├── .gitignore
├── LICENSE
├── README.md
├── assets
├── 1.png
└── 2.png
├── configuration.py
├── convert_to_tflite.py
├── data_process
├── __init__.py
├── make_dataset.py
├── parse_coco.py
├── parse_voc.py
└── read_txt.py
├── dataset
└── README.md
├── detect_objects_in_video.py
├── parse_cfg.py
├── saved_model
└── README.md
├── test_data
└── README.md
├── test_on_single_image.py
├── test_results_during_training
└── README.md
├── train_from_scratch.py
├── utils
├── __init__.py
├── iou.py
├── nms.py
├── preprocess.py
├── resize_image.py
└── visualize.py
├── write_coco_to_txt.py
├── write_voc_to_txt.py
└── yolo
├── __init__.py
├── anchor.py
├── bounding_box.py
├── inference.py
├── loss.py
├── make_label.py
└── yolo_v3.py
/.gitignore:
--------------------------------------------------------------------------------
1 | .idea
2 | __pycache__
3 | /dataset/*
4 | !/dataset/README.md
5 | /data_process/data.txt
6 | /saved_model/*
7 | !/saved_model/README.md
8 | /test_data/*
9 | !/test_data/README.md
10 | /test_results_during_training/*
11 | !/test_results_during_training/README.md
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2019 calmisential
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # YOLOv3_TensorFlow2
2 | A tensorflow2 implementation of YOLO_V3.
3 |
4 | ## Requirements:
5 | + Python == 3.7
6 | + TensorFlow == 2.1.0
7 | + numpy == 1.17.0
8 | + opencv-python == 4.1.0
9 |
10 | ## Usage
11 | ### Train on PASCAL VOC 2012
12 | 1. Download the [PASCAL VOC 2012 dataset](http://host.robots.ox.ac.uk/pascal/VOC/).
13 | 2. Unzip the file and place it in the 'dataset' folder, make sure the directory is like this :
14 | ```
15 | |——dataset
16 | |——VOCdevkit
17 | |——VOC2012
18 | |——Annotations
19 | |——ImageSets
20 | |——JPEGImages
21 | |——SegmentationClass
22 | |——SegmentationObject
23 | ```
24 | 3. Change the parameters in **configuration.py** according to the specific situation. Specially, you can set *"load_weights_before_training"* to **True** if you would like to restore training from saved weights. You
25 | can also set *"test_images_during_training"* to **True**, so that the detect results will be show after each epoch.
26 | 4. Run **write_voc_to_txt.py** to generate *data.txt*, and then run **train_from_scratch.py** to start training.
27 |
28 | ### Train on COCO2017
29 | 1. Download the COCO2017 dataset.
30 | 2. Unzip the **train2017.zip**, **annotations_trainval2017.zip** and place them in the 'dataset' folder, make sure the directory is like this :
31 | ```
32 | |——dataset
33 | |——COCO
34 | |——2017
35 | |——annotations
36 | |——train2017
37 | ```
38 | 3. Change the parameters in **configuration.py** according to the specific situation. Specially, you can set *"load_weights_before_training"* to **True** if you would like to restore training from saved weights. You
39 | can also set *"test_images_during_training"* to **True**, so that the detect results will be show after each epoch.
40 | 4. Run **write_coco_to_txt.py** to generate *data.txt*, and then run **train_from_scratch.py** to start training.
41 |
42 |
43 |
44 | ### Train on custom dataset
45 | 1. Turn your custom dataset's labels into this form:
46 | ```xxx.jpg 100 200 300 400 1 300 600 500 800 2```.
47 | The first position is the image name, and the next 5 elements are [xmin, ymin, xmax, ymax, class_id]. If there are multiple boxes, continue to add elements later.
**Considering that the image will be resized before it is entered into the network, the values of xmin, ymin, xmax, and ymax will also change accordingly.**
48 | The example of **original picture**(from PASCAL VOC 2012 dataset) and **resized picture**:
49 | 
50 | 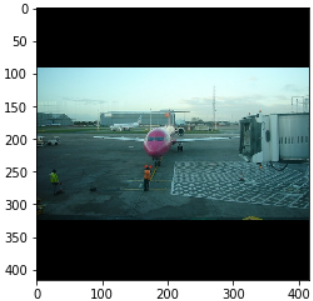
51 | Create a new file *data.txt* in the data_process directory and write the label of each picture into it, each line is a label for an image.
52 | 2. Change the parameters *CATEGORY_NUM*, *use_dataset*, *custom_dataset_dir*, *custom_dataset_classes* in **configuration.py**.
53 | 3. Run **write_to_txt.py** to generate *data.txt*, and then run **train_from_scratch.py** to start training.
54 |
55 | ### Test
56 | 1. Change *"test_picture_dir"* in **configuration.py** according to the specific situation.
57 | 2. Run **test_on_single_image.py** to test single picture.
58 |
59 | ### Convert model to TensorFlow Lite format
60 | 1. Change the *"TFLite_model_dir"* in **configuration.py** according to the specific situation.
61 | 2. Run **convert_to_tflite.py** to generate TensorFlow Lite model.
62 |
63 |
64 | ## References
65 | 1. YOLO_v3 paper: https://pjreddie.com/media/files/papers/YOLOv3.pdf or https://arxiv.org/abs/1804.02767
66 | 2. Keras implementation of YOLOV3: https://github.com/qqwweee/keras-yolo3
67 | 3. [blog 1](https://www.cnblogs.com/wangxinzhe/p/10592184.html), [blog 2](https://www.cnblogs.com/wangxinzhe/p/10648465.html), [blog 3](https://blog.csdn.net/leviopku/article/details/82660381), [blog 4](https://blog.csdn.net/qq_37541097/article/details/81214953), [blog 5](https://blog.csdn.net/Gentleman_Qin/article/details/84349144), [blog 6](https://blog.csdn.net/qq_34199326/article/details/84109828), [blog 7](https://blog.csdn.net/weixin_38145317/article/details/95349201)
68 | 5. 李金洪. 深度学习之TensorFlow工程化项目实战[M]. 北京: 电子工业出版社, 2019: 343-375
69 | 6. https://zhuanlan.zhihu.com/p/49556105
--------------------------------------------------------------------------------
/assets/1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/calmiLovesAI/YOLOv3_TensorFlow2/7789280e4974f62b20304f9746aa4121be4c5333/assets/1.png
--------------------------------------------------------------------------------
/assets/2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/calmiLovesAI/YOLOv3_TensorFlow2/7789280e4974f62b20304f9746aa4121be4c5333/assets/2.png
--------------------------------------------------------------------------------
/configuration.py:
--------------------------------------------------------------------------------
1 | # training
2 | EPOCHS = 1000
3 | BATCH_SIZE = 8
4 | load_weights_before_training = False
5 | load_weights_from_epoch = 10
6 |
7 | # input image
8 | IMAGE_HEIGHT = 416
9 | IMAGE_WIDTH = 416
10 | CHANNELS = 3
11 |
12 | # Dataset
13 | CATEGORY_NUM = 80
14 | ANCHOR_NUM_EACH_SCALE = 3
15 | COCO_ANCHORS = [[116, 90], [156, 198], [373, 326], [30, 61], [62, 45], [59, 119], [10, 13], [16, 30], [33, 23]]
16 | COCO_ANCHOR_INDEX = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
17 | SCALE_SIZE = [13, 26, 52]
18 |
19 | use_dataset = "pascal_voc" # "custom", "pascal_voc", "coco"
20 |
21 | PASCAL_VOC_DIR = "./dataset/VOCdevkit/VOC2012/"
22 | PASCAL_VOC_ANNOTATION = PASCAL_VOC_DIR + "Annotations"
23 | PASCAL_VOC_IMAGE = PASCAL_VOC_DIR + "JPEGImages"
24 | # The 20 object classes of PASCAL VOC
25 | PASCAL_VOC_CLASSES = {"person": 1, "bird": 2, "cat": 3, "cow": 4, "dog": 5,
26 | "horse": 6, "sheep": 7, "aeroplane": 8, "bicycle": 9,
27 | "boat": 10, "bus": 11, "car": 12, "motorbike": 13,
28 | "train": 14, "bottle": 15, "chair": 16, "diningtable": 17,
29 | "pottedplant": 18, "sofa": 19, "tvmonitor": 20}
30 |
31 | COCO_DIR = "./dataset/COCO/2017/"
32 | COCO_CLASSES = {"person": 1, "bicycle": 2, "car": 3, "motorcycle": 4, "airplane": 5,
33 | "bus": 6, "train": 7, "truck": 8, "boat": 9, "traffic light": 10,
34 | "fire hydrant": 11, "stop sign": 12, "parking meter": 13, "bench": 14,
35 | "bird": 15, "cat": 16, "dog": 17, "horse": 18, "sheep": 19, "cow": 20,
36 | "elephant": 21, "bear": 22, "zebra": 23, "giraffe": 24, "backpack": 25,
37 | "umbrella": 26, "handbag": 27, "tie": 28, "suitcase": 29, "frisbee": 30,
38 | "skis": 31, "snowboard": 32, "sports ball": 33, "kite": 34, "baseball bat": 35,
39 | "baseball glove": 36, "skateboard": 37, "surfboard": 38, "tennis racket": 39,
40 | "bottle": 40, "wine glass": 41, "cup": 42, "fork": 43, "knife": 44, "spoon": 45,
41 | "bowl": 46, "banana": 47, "apple": 48, "sandwich": 49, "orange": 50, "broccoli": 51,
42 | "carrot": 52, "hot dog": 53, "pizza": 54, "donut": 55, "cake": 56, "chair": 57,
43 | "couch": 58, "potted plant": 59, "bed": 60, "dining table": 61, "toilet": 62,
44 | "tv": 63, "laptop": 64, "mouse": 65, "remote": 66, "keyboard": 67, "cell phone": 68,
45 | "microwave": 69, "oven": 70, "toaster": 71, "sink": 72, "refrigerator": 73,
46 | "book": 74, "clock": 75, "vase": 76, "scissors": 77, "teddy bear": 78,
47 | "hair drier": 79, "toothbrush": 80}
48 |
49 |
50 |
51 | TXT_DIR = "./data_process/data.txt"
52 |
53 | custom_dataset_dir = ""
54 | custom_dataset_classes = {}
55 |
56 |
57 |
58 | # loss
59 | IGNORE_THRESHOLD = 0.5
60 |
61 |
62 | # NMS
63 | CONFIDENCE_THRESHOLD = 0.6
64 | IOU_THRESHOLD = 0.5
65 | MAX_BOX_NUM = 50
66 |
67 | MAX_TRUE_BOX_NUM_PER_IMG = 20
68 |
69 |
70 | # save model
71 | save_model_dir = "saved_model/"
72 | save_frequency = 5
73 |
74 | # tensorflow lite model
75 | TFLite_model_dir = "yolov3_model.tflite"
76 |
77 | test_images_during_training = True
78 | training_results_save_dir = "./test_results_during_training/"
79 | test_images = ["", ""]
80 |
81 | test_picture_dir = "./test_data/1.jpg"
82 | test_video_dir = "./test_data/test_video.mp4"
83 | temp_frame_dir = "./test_data/temp.jpg"
--------------------------------------------------------------------------------
/convert_to_tflite.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from configuration import CATEGORY_NUM, save_model_dir, IMAGE_HEIGHT, IMAGE_WIDTH, CHANNELS, TFLite_model_dir
4 | from yolo.yolo_v3 import YOLOV3
5 |
6 | if __name__ == '__main__':
7 | # GPU settings
8 | gpus = tf.config.list_physical_devices(device_type="GPU")
9 | if gpus:
10 | for gpu in gpus:
11 | tf.config.experimental.set_memory_growth(device=gpu, enable=True)
12 |
13 | # load model
14 | yolo_v3 = YOLOV3(out_channels=3 * (CATEGORY_NUM + 5))
15 | yolo_v3.load_weights(filepath=save_model_dir+"saved_model")
16 | yolo_v3._set_inputs(inputs=tf.random.normal(shape=(1, IMAGE_HEIGHT, IMAGE_WIDTH, CHANNELS)))
17 |
18 | converter = tf.lite.TFLiteConverter.from_keras_model(yolo_v3)
19 | tflite_model = converter.convert()
20 | open(TFLite_model_dir, "wb").write(tflite_model)
--------------------------------------------------------------------------------
/data_process/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/calmiLovesAI/YOLOv3_TensorFlow2/7789280e4974f62b20304f9746aa4121be4c5333/data_process/__init__.py
--------------------------------------------------------------------------------
/data_process/make_dataset.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from data_process.read_txt import ReadTxt
3 | from configuration import BATCH_SIZE, TXT_DIR
4 | import numpy as np
5 |
6 |
7 | def get_length_of_dataset(dataset):
8 | count = 0
9 | for _ in dataset:
10 | count += 1
11 | return count
12 |
13 |
14 | def generate_dataset():
15 | txt_dataset = tf.data.TextLineDataset(filenames=TXT_DIR)
16 |
17 | train_count = get_length_of_dataset(txt_dataset)
18 | train_dataset = txt_dataset.batch(batch_size=BATCH_SIZE)
19 |
20 | return train_dataset, train_count
21 |
22 |
23 | # Return :
24 | # image_name_list : list, length is N (N is the batch size.)
25 | # boxes_array : numpy.ndarrray, shape is (N, MAX_TRUE_BOX_NUM_PER_IMG, 5)
26 | def parse_dataset_batch(dataset):
27 | image_name_list = []
28 | boxes_list = []
29 | len_of_batch = dataset.shape[0]
30 | for i in range(len_of_batch):
31 | image_name, boxes = ReadTxt(line_bytes=dataset[i].numpy()).parse_line()
32 | image_name_list.append(image_name)
33 | boxes_list.append(boxes)
34 | boxes_array = np.array(boxes_list)
35 | return image_name_list, boxes_array
36 |
--------------------------------------------------------------------------------
/data_process/parse_coco.py:
--------------------------------------------------------------------------------
1 | from configuration import COCO_DIR, COCO_CLASSES
2 | import json
3 | from pathlib import Path
4 | import time
5 |
6 | from utils.resize_image import ResizeWithPad
7 |
8 |
9 | class ParseCOCO(object):
10 | def __init__(self):
11 | self.annotation_dir = COCO_DIR + "annotations/"
12 | self.images_dir = COCO_DIR + "train2017/"
13 | self.train_annotation = Path(self.annotation_dir + "instances_train2017.json")
14 | start_time = time.time()
15 | self.train_dict = self.__load_json(self.train_annotation)
16 | print("It took {:.2f} seconds to load the json files.".format(time.time() - start_time))
17 | print(self.__get_category_id_information(self.train_dict))
18 |
19 | def __load_json(self, json_file):
20 | print("Start loading {}...".format(json_file.name))
21 | with json_file.open(mode='r') as f:
22 | load_dict = json.load(f)
23 | print("Loading is complete!")
24 | return load_dict
25 |
26 | def __find_all(self, x, value):
27 | list_data = []
28 | for i in range(len(x)):
29 | if x[i] == value:
30 | list_data.append(i)
31 | return list_data
32 |
33 | def __get_image_information(self, data_dict):
34 | images = data_dict["images"]
35 | image_file_list = []
36 | image_id_list = []
37 | image_height_list = []
38 | image_width_list = []
39 | for image in images:
40 | image_file_list.append(image["file_name"])
41 | image_id_list.append(image["id"])
42 | image_height_list.append(image["height"])
43 | image_width_list.append(image["width"])
44 | return image_file_list, image_id_list, image_height_list, image_width_list
45 |
46 | def __get_bounding_box_information(self, data_dict):
47 | annotations = data_dict["annotations"]
48 | image_id_list = []
49 | bbox_list = []
50 | category_id_list = []
51 | for annotation in annotations:
52 | category_id_list.append(annotation["category_id"])
53 | image_id_list.append(annotation["image_id"])
54 | bbox_list.append(annotation["bbox"])
55 | return image_id_list, bbox_list, category_id_list
56 |
57 | def __get_category_id_information(self, data_dict):
58 | categories = data_dict["categories"]
59 | category_dict = {}
60 | for category in categories:
61 | category_dict[category["name"]] = category["id"]
62 | return category_dict
63 |
64 | def __process_coord(self, h, w, x_min, y_min, x_max, y_max):
65 | x_min, y_min, x_max, y_max = ResizeWithPad(h=h, w=w).raw_to_resized(x_min=x_min, y_min=y_min, x_max=x_max, y_max=y_max)
66 | return int(x_min), int(y_min), int(x_max), int(y_max)
67 |
68 | def __bbox_information(self, image_id, image_ids_from_annotation, bboxes, image_height, image_width, category_ids):
69 | processed_bboxes = []
70 | index_list = self.__find_all(x=image_ids_from_annotation, value=image_id)
71 | for index in index_list:
72 | x, y, w, h = bboxes[index]
73 | xmax = int(x + w)
74 | ymax = int(y + h)
75 | x_min, y_min, x_max, y_max = self.__process_coord(h=image_height, w=image_width, x_min=x, y_min=y, x_max=xmax, y_max=ymax)
76 | processed_bboxes.append([x_min, y_min, x_max, y_max, self.__category_id_transform(category_ids[index])])
77 | return processed_bboxes
78 |
79 | def __category_id_transform(self, original_id):
80 | category_id_dict = self.__get_category_id_information(self.train_dict)
81 | original_name = "none"
82 | for category_name, category_id in category_id_dict.items():
83 | if category_id == original_id:
84 | original_name = category_name
85 | if original_name == "none":
86 | raise ValueError("An error occurred while transforming the category id.")
87 | return COCO_CLASSES[original_name]
88 |
89 | def __bbox_str(self, bboxes):
90 | bbox_info = ""
91 | for bbox in bboxes:
92 | for item in bbox:
93 | bbox_info += str(item)
94 | bbox_info += " "
95 | return bbox_info.strip()
96 |
97 | def write_data_to_txt(self, txt_dir):
98 | image_files, image_ids, image_heights, image_widths = self.__get_image_information(self.train_dict)
99 | image_ids_from_annotation, bboxes, category_ids = self.__get_bounding_box_information(self.train_dict)
100 | with open(file=txt_dir, mode="a+") as f:
101 | picture_index = 0
102 | for i in range(len(image_files)):
103 | write_line_start_time = time.time()
104 | line_info = ""
105 | line_info += image_files[i] + " "
106 | processed_bboxes = self.__bbox_information(image_ids[i],
107 | image_ids_from_annotation,
108 | bboxes,
109 | image_heights[i],
110 | image_widths[i],
111 | category_ids)
112 | if processed_bboxes:
113 | picture_index += 1
114 | line_info += self.__bbox_str(bboxes=processed_bboxes)
115 | line_info += "\n"
116 | print("Writing information of the {}th picture {} to {}, which took {:.2f}s".format(picture_index, image_files[i], txt_dir, time.time() - write_line_start_time))
117 | f.write(line_info)
118 |
119 |
120 |
121 |
--------------------------------------------------------------------------------
/data_process/parse_voc.py:
--------------------------------------------------------------------------------
1 | import xml.dom.minidom as xdom
2 | from configuration import PASCAL_VOC_CLASSES, PASCAL_VOC_ANNOTATION, PASCAL_VOC_IMAGE
3 | import os
4 | from utils.resize_image import ResizeWithPad
5 |
6 |
7 | class ParsePascalVOC(object):
8 | def __init__(self):
9 | super(ParsePascalVOC, self).__init__()
10 | self.all_xml_dir = PASCAL_VOC_ANNOTATION
11 | self.all_image_dir = PASCAL_VOC_IMAGE
12 |
13 | def __str_to_int(self, x):
14 | return int(float(x))
15 |
16 | def __process_coord(self, h, w, x_min, y_min, x_max, y_max):
17 | h = self.__str_to_int(h)
18 | w = self.__str_to_int(w)
19 | x_min = self.__str_to_int(x_min)
20 | y_min = self.__str_to_int(y_min)
21 | x_max = self.__str_to_int(x_max)
22 | y_max = self.__str_to_int(y_max)
23 |
24 | x_min, y_min, x_max, y_max = ResizeWithPad(h=h, w=w).raw_to_resized(x_min=x_min, y_min=y_min, x_max=x_max, y_max=y_max)
25 |
26 | return int(x_min), int(y_min), int(x_max), int(y_max)
27 |
28 | # parse one xml file
29 | def __parse_xml(self, xml):
30 | obj_and_box_list = []
31 | DOMTree = xdom.parse(os.path.join(self.all_xml_dir, xml))
32 | annotation = DOMTree.documentElement
33 | image_name = annotation.getElementsByTagName("filename")[0].childNodes[0].data
34 | size = annotation.getElementsByTagName("size")
35 | image_height = 0
36 | image_width = 0
37 | for s in size:
38 | image_height = s.getElementsByTagName("height")[0].childNodes[0].data
39 | image_width = s.getElementsByTagName("width")[0].childNodes[0].data
40 |
41 | obj = annotation.getElementsByTagName("object")
42 | for o in obj:
43 | o_list = []
44 | obj_name = o.getElementsByTagName("name")[0].childNodes[0].data
45 | bndbox = o.getElementsByTagName("bndbox")
46 | for box in bndbox:
47 | xmin = box.getElementsByTagName("xmin")[0].childNodes[0].data
48 | ymin = box.getElementsByTagName("ymin")[0].childNodes[0].data
49 | xmax = box.getElementsByTagName("xmax")[0].childNodes[0].data
50 | ymax = box.getElementsByTagName("ymax")[0].childNodes[0].data
51 | xmin, ymin, xmax, ymax = self.__process_coord(image_height, image_width, xmin, ymin, xmax, ymax)
52 | o_list.append(xmin)
53 | o_list.append(ymin)
54 | o_list.append(xmax)
55 | o_list.append(ymax)
56 | break
57 | o_list.append(PASCAL_VOC_CLASSES[obj_name])
58 | obj_and_box_list.append(o_list)
59 | return image_name, obj_and_box_list
60 |
61 | def __combine_info(self, image_name, box_list):
62 | line_str = image_name
63 | line_str += " "
64 | for box in box_list:
65 | for item in box:
66 | item_str = str(item)
67 | line_str += item_str
68 | line_str += " "
69 | line_str = line_str.strip()
70 | return line_str
71 |
72 | def write_data_to_txt(self, txt_dir):
73 | for item in os.listdir(self.all_xml_dir):
74 | image_name, box_list = self.__parse_xml(xml=item)
75 | print("Writing information of picture {} to {}".format(image_name, txt_dir))
76 | # Combine the information into one line.
77 | line_info = self.__combine_info(image_name, box_list)
78 | line_info += "\n"
79 | with open(txt_dir, mode="a+") as f:
80 | f.write(line_info)
81 |
--------------------------------------------------------------------------------
/data_process/read_txt.py:
--------------------------------------------------------------------------------
1 | from configuration import MAX_TRUE_BOX_NUM_PER_IMG
2 |
3 |
4 | class ReadTxt(object):
5 | def __init__(self, line_bytes):
6 | super(ReadTxt, self).__init__()
7 | # bytes -> string
8 | self.line_str = bytes.decode(line_bytes, encoding="utf-8")
9 |
10 | def parse_line(self):
11 | line_info = self.line_str.strip('\n')
12 | split_line = line_info.split(" ")
13 | box_num = (len(split_line) - 1) / 5
14 | image_name = split_line[0]
15 | # print("Reading {}".format(image_name))
16 | split_line = split_line[1:]
17 | boxes = []
18 | for i in range(MAX_TRUE_BOX_NUM_PER_IMG):
19 | if i < box_num:
20 | box_xmin = int(float(split_line[i * 5]))
21 | box_ymin = int(float(split_line[i * 5 + 1]))
22 | box_xmax = int(float(split_line[i * 5 + 2]))
23 | box_ymax = int(float(split_line[i * 5 + 3]))
24 | class_id = int(split_line[i * 5 + 4])
25 | boxes.append([box_xmin, box_ymin, box_xmax, box_ymax, class_id])
26 | else:
27 | box_xmin = 0
28 | box_ymin = 0
29 | box_xmax = 0
30 | box_ymax = 0
31 | class_id = 0
32 | boxes.append([box_xmin, box_ymin, box_xmax, box_ymax, class_id])
33 |
34 | return image_name, boxes
35 |
36 |
--------------------------------------------------------------------------------
/dataset/README.md:
--------------------------------------------------------------------------------
1 | Dataset
--------------------------------------------------------------------------------
/detect_objects_in_video.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | import cv2
3 | from configuration import test_video_dir, temp_frame_dir, CATEGORY_NUM, save_model_dir
4 | from test_on_single_image import single_image_inference
5 | from yolo.yolo_v3 import YOLOV3
6 |
7 |
8 | def frame_detection(frame, model):
9 | cv2.imwrite(filename=temp_frame_dir, img=frame)
10 | frame = single_image_inference(image_dir=temp_frame_dir, model=model)
11 | return frame
12 |
13 |
14 | if __name__ == '__main__':
15 | # GPU settings
16 | gpus = tf.config.experimental.list_physical_devices('GPU')
17 | if gpus:
18 | for gpu in gpus:
19 | tf.config.experimental.set_memory_growth(gpu, True)
20 |
21 | # load model
22 | yolo_v3 = YOLOV3(out_channels=3 * (CATEGORY_NUM + 5))
23 | yolo_v3.load_weights(filepath=save_model_dir+"saved_model")
24 |
25 | capture = cv2.VideoCapture(test_video_dir)
26 | fps = capture.get(cv2.CAP_PROP_FPS)
27 | while True:
28 | ret, frame = capture.read()
29 | if ret:
30 | new_frame = frame_detection(frame, yolo_v3)
31 | cv2.namedWindow("detect result", flags=cv2.WINDOW_NORMAL)
32 | cv2.imshow("detect result", new_frame)
33 | cv2.waitKey(int(1000 / fps))
34 | else:
35 | break
36 | capture.release()
37 | cv2.destroyAllWindows()
--------------------------------------------------------------------------------
/parse_cfg.py:
--------------------------------------------------------------------------------
1 | from configuration import PASCAL_VOC_DIR, PASCAL_VOC_CLASSES, \
2 | custom_dataset_classes, custom_dataset_dir, use_dataset, COCO_CLASSES, COCO_DIR
3 |
4 |
5 | class ParseCfg():
6 |
7 | def get_images_dir(self):
8 | if use_dataset == "custom":
9 | return custom_dataset_dir
10 | elif use_dataset == "pascal_voc":
11 | return PASCAL_VOC_DIR + "JPEGImages"
12 | elif use_dataset == "coco":
13 | return COCO_DIR + "train2017"
14 |
15 | def get_classes(self):
16 | if use_dataset == "custom":
17 | return custom_dataset_classes
18 | elif use_dataset == "pascal_voc":
19 | return PASCAL_VOC_CLASSES
20 | elif use_dataset == "coco":
21 | return COCO_CLASSES
22 |
23 |
24 |
--------------------------------------------------------------------------------
/saved_model/README.md:
--------------------------------------------------------------------------------
1 | The model will be saved here.
--------------------------------------------------------------------------------
/test_data/README.md:
--------------------------------------------------------------------------------
1 | Test pictures and videos
--------------------------------------------------------------------------------
/test_on_single_image.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | import cv2
3 | from configuration import test_picture_dir, save_model_dir, CHANNELS, CATEGORY_NUM
4 | from parse_cfg import ParseCfg
5 | from yolo.inference import Inference
6 | from yolo.yolo_v3 import YOLOV3
7 | from utils.preprocess import resize_image_with_pad
8 |
9 |
10 | def find_class_name(class_id):
11 | for k, v in ParseCfg().get_classes().items():
12 | if v == class_id:
13 | return k
14 |
15 |
16 | # shape of boxes : (N, 4) (xmin, ymin, xmax, ymax)
17 | # shape of scores : (N,)
18 | # shape of classes : (N,)
19 | def draw_boxes_on_image(image, boxes, scores, classes):
20 |
21 | num_boxes = boxes.shape[0]
22 | for i in range(num_boxes):
23 | class_and_score = str(find_class_name(classes[i] + 1)) + ": " + str(scores[i].numpy())
24 | cv2.rectangle(img=image, pt1=(boxes[i, 0], boxes[i, 1]), pt2=(boxes[i, 2], boxes[i, 3]), color=(255, 0, 0), thickness=2)
25 | cv2.putText(img=image, text=class_and_score, org=(boxes[i, 0], boxes[i, 1] - 10), fontFace=cv2.FONT_HERSHEY_COMPLEX, fontScale=1.5, color=(0, 255, 255), thickness=2)
26 | return image
27 |
28 |
29 | def single_image_inference(image_dir, model):
30 | image = tf.io.decode_image(contents=tf.io.read_file(image_dir), channels=CHANNELS)
31 | h = image.shape[0]
32 | w = image.shape[1]
33 | input_image_shape = tf.constant([h, w], dtype=tf.dtypes.float32)
34 | img_tensor = resize_image_with_pad(image)
35 | img_tensor = tf.dtypes.cast(img_tensor, dtype=tf.dtypes.float32)
36 | # img_tensor = img_tensor / 255.0
37 | yolo_output = model(img_tensor, training=False)
38 | boxes, scores, classes = Inference(yolo_output=yolo_output, input_image_shape=input_image_shape).get_final_boxes()
39 | image_with_boxes = draw_boxes_on_image(cv2.imread(image_dir), boxes, scores, classes)
40 | return image_with_boxes
41 |
42 |
43 | if __name__ == '__main__':
44 | # GPU settings
45 | gpus = tf.config.list_physical_devices(device_type="GPU")
46 | if gpus:
47 | for gpu in gpus:
48 | tf.config.experimental.set_memory_growth(device=gpu, enable=True)
49 |
50 | # load model
51 | yolo_v3 = YOLOV3(out_channels=3 * (CATEGORY_NUM + 5))
52 | yolo_v3.load_weights(filepath=save_model_dir+"saved_model")
53 | # inference
54 | image = single_image_inference(image_dir=test_picture_dir, model=yolo_v3)
55 |
56 | cv2.namedWindow("detect result", flags=cv2.WINDOW_NORMAL)
57 | cv2.imshow("detect result", image)
58 | cv2.waitKey(0)
--------------------------------------------------------------------------------
/test_results_during_training/README.md:
--------------------------------------------------------------------------------
1 | The test results on the sample images during training will be saved here.
--------------------------------------------------------------------------------
/train_from_scratch.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 | from utils.visualize import visualize_training_results
4 | from yolo.yolo_v3 import YOLOV3
5 | from configuration import CATEGORY_NUM, IMAGE_HEIGHT, IMAGE_WIDTH, CHANNELS, EPOCHS, BATCH_SIZE, \
6 | save_model_dir, save_frequency, load_weights_before_training, load_weights_from_epoch, \
7 | test_images_during_training, test_images
8 | from yolo.loss import YoloLoss
9 | from data_process.make_dataset import generate_dataset, parse_dataset_batch
10 | from yolo.make_label import GenerateLabel
11 | from utils.preprocess import process_image_filenames
12 |
13 |
14 | def print_model_summary(network):
15 | network.build(input_shape=(None, IMAGE_HEIGHT, IMAGE_WIDTH, CHANNELS))
16 | network.summary()
17 |
18 |
19 | def generate_label_batch(true_boxes):
20 | true_label = GenerateLabel(true_boxes=true_boxes, input_shape=[IMAGE_HEIGHT, IMAGE_WIDTH]).generate_label()
21 | return true_label
22 |
23 |
24 | if __name__ == '__main__':
25 | # GPU settings
26 | gpus = tf.config.list_physical_devices(device_type="GPU")
27 | if gpus:
28 | for gpu in gpus:
29 | tf.config.experimental.set_memory_growth(device=gpu, enable=True)
30 |
31 | # dataset
32 | train_dataset, train_count = generate_dataset()
33 |
34 | net = YOLOV3(out_channels=3 * (CATEGORY_NUM + 5))
35 | print_model_summary(network=net)
36 |
37 | if load_weights_before_training:
38 | net.load_weights(filepath=save_model_dir+"epoch-{}".format(load_weights_from_epoch))
39 | print("Successfully load weights!")
40 | else:
41 | load_weights_from_epoch = -1
42 |
43 | # loss and optimizer
44 | yolo_loss = YoloLoss()
45 | lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
46 | initial_learning_rate=0.001,
47 | decay_steps=3000,
48 | decay_rate=0.96,
49 | staircase=True
50 | )
51 | optimizer = tf.optimizers.Adam(learning_rate=lr_schedule)
52 |
53 |
54 | # metrics
55 | loss_metric = tf.metrics.Mean()
56 |
57 | def train_step(image_batch, label_batch):
58 | with tf.GradientTape() as tape:
59 | yolo_output = net(image_batch, training=True)
60 | loss = yolo_loss(y_true=label_batch, y_pred=yolo_output)
61 | gradients = tape.gradient(loss, net.trainable_variables)
62 | optimizer.apply_gradients(grads_and_vars=zip(gradients, net.trainable_variables))
63 | loss_metric.update_state(values=loss)
64 |
65 |
66 | for epoch in range(load_weights_from_epoch + 1, EPOCHS):
67 | step = 0
68 | for dataset_batch in train_dataset:
69 | step += 1
70 | images, boxes = parse_dataset_batch(dataset=dataset_batch)
71 | labels = generate_label_batch(true_boxes=boxes)
72 | train_step(image_batch=process_image_filenames(images), label_batch=labels)
73 | print("Epoch: {}/{}, step: {}/{}, loss: {:.5f}".format(epoch,
74 | EPOCHS,
75 | step,
76 | tf.math.ceil(train_count / BATCH_SIZE),
77 | loss_metric.result()))
78 |
79 | loss_metric.reset_states()
80 |
81 | if epoch % save_frequency == 0:
82 | net.save_weights(filepath=save_model_dir+"epoch-{}".format(epoch), save_format='tf')
83 |
84 | if test_images_during_training:
85 | visualize_training_results(pictures=test_images, model=net, epoch=epoch)
86 |
87 | net.save_weights(filepath=save_model_dir+"saved_model", save_format='tf')
--------------------------------------------------------------------------------
/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/calmiLovesAI/YOLOv3_TensorFlow2/7789280e4974f62b20304f9746aa4121be4c5333/utils/__init__.py
--------------------------------------------------------------------------------
/utils/iou.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 |
3 |
4 | # Box_1 and box_2 have different center points, and their last dimension is 4 (x, y, w, h).
5 | class IOUDifferentXY():
6 | def __init__(self, box_1, box_2):
7 | super(IOUDifferentXY, self).__init__()
8 | self.box_1_min, self.box_1_max = IOUDifferentXY.__get_box_min_and_max(box_1)
9 | self.box_2_min, self.box_2_max = IOUDifferentXY.__get_box_min_and_max(box_2)
10 | self.box_1_area = IOUDifferentXY.__get_box_area(box_1)
11 | self.box_2_area = IOUDifferentXY.__get_box_area(box_2)
12 |
13 | @staticmethod
14 | def __get_box_min_and_max(box):
15 | box_xy = box[..., 0:2]
16 | box_wh = box[..., 2:4]
17 | box_min = box_xy - box_wh / 2
18 | box_max = box_xy + box_wh / 2
19 | return box_min, box_max
20 |
21 | @staticmethod
22 | def __get_box_area(box):
23 | return box[..., 2] * box[..., 3]
24 |
25 | def calculate_iou(self):
26 | intersect_min = np.maximum(self.box_1_min, self.box_2_min)
27 | intersect_max = np.minimum(self.box_1_max, self.box_2_max)
28 | intersect_wh = np.maximum(intersect_max - intersect_min, 0.0)
29 | intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
30 | union_area = self.box_1_area + self.box_2_area - intersect_area
31 | iou = intersect_area / union_area
32 | return iou
33 |
34 |
35 | # Calculate the IOU between two boxes, both center points are (0, 0).
36 | # The shape of anchors : [1, 9, 2]
37 | # The shape of boxes : [N, 1, 2]
38 | class IOUSameXY():
39 | def __init__(self, anchors, boxes):
40 | super(IOUSameXY, self).__init__()
41 | self.anchor_max = anchors / 2
42 | self.anchor_min = - self.anchor_max
43 | self.box_max = boxes / 2
44 | self.box_min = - self.box_max
45 | self.anchor_area = anchors[..., 0] * anchors[..., 1]
46 | self.box_area = boxes[..., 0] * boxes[..., 1]
47 |
48 | def calculate_iou(self):
49 | intersect_min = np.maximum(self.box_min, self.anchor_min)
50 | intersect_max = np.minimum(self.box_max, self.anchor_max)
51 | intersect_wh = np.maximum(intersect_max - intersect_min + 1.0, 0.0)
52 | intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1] # w * h
53 | union_area = self.anchor_area + self.box_area - intersect_area
54 | iou = intersect_area / union_area # shape : [N, 9]
55 |
56 | return iou
57 |
58 |
59 |
--------------------------------------------------------------------------------
/utils/nms.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from configuration import IOU_THRESHOLD, CONFIDENCE_THRESHOLD, MAX_BOX_NUM, CATEGORY_NUM
3 |
4 |
5 | class NMS():
6 | def __init__(self):
7 | super(NMS, self).__init__()
8 | self.max_box_num = MAX_BOX_NUM
9 | self.num_class = CATEGORY_NUM
10 |
11 | def nms(self, boxes, box_scores):
12 | mask = box_scores >= CONFIDENCE_THRESHOLD
13 | box_list = []
14 | score_list = []
15 | class_list = []
16 | for i in range(self.num_class):
17 | box_of_class = tf.boolean_mask(boxes, mask[:, i])
18 | score_of_class = tf.boolean_mask(box_scores[:, i], mask[:, i])
19 | selected_indices = tf.image.non_max_suppression(boxes=box_of_class,
20 | scores=score_of_class,
21 | max_output_size=self.max_box_num,
22 | iou_threshold=IOU_THRESHOLD)
23 | selected_boxes = tf.gather(box_of_class, selected_indices)
24 | selected_scores = tf.gather(score_of_class, selected_indices)
25 | classes = tf.ones_like(selected_scores, dtype=tf.dtypes.int32) * i
26 | box_list.append(selected_boxes)
27 | score_list.append(selected_scores)
28 | class_list.append(classes)
29 | box_array = tf.concat(values=box_list, axis=0)
30 | score_array = tf.concat(values=score_list, axis=0)
31 | class_array = tf.concat(values=class_list, axis=0)
32 |
33 | return box_array, score_array, class_array
34 |
--------------------------------------------------------------------------------
/utils/preprocess.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from configuration import IMAGE_WIDTH, IMAGE_HEIGHT, CHANNELS
3 | from parse_cfg import ParseCfg
4 | import os
5 |
6 |
7 | def resize_image_with_pad(image):
8 | image_tensor = tf.image.resize_with_pad(image=image, target_height=IMAGE_HEIGHT, target_width=IMAGE_WIDTH)
9 | image_tensor = tf.cast(image_tensor, tf.float32)
10 | image_tensor = image_tensor / 255.0
11 | image_tensor = tf.expand_dims(image_tensor, axis=0)
12 | return image_tensor
13 |
14 |
15 | def process_single_image(image_filename):
16 | img_raw = tf.io.read_file(image_filename)
17 | image = tf.io.decode_jpeg(img_raw, channels=CHANNELS)
18 | image = resize_image_with_pad(image=image)
19 | image = tf.dtypes.cast(image, dtype=tf.dtypes.float32)
20 | image = image / 255.0
21 | return image
22 |
23 |
24 | def process_image_filenames(filenames):
25 | image_list = []
26 | for filename in filenames:
27 | image_path = os.path.join(ParseCfg().get_images_dir(), filename)
28 | image_tensor = process_single_image(image_path)
29 | image_list.append(image_tensor)
30 | return tf.concat(values=image_list, axis=0)
31 |
32 |
--------------------------------------------------------------------------------
/utils/resize_image.py:
--------------------------------------------------------------------------------
1 | from configuration import IMAGE_HEIGHT, IMAGE_WIDTH
2 |
3 |
4 | class ResizeWithPad():
5 | def __init__(self, h, w):
6 | super(ResizeWithPad, self).__init__()
7 | self.H = IMAGE_HEIGHT
8 | self.W = IMAGE_WIDTH
9 | self.h = h
10 | self.w = w
11 |
12 | def get_transform_coefficient(self):
13 | if self.h <= self.w:
14 | longer_edge = "w"
15 | scale = self.W / self.w
16 | padding_length = (self.H - self.h * scale) / 2
17 | else:
18 | longer_edge = "h"
19 | scale = self.H / self.h
20 | padding_length = (self.W - self.w * scale) / 2
21 | return longer_edge, scale, padding_length
22 |
23 | def raw_to_resized(self, x_min, y_min, x_max, y_max):
24 | longer_edge, scale, padding_length = self.get_transform_coefficient()
25 | x_min = x_min * scale
26 | x_max = x_max * scale
27 | y_min = y_min * scale
28 | y_max = y_max * scale
29 | if longer_edge == "h":
30 | x_min += padding_length
31 | x_max += padding_length
32 | else:
33 | y_min += padding_length
34 | y_max += padding_length
35 | return x_min, y_min, x_max, y_max
36 |
37 | def resized_to_raw(self, center_x, center_y, width, height):
38 | longer_edge, scale, padding_length = self.get_transform_coefficient()
39 | center_x *= self.W
40 | width *= self.W
41 | center_y *= self.H
42 | height *= self.H
43 | if longer_edge == "h":
44 | center_x -= padding_length
45 | else:
46 | center_y -= padding_length
47 | center_x = center_x / scale
48 | center_y = center_y / scale
49 | width = width / scale
50 | height = height / scale
51 | return center_x, center_y, width, height
--------------------------------------------------------------------------------
/utils/visualize.py:
--------------------------------------------------------------------------------
1 | import cv2
2 | from test_on_single_image import single_image_inference
3 | from configuration import training_results_save_dir
4 |
5 |
6 | def visualize_training_results(pictures, model, epoch):
7 | # pictures : List of image directories.
8 | index = 0
9 | for picture in pictures:
10 | index += 1
11 | result = single_image_inference(image_dir=picture, model=model)
12 | cv2.imwrite(filename=training_results_save_dir + "epoch-{}-picture-{}.jpg".format(epoch, index), img=result)
13 |
14 |
--------------------------------------------------------------------------------
/write_coco_to_txt.py:
--------------------------------------------------------------------------------
1 | from data_process.parse_coco import ParseCOCO
2 | from configuration import TXT_DIR
3 |
4 |
5 | if __name__ == '__main__':
6 | coco = ParseCOCO()
7 | coco.write_data_to_txt(txt_dir=TXT_DIR)
--------------------------------------------------------------------------------
/write_voc_to_txt.py:
--------------------------------------------------------------------------------
1 | from data_process.parse_voc import ParsePascalVOC
2 | from configuration import TXT_DIR
3 |
4 |
5 | if __name__ == '__main__':
6 | ParsePascalVOC().write_data_to_txt(txt_dir=TXT_DIR)
--------------------------------------------------------------------------------
/yolo/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/calmiLovesAI/YOLOv3_TensorFlow2/7789280e4974f62b20304f9746aa4121be4c5333/yolo/__init__.py
--------------------------------------------------------------------------------
/yolo/anchor.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from configuration import COCO_ANCHORS, COCO_ANCHOR_INDEX
3 |
4 |
5 | def get_coco_anchors(scale_type):
6 | index_list = COCO_ANCHOR_INDEX[scale_type]
7 | return tf.convert_to_tensor(COCO_ANCHORS[index_list[0]: index_list[-1] + 1], dtype=tf.dtypes.float32)
--------------------------------------------------------------------------------
/yolo/bounding_box.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from configuration import ANCHOR_NUM_EACH_SCALE, CATEGORY_NUM, IMAGE_HEIGHT
3 | from yolo.anchor import get_coco_anchors
4 |
5 |
6 | def generate_grid_index(grid_dim):
7 | x = tf.range(grid_dim, dtype=tf.dtypes.float32)
8 | y = tf.range(grid_dim, dtype=tf.dtypes.float32)
9 | X, Y = tf.meshgrid(x, y)
10 | X = tf.reshape(X, shape=(-1, 1))
11 | Y = tf.reshape(Y, shape=(-1, 1))
12 | return tf.concat(values=[X, Y], axis=-1)
13 |
14 |
15 | def bounding_box_predict(feature_map, scale_type, is_training=False):
16 | h = feature_map.shape[1]
17 | w = feature_map.shape[2]
18 | if h != w:
19 | raise ValueError("The shape[1] and shape[2] of feature map must be the same value.")
20 | area = h * w
21 | pred = tf.reshape(feature_map, shape=(-1, ANCHOR_NUM_EACH_SCALE * area, CATEGORY_NUM + 5))
22 | # pred = tf.nn.sigmoid(pred)
23 | tx_ty, tw_th, confidence, class_prob = tf.split(pred, num_or_size_splits=[2, 2, 1, CATEGORY_NUM], axis=-1)
24 | confidence = tf.nn.sigmoid(confidence)
25 | class_prob = tf.nn.sigmoid(class_prob)
26 | center_index = generate_grid_index(grid_dim=h)
27 | center_index = tf.tile(center_index, [1, ANCHOR_NUM_EACH_SCALE])
28 | center_index = tf.reshape(center_index, shape=(1, -1, 2))
29 | # shape : (1, 507, 2), (1, 2028, 2), (1, 8112, 2)
30 |
31 | center_coord = center_index + tf.nn.sigmoid(tx_ty)
32 | anchors = tf.tile(get_coco_anchors(scale_type) / IMAGE_HEIGHT, [area, 1]) # shape: (507, 2), (2028, 2), (8112, 2)
33 | bw_bh = tf.math.exp(tw_th) * anchors
34 |
35 | box_xy = center_coord / h
36 | box_wh = bw_bh
37 |
38 |
39 | # reshape
40 | center_index = tf.reshape(center_index, shape=(-1, h, w, ANCHOR_NUM_EACH_SCALE, 2))
41 | box_xy = tf.reshape(box_xy, shape=(-1, h, w, ANCHOR_NUM_EACH_SCALE, 2))
42 | box_wh = tf.reshape(box_wh, shape=(-1, h, w, ANCHOR_NUM_EACH_SCALE, 2))
43 | feature_map = tf.reshape(feature_map, shape=(-1, h, w, ANCHOR_NUM_EACH_SCALE, CATEGORY_NUM + 5))
44 |
45 | # cast dtype
46 | center_index = tf.cast(center_index, dtype=tf.dtypes.float32)
47 | box_xy = tf.cast(box_xy, dtype=tf.dtypes.float32)
48 | box_wh = tf.cast(box_wh, dtype=tf.dtypes.float32)
49 |
50 | if is_training:
51 | return box_xy, box_wh, center_index, feature_map
52 | else:
53 | return box_xy, box_wh, confidence, class_prob
54 |
--------------------------------------------------------------------------------
/yolo/inference.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from yolo.bounding_box import bounding_box_predict
3 | from configuration import CATEGORY_NUM, SCALE_SIZE
4 | from utils.nms import NMS
5 | from utils.resize_image import ResizeWithPad
6 |
7 |
8 | class Inference():
9 | def __init__(self, yolo_output, input_image_shape):
10 | super(Inference, self).__init__()
11 | self.yolo_output = yolo_output
12 | self.input_image_h = input_image_shape[0]
13 | self.input_image_w = input_image_shape[1]
14 |
15 | def __yolo_post_processing(self, feature, scale_type):
16 | box_xy, box_wh, confidence, class_prob = bounding_box_predict(feature_map=feature,
17 | scale_type=scale_type,
18 | is_training=False)
19 | boxes = self.__boxes_to_original_image(box_xy, box_wh)
20 | boxes = tf.reshape(boxes, shape=(-1, 4))
21 | box_scores = confidence * class_prob
22 | box_scores = tf.reshape(box_scores, shape=(-1, CATEGORY_NUM))
23 | return boxes, box_scores
24 |
25 | def __boxes_to_original_image(self, box_xy, box_wh):
26 | x = tf.expand_dims(box_xy[..., 0], axis=-1)
27 | y = tf.expand_dims(box_xy[..., 1], axis=-1)
28 | w = tf.expand_dims(box_wh[..., 0], axis=-1)
29 | h = tf.expand_dims(box_wh[..., 1], axis=-1)
30 | x, y, w, h = ResizeWithPad(h=self.input_image_h, w=self.input_image_w).resized_to_raw(center_x=x, center_y=y, width=w, height=h)
31 | xmin = x - w / 2
32 | ymin = y - h / 2
33 | xmax = x + w / 2
34 | ymax = y + h / 2
35 | boxes = tf.concat(values=[xmin, ymin, xmax, ymax], axis=-1)
36 | return boxes
37 |
38 | def get_final_boxes(self):
39 | boxes_list = []
40 | box_scores_list = []
41 | for i in range(len(SCALE_SIZE)):
42 | boxes, box_scores = self.__yolo_post_processing(feature=self.yolo_output[i],
43 | scale_type=i)
44 | boxes_list.append(boxes)
45 | box_scores_list.append(box_scores)
46 | boxes_array = tf.concat(boxes_list, axis=0)
47 | box_scores_array = tf.concat(box_scores_list, axis=0)
48 | return NMS().nms(boxes=boxes_array, box_scores=box_scores_array)
49 |
50 |
--------------------------------------------------------------------------------
/yolo/loss.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | from configuration import SCALE_SIZE, IMAGE_HEIGHT, IMAGE_WIDTH, IGNORE_THRESHOLD
3 | from utils.iou import IOUDifferentXY
4 | from yolo.bounding_box import bounding_box_predict
5 | from yolo.anchor import get_coco_anchors
6 |
7 |
8 | class YoloLoss(tf.keras.losses.Loss):
9 | def __init__(self):
10 | super(YoloLoss, self).__init__()
11 | self.scale_num = len(SCALE_SIZE)
12 |
13 | def call(self, y_true, y_pred):
14 | loss = self.__calculate_loss(y_true=y_true, y_pred=y_pred)
15 | return loss
16 |
17 | def __generate_grid_shape(self):
18 | scale_tensor = tf.convert_to_tensor(SCALE_SIZE, dtype=tf.dtypes.float32)
19 | grid_shape = tf.stack(values=[scale_tensor, scale_tensor], axis=-1)
20 | return grid_shape
21 |
22 | def __get_scale_size(self, scale):
23 | return tf.convert_to_tensor([IMAGE_HEIGHT, IMAGE_WIDTH], dtype=tf.dtypes.float32) / get_coco_anchors(scale_type=scale)
24 |
25 | def __binary_crossentropy_keep_dim(self, y_true, y_pred, from_logits):
26 | x = tf.keras.losses.binary_crossentropy(y_true=y_true, y_pred=y_pred, from_logits=from_logits)
27 | x = tf.expand_dims(x, axis=-1)
28 | return x
29 |
30 | def __calculate_loss(self, y_true, y_pred):
31 | grid_shapes = self.__generate_grid_shape()
32 | total_loss = 0
33 | # batch size
34 | B = y_pred[0].shape[0]
35 | B_int = tf.convert_to_tensor(B, dtype=tf.dtypes.int32) # tf.Tensor(4, shape=(), dtype=int32)
36 | B_float = tf.convert_to_tensor(B, dtype=tf.dtypes.float32) # tf.Tensor(4.0, shape=(), dtype=float32)
37 | for i in range(self.scale_num):
38 | true_object_mask = y_true[i][..., 4:5]
39 | true_object_mask_bool = tf.cast(true_object_mask, dtype=tf.dtypes.bool)
40 | true_class_probs = y_true[i][..., 5:]
41 |
42 | pred_xy, pred_wh, grid, pred_features = bounding_box_predict(feature_map=y_pred[i],
43 | scale_type=i,
44 | is_training=True)
45 |
46 | pred_box = tf.concat(values=[pred_xy, pred_wh], axis=-1)
47 | true_xy_offset = y_true[i][..., 0:2] * grid_shapes[i] - grid
48 | true_wh_offset = tf.math.log(y_true[i][..., 2:4] * self.__get_scale_size(scale=i) + 1e-10)
49 | true_wh_offset = tf.keras.backend.switch(true_object_mask_bool, true_wh_offset, tf.zeros_like(true_wh_offset))
50 |
51 |
52 | box_loss_scale = 2 - y_true[i][..., 2:3] * y_true[i][..., 3:4]
53 |
54 | ignore_mask = tf.TensorArray(dtype=tf.dtypes.float32, size=1, dynamic_size=True)
55 |
56 | def loop_body(b, ignore_mask):
57 | true_box = tf.boolean_mask(y_true[i][b, ..., 0:4], true_object_mask_bool[b, ..., 0])
58 | true_box = tf.cast(true_box, dtype=tf.dtypes.float32)
59 | # expand dim for broadcasting
60 | box_1 = tf.expand_dims(pred_box[b], axis=-2)
61 | box_2 = tf.expand_dims(true_box, axis=0)
62 | iou = IOUDifferentXY(box_1=box_1, box_2=box_2).calculate_iou()
63 | best_iou = tf.keras.backend.max(iou, axis=-1)
64 | ignore_mask = ignore_mask.write(b, tf.cast(best_iou < IGNORE_THRESHOLD, dtype=tf.dtypes.float32))
65 | return b + 1, ignore_mask
66 |
67 | _, ignore_mask = tf.while_loop(lambda b, *args: b < B_int, loop_body, [0, ignore_mask])
68 | ignore_mask = ignore_mask.stack()
69 | ignore_mask = tf.expand_dims(ignore_mask, axis=-1)
70 |
71 | xy_loss = true_object_mask * box_loss_scale * self.__binary_crossentropy_keep_dim(true_xy_offset, pred_features[..., 0:2], from_logits=True)
72 | wh_loss = true_object_mask * box_loss_scale * 0.5 * tf.math.square(true_wh_offset - pred_features[..., 2:4])
73 | confidence_loss = true_object_mask * self.__binary_crossentropy_keep_dim(true_object_mask, pred_features[..., 4:5], from_logits=True) + (1 - true_object_mask) * self.__binary_crossentropy_keep_dim(true_object_mask, pred_features[..., 4:5], from_logits=True) * ignore_mask
74 | class_loss = true_object_mask * self.__binary_crossentropy_keep_dim(true_class_probs, pred_features[..., 5:], from_logits=True)
75 |
76 | average_xy_loss = tf.keras.backend.sum(xy_loss) / B_float
77 | average_wh_loss = tf.keras.backend.sum(wh_loss) / B_float
78 | average_confidence_loss = tf.keras.backend.sum(confidence_loss) / B_float
79 | average_class_loss = tf.keras.backend.sum(class_loss) / B_float
80 | total_loss += average_xy_loss + average_wh_loss + average_confidence_loss + average_class_loss
81 |
82 | return total_loss
83 |
--------------------------------------------------------------------------------
/yolo/make_label.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from configuration import CATEGORY_NUM, SCALE_SIZE, \
3 | COCO_ANCHORS, ANCHOR_NUM_EACH_SCALE, COCO_ANCHOR_INDEX
4 | from utils import iou
5 |
6 |
7 | class GenerateLabel():
8 | def __init__(self, true_boxes, input_shape):
9 | super(GenerateLabel, self).__init__()
10 | self.true_boxes = np.array(true_boxes, dtype=np.float32)
11 | self.input_shape = np.array(input_shape, dtype=np.int32)
12 | self.anchors = np.array(COCO_ANCHORS, dtype=np.float32)
13 | self.batch_size = self.true_boxes.shape[0]
14 |
15 | def generate_label(self):
16 | center_xy = (self.true_boxes[..., 0:2] + self.true_boxes[..., 2:4]) // 2 # shape : [B, N, 2]
17 | box_wh = self.true_boxes[..., 2:4] - self.true_boxes[..., 0:2] # shape : [B, N, 2]
18 | self.true_boxes[..., 0:2] = center_xy / self.input_shape # Normalization
19 | self.true_boxes[..., 2:4] = box_wh / self.input_shape # Normalization
20 | true_label_1 = np.zeros((self.batch_size, SCALE_SIZE[0], SCALE_SIZE[0], ANCHOR_NUM_EACH_SCALE, CATEGORY_NUM + 5))
21 | true_label_2 = np.zeros((self.batch_size, SCALE_SIZE[1], SCALE_SIZE[1], ANCHOR_NUM_EACH_SCALE, CATEGORY_NUM + 5))
22 | true_label_3 = np.zeros((self.batch_size, SCALE_SIZE[2], SCALE_SIZE[2], ANCHOR_NUM_EACH_SCALE, CATEGORY_NUM + 5))
23 | # true_label : list of 3 arrays of type numpy.ndarray(all elements are 0), which shapes are:
24 | # (self.batch_size, 13, 13, 3, 5 + C)
25 | # (self.batch_size, 26, 26, 3, 5 + C)
26 | # (self.batch_size, 52, 52, 3, 5 + C)
27 | true_label = [true_label_1, true_label_2, true_label_3]
28 | # shape : (9, 2) --> (1, 9, 2)
29 | anchors = np.expand_dims(self.anchors, axis=0)
30 | # valid_mask filters out the valid boxes.
31 | valid_mask = box_wh[..., 0] > 0
32 |
33 | for b in range(self.batch_size):
34 | wh = box_wh[b, valid_mask[b]]
35 | if len(wh) == 0:
36 | # For pictures without boxes, iou is not calculated.
37 | continue
38 | # shape of wh : [N, 1, 2], N is the actual number of boxes per picture
39 | wh = np.expand_dims(wh, axis=1)
40 | # Calculate the iou between the box and the anchor, both center points are (0, 0).
41 | iou_value = iou.IOUSameXY(anchors=anchors, boxes=wh).calculate_iou()
42 | # shape of best_anchor : [N]
43 | best_anchor = np.argmax(iou_value, axis=-1)
44 | for i, n in enumerate(best_anchor):
45 | for s in range(ANCHOR_NUM_EACH_SCALE):
46 | if n in COCO_ANCHOR_INDEX[s]:
47 | x = np.floor(self.true_boxes[b, i, 0] * SCALE_SIZE[s]).astype('int32')
48 | y = np.floor(self.true_boxes[b, i, 1] * SCALE_SIZE[s]).astype('int32')
49 | anchor_id = COCO_ANCHOR_INDEX[s].index(n)
50 | class_id = self.true_boxes[b, i, 4].astype('int32')
51 | true_label[s][b, y, x, anchor_id, 0:4] = self.true_boxes[b, i, 0:4]
52 | true_label[s][b, y, x, anchor_id, 4] = 1
53 | true_label[s][b, y, x, anchor_id, 5 + class_id - 1] = 1
54 |
55 | return true_label
56 |
--------------------------------------------------------------------------------
/yolo/yolo_v3.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 |
3 |
4 | class DarkNetConv2D(tf.keras.layers.Layer):
5 | def __init__(self, filters, kernel_size, strides):
6 | super(DarkNetConv2D, self).__init__()
7 | self.conv = tf.keras.layers.Conv2D(filters=filters,
8 | kernel_size=kernel_size,
9 | strides=strides,
10 | padding="same")
11 | self.bn = tf.keras.layers.BatchNormalization()
12 |
13 | def call(self, inputs, training=None, **kwargs):
14 | x = self.conv(inputs)
15 | x = self.bn(x, training=training)
16 | x = tf.nn.leaky_relu(x, alpha=0.1)
17 | return x
18 |
19 |
20 | class ResidualBlock(tf.keras.layers.Layer):
21 | def __init__(self, filters):
22 | super(ResidualBlock, self).__init__()
23 | self.conv1 = DarkNetConv2D(filters=filters, kernel_size=(1, 1), strides=1)
24 | self.conv2 = DarkNetConv2D(filters=filters * 2, kernel_size=(3, 3), strides=1)
25 |
26 | def call(self, inputs, training=None, **kwargs):
27 | x = self.conv1(inputs, training=training)
28 | x = self.conv2(x, training=training)
29 | x = tf.keras.layers.add([x, inputs])
30 | return x
31 |
32 |
33 | def make_residual_block(filters, num_blocks):
34 | x = tf.keras.Sequential()
35 | x.add(DarkNetConv2D(filters=2 * filters, kernel_size=(3, 3), strides=2))
36 | for _ in range(num_blocks):
37 | x.add(ResidualBlock(filters=filters))
38 | return x
39 |
40 |
41 | class DarkNet53(tf.keras.Model):
42 | def __init__(self):
43 | super(DarkNet53, self).__init__()
44 | self.conv1 = DarkNetConv2D(filters=32, kernel_size=(3, 3), strides=1)
45 | self.block1 = make_residual_block(filters=32, num_blocks=1)
46 | self.block2 = make_residual_block(filters=64, num_blocks=2)
47 | self.block3 = make_residual_block(filters=128, num_blocks=8)
48 | self.block4 = make_residual_block(filters=256, num_blocks=8)
49 | self.block5 = make_residual_block(filters=512, num_blocks=4)
50 |
51 | def call(self, inputs, training=None, **kwargs):
52 | x = self.conv1(inputs, training=training)
53 | x = self.block1(x, training=training)
54 | x = self.block2(x, training=training)
55 | output_1 = self.block3(x, training=training)
56 | output_2 = self.block4(output_1, training=training)
57 | output_3 = self.block5(output_2, training=training)
58 | # print(output_1.shape, output_2.shape, output_3.shape)
59 | return output_3, output_2, output_1
60 |
61 |
62 | class YOLOTail(tf.keras.layers.Layer):
63 | def __init__(self, in_channels, out_channels):
64 | super(YOLOTail, self).__init__()
65 | self.conv1 = DarkNetConv2D(filters=in_channels, kernel_size=(1, 1), strides=1)
66 | self.conv2 = DarkNetConv2D(filters=2 * in_channels, kernel_size=(3, 3), strides=1)
67 | self.conv3 = DarkNetConv2D(filters=in_channels, kernel_size=(1, 1), strides=1)
68 | self.conv4 = DarkNetConv2D(filters=2 * in_channels, kernel_size=(3, 3), strides=1)
69 | self.conv5 = DarkNetConv2D(filters=in_channels, kernel_size=(1, 1), strides=1)
70 |
71 | self.conv6 = DarkNetConv2D(filters=2 * in_channels, kernel_size=(3, 3), strides=1)
72 | self.normal_conv = tf.keras.layers.Conv2D(filters=out_channels,
73 | kernel_size=(1, 1),
74 | strides=1,
75 | padding="same")
76 |
77 | def call(self, inputs, training=None, **kwargs):
78 | x = self.conv1(inputs, training=training)
79 | x = self.conv2(x, training=training)
80 | x = self.conv3(x, training=training)
81 | x = self.conv4(x, training=training)
82 | branch = self.conv5(x, training=training)
83 |
84 | stem = self.conv6(branch, training=training)
85 | stem = self.normal_conv(stem)
86 | return stem, branch
87 |
88 |
89 | class YOLOV3(tf.keras.Model):
90 | def __init__(self, out_channels):
91 | super(YOLOV3, self).__init__()
92 | self.darknet = DarkNet53()
93 | self.tail_1 = YOLOTail(in_channels=512, out_channels=out_channels)
94 | self.upsampling_1 = self._make_upsampling(num_filter=256)
95 | self.tail_2 = YOLOTail(in_channels=256, out_channels=out_channels)
96 | self.upsampling_2 = self._make_upsampling(num_filter=128)
97 | self.tail_3 = YOLOTail(in_channels=128, out_channels=out_channels)
98 |
99 | def _make_upsampling(self, num_filter):
100 | layer = tf.keras.Sequential()
101 | layer.add(DarkNetConv2D(filters=num_filter, kernel_size=(1, 1), strides=1))
102 | layer.add(tf.keras.layers.UpSampling2D(size=(2, 2)))
103 | return layer
104 |
105 | def call(self, inputs, training=None, mask=None):
106 | x_1, x_2, x_3 = self.darknet(inputs, training=training)
107 | stem_1, branch_1 = self.tail_1(x_1, training=training)
108 | branch_1 = self.upsampling_1(branch_1, training=training)
109 | x_2 = tf.keras.layers.concatenate([branch_1, x_2])
110 | stem_2, branch_2 = self.tail_2(x_2, training=training)
111 | branch_2 = self.upsampling_2(branch_2, training=training)
112 | x_3 = tf.keras.layers.concatenate([branch_2, x_3])
113 | stem_3, _ = self.tail_3(x_3, training=training)
114 |
115 | return [stem_1, stem_2, stem_3]
116 |
117 |
--------------------------------------------------------------------------------