├── README.md
├── conv_modules.py
├── data
├── KITTI.py
├── __pycache__
│ ├── Ego4D.cpython-310.pyc
│ ├── KITTI.cpython-310.pyc
│ ├── KITTI.cpython-39.pyc
│ ├── MultiFrameShapenet.cpython-310.pyc
│ ├── co3d.cpython-310.pyc
│ ├── co3d.cpython-39.pyc
│ ├── co3dv1.cpython-310.pyc
│ ├── realestate10k_dataio.cpython-310.pyc
│ └── realestate10k_dataio.cpython-39.pyc
├── co3d.py
└── realestate10k_dataio.py
├── demo.py
├── eval.py
├── geometry.py
├── mlp_modules.py
├── models.py
├── renderer.py
├── run.py
├── train.py
├── vis_scripts.py
└── wandb_logging.py
/README.md:
--------------------------------------------------------------------------------
1 | # FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow
2 | ### [Project Page](https://cameronosmith.github.io/flowcam) | [Paper](https://arxiv.org/abs/2306.00180) | [Pretrained Models](https://drive.google.com/drive/folders/1t7vmvBg9OAo4S8I2zjwfqhL656H1r2JP?usp=sharing)
3 |
4 | [Cameron Smith](https://cameronosmith.github.io/),
5 | [Yilun Du](https://yilundu.github.io/),
6 | [Ayush Tewari](https://ayushtewari.com),
7 | [Vincent Sitzmann](https://vsitzmann.github.io/)
8 |
9 | MIT
10 |
11 | This is the official implementation of the paper "FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow".
12 |
13 | 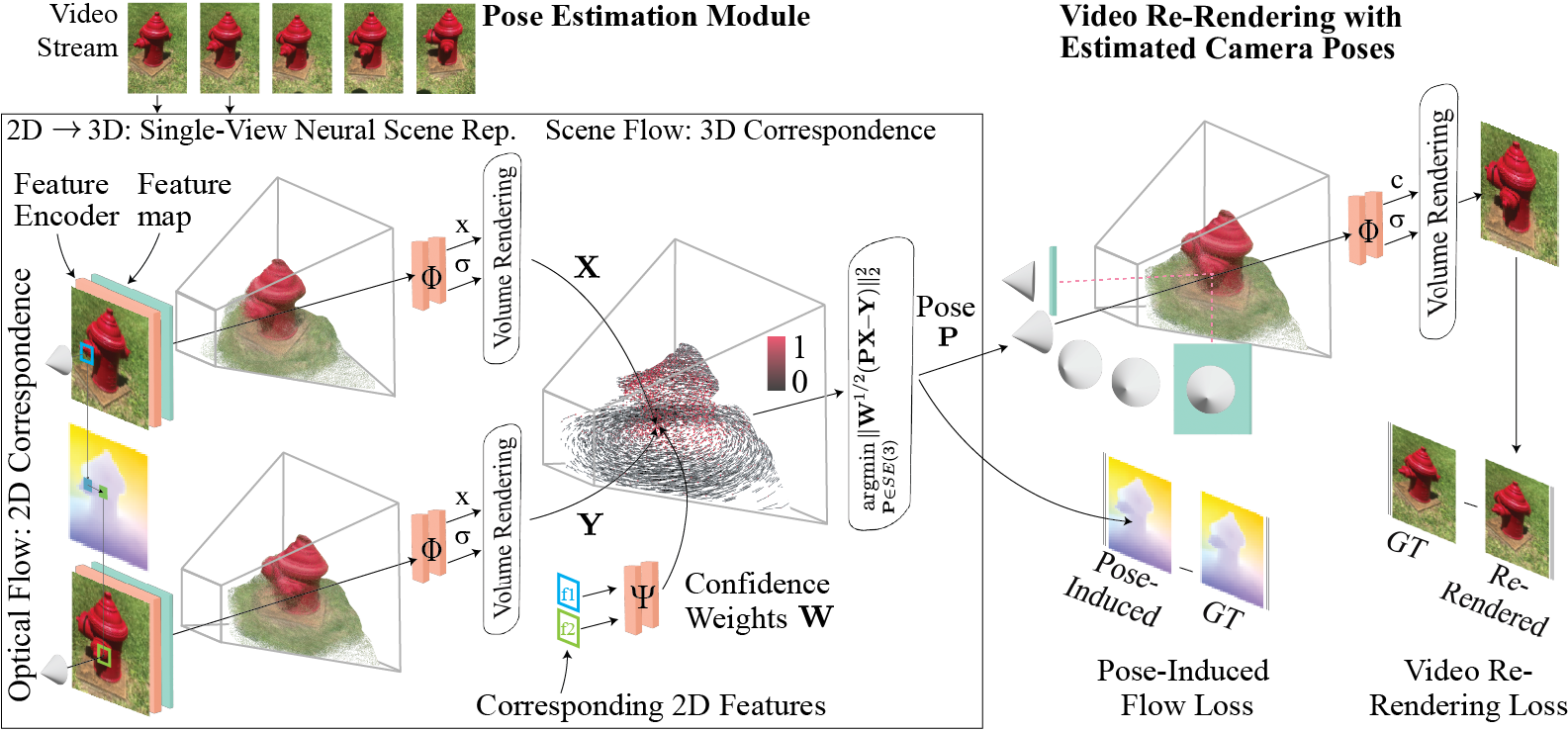 14 |
15 | ## High-Level structure
16 | The code is organized as follows:
17 | * models.py contains the model definition
18 | * run.py contains a generic argument parser which creates the model and dataloaders for both training and evaluation
19 | * train.py and eval.py contains train and evaluation loops
20 | * mlp_modules.py and conv_modules.py contain common MLP and CNN blocks
21 | * vis_scripts.py contains plotting and wandb logging code
22 | * renderer.py implements volume rendering helper functions
23 | * geometry.py implements various geometric operations (projections, 3D lifting, rigid transforms, etc.)
24 | * data contains a list of dataset scripts
25 | * demo.py contains a script to run our model on any image directory for pose estimates. See the file header for an example on running it.
26 |
27 | ## Reproducing experiments
28 |
29 | See `python run.py --help` for a list of command line arguments.
30 | An example training command for CO3D-Hydrants is `python train.py --dataset hydrant --vid_len 8 --batch_size 2 --online --name hydrants_flowcam --n_skip 1 2.`
31 | Similarly, replace `--dataset hydrants` with any of `[realestate,kitti,10cat]` for training on RealEstate10K, KITTI, or CO3D-10Category.
32 |
33 | Example training commands for each dataset are listed below:
34 | `python train.py --dataset hydrant --vid_len 8 --batch_size 2 --online --name hydrant_flowcam --n_skip 1 2`
35 | `python train.py --dataset 10cat --vid_len 8 --batch_size 2 --online --name 10cat_flowcam --n_skip 1`
36 | `python train.py --dataset realestate --vid_len 8 --batch_size 2 --online --name realestate_flowcam --n_skip 9`
37 | `python train.py --dataset kitti --vid_len 8 --batch_size 2 --online --name kitti_flowcam --n_skip 0`
38 |
39 | Use the `--online` flag for summaries to be logged to your wandb account or omit it otherwise.
40 |
41 | ## Environment variables
42 |
43 | We use environment variables to set the dataset and logging paths, though you can easily hardcode the paths in each respective dataset script. Specifically, we use the environment variables `CO3D_ROOT, RE10K_IMG_ROOT, RE10K_POSE_ROOT, KITTI_ROOT, and LOGDIR`. For instance, you can add the line `export CO3D_ROOT="/nobackup/projects/public/facebook-co3dv2"` to your `.bashrc`.
44 |
45 | ## Data
46 |
47 | The KITTI dataset we use can be downloaded here: https://www.cvlibs.net/datasets/kitti/raw_data.php
48 |
49 | Instructions for downloading the RealEstate10K dataset can be found here: https://github.com/yilundu/cross_attention_renderer/blob/master/data_download/README.md
50 |
51 | We use the V2 version of the CO3D dataset, which can be downloaded here: https://github.com/facebookresearch/co3d
52 |
53 | ## Using FlowCam to estimate poses for your own scenes
54 |
55 | You can query FlowCam for any set of images using the script in `demo.py` and specifying the rgb_path, intrinsics (fx,fy,cx,cy), the pretrained checkpoint, whether to render out the reconstructed images or not (slower but illustrates how accurate the geometry is estimated by the model), and the image resolution to resize to in preprocessing (should be around 128 width to avoid memory issues).
56 | For example: `python demo.py --demo_rgb /nobackup/projects/public/facebook-co3dv2/hydrant/615_99120_197713/images --intrinsics 1.7671e+03,3.1427e+03,5.3550e+02,9.5150e+02 -c pretrained_models/co3d_hydrant.pt --render_imgs --low_res 144 128`. The script will write the poses, a rendered pose plot, and re-rendered rgb and depth (if requested) to the folder `demo_output`.
57 | The RealEstate10K pretrained (`pretrained_models/re10k.pt`) model probably has the most general prior to use for your own scenes. We are planning on training and releasing a model on all datasets for a more general prior, so stay tuned for that.
58 |
59 | ### Coordinate and camera parameter conventions
60 | This code uses an "OpenCV" style camera coordinate system, where the Y-axis points downwards (the up-vector points in the negative Y-direction), the X-axis points right, and the Z-axis points into the image plane.
61 |
62 | ### Citation
63 | If you find our work useful in your research, please cite:
64 | ```
65 | @misc{smith2023flowcam,
66 | title={FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow},
67 | author={Cameron Smith and Yilun Du and Ayush Tewari and Vincent Sitzmann},
68 | year={2023},
69 | eprint={2306.00180},
70 | archivePrefix={arXiv},
71 | primaryClass={cs.CV}
72 | }
73 | ```
74 |
75 | ### Contact
76 | If you have any questions, please email Cameron Smith at omid.smith.cameron@gmail.com or open an issue.
77 |
--------------------------------------------------------------------------------
/conv_modules.py:
--------------------------------------------------------------------------------
1 | import torch, torchvision
2 | from torch import nn
3 | import functools
4 | from einops import rearrange, repeat
5 | from torch.nn import functional as F
6 | import numpy as np
7 |
8 | def get_norm_layer(norm_type="instance", group_norm_groups=32):
9 | """Return a normalization layer
10 | Parameters:
11 | norm_type (str) -- the name of the normalization layer: batch | instance | none
12 | For BatchNorm, we use learnable affine parameters and track running statistics (mean/stddev).
13 | For InstanceNorm, we do not use learnable affine parameters. We do not track running statistics.
14 | """
15 | if norm_type == "batch":
16 | norm_layer = functools.partial(
17 | nn.BatchNorm2d, affine=True, track_running_stats=True
18 | )
19 | elif norm_type == "instance":
20 | norm_layer = functools.partial(
21 | nn.InstanceNorm2d, affine=False, track_running_stats=False
22 | )
23 | elif norm_type == "group":
24 | norm_layer = functools.partial(nn.GroupNorm, group_norm_groups)
25 | elif norm_type == "none":
26 | norm_layer = None
27 | else:
28 | raise NotImplementedError("normalization layer [%s] is not found" % norm_type)
29 | return norm_layer
30 |
31 |
32 | class PixelNeRFEncoder(nn.Module):
33 | def __init__(
34 | self,
35 | backbone="resnet34",
36 | pretrained=True,
37 | num_layers=4,
38 | index_interp="bilinear",
39 | index_padding="border",
40 | upsample_interp="bilinear",
41 | feature_scale=1.0,
42 | use_first_pool=True,
43 | norm_type="batch",
44 | in_ch=3,
45 | ):
46 | super().__init__()
47 |
48 | self.use_custom_resnet = backbone == "custom"
49 | self.feature_scale = feature_scale
50 | self.use_first_pool = use_first_pool
51 | norm_layer = get_norm_layer(norm_type)
52 |
53 | print("Using torchvision", backbone, "encoder")
54 | self.model = getattr(torchvision.models, backbone)(
55 | pretrained=pretrained, norm_layer=norm_layer
56 | )
57 |
58 | if in_ch != 3:
59 | self.model.conv1 = nn.Conv2d(
60 | in_ch,
61 | self.model.conv1.weight.shape[0],
62 | self.model.conv1.kernel_size,
63 | self.model.conv1.stride,
64 | self.model.conv1.padding,
65 | padding_mode=self.model.conv1.padding_mode,
66 | )
67 |
68 | # Following 2 lines need to be uncommented for older configs
69 | self.model.fc = nn.Sequential()
70 | self.model.avgpool = nn.Sequential()
71 | self.latent_size = [0, 64, 128, 256, 512, 1024][num_layers]
72 |
73 | self.num_layers = num_layers
74 | self.index_interp = index_interp
75 | self.index_padding = index_padding
76 | self.upsample_interp = upsample_interp
77 | self.register_buffer("latent", torch.empty(1, 1, 1, 1), persistent=False)
78 | self.register_buffer(
79 | "latent_scaling", torch.empty(2, dtype=torch.float32), persistent=False
80 | )
81 |
82 | self.out = nn.Sequential(
83 | nn.Conv2d(self.latent_size, 512, 1),
84 | )
85 |
86 | def forward(self, x, custom_size=None):
87 |
88 |
89 | if len(x.shape)>4: return self(x.flatten(0,1),custom_size).unflatten(0,x.shape[:2])
90 |
91 | if self.feature_scale != 1.0:
92 | x = F.interpolate(
93 | x,
94 | scale_factor=self.feature_scale,
95 | mode="bilinear" if self.feature_scale > 1.0 else "area",
96 | align_corners=True if self.feature_scale > 1.0 else None,
97 | recompute_scale_factor=True,
98 | )
99 | x = x.to(device=self.latent.device)
100 |
101 | if self.use_custom_resnet:
102 | self.latent = self.model(x)
103 | else:
104 | x = self.model.conv1(x)
105 | x = self.model.bn1(x)
106 | x = self.model.relu(x)
107 |
108 | latents = [x]
109 | if self.num_layers > 1:
110 | if self.use_first_pool:
111 | x = self.model.maxpool(x)
112 | x = self.model.layer1(x)
113 | latents.append(x)
114 | if self.num_layers > 2:
115 | x = self.model.layer2(x)
116 | latents.append(x)
117 | if self.num_layers > 3:
118 | x = self.model.layer3(x)
119 | latents.append(x)
120 | if self.num_layers > 4:
121 | x = self.model.layer4(x)
122 | latents.append(x)
123 |
124 | self.latents = latents
125 | align_corners = None if self.index_interp == "nearest " else True
126 | latent_sz = latents[0].shape[-2:]
127 | for i in range(len(latents)):
128 | latents[i] = F.interpolate(
129 | latents[i],
130 | latent_sz if custom_size is None else custom_size,
131 | mode=self.upsample_interp,
132 | align_corners=align_corners,
133 | )
134 | self.latent = torch.cat(latents, dim=1)
135 | self.latent_scaling[0] = self.latent.shape[-1]
136 | self.latent_scaling[1] = self.latent.shape[-2]
137 | self.latent_scaling = self.latent_scaling / (self.latent_scaling - 1) * 2.0
138 | return self.out(self.latent)
139 |
--------------------------------------------------------------------------------
/data/KITTI.py:
--------------------------------------------------------------------------------
1 | import os
2 | import multiprocessing as mp
3 | import torch.nn.functional as F
4 | import torch
5 | import random
6 | import imageio
7 | import numpy as np
8 | from glob import glob
9 | from collections import defaultdict
10 | from pdb import set_trace as pdb
11 | from itertools import combinations
12 | from random import choice
13 | import matplotlib.pyplot as plt
14 |
15 | from torchvision import transforms
16 | from einops import rearrange, repeat
17 |
18 | import sys
19 |
20 | # Geometry functions below used for calculating depth, ignore
21 | def glob_imgs(path):
22 | imgs = []
23 | for ext in ["*.png", "*.jpg", "*.JPEG", "*.JPG"]:
24 | imgs.extend(glob(os.path.join(path, ext)))
25 | return imgs
26 |
27 |
28 | def pick(list, item_idcs):
29 | if not list:
30 | return list
31 | return [list[i] for i in item_idcs]
32 |
33 |
34 | def parse_intrinsics(intrinsics):
35 | fx = intrinsics[..., 0, :1]
36 | fy = intrinsics[..., 1, 1:2]
37 | cx = intrinsics[..., 0, 2:3]
38 | cy = intrinsics[..., 1, 2:3]
39 | return fx, fy, cx, cy
40 |
41 |
42 | hom = lambda x, i=-1: torch.cat((x, torch.ones_like(x.unbind(i)[0].unsqueeze(i))), i)
43 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
44 |
45 | def expand_as(x, y):
46 | if len(x.shape) == len(y.shape):
47 | return x
48 |
49 | for i in range(len(y.shape) - len(x.shape)):
50 | x = x.unsqueeze(-1)
51 |
52 | return x
53 |
54 |
55 | def lift(x, y, z, intrinsics, homogeneous=False):
56 | """
57 |
58 | :param self:
59 | :param x: Shape (batch_size, num_points)
60 | :param y:
61 | :param z:
62 | :param intrinsics:
63 | :return:
64 | """
65 | fx, fy, cx, cy = parse_intrinsics(intrinsics)
66 |
67 | x_lift = (x - expand_as(cx, x)) / expand_as(fx, x) * z
68 | y_lift = (y - expand_as(cy, y)) / expand_as(fy, y) * z
69 |
70 | if homogeneous:
71 | return torch.stack((x_lift, y_lift, z, torch.ones_like(z).to(x.device)), dim=-1)
72 | else:
73 | return torch.stack((x_lift, y_lift, z), dim=-1)
74 |
75 |
76 | def world_from_xy_depth(xy, depth, cam2world, intrinsics):
77 | batch_size, *_ = cam2world.shape
78 |
79 | x_cam = xy[..., 0]
80 | y_cam = xy[..., 1]
81 | z_cam = depth
82 |
83 | pixel_points_cam = lift(
84 | x_cam, y_cam, z_cam, intrinsics=intrinsics, homogeneous=True
85 | )
86 | world_coords = torch.einsum("b...ij,b...kj->b...ki", cam2world, pixel_points_cam)[
87 | ..., :3
88 | ]
89 |
90 | return world_coords
91 |
92 |
93 | def get_ray_directions(xy, cam2world, intrinsics, normalize=True):
94 | z_cam = torch.ones(xy.shape[:-1]).to(xy.device)
95 | pixel_points = world_from_xy_depth(
96 | xy, z_cam, intrinsics=intrinsics, cam2world=cam2world
97 | ) # (batch, num_samples, 3)
98 |
99 | cam_pos = cam2world[..., :3, 3]
100 | ray_dirs = pixel_points - cam_pos[..., None, :] # (batch, num_samples, 3)
101 | if normalize:
102 | ray_dirs = F.normalize(ray_dirs, dim=-1)
103 | return ray_dirs
104 |
105 |
106 | class SceneInstanceDataset(torch.utils.data.Dataset):
107 | """This creates a dataset class for a single object instance (such as a single car)."""
108 |
109 | def __init__(
110 | self,
111 | instance_idx,
112 | instance_dir,
113 | specific_observation_idcs=None,
114 | input_img_sidelength=None,
115 | img_sidelength=None,
116 | num_images=None,
117 | cache=None,
118 | raft=None,
119 | low_res=(64,208),
120 | ):
121 | self.instance_idx = instance_idx
122 | self.img_sidelength = img_sidelength
123 | self.input_img_sidelength = input_img_sidelength
124 | self.instance_dir = instance_dir
125 | self.cache = {}
126 |
127 | self.low_res=low_res
128 |
129 | pose_dir = os.path.join(instance_dir, "pose")
130 | color_dir = os.path.join(instance_dir, "image")
131 |
132 | import pykitti
133 |
134 | drive = self.instance_dir.strip("/").split("/")[-1].split("_")[-2]
135 | date = self.instance_dir.strip("/").split("/")[-2]
136 | self.kitti_raw = pykitti.raw(
137 | "/".join(self.instance_dir.rstrip("/").split("/")[:-2]), date, drive
138 | )
139 | self.num_img = len(
140 | os.listdir(
141 | os.path.join(self.instance_dir, self.instance_dir, "image_02/data")
142 | )
143 | )
144 |
145 | self.color_paths = sorted(glob_imgs(color_dir))
146 | self.pose_paths = sorted(glob(os.path.join(pose_dir, "*.txt")))
147 | self.instance_name = os.path.basename(os.path.dirname(self.instance_dir))
148 |
149 | if specific_observation_idcs is not None:
150 | self.color_paths = pick(self.color_paths, specific_observation_idcs)
151 | self.pose_paths = pick(self.pose_paths, specific_observation_idcs)
152 | elif num_images is not None:
153 | idcs = np.linspace(
154 | 0, stop=len(self.color_paths), num=num_images, endpoint=False, dtype=int
155 | )
156 | self.color_paths = pick(self.color_paths, idcs)
157 | self.pose_paths = pick(self.pose_paths, idcs)
158 |
159 | def set_img_sidelength(self, new_img_sidelength):
160 | """For multi-resolution training: Updates the image sidelength with whichimages are loaded."""
161 | self.img_sidelength = new_img_sidelength
162 |
163 | def __len__(self):
164 | return self.num_img
165 |
166 | def __getitem__(self, idx, context=False, input_context=True):
167 | # print("trgt load")
168 |
169 | rgb = transforms.ToTensor()(self.kitti_raw.get_cam2(idx)) * 2 - 1
170 |
171 | K = torch.from_numpy(self.kitti_raw.calib.K_cam2.copy())
172 | cam2imu = torch.from_numpy(self.kitti_raw.calib.T_cam2_imu).inverse()
173 | imu2world = torch.from_numpy(self.kitti_raw.oxts[idx].T_w_imu)
174 | cam2world = (imu2world @ cam2imu).float()
175 |
176 | uv = np.mgrid[0 : rgb.size(1), 0 : rgb.size(2)].astype(float).transpose(1, 2, 0)
177 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
178 |
179 | # Downsample
180 | h, w = rgb.shape[-2:]
181 |
182 | K = torch.stack((K[0] / w, K[1] / h, K[2])) #normalize intrinsics to be resolution independent
183 |
184 | scale = 2;
185 | lowh, loww = int(64 * scale), int(208 * scale)
186 | med_rgb = F.interpolate( rgb[None], (lowh, loww), mode="bilinear", align_corners=True)[0]
187 | scale = 3;
188 | lowh, loww = int(64 * scale), int(208 * scale)
189 | large_rgb = F.interpolate( rgb[None], (lowh, loww), mode="bilinear", align_corners=True)[0]
190 | uv_large = np.mgrid[0:lowh, 0:loww].astype(float).transpose(1, 2, 0)
191 | uv_large = torch.from_numpy(np.flip(uv_large, axis=-1).copy()).long()
192 | uv_large = uv_large / torch.tensor([loww, lowh]) # uv in [0,1]
193 |
194 | #scale = 1;
195 | lowh, loww = self.low_res#int(64 * scale), int(208 * scale)
196 | rgb = F.interpolate(
197 | rgb[None], (lowh, loww), mode="bilinear", align_corners=True
198 | )[0]
199 | uv = np.mgrid[0:lowh, 0:loww].astype(float).transpose(1, 2, 0)
200 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
201 | uv = uv / torch.tensor([loww, lowh]) # uv in [0,1]
202 |
203 | tmp = torch.eye(4)
204 | tmp[:3, :3] = K
205 | K = tmp
206 |
207 | sample = {
208 | "instance_name": self.instance_name,
209 | "instance_idx": torch.Tensor([self.instance_idx]).squeeze().long(),
210 | "cam2world": cam2world,
211 | "img_idx": torch.Tensor([idx]).squeeze().long(),
212 | "img_id": "%s_%02d_%02d" % (self.instance_name, self.instance_idx, idx),
213 | "rgb": rgb,
214 | "large_rgb": large_rgb,
215 | "med_rgb": med_rgb,
216 | "intrinsics": K.float(),
217 | "uv": uv,
218 | "uv_large": uv_large,
219 | }
220 |
221 | return sample
222 |
223 |
224 | def get_instance_datasets(
225 | root,
226 | max_num_instances=None,
227 | specific_observation_idcs=None,
228 | cache=None,
229 | sidelen=None,
230 | max_observations_per_instance=None,
231 | ):
232 | instance_dirs = sorted(glob(os.path.join(root, "*/")))
233 | assert len(instance_dirs) != 0, f"No objects in the directory {root}"
234 |
235 | if max_num_instances != None:
236 | instance_dirs = instance_dirs[:max_num_instances]
237 |
238 | all_instances = [
239 | SceneInstanceDataset(
240 | instance_idx=idx,
241 | instance_dir=dir,
242 | specific_observation_idcs=specific_observation_idcs,
243 | img_sidelength=sidelen,
244 | cache=cache,
245 | num_images=max_observations_per_instance,
246 | )
247 | for idx, dir in enumerate(instance_dirs)
248 | ]
249 | return all_instances
250 |
251 |
252 | class KittiDataset(torch.utils.data.Dataset):
253 | """Dataset for a class of objects, where each datapoint is a SceneInstanceDataset."""
254 |
255 | def __init__(
256 | self,
257 | num_context=2,
258 | num_trgt=1,
259 | vary_context_number=False,
260 | query_sparsity=None,
261 | img_sidelength=None,
262 | input_img_sidelength=None,
263 | max_num_instances=None,
264 | max_observations_per_instance=None,
265 | specific_observation_idcs=None,
266 | val=False,
267 | test_context_idcs=None,
268 | context_is_last=False,
269 | context_is_first=False,
270 | cache=None,
271 | video=True,
272 | low_res=(64,208),
273 | n_skip=0,
274 | ):
275 |
276 | max_num_instances = None
277 |
278 | root_dir = os.environ['KITTI_ROOT']
279 |
280 | basedirs = list(
281 | filter(lambda x: "20" in x and "zip" not in x, os.listdir(root_dir))
282 | )
283 | drive_paths = []
284 | for basedir in basedirs:
285 | dirs = list(
286 | filter(
287 | lambda x: "txt" not in x,
288 | os.listdir(os.path.join(root_dir, basedir)),
289 | )
290 | )
291 | drive_paths += [
292 | os.path.abspath(os.path.join(root_dir, basedir, dir_)) for dir_ in dirs
293 | ]
294 | self.instance_dirs = sorted(drive_paths)
295 |
296 | if type(n_skip)==type([]):n_skip=n_skip[0]
297 | self.n_skip = n_skip+1
298 | self.num_context = num_context
299 | self.num_trgt = num_trgt
300 | self.query_sparsity = query_sparsity
301 | self.img_sidelength = img_sidelength
302 | self.vary_context_number = vary_context_number
303 | self.cache = {}
304 | self.test = val
305 | self.test_context_idcs = test_context_idcs
306 | self.context_is_last = context_is_last
307 | self.context_is_first = context_is_first
308 |
309 | print(f"Root dir {root_dir}, {len(self.instance_dirs)} instances")
310 |
311 | assert len(self.instance_dirs) != 0, "No objects in the data directory"
312 |
313 | self.max_num_instances = max_num_instances
314 | if max_num_instances == 1:
315 | self.instance_dirs = [
316 | x for x in self.instance_dirs if "2011_09_26_drive_0027_sync" in x
317 | ]
318 | print("note testing single dir") # testing dir
319 |
320 | self.all_instances = [
321 | SceneInstanceDataset(
322 | instance_idx=idx,
323 | instance_dir=dir,
324 | specific_observation_idcs=specific_observation_idcs,
325 | img_sidelength=img_sidelength,
326 | input_img_sidelength=input_img_sidelength,
327 | num_images=max_observations_per_instance,
328 | cache=cache,
329 | low_res=low_res,
330 | )
331 | for idx, dir in enumerate(self.instance_dirs)
332 | ]
333 | self.all_instances = [x for x in self.all_instances if len(x) > 40]
334 | if max_num_instances is not None:
335 | self.all_instances = self.all_instances[:max_num_instances]
336 |
337 | test_idcs = list(range(len(self.all_instances)))[::8]
338 | self.all_instances = [x for i,x in enumerate(self.all_instances) if (i in test_idcs and val) or (i not in test_idcs and not val)]
339 | print("validation: ",val,len(self.all_instances))
340 |
341 | self.num_per_instance_observations = [len(obj) for obj in self.all_instances]
342 | self.num_instances = len(self.all_instances)
343 |
344 | self.instance_img_pairs = []
345 | for i,instance_dir in enumerate(self.all_instances):
346 | for j in range(len(instance_dir)-n_skip*(num_trgt+1)):
347 | self.instance_img_pairs.append((i,j))
348 |
349 | def sparsify(self, dict, sparsity):
350 | new_dict = {}
351 | if sparsity is None:
352 | return dict
353 | else:
354 | # Sample upper_limit pixel idcs at random.
355 | rand_idcs = np.random.choice(
356 | self.img_sidelength ** 2, size=sparsity, replace=False
357 | )
358 | for key in ["rgb", "uv"]:
359 | new_dict[key] = dict[key][rand_idcs]
360 |
361 | for key, v in dict.items():
362 | if key not in ["rgb", "uv"]:
363 | new_dict[key] = dict[key]
364 |
365 | return new_dict
366 |
367 | def set_img_sidelength(self, new_img_sidelength):
368 | """For multi-resolution training: Updates the image sidelength with which images are loaded."""
369 | self.img_sidelength = new_img_sidelength
370 | for instance in self.all_instances:
371 | instance.set_img_sidelength(new_img_sidelength)
372 |
373 | def __len__(self):
374 | return len(self.instance_img_pairs)
375 |
376 | def get_instance_idx(self, idx):
377 | if self.test:
378 | obj_idx = 0
379 | while idx >= 0:
380 | idx -= self.num_per_instance_observations[obj_idx]
381 | obj_idx += 1
382 | return (
383 | obj_idx - 1,
384 | int(idx + self.num_per_instance_observations[obj_idx - 1]),
385 | )
386 | else:
387 | return np.random.randint(self.num_instances), 0
388 |
389 | def collate_fn(self, batch_list):
390 | keys = batch_list[0].keys()
391 | result = defaultdict(list)
392 |
393 | for entry in batch_list:
394 | # make them all into a new dict
395 | for key in keys:
396 | result[key].append(entry[key])
397 |
398 | for key in keys:
399 | try:
400 | result[key] = torch.stack(result[key], dim=0)
401 | except:
402 | continue
403 |
404 | return result
405 |
406 | def getframe(self, obj_idx, x):
407 | return (
408 | self.all_instances[obj_idx].__getitem__(
409 | x, context=True, input_context=True
410 | ),
411 | x,
412 | )
413 |
414 | def __getitem__(self, idx, sceneidx=None):
415 |
416 | context = []
417 | trgt = []
418 | post_input = []
419 | #obj_idx,det_idx= np.random.randint(self.num_instances), 0
420 | of=0
421 |
422 | obj_idx, i = self.instance_img_pairs[idx]
423 |
424 | if of: obj_idx = 0
425 |
426 | if sceneidx is not None:
427 | obj_idx, det_idx = sceneidx[0], sceneidx[0]
428 |
429 | if len(self.all_instances[obj_idx])<=i+self.num_trgt*self.n_skip:
430 | i=0
431 | if sceneidx is not None:
432 | i=sceneidx[1]
433 | for _ in range(self.num_trgt):
434 | if sceneidx is not None:
435 | print(i)
436 | i += self.n_skip
437 | sample = self.all_instances[obj_idx].__getitem__(
438 | i, context=True, input_context=True
439 | )
440 | post_input.append(sample)
441 | post_input[-1]["mask"] = torch.Tensor([1.0])
442 | sub_sample = self.sparsify(sample, self.query_sparsity)
443 | trgt.append(sub_sample)
444 |
445 | post_input = self.collate_fn(post_input)
446 | trgt = self.collate_fn(trgt)
447 |
448 | out_dict = {"query": trgt, "post_input": post_input, "context": None}, trgt
449 |
450 | imgs = trgt["rgb"]
451 | imgs_large = (trgt["large_rgb"]*.5+.5)*255
452 | imgs_med = (trgt["large_rgb"]*.5+.5)*255
453 | Ks = trgt["intrinsics"][:,:3,:3]
454 | uv = trgt["uv"].flatten(1,2)
455 |
456 | #imgs large in [0,255],
457 | #imgs in [-1,1],
458 | #gt_rgb in [0,1],
459 | model_input = {
460 | "trgt_rgb": imgs[1:],
461 | "ctxt_rgb": imgs[:-1],
462 | "trgt_rgb_large": imgs_large[1:],
463 | "ctxt_rgb_large": imgs_large[:-1],
464 | "trgt_rgb_med": imgs_med[1:],
465 | "ctxt_rgb_med": imgs_med[:-1],
466 | "intrinsics": Ks[1:],
467 | "x_pix": uv[1:],
468 | "trgt_c2w": trgt["cam2world"][1:],
469 | "ctxt_c2w": trgt["cam2world"][:-1],
470 | }
471 | gt = {
472 | "trgt_rgb": ch_sec(imgs[1:])*.5+.5,
473 | "ctxt_rgb": ch_sec(imgs[:-1])*.5+.5,
474 | "intrinsics": Ks[1:],
475 | "x_pix": uv[1:],
476 | }
477 | return model_input,gt
478 |
--------------------------------------------------------------------------------
/data/__pycache__/Ego4D.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/Ego4D.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/KITTI.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/KITTI.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/KITTI.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/KITTI.cpython-39.pyc
--------------------------------------------------------------------------------
/data/__pycache__/MultiFrameShapenet.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/MultiFrameShapenet.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/co3d.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/co3d.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/co3d.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/co3d.cpython-39.pyc
--------------------------------------------------------------------------------
/data/__pycache__/co3dv1.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/co3dv1.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/realestate10k_dataio.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/realestate10k_dataio.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/realestate10k_dataio.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/realestate10k_dataio.cpython-39.pyc
--------------------------------------------------------------------------------
/data/co3d.py:
--------------------------------------------------------------------------------
1 | # note for davis dataloader later: temporally consistent depth estimator: https://github.com/yu-li/TCMonoDepth
2 | # note for cool idea of not even downloading data and just streaming from youtube:https://gist.github.com/Mxhmovd/41e7690114e7ddad8bcd761a76272cc3
3 | import matplotlib.pyplot as plt;
4 | import cv2
5 | import os
6 | import multiprocessing as mp
7 | import torch.nn.functional as F
8 | import torch
9 | import random
10 | import imageio
11 | import numpy as np
12 | from glob import glob
13 | from collections import defaultdict
14 | from pdb import set_trace as pdb
15 | from itertools import combinations
16 | from random import choice
17 | import matplotlib.pyplot as plt
18 | import imageio.v3 as iio
19 |
20 | from torchvision import transforms
21 |
22 | import sys
23 |
24 | from glob import glob
25 | import os
26 | import gzip
27 | import json
28 | import numpy as np
29 |
30 | from PIL import Image
31 | def _load_16big_png_depth(depth_png) -> np.ndarray:
32 | with Image.open(depth_png) as depth_pil:
33 | # the image is stored with 16-bit depth but PIL reads it as I (32 bit).
34 | # we cast it to uint16, then reinterpret as float16, then cast to float32
35 | depth = (
36 | np.frombuffer(np.array(depth_pil, dtype=np.uint16), dtype=np.float16)
37 | .astype(np.float32)
38 | .reshape((depth_pil.size[1], depth_pil.size[0]))
39 | )
40 | return depth
41 | def _load_depth(path, scale_adjustment) -> np.ndarray:
42 | d = _load_16big_png_depth(path) * scale_adjustment
43 | d[~np.isfinite(d)] = 0.0
44 | return d[None] # fake feature channel
45 |
46 | # Geometry functions below used for calculating depth, ignore
47 | def glob_imgs(path):
48 | imgs = []
49 | for ext in ["*.png", "*.jpg", "*.JPEG", "*.JPG"]:
50 | imgs.extend(glob(os.path.join(path, ext)))
51 | return imgs
52 |
53 |
54 | def pick(list, item_idcs):
55 | if not list:
56 | return list
57 | return [list[i] for i in item_idcs]
58 |
59 |
60 | def parse_intrinsics(intrinsics):
61 | fx = intrinsics[..., 0, :1]
62 | fy = intrinsics[..., 1, 1:2]
63 | cx = intrinsics[..., 0, 2:3]
64 | cy = intrinsics[..., 1, 2:3]
65 | return fx, fy, cx, cy
66 |
67 |
68 | from einops import rearrange, repeat
69 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
70 | hom = lambda x, i=-1: torch.cat((x, torch.ones_like(x.unbind(i)[0].unsqueeze(i))), i)
71 |
72 |
73 | def expand_as(x, y):
74 | if len(x.shape) == len(y.shape):
75 | return x
76 |
77 | for i in range(len(y.shape) - len(x.shape)):
78 | x = x.unsqueeze(-1)
79 |
80 | return x
81 |
82 |
83 | def lift(x, y, z, intrinsics, homogeneous=False):
84 | """
85 |
86 | :param self:
87 | :param x: Shape (batch_size, num_points)
88 | :param y:
89 | :param z:
90 | :param intrinsics:
91 | :return:
92 | """
93 | fx, fy, cx, cy = parse_intrinsics(intrinsics)
94 |
95 | x_lift = (x - expand_as(cx, x)) / expand_as(fx, x) * z
96 | y_lift = (y - expand_as(cy, y)) / expand_as(fy, y) * z
97 |
98 | if homogeneous:
99 | return torch.stack((x_lift, y_lift, z, torch.ones_like(z).to(x.device)), dim=-1)
100 | else:
101 | return torch.stack((x_lift, y_lift, z), dim=-1)
102 |
103 |
104 | def world_from_xy_depth(xy, depth, cam2world, intrinsics):
105 | batch_size, *_ = cam2world.shape
106 |
107 | x_cam = xy[..., 0]
108 | y_cam = xy[..., 1]
109 | z_cam = depth
110 |
111 | pixel_points_cam = lift(
112 | x_cam, y_cam, z_cam, intrinsics=intrinsics, homogeneous=True
113 | )
114 | world_coords = torch.einsum("b...ij,b...kj->b...ki", cam2world, pixel_points_cam)[
115 | ..., :3
116 | ]
117 |
118 | return world_coords
119 |
120 |
121 | def get_ray_directions(xy, cam2world, intrinsics, normalize=True):
122 | z_cam = torch.ones(xy.shape[:-1]).to(xy.device)
123 | pixel_points = world_from_xy_depth(
124 | xy, z_cam, intrinsics=intrinsics, cam2world=cam2world
125 | ) # (batch, num_samples, 3)
126 |
127 | cam_pos = cam2world[..., :3, 3]
128 | ray_dirs = pixel_points - cam_pos[..., None, :] # (batch, num_samples, 3)
129 | if normalize:
130 | ray_dirs = F.normalize(ray_dirs, dim=-1)
131 | return ray_dirs
132 |
133 | from PIL import Image
134 | def _load_16big_png_depth(depth_png) -> np.ndarray:
135 | with Image.open(depth_png) as depth_pil:
136 | # the image is stored with 16-bit depth but PIL reads it as I (32 bit).
137 | # we cast it to uint16, then reinterpret as float16, then cast to float32
138 | depth = (
139 | np.frombuffer(np.array(depth_pil, dtype=np.uint16), dtype=np.float16)
140 | .astype(np.float32)
141 | .reshape((depth_pil.size[1], depth_pil.size[0]))
142 | )
143 | return depth
144 | def _load_depth(path, scale_adjustment) -> np.ndarray:
145 | d = _load_16big_png_depth(path) * scale_adjustment
146 | d[~np.isfinite(d)] = 0.0
147 | return d[None] # fake feature channel
148 |
149 | # NOTE currently using CO3D V1 because they switch to NDC cameras in 2. TODO is to make conversion code (different intrinsics), verify pointclouds, and switch.
150 |
151 | class Co3DNoCams(torch.utils.data.Dataset):
152 | """Dataset for a class of objects, where each datapoint is a SceneInstanceDataset."""
153 |
154 | def __init__(
155 | self,
156 | num_context=2,
157 | n_skip=1,
158 | num_trgt=1,
159 | low_res=(128,144),
160 | depth_scale=1,#1.8/5,
161 | val=False,
162 | num_cat=1000,
163 | overfit=False,
164 | category=None,
165 | use_mask=False,
166 | use_v1=True,
167 | # delete below, not used
168 | vary_context_number=False,
169 | query_sparsity=None,
170 | img_sidelength=None,
171 | input_img_sidelength=None,
172 | max_num_instances=None,
173 | max_observations_per_instance=None,
174 | specific_observation_idcs=None,
175 | test=False,
176 | test_context_idcs=None,
177 | context_is_last=False,
178 | context_is_first=False,
179 | cache=None,
180 | video=True,
181 | ):
182 |
183 | if num_cat is None: num_cat=1000
184 |
185 | self.n_trgt=num_trgt
186 | self.use_mask=use_mask
187 | self.depth_scale=depth_scale
188 | self.of=overfit
189 | self.val=val
190 |
191 | self.num_skip=n_skip
192 | self.low_res=low_res
193 | max_num_instances = None
194 |
195 | self.base_path=os.environ['CO3D_ROOT']
196 | print(self.base_path)
197 |
198 | # Get sequences!
199 | from collections import defaultdict
200 | sequences = defaultdict(list)
201 | self.total_num_data=0
202 | self.all_frame_names=[]
203 | all_cats = [ "hydrant","teddybear","apple", "ball", "bench", "cake", "donut", "plant", "suitcase", "vase","backpack", "banana", "baseballbat", "baseballglove", "bicycle", "book", "bottle", "bowl", "broccoli", "car", "carrot", "cellphone", "chair", "couch", "cup", "frisbee", "hairdryer", "handbag", "hotdog", "keyboard", "kite", "laptop", "microwave", "motorcycle", "mouse", "orange", "parkingmeter", "pizza", "remote", "sandwich", "skateboard", "stopsign", "toaster", "toilet", "toybus", "toyplane", "toytrain", "toytruck", "tv", "umbrella", "wineglass", ]
204 |
205 | for cat in (all_cats[:num_cat]) if category is None else [category]:
206 | print(cat)
207 | dataset = json.loads(gzip.GzipFile(os.path.join(self.base_path,cat,"frame_annotations.jgz"),"rb").read().decode("utf8"))
208 | val_amt = int(len(dataset)*.03)
209 | dataset = dataset[:-val_amt] if not val else dataset[-val_amt:]
210 | self.total_num_data+=len(dataset)
211 | for i,data in enumerate(dataset):
212 | self.all_frame_names.append((data["sequence_name"],data["frame_number"]))
213 | sequences[data["sequence_name"]].append(data)
214 |
215 | sorted_seq={}
216 | for k,v in sequences.items():
217 | sorted_seq[k]=sorted(sequences[k],key=lambda x:x["frame_number"])
218 | #for k,v in sequences.items(): sequences[k]=v[:-(max(self.num_skip) if type(self.num_skip)==list else self.num_skip)*self.n_trgt]
219 | self.seqs = sorted_seq
220 |
221 | print("done with dataloader init")
222 |
223 | def sparsify(self, dict, sparsity):
224 | new_dict = {}
225 | if sparsity is None:
226 | return dict
227 | else:
228 | # Sample upper_limit pixel idcs at random.
229 | rand_idcs = np.random.choice(
230 | self.img_sidelength ** 2, size=sparsity, replace=False
231 | )
232 | for key in ["rgb", "uv"]:
233 | new_dict[key] = dict[key][rand_idcs]
234 |
235 | for key, v in dict.items():
236 | if key not in ["rgb", "uv"]:
237 | new_dict[key] = dict[key]
238 |
239 | return new_dict
240 |
241 | def set_img_sidelength(self, new_img_sidelength):
242 | """For multi-resolution training: Updates the image sidelength with which images are loaded."""
243 | self.img_sidelength = new_img_sidelength
244 | for instance in self.all_instances:
245 | instance.set_img_sidelength(new_img_sidelength)
246 |
247 | def __len__(self):
248 | return self.total_num_data
249 |
250 | def collate_fn(self, batch_list):
251 | keys = batch_list[0].keys()
252 | result = defaultdict(list)
253 |
254 | for entry in batch_list:
255 | # make them all into a new dict
256 | for key in keys:
257 | result[key].append(entry[key])
258 |
259 | for key in keys:
260 | try:
261 | result[key] = torch.stack(result[key], dim=0)
262 | except:
263 | continue
264 |
265 | return result
266 |
267 | def __getitem__(self, idx,seq_query=None):
268 |
269 | context = []
270 | trgt = []
271 | post_input = []
272 |
273 | n_skip = (random.choice(self.num_skip) if type(self.num_skip)==list else self.num_skip) + 1
274 |
275 | if seq_query is None:
276 | try:
277 | seq_name,frame_idx=self.all_frame_names[idx]
278 | except:
279 | print(f"Out of bounds erorr at {idx}. Investigate.")
280 | return self[-2*n_skip*self.n_trgt if self.val else np.random.randint(len(self))]
281 |
282 | if seq_query is not None:
283 | frame_idx=idx
284 | seq_name = list(self.seqs.keys())[seq_query]
285 | all_frames= self.seqs[seq_name]
286 | else:
287 | all_frames=self.seqs[seq_name] if not self.of else self.seqs[random.choice(list(self.seqs.keys())[:int(self.of)])]
288 |
289 | if len(all_frames)<=self.n_trgt*n_skip or frame_idx >= (len(all_frames)-self.n_trgt*n_skip):
290 | frame_idx=0
291 | if len(all_frames)<=self.n_trgt*n_skip or frame_idx >= (len(all_frames)-self.n_trgt*n_skip):
292 | if len(all_frames)<=self.n_trgt*n_skip:
293 | print(len(all_frames) ," frames < ",self.n_trgt*n_skip," queries")
294 | print("returning low/high")
295 | return self[-2*n_skip*self.n_trgt if self.val else np.random.randint(len(self))]
296 | start_idx = frame_idx
297 |
298 | if self.of and 1: start_idx=0
299 |
300 | frames = all_frames[start_idx:start_idx+self.n_trgt*n_skip:n_skip]
301 | if np.random.rand()<.5 and not self.of and not self.val: frames=frames[::-1]
302 |
303 | paths = [os.path.join(self.base_path,x["image"]["path"]) for x in frames]
304 | for path in paths:
305 | if not os.path.exists(path):
306 | print("path missing")
307 | return self[np.random.randint(len(self))]
308 |
309 | #masks=[torch.from_numpy(plt.imread(os.path.join(self.base_path,x["mask"]["path"]))) for x in frames]
310 | imgs=[torch.from_numpy(plt.imread(path)) for path in paths]
311 |
312 | Ks=[]
313 | c2ws=[]
314 | depths=[]
315 | for data in frames:
316 |
317 | #depths.append(torch.from_numpy(_load_depth(os.path.join(self.base_path,data["depth"]["path"]), data["depth"]["scale_adjustment"])[0])) # commenting out since slow to load; uncomment when needed
318 |
319 | # Below pose processing taken from co3d github issue
320 | p = data["viewpoint"]["principal_point"]
321 | f = data["viewpoint"]["focal_length"]
322 | h, w = data["image"]["size"]
323 | K = np.eye(3)
324 | s = (min(h, w)) / 2
325 | K[0, 0] = f[0] * (w) / 2
326 | K[1, 1] = f[1] * (h) / 2
327 | K[0, 2] = -p[0] * s + (w) / 2
328 | K[1, 2] = -p[1] * s + (h) / 2
329 |
330 | # Normalize intrinsics to [-1,1]
331 | #print(K)
332 | raw_K=[torch.from_numpy(K).clone(),[h,w]]
333 | K[:2] /= torch.tensor([w, h])[:, None]
334 | Ks.append(torch.from_numpy(K).float())
335 |
336 | R = np.asarray(data["viewpoint"]["R"]).T # note the transpose here
337 | T = np.asarray(data["viewpoint"]["T"]) * self.depth_scale
338 | pose = np.concatenate([R,T[:,None]],1)
339 | pose = torch.from_numpy( np.diag([-1,-1,1]).astype(np.float32) @ pose )# flip the direction of x,y axis
340 | tmp=torch.eye(4)
341 | tmp[:3,:4]=pose
342 | c2ws.append(tmp.inverse())
343 |
344 | Ks=torch.stack(Ks)
345 | c2w=torch.stack(c2ws).float()
346 |
347 | no_mask=0
348 | if no_mask:
349 | masks=[x*0+1 for x in masks]
350 |
351 | low_res=self.low_res#(128,144)#(108,144)
352 | minx,miny=min([x.size(0) for x in imgs]),min([x.size(1) for x in imgs])
353 |
354 | imgs=[x[:minx,:miny].float() for x in imgs]
355 |
356 | if self.use_mask: # mask images and depths
357 | imgs = [x*y.unsqueeze(-1)+(255*(1-y).unsqueeze(-1)) for x,y in zip(imgs,masks)]
358 | depths = [x*y for x,y in zip(depths,masks)]
359 |
360 | large_scale=2
361 | imgs_large = F.interpolate(torch.stack([x.permute(2,0,1) for x in imgs]),(int(256*large_scale),int(288*large_scale)),antialias=True,mode="bilinear")
362 | imgs_med = F.interpolate(torch.stack([x.permute(2,0,1) for x in imgs]),(int(256),int(288)),antialias=True,mode="bilinear")
363 | imgs = F.interpolate(torch.stack([x.permute(2,0,1) for x in imgs]),low_res,antialias=True,mode="bilinear")
364 |
365 | if self.use_mask:
366 | imgs = imgs*masks[:,None]+255*(1-masks[:,None])
367 |
368 | imgs = imgs/255 * 2 - 1
369 |
370 | uv = np.mgrid[0:low_res[0], 0:low_res[1]].astype(float).transpose(1, 2, 0)
371 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
372 | uv = uv/ torch.tensor([low_res[1]-1, low_res[0]-1]) # uv in [0,1]
373 | uv = uv[None].expand(len(imgs),-1,-1,-1).flatten(1,2)
374 |
375 | model_input = {
376 | "trgt_rgb": imgs[1:],
377 | "ctxt_rgb": imgs[:-1],
378 | "trgt_rgb_large": imgs_large[1:],
379 | "ctxt_rgb_large": imgs_large[:-1],
380 | "trgt_rgb_med": imgs_med[1:],
381 | "ctxt_rgb_med": imgs_med[:-1],
382 | #"ctxt_depth": depths.squeeze(1)[:-1],
383 | #"trgt_depth": depths.squeeze(1)[1:],
384 | "intrinsics": Ks[1:],
385 | "trgt_c2w": c2w[1:],
386 | "ctxt_c2w": c2w[:-1],
387 | "x_pix": uv[1:],
388 | #"trgt_mask": masks[1:],
389 | #"ctxt_mask": masks[:-1],
390 | }
391 |
392 | gt = {
393 | #"paths": paths,
394 | #"raw_K": raw_K,
395 | #"seq_name": seq_name,
396 | "trgt_rgb": ch_sec(imgs[1:])*.5+.5,
397 | "ctxt_rgb": ch_sec(imgs[:-1])*.5+.5,
398 | #"ctxt_depth": depths.squeeze(1)[:-1].flatten(1,2).unsqueeze(-1),
399 | #"trgt_depth": depths.squeeze(1)[1:].flatten(1,2).unsqueeze(-1),
400 | "intrinsics": Ks[1:],
401 | "x_pix": uv[1:],
402 | #"seq_name": [seq_name],
403 | #"trgt_mask": masks[1:].flatten(1,2).unsqueeze(-1),
404 | #"ctxt_mask": masks[:-1].flatten(1,2).unsqueeze(-1),
405 | }
406 |
407 | return model_input,gt
408 |
--------------------------------------------------------------------------------
/data/realestate10k_dataio.py:
--------------------------------------------------------------------------------
1 | import random
2 | from torch.nn import functional as F
3 | import os
4 | import torch
5 | import numpy as np
6 | from glob import glob
7 | import json
8 | from collections import defaultdict
9 | import os.path as osp
10 | from imageio import imread
11 | from torch.utils.data import Dataset
12 | from pathlib import Path
13 | import cv2
14 | from tqdm import tqdm
15 | from scipy.io import loadmat
16 |
17 | import functools
18 | import cv2
19 | import numpy as np
20 | import imageio
21 | from glob import glob
22 | import os
23 | import shutil
24 | import io
25 |
26 | not_of=1
27 |
28 | def load_rgb(path, sidelength=None):
29 | img = imageio.imread(path)[:, :, :3]
30 | img = skimage.img_as_float32(img)
31 |
32 | img = square_crop_img(img)
33 |
34 | if sidelength is not None:
35 | img = cv2.resize(img, (sidelength, sidelength), interpolation=cv2.INTER_NEAREST)
36 |
37 | img -= 0.5
38 | img *= 2.
39 | return img
40 |
41 | def load_depth(path, sidelength=None):
42 | img = cv2.imread(path, cv2.IMREAD_UNCHANGED).astype(np.float32)
43 |
44 | if sidelength is not None:
45 | img = cv2.resize(img, (sidelength, sidelength), interpolation=cv2.INTER_NEAREST)
46 |
47 | img *= 1e-4
48 |
49 | if len(img.shape) == 3:
50 | img = img[:, :, :1]
51 | img = img.transpose(2, 0, 1)
52 | else:
53 | img = img[None, :, :]
54 | return img
55 |
56 |
57 | def load_pose(filename):
58 | lines = open(filename).read().splitlines()
59 | if len(lines) == 1:
60 | pose = np.zeros((4, 4), dtype=np.float32)
61 | for i in range(16):
62 | pose[i // 4, i % 4] = lines[0].split(" ")[i]
63 | return pose.squeeze()
64 | else:
65 | lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines[:4])]
66 | return np.asarray(lines).astype(np.float32).squeeze()
67 |
68 |
69 | def load_numpy_hdf5(instance_ds, key):
70 | rgb_ds = instance_ds['rgb']
71 | raw = rgb_ds[key][...]
72 | s = raw.tostring()
73 | f = io.BytesIO(s)
74 |
75 | img = imageio.imread(f)[:, :, :3]
76 | img = skimage.img_as_float32(img)
77 |
78 | img = square_crop_img(img)
79 |
80 | img -= 0.5
81 | img *= 2.
82 |
83 | return img
84 |
85 |
86 | def load_rgb_hdf5(instance_ds, key, sidelength=None):
87 | rgb_ds = instance_ds['rgb']
88 | raw = rgb_ds[key][...]
89 | s = raw.tostring()
90 | f = io.BytesIO(s)
91 |
92 | img = imageio.imread(f)[:, :, :3]
93 | img = skimage.img_as_float32(img)
94 |
95 | img = square_crop_img(img)
96 |
97 | if sidelength is not None:
98 | img = cv2.resize(img, (sidelength, sidelength), interpolation=cv2.INTER_AREA)
99 |
100 | img -= 0.5
101 | img *= 2.
102 |
103 | return img
104 |
105 |
106 | def load_pose_hdf5(instance_ds, key):
107 | pose_ds = instance_ds['pose']
108 | raw = pose_ds[key][...]
109 | ba = bytearray(raw)
110 | s = ba.decode('ascii')
111 |
112 | lines = s.splitlines()
113 |
114 | if len(lines) == 1:
115 | pose = np.zeros((4, 4), dtype=np.float32)
116 | for i in range(16):
117 | pose[i // 4, i % 4] = lines[0].split(" ")[i]
118 | # processed_pose = pose.squeeze()
119 | return pose.squeeze()
120 | else:
121 | lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines[:4])]
122 | return np.asarray(lines).astype(np.float32).squeeze()
123 |
124 |
125 | def cond_mkdir(path):
126 | if not os.path.exists(path):
127 | os.makedirs(path)
128 |
129 |
130 | def square_crop_img(img):
131 | min_dim = np.amin(img.shape[:2])
132 | center_coord = np.array(img.shape[:2]) // 2
133 | img = img[center_coord[0] - min_dim // 2:center_coord[0] + min_dim // 2,
134 | center_coord[1] - min_dim // 2:center_coord[1] + min_dim // 2]
135 | return img
136 |
137 |
138 | def glob_imgs(path):
139 | imgs = []
140 | for ext in ['*.png', '*.jpg', '*.JPEG', '*.JPG']:
141 | imgs.extend(glob(os.path.join(path, ext)))
142 | return imgs
143 |
144 | def augment(rgb, intrinsics, c2w_mat):
145 |
146 | # Horizontal Flip with 50% Probability
147 | if np.random.uniform(0, 1) < 0.5:
148 | rgb = rgb[:, ::-1, :]
149 | tf_flip = np.array([[-1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
150 | c2w_mat = c2w_mat @ tf_flip
151 |
152 | # Crop by aspect ratio
153 | if np.random.uniform(0, 1) < 0.5:
154 | py = np.random.randint(1, 32)
155 | rgb = rgb[py:-py, :, :]
156 | else:
157 | py = 0
158 |
159 | if np.random.uniform(0, 1) < 0.5:
160 | px = np.random.randint(1, 32)
161 | rgb = rgb[:, px:-px, :]
162 | else:
163 | px = 0
164 |
165 | H, W, _ = rgb.shape
166 | rgb = cv2.resize(rgb, (256, 256))
167 | xscale = 256 / W
168 | yscale = 256 / H
169 |
170 | intrinsics[0, 0] = intrinsics[0, 0] * xscale
171 | intrinsics[1, 1] = intrinsics[1, 1] * yscale
172 |
173 | return rgb, intrinsics, c2w_mat
174 |
175 | class Camera(object):
176 | def __init__(self, entry):
177 | fx, fy, cx, cy = entry[1:5]
178 | self.intrinsics = np.array([[fx, 0, cx, 0],
179 | [0, fy, cy, 0],
180 | [0, 0, 1, 0],
181 | [0, 0, 0, 1]])
182 | w2c_mat = np.array(entry[7:]).reshape(3, 4)
183 | w2c_mat_4x4 = np.eye(4)
184 | w2c_mat_4x4[:3, :] = w2c_mat
185 | self.w2c_mat = w2c_mat_4x4
186 | self.c2w_mat = np.linalg.inv(w2c_mat_4x4)
187 |
188 |
189 | def unnormalize_intrinsics(intrinsics, h, w):
190 | intrinsics = intrinsics.copy()
191 | intrinsics[0] *= w
192 | intrinsics[1] *= h
193 | return intrinsics
194 |
195 |
196 | def parse_pose_file(file):
197 | f = open(file, 'r')
198 | cam_params = {}
199 | for i, line in enumerate(f):
200 | if i == 0:
201 | continue
202 | entry = [float(x) for x in line.split()]
203 | id = int(entry[0])
204 | cam_params[id] = Camera(entry)
205 | return cam_params
206 |
207 |
208 | def parse_pose(pose, timestep):
209 | timesteps = pose[:, :1]
210 | timesteps = np.around(timesteps)
211 | mask = (timesteps == timestep)[:, 0]
212 | pose_entry = pose[mask][0]
213 | camera = Camera(pose_entry)
214 |
215 | return camera
216 |
217 |
218 | def get_camera_pose(scene_path, all_pose_dir, uv, views=1):
219 | npz_files = sorted(scene_path.glob("*.npz"))
220 | npz_file = npz_files[0]
221 | data = np.load(npz_file)
222 | all_pose_dir = Path(all_pose_dir)
223 |
224 | rgb_files = list(data.keys())
225 |
226 | timestamps = [int(rgb_file.split('.')[0]) for rgb_file in rgb_files]
227 | sorted_ids = np.argsort(timestamps)
228 |
229 | rgb_files = np.array(rgb_files)[sorted_ids]
230 | timestamps = np.array(timestamps)[sorted_ids]
231 |
232 | camera_file = all_pose_dir / (str(scene_path.name) + '.txt')
233 | cam_params = parse_pose_file(camera_file)
234 | # H, W, _ = data[rgb_files[0]].shape
235 |
236 | # Weird cropping of images
237 | H, W = 256, 456
238 |
239 | xscale = W / min(H, W)
240 | yscale = H / min(H, W)
241 |
242 |
243 | query = {}
244 | context = {}
245 |
246 | render_frame = min(128, rgb_files.shape[0])
247 |
248 | query_intrinsics = []
249 | query_c2w = []
250 | query_rgbs = []
251 | for i in range(1, render_frame):
252 | rgb = data[rgb_files[i]]
253 | timestep = timestamps[i]
254 |
255 | # rgb = cv2.resize(rgb, (W, H))
256 | intrinsics = unnormalize_intrinsics(cam_params[timestep].intrinsics, H, W)
257 |
258 | intrinsics[0, 2] = intrinsics[0, 2] / xscale
259 | intrinsics[1, 2] = intrinsics[1, 2] / yscale
260 | rgb = rgb.astype(np.float32) / 127.5 - 1
261 |
262 | query_intrinsics.append(intrinsics)
263 | query_c2w.append(cam_params[timestep].c2w_mat)
264 | query_rgbs.append(rgb)
265 |
266 | context_intrinsics = []
267 | context_c2w = []
268 | context_rgbs = []
269 |
270 | if views == 1:
271 | render_ids = [0]
272 | elif views == 2:
273 | render_ids = [0, min(len(rgb_files) - 1, 128)]
274 | else:
275 | assert False
276 |
277 | for i in render_ids:
278 | rgb = data[rgb_files[i]]
279 | timestep = timestamps[i]
280 | # print("render: ", i)
281 | # rgb = cv2.resize(rgb, (W, H))
282 | intrinsics = unnormalize_intrinsics(cam_params[timestep].intrinsics, H, W)
283 | intrinsics[0, 2] = intrinsics[0, 2] / xscale
284 | intrinsics[1, 2] = intrinsics[1, 2] / yscale
285 |
286 | rgb = rgb.astype(np.float32) / 127.5 - 1
287 |
288 | context_intrinsics.append(intrinsics)
289 | context_c2w.append(cam_params[timestep].c2w_mat)
290 | context_rgbs.append(rgb)
291 |
292 | query = {'rgb': torch.Tensor(query_rgbs)[None].float(),
293 | 'cam2world': torch.Tensor(query_c2w)[None].float(),
294 | 'intrinsics': torch.Tensor(query_intrinsics)[None].float(),
295 | 'uv': uv.view(-1, 2)[None, None].expand(1, render_frame - 1, -1, -1)}
296 | ctxt = {'rgb': torch.Tensor(context_rgbs)[None].float(),
297 | 'cam2world': torch.Tensor(context_c2w)[None].float(),
298 | 'intrinsics': torch.Tensor(context_intrinsics)[None].float()}
299 |
300 | return {'query': query, 'context': ctxt}
301 |
302 | class RealEstate10k():
303 | def __init__(self, img_root=None, pose_root=None,
304 | num_ctxt_views=2, num_query_views=2, query_sparsity=None,imsl=256,
305 | max_num_scenes=None, square_crop=True, augment=False, lpips=False, dual_view=False, val=False,n_skip=12):
306 |
307 | self.n_skip =n_skip[0] if type(n_skip)==type([]) else n_skip
308 | print(self.n_skip,"n_skip")
309 | self.val = val
310 | if img_root is None: img_root = os.path.join(os.environ['RE10K_IMG_ROOT'],"test" if val else "train")
311 | if pose_root is None: pose_root = os.path.join(os.environ['RE10K_POSE_ROOT'],"test" if val else "train")
312 | print("Loading RealEstate10k...")
313 | self.num_ctxt_views = num_ctxt_views
314 | self.num_query_views = num_query_views
315 | self.query_sparsity = query_sparsity
316 | self.dual_view = dual_view
317 |
318 | self.imsl=imsl
319 |
320 | all_im_dir = Path(img_root)
321 | #self.all_pose_dir = Path(pose_root)
322 | self.all_pose = loadmat(pose_root)
323 | self.lpips = lpips
324 |
325 | self.all_scenes = sorted(all_im_dir.glob('*/'))
326 |
327 | dummy_img_path = str(next(self.all_scenes[0].glob("*.npz")))
328 |
329 | if max_num_scenes:
330 | self.all_scenes = list(self.all_scenes)[:max_num_scenes]
331 |
332 | data = np.load(dummy_img_path)
333 | key = list(data.keys())[0]
334 | im = data[key]
335 |
336 | H, W = im.shape[:2]
337 | H, W = 256, 455
338 | self.H, self.W = H, W
339 | self.augment = augment
340 |
341 | self.square_crop = square_crop
342 | # Downsample to be 256 x 256 image
343 | # self.H, self.W = 256, 455
344 |
345 | xscale = W / min(H, W)
346 | yscale = H / min(H, W)
347 |
348 | dim = min(H, W)
349 |
350 | self.xscale = xscale
351 | self.yscale = yscale
352 |
353 | # For now the images are already square cropped
354 | self.H = 256
355 | self.W = 455
356 |
357 | print(f"Resolution is {H}, {W}.")
358 |
359 | if self.square_crop:
360 | i, j = torch.meshgrid(torch.arange(0, self.imsl), torch.arange(0, self.imsl))
361 | else:
362 | i, j = torch.meshgrid(torch.arange(0, W), torch.arange(0, H))
363 |
364 | self.uv = torch.stack([i.float(), j.float()], dim=-1).permute(1, 0, 2)
365 |
366 | # if self.square_crop:
367 | # self.uv = data_util.square_crop_img(self.uv)
368 |
369 | self.uv = self.uv[None].permute(0, -1, 1, 2).permute(0, 2, 3, 1)
370 | self.uv = self.uv.reshape(-1, 2)
371 |
372 | self.scene_path_list = list(Path(img_root).glob("*/"))
373 |
374 | def __len__(self):
375 | return len(self.all_scenes)
376 |
377 | def __getitem__(self, idx,scene_query=None):
378 | idx = idx if not_of else 0
379 | scene_path = self.all_scenes[idx if scene_query is None else scene_query]
380 | npz_files = sorted(scene_path.glob("*.npz"))
381 |
382 | name = scene_path.name
383 |
384 | def get_another():
385 | if self.val:
386 | return self[idx-1 if idx >200 else idx+1]
387 | return self.__getitem__(random.randint(0, len(self.all_scenes) - 1))
388 |
389 | if name not in self.all_pose: return get_another()
390 |
391 | pose = self.all_pose[name]
392 |
393 | if len(npz_files) == 0:
394 | print("npz get another")
395 | return get_another()
396 |
397 | npz_file = npz_files[0]
398 | try:
399 | data = np.load(npz_file)
400 | except:
401 | print("npz load error get another")
402 | return get_another()
403 |
404 | rgb_files = list(data.keys())
405 | window_size = 128
406 |
407 | if len(rgb_files) <= 20:
408 | print("<20 rgbs error get another")
409 | return get_another()
410 |
411 | timestamps = [int(rgb_file.split('.')[0]) for rgb_file in rgb_files]
412 | sorted_ids = np.argsort(timestamps)
413 |
414 | rgb_files = np.array(rgb_files)[sorted_ids]
415 | timestamps = np.array(timestamps)[sorted_ids]
416 |
417 | assert (timestamps == sorted(timestamps)).all()
418 | num_frames = len(rgb_files)
419 | left_bound = 0
420 | right_bound = num_frames - 1
421 | candidate_ids = np.arange(left_bound, right_bound)
422 |
423 | # remove windows between frame -32 to 32
424 | nframe = 1
425 | nframe_view = 140 if self.val else 92
426 |
427 | id_feats = []
428 |
429 | n_skip=self.n_skip
430 |
431 | id_feat = np.array(id_feats)
432 | low = 0
433 | high = num_frames-1-n_skip*self.num_query_views
434 |
435 | if high <= low:
436 | n_skip = int(num_frames//(self.num_query_views+1))
437 | high = num_frames-1-n_skip*self.num_query_views
438 | print("high ... (x y) c")
18 |
19 | # A quick dummy dataset for the demo rgb folder
20 | class SingleVid(Dataset):
21 |
22 | # If specified here, intrinsics should be a 4-element array of [fx,fy,cx,cy] at input image resolution
23 | def __init__(self, img_dir,intrinsics=None,n_trgt=6,num_skip=0,low_res=None,hi_res=None):
24 | self.low_res,self.intrinsics,self.n_trgt,self.num_skip,self.hi_res=low_res,intrinsics,n_trgt,num_skip,hi_res
25 | if self.hi_res is None:self.hi_res=[x*2 for x in self.low_res]
26 | self.hi_res = [(x+x%64) for x in self.hi_res]
27 |
28 | self.img_paths = glob(img_dir + '/*.png') + glob(img_dir + '/*.jpg')
29 | self.img_paths.sort()
30 |
31 | def __len__(self):
32 | return len(self.img_paths)-(1+self.n_trgt)*(1+self.num_skip)
33 |
34 | def __getitem__(self, idx):
35 |
36 | n_skip=self.num_skip+1
37 | paths = self.img_paths[idx:idx+self.n_trgt*n_skip:n_skip]
38 | imgs=torch.stack([torch.from_numpy(plt.imread(path)).permute(2,0,1) for path in paths]).float()
39 |
40 | imgs_large = F.interpolate(imgs,self.hi_res,antialias=True,mode="bilinear")
41 | frames = F.interpolate(imgs,self.low_res)
42 |
43 | frames = frames/255 * 2 - 1
44 |
45 | uv = np.mgrid[0:self.low_res[0], 0:self.low_res[1]].astype(float).transpose(1, 2, 0)
46 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
47 | uv = uv/ torch.tensor([self.low_res[1], self.low_res[0]]) # uv in [0,1]
48 | uv = uv[None].expand(len(frames),-1,-1,-1).flatten(1,2)
49 |
50 | #imgs large values in [0,255], imgs in [-1,1], gt_rgb in [0,1],
51 |
52 | model_input = {
53 | "trgt_rgb": frames[1:],
54 | "ctxt_rgb": frames[:-1],
55 | "trgt_rgb_large": imgs_large[1:],
56 | "ctxt_rgb_large": imgs_large[:-1],
57 | "x_pix": uv[1:],
58 | }
59 | gt = {
60 | "trgt_rgb": ch_sec(frames[1:])*.5+.5,
61 | "ctxt_rgb": ch_sec(frames[:-1])*.5+.5,
62 | "x_pix": uv[1:],
63 | }
64 |
65 | if self.intrinsics is not None:
66 | K = torch.eye(3)
67 | K[0,0],K[1,1],K[0,2],K[1,2]=[float(x) for x in self.intrinsics.strip().split(",")]
68 | h,w=imgs[0].shape[-2:]
69 | K[:2] /= torch.tensor([w, h])[:, None]
70 | model_input["intrinsics"] = K[None].expand(self.n_trgt-1,-1,-1)
71 |
72 | return model_input,gt
73 |
74 | dataset=SingleVid(args.demo_rgb,args.intrinsics,args.vid_len,args.n_skip,args.low_res)
75 |
76 | all_poses = torch.tensor([]).cuda()
77 | all_render_rgb=torch.tensor([]).cuda()
78 | all_render_depth=torch.tensor([])
79 | for seq_i in range(len(dataset)//(dataset.n_trgt)):
80 | print(seq_i*(dataset.n_trgt),"/",len(dataset))
81 | model_input = {k:to_gpu(v)[None] for k,v in dataset.__getitem__(seq_i*(dataset.n_trgt-1))[0].items()}
82 | with torch.no_grad(): out = (model.forward if not args.render_imgs else model.render_full_img)(model_input)
83 | curr_transfs = out["poses"][0]
84 | if len(all_poses): curr_transfs = all_poses[[-1]] @ curr_transfs # integrate poses
85 | all_poses = torch.cat((all_poses,curr_transfs))
86 | all_render_rgb = torch.cat((all_render_rgb,out["rgb"][0]))
87 | all_render_depth = torch.cat((all_render_depth,out["depth"][0]))
88 |
89 | out_dir="demo_output/"+args.demo_rgb.replace("/","_")
90 | os.makedirs(out_dir,exist_ok=True)
91 | fig = plt.figure()
92 | ax = fig.add_subplot(111, projection='3d')
93 | ax.plot(*all_poses[:,:3,-1].T.cpu().numpy())
94 | ax.xaxis.set_tick_params(labelbottom=False);ax.yaxis.set_tick_params(labelleft=False);ax.zaxis.set_tick_params(labelleft=False)
95 | ax.view_init(elev=10., azim=45)
96 | plt.tight_layout()
97 | fp = os.path.join(out_dir,f"pose_plot.png");plt.savefig(fp,bbox_inches='tight');plt.close()
98 |
99 | fp = os.path.join(out_dir,f"poses.npy");np.save(fp,all_poses.cpu())
100 | if args.render_imgs:
101 | out_dir=os.path.join(out_dir,"renders")
102 | os.makedirs(out_dir,exist_ok=True)
103 | for i,(rgb,depth) in enumerate(zip(all_render_rgb.unflatten(1,model_input["trgt_rgb"].shape[-2:]),all_render_depth.unflatten(1,model_input["trgt_rgb"].shape[-2:]))):
104 | plt.imsave(os.path.join(out_dir,"render_rgb_%04d.png"%i),rgb.clip(0,1).cpu().numpy())
105 | plt.imsave(os.path.join(out_dir,"render_depth_%04d.png"%i),depth.clip(0,1).cpu().numpy())
106 |
107 |
--------------------------------------------------------------------------------
/eval.py:
--------------------------------------------------------------------------------
1 | from run import *
2 |
3 | # Evaluation script
4 | import piqa,lpips
5 | from torchvision.utils import make_grid
6 | import matplotlib.pyplot as plt
7 | loss_fn_vgg = lpips.LPIPS(net='vgg').cuda()
8 | lpips,psnr,ate=0,0,0
9 |
10 | eval_dir = save_dir+"/"+args.name+datetime.datetime.now().strftime("%b%d%Y_")+str(random.randint(0,1e3))
11 | try: os.mkdir(eval_dir)
12 | except: pass
13 | torch.set_grad_enabled(False)
14 |
15 | model.n_samples=128
16 |
17 | val_dataset = get_dataset(val=True,)
18 |
19 | for eval_idx,eval_dataset_idx in enumerate(tqdm(torch.linspace(0,len(val_dataset)-1,min(args.n_eval,len(val_dataset))).int())):
20 | model_input,ground_truth = val_dataset[eval_dataset_idx]
21 |
22 | for x in (model_input,ground_truth):
23 | for k,v in x.items(): x[k] = v[None].cuda() # collate
24 |
25 | model_out = model.render_full_img(model_input)
26 |
27 | # remove last frame since used as ctxt when n_ctxt=2
28 | rgb_est,rgb_gt = [rearrange(img[:,:-1].clip(0,1),"b trgt (x y) c -> (b trgt) c x y",x=model_input["trgt_rgb"].size(-2))
29 | for img in (model_out["fine_rgb" if "fine_rgb" in model_out else "rgb"],ground_truth["trgt_rgb"])]
30 | depth_est = rearrange(model_out["depth"][:,:-1],"b trgt (x y) c -> (b trgt) c x y",x=model_input["trgt_rgb"].size(-2))
31 |
32 | psnr += piqa.PSNR()(rgb_est.clip(0,1).contiguous(),rgb_gt.clip(0,1).contiguous())
33 | lpips += loss_fn_vgg(rgb_est*2-1,rgb_gt*2-1).mean()
34 |
35 | print(args.save_imgs)
36 | if args.save_imgs:
37 | fp = os.path.join(eval_dir,f"{eval_idx}_est.png");plt.imsave(fp,make_grid(rgb_est).permute(1,2,0).clip(0,1).cpu().numpy())
38 | if depth_est.size(1)==3: fp = os.path.join(eval_dir,f"{eval_idx}_depth.png");plt.imsave(fp,make_grid(depth_est).clip(0,1).permute(1,2,0).cpu().numpy())
39 | fp = os.path.join(eval_dir,f"{eval_idx}_gt.png");plt.imsave(fp,make_grid(rgb_gt).permute(1,2,0).cpu().numpy())
40 | print(fp)
41 |
42 |
43 | if args.save_imgs and args.save_ind: # save individual images separately
44 | eval_idx_dir = os.path.join(eval_dir,f"dir_{eval_idx}")
45 |
46 | try: os.mkdir(eval_idx_dir)
47 | except: pass
48 | ctxt_rgbs = torch.cat((model_input["ctxt_rgb"][:,0],model_input["trgt_rgb"][:,model_input["trgt_rgb"].size(1)//2],model_input["trgt_rgb"][:,-1]))*.5+.5
49 | fp = os.path.join(eval_idx_dir,f"ctxt0.png");plt.imsave(fp,ctxt_rgbs[0].clip(0,1).permute(1,2,0).cpu().numpy())
50 | fp = os.path.join(eval_idx_dir,f"ctxt1.png");plt.imsave(fp,ctxt_rgbs[1].clip(0,1).permute(1,2,0).cpu().numpy())
51 | fp = os.path.join(eval_idx_dir,f"ctxt2.png");plt.imsave(fp,ctxt_rgbs[2].clip(0,1).permute(1,2,0).cpu().numpy())
52 | for i,(rgb_est,rgb_gt,depth) in enumerate(zip(rgb_est,rgb_gt,depth_est)):
53 | fp = os.path.join(eval_idx_dir,f"{i}_est.png");plt.imsave(fp,rgb_est.clip(0,1).permute(1,2,0).cpu().numpy())
54 | print(fp)
55 | fp = os.path.join(eval_idx_dir,f"{i}_gt.png");plt.imsave(fp,rgb_gt.clip(0,1).permute(1,2,0).cpu().numpy())
56 | if depth_est.size(1)==3: fp = os.path.join(eval_idx_dir,f"{i}_depth.png");plt.imsave(fp,depth.permute(1,2,0).cpu().clip(1e-4,1-1e-4).numpy())
57 |
58 | # Pose plotting/evaluation
59 | if "poses" in model_out:
60 | import scipy.spatial
61 | pose_est,pose_gt = model_out["poses"][0][:,:3,-1].cpu(),model_input["trgt_c2w"][0][:,:3,-1].cpu()
62 | pose_gt,pose_est,_ = scipy.spatial.procrustes(pose_gt.numpy(),pose_est.numpy())
63 | ate += ((pose_est-pose_gt)**2).mean()
64 | if args.save_imgs:
65 | fig = plt.figure()
66 | ax = fig.add_subplot(111, projection='3d')
67 | ax.plot(*pose_gt.T)
68 | ax.plot(*pose_est.T)
69 | ax.xaxis.set_tick_params(labelbottom=False)
70 | ax.yaxis.set_tick_params(labelleft=False)
71 | ax.zaxis.set_tick_params(labelleft=False)
72 | ax.view_init(elev=10., azim=45)
73 | plt.tight_layout()
74 | fp = os.path.join(eval_dir,f"{eval_idx}_pose_plot.png");plt.savefig(fp,bbox_inches='tight');plt.close()
75 | if args.save_ind:
76 | for i in range(len(pose_est)):
77 | fig = plt.figure()
78 | ax = fig.add_subplot(111, projection='3d')
79 | ax.plot(*pose_gt.T,color="black")
80 | ax.plot(*pose_est.T,alpha=0)
81 | ax.plot(*pose_est[:i].T,alpha=1,color="red")
82 | ax.xaxis.set_tick_params(labelbottom=False)
83 | ax.yaxis.set_tick_params(labelleft=False)
84 | ax.zaxis.set_tick_params(labelleft=False)
85 | ax.view_init(elev=10., azim=45)
86 | plt.tight_layout()
87 | fp = os.path.join(eval_idx_dir,f"pose_{i}.png"); plt.savefig(fp,bbox_inches='tight');plt.close()
88 |
89 | print(f"psnr {psnr/(1+eval_idx)}, lpips {lpips/(1+eval_idx)}, ate {(ate/(1+eval_idx))**.5}, eval_idx {eval_idx}", flush=True)
90 |
91 |
--------------------------------------------------------------------------------
/geometry.py:
--------------------------------------------------------------------------------
1 | """Multi-view geometry & proejction code.."""
2 | import torch
3 | from einops import rearrange, repeat
4 | from torch.nn import functional as F
5 | import numpy as np
6 |
7 | def d6_to_rotmat(d6):
8 | a1, a2 = d6[..., :3], d6[..., 3:]
9 | b1 = F.normalize(a1, dim=-1)
10 | b2 = a2 - (b1 * a2).sum(-1, keepdim=True) * b1
11 | b2 = F.normalize(b2, dim=-1)
12 | b3 = torch.cross(b1, b2, dim=-1)
13 | return torch.stack((b1, b2, b3), dim=-2)
14 |
15 | def time_interp_poses(pose_inp,time_i,n_trgt,eye_pts):
16 | i,j = max(0,int(time_i*(n_trgt-1))-1),int(time_i*(n_trgt-1))
17 | pose_interp = camera_interp(*pose_inp[:,[i,j]].unbind(1),time_i)
18 | if i==j: pose_interp=pose_inp[:,0]
19 | pose_interp = repeat(pose_interp,"b x y -> b trgt x y",trgt=n_trgt)
20 | return pose_interp
21 | eye_pts = torch.cat((eye_pts,torch.ones_like(eye_pts[...,[0]])),-1)
22 | query_pts = torch.einsum("bcij,bcdkj->bcdki",pose_interp,eye_pts)[...,:3]
23 | return query_pts
24 |
25 | def pixel_aligned_features(
26 | coords_3d_world, cam2world, intrinsics, img_features, interp="bilinear",padding_mode="border",
27 | ):
28 | # Args:
29 | # coords_3d_world: shape (b, n, 3)
30 | # cam2world: camera pose of shape (..., 4, 4)
31 |
32 | # project 3d points to 2D
33 | c3d_world_hom = homogenize_points(coords_3d_world)
34 | c3d_cam_hom = transform_world2cam(c3d_world_hom, cam2world)
35 | c2d_cam, depth = project(c3d_cam_hom, intrinsics.unsqueeze(1))
36 |
37 | # now between 0 and 1. Map to -1 and 1
38 | c2d_norm = (c2d_cam - 0.5) * 2
39 | c2d_norm = rearrange(c2d_norm, "b n ch -> b n () ch")
40 | c2d_norm = c2d_norm[..., :2]
41 |
42 | # grid_sample
43 | feats = F.grid_sample(
44 | img_features, c2d_norm, align_corners=True, padding_mode=padding_mode, mode=interp
45 | )
46 | feats = feats.squeeze(-1) # b ch n
47 |
48 | feats = rearrange(feats, "b ch n -> b n ch")
49 | return feats, c3d_cam_hom[..., :3], c2d_cam
50 |
51 | # https://gist.github.com/mkocabas/54ea2ff3b03260e3fedf8ad22536f427
52 | def procrustes(S1, S2,weights=None):
53 |
54 | if len(S1.shape)==4:
55 | out = procrustes(S1.flatten(0,1),S2.flatten(0,1),weights.flatten(0,1) if weights is not None else None)
56 | return out[0],out[1].unflatten(0,S1.shape[:2])
57 | '''
58 | Computes a similarity transform (sR, t) that takes
59 | a set of 3D points S1 (BxNx3) closest to a set of 3D points, S2,
60 | where R is an 3x3 rotation matrix, t 3x1 translation, s scale. / mod : assuming scale is 1
61 | i.e. solves the orthogonal Procrutes problem.
62 | '''
63 | with torch.autocast(device_type='cuda', dtype=torch.float32):
64 | S1 = S1.permute(0,2,1)
65 | S2 = S2.permute(0,2,1)
66 | if weights is not None:
67 | weights=weights.permute(0,2,1)
68 | transposed = True
69 |
70 | if weights is None:
71 | weights = torch.ones_like(S1[:,:1])
72 |
73 | # 1. Remove mean.
74 | weights_norm = weights/(weights.sum(-1,keepdim=True)+1e-6)
75 | mu1 = (S1*weights_norm).sum(2,keepdim=True)
76 | mu2 = (S2*weights_norm).sum(2,keepdim=True)
77 |
78 | X1 = S1 - mu1
79 | X2 = S2 - mu2
80 |
81 | diags = torch.stack([torch.diag(w.squeeze(0)) for w in weights]) # does batched version exist?
82 |
83 | # 3. The outer product of X1 and X2.
84 | K = (X1@diags).bmm(X2.permute(0,2,1))
85 |
86 | # 4. Solution that Maximizes trace(R'K) is R=U*V', where U, V are singular vectors of K.
87 | U, s, V = torch.svd(K)
88 |
89 | # Construct Z that fixes the orientation of R to get det(R)=1.
90 | Z = torch.eye(U.shape[1], device=S1.device).unsqueeze(0)
91 | Z = Z.repeat(U.shape[0],1,1)
92 | Z[:,-1, -1] *= torch.sign(torch.det(U.bmm(V.permute(0,2,1))))
93 |
94 | # Construct R.
95 | R = V.bmm(Z.bmm(U.permute(0,2,1)))
96 |
97 | # 6. Recover translation.
98 | t = mu2 - ((R.bmm(mu1)))
99 |
100 | # 7. Error:
101 | S1_hat = R.bmm(S1) + t
102 |
103 | # Combine recovered transformation as single matrix
104 | R_=torch.eye(4)[None].expand(S1.size(0),-1,-1).to(S1)
105 | R_[:,:3,:3]=R
106 | T_=torch.eye(4)[None].expand(S1.size(0),-1,-1).to(S1)
107 | T_[:,:3,-1]=t.squeeze(-1)
108 | S_=torch.eye(4)[None].expand(S1.size(0),-1,-1).to(S1)
109 | transf = T_@S_@R_
110 |
111 | return (S1_hat-S2).square().mean(),transf
112 |
113 | def symmetric_orthogonalization(x):
114 | # https://github.com/amakadia/svd_for_pose
115 | m = x.view(-1, 3, 3).type(torch.float)
116 | u, s, v = torch.svd(m)
117 | vt = torch.transpose(v, 1, 2)
118 | det = torch.det(torch.matmul(u, vt))
119 | det = det.view(-1, 1, 1)
120 | vt = torch.cat((vt[:, :2, :], vt[:, -1:, :] * det), 1)
121 | r = torch.matmul(u, vt)
122 | return r
123 |
124 | def rigidity_loss(ctx_xyz,trgt_xyz):
125 |
126 | x_points = ctx_xyz #.view(-1, 3)
127 | y_points = trgt_xyz #.view(-1, 3)
128 |
129 | x_mean = x_points.mean(1, keepdim=True) # x_mean and y_mean define the global translation
130 | y_mean = y_points.mean(1, keepdim=True)
131 |
132 | x_points_centered = x_points - x_mean
133 | y_points_centered = y_points - y_mean
134 |
135 | x_scale = torch.sqrt(x_points_centered.pow(2).sum(2, keepdim=True)).mean(1, keepdim=True)
136 | x_points_normalized = x_points_centered / x_scale # x_scale and y_scale define the global scales
137 |
138 | y_scale = torch.sqrt(y_points_centered.pow(2).sum(2, keepdim=True)).mean(1, keepdim=True)
139 | y_points_normalized = y_points_centered / y_scale
140 |
141 | M = torch.einsum('b i k, b i j -> b k j', x_points_normalized, y_points_normalized) # M is the covariance matrix
142 | R = symmetric_orthogonalization(M) #this is the rotation matrix
143 |
144 | # Compute the transformed ctxt points
145 | x_points_transformed = torch.matmul(x_points_normalized, R)
146 |
147 | loss = (x_points_transformed - y_points_normalized).pow(2).mean()
148 | return loss
149 |
150 |
151 | def homogenize_points(points: torch.Tensor):
152 | """Appends a "1" to the coordinates of a (batch of) points of dimension DIM.
153 |
154 | Args:
155 | points: points of shape (..., DIM)
156 |
157 | Returns:
158 | points_hom: points with appended "1" dimension.
159 | """
160 | ones = torch.ones_like(points[..., :1], device=points.device)
161 | return torch.cat((points, ones), dim=-1)
162 |
163 |
164 | def homogenize_vecs(vectors: torch.Tensor):
165 | """Appends a "0" to the coordinates of a (batch of) vectors of dimension DIM.
166 |
167 | Args:
168 | vectors: vectors of shape (..., DIM)
169 |
170 | Returns:
171 | vectors_hom: points with appended "0" dimension.
172 | """
173 | zeros = torch.zeros_like(vectors[..., :1], device=vectors.device)
174 | return torch.cat((vectors, zeros), dim=-1)
175 |
176 |
177 | def unproject(
178 | xy_pix: torch.Tensor, z: torch.Tensor, intrinsics: torch.Tensor
179 | ) -> torch.Tensor:
180 | """Unproject (lift) 2D pixel coordinates x_pix and per-pixel z coordinate
181 | to 3D points in camera coordinates.
182 |
183 | Args:
184 | xy_pix: 2D pixel coordinates of shape (..., 2)
185 | z: per-pixel depth, defined as z coordinate of shape (..., 1)
186 | intrinscis: camera intrinscics of shape (..., 3, 3)
187 |
188 | Returns:
189 | xyz_cam: points in 3D camera coordinates.
190 | """
191 | xy_pix_hom = homogenize_points(xy_pix)
192 | xyz_cam = torch.einsum("...ij,...kj->...ki", intrinsics.inverse(), xy_pix_hom)
193 | xyz_cam *= z
194 | return xyz_cam
195 |
196 |
197 | def transform_world2cam(
198 | xyz_world_hom: torch.Tensor, cam2world: torch.Tensor
199 | ) -> torch.Tensor:
200 | """Transforms points from 3D world coordinates to 3D camera coordinates.
201 |
202 | Args:
203 | xyz_world_hom: homogenized 3D points of shape (..., 4)
204 | cam2world: camera pose of shape (..., 4, 4)
205 |
206 | Returns:
207 | xyz_cam: points in camera coordinates.
208 | """
209 | world2cam = torch.inverse(cam2world)
210 | return transform_rigid(xyz_world_hom, world2cam)
211 |
212 |
213 | def transform_cam2world(
214 | xyz_cam_hom: torch.Tensor, cam2world: torch.Tensor
215 | ) -> torch.Tensor:
216 | """Transforms points from 3D world coordinates to 3D camera coordinates.
217 |
218 | Args:
219 | xyz_cam_hom: homogenized 3D points of shape (..., 4)
220 | cam2world: camera pose of shape (..., 4, 4)
221 |
222 | Returns:
223 | xyz_world: points in camera coordinates.
224 | """
225 | return transform_rigid(xyz_cam_hom, cam2world)
226 |
227 |
228 | def transform_rigid(xyz_hom: torch.Tensor, T: torch.Tensor) -> torch.Tensor:
229 | """Apply a rigid-body transform to a (batch of) points / vectors.
230 |
231 | Args:
232 | xyz_hom: homogenized 3D points of shape (..., 4)
233 | T: rigid-body transform matrix of shape (..., 4, 4)
234 |
235 | Returns:
236 | xyz_trans: transformed points.
237 | """
238 | return torch.einsum("...ij,...kj->...ki", T, xyz_hom)
239 |
240 |
241 | def get_unnormalized_cam_ray_directions(
242 | xy_pix: torch.Tensor, intrinsics: torch.Tensor
243 | ) -> torch.Tensor:
244 | return unproject(
245 | xy_pix,
246 | torch.ones_like(xy_pix[..., :1], device=xy_pix.device),
247 | intrinsics=intrinsics,
248 | )
249 |
250 |
251 | def get_world_rays_(
252 | xy_pix: torch.Tensor,
253 | intrinsics: torch.Tensor,
254 | cam2world: torch.Tensor,
255 | ) -> torch.Tensor:
256 |
257 | if cam2world is None:
258 | cam2world = torch.eye(4)[None].expand(xy_pix.size(0),-1,-1).to(xy_pix)
259 |
260 | # Get camera origin of camera 1
261 | cam_origin_world = cam2world[..., :3, -1]
262 |
263 | # Get ray directions in cam coordinates
264 | ray_dirs_cam = get_unnormalized_cam_ray_directions(xy_pix, intrinsics)
265 | ray_dirs_cam = ray_dirs_cam / ray_dirs_cam.norm(dim=-1, keepdim=True)
266 |
267 | # Homogenize ray directions
268 | rd_cam_hom = homogenize_vecs(ray_dirs_cam)
269 |
270 | # Transform ray directions to world coordinates
271 | rd_world_hom = transform_cam2world(rd_cam_hom, cam2world)
272 |
273 | # Tile the ray origins to have the same shape as the ray directions.
274 | # Currently, ray origins have shape (batch, 3), while ray directions have shape
275 | cam_origin_world = repeat(
276 | cam_origin_world, "b ch -> b num_rays ch", num_rays=ray_dirs_cam.shape[1]
277 | )
278 |
279 | # Return tuple of cam_origins, ray_world_directions
280 | return cam_origin_world, rd_world_hom[..., :3]
281 |
282 | def get_world_rays(
283 | xy_pix: torch.Tensor,
284 | intrinsics: torch.Tensor,
285 | cam2world: torch.Tensor,
286 | ) -> torch.Tensor:
287 | if len(xy_pix.shape)==4:
288 | out = get_world_rays_(xy_pix.flatten(0,1),intrinsics.flatten(0,1),cam2world.flatten(0,1) if cam2world is not None else None)
289 | return [x.unflatten(0,xy_pix.shape[:2]) for x in out]
290 | return get_world_rays_(xy_pix,intrinsics,cam2world)
291 |
292 |
293 |
294 |
295 | def get_opencv_pixel_coordinates(
296 | y_resolution: int,
297 | x_resolution: int,
298 | device='cpu'
299 | ):
300 | """For an image with y_resolution and x_resolution, return a tensor of pixel coordinates
301 | normalized to lie in [0, 1], with the origin (0, 0) in the top left corner,
302 | the x-axis pointing right, the y-axis pointing down, and the bottom right corner
303 | being at (1, 1).
304 |
305 | Returns:
306 | xy_pix: a meshgrid of values from [0, 1] of shape
307 | (y_resolution, x_resolution, 2)
308 | """
309 | i, j = torch.meshgrid(
310 | torch.linspace(0, 1, steps=x_resolution, device=device),
311 | torch.linspace(0, 1, steps=y_resolution, device=device),
312 | )
313 |
314 | xy_pix = torch.stack([i.float(), j.float()], dim=-1).permute(1, 0, 2)
315 | return xy_pix
316 |
317 |
318 | def project(xyz_cam_hom: torch.Tensor, intrinsics: torch.Tensor) -> torch.Tensor:
319 | """Projects homogenized 3D points xyz_cam_hom in camera coordinates
320 | to pixel coordinates.
321 |
322 | Args:
323 | xyz_cam_hom: 3D points of shape (..., 4)
324 | intrinsics: camera intrinscics of shape (..., 3, 3)
325 |
326 | Returns:
327 | xy: homogeneous pixel coordinates of shape (..., 3) (final coordinate is 1)
328 | """
329 | if len(intrinsics.shape)==len(xyz_cam_hom.shape): intrinsics=intrinsics.unsqueeze(1)
330 | xyw = torch.einsum("...ij,...j->...i", intrinsics, xyz_cam_hom[..., :3])
331 | z = xyw[..., -1:]
332 | xyw = xyw / (z + 1e-5) # z-divide
333 | return xyw[..., :2], z
334 |
335 | def _sqrt_positive_part(x: torch.Tensor) -> torch.Tensor:
336 | # from pytorch3d
337 | """
338 | Returns torch.sqrt(torch.max(0, x))
339 | but with a zero subgradient where x is 0.
340 | """
341 | ret = torch.zeros_like(x)
342 | positive_mask = x > 0
343 | ret[positive_mask] = torch.sqrt(x[positive_mask])
344 | return ret
345 | def matrix_to_quaternion(matrix: torch.Tensor) -> torch.Tensor:
346 | # from pytorch3d
347 | """
348 | Convert rotations given as rotation matrices to quaternions.
349 | Args:
350 | matrix: Rotation matrices as tensor of shape (..., 3, 3).
351 | Returns:
352 | quaternions with real part first, as tensor of shape (..., 4).
353 | """
354 | if matrix.size(-1) != 3 or matrix.size(-2) != 3:
355 | raise ValueError(f"Invalid rotation matrix shape {matrix.shape}.")
356 |
357 | batch_dim = matrix.shape[:-2]
358 | m00, m01, m02, m10, m11, m12, m20, m21, m22 = torch.unbind(
359 | matrix.reshape(batch_dim + (9,)), dim=-1
360 | )
361 |
362 | q_abs = _sqrt_positive_part(
363 | torch.stack(
364 | [
365 | 1.0 + m00 + m11 + m22,
366 | 1.0 + m00 - m11 - m22,
367 | 1.0 - m00 + m11 - m22,
368 | 1.0 - m00 - m11 + m22,
369 | ],
370 | dim=-1,
371 | )
372 | )
373 |
374 | # we produce the desired quaternion multiplied by each of r, i, j, k
375 | quat_by_rijk = torch.stack(
376 | [
377 | torch.stack([q_abs[..., 0] ** 2, m21 - m12, m02 - m20, m10 - m01], dim=-1),
378 | torch.stack([m21 - m12, q_abs[..., 1] ** 2, m10 + m01, m02 + m20], dim=-1),
379 | torch.stack([m02 - m20, m10 + m01, q_abs[..., 2] ** 2, m12 + m21], dim=-1),
380 | torch.stack([m10 - m01, m20 + m02, m21 + m12, q_abs[..., 3] ** 2], dim=-1),
381 | ],
382 | dim=-2,
383 | )
384 |
385 | # We floor here at 0.1 but the exact level is not important; if q_abs is small,
386 | # the candidate won't be picked.
387 | flr = torch.tensor(0.1).to(dtype=q_abs.dtype, device=q_abs.device)
388 | quat_candidates = quat_by_rijk / (2.0 * q_abs[..., None].max(flr))
389 |
390 | # if not for numerical problems, quat_candidates[i] should be same (up to a sign),
391 | # forall i; we pick the best-conditioned one (with the largest denominator)
392 |
393 | return quat_candidates[
394 | F.one_hot(q_abs.argmax(dim=-1), num_classes=4) > 0.5, :
395 | ].reshape(batch_dim + (4,))
396 | def quaternion_to_matrix(quaternions: torch.Tensor) -> torch.Tensor:
397 | # from pytorch3d
398 | """
399 | Convert rotations given as quaternions to rotation matrices.
400 | Args:
401 | quaternions: quaternions with real part first,
402 | as tensor of shape (..., 4).
403 | Returns:
404 | Rotation matrices as tensor of shape (..., 3, 3).
405 | """
406 | r, i, j, k = torch.unbind(quaternions, -1)
407 | two_s = 2.0 / (quaternions * quaternions).sum(-1)
408 |
409 | o = torch.stack(
410 | (
411 | 1 - two_s * (j * j + k * k),
412 | two_s * (i * j - k * r),
413 | two_s * (i * k + j * r),
414 | two_s * (i * j + k * r),
415 | 1 - two_s * (i * i + k * k),
416 | two_s * (j * k - i * r),
417 | two_s * (i * k - j * r),
418 | two_s * (j * k + i * r),
419 | 1 - two_s * (i * i + j * j),
420 | ),
421 | -1,
422 | )
423 | return o.reshape(quaternions.shape[:-1] + (3, 3))
424 | def camera_interp(camera1, camera2, t):
425 | if len(camera1.shape)==3:
426 | return torch.stack([camera_interp(cam1,cam2,t) for cam1,cam2 in zip(camera1,camera2)])
427 | # Extract the rotation component from the camera matrices
428 | q1 = matrix_to_quaternion(camera1[:3, :3])
429 | q2 = matrix_to_quaternion(camera2[:3, :3])
430 |
431 | # todo add negative quaternion check to not go long way around
432 |
433 | # Interpolate the quaternions using slerp
434 | cos_angle = (q1 * q2).sum(dim=0)
435 | angle = torch.acos(cos_angle.clamp(-1, 1))
436 | q_interpolated = (q1 * torch.sin((1 - t) * angle) + q2 * torch.sin(t * angle)) / torch.sin(angle)
437 | rotation_interpolated = quaternion_to_matrix(q_interpolated)
438 |
439 | # Interpolate the translation component
440 | translation_interpolated = torch.lerp(camera1[:3,-1], camera2[:3,-1], t)
441 |
442 | cam_interpolated = torch.eye(4)
443 | cam_interpolated[:3,:3]=rotation_interpolated
444 | cam_interpolated[:3,-1]=translation_interpolated
445 |
446 | return cam_interpolated.cuda()
447 |
--------------------------------------------------------------------------------
/mlp_modules.py:
--------------------------------------------------------------------------------
1 | import torch.nn.functional as F
2 | import numpy as np
3 | from collections import OrderedDict
4 | import torch
5 | from torch import nn
6 | from einops import repeat,rearrange
7 |
8 | def init_weights_normal(m):
9 | if type(m) == nn.Linear:
10 | if hasattr(m, 'weight'):
11 | nn.init.kaiming_normal_(m.weight, a=0.0, nonlinearity='relu', mode='fan_in')
12 |
13 | class ResMLP(nn.Module):
14 | def __init__(self, ch_in, ch_mod, out_ch, num_res_block=1 ):
15 | super().__init__()
16 |
17 | self.res_blocks = nn.ModuleList([
18 | nn.Sequential(nn.Linear(ch_mod,ch_mod),nn.ReLU(),
19 | nn.LayerNorm([ch_mod], elementwise_affine=True),
20 | nn.Linear(ch_mod,ch_mod),nn.ReLU())
21 | for _ in range(num_res_block)
22 | ])
23 |
24 | self.proj_in = nn.Linear(ch_in,ch_mod)
25 | self.out = nn.Linear(ch_mod,out_ch)
26 |
27 | def forward(self,x):
28 |
29 | x = self.proj_in(x)
30 |
31 | for i,block in enumerate(self.res_blocks):
32 |
33 | x_in = x
34 |
35 | x = block(x)
36 |
37 | if i!=len(self.res_blocks)-1: x = x + x_in
38 |
39 | return self.out(x)
40 |
41 | # FILM, but just the biases, not scalings - featurewise additive modulation
42 | # "x" is the input coordinate and "y" is the conditioning feature (img features, for exmaple)
43 | class ResFAMLP(nn.Module):
44 | def __init__(self, ch_in_x,ch_in_y, ch_mod, out_ch, num_res_block=1, last_res=False):
45 | super().__init__()
46 |
47 | self.res_blocks = nn.ModuleList([
48 | nn.Sequential(nn.Linear(ch_mod,ch_mod),nn.ReLU(),
49 | nn.LayerNorm([ch_mod], elementwise_affine=True),
50 | nn.Linear(ch_mod,ch_mod),nn.ReLU())
51 | for _ in range(num_res_block)
52 | ])
53 |
54 | self.last_res=last_res
55 | self.proj_in = nn.Linear(ch_in_x,ch_mod)
56 | self.modulators = nn.ModuleList([nn.Linear(ch_in_y,ch_mod) for _ in range(num_res_block)])
57 | self.out = nn.Linear(ch_mod,out_ch)
58 |
59 | def forward(self,x,y):
60 |
61 | x = self.proj_in(x)
62 |
63 | for i,(block,modulator) in enumerate(zip(self.res_blocks,self.modulators)):
64 |
65 | x_in = x + modulator(y)
66 |
67 | x = block(x)
68 |
69 | if i!=len(self.res_blocks)-1 or self.last_res: x = x + x_in
70 |
71 | return self.out(x)
72 |
73 |
74 |
--------------------------------------------------------------------------------
/models.py:
--------------------------------------------------------------------------------
1 | """Code for pixelnerf and alternatives."""
2 | import torch, torchvision
3 | from torch import nn
4 | from einops import rearrange, repeat
5 | from torch.nn import functional as F
6 | import numpy as np
7 | import time
8 | import timm
9 | from matplotlib import cm
10 | import kornia
11 | from tqdm import tqdm
12 |
13 | import conv_modules
14 | import mlp_modules
15 | import geometry
16 | import renderer
17 | from geometry import procrustes
18 |
19 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
20 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
21 | hom = lambda x: torch.cat((x,torch.ones_like(x[...,[0]])),-1)
22 |
23 | class FlowCam(nn.Module):
24 | def __init__(self, near=1.75, far=8, n_samples=64,num_view=2,logspace=True,use_trgt_crop=False,use_midas=False):
25 | super().__init__()
26 |
27 | self.raft_midas_net = RaftAndMidas(raft=True,midas=use_midas)
28 |
29 | self.near,self.far,self.n_samples = near,far,n_samples
30 | self.logspace=logspace
31 | self.use_trgt_crop=use_trgt_crop
32 |
33 | self.num_view=num_view
34 |
35 | self.nerf_enc_flow = conv_modules.PixelNeRFEncoder(in_ch=5,use_first_pool=False)
36 | #self.nerf_enc_flow = conv_modules.PixelNeRFEncoder(in_ch=3,use_first_pool=False)
37 | phi_latent=64
38 | self.renderer = MLPImplicit(latent_in=phi_latent,inner_latent=phi_latent,white_back=False,num_first_res_block=2)
39 |
40 | self.pos_encoder = PositionalEncodingNoFreqFactor(3,5)
41 |
42 | self.ray_comb = nn.Sequential(torch.nn.Conv2d(512+33,512,3,padding=1),nn.ReLU(),
43 | torch.nn.Conv2d(512,512,3,padding=1),nn.ReLU(),
44 | torch.nn.Conv2d(512,phi_latent-3,3,padding=1)
45 | )
46 | self.corr_weighter_perpoint = nn.Sequential(
47 | nn.Linear(128,128),nn.ReLU(),
48 | nn.Linear(128,128),nn.ReLU(),
49 | nn.Linear(128,128),nn.ReLU(),
50 | nn.Linear(128,1),
51 | )
52 | self.corr_weighter_perpoint.apply(mlp_modules.init_weights_normal)
53 |
54 | def encoder(self,model_input):
55 | imsize=model_input["ctxt_rgb"].shape[-2:]
56 |
57 | if "backbone_feats" in model_input: return model_input["backbone_feats"]
58 | if "bwd_flow" not in model_input: model_input = self.raft_midas_net(model_input)
59 |
60 | # ctxt[1:]==trgt[:-1], using this property to avoid redundant computation
61 | all_rgb = torch.cat((model_input["ctxt_rgb"][:,:1],model_input["trgt_rgb"]),1)
62 | all_flow = torch.cat((model_input["bwd_flow"][:,:1],model_input["bwd_flow"]),1)
63 |
64 | # Resnet rgb+flow feats
65 | rgb_flow = torch.cat((all_rgb,all_flow*4),2)
66 | rgb_flow_feats = self.nerf_enc_flow(rgb_flow,imsize)
67 |
68 | # Add rays to features for some amount of focal length information
69 | rds = self.pos_encoder(geometry.get_world_rays(model_input["x_pix"], model_input["intrinsics"], None)[1])
70 | rds = ch_fst(torch.cat((rds[:,:1],rds),1),imsize[0])
71 |
72 | all_feats = self.ray_comb(torch.cat((rgb_flow_feats,rds),2).flatten(0,1)).unflatten(0,all_rgb.shape[:2])
73 | all_feats = torch.cat((all_feats,all_rgb),2)
74 | model_input["backbone_feats"] = all_feats
75 |
76 | return all_feats
77 |
78 | def forward(self, model_input, trgt_rays=None,ctxt_rays=None,poses=None):
79 |
80 | imsize=model_input["ctxt_rgb"].shape[-2:]
81 | (b,n_ctxt),n_trgt=model_input["ctxt_rgb"].shape[:2],model_input["trgt_rgb"].size(1)
82 | add_ctxt = lambda x: torch.cat((x[:,:1],x),1)
83 | if trgt_rays is None: trgt_rays,ctxt_rays = self.make_rays(model_input)
84 |
85 | # Encode images
86 | backbone_feats= self.encoder(model_input)
87 |
88 | # Expand identity camera into 3d points and render rays
89 | ros, rds = geometry.get_world_rays(add_ctxt(model_input["x_pix"]), add_ctxt(model_input["intrinsics"]), None)
90 | eye_pts, z_vals = renderer.sample_points_along_rays(self.near, self.far, self.n_samples, ros, rds, device=model_input["x_pix"].device,logspace=self.logspace)
91 | eye_render, eye_depth, eye_weights= self.renderer( backbone_feats, eye_pts[:,:,ctxt_rays], add_ctxt(model_input["intrinsics"]), z_vals,identity=True)
92 |
93 | # Render out correspondence's surface point now
94 | corresp_uv = (model_input["x_pix"]+ch_sec(model_input["bwd_flow"]))[:,:,ctxt_rays]
95 | ros, rds = geometry.get_world_rays(corresp_uv, model_input["intrinsics"], None)
96 | corresp_pts, _ = renderer.sample_points_along_rays(self.near, self.far, self.n_samples, ros, rds, device=model_input["x_pix"].device,logspace=self.logspace)
97 | _, _, corresp_weights= self.renderer( backbone_feats[:,:-1], corresp_pts, model_input["intrinsics"], z_vals,identity=True)
98 |
99 | # Predict correspondence weights as function of source feature and correspondence
100 | corresp_feat = F.grid_sample(backbone_feats[:,:-1].flatten(0,1),corresp_uv.flatten(0,1).unsqueeze(1)*2-1).squeeze(-2).permute(0,2,1).unflatten(0,(b,n_trgt))
101 | corr_weights = self.corr_weighter_perpoint(torch.cat((corresp_feat,ch_sec(backbone_feats)[:,1:,ctxt_rays]),-1)).sigmoid()
102 |
103 | # Weighted procrustes on scene flow
104 | if poses is None:
105 | adj_transf = procrustes((eye_pts[:,1:,ctxt_rays]*eye_weights[:,1:]).sum(-2), (corresp_weights*corresp_pts).sum(-2), corr_weights)[1]
106 | poses = adj_transf
107 | for i in range(n_trgt-1,0,-1):
108 | poses = torch.cat((poses[:,:i],poses[:,[i-1]]@poses[:,i:]),1)
109 | else: adj_transf = torch.cat((poses[:,:1],poses[:,:-1].inverse()@poses[:,1:]),1)
110 |
111 | # Render out trgt frames from [ctxt=0, ctxt=-1, ctxt=middle][: num context frames ]
112 | render = self.render(model_input,poses,trgt_rays)
113 |
114 | # Pose induced flow using ctxt depth and then multiview rendered depth (latter not used in paper experiments)
115 | corresp_surf_from_pose = (torch.einsum("bcij,bcdkj->bcdki",adj_transf,hom(eye_pts[:,1:]))[:,:,ctxt_rays,...,:3]*eye_weights[:,1:]).sum(-2)
116 | flow_from_pose = geometry.project(corresp_surf_from_pose.flatten(0,1), model_input["intrinsics"].flatten(0,1))[0].unflatten(0,(b,n_trgt))-model_input["x_pix"][:,:,ctxt_rays]
117 | corresp_surf_from_pose_render = (torch.einsum("bcij,bcdkj->bcdki",adj_transf,hom(eye_pts[:,1:]))[:,:,trgt_rays,...,:3]*render["weights"]).sum(-2)
118 | flow_from_pose_render = geometry.project(corresp_surf_from_pose_render.flatten(0,1), model_input["intrinsics"].flatten(0,1))[0].unflatten(0,(b,n_trgt))-model_input["x_pix"][:,:,trgt_rays]
119 |
120 | out= {
121 | "rgb":render["rgb"],
122 | "ctxt_rgb":eye_render[:,:-1],
123 | "poses":poses,
124 | "depth":render["depth"],
125 | "ctxt_depth":eye_depth[:,:-1],
126 | "corr_weights": corr_weights,
127 | "flow_from_pose": flow_from_pose,
128 | "flow_from_pose_render": flow_from_pose_render,
129 | "ctxt_rays": ctxt_rays.to(eye_render)[None].expand(b,-1),
130 | "trgt_rays": trgt_rays.to(eye_render)[None].expand(b,-1),
131 | "flow_inp": model_input["bwd_flow"],
132 | }
133 | if "ctxt_depth" in model_input:
134 | out["ctxt_depth_inp"]=model_input["ctxt_depth"]
135 | out["trgt_depth_inp"]=model_input["trgt_depth"]
136 | return out
137 |
138 | def render(self,model_input,poses,trgt_rays,query_pose=None):
139 | if query_pose is None: query_pose=poses
140 |
141 | ros, rds = geometry.get_world_rays(model_input["x_pix"][:,:query_pose.size(1),trgt_rays], model_input["intrinsics"][:,:query_pose.size(1)], query_pose)
142 | query_pts, z_vals = renderer.sample_points_along_rays(self.near, self.far, self.n_samples, ros, rds, device=model_input["x_pix"].device,logspace=self.logspace)
143 |
144 | ctxt_poses = torch.cat((torch.eye(4).cuda()[None].expand(poses.size(0),-1,-1)[:,None],poses),1)
145 | ctxt_idxs = [0,-1,model_input["trgt_rgb"].size(1)//2][:self.num_view]
146 | ctxt_pts = torch.einsum("bvcij,bcdkj->bvcdki",ctxt_poses[:,ctxt_idxs].inverse().unsqueeze(2),hom(query_pts))[...,:3] # in coord system of ctxt frames
147 | rgb, depth, weights = self.renderer(model_input["backbone_feats"][:,ctxt_idxs], ctxt_pts,model_input["intrinsics"][:,:query_pose.size(1)],z_vals)
148 | return {"rgb":rgb,"depth":depth,"weights":weights}
149 |
150 | def make_rays(self,model_input):
151 |
152 | imsize=model_input["ctxt_rgb"].shape[-2:]
153 |
154 | # Pick random subset of rays
155 | crop_res=32 if self.n_samples<100 else 16
156 | if self.use_trgt_crop: # choose random crop of rays instead of random set
157 | start_x,start_y = np.random.randint(0,imsize[1]-crop_res-1),np.random.randint(0,imsize[0]-crop_res-1)
158 | trgt_rays = torch.arange(imsize[0]*imsize[1]).view(imsize[0],imsize[1])[start_y:start_y+crop_res,start_x:start_x+crop_res].flatten()
159 | else:
160 | trgt_rays = torch.randperm(imsize[0]*imsize[1]-2)[:crop_res**2]
161 |
162 | ctxt_rays = torch.randperm(imsize[0]*imsize[1]-2)[:(32 if torch.is_grad_enabled() else 48)**2]
163 | return trgt_rays,ctxt_rays
164 |
165 | def render_full_img(self,model_input, query_pose=None,sample_out=None):
166 | num_chunk=8 if self.n_samples<90 else 16
167 |
168 | imsize=model_input["ctxt_rgb"].shape[-2:]
169 | (b,n_ctxt),n_trgt=model_input["ctxt_rgb"].shape[:2],model_input["trgt_rgb"].size(1)
170 |
171 | if sample_out is None: sample_out = self(model_input)
172 |
173 | # Render out image iteratively and aggregate outputs
174 | outs=[]
175 | for j,trgt_rays in enumerate(torch.arange(imsize[0]*imsize[1]).chunk(num_chunk)):
176 | with torch.no_grad():
177 | outs.append( self(model_input,trgt_rays=trgt_rays,ctxt_rays=trgt_rays,poses=sample_out["poses"]) if query_pose is None else
178 | self.render(model_input,sample_out["poses"],trgt_rays,query_pose[:,None]))
179 |
180 | out_all = {}
181 | for k,v in outs[0].items():
182 | if len(v.shape)>3 and "inp" not in k and "poses" not in k: out_all[k]=torch.cat([out[k] for out in outs],2)
183 | else:out_all[k]=v
184 | out_all["depth_raw"] = out_all["depth"]
185 | for k,v in out_all.items():
186 | if "depth" in k: out_all[k] = torch.from_numpy(cm.get_cmap('magma')(v.min().item()/v.cpu().numpy())).squeeze(-2)[...,:3]
187 |
188 | return out_all
189 |
190 | # Implicit function which performs pixel-aligned nerf
191 | class MLPImplicit(nn.Module):
192 |
193 | def __init__(self,latent_in=512,inner_latent=128,white_back=True,num_first_res_block=2,add_view_dir=False):
194 | super().__init__()
195 | self.white_back=white_back
196 |
197 | self.pos_encoder = PositionalEncodingNoFreqFactor(3,5)
198 |
199 | self.phi1= mlp_modules.ResFAMLP(3,latent_in,inner_latent,inner_latent,num_first_res_block,last_res=True) # 2 res blocks, outputs deep feature to be averaged over ctxts
200 | self.phi1.apply(mlp_modules.init_weights_normal)
201 | self.phi2= mlp_modules.ResMLP(inner_latent,inner_latent,4)
202 | self.phi2.apply(mlp_modules.init_weights_normal)
203 |
204 | # Note this method does not use cam2world and assumes `pos` is transformed to each context view's coordinate system and duplicated for each context view
205 | def forward(self,ctxt_feats,pos,intrinsics,samp_dists,flow_feats=None,identity=False):
206 |
207 | if identity: # 1:1 correspondence of ctxt img to trgt render, used for rendering out identity camera
208 | b_org,n_trgt_org = ctxt_feats.shape[:2]
209 | ctxt_feats,pos,intrinsics = [x.flatten(0,1)[:,None] for x in [ctxt_feats,pos,intrinsics]]
210 |
211 | if len(pos.shape)==5: pos=pos.unsqueeze(1) # unsqueeze ctxt if no ctxt dim (means only 1 ctxt supplied)
212 | (b,n_ctxt),n_trgt=(ctxt_feats.shape[:2],pos.size(2))
213 |
214 | # Projection onto identity camera
215 | img_feat, pos_,_ = geometry.pixel_aligned_features(
216 | repeat(pos,"b ctxt trgt xy d c -> (b ctxt trgt) (xy d) c"),
217 | repeat(torch.eye(4)[None,None].to(ctxt_feats),"1 1 x y -> (b ctxt trgt) x y",b=b,ctxt=n_ctxt,trgt=n_trgt),
218 | repeat(intrinsics,"b trgt x y -> (b ctxt trgt) x y",ctxt=n_ctxt),
219 | repeat(ctxt_feats,"b ctxt c x y -> (b ctxt trgt) c x y",trgt=n_trgt),
220 | )
221 | img_feat,pos= [rearrange(x,"(b ctxt trgt) (xy d) c -> (b trgt) xy d ctxt c",b=b,ctxt=n_ctxt,d=samp_dists.size(-1)) for x in [img_feat,pos_]]
222 |
223 | # Map (3d crd,projecting img feature) to (rgb,sigma)
224 | out = self.phi2(self.phi1(pos,img_feat).mean(dim=-2))
225 | rgb,sigma= out[...,:3].sigmoid(),out[...,3:4].relu()
226 |
227 | # Alphacomposite
228 | rgb, depth, weights = renderer.volume_integral(z_vals=samp_dists, sigmas=sigma, radiances=rgb, white_back=self.white_back)
229 |
230 | out = [x.unflatten(0,(b,n_trgt)) for x in [rgb,depth, weights]]
231 | return [x.squeeze(1).unflatten(0,(b_org,n_trgt_org)) for x in out] if identity else out
232 |
233 | # Adds RAFT flow and Midas depth to the model input
234 | class RaftAndMidas(nn.Module):
235 | def __init__(self,raft=True,midas=True):
236 | super().__init__()
237 | self.run_raft,self.run_midas=raft,midas
238 |
239 | if self.run_raft:
240 | from torchvision.models.optical_flow import Raft_Small_Weights
241 | from torchvision.models.optical_flow import raft_small
242 | print("making raft")
243 | self.raft_transforms = Raft_Small_Weights.DEFAULT.transforms()
244 | self.raft = raft_small(weights=Raft_Small_Weights.DEFAULT, progress=False)
245 | print("done making raft")
246 | if self.run_midas:
247 | print("making midas")
248 | self.midas_transforms = torch.hub.load("intel-isl/MiDaS", "transforms").dpt_transform
249 | self.midas_large = torch.hub.load("intel-isl/MiDaS", "DPT_Hybrid")
250 | print("done making midas")
251 | else: print("no midas")
252 |
253 | def forward(self,model_input):
254 |
255 | # Estimate raft flow and midas depth if no flow/depth in dataset
256 | imsize=model_input["ctxt_rgb"].shape[-2:]
257 | (b,n_ctxt),n_trgt=model_input["ctxt_rgb"].shape[:2],model_input["trgt_rgb"].size(1)
258 | # Inputs should be in range [0,255]; TODO change to [-1,1] to stay consistent with other RGB range
259 |
260 | with torch.no_grad():
261 | # Compute RAFT flow from each frame to next frame forward and backward - note image shape must be > 128 for raft to work
262 | if "bwd_flow" not in model_input and self.run_raft:
263 | raft = lambda x,y: F.interpolate(self.raft(x,y,num_flow_updates=12)[-1]/(torch.tensor(x.shape[-2:][::-1])-1).to(x)[None,:,None,None],imsize)
264 | #raft_rgbs = torch.cat([self.midas_transforms(raft_rgb.permute(1,2,0).cpu().numpy()) for raft_rgb in raft_rgbs]).cuda()
265 | raft_inputs = self.raft_transforms(model_input["trgt_rgb_large"].flatten(0,1).to(torch.uint8),model_input["ctxt_rgb_large"].flatten(0,1).to(torch.uint8))
266 | model_input["bwd_flow"] = raft(*raft_inputs).unflatten(0,(b,n_trgt))
267 |
268 | # Compute midas depth if not on a datastet with depth
269 | if "trgt_depth" not in model_input and self.run_midas:
270 | # Compute midas depth for sup.
271 | # TODO normalize this input correctly based on torch transform. I think it's just imagenet + [0,1] mapping but check
272 | midas = lambda x: F.interpolate(1/(1e-3+self.midas_large(x)).unsqueeze(1),imsize)
273 | midas_rgbs = torch.cat((model_input["ctxt_rgb_med"],model_input["trgt_rgb_med"][:,-1:]),1).flatten(0,1)
274 | midas_rgbs = (midas_rgbs/255)*2-1
275 | all_depth = midas(midas_rgbs).unflatten(0,(b,n_trgt+1))
276 | model_input["trgt_depth"] = all_depth[:,1:]
277 | model_input["ctxt_depth"] = all_depth[:,:-1]
278 | return model_input
279 |
280 | class PositionalEncodingNoFreqFactor(nn.Module):
281 | """PositionalEncoding module
282 |
283 | Maps v to positional encoding representation phi(v)
284 |
285 | Arguments:
286 | i_dim (int): input dimension for v
287 | N_freqs (int): #frequency to sample (default: 10)
288 | """
289 | def __init__(
290 | self,
291 | i_dim: int,
292 | N_freqs: int = 10,
293 | ) -> None:
294 |
295 | super().__init__()
296 |
297 | self.i_dim = i_dim
298 | self.out_dim = i_dim + (2 * N_freqs) * i_dim
299 | self.N_freqs = N_freqs
300 |
301 | a, b = 1, self.N_freqs - 1
302 | self.freq_bands = 2 ** torch.linspace(a, b, self.N_freqs)
303 |
304 | def forward(self, v):
305 | pe = [v]
306 | for freq in self.freq_bands:
307 | fv = freq * v
308 | pe += [torch.sin(fv), torch.cos(fv)]
309 | return torch.cat(pe, dim=-1)
310 |
311 |
--------------------------------------------------------------------------------
/renderer.py:
--------------------------------------------------------------------------------
1 | """Volume rendering code."""
2 | from geometry import *
3 | from typing import Callable, List, Optional, Tuple, Generator, Dict
4 | import torch
5 | from torch import nn
6 | from torch.nn import functional as F
7 | import numpy as np
8 | from torch import Tensor,device
9 |
10 |
11 | def pdf_z_values(
12 | bins: Tensor,
13 | weights: Tensor,
14 | samples: int,
15 | d: device,
16 | perturb: bool,
17 | ) -> Tensor:
18 | """Generate z-values from pdf
19 | Arguments:
20 | bins (Tensor): z-value bins (B, N - 2)
21 | weights (Tensor): bin weights gathered from first pass (B, N - 1)
22 | samples (int): number of samples N
23 | d (device): torch device
24 | perturb (bool): peturb ray query segment
25 | Returns:
26 | t (Tensor): z-values sampled from pdf (B, N)
27 | """
28 | EPS = 1e-5
29 | B, N = weights.size()
30 |
31 | weights = weights + EPS
32 | pdf = weights / torch.sum(weights, dim=-1, keepdim=True)
33 | cdf = torch.cumsum(pdf, dim=-1)
34 | cdf = torch.cat((torch.zeros_like(cdf[:, :1]), cdf), dim=-1)
35 |
36 | if perturb:
37 | u = torch.rand((B, samples), device=d)
38 | u = u.contiguous()
39 | else:
40 | u = torch.linspace(0, 1, samples, device=d)
41 | u = u.expand(B, samples)
42 | u = u.contiguous()
43 |
44 | idxs = torch.searchsorted(cdf, u, right=True)
45 | idxs_below = torch.clamp_min(idxs - 1, 0)
46 | idxs_above = torch.clamp_max(idxs, N)
47 | idxs = torch.stack((idxs_below, idxs_above), dim=-1).view(B, 2 * samples)
48 |
49 | cdf = torch.gather(cdf, dim=1, index=idxs).view(B, samples, 2)
50 | bins = torch.gather(bins, dim=1, index=idxs).view(B, samples, 2)
51 |
52 | den = cdf[:, :, 1] - cdf[:, :, 0]
53 | den[den < EPS] = 1.0
54 |
55 | t = (u - cdf[:, :, 0]) / den
56 | t = bins[:, :, 0] + t * (bins[:, :, 1] - bins[:, :, 0])
57 |
58 | return t
59 |
60 |
61 | def sample_pdf(bins, weights, N_importance, det=False, eps=1e-5):
62 | """
63 | Sample @N_importance samples from @bins with distribution defined by @weights.
64 | Inputs:
65 | bins: (N_rays, N_samples_+1) where N_samples_ is "the number of coarse samples per ray - 2"
66 | weights: (N_rays, N_samples_)
67 | N_importance: the number of samples to draw from the distribution
68 | det: deterministic or not
69 | eps: a small number to prevent division by zero
70 | Outputs:
71 | samples: the sampled samples
72 | Source: https://github.com/kwea123/nerf_pl/blob/master/models/rendering.py
73 | """
74 | N_rays, N_samples_ = weights.shape
75 | weights = weights + eps # prevent division by zero (don't do inplace op!)
76 | pdf = weights / torch.sum(weights, -1, keepdim=True) # (N_rays, N_samples_)
77 | cdf = torch.cumsum(pdf, -1) # (N_rays, N_samples), cumulative distribution function
78 | cdf = torch.cat([torch.zeros_like(cdf[:, :1]), cdf], -1) # (N_rays, N_samples_+1)
79 | # padded to 0~1 inclusive
80 |
81 | if det:
82 | u = torch.linspace(0, 1, N_importance, device=bins.device)
83 | u = u.expand(N_rays, N_importance)
84 | else:
85 | u = torch.rand(N_rays, N_importance, device=bins.device)
86 | u = u.contiguous()
87 |
88 | inds = torch.searchsorted(cdf, u)
89 | below = torch.clamp_min(inds - 1, 0)
90 | above = torch.clamp_max(inds, N_samples_)
91 |
92 | inds_sampled = torch.stack([below, above], -1).view(N_rays, 2 * N_importance)
93 | cdf_g = torch.gather(cdf, 1, inds_sampled)
94 | cdf_g = cdf_g.view(N_rays, N_importance, 2)
95 | bins_g = torch.gather(bins, 1, inds_sampled).view(N_rays, N_importance, 2)
96 |
97 | denom = cdf_g[..., 1] - cdf_g[..., 0]
98 | denom[
99 | denom < eps
100 | ] = 1 # denom equals 0 means a bin has weight 0, in which case it will not be sampled
101 | # anyway, therefore any value for it is fine (set to 1 here)
102 |
103 | samples = bins_g[..., 0] + (u - cdf_g[..., 0]) / denom * (
104 | bins_g[..., 1] - bins_g[..., 0]
105 | )
106 | return samples
107 |
108 |
109 | def pdf_rays(
110 | ro: Tensor,
111 | rd: Tensor,
112 | t: Tensor,
113 | weights: Tensor,
114 | samples: int,
115 | perturb: bool,
116 | ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
117 | """Sample pdf along rays given computed weights
118 | Arguments:
119 | ro (Tensor): rays origin (B, 3)
120 | rd (Tensor): rays direction (B, 3)
121 | t (Tensor): coarse z-value (B, N)
122 | weights (Tensor): weights gathered from first pass (B, N)
123 | samples (int): number of samples along the ray
124 | perturb (bool): peturb ray query segment
125 | Returns:
126 | rx (Tensor): rays position queries (B, Nc + Nf, 3)
127 | rd (Tensor): rays direction (B, Nc + Nf, 3)
128 | t (Tensor): z-values from near to far (B, Nc + Nf)
129 | delta (Tensor): rays segment lengths (B, Nc + Nf)
130 | """
131 | B, S, N_coarse, _ = weights.shape
132 | weights = rearrange(weights, "b n s 1 -> (b n) s")
133 | t = rearrange(t, "b n s 1 -> (b n) s")
134 |
135 | Nf = samples
136 | tm = 0.5 * (t[:, :-1] + t[:, 1:])
137 | t_pdf = sample_pdf(tm, weights[..., 1:-1], Nf, det=False).detach().view(B, S, Nf)
138 | rx = ro[..., None, :] + rd[..., None, :] * t_pdf[..., None]
139 |
140 | return rx, t_pdf
141 |
142 |
143 | def sample_points_along_rays(
144 | near_depth: float,
145 | far_depth: float,
146 | num_samples: int,
147 | ray_origins: torch.Tensor,
148 | ray_directions: torch.Tensor,
149 | device: torch.device,
150 | logspace=False,
151 | perturb=False,
152 | ):
153 | # Compute a linspace of num_samples depth values beetween near_depth and far_depth.
154 | if logspace:
155 | z_vals = torch.logspace(np.log10(near_depth), np.log10(far_depth), num_samples, device=device)
156 | else:
157 | z_vals = torch.linspace(near_depth, far_depth, num_samples, device=device)
158 |
159 | if perturb:
160 | z_vals = z_vals + .5*(torch.rand_like(z_vals)-.5)*torch.cat([(z_vals[:-1]-z_vals[1:]).abs(),torch.tensor([0]).cuda()])
161 |
162 | # Using the ray_origins, ray_directions, generate 3D points along
163 | # the camera rays according to the z_vals.
164 | pts = (
165 | ray_origins[..., None, :] + ray_directions[..., None, :] * z_vals[..., :, None]
166 | )
167 |
168 | return pts, z_vals
169 |
170 |
171 | def volume_integral(
172 | z_vals: torch.tensor, sigmas: torch.tensor, radiances: torch.tensor, white_back=False,dist_scale=True,
173 | ) -> Tuple[torch.tensor, torch.tensor, torch.tensor]:
174 | # Compute the deltas in depth between the points.
175 | dists = torch.cat(
176 | [
177 | z_vals[..., 1:] - z_vals[..., :-1],
178 | (z_vals[..., 1:] - z_vals[..., :-1])[..., -1:],
179 | ],
180 | -1,
181 | )
182 |
183 | # Compute the alpha values from the densities and the dists.
184 | # Tip: use torch.einsum for a convenient way of multiplying the correct
185 | # dimensions of the sigmas and the dists.
186 | # TODO switch to just expanding shape of dists for less code
187 | dist_scaling=dists if dist_scale else torch.ones_like(dists)
188 | if len(dists.shape)==1: alpha = 1.0 - torch.exp(-torch.einsum("brzs, z -> brzs", F.relu(sigmas), dist_scaling))
189 | else: alpha = 1.0 - torch.exp(-torch.einsum("brzs, brz -> brzs", F.relu(sigmas), dist_scaling.flatten(0,1)))
190 |
191 | alpha_shifted = torch.cat(
192 | [torch.ones_like(alpha[:, :, :1]), 1.0 - alpha + 1e-10], -2
193 | )
194 |
195 | # Compute the Ts from the alpha values. Use torch.cumprod.
196 | Ts = torch.cumprod(alpha_shifted, -2)
197 |
198 | # Compute the weights from the Ts and the alphas.
199 | weights = alpha * Ts[..., :-1, :]
200 |
201 | # Compute the pixel color as the weighted sum of the radiance values.
202 | rgb = torch.einsum("brzs, brzs -> brs", weights, radiances)
203 |
204 | # Compute the depths as the weighted sum of z_vals.
205 | # Tip: use torch.einsum for a convenient way of computing the weighted sum,
206 | # without the need to reshape the z_vals.
207 | if len(dists.shape)==1:
208 | depth_map = torch.einsum("brzs, z -> brs", weights, z_vals)
209 | else:
210 | depth_map = torch.einsum("brzs, brz -> brs", weights, z_vals.flatten(0,1))
211 |
212 | if white_back:
213 | accum = weights.sum(dim=-2)
214 | backgrd_color = torch.tensor([1,1,1]+[0]*(rgb.size(-1)-3)).broadcast_to(rgb.shape).to(rgb)
215 | #backgrd_color = torch.ones(rgb.size(-1)).broadcast_to(rgb.shape).to(rgb)
216 | rgb = rgb + (backgrd_color - accum)
217 |
218 | return rgb, depth_map, weights
219 |
220 |
221 | class VolumeRenderer(nn.Module):
222 | def __init__(self, near, far, n_samples=32, backgrd_color=None):
223 | super().__init__()
224 | self.near = near
225 | self.far = far
226 | self.n_samples = n_samples
227 |
228 | if backgrd_color is not None:
229 | self.register_buffer('backgrd_color', backgrd_color)
230 | else:
231 | self.backgrd_color = None
232 |
233 | def forward(
234 | self, cam2world, intrinsics, x_pix, radiance_field: nn.Module
235 | ) -> Tuple[torch.tensor, torch.tensor]:
236 | """
237 | Takes as inputs ray origins and directions - samples points along the
238 | rays and then calculates the volume rendering integral.
239 |
240 | Params:
241 | input_dict: Dictionary with keys 'cam2world', 'intrinsics', and 'x_pix'
242 | radiance_field: nn.Module instance of the radiance field we want to render.
243 |
244 | Returns:
245 | Tuple of rgb, depth_map
246 | rgb: for each pixel coordinate x_pix, the color of the respective ray.
247 | depth_map: for each pixel coordinate x_pix, the depth of the respective ray.
248 |
249 | """
250 | batch_size, num_rays = x_pix.shape[0], x_pix.shape[1]
251 |
252 | # Compute the ray directions in world coordinates.
253 | # Use the function get_world_rays.
254 | ros, rds = get_world_rays(x_pix, intrinsics, cam2world)
255 |
256 | # Generate the points along rays and their depth values
257 | # Use the function sample_points_along_rays.
258 | pts, z_vals = sample_points_along_rays(
259 | self.near, self.far, self.n_samples, ros, rds, device=x_pix.device
260 | )
261 |
262 | # Reshape pts to (batch_size, -1, 3).
263 | pts = pts.reshape(batch_size, -1, 3)
264 |
265 | # Sample the radiance field with the points along the rays.
266 | sigma, feats, misc = radiance_field(pts)
267 |
268 | # Reshape sigma and feats back to (batch_size, num_rays, self.n_samples, -1)
269 | sigma = sigma.view(batch_size, num_rays, self.n_samples, 1)
270 | feats = feats.view(batch_size, num_rays, self.n_samples, -1)
271 |
272 | # Compute pixel colors, depths, and weights via the volume integral.
273 | rendering, depth_map, weights = volume_integral(z_vals, sigma, feats)
274 |
275 | if self.backgrd_color is not None:
276 | accum = weights.sum(dim=-2)
277 | backgrd_color = self.backgrd_color.broadcast_to(rendering.shape)
278 | rendering = rendering + (backgrd_color - accum)
279 |
280 | return rendering, depth_map, misc
281 |
--------------------------------------------------------------------------------
/run.py:
--------------------------------------------------------------------------------
1 | import os,random,time,datetime,glob
2 |
3 | import numpy as np
4 | from functools import partial
5 | from tqdm import tqdm,trange
6 | from einops import rearrange
7 |
8 | import wandb
9 | import torch
10 |
11 | import models
12 | import vis_scripts
13 |
14 | from data.KITTI import KittiDataset
15 | from data.co3d import Co3DNoCams
16 | from data.realestate10k_dataio import RealEstate10k
17 |
18 | def to_gpu(ob): return {k: to_gpu(v) for k, v in ob.items()} if isinstance(ob, dict) else ob.cuda()
19 |
20 | import argparse
21 | parser = argparse.ArgumentParser(description='simple training job')
22 | # logging parameters
23 | parser.add_argument('-n','--name', type=str,default="",required=False,help="wandb training name")
24 | parser.add_argument('-c','--init_ckpt', type=str,default=None,required=False,help="File for checkpoint loading. If folder specific, will use latest .pt file")
25 | parser.add_argument('-d','--dataset', type=str,default="hydrant")
26 | parser.add_argument('-o','--online', default=False, action=argparse.BooleanOptionalAction)
27 | # data/training parameters
28 | parser.add_argument('-b','--batch_size', type=int,default=1,help="number of videos/sequences per training step")
29 | parser.add_argument('-v','--vid_len', type=int,default=6,help="video length or number of images per batch")
30 | parser.add_argument('--midas_sup', default=False, action=argparse.BooleanOptionalAction,help="Whether to use midas depth supervision or not")
31 | parser.add_argument('--category', type=str,default=None,help="if want to use a specific co3d category, such as 'bicycle', specify here")
32 | # model parameters
33 | parser.add_argument('--n_skip', nargs="+",type=int,default=0,help="Number of frames to skip between adjacent frames in dataloader. If list, dataset randomly chooses between skips. Only used for co3d")
34 | parser.add_argument('--n_ctxt', type=int,default=2,help="Number of context views to use. 1 is just first frame, 2 is second and last, 3 is also middle, etc")
35 | # eval/vis
36 | parser.add_argument('--eval', default=False, action=argparse.BooleanOptionalAction,help="whether to train or run evaluation")
37 | parser.add_argument('--n_eval', type=int,default=int(1e8),help="Number of eval samples to run")
38 | parser.add_argument('--save_ind', default=False, action=argparse.BooleanOptionalAction,help="whether to save out each individual image (in rendering images) or just save the all-trajectory image")
39 | parser.add_argument('--save_imgs', default=False, action=argparse.BooleanOptionalAction,help="whether to save out the all-trajectory images")
40 | # demo args
41 | parser.add_argument('--demo_rgb', default="", type=str,required=False,help="The image folder path for demo inference.")
42 | parser.add_argument('--render_imgs', default=False, action=argparse.BooleanOptionalAction,help="whether to rerender out images (video reconstructions) during the demo inference (slower than just estimating poses)")
43 | parser.add_argument('--intrinsics', default=None, type=str,required=False,help="The intrinsics corresponding to the image path for demo inference as fx,fy,cx,cy. To use predicted intrinsics, leave as None")
44 | parser.add_argument('--low_res', nargs="+",type=int,default=[128,128],help="Low resolution to perform renderings at. Default (128,128)")
45 |
46 | args = parser.parse_args()
47 | if args.n_skip==0 and args.dataset=="realestate": args.n_skip=9 # realestate is the only dataset where 0 frameskip isn't meaningful
48 |
49 | # Wandb init: install wandb and initialize via wandb.login() before running
50 | run = wandb.init(project="flowcam",mode="online" if args.online else "disabled",name=args.name)
51 | wandb.run.log_code(".")
52 | save_dir = os.path.join(os.environ.get('LOGDIR', "") , run.name)
53 | print(save_dir)
54 | os.makedirs(save_dir,exist_ok=True)
55 | wandb.save(os.path.join(save_dir, "checkpoint*"))
56 | wandb.save(os.path.join(save_dir, "video*"))
57 |
58 | # Make dataset
59 | get_dataset = lambda val=False: ( Co3DNoCams(num_trgt=args.vid_len+1,low_res=(156,102),num_cat=1 if args.dataset=="hydrant" else 10 if args.dataset=="10cat" else 30,
60 | n_skip=args.n_skip,val=val,category=args.category) if args.dataset in ["hydrant","10cat","allcat"]
61 | else RealEstate10k(imsl=128, num_ctxt_views=2, num_query_views=args.vid_len+1, val=val, n_skip = args.n_skip) if args.dataset == "realestate"
62 | else KittiDataset(num_context=1,num_trgt=args.vid_len+1,low_res=(76,250),val=val,n_skip=args.n_skip)
63 | )
64 | get_dataloader = lambda dataset: iter(torch.utils.data.DataLoader(dataset, batch_size=args.batch_size*torch.cuda.device_count(),num_workers=args.batch_size,shuffle=True,pin_memory=True))
65 |
66 | # Make model + optimizer
67 | model = models.FlowCam(near=1,far=8,num_view=args.n_ctxt,use_midas=args.midas_sup).cuda()
68 | if args.init_ckpt is not None:
69 | ckpt_file = args.init_ckpt if os.path.isfile(os.path.expanduser(args.init_ckpt)) else max(glob.glob(os.path.join(args.init_ckpt,"*.pt")), key=os.path.getctime)
70 | model.load_state_dict(torch.load(ckpt_file)["model_state_dict"],strict=False)
71 | optim = torch.optim.Adam(lr=1e-4, params=model.parameters())
72 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | # todo get rid of start import, just import run and access run.train_dataset, etc
2 | from run import *
3 |
4 | train_dataset,val_dataset = get_dataset(),get_dataset(val=True,)
5 | train_dataset[0]
6 | train_dataloader,val_dataloader = get_dataloader(train_dataset),get_dataloader(val_dataset)
7 |
8 | def loss_fn(model_out, gt, model_input):
9 |
10 | rays = lambda x,y: torch.stack([x[i,:,y[i].long()] for i in range(len(x))])
11 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
12 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
13 | losses = { "metrics/rgb_loss": (model_out["rgb"] - rays(gt["trgt_rgb"],model_out["trgt_rays"])).square().mean() * (1e1 if args.dataset=="shapenet" else 2e2) }
14 |
15 | losses["metrics/ctxt_rgb_loss"]= (model_out["ctxt_rgb"] - rays(gt["ctxt_rgb"],model_out["ctxt_rays"])).square().mean() * 1e2
16 | gt_bwd_flow = rays(gt["bwd_flow"] if "bwd_flow" in gt else ch_sec(model_out["flow_inp"]),model_out["ctxt_rays"])
17 | losses["metrics/flow_from_pose"] = ((model_out["flow_from_pose"].clip(-.2,.2) - gt_bwd_flow.clip(-.2,.2)).square().mean() * 6e3).clip(0,10)
18 |
19 | gt_bwd_flow_trgt = rays(gt["bwd_flow"] if "bwd_flow" in gt else ch_sec(model_out["flow_inp"]),model_out["trgt_rays"])
20 |
21 | # monodepth loss (not used in paper but may be useful later)
22 | if args.midas_sup:
23 | def depth_lstsq_fit(depthgt,depthest):
24 | depthgt,depthest=1/(1e-8+depthgt),1/(1e-8+depthest)
25 | lstsq=torch.linalg.lstsq(depthgt,depthest)
26 | return ((depthgt@lstsq.solution)-depthest).square().mean() * 1e2
27 |
28 | losses["metrics/ctxt_depth_loss_lstsq"] = (depth_lstsq_fit(rays(ch_sec(model_out["ctxt_depth_inp"]),model_out["ctxt_rays"]).flatten(0,1),model_out["ctxt_depth"].flatten(0,1))*2e0).clip(0,2)/2
29 | losses["metrics/depth_loss_lstsq"] = (depth_lstsq_fit(rays(ch_sec(model_out["trgt_depth_inp"]),model_out["trgt_rays"]).flatten(0,1),model_out["depth"].flatten(0,1))*2e0).clip(0,2)/2
30 |
31 | return losses
32 |
33 | model = torch.nn.DataParallel(model)
34 |
35 | # Train loop
36 | for step in trange(0 if args.eval else int(1e8), desc="Fitting"): # train until user interruption
37 |
38 | # Run val set every n iterations
39 | val_step = step>10 and step%150<10
40 | prefix = "val" if val_step else ""
41 | torch.set_grad_enabled(not val_step)
42 | if val_step: print("\n\n\nval step\n\n\n")
43 |
44 | # Get data
45 | try: model_input, ground_truth = next(train_dataloader if not val_step else val_dataloader)
46 | except StopIteration:
47 | if val_step: val_dataloader = get_dataloader(val_dataset)
48 | else: train_dataloader = get_dataloader(train_dataset)
49 | continue
50 |
51 | model_input, ground_truth = to_gpu(model_input), to_gpu(ground_truth)
52 |
53 | # Run model and calculate losses
54 | total_loss = 0.
55 | for loss_name, loss in loss_fn(model(model_input), ground_truth, model_input).items():
56 | wandb.log({prefix+loss_name: loss.item()}, step=step)
57 | total_loss += loss
58 |
59 | wandb.log({prefix+"loss": total_loss.item()}, step=step)
60 | wandb.log({"epoch": (step*args.batch_size)/len(train_dataset)}, step=step)
61 |
62 | if not val_step:
63 | optim.zero_grad(); total_loss.backward(); optim.step();
64 |
65 | # Image summaries and checkpoint
66 | if step%50==0 : # write image summaries
67 | print("writing summary")
68 | with torch.no_grad(): model_output = model.module.render_full_img(model_input=model_input)
69 | vis_scripts.wandb_summary( total_loss, model_output, model_input, ground_truth, None,prefix=prefix)
70 | if step%100==0: #write video summaries
71 | print("writing video summary")
72 | try: vis_scripts.write_video(save_dir, vis_scripts.render_time_interp(model_input,model.module,None,16), prefix+"time_interp",step)
73 | except Exception as e: print("error in writing video",e)
74 | if step%500 == 0 and step: # save model
75 | print(f"Saving to {save_dir}"); torch.save({ 'step': step, 'model_state_dict': model.module.state_dict(), }, os.path.join(save_dir, f"checkpoint_{step}.pt"))
76 |
77 |
78 |
--------------------------------------------------------------------------------
/vis_scripts.py:
--------------------------------------------------------------------------------
1 | import os
2 | import geometry
3 | import wandb
4 | from matplotlib import cm
5 | from torchvision.utils import make_grid
6 | import torch.nn.functional as F
7 | import numpy as np
8 | import torch
9 | import flow_vis
10 | import flow_vis_torch
11 | import matplotlib.pyplot as plt;
12 | from einops import rearrange, repeat
13 | import piqa
14 | import imageio
15 | import splines.quaternion
16 | from torchcubicspline import (natural_cubic_spline_coeffs, NaturalCubicSpline)
17 |
18 | def write_video(save_dir,frames,vid_name,step,write_frames=False):
19 | frames = [(255*x).astype(np.uint8) for x in frames]
20 | if "time" in vid_name: frames = frames + frames[::-1]
21 | f = os.path.join(save_dir, f'{vid_name}.mp4')
22 | imageio.mimwrite(f, frames, fps=8, quality=7)
23 | wandb.log({f'vid/{vid_name}':wandb.Video(f, format='mp4', fps=8)})
24 | print("writing video at",f)
25 | if write_frames:
26 | for i,img in enumerate(frames):
27 | try: os.mkdir(os.path.join(save_dir, f'{vid_name}_{step}'))
28 | except:pass
29 | f=os.path.join(save_dir, f'{vid_name}/{i}.png');plt.imsave(f,img);print(f)
30 |
31 | def normalize(a):
32 | return (a - a.min()) / (a.max() - a.min())
33 |
34 | def cvt(a):
35 | a = a.permute(1, 2, 0).detach().cpu()
36 | a = (a - a.min()) / (a.max() - a.min())
37 | a = a.numpy()
38 | return a
39 |
40 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
41 |
42 | # Renders out query frame with interpolated motion field
43 | def render_time_interp(model_input,model,resolution,n):
44 |
45 | b=model_input["ctxt_rgb"].size(0)
46 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
47 | frames=[]
48 | thetas = np.linspace(0, 1, n)
49 | with torch.no_grad(): sample_out = model(model_input)
50 | if "flow_inp" in sample_out:model_input["bwd_flow"]=sample_out["flow_inp"]
51 |
52 | # TODO add wobble flag back in here from satori code
53 |
54 | all_poses=sample_out["poses"]
55 | pos_spline_idxs=torch.linspace(0,all_poses.size(1)-1,all_poses.size(1)) # no compression
56 | rot_spline_idxs=torch.linspace(0,all_poses.size(1)-1,all_poses.size(1)) # no compression
57 | all_pos_spline=[]
58 | all_quat_spline=[]
59 | for b_i in range(b):
60 | all_pos_spline.append(NaturalCubicSpline(natural_cubic_spline_coeffs(pos_spline_idxs, all_poses[b_i,pos_spline_idxs.long(),:3,-1].cpu())))
61 | quats=geometry.matrix_to_quaternion(all_poses[b_i,:,:3,:3])
62 | all_quat_spline.append(splines.quaternion.PiecewiseSlerp([splines.quaternion.UnitQuaternion.from_unit_xyzw(quat_)
63 | for quat_ in quats[rot_spline_idxs.long()].cpu().numpy()],grid=rot_spline_idxs.tolist()))
64 |
65 | for t in torch.linspace(0,all_poses.size(1)-1,n):
66 | print(t)
67 |
68 | custom_poses=[]
69 | for b_i,(pos_spline,quat_spline_) in enumerate(zip(all_pos_spline,all_quat_spline)):
70 | custom_pose=torch.eye(4).cuda()
71 | custom_pose[:3,-1]=pos_spline.evaluate(t)
72 | closest_t = (custom_pose[:3,-1]-all_poses[b_i,:,:3,-1]).square().sum(-1).argmin()
73 | quat_eval=quat_spline_.evaluate(t.item())
74 | curr_quats = torch.tensor(list(quat_eval.vector)+[quat_eval.scalar])
75 | custom_pose[:3,:3] = geometry.quaternion_to_matrix(curr_quats)
76 | custom_poses.append(custom_pose)
77 | custom_pose=torch.stack(custom_poses)
78 | with torch.no_grad(): model_out = model.render_full_img(model_input,query_pose=custom_pose,sample_out=sample_out)
79 |
80 | rgb_pred = model_out["rgb"]
81 | resolution = list(model_input["ctxt_rgb"][:,:1].flatten(0,1).permute(0,2,3,1).shape)
82 | rgb_pred=rgb_pred[:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
83 | magma_depth=model_out["depth"][:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
84 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
85 | frames.append(rgbd_im)
86 | return frames
87 |
88 |
89 | for i in range(n):
90 | print(i,n)
91 | query_pose = geometry.time_interp_poses(sample_out["poses"],i/(n-1), model_input["trgt_rgb"].size(1),None)[:,0]
92 | # todo fix this interpolation -- is it incorrect to interpolate here?
93 | with torch.no_grad(): model_out = model.render_full_img(model_input,query_pose=query_pose,sample_out=sample_out)
94 | rgb_pred = model_out["rgb"]
95 | resolution = list(model_input["ctxt_rgb"][:,:1].flatten(0,1).permute(0,2,3,1).shape)
96 | rgb_pred=rgb_pred[:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
97 | magma_depth=model_out["depth"][:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
98 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
99 | frames.append(rgbd_im)
100 | return frames
101 |
102 | def look_at(eye, at=torch.Tensor([0, 0, 0]).cuda(), up=torch.Tensor([0, 1, 0]).cuda(), eps=1e-5):
103 | #at = at.unsqueeze(0).unsqueeze(0)
104 | #up = up.unsqueeze(0).unsqueeze(0)
105 |
106 | z_axis = eye - at
107 | #z_axis /= z_axis.norm(dim=-1, keepdim=True) + eps
108 | z_axis = z_axis/(z_axis.norm(dim=-1, keepdim=True) + eps)
109 |
110 | up = up.expand(z_axis.shape)
111 | x_axis = torch.cross(up, z_axis)
112 | #x_axis /= x_axis.norm(dim=-1, keepdim=True) + eps
113 | x_axis = x_axis/(x_axis.norm(dim=-1, keepdim=True) + eps)
114 |
115 | y_axis = torch.cross(z_axis, x_axis)
116 | #y_axis /= y_axis.norm(dim=-1, keepdim=True) + eps
117 | y_axis = y_axis/(y_axis.norm(dim=-1, keepdim=True) + eps)
118 |
119 | r_mat = torch.stack((x_axis, y_axis, z_axis), axis=-1)
120 | return r_mat
121 |
122 | def render_cam_traj_wobble(model_input,model,resolution,n):
123 |
124 | c2w = torch.eye(4, device='cuda')[None]
125 | tmp = torch.eye(4).cuda()
126 | circ_scale = .1
127 | thetas = np.linspace(0, 2 * np.pi, n)
128 | frames = []
129 |
130 | if "ctxt_c2w" not in model_input:
131 | model_input["ctxt_c2w"] = torch.tensor([[-2.5882e-01, -4.8296e-01, 8.3652e-01, -2.2075e+00],
132 | [ 2.1187e-08, -8.6603e-01, -5.0000e-01, 2.3660e+00],
133 | [-9.6593e-01, 1.2941e-01, -2.2414e-01, 5.9150e-01],
134 | [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00]]
135 | )[None,None].expand(model_input["trgt_rgb"].size(0),model_input["trgt_rgb"].size(1),-1,-1).cuda()
136 |
137 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
138 |
139 | c2w = model_input["ctxt_c2w"]
140 | circ_scale = c2w[0,0,[0,2],-1].norm()
141 | #circ_scale = c2w[0,[0,1],-1].norm()
142 | thetas=np.linspace(0,np.pi*2,n)
143 | rgb_imgs=[]
144 | depth_imgs=[]
145 | start_theta=0#(model_input["ctxt_c2w"][0,0,0,-1]/circ_scale).arccos()
146 | with torch.no_grad(): sample_out = model(model_input)
147 | if "flow_inp" in sample_out: model_input["bwd_flow"]=sample_out["flow_inp"]
148 | step=2 if n==8 else 4
149 | zs = torch.cat((torch.linspace(0,-n//4,n//step),torch.linspace(-n//4,0,n//step),torch.linspace(0,n//4,n//step),torch.linspace(n//4,0,n//step)))
150 | for i in range(n):
151 | print(i,n)
152 | theta=float(thetas[i] + start_theta)
153 | x=np.cos(theta) * circ_scale * .075
154 | y=np.sin(theta) * circ_scale * .075
155 | tmp=torch.eye(4).cuda()
156 | newpos=torch.tensor([x,y,zs[i]*1e-1]).cuda().float()
157 | tmp[:3,-1] = newpos
158 | custom_c2w = tmp[None].expand(c2w.size(0),c2w.size(1),-1,-1)
159 | with torch.no_grad(): model_out = model(model_input,custom_transf=custom_c2w,full_img=True)
160 |
161 | resolution = [model_input["trgt_rgb"].size(0)]+list(resolution[1:])
162 | b = model_out["rgb"].size(0)
163 | rgb_pred = model_out["rgb"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
164 | magma_depth = model_out["depth"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
165 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
166 | frames.append(rgbd_im)
167 | return frames
168 |
169 |
170 |
171 | def render_cam_traj_time_wobble(model_input,model,resolution,n):
172 |
173 | c2w = torch.eye(4, device='cuda')[None]
174 | if "ctxt_c2w" not in model_input:
175 | model_input["ctxt_c2w"] = torch.tensor([[-2.5882e-01, -4.8296e-01, 8.3652e-01, -2.2075e+00],
176 | [ 2.1187e-08, -8.6603e-01, -5.0000e-01, 2.3660e+00],
177 | [-9.6593e-01, 1.2941e-01, -2.2414e-01, 5.9150e-01],
178 | [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00]]
179 | )[None,None].expand(model_input["trgt_rgb"].size(0),model_input["trgt_rgb"].size(1),-1,-1).cuda()
180 |
181 | c2w = model_input["ctxt_c2w"]
182 | circ_scale = c2w[0,0,[0,2],-1].norm()
183 | thetas=np.linspace(0,np.pi*2,n)
184 | rgb_imgs=[]
185 | depth_imgs=[]
186 | start_theta=0#(model_input["ctxt_c2w"][0,0,0,-1]/circ_scale).arccos()
187 |
188 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
189 | frames=[]
190 | thetas = np.linspace(0, 1, n)
191 | with torch.no_grad(): sample_out = model(model_input)
192 | if "flow_inp" in sample_out: model_input["bwd_flow"]=sample_out["flow_inp"]
193 | step=2 if n==8 else 4
194 | zs = torch.cat((torch.linspace(0,-n//4,n//step),torch.linspace(-n//4,0,n//step),torch.linspace(0,n//4,n//step),torch.linspace(n//4,0,n//step)))
195 | for i in range(n):
196 |
197 | print(i,n)
198 | theta=float(thetas[i] + start_theta)
199 | x=np.cos(theta) * circ_scale * .005
200 | y=np.sin(theta) * circ_scale * .005
201 | tmp=torch.eye(4).cuda()
202 | newpos=torch.tensor([x,y,zs[i]*2e-1]).cuda().float()
203 | tmp[:3,-1] = newpos
204 | custom_c2w = tmp[None].expand(c2w.size(0),c2w.size(1),-1,-1)
205 |
206 | with torch.no_grad(): model_out = model(model_input,time_i=i/(n-1),full_img=True,custom_transf=custom_c2w)
207 | rgb_pred = model_out["rgb"]
208 | same_all=True
209 | if same_all:
210 | resolution = list(model_input["ctxt_rgb"][:,:1].flatten(0,1).permute(0,2,3,1).shape)
211 | rgb_pred=rgb_pred[:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
212 | else:
213 | rgb_pred=rgb_pred.view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
214 | depth_pred = model_out["depth"].clone()
215 | mind,maxd=sample_out["depth"].cpu().min(),sample_out["depth"].cpu().max()
216 | depth_pred[0,0,0]=mind #normalize
217 | depth_pred[0,0,1]=maxd #normalize
218 | if same_all:
219 | depth_pred = (mind/(1e-3+depth_pred[:,:1]).view(resolution[:-1]).permute(1,0,2).flatten(1,2).cpu().numpy())
220 | else:
221 | depth_pred = (mind/(1e-3+depth_pred).view(resolution[:-1]).permute(1,0,2).flatten(1,2).cpu().numpy())
222 | magma = cm.get_cmap('magma')
223 | magma_depth = torch.from_numpy(magma(depth_pred))[...,:3]
224 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
225 | frames.append(rgbd_im)
226 |
227 | return frames
228 |
229 | # Renders out context frame with novel camera pose
230 | def render_view_interp(model_input,model,resolution,n):
231 |
232 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
233 |
234 | c2w = torch.eye(4, device='cuda')[None]
235 | tmp = torch.eye(4).cuda()
236 | circ_scale = .1
237 | thetas = np.linspace(0, 2 * np.pi, n)
238 | frames = []
239 |
240 | if "ctxt_c2w" not in model_input:
241 | model_input["ctxt_c2w"] = torch.tensor([[-2.5882e-01, -4.8296e-01, 8.3652e-01, -2.2075e+00],
242 | [ 2.1187e-08, -8.6603e-01, -5.0000e-01, 2.3660e+00],
243 | [-9.6593e-01, 1.2941e-01, -2.2414e-01, 5.9150e-01],
244 | [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00]]
245 | )[None,None].expand(model_input["trgt_rgb"].size(0),model_input["trgt_rgb"].size(1),-1,-1).cuda()
246 |
247 | c2w = model_input["ctxt_c2w"]
248 | circ_scale = c2w[0,0,[0,2],-1].norm()
249 | #circ_scale = c2w[0,[0,1],-1].norm()
250 | thetas=np.linspace(0,np.pi*2,n)
251 | rgb_imgs=[]
252 | depth_imgs=[]
253 | start_theta=0#(model_input["ctxt_c2w"][0,0,0,-1]/circ_scale).arccos()
254 | with torch.no_grad(): sample_out = model(model_input)
255 | if "flow_inp" in sample_out: model_input["bwd_flow"]=sample_out["flow_inp"]
256 | for i in range(n):
257 | print(i,n)
258 | theta=float(thetas[i] + start_theta)
259 | x=np.cos(theta) * circ_scale * 1
260 | y=np.sin(theta) * circ_scale * 1
261 | tmp=torch.eye(4).cuda()
262 | #newpos=torch.tensor([x,y,c2w[0,2,-1]]).cuda().float()
263 | newpos=torch.tensor([x,c2w[0,0,1,-1],y]).cuda().float()
264 | rot = look_at(newpos,torch.tensor([0,0,0]).cuda())
265 | rot[:,1:]*=-1
266 | tmp[:3,:3]=rot
267 | newpos=torch.tensor([x,c2w[0,0,1,-1],y]).cuda().float()
268 | tmp[:3,-1] = newpos
269 | #with torch.no_grad(): model_out = model(model_input,custom_transf=tmp[None].expand(c2w.size(0),-1,-1))
270 | custom_c2w = tmp[None].expand(c2w.size(0),c2w.size(1),-1,-1)
271 | #TODO make circle radius and only use first img
272 | #from pdb import set_trace as pdb_;pdb_()
273 | if 1:
274 | custom_c2w = custom_c2w.inverse()@model_input["ctxt_c2w"]
275 | #custom_c2w = model_input["ctxt_c2w"].inverse()@custom_c2w
276 | with torch.no_grad(): model_out = model(model_input,custom_transf=custom_c2w,full_img=True)
277 |
278 | resolution = [model_input["trgt_rgb"].size(0)]+list(resolution[1:])
279 |
280 | b = model_out["rgb"].size(0)
281 | rgb_pred = model_out["rgb"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
282 | magma_depth = model_out["depth"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
283 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
284 | frames.append(rgbd_im)
285 | return frames
286 |
287 | def wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
288 |
289 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
290 | resolution[0]=ground_truth["trgt_rgb"].size(1)*ground_truth["trgt_rgb"].size(0)
291 | nrow=model_input["trgt_rgb"].size(1)
292 | imsl=model_input["ctxt_rgb"].shape[-2:]
293 | inv = lambda x : 1/(x+1e-8)
294 |
295 | depth = make_grid(model_output["depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
296 |
297 | wandb_out = {
298 | "est/rgb_pred": make_grid(model_output["rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow),
299 | "ref/rgb_gt": make_grid(ground_truth["trgt_rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow),
300 | #"ref/rgb_gt": make_grid(ground_truth["trgt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow),
301 | "ref/ctxt_img": make_grid(model_input["ctxt_rgb"][:,0].cpu().detach(),nrow=1)*.5+.5,
302 | "est/depth": depth,
303 | "est/depth_1ch":make_grid(model_output["depth_raw"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl).cpu(),normalize=True,nrow=nrow),
304 | }
305 |
306 | depthgt = (ground_truth["trgt_depth"] if "trgt_depth" in ground_truth else model_output["trgt_depth_inp"] if "trgt_depth_inp" in model_output
307 | else model_input["trgt_depth"] if "trgt_depth" in model_input else None)
308 |
309 | if "ctxt_rgb" in model_output:
310 | wandb_out["est/ctxt_depth"] =make_grid(model_output["ctxt_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
311 | wandb_out["est/ctxt_rgb_pred"] = ctxt_rgb_pred = make_grid(model_output["ctxt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow)
312 |
313 | if "corr_weights" in model_output:
314 | #corr_weights = make_grid(model_output["corr_weights"].flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
315 | corr_weights = make_grid(ch_fst(model_output["corr_weights"],resolution[1]).flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
316 | wandb_out["est/corr_weights"] = corr_weights
317 |
318 | if "flow_from_pose" in model_output and not torch.isnan(model_output["flow_from_pose"]).any() and not torch.isnan(model_output["flow_from_pose"]).any():
319 | #psnr = piqa.PSNR()(ch_fst(model_output["rgb"],imsl[0]).flatten(0,1).contiguous(),ch_fst(ground_truth["trgt_rgb"],imsl[0]).flatten(0,1).contiguous())
320 | #wandb.log({prefix+"metrics/psnr": psnr})
321 |
322 | gt_flow_bwd = flow_vis_torch.flow_to_color(make_grid(model_output["flow_inp"].flatten(0,1),nrow=nrow))/255
323 | wandb_out["ref/flow_gt_bwd"]=gt_flow_bwd
324 | if "flow_from_pose" in model_output:
325 | wandb_out["est/flow_est_pose"] = flow_vis_torch.flow_to_color(make_grid(model_output["flow_from_pose"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
326 | if "flow_from_pose_render" in model_output:
327 | wandb_out["est/flow_est_pose_render"] = flow_vis_torch.flow_to_color(make_grid(model_output["flow_from_pose_render"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
328 | else:
329 | print("skipping flow plotting")
330 |
331 | wandb_out = {prefix+k:wandb.Image(v.permute(1, 2, 0).float().detach().clip(0,1).cpu().numpy()) for k,v in wandb_out.items()}
332 |
333 | wandb.log(wandb_out)
334 |
335 |
336 | def pose_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
337 | # Log points and boxes in W&B
338 | point_scene = wandb.Object3D({
339 | "type": "lidar/beta",
340 | "points": model_output["poses"][:,:3,-1].cpu().numpy(),
341 | })
342 | wandb.log({"camera positions": point_scene})
343 |
344 |
345 |
346 |
--------------------------------------------------------------------------------
/wandb_logging.py:
--------------------------------------------------------------------------------
1 | import os
2 | import wandb
3 | from matplotlib import cm
4 | from torchvision.utils import make_grid
5 | import torch.nn.functional as F
6 | import numpy as np
7 | import torch
8 | import flow_vis
9 | import flow_vis_torch
10 | import matplotlib.pyplot as plt; imsave = lambda x,y=0: plt.imsave("/nobackup/users/camsmith/img/tmp%s.png"%y,x.cpu().numpy());
11 | from einops import rearrange, repeat
12 | import piqa
13 | import imageio
14 |
15 | def write_video(save_dir,frames,vid_name,step,write_frames=False):
16 | frames = [(255*x).astype(np.uint8) for x in frames]
17 | if "time" in vid_name: frames = frames + frames[::-1]
18 | f = os.path.join(save_dir, f'{vid_name}_{step}.mp4')
19 | imageio.mimwrite(f, frames, fps=8, quality=7)
20 | wandb.log({f'vid/{vid_name}':wandb.Video(f, format='mp4', fps=8)})
21 | print("writing video at",f)
22 | if write_frames:
23 | for i,img in enumerate(frames):
24 | try: os.mkdir(os.path.join(save_dir, f'{vid_name}_{step}'))
25 | except:pass
26 | f=os.path.join(save_dir, f'{vid_name}_{step}/{i}.png');plt.imsave(f,img);print(f)
27 |
28 | def normalize(a):
29 | return (a - a.min()) / (a.max() - a.min())
30 |
31 | def cvt(a):
32 | a = a.permute(1, 2, 0).detach().cpu()
33 | a = (a - a.min()) / (a.max() - a.min())
34 | a = a.numpy()
35 | return a
36 |
37 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
38 |
39 | def _wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
40 |
41 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).shape)
42 |
43 | nrow=model_input["trgt_rgb"].size(1)
44 | imsly,imslx=model_input["ctxt_rgb"].shape[-2:]
45 |
46 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
47 |
48 | rgb_gt= ground_truth["trgt_rgb"]
49 | rgb_pred,depth,=[model_output[x] for x in ["rgb","depth"]]
50 |
51 | inv = lambda x : 1/(x+1e-3)
52 | depth = make_grid(model_output["depth"].flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)).cpu(),normalize=True,nrow=nrow)
53 |
54 | rgb_pred = make_grid(model_output["rgb"].flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)),normalize=True,nrow=nrow)
55 | rgb_gt = make_grid(ground_truth["trgt_rgb"].flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)),normalize=True,nrow=nrow)
56 | ctxt_img = make_grid(model_input["ctxt_rgb"].cpu().flatten(0,1),normalize=True,nrow=nrow)
57 |
58 | print("add psnr metric here")
59 |
60 | wandb_out = {
61 | "est/rgb_pred": rgb_pred,
62 | "ref/rgb_gt": rgb_gt,
63 | "ref/ctxt_img": ctxt_img,
64 | "est/depth": depth,
65 | }
66 | if "trgt_depth" in ground_truth:
67 | wandb_out["depthgt"]=make_grid(ground_truth["trgt_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)).cpu(),normalize=True,nrow=nrow)
68 |
69 | for k,v in wandb_out.items(): print(k,v.max(),v.min(),v.shape)
70 | #for k,v in wandb_out.items():plt.imsave("/nobackup/users/camsmith/img/%s.png"%k,v.permute(1,2,0).detach().cpu().numpy().clip(0,1));
71 | wandb.log({"sanity/"+k+"_min":v.min() for k,v in wandb_out.items()})
72 | wandb.log({"sanity/"+k+"_max":v.max() for k,v in wandb_out.items()})
73 | wandb_out = {prefix+k:wandb.Image(v.permute(1, 2, 0).detach().clip(0,1).cpu().numpy()) for k,v in wandb_out.items()}
74 |
75 | wandb.log(wandb_out)
76 |
77 | #def dyn_wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
78 | def wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
79 |
80 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
81 | nrow=model_input["trgt_rgb"].size(1)
82 | imsl=model_input["ctxt_rgb"].shape[-2:]
83 | inv = lambda x : 1/(x+1e-8)
84 |
85 | depth = make_grid(model_output["depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
86 |
87 | wandb_out = {
88 | "est/rgb_pred": make_grid(model_output["rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow),
89 | "ref/rgb_gt": make_grid(ground_truth["trgt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow),
90 | "ref/ctxt_img": make_grid(model_input["ctxt_rgb"][:,0].cpu().detach(),nrow=1)*.5+.5,
91 | "est/depth": depth,
92 | "est/depth_1ch":make_grid(model_output["depth_raw"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl).cpu(),normalize=True,nrow=nrow),
93 | }
94 |
95 | depthgt = (ground_truth["trgt_depth"] if "trgt_depth" in ground_truth else model_output["trgt_depth_inp"] if "trgt_depth_inp" in model_output
96 | else model_input["trgt_depth"] if "trgt_depth" in model_input else None)
97 | if depthgt is not None:
98 | depthgt = make_grid(inv(depthgt).cpu().view(*resolution[:3]).detach().unsqueeze(1),normalize=True,nrow=nrow)
99 | wandb_out["ref/depthgt"]= depthgt
100 |
101 | if "fine_rgb" in model_output:
102 | wandb_out["est/fine_rgb_pred"] = make_grid(model_output["fine_rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
103 | wandb_out["est/fine_depth_pred"] = make_grid(model_output["fine_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow,normalize=True)
104 |
105 | if "ctxt_rgb" in model_output:
106 | wandb_out["est/ctxt_depth"] =make_grid(model_output["ctxt_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
107 | wandb_out["est/ctxt_rgb_pred"] = ctxt_rgb_pred = make_grid(model_output["ctxt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow)
108 |
109 | if "corr_weights" in model_output:
110 | #corr_weights = make_grid(model_output["corr_weights"].flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
111 | corr_weights = make_grid(ch_fst(model_output["corr_weights"],resolution[1]).flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
112 | wandb_out["est/corr_weights"] = corr_weights
113 |
114 | if "flow" in model_output and not torch.isnan(model_output["flow"]).any() and not torch.isnan(model_output["flow_from_pose"]).any():
115 | psnr = piqa.PSNR()(ch_fst(model_output["rgb"],imsl[0]).flatten(0,1).contiguous(),ch_fst(ground_truth["trgt_rgb"],imsl[0]).flatten(0,1).contiguous())
116 | wandb.log({prefix+"metrics/psnr": psnr})
117 |
118 | gt_flow_bwd = flow_vis_torch.flow_to_color(make_grid(model_output["flow_inp"].flatten(0,1),nrow=nrow))/255
119 | est_flow = flow_vis_torch.flow_to_color(make_grid(model_output["flow"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
120 | wandb_out["est/flow_est"]= est_flow
121 | wandb_out["ref/flow_gt_bwd"]=gt_flow_bwd
122 | if "flow_from_pose" in model_output:
123 | wandb_out["est/flow_est_pose"] = flow_vis_torch.flow_to_color(make_grid(model_output["flow_from_pose"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
124 | elif "flow" in model_output:
125 | print("skipping nan flow")
126 | for k,v in wandb_out.items(): print(k,v.max(),v.min())
127 | #for k,v in wandb_out.items():plt.imsave("/nobackup/users/camsmith/img/%s.png"%k,v.permute(1,2,0).detach().cpu().numpy().clip(0,1));
128 | #zz
129 | #wandb.log({"sanity/"+k+"_min":v.min() for k,v in wandb_out.items()})
130 | #wandb.log({"sanity/"+k+"_max":v.max() for k,v in wandb_out.items()})
131 | #for k,v in wandb_out.items(): print(v.shape)
132 | wandb_out = {prefix+k:wandb.Image(v.permute(1, 2, 0).float().detach().clip(0,1).cpu().numpy()) for k,v in wandb_out.items()}
133 |
134 | wandb.log(wandb_out)
135 |
--------------------------------------------------------------------------------
14 |
15 | ## High-Level structure
16 | The code is organized as follows:
17 | * models.py contains the model definition
18 | * run.py contains a generic argument parser which creates the model and dataloaders for both training and evaluation
19 | * train.py and eval.py contains train and evaluation loops
20 | * mlp_modules.py and conv_modules.py contain common MLP and CNN blocks
21 | * vis_scripts.py contains plotting and wandb logging code
22 | * renderer.py implements volume rendering helper functions
23 | * geometry.py implements various geometric operations (projections, 3D lifting, rigid transforms, etc.)
24 | * data contains a list of dataset scripts
25 | * demo.py contains a script to run our model on any image directory for pose estimates. See the file header for an example on running it.
26 |
27 | ## Reproducing experiments
28 |
29 | See `python run.py --help` for a list of command line arguments.
30 | An example training command for CO3D-Hydrants is `python train.py --dataset hydrant --vid_len 8 --batch_size 2 --online --name hydrants_flowcam --n_skip 1 2.`
31 | Similarly, replace `--dataset hydrants` with any of `[realestate,kitti,10cat]` for training on RealEstate10K, KITTI, or CO3D-10Category.
32 |
33 | Example training commands for each dataset are listed below:
34 | `python train.py --dataset hydrant --vid_len 8 --batch_size 2 --online --name hydrant_flowcam --n_skip 1 2`
35 | `python train.py --dataset 10cat --vid_len 8 --batch_size 2 --online --name 10cat_flowcam --n_skip 1`
36 | `python train.py --dataset realestate --vid_len 8 --batch_size 2 --online --name realestate_flowcam --n_skip 9`
37 | `python train.py --dataset kitti --vid_len 8 --batch_size 2 --online --name kitti_flowcam --n_skip 0`
38 |
39 | Use the `--online` flag for summaries to be logged to your wandb account or omit it otherwise.
40 |
41 | ## Environment variables
42 |
43 | We use environment variables to set the dataset and logging paths, though you can easily hardcode the paths in each respective dataset script. Specifically, we use the environment variables `CO3D_ROOT, RE10K_IMG_ROOT, RE10K_POSE_ROOT, KITTI_ROOT, and LOGDIR`. For instance, you can add the line `export CO3D_ROOT="/nobackup/projects/public/facebook-co3dv2"` to your `.bashrc`.
44 |
45 | ## Data
46 |
47 | The KITTI dataset we use can be downloaded here: https://www.cvlibs.net/datasets/kitti/raw_data.php
48 |
49 | Instructions for downloading the RealEstate10K dataset can be found here: https://github.com/yilundu/cross_attention_renderer/blob/master/data_download/README.md
50 |
51 | We use the V2 version of the CO3D dataset, which can be downloaded here: https://github.com/facebookresearch/co3d
52 |
53 | ## Using FlowCam to estimate poses for your own scenes
54 |
55 | You can query FlowCam for any set of images using the script in `demo.py` and specifying the rgb_path, intrinsics (fx,fy,cx,cy), the pretrained checkpoint, whether to render out the reconstructed images or not (slower but illustrates how accurate the geometry is estimated by the model), and the image resolution to resize to in preprocessing (should be around 128 width to avoid memory issues).
56 | For example: `python demo.py --demo_rgb /nobackup/projects/public/facebook-co3dv2/hydrant/615_99120_197713/images --intrinsics 1.7671e+03,3.1427e+03,5.3550e+02,9.5150e+02 -c pretrained_models/co3d_hydrant.pt --render_imgs --low_res 144 128`. The script will write the poses, a rendered pose plot, and re-rendered rgb and depth (if requested) to the folder `demo_output`.
57 | The RealEstate10K pretrained (`pretrained_models/re10k.pt`) model probably has the most general prior to use for your own scenes. We are planning on training and releasing a model on all datasets for a more general prior, so stay tuned for that.
58 |
59 | ### Coordinate and camera parameter conventions
60 | This code uses an "OpenCV" style camera coordinate system, where the Y-axis points downwards (the up-vector points in the negative Y-direction), the X-axis points right, and the Z-axis points into the image plane.
61 |
62 | ### Citation
63 | If you find our work useful in your research, please cite:
64 | ```
65 | @misc{smith2023flowcam,
66 | title={FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow},
67 | author={Cameron Smith and Yilun Du and Ayush Tewari and Vincent Sitzmann},
68 | year={2023},
69 | eprint={2306.00180},
70 | archivePrefix={arXiv},
71 | primaryClass={cs.CV}
72 | }
73 | ```
74 |
75 | ### Contact
76 | If you have any questions, please email Cameron Smith at omid.smith.cameron@gmail.com or open an issue.
77 |
--------------------------------------------------------------------------------
/conv_modules.py:
--------------------------------------------------------------------------------
1 | import torch, torchvision
2 | from torch import nn
3 | import functools
4 | from einops import rearrange, repeat
5 | from torch.nn import functional as F
6 | import numpy as np
7 |
8 | def get_norm_layer(norm_type="instance", group_norm_groups=32):
9 | """Return a normalization layer
10 | Parameters:
11 | norm_type (str) -- the name of the normalization layer: batch | instance | none
12 | For BatchNorm, we use learnable affine parameters and track running statistics (mean/stddev).
13 | For InstanceNorm, we do not use learnable affine parameters. We do not track running statistics.
14 | """
15 | if norm_type == "batch":
16 | norm_layer = functools.partial(
17 | nn.BatchNorm2d, affine=True, track_running_stats=True
18 | )
19 | elif norm_type == "instance":
20 | norm_layer = functools.partial(
21 | nn.InstanceNorm2d, affine=False, track_running_stats=False
22 | )
23 | elif norm_type == "group":
24 | norm_layer = functools.partial(nn.GroupNorm, group_norm_groups)
25 | elif norm_type == "none":
26 | norm_layer = None
27 | else:
28 | raise NotImplementedError("normalization layer [%s] is not found" % norm_type)
29 | return norm_layer
30 |
31 |
32 | class PixelNeRFEncoder(nn.Module):
33 | def __init__(
34 | self,
35 | backbone="resnet34",
36 | pretrained=True,
37 | num_layers=4,
38 | index_interp="bilinear",
39 | index_padding="border",
40 | upsample_interp="bilinear",
41 | feature_scale=1.0,
42 | use_first_pool=True,
43 | norm_type="batch",
44 | in_ch=3,
45 | ):
46 | super().__init__()
47 |
48 | self.use_custom_resnet = backbone == "custom"
49 | self.feature_scale = feature_scale
50 | self.use_first_pool = use_first_pool
51 | norm_layer = get_norm_layer(norm_type)
52 |
53 | print("Using torchvision", backbone, "encoder")
54 | self.model = getattr(torchvision.models, backbone)(
55 | pretrained=pretrained, norm_layer=norm_layer
56 | )
57 |
58 | if in_ch != 3:
59 | self.model.conv1 = nn.Conv2d(
60 | in_ch,
61 | self.model.conv1.weight.shape[0],
62 | self.model.conv1.kernel_size,
63 | self.model.conv1.stride,
64 | self.model.conv1.padding,
65 | padding_mode=self.model.conv1.padding_mode,
66 | )
67 |
68 | # Following 2 lines need to be uncommented for older configs
69 | self.model.fc = nn.Sequential()
70 | self.model.avgpool = nn.Sequential()
71 | self.latent_size = [0, 64, 128, 256, 512, 1024][num_layers]
72 |
73 | self.num_layers = num_layers
74 | self.index_interp = index_interp
75 | self.index_padding = index_padding
76 | self.upsample_interp = upsample_interp
77 | self.register_buffer("latent", torch.empty(1, 1, 1, 1), persistent=False)
78 | self.register_buffer(
79 | "latent_scaling", torch.empty(2, dtype=torch.float32), persistent=False
80 | )
81 |
82 | self.out = nn.Sequential(
83 | nn.Conv2d(self.latent_size, 512, 1),
84 | )
85 |
86 | def forward(self, x, custom_size=None):
87 |
88 |
89 | if len(x.shape)>4: return self(x.flatten(0,1),custom_size).unflatten(0,x.shape[:2])
90 |
91 | if self.feature_scale != 1.0:
92 | x = F.interpolate(
93 | x,
94 | scale_factor=self.feature_scale,
95 | mode="bilinear" if self.feature_scale > 1.0 else "area",
96 | align_corners=True if self.feature_scale > 1.0 else None,
97 | recompute_scale_factor=True,
98 | )
99 | x = x.to(device=self.latent.device)
100 |
101 | if self.use_custom_resnet:
102 | self.latent = self.model(x)
103 | else:
104 | x = self.model.conv1(x)
105 | x = self.model.bn1(x)
106 | x = self.model.relu(x)
107 |
108 | latents = [x]
109 | if self.num_layers > 1:
110 | if self.use_first_pool:
111 | x = self.model.maxpool(x)
112 | x = self.model.layer1(x)
113 | latents.append(x)
114 | if self.num_layers > 2:
115 | x = self.model.layer2(x)
116 | latents.append(x)
117 | if self.num_layers > 3:
118 | x = self.model.layer3(x)
119 | latents.append(x)
120 | if self.num_layers > 4:
121 | x = self.model.layer4(x)
122 | latents.append(x)
123 |
124 | self.latents = latents
125 | align_corners = None if self.index_interp == "nearest " else True
126 | latent_sz = latents[0].shape[-2:]
127 | for i in range(len(latents)):
128 | latents[i] = F.interpolate(
129 | latents[i],
130 | latent_sz if custom_size is None else custom_size,
131 | mode=self.upsample_interp,
132 | align_corners=align_corners,
133 | )
134 | self.latent = torch.cat(latents, dim=1)
135 | self.latent_scaling[0] = self.latent.shape[-1]
136 | self.latent_scaling[1] = self.latent.shape[-2]
137 | self.latent_scaling = self.latent_scaling / (self.latent_scaling - 1) * 2.0
138 | return self.out(self.latent)
139 |
--------------------------------------------------------------------------------
/data/KITTI.py:
--------------------------------------------------------------------------------
1 | import os
2 | import multiprocessing as mp
3 | import torch.nn.functional as F
4 | import torch
5 | import random
6 | import imageio
7 | import numpy as np
8 | from glob import glob
9 | from collections import defaultdict
10 | from pdb import set_trace as pdb
11 | from itertools import combinations
12 | from random import choice
13 | import matplotlib.pyplot as plt
14 |
15 | from torchvision import transforms
16 | from einops import rearrange, repeat
17 |
18 | import sys
19 |
20 | # Geometry functions below used for calculating depth, ignore
21 | def glob_imgs(path):
22 | imgs = []
23 | for ext in ["*.png", "*.jpg", "*.JPEG", "*.JPG"]:
24 | imgs.extend(glob(os.path.join(path, ext)))
25 | return imgs
26 |
27 |
28 | def pick(list, item_idcs):
29 | if not list:
30 | return list
31 | return [list[i] for i in item_idcs]
32 |
33 |
34 | def parse_intrinsics(intrinsics):
35 | fx = intrinsics[..., 0, :1]
36 | fy = intrinsics[..., 1, 1:2]
37 | cx = intrinsics[..., 0, 2:3]
38 | cy = intrinsics[..., 1, 2:3]
39 | return fx, fy, cx, cy
40 |
41 |
42 | hom = lambda x, i=-1: torch.cat((x, torch.ones_like(x.unbind(i)[0].unsqueeze(i))), i)
43 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
44 |
45 | def expand_as(x, y):
46 | if len(x.shape) == len(y.shape):
47 | return x
48 |
49 | for i in range(len(y.shape) - len(x.shape)):
50 | x = x.unsqueeze(-1)
51 |
52 | return x
53 |
54 |
55 | def lift(x, y, z, intrinsics, homogeneous=False):
56 | """
57 |
58 | :param self:
59 | :param x: Shape (batch_size, num_points)
60 | :param y:
61 | :param z:
62 | :param intrinsics:
63 | :return:
64 | """
65 | fx, fy, cx, cy = parse_intrinsics(intrinsics)
66 |
67 | x_lift = (x - expand_as(cx, x)) / expand_as(fx, x) * z
68 | y_lift = (y - expand_as(cy, y)) / expand_as(fy, y) * z
69 |
70 | if homogeneous:
71 | return torch.stack((x_lift, y_lift, z, torch.ones_like(z).to(x.device)), dim=-1)
72 | else:
73 | return torch.stack((x_lift, y_lift, z), dim=-1)
74 |
75 |
76 | def world_from_xy_depth(xy, depth, cam2world, intrinsics):
77 | batch_size, *_ = cam2world.shape
78 |
79 | x_cam = xy[..., 0]
80 | y_cam = xy[..., 1]
81 | z_cam = depth
82 |
83 | pixel_points_cam = lift(
84 | x_cam, y_cam, z_cam, intrinsics=intrinsics, homogeneous=True
85 | )
86 | world_coords = torch.einsum("b...ij,b...kj->b...ki", cam2world, pixel_points_cam)[
87 | ..., :3
88 | ]
89 |
90 | return world_coords
91 |
92 |
93 | def get_ray_directions(xy, cam2world, intrinsics, normalize=True):
94 | z_cam = torch.ones(xy.shape[:-1]).to(xy.device)
95 | pixel_points = world_from_xy_depth(
96 | xy, z_cam, intrinsics=intrinsics, cam2world=cam2world
97 | ) # (batch, num_samples, 3)
98 |
99 | cam_pos = cam2world[..., :3, 3]
100 | ray_dirs = pixel_points - cam_pos[..., None, :] # (batch, num_samples, 3)
101 | if normalize:
102 | ray_dirs = F.normalize(ray_dirs, dim=-1)
103 | return ray_dirs
104 |
105 |
106 | class SceneInstanceDataset(torch.utils.data.Dataset):
107 | """This creates a dataset class for a single object instance (such as a single car)."""
108 |
109 | def __init__(
110 | self,
111 | instance_idx,
112 | instance_dir,
113 | specific_observation_idcs=None,
114 | input_img_sidelength=None,
115 | img_sidelength=None,
116 | num_images=None,
117 | cache=None,
118 | raft=None,
119 | low_res=(64,208),
120 | ):
121 | self.instance_idx = instance_idx
122 | self.img_sidelength = img_sidelength
123 | self.input_img_sidelength = input_img_sidelength
124 | self.instance_dir = instance_dir
125 | self.cache = {}
126 |
127 | self.low_res=low_res
128 |
129 | pose_dir = os.path.join(instance_dir, "pose")
130 | color_dir = os.path.join(instance_dir, "image")
131 |
132 | import pykitti
133 |
134 | drive = self.instance_dir.strip("/").split("/")[-1].split("_")[-2]
135 | date = self.instance_dir.strip("/").split("/")[-2]
136 | self.kitti_raw = pykitti.raw(
137 | "/".join(self.instance_dir.rstrip("/").split("/")[:-2]), date, drive
138 | )
139 | self.num_img = len(
140 | os.listdir(
141 | os.path.join(self.instance_dir, self.instance_dir, "image_02/data")
142 | )
143 | )
144 |
145 | self.color_paths = sorted(glob_imgs(color_dir))
146 | self.pose_paths = sorted(glob(os.path.join(pose_dir, "*.txt")))
147 | self.instance_name = os.path.basename(os.path.dirname(self.instance_dir))
148 |
149 | if specific_observation_idcs is not None:
150 | self.color_paths = pick(self.color_paths, specific_observation_idcs)
151 | self.pose_paths = pick(self.pose_paths, specific_observation_idcs)
152 | elif num_images is not None:
153 | idcs = np.linspace(
154 | 0, stop=len(self.color_paths), num=num_images, endpoint=False, dtype=int
155 | )
156 | self.color_paths = pick(self.color_paths, idcs)
157 | self.pose_paths = pick(self.pose_paths, idcs)
158 |
159 | def set_img_sidelength(self, new_img_sidelength):
160 | """For multi-resolution training: Updates the image sidelength with whichimages are loaded."""
161 | self.img_sidelength = new_img_sidelength
162 |
163 | def __len__(self):
164 | return self.num_img
165 |
166 | def __getitem__(self, idx, context=False, input_context=True):
167 | # print("trgt load")
168 |
169 | rgb = transforms.ToTensor()(self.kitti_raw.get_cam2(idx)) * 2 - 1
170 |
171 | K = torch.from_numpy(self.kitti_raw.calib.K_cam2.copy())
172 | cam2imu = torch.from_numpy(self.kitti_raw.calib.T_cam2_imu).inverse()
173 | imu2world = torch.from_numpy(self.kitti_raw.oxts[idx].T_w_imu)
174 | cam2world = (imu2world @ cam2imu).float()
175 |
176 | uv = np.mgrid[0 : rgb.size(1), 0 : rgb.size(2)].astype(float).transpose(1, 2, 0)
177 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
178 |
179 | # Downsample
180 | h, w = rgb.shape[-2:]
181 |
182 | K = torch.stack((K[0] / w, K[1] / h, K[2])) #normalize intrinsics to be resolution independent
183 |
184 | scale = 2;
185 | lowh, loww = int(64 * scale), int(208 * scale)
186 | med_rgb = F.interpolate( rgb[None], (lowh, loww), mode="bilinear", align_corners=True)[0]
187 | scale = 3;
188 | lowh, loww = int(64 * scale), int(208 * scale)
189 | large_rgb = F.interpolate( rgb[None], (lowh, loww), mode="bilinear", align_corners=True)[0]
190 | uv_large = np.mgrid[0:lowh, 0:loww].astype(float).transpose(1, 2, 0)
191 | uv_large = torch.from_numpy(np.flip(uv_large, axis=-1).copy()).long()
192 | uv_large = uv_large / torch.tensor([loww, lowh]) # uv in [0,1]
193 |
194 | #scale = 1;
195 | lowh, loww = self.low_res#int(64 * scale), int(208 * scale)
196 | rgb = F.interpolate(
197 | rgb[None], (lowh, loww), mode="bilinear", align_corners=True
198 | )[0]
199 | uv = np.mgrid[0:lowh, 0:loww].astype(float).transpose(1, 2, 0)
200 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
201 | uv = uv / torch.tensor([loww, lowh]) # uv in [0,1]
202 |
203 | tmp = torch.eye(4)
204 | tmp[:3, :3] = K
205 | K = tmp
206 |
207 | sample = {
208 | "instance_name": self.instance_name,
209 | "instance_idx": torch.Tensor([self.instance_idx]).squeeze().long(),
210 | "cam2world": cam2world,
211 | "img_idx": torch.Tensor([idx]).squeeze().long(),
212 | "img_id": "%s_%02d_%02d" % (self.instance_name, self.instance_idx, idx),
213 | "rgb": rgb,
214 | "large_rgb": large_rgb,
215 | "med_rgb": med_rgb,
216 | "intrinsics": K.float(),
217 | "uv": uv,
218 | "uv_large": uv_large,
219 | }
220 |
221 | return sample
222 |
223 |
224 | def get_instance_datasets(
225 | root,
226 | max_num_instances=None,
227 | specific_observation_idcs=None,
228 | cache=None,
229 | sidelen=None,
230 | max_observations_per_instance=None,
231 | ):
232 | instance_dirs = sorted(glob(os.path.join(root, "*/")))
233 | assert len(instance_dirs) != 0, f"No objects in the directory {root}"
234 |
235 | if max_num_instances != None:
236 | instance_dirs = instance_dirs[:max_num_instances]
237 |
238 | all_instances = [
239 | SceneInstanceDataset(
240 | instance_idx=idx,
241 | instance_dir=dir,
242 | specific_observation_idcs=specific_observation_idcs,
243 | img_sidelength=sidelen,
244 | cache=cache,
245 | num_images=max_observations_per_instance,
246 | )
247 | for idx, dir in enumerate(instance_dirs)
248 | ]
249 | return all_instances
250 |
251 |
252 | class KittiDataset(torch.utils.data.Dataset):
253 | """Dataset for a class of objects, where each datapoint is a SceneInstanceDataset."""
254 |
255 | def __init__(
256 | self,
257 | num_context=2,
258 | num_trgt=1,
259 | vary_context_number=False,
260 | query_sparsity=None,
261 | img_sidelength=None,
262 | input_img_sidelength=None,
263 | max_num_instances=None,
264 | max_observations_per_instance=None,
265 | specific_observation_idcs=None,
266 | val=False,
267 | test_context_idcs=None,
268 | context_is_last=False,
269 | context_is_first=False,
270 | cache=None,
271 | video=True,
272 | low_res=(64,208),
273 | n_skip=0,
274 | ):
275 |
276 | max_num_instances = None
277 |
278 | root_dir = os.environ['KITTI_ROOT']
279 |
280 | basedirs = list(
281 | filter(lambda x: "20" in x and "zip" not in x, os.listdir(root_dir))
282 | )
283 | drive_paths = []
284 | for basedir in basedirs:
285 | dirs = list(
286 | filter(
287 | lambda x: "txt" not in x,
288 | os.listdir(os.path.join(root_dir, basedir)),
289 | )
290 | )
291 | drive_paths += [
292 | os.path.abspath(os.path.join(root_dir, basedir, dir_)) for dir_ in dirs
293 | ]
294 | self.instance_dirs = sorted(drive_paths)
295 |
296 | if type(n_skip)==type([]):n_skip=n_skip[0]
297 | self.n_skip = n_skip+1
298 | self.num_context = num_context
299 | self.num_trgt = num_trgt
300 | self.query_sparsity = query_sparsity
301 | self.img_sidelength = img_sidelength
302 | self.vary_context_number = vary_context_number
303 | self.cache = {}
304 | self.test = val
305 | self.test_context_idcs = test_context_idcs
306 | self.context_is_last = context_is_last
307 | self.context_is_first = context_is_first
308 |
309 | print(f"Root dir {root_dir}, {len(self.instance_dirs)} instances")
310 |
311 | assert len(self.instance_dirs) != 0, "No objects in the data directory"
312 |
313 | self.max_num_instances = max_num_instances
314 | if max_num_instances == 1:
315 | self.instance_dirs = [
316 | x for x in self.instance_dirs if "2011_09_26_drive_0027_sync" in x
317 | ]
318 | print("note testing single dir") # testing dir
319 |
320 | self.all_instances = [
321 | SceneInstanceDataset(
322 | instance_idx=idx,
323 | instance_dir=dir,
324 | specific_observation_idcs=specific_observation_idcs,
325 | img_sidelength=img_sidelength,
326 | input_img_sidelength=input_img_sidelength,
327 | num_images=max_observations_per_instance,
328 | cache=cache,
329 | low_res=low_res,
330 | )
331 | for idx, dir in enumerate(self.instance_dirs)
332 | ]
333 | self.all_instances = [x for x in self.all_instances if len(x) > 40]
334 | if max_num_instances is not None:
335 | self.all_instances = self.all_instances[:max_num_instances]
336 |
337 | test_idcs = list(range(len(self.all_instances)))[::8]
338 | self.all_instances = [x for i,x in enumerate(self.all_instances) if (i in test_idcs and val) or (i not in test_idcs and not val)]
339 | print("validation: ",val,len(self.all_instances))
340 |
341 | self.num_per_instance_observations = [len(obj) for obj in self.all_instances]
342 | self.num_instances = len(self.all_instances)
343 |
344 | self.instance_img_pairs = []
345 | for i,instance_dir in enumerate(self.all_instances):
346 | for j in range(len(instance_dir)-n_skip*(num_trgt+1)):
347 | self.instance_img_pairs.append((i,j))
348 |
349 | def sparsify(self, dict, sparsity):
350 | new_dict = {}
351 | if sparsity is None:
352 | return dict
353 | else:
354 | # Sample upper_limit pixel idcs at random.
355 | rand_idcs = np.random.choice(
356 | self.img_sidelength ** 2, size=sparsity, replace=False
357 | )
358 | for key in ["rgb", "uv"]:
359 | new_dict[key] = dict[key][rand_idcs]
360 |
361 | for key, v in dict.items():
362 | if key not in ["rgb", "uv"]:
363 | new_dict[key] = dict[key]
364 |
365 | return new_dict
366 |
367 | def set_img_sidelength(self, new_img_sidelength):
368 | """For multi-resolution training: Updates the image sidelength with which images are loaded."""
369 | self.img_sidelength = new_img_sidelength
370 | for instance in self.all_instances:
371 | instance.set_img_sidelength(new_img_sidelength)
372 |
373 | def __len__(self):
374 | return len(self.instance_img_pairs)
375 |
376 | def get_instance_idx(self, idx):
377 | if self.test:
378 | obj_idx = 0
379 | while idx >= 0:
380 | idx -= self.num_per_instance_observations[obj_idx]
381 | obj_idx += 1
382 | return (
383 | obj_idx - 1,
384 | int(idx + self.num_per_instance_observations[obj_idx - 1]),
385 | )
386 | else:
387 | return np.random.randint(self.num_instances), 0
388 |
389 | def collate_fn(self, batch_list):
390 | keys = batch_list[0].keys()
391 | result = defaultdict(list)
392 |
393 | for entry in batch_list:
394 | # make them all into a new dict
395 | for key in keys:
396 | result[key].append(entry[key])
397 |
398 | for key in keys:
399 | try:
400 | result[key] = torch.stack(result[key], dim=0)
401 | except:
402 | continue
403 |
404 | return result
405 |
406 | def getframe(self, obj_idx, x):
407 | return (
408 | self.all_instances[obj_idx].__getitem__(
409 | x, context=True, input_context=True
410 | ),
411 | x,
412 | )
413 |
414 | def __getitem__(self, idx, sceneidx=None):
415 |
416 | context = []
417 | trgt = []
418 | post_input = []
419 | #obj_idx,det_idx= np.random.randint(self.num_instances), 0
420 | of=0
421 |
422 | obj_idx, i = self.instance_img_pairs[idx]
423 |
424 | if of: obj_idx = 0
425 |
426 | if sceneidx is not None:
427 | obj_idx, det_idx = sceneidx[0], sceneidx[0]
428 |
429 | if len(self.all_instances[obj_idx])<=i+self.num_trgt*self.n_skip:
430 | i=0
431 | if sceneidx is not None:
432 | i=sceneidx[1]
433 | for _ in range(self.num_trgt):
434 | if sceneidx is not None:
435 | print(i)
436 | i += self.n_skip
437 | sample = self.all_instances[obj_idx].__getitem__(
438 | i, context=True, input_context=True
439 | )
440 | post_input.append(sample)
441 | post_input[-1]["mask"] = torch.Tensor([1.0])
442 | sub_sample = self.sparsify(sample, self.query_sparsity)
443 | trgt.append(sub_sample)
444 |
445 | post_input = self.collate_fn(post_input)
446 | trgt = self.collate_fn(trgt)
447 |
448 | out_dict = {"query": trgt, "post_input": post_input, "context": None}, trgt
449 |
450 | imgs = trgt["rgb"]
451 | imgs_large = (trgt["large_rgb"]*.5+.5)*255
452 | imgs_med = (trgt["large_rgb"]*.5+.5)*255
453 | Ks = trgt["intrinsics"][:,:3,:3]
454 | uv = trgt["uv"].flatten(1,2)
455 |
456 | #imgs large in [0,255],
457 | #imgs in [-1,1],
458 | #gt_rgb in [0,1],
459 | model_input = {
460 | "trgt_rgb": imgs[1:],
461 | "ctxt_rgb": imgs[:-1],
462 | "trgt_rgb_large": imgs_large[1:],
463 | "ctxt_rgb_large": imgs_large[:-1],
464 | "trgt_rgb_med": imgs_med[1:],
465 | "ctxt_rgb_med": imgs_med[:-1],
466 | "intrinsics": Ks[1:],
467 | "x_pix": uv[1:],
468 | "trgt_c2w": trgt["cam2world"][1:],
469 | "ctxt_c2w": trgt["cam2world"][:-1],
470 | }
471 | gt = {
472 | "trgt_rgb": ch_sec(imgs[1:])*.5+.5,
473 | "ctxt_rgb": ch_sec(imgs[:-1])*.5+.5,
474 | "intrinsics": Ks[1:],
475 | "x_pix": uv[1:],
476 | }
477 | return model_input,gt
478 |
--------------------------------------------------------------------------------
/data/__pycache__/Ego4D.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/Ego4D.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/KITTI.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/KITTI.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/KITTI.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/KITTI.cpython-39.pyc
--------------------------------------------------------------------------------
/data/__pycache__/MultiFrameShapenet.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/MultiFrameShapenet.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/co3d.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/co3d.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/co3d.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/co3d.cpython-39.pyc
--------------------------------------------------------------------------------
/data/__pycache__/co3dv1.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/co3dv1.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/realestate10k_dataio.cpython-310.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/realestate10k_dataio.cpython-310.pyc
--------------------------------------------------------------------------------
/data/__pycache__/realestate10k_dataio.cpython-39.pyc:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cameronosmith/FlowCam/aff310543a858df2ddbf4c6ac6f01372e2f4562e/data/__pycache__/realestate10k_dataio.cpython-39.pyc
--------------------------------------------------------------------------------
/data/co3d.py:
--------------------------------------------------------------------------------
1 | # note for davis dataloader later: temporally consistent depth estimator: https://github.com/yu-li/TCMonoDepth
2 | # note for cool idea of not even downloading data and just streaming from youtube:https://gist.github.com/Mxhmovd/41e7690114e7ddad8bcd761a76272cc3
3 | import matplotlib.pyplot as plt;
4 | import cv2
5 | import os
6 | import multiprocessing as mp
7 | import torch.nn.functional as F
8 | import torch
9 | import random
10 | import imageio
11 | import numpy as np
12 | from glob import glob
13 | from collections import defaultdict
14 | from pdb import set_trace as pdb
15 | from itertools import combinations
16 | from random import choice
17 | import matplotlib.pyplot as plt
18 | import imageio.v3 as iio
19 |
20 | from torchvision import transforms
21 |
22 | import sys
23 |
24 | from glob import glob
25 | import os
26 | import gzip
27 | import json
28 | import numpy as np
29 |
30 | from PIL import Image
31 | def _load_16big_png_depth(depth_png) -> np.ndarray:
32 | with Image.open(depth_png) as depth_pil:
33 | # the image is stored with 16-bit depth but PIL reads it as I (32 bit).
34 | # we cast it to uint16, then reinterpret as float16, then cast to float32
35 | depth = (
36 | np.frombuffer(np.array(depth_pil, dtype=np.uint16), dtype=np.float16)
37 | .astype(np.float32)
38 | .reshape((depth_pil.size[1], depth_pil.size[0]))
39 | )
40 | return depth
41 | def _load_depth(path, scale_adjustment) -> np.ndarray:
42 | d = _load_16big_png_depth(path) * scale_adjustment
43 | d[~np.isfinite(d)] = 0.0
44 | return d[None] # fake feature channel
45 |
46 | # Geometry functions below used for calculating depth, ignore
47 | def glob_imgs(path):
48 | imgs = []
49 | for ext in ["*.png", "*.jpg", "*.JPEG", "*.JPG"]:
50 | imgs.extend(glob(os.path.join(path, ext)))
51 | return imgs
52 |
53 |
54 | def pick(list, item_idcs):
55 | if not list:
56 | return list
57 | return [list[i] for i in item_idcs]
58 |
59 |
60 | def parse_intrinsics(intrinsics):
61 | fx = intrinsics[..., 0, :1]
62 | fy = intrinsics[..., 1, 1:2]
63 | cx = intrinsics[..., 0, 2:3]
64 | cy = intrinsics[..., 1, 2:3]
65 | return fx, fy, cx, cy
66 |
67 |
68 | from einops import rearrange, repeat
69 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
70 | hom = lambda x, i=-1: torch.cat((x, torch.ones_like(x.unbind(i)[0].unsqueeze(i))), i)
71 |
72 |
73 | def expand_as(x, y):
74 | if len(x.shape) == len(y.shape):
75 | return x
76 |
77 | for i in range(len(y.shape) - len(x.shape)):
78 | x = x.unsqueeze(-1)
79 |
80 | return x
81 |
82 |
83 | def lift(x, y, z, intrinsics, homogeneous=False):
84 | """
85 |
86 | :param self:
87 | :param x: Shape (batch_size, num_points)
88 | :param y:
89 | :param z:
90 | :param intrinsics:
91 | :return:
92 | """
93 | fx, fy, cx, cy = parse_intrinsics(intrinsics)
94 |
95 | x_lift = (x - expand_as(cx, x)) / expand_as(fx, x) * z
96 | y_lift = (y - expand_as(cy, y)) / expand_as(fy, y) * z
97 |
98 | if homogeneous:
99 | return torch.stack((x_lift, y_lift, z, torch.ones_like(z).to(x.device)), dim=-1)
100 | else:
101 | return torch.stack((x_lift, y_lift, z), dim=-1)
102 |
103 |
104 | def world_from_xy_depth(xy, depth, cam2world, intrinsics):
105 | batch_size, *_ = cam2world.shape
106 |
107 | x_cam = xy[..., 0]
108 | y_cam = xy[..., 1]
109 | z_cam = depth
110 |
111 | pixel_points_cam = lift(
112 | x_cam, y_cam, z_cam, intrinsics=intrinsics, homogeneous=True
113 | )
114 | world_coords = torch.einsum("b...ij,b...kj->b...ki", cam2world, pixel_points_cam)[
115 | ..., :3
116 | ]
117 |
118 | return world_coords
119 |
120 |
121 | def get_ray_directions(xy, cam2world, intrinsics, normalize=True):
122 | z_cam = torch.ones(xy.shape[:-1]).to(xy.device)
123 | pixel_points = world_from_xy_depth(
124 | xy, z_cam, intrinsics=intrinsics, cam2world=cam2world
125 | ) # (batch, num_samples, 3)
126 |
127 | cam_pos = cam2world[..., :3, 3]
128 | ray_dirs = pixel_points - cam_pos[..., None, :] # (batch, num_samples, 3)
129 | if normalize:
130 | ray_dirs = F.normalize(ray_dirs, dim=-1)
131 | return ray_dirs
132 |
133 | from PIL import Image
134 | def _load_16big_png_depth(depth_png) -> np.ndarray:
135 | with Image.open(depth_png) as depth_pil:
136 | # the image is stored with 16-bit depth but PIL reads it as I (32 bit).
137 | # we cast it to uint16, then reinterpret as float16, then cast to float32
138 | depth = (
139 | np.frombuffer(np.array(depth_pil, dtype=np.uint16), dtype=np.float16)
140 | .astype(np.float32)
141 | .reshape((depth_pil.size[1], depth_pil.size[0]))
142 | )
143 | return depth
144 | def _load_depth(path, scale_adjustment) -> np.ndarray:
145 | d = _load_16big_png_depth(path) * scale_adjustment
146 | d[~np.isfinite(d)] = 0.0
147 | return d[None] # fake feature channel
148 |
149 | # NOTE currently using CO3D V1 because they switch to NDC cameras in 2. TODO is to make conversion code (different intrinsics), verify pointclouds, and switch.
150 |
151 | class Co3DNoCams(torch.utils.data.Dataset):
152 | """Dataset for a class of objects, where each datapoint is a SceneInstanceDataset."""
153 |
154 | def __init__(
155 | self,
156 | num_context=2,
157 | n_skip=1,
158 | num_trgt=1,
159 | low_res=(128,144),
160 | depth_scale=1,#1.8/5,
161 | val=False,
162 | num_cat=1000,
163 | overfit=False,
164 | category=None,
165 | use_mask=False,
166 | use_v1=True,
167 | # delete below, not used
168 | vary_context_number=False,
169 | query_sparsity=None,
170 | img_sidelength=None,
171 | input_img_sidelength=None,
172 | max_num_instances=None,
173 | max_observations_per_instance=None,
174 | specific_observation_idcs=None,
175 | test=False,
176 | test_context_idcs=None,
177 | context_is_last=False,
178 | context_is_first=False,
179 | cache=None,
180 | video=True,
181 | ):
182 |
183 | if num_cat is None: num_cat=1000
184 |
185 | self.n_trgt=num_trgt
186 | self.use_mask=use_mask
187 | self.depth_scale=depth_scale
188 | self.of=overfit
189 | self.val=val
190 |
191 | self.num_skip=n_skip
192 | self.low_res=low_res
193 | max_num_instances = None
194 |
195 | self.base_path=os.environ['CO3D_ROOT']
196 | print(self.base_path)
197 |
198 | # Get sequences!
199 | from collections import defaultdict
200 | sequences = defaultdict(list)
201 | self.total_num_data=0
202 | self.all_frame_names=[]
203 | all_cats = [ "hydrant","teddybear","apple", "ball", "bench", "cake", "donut", "plant", "suitcase", "vase","backpack", "banana", "baseballbat", "baseballglove", "bicycle", "book", "bottle", "bowl", "broccoli", "car", "carrot", "cellphone", "chair", "couch", "cup", "frisbee", "hairdryer", "handbag", "hotdog", "keyboard", "kite", "laptop", "microwave", "motorcycle", "mouse", "orange", "parkingmeter", "pizza", "remote", "sandwich", "skateboard", "stopsign", "toaster", "toilet", "toybus", "toyplane", "toytrain", "toytruck", "tv", "umbrella", "wineglass", ]
204 |
205 | for cat in (all_cats[:num_cat]) if category is None else [category]:
206 | print(cat)
207 | dataset = json.loads(gzip.GzipFile(os.path.join(self.base_path,cat,"frame_annotations.jgz"),"rb").read().decode("utf8"))
208 | val_amt = int(len(dataset)*.03)
209 | dataset = dataset[:-val_amt] if not val else dataset[-val_amt:]
210 | self.total_num_data+=len(dataset)
211 | for i,data in enumerate(dataset):
212 | self.all_frame_names.append((data["sequence_name"],data["frame_number"]))
213 | sequences[data["sequence_name"]].append(data)
214 |
215 | sorted_seq={}
216 | for k,v in sequences.items():
217 | sorted_seq[k]=sorted(sequences[k],key=lambda x:x["frame_number"])
218 | #for k,v in sequences.items(): sequences[k]=v[:-(max(self.num_skip) if type(self.num_skip)==list else self.num_skip)*self.n_trgt]
219 | self.seqs = sorted_seq
220 |
221 | print("done with dataloader init")
222 |
223 | def sparsify(self, dict, sparsity):
224 | new_dict = {}
225 | if sparsity is None:
226 | return dict
227 | else:
228 | # Sample upper_limit pixel idcs at random.
229 | rand_idcs = np.random.choice(
230 | self.img_sidelength ** 2, size=sparsity, replace=False
231 | )
232 | for key in ["rgb", "uv"]:
233 | new_dict[key] = dict[key][rand_idcs]
234 |
235 | for key, v in dict.items():
236 | if key not in ["rgb", "uv"]:
237 | new_dict[key] = dict[key]
238 |
239 | return new_dict
240 |
241 | def set_img_sidelength(self, new_img_sidelength):
242 | """For multi-resolution training: Updates the image sidelength with which images are loaded."""
243 | self.img_sidelength = new_img_sidelength
244 | for instance in self.all_instances:
245 | instance.set_img_sidelength(new_img_sidelength)
246 |
247 | def __len__(self):
248 | return self.total_num_data
249 |
250 | def collate_fn(self, batch_list):
251 | keys = batch_list[0].keys()
252 | result = defaultdict(list)
253 |
254 | for entry in batch_list:
255 | # make them all into a new dict
256 | for key in keys:
257 | result[key].append(entry[key])
258 |
259 | for key in keys:
260 | try:
261 | result[key] = torch.stack(result[key], dim=0)
262 | except:
263 | continue
264 |
265 | return result
266 |
267 | def __getitem__(self, idx,seq_query=None):
268 |
269 | context = []
270 | trgt = []
271 | post_input = []
272 |
273 | n_skip = (random.choice(self.num_skip) if type(self.num_skip)==list else self.num_skip) + 1
274 |
275 | if seq_query is None:
276 | try:
277 | seq_name,frame_idx=self.all_frame_names[idx]
278 | except:
279 | print(f"Out of bounds erorr at {idx}. Investigate.")
280 | return self[-2*n_skip*self.n_trgt if self.val else np.random.randint(len(self))]
281 |
282 | if seq_query is not None:
283 | frame_idx=idx
284 | seq_name = list(self.seqs.keys())[seq_query]
285 | all_frames= self.seqs[seq_name]
286 | else:
287 | all_frames=self.seqs[seq_name] if not self.of else self.seqs[random.choice(list(self.seqs.keys())[:int(self.of)])]
288 |
289 | if len(all_frames)<=self.n_trgt*n_skip or frame_idx >= (len(all_frames)-self.n_trgt*n_skip):
290 | frame_idx=0
291 | if len(all_frames)<=self.n_trgt*n_skip or frame_idx >= (len(all_frames)-self.n_trgt*n_skip):
292 | if len(all_frames)<=self.n_trgt*n_skip:
293 | print(len(all_frames) ," frames < ",self.n_trgt*n_skip," queries")
294 | print("returning low/high")
295 | return self[-2*n_skip*self.n_trgt if self.val else np.random.randint(len(self))]
296 | start_idx = frame_idx
297 |
298 | if self.of and 1: start_idx=0
299 |
300 | frames = all_frames[start_idx:start_idx+self.n_trgt*n_skip:n_skip]
301 | if np.random.rand()<.5 and not self.of and not self.val: frames=frames[::-1]
302 |
303 | paths = [os.path.join(self.base_path,x["image"]["path"]) for x in frames]
304 | for path in paths:
305 | if not os.path.exists(path):
306 | print("path missing")
307 | return self[np.random.randint(len(self))]
308 |
309 | #masks=[torch.from_numpy(plt.imread(os.path.join(self.base_path,x["mask"]["path"]))) for x in frames]
310 | imgs=[torch.from_numpy(plt.imread(path)) for path in paths]
311 |
312 | Ks=[]
313 | c2ws=[]
314 | depths=[]
315 | for data in frames:
316 |
317 | #depths.append(torch.from_numpy(_load_depth(os.path.join(self.base_path,data["depth"]["path"]), data["depth"]["scale_adjustment"])[0])) # commenting out since slow to load; uncomment when needed
318 |
319 | # Below pose processing taken from co3d github issue
320 | p = data["viewpoint"]["principal_point"]
321 | f = data["viewpoint"]["focal_length"]
322 | h, w = data["image"]["size"]
323 | K = np.eye(3)
324 | s = (min(h, w)) / 2
325 | K[0, 0] = f[0] * (w) / 2
326 | K[1, 1] = f[1] * (h) / 2
327 | K[0, 2] = -p[0] * s + (w) / 2
328 | K[1, 2] = -p[1] * s + (h) / 2
329 |
330 | # Normalize intrinsics to [-1,1]
331 | #print(K)
332 | raw_K=[torch.from_numpy(K).clone(),[h,w]]
333 | K[:2] /= torch.tensor([w, h])[:, None]
334 | Ks.append(torch.from_numpy(K).float())
335 |
336 | R = np.asarray(data["viewpoint"]["R"]).T # note the transpose here
337 | T = np.asarray(data["viewpoint"]["T"]) * self.depth_scale
338 | pose = np.concatenate([R,T[:,None]],1)
339 | pose = torch.from_numpy( np.diag([-1,-1,1]).astype(np.float32) @ pose )# flip the direction of x,y axis
340 | tmp=torch.eye(4)
341 | tmp[:3,:4]=pose
342 | c2ws.append(tmp.inverse())
343 |
344 | Ks=torch.stack(Ks)
345 | c2w=torch.stack(c2ws).float()
346 |
347 | no_mask=0
348 | if no_mask:
349 | masks=[x*0+1 for x in masks]
350 |
351 | low_res=self.low_res#(128,144)#(108,144)
352 | minx,miny=min([x.size(0) for x in imgs]),min([x.size(1) for x in imgs])
353 |
354 | imgs=[x[:minx,:miny].float() for x in imgs]
355 |
356 | if self.use_mask: # mask images and depths
357 | imgs = [x*y.unsqueeze(-1)+(255*(1-y).unsqueeze(-1)) for x,y in zip(imgs,masks)]
358 | depths = [x*y for x,y in zip(depths,masks)]
359 |
360 | large_scale=2
361 | imgs_large = F.interpolate(torch.stack([x.permute(2,0,1) for x in imgs]),(int(256*large_scale),int(288*large_scale)),antialias=True,mode="bilinear")
362 | imgs_med = F.interpolate(torch.stack([x.permute(2,0,1) for x in imgs]),(int(256),int(288)),antialias=True,mode="bilinear")
363 | imgs = F.interpolate(torch.stack([x.permute(2,0,1) for x in imgs]),low_res,antialias=True,mode="bilinear")
364 |
365 | if self.use_mask:
366 | imgs = imgs*masks[:,None]+255*(1-masks[:,None])
367 |
368 | imgs = imgs/255 * 2 - 1
369 |
370 | uv = np.mgrid[0:low_res[0], 0:low_res[1]].astype(float).transpose(1, 2, 0)
371 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
372 | uv = uv/ torch.tensor([low_res[1]-1, low_res[0]-1]) # uv in [0,1]
373 | uv = uv[None].expand(len(imgs),-1,-1,-1).flatten(1,2)
374 |
375 | model_input = {
376 | "trgt_rgb": imgs[1:],
377 | "ctxt_rgb": imgs[:-1],
378 | "trgt_rgb_large": imgs_large[1:],
379 | "ctxt_rgb_large": imgs_large[:-1],
380 | "trgt_rgb_med": imgs_med[1:],
381 | "ctxt_rgb_med": imgs_med[:-1],
382 | #"ctxt_depth": depths.squeeze(1)[:-1],
383 | #"trgt_depth": depths.squeeze(1)[1:],
384 | "intrinsics": Ks[1:],
385 | "trgt_c2w": c2w[1:],
386 | "ctxt_c2w": c2w[:-1],
387 | "x_pix": uv[1:],
388 | #"trgt_mask": masks[1:],
389 | #"ctxt_mask": masks[:-1],
390 | }
391 |
392 | gt = {
393 | #"paths": paths,
394 | #"raw_K": raw_K,
395 | #"seq_name": seq_name,
396 | "trgt_rgb": ch_sec(imgs[1:])*.5+.5,
397 | "ctxt_rgb": ch_sec(imgs[:-1])*.5+.5,
398 | #"ctxt_depth": depths.squeeze(1)[:-1].flatten(1,2).unsqueeze(-1),
399 | #"trgt_depth": depths.squeeze(1)[1:].flatten(1,2).unsqueeze(-1),
400 | "intrinsics": Ks[1:],
401 | "x_pix": uv[1:],
402 | #"seq_name": [seq_name],
403 | #"trgt_mask": masks[1:].flatten(1,2).unsqueeze(-1),
404 | #"ctxt_mask": masks[:-1].flatten(1,2).unsqueeze(-1),
405 | }
406 |
407 | return model_input,gt
408 |
--------------------------------------------------------------------------------
/data/realestate10k_dataio.py:
--------------------------------------------------------------------------------
1 | import random
2 | from torch.nn import functional as F
3 | import os
4 | import torch
5 | import numpy as np
6 | from glob import glob
7 | import json
8 | from collections import defaultdict
9 | import os.path as osp
10 | from imageio import imread
11 | from torch.utils.data import Dataset
12 | from pathlib import Path
13 | import cv2
14 | from tqdm import tqdm
15 | from scipy.io import loadmat
16 |
17 | import functools
18 | import cv2
19 | import numpy as np
20 | import imageio
21 | from glob import glob
22 | import os
23 | import shutil
24 | import io
25 |
26 | not_of=1
27 |
28 | def load_rgb(path, sidelength=None):
29 | img = imageio.imread(path)[:, :, :3]
30 | img = skimage.img_as_float32(img)
31 |
32 | img = square_crop_img(img)
33 |
34 | if sidelength is not None:
35 | img = cv2.resize(img, (sidelength, sidelength), interpolation=cv2.INTER_NEAREST)
36 |
37 | img -= 0.5
38 | img *= 2.
39 | return img
40 |
41 | def load_depth(path, sidelength=None):
42 | img = cv2.imread(path, cv2.IMREAD_UNCHANGED).astype(np.float32)
43 |
44 | if sidelength is not None:
45 | img = cv2.resize(img, (sidelength, sidelength), interpolation=cv2.INTER_NEAREST)
46 |
47 | img *= 1e-4
48 |
49 | if len(img.shape) == 3:
50 | img = img[:, :, :1]
51 | img = img.transpose(2, 0, 1)
52 | else:
53 | img = img[None, :, :]
54 | return img
55 |
56 |
57 | def load_pose(filename):
58 | lines = open(filename).read().splitlines()
59 | if len(lines) == 1:
60 | pose = np.zeros((4, 4), dtype=np.float32)
61 | for i in range(16):
62 | pose[i // 4, i % 4] = lines[0].split(" ")[i]
63 | return pose.squeeze()
64 | else:
65 | lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines[:4])]
66 | return np.asarray(lines).astype(np.float32).squeeze()
67 |
68 |
69 | def load_numpy_hdf5(instance_ds, key):
70 | rgb_ds = instance_ds['rgb']
71 | raw = rgb_ds[key][...]
72 | s = raw.tostring()
73 | f = io.BytesIO(s)
74 |
75 | img = imageio.imread(f)[:, :, :3]
76 | img = skimage.img_as_float32(img)
77 |
78 | img = square_crop_img(img)
79 |
80 | img -= 0.5
81 | img *= 2.
82 |
83 | return img
84 |
85 |
86 | def load_rgb_hdf5(instance_ds, key, sidelength=None):
87 | rgb_ds = instance_ds['rgb']
88 | raw = rgb_ds[key][...]
89 | s = raw.tostring()
90 | f = io.BytesIO(s)
91 |
92 | img = imageio.imread(f)[:, :, :3]
93 | img = skimage.img_as_float32(img)
94 |
95 | img = square_crop_img(img)
96 |
97 | if sidelength is not None:
98 | img = cv2.resize(img, (sidelength, sidelength), interpolation=cv2.INTER_AREA)
99 |
100 | img -= 0.5
101 | img *= 2.
102 |
103 | return img
104 |
105 |
106 | def load_pose_hdf5(instance_ds, key):
107 | pose_ds = instance_ds['pose']
108 | raw = pose_ds[key][...]
109 | ba = bytearray(raw)
110 | s = ba.decode('ascii')
111 |
112 | lines = s.splitlines()
113 |
114 | if len(lines) == 1:
115 | pose = np.zeros((4, 4), dtype=np.float32)
116 | for i in range(16):
117 | pose[i // 4, i % 4] = lines[0].split(" ")[i]
118 | # processed_pose = pose.squeeze()
119 | return pose.squeeze()
120 | else:
121 | lines = [[x[0], x[1], x[2], x[3]] for x in (x.split(" ") for x in lines[:4])]
122 | return np.asarray(lines).astype(np.float32).squeeze()
123 |
124 |
125 | def cond_mkdir(path):
126 | if not os.path.exists(path):
127 | os.makedirs(path)
128 |
129 |
130 | def square_crop_img(img):
131 | min_dim = np.amin(img.shape[:2])
132 | center_coord = np.array(img.shape[:2]) // 2
133 | img = img[center_coord[0] - min_dim // 2:center_coord[0] + min_dim // 2,
134 | center_coord[1] - min_dim // 2:center_coord[1] + min_dim // 2]
135 | return img
136 |
137 |
138 | def glob_imgs(path):
139 | imgs = []
140 | for ext in ['*.png', '*.jpg', '*.JPEG', '*.JPG']:
141 | imgs.extend(glob(os.path.join(path, ext)))
142 | return imgs
143 |
144 | def augment(rgb, intrinsics, c2w_mat):
145 |
146 | # Horizontal Flip with 50% Probability
147 | if np.random.uniform(0, 1) < 0.5:
148 | rgb = rgb[:, ::-1, :]
149 | tf_flip = np.array([[-1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
150 | c2w_mat = c2w_mat @ tf_flip
151 |
152 | # Crop by aspect ratio
153 | if np.random.uniform(0, 1) < 0.5:
154 | py = np.random.randint(1, 32)
155 | rgb = rgb[py:-py, :, :]
156 | else:
157 | py = 0
158 |
159 | if np.random.uniform(0, 1) < 0.5:
160 | px = np.random.randint(1, 32)
161 | rgb = rgb[:, px:-px, :]
162 | else:
163 | px = 0
164 |
165 | H, W, _ = rgb.shape
166 | rgb = cv2.resize(rgb, (256, 256))
167 | xscale = 256 / W
168 | yscale = 256 / H
169 |
170 | intrinsics[0, 0] = intrinsics[0, 0] * xscale
171 | intrinsics[1, 1] = intrinsics[1, 1] * yscale
172 |
173 | return rgb, intrinsics, c2w_mat
174 |
175 | class Camera(object):
176 | def __init__(self, entry):
177 | fx, fy, cx, cy = entry[1:5]
178 | self.intrinsics = np.array([[fx, 0, cx, 0],
179 | [0, fy, cy, 0],
180 | [0, 0, 1, 0],
181 | [0, 0, 0, 1]])
182 | w2c_mat = np.array(entry[7:]).reshape(3, 4)
183 | w2c_mat_4x4 = np.eye(4)
184 | w2c_mat_4x4[:3, :] = w2c_mat
185 | self.w2c_mat = w2c_mat_4x4
186 | self.c2w_mat = np.linalg.inv(w2c_mat_4x4)
187 |
188 |
189 | def unnormalize_intrinsics(intrinsics, h, w):
190 | intrinsics = intrinsics.copy()
191 | intrinsics[0] *= w
192 | intrinsics[1] *= h
193 | return intrinsics
194 |
195 |
196 | def parse_pose_file(file):
197 | f = open(file, 'r')
198 | cam_params = {}
199 | for i, line in enumerate(f):
200 | if i == 0:
201 | continue
202 | entry = [float(x) for x in line.split()]
203 | id = int(entry[0])
204 | cam_params[id] = Camera(entry)
205 | return cam_params
206 |
207 |
208 | def parse_pose(pose, timestep):
209 | timesteps = pose[:, :1]
210 | timesteps = np.around(timesteps)
211 | mask = (timesteps == timestep)[:, 0]
212 | pose_entry = pose[mask][0]
213 | camera = Camera(pose_entry)
214 |
215 | return camera
216 |
217 |
218 | def get_camera_pose(scene_path, all_pose_dir, uv, views=1):
219 | npz_files = sorted(scene_path.glob("*.npz"))
220 | npz_file = npz_files[0]
221 | data = np.load(npz_file)
222 | all_pose_dir = Path(all_pose_dir)
223 |
224 | rgb_files = list(data.keys())
225 |
226 | timestamps = [int(rgb_file.split('.')[0]) for rgb_file in rgb_files]
227 | sorted_ids = np.argsort(timestamps)
228 |
229 | rgb_files = np.array(rgb_files)[sorted_ids]
230 | timestamps = np.array(timestamps)[sorted_ids]
231 |
232 | camera_file = all_pose_dir / (str(scene_path.name) + '.txt')
233 | cam_params = parse_pose_file(camera_file)
234 | # H, W, _ = data[rgb_files[0]].shape
235 |
236 | # Weird cropping of images
237 | H, W = 256, 456
238 |
239 | xscale = W / min(H, W)
240 | yscale = H / min(H, W)
241 |
242 |
243 | query = {}
244 | context = {}
245 |
246 | render_frame = min(128, rgb_files.shape[0])
247 |
248 | query_intrinsics = []
249 | query_c2w = []
250 | query_rgbs = []
251 | for i in range(1, render_frame):
252 | rgb = data[rgb_files[i]]
253 | timestep = timestamps[i]
254 |
255 | # rgb = cv2.resize(rgb, (W, H))
256 | intrinsics = unnormalize_intrinsics(cam_params[timestep].intrinsics, H, W)
257 |
258 | intrinsics[0, 2] = intrinsics[0, 2] / xscale
259 | intrinsics[1, 2] = intrinsics[1, 2] / yscale
260 | rgb = rgb.astype(np.float32) / 127.5 - 1
261 |
262 | query_intrinsics.append(intrinsics)
263 | query_c2w.append(cam_params[timestep].c2w_mat)
264 | query_rgbs.append(rgb)
265 |
266 | context_intrinsics = []
267 | context_c2w = []
268 | context_rgbs = []
269 |
270 | if views == 1:
271 | render_ids = [0]
272 | elif views == 2:
273 | render_ids = [0, min(len(rgb_files) - 1, 128)]
274 | else:
275 | assert False
276 |
277 | for i in render_ids:
278 | rgb = data[rgb_files[i]]
279 | timestep = timestamps[i]
280 | # print("render: ", i)
281 | # rgb = cv2.resize(rgb, (W, H))
282 | intrinsics = unnormalize_intrinsics(cam_params[timestep].intrinsics, H, W)
283 | intrinsics[0, 2] = intrinsics[0, 2] / xscale
284 | intrinsics[1, 2] = intrinsics[1, 2] / yscale
285 |
286 | rgb = rgb.astype(np.float32) / 127.5 - 1
287 |
288 | context_intrinsics.append(intrinsics)
289 | context_c2w.append(cam_params[timestep].c2w_mat)
290 | context_rgbs.append(rgb)
291 |
292 | query = {'rgb': torch.Tensor(query_rgbs)[None].float(),
293 | 'cam2world': torch.Tensor(query_c2w)[None].float(),
294 | 'intrinsics': torch.Tensor(query_intrinsics)[None].float(),
295 | 'uv': uv.view(-1, 2)[None, None].expand(1, render_frame - 1, -1, -1)}
296 | ctxt = {'rgb': torch.Tensor(context_rgbs)[None].float(),
297 | 'cam2world': torch.Tensor(context_c2w)[None].float(),
298 | 'intrinsics': torch.Tensor(context_intrinsics)[None].float()}
299 |
300 | return {'query': query, 'context': ctxt}
301 |
302 | class RealEstate10k():
303 | def __init__(self, img_root=None, pose_root=None,
304 | num_ctxt_views=2, num_query_views=2, query_sparsity=None,imsl=256,
305 | max_num_scenes=None, square_crop=True, augment=False, lpips=False, dual_view=False, val=False,n_skip=12):
306 |
307 | self.n_skip =n_skip[0] if type(n_skip)==type([]) else n_skip
308 | print(self.n_skip,"n_skip")
309 | self.val = val
310 | if img_root is None: img_root = os.path.join(os.environ['RE10K_IMG_ROOT'],"test" if val else "train")
311 | if pose_root is None: pose_root = os.path.join(os.environ['RE10K_POSE_ROOT'],"test" if val else "train")
312 | print("Loading RealEstate10k...")
313 | self.num_ctxt_views = num_ctxt_views
314 | self.num_query_views = num_query_views
315 | self.query_sparsity = query_sparsity
316 | self.dual_view = dual_view
317 |
318 | self.imsl=imsl
319 |
320 | all_im_dir = Path(img_root)
321 | #self.all_pose_dir = Path(pose_root)
322 | self.all_pose = loadmat(pose_root)
323 | self.lpips = lpips
324 |
325 | self.all_scenes = sorted(all_im_dir.glob('*/'))
326 |
327 | dummy_img_path = str(next(self.all_scenes[0].glob("*.npz")))
328 |
329 | if max_num_scenes:
330 | self.all_scenes = list(self.all_scenes)[:max_num_scenes]
331 |
332 | data = np.load(dummy_img_path)
333 | key = list(data.keys())[0]
334 | im = data[key]
335 |
336 | H, W = im.shape[:2]
337 | H, W = 256, 455
338 | self.H, self.W = H, W
339 | self.augment = augment
340 |
341 | self.square_crop = square_crop
342 | # Downsample to be 256 x 256 image
343 | # self.H, self.W = 256, 455
344 |
345 | xscale = W / min(H, W)
346 | yscale = H / min(H, W)
347 |
348 | dim = min(H, W)
349 |
350 | self.xscale = xscale
351 | self.yscale = yscale
352 |
353 | # For now the images are already square cropped
354 | self.H = 256
355 | self.W = 455
356 |
357 | print(f"Resolution is {H}, {W}.")
358 |
359 | if self.square_crop:
360 | i, j = torch.meshgrid(torch.arange(0, self.imsl), torch.arange(0, self.imsl))
361 | else:
362 | i, j = torch.meshgrid(torch.arange(0, W), torch.arange(0, H))
363 |
364 | self.uv = torch.stack([i.float(), j.float()], dim=-1).permute(1, 0, 2)
365 |
366 | # if self.square_crop:
367 | # self.uv = data_util.square_crop_img(self.uv)
368 |
369 | self.uv = self.uv[None].permute(0, -1, 1, 2).permute(0, 2, 3, 1)
370 | self.uv = self.uv.reshape(-1, 2)
371 |
372 | self.scene_path_list = list(Path(img_root).glob("*/"))
373 |
374 | def __len__(self):
375 | return len(self.all_scenes)
376 |
377 | def __getitem__(self, idx,scene_query=None):
378 | idx = idx if not_of else 0
379 | scene_path = self.all_scenes[idx if scene_query is None else scene_query]
380 | npz_files = sorted(scene_path.glob("*.npz"))
381 |
382 | name = scene_path.name
383 |
384 | def get_another():
385 | if self.val:
386 | return self[idx-1 if idx >200 else idx+1]
387 | return self.__getitem__(random.randint(0, len(self.all_scenes) - 1))
388 |
389 | if name not in self.all_pose: return get_another()
390 |
391 | pose = self.all_pose[name]
392 |
393 | if len(npz_files) == 0:
394 | print("npz get another")
395 | return get_another()
396 |
397 | npz_file = npz_files[0]
398 | try:
399 | data = np.load(npz_file)
400 | except:
401 | print("npz load error get another")
402 | return get_another()
403 |
404 | rgb_files = list(data.keys())
405 | window_size = 128
406 |
407 | if len(rgb_files) <= 20:
408 | print("<20 rgbs error get another")
409 | return get_another()
410 |
411 | timestamps = [int(rgb_file.split('.')[0]) for rgb_file in rgb_files]
412 | sorted_ids = np.argsort(timestamps)
413 |
414 | rgb_files = np.array(rgb_files)[sorted_ids]
415 | timestamps = np.array(timestamps)[sorted_ids]
416 |
417 | assert (timestamps == sorted(timestamps)).all()
418 | num_frames = len(rgb_files)
419 | left_bound = 0
420 | right_bound = num_frames - 1
421 | candidate_ids = np.arange(left_bound, right_bound)
422 |
423 | # remove windows between frame -32 to 32
424 | nframe = 1
425 | nframe_view = 140 if self.val else 92
426 |
427 | id_feats = []
428 |
429 | n_skip=self.n_skip
430 |
431 | id_feat = np.array(id_feats)
432 | low = 0
433 | high = num_frames-1-n_skip*self.num_query_views
434 |
435 | if high <= low:
436 | n_skip = int(num_frames//(self.num_query_views+1))
437 | high = num_frames-1-n_skip*self.num_query_views
438 | print("high ... (x y) c")
18 |
19 | # A quick dummy dataset for the demo rgb folder
20 | class SingleVid(Dataset):
21 |
22 | # If specified here, intrinsics should be a 4-element array of [fx,fy,cx,cy] at input image resolution
23 | def __init__(self, img_dir,intrinsics=None,n_trgt=6,num_skip=0,low_res=None,hi_res=None):
24 | self.low_res,self.intrinsics,self.n_trgt,self.num_skip,self.hi_res=low_res,intrinsics,n_trgt,num_skip,hi_res
25 | if self.hi_res is None:self.hi_res=[x*2 for x in self.low_res]
26 | self.hi_res = [(x+x%64) for x in self.hi_res]
27 |
28 | self.img_paths = glob(img_dir + '/*.png') + glob(img_dir + '/*.jpg')
29 | self.img_paths.sort()
30 |
31 | def __len__(self):
32 | return len(self.img_paths)-(1+self.n_trgt)*(1+self.num_skip)
33 |
34 | def __getitem__(self, idx):
35 |
36 | n_skip=self.num_skip+1
37 | paths = self.img_paths[idx:idx+self.n_trgt*n_skip:n_skip]
38 | imgs=torch.stack([torch.from_numpy(plt.imread(path)).permute(2,0,1) for path in paths]).float()
39 |
40 | imgs_large = F.interpolate(imgs,self.hi_res,antialias=True,mode="bilinear")
41 | frames = F.interpolate(imgs,self.low_res)
42 |
43 | frames = frames/255 * 2 - 1
44 |
45 | uv = np.mgrid[0:self.low_res[0], 0:self.low_res[1]].astype(float).transpose(1, 2, 0)
46 | uv = torch.from_numpy(np.flip(uv, axis=-1).copy()).long()
47 | uv = uv/ torch.tensor([self.low_res[1], self.low_res[0]]) # uv in [0,1]
48 | uv = uv[None].expand(len(frames),-1,-1,-1).flatten(1,2)
49 |
50 | #imgs large values in [0,255], imgs in [-1,1], gt_rgb in [0,1],
51 |
52 | model_input = {
53 | "trgt_rgb": frames[1:],
54 | "ctxt_rgb": frames[:-1],
55 | "trgt_rgb_large": imgs_large[1:],
56 | "ctxt_rgb_large": imgs_large[:-1],
57 | "x_pix": uv[1:],
58 | }
59 | gt = {
60 | "trgt_rgb": ch_sec(frames[1:])*.5+.5,
61 | "ctxt_rgb": ch_sec(frames[:-1])*.5+.5,
62 | "x_pix": uv[1:],
63 | }
64 |
65 | if self.intrinsics is not None:
66 | K = torch.eye(3)
67 | K[0,0],K[1,1],K[0,2],K[1,2]=[float(x) for x in self.intrinsics.strip().split(",")]
68 | h,w=imgs[0].shape[-2:]
69 | K[:2] /= torch.tensor([w, h])[:, None]
70 | model_input["intrinsics"] = K[None].expand(self.n_trgt-1,-1,-1)
71 |
72 | return model_input,gt
73 |
74 | dataset=SingleVid(args.demo_rgb,args.intrinsics,args.vid_len,args.n_skip,args.low_res)
75 |
76 | all_poses = torch.tensor([]).cuda()
77 | all_render_rgb=torch.tensor([]).cuda()
78 | all_render_depth=torch.tensor([])
79 | for seq_i in range(len(dataset)//(dataset.n_trgt)):
80 | print(seq_i*(dataset.n_trgt),"/",len(dataset))
81 | model_input = {k:to_gpu(v)[None] for k,v in dataset.__getitem__(seq_i*(dataset.n_trgt-1))[0].items()}
82 | with torch.no_grad(): out = (model.forward if not args.render_imgs else model.render_full_img)(model_input)
83 | curr_transfs = out["poses"][0]
84 | if len(all_poses): curr_transfs = all_poses[[-1]] @ curr_transfs # integrate poses
85 | all_poses = torch.cat((all_poses,curr_transfs))
86 | all_render_rgb = torch.cat((all_render_rgb,out["rgb"][0]))
87 | all_render_depth = torch.cat((all_render_depth,out["depth"][0]))
88 |
89 | out_dir="demo_output/"+args.demo_rgb.replace("/","_")
90 | os.makedirs(out_dir,exist_ok=True)
91 | fig = plt.figure()
92 | ax = fig.add_subplot(111, projection='3d')
93 | ax.plot(*all_poses[:,:3,-1].T.cpu().numpy())
94 | ax.xaxis.set_tick_params(labelbottom=False);ax.yaxis.set_tick_params(labelleft=False);ax.zaxis.set_tick_params(labelleft=False)
95 | ax.view_init(elev=10., azim=45)
96 | plt.tight_layout()
97 | fp = os.path.join(out_dir,f"pose_plot.png");plt.savefig(fp,bbox_inches='tight');plt.close()
98 |
99 | fp = os.path.join(out_dir,f"poses.npy");np.save(fp,all_poses.cpu())
100 | if args.render_imgs:
101 | out_dir=os.path.join(out_dir,"renders")
102 | os.makedirs(out_dir,exist_ok=True)
103 | for i,(rgb,depth) in enumerate(zip(all_render_rgb.unflatten(1,model_input["trgt_rgb"].shape[-2:]),all_render_depth.unflatten(1,model_input["trgt_rgb"].shape[-2:]))):
104 | plt.imsave(os.path.join(out_dir,"render_rgb_%04d.png"%i),rgb.clip(0,1).cpu().numpy())
105 | plt.imsave(os.path.join(out_dir,"render_depth_%04d.png"%i),depth.clip(0,1).cpu().numpy())
106 |
107 |
--------------------------------------------------------------------------------
/eval.py:
--------------------------------------------------------------------------------
1 | from run import *
2 |
3 | # Evaluation script
4 | import piqa,lpips
5 | from torchvision.utils import make_grid
6 | import matplotlib.pyplot as plt
7 | loss_fn_vgg = lpips.LPIPS(net='vgg').cuda()
8 | lpips,psnr,ate=0,0,0
9 |
10 | eval_dir = save_dir+"/"+args.name+datetime.datetime.now().strftime("%b%d%Y_")+str(random.randint(0,1e3))
11 | try: os.mkdir(eval_dir)
12 | except: pass
13 | torch.set_grad_enabled(False)
14 |
15 | model.n_samples=128
16 |
17 | val_dataset = get_dataset(val=True,)
18 |
19 | for eval_idx,eval_dataset_idx in enumerate(tqdm(torch.linspace(0,len(val_dataset)-1,min(args.n_eval,len(val_dataset))).int())):
20 | model_input,ground_truth = val_dataset[eval_dataset_idx]
21 |
22 | for x in (model_input,ground_truth):
23 | for k,v in x.items(): x[k] = v[None].cuda() # collate
24 |
25 | model_out = model.render_full_img(model_input)
26 |
27 | # remove last frame since used as ctxt when n_ctxt=2
28 | rgb_est,rgb_gt = [rearrange(img[:,:-1].clip(0,1),"b trgt (x y) c -> (b trgt) c x y",x=model_input["trgt_rgb"].size(-2))
29 | for img in (model_out["fine_rgb" if "fine_rgb" in model_out else "rgb"],ground_truth["trgt_rgb"])]
30 | depth_est = rearrange(model_out["depth"][:,:-1],"b trgt (x y) c -> (b trgt) c x y",x=model_input["trgt_rgb"].size(-2))
31 |
32 | psnr += piqa.PSNR()(rgb_est.clip(0,1).contiguous(),rgb_gt.clip(0,1).contiguous())
33 | lpips += loss_fn_vgg(rgb_est*2-1,rgb_gt*2-1).mean()
34 |
35 | print(args.save_imgs)
36 | if args.save_imgs:
37 | fp = os.path.join(eval_dir,f"{eval_idx}_est.png");plt.imsave(fp,make_grid(rgb_est).permute(1,2,0).clip(0,1).cpu().numpy())
38 | if depth_est.size(1)==3: fp = os.path.join(eval_dir,f"{eval_idx}_depth.png");plt.imsave(fp,make_grid(depth_est).clip(0,1).permute(1,2,0).cpu().numpy())
39 | fp = os.path.join(eval_dir,f"{eval_idx}_gt.png");plt.imsave(fp,make_grid(rgb_gt).permute(1,2,0).cpu().numpy())
40 | print(fp)
41 |
42 |
43 | if args.save_imgs and args.save_ind: # save individual images separately
44 | eval_idx_dir = os.path.join(eval_dir,f"dir_{eval_idx}")
45 |
46 | try: os.mkdir(eval_idx_dir)
47 | except: pass
48 | ctxt_rgbs = torch.cat((model_input["ctxt_rgb"][:,0],model_input["trgt_rgb"][:,model_input["trgt_rgb"].size(1)//2],model_input["trgt_rgb"][:,-1]))*.5+.5
49 | fp = os.path.join(eval_idx_dir,f"ctxt0.png");plt.imsave(fp,ctxt_rgbs[0].clip(0,1).permute(1,2,0).cpu().numpy())
50 | fp = os.path.join(eval_idx_dir,f"ctxt1.png");plt.imsave(fp,ctxt_rgbs[1].clip(0,1).permute(1,2,0).cpu().numpy())
51 | fp = os.path.join(eval_idx_dir,f"ctxt2.png");plt.imsave(fp,ctxt_rgbs[2].clip(0,1).permute(1,2,0).cpu().numpy())
52 | for i,(rgb_est,rgb_gt,depth) in enumerate(zip(rgb_est,rgb_gt,depth_est)):
53 | fp = os.path.join(eval_idx_dir,f"{i}_est.png");plt.imsave(fp,rgb_est.clip(0,1).permute(1,2,0).cpu().numpy())
54 | print(fp)
55 | fp = os.path.join(eval_idx_dir,f"{i}_gt.png");plt.imsave(fp,rgb_gt.clip(0,1).permute(1,2,0).cpu().numpy())
56 | if depth_est.size(1)==3: fp = os.path.join(eval_idx_dir,f"{i}_depth.png");plt.imsave(fp,depth.permute(1,2,0).cpu().clip(1e-4,1-1e-4).numpy())
57 |
58 | # Pose plotting/evaluation
59 | if "poses" in model_out:
60 | import scipy.spatial
61 | pose_est,pose_gt = model_out["poses"][0][:,:3,-1].cpu(),model_input["trgt_c2w"][0][:,:3,-1].cpu()
62 | pose_gt,pose_est,_ = scipy.spatial.procrustes(pose_gt.numpy(),pose_est.numpy())
63 | ate += ((pose_est-pose_gt)**2).mean()
64 | if args.save_imgs:
65 | fig = plt.figure()
66 | ax = fig.add_subplot(111, projection='3d')
67 | ax.plot(*pose_gt.T)
68 | ax.plot(*pose_est.T)
69 | ax.xaxis.set_tick_params(labelbottom=False)
70 | ax.yaxis.set_tick_params(labelleft=False)
71 | ax.zaxis.set_tick_params(labelleft=False)
72 | ax.view_init(elev=10., azim=45)
73 | plt.tight_layout()
74 | fp = os.path.join(eval_dir,f"{eval_idx}_pose_plot.png");plt.savefig(fp,bbox_inches='tight');plt.close()
75 | if args.save_ind:
76 | for i in range(len(pose_est)):
77 | fig = plt.figure()
78 | ax = fig.add_subplot(111, projection='3d')
79 | ax.plot(*pose_gt.T,color="black")
80 | ax.plot(*pose_est.T,alpha=0)
81 | ax.plot(*pose_est[:i].T,alpha=1,color="red")
82 | ax.xaxis.set_tick_params(labelbottom=False)
83 | ax.yaxis.set_tick_params(labelleft=False)
84 | ax.zaxis.set_tick_params(labelleft=False)
85 | ax.view_init(elev=10., azim=45)
86 | plt.tight_layout()
87 | fp = os.path.join(eval_idx_dir,f"pose_{i}.png"); plt.savefig(fp,bbox_inches='tight');plt.close()
88 |
89 | print(f"psnr {psnr/(1+eval_idx)}, lpips {lpips/(1+eval_idx)}, ate {(ate/(1+eval_idx))**.5}, eval_idx {eval_idx}", flush=True)
90 |
91 |
--------------------------------------------------------------------------------
/geometry.py:
--------------------------------------------------------------------------------
1 | """Multi-view geometry & proejction code.."""
2 | import torch
3 | from einops import rearrange, repeat
4 | from torch.nn import functional as F
5 | import numpy as np
6 |
7 | def d6_to_rotmat(d6):
8 | a1, a2 = d6[..., :3], d6[..., 3:]
9 | b1 = F.normalize(a1, dim=-1)
10 | b2 = a2 - (b1 * a2).sum(-1, keepdim=True) * b1
11 | b2 = F.normalize(b2, dim=-1)
12 | b3 = torch.cross(b1, b2, dim=-1)
13 | return torch.stack((b1, b2, b3), dim=-2)
14 |
15 | def time_interp_poses(pose_inp,time_i,n_trgt,eye_pts):
16 | i,j = max(0,int(time_i*(n_trgt-1))-1),int(time_i*(n_trgt-1))
17 | pose_interp = camera_interp(*pose_inp[:,[i,j]].unbind(1),time_i)
18 | if i==j: pose_interp=pose_inp[:,0]
19 | pose_interp = repeat(pose_interp,"b x y -> b trgt x y",trgt=n_trgt)
20 | return pose_interp
21 | eye_pts = torch.cat((eye_pts,torch.ones_like(eye_pts[...,[0]])),-1)
22 | query_pts = torch.einsum("bcij,bcdkj->bcdki",pose_interp,eye_pts)[...,:3]
23 | return query_pts
24 |
25 | def pixel_aligned_features(
26 | coords_3d_world, cam2world, intrinsics, img_features, interp="bilinear",padding_mode="border",
27 | ):
28 | # Args:
29 | # coords_3d_world: shape (b, n, 3)
30 | # cam2world: camera pose of shape (..., 4, 4)
31 |
32 | # project 3d points to 2D
33 | c3d_world_hom = homogenize_points(coords_3d_world)
34 | c3d_cam_hom = transform_world2cam(c3d_world_hom, cam2world)
35 | c2d_cam, depth = project(c3d_cam_hom, intrinsics.unsqueeze(1))
36 |
37 | # now between 0 and 1. Map to -1 and 1
38 | c2d_norm = (c2d_cam - 0.5) * 2
39 | c2d_norm = rearrange(c2d_norm, "b n ch -> b n () ch")
40 | c2d_norm = c2d_norm[..., :2]
41 |
42 | # grid_sample
43 | feats = F.grid_sample(
44 | img_features, c2d_norm, align_corners=True, padding_mode=padding_mode, mode=interp
45 | )
46 | feats = feats.squeeze(-1) # b ch n
47 |
48 | feats = rearrange(feats, "b ch n -> b n ch")
49 | return feats, c3d_cam_hom[..., :3], c2d_cam
50 |
51 | # https://gist.github.com/mkocabas/54ea2ff3b03260e3fedf8ad22536f427
52 | def procrustes(S1, S2,weights=None):
53 |
54 | if len(S1.shape)==4:
55 | out = procrustes(S1.flatten(0,1),S2.flatten(0,1),weights.flatten(0,1) if weights is not None else None)
56 | return out[0],out[1].unflatten(0,S1.shape[:2])
57 | '''
58 | Computes a similarity transform (sR, t) that takes
59 | a set of 3D points S1 (BxNx3) closest to a set of 3D points, S2,
60 | where R is an 3x3 rotation matrix, t 3x1 translation, s scale. / mod : assuming scale is 1
61 | i.e. solves the orthogonal Procrutes problem.
62 | '''
63 | with torch.autocast(device_type='cuda', dtype=torch.float32):
64 | S1 = S1.permute(0,2,1)
65 | S2 = S2.permute(0,2,1)
66 | if weights is not None:
67 | weights=weights.permute(0,2,1)
68 | transposed = True
69 |
70 | if weights is None:
71 | weights = torch.ones_like(S1[:,:1])
72 |
73 | # 1. Remove mean.
74 | weights_norm = weights/(weights.sum(-1,keepdim=True)+1e-6)
75 | mu1 = (S1*weights_norm).sum(2,keepdim=True)
76 | mu2 = (S2*weights_norm).sum(2,keepdim=True)
77 |
78 | X1 = S1 - mu1
79 | X2 = S2 - mu2
80 |
81 | diags = torch.stack([torch.diag(w.squeeze(0)) for w in weights]) # does batched version exist?
82 |
83 | # 3. The outer product of X1 and X2.
84 | K = (X1@diags).bmm(X2.permute(0,2,1))
85 |
86 | # 4. Solution that Maximizes trace(R'K) is R=U*V', where U, V are singular vectors of K.
87 | U, s, V = torch.svd(K)
88 |
89 | # Construct Z that fixes the orientation of R to get det(R)=1.
90 | Z = torch.eye(U.shape[1], device=S1.device).unsqueeze(0)
91 | Z = Z.repeat(U.shape[0],1,1)
92 | Z[:,-1, -1] *= torch.sign(torch.det(U.bmm(V.permute(0,2,1))))
93 |
94 | # Construct R.
95 | R = V.bmm(Z.bmm(U.permute(0,2,1)))
96 |
97 | # 6. Recover translation.
98 | t = mu2 - ((R.bmm(mu1)))
99 |
100 | # 7. Error:
101 | S1_hat = R.bmm(S1) + t
102 |
103 | # Combine recovered transformation as single matrix
104 | R_=torch.eye(4)[None].expand(S1.size(0),-1,-1).to(S1)
105 | R_[:,:3,:3]=R
106 | T_=torch.eye(4)[None].expand(S1.size(0),-1,-1).to(S1)
107 | T_[:,:3,-1]=t.squeeze(-1)
108 | S_=torch.eye(4)[None].expand(S1.size(0),-1,-1).to(S1)
109 | transf = T_@S_@R_
110 |
111 | return (S1_hat-S2).square().mean(),transf
112 |
113 | def symmetric_orthogonalization(x):
114 | # https://github.com/amakadia/svd_for_pose
115 | m = x.view(-1, 3, 3).type(torch.float)
116 | u, s, v = torch.svd(m)
117 | vt = torch.transpose(v, 1, 2)
118 | det = torch.det(torch.matmul(u, vt))
119 | det = det.view(-1, 1, 1)
120 | vt = torch.cat((vt[:, :2, :], vt[:, -1:, :] * det), 1)
121 | r = torch.matmul(u, vt)
122 | return r
123 |
124 | def rigidity_loss(ctx_xyz,trgt_xyz):
125 |
126 | x_points = ctx_xyz #.view(-1, 3)
127 | y_points = trgt_xyz #.view(-1, 3)
128 |
129 | x_mean = x_points.mean(1, keepdim=True) # x_mean and y_mean define the global translation
130 | y_mean = y_points.mean(1, keepdim=True)
131 |
132 | x_points_centered = x_points - x_mean
133 | y_points_centered = y_points - y_mean
134 |
135 | x_scale = torch.sqrt(x_points_centered.pow(2).sum(2, keepdim=True)).mean(1, keepdim=True)
136 | x_points_normalized = x_points_centered / x_scale # x_scale and y_scale define the global scales
137 |
138 | y_scale = torch.sqrt(y_points_centered.pow(2).sum(2, keepdim=True)).mean(1, keepdim=True)
139 | y_points_normalized = y_points_centered / y_scale
140 |
141 | M = torch.einsum('b i k, b i j -> b k j', x_points_normalized, y_points_normalized) # M is the covariance matrix
142 | R = symmetric_orthogonalization(M) #this is the rotation matrix
143 |
144 | # Compute the transformed ctxt points
145 | x_points_transformed = torch.matmul(x_points_normalized, R)
146 |
147 | loss = (x_points_transformed - y_points_normalized).pow(2).mean()
148 | return loss
149 |
150 |
151 | def homogenize_points(points: torch.Tensor):
152 | """Appends a "1" to the coordinates of a (batch of) points of dimension DIM.
153 |
154 | Args:
155 | points: points of shape (..., DIM)
156 |
157 | Returns:
158 | points_hom: points with appended "1" dimension.
159 | """
160 | ones = torch.ones_like(points[..., :1], device=points.device)
161 | return torch.cat((points, ones), dim=-1)
162 |
163 |
164 | def homogenize_vecs(vectors: torch.Tensor):
165 | """Appends a "0" to the coordinates of a (batch of) vectors of dimension DIM.
166 |
167 | Args:
168 | vectors: vectors of shape (..., DIM)
169 |
170 | Returns:
171 | vectors_hom: points with appended "0" dimension.
172 | """
173 | zeros = torch.zeros_like(vectors[..., :1], device=vectors.device)
174 | return torch.cat((vectors, zeros), dim=-1)
175 |
176 |
177 | def unproject(
178 | xy_pix: torch.Tensor, z: torch.Tensor, intrinsics: torch.Tensor
179 | ) -> torch.Tensor:
180 | """Unproject (lift) 2D pixel coordinates x_pix and per-pixel z coordinate
181 | to 3D points in camera coordinates.
182 |
183 | Args:
184 | xy_pix: 2D pixel coordinates of shape (..., 2)
185 | z: per-pixel depth, defined as z coordinate of shape (..., 1)
186 | intrinscis: camera intrinscics of shape (..., 3, 3)
187 |
188 | Returns:
189 | xyz_cam: points in 3D camera coordinates.
190 | """
191 | xy_pix_hom = homogenize_points(xy_pix)
192 | xyz_cam = torch.einsum("...ij,...kj->...ki", intrinsics.inverse(), xy_pix_hom)
193 | xyz_cam *= z
194 | return xyz_cam
195 |
196 |
197 | def transform_world2cam(
198 | xyz_world_hom: torch.Tensor, cam2world: torch.Tensor
199 | ) -> torch.Tensor:
200 | """Transforms points from 3D world coordinates to 3D camera coordinates.
201 |
202 | Args:
203 | xyz_world_hom: homogenized 3D points of shape (..., 4)
204 | cam2world: camera pose of shape (..., 4, 4)
205 |
206 | Returns:
207 | xyz_cam: points in camera coordinates.
208 | """
209 | world2cam = torch.inverse(cam2world)
210 | return transform_rigid(xyz_world_hom, world2cam)
211 |
212 |
213 | def transform_cam2world(
214 | xyz_cam_hom: torch.Tensor, cam2world: torch.Tensor
215 | ) -> torch.Tensor:
216 | """Transforms points from 3D world coordinates to 3D camera coordinates.
217 |
218 | Args:
219 | xyz_cam_hom: homogenized 3D points of shape (..., 4)
220 | cam2world: camera pose of shape (..., 4, 4)
221 |
222 | Returns:
223 | xyz_world: points in camera coordinates.
224 | """
225 | return transform_rigid(xyz_cam_hom, cam2world)
226 |
227 |
228 | def transform_rigid(xyz_hom: torch.Tensor, T: torch.Tensor) -> torch.Tensor:
229 | """Apply a rigid-body transform to a (batch of) points / vectors.
230 |
231 | Args:
232 | xyz_hom: homogenized 3D points of shape (..., 4)
233 | T: rigid-body transform matrix of shape (..., 4, 4)
234 |
235 | Returns:
236 | xyz_trans: transformed points.
237 | """
238 | return torch.einsum("...ij,...kj->...ki", T, xyz_hom)
239 |
240 |
241 | def get_unnormalized_cam_ray_directions(
242 | xy_pix: torch.Tensor, intrinsics: torch.Tensor
243 | ) -> torch.Tensor:
244 | return unproject(
245 | xy_pix,
246 | torch.ones_like(xy_pix[..., :1], device=xy_pix.device),
247 | intrinsics=intrinsics,
248 | )
249 |
250 |
251 | def get_world_rays_(
252 | xy_pix: torch.Tensor,
253 | intrinsics: torch.Tensor,
254 | cam2world: torch.Tensor,
255 | ) -> torch.Tensor:
256 |
257 | if cam2world is None:
258 | cam2world = torch.eye(4)[None].expand(xy_pix.size(0),-1,-1).to(xy_pix)
259 |
260 | # Get camera origin of camera 1
261 | cam_origin_world = cam2world[..., :3, -1]
262 |
263 | # Get ray directions in cam coordinates
264 | ray_dirs_cam = get_unnormalized_cam_ray_directions(xy_pix, intrinsics)
265 | ray_dirs_cam = ray_dirs_cam / ray_dirs_cam.norm(dim=-1, keepdim=True)
266 |
267 | # Homogenize ray directions
268 | rd_cam_hom = homogenize_vecs(ray_dirs_cam)
269 |
270 | # Transform ray directions to world coordinates
271 | rd_world_hom = transform_cam2world(rd_cam_hom, cam2world)
272 |
273 | # Tile the ray origins to have the same shape as the ray directions.
274 | # Currently, ray origins have shape (batch, 3), while ray directions have shape
275 | cam_origin_world = repeat(
276 | cam_origin_world, "b ch -> b num_rays ch", num_rays=ray_dirs_cam.shape[1]
277 | )
278 |
279 | # Return tuple of cam_origins, ray_world_directions
280 | return cam_origin_world, rd_world_hom[..., :3]
281 |
282 | def get_world_rays(
283 | xy_pix: torch.Tensor,
284 | intrinsics: torch.Tensor,
285 | cam2world: torch.Tensor,
286 | ) -> torch.Tensor:
287 | if len(xy_pix.shape)==4:
288 | out = get_world_rays_(xy_pix.flatten(0,1),intrinsics.flatten(0,1),cam2world.flatten(0,1) if cam2world is not None else None)
289 | return [x.unflatten(0,xy_pix.shape[:2]) for x in out]
290 | return get_world_rays_(xy_pix,intrinsics,cam2world)
291 |
292 |
293 |
294 |
295 | def get_opencv_pixel_coordinates(
296 | y_resolution: int,
297 | x_resolution: int,
298 | device='cpu'
299 | ):
300 | """For an image with y_resolution and x_resolution, return a tensor of pixel coordinates
301 | normalized to lie in [0, 1], with the origin (0, 0) in the top left corner,
302 | the x-axis pointing right, the y-axis pointing down, and the bottom right corner
303 | being at (1, 1).
304 |
305 | Returns:
306 | xy_pix: a meshgrid of values from [0, 1] of shape
307 | (y_resolution, x_resolution, 2)
308 | """
309 | i, j = torch.meshgrid(
310 | torch.linspace(0, 1, steps=x_resolution, device=device),
311 | torch.linspace(0, 1, steps=y_resolution, device=device),
312 | )
313 |
314 | xy_pix = torch.stack([i.float(), j.float()], dim=-1).permute(1, 0, 2)
315 | return xy_pix
316 |
317 |
318 | def project(xyz_cam_hom: torch.Tensor, intrinsics: torch.Tensor) -> torch.Tensor:
319 | """Projects homogenized 3D points xyz_cam_hom in camera coordinates
320 | to pixel coordinates.
321 |
322 | Args:
323 | xyz_cam_hom: 3D points of shape (..., 4)
324 | intrinsics: camera intrinscics of shape (..., 3, 3)
325 |
326 | Returns:
327 | xy: homogeneous pixel coordinates of shape (..., 3) (final coordinate is 1)
328 | """
329 | if len(intrinsics.shape)==len(xyz_cam_hom.shape): intrinsics=intrinsics.unsqueeze(1)
330 | xyw = torch.einsum("...ij,...j->...i", intrinsics, xyz_cam_hom[..., :3])
331 | z = xyw[..., -1:]
332 | xyw = xyw / (z + 1e-5) # z-divide
333 | return xyw[..., :2], z
334 |
335 | def _sqrt_positive_part(x: torch.Tensor) -> torch.Tensor:
336 | # from pytorch3d
337 | """
338 | Returns torch.sqrt(torch.max(0, x))
339 | but with a zero subgradient where x is 0.
340 | """
341 | ret = torch.zeros_like(x)
342 | positive_mask = x > 0
343 | ret[positive_mask] = torch.sqrt(x[positive_mask])
344 | return ret
345 | def matrix_to_quaternion(matrix: torch.Tensor) -> torch.Tensor:
346 | # from pytorch3d
347 | """
348 | Convert rotations given as rotation matrices to quaternions.
349 | Args:
350 | matrix: Rotation matrices as tensor of shape (..., 3, 3).
351 | Returns:
352 | quaternions with real part first, as tensor of shape (..., 4).
353 | """
354 | if matrix.size(-1) != 3 or matrix.size(-2) != 3:
355 | raise ValueError(f"Invalid rotation matrix shape {matrix.shape}.")
356 |
357 | batch_dim = matrix.shape[:-2]
358 | m00, m01, m02, m10, m11, m12, m20, m21, m22 = torch.unbind(
359 | matrix.reshape(batch_dim + (9,)), dim=-1
360 | )
361 |
362 | q_abs = _sqrt_positive_part(
363 | torch.stack(
364 | [
365 | 1.0 + m00 + m11 + m22,
366 | 1.0 + m00 - m11 - m22,
367 | 1.0 - m00 + m11 - m22,
368 | 1.0 - m00 - m11 + m22,
369 | ],
370 | dim=-1,
371 | )
372 | )
373 |
374 | # we produce the desired quaternion multiplied by each of r, i, j, k
375 | quat_by_rijk = torch.stack(
376 | [
377 | torch.stack([q_abs[..., 0] ** 2, m21 - m12, m02 - m20, m10 - m01], dim=-1),
378 | torch.stack([m21 - m12, q_abs[..., 1] ** 2, m10 + m01, m02 + m20], dim=-1),
379 | torch.stack([m02 - m20, m10 + m01, q_abs[..., 2] ** 2, m12 + m21], dim=-1),
380 | torch.stack([m10 - m01, m20 + m02, m21 + m12, q_abs[..., 3] ** 2], dim=-1),
381 | ],
382 | dim=-2,
383 | )
384 |
385 | # We floor here at 0.1 but the exact level is not important; if q_abs is small,
386 | # the candidate won't be picked.
387 | flr = torch.tensor(0.1).to(dtype=q_abs.dtype, device=q_abs.device)
388 | quat_candidates = quat_by_rijk / (2.0 * q_abs[..., None].max(flr))
389 |
390 | # if not for numerical problems, quat_candidates[i] should be same (up to a sign),
391 | # forall i; we pick the best-conditioned one (with the largest denominator)
392 |
393 | return quat_candidates[
394 | F.one_hot(q_abs.argmax(dim=-1), num_classes=4) > 0.5, :
395 | ].reshape(batch_dim + (4,))
396 | def quaternion_to_matrix(quaternions: torch.Tensor) -> torch.Tensor:
397 | # from pytorch3d
398 | """
399 | Convert rotations given as quaternions to rotation matrices.
400 | Args:
401 | quaternions: quaternions with real part first,
402 | as tensor of shape (..., 4).
403 | Returns:
404 | Rotation matrices as tensor of shape (..., 3, 3).
405 | """
406 | r, i, j, k = torch.unbind(quaternions, -1)
407 | two_s = 2.0 / (quaternions * quaternions).sum(-1)
408 |
409 | o = torch.stack(
410 | (
411 | 1 - two_s * (j * j + k * k),
412 | two_s * (i * j - k * r),
413 | two_s * (i * k + j * r),
414 | two_s * (i * j + k * r),
415 | 1 - two_s * (i * i + k * k),
416 | two_s * (j * k - i * r),
417 | two_s * (i * k - j * r),
418 | two_s * (j * k + i * r),
419 | 1 - two_s * (i * i + j * j),
420 | ),
421 | -1,
422 | )
423 | return o.reshape(quaternions.shape[:-1] + (3, 3))
424 | def camera_interp(camera1, camera2, t):
425 | if len(camera1.shape)==3:
426 | return torch.stack([camera_interp(cam1,cam2,t) for cam1,cam2 in zip(camera1,camera2)])
427 | # Extract the rotation component from the camera matrices
428 | q1 = matrix_to_quaternion(camera1[:3, :3])
429 | q2 = matrix_to_quaternion(camera2[:3, :3])
430 |
431 | # todo add negative quaternion check to not go long way around
432 |
433 | # Interpolate the quaternions using slerp
434 | cos_angle = (q1 * q2).sum(dim=0)
435 | angle = torch.acos(cos_angle.clamp(-1, 1))
436 | q_interpolated = (q1 * torch.sin((1 - t) * angle) + q2 * torch.sin(t * angle)) / torch.sin(angle)
437 | rotation_interpolated = quaternion_to_matrix(q_interpolated)
438 |
439 | # Interpolate the translation component
440 | translation_interpolated = torch.lerp(camera1[:3,-1], camera2[:3,-1], t)
441 |
442 | cam_interpolated = torch.eye(4)
443 | cam_interpolated[:3,:3]=rotation_interpolated
444 | cam_interpolated[:3,-1]=translation_interpolated
445 |
446 | return cam_interpolated.cuda()
447 |
--------------------------------------------------------------------------------
/mlp_modules.py:
--------------------------------------------------------------------------------
1 | import torch.nn.functional as F
2 | import numpy as np
3 | from collections import OrderedDict
4 | import torch
5 | from torch import nn
6 | from einops import repeat,rearrange
7 |
8 | def init_weights_normal(m):
9 | if type(m) == nn.Linear:
10 | if hasattr(m, 'weight'):
11 | nn.init.kaiming_normal_(m.weight, a=0.0, nonlinearity='relu', mode='fan_in')
12 |
13 | class ResMLP(nn.Module):
14 | def __init__(self, ch_in, ch_mod, out_ch, num_res_block=1 ):
15 | super().__init__()
16 |
17 | self.res_blocks = nn.ModuleList([
18 | nn.Sequential(nn.Linear(ch_mod,ch_mod),nn.ReLU(),
19 | nn.LayerNorm([ch_mod], elementwise_affine=True),
20 | nn.Linear(ch_mod,ch_mod),nn.ReLU())
21 | for _ in range(num_res_block)
22 | ])
23 |
24 | self.proj_in = nn.Linear(ch_in,ch_mod)
25 | self.out = nn.Linear(ch_mod,out_ch)
26 |
27 | def forward(self,x):
28 |
29 | x = self.proj_in(x)
30 |
31 | for i,block in enumerate(self.res_blocks):
32 |
33 | x_in = x
34 |
35 | x = block(x)
36 |
37 | if i!=len(self.res_blocks)-1: x = x + x_in
38 |
39 | return self.out(x)
40 |
41 | # FILM, but just the biases, not scalings - featurewise additive modulation
42 | # "x" is the input coordinate and "y" is the conditioning feature (img features, for exmaple)
43 | class ResFAMLP(nn.Module):
44 | def __init__(self, ch_in_x,ch_in_y, ch_mod, out_ch, num_res_block=1, last_res=False):
45 | super().__init__()
46 |
47 | self.res_blocks = nn.ModuleList([
48 | nn.Sequential(nn.Linear(ch_mod,ch_mod),nn.ReLU(),
49 | nn.LayerNorm([ch_mod], elementwise_affine=True),
50 | nn.Linear(ch_mod,ch_mod),nn.ReLU())
51 | for _ in range(num_res_block)
52 | ])
53 |
54 | self.last_res=last_res
55 | self.proj_in = nn.Linear(ch_in_x,ch_mod)
56 | self.modulators = nn.ModuleList([nn.Linear(ch_in_y,ch_mod) for _ in range(num_res_block)])
57 | self.out = nn.Linear(ch_mod,out_ch)
58 |
59 | def forward(self,x,y):
60 |
61 | x = self.proj_in(x)
62 |
63 | for i,(block,modulator) in enumerate(zip(self.res_blocks,self.modulators)):
64 |
65 | x_in = x + modulator(y)
66 |
67 | x = block(x)
68 |
69 | if i!=len(self.res_blocks)-1 or self.last_res: x = x + x_in
70 |
71 | return self.out(x)
72 |
73 |
74 |
--------------------------------------------------------------------------------
/models.py:
--------------------------------------------------------------------------------
1 | """Code for pixelnerf and alternatives."""
2 | import torch, torchvision
3 | from torch import nn
4 | from einops import rearrange, repeat
5 | from torch.nn import functional as F
6 | import numpy as np
7 | import time
8 | import timm
9 | from matplotlib import cm
10 | import kornia
11 | from tqdm import tqdm
12 |
13 | import conv_modules
14 | import mlp_modules
15 | import geometry
16 | import renderer
17 | from geometry import procrustes
18 |
19 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
20 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
21 | hom = lambda x: torch.cat((x,torch.ones_like(x[...,[0]])),-1)
22 |
23 | class FlowCam(nn.Module):
24 | def __init__(self, near=1.75, far=8, n_samples=64,num_view=2,logspace=True,use_trgt_crop=False,use_midas=False):
25 | super().__init__()
26 |
27 | self.raft_midas_net = RaftAndMidas(raft=True,midas=use_midas)
28 |
29 | self.near,self.far,self.n_samples = near,far,n_samples
30 | self.logspace=logspace
31 | self.use_trgt_crop=use_trgt_crop
32 |
33 | self.num_view=num_view
34 |
35 | self.nerf_enc_flow = conv_modules.PixelNeRFEncoder(in_ch=5,use_first_pool=False)
36 | #self.nerf_enc_flow = conv_modules.PixelNeRFEncoder(in_ch=3,use_first_pool=False)
37 | phi_latent=64
38 | self.renderer = MLPImplicit(latent_in=phi_latent,inner_latent=phi_latent,white_back=False,num_first_res_block=2)
39 |
40 | self.pos_encoder = PositionalEncodingNoFreqFactor(3,5)
41 |
42 | self.ray_comb = nn.Sequential(torch.nn.Conv2d(512+33,512,3,padding=1),nn.ReLU(),
43 | torch.nn.Conv2d(512,512,3,padding=1),nn.ReLU(),
44 | torch.nn.Conv2d(512,phi_latent-3,3,padding=1)
45 | )
46 | self.corr_weighter_perpoint = nn.Sequential(
47 | nn.Linear(128,128),nn.ReLU(),
48 | nn.Linear(128,128),nn.ReLU(),
49 | nn.Linear(128,128),nn.ReLU(),
50 | nn.Linear(128,1),
51 | )
52 | self.corr_weighter_perpoint.apply(mlp_modules.init_weights_normal)
53 |
54 | def encoder(self,model_input):
55 | imsize=model_input["ctxt_rgb"].shape[-2:]
56 |
57 | if "backbone_feats" in model_input: return model_input["backbone_feats"]
58 | if "bwd_flow" not in model_input: model_input = self.raft_midas_net(model_input)
59 |
60 | # ctxt[1:]==trgt[:-1], using this property to avoid redundant computation
61 | all_rgb = torch.cat((model_input["ctxt_rgb"][:,:1],model_input["trgt_rgb"]),1)
62 | all_flow = torch.cat((model_input["bwd_flow"][:,:1],model_input["bwd_flow"]),1)
63 |
64 | # Resnet rgb+flow feats
65 | rgb_flow = torch.cat((all_rgb,all_flow*4),2)
66 | rgb_flow_feats = self.nerf_enc_flow(rgb_flow,imsize)
67 |
68 | # Add rays to features for some amount of focal length information
69 | rds = self.pos_encoder(geometry.get_world_rays(model_input["x_pix"], model_input["intrinsics"], None)[1])
70 | rds = ch_fst(torch.cat((rds[:,:1],rds),1),imsize[0])
71 |
72 | all_feats = self.ray_comb(torch.cat((rgb_flow_feats,rds),2).flatten(0,1)).unflatten(0,all_rgb.shape[:2])
73 | all_feats = torch.cat((all_feats,all_rgb),2)
74 | model_input["backbone_feats"] = all_feats
75 |
76 | return all_feats
77 |
78 | def forward(self, model_input, trgt_rays=None,ctxt_rays=None,poses=None):
79 |
80 | imsize=model_input["ctxt_rgb"].shape[-2:]
81 | (b,n_ctxt),n_trgt=model_input["ctxt_rgb"].shape[:2],model_input["trgt_rgb"].size(1)
82 | add_ctxt = lambda x: torch.cat((x[:,:1],x),1)
83 | if trgt_rays is None: trgt_rays,ctxt_rays = self.make_rays(model_input)
84 |
85 | # Encode images
86 | backbone_feats= self.encoder(model_input)
87 |
88 | # Expand identity camera into 3d points and render rays
89 | ros, rds = geometry.get_world_rays(add_ctxt(model_input["x_pix"]), add_ctxt(model_input["intrinsics"]), None)
90 | eye_pts, z_vals = renderer.sample_points_along_rays(self.near, self.far, self.n_samples, ros, rds, device=model_input["x_pix"].device,logspace=self.logspace)
91 | eye_render, eye_depth, eye_weights= self.renderer( backbone_feats, eye_pts[:,:,ctxt_rays], add_ctxt(model_input["intrinsics"]), z_vals,identity=True)
92 |
93 | # Render out correspondence's surface point now
94 | corresp_uv = (model_input["x_pix"]+ch_sec(model_input["bwd_flow"]))[:,:,ctxt_rays]
95 | ros, rds = geometry.get_world_rays(corresp_uv, model_input["intrinsics"], None)
96 | corresp_pts, _ = renderer.sample_points_along_rays(self.near, self.far, self.n_samples, ros, rds, device=model_input["x_pix"].device,logspace=self.logspace)
97 | _, _, corresp_weights= self.renderer( backbone_feats[:,:-1], corresp_pts, model_input["intrinsics"], z_vals,identity=True)
98 |
99 | # Predict correspondence weights as function of source feature and correspondence
100 | corresp_feat = F.grid_sample(backbone_feats[:,:-1].flatten(0,1),corresp_uv.flatten(0,1).unsqueeze(1)*2-1).squeeze(-2).permute(0,2,1).unflatten(0,(b,n_trgt))
101 | corr_weights = self.corr_weighter_perpoint(torch.cat((corresp_feat,ch_sec(backbone_feats)[:,1:,ctxt_rays]),-1)).sigmoid()
102 |
103 | # Weighted procrustes on scene flow
104 | if poses is None:
105 | adj_transf = procrustes((eye_pts[:,1:,ctxt_rays]*eye_weights[:,1:]).sum(-2), (corresp_weights*corresp_pts).sum(-2), corr_weights)[1]
106 | poses = adj_transf
107 | for i in range(n_trgt-1,0,-1):
108 | poses = torch.cat((poses[:,:i],poses[:,[i-1]]@poses[:,i:]),1)
109 | else: adj_transf = torch.cat((poses[:,:1],poses[:,:-1].inverse()@poses[:,1:]),1)
110 |
111 | # Render out trgt frames from [ctxt=0, ctxt=-1, ctxt=middle][: num context frames ]
112 | render = self.render(model_input,poses,trgt_rays)
113 |
114 | # Pose induced flow using ctxt depth and then multiview rendered depth (latter not used in paper experiments)
115 | corresp_surf_from_pose = (torch.einsum("bcij,bcdkj->bcdki",adj_transf,hom(eye_pts[:,1:]))[:,:,ctxt_rays,...,:3]*eye_weights[:,1:]).sum(-2)
116 | flow_from_pose = geometry.project(corresp_surf_from_pose.flatten(0,1), model_input["intrinsics"].flatten(0,1))[0].unflatten(0,(b,n_trgt))-model_input["x_pix"][:,:,ctxt_rays]
117 | corresp_surf_from_pose_render = (torch.einsum("bcij,bcdkj->bcdki",adj_transf,hom(eye_pts[:,1:]))[:,:,trgt_rays,...,:3]*render["weights"]).sum(-2)
118 | flow_from_pose_render = geometry.project(corresp_surf_from_pose_render.flatten(0,1), model_input["intrinsics"].flatten(0,1))[0].unflatten(0,(b,n_trgt))-model_input["x_pix"][:,:,trgt_rays]
119 |
120 | out= {
121 | "rgb":render["rgb"],
122 | "ctxt_rgb":eye_render[:,:-1],
123 | "poses":poses,
124 | "depth":render["depth"],
125 | "ctxt_depth":eye_depth[:,:-1],
126 | "corr_weights": corr_weights,
127 | "flow_from_pose": flow_from_pose,
128 | "flow_from_pose_render": flow_from_pose_render,
129 | "ctxt_rays": ctxt_rays.to(eye_render)[None].expand(b,-1),
130 | "trgt_rays": trgt_rays.to(eye_render)[None].expand(b,-1),
131 | "flow_inp": model_input["bwd_flow"],
132 | }
133 | if "ctxt_depth" in model_input:
134 | out["ctxt_depth_inp"]=model_input["ctxt_depth"]
135 | out["trgt_depth_inp"]=model_input["trgt_depth"]
136 | return out
137 |
138 | def render(self,model_input,poses,trgt_rays,query_pose=None):
139 | if query_pose is None: query_pose=poses
140 |
141 | ros, rds = geometry.get_world_rays(model_input["x_pix"][:,:query_pose.size(1),trgt_rays], model_input["intrinsics"][:,:query_pose.size(1)], query_pose)
142 | query_pts, z_vals = renderer.sample_points_along_rays(self.near, self.far, self.n_samples, ros, rds, device=model_input["x_pix"].device,logspace=self.logspace)
143 |
144 | ctxt_poses = torch.cat((torch.eye(4).cuda()[None].expand(poses.size(0),-1,-1)[:,None],poses),1)
145 | ctxt_idxs = [0,-1,model_input["trgt_rgb"].size(1)//2][:self.num_view]
146 | ctxt_pts = torch.einsum("bvcij,bcdkj->bvcdki",ctxt_poses[:,ctxt_idxs].inverse().unsqueeze(2),hom(query_pts))[...,:3] # in coord system of ctxt frames
147 | rgb, depth, weights = self.renderer(model_input["backbone_feats"][:,ctxt_idxs], ctxt_pts,model_input["intrinsics"][:,:query_pose.size(1)],z_vals)
148 | return {"rgb":rgb,"depth":depth,"weights":weights}
149 |
150 | def make_rays(self,model_input):
151 |
152 | imsize=model_input["ctxt_rgb"].shape[-2:]
153 |
154 | # Pick random subset of rays
155 | crop_res=32 if self.n_samples<100 else 16
156 | if self.use_trgt_crop: # choose random crop of rays instead of random set
157 | start_x,start_y = np.random.randint(0,imsize[1]-crop_res-1),np.random.randint(0,imsize[0]-crop_res-1)
158 | trgt_rays = torch.arange(imsize[0]*imsize[1]).view(imsize[0],imsize[1])[start_y:start_y+crop_res,start_x:start_x+crop_res].flatten()
159 | else:
160 | trgt_rays = torch.randperm(imsize[0]*imsize[1]-2)[:crop_res**2]
161 |
162 | ctxt_rays = torch.randperm(imsize[0]*imsize[1]-2)[:(32 if torch.is_grad_enabled() else 48)**2]
163 | return trgt_rays,ctxt_rays
164 |
165 | def render_full_img(self,model_input, query_pose=None,sample_out=None):
166 | num_chunk=8 if self.n_samples<90 else 16
167 |
168 | imsize=model_input["ctxt_rgb"].shape[-2:]
169 | (b,n_ctxt),n_trgt=model_input["ctxt_rgb"].shape[:2],model_input["trgt_rgb"].size(1)
170 |
171 | if sample_out is None: sample_out = self(model_input)
172 |
173 | # Render out image iteratively and aggregate outputs
174 | outs=[]
175 | for j,trgt_rays in enumerate(torch.arange(imsize[0]*imsize[1]).chunk(num_chunk)):
176 | with torch.no_grad():
177 | outs.append( self(model_input,trgt_rays=trgt_rays,ctxt_rays=trgt_rays,poses=sample_out["poses"]) if query_pose is None else
178 | self.render(model_input,sample_out["poses"],trgt_rays,query_pose[:,None]))
179 |
180 | out_all = {}
181 | for k,v in outs[0].items():
182 | if len(v.shape)>3 and "inp" not in k and "poses" not in k: out_all[k]=torch.cat([out[k] for out in outs],2)
183 | else:out_all[k]=v
184 | out_all["depth_raw"] = out_all["depth"]
185 | for k,v in out_all.items():
186 | if "depth" in k: out_all[k] = torch.from_numpy(cm.get_cmap('magma')(v.min().item()/v.cpu().numpy())).squeeze(-2)[...,:3]
187 |
188 | return out_all
189 |
190 | # Implicit function which performs pixel-aligned nerf
191 | class MLPImplicit(nn.Module):
192 |
193 | def __init__(self,latent_in=512,inner_latent=128,white_back=True,num_first_res_block=2,add_view_dir=False):
194 | super().__init__()
195 | self.white_back=white_back
196 |
197 | self.pos_encoder = PositionalEncodingNoFreqFactor(3,5)
198 |
199 | self.phi1= mlp_modules.ResFAMLP(3,latent_in,inner_latent,inner_latent,num_first_res_block,last_res=True) # 2 res blocks, outputs deep feature to be averaged over ctxts
200 | self.phi1.apply(mlp_modules.init_weights_normal)
201 | self.phi2= mlp_modules.ResMLP(inner_latent,inner_latent,4)
202 | self.phi2.apply(mlp_modules.init_weights_normal)
203 |
204 | # Note this method does not use cam2world and assumes `pos` is transformed to each context view's coordinate system and duplicated for each context view
205 | def forward(self,ctxt_feats,pos,intrinsics,samp_dists,flow_feats=None,identity=False):
206 |
207 | if identity: # 1:1 correspondence of ctxt img to trgt render, used for rendering out identity camera
208 | b_org,n_trgt_org = ctxt_feats.shape[:2]
209 | ctxt_feats,pos,intrinsics = [x.flatten(0,1)[:,None] for x in [ctxt_feats,pos,intrinsics]]
210 |
211 | if len(pos.shape)==5: pos=pos.unsqueeze(1) # unsqueeze ctxt if no ctxt dim (means only 1 ctxt supplied)
212 | (b,n_ctxt),n_trgt=(ctxt_feats.shape[:2],pos.size(2))
213 |
214 | # Projection onto identity camera
215 | img_feat, pos_,_ = geometry.pixel_aligned_features(
216 | repeat(pos,"b ctxt trgt xy d c -> (b ctxt trgt) (xy d) c"),
217 | repeat(torch.eye(4)[None,None].to(ctxt_feats),"1 1 x y -> (b ctxt trgt) x y",b=b,ctxt=n_ctxt,trgt=n_trgt),
218 | repeat(intrinsics,"b trgt x y -> (b ctxt trgt) x y",ctxt=n_ctxt),
219 | repeat(ctxt_feats,"b ctxt c x y -> (b ctxt trgt) c x y",trgt=n_trgt),
220 | )
221 | img_feat,pos= [rearrange(x,"(b ctxt trgt) (xy d) c -> (b trgt) xy d ctxt c",b=b,ctxt=n_ctxt,d=samp_dists.size(-1)) for x in [img_feat,pos_]]
222 |
223 | # Map (3d crd,projecting img feature) to (rgb,sigma)
224 | out = self.phi2(self.phi1(pos,img_feat).mean(dim=-2))
225 | rgb,sigma= out[...,:3].sigmoid(),out[...,3:4].relu()
226 |
227 | # Alphacomposite
228 | rgb, depth, weights = renderer.volume_integral(z_vals=samp_dists, sigmas=sigma, radiances=rgb, white_back=self.white_back)
229 |
230 | out = [x.unflatten(0,(b,n_trgt)) for x in [rgb,depth, weights]]
231 | return [x.squeeze(1).unflatten(0,(b_org,n_trgt_org)) for x in out] if identity else out
232 |
233 | # Adds RAFT flow and Midas depth to the model input
234 | class RaftAndMidas(nn.Module):
235 | def __init__(self,raft=True,midas=True):
236 | super().__init__()
237 | self.run_raft,self.run_midas=raft,midas
238 |
239 | if self.run_raft:
240 | from torchvision.models.optical_flow import Raft_Small_Weights
241 | from torchvision.models.optical_flow import raft_small
242 | print("making raft")
243 | self.raft_transforms = Raft_Small_Weights.DEFAULT.transforms()
244 | self.raft = raft_small(weights=Raft_Small_Weights.DEFAULT, progress=False)
245 | print("done making raft")
246 | if self.run_midas:
247 | print("making midas")
248 | self.midas_transforms = torch.hub.load("intel-isl/MiDaS", "transforms").dpt_transform
249 | self.midas_large = torch.hub.load("intel-isl/MiDaS", "DPT_Hybrid")
250 | print("done making midas")
251 | else: print("no midas")
252 |
253 | def forward(self,model_input):
254 |
255 | # Estimate raft flow and midas depth if no flow/depth in dataset
256 | imsize=model_input["ctxt_rgb"].shape[-2:]
257 | (b,n_ctxt),n_trgt=model_input["ctxt_rgb"].shape[:2],model_input["trgt_rgb"].size(1)
258 | # Inputs should be in range [0,255]; TODO change to [-1,1] to stay consistent with other RGB range
259 |
260 | with torch.no_grad():
261 | # Compute RAFT flow from each frame to next frame forward and backward - note image shape must be > 128 for raft to work
262 | if "bwd_flow" not in model_input and self.run_raft:
263 | raft = lambda x,y: F.interpolate(self.raft(x,y,num_flow_updates=12)[-1]/(torch.tensor(x.shape[-2:][::-1])-1).to(x)[None,:,None,None],imsize)
264 | #raft_rgbs = torch.cat([self.midas_transforms(raft_rgb.permute(1,2,0).cpu().numpy()) for raft_rgb in raft_rgbs]).cuda()
265 | raft_inputs = self.raft_transforms(model_input["trgt_rgb_large"].flatten(0,1).to(torch.uint8),model_input["ctxt_rgb_large"].flatten(0,1).to(torch.uint8))
266 | model_input["bwd_flow"] = raft(*raft_inputs).unflatten(0,(b,n_trgt))
267 |
268 | # Compute midas depth if not on a datastet with depth
269 | if "trgt_depth" not in model_input and self.run_midas:
270 | # Compute midas depth for sup.
271 | # TODO normalize this input correctly based on torch transform. I think it's just imagenet + [0,1] mapping but check
272 | midas = lambda x: F.interpolate(1/(1e-3+self.midas_large(x)).unsqueeze(1),imsize)
273 | midas_rgbs = torch.cat((model_input["ctxt_rgb_med"],model_input["trgt_rgb_med"][:,-1:]),1).flatten(0,1)
274 | midas_rgbs = (midas_rgbs/255)*2-1
275 | all_depth = midas(midas_rgbs).unflatten(0,(b,n_trgt+1))
276 | model_input["trgt_depth"] = all_depth[:,1:]
277 | model_input["ctxt_depth"] = all_depth[:,:-1]
278 | return model_input
279 |
280 | class PositionalEncodingNoFreqFactor(nn.Module):
281 | """PositionalEncoding module
282 |
283 | Maps v to positional encoding representation phi(v)
284 |
285 | Arguments:
286 | i_dim (int): input dimension for v
287 | N_freqs (int): #frequency to sample (default: 10)
288 | """
289 | def __init__(
290 | self,
291 | i_dim: int,
292 | N_freqs: int = 10,
293 | ) -> None:
294 |
295 | super().__init__()
296 |
297 | self.i_dim = i_dim
298 | self.out_dim = i_dim + (2 * N_freqs) * i_dim
299 | self.N_freqs = N_freqs
300 |
301 | a, b = 1, self.N_freqs - 1
302 | self.freq_bands = 2 ** torch.linspace(a, b, self.N_freqs)
303 |
304 | def forward(self, v):
305 | pe = [v]
306 | for freq in self.freq_bands:
307 | fv = freq * v
308 | pe += [torch.sin(fv), torch.cos(fv)]
309 | return torch.cat(pe, dim=-1)
310 |
311 |
--------------------------------------------------------------------------------
/renderer.py:
--------------------------------------------------------------------------------
1 | """Volume rendering code."""
2 | from geometry import *
3 | from typing import Callable, List, Optional, Tuple, Generator, Dict
4 | import torch
5 | from torch import nn
6 | from torch.nn import functional as F
7 | import numpy as np
8 | from torch import Tensor,device
9 |
10 |
11 | def pdf_z_values(
12 | bins: Tensor,
13 | weights: Tensor,
14 | samples: int,
15 | d: device,
16 | perturb: bool,
17 | ) -> Tensor:
18 | """Generate z-values from pdf
19 | Arguments:
20 | bins (Tensor): z-value bins (B, N - 2)
21 | weights (Tensor): bin weights gathered from first pass (B, N - 1)
22 | samples (int): number of samples N
23 | d (device): torch device
24 | perturb (bool): peturb ray query segment
25 | Returns:
26 | t (Tensor): z-values sampled from pdf (B, N)
27 | """
28 | EPS = 1e-5
29 | B, N = weights.size()
30 |
31 | weights = weights + EPS
32 | pdf = weights / torch.sum(weights, dim=-1, keepdim=True)
33 | cdf = torch.cumsum(pdf, dim=-1)
34 | cdf = torch.cat((torch.zeros_like(cdf[:, :1]), cdf), dim=-1)
35 |
36 | if perturb:
37 | u = torch.rand((B, samples), device=d)
38 | u = u.contiguous()
39 | else:
40 | u = torch.linspace(0, 1, samples, device=d)
41 | u = u.expand(B, samples)
42 | u = u.contiguous()
43 |
44 | idxs = torch.searchsorted(cdf, u, right=True)
45 | idxs_below = torch.clamp_min(idxs - 1, 0)
46 | idxs_above = torch.clamp_max(idxs, N)
47 | idxs = torch.stack((idxs_below, idxs_above), dim=-1).view(B, 2 * samples)
48 |
49 | cdf = torch.gather(cdf, dim=1, index=idxs).view(B, samples, 2)
50 | bins = torch.gather(bins, dim=1, index=idxs).view(B, samples, 2)
51 |
52 | den = cdf[:, :, 1] - cdf[:, :, 0]
53 | den[den < EPS] = 1.0
54 |
55 | t = (u - cdf[:, :, 0]) / den
56 | t = bins[:, :, 0] + t * (bins[:, :, 1] - bins[:, :, 0])
57 |
58 | return t
59 |
60 |
61 | def sample_pdf(bins, weights, N_importance, det=False, eps=1e-5):
62 | """
63 | Sample @N_importance samples from @bins with distribution defined by @weights.
64 | Inputs:
65 | bins: (N_rays, N_samples_+1) where N_samples_ is "the number of coarse samples per ray - 2"
66 | weights: (N_rays, N_samples_)
67 | N_importance: the number of samples to draw from the distribution
68 | det: deterministic or not
69 | eps: a small number to prevent division by zero
70 | Outputs:
71 | samples: the sampled samples
72 | Source: https://github.com/kwea123/nerf_pl/blob/master/models/rendering.py
73 | """
74 | N_rays, N_samples_ = weights.shape
75 | weights = weights + eps # prevent division by zero (don't do inplace op!)
76 | pdf = weights / torch.sum(weights, -1, keepdim=True) # (N_rays, N_samples_)
77 | cdf = torch.cumsum(pdf, -1) # (N_rays, N_samples), cumulative distribution function
78 | cdf = torch.cat([torch.zeros_like(cdf[:, :1]), cdf], -1) # (N_rays, N_samples_+1)
79 | # padded to 0~1 inclusive
80 |
81 | if det:
82 | u = torch.linspace(0, 1, N_importance, device=bins.device)
83 | u = u.expand(N_rays, N_importance)
84 | else:
85 | u = torch.rand(N_rays, N_importance, device=bins.device)
86 | u = u.contiguous()
87 |
88 | inds = torch.searchsorted(cdf, u)
89 | below = torch.clamp_min(inds - 1, 0)
90 | above = torch.clamp_max(inds, N_samples_)
91 |
92 | inds_sampled = torch.stack([below, above], -1).view(N_rays, 2 * N_importance)
93 | cdf_g = torch.gather(cdf, 1, inds_sampled)
94 | cdf_g = cdf_g.view(N_rays, N_importance, 2)
95 | bins_g = torch.gather(bins, 1, inds_sampled).view(N_rays, N_importance, 2)
96 |
97 | denom = cdf_g[..., 1] - cdf_g[..., 0]
98 | denom[
99 | denom < eps
100 | ] = 1 # denom equals 0 means a bin has weight 0, in which case it will not be sampled
101 | # anyway, therefore any value for it is fine (set to 1 here)
102 |
103 | samples = bins_g[..., 0] + (u - cdf_g[..., 0]) / denom * (
104 | bins_g[..., 1] - bins_g[..., 0]
105 | )
106 | return samples
107 |
108 |
109 | def pdf_rays(
110 | ro: Tensor,
111 | rd: Tensor,
112 | t: Tensor,
113 | weights: Tensor,
114 | samples: int,
115 | perturb: bool,
116 | ) -> Tuple[Tensor, Tensor, Tensor, Tensor]:
117 | """Sample pdf along rays given computed weights
118 | Arguments:
119 | ro (Tensor): rays origin (B, 3)
120 | rd (Tensor): rays direction (B, 3)
121 | t (Tensor): coarse z-value (B, N)
122 | weights (Tensor): weights gathered from first pass (B, N)
123 | samples (int): number of samples along the ray
124 | perturb (bool): peturb ray query segment
125 | Returns:
126 | rx (Tensor): rays position queries (B, Nc + Nf, 3)
127 | rd (Tensor): rays direction (B, Nc + Nf, 3)
128 | t (Tensor): z-values from near to far (B, Nc + Nf)
129 | delta (Tensor): rays segment lengths (B, Nc + Nf)
130 | """
131 | B, S, N_coarse, _ = weights.shape
132 | weights = rearrange(weights, "b n s 1 -> (b n) s")
133 | t = rearrange(t, "b n s 1 -> (b n) s")
134 |
135 | Nf = samples
136 | tm = 0.5 * (t[:, :-1] + t[:, 1:])
137 | t_pdf = sample_pdf(tm, weights[..., 1:-1], Nf, det=False).detach().view(B, S, Nf)
138 | rx = ro[..., None, :] + rd[..., None, :] * t_pdf[..., None]
139 |
140 | return rx, t_pdf
141 |
142 |
143 | def sample_points_along_rays(
144 | near_depth: float,
145 | far_depth: float,
146 | num_samples: int,
147 | ray_origins: torch.Tensor,
148 | ray_directions: torch.Tensor,
149 | device: torch.device,
150 | logspace=False,
151 | perturb=False,
152 | ):
153 | # Compute a linspace of num_samples depth values beetween near_depth and far_depth.
154 | if logspace:
155 | z_vals = torch.logspace(np.log10(near_depth), np.log10(far_depth), num_samples, device=device)
156 | else:
157 | z_vals = torch.linspace(near_depth, far_depth, num_samples, device=device)
158 |
159 | if perturb:
160 | z_vals = z_vals + .5*(torch.rand_like(z_vals)-.5)*torch.cat([(z_vals[:-1]-z_vals[1:]).abs(),torch.tensor([0]).cuda()])
161 |
162 | # Using the ray_origins, ray_directions, generate 3D points along
163 | # the camera rays according to the z_vals.
164 | pts = (
165 | ray_origins[..., None, :] + ray_directions[..., None, :] * z_vals[..., :, None]
166 | )
167 |
168 | return pts, z_vals
169 |
170 |
171 | def volume_integral(
172 | z_vals: torch.tensor, sigmas: torch.tensor, radiances: torch.tensor, white_back=False,dist_scale=True,
173 | ) -> Tuple[torch.tensor, torch.tensor, torch.tensor]:
174 | # Compute the deltas in depth between the points.
175 | dists = torch.cat(
176 | [
177 | z_vals[..., 1:] - z_vals[..., :-1],
178 | (z_vals[..., 1:] - z_vals[..., :-1])[..., -1:],
179 | ],
180 | -1,
181 | )
182 |
183 | # Compute the alpha values from the densities and the dists.
184 | # Tip: use torch.einsum for a convenient way of multiplying the correct
185 | # dimensions of the sigmas and the dists.
186 | # TODO switch to just expanding shape of dists for less code
187 | dist_scaling=dists if dist_scale else torch.ones_like(dists)
188 | if len(dists.shape)==1: alpha = 1.0 - torch.exp(-torch.einsum("brzs, z -> brzs", F.relu(sigmas), dist_scaling))
189 | else: alpha = 1.0 - torch.exp(-torch.einsum("brzs, brz -> brzs", F.relu(sigmas), dist_scaling.flatten(0,1)))
190 |
191 | alpha_shifted = torch.cat(
192 | [torch.ones_like(alpha[:, :, :1]), 1.0 - alpha + 1e-10], -2
193 | )
194 |
195 | # Compute the Ts from the alpha values. Use torch.cumprod.
196 | Ts = torch.cumprod(alpha_shifted, -2)
197 |
198 | # Compute the weights from the Ts and the alphas.
199 | weights = alpha * Ts[..., :-1, :]
200 |
201 | # Compute the pixel color as the weighted sum of the radiance values.
202 | rgb = torch.einsum("brzs, brzs -> brs", weights, radiances)
203 |
204 | # Compute the depths as the weighted sum of z_vals.
205 | # Tip: use torch.einsum for a convenient way of computing the weighted sum,
206 | # without the need to reshape the z_vals.
207 | if len(dists.shape)==1:
208 | depth_map = torch.einsum("brzs, z -> brs", weights, z_vals)
209 | else:
210 | depth_map = torch.einsum("brzs, brz -> brs", weights, z_vals.flatten(0,1))
211 |
212 | if white_back:
213 | accum = weights.sum(dim=-2)
214 | backgrd_color = torch.tensor([1,1,1]+[0]*(rgb.size(-1)-3)).broadcast_to(rgb.shape).to(rgb)
215 | #backgrd_color = torch.ones(rgb.size(-1)).broadcast_to(rgb.shape).to(rgb)
216 | rgb = rgb + (backgrd_color - accum)
217 |
218 | return rgb, depth_map, weights
219 |
220 |
221 | class VolumeRenderer(nn.Module):
222 | def __init__(self, near, far, n_samples=32, backgrd_color=None):
223 | super().__init__()
224 | self.near = near
225 | self.far = far
226 | self.n_samples = n_samples
227 |
228 | if backgrd_color is not None:
229 | self.register_buffer('backgrd_color', backgrd_color)
230 | else:
231 | self.backgrd_color = None
232 |
233 | def forward(
234 | self, cam2world, intrinsics, x_pix, radiance_field: nn.Module
235 | ) -> Tuple[torch.tensor, torch.tensor]:
236 | """
237 | Takes as inputs ray origins and directions - samples points along the
238 | rays and then calculates the volume rendering integral.
239 |
240 | Params:
241 | input_dict: Dictionary with keys 'cam2world', 'intrinsics', and 'x_pix'
242 | radiance_field: nn.Module instance of the radiance field we want to render.
243 |
244 | Returns:
245 | Tuple of rgb, depth_map
246 | rgb: for each pixel coordinate x_pix, the color of the respective ray.
247 | depth_map: for each pixel coordinate x_pix, the depth of the respective ray.
248 |
249 | """
250 | batch_size, num_rays = x_pix.shape[0], x_pix.shape[1]
251 |
252 | # Compute the ray directions in world coordinates.
253 | # Use the function get_world_rays.
254 | ros, rds = get_world_rays(x_pix, intrinsics, cam2world)
255 |
256 | # Generate the points along rays and their depth values
257 | # Use the function sample_points_along_rays.
258 | pts, z_vals = sample_points_along_rays(
259 | self.near, self.far, self.n_samples, ros, rds, device=x_pix.device
260 | )
261 |
262 | # Reshape pts to (batch_size, -1, 3).
263 | pts = pts.reshape(batch_size, -1, 3)
264 |
265 | # Sample the radiance field with the points along the rays.
266 | sigma, feats, misc = radiance_field(pts)
267 |
268 | # Reshape sigma and feats back to (batch_size, num_rays, self.n_samples, -1)
269 | sigma = sigma.view(batch_size, num_rays, self.n_samples, 1)
270 | feats = feats.view(batch_size, num_rays, self.n_samples, -1)
271 |
272 | # Compute pixel colors, depths, and weights via the volume integral.
273 | rendering, depth_map, weights = volume_integral(z_vals, sigma, feats)
274 |
275 | if self.backgrd_color is not None:
276 | accum = weights.sum(dim=-2)
277 | backgrd_color = self.backgrd_color.broadcast_to(rendering.shape)
278 | rendering = rendering + (backgrd_color - accum)
279 |
280 | return rendering, depth_map, misc
281 |
--------------------------------------------------------------------------------
/run.py:
--------------------------------------------------------------------------------
1 | import os,random,time,datetime,glob
2 |
3 | import numpy as np
4 | from functools import partial
5 | from tqdm import tqdm,trange
6 | from einops import rearrange
7 |
8 | import wandb
9 | import torch
10 |
11 | import models
12 | import vis_scripts
13 |
14 | from data.KITTI import KittiDataset
15 | from data.co3d import Co3DNoCams
16 | from data.realestate10k_dataio import RealEstate10k
17 |
18 | def to_gpu(ob): return {k: to_gpu(v) for k, v in ob.items()} if isinstance(ob, dict) else ob.cuda()
19 |
20 | import argparse
21 | parser = argparse.ArgumentParser(description='simple training job')
22 | # logging parameters
23 | parser.add_argument('-n','--name', type=str,default="",required=False,help="wandb training name")
24 | parser.add_argument('-c','--init_ckpt', type=str,default=None,required=False,help="File for checkpoint loading. If folder specific, will use latest .pt file")
25 | parser.add_argument('-d','--dataset', type=str,default="hydrant")
26 | parser.add_argument('-o','--online', default=False, action=argparse.BooleanOptionalAction)
27 | # data/training parameters
28 | parser.add_argument('-b','--batch_size', type=int,default=1,help="number of videos/sequences per training step")
29 | parser.add_argument('-v','--vid_len', type=int,default=6,help="video length or number of images per batch")
30 | parser.add_argument('--midas_sup', default=False, action=argparse.BooleanOptionalAction,help="Whether to use midas depth supervision or not")
31 | parser.add_argument('--category', type=str,default=None,help="if want to use a specific co3d category, such as 'bicycle', specify here")
32 | # model parameters
33 | parser.add_argument('--n_skip', nargs="+",type=int,default=0,help="Number of frames to skip between adjacent frames in dataloader. If list, dataset randomly chooses between skips. Only used for co3d")
34 | parser.add_argument('--n_ctxt', type=int,default=2,help="Number of context views to use. 1 is just first frame, 2 is second and last, 3 is also middle, etc")
35 | # eval/vis
36 | parser.add_argument('--eval', default=False, action=argparse.BooleanOptionalAction,help="whether to train or run evaluation")
37 | parser.add_argument('--n_eval', type=int,default=int(1e8),help="Number of eval samples to run")
38 | parser.add_argument('--save_ind', default=False, action=argparse.BooleanOptionalAction,help="whether to save out each individual image (in rendering images) or just save the all-trajectory image")
39 | parser.add_argument('--save_imgs', default=False, action=argparse.BooleanOptionalAction,help="whether to save out the all-trajectory images")
40 | # demo args
41 | parser.add_argument('--demo_rgb', default="", type=str,required=False,help="The image folder path for demo inference.")
42 | parser.add_argument('--render_imgs', default=False, action=argparse.BooleanOptionalAction,help="whether to rerender out images (video reconstructions) during the demo inference (slower than just estimating poses)")
43 | parser.add_argument('--intrinsics', default=None, type=str,required=False,help="The intrinsics corresponding to the image path for demo inference as fx,fy,cx,cy. To use predicted intrinsics, leave as None")
44 | parser.add_argument('--low_res', nargs="+",type=int,default=[128,128],help="Low resolution to perform renderings at. Default (128,128)")
45 |
46 | args = parser.parse_args()
47 | if args.n_skip==0 and args.dataset=="realestate": args.n_skip=9 # realestate is the only dataset where 0 frameskip isn't meaningful
48 |
49 | # Wandb init: install wandb and initialize via wandb.login() before running
50 | run = wandb.init(project="flowcam",mode="online" if args.online else "disabled",name=args.name)
51 | wandb.run.log_code(".")
52 | save_dir = os.path.join(os.environ.get('LOGDIR', "") , run.name)
53 | print(save_dir)
54 | os.makedirs(save_dir,exist_ok=True)
55 | wandb.save(os.path.join(save_dir, "checkpoint*"))
56 | wandb.save(os.path.join(save_dir, "video*"))
57 |
58 | # Make dataset
59 | get_dataset = lambda val=False: ( Co3DNoCams(num_trgt=args.vid_len+1,low_res=(156,102),num_cat=1 if args.dataset=="hydrant" else 10 if args.dataset=="10cat" else 30,
60 | n_skip=args.n_skip,val=val,category=args.category) if args.dataset in ["hydrant","10cat","allcat"]
61 | else RealEstate10k(imsl=128, num_ctxt_views=2, num_query_views=args.vid_len+1, val=val, n_skip = args.n_skip) if args.dataset == "realestate"
62 | else KittiDataset(num_context=1,num_trgt=args.vid_len+1,low_res=(76,250),val=val,n_skip=args.n_skip)
63 | )
64 | get_dataloader = lambda dataset: iter(torch.utils.data.DataLoader(dataset, batch_size=args.batch_size*torch.cuda.device_count(),num_workers=args.batch_size,shuffle=True,pin_memory=True))
65 |
66 | # Make model + optimizer
67 | model = models.FlowCam(near=1,far=8,num_view=args.n_ctxt,use_midas=args.midas_sup).cuda()
68 | if args.init_ckpt is not None:
69 | ckpt_file = args.init_ckpt if os.path.isfile(os.path.expanduser(args.init_ckpt)) else max(glob.glob(os.path.join(args.init_ckpt,"*.pt")), key=os.path.getctime)
70 | model.load_state_dict(torch.load(ckpt_file)["model_state_dict"],strict=False)
71 | optim = torch.optim.Adam(lr=1e-4, params=model.parameters())
72 |
--------------------------------------------------------------------------------
/train.py:
--------------------------------------------------------------------------------
1 | # todo get rid of start import, just import run and access run.train_dataset, etc
2 | from run import *
3 |
4 | train_dataset,val_dataset = get_dataset(),get_dataset(val=True,)
5 | train_dataset[0]
6 | train_dataloader,val_dataloader = get_dataloader(train_dataset),get_dataloader(val_dataset)
7 |
8 | def loss_fn(model_out, gt, model_input):
9 |
10 | rays = lambda x,y: torch.stack([x[i,:,y[i].long()] for i in range(len(x))])
11 | ch_sec = lambda x: rearrange(x,"... c x y -> ... (x y) c")
12 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
13 | losses = { "metrics/rgb_loss": (model_out["rgb"] - rays(gt["trgt_rgb"],model_out["trgt_rays"])).square().mean() * (1e1 if args.dataset=="shapenet" else 2e2) }
14 |
15 | losses["metrics/ctxt_rgb_loss"]= (model_out["ctxt_rgb"] - rays(gt["ctxt_rgb"],model_out["ctxt_rays"])).square().mean() * 1e2
16 | gt_bwd_flow = rays(gt["bwd_flow"] if "bwd_flow" in gt else ch_sec(model_out["flow_inp"]),model_out["ctxt_rays"])
17 | losses["metrics/flow_from_pose"] = ((model_out["flow_from_pose"].clip(-.2,.2) - gt_bwd_flow.clip(-.2,.2)).square().mean() * 6e3).clip(0,10)
18 |
19 | gt_bwd_flow_trgt = rays(gt["bwd_flow"] if "bwd_flow" in gt else ch_sec(model_out["flow_inp"]),model_out["trgt_rays"])
20 |
21 | # monodepth loss (not used in paper but may be useful later)
22 | if args.midas_sup:
23 | def depth_lstsq_fit(depthgt,depthest):
24 | depthgt,depthest=1/(1e-8+depthgt),1/(1e-8+depthest)
25 | lstsq=torch.linalg.lstsq(depthgt,depthest)
26 | return ((depthgt@lstsq.solution)-depthest).square().mean() * 1e2
27 |
28 | losses["metrics/ctxt_depth_loss_lstsq"] = (depth_lstsq_fit(rays(ch_sec(model_out["ctxt_depth_inp"]),model_out["ctxt_rays"]).flatten(0,1),model_out["ctxt_depth"].flatten(0,1))*2e0).clip(0,2)/2
29 | losses["metrics/depth_loss_lstsq"] = (depth_lstsq_fit(rays(ch_sec(model_out["trgt_depth_inp"]),model_out["trgt_rays"]).flatten(0,1),model_out["depth"].flatten(0,1))*2e0).clip(0,2)/2
30 |
31 | return losses
32 |
33 | model = torch.nn.DataParallel(model)
34 |
35 | # Train loop
36 | for step in trange(0 if args.eval else int(1e8), desc="Fitting"): # train until user interruption
37 |
38 | # Run val set every n iterations
39 | val_step = step>10 and step%150<10
40 | prefix = "val" if val_step else ""
41 | torch.set_grad_enabled(not val_step)
42 | if val_step: print("\n\n\nval step\n\n\n")
43 |
44 | # Get data
45 | try: model_input, ground_truth = next(train_dataloader if not val_step else val_dataloader)
46 | except StopIteration:
47 | if val_step: val_dataloader = get_dataloader(val_dataset)
48 | else: train_dataloader = get_dataloader(train_dataset)
49 | continue
50 |
51 | model_input, ground_truth = to_gpu(model_input), to_gpu(ground_truth)
52 |
53 | # Run model and calculate losses
54 | total_loss = 0.
55 | for loss_name, loss in loss_fn(model(model_input), ground_truth, model_input).items():
56 | wandb.log({prefix+loss_name: loss.item()}, step=step)
57 | total_loss += loss
58 |
59 | wandb.log({prefix+"loss": total_loss.item()}, step=step)
60 | wandb.log({"epoch": (step*args.batch_size)/len(train_dataset)}, step=step)
61 |
62 | if not val_step:
63 | optim.zero_grad(); total_loss.backward(); optim.step();
64 |
65 | # Image summaries and checkpoint
66 | if step%50==0 : # write image summaries
67 | print("writing summary")
68 | with torch.no_grad(): model_output = model.module.render_full_img(model_input=model_input)
69 | vis_scripts.wandb_summary( total_loss, model_output, model_input, ground_truth, None,prefix=prefix)
70 | if step%100==0: #write video summaries
71 | print("writing video summary")
72 | try: vis_scripts.write_video(save_dir, vis_scripts.render_time_interp(model_input,model.module,None,16), prefix+"time_interp",step)
73 | except Exception as e: print("error in writing video",e)
74 | if step%500 == 0 and step: # save model
75 | print(f"Saving to {save_dir}"); torch.save({ 'step': step, 'model_state_dict': model.module.state_dict(), }, os.path.join(save_dir, f"checkpoint_{step}.pt"))
76 |
77 |
78 |
--------------------------------------------------------------------------------
/vis_scripts.py:
--------------------------------------------------------------------------------
1 | import os
2 | import geometry
3 | import wandb
4 | from matplotlib import cm
5 | from torchvision.utils import make_grid
6 | import torch.nn.functional as F
7 | import numpy as np
8 | import torch
9 | import flow_vis
10 | import flow_vis_torch
11 | import matplotlib.pyplot as plt;
12 | from einops import rearrange, repeat
13 | import piqa
14 | import imageio
15 | import splines.quaternion
16 | from torchcubicspline import (natural_cubic_spline_coeffs, NaturalCubicSpline)
17 |
18 | def write_video(save_dir,frames,vid_name,step,write_frames=False):
19 | frames = [(255*x).astype(np.uint8) for x in frames]
20 | if "time" in vid_name: frames = frames + frames[::-1]
21 | f = os.path.join(save_dir, f'{vid_name}.mp4')
22 | imageio.mimwrite(f, frames, fps=8, quality=7)
23 | wandb.log({f'vid/{vid_name}':wandb.Video(f, format='mp4', fps=8)})
24 | print("writing video at",f)
25 | if write_frames:
26 | for i,img in enumerate(frames):
27 | try: os.mkdir(os.path.join(save_dir, f'{vid_name}_{step}'))
28 | except:pass
29 | f=os.path.join(save_dir, f'{vid_name}/{i}.png');plt.imsave(f,img);print(f)
30 |
31 | def normalize(a):
32 | return (a - a.min()) / (a.max() - a.min())
33 |
34 | def cvt(a):
35 | a = a.permute(1, 2, 0).detach().cpu()
36 | a = (a - a.min()) / (a.max() - a.min())
37 | a = a.numpy()
38 | return a
39 |
40 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
41 |
42 | # Renders out query frame with interpolated motion field
43 | def render_time_interp(model_input,model,resolution,n):
44 |
45 | b=model_input["ctxt_rgb"].size(0)
46 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
47 | frames=[]
48 | thetas = np.linspace(0, 1, n)
49 | with torch.no_grad(): sample_out = model(model_input)
50 | if "flow_inp" in sample_out:model_input["bwd_flow"]=sample_out["flow_inp"]
51 |
52 | # TODO add wobble flag back in here from satori code
53 |
54 | all_poses=sample_out["poses"]
55 | pos_spline_idxs=torch.linspace(0,all_poses.size(1)-1,all_poses.size(1)) # no compression
56 | rot_spline_idxs=torch.linspace(0,all_poses.size(1)-1,all_poses.size(1)) # no compression
57 | all_pos_spline=[]
58 | all_quat_spline=[]
59 | for b_i in range(b):
60 | all_pos_spline.append(NaturalCubicSpline(natural_cubic_spline_coeffs(pos_spline_idxs, all_poses[b_i,pos_spline_idxs.long(),:3,-1].cpu())))
61 | quats=geometry.matrix_to_quaternion(all_poses[b_i,:,:3,:3])
62 | all_quat_spline.append(splines.quaternion.PiecewiseSlerp([splines.quaternion.UnitQuaternion.from_unit_xyzw(quat_)
63 | for quat_ in quats[rot_spline_idxs.long()].cpu().numpy()],grid=rot_spline_idxs.tolist()))
64 |
65 | for t in torch.linspace(0,all_poses.size(1)-1,n):
66 | print(t)
67 |
68 | custom_poses=[]
69 | for b_i,(pos_spline,quat_spline_) in enumerate(zip(all_pos_spline,all_quat_spline)):
70 | custom_pose=torch.eye(4).cuda()
71 | custom_pose[:3,-1]=pos_spline.evaluate(t)
72 | closest_t = (custom_pose[:3,-1]-all_poses[b_i,:,:3,-1]).square().sum(-1).argmin()
73 | quat_eval=quat_spline_.evaluate(t.item())
74 | curr_quats = torch.tensor(list(quat_eval.vector)+[quat_eval.scalar])
75 | custom_pose[:3,:3] = geometry.quaternion_to_matrix(curr_quats)
76 | custom_poses.append(custom_pose)
77 | custom_pose=torch.stack(custom_poses)
78 | with torch.no_grad(): model_out = model.render_full_img(model_input,query_pose=custom_pose,sample_out=sample_out)
79 |
80 | rgb_pred = model_out["rgb"]
81 | resolution = list(model_input["ctxt_rgb"][:,:1].flatten(0,1).permute(0,2,3,1).shape)
82 | rgb_pred=rgb_pred[:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
83 | magma_depth=model_out["depth"][:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
84 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
85 | frames.append(rgbd_im)
86 | return frames
87 |
88 |
89 | for i in range(n):
90 | print(i,n)
91 | query_pose = geometry.time_interp_poses(sample_out["poses"],i/(n-1), model_input["trgt_rgb"].size(1),None)[:,0]
92 | # todo fix this interpolation -- is it incorrect to interpolate here?
93 | with torch.no_grad(): model_out = model.render_full_img(model_input,query_pose=query_pose,sample_out=sample_out)
94 | rgb_pred = model_out["rgb"]
95 | resolution = list(model_input["ctxt_rgb"][:,:1].flatten(0,1).permute(0,2,3,1).shape)
96 | rgb_pred=rgb_pred[:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
97 | magma_depth=model_out["depth"][:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
98 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
99 | frames.append(rgbd_im)
100 | return frames
101 |
102 | def look_at(eye, at=torch.Tensor([0, 0, 0]).cuda(), up=torch.Tensor([0, 1, 0]).cuda(), eps=1e-5):
103 | #at = at.unsqueeze(0).unsqueeze(0)
104 | #up = up.unsqueeze(0).unsqueeze(0)
105 |
106 | z_axis = eye - at
107 | #z_axis /= z_axis.norm(dim=-1, keepdim=True) + eps
108 | z_axis = z_axis/(z_axis.norm(dim=-1, keepdim=True) + eps)
109 |
110 | up = up.expand(z_axis.shape)
111 | x_axis = torch.cross(up, z_axis)
112 | #x_axis /= x_axis.norm(dim=-1, keepdim=True) + eps
113 | x_axis = x_axis/(x_axis.norm(dim=-1, keepdim=True) + eps)
114 |
115 | y_axis = torch.cross(z_axis, x_axis)
116 | #y_axis /= y_axis.norm(dim=-1, keepdim=True) + eps
117 | y_axis = y_axis/(y_axis.norm(dim=-1, keepdim=True) + eps)
118 |
119 | r_mat = torch.stack((x_axis, y_axis, z_axis), axis=-1)
120 | return r_mat
121 |
122 | def render_cam_traj_wobble(model_input,model,resolution,n):
123 |
124 | c2w = torch.eye(4, device='cuda')[None]
125 | tmp = torch.eye(4).cuda()
126 | circ_scale = .1
127 | thetas = np.linspace(0, 2 * np.pi, n)
128 | frames = []
129 |
130 | if "ctxt_c2w" not in model_input:
131 | model_input["ctxt_c2w"] = torch.tensor([[-2.5882e-01, -4.8296e-01, 8.3652e-01, -2.2075e+00],
132 | [ 2.1187e-08, -8.6603e-01, -5.0000e-01, 2.3660e+00],
133 | [-9.6593e-01, 1.2941e-01, -2.2414e-01, 5.9150e-01],
134 | [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00]]
135 | )[None,None].expand(model_input["trgt_rgb"].size(0),model_input["trgt_rgb"].size(1),-1,-1).cuda()
136 |
137 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
138 |
139 | c2w = model_input["ctxt_c2w"]
140 | circ_scale = c2w[0,0,[0,2],-1].norm()
141 | #circ_scale = c2w[0,[0,1],-1].norm()
142 | thetas=np.linspace(0,np.pi*2,n)
143 | rgb_imgs=[]
144 | depth_imgs=[]
145 | start_theta=0#(model_input["ctxt_c2w"][0,0,0,-1]/circ_scale).arccos()
146 | with torch.no_grad(): sample_out = model(model_input)
147 | if "flow_inp" in sample_out: model_input["bwd_flow"]=sample_out["flow_inp"]
148 | step=2 if n==8 else 4
149 | zs = torch.cat((torch.linspace(0,-n//4,n//step),torch.linspace(-n//4,0,n//step),torch.linspace(0,n//4,n//step),torch.linspace(n//4,0,n//step)))
150 | for i in range(n):
151 | print(i,n)
152 | theta=float(thetas[i] + start_theta)
153 | x=np.cos(theta) * circ_scale * .075
154 | y=np.sin(theta) * circ_scale * .075
155 | tmp=torch.eye(4).cuda()
156 | newpos=torch.tensor([x,y,zs[i]*1e-1]).cuda().float()
157 | tmp[:3,-1] = newpos
158 | custom_c2w = tmp[None].expand(c2w.size(0),c2w.size(1),-1,-1)
159 | with torch.no_grad(): model_out = model(model_input,custom_transf=custom_c2w,full_img=True)
160 |
161 | resolution = [model_input["trgt_rgb"].size(0)]+list(resolution[1:])
162 | b = model_out["rgb"].size(0)
163 | rgb_pred = model_out["rgb"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
164 | magma_depth = model_out["depth"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
165 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
166 | frames.append(rgbd_im)
167 | return frames
168 |
169 |
170 |
171 | def render_cam_traj_time_wobble(model_input,model,resolution,n):
172 |
173 | c2w = torch.eye(4, device='cuda')[None]
174 | if "ctxt_c2w" not in model_input:
175 | model_input["ctxt_c2w"] = torch.tensor([[-2.5882e-01, -4.8296e-01, 8.3652e-01, -2.2075e+00],
176 | [ 2.1187e-08, -8.6603e-01, -5.0000e-01, 2.3660e+00],
177 | [-9.6593e-01, 1.2941e-01, -2.2414e-01, 5.9150e-01],
178 | [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00]]
179 | )[None,None].expand(model_input["trgt_rgb"].size(0),model_input["trgt_rgb"].size(1),-1,-1).cuda()
180 |
181 | c2w = model_input["ctxt_c2w"]
182 | circ_scale = c2w[0,0,[0,2],-1].norm()
183 | thetas=np.linspace(0,np.pi*2,n)
184 | rgb_imgs=[]
185 | depth_imgs=[]
186 | start_theta=0#(model_input["ctxt_c2w"][0,0,0,-1]/circ_scale).arccos()
187 |
188 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
189 | frames=[]
190 | thetas = np.linspace(0, 1, n)
191 | with torch.no_grad(): sample_out = model(model_input)
192 | if "flow_inp" in sample_out: model_input["bwd_flow"]=sample_out["flow_inp"]
193 | step=2 if n==8 else 4
194 | zs = torch.cat((torch.linspace(0,-n//4,n//step),torch.linspace(-n//4,0,n//step),torch.linspace(0,n//4,n//step),torch.linspace(n//4,0,n//step)))
195 | for i in range(n):
196 |
197 | print(i,n)
198 | theta=float(thetas[i] + start_theta)
199 | x=np.cos(theta) * circ_scale * .005
200 | y=np.sin(theta) * circ_scale * .005
201 | tmp=torch.eye(4).cuda()
202 | newpos=torch.tensor([x,y,zs[i]*2e-1]).cuda().float()
203 | tmp[:3,-1] = newpos
204 | custom_c2w = tmp[None].expand(c2w.size(0),c2w.size(1),-1,-1)
205 |
206 | with torch.no_grad(): model_out = model(model_input,time_i=i/(n-1),full_img=True,custom_transf=custom_c2w)
207 | rgb_pred = model_out["rgb"]
208 | same_all=True
209 | if same_all:
210 | resolution = list(model_input["ctxt_rgb"][:,:1].flatten(0,1).permute(0,2,3,1).shape)
211 | rgb_pred=rgb_pred[:,:1].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
212 | else:
213 | rgb_pred=rgb_pred.view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
214 | depth_pred = model_out["depth"].clone()
215 | mind,maxd=sample_out["depth"].cpu().min(),sample_out["depth"].cpu().max()
216 | depth_pred[0,0,0]=mind #normalize
217 | depth_pred[0,0,1]=maxd #normalize
218 | if same_all:
219 | depth_pred = (mind/(1e-3+depth_pred[:,:1]).view(resolution[:-1]).permute(1,0,2).flatten(1,2).cpu().numpy())
220 | else:
221 | depth_pred = (mind/(1e-3+depth_pred).view(resolution[:-1]).permute(1,0,2).flatten(1,2).cpu().numpy())
222 | magma = cm.get_cmap('magma')
223 | magma_depth = torch.from_numpy(magma(depth_pred))[...,:3]
224 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
225 | frames.append(rgbd_im)
226 |
227 | return frames
228 |
229 | # Renders out context frame with novel camera pose
230 | def render_view_interp(model_input,model,resolution,n):
231 |
232 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
233 |
234 | c2w = torch.eye(4, device='cuda')[None]
235 | tmp = torch.eye(4).cuda()
236 | circ_scale = .1
237 | thetas = np.linspace(0, 2 * np.pi, n)
238 | frames = []
239 |
240 | if "ctxt_c2w" not in model_input:
241 | model_input["ctxt_c2w"] = torch.tensor([[-2.5882e-01, -4.8296e-01, 8.3652e-01, -2.2075e+00],
242 | [ 2.1187e-08, -8.6603e-01, -5.0000e-01, 2.3660e+00],
243 | [-9.6593e-01, 1.2941e-01, -2.2414e-01, 5.9150e-01],
244 | [ 0.0000e+00, 0.0000e+00, 0.0000e+00, 1.0000e+00]]
245 | )[None,None].expand(model_input["trgt_rgb"].size(0),model_input["trgt_rgb"].size(1),-1,-1).cuda()
246 |
247 | c2w = model_input["ctxt_c2w"]
248 | circ_scale = c2w[0,0,[0,2],-1].norm()
249 | #circ_scale = c2w[0,[0,1],-1].norm()
250 | thetas=np.linspace(0,np.pi*2,n)
251 | rgb_imgs=[]
252 | depth_imgs=[]
253 | start_theta=0#(model_input["ctxt_c2w"][0,0,0,-1]/circ_scale).arccos()
254 | with torch.no_grad(): sample_out = model(model_input)
255 | if "flow_inp" in sample_out: model_input["bwd_flow"]=sample_out["flow_inp"]
256 | for i in range(n):
257 | print(i,n)
258 | theta=float(thetas[i] + start_theta)
259 | x=np.cos(theta) * circ_scale * 1
260 | y=np.sin(theta) * circ_scale * 1
261 | tmp=torch.eye(4).cuda()
262 | #newpos=torch.tensor([x,y,c2w[0,2,-1]]).cuda().float()
263 | newpos=torch.tensor([x,c2w[0,0,1,-1],y]).cuda().float()
264 | rot = look_at(newpos,torch.tensor([0,0,0]).cuda())
265 | rot[:,1:]*=-1
266 | tmp[:3,:3]=rot
267 | newpos=torch.tensor([x,c2w[0,0,1,-1],y]).cuda().float()
268 | tmp[:3,-1] = newpos
269 | #with torch.no_grad(): model_out = model(model_input,custom_transf=tmp[None].expand(c2w.size(0),-1,-1))
270 | custom_c2w = tmp[None].expand(c2w.size(0),c2w.size(1),-1,-1)
271 | #TODO make circle radius and only use first img
272 | #from pdb import set_trace as pdb_;pdb_()
273 | if 1:
274 | custom_c2w = custom_c2w.inverse()@model_input["ctxt_c2w"]
275 | #custom_c2w = model_input["ctxt_c2w"].inverse()@custom_c2w
276 | with torch.no_grad(): model_out = model(model_input,custom_transf=custom_c2w,full_img=True)
277 |
278 | resolution = [model_input["trgt_rgb"].size(0)]+list(resolution[1:])
279 |
280 | b = model_out["rgb"].size(0)
281 | rgb_pred = model_out["rgb"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu().numpy()
282 | magma_depth = model_out["depth"][:,0].view(resolution).permute(1,0,2,3).flatten(1,2).cpu()
283 | rgbd_im=torch.cat((torch.from_numpy(rgb_pred),magma_depth),0).numpy()
284 | frames.append(rgbd_im)
285 | return frames
286 |
287 | def wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
288 |
289 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
290 | resolution[0]=ground_truth["trgt_rgb"].size(1)*ground_truth["trgt_rgb"].size(0)
291 | nrow=model_input["trgt_rgb"].size(1)
292 | imsl=model_input["ctxt_rgb"].shape[-2:]
293 | inv = lambda x : 1/(x+1e-8)
294 |
295 | depth = make_grid(model_output["depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
296 |
297 | wandb_out = {
298 | "est/rgb_pred": make_grid(model_output["rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow),
299 | "ref/rgb_gt": make_grid(ground_truth["trgt_rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow),
300 | #"ref/rgb_gt": make_grid(ground_truth["trgt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow),
301 | "ref/ctxt_img": make_grid(model_input["ctxt_rgb"][:,0].cpu().detach(),nrow=1)*.5+.5,
302 | "est/depth": depth,
303 | "est/depth_1ch":make_grid(model_output["depth_raw"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl).cpu(),normalize=True,nrow=nrow),
304 | }
305 |
306 | depthgt = (ground_truth["trgt_depth"] if "trgt_depth" in ground_truth else model_output["trgt_depth_inp"] if "trgt_depth_inp" in model_output
307 | else model_input["trgt_depth"] if "trgt_depth" in model_input else None)
308 |
309 | if "ctxt_rgb" in model_output:
310 | wandb_out["est/ctxt_depth"] =make_grid(model_output["ctxt_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
311 | wandb_out["est/ctxt_rgb_pred"] = ctxt_rgb_pred = make_grid(model_output["ctxt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow)
312 |
313 | if "corr_weights" in model_output:
314 | #corr_weights = make_grid(model_output["corr_weights"].flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
315 | corr_weights = make_grid(ch_fst(model_output["corr_weights"],resolution[1]).flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
316 | wandb_out["est/corr_weights"] = corr_weights
317 |
318 | if "flow_from_pose" in model_output and not torch.isnan(model_output["flow_from_pose"]).any() and not torch.isnan(model_output["flow_from_pose"]).any():
319 | #psnr = piqa.PSNR()(ch_fst(model_output["rgb"],imsl[0]).flatten(0,1).contiguous(),ch_fst(ground_truth["trgt_rgb"],imsl[0]).flatten(0,1).contiguous())
320 | #wandb.log({prefix+"metrics/psnr": psnr})
321 |
322 | gt_flow_bwd = flow_vis_torch.flow_to_color(make_grid(model_output["flow_inp"].flatten(0,1),nrow=nrow))/255
323 | wandb_out["ref/flow_gt_bwd"]=gt_flow_bwd
324 | if "flow_from_pose" in model_output:
325 | wandb_out["est/flow_est_pose"] = flow_vis_torch.flow_to_color(make_grid(model_output["flow_from_pose"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
326 | if "flow_from_pose_render" in model_output:
327 | wandb_out["est/flow_est_pose_render"] = flow_vis_torch.flow_to_color(make_grid(model_output["flow_from_pose_render"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
328 | else:
329 | print("skipping flow plotting")
330 |
331 | wandb_out = {prefix+k:wandb.Image(v.permute(1, 2, 0).float().detach().clip(0,1).cpu().numpy()) for k,v in wandb_out.items()}
332 |
333 | wandb.log(wandb_out)
334 |
335 |
336 | def pose_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
337 | # Log points and boxes in W&B
338 | point_scene = wandb.Object3D({
339 | "type": "lidar/beta",
340 | "points": model_output["poses"][:,:3,-1].cpu().numpy(),
341 | })
342 | wandb.log({"camera positions": point_scene})
343 |
344 |
345 |
346 |
--------------------------------------------------------------------------------
/wandb_logging.py:
--------------------------------------------------------------------------------
1 | import os
2 | import wandb
3 | from matplotlib import cm
4 | from torchvision.utils import make_grid
5 | import torch.nn.functional as F
6 | import numpy as np
7 | import torch
8 | import flow_vis
9 | import flow_vis_torch
10 | import matplotlib.pyplot as plt; imsave = lambda x,y=0: plt.imsave("/nobackup/users/camsmith/img/tmp%s.png"%y,x.cpu().numpy());
11 | from einops import rearrange, repeat
12 | import piqa
13 | import imageio
14 |
15 | def write_video(save_dir,frames,vid_name,step,write_frames=False):
16 | frames = [(255*x).astype(np.uint8) for x in frames]
17 | if "time" in vid_name: frames = frames + frames[::-1]
18 | f = os.path.join(save_dir, f'{vid_name}_{step}.mp4')
19 | imageio.mimwrite(f, frames, fps=8, quality=7)
20 | wandb.log({f'vid/{vid_name}':wandb.Video(f, format='mp4', fps=8)})
21 | print("writing video at",f)
22 | if write_frames:
23 | for i,img in enumerate(frames):
24 | try: os.mkdir(os.path.join(save_dir, f'{vid_name}_{step}'))
25 | except:pass
26 | f=os.path.join(save_dir, f'{vid_name}_{step}/{i}.png');plt.imsave(f,img);print(f)
27 |
28 | def normalize(a):
29 | return (a - a.min()) / (a.max() - a.min())
30 |
31 | def cvt(a):
32 | a = a.permute(1, 2, 0).detach().cpu()
33 | a = (a - a.min()) / (a.max() - a.min())
34 | a = a.numpy()
35 | return a
36 |
37 | ch_fst = lambda src,x=None:rearrange(src,"... (x y) c -> ... c x y",x=int(src.size(-2)**(.5)) if x is None else x)
38 |
39 | def _wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
40 |
41 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).shape)
42 |
43 | nrow=model_input["trgt_rgb"].size(1)
44 | imsly,imslx=model_input["ctxt_rgb"].shape[-2:]
45 |
46 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
47 |
48 | rgb_gt= ground_truth["trgt_rgb"]
49 | rgb_pred,depth,=[model_output[x] for x in ["rgb","depth"]]
50 |
51 | inv = lambda x : 1/(x+1e-3)
52 | depth = make_grid(model_output["depth"].flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)).cpu(),normalize=True,nrow=nrow)
53 |
54 | rgb_pred = make_grid(model_output["rgb"].flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)),normalize=True,nrow=nrow)
55 | rgb_gt = make_grid(ground_truth["trgt_rgb"].flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)),normalize=True,nrow=nrow)
56 | ctxt_img = make_grid(model_input["ctxt_rgb"].cpu().flatten(0,1),normalize=True,nrow=nrow)
57 |
58 | print("add psnr metric here")
59 |
60 | wandb_out = {
61 | "est/rgb_pred": rgb_pred,
62 | "ref/rgb_gt": rgb_gt,
63 | "ref/ctxt_img": ctxt_img,
64 | "est/depth": depth,
65 | }
66 | if "trgt_depth" in ground_truth:
67 | wandb_out["depthgt"]=make_grid(ground_truth["trgt_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,(imsly,imslx)).cpu(),normalize=True,nrow=nrow)
68 |
69 | for k,v in wandb_out.items(): print(k,v.max(),v.min(),v.shape)
70 | #for k,v in wandb_out.items():plt.imsave("/nobackup/users/camsmith/img/%s.png"%k,v.permute(1,2,0).detach().cpu().numpy().clip(0,1));
71 | wandb.log({"sanity/"+k+"_min":v.min() for k,v in wandb_out.items()})
72 | wandb.log({"sanity/"+k+"_max":v.max() for k,v in wandb_out.items()})
73 | wandb_out = {prefix+k:wandb.Image(v.permute(1, 2, 0).detach().clip(0,1).cpu().numpy()) for k,v in wandb_out.items()}
74 |
75 | wandb.log(wandb_out)
76 |
77 | #def dyn_wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
78 | def wandb_summary(loss, model_output, model_input, ground_truth, resolution,prefix=""):
79 |
80 | resolution = list(model_input["ctxt_rgb"].flatten(0,1).permute(0,2,3,1).shape)
81 | nrow=model_input["trgt_rgb"].size(1)
82 | imsl=model_input["ctxt_rgb"].shape[-2:]
83 | inv = lambda x : 1/(x+1e-8)
84 |
85 | depth = make_grid(model_output["depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
86 |
87 | wandb_out = {
88 | "est/rgb_pred": make_grid(model_output["rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow),
89 | "ref/rgb_gt": make_grid(ground_truth["trgt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow),
90 | "ref/ctxt_img": make_grid(model_input["ctxt_rgb"][:,0].cpu().detach(),nrow=1)*.5+.5,
91 | "est/depth": depth,
92 | "est/depth_1ch":make_grid(model_output["depth_raw"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl).cpu(),normalize=True,nrow=nrow),
93 | }
94 |
95 | depthgt = (ground_truth["trgt_depth"] if "trgt_depth" in ground_truth else model_output["trgt_depth_inp"] if "trgt_depth_inp" in model_output
96 | else model_input["trgt_depth"] if "trgt_depth" in model_input else None)
97 | if depthgt is not None:
98 | depthgt = make_grid(inv(depthgt).cpu().view(*resolution[:3]).detach().unsqueeze(1),normalize=True,nrow=nrow)
99 | wandb_out["ref/depthgt"]= depthgt
100 |
101 | if "fine_rgb" in model_output:
102 | wandb_out["est/fine_rgb_pred"] = make_grid(model_output["fine_rgb"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
103 | wandb_out["est/fine_depth_pred"] = make_grid(model_output["fine_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow,normalize=True)
104 |
105 | if "ctxt_rgb" in model_output:
106 | wandb_out["est/ctxt_depth"] =make_grid(model_output["ctxt_depth"].cpu().flatten(0,1).permute(0,2,1).unflatten(-1,imsl).detach(),nrow=nrow)
107 | wandb_out["est/ctxt_rgb_pred"] = ctxt_rgb_pred = make_grid(model_output["ctxt_rgb"].cpu().view(*resolution).detach().permute(0, -1, 1, 2),nrow=nrow)
108 |
109 | if "corr_weights" in model_output:
110 | #corr_weights = make_grid(model_output["corr_weights"].flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
111 | corr_weights = make_grid(ch_fst(model_output["corr_weights"],resolution[1]).flatten(0,1)[:,:1].cpu().detach(),normalize=False,nrow=nrow)
112 | wandb_out["est/corr_weights"] = corr_weights
113 |
114 | if "flow" in model_output and not torch.isnan(model_output["flow"]).any() and not torch.isnan(model_output["flow_from_pose"]).any():
115 | psnr = piqa.PSNR()(ch_fst(model_output["rgb"],imsl[0]).flatten(0,1).contiguous(),ch_fst(ground_truth["trgt_rgb"],imsl[0]).flatten(0,1).contiguous())
116 | wandb.log({prefix+"metrics/psnr": psnr})
117 |
118 | gt_flow_bwd = flow_vis_torch.flow_to_color(make_grid(model_output["flow_inp"].flatten(0,1),nrow=nrow))/255
119 | est_flow = flow_vis_torch.flow_to_color(make_grid(model_output["flow"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
120 | wandb_out["est/flow_est"]= est_flow
121 | wandb_out["ref/flow_gt_bwd"]=gt_flow_bwd
122 | if "flow_from_pose" in model_output:
123 | wandb_out["est/flow_est_pose"] = flow_vis_torch.flow_to_color(make_grid(model_output["flow_from_pose"].flatten(0,1).permute(0,2,1).unflatten(-1,imsl),nrow=nrow))/255
124 | elif "flow" in model_output:
125 | print("skipping nan flow")
126 | for k,v in wandb_out.items(): print(k,v.max(),v.min())
127 | #for k,v in wandb_out.items():plt.imsave("/nobackup/users/camsmith/img/%s.png"%k,v.permute(1,2,0).detach().cpu().numpy().clip(0,1));
128 | #zz
129 | #wandb.log({"sanity/"+k+"_min":v.min() for k,v in wandb_out.items()})
130 | #wandb.log({"sanity/"+k+"_max":v.max() for k,v in wandb_out.items()})
131 | #for k,v in wandb_out.items(): print(v.shape)
132 | wandb_out = {prefix+k:wandb.Image(v.permute(1, 2, 0).float().detach().clip(0,1).cpu().numpy()) for k,v in wandb_out.items()}
133 |
134 | wandb.log(wandb_out)
135 |
--------------------------------------------------------------------------------