├── README.md
├── data
└── scripts
│ ├── eval_subroot.py
│ ├── make_dp_dataset.py
│ ├── make_subroot_dataset.py
│ ├── make_wsd_pred.py
│ ├── mergy_subroot_feature.py
│ ├── recover_dataset.py
│ ├── subroot_decomposition.py
│ └── subroot_replace_unk.py
├── node2vec
└── train.py
├── onmt
├── Highway.py
├── Loss.py
├── ModelConstructor.py
├── Models.py
├── Optim.py
├── SubwordElmo.py
├── Trainer.py
├── Utils.py
├── __init__.py
├── __init__.pyc
├── io
│ ├── AudioDataset.py
│ ├── DatasetBase.py
│ ├── IO.py
│ ├── IO.pyc
│ ├── ImageDataset.py
│ ├── TextDataset.py
│ ├── __init__.py
│ ├── __init__.pyc
│ └── __pycache__
│ │ ├── AudioDataset.cpython-36.pyc
│ │ ├── DatasetBase.cpython-36.pyc
│ │ ├── IO.cpython-36.pyc
│ │ ├── ImageDataset.cpython-36.pyc
│ │ ├── TextDataset.cpython-36.pyc
│ │ └── __init__.cpython-36.pyc
├── modules
│ ├── AudioEncoder.py
│ ├── Conv2Conv.py
│ ├── ConvMultiStepAttention.py
│ ├── CopyGenerator.py
│ ├── Embeddings.py
│ ├── Gate.py
│ ├── GlobalAttention.py
│ ├── ImageEncoder.py
│ ├── MultiHeadedAttn.py
│ ├── SRU.py
│ ├── StackedRNN.py
│ ├── StructuredAttention.py
│ ├── Transformer.py
│ ├── UtilClass.py
│ ├── WeightNorm.py
│ ├── __init__.py
│ └── __pycache__
│ │ ├── AudioEncoder.cpython-36.pyc
│ │ ├── Conv2Conv.cpython-36.pyc
│ │ ├── ConvMultiStepAttention.cpython-36.pyc
│ │ ├── CopyGenerator.cpython-36.pyc
│ │ ├── Embeddings.cpython-36.pyc
│ │ ├── Gate.cpython-36.pyc
│ │ ├── GlobalAttention.cpython-36.pyc
│ │ ├── ImageEncoder.cpython-36.pyc
│ │ ├── MultiHeadedAttn.cpython-36.pyc
│ │ ├── SRU.cpython-36.pyc
│ │ ├── StackedRNN.cpython-36.pyc
│ │ ├── StructuredAttention.cpython-36.pyc
│ │ ├── Transformer.cpython-36.pyc
│ │ ├── UtilClass.cpython-36.pyc
│ │ ├── WeightNorm.cpython-36.pyc
│ │ └── __init__.cpython-36.pyc
├── opts.py
└── translate
│ ├── Beam.py
│ ├── Penalties.py
│ ├── Translation.py
│ ├── TranslationServer.py
│ ├── Translator.py
│ ├── __init__.py
│ └── __pycache__
│ ├── Beam.cpython-36.pyc
│ ├── Penalties.cpython-36.pyc
│ ├── Translation.cpython-36.pyc
│ ├── TranslationServer.cpython-36.pyc
│ ├── Translator.cpython-36.pyc
│ └── __init__.cpython-36.pyc
├── preprocess.py
├── requirements.opt.txt
├── requirements.txt
├── resources
└── seq2seq4dp.pdf
├── screenshots
└── seq2seq_model.png
├── server.py
├── setup.py
├── subroot
├── README.md
├── RUN.md
├── dnn_pytorch
│ ├── dnn_utils.py
│ ├── generate_features.py
│ ├── loader.py
│ ├── nn.py
│ ├── tag.py
│ ├── train.py
│ └── utils.py
└── subroot
│ ├── preprocess.py
│ ├── stat.py
│ ├── test.py
│ └── train.py
├── tools
├── README.md
├── apply_bpe.py
├── average_models.py
├── bpe_pipeline.sh
├── detokenize.perl
├── embeddings_to_torch.py
├── extract_embeddings.py
├── learn_bpe.py
├── multi-bleu-detok.perl
├── multi-bleu.perl
├── nonbreaking_prefixes
│ ├── README.txt
│ ├── nonbreaking_prefix.ca
│ ├── nonbreaking_prefix.cs
│ ├── nonbreaking_prefix.de
│ ├── nonbreaking_prefix.el
│ ├── nonbreaking_prefix.en
│ ├── nonbreaking_prefix.es
│ ├── nonbreaking_prefix.fi
│ ├── nonbreaking_prefix.fr
│ ├── nonbreaking_prefix.ga
│ ├── nonbreaking_prefix.hu
│ ├── nonbreaking_prefix.is
│ ├── nonbreaking_prefix.it
│ ├── nonbreaking_prefix.lt
│ ├── nonbreaking_prefix.lv
│ ├── nonbreaking_prefix.nl
│ ├── nonbreaking_prefix.pl
│ ├── nonbreaking_prefix.ro
│ ├── nonbreaking_prefix.ru
│ ├── nonbreaking_prefix.sk
│ ├── nonbreaking_prefix.sl
│ ├── nonbreaking_prefix.sv
│ ├── nonbreaking_prefix.ta
│ ├── nonbreaking_prefix.yue
│ └── nonbreaking_prefix.zh
├── release_model.py
├── test_rouge.py
└── tokenizer.perl
├── train.py
└── translate.py
/README.md:
--------------------------------------------------------------------------------
1 | # Sequence to sequence model for dependency parsing based on OpenNMT-py
2 |
3 | This is a Seq2seq model implemented based on [OpenNMT-py](http://opennmt.net/OpenNMT-py/). It is designed to be presents a seq2seq dependency parser by directly predicting the relative position of head for each given presents a seq2seq dependency parser by directly predicting the relative position of head for each given word, which therefore results in a truly end-to-end seq2seq dependency parser for the first time.word, which therefore results in a truly end-to-end seq2seq dependency parser.
4 |
5 | Enjoying the advantage of seq2seq modeling, we enrich a series of embedding enhancement, including firstly introduced subword and node2vec augmentation. Meanwhile, we propose a beam search decoder with tree constraint and subroot decomposition over the sequence to furthermore enhance our seq2seq parser.
6 |
7 | The framework of the proposed seq2seq model:
8 | 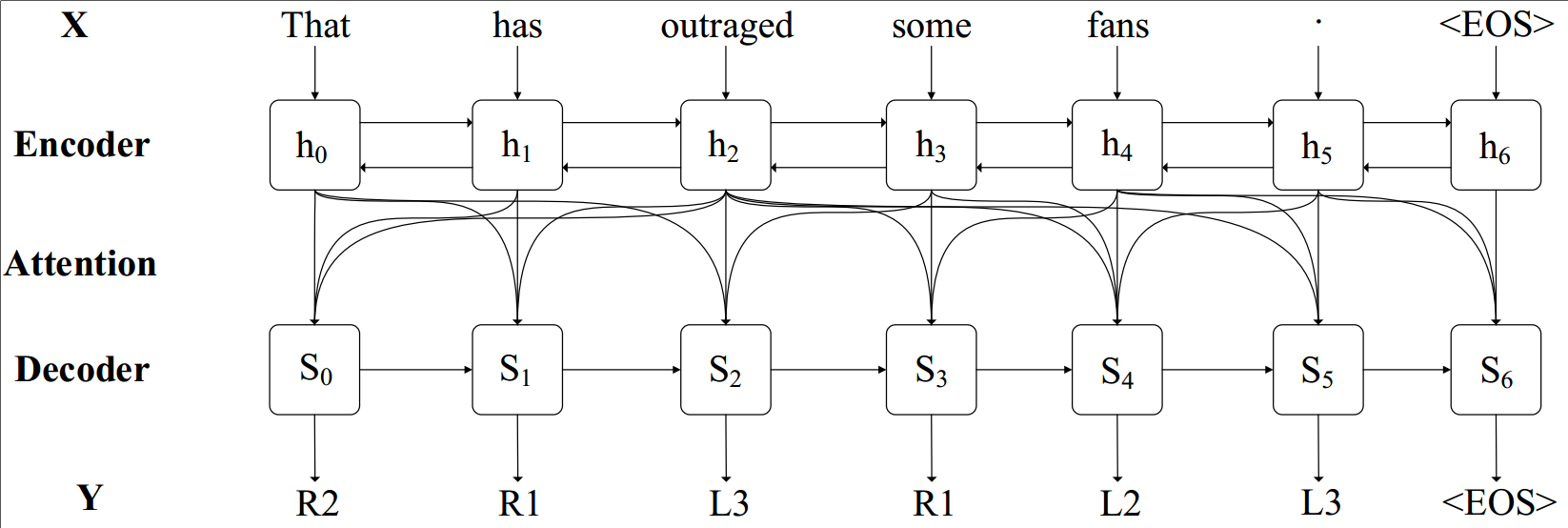 9 |
10 | ## Requirements
11 |
12 | ```bash
13 | pip install -r requirements.txt
14 | ```
15 | this project is tested on pytorch 0.3.1, the other version may need some modification.
16 |
17 | ## Quickstart
18 |
19 | ### Step 1: Convert the dependency parsing dataset
20 |
21 | ```bash
22 | python data/scripts/make_dp_dataset.py
23 | ```
24 |
25 |
26 | ### Step 2: Preprocessing the data
27 |
28 | ```bash
29 | python preprocess.py -train_src data/input/dp/src_ptb_sd_train.input -train_tgt data/input/dp/tgt_ptb_sd_train.input -valid_src data/input/dp/src_ptb_sd_dev.input -valid_tgt data/input/dp/tgt_ptb_sd_dev.input -save_data data/temp/dp/dp
30 | ```
31 | We will be working with some example data in `data/` folder.
32 |
33 | The data consists of parallel source (`src`) and target (`tgt`) data containing one sentence per line with tokens separated by a space:
34 |
35 | * `src-train.txt`
36 | * `tgt-train.txt`
37 | * `src-val.txt`
38 | * `tgt-val.txt`
39 |
40 | Validation files are required and used to evaluate the convergence of the training. It usually contains no more than 5000 sentences.
41 |
42 |
43 | After running the preprocessing, the following files are generated:
44 |
45 | * `dp.train.pt`: serialized PyTorch file containing training data
46 | * `dp.valid.pt`: serialized PyTorch file containing validation data
47 | * `dp.vocab.pt`: serialized PyTorch file containing vocabulary data
48 |
49 |
50 | Internally the system never touches the words themselves, but uses these indices.
51 |
52 | ### Step 2: Make the pretrain embedding
53 |
54 | ```bash
55 | python tools/embeddings_to_torch.py -emb_file_enc data/pretrain/glove.6B.100d.txt -dict_file data/temp/dp/dp.vocab.pt -output_file data/temp/dp/en_embeddings -type GloVe
56 | ```
57 |
58 |
59 | ### Step 3: Train the model
60 |
61 | ```bash
62 | python train.py -save_model data/model/dp/dp -batch_size 64 -enc_layers 4 -dec_layers 2 -rnn_size 800 -word_vec_size 100 -feat_vec_size 100 -pre_word_vecs_enc data/temp/dp/en_embeddings.enc.pt -data data/temp/dp/dp -encoder_type brnn -gpuid 0 -position_encoding -bridge -global_attention mlp -optim adam -learning_rate 0.001 -tensorboard -tensorboard_log_dir logs -elmo -elmo_size 500 -elmo_options data/pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json -elmo_weight data/pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 -subword_elmo -subword_elmo_size 500 -subword_elmo_options data/pretrain/subword_elmo_options.json -subword_weight data/pretrain/en.wiki.bpe.op10000.d50.w2v.txt -subword_spm_model data/pretrain/en.wiki.bpe.op10000.model
63 | ```
64 |
65 | - elmo_2x4096_512_2048cnn_2xhighway_options.json
66 | - elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5
67 | - subword_elmo_options.json
68 | - en.wiki.bpe.op10000.d50.w2v.txt
69 | - en.wiki.bpe.op10000.model
70 |
71 | You can download these files from [here](https://drive.google.com/drive/folders/1ug6ab14fpM22ed_vomOTjjUB8Awh66VM?usp=sharing).
72 |
73 |
74 | ### Step 3: Translate
75 |
76 | ```bash
77 | python translate.py -model data/model/dp/xxx.pt -src data/input/dp/src_ptb_sd_test.input -tgt data/input/dp/tgt_ptb_sd_test.input -output data/results/dp/tgt_ptb_sd_test.pred -replace_unk -verbose -gpu 0 -beam_size 64 -constraint_length 8 -alpha_c 0.8 -alpha_p 0.8
78 | ```
79 |
80 | Now you have a model which you can use to predict on new data. We do this by running beam search where `constraint_length`, `alpha_c`, `alpha_p` are parameters used in tree constraints.
81 |
82 | # Notes
83 | You can refer to our paper for more details. Thank you!
84 |
85 | ## Citation
86 |
87 | [Seq2seq Dependency Parsing](./resources/seq2seq4dp.pdf)
88 |
89 | ```
90 | @inproceedings{li2018seq2seq,
91 | title={Seq2seq dependency parsing},
92 | author={Li, Zuchao and He, Shexia and Zhao, Hai},
93 | booktitle={Proceedings of the 27th International Conference on Computational Linguistics (COLING 2018)},
94 | year={2018}
95 | }
96 | ```
97 |
--------------------------------------------------------------------------------
/data/scripts/eval_subroot.py:
--------------------------------------------------------------------------------
1 | import os
2 | from collections import Counter
3 |
4 | def load_data(path):
5 | with open(path, 'r') as f:
6 | data = f.readlines()
7 |
8 | data = [line.strip().split() for line in data if len(line.strip())>0]
9 |
10 | return data
11 |
12 |
13 | def f1(target, predict):
14 | TP = 0
15 | TN = 0
16 | FP = 0
17 | FN = 0
18 | total = 0
19 | correct = 0
20 | assert len(target) == len(predict)
21 | for i in range(len(target)):
22 | assert len(target[i]) == len(predict[i])
23 | for j in range(len(target[i])):
24 | total += 1
25 | if target[i][j] == predict[i][j]:
26 | correct += 1
27 | assert predict[i][j] == '0' or predict[i][j] == '1'
28 | if target[i][j] == '1' and target[i][j] == predict[i][j]:
29 | TP += 1
30 | if target[i][j] == '0' and target[i][j] == predict[i][j]:
31 | TN += 1
32 | if target[i][j] == '0' and target[i][j] != predict[i][j]:
33 | FP += 1
34 | if target[i][j] == '1' and target[i][j] != predict[i][j]:
35 | FN += 1
36 | P = TP / (TP + FP)
37 | R = TP / (TP + FN)
38 | F1 = 2 * P * R / (P + R)
39 |
40 | print('eval Acc:{:.2f} P:{:.2f} R:{:.2f} F1:{:.2f}'.format(correct/total*100, P * 100, R * 100, F1 * 100))
41 |
42 | if __name__ == '__main__':
43 | f1(load_data(os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_train.input')),
44 | load_data(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_train.pred')))
45 |
46 | f1(load_data(os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_dev.input')),
47 | load_data(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_dev.pred')))
48 |
49 | f1(load_data(os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_test.input')),
50 | load_data(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_test.pred')))
51 |
--------------------------------------------------------------------------------
/data/scripts/make_dp_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tqdm
3 |
4 | # def is_scientific_notation(s):
5 | # s = str(s)
6 | # if s.count(',')>=1:
7 | # sl = s.split(',')
8 | # for item in sl:
9 | # if not item.isdigit():
10 | # return False
11 | # return True
12 | # return False
13 |
14 | # def is_float(s):
15 | # s = str(s)
16 | # if s.count('.')==1:
17 | # sl = s.split('.')
18 | # left = sl[0]
19 | # right = sl[1]
20 | # if left.startswith('-') and left.count('-')==1 and right.isdigit():
21 | # lleft = left.split('-')[1]
22 | # if lleft.isdigit() or is_scientific_notation(lleft):
23 | # return True
24 | # elif (left.isdigit() or is_scientific_notation(left)) and right.isdigit():
25 | # return True
26 | # return False
27 |
28 | # def is_fraction(s):
29 | # s = str(s)
30 | # if s.count('\/')==1:
31 | # sl = s.split('\/')
32 | # if len(sl)== 2 and sl[0].isdigit() and sl[1].isdigit():
33 | # return True
34 | # if s.count('/')==1:
35 | # sl = s.split('/')
36 | # if len(sl)== 2 and sl[0].isdigit() and sl[1].isdigit():
37 | # return True
38 | # if s[-1]=='%' and len(s)>1:
39 | # return True
40 | # return False
41 |
42 | # def is_number(s):
43 | # s = str(s)
44 | # if s.isdigit() or is_float(s) or is_fraction(s) or is_scientific_notation(s):
45 | # return True
46 | # else:
47 | # return False
48 |
49 | def make_input(file_name, src_path, tgt_path):
50 | with open(file_name, 'r') as f:
51 | data = f.readlines()
52 |
53 | origin_data = []
54 | sentence = []
55 |
56 | for i in range(len(data)):
57 | if len(data[i].strip()) > 0:
58 | sentence.append(data[i].strip().split('\t'))
59 | else:
60 | origin_data.append(sentence)
61 | sentence = []
62 |
63 | if len(sentence) > 0:
64 | origin_data.append(sentence)
65 |
66 | src_data = []
67 | tgt_data = []
68 | for sentence in origin_data:
69 | src_line = []
70 | tgt_line = []
71 | for line in sentence:
72 | dep_ind = int(line[0])
73 | head_ind = int(line[6])
74 | if dep_ind > head_ind:
75 | tag = 'L' + str(abs(dep_ind - head_ind))
76 | else:
77 | tag = 'R' + str(abs(dep_ind - head_ind))
78 | # word = ''.join([c if not c.isdigit() else '0' for c in line[1].lower()])
79 | is_number = False
80 | word = line[1].lower()
81 | for c in word:
82 | if c.isdigit():
83 | is_number = True
84 | break
85 | if is_number:
86 | word = 'number'
87 | src_line.append([word, line[4]])
88 | tgt_line.append(tag)
89 | if len(src_line) >= 1:
90 | src_data.append(src_line)
91 | tgt_data.append(tgt_line)
92 |
93 | with open(src_path, 'w') as f:
94 | for line in src_data:
95 | f.write(' '.join(['|'.join(item) for item in line]))
96 | f.write('\n')
97 |
98 |
99 | with open(tgt_path, 'w') as f:
100 | for line in tgt_data:
101 | f.write(' '.join(line))
102 | f.write('\n')
103 |
104 | if __name__ == '__main__':
105 | train_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/train_pro_wsd.conll')
106 | dev_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/dev_pro.conll')
107 | test_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/test_pro.conll')
108 |
109 | make_input(train_file, os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_train.input'),
110 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_train.input'))
111 | make_input(dev_file, os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_dev.input'),
112 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_dev.input'))
113 | make_input(test_file, os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_test.input'),
114 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_test.input'))
115 |
--------------------------------------------------------------------------------
/data/scripts/make_subroot_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tqdm
3 |
4 | def make_input(file_name, src_path, tgt_path):
5 | with open(file_name, 'r') as f:
6 | data = f.readlines()
7 |
8 | origin_data = []
9 | sentence = []
10 |
11 | for i in range(len(data)):
12 | if len(data[i].strip()) > 0:
13 | sentence.append(data[i].strip().split('\t'))
14 | else:
15 | origin_data.append(sentence)
16 | sentence = []
17 |
18 | if len(sentence) > 0:
19 | origin_data.append(sentence)
20 |
21 | src_data = []
22 | tgt_data = []
23 | for sentence in origin_data:
24 | src_line = []
25 | tgt_line = []
26 | for line in sentence:
27 | dep_ind = int(line[0])
28 | head_ind = int(line[6])
29 | if head_ind == 0:
30 | tag = '1'
31 | else:
32 | tag = '0'
33 | # word = ''.join([c if not c.isdigit() else '0' for c in line[1].lower()])
34 | is_number = False
35 | word = line[1].lower()
36 | for c in word:
37 | if c.isdigit():
38 | is_number = True
39 | break
40 | if is_number:
41 | word = 'number'
42 | src_line.append([word, line[4]])
43 | tgt_line.append(tag)
44 | if len(src_line) > 1:
45 | src_data.append(src_line)
46 | tgt_data.append(tgt_line)
47 |
48 | with open(src_path, 'w') as f:
49 | for line in src_data:
50 | f.write(' '.join(['|'.join(item) for item in line]))
51 | f.write('\n')
52 |
53 |
54 | with open(tgt_path, 'w') as f:
55 | for line in tgt_data:
56 | f.write(' '.join(line))
57 | f.write('\n')
58 |
59 | if __name__ == '__main__':
60 | train_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/train_pro_wsd.conll')
61 | dev_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/dev_pro.conll')
62 | test_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/test_pro.conll')
63 |
64 | make_input(train_file,
65 | os.path.join(os.path.dirname(__file__), '../input/subroot/src_ptb_sd_subroot_train.input'),
66 | os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_train.input'))
67 |
68 | make_input(dev_file,
69 | os.path.join(os.path.dirname(__file__), '../input/subroot/src_ptb_sd_subroot_dev.input'),
70 | os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_dev.input'))
71 |
72 | make_input(test_file,
73 | os.path.join(os.path.dirname(__file__), '../input/subroot/src_ptb_sd_subroot_test.input'),
74 | os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_test.input'))
75 |
--------------------------------------------------------------------------------
/data/scripts/make_wsd_pred.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | def make_wsd_pred(pred_file, map_file, output_file):
4 | with open(pred_file, 'r') as f:
5 | pred_data = f.readlines()
6 |
7 | pred_data = [line.split() for line in pred_data if len(line.strip())>0]
8 |
9 |
10 | with open(map_file, 'r') as f:
11 | map_data = f.readlines()
12 |
13 | map_data = [line.strip() for line in map_data if len(line.strip())>0]
14 |
15 | output_data = []
16 |
17 | assert len(map_data) == len(pred_data)
18 |
19 | sent_len = len(map_data)
20 | sent_line = []
21 | for i in range(sent_len):
22 | if len(sent_line) == 0:
23 | sent_line = pred_data[i]
24 | else:
25 | if map_data[i] == map_data[i-1]:
26 | sent_line[-1] = ''
27 | sent_line += pred_data[i][1:]
28 | else:
29 | output_data.append(sent_line)
30 | sent_line = pred_data[i]
31 |
32 | if len(sent_line)>0:
33 | output_data.append(sent_line)
34 |
35 | with open(output_file, 'w') as f:
36 | for i in range(len(output_data)):
37 | for j in range(len(output_data[i])):
38 | if output_data[i][j] == '':
39 | output_data[i][j] = 'L'+str(j+1)
40 | f.write(' '.join(output_data[i]))
41 | f.write('\n')
42 |
43 |
44 | if __name__ == '__main__':
45 | # make_wsd_pred(os.path.join(os.path.dirname(__file__), '../results/dp/tgt_ptb_sd_dev_wsd_30.pred'),
46 | # os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_dev_wsd_30_map.input'))
47 |
48 | make_wsd_pred(os.path.join(os.path.dirname(__file__), '../results/dp/tgt_ptb_sd_test_wsd_40.pred'),
49 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_test_wsd_40_map.input'),
50 | os.path.join(os.path.dirname(__file__), '../results/dp/tgt_ptb_sd_test_wsd_40_org.pred'))
51 |
52 |
--------------------------------------------------------------------------------
/data/scripts/mergy_subroot_feature.py:
--------------------------------------------------------------------------------
1 | # we merge the golden subroot feature into train dataset for training
2 | # and we use the predict subroot (by BiLSTM+CRF) feature into dev/train dataset
3 |
4 | import os
5 |
6 | def merge_train(input_file, origin_file, output_file):
7 | with open(input_file, 'r') as f:
8 | input_data = f.readlines()
9 |
10 | input_data = [line.split() for line in input_data if len(line.strip())>0]
11 |
12 | with open(origin_file, 'r') as f:
13 | data = f.readlines()
14 |
15 | origin_data = []
16 | sentence = []
17 |
18 | for i in range(len(data)):
19 | if len(data[i].strip()) > 0:
20 | sentence.append(data[i].strip().split('\t'))
21 | else:
22 | origin_data.append(sentence)
23 | sentence = []
24 |
25 | if len(sentence) > 0:
26 | origin_data.append(sentence)
27 |
28 | assert len(input_data) == len(origin_data)
29 |
30 | with open(output_file, 'w') as f:
31 | for i in range(len(input_data)):
32 | assert len(input_data[i]) == len(origin_data[i])
33 | line = []
34 | for j in range(len(input_data[i])):
35 | if int(origin_data[i][j][6]) == 0:
36 | line.append(input_data[i][j]+'|1')
37 | else:
38 | line.append(input_data[i][j]+'|0')
39 | f.write(' '.join(line))
40 | f.write('\n')
41 |
42 |
43 | def merge_pred(input_file, subroot_pred_file, output_file):
44 | with open(input_file, 'r') as f:
45 | input_data = f.readlines()
46 |
47 | input_data = [line.split() for line in input_data if len(line.strip())>0]
48 |
49 | with open(subroot_pred_file, 'r') as f:
50 | data = f.readlines()
51 |
52 | pred_data = []
53 | sentence = []
54 |
55 | for i in range(len(data)):
56 | if len(data[i].strip()) > 0:
57 | sentence.append(data[i].strip().split('\t'))
58 | else:
59 | pred_data.append(sentence)
60 | sentence = []
61 |
62 | if len(sentence) > 0:
63 | pred_data.append(sentence)
64 |
65 | assert len(input_data) == len(pred_data)
66 |
67 | with open(output_file, 'w') as f:
68 | for i in range(len(input_data)):
69 | assert len(input_data[i]) == len(pred_data[i])
70 | line = []
71 | for j in range(len(input_data[i])):
72 | line.append(input_data[i][j]+'|'+pred_data[i][j][1])
73 | f.write(' '.join(line))
74 | f.write('\n')
75 |
76 |
77 | if __name__ == '__main__':
78 | merge_train(os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_train.input'),
79 | os.path.join(os.path.dirname(__file__), '../ptb-sd/train_pro.conll'),
80 | os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_train_ws.input'))
81 |
82 | merge_pred(os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_dev.input'),
83 | os.path.join(os.path.dirname(__file__), '../../subroot/result/dev_predicate_95.94.pred'),
84 | os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_dev_ws.input'))
85 |
86 | merge_pred(os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_test.input'),
87 | os.path.join(os.path.dirname(__file__), '../../subroot/result/test_predicate_95.16.pred'),
88 | os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_test_ws.input'))
--------------------------------------------------------------------------------
/data/scripts/recover_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 |
4 | def recover_data(file_name, pred_data, output_path):
5 | with open(file_name, 'r') as f:
6 | data = f.readlines()
7 |
8 |
9 | golden_data = []
10 | sentence = []
11 |
12 | for i in range(len(data)):
13 | if len(data[i].strip()) > 0:
14 | sentence.append(data[i].strip().split('\t'))
15 | else:
16 | golden_data.append(sentence)
17 | sentence = []
18 |
19 | if len(sentence) > 0:
20 | golden_data.append(sentence)
21 |
22 | with open(pred_data, 'r') as f:
23 | data = f.readlines()
24 |
25 | pred_data = [item.strip().split() for item in data if len(item.strip()) > 0]
26 |
27 | pred_index = 0
28 | for i in range(len(golden_data)):
29 | predicate_idx = 0
30 | for j in range(len(golden_data[i])):
31 | if golden_data[i][j][12] == 'Y':
32 | predicate_idx += 1
33 | for k in range(len(golden_data[i])):
34 | golden_data[i][k][13 + predicate_idx] = pred_data[pred_index][k]
35 | pred_index += 1
36 |
37 | with open(output_path, 'w') as f:
38 | for sentence in golden_data:
39 | for line in sentence:
40 | f.write('\t'.join(line))
41 | f.write('\n')
42 | f.write('\n')
43 |
44 | if __name__ == '__main__':
45 | recover_data(os.path.join(os.path.dirname(__file__), 'conll09-english/conll09_test.dataset'),
46 | os.path.join(os.path.dirname(__file__), 'tgt_conll09_en_test.pred'),
47 | os.path.join(os.path.dirname(__file__), 'conll09_en_test.dataset.pred'))
48 |
--------------------------------------------------------------------------------
/data/scripts/subroot_replace_unk.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | def replace_unk(input_file):
4 | with open(input_file, 'r') as f:
5 | input_data = f.readlines()
6 |
7 | input_data = [line.split() for line in input_data if len(line.strip())>0]
8 |
9 | with open(input_file, 'w') as f:
10 | for i in range(len(input_data)):
11 | line = []
12 | for j in range(len(input_data[i])):
13 | if input_data[i][j] == '0' or input_data[i][j]=='1':
14 | line.append(input_data[i][j])
15 | else:
16 | line.append('0')
17 | f.write(' '.join(line))
18 | f.write('\n')
19 |
20 |
21 | if __name__ == '__main__':
22 | replace_unk(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_train.pred'))
23 |
24 | replace_unk(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_dev.pred'))
25 |
26 | replace_unk(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_test.pred'))
--------------------------------------------------------------------------------
/node2vec/train.py:
--------------------------------------------------------------------------------
1 | import networkx as nx
2 | from node2vec import Node2Vec
3 |
4 | # FILES
5 | EMBEDDING_FILENAME = './node2vec_en.emb'
6 | EMBEDDING_MODEL_FILENAME = './node2vec_en.model'
7 |
8 | # Create a graph
9 | # graph = nx.fast_gnp_random_graph(n=100, p=0.5)
10 | graph = nx.Graph()
11 |
12 | raw_train_file = '../data/ptb-sd/train_pro.conll'
13 |
14 | with open(raw_train_file, 'r') as f:
15 | data = f.readlines()
16 |
17 | # read data
18 | train_data = []
19 | sentence = []
20 | for line in data:
21 | if len(line.strip()) > 0:
22 | line = line.strip().split('\t')
23 | sentence.append(line)
24 | else:
25 | train_data.append(sentence)
26 | sentence = []
27 | if len(sentence)>0:
28 | train_data.append(sentence)
29 | sentence = []
30 |
31 | for sentence in train_data:
32 | for line in sentence:
33 | head_idx = int(line[6])-1
34 | if head_idx == -1:
35 | is_number = False
36 | word = line[1].lower()
37 | for c in word:
38 | if c.isdigit():
39 | is_number = True
40 | break
41 | if is_number:
42 | word = 'number'
43 | graph.add_edge('', word, weight=1)
44 | else:
45 | hw = sentence[head_idx][1].lower()
46 | is_number = False
47 | for c in hw:
48 | if c.isdigit():
49 | is_number = True
50 | break
51 | if is_number:
52 | hw = 'number'
53 | w = line[1].lower()
54 | is_number = False
55 | for c in w:
56 | if c.isdigit():
57 | is_number = True
58 | break
59 | if is_number:
60 | w = 'number'
61 | graph.add_edge(hw, w, weight=0.5)
62 |
63 | # Precompute probabilities and generate walks
64 | node2vec = Node2Vec(graph, dimensions=100, walk_length=100, num_walks=18, workers=1)
65 |
66 | # Embed
67 | model = node2vec.fit(window=16, min_count=1, batch_words=64) # Any keywords acceptable by gensim.Word2Vec can be passed, `diemnsions` and `workers` are automatically passed (from the Node2Vec constructor)
68 |
69 | # Look for most similar nodes
70 | model.wv.most_similar('') # Output node names are always strings
71 |
72 | # Save embeddings for later use
73 | model.wv.save_word2vec_format(EMBEDDING_FILENAME)
74 |
75 | # Save model for later use
76 | model.save(EMBEDDING_MODEL_FILENAME)
--------------------------------------------------------------------------------
/onmt/Highway.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 |
5 | class HighwayMLP(nn.Module):
6 |
7 | def __init__(self,
8 | input_size,
9 | gate_bias=-2,
10 | activation_function=nn.functional.relu,
11 | gate_activation=nn.functional.softmax):
12 |
13 | super(HighwayMLP, self).__init__()
14 |
15 | self.activation_function = activation_function
16 | self.gate_activation = gate_activation
17 |
18 | self.normal_layer = nn.Linear(input_size, input_size)
19 |
20 | self.gate_layer = nn.Linear(input_size, input_size)
21 | self.gate_layer.bias.data.fill_(gate_bias)
22 |
23 | def forward(self, x):
24 |
25 | normal_layer_result = self.activation_function(self.normal_layer(x))
26 | gate_layer_result = self.gate_activation(self.gate_layer(x),dim=0)
27 |
28 | multiplyed_gate_and_normal = torch.mul(normal_layer_result, gate_layer_result)
29 | multiplyed_gate_and_input = torch.mul((1 - gate_layer_result), x)
30 |
31 | return torch.add(multiplyed_gate_and_normal,
32 | multiplyed_gate_and_input)
33 |
34 |
35 | class HighwayCNN(nn.Module):
36 | def __init__(self,
37 | input_size,
38 | gate_bias=-1,
39 | activation_function=nn.functional.relu,
40 | gate_activation=nn.functional.softmax):
41 |
42 | super(HighwayCNN, self).__init__()
43 |
44 | self.activation_function = activation_function
45 | self.gate_activation = gate_activation
46 |
47 | self.normal_layer = nn.Linear(input_size, input_size)
48 |
49 | self.gate_layer = nn.Linear(input_size, input_size)
50 | self.gate_layer.bias.data.fill_(gate_bias)
51 |
52 | def forward(self, x):
53 |
54 | normal_layer_result = self.activation_function(self.normal_layer(x))
55 | gate_layer_result = self.gate_activation(self.gate_layer(x))
56 |
57 | multiplyed_gate_and_normal = torch.mul(normal_layer_result, gate_layer_result)
58 | multiplyed_gate_and_input = torch.mul((1 - gate_layer_result), x)
59 |
60 | return torch.add(multiplyed_gate_and_normal,
61 | multiplyed_gate_and_input)
--------------------------------------------------------------------------------
/onmt/Optim.py:
--------------------------------------------------------------------------------
1 | import torch.optim as optim
2 | from torch.nn.utils import clip_grad_norm
3 |
4 |
5 | class MultipleOptimizer(object):
6 | def __init__(self, op):
7 | self.optimizers = op
8 |
9 | def zero_grad(self):
10 | for op in self.optimizers:
11 | op.zero_grad()
12 |
13 | def step(self):
14 | for op in self.optimizers:
15 | op.step()
16 |
17 |
18 | class Optim(object):
19 | """
20 | Controller class for optimization. Mostly a thin
21 | wrapper for `optim`, but also useful for implementing
22 | rate scheduling beyond what is currently available.
23 | Also implements necessary methods for training RNNs such
24 | as grad manipulations.
25 |
26 | Args:
27 | method (:obj:`str`): one of [sgd, adagrad, adadelta, adam]
28 | lr (float): learning rate
29 | lr_decay (float, optional): learning rate decay multiplier
30 | start_decay_at (int, optional): epoch to start learning rate decay
31 | beta1, beta2 (float, optional): parameters for adam
32 | adagrad_accum (float, optional): initialization parameter for adagrad
33 | decay_method (str, option): custom decay options
34 | warmup_steps (int, option): parameter for `noam` decay
35 | model_size (int, option): parameter for `noam` decay
36 | """
37 | # We use the default parameters for Adam that are suggested by
38 | # the original paper https://arxiv.org/pdf/1412.6980.pdf
39 | # These values are also used by other established implementations,
40 | # e.g. https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer
41 | # https://keras.io/optimizers/
42 | # Recently there are slightly different values used in the paper
43 | # "Attention is all you need"
44 | # https://arxiv.org/pdf/1706.03762.pdf, particularly the value beta2=0.98
45 | # was used there however, beta2=0.999 is still arguably the more
46 | # established value, so we use that here as well
47 | def __init__(self, method, lr, max_grad_norm,
48 | lr_decay=1, start_decay_at=None,
49 | beta1=0.9, beta2=0.999,
50 | adagrad_accum=0.0,
51 | decay_method=None,
52 | warmup_steps=4000,
53 | model_size=None):
54 | self.last_ppl = None
55 | self.lr = lr
56 | self.original_lr = lr
57 | self.max_grad_norm = max_grad_norm
58 | self.method = method
59 | self.lr_decay = lr_decay
60 | self.start_decay_at = start_decay_at
61 | self.start_decay = False
62 | self._step = 0
63 | self.betas = [beta1, beta2]
64 | self.adagrad_accum = adagrad_accum
65 | self.decay_method = decay_method
66 | self.warmup_steps = warmup_steps
67 | self.model_size = model_size
68 |
69 | def set_parameters(self, params):
70 | self.params = []
71 | self.sparse_params = []
72 | for k, p in params:
73 | if p.requires_grad:
74 | if self.method != 'sparseadam' or "embed" not in k:
75 | self.params.append(p)
76 | else:
77 | self.sparse_params.append(p)
78 | if self.method == 'sgd':
79 | self.optimizer = optim.SGD(self.params, lr=self.lr)
80 | elif self.method == 'adagrad':
81 | self.optimizer = optim.Adagrad(self.params, lr=self.lr)
82 | for group in self.optimizer.param_groups:
83 | for p in group['params']:
84 | self.optimizer.state[p]['sum'] = self.optimizer\
85 | .state[p]['sum'].fill_(self.adagrad_accum)
86 | elif self.method == 'adadelta':
87 | self.optimizer = optim.Adadelta(self.params, lr=self.lr)
88 | elif self.method == 'adam':
89 | self.optimizer = optim.Adam(self.params, lr=self.lr,
90 | betas=self.betas, eps=1e-9)
91 | elif self.method == 'sparseadam':
92 | self.optimizer = MultipleOptimizer(
93 | [optim.Adam(self.params, lr=self.lr,
94 | betas=self.betas, eps=1e-8),
95 | optim.SparseAdam(self.sparse_params, lr=self.lr,
96 | betas=self.betas, eps=1e-8)])
97 | else:
98 | raise RuntimeError("Invalid optim method: " + self.method)
99 |
100 | def _set_rate(self, lr):
101 | self.lr = lr
102 | if self.method != 'sparseadam':
103 | self.optimizer.param_groups[0]['lr'] = self.lr
104 | else:
105 | for op in self.optimizer.optimizers:
106 | op.param_groups[0]['lr'] = self.lr
107 |
108 | def step(self):
109 | """Update the model parameters based on current gradients.
110 |
111 | Optionally, will employ gradient modification or update learning
112 | rate.
113 | """
114 | self._step += 1
115 |
116 | # Decay method used in tensor2tensor.
117 | if self.decay_method == "noam":
118 | self._set_rate(
119 | self.original_lr *
120 | (self.model_size ** (-0.5) *
121 | min(self._step ** (-0.5),
122 | self._step * self.warmup_steps**(-1.5))))
123 |
124 | if self.max_grad_norm:
125 | clip_grad_norm(self.params, self.max_grad_norm)
126 | self.optimizer.step()
127 |
128 | def update_learning_rate(self, ppl, epoch):
129 | """
130 | Decay learning rate if val perf does not improve
131 | or we hit the start_decay_at limit.
132 | """
133 |
134 | if self.start_decay_at is not None and epoch >= self.start_decay_at:
135 | self.start_decay = True
136 | if self.last_ppl is not None and ppl > self.last_ppl:
137 | self.start_decay = True
138 |
139 | if self.start_decay:
140 | self.lr = self.lr * self.lr_decay
141 | print("Decaying learning rate to %g" % self.lr)
142 |
143 | self.last_ppl = ppl
144 | if self.method != 'sparseadam':
145 | self.optimizer.param_groups[0]['lr'] = self.lr
146 |
--------------------------------------------------------------------------------
/onmt/Utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def aeq(*args):
5 | """
6 | Assert all arguments have the same value
7 | """
8 | arguments = (arg for arg in args)
9 | first = next(arguments)
10 | assert all(arg == first for arg in arguments), \
11 | "Not all arguments have the same value: " + str(args)
12 |
13 |
14 | def sequence_mask(lengths, max_len=None):
15 | """
16 | Creates a boolean mask from sequence lengths.
17 | """
18 | batch_size = lengths.numel()
19 | max_len = max_len or lengths.max()
20 | return (torch.arange(0, max_len)
21 | .type_as(lengths)
22 | .repeat(batch_size, 1)
23 | .lt(lengths.unsqueeze(1)))
24 |
25 |
26 | def use_gpu(opt):
27 | return (hasattr(opt, 'gpuid') and len(opt.gpuid) > 0) or \
28 | (hasattr(opt, 'gpu') and opt.gpu > -1)
29 |
--------------------------------------------------------------------------------
/onmt/__init__.py:
--------------------------------------------------------------------------------
1 | import onmt.io
2 | import onmt.Models
3 | import onmt.Loss
4 | import onmt.translate
5 | import onmt.opts
6 | from onmt.Trainer import Trainer, Statistics
7 | from onmt.Optim import Optim
8 |
9 | # For flake8 compatibility
10 | __all__ = [onmt.Loss, onmt.Models, onmt.opts,
11 | Trainer, Optim, Statistics, onmt.io, onmt.translate]
12 |
--------------------------------------------------------------------------------
/onmt/__init__.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/__init__.pyc
--------------------------------------------------------------------------------
/onmt/io/DatasetBase.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | from itertools import chain
4 | import torchtext
5 |
6 |
7 | PAD_WORD = ''
8 | UNK_WORD = ''
9 | UNK = 0
10 | BOS_WORD = '
9 |
10 | ## Requirements
11 |
12 | ```bash
13 | pip install -r requirements.txt
14 | ```
15 | this project is tested on pytorch 0.3.1, the other version may need some modification.
16 |
17 | ## Quickstart
18 |
19 | ### Step 1: Convert the dependency parsing dataset
20 |
21 | ```bash
22 | python data/scripts/make_dp_dataset.py
23 | ```
24 |
25 |
26 | ### Step 2: Preprocessing the data
27 |
28 | ```bash
29 | python preprocess.py -train_src data/input/dp/src_ptb_sd_train.input -train_tgt data/input/dp/tgt_ptb_sd_train.input -valid_src data/input/dp/src_ptb_sd_dev.input -valid_tgt data/input/dp/tgt_ptb_sd_dev.input -save_data data/temp/dp/dp
30 | ```
31 | We will be working with some example data in `data/` folder.
32 |
33 | The data consists of parallel source (`src`) and target (`tgt`) data containing one sentence per line with tokens separated by a space:
34 |
35 | * `src-train.txt`
36 | * `tgt-train.txt`
37 | * `src-val.txt`
38 | * `tgt-val.txt`
39 |
40 | Validation files are required and used to evaluate the convergence of the training. It usually contains no more than 5000 sentences.
41 |
42 |
43 | After running the preprocessing, the following files are generated:
44 |
45 | * `dp.train.pt`: serialized PyTorch file containing training data
46 | * `dp.valid.pt`: serialized PyTorch file containing validation data
47 | * `dp.vocab.pt`: serialized PyTorch file containing vocabulary data
48 |
49 |
50 | Internally the system never touches the words themselves, but uses these indices.
51 |
52 | ### Step 2: Make the pretrain embedding
53 |
54 | ```bash
55 | python tools/embeddings_to_torch.py -emb_file_enc data/pretrain/glove.6B.100d.txt -dict_file data/temp/dp/dp.vocab.pt -output_file data/temp/dp/en_embeddings -type GloVe
56 | ```
57 |
58 |
59 | ### Step 3: Train the model
60 |
61 | ```bash
62 | python train.py -save_model data/model/dp/dp -batch_size 64 -enc_layers 4 -dec_layers 2 -rnn_size 800 -word_vec_size 100 -feat_vec_size 100 -pre_word_vecs_enc data/temp/dp/en_embeddings.enc.pt -data data/temp/dp/dp -encoder_type brnn -gpuid 0 -position_encoding -bridge -global_attention mlp -optim adam -learning_rate 0.001 -tensorboard -tensorboard_log_dir logs -elmo -elmo_size 500 -elmo_options data/pretrain/elmo_2x4096_512_2048cnn_2xhighway_options.json -elmo_weight data/pretrain/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5 -subword_elmo -subword_elmo_size 500 -subword_elmo_options data/pretrain/subword_elmo_options.json -subword_weight data/pretrain/en.wiki.bpe.op10000.d50.w2v.txt -subword_spm_model data/pretrain/en.wiki.bpe.op10000.model
63 | ```
64 |
65 | - elmo_2x4096_512_2048cnn_2xhighway_options.json
66 | - elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5
67 | - subword_elmo_options.json
68 | - en.wiki.bpe.op10000.d50.w2v.txt
69 | - en.wiki.bpe.op10000.model
70 |
71 | You can download these files from [here](https://drive.google.com/drive/folders/1ug6ab14fpM22ed_vomOTjjUB8Awh66VM?usp=sharing).
72 |
73 |
74 | ### Step 3: Translate
75 |
76 | ```bash
77 | python translate.py -model data/model/dp/xxx.pt -src data/input/dp/src_ptb_sd_test.input -tgt data/input/dp/tgt_ptb_sd_test.input -output data/results/dp/tgt_ptb_sd_test.pred -replace_unk -verbose -gpu 0 -beam_size 64 -constraint_length 8 -alpha_c 0.8 -alpha_p 0.8
78 | ```
79 |
80 | Now you have a model which you can use to predict on new data. We do this by running beam search where `constraint_length`, `alpha_c`, `alpha_p` are parameters used in tree constraints.
81 |
82 | # Notes
83 | You can refer to our paper for more details. Thank you!
84 |
85 | ## Citation
86 |
87 | [Seq2seq Dependency Parsing](./resources/seq2seq4dp.pdf)
88 |
89 | ```
90 | @inproceedings{li2018seq2seq,
91 | title={Seq2seq dependency parsing},
92 | author={Li, Zuchao and He, Shexia and Zhao, Hai},
93 | booktitle={Proceedings of the 27th International Conference on Computational Linguistics (COLING 2018)},
94 | year={2018}
95 | }
96 | ```
97 |
--------------------------------------------------------------------------------
/data/scripts/eval_subroot.py:
--------------------------------------------------------------------------------
1 | import os
2 | from collections import Counter
3 |
4 | def load_data(path):
5 | with open(path, 'r') as f:
6 | data = f.readlines()
7 |
8 | data = [line.strip().split() for line in data if len(line.strip())>0]
9 |
10 | return data
11 |
12 |
13 | def f1(target, predict):
14 | TP = 0
15 | TN = 0
16 | FP = 0
17 | FN = 0
18 | total = 0
19 | correct = 0
20 | assert len(target) == len(predict)
21 | for i in range(len(target)):
22 | assert len(target[i]) == len(predict[i])
23 | for j in range(len(target[i])):
24 | total += 1
25 | if target[i][j] == predict[i][j]:
26 | correct += 1
27 | assert predict[i][j] == '0' or predict[i][j] == '1'
28 | if target[i][j] == '1' and target[i][j] == predict[i][j]:
29 | TP += 1
30 | if target[i][j] == '0' and target[i][j] == predict[i][j]:
31 | TN += 1
32 | if target[i][j] == '0' and target[i][j] != predict[i][j]:
33 | FP += 1
34 | if target[i][j] == '1' and target[i][j] != predict[i][j]:
35 | FN += 1
36 | P = TP / (TP + FP)
37 | R = TP / (TP + FN)
38 | F1 = 2 * P * R / (P + R)
39 |
40 | print('eval Acc:{:.2f} P:{:.2f} R:{:.2f} F1:{:.2f}'.format(correct/total*100, P * 100, R * 100, F1 * 100))
41 |
42 | if __name__ == '__main__':
43 | f1(load_data(os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_train.input')),
44 | load_data(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_train.pred')))
45 |
46 | f1(load_data(os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_dev.input')),
47 | load_data(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_dev.pred')))
48 |
49 | f1(load_data(os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_test.input')),
50 | load_data(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_test.pred')))
51 |
--------------------------------------------------------------------------------
/data/scripts/make_dp_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tqdm
3 |
4 | # def is_scientific_notation(s):
5 | # s = str(s)
6 | # if s.count(',')>=1:
7 | # sl = s.split(',')
8 | # for item in sl:
9 | # if not item.isdigit():
10 | # return False
11 | # return True
12 | # return False
13 |
14 | # def is_float(s):
15 | # s = str(s)
16 | # if s.count('.')==1:
17 | # sl = s.split('.')
18 | # left = sl[0]
19 | # right = sl[1]
20 | # if left.startswith('-') and left.count('-')==1 and right.isdigit():
21 | # lleft = left.split('-')[1]
22 | # if lleft.isdigit() or is_scientific_notation(lleft):
23 | # return True
24 | # elif (left.isdigit() or is_scientific_notation(left)) and right.isdigit():
25 | # return True
26 | # return False
27 |
28 | # def is_fraction(s):
29 | # s = str(s)
30 | # if s.count('\/')==1:
31 | # sl = s.split('\/')
32 | # if len(sl)== 2 and sl[0].isdigit() and sl[1].isdigit():
33 | # return True
34 | # if s.count('/')==1:
35 | # sl = s.split('/')
36 | # if len(sl)== 2 and sl[0].isdigit() and sl[1].isdigit():
37 | # return True
38 | # if s[-1]=='%' and len(s)>1:
39 | # return True
40 | # return False
41 |
42 | # def is_number(s):
43 | # s = str(s)
44 | # if s.isdigit() or is_float(s) or is_fraction(s) or is_scientific_notation(s):
45 | # return True
46 | # else:
47 | # return False
48 |
49 | def make_input(file_name, src_path, tgt_path):
50 | with open(file_name, 'r') as f:
51 | data = f.readlines()
52 |
53 | origin_data = []
54 | sentence = []
55 |
56 | for i in range(len(data)):
57 | if len(data[i].strip()) > 0:
58 | sentence.append(data[i].strip().split('\t'))
59 | else:
60 | origin_data.append(sentence)
61 | sentence = []
62 |
63 | if len(sentence) > 0:
64 | origin_data.append(sentence)
65 |
66 | src_data = []
67 | tgt_data = []
68 | for sentence in origin_data:
69 | src_line = []
70 | tgt_line = []
71 | for line in sentence:
72 | dep_ind = int(line[0])
73 | head_ind = int(line[6])
74 | if dep_ind > head_ind:
75 | tag = 'L' + str(abs(dep_ind - head_ind))
76 | else:
77 | tag = 'R' + str(abs(dep_ind - head_ind))
78 | # word = ''.join([c if not c.isdigit() else '0' for c in line[1].lower()])
79 | is_number = False
80 | word = line[1].lower()
81 | for c in word:
82 | if c.isdigit():
83 | is_number = True
84 | break
85 | if is_number:
86 | word = 'number'
87 | src_line.append([word, line[4]])
88 | tgt_line.append(tag)
89 | if len(src_line) >= 1:
90 | src_data.append(src_line)
91 | tgt_data.append(tgt_line)
92 |
93 | with open(src_path, 'w') as f:
94 | for line in src_data:
95 | f.write(' '.join(['|'.join(item) for item in line]))
96 | f.write('\n')
97 |
98 |
99 | with open(tgt_path, 'w') as f:
100 | for line in tgt_data:
101 | f.write(' '.join(line))
102 | f.write('\n')
103 |
104 | if __name__ == '__main__':
105 | train_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/train_pro_wsd.conll')
106 | dev_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/dev_pro.conll')
107 | test_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/test_pro.conll')
108 |
109 | make_input(train_file, os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_train.input'),
110 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_train.input'))
111 | make_input(dev_file, os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_dev.input'),
112 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_dev.input'))
113 | make_input(test_file, os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_test.input'),
114 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_test.input'))
115 |
--------------------------------------------------------------------------------
/data/scripts/make_subroot_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 | import tqdm
3 |
4 | def make_input(file_name, src_path, tgt_path):
5 | with open(file_name, 'r') as f:
6 | data = f.readlines()
7 |
8 | origin_data = []
9 | sentence = []
10 |
11 | for i in range(len(data)):
12 | if len(data[i].strip()) > 0:
13 | sentence.append(data[i].strip().split('\t'))
14 | else:
15 | origin_data.append(sentence)
16 | sentence = []
17 |
18 | if len(sentence) > 0:
19 | origin_data.append(sentence)
20 |
21 | src_data = []
22 | tgt_data = []
23 | for sentence in origin_data:
24 | src_line = []
25 | tgt_line = []
26 | for line in sentence:
27 | dep_ind = int(line[0])
28 | head_ind = int(line[6])
29 | if head_ind == 0:
30 | tag = '1'
31 | else:
32 | tag = '0'
33 | # word = ''.join([c if not c.isdigit() else '0' for c in line[1].lower()])
34 | is_number = False
35 | word = line[1].lower()
36 | for c in word:
37 | if c.isdigit():
38 | is_number = True
39 | break
40 | if is_number:
41 | word = 'number'
42 | src_line.append([word, line[4]])
43 | tgt_line.append(tag)
44 | if len(src_line) > 1:
45 | src_data.append(src_line)
46 | tgt_data.append(tgt_line)
47 |
48 | with open(src_path, 'w') as f:
49 | for line in src_data:
50 | f.write(' '.join(['|'.join(item) for item in line]))
51 | f.write('\n')
52 |
53 |
54 | with open(tgt_path, 'w') as f:
55 | for line in tgt_data:
56 | f.write(' '.join(line))
57 | f.write('\n')
58 |
59 | if __name__ == '__main__':
60 | train_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/train_pro_wsd.conll')
61 | dev_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/dev_pro.conll')
62 | test_file = os.path.join(os.path.dirname(__file__), '../ptb-sd/test_pro.conll')
63 |
64 | make_input(train_file,
65 | os.path.join(os.path.dirname(__file__), '../input/subroot/src_ptb_sd_subroot_train.input'),
66 | os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_train.input'))
67 |
68 | make_input(dev_file,
69 | os.path.join(os.path.dirname(__file__), '../input/subroot/src_ptb_sd_subroot_dev.input'),
70 | os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_dev.input'))
71 |
72 | make_input(test_file,
73 | os.path.join(os.path.dirname(__file__), '../input/subroot/src_ptb_sd_subroot_test.input'),
74 | os.path.join(os.path.dirname(__file__), '../input/subroot/tgt_ptb_sd_subroot_test.input'))
75 |
--------------------------------------------------------------------------------
/data/scripts/make_wsd_pred.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | def make_wsd_pred(pred_file, map_file, output_file):
4 | with open(pred_file, 'r') as f:
5 | pred_data = f.readlines()
6 |
7 | pred_data = [line.split() for line in pred_data if len(line.strip())>0]
8 |
9 |
10 | with open(map_file, 'r') as f:
11 | map_data = f.readlines()
12 |
13 | map_data = [line.strip() for line in map_data if len(line.strip())>0]
14 |
15 | output_data = []
16 |
17 | assert len(map_data) == len(pred_data)
18 |
19 | sent_len = len(map_data)
20 | sent_line = []
21 | for i in range(sent_len):
22 | if len(sent_line) == 0:
23 | sent_line = pred_data[i]
24 | else:
25 | if map_data[i] == map_data[i-1]:
26 | sent_line[-1] = ''
27 | sent_line += pred_data[i][1:]
28 | else:
29 | output_data.append(sent_line)
30 | sent_line = pred_data[i]
31 |
32 | if len(sent_line)>0:
33 | output_data.append(sent_line)
34 |
35 | with open(output_file, 'w') as f:
36 | for i in range(len(output_data)):
37 | for j in range(len(output_data[i])):
38 | if output_data[i][j] == '':
39 | output_data[i][j] = 'L'+str(j+1)
40 | f.write(' '.join(output_data[i]))
41 | f.write('\n')
42 |
43 |
44 | if __name__ == '__main__':
45 | # make_wsd_pred(os.path.join(os.path.dirname(__file__), '../results/dp/tgt_ptb_sd_dev_wsd_30.pred'),
46 | # os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_dev_wsd_30_map.input'))
47 |
48 | make_wsd_pred(os.path.join(os.path.dirname(__file__), '../results/dp/tgt_ptb_sd_test_wsd_40.pred'),
49 | os.path.join(os.path.dirname(__file__), '../input/dp/tgt_ptb_sd_test_wsd_40_map.input'),
50 | os.path.join(os.path.dirname(__file__), '../results/dp/tgt_ptb_sd_test_wsd_40_org.pred'))
51 |
52 |
--------------------------------------------------------------------------------
/data/scripts/mergy_subroot_feature.py:
--------------------------------------------------------------------------------
1 | # we merge the golden subroot feature into train dataset for training
2 | # and we use the predict subroot (by BiLSTM+CRF) feature into dev/train dataset
3 |
4 | import os
5 |
6 | def merge_train(input_file, origin_file, output_file):
7 | with open(input_file, 'r') as f:
8 | input_data = f.readlines()
9 |
10 | input_data = [line.split() for line in input_data if len(line.strip())>0]
11 |
12 | with open(origin_file, 'r') as f:
13 | data = f.readlines()
14 |
15 | origin_data = []
16 | sentence = []
17 |
18 | for i in range(len(data)):
19 | if len(data[i].strip()) > 0:
20 | sentence.append(data[i].strip().split('\t'))
21 | else:
22 | origin_data.append(sentence)
23 | sentence = []
24 |
25 | if len(sentence) > 0:
26 | origin_data.append(sentence)
27 |
28 | assert len(input_data) == len(origin_data)
29 |
30 | with open(output_file, 'w') as f:
31 | for i in range(len(input_data)):
32 | assert len(input_data[i]) == len(origin_data[i])
33 | line = []
34 | for j in range(len(input_data[i])):
35 | if int(origin_data[i][j][6]) == 0:
36 | line.append(input_data[i][j]+'|1')
37 | else:
38 | line.append(input_data[i][j]+'|0')
39 | f.write(' '.join(line))
40 | f.write('\n')
41 |
42 |
43 | def merge_pred(input_file, subroot_pred_file, output_file):
44 | with open(input_file, 'r') as f:
45 | input_data = f.readlines()
46 |
47 | input_data = [line.split() for line in input_data if len(line.strip())>0]
48 |
49 | with open(subroot_pred_file, 'r') as f:
50 | data = f.readlines()
51 |
52 | pred_data = []
53 | sentence = []
54 |
55 | for i in range(len(data)):
56 | if len(data[i].strip()) > 0:
57 | sentence.append(data[i].strip().split('\t'))
58 | else:
59 | pred_data.append(sentence)
60 | sentence = []
61 |
62 | if len(sentence) > 0:
63 | pred_data.append(sentence)
64 |
65 | assert len(input_data) == len(pred_data)
66 |
67 | with open(output_file, 'w') as f:
68 | for i in range(len(input_data)):
69 | assert len(input_data[i]) == len(pred_data[i])
70 | line = []
71 | for j in range(len(input_data[i])):
72 | line.append(input_data[i][j]+'|'+pred_data[i][j][1])
73 | f.write(' '.join(line))
74 | f.write('\n')
75 |
76 |
77 | if __name__ == '__main__':
78 | merge_train(os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_train.input'),
79 | os.path.join(os.path.dirname(__file__), '../ptb-sd/train_pro.conll'),
80 | os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_train_ws.input'))
81 |
82 | merge_pred(os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_dev.input'),
83 | os.path.join(os.path.dirname(__file__), '../../subroot/result/dev_predicate_95.94.pred'),
84 | os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_dev_ws.input'))
85 |
86 | merge_pred(os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_test.input'),
87 | os.path.join(os.path.dirname(__file__), '../../subroot/result/test_predicate_95.16.pred'),
88 | os.path.join(os.path.dirname(__file__), '../input/dp/src_ptb_sd_test_ws.input'))
--------------------------------------------------------------------------------
/data/scripts/recover_dataset.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 |
4 | def recover_data(file_name, pred_data, output_path):
5 | with open(file_name, 'r') as f:
6 | data = f.readlines()
7 |
8 |
9 | golden_data = []
10 | sentence = []
11 |
12 | for i in range(len(data)):
13 | if len(data[i].strip()) > 0:
14 | sentence.append(data[i].strip().split('\t'))
15 | else:
16 | golden_data.append(sentence)
17 | sentence = []
18 |
19 | if len(sentence) > 0:
20 | golden_data.append(sentence)
21 |
22 | with open(pred_data, 'r') as f:
23 | data = f.readlines()
24 |
25 | pred_data = [item.strip().split() for item in data if len(item.strip()) > 0]
26 |
27 | pred_index = 0
28 | for i in range(len(golden_data)):
29 | predicate_idx = 0
30 | for j in range(len(golden_data[i])):
31 | if golden_data[i][j][12] == 'Y':
32 | predicate_idx += 1
33 | for k in range(len(golden_data[i])):
34 | golden_data[i][k][13 + predicate_idx] = pred_data[pred_index][k]
35 | pred_index += 1
36 |
37 | with open(output_path, 'w') as f:
38 | for sentence in golden_data:
39 | for line in sentence:
40 | f.write('\t'.join(line))
41 | f.write('\n')
42 | f.write('\n')
43 |
44 | if __name__ == '__main__':
45 | recover_data(os.path.join(os.path.dirname(__file__), 'conll09-english/conll09_test.dataset'),
46 | os.path.join(os.path.dirname(__file__), 'tgt_conll09_en_test.pred'),
47 | os.path.join(os.path.dirname(__file__), 'conll09_en_test.dataset.pred'))
48 |
--------------------------------------------------------------------------------
/data/scripts/subroot_replace_unk.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | def replace_unk(input_file):
4 | with open(input_file, 'r') as f:
5 | input_data = f.readlines()
6 |
7 | input_data = [line.split() for line in input_data if len(line.strip())>0]
8 |
9 | with open(input_file, 'w') as f:
10 | for i in range(len(input_data)):
11 | line = []
12 | for j in range(len(input_data[i])):
13 | if input_data[i][j] == '0' or input_data[i][j]=='1':
14 | line.append(input_data[i][j])
15 | else:
16 | line.append('0')
17 | f.write(' '.join(line))
18 | f.write('\n')
19 |
20 |
21 | if __name__ == '__main__':
22 | replace_unk(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_train.pred'))
23 |
24 | replace_unk(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_dev.pred'))
25 |
26 | replace_unk(os.path.join(os.path.dirname(__file__), '../results/subroot/tgt_ptb_sd_subroot_test.pred'))
--------------------------------------------------------------------------------
/node2vec/train.py:
--------------------------------------------------------------------------------
1 | import networkx as nx
2 | from node2vec import Node2Vec
3 |
4 | # FILES
5 | EMBEDDING_FILENAME = './node2vec_en.emb'
6 | EMBEDDING_MODEL_FILENAME = './node2vec_en.model'
7 |
8 | # Create a graph
9 | # graph = nx.fast_gnp_random_graph(n=100, p=0.5)
10 | graph = nx.Graph()
11 |
12 | raw_train_file = '../data/ptb-sd/train_pro.conll'
13 |
14 | with open(raw_train_file, 'r') as f:
15 | data = f.readlines()
16 |
17 | # read data
18 | train_data = []
19 | sentence = []
20 | for line in data:
21 | if len(line.strip()) > 0:
22 | line = line.strip().split('\t')
23 | sentence.append(line)
24 | else:
25 | train_data.append(sentence)
26 | sentence = []
27 | if len(sentence)>0:
28 | train_data.append(sentence)
29 | sentence = []
30 |
31 | for sentence in train_data:
32 | for line in sentence:
33 | head_idx = int(line[6])-1
34 | if head_idx == -1:
35 | is_number = False
36 | word = line[1].lower()
37 | for c in word:
38 | if c.isdigit():
39 | is_number = True
40 | break
41 | if is_number:
42 | word = 'number'
43 | graph.add_edge('', word, weight=1)
44 | else:
45 | hw = sentence[head_idx][1].lower()
46 | is_number = False
47 | for c in hw:
48 | if c.isdigit():
49 | is_number = True
50 | break
51 | if is_number:
52 | hw = 'number'
53 | w = line[1].lower()
54 | is_number = False
55 | for c in w:
56 | if c.isdigit():
57 | is_number = True
58 | break
59 | if is_number:
60 | w = 'number'
61 | graph.add_edge(hw, w, weight=0.5)
62 |
63 | # Precompute probabilities and generate walks
64 | node2vec = Node2Vec(graph, dimensions=100, walk_length=100, num_walks=18, workers=1)
65 |
66 | # Embed
67 | model = node2vec.fit(window=16, min_count=1, batch_words=64) # Any keywords acceptable by gensim.Word2Vec can be passed, `diemnsions` and `workers` are automatically passed (from the Node2Vec constructor)
68 |
69 | # Look for most similar nodes
70 | model.wv.most_similar('') # Output node names are always strings
71 |
72 | # Save embeddings for later use
73 | model.wv.save_word2vec_format(EMBEDDING_FILENAME)
74 |
75 | # Save model for later use
76 | model.save(EMBEDDING_MODEL_FILENAME)
--------------------------------------------------------------------------------
/onmt/Highway.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 |
5 | class HighwayMLP(nn.Module):
6 |
7 | def __init__(self,
8 | input_size,
9 | gate_bias=-2,
10 | activation_function=nn.functional.relu,
11 | gate_activation=nn.functional.softmax):
12 |
13 | super(HighwayMLP, self).__init__()
14 |
15 | self.activation_function = activation_function
16 | self.gate_activation = gate_activation
17 |
18 | self.normal_layer = nn.Linear(input_size, input_size)
19 |
20 | self.gate_layer = nn.Linear(input_size, input_size)
21 | self.gate_layer.bias.data.fill_(gate_bias)
22 |
23 | def forward(self, x):
24 |
25 | normal_layer_result = self.activation_function(self.normal_layer(x))
26 | gate_layer_result = self.gate_activation(self.gate_layer(x),dim=0)
27 |
28 | multiplyed_gate_and_normal = torch.mul(normal_layer_result, gate_layer_result)
29 | multiplyed_gate_and_input = torch.mul((1 - gate_layer_result), x)
30 |
31 | return torch.add(multiplyed_gate_and_normal,
32 | multiplyed_gate_and_input)
33 |
34 |
35 | class HighwayCNN(nn.Module):
36 | def __init__(self,
37 | input_size,
38 | gate_bias=-1,
39 | activation_function=nn.functional.relu,
40 | gate_activation=nn.functional.softmax):
41 |
42 | super(HighwayCNN, self).__init__()
43 |
44 | self.activation_function = activation_function
45 | self.gate_activation = gate_activation
46 |
47 | self.normal_layer = nn.Linear(input_size, input_size)
48 |
49 | self.gate_layer = nn.Linear(input_size, input_size)
50 | self.gate_layer.bias.data.fill_(gate_bias)
51 |
52 | def forward(self, x):
53 |
54 | normal_layer_result = self.activation_function(self.normal_layer(x))
55 | gate_layer_result = self.gate_activation(self.gate_layer(x))
56 |
57 | multiplyed_gate_and_normal = torch.mul(normal_layer_result, gate_layer_result)
58 | multiplyed_gate_and_input = torch.mul((1 - gate_layer_result), x)
59 |
60 | return torch.add(multiplyed_gate_and_normal,
61 | multiplyed_gate_and_input)
--------------------------------------------------------------------------------
/onmt/Optim.py:
--------------------------------------------------------------------------------
1 | import torch.optim as optim
2 | from torch.nn.utils import clip_grad_norm
3 |
4 |
5 | class MultipleOptimizer(object):
6 | def __init__(self, op):
7 | self.optimizers = op
8 |
9 | def zero_grad(self):
10 | for op in self.optimizers:
11 | op.zero_grad()
12 |
13 | def step(self):
14 | for op in self.optimizers:
15 | op.step()
16 |
17 |
18 | class Optim(object):
19 | """
20 | Controller class for optimization. Mostly a thin
21 | wrapper for `optim`, but also useful for implementing
22 | rate scheduling beyond what is currently available.
23 | Also implements necessary methods for training RNNs such
24 | as grad manipulations.
25 |
26 | Args:
27 | method (:obj:`str`): one of [sgd, adagrad, adadelta, adam]
28 | lr (float): learning rate
29 | lr_decay (float, optional): learning rate decay multiplier
30 | start_decay_at (int, optional): epoch to start learning rate decay
31 | beta1, beta2 (float, optional): parameters for adam
32 | adagrad_accum (float, optional): initialization parameter for adagrad
33 | decay_method (str, option): custom decay options
34 | warmup_steps (int, option): parameter for `noam` decay
35 | model_size (int, option): parameter for `noam` decay
36 | """
37 | # We use the default parameters for Adam that are suggested by
38 | # the original paper https://arxiv.org/pdf/1412.6980.pdf
39 | # These values are also used by other established implementations,
40 | # e.g. https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer
41 | # https://keras.io/optimizers/
42 | # Recently there are slightly different values used in the paper
43 | # "Attention is all you need"
44 | # https://arxiv.org/pdf/1706.03762.pdf, particularly the value beta2=0.98
45 | # was used there however, beta2=0.999 is still arguably the more
46 | # established value, so we use that here as well
47 | def __init__(self, method, lr, max_grad_norm,
48 | lr_decay=1, start_decay_at=None,
49 | beta1=0.9, beta2=0.999,
50 | adagrad_accum=0.0,
51 | decay_method=None,
52 | warmup_steps=4000,
53 | model_size=None):
54 | self.last_ppl = None
55 | self.lr = lr
56 | self.original_lr = lr
57 | self.max_grad_norm = max_grad_norm
58 | self.method = method
59 | self.lr_decay = lr_decay
60 | self.start_decay_at = start_decay_at
61 | self.start_decay = False
62 | self._step = 0
63 | self.betas = [beta1, beta2]
64 | self.adagrad_accum = adagrad_accum
65 | self.decay_method = decay_method
66 | self.warmup_steps = warmup_steps
67 | self.model_size = model_size
68 |
69 | def set_parameters(self, params):
70 | self.params = []
71 | self.sparse_params = []
72 | for k, p in params:
73 | if p.requires_grad:
74 | if self.method != 'sparseadam' or "embed" not in k:
75 | self.params.append(p)
76 | else:
77 | self.sparse_params.append(p)
78 | if self.method == 'sgd':
79 | self.optimizer = optim.SGD(self.params, lr=self.lr)
80 | elif self.method == 'adagrad':
81 | self.optimizer = optim.Adagrad(self.params, lr=self.lr)
82 | for group in self.optimizer.param_groups:
83 | for p in group['params']:
84 | self.optimizer.state[p]['sum'] = self.optimizer\
85 | .state[p]['sum'].fill_(self.adagrad_accum)
86 | elif self.method == 'adadelta':
87 | self.optimizer = optim.Adadelta(self.params, lr=self.lr)
88 | elif self.method == 'adam':
89 | self.optimizer = optim.Adam(self.params, lr=self.lr,
90 | betas=self.betas, eps=1e-9)
91 | elif self.method == 'sparseadam':
92 | self.optimizer = MultipleOptimizer(
93 | [optim.Adam(self.params, lr=self.lr,
94 | betas=self.betas, eps=1e-8),
95 | optim.SparseAdam(self.sparse_params, lr=self.lr,
96 | betas=self.betas, eps=1e-8)])
97 | else:
98 | raise RuntimeError("Invalid optim method: " + self.method)
99 |
100 | def _set_rate(self, lr):
101 | self.lr = lr
102 | if self.method != 'sparseadam':
103 | self.optimizer.param_groups[0]['lr'] = self.lr
104 | else:
105 | for op in self.optimizer.optimizers:
106 | op.param_groups[0]['lr'] = self.lr
107 |
108 | def step(self):
109 | """Update the model parameters based on current gradients.
110 |
111 | Optionally, will employ gradient modification or update learning
112 | rate.
113 | """
114 | self._step += 1
115 |
116 | # Decay method used in tensor2tensor.
117 | if self.decay_method == "noam":
118 | self._set_rate(
119 | self.original_lr *
120 | (self.model_size ** (-0.5) *
121 | min(self._step ** (-0.5),
122 | self._step * self.warmup_steps**(-1.5))))
123 |
124 | if self.max_grad_norm:
125 | clip_grad_norm(self.params, self.max_grad_norm)
126 | self.optimizer.step()
127 |
128 | def update_learning_rate(self, ppl, epoch):
129 | """
130 | Decay learning rate if val perf does not improve
131 | or we hit the start_decay_at limit.
132 | """
133 |
134 | if self.start_decay_at is not None and epoch >= self.start_decay_at:
135 | self.start_decay = True
136 | if self.last_ppl is not None and ppl > self.last_ppl:
137 | self.start_decay = True
138 |
139 | if self.start_decay:
140 | self.lr = self.lr * self.lr_decay
141 | print("Decaying learning rate to %g" % self.lr)
142 |
143 | self.last_ppl = ppl
144 | if self.method != 'sparseadam':
145 | self.optimizer.param_groups[0]['lr'] = self.lr
146 |
--------------------------------------------------------------------------------
/onmt/Utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 |
4 | def aeq(*args):
5 | """
6 | Assert all arguments have the same value
7 | """
8 | arguments = (arg for arg in args)
9 | first = next(arguments)
10 | assert all(arg == first for arg in arguments), \
11 | "Not all arguments have the same value: " + str(args)
12 |
13 |
14 | def sequence_mask(lengths, max_len=None):
15 | """
16 | Creates a boolean mask from sequence lengths.
17 | """
18 | batch_size = lengths.numel()
19 | max_len = max_len or lengths.max()
20 | return (torch.arange(0, max_len)
21 | .type_as(lengths)
22 | .repeat(batch_size, 1)
23 | .lt(lengths.unsqueeze(1)))
24 |
25 |
26 | def use_gpu(opt):
27 | return (hasattr(opt, 'gpuid') and len(opt.gpuid) > 0) or \
28 | (hasattr(opt, 'gpu') and opt.gpu > -1)
29 |
--------------------------------------------------------------------------------
/onmt/__init__.py:
--------------------------------------------------------------------------------
1 | import onmt.io
2 | import onmt.Models
3 | import onmt.Loss
4 | import onmt.translate
5 | import onmt.opts
6 | from onmt.Trainer import Trainer, Statistics
7 | from onmt.Optim import Optim
8 |
9 | # For flake8 compatibility
10 | __all__ = [onmt.Loss, onmt.Models, onmt.opts,
11 | Trainer, Optim, Statistics, onmt.io, onmt.translate]
12 |
--------------------------------------------------------------------------------
/onmt/__init__.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/__init__.pyc
--------------------------------------------------------------------------------
/onmt/io/DatasetBase.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 |
3 | from itertools import chain
4 | import torchtext
5 |
6 |
7 | PAD_WORD = ''
8 | UNK_WORD = ''
9 | UNK = 0
10 | BOS_WORD = ''
11 | EOS_WORD = ''
12 |
13 |
14 | class ONMTDatasetBase(torchtext.data.Dataset):
15 | """
16 | A dataset basically supports iteration over all the examples
17 | it contains. We currently have 3 datasets inheriting this base
18 | for 3 types of corpus respectively: "text", "img", "audio".
19 |
20 | Internally it initializes an `torchtext.data.Dataset` object with
21 | the following attributes:
22 |
23 | `examples`: a sequence of `torchtext.data.Example` objects.
24 | `fields`: a dictionary associating str keys with `torchtext.data.Field`
25 | objects, and not necessarily having the same keys as the input fields.
26 | """
27 | def __getstate__(self):
28 | return self.__dict__
29 |
30 | def __setstate__(self, d):
31 | self.__dict__.update(d)
32 |
33 | def __reduce_ex__(self, proto):
34 | "This is a hack. Something is broken with torch pickle."
35 | return super(ONMTDatasetBase, self).__reduce_ex__()
36 |
37 | def load_fields(self, vocab_dict):
38 | """ Load fields from vocab.pt, and set the `fields` attribute.
39 |
40 | Args:
41 | vocab_dict (dict): a dict of loaded vocab from vocab.pt file.
42 | """
43 | from onmt.io.IO import load_fields_from_vocab
44 |
45 | fields = load_fields_from_vocab(vocab_dict.items(), self.data_type)
46 | self.fields = dict([(k, f) for (k, f) in fields.items()
47 | if k in self.examples[0].__dict__])
48 |
49 | @staticmethod
50 | def extract_text_features(tokens):
51 | """
52 | Args:
53 | tokens: A list of tokens, where each token consists of a word,
54 | optionally followed by u"│"-delimited features.
55 | Returns:
56 | A sequence of words, a sequence of features, and num of features.
57 | """
58 | if not tokens:
59 | return [], [], -1
60 |
61 | split_tokens = [token.split('|') for token in tokens] # u"│"
62 | split_tokens = [token for token in split_tokens if token[0]]
63 | token_size = len(split_tokens[0])
64 |
65 | assert all(len(token) == token_size for token in split_tokens), \
66 | "all words must have the same number of features"
67 | words_and_features = list(zip(*split_tokens))
68 | words = words_and_features[0]
69 | features = words_and_features[1:]
70 |
71 | return words, features, token_size - 1
72 |
73 | # Below are helper functions for intra-class use only.
74 |
75 | def _join_dicts(self, *args):
76 | """
77 | Args:
78 | dictionaries with disjoint keys.
79 |
80 | Returns:
81 | a single dictionary that has the union of these keys.
82 | """
83 | return dict(chain(*[d.items() for d in args]))
84 |
85 | def _peek(self, seq):
86 | """
87 | Args:
88 | seq: an iterator.
89 |
90 | Returns:
91 | the first thing returned by calling next() on the iterator
92 | and an iterator created by re-chaining that value to the beginning
93 | of the iterator.
94 | """
95 | first = next(seq)
96 | return first, chain([first], seq)
97 |
98 | def _construct_example_fromlist(self, data, fields):
99 | """
100 | Args:
101 | data: the data to be set as the value of the attributes of
102 | the to-be-created `Example`, associating with respective
103 | `Field` objects with same key.
104 | fields: a dict of `torchtext.data.Field` objects. The keys
105 | are attributes of the to-be-created `Example`.
106 |
107 | Returns:
108 | the created `Example` object.
109 | """
110 | ex = torchtext.data.Example()
111 | for (name, field), val in zip(fields, data):
112 | if field is not None:
113 | setattr(ex, name, field.preprocess(val))
114 | else:
115 | setattr(ex, name, val)
116 | return ex
117 |
--------------------------------------------------------------------------------
/onmt/io/IO.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/IO.pyc
--------------------------------------------------------------------------------
/onmt/io/__init__.py:
--------------------------------------------------------------------------------
1 | from onmt.io.IO import collect_feature_vocabs, make_features, \
2 | collect_features, get_num_features, \
3 | load_fields_from_vocab, get_fields, \
4 | save_fields_to_vocab, build_dataset, \
5 | build_vocab, merge_vocabs, OrderedIterator
6 | from onmt.io.DatasetBase import ONMTDatasetBase, PAD_WORD, BOS_WORD, \
7 | EOS_WORD, UNK
8 | from onmt.io.TextDataset import TextDataset, ShardedTextCorpusIterator
9 | from onmt.io.ImageDataset import ImageDataset
10 | from onmt.io.AudioDataset import AudioDataset
11 |
12 |
13 | __all__ = [PAD_WORD, BOS_WORD, EOS_WORD, UNK, ONMTDatasetBase,
14 | collect_feature_vocabs, make_features,
15 | collect_features, get_num_features,
16 | load_fields_from_vocab, get_fields,
17 | save_fields_to_vocab, build_dataset,
18 | build_vocab, merge_vocabs, OrderedIterator,
19 | TextDataset, ImageDataset, AudioDataset,
20 | ShardedTextCorpusIterator]
21 |
--------------------------------------------------------------------------------
/onmt/io/__init__.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/__init__.pyc
--------------------------------------------------------------------------------
/onmt/io/__pycache__/AudioDataset.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/__pycache__/AudioDataset.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/io/__pycache__/DatasetBase.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/__pycache__/DatasetBase.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/io/__pycache__/IO.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/__pycache__/IO.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/io/__pycache__/ImageDataset.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/__pycache__/ImageDataset.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/io/__pycache__/TextDataset.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/__pycache__/TextDataset.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/io/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/io/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/AudioEncoder.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 |
5 |
6 | class AudioEncoder(nn.Module):
7 | """
8 | A simple encoder convolutional -> recurrent neural network for
9 | audio input.
10 |
11 | Args:
12 | num_layers (int): number of encoder layers.
13 | bidirectional (bool): bidirectional encoder.
14 | rnn_size (int): size of hidden states of the rnn.
15 | dropout (float): dropout probablity.
16 | sample_rate (float): input spec
17 | window_size (int): input spec
18 |
19 | """
20 | def __init__(self, num_layers, bidirectional, rnn_size, dropout,
21 | sample_rate, window_size):
22 | super(AudioEncoder, self).__init__()
23 | self.num_layers = num_layers
24 | self.num_directions = 2 if bidirectional else 1
25 | self.hidden_size = rnn_size
26 |
27 | self.layer1 = nn.Conv2d(1, 32, kernel_size=(41, 11),
28 | padding=(0, 10), stride=(2, 2))
29 | self.batch_norm1 = nn.BatchNorm2d(32)
30 | self.layer2 = nn.Conv2d(32, 32, kernel_size=(21, 11),
31 | padding=(0, 0), stride=(2, 1))
32 | self.batch_norm2 = nn.BatchNorm2d(32)
33 |
34 | input_size = int(math.floor((sample_rate * window_size) / 2) + 1)
35 | input_size = int(math.floor(input_size - 41) / 2 + 1)
36 | input_size = int(math.floor(input_size - 21) / 2 + 1)
37 | input_size *= 32
38 | self.rnn = nn.LSTM(input_size, rnn_size,
39 | num_layers=num_layers,
40 | dropout=dropout,
41 | bidirectional=bidirectional)
42 |
43 | def load_pretrained_vectors(self, opt):
44 | # Pass in needed options only when modify function definition.
45 | pass
46 |
47 | def forward(self, input, lengths=None):
48 | "See :obj:`onmt.modules.EncoderBase.forward()`"
49 | # (batch_size, 1, nfft, t)
50 | # layer 1
51 | input = self.batch_norm1(self.layer1(input[:, :, :, :]))
52 |
53 | # (batch_size, 32, nfft/2, t/2)
54 | input = F.hardtanh(input, 0, 20, inplace=True)
55 |
56 | # (batch_size, 32, nfft/2/2, t/2)
57 | # layer 2
58 | input = self.batch_norm2(self.layer2(input))
59 |
60 | # (batch_size, 32, nfft/2/2, t/2)
61 | input = F.hardtanh(input, 0, 20, inplace=True)
62 |
63 | batch_size = input.size(0)
64 | length = input.size(3)
65 | input = input.view(batch_size, -1, length)
66 | input = input.transpose(0, 2).transpose(1, 2)
67 |
68 | output, hidden = self.rnn(input)
69 |
70 | return hidden, output
71 |
--------------------------------------------------------------------------------
/onmt/modules/ConvMultiStepAttention.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import torch.nn.functional as F
4 | from onmt.Utils import aeq
5 |
6 |
7 | SCALE_WEIGHT = 0.5 ** 0.5
8 |
9 |
10 | def seq_linear(linear, x):
11 | # linear transform for 3-d tensor
12 | batch, hidden_size, length, _ = x.size()
13 | h = linear(torch.transpose(x, 1, 2).contiguous().view(
14 | batch * length, hidden_size))
15 | return torch.transpose(h.view(batch, length, hidden_size, 1), 1, 2)
16 |
17 |
18 | class ConvMultiStepAttention(nn.Module):
19 | """
20 |
21 | Conv attention takes a key matrix, a value matrix and a query vector.
22 | Attention weight is calculated by key matrix with the query vector
23 | and sum on the value matrix. And the same operation is applied
24 | in each decode conv layer.
25 |
26 | """
27 |
28 | def __init__(self, input_size):
29 | super(ConvMultiStepAttention, self).__init__()
30 | self.linear_in = nn.Linear(input_size, input_size)
31 | self.mask = None
32 |
33 | def apply_mask(self, mask):
34 | self.mask = mask
35 |
36 | def forward(self, base_target_emb, input, encoder_out_top,
37 | encoder_out_combine):
38 | """
39 | Args:
40 | base_target_emb: target emb tensor
41 | input: output of decode conv
42 | encoder_out_t: the key matrix for calculation of attetion weight,
43 | which is the top output of encode conv
44 | encoder_out_combine:
45 | the value matrix for the attention-weighted sum,
46 | which is the combination of base emb and top output of encode
47 |
48 | """
49 | # checks
50 | batch, channel, height, width = base_target_emb.size()
51 | batch_, channel_, height_, width_ = input.size()
52 | aeq(batch, batch_)
53 | aeq(height, height_)
54 |
55 | enc_batch, enc_channel, enc_height = encoder_out_top.size()
56 | enc_batch_, enc_channel_, enc_height_ = encoder_out_combine.size()
57 |
58 | aeq(enc_batch, enc_batch_)
59 | aeq(enc_height, enc_height_)
60 |
61 | preatt = seq_linear(self.linear_in, input)
62 | target = (base_target_emb + preatt) * SCALE_WEIGHT
63 | target = torch.squeeze(target, 3)
64 | target = torch.transpose(target, 1, 2)
65 | pre_attn = torch.bmm(target, encoder_out_top)
66 |
67 | if self.mask is not None:
68 | pre_attn.data.masked_fill_(self.mask, -float('inf'))
69 |
70 | pre_attn = pre_attn.transpose(0, 2)
71 | attn = F.softmax(pre_attn)
72 | attn = attn.transpose(0, 2).contiguous()
73 | context_output = torch.bmm(
74 | attn, torch.transpose(encoder_out_combine, 1, 2))
75 | context_output = torch.transpose(
76 | torch.unsqueeze(context_output, 3), 1, 2)
77 | return context_output, attn
78 |
--------------------------------------------------------------------------------
/onmt/modules/Gate.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 |
5 | def context_gate_factory(type, embeddings_size, decoder_size,
6 | attention_size, output_size):
7 | """Returns the correct ContextGate class"""
8 |
9 | gate_types = {'source': SourceContextGate,
10 | 'target': TargetContextGate,
11 | 'both': BothContextGate}
12 |
13 | assert type in gate_types, "Not valid ContextGate type: {0}".format(type)
14 | return gate_types[type](embeddings_size, decoder_size, attention_size,
15 | output_size)
16 |
17 |
18 | class ContextGate(nn.Module):
19 | """
20 | Context gate is a decoder module that takes as input the previous word
21 | embedding, the current decoder state and the attention state, and
22 | produces a gate.
23 | The gate can be used to select the input from the target side context
24 | (decoder state), from the source context (attention state) or both.
25 | """
26 | def __init__(self, embeddings_size, decoder_size,
27 | attention_size, output_size):
28 | super(ContextGate, self).__init__()
29 | input_size = embeddings_size + decoder_size + attention_size
30 | self.gate = nn.Linear(input_size, output_size, bias=True)
31 | self.sig = nn.Sigmoid()
32 | self.source_proj = nn.Linear(attention_size, output_size)
33 | self.target_proj = nn.Linear(embeddings_size + decoder_size,
34 | output_size)
35 |
36 | def forward(self, prev_emb, dec_state, attn_state):
37 | input_tensor = torch.cat((prev_emb, dec_state, attn_state), dim=1)
38 | z = self.sig(self.gate(input_tensor))
39 | proj_source = self.source_proj(attn_state)
40 | proj_target = self.target_proj(
41 | torch.cat((prev_emb, dec_state), dim=1))
42 | return z, proj_source, proj_target
43 |
44 |
45 | class SourceContextGate(nn.Module):
46 | """Apply the context gate only to the source context"""
47 |
48 | def __init__(self, embeddings_size, decoder_size,
49 | attention_size, output_size):
50 | super(SourceContextGate, self).__init__()
51 | self.context_gate = ContextGate(embeddings_size, decoder_size,
52 | attention_size, output_size)
53 | self.tanh = nn.Tanh()
54 |
55 | def forward(self, prev_emb, dec_state, attn_state):
56 | z, source, target = self.context_gate(
57 | prev_emb, dec_state, attn_state)
58 | return self.tanh(target + z * source)
59 |
60 |
61 | class TargetContextGate(nn.Module):
62 | """Apply the context gate only to the target context"""
63 |
64 | def __init__(self, embeddings_size, decoder_size,
65 | attention_size, output_size):
66 | super(TargetContextGate, self).__init__()
67 | self.context_gate = ContextGate(embeddings_size, decoder_size,
68 | attention_size, output_size)
69 | self.tanh = nn.Tanh()
70 |
71 | def forward(self, prev_emb, dec_state, attn_state):
72 | z, source, target = self.context_gate(prev_emb, dec_state, attn_state)
73 | return self.tanh(z * target + source)
74 |
75 |
76 | class BothContextGate(nn.Module):
77 | """Apply the context gate to both contexts"""
78 |
79 | def __init__(self, embeddings_size, decoder_size,
80 | attention_size, output_size):
81 | super(BothContextGate, self).__init__()
82 | self.context_gate = ContextGate(embeddings_size, decoder_size,
83 | attention_size, output_size)
84 | self.tanh = nn.Tanh()
85 |
86 | def forward(self, prev_emb, dec_state, attn_state):
87 | z, source, target = self.context_gate(prev_emb, dec_state, attn_state)
88 | return self.tanh((1. - z) * target + z * source)
89 |
--------------------------------------------------------------------------------
/onmt/modules/GlobalAttention.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 | from onmt.Utils import aeq, sequence_mask
5 |
6 |
7 | class GlobalAttention(nn.Module):
8 | """
9 | Global attention takes a matrix and a query vector. It
10 | then computes a parameterized convex combination of the matrix
11 | based on the input query.
12 |
13 | Constructs a unit mapping a query `q` of size `dim`
14 | and a source matrix `H` of size `n x dim`, to an output
15 | of size `dim`.
16 |
17 |
18 | .. mermaid::
19 |
20 | graph BT
21 | A[Query]
22 | subgraph RNN
23 | C[H 1]
24 | D[H 2]
25 | E[H N]
26 | end
27 | F[Attn]
28 | G[Output]
29 | A --> F
30 | C --> F
31 | D --> F
32 | E --> F
33 | C -.-> G
34 | D -.-> G
35 | E -.-> G
36 | F --> G
37 |
38 | All models compute the output as
39 | :math:`c = \sum_{j=1}^{SeqLength} a_j H_j` where
40 | :math:`a_j` is the softmax of a score function.
41 | Then then apply a projection layer to [q, c].
42 |
43 | However they
44 | differ on how they compute the attention score.
45 |
46 | * Luong Attention (dot, general):
47 | * dot: :math:`score(H_j,q) = H_j^T q`
48 | * general: :math:`score(H_j, q) = H_j^T W_a q`
49 |
50 |
51 | * Bahdanau Attention (mlp):
52 | * :math:`score(H_j, q) = v_a^T tanh(W_a q + U_a h_j)`
53 |
54 |
55 | Args:
56 | dim (int): dimensionality of query and key
57 | coverage (bool): use coverage term
58 | attn_type (str): type of attention to use, options [dot,general,mlp]
59 |
60 | """
61 | def __init__(self, dim, coverage=False, attn_type="dot"):
62 | super(GlobalAttention, self).__init__()
63 |
64 | self.dim = dim
65 | self.attn_type = attn_type
66 | assert (self.attn_type in ["dot", "general", "mlp"]), (
67 | "Please select a valid attention type.")
68 |
69 | if self.attn_type == "general":
70 | self.linear_in = nn.Linear(dim, dim, bias=False)
71 | elif self.attn_type == "mlp":
72 | self.linear_context = nn.Linear(dim, dim, bias=False)
73 | self.linear_query = nn.Linear(dim, dim, bias=True)
74 | self.v = nn.Linear(dim, 1, bias=False)
75 | # mlp wants it with bias
76 | out_bias = self.attn_type == "mlp"
77 | self.linear_out = nn.Linear(dim*2, dim, bias=out_bias)
78 |
79 | self.sm = nn.Softmax(dim=-1)
80 | self.tanh = nn.Tanh()
81 |
82 | if coverage:
83 | self.linear_cover = nn.Linear(1, dim, bias=False)
84 |
85 | def score(self, h_t, h_s):
86 | """
87 | Args:
88 | h_t (`FloatTensor`): sequence of queries `[batch x tgt_len x dim]`
89 | h_s (`FloatTensor`): sequence of sources `[batch x src_len x dim]`
90 |
91 | Returns:
92 | :obj:`FloatTensor`:
93 | raw attention scores (unnormalized) for each src index
94 | `[batch x tgt_len x src_len]`
95 |
96 | """
97 |
98 | # Check input sizes
99 | src_batch, src_len, src_dim = h_s.size()
100 | tgt_batch, tgt_len, tgt_dim = h_t.size()
101 | aeq(src_batch, tgt_batch)
102 | aeq(src_dim, tgt_dim)
103 | aeq(self.dim, src_dim)
104 |
105 | if self.attn_type in ["general", "dot"]:
106 | if self.attn_type == "general":
107 | h_t_ = h_t.view(tgt_batch*tgt_len, tgt_dim)
108 | h_t_ = self.linear_in(h_t_)
109 | h_t = h_t_.view(tgt_batch, tgt_len, tgt_dim)
110 | h_s_ = h_s.transpose(1, 2)
111 | # (batch, t_len, d) x (batch, d, s_len) --> (batch, t_len, s_len)
112 | return torch.bmm(h_t, h_s_)
113 | else:
114 | dim = self.dim
115 | wq = self.linear_query(h_t.view(-1, dim))
116 | wq = wq.view(tgt_batch, tgt_len, 1, dim)
117 | wq = wq.expand(tgt_batch, tgt_len, src_len, dim)
118 |
119 | uh = self.linear_context(h_s.contiguous().view(-1, dim))
120 | uh = uh.view(src_batch, 1, src_len, dim)
121 | uh = uh.expand(src_batch, tgt_len, src_len, dim)
122 |
123 | # (batch, t_len, s_len, d)
124 | wquh = self.tanh(wq + uh)
125 |
126 | return self.v(wquh.view(-1, dim)).view(tgt_batch, tgt_len, src_len)
127 |
128 | def forward(self, input, memory_bank, memory_lengths=None, coverage=None):
129 | """
130 |
131 | Args:
132 | input (`FloatTensor`): query vectors `[batch x tgt_len x dim]`
133 | memory_bank (`FloatTensor`): source vectors `[batch x src_len x dim]`
134 | memory_lengths (`LongTensor`): the source context lengths `[batch]`
135 | coverage (`FloatTensor`): None (not supported yet)
136 |
137 | Returns:
138 | (`FloatTensor`, `FloatTensor`):
139 |
140 | * Computed vector `[tgt_len x batch x dim]`
141 | * Attention distribtutions for each query
142 | `[tgt_len x batch x src_len]`
143 | """
144 |
145 | # one step input
146 | if input.dim() == 2:
147 | one_step = True
148 | input = input.unsqueeze(1)
149 | else:
150 | one_step = False
151 |
152 | batch, sourceL, dim = memory_bank.size()
153 | batch_, targetL, dim_ = input.size()
154 | aeq(batch, batch_)
155 | aeq(dim, dim_)
156 | aeq(self.dim, dim)
157 | if coverage is not None:
158 | batch_, sourceL_ = coverage.size()
159 | aeq(batch, batch_)
160 | aeq(sourceL, sourceL_)
161 |
162 | if coverage is not None:
163 | cover = coverage.view(-1).unsqueeze(1)
164 | memory_bank += self.linear_cover(cover).view_as(memory_bank)
165 | memory_bank = self.tanh(memory_bank)
166 |
167 | # compute attention scores, as in Luong et al.
168 | align = self.score(input, memory_bank)
169 |
170 | if memory_lengths is not None:
171 | mask = sequence_mask(memory_lengths)
172 | mask = mask.unsqueeze(1) # Make it broadcastable.
173 | align.data.masked_fill_(1 - mask, -float('inf'))
174 |
175 | # Softmax to normalize attention weights
176 | align_vectors = self.sm(align.view(batch*targetL, sourceL))
177 | align_vectors = align_vectors.view(batch, targetL, sourceL)
178 |
179 | # each context vector c_t is the weighted average
180 | # over all the source hidden states
181 | c = torch.bmm(align_vectors, memory_bank)
182 |
183 | # concatenate
184 | concat_c = torch.cat([c, input], 2).view(batch*targetL, dim*2)
185 | attn_h = self.linear_out(concat_c).view(batch, targetL, dim)
186 | if self.attn_type in ["general", "dot"]:
187 | attn_h = self.tanh(attn_h)
188 |
189 | if one_step:
190 | attn_h = attn_h.squeeze(1)
191 | align_vectors = align_vectors.squeeze(1)
192 |
193 | # Check output sizes
194 | batch_, dim_ = attn_h.size()
195 | aeq(batch, batch_)
196 | aeq(dim, dim_)
197 | batch_, sourceL_ = align_vectors.size()
198 | aeq(batch, batch_)
199 | aeq(sourceL, sourceL_)
200 | else:
201 | attn_h = attn_h.transpose(0, 1).contiguous()
202 | align_vectors = align_vectors.transpose(0, 1).contiguous()
203 |
204 | # Check output sizes
205 | targetL_, batch_, dim_ = attn_h.size()
206 | aeq(targetL, targetL_)
207 | aeq(batch, batch_)
208 | aeq(dim, dim_)
209 | targetL_, batch_, sourceL_ = align_vectors.size()
210 | aeq(targetL, targetL_)
211 | aeq(batch, batch_)
212 | aeq(sourceL, sourceL_)
213 |
214 | return attn_h, align_vectors
215 |
--------------------------------------------------------------------------------
/onmt/modules/ImageEncoder.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch.nn.functional as F
3 | import torch
4 | from torch.autograd import Variable
5 |
6 |
7 | class ImageEncoder(nn.Module):
8 | """
9 | A simple encoder convolutional -> recurrent neural network for
10 | image input.
11 |
12 | Args:
13 | num_layers (int): number of encoder layers.
14 | bidirectional (bool): bidirectional encoder.
15 | rnn_size (int): size of hidden states of the rnn.
16 | dropout (float): dropout probablity.
17 | """
18 | def __init__(self, num_layers, bidirectional, rnn_size, dropout):
19 | super(ImageEncoder, self).__init__()
20 | self.num_layers = num_layers
21 | self.num_directions = 2 if bidirectional else 1
22 | self.hidden_size = rnn_size
23 |
24 | self.layer1 = nn.Conv2d(3, 64, kernel_size=(3, 3),
25 | padding=(1, 1), stride=(1, 1))
26 | self.layer2 = nn.Conv2d(64, 128, kernel_size=(3, 3),
27 | padding=(1, 1), stride=(1, 1))
28 | self.layer3 = nn.Conv2d(128, 256, kernel_size=(3, 3),
29 | padding=(1, 1), stride=(1, 1))
30 | self.layer4 = nn.Conv2d(256, 256, kernel_size=(3, 3),
31 | padding=(1, 1), stride=(1, 1))
32 | self.layer5 = nn.Conv2d(256, 512, kernel_size=(3, 3),
33 | padding=(1, 1), stride=(1, 1))
34 | self.layer6 = nn.Conv2d(512, 512, kernel_size=(3, 3),
35 | padding=(1, 1), stride=(1, 1))
36 |
37 | self.batch_norm1 = nn.BatchNorm2d(256)
38 | self.batch_norm2 = nn.BatchNorm2d(512)
39 | self.batch_norm3 = nn.BatchNorm2d(512)
40 |
41 | input_size = 512
42 | self.rnn = nn.LSTM(input_size, rnn_size,
43 | num_layers=num_layers,
44 | dropout=dropout,
45 | bidirectional=bidirectional)
46 | self.pos_lut = nn.Embedding(1000, input_size)
47 |
48 | def load_pretrained_vectors(self, opt):
49 | # Pass in needed options only when modify function definition.
50 | pass
51 |
52 | def forward(self, input, lengths=None):
53 | "See :obj:`onmt.modules.EncoderBase.forward()`"
54 |
55 | batch_size = input.size(0)
56 | # (batch_size, 64, imgH, imgW)
57 | # layer 1
58 | input = F.relu(self.layer1(input[:, :, :, :]-0.5), True)
59 |
60 | # (batch_size, 64, imgH/2, imgW/2)
61 | input = F.max_pool2d(input, kernel_size=(2, 2), stride=(2, 2))
62 |
63 | # (batch_size, 128, imgH/2, imgW/2)
64 | # layer 2
65 | input = F.relu(self.layer2(input), True)
66 |
67 | # (batch_size, 128, imgH/2/2, imgW/2/2)
68 | input = F.max_pool2d(input, kernel_size=(2, 2), stride=(2, 2))
69 |
70 | # (batch_size, 256, imgH/2/2, imgW/2/2)
71 | # layer 3
72 | # batch norm 1
73 | input = F.relu(self.batch_norm1(self.layer3(input)), True)
74 |
75 | # (batch_size, 256, imgH/2/2, imgW/2/2)
76 | # layer4
77 | input = F.relu(self.layer4(input), True)
78 |
79 | # (batch_size, 256, imgH/2/2/2, imgW/2/2)
80 | input = F.max_pool2d(input, kernel_size=(1, 2), stride=(1, 2))
81 |
82 | # (batch_size, 512, imgH/2/2/2, imgW/2/2)
83 | # layer 5
84 | # batch norm 2
85 | input = F.relu(self.batch_norm2(self.layer5(input)), True)
86 |
87 | # (batch_size, 512, imgH/2/2/2, imgW/2/2/2)
88 | input = F.max_pool2d(input, kernel_size=(2, 1), stride=(2, 1))
89 |
90 | # (batch_size, 512, imgH/2/2/2, imgW/2/2/2)
91 | input = F.relu(self.batch_norm3(self.layer6(input)), True)
92 |
93 | # # (batch_size, 512, H, W)
94 | all_outputs = []
95 | for row in range(input.size(2)):
96 | inp = input[:, :, row, :].transpose(0, 2)\
97 | .transpose(1, 2)
98 | row_vec = torch.Tensor(batch_size).type_as(inp.data)\
99 | .long().fill_(row)
100 | pos_emb = self.pos_lut(Variable(row_vec))
101 | with_pos = torch.cat(
102 | (pos_emb.view(1, pos_emb.size(0), pos_emb.size(1)), inp), 0)
103 | outputs, hidden_t = self.rnn(with_pos)
104 | all_outputs.append(outputs)
105 | out = torch.cat(all_outputs, 0)
106 |
107 | return hidden_t, out
108 |
--------------------------------------------------------------------------------
/onmt/modules/MultiHeadedAttn.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | import torch.nn as nn
4 | from torch.autograd import Variable
5 |
6 | from onmt.Utils import aeq
7 |
8 |
9 | class MultiHeadedAttention(nn.Module):
10 | """
11 | Multi-Head Attention module from
12 | "Attention is All You Need"
13 | :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.
14 |
15 | Similar to standard `dot` attention but uses
16 | multiple attention distributions simulataneously
17 | to select relevant items.
18 |
19 | .. mermaid::
20 |
21 | graph BT
22 | A[key]
23 | B[value]
24 | C[query]
25 | O[output]
26 | subgraph Attn
27 | D[Attn 1]
28 | E[Attn 2]
29 | F[Attn N]
30 | end
31 | A --> D
32 | C --> D
33 | A --> E
34 | C --> E
35 | A --> F
36 | C --> F
37 | D --> O
38 | E --> O
39 | F --> O
40 | B --> O
41 |
42 | Also includes several additional tricks.
43 |
44 | Args:
45 | head_count (int): number of parallel heads
46 | model_dim (int): the dimension of keys/values/queries,
47 | must be divisible by head_count
48 | dropout (float): dropout parameter
49 | """
50 | def __init__(self, head_count, model_dim, dropout=0.1):
51 | assert model_dim % head_count == 0
52 | self.dim_per_head = model_dim // head_count
53 | self.model_dim = model_dim
54 |
55 | super(MultiHeadedAttention, self).__init__()
56 | self.head_count = head_count
57 |
58 | self.linear_keys = nn.Linear(model_dim,
59 | head_count * self.dim_per_head)
60 | self.linear_values = nn.Linear(model_dim,
61 | head_count * self.dim_per_head)
62 | self.linear_query = nn.Linear(model_dim,
63 | head_count * self.dim_per_head)
64 | self.sm = nn.Softmax(dim=-1)
65 | self.dropout = nn.Dropout(dropout)
66 | self.final_linear = nn.Linear(model_dim, model_dim)
67 |
68 | def forward(self, key, value, query, mask=None):
69 | """
70 | Compute the context vector and the attention vectors.
71 |
72 | Args:
73 | key (`FloatTensor`): set of `key_len`
74 | key vectors `[batch, key_len, dim]`
75 | value (`FloatTensor`): set of `key_len`
76 | value vectors `[batch, key_len, dim]`
77 | query (`FloatTensor`): set of `query_len`
78 | query vectors `[batch, query_len, dim]`
79 | mask: binary mask indicating which keys have
80 | non-zero attention `[batch, query_len, key_len]`
81 | Returns:
82 | (`FloatTensor`, `FloatTensor`) :
83 |
84 | * output context vectors `[batch, query_len, dim]`
85 | * one of the attention vectors `[batch, query_len, key_len]`
86 | """
87 |
88 | # CHECKS
89 | batch, k_len, d = key.size()
90 | batch_, k_len_, d_ = value.size()
91 | aeq(batch, batch_)
92 | aeq(k_len, k_len_)
93 | aeq(d, d_)
94 | batch_, q_len, d_ = query.size()
95 | aeq(batch, batch_)
96 | aeq(d, d_)
97 | aeq(self.model_dim % 8, 0)
98 | if mask is not None:
99 | batch_, q_len_, k_len_ = mask.size()
100 | aeq(batch_, batch)
101 | aeq(k_len_, k_len)
102 | aeq(q_len_ == q_len)
103 | # END CHECKS
104 |
105 | batch_size = key.size(0)
106 | dim_per_head = self.dim_per_head
107 | head_count = self.head_count
108 | key_len = key.size(1)
109 | query_len = query.size(1)
110 |
111 | def shape(x):
112 | return x.view(batch_size, -1, head_count, dim_per_head) \
113 | .transpose(1, 2)
114 |
115 | def unshape(x):
116 | return x.transpose(1, 2).contiguous() \
117 | .view(batch_size, -1, head_count * dim_per_head)
118 |
119 | # 1) Project key, value, and query.
120 | key_up = shape(self.linear_keys(key))
121 | value_up = shape(self.linear_values(value))
122 | query_up = shape(self.linear_query(query))
123 |
124 | # 2) Calculate and scale scores.
125 | query_up = query_up / math.sqrt(dim_per_head)
126 | scores = torch.matmul(query_up, key_up.transpose(2, 3))
127 |
128 | if mask is not None:
129 | mask = mask.unsqueeze(1).expand_as(scores)
130 | scores = scores.masked_fill(Variable(mask), -1e18)
131 |
132 | # 3) Apply attention dropout and compute context vectors.
133 | attn = self.sm(scores)
134 | drop_attn = self.dropout(attn)
135 | context = unshape(torch.matmul(drop_attn, value_up))
136 |
137 | output = self.final_linear(context)
138 | # CHECK
139 | batch_, q_len_, d_ = output.size()
140 | aeq(q_len, q_len_)
141 | aeq(batch, batch_)
142 | aeq(d, d_)
143 |
144 | # Return one attn
145 | top_attn = attn \
146 | .view(batch_size, head_count,
147 | query_len, key_len)[:, 0, :, :] \
148 | .contiguous()
149 | # END CHECK
150 | return output, top_attn
151 |
--------------------------------------------------------------------------------
/onmt/modules/StackedRNN.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 |
5 | class StackedLSTM(nn.Module):
6 | """
7 | Our own implementation of stacked LSTM.
8 | Needed for the decoder, because we do input feeding.
9 | """
10 | def __init__(self, num_layers, input_size, rnn_size, dropout):
11 | super(StackedLSTM, self).__init__()
12 | self.dropout = nn.Dropout(dropout)
13 | self.num_layers = num_layers
14 | self.layers = nn.ModuleList()
15 |
16 | for i in range(num_layers):
17 | self.layers.append(nn.LSTMCell(input_size, rnn_size))
18 | input_size = rnn_size
19 |
20 | def forward(self, input, hidden):
21 | h_0, c_0 = hidden
22 | h_1, c_1 = [], []
23 | for i, layer in enumerate(self.layers):
24 | h_1_i, c_1_i = layer(input, (h_0[i], c_0[i]))
25 | input = h_1_i
26 | if i + 1 != self.num_layers:
27 | input = self.dropout(input)
28 | h_1 += [h_1_i]
29 | c_1 += [c_1_i]
30 |
31 | h_1 = torch.stack(h_1)
32 | c_1 = torch.stack(c_1)
33 |
34 | return input, (h_1, c_1)
35 |
36 |
37 | class StackedGRU(nn.Module):
38 |
39 | def __init__(self, num_layers, input_size, rnn_size, dropout):
40 | super(StackedGRU, self).__init__()
41 | self.dropout = nn.Dropout(dropout)
42 | self.num_layers = num_layers
43 | self.layers = nn.ModuleList()
44 |
45 | for i in range(num_layers):
46 | self.layers.append(nn.GRUCell(input_size, rnn_size))
47 | input_size = rnn_size
48 |
49 | def forward(self, input, hidden):
50 | h_1 = []
51 | for i, layer in enumerate(self.layers):
52 | h_1_i = layer(input, hidden[0][i])
53 | input = h_1_i
54 | if i + 1 != self.num_layers:
55 | input = self.dropout(input)
56 | h_1 += [h_1_i]
57 |
58 | h_1 = torch.stack(h_1)
59 | return input, (h_1,)
60 |
--------------------------------------------------------------------------------
/onmt/modules/StructuredAttention.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch
3 | import torch.cuda
4 | from torch.autograd import Variable
5 |
6 |
7 | class MatrixTree(nn.Module):
8 | """Implementation of the matrix-tree theorem for computing marginals
9 | of non-projective dependency parsing. This attention layer is used
10 | in the paper "Learning Structured Text Representations."
11 |
12 |
13 | :cite:`DBLP:journals/corr/LiuL17d`
14 | """
15 | def __init__(self, eps=1e-5):
16 | self.eps = eps
17 | super(MatrixTree, self).__init__()
18 |
19 | def forward(self, input):
20 | laplacian = input.exp() + self.eps
21 | output = input.clone()
22 | for b in range(input.size(0)):
23 | lap = laplacian[b].masked_fill(
24 | Variable(torch.eye(input.size(1)).cuda().ne(0)), 0)
25 | lap = -lap + torch.diag(lap.sum(0))
26 | # store roots on diagonal
27 | lap[0] = input[b].diag().exp()
28 | inv_laplacian = lap.inverse()
29 |
30 | factor = inv_laplacian.diag().unsqueeze(1)\
31 | .expand_as(input[b]).transpose(0, 1)
32 | term1 = input[b].exp().mul(factor).clone()
33 | term2 = input[b].exp().mul(inv_laplacian.transpose(0, 1)).clone()
34 | term1[:, 0] = 0
35 | term2[0] = 0
36 | output[b] = term1 - term2
37 | roots_output = input[b].diag().exp().mul(
38 | inv_laplacian.transpose(0, 1)[0])
39 | output[b] = output[b] + torch.diag(roots_output)
40 | return output
41 |
42 |
43 | if __name__ == "__main__":
44 | dtree = MatrixTree()
45 | q = torch.rand(1, 5, 5).cuda()
46 | marg = dtree.forward(Variable(q))
47 | print(marg.sum(1))
48 |
--------------------------------------------------------------------------------
/onmt/modules/UtilClass.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 |
4 |
5 | class LayerNorm(nn.Module):
6 | def __init__(self, features, eps=1e-6):
7 | super(LayerNorm, self).__init__()
8 | self.a_2 = nn.Parameter(torch.ones(features))
9 | self.b_2 = nn.Parameter(torch.zeros(features))
10 | self.eps = eps
11 |
12 | def forward(self, x):
13 | mean = x.mean(-1, keepdim=True)
14 | std = x.std(-1, keepdim=True)
15 | return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
16 |
17 |
18 | class Elementwise(nn.ModuleList):
19 | """
20 | A simple network container.
21 | Parameters are a list of modules.
22 | Inputs are a 3d Variable whose last dimension is the same length
23 | as the list.
24 | Outputs are the result of applying modules to inputs elementwise.
25 | An optional merge parameter allows the outputs to be reduced to a
26 | single Variable.
27 | """
28 |
29 | def __init__(self, merge=None, *args):
30 | assert merge in [None, 'first', 'concat', 'sum', 'mlp']
31 | self.merge = merge
32 | super(Elementwise, self).__init__(*args)
33 |
34 | def forward(self, input):
35 | inputs = [feat.squeeze(2) for feat in input.split(1, dim=2)]
36 | assert len(self) == len(inputs)
37 | outputs = [f(x) for f, x in zip(self, inputs)]
38 | if self.merge == 'first':
39 | return outputs[0]
40 | elif self.merge == 'concat' or self.merge == 'mlp':
41 | return torch.cat(outputs, 2)
42 | elif self.merge == 'sum':
43 | return sum(outputs)
44 | else:
45 | return outputs
46 |
--------------------------------------------------------------------------------
/onmt/modules/__init__.py:
--------------------------------------------------------------------------------
1 | from onmt.modules.UtilClass import LayerNorm, Elementwise
2 | from onmt.modules.Gate import context_gate_factory, ContextGate
3 | from onmt.modules.GlobalAttention import GlobalAttention
4 | from onmt.modules.ConvMultiStepAttention import ConvMultiStepAttention
5 | from onmt.modules.ImageEncoder import ImageEncoder
6 | from onmt.modules.AudioEncoder import AudioEncoder
7 | from onmt.modules.CopyGenerator import CopyGenerator, CopyGeneratorLossCompute
8 | from onmt.modules.StructuredAttention import MatrixTree
9 | from onmt.modules.Transformer import \
10 | TransformerEncoder, TransformerDecoder, PositionwiseFeedForward
11 | from onmt.modules.Conv2Conv import CNNEncoder, CNNDecoder
12 | from onmt.modules.MultiHeadedAttn import MultiHeadedAttention
13 | from onmt.modules.StackedRNN import StackedLSTM, StackedGRU
14 | from onmt.modules.Embeddings import Embeddings, PositionalEncoding
15 | from onmt.modules.WeightNorm import WeightNormConv2d
16 |
17 | from onmt.Models import EncoderBase, MeanEncoder, StdRNNDecoder, \
18 | RNNDecoderBase, InputFeedRNNDecoder, RNNEncoder, NMTModel#, HighwayMLPDecoder
19 |
20 | from onmt.modules.SRU import check_sru_requirement
21 | can_use_sru = check_sru_requirement()
22 | if can_use_sru:
23 | from onmt.modules.SRU import SRU
24 |
25 |
26 | # For flake8 compatibility.
27 | __all__ = [EncoderBase, MeanEncoder, RNNDecoderBase, InputFeedRNNDecoder,
28 | RNNEncoder, NMTModel, #HighwayMLPDecoder,
29 | StdRNNDecoder, ContextGate, GlobalAttention, ImageEncoder,
30 | PositionwiseFeedForward, PositionalEncoding,
31 | CopyGenerator, MultiHeadedAttention,
32 | LayerNorm,
33 | TransformerEncoder, TransformerDecoder, Embeddings, Elementwise,
34 | MatrixTree, WeightNormConv2d, ConvMultiStepAttention,
35 | CNNEncoder, CNNDecoder, StackedLSTM, StackedGRU,
36 | context_gate_factory, CopyGeneratorLossCompute, AudioEncoder]
37 |
38 | if can_use_sru:
39 | __all__.extend([SRU, check_sru_requirement])
40 |
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/AudioEncoder.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/AudioEncoder.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/Conv2Conv.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/Conv2Conv.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/ConvMultiStepAttention.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/ConvMultiStepAttention.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/CopyGenerator.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/CopyGenerator.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/Embeddings.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/Embeddings.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/Gate.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/Gate.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/GlobalAttention.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/GlobalAttention.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/ImageEncoder.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/ImageEncoder.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/MultiHeadedAttn.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/MultiHeadedAttn.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/SRU.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/SRU.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/StackedRNN.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/StackedRNN.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/StructuredAttention.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/StructuredAttention.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/Transformer.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/Transformer.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/UtilClass.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/UtilClass.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/WeightNorm.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/WeightNorm.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/modules/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/modules/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/translate/Penalties.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 | import torch
3 |
4 |
5 | class PenaltyBuilder(object):
6 | """
7 | Returns the Length and Coverage Penalty function for Beam Search.
8 |
9 | Args:
10 | length_pen (str): option name of length pen
11 | cov_pen (str): option name of cov pen
12 | """
13 | def __init__(self, cov_pen, length_pen):
14 | self.length_pen = length_pen
15 | self.cov_pen = cov_pen
16 |
17 | def coverage_penalty(self):
18 | if self.cov_pen == "wu":
19 | return self.coverage_wu
20 | elif self.cov_pen == "summary":
21 | return self.coverage_summary
22 | else:
23 | return self.coverage_none
24 |
25 | def length_penalty(self):
26 | if self.length_pen == "wu":
27 | return self.length_wu
28 | elif self.length_pen == "avg":
29 | return self.length_average
30 | else:
31 | return self.length_none
32 |
33 | """
34 | Below are all the different penalty terms implemented so far
35 | """
36 |
37 | def coverage_wu(self, beam, cov, beta=0.):
38 | """
39 | NMT coverage re-ranking score from
40 | "Google's Neural Machine Translation System" :cite:`wu2016google`.
41 | """
42 | penalty = -torch.min(cov, cov.clone().fill_(1.0)).log().sum(1)
43 | return beta * penalty
44 |
45 | def coverage_summary(self, beam, cov, beta=0.):
46 | """
47 | Our summary penalty.
48 | """
49 | penalty = torch.max(cov, cov.clone().fill_(1.0)).sum(1)
50 | penalty -= cov.size(1)
51 | return beta * penalty
52 |
53 | def coverage_none(self, beam, cov, beta=0.):
54 | """
55 | returns zero as penalty
56 | """
57 | return beam.scores.clone().fill_(0.0)
58 |
59 | def length_wu(self, beam, logprobs, alpha=0.):
60 | """
61 | NMT length re-ranking score from
62 | "Google's Neural Machine Translation System" :cite:`wu2016google`.
63 | """
64 |
65 | modifier = (((5 + len(beam.next_ys)) ** alpha) /
66 | ((5 + 1) ** alpha))
67 | return (logprobs / modifier)
68 |
69 | def length_average(self, beam, logprobs, alpha=0.):
70 | """
71 | Returns the average probability of tokens in a sequence.
72 | """
73 | return logprobs / len(beam.next_ys)
74 |
75 | def length_none(self, beam, logprobs, alpha=0., beta=0.):
76 | """
77 | Returns unmodified scores.
78 | """
79 | return logprobs
80 |
--------------------------------------------------------------------------------
/onmt/translate/Translation.py:
--------------------------------------------------------------------------------
1 | from __future__ import division, unicode_literals
2 |
3 | import torch
4 | import onmt.io
5 |
6 |
7 | class TranslationBuilder(object):
8 | """
9 | Build a word-based translation from the batch output
10 | of translator and the underlying dictionaries.
11 |
12 | Replacement based on "Addressing the Rare Word
13 | Problem in Neural Machine Translation" :cite:`Luong2015b`
14 |
15 | Args:
16 | data (DataSet):
17 | fields (dict of Fields): data fields
18 | n_best (int): number of translations produced
19 | replace_unk (bool): replace unknown words using attention
20 | has_tgt (bool): will the batch have gold targets
21 | """
22 | def __init__(self, data, fields, n_best=1, replace_unk=False,
23 | has_tgt=False):
24 | self.data = data
25 | self.fields = fields
26 | self.n_best = n_best
27 | self.replace_unk = replace_unk
28 | self.has_tgt = has_tgt
29 |
30 | def _build_target_tokens(self, src, src_vocab, src_raw, pred, attn):
31 | vocab = self.fields["tgt"].vocab
32 | tokens = []
33 | for tok in pred:
34 | if tok < len(vocab):
35 | tokens.append(vocab.itos[tok])
36 | else:
37 | tokens.append(src_vocab.itos[tok - len(vocab)])
38 | if tokens[-1] == onmt.io.EOS_WORD:
39 | tokens = tokens[:-1]
40 | break
41 | if self.replace_unk and (attn is not None) and (src is not None):
42 | for i in range(len(tokens)):
43 | if tokens[i] == vocab.itos[onmt.io.UNK]:
44 | _, maxIndex = attn[i].max(0)
45 | tokens[i] = src_raw[maxIndex[0]]
46 | return tokens
47 |
48 | def from_batch(self, translation_batch):
49 | batch = translation_batch["batch"]
50 | assert(len(translation_batch["gold_score"]) ==
51 | len(translation_batch["predictions"]))
52 | batch_size = batch.batch_size
53 |
54 | preds, pred_score, attn, gold_score, indices = list(zip(
55 | *sorted(zip(translation_batch["predictions"],
56 | translation_batch["scores"],
57 | translation_batch["attention"],
58 | translation_batch["gold_score"],
59 | batch.indices.data),
60 | key=lambda x: x[-1])))
61 |
62 | # Sorting
63 | inds, perm = torch.sort(batch.indices.data)
64 | data_type = self.data.data_type
65 | if data_type == 'text':
66 | src = batch.src[0].data.index_select(1, perm)
67 | else:
68 | src = None
69 |
70 | if self.has_tgt:
71 | tgt = batch.tgt.data.index_select(1, perm)
72 | else:
73 | tgt = None
74 |
75 | translations = []
76 | for b in range(batch_size):
77 | if data_type == 'text':
78 | src_vocab = self.data.src_vocabs[inds[b]] \
79 | if self.data.src_vocabs else None
80 | src_raw = self.data.examples[inds[b]].src
81 | else:
82 | src_vocab = None
83 | src_raw = None
84 | pred_sents = [self._build_target_tokens(
85 | src[:, b] if src is not None else None,
86 | src_vocab, src_raw,
87 | preds[b][n], attn[b][n])
88 | for n in range(self.n_best)]
89 | gold_sent = None
90 | if tgt is not None:
91 | gold_sent = self._build_target_tokens(
92 | src[:, b] if src is not None else None,
93 | src_vocab, src_raw,
94 | tgt[1:, b] if tgt is not None else None, None)
95 |
96 | translation = Translation(src[:, b] if src is not None else None,
97 | src_raw, pred_sents,
98 | attn[b], pred_score[b], gold_sent,
99 | gold_score[b])
100 | translations.append(translation)
101 |
102 | return translations
103 |
104 |
105 | class Translation(object):
106 | """
107 | Container for a translated sentence.
108 |
109 | Attributes:
110 | src (`LongTensor`): src word ids
111 | src_raw ([str]): raw src words
112 |
113 | pred_sents ([[str]]): words from the n-best translations
114 | pred_scores ([[float]]): log-probs of n-best translations
115 | attns ([`FloatTensor`]) : attention dist for each translation
116 | gold_sent ([str]): words from gold translation
117 | gold_score ([float]): log-prob of gold translation
118 |
119 | """
120 | def __init__(self, src, src_raw, pred_sents,
121 | attn, pred_scores, tgt_sent, gold_score):
122 | self.src = src
123 | self.src_raw = src_raw
124 | self.pred_sents = pred_sents
125 | self.attns = attn
126 | self.pred_scores = pred_scores
127 | self.gold_sent = tgt_sent
128 | self.gold_score = gold_score
129 |
130 | def log(self, sent_number):
131 | """
132 | Log translation to stdout.
133 | """
134 | output = '\nSENT {}: {}\n'.format(sent_number, self.src_raw)
135 |
136 | best_pred = self.pred_sents[0]
137 | best_score = self.pred_scores[0]
138 | pred_sent = ' '.join(best_pred)
139 | output += 'PRED {}: {}\n'.format(sent_number, pred_sent)
140 | print("PRED SCORE: {:.4f}".format(best_score))
141 |
142 | if self.gold_sent is not None:
143 | tgt_sent = ' '.join(self.gold_sent)
144 | output += 'GOLD {}: {}\n'.format(sent_number, tgt_sent)
145 | # output += ("GOLD SCORE: {:.4f}".format(self.gold_score))
146 | print("GOLD SCORE: {:.4f}".format(self.gold_score))
147 | if len(self.pred_sents) > 1:
148 | print('\nBEST HYP:')
149 | for score, sent in zip(self.pred_scores, self.pred_sents):
150 | output += "[{:.4f}] {}\n".format(score, sent)
151 |
152 | return output
153 |
--------------------------------------------------------------------------------
/onmt/translate/__init__.py:
--------------------------------------------------------------------------------
1 | from onmt.translate.Translator import Translator
2 | from onmt.translate.Translation import Translation, TranslationBuilder
3 | from onmt.translate.Beam import Beam, GNMTGlobalScorer
4 | from onmt.translate.Penalties import PenaltyBuilder
5 | from onmt.translate.TranslationServer import TranslationServer, \
6 | ServerModelError
7 |
8 | __all__ = [Translator, Translation, Beam,
9 | GNMTGlobalScorer, TranslationBuilder,
10 | PenaltyBuilder, TranslationServer, ServerModelError]
11 |
--------------------------------------------------------------------------------
/onmt/translate/__pycache__/Beam.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/translate/__pycache__/Beam.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/translate/__pycache__/Penalties.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/translate/__pycache__/Penalties.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/translate/__pycache__/Translation.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/translate/__pycache__/Translation.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/translate/__pycache__/TranslationServer.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/translate/__pycache__/TranslationServer.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/translate/__pycache__/Translator.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/translate/__pycache__/Translator.cpython-36.pyc
--------------------------------------------------------------------------------
/onmt/translate/__pycache__/__init__.cpython-36.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/onmt/translate/__pycache__/__init__.cpython-36.pyc
--------------------------------------------------------------------------------
/preprocess.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 |
4 | import argparse
5 | import os
6 | import glob
7 | import sys
8 |
9 | import torch
10 |
11 | import onmt.io
12 | import onmt.opts
13 |
14 |
15 | def check_existing_pt_files(opt):
16 | # We will use glob.glob() to find sharded {train|valid}.[0-9]*.pt
17 | # when training, so check to avoid tampering with existing pt files
18 | # or mixing them up.
19 | for t in ['train', 'valid', 'vocab']:
20 | pattern = opt.save_data + '.' + t + '*.pt'
21 | if glob.glob(pattern):
22 | sys.stderr.write("Please backup exisiting pt file: %s, "
23 | "to avoid tampering!\n" % pattern)
24 | sys.exit(1)
25 |
26 |
27 | def parse_args():
28 | parser = argparse.ArgumentParser(
29 | description='preprocess.py',
30 | formatter_class=argparse.ArgumentDefaultsHelpFormatter)
31 |
32 | onmt.opts.add_md_help_argument(parser)
33 | onmt.opts.preprocess_opts(parser)
34 |
35 | opt = parser.parse_args()
36 | torch.manual_seed(opt.seed)
37 |
38 | check_existing_pt_files(opt)
39 |
40 | return opt
41 |
42 |
43 | def build_save_text_dataset_in_shards(src_corpus, tgt_corpus, fields,
44 | corpus_type, opt):
45 | '''
46 | Divide the big corpus into shards, and build dataset separately.
47 | This is currently only for data_type=='text'.
48 |
49 | The reason we do this is to avoid taking up too much memory due
50 | to sucking in a huge corpus file.
51 |
52 | To tackle this, we only read in part of the corpus file of size
53 | `max_shard_size`(actually it is multiples of 64 bytes that equals
54 | or is slightly larger than this size), and process it into dataset,
55 | then write it to disk along the way. By doing this, we only focus on
56 | part of the corpus at any moment, thus effectively reducing memory use.
57 | According to test, this method can reduce memory footprint by ~50%.
58 |
59 | Note! As we process along the shards, previous shards might still
60 | stay in memory, but since we are done with them, and no more
61 | reference to them, if there is memory tight situation, the OS could
62 | easily reclaim these memory.
63 |
64 | If `max_shard_size` is 0 or is larger than the corpus size, it is
65 | effectively preprocessed into one dataset, i.e. no sharding.
66 |
67 | NOTE! `max_shard_size` is measuring the input corpus size, not the
68 | output pt file size. So a shard pt file consists of examples of size
69 | 2 * `max_shard_size`(source + target).
70 | '''
71 |
72 | corpus_size = os.path.getsize(src_corpus)
73 | if corpus_size > 10 * (1024**2) and opt.max_shard_size == 0:
74 | print("Warning. The corpus %s is larger than 10M bytes, you can "
75 | "set '-max_shard_size' to process it by small shards "
76 | "to use less memory." % src_corpus)
77 |
78 | if opt.max_shard_size != 0:
79 | print(' * divide corpus into shards and build dataset separately'
80 | '(shard_size = %d bytes).' % opt.max_shard_size)
81 |
82 | ret_list = []
83 | src_iter = onmt.io.ShardedTextCorpusIterator(
84 | src_corpus, opt.src_seq_length_trunc,
85 | "src", opt.max_shard_size)
86 | tgt_iter = onmt.io.ShardedTextCorpusIterator(
87 | tgt_corpus, opt.tgt_seq_length_trunc,
88 | "tgt", opt.max_shard_size,
89 | assoc_iter=src_iter)
90 |
91 | index = 0
92 | while not src_iter.hit_end():
93 | index += 1
94 | dataset = onmt.io.TextDataset(
95 | fields, src_iter, tgt_iter,
96 | src_iter.num_feats, tgt_iter.num_feats,
97 | src_seq_length=opt.src_seq_length,
98 | tgt_seq_length=opt.tgt_seq_length,
99 | dynamic_dict=opt.dynamic_dict)
100 |
101 | # We save fields in vocab.pt seperately, so make it empty.
102 | dataset.fields = []
103 |
104 | pt_file = "{:s}.{:s}.{:d}.pt".format(
105 | opt.save_data, corpus_type, index)
106 | print(" * saving %s data shard to %s." % (corpus_type, pt_file))
107 | torch.save(dataset, pt_file)
108 |
109 | ret_list.append(pt_file)
110 |
111 | return ret_list
112 |
113 |
114 | def build_save_dataset(corpus_type, fields, opt):
115 | assert corpus_type in ['train', 'valid']
116 |
117 | if corpus_type == 'train':
118 | src_corpus = opt.train_src
119 | tgt_corpus = opt.train_tgt
120 | else:
121 | src_corpus = opt.valid_src
122 | tgt_corpus = opt.valid_tgt
123 |
124 | # Currently we only do preprocess sharding for corpus: data_type=='text'.
125 | if opt.data_type == 'text':
126 | return build_save_text_dataset_in_shards(
127 | src_corpus, tgt_corpus, fields,
128 | corpus_type, opt)
129 |
130 | # For data_type == 'img' or 'audio', currently we don't do
131 | # preprocess sharding. We only build a monolithic dataset.
132 | # But since the interfaces are uniform, it would be not hard
133 | # to do this should users need this feature.
134 | dataset = onmt.io.build_dataset(
135 | fields, opt.data_type, src_corpus, tgt_corpus,
136 | src_dir=opt.src_dir,
137 | src_seq_length=opt.src_seq_length,
138 | tgt_seq_length=opt.tgt_seq_length,
139 | src_seq_length_trunc=opt.src_seq_length_trunc,
140 | tgt_seq_length_trunc=opt.tgt_seq_length_trunc,
141 | dynamic_dict=opt.dynamic_dict,
142 | sample_rate=opt.sample_rate,
143 | window_size=opt.window_size,
144 | window_stride=opt.window_stride,
145 | window=opt.window)
146 |
147 | # We save fields in vocab.pt seperately, so make it empty.
148 | dataset.fields = []
149 |
150 | pt_file = "{:s}.{:s}.pt".format(opt.save_data, corpus_type)
151 | print(" * saving %s dataset to %s." % (corpus_type, pt_file))
152 | torch.save(dataset, pt_file)
153 |
154 | return [pt_file]
155 |
156 |
157 | def build_save_vocab(train_dataset, fields, opt):
158 | fields = onmt.io.build_vocab(train_dataset, fields, opt.data_type,
159 | opt.share_vocab,
160 | opt.src_vocab,
161 | opt.src_vocab_size,
162 | opt.src_words_min_frequency,
163 | opt.tgt_vocab,
164 | opt.tgt_vocab_size,
165 | opt.tgt_words_min_frequency)
166 |
167 | # Can't save fields, so remove/reconstruct at training time.
168 | vocab_file = opt.save_data + '.vocab.pt'
169 | torch.save(onmt.io.save_fields_to_vocab(fields), vocab_file)
170 |
171 |
172 | def main():
173 | opt = parse_args()
174 |
175 | print("Extracting features...")
176 | src_nfeats = onmt.io.get_num_features(opt.data_type, opt.train_src, 'src')
177 | tgt_nfeats = onmt.io.get_num_features(opt.data_type, opt.train_tgt, 'tgt')
178 | print(" * number of source features: %d." % src_nfeats)
179 | print(" * number of target features: %d." % tgt_nfeats)
180 |
181 | print("Building `Fields` object...")
182 | fields = onmt.io.get_fields(opt.data_type, src_nfeats, tgt_nfeats)
183 |
184 | print("Building & saving training data...")
185 | train_dataset_files = build_save_dataset('train', fields, opt)
186 |
187 | print("Building & saving vocabulary...")
188 | build_save_vocab(train_dataset_files, fields, opt)
189 |
190 | print("Building & saving validation data...")
191 | build_save_dataset('valid', fields, opt)
192 |
193 |
194 | if __name__ == "__main__":
195 | main()
196 |
--------------------------------------------------------------------------------
/requirements.opt.txt:
--------------------------------------------------------------------------------
1 | cffi
2 | torchvision==0.1.8
3 | librosa
4 | Pillow
5 | git+https://github.com/pytorch/audio
6 | pyrouge
7 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | six
2 | tqdm
3 | pytorch=0.3.1
4 | torchtext>=0.2.1
5 | future
6 | allennlp
7 | sentencepiece
8 | gensim
--------------------------------------------------------------------------------
/resources/seq2seq4dp.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/resources/seq2seq4dp.pdf
--------------------------------------------------------------------------------
/screenshots/seq2seq_model.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bcmi220/seq2seq_parser/4143c2f9b3164c0fe8b8374f6bcca747184193d9/screenshots/seq2seq_model.png
--------------------------------------------------------------------------------
/server.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | import argparse
3 |
4 | from flask import Flask, jsonify, request
5 | from onmt.translate import TranslationServer, ServerModelError
6 |
7 | STATUS_OK = "ok"
8 | STATUS_ERROR = "error"
9 |
10 |
11 | def start(config_file,
12 | url_root="./translator",
13 | host="0.0.0.0",
14 | port=5000,
15 | debug=True):
16 | def prefix_route(route_function, prefix='', mask='{0}{1}'):
17 | def newroute(route, *args, **kwargs):
18 | return route_function(mask.format(prefix, route), *args, **kwargs)
19 | return newroute
20 |
21 | app = Flask(__name__)
22 | app.route = prefix_route(app.route, url_root)
23 | translation_server = TranslationServer()
24 | translation_server.start(config_file)
25 |
26 | @app.route('/models', methods=['GET'])
27 | def get_models():
28 | out = translation_server.list_models()
29 | return jsonify(out)
30 |
31 | @app.route('/clone_model/', methods=['POST'])
32 | def clone_model(model_id):
33 | out = {}
34 | data = request.get_json(force=True)
35 | timeout = -1
36 | if 'timeout' in data:
37 | timeout = data['timeout']
38 | del data['timeout']
39 |
40 | opt = data.get('opt', None)
41 | try:
42 | model_id, load_time = translation_server.clone_model(
43 | model_id, opt, timeout)
44 | except ServerModelError as e:
45 | out['status'] = STATUS_ERROR
46 | out['error'] = str(e)
47 | else:
48 | out['status'] = STATUS_OK
49 | out['model_id'] = model_id
50 | out['load_time'] = load_time
51 |
52 | return jsonify(out)
53 |
54 | @app.route('/unload_model/', methods=['GET'])
55 | def unload_model(model_id):
56 | out = {"model_id": model_id}
57 |
58 | try:
59 | translation_server.unload_model(model_id)
60 | out['status'] = STATUS_OK
61 | except Exception as e:
62 | out['status'] = STATUS_ERROR
63 | out['error'] = str(e)
64 |
65 | return jsonify(out)
66 |
67 | @app.route('/translate', methods=['POST'])
68 | def translate():
69 | inputs = request.get_json(force=True)
70 | out = {}
71 | try:
72 | translation, scores, n_best, times = translation_server.run(inputs)
73 | assert len(translation) == len(inputs)
74 | assert len(scores) == len(inputs)
75 |
76 | out = [[{"src": inputs[i]['src'], "tgt": translation[i],
77 | "n_best": n_best,
78 | "pred_score": scores[i]}
79 | for i in range(len(translation))]]
80 | except ServerModelError as e:
81 | out['error'] = str(e)
82 | out['status'] = STATUS_ERROR
83 |
84 | return jsonify(out)
85 |
86 | @app.route('/to_cpu/', methods=['GET'])
87 | def to_cpu(model_id):
88 | out = {'model_id': model_id}
89 | translation_server.models[model_id].to_cpu()
90 |
91 | out['status'] = STATUS_OK
92 | return jsonify(out)
93 |
94 | @app.route('/to_gpu/', methods=['GET'])
95 | def to_gpu(model_id):
96 | out = {'model_id': model_id}
97 | translation_server.models[model_id].to_gpu()
98 |
99 | out['status'] = STATUS_OK
100 | return jsonify(out)
101 |
102 | app.run(debug=debug, host=host, port=port, use_reloader=False)
103 |
104 |
105 | if __name__ == '__main__':
106 | parser = argparse.ArgumentParser(description="OpenNMT-py REST Server")
107 | parser.add_argument("--ip", type=str, default="0.0.0.0")
108 | parser.add_argument("--port", type=int, default="5000")
109 | parser.add_argument("--url_root", type=str, default="/translator")
110 | parser.add_argument("--debug", "-d", action="store_true")
111 | parser.add_argument("--config", "-c", type=str,
112 | default="./available_models/conf.json")
113 | args = parser.parse_args()
114 | start(args.config, url_root=args.url_root, host=args.ip, port=args.port,
115 | debug=args.debug)
116 |
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 |
3 | from setuptools import setup
4 |
5 | setup(name='OpenNMT-py',
6 | description='A python implementation of OpenNMT',
7 | version='0.1',
8 | packages=['onmt', 'onmt.io', 'onmt.translate', 'onmt.modules'])
9 |
--------------------------------------------------------------------------------
/subroot/README.md:
--------------------------------------------------------------------------------
1 | # DNN Pytorch
2 |
3 | This repository includes a name tagger implemented with bidirectional LSTMs CRF network. It has an interface for external features.
4 |
5 |
6 | ## Model
7 |
8 | 
9 |
10 | ## Requirements
11 |
12 | Python3, Pytorch
13 |
14 | ## Data Format
15 |
16 | * Label format
17 |
18 | The name tagger follows *BIO* or *BIOES* scheme:
19 |
20 | 
21 |
22 | * Sentence format
23 |
24 | Document is segmented into sentences. Each sentence is tokenized into multiple tokens.
25 |
26 | In the training file, sentences are separated by an empty line. Tokens are separated by linebreak. For each token, label should be always at the end. Token and label are separated by space.
27 |
28 | CRF style features can be added between token and labels.
29 |
30 | Example:
31 | ```
32 | George B-PER
33 | W. I-PER
34 | Bush I-PER
35 | went O
36 | to O
37 | Germany B-GPE
38 | yesterday O
39 | . O
40 |
41 | New B-ORG
42 | York I-ORG
43 | Times I-ORG
44 | ```
45 |
46 | A real example of a bio file: `example/seq_labeling/data/eng.train.bio`
47 |
48 | A real example of a bio file with features: `example/seq_labeling/data/eng.train.feat.bio`
49 |
50 |
51 | ## Usage
52 |
53 | Training and testing examples are provided in `example/seq_labeling/`.
54 |
55 | ## Citation
56 |
57 | [1] Boliang Zhang, Di Lu, Xiaoman Pan, Ying Lin, Halidanmu Abudukelimu, Heng Ji, Kevin Knight. [Embracing Non-Traditional Linguistic Resources for Low-resource Language Name Tagging](http://aclweb.org/anthology/I17-1037), Proc. IJCNLP, 2017
58 |
59 | [2] Boliang Zhang, Xiaoman Pan, Tianlu Wang, Ashish Vaswani, Heng Ji, Kevin Knight, and Daniel Marcu. [Name Tagging for Low-Resource Incident Languages Based on Expectation-Driven Learning](http://nlp.cs.rpi.edu/paper/expectation2016.pdf), Proc. NAACL, 2016
60 |
61 |
62 |
--------------------------------------------------------------------------------
/subroot/RUN.md:
--------------------------------------------------------------------------------
1 | python3 ./srl_pytorch/train.py --train ./srl/data/predicate-train.txt --dev ./srl/data/predicate-dev.txt --test ./srl/data/predicate-test.txt --model_dp ./model/ --tag_scheme classification --lower 1 --zeros 1 --char_dim 0 --char_lstm_dim 0 --char_conv_channel 0 --word_dim 100 --word_lstm_dim 512 --word_lstm_layer 4 --pre_emb '' --all_emb 0 --cap_dim 0 --feat_dim 100 --feat_column 2 --crf 1 --dropout 0.1 --lr_method sgd-init_lr=.001-lr_decay_epoch=100 --batch_size 64 --gpu 1
2 |
--------------------------------------------------------------------------------
/subroot/dnn_pytorch/dnn_utils.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import torch
3 | from argparse import ArgumentParser
4 |
5 | parser = ArgumentParser(add_help=False)
6 | parser.add_argument(
7 | "--gpu", default="0",
8 | type=int, help="set 1 to use gpu."
9 | )
10 | args = parser.parse_known_args()
11 |
12 | # set global torch tensor variables. default is using cpu
13 | if args[0].gpu == 1:
14 | FloatTensor = torch.cuda.FloatTensor
15 | LongTensor = torch.cuda.LongTensor
16 | else:
17 | FloatTensor = torch.FloatTensor
18 | LongTensor = torch.LongTensor
19 |
20 |
21 | def exp_lr_scheduler(optimizer, epoch, init_lr=0.01, lr_decay_epoch=7):
22 | """Decay learning rate by a factor of 0.1 every lr_decay_epoch epochs."""
23 | lr = init_lr * (0.1**(epoch // lr_decay_epoch))
24 |
25 | if epoch % lr_decay_epoch == 0:
26 | print('LR is set to {}'.format(lr))
27 |
28 | for param_group in optimizer.param_groups:
29 | param_group['lr'] = lr
30 |
31 | return optimizer
32 |
33 |
34 | def init_variable(shape):
35 | if len(shape) == 1:
36 | value = np.zeros(shape) # bias are initialized with zeros
37 | else:
38 | drange = np.sqrt(6. / (np.sum(shape)))
39 | value = drange * np.random.uniform(low=-1.0, high=1.0, size=shape)
40 | return value
41 |
42 |
43 | def init_param(layer):
44 | """
45 | randomly initialize parameters of the given layer
46 | """
47 | for p in layer.parameters():
48 | p.data = torch.from_numpy(init_variable(p.size())).type(FloatTensor)
49 |
50 | return layer
51 |
52 |
53 | def log_sum_exp(x, dim=None):
54 | """
55 | Sum probabilities in the log-space.
56 | """
57 | xmax, _ = x.max(dim=dim, keepdim=True)
58 | xmax_, _ = x.max(dim=dim)
59 | # return xmax_
60 | return xmax_ + torch.log(torch.exp(x - xmax).sum(dim=dim))
61 |
62 |
63 | def sequence_mask(batch_len, max_len=None):
64 | if not max_len:
65 | max_len = np.max(batch_len)
66 |
67 | mask = np.zeros((len(batch_len), max_len))
68 | for i in range(len(batch_len)):
69 | mask[i, range(batch_len[i])] = 1
70 |
71 | return mask
72 |
--------------------------------------------------------------------------------
/subroot/dnn_pytorch/tag.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | import time
3 | import torch
4 |
5 | from nn import SeqLabeling
6 | from utils import create_input, iobes_iob
7 | from loader import prepare_dataset, load_sentences
8 |
9 |
10 | # Read parameters from command line
11 | parser = argparse.ArgumentParser()
12 | parser.add_argument(
13 | "--model", default="",
14 | help="Model location"
15 | )
16 | parser.add_argument(
17 | "--input", default="",
18 | help="Input bio file location"
19 | )
20 | parser.add_argument(
21 | "--output", default="",
22 | help="Output bio file location"
23 | )
24 | parser.add_argument(
25 | "--batch_size", default="50",
26 | type=int, help="batch size"
27 | )
28 | parser.add_argument(
29 | "--gpu", default="0",
30 | type=int, help="default is 0. set 1 to use gpu."
31 | )
32 | args = parser.parse_args()
33 |
34 | print('loading model from:', args.model)
35 | if args.gpu:
36 | state = torch.load(args.model)
37 | else:
38 | state = torch.load(args.model, map_location=lambda storage, loc: storage)
39 |
40 | parameters = state['parameters']
41 | mappings = state['mappings']
42 |
43 | # Load reverse mappings
44 | word_to_id, char_to_id, tag_to_id = [
45 | {v: k for k, v in x.items()}
46 | for x in [mappings['id_to_word'], mappings['id_to_char'], mappings['id_to_tag']]
47 | ]
48 | feat_to_id_list = [
49 | {v: k for k, v in id_to_feat.items()}
50 | for id_to_feat in mappings['id_to_feat_list']
51 | ]
52 |
53 | # eval sentences
54 | eval_sentences = load_sentences(
55 | args.input,
56 | parameters['lower'],
57 | parameters['zeros']
58 | )
59 |
60 | eval_dataset = prepare_dataset(
61 | eval_sentences, parameters['feat_column'],
62 | word_to_id, char_to_id, tag_to_id, feat_to_id_list, parameters['lower'],
63 | is_train=False
64 | )
65 |
66 | print("%i sentences in eval set." % len(eval_dataset))
67 |
68 | # initialize model
69 | model = SeqLabeling(parameters)
70 | model.load_state_dict(state['state_dict'])
71 | model.train(False)
72 |
73 | since = time.time()
74 | batch_size = args.batch_size
75 | f_output = open(args.output, 'w')
76 |
77 | # Iterate over data.
78 | print('tagging...')
79 | for i in range(0, len(eval_dataset), batch_size):
80 | inputs, seq_index_mapping, char_index_mapping, seq_len, char_len = \
81 | create_input(eval_dataset[i:i+batch_size], parameters, add_label=False)
82 |
83 | # forward
84 | outputs, loss = model.forward(inputs, seq_len, char_len, char_index_mapping)
85 | if parameters['crf']:
86 | preds = [outputs[seq_index_mapping[j]].data
87 | for j in range(len(outputs))]
88 | else:
89 | _, _preds = torch.max(outputs.data, 2)
90 |
91 | preds = [
92 | _preds[seq_index_mapping[j]][:seq_len[seq_index_mapping[j]]]
93 | for j in range(len(seq_index_mapping))
94 | ]
95 | for j, pred in enumerate(preds):
96 | pred = [mappings['id_to_tag'][p] for p in pred]
97 | # Output tags in the IOB2 format
98 | if parameters['tag_scheme'] == 'iobes':
99 | pred = iobes_iob(pred)
100 | # Write tags
101 | assert len(pred) == len(eval_sentences[i+j])
102 | f_output.write('%s\n\n' % '\n'.join('%s%s%s' % (' '.join(w), ' ', z)
103 | for w, z in zip(eval_sentences[i+j],
104 | pred)))
105 | if (i + j + 1) % 500 == 0:
106 | print(i+j+1)
107 |
108 | end = time.time() # epoch end time
109 | print('time elapssed: %f seconds' % round(
110 | (end - since), 2))
111 |
112 |
--------------------------------------------------------------------------------
/subroot/dnn_pytorch/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import re
3 | import io
4 | import itertools
5 | import codecs
6 | import time
7 | import numpy as np
8 | import collections
9 | from torch.autograd import Variable
10 | from dnn_utils import LongTensor,FloatTensor
11 |
12 | try:
13 | import _pickle as cPickle
14 | except ImportError:
15 | import cPickle
16 |
17 | models_path = "./models"
18 |
19 |
20 | def create_dico(item_list):
21 | """
22 | Create a dictionary of items from a list of list of items.
23 | """
24 | assert type(item_list) is list
25 | dico = {}
26 | for items in item_list:
27 | for item in items:
28 | if item not in dico:
29 | dico[item] = 1
30 | else:
31 | dico[item] += 1
32 | return dico
33 |
34 |
35 | def create_mapping(dico):
36 | """
37 | Create a mapping (item to ID / ID to item) from a dictionary.
38 | Items are ordered by decreasing frequency.
39 | """
40 | sorted_items = sorted(dico.items(), key=lambda x: (-x[1], x[0]))
41 | id_to_item = {i: v[0] for i, v in enumerate(sorted_items)}
42 | item_to_id = {v: k for k, v in id_to_item.items()}
43 | return item_to_id, id_to_item
44 |
45 |
46 | def zero_digits(s):
47 | """
48 | Replace every digit in a string by a zero.
49 | """
50 | return re.sub('\d', '0', s)
51 |
52 | def insert_singletons(words, singletons, p=0.5):
53 | """
54 | Replace singletons by the unknown word with a probability p.
55 | """
56 | new_words = []
57 | for word in words:
58 | if word in singletons and np.random.uniform() < p:
59 | new_words.append(0)
60 | else:
61 | new_words.append(word)
62 | return new_words
63 |
64 |
65 | def pad_word(inputs, seq_len):
66 | # get the max sequence length in the batch
67 | max_len = seq_len[0]
68 |
69 | padding = np.zeros_like([inputs[0][0]]).tolist()
70 |
71 | padded_inputs = []
72 | for item in inputs:
73 | padded_inputs.append(item + padding * (max_len - len(item)))
74 |
75 | return padded_inputs
76 |
77 |
78 | def pad_chars(inputs):
79 | chained_chars = list(itertools.chain.from_iterable(inputs))
80 |
81 | char_index_mapping, chars = zip(
82 | *[item for item in sorted(
83 | enumerate(chained_chars), key=lambda x: len(x[1]), reverse=True
84 | )]
85 | )
86 | char_index_mapping = {v: i for i, v in enumerate(char_index_mapping)}
87 |
88 | char_len = [len(c) for c in chars]
89 |
90 | chars = pad_word(chars, char_len)
91 |
92 | # pad chars to length of 25 if max char len less than 25
93 | # char CNN layer requires at least 25 chars
94 | if len(chars[0]) < 25:
95 | chars = [c + [0]*(25-len(c)) for c in chars]
96 |
97 | return chars, char_index_mapping, char_len
98 |
99 |
100 | def create_input(data, parameters, add_label=True):
101 | """
102 | Take sentence data and return an input for
103 | the training or the evaluation function.
104 | """
105 | # sort data by sequence length
106 | seq_index_mapping, data = zip(*[item for item in sorted(enumerate(data), key=lambda x: len(x[1]['words']), reverse=True)])
107 | seq_index_mapping = {v: i for i, v in enumerate(seq_index_mapping)}
108 |
109 | inputs = collections.defaultdict(list)
110 | seq_len = []
111 |
112 | for d in data:
113 | words = d['words']
114 |
115 | seq_len.append(len(words))
116 |
117 | chars = d['chars']
118 |
119 | if parameters['word_dim']:
120 | inputs['words'].append(words)
121 | if parameters['char_dim']:
122 | inputs['chars'].append(chars)
123 | if parameters['cap_dim']:
124 | caps = d['caps']
125 | inputs['caps'].append(caps)
126 |
127 | # boliang: add expectation features into input
128 | if d['feats']:
129 | inputs['feats'].append(d['feats'])
130 |
131 | if add_label:
132 | tags = d['tags']
133 | inputs['tags'].append(tags)
134 |
135 | char_index_mapping = []
136 | char_len = []
137 | for k, v in inputs.items():
138 | if k == 'chars':
139 | padded_chars, char_index_mapping, char_len = pad_chars(v)
140 | inputs[k] = padded_chars
141 | else:
142 | inputs[k] = pad_word(v, seq_len)
143 |
144 | # convert inputs and labels to Variable
145 | for k, v in inputs.items():
146 | inputs[k] = Variable(LongTensor(v))
147 |
148 | return inputs, seq_index_mapping, char_index_mapping, seq_len, char_len
149 |
150 | def count_sentence_predicate(sentence):
151 | count = 0
152 | for item in sentence:
153 | if item[-2] == 'Y':
154 | count += 1
155 | return count
156 |
157 | def evaluate(phase, preds, dataset, id_to_tag, eval_out_dir=None):
158 | """
159 | Evaluate current model using CoNLL script.
160 | """
161 | n_tags = len(id_to_tag)
162 |
163 | tp = 0
164 | fp = 0
165 | fn = 0
166 | correct = 0
167 | total = 0
168 |
169 | output = []
170 | for d, p in zip(dataset, preds):
171 |
172 | assert len(d['words']) == len(p)
173 | str_words = d['str_words']
174 | p_tags = [id_to_tag[y_pred] for y_pred in p]
175 | r_tags = [id_to_tag[y_real] for y_real in d['tags']]
176 |
177 | block = []
178 | for i in range(len(p_tags)):
179 | if r_tags[i]!='0' and p_tags[i] == r_tags[i]:
180 | tp += 1
181 | if r_tags[i]!='0' and p_tags[i] != r_tags[i]:
182 | fp += 1
183 | if r_tags[i]=='0' and p_tags[i] != r_tags[i]:
184 | fn += 1
185 | if p_tags[i] == r_tags[i]:
186 | correct += 1
187 | total += 1
188 | block.append([r_tags[i],p_tags[i]])
189 | output.append(block)
190 |
191 | p = tp / (tp + fp + 1e-13)
192 |
193 | r = tp / (tp + fn + 1e-13)
194 |
195 | f1 = 2 * p * r / ( p + r + 1e-13)
196 |
197 | acc = correct / total
198 |
199 | # Global accuracy
200 | print("Acc:%.5f%% P:%.5f R:%.5f F1:%.5f" % (
201 | acc * 100, p * 100, r * 100, f1 * 100
202 | ))
203 |
204 | if eval_out_dir is not None:
205 | output_file = os.path.join(eval_out_dir,'{}_predicate_{:.2f}.pred'.format(phase,p*100))
206 | with open(output_file, 'w') as fout:
207 | for block in output:
208 | for line in block:
209 | fout.write('\t'.join(line))
210 | fout.write('\n')
211 | fout.write('\n')
212 |
213 | return f1, acc
214 |
215 |
216 | ########################################################################################################################
217 | # temporal script below
218 | #
219 | def load_exp_feats(fp):
220 | bio_feats_fp = fp
221 | res = []
222 | for sent in io.open(bio_feats_fp, 'r', -1, 'utf-8').read().split('\n\n'):
223 | sent_feats = []
224 | for line in sent.splitlines():
225 | feats = line.split('\t')[1:]
226 | sent_feats.append(feats)
227 | res.append(sent_feats)
228 |
229 | return res
230 |
231 |
232 | class Tee(object):
233 | def __init__(self, *files):
234 | self.files = files
235 |
236 | def write(self, obj):
237 | for f in self.files:
238 | f.write(obj)
239 | f.flush() # If you want the output to be visible immediately
240 |
241 | def flush(self) :
242 | for f in self.files:
243 | f.flush()
244 |
245 |
246 |
247 |
248 |
--------------------------------------------------------------------------------
/subroot/subroot/preprocess.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | def preprocess():
4 | raw_train_file = os.path.join(os.path.dirname(__file__),'./data/ptb-sd/train_pro.conll')
5 | raw_dev_file = os.path.join(os.path.dirname(__file__),'./data/ptb-sd/dev_pro.conll')
6 | raw_test_file = os.path.join(os.path.dirname(__file__),'./data/ptb-sd/test_pro.conll')
7 |
8 | predicate_train_file = os.path.join(os.path.dirname(__file__),'./data/subroot-train.txt')
9 | predicate_dev_file = os.path.join(os.path.dirname(__file__),'./data/subroot-dev.txt')
10 | predicate_test_file = os.path.join(os.path.dirname(__file__),'./data/subroot-test.txt')
11 |
12 | with open(raw_train_file, 'r') as f:
13 | with open(predicate_train_file, 'w') as fo:
14 | data = f.readlines()
15 |
16 | # read data
17 | sentence_data = []
18 | sentence = []
19 | for line in data:
20 | if len(line.strip()) > 0:
21 | line = line.strip().split('\t')
22 | sentence.append(line)
23 | else:
24 | sentence_data.append(sentence)
25 | sentence = []
26 | if len(sentence)>0:
27 | sentence_data.append(sentence)
28 | sentence = []
29 |
30 | # process data
31 | # copy the data by predicate num
32 | train_data = []
33 | for sentence in sentence_data:
34 | lines = []
35 | for i in range(len(sentence)):
36 | is_subroot = '0'
37 | if sentence[i][6] == '0':
38 | is_subroot = '1'
39 | word = sentence[i][1].lower()
40 | # is_number = False
41 | # for c in word:
42 | # if c.isdigit():
43 | # is_number = True
44 | # break
45 | # if is_number:
46 | # word = 'number'
47 | lines.append([word, sentence[i][4], is_subroot])
48 | train_data.append(lines)
49 |
50 | for sentence in train_data:
51 | fo.write('\n'.join(['\t'.join(line) for line in sentence]))
52 | fo.write('\n\n')
53 |
54 | with open(raw_dev_file, 'r') as f:
55 | with open(predicate_dev_file, 'w') as fo:
56 | data = f.readlines()
57 |
58 | # read data
59 | sentence_data = []
60 | sentence = []
61 | for line in data:
62 | if len(line.strip()) > 0:
63 | line = line.strip().split('\t')
64 | sentence.append(line)
65 | else:
66 | sentence_data.append(sentence)
67 | sentence = []
68 | if len(sentence)>0:
69 | sentence_data.append(sentence)
70 | sentence = []
71 |
72 | # process data
73 | # copy the data by predicate num
74 | dev_data = []
75 | for sentence in sentence_data:
76 | lines = []
77 | for i in range(len(sentence)):
78 | is_subroot = '0'
79 | if sentence[i][6] == '0':
80 | is_subroot = '1'
81 | word = sentence[i][1].lower()
82 | # is_number = False
83 | # for c in word:
84 | # if c.isdigit():
85 | # is_number = True
86 | # break
87 | # if is_number:
88 | # word = 'number'
89 | lines.append([word, sentence[i][4], is_subroot])
90 | dev_data.append(lines)
91 |
92 | for sentence in dev_data:
93 | fo.write('\n'.join(['\t'.join(line) for line in sentence]))
94 | fo.write('\n\n')
95 |
96 | with open(raw_test_file, 'r') as f:
97 | with open(predicate_test_file, 'w') as fo:
98 | data = f.readlines()
99 |
100 | # read data
101 | sentence_data = []
102 | sentence = []
103 | for line in data:
104 | if len(line.strip()) > 0:
105 | line = line.strip().split('\t')
106 | sentence.append(line)
107 | else:
108 | sentence_data.append(sentence)
109 | sentence = []
110 | if len(sentence)>0:
111 | sentence_data.append(sentence)
112 | sentence = []
113 |
114 | # process data
115 | # copy the data by predicate num
116 | test_data = []
117 | for sentence in sentence_data:
118 | lines = []
119 | for i in range(len(sentence)):
120 | is_subroot = '0'
121 | if sentence[i][6] == '0':
122 | is_subroot = '1'
123 | word = sentence[i][1].lower()
124 | # is_number = False
125 | # for c in word:
126 | # if c.isdigit():
127 | # is_number = True
128 | # break
129 | # if is_number:
130 | # word = 'number'
131 | lines.append([word, sentence[i][4], is_subroot])
132 | test_data.append(lines)
133 |
134 | for sentence in test_data:
135 | fo.write('\n'.join(['\t'.join(line) for line in sentence]))
136 | fo.write('\n\n')
137 |
138 |
139 | if __name__ == '__main__':
140 | preprocess()
--------------------------------------------------------------------------------
/subroot/subroot/stat.py:
--------------------------------------------------------------------------------
1 | import math
2 |
3 | def stat_f1(pred_file):
4 | with open(pred_file,'r') as f:
5 | data_lines = f.readlines()
6 |
7 | # split by sentence
8 | pred_data = []
9 | sentence_data = []
10 | for line in data_lines:
11 | if len(line.strip()) > 0:
12 | sentence_data.append(line.strip().split("\t"))
13 | else:
14 | pred_data.append(sentence_data)
15 | sentence_data = []
16 | if len(sentence_data)>0:
17 | pred_data.append(sentence_data)
18 | sentence_data = []
19 |
20 | tps = [0 for _ in range(7)]
21 | fps = [0 for _ in range(7)]
22 | fns = [0 for _ in range(7)]
23 | f1s = [0 for _ in range(7)]
24 | for sentence in pred_data:
25 | idx = math.ceil(len(sentence)/10)-1
26 | if idx >= 7:
27 | continue
28 | for line in sentence:
29 | if line[0]!='0' and line[1] == line[0]:
30 | tps[idx] += 1
31 | if line[0]!='0' and line[1] != line[0]:
32 | fps[idx] += 1
33 | if line[0]=='0' and line[1] != line[0]:
34 | fns[idx] += 1
35 |
36 | for i in range(7):
37 | p = tps[i] / (tps[i] + fps[i] + 1e-13)
38 | r = tps[i] / (tps[i] + fns[i] + 1e-13)
39 | f1s[i] = 2 * p * r / ( p + r + 1e-13)
40 |
41 | return f1s
42 |
43 |
44 | if __name__ == '__main__':
45 | print('\ndev:')
46 | print(stat_f1('../result/dev_predicate_96.53.pred'))
47 |
48 | print('\ntest:')
49 | print(stat_f1('../result/test_predicate_95.45.pred'))
--------------------------------------------------------------------------------
/subroot/subroot/test.py:
--------------------------------------------------------------------------------
1 | import subprocess
2 | import os
3 |
4 |
5 | dnn_tagger_script = '../../dnn_pytorch/seq_labeling/tag.py'
6 | model_dir = 'model/tag_scheme=iobes,zeros=True,char_dim=25,char_lstm_dim=25,char_conv_channel=25,word_dim=100,word_lstm_dim=100,feat_dim=5,feat_column=1,crf=True,dropout=0.5,lr_method=sgd-init_lr=.005-lr_decay_epoch=100,num_epochs=100,batch_size=20/best_model.pth.tar'
7 |
8 | input_file = 'data/eng.testb.bio'
9 | output_file = 'result/eng.test.output'
10 |
11 | cmd = [
12 | 'python3',
13 | dnn_tagger_script,
14 | '--model', model_dir,
15 | '--input', input_file,
16 | '--output', output_file,
17 | '--batch_size', '50',
18 | '--gpu', '0'
19 | ]
20 |
21 | # set OMP threads to 1
22 | os.environ.update({'OMP_NUM_THREADS': '1'})
23 | # set which gpu to use if gpu option is turned on
24 | gpu_device = '0'
25 | os.environ.update({'CUDA_VISIBLE_DEVICES': gpu_device})
26 |
27 | print(' '.join(cmd))
28 | subprocess.call(cmd)
--------------------------------------------------------------------------------
/subroot/subroot/train.py:
--------------------------------------------------------------------------------
1 | import os
2 | import subprocess
3 |
4 |
5 | train = './subroot/data/subroot-train.txt'
6 | dev = './subroot/data/subroot-dev.txt'
7 | test = './subroot/data/subroot-test.txt'
8 |
9 | model_dir = 'model/'
10 | result_dir = 'result/'
11 |
12 | # use word2vec to generate pre-trained embeddings.
13 | # tutorial: https://code.google.com/archive/p/word2vec/
14 | pre_emb = './subroot/data/glove.6B.100d.txt'
15 | # pre_emb = '/nas/data/m1/zhangb8/ml/data/embeddings/lample_pretrained/eng.Skip100'
16 |
17 | #
18 | # run command
19 | #
20 | script = 'dnn_pytorch/train.py'
21 | cmd = [
22 | 'python3',
23 | script,
24 | # data settings
25 | '--train', train,
26 | '--dev', dev,
27 | '--test', test,
28 | '--model_dp', model_dir,
29 | '--result_dp', result_dir,
30 | # parameter settings
31 | '--lower', '0',
32 | '--zeros', '1',
33 | '--char_dim', '25',
34 | '--char_lstm_dim', '25',
35 | '--char_conv_channel', '25',
36 | '--word_dim', '100',
37 | '--word_lstm_dim', '100',
38 | '--pre_emb', pre_emb,
39 | '--all_emb', '0',
40 | '--cap_dim', '0',
41 | '--feat_dim', '100',
42 | '--feat_column', '1',
43 | '--crf', '1',
44 | '--dropout', '0.5',
45 | '--lr_method', 'sgd-init_lr=.005-lr_decay_epoch=100',
46 | '--batch_size', '72',
47 | '--gpu', '1',
48 | ]
49 |
50 | # set OMP threads to 1
51 | os.environ.update({'OMP_NUM_THREADS': '1'})
52 | # set which gpu to use if gpu option is turned on
53 | gpu_device = '0'
54 | os.environ.update({'CUDA_VISIBLE_DEVICES': gpu_device})
55 |
56 | print(' '.join(cmd))
57 | #subprocess.call(cmd, env=os.environ)
58 |
--------------------------------------------------------------------------------
/tools/README.md:
--------------------------------------------------------------------------------
1 | This directly contains scripts and tools adopted from other open source projects such as Apache Joshua and Moses Decoder.
2 |
3 | TODO: credit the authors and resolve license issues (if any)
4 |
--------------------------------------------------------------------------------
/tools/average_models.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | import argparse
3 | import torch
4 |
5 |
6 | def average_models(model_files):
7 | vocab = None
8 | opt = None
9 | epoch = None
10 | avg_model = None
11 | avg_generator = None
12 |
13 | for i, model_file in enumerate(model_files):
14 | m = torch.load(model_file)
15 | model_weights = m['model']
16 | generator_weights = m['generator']
17 |
18 | if i == 0:
19 | vocab, opt, epoch = m['vocab'], m['opt'], m['epoch']
20 | avg_model = model_weights
21 | avg_generator = generator_weights
22 | else:
23 | for (k, v) in avg_model.items():
24 | avg_model[k].mul_(i).add_(model_weights[k]).div_(i + 1)
25 |
26 | for (k, v) in avg_generator.items():
27 | avg_generator[k].mul_(i).add_(generator_weights[k]).div_(i + 1)
28 |
29 | final = {"vocab": vocab, "opt": opt, "epoch": epoch, "optim": None,
30 | "generator": avg_generator, "model": avg_model}
31 | return final
32 |
33 |
34 | def main():
35 | parser = argparse.ArgumentParser(description="")
36 | parser.add_argument("-models", "-m", nargs="+", required=True,
37 | help="List of models")
38 | parser.add_argument("-output", "-o", required=True,
39 | help="Output file")
40 | opt = parser.parse_args()
41 |
42 | final = average_models(opt.models)
43 | torch.save(final, opt.output)
44 |
45 |
46 | if __name__ == "__main__":
47 | main()
48 |
--------------------------------------------------------------------------------
/tools/bpe_pipeline.sh:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env bash
2 | # Author : Thamme Gowda
3 | # Created : Nov 06, 2017
4 |
5 | ONMT="$( cd "$( dirname "${BASH_SOURCE[0]}" )/.." && pwd )"
6 |
7 | #======= EXPERIMENT SETUP ======
8 | # Activate python environment if needed
9 | source ~/.bashrc
10 | # source activate py3
11 |
12 | # update these variables
13 | NAME="run1"
14 | OUT="onmt-runs/$NAME"
15 |
16 | DATA="$ONMT/onmt-runs/data"
17 | TRAIN_SRC=$DATA/*train.src
18 | TRAIN_TGT=$DATA/*train.tgt
19 | VALID_SRC=$DATA/*dev.src
20 | VALID_TGT=$DATA/*dev.tgt
21 | TEST_SRC=$DATA/*test.src
22 | TEST_TGT=$DATA/*test.tgt
23 |
24 | BPE="" # default
25 | BPE="src" # src, tgt, src+tgt
26 |
27 | # applicable only when BPE="src" or "src+tgt"
28 | BPE_SRC_OPS=10000
29 |
30 | # applicable only when BPE="tgt" or "src+tgt"
31 | BPE_TGT_OPS=10000
32 |
33 | GPUARG="" # default
34 | GPUARG="0"
35 |
36 |
37 | #====== EXPERIMENT BEGIN ======
38 |
39 | # Check if input exists
40 | for f in $TRAIN_SRC $TRAIN_TGT $VALID_SRC $VALID_TGT $TEST_SRC $TEST_TGT; do
41 | if [[ ! -f "$f" ]]; then
42 | echo "Input File $f doesnt exist. Please fix the paths"
43 | exit 1
44 | fi
45 | done
46 |
47 | function lines_check {
48 | l1=`wc -l $1`
49 | l2=`wc -l $2`
50 | if [[ $l1 != $l2 ]]; then
51 | echo "ERROR: Record counts doesnt match between: $1 and $2"
52 | exit 2
53 | fi
54 | }
55 | lines_check $TRAIN_SRC $TRAIN_TGT
56 | lines_check $VALID_SRC $VALID_TGT
57 | lines_check $TEST_SRC $TEST_TGT
58 |
59 |
60 | echo "Output dir = $OUT"
61 | [ -d $OUT ] || mkdir -p $OUT
62 | [ -d $OUT/data ] || mkdir -p $OUT/data
63 | [ -d $OUT/models ] || mkdir $OUT/models
64 | [ -d $OUT/test ] || mkdir -p $OUT/test
65 |
66 |
67 | echo "Step 1a: Preprocess inputs"
68 | if [[ "$BPE" == *"src"* ]]; then
69 | echo "BPE on source"
70 | # Here we could use more monolingual data
71 | $ONMT/tools/learn_bpe.py -s $BPE_SRC_OPS < $TRAIN_SRC > $OUT/data/bpe-codes.src
72 |
73 | $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.src < $TRAIN_SRC > $OUT/data/train.src
74 | $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.src < $VALID_SRC > $OUT/data/valid.src
75 | $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.src < $TEST_SRC > $OUT/data/test.src
76 | else
77 | ln -sf $TRAIN_SRC $OUT/data/train.src
78 | ln -sf $VALID_SRC $OUT/data/valid.src
79 | ln -sf $TEST_SRC $OUT/data/test.src
80 | fi
81 |
82 |
83 | if [[ "$BPE" == *"tgt"* ]]; then
84 | echo "BPE on target"
85 | # Here we could use more monolingual data
86 | $ONMT/tools/learn_bpe.py -s $BPE_SRC_OPS < $TRAIN_TGT > $OUT/data/bpe-codes.tgt
87 |
88 | $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.tgt < $TRAIN_TGT > $OUT/data/train.tgt
89 | $ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.tgt < $VALID_TGT > $OUT/data/valid.tgt
90 | #$ONMT/tools/apply_bpe.py -c $OUT/data/bpe-codes.tgt < $TEST_TGT > $OUT/data/test.tgt
91 | # We dont touch the test References, No BPE on them!
92 | ln -sf $TEST_TGT $OUT/data/test.tgt
93 | else
94 | ln -sf $TRAIN_TGT $OUT/data/train.tgt
95 | ln -sf $VALID_TGT $OUT/data/valid.tgt
96 | ln -sf $TEST_TGT $OUT/data/test.tgt
97 | fi
98 |
99 |
100 | #: < maxv) {maxv=score; max=$0}} END{ print max}'`
124 | echo "Chosen Model = $model"
125 | if [[ -z "$model" ]]; then
126 | echo "Model not found. Looked in $OUT/models/"
127 | exit 1
128 | fi
129 |
130 | GPU_OPTS=""
131 | if [ ! -z $GPUARG ]; then
132 | GPU_OPTS="-gpu $GPUARG"
133 | fi
134 |
135 | echo "Step 3a: Translate Test"
136 | python $ONMT/translate.py -model $model \
137 | -src $OUT/data/test.src \
138 | -output $OUT/test/test.out \
139 | -replace_unk -verbose $GPU_OPTS > $OUT/test/test.log
140 |
141 | echo "Step 3b: Translate Dev"
142 | python $ONMT/translate.py -model $model \
143 | -src $OUT/data/valid.src \
144 | -output $OUT/test/valid.out \
145 | -replace_unk -verbose $GPU_OPTS > $OUT/test/valid.log
146 |
147 | if [[ "$BPE" == *"tgt"* ]]; then
148 | echo "BPE decoding/detokenising target to match with references"
149 | mv $OUT/test/test.out{,.bpe}
150 | mv $OUT/test/valid.out{,.bpe}
151 | cat $OUT/test/valid.out.bpe | sed -E 's/(@@ )|(@@ ?$)//g' > $OUT/test/valid.out
152 | cat $OUT/test/test.out.bpe | sed -E 's/(@@ )|(@@ ?$)//g' > $OUT/test/test.out
153 | fi
154 |
155 | echo "Step 4a: Evaluate Test"
156 | $ONMT/tools/multi-bleu-detok.perl $OUT/data/test.tgt < $OUT/test/test.out > $OUT/test/test.tc.bleu
157 | $ONMT/tools/multi-bleu-detok.perl -lc $OUT/data/test.tgt < $OUT/test/test.out > $OUT/test/test.lc.bleu
158 |
159 | echo "Step 4b: Evaluate Dev"
160 | $ONMT/tools/multi-bleu-detok.perl $OUT/data/valid.tgt < $OUT/test/valid.out > $OUT/test/valid.tc.bleu
161 | $ONMT/tools/multi-bleu-detok.perl -lc $OUT/data/valid.tgt < $OUT/test/valid.out > $OUT/test/valid.lc.bleu
162 |
163 | #===== EXPERIMENT END ======
164 |
--------------------------------------------------------------------------------
/tools/detokenize.perl:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env perl
2 |
3 | # Note: retrieved from https://github.com/apache/incubator-joshua/blob/master/scripts/preparation/detokenize.pl
4 |
5 | # Licensed to the Apache Software Foundation (ASF) under one or more
6 | # contributor license agreements. See the NOTICE file distributed with
7 | # this work for additional information regarding copyright ownership.
8 | # The ASF licenses this file to You under the Apache License, Version 2.0
9 | # (the "License"); you may not use this file except in compliance with
10 | # the License. You may obtain a copy of the License at
11 | #
12 | # http://www.apache.org/licenses/LICENSE-2.0
13 | #
14 | # Unless required by applicable law or agreed to in writing, software
15 | # distributed under the License is distributed on an "AS IS" BASIS,
16 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
17 | # See the License for the specific language governing permissions and
18 | # limitations under the License.
19 |
20 | use warnings;
21 | use strict;
22 |
23 | # Sample De-Tokenizer
24 | # written by Josh Schroeder, based on code by Philipp Koehn
25 | # modified later by ByungGyu Ahn, bahn@cs.jhu.edu, Luke Orland
26 |
27 | binmode(STDIN, ":utf8");
28 | binmode(STDOUT, ":utf8");
29 |
30 | my $language = "en";
31 | my $QUIET = 1;
32 | my $HELP = 0;
33 |
34 | while (@ARGV) {
35 | $_ = shift;
36 | /^-l$/ && ($language = shift, next);
37 | /^-v$/ && ($QUIET = 0, next);
38 | /^-h$/ && ($HELP = 1, next);
39 | }
40 |
41 | if ($HELP) {
42 | print "Usage ./detokenizer.perl (-l [en|de|...]) < tokenizedfile > detokenizedfile\n";
43 | exit;
44 | }
45 | if (!$QUIET) {
46 | print STDERR "Detokenizer Version 1.1\n";
47 | print STDERR "Language: $language\n";
48 | }
49 |
50 | while() {
51 | if (/^<.+>$/ || /^\s*$/) {
52 | #don't try to detokenize XML/HTML tag lines
53 | print $_;
54 | }
55 | else {
56 | print &detokenize($_);
57 | }
58 | }
59 |
60 | sub detokenize {
61 | my($text) = @_;
62 | chomp($text);
63 | $text = " $text ";
64 |
65 | # convert curly quotes to ASCII e.g. ‘“”’
66 | $text =~ s/\x{2018}/'/gs;
67 | $text =~ s/\x{2019}/'/gs;
68 | $text =~ s/\x{201c}/"/gs;
69 | $text =~ s/\x{201d}/"/gs;
70 | $text =~ s/\x{e2}\x{80}\x{98}/'/gs;
71 | $text =~ s/\x{e2}\x{80}\x{99}/'/gs;
72 | $text =~ s/\x{e2}\x{80}\x{9c}/"/gs;
73 | $text =~ s/\x{e2}\x{80}\x{9d}/"/gs;
74 |
75 | $text =~ s/ '\s+' / " /g;
76 | $text =~ s/ ` / ' /g;
77 | $text =~ s/ ' / ' /g;
78 | $text =~ s/ `` / " /g;
79 | $text =~ s/ '' / " /g;
80 |
81 | # replace the pipe character, which is
82 | # a special reserved character in Moses
83 | $text =~ s/ -PIPE- / \| /g;
84 |
85 | $text =~ s/ -LRB- / \( /g;
86 | $text =~ s/ -RRB- / \) /g;
87 | $text =~ s/ -LSB- / \[ /g;
88 | $text =~ s/ -RSB- / \] /g;
89 | $text =~ s/ -LCB- / \{ /g;
90 | $text =~ s/ -RCB- / \} /g;
91 | $text =~ s/ -lrb- / \( /g;
92 | $text =~ s/ -rrb- / \) /g;
93 | $text =~ s/ -lsb- / \[ /g;
94 | $text =~ s/ -rsb- / \] /g;
95 | $text =~ s/ -lcb- / \{ /g;
96 | $text =~ s/ -rcb- / \} /g;
97 |
98 | $text =~ s/ 'll /'ll /g;
99 | $text =~ s/ 're /'re /g;
100 | $text =~ s/ 've /'ve /g;
101 | $text =~ s/ n't /n't /g;
102 | $text =~ s/ 'LL /'LL /g;
103 | $text =~ s/ 'RE /'RE /g;
104 | $text =~ s/ 'VE /'VE /g;
105 | $text =~ s/ N'T /N'T /g;
106 | $text =~ s/ can not / cannot /g;
107 | $text =~ s/ Can not / Cannot /g;
108 |
109 | # just in case the contraction was not properly treated
110 | $text =~ s/ ' ll /'ll /g;
111 | $text =~ s/ ' re /'re /g;
112 | $text =~ s/ ' ve /'ve /g;
113 | $text =~ s/n ' t /n't /g;
114 | $text =~ s/ ' LL /'LL /g;
115 | $text =~ s/ ' RE /'RE /g;
116 | $text =~ s/ ' VE /'VE /g;
117 | $text =~ s/N ' T /N'T /g;
118 |
119 | my $word;
120 | my $i;
121 | my @words = split(/ /,$text);
122 | $text = "";
123 | my %quoteCount = ("\'"=>0,"\""=>0);
124 | my $prependSpace = " ";
125 | for ($i=0;$i<(scalar(@words));$i++) {
126 | if ($words[$i] =~ /^[\p{IsSc}]+$/) {
127 | #perform shift on currency
128 | if (($i<(scalar(@words)-1)) && ($words[$i+1] =~ /^[0-9]/)) {
129 | $text = $text.$prependSpace.$words[$i];
130 | $prependSpace = "";
131 | } else {
132 | $text=$text.$words[$i];
133 | $prependSpace = " ";
134 | }
135 | } elsif ($words[$i] =~ /^[\(\[\{\¿\¡]+$/) {
136 | #perform right shift on random punctuation items
137 | $text = $text.$prependSpace.$words[$i];
138 | $prependSpace = "";
139 | } elsif ($words[$i] =~ /^[\,\.\?\!\:\;\\\%\}\]\)]+$/){
140 | #perform left shift on punctuation items
141 | $text=$text.$words[$i];
142 | $prependSpace = " ";
143 | } elsif (($language eq "en") && ($i>0) && ($words[$i] =~ /^[\'][\p{IsAlpha}]/) && ($words[$i-1] =~ /[\p{IsAlnum}]$/)) {
144 | #left-shift the contraction for English
145 | $text=$text.$words[$i];
146 | $prependSpace = " ";
147 | } elsif (($language eq "en") && ($i>0) && ($i<(scalar(@words)-1)) && ($words[$i] eq "&") && ($words[$i-1] =~ /^[A-Z]$/) && ($words[$i+1] =~ /^[A-Z]$/)) {
148 | #some contraction with an ampersand e.g. "R&D"
149 | $text .= $words[$i];
150 | $prependSpace = "";
151 | } elsif (($language eq "fr") && ($i<(scalar(@words)-1)) && ($words[$i] =~ /[\p{IsAlpha}][\']$/) && ($words[$i+1] =~ /^[\p{IsAlpha}]/)) {
152 | #right-shift the contraction for French
153 | $text = $text.$prependSpace.$words[$i];
154 | $prependSpace = "";
155 | } elsif ($words[$i] =~ /^[\'\"]+$/) {
156 | #combine punctuation smartly
157 | if (($quoteCount{$words[$i]} % 2) eq 0) {
158 | if(($language eq "en") && ($words[$i] eq "'") && ($i > 0) && ($words[$i-1] =~ /[s]$/)) {
159 | #single quote for posesssives ending in s... "The Jones' house"
160 | #left shift
161 | $text=$text.$words[$i];
162 | $prependSpace = " ";
163 | } elsif (($language eq "en") && ($words[$i] eq "'") && ($i < (scalar(@words)-1)) && ($words[$i+1] eq "s")) {
164 | #single quote for possessive construction. "John's"
165 | $text .= $words[$i];
166 | $prependSpace = "";
167 | } elsif (($quoteCount{$words[$i]} == 0) &&
168 | ($language eq "en") && ($words[$i] eq '"') && ($i>1) && ($words[$i-1] =~ /^[,.]$/) && ($words[$i-2] ne "said")) {
169 | #emergency case in which the opening quote is missing
170 | #ending double quote for direct quotes. e.g. Blah," he said. but not like he said, "Blah.
171 | $text .= $words[$i];
172 | $prependSpace = " ";
173 | } elsif (($language eq "en") && ($words[$i] eq '"') && ($i < (scalar(@words)-1)) && ($words[$i+1] =~ /^[,.]$/)) {
174 | $text .= $words[$i];
175 | $prependSpace = " ";
176 | } else {
177 | #right shift
178 | $text = $text.$prependSpace.$words[$i];
179 | $prependSpace = "";
180 | $quoteCount{$words[$i]} = $quoteCount{$words[$i]} + 1;
181 |
182 | }
183 | } else {
184 | #left shift
185 | $text=$text.$words[$i];
186 | $prependSpace = " ";
187 | $quoteCount{$words[$i]} = $quoteCount{$words[$i]} + 1;
188 |
189 | }
190 |
191 | } else {
192 | $text=$text.$prependSpace.$words[$i];
193 | $prependSpace = " ";
194 | }
195 | }
196 |
197 | #clean continuing spaces
198 | $text =~ s/ +/ /g;
199 |
200 | #delete spaces around double angle brackets «»
201 | # Uh-oh. not a good idea. it is not consistent.
202 | $text =~ s/(\x{c2}\x{ab}|\x{ab}) /$1/g;
203 | $text =~ s/ (\x{c2}\x{bb}|\x{bb})/$1/g;
204 |
205 | # delete spaces around all other special characters
206 | # Uh-oh. not a good idea. "Men&Women"
207 | #$text =~ s/ ([^\p{IsAlnum}\s\.\'\`\,\-\"\|]) /$1/g;
208 | $text =~ s/ \/ /\//g;
209 |
210 | # clean up spaces at head and tail of each line as well as any double-spacing
211 | $text =~ s/\n /\n/g;
212 | $text =~ s/ \n/\n/g;
213 | $text =~ s/^ //g;
214 | $text =~ s/ $//g;
215 |
216 | #add trailing break
217 | $text .= "\n" unless $text =~ /\n$/;
218 |
219 | return $text;
220 | }
221 |
--------------------------------------------------------------------------------
/tools/embeddings_to_torch.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | # -*- coding: utf-8 -*-
3 | from __future__ import print_function
4 | from __future__ import division
5 | import six
6 | import sys
7 | import numpy as np
8 | import argparse
9 | import torch
10 |
11 |
12 | def get_vocabs(dict_file):
13 | vocabs = torch.load(dict_file)
14 |
15 | enc_vocab, dec_vocab = None, None
16 |
17 | # the vocab object is a list of tuple (name, torchtext.Vocab)
18 | # we iterate over this list and associate vocabularies based on the name
19 | for vocab in vocabs:
20 | if vocab[0] == 'src':
21 | enc_vocab = vocab[1]
22 | if vocab[0] == 'tgt':
23 | dec_vocab = vocab[1]
24 | assert type(None) not in [type(enc_vocab), type(dec_vocab)]
25 |
26 | print("From: %s" % dict_file)
27 | print("\t* source vocab: %d words" % len(enc_vocab))
28 | print("\t* target vocab: %d words" % len(dec_vocab))
29 |
30 | return enc_vocab, dec_vocab
31 |
32 |
33 | def get_embeddings(file_enc, opt, flag):
34 | embs = dict()
35 | if flag == 'enc':
36 | for (i, l) in enumerate(open(file_enc, 'rb')):
37 | if i < opt.skip_lines:
38 | continue
39 | if not l:
40 | break
41 | if len(l) == 0:
42 | continue
43 |
44 | l_split = l.decode('utf8').strip().split(' ')
45 | if len(l_split) == 2:
46 | continue
47 | embs[l_split[0]] = [float(em) for em in l_split[1:]]
48 | print("Got {} encryption embeddings from {}".format(len(embs),
49 | file_enc))
50 | else:
51 |
52 | for (i, l) in enumerate(open(file_enc, 'rb')):
53 | if not l:
54 | break
55 | if len(l) == 0:
56 | continue
57 |
58 | l_split = l.decode('utf8').strip().split(' ')
59 | if len(l_split) == 2:
60 | continue
61 | embs[l_split[0]] = [float(em) for em in l_split[1:]]
62 | print("Got {} decryption embeddings from {}".format(len(embs),
63 | file_enc))
64 |
65 | return embs
66 |
67 |
68 | def match_embeddings(vocab, emb, opt):
69 | dim = len(six.next(six.itervalues(emb)))
70 | filtered_embeddings = np.zeros((len(vocab), dim))
71 | count = {"match": 0, "miss": 0}
72 | for w, w_id in vocab.stoi.items():
73 | if w in emb:
74 | filtered_embeddings[w_id] = emb[w]
75 | count['match'] += 1
76 | else:
77 | if opt.verbose:
78 | print(u"not found:\t{}".format(w), file=sys.stderr)
79 | count['miss'] += 1
80 |
81 | return torch.Tensor(filtered_embeddings), count
82 |
83 |
84 | TYPES = ["GloVe", "word2vec"]
85 |
86 |
87 | def main():
88 |
89 | parser = argparse.ArgumentParser(description='embeddings_to_torch.py')
90 | parser.add_argument('-emb_file_enc', required=True,
91 | help="source Embeddings from this file")
92 | parser.add_argument('-output_file', required=True,
93 | help="Output file for the prepared data")
94 | parser.add_argument('-dict_file', required=True,
95 | help="Dictionary file")
96 | parser.add_argument('-verbose', action="store_true", default=False)
97 | parser.add_argument('-skip_lines', type=int, default=0,
98 | help="Skip first lines of the embedding file")
99 | parser.add_argument('-type', choices=TYPES, default="GloVe")
100 | opt = parser.parse_args()
101 |
102 | enc_vocab, dec_vocab = get_vocabs(opt.dict_file)
103 | if opt.type == "word2vec":
104 | opt.skip_lines = 1
105 |
106 | embeddings_enc = get_embeddings(opt.emb_file_enc, opt, flag='enc')
107 |
108 |
109 | filtered_enc_embeddings, enc_count = match_embeddings(enc_vocab,
110 | embeddings_enc,
111 | opt)
112 |
113 | print("\nMatching: ")
114 | match_percent = [_['match'] / (_['match'] + _['miss']) * 100
115 | for _ in [enc_count]]
116 | print("\t* enc: %d match, %d missing, (%.2f%%)" % (enc_count['match'],
117 | enc_count['miss'],
118 | match_percent[0]))
119 |
120 | print("\nFiltered embeddings:")
121 | print("\t* enc: ", filtered_enc_embeddings.size())
122 |
123 | enc_output_file = opt.output_file + ".enc.pt"
124 |
125 | print("\nSaving embedding as:\n\t* enc: %s"
126 | % (enc_output_file))
127 | torch.save(filtered_enc_embeddings, enc_output_file)
128 |
129 | print("\nDone.")
130 |
131 |
132 | if __name__ == "__main__":
133 | main()
134 |
--------------------------------------------------------------------------------
/tools/extract_embeddings.py:
--------------------------------------------------------------------------------
1 | from __future__ import division
2 | import torch
3 | import argparse
4 | import onmt
5 | import onmt.ModelConstructor
6 | import onmt.io
7 | import onmt.opts
8 | from onmt.Utils import use_gpu
9 |
10 | parser = argparse.ArgumentParser(description='translate.py')
11 |
12 | parser.add_argument('-model', required=True,
13 | help='Path to model .pt file')
14 | parser.add_argument('-output_dir', default='.',
15 | help="""Path to output the embeddings""")
16 | parser.add_argument('-gpu', type=int, default=-1,
17 | help="Device to run on")
18 |
19 |
20 | def write_embeddings(filename, dict, embeddings):
21 | with open(filename, 'wb') as file:
22 | for i in range(min(len(embeddings), len(dict.itos))):
23 | str = dict.itos[i].encode("utf-8")
24 | for j in range(len(embeddings[0])):
25 | str = str + (" %5f" % (embeddings[i][j])).encode("utf-8")
26 | file.write(str + b"\n")
27 |
28 |
29 | def main():
30 | dummy_parser = argparse.ArgumentParser(description='train.py')
31 | onmt.opts.model_opts(dummy_parser)
32 | dummy_opt = dummy_parser.parse_known_args([])[0]
33 | opt = parser.parse_args()
34 | opt.cuda = opt.gpu > -1
35 | if opt.cuda:
36 | torch.cuda.set_device(opt.gpu)
37 |
38 | # Add in default model arguments, possibly added since training.
39 | checkpoint = torch.load(opt.model,
40 | map_location=lambda storage, loc: storage)
41 | model_opt = checkpoint['opt']
42 | src_dict = checkpoint['vocab'][1][1]
43 | tgt_dict = checkpoint['vocab'][0][1]
44 |
45 | fields = onmt.io.load_fields_from_vocab(checkpoint['vocab'])
46 |
47 | model_opt = checkpoint['opt']
48 | for arg in dummy_opt.__dict__:
49 | if arg not in model_opt:
50 | model_opt.__dict__[arg] = dummy_opt.__dict__[arg]
51 |
52 | model = onmt.ModelConstructor.make_base_model(
53 | model_opt, fields, use_gpu(opt), checkpoint)
54 | encoder = model.encoder
55 | decoder = model.decoder
56 |
57 | encoder_embeddings = encoder.embeddings.word_lut.weight.data.tolist()
58 | decoder_embeddings = decoder.embeddings.word_lut.weight.data.tolist()
59 |
60 | print("Writing source embeddings")
61 | write_embeddings(opt.output_dir + "/src_embeddings.txt", src_dict,
62 | encoder_embeddings)
63 |
64 | print("Writing target embeddings")
65 | write_embeddings(opt.output_dir + "/tgt_embeddings.txt", tgt_dict,
66 | decoder_embeddings)
67 |
68 | print('... done.')
69 | print('Converting model...')
70 |
71 |
72 | if __name__ == "__main__":
73 | main()
74 |
--------------------------------------------------------------------------------
/tools/multi-bleu-detok.perl:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env perl
2 | #
3 | # This file is part of moses. Its use is licensed under the GNU Lesser General
4 | # Public License version 2.1 or, at your option, any later version.
5 |
6 | # This file uses the internal tokenization of mteval-v13a.pl,
7 | # giving the exact same (case-sensitive) results on untokenized text.
8 | # Using this script with detokenized output and untokenized references is
9 | # preferrable over multi-bleu.perl, since scores aren't affected by tokenization differences.
10 | #
11 | # like multi-bleu.perl , it supports plain text input and multiple references.
12 |
13 | # This file is retrieved from Moses Decoder :: https://github.com/moses-smt/mosesdecoder
14 | # $Id$
15 | use warnings;
16 | use strict;
17 |
18 | my $lowercase = 0;
19 | if ($ARGV[0] eq "-lc") {
20 | $lowercase = 1;
21 | shift;
22 | }
23 |
24 | my $stem = $ARGV[0];
25 | if (!defined $stem) {
26 | print STDERR "usage: multi-bleu-detok.pl [-lc] reference < hypothesis\n";
27 | print STDERR "Reads the references from reference or reference0, reference1, ...\n";
28 | exit(1);
29 | }
30 |
31 | $stem .= ".ref" if !-e $stem && !-e $stem."0" && -e $stem.".ref0";
32 |
33 | my @REF;
34 | my $ref=0;
35 | while(-e "$stem$ref") {
36 | &add_to_ref("$stem$ref",\@REF);
37 | $ref++;
38 | }
39 | &add_to_ref($stem,\@REF) if -e $stem;
40 | die("ERROR: could not find reference file $stem") unless scalar @REF;
41 |
42 | # add additional references explicitly specified on the command line
43 | shift;
44 | foreach my $stem (@ARGV) {
45 | &add_to_ref($stem,\@REF) if -e $stem;
46 | }
47 |
48 |
49 |
50 | sub add_to_ref {
51 | my ($file,$REF) = @_;
52 | my $s=0;
53 | if ($file =~ /.gz$/) {
54 | open(REF,"gzip -dc $file|") or die "Can't read $file";
55 | } else {
56 | open(REF,$file) or die "Can't read $file";
57 | }
58 | while([) {
59 | chop;
60 | $_ = tokenization($_);
61 | push @{$$REF[$s++]}, $_;
62 | }
63 | close(REF);
64 | }
65 |
66 | my(@CORRECT,@TOTAL,$length_translation,$length_reference);
67 | my $s=0;
68 | while() {
69 | chop;
70 | $_ = lc if $lowercase;
71 | $_ = tokenization($_);
72 | my @WORD = split;
73 | my %REF_NGRAM = ();
74 | my $length_translation_this_sentence = scalar(@WORD);
75 | my ($closest_diff,$closest_length) = (9999,9999);
76 | foreach my $reference (@{$REF[$s]}) {
77 | # print "$s $_ <=> $reference\n";
78 | $reference = lc($reference) if $lowercase;
79 | my @WORD = split(' ',$reference);
80 | my $length = scalar(@WORD);
81 | my $diff = abs($length_translation_this_sentence-$length);
82 | if ($diff < $closest_diff) {
83 | $closest_diff = $diff;
84 | $closest_length = $length;
85 | # print STDERR "$s: closest diff ".abs($length_translation_this_sentence-$length)." = abs($length_translation_this_sentence-$length), setting len: $closest_length\n";
86 | } elsif ($diff == $closest_diff) {
87 | $closest_length = $length if $length < $closest_length;
88 | # from two references with the same closeness to me
89 | # take the *shorter* into account, not the "first" one.
90 | }
91 | for(my $n=1;$n<=4;$n++) {
92 | my %REF_NGRAM_N = ();
93 | for(my $start=0;$start<=$#WORD-($n-1);$start++) {
94 | my $ngram = "$n";
95 | for(my $w=0;$w<$n;$w++) {
96 | $ngram .= " ".$WORD[$start+$w];
97 | }
98 | $REF_NGRAM_N{$ngram}++;
99 | }
100 | foreach my $ngram (keys %REF_NGRAM_N) {
101 | if (!defined($REF_NGRAM{$ngram}) ||
102 | $REF_NGRAM{$ngram} < $REF_NGRAM_N{$ngram}) {
103 | $REF_NGRAM{$ngram} = $REF_NGRAM_N{$ngram};
104 | # print "$i: REF_NGRAM{$ngram} = $REF_NGRAM{$ngram}]
\n";
105 | }
106 | }
107 | }
108 | }
109 | $length_translation += $length_translation_this_sentence;
110 | $length_reference += $closest_length;
111 | for(my $n=1;$n<=4;$n++) {
112 | my %T_NGRAM = ();
113 | for(my $start=0;$start<=$#WORD-($n-1);$start++) {
114 | my $ngram = "$n";
115 | for(my $w=0;$w<$n;$w++) {
116 | $ngram .= " ".$WORD[$start+$w];
117 | }
118 | $T_NGRAM{$ngram}++;
119 | }
120 | foreach my $ngram (keys %T_NGRAM) {
121 | $ngram =~ /^(\d+) /;
122 | my $n = $1;
123 | # my $corr = 0;
124 | # print "$i e $ngram $T_NGRAM{$ngram}
\n";
125 | $TOTAL[$n] += $T_NGRAM{$ngram};
126 | if (defined($REF_NGRAM{$ngram})) {
127 | if ($REF_NGRAM{$ngram} >= $T_NGRAM{$ngram}) {
128 | $CORRECT[$n] += $T_NGRAM{$ngram};
129 | # $corr = $T_NGRAM{$ngram};
130 | # print "$i e correct1 $T_NGRAM{$ngram}
\n";
131 | }
132 | else {
133 | $CORRECT[$n] += $REF_NGRAM{$ngram};
134 | # $corr = $REF_NGRAM{$ngram};
135 | # print "$i e correct2 $REF_NGRAM{$ngram}
\n";
136 | }
137 | }
138 | # $REF_NGRAM{$ngram} = 0 if !defined $REF_NGRAM{$ngram};
139 | # print STDERR "$ngram: {$s, $REF_NGRAM{$ngram}, $T_NGRAM{$ngram}, $corr}\n"
140 | }
141 | }
142 | $s++;
143 | }
144 | my $brevity_penalty = 1;
145 | my $bleu = 0;
146 |
147 | my @bleu=();
148 |
149 | for(my $n=1;$n<=4;$n++) {
150 | if (defined ($TOTAL[$n])){
151 | $bleu[$n]=($TOTAL[$n])?$CORRECT[$n]/$TOTAL[$n]:0;
152 | # print STDERR "CORRECT[$n]:$CORRECT[$n] TOTAL[$n]:$TOTAL[$n]\n";
153 | }else{
154 | $bleu[$n]=0;
155 | }
156 | }
157 |
158 | if ($length_reference==0){
159 | printf "BLEU = 0, 0/0/0/0 (BP=0, ratio=0, hyp_len=0, ref_len=0)\n";
160 | exit(1);
161 | }
162 |
163 | if ($length_translation<$length_reference) {
164 | $brevity_penalty = exp(1-$length_reference/$length_translation);
165 | }
166 | $bleu = $brevity_penalty * exp((my_log( $bleu[1] ) +
167 | my_log( $bleu[2] ) +
168 | my_log( $bleu[3] ) +
169 | my_log( $bleu[4] ) ) / 4) ;
170 | printf "BLEU = %.2f, %.1f/%.1f/%.1f/%.1f (BP=%.3f, ratio=%.3f, hyp_len=%d, ref_len=%d)\n",
171 | 100*$bleu,
172 | 100*$bleu[1],
173 | 100*$bleu[2],
174 | 100*$bleu[3],
175 | 100*$bleu[4],
176 | $brevity_penalty,
177 | $length_translation / $length_reference,
178 | $length_translation,
179 | $length_reference;
180 |
181 | sub my_log {
182 | return -9999999999 unless $_[0];
183 | return log($_[0]);
184 | }
185 |
186 |
187 |
188 | sub tokenization
189 | {
190 | my ($norm_text) = @_;
191 |
192 | # language-independent part:
193 | $norm_text =~ s///g; # strip "skipped" tags
194 | $norm_text =~ s/-\n//g; # strip end-of-line hyphenation and join lines
195 | $norm_text =~ s/\n/ /g; # join lines
196 | $norm_text =~ s/"/"/g; # convert SGML tag for quote to "
197 | $norm_text =~ s/&/&/g; # convert SGML tag for ampersand to &
198 | $norm_text =~ s/</
199 | $norm_text =~ s/>/>/g; # convert SGML tag for greater-than to <
200 |
201 | # language-dependent part (assuming Western languages):
202 | $norm_text = " $norm_text ";
203 | $norm_text =~ s/([\{-\~\[-\` -\&\(-\+\:-\@\/])/ $1 /g; # tokenize punctuation
204 | $norm_text =~ s/([^0-9])([\.,])/$1 $2 /g; # tokenize period and comma unless preceded by a digit
205 | $norm_text =~ s/([\.,])([^0-9])/ $1 $2/g; # tokenize period and comma unless followed by a digit
206 | $norm_text =~ s/([0-9])(-)/$1 $2 /g; # tokenize dash when preceded by a digit
207 | $norm_text =~ s/\s+/ /g; # one space only between words
208 | $norm_text =~ s/^\s+//; # no leading space
209 | $norm_text =~ s/\s+$//; # no trailing space
210 |
211 | return $norm_text;
212 | }
213 |
--------------------------------------------------------------------------------
/tools/multi-bleu.perl:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env perl
2 | #
3 | # This file is part of moses. Its use is licensed under the GNU Lesser General
4 | # Public License version 2.1 or, at your option, any later version.
5 |
6 | # $Id$
7 | use warnings;
8 | use strict;
9 |
10 | my $lowercase = 0;
11 | if ($ARGV[0] eq "-lc") {
12 | $lowercase = 1;
13 | shift;
14 | }
15 |
16 | my $stem = $ARGV[0];
17 | if (!defined $stem) {
18 | print STDERR "usage: multi-bleu.pl [-lc] reference < hypothesis\n";
19 | print STDERR "Reads the references from reference or reference0, reference1, ...\n";
20 | exit(1);
21 | }
22 |
23 | $stem .= ".ref" if !-e $stem && !-e $stem."0" && -e $stem.".ref0";
24 |
25 | my @REF;
26 | my $ref=0;
27 | while(-e "$stem$ref") {
28 | &add_to_ref("$stem$ref",\@REF);
29 | $ref++;
30 | }
31 | &add_to_ref($stem,\@REF) if -e $stem;
32 | die("ERROR: could not find reference file $stem") unless scalar @REF;
33 |
34 | # add additional references explicitly specified on the command line
35 | shift;
36 | foreach my $stem (@ARGV) {
37 | &add_to_ref($stem,\@REF) if -e $stem;
38 | }
39 |
40 |
41 |
42 | sub add_to_ref {
43 | my ($file,$REF) = @_;
44 | my $s=0;
45 | if ($file =~ /.gz$/) {
46 | open(REF,"gzip -dc $file|") or die "Can't read $file";
47 | } else {
48 | open(REF,$file) or die "Can't read $file";
49 | }
50 | while([) {
51 | chop;
52 | push @{$$REF[$s++]}, $_;
53 | }
54 | close(REF);
55 | }
56 |
57 | my(@CORRECT,@TOTAL,$length_translation,$length_reference);
58 | my $s=0;
59 | while() {
60 | chop;
61 | $_ = lc if $lowercase;
62 | my @WORD = split;
63 | my %REF_NGRAM = ();
64 | my $length_translation_this_sentence = scalar(@WORD);
65 | my ($closest_diff,$closest_length) = (9999,9999);
66 | foreach my $reference (@{$REF[$s]}) {
67 | # print "$s $_ <=> $reference\n";
68 | $reference = lc($reference) if $lowercase;
69 | my @WORD = split(' ',$reference);
70 | my $length = scalar(@WORD);
71 | my $diff = abs($length_translation_this_sentence-$length);
72 | if ($diff < $closest_diff) {
73 | $closest_diff = $diff;
74 | $closest_length = $length;
75 | # print STDERR "$s: closest diff ".abs($length_translation_this_sentence-$length)." = abs($length_translation_this_sentence-$length), setting len: $closest_length\n";
76 | } elsif ($diff == $closest_diff) {
77 | $closest_length = $length if $length < $closest_length;
78 | # from two references with the same closeness to me
79 | # take the *shorter* into account, not the "first" one.
80 | }
81 | for(my $n=1;$n<=4;$n++) {
82 | my %REF_NGRAM_N = ();
83 | for(my $start=0;$start<=$#WORD-($n-1);$start++) {
84 | my $ngram = "$n";
85 | for(my $w=0;$w<$n;$w++) {
86 | $ngram .= " ".$WORD[$start+$w];
87 | }
88 | $REF_NGRAM_N{$ngram}++;
89 | }
90 | foreach my $ngram (keys %REF_NGRAM_N) {
91 | if (!defined($REF_NGRAM{$ngram}) ||
92 | $REF_NGRAM{$ngram} < $REF_NGRAM_N{$ngram}) {
93 | $REF_NGRAM{$ngram} = $REF_NGRAM_N{$ngram};
94 | # print "$i: REF_NGRAM{$ngram} = $REF_NGRAM{$ngram}]
\n";
95 | }
96 | }
97 | }
98 | }
99 | $length_translation += $length_translation_this_sentence;
100 | $length_reference += $closest_length;
101 | for(my $n=1;$n<=4;$n++) {
102 | my %T_NGRAM = ();
103 | for(my $start=0;$start<=$#WORD-($n-1);$start++) {
104 | my $ngram = "$n";
105 | for(my $w=0;$w<$n;$w++) {
106 | $ngram .= " ".$WORD[$start+$w];
107 | }
108 | $T_NGRAM{$ngram}++;
109 | }
110 | foreach my $ngram (keys %T_NGRAM) {
111 | $ngram =~ /^(\d+) /;
112 | my $n = $1;
113 | # my $corr = 0;
114 | # print "$i e $ngram $T_NGRAM{$ngram}
\n";
115 | $TOTAL[$n] += $T_NGRAM{$ngram};
116 | if (defined($REF_NGRAM{$ngram})) {
117 | if ($REF_NGRAM{$ngram} >= $T_NGRAM{$ngram}) {
118 | $CORRECT[$n] += $T_NGRAM{$ngram};
119 | # $corr = $T_NGRAM{$ngram};
120 | # print "$i e correct1 $T_NGRAM{$ngram}
\n";
121 | }
122 | else {
123 | $CORRECT[$n] += $REF_NGRAM{$ngram};
124 | # $corr = $REF_NGRAM{$ngram};
125 | # print "$i e correct2 $REF_NGRAM{$ngram}
\n";
126 | }
127 | }
128 | # $REF_NGRAM{$ngram} = 0 if !defined $REF_NGRAM{$ngram};
129 | # print STDERR "$ngram: {$s, $REF_NGRAM{$ngram}, $T_NGRAM{$ngram}, $corr}\n"
130 | }
131 | }
132 | $s++;
133 | }
134 | my $brevity_penalty = 1;
135 | my $bleu = 0;
136 |
137 | my @bleu=();
138 |
139 | for(my $n=1;$n<=4;$n++) {
140 | if (defined ($TOTAL[$n])){
141 | $bleu[$n]=($TOTAL[$n])?$CORRECT[$n]/$TOTAL[$n]:0;
142 | # print STDERR "CORRECT[$n]:$CORRECT[$n] TOTAL[$n]:$TOTAL[$n]\n";
143 | }else{
144 | $bleu[$n]=0;
145 | }
146 | }
147 |
148 | if ($length_reference==0){
149 | printf "BLEU = 0, 0/0/0/0 (BP=0, ratio=0, hyp_len=0, ref_len=0)\n";
150 | exit(1);
151 | }
152 |
153 | if ($length_translation<$length_reference) {
154 | $brevity_penalty = exp(1-$length_reference/$length_translation);
155 | }
156 | $bleu = $brevity_penalty * exp((my_log( $bleu[1] ) +
157 | my_log( $bleu[2] ) +
158 | my_log( $bleu[3] ) +
159 | my_log( $bleu[4] ) ) / 4) ;
160 | printf "BLEU = %.2f, %.1f/%.1f/%.1f/%.1f (BP=%.3f, ratio=%.3f, hyp_len=%d, ref_len=%d)\n",
161 | 100*$bleu,
162 | 100*$bleu[1],
163 | 100*$bleu[2],
164 | 100*$bleu[3],
165 | 100*$bleu[4],
166 | $brevity_penalty,
167 | $length_translation / $length_reference,
168 | $length_translation,
169 | $length_reference;
170 |
171 | sub my_log {
172 | return -9999999999 unless $_[0];
173 | return log($_[0]);
174 | }
175 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/README.txt:
--------------------------------------------------------------------------------
1 | The language suffix can be found here:
2 |
3 | http://www.loc.gov/standards/iso639-2/php/code_list.php
4 |
5 | This code includes data from Daniel Naber's Language Tools (czech abbreviations).
6 | This code includes data from czech wiktionary (also czech abbreviations).
7 |
8 |
9 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.ca:
--------------------------------------------------------------------------------
1 | Dr
2 | Dra
3 | pàg
4 | p
5 | c
6 | av
7 | Sr
8 | Sra
9 | adm
10 | esq
11 | Prof
12 | S.A
13 | S.L
14 | p.e
15 | ptes
16 | Sta
17 | St
18 | pl
19 | màx
20 | cast
21 | dir
22 | nre
23 | fra
24 | admdora
25 | Emm
26 | Excma
27 | espf
28 | dc
29 | admdor
30 | tel
31 | angl
32 | aprox
33 | ca
34 | dept
35 | dj
36 | dl
37 | dt
38 | ds
39 | dg
40 | dv
41 | ed
42 | entl
43 | al
44 | i.e
45 | maj
46 | smin
47 | n
48 | núm
49 | pta
50 | A
51 | B
52 | C
53 | D
54 | E
55 | F
56 | G
57 | H
58 | I
59 | J
60 | K
61 | L
62 | M
63 | N
64 | O
65 | P
66 | Q
67 | R
68 | S
69 | T
70 | U
71 | V
72 | W
73 | X
74 | Y
75 | Z
76 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.cs:
--------------------------------------------------------------------------------
1 | Bc
2 | BcA
3 | Ing
4 | Ing.arch
5 | MUDr
6 | MVDr
7 | MgA
8 | Mgr
9 | JUDr
10 | PhDr
11 | RNDr
12 | PharmDr
13 | ThLic
14 | ThDr
15 | Ph.D
16 | Th.D
17 | prof
18 | doc
19 | CSc
20 | DrSc
21 | dr. h. c
22 | PaedDr
23 | Dr
24 | PhMr
25 | DiS
26 | abt
27 | ad
28 | a.i
29 | aj
30 | angl
31 | anon
32 | apod
33 | atd
34 | atp
35 | aut
36 | bd
37 | biogr
38 | b.m
39 | b.p
40 | b.r
41 | cca
42 | cit
43 | cizojaz
44 | c.k
45 | col
46 | čes
47 | čín
48 | čj
49 | ed
50 | facs
51 | fasc
52 | fol
53 | fot
54 | franc
55 | h.c
56 | hist
57 | hl
58 | hrsg
59 | ibid
60 | il
61 | ind
62 | inv.č
63 | jap
64 | jhdt
65 | jv
66 | koed
67 | kol
68 | korej
69 | kl
70 | krit
71 | lat
72 | lit
73 | m.a
74 | maď
75 | mj
76 | mp
77 | násl
78 | např
79 | nepubl
80 | něm
81 | no
82 | nr
83 | n.s
84 | okr
85 | odd
86 | odp
87 | obr
88 | opr
89 | orig
90 | phil
91 | pl
92 | pokrač
93 | pol
94 | port
95 | pozn
96 | př.kr
97 | př.n.l
98 | přel
99 | přeprac
100 | příl
101 | pseud
102 | pt
103 | red
104 | repr
105 | resp
106 | revid
107 | rkp
108 | roč
109 | roz
110 | rozš
111 | samost
112 | sect
113 | sest
114 | seš
115 | sign
116 | sl
117 | srv
118 | stol
119 | sv
120 | šk
121 | šk.ro
122 | špan
123 | tab
124 | t.č
125 | tis
126 | tj
127 | tř
128 | tzv
129 | univ
130 | uspoř
131 | vol
132 | vl.jm
133 | vs
134 | vyd
135 | vyobr
136 | zal
137 | zejm
138 | zkr
139 | zprac
140 | zvl
141 | n.p
142 | např
143 | než
144 | MUDr
145 | abl
146 | absol
147 | adj
148 | adv
149 | ak
150 | ak. sl
151 | akt
152 | alch
153 | amer
154 | anat
155 | angl
156 | anglosas
157 | arab
158 | arch
159 | archit
160 | arg
161 | astr
162 | astrol
163 | att
164 | bás
165 | belg
166 | bibl
167 | biol
168 | boh
169 | bot
170 | bulh
171 | círk
172 | csl
173 | č
174 | čas
175 | čes
176 | dat
177 | děj
178 | dep
179 | dět
180 | dial
181 | dór
182 | dopr
183 | dosl
184 | ekon
185 | epic
186 | etnonym
187 | eufem
188 | f
189 | fam
190 | fem
191 | fil
192 | film
193 | form
194 | fot
195 | fr
196 | fut
197 | fyz
198 | gen
199 | geogr
200 | geol
201 | geom
202 | germ
203 | gram
204 | hebr
205 | herald
206 | hist
207 | hl
208 | hovor
209 | hud
210 | hut
211 | chcsl
212 | chem
213 | ie
214 | imp
215 | impf
216 | ind
217 | indoevr
218 | inf
219 | instr
220 | interj
221 | ión
222 | iron
223 | it
224 | kanad
225 | katalán
226 | klas
227 | kniž
228 | komp
229 | konj
230 |
231 | konkr
232 | kř
233 | kuch
234 | lat
235 | lék
236 | les
237 | lid
238 | lit
239 | liturg
240 | lok
241 | log
242 | m
243 | mat
244 | meteor
245 | metr
246 | mod
247 | ms
248 | mysl
249 | n
250 | náb
251 | námoř
252 | neklas
253 | něm
254 | nesklon
255 | nom
256 | ob
257 | obch
258 | obyč
259 | ojed
260 | opt
261 | part
262 | pas
263 | pejor
264 | pers
265 | pf
266 | pl
267 | plpf
268 |
269 | práv
270 | prep
271 | předl
272 | přivl
273 | r
274 | rcsl
275 | refl
276 | reg
277 | rkp
278 | ř
279 | řec
280 | s
281 | samohl
282 | sg
283 | sl
284 | souhl
285 | spec
286 | srov
287 | stfr
288 | střv
289 | stsl
290 | subj
291 | subst
292 | superl
293 | sv
294 | sz
295 | táz
296 | tech
297 | telev
298 | teol
299 | trans
300 | typogr
301 | var
302 | vedl
303 | verb
304 | vl. jm
305 | voj
306 | vok
307 | vůb
308 | vulg
309 | výtv
310 | vztaž
311 | zahr
312 | zájm
313 | zast
314 | zejm
315 |
316 | zeměd
317 | zkr
318 | zř
319 | mj
320 | dl
321 | atp
322 | sport
323 | Mgr
324 | horn
325 | MVDr
326 | JUDr
327 | RSDr
328 | Bc
329 | PhDr
330 | ThDr
331 | Ing
332 | aj
333 | apod
334 | PharmDr
335 | pomn
336 | ev
337 | slang
338 | nprap
339 | odp
340 | dop
341 | pol
342 | st
343 | stol
344 | p. n. l
345 | před n. l
346 | n. l
347 | př. Kr
348 | po Kr
349 | př. n. l
350 | odd
351 | RNDr
352 | tzv
353 | atd
354 | tzn
355 | resp
356 | tj
357 | p
358 | br
359 | č. j
360 | čj
361 | č. p
362 | čp
363 | a. s
364 | s. r. o
365 | spol. s r. o
366 | p. o
367 | s. p
368 | v. o. s
369 | k. s
370 | o. p. s
371 | o. s
372 | v. r
373 | v z
374 | ml
375 | vč
376 | kr
377 | mld
378 | hod
379 | popř
380 | ap
381 | event
382 | rus
383 | slov
384 | rum
385 | švýc
386 | P. T
387 | zvl
388 | hor
389 | dol
390 | S.O.S
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.de:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 |
4 | #any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)
5 | #usually upper case letters are initials in a name
6 | #no german words end in single lower-case letters, so we throw those in too.
7 | A
8 | B
9 | C
10 | D
11 | E
12 | F
13 | G
14 | H
15 | I
16 | J
17 | K
18 | L
19 | M
20 | N
21 | O
22 | P
23 | Q
24 | R
25 | S
26 | T
27 | U
28 | V
29 | W
30 | X
31 | Y
32 | Z
33 | a
34 | b
35 | c
36 | d
37 | e
38 | f
39 | g
40 | h
41 | i
42 | j
43 | k
44 | l
45 | m
46 | n
47 | o
48 | p
49 | q
50 | r
51 | s
52 | t
53 | u
54 | v
55 | w
56 | x
57 | y
58 | z
59 |
60 |
61 | #Roman Numerals. A dot after one of these is not a sentence break in German.
62 | I
63 | II
64 | III
65 | IV
66 | V
67 | VI
68 | VII
69 | VIII
70 | IX
71 | X
72 | XI
73 | XII
74 | XIII
75 | XIV
76 | XV
77 | XVI
78 | XVII
79 | XVIII
80 | XIX
81 | XX
82 | i
83 | ii
84 | iii
85 | iv
86 | v
87 | vi
88 | vii
89 | viii
90 | ix
91 | x
92 | xi
93 | xii
94 | xiii
95 | xiv
96 | xv
97 | xvi
98 | xvii
99 | xviii
100 | xix
101 | xx
102 |
103 | #Titles and Honorifics
104 | Adj
105 | Adm
106 | Adv
107 | Asst
108 | Bart
109 | Bldg
110 | Brig
111 | Bros
112 | Capt
113 | Cmdr
114 | Col
115 | Comdr
116 | Con
117 | Corp
118 | Cpl
119 | DR
120 | Dr
121 | Ens
122 | Gen
123 | Gov
124 | Hon
125 | Hosp
126 | Insp
127 | Lt
128 | MM
129 | MR
130 | MRS
131 | MS
132 | Maj
133 | Messrs
134 | Mlle
135 | Mme
136 | Mr
137 | Mrs
138 | Ms
139 | Msgr
140 | Op
141 | Ord
142 | Pfc
143 | Ph
144 | Prof
145 | Pvt
146 | Rep
147 | Reps
148 | Res
149 | Rev
150 | Rt
151 | Sen
152 | Sens
153 | Sfc
154 | Sgt
155 | Sr
156 | St
157 | Supt
158 | Surg
159 |
160 | #Misc symbols
161 | Mio
162 | Mrd
163 | bzw
164 | v
165 | vs
166 | usw
167 | d.h
168 | z.B
169 | u.a
170 | etc
171 | Mrd
172 | MwSt
173 | ggf
174 | d.J
175 | D.h
176 | m.E
177 | vgl
178 | I.F
179 | z.T
180 | sogen
181 | ff
182 | u.E
183 | g.U
184 | g.g.A
185 | c.-à-d
186 | Buchst
187 | u.s.w
188 | sog
189 | u.ä
190 | Std
191 | evtl
192 | Zt
193 | Chr
194 | u.U
195 | o.ä
196 | Ltd
197 | b.A
198 | z.Zt
199 | spp
200 | sen
201 | SA
202 | k.o
203 | jun
204 | i.H.v
205 | dgl
206 | dergl
207 | Co
208 | zzt
209 | usf
210 | s.p.a
211 | Dkr
212 | Corp
213 | bzgl
214 | BSE
215 |
216 | #Number indicators
217 | # add #NUMERIC_ONLY# after the word if it should ONLY be non-breaking when a 0-9 digit follows it
218 | No
219 | Nos
220 | Art
221 | Nr
222 | pp
223 | ca
224 | Ca
225 |
226 | #Ordinals are done with . in German - "1." = "1st" in English
227 | 1
228 | 2
229 | 3
230 | 4
231 | 5
232 | 6
233 | 7
234 | 8
235 | 9
236 | 10
237 | 11
238 | 12
239 | 13
240 | 14
241 | 15
242 | 16
243 | 17
244 | 18
245 | 19
246 | 20
247 | 21
248 | 22
249 | 23
250 | 24
251 | 25
252 | 26
253 | 27
254 | 28
255 | 29
256 | 30
257 | 31
258 | 32
259 | 33
260 | 34
261 | 35
262 | 36
263 | 37
264 | 38
265 | 39
266 | 40
267 | 41
268 | 42
269 | 43
270 | 44
271 | 45
272 | 46
273 | 47
274 | 48
275 | 49
276 | 50
277 | 51
278 | 52
279 | 53
280 | 54
281 | 55
282 | 56
283 | 57
284 | 58
285 | 59
286 | 60
287 | 61
288 | 62
289 | 63
290 | 64
291 | 65
292 | 66
293 | 67
294 | 68
295 | 69
296 | 70
297 | 71
298 | 72
299 | 73
300 | 74
301 | 75
302 | 76
303 | 77
304 | 78
305 | 79
306 | 80
307 | 81
308 | 82
309 | 83
310 | 84
311 | 85
312 | 86
313 | 87
314 | 88
315 | 89
316 | 90
317 | 91
318 | 92
319 | 93
320 | 94
321 | 95
322 | 96
323 | 97
324 | 98
325 | 99
326 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.en:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 |
4 | #any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)
5 | #usually upper case letters are initials in a name
6 | A
7 | B
8 | C
9 | D
10 | E
11 | F
12 | G
13 | H
14 | I
15 | J
16 | K
17 | L
18 | M
19 | N
20 | O
21 | P
22 | Q
23 | R
24 | S
25 | T
26 | U
27 | V
28 | W
29 | X
30 | Y
31 | Z
32 |
33 | #List of titles. These are often followed by upper-case names, but do not indicate sentence breaks
34 | Adj
35 | Adm
36 | Adv
37 | Asst
38 | Bart
39 | Bldg
40 | Brig
41 | Bros
42 | Capt
43 | Cmdr
44 | Col
45 | Comdr
46 | Con
47 | Corp
48 | Cpl
49 | DR
50 | Dr
51 | Drs
52 | Ens
53 | Gen
54 | Gov
55 | Hon
56 | Hr
57 | Hosp
58 | Insp
59 | Lt
60 | MM
61 | MR
62 | MRS
63 | MS
64 | Maj
65 | Messrs
66 | Mlle
67 | Mme
68 | Mr
69 | Mrs
70 | Ms
71 | Msgr
72 | Op
73 | Ord
74 | Pfc
75 | Ph
76 | Prof
77 | Pvt
78 | Rep
79 | Reps
80 | Res
81 | Rev
82 | Rt
83 | Sen
84 | Sens
85 | Sfc
86 | Sgt
87 | Sr
88 | St
89 | Supt
90 | Surg
91 |
92 | #misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)
93 | v
94 | vs
95 | i.e
96 | rev
97 | e.g
98 |
99 | #Numbers only. These should only induce breaks when followed by a numeric sequence
100 | # add NUMERIC_ONLY after the word for this function
101 | #This case is mostly for the english "No." which can either be a sentence of its own, or
102 | #if followed by a number, a non-breaking prefix
103 | No #NUMERIC_ONLY#
104 | Nos
105 | Art #NUMERIC_ONLY#
106 | Nr
107 | pp #NUMERIC_ONLY#
108 |
109 | #month abbreviations
110 | Jan
111 | Feb
112 | Mar
113 | Apr
114 | #May is a full word
115 | Jun
116 | Jul
117 | Aug
118 | Sep
119 | Oct
120 | Nov
121 | Dec
122 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.es:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 |
4 | #any single upper case letter followed by a period is not a sentence ender
5 | #usually upper case letters are initials in a name
6 | A
7 | B
8 | C
9 | D
10 | E
11 | F
12 | G
13 | H
14 | I
15 | J
16 | K
17 | L
18 | M
19 | N
20 | O
21 | P
22 | Q
23 | R
24 | S
25 | T
26 | U
27 | V
28 | W
29 | X
30 | Y
31 | Z
32 |
33 | # Period-final abbreviation list from http://www.ctspanish.com/words/abbreviations.htm
34 |
35 | A.C
36 | Apdo
37 | Av
38 | Bco
39 | CC.AA
40 | Da
41 | Dep
42 | Dn
43 | Dr
44 | Dra
45 | EE.UU
46 | Excmo
47 | FF.CC
48 | Fil
49 | Gral
50 | J.C
51 | Let
52 | Lic
53 | N.B
54 | P.D
55 | P.V.P
56 | Prof
57 | Pts
58 | Rte
59 | S.A
60 | S.A.R
61 | S.E
62 | S.L
63 | S.R.C
64 | Sr
65 | Sra
66 | Srta
67 | Sta
68 | Sto
69 | T.V.E
70 | Tel
71 | Ud
72 | Uds
73 | V.B
74 | V.E
75 | Vd
76 | Vds
77 | a/c
78 | adj
79 | admón
80 | afmo
81 | apdo
82 | av
83 | c
84 | c.f
85 | c.g
86 | cap
87 | cm
88 | cta
89 | dcha
90 | doc
91 | ej
92 | entlo
93 | esq
94 | etc
95 | f.c
96 | gr
97 | grs
98 | izq
99 | kg
100 | km
101 | mg
102 | mm
103 | núm
104 | núm
105 | p
106 | p.a
107 | p.ej
108 | ptas
109 | pág
110 | págs
111 | pág
112 | págs
113 | q.e.g.e
114 | q.e.s.m
115 | s
116 | s.s.s
117 | vid
118 | vol
119 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.fi:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT
2 | #indicate an end-of-sentence marker. Special cases are included for prefixes
3 | #that ONLY appear before 0-9 numbers.
4 |
5 | #This list is compiled from omorfi database
6 | #by Tommi A Pirinen.
7 |
8 |
9 | #any single upper case letter followed by a period is not a sentence ender
10 | A
11 | B
12 | C
13 | D
14 | E
15 | F
16 | G
17 | H
18 | I
19 | J
20 | K
21 | L
22 | M
23 | N
24 | O
25 | P
26 | Q
27 | R
28 | S
29 | T
30 | U
31 | V
32 | W
33 | X
34 | Y
35 | Z
36 | Å
37 | Ä
38 | Ö
39 |
40 | #List of titles. These are often followed by upper-case names, but do not indicate sentence breaks
41 | alik
42 | alil
43 | amir
44 | apul
45 | apul.prof
46 | arkkit
47 | ass
48 | assist
49 | dipl
50 | dipl.arkkit
51 | dipl.ekon
52 | dipl.ins
53 | dipl.kielenk
54 | dipl.kirjeenv
55 | dipl.kosm
56 | dipl.urk
57 | dos
58 | erikoiseläinl
59 | erikoishammasl
60 | erikoisl
61 | erikoist
62 | ev.luutn
63 | evp
64 | fil
65 | ft
66 | hallinton
67 | hallintot
68 | hammaslääket
69 | jatk
70 | jääk
71 | kansaned
72 | kapt
73 | kapt.luutn
74 | kenr
75 | kenr.luutn
76 | kenr.maj
77 | kers
78 | kirjeenv
79 | kom
80 | kom.kapt
81 | komm
82 | konst
83 | korpr
84 | luutn
85 | maist
86 | maj
87 | Mr
88 | Mrs
89 | Ms
90 | M.Sc
91 | neuv
92 | nimim
93 | Ph.D
94 | prof
95 | puh.joht
96 | pääll
97 | res
98 | san
99 | siht
100 | suom
101 | sähköp
102 | säv
103 | toht
104 | toim
105 | toim.apul
106 | toim.joht
107 | toim.siht
108 | tuom
109 | ups
110 | vänr
111 | vääp
112 | ye.ups
113 | ylik
114 | ylil
115 | ylim
116 | ylimatr
117 | yliop
118 | yliopp
119 | ylip
120 | yliv
121 |
122 | #misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall
123 | #into this category - it sometimes ends a sentence)
124 | e.g
125 | ent
126 | esim
127 | huom
128 | i.e
129 | ilm
130 | l
131 | mm
132 | myöh
133 | nk
134 | nyk
135 | par
136 | po
137 | t
138 | v
139 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.fr:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 | #
4 | #any single upper case letter followed by a period is not a sentence ender
5 | #usually upper case letters are initials in a name
6 | #no French words end in single lower-case letters, so we throw those in too?
7 | A
8 | B
9 | C
10 | D
11 | E
12 | F
13 | G
14 | H
15 | I
16 | J
17 | K
18 | L
19 | M
20 | N
21 | O
22 | P
23 | Q
24 | R
25 | S
26 | T
27 | U
28 | V
29 | W
30 | X
31 | Y
32 | Z
33 | #a
34 | b
35 | c
36 | d
37 | e
38 | f
39 | g
40 | h
41 | i
42 | j
43 | k
44 | l
45 | m
46 | n
47 | o
48 | p
49 | q
50 | r
51 | s
52 | t
53 | u
54 | v
55 | w
56 | x
57 | y
58 | z
59 |
60 | # Period-final abbreviation list for French
61 | A.C.N
62 | A.M
63 | art
64 | ann
65 | apr
66 | av
67 | auj
68 | lib
69 | B.P
70 | boul
71 | ca
72 | c.-à-d
73 | cf
74 | ch.-l
75 | chap
76 | contr
77 | C.P.I
78 | C.Q.F.D
79 | C.N
80 | C.N.S
81 | C.S
82 | dir
83 | éd
84 | e.g
85 | env
86 | al
87 | etc
88 | E.V
89 | ex
90 | fasc
91 | fém
92 | fig
93 | fr
94 | hab
95 | ibid
96 | id
97 | i.e
98 | inf
99 | LL.AA
100 | LL.AA.II
101 | LL.AA.RR
102 | LL.AA.SS
103 | L.D
104 | LL.EE
105 | LL.MM
106 | LL.MM.II.RR
107 | loc.cit
108 | masc
109 | MM
110 | ms
111 | N.B
112 | N.D.A
113 | N.D.L.R
114 | N.D.T
115 | n/réf
116 | NN.SS
117 | N.S
118 | N.D
119 | N.P.A.I
120 | p.c.c
121 | pl
122 | pp
123 | p.ex
124 | p.j
125 | P.S
126 | R.A.S
127 | R.-V
128 | R.P
129 | R.I.P
130 | SS
131 | S.S
132 | S.A
133 | S.A.I
134 | S.A.R
135 | S.A.S
136 | S.E
137 | sec
138 | sect
139 | sing
140 | S.M
141 | S.M.I.R
142 | sq
143 | sqq
144 | suiv
145 | sup
146 | suppl
147 | tél
148 | T.S.V.P
149 | vb
150 | vol
151 | vs
152 | X.O
153 | Z.I
154 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.ga:
--------------------------------------------------------------------------------
1 |
2 | A
3 | B
4 | C
5 | D
6 | E
7 | F
8 | G
9 | H
10 | I
11 | J
12 | K
13 | L
14 | M
15 | N
16 | O
17 | P
18 | Q
19 | R
20 | S
21 | T
22 | U
23 | V
24 | W
25 | X
26 | Y
27 | Z
28 | Á
29 | É
30 | Í
31 | Ó
32 | Ú
33 |
34 | Uacht
35 | Dr
36 | B.Arch
37 |
38 | m.sh
39 | .i
40 | Co
41 | Cf
42 | cf
43 | i.e
44 | r
45 | Chr
46 | lch #NUMERIC_ONLY#
47 | lgh #NUMERIC_ONLY#
48 | uimh #NUMERIC_ONLY#
49 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.hu:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 |
4 | #any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)
5 | #usually upper case letters are initials in a name
6 | A
7 | B
8 | C
9 | D
10 | E
11 | F
12 | G
13 | H
14 | I
15 | J
16 | K
17 | L
18 | M
19 | N
20 | O
21 | P
22 | Q
23 | R
24 | S
25 | T
26 | U
27 | V
28 | W
29 | X
30 | Y
31 | Z
32 | Á
33 | É
34 | Í
35 | Ó
36 | Ö
37 | Ő
38 | Ú
39 | Ü
40 | Ű
41 |
42 | #List of titles. These are often followed by upper-case names, but do not indicate sentence breaks
43 | Dr
44 | dr
45 | kb
46 | Kb
47 | vö
48 | Vö
49 | pl
50 | Pl
51 | ca
52 | Ca
53 | min
54 | Min
55 | max
56 | Max
57 | ún
58 | Ún
59 | prof
60 | Prof
61 | de
62 | De
63 | du
64 | Du
65 | Szt
66 | St
67 |
68 | #Numbers only. These should only induce breaks when followed by a numeric sequence
69 | # add NUMERIC_ONLY after the word for this function
70 | #This case is mostly for the english "No." which can either be a sentence of its own, or
71 | #if followed by a number, a non-breaking prefix
72 |
73 | # Month name abbreviations
74 | jan #NUMERIC_ONLY#
75 | Jan #NUMERIC_ONLY#
76 | Feb #NUMERIC_ONLY#
77 | feb #NUMERIC_ONLY#
78 | márc #NUMERIC_ONLY#
79 | Márc #NUMERIC_ONLY#
80 | ápr #NUMERIC_ONLY#
81 | Ápr #NUMERIC_ONLY#
82 | máj #NUMERIC_ONLY#
83 | Máj #NUMERIC_ONLY#
84 | jún #NUMERIC_ONLY#
85 | Jún #NUMERIC_ONLY#
86 | Júl #NUMERIC_ONLY#
87 | júl #NUMERIC_ONLY#
88 | aug #NUMERIC_ONLY#
89 | Aug #NUMERIC_ONLY#
90 | Szept #NUMERIC_ONLY#
91 | szept #NUMERIC_ONLY#
92 | okt #NUMERIC_ONLY#
93 | Okt #NUMERIC_ONLY#
94 | nov #NUMERIC_ONLY#
95 | Nov #NUMERIC_ONLY#
96 | dec #NUMERIC_ONLY#
97 | Dec #NUMERIC_ONLY#
98 |
99 | # Other abbreviations
100 | tel #NUMERIC_ONLY#
101 | Tel #NUMERIC_ONLY#
102 | Fax #NUMERIC_ONLY#
103 | fax #NUMERIC_ONLY#
104 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.is:
--------------------------------------------------------------------------------
1 | no #NUMERIC_ONLY#
2 | No #NUMERIC_ONLY#
3 | nr #NUMERIC_ONLY#
4 | Nr #NUMERIC_ONLY#
5 | nR #NUMERIC_ONLY#
6 | NR #NUMERIC_ONLY#
7 | a
8 | b
9 | c
10 | d
11 | e
12 | f
13 | g
14 | h
15 | i
16 | j
17 | k
18 | l
19 | m
20 | n
21 | o
22 | p
23 | q
24 | r
25 | s
26 | t
27 | u
28 | v
29 | w
30 | x
31 | y
32 | z
33 | ^
34 | í
35 | á
36 | ó
37 | æ
38 | A
39 | B
40 | C
41 | D
42 | E
43 | F
44 | G
45 | H
46 | I
47 | J
48 | K
49 | L
50 | M
51 | N
52 | O
53 | P
54 | Q
55 | R
56 | S
57 | T
58 | U
59 | V
60 | W
61 | X
62 | Y
63 | Z
64 | ab.fn
65 | a.fn
66 | afs
67 | al
68 | alm
69 | alg
70 | andh
71 | ath
72 | aths
73 | atr
74 | ao
75 | au
76 | aukaf
77 | áfn
78 | áhrl.s
79 | áhrs
80 | ákv.gr
81 | ákv
82 | bh
83 | bls
84 | dr
85 | e.Kr
86 | et
87 | ef
88 | efn
89 | ennfr
90 | eink
91 | end
92 | e.st
93 | erl
94 | fél
95 | fskj
96 | fh
97 | f.hl
98 | físl
99 | fl
100 | fn
101 | fo
102 | forl
103 | frb
104 | frl
105 | frh
106 | frt
107 | fsl
108 | fsh
109 | fs
110 | fsk
111 | fst
112 | f.Kr
113 | ft
114 | fv
115 | fyrrn
116 | fyrrv
117 | germ
118 | gm
119 | gr
120 | hdl
121 | hdr
122 | hf
123 | hl
124 | hlsk
125 | hljsk
126 | hljv
127 | hljóðv
128 | hr
129 | hv
130 | hvk
131 | holl
132 | Hos
133 | höf
134 | hk
135 | hrl
136 | ísl
137 | kaf
138 | kap
139 | Khöfn
140 | kk
141 | kg
142 | kk
143 | km
144 | kl
145 | klst
146 | kr
147 | kt
148 | kgúrsk
149 | kvk
150 | leturbr
151 | lh
152 | lh.nt
153 | lh.þt
154 | lo
155 | ltr
156 | mlja
157 | mljó
158 | millj
159 | mm
160 | mms
161 | m.fl
162 | miðm
163 | mgr
164 | mst
165 | mín
166 | nf
167 | nh
168 | nhm
169 | nl
170 | nk
171 | nmgr
172 | no
173 | núv
174 | nt
175 | o.áfr
176 | o.m.fl
177 | ohf
178 | o.fl
179 | o.s.frv
180 | ófn
181 | ób
182 | óákv.gr
183 | óákv
184 | pfn
185 | PR
186 | pr
187 | Ritstj
188 | Rvík
189 | Rvk
190 | samb
191 | samhlj
192 | samn
193 | samn
194 | sbr
195 | sek
196 | sérn
197 | sf
198 | sfn
199 | sh
200 | sfn
201 | sh
202 | s.hl
203 | sk
204 | skv
205 | sl
206 | sn
207 | so
208 | ss.us
209 | s.st
210 | samþ
211 | sbr
212 | shlj
213 | sign
214 | skál
215 | st
216 | st.s
217 | stk
218 | sþ
219 | teg
220 | tbl
221 | tfn
222 | tl
223 | tvíhlj
224 | tvt
225 | till
226 | to
227 | umr
228 | uh
229 | us
230 | uppl
231 | útg
232 | vb
233 | Vf
234 | vh
235 | vkf
236 | Vl
237 | vl
238 | vlf
239 | vmf
240 | 8vo
241 | vsk
242 | vth
243 | þt
244 | þf
245 | þjs
246 | þgf
247 | þlt
248 | þolm
249 | þm
250 | þml
251 | þýð
252 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.it:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 |
4 | #any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)
5 | #usually upper case letters are initials in a name
6 | A
7 | B
8 | C
9 | D
10 | E
11 | F
12 | G
13 | H
14 | I
15 | J
16 | K
17 | L
18 | M
19 | N
20 | O
21 | P
22 | Q
23 | R
24 | S
25 | T
26 | U
27 | V
28 | W
29 | X
30 | Y
31 | Z
32 |
33 | #List of titles. These are often followed by upper-case names, but do not indicate sentence breaks
34 | Adj
35 | Adm
36 | Adv
37 | Amn
38 | Arch
39 | Asst
40 | Avv
41 | Bart
42 | Bcc
43 | Bldg
44 | Brig
45 | Bros
46 | C.A.P
47 | C.P
48 | Capt
49 | Cc
50 | Cmdr
51 | Co
52 | Col
53 | Comdr
54 | Con
55 | Corp
56 | Cpl
57 | DR
58 | Dott
59 | Dr
60 | Drs
61 | Egr
62 | Ens
63 | Gen
64 | Geom
65 | Gov
66 | Hon
67 | Hosp
68 | Hr
69 | Id
70 | Ing
71 | Insp
72 | Lt
73 | MM
74 | MR
75 | MRS
76 | MS
77 | Maj
78 | Messrs
79 | Mlle
80 | Mme
81 | Mo
82 | Mons
83 | Mr
84 | Mrs
85 | Ms
86 | Msgr
87 | N.B
88 | Op
89 | Ord
90 | P.S
91 | P.T
92 | Pfc
93 | Ph
94 | Prof
95 | Pvt
96 | RP
97 | RSVP
98 | Rag
99 | Rep
100 | Reps
101 | Res
102 | Rev
103 | Rif
104 | Rt
105 | S.A
106 | S.B.F
107 | S.P.M
108 | S.p.A
109 | S.r.l
110 | Sen
111 | Sens
112 | Sfc
113 | Sgt
114 | Sig
115 | Sigg
116 | Soc
117 | Spett
118 | Sr
119 | St
120 | Supt
121 | Surg
122 | V.P
123 |
124 | # other
125 | a.c
126 | acc
127 | all
128 | banc
129 | c.a
130 | c.c.p
131 | c.m
132 | c.p
133 | c.s
134 | c.v
135 | corr
136 | dott
137 | e.p.c
138 | ecc
139 | es
140 | fatt
141 | gg
142 | int
143 | lett
144 | ogg
145 | on
146 | p.c
147 | p.c.c
148 | p.es
149 | p.f
150 | p.r
151 | p.v
152 | post
153 | pp
154 | racc
155 | ric
156 | s.n.c
157 | seg
158 | sgg
159 | ss
160 | tel
161 | u.s
162 | v.r
163 | v.s
164 |
165 | #misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)
166 | v
167 | vs
168 | i.e
169 | rev
170 | e.g
171 |
172 | #Numbers only. These should only induce breaks when followed by a numeric sequence
173 | # add NUMERIC_ONLY after the word for this function
174 | #This case is mostly for the english "No." which can either be a sentence of its own, or
175 | #if followed by a number, a non-breaking prefix
176 | No #NUMERIC_ONLY#
177 | Nos
178 | Art #NUMERIC_ONLY#
179 | Nr
180 | pp #NUMERIC_ONLY#
181 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.lv:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 |
4 | #any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)
5 | #usually upper case letters are initials in a name
6 | A
7 | Ā
8 | B
9 | C
10 | Č
11 | D
12 | E
13 | Ē
14 | F
15 | G
16 | Ģ
17 | H
18 | I
19 | Ī
20 | J
21 | K
22 | Ķ
23 | L
24 | Ļ
25 | M
26 | N
27 | Ņ
28 | O
29 | P
30 | Q
31 | R
32 | S
33 | Š
34 | T
35 | U
36 | Ū
37 | V
38 | W
39 | X
40 | Y
41 | Z
42 | Ž
43 |
44 | #List of titles. These are often followed by upper-case names, but do not indicate sentence breaks
45 | dr
46 | Dr
47 | med
48 | prof
49 | Prof
50 | inž
51 | Inž
52 | ist.loc
53 | Ist.loc
54 | kor.loc
55 | Kor.loc
56 | v.i
57 | vietn
58 | Vietn
59 |
60 | #misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)
61 | a.l
62 | t.p
63 | pārb
64 | Pārb
65 | vec
66 | Vec
67 | inv
68 | Inv
69 | sk
70 | Sk
71 | spec
72 | Spec
73 | vienk
74 | Vienk
75 | virz
76 | Virz
77 | māksl
78 | Māksl
79 | mūz
80 | Mūz
81 | akad
82 | Akad
83 | soc
84 | Soc
85 | galv
86 | Galv
87 | vad
88 | Vad
89 | sertif
90 | Sertif
91 | folkl
92 | Folkl
93 | hum
94 | Hum
95 |
96 | #Numbers only. These should only induce breaks when followed by a numeric sequence
97 | # add NUMERIC_ONLY after the word for this function
98 | #This case is mostly for the english "No." which can either be a sentence of its own, or
99 | #if followed by a number, a non-breaking prefix
100 | Nr #NUMERIC_ONLY#
101 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.nl:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 | #Sources: http://nl.wikipedia.org/wiki/Lijst_van_afkortingen
4 | # http://nl.wikipedia.org/wiki/Aanspreekvorm
5 | # http://nl.wikipedia.org/wiki/Titulatuur_in_het_Nederlands_hoger_onderwijs
6 | #any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)
7 | #usually upper case letters are initials in a name
8 | A
9 | B
10 | C
11 | D
12 | E
13 | F
14 | G
15 | H
16 | I
17 | J
18 | K
19 | L
20 | M
21 | N
22 | O
23 | P
24 | Q
25 | R
26 | S
27 | T
28 | U
29 | V
30 | W
31 | X
32 | Y
33 | Z
34 |
35 | #List of titles. These are often followed by upper-case names, but do not indicate sentence breaks
36 | bacc
37 | bc
38 | bgen
39 | c.i
40 | dhr
41 | dr
42 | dr.h.c
43 | drs
44 | drs
45 | ds
46 | eint
47 | fa
48 | Fa
49 | fam
50 | gen
51 | genm
52 | ing
53 | ir
54 | jhr
55 | jkvr
56 | jr
57 | kand
58 | kol
59 | lgen
60 | lkol
61 | Lt
62 | maj
63 | Mej
64 | mevr
65 | Mme
66 | mr
67 | mr
68 | Mw
69 | o.b.s
70 | plv
71 | prof
72 | ritm
73 | tint
74 | Vz
75 | Z.D
76 | Z.D.H
77 | Z.E
78 | Z.Em
79 | Z.H
80 | Z.K.H
81 | Z.K.M
82 | Z.M
83 | z.v
84 |
85 | #misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)
86 | #we seem to have a lot of these in dutch i.e.: i.p.v - in plaats van (in stead of) never ends a sentence
87 | a.g.v
88 | bijv
89 | bijz
90 | bv
91 | d.w.z
92 | e.c
93 | e.g
94 | e.k
95 | ev
96 | i.p.v
97 | i.s.m
98 | i.t.t
99 | i.v.m
100 | m.a.w
101 | m.b.t
102 | m.b.v
103 | m.h.o
104 | m.i
105 | m.i.v
106 | v.w.t
107 |
108 | #Numbers only. These should only induce breaks when followed by a numeric sequence
109 | # add NUMERIC_ONLY after the word for this function
110 | #This case is mostly for the english "No." which can either be a sentence of its own, or
111 | #if followed by a number, a non-breaking prefix
112 | Nr #NUMERIC_ONLY#
113 | Nrs
114 | nrs
115 | nr #NUMERIC_ONLY#
116 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.pl:
--------------------------------------------------------------------------------
1 | adw
2 | afr
3 | akad
4 | al
5 | Al
6 | am
7 | amer
8 | arch
9 | art
10 | Art
11 | artyst
12 | astr
13 | austr
14 | bałt
15 | bdb
16 | bł
17 | bm
18 | br
19 | bryg
20 | bryt
21 | centr
22 | ces
23 | chem
24 | chiń
25 | chir
26 | c.k
27 | c.o
28 | cyg
29 | cyw
30 | cyt
31 | czes
32 | czw
33 | cd
34 | Cd
35 | czyt
36 | ćw
37 | ćwicz
38 | daw
39 | dcn
40 | dekl
41 | demokr
42 | det
43 | diec
44 | dł
45 | dn
46 | dot
47 | dol
48 | dop
49 | dost
50 | dosł
51 | h.c
52 | ds
53 | dst
54 | duszp
55 | dypl
56 | egz
57 | ekol
58 | ekon
59 | elektr
60 | em
61 | ew
62 | fab
63 | farm
64 | fot
65 | fr
66 | gat
67 | gastr
68 | geogr
69 | geol
70 | gimn
71 | głęb
72 | gm
73 | godz
74 | górn
75 | gosp
76 | gr
77 | gram
78 | hist
79 | hiszp
80 | hr
81 | Hr
82 | hot
83 | id
84 | in
85 | im
86 | iron
87 | jn
88 | kard
89 | kat
90 | katol
91 | k.k
92 | kk
93 | kol
94 | kl
95 | k.p.a
96 | kpc
97 | k.p.c
98 | kpt
99 | kr
100 | k.r
101 | krak
102 | k.r.o
103 | kryt
104 | kult
105 | laic
106 | łac
107 | niem
108 | woj
109 | nb
110 | np
111 | Nb
112 | Np
113 | pol
114 | pow
115 | m.in
116 | pt
117 | ps
118 | Pt
119 | Ps
120 | cdn
121 | jw
122 | ryc
123 | rys
124 | Ryc
125 | Rys
126 | tj
127 | tzw
128 | Tzw
129 | tzn
130 | zob
131 | ang
132 | ub
133 | ul
134 | pw
135 | pn
136 | pl
137 | al
138 | k
139 | n
140 | nr #NUMERIC_ONLY#
141 | Nr #NUMERIC_ONLY#
142 | ww
143 | wł
144 | ur
145 | zm
146 | żyd
147 | żarg
148 | żyw
149 | wył
150 | bp
151 | bp
152 | wyst
153 | tow
154 | Tow
155 | o
156 | sp
157 | Sp
158 | st
159 | spółdz
160 | Spółdz
161 | społ
162 | spółgł
163 | stoł
164 | stow
165 | Stoł
166 | Stow
167 | zn
168 | zew
169 | zewn
170 | zdr
171 | zazw
172 | zast
173 | zaw
174 | zał
175 | zal
176 | zam
177 | zak
178 | zakł
179 | zagr
180 | zach
181 | adw
182 | Adw
183 | lek
184 | Lek
185 | med
186 | mec
187 | Mec
188 | doc
189 | Doc
190 | dyw
191 | dyr
192 | Dyw
193 | Dyr
194 | inż
195 | Inż
196 | mgr
197 | Mgr
198 | dh
199 | dr
200 | Dh
201 | Dr
202 | p
203 | P
204 | red
205 | Red
206 | prof
207 | prok
208 | Prof
209 | Prok
210 | hab
211 | płk
212 | Płk
213 | nadkom
214 | Nadkom
215 | podkom
216 | Podkom
217 | ks
218 | Ks
219 | gen
220 | Gen
221 | por
222 | Por
223 | reż
224 | Reż
225 | przyp
226 | Przyp
227 | śp
228 | św
229 | śW
230 | Śp
231 | Św
232 | ŚW
233 | szer
234 | Szer
235 | pkt #NUMERIC_ONLY#
236 | str #NUMERIC_ONLY#
237 | tab #NUMERIC_ONLY#
238 | Tab #NUMERIC_ONLY#
239 | tel
240 | ust #NUMERIC_ONLY#
241 | par #NUMERIC_ONLY#
242 | poz
243 | pok
244 | oo
245 | oO
246 | Oo
247 | OO
248 | r #NUMERIC_ONLY#
249 | l #NUMERIC_ONLY#
250 | s #NUMERIC_ONLY#
251 | najśw
252 | Najśw
253 | A
254 | B
255 | C
256 | D
257 | E
258 | F
259 | G
260 | H
261 | I
262 | J
263 | K
264 | L
265 | M
266 | N
267 | O
268 | P
269 | Q
270 | R
271 | S
272 | T
273 | U
274 | V
275 | W
276 | X
277 | Y
278 | Z
279 | Ś
280 | Ć
281 | Ż
282 | Ź
283 | Dz
284 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.ro:
--------------------------------------------------------------------------------
1 | A
2 | B
3 | C
4 | D
5 | E
6 | F
7 | G
8 | H
9 | I
10 | J
11 | K
12 | L
13 | M
14 | N
15 | O
16 | P
17 | Q
18 | R
19 | S
20 | T
21 | U
22 | V
23 | W
24 | X
25 | Y
26 | Z
27 | dpdv
28 | etc
29 | șamd
30 | M.Ap.N
31 | dl
32 | Dl
33 | d-na
34 | D-na
35 | dvs
36 | Dvs
37 | pt
38 | Pt
39 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.ru:
--------------------------------------------------------------------------------
1 | # added Cyrillic uppercase letters [А-Я]
2 | # removed 000D carriage return (this is not removed by chomp in tokenizer.perl, and prevents recognition of the prefixes)
3 | # edited by Kate Young (nspaceanalysis@earthlink.net) 21 May 2013
4 | А
5 | Б
6 | В
7 | Г
8 | Д
9 | Е
10 | Ж
11 | З
12 | И
13 | Й
14 | К
15 | Л
16 | М
17 | Н
18 | О
19 | П
20 | Р
21 | С
22 | Т
23 | У
24 | Ф
25 | Х
26 | Ц
27 | Ч
28 | Ш
29 | Щ
30 | Ъ
31 | Ы
32 | Ь
33 | Э
34 | Ю
35 | Я
36 | A
37 | B
38 | C
39 | D
40 | E
41 | F
42 | G
43 | H
44 | I
45 | J
46 | K
47 | L
48 | M
49 | N
50 | O
51 | P
52 | Q
53 | R
54 | S
55 | T
56 | U
57 | V
58 | W
59 | X
60 | Y
61 | Z
62 | 0гг
63 | 1гг
64 | 2гг
65 | 3гг
66 | 4гг
67 | 5гг
68 | 6гг
69 | 7гг
70 | 8гг
71 | 9гг
72 | 0г
73 | 1г
74 | 2г
75 | 3г
76 | 4г
77 | 5г
78 | 6г
79 | 7г
80 | 8г
81 | 9г
82 | Xвв
83 | Vвв
84 | Iвв
85 | Lвв
86 | Mвв
87 | Cвв
88 | Xв
89 | Vв
90 | Iв
91 | Lв
92 | Mв
93 | Cв
94 | 0м
95 | 1м
96 | 2м
97 | 3м
98 | 4м
99 | 5м
100 | 6м
101 | 7м
102 | 8м
103 | 9м
104 | 0мм
105 | 1мм
106 | 2мм
107 | 3мм
108 | 4мм
109 | 5мм
110 | 6мм
111 | 7мм
112 | 8мм
113 | 9мм
114 | 0см
115 | 1см
116 | 2см
117 | 3см
118 | 4см
119 | 5см
120 | 6см
121 | 7см
122 | 8см
123 | 9см
124 | 0дм
125 | 1дм
126 | 2дм
127 | 3дм
128 | 4дм
129 | 5дм
130 | 6дм
131 | 7дм
132 | 8дм
133 | 9дм
134 | 0л
135 | 1л
136 | 2л
137 | 3л
138 | 4л
139 | 5л
140 | 6л
141 | 7л
142 | 8л
143 | 9л
144 | 0км
145 | 1км
146 | 2км
147 | 3км
148 | 4км
149 | 5км
150 | 6км
151 | 7км
152 | 8км
153 | 9км
154 | 0га
155 | 1га
156 | 2га
157 | 3га
158 | 4га
159 | 5га
160 | 6га
161 | 7га
162 | 8га
163 | 9га
164 | 0кг
165 | 1кг
166 | 2кг
167 | 3кг
168 | 4кг
169 | 5кг
170 | 6кг
171 | 7кг
172 | 8кг
173 | 9кг
174 | 0т
175 | 1т
176 | 2т
177 | 3т
178 | 4т
179 | 5т
180 | 6т
181 | 7т
182 | 8т
183 | 9т
184 | 0г
185 | 1г
186 | 2г
187 | 3г
188 | 4г
189 | 5г
190 | 6г
191 | 7г
192 | 8г
193 | 9г
194 | 0мг
195 | 1мг
196 | 2мг
197 | 3мг
198 | 4мг
199 | 5мг
200 | 6мг
201 | 7мг
202 | 8мг
203 | 9мг
204 | бульв
205 | в
206 | вв
207 | г
208 | га
209 | гг
210 | гл
211 | гос
212 | д
213 | дм
214 | доп
215 | др
216 | е
217 | ед
218 | ед
219 | зам
220 | и
221 | инд
222 | исп
223 | Исп
224 | к
225 | кап
226 | кг
227 | кв
228 | кл
229 | км
230 | кол
231 | комн
232 | коп
233 | куб
234 | л
235 | лиц
236 | лл
237 | м
238 | макс
239 | мг
240 | мин
241 | мл
242 | млн
243 | млрд
244 | мм
245 | н
246 | наб
247 | нач
248 | неуд
249 | ном
250 | о
251 | обл
252 | обр
253 | общ
254 | ок
255 | ост
256 | отл
257 | п
258 | пер
259 | перераб
260 | пл
261 | пос
262 | пр
263 | просп
264 | проф
265 | р
266 | ред
267 | руб
268 | с
269 | сб
270 | св
271 | см
272 | соч
273 | ср
274 | ст
275 | стр
276 | т
277 | тел
278 | Тел
279 | тех
280 | тт
281 | туп
282 | тыс
283 | уд
284 | ул
285 | уч
286 | физ
287 | х
288 | хор
289 | ч
290 | чел
291 | шт
292 | экз
293 | э
294 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.sk:
--------------------------------------------------------------------------------
1 | Bc
2 | Mgr
3 | RNDr
4 | PharmDr
5 | PhDr
6 | JUDr
7 | PaedDr
8 | ThDr
9 | Ing
10 | MUDr
11 | MDDr
12 | MVDr
13 | Dr
14 | ThLic
15 | PhD
16 | ArtD
17 | ThDr
18 | Dr
19 | DrSc
20 | CSs
21 | prof
22 | obr
23 | Obr
24 | Č
25 | č
26 | absol
27 | adj
28 | admin
29 | adr
30 | Adr
31 | adv
32 | advok
33 | afr
34 | ak
35 | akad
36 | akc
37 | akuz
38 | et
39 | al
40 | alch
41 | amer
42 | anat
43 | angl
44 | Angl
45 | anglosas
46 | anorg
47 | ap
48 | apod
49 | arch
50 | archeol
51 | archit
52 | arg
53 | art
54 | astr
55 | astrol
56 | astron
57 | atp
58 | atď
59 | austr
60 | Austr
61 | aut
62 | belg
63 | Belg
64 | bibl
65 | Bibl
66 | biol
67 | bot
68 | bud
69 | bás
70 | býv
71 | cest
72 | chem
73 | cirk
74 | csl
75 | čs
76 | Čs
77 | dat
78 | dep
79 | det
80 | dial
81 | diaľ
82 | dipl
83 | distrib
84 | dokl
85 | dosl
86 | dopr
87 | dram
88 | duš
89 | dv
90 | dvojčl
91 | dór
92 | ekol
93 | ekon
94 | el
95 | elektr
96 | elektrotech
97 | energet
98 | epic
99 | est
100 | etc
101 | etonym
102 | eufem
103 | európ
104 | Európ
105 | ev
106 | evid
107 | expr
108 | fa
109 | fam
110 | farm
111 | fem
112 | feud
113 | fil
114 | filat
115 | filoz
116 | fi
117 | fon
118 | form
119 | fot
120 | fr
121 | Fr
122 | franc
123 | Franc
124 | fraz
125 | fut
126 | fyz
127 | fyziol
128 | garb
129 | gen
130 | genet
131 | genpor
132 | geod
133 | geogr
134 | geol
135 | geom
136 | germ
137 | gr
138 | Gr
139 | gréc
140 | Gréc
141 | gréckokat
142 | hebr
143 | herald
144 | hist
145 | hlav
146 | hosp
147 | hromad
148 | hud
149 | hypok
150 | ident
151 | i.e
152 | ident
153 | imp
154 | impf
155 | indoeur
156 | inf
157 | inform
158 | instr
159 | int
160 | interj
161 | inšt
162 | inštr
163 | iron
164 | jap
165 | Jap
166 | jaz
167 | jedn
168 | juhoamer
169 | juhových
170 | juhozáp
171 | juž
172 | kanad
173 | Kanad
174 | kanc
175 | kapit
176 | kpt
177 | kart
178 | katastr
179 | knih
180 | kniž
181 | komp
182 | konj
183 | konkr
184 | kozmet
185 | krajč
186 | kresť
187 | kt
188 | kuch
189 | lat
190 | latinskoamer
191 | lek
192 | lex
193 | lingv
194 | lit
195 | litur
196 | log
197 | lok
198 | max
199 | Max
200 | maď
201 | Maď
202 | medzinár
203 | mest
204 | metr
205 | mil
206 | Mil
207 | min
208 | Min
209 | miner
210 | ml
211 | mld
212 | mn
213 | mod
214 | mytol
215 | napr
216 | nar
217 | Nar
218 | nasl
219 | nedok
220 | neg
221 | negat
222 | neklas
223 | nem
224 | Nem
225 | neodb
226 | neos
227 | neskl
228 | nesklon
229 | nespis
230 | nespráv
231 | neved
232 | než
233 | niekt
234 | niž
235 | nom
236 | náb
237 | nákl
238 | námor
239 | nár
240 | obch
241 | obj
242 | obv
243 | obyč
244 | obč
245 | občian
246 | odb
247 | odd
248 | ods
249 | ojed
250 | okr
251 | Okr
252 | opt
253 | opyt
254 | org
255 | os
256 | osob
257 | ot
258 | ovoc
259 | par
260 | part
261 | pejor
262 | pers
263 | pf
264 | Pf
265 | P.f
266 | p.f
267 | pl
268 | Plk
269 | pod
270 | podst
271 | pokl
272 | polit
273 | politol
274 | polygr
275 | pomn
276 | popl
277 | por
278 | porad
279 | porov
280 | posch
281 | potrav
282 | použ
283 | poz
284 | pozit
285 | poľ
286 | poľno
287 | poľnohosp
288 | poľov
289 | pošt
290 | pož
291 | prac
292 | predl
293 | pren
294 | prep
295 | preuk
296 | priezv
297 | Priezv
298 | privl
299 | prof
300 | práv
301 | príd
302 | príj
303 | prík
304 | príp
305 | prír
306 | prísl
307 | príslov
308 | príč
309 | psych
310 | publ
311 | pís
312 | písm
313 | pôv
314 | refl
315 | reg
316 | rep
317 | resp
318 | rozk
319 | rozlič
320 | rozpráv
321 | roč
322 | Roč
323 | ryb
324 | rádiotech
325 | rím
326 | samohl
327 | semest
328 | sev
329 | severoamer
330 | severových
331 | severozáp
332 | sg
333 | skr
334 | skup
335 | sl
336 | Sloven
337 | soc
338 | soch
339 | sociol
340 | sp
341 | spol
342 | Spol
343 | spoloč
344 | spoluhl
345 | správ
346 | spôs
347 | st
348 | star
349 | starogréc
350 | starorím
351 | s.r.o
352 | stol
353 | stor
354 | str
355 | stredoamer
356 | stredoškol
357 | subj
358 | subst
359 | superl
360 | sv
361 | sz
362 | súkr
363 | súp
364 | súvzť
365 | tal
366 | Tal
367 | tech
368 | tel
369 | Tel
370 | telef
371 | teles
372 | telev
373 | teol
374 | trans
375 | turist
376 | tuzem
377 | typogr
378 | tzn
379 | tzv
380 | ukaz
381 | ul
382 | Ul
383 | umel
384 | univ
385 | ust
386 | ved
387 | vedľ
388 | verb
389 | veter
390 | vin
391 | viď
392 | vl
393 | vod
394 | vodohosp
395 | pnl
396 | vulg
397 | vyj
398 | vys
399 | vysokoškol
400 | vzťaž
401 | vôb
402 | vých
403 | výd
404 | výrob
405 | výsk
406 | výsl
407 | výtv
408 | výtvar
409 | význ
410 | včel
411 | vš
412 | všeob
413 | zahr
414 | zar
415 | zariad
416 | zast
417 | zastar
418 | zastaráv
419 | zb
420 | zdravot
421 | združ
422 | zjemn
423 | zlat
424 | zn
425 | Zn
426 | zool
427 | zr
428 | zried
429 | zv
430 | záhr
431 | zák
432 | zákl
433 | zám
434 | záp
435 | západoeur
436 | zázn
437 | územ
438 | účt
439 | čast
440 | čes
441 | Čes
442 | čl
443 | čísl
444 | živ
445 | pr
446 | fak
447 | Kr
448 | p.n.l
449 | A
450 | B
451 | C
452 | D
453 | E
454 | F
455 | G
456 | H
457 | I
458 | J
459 | K
460 | L
461 | M
462 | N
463 | O
464 | P
465 | Q
466 | R
467 | S
468 | T
469 | U
470 | V
471 | W
472 | X
473 | Y
474 | Z
475 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.sl:
--------------------------------------------------------------------------------
1 | dr
2 | Dr
3 | itd
4 | itn
5 | št #NUMERIC_ONLY#
6 | Št #NUMERIC_ONLY#
7 | d
8 | jan
9 | Jan
10 | feb
11 | Feb
12 | mar
13 | Mar
14 | apr
15 | Apr
16 | jun
17 | Jun
18 | jul
19 | Jul
20 | avg
21 | Avg
22 | sept
23 | Sept
24 | sep
25 | Sep
26 | okt
27 | Okt
28 | nov
29 | Nov
30 | dec
31 | Dec
32 | tj
33 | Tj
34 | npr
35 | Npr
36 | sl
37 | Sl
38 | op
39 | Op
40 | gl
41 | Gl
42 | oz
43 | Oz
44 | prev
45 | dipl
46 | ing
47 | prim
48 | Prim
49 | cf
50 | Cf
51 | gl
52 | Gl
53 | A
54 | B
55 | C
56 | D
57 | E
58 | F
59 | G
60 | H
61 | I
62 | J
63 | K
64 | L
65 | M
66 | N
67 | O
68 | P
69 | Q
70 | R
71 | S
72 | T
73 | U
74 | V
75 | W
76 | X
77 | Y
78 | Z
79 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.sv:
--------------------------------------------------------------------------------
1 | #single upper case letter are usually initials
2 | A
3 | B
4 | C
5 | D
6 | E
7 | F
8 | G
9 | H
10 | I
11 | J
12 | K
13 | L
14 | M
15 | N
16 | O
17 | P
18 | Q
19 | R
20 | S
21 | T
22 | U
23 | V
24 | W
25 | X
26 | Y
27 | Z
28 | #misc abbreviations
29 | AB
30 | G
31 | VG
32 | dvs
33 | etc
34 | from
35 | iaf
36 | jfr
37 | kl
38 | kr
39 | mao
40 | mfl
41 | mm
42 | osv
43 | pga
44 | tex
45 | tom
46 | vs
47 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.ta:
--------------------------------------------------------------------------------
1 | #Anything in this file, followed by a period (and an upper-case word), does NOT indicate an end-of-sentence marker.
2 | #Special cases are included for prefixes that ONLY appear before 0-9 numbers.
3 |
4 | #any single upper case letter followed by a period is not a sentence ender (excluding I occasionally, but we leave it in)
5 | #usually upper case letters are initials in a name
6 | அ
7 | ஆ
8 | இ
9 | ஈ
10 | உ
11 | ஊ
12 | எ
13 | ஏ
14 | ஐ
15 | ஒ
16 | ஓ
17 | ஔ
18 | ஃ
19 | க
20 | கா
21 | கி
22 | கீ
23 | கு
24 | கூ
25 | கெ
26 | கே
27 | கை
28 | கொ
29 | கோ
30 | கௌ
31 | க்
32 | ச
33 | சா
34 | சி
35 | சீ
36 | சு
37 | சூ
38 | செ
39 | சே
40 | சை
41 | சொ
42 | சோ
43 | சௌ
44 | ச்
45 | ட
46 | டா
47 | டி
48 | டீ
49 | டு
50 | டூ
51 | டெ
52 | டே
53 | டை
54 | டொ
55 | டோ
56 | டௌ
57 | ட்
58 | த
59 | தா
60 | தி
61 | தீ
62 | து
63 | தூ
64 | தெ
65 | தே
66 | தை
67 | தொ
68 | தோ
69 | தௌ
70 | த்
71 | ப
72 | பா
73 | பி
74 | பீ
75 | பு
76 | பூ
77 | பெ
78 | பே
79 | பை
80 | பொ
81 | போ
82 | பௌ
83 | ப்
84 | ற
85 | றா
86 | றி
87 | றீ
88 | று
89 | றூ
90 | றெ
91 | றே
92 | றை
93 | றொ
94 | றோ
95 | றௌ
96 | ற்
97 | ய
98 | யா
99 | யி
100 | யீ
101 | யு
102 | யூ
103 | யெ
104 | யே
105 | யை
106 | யொ
107 | யோ
108 | யௌ
109 | ய்
110 | ர
111 | ரா
112 | ரி
113 | ரீ
114 | ரு
115 | ரூ
116 | ரெ
117 | ரே
118 | ரை
119 | ரொ
120 | ரோ
121 | ரௌ
122 | ர்
123 | ல
124 | லா
125 | லி
126 | லீ
127 | லு
128 | லூ
129 | லெ
130 | லே
131 | லை
132 | லொ
133 | லோ
134 | லௌ
135 | ல்
136 | வ
137 | வா
138 | வி
139 | வீ
140 | வு
141 | வூ
142 | வெ
143 | வே
144 | வை
145 | வொ
146 | வோ
147 | வௌ
148 | வ்
149 | ள
150 | ளா
151 | ளி
152 | ளீ
153 | ளு
154 | ளூ
155 | ளெ
156 | ளே
157 | ளை
158 | ளொ
159 | ளோ
160 | ளௌ
161 | ள்
162 | ழ
163 | ழா
164 | ழி
165 | ழீ
166 | ழு
167 | ழூ
168 | ழெ
169 | ழே
170 | ழை
171 | ழொ
172 | ழோ
173 | ழௌ
174 | ழ்
175 | ங
176 | ஙா
177 | ஙி
178 | ஙீ
179 | ஙு
180 | ஙூ
181 | ஙெ
182 | ஙே
183 | ஙை
184 | ஙொ
185 | ஙோ
186 | ஙௌ
187 | ங்
188 | ஞ
189 | ஞா
190 | ஞி
191 | ஞீ
192 | ஞு
193 | ஞூ
194 | ஞெ
195 | ஞே
196 | ஞை
197 | ஞொ
198 | ஞோ
199 | ஞௌ
200 | ஞ்
201 | ண
202 | ணா
203 | ணி
204 | ணீ
205 | ணு
206 | ணூ
207 | ணெ
208 | ணே
209 | ணை
210 | ணொ
211 | ணோ
212 | ணௌ
213 | ண்
214 | ந
215 | நா
216 | நி
217 | நீ
218 | நு
219 | நூ
220 | நெ
221 | நே
222 | நை
223 | நொ
224 | நோ
225 | நௌ
226 | ந்
227 | ம
228 | மா
229 | மி
230 | மீ
231 | மு
232 | மூ
233 | மெ
234 | மே
235 | மை
236 | மொ
237 | மோ
238 | மௌ
239 | ம்
240 | ன
241 | னா
242 | னி
243 | னீ
244 | னு
245 | னூ
246 | னெ
247 | னே
248 | னை
249 | னொ
250 | னோ
251 | னௌ
252 | ன்
253 |
254 |
255 | #List of titles. These are often followed by upper-case names, but do not indicate sentence breaks
256 | திரு
257 | திருமதி
258 | வண
259 | கௌரவ
260 |
261 |
262 | #misc - odd period-ending items that NEVER indicate breaks (p.m. does NOT fall into this category - it sometimes ends a sentence)
263 | உ.ம்
264 | #கா.ம்
265 | #எ.ம்
266 |
267 |
268 | #Numbers only. These should only induce breaks when followed by a numeric sequence
269 | # add NUMERIC_ONLY after the word for this function
270 | #This case is mostly for the english "No." which can either be a sentence of its own, or
271 | #if followed by a number, a non-breaking prefix
272 | No #NUMERIC_ONLY#
273 | Nos
274 | Art #NUMERIC_ONLY#
275 | Nr
276 | pp #NUMERIC_ONLY#
277 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.yue:
--------------------------------------------------------------------------------
1 | #
2 | # Cantonese (Chinese)
3 | #
4 | # Anything in this file, followed by a period,
5 | # does NOT indicate an end-of-sentence marker.
6 | #
7 | # English/Euro-language given-name initials (appearing in
8 | # news, periodicals, etc.)
9 | A
10 | Ā
11 | B
12 | C
13 | Č
14 | D
15 | E
16 | Ē
17 | F
18 | G
19 | Ģ
20 | H
21 | I
22 | Ī
23 | J
24 | K
25 | Ķ
26 | L
27 | Ļ
28 | M
29 | N
30 | Ņ
31 | O
32 | P
33 | Q
34 | R
35 | S
36 | Š
37 | T
38 | U
39 | Ū
40 | V
41 | W
42 | X
43 | Y
44 | Z
45 | Ž
46 |
47 | # Numbers only. These should only induce breaks when followed by
48 | # a numeric sequence.
49 | # Add NUMERIC_ONLY after the word for this function. This case is
50 | # mostly for the english "No." which can either be a sentence of its
51 | # own, or if followed by a number, a non-breaking prefix.
52 | No #NUMERIC_ONLY#
53 | Nr #NUMERIC_ONLY#
54 |
--------------------------------------------------------------------------------
/tools/nonbreaking_prefixes/nonbreaking_prefix.zh:
--------------------------------------------------------------------------------
1 | #
2 | # Mandarin (Chinese)
3 | #
4 | # Anything in this file, followed by a period,
5 | # does NOT indicate an end-of-sentence marker.
6 | #
7 | # English/Euro-language given-name initials (appearing in
8 | # news, periodicals, etc.)
9 | A
10 | Ā
11 | B
12 | C
13 | Č
14 | D
15 | E
16 | Ē
17 | F
18 | G
19 | Ģ
20 | H
21 | I
22 | Ī
23 | J
24 | K
25 | Ķ
26 | L
27 | Ļ
28 | M
29 | N
30 | Ņ
31 | O
32 | P
33 | Q
34 | R
35 | S
36 | Š
37 | T
38 | U
39 | Ū
40 | V
41 | W
42 | X
43 | Y
44 | Z
45 | Ž
46 |
47 | # Numbers only. These should only induce breaks when followed by
48 | # a numeric sequence.
49 | # Add NUMERIC_ONLY after the word for this function. This case is
50 | # mostly for the english "No." which can either be a sentence of its
51 | # own, or if followed by a number, a non-breaking prefix.
52 | No #NUMERIC_ONLY#
53 | Nr #NUMERIC_ONLY#
54 |
--------------------------------------------------------------------------------
/tools/release_model.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | import argparse
3 | import torch
4 |
5 | if __name__ == "__main__":
6 | parser = argparse.ArgumentParser(
7 | description="Removes the optim data of PyTorch models")
8 | parser.add_argument("--model", "-m",
9 | help="The model filename (*.pt)", required=True)
10 | parser.add_argument("--output", "-o",
11 | help="The output filename (*.pt)", required=True)
12 | opt = parser.parse_args()
13 |
14 | model = torch.load(opt.model)
15 | model['optim'] = None
16 | torch.save(model, opt.output)
17 |
--------------------------------------------------------------------------------
/tools/test_rouge.py:
--------------------------------------------------------------------------------
1 | # -*- encoding: utf-8 -*-
2 | import argparse
3 | import os
4 | import time
5 | import pyrouge
6 | import shutil
7 | import sys
8 |
9 |
10 | def test_rouge(cand, ref):
11 | """Calculate ROUGE scores of sequences passed as an iterator
12 | e.g. a list of str, an open file, StringIO or even sys.stdin
13 | """
14 | current_time = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime())
15 | tmp_dir = ".rouge-tmp-{}".format(current_time)
16 | try:
17 | if not os.path.isdir(tmp_dir):
18 | os.mkdir(tmp_dir)
19 | os.mkdir(tmp_dir + "/candidate")
20 | os.mkdir(tmp_dir + "/reference")
21 | candidates = [line.strip() for line in cand]
22 | references = [line.strip() for line in ref]
23 | assert len(candidates) == len(references)
24 | cnt = len(candidates)
25 | for i in range(cnt):
26 | if len(references[i]) < 1:
27 | continue
28 | with open(tmp_dir + "/candidate/cand.{}.txt".format(i), "w",
29 | encoding="utf-8") as f:
30 | f.write(candidates[i])
31 | with open(tmp_dir + "/reference/ref.{}.txt".format(i), "w",
32 | encoding="utf-8") as f:
33 | f.write(references[i])
34 | r = pyrouge.Rouge155()
35 | r.model_dir = tmp_dir + "/reference/"
36 | r.system_dir = tmp_dir + "/candidate/"
37 | r.model_filename_pattern = 'ref.#ID#.txt'
38 | r.system_filename_pattern = 'cand.(\d+).txt'
39 | rouge_results = r.convert_and_evaluate()
40 | results_dict = r.output_to_dict(rouge_results)
41 | return results_dict
42 | finally:
43 | pass
44 | if os.path.isdir(tmp_dir):
45 | shutil.rmtree(tmp_dir)
46 |
47 |
48 | def rouge_results_to_str(results_dict):
49 | return ">> ROUGE(1/2/3/L/SU4): {:.2f}/{:.2f}/{:.2f}/{:.2f}/{:.2f}".format(
50 | results_dict["rouge_1_f_score"] * 100,
51 | results_dict["rouge_2_f_score"] * 100,
52 | results_dict["rouge_3_f_score"] * 100,
53 | results_dict["rouge_l_f_score"] * 100,
54 | results_dict["rouge_su*_f_score"] * 100)
55 |
56 |
57 | if __name__ == "__main__":
58 | parser = argparse.ArgumentParser()
59 | parser.add_argument('-c', type=str, default="candidate.txt",
60 | help='candidate file')
61 | parser.add_argument('-r', type=str, default="reference.txt",
62 | help='reference file')
63 | args = parser.parse_args()
64 | if args.c.upper() == "STDIN":
65 | args.c = sys.stdin
66 | results_dict = test_rouge(args.c, args.r)
67 | print(rouge_results_to_str(results_dict))
68 |
--------------------------------------------------------------------------------
/translate.py:
--------------------------------------------------------------------------------
1 | #!/usr/bin/env python
2 | from __future__ import division, unicode_literals
3 | import argparse
4 |
5 | from onmt.translate.Translator import make_translator
6 |
7 | import onmt.io
8 | import onmt.translate
9 | import onmt
10 | import onmt.ModelConstructor
11 | import onmt.modules
12 | import onmt.opts
13 |
14 |
15 | def main(opt):
16 | translator = make_translator(opt, report_score=True)
17 | translator.translate(opt.src_dir, opt.src, opt.tgt,
18 | opt.batch_size, opt.attn_debug)
19 |
20 |
21 | if __name__ == "__main__":
22 | parser = argparse.ArgumentParser(
23 | description='translate.py',
24 | formatter_class=argparse.ArgumentDefaultsHelpFormatter)
25 | onmt.opts.add_md_help_argument(parser)
26 | onmt.opts.translate_opts(parser)
27 |
28 | opt = parser.parse_args()
29 | main(opt)
30 |
--------------------------------------------------------------------------------