├── README.md
├── colab
└── my_openai_api.ipynb
├── my_openai_api.py
└── requirements.txt
/README.md:
--------------------------------------------------------------------------------
1 | # my_openai_api
2 |
3 | 部署你自己的**OpenAI** 格式api😆,基于**flask, transformers** (使用 **Baichuan2-13B-Chat-4bits** 模型,可以运行在单张Tesla T4显卡) ,实现以下**OpenAI**接口:
4 | - **Chat** /v1/chat/completions
5 | - **Models** /v1/models
6 | - **Completions** /v1/completions
7 |
8 | 同时实现接口相应的STREAMING模式,保证在**langchain**中基础调用
9 |
10 | ## 起因
11 |
12 | 目前Baichuan2-13B-Chat int4量化后可在单张tesla T4显卡运行,并且效果和速度还可以,可以和gpt-3.5媲美。
13 | - **Baichuan2-13B-Chat-4bits**:[https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits](https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits)
14 |
15 | ## 最低配置
16 |
17 | 需要16g显存,如果主机显存不够可以考虑~~腾讯云的活动,60块钱15天32g内存、T4显卡的主机~~(**活动已经下架,可以考虑使用Colab**),非常划算😝,可以跑动baichuan2-13b-chat-4bits。
18 |
19 | 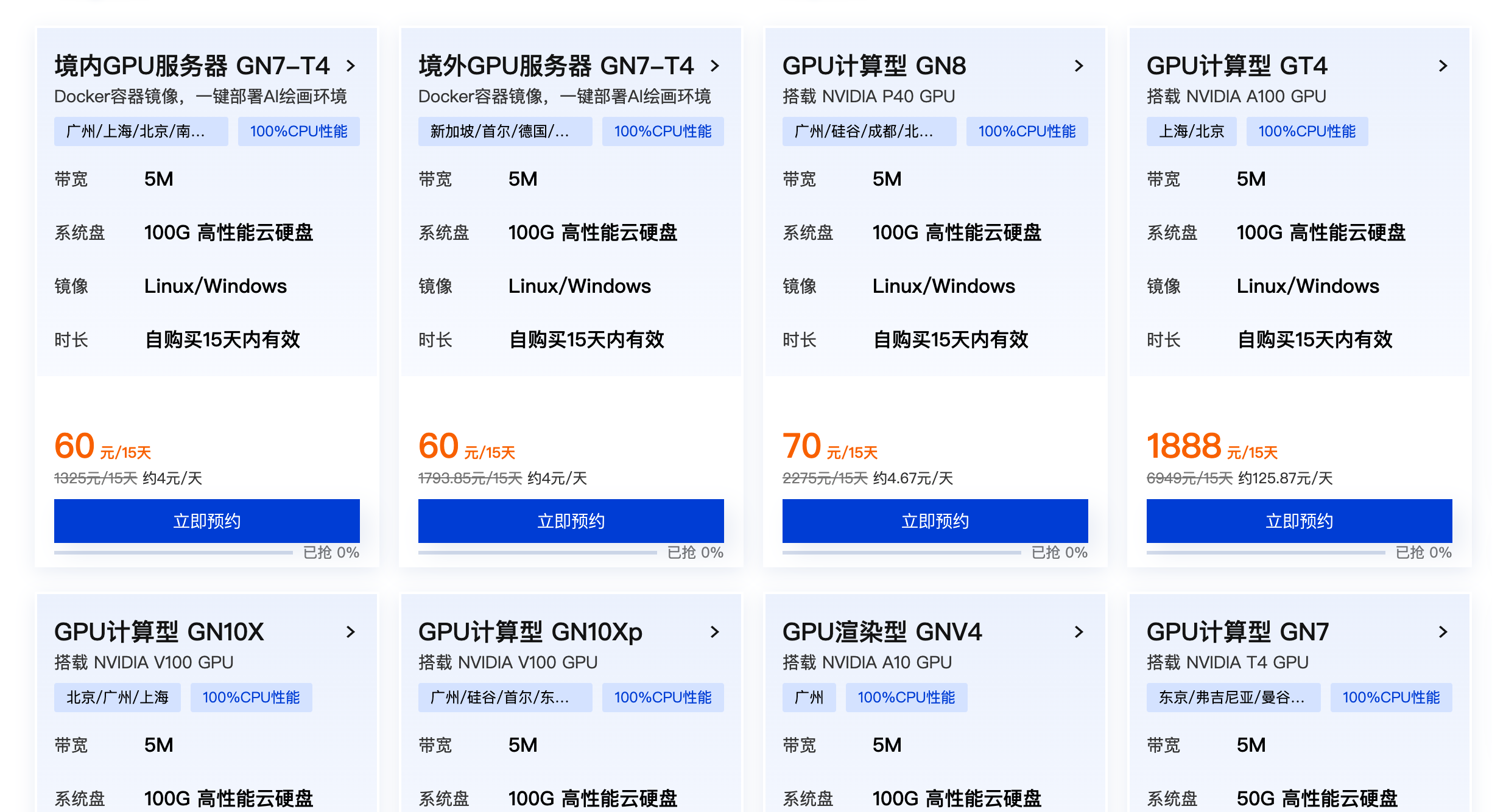 20 |
21 | ~~地址: https://cloud.tencent.com/act/pro/gpu-study~~
22 |
23 | 如果想要本地运行,T4显卡价格在5600元左右,也可以考虑2080ti魔改22g版本,某宝只要2600元左右 🤓️。
24 |
25 | ## Colab
26 | 免费的Colab可以使用12G内存和T4显卡🤓️,可以考虑免费的Colab结合ngrok运行
27 |
28 | ### 步骤
29 | 1. 打开 [](https://colab.research.google.com/github/billvsme/my_openai_api/blob/main/colab/my_openai_api.ipynb)
30 | 2. 修改 NGROK_AUTHTOKEN,注意不要带双引号
31 | 3. 修改运行配置,点击 修改 -> 笔记本设置 中把显卡改成T4
32 | 4. 运行,点击 代码执行程序 -> 全部运行 (下载模型时间较长,请耐心等在)
33 | 5. 运行结束后查看输出的ngrok外网访问链接,使用该链接请求
34 |
35 |
36 | ## 安装
37 |
38 | 1. 下载代码
39 | ```
40 | git clone https://github.com/billvsme/my_openai_api.git
41 | ```
42 | 2. 下载Baichuan2-13B-Chat-4bits模型
43 | ```
44 | cd my_openai_api
45 |
46 | git lfs install #需要先安装好git-lfs
47 | git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
48 | ```
49 | 3. 安装venv环境
50 | ```
51 | mkdir ~/.venv
52 | python -m venv ~/.venv/ai
53 | . ~/.venv/ai/bin/activate
54 |
55 | pip install -r requirements.txt
56 | ```
57 |
58 | ## 启动
59 | ```
60 | python my_openai_api.py
61 | 或者
62 | gunicorn -b 0.0.0.0:5000 --workers=1 my_openai_api:app
63 | ```
64 |
65 | ## 文档
66 | 实现了openai的models, chat, moderations 3个接口
67 | 可以参考https://platform.openai.com/docs/api-reference/chat
68 | ```
69 | 打开 http://127.0.0.1:5000/apidocs/
70 | ```
71 |
72 | 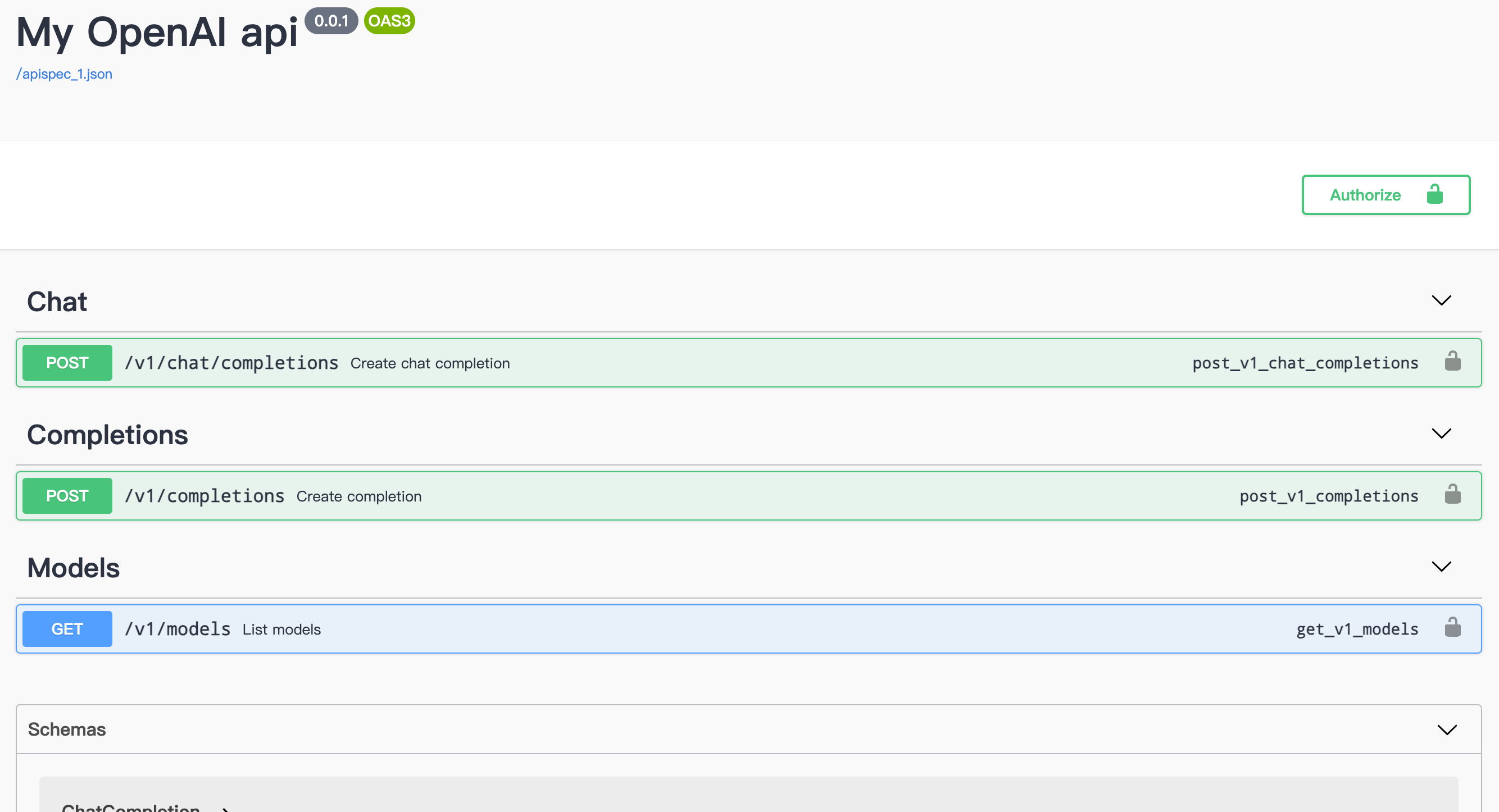
73 |
74 |
75 | ## 使用
76 |
77 | ### langchain
78 |
79 | 替换openai_base_api
80 | ```
81 | # coding: utf-8
82 | from langchain.llms import OpenAI
83 | from langchain.chat_models import ChatOpenAI
84 | from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
85 | from langchain.schema import (
86 | HumanMessage,
87 | )
88 |
89 | openai_api_base = "http://127.0.0.1:5000/v1"
90 | openai_api_key = "test"
91 |
92 | # /v1/chat/completions流式响应
93 | chat_model = ChatOpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], openai_api_base=openai_api_base, openai_api_key=openai_api_key)
94 | resp = chat_model([HumanMessage(content="给我一个django admin的demo代码")])
95 | chat_model.predict("你叫什么?")
96 |
97 | # /v1/chat/completions普通响应
98 | chat_model = ChatOpenAI(openai_api_base=openai_api_base, openai_api_key=openai_api_key)
99 | resp = chat_model.predict("给我一个django admin的demo代码")
100 | print(resp)
101 |
102 | # /v1/completions流式响应
103 | llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0, openai_api_base=openai_api_base, openai_api_key=openai_api_key)
104 | llm("登鹳雀楼->王之涣\n夜雨寄北->")
105 |
106 | # /v1/completions普通响应
107 | llm = OpenAI(openai_api_base=openai_api_base, openai_api_key=openai_api_key)
108 | print(llm("登鹳雀楼->王之涣\n夜雨寄北->"))
109 | ```
110 |
111 | ### ChatGPT Next
112 |
113 | 设置中把接口地址修改为你的ip,如果部署网页为https,注意在Chrome设置中“不安全内容”选择“允许”
114 |
115 |
20 |
21 | ~~地址: https://cloud.tencent.com/act/pro/gpu-study~~
22 |
23 | 如果想要本地运行,T4显卡价格在5600元左右,也可以考虑2080ti魔改22g版本,某宝只要2600元左右 🤓️。
24 |
25 | ## Colab
26 | 免费的Colab可以使用12G内存和T4显卡🤓️,可以考虑免费的Colab结合ngrok运行
27 |
28 | ### 步骤
29 | 1. 打开 [](https://colab.research.google.com/github/billvsme/my_openai_api/blob/main/colab/my_openai_api.ipynb)
30 | 2. 修改 NGROK_AUTHTOKEN,注意不要带双引号
31 | 3. 修改运行配置,点击 修改 -> 笔记本设置 中把显卡改成T4
32 | 4. 运行,点击 代码执行程序 -> 全部运行 (下载模型时间较长,请耐心等在)
33 | 5. 运行结束后查看输出的ngrok外网访问链接,使用该链接请求
34 |
35 |
36 | ## 安装
37 |
38 | 1. 下载代码
39 | ```
40 | git clone https://github.com/billvsme/my_openai_api.git
41 | ```
42 | 2. 下载Baichuan2-13B-Chat-4bits模型
43 | ```
44 | cd my_openai_api
45 |
46 | git lfs install #需要先安装好git-lfs
47 | git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits
48 | ```
49 | 3. 安装venv环境
50 | ```
51 | mkdir ~/.venv
52 | python -m venv ~/.venv/ai
53 | . ~/.venv/ai/bin/activate
54 |
55 | pip install -r requirements.txt
56 | ```
57 |
58 | ## 启动
59 | ```
60 | python my_openai_api.py
61 | 或者
62 | gunicorn -b 0.0.0.0:5000 --workers=1 my_openai_api:app
63 | ```
64 |
65 | ## 文档
66 | 实现了openai的models, chat, moderations 3个接口
67 | 可以参考https://platform.openai.com/docs/api-reference/chat
68 | ```
69 | 打开 http://127.0.0.1:5000/apidocs/
70 | ```
71 |
72 | 
73 |
74 |
75 | ## 使用
76 |
77 | ### langchain
78 |
79 | 替换openai_base_api
80 | ```
81 | # coding: utf-8
82 | from langchain.llms import OpenAI
83 | from langchain.chat_models import ChatOpenAI
84 | from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
85 | from langchain.schema import (
86 | HumanMessage,
87 | )
88 |
89 | openai_api_base = "http://127.0.0.1:5000/v1"
90 | openai_api_key = "test"
91 |
92 | # /v1/chat/completions流式响应
93 | chat_model = ChatOpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], openai_api_base=openai_api_base, openai_api_key=openai_api_key)
94 | resp = chat_model([HumanMessage(content="给我一个django admin的demo代码")])
95 | chat_model.predict("你叫什么?")
96 |
97 | # /v1/chat/completions普通响应
98 | chat_model = ChatOpenAI(openai_api_base=openai_api_base, openai_api_key=openai_api_key)
99 | resp = chat_model.predict("给我一个django admin的demo代码")
100 | print(resp)
101 |
102 | # /v1/completions流式响应
103 | llm = OpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0, openai_api_base=openai_api_base, openai_api_key=openai_api_key)
104 | llm("登鹳雀楼->王之涣\n夜雨寄北->")
105 |
106 | # /v1/completions普通响应
107 | llm = OpenAI(openai_api_base=openai_api_base, openai_api_key=openai_api_key)
108 | print(llm("登鹳雀楼->王之涣\n夜雨寄北->"))
109 | ```
110 |
111 | ### ChatGPT Next
112 |
113 | 设置中把接口地址修改为你的ip,如果部署网页为https,注意在Chrome设置中“不安全内容”选择“允许”
114 |
115 | 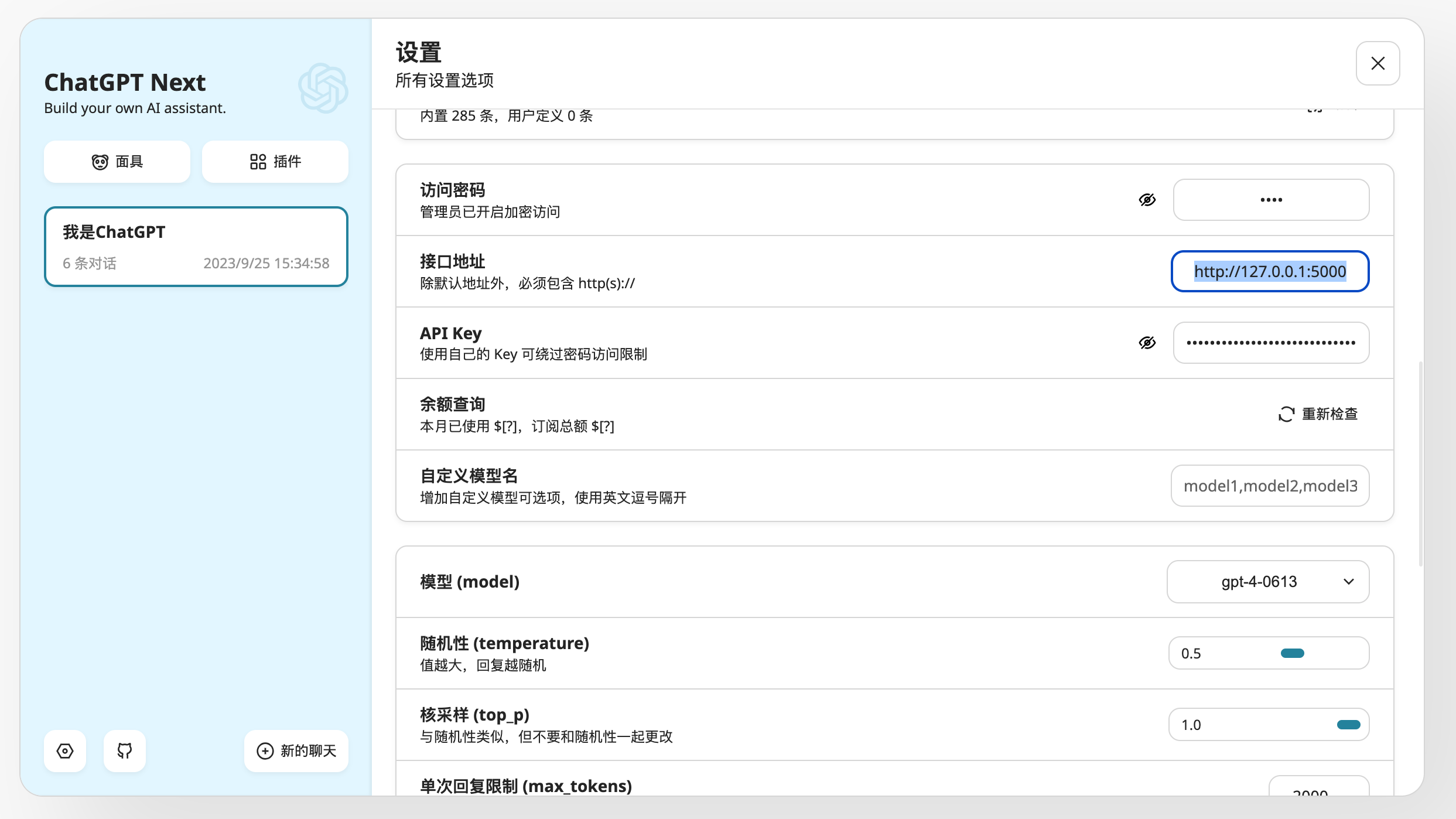 116 |
117 | ### OpenAI Translator
118 |
119 | 设置中把api url修改为你的ip
120 |
121 |
116 |
117 | ### OpenAI Translator
118 |
119 | 设置中把api url修改为你的ip
120 |
121 | 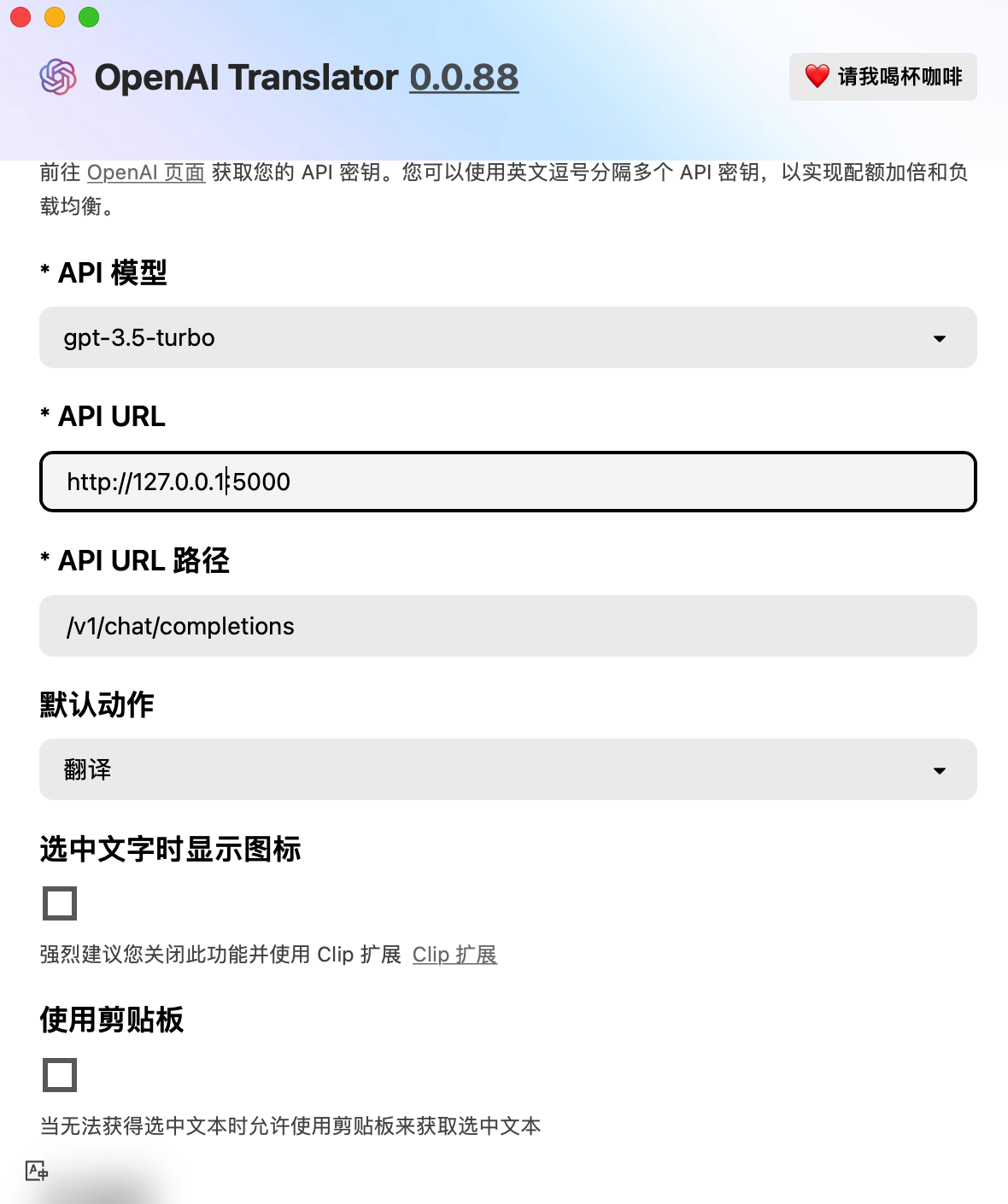 122 |
123 |
--------------------------------------------------------------------------------
/colab/my_openai_api.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "gpuType": "T4"
8 | },
9 | "kernelspec": {
10 | "name": "python3",
11 | "display_name": "Python 3"
12 | },
13 | "language_info": {
14 | "name": "python"
15 | },
16 | "accelerator": "GPU"
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "code",
21 | "execution_count": null,
22 | "metadata": {
23 | "id": "-50AbTRLCh5D"
24 | },
25 | "outputs": [],
26 | "source": [
27 | "\"\"\"下载代码\n",
28 | "\"\"\"\n",
29 | "%cd /content/\n",
30 | "!git clone https://github.com/billvsme/my_openai_api.git"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "source": [
36 | "\"\"\"下载模型\n",
37 | "\"\"\"\n",
38 | "%cd /content/my_openai_api\n",
39 | "!git clone --depth=1 https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits"
40 | ],
41 | "metadata": {
42 | "id": "vtbxBPhlC60S"
43 | },
44 | "execution_count": null,
45 | "outputs": []
46 | },
47 | {
48 | "cell_type": "code",
49 | "source": [
50 | "\"\"\"安装环境\n",
51 | "\"\"\"\n",
52 | "%cd /content/my_openai_api\n",
53 | "\n",
54 | "!apt install python3.10-venv\n",
55 | "!mkdir ~/.venv\n",
56 | "!python -m venv ~/.venv/ai\n",
57 | "!~/.venv/ai/bin/pip install -r requirements.txt"
58 | ],
59 | "metadata": {
60 | "id": "33opJSj6DVYr"
61 | },
62 | "execution_count": null,
63 | "outputs": []
64 | },
65 | {
66 | "cell_type": "code",
67 | "source": [
68 | "\"\"\"运行\n",
69 | "\"\"\"\n",
70 | "%cd /content/my_openai_api\n",
71 | "# 获取ngrok的tokn,https://dashboard.ngrok.com/get-started/your-authtoken\n",
72 | "# 注意不要带双引号\n",
73 | "%env NGROK_AUTHTOKEN=yourtoken\n",
74 | "!~/.venv/ai/bin/python my_openai_api.py"
75 | ],
76 | "metadata": {
77 | "id": "NKGQRhxkDddZ"
78 | },
79 | "execution_count": null,
80 | "outputs": []
81 | }
82 | ]
83 | }
--------------------------------------------------------------------------------
/my_openai_api.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 | import json
3 | import time
4 | import uuid
5 | from threading import Thread
6 |
7 | import torch
8 | from flask import Flask, current_app, request, Blueprint, stream_with_context
9 | from flask_cors import CORS
10 | from transformers import AutoTokenizer, AutoModelForCausalLM
11 | from transformers.generation.utils import GenerationConfig
12 | from transformers.generation.streamers import TextIteratorStreamer
13 | from marshmallow import validate
14 | from flasgger import APISpec, Schema, Swagger, fields
15 | from apispec.ext.marshmallow import MarshmallowPlugin
16 | from apispec_webframeworks.flask import FlaskPlugin
17 |
18 |
19 | class Transformers():
20 | def __init__(self, app=None, tokenizer=None, model=None):
21 | self.chat = None
22 | if app is not None:
23 | self.init_app(app, tokenizer, model)
24 |
25 | def init_app(self, app, tokenizer=None, model=None, chat=None):
26 | self.tokenizer = tokenizer
27 | self.model = model
28 | if chat is None:
29 | self.chat = model.chat
30 |
31 |
32 | tfs = Transformers()
33 | base_tfs = Transformers()
34 |
35 |
36 | models_bp = Blueprint('Models', __name__, url_prefix='/v1/models')
37 | chat_bp = Blueprint('Chat', __name__, url_prefix='/v1/chat')
38 | completions_bp = Blueprint('Completions', __name__, url_prefix='/v1/completions')
39 |
40 |
41 | def sse(line, field="data"):
42 | return "{}: {}\n\n".format(
43 | field, json.dumps(line, ensure_ascii=False) if isinstance(line, dict) else line)
44 |
45 |
46 | def empty_cache():
47 | if torch.backends.mps.is_available():
48 | torch.mps.empty_cache()
49 |
50 |
51 | def create_app():
52 | app = Flask(__name__)
53 | CORS(app)
54 | app.register_blueprint(models_bp)
55 | app.register_blueprint(chat_bp)
56 | app.register_blueprint(completions_bp)
57 |
58 | @app.after_request
59 | def after_request(resp):
60 | empty_cache()
61 | return resp
62 |
63 | # Init Swagger
64 | spec = APISpec(
65 | title='My OpenAI api',
66 | version='0.0.1',
67 | openapi_version='3.0.2',
68 | plugins=[
69 | FlaskPlugin(),
70 | MarshmallowPlugin(),
71 | ],
72 | )
73 |
74 | bearer_scheme = {"type": "http", "scheme": "bearer"}
75 | spec.components.security_scheme("bearer", bearer_scheme)
76 | template = spec.to_flasgger(
77 | app,
78 | paths=[list_models, create_chat_completion, create_completion]
79 | )
80 |
81 | app.config['SWAGGER'] = {"openapi": "3.0.2"}
82 | Swagger(app, template=template)
83 |
84 | # Init transformers
85 | model_name = "./Baichuan2-13B-Chat-4bits"
86 | tokenizer = AutoTokenizer.from_pretrained(
87 | model_name, use_fast=False, trust_remote_code=True)
88 | model = AutoModelForCausalLM.from_pretrained(
89 | model_name, device_map="auto", trust_remote_code=True)
90 | model.generation_config = GenerationConfig.from_pretrained(model_name)
91 |
92 | tfs.init_app(app, tokenizer, model)
93 | base_tfs.init_app(app, tokenizer, model)
94 |
95 | return app
96 |
97 |
98 | class ModelSchema(Schema):
99 | id = fields.Str()
100 | object = fields.Str(dump_default="model", metadata={"example": "model"})
101 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
102 | owned_by = fields.Str(dump_default="owner", metadata={"example": "owner"})
103 |
104 |
105 | class ModelListSchema(Schema):
106 | object = fields.Str(dump_default="list", metadata={"example": "list"})
107 | data = fields.List(fields.Nested(ModelSchema), dump_default=[])
108 |
109 |
110 | class ChatMessageSchema(Schema):
111 | role = fields.Str(required=True, metadata={"example": "system"})
112 | content = fields.Str(required=True, metadata={"example": "You are a helpful assistant."})
113 |
114 |
115 | class CreateChatCompletionSchema(Schema):
116 | model = fields.Str(required=True, metadata={"example": "gpt-3.5-turbo"})
117 | messages = fields.List(
118 | fields.Nested(ChatMessageSchema), required=True,
119 | metadata={"example": [
120 | ChatMessageSchema().dump({"role": "system", "content": "You are a helpful assistant."}),
121 | ChatMessageSchema().dump({"role": "user", "content": "Hello!"})
122 | ]}
123 | )
124 | temperature = fields.Float(load_default=1.0, metadata={"example": 1.0})
125 | top_p = fields.Float(load_default=1.0, metadata={"example": 1.0})
126 | n = fields.Int(load_default=1, metadata={"example": 1})
127 | max_tokens = fields.Int(load_default=None, metadata={"example": None})
128 | stream = fields.Bool(load_default=False, example=False)
129 | presence_penalty = fields.Float(load_default=0.0, example=0.0)
130 | frequency_penalty = fields.Float(load_default=0.0, example=0.0)
131 |
132 |
133 | class ChatCompletionChoiceSchema(Schema):
134 | index = fields.Int(metadata={"example": 0})
135 | message = fields.Nested(ChatMessageSchema, metadata={
136 | "example": ChatMessageSchema().dump(
137 | {"role": "assistant", "content": "\n\nHello there, how may I assist you today?"}
138 | )})
139 | finish_reason = fields.Str(
140 | validate=validate.OneOf(["stop", "length", "content_filter", "function_call"]),
141 | metadata={"example": "stop"})
142 |
143 |
144 | class ChatCompletionSchema(Schema):
145 | id = fields.Str(
146 | dump_default=lambda: uuid.uuid4().hex,
147 | metadata={"example": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7"})
148 | object = fields.Constant("chat.completion")
149 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
150 | model = fields.Str(metadata={"example": "gpt-3.5-turbo"})
151 | choices = fields.List(fields.Nested(ChatCompletionChoiceSchema))
152 |
153 |
154 | class ChatDeltaSchema(Schema):
155 | role = fields.Str(metadata={"example": "assistant"})
156 | content = fields.Str(required=True, metadata={"example": "Hello"})
157 |
158 |
159 | class ChatCompletionChunkChoiceSchema(Schema):
160 | index = fields.Int(metadata={"example": 0})
161 | delta = fields.Nested(ChatDeltaSchema, metadata={"example": ChatDeltaSchema().dump(
162 | {"role": "assistant", "example": "Hello"})})
163 | finish_reason = fields.Str(
164 | validate=validate.OneOf(["stop", "length", "content_filter", "function_call"]),
165 | metadata={"example": "stop"})
166 |
167 |
168 | class ChatCompletionChunkShema(Schema):
169 | id = fields.Str(
170 | dump_default=lambda: uuid.uuid4().hex,
171 | metadata={"example": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7"})
172 | object = fields.Constant("chat.completion.chunk")
173 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
174 | model = fields.Str(metadata={"example": "gpt-3.5-turbo"})
175 | choices = fields.List(fields.Nested(ChatCompletionChunkChoiceSchema))
176 |
177 |
178 | class CreateCompletionSchema(Schema):
179 | model = fields.Str(required=True, metadata={"example": "gpt-3.5-turbo"})
180 | prompt = fields.Raw(metadata={"example": "Say this is a test"})
181 | max_tokens = fields.Int(load_default=16, metadata={"example": 256})
182 | temperature = fields.Float(load_default=1.0, metadata={"example": 1.0})
183 | top_p = fields.Float(load_default=1.0, metadata={"example": 1.0})
184 | n = fields.Int(load_default=1, metadata={"example": 1})
185 | stream = fields.Bool(load_default=False, example=False)
186 | logit_bias = fields.Dict(load_default=None, example={})
187 | presence_penalty = fields.Float(load_default=0.0, example=0.0)
188 | frequency_penalty = fields.Float(load_default=0.0, example=0.0)
189 |
190 |
191 | class CompletionChoiceSchema(Schema):
192 | index = fields.Int(load_default=0, metadata={"example": 0})
193 | text = fields.Str(required=True, metadata={"example": "登鹳雀楼->王之涣\n夜雨寄北->"})
194 | logprobs = fields.Dict(load_default=None, metadata={"example": {}})
195 | finish_reason = fields.Str(
196 | validate=validate.OneOf(["stop", "length", "content_filter", "function_call"]),
197 | metadata={"example": "stop"})
198 |
199 |
200 | class CompletionUsageSchema(Schema):
201 | prompt_tokens = fields.Int(metadata={"example": 5})
202 | completion_tokens = fields.Int(metadata={"example": 7})
203 | total_tokens = fields.Int(metadata={"example": 12})
204 |
205 |
206 | class CompletionSchema(Schema):
207 | id = fields.Str(
208 | dump_default=lambda: uuid.uuid4().hex,
209 | metadata={"example": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7"})
210 | object = fields.Constant("text_completion")
211 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
212 | model = fields.Str(metadata={"example": "gpt-3.5-turbo"})
213 | choices = fields.List(fields.Nested(CompletionChoiceSchema))
214 | usage = fields.Nested(CompletionUsageSchema)
215 |
216 |
217 | @models_bp.route("")
218 | def list_models():
219 | """
220 | List models
221 | ---
222 | get:
223 | tags:
224 | - Models
225 | description: Lists the currently available models, \
226 | and provides basic information about each one such as the owner and availability.
227 | security:
228 | - bearer: []
229 | responses:
230 | 200:
231 | description: Models returned
232 | content:
233 | application/json:
234 | schema: ModelListSchema
235 | """
236 |
237 | model = ModelSchema().dump({"id": "gpt-3.5-turbo"})
238 | return ModelListSchema().dump({"data": [model]})
239 |
240 |
241 | @stream_with_context
242 | def stream_chat_generate(messages):
243 | delta = ChatDeltaSchema().dump(
244 | {"role": "assistant"})
245 | choice = ChatCompletionChunkChoiceSchema().dump(
246 | {"index": 0, "delta": delta, "finish_reason": None})
247 |
248 | yield sse(
249 | ChatCompletionChunkShema().dump({
250 | "model": "gpt-3.5-turbo",
251 | "choices": [choice]})
252 | )
253 |
254 | position = 0
255 | for response in tfs.chat(
256 | tfs.tokenizer,
257 | messages,
258 | stream=True):
259 | content = response[position:]
260 | if not content:
261 | continue
262 | empty_cache()
263 | delta = ChatDeltaSchema().dump(
264 | {"content": content})
265 | choice = ChatCompletionChunkChoiceSchema().dump(
266 | {"index": 0, "delta": delta, "finish_reason": None})
267 |
268 | yield sse(
269 | ChatCompletionChunkShema().dump({
270 | "model": "gpt-3.5-turbo",
271 | "choices": [choice]})
272 | )
273 | position = len(response)
274 |
275 | choice = ChatCompletionChunkChoiceSchema().dump(
276 | {"index": 0, "delta": {}, "finish_reason": "stop"})
277 |
278 | yield sse(
279 | ChatCompletionChunkShema().dump({
280 | "model": "gpt-3.5-turbo",
281 | "choices": [choice]})
282 | )
283 |
284 | yield sse('[DONE]')
285 |
286 |
287 | @chat_bp.route("/completions", methods=['POST'])
288 | def create_chat_completion():
289 | """Create chat completion
290 | ---
291 | post:
292 | tags:
293 | - Chat
294 | description: Creates a model response for the given chat conversation.
295 | requestBody:
296 | request: True
297 | content:
298 | application/json:
299 | schema: CreateChatCompletionSchema
300 | security:
301 | - bearer: []
302 | responses:
303 | 200:
304 | description: ChatCompletion return
305 | content:
306 | application/json:
307 | schema:
308 | oneOf:
309 | - ChatCompletionSchema
310 | - ChatCompletionChunkShema
311 | """
312 |
313 | create_chat_completion = CreateChatCompletionSchema().load(request.json)
314 |
315 | if create_chat_completion["stream"]:
316 | return current_app.response_class(
317 | stream_chat_generate(create_chat_completion["messages"]),
318 | mimetype="text/event-stream"
319 | )
320 | else:
321 | response = tfs.chat(tfs.tokenizer, create_chat_completion["messages"])
322 |
323 | message = ChatMessageSchema().dump(
324 | {"role": "assistant", "content": response})
325 | choice = ChatCompletionChoiceSchema().dump(
326 | {"index": 0, "message": message, "finish_reason": "stop"})
327 | return ChatCompletionSchema().dump({
328 | "model": "gpt-3.5-turbo",
329 | "choices": [choice]})
330 |
331 |
332 | @stream_with_context
333 | def stream_generate(prompts, **generate_kwargs):
334 | finish_choices = []
335 | for index, prompt in enumerate(prompts):
336 | choice = CompletionChoiceSchema().dump(
337 | {"index": index, "text": "\n\n", "logprobs": None, "finish_reason": None})
338 |
339 | yield sse(
340 | CompletionSchema().dump(
341 | {"model": "gpt-3.5-turbo-instruct", "choices": [choice]})
342 | )
343 |
344 | inputs = base_tfs.tokenizer(prompt, padding=True, return_tensors='pt')
345 | inputs = inputs.to(base_tfs.model.device)
346 | streamer = TextIteratorStreamer(
347 | base_tfs.tokenizer,
348 | decode_kwargs={"skip_special_tokens": True})
349 | Thread(
350 | target=base_tfs.model.generate, kwargs=dict(
351 | inputs, streamer=streamer,
352 | repetition_penalty=1.1, **generate_kwargs)
353 | ).start()
354 |
355 | finish_reason = None
356 | for text in streamer:
357 | if not text:
358 | continue
359 | empty_cache()
360 | if text.endswith(base_tfs.tokenizer.eos_token):
361 | finish_reason = "stop"
362 | break
363 |
364 | choice = CompletionChoiceSchema().dump(
365 | {"index": index, "text": text, "logprobs": None, "finish_reason": None})
366 |
367 | yield sse(
368 | CompletionSchema().dump(
369 | {"model": "gpt-3.5-turbo-instruct", "choices": [choice]})
370 | )
371 | else:
372 | finish_reason = "length"
373 | choice = CompletionChoiceSchema().dump(
374 | {"index": index, "text": text, "logprobs": None, "finish_reason": finish_reason})
375 | yield sse(
376 | CompletionSchema().dump(
377 | {"model": "gpt-3.5-turbo-instruct", "choices": [choice]})
378 | )
379 |
380 | choice = CompletionChoiceSchema().dump(
381 | {"index": index, "text": "", "logprobs": None, "finish_reason": finish_reason})
382 | finish_choices.append(choice)
383 |
384 | yield sse(
385 | CompletionSchema().dump(
386 | {"model": "gpt-3.5-turbo-instruct", "choices": finish_choices})
387 | )
388 |
389 | yield sse('[DONE]')
390 |
391 |
392 | @completions_bp.route("", methods=["POST"])
393 | def create_completion():
394 | """Create completion
395 | ---
396 | post:
397 | tags:
398 | - Completions
399 | description: Creates a completion for the provided prompt and parameters.
400 | requestBody:
401 | request: True
402 | content:
403 | application/json:
404 | schema: CreateCompletionSchema
405 | security:
406 | - bearer: []
407 | responses:
408 | 200:
409 | description: Completion return
410 | content:
411 | application/json:
412 | schema:
413 | CompletionSchema
414 | """
415 | create_completion = CreateCompletionSchema().load(request.json)
416 |
417 | prompt = create_completion["prompt"]
418 | prompts = prompt if isinstance(prompt, list) else [prompt]
419 |
420 | if create_completion["stream"]:
421 | return current_app.response_class(
422 | stream_generate(prompts, max_new_tokens=create_completion["max_tokens"]),
423 | mimetype="text/event-stream"
424 | )
425 | else:
426 | choices = []
427 | prompt_tokens = 0
428 | completion_tokens = 0
429 | for index, prompt in enumerate(prompts):
430 | inputs = base_tfs.tokenizer(prompt, return_tensors='pt')
431 | inputs = inputs.to(base_tfs.model.device)
432 | prompt_tokens += len(inputs["input_ids"][0])
433 | pred = base_tfs.model.generate(
434 | **inputs, max_new_tokens=create_completion["max_tokens"], repetition_penalty=1.1)
435 |
436 | completion_tokens += len(pred.cpu()[0])
437 | resp = base_tfs.tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
438 |
439 | finish_reason = None
440 | if resp.endswith(base_tfs.tokenizer.eos_token):
441 | finish_reason = "stop"
442 | resp = resp[:-len(base_tfs.tokenizer.eos_token)]
443 | else:
444 | finish_reason = "length"
445 |
446 | choices.append(
447 | CompletionChoiceSchema().dump(
448 | {"index": index, "text": resp, "logprobs": {}, "finish_reason": finish_reason})
449 | )
450 | usage = CompletionUsageSchema().dump({
451 | "prompt_tokens": prompt_tokens,
452 | "completion_tokens": completion_tokens,
453 | "total_tokens": prompt_tokens+completion_tokens})
454 |
455 | return CompletionSchema().dump(
456 | {"model": "gpt-3.5-turbo-instruct", "choices": choices, "usage": usage})
457 |
458 |
459 | app = create_app()
460 |
461 | if __name__ == '__main__':
462 | try:
463 | import ngrok
464 | import logging
465 |
466 | logging.basicConfig(level=logging.INFO)
467 | listener = ngrok.werkzeug_develop()
468 | except Exception:
469 | pass
470 |
471 | app.run(debug=False, host="0.0.0.0", port=5000)
472 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | Flask==2.3.3
2 | Flask-Cors==4.0.0
3 | gunicorn==21.2.0
4 | transformers==4.30.2
5 | torch==2.0.1
6 | torchvision==0.15.2
7 | xformers==0.0.21
8 | flasgger==0.9.7.1
9 | marshmallow==3.20.1
10 | apispec==6.3.0
11 | apispec-webframeworks==0.5.2
12 | accelerate==0.23.0
13 | colorama==0.4.6
14 | bitsandbytes==0.41.1
15 | sentencepiece==0.1.99
16 | streamlit==1.26.0
17 | scipy==1.11.2
18 | ngrok==0.12.0
19 |
--------------------------------------------------------------------------------
122 |
123 |
--------------------------------------------------------------------------------
/colab/my_openai_api.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "nbformat": 4,
3 | "nbformat_minor": 0,
4 | "metadata": {
5 | "colab": {
6 | "provenance": [],
7 | "gpuType": "T4"
8 | },
9 | "kernelspec": {
10 | "name": "python3",
11 | "display_name": "Python 3"
12 | },
13 | "language_info": {
14 | "name": "python"
15 | },
16 | "accelerator": "GPU"
17 | },
18 | "cells": [
19 | {
20 | "cell_type": "code",
21 | "execution_count": null,
22 | "metadata": {
23 | "id": "-50AbTRLCh5D"
24 | },
25 | "outputs": [],
26 | "source": [
27 | "\"\"\"下载代码\n",
28 | "\"\"\"\n",
29 | "%cd /content/\n",
30 | "!git clone https://github.com/billvsme/my_openai_api.git"
31 | ]
32 | },
33 | {
34 | "cell_type": "code",
35 | "source": [
36 | "\"\"\"下载模型\n",
37 | "\"\"\"\n",
38 | "%cd /content/my_openai_api\n",
39 | "!git clone --depth=1 https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat-4bits"
40 | ],
41 | "metadata": {
42 | "id": "vtbxBPhlC60S"
43 | },
44 | "execution_count": null,
45 | "outputs": []
46 | },
47 | {
48 | "cell_type": "code",
49 | "source": [
50 | "\"\"\"安装环境\n",
51 | "\"\"\"\n",
52 | "%cd /content/my_openai_api\n",
53 | "\n",
54 | "!apt install python3.10-venv\n",
55 | "!mkdir ~/.venv\n",
56 | "!python -m venv ~/.venv/ai\n",
57 | "!~/.venv/ai/bin/pip install -r requirements.txt"
58 | ],
59 | "metadata": {
60 | "id": "33opJSj6DVYr"
61 | },
62 | "execution_count": null,
63 | "outputs": []
64 | },
65 | {
66 | "cell_type": "code",
67 | "source": [
68 | "\"\"\"运行\n",
69 | "\"\"\"\n",
70 | "%cd /content/my_openai_api\n",
71 | "# 获取ngrok的tokn,https://dashboard.ngrok.com/get-started/your-authtoken\n",
72 | "# 注意不要带双引号\n",
73 | "%env NGROK_AUTHTOKEN=yourtoken\n",
74 | "!~/.venv/ai/bin/python my_openai_api.py"
75 | ],
76 | "metadata": {
77 | "id": "NKGQRhxkDddZ"
78 | },
79 | "execution_count": null,
80 | "outputs": []
81 | }
82 | ]
83 | }
--------------------------------------------------------------------------------
/my_openai_api.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 | import json
3 | import time
4 | import uuid
5 | from threading import Thread
6 |
7 | import torch
8 | from flask import Flask, current_app, request, Blueprint, stream_with_context
9 | from flask_cors import CORS
10 | from transformers import AutoTokenizer, AutoModelForCausalLM
11 | from transformers.generation.utils import GenerationConfig
12 | from transformers.generation.streamers import TextIteratorStreamer
13 | from marshmallow import validate
14 | from flasgger import APISpec, Schema, Swagger, fields
15 | from apispec.ext.marshmallow import MarshmallowPlugin
16 | from apispec_webframeworks.flask import FlaskPlugin
17 |
18 |
19 | class Transformers():
20 | def __init__(self, app=None, tokenizer=None, model=None):
21 | self.chat = None
22 | if app is not None:
23 | self.init_app(app, tokenizer, model)
24 |
25 | def init_app(self, app, tokenizer=None, model=None, chat=None):
26 | self.tokenizer = tokenizer
27 | self.model = model
28 | if chat is None:
29 | self.chat = model.chat
30 |
31 |
32 | tfs = Transformers()
33 | base_tfs = Transformers()
34 |
35 |
36 | models_bp = Blueprint('Models', __name__, url_prefix='/v1/models')
37 | chat_bp = Blueprint('Chat', __name__, url_prefix='/v1/chat')
38 | completions_bp = Blueprint('Completions', __name__, url_prefix='/v1/completions')
39 |
40 |
41 | def sse(line, field="data"):
42 | return "{}: {}\n\n".format(
43 | field, json.dumps(line, ensure_ascii=False) if isinstance(line, dict) else line)
44 |
45 |
46 | def empty_cache():
47 | if torch.backends.mps.is_available():
48 | torch.mps.empty_cache()
49 |
50 |
51 | def create_app():
52 | app = Flask(__name__)
53 | CORS(app)
54 | app.register_blueprint(models_bp)
55 | app.register_blueprint(chat_bp)
56 | app.register_blueprint(completions_bp)
57 |
58 | @app.after_request
59 | def after_request(resp):
60 | empty_cache()
61 | return resp
62 |
63 | # Init Swagger
64 | spec = APISpec(
65 | title='My OpenAI api',
66 | version='0.0.1',
67 | openapi_version='3.0.2',
68 | plugins=[
69 | FlaskPlugin(),
70 | MarshmallowPlugin(),
71 | ],
72 | )
73 |
74 | bearer_scheme = {"type": "http", "scheme": "bearer"}
75 | spec.components.security_scheme("bearer", bearer_scheme)
76 | template = spec.to_flasgger(
77 | app,
78 | paths=[list_models, create_chat_completion, create_completion]
79 | )
80 |
81 | app.config['SWAGGER'] = {"openapi": "3.0.2"}
82 | Swagger(app, template=template)
83 |
84 | # Init transformers
85 | model_name = "./Baichuan2-13B-Chat-4bits"
86 | tokenizer = AutoTokenizer.from_pretrained(
87 | model_name, use_fast=False, trust_remote_code=True)
88 | model = AutoModelForCausalLM.from_pretrained(
89 | model_name, device_map="auto", trust_remote_code=True)
90 | model.generation_config = GenerationConfig.from_pretrained(model_name)
91 |
92 | tfs.init_app(app, tokenizer, model)
93 | base_tfs.init_app(app, tokenizer, model)
94 |
95 | return app
96 |
97 |
98 | class ModelSchema(Schema):
99 | id = fields.Str()
100 | object = fields.Str(dump_default="model", metadata={"example": "model"})
101 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
102 | owned_by = fields.Str(dump_default="owner", metadata={"example": "owner"})
103 |
104 |
105 | class ModelListSchema(Schema):
106 | object = fields.Str(dump_default="list", metadata={"example": "list"})
107 | data = fields.List(fields.Nested(ModelSchema), dump_default=[])
108 |
109 |
110 | class ChatMessageSchema(Schema):
111 | role = fields.Str(required=True, metadata={"example": "system"})
112 | content = fields.Str(required=True, metadata={"example": "You are a helpful assistant."})
113 |
114 |
115 | class CreateChatCompletionSchema(Schema):
116 | model = fields.Str(required=True, metadata={"example": "gpt-3.5-turbo"})
117 | messages = fields.List(
118 | fields.Nested(ChatMessageSchema), required=True,
119 | metadata={"example": [
120 | ChatMessageSchema().dump({"role": "system", "content": "You are a helpful assistant."}),
121 | ChatMessageSchema().dump({"role": "user", "content": "Hello!"})
122 | ]}
123 | )
124 | temperature = fields.Float(load_default=1.0, metadata={"example": 1.0})
125 | top_p = fields.Float(load_default=1.0, metadata={"example": 1.0})
126 | n = fields.Int(load_default=1, metadata={"example": 1})
127 | max_tokens = fields.Int(load_default=None, metadata={"example": None})
128 | stream = fields.Bool(load_default=False, example=False)
129 | presence_penalty = fields.Float(load_default=0.0, example=0.0)
130 | frequency_penalty = fields.Float(load_default=0.0, example=0.0)
131 |
132 |
133 | class ChatCompletionChoiceSchema(Schema):
134 | index = fields.Int(metadata={"example": 0})
135 | message = fields.Nested(ChatMessageSchema, metadata={
136 | "example": ChatMessageSchema().dump(
137 | {"role": "assistant", "content": "\n\nHello there, how may I assist you today?"}
138 | )})
139 | finish_reason = fields.Str(
140 | validate=validate.OneOf(["stop", "length", "content_filter", "function_call"]),
141 | metadata={"example": "stop"})
142 |
143 |
144 | class ChatCompletionSchema(Schema):
145 | id = fields.Str(
146 | dump_default=lambda: uuid.uuid4().hex,
147 | metadata={"example": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7"})
148 | object = fields.Constant("chat.completion")
149 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
150 | model = fields.Str(metadata={"example": "gpt-3.5-turbo"})
151 | choices = fields.List(fields.Nested(ChatCompletionChoiceSchema))
152 |
153 |
154 | class ChatDeltaSchema(Schema):
155 | role = fields.Str(metadata={"example": "assistant"})
156 | content = fields.Str(required=True, metadata={"example": "Hello"})
157 |
158 |
159 | class ChatCompletionChunkChoiceSchema(Schema):
160 | index = fields.Int(metadata={"example": 0})
161 | delta = fields.Nested(ChatDeltaSchema, metadata={"example": ChatDeltaSchema().dump(
162 | {"role": "assistant", "example": "Hello"})})
163 | finish_reason = fields.Str(
164 | validate=validate.OneOf(["stop", "length", "content_filter", "function_call"]),
165 | metadata={"example": "stop"})
166 |
167 |
168 | class ChatCompletionChunkShema(Schema):
169 | id = fields.Str(
170 | dump_default=lambda: uuid.uuid4().hex,
171 | metadata={"example": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7"})
172 | object = fields.Constant("chat.completion.chunk")
173 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
174 | model = fields.Str(metadata={"example": "gpt-3.5-turbo"})
175 | choices = fields.List(fields.Nested(ChatCompletionChunkChoiceSchema))
176 |
177 |
178 | class CreateCompletionSchema(Schema):
179 | model = fields.Str(required=True, metadata={"example": "gpt-3.5-turbo"})
180 | prompt = fields.Raw(metadata={"example": "Say this is a test"})
181 | max_tokens = fields.Int(load_default=16, metadata={"example": 256})
182 | temperature = fields.Float(load_default=1.0, metadata={"example": 1.0})
183 | top_p = fields.Float(load_default=1.0, metadata={"example": 1.0})
184 | n = fields.Int(load_default=1, metadata={"example": 1})
185 | stream = fields.Bool(load_default=False, example=False)
186 | logit_bias = fields.Dict(load_default=None, example={})
187 | presence_penalty = fields.Float(load_default=0.0, example=0.0)
188 | frequency_penalty = fields.Float(load_default=0.0, example=0.0)
189 |
190 |
191 | class CompletionChoiceSchema(Schema):
192 | index = fields.Int(load_default=0, metadata={"example": 0})
193 | text = fields.Str(required=True, metadata={"example": "登鹳雀楼->王之涣\n夜雨寄北->"})
194 | logprobs = fields.Dict(load_default=None, metadata={"example": {}})
195 | finish_reason = fields.Str(
196 | validate=validate.OneOf(["stop", "length", "content_filter", "function_call"]),
197 | metadata={"example": "stop"})
198 |
199 |
200 | class CompletionUsageSchema(Schema):
201 | prompt_tokens = fields.Int(metadata={"example": 5})
202 | completion_tokens = fields.Int(metadata={"example": 7})
203 | total_tokens = fields.Int(metadata={"example": 12})
204 |
205 |
206 | class CompletionSchema(Schema):
207 | id = fields.Str(
208 | dump_default=lambda: uuid.uuid4().hex,
209 | metadata={"example": "cmpl-uqkvlQyYK7bGYrRHQ0eXlWi7"})
210 | object = fields.Constant("text_completion")
211 | created = fields.Int(dump_default=lambda: int(time.time()), metadata={"example": 1695402567})
212 | model = fields.Str(metadata={"example": "gpt-3.5-turbo"})
213 | choices = fields.List(fields.Nested(CompletionChoiceSchema))
214 | usage = fields.Nested(CompletionUsageSchema)
215 |
216 |
217 | @models_bp.route("")
218 | def list_models():
219 | """
220 | List models
221 | ---
222 | get:
223 | tags:
224 | - Models
225 | description: Lists the currently available models, \
226 | and provides basic information about each one such as the owner and availability.
227 | security:
228 | - bearer: []
229 | responses:
230 | 200:
231 | description: Models returned
232 | content:
233 | application/json:
234 | schema: ModelListSchema
235 | """
236 |
237 | model = ModelSchema().dump({"id": "gpt-3.5-turbo"})
238 | return ModelListSchema().dump({"data": [model]})
239 |
240 |
241 | @stream_with_context
242 | def stream_chat_generate(messages):
243 | delta = ChatDeltaSchema().dump(
244 | {"role": "assistant"})
245 | choice = ChatCompletionChunkChoiceSchema().dump(
246 | {"index": 0, "delta": delta, "finish_reason": None})
247 |
248 | yield sse(
249 | ChatCompletionChunkShema().dump({
250 | "model": "gpt-3.5-turbo",
251 | "choices": [choice]})
252 | )
253 |
254 | position = 0
255 | for response in tfs.chat(
256 | tfs.tokenizer,
257 | messages,
258 | stream=True):
259 | content = response[position:]
260 | if not content:
261 | continue
262 | empty_cache()
263 | delta = ChatDeltaSchema().dump(
264 | {"content": content})
265 | choice = ChatCompletionChunkChoiceSchema().dump(
266 | {"index": 0, "delta": delta, "finish_reason": None})
267 |
268 | yield sse(
269 | ChatCompletionChunkShema().dump({
270 | "model": "gpt-3.5-turbo",
271 | "choices": [choice]})
272 | )
273 | position = len(response)
274 |
275 | choice = ChatCompletionChunkChoiceSchema().dump(
276 | {"index": 0, "delta": {}, "finish_reason": "stop"})
277 |
278 | yield sse(
279 | ChatCompletionChunkShema().dump({
280 | "model": "gpt-3.5-turbo",
281 | "choices": [choice]})
282 | )
283 |
284 | yield sse('[DONE]')
285 |
286 |
287 | @chat_bp.route("/completions", methods=['POST'])
288 | def create_chat_completion():
289 | """Create chat completion
290 | ---
291 | post:
292 | tags:
293 | - Chat
294 | description: Creates a model response for the given chat conversation.
295 | requestBody:
296 | request: True
297 | content:
298 | application/json:
299 | schema: CreateChatCompletionSchema
300 | security:
301 | - bearer: []
302 | responses:
303 | 200:
304 | description: ChatCompletion return
305 | content:
306 | application/json:
307 | schema:
308 | oneOf:
309 | - ChatCompletionSchema
310 | - ChatCompletionChunkShema
311 | """
312 |
313 | create_chat_completion = CreateChatCompletionSchema().load(request.json)
314 |
315 | if create_chat_completion["stream"]:
316 | return current_app.response_class(
317 | stream_chat_generate(create_chat_completion["messages"]),
318 | mimetype="text/event-stream"
319 | )
320 | else:
321 | response = tfs.chat(tfs.tokenizer, create_chat_completion["messages"])
322 |
323 | message = ChatMessageSchema().dump(
324 | {"role": "assistant", "content": response})
325 | choice = ChatCompletionChoiceSchema().dump(
326 | {"index": 0, "message": message, "finish_reason": "stop"})
327 | return ChatCompletionSchema().dump({
328 | "model": "gpt-3.5-turbo",
329 | "choices": [choice]})
330 |
331 |
332 | @stream_with_context
333 | def stream_generate(prompts, **generate_kwargs):
334 | finish_choices = []
335 | for index, prompt in enumerate(prompts):
336 | choice = CompletionChoiceSchema().dump(
337 | {"index": index, "text": "\n\n", "logprobs": None, "finish_reason": None})
338 |
339 | yield sse(
340 | CompletionSchema().dump(
341 | {"model": "gpt-3.5-turbo-instruct", "choices": [choice]})
342 | )
343 |
344 | inputs = base_tfs.tokenizer(prompt, padding=True, return_tensors='pt')
345 | inputs = inputs.to(base_tfs.model.device)
346 | streamer = TextIteratorStreamer(
347 | base_tfs.tokenizer,
348 | decode_kwargs={"skip_special_tokens": True})
349 | Thread(
350 | target=base_tfs.model.generate, kwargs=dict(
351 | inputs, streamer=streamer,
352 | repetition_penalty=1.1, **generate_kwargs)
353 | ).start()
354 |
355 | finish_reason = None
356 | for text in streamer:
357 | if not text:
358 | continue
359 | empty_cache()
360 | if text.endswith(base_tfs.tokenizer.eos_token):
361 | finish_reason = "stop"
362 | break
363 |
364 | choice = CompletionChoiceSchema().dump(
365 | {"index": index, "text": text, "logprobs": None, "finish_reason": None})
366 |
367 | yield sse(
368 | CompletionSchema().dump(
369 | {"model": "gpt-3.5-turbo-instruct", "choices": [choice]})
370 | )
371 | else:
372 | finish_reason = "length"
373 | choice = CompletionChoiceSchema().dump(
374 | {"index": index, "text": text, "logprobs": None, "finish_reason": finish_reason})
375 | yield sse(
376 | CompletionSchema().dump(
377 | {"model": "gpt-3.5-turbo-instruct", "choices": [choice]})
378 | )
379 |
380 | choice = CompletionChoiceSchema().dump(
381 | {"index": index, "text": "", "logprobs": None, "finish_reason": finish_reason})
382 | finish_choices.append(choice)
383 |
384 | yield sse(
385 | CompletionSchema().dump(
386 | {"model": "gpt-3.5-turbo-instruct", "choices": finish_choices})
387 | )
388 |
389 | yield sse('[DONE]')
390 |
391 |
392 | @completions_bp.route("", methods=["POST"])
393 | def create_completion():
394 | """Create completion
395 | ---
396 | post:
397 | tags:
398 | - Completions
399 | description: Creates a completion for the provided prompt and parameters.
400 | requestBody:
401 | request: True
402 | content:
403 | application/json:
404 | schema: CreateCompletionSchema
405 | security:
406 | - bearer: []
407 | responses:
408 | 200:
409 | description: Completion return
410 | content:
411 | application/json:
412 | schema:
413 | CompletionSchema
414 | """
415 | create_completion = CreateCompletionSchema().load(request.json)
416 |
417 | prompt = create_completion["prompt"]
418 | prompts = prompt if isinstance(prompt, list) else [prompt]
419 |
420 | if create_completion["stream"]:
421 | return current_app.response_class(
422 | stream_generate(prompts, max_new_tokens=create_completion["max_tokens"]),
423 | mimetype="text/event-stream"
424 | )
425 | else:
426 | choices = []
427 | prompt_tokens = 0
428 | completion_tokens = 0
429 | for index, prompt in enumerate(prompts):
430 | inputs = base_tfs.tokenizer(prompt, return_tensors='pt')
431 | inputs = inputs.to(base_tfs.model.device)
432 | prompt_tokens += len(inputs["input_ids"][0])
433 | pred = base_tfs.model.generate(
434 | **inputs, max_new_tokens=create_completion["max_tokens"], repetition_penalty=1.1)
435 |
436 | completion_tokens += len(pred.cpu()[0])
437 | resp = base_tfs.tokenizer.decode(pred.cpu()[0], skip_special_tokens=False)
438 |
439 | finish_reason = None
440 | if resp.endswith(base_tfs.tokenizer.eos_token):
441 | finish_reason = "stop"
442 | resp = resp[:-len(base_tfs.tokenizer.eos_token)]
443 | else:
444 | finish_reason = "length"
445 |
446 | choices.append(
447 | CompletionChoiceSchema().dump(
448 | {"index": index, "text": resp, "logprobs": {}, "finish_reason": finish_reason})
449 | )
450 | usage = CompletionUsageSchema().dump({
451 | "prompt_tokens": prompt_tokens,
452 | "completion_tokens": completion_tokens,
453 | "total_tokens": prompt_tokens+completion_tokens})
454 |
455 | return CompletionSchema().dump(
456 | {"model": "gpt-3.5-turbo-instruct", "choices": choices, "usage": usage})
457 |
458 |
459 | app = create_app()
460 |
461 | if __name__ == '__main__':
462 | try:
463 | import ngrok
464 | import logging
465 |
466 | logging.basicConfig(level=logging.INFO)
467 | listener = ngrok.werkzeug_develop()
468 | except Exception:
469 | pass
470 |
471 | app.run(debug=False, host="0.0.0.0", port=5000)
472 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | Flask==2.3.3
2 | Flask-Cors==4.0.0
3 | gunicorn==21.2.0
4 | transformers==4.30.2
5 | torch==2.0.1
6 | torchvision==0.15.2
7 | xformers==0.0.21
8 | flasgger==0.9.7.1
9 | marshmallow==3.20.1
10 | apispec==6.3.0
11 | apispec-webframeworks==0.5.2
12 | accelerate==0.23.0
13 | colorama==0.4.6
14 | bitsandbytes==0.41.1
15 | sentencepiece==0.1.99
16 | streamlit==1.26.0
17 | scipy==1.11.2
18 | ngrok==0.12.0
19 |
--------------------------------------------------------------------------------