도 이상현상이 존재한다
84 | - 삽입 이상 : 불필요한 정보가 필요함
85 | - 삭제 이상 : 불필요한 정보까지 삭제됨
86 | - 갱신 이상 : 불필요한 정보까지 갱신 필요
87 | >여전히 이상현상이 발생하는 이유는 **'이행적 함수 종속성'** 때문이다
88 | >이행적 함수 종속성은 속성이 A->B,B->C,이면서, A->C의 관계가 있는 것을 말한다
89 | ### 3) 제3정규형
90 | - 제2정규형이고, PK가 아닌 모든 속성이 이행적 함수 종석을 만족하지 않는 상태
91 | - PK 이외의 속성이 그 외 다른 속성을 결정할 수 없다는 것
92 |
93 | 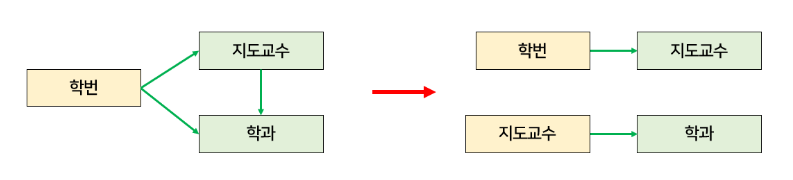
94 | 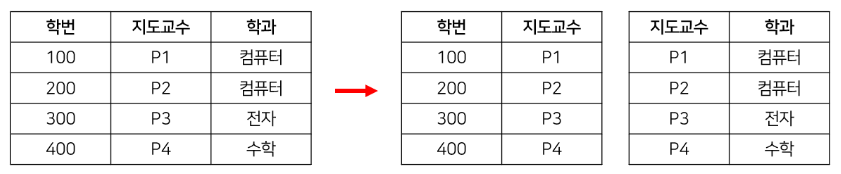
95 | 위 사진은 이행적 함수 종속 관계에 있는 속성을 분리하고 테이블로 나타낸 것이다. ([출처](https://rebro.kr/160))
96 | 제 3정규형은 1,2정규형에서 발생했던 이상현상이 해결됩니다.
97 | ### 4) 보이스/코드 정규형
98 | - 제3정규형이고, 결정자가 후보키가 아닌 함수 종속 관계를 제거하여 릴레이션의 함수 종속 관계에서 모든 결정자가 후보키인 상태를 말한다
99 | - 즉 제3정규형을 강화시킨 개념
100 | - [이해에 도움이 되는 관련 자료](https://rebro.kr/160)
101 | ### 정규형의 장단점
102 | - 장점 :
103 | - 응용프로그램 단에서 불필요한 로직을 없앨 수 있다
104 | - 올바른 데이터만 얻을 수 있다 (변칙 방지)
105 | - 불필요한 쿼리(ex. 서브쿼리) 제거로 성능 향상
106 | - 단점 :
107 | - 릴레이션의 분해로 인해 릴레이션간의 연산(JOIN 연산)이 많아져 응답 시간이 느려질 수 있다
108 | # 4.3 트랜잭션과 무결성
109 | ## 1. 트랜잭션
110 | >트랜잭션은 DB에서 하나의 논리적 기능을 수행하기 위한 연산 단위를 말한다
111 | >즉 여러 개의 쿼리들을 하나로 묶는 단위를 말한다
112 |
113 | A->B로 돈을 보내려고 한다 이런 상황에서
114 | - A의 통장 잔고를 조회하여, 보내려는 금액 이상이 존재하는지 확인한다
115 | - A의 통장 잔고에서 보내려는 금액만큼 값을 뺀다
116 | - B의 통장 잔고에는 받는 금액만큼을 더한다
117 |
118 | 위 세가지 과정 중 연결 불안정 등의 문제가 발생한다면?
119 |
120 | - A의 통장에서 돈이 빠져나가고, B의 통장으로 입금되지 않는다
121 | - A의 잔고를 조회하고 보내려는 금액만큼을 빼려는 사이 A가 다른 곳에 돈을 쓴다. 그러면 남은 잔고는 보내려는 금액보다 적어지는데, 앞에서 확인할 때는 보내려는 금액 이상 있었으므로 통장 잔고에서 금액을 그대로 뺀다
122 |
123 | 트랜잭션은 위와 같은 경우가 발생하는 것을 방지하기 위해 존재하며, 트랜 잭션의 특징 4개를 ACID (Atomicity, Consistency, Isolation, Durability)라고 부른다
124 |
125 | ### 1) 원자성 (Atomicity)
126 | - 트랜잭션 내의 내용들이 하나의 단위(atomic)로 묶여서, 전체가 수행되거나 전체가 수행되지 않아야 한다는 속성을 가리킨다
127 | - 위의 예시에서 A가 B에게 돈을 보내줄 때 일어나는 세 가지 연산이 모두 실행되거나, 모두 실행되지 않아야 하는 성질을 말한다
128 | - 여기서 커밋과 롤백의 개념이 등장한다
129 | - `commit` :
130 | - 여러 쿼리가 성공적으로 처리되었다고 확정하는 명령어
131 | - 트랜잭션 단위로 수행되며 변경된 내용이 모두 영구적으로 저장되는 것을 말한다
132 | - `rollback` :
133 | - 에러나 여러 이슈 때문에 트랜잭션 전으로 돌려야 할 때 사용한다
134 | - 트랜잭션으로 처리한 하나의 묶음 과정을 일어나기 전으로 돌리는 일(취소)을 말한다
135 | - DBMS는 commit과 rollback을 통해 트랜잭션의 원자성을 보장해 준다
136 | ```java
137 | @Service
138 | public Class MemberService {
139 | ...
140 | @Transactional
141 | public HashMap updateClassMember(Map param) throws Exception {
142 | ...
143 | }
144 | }
145 | ```
146 | Spring 프레임워크에서는 Service 계층에서 `@Transactional`이라는 어노테이션을 통해 메소드 내의 로직의 원자성을 보장한다
147 | ### 2) 일관성 (Consistency)
148 | - 허용된 방식으로만 데이터를 변경해야하는 것을 의미한다
149 | - DB에 기록된 모든 데이터는 여러 가지 조건, 규칙에 따라 유효함을 가져야한다
150 | ### 3) 격리성 (Isolation)
151 | - 각 트랜잭션의 수행은 독립적이어야 함을 의미한다
152 | - 위의 예시 중, A의 금액을 조회하고 A로부터 금액을 빼오는 사이에 다른 트랜잭션이 수행되어서 A의 잔고값이 변했다면, 격리성을 해치는 일이다
153 | - 작업이 수행되는 중 다른 작업이 끼어들지 못하도록 하는 개념이며, 격리 단계가 총 4가지 존재한다
154 | - Read Uncommitted
155 | - Read Committed
156 | - Repeatable Read
157 | - Serializable
158 | - 위로 갈수록 동시성이 강해지지만 격리성은 약해지고 아래로 갈수록 동시성은 약해지고 격리성은 강해진다
159 | ### 격리 수준
160 | | 수준 |내용|단점|
161 | |:------------------:|-----|------|
162 | | SERIALIZABLE |순차적으로 진행시키는 것|교착 상태가 일어날 확률이 높음|
163 | | REPEATABLE_READ |행 수정은 불가능하지만 행 추가는 가능|이후에 추가된 행이 발견될 수 있음|
164 | | READ_COMMITTED |커밋하지 않은 정보는 읽을 수 없음|동시에 접근 가능하여 다른 내용이 발견될 수 있음|
165 | | READ_UNCOMMITTED |커밋되기 이전에 다른 트랜잭션에 노출됨|무결성이 유지되지 않을 수 있음|
166 | ### 격리 수준에 따라 발생하는 현상
167 | #### Phantom read, 팬텀 리드
168 | 한 트랜잭션 내에서 **동일한 쿼리**를 보냈을 때 해당 조회 결과가 다른 경우를 말합니다
169 |
170 | #### non-repeatable read, 반복 가능하지 않은 조회
171 | 한 트랜잭션 내의 같은 행에 두 번 이상 조회가 발생했는데, 그 값이 다른 경우
172 | 예를 들어
173 | 1. 현재 A의 잔고가 100원일 때,
174 | 2. 은행원1이 A의 잔고를 조회했는데,
175 | 3. 그 이후 은행원2가 그 값을 1원으로 변경해서 커밋하면
176 | 4. 은행원1은 100원이 아닌 1원을 읽게됩니다.
177 |
178 | #### Dirty read, 더티 리드
179 | 한 트랜잭션이 실행 중일 때 다른 트랜잭션에 의해 수정되었지만 아직 `커밋되지 않은` 행의 데이터를 읽을 수 있을 때 발생합니다.
180 |
181 | 예를 들어
182 | 1. 은행원1이 A의 잔고를 100원에서 1원으로 수정했는데 아직 커밋을 하지 않았을 때,
183 | 2. 은행원2는 A의 잔고를 1원 이라고 조회함
184 |
185 | ### 4) 지속성 (Durability)
186 | - 성공적으로 수행된 트랜잭션은 영원히 반영되어야 하는 것을 의미한다
187 | - DB에 시스템 장애가 발생해도, DBMS는 자체적으로 복구하는 능력을 가지고 있으며, 이를 통해 지속성을 만족한다
188 | - 체크섬 : 중복 검사의 한 형태로, 오류 정정을 통해 송신된 자료의 무결성을 보호하는 단순한 방법
189 | - 저널링 : 변경사항을 commit 하기전에 로깅하는 것
190 | - 롤백
191 | ## 2.무결성
192 | - 데이터의 정확성, 일관성, 유효성을 유지하는 것을 말한다
193 | - 무결성이 유지되어야 DB에 저장된 데이터 값과 그 값에 해당하는 현실 세계의 실제 값이 일치하는지에 대한 신뢰가 생긴다
194 |
195 | ### 무결성의 종류
196 |
197 | |이름| 설명 |
198 | |-----|-----------------------------------------------------------------|
199 | |개체 무결성| 기본키로 선택된 필드는 빈 값을 허용하지 않음 |
200 | |참조 무결성| 서로 참조 관계에 있는 두 테이블의 데이터는 항상 일관된 값을 유지해야함 |
201 | |고유 무결성| 특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우 그 속성 값은 모두 고유한 값을 가짐 |
202 | |NULL 무결성| 특정 속성 값에 NULL이 나올 수 없다는 조건이 주어진 경우 그 속성 값은 NULL이 될 수 없다는 제약 조건 |
--------------------------------------------------------------------------------
/3. 운영체제(1)/운영체제(1)_송민진.md:
--------------------------------------------------------------------------------
1 | # 3.1 운영체제와 컴퓨터
2 |
3 | ## 운영체제란?
4 |
5 | 운영체제는 컴퓨터의 하드웨어를 총체적으로 관리하는 소프트웨어입니다.
6 |
7 | 이는 사용자와 컴퓨터 하드웨어, 어플리케이션과 컴퓨터 하드웨어 사이를 중개하는 역할도 합니다.
8 |
9 | >컴퓨터란?
10 | : CPU, 메모리 등으로 이루어진 것
11 |
12 | >펌웨어란?
13 | : 운영체제와 유사하지만 소프트웨어를 추가로 설치할 수 없는 것
14 |
15 |
16 | ## 운영체제가 하는 일
17 |
18 | 컴퓨터의 시스템은 하드웨어, 운영체제, 어플리케이션 프로그램, 사용자 이렇게 4가지로 나눌 수 있습니다.
19 |
20 | 하드웨어는 크게 CPU, memory, I/O device 로 나눌 수 있습니다. 이 하드웨어들은 기본적인 컴퓨터 자원이라고도 불립니다. 워드 프로세서, 엑셀, 컴파일러, 웹브라우저 등 어플리케이션 프로그램들은 컴퓨터 자원(하드웨어) 를 사용하여 사용자의 computing problem 들을 해결합니다.
21 |
22 | 여기에서 운영체제는
23 | - 이 **하드웨어를 컨트롤**하고
24 | - 다양한 **어플리케이션 프로그램들이 사용할 수 있도록 조정하는 역할**을 합니다.
25 |
26 |
27 |
28 | ## 운영체제의 역할
29 |
30 | **1. CPU 스케줄링과 프로세스 관리**
31 | CPU 소유권을 어떤 프로세스에 할당할지, 프로세스의 생성과 삭제, 자원 할당 및 반환 관리
32 |
33 | **2. 메모리 관리**
34 | 한정된 메모리를 어떤 프로세스에 얼만틈 할당해야 하는지 관리
35 |
36 | **3. 디스크 파일 관리**
37 | 디스크 파일을 어떠한 방법으로 보관할지 관리
38 |
39 | **4. I/O 디바이스 관리**
40 | I/O 디바이스들인 마우스, 키보드와 컴퓨터 간에 데이터를 주고받는 것을 관리함
41 |
42 |
43 |
44 | ## 운영체제의 구조
45 |
46 | 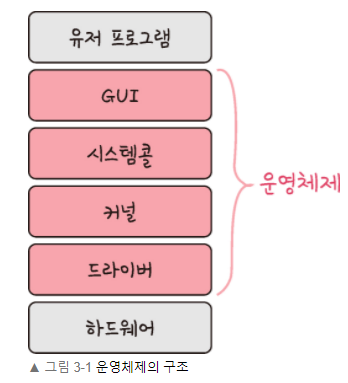
47 |
48 | ※ GUI가 없고 CUI만 있는 리눅스 서버도 있음
49 |
50 | >**GUI**
51 | : 사용자가 전자장치와 상호작용할 수 있도록 하는 사용자 인터페이스의 한 형태. 단순 명령어 창이 아닌, 아이콘을 마우스로 클릭하는 단순한 동작으로 컴퓨터와 상호작용할 수 있도록 해줌
52 |
53 | >**드라이버**
54 | : 하드웨어를 제어하기 위한 소프트웨어
55 |
56 | >**CUI**
57 | : 그래픽이 아닌 명령어로 처리하는 인터페이스
58 |
59 |
60 |
61 | ### **프로세스/스레드의 요청 전달 과정**
62 |
63 | 
64 |
65 | 프로세스/스레드 -> 시스템콜 -> 커널 -> OS
66 |
67 |
68 | > **시스템콜**
69 | > 운영체제가 커널에 접근하기 위한 인터페이스
70 | > 유저 프로그램이 운영 체제의 서비스를 받기 위해 커널 함수를 호출할 때 쓰인다. 이 과정을 통해 컴퓨터 자원에 대한 직접 접근을 차단하고, 프로그램을 다른 프로그램으로부터 보호할 수 있다.
71 | >
72 | >시스템콜이 작동될 때 Modebit을 참고해서 유저모드와 커널 모드를 구분한다. modebit은 1 또는 0의 값을 가지는 플래그 변수. (0 = 커널 모드, 1 = 유저 모드)
73 |
74 | 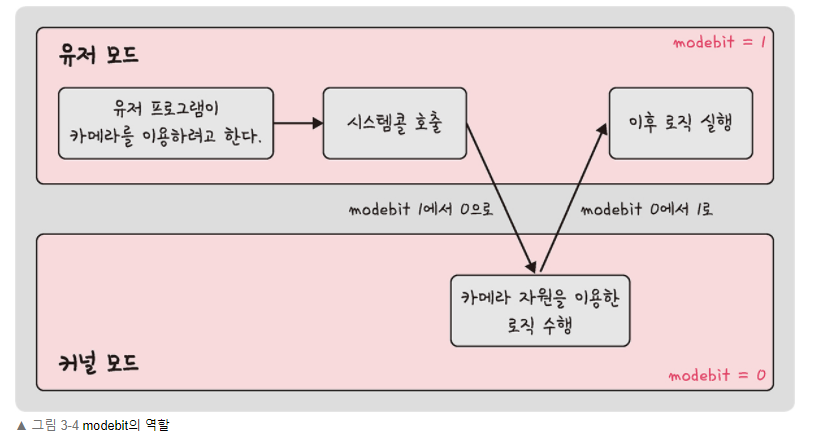
75 |
76 |
77 |
78 | >**유저 모드**
79 | >: 유저가 접근할 수 있는 영역이 제한적임. 컴퓨터 자원에 함부로 침범하지 못 하는 모드
80 |
81 | >**커널 모드**
82 | >: 모든 컴퓨터 자원에 접근할 수 있는 모드
83 |
84 |
85 | >**커널**
86 | >: 운영체제의 핵심 부분이자 시스템콜 인터페이스를 제공하며, 보안, 메모리, 프로세스, 파일 시스템, I/O 디바이스, I/O 요청 관리 등 운영체제의 중추적인 역할
87 |
88 | > **그래서 운영체제란?**
89 | > 사실 운영체제는 컴퓨터, 토스터기, 차, 선박, 우주선, 가구 등 다양한 기기들 안에 다양한 형태로 존재함. 이렇게 운영체제는 다양한 형태로 존재하므로 적합한 정의를 하는건 쉽지 않다.
90 | >
91 | 그러나 다양한 운영체제의 일반적이고 공통적인 부분을 모으면, 운영체제는 컴퓨터에서 **항상 실행되는 프로그램** 이라고 정의할 수 있고 이는 **kernel** 이라고도 불리기도 한다.
92 |
93 | ---
94 |
95 |
96 | ## 컴퓨터의 요소
97 |
98 | CPU, DMA 컨트롤러, 메모리, 타이머, 디바이스 컨트롤러 등
99 |
100 | 
101 |
102 | 1. CPU(Central Processing Unit) : 프로그램의 연산을 실행, 처리하는 곳
103 | 2. DMA 컨트롤러 : I/O 디바이스가 메모리에 직접 접근할 수 있도록 하는 장치
104 | 3. 메모리 : RAM을 일컫음, 기록하는 장치
105 | 4. 타이머 : 특정 프로그램에 시간 제한 걺. 시간이 많이 걸리는 프로그램에 제한을 걸기 위해 존재
106 | 5. 디바이스 컨트롤러 : IO 디바이스들의 작은 CPU
107 |
108 |
109 | ### 1. CPU
110 | - 산술논리연산장치, 제어장치, 레지스터로 구성되어 있는 컴퓨터 장치로 구성
111 | - 인터럽트에 의해 단순히 메모리에 존재하는 명령어를 해석해서 실행하는 일꾼
112 |
113 | 1) 제어장치
114 | - 프로세스 조작을 지시하는 CPU의 한 부품
115 | - 입출력장치 간 통신을 제어하고 명령어들을 읽고 해석하며 데이터 처리를 위한 순서를 결정
116 |
117 | 2) 레지스터
118 | - CPU 안에 있는 매우 빠른 임시저장장치
119 | - 연산속도가 메모리보다 수십 배에서 수백 배까지 빠르다.
120 |
121 | 3) 산술논리연산장치
122 | - 산술 연산과 논리 연산을 계산하는 디지털 회로
123 |
124 | 4) 인터럽트
125 | - 어떤 신호가 들어왔을 때 CPU를 잠깐 정지시키는 것
126 | - 인터럽트 간에는 우선순위가 있다.
127 | - 하드웨어 인터럽트 : IO 디바이스에서 발생하는 인터럽트
128 | - 소프트웨어 인터럽트 : 트랩이라고도 한다. 프로세스가 시스템콜을 호출할 때 발동
129 |
130 |
131 | ### 2. DMA 컨트롤러
132 | - I/O 디바이스가 메모리에 직접 접근할 수 있도록 하는 하드웨어 장치
133 | - CPU에만 너무 많은 인터럽트 요청이 들어오기 때문에 CPU 부하를 막아주며 CPU의 일을 부담하는 보조 일꾼
134 |
135 |
136 | ### 3. 메모리
137 | - 데이터나 상태, 명령어 등을 기록하는 장치
138 | - RAM을 일컬어 메모리라고 함
139 | - CPU는 계산 담당, 메모리는 기억 담당
140 |
141 | ---
142 |
143 | # 3.2 메모리
144 |
145 | # 자원 관리자로서의 운영체제
146 |
147 | 앞서 본 것처럼 운영체제는 resource manager이다. Resource manager 로서 운영체제는 시스템의 CPU, 메모리, storage, I/O 장치 등의 resource 들을 관리해야 한다.
148 |
149 | ## 메모리 계층
150 |
151 | 램은 하드디스크로부터 일정량의 데이터를 복사해서 임시 저장하고 이를 필요시마다 CPU에 빠르게 전달하는 역할을 함
152 |
153 | 1. 레지스터 : CPU안에 있는 작은 메모리, 휘발성, 속도 가장 빠름, 기억 용량이 가장 적음
154 | 2. 캐시 : L1, L2캐시를 지칭
155 | 3. 주기억장치 : 메모리 즉 RAM 지칭
156 | 4. 보조기억장치 : HDD, SDD 지칭
157 |
158 | **계층이 위로 올라갈수록 가격은 비싸지는데 용량은 작아지고 속도는 빨라짐
159 | *계층이 있는 이유는 경제성과 캐시 때문!
160 |
161 |
162 |
163 |
164 | # Caching
165 |
166 | 캐싱은 컴퓨터 시스템의 중요한 개념 중 하나이다.
167 |
168 | 정보는 보통 어떤 저장장치에 보관되는데, 정보가 저장된 저장공간에 따라 불러오는 속도가 다르다. 예를 들어 main memory 에 있는 프로그램이나 데이터들은 mass-storage 에서 불러올 때보다 훨씬 빠르게 불러옵니다.
169 |
170 | 그러나 중복되어 불려지는 데이터나 프로그램의 부분은 더욱 빨리 불러와질 필요가 있었고, 이를 위해 우리는 더 빠른 장치인 캐시에 해당 데이터를 저장하여 불러와 성능을 향상시킬 수 있다.
171 |
172 | 그러나 캐시는 크기가 제한되어 있기 때문에 캐시 관리는 중요한 설계 문제로 성능을 크게 좌지우지한다.
173 |
174 |
175 | ## Cache
176 |
177 | : 데이터를 미리 복사해놓는 임시저장소
178 |
179 | - 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리
180 | → 메모리와 CPU 사이의 속도차이가 너무 커서 그 중간에 레지스터 계층을 두어 속도 차이를 해결한다.
181 |
182 | → 이러한 속도 차이를 위해 만든 계층을 캐싱 계층이라 한다.
183 |
184 | - 캐시의 직접 설정
185 | : 자주 사용하는 데이터를 기반으로 설정해야 함
186 |
187 | 자주 사용하는 데이터에 대한 근거?
188 |
189 | → **지역성의 원리**
190 | 1) 시간 지역성 : 최근 사용한 데이터에 다시 접근하려는 특성
191 | 2) 공간 지역성: 최근 접근한 데이터를 이루고 있는 공간 혹은 그 근접 공간에 접근하는 특성
192 |
193 |
194 | ## Cache Hit
195 | : 캐시에서 원하는 데이터를 찾은 것
196 |
197 | ## Cache Miss
198 | : 해당 데이터가 캐시에 없다면 주 메모리로 가서 데이터를 찾아오는 것
199 |
200 | 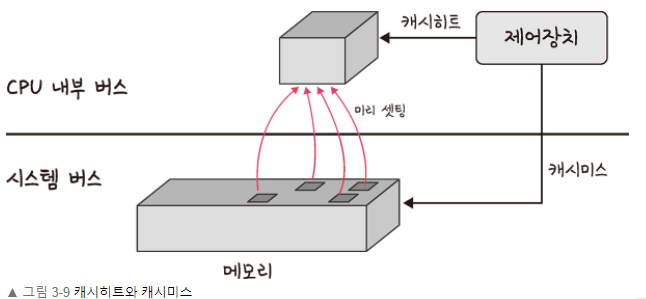
201 |
202 |
203 | ## Cache Mapping
204 | : 캐시가 히트되기 위해 하는 매핑
205 |
206 | - CPU의 레지스터와 주 메모리(RAM) 간에 데이터를 주고 받을 때를 기반으로 설명
207 |
208 | 1) 직접 매핑 : 처리가 빠르지만 충돌 발생이 잦음
209 | 2) 연관 매핑 : 순서를 일치 X. 관련 있는 캐시와 메모리를 매핑. 충돌이 적지만 모든 블록을 탐색해야 해서 속도 느림
210 | 3) 집합 연관 매핑 : 직접 매핑과 연관 매핑을 합쳐 놓은 것. 순서는 일치시키지만 집합을 둬서 저장하며, 블록화되어 있기 때문에 검색은 좀 더 효율적임
211 |
212 |
213 | ## 웹 브라우저의 캐시
214 |
215 | - **쿠키**
216 | - 만료기한이 있는 키-값 저장소
217 | - 4KB까지 데이터를 저장할 수 있고 만료 기한을 정할 수 있음
218 | - 쿠키 설정시 : document cookie로 쿠키를 볼 수 없게 httponly섷정 거는 것이 중요함
219 | - 클라이언트 혹은 서버에서 만료기한 설정 - 보통 서버에서 정함
220 |
221 | - **로컬 스토리지**
222 | - 만료기한이 없는 키-값 저장소
223 | - 10MB까지 저장 가능
224 | - 웹 브라우저를 닫아도 유지되고 도메인 단위로 저장, 생성
225 | - 클라이언트에서만 수정 가능
226 | - HTML5 지원 브라우저에서만 가용 가능
227 |
228 | - **세션 스토리지**
229 | - 만료기한이 없는 키-값 저장소
230 | - 5MB까지 저장 가능
231 | - 탭 단위로 세션 스토리지를 생성, 탭을 닫을 때 해당 데이터가 삭제
232 | - 클라이언트에서만 수정 가능
233 | - HTML5 지원 브라우저에서만 가용 가능
234 |
235 |
236 |
237 | ## 데이터베이스의 캐싱 계층
238 |
239 | 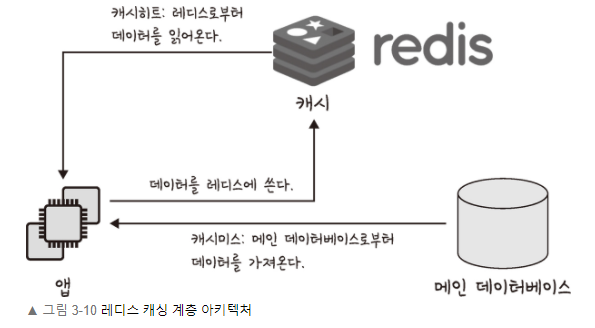
240 |
241 | 데이터베이스 위에 레디스 데이터 베이스 게층을 ‘캐싱 계층’으로 두어 성능을 향상시키기도 함
242 |
243 |
244 |
245 | # 메모리 관리
246 |
247 | ### 1. 가상 메모리
248 |
249 | - 컴퓨터가 실제로 이용 가능한 메모리 자원을 추상화하여 사용자들에게 매우 큰 메모리로 보이게 만드는 것
250 | - 가상 메모리는 가상 주소와 실제 주소가 매핑되어 있음
251 | - 프로세스의 주소 정보가 들어있는 ‘페이지 테이블’로 관리
252 |
253 | **스와핑**
254 | - 당장 사용하지 않는 영역을 하드디스크로 옮겨 필요할 때 다시 RAM으로 불러와 올리고, 사용하지 않으면 다시 하드디스크로 내림을 반복하여 RAM을 효과적으로 관리하는 것
255 | - 가상 메모리에는 존재하지만 실제 RAM에는 없는 데이터에 접근할 때 발생하는 페이지 폴트를 방지하기 위함
256 |
257 | **페이지 폴트**
258 | - 프로세스의 주소 공간에는 존재하지만 지금 이 컴퓨터의 RAM에는 없는 데이터에 접근했을 경우 발생
259 |
260 |
261 | ### 2. 스레싱
262 |
263 | - 메모리의 페이지 폴트율이 높은 것 → 심각한 성능 저하를 초래
264 | - 메모리에 너무 많은 프로세스가 동시에 올라가면 스와핑이 많이 일어나서 발생
265 | - 페이지 폴트 발생 → CPU 이용률 낮아짐 → 더 많은 프로세스를 메모리에 올림 → 악순환 반복… ⇒ 스레싱 발생
266 |
267 | >**_운영체제에서 스레싱을 해결하는 법_**
268 | >1) 작업세트
269 | > 프로세스의 과거 사용 이력인 지역성을 통해 결정된 페이지 집합을 만들어서 미리 메모리에 로드
270 | >2) PFF (Page Fault Frequency)
271 | 페이지 폴트 빈도를 조절하는 방법. 상한선과 하한선을 만들어, 상한선에 도달하면 페이지를 늘리고 하한선에 도달하면 페이지를 줄임
272 |
273 |
274 | ### 3. 메모리 할당
275 | - 시작 메모리 위치, 메모리의 할당 크기를 기반으로 할당
276 |
277 | **연속 할당**
278 | - 프로세스를 순차적으로 공간에 할당하는 것
279 | - 고정 분할 방식 : 메모리를 미리 나누어 관리
280 | - 가변 분할 방식 : 매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용
281 |
282 | **불연속 할당**
283 | - 페이징 : 동일한 크기의 페이지 단위로 나누어 메모리의 서로 다른 위치에 프로세스를 할당
284 | - 세그멘테이션 : 의미단위인 세그먼트로 나눈다.
285 | - 페이지드 세그멘테이션 : 공유나 보안을 의미 단위의 세그먼트로 나누고, 물리적 메모리는 페이지로 나누는 것
286 |
287 |
288 | ### 4. 페이지 교체 알고리즘
289 |
290 | - 페이지 교체 알고리즘을 기반으로 스와핑 발생
291 |
292 | **오프라인 알고리즘**
293 | : 먼 미래에 참조되는 페이지와 현재 할당하는 페이지를 바꾸는 것
294 |
295 | **FIFO (First In First Out)**
296 | : 가장 먼저 온 페이지를 교체 영역에 먼저 놓는 방법
297 |
298 | **LRU (Least Recentle Used)**
299 | - 참조가 가장 오래된 페이지를 바꾸는 것
300 | - 해시 테이블과 이중 연결 리스트로 구현
301 |
302 | **LFU (Least Frequently Used)**
303 | : 가장 참조 횟수가 적은 페이지를 교체 (많이 사용되지 않은 것)
304 |
305 |
306 |
307 | ### 참고 문헌
308 |
309 | Operating System Concepts 10th (공룡책)
310 |
311 | 양햄찌님 블로그 : [https://jhnyang.tistory.com/16](https://jhnyang.tistory.com/16)
312 |
313 | Suhwanc님 블로그 : [https://suhwanc.tistory.com/175](https://suhwanc.tistory.com/175)
314 |
315 | angie님 블로그 : https://velog.io/@94applekoo/CS-3.1-%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C%EC%99%80-%EC%BB%B4%ED%93%A8%ED%84%B0
316 |
--------------------------------------------------------------------------------
/2. 네트워크(1)/네트워크(1)_이홍섭.md:
--------------------------------------------------------------------------------
1 | # 2. 네트워크(1)
2 |
3 | ## 목차
4 |
5 | ### 2.1 네트워크의 기초
6 | - 2.1.1 처리량과 지연 시간
7 | - 2.1.2 네트워크 토폴로지와 병목 현상
8 | - 2.1.3 네트워크 분류
9 | - 2.1.4 네트워크 성능 분석 명령어
10 | - 2.1.5 네트워크 프로토콜 표준화
11 | ### 2.2 TCP/IP 4계층 모델
12 | - 2.2.1 계층 구조
13 | - 2.2.2 PDU
14 | ---
15 | ## 2.1.1 네트워크의 기초
16 |
17 | ### 정의
18 | - 노드(node)와 링크(link)가 서로 연결되어 있거나 연결되어 있지 않은 집합체를 의미
19 | - 여기서 **노드**란 서버,라우터,스위치 등 네트워크 장치를 의미하고, **링크**는 유무선 형태의 연결 수단을 의미
20 |
21 | ### 처리량과 지연 시간
22 | > 네트워크를 구축할 때는 당연하게도 '좋은' 네트워크로 만드는 것이 중요하다
23 | > **좋은 네트워크**란
24 | > - 많은 처리량을 처리할 수 있다
25 | > - 지연 시간이 짧다
26 | > - 장애 빈도가 적다
27 | > - 좋은 보안을 갖춘 네트워크
28 | #### 처리량(throughput)
29 | - 처리량이란 링크를 통해 전달되는 단위 시간당 데이터양
30 | - 단위로는 bps(bits per second)를 사용 : 초당 전송 또는 수신되는 비트 수라는 의미
31 | - 트래픽,네트워크 장치 간의 •대역폭,네트워크 중간에 발생하는 에러,하드웨어 스펙등에 영향을 받는다
32 | - • 대역폭 : 주어신 시간 동안 네트워크 연결을 통해 흐를 수 있는 최대 비트 수
33 | #### 지연 시간(latency)
34 | - 요청이 처리되는 시간. 즉 어떤 메세지가 두 장치 사이를 왕복하는 데 걸린 시간
35 | - 매체 타입(유무선), 패킷 크기, 라우터의 패킷 처리 시간에 영향을 받음
36 |
37 | ## 2.1.2 네트워크 토폴로지와 병목 현상
38 |
39 | > **네트워크 토폴로지** : 노드와 링크가 어떻게 배치되어 있는지에 대한 방식/연결 형태
40 |
41 | ### 트리 토폴로지
42 | - 계층형 토폴로지라고 하며 트리 형태로 배치한 네트워크 구성
43 | - 장점
44 | - 노드의 추가,삭제가 쉽다
45 | - 단점
46 | - 특정 노드에 트래픽이 집중될 때 하위 노드에 영향을 끼칠 수 있다
47 | - 중앙이 고장나면 통신을 아예 할 수 없게 된다
48 |
49 | ### 버스 토폴로지
50 | - 중앙 통신 회선 하나에 여러 개의 노드가 연결되어 공유하는 네트워크 구성
51 | - 근거리 통신망(LAN)에서 사용한다
52 | - 장점
53 | - 설치 비용이 적고 신뢰성이 우수하다
54 | - 중앙 통신 회선에 노드를 추가/삭제가 쉽다
55 | - 단점
56 | - •**스푸핑**이 가능한 문제점이 있다
57 | - > •스푸핑(spoofing) : LAN상에서 송신부의 패킷을 송신과 관련 없는 다른 호스트에 가지 않도록 하는 스위칭 기능을 마비시키거나,속여서 특정 노드에 해당 패킷이 오도록 함
58 | > (A -> B로 갈 요청이, A -> X -> B로 가도록 중간에서 요청을 가로채는 것)
59 |
60 | ### 스타 토폴로지
61 | - 중앙에 있는 노드에 모두 연결된 네트워크 구성
62 | - 장점 :
63 | - 노드를 추가하거나 에러를 탐지하기 쉽다
64 | - 패킷의 충돌 발생 가능성이 적다
65 | - 노드에 장애가 발생해도 쉽게 에러를 발견할 수 있다
66 | - 장애 노드가 중앙 노드가 아닐 경우 다른 노드에 영양을 끼칠 확률이 적다
67 | - 단점 :
68 | - 중앙 노드에 장애가 발생하면 네트워크 전체 사용 불가
69 | - 설치 비용이 비싸다
70 |
71 | ### 링형 토폴로지
72 | - 각각의 노드가 양 옆의 두 노드와 연결하여 전체적으로 **하나의 고리(원)** 처럼 형성
73 | - 고리처럼 하나의 연속된 길을 통해 통신 하는 망 구성 방식
74 | - 장점 :
75 | - 노드 수가 증가되어도 네트워크상의 손실이 거의 없다
76 | - 충돌이 발생되는 가능성이 적다
77 | - 노드의 고장 발견을 쉽게 찾을 수 있다
78 | - 단점 :
79 | - 네트워크 구성 변경이 어렵다
80 | - 회선에 장애가 발생하면 전체 네트워크에 영향을 크게 끼친다
81 |
82 | ### 메시(mesh) 토폴로지
83 | - 망형 토폴로지라고도 하며 **그물망**처럼 연결되어 있는 구조
84 | - 장점 :
85 | - 노드 하나에 장애가 발생해도 경로가 여러개 존재하므로 시스템에 영향을 거의 끼치지 않음
86 | - 트래픽 분산 처리 가능
87 | - 단점 :
88 | - 노드의 추가가 어렵다
89 | - 구축 비용과 운용 비용이 비싸다
90 |
91 | ### 병목 현상
92 | - 병목 현상이란 : 하나의 구성 요소로 인해 전체 시스템의 성능이나 용량이 제한을 받는 현상
93 | - 네트워크 토폴로지가 중요한 이유는 병목 현상을 찾을 때 중요한 기준이 되기 때문이다
94 |
95 | ## 2.1.3 네트워크 분류
96 |
97 | >네트워크는 규모를 기반으로 분류할 수 있다
98 | >개인적인 규모의 LAN(Local Area Network), 도시 정도의 규모의 MAN(Metropolitan Area Network), 세계적인 규모의 WAN(Wide Area Network)
99 |
100 | ### LAN
101 | - 근거리 통신망을 의미
102 | - 같은 건물등의 좁은 공간에서 운영된다
103 | - 전송 속도가 빠르고 혼잡하지 않다
104 |
105 | ### MAN
106 | - 대도시 지역 네트워크를 나타낸다
107 | - 도시 같은 넓은 지역에서 운영된다
108 | - 전송 속도는 평균이며 LAN보다 더 많이 혼잡하다
109 |
110 | ### WAN
111 | - 광역 네트워크를 의미한다
112 | - 국가 또는 대륙 같은 더 넓은 지역에서 운영된다
113 | - 전송 속도는 낮고, MAN보다 더 혼잡하다
114 |
115 | ## 2.1.4 네트워크 성능 분석 명령어
116 |
117 | 애플리케이션 로직 상으로는 문제가 없어도, 네트워크 상태에 따라 데이터를 가져오지 못 하는 등의 장애가 발생할 수 있다
118 | 이는 **네트워크 병목**이 원인일 수 있으며, 주로
119 | - 네트워크 대역폭
120 | - 네트워크 토폴로지
121 | - 서버 CPU, 메모리 사용량
122 | - 비효율적인 네트워크 구성
123 | 위와 같은 경우에는, 네트워크 관련 테스트를 통해 **네트워크 관련 문제점**인 것을 확인한 후 네트워크 성능 분석을 해봐야 한다
124 | **네트워크 성능 분석 명령어**에는
125 | ### ping (Packet INternet Groper)
126 | - 목적 대상 노드를 향해 일정 크기의 패킷을 전송하는 명령어
127 | - 해당 노드의 패킷 수신 상태와 도달하기까지 시간을 알 수 있다
128 | - 해당 노드까지 네트워크가 잘 연결되어 있는지 확인할 수 있다
129 | - TCP/IP 프로토콜 중 ICMP 프로토콜을 통해 동작
130 |
131 | ### netstat
132 | - 접속되어 있는 서비스들의 네트워크 상태를 표시
133 | - 네트워크 접속, 라우팅 테이블, 네트워크 프로토콜 등 리스트를 보여준다
134 | - 주로 서비스의 포트가 열려있는지 확인할 때 사용
135 |
136 | ### nslookup
137 | - DNS에 관련된 내용을 확인하기 위해 쓰는 명령어
138 | - 특정 도메인에 매핑된 IP를 확인
139 | > DNS(Domain Name System)는 범국제적 단위로 웹사이트의 IP 주소와 도메인 주소를 이어주는 환경/시스템
140 |
141 | ### tracert
142 | - 윈도우에서는 `tracert`,리눅스에서는 `traceroute`
143 | - 목적지 노드까지 네트워크 경로를 확인할 때 사용하는 명령어
144 | - 어느 구간에서 응답이 느려지는지 확인 가능
145 |
146 | ## 2.1.5 네트워크 프로토콜 표준화
147 |
148 | **네트워크 프로토콜**이란
149 | - 다른 장치들끼리 데이터를 주고받기 위해 설정된 공통된 인터페이스
150 | - IEEE 또는 IETF에서 표준을 정함
151 | - 예시 :
152 | - IEEE802.3 : 유선 LAN 프로토콜
153 | - HTTP : 웹 애플리케이션 계층에서 데이터를 주고 받기 위한 프로토콜
154 | ---
155 | ## 2.2 TCP/IP 4계층 모델
156 |
157 | ### 정의
158 | - 인터넷 프로토콜 스위트(internet protocol suite)는 인터넷에서 컴퓨터들이 서로 정보를 주고받는 데에 쓰이는 프로토콜의 집합
159 | - **TCP/IP 4계층** 혹은 **OSI 7계층** 모델이 많이 쓰인다
160 | - 계층 모델이란, 네트워크에서 사용되는 통신 프로토콜의 집합
161 | - TCP/IP 4계층 모델의 계층들은 프로토콜의 네트워킹 범위에 따라 네 개의 추상화 계층으로 구성된다
162 |
163 | ## 2.2.1 계층 구조
164 |
165 | ### TCP/IP 4계층
166 | - 애플리케이션 계층 (FTP/HTTP/SSH/DNS 등)
167 | - 전송 계층 (TCP/UDP 등)
168 | - 인터넷 계층 (IP/ARP/ICMP 등)
169 | - 링크 계층 (이더넷 등)
170 |
171 | ### 1. 애플리케이션 계층
172 | - HTTP, FTP, SSH, DNS 등 응용 프로그램이 사용되는 프로토콜 계층
173 | - 웹 서비스, 이메일 등 서비스를 실질적으로 제공하는 계층
174 | > - FTP : 장치와 장치 간의 파일을 전송하는 데 사용되는 표준 통신 프로토콜
175 | > - SSH : 보안되지 않은 네트워크에서 네트워크 서비스를 안전하게 운영하기 위한 암호화 네트워크 프로토콜
176 | > - HTTP : World Wide Web을 위한 데이터 통신의 기초이자 웹 사이트를 이용하는 데 쓰는 프로토콜
177 |
178 | ### 2. 전송(transport) 계층
179 | - 송신자와 수신자를 연결하는 통신 서비스를 제공
180 | - 애플리케이션과 인터넷 계층 사이의 데이터가 전달될 때의 중계 역할
181 | - 연결 지향 데이터 스트림 지원, 신뢰성, 흐름 제어 등 프로토콜마다 다양한 기능 제공
182 | - TCP ,UDP 등이 이 계층에 속한다
183 | - **TCP**(Transmission Control Protocol) :
184 | - 가장 널리 쓰이는 전송 계층 프로토콜 (HTTP 2.0까지는 TCP를 사용)
185 | - 패킷 사이의 순서를 보장하고 연결을 통한 **신뢰성 구축**(3-way handshake)등 다양한 기능 제공
186 | - 패킷 교환 방식은 **가상 회선 방식**
187 | - **UDP**(User Datagram Protocol)
188 | - 순서를 보장 하지 않고, 수신 여부를 확인하지 않는다
189 | - 패킷 교환 방식은 단순히 데이터만 주는 **데이터그램 패킷 교환 방식** 사용
190 |
191 | ### TCP vs UDP
192 | - TCP
193 | - TCP는 전송 순서 보장, 수신 여부 확인, 논리적 연결 수립/해제, 데이터의 흐름 제어나 혼잡 제어 등 **안정성**과 **신뢰성을 강점**으로 가진다
194 | - 위의 이유들 때문에 UDP 보다 속도가 느리다
195 | - **연속성보다 신뢰성**있는 전송이 중요할 때에 사용하는 프로토콜
196 | - ex) 파일 전송. 하지만 최근에는 동영상 스트리밍등에도 사용 된다 -> [넷플릭스](https://victoria-k.tistory.com/entry/%EC%99%9C-%EB%84%B7%ED%94%8C%EB%A6%AD%EC%8A%A4%EB%8A%94-%EB%B9%84%EB%94%94%EC%98%A4-%EC%8A%A4%ED%8A%B8%EB%A6%AC%EB%B0%8D%EC%97%90-UDP-%EB%8C%80%EC%8B%A0-TCP%EB%A5%BC-%EC%93%B0%EB%8A%94%EA%B0%80)
197 | - UDP
198 | - UDP는 TCP보다 **빠른 속도**를 가진다
199 | - UDP는 비연결형 서비스이기 때문에, 연결을 설정하고 해제하는 과정이 존재하지 않는다
200 | - 결국 3way handshake 같은 논리적 연결 과정(흐름 제어 또는 혼잡 제어)이 별도로 없다
201 | - **신뢰성보다는 연속성**이 중요한 서비스에 사용
202 | - ex) 실시간 서비스 (streaming)
203 |
204 | > #### 가상회선 패킷 교환 방식
205 | > - 각 패킷에는 가상회선 식별자가 포함된다
206 | > - 모드 패킷을 전송하면 가상회선이 해제되고 패킷들은 **전송된 순서대로** 도착하는 방식
207 | > #### 데이터그램 패킷 교환 방식
208 | > - 패킷이 독립적으로 이동하며 최적의 경로로 간다
209 | > - 하나의 메세지에서 분할된 여러 패킷은 서로 다른 경로로 전송될 수 있다
210 | > - 도착한 **순서가 다를 수 있다**
211 |
212 | ### 3way handshake
213 | - TCP에서 서버와 클라이언트 사이에 서로 **연결을 논리적으로 수립**하는 과정
214 | - 아래 과정을 통해서 진행된다
215 | 1. SYN 단계:
216 | - 클라이언트는 ISN(고유 시퀀스)을 담아 -> 서버로 SYN(연결 요청 플래그) 전송
217 | 2. SYN+ACK 단계:
218 | - 서버는 SYN 수신 -> 서버의 ISN을 클라이언트로 보냄 (승인번호 : 클라이언트 ISN + 1)
219 | 3. ACK 단계:
220 | - 클라이언트는 승인번호를 담아 -> ACK(응답 플래그)를 서버로 전송
221 | - **딱 봐도 신뢰성이 있어 보인다**
222 |
223 | ### 4way handshake
224 | - TCP에서 서버와 클라이언트 사이에 서로 **연결을 논리적으로 해제**하는 과정
225 | - 아래 과정을 통해서 진행된다
226 | - 클라이언트가 연결을 닫으려 할때 -> 서버로 FIN 전송
227 | - 서버는 FIN 수신에 대한 응답으로 ACK 전송 -> 클라이언트가 받으면 일정 시간 대기 (`TIME_WAIT`)
228 | - 일정 시간 이후, 서버 -> 클라이언트로 FIN 전송
229 | - 클라이언트는 FIN 수신에 대한 응답으로 ACK 전송 -> 서버 닫힘 -> 어느 정도 대기 후 클라이언트도 닫힘
230 | - `TIME_WAIT`은 왜 존재하는가?
231 | - 지연 패킷이 발생할 수 있다, 지연 패킷을 처리하지 못한다면 **데이터 무결성** 문제 발생 -> 해당 패킷이 도착하도록 잠시 기다린다
232 | - 두 장치가 연결이 닫혔는지 확인한다
233 |
234 | ### 3. 인터넷 계층
235 | - 장치로부터 받은 패킷을 지정된 목적지로 전송하기 위해 사용되는 계층
236 | - IP 등이 존재하며, 패킷을 수신해야 하는 상대의 주소를 지정하여 (예: IP 주소) 데이터를 전달한다
237 | - 상대방이 제대로 받았는지에 보장하지 않는 비연결형적인 특징이 있다
238 |
239 | ### 4. 링크 계층
240 | - 실질적으로 데이터를 전달하며 장치 간에 신호를 주고 받는 '규칙'을 정하는 계층
241 | - 네트워크 접근 계층이라고도 한다
242 | - `물리 계층`과 `데이터 링크 계층`으로 나뉜다
243 | - 물리 계층 : 무선 LAN과 유선 LAN을 통해 0,1로 이루어진 데이터를 보내는 계층
244 | - 데이터 링크 계층 : 이더넷 프레임을 통해 여러 에러 확인 및 흐름,접근 제어를 담당하는 계층
245 |
246 | #### 유선 LAN
247 | - 유선 LAN을 이루는 이더넷은 IEEE802.3이라는 프로토콜을 따른다
248 | - 이는 여러 제조업자들이 만들어내는 장치들 간에 상호 통신이 가능하게 하는 표준을 제정하기 위함이였으며, 주요 LAN 프로토콜인 물리층과 데이터링크 층의 기능들을 규정하였고 `전이중화` 통신을 쓴다
249 | #### 전이중화 통신
250 | - 전이중화(full duplex) 통신은 **양쪽 장치가 동시에 송수신** 할 수 있는 방식을 말한다
251 | - 현대의 고속 이더넷은 이 방식을 기반으로 통신한다
252 | #### 무선 LAN
253 | - 무선 LAN 장치들은 송신과 수신에 같은 채널을 공유하기 때문에 `반이중화` 통신을 사용한다
254 | #### 반이중화 통신
255 | - 반이중화(half duplex) 통신은 **송수신을 동시에 통신할 수 없으며, 한 번에 한 방향만 통신**할 수 있는 방식을 말한다
256 |
257 | ### 계층 간 데이터 송수신 과정
258 | - 데이터 전송 시
259 | - 애플리케이션 -> 전송 -> 인터넷 -> 링크
260 | - 전송시엔 `캡슐화`의 과정을 거친다
261 | - 데이터 수신 시
262 | - 링크 -> 인터넷 -> 전송 -> 애플리케이션
263 | - 수신시엔 `비캡슐화`의 과정을 거친다
264 | > #### 캡슐화
265 | > - 상위 계층의 헤더와 데이터를, 하위 계층의 데이터 부분에 포함 시키고 해당 계층의 헤더를 삽입 하는 과정
266 | > #### 비캡슐화
267 | > - 하위 계층에서 상위 계층으로 가며 각 계층의 헤더 부분을 제거하는 과정
268 |
`객체지향의 캡슐화와 동일하지는 않지만 유사한 정의를 가진다`
269 |
270 | ## 2.2.2 PDU (Protocol Data Unit)
271 | - 네트워크의 계층 간 데이터가 전달될 때, 한 덩어리의 단위를 말한다
272 | - 제어 관련 정보들이 포함된 `헤더`, 데이터를 의미하는 `페이로드`로 구성되어 있다
273 | - 계층마다 부르는 명칭이 다르다
274 | - **애플리케이션 계층** : 메시지
275 | - **전송 계층** : 세그먼트(TCP), 데이터그램(UDP)
276 | - **인터넷 계층** : 패킷
277 | - **링크 계층** : 프레임(데이터 링크 계층), 비트(물리 계층)
278 | - ex) 애플리케이션 계층은 ‘메시지’를 기반으로 데이터를 전달하는데, HTTP의 헤더가 문자열이다
--------------------------------------------------------------------------------
/2. 네트워크(1)/OSI 7계층 모델(2)_송민진.md:
--------------------------------------------------------------------------------
1 | # Internet Protocol Suite
2 |
3 |
4 | : 인터넷 프로토콜 스위트
5 |
6 | - 인터넷에서 컴퓨터들이 서로 정보를 주고받는 데 쓰이는 프로토콜의 집합
7 |
8 | - 이를 TCP/IP 4계층 모델로 설명하거나, OSI 7계층 모델로 설명하기도 함
9 |
10 | - TCP/IP(Transmission Control Protocol/Internet Protocol) 4계층 모델을 중심으로 설명하며, 이 계층 모델은 네트워크에서 사용되는 통신 프로토콜의 집합으로 계층들은 프로토콜의 네트워킹 범위에 따라 4개의 추상 계층으로 구성됨
11 |
12 | 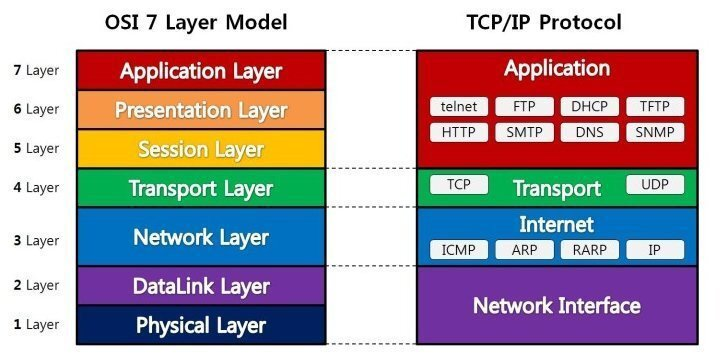
13 |
14 |
15 | ## OSI 7계층
16 |
17 |
18 | : 네트워크에서 통신이 일어나는 과정을 7단계로 나눈 것
19 |
20 | 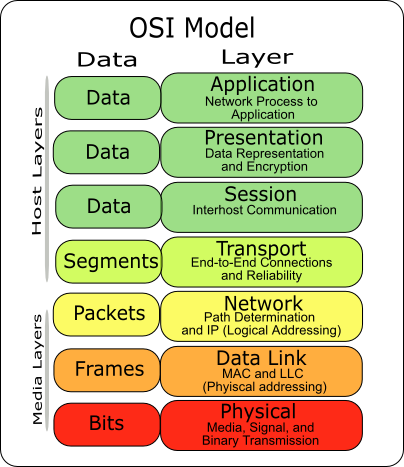
21 |
22 | > 📌 **OSI 7계층을 나눈 이유?**
23 | > : 통신이 일어나는 과정을 단계별로 파악할 수 있기 때문!
24 | > - 흐름을 한 눈에 알아보기 쉬움
25 | > - 특정한 곳에 이상이 생기면, 다른 단계의 장비/소프트웨어를 건드리지 않고 이상이 생긴 단계만 고치면 되기 때문!
26 |
27 |
28 |
29 |
30 | ### **1계층 - 물리계층 (Physical Layer)**
31 |
32 |
33 | : 주로 전기적, 기계적, 기능적인 특성을 이용해서 통신 케이블로 데이터를 전송하는 단계
34 | - 통신 단위 : 비트 (1, 0으로 나타내어짐)
35 | - 단지 데이터를 전달만 할 뿐, 송수신하는 데이터가 무엇인지, 어떤 에러가 있는지 등에는 전혀 신경 쓰지 않는다.
36 | - 데이터를 전기적인 신호로 변환해서 주고받는 기능만 할 뿐
37 | - 대표적인 통신 장비 : 통신 케이블, 리피터, 허브 등
38 | 
39 |
40 |
41 |
42 | ### 2계층 - 데이터링크 계층 (DataLink Layer)
43 |
44 |
45 | : Point to Point간 신뢰성 있는 전송을 보장하기 위한 계층
46 |
47 |
48 | - 물리계층을 통해 송수신되는 정보의 오류와 흐름을 관리하여, 안전한 정보의 전달을 수행할 수 있도록 도와주는 역할을 함
49 |
50 | - 통신에서의 오류를 찾아주고, 재전송도 해줌
51 |
52 | - MAC주소를 가지고 통신
53 | > 📌 **MAC 주소란?**
54 | > MAC 주소는 사람의 이름처럼 네트워크 카드마다 붙는 고유한 이름이다. 즉, LAN카드 별로 MAC주소를 각각 부여한다.
55 | > (컴퓨터 네트워크 카드의 MAC 주소는 윈도우 명령창에서 ipconfig /all 명령을 실행해 확인할 수 있다.)
56 |
57 | - 통신 단위 : 프레임
58 |
59 | - CRC 기반의 오류 제어와 흐름 제어가 필요하다. 네트워크 위의 개체들 간 데이터를 전달하고, 물리 계층에서 발생할 수 있는 오류를 찾아 내고, 수정하는 데 필요한 기능적, 절차적 수단을 제공함
60 |
61 | - 주소 체계는 계층이 없는 단일 구조
62 |
63 | - 데이터 링크 계층 프로토콜의 예 : 이더넷, HDLC·ADCCP 등의 포인트 투 포인트 프로토콜, 패킷 스위칭 네트워크, LLC·ALOHA 같은 근거리 네트워크용 프로토콜
64 |
65 | - 대표적 통신 장비 : 브릿지, 스위치 (MAC주소 사용)
66 |
67 |
68 |
69 | ### 3계층 - 네트워크 계층(Network Layer)
70 |
71 |
72 | : 여러개의 노드를 거칠때마다 경로를 찾아주는 역할을 하는 계층
73 |
74 | - 이 계층에서 가장 중요한 기능은 데이터를 목적지까지 가장 안전하고 빠르게 전달하는 기능(라우팅)
75 |
76 | - 논리적인 주소 구조(IP) 부여
77 | > 📌 **IP**
78 | > 네트워크 관리자가 직접 주소를 할당하는 구조. 계층적임
79 |
80 | - 다양한 길이의 데이터를 네트워크들을 통해 전달하고, 그 과정에서 전송 계층이 요구하는 서비스 품질(QoS)을 제공하기 위한 기능적, 절차적 수단을 제공
81 |
82 | - 라우팅, 흐름 제어, 세그멘테이션(segmentation/desegmentation), 오류 제어, 인터네트워킹(Internetworking) 등을 수행
83 |
84 | - 대표적 통신 장비 : 라우터, Layer 3 스위치
85 |
86 | > 📌 **IP 계층이란?**
87 | > TCP/IP 상에서 IP계층이란, 네트워크의 주소(IP주소)를 정의하고, IP 패킷의 전달 및 라우팅을 담당하는 계층
88 | > - OSI 7계층의 네트워크 계층
89 | > - 하위계층인 데이터링크 계층의 하드웨어적인 특성에 관계 없이 독립적인 역할을 수행
90 | > - 주요 프로토콜
91 | > - IP : 패킷의 전달
92 | > - ICMP :패킷 전달 에러의 보고 및 진단
93 | > - 라우팅 프로토콜 : 복잡한 네트워크에서 인터네트워킹을 위한 경로를 찾게 해줌
94 |
95 | > 📌 **IP 프로토콜(Internet Protocol)이란?**
96 | > : TCP/IP 기반의 인터넷 망을 통하여 데이타그램의 전달을 담당하는 프로토콜
97 | > - 주요 기능
98 | > - Routing : IP 계층에서 IP 패킷의 라우팅 대상이 됨
99 | > - Addressing : IP 주소 지정
100 | > - 비연결성 데이터그램 방식으로 전달됨
101 | > ➡ 패킷의 완전한 전달을 보장하지 않음
102 | > - IP 패킷 헤더 내 수신 및 발신 주소를 포함 - IPv4 헤더, IPv6 헤더, IP 주소
103 | > - 경우에 따라, 단편화가 필요함
104 | > - TCP, UDP, ICMP, IGMP 등이 IP 데이타그램에 실려서 전송
105 |
106 |
107 |
108 | ### 4계층 - 전송 계층(Transport Layer)
109 |
110 |
111 | : 통신을 활성화하기 위한 계층
112 |
113 | - 보통 TCP프로토콜을 이용함
114 |
115 | - 포트를 열어서 응용프로그램들이 전송을 할 수 있게 함
116 |
117 | - 양 끝단(End to end)의 사용자들이 신뢰성있는 데이터를 주고 받을 수 있도록 해 주어, 상위 계층들이 데이터 전달의 유효성이나 효율성을 생각하지 않도록 해줌
118 |
119 | - 패킷들의 전송이 유효한지 확인하고 전송 실패한 패킷들을 다시 전송
120 |
121 | - 종단간(end-to-end) 통신을 다루는 최하위 계층으로 종단간 신뢰성 있고 효율적인 데이터를 전송
122 |
123 | - 기능 : 오류검출 및 복구, 흐름제어, 중복검사 등
124 |
125 | > 📌 **TCP 프로토콜(Transmission Control Protocol)이란?**
126 | > : 전송 계층의 통신 프로토콜의 하나
127 | > - 양종단 호스트 내 프로세스 상호 간에 신뢰적인 연결지향성 서비스를 제공
128 | > - 신뢰적인 전송을 보장
129 | > - TCP 하위계층인 IP 계층의 신뢰성 없는 서비스에 대해 다방면으로 신뢰성을 제공
130 | > - 패킷 손실, 중복, 순서바뀜 등이 없도록 보장
131 | > - 연결지향적 (Connection-oriented)
132 | > - 연결 관리를 위한 연결설정 및 연결해제 필요
133 |
134 | > 📌 **TCP의 연결 성립, 연결 해제 과정**
135 | >
136 | > **3-way handshaking** - 연결 과정
137 | > : 신뢰성을 확보하기 위한 작업
138 | > 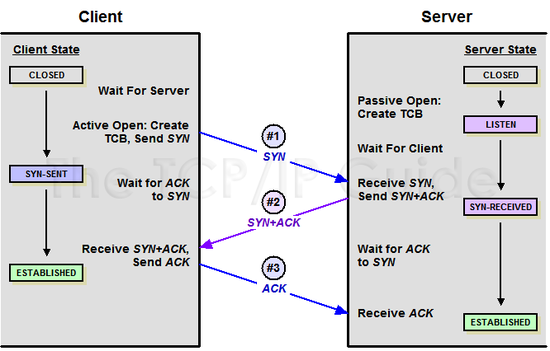
139 | > 1. **SYN 단계**
140 | > A클라이언트는 B서버에 접속을 요청하는 SYN 패킷을 보낸다. 이때 A클라이언트는 SYN을 보내고 SYN/ACK 응답을 기다리는 SYN_SENT 상태가 된다.
141 | > 2. **SYN + ACK 단계**
142 | > B서버는 SYN요청을 받고 A클라이언트에게 요청을 수락한다는 ACK 와 SYN flag 가 설정된 패킷을 발송하고 A가 다시 ACK으로 응답하기를 기다린다. 이때 B서버는 SYN_RECEIVED 상태가 된다.
143 | > 3. **ACK 단계**
144 | > A클라이언트는 B서버에게 ACK을 보내고 이후로부터는 연결이 이루어지고 데이터가 오가게 되는것이다. 이때의 B서버 상태가 ESTABLISHED 이다.
145 | >
146 | > ➡ 위와 같은 방식의 통신이 신뢰성 있는 연결을 맺어 준다는 TCP의 3 Way handshake 방식이다.
147 | >
148 | > **4-way handshaking** - 연결 해제 과정
149 | > : 세션을 종료하기 위해 수행되는 절차
150 | > 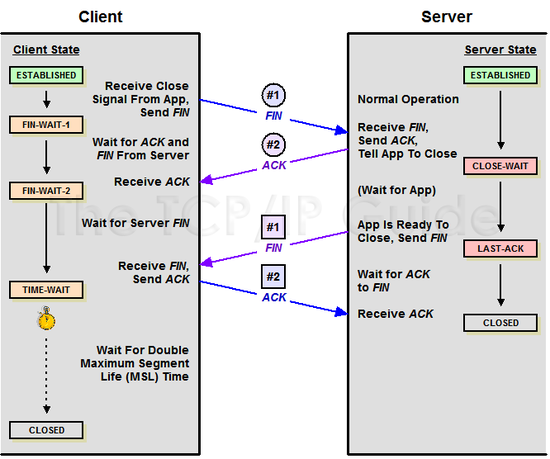
151 | > 1. 클라이언트가 연결을 종료하겠다는 FIN플래그를 전송
152 | > 2. 서버는 일단 확인메시지를 보내고 자신의 통신이 끝날때까지 기다리는데 이 상태가 TIME_WAIT상태다.
153 | > 3. 서버가 통신이 끝났으면 연결이 종료되었다고 클라이언트에게 FIN플래그를 전송한다.
154 | > 4. 클라이언트는 확인했다는 메시지를 보낸다.
155 | >
156 | >
157 | > - **지연 패킷** : 패킷이 뒤늦게 도달하고, 이를 처리하지 못한다면 데이터 무결성 문제가 발생함
158 | > - **TIME_WAIT** : 소켓이 바로 소멸되지 않고, 일정 시간 유지되는 상태. 지연 패킷 등의 문제점을 해결하기 위해 쓰임. 두 장치가 연결이 닫혔는지 확인하기 위해서도 필요함. (참고 - 윈도우는 4분, 우분투는 60초)
159 | > - **데이터 무결성(Data Integrity)** : 데이터의 정확성과 일관성을 유지하고 보증하는 것
160 |
161 | > 👉 **TCP - 가상회선 패킷 교환 방식**
162 | > 가상회선 : 데이터를 전송하기 전에 설정되는 논리적 연결(연결 지향형)
163 | > - 각 패킷에는 가상회선 식별 번호(VCI)가 포함되고, 모든 패킷을 전송하면 가상회선이 해제되고 패킷들은 전송된 순서대로 도착한다.
164 | > - 패킷마다 라우터가 경로를 선택하는 것이 아니라, 경로를 설정할 때 한 번만 수행한다.
165 | > 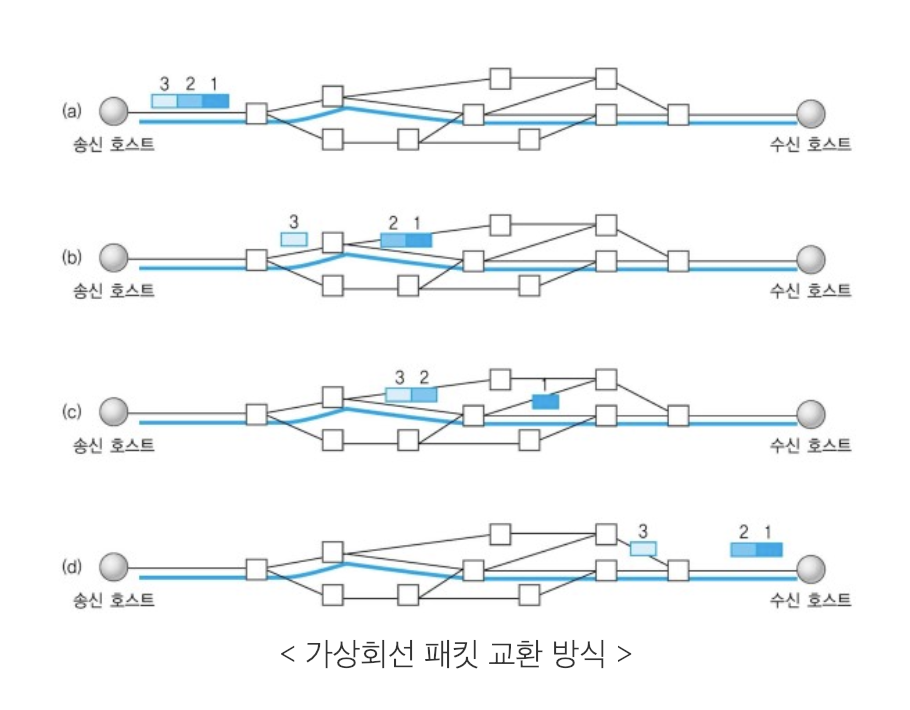
166 |
167 | > 📌 **UDP 프로토콜(User Datagram Protocol)이란?**
168 | > : 전송 계층의 통신 프로토콜의 하나 (TCP에 대비됨)
169 | > - 비연결성이고, 신뢰성이 없으며, 순서화되지 않은 Datagram 서비스 제공
170 | > - 실시간 응용 및 멀티캐스팅 가능
171 | > - 빠른 요청과 응답이 필요한 실시간 응용에 적합
172 | > - 여러 다수 지점에 전송 가능 (1:多)
173 | > - 헤더가 단순함
174 | > - UDP는 TCP처럼 16 비트의 포트 번호를 사용하나, 헤더는 고정크기의 8 바이트(TCP는 20 바이트) 만 사용. (헤더 처리에 많은 시간과 노력을 요하지 않음)
175 |
176 | > 👉 **UDP - 데이터그램 패킷 교환 방식**
177 | > 데이터그램 : 데이터를 전송하기 전에 논리적 연결이 설정되지 않으며 패킷이 독립적으로 전송되는 것
178 | > - 패킷을 수신한 라우터는 최적의 경로를 선택하여 패킷을 전송하는데 하나의 메시지에서 분할된 여러 패킷은 서로 다른 경로로 전송될 수 있다.(비연결 지향형)
179 | > - 송신 측에서 전송한 순서와 수신 측에 도착한 순서가 다를 수 있다.
180 | > 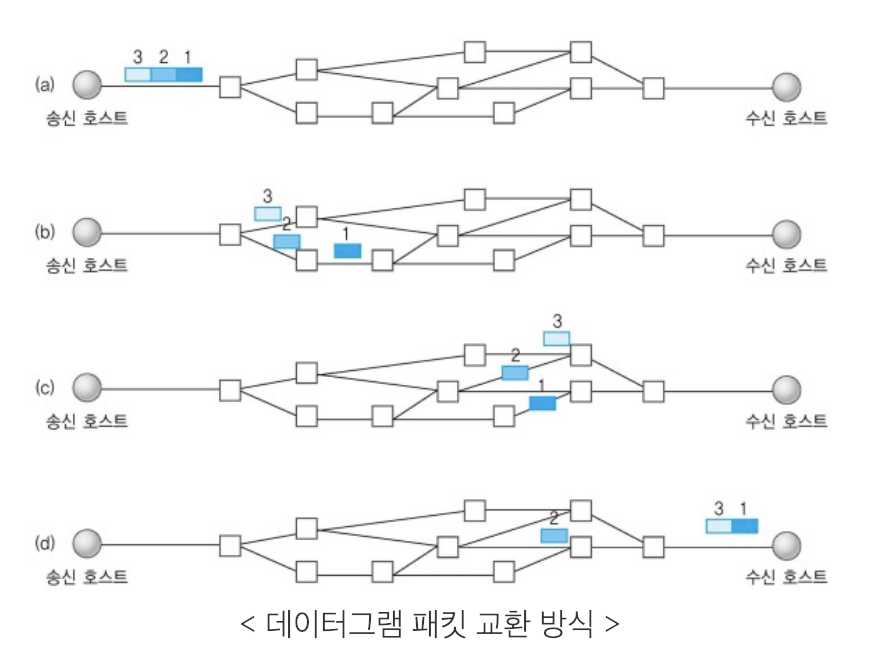
181 |
182 | > 👉 **정리**
183 | > - 가상 회선 방식 : 정해진 시간 안이나 다량의 데이터를 연속으로 보낼 때 적합
184 | > - 데이터그램 방식 : 짧은 메시지의 일시적인 전송에 적합
185 |
186 |
187 |
188 | ### 5계층 - 세션 계층(Session Layer)
189 |
190 |
191 | : 양 끝단의 응용 프로세스가 통신을 관리하기 위한 방법을 제공하는 계층
192 |
193 | - 데이터가 통신하기 위한 논리적인 연결을 함
194 |
195 | - 동시 송수신 방식(duplex), 반이중 방식(half-duplex), 전이중 방식(Full Duplex)의 통신과 함께, 체크 포인팅과 유휴, 종료, 다시 시작 과정 등을 수행
196 |
197 | - TCP/IP 세션을 만들고 없애는 책임을 짐
198 |
199 | - 통신하는 사용자들을 동기화하고 오류복구 명령들을 일괄적으로 다룬다.
200 |
201 | - 통신을 하기 위한 세션을 확립/유지/중단 (운영체제가 해줌)
202 |
203 |
204 |
205 | ### 6계층 - 표현 계층(Presentation Layer)
206 |
207 |
208 | :코드 간의 번역을 담당하여 사용자 시스템에서 데이터의 형식상 차이를 다루는 부담을 응용 계층으로부터 덜어 주는 계층
209 |
210 | - MIME 인코딩이나 암호화 등의 동작이 이 계층에서 이루어짐
211 |
212 | - ex: EBCDIC로 인코딩된 문서 파일을 ASCII로 인코딩된 파일로 바꿔 주는 것, 해당 데이터가 TEXT/JPG/PNG/GIF인지의 구분 등
213 |
214 |
215 |
216 |
217 | ### 7계층 - 응용 계층(Application Layer)
218 |
219 |
220 | : 최종 목적지로써, 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행하는 계층
221 |
222 | - HTTP, FTP, SMTP, POP3, IMAP, Telnet 등과 같은 프로토콜이 있다.
223 | - FTP : 장치와 장치간의 파일을 전송하는 데에 사용되는 표준 통신 프로토콜
224 | - SSH : 보안되지 않은 네트워크에서 네트워크 서비스를 안전하게 운영하기 위한 암호화 네트워크 프로토콜
225 | - SMTP : 전자 메일 전송을 위한 인터넷 표준 통신 프로토콜
226 |
227 | > 모든 통신의 양 끝단은 HTTP와 같은 프로토콜이지 응용프로그램이 아니다.
228 |
229 | > 📌 **HTTP 프로토콜(HyperText Transfer Protocol)이란?**
230 | > : 웹 상에서 웹 서버 및 웹브라우저 상호 간의 데이터 전송을 위한 응용계층 프로토콜
231 | > - 처음에는, WWW 상의 하이퍼텍스트 형태의 문서를 전달하는데 주로 이용. 현재에는, 이미지,비디오,음성 등 거의 모든 형식의 데이터 전송 가능
232 | > - 요청 및 응답의 구조 - 동작형태가 클라이언트/서버 모델
233 | > - 메세지 교환 형태의 프로토콜
234 | > - 트랜잭션 중심의 비연결성 프로토콜
235 | > - 종단간 연결이 없음 (Connectionless)
236 | > - 이전의 상태를 유지하지 않음 (Stateless)
237 |
238 |
239 |
240 | ## 계층간 데이터 송수신 과정
241 |
242 | 
243 |
244 |
245 | **캡슐화 (encapsulation)** : 상위 계층의 헤더와 데이터를 하위 계층의 데이터 부분에 포함시키고, 해당 계층의 헤더를 삽입하는 과정
246 |
247 | **비캡슐화 (decapsulation)** : 하위 계층에서 상위 계층으로 가며, 각 계층의 헤더 부분을 제거하는 과정
248 |
249 | **PDU (Protocol Data Unit)** : 한 계층에서 다른 계층으로 데이터가 전달될 때, 한 덩어리의 단위
250 |
251 | 
252 |
253 | - 애플리케이션 계층 - 데이터, 메시지
254 | - 전송계층 - 세그먼트
255 | - 네트워크 계층 - 패킷
256 | - 데이터링크 계층 - 프레임
257 | - 물리 계층 - 비트
258 |
259 |
260 |
261 |
262 | ---
263 |
264 | **참고자료**
265 |
266 | - [OSI 7계층이란? OSI 7계층을 나눈 이유 - 티스토리 블로그](https://shlee0882.tistory.com/110)
267 |
268 | - [[네트워크] 가상회선 패킷 교환 vs 데이터그램 패킷 교 - github 블로그](https://woovictory.github.io/2018/12/28/Network-Packet-Switching-Method/)
269 |
270 | - [[ 네트워크 쉽게 이해하기 22편 ] TCP 3 Way-Handshake & 4 Way-Handshake = 티스토리 블로그](https://mindnet.tistory.com/entry/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EC%89%BD%EA%B2%8C-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-22%ED%8E%B8-TCP-3-WayHandshake-4-WayHandshake)
271 |
272 | - [[네트워크] 캡슐화와 역캡슐화 - 티스토리 블로그](https://davinchicoder.tistory.com/entry/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EC%BA%A1%EC%8A%90%ED%99%94%EC%99%80-%EC%97%AD%EC%BA%A1%EC%8A%90%ED%99%94)
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_이홍섭.md:
--------------------------------------------------------------------------------
1 | # 3. 운영체제(2)
2 |
3 | ## 목차
4 |
5 | ### 3.3 프로세스와 스레드
6 | - 3.3.1 프로세스와 컴파일 과정
7 | - 3.3.2 프로세스의 상태
8 | - 3.3.3 프로세스의 메모리 구조
9 | - 3.3.4 PCB
10 | - 3.3.5 멀티프로세싱
11 | - 3.3.6 스레드와 멀티스레딩
12 | - 3.3.7 공유 자원과 임계 영역
13 | - 3.3.8 교착 상태
14 | ### 3.4 CPU 스케줄링 알고리즘
15 | - 3.4.1 비선점형 방식
16 | - 3.4.2 선점형 방식
17 | ---
18 | # 3.3 프로세스와 스레드
19 | >컴퓨터에 설치된 프로그램이 실행되면, 코드가 스토리지에서 메모리로 옮겨지고, CPU 등의 자원이 할당 된다
20 | >이렇게 **실행중인 상태**의 프로그램을 `프로세스`라고 부른다. Task 라고도 한다
21 | >프로세스 내에 존재하는 1개 이상의 작업 흐름을 `스레드(thread)`라고 부른다.
22 | >한 프로세스 내의 여러 스레드는 메모리 공간을 공유하며, 각 프로세스는 고유의 메모리 공간을 가집니다.
23 |
24 | ## 1. 프로세스와 컴파일 과정
25 | 컴파일 과정은 [4가지 단계](https://velog.io/@dhwltnoooh/gcc-%EC%BB%B4%ED%8C%8C%EC%9D%BC%EB%9F%AC)(`전처리 과정 - 컴파일 과정 - 어셈블리 과정 - 링킹 과정`)로 나누어 진다.
26 | - 전처리 과정 : 소스 코드의 주석을 제거하고 #include 등 헤더 파일을 병합하여 매크로를 치환
27 | - 컴파일러 과정 : 오류 처리, 코드 최적화 작업을 하며, 어셈블리어로 변환
28 | - 어셈블리 과정 : 어셈블리어를 목적 코드(object code)로 변환. 확장자는 운영체제마다 다른데 리눅스에서는 .o 이다
29 | - 링킹 과정 : 프로그램 내에 있는 라이브러리 함수 또는 다른 파일들과 목적 모드를 결합하여 실행 파일을 만든다. 확장자는 .exe 또는 .out을 가진다
30 |
31 | ## 2. 프로세스의 상태
32 | 프로세스의 상태는 여러 가지 상태 값을 갖는다
33 | ### 생성 상태(create)
34 | - 프로세스가 생성된 상태를 의미하며 fork() 또는 exec() 함수를 통해 생성한다 이때 PCB•가 할당된다
35 | - `fork()`:
36 | - 부모 프로세스의 주소 공간을 그대로 복사해서, 새로운 자식 프로세스를 생성하는 함수
37 | - 주소 공간만 복사할 뿐, 메모리 공간은 공유하지 않고, 두 프로세스는 같은 프로세스 그룹에 속한다
38 | - `exec()`:
39 | - 신규 프로세스를 생성하는 함수
40 | ### 대기 상태(ready)
41 | - 메모리 공간이 충분하면 메모리를 할당받고, 아니면 CPU 스케쥴러로부터 CPU 제어권이 넘어오기를 기다리는 상태
42 | ### 대기 중단 상태(ready suspended)
43 | - 메모리 부족으로 프로세스가 일시 중단된 상태
44 | ### 실행 상태(running)
45 | - 프로세스가 CPU,메모리를 할당받고 명령어를 수행중인 상태
46 | ### 중단 상태(blocked)
47 | - 어떤 이벤트가 발생한 이후 기다리며 프로세스가 차단된 상태
48 | - 대표적인 예로 I/O 디바이스에 의한 인터럽트로 인해 프로세스가 block 될수도 있다
49 | ### 일시 중단 상태(blocked suspended)
50 | - 중단된 상태에서 프로세스가 실행되려고 했지만 메모리 부족으로 일시 중단된 상태
51 | ### 종료 상태(terminated)
52 | - 프로세스가 메모리와 CPU등의 자원을 반환하고 사라지는 상태
53 | - 비자발적 종료: 부모 프로세스 -> 자식 프로세스 강제 종료 시킨다
54 |
55 | ## 3. 프로세스의 메모리 구조
56 | OS는 프로세스에 적절한 [메모리를 할당하는 구조](https://zangzangs.tistory.com/107)는 다음과 같다
57 | 낮은 메모리 주소 -> 높은 메모리 주소쪽으로 보면
58 | - 코드
59 | - 데이터
60 | - 힙(Heap)
61 | - 스택(Stack)
62 | ### 코드
63 | - 프로그램에 내장되어 있는 소스 코드가 들어간다
64 | - 수정 불가능한 기계어로 저장되어 있고, 정적인 특징을 가진다
65 | ### 데이터
66 | - 전역변수,정적변수가 저장된다
67 | - 정적인 특징을 갖는, 프로그램이 종료되면 사라지는 변수가 들어있다
68 | - BSS 영역 : 초기화가 되지 않은 변수가 0으로 초기화되어 저장됨
69 | - Data 영역 (Data segment): 0이 아닌 다른 값으로 할당된 변수들이 저장됨
70 | ### 힙
71 | - 동적으로 할당되는 변수들을 담는다
72 | - 런타임 시 크기가 결정된다
73 | - vector와 같은 동적 배열이 이 영역에 저장된다
74 | ### 스택
75 | - 지역 변수, 매개변수, 함수등이 저장된다
76 | - 컴파일 시에 크기가 결정되고, 마찬가지로 동적인 영역이다
77 | - 재귀 함수가 호출되면, 동적으로 크기가 늘어날 수 있으며, 힙과 메로리 영역이 충돌하지 않도록 둘 사이의 공간을 비워둔다
78 |
79 | ## 4. PCB
80 | >프로세스 제어 블록(Process Control Block, PCB)는 CPU에 의해 실행 중인 특정한 프로세스를 관리할 필요가 있는 정보를 포함하는 운영 체제 커널의 자료 구조이다
81 | - OS에서 프로세스에 대한 메타데이터를 저장한 '데이터'를 말한다
82 | - 프로세스의 메타데이터들이 PCB에 저장되고 관리된다
83 | - 프로세스의 중요한 정보를 포함하고 있기 때문에 일반 사용자가 접근하지 못하도록 커널 스택의 가장 앞부분에서 관리된다
84 | - `메타데이터` : 데이터에 관한 구조화된 데이터이자 데이터를 설명하는 작은 데이터, 대량의 정보 가운데에서 찾고 있는 정보를 효율적으로 찾아내서 이용하기 위해 일정한 규칙에 따라 콘텐츠에 대해 부여되는 데이터이다
85 | ### PCB의 구조
86 | - 프로세스 스케줄링 상태 : '준비','일시중단'등 프로세스가 CPU에 대한 소유권을 얻은 이후의 상태
87 | - 프로세스 ID : 프로세스 ID, 해당 프로세스의 자식 프로세스 ID
88 | - 프로세스 권한 : 컴퓨터 자원 또는 I/O 디바이스에 대한 권한 정보
89 | - 프로그램 카운터 : 프로세스에서 실행해야 할 다음 명령어의 주소에 대한 포인터
90 | - CPU 레지스터 : 프로세스를 실행하기 위해 저장해야 할 레지스터에 대한 정보
91 | - CPU 스케줄링 정보 : CPU 스케줄러에 의해 중단된 시간 등에 대한 정보
92 | - 계정 정보 : 프로세스 실행에 사용된 CPU 사용량, 실행한 유저의 정보
93 | - I/O 상태 정보 : 프로세스에 할당된 I/O 디바이스 목록
94 |
95 | ### 컨텍스트 스위칭
96 | - OS가 실행 중인 한 프로세스에서 다른 프로세스로 넘어가는 과정을 컨텍스트 스위칭이라고 부른다 <-> PCB를 교환하는 과정
97 | - 책을 하나 읽다가 다른 책을 펼 때, 기존 책을 어디까지 읽었는지 책갈피를 끼워 두듯, 프로세스 간에 넘어갈 때 기존 프로세스의 상태에 대한 정보를 기록해 두어야 한다
98 | - 한 프로세스에 할당된 시간이 끝나거나 인터럽트에 의해 발생한다
99 | - 컨텍스트 스위칭이 일어날 때 프로세스가 가지고 있는 메모리 주소가 그대로 있으 잘못된 주소 변환이 생기므로 캐시클리어 과정을 겪게 되고 이 때문에 캐시미스가 발생한다
100 | - 이 컨텐스트 스위칭은 **스레드**에서 또한 일어난다
101 | - 스레드는 스택 영역을 제외한 모든 메모리를 공유하기 때문에 **스레드 컨텍스 스위칭**의 경우 비용이 더 적고 시간도 더 적게 걸린다
102 |
103 | ## 5. 멀티프로세싱과 IPC (Inter-Process Communication)
104 | ### 멀티프로세싱
105 | >컴퓨터는 한 번에 두 개 이상의 프로세스가 실행된다. 이 때 멀티프로세스를 통해 동시에 두 가지 이상의 일을 수행할 수 있다
106 | >이를 통해 하나 이상의 일을 병렬로 처리할수 있고, 특정 프로세스중 일부에 문제가 생기더라도 다른 프로세스를 이용해서 처리할 수 있어 신뢰성이 높은 강점이 있다
107 |
108 | ### IPC
109 | IPC는 프로세스끼리 데이터를 주고받고 공유 데이터를 관리하는 메커니즘을 뜻한다
110 | 프로세스 간의 커뮤니케이션을 위한 다양한 방법이 생겼는데, 이 중 대표적인 몇 가지 방법을 소개한다
111 |
112 | #### 1) 공유 메모리
113 | - 여러 프로세스가 동일한 메모리 블럭에 대한 접근 권한을 가지는 것
114 | - 프로세스가 서로 통신할 수 있도록 공유 메모리를 생성해서 통신하는 것
115 | - 메모리 자체를 공유하기 때문에 불필요한 데이터 복사의 오버헤드가 발생하지 않아 가장 빠르며, 같은 메모리 영역을 여러 프로세스가 공유하기 때문에 동기화가 필요하다
116 | - 그만큼 구현 난이도가 있어, 메세지 큐에 비해 덜 선호 된다
117 | #### 2) 파일
118 | - 디스크에 저장된 데이터 또는 파일 서버에서 제공된 데이터를 말한다. 이를 기반으로 프로세스간 통신 한다
119 | #### 3) 소켓
120 | - 동일한 컴퓨터의 다른 프로세스나 네트워크의 다른 컴퓨터로 네트워크 인터페이스를 통해 전송하는 데이터를 말한다 (TCP/UDP가 있다)
121 | #### 4) 익명 파이프
122 | - 프로세스 간에 FIFO 방식으로 읽히는 임시 공간인 파이프를 기반으로 데이터를 주고받는다
123 | - 단방향 방식의 읽기 전용, 쓰기 전용 파이프를 만들어 작동하는 방식
124 | #### 5) 명명된 파이프
125 | - 파이프 서버와 하나 이상의 파이프 클라이언트 간의 통신을 위한 명명된 단방향 또는 이중 파이프를 말한다
126 | - 컴퓨터의 프로세스끼리 혹은 네트워크 상의 다른 컴퓨터의 프로세스와도 통신할 수 있다
127 | #### 6) 메세지 큐
128 | - 메시지를 큐(queue) 데이터 구조 형태로 관리하는 것
129 | - 이는 커널의 전역변수 형태 등 커널에서 전역적으로 관리된다
130 | - 다른 IPC 방식에 비해서 사용 방법이 매우 직관적이고 간단하여 다른 코드의 수정 없이 몇 줄의 코드를 추가시켜 메시지 큐에 접근할 수 있는 장점이 있다
131 |
132 | ## 6. 스레드와 멀티스레딩
133 | ### 스레드
134 | - 스레드는 프로세스 실행의 가장 작은 단위이다
135 | - 프로세스는 하나이상의 스레드를 가질 수 있고, 각 스레드는 병렬적으로 동작할 수 있다
136 | - **한 프로세스 내의 스레드는 코드,데이터,힙 영역을 공유한다. 즉 스택은 별도로 가지게 된다**
137 | ### 멀티스레딩
138 | - 프로세스 내 작업을 여러 개의 스레드,멀티스레드로 처리하는 기법이다
139 | - 서로 자원을 공유하기에 효율성이 높다
140 | - 한 스레드가 block되어도 다른 스레드가 여전히 실행 중이기 때문에 빠른 처리가 가능하다
141 | - 동시성• 에도 장점이 있다
142 | - 하지만 한 스레드에 문제가 생기면, 메모리를 공유하기 때문에 다른 스레드에도 영향을 준다
143 | >•**동시성**
144 | > - 서로 독립적인 작업들을 작은 단위로 나누고 동시에 실행되는 것처럼 보여주는 것
145 | > - 싱글 코어에서 멀티 쓰레드를 동작 시키는 방식
146 | > - 한번에 많은 것을 처리
147 | > - 논리적인 개념
148 |
149 | ## 7. 공유 자원과 임계 영역
150 | ### 공유 자원
151 | - 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 자원(모니터,프린터,메모리...)이나 변수등을 의미
152 | - 여러 프로세스 혹은 스레드가 공유하는 자원
153 | - 두 개 이상의 프로세스가 동시에 읽거나 쓰는 상황을 **경쟁 상태(race condition)**이라고 한다
154 | ### 임계 영역
155 | - 동시에 둘 이상의 프로세스,스레드가 공유 자원에 접근할 때 순서 등의 이유로 결과가 달라지는 코드 영역
156 | - 해결의 방법으로는 크게 `뮤텍스`,`세마포어`,`모니터` 세 가지가 있다
157 | - 모두 **상호 배제**, **한정 대기**, **융통성**이란 조건을 만족한다
158 | - >운영체제가 임계구역 문제를 해결하는 세 가지 원칙 (상호 배제를 위한 동기화!를 위한 세 가지 원칙)
159 | >- 상호 배제 : 한 프로세스가 임계 구역에 진입했다면 다른 프로세스는 들어올 수 없다
160 | >- 한정 대기 : 한 프로세스가 임계 구역에 진입하고 싶다면 언젠가는 임계 구역에 들어올 수 있어야 한다 (무한정 대기하면 안 된다)
161 | >- 융통성 : 한 프로세스가 다른 프로세스의 일을 방해해서는 안 된다
162 | >- 진행 : 임계 구역에 어떤 프로세스도 진입하지 않았다면 진입하고자 하는 프로세스는 들어갈 수 있어야 한다
163 | - 토대가 되는 핵심 개념은 `lock`이다. 자주 사용하는 비유로 화장실 열쇠가 있는데, A라는 사람이 화장실 열쇠를 통해 화장실을 열고 들어가면, B라는 사람은 A가 화장실에서 나와서 열쇠를 제자리에 둘 때까지 화장실에 접근할 수 없는 것이다
164 | #### 뮤텍스
165 | - 공유 자원을 사용하기 전에 설정하고, 사용한 후에는 해제되는 잠금
166 | - 잠금이 설정되면 다른 프로세스나 스레드는 잠긴 해당 코드 영역에 접근 불가
167 | - 한 번에 하나의 잠금만 가진다
168 | #### 세마포어
169 | - 일반화된 뮤텍스. 정수 값과 두 가지 함수(wait,signal)를 통해 공유 자원에 대한 접근을 처리한다
170 | - wait() : 자신의 차례가 올 때까지 기다리는 함수
171 | - signal() : 다음 프로세스로 순서를 넘겨주는 함수
172 | - 바이너리 세마포어 : 0과 1의 두 가지 값만 가질 수 있는 세마포어. 뮤텍스와 비슷하다
173 | - but 뮤텍스는 **잠금**기반의 상호배제, 세마포어는 **신호**기반의 상호 배제
174 | - 카운팅 세마포어 : 여러 개의 자원을 가질 수 있는 세마포어, 여러개의 자원에 대한 접근을 제어할 때 사용
175 |
176 | ## 8. 교착상태 (deadlock)
177 | 두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태를 말한다
178 | 교착 상태는 아래와 같은 원인과 해결책을 가진다
179 | ### 원인
180 | - 상호 배제 : 한 프로세스가 자원을 독점하고 있으며 다른 프로세스는 해당 자원에 접근이 불가능하다
181 | - 점유 대기 : 특정 프로세스가 점유한 자원을 다른 프로세스가 요청하는 상태
182 | - 비선점 : 다른 프로세스의 자원을 강제로 가져올 수 없다
183 | - 환형 대기 : 프로세스 A는 프로세스 B의 자원을, 프로세스 B는 프로세스 C의 자원을, 프로세스 C는 프로세스 A의 자원을 기다리는 등 서로사 서로의 자원을 요구하는 상황
184 | ### 해결 방법
185 | - 1.자원을 할당 할 때 애초에 조건이 성립되지 않도록 설계
186 | - 2.교착 상태 가능성이 없을 때만 자원 할당되며, 프로세스당 요청할 자원들의 최대치를 통해 자원 할당 가능 여부를 파악하는 '은행원 알고리즘'을 쓴다
187 | - 3.교착 상태가 발생하면 사이클이 있는지 찾아보고 이에 관련된 프로세스를 한 개씩 지운다
188 | - **4.교착상태는 매우 드물게 일어나기 때문에 이를 처리하는 비용이 더 커서 교착 상태가 발생하면 사용자가 작업을 종료한다**
189 | - 현대에서 쓰는 방법 ex) 교착 상태가 발생한 경우 '응답 없음'으로 처리
190 |
191 | # 3.4 CPU 스케줄링 알고리즘
192 | >OS는 CPU, 메모리 등의 자원을 프로세스들에게 최대한 효율적으로 분배해야 한다
193 | >이를 위해 다양한 스케줄링 알고리즘이 고안되었다
194 | 스케줄링 알고리즘은 크게 선점형 (preemptive), 비선점형 (non-preemptive) 알고리즘으로 나뉜다
195 | ## 1. 비선점형(non) 알고리즘
196 | - 프로세스가 스스로 CPU 소유권을 포기하는 방식
197 | - 강제로 프로세스를 중지하지 않는다 -> 컨텍스트 스위칭으로 인한 부하가 적다
198 | - 단점으로는 하나의 프로세스가 자원을 사용 중이라면 당장 자원을 사용해야 하는 상황에서도 무작정 기다려야 한다 -> 모든 프로세스가 골고루 자원을 이용하기 어렵다
199 | ### FCFS (First Come First Served)
200 | - **가장 먼저 온 프로세스를 먼저 처리한다**
201 | - 구현이 쉽지만, 먼저 온 프로세스가 수행 시간이 길다면, 나중에 온 프로세스가 ready queue에서 오래 기다리는 현상(convoy effect)가 발생하는 단점이 있다
202 | ### SJF(Shortest Hob First)
203 | - FCFS 스케줄링의 호위 효과(convoy effect)를 방지하기 위해
204 | - **실행 시간이 가장 짧은 프로세스를 가장 먼저 실행한다**
205 | - CPU 사용이 긴 프로세스는 나중에 실행, CPU 사용 시간이 짧은 프로세스는 먼저 실행한다
206 | - 수행 시간이 오래 걸리는 프로세스가 오랜 시간 동안 실행되지 않는 기아 현상(starvation) 현상이 발생할 수 있습니다.
207 | ### 우선순위
208 | - SJF 스케줄링의 긴 시간을 가진 프로세스가 실행되지 않는 기아 현상(starvation)을 방지하기 위해
209 | - 프로세스들에게 우선순위를 부여하고, 우선순위 높은 프로세스부터 실행
210 | - 하지만 우선 순위가 계속 높은 프로세스만 실행이 되어, 다시 기아 현상(starvation)이 발생한다
211 | - 오랫동안 대기한 프로세스의 우선순위를 점차 높이는 방식 (에이징)
212 | ## 1. 선점형(preemptive) 알고리즘
213 | >현대 OS가 쓰는 방식으로, 지금 사용하고 있는 프로세스로부터 CPU를 뺏어서, 다른 적절한 프로세스에게 할당해 줄 수 있는 알고리즘
214 | ### 라운드 로빈(Round Robin)
215 | - **타임 슬라이스(Time Slice)** : 대기 중인 모든 프로세스를 일정한 크기로 잘개 쪼개어 각 프로세스별로 CPU 이용시간을 균등하게 부여
216 | - 정해진 타임 슬라이스만큼의 시간 동안 돌아가며 CPU를 이용하는 선점형 스케줄링 방식
217 | - 큐에 삽입된 프로세스들은 순서대로 CPU를 이용하되, 정해진 시간만큼만 이용
218 | - 정해진 시간을 모두 사용하였음에도 아직 프로세스가 완료되지 않았다면 다시 큐의 맨 뒤에 삽입(컨텍스트 스위칭)
219 | - 전체 작업 시간을 길어지지만 평균 응답 시간은 짧아진다
220 | - 현대 컴퓨터 및 로드밸런서에서 트래픽 분산 알고리즘으로도 쓰인다
221 | ### SRF(Shortest Remaning Time First)
222 | - SJF와 유사하게, 실행 시간이 더 짧은 프로세스를 우선으로 하여 CPU를 할당
223 | - 하지만 실행중인 프로세스보다 실행 시간이 더 짧은 작업이 중간에 들어오면 SRF는 새 프로세스에게 CPU를 넘겨준다
224 | ### 다단계 큐(Multi-Level Queue)
225 | - 우선 순위에 따른 큐를 여러개 사용한다
226 | - 큐마다 라운드 로빈이나 FCFS등 다른 스케줄링 알고리즘을 적용한 것을 말한다
227 | - 큐 사이의 프로세스 이동이 안되므로 스케줄링 부담은 적지만 유연성이 떨어지는 특징이 있다
--------------------------------------------------------------------------------
/3. 운영체제(2)/운영체제(2)_송민진/운영체제(2)_송민진.md:
--------------------------------------------------------------------------------
1 |
2 | # 프로세스와 스레드
3 |
4 |
5 | ### Process
6 | : 컴퓨터에서 실행되고 있는 프로그램
7 |
8 | - CPU 스케줄링의 대상이 되는 작업(task)
9 | - 프로그램이 메모리에 올라가면 프로세스가 되는 인스턴스화가 일어남
10 | - 운영체제의 스케줄러에 따라 CPU가 프로세스를 실행함
11 |
12 |
13 | ### Thread
14 | : 프로세스 내 작업의 흐름
15 |
16 |
17 | > 👉🏻 **프로그램이란?**
18 | > 컴파일러가 컴파일 과정을 거쳐 컴퓨터가 이해할 수 있는 기계어로 번역되어 실행될 수 있는 파일이 되는 것
19 | > (단, 컴파일 언어로 된 프로그램 기준)
20 |
21 | > 📌 **컴파일이란?**
22 | > ![[Pasted image 20230224001244.png]]
23 | > - 전처리 : 소스코드의 주석 제거, `#include` 등 헤더 파일을 병합하여 매크로 치환
24 | > - 컴파일러 : 오류 처리, 코드 최적화 작업을 하며 어셈블리어로 변환
25 | > - 어셈블러 : 어셈블리어는 목적 코드로 변환됨. 이 때 확장자는 운영체제마다 다른데, 리눅스에서는 o임.
26 | > - 링커 : 프로그램 내에 있는 라이브러리 함수 또는 다른 파일들과 목적 코드를 결합하여 실행 파일을 만듦
27 |
28 |
29 | ## 프로세스 vs 스레드
30 |
31 |
32 | ![[Pasted image 20230224172321.png]]
33 |
34 | #### **스택**
35 | : 지역변수, 매개변수, 함수가 저장되는 공간
36 | - 스택 내 변수들의 크기가 컴파일시 크기가 결정되며, 스택 자체의 크기는 동적인 특징을 가짐
37 | - 함수가 함수를 재귀적으로 호출하면 동적으로 크기가 늘어날 수 있는데, 이 때 힙과 스택의 메모리 영역이 겹치면 안 되기 때문에 둘 사이 공간을 비워둠
38 |
39 | #### 힙
40 | : 동적 할당할 때 사용되며, 힙 내 변수들의 크기가 런타임시 크기가 결정됨. (ex. vector 등의 동적 배열은 힙에 할당).
41 | - '동적'인 특징을 가짐
42 |
43 | #### 데이터 영역
44 | : 전역 변수, 정적 변수가 저장되는 공간
45 | - 정적인 특징을 갖는, 프로그램이 종료되면 사라지는 변수가 들어 있는 영역
46 | - BSS 영역과 Data 영역으로 나뉨
47 | - BSS 영역은 초기화되지 않은 변수가 0으로 초기화되어 저장됨
48 | - Data 영역은 0이 아닌 다른 값으로 할당(초기화)된 변수들이 저장됨
49 |
50 | #### 코드 영역
51 | : 프로그램에 내장되어 있는 소스 코드가 들어가는 영역
52 | - 수정 불가능한 기계어로 저장되어 있으며, 정적인 특징을 가짐
53 |
54 |
55 | >**프로세스**는 최소 하나의 스레드를 보유하고 있으며, 각각 별도의 주소공간을 독립적으로 할당 받는다.(code, heap, stack)
56 | >
57 | **스레드**는 이중에 stack만 따로 할당받고 나머지 영역은 스레드끼리 서로 공유한다.
58 |
59 |
60 |
61 | ## 정적 라이브러리와 동적 라이브러리
62 |
63 | **정적 라이브러리**
64 | : 프로그램 빌드 시 라이브러리가 제공하는 모든 코드를 실행 파일에 넣는 방식
65 |
66 | - 시스템 환경 등 외부 의존도가 낮음
67 | - 코드 중복 등 메모리 효율성이 떨어짐
68 | - (compile시 주입됨 ??)
69 |
70 |
71 | **동적 라이브러리**
72 | : 프로그램 실행 시 필요할 때만 DLL(Windows), shared library(Mac, Linux 등)이라는 함수 정보를 통해 참조하는 방식
73 |
74 | - 메모리 효율이 좋다는 장점
75 | - 외부 의존도가 높아진다는 단점
76 | - 코드 영역에 포함되지 않고, 운영체제 shared memory에 포함됨
77 | - (Java - `Class.forName()` 등)
78 |
79 |
80 |
81 |
82 | ## 프로세스의 상태
83 |
84 | 프로세스의 상태는 여러 가지 상태값을 가짐
85 |
86 | ![[Pasted image 20230224004257.png]]
87 |
88 | **생성 (create)**
89 | : 프로세스가 생성된 상태. fork() 또는 exec() 함수를 통해 생성됨. 이 때 PCB가 할당됨
90 | - fork() : 부모 프로세스의 주소 공간을 그대로 복사하며, 새로운 자식 프로세스를 생성하는 함수. 주소 공간만 복사할 뿐이지, 부모 프로세스의 비동기 작업 등을 상속하지는 않음
91 | - exec() : 새롭게 프로세스를 생성하는 함수
92 |
93 | **대기 (ready)**
94 | : 메모리 공간이 충분하면 메모리를 할당받고, 아니면 아닌 상태로 대기하고 있으며 CPU 스케줄러로부터 CPU 소유권이 넘어오기를 기다리는 상태
95 |
96 | **대기 중단 상태 (ready suspended)**
97 | 메모리 부족 등으로 일시 중단된 상태
98 |
99 | **실행 상태 (running)**
100 | : CPU 소유권과 메모리를 할당받고, 인스트럭션을 수행 중인 상태
101 | - CPU burst가 일어났다고도 표현함
102 |
103 | **중단 상태 (blocked)**
104 | : 어떤 이벤트가 발생한 이후 기다리며 프로세스가 차단된 상태
105 | - I/O 디바이스에 의한 인터럽트로 이런 현상이 많이 발생하기도 함
106 | - 프린트 인쇄 버튼을 눌렀을 때 프로세스가 잠깐 멈춘 듯할 때 : 바로 이 상태
107 |
108 | **일시 중단 상태(blocked suspended)**
109 | : 대기 중단과 유사함. 중단된 상태에서 프로세스가 실행되려 했지만 메모리 부족으로 일시 중단된 상태
110 |
111 | **종료 상태(terminated)**
112 | : 메모리와 CPU 소유권을 모두 놓고 가는 상태. 자연스러운 종료와 비자발적 종료(abort - 부모 프로세스가 자식 프로세스를 강제 종료시킴)를 포함함. 자식 프로세스에 할당된 자원의 한계치를 넘어서거나, 부모 프로세스가 종료되거나 사용자가 process.kill 등 여러 명령어로 프로세스를 종료할 때 발생함
113 |
114 |
115 | ## PCB
116 | **: Process Control Block**
117 |
118 | - 운영체제에서 프로세스에 대한 메타데이터를 저장한 '데이터'를 말함
119 | - 프로세스 제어 블록이라고도 함
120 | - 프로세스가 생성되면 운영체제는 해당 PCB를 생성함
121 | - PCB에 저장된 프로세스의 메타데이터들은 중요한 정보를 포함하고 있기 때문에, 일반 사용자가 접근하지 못하도록 커널 스택의 가장 앞부분에서 관리됨
122 |
123 | > **프로그램이 실행되면?**
124 | > - 프로세스가 생성됨
125 | > -> 프로세스 주소 값들에 스택/힙 등의 구조를 기반으로 메모리가 할당됨
126 | > -> 이 프로세스의 메타 데이터들이 PCB에 저장되어 관리됨
127 |
128 | >**메타 데이터**
129 | >: 데이터에 관한 구조화된 데이터
130 | >- 대량의 정보 가운데에서 찾고 있는 정보를 효율적으로 찾아내서 이용하기 위해 일정한 규칙에 따라 콘텐츠에 대해 부여되는 데이터
131 |
132 |
133 | ### PCB의 구조
134 | 다음과 같은 정보들로 이루어짐
135 |
136 | - 프로세스 스케줄링 상태
137 | - 프로세스 ID
138 | - 프로세스 권한
139 | - 프로그램 카운터
140 | - CPU 레지스터
141 | - CPU 스케줄링 정보
142 | - 계정 정보
143 | - I/O 상태 정보
144 |
145 |
146 | ### Context Switching
147 |
148 | - 앞서 설명한 PCB를 교환하는 과정
149 | - 한 프로세스에 할당된 시간이 끝나거나, 인터럽트에 의해 발생함
150 | - 싱글 코어 환경에서는 어떤 시점에서 실행되고 있는 프로세스는 단 1개이며, 많은 프로세스가 동시에 구동되는 것처럼 보이는 건 컨텍스트 스위칭이 아주 빠르게 실행되기 때문
151 | - 단, 현대 컴퓨터는 멀티 코어의 CPU를 가짐 -> 멀티 프로세스 환경
152 | ![[Pasted image 20230224174152.png]]
153 |
154 | **유휴시간 (idle time)**
155 | : 컨텍스트 스위칭이 일어날 때 발생하는 시간
156 |
157 | **비용 캐시 미스 (Cache Miss)**
158 | : 프로세스가 가지고 있는 메모리 주소가 그대로 있으면 잘못된 주소 변환이 생김 -> 캐시 클리어 과정을 겪게 됨 -> 캐시 미스 발생
159 |
160 |
161 |
162 | ### 스레드에서의 컨텍스트 스위칭
163 | - 스레드에서도 컨텍스트 스위칭이 일어남.
164 | - 스레드는 스택 영역을 제외한 모든 메모리를 공유하기 때문에 스레드 컨텍스트 스위칭이 비용도 적고 시간도 적게 걸림
165 |
166 |
167 | ### Q. 프로세스의 문제점?
168 |
169 | - 프로세스 생성에 큰 오버헤드가 있다. ( 프로세스를 생성할때 많은 시간이 소요됨)
170 | - 프로세스 컨텍스트 스위칭의 비효율성, 오버헤드가 큼
171 | - 프로세스 사이에 통신이 어렵다는점 (IPC(Inter-Process Communication) 사용해야 함)
172 |
173 |
174 | ### Q. 스레드의 출현 목적?
175 |
176 | - 프로세스보다 크기가 작은 실행 단위 필요
177 | - 프로세스의 생성 및 소멸에 따른 오버헤드 감소
178 | - 빠른 컨텍스트 스위칭
179 | - 프로세스들의 통신 시간, 방법 어려움 해소
180 |
181 |
182 |
183 |
184 | ## 멀티 프로세싱
185 |
186 | : 여러 개의 프로세스 즉 멀티 프로세스를 통해 동시에 두 가지 이상의 일을 수행할 수 있는 것
187 |
188 | - 하나 이상의 일을 병렬로 처리할 수 있음
189 | - 특정 프로세스의 메모리, 프로세스 중 일부에 문제가 생기더라도 다른 프로세스를 이용하여 처리 가능
190 | - 신뢰성이 높다는 강점
191 | - IPC가 가능함
192 |
193 |
194 | ### 웹 브라우저
195 |
196 | - 브라우저 프로세스 : 주소 표시줄, 북마크 막대, 뒤로 가기 버튼, 앞으로 가기 버튼 등을 담당. 네트워크 요청, 파일 접근 등의 권한 담당
197 | - 렌더러 프로세스 : 웹사이트가 '보이는' 부분의 모든 것 제어
198 | - 플러그인 프로세스 : 웹사이트에서 사용하는 플러그인 제어
199 | - GPU 프로세스 : GPU를 이용해서 화면을 그리는 부분을 제어
200 |
201 | > **GPU 프로세스 vs 렌더러 프로세스**
202 | > - 렌더러 프로세스 : 예전 렌더러 프로세스는 여러 개가 만들어져 각 탭마다 할당되었지만, 지금은 사이트마다 프로세스를 할당한다. 여기서 말하는 렌더러 프로세스는 주요 렌더링 경로(Critical Rendering Path)이다.
203 | > - GPU 프로세스 : GPU 작업을 다른 프로세스와 격리해서 처리한다. GPU는 여러 애플리케이션의 요청을 처리하고 같은 화면에 요청받은 내용을 그리기 때문에 GPU 프로세스는 별도 프로세스로 분리되어 있다.
204 |
205 |
206 | #### IPC (Inter Process Communication)
207 |
208 | : 프로세스끼리 데이터를 주고받고 공유 데이터를 관리하는 메커니즘
209 |
210 | >메모리가 거의 완전히 공유되는 스레드보다는 속도가 떨어짐
211 |
212 | **종류**
213 | - **공유 메모리(shared memory)**
214 | - 여러 프로세스에 동일한 메모리 블록에 대한 접근 권한이 부여되어 프로세스가 서로 통신할 수 있도록 **공유 버퍼**를 생성하는 것
215 | - 각 프로세스의 메모리를 다른 프로세스가 접근할 수 없지만, 공유 메모리를 통해 여러 프로세스가 하나의 메모리를 공유할 수 있음
216 | - 어떠한 매개체를 통해 데이터를 주고받는 방식이 아닌, 메모리 자체를 공유하는 방식
217 | → 불필요한 데이터 복사의 오버헤드가 발생하지 않아 가장 빠르며, 같은 메모리 영역을 여러 프로세스가 공유하기 때문에 동기화가 필요함
218 |
219 | - **파일**
220 | - 디스크에 저장된 데이터 또는 파일 서버에서 제공한 데이터. 이를 기반으로 프로세스 간 통신을 함
221 |
222 | - **소켓**
223 | - 동일한 컴퓨터의 다른 프로세스나, 네트워크의 다른 컴퓨터로 네트워크 인터페이스를 통해 전송하는 데이터
224 | - TCP, UDP가 있음
225 |
226 | - **익명 파이프(anonymous pipe, unnamed pipe)**
227 | - 파이프 : 프로세스 간에 FIFO 방식으로 읽히는 임시공간
228 | - 파이프를 기반으로 데이터를 주고받으며, 단방향 방식의 읽기 전용/쓰기 전용 파이프를 만들어서 작동하는 방식
229 | - 부모, 자식 프로세스 간에만 사용할 수 있으며, 다른 네트워크상에서는 사용이 불가함
230 | ![[Pasted image 20230306001212.png]]
231 |
232 | - **명명 파이프(named pipe)**
233 | - 파이프 서버와 하나 이상의 파이프 클라이언트 간의 통신을 위한 명명된 단방향 또는 이중 파이프
234 | - 클라이언트/서버 통신을 위한 별도의 파이프 제공
235 | - 여러 파이프를 동시에 사용할 수 있음
236 | - 보통 서버용 파이프/클라이언트용 파이프로 구분해서 작동하며, 하나의 인스턴스를 열거나 여러 개의 인스턴스를 기반으로 통신함
237 | ![[Pasted image 20230306001403.png]]
238 |
239 | - **메시지 큐**
240 | - 메시지를 Queue 데이터 구조 형태로 관리하는 것
241 | - 커널의 전역변수 형태 등 커널에서 전역적으로 관리되며, 다른 IPC 방식에 비해서 사용 방법이 매우 직관적이고 간단함
242 | - 다른 코드의 수정 없이 단지 몇 줄의 코드를 추가시켜 간단하게 메시지 큐에 접근할 수 있다는 장점이 있음
243 | - 공유 메모리를 통해 IPC를 구현할 때 쓰기/읽기 빈도가 높으면 동기화 때문에 기능을 구현하는 것이 매우 복잡해짐 → 이 때 대안으로 메시지 큐를 사용하기도 함
244 | ![[Pasted image 20230306001649.png]]
245 |
246 |
247 |
248 |
249 | ## 멀티 스레딩
250 |
251 | #### 스레드
252 | : 프로세스의 실행 가능한 가장 작은 단위
253 |
254 | - 프로세스는 여러 스레드를 가질 수 있음
255 | ![[Pasted image 20230306001757.png]]
256 |
257 | - **프로세스** : 코드, 데이터, 스택, 힙 영역을 각각 생성함
258 | - **스레드** : 코드, 데이터, 힙은 서로 공유함. 스택 영역은 각각 생성함
259 |
260 |
261 | #### 멀티 스레딩
262 |
263 | - 프로세스 내 작업을 여러 개의 스레드, 멀티 스레드로 처리하는 기법
264 | - 스레드끼리 서로 자원을 공유하기 때문에 효율성이 높음
265 | - ex) 웹 요청을 처리할 때, 웹 서버가 멀티스레드로 작동한다.
266 | - 새 프로세스를 생성하는 대신 스레드를 사용함 → 훨씬 적은 리소스를 소비함
267 | - 한 스레드가 중단 되어도 다른 스레드가 실행 상태일 수 있기 때문에 중단되지 않은 빠른 처리가 가능함
268 | - 동시성에도 큰 장점이 있음
269 | - 한 스레드에 문제가 생기면 다른 스레드에도 영향을 끼쳐, 스레드로 이루어져 있는 프로세스에 영향을 줄 수 있다는 단점이 있음
270 | - ex) 웹 브라우저의 렌더러 프로세스
271 | - 메인 스레드, 워커 스레드, 컴포지터 스레드, 레스터 스레드로 구성되어 있음
272 |
273 | > 동시성 : 서로 독립적인 작업들을 작은 단위로 나누고, 동시에 실행되는 것처럼 보여주는 것
274 |
275 |
276 |
277 | #### 공유 자원과 임계 영역
278 |
279 | - **공유 자원(shared resource)**
280 | - 시스템 안에서 각 프로세스, 스레드가 함께 접근할 수 있는 모니터, 프린터, 메모리, 파일, 데이터 등의 자원이나 변수 등을 의미함
281 |
282 | - **Race Condition**
283 | - 이 공유 자원을 두 개 이상의 프로세스가 동시에 읽거나 쓰는 상태
284 | - 동시에 접근을 시도할 때, 접근의 타이밍이나 순서 등이 결괏값에 영향을 줄 수 있는 상태
285 |
286 | - **임계 영역(critical section)**
287 | - 둘 이상의 프로세스, 스레드가 공유 자원에 접근할 때 순서 등의 이유로 결과가 달라지는 코드 영역
288 |
289 | - **임계 영역을 해결하기 위한 방법**
290 | - 크게 **뮤텍스**, **세마포어**, **모니터** 세 가지가 있음
291 | - **mutex**
292 | : 프로세스나 스레드가 공유 자원을 lock()을 통해 잠금 설정 / 사용한 후에는 unlock()을 통해 잠금 해제하는 객체
293 | - 잠금이 설정되면 다른 프로세스나 스레드는 잠긴 코드 영역에 접근할 수 없음
294 | - 뮤텍스는 잠금 또는 잠금 해제하는 상태만 가짐
295 |
296 | - **semaphore**
297 | : 일반화된 뮤텍스
298 | - 간단한 정수 값과 두 가지 함수 wait(P 함수) 및 signal(V 함수)로 공유 자원에 대한 접근을 처리함
299 | - wait() : 자신의 차례가 올 때까지 기다리는 함수
300 | - signal() : 다음 프로세스로 순서를 넘겨주는 함수
301 | - 프로세스/스레드가 공유 자원에 접근하면, 세마포어에서 wait() 작업을 수행하고 프로세스/스레드가 공유 자원을 해제하면 세마포어에서 signal() 작업 수행
302 | - 세마포어 : 조건 변수가 없고, 프로세스나 스레드가 세마포어 값을 수정할 때 다른 프로세스/스레드는 동시에 세마포어 값을 수정할 수 없음
303 | ![[Pasted image 20230306003458.png]]
304 |
305 | - **binary semaphore**
306 | : 0과 1의 두 가지 값만 가질 수 있는 세마포어
307 | - 뮤텍스는 바이너리 세마포어라고 할 수 있음. 단, 뮤텍스는 '잠금 메커니즘'(잠금을 기반으로 상호 배제가 일어남). 세마포어는 '신호 메커니즘'(신호를 기반으로 상호 배제가 일어남)
308 |
309 | - **counting semaphore**
310 | : 여러 개의 값을 가질 수 있는 세마포어
311 | - 여러 자원에 대한 접근을 제어하는 데에 사용됨
312 |
313 | - **모니터**
314 | - 둘 이상의 스레드/프로세스가 공유 자원에 안전하게 접근할 수 있도록 공유 자원을 숨기고, 해당 접근에 대해 인터페이스만 제공
315 | - 모니터큐를 통해 공유 자원에 대한 작업들을 순차적으로 처리함
316 | - 세마포어보다 구현하기 쉬움
317 | - 모니터 : 상호 배제가 자동
318 | - 세마포어 : 상호 배제를 명시적으로 구현해야 하는 차이점
319 | ![[Pasted image 20230306004212.png]]
320 | - 모두 상호 배제, 한정 대기, 융통성 이라는 조건을 만족함
321 | - 이 방법에 토대가 되는 메커니즘 : **lock**
322 |
323 | > **용어 설명**
324 | > - 상호 배제 : 한 프로세스가 임계 영역에 들어갔을 때, 다른 프로세스는 들어갈 수 없다
325 | > - 한정 대기 : 특정 프로세스가 영원히 임계 영역에 들어가지 못하면 안 된다.
326 | > - 융통성 : 한 프로세스가 다른 프로세스의 일을 방해해서는 안 된다.
327 |
328 |
329 |
330 | #### 교착 상태(dead lock)
331 |
332 | : 두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태
333 |
334 | **원인**
335 | - 상호 배제 : 한 프로세스가 자원을 독점하고 있으며, 다른 프로세스들은 접근이 불가능함
336 | - 점유 대기 : 특정 프로세스가 점유한 자워을 다른 프로세스가 요청하는 상태
337 | - 비선점 : 다른 프로세스의 자원을 강제적으로 가져올 수 없음
338 | - 환형 대기 : 프로세스 A는 프로세스 B의 자원 요구, 프로세스 B는 프로세스 A의 자원을 요구하는 등 서로의 자원을 요구하는 상황
339 |
340 | **해결 방법**
341 | 1. 자원을 할당할 때, 애초에 조건이 성립되지 않도록 설계 (교착 상태 가능성이 없을 때만 자원 할당됨)
342 | 2. 프로세스당 요청할 자원들의 최대치를 통해, 자원 할당 가능 여부를 파악하는 은행원 알고리즘을 사용함
343 | 3. 교착 상태가 발생하면, 사이클이 있는지 찾아보고 이에 관련된 프로세스를 한 개씩 지움
344 | 4. 교착 상태는 매우 드물게 일어나기 때문에, 이를 처리하는 비용이 더 큼. 따라서 교착상태가 발생하면 사용자가 작업을 종료함. 현재 운영체제가 선택한 방법.
345 |
346 | > **은행원 알고리즘 (banker's algorithm)**
347 | > - 총 자원의 양과, 현재 할당한 자원의 양을 기준으로 안정/불안정 상태를 나눔
348 | > - 안정 상태로 가도록 자원을 할당하는 알고리즘
--------------------------------------------------------------------------------
/1. 디자인 패턴과 프로그래밍 패러다임(1)/디자인 패턴과 프로그래밍 패러다임(1)_이홍섭.md:
--------------------------------------------------------------------------------
1 | # 디자인 패턴과 프로그래밍 패러다임(1) - 디자인 패턴
2 | ---
3 | ## 목차
4 | 1. 싱글톤 패턴
5 | 2. 팩토리 패턴
6 | 3. 전략 패턴
7 | 4. 옵저버 패턴
8 | 5. 프록시 패턴과 프록시 서버
9 | 6. 이터레이터 패턴
10 | 7. 노출모듈 패턴
11 | 8. MVC 패턴
12 | 9. MVP 패턴
13 | 10. MVVM 패턴
14 | ---
15 |
16 | ## 1. 싱글톤 패턴
17 |
18 | - 싱글톤 패턴이란
19 | - App이 실행할 때, 최초 한번만 메모리에 할당하여 해당 인스턴스를 사용하는 디자인 패턴
20 | - 즉 하나의 클래스에 오직 하나의 인스턴스만 가지는 패턴
21 | - 객체를 미리 생성해두고 가져다 쓰는 방법
22 | ```java
23 | public class Singleton {
24 |
25 | private static Singleton instance = new Singleton();
26 |
27 | private Singleton() {
28 | // 생성자는 외부에서 호출못하게 private 으로 지정해야 한다.
29 | }
30 |
31 | public static Singleton getInstance() { //getInstance를 사용해서 새로운 Singleton 객체 사용을 막는다
32 | return instance;
33 | }
34 |
35 | public void say() {
36 | System.out.println("hello");
37 | }
38 | }
39 | ```
40 | - 장점 :
41 | - 인스턴스를 생성할 때 드는 비용이 줄어든다
42 | - 최초 한번의 new 연산자를 통해서 고정된 메모리 영역을 사용하기 때문에 추후 해당 객체에 접근할 때 메모리 낭비를 방지할 수 있다
43 | - 다른 클래스간 **데이터 공유**가 쉽다
44 | > 전역으로 사용되는 인스턴스 이기에, 다른 클래스의 인스턴스들이 접근하여 사용 가능
45 | - 단점 :
46 | - 모듈간의 결합이 강해진다(의존성이 높아진다)
47 | - 구체화 클래스에 의존도가 높아진다 -> DIP를 위반 -> OCP원칙을 위반할 수 있다
48 | - 싱글톤 패턴을 구현하는 코드 자체가 많이 필요하다
49 | - 자원을 공유하고 있기에 **테스트** 하기 어렵다 -> 격리된 환경에서 테스트가 수행될 수 있게 매번 인스턴스 상태를 초기화 필요
50 | - 참고 사이트
51 | - [우테코-싱글톤(Singleton) 패턴이란?](https://tecoble.techcourse.co.kr/post/2020-11-07-singleton/)
52 |
53 | - [SOLID 객체지향 설계](https://ko.wikipedia.org/wiki/SOLID_(%EA%B0%9D%EC%B2%B4_%EC%A7%80%ED%96%A5_%EC%84%A4%EA%B3%84))
54 |
55 | ## 2. 팩토리 패턴
56 |
57 | - 팩토리 패턴이란
58 | - 객체의 사용 부분과 생성 부분을 따로 떼어 내어 별도의 객체로서 생성,사용 하는 것
59 | - (객체 생성을 대신 수행해주는 공장이라고 생각하자)
60 | - 상속 관계에 있는 두 클래스에서, 상위 클래스가 중요한 뼈대를 결정하고, 하위 클래스에서 객체 생성에 관한 구체적인 내용 결정
61 | - 예 : 상위 클래스에서 자동차에 필요한 필수 요소만 가지고, 하위 클래스에서는 각 자동차에 대한 구체적인 애용이 결정됨 (추상화)
62 | - 장점 :
63 | - 객체 생성부를 캡슐화하여, 객체 간의 결합도를 낮출 수 있다 (느슨한 결합->구현체 클래스에 의존하지 않음)
64 | - OCP (개방 폐쇄 원칙)를 따른다
65 | - 클래스 내부 코드를 직접 수정하지 않아도 기능 확장/변경이 가능
66 | - SRP (단일 책임 원칙)를 따른다
67 | - 클라이언트가 특정 객체의 생성을 직접 생성하지 않고 생성 역할을 하는 클래스를 만들어 그 클래스에게 위임
68 | - 단점 :
69 | - 새로 생성할 객체가 늘어날 때마다, Factory 클래스에 추가해야 되기 때문에 클래스가 많아진다
70 | - 참고 사이트
71 | - [Factory Method Pattern 팩토리 메소드 패턴](https://bangu4.tistory.com/334)
72 | - [팩토리 메소드 패턴(Factory Method Pattern)](https://dev-youngjun.tistory.com/195)
73 |
74 | ## 3. 전략 패턴
75 |
76 | - 전략 패턴이란
77 | - 정책 패턴이라고도 한다
78 | - 특정 객체의 **행위**를 직접 구현하지 않고, 캡슐화된 객체로 구현하여, 컨텍스트 내에서 상호 교체가 가능하도록 만드는 패턴
79 | - 예 : 어떤 물건을 살 때 결제수단은 여러 가지이고, 그중 어떤 것을 선택해도 성공적으로 결제가 된다
80 | - 장점 :
81 | - 팩토리 패턴과 유사하게 공통 로직이 부모 클래스에 있지 않고 Context 라는 별도의 클래스에 존재하기 때문에 구현체들에 대한 영향도가 적음
82 | - 쉽게 변하지 않는 상위 인터페이스(클래스)에 의존하기 때문에 확장/삭제에 용이하다
83 | - 단점 :
84 | - 로직이 늘어날 때 마다 구현체 클래스가 늘어난다
85 | - 앱에 들어가는 모든 전략을 알고 있어야 해서, 한번 전략을 조립하면 변경하기가 힘들다
86 | - 참고 사이트
87 | - [저는 전략 패턴이 처음이라니까요?](https://joel-dev.site/75)
88 |
89 | ## 4. 옵저버 패턴
90 |
91 | - 옵저버 패턴이란
92 | - 주체가 어떤 객체의 상태 변화를 관찰하다가 상태 변화가 발생하면 옵저버 목록에 있는 옵저버들에게 변화를 알려주는 디자인 패턴
93 | - 특정 변화에 따른 동작이 미리 정의되어 있고, 변화가 발생하면 이러한 동작이 즉각 수행된다.
94 | - 이벤트의 처리를 효율적으로 할 수 있다
95 | - 장점 :
96 | - 변경 사항이 생겨도 무난히 처리할 수 있는 유연한 객체지향 시스템을 구축할 수 있다
97 | - OCP (개방 폐쇄 원칙)를 지킬 수 있다
98 | - 단점 :
99 | - 알림이 가는 순서를 보장할 수 없다
100 | - 옵저버와 알림을 받는 Subject간의 관계가 잘 정의되지 않으면 원치 않는 동작이 발생할 확률이 높다
101 | - 참고 사이트
102 | - [iOS 옵저버 패턴](https://jiseok-zip.tistory.com/entry/iOS%EC%98%B5%EC%A0%80%EB%B2%84-%ED%8C%A8%ED%84%B4Observer-Pattern#toc-%EC%98%B5%EC%A0%80%EB%B2%84%20%ED%8C%A8%ED%84%B4%20%EC%9E%A5&%EB%8B%A8%EC%A0%90%20%F0%9F%97%A1)
103 |
104 | ## 5. 프록시 패턴과 프록시 서버
105 |
106 | - 프록시 패턴이란
107 | - 대상 객체에 접근하기 전에 그 접근에 대한 흐름을 가로채, 대상 객체 앞단의 인터페이스 역할을 하는 디자인 패턴
108 | - 프록시 서버란
109 | - 서버와 클라이언트 사이에서 클라이언트가 자신을 통해 다른 네트워크 서비스에 간접적으로 접속할 수 있게 해주는 컴퓨터 시스템이나 응용 프로그램을 가리킨다
110 | - `클라이언트 -> 웹 서버` 로의 요청이 `클라이언트 -> 프록시 서버 -> 웹서버`로, 중간에 하나의 계층이 더 생긴다
111 | - 장점 :
112 | - 사이즈가 큰 객체가 로딩되기 전에도 프록시를 통해 참조를 할 수 있다(전처리 및 후처리 사용 용이)
113 | - 특정 메서드에 대한 보안이 좋다. (B가 C에게 요청을 하여 A는 C가 무슨 일이 일어나는지 정확히 알기 힘들다는 점)
114 | - 단점 :
115 | - 가독성이 떨어진다. (A->B->C라는 구조로 누군가 거쳐가야 한다는 점 이런 경우가 많아지면 가독성이 떨어질 우려된다)
116 | - 참고 사이트
117 | - [프록시 서버란 무엇인가? (Proxy Server)](https://digiconfactory.tistory.com/entry/%ED%94%84%EB%A1%9D%EC%8B%9C-%EC%84%9C%EB%B2%84-Proxy-Server-%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80)
118 | - [프록시 패턴 셜명 및 장단점](https://min94programming.tistory.com/30)
119 |
120 | ## 6. 이터레이터 패턴
121 | - 이터레이터 패턴이란
122 | - 각기 다른 자료구조 구현체(array,linkedList,set)가 `iterator`라는 하나의 인터페이스를 통해 순회할 수 있도록 해주는 디자인 패턴
123 | - 컬렉션 구현 방법을 노출시키지 않으면서도 그 집합체안에 들어있는 모든 항목에 접근할 수 있게 해 주는 방법을 제공해 주는 패턴
124 | - 장점 :
125 | - 내부적인 구현 방법을 외부로 노출시키지 않으면서도 집합체에 있는 모든 항목에 일일이 접근할 수 있다
126 | - 단점 :
127 | - 간단한 컬랙션인 경우, 이터레이터를 사용하는 것은 일부 특수 컬렉션의 요소를 직접 탐색하는 것 보다 덜 효율적일 수 있다
128 | - 참고 사이트
129 | - [[Design Pattern] 이터레이터 패턴 (iterator pattern)](https://velog.io/@cham/Design-Pattern-%EC%9D%B4%ED%84%B0%EB%A0%88%EC%9D%B4%ED%84%B0-%ED%8C%A8%ED%84%B4-iterator-pattern)
130 |
131 | ## 7. 노출모듈 패턴
132 |
133 | - 노출모듈 패턴이란
134 | - `즉시 실행 함수`를 통해 private,public같은 접근 제어자를 만드는 패턴
135 | - 즉시 실행 함수 : 함수를 정의 하자마자 바로 호출하는 함수. 초기화 코드, 라이브러리 내 전역 변수의 충돌 방지 등에 사용한다
136 | - JavaScript는 언어 레벨에서 접근 제어자가 존재하지 않고, 전역 변위에서 스크립트가 실행된다
137 | - ```js
138 | const rmp = (() => {
139 | const a = 1;
140 | const b = () => 2;
141 |
142 | const public = {
143 | c: 2,
144 | d: () => 3,
145 | };
146 | return public;
147 | })();
148 |
149 | console.log(rmp);
150 | console.log(rmp.a);
151 | // { c: 2, d: [Function: d] }
152 | // undefined
153 | ```
154 | >a와 b는 다른 모듈에서 접근할 수 없는 private 범위를 가진다. c와 d는 다른 모듈에서도 사용할 수 있는 public 범위를 가지게 된다
155 | > 이 원리를 기반으로 만든 자바스크립트 모듈 방식이 바로 CJS(CommonJS)입니다.
156 |
157 |
158 | ## 8. MVC 패턴
159 |
160 | ### 정의
161 | - Model, View, Controller로 어플리케이션의 구성 요소를 세 가지 역할로 구분하고, 각 기능에 집중하는 디자인 패턴
162 |
163 | ### 상세 내용
164 | - 모델 (Model) : 어플리케이션을 구성하는 DB,정보,상수,변수등의 데이터 계층
165 | - 비즈니스 로직을 처리한다
166 | - 사용자가 편집하길 원하는 모든 데이터를 가지고 있어야 한다
167 | - **View나 Controller에 대해서 어떤 정보도 알지 말아야 한다**
168 | - 변경이 일어나면, 변경 통지에 대한 처리방법을 구현해야만 한다
169 | - 뷰 (View) :사용자에게 보여지는 화면,UI등을 말한다
170 | - 데이터 및 객체의 입력, 그리고 보여주는 출력을 담당한다
171 | - Model이 가지고 있는 정보를 따로 저장해서는 안 된다
172 | - **Model이나 Controller와 같이 다른 구성요소들을 몰라야 된다**
173 | - 변경이 일어나면 변경 통지에 대한 처리방법을 구현해야만 한다
174 | - 컨트롤러 (Controller) : 데이터(Model)와 UI(View) 요소들을 잇는 다리 역할의 레이어
175 | - 사용자의 요청에 맞는 이벤트 등, 메인 로직을 담당한다
176 | - Model이나 View의 변경 통지를 받으면 이를 해석하여 각각의 구성 요소에 해당 내용에 대해 알려준다
177 | - Model이나 View에 대해서 알고 있어야 한다 (모델과 뷰의 생명주기도 관리한다)
178 | - 장점 :
179 | - 서로 분리되어 각각의 역할만 담당함으로써 유지보수,확장성,유연성이 증가됨
180 | - 중복 코딩이라는 문제점 또한 사라진다
181 | - 단점 :
182 | - View와 Model 사이의 의존성이 높다 -> 어플리케이션이 커질수록 복잡해지고 유지 보수가 어렵다
183 | > #### Repository, Service는 무엇인가?
184 | > 위처럼 MVC 패턴을 이용하면 비즈니스 로직과 뷰는 분리가 된다.
185 | 하지만, Controller에서는 HTTP 연결을 담당하는 컨트롤러 로직이 있기 때문에
186 | 컨트롤러가 너무 많은 일을 담당하게 된다.
187 | > 위 문제점 때문에 Service, Repository 계층을 따로 만들어서 Controller는 컨트롤러 로직에만 집중할 수 있게한다.
188 | > 그렇게 분리된 Repository, Service , DTO ,DAO 등은 사실상 Controller 레이어에 속한다
189 |
190 | ### 참고 자료
191 | - [[Spring MVC] Spring MVC 패턴](https://ppusda.tistory.com/55)
192 | - [[개발자 면접준비]#1. MVC패턴이란](https://m.blog.naver.com/jhc9639/220967034588)
193 |
194 | ## 9. MVP 패턴
195 |
196 | ### 정의
197 | - MVC 패턴으로부터 파생되었으며 MVC의 Controller 가 Presenter로 교체된 패턴
198 |
199 | ### 상세 내용
200 | - Presenter
201 | - View에서 요청한 정보로 Model을 가공하여 View에 전달해 주는 부분. View와 Model을 붙여주는 접착제 역할을 한다(컨트롤러와 유사)
202 | - Presenter는 기존 MVC 패턴의 단점이었던 Model과 View 사이의 **높은 의존성**을 해소하기 위하여 등장
203 | - 장점 :
204 | - View와 Model 사이에 Presenter라는 연결 부분을 두어 MVC 패턴의 단점인 의존성을 보완했다
205 | - MVC 패턴의 단점인 View와 Model사이의 의존성이 없다
206 | - 단점 :
207 | - View와 Presenter사이는 1대1관계를 유지해야해서 의존성이 높고, 앱이 커질수록 이 의존성은 더 강해진다
208 |
209 | ### 참고 자료
210 | - [[디자인패턴] MVC, MVP, MVVM 비교](https://beomy.tistory.com/43)
211 | - [MVC, MVP, MVVM 패턴의 특징](https://velog.io/@blucky8649/MVC-MVP-MVVM-%ED%8C%A8%ED%84%B4%EC%9D%98-%ED%8A%B9%EC%A7%95)
212 |
213 | ## 10. MVVM 패턴
214 |
215 | ### 정의
216 | MVC의 C에 해당하는 컨트롤러가 뷰 모델(View Model)로 바뀐 패턴
217 |
218 | ### 상세 내용
219 | - View Model(VM)
220 | - View Model은 View를 더 추상화한 계층
221 | - View 상태를 유지 및 변화시키고, View에 대한 작업의 결과로 Model을 조작한다
222 | - View에서 발생되는 이벤트를 전달 하는데 도움이 되는 메서드, 명령, 또는 다른 속성들을 노출하는 역할을 한다
223 | - MVVM은 View와 ViewModel사이의 관계가 1대N으로 되어있다
224 | - 장점 :
225 | - View와 View Model 사이 양방향 데이터 바인딩을 지원한다
226 | - View와 Model 사이의 의존성이 없다. View와 View Model 사이의 의존성이 없다
227 | - UI를 별도의 코드 수정 없이 재사용할 수 있고 단위 테스팅하기 쉽다
228 | - 단점 :
229 | - View Model의 설계가 어려움
230 |
231 | ---
232 |
233 | # 디자인 패턴과 프로그래밍 패러다임(2) - 프로그래밍 패러다임
234 |
235 | ## 0. 프로그래밍 패러다임이란
236 | 프로그래머에게 프로그래밍의 관점을 갖게 해주는 역할을 하는 개발 방법론
237 | - 객체지향 프로그래밍
238 | - 함수형 프로그래밍
239 | - 절차형 프로그래밍
240 | - 등등..
241 |
242 | 크게 선언형,명령형으로 나누며, 선언형은 함수형이라는 하위 집합을 갖는다
243 | 또한 명령형은 다시 객체지향,절차지향으로 나눈다
244 |
245 | ## 1. 선언형 프로그래밍
246 |
247 | - 선언형 프로그래밍이란
248 | - 무엇을 풀어내는가에 집중하는 패러다임
249 | - 함수형 프로그래밍은 선언형 패러다임의 일종이다
250 |
251 | ### 특징
252 | 예시 코드
253 | ```java
254 | public class Calc {
255 |
256 | public int getMax(List nums) {
257 |
258 | int result = 0;
259 |
260 | for (int num : nums) {
261 | result = Math.max(result, num);
262 | }
263 |
264 | return result;
265 | }
266 | }
267 | ```
268 | 위 코드에서 `getMax`는 '숫자 리스트'만 받아서, 리스트 내의 정수 최댓값을 리턴한다
269 | 함수형 프로그래밍은 이와 같은 작은 ‘**순수 함수**’들을 블록처럼 쌓아 로직을 구현하고 ‘**고차 함수**’를 통해 재사용성을 높인 프로그래밍 패러다임이다
270 | >자바의 경우 jdk 1.8부터 함수형 프로그래밍 패러다임을 지원하기 위해 람다식, 생성자 레퍼런스, 메서드 레퍼런스를 도입했고 선언형 프로그래밍을 위해 스트림(stream) 같은 표준 API 등도 추가되었다.
271 |
272 | - 순수 함수
273 | - 출력이 입력에만 의존하는 함수를 의미한다. 위 코드에서 `getMax()`메소드가 순수 함수이다
274 | - 고차 함수
275 | - 함수가 함수를 값처럼 매개변수로 받아 로직을 생성할 수 있는 것을 말한다
276 | - 고차 함수를 쓰기 위해서는 해당 언어가 **일급 객체**라는 특징을 가져야 한다
277 | - 일급 객체
278 | - 변수나 메서드에 함수를 할당할 수 있다
279 | - 자바의 메소드는 변수에 할당할 순 없다
280 | - 반면 자바스크립트는 함수 표현식으로 자유롭게 대입이 가능하다
281 | - ```java
282 | //java
283 | public class Main {
284 |
285 | public static void hello(){
286 | System.out.println("Hello World");
287 | }
288 |
289 | public static void main(String[] args) {
290 | Object a = hello; // !! 메서드를 변수에 할당 불가능
291 | }
292 | }
293 | ```
294 | ```js
295 | //js
296 | const hello = function() {
297 | console.log("Hello World");
298 | }
299 | ```
300 | - 함수 안에 함수를 매개변수로 담을 수 있다
301 | - 자바의 메소드를 메소드 입력값으로 보내는 행위는 불가능하다
302 | - 자바스크립트는 콜백 함수 형태로 자유롭게 전달이 가능하다
303 | - 함수가 함수를 반환할 수 있다
304 | - 자바의 메소드의 리턴값을 메소드 자체를 반환 행위는 불가능하다
305 | - 자바스크립트는 클로저(Closure) 기법을 통해 구성할 수 있다
306 |
307 | ### 참고 자료
308 | - [일급 객체(first-class object) 란?](https://inpa.tistory.com/entry/CS-%F0%9F%91%A8%E2%80%8D%F0%9F%92%BB-%EC%9D%BC%EA%B8%89-%EA%B0%9D%EC%B2%B4first-class-object)
309 |
310 | ## 2. 객체지향 프로그래밍
311 |
312 | - 객체지향 프로그래밍이란
313 | - 객체들의 집합으로 프로그램의 상호 작용을 표현한다(애플리케이션은 객체들의 집합으로 본다)
314 | - 데이터를 객체로 취급하여 객체 내부에 선언된 메서드를 활용하는 방식
315 | - 설계에 많은 시간이 소요되고, 처리 속도가 다른 프로그래밍 패러다임에 비해 상대적 느리다
316 |
317 | ### 핵심 개념
318 |
319 | - 추상화 (abstraction)
320 | - 캡슐화 (encapsulation)
321 | - 상속성 (inheritance)
322 | - 다형성 (polymorphism)
323 |
324 | ### 추상화
325 |
326 | - 복잡한 시스템으로부터 핵심적인 개념 또는 기능을 간추려내는 것을 의미한다
327 | - 특정 개념을 구체화 시키지 않고 모호화 하는 것
328 | - 여러가지 사물/개념에서 공통되는 특성을 묶어 이름을 붙이는 것
329 | ```java
330 | public interface Vehicle {
331 | public void time();
332 | }
333 |
334 | public class Car implements Vehicle {
335 |
336 | private String color;
337 |
338 | @Override
339 | public void time(){
340 | //얼마나 걸리는지 시간에 대한 메서드
341 | }
342 | }
343 |
344 | public class Ship implements Vehicle {
345 |
346 | private String color;
347 |
348 | @Override
349 | public void time(){
350 | //얼마나 걸리는지 시간에 대한 메서드
351 | }
352 | }
353 | ```
354 | - 이동 수단으로 배를 이용할지, 자동차를 이용할지 못 정했지만, 이동 수단을 이용하기로 했으면 먼저 인터페이스(이동 수단)를 정의하고, 실제 구현체(배, 자동차)는 추후에 구현하면 된다
355 | - 구현체를 쉽게 교체할 수 있다는 장점이 있다
356 |
357 | ### 캡슐화
358 |
359 | - 객체의 속성과 메서드를 하나로 묶고 일부를 외부에 감추어 은닉하는 것
360 | - 일종의 리모콘과 같다. 필요한 기능은 버튼으로 외부에 노출되고,그 눈으로 보여질 필요가 없는 내용은 숨겨져 있다
361 |
362 | ### 상속화
363 |
364 | - 부모(상위) 클래스의 특성을 자식(하위) 클래스가 이어받아서 재사용하거나 추가, 확장하는 것을 말한다
365 | - 코드의 재사용 측면, 계층적인 관계 생성, 유지 보수성 측면에서 중요하다
366 |
367 | ```java
368 | public class Vehicle{
369 |
370 | private String door;
371 |
372 | public void setDoor(String door){
373 | this.door=door;
374 | }
375 | }
376 |
377 | public class Car extends Vehicle{
378 |
379 | private String wheel;
380 | private String audio;
381 | //--getter...setter...
382 | }
383 | ```
384 | - 위 코드에서 '모든 탈 것은 문이 있다'라고 가정하고, `Vehicle`에는 모든 탈것의 기본 사항만 포함
385 | - 그 외에 `Car`에게만 있는 내용은 바퀴와,음향장치 라고 가정한다
386 | - `Car` 클래스는 `Vehicle` 클래스에는 없는 변수와 메소드를 가진다
387 | - 그렇게 해도 `Car` 클래스는 `Vehicle`의 `door`의 get,set 메소드를 사용할 수 있다
388 |
389 | ### 다형성
390 |
391 | - 하나의 메소드나 클래스가 다양한 방법으로 동작하는 것
392 | - 대표적으로 `오버로딩` & `오버라이딩`이 있다
393 |
394 | #### 오버로딩
395 | - 같은 이름의 메서드(함수)를 여러개 가지면서 매개변수 유형과 개수가 다르도록 하는 것
396 | - 한 클래스내에서 유사하지만 기능은 다르고, 이름이 같은 메소드를 여러개 정의하는 것
397 |
398 | ```java
399 | class Person {
400 |
401 | public void eat(String a) {
402 | System.out.println("I eat " + a);
403 | }
404 |
405 | public void eat(String a, String b) {
406 | System.out.println("I eat " + a + " and " + b);
407 | }
408 | }
409 |
410 | public class CalculateArea {
411 |
412 | public static void main(String[] args) {
413 | Person a = new Person();
414 | a.eat("apple");
415 | a.eat("tomato", "phodo");
416 | }
417 | }
418 |
419 | /*
420 | I eat apple
421 | I eat tomato and phodo
422 | */
423 | ```
424 | >매개변수의 개수에 따라 다른 함수가 호출되는 것을 알 수 있다
425 |
426 | #### 오버라이딩
427 |
428 | - 부모(상위) 클래스가 가지고 있는 메소드를 자식(하위) 클래스가 상속받아 재정의해서 사용
429 |
430 | ```java
431 | class Animal {
432 |
433 | public void bark() {
434 | System.out.println("멍멍");
435 | }
436 | }
437 |
438 | class Dog extends Animal {
439 |
440 | @Override
441 | public void bark() {
442 | System.out.println("왈왈");
443 | }
444 | }
445 |
446 | public class Main {
447 | public static void main(String[] args) {
448 | Dog d = new Dog();
449 | d.bark();
450 | }
451 | }
452 | /*
453 | 왈왈
454 | */
455 | ```
456 | > - 부모 클래스는 "멍멍"으로 짖게 해두었지만, 자식 클래스에서 "왈왈"로 짖게 바꾸었다
457 | > - 자식 클래스 기반으로 부모의 메서드가 **재정의**됨을 알 수 있다
458 |
459 | ### 참고 자료
460 | - [객체 지향 프로그래밍의 4가지 특징](https://hyunmin1906.tistory.com/204)
461 | - [[Java] 오버로딩과 오버라이딩 차이와 예제](https://velog.io/@ohsol/JAVA-%EC%98%A4%EB%B2%84%EB%A1%9C%EB%94%A9%EA%B3%BC-%EC%98%A4%EB%B2%84%EB%9D%BC%EC%9D%B4%EB%94%A9-%EC%B0%A8%EC%9D%B4%EC%99%80-%EC%98%88%EC%A0%9C)
462 |
463 | ## 객체지향 설계 원칙 SOLID
464 |
465 | 객체지향 프로그래밍을 설계할 때는 SOLID 원칙. 즉 지켜야 하는 5가지 원칙이 있다
466 |
467 | - S : 단일 책임 원칙 (SRP; Single Responsibility Principle)
468 | - 모든 클래스는 반드시 단 하나의 책임만을 가져야 한다.
469 | - O : 개방 폐쇄 원칙 (OCP; Open-Closed Principle)
470 | - 모든 클래스는, 확장에는 열려 있고 수정에는 닫혀 있어야 한다.
471 | - 즉, 기존의 코드는 건드리지 않으며 신규 기능을 확장할 수 있어야 한다.
472 | - L : 리스코프 치환 원칙 (LSP; Liskov Substitution Principle)
473 | - 프로그램의 객체는, 프로그램의 정확성을 깨뜨리지 않으며 하위 타임의 인스턴스로 바꿀 수 있어야 한다.
474 | - 즉, 부모 객체 대신 자식 객체를 넣어도 기능이 동작해야 한다.
475 | - I : 인터페이스 분리 원칙 (ISP; Interface Segregation Principle)
476 | - 하나의 일반적인 (general) 인터페이스보다, 여러 개의 구체적인 (specific) 인터페이스를 만들어야 한다.
477 | - D : 의존 역전 원칙 (DIP; Dependency Inversion Principle)
478 | >- "고차원 모듈은 저차원 모듈에 의존하면 안된다. 이 두 모듈 모두 다른 추상화된 것에 의존해야 한다."
479 | >- "추상화된 것은 구체적인 것에 의존하면 안된다. 구체적인 것이 추상화된 것에 의존해야 한다."
480 | >- "자주 변경되는 구체(Concrete) 클래스에 의존하지 마라"
481 | >- "자신보다 변하기 쉬운 것에 의존하지 마라"
482 | >- 로버트 C 마틴
483 |
484 | ### 관련 자료
485 | - [자바 객체 지향의 원리 SOLID - DIP : 의존 역전 원칙](https://ktko.tistory.com/entry/%EC%9E%90%EB%B0%94-%EA%B0%9D%EC%B2%B4-%EC%A7%80%ED%96%A5%EC%9D%98-%EC%9B%90%EB%A6%AC-SOLID-DIP-%EC%9D%98%EC%A1%B4-%EC%97%AD%EC%A0%84-%EC%9B%90%EC%B9%99)
486 |
487 | ## 3. 절차형 프로그래밍
488 |
489 | - 절차형 프로그래밍이란
490 | - 수행되어야 할 로직을 따라서 코드가 작성되는 패러다임
491 |
492 | ### 특징
493 | - 일이 진행되는 방식으로 그저 코드를 구현하기만 하면 되기 때문에 코드의 가독성이 좋고, 실행 속도도 빠르다
494 | - 모듈화하기가 어렵고 유지 보수성이 떨어진다는 점이 있다
--------------------------------------------------------------------------------