├── utils
└── __init__.py
├── xadapter
└── model
│ ├── __init__.py
│ ├── utils.py
│ ├── adapter.py
│ └── unet_adapter.py
├── assets
├── Dog.png
├── CuteCat.jpeg
└── Lotus.jpeg
├── scripts
├── utils.py
├── __pycache__
│ ├── utils.cpython-310.pyc
│ ├── inference_lora.cpython-310.pyc
│ ├── inference_controlnet.cpython-310.pyc
│ └── inference_ctrlnet_tile.cpython-310.pyc
├── inference_ctrlnet_tile.py
├── inference_controlnet.py
└── inference_lora.py
├── .gitignore
├── __init__.py
├── requirements.txt
├── bash_scripts
├── controlnet_tile_inference.sh
├── canny_controlnet_inference.sh
├── depth_controlnet_inference.sh
└── lora_inference.sh
├── configs
├── scheduler_config.json
├── sdxl_scheduler_config.json
├── text_encoder_config.json
├── sdxl_tokenizer2_config.json
├── sdxl_tokenizer_config.json
├── tokenizer_config.json
├── v1-inference.yaml
├── control_v11p_sd15.yaml
├── controlnet_sd_1_5.yaml
└── sd_xl_base.yaml
├── model
├── utils.py
└── adapter.py
├── README.md
├── inference.py
├── LICENSE
└── nodes.py
/utils/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/xadapter/model/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/assets/Dog.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bushc7/ComfyUI-Diffusers-X-Adapter/HEAD/assets/Dog.png
--------------------------------------------------------------------------------
/assets/CuteCat.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bushc7/ComfyUI-Diffusers-X-Adapter/HEAD/assets/CuteCat.jpeg
--------------------------------------------------------------------------------
/assets/Lotus.jpeg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bushc7/ComfyUI-Diffusers-X-Adapter/HEAD/assets/Lotus.jpeg
--------------------------------------------------------------------------------
/scripts/utils.py:
--------------------------------------------------------------------------------
1 | def str2float(x):
2 | for i in range(len(x)):
3 | x[i] = float(x[i])
4 | return x
5 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | wandb/
2 | *debug*
3 | debugs/
4 | outputs/
5 | __pycache__/
6 | checkpoints/*
7 | *.ipynb
8 | *.safetensors
9 | *.ckpt
10 | *.bak
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
1 | from .nodes import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
2 |
3 | __all__ = ["NODE_CLASS_MAPPINGS", "NODE_DISPLAY_NAME_MAPPINGS"]
--------------------------------------------------------------------------------
/scripts/__pycache__/utils.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bushc7/ComfyUI-Diffusers-X-Adapter/HEAD/scripts/__pycache__/utils.cpython-310.pyc
--------------------------------------------------------------------------------
/scripts/__pycache__/inference_lora.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bushc7/ComfyUI-Diffusers-X-Adapter/HEAD/scripts/__pycache__/inference_lora.cpython-310.pyc
--------------------------------------------------------------------------------
/scripts/__pycache__/inference_controlnet.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bushc7/ComfyUI-Diffusers-X-Adapter/HEAD/scripts/__pycache__/inference_controlnet.cpython-310.pyc
--------------------------------------------------------------------------------
/scripts/__pycache__/inference_ctrlnet_tile.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/bushc7/ComfyUI-Diffusers-X-Adapter/HEAD/scripts/__pycache__/inference_ctrlnet_tile.cpython-310.pyc
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | accelerate >= 0.18.0
2 | diffusers >= 0.26.0
3 | einops >= 0.4.1
4 | huggingface_hub >= 0.17.2
5 | matplotlib
6 | numpy
7 | safetensors >= 0.3.3
8 | tqdm >= 4.64.1
9 | transformers >= 4.25.1
10 | Pillow >= 10.2.0
11 | omegaconf
--------------------------------------------------------------------------------
/bash_scripts/controlnet_tile_inference.sh:
--------------------------------------------------------------------------------
1 | python inference.py --plugin_type "controlnet_tile" --prompt "best quality, extremely datailed" --controlnet_condition_scale_list 1.0 --adapter_guidance_start_list 0.7 --adapter_condition_scale_list 1.2 --input_image_path "./assets/Dog.png"
--------------------------------------------------------------------------------
/bash_scripts/canny_controlnet_inference.sh:
--------------------------------------------------------------------------------
1 | python inference.py --plugin_type "controlnet" --prompt "A cute cat, high quality, extremely detailed" --condition_type "canny" --input_image_path "./assets/CuteCat.jpeg" --controlnet_condition_scale_list 1.5 --adapter_guidance_start_list 0.80 --adapter_condition_scale_list 1.00
--------------------------------------------------------------------------------
/bash_scripts/depth_controlnet_inference.sh:
--------------------------------------------------------------------------------
1 | python inference.py --plugin_type "controlnet" --prompt "A colorful lotus, ink, high quality, extremely detailed" --condition_type "depth" --input_image_path "./assets/Lotus.jpeg" --controlnet_condition_scale_list 1.0 --adapter_guidance_start_list 0.80 --adapter_condition_scale_list 1.0
--------------------------------------------------------------------------------
/configs/scheduler_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "_class_name": "PNDMScheduler",
3 | "_diffusers_version": "0.6.0",
4 | "beta_end": 0.012,
5 | "beta_schedule": "scaled_linear",
6 | "beta_start": 0.00085,
7 | "num_train_timesteps": 1000,
8 | "set_alpha_to_one": false,
9 | "skip_prk_steps": true,
10 | "steps_offset": 1,
11 | "trained_betas": null,
12 | "clip_sample": false
13 | }
14 |
--------------------------------------------------------------------------------
/bash_scripts/lora_inference.sh:
--------------------------------------------------------------------------------
1 | python inference.py --plugin_type "lora" --prompt "masterpiece, best quality, ultra detailed, 1 girl , solo, smile, looking at viewer, holding flowers" --prompt_sd1_5 "masterpiece, best quality, ultra detailed, 1 girl, solo, smile, looking at viewer, holding flowers, shuimobysim, wuchangshuo, bonian, zhenbanqiao, badashanren" --adapter_guidance_start_list 0.7 --adapter_condition_scale_list 1.00 --seed 3943946911
--------------------------------------------------------------------------------
/model/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import imageio
3 | import numpy as np
4 | from typing import Union
5 |
6 | import torch
7 | import torchvision
8 | import torch.distributed as dist
9 |
10 | from safetensors import safe_open
11 | from tqdm import tqdm
12 | from einops import rearrange
13 | from model.convert_from_ckpt import convert_ldm_unet_checkpoint, convert_ldm_clip_checkpoint, convert_ldm_vae_checkpoint
14 | # from animatediff.utils.convert_lora_safetensor_to_diffusers import convert_lora, convert_motion_lora_ckpt_to_diffusers
--------------------------------------------------------------------------------
/xadapter/model/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 | import imageio
3 | import numpy as np
4 | from typing import Union
5 |
6 | import torch
7 | import torchvision
8 | import torch.distributed as dist
9 |
10 | from safetensors import safe_open
11 | from tqdm import tqdm
12 | from einops import rearrange
13 | from model.convert_from_ckpt import convert_ldm_unet_checkpoint, convert_ldm_clip_checkpoint, convert_ldm_vae_checkpoint
14 | # from animatediff.utils.convert_lora_safetensor_to_diffusers import convert_lora, convert_motion_lora_ckpt_to_diffusers
--------------------------------------------------------------------------------
/configs/sdxl_scheduler_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "_class_name": "EulerDiscreteScheduler",
3 | "_diffusers_version": "0.19.0.dev0",
4 | "beta_end": 0.012,
5 | "beta_schedule": "scaled_linear",
6 | "beta_start": 0.00085,
7 | "clip_sample": false,
8 | "interpolation_type": "linear",
9 | "num_train_timesteps": 1000,
10 | "prediction_type": "epsilon",
11 | "sample_max_value": 1.0,
12 | "set_alpha_to_one": false,
13 | "skip_prk_steps": true,
14 | "steps_offset": 1,
15 | "timestep_spacing": "leading",
16 | "trained_betas": null,
17 | "use_karras_sigmas": false
18 | }
19 |
--------------------------------------------------------------------------------
/configs/text_encoder_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "_name_or_path": "openai/clip-vit-large-patch14",
3 | "architectures": [
4 | "CLIPTextModel"
5 | ],
6 | "attention_dropout": 0.0,
7 | "bos_token_id": 0,
8 | "dropout": 0.0,
9 | "eos_token_id": 2,
10 | "hidden_act": "quick_gelu",
11 | "hidden_size": 768,
12 | "initializer_factor": 1.0,
13 | "initializer_range": 0.02,
14 | "intermediate_size": 3072,
15 | "layer_norm_eps": 1e-05,
16 | "max_position_embeddings": 77,
17 | "model_type": "clip_text_model",
18 | "num_attention_heads": 12,
19 | "num_hidden_layers": 12,
20 | "pad_token_id": 1,
21 | "projection_dim": 768,
22 | "torch_dtype": "float32",
23 | "transformers_version": "4.22.0.dev0",
24 | "vocab_size": 49408
25 | }
26 |
--------------------------------------------------------------------------------
/configs/sdxl_tokenizer2_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "add_prefix_space": false,
3 | "bos_token": {
4 | "__type": "AddedToken",
5 | "content": "<|startoftext|>",
6 | "lstrip": false,
7 | "normalized": true,
8 | "rstrip": false,
9 | "single_word": false
10 | },
11 | "clean_up_tokenization_spaces": true,
12 | "do_lower_case": true,
13 | "eos_token": {
14 | "__type": "AddedToken",
15 | "content": "<|endoftext|>",
16 | "lstrip": false,
17 | "normalized": true,
18 | "rstrip": false,
19 | "single_word": false
20 | },
21 | "errors": "replace",
22 | "model_max_length": 77,
23 | "pad_token": "!",
24 | "tokenizer_class": "CLIPTokenizer",
25 | "unk_token": {
26 | "__type": "AddedToken",
27 | "content": "<|endoftext|>",
28 | "lstrip": false,
29 | "normalized": true,
30 | "rstrip": false,
31 | "single_word": false
32 | }
33 | }
34 |
--------------------------------------------------------------------------------
/configs/sdxl_tokenizer_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "add_prefix_space": false,
3 | "bos_token": {
4 | "__type": "AddedToken",
5 | "content": "<|startoftext|>",
6 | "lstrip": false,
7 | "normalized": true,
8 | "rstrip": false,
9 | "single_word": false
10 | },
11 | "clean_up_tokenization_spaces": true,
12 | "do_lower_case": true,
13 | "eos_token": {
14 | "__type": "AddedToken",
15 | "content": "<|endoftext|>",
16 | "lstrip": false,
17 | "normalized": true,
18 | "rstrip": false,
19 | "single_word": false
20 | },
21 | "errors": "replace",
22 | "model_max_length": 77,
23 | "pad_token": "<|endoftext|>",
24 | "tokenizer_class": "CLIPTokenizer",
25 | "unk_token": {
26 | "__type": "AddedToken",
27 | "content": "<|endoftext|>",
28 | "lstrip": false,
29 | "normalized": true,
30 | "rstrip": false,
31 | "single_word": false
32 | }
33 | }
34 |
--------------------------------------------------------------------------------
/configs/tokenizer_config.json:
--------------------------------------------------------------------------------
1 | {
2 | "add_prefix_space": false,
3 | "bos_token": {
4 | "__type": "AddedToken",
5 | "content": "<|startoftext|>",
6 | "lstrip": false,
7 | "normalized": true,
8 | "rstrip": false,
9 | "single_word": false
10 | },
11 | "do_lower_case": true,
12 | "eos_token": {
13 | "__type": "AddedToken",
14 | "content": "<|endoftext|>",
15 | "lstrip": false,
16 | "normalized": true,
17 | "rstrip": false,
18 | "single_word": false
19 | },
20 | "errors": "replace",
21 | "model_max_length": 77,
22 | "name_or_path": "openai/clip-vit-large-patch14",
23 | "pad_token": "<|endoftext|>",
24 | "special_tokens_map_file": "./special_tokens_map.json",
25 | "tokenizer_class": "CLIPTokenizer",
26 | "unk_token": {
27 | "__type": "AddedToken",
28 | "content": "<|endoftext|>",
29 | "lstrip": false,
30 | "normalized": true,
31 | "rstrip": false,
32 | "single_word": false
33 | }
34 | }
35 |
--------------------------------------------------------------------------------
/configs/v1-inference.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | base_learning_rate: 1.0e-04
3 | target: ldm.models.diffusion.ddpm.LatentDiffusion
4 | params:
5 | linear_start: 0.00085
6 | linear_end: 0.0120
7 | num_timesteps_cond: 1
8 | log_every_t: 200
9 | timesteps: 1000
10 | first_stage_key: "jpg"
11 | cond_stage_key: "txt"
12 | image_size: 64
13 | channels: 4
14 | cond_stage_trainable: false # Note: different from the one we trained before
15 | conditioning_key: crossattn
16 | monitor: val/loss_simple_ema
17 | scale_factor: 0.18215
18 | use_ema: False
19 |
20 | scheduler_config: # 10000 warmup steps
21 | target: ldm.lr_scheduler.LambdaLinearScheduler
22 | params:
23 | warm_up_steps: [ 10000 ]
24 | cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
25 | f_start: [ 1.e-6 ]
26 | f_max: [ 1. ]
27 | f_min: [ 1. ]
28 |
29 | unet_config:
30 | target: ldm.modules.diffusionmodules.openaimodel.UNetModel
31 | params:
32 | image_size: 32 # unused
33 | in_channels: 4
34 | out_channels: 4
35 | model_channels: 320
36 | attention_resolutions: [ 4, 2, 1 ]
37 | num_res_blocks: 2
38 | channel_mult: [ 1, 2, 4, 4 ]
39 | num_heads: 8
40 | use_spatial_transformer: True
41 | transformer_depth: 1
42 | context_dim: 768
43 | use_checkpoint: True
44 | legacy: False
45 |
46 | first_stage_config:
47 | target: ldm.models.autoencoder.AutoencoderKL
48 | params:
49 | embed_dim: 4
50 | monitor: val/rec_loss
51 | ddconfig:
52 | double_z: true
53 | z_channels: 4
54 | resolution: 256
55 | in_channels: 3
56 | out_ch: 3
57 | ch: 128
58 | ch_mult:
59 | - 1
60 | - 2
61 | - 4
62 | - 4
63 | num_res_blocks: 2
64 | attn_resolutions: []
65 | dropout: 0.0
66 | lossconfig:
67 | target: torch.nn.Identity
68 |
69 | cond_stage_config:
70 | target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
71 |
--------------------------------------------------------------------------------
/configs/control_v11p_sd15.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | target: cldm.cldm.ControlLDM
3 | params:
4 | linear_start: 0.00085
5 | linear_end: 0.0120
6 | num_timesteps_cond: 1
7 | log_every_t: 200
8 | timesteps: 1000
9 | first_stage_key: "jpg"
10 | cond_stage_key: "txt"
11 | control_key: "hint"
12 | image_size: 64
13 | channels: 4
14 | cond_stage_trainable: false
15 | conditioning_key: crossattn
16 | monitor: val/loss_simple_ema
17 | scale_factor: 0.18215
18 | use_ema: False
19 | only_mid_control: False
20 |
21 | control_stage_config:
22 | target: cldm.cldm.ControlNet
23 | params:
24 | image_size: 32 # unused
25 | in_channels: 4
26 | hint_channels: 3
27 | model_channels: 320
28 | attention_resolutions: [ 4, 2, 1 ]
29 | num_res_blocks: 2
30 | channel_mult: [ 1, 2, 4, 4 ]
31 | num_heads: 8
32 | use_spatial_transformer: True
33 | transformer_depth: 1
34 | context_dim: 768
35 | use_checkpoint: True
36 | legacy: False
37 |
38 | unet_config:
39 | target: cldm.cldm.ControlledUnetModel
40 | params:
41 | image_size: 32 # unused
42 | in_channels: 4
43 | out_channels: 4
44 | model_channels: 320
45 | attention_resolutions: [ 4, 2, 1 ]
46 | num_res_blocks: 2
47 | channel_mult: [ 1, 2, 4, 4 ]
48 | num_heads: 8
49 | use_spatial_transformer: True
50 | transformer_depth: 1
51 | context_dim: 768
52 | use_checkpoint: True
53 | legacy: False
54 |
55 | first_stage_config:
56 | target: ldm.models.autoencoder.AutoencoderKL
57 | params:
58 | embed_dim: 4
59 | monitor: val/rec_loss
60 | ddconfig:
61 | double_z: true
62 | z_channels: 4
63 | resolution: 256
64 | in_channels: 3
65 | out_ch: 3
66 | ch: 128
67 | ch_mult:
68 | - 1
69 | - 2
70 | - 4
71 | - 4
72 | num_res_blocks: 2
73 | attn_resolutions: []
74 | dropout: 0.0
75 | lossconfig:
76 | target: torch.nn.Identity
77 |
78 | cond_stage_config:
79 | target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
80 |
--------------------------------------------------------------------------------
/configs/controlnet_sd_1_5.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | target: cldm.cldm.ControlLDM
3 | params:
4 | linear_start: 0.00085
5 | linear_end: 0.0120
6 | num_timesteps_cond: 1
7 | log_every_t: 200
8 | timesteps: 1000
9 | first_stage_key: "jpg"
10 | cond_stage_key: "txt"
11 | control_key: "hint"
12 | image_size: 64
13 | channels: 4
14 | cond_stage_trainable: false
15 | conditioning_key: crossattn
16 | monitor: val/loss_simple_ema
17 | scale_factor: 0.18215
18 | use_ema: False
19 | only_mid_control: False
20 |
21 | control_stage_config:
22 | target: cldm.cldm.ControlNet
23 | params:
24 | image_size: 32 # unused
25 | in_channels: 4
26 | hint_channels: 3
27 | model_channels: 320
28 | attention_resolutions: [ 4, 2, 1 ]
29 | num_res_blocks: 2
30 | channel_mult: [ 1, 2, 4, 4 ]
31 | num_heads: 8
32 | use_spatial_transformer: True
33 | transformer_depth: 1
34 | context_dim: 768
35 | use_checkpoint: True
36 | legacy: False
37 |
38 | unet_config:
39 | target: cldm.cldm.ControlledUnetModel
40 | params:
41 | image_size: 32 # unused
42 | in_channels: 4
43 | out_channels: 4
44 | model_channels: 320
45 | attention_resolutions: [ 4, 2, 1 ]
46 | num_res_blocks: 2
47 | channel_mult: [ 1, 2, 4, 4 ]
48 | num_heads: 8
49 | use_spatial_transformer: True
50 | transformer_depth: 1
51 | context_dim: 768
52 | use_checkpoint: True
53 | legacy: False
54 |
55 | first_stage_config:
56 | target: ldm.models.autoencoder.AutoencoderKL
57 | params:
58 | embed_dim: 4
59 | monitor: val/rec_loss
60 | ddconfig:
61 | double_z: true
62 | z_channels: 4
63 | resolution: 256
64 | in_channels: 3
65 | out_ch: 3
66 | ch: 128
67 | ch_mult:
68 | - 1
69 | - 2
70 | - 4
71 | - 4
72 | num_res_blocks: 2
73 | attn_resolutions: []
74 | dropout: 0.0
75 | lossconfig:
76 | target: torch.nn.Identity
77 |
78 | cond_stage_config:
79 | target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
80 |
--------------------------------------------------------------------------------
/configs/sd_xl_base.yaml:
--------------------------------------------------------------------------------
1 | model:
2 | target: sgm.models.diffusion.DiffusionEngine
3 | params:
4 | scale_factor: 0.13025
5 | disable_first_stage_autocast: True
6 |
7 | denoiser_config:
8 | target: sgm.modules.diffusionmodules.denoiser.DiscreteDenoiser
9 | params:
10 | num_idx: 1000
11 |
12 | scaling_config:
13 | target: sgm.modules.diffusionmodules.denoiser_scaling.EpsScaling
14 | discretization_config:
15 | target: sgm.modules.diffusionmodules.discretizer.LegacyDDPMDiscretization
16 |
17 | network_config:
18 | target: sgm.modules.diffusionmodules.openaimodel.UNetModel
19 | params:
20 | adm_in_channels: 2816
21 | num_classes: sequential
22 | use_checkpoint: True
23 | in_channels: 4
24 | out_channels: 4
25 | model_channels: 320
26 | attention_resolutions: [4, 2]
27 | num_res_blocks: 2
28 | channel_mult: [1, 2, 4]
29 | num_head_channels: 64
30 | use_linear_in_transformer: True
31 | transformer_depth: [1, 2, 10]
32 | context_dim: 2048
33 | spatial_transformer_attn_type: softmax-xformers
34 |
35 | conditioner_config:
36 | target: sgm.modules.GeneralConditioner
37 | params:
38 | emb_models:
39 | - is_trainable: False
40 | input_key: txt
41 | target: sgm.modules.encoders.modules.FrozenCLIPEmbedder
42 | params:
43 | layer: hidden
44 | layer_idx: 11
45 |
46 | - is_trainable: False
47 | input_key: txt
48 | target: sgm.modules.encoders.modules.FrozenOpenCLIPEmbedder2
49 | params:
50 | arch: ViT-bigG-14
51 | version: laion2b_s39b_b160k
52 | freeze: True
53 | layer: penultimate
54 | always_return_pooled: True
55 | legacy: False
56 |
57 | - is_trainable: False
58 | input_key: original_size_as_tuple
59 | target: sgm.modules.encoders.modules.ConcatTimestepEmbedderND
60 | params:
61 | outdim: 256
62 |
63 | - is_trainable: False
64 | input_key: crop_coords_top_left
65 | target: sgm.modules.encoders.modules.ConcatTimestepEmbedderND
66 | params:
67 | outdim: 256
68 |
69 | - is_trainable: False
70 | input_key: target_size_as_tuple
71 | target: sgm.modules.encoders.modules.ConcatTimestepEmbedderND
72 | params:
73 | outdim: 256
74 |
75 | first_stage_config:
76 | target: sgm.models.autoencoder.AutoencoderKL
77 | params:
78 | embed_dim: 4
79 | monitor: val/rec_loss
80 | ddconfig:
81 | attn_type: vanilla-xformers
82 | double_z: true
83 | z_channels: 4
84 | resolution: 256
85 | in_channels: 3
86 | out_ch: 3
87 | ch: 128
88 | ch_mult: [1, 2, 4, 4]
89 | num_res_blocks: 2
90 | attn_resolutions: []
91 | dropout: 0.0
92 | lossconfig:
93 | target: torch.nn.Identity
94 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Some mofications to make the wrapper node more ComfyUI-node-like
2 | This is meant for testing only.
3 | Some ComfyUI nodes, e.g. the "Load LoRA", "CLIP Set Last Layer" nodes, can now be connected to the wrapper.
4 | You can now use multiple LoRAs on the node and Clip skip is also effective.
5 |
6 | ## Sample Workflow
7 | 
8 |
9 |
10 | # Original README
11 | # ComfyUI wrapper node for X-Adapter diffusers implementation.
12 |
13 | This is meant for testing only, with the ability to use same models and python env as ComfyUI, it is NOT a proper ComfyUI implementation!
14 | ### I won't be bothering with backwards compability with this node, in many updates you will have to remake any existing nodes (or set widget values again)
15 |
16 | # Known limitations:
17 | - As this is only a wrapper, it's not compatible with anything else in ComfyUI, besides input preprocessing and being able to load and convert most models for the Diffusers pipeline
18 | - Ohe ratio between 1.5 and SDXL resolution also has to be exactly 1:2
19 | - Some ControlNets/LoRAs won't load, and results with some combos seem broken
20 |
21 | 
22 | 
23 | 
24 |
25 | # X-Adapter
26 |
27 | This repository is the official implementation of [X-Adapter](https://arxiv.org/abs/2312.02238).
28 |
29 | **[X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model](https://arxiv.org/abs/2312.02238)**
30 |
31 | [Lingmin Ran](),
32 | [Xiaodong Cun](https://vinthony.github.io/academic/),
33 | [Jia-Wei Liu](https://jia-wei-liu.github.io/),
34 | [Rui Zhao](https://ruizhaocv.github.io/),
35 | [Song Zijie](),
36 | [Xintao Wang](https://xinntao.github.io/),
37 | [Jussi Keppo](https://www.jussikeppo.com/),
38 | [Mike Zheng Shou](https://sites.google.com/view/showlab)
39 |
40 |
41 | [](https://showlab.github.io/X-Adapter/)
42 | [](https://arxiv.org/abs/2312.02238)
43 |
44 | 
45 |
46 | X-Adapter enable plugins pretrained on old version (e.g. SD1.5) directly work with the upgraded Model (e.g., SDXL) without further retraining.
47 |
48 | [//]: # ()
49 |
50 | [//]: # (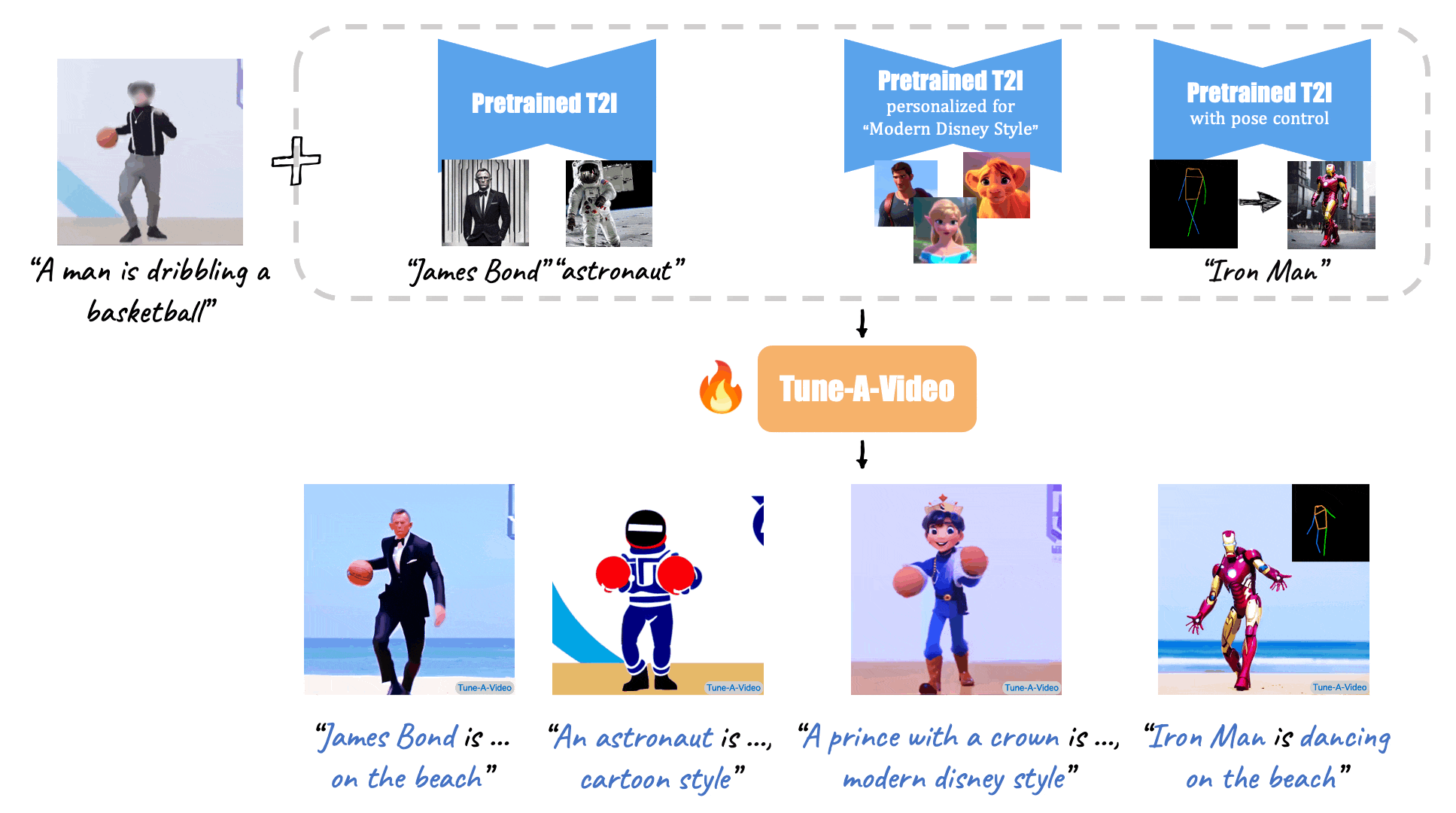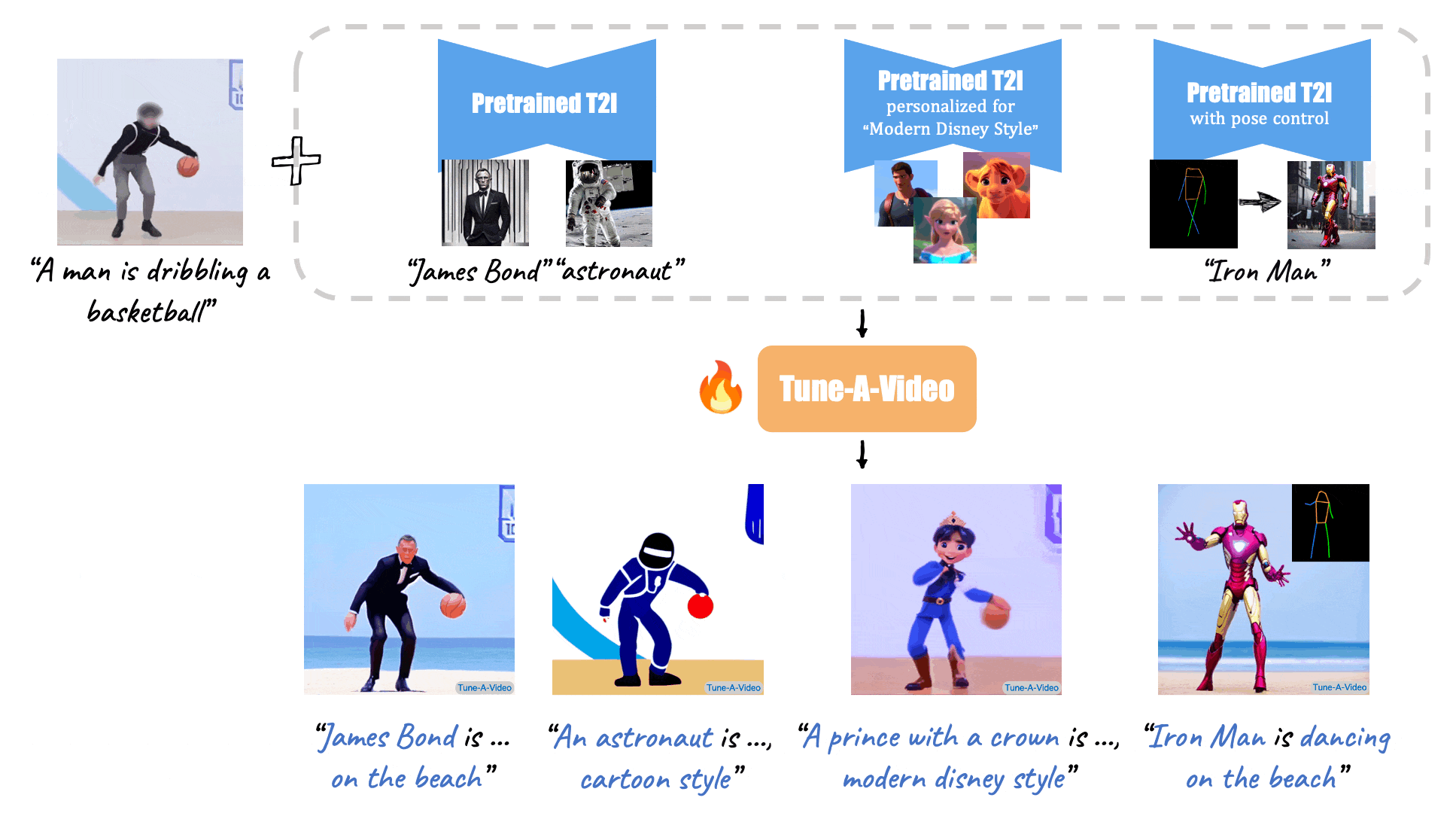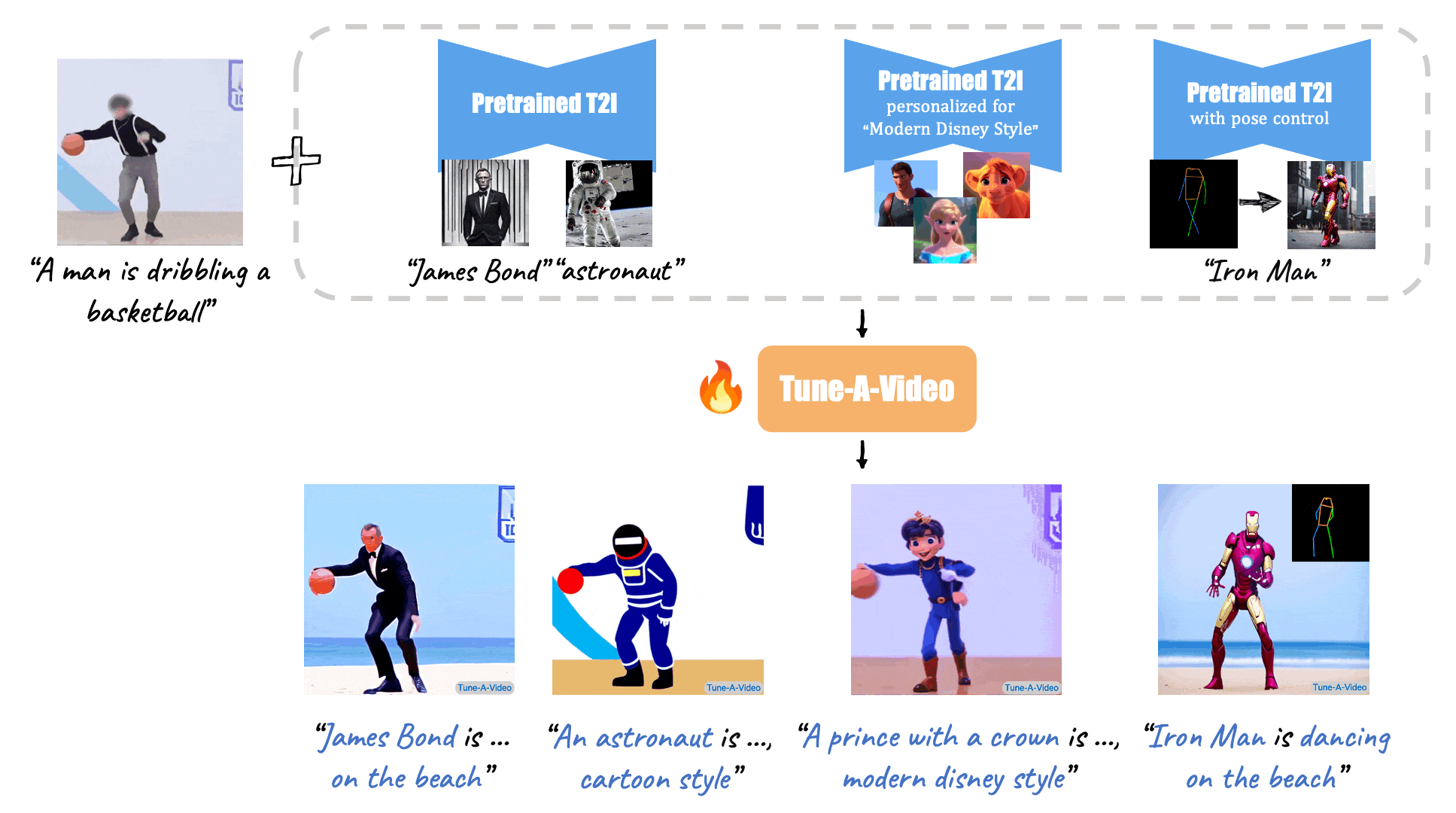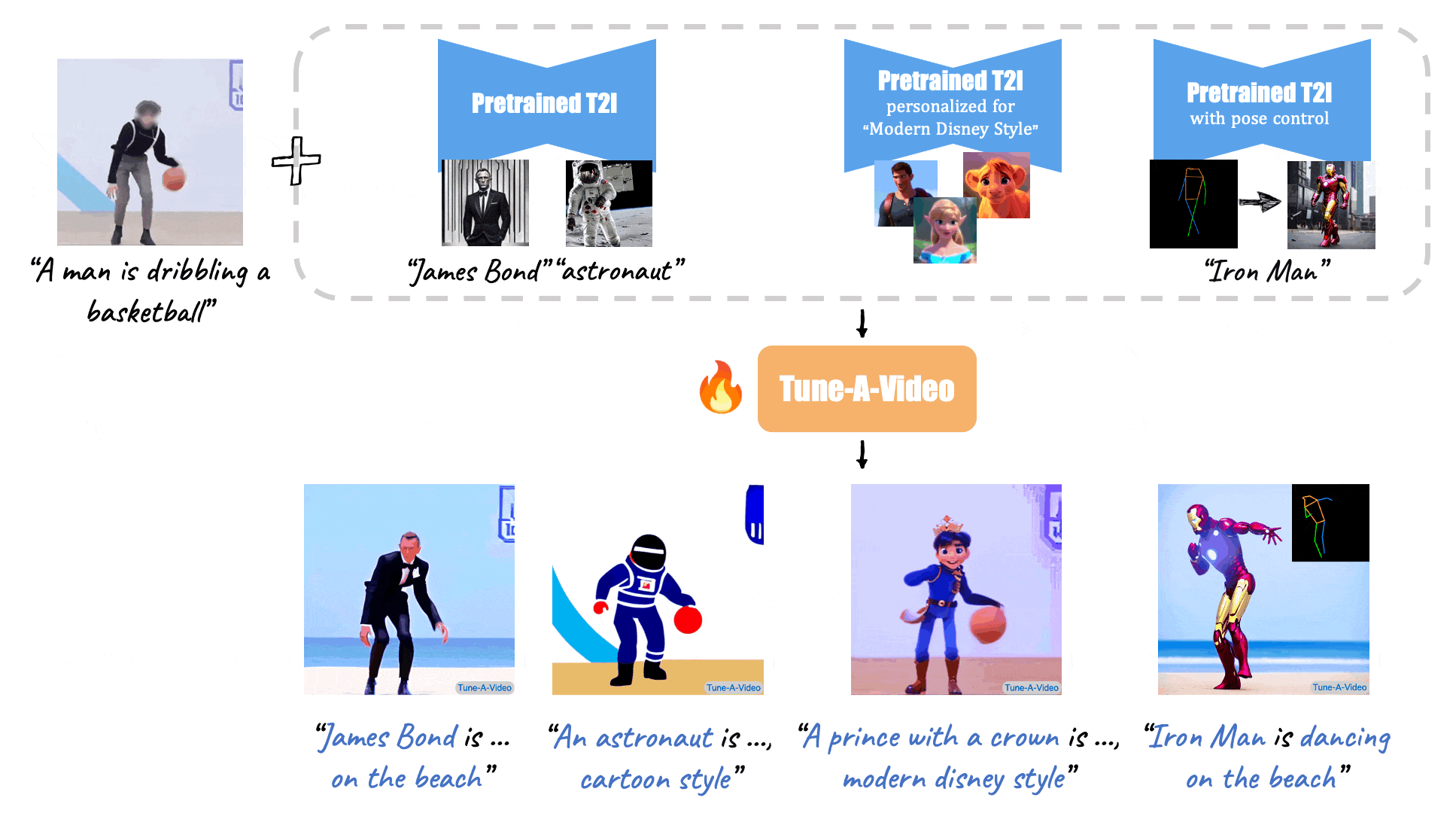 )
51 |
52 | [//]: # (
)
51 |
52 | [//]: # (
)
53 |
54 | [//]: # (Given a video-text pair as input, our method, Tune-A-Video, fine-tunes a pre-trained text-to-image diffusion model for text-to-video generation.)
55 |
56 | [//]: # (
)
57 |
58 |
59 | ## Cite
60 | If you find X-Adapter useful for your research and applications, please cite us using this BibTeX:
61 |
62 | ```bibtex
63 | @article{ran2023xadapter,
64 | title={X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model},
65 | author={Lingmin Ran and Xiaodong Cun and Jia-Wei Liu and Rui Zhao and Song Zijie and Xintao Wang and Jussi Keppo and Mike Zheng Shou},
66 | journal={arXiv preprint arXiv:2312.02238},
67 | year={2023}
68 | }
69 | ```
70 |
--------------------------------------------------------------------------------
/inference.py:
--------------------------------------------------------------------------------
1 | import os
2 | import datetime
3 | import argparse
4 |
5 | from scripts.inference_controlnet import inference_controlnet
6 | from scripts.inference_lora import inference_lora
7 | from scripts.inference_ctrlnet_tile import inference_ctrlnet_tile
8 |
9 |
10 | def parse_args(input_args=None):
11 | parser = argparse.ArgumentParser(description="Inference setting for X-Adapter.")
12 |
13 | parser.add_argument(
14 | "--plugin_type",
15 | type=str, help='lora or controlnet', default="controlnet"
16 | )
17 | parser.add_argument(
18 | "--controlnet_condition_scale_list",
19 | nargs='+', help='controlnet_scale', default=[1.0, 2.0]
20 | )
21 | parser.add_argument(
22 | "--adapter_guidance_start_list",
23 | nargs='+', help='start of 2nd stage', default=[0.6, 0.65, 0.7, 0.75, 0.8]
24 | )
25 | parser.add_argument(
26 | "--adapter_condition_scale_list",
27 | nargs='+', help='X-Adapter scale', default=[0.8, 1.0, 1.2]
28 | )
29 | parser.add_argument(
30 | "--base_path",
31 | type=str, help='path to base model', default="runwayml/stable-diffusion-v1-5"
32 | )
33 | parser.add_argument(
34 | "--sdxl_path",
35 | type=str, help='path to SDXL', default="stabilityai/stable-diffusion-xl-base-1.0"
36 | )
37 | parser.add_argument(
38 | "--path_vae_sdxl",
39 | type=str, help='path to SDXL vae', default="madebyollin/sdxl-vae-fp16-fix"
40 | )
41 | parser.add_argument(
42 | "--adapter_checkpoint",
43 | type=str, help='path to X-Adapter', default="./checkpoint/X-Adapter/X_Adapter_v1.bin"
44 | )
45 | parser.add_argument(
46 | "--condition_type",
47 | type=str, help='condition type', default="canny"
48 | )
49 | parser.add_argument(
50 | "--controlnet_canny_path",
51 | type=str, help='path to canny controlnet', default="lllyasviel/sd-controlnet-canny"
52 | )
53 | parser.add_argument(
54 | "--controlnet_depth_path",
55 | type=str, help='path to depth controlnet', default="lllyasviel/sd-controlnet-depth"
56 | )
57 | parser.add_argument(
58 | "--controlnet_tile_path",
59 | type=str, help='path to controlnet tile', default="lllyasviel/control_v11f1e_sd15_tile"
60 | )
61 | parser.add_argument(
62 | "--lora_model_path",
63 | type=str, help='path to lora', default="./checkpoint/lora/MoXinV1.safetensors"
64 | )
65 | parser.add_argument(
66 | "--prompt",
67 | type=str, help='SDXL prompt', default=None, required=True
68 | )
69 | parser.add_argument(
70 | "--prompt_sd1_5",
71 | type=str, help='SD1.5 prompt', default=None
72 | )
73 | parser.add_argument(
74 | "--negative_prompt",
75 | type=str, default=None
76 | )
77 | parser.add_argument(
78 | "--iter_num",
79 | type=int, default=1
80 | )
81 | parser.add_argument(
82 | "--input_image_path",
83 | type=str, default="./controlnet_test_image/CuteCat.jpeg"
84 | )
85 | parser.add_argument(
86 | "--num_inference_steps",
87 | type=int, default=50
88 | )
89 | parser.add_argument(
90 | "--guidance_scale",
91 | type=float, default=7.5
92 | )
93 | parser.add_argument(
94 | "--seed",
95 | type=int, default=1674753452
96 | )
97 |
98 | if input_args is not None:
99 | args = parser.parse_args(input_args)
100 | else:
101 | args = parser.parse_args()
102 |
103 | return args
104 |
105 |
106 | def run_inference(args):
107 | current_datetime = datetime.datetime.now()
108 | save_path = f"./result/{current_datetime}_lora" if args.plugin_type == "lora" else f"./result/{current_datetime}_controlnet"
109 | os.makedirs(save_path)
110 | args.save_path = save_path
111 |
112 | if args.plugin_type == "controlnet":
113 | inference_controlnet(args)
114 | elif args.plugin_type == "controlnet_tile":
115 | inference_ctrlnet_tile(args)
116 | elif args.plugin_type == "lora":
117 | inference_lora(args)
118 | else:
119 | raise NotImplementedError("not implemented yet")
120 |
121 |
122 | if __name__ == "__main__":
123 | args = parse_args()
124 | run_inference(args)
125 |
--------------------------------------------------------------------------------
/scripts/inference_ctrlnet_tile.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import json
3 | import os
4 | import numpy as np
5 | import cv2
6 | from tqdm import tqdm
7 | from diffusers import DiffusionPipeline
8 | from diffusers import DPMSolverMultistepScheduler
9 | from diffusers.utils import load_image
10 | from torch import Generator
11 | from safetensors.torch import load_file
12 | from PIL import Image
13 | from packaging import version
14 | from huggingface_hub import HfApi
15 | from pathlib import Path
16 |
17 | from transformers import CLIPTextModel, CLIPTokenizer, AutoTokenizer, PretrainedConfig
18 |
19 | import diffusers
20 | from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel, ControlNetModel, T2IAdapter, StableDiffusionControlNetPipeline
21 | from diffusers.optimization import get_scheduler
22 | from diffusers.training_utils import EMAModel
23 | from diffusers.utils import check_min_version, deprecate, is_wandb_available
24 | from diffusers.utils.import_utils import is_xformers_available
25 |
26 | from model.unet_adapter import UNet2DConditionModel as UNet2DConditionModel_v2
27 | from model.adapter import Adapter_XL
28 | from pipeline.pipeline_sd_xl_adapter_controlnet_img2img import StableDiffusionXLAdapterControlnetI2IPipeline
29 | from scripts.utils import str2float
30 |
31 | def import_model_class_from_model_name_or_path(
32 | pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
33 | ):
34 | text_encoder_config = PretrainedConfig.from_pretrained(
35 | pretrained_model_name_or_path, subfolder=subfolder, revision=revision
36 | )
37 | model_class = text_encoder_config.architectures[0]
38 |
39 | if model_class == "CLIPTextModel":
40 | from transformers import CLIPTextModel
41 |
42 | return CLIPTextModel
43 | elif model_class == "CLIPTextModelWithProjection":
44 | from transformers import CLIPTextModelWithProjection
45 |
46 | return CLIPTextModelWithProjection
47 | else:
48 | raise ValueError(f"{model_class} is not supported.")
49 |
50 |
51 | def resize_for_condition_image(input_image: Image, resolution: int):
52 | input_image = input_image.convert("RGB")
53 | W, H = input_image.size
54 | k = float(resolution) / min(H, W)
55 | H *= k
56 | W *= k
57 | H = int(round(H / 64.0)) * 64
58 | W = int(round(W / 64.0)) * 64
59 | img = input_image.resize((W, H), resample=Image.LANCZOS)
60 | return img
61 |
62 |
63 | def inference_ctrlnet_tile(args):
64 | device = 'cuda'
65 | weight_dtype = torch.float16
66 |
67 | controlnet_condition_scale_list = str2float(args.controlnet_condition_scale_list)
68 | adapter_guidance_start_list = str2float(args.adapter_guidance_start_list)
69 | adapter_condition_scale_list = str2float(args.adapter_condition_scale_list)
70 |
71 | path = args.base_path
72 | path_sdxl = args.sdxl_path
73 | path_vae_sdxl = args.path_vae_sdxl
74 | adapter_path = args.adapter_checkpoint
75 | controlnet_path = args.controlnet_tile_path
76 |
77 | prompt = args.prompt
78 | if args.prompt_sd1_5 is None:
79 | prompt_sd1_5 = prompt
80 | else:
81 | prompt_sd1_5 = args.prompt_sd1_5
82 |
83 | if args.negative_prompt is None:
84 | negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
85 | else:
86 | negative_prompt = args.negative_prompt
87 |
88 | torch.set_grad_enabled(False)
89 | torch.backends.cudnn.benchmark = True
90 |
91 | # load controlnet
92 | controlnet = ControlNetModel.from_pretrained(
93 | controlnet_path, torch_dtype=weight_dtype
94 | )
95 |
96 | source_image = Image.open(args.input_image_path)
97 | control_image = resize_for_condition_image(source_image, 512)
98 |
99 | print('successfully load controlnet')
100 | # load adapter
101 | adapter = Adapter_XL()
102 | ckpt = torch.load(adapter_path)
103 | adapter.load_state_dict(ckpt)
104 | adapter.to(weight_dtype)
105 | print('successfully load adapter')
106 | # load SD1.5
107 | noise_scheduler_sd1_5 = DDPMScheduler.from_pretrained(
108 | path, subfolder="scheduler"
109 | )
110 | tokenizer_sd1_5 = CLIPTokenizer.from_pretrained(
111 | path, subfolder="tokenizer", revision=None, torch_dtype=weight_dtype
112 | )
113 | text_encoder_sd1_5 = CLIPTextModel.from_pretrained(
114 | path, subfolder="text_encoder", revision=None, torch_dtype=weight_dtype
115 | )
116 | vae_sd1_5 = AutoencoderKL.from_pretrained(
117 | path, subfolder="vae", revision=None, torch_dtype=weight_dtype
118 | )
119 | unet_sd1_5 = UNet2DConditionModel_v2.from_pretrained(
120 | path, subfolder="unet", revision=None, torch_dtype=weight_dtype
121 | )
122 | print('successfully load SD1.5')
123 | # load SDXL
124 | tokenizer_one = AutoTokenizer.from_pretrained(
125 | path_sdxl, subfolder="tokenizer", revision=None, use_fast=False, torch_dtype=weight_dtype
126 | )
127 | tokenizer_two = AutoTokenizer.from_pretrained(
128 | path_sdxl, subfolder="tokenizer_2", revision=None, use_fast=False, torch_dtype=weight_dtype
129 | )
130 | # import correct text encoder classes
131 | text_encoder_cls_one = import_model_class_from_model_name_or_path(
132 | path_sdxl, None
133 | )
134 | text_encoder_cls_two = import_model_class_from_model_name_or_path(
135 | path_sdxl, None, subfolder="text_encoder_2"
136 | )
137 | # Load scheduler and models
138 | noise_scheduler = DDPMScheduler.from_pretrained(path_sdxl, subfolder="scheduler")
139 | text_encoder_one = text_encoder_cls_one.from_pretrained(
140 | path_sdxl, subfolder="text_encoder", revision=None, torch_dtype=weight_dtype
141 | )
142 | text_encoder_two = text_encoder_cls_two.from_pretrained(
143 | path_sdxl, subfolder="text_encoder_2", revision=None, torch_dtype=weight_dtype
144 | )
145 | vae = AutoencoderKL.from_pretrained(
146 | path_vae_sdxl, revision=None, torch_dtype=weight_dtype
147 | )
148 | unet = UNet2DConditionModel_v2.from_pretrained(
149 | path_sdxl, subfolder="unet", revision=None, torch_dtype=weight_dtype
150 | )
151 | print('successfully load SDXL')
152 |
153 | if is_xformers_available():
154 | import xformers
155 |
156 | xformers_version = version.parse(xformers.__version__)
157 | if xformers_version == version.parse("0.0.16"):
158 | logger.warn(
159 | "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
160 | )
161 | unet.enable_xformers_memory_efficient_attention()
162 | unet_sd1_5.enable_xformers_memory_efficient_attention()
163 | controlnet.enable_xformers_memory_efficient_attention()
164 |
165 | with torch.inference_mode():
166 | gen = Generator(device)
167 | gen.manual_seed(args.seed)
168 | pipe = StableDiffusionXLAdapterControlnetI2IPipeline(
169 | vae=vae,
170 | text_encoder=text_encoder_one,
171 | text_encoder_2=text_encoder_two,
172 | tokenizer=tokenizer_one,
173 | tokenizer_2=tokenizer_two,
174 | unet=unet,
175 | scheduler=noise_scheduler,
176 | vae_sd1_5=vae_sd1_5,
177 | text_encoder_sd1_5=text_encoder_sd1_5,
178 | tokenizer_sd1_5=tokenizer_sd1_5,
179 | unet_sd1_5=unet_sd1_5,
180 | scheduler_sd1_5=noise_scheduler_sd1_5,
181 | adapter=adapter,
182 | controlnet=controlnet
183 | )
184 | pipe.enable_model_cpu_offload()
185 |
186 | pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
187 | pipe.scheduler_sd1_5 = DPMSolverMultistepScheduler.from_config(pipe.scheduler_sd1_5.config)
188 | pipe.scheduler_sd1_5.config.timestep_spacing = "leading"
189 | pipe.unet.to(device=device, dtype=weight_dtype, memory_format=torch.channels_last)
190 |
191 |
192 | for i in range(args.iter_num):
193 | for controlnet_condition_scale in controlnet_condition_scale_list:
194 | for adapter_guidance_start in adapter_guidance_start_list:
195 | for adapter_condition_scale in adapter_condition_scale_list:
196 | img = \
197 | pipe(prompt=prompt, negative_prompt=negative_prompt, prompt_sd1_5=prompt_sd1_5,
198 | width=1024, height=1024, height_sd1_5=512, width_sd1_5=512,
199 | source_img=control_image, image=control_image,
200 | num_inference_steps=args.num_inference_steps, guidance_scale=args.guidance_scale,
201 | num_images_per_prompt=1, generator=gen,
202 | controlnet_conditioning_scale=controlnet_condition_scale,
203 | adapter_condition_scale=adapter_condition_scale,
204 | adapter_guidance_start=adapter_guidance_start).images[0]
205 | img.save(
206 | f"{args.save_path}/{prompt[:10]}_{i}_ccs_{controlnet_condition_scale:.2f}_ags_{adapter_guidance_start:.2f}_acs_{adapter_condition_scale:.2f}.png")
207 |
208 | print(f"results saved in {args.save_path}")
209 |
210 |
--------------------------------------------------------------------------------
/scripts/inference_controlnet.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import json
3 | import os
4 | import numpy as np
5 | import cv2
6 | import matplotlib
7 | from tqdm import tqdm
8 | from diffusers import DiffusionPipeline
9 | from diffusers import DPMSolverMultistepScheduler
10 | from diffusers.utils import load_image
11 | from torch import Generator
12 | from PIL import Image
13 | from packaging import version
14 |
15 | from transformers import CLIPTextModel, CLIPTokenizer, AutoTokenizer, PretrainedConfig
16 |
17 | import diffusers
18 | from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel, ControlNetModel, T2IAdapter
19 | from diffusers.optimization import get_scheduler
20 | from diffusers.training_utils import EMAModel
21 | from diffusers.utils import check_min_version, deprecate, is_wandb_available
22 | from diffusers.utils.import_utils import is_xformers_available
23 |
24 | from model.unet_adapter import UNet2DConditionModel
25 | from model.adapter import Adapter_XL
26 | from pipeline.pipeline_sd_xl_adapter_controlnet import StableDiffusionXLAdapterControlnetPipeline
27 | from controlnet_aux import MidasDetector, CannyDetector
28 |
29 | from scripts.utils import str2float
30 |
31 |
32 | def import_model_class_from_model_name_or_path(
33 | pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
34 | ):
35 | text_encoder_config = PretrainedConfig.from_pretrained(
36 | pretrained_model_name_or_path, subfolder=subfolder, revision=revision
37 | )
38 | model_class = text_encoder_config.architectures[0]
39 |
40 | if model_class == "CLIPTextModel":
41 | from transformers import CLIPTextModel
42 |
43 | return CLIPTextModel
44 | elif model_class == "CLIPTextModelWithProjection":
45 | from transformers import CLIPTextModelWithProjection
46 |
47 | return CLIPTextModelWithProjection
48 | else:
49 | raise ValueError(f"{model_class} is not supported.")
50 |
51 |
52 | def inference_controlnet(args):
53 | device = 'cuda'
54 | weight_dtype = torch.float16
55 |
56 | controlnet_condition_scale_list = str2float(args.controlnet_condition_scale_list)
57 | adapter_guidance_start_list = str2float(args.adapter_guidance_start_list)
58 | adapter_condition_scale_list = str2float(args.adapter_condition_scale_list)
59 |
60 | path = args.base_path
61 | path_sdxl = args.sdxl_path
62 | path_vae_sdxl = args.path_vae_sdxl
63 | adapter_path = args.adapter_checkpoint
64 |
65 | if args.condition_type == "canny":
66 | controlnet_path = args.controlnet_canny_path
67 | canny = CannyDetector()
68 | elif args.condition_type == "depth":
69 | controlnet_path = args.controlnet_depth_path # todo: haven't defined in args
70 | depth = MidasDetector.from_pretrained("lllyasviel/Annotators")
71 | else:
72 | raise NotImplementedError("not implemented yet")
73 |
74 | prompt = args.prompt
75 | if args.prompt_sd1_5 is None:
76 | prompt_sd1_5 = prompt
77 | else:
78 | prompt_sd1_5 = args.prompt_sd1_5
79 |
80 | if args.negative_prompt is None:
81 | negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
82 | else:
83 | negative_prompt = args.negative_prompt
84 |
85 | torch.set_grad_enabled(False)
86 | torch.backends.cudnn.benchmark = True
87 |
88 | # load controlnet
89 | controlnet = ControlNetModel.from_pretrained(
90 | controlnet_path, torch_dtype=weight_dtype
91 | )
92 | print('successfully load controlnet')
93 |
94 | input_image = Image.open(args.input_image_path)
95 | input_image = input_image.resize((512, 512), Image.LANCZOS)
96 | if args.condition_type == "canny":
97 | control_image = canny(input_image)
98 | control_image.save(f'{args.save_path}/{prompt[:10]}_canny_condition.png')
99 | elif args.condition_type == "depth":
100 | control_image = depth(input_image)
101 | control_image.save(f'{args.save_path}/{prompt[:10]}_depth_condition.png')
102 |
103 | # load adapter
104 | adapter = Adapter_XL()
105 | ckpt = torch.load(adapter_path)
106 | adapter.load_state_dict(ckpt)
107 | adapter.to(weight_dtype)
108 | print('successfully load adapter')
109 | # load SD1.5
110 | noise_scheduler_sd1_5 = DDPMScheduler.from_pretrained(
111 | path, subfolder="scheduler"
112 | )
113 | tokenizer_sd1_5 = CLIPTokenizer.from_pretrained(
114 | path, subfolder="tokenizer", revision=None, torch_dtype=weight_dtype
115 | )
116 | text_encoder_sd1_5 = CLIPTextModel.from_pretrained(
117 | path, subfolder="text_encoder", revision=None, torch_dtype=weight_dtype
118 | )
119 | vae_sd1_5 = AutoencoderKL.from_pretrained(
120 | path, subfolder="vae", revision=None, torch_dtype=weight_dtype
121 | )
122 | unet_sd1_5 = UNet2DConditionModel.from_pretrained(
123 | path, subfolder="unet", revision=None, torch_dtype=weight_dtype
124 | )
125 | print('successfully load SD1.5')
126 | # load SDXL
127 | tokenizer_one = AutoTokenizer.from_pretrained(
128 | path_sdxl, subfolder="tokenizer", revision=None, use_fast=False, torch_dtype=weight_dtype
129 | )
130 | tokenizer_two = AutoTokenizer.from_pretrained(
131 | path_sdxl, subfolder="tokenizer_2", revision=None, use_fast=False, torch_dtype=weight_dtype
132 | )
133 | # import correct text encoder classes
134 | text_encoder_cls_one = import_model_class_from_model_name_or_path(
135 | path_sdxl, None
136 | )
137 | text_encoder_cls_two = import_model_class_from_model_name_or_path(
138 | path_sdxl, None, subfolder="text_encoder_2"
139 | )
140 | # Load scheduler and models
141 | noise_scheduler = DDPMScheduler.from_pretrained(path_sdxl, subfolder="scheduler")
142 | text_encoder_one = text_encoder_cls_one.from_pretrained(
143 | path_sdxl, subfolder="text_encoder", revision=None, torch_dtype=weight_dtype
144 | )
145 | text_encoder_two = text_encoder_cls_two.from_pretrained(
146 | path_sdxl, subfolder="text_encoder_2", revision=None, torch_dtype=weight_dtype
147 | )
148 | vae = AutoencoderKL.from_pretrained(
149 | path_vae_sdxl, revision=None, torch_dtype=weight_dtype
150 | )
151 | unet = UNet2DConditionModel.from_pretrained(
152 | path_sdxl, subfolder="unet", revision=None, torch_dtype=weight_dtype
153 | )
154 | print('successfully load SDXL')
155 |
156 |
157 | if is_xformers_available():
158 | import xformers
159 |
160 | xformers_version = version.parse(xformers.__version__)
161 | if xformers_version == version.parse("0.0.16"):
162 | logger.warn(
163 | "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
164 | )
165 | unet.enable_xformers_memory_efficient_attention()
166 | unet_sd1_5.enable_xformers_memory_efficient_attention()
167 | controlnet.enable_xformers_memory_efficient_attention()
168 |
169 |
170 | with torch.inference_mode():
171 | gen = Generator("cuda")
172 | gen.manual_seed(args.seed)
173 | pipe = StableDiffusionXLAdapterControlnetPipeline(
174 | vae=vae,
175 | text_encoder=text_encoder_one,
176 | text_encoder_2=text_encoder_two,
177 | tokenizer=tokenizer_one,
178 | tokenizer_2=tokenizer_two,
179 | unet=unet,
180 | scheduler=noise_scheduler,
181 | vae_sd1_5=vae_sd1_5,
182 | text_encoder_sd1_5=text_encoder_sd1_5,
183 | tokenizer_sd1_5=tokenizer_sd1_5,
184 | unet_sd1_5=unet_sd1_5,
185 | scheduler_sd1_5=noise_scheduler_sd1_5,
186 | adapter=adapter,
187 | controlnet=controlnet
188 | )
189 |
190 | pipe.enable_model_cpu_offload()
191 |
192 | pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
193 | pipe.scheduler_sd1_5 = DPMSolverMultistepScheduler.from_config(pipe.scheduler_sd1_5.config)
194 | pipe.scheduler_sd1_5.config.timestep_spacing = "leading"
195 | pipe.unet.to(device=device, dtype=torch.float16, memory_format=torch.channels_last)
196 |
197 | for i in range(args.iter_num):
198 | for controlnet_condition_scale in controlnet_condition_scale_list:
199 | for adapter_guidance_start in adapter_guidance_start_list:
200 | for adapter_condition_scale in adapter_condition_scale_list:
201 | img = \
202 | pipe(prompt=prompt, negative_prompt=negative_prompt, prompt_sd1_5=prompt_sd1_5,
203 | width=1024, height=1024, height_sd1_5=512, width_sd1_5=512,
204 | image=control_image,
205 | num_inference_steps=args.num_inference_steps, guidance_scale=args.guidance_scale,
206 | num_images_per_prompt=1, generator=gen,
207 | controlnet_conditioning_scale=controlnet_condition_scale,
208 | adapter_condition_scale=adapter_condition_scale,
209 | adapter_guidance_start=adapter_guidance_start).images[0]
210 | img.save(
211 | f"{args.save_path}/{prompt[:10]}_{i}_ccs_{controlnet_condition_scale:.2f}_ags_{adapter_guidance_start:.2f}_acs_{adapter_condition_scale:.2f}.png")
212 |
213 | print(f"results saved in {args.save_path}")
214 |
--------------------------------------------------------------------------------
/scripts/inference_lora.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import json
3 | import os
4 | import numpy as np
5 | import cv2
6 | from tqdm import tqdm
7 | from diffusers import DiffusionPipeline
8 | from diffusers import DPMSolverMultistepScheduler
9 | from diffusers.utils import load_image
10 | from torch import Generator
11 | from safetensors.torch import load_file
12 | from PIL import Image
13 | from packaging import version
14 |
15 | from transformers import CLIPTextModel, CLIPTokenizer, AutoTokenizer, PretrainedConfig
16 |
17 | import diffusers
18 | from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel, ControlNetModel, \
19 | T2IAdapter
20 | from diffusers.optimization import get_scheduler
21 | from diffusers.training_utils import EMAModel
22 | from diffusers.utils import check_min_version, deprecate, is_wandb_available
23 | from diffusers.utils.import_utils import is_xformers_available
24 |
25 | from model.unet_adapter import UNet2DConditionModel
26 | from pipeline.pipeline_sd_xl_adapter import StableDiffusionXLAdapterPipeline
27 | from model.adapter import Adapter_XL
28 | from scripts.utils import str2float
29 |
30 |
31 | def import_model_class_from_model_name_or_path(
32 | pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
33 | ):
34 | text_encoder_config = PretrainedConfig.from_pretrained(
35 | pretrained_model_name_or_path, subfolder=subfolder, revision=revision
36 | )
37 | model_class = text_encoder_config.architectures[0]
38 |
39 | if model_class == "CLIPTextModel":
40 | from transformers import CLIPTextModel
41 |
42 | return CLIPTextModel
43 | elif model_class == "CLIPTextModelWithProjection":
44 | from transformers import CLIPTextModelWithProjection
45 |
46 | return CLIPTextModelWithProjection
47 | else:
48 | raise ValueError(f"{model_class} is not supported.")
49 |
50 |
51 | def load_lora(pipeline, lora_model_path, alpha):
52 | state_dict = load_file(lora_model_path)
53 |
54 | LORA_PREFIX_UNET = 'lora_unet'
55 | LORA_PREFIX_TEXT_ENCODER = 'lora_te'
56 |
57 | visited = []
58 |
59 | # directly update weight in diffusers model
60 | for key in state_dict:
61 |
62 | # it is suggested to print out the key, it usually will be something like below
63 | # "lora_te_text_model_encoder_layers_0_self_attn_k_proj.lora_down.weight"
64 |
65 | # as we have set the alpha beforehand, so just skip
66 | if '.alpha' in key or key in visited:
67 | continue
68 |
69 | if 'text' in key:
70 | layer_infos = key.split('.')[0].split(LORA_PREFIX_TEXT_ENCODER + '_')[-1].split('_')
71 | curr_layer = pipeline.text_encoder_sd1_5
72 | else:
73 | layer_infos = key.split('.')[0].split(LORA_PREFIX_UNET + '_')[-1].split('_')
74 | curr_layer = pipeline.unet_sd1_5
75 |
76 | # find the target layer
77 | temp_name = layer_infos.pop(0)
78 | while len(layer_infos) > -1:
79 | try:
80 | curr_layer = curr_layer.__getattr__(temp_name)
81 | if len(layer_infos) > 0:
82 | temp_name = layer_infos.pop(0)
83 | elif len(layer_infos) == 0:
84 | break
85 | except Exception:
86 | if len(temp_name) > 0:
87 | temp_name += '_' + layer_infos.pop(0)
88 | else:
89 | temp_name = layer_infos.pop(0)
90 |
91 | # org_forward(x) + lora_up(lora_down(x)) * multiplier
92 | pair_keys = []
93 | if 'lora_down' in key:
94 | pair_keys.append(key.replace('lora_down', 'lora_up'))
95 | pair_keys.append(key)
96 | else:
97 | pair_keys.append(key)
98 | pair_keys.append(key.replace('lora_up', 'lora_down'))
99 |
100 | # update weight
101 | if len(state_dict[pair_keys[0]].shape) == 4:
102 | weight_up = state_dict[pair_keys[0]].squeeze(3).squeeze(2).to(torch.float32)
103 | weight_down = state_dict[pair_keys[1]].squeeze(3).squeeze(2).to(torch.float32)
104 | curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down).unsqueeze(2).unsqueeze(3)
105 | else:
106 | weight_up = state_dict[pair_keys[0]].to(torch.float32)
107 | weight_down = state_dict[pair_keys[1]].to(torch.float32)
108 | curr_layer.weight.data += alpha * torch.mm(weight_up, weight_down)
109 |
110 | # update visited list
111 | for item in pair_keys:
112 | visited.append(item)
113 |
114 |
115 | def inference_lora(args):
116 | device = 'cuda'
117 | weight_dtype = torch.float16
118 |
119 | adapter_guidance_start_list = str2float(args.adapter_guidance_start_list)
120 | adapter_condition_scale_list = str2float(args.adapter_condition_scale_list)
121 |
122 | path = args.base_path
123 | path_sdxl = args.sdxl_path
124 | path_vae_sdxl = args.path_vae_sdxl
125 | adapter_path = args.adapter_checkpoint
126 | lora_model_path = args.lora_model_path
127 |
128 | prompt = args.prompt
129 | if args.prompt_sd1_5 is None:
130 | prompt_sd1_5 = prompt
131 | else:
132 | prompt_sd1_5 = args.prompt_sd1_5
133 |
134 | if args.negative_prompt is None:
135 | negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
136 | else:
137 | negative_prompt = args.negative_prompt
138 |
139 | torch.set_grad_enabled(False)
140 | torch.backends.cudnn.benchmark = True
141 |
142 | # load adapter
143 | adapter = Adapter_XL()
144 | ckpt = torch.load(adapter_path)
145 | adapter.load_state_dict(ckpt)
146 | print('successfully load adapter')
147 | # load SD1.5
148 | noise_scheduler_sd1_5 = DDPMScheduler.from_pretrained(
149 | path, subfolder="scheduler"
150 | )
151 | tokenizer_sd1_5 = CLIPTokenizer.from_pretrained(
152 | path, subfolder="tokenizer", revision=None
153 | )
154 | text_encoder_sd1_5 = CLIPTextModel.from_pretrained(
155 | path, subfolder="text_encoder", revision=None
156 | )
157 | vae_sd1_5 = AutoencoderKL.from_pretrained(
158 | path, subfolder="vae", revision=None
159 | )
160 | unet_sd1_5 = UNet2DConditionModel.from_pretrained(
161 | path, subfolder="unet", revision=None
162 | )
163 | print('successfully load SD1.5')
164 | # load SDXL
165 | tokenizer_one = AutoTokenizer.from_pretrained(
166 | path_sdxl, subfolder="tokenizer", revision=None, use_fast=False
167 | )
168 | tokenizer_two = AutoTokenizer.from_pretrained(
169 | path_sdxl, subfolder="tokenizer_2", revision=None, use_fast=False
170 | )
171 | # import correct text encoder classes
172 | text_encoder_cls_one = import_model_class_from_model_name_or_path(
173 | path_sdxl, None
174 | )
175 | text_encoder_cls_two = import_model_class_from_model_name_or_path(
176 | path_sdxl, None, subfolder="text_encoder_2"
177 | )
178 | # Load scheduler and models
179 | noise_scheduler = DDPMScheduler.from_pretrained(path_sdxl, subfolder="scheduler")
180 | text_encoder_one = text_encoder_cls_one.from_pretrained(
181 | path_sdxl, subfolder="text_encoder", revision=None
182 | )
183 | text_encoder_two = text_encoder_cls_two.from_pretrained(
184 | path_sdxl, subfolder="text_encoder_2", revision=None
185 | )
186 | vae = AutoencoderKL.from_pretrained(
187 | path_vae_sdxl, revision=None
188 | )
189 | unet = UNet2DConditionModel.from_pretrained(
190 | path_sdxl, subfolder="unet", revision=None
191 | )
192 | print('successfully load SDXL')
193 |
194 | if is_xformers_available():
195 | import xformers
196 |
197 | xformers_version = version.parse(xformers.__version__)
198 | if xformers_version == version.parse("0.0.16"):
199 | logger.warn(
200 | "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
201 | )
202 | unet.enable_xformers_memory_efficient_attention()
203 | unet_sd1_5.enable_xformers_memory_efficient_attention()
204 |
205 | with torch.inference_mode():
206 | gen = Generator("cuda")
207 | gen.manual_seed(args.seed)
208 |
209 | pipe = StableDiffusionXLAdapterPipeline(
210 | vae=vae,
211 | text_encoder=text_encoder_one,
212 | text_encoder_2=text_encoder_two,
213 | tokenizer=tokenizer_one,
214 | tokenizer_2=tokenizer_two,
215 | unet=unet,
216 | scheduler=noise_scheduler,
217 | vae_sd1_5=vae_sd1_5,
218 | text_encoder_sd1_5=text_encoder_sd1_5,
219 | tokenizer_sd1_5=tokenizer_sd1_5,
220 | unet_sd1_5=unet_sd1_5,
221 | scheduler_sd1_5=noise_scheduler_sd1_5,
222 | adapter=adapter,
223 | )
224 | # load lora
225 | load_lora(pipe, lora_model_path, 1)
226 | print('successfully load lora')
227 |
228 | pipe.to('cuda', weight_dtype)
229 | pipe.enable_model_cpu_offload()
230 | pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
231 | pipe.scheduler_sd1_5 = DPMSolverMultistepScheduler.from_config(pipe.scheduler_sd1_5.config)
232 | pipe.scheduler_sd1_5.config.timestep_spacing = "leading"
233 |
234 | for i in range(args.iter_num):
235 | for adapter_guidance_start in adapter_guidance_start_list:
236 | for adapter_condition_scale in adapter_condition_scale_list:
237 | img = \
238 | pipe(prompt=prompt, prompt_sd1_5=prompt_sd1_5, negative_prompt=negative_prompt, width=1024,
239 | height=1024, height_sd1_5=512, width_sd1_5=512,
240 | num_inference_steps=args.num_inference_steps, guidance_scale=args.guidance_scale,
241 | num_images_per_prompt=1, generator=gen,
242 | adapter_guidance_start=adapter_guidance_start,
243 | adapter_condition_scale=adapter_condition_scale).images[0]
244 | img.save(
245 | f"{args.save_path}/{prompt[:10]}_{i}_ags_{adapter_guidance_start:.2f}_acs_{adapter_condition_scale:.2f}.png")
246 | print(f"results saved in {args.save_path}")
247 |
248 |
249 |
250 |
251 |
252 |
253 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/model/adapter.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from collections import OrderedDict
4 | from diffusers.models.embeddings import (
5 | TimestepEmbedding,
6 | Timesteps,
7 | )
8 |
9 |
10 | def conv_nd(dims, *args, **kwargs):
11 | """
12 | Create a 1D, 2D, or 3D convolution module.
13 | """
14 | if dims == 1:
15 | return nn.Conv1d(*args, **kwargs)
16 | elif dims == 2:
17 | return nn.Conv2d(*args, **kwargs)
18 | elif dims == 3:
19 | return nn.Conv3d(*args, **kwargs)
20 | raise ValueError(f"unsupported dimensions: {dims}")
21 |
22 |
23 | def avg_pool_nd(dims, *args, **kwargs):
24 | """
25 | Create a 1D, 2D, or 3D average pooling module.
26 | """
27 | if dims == 1:
28 | return nn.AvgPool1d(*args, **kwargs)
29 | elif dims == 2:
30 | return nn.AvgPool2d(*args, **kwargs)
31 | elif dims == 3:
32 | return nn.AvgPool3d(*args, **kwargs)
33 | raise ValueError(f"unsupported dimensions: {dims}")
34 |
35 |
36 | def get_parameter_dtype(parameter: torch.nn.Module):
37 | try:
38 | params = tuple(parameter.parameters())
39 | if len(params) > 0:
40 | return params[0].dtype
41 |
42 | buffers = tuple(parameter.buffers())
43 | if len(buffers) > 0:
44 | return buffers[0].dtype
45 |
46 | except StopIteration:
47 | # For torch.nn.DataParallel compatibility in PyTorch 1.5
48 |
49 | def find_tensor_attributes(module: torch.nn.Module) -> List[Tuple[str, Tensor]]:
50 | tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
51 | return tuples
52 |
53 | gen = parameter._named_members(get_members_fn=find_tensor_attributes)
54 | first_tuple = next(gen)
55 | return first_tuple[1].dtype
56 |
57 |
58 | class Downsample(nn.Module):
59 | """
60 | A downsampling layer with an optional convolution.
61 | :param channels: channels in the inputs and outputs.
62 | :param use_conv: a bool determining if a convolution is applied.
63 | :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
64 | downsampling occurs in the inner-two dimensions.
65 | """
66 |
67 | def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
68 | super().__init__()
69 | self.channels = channels
70 | self.out_channels = out_channels or channels
71 | self.use_conv = use_conv
72 | self.dims = dims
73 | stride = 2 if dims != 3 else (1, 2, 2)
74 | if use_conv:
75 | self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=padding)
76 | else:
77 | assert self.channels == self.out_channels
78 | from torch.nn import MaxUnpool2d
79 | self.op = MaxUnpool2d(dims, kernel_size=stride, stride=stride)
80 |
81 | def forward(self, x):
82 | assert x.shape[1] == self.channels
83 | return self.op(x)
84 |
85 |
86 | class Upsample(nn.Module):
87 | def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
88 | super().__init__()
89 | self.channels = channels
90 | self.out_channels = out_channels or channels
91 | self.use_conv = use_conv
92 | self.dims = dims
93 | stride = 2 if dims != 3 else (1, 2, 2)
94 | if use_conv:
95 | self.op = nn.ConvTranspose2d(self.channels, self.out_channels, 3, stride=stride, padding=1)
96 | else:
97 | assert self.channels == self.out_channels
98 | self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
99 |
100 | def forward(self, x, output_size):
101 | assert x.shape[1] == self.channels
102 | return self.op(x, output_size)
103 |
104 |
105 | class Linear(nn.Module):
106 | def __init__(self, temb_channels, out_channels):
107 | super(Linear, self).__init__()
108 | self.linear = nn.Linear(temb_channels, out_channels)
109 |
110 | def forward(self, x):
111 | return self.linear(x)
112 |
113 |
114 |
115 | class ResnetBlock(nn.Module):
116 |
117 | def __init__(self, in_c, out_c, down, up, ksize=3, sk=False, use_conv=True, enable_timestep=False, temb_channels=None, use_norm=False):
118 | super().__init__()
119 | self.use_norm = use_norm
120 | self.enable_timestep = enable_timestep
121 | ps = ksize // 2
122 | if in_c != out_c or sk == False:
123 | self.in_conv = nn.Conv2d(in_c, out_c, ksize, 1, ps)
124 | else:
125 | self.in_conv = None
126 | self.block1 = nn.Conv2d(out_c, out_c, 3, 1, 1)
127 | self.act = nn.ReLU()
128 | if use_norm:
129 | self.norm1 = nn.GroupNorm(num_groups=32, num_channels=out_c, eps=1e-6, affine=True)
130 | self.block2 = nn.Conv2d(out_c, out_c, ksize, 1, ps)
131 | if sk == False:
132 | self.skep = nn.Conv2d(in_c, out_c, ksize, 1, ps)
133 | else:
134 | self.skep = None
135 |
136 | self.down = down
137 | self.up = up
138 | if self.down:
139 | self.down_opt = Downsample(in_c, use_conv=use_conv)
140 | if self.up:
141 | self.up_opt = Upsample(in_c, use_conv=use_conv)
142 | if enable_timestep:
143 | self.timestep_proj = Linear(temb_channels, out_c)
144 |
145 |
146 | def forward(self, x, output_size=None, temb=None):
147 | if self.down == True:
148 | x = self.down_opt(x)
149 | if self.up == True:
150 | x = self.up_opt(x, output_size)
151 | if self.in_conv is not None: # edit
152 | x = self.in_conv(x)
153 |
154 | h = self.block1(x)
155 | if temb is not None:
156 | temb = self.timestep_proj(temb)[:, :, None, None]
157 | h = h + temb
158 | if self.use_norm:
159 | h = self.norm1(h)
160 | h = self.act(h)
161 | h = self.block2(h)
162 | if self.skep is not None:
163 | return h + self.skep(x)
164 | else:
165 | return h + x
166 |
167 |
168 | class Adapter_XL(nn.Module):
169 |
170 | def __init__(self, in_channels=[1280, 640, 320], out_channels=[1280, 1280, 640], nums_rb=3, ksize=3, sk=True, use_conv=False, use_zero_conv=True,
171 | enable_timestep=False, use_norm=False, temb_channels=None, fusion_type='ADD'):
172 | super(Adapter_XL, self).__init__()
173 | self.channels = in_channels
174 | self.nums_rb = nums_rb
175 | self.body = []
176 | self.out = []
177 | self.use_zero_conv = use_zero_conv
178 | self.fusion_type = fusion_type
179 | self.gamma = []
180 | self.beta = []
181 | self.norm = []
182 | if fusion_type == "SPADE":
183 | self.use_zero_conv = False
184 | for i in range(len(self.channels)):
185 | if self.fusion_type == 'SPADE':
186 | # Corresponding to SPADE
187 | self.gamma.append(nn.Conv2d(out_channels[i], out_channels[i], 1, padding=0))
188 | self.beta.append(nn.Conv2d(out_channels[i], out_channels[i], 1, padding=0))
189 | self.norm.append(nn.BatchNorm2d(out_channels[i]))
190 | elif use_zero_conv:
191 | self.out.append(self.make_zero_conv(out_channels[i]))
192 | else:
193 | self.out.append(nn.Conv2d(out_channels[i], out_channels[i], 1, padding=0))
194 | for j in range(nums_rb):
195 | if i==0:
196 | # 1280, 32, 32 -> 1280, 32, 32
197 | self.body.append(
198 | ResnetBlock(in_channels[i], out_channels[i], down=False, up=False, ksize=ksize, sk=sk, use_conv=use_conv,
199 | enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
200 | # 1280, 32, 32 -> 1280, 32, 32
201 | elif i==1:
202 | # 640, 64, 64 -> 1280, 64, 64
203 | if j==0:
204 | self.body.append(
205 | ResnetBlock(in_channels[i], out_channels[i], down=False, up=False, ksize=ksize, sk=sk,
206 | use_conv=use_conv, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
207 | else:
208 | self.body.append(
209 | ResnetBlock(out_channels[i], out_channels[i], down=False, up=False, ksize=ksize,sk=sk,
210 | use_conv=use_conv, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
211 | else:
212 | # 320, 64, 64 -> 640, 128, 128
213 | if j==0:
214 | self.body.append(
215 | ResnetBlock(in_channels[i], out_channels[i], down=False, up=True, ksize=ksize, sk=sk,
216 | use_conv=True, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
217 | # use convtranspose2d
218 | else:
219 | self.body.append(
220 | ResnetBlock(out_channels[i], out_channels[i], down=False, up=False, ksize=ksize, sk=sk,
221 | use_conv=use_conv, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
222 |
223 |
224 | self.body = nn.ModuleList(self.body)
225 | if self.use_zero_conv:
226 | self.zero_out = nn.ModuleList(self.out)
227 |
228 | # if self.fusion_type == 'SPADE':
229 | # self.norm = nn.ModuleList(self.norm)
230 | # self.gamma = nn.ModuleList(self.gamma)
231 | # self.beta = nn.ModuleList(self.beta)
232 | # else:
233 | # self.zero_out = nn.ModuleList(self.out)
234 |
235 |
236 | # if enable_timestep:
237 | # a = 320
238 | #
239 | # time_embed_dim = a * 4
240 | # self.time_proj = Timesteps(a, True, 0)
241 | # timestep_input_dim = a
242 | #
243 | # self.time_embedding = TimestepEmbedding(
244 | # timestep_input_dim,
245 | # time_embed_dim,
246 | # act_fn='silu',
247 | # post_act_fn=None,
248 | # cond_proj_dim=None,
249 | # )
250 |
251 |
252 | def make_zero_conv(self, channels):
253 |
254 | return zero_module(nn.Conv2d(channels, channels, 1, padding=0))
255 |
256 | @property
257 | def dtype(self) -> torch.dtype:
258 | """
259 | `torch.dtype`: The dtype of the module (assuming that all the module parameters have the same dtype).
260 | """
261 | return get_parameter_dtype(self)
262 |
263 | def forward(self, x, t=None):
264 | # extract features
265 | features = []
266 | b, c, _, _ = x[-1].shape
267 | if t is not None:
268 | if not torch.is_tensor(t):
269 | # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
270 | # This would be a good case for the `match` statement (Python 3.10+)
271 | is_mps = x[0].device.type == "mps"
272 | if isinstance(timestep, float):
273 | dtype = torch.float32 if is_mps else torch.float64
274 | else:
275 | dtype = torch.int32 if is_mps else torch.int64
276 | t = torch.tensor([t], dtype=dtype, device=x[0].device)
277 | elif len(t.shape) == 0:
278 | t = t[None].to(x[0].device)
279 |
280 | t = t.expand(b)
281 | t = self.time_proj(t) # b, 320
282 | t = t.to(dtype=x[0].dtype)
283 | t = self.time_embedding(t) # b, 1280
284 | output_size = (b, 640, 128, 128) # last CA layer output
285 | for i in range(len(self.channels)):
286 | for j in range(self.nums_rb):
287 | idx = i * self.nums_rb + j
288 | if j == 0:
289 | if i < 2:
290 | out = self.body[idx](x[i], temb=t)
291 | else:
292 | out = self.body[idx](x[i], output_size=output_size, temb=t)
293 | else:
294 | out = self.body[idx](out, temb=t)
295 | if self.fusion_type == 'SPADE':
296 | out_gamma = self.gamma[i](out)
297 | out_beta = self.beta[i](out)
298 | out = [out_gamma, out_beta]
299 | else:
300 | out = self.zero_out[i](out)
301 | features.append(out)
302 |
303 | return features
304 |
305 |
306 | def zero_module(module):
307 | """
308 | Zero out the parameters of a module and return it.
309 | """
310 | for p in module.parameters():
311 | p.detach().zero_()
312 | return module
313 |
314 |
315 | if __name__=='__main__':
316 | adapter = Adapter_XL(use_zero_conv=True,
317 | enable_timestep=True, use_norm=True, temb_channels=1280, fusion_type='SPADE').cuda()
318 | x = [torch.randn(4, 1280, 32, 32).cuda(), torch.randn(4, 640, 64, 64).cuda(), torch.randn(4, 320, 64, 64).cuda()]
319 | t = torch.tensor([1,2,3,4]).cuda()
320 | result = adapter(x, t=t)
321 | for xx in result:
322 | print(xx[0].shape)
323 | print(xx[1].shape)
324 |
325 |
326 |
327 |
328 |
--------------------------------------------------------------------------------
/xadapter/model/adapter.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from collections import OrderedDict
4 | from diffusers.models.embeddings import (
5 | TimestepEmbedding,
6 | Timesteps,
7 | )
8 |
9 |
10 | def conv_nd(dims, *args, **kwargs):
11 | """
12 | Create a 1D, 2D, or 3D convolution module.
13 | """
14 | if dims == 1:
15 | return nn.Conv1d(*args, **kwargs)
16 | elif dims == 2:
17 | return nn.Conv2d(*args, **kwargs)
18 | elif dims == 3:
19 | return nn.Conv3d(*args, **kwargs)
20 | raise ValueError(f"unsupported dimensions: {dims}")
21 |
22 |
23 | def avg_pool_nd(dims, *args, **kwargs):
24 | """
25 | Create a 1D, 2D, or 3D average pooling module.
26 | """
27 | if dims == 1:
28 | return nn.AvgPool1d(*args, **kwargs)
29 | elif dims == 2:
30 | return nn.AvgPool2d(*args, **kwargs)
31 | elif dims == 3:
32 | return nn.AvgPool3d(*args, **kwargs)
33 | raise ValueError(f"unsupported dimensions: {dims}")
34 |
35 |
36 | def get_parameter_dtype(parameter: torch.nn.Module):
37 | try:
38 | params = tuple(parameter.parameters())
39 | if len(params) > 0:
40 | return params[0].dtype
41 |
42 | buffers = tuple(parameter.buffers())
43 | if len(buffers) > 0:
44 | return buffers[0].dtype
45 |
46 | except StopIteration:
47 | # For torch.nn.DataParallel compatibility in PyTorch 1.5
48 |
49 | def find_tensor_attributes(module: torch.nn.Module) -> List[Tuple[str, Tensor]]:
50 | tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
51 | return tuples
52 |
53 | gen = parameter._named_members(get_members_fn=find_tensor_attributes)
54 | first_tuple = next(gen)
55 | return first_tuple[1].dtype
56 |
57 |
58 | class Downsample(nn.Module):
59 | """
60 | A downsampling layer with an optional convolution.
61 | :param channels: channels in the inputs and outputs.
62 | :param use_conv: a bool determining if a convolution is applied.
63 | :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
64 | downsampling occurs in the inner-two dimensions.
65 | """
66 |
67 | def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
68 | super().__init__()
69 | self.channels = channels
70 | self.out_channels = out_channels or channels
71 | self.use_conv = use_conv
72 | self.dims = dims
73 | stride = 2 if dims != 3 else (1, 2, 2)
74 | if use_conv:
75 | self.op = conv_nd(dims, self.channels, self.out_channels, 3, stride=stride, padding=padding)
76 | else:
77 | assert self.channels == self.out_channels
78 | from torch.nn import MaxUnpool2d
79 | self.op = MaxUnpool2d(dims, kernel_size=stride, stride=stride)
80 |
81 | def forward(self, x):
82 | assert x.shape[1] == self.channels
83 | return self.op(x)
84 |
85 |
86 | class Upsample(nn.Module):
87 | def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
88 | super().__init__()
89 | self.channels = channels
90 | self.out_channels = out_channels or channels
91 | self.use_conv = use_conv
92 | self.dims = dims
93 | stride = 2 if dims != 3 else (1, 2, 2)
94 | if use_conv:
95 | self.op = nn.ConvTranspose2d(self.channels, self.out_channels, 3, stride=stride, padding=1)
96 | else:
97 | assert self.channels == self.out_channels
98 | self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
99 |
100 | def forward(self, x, output_size):
101 | assert x.shape[1] == self.channels
102 | return self.op(x, output_size)
103 |
104 |
105 | class Linear(nn.Module):
106 | def __init__(self, temb_channels, out_channels):
107 | super(Linear, self).__init__()
108 | self.linear = nn.Linear(temb_channels, out_channels)
109 |
110 | def forward(self, x):
111 | return self.linear(x)
112 |
113 |
114 |
115 | class ResnetBlock(nn.Module):
116 |
117 | def __init__(self, in_c, out_c, down, up, ksize=3, sk=False, use_conv=True, enable_timestep=False, temb_channels=None, use_norm=False):
118 | super().__init__()
119 | self.use_norm = use_norm
120 | self.enable_timestep = enable_timestep
121 | ps = ksize // 2
122 | if in_c != out_c or sk == False:
123 | self.in_conv = nn.Conv2d(in_c, out_c, ksize, 1, ps)
124 | else:
125 | self.in_conv = None
126 | self.block1 = nn.Conv2d(out_c, out_c, 3, 1, 1)
127 | self.act = nn.ReLU()
128 | if use_norm:
129 | self.norm1 = nn.GroupNorm(num_groups=32, num_channels=out_c, eps=1e-6, affine=True)
130 | self.block2 = nn.Conv2d(out_c, out_c, ksize, 1, ps)
131 | if sk == False:
132 | self.skep = nn.Conv2d(in_c, out_c, ksize, 1, ps)
133 | else:
134 | self.skep = None
135 |
136 | self.down = down
137 | self.up = up
138 | if self.down:
139 | self.down_opt = Downsample(in_c, use_conv=use_conv)
140 | if self.up:
141 | self.up_opt = Upsample(in_c, use_conv=use_conv)
142 | if enable_timestep:
143 | self.timestep_proj = Linear(temb_channels, out_c)
144 |
145 |
146 | def forward(self, x, output_size=None, temb=None):
147 | if self.down == True:
148 | x = self.down_opt(x)
149 | if self.up == True:
150 | x = self.up_opt(x, output_size)
151 | if self.in_conv is not None: # edit
152 | x = self.in_conv(x)
153 |
154 | h = self.block1(x)
155 | if temb is not None:
156 | temb = self.timestep_proj(temb)[:, :, None, None]
157 | h = h + temb
158 | if self.use_norm:
159 | h = self.norm1(h)
160 | h = self.act(h)
161 | h = self.block2(h)
162 | if self.skep is not None:
163 | return h + self.skep(x)
164 | else:
165 | return h + x
166 |
167 |
168 | class Adapter_XL(nn.Module):
169 |
170 | def __init__(self, in_channels=[1280, 640, 320], out_channels=[1280, 1280, 640], nums_rb=3, ksize=3, sk=True, use_conv=False, use_zero_conv=True,
171 | enable_timestep=False, use_norm=False, temb_channels=None, fusion_type='ADD'):
172 | super(Adapter_XL, self).__init__()
173 | self.channels = in_channels
174 | self.nums_rb = nums_rb
175 | self.body = []
176 | self.out = []
177 | self.use_zero_conv = use_zero_conv
178 | self.fusion_type = fusion_type
179 | self.gamma = []
180 | self.beta = []
181 | self.norm = []
182 | if fusion_type == "SPADE":
183 | self.use_zero_conv = False
184 | for i in range(len(self.channels)):
185 | if self.fusion_type == 'SPADE':
186 | # Corresponding to SPADE
187 | self.gamma.append(nn.Conv2d(out_channels[i], out_channels[i], 1, padding=0))
188 | self.beta.append(nn.Conv2d(out_channels[i], out_channels[i], 1, padding=0))
189 | self.norm.append(nn.BatchNorm2d(out_channels[i]))
190 | elif use_zero_conv:
191 | self.out.append(self.make_zero_conv(out_channels[i]))
192 | else:
193 | self.out.append(nn.Conv2d(out_channels[i], out_channels[i], 1, padding=0))
194 | for j in range(nums_rb):
195 | if i==0:
196 | # 1280, 32, 32 -> 1280, 32, 32
197 | self.body.append(
198 | ResnetBlock(in_channels[i], out_channels[i], down=False, up=False, ksize=ksize, sk=sk, use_conv=use_conv,
199 | enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
200 | # 1280, 32, 32 -> 1280, 32, 32
201 | elif i==1:
202 | # 640, 64, 64 -> 1280, 64, 64
203 | if j==0:
204 | self.body.append(
205 | ResnetBlock(in_channels[i], out_channels[i], down=False, up=False, ksize=ksize, sk=sk,
206 | use_conv=use_conv, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
207 | else:
208 | self.body.append(
209 | ResnetBlock(out_channels[i], out_channels[i], down=False, up=False, ksize=ksize,sk=sk,
210 | use_conv=use_conv, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
211 | else:
212 | # 320, 64, 64 -> 640, 128, 128
213 | if j==0:
214 | self.body.append(
215 | ResnetBlock(in_channels[i], out_channels[i], down=False, up=True, ksize=ksize, sk=sk,
216 | use_conv=True, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
217 | # use convtranspose2d
218 | else:
219 | self.body.append(
220 | ResnetBlock(out_channels[i], out_channels[i], down=False, up=False, ksize=ksize, sk=sk,
221 | use_conv=use_conv, enable_timestep=enable_timestep, temb_channels=temb_channels, use_norm=use_norm))
222 |
223 |
224 | self.body = nn.ModuleList(self.body)
225 | if self.use_zero_conv:
226 | self.zero_out = nn.ModuleList(self.out)
227 |
228 | # if self.fusion_type == 'SPADE':
229 | # self.norm = nn.ModuleList(self.norm)
230 | # self.gamma = nn.ModuleList(self.gamma)
231 | # self.beta = nn.ModuleList(self.beta)
232 | # else:
233 | # self.zero_out = nn.ModuleList(self.out)
234 |
235 |
236 | # if enable_timestep:
237 | # a = 320
238 | #
239 | # time_embed_dim = a * 4
240 | # self.time_proj = Timesteps(a, True, 0)
241 | # timestep_input_dim = a
242 | #
243 | # self.time_embedding = TimestepEmbedding(
244 | # timestep_input_dim,
245 | # time_embed_dim,
246 | # act_fn='silu',
247 | # post_act_fn=None,
248 | # cond_proj_dim=None,
249 | # )
250 |
251 |
252 | def make_zero_conv(self, channels):
253 |
254 | return zero_module(nn.Conv2d(channels, channels, 1, padding=0))
255 |
256 | @property
257 | def dtype(self) -> torch.dtype:
258 | """
259 | `torch.dtype`: The dtype of the module (assuming that all the module parameters have the same dtype).
260 | """
261 | return get_parameter_dtype(self)
262 |
263 | def forward(self, x, t=None):
264 | # extract features
265 | features = []
266 | b, c, _, _ = x[-1].shape
267 | if t is not None:
268 | if not torch.is_tensor(t):
269 | # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
270 | # This would be a good case for the `match` statement (Python 3.10+)
271 | is_mps = x[0].device.type == "mps"
272 | if isinstance(timestep, float):
273 | dtype = torch.float32 if is_mps else torch.float64
274 | else:
275 | dtype = torch.int32 if is_mps else torch.int64
276 | t = torch.tensor([t], dtype=dtype, device=x[0].device)
277 | elif len(t.shape) == 0:
278 | t = t[None].to(x[0].device)
279 |
280 | t = t.expand(b)
281 | t = self.time_proj(t) # b, 320
282 | t = t.to(dtype=x[0].dtype)
283 | t = self.time_embedding(t) # b, 1280
284 | #output_size = (b, 640, 128, 128) # last CA layer output
285 | output_size = (b, self.channels[-1], x[-1].shape[2] * 2, x[-1].shape[3] * 2)
286 | for i in range(len(self.channels)):
287 | for j in range(self.nums_rb):
288 | idx = i * self.nums_rb + j
289 | if j == 0:
290 | if i < 2:
291 | out = self.body[idx](x[i], temb=t)
292 | else:
293 | out = self.body[idx](x[i], output_size=output_size, temb=t)
294 | else:
295 | out = self.body[idx](out, temb=t)
296 | if self.fusion_type == 'SPADE':
297 | out_gamma = self.gamma[i](out)
298 | out_beta = self.beta[i](out)
299 | out = [out_gamma, out_beta]
300 | else:
301 | out = self.zero_out[i](out)
302 | features.append(out)
303 |
304 | return features
305 |
306 |
307 | def zero_module(module):
308 | """
309 | Zero out the parameters of a module and return it.
310 | """
311 | for p in module.parameters():
312 | p.detach().zero_()
313 | return module
314 |
315 |
316 | if __name__=='__main__':
317 | adapter = Adapter_XL(use_zero_conv=True,
318 | enable_timestep=True, use_norm=True, temb_channels=1280, fusion_type='SPADE').cuda()
319 | x = [torch.randn(4, 1280, 32, 32).cuda(), torch.randn(4, 640, 64, 64).cuda(), torch.randn(4, 320, 64, 64).cuda()]
320 | t = torch.tensor([1,2,3,4]).cuda()
321 | result = adapter(x, t=t)
322 | for xx in result:
323 | print(xx[0].shape)
324 | print(xx[1].shape)
325 |
326 |
327 |
328 |
329 |
--------------------------------------------------------------------------------
/nodes.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import os
3 | from diffusers import DPMSolverMultistepScheduler
4 | from torch import Generator
5 | from torchvision import transforms
6 |
7 | from transformers import CLIPTokenizer, PretrainedConfig
8 |
9 | from diffusers import AutoencoderKL, DDPMScheduler, PNDMScheduler, EulerDiscreteScheduler, ControlNetModel
10 |
11 | from .xadapter.model.unet_adapter import UNet2DConditionModel as UNet2DConditionModel_v2
12 | from .xadapter.model.adapter import Adapter_XL
13 | from .pipeline.pipeline_sd_xl_adapter_controlnet_img2img import StableDiffusionXLAdapterControlnetI2IPipeline
14 | from .pipeline.pipeline_sd_xl_adapter_controlnet import StableDiffusionXLAdapterControlnetPipeline
15 | from omegaconf import OmegaConf
16 |
17 | from .utils.single_file_utils import (create_scheduler_from_ldm, create_text_encoders_and_tokenizers_from_ldm, convert_ldm_vae_checkpoint,
18 | convert_ldm_unet_checkpoint, create_text_encoder_from_ldm_clip_checkpoint, create_vae_diffusers_config,
19 | create_diffusers_controlnet_model_from_ldm, create_unet_diffusers_config)
20 | from safetensors import safe_open
21 |
22 | import comfy.model_management
23 | import comfy.utils
24 | import folder_paths
25 | import math
26 |
27 | script_directory = os.path.dirname(os.path.abspath(__file__))
28 |
29 | class Diffusers_X_Adapter:
30 | def __init__(self):
31 | print("Initializing Diffusers_X_Adapter")
32 | self.device = comfy.model_management.get_torch_device()
33 | self.dtype = torch.float16 if comfy.model_management.should_use_fp16() and not comfy.model_management.is_device_mps(self.device) else torch.float32
34 | self.current_1_5_checkpoint = None
35 | self.current_lora = None
36 | self.current_controlnet_checkpoint = None
37 | self.original_config = OmegaConf.load(os.path.join(script_directory, f"configs/v1-inference.yaml"))
38 | self.sdxl_original_config = OmegaConf.load(os.path.join(script_directory, f"configs/sd_xl_base.yaml"))
39 | self.controlnet_original_config = OmegaConf.load(os.path.join(script_directory, f"configs/control_v11p_sd15.yaml"))
40 | @classmethod
41 | def IS_CHANGED(s):
42 | return ""
43 | @classmethod
44 | def INPUT_TYPES(cls):
45 |
46 | return {"required":
47 | {
48 | "width_sd1_5": ("INT", {"default": 512, "min": 64, "max": 4096, "step": 8}),
49 | "height_sd1_5": ("INT", {"default": 512, "min": 64, "max": 4096, "step": 8}),
50 | "batch_size": ("INT", {"default": 1, "min": 1, "max": 100, "step": 1}),
51 | "resolution_multiplier": ("INT", {"default": 2, "min": 2, "max": 2, "step": 1}),
52 |
53 | "sd_1_5_model": ("MODEL",),
54 | "sd_1_5_clip": ("CLIP", ),
55 | "sd_1_5_vae": ("VAE", ),
56 | "sdxl_model": ("MODEL",),
57 | "sdxl_clip": ("CLIP", ),
58 | "sdxl_vae": ("VAE", ),
59 |
60 | "positive": ("CONDITIONING", ),
61 | "negative": ("CONDITIONING", ),
62 | "positive_sd1_5": ("CONDITIONING", ),
63 | "negative_sd1_5": ("CONDITIONING", ),
64 |
65 | "controlnet_name": (folder_paths.get_filename_list("controlnet"), ),
66 | "guess_mode": ("BOOLEAN", {"default": False}),
67 | "control_guidance_start": ("FLOAT", {"default": 0.0, "min": 0.0, "max": 1.0, "step": 0.01}),
68 | "control_guidance_end": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 1.0, "step": 0.01}),
69 | "seed": ("INT", {"default": 123,"min": 0, "max": 0xffffffffffffffff, "step": 1}),
70 | "steps": ("INT", {"default": 20, "min": 1, "max": 4096, "step": 1}),
71 | "cfg": ("FLOAT", {"default": 8.0, "min": 0.1, "max": 100.0, "step": 0.1}),
72 | "controlnet_condition_scale": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 10.0, "step": 0.01}),
73 | "adapter_condition_scale": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 10.0, "step": 0.01}),
74 | "adapter_guidance_start": ("FLOAT", {"default": 0.7, "min": 0.0, "max": 10.0, "step": 0.01}),
75 | "use_xformers": ("BOOLEAN", {"default": False}),
76 | },
77 | "optional": {
78 | "controlnet_image" : ("IMAGE",),
79 | "latent_source_image" : ("IMAGE",),
80 | },
81 | }
82 | RETURN_TYPES = ("IMAGE",)
83 |
84 | FUNCTION = "load_checkpoint"
85 |
86 | CATEGORY = "Diffusers-X-Adapter"
87 |
88 | def load_checkpoint(self, use_xformers, sd_1_5_model, sd_1_5_vae, sdxl_model, sdxl_vae, positive, negative, positive_sd1_5, negative_sd1_5, sdxl_clip, sd_1_5_clip, resolution_multiplier,
89 | controlnet_name, seed, steps, cfg, width_sd1_5, height_sd1_5, batch_size, #width_sdxl, height_sdxl, lora_checkpoint, use_lora, prompt_sdxl, prompt_sd1_5, negative_prompt,
90 | adapter_condition_scale, adapter_guidance_start, controlnet_condition_scale, guess_mode, control_guidance_start, control_guidance_end, controlnet_image=None, latent_source_image=None):
91 |
92 |
93 | if latent_source_image is not None:
94 | latent_source_image = latent_source_image.permute(0, 3, 1, 2)
95 |
96 | #model_path_sd1_5 = folder_paths.get_full_path("checkpoints", sd_1_5_checkpoint)
97 | #lora_path = folder_paths.get_full_path("loras", lora_checkpoint)
98 | #model_path_sdxl = folder_paths.get_full_path("checkpoints", sdxl_checkpoint)
99 | controlnet_path = folder_paths.get_full_path("controlnet", controlnet_name)
100 |
101 | #if not use_lora:
102 | # self.current_lora = None
103 |
104 | #if not hasattr(self, 'unet_sd1_5')
105 | self.pipeline = None
106 | self.unet_sd1_5 = None
107 | # sd_1_5_clip.load_model()
108 | #comfy.model_management.soft_empty_cache()
109 | #print("Loading SD_1_5 checkpoint: ", sd_1_5_checkpoint)
110 | #self.current_1_5_checkpoint = sd_1_5_checkpoint
111 | #self.current_lora = lora_checkpoint
112 | #if model_path_sd1_5.endswith(".safetensors"):
113 | # state_dict_sd1_5 = {}
114 | # with safe_open(model_path_sd1_5, framework="pt", device="cpu") as f:
115 | # for key in f.keys():
116 | # state_dict_sd1_5[key] = f.get_tensor(key)
117 | #elif model_path_sd1_5.endswith(".ckpt"):
118 | # state_dict_sd1_5 = torch.load(model_path_sd1_5, map_location="cpu")
119 | # while "state_dict" in state_dict_sd1_5:
120 | # state_dict_sd1_5 = state_dict_sd1_5["state_dict"]
121 | print("patching model sd15...")
122 | # sd_1_5_model.patch_model()
123 | comfy.model_management.load_models_gpu([sd_1_5_model], memory_required=0, force_patch_weights=True)
124 | print("finsihed")
125 | print("constructing state dictionary sd15...")
126 | state_dict_sd1_5 = sd_1_5_model.model.state_dict_for_saving(sd_1_5_clip.get_sd(), sd_1_5_vae.get_sd(), None)
127 | #state_dict_sd1_5 = sd_1_5_model.model.state_dict
128 | print("finished")
129 |
130 | # 1. vae
131 | converted_vae_config = create_vae_diffusers_config(self.original_config, image_size=512)
132 | converted_vae = convert_ldm_vae_checkpoint(state_dict_sd1_5, converted_vae_config)
133 | self.vae_sd1_5 = AutoencoderKL(**converted_vae_config)
134 | self.vae_sd1_5.load_state_dict(converted_vae, strict=False)
135 | self.vae_sd1_5.to(self.dtype)
136 |
137 | # 2. unet
138 | converted_unet_config = create_unet_diffusers_config(self.original_config, image_size=512)
139 | converted_unet = convert_ldm_unet_checkpoint(state_dict_sd1_5, converted_unet_config)
140 | self.unet_sd1_5 = UNet2DConditionModel_v2(**converted_unet_config)
141 | self.unet_sd1_5.load_state_dict(converted_unet, strict=False)
142 | self.unet_sd1_5.to(self.dtype)
143 |
144 | # 3. text encoder and tokenizer
145 | converted_text_encoder_and_tokenizer = create_text_encoders_and_tokenizers_from_ldm(self.original_config, state_dict_sd1_5)
146 | self.tokenizer_sd1_5 = converted_text_encoder_and_tokenizer['tokenizer']
147 | self.text_encoder_sd1_5 = converted_text_encoder_and_tokenizer['text_encoder']
148 | self.text_encoder_sd1_5.to(self.dtype)
149 |
150 | # 4. scheduler
151 | self.scheduler_sd1_5 = create_scheduler_from_ldm("DPMSolverMultistepScheduler", self.original_config, state_dict_sd1_5, scheduler_type="ddim")['scheduler']
152 |
153 | del state_dict_sd1_5, converted_unet, converted_vae
154 |
155 | #if not self.current_lora != lora_checkpoint:
156 | # 5. lora
157 | # if use_lora:
158 | # print("Loading LoRA: ", lora_checkpoint)
159 | # self.lora_checkpoint1 = lora_checkpoint
160 | # if lora_path.endswith(".safetensors"):
161 | # state_dict_lora = {}
162 | # with safe_open(lora_path, framework="pt", device="cpu") as f:
163 | # for key in f.keys():
164 | # state_dict_lora[key] = f.get_tensor(key)
165 | # elif lora_path.endswith(".ckpt"):
166 | # state_dict_lora = torch.load(lora_path, map_location="cpu")
167 | # while "state_dict" in state_dict_lora:
168 | # state_dict_lora = state_dict_lora["state_dict"]
169 |
170 | # load controlnet
171 | if controlnet_image is not None:
172 | if not hasattr(self, 'controlnet') or self.current_controlnet_checkpoint != controlnet_name:
173 | self.pipeline = None
174 | print("Loading controlnet: ", controlnet_name)
175 | self.current_controlnet_checkpoint = controlnet_name
176 |
177 | if controlnet_path.endswith(".safetensors"):
178 | state_dict_controlnet = {}
179 | with safe_open(controlnet_path, framework="pt", device="cpu") as f:
180 | for key in f.keys():
181 | state_dict_controlnet[key] = f.get_tensor(key)
182 | else:
183 | state_dict_controlnet = torch.load(controlnet_path, map_location="cpu")
184 | while "state_dict" in state_dict_controlnet:
185 | state_dict_controlnet = state_dict_controlnet["state_dict"]
186 | self.controlnet = create_diffusers_controlnet_model_from_ldm("ControlNet", self.controlnet_original_config, state_dict_controlnet)['controlnet']
187 | self.controlnet.to(self.dtype)
188 |
189 | del state_dict_controlnet
190 | else:
191 | self.controlnet = None
192 | self.current_controlnet_checkpoint = None
193 |
194 | # load Adapter_XL
195 | if not hasattr(self, 'adapter'):
196 | adapter_checkpoint_path = os.path.join(script_directory, "checkpoints","X-Adapter")
197 | if not os.path.exists(adapter_checkpoint_path):
198 | try:
199 | from huggingface_hub import snapshot_download
200 | snapshot_download(repo_id="Lingmin-Ran/X-Adapter", local_dir=adapter_checkpoint_path, local_dir_use_symlinks=False)
201 | except:
202 | raise FileNotFoundError(f"No checkpoint directory found at {adapter_checkpoint_path}")
203 | adapter_ckpt = torch.load(os.path.join(adapter_checkpoint_path, "X_Adapter_v1.bin"))
204 | adapter = Adapter_XL()
205 | adapter.load_state_dict(adapter_ckpt)
206 | adapter.to(self.dtype)
207 |
208 | # load SDXL
209 | # sdxl_clip.load_model()
210 | print("patching model sdxl...")
211 | # sdxl_model.patch_model()
212 | comfy.model_management.load_models_gpu([sdxl_model], memory_required=0, force_patch_weights=True)
213 | print("finished")
214 | print("constructing state dictionary sdxl...")
215 | state_dict_sdxl = sdxl_model.model.state_dict_for_saving(sdxl_clip.get_sd(), sdxl_vae.get_sd(), None)
216 | #state_dict_sdxl = sdxl_model.model.state_dict
217 | print("finished")
218 |
219 | #if not hasattr(self, 'unet_sdxl') or self.current_sdxl_checkpoint != sdxl_checkpoint:
220 | # self.pipeline = None
221 | # comfy.model_management.soft_empty_cache()
222 | # print("Loading SDXL checkpoint: ", sdxl_checkpoint)
223 | # self.current_sdxl_checkpoint = sdxl_checkpoint
224 | # if model_path_sdxl.endswith(".safetensors"):
225 | # state_dict_sdxl = {}
226 | # with safe_open(model_path_sdxl, framework="pt", device="cpu") as f:
227 | # for key in f.keys():
228 | # state_dict_sdxl[key] = f.get_tensor(key)
229 | # elif model_path_sdxl.endswith(".ckpt"):
230 | # state_dict_sdxl = torch.load(model_path_sdxl, map_location="cpu")
231 | # while "state_dict" in state_dict_sdxl:
232 | # state_dict_sdxl = state_dict_sdxl["state_dict"]
233 |
234 | # 1. vae
235 | converted_vae_config = create_vae_diffusers_config(self.sdxl_original_config, image_size=1024)
236 | converted_vae = convert_ldm_vae_checkpoint(state_dict_sdxl, converted_vae_config)
237 | self.vae_sdxl = AutoencoderKL(**converted_vae_config)
238 | self.vae_sdxl.load_state_dict(converted_vae, strict=False)
239 | self.vae_sdxl.to(self.dtype)
240 |
241 | # 2. unet
242 | converted_unet_config = create_unet_diffusers_config(self.sdxl_original_config, image_size=1024)
243 | converted_unet = convert_ldm_unet_checkpoint(state_dict_sdxl, converted_unet_config)
244 | self.unet_sdxl = UNet2DConditionModel_v2(**converted_unet_config)
245 | self.unet_sdxl.load_state_dict(converted_unet, strict=False)
246 | self.unet_sdxl.to(self.dtype)
247 | #cross_attn_dim = converted_unet_config["cross_attention_dim"]
248 | #print(f"context_dim: {cross_attn_dim}")
249 |
250 | # 3. text encoders and tokenizers
251 | converted_sdxl_stuff = create_text_encoders_and_tokenizers_from_ldm(self.sdxl_original_config, state_dict_sdxl)
252 | self.tokenizer_one = converted_sdxl_stuff['tokenizer']
253 | self.sdxl_text_encoder = converted_sdxl_stuff['text_encoder']
254 | self.tokenizer_two = converted_sdxl_stuff['tokenizer_2']
255 | self.sdxl_text_encoder2 = converted_sdxl_stuff['text_encoder_2']
256 | self.sdxl_text_encoder.to(self.dtype)
257 | self.sdxl_text_encoder2.to(self.dtype)
258 |
259 | # 4. scheduler
260 | self.scheduler_sdxl = create_scheduler_from_ldm("DPMSolverMultistepScheduler", self.sdxl_original_config, state_dict_sdxl, scheduler_type="ddim",)['scheduler']
261 |
262 | del state_dict_sdxl, converted_unet, converted_vae
263 |
264 | #xformers
265 | if use_xformers:
266 | self.unet_sd1_5.enable_xformers_memory_efficient_attention()
267 | self.unet_sdxl.enable_xformers_memory_efficient_attention()
268 | if self.controlnet is not None:
269 | self.controlnet.enable_xformers_memory_efficient_attention()
270 | else:
271 | self.unet_sd1_5.disable_xformers_memory_efficient_attention()
272 | self.unet_sdxl.disable_xformers_memory_efficient_attention()
273 | if self.controlnet is not None:
274 | self.controlnet.disable_xformers_memory_efficient_attention()
275 |
276 |
277 | self.pipeline = StableDiffusionXLAdapterControlnetPipeline(
278 | vae=self.vae_sdxl,
279 | text_encoder=self.sdxl_text_encoder,
280 | text_encoder_2=self.sdxl_text_encoder2,
281 | tokenizer=self.tokenizer_one,
282 | tokenizer_2=self.tokenizer_two,
283 | unet=self.unet_sdxl,
284 | scheduler=self.scheduler_sdxl,
285 | vae_sd1_5=self.vae_sd1_5,
286 | text_encoder_sd1_5=self.text_encoder_sd1_5,
287 | tokenizer_sd1_5=self.tokenizer_sd1_5,
288 | unet_sd1_5=self.unet_sd1_5,
289 | scheduler_sd1_5=self.scheduler_sd1_5,
290 | adapter=adapter,
291 | controlnet=self.controlnet)
292 |
293 | self.pipeline.enable_model_cpu_offload()
294 |
295 | self.pipeline.scheduler_sd1_5.config.timestep_spacing = "leading"
296 | #self.pipeline.scheduler.config.timestep_spacing = "trailing"
297 | self.pipeline.unet.to(device=self.device, dtype=self.dtype)
298 |
299 | if controlnet_image is not None:
300 | control_image = controlnet_image.permute(0, 3, 1, 2)
301 | else:
302 | control_image = None
303 |
304 | width_sdxl = resolution_multiplier * width_sd1_5
305 | height_sdxl = resolution_multiplier * height_sd1_5
306 |
307 | #get prompt embeddings from conditioning
308 | positive_embed = positive[0][0]
309 | negative_embed = negative[0][0]
310 | crossattn_max_len = math.lcm(positive_embed.shape[1], negative_embed.shape[1])
311 | positive_embed = positive_embed.repeat(1, crossattn_max_len // positive_embed.shape[1], 1)
312 | negative_embed = negative_embed.repeat(1, crossattn_max_len // negative_embed.shape[1], 1)
313 |
314 | positive_embed_sd1_5 = positive_sd1_5[0][0]
315 | negative_embed_sd1_5 = negative_sd1_5[0][0]
316 | crossattn_max_len = math.lcm(positive_embed_sd1_5.shape[1], negative_embed_sd1_5.shape[1])
317 | positive_embed_sd1_5 = positive_embed_sd1_5.repeat(1, crossattn_max_len // positive_embed_sd1_5.shape[1], 1)
318 | negative_embed_sd1_5 = negative_embed_sd1_5.repeat(1, crossattn_max_len // negative_embed_sd1_5.shape[1], 1)
319 |
320 | positive_pooled_out = positive[0][1]["pooled_output"]
321 | negative_pooled_out = positive[0][1]["pooled_output"]
322 |
323 | #run inference
324 | gen = Generator(self.device)
325 | gen.manual_seed(seed)
326 |
327 | img = \
328 | self.pipeline(prompt=None, negative_prompt=None, prompt_sd1_5=None,
329 | prompt_embeds=positive_embed, negative_prompt_embeds=negative_embed, prompt_embeds_sd_1_5=positive_embed_sd1_5, negative_prompt_embeds_sd_1_5=negative_embed_sd1_5, pooled_prompt_embeds=positive_pooled_out, negative_pooled_prompt_embeds=negative_pooled_out,
330 | width=width_sdxl, height=height_sdxl, height_sd1_5=height_sd1_5, width_sd1_5=width_sd1_5,
331 | image=control_image,
332 | num_inference_steps=steps, guidance_scale=cfg,
333 | num_images_per_prompt=batch_size, generator=gen,
334 | controlnet_conditioning_scale=controlnet_condition_scale,
335 | adapter_condition_scale=adapter_condition_scale,
336 | adapter_guidance_start=adapter_guidance_start, guess_mode=guess_mode, control_guidance_start=control_guidance_start,
337 | control_guidance_end=control_guidance_end, source_img=latent_source_image).images
338 |
339 | image_tensor = (img - img.min()) / (img.max() - img.min())
340 | if image_tensor.dim() == 3:
341 | image_tensor = image_tensor.unsqueeze(0)
342 | image_tensor = image_tensor.permute(0, 2, 3, 1)
343 |
344 | return (image_tensor,)
345 |
346 | NODE_CLASS_MAPPINGS = {
347 | "Diffusers_X_Adapter": Diffusers_X_Adapter,
348 | }
349 | NODE_DISPLAY_NAME_MAPPINGS = {
350 | "Diffusers_X_Adapter": "Diffusers_X_Adapter",
351 | }
--------------------------------------------------------------------------------
/xadapter/model/unet_adapter.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 The HuggingFace Team. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | from dataclasses import dataclass
15 | from typing import Any, Dict, List, Optional, Tuple, Union
16 |
17 | import torch
18 | import torch.nn as nn
19 | import torch.utils.checkpoint
20 |
21 | from diffusers.configuration_utils import ConfigMixin, register_to_config
22 | from diffusers.loaders import UNet2DConditionLoadersMixin
23 | from diffusers.utils import BaseOutput, logging
24 | from diffusers.models.activations import get_activation
25 | from diffusers.models.attention_processor import AttentionProcessor, AttnProcessor
26 | from diffusers.models.embeddings import (
27 | GaussianFourierProjection,
28 | ImageHintTimeEmbedding,
29 | ImageProjection,
30 | ImageTimeEmbedding,
31 | #PositionNet,
32 | TextImageProjection,
33 | TextImageTimeEmbedding,
34 | TextTimeEmbedding,
35 | TimestepEmbedding,
36 | Timesteps,
37 | )
38 | from diffusers.models.modeling_utils import ModelMixin
39 | from diffusers.models.unets.unet_2d_blocks import get_down_block, get_up_block, UNetMidBlock2DCrossAttn, UNetMidBlock2DSimpleCrossAttn
40 |
41 | logger = logging.get_logger(__name__) # pylint: disable=invalid-name
42 |
43 |
44 | @dataclass
45 | class UNet2DConditionOutput(BaseOutput):
46 | """
47 | The output of [`UNet2DConditionModel`].
48 |
49 | Args:
50 | sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
51 | The hidden states output conditioned on `encoder_hidden_states` input. Output of last layer of model.
52 | """
53 |
54 | sample: torch.FloatTensor = None
55 | hidden_states: Optional[list] = None
56 | encoder_feature: Optional[list] = None
57 |
58 |
59 | class UNet2DConditionModel(ModelMixin, ConfigMixin, UNet2DConditionLoadersMixin):
60 | r"""
61 | A conditional 2D UNet model that takes a noisy sample, conditional state, and a timestep and returns a sample
62 | shaped output.
63 |
64 | This model inherits from [`ModelMixin`]. Check the superclass documentation for it's generic methods implemented
65 | for all models (such as downloading or saving).
66 |
67 | Parameters:
68 | sample_size (`int` or `Tuple[int, int]`, *optional*, defaults to `None`):
69 | Height and width of input/output sample.
70 | in_channels (`int`, *optional*, defaults to 4): Number of channels in the input sample.
71 | out_channels (`int`, *optional*, defaults to 4): Number of channels in the output.
72 | center_input_sample (`bool`, *optional*, defaults to `False`): Whether to center the input sample.
73 | flip_sin_to_cos (`bool`, *optional*, defaults to `False`):
74 | Whether to flip the sin to cos in the time embedding.
75 | freq_shift (`int`, *optional*, defaults to 0): The frequency shift to apply to the time embedding.
76 | down_block_types (`Tuple[str]`, *optional*, defaults to `("CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D")`):
77 | The tuple of downsample blocks to use.
78 | mid_block_type (`str`, *optional*, defaults to `"UNetMidBlock2DCrossAttn"`):
79 | Block type for middle of UNet, it can be either `UNetMidBlock2DCrossAttn` or
80 | `UNetMidBlock2DSimpleCrossAttn`. If `None`, the mid block layer is skipped.
81 | up_block_types (`Tuple[str]`, *optional*, defaults to `("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D")`):
82 | The tuple of upsample blocks to use.
83 | only_cross_attention(`bool` or `Tuple[bool]`, *optional*, default to `False`):
84 | Whether to include self-attention in the basic transformer blocks, see
85 | [`~models.attention.BasicTransformerBlock`].
86 | block_out_channels (`Tuple[int]`, *optional*, defaults to `(320, 640, 1280, 1280)`):
87 | The tuple of output channels for each block.
88 | layers_per_block (`int`, *optional*, defaults to 2): The number of layers per block.
89 | downsample_padding (`int`, *optional*, defaults to 1): The padding to use for the downsampling convolution.
90 | mid_block_scale_factor (`float`, *optional*, defaults to 1.0): The scale factor to use for the mid block.
91 | act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
92 | norm_num_groups (`int`, *optional*, defaults to 32): The number of groups to use for the normalization.
93 | If `None`, normalization and activation layers is skipped in post-processing.
94 | norm_eps (`float`, *optional*, defaults to 1e-5): The epsilon to use for the normalization.
95 | cross_attention_dim (`int` or `Tuple[int]`, *optional*, defaults to 1280):
96 | The dimension of the cross attention features.
97 | transformer_layers_per_block (`int` or `Tuple[int]`, *optional*, defaults to 1):
98 | The number of transformer blocks of type [`~models.attention.BasicTransformerBlock`]. Only relevant for
99 | [`~models.unet_2d_blocks.CrossAttnDownBlock2D`], [`~models.unet_2d_blocks.CrossAttnUpBlock2D`],
100 | [`~models.unet_2d_blocks.UNetMidBlock2DCrossAttn`].
101 | encoder_hid_dim (`int`, *optional*, defaults to None):
102 | If `encoder_hid_dim_type` is defined, `encoder_hidden_states` will be projected from `encoder_hid_dim`
103 | dimension to `cross_attention_dim`.
104 | encoder_hid_dim_type (`str`, *optional*, defaults to `None`):
105 | If given, the `encoder_hidden_states` and potentially other embeddings are down-projected to text
106 | embeddings of dimension `cross_attention` according to `encoder_hid_dim_type`.
107 | attention_head_dim (`int`, *optional*, defaults to 8): The dimension of the attention heads.
108 | num_attention_heads (`int`, *optional*):
109 | The number of attention heads. If not defined, defaults to `attention_head_dim`
110 | resnet_time_scale_shift (`str`, *optional*, defaults to `"default"`): Time scale shift config
111 | for ResNet blocks (see [`~models.resnet.ResnetBlock2D`]). Choose from `default` or `scale_shift`.
112 | class_embed_type (`str`, *optional*, defaults to `None`):
113 | The type of class embedding to use which is ultimately summed with the time embeddings. Choose from `None`,
114 | `"timestep"`, `"identity"`, `"projection"`, or `"simple_projection"`.
115 | addition_embed_type (`str`, *optional*, defaults to `None`):
116 | Configures an optional embedding which will be summed with the time embeddings. Choose from `None` or
117 | "text". "text" will use the `TextTimeEmbedding` layer.
118 | addition_time_embed_dim: (`int`, *optional*, defaults to `None`):
119 | Dimension for the timestep embeddings.
120 | num_class_embeds (`int`, *optional*, defaults to `None`):
121 | Input dimension of the learnable embedding matrix to be projected to `time_embed_dim`, when performing
122 | class conditioning with `class_embed_type` equal to `None`.
123 | time_embedding_type (`str`, *optional*, defaults to `positional`):
124 | The type of position embedding to use for timesteps. Choose from `positional` or `fourier`.
125 | time_embedding_dim (`int`, *optional*, defaults to `None`):
126 | An optional override for the dimension of the projected time embedding.
127 | time_embedding_act_fn (`str`, *optional*, defaults to `None`):
128 | Optional activation function to use only once on the time embeddings before they are passed to the rest of
129 | the UNet. Choose from `silu`, `mish`, `gelu`, and `swish`.
130 | timestep_post_act (`str`, *optional*, defaults to `None`):
131 | The second activation function to use in timestep embedding. Choose from `silu`, `mish` and `gelu`.
132 | time_cond_proj_dim (`int`, *optional*, defaults to `None`):
133 | The dimension of `cond_proj` layer in the timestep embedding.
134 | conv_in_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_in` layer.
135 | conv_out_kernel (`int`, *optional*, default to `3`): The kernel size of `conv_out` layer.
136 | projection_class_embeddings_input_dim (`int`, *optional*): The dimension of the `class_labels` input when
137 | `class_embed_type="projection"`. Required when `class_embed_type="projection"`.
138 | class_embeddings_concat (`bool`, *optional*, defaults to `False`): Whether to concatenate the time
139 | embeddings with the class embeddings.
140 | mid_block_only_cross_attention (`bool`, *optional*, defaults to `None`):
141 | Whether to use cross attention with the mid block when using the `UNetMidBlock2DSimpleCrossAttn`. If
142 | `only_cross_attention` is given as a single boolean and `mid_block_only_cross_attention` is `None`, the
143 | `only_cross_attention` value is used as the value for `mid_block_only_cross_attention`. Default to `False`
144 | otherwise.
145 | """
146 |
147 | _supports_gradient_checkpointing = True
148 |
149 | @register_to_config
150 | def __init__(
151 | self,
152 | sample_size: Optional[int] = None,
153 | in_channels: int = 4,
154 | out_channels: int = 4,
155 | center_input_sample: bool = False,
156 | flip_sin_to_cos: bool = True,
157 | freq_shift: int = 0,
158 | down_block_types: Tuple[str] = (
159 | "CrossAttnDownBlock2D",
160 | "CrossAttnDownBlock2D",
161 | "CrossAttnDownBlock2D",
162 | "DownBlock2D",
163 | ),
164 | mid_block_type: Optional[str] = "UNetMidBlock2DCrossAttn",
165 | up_block_types: Tuple[str] = ("UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"),
166 | only_cross_attention: Union[bool, Tuple[bool]] = False,
167 | block_out_channels: Tuple[int] = (320, 640, 1280, 1280),
168 | layers_per_block: Union[int, Tuple[int]] = 2,
169 | downsample_padding: int = 1,
170 | mid_block_scale_factor: float = 1,
171 | act_fn: str = "silu",
172 | norm_num_groups: Optional[int] = 32,
173 | norm_eps: float = 1e-5,
174 | cross_attention_dim: Union[int, Tuple[int]] = 1280,
175 | transformer_layers_per_block: Union[int, Tuple[int]] = 1,
176 | encoder_hid_dim: Optional[int] = None,
177 | encoder_hid_dim_type: Optional[str] = None,
178 | attention_head_dim: Union[int, Tuple[int]] = 8,
179 | num_attention_heads: Optional[Union[int, Tuple[int]]] = None,
180 | dual_cross_attention: bool = False,
181 | use_linear_projection: bool = False,
182 | class_embed_type: Optional[str] = None,
183 | addition_embed_type: Optional[str] = None,
184 | addition_time_embed_dim: Optional[int] = None,
185 | num_class_embeds: Optional[int] = None,
186 | upcast_attention: bool = False,
187 | resnet_time_scale_shift: str = "default",
188 | resnet_skip_time_act: bool = False,
189 | resnet_out_scale_factor: int = 1.0,
190 | time_embedding_type: str = "positional",
191 | time_embedding_dim: Optional[int] = None,
192 | time_embedding_act_fn: Optional[str] = None,
193 | timestep_post_act: Optional[str] = None,
194 | time_cond_proj_dim: Optional[int] = None,
195 | conv_in_kernel: int = 3,
196 | conv_out_kernel: int = 3,
197 | projection_class_embeddings_input_dim: Optional[int] = None,
198 | attention_type: str = "default",
199 | class_embeddings_concat: bool = False,
200 | mid_block_only_cross_attention: Optional[bool] = None,
201 | cross_attention_norm: Optional[str] = None,
202 | addition_embed_type_num_heads=64,
203 | ):
204 | super().__init__()
205 |
206 | self.sample_size = sample_size
207 |
208 | if num_attention_heads is not None:
209 | raise ValueError(
210 | "At the moment it is not possible to define the number of attention heads via `num_attention_heads` because of a naming issue as described in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131. Passing `num_attention_heads` will only be supported in diffusers v0.19."
211 | )
212 |
213 | # If `num_attention_heads` is not defined (which is the case for most models)
214 | # it will default to `attention_head_dim`. This looks weird upon first reading it and it is.
215 | # The reason for this behavior is to correct for incorrectly named variables that were introduced
216 | # when this library was created. The incorrect naming was only discovered much later in https://github.com/huggingface/diffusers/issues/2011#issuecomment-1547958131
217 | # Changing `attention_head_dim` to `num_attention_heads` for 40,000+ configurations is too backwards breaking
218 | # which is why we correct for the naming here.
219 | num_attention_heads = num_attention_heads or attention_head_dim
220 |
221 | # Check inputs
222 | if len(down_block_types) != len(up_block_types):
223 | raise ValueError(
224 | f"Must provide the same number of `down_block_types` as `up_block_types`. `down_block_types`: {down_block_types}. `up_block_types`: {up_block_types}."
225 | )
226 |
227 | if len(block_out_channels) != len(down_block_types):
228 | raise ValueError(
229 | f"Must provide the same number of `block_out_channels` as `down_block_types`. `block_out_channels`: {block_out_channels}. `down_block_types`: {down_block_types}."
230 | )
231 |
232 | if not isinstance(only_cross_attention, bool) and len(only_cross_attention) != len(down_block_types):
233 | raise ValueError(
234 | f"Must provide the same number of `only_cross_attention` as `down_block_types`. `only_cross_attention`: {only_cross_attention}. `down_block_types`: {down_block_types}."
235 | )
236 |
237 | if not isinstance(num_attention_heads, int) and len(num_attention_heads) != len(down_block_types):
238 | raise ValueError(
239 | f"Must provide the same number of `num_attention_heads` as `down_block_types`. `num_attention_heads`: {num_attention_heads}. `down_block_types`: {down_block_types}."
240 | )
241 |
242 | if not isinstance(attention_head_dim, int) and len(attention_head_dim) != len(down_block_types):
243 | raise ValueError(
244 | f"Must provide the same number of `attention_head_dim` as `down_block_types`. `attention_head_dim`: {attention_head_dim}. `down_block_types`: {down_block_types}."
245 | )
246 |
247 | if isinstance(cross_attention_dim, list) and len(cross_attention_dim) != len(down_block_types):
248 | raise ValueError(
249 | f"Must provide the same number of `cross_attention_dim` as `down_block_types`. `cross_attention_dim`: {cross_attention_dim}. `down_block_types`: {down_block_types}."
250 | )
251 |
252 | if not isinstance(layers_per_block, int) and len(layers_per_block) != len(down_block_types):
253 | raise ValueError(
254 | f"Must provide the same number of `layers_per_block` as `down_block_types`. `layers_per_block`: {layers_per_block}. `down_block_types`: {down_block_types}."
255 | )
256 |
257 | # input
258 | conv_in_padding = (conv_in_kernel - 1) // 2
259 | self.conv_in = nn.Conv2d(
260 | in_channels, block_out_channels[0], kernel_size=conv_in_kernel, padding=conv_in_padding
261 | )
262 |
263 | # time
264 | if time_embedding_type == "fourier":
265 | time_embed_dim = time_embedding_dim or block_out_channels[0] * 2
266 | if time_embed_dim % 2 != 0:
267 | raise ValueError(f"`time_embed_dim` should be divisible by 2, but is {time_embed_dim}.")
268 | self.time_proj = GaussianFourierProjection(
269 | time_embed_dim // 2, set_W_to_weight=False, log=False, flip_sin_to_cos=flip_sin_to_cos
270 | )
271 | timestep_input_dim = time_embed_dim
272 | elif time_embedding_type == "positional":
273 | time_embed_dim = time_embedding_dim or block_out_channels[0] * 4
274 |
275 | self.time_proj = Timesteps(block_out_channels[0], flip_sin_to_cos, freq_shift)
276 | timestep_input_dim = block_out_channels[0]
277 | else:
278 | raise ValueError(
279 | f"{time_embedding_type} does not exist. Please make sure to use one of `fourier` or `positional`."
280 | )
281 |
282 | self.time_embedding = TimestepEmbedding(
283 | timestep_input_dim,
284 | time_embed_dim,
285 | act_fn=act_fn,
286 | post_act_fn=timestep_post_act,
287 | cond_proj_dim=time_cond_proj_dim,
288 | )
289 |
290 | if encoder_hid_dim_type is None and encoder_hid_dim is not None:
291 | encoder_hid_dim_type = "text_proj"
292 | self.register_to_config(encoder_hid_dim_type=encoder_hid_dim_type)
293 | logger.info("encoder_hid_dim_type defaults to 'text_proj' as `encoder_hid_dim` is defined.")
294 |
295 | if encoder_hid_dim is None and encoder_hid_dim_type is not None:
296 | raise ValueError(
297 | f"`encoder_hid_dim` has to be defined when `encoder_hid_dim_type` is set to {encoder_hid_dim_type}."
298 | )
299 |
300 | if encoder_hid_dim_type == "text_proj":
301 | self.encoder_hid_proj = nn.Linear(encoder_hid_dim, cross_attention_dim)
302 | elif encoder_hid_dim_type == "text_image_proj":
303 | # image_embed_dim DOESN'T have to be `cross_attention_dim`. To not clutter the __init__ too much
304 | # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
305 | # case when `addition_embed_type == "text_image_proj"` (Kadinsky 2.1)`
306 | self.encoder_hid_proj = TextImageProjection(
307 | text_embed_dim=encoder_hid_dim,
308 | image_embed_dim=cross_attention_dim,
309 | cross_attention_dim=cross_attention_dim,
310 | )
311 | elif encoder_hid_dim_type == "image_proj":
312 | # Kandinsky 2.2
313 | self.encoder_hid_proj = ImageProjection(
314 | image_embed_dim=encoder_hid_dim,
315 | cross_attention_dim=cross_attention_dim,
316 | )
317 | elif encoder_hid_dim_type is not None:
318 | raise ValueError(
319 | f"encoder_hid_dim_type: {encoder_hid_dim_type} must be None, 'text_proj' or 'text_image_proj'."
320 | )
321 | else:
322 | self.encoder_hid_proj = None
323 |
324 | # class embedding
325 | if class_embed_type is None and num_class_embeds is not None:
326 | self.class_embedding = nn.Embedding(num_class_embeds, time_embed_dim)
327 | elif class_embed_type == "timestep":
328 | self.class_embedding = TimestepEmbedding(timestep_input_dim, time_embed_dim, act_fn=act_fn)
329 | elif class_embed_type == "identity":
330 | self.class_embedding = nn.Identity(time_embed_dim, time_embed_dim)
331 | elif class_embed_type == "projection":
332 | if projection_class_embeddings_input_dim is None:
333 | raise ValueError(
334 | "`class_embed_type`: 'projection' requires `projection_class_embeddings_input_dim` be set"
335 | )
336 | # The projection `class_embed_type` is the same as the timestep `class_embed_type` except
337 | # 1. the `class_labels` inputs are not first converted to sinusoidal embeddings
338 | # 2. it projects from an arbitrary input dimension.
339 | #
340 | # Note that `TimestepEmbedding` is quite general, being mainly linear layers and activations.
341 | # When used for embedding actual timesteps, the timesteps are first converted to sinusoidal embeddings.
342 | # As a result, `TimestepEmbedding` can be passed arbitrary vectors.
343 | self.class_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
344 | elif class_embed_type == "simple_projection":
345 | if projection_class_embeddings_input_dim is None:
346 | raise ValueError(
347 | "`class_embed_type`: 'simple_projection' requires `projection_class_embeddings_input_dim` be set"
348 | )
349 | self.class_embedding = nn.Linear(projection_class_embeddings_input_dim, time_embed_dim)
350 | else:
351 | self.class_embedding = None
352 |
353 | if addition_embed_type == "text":
354 | if encoder_hid_dim is not None:
355 | text_time_embedding_from_dim = encoder_hid_dim
356 | else:
357 | text_time_embedding_from_dim = cross_attention_dim
358 |
359 | self.add_embedding = TextTimeEmbedding(
360 | text_time_embedding_from_dim, time_embed_dim, num_heads=addition_embed_type_num_heads
361 | )
362 | elif addition_embed_type == "text_image":
363 | # text_embed_dim and image_embed_dim DON'T have to be `cross_attention_dim`. To not clutter the __init__ too much
364 | # they are set to `cross_attention_dim` here as this is exactly the required dimension for the currently only use
365 | # case when `addition_embed_type == "text_image"` (Kadinsky 2.1)`
366 | self.add_embedding = TextImageTimeEmbedding(
367 | text_embed_dim=cross_attention_dim, image_embed_dim=cross_attention_dim, time_embed_dim=time_embed_dim
368 | )
369 | elif addition_embed_type == "text_time":
370 | self.add_time_proj = Timesteps(addition_time_embed_dim, flip_sin_to_cos, freq_shift)
371 | self.add_embedding = TimestepEmbedding(projection_class_embeddings_input_dim, time_embed_dim)
372 | elif addition_embed_type == "image":
373 | # Kandinsky 2.2
374 | self.add_embedding = ImageTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
375 | elif addition_embed_type == "image_hint":
376 | # Kandinsky 2.2 ControlNet
377 | self.add_embedding = ImageHintTimeEmbedding(image_embed_dim=encoder_hid_dim, time_embed_dim=time_embed_dim)
378 | elif addition_embed_type is not None:
379 | raise ValueError(f"addition_embed_type: {addition_embed_type} must be None, 'text' or 'text_image'.")
380 |
381 | if time_embedding_act_fn is None:
382 | self.time_embed_act = None
383 | else:
384 | self.time_embed_act = get_activation(time_embedding_act_fn)
385 |
386 | self.down_blocks = nn.ModuleList([])
387 | self.up_blocks = nn.ModuleList([])
388 |
389 | if isinstance(only_cross_attention, bool):
390 | if mid_block_only_cross_attention is None:
391 | mid_block_only_cross_attention = only_cross_attention
392 |
393 | only_cross_attention = [only_cross_attention] * len(down_block_types)
394 |
395 | if mid_block_only_cross_attention is None:
396 | mid_block_only_cross_attention = False
397 |
398 | if isinstance(num_attention_heads, int):
399 | num_attention_heads = (num_attention_heads,) * len(down_block_types)
400 |
401 | if isinstance(attention_head_dim, int):
402 | attention_head_dim = (attention_head_dim,) * len(down_block_types)
403 |
404 | if isinstance(cross_attention_dim, int):
405 | cross_attention_dim = (cross_attention_dim,) * len(down_block_types)
406 |
407 | if isinstance(layers_per_block, int):
408 | layers_per_block = [layers_per_block] * len(down_block_types)
409 |
410 | if isinstance(transformer_layers_per_block, int):
411 | transformer_layers_per_block = [transformer_layers_per_block] * len(down_block_types)
412 |
413 | if class_embeddings_concat:
414 | # The time embeddings are concatenated with the class embeddings. The dimension of the
415 | # time embeddings passed to the down, middle, and up blocks is twice the dimension of the
416 | # regular time embeddings
417 | blocks_time_embed_dim = time_embed_dim * 2
418 | else:
419 | blocks_time_embed_dim = time_embed_dim
420 |
421 | # down
422 | output_channel = block_out_channels[0]
423 | for i, down_block_type in enumerate(down_block_types):
424 | input_channel = output_channel
425 | output_channel = block_out_channels[i]
426 | is_final_block = i == len(block_out_channels) - 1
427 |
428 | down_block = get_down_block(
429 | down_block_type,
430 | num_layers=layers_per_block[i],
431 | transformer_layers_per_block=transformer_layers_per_block[i],
432 | in_channels=input_channel,
433 | out_channels=output_channel,
434 | temb_channels=blocks_time_embed_dim,
435 | add_downsample=not is_final_block,
436 | resnet_eps=norm_eps,
437 | resnet_act_fn=act_fn,
438 | resnet_groups=norm_num_groups,
439 | cross_attention_dim=cross_attention_dim[i],
440 | num_attention_heads=num_attention_heads[i],
441 | downsample_padding=downsample_padding,
442 | dual_cross_attention=dual_cross_attention,
443 | use_linear_projection=use_linear_projection,
444 | only_cross_attention=only_cross_attention[i],
445 | upcast_attention=upcast_attention,
446 | resnet_time_scale_shift=resnet_time_scale_shift,
447 | attention_type=attention_type,
448 | resnet_skip_time_act=resnet_skip_time_act,
449 | resnet_out_scale_factor=resnet_out_scale_factor,
450 | cross_attention_norm=cross_attention_norm,
451 | attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
452 | )
453 | self.down_blocks.append(down_block)
454 |
455 | # mid
456 | if mid_block_type == "UNetMidBlock2DCrossAttn":
457 | self.mid_block = UNetMidBlock2DCrossAttn(
458 | transformer_layers_per_block=transformer_layers_per_block[-1],
459 | in_channels=block_out_channels[-1],
460 | temb_channels=blocks_time_embed_dim,
461 | resnet_eps=norm_eps,
462 | resnet_act_fn=act_fn,
463 | output_scale_factor=mid_block_scale_factor,
464 | resnet_time_scale_shift=resnet_time_scale_shift,
465 | cross_attention_dim=cross_attention_dim[-1],
466 | num_attention_heads=num_attention_heads[-1],
467 | resnet_groups=norm_num_groups,
468 | dual_cross_attention=dual_cross_attention,
469 | use_linear_projection=use_linear_projection,
470 | upcast_attention=upcast_attention,
471 | attention_type=attention_type,
472 | )
473 | elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
474 | self.mid_block = UNetMidBlock2DSimpleCrossAttn(
475 | in_channels=block_out_channels[-1],
476 | temb_channels=blocks_time_embed_dim,
477 | resnet_eps=norm_eps,
478 | resnet_act_fn=act_fn,
479 | output_scale_factor=mid_block_scale_factor,
480 | cross_attention_dim=cross_attention_dim[-1],
481 | attention_head_dim=attention_head_dim[-1],
482 | resnet_groups=norm_num_groups,
483 | resnet_time_scale_shift=resnet_time_scale_shift,
484 | skip_time_act=resnet_skip_time_act,
485 | only_cross_attention=mid_block_only_cross_attention,
486 | cross_attention_norm=cross_attention_norm,
487 | )
488 | elif mid_block_type is None:
489 | self.mid_block = None
490 | else:
491 | raise ValueError(f"unknown mid_block_type : {mid_block_type}")
492 |
493 | # count how many layers upsample the images
494 | self.num_upsamplers = 0
495 |
496 | # up
497 | reversed_block_out_channels = list(reversed(block_out_channels))
498 | reversed_num_attention_heads = list(reversed(num_attention_heads))
499 | reversed_layers_per_block = list(reversed(layers_per_block))
500 | reversed_cross_attention_dim = list(reversed(cross_attention_dim))
501 | reversed_transformer_layers_per_block = list(reversed(transformer_layers_per_block))
502 | only_cross_attention = list(reversed(only_cross_attention))
503 |
504 | output_channel = reversed_block_out_channels[0]
505 | for i, up_block_type in enumerate(up_block_types):
506 | is_final_block = i == len(block_out_channels) - 1
507 |
508 | prev_output_channel = output_channel
509 | output_channel = reversed_block_out_channels[i]
510 | input_channel = reversed_block_out_channels[min(i + 1, len(block_out_channels) - 1)]
511 |
512 | # add upsample block for all BUT final layer
513 | if not is_final_block:
514 | add_upsample = True
515 | self.num_upsamplers += 1
516 | else:
517 | add_upsample = False
518 |
519 | up_block = get_up_block(
520 | up_block_type,
521 | num_layers=reversed_layers_per_block[i] + 1,
522 | transformer_layers_per_block=reversed_transformer_layers_per_block[i],
523 | in_channels=input_channel,
524 | out_channels=output_channel,
525 | prev_output_channel=prev_output_channel,
526 | temb_channels=blocks_time_embed_dim,
527 | add_upsample=add_upsample,
528 | resnet_eps=norm_eps,
529 | resnet_act_fn=act_fn,
530 | resnet_groups=norm_num_groups,
531 | cross_attention_dim=reversed_cross_attention_dim[i],
532 | num_attention_heads=reversed_num_attention_heads[i],
533 | dual_cross_attention=dual_cross_attention,
534 | use_linear_projection=use_linear_projection,
535 | only_cross_attention=only_cross_attention[i],
536 | upcast_attention=upcast_attention,
537 | resnet_time_scale_shift=resnet_time_scale_shift,
538 | attention_type=attention_type,
539 | resnet_skip_time_act=resnet_skip_time_act,
540 | resnet_out_scale_factor=resnet_out_scale_factor,
541 | cross_attention_norm=cross_attention_norm,
542 | attention_head_dim=attention_head_dim[i] if attention_head_dim[i] is not None else output_channel,
543 | )
544 | self.up_blocks.append(up_block)
545 | prev_output_channel = output_channel
546 |
547 | # out
548 | if norm_num_groups is not None:
549 | self.conv_norm_out = nn.GroupNorm(
550 | num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=norm_eps
551 | )
552 |
553 | self.conv_act = get_activation(act_fn)
554 |
555 | else:
556 | self.conv_norm_out = None
557 | self.conv_act = None
558 |
559 | conv_out_padding = (conv_out_kernel - 1) // 2
560 | self.conv_out = nn.Conv2d(
561 | block_out_channels[0], out_channels, kernel_size=conv_out_kernel, padding=conv_out_padding
562 | )
563 |
564 | if attention_type == "gated":
565 | positive_len = 768
566 | if isinstance(cross_attention_dim, int):
567 | positive_len = cross_attention_dim
568 | elif isinstance(cross_attention_dim, tuple) or isinstance(cross_attention_dim, list):
569 | positive_len = cross_attention_dim[0]
570 | self.position_net = PositionNet(positive_len=positive_len, out_dim=cross_attention_dim)
571 |
572 |
573 | @property
574 | def attn_processors(self) -> Dict[str, AttentionProcessor]:
575 | r"""
576 | Returns:
577 | `dict` of attention processors: A dictionary containing all attention processors used in the model with
578 | indexed by its weight name.
579 | """
580 | # set recursively
581 | processors = {}
582 |
583 | def fn_recursive_add_processors(name: str, module: torch.nn.Module, processors: Dict[str, AttentionProcessor]):
584 | if hasattr(module, "set_processor"):
585 | processors[f"{name}.processor"] = module.processor
586 |
587 | for sub_name, child in module.named_children():
588 | fn_recursive_add_processors(f"{name}.{sub_name}", child, processors)
589 |
590 | return processors
591 |
592 | for name, module in self.named_children():
593 | fn_recursive_add_processors(name, module, processors)
594 |
595 | return processors
596 |
597 | def set_attn_processor(self, processor: Union[AttentionProcessor, Dict[str, AttentionProcessor]]):
598 | r"""
599 | Sets the attention processor to use to compute attention.
600 |
601 | Parameters:
602 | processor (`dict` of `AttentionProcessor` or only `AttentionProcessor`):
603 | The instantiated processor class or a dictionary of processor classes that will be set as the processor
604 | for **all** `Attention` layers.
605 |
606 | If `processor` is a dict, the key needs to define the path to the corresponding cross attention
607 | processor. This is strongly recommended when setting trainable attention processors.
608 |
609 | """
610 | count = len(self.attn_processors.keys())
611 |
612 | if isinstance(processor, dict) and len(processor) != count:
613 | raise ValueError(
614 | f"A dict of processors was passed, but the number of processors {len(processor)} does not match the"
615 | f" number of attention layers: {count}. Please make sure to pass {count} processor classes."
616 | )
617 |
618 | def fn_recursive_attn_processor(name: str, module: torch.nn.Module, processor):
619 | if hasattr(module, "set_processor"):
620 | if not isinstance(processor, dict):
621 | module.set_processor(processor)
622 | else:
623 | module.set_processor(processor.pop(f"{name}.processor"))
624 |
625 | for sub_name, child in module.named_children():
626 | fn_recursive_attn_processor(f"{name}.{sub_name}", child, processor)
627 |
628 | for name, module in self.named_children():
629 | fn_recursive_attn_processor(name, module, processor)
630 |
631 | def set_default_attn_processor(self):
632 | """
633 | Disables custom attention processors and sets the default attention implementation.
634 | """
635 | self.set_attn_processor(AttnProcessor())
636 |
637 | def set_attention_slice(self, slice_size):
638 | r"""
639 | Enable sliced attention computation.
640 |
641 | When this option is enabled, the attention module splits the input tensor in slices to compute attention in
642 | several steps. This is useful for saving some memory in exchange for a small decrease in speed.
643 |
644 | Args:
645 | slice_size (`str` or `int` or `list(int)`, *optional*, defaults to `"auto"`):
646 | When `"auto"`, input to the attention heads is halved, so attention is computed in two steps. If
647 | `"max"`, maximum amount of memory is saved by running only one slice at a time. If a number is
648 | provided, uses as many slices as `attention_head_dim // slice_size`. In this case, `attention_head_dim`
649 | must be a multiple of `slice_size`.
650 | """
651 | sliceable_head_dims = []
652 |
653 | def fn_recursive_retrieve_sliceable_dims(module: torch.nn.Module):
654 | if hasattr(module, "set_attention_slice"):
655 | sliceable_head_dims.append(module.sliceable_head_dim)
656 |
657 | for child in module.children():
658 | fn_recursive_retrieve_sliceable_dims(child)
659 |
660 | # retrieve number of attention layers
661 | for module in self.children():
662 | fn_recursive_retrieve_sliceable_dims(module)
663 |
664 | num_sliceable_layers = len(sliceable_head_dims)
665 |
666 | if slice_size == "auto":
667 | # half the attention head size is usually a good trade-off between
668 | # speed and memory
669 | slice_size = [dim // 2 for dim in sliceable_head_dims]
670 | elif slice_size == "max":
671 | # make smallest slice possible
672 | slice_size = num_sliceable_layers * [1]
673 |
674 | slice_size = num_sliceable_layers * [slice_size] if not isinstance(slice_size, list) else slice_size
675 |
676 | if len(slice_size) != len(sliceable_head_dims):
677 | raise ValueError(
678 | f"You have provided {len(slice_size)}, but {self.config} has {len(sliceable_head_dims)} different"
679 | f" attention layers. Make sure to match `len(slice_size)` to be {len(sliceable_head_dims)}."
680 | )
681 |
682 | for i in range(len(slice_size)):
683 | size = slice_size[i]
684 | dim = sliceable_head_dims[i]
685 | if size is not None and size > dim:
686 | raise ValueError(f"size {size} has to be smaller or equal to {dim}.")
687 |
688 | # Recursively walk through all the children.
689 | # Any children which exposes the set_attention_slice method
690 | # gets the message
691 | def fn_recursive_set_attention_slice(module: torch.nn.Module, slice_size: List[int]):
692 | if hasattr(module, "set_attention_slice"):
693 | module.set_attention_slice(slice_size.pop())
694 |
695 | for child in module.children():
696 | fn_recursive_set_attention_slice(child, slice_size)
697 |
698 | reversed_slice_size = list(reversed(slice_size))
699 | for module in self.children():
700 | fn_recursive_set_attention_slice(module, reversed_slice_size)
701 |
702 | def _set_gradient_checkpointing(self, module, value=False):
703 | if hasattr(module, "gradient_checkpointing"):
704 | module.gradient_checkpointing = value
705 |
706 | def forward(
707 | self,
708 | sample: torch.FloatTensor,
709 | timestep: Union[torch.Tensor, float, int],
710 | encoder_hidden_states: torch.Tensor,
711 | class_labels: Optional[torch.Tensor] = None,
712 | timestep_cond: Optional[torch.Tensor] = None,
713 | attention_mask: Optional[torch.Tensor] = None,
714 | cross_attention_kwargs: Optional[Dict[str, Any]] = None,
715 | added_cond_kwargs: Optional[Dict[str, torch.Tensor]] = None,
716 | down_block_additional_residuals: Optional[Tuple[torch.Tensor]] = None,
717 | mid_block_additional_residual: Optional[torch.Tensor] = None,
718 | up_block_additional_residual: Optional[torch.Tensor] = None,
719 | encoder_attention_mask: Optional[torch.Tensor] = None,
720 | return_dict: bool = True,
721 | return_hidden_states: bool = False,
722 | return_encoder_feature: bool = False,
723 | return_early: bool = False,
724 | down_bridge_residuals: Optional[Tuple[torch.Tensor]] = None,
725 | fusion_guidance_scale: Optional[torch.FloatTensor] = None,
726 | fusion_type: Optional[str] = 'ADD',
727 | adapter: Optional = None
728 | ) -> Union[UNet2DConditionOutput, Tuple]:
729 | r"""
730 | The [`UNet2DConditionModel`] forward method.
731 |
732 | Args:
733 | sample (`torch.FloatTensor`):
734 | The noisy input tensor with the following shape `(batch, channel, height, width)`.
735 | timestep (`torch.FloatTensor` or `float` or `int`): The number of timesteps to denoise an input.
736 | encoder_hidden_states (`torch.FloatTensor`):
737 | The encoder hidden states with shape `(batch, sequence_length, feature_dim)`.
738 | encoder_attention_mask (`torch.Tensor`):
739 | A cross-attention mask of shape `(batch, sequence_length)` is applied to `encoder_hidden_states`. If
740 | `True` the mask is kept, otherwise if `False` it is discarded. Mask will be converted into a bias,
741 | which adds large negative values to the attention scores corresponding to "discard" tokens.
742 | return_dict (`bool`, *optional*, defaults to `True`):
743 | Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
744 | tuple.
745 | cross_attention_kwargs (`dict`, *optional*):
746 | A kwargs dictionary that if specified is passed along to the [`AttnProcessor`].
747 | added_cond_kwargs: (`dict`, *optional*):
748 | A kwargs dictionary containin additional embeddings that if specified are added to the embeddings that
749 | are passed along to the UNet blocks.
750 |
751 | Returns:
752 | [`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
753 | If `return_dict` is True, an [`~models.unet_2d_condition.UNet2DConditionOutput`] is returned, otherwise
754 | a `tuple` is returned where the first element is the sample tensor.
755 | """
756 | # By default samples have to be AT least a multiple of the overall upsampling factor.
757 | # The overall upsampling factor is equal to 2 ** (# num of upsampling layers).
758 | # However, the upsampling interpolation output size can be forced to fit any upsampling size
759 | # on the fly if necessary.
760 | ############## bridge usage ##################
761 | if return_hidden_states:
762 | hidden_states = []
763 | return_dict = True
764 | ############## end of bridge usage ##################
765 |
766 |
767 |
768 | default_overall_up_factor = 2**self.num_upsamplers
769 |
770 | # upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
771 | forward_upsample_size = False
772 | upsample_size = None
773 |
774 | if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
775 | logger.info("Forward upsample size to force interpolation output size.")
776 | forward_upsample_size = True
777 |
778 | # ensure attention_mask is a bias, and give it a singleton query_tokens dimension
779 | # expects mask of shape:
780 | # [batch, key_tokens]
781 | # adds singleton query_tokens dimension:
782 | # [batch, 1, key_tokens]
783 | # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
784 | # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
785 | # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
786 | if attention_mask is not None:
787 | # assume that mask is expressed as:
788 | # (1 = keep, 0 = discard)
789 | # convert mask into a bias that can be added to attention scores:
790 | # (keep = +0, discard = -10000.0)
791 | attention_mask = (1 - attention_mask.to(sample.dtype)) * -10000.0
792 | attention_mask = attention_mask.unsqueeze(1)
793 |
794 | # convert encoder_attention_mask to a bias the same way we do for attention_mask
795 | if encoder_attention_mask is not None:
796 | encoder_attention_mask = (1 - encoder_attention_mask.to(sample.dtype)) * -10000.0
797 | encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
798 |
799 | # 0. center input if necessary
800 | if self.config.center_input_sample:
801 | sample = 2 * sample - 1.0
802 |
803 | # 1. time
804 | timesteps = timestep
805 | if not torch.is_tensor(timesteps):
806 | # TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
807 | # This would be a good case for the `match` statement (Python 3.10+)
808 | is_mps = sample.device.type == "mps"
809 | if isinstance(timestep, float):
810 | dtype = torch.float32 if is_mps else torch.float64
811 | else:
812 | dtype = torch.int32 if is_mps else torch.int64
813 | timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
814 | elif len(timesteps.shape) == 0:
815 | timesteps = timesteps[None].to(sample.device)
816 |
817 | # broadcast to batch dimension in a way that's compatible with ONNX/Core ML
818 | timesteps = timesteps.expand(sample.shape[0])
819 |
820 | t_emb = self.time_proj(timesteps) # 2, 320
821 |
822 | # `Timesteps` does not contain any weights and will always return f32 tensors
823 | # but time_embedding might actually be running in fp16. so we need to cast here.
824 | # there might be better ways to encapsulate this.
825 | t_emb = t_emb.to(dtype=sample.dtype)
826 |
827 | emb = self.time_embedding(t_emb, timestep_cond)
828 |
829 | aug_emb = None
830 |
831 | if self.class_embedding is not None:
832 | if class_labels is None:
833 | raise ValueError("class_labels should be provided when num_class_embeds > 0")
834 |
835 | if self.config.class_embed_type == "timestep":
836 | class_labels = self.time_proj(class_labels)
837 |
838 | # `Timesteps` does not contain any weights and will always return f32 tensors
839 | # there might be better ways to encapsulate this.
840 | class_labels = class_labels.to(dtype=sample.dtype)
841 |
842 | class_emb = self.class_embedding(class_labels).to(dtype=sample.dtype)
843 |
844 | if self.config.class_embeddings_concat:
845 | emb = torch.cat([emb, class_emb], dim=-1)
846 | else:
847 | emb = emb + class_emb
848 |
849 | if self.config.addition_embed_type == "text":
850 | aug_emb = self.add_embedding(encoder_hidden_states)
851 | elif self.config.addition_embed_type == "text_image":
852 | # Kandinsky 2.1 - style
853 | if "image_embeds" not in added_cond_kwargs:
854 | raise ValueError(
855 | f"{self.__class__} has the config param `addition_embed_type` set to 'text_image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
856 | )
857 |
858 | image_embs = added_cond_kwargs.get("image_embeds")
859 | text_embs = added_cond_kwargs.get("text_embeds", encoder_hidden_states)
860 | aug_emb = self.add_embedding(text_embs, image_embs)
861 | elif self.config.addition_embed_type == "text_time":
862 | # SDXL - style
863 | if "text_embeds" not in added_cond_kwargs:
864 | raise ValueError(
865 | f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `text_embeds` to be passed in `added_cond_kwargs`"
866 | )
867 | text_embeds = added_cond_kwargs.get("text_embeds")
868 | if "time_ids" not in added_cond_kwargs:
869 | raise ValueError(
870 | f"{self.__class__} has the config param `addition_embed_type` set to 'text_time' which requires the keyword argument `time_ids` to be passed in `added_cond_kwargs`"
871 | )
872 | time_ids = added_cond_kwargs.get("time_ids")
873 | time_embeds = self.add_time_proj(time_ids.flatten())
874 | time_embeds = time_embeds.reshape((text_embeds.shape[0], -1))
875 |
876 | add_embeds = torch.concat([text_embeds, time_embeds], dim=-1)
877 | add_embeds = add_embeds.to(emb.dtype)
878 | aug_emb = self.add_embedding(add_embeds)
879 | elif self.config.addition_embed_type == "image":
880 | # Kandinsky 2.2 - style
881 | if "image_embeds" not in added_cond_kwargs:
882 | raise ValueError(
883 | f"{self.__class__} has the config param `addition_embed_type` set to 'image' which requires the keyword argument `image_embeds` to be passed in `added_cond_kwargs`"
884 | )
885 | image_embs = added_cond_kwargs.get("image_embeds")
886 | aug_emb = self.add_embedding(image_embs)
887 | elif self.config.addition_embed_type == "image_hint":
888 | # Kandinsky 2.2 - style
889 | if "image_embeds" not in added_cond_kwargs or "hint" not in added_cond_kwargs:
890 | raise ValueError(
891 | f"{self.__class__} has the config param `addition_embed_type` set to 'image_hint' which requires the keyword arguments `image_embeds` and `hint` to be passed in `added_cond_kwargs`"
892 | )
893 | image_embs = added_cond_kwargs.get("image_embeds")
894 | hint = added_cond_kwargs.get("hint")
895 | aug_emb, hint = self.add_embedding(image_embs, hint)
896 | sample = torch.cat([sample, hint], dim=1)
897 |
898 | emb = emb + aug_emb if aug_emb is not None else emb
899 |
900 | if self.time_embed_act is not None:
901 | emb = self.time_embed_act(emb)
902 |
903 | if self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_proj":
904 | encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states)
905 | elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "text_image_proj":
906 | # Kadinsky 2.1 - style
907 | if "image_embeds" not in added_cond_kwargs:
908 | raise ValueError(
909 | f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'text_image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
910 | )
911 |
912 | image_embeds = added_cond_kwargs.get("image_embeds")
913 | encoder_hidden_states = self.encoder_hid_proj(encoder_hidden_states, image_embeds)
914 | elif self.encoder_hid_proj is not None and self.config.encoder_hid_dim_type == "image_proj":
915 | # Kandinsky 2.2 - style
916 | if "image_embeds" not in added_cond_kwargs:
917 | raise ValueError(
918 | f"{self.__class__} has the config param `encoder_hid_dim_type` set to 'image_proj' which requires the keyword argument `image_embeds` to be passed in `added_conditions`"
919 | )
920 | image_embeds = added_cond_kwargs.get("image_embeds")
921 | encoder_hidden_states = self.encoder_hid_proj(image_embeds)
922 | # 2. pre-process
923 | sample = self.conv_in(sample)
924 |
925 | # 2.5 GLIGEN position net
926 | if cross_attention_kwargs is not None and cross_attention_kwargs.get("gligen", None) is not None:
927 | cross_attention_kwargs = cross_attention_kwargs.copy()
928 | gligen_args = cross_attention_kwargs.pop("gligen")
929 | cross_attention_kwargs["gligen"] = {"objs": self.position_net(**gligen_args)}
930 |
931 | # 3. down
932 |
933 | if return_encoder_feature:
934 | encoder_feature = []
935 |
936 | is_controlnet = mid_block_additional_residual is not None and down_block_additional_residuals is not None
937 | is_adapter = mid_block_additional_residual is None and down_block_additional_residuals is not None
938 | is_bridge_encoder = down_bridge_residuals is not None
939 | is_bridge = up_block_additional_residual is not None
940 |
941 | down_block_res_samples = (sample,)
942 |
943 |
944 |
945 | for downsample_block in self.down_blocks:
946 | if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
947 | # For t2i-adapter CrossAttnDownBlock2D
948 | additional_residuals = {}
949 | if is_adapter and len(down_block_additional_residuals) > 0:
950 | additional_residuals["additional_residuals"] = down_block_additional_residuals.pop(0)
951 |
952 | sample, res_samples = downsample_block(
953 | hidden_states=sample,
954 | temb=emb,
955 | encoder_hidden_states=encoder_hidden_states,
956 | attention_mask=attention_mask,
957 | cross_attention_kwargs=cross_attention_kwargs,
958 | encoder_attention_mask=encoder_attention_mask,
959 | **additional_residuals,
960 | )
961 |
962 | if is_bridge_encoder and len(down_bridge_residuals) > 0:
963 | sample += down_bridge_residuals.pop(0)
964 |
965 | if return_encoder_feature:
966 | encoder_feature.append(sample)
967 | else:
968 | sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
969 |
970 | if is_adapter and len(down_block_additional_residuals) > 0:
971 | sample += down_block_additional_residuals.pop(0)
972 |
973 | if is_bridge_encoder and len(down_bridge_residuals) > 0:
974 | sample += down_bridge_residuals.pop(0)
975 |
976 | down_block_res_samples += res_samples
977 |
978 |
979 | if is_controlnet:
980 | new_down_block_res_samples = ()
981 |
982 | for down_block_res_sample, down_block_additional_residual in zip(
983 | down_block_res_samples, down_block_additional_residuals
984 | ):
985 | down_block_res_sample = down_block_res_sample + down_block_additional_residual
986 | new_down_block_res_samples = new_down_block_res_samples + (down_block_res_sample,)
987 |
988 | down_block_res_samples = new_down_block_res_samples
989 |
990 | if return_encoder_feature and return_early:
991 | return encoder_feature
992 |
993 | # 4. mid
994 | if self.mid_block is not None:
995 | sample = self.mid_block(
996 | sample,
997 | emb,
998 | encoder_hidden_states=encoder_hidden_states,
999 | attention_mask=attention_mask,
1000 | cross_attention_kwargs=cross_attention_kwargs,
1001 | encoder_attention_mask=encoder_attention_mask,
1002 | )
1003 |
1004 | if is_controlnet:
1005 | sample = sample + mid_block_additional_residual
1006 |
1007 | ################# bridge usage #################
1008 |
1009 | if is_bridge:
1010 | if fusion_guidance_scale is not None:
1011 | sample = sample + fusion_guidance_scale * (up_block_additional_residual.pop(0) - sample)
1012 | else:
1013 | sample += up_block_additional_residual.pop(0)
1014 | ################# end of bridge usage #################
1015 | # 5. up
1016 |
1017 | for i, upsample_block in enumerate(self.up_blocks):
1018 | is_final_block = i == len(self.up_blocks) - 1
1019 |
1020 | res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
1021 | down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
1022 |
1023 | # if we have not reached the final block and need to forward the
1024 | # upsample size, we do it here
1025 | if not is_final_block and forward_upsample_size:
1026 | upsample_size = down_block_res_samples[-1].shape[2:]
1027 |
1028 | if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
1029 | sample = upsample_block(
1030 | hidden_states=sample,
1031 | temb=emb,
1032 | res_hidden_states_tuple=res_samples,
1033 | encoder_hidden_states=encoder_hidden_states,
1034 | cross_attention_kwargs=cross_attention_kwargs,
1035 | upsample_size=upsample_size,
1036 | attention_mask=attention_mask,
1037 | encoder_attention_mask=encoder_attention_mask,
1038 | )
1039 | else:
1040 | sample = upsample_block(
1041 | hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
1042 | )
1043 |
1044 |
1045 | ################# bridge usage #################
1046 | if is_bridge and len(up_block_additional_residual) > 0:
1047 | if fusion_guidance_scale is not None:
1048 | sample = sample + fusion_guidance_scale * (up_block_additional_residual.pop(0) - sample)
1049 | else:
1050 | sample += up_block_additional_residual.pop(0)
1051 |
1052 | if return_hidden_states and i > 0:
1053 | # Collect last three up blk in SD1.5
1054 | hidden_states.append(sample)
1055 | ################# end of bridge usage #################
1056 |
1057 | # 6. post-process
1058 | if self.conv_norm_out:
1059 | sample = self.conv_norm_out(sample)
1060 | sample = self.conv_act(sample)
1061 | sample = self.conv_out(sample)
1062 |
1063 | if not return_dict:
1064 | return (sample,)
1065 |
1066 | return UNet2DConditionOutput(sample=sample, hidden_states=hidden_states if return_hidden_states else None,
1067 | encoder_feature=encoder_feature if return_encoder_feature else None)
1068 |
--------------------------------------------------------------------------------