├── .gitignore
├── cam.jpg
├── sample.jpg
├── data.py
├── README.md
├── update.py
├── train.py
├── main.py
└── inception.py
/.gitignore:
--------------------------------------------------------------------------------
1 | __pycache__
2 | .idea
3 | kaggle/*
4 | result*/
5 | result*
6 |
--------------------------------------------------------------------------------
/cam.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaeyoung-lee/pytorch-CAM/HEAD/cam.jpg
--------------------------------------------------------------------------------
/sample.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaeyoung-lee/pytorch-CAM/HEAD/sample.jpg
--------------------------------------------------------------------------------
/data.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import io
3 | import requests
4 | from PIL import Image
5 |
6 | def read_data(img_num, txt, idx):
7 | f = open(txt, 'r')
8 | IMG_URLs = []
9 | for i in range(img_num):
10 | line = f.readline()
11 | url = line.split()[idx]
12 | IMG_URLs = np.append(IMG_URLs,url)
13 | f.close()
14 | return IMG_URLs
15 |
16 | def get_img(num, IMG_URL, root):
17 | response = requests.get(IMG_URL)
18 | img_pil = Image.open(io.BytesIO(response.content))
19 | #img_pil.save(str(idx) + '.jpg')
20 | img_pil.save(root + str(num) + '.jpg')
21 | return img_pil
22 |
23 | """
24 | # 이미지넷 이미지 추출
25 | IMG_URLs = read_data(1071, 'data/ear.txt', 0)
26 |
27 | for i in range(len(IMG_URLs)):
28 | try:
29 | print(i)
30 | IMG_URL = IMG_URLs[i]
31 | img = get_img(i, IMG_URL, root='image/train/ear/')
32 | if img == 0: continue
33 | print()
34 | except:
35 | print('에러')
36 | print()
37 | """
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # pytorch-CAM
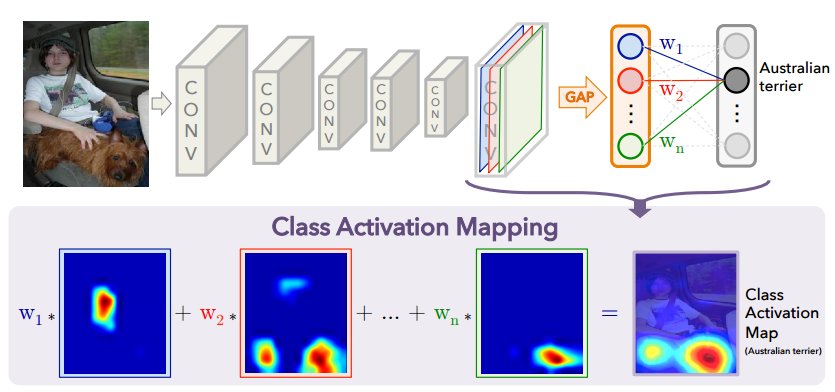
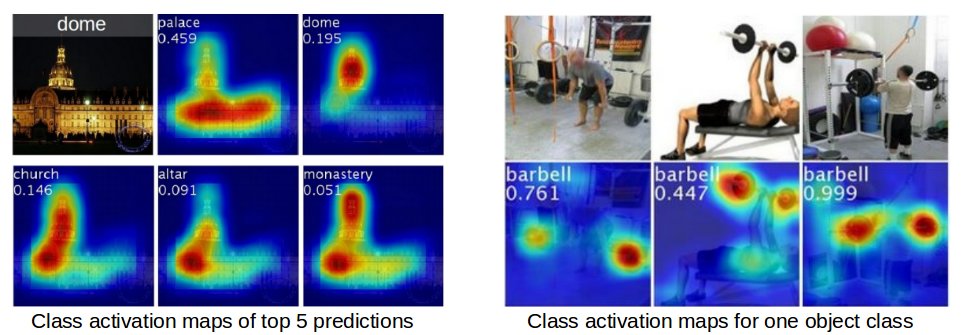
2 | This repository is an unofficial version of Class Activation Mapping written in PyTorch, modified for a simple use case.
3 |
4 | ## Class Activation Mapping (CAM)
5 | Paper and Archiecture: [Learning Deep Features for Discriminative Localization][1]
6 |
7 | Paper Author Implementation: [metalbubble/CAM][2]
8 |
9 | In the paper:
10 |
11 | *We propose a technique for generating class activation maps using the global average pooling (GAP) in CNNs. A class activation map for a particular category indicates the discriminative image regions used by the CNN to identify that category. The procedure for generating these maps is illustrated as follows:*
12 |
13 |
14 |
15 |
20 |
21 |