├── LICENSE.txt
├── README.md
├── assets
├── model_classic.png
└── model_rubi.png
├── requirements.txt
├── rubi
├── __init__.py
├── __version__.py
├── compare_vqa2_rubi_val.py
├── compare_vqa2_val.py
├── compare_vqacp2_rubi.py
├── datasets
│ ├── __init__.py
│ ├── factory.py
│ ├── scripts
│ │ ├── download_vqa2.sh
│ │ └── download_vqacp2.sh
│ ├── vqa2.py
│ └── vqacp2.py
├── models
│ ├── criterions
│ │ ├── __init__.py
│ │ ├── factory.py
│ │ └── rubi_criterion.py
│ ├── metrics
│ │ ├── __init__.py
│ │ ├── factory.py
│ │ └── vqa_rubi_metrics.py
│ └── networks
│ │ ├── __init__.py
│ │ ├── baseline_net.py
│ │ ├── factory.py
│ │ ├── rubi.py
│ │ └── utils.py
├── optimizers
│ ├── __init__.py
│ └── factory.py
└── options
│ ├── vqa2
│ ├── baseline.yaml
│ └── rubi.yaml
│ └── vqacp2
│ ├── baseline.yaml
│ └── rubi.yaml
├── setup.cfg
└── setup.py
/LICENSE.txt:
--------------------------------------------------------------------------------
1 | BSD 3-Clause License
2 |
3 | Copyright (c) 2019+, Remi Cadene, Corentin Dancette
4 | All rights reserved.
5 |
6 | Redistribution and use in source and binary forms, with or without
7 | modification, are permitted provided that the following conditions are met:
8 |
9 | * Redistributions of source code must retain the above copyright notice, this
10 | list of conditions and the following disclaimer.
11 |
12 | * Redistributions in binary form must reproduce the above copyright notice,
13 | this list of conditions and the following disclaimer in the documentation
14 | and/or other materials provided with the distribution.
15 |
16 | * Neither the name of the copyright holder nor the names of its
17 | contributors may be used to endorse or promote products derived from
18 | this software without specific prior written permission.
19 |
20 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 | AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 | IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 | DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 | FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 | DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 | SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 | CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 | OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 | OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # RUBi : Reducing Unimodal Biases for Visual Question Answering
2 |
3 | This is the code for the NeurIPS 2019 article available here: https://arxiv.org/abs/1906.10169.
4 |
5 | This paper was written by [Rémi Cadene](http://www.remicadene.com/), [Corentin Dancette](https://cdancette.fr), Hedi Ben Younes, [Matthieu Cord](http://webia.lip6.fr/~cord/) and [Devi Parikh](https://www.cc.gatech.edu/~parikh/).
6 |
7 |
8 | **RUBi** is a learning strategy to reduce biases in VQA models.
9 | It relies on a question-only branch plugged at the end of a VQA model.
10 |
11 |
12 |
13 | 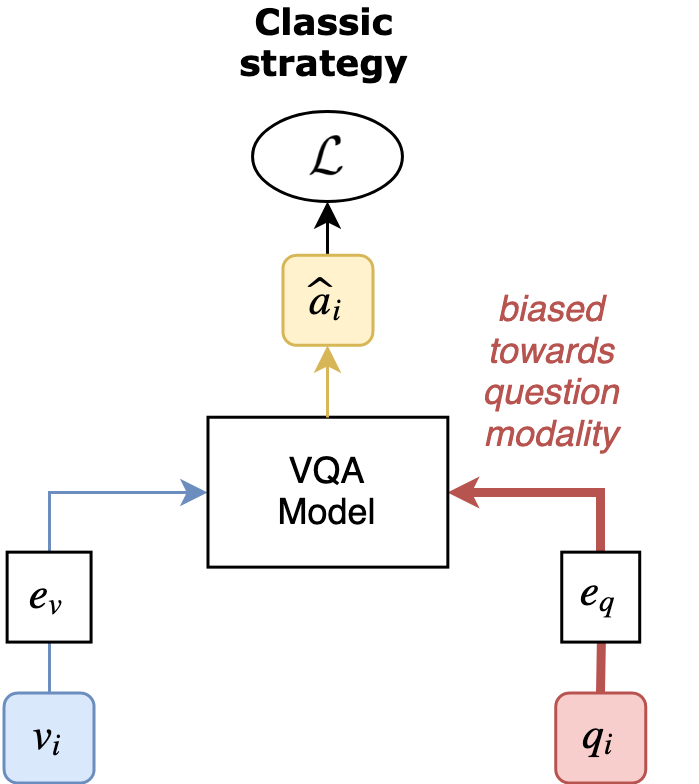 14 |
14 | 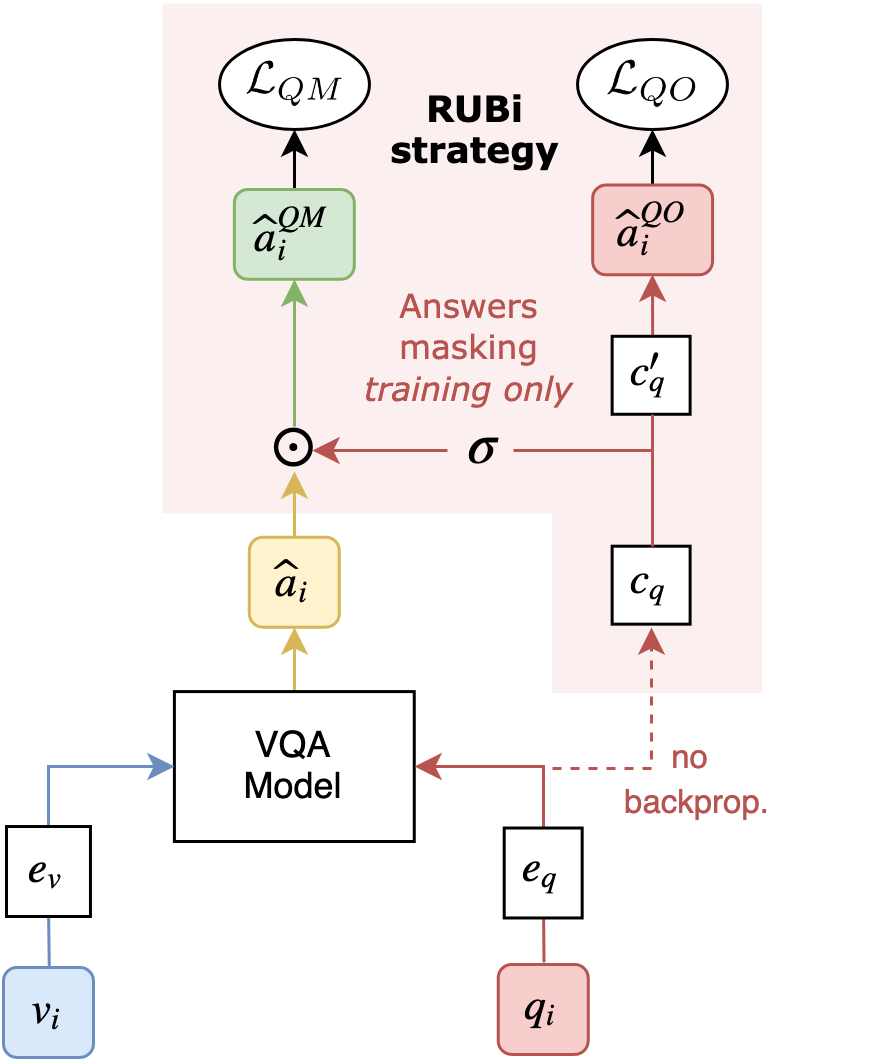 15 |
15 |
16 |
17 | #### Summary
18 |
19 | * [Installation](#installation)
20 | * [As a standalone project](#1-as-standalone-project)
21 | * [As a python library](#1-as-a-python-library)
22 | * [Download datasets](#3-download-datasets)
23 | * [Quick start](#quick-start)
24 | * [Train a model](#train-a-model)
25 | * [Evaluate a model](#evaluate-a-model)
26 | * [Reproduce results](#reproduce-results)
27 | * [VQACP2](#vqa-CP-v2-dataset)
28 | * [VQA2](#vqa-v2-dataset)
29 | * [Useful commands](#useful-commands)
30 | * [Authors](#authors)
31 | * [Acknowledgment](#acknowledgment)
32 |
33 |
34 | ## Installation
35 |
36 | We don't provide support for python 2. We advise you to install python 3 with [Anaconda](https://www.continuum.io/downloads). Then, you can create an environment.
37 |
38 | ### 1. As standalone project
39 |
40 | ```
41 | conda create --name rubi python=3.7
42 | source activate rubi
43 | git clone --recursive https://github.com/cdancette/rubi.bootstrap.pytorch.git
44 | cd rubi.bootstrap.pytorch
45 | pip install -r requirements.txt
46 | ```
47 |
48 | ### (1. As a python library)
49 |
50 | To install the library
51 | ```
52 | git clone https://github.com/cdancette/rubi.bootstrap.pytorch.git
53 | python setup.py install
54 | ```
55 |
56 | Then by importing the `rubi` python module, you can access datasets and models in a simple way.
57 |
58 | ```python
59 | from rubi.models.networks.rubi import RUBiNet
60 | ```
61 |
62 |
63 | **Note:** This repo is built on top of [block.bootstrap.pytorch](https://github.com/Cadene/block.bootstrap.pytorch). We import VQA2, TDIUC, VGenome from this library.
64 |
65 | ### 2. Download datasets
66 |
67 | Download annotations, images and features for VQA experiments:
68 | ```
69 | bash rubi/datasets/scripts/download_vqa2.sh
70 | bash rubi/datasets/scripts/download_vqacp2.sh
71 | ```
72 |
73 |
74 | ## Quick start
75 |
76 | ### The RUBi model
77 |
78 | The main model is RUBi.
79 |
80 | ```python
81 | from rubi.models.networks.rubi import RUBiNet
82 | ```
83 |
84 | RUBi takes as input another VQA model, adds a question branch around it. The question predictions are merged with the original predictions.
85 | RUBi returns the new predictions that are used to train the VQA model.
86 |
87 | For an example base model, you can check the [baseline model](https://github.com/cdancette/rubi.pytorch/blob/master/rubi/models/networks/baseline_net.py). The model must return the raw predictions (before softmax) in a dictionnary, with the key `logits`.
88 |
89 |
90 | ### Train a model
91 |
92 | The [boostrap/run.py](https://github.com/Cadene/bootstrap.pytorch/blob/master/bootstrap/run.py) file load the options contained in a yaml file, create the corresponding experiment directory and start the training procedure. For instance, you can train our best model on VQA2 by running:
93 | ```
94 | python -m bootstrap.run -o rubi/options/vqacp2/rubi.yaml
95 | ```
96 | Then, several files are going to be created in `logs/vqa2/rubi`:
97 | - [options.yaml](https://github.com/Cadene/block.bootstrap.pytorch/blob/master/assets/logs/vrd/block/options.yaml) (copy of options)
98 | - [logs.txt](https://github.com/Cadene/block.bootstrap.pytorch/blob/master/assets/logs/vrd/block/logs.txt) (history of print)
99 | - [logs.json](https://github.com/Cadene/block.bootstrap.pytorch/blob/master/assets/logs/vrd/block/logs.json) (batchs and epochs statistics)
100 | - [view.html](http://htmlpreview.github.io/?https://raw.githubusercontent.com/Cadene/block.bootstrap.pytorch/master/assets/logs/vrd/block/view.html?token=AEdvLlDSYaSn3Hsr7gO5sDBxeyuKNQhEks5cTF6-wA%3D%3D) (learning curves)
101 | - ckpt_last_engine.pth.tar (checkpoints of last epoch)
102 | - ckpt_last_model.pth.tar
103 | - ckpt_last_optimizer.pth.tar
104 | - ckpt_best_eval_epoch.accuracy_top1_engine.pth.tar (checkpoints of best epoch)
105 | - ckpt_best_eval_epoch.accuracy_top1_model.pth.tar
106 | - ckpt_best_eval_epoch.accuracy_top1_optimizer.pth.tar
107 |
108 | Many options are available in the [options directory](https://github.com/cdancette/rubi.bootstrap.pytorch/blob/master/rubi/options).
109 |
110 | ### Evaluate a model
111 |
112 | There is no testing set on VQA-CP v2, our main dataset. The evaluation is done on the validation set.
113 |
114 | For a model trained on VQA v2, you can evaluate your model on the testing set. In this example, [boostrap/run.py](https://github.com/Cadene/bootstrap.pytorch/blob/master/bootstrap/run.py) load the options from your experiment directory, resume the best checkpoint on the validation set and start an evaluation on the testing set instead of the validation set while skipping the training set (train_split is empty). Thanks to `--misc.logs_name`, the logs will be written in the new `logs_predicate.txt` and `logs_predicate.json` files, instead of being appended to the `logs.txt` and `logs.json` files.
115 | ```
116 | python -m bootstrap.run \
117 | -o logs/vqa2/rubi/baseline.yaml \
118 | --exp.resume best_accuracy_top1 \
119 | --dataset.train_split \
120 | --dataset.eval_split test \
121 | --misc.logs_name test
122 | ```
123 |
124 |
125 | ## Reproduce results
126 |
127 | ### VQA-CP v2 dataset
128 |
129 | Use this simple setup to reproduce our results on the valset of VQA-CP v2.
130 |
131 | Baseline:
132 |
133 | ```bash
134 | python -m bootstrap.run \
135 | -o rubi/options/vqacp2/baseline.yaml \
136 | --exp.dir logs/vqacp2/baseline
137 | ```
138 |
139 | RUBi :
140 |
141 | ```bash
142 | python -m bootstrap.run \
143 | -o rubi/options/vqacp2/rubi.yaml \
144 | --exp.dir logs/vqacp2/rubi
145 | ```
146 |
147 | #### Compare experiments on valset
148 |
149 | You can compare experiments by displaying their best metrics on the valset.
150 |
151 | ```
152 | python -m rubi.compare_vqacp2_rubi -d logs/vqacp2/rubi logs/vqacp2/baseline
153 | ```
154 |
155 | ### VQA v2 dataset
156 |
157 | Baseline:
158 |
159 | ```bash
160 | python -m bootstrap.run \
161 | -o rubi/options/vqa2/baseline.yaml \
162 | --exp.dir logs/vqa2/baseline
163 | ```
164 |
165 | RUBi :
166 |
167 | ```bash
168 | python -m bootstrap.run \
169 | -o rubi/options/vqa2/rubi.yaml \
170 | --exp.dir logs/vqa2/rubi
171 | ```
172 |
173 |
174 | You can compare experiments by displaying their best metrics on the valset.
175 |
176 | ```
177 | python -m rubi.compare_vqa2_rubi_val -d logs/vqa2/rubi logs/vqa2/baseline
178 | ```
179 |
180 | #### Evaluation on test set
181 |
182 | ```bash
183 | python -m bootstrap.run \
184 | -o logs/vqa2/rubi/options.yaml \
185 | --exp.resume best_eval_epoch.accuracy_top1 \
186 | --dataset.train_split '' \
187 | --dataset.eval_split test \
188 | --misc.logs_name test
189 | ```
190 |
191 | ## Weights of best model
192 |
193 |
194 | The weights for the model trained on VQA-CP v2 can be downloaded here : http://webia.lip6.fr/~cadene/rubi/ckpt_last_model.pth.tar
195 |
196 | To use it :
197 | * Run this command once to create the experiment folder. Cancel it when the training starts
198 |
199 | ```bash
200 | python -m bootstrap.run \
201 | -o rubi/options/vqacp2/rubi.yaml \
202 | --exp.dir logs/vqacp2/rubi
203 | ```
204 |
205 | * Move the downloaded file to the experiment folder, and use the flag `--exp.resume last` to use this checkpoint :
206 |
207 | ```bash
208 | python -m bootstrap.run \
209 | -o logs/vqacp2/rubi/options.yaml \
210 | --exp.resume last
211 | ```
212 |
213 |
214 | ## Useful commands
215 |
216 | ### Use tensorboard instead of plotly
217 |
218 | Instead of creating a `view.html` file, a tensorboard file will be created:
219 | ```
220 | python -m bootstrap.run -o rubi/options/vqacp2/rubi.yaml \
221 | --view.name tensorboard
222 | ```
223 |
224 | ```
225 | tensorboard --logdir=logs/vqa2
226 | ```
227 |
228 | You can use plotly and tensorboard at the same time by updating the yaml file like [this one](https://github.com/Cadene/bootstrap.pytorch/blob/master/bootstrap/options/mnist_plotly_tensorboard.yaml#L38).
229 |
230 |
231 | ### Use a specific GPU
232 |
233 | For a specific experiment:
234 | ```
235 | CUDA_VISIBLE_DEVICES=0 python -m boostrap.run -o rubi/options/vqacp2/rubi.yaml
236 | ```
237 |
238 | For the current terminal session:
239 | ```
240 | export CUDA_VISIBLE_DEVICES=0
241 | ```
242 |
243 | ### Overwrite an option
244 |
245 | The boostrap.pytorch framework makes it easy to overwrite a hyperparameter. In this example, we run an experiment with a non-default learning rate. Thus, I also overwrite the experiment directory path:
246 | ```
247 | python -m bootstrap.run -o rubi/options/vqacp2/rubi.yaml \
248 | --optimizer.lr 0.0003 \
249 | --exp.dir logs/vqacp2/rubi_lr,0.0003
250 | ```
251 |
252 | ### Resume training
253 |
254 | If a problem occurs, it is easy to resume the last epoch by specifying the options file from the experiment directory while overwritting the `exp.resume` option (default is None):
255 | ```
256 | python -m bootstrap.run -o logs/vqacp2/rubi/options.yaml \
257 | --exp.resume last
258 | ```
259 |
260 | ## Cite
261 |
262 | ```
263 | @article{cadene2019rubi,
264 | title={RUBi: Reducing Unimodal Biases for Visual Question Answering},
265 | author={Cadene, Remi and Dancette, Corentin and Cord, Matthieu and Parikh, Devi and others},
266 | journal={Advances in Neural Information Processing Systems},
267 | volume={32},
268 | pages={841--852},
269 | year={2019}
270 | }
271 | ```
272 |
273 | ## Authors
274 |
275 | This code was made available by [Corentin Dancette](https://cdancette.fr) and [Rémi Cadene](http://www.remicadene.com/)
276 |
277 | ## Acknowledgment
278 |
279 | Special thanks to the authors of [VQA2](TODO), [TDIUC](TODO), [VisualGenome](TODO) and [VQACP2](TODO), the datasets used in this research project.
280 |
281 |
282 |
--------------------------------------------------------------------------------
/assets/model_classic.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cdancette/rubi.bootstrap.pytorch/36180e51e4692424d6f6ed284a40a01c6fb97104/assets/model_classic.png
--------------------------------------------------------------------------------
/assets/model_rubi.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cdancette/rubi.bootstrap.pytorch/36180e51e4692424d6f6ed284a40a01c6fb97104/assets/model_rubi.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | block.bootstrap.pytorch
2 | h5py
3 |
--------------------------------------------------------------------------------
/rubi/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cdancette/rubi.bootstrap.pytorch/36180e51e4692424d6f6ed284a40a01c6fb97104/rubi/__init__.py
--------------------------------------------------------------------------------
/rubi/__version__.py:
--------------------------------------------------------------------------------
1 | __version__ = '0.0.0'
2 |
--------------------------------------------------------------------------------
/rubi/compare_vqa2_rubi_val.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from bootstrap.compare import main
3 |
4 | if __name__ == '__main__':
5 | parser = argparse.ArgumentParser(description='')
6 | parser.add_argument('-n', '--nb_epochs', default=-1, type=int)
7 | parser.add_argument('-d', '--dir_logs', default='', type=str, nargs='*')
8 | parser.add_argument('-m', '--metrics', type=str, action='append', nargs=3,
9 | metavar=('json', 'name', 'order'),
10 | default=[['logs', 'eval_epoch.accuracy_top1', 'max'],
11 | ['logs', 'eval_epoch.loss', 'min'],
12 | ['logs', 'eval_epoch.loss', 'min'],
13 | ['logs', 'eval_epoch.loss', 'min'],
14 | ['logs', 'eval_epoch.loss', 'min'],
15 | ['logs', 'eval_epoch.loss', 'min'],
16 | ['logs', 'eval_epoch.loss', 'min'],
17 | ['logs_val_oe', 'eval_epoch.overall', 'max'],
18 | ['logs_val_oe', 'eval_epoch.overall', 'max'],
19 | ['logs_q_val_oe', 'eval_epoch.overall', 'max'],
20 | ['logs_v_val_oe', 'eval_epoch.overall', 'max'],
21 | ['logs_mm_val_oe', 'eval_epoch.overall', 'max'],
22 | ['logs_mm_v_val_oe', 'eval_epoch.overall', 'max'],
23 | ['logs_mm_q_val_oe', 'eval_epoch.overall', 'max'],
24 | ['logs_mm_v_q_val_oe', 'eval_epoch.overall', 'max'],
25 | ])
26 | parser.add_argument('-b', '--best', type=str, nargs=3,
27 | metavar=('json', 'name', 'order'),
28 | default=None)
29 | args = parser.parse_args()
30 | main(args)
31 |
--------------------------------------------------------------------------------
/rubi/compare_vqa2_val.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from bootstrap.compare import main
3 |
4 | if __name__ == '__main__':
5 | parser = argparse.ArgumentParser(description='')
6 | parser.add_argument('-n', '--nb_epochs', default=-1, type=int)
7 | parser.add_argument('-d', '--dir_logs', default='', type=str, nargs='*')
8 | parser.add_argument('-m', '--metrics', type=str, action='append', nargs=3,
9 | metavar=('json', 'name', 'order'),
10 | default=[['logs', 'eval_epoch.accuracy_top1', 'max'],
11 | ['logs_val_oe', 'eval_epoch.overall', 'max'],
12 | ['logs', 'eval_epoch.loss', 'min']])
13 | parser.add_argument('-b', '--best', type=str, nargs=3,
14 | metavar=('json', 'name', 'order'),
15 | default=['logs', 'eval_epoch.accuracy_top1', 'max'])
16 | args = parser.parse_args()
17 | main(args)
18 |
--------------------------------------------------------------------------------
/rubi/compare_vqacp2_rubi.py:
--------------------------------------------------------------------------------
1 | import argparse
2 | from bootstrap.compare import main
3 |
4 | if __name__ == '__main__':
5 | parser = argparse.ArgumentParser(description='')
6 | parser.add_argument('-n', '--nb_epochs', default=-1, type=int)
7 | parser.add_argument('-d', '--dir_logs', default='', type=str, nargs='*')
8 | parser.add_argument('-m', '--metrics', type=str, action='append', nargs=3,
9 | metavar=('json', 'name', 'order'),
10 | default=[
11 | ['logs', 'eval_epoch.accuracy_top1', 'max'],
12 | # overall
13 | ['logs_val_oe', 'eval_epoch.overall', 'max'],
14 | ['logs_rubi_val_oe', 'eval_epoch.overall', 'max'],
15 | ['logs_q_val_oe', 'eval_epoch.overall', 'max'],
16 | # question type
17 | ['logs_val_oe', 'eval_epoch.perAnswerType.yes/no', 'max'],
18 | ['logs_val_oe', 'eval_epoch.perAnswerType.number', 'max'],
19 | ['logs_val_oe', 'eval_epoch.perAnswerType.other', 'max'],
20 | ['logs_rubi_val_oe', 'eval_epoch.perAnswerType.yes/no', 'max'],
21 | ['logs_rubi_val_oe', 'eval_epoch.perAnswerType.number', 'max'],
22 | ['logs_rubi_val_oe', 'eval_epoch.perAnswerType.other', 'max'],
23 | ['logs_q_val_oe', 'eval_epoch.perAnswerType.yes/no', 'max'],
24 | ['logs_q_val_oe', 'eval_epoch.perAnswerType.number', 'max'],
25 | ['logs_q_val_oe', 'eval_epoch.perAnswerType.other', 'max'],
26 | ])
27 | parser.add_argument('-b', '--best', type=str, nargs=3,
28 | metavar=('json', 'name', 'order'),
29 | default=['logs_val_oe', 'eval_epoch.overall', 'max'])
30 | args = parser.parse_args()
31 | main(args)
32 |
--------------------------------------------------------------------------------
/rubi/datasets/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cdancette/rubi.bootstrap.pytorch/36180e51e4692424d6f6ed284a40a01c6fb97104/rubi/datasets/__init__.py
--------------------------------------------------------------------------------
/rubi/datasets/factory.py:
--------------------------------------------------------------------------------
1 | from bootstrap.lib.options import Options
2 | from block.datasets.tdiuc import TDIUC
3 | from block.datasets.vrd import VRD
4 | from block.datasets.vg import VG
5 | from block.datasets.vqa_utils import ListVQADatasets
6 | from .vqa2 import VQA2
7 | from .vqacp2 import VQACP2
8 |
9 | def factory(engine=None):
10 | opt = Options()['dataset']
11 |
12 | dataset = {}
13 | if opt.get('train_split', None):
14 | dataset['train'] = factory_split(opt['train_split'])
15 | if opt.get('eval_split', None):
16 | dataset['eval'] = factory_split(opt['eval_split'])
17 |
18 | return dataset
19 |
20 | def factory_split(split):
21 | opt = Options()['dataset']
22 | shuffle = ('train' in split)
23 |
24 | if opt['name'] == 'vqacp2':
25 | assert(split in ['train', 'val', 'test'])
26 | samplingans = (opt['samplingans'] and split == 'train')
27 |
28 | dataset = VQACP2(
29 | dir_data=opt['dir'],
30 | split=split,
31 | batch_size=opt['batch_size'],
32 | nb_threads=opt['nb_threads'],
33 | pin_memory=Options()['misc']['cuda'],
34 | shuffle=shuffle,
35 | nans=opt['nans'],
36 | minwcount=opt['minwcount'],
37 | nlp=opt['nlp'],
38 | proc_split=opt['proc_split'],
39 | samplingans=samplingans,
40 | dir_rcnn=opt['dir_rcnn'],
41 | dir_cnn=opt.get('dir_cnn', None),
42 | dir_vgg16=opt.get('dir_vgg16', None),
43 | )
44 |
45 | elif opt['name'] == 'vqacpv2-with-testdev':
46 | assert(split in ['train', 'val', 'test'])
47 | samplingans = (opt['samplingans'] and split == 'train')
48 | dataset = VQACP2(
49 | dir_data=opt['dir'],
50 | split=split,
51 | batch_size=opt['batch_size'],
52 | nb_threads=opt['nb_threads'],
53 | pin_memory=Options()['misc']['cuda'],
54 | shuffle=shuffle,
55 | nans=opt['nans'],
56 | minwcount=opt['minwcount'],
57 | nlp=opt['nlp'],
58 | proc_split=opt['proc_split'],
59 | samplingans=samplingans,
60 | dir_rcnn=opt['dir_rcnn'],
61 | dir_cnn=opt.get('dir_cnn', None),
62 | dir_vgg16=opt.get('dir_vgg16', None),
63 | has_testdevset=True,
64 | )
65 |
66 | elif opt['name'] == 'vqa2':
67 | assert(split in ['train', 'val', 'test'])
68 | samplingans = (opt['samplingans'] and split == 'train')
69 |
70 | if opt['vg']:
71 | assert(opt['proc_split'] == 'trainval')
72 |
73 | # trainvalset
74 | vqa2 = VQA2(
75 | dir_data=opt['dir'],
76 | split='train',
77 | nans=opt['nans'],
78 | minwcount=opt['minwcount'],
79 | nlp=opt['nlp'],
80 | proc_split=opt['proc_split'],
81 | samplingans=samplingans,
82 | dir_rcnn=opt['dir_rcnn'])
83 |
84 | vg = VG(
85 | dir_data=opt['dir_vg'],
86 | split='train',
87 | nans=10000,
88 | minwcount=0,
89 | nlp=opt['nlp'],
90 | dir_rcnn=opt['dir_rcnn_vg'])
91 |
92 | vqa2vg = ListVQADatasets(
93 | [vqa2,vg],
94 | split='train',
95 | batch_size=opt['batch_size'],
96 | nb_threads=opt['nb_threads'],
97 | pin_memory=Options()['misc.cuda'],
98 | shuffle=shuffle)
99 |
100 | if split == 'train':
101 | dataset = vqa2vg
102 | else:
103 | dataset = VQA2(
104 | dir_data=opt['dir'],
105 | split=split,
106 | batch_size=opt['batch_size'],
107 | nb_threads=opt['nb_threads'],
108 | pin_memory=Options()['misc.cuda'],
109 | shuffle=False,
110 | nans=opt['nans'],
111 | minwcount=opt['minwcount'],
112 | nlp=opt['nlp'],
113 | proc_split=opt['proc_split'],
114 | samplingans=samplingans,
115 | dir_rcnn=opt['dir_rcnn'])
116 | dataset.sync_from(vqa2vg)
117 |
118 | else:
119 | dataset = VQA2(
120 | dir_data=opt['dir'],
121 | split=split,
122 | batch_size=opt['batch_size'],
123 | nb_threads=opt['nb_threads'],
124 | pin_memory=Options()['misc.cuda'],
125 | shuffle=shuffle,
126 | nans=opt['nans'],
127 | minwcount=opt['minwcount'],
128 | nlp=opt['nlp'],
129 | proc_split=opt['proc_split'],
130 | samplingans=samplingans,
131 | dir_rcnn=opt['dir_rcnn'],
132 | dir_cnn=opt.get('dir_cnn', None),
133 | )
134 |
135 | return dataset
136 |
--------------------------------------------------------------------------------
/rubi/datasets/scripts/download_vqa2.sh:
--------------------------------------------------------------------------------
1 | mkdir -p data/vqa
2 | cd data/vqa
3 | wget http://data.lip6.fr/cadene/block/vqa2.tar.gz
4 | wget http://data.lip6.fr/cadene/block/coco.tar.gz
5 | tar -xzvf vqa2.tar.gz
6 | tar -xzvf coco.tar.gz
7 |
8 | mkdir -p data/vqa/coco/extract_rcnn
9 | cd data/vqa/coco/extract_rcnn
10 | wget http://data.lip6.fr/cadene/block/coco/extract_rcnn/2018-04-27_bottom-up-attention_fixed_36.tar
11 | tar -xvf 2018-04-27_bottom-up-attention_fixed_36.tar
12 |
--------------------------------------------------------------------------------
/rubi/datasets/scripts/download_vqacp2.sh:
--------------------------------------------------------------------------------
1 | mkdir -p data/vqa
2 | cd data/vqa
3 | wget http://data.lip6.fr/cadene/murel/vqacp2.tar.gz
4 | tar -xzvf vqacp2.tar.gz
5 |
--------------------------------------------------------------------------------
/rubi/datasets/vqa2.py:
--------------------------------------------------------------------------------
1 | import os
2 | import csv
3 | import copy
4 | import json
5 | import torch
6 | import numpy as np
7 | from os import path as osp
8 | from bootstrap.lib.logger import Logger
9 | from bootstrap.lib.options import Options
10 | from block.datasets.vqa_utils import AbstractVQA
11 | from copy import deepcopy
12 | import random
13 | import tqdm
14 | import h5py
15 |
16 | class VQA2(AbstractVQA):
17 |
18 | def __init__(self,
19 | dir_data='data/vqa2',
20 | split='train',
21 | batch_size=10,
22 | nb_threads=4,
23 | pin_memory=False,
24 | shuffle=False,
25 | nans=1000,
26 | minwcount=10,
27 | nlp='mcb',
28 | proc_split='train',
29 | samplingans=False,
30 | dir_rcnn='data/coco/extract_rcnn',
31 | adversarial=False,
32 | dir_cnn=None
33 | ):
34 |
35 | super(VQA2, self).__init__(
36 | dir_data=dir_data,
37 | split=split,
38 | batch_size=batch_size,
39 | nb_threads=nb_threads,
40 | pin_memory=pin_memory,
41 | shuffle=shuffle,
42 | nans=nans,
43 | minwcount=minwcount,
44 | nlp=nlp,
45 | proc_split=proc_split,
46 | samplingans=samplingans,
47 | has_valset=True,
48 | has_testset=True,
49 | has_answers_occurence=True,
50 | do_tokenize_answers=False)
51 |
52 | self.dir_rcnn = dir_rcnn
53 | self.dir_cnn = dir_cnn
54 | self.load_image_features()
55 | # to activate manually in visualization context (notebo# to activate manually in visualization context (notebook)
56 | self.load_original_annotation = False
57 |
58 | def add_rcnn_to_item(self, item):
59 | path_rcnn = os.path.join(self.dir_rcnn, '{}.pth'.format(item['image_name']))
60 | item_rcnn = torch.load(path_rcnn)
61 | item['visual'] = item_rcnn['pooled_feat']
62 | item['coord'] = item_rcnn['rois']
63 | item['norm_coord'] = item_rcnn.get('norm_rois', None)
64 | item['nb_regions'] = item['visual'].size(0)
65 | return item
66 |
67 | def add_cnn_to_item(self, item):
68 | image_name = item['image_name']
69 | if image_name in self.image_names_to_index_train:
70 | index = self.image_names_to_index_train[image_name]
71 | image = torch.tensor(self.image_features_train['att'][index])
72 | elif image_name in self.image_names_to_index_val:
73 | index = self.image_names_to_index_val[image_name]
74 | image = torch.tensor(self.image_features_val['att'][index])
75 | image = image.permute(1, 2, 0).view(196, 2048)
76 | item['visual'] = image
77 | return item
78 |
79 | def load_image_features(self):
80 | if self.dir_cnn:
81 | filename_train = os.path.join(self.dir_cnn, 'trainset.hdf5')
82 | filename_val = os.path.join(self.dir_cnn, 'valset.hdf5')
83 | Logger()(f"Opening file {filename_train}, {filename_val}")
84 | self.image_features_train = h5py.File(filename_train, 'r', swmr=True)
85 | self.image_features_val = h5py.File(filename_val, 'r', swmr=True)
86 | # load txt
87 | with open(os.path.join(self.dir_cnn, 'trainset.txt'.format(self.split)), 'r') as f:
88 | self.image_names_to_index_train = {}
89 | for i, line in enumerate(f):
90 | self.image_names_to_index_train[line.strip()] = i
91 | with open(os.path.join(self.dir_cnn, 'valset.txt'.format(self.split)), 'r') as f:
92 | self.image_names_to_index_val = {}
93 | for i, line in enumerate(f):
94 | self.image_names_to_index_val[line.strip()] = i
95 |
96 | def __getitem__(self, index):
97 | item = {}
98 | item['index'] = index
99 |
100 | # Process Question (word token)
101 | question = self.dataset['questions'][index]
102 | if self.load_original_annotation:
103 | item['original_question'] = question
104 |
105 | item['question_id'] = question['question_id']
106 |
107 | item['question'] = torch.tensor(question['question_wids'], dtype=torch.long)
108 | item['lengths'] = torch.tensor([len(question['question_wids'])], dtype=torch.long)
109 | item['image_name'] = question['image_name']
110 |
111 | # Process Object, Attribut and Relational features
112 | # Process Object, Attribut and Relational features
113 | if self.dir_rcnn:
114 | item = self.add_rcnn_to_item(item)
115 | elif self.dir_cnn:
116 | item = self.add_cnn_to_item(item)
117 |
118 | # Process Answer if exists
119 | if 'annotations' in self.dataset:
120 | annotation = self.dataset['annotations'][index]
121 | if self.load_original_annotation:
122 | item['original_annotation'] = annotation
123 | if 'train' in self.split and self.samplingans:
124 | proba = annotation['answers_count']
125 | proba = proba / np.sum(proba)
126 | item['answer_id'] = int(np.random.choice(annotation['answers_id'], p=proba))
127 | else:
128 | item['answer_id'] = annotation['answer_id']
129 | item['class_id'] = torch.tensor([item['answer_id']], dtype=torch.long)
130 | item['answer'] = annotation['answer']
131 | item['question_type'] = annotation['question_type']
132 | else:
133 | if item['question_id'] in self.is_qid_testdev:
134 | item['is_testdev'] = True
135 | else:
136 | item['is_testdev'] = False
137 |
138 | # if Options()['model.network.name'] == 'xmn_net':
139 | # num_feat = 36
140 | # relation_mask = np.zeros((num_feat, num_feat))
141 | # boxes = item['coord']
142 | # for i in range(num_feat):
143 | # for j in range(i+1, num_feat):
144 | # # if there is no overlap between two bounding box
145 | # if boxes[0,i]>boxes[2,j] or boxes[0,j]>boxes[2,i] or boxes[1,i]>boxes[3,j] or boxes[1,j]>boxes[3,i]:
146 | # pass
147 | # else:
148 | # relation_mask[i,j] = relation_mask[j,i] = 1
149 | # relation_mask = torch.from_numpy(relation_mask).byte()
150 | # item['relation_mask'] = relation_mask
151 |
152 | return item
153 |
154 | def download(self):
155 | dir_zip = osp.join(self.dir_raw, 'zip')
156 | os.system('mkdir -p '+dir_zip)
157 | dir_ann = osp.join(self.dir_raw, 'annotations')
158 | os.system('mkdir -p '+dir_ann)
159 | os.system('wget http://visualqa.org/data/mscoco/vqa/v2_Questions_Train_mscoco.zip -P '+dir_zip)
160 | os.system('wget http://visualqa.org/data/mscoco/vqa/v2_Questions_Val_mscoco.zip -P '+dir_zip)
161 | os.system('wget http://visualqa.org/data/mscoco/vqa/v2_Questions_Test_mscoco.zip -P '+dir_zip)
162 | os.system('wget http://visualqa.org/data/mscoco/vqa/v2_Annotations_Train_mscoco.zip -P '+dir_zip)
163 | os.system('wget http://visualqa.org/data/mscoco/vqa/v2_Annotations_Val_mscoco.zip -P '+dir_zip)
164 | os.system('unzip '+osp.join(dir_zip, 'v2_Questions_Train_mscoco.zip')+' -d '+dir_ann)
165 | os.system('unzip '+osp.join(dir_zip, 'v2_Questions_Val_mscoco.zip')+' -d '+dir_ann)
166 | os.system('unzip '+osp.join(dir_zip, 'v2_Questions_Test_mscoco.zip')+' -d '+dir_ann)
167 | os.system('unzip '+osp.join(dir_zip, 'v2_Annotations_Train_mscoco.zip')+' -d '+dir_ann)
168 | os.system('unzip '+osp.join(dir_zip, 'v2_Annotations_Val_mscoco.zip')+' -d '+dir_ann)
169 | os.system('mv '+osp.join(dir_ann, 'v2_mscoco_train2014_annotations.json')+' '
170 | +osp.join(dir_ann, 'mscoco_train2014_annotations.json'))
171 | os.system('mv '+osp.join(dir_ann, 'v2_mscoco_val2014_annotations.json')+' '
172 | +osp.join(dir_ann, 'mscoco_val2014_annotations.json'))
173 | os.system('mv '+osp.join(dir_ann, 'v2_OpenEnded_mscoco_train2014_questions.json')+' '
174 | +osp.join(dir_ann, 'OpenEnded_mscoco_train2014_questions.json'))
175 | os.system('mv '+osp.join(dir_ann, 'v2_OpenEnded_mscoco_val2014_questions.json')+' '
176 | +osp.join(dir_ann, 'OpenEnded_mscoco_val2014_questions.json'))
177 | os.system('mv '+osp.join(dir_ann, 'v2_OpenEnded_mscoco_test2015_questions.json')+' '
178 | +osp.join(dir_ann, 'OpenEnded_mscoco_test2015_questions.json'))
179 | os.system('mv '+osp.join(dir_ann, 'v2_OpenEnded_mscoco_test-dev2015_questions.json')+' '
180 | +osp.join(dir_ann, 'OpenEnded_mscoco_test-dev2015_questions.json'))
181 |
--------------------------------------------------------------------------------
/rubi/datasets/vqacp2.py:
--------------------------------------------------------------------------------
1 | import os
2 | import csv
3 | import copy
4 | import json
5 | import torch
6 | import numpy as np
7 | from tqdm import tqdm
8 | from os import path as osp
9 | from bootstrap.lib.logger import Logger
10 | from block.datasets.vqa_utils import AbstractVQA
11 | from copy import deepcopy
12 | import random
13 | import h5py
14 |
15 | class VQACP2(AbstractVQA):
16 |
17 | def __init__(self,
18 | dir_data='data/vqa/vqacp2',
19 | split='train',
20 | batch_size=80,
21 | nb_threads=4,
22 | pin_memory=False,
23 | shuffle=False,
24 | nans=1000,
25 | minwcount=10,
26 | nlp='mcb',
27 | proc_split='train',
28 | samplingans=False,
29 | dir_rcnn='data/coco/extract_rcnn',
30 | dir_cnn=None,
31 | dir_vgg16=None,
32 | has_testdevset=False,
33 | ):
34 | super(VQACP2, self).__init__(
35 | dir_data=dir_data,
36 | split=split,
37 | batch_size=batch_size,
38 | nb_threads=nb_threads,
39 | pin_memory=pin_memory,
40 | shuffle=shuffle,
41 | nans=nans,
42 | minwcount=minwcount,
43 | nlp=nlp,
44 | proc_split=proc_split,
45 | samplingans=samplingans,
46 | has_valset=True,
47 | has_testset=False,
48 | has_testdevset=has_testdevset,
49 | has_testset_anno=False,
50 | has_answers_occurence=True,
51 | do_tokenize_answers=False)
52 | self.dir_rcnn = dir_rcnn
53 | self.dir_cnn = dir_cnn
54 | self.dir_vgg16 = dir_vgg16
55 | self.load_image_features()
56 | self.load_original_annotation = False
57 |
58 | def add_rcnn_to_item(self, item):
59 | path_rcnn = os.path.join(self.dir_rcnn, '{}.pth'.format(item['image_name']))
60 | item_rcnn = torch.load(path_rcnn)
61 | item['visual'] = item_rcnn['pooled_feat']
62 | item['coord'] = item_rcnn['rois']
63 | item['norm_coord'] = item_rcnn['norm_rois']
64 | item['nb_regions'] = item['visual'].size(0)
65 | return item
66 |
67 | def load_image_features(self):
68 | if self.dir_cnn:
69 | filename_train = os.path.join(self.dir_cnn, 'trainset.hdf5')
70 | filename_val = os.path.join(self.dir_cnn, 'valset.hdf5')
71 | Logger()(f"Opening file {filename_train}, {filename_val}")
72 | self.image_features_train = h5py.File(filename_train, 'r', swmr=True)
73 | self.image_features_val = h5py.File(filename_val, 'r', swmr=True)
74 | # load txt
75 | with open(os.path.join(self.dir_cnn, 'trainset.txt'.format(self.split)), 'r') as f:
76 | self.image_names_to_index_train = {}
77 | for i, line in enumerate(f):
78 | self.image_names_to_index_train[line.strip()] = i
79 | with open(os.path.join(self.dir_cnn, 'valset.txt'.format(self.split)), 'r') as f:
80 | self.image_names_to_index_val = {}
81 | for i, line in enumerate(f):
82 | self.image_names_to_index_val[line.strip()] = i
83 | elif self.dir_vgg16:
84 | # list filenames
85 | self.filenames_train = os.listdir(os.path.join(self.dir_vgg16, 'train'))
86 | self.filenames_val = os.listdir(os.path.join(self.dir_vgg16, 'val'))
87 |
88 |
89 | def add_vgg_to_item(self, item):
90 | image_name = item['image_name']
91 | filename = image_name + '.pth'
92 | if filename in self.filenames_train:
93 | path = os.path.join(self.dir_vgg16, 'train', filename)
94 | elif filename in self.filenames_val:
95 | path = os.path.join(self.dir_vgg16, 'val', filename)
96 | visual = torch.load(path)
97 | visual = visual.permute(1, 2, 0).view(14*14, 512)
98 | item['visual'] = visual
99 | return item
100 |
101 | def add_cnn_to_item(self, item):
102 | image_name = item['image_name']
103 | if image_name in self.image_names_to_index_train:
104 | index = self.image_names_to_index_train[image_name]
105 | image = torch.tensor(self.image_features_train['att'][index])
106 | elif image_name in self.image_names_to_index_val:
107 | index = self.image_names_to_index_val[image_name]
108 | image = torch.tensor(self.image_features_val['att'][index])
109 | image = image.permute(1, 2, 0).view(196, 2048)
110 | item['visual'] = image
111 | return item
112 |
113 | def __getitem__(self, index):
114 | item = {}
115 | item['index'] = index
116 |
117 | # Process Question (word token)
118 | question = self.dataset['questions'][index]
119 | if self.load_original_annotation:
120 | item['original_question'] = question
121 | item['question_id'] = question['question_id']
122 | item['question'] = torch.LongTensor(question['question_wids'])
123 | item['lengths'] = torch.LongTensor([len(question['question_wids'])])
124 | item['image_name'] = question['image_name']
125 |
126 | # Process Object, Attribut and Relational features
127 | if self.dir_rcnn:
128 | item = self.add_rcnn_to_item(item)
129 | elif self.dir_cnn:
130 | item = self.add_cnn_to_item(item)
131 | elif self.dir_vgg16:
132 | item = self.add_vgg_to_item(item)
133 |
134 | # Process Answer if exists
135 | if 'annotations' in self.dataset:
136 | annotation = self.dataset['annotations'][index]
137 | if self.load_original_annotation:
138 | item['original_annotation'] = annotation
139 | if 'train' in self.split and self.samplingans:
140 | proba = annotation['answers_count']
141 | proba = proba / np.sum(proba)
142 | item['answer_id'] = int(np.random.choice(annotation['answers_id'], p=proba))
143 | else:
144 | item['answer_id'] = annotation['answer_id']
145 | item['class_id'] = torch.LongTensor([item['answer_id']])
146 | item['answer'] = annotation['answer']
147 | item['question_type'] = annotation['question_type']
148 |
149 | return item
150 |
151 | def download(self):
152 | dir_ann = osp.join(self.dir_raw, 'annotations')
153 | os.system('mkdir -p '+dir_ann)
154 | os.system('wget https://computing.ece.vt.edu/~aish/vqacp/vqacp_v2_train_questions.json -P' + dir_ann)
155 | os.system('wget https://computing.ece.vt.edu/~aish/vqacp/vqacp_v2_test_questions.json -P' + dir_ann)
156 | os.system('wget https://computing.ece.vt.edu/~aish/vqacp/vqacp_v2_train_annotations.json -P' + dir_ann)
157 | os.system('wget https://computing.ece.vt.edu/~aish/vqacp/vqacp_v2_test_annotations.json -P' + dir_ann)
158 | train_q = {"questions":json.load(open(osp.join(dir_ann, "vqacp_v2_train_questions.json")))}
159 | val_q = {"questions":json.load(open(osp.join(dir_ann, "vqacp_v2_test_questions.json")))}
160 | train_ann = {"annotations":json.load(open(osp.join(dir_ann, "vqacp_v2_train_annotations.json")))}
161 | val_ann = {"annotations":json.load(open(osp.join(dir_ann, "vqacp_v2_test_annotations.json")))}
162 | train_q['info'] = {}
163 | train_q['data_type'] = 'mscoco'
164 | train_q['data_subtype'] = "train2014cp"
165 | train_q['task_type'] = "Open-Ended"
166 | train_q['license'] = {}
167 | val_q['info'] = {}
168 | val_q['data_type'] = 'mscoco'
169 | val_q['data_subtype'] = "val2014cp"
170 | val_q['task_type'] = "Open-Ended"
171 | val_q['license'] = {}
172 | for k in ["info", 'data_type','data_subtype', 'license']:
173 | train_ann[k] = train_q[k]
174 | val_ann[k] = val_q[k]
175 | with open(osp.join(dir_ann, "OpenEnded_mscoco_train2014_questions.json"), 'w') as F:
176 | F.write(json.dumps(train_q))
177 | with open(osp.join(dir_ann, "OpenEnded_mscoco_val2014_questions.json"), 'w') as F:
178 | F.write(json.dumps(val_q))
179 | with open(osp.join(dir_ann, "mscoco_train2014_annotations.json"), 'w') as F:
180 | F.write(json.dumps(train_ann))
181 | with open(osp.join(dir_ann, "mscoco_val2014_annotations.json"), 'w') as F:
182 | F.write(json.dumps(val_ann))
183 |
184 | def add_image_names(self, dataset):
185 | for q in dataset['questions']:
186 | q['image_name'] = 'COCO_%s_%012d.jpg'%(q['coco_split'],q['image_id'])
187 | return dataset
188 |
189 |
--------------------------------------------------------------------------------
/rubi/models/criterions/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cdancette/rubi.bootstrap.pytorch/36180e51e4692424d6f6ed284a40a01c6fb97104/rubi/models/criterions/__init__.py
--------------------------------------------------------------------------------
/rubi/models/criterions/factory.py:
--------------------------------------------------------------------------------
1 | from bootstrap.lib.options import Options
2 | from block.models.criterions.vqa_cross_entropy import VQACrossEntropyLoss
3 | from .rubi_criterion import RUBiCriterion
4 |
5 | def factory(engine, mode):
6 | name = Options()['model.criterion.name']
7 | split = engine.dataset[mode].split
8 | eval_only = 'train' not in engine.dataset
9 |
10 | opt = Options()['model.criterion']
11 | if split == "test" and 'tdiuc' not in Options()['dataset.name']:
12 | return None
13 | if name == 'vqa_cross_entropy':
14 | criterion = VQACrossEntropyLoss()
15 | elif name == "rubi_criterion":
16 | criterion = RUBiCriterion(
17 | question_loss_weight=opt['question_loss_weight']
18 | )
19 | else:
20 | raise ValueError(name)
21 | return criterion
22 |
--------------------------------------------------------------------------------
/rubi/models/criterions/rubi_criterion.py:
--------------------------------------------------------------------------------
1 | import torch.nn as nn
2 | import torch
3 | import torch.nn.functional as F
4 | from bootstrap.lib.logger import Logger
5 | from bootstrap.lib.options import Options
6 |
7 | class RUBiCriterion(nn.Module):
8 |
9 | def __init__(self, question_loss_weight=1.0):
10 | super().__init__()
11 |
12 | Logger()(f'RUBiCriterion, with question_loss_weight = ({question_loss_weight})')
13 |
14 | self.question_loss_weight = question_loss_weight
15 | self.fusion_loss = nn.CrossEntropyLoss()
16 | self.question_loss = nn.CrossEntropyLoss()
17 |
18 | def forward(self, net_out, batch):
19 | out = {}
20 | # logits = net_out['logits']
21 | logits_q = net_out['logits_q']
22 | logits_rubi = net_out['logits_rubi']
23 | class_id = batch['class_id'].squeeze(1)
24 | fusion_loss = self.fusion_loss(logits_rubi, class_id)
25 | question_loss = self.question_loss(logits_q, class_id)
26 | loss = fusion_loss + self.question_loss_weight * question_loss
27 |
28 | out['loss'] = loss
29 | out['loss_mm_q'] = fusion_loss
30 | out['loss_q'] = question_loss
31 | return out
32 |
--------------------------------------------------------------------------------
/rubi/models/metrics/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cdancette/rubi.bootstrap.pytorch/36180e51e4692424d6f6ed284a40a01c6fb97104/rubi/models/metrics/__init__.py
--------------------------------------------------------------------------------
/rubi/models/metrics/factory.py:
--------------------------------------------------------------------------------
1 | from bootstrap.lib.options import Options
2 | from block.models.metrics.vqa_accuracies import VQAAccuracies
3 | from .vqa_rubi_metrics import VQARUBiMetrics
4 |
5 | def factory(engine, mode):
6 | name = Options()['model.metric.name']
7 | metric = None
8 |
9 | if name == 'vqa_accuracies':
10 | open_ended = ('tdiuc' not in Options()['dataset.name'] and 'gqa' not in Options()['dataset.name'])
11 | if mode == 'train':
12 | split = engine.dataset['train'].split
13 | if split == 'train':
14 | metric = VQAAccuracies(engine,
15 | mode='train',
16 | open_ended=open_ended,
17 | tdiuc=True,
18 | dir_exp=Options()['exp.dir'],
19 | dir_vqa=Options()['dataset.dir'])
20 | elif split == 'trainval':
21 | metric = None
22 | else:
23 | raise ValueError(split)
24 | elif mode == 'eval':
25 | metric = VQAAccuracies(engine,
26 | mode='eval',
27 | open_ended=open_ended,
28 | tdiuc=('tdiuc' in Options()['dataset.name'] or Options()['dataset.eval_split'] != 'test'),
29 | dir_exp=Options()['exp.dir'],
30 | dir_vqa=Options()['dataset.dir'])
31 | else:
32 | metric = None
33 |
34 | elif name == "vqa_rubi_metrics":
35 | open_ended = ('tdiuc' not in Options()['dataset.name'] and 'gqa' not in Options()['dataset.name'])
36 | metric = VQARUBiMetrics(engine,
37 | mode=mode,
38 | open_ended=open_ended,
39 | tdiuc=True,
40 | dir_exp=Options()['exp.dir'],
41 | dir_vqa=Options()['dataset.dir']
42 | )
43 |
44 | else:
45 | raise ValueError(name)
46 | return metric
47 |
--------------------------------------------------------------------------------
/rubi/models/metrics/vqa_rubi_metrics.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | import os
4 | import json
5 | from scipy import stats
6 | import numpy as np
7 | from collections import defaultdict
8 |
9 | from bootstrap.models.metrics.accuracy import accuracy
10 | from block.models.metrics.vqa_accuracies import VQAAccuracies
11 | from bootstrap.lib.logger import Logger
12 | from bootstrap.lib.options import Options
13 | from bootstrap.lib.logger import Logger
14 |
15 | class VQAAccuracy(nn.Module):
16 |
17 | def __init__(self, topk=[1,5]):
18 | super().__init__()
19 | self.topk = topk
20 |
21 | def forward(self, cri_out, net_out, batch):
22 | out = {}
23 | class_id = batch['class_id'].data.cpu()
24 | for key in ['', '_rubi', '_q']:
25 | logits = net_out[f'logits{key}'].data.cpu()
26 | acc_out = accuracy(logits, class_id, topk=self.topk)
27 | for i, k in enumerate(self.topk):
28 | out[f'accuracy{key}_top{k}'] = acc_out[i]
29 | return out
30 |
31 |
32 | class VQARUBiMetrics(VQAAccuracies):
33 |
34 | def __init__(self, *args, **kwargs):
35 | super().__init__(*args, **kwargs)
36 | self.accuracy = VQAAccuracy()
37 | self.rm_dir_rslt = 1 if Options()['dataset.train_split'] is not None else 0
38 |
39 | def forward(self, cri_out, net_out, batch):
40 | out = {}
41 | if self.accuracy is not None:
42 | out = self.accuracy(cri_out, net_out, batch)
43 |
44 | # add answers and answer_ids keys to net_out
45 | net_out = self.engine.model.network.process_answers(net_out)
46 |
47 | batch_size = len(batch['index'])
48 | for i in range(batch_size):
49 |
50 | # Open Ended Accuracy (VQA-VQA2)
51 | if self.open_ended:
52 | for key in ['', '_rubi', '_q']:
53 | pred_item = {
54 | 'question_id': batch['question_id'][i],
55 | 'answer': net_out[f'answers{key}'][i]
56 | }
57 | self.results[key].append(pred_item)
58 |
59 | if self.dataset.split == 'test':
60 | pred_item = {
61 | 'question_id': batch['question_id'][i],
62 | 'answer': net_out[f'answers'][i]
63 | }
64 | if 'is_testdev' in batch and batch['is_testdev'][i]:
65 | self.results_testdev.append(pred_item)
66 |
67 | if self.logits['tensor'] is None:
68 | self.logits['tensor'] = torch.FloatTensor(len(self.dataset), logits.size(1))
69 |
70 | self.logits['tensor'][self.idx] = logits[i]
71 | self.logits['qid_to_idx'][batch['question_id'][i]] = self.idx
72 |
73 | self.idx += 1
74 |
75 | # TDIUC metrics
76 | if self.tdiuc:
77 | gt_aid = batch['answer_id'][i]
78 | gt_ans = batch['answer'][i]
79 | gt_type = batch['question_type'][i]
80 | self.gt_types.append(gt_type)
81 | if gt_ans in self.ans_to_aid:
82 | self.gt_aids.append(gt_aid)
83 | else:
84 | self.gt_aids.append(-1)
85 | self.gt_aid_not_found += 1
86 |
87 | for key in ['', '_rubi', '_q']:
88 | qid = batch['question_id'][i]
89 | pred_aid = net_out[f'answer_ids{key}'][i]
90 | self.pred_aids[key].append(pred_aid)
91 |
92 | self.res_by_type[key][gt_type+'_pred'].append(pred_aid)
93 |
94 | if gt_ans in self.ans_to_aid:
95 | self.res_by_type[key][gt_type+'_gt'].append(gt_aid)
96 | if gt_aid == pred_aid:
97 | self.res_by_type[key][gt_type+'_t'].append(pred_aid)
98 | else:
99 | self.res_by_type[key][gt_type+'_f'].append(pred_aid)
100 | else:
101 | self.res_by_type[key][gt_type+'_gt'].append(-1)
102 | self.res_by_type[key][gt_type+'_f'].append(pred_aid)
103 | return out
104 |
105 | def reset_oe(self):
106 | self.results = dict()
107 | self.dir_rslt = dict()
108 | self.path_rslt = dict()
109 | for key in ['', '_q', '_rubi']:
110 | self.results[key] = []
111 | self.dir_rslt[key] = os.path.join(
112 | self.dir_exp,
113 | f'results{key}',
114 | self.dataset.split,
115 | 'epoch,{}'.format(self.engine.epoch))
116 | os.system('mkdir -p '+self.dir_rslt[key])
117 | self.path_rslt[key] = os.path.join(
118 | self.dir_rslt[key],
119 | 'OpenEnded_mscoco_{}_model_results.json'.format(
120 | self.dataset.get_subtype()))
121 |
122 | if self.dataset.split == 'test':
123 | pass
124 | # self.results_testdev = []
125 | # self.path_rslt_testdev = os.path.join(
126 | # self.dir_rslt,
127 | # 'OpenEnded_mscoco_{}_model_results.json'.format(
128 | # self.dataset.get_subtype(testdev=True)))
129 |
130 | # self.path_logits = os.path.join(self.dir_rslt, 'logits.pth')
131 | # os.system('mkdir -p '+os.path.dirname(self.path_logits))
132 |
133 | # self.logits = {}
134 | # self.logits['aid_to_ans'] = self.engine.model.network.aid_to_ans
135 | # self.logits['qid_to_idx'] = {}
136 | # self.logits['tensor'] = None
137 |
138 | # self.idx = 0
139 |
140 | # path_aid_to_ans = os.path.join(self.dir_rslt, 'aid_to_ans.json')
141 | # with open(path_aid_to_ans, 'w') as f:
142 | # json.dump(self.engine.model.network.aid_to_ans, f)
143 |
144 |
145 | def reset_tdiuc(self):
146 | self.pred_aids = defaultdict(list)
147 | self.gt_aids = []
148 | self.gt_types = []
149 | self.gt_aid_not_found = 0
150 | self.res_by_type = {key: defaultdict(list) for key in ['', '_rubi', '_q']}
151 |
152 |
153 | def compute_oe_accuracy(self):
154 | logs_name_prefix = Options()['misc'].get('logs_name', '') or ''
155 |
156 | for key in ['', '_rubi', '_q']:
157 | logs_name = (logs_name_prefix + key) or "logs"
158 | with open(self.path_rslt[key], 'w') as f:
159 | json.dump(self.results[key], f)
160 |
161 | # if self.dataset.split == 'test':
162 | # with open(self.path_rslt_testdev, 'w') as f:
163 | # json.dump(self.results_testdev, f)
164 |
165 | if 'test' not in self.dataset.split:
166 | call_to_prog = 'python -m block.models.metrics.compute_oe_accuracy '\
167 | + '--dir_vqa {} --dir_exp {} --dir_rslt {} --epoch {} --split {} --logs_name {} --rm {} &'\
168 | .format(self.dir_vqa, self.dir_exp, self.dir_rslt[key], self.engine.epoch, self.dataset.split, logs_name, self.rm_dir_rslt)
169 | Logger()('`'+call_to_prog+'`')
170 | os.system(call_to_prog)
171 |
172 |
173 | def compute_tdiuc_metrics(self):
174 | Logger()('{} of validation answers were not found in ans_to_aid'.format(self.gt_aid_not_found))
175 |
176 | for key in ['', '_rubi', '_q']:
177 | Logger()(f'Computing TDIUC metrics for logits{key}')
178 | accuracy = float(100*np.mean(np.array(self.pred_aids[key])==np.array(self.gt_aids)))
179 | Logger()('Overall Traditional Accuracy is {:.2f}'.format(accuracy))
180 | Logger().log_value('{}_epoch.tdiuc.accuracy{}'.format(self.mode, key), accuracy, should_print=False)
181 |
182 | types = list(set(self.gt_types))
183 | sum_acc = []
184 | eps = 1e-10
185 |
186 | Logger()('---------------------------------------')
187 | Logger()('Not using per-answer normalization...')
188 | for tp in types:
189 | acc = 100*(len(self.res_by_type[key][tp+'_t'])/len(self.res_by_type[key][tp+'_t']+self.res_by_type[key][tp+'_f']))
190 | sum_acc.append(acc+eps)
191 | Logger()(f"Accuracy {key} for class '{tp}' is {acc:.2f}")
192 | Logger().log_value('{}_epoch.tdiuc{}.perQuestionType.{}'.format(self.mode, key, tp), acc, should_print=False)
193 |
194 | acc_mpt_a = float(np.mean(np.array(sum_acc)))
195 | Logger()('Arithmetic MPT Accuracy {} is {:.2f}'.format(key, acc_mpt_a))
196 | Logger().log_value('{}_epoch.tdiuc{}.acc_mpt_a'.format(self.mode, key), acc_mpt_a, should_print=False)
197 |
198 | acc_mpt_h = float(stats.hmean(sum_acc))
199 | Logger()('Harmonic MPT Accuracy {} is {:.2f}'.format(key, acc_mpt_h))
200 | Logger().log_value('{}_epoch.tdiuc{}.acc_mpt_h'.format(self.mode, key), acc_mpt_h, should_print=False)
201 |
202 | Logger()('---------------------------------------')
203 | Logger()('Using per-answer normalization...')
204 | for tp in types:
205 | per_ans_stat = defaultdict(int)
206 | for g,p in zip(self.res_by_type[key][tp+'_gt'],self.res_by_type[key][tp+'_pred']):
207 | per_ans_stat[str(g)+'_gt']+=1
208 | if g==p:
209 | per_ans_stat[str(g)]+=1
210 | unq_acc = 0
211 | for unq_ans in set(self.res_by_type[key][tp+'_gt']):
212 | acc_curr_ans = per_ans_stat[str(unq_ans)]/per_ans_stat[str(unq_ans)+'_gt']
213 | unq_acc +=acc_curr_ans
214 | acc = 100*unq_acc/len(set(self.res_by_type[key][tp+'_gt']))
215 | sum_acc.append(acc+eps)
216 | Logger()("Accuracy {} for class '{}' is {:.2f}".format(key, tp, acc))
217 | Logger().log_value('{}_epoch.tdiuc{}.perQuestionType_norm.{}'.format(self.mode, key, tp), acc, should_print=False)
218 |
219 | acc_mpt_a = float(np.mean(np.array(sum_acc)))
220 | Logger()('Arithmetic MPT Accuracy is {:.2f}'.format(acc_mpt_a))
221 | Logger().log_value('{}_epoch.tdiuc{}.acc_mpt_a_norm'.format(self.mode, key), acc_mpt_a, should_print=False)
222 |
223 | acc_mpt_h = float(stats.hmean(sum_acc))
224 | Logger()('Harmonic MPT Accuracy is {:.2f}'.format(acc_mpt_h))
225 | Logger().log_value('{}_epoch.tdiuc{}.acc_mpt_h_norm'.format(self.mode, key), acc_mpt_h, should_print=False)
226 |
--------------------------------------------------------------------------------
/rubi/models/networks/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cdancette/rubi.bootstrap.pytorch/36180e51e4692424d6f6ed284a40a01c6fb97104/rubi/models/networks/__init__.py
--------------------------------------------------------------------------------
/rubi/models/networks/baseline_net.py:
--------------------------------------------------------------------------------
1 | from copy import deepcopy
2 | import itertools
3 | import os
4 | import numpy as np
5 | import scipy
6 | import torch
7 | import torch.nn as nn
8 | import torch.nn.functional as F
9 | from bootstrap.lib.options import Options
10 | from bootstrap.lib.logger import Logger
11 | import block
12 | from block.models.networks.vqa_net import factory_text_enc
13 | from block.models.networks.mlp import MLP
14 |
15 | from .utils import mask_softmax
16 |
17 | class BaselineNet(nn.Module):
18 |
19 | def __init__(self,
20 | txt_enc={},
21 | self_q_att=False,
22 | agg={},
23 | classif={},
24 | wid_to_word={},
25 | word_to_wid={},
26 | aid_to_ans=[],
27 | ans_to_aid={},
28 | fusion={},
29 | residual=False,
30 | ):
31 | super().__init__()
32 | self.self_q_att = self_q_att
33 | self.agg = agg
34 | assert self.agg['type'] in ['max', 'mean']
35 | self.classif = classif
36 | self.wid_to_word = wid_to_word
37 | self.word_to_wid = word_to_wid
38 | self.aid_to_ans = aid_to_ans
39 | self.ans_to_aid = ans_to_aid
40 | self.fusion = fusion
41 | self.residual = residual
42 |
43 | # Modules
44 | self.txt_enc = self.get_text_enc(self.wid_to_word, txt_enc)
45 | if self.self_q_att:
46 | self.q_att_linear0 = nn.Linear(2400, 512)
47 | self.q_att_linear1 = nn.Linear(512, 2)
48 |
49 | self.fusion_module = block.factory_fusion(self.fusion)
50 |
51 | if self.classif['mlp']['dimensions'][-1] != len(self.aid_to_ans):
52 | Logger()(f"Warning, the classif_mm output dimension ({self.classif['mlp']['dimensions'][-1]})"
53 | f"doesn't match the number of answers ({len(self.aid_to_ans)}). Modifying the output dimension.")
54 | self.classif['mlp']['dimensions'][-1] = len(self.aid_to_ans)
55 |
56 | self.classif_module = MLP(**self.classif['mlp'])
57 |
58 | Logger().log_value('nparams',
59 | sum(p.numel() for p in self.parameters() if p.requires_grad),
60 | should_print=True)
61 |
62 | Logger().log_value('nparams_txt_enc',
63 | self.get_nparams_txt_enc(),
64 | should_print=True)
65 |
66 |
67 | def get_text_enc(self, vocab_words, options):
68 | """
69 | returns the text encoding network.
70 | """
71 | return factory_text_enc(self.wid_to_word, options)
72 |
73 | def get_nparams_txt_enc(self):
74 | params = [p.numel() for p in self.txt_enc.parameters() if p.requires_grad]
75 | if self.self_q_att:
76 | params += [p.numel() for p in self.q_att_linear0.parameters() if p.requires_grad]
77 | params += [p.numel() for p in self.q_att_linear1.parameters() if p.requires_grad]
78 | return sum(params)
79 |
80 | def process_fusion(self, q, mm):
81 | bsize = mm.shape[0]
82 | n_regions = mm.shape[1]
83 |
84 | mm = mm.contiguous().view(bsize*n_regions, -1)
85 | mm = self.fusion_module([q, mm])
86 | mm = mm.view(bsize, n_regions, -1)
87 | return mm
88 |
89 | def forward(self, batch):
90 | v = batch['visual']
91 | q = batch['question']
92 | l = batch['lengths'].data
93 | c = batch['norm_coord']
94 | nb_regions = batch.get('nb_regions')
95 | bsize = v.shape[0]
96 | n_regions = v.shape[1]
97 |
98 | out = {}
99 |
100 | q = self.process_question(q, l,)
101 | out['q_emb'] = q
102 | q_expand = q[:,None,:].expand(bsize, n_regions, q.shape[1])
103 | q_expand = q_expand.contiguous().view(bsize*n_regions, -1)
104 |
105 | mm = self.process_fusion(q_expand, v,)
106 |
107 | if self.residual:
108 | mm = v + mm
109 |
110 | if self.agg['type'] == 'max':
111 | mm, mm_argmax = torch.max(mm, 1)
112 | elif self.agg['type'] == 'mean':
113 | mm = mm.mean(1)
114 |
115 | out['mm'] = mm
116 | out['mm_argmax'] = mm_argmax
117 |
118 | logits = self.classif_module(mm)
119 | out['logits'] = logits
120 | return out
121 |
122 | def process_question(self, q, l, txt_enc=None, q_att_linear0=None, q_att_linear1=None):
123 | if txt_enc is None:
124 | txt_enc = self.txt_enc
125 | if q_att_linear0 is None:
126 | q_att_linear0 = self.q_att_linear0
127 | if q_att_linear1 is None:
128 | q_att_linear1 = self.q_att_linear1
129 | q_emb = txt_enc.embedding(q)
130 |
131 | q, _ = txt_enc.rnn(q_emb)
132 |
133 | if self.self_q_att:
134 | q_att = q_att_linear0(q)
135 | q_att = F.relu(q_att)
136 | q_att = q_att_linear1(q_att)
137 | q_att = mask_softmax(q_att, l)
138 | #self.q_att_coeffs = q_att
139 | if q_att.size(2) > 1:
140 | q_atts = torch.unbind(q_att, dim=2)
141 | q_outs = []
142 | for q_att in q_atts:
143 | q_att = q_att.unsqueeze(2)
144 | q_att = q_att.expand_as(q)
145 | q_out = q_att*q
146 | q_out = q_out.sum(1)
147 | q_outs.append(q_out)
148 | q = torch.cat(q_outs, dim=1)
149 | else:
150 | q_att = q_att.expand_as(q)
151 | q = q_att * q
152 | q = q.sum(1)
153 | else:
154 | # l contains the number of words for each question
155 | # in case of multi-gpus it must be a Tensor
156 | # thus we convert it into a list during the forward pass
157 | l = list(l.data[:,0])
158 | q = txt_enc._select_last(q, l)
159 |
160 | return q
161 |
162 | def process_answers(self, out, key=''):
163 | batch_size = out[f'logits{key}'].shape[0]
164 | _, pred = out[f'logits{key}'].data.max(1)
165 | pred.squeeze_()
166 | if batch_size != 1:
167 | out[f'answers{key}'] = [self.aid_to_ans[pred[i].item()] for i in range(batch_size)]
168 | out[f'answer_ids{key}'] = [pred[i].item() for i in range(batch_size)]
169 | else:
170 | out[f'answers{key}'] = [self.aid_to_ans[pred.item()]]
171 | out[f'answer_ids{key}'] = [pred.item()]
172 | return out
173 |
--------------------------------------------------------------------------------
/rubi/models/networks/factory.py:
--------------------------------------------------------------------------------
1 | import sys
2 | import copy
3 | import torch
4 | import torch.nn as nn
5 | import os
6 | import json
7 | from bootstrap.lib.options import Options
8 | from bootstrap.models.networks.data_parallel import DataParallel
9 | from block.models.networks.vqa_net import VQANet as AttentionNet
10 | from bootstrap.lib.logger import Logger
11 |
12 | from .baseline_net import BaselineNet
13 | from .rubi import RUBiNet
14 |
15 | def factory(engine):
16 | mode = list(engine.dataset.keys())[0]
17 | dataset = engine.dataset[mode]
18 | opt = Options()['model.network']
19 |
20 | if opt['name'] == 'baseline':
21 | net = BaselineNet(
22 | txt_enc=opt['txt_enc'],
23 | self_q_att=opt['self_q_att'],
24 | agg=opt['agg'],
25 | classif=opt['classif'],
26 | wid_to_word=dataset.wid_to_word,
27 | word_to_wid=dataset.word_to_wid,
28 | aid_to_ans=dataset.aid_to_ans,
29 | ans_to_aid=dataset.ans_to_aid,
30 | fusion=opt['fusion'],
31 | residual=opt['residual'],
32 | )
33 |
34 | elif opt['name'] == 'rubi':
35 | orig_net = BaselineNet(
36 | txt_enc=opt['txt_enc'],
37 | self_q_att=opt['self_q_att'],
38 | agg=opt['agg'],
39 | classif=opt['classif'],
40 | wid_to_word=dataset.wid_to_word,
41 | word_to_wid=dataset.word_to_wid,
42 | aid_to_ans=dataset.aid_to_ans,
43 | ans_to_aid=dataset.ans_to_aid,
44 | fusion=opt['fusion'],
45 | residual=opt['residual'],
46 | )
47 | net = RUBiNet(
48 | model=orig_net,
49 | output_size=len(dataset.aid_to_ans),
50 | classif=opt['rubi_params']['mlp_q']
51 | )
52 | else:
53 | raise ValueError(opt['name'])
54 |
55 | if Options()['misc.cuda'] and torch.cuda.device_count() > 1:
56 | net = DataParallel(net)
57 |
58 | return net
59 |
60 |
--------------------------------------------------------------------------------
/rubi/models/networks/rubi.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from block.models.networks.mlp import MLP
4 | from .utils import grad_mul_const # mask_softmax, grad_reverse, grad_reverse_mask,
5 |
6 |
7 | class RUBiNet(nn.Module):
8 | """
9 | Wraps another model
10 | The original model must return a dictionnary containing the 'logits' key (predictions before softmax)
11 | Returns:
12 | - logits: the original predictions of the model
13 | - logits_q: the predictions from the question-only branch
14 | - logits_rubi: the updated predictions from the model by the mask.
15 | => Use `logits_rubi` and `logits_q` for the loss
16 | """
17 | def __init__(self, model, output_size, classif, end_classif=True):
18 | super().__init__()
19 | self.net = model
20 | self.c_1 = MLP(**classif)
21 | self.end_classif = end_classif
22 | if self.end_classif:
23 | self.c_2 = nn.Linear(output_size, output_size)
24 |
25 | def forward(self, batch):
26 | out = {}
27 | # model prediction
28 | net_out = self.net(batch)
29 | logits = net_out['logits']
30 |
31 | q_embedding = net_out['q_emb'] # N * q_emb
32 | q_embedding = grad_mul_const(q_embedding, 0.0) # don't backpropagate through question encoder
33 | q_pred = self.c_1(q_embedding)
34 | fusion_pred = logits * torch.sigmoid(q_pred)
35 |
36 | if self.end_classif:
37 | q_out = self.c_2(q_pred)
38 | else:
39 | q_out = q_pred
40 |
41 | out['logits'] = net_out['logits']
42 | out['logits_rubi'] = fusion_pred
43 | out['logits_q'] = q_out
44 | return out
45 |
46 | def process_answers(self, out, key=''):
47 | out = self.net.process_answers(out)
48 | out = self.net.process_answers(out, key='_rubi')
49 | out = self.net.process_answers(out, key='_q')
50 | return out
51 |
--------------------------------------------------------------------------------
/rubi/models/networks/utils.py:
--------------------------------------------------------------------------------
1 | import torch
2 |
3 | def mask_softmax(x, lengths):#, dim=1)
4 | mask = torch.zeros_like(x).to(device=x.device, non_blocking=True)
5 | t_lengths = lengths[:,:,None].expand_as(mask)
6 | arange_id = torch.arange(mask.size(1)).to(device=x.device, non_blocking=True)
7 | arange_id = arange_id[None,:,None].expand_as(mask)
8 |
9 | mask[arange_id=2:
26 | nn.init.xavier_uniform_(p.data)
27 | else:
28 | raise ValueError(p.dim())
29 |
30 | return optimizer
31 |
--------------------------------------------------------------------------------
/rubi/options/vqa2/baseline.yaml:
--------------------------------------------------------------------------------
1 | exp:
2 | dir: logs/vqa2/baseline
3 | resume: # last, best_[...], or empty (from scratch)
4 | dataset:
5 | import: rubi.datasets.factory
6 | name: vqa2 # or vqa2vg
7 | dir: data/vqa/vqa2
8 | train_split: train
9 | eval_split: val # or test
10 | proc_split: train # or trainval (preprocessing split, must be equal to train_split)
11 | nb_threads: 4
12 | batch_size: 256
13 | nans: 3000
14 | minwcount: 0
15 | nlp: mcb
16 | samplingans: True
17 | dir_rcnn: data/vqa/coco/extract_rcnn/2018-04-27_bottom-up-attention_fixed_36
18 | vg: false
19 | model:
20 | name: default
21 | network:
22 | import: rubi.models.networks.factory
23 | name: baseline
24 | txt_enc:
25 | name: skipthoughts
26 | type: BayesianUniSkip
27 | dropout: 0.25
28 | fixed_emb: False
29 | dir_st: data/skip-thoughts
30 | self_q_att: True
31 | residual: False
32 | fusion:
33 | type: block
34 | input_dims: [4800, 2048]
35 | output_dim: 2048
36 | mm_dim: 1000
37 | chunks: 20
38 | rank: 15
39 | dropout_input: 0.
40 | dropout_pre_lin: 0.
41 | agg:
42 | type: max
43 | classif:
44 | mlp:
45 | input_dim: 2048
46 | dimensions: [1024,1024,3000]
47 | criterion:
48 | import: rubi.models.criterions.factory
49 | name: vqa_cross_entropy
50 | metric:
51 | import: rubi.models.metrics.factory
52 | name: vqa_accuracies
53 | optimizer:
54 | import: rubi.optimizers.factory
55 | name: Adam
56 | lr: 0.0003
57 | gradual_warmup_steps: [0.5, 2.0, 7.0] #torch.linspace
58 | lr_decay_epochs: [14, 24, 2] #range
59 | lr_decay_rate: .25
60 | engine:
61 | name: logger
62 | debug: False
63 | print_freq: 10
64 | nb_epochs: 22
65 | saving_criteria:
66 | - eval_epoch.accuracy_top1:max
67 | misc:
68 | logs_name:
69 | cuda: True
70 | seed: 1337
71 | view:
72 | name: plotly
73 | items:
74 | - logs:train_epoch.loss+logs:eval_epoch.loss
75 | - logs:train_epoch.accuracy_top1+logs:eval_epoch.accuracy_top1
76 | - logs_train_oe:train_epoch.overall+logs_val_oe:eval_epoch.overall
77 |
--------------------------------------------------------------------------------
/rubi/options/vqa2/rubi.yaml:
--------------------------------------------------------------------------------
1 | exp:
2 | dir: logs/vqacp2/rubi
3 | resume: # last, best_[...], or empty (from scratch)
4 | dataset:
5 | import: rubi.datasets.factory
6 | name: vqa2 # or vqa2vg
7 | dir: data/vqa/vqa2
8 | train_split: train
9 | eval_split: val # or test
10 | proc_split: train # or trainval (preprocessing split, must be equal to train_split)
11 | nb_threads: 4
12 | batch_size: 256
13 | nans: 3000
14 | minwcount: 0
15 | nlp: mcb
16 | samplingans: True
17 | dir_rcnn: data/vqa/coco/extract_rcnn/2018-04-27_bottom-up-attention_fixed_36
18 | model:
19 | name: default
20 | network:
21 | import: rubi.models.networks.factory
22 | name: rubi
23 | rubi_params:
24 | mlp_q:
25 | input_dim: 4800
26 | dimensions: [1024,1024,3000]
27 | txt_enc:
28 | name: skipthoughts
29 | type: BayesianUniSkip
30 | dropout: 0.25
31 | fixed_emb: False
32 | dir_st: data/skip-thoughts
33 | self_q_att: True
34 | residual: False
35 | fusion:
36 | type: block
37 | input_dims: [4800, 2048]
38 | output_dim: 2048
39 | mm_dim: 1000
40 | chunks: 20
41 | rank: 15
42 | dropout_input: 0.
43 | dropout_pre_lin: 0.
44 | agg:
45 | type: max
46 | classif:
47 | mlp:
48 | input_dim: 2048
49 | dimensions: [1024,1024,3000]
50 | criterion:
51 | import: rubi.models.criterions.factory
52 | name: rubi_criterion
53 | question_loss_weight: 1.0
54 | metric:
55 | import: rubi.models.metrics.factory
56 | name: vqa_rubi_metrics
57 | optimizer:
58 | import: rubi.optimizers.factory
59 | name: Adam
60 | lr: 0.0003
61 | gradual_warmup_steps: [0.5, 2.0, 7.0] #torch.linspace
62 | gradual_warmup_steps_mm: [0.5, 2.0, 7.0] #torch.linspace
63 | lr_decay_epochs: [14, 24, 2] #range
64 | lr_decay_rate: .25
65 | engine:
66 | name: logger
67 | debug: False
68 | print_freq: 10
69 | nb_epochs: 22
70 | saving_criteria:
71 | - eval_epoch.accuracy_top1:max
72 | - eval_epoch.accuracy_rubi_top1:max
73 | misc:
74 | logs_name:
75 | cuda: True
76 | seed: 1337
77 | view:
78 | name: plotly
79 | items:
80 | - logs:train_epoch.loss+logs:eval_epoch.loss
81 | - logs:train_epoch.loss_mm_q+logs:eval_epoch.loss_mm_q
82 | - logs:train_epoch.loss_q+logs:eval_epoch.loss_q
83 | - logs:train_epoch.reconstruction_loss+logs:eval_epoch.reconstruction_loss
84 | ######
85 | - logs:train_epoch.rubi_loss+logs:eval_epoch.rubi_loss
86 | - logs:train_epoch.accuracy_top1+logs:eval_epoch.accuracy_top1
87 | - logs:train_epoch.accuracy_rubi_top1+logs:eval_epoch.accuracy_rubi_top1
88 | - logs:train_epoch.accuracy_q_top1+logs:eval_epoch.accuracy_q_top1
89 | - logs_train_oe:train_epoch.overall+logs_val_oe:eval_epoch.overall
90 | - logs_q_train_oe:train_epoch.overall+logs_q_val_oe:eval_epoch.overall
91 | - logs_rubi_train_oe:train_epoch.overall+logs_rubi_val_oe:eval_epoch.overall
92 |
--------------------------------------------------------------------------------
/rubi/options/vqacp2/baseline.yaml:
--------------------------------------------------------------------------------
1 | exp:
2 | dir: logs/vqacp2/baseline
3 | resume: # last, best_[...], or empty (from scratch)
4 | dataset:
5 | import: rubi.datasets.factory
6 | name: vqacp2 # or vqa2vg
7 | dir: data/vqa/vqacp2
8 | train_split: train
9 | eval_split: val # or test
10 | proc_split: train # or trainval (preprocessing split, must be equal to train_split)
11 | nb_threads: 4
12 | batch_size: 256
13 | nans: 3000
14 | minwcount: 0
15 | nlp: mcb
16 | samplingans: True
17 | dir_rcnn: data/vqa/coco/extract_rcnn/2018-04-27_bottom-up-attention_fixed_36
18 | adversarial_method:
19 | model:
20 | name: default
21 | network:
22 | import: rubi.models.networks.factory
23 | name: baseline
24 | txt_enc:
25 | name: skipthoughts
26 | type: BayesianUniSkip
27 | dropout: 0.25
28 | fixed_emb: False
29 | dir_st: data/skip-thoughts
30 | self_q_att: True
31 | residual: False
32 | fusion:
33 | type: block
34 | input_dims: [4800, 2048]
35 | output_dim: 2048
36 | mm_dim: 1000
37 | chunks: 20
38 | rank: 15
39 | dropout_input: 0.
40 | dropout_pre_lin: 0.
41 | agg:
42 | type: max
43 | classif:
44 | mlp:
45 | input_dim: 2048
46 | dimensions: [1024,1024,3000]
47 | criterion:
48 | import: rubi.models.criterions.factory
49 | name: vqa_cross_entropy
50 | metric:
51 | import: rubi.models.metrics.factory
52 | name: vqa_accuracies
53 | optimizer:
54 | import: rubi.optimizers.factory
55 | name: Adam
56 | lr: 0.0003
57 | gradual_warmup_steps: [0.5, 2.0, 7.0] #torch.linspace
58 | lr_decay_epochs: [14, 24, 2] #range
59 | lr_decay_rate: .25
60 | engine:
61 | name: logger
62 | debug: False
63 | print_freq: 10
64 | nb_epochs: 22
65 | saving_criteria:
66 | - eval_epoch.accuracy_top1:max
67 | misc:
68 | logs_name:
69 | cuda: True
70 | seed: 1337
71 | view:
72 | name: plotly
73 | items:
74 | - logs:train_epoch.loss+logs:eval_epoch.loss
75 | - logs:train_epoch.accuracy_top1+logs:eval_epoch.accuracy_top1
76 | - logs_train_oe:train_epoch.overall+logs_val_oe:eval_epoch.overall
77 |
--------------------------------------------------------------------------------
/rubi/options/vqacp2/rubi.yaml:
--------------------------------------------------------------------------------
1 | exp:
2 | dir: logs/vqacp2/rubi
3 | resume: # last, best_[...], or empty (from scratch)
4 | dataset:
5 | import: rubi.datasets.factory
6 | name: vqacp2 # or vqa2vg
7 | dir: data/vqa/vqacp2
8 | train_split: train
9 | eval_split: val # or test
10 | proc_split: train # or trainval (preprocessing split, must be equal to train_split)
11 | nb_threads: 4
12 | batch_size: 256
13 | nans: 3000
14 | minwcount: 0
15 | nlp: mcb
16 | samplingans: True
17 | dir_rcnn: data/vqa/coco/extract_rcnn/2018-04-27_bottom-up-attention_fixed_36
18 | model:
19 | name: default
20 | network:
21 | import: rubi.models.networks.factory
22 | name: rubi
23 | rubi_params:
24 | mlp_q:
25 | input_dim: 4800
26 | dimensions: [1024,1024,3000]
27 | txt_enc:
28 | name: skipthoughts
29 | type: BayesianUniSkip
30 | dropout: 0.25
31 | fixed_emb: False
32 | dir_st: data/skip-thoughts
33 | self_q_att: True
34 | residual: False
35 | fusion:
36 | type: block
37 | input_dims: [4800, 2048]
38 | output_dim: 2048
39 | mm_dim: 1000
40 | chunks: 20
41 | rank: 15
42 | dropout_input: 0.
43 | dropout_pre_lin: 0.
44 | agg:
45 | type: max
46 | classif:
47 | mlp:
48 | input_dim: 2048
49 | dimensions: [1024,1024,3000]
50 | criterion:
51 | import: rubi.models.criterions.factory
52 | name: rubi_criterion
53 | question_loss_weight: 1.0
54 | metric:
55 | import: rubi.models.metrics.factory
56 | name: vqa_rubi_metrics
57 | optimizer:
58 | import: rubi.optimizers.factory
59 | name: Adam
60 | lr: 0.0003
61 | gradual_warmup_steps: [0.5, 2.0, 7.0] #torch.linspace
62 | gradual_warmup_steps_mm: [0.5, 2.0, 7.0] #torch.linspace
63 | lr_decay_epochs: [14, 24, 2] #range
64 | lr_decay_rate: .25
65 | engine:
66 | name: logger
67 | debug: False
68 | print_freq: 10
69 | nb_epochs: 22
70 | saving_criteria:
71 | - eval_epoch.accuracy_top1:max
72 | - eval_epoch.accuracy_rubi_top1:max
73 | misc:
74 | logs_name:
75 | cuda: True
76 | seed: 1337
77 | view:
78 | name: plotly
79 | items:
80 | - logs:train_epoch.loss+logs:eval_epoch.loss
81 | - logs:train_epoch.loss_mm_q+logs:eval_epoch.loss_mm_q
82 | - logs:train_epoch.loss_q+logs:eval_epoch.loss_q
83 | ######
84 | - logs:train_epoch.accuracy_top1+logs:eval_epoch.accuracy_top1
85 | - logs:train_epoch.accuracy_rubi_top1+logs:eval_epoch.accuracy_rubi_top1
86 | - logs:train_epoch.accuracy_q_top1+logs:eval_epoch.accuracy_q_top1
87 | - logs_train_oe:train_epoch.overall+logs_val_oe:eval_epoch.overall
88 | - logs_q_train_oe:train_epoch.overall+logs_q_val_oe:eval_epoch.overall
89 | - logs_rubi_train_oe:train_epoch.overall+logs_rubi_val_oe:eval_epoch.overall
90 |
--------------------------------------------------------------------------------
/setup.cfg:
--------------------------------------------------------------------------------
1 | [metadata]
2 | description-file = README.md
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | """A setuptools based setup module.
2 |
3 | See:
4 | https://packaging.python.org/en/latest/distributing.html
5 | https://github.com/pypa/sampleproject
6 | """
7 |
8 | # Always prefer setuptools over distutils
9 | from setuptools import setup, find_packages
10 | # To use a consistent encoding
11 | from codecs import open
12 | from os import path
13 |
14 | here = path.abspath(path.dirname(__file__))
15 |
16 | # Get the long description from the README file
17 | with open(path.join(here, 'README.md'), encoding='utf-8') as f:
18 | long_description = f.read()
19 |
20 | # Arguments marked as "Required" below must be included for upload to PyPI.
21 | # Fields marked as "Optional" may be commented out.
22 |
23 | # https://stackoverflow.com/questions/458550/standard-way-to-embed-version-into-python-package/16084844#16084844
24 | exec(open(path.join(here, 'rubi', '__version__.py')).read())
25 | setup(
26 | # This is the name of your project. The first time you publish this
27 | # package, this name will be registered for you. It will determine how
28 | # users can install this project, e.g.:
29 | #
30 | # $ pip install sampleproject
31 | #
32 | # And where it will live on PyPI: https://pypi.org/project/sampleproject/
33 | #
34 | # There are some restrictions on what makes a valid project name
35 | # specification here:
36 | # https://packaging.python.org/specifications/core-metadata/#name
37 | name='rubi.bootstrap.pytorch', # Required
38 |
39 | # Versions should comply with PEP 440:
40 | # https://www.python.org/dev/peps/pep-0440/
41 | #
42 | # For a discussion on single-sourcing the version across setup.py and the
43 | # project code, see
44 | # https://packaging.python.org/en/latest/single_source_version.html
45 | version=__version__, # Required
46 |
47 | # This is a one-line description or tagline of what your project does. This
48 | # corresponds to the "Summary" metadata field:
49 | # https://packaging.python.org/specifications/core-metadata/#summary
50 | description='RUBi: Reducing Unimodal Biases for Visual Question Answering', # Required
51 |
52 | # This is an optional longer description of your project that represents
53 | # the body of text which users will see when they visit PyPI.
54 | #
55 | # Often, this is the same as your README, so you can just read it in from
56 | # that file directly (as we have already done above)
57 | #
58 | # This field corresponds to the "Description" metadata field:
59 | # https://packaging.python.org/specifications/core-metadata/#description-optional
60 | long_description=long_description, # Optional
61 |
62 | # This should be a valid link to your project's main homepage.
63 | #
64 | # This field corresponds to the "Home-Page" metadata field:
65 | # https://packaging.python.org/specifications/core-metadata/#home-page-optional
66 | url='https://github.com/', # Optional
67 |
68 | # This should be your name or the name of the organization which owns the
69 | # project.
70 | author='', # Optional
71 |
72 | # This should be a valid email address corresponding to the author listed
73 | # above.
74 | author_email='', # Optional
75 |
76 | # Classifiers help users find your project by categorizing it.
77 | #
78 | # For a list of valid classifiers, see
79 | # https://pypi.python.org/pypi?%3Aaction=list_classifiers
80 | classifiers=[ # Optional
81 | # How mature is this project? Common values are
82 | # 3 - Alpha
83 | # 4 - Beta
84 | # 5 - Production/Stable
85 | 'Development Status :: 3 - Alpha',
86 |
87 | # Indicate who your project is intended for
88 | 'Intended Audience :: Developers',
89 | 'Topic :: Software Development :: Build Tools',
90 |
91 | # Pick your license as you wish
92 | 'License :: OSI Approved :: MIT License',
93 |
94 | # Specify the Python versions you support here. In particular, ensure
95 | # that you indicate whether you support Python 2, Python 3 or both.
96 | 'Programming Language :: Python :: 3.7',
97 | ],
98 |
99 | # This field adds keywords for your project which will appear on the
100 | # project page. What does your project relate to?
101 | #
102 | # Note that this is a string of words separated by whitespace, not a list.
103 | keywords='pytorch rubi vqa bias block murel tdiuc visual question answering visual relationship detection relation bootstrap deep learning neurips nips', # Optional
104 |
105 | # You can just specify package directories manually here if your project is
106 | # simple. Or you can use find_packages().
107 | #
108 | # Alternatively, if you just want to distribute a single Python file, use
109 | # the `py_modules` argument instead as follows, which will expect a file
110 | # called `my_module.py` to exist:
111 | #
112 | # py_modules=["my_module"],
113 | #
114 | packages=find_packages(exclude=['data', 'logs', 'tests', 'bootstrap', 'block']), # Required
115 |
116 | # This field lists other packages that your project depends on to run.
117 | # Any package you put here will be installed by pip when your project is
118 | # installed, so they must be valid existing projects.
119 | #
120 | # For an analysis of "install_requires" vs pip's requirements files see:
121 | # https://packaging.python.org/en/latest/requirements.html
122 | install_requires=[
123 | 'bootstrap.pytorch',
124 | 'skipthoughts',
125 | 'pretrainedmodels',
126 | 'opencv-python',
127 | 'block.bootstrap.pytorch',
128 | #'cfft'
129 | ],
130 |
131 | # pip install pytorch-fft does not install the last version
132 | # we need to add a dependency link
133 | # https://python-packaging.readthedocs.io/en/latest/dependencies.html
134 | # dependency_links=[
135 | # 'https://github.com/locuslab/pytorch_fft'
136 | # ],
137 |
138 | # List additional groups of dependencies here (e.g. development
139 | # dependencies). Users will be able to install these using the "extras"
140 | # syntax, for example:
141 | #
142 | # $ pip install sampleproject[dev]
143 | #
144 | # Similar to `install_requires` above, these must be valid existing
145 | # projects.
146 | extras_require={ # Optional
147 | # 'dev': ['check-manifest'],
148 | 'test': ['pytest'],
149 | },
150 |
151 | # If there are data files included in your packages that need to be
152 | # installed, specify them here.
153 | #
154 | # If using Python 2.6 or earlier, then these have to be included in
155 | # MANIFEST.in as well.
156 | # package_data={ # Optional
157 | # 'sample': ['package_data.dat'],
158 | # },
159 |
160 | # Although 'package_data' is the preferred approach, in some case you may
161 | # need to place data files outside of your packages. See:
162 | # http://docs.python.org/3.4/distutils/setupscript.html#installing-additional-files
163 | #
164 | # In this case, 'data_file' will be installed into '/my_data'
165 | # data_files=[('my_data', ['data/data_file'])], # Optional
166 |
167 | # To provide executable scripts, use entry points in preference to the
168 | # "scripts" keyword. Entry points provide cross-platform support and allow
169 | # `pip` to create the appropriate form of executable for the target
170 | # platform.
171 | #
172 | # For example, the following would provide a command called `sample` which
173 | # executes the function `main` from this package when invoked:
174 | # entry_points={ # Optional
175 | # 'console_scripts': [
176 | # 'sample=sample:main',
177 | # ],
178 | # },
179 | )
180 |
--------------------------------------------------------------------------------