├── NER
├── metrics
│ ├── __init__.py
│ ├── functional
│ │ ├── __init__.py
│ │ └── query_span_f1.py
│ └── query_span_f1.py
├── models
│ ├── __init__.py
│ ├── query_ner_config.py
│ ├── classifier.py
│ └── bert_query_ner.py
├── ner2mrc
│ ├── __init__.py
│ ├── queries
│ │ ├── zh_msra.json
│ │ └── genia.json
│ ├── download.md
│ ├── genia2mrc.py
│ └── msra2mrc.py
├── utils
│ ├── __init__.py
│ ├── convert_tf2torch.sh
│ ├── radom_seed.py
│ ├── get_parser.py
│ └── bmes_decode.py
├── datasets
│ ├── __init__.py
│ ├── truncate_dataset.py
│ ├── collate_functions.py
│ ├── mrc_ner_dataset.py
│ ├── compute_acc.py
│ ├── compute_acc_linux.py
│ └── doc-paragraph-sentence-id
│ │ ├── mrc-ner.test-id
│ │ └── mrc-ner.dev-id
├── loss
│ ├── __init__.py
│ ├── adaptive_dice_loss.py
│ └── dice_loss.py
├── requirements.txt
├── scripts
│ └── reproduce
│ │ ├── zh_msra.sh
│ │ ├── ace04.sh
│ │ └── ace05.sh
├── parameters
├── evaluate.py
├── README.md
└── trainer.py
├── RE
├── requirements.txt
├── data
│ └── relation2id.txt
├── README.md
├── process_data.py
├── train_GRU.py
├── network.py
├── initial.py
└── test_GRU.py
├── data
└── annotation-guidelines.pdf
├── .gitignore
├── README.md
└── LICENSE
/NER/metrics/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/NER/models/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/NER/ner2mrc/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/NER/utils/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/NER/datasets/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/NER/metrics/functional/__init__.py:
--------------------------------------------------------------------------------
1 |
--------------------------------------------------------------------------------
/NER/loss/__init__.py:
--------------------------------------------------------------------------------
1 | from .dice_loss import DiceLoss
2 |
--------------------------------------------------------------------------------
/RE/requirements.txt:
--------------------------------------------------------------------------------
1 | tensorflow==1.15.4
2 | scikit_learn==0.23.2
3 | jieba==0.42.1
4 |
--------------------------------------------------------------------------------
/NER/requirements.txt:
--------------------------------------------------------------------------------
1 | torch
2 | pytorch-lightning==0.9.0
3 | tokenizers
4 | transformers
5 |
--------------------------------------------------------------------------------
/data/annotation-guidelines.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/changdejie/diaKG-code/HEAD/data/annotation-guidelines.pdf
--------------------------------------------------------------------------------
/NER/ner2mrc/queries/zh_msra.json:
--------------------------------------------------------------------------------
1 | {
2 | "NR": "人名和虚构的人物形象",
3 | "NS": "按照地理位置划分的国家,城市,乡镇,大洲",
4 | "NT": "组织包括公司,政府党派,学校,政府,新闻机构"
5 | }
--------------------------------------------------------------------------------
/NER/models/query_ner_config.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | from transformers import BertConfig
5 |
6 |
7 | class BertQueryNerConfig(BertConfig):
8 | def __init__(self, **kwargs):
9 | super(BertQueryNerConfig, self).__init__(**kwargs)
10 | self.mrc_dropout = kwargs.get("mrc_dropout", 0.1)
11 |
--------------------------------------------------------------------------------
/NER/utils/convert_tf2torch.sh:
--------------------------------------------------------------------------------
1 | # convert tf model to pytorch format
2 |
3 | export BERT_BASE_DIR=/mnt/mrc/wwm_uncased_L-24_H-1024_A-16
4 |
5 | transformers-cli convert --model_type bert \
6 | --tf_checkpoint $BERT_BASE_DIR/model.ckpt \
7 | --config $BERT_BASE_DIR/config.json \
8 | --pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
9 |
--------------------------------------------------------------------------------
/NER/ner2mrc/queries/genia.json:
--------------------------------------------------------------------------------
1 | {
2 | "DNA": "deoxyribonucleic acid",
3 | "RNA": "ribonucleic acid",
4 | "cell_line": "cell line",
5 | "cell_type": "cell type",
6 | "protein": "protein entities are limited to nitrogenous organic compounds and are parts of all living organisms, as structural components of body tissues such as muscle, hair, collagen and as enzymes and antibodies."
7 | }
8 |
--------------------------------------------------------------------------------
/RE/data/relation2id.txt:
--------------------------------------------------------------------------------
1 | Rel_Method_Drug 0
2 | Rel_Test_items_Disease 1
3 | Rel_Anatomy_Disease 2
4 | Rel_Drug_Disease 3
5 | Rel_SideEff_Disease 4
6 | Rel_Treatment_Disease 5
7 | Rel_Pathogenesis_Disease 6
8 | Rel_Frequency_Drug 7
9 | Rel_Test_Disease 8
10 | Rel_Operation_Disese 9
11 | Rel_Symptom_Disease 10
12 | Rel_Type_Disease 11
13 | Rel_Amount_Drug 12
14 | Rel_SideEff_Drug 13
15 | Rel_Reason_Disease 14
16 | Rel_Duration_Drug 15
--------------------------------------------------------------------------------
/NER/utils/radom_seed.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import numpy as np
5 | import torch
6 |
7 |
8 | def set_random_seed(seed: int):
9 | """set seeds for reproducibility"""
10 | np.random.seed(seed)
11 | torch.manual_seed(seed)
12 | torch.backends.cudnn.deterministic = True
13 | torch.backends.cudnn.benchmark = False
14 |
15 |
16 | if __name__ == '__main__':
17 | # without this line, x would be different in every execution.
18 | set_random_seed(0)
19 |
20 | x = np.random.random()
21 | print(x)
22 |
--------------------------------------------------------------------------------
/NER/ner2mrc/download.md:
--------------------------------------------------------------------------------
1 | ## Download Processed MRC-NER Datasets
2 | ZH:
3 | - [MSRA](https://drive.google.com/file/d/1bAoSJfT1IBdpbQWSrZPjQPPbAsDGlN2D/view?usp=sharing)
4 | - [OntoNotes4](https://drive.google.com/file/d/1CRVgZJDDGuj0O1NLK5DgujQBTLKyMR-g/view?usp=sharing)
5 |
6 | EN:
7 | - [CoNLL03](https://drive.google.com/file/d/1COt5bSHgwfl3oIZ6sCBVAenJKlfy3LI_/view?usp=sharing)
8 | - [ACE2004](https://drive.google.com/file/d/1zxLjecKK7CeLjxvPa-9QU9xsRJTVI5vb/view?usp=sharing)
9 | - [ACE2005](https://drive.google.com/file/d/1yxfwlrBmYIECqL_4K5xRve-pfBeIt58z/view?usp=sharing)
10 |
--------------------------------------------------------------------------------
/NER/datasets/truncate_dataset.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 | from torch.utils.data import Dataset
4 |
5 |
6 | class TruncateDataset(Dataset):
7 | """Truncate dataset to certain num"""
8 | def __init__(self, dataset: Dataset, max_num: int = 100):
9 | self.dataset = dataset
10 | self.max_num = min(max_num, len(self.dataset))
11 |
12 | def __len__(self):
13 | return self.max_num
14 |
15 | def __getitem__(self, item):
16 | return self.dataset[item]
17 |
18 | def __getattr__(self, item):
19 | """other dataset func"""
20 | return getattr(self.dataset, item)
21 |
--------------------------------------------------------------------------------
/NER/metrics/query_span_f1.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | from pytorch_lightning.metrics.metric import TensorMetric
5 | from .functional.query_span_f1 import query_span_f1
6 |
7 |
8 | class QuerySpanF1(TensorMetric):
9 | """
10 | Query Span F1
11 | Args:
12 | flat: is flat-ner
13 | """
14 | def __init__(self, reduce_group=None, reduce_op=None, flat=False):
15 | super(QuerySpanF1, self).__init__(name="query_span_f1",
16 | reduce_group=reduce_group,
17 | reduce_op=reduce_op)
18 | self.flat = flat
19 |
20 | def forward(self, start_preds, end_preds, match_logits, start_label_mask, end_label_mask, match_labels):
21 | return query_span_f1(start_preds, end_preds, match_logits, start_label_mask, end_label_mask, match_labels,
22 | flat=self.flat)
23 |
--------------------------------------------------------------------------------
/NER/scripts/reproduce/zh_msra.sh:
--------------------------------------------------------------------------------
1 | export PYTHONPATH="$PWD"
2 | export TOKENIZERS_PARALLELISM=false
3 | DATA_DIR="/mnt/mrc/zh_msra"
4 | BERT_DIR="/mnt/mrc/chinese_roberta_wwm_large_ext_pytorch"
5 | SPAN_WEIGHT=0.1
6 | DROPOUT=0.2
7 | LR=8e-6
8 | MAXLEN=128
9 |
10 | OUTPUT_DIR="/mnt/mrc/train_logs/zh_msra/zh_msra_bertlarge_lr${LR}20200913_dropout${DROPOUT}_bsz16_maxlen${MAXLEN}"
11 |
12 | mkdir -p $OUTPUT_DIR
13 |
14 | python trainer.py \
15 | --chinese \
16 | --data_dir $DATA_DIR \
17 | --bert_config_dir $BERT_DIR \
18 | --max_length $MAXLEN \
19 | --batch_size 4 \
20 | --gpus="0,1,2,3" \
21 | --precision=16 \
22 | --progress_bar_refresh_rate 1 \
23 | --lr ${LR} \
24 | --distributed_backend=ddp \
25 | --val_check_interval 0.5 \
26 | --accumulate_grad_batches 1 \
27 | --default_root_dir $OUTPUT_DIR \
28 | --mrc_dropout $DROPOUT \
29 | --max_epochs 20 \
30 | --weight_span $SPAN_WEIGHT \
31 | --span_loss_candidates "pred_and_gold"
32 |
--------------------------------------------------------------------------------
/NER/scripts/reproduce/ace04.sh:
--------------------------------------------------------------------------------
1 | export PYTHONPATH="$PWD"
2 | DATA_DIR="/mnt/mrc/ace2004"
3 | BERT_DIR="/mnt/mrc/bert-large-uncased"
4 |
5 | BERT_DROPOUT=0.1
6 | MRC_DROPOUT=0.3
7 | LR=3e-5
8 | SPAN_WEIGHT=0.1
9 | WARMUP=0
10 | MAXLEN=128
11 | MAXNORM=1.0
12 |
13 | OUTPUT_DIR="/mnt/mrc/train_logs/ace2004/ace2004_20200915reproduce_lr${LR}_drop${MRC_DROPOUT}_norm${MAXNORM}_bsz32_hard_span_weight${SPAN_WEIGHT}_warmup${WARMUP}_maxlen${MAXLEN}_newtrunc_debug"
14 | mkdir -p $OUTPUT_DIR
15 | python trainer.py \
16 | --data_dir $DATA_DIR \
17 | --bert_config_dir $BERT_DIR \
18 | --max_length $MAXLEN \
19 | --batch_size 4 \
20 | --gpus="0,1,2,3" \
21 | --precision=16 \
22 | --progress_bar_refresh_rate 1 \
23 | --lr $LR \
24 | --distributed_backend=ddp \
25 | --val_check_interval 0.5 \
26 | --accumulate_grad_batches 2 \
27 | --default_root_dir $OUTPUT_DIR \
28 | --mrc_dropout $MRC_DROPOUT \
29 | --bert_dropout $BERT_DROPOUT \
30 | --max_epochs 20 \
31 | --span_loss_candidates "pred_and_gold" \
32 | --weight_span $SPAN_WEIGHT \
33 | --warmup_steps $WARMUP \
34 | --max_length $MAXLEN \
35 | --gradient_clip_val $MAXNORM
36 |
--------------------------------------------------------------------------------
/NER/scripts/reproduce/ace05.sh:
--------------------------------------------------------------------------------
1 | export PYTHONPATH="$PWD"
2 | DATA_DIR="/mnt/mrc/ace2005"
3 | BERT_DIR="/mnt/mrc/wwm_uncased_L-24_H-1024_A-16"
4 |
5 | BERT_DROPOUT=0.1
6 | MRC_DROPOUT=0.4
7 | LR=1e-5
8 | SPAN_WEIGHT=0.1
9 | WARMUP=0
10 | MAXLEN=128
11 | MAXNORM=1.0
12 |
13 | OUTPUT_DIR="/mnt/mrc/train_logs/ace2005/ace2005_20200917_wwmlarge_sgd_warm${WARMUP}lr${LR}_drop${MRC_DROPOUT}_norm${MAXNORM}_bsz32_gold_span_weight${SPAN_WEIGHT}_warmup${WARMUP}_maxlen${MAXLEN}"
14 | mkdir -p $OUTPUT_DIR
15 |
16 | python trainer.py \
17 | --data_dir $DATA_DIR \
18 | --bert_config_dir $BERT_DIR \
19 | --max_length $MAXLEN \
20 | --batch_size 8 \
21 | --gpus="0,1,2,3" \
22 | --precision=16 \
23 | --progress_bar_refresh_rate 1 \
24 | --lr $LR \
25 | --distributed_backend=ddp \
26 | --val_check_interval 0.25 \
27 | --accumulate_grad_batches 1 \
28 | --default_root_dir $OUTPUT_DIR \
29 | --mrc_dropout $MRC_DROPOUT \
30 | --bert_dropout $BERT_DROPOUT \
31 | --max_epochs 20 \
32 | --span_loss_candidates "pred_and_gold" \
33 | --weight_span $SPAN_WEIGHT \
34 | --warmup_steps $WARMUP \
35 | --max_length $MAXLEN \
36 | --gradient_clip_val $MAXNORM \
37 | --optimizer "adamw"
38 |
--------------------------------------------------------------------------------
/NER/models/classifier.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import torch.nn as nn
5 | from torch.nn import functional as F
6 |
7 |
8 | class SingleLinearClassifier(nn.Module):
9 | def __init__(self, hidden_size, num_label):
10 | super(SingleLinearClassifier, self).__init__()
11 | self.num_label = num_label
12 | self.classifier = nn.Linear(hidden_size, num_label)
13 |
14 | def forward(self, input_features):
15 | features_output = self.classifier(input_features)
16 | return features_output
17 |
18 |
19 | class MultiNonLinearClassifier(nn.Module):
20 | def __init__(self, hidden_size, num_label, dropout_rate):
21 | super(MultiNonLinearClassifier, self).__init__()
22 | self.num_label = num_label
23 | self.classifier1 = nn.Linear(hidden_size, hidden_size)
24 | self.classifier2 = nn.Linear(hidden_size, num_label)
25 | self.dropout = nn.Dropout(dropout_rate)
26 |
27 | def forward(self, input_features):
28 | features_output1 = self.classifier1(input_features)
29 | # features_output1 = F.relu(features_output1)
30 | features_output1 = F.gelu(features_output1)
31 | features_output1 = self.dropout(features_output1)
32 | features_output2 = self.classifier2(features_output1)
33 | return features_output2
34 |
--------------------------------------------------------------------------------
/NER/utils/get_parser.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import argparse
5 |
6 |
7 | def get_parser() -> argparse.ArgumentParser:
8 | """
9 | return basic arg parser
10 | """
11 | parser = argparse.ArgumentParser(description="Training")
12 |
13 | parser.add_argument("--data_dir", type=str, required=False, default="E:\\data\\nested",help="data dir")
14 | parser.add_argument("--bert_config_dir", type=str, required=False, default="E:\data\chinese_roberta_wwm_large_ext_pytorch",help="bert config dir")
15 | parser.add_argument("--pretrained_checkpoint", default="", type=str, help="pretrained checkpoint path")
16 | parser.add_argument("--max_length", type=int, default=128, help="max length of dataset")
17 | parser.add_argument("--batch_size", type=int, default=2, help="batch size")
18 | parser.add_argument("--lr", type=float, default=2e-5, help="learning rate")
19 | parser.add_argument("--workers", type=int, default=0, help="num workers for dataloader")
20 | parser.add_argument("--weight_decay", default=0.01, type=float,
21 | help="Weight decay if we apply some.")
22 | parser.add_argument("--warmup_steps", default=0, type=int,
23 | help="warmup steps used for scheduler.")
24 | parser.add_argument("--adam_epsilon", default=1e-8, type=float,
25 | help="Epsilon for Adam optimizer.")
26 |
27 | return parser
28 |
--------------------------------------------------------------------------------
/NER/datasets/collate_functions.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 | import torch
4 | from typing import List
5 |
6 |
7 | def collate_to_max_length(batch: List[List[torch.Tensor]]) -> List[torch.Tensor]:
8 | """
9 | pad to maximum length of this batch
10 | Args:
11 | batch: a batch of samples, each contains a list of field data(Tensor):
12 | tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx
13 | Returns:
14 | output: list of field batched data, which shape is [batch, max_length]
15 | """
16 | batch_size = len(batch)
17 | max_length = max(x[0].shape[0] for x in batch)
18 | output = []
19 |
20 | for field_idx in range(6):
21 | pad_output = torch.full([batch_size, max_length], 0, dtype=batch[0][field_idx].dtype)
22 | for sample_idx in range(batch_size):
23 | data = batch[sample_idx][field_idx]
24 | pad_output[sample_idx][: data.shape[0]] = data
25 | output.append(pad_output)
26 |
27 | pad_match_labels = torch.zeros([batch_size, max_length, max_length], dtype=torch.long)
28 | for sample_idx in range(batch_size):
29 | data = batch[sample_idx][6]
30 | pad_match_labels[sample_idx, : data.shape[1], : data.shape[1]] = data
31 | output.append(pad_match_labels)
32 |
33 | output.append(torch.stack([x[-2] for x in batch]))
34 | output.append(torch.stack([x[-1] for x in batch]))
35 |
36 | return output
37 |
--------------------------------------------------------------------------------
/NER/parameters:
--------------------------------------------------------------------------------
1 | accumulate_grad_batches: 1
2 | adam_epsilon: 1.0e-08
3 | amp_backend: native
4 | amp_level: O2
5 | auto_lr_find: false
6 | auto_scale_batch_size: false
7 | auto_select_gpus: false
8 | batch_size: 32
9 | benchmark: false
10 | bert_config_dir: chinese_roberta_wwm_large_ext_pytorch
11 | bert_dropout: 0.1
12 | check_val_every_n_epoch: 1
13 | checkpoint_callback: true
14 | chinese: false
15 | data_dir: nested
16 | default_root_dir: null
17 | deterministic: false
18 | dice_smooth: 1.0e-08
19 | distributed_backend: null
20 | early_stop_callback: false
21 | fast_dev_run: false
22 | final_div_factor: 10000.0
23 | flat: false
24 | gradient_clip_val: 0
25 | limit_test_batches: 1.0
26 | limit_train_batches: 1.0
27 | limit_val_batches: 1.0
28 | log_gpu_memory: null
29 | log_save_interval: 100
30 | logger: true
31 | loss_type: bce
32 | lr: 2.0e-05
33 | gpus: 0
34 | max_epochs: 10
35 | max_length: 128
36 | max_steps: null
37 | min_epochs: 1
38 | min_steps: null
39 | mrc_dropout: 0.1
40 | num_nodes: 1
41 | num_processes: 1
42 | num_sanity_val_steps: 2
43 | optimizer: adamw
44 | overfit_batches: 0.0
45 | overfit_pct: null
46 | precision: 32
47 | prepare_data_per_node: true
48 | pretrained_checkpoint: ''
49 | process_position: 0
50 | profiler: null
51 | progress_bar_refresh_rate: 1
52 | reload_dataloaders_every_epoch: false
53 | replace_sampler_ddp: true
54 | resume_from_checkpoint: null
55 | row_log_interval: 50
56 | span_loss_candidates: all
57 | sync_batchnorm: false
58 | terminate_on_nan: false
59 | test_percent_check: null
60 | track_grad_norm: -1
61 | train_percent_check: null
62 | truncated_bptt_steps: null
63 | val_check_interval: 1.0
64 | val_percent_check: null
65 | warmup_steps: 0
66 | weight_decay: 0.01
67 | weight_end: 1.0
68 | weight_span: 1.0
69 | weight_start: 1.0
70 | weights_save_path: null
71 | weights_summary: top
72 | workers: 0
73 |
--------------------------------------------------------------------------------
/NER/ner2mrc/genia2mrc.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import os
5 | from utils.bmes_decode import bmes_decode
6 | import json
7 |
8 |
9 | def convert_file(input_file, output_file, tag2query_file):
10 | """
11 | Convert GENIA(xiaoya) data to MRC format
12 | """
13 | all_data = json.load(open(input_file))
14 | tag2query = json.load(open(tag2query_file))
15 |
16 | output = []
17 | origin_count = 0
18 | new_count = 0
19 |
20 | for data in all_data:
21 | origin_count += 1
22 | context = data["context"]
23 | label2positions = data["label"]
24 | for tag_idx, (tag, query) in enumerate(tag2query.items()):
25 | positions = label2positions.get(tag, [])
26 | mrc_sample = {
27 | "context": context,
28 | "query": query,
29 | "start_position": [int(x.split(";")[0]) for x in positions],
30 | "end_position": [int(x.split(";")[1]) for x in positions],
31 | "qas_id": f"{origin_count}.{tag_idx}"
32 | }
33 | output.append(mrc_sample)
34 | new_count += 1
35 |
36 | json.dump(output, open(output_file, "w"), ensure_ascii=False, indent=2)
37 | print(f"Convert {origin_count} samples to {new_count} samples and save to {output_file}")
38 |
39 |
40 | def main():
41 | genia_raw_dir = "/mnt/mrc/genia/genia_raw"
42 | genia_mrc_dir = "/mnt/mrc/genia/genia_raw/mrc_format"
43 | tag2query_file = "queries/genia.json"
44 | os.makedirs(genia_mrc_dir, exist_ok=True)
45 | for phase in ["train", "dev", "test"]:
46 | old_file = os.path.join(genia_raw_dir, f"{phase}.genia.json")
47 | new_file = os.path.join(genia_mrc_dir, f"mrc-ner.{phase}")
48 | convert_file(old_file, new_file, tag2query_file)
49 |
50 |
51 | if __name__ == '__main__':
52 | main()
53 |
--------------------------------------------------------------------------------
/NER/evaluate.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import os
5 | from pytorch_lightning import Trainer
6 |
7 | from trainer import BertLabeling
8 |
9 |
10 | def evaluate(ckpt, hparams_file):
11 | """main"""
12 |
13 | trainer = Trainer(distributed_backend="ddp")
14 |
15 | model = BertLabeling.load_from_checkpoint(
16 | checkpoint_path=ckpt,
17 | hparams_file=hparams_file,
18 | map_location=None,
19 | batch_size=1,
20 | max_length=128,
21 | workers=0
22 | )
23 | trainer.test(model=model)
24 |
25 | if __name__ == '__main__':
26 | # ace04
27 | # HPARAMS = "/mnt/mrc/train_logs/ace2004/ace2004_20200911reproduce_epoch15_lr3e-5_drop0.3_norm1.0_bsz32_hard_span_weight0.1_warmup0_maxlen128_newtrunc_debug/lightning_logs/version_0/hparams.yaml"
28 | # CHECKPOINTS = "/mnt/mrc/train_logs/ace2004/ace2004_20200911reproduce_epoch15_lr3e-5_drop0.3_norm1.0_bsz32_hard_span_weight0.1_warmup0_maxlen128_newtrunc_debug/epoch=10_v0.ckpt"
29 | # DIR = "/mnt/mrc/train_logs/ace2004/ace2004_20200910_lr3e-5_drop0.3_bert0.1_bsz32_hard_loss_bce_weight_span0.05"
30 | # CHECKPOINTS = [os.path.join(DIR, x) for x in os.listdir(DIR)]
31 |
32 | # ace04-large
33 | # HPARAMS = "/mnt/mrc/train_logs/ace2004/ace2004_20200910reproduce_lr3e-5_drop0.3_norm1.0_bsz32_hard_span_weight0.1_warmup0_maxlen128_newtrunc_debug/lightning_logs/version_2/hparams.yaml"
34 | # CHECKPOINTS = "/mnt/mrc/train_logs/ace2004/ace2004_20200910reproduce_lr3e-5_drop0.3_norm1.0_bsz32_hard_span_weight0.1_warmup0_maxlen128_newtrunc_debug/epoch=10.ckpt"
35 |
36 | # ace05
37 | # HPARAMS = "/mnt/mrc/train_logs/ace2005/ace2005_20200911_lr3e-5_drop0.3_norm1.0_bsz32_hard_span_weight0.1_warmup0_maxlen128_newtrunc_debug/lightning_logs/version_0/hparams.yaml"
38 | # CHECKPOINTS = "/mnt/mrc/train_logs/ace2005/ace2005_20200911_lr3e-5_drop0.3_norm1.0_bsz32_hard_span_weight0.1_warmup0_maxlen128_newtrunc_debug/epoch=15.ckpt"
39 |
40 | # zh_msra
41 | CHECKPOINTS = "E:\\data\\modelNER\\version_7\\checkpoints\\epoch=2.ckpt"
42 | HPARAMS = "E:\\data\\modelNER\\version_7\\hparams.yaml"
43 |
44 | evaluate(ckpt=CHECKPOINTS, hparams_file=HPARAMS)
45 |
--------------------------------------------------------------------------------
/NER/ner2mrc/msra2mrc.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import os
5 | from utils.bmes_decode import bmes_decode
6 | import json
7 |
8 |
9 | def convert_file(input_file, output_file, tag2query_file):
10 | """
11 | Convert MSRA raw data to MRC format
12 | """
13 | origin_count = 0
14 | new_count = 0
15 | tag2query = json.load(open(tag2query_file))
16 | mrc_samples = []
17 | with open(input_file) as fin:
18 | for line in fin:
19 | line = line.strip()
20 | if not line:
21 | continue
22 | origin_count += 1
23 | src, labels = line.split("\t")
24 | tags = bmes_decode(char_label_list=[(char, label) for char, label in zip(src.split(), labels.split())])
25 | for label, query in tag2query.items():
26 | mrc_samples.append(
27 | {
28 | "context": src,
29 | "start_position": [tag.begin for tag in tags if tag.tag == label],
30 | "end_position": [tag.end-1 for tag in tags if tag.tag == label],
31 | "query": query
32 | }
33 | )
34 | new_count += 1
35 |
36 | json.dump(mrc_samples, open(output_file, "w"), ensure_ascii=False, sort_keys=True, indent=2)
37 | print(f"Convert {origin_count} samples to {new_count} samples and save to {output_file}")
38 |
39 |
40 | def main():
41 | # msra_raw_dir = "/mnt/mrc/zh_msra_yuxian"
42 | # msra_mrc_dir = "/mnt/mrc/zh_msra_yuxian/mrc_format"
43 | msra_raw_dir = "./queries/zh_msra"
44 | msra_mrc_dir = "/mnt/mrc/zh_msra/mrc_format"
45 | tag2query_file = "queries/zh_msra.json"
46 | os.makedirs(msra_mrc_dir, exist_ok=True)
47 | for phase in ["train", "dev", "test"]:
48 | old_file = os.path.join(msra_raw_dir, f"{phase}.tsv")
49 | new_file = os.path.join(msra_mrc_dir, f"mrc-ner.{phase}")
50 | # old_file = os.path.join(msra_raw_dir, f"mrc-ner.{phase}")
51 | # new_file = os.path.join(msra_mrc_dir, f"mrc-ner.{phase}")
52 | convert_file(old_file, new_file, tag2query_file)
53 |
54 |
55 | if __name__ == '__main__':
56 | main()
57 |
--------------------------------------------------------------------------------
/NER/utils/bmes_decode.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | from typing import Tuple, List
5 |
6 |
7 | class Tag(object):
8 | def __init__(self, term, tag, begin, end):
9 | self.term = term
10 | self.tag = tag
11 | self.begin = begin
12 | self.end = end
13 |
14 | def to_tuple(self):
15 | return tuple([self.term, self.begin, self.end])
16 |
17 | def __str__(self):
18 | return str({key: value for key, value in self.__dict__.items()})
19 |
20 | def __repr__(self):
21 | return str({key: value for key, value in self.__dict__.items()})
22 |
23 |
24 | def bmes_decode(char_label_list: List[Tuple[str, str]]) -> List[Tag]:
25 | """
26 | decode inputs to tags
27 | Args:
28 | char_label_list: list of tuple (word, bmes-tag)
29 | Returns:
30 | tags
31 | Examples:
32 | >>> x = [("Hi", "O"), ("Beijing", "S-LOC")]
33 | >>> bmes_decode(x)
34 | [{'term': 'Beijing', 'tag': 'LOC', 'begin': 1, 'end': 2}]
35 | """
36 | idx = 0
37 | length = len(char_label_list)
38 | tags = []
39 | while idx < length:
40 | term, label = char_label_list[idx]
41 | current_label = label[0]
42 |
43 | # correct labels
44 | if current_label in ["M", "E"]:
45 | current_label = "B"
46 | if idx + 1 == length and current_label == "B":
47 | current_label = "S"
48 |
49 | # merge chars
50 | if current_label == "O":
51 | idx += 1
52 | continue
53 | if current_label == "S":
54 | tags.append(Tag(term, label[2:], idx, idx + 1))
55 | idx += 1
56 | continue
57 | if current_label == "B":
58 | end = idx + 1
59 | while end + 1 < length and char_label_list[end][1][0] == "M":
60 | end += 1
61 | if char_label_list[end][1][0] == "E": # end with E
62 | entity = "".join(char_label_list[i][0] for i in range(idx, end + 1))
63 | tags.append(Tag(entity, label[2:], idx, end + 1))
64 | idx = end + 1
65 | else: # end with M/B
66 | entity = "".join(char_label_list[i][0] for i in range(idx, end))
67 | tags.append(Tag(entity, label[2:], idx, end))
68 | idx = end
69 | continue
70 | else:
71 | raise Exception("Invalid Inputs")
72 | return tags
73 |
--------------------------------------------------------------------------------
/NER/README.md:
--------------------------------------------------------------------------------
1 | # A Unified MRC Framework for Named Entity Recognition
2 | The repository contains the code of the recent research advances in [Shannon.AI](http://www.shannonai.com).
3 |
4 | **A Unified MRC Framework for Named Entity Recognition**
5 | Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu and Jiwei Li
6 | In ACL 2020. [paper](https://arxiv.org/abs/1910.11476)
7 | If you find this repo helpful, please cite the following:
8 | ```latex
9 | @article{li2019unified,
10 | title={A Unified MRC Framework for Named Entity Recognition},
11 | author={Li, Xiaoya and Feng, Jingrong and Meng, Yuxian and Han, Qinghong and Wu, Fei and Li, Jiwei},
12 | journal={arXiv preprint arXiv:1910.11476},
13 | year={2019}
14 | }
15 | ```
16 | For any question, please feel free to post Github issues.
17 |
18 | ## Install Requirements
19 | `pip install -r requirements.txt`
20 |
21 | We build our project on [pytorch-lightning.](https://github.com/PyTorchLightning/pytorch-lightning)
22 | If you want to know more about the arguments used in our training scripts, please
23 | refer to [pytorch-lightning documentation.](https://pytorch-lightning.readthedocs.io/en/latest/)
24 |
25 | ## Prepare Datasets
26 | You can [download](./ner2mrc/download.md) our preprocessed MRC-NER datasets or
27 | write your own preprocess scripts. We provide `ner2mrc/mrsa2mrc.py` for reference.
28 |
29 | ## Prepare Models
30 | For English Datasets, we use [BERT-Large](https://github.com/google-research/bert)
31 |
32 | For Chinese Datasets, we use [RoBERTa-wwm-ext-large](https://github.com/ymcui/Chinese-BERT-wwm)
33 |
34 | ## Train
35 | The main training procedure is in `trainer.py`
36 |
37 | Examples to start training are in `scripts/reproduce`.
38 |
39 | Note that you may need to change `DATA_DIR`, `BERT_DIR`, `OUTPUT_DIR` to your own
40 | dataset path, bert model path and log path, respectively.
41 |
42 | ## Evaluate
43 | `trainer.py` will automatically evaluate on dev set every `val_check_interval` epochs,
44 | and save the topk checkpoints to `default_root_dir`.
45 |
46 | To evaluate them, use `evaluate.py`
47 |
48 | # 模型经改造后使用如下
49 | ## 训练模型
50 | ```
51 | 训练的时候依据自己的机器情况设置参数,参数过大容易导致显存溢出
52 | python trainer.py --data_dir entity_type_data --bert_config models/chinese_roberta_wwm_large_ext_pytorch --batch_size 16 --max_epochs 10 --gpus 1
53 | ```
54 | ## 评估模型
55 | ```
56 | 需要修改evaluate里面新模型的路径
57 | python evaluate.py
58 |
59 | ```
60 | ## 统计详细不同实体信息
61 | ```
62 | datasets/compute_acc_linux.py or datasets/compute_acc.py
63 |
64 | ```
65 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | .idea/
21 | sdist/
22 | var/
23 | wheels/
24 | pip-wheel-metadata/
25 | share/python-wheels/
26 | *.egg-info/
27 | .installed.cfg
28 | *.egg
29 | MANIFEST
30 |
31 | # PyInstaller
32 | # Usually these files are written by a python script from a template
33 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
34 | *.manifest
35 | *.spec
36 |
37 | # Installer logs
38 | pip-log.txt
39 | pip-delete-this-directory.txt
40 |
41 | # Unit test / coverage reports
42 | htmlcov/
43 | .tox/
44 | .nox/
45 | .coverage
46 | .coverage.*
47 | .cache
48 | nosetests.xml
49 | coverage.xml
50 | *.cover
51 | *.py,cover
52 | .hypothesis/
53 | .pytest_cache/
54 |
55 | # Translations
56 | *.mo
57 | *.pot
58 |
59 | # Django stuff:
60 | *.log
61 | local_settings.py
62 | db.sqlite3
63 | db.sqlite3-journal
64 |
65 | # Flask stuff:
66 | instance/
67 | .webassets-cache
68 |
69 | # Scrapy stuff:
70 | .scrapy
71 |
72 | # Sphinx documentation
73 | docs/_build/
74 |
75 | # PyBuilder
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | .python-version
87 |
88 | # pipenv
89 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
90 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
91 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
92 | # install all needed dependencies.
93 | #Pipfile.lock
94 |
95 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow
96 | __pypackages__/
97 |
98 | # Celery stuff
99 | celerybeat-schedule
100 | celerybeat.pid
101 |
102 | # SageMath parsed files
103 | *.sage.py
104 |
105 | # Environments
106 | .env
107 | .venv
108 | env/
109 | venv/
110 | ENV/
111 | env.bak/
112 | venv.bak/
113 |
114 | # Spyder project settings
115 | .spyderproject
116 | .spyproject
117 |
118 | # Rope project settings
119 | .ropeproject
120 |
121 | # mkdocs documentation
122 | /site
123 |
124 | # mypy
125 | .mypy_cache/
126 | .dmypy.json
127 | dmypy.json
128 |
129 | # Pyre type checker
130 | .pyre/
131 |
132 | # mac
133 | .DS_Store
134 |
--------------------------------------------------------------------------------
/NER/models/bert_query_ner.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import torch
5 | import torch.nn as nn
6 | from transformers import BertModel, BertPreTrainedModel
7 |
8 | from models.classifier import MultiNonLinearClassifier, SingleLinearClassifier
9 |
10 |
11 | class BertQueryNER(BertPreTrainedModel):
12 | def __init__(self, config):
13 | super(BertQueryNER, self).__init__(config)
14 | self.bert = BertModel(config)
15 |
16 | # self.start_outputs = nn.Linear(config.hidden_size, 2)
17 | # self.end_outputs = nn.Linear(config.hidden_size, 2)
18 | self.start_outputs = nn.Linear(config.hidden_size, 1)
19 | self.end_outputs = nn.Linear(config.hidden_size, 1)
20 | self.span_embedding = MultiNonLinearClassifier(config.hidden_size * 2, 1, config.mrc_dropout)
21 | # self.span_embedding = SingleLinearClassifier(config.hidden_size * 2, 1)
22 |
23 | self.hidden_size = config.hidden_size
24 |
25 | self.init_weights()
26 |
27 | def forward(self, input_ids, token_type_ids=None, attention_mask=None):
28 | """
29 | Args:
30 | input_ids: bert input tokens, tensor of shape [seq_len]
31 | token_type_ids: 0 for query, 1 for context, tensor of shape [seq_len]
32 | attention_mask: attention mask, tensor of shape [seq_len]
33 | Returns:
34 | start_logits: start/non-start probs of shape [seq_len]
35 | end_logits: end/non-end probs of shape [seq_len]
36 | match_logits: start-end-match probs of shape [seq_len, 1]
37 | """
38 |
39 | bert_outputs = self.bert(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
40 | sequence_heatmap = bert_outputs[0] # [batch, seq_len, hidden]
41 | batch_size, seq_len, hid_size = sequence_heatmap.size()
42 |
43 | start_logits = self.start_outputs(sequence_heatmap).squeeze(-1) # [batch, seq_len, 1]
44 | end_logits = self.end_outputs(sequence_heatmap).squeeze(-1) # [batch, seq_len, 1]
45 |
46 | # for every position $i$ in sequence, should concate $j$ to
47 | # predict if $i$ and $j$ are start_pos and end_pos for an entity.
48 | # [batch, seq_len, seq_len, hidden]
49 | start_extend = sequence_heatmap.unsqueeze(2).expand(-1, -1, seq_len, -1)
50 | # [batch, seq_len, seq_len, hidden]
51 | end_extend = sequence_heatmap.unsqueeze(1).expand(-1, seq_len, -1, -1)
52 | # [batch, seq_len, seq_len, hidden*2]
53 | span_matrix = torch.cat([start_extend, end_extend], 3)
54 | # [batch, seq_len, seq_len]
55 | span_logits = self.span_embedding(span_matrix).squeeze(-1)
56 |
57 | return start_logits, end_logits, span_logits
58 |
--------------------------------------------------------------------------------
/NER/loss/adaptive_dice_loss.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import torch
5 | import torch.nn as nn
6 | from torch import Tensor
7 | from typing import Optional
8 |
9 |
10 | class AdaptiveDiceLoss(nn.Module):
11 | """
12 | Dice coefficient for short, is an F1-oriented statistic used to gauge the similarity of two sets.
13 |
14 | Math Function:
15 | https://arxiv.org/abs/1911.02855.pdf
16 | adaptive_dice_loss(p, y) = 1 - numerator / denominator
17 | numerator = 2 * \sum_{1}^{t} (1 - p_i) ** alpha * p_i * y_i + smooth
18 | denominator = \sum_{1}^{t} (1 - p_i) ** alpha * p_i + \sum_{1} ^{t} y_i + smooth
19 |
20 | Args:
21 | alpha: alpha in math function
22 | smooth (float, optional): smooth in math function
23 | square_denominator (bool, optional): [True, False], specifies whether to square the denominator in the loss function.
24 | with_logits (bool, optional): [True, False], specifies whether the input tensor is normalized by Sigmoid/Softmax funcs.
25 | True: the loss combines a `sigmoid` layer and the `BCELoss` in one single class.
26 | False: the loss contains `BCELoss`.
27 | Shape:
28 | - input: (*)
29 | - target: (*)
30 | - mask: (*) 0,1 mask for the input sequence.
31 | - Output: Scalar loss
32 | Examples:
33 | >>> loss = AdaptiveDiceLoss()
34 | >>> input = torch.randn(3, 1, requires_grad=True)
35 | >>> target = torch.empty(3, dtype=torch.long).random_(5)
36 | >>> output = loss(input, target)
37 | >>> output.backward()
38 | """
39 | def __init__(self,
40 | alpha: float = 0.1,
41 | smooth: Optional[float] = 1e-8,
42 | square_denominator: Optional[bool] = False,
43 | with_logits: Optional[bool] = True,
44 | reduction: Optional[str] = "mean") -> None:
45 | super(AdaptiveDiceLoss, self).__init__()
46 |
47 | self.reduction = reduction
48 | self.with_logits = with_logits
49 | self.alpha = alpha
50 | self.smooth = smooth
51 | self.square_denominator = square_denominator
52 |
53 | def forward(self,
54 | input: Tensor,
55 | target: Tensor,
56 | mask: Optional[Tensor] = None) -> Tensor:
57 |
58 | flat_input = input.view(-1)
59 | flat_target = target.view(-1)
60 |
61 | if self.with_logits:
62 | flat_input = torch.sigmoid(flat_input)
63 |
64 | if mask is not None:
65 | mask = mask.view(-1).float()
66 | flat_input = flat_input * mask
67 | flat_target = flat_target * mask
68 |
69 | intersection = torch.sum((1-flat_input)**self.alpha * flat_input * flat_target, -1) + self.smooth
70 | denominator = torch.sum((1-flat_input)**self.alpha * flat_input) + flat_target.sum() + self.smooth
71 | return 1 - 2 * intersection / denominator
72 |
73 | def __str__(self):
74 | return f"Adaptive Dice Loss, smooth:{self.smooth}; alpha:{self.alpha}"
75 |
--------------------------------------------------------------------------------
/NER/loss/dice_loss.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import torch
5 | import torch.nn as nn
6 | from torch import Tensor
7 | from typing import Optional
8 |
9 |
10 | class DiceLoss(nn.Module):
11 | """
12 | Dice coefficient for short, is an F1-oriented statistic used to gauge the similarity of two sets.
13 | Given two sets A and B, the vanilla dice coefficient between them is given as follows:
14 | Dice(A, B) = 2 * True_Positive / (2 * True_Positive + False_Positive + False_Negative)
15 | = 2 * |A and B| / (|A| + |B|)
16 |
17 | Math Function:
18 | U-NET: https://arxiv.org/abs/1505.04597.pdf
19 | dice_loss(p, y) = 1 - numerator / denominator
20 | numerator = 2 * \sum_{1}^{t} p_i * y_i + smooth
21 | denominator = \sum_{1}^{t} p_i + \sum_{1} ^{t} y_i + smooth
22 | if square_denominator is True, the denominator is \sum_{1}^{t} (p_i ** 2) + \sum_{1} ^{t} (y_i ** 2) + smooth
23 | V-NET: https://arxiv.org/abs/1606.04797.pdf
24 | Args:
25 | smooth (float, optional): a manual smooth value for numerator and denominator.
26 | square_denominator (bool, optional): [True, False], specifies whether to square the denominator in the loss function.
27 | with_logits (bool, optional): [True, False], specifies whether the input tensor is normalized by Sigmoid/Softmax funcs.
28 | True: the loss combines a `sigmoid` layer and the `BCELoss` in one single class.
29 | False: the loss contains `BCELoss`.
30 | Shape:
31 | - input: (*)
32 | - target: (*)
33 | - mask: (*) 0,1 mask for the input sequence.
34 | - Output: Scalar loss
35 | Examples:
36 | >>> loss = DiceLoss()
37 | >>> input = torch.randn(3, 1, requires_grad=True)
38 | >>> target = torch.empty(3, dtype=torch.long).random_(5)
39 | >>> output = loss(input, target)
40 | >>> output.backward()
41 | """
42 | def __init__(self,
43 | smooth: Optional[float] = 1e-8,
44 | square_denominator: Optional[bool] = False,
45 | with_logits: Optional[bool] = True,
46 | reduction: Optional[str] = "mean") -> None:
47 | super(DiceLoss, self).__init__()
48 |
49 | self.reduction = reduction
50 | self.with_logits = with_logits
51 | self.smooth = smooth
52 | self.square_denominator = square_denominator
53 |
54 | def forward(self,
55 | input: Tensor,
56 | target: Tensor,
57 | mask: Optional[Tensor] = None) -> Tensor:
58 |
59 | flat_input = input.view(-1)
60 | flat_target = target.view(-1)
61 |
62 | if self.with_logits:
63 | flat_input = torch.sigmoid(flat_input)
64 |
65 | if mask is not None:
66 | mask = mask.view(-1).float()
67 | flat_input = flat_input * mask
68 | flat_target = flat_target * mask
69 |
70 | interection = torch.sum(flat_input * flat_target, -1)
71 | if not self.square_denominator:
72 | return 1 - ((2 * interection + self.smooth) /
73 | (flat_input.sum() + flat_target.sum() + self.smooth))
74 | else:
75 | return 1 - ((2 * interection + self.smooth) /
76 | (torch.sum(torch.square(flat_input,), -1) + torch.sum(torch.square(flat_target), -1) + self.smooth))
77 |
78 | def __str__(self):
79 | return f"Dice Loss smooth:{self.smooth}"
80 |
--------------------------------------------------------------------------------
/RE/README.md:
--------------------------------------------------------------------------------
1 |
2 | # Chinese Relation Extraction by biGRU with Character and Sentence Attentions
3 |
4 | ### [中文Blog](http://www.crownpku.com//2017/08/19/%E7%94%A8Bi-GRU%E5%92%8C%E5%AD%97%E5%90%91%E9%87%8F%E5%81%9A%E7%AB%AF%E5%88%B0%E7%AB%AF%E7%9A%84%E4%B8%AD%E6%96%87%E5%85%B3%E7%B3%BB%E6%8A%BD%E5%8F%96.html)
5 |
6 | Bi-directional GRU with Word and Sentence Dual Attentions for End-to End Relation Extraction
7 |
8 | Original Code in https://github.com/thunlp/TensorFlow-NRE, modified for Chinese.
9 |
10 | Original paper [Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification](http://anthology.aclweb.org/P16-2034) and [Neural Relation Extraction with Selective Attention over Instances](http://aclweb.org/anthology/P16-1200)
11 |
12 | 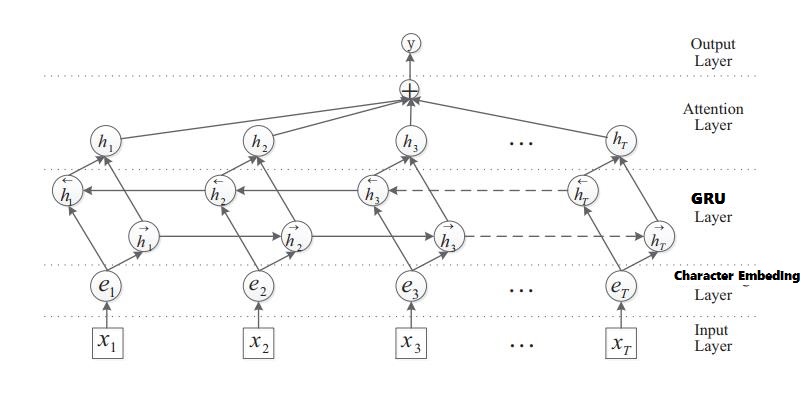
13 |
14 | 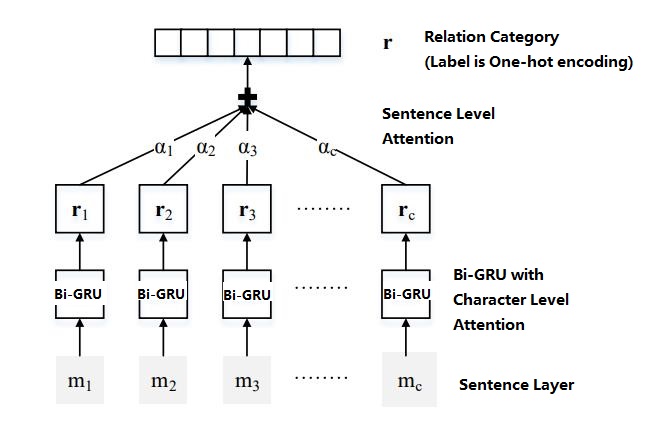
15 |
16 |
17 | ## Requrements
18 |
19 | * Python (>=3.5)
20 |
21 | * TensorFlow (>=r1.0)
22 |
23 | * scikit-learn (>=0.18)
24 |
25 |
26 | ## Usage
27 |
28 |
29 | ### * Training:
30 |
31 | 1. Prepare data in origin_data/ , including relation types (relation2id.txt), training data (train.txt), testing data (test.txt) and Chinese word vectors (vec.txt).
32 |
33 | ```
34 | Current sample data includes the following 12 relationships:
35 | unknown, 父母, 夫妻, 师生, 兄弟姐妹, 合作, 情侣, 祖孙, 好友, 亲戚, 同门, 上下级
36 | ```
37 |
38 | 2. Organize data into npy files, which will be save at data/
39 | ```
40 | #python3 initial.py
41 | ```
42 |
43 | 3. Training, models will be save at model/
44 | ```
45 | #python3 train_GRU.py
46 | ```
47 |
48 |
49 | ### * Inference
50 |
51 | **If you have trained a new model, please remember to change the pathname in main_for_evaluation() and main() in test_GRU.py with your own model name.**
52 |
53 | ```
54 | #python3 test_GRU.py
55 | ```
56 |
57 | Program will ask for data input in the format of "name1 name2 sentence".
58 |
59 | We have pre-trained model in /model. To test the pre-trained model, simply initialize the data and run test_GRU.py:
60 |
61 | ```
62 | #python3 initial.py
63 | #python3 test_GRU.py
64 | ```
65 |
66 |
67 | ## Sample Results
68 |
69 | We make up some sentences and test the performance. The model gives good results, sometimes wrong but reasonable.
70 |
71 | More data is needed for better performance.
72 |
73 | ```
74 | INFO:tensorflow:Restoring parameters from ./model/ATT_GRU_model-9000
75 | reading word embedding data...
76 | reading relation to id
77 |
78 | 实体1: 李晓华
79 | 实体2: 王大牛
80 | 李晓华和她的丈夫王大牛前日一起去英国旅行了。
81 | 关系是:
82 | No.1: 夫妻, Probability is 0.996217
83 | No.2: 父母, Probability is 0.00193673
84 | No.3: 兄弟姐妹, Probability is 0.00128172
85 |
86 | 实体1: 李晓华
87 | 实体2: 王大牛
88 | 李晓华和她的高中同学王大牛两个人前日一起去英国旅行。
89 | 关系是:
90 | No.1: 好友, Probability is 0.526823
91 | No.2: 兄弟姐妹, Probability is 0.177491
92 | No.3: 夫妻, Probability is 0.132977
93 |
94 | 实体1: 李晓华
95 | 实体2: 王大牛
96 | 王大牛命令李晓华在周末前完成这份代码。
97 | 关系是:
98 | No.1: 上下级, Probability is 0.965674
99 | No.2: 亲戚, Probability is 0.0185355
100 | No.3: 父母, Probability is 0.00953698
101 |
102 | 实体1: 李晓华
103 | 实体2: 王大牛
104 | 王大牛非常疼爱他的孙女李晓华小朋友。
105 | 关系是:
106 | No.1: 祖孙, Probability is 0.785542
107 | No.2: 好友, Probability is 0.0829895
108 | No.3: 同门, Probability is 0.0728216
109 |
110 | 实体1: 李晓华
111 | 实体2: 王大牛
112 | 谈起曾经一起求学的日子,王大牛非常怀念他的师妹李晓华。
113 | 关系是:
114 | No.1: 师生, Probability is 0.735982
115 | No.2: 同门, Probability is 0.159495
116 | No.3: 兄弟姐妹, Probability is 0.0440367
117 |
118 | 实体1: 李晓华
119 | 实体2: 王大牛
120 | 王大牛对于他的学生李晓华做出的成果非常骄傲!
121 | 关系是:
122 | No.1: 师生, Probability is 0.994964
123 | No.2: 父母, Probability is 0.00460191
124 | No.3: 夫妻, Probability is 0.000108601
125 |
126 | 实体1: 李晓华
127 | 实体2: 王大牛
128 | 王大牛和李晓华是从小一起长大的好哥们
129 | 关系是:
130 | No.1: 兄弟姐妹, Probability is 0.852632
131 | No.2: 亲戚, Probability is 0.0477967
132 | No.3: 好友, Probability is 0.0433101
133 |
134 | 实体1: 李晓华
135 | 实体2: 王大牛
136 | 王大牛的表舅叫李晓华的二妈为大姐
137 | 关系是:
138 | No.1: 亲戚, Probability is 0.766272
139 | No.2: 父母, Probability is 0.162108
140 | No.3: 兄弟姐妹, Probability is 0.0623203
141 |
142 | 实体1: 李晓华
143 | 实体2: 王大牛
144 | 这篇论文是王大牛负责编程,李晓华负责写作的。
145 | 关系是:
146 | No.1: 合作, Probability is 0.907599
147 | No.2: unknown, Probability is 0.082604
148 | No.3: 上下级, Probability is 0.00730342
149 |
150 | 实体1: 李晓华
151 | 实体2: 王大牛
152 | 王大牛和李晓华为谁是论文的第一作者争得头破血流。
153 | 关系是:
154 | No.1: 合作, Probability is 0.819008
155 | No.2: 上下级, Probability is 0.116768
156 | No.3: 师生, Probability is 0.0448312
157 | ```
158 |
159 |
--------------------------------------------------------------------------------
/NER/metrics/functional/query_span_f1.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 | import os
3 |
4 | import torch
5 | from tokenizers import BertWordPieceTokenizer
6 |
7 | from utils.bmes_decode import bmes_decode
8 |
9 | bert_path = "E:\data\chinese_roberta_wwm_large_ext_pytorch\\"
10 | json_path = "E:\\data\\nested\\mrc-ner.dev"
11 | is_chinese = True
12 |
13 | vocab_file = os.path.join(bert_path, "vocab.txt")
14 | tokenizer = BertWordPieceTokenizer(vocab_file)
15 |
16 |
17 | def query_span_f1(start_preds, end_preds, match_logits, start_label_mask, end_label_mask, match_labels, flat=False):
18 | """
19 | Compute span f1 according to query-based model output
20 | Args:
21 | start_preds: [bsz, seq_len]
22 | end_preds: [bsz, seq_len]
23 | match_logits: [bsz, seq_len, seq_len]
24 | start_label_mask: [bsz, seq_len]
25 | end_label_mask: [bsz, seq_len]
26 | match_labels: [bsz, seq_len, seq_len]
27 | flat: if True, decode as flat-ner
28 | Returns:
29 | span-f1 counts, tensor of shape [3]: tp, fp, fn
30 | """
31 | start_label_mask = start_label_mask.bool()
32 | end_label_mask = end_label_mask.bool()
33 | match_labels = match_labels.bool()
34 | bsz, seq_len = start_label_mask.size()
35 | # [bsz, seq_len, seq_len]
36 | match_preds = match_logits > 0
37 | # [bsz, seq_len]
38 | start_preds = start_preds.bool()
39 | # [bsz, seq_len]
40 | end_preds = end_preds.bool()
41 |
42 | match_preds = (match_preds
43 | & start_preds.unsqueeze(-1).expand(-1, -1, seq_len)
44 | & end_preds.unsqueeze(1).expand(-1, seq_len, -1))
45 | match_label_mask = (start_label_mask.unsqueeze(-1).expand(-1, -1, seq_len)
46 | & end_label_mask.unsqueeze(1).expand(-1, seq_len, -1))
47 | match_label_mask = torch.triu(match_label_mask, 0) # start should be less or equal to end
48 | match_preds = match_label_mask & match_preds
49 |
50 | tp = (match_labels & match_preds).long().sum()
51 | fp = (~match_labels & match_preds).long().sum()
52 | fn = (match_labels & ~match_preds).long().sum()
53 | return torch.stack([tp, fp, fn])
54 |
55 |
56 | def extract_flat_spans(start_pred, end_pred, match_pred, label_mask):
57 | """
58 | Extract flat-ner spans from start/end/match logits
59 | Args:
60 | start_pred: [seq_len], 1/True for start, 0/False for non-start
61 | end_pred: [seq_len, 2], 1/True for end, 0/False for non-end
62 | match_pred: [seq_len, seq_len], 1/True for match, 0/False for non-match
63 | label_mask: [seq_len], 1 for valid boundary.
64 | Returns:
65 | tags: list of tuple (start, end)
66 | Examples:
67 | >>> start_pred = [0, 1]
68 | >>> end_pred = [0, 1]
69 | >>> match_pred = [[0, 0], [0, 1]]
70 | >>> label_mask = [1, 1]
71 | >>> extract_flat_spans(start_pred, end_pred, match_pred, label_mask)
72 | [(1, 2)]
73 | """
74 | pseudo_tag = "TAG"
75 | pseudo_input = "a"
76 |
77 | bmes_labels = ["O"] * len(start_pred)
78 | start_positions = [idx for idx, tmp in enumerate(start_pred) if tmp and label_mask[idx]]
79 | end_positions = [idx for idx, tmp in enumerate(end_pred) if tmp and label_mask[idx]]
80 |
81 | for start_item in start_positions:
82 | bmes_labels[start_item] = f"B-{pseudo_tag}"
83 | for end_item in end_positions:
84 | bmes_labels[end_item] = f"E-{pseudo_tag}"
85 |
86 | for tmp_start in start_positions:
87 | tmp_end = [tmp for tmp in end_positions if tmp >= tmp_start]
88 | if len(tmp_end) == 0:
89 | continue
90 | else:
91 | tmp_end = min(tmp_end)
92 | if match_pred[tmp_start][tmp_end]:
93 | if tmp_start != tmp_end:
94 | for i in range(tmp_start + 1, tmp_end):
95 | bmes_labels[i] = f"M-{pseudo_tag}"
96 | else:
97 | bmes_labels[tmp_end] = f"S-{pseudo_tag}"
98 |
99 | tags = bmes_decode([(pseudo_input, label) for label in bmes_labels])
100 |
101 | return [(tag.begin, tag.end) for tag in tags]
102 |
103 |
104 | def remove_overlap(spans):
105 | """
106 | remove overlapped spans greedily for flat-ner
107 | Args:
108 | spans: list of tuple (start, end), which means [start, end] is a ner-span
109 | Returns:
110 | spans without overlap
111 | """
112 | output = []
113 | occupied = set()
114 | for start, end in spans:
115 | if any(x for x in range(start, end + 1)) in occupied:
116 | continue
117 | output.append((start, end))
118 | for x in range(start, end + 1):
119 | occupied.add(x)
120 | return output
121 |
--------------------------------------------------------------------------------
/RE/process_data.py:
--------------------------------------------------------------------------------
1 | # -*- coding: utf-8 -*-
2 | # @Time : 2021/5/7 下午2:08
3 | # @Author : liuliping
4 | # @File : process_data.py.py
5 | # @description: 从原始数据抽取实体-关系
6 |
7 | import json
8 | import os
9 | import glob
10 | import copy
11 | import random
12 |
13 | total_count = {}
14 |
15 | def custom_RE(file_path, output_path):
16 | #
17 | with open(file_path, 'r', encoding='utf-8') as f:
18 | data = [json.loads(line.strip()) for line in f.readlines()]
19 |
20 | result = []
21 | relation_count = {}
22 | for sub in data: # 行
23 | ner_relation = {}
24 | relation_set = set()
25 | ner_data = sub['sd_result']['items']
26 | text = sub['text']
27 | segments = [i for i in range(len(text)) if text[i] in {'。', '?', '!', ';', ':', ','}]
28 | for ner in ner_data:
29 | ner_text = ner['meta']['text']
30 | start, end = ner['meta']['segment_range']
31 | ner_label = ner['labels']['Entity']
32 | relations = ner['labels'].get('Relation', [])
33 | for rel in relations:
34 | relation_set.add(rel)
35 |
36 | ner_relation[f'{ner_text}#{ner_label}#{start}#{end}'] = relations
37 |
38 | for rel in relation_set:
39 | tmp = []
40 | for ner, rels in ner_relation.items():
41 |
42 | if rel in rels and (len(tmp) == 0 or tmp[0].split('#')[1] != ner.split('#')[1]):
43 | tmp.append(ner)
44 |
45 | if len(tmp) == 2:
46 | ner_1 = tmp[0].split('#')
47 | ner_2 = tmp[1].split('#')
48 |
49 | index = [int(d) for d in ner_1[2:]] + [int(d) for d in ner_2[2:]]
50 |
51 | min_idx, max_idx = min(index), max(index)
52 |
53 | sub_text = text[:segments[0]] if segments and segments[0] >= max_idx else text[:]
54 |
55 | min_seg = 0
56 | max_seg = len(text)
57 | for i in range(len(segments) - 1):
58 | if segments[i] <= min_idx <= segments[i + 1]:
59 | min_seg = segments[i]
60 | break
61 | for i in range(len(segments) - 1):
62 | if segments[i] <= max_idx <= segments[i + 1]:
63 | max_seg = segments[i + 1]
64 | break
65 |
66 | if min_seg != 0 or max_seg != len(text):
67 | sub_text = text[min_seg + 1: max_seg]
68 | rel = rel.split('-'[0])[0].strip().replace('?', '')
69 | result.append([t.split('#')[0] for t in tmp] + [rel, sub_text])
70 | relation_count[rel] = relation_count.setdefault(rel, 0) + 1
71 | total_count[rel] = total_count.setdefault(rel, 0) + 1
72 | break
73 |
74 | with open(os.path.join(output_path, 'custom_RE_{}.txt'.format(os.path.split(file_path)[1].split('.')[0])),
75 | 'w', encoding='utf-8') as fw:
76 | fw.write('\n'.join(['\t'.join(t) for t in result]))
77 |
78 | print(os.path.basename(file_path), relation_count)
79 |
80 |
81 | if __name__ == '__main__':
82 | input_path = '../data/糖尿病标注数据4.28/' # 原始数据path
83 | output_path = 'data/custom_RE'
84 | os.makedirs('data/custom_RE/', exist_ok=True)
85 |
86 | files = glob.glob(f'{input_path}/*.txt')
87 | for fil in files:
88 | custom_RE(fil, output_path)
89 | print('total', total_count)
90 |
91 | relations = {}
92 | files = glob.glob(f'{output_path}/*.txt')
93 | for fil in files:
94 | with open(fil, 'r', encoding='utf-8') as f:
95 | data = f.readlines()
96 | for sub in data:
97 | l = sub.strip().split('\t')
98 | relations.setdefault(l[2], []).append(sub)
99 | # 拆分数据集 train:dev:test=6:2:2
100 | train_data, dev_data, test_data = [], [], []
101 | for rel, val in relations.items():
102 | print(rel, len(val))
103 | length = len(val)
104 | random.shuffle(val)
105 | train_data.extend(val[:length // 10 * 6])
106 | dev_data.extend(val[length // 10 * 6: length // 10 * 8])
107 | test_data.extend(val[length // 10 * 8:])
108 |
109 | with open('data/train.txt', 'w', encoding='utf-8') as fw:
110 | random.shuffle(train_data)
111 | fw.write(''.join(train_data))
112 |
113 | with open('data/dev.txt', 'w', encoding='utf-8') as fw:
114 | random.shuffle(dev_data)
115 | fw.write(''.join(dev_data))
116 |
117 | with open('data/test.txt', 'w', encoding='utf-8') as fw:
118 | random.shuffle(test_data)
119 | fw.write(''.join(test_data))
120 |
--------------------------------------------------------------------------------
/RE/train_GRU.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | import numpy as np
3 | import time
4 | import datetime
5 | import os
6 | import network
7 | # from tensorflow.contrib.tensorboard.plugins import projector
8 |
9 | FLAGS = tf.app.flags.FLAGS
10 |
11 | tf.app.flags.DEFINE_string('summary_dir', '.', 'path to store summary')
12 |
13 | import os
14 | os.environ["CUDA_VISIBLE_DEVICES"] = "1"
15 | # os.environ["CUDA_VISIBLE_DEVICES"] = "1"
16 |
17 | def main(_):
18 | # the path to save models
19 | save_path = './model'
20 | if not os.path.isdir(save_path):
21 | os.makedirs(save_path)
22 |
23 | print('reading wordembedding')
24 | wordembedding = np.load('./data/vec.npy', allow_pickle=True)
25 |
26 | print('reading training data')
27 | train_y = np.load('./data/train_y.npy', allow_pickle=True)
28 | train_word = np.load('./data/train_word.npy', allow_pickle=True)
29 | train_pos1 = np.load('./data/train_pos1.npy', allow_pickle=True)
30 | train_pos2 = np.load('./data/train_pos2.npy', allow_pickle=True)
31 |
32 | settings = network.Settings()
33 | settings.vocab_size = len(wordembedding)
34 | settings.num_classes = len(train_y[0])
35 |
36 | # big_num = settings.big_num
37 |
38 | with tf.Graph().as_default():
39 |
40 | sess = tf.Session()
41 | with sess.as_default():
42 |
43 | initializer = tf.contrib.layers.xavier_initializer()
44 | with tf.variable_scope("model", reuse=None, initializer=initializer):
45 | m = network.GRU(is_training=True, word_embeddings=wordembedding, settings=settings)
46 | global_step = tf.Variable(0, name="global_step", trainable=False)
47 | optimizer = tf.train.AdamOptimizer(0.0005)
48 |
49 | train_op = optimizer.minimize(m.final_loss, global_step=global_step)
50 | sess.run(tf.global_variables_initializer())
51 | saver = tf.train.Saver(max_to_keep=None)
52 |
53 | merged_summary = tf.summary.merge_all()
54 | summary_writer = tf.summary.FileWriter(FLAGS.summary_dir + '/train_loss', sess.graph)
55 |
56 | def train_step(word_batch, pos1_batch, pos2_batch, y_batch, big_num):
57 |
58 | feed_dict = {}
59 | total_shape = []
60 | total_num = 0
61 | total_word = []
62 | total_pos1 = []
63 | total_pos2 = []
64 | for i in range(len(word_batch)):
65 | total_shape.append(total_num)
66 | total_num += len(word_batch[i])
67 | for word in word_batch[i]:
68 | total_word.append(word)
69 | for pos1 in pos1_batch[i]:
70 | total_pos1.append(pos1)
71 | for pos2 in pos2_batch[i]:
72 | total_pos2.append(pos2)
73 | total_shape.append(total_num)
74 | total_shape = np.array(total_shape)
75 | total_word = np.array(total_word)
76 | total_pos1 = np.array(total_pos1)
77 | total_pos2 = np.array(total_pos2)
78 |
79 | feed_dict[m.total_shape] = total_shape
80 | feed_dict[m.input_word] = total_word
81 | feed_dict[m.input_pos1] = total_pos1
82 | feed_dict[m.input_pos2] = total_pos2
83 | feed_dict[m.input_y] = y_batch
84 |
85 | temp, step, loss, accuracy, summary, l2_loss, final_loss = sess.run(
86 | [train_op, global_step, m.total_loss, m.accuracy, merged_summary, m.l2_loss, m.final_loss],
87 | feed_dict)
88 | time_str = datetime.datetime.now().isoformat()
89 | accuracy = np.reshape(np.array(accuracy), (big_num))
90 | acc = np.mean(accuracy)
91 | summary_writer.add_summary(summary, step)
92 |
93 | if step % 50 == 0:
94 | tempstr = "{}: step {}, softmax_loss {:g}, acc {:g}".format(time_str, step, loss, acc)
95 | print(tempstr)
96 |
97 | for one_epoch in range(settings.num_epochs):
98 |
99 | temp_order = list(range(len(train_word)))
100 | np.random.shuffle(temp_order)
101 | for i in range(int(len(temp_order) / float(settings.big_num))):
102 |
103 | temp_word = []
104 | temp_pos1 = []
105 | temp_pos2 = []
106 | temp_y = []
107 |
108 | temp_input = temp_order[i * settings.big_num:(i + 1) * settings.big_num]
109 | for k in temp_input:
110 | temp_word.append(train_word[k])
111 | temp_pos1.append(train_pos1[k])
112 | temp_pos2.append(train_pos2[k])
113 | temp_y.append(train_y[k])
114 | num = 0
115 | for single_word in temp_word:
116 | num += len(single_word)
117 |
118 | if num > 1500:
119 | print('out of range')
120 | continue
121 |
122 | temp_word = np.array(temp_word)
123 | temp_pos1 = np.array(temp_pos1)
124 | temp_pos2 = np.array(temp_pos2)
125 | temp_y = np.array(temp_y)
126 |
127 | train_step(temp_word, temp_pos1, temp_pos2, temp_y, settings.big_num)
128 |
129 | current_step = tf.train.global_step(sess, global_step)
130 | if current_step > 8000 and current_step % 100 == 0:
131 | print('saving model')
132 | path = saver.save(sess, save_path + 'ATT_GRU_model', global_step=current_step)
133 | tempstr = 'have saved model to ' + path
134 | print(tempstr)
135 |
136 |
137 | if __name__ == "__main__":
138 | tf.app.run()
139 |
--------------------------------------------------------------------------------
/RE/network.py:
--------------------------------------------------------------------------------
1 | import tensorflow as tf
2 | import numpy as np
3 |
4 |
5 | class Settings(object):
6 | def __init__(self):
7 | self.vocab_size = 16691
8 | self.num_steps = 70
9 | self.num_epochs = 200
10 | self.num_classes = 16
11 | self.gru_size = 230
12 | self.keep_prob = 0.5
13 | self.num_layers = 1
14 | self.pos_size = 5
15 | self.pos_num = 123
16 | # the number of entity pairs of each batch during training or testing
17 | self.big_num = 50
18 |
19 |
20 | class GRU:
21 | def __init__(self, is_training, word_embeddings, settings):
22 |
23 | self.num_steps = num_steps = settings.num_steps
24 | self.vocab_size = vocab_size = settings.vocab_size
25 | self.num_classes = num_classes = settings.num_classes
26 | self.gru_size = gru_size = settings.gru_size
27 | self.big_num = big_num = settings.big_num
28 |
29 | self.input_word = tf.placeholder(dtype=tf.int32, shape=[None, num_steps], name='input_word')
30 | self.input_pos1 = tf.placeholder(dtype=tf.int32, shape=[None, num_steps], name='input_pos1')
31 | self.input_pos2 = tf.placeholder(dtype=tf.int32, shape=[None, num_steps], name='input_pos2')
32 | self.input_y = tf.placeholder(dtype=tf.float32, shape=[None, num_classes], name='input_y')
33 | self.total_shape = tf.placeholder(dtype=tf.int32, shape=[big_num + 1], name='total_shape')
34 | total_num = self.total_shape[-1]
35 |
36 | word_embedding = tf.get_variable(initializer=word_embeddings, name='word_embedding')
37 | pos1_embedding = tf.get_variable('pos1_embedding', [settings.pos_num, settings.pos_size])
38 | pos2_embedding = tf.get_variable('pos2_embedding', [settings.pos_num, settings.pos_size])
39 |
40 | attention_w = tf.get_variable('attention_omega', [gru_size, 1])
41 | sen_a = tf.get_variable('attention_A', [gru_size])
42 | sen_r = tf.get_variable('query_r', [gru_size, 1])
43 | relation_embedding = tf.get_variable('relation_embedding', [self.num_classes, gru_size])
44 | sen_d = tf.get_variable('bias_d', [self.num_classes])
45 |
46 | gru_cell_forward = tf.contrib.rnn.GRUCell(gru_size)
47 | gru_cell_backward = tf.contrib.rnn.GRUCell(gru_size)
48 |
49 | if is_training and settings.keep_prob < 1:
50 | gru_cell_forward = tf.contrib.rnn.DropoutWrapper(gru_cell_forward, output_keep_prob=settings.keep_prob)
51 | gru_cell_backward = tf.contrib.rnn.DropoutWrapper(gru_cell_backward, output_keep_prob=settings.keep_prob)
52 |
53 | cell_forward = tf.contrib.rnn.MultiRNNCell([gru_cell_forward] * settings.num_layers)
54 | cell_backward = tf.contrib.rnn.MultiRNNCell([gru_cell_backward] * settings.num_layers)
55 |
56 | sen_repre = []
57 | sen_alpha = []
58 | sen_s = []
59 | sen_out = []
60 | self.prob = []
61 | self.predictions = []
62 | self.loss = []
63 | self.accuracy = []
64 | self.total_loss = 0.0
65 |
66 | self._initial_state_forward = cell_forward.zero_state(total_num, tf.float32)
67 | self._initial_state_backward = cell_backward.zero_state(total_num, tf.float32)
68 |
69 | # embedding layer
70 | inputs_forward = tf.concat(axis=2, values=[tf.nn.embedding_lookup(word_embedding, self.input_word),
71 | tf.nn.embedding_lookup(pos1_embedding, self.input_pos1),
72 | tf.nn.embedding_lookup(pos2_embedding, self.input_pos2)])
73 | inputs_backward = tf.concat(axis=2,
74 | values=[tf.nn.embedding_lookup(word_embedding, tf.reverse(self.input_word, [1])),
75 | tf.nn.embedding_lookup(pos1_embedding, tf.reverse(self.input_pos1, [1])),
76 | tf.nn.embedding_lookup(pos2_embedding,
77 | tf.reverse(self.input_pos2, [1]))])
78 |
79 | outputs_forward = []
80 |
81 | state_forward = self._initial_state_forward
82 |
83 | # Bi-GRU layer
84 | with tf.variable_scope('GRU_FORWARD') as scope:
85 | for step in range(num_steps):
86 | if step > 0:
87 | scope.reuse_variables()
88 | (cell_output_forward, state_forward) = cell_forward(inputs_forward[:, step, :], state_forward)
89 | outputs_forward.append(cell_output_forward)
90 |
91 | outputs_backward = []
92 |
93 | state_backward = self._initial_state_backward
94 | with tf.variable_scope('GRU_BACKWARD') as scope:
95 | for step in range(num_steps):
96 | if step > 0:
97 | scope.reuse_variables()
98 | (cell_output_backward, state_backward) = cell_backward(inputs_backward[:, step, :], state_backward)
99 | outputs_backward.append(cell_output_backward)
100 |
101 | output_forward = tf.reshape(tf.concat(axis=1, values=outputs_forward), [total_num, num_steps, gru_size])
102 | output_backward = tf.reverse(
103 | tf.reshape(tf.concat(axis=1, values=outputs_backward), [total_num, num_steps, gru_size]),
104 | [1])
105 |
106 | # word-level attention layer
107 | output_h = tf.add(output_forward, output_backward)
108 | attention_r = tf.reshape(tf.matmul(tf.reshape(tf.nn.softmax(
109 | tf.reshape(tf.matmul(tf.reshape(tf.tanh(output_h), [total_num * num_steps, gru_size]), attention_w),
110 | [total_num, num_steps])), [total_num, 1, num_steps]), output_h), [total_num, gru_size])
111 |
112 | # sentence-level attention layer
113 | for i in range(big_num):
114 |
115 | sen_repre.append(tf.tanh(attention_r[self.total_shape[i]:self.total_shape[i + 1]]))
116 | batch_size = self.total_shape[i + 1] - self.total_shape[i]
117 |
118 | sen_alpha.append(
119 | tf.reshape(tf.nn.softmax(tf.reshape(tf.matmul(tf.multiply(sen_repre[i], sen_a), sen_r), [batch_size])),
120 | [1, batch_size]))
121 |
122 | sen_s.append(tf.reshape(tf.matmul(sen_alpha[i], sen_repre[i]), [gru_size, 1]))
123 | sen_out.append(tf.add(tf.reshape(tf.matmul(relation_embedding, sen_s[i]), [self.num_classes]), sen_d))
124 |
125 | self.prob.append(tf.nn.softmax(sen_out[i]))
126 |
127 | with tf.name_scope("output"):
128 | self.predictions.append(tf.argmax(self.prob[i], 0, name="predictions"))
129 |
130 | with tf.name_scope("loss"):
131 | self.loss.append(
132 | tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=sen_out[i], labels=self.input_y[i])))
133 | if i == 0:
134 | self.total_loss = self.loss[i]
135 | else:
136 | self.total_loss += self.loss[i]
137 |
138 | # tf.summary.scalar('loss',self.total_loss)
139 | # tf.scalar_summary(['loss'],[self.total_loss])
140 | with tf.name_scope("accuracy"):
141 | self.accuracy.append(
142 | tf.reduce_mean(tf.cast(tf.equal(self.predictions[i], tf.argmax(self.input_y[i], 0)), "float"),
143 | name="accuracy"))
144 |
145 | # tf.summary.scalar('loss',self.total_loss)
146 | tf.summary.scalar('loss', self.total_loss)
147 | # regularization
148 | self.l2_loss = tf.contrib.layers.apply_regularization(regularizer=tf.contrib.layers.l2_regularizer(0.0001),
149 | weights_list=tf.trainable_variables())
150 | self.final_loss = self.total_loss + self.l2_loss
151 | tf.summary.scalar('l2_loss', self.l2_loss)
152 | tf.summary.scalar('final_loss', self.final_loss)
153 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 |
2 | # DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction
3 |
4 | This is the source code of the DiaKG [paper](https://arxiv.org/abs/2105.15033).
5 |
6 | ## DataSet
7 |
8 | ### Overview
9 | The DiaKG dataset is derived from 41 diabetes guidelines and consensus, which are from authoritative Chinese journals including basic research, clinical research, drug usage, clinical cases, diagnosis and treatment methods, etc. The dataset covers the most extensive field of research content and hotspot in recent years. The annotation process is done by 2 seasoned endocrinologists and 6 M.D. candidates, and finally conduct a high-quality diabates database which contains 22,050 entities and 6,890 relations in total.
10 |
11 | ### Get the Data
12 | The codebase only provides some sample annotation files. If you want to download the fullset, please apply at [Tianchi Platform](https://tianchi.aliyun.com/dataset/dataDetail?dataId=88836).
13 |
14 | ### Data Format
15 | The dataset is exhibited as a hierachical structure with "document-paragraph-sentence" information. All the entities and sentences are labelled on the sentence level. Below is an example:
16 |
17 | ```
18 | {
19 | "doc_id": "1", // string, document id
20 | "paragraphs": [ // array, paragraphs
21 | {
22 | "paragraph_id": "0", // string, paragraph id
23 | "paragraph": "中国成人2型糖尿病胰岛素促泌剂应用的专家共识", // string, paragraph text
24 | "sentences": [ // array, sentences
25 | {
26 | "sentence_id": "0", // string, sentence id
27 | "sentence": "中国成人2型糖尿病胰岛素促泌剂应用的专家共识", // string, sentence text
28 | "start_idx": 0, // int, sentence start index in the current paragraph
29 | "end_idx": 22, // int, sentence end index in the current paragraph
30 | "entities": [ // array, entities in the current sentence
31 | {
32 | "entity_id": "T0", // string, entity id
33 | "entity": "2型糖尿病", // string, entity text
34 | "entity_type": "Disease", // string, entity type
35 | "start_idx": 4, // int, entity start index in the sentence
36 | "end_idx": 9 // int, entity end index in the sentence
37 | },
38 | {
39 | "entity_id": "T1",
40 | "entity": "2型",
41 | "entity_type": "Class",
42 | "start_idx": 4,
43 | "end_idx": 6
44 | },
45 | {
46 | "entity_id": "T2",
47 | "entity": "胰岛素促泌剂",
48 | "entity_type": "Drug",
49 | "start_idx": 9,
50 | "end_idx": 15
51 | }
52 | ],
53 | "relations": [ // array, relations in the current sentence
54 | {
55 | "relation_type": "Drug_Disease", // string, relation type
56 | "relation_id": "R0", // string, relation id
57 | "head_entity_id": "T2", // string, head entity id
58 | "tail_entity_id": "T0" // string, tail entity id
59 | },
60 | {
61 | "relation_type": "Class_Disease",
62 | "relation_id": "R1",
63 | "head_entity_id": "T1",
64 | "tail_entity_id": "T0"
65 | }
66 | ]
67 | }
68 | ]
69 | },
70 | {
71 | "paragraph_id": "1", // string, paragraph id
72 | "paragraph": "xxx" // string, paragraph text
73 | "sentences": [
74 | ...
75 | ]
76 | },
77 | ...
78 | ]
79 | }
80 | ```
81 |
82 | ### Data Statistic
83 |
84 | #### Entity
85 |
86 |
87 | |Entity | Freq | Fraction(%) | Avg Length |Entity | Freq | Fraction(%) | Avg Length |
88 | |-----|--------|--------|---------|-------|-----------|----------|----------|
89 | |Disease |5743 |26.05% |7.27 |Frequency |156 |0.71% |4.71
90 | |Class |1262 |5.72% |4.27 |Method |399 |1.81% |6.09
91 | |Reason |175 |0.79% |7.34 |Treatment |756 |3.43% |7.97
92 | |Pathogenesis |202 |0.92% |10.27|Operation |133 |0.60% |9.02
93 | |Symptom |479 |2.17% |5.82 |ADE |874 |3.96% |5.06
94 | |Test |489 |2.22% |6.1 |Anatomy |1876 |8.51% |3.1
95 | |Test_items |2718 |12.33% |7.65 |Level |280 |1.27% |2.93
96 | |Test_Value |1356 |6.15% |9.49 |Duration |69 |0.31% |3.68
97 | |Drug |4782 |21.69% |7.79 |Amount |301 |1.37% |6.74
98 | |Total |22050|100% |6.5
99 |
100 |
101 | #### Relation
102 |
103 | |Relation|Freq |Fraction(%)|Avg Cross-sentence Number |Relation|Freq |Fraction(%)|Avg Cross-sentence Number |
104 | |-----------|------|-------|---------|--------|----------|------|-------|
105 | |Test_items_Disease |1171 |17% |2.3 |Class_Disease |854 |12.39% |2.13 |
106 | |Anatomy_Disease |1072 |15.56% |2.07 |Reason_Disease |164 |2.38% |2.42 |
107 | |Drug_Disease |1315 |19.09% |2.5 |Duration_Drug |61 |0.89% |2.79 |
108 | |Method_Drug |185 |2.69% |2.41 |Symptom_Disease |283 |4.11% |2.08 |
109 | |Treatment_Disease |354 |5.14% |2.6 |Amount_Drug |195 |2.83% |2.62 |
110 | |Pathogenesis_Disease|130 |1.89% |1.97 |ADE_Drug |693 |10.06% |2.65 |
111 | |Test_Disease |271 |3.93% |2.27 |Frequency_Drug |103 |1.49% |1.97 |
112 | |Operation_Disese |37 |0.54% |2.57
113 | |Total |6890 |100% |2.33 |
114 |
115 |
116 | * Note: **Avg Cross-sentence Number** means the average sentences that the two entities that compose a relation locate, since the annotation is conducted on document level and cross-sentence relation is allowed.
117 |
118 | ## Experiments
119 |
120 | ### NER
121 |
122 | We use [MRC-BERT](https://github.com/changdejie/diaKG-code/tree/mrcforner) as our baseline model, and the source code is in the **NER** directory.
123 |
124 | #### How to run
125 | ```
126 | cd NER
127 |
128 | ## Training:
129 | python trainer.py --data_dir entity_type_data --bert_config models/chinese_roberta_wwm_large_ext_pytorch --batch_size 16 --max_epochs 10 --gpus 1
130 |
131 | ## Inference:
132 | python evaluate.py
133 |
134 | ```
135 |
136 | #### Results
137 |
138 | |Entity |precision|recall |F1 |Entity |precision|recall |F1 |
139 | |-------------|---------|---------|-------|-------------|---------|---------|-------|
140 | |Frequency |1.0 |0.9 |0.947 |ADE | 0.791 | 0.815 | 0.803 |
141 | |Method | 0.895 | 0.927 | 0.911 |Duration | 0.833 | 0.714 | 0.769 |
142 | |Class | 0.852 | 0.949 | 0.898 |Amount | 0.73 | 0.75 | 0.74 |
143 | |Drug | 0.881 | 0.902 | 0.892 |Operation | 0.75 | 0.714 | 0.732 |
144 | |Level | 0.841 | 0.902 | 0.871 |Treatment | 0.679 | 0.783 | 0.727 |
145 | |Anatomy | 0.834 | 0.869 | 0.851 |Test | 0.855 | 0.609 | 0.711 |
146 | |Disease | 0.794 | 0.91 | 0.848 |Pathogenesis | 0.595 | 0.667 | 0.629 |
147 | |Test\_Items | 0.823 | 0.815 | 0.818 |Symptom | 0.535 | 0.535 | 0.535 |
148 | |Test\_Value | 0.828 | 0.787 | 0.807 |Reason | 0.333 | 0.3 | 0.316 |
149 | |total |0.814 |0.853 |0.833 |
150 |
151 |
152 | ### RE
153 |
154 | We use [Bi-directional GRU-Attention](https://github.com/crownpku/Information-Extraction-Chinese) as our baseline model, and the source code is in the **RE** directory.
155 |
156 | #### How to run
157 |
158 | Details in folder [RE/README.md](https://github.com/changdejie/diaKG-code/edit/main/RE/README.md)
159 |
160 |
161 | #### Results
162 | |Relation |precision |recall |F1 |Relation |precision |recall |F1 |
163 | |-------------|---------|---------|-------|-------------|---------|---------|-------|
164 | Class\_Disease | 0.968 | 0.874 | 0.918 |Duration\_Drug | 0.833 | 0.769 | 0.8 |
165 | ADE\_Drug | 0.892 | 0.892 | 0.892 |Frequency\_Drug | 0.750 | 0.783 | 0.766 |
166 | Drug\_Disease | 0.864 | 0.913 | 0.888 |Symptom\_Disease | 0.689 | 0.712 | 0.7 |
167 | Anatomy\_Disease | 0.869 | 0.864 | 0.867 |Reason\_Disease | 0.769 | 0.571 | 0.656 |
168 | Method\_Drug | 0.833 | 0.854 | 0.843 |Test\_Disease | 0.648 | 0.636 | 0.642 |
169 | Test\_Items\_Disease | 0.833 | 0.833 | 0.833 |Pathogenesis\_Disease | 0.486 | 0.692 | 0.571 |
170 | Treatment\_Disease | 0.771 | 0.877 | 0.821 |Operation\_Disese | 0.6 | 0.231 | 0.333 |
171 | Amount\_Drug | 0.850 | 0.791 | 0.819 |
172 | total |0.839 |0.837 |0.836 |
173 |
174 |
175 | ## Citation
176 |
177 | If you use DiaKG in your research, please cite our [paper](https://arxiv.org/abs/2105.15033):
178 | ```
179 | @article{chang2021diakg,
180 | title={DiaKG: an Annotated Diabetes Dataset for Medical Knowledge Graph Construction},
181 | author={Dejie Chang and Mosha Chen and Chaozhen Liu and Liping Liu and Dongdong Li and Wei Li and Fei Kong and Bangchang Liu and Xiaobin Luo and Ji Qi and Qiao Jin and Bin Xu},
182 | journal={arXiv preprint arXiv:2105.15033},
183 | year={2021}
184 | }
185 | ```
186 |
--------------------------------------------------------------------------------
/NER/datasets/mrc_ner_dataset.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import json
5 | import torch
6 | from tokenizers import BertWordPieceTokenizer
7 | from torch.utils.data import Dataset
8 |
9 |
10 | class MRCNERDataset(Dataset):
11 | """
12 | MRC NER Dataset
13 | Args:
14 | json_path: path to mrc-ner style json
15 | tokenizer: BertTokenizer
16 | max_length: int, max length of query+context
17 | possible_only: if True, only use possible samples that contain answer for the query/context
18 | is_chinese: is chinese dataset
19 | """
20 |
21 | def __init__(self, json_path, tokenizer: BertWordPieceTokenizer, max_length: int = 128, possible_only=False,
22 | is_chinese=False, pad_to_maxlen=False):
23 | self.all_data = json.load(open(json_path, encoding="utf-8"))
24 | self.tokenzier = tokenizer
25 | self.max_length = max_length
26 | self.possible_only = possible_only
27 | if self.possible_only:
28 | self.all_data = [
29 | x for x in self.all_data if x["start_position"]
30 | ]
31 | self.is_chinese = is_chinese
32 | self.pad_to_maxlen = pad_to_maxlen
33 |
34 | def __len__(self):
35 | return len(self.all_data)
36 |
37 | def __getitem__(self, item):
38 | """
39 | Args:
40 | item: int, idx
41 | Returns:
42 | tokens: tokens of query + context, [seq_len]
43 | token_type_ids: token type ids, 0 for query, 1 for context, [seq_len]
44 | start_labels: start labels of NER in tokens, [seq_len]
45 | end_labels: end labelsof NER in tokens, [seq_len]
46 | label_mask: label mask, 1 for counting into loss, 0 for ignoring. [seq_len]
47 | match_labels: match labels, [seq_len, seq_len]
48 | sample_idx: sample id
49 | label_idx: label id
50 |
51 | """
52 | data = self.all_data[item]
53 | tokenizer = self.tokenzier
54 |
55 | qas_id = data.get("qas_id", "0.0")
56 | sample_idx, label_idx = qas_id.split(".")
57 | sample_idx = torch.LongTensor([int(sample_idx)])
58 | label_idx = torch.LongTensor([int(label_idx)])
59 |
60 | query = data["query"]
61 | context = data["context"]
62 | start_positions = data["start_position"]
63 | end_positions = data["end_position"]
64 | if self.is_chinese:
65 | context = "".join(context.split())
66 | end_positions = [x + 1 for x in end_positions]
67 | else:
68 | # add space offsets
69 | words = context.split()
70 | start_positions = [x + sum([len(w) for w in words[:x]]) for x in start_positions]
71 | end_positions = [x + sum([len(w) for w in words[:x + 1]]) for x in end_positions]
72 |
73 | query_context_tokens = tokenizer.encode(query, context, add_special_tokens=True)
74 | tokens = query_context_tokens.ids
75 | type_ids = query_context_tokens.type_ids
76 | offsets = query_context_tokens.offsets
77 |
78 | # find new start_positions/end_positions, considering
79 | # 1. we add query tokens at the beginning
80 | # 2. word-piece tokenize
81 | origin_offset2token_idx_start = {}
82 | origin_offset2token_idx_end = {}
83 | for token_idx in range(len(tokens)):
84 | # skip query tokens
85 | if type_ids[token_idx] == 0:
86 | continue
87 | token_start, token_end = offsets[token_idx]
88 | # skip [CLS] or [SEP]
89 | if token_start == token_end == 0:
90 | continue
91 | origin_offset2token_idx_start[token_start] = token_idx
92 | origin_offset2token_idx_end[token_end] = token_idx
93 | new_start_positions = [origin_offset2token_idx_start[start] for start in start_positions]
94 | new_end_positions = [origin_offset2token_idx_end[end] for end in end_positions]
95 |
96 | label_mask = [
97 | (0 if type_ids[token_idx] == 0 or offsets[token_idx] == (0, 0) else 1)
98 | for token_idx in range(len(tokens))
99 | ]
100 | start_label_mask = label_mask.copy()
101 | end_label_mask = label_mask.copy()
102 |
103 | # the start/end position must be whole word
104 | if not self.is_chinese:
105 | for token_idx in range(len(tokens)):
106 | current_word_idx = query_context_tokens.words[token_idx]
107 | next_word_idx = query_context_tokens.words[token_idx + 1] if token_idx + 1 < len(tokens) else None
108 | prev_word_idx = query_context_tokens.words[token_idx - 1] if token_idx - 1 > 0 else None
109 | if prev_word_idx is not None and current_word_idx == prev_word_idx:
110 | start_label_mask[token_idx] = 0
111 | if next_word_idx is not None and current_word_idx == next_word_idx:
112 | end_label_mask[token_idx] = 0
113 |
114 | assert all(start_label_mask[p] != 0 for p in new_start_positions)
115 | assert all(end_label_mask[p] != 0 for p in new_end_positions)
116 |
117 | assert len(new_start_positions) == len(new_end_positions) == len(start_positions)
118 | assert len(label_mask) == len(tokens)
119 | start_labels = [(1 if idx in new_start_positions else 0)
120 | for idx in range(len(tokens))]
121 | end_labels = [(1 if idx in new_end_positions else 0)
122 | for idx in range(len(tokens))]
123 |
124 | # truncate
125 | tokens = tokens[: self.max_length]
126 | type_ids = type_ids[: self.max_length]
127 | start_labels = start_labels[: self.max_length]
128 | end_labels = end_labels[: self.max_length]
129 | start_label_mask = start_label_mask[: self.max_length]
130 | end_label_mask = end_label_mask[: self.max_length]
131 |
132 | # make sure last token is [SEP]
133 | sep_token = tokenizer.token_to_id("[SEP]")
134 | if tokens[-1] != sep_token:
135 | assert len(tokens) == self.max_length
136 | tokens = tokens[: -1] + [sep_token]
137 | start_labels[-1] = 0
138 | end_labels[-1] = 0
139 | start_label_mask[-1] = 0
140 | end_label_mask[-1] = 0
141 |
142 | if self.pad_to_maxlen:
143 | tokens = self.pad(tokens, 0)
144 | type_ids = self.pad(type_ids, 1)
145 | start_labels = self.pad(start_labels)
146 | end_labels = self.pad(end_labels)
147 | start_label_mask = self.pad(start_label_mask)
148 | end_label_mask = self.pad(end_label_mask)
149 |
150 | seq_len = len(tokens)
151 | match_labels = torch.zeros([seq_len, seq_len], dtype=torch.long)
152 | for start, end in zip(new_start_positions, new_end_positions):
153 | if start >= seq_len or end >= seq_len:
154 | continue
155 | match_labels[start, end] = 1
156 |
157 | return [
158 | torch.LongTensor(tokens),
159 | torch.LongTensor(type_ids),
160 | torch.LongTensor(start_labels),
161 | torch.LongTensor(end_labels),
162 | torch.LongTensor(start_label_mask),
163 | torch.LongTensor(end_label_mask),
164 | match_labels,
165 | sample_idx,
166 | label_idx
167 | ]
168 |
169 | def pad(self, lst, value=0, max_length=None):
170 | max_length = max_length or self.max_length
171 | while len(lst) < max_length:
172 | lst.append(value)
173 | return lst
174 | import numpy as np
175 |
176 | def run_dataset():
177 | """test dataset"""
178 | import os
179 | from datasets.collate_functions import collate_to_max_length
180 | from torch.utils.data import DataLoader
181 | # zh datasets
182 | # bert_path = "/mnt/mrc/chinese_L-12_H-768_A-12"
183 | # json_path = "/mnt/mrc/zh_msra/mrc-ner.test"
184 | # # json_path = "/mnt/mrc/zh_onto4/mrc-ner.train"
185 | # is_chinese = True
186 |
187 | # en datasets
188 | bert_path = "E:\data\chinese_roberta_wwm_large_ext_pytorch\\"
189 | json_path = "E:\\data\\nested\\mrc-ner.evl"
190 | # json_path = "/mnt/mrc/genia/mrc-ner.train"
191 | is_chinese = True
192 |
193 | vocab_file = os.path.join(bert_path, "vocab.txt")
194 | tokenizer = BertWordPieceTokenizer(vocab_file)
195 | dataset = MRCNERDataset(json_path=json_path, tokenizer=tokenizer,
196 | is_chinese=is_chinese)
197 |
198 | dataloader = DataLoader(dataset, batch_size=32,
199 | collate_fn=collate_to_max_length)
200 | for batch in dataloader:
201 | for tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx in zip(
202 | *batch):
203 | tokens = tokens.tolist()
204 | start_positions, end_positions = torch.where(match_labels > 0)
205 | start_positions = start_positions.tolist()
206 | end_positions = end_positions.tolist()
207 | if not start_positions:
208 | continue
209 |
210 |
211 | print("=" * 20)
212 | print(f"len: {len(tokens)}", tokenizer.decode(tokens, skip_special_tokens=False))
213 | for start, end in zip(start_positions, end_positions):
214 | print(sample_idx)
215 | print(label_idx)
216 |
217 | print(str(sample_idx.item())+"---", str(label_idx.item()) + "---" + tokenizer.decode(tokens[start: end + 1]))
218 |
219 |
220 |
221 | if __name__ == '__main__':
222 | run_dataset()
223 |
--------------------------------------------------------------------------------
/NER/datasets/compute_acc.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import json
5 | import torch
6 | from tokenizers import BertWordPieceTokenizer
7 | from torch.utils.data import Dataset
8 | import trainer
9 | from tqdm import tqdm
10 |
11 | class MRCNERDataset(Dataset):
12 | """
13 | MRC NER Dataset
14 | Args:
15 | json_path: path to mrc-ner style json
16 | tokenizer: BertTokenizer
17 | max_length: int, max length of query+context
18 | possible_only: if True, only use possible samples that contain answer for the query/context
19 | is_chinese: is chinese dataset
20 | """
21 |
22 | def __init__(self, json_path, tokenizer: BertWordPieceTokenizer, max_length: int = 128, possible_only=False,
23 | is_chinese=False, pad_to_maxlen=False):
24 | self.all_data = json.load(open(json_path, encoding="utf-8"))
25 | self.tokenzier = tokenizer
26 | self.max_length = max_length
27 | self.possible_only = possible_only
28 | if self.possible_only:
29 | self.all_data = [
30 | x for x in self.all_data if x["start_position"]
31 | ]
32 | self.is_chinese = is_chinese
33 | self.pad_to_maxlen = pad_to_maxlen
34 |
35 | def __len__(self):
36 | return len(self.all_data)
37 |
38 | def __getitem__(self, item):
39 | """
40 | Args:
41 | item: int, idx
42 | Returns:
43 | tokens: tokens of query + context, [seq_len]
44 | token_type_ids: token type ids, 0 for query, 1 for context, [seq_len]
45 | start_labels: start labels of NER in tokens, [seq_len]
46 | end_labels: end labelsof NER in tokens, [seq_len]
47 | label_mask: label mask, 1 for counting into loss, 0 for ignoring. [seq_len]
48 | match_labels: match labels, [seq_len, seq_len]
49 | sample_idx: sample id
50 | label_idx: label id
51 |
52 | """
53 | data = self.all_data[item]
54 | tokenizer = self.tokenzier
55 |
56 | qas_id = data.get("qas_id", "0.0")
57 | sample_idx, label_idx = qas_id.split(".")
58 | sample_idx = torch.LongTensor([int(sample_idx)])
59 | label_idx = torch.LongTensor([int(label_idx)])
60 |
61 | query = data["query"]
62 | context = data["context"]
63 | start_positions = data["start_position"]
64 | end_positions = data["end_position"]
65 |
66 | if self.is_chinese:
67 | context = "".join(context.split())
68 | end_positions = [x + 1 for x in end_positions]
69 | else:
70 | # add space offsets
71 | words = context.split()
72 | start_positions = [x + sum([len(w) for w in words[:x]]) for x in start_positions]
73 | end_positions = [x + sum([len(w) for w in words[:x + 1]]) for x in end_positions]
74 |
75 | query_context_tokens = tokenizer.encode(query, context, add_special_tokens=True)
76 | tokens = query_context_tokens.ids
77 | type_ids = query_context_tokens.type_ids
78 | offsets = query_context_tokens.offsets
79 |
80 | # find new start_positions/end_positions, considering
81 | # 1. we add query tokens at the beginning
82 | # 2. word-piece tokenize
83 | origin_offset2token_idx_start = {}
84 | origin_offset2token_idx_end = {}
85 | for token_idx in range(len(tokens)):
86 | # skip query tokens
87 | if type_ids[token_idx] == 0:
88 | continue
89 | token_start, token_end = offsets[token_idx]
90 | # skip [CLS] or [SEP]
91 | if token_start == token_end == 0:
92 | continue
93 | origin_offset2token_idx_start[token_start] = token_idx
94 | origin_offset2token_idx_end[token_end] = token_idx
95 | new_start_positions = [origin_offset2token_idx_start[start] for start in start_positions]
96 | new_end_positions = [origin_offset2token_idx_end[end] for end in end_positions]
97 |
98 | label_mask = [
99 | (0 if type_ids[token_idx] == 0 or offsets[token_idx] == (0, 0) else 1)
100 | for token_idx in range(len(tokens))
101 | ]
102 | start_label_mask = label_mask.copy()
103 | end_label_mask = label_mask.copy()
104 |
105 | # the start/end position must be whole word
106 | if not self.is_chinese:
107 | for token_idx in range(len(tokens)):
108 | current_word_idx = query_context_tokens.words[token_idx]
109 | next_word_idx = query_context_tokens.words[token_idx + 1] if token_idx + 1 < len(tokens) else None
110 | prev_word_idx = query_context_tokens.words[token_idx - 1] if token_idx - 1 > 0 else None
111 | if prev_word_idx is not None and current_word_idx == prev_word_idx:
112 | start_label_mask[token_idx] = 0
113 | if next_word_idx is not None and current_word_idx == next_word_idx:
114 | end_label_mask[token_idx] = 0
115 |
116 | assert all(start_label_mask[p] != 0 for p in new_start_positions)
117 | assert all(end_label_mask[p] != 0 for p in new_end_positions)
118 |
119 | assert len(new_start_positions) == len(new_end_positions) == len(start_positions)
120 | assert len(label_mask) == len(tokens)
121 | start_labels = [(1 if idx in new_start_positions else 0)
122 | for idx in range(len(tokens))]
123 | end_labels = [(1 if idx in new_end_positions else 0)
124 | for idx in range(len(tokens))]
125 |
126 | # truncate
127 | tokens = tokens[: self.max_length]
128 | type_ids = type_ids[: self.max_length]
129 | start_labels = start_labels[: self.max_length]
130 | end_labels = end_labels[: self.max_length]
131 | start_label_mask = start_label_mask[: self.max_length]
132 | end_label_mask = end_label_mask[: self.max_length]
133 |
134 | # make sure last token is [SEP]
135 | sep_token = tokenizer.token_to_id("[SEP]")
136 | if tokens[-1] != sep_token:
137 | assert len(tokens) == self.max_length
138 | tokens = tokens[: -1] + [sep_token]
139 | start_labels[-1] = 0
140 | end_labels[-1] = 0
141 | start_label_mask[-1] = 0
142 | end_label_mask[-1] = 0
143 |
144 | if self.pad_to_maxlen:
145 | tokens = self.pad(tokens, 0)
146 | type_ids = self.pad(type_ids, 1)
147 | start_labels = self.pad(start_labels)
148 | end_labels = self.pad(end_labels)
149 | start_label_mask = self.pad(start_label_mask)
150 | end_label_mask = self.pad(end_label_mask)
151 |
152 | seq_len = len(tokens)
153 | match_labels = torch.zeros([seq_len, seq_len], dtype=torch.long)
154 | for start, end in zip(new_start_positions, new_end_positions):
155 | if start >= seq_len or end >= seq_len:
156 | continue
157 | match_labels[start, end] = 1
158 |
159 | return [
160 | torch.LongTensor(tokens),
161 | torch.LongTensor(type_ids),
162 | torch.LongTensor(start_labels),
163 | torch.LongTensor(end_labels),
164 | torch.LongTensor(start_label_mask),
165 | torch.LongTensor(end_label_mask),
166 | match_labels,
167 | sample_idx,
168 | label_idx
169 | ]
170 |
171 | def pad(self, lst, value=0, max_length=None):
172 | max_length = max_length or self.max_length
173 | while len(lst) < max_length:
174 | lst.append(value)
175 | return lst
176 |
177 |
178 | def load_model_for_compute():
179 | CHECKPOINTS = "E:\\data\\modelNER\\version_7\\checkpoints\\epoch=2.ckpt"
180 | HPARAMS = "E:\\data\\modelNER\\version_7\\hparams.yaml"
181 | model = trainer.BertLabeling.load_from_checkpoint(
182 | checkpoint_path=CHECKPOINTS,
183 | hparams_file=HPARAMS,
184 | map_location=None,
185 | batch_size=1,
186 | max_length=128,
187 | workers=0
188 | )
189 | return model
190 |
191 |
192 | def load_dataset_for_compute():
193 | """test dataset"""
194 | import os
195 | from datasets.collate_functions import collate_to_max_length
196 | from torch.utils.data import DataLoader
197 | bert_path = "E:\data\chinese_roberta_wwm_large_ext_pytorch"
198 | json_path = "E:\\data\\nested\\mrc-ner.evl"
199 | is_chinese = True
200 | vocab_file = os.path.join(bert_path, "vocab.txt")
201 | tokenizer = BertWordPieceTokenizer(vocab_file)
202 | dataset = MRCNERDataset(json_path=json_path, tokenizer=tokenizer,
203 | is_chinese=is_chinese)
204 | dataloader = DataLoader(dataset, batch_size=1,
205 | collate_fn=collate_to_max_length)
206 | return dataloader, tokenizer
207 |
208 |
209 |
210 | def write_json_to_file(origin_path, des_path, data):
211 | with open(origin_path + des_path, "w", encoding="utf8") as fp:
212 | fp.write(json.dumps(data, ensure_ascii=False))
213 | fp.write("\n")
214 | fp.flush()
215 | fp.close()
216 |
217 | def compute_result_by_query():
218 | model = load_model_for_compute()
219 | data, tokenizer = load_dataset_for_compute()
220 | entity_total = {}
221 | with tqdm(total=len(data)) as pbar:
222 | try:
223 | for batch_idx, batch in enumerate(data):
224 | sample = data.dataset.all_data[batch_idx]
225 | entity_label = sample["entity_label"]
226 | if entity_label not in entity_total.keys():
227 | entity_total[entity_label] = {"tp": 0, "fp": 0, "fn": 0}
228 | out_puts = model.validation_step(batch, batch_idx)
229 | tp, fp, fn = out_puts["span_f1_stats"]
230 | entity_total[entity_label]["tp"] = entity_total[entity_label]["tp"] + tp.item()
231 | entity_total[entity_label]["fp"] = entity_total[entity_label]["fp"] + fp.item()
232 | entity_total[entity_label]["fn"] = entity_total[entity_label]["fn"] + fn.item()
233 | pbar.update(1)
234 | except Exception as e:
235 | print("ERROR,PLEASE CHECK CODE!{}".format(e))
236 | entity_total_result = {}
237 | tp_total = 0
238 | fp_total = 0
239 | fn_total = 0
240 | for k, v in entity_total.items():
241 | tp = v["tp"]
242 | fp = v["fp"]
243 | fn = v["fn"]
244 | tp_total += tp
245 | fp_total += fp
246 | fn_total += fn
247 | P = tp * 100.0 / (tp + fp)
248 | R = tp * 100.0 / (tp + fn)
249 | F1 = 0 if (P + R) == 0 else (2 * P * R) / (P + R)
250 | entity_total_result[k] = {"precision": "{:.2f}".format(P), "recall": "{:.2f}".format(R), "f1": "{:.2f}".format(F1)}
251 | P_Tol = tp_total * 100.0 / (tp_total + fp_total)
252 | R_Tol = tp_total * 100.0 / (tp_total + fn_total)
253 | F1_Tol = 0 if (P_Tol + R_Tol) == 0 else (2 * P_Tol * R_Tol) / (P_Tol + R_Tol)
254 | write_json_to_file("", "query_entity_result.txt", entity_total_result)
255 | print("total precision:{:.2f},total recall:{:.2f},total f1:{:.2f}".format(P_Tol, R_Tol, F1_Tol))
256 |
257 |
258 | if __name__ == '__main__':
259 | # run_dataset()
260 | compute_result_by_query()
261 |
--------------------------------------------------------------------------------
/RE/initial.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import os
3 |
4 |
5 | # embedding the position
6 | def pos_embed(x):
7 | if x < -60:
8 | return 0
9 | if -60 <= x <= 60:
10 | return x + 61
11 | if x > 60:
12 | return 122
13 |
14 |
15 | # find the index of x in y, if x not in y, return -1
16 | def find_index(x, y):
17 | flag = -1
18 | for i in range(len(y)):
19 | if x != y[i]:
20 | continue
21 | else:
22 | return i
23 | return flag
24 |
25 |
26 | # reading data
27 | def init():
28 | print('reading word embedding data...')
29 | vec = []
30 | word2id = {}
31 | f = open('./data/vec.txt', encoding='utf-8')
32 | content = f.readline()
33 | content = content.strip().split()
34 | dim = int(content[1])
35 | while True:
36 | content = f.readline()
37 | if content == '':
38 | break
39 | content = content.strip().split()
40 | word2id[content[0]] = len(word2id)
41 | content = content[1:]
42 | content = [(float)(i) for i in content]
43 | vec.append(content)
44 | f.close()
45 | word2id['UNK'] = len(word2id)
46 | word2id['BLANK'] = len(word2id)
47 |
48 | vec.append(np.random.normal(size=dim, loc=0, scale=0.05))
49 | vec.append(np.random.normal(size=dim, loc=0, scale=0.05))
50 | vec = np.array(vec, dtype=np.float32)
51 |
52 | print('reading relation to id')
53 | relation2id = {}
54 | f = open('./data/relation2id.txt', 'r', encoding='utf-8')
55 | while True:
56 | content = f.readline()
57 | if content == '':
58 | break
59 | content = content.strip().split()
60 | relation2id[content[0]] = int(content[1])
61 | f.close()
62 |
63 | # length of sentence is 70
64 | fixlen = 70
65 | # max length of position embedding is 60 (-60~+60)
66 | maxlen = 60
67 |
68 | train_sen = {} # {entity pair:[[[label1-sentence 1],[label1-sentence 2]...],[[label2-sentence 1],[label2-sentence 2]...]}
69 | train_ans = {} # {entity pair:[label1,label2,...]} the label is one-hot vector
70 |
71 | print('reading train data...')
72 | f = open('./data/train.txt', 'r', encoding='utf-8')
73 |
74 | while True:
75 | content = f.readline()
76 | if content == '':
77 | break
78 |
79 | content = content.strip().split('\t')
80 | # get entity name
81 | en1 = content[0]
82 | en2 = content[1]
83 | relation = 0
84 | if content[2] not in relation2id:
85 | print(content[2])
86 | relation = relation2id['NA']
87 | else:
88 | relation = relation2id[content[2]]
89 | # put the same entity pair sentences into a dict
90 | tup = (en1, en2)
91 | label_tag = 0
92 | if tup not in train_sen:
93 | train_sen[tup] = []
94 | train_sen[tup].append([])
95 | y_id = relation
96 | label_tag = 0
97 | label = [0 for i in range(len(relation2id))]
98 | label[y_id] = 1
99 | train_ans[tup] = []
100 | train_ans[tup].append(label)
101 | else:
102 | y_id = relation
103 | label_tag = 0
104 | label = [0 for i in range(len(relation2id))]
105 | label[y_id] = 1
106 |
107 | temp = find_index(label, train_ans[tup])
108 | if temp == -1:
109 | train_ans[tup].append(label)
110 | label_tag = len(train_ans[tup]) - 1
111 | train_sen[tup].append([])
112 | else:
113 | label_tag = temp
114 |
115 | sentence = content[3]
116 |
117 | en1pos = 0
118 | en2pos = 0
119 |
120 | #For Chinese
121 | en1pos = sentence.find(en1)
122 | if en1pos == -1:
123 | en1pos = 0
124 | en2pos = sentence.find(en2)
125 | if en2pos == -1:
126 | en2pos = 0
127 |
128 | output = []
129 |
130 | #Embeding the position
131 | for i in range(fixlen):
132 | word = word2id['BLANK']
133 | rel_e1 = pos_embed(i - en1pos)
134 | rel_e2 = pos_embed(i - en2pos)
135 | output.append([word, rel_e1, rel_e2])
136 |
137 | for i in range(min(fixlen, len(sentence))):
138 | word = 0
139 | if sentence[i] not in word2id:
140 | word = word2id['UNK']
141 | else:
142 | word = word2id[sentence[i]]
143 |
144 | output[i][0] = word
145 |
146 | train_sen[tup][label_tag].append(output)
147 |
148 | print('reading test data ...')
149 |
150 | test_sen = {} # {entity pair:[[sentence 1],[sentence 2]...]}
151 | test_ans = {} # {entity pair:[labels,...]} the labels is N-hot vector (N is the number of multi-label)
152 |
153 | f = open('./data/test.txt', 'r', encoding='utf-8')
154 |
155 | while True:
156 | content = f.readline()
157 | if content == '':
158 | break
159 |
160 | content = content.strip().split('\t')
161 | en1 = content[0]
162 | en2 = content[1]
163 | relation = 0
164 | if content[2] not in relation2id:
165 | relation = relation2id['NA']
166 | else:
167 | relation = relation2id[content[2]]
168 | tup = (en1, en2)
169 |
170 | if tup not in test_sen:
171 | test_sen[tup] = []
172 | y_id = relation
173 | label_tag = 0
174 | label = [0 for i in range(len(relation2id))]
175 | label[y_id] = 1
176 | test_ans[tup] = label
177 | else:
178 | y_id = relation
179 | test_ans[tup][y_id] = 1
180 |
181 | sentence = content[3]
182 |
183 | en1pos = 0
184 | en2pos = 0
185 |
186 | #For Chinese
187 | en1pos = sentence.find(en1)
188 | if en1pos == -1:
189 | en1pos = 0
190 | en2pos = sentence.find(en2)
191 | if en2pos == -1:
192 | en2pos = 0
193 |
194 | output = []
195 |
196 | for i in range(fixlen):
197 | word = word2id['BLANK']
198 | rel_e1 = pos_embed(i - en1pos)
199 | rel_e2 = pos_embed(i - en2pos)
200 | output.append([word, rel_e1, rel_e2])
201 |
202 | for i in range(min(fixlen, len(sentence))):
203 | word = 0
204 | if sentence[i] not in word2id:
205 | word = word2id['UNK']
206 | else:
207 | word = word2id[sentence[i]]
208 |
209 | output[i][0] = word
210 | test_sen[tup].append(output)
211 |
212 | train_x = []
213 | train_y = []
214 | test_x = []
215 | test_y = []
216 |
217 | if not os.path.exists("data"):
218 | os.makedirs("data")
219 |
220 | print('organizing train data')
221 | f = open('./data/train_q&a.txt', 'w', encoding='utf-8')
222 | temp = 0
223 | for i in train_sen:
224 | if len(train_ans[i]) != len(train_sen[i]):
225 | print('ERROR')
226 | lenth = len(train_ans[i])
227 | for j in range(lenth):
228 | train_x.append(train_sen[i][j])
229 | train_y.append(train_ans[i][j])
230 | f.write(str(temp) + '\t' + i[0] + '\t' + i[1] + '\t' + str(np.argmax(train_ans[i][j])) + '\n')
231 | temp += 1
232 | f.close()
233 |
234 | print('organizing test data')
235 | f = open('./data/test_q&a.txt', 'w', encoding='utf-8')
236 | temp = 0
237 | for i in test_sen:
238 | test_x.append(test_sen[i])
239 | test_y.append(test_ans[i])
240 | tempstr = ''
241 | for j in range(len(test_ans[i])):
242 | if test_ans[i][j] != 0:
243 | tempstr = tempstr + str(j) + '\t'
244 | f.write(str(temp) + '\t' + i[0] + '\t' + i[1] + '\t' + tempstr + '\n')
245 | temp += 1
246 | f.close()
247 |
248 | train_x = np.array(train_x)
249 | train_y = np.array(train_y)
250 | test_x = np.array(test_x)
251 | test_y = np.array(test_y)
252 |
253 | np.save('./data/vec.npy', vec)
254 | np.save('./data/train_x.npy', train_x)
255 | np.save('./data/train_y.npy', train_y)
256 | np.save('./data/testall_x.npy', test_x)
257 | np.save('./data/testall_y.npy', test_y)
258 |
259 |
260 | def seperate():
261 | print('reading training data')
262 | x_train = np.load('./data/train_x.npy', allow_pickle=True)
263 |
264 | train_word = []
265 | train_pos1 = []
266 | train_pos2 = []
267 |
268 | print('seprating train data')
269 | for i in range(len(x_train)):
270 | word = []
271 | pos1 = []
272 | pos2 = []
273 | for j in x_train[i]:
274 | temp_word = []
275 | temp_pos1 = []
276 | temp_pos2 = []
277 | for k in j:
278 | temp_word.append(k[0])
279 | temp_pos1.append(k[1])
280 | temp_pos2.append(k[2])
281 | word.append(temp_word)
282 | pos1.append(temp_pos1)
283 | pos2.append(temp_pos2)
284 | train_word.append(word)
285 | train_pos1.append(pos1)
286 | train_pos2.append(pos2)
287 |
288 | train_word = np.array(train_word)
289 | train_pos1 = np.array(train_pos1)
290 | train_pos2 = np.array(train_pos2)
291 | np.save('./data/train_word.npy', train_word)
292 | np.save('./data/train_pos1.npy', train_pos1)
293 | np.save('./data/train_pos2.npy', train_pos2)
294 |
295 | print('seperating test all data')
296 | x_test = np.load('./data/testall_x.npy', allow_pickle=True)
297 | test_word = []
298 | test_pos1 = []
299 | test_pos2 = []
300 |
301 | for i in range(len(x_test)):
302 | word = []
303 | pos1 = []
304 | pos2 = []
305 | for j in x_test[i]:
306 | temp_word = []
307 | temp_pos1 = []
308 | temp_pos2 = []
309 | for k in j:
310 | temp_word.append(k[0])
311 | temp_pos1.append(k[1])
312 | temp_pos2.append(k[2])
313 | word.append(temp_word)
314 | pos1.append(temp_pos1)
315 | pos2.append(temp_pos2)
316 | test_word.append(word)
317 | test_pos1.append(pos1)
318 | test_pos2.append(pos2)
319 |
320 | test_word = np.array(test_word)
321 | test_pos1 = np.array(test_pos1)
322 | test_pos2 = np.array(test_pos2)
323 |
324 | np.save('./data/testall_word.npy', test_word)
325 | np.save('./data/testall_pos1.npy', test_pos1)
326 | np.save('./data/testall_pos2.npy', test_pos2)
327 |
328 |
329 |
330 | # get answer metric for PR curve evaluation
331 | def getans():
332 | test_y = np.load('./data/testall_y.npy', allow_pickle=True)
333 | eval_y = []
334 | for i in test_y:
335 | eval_y.append(i[1:])
336 | allans = np.reshape(eval_y, (-1))
337 | np.save('./data/allans.npy', allans)
338 |
339 |
340 | def get_metadata():
341 | fwrite = open('./data/metadata.tsv', 'w', encoding='utf-8')
342 | f = open('./origin_data/vec.txt', encoding='utf-8')
343 | f.readline()
344 | while True:
345 | content = f.readline().strip()
346 | if content == '':
347 | break
348 | name = content.split()[0]
349 | fwrite.write(name + '\n')
350 | f.close()
351 | fwrite.close()
352 |
353 |
354 | init()
355 | seperate()
356 | getans()
357 | get_metadata()
358 |
--------------------------------------------------------------------------------
/NER/datasets/compute_acc_linux.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import json
5 | import torch
6 | from tokenizers import BertWordPieceTokenizer
7 | from torch.utils.data import Dataset
8 | import trainer
9 | from tqdm import tqdm
10 |
11 | class MRCNERDataset(Dataset):
12 | """
13 | MRC NER Dataset
14 | Args:
15 | json_path: path to mrc-ner style json
16 | tokenizer: BertTokenizer
17 | max_length: int, max length of query+context
18 | possible_only: if True, only use possible samples that contain answer for the query/context
19 | is_chinese: is chinese dataset
20 | """
21 |
22 | def __init__(self, json_path, tokenizer: BertWordPieceTokenizer, max_length: int = 128, possible_only=False,
23 | is_chinese=False, pad_to_maxlen=False):
24 | self.all_data = json.load(open(json_path, encoding="utf-8"))
25 | self.tokenzier = tokenizer
26 | self.max_length = max_length
27 | self.possible_only = possible_only
28 | if self.possible_only:
29 | self.all_data = [
30 | x for x in self.all_data if x["start_position"]
31 | ]
32 | self.is_chinese = is_chinese
33 | self.pad_to_maxlen = pad_to_maxlen
34 |
35 | def __len__(self):
36 | return len(self.all_data)
37 |
38 | def __getitem__(self, item):
39 | """
40 | Args:
41 | item: int, idx
42 | Returns:
43 | tokens: tokens of query + context, [seq_len]
44 | token_type_ids: token type ids, 0 for query, 1 for context, [seq_len]
45 | start_labels: start labels of NER in tokens, [seq_len]
46 | end_labels: end labelsof NER in tokens, [seq_len]
47 | label_mask: label mask, 1 for counting into loss, 0 for ignoring. [seq_len]
48 | match_labels: match labels, [seq_len, seq_len]
49 | sample_idx: sample id
50 | label_idx: label id
51 |
52 | """
53 | data = self.all_data[item]
54 | tokenizer = self.tokenzier
55 |
56 | qas_id = data.get("qas_id", "0.0")
57 | sample_idx, label_idx = qas_id.split(".")
58 | sample_idx = torch.LongTensor([int(sample_idx)])
59 | label_idx = torch.LongTensor([int(label_idx)])
60 |
61 | query = data["query"]
62 | context = data["context"]
63 | start_positions = data["start_position"]
64 | end_positions = data["end_position"]
65 |
66 | if self.is_chinese:
67 | context = "".join(context.split())
68 | end_positions = [x + 1 for x in end_positions]
69 | else:
70 | # add space offsets
71 | words = context.split()
72 | start_positions = [x + sum([len(w) for w in words[:x]]) for x in start_positions]
73 | end_positions = [x + sum([len(w) for w in words[:x + 1]]) for x in end_positions]
74 |
75 | query_context_tokens = tokenizer.encode(query, context, add_special_tokens=True)
76 | tokens = query_context_tokens.ids
77 | type_ids = query_context_tokens.type_ids
78 | offsets = query_context_tokens.offsets
79 |
80 | # find new start_positions/end_positions, considering
81 | # 1. we add query tokens at the beginning
82 | # 2. word-piece tokenize
83 | origin_offset2token_idx_start = {}
84 | origin_offset2token_idx_end = {}
85 | for token_idx in range(len(tokens)):
86 | # skip query tokens
87 | if type_ids[token_idx] == 0:
88 | continue
89 | token_start, token_end = offsets[token_idx]
90 | # skip [CLS] or [SEP]
91 | if token_start == token_end == 0:
92 | continue
93 | origin_offset2token_idx_start[token_start] = token_idx
94 | origin_offset2token_idx_end[token_end] = token_idx
95 | new_start_positions = [origin_offset2token_idx_start[start] for start in start_positions]
96 | new_end_positions = [origin_offset2token_idx_end[end] for end in end_positions]
97 |
98 | label_mask = [
99 | (0 if type_ids[token_idx] == 0 or offsets[token_idx] == (0, 0) else 1)
100 | for token_idx in range(len(tokens))
101 | ]
102 | start_label_mask = label_mask.copy()
103 | end_label_mask = label_mask.copy()
104 |
105 | # the start/end position must be whole word
106 | if not self.is_chinese:
107 | for token_idx in range(len(tokens)):
108 | current_word_idx = query_context_tokens.words[token_idx]
109 | next_word_idx = query_context_tokens.words[token_idx + 1] if token_idx + 1 < len(tokens) else None
110 | prev_word_idx = query_context_tokens.words[token_idx - 1] if token_idx - 1 > 0 else None
111 | if prev_word_idx is not None and current_word_idx == prev_word_idx:
112 | start_label_mask[token_idx] = 0
113 | if next_word_idx is not None and current_word_idx == next_word_idx:
114 | end_label_mask[token_idx] = 0
115 |
116 | assert all(start_label_mask[p] != 0 for p in new_start_positions)
117 | assert all(end_label_mask[p] != 0 for p in new_end_positions)
118 |
119 | assert len(new_start_positions) == len(new_end_positions) == len(start_positions)
120 | assert len(label_mask) == len(tokens)
121 | start_labels = [(1 if idx in new_start_positions else 0)
122 | for idx in range(len(tokens))]
123 | end_labels = [(1 if idx in new_end_positions else 0)
124 | for idx in range(len(tokens))]
125 |
126 | # truncate
127 | tokens = tokens[: self.max_length]
128 | type_ids = type_ids[: self.max_length]
129 | start_labels = start_labels[: self.max_length]
130 | end_labels = end_labels[: self.max_length]
131 | start_label_mask = start_label_mask[: self.max_length]
132 | end_label_mask = end_label_mask[: self.max_length]
133 |
134 | # make sure last token is [SEP]
135 | sep_token = tokenizer.token_to_id("[SEP]")
136 | if tokens[-1] != sep_token:
137 | assert len(tokens) == self.max_length
138 | tokens = tokens[: -1] + [sep_token]
139 | start_labels[-1] = 0
140 | end_labels[-1] = 0
141 | start_label_mask[-1] = 0
142 | end_label_mask[-1] = 0
143 |
144 | if self.pad_to_maxlen:
145 | tokens = self.pad(tokens, 0)
146 | type_ids = self.pad(type_ids, 1)
147 | start_labels = self.pad(start_labels)
148 | end_labels = self.pad(end_labels)
149 | start_label_mask = self.pad(start_label_mask)
150 | end_label_mask = self.pad(end_label_mask)
151 |
152 | seq_len = len(tokens)
153 | match_labels = torch.zeros([seq_len, seq_len], dtype=torch.long)
154 | for start, end in zip(new_start_positions, new_end_positions):
155 | if start >= seq_len or end >= seq_len:
156 | continue
157 | match_labels[start, end] = 1
158 |
159 | return [
160 | torch.LongTensor(tokens),
161 | torch.LongTensor(type_ids),
162 | torch.LongTensor(start_labels),
163 | torch.LongTensor(end_labels),
164 | torch.LongTensor(start_label_mask),
165 | torch.LongTensor(end_label_mask),
166 | match_labels,
167 | sample_idx,
168 | label_idx
169 | ]
170 |
171 | def pad(self, lst, value=0, max_length=None):
172 | max_length = max_length or self.max_length
173 | while len(lst) < max_length:
174 | lst.append(value)
175 | return lst
176 |
177 |
178 | def load_model_for_compute():
179 | CHECKPOINTS = "/ml/home/mcldd/ner-rel/diabete-kno-dataset-code/mrc-for-flat-nested-ner-master/lightning_logs/version_17/checkpoints/epoch=7.ckpt"
180 | HPARAMS = "/ml/home/mcldd/ner-rel/diabete-kno-dataset-code/mrc-for-flat-nested-ner-master/lightning_logs/version_17/hparams.yaml"
181 |
182 | model = trainer.BertLabeling.load_from_checkpoint(
183 | checkpoint_path=CHECKPOINTS,
184 | hparams_file=HPARAMS,
185 | map_location=None,
186 | batch_size=1,
187 | max_length=128,
188 | workers=0
189 | )
190 | return model
191 |
192 |
193 | def load_dataset_for_compute():
194 | """test dataset"""
195 | import os
196 | from datasets.collate_functions import collate_to_max_length
197 | from torch.utils.data import DataLoader
198 | bert_path = "/ml/home/mcldd/ner-rel/diabete-kno-dataset-code/mrc-for-flat-nested-ner-master/models/chinese_roberta_wwm_large_ext_pytorch"
199 | json_path = "/ml/home/mcldd/ner-rel/diabete-kno-dataset-code/mrc-for-flat-nested-ner-master/entity_type_data/mrc-ner.test"
200 |
201 | is_chinese = False
202 | vocab_file = os.path.join(bert_path, "vocab.txt")
203 | tokenizer = BertWordPieceTokenizer(vocab_file)
204 | dataset = MRCNERDataset(json_path=json_path, tokenizer=tokenizer,
205 | is_chinese=is_chinese)
206 | dataloader = DataLoader(dataset, batch_size=1,
207 | collate_fn=collate_to_max_length)
208 | return dataloader, tokenizer
209 |
210 |
211 |
212 |
213 | def write_json_to_file(origin_path, des_path, data):
214 | with open(origin_path + des_path, "w", encoding="utf8") as fp:
215 | fp.write(json.dumps(data, ensure_ascii=False))
216 | fp.write("\n")
217 | fp.flush()
218 | fp.close()
219 |
220 |
221 | def compute_result_by_query():
222 | model = load_model_for_compute()
223 | data, tokenizer = load_dataset_for_compute()
224 | entity_total = {}
225 | with tqdm(total=len(data)) as pbar:
226 | try:
227 | for batch_idx, batch in enumerate(data):
228 | sample = data.dataset.all_data[batch_idx]
229 | entity_label = sample["entity_label"]
230 | if entity_label not in entity_total.keys():
231 | entity_total[entity_label] = {"tp": 0, "fp": 0, "fn": 0}
232 | out_puts = model.validation_step(batch, batch_idx)
233 | tp, fp, fn = out_puts["span_f1_stats"]
234 | entity_total[entity_label]["tp"] = entity_total[entity_label]["tp"] + tp.item()
235 | entity_total[entity_label]["fp"] = entity_total[entity_label]["fp"] + fp.item()
236 | entity_total[entity_label]["fn"] = entity_total[entity_label]["fn"] + fn.item()
237 | pbar.update(1)
238 | except Exception as e:
239 | print("ERROR,PLEASE CHECK CODE!{}".format(e))
240 | entity_total_result = {}
241 | tp_total = 0
242 | fp_total = 0
243 | fn_total = 0
244 | for k, v in entity_total.items():
245 | tp = v["tp"]
246 | fp = v["fp"]
247 | fn = v["fn"]
248 | tp_total += tp
249 | fp_total += fp
250 | fn_total += fn
251 | P = tp * 100.0 / (tp + fp)
252 | R = tp * 100.0 / (tp + fn)
253 | F1 = 0 if (P + R) == 0 else (2 * P * R) / (P + R)
254 | entity_total_result[k] = {"precision": "{:.2f}%".format(P), "recall": "{:.2f}%".format(R), "f1": "{:.2f}%".format(F1)}
255 | P_Tol = tp_total * 100.0 / (tp_total + fp_total)
256 | R_Tol = tp_total * 100.0 / (tp_total + fn_total)
257 | F1_Tol = 0 if (P_Tol + R_Tol) == 0 else (2 * P_Tol * R_Tol) / (P_Tol + R_Tol)
258 | write_json_to_file("", "query_entity_result.txt", entity_total_result)
259 | print("total precision:{:.2f},total recall:{:.2f},total f1:{:.2f}".format(P_Tol, R_Tol, F1_Tol))
260 |
261 |
262 | if __name__ == '__main__':
263 | # run_dataset()
264 | compute_result_by_query()
265 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/RE/test_GRU.py:
--------------------------------------------------------------------------------
1 | from pprint import pprint
2 |
3 | import tensorflow as tf
4 | import numpy as np
5 | import time
6 | import datetime
7 | import os
8 | import network
9 | from sklearn import metrics
10 |
11 | FLAGS = tf.app.flags.FLAGS
12 |
13 | import os
14 | os.environ["CUDA_VISIBLE_DEVICES"] = "1"
15 |
16 | # embedding the position
17 | def pos_embed(x):
18 | if x < -60:
19 | return 0
20 | if -60 <= x <= 60:
21 | return x + 61
22 | if x > 60:
23 | return 122
24 |
25 |
26 | def main_for_evaluation():
27 | # def main(_):
28 | pathname = "./model_custom/ATT_GRU_model-"
29 |
30 | wordembedding = np.load('chinese_RE/custom_RE/vec.npy')
31 |
32 | test_settings = network.Settings()
33 | test_settings.vocab_size = 16693
34 | test_settings.num_classes = 16
35 | test_settings.big_num = 5561
36 |
37 | big_num_test = test_settings.big_num
38 |
39 | with tf.Graph().as_default():
40 |
41 | sess = tf.Session()
42 | with sess.as_default():
43 |
44 | def test_step(word_batch, pos1_batch, pos2_batch, y_batch):
45 |
46 | feed_dict = {}
47 | total_shape = []
48 | total_num = 0
49 | total_word = []
50 | total_pos1 = []
51 | total_pos2 = []
52 |
53 | for i in range(len(word_batch)):
54 | total_shape.append(total_num)
55 | total_num += len(word_batch[i])
56 | for word in word_batch[i]:
57 | total_word.append(word)
58 | for pos1 in pos1_batch[i]:
59 | total_pos1.append(pos1)
60 | for pos2 in pos2_batch[i]:
61 | total_pos2.append(pos2)
62 |
63 | total_shape.append(total_num)
64 | total_shape = np.array(total_shape)
65 | total_word = np.array(total_word)
66 | total_pos1 = np.array(total_pos1)
67 | total_pos2 = np.array(total_pos2)
68 |
69 | feed_dict[mtest.total_shape] = total_shape
70 | feed_dict[mtest.input_word] = total_word
71 | feed_dict[mtest.input_pos1] = total_pos1
72 | feed_dict[mtest.input_pos2] = total_pos2
73 | feed_dict[mtest.input_y] = y_batch
74 |
75 | loss, accuracy, prob = sess.run(
76 | [mtest.loss, mtest.accuracy, mtest.prob], feed_dict)
77 | return prob, accuracy
78 |
79 |
80 | with tf.variable_scope("model"):
81 | mtest = network.GRU(is_training=False, word_embeddings=wordembedding, settings=test_settings)
82 |
83 | names_to_vars = {v.op.name: v for v in tf.global_variables()}
84 | saver = tf.train.Saver(names_to_vars)
85 |
86 |
87 | #testlist = range(1000, 1800, 100)
88 | testlist = [8100, 8200, 8300, 8400, 8500, 8600, 8700, 8800]
89 |
90 | for model_iter in testlist:
91 | # for compatibility purposes only, name key changes from tf 0.x to 1.x, compat_layer
92 | saver.restore(sess, pathname + str(model_iter))
93 |
94 |
95 | time_str = datetime.datetime.now().isoformat()
96 | print(time_str)
97 | print('Evaluating all test data and save data for PR curve')
98 |
99 | test_y = np.load('chinese_RE/custom_RE/testall_y.npy', allow_pickle=True)
100 | test_word = np.load('chinese_RE/custom_RE/testall_word.npy', allow_pickle=True)
101 | test_pos1 = np.load('chinese_RE/custom_RE/testall_pos1.npy', allow_pickle=True)
102 | test_pos2 = np.load('chinese_RE/custom_RE/testall_pos2.npy', allow_pickle=True)
103 | allprob = []
104 | acc = []
105 | for i in range(int(len(test_word) / float(test_settings.big_num))):
106 | prob, accuracy = test_step(test_word[i * test_settings.big_num:(i + 1) * test_settings.big_num],
107 | test_pos1[i * test_settings.big_num:(i + 1) * test_settings.big_num],
108 | test_pos2[i * test_settings.big_num:(i + 1) * test_settings.big_num],
109 | test_y[i * test_settings.big_num:(i + 1) * test_settings.big_num])
110 | acc.append(np.mean(np.reshape(np.array(accuracy), (test_settings.big_num))))
111 | prob = np.reshape(np.array(prob), (test_settings.big_num, test_settings.num_classes))
112 | for single_prob in prob:
113 | allprob.append(single_prob[1:])
114 | allprob = np.reshape(np.array(allprob), (-1))
115 | order = np.argsort(-allprob)
116 |
117 | print('saving all test result...')
118 | current_step = model_iter
119 |
120 | np.save('./out/allprob_iter_' + str(current_step) + '.npy', allprob)
121 | allans = np.load('chinese_RE/custom_RE/allans.npy', allow_pickle=True)
122 |
123 | # caculate the pr curve area
124 | average_precision = metrics.average_precision_score(allans, allprob)
125 | print('PR curve area:' + str(average_precision))
126 |
127 |
128 | def main(_):
129 |
130 | #If you retrain the model, please remember to change the path to your own model below:
131 | pathname = "./model_custom/ATT_GRU_model-8800"
132 |
133 | wordembedding = np.load('chinese_RE/custom_RE/vec.npy')
134 | test_settings = network.Settings()
135 | test_settings.vocab_size = 16693
136 | test_settings.num_classes = 16
137 | test_settings.big_num = 1
138 |
139 | with tf.Graph().as_default():
140 | sess = tf.Session()
141 | with sess.as_default():
142 | def test_step(word_batch, pos1_batch, pos2_batch, y_batch):
143 |
144 | feed_dict = {}
145 | total_shape = []
146 | total_num = 0
147 | total_word = []
148 | total_pos1 = []
149 | total_pos2 = []
150 |
151 | for i in range(len(word_batch)):
152 | total_shape.append(total_num)
153 | total_num += len(word_batch[i])
154 | for word in word_batch[i]:
155 | total_word.append(word)
156 | for pos1 in pos1_batch[i]:
157 | total_pos1.append(pos1)
158 | for pos2 in pos2_batch[i]:
159 | total_pos2.append(pos2)
160 |
161 | total_shape.append(total_num)
162 | total_shape = np.array(total_shape)
163 | total_word = np.array(total_word)
164 | total_pos1 = np.array(total_pos1)
165 | total_pos2 = np.array(total_pos2)
166 |
167 | feed_dict[mtest.total_shape] = total_shape
168 | feed_dict[mtest.input_word] = total_word
169 | feed_dict[mtest.input_pos1] = total_pos1
170 | feed_dict[mtest.input_pos2] = total_pos2
171 | feed_dict[mtest.input_y] = y_batch
172 |
173 | loss, accuracy, prob = sess.run(
174 | [mtest.loss, mtest.accuracy, mtest.prob], feed_dict)
175 | return prob, accuracy
176 |
177 |
178 | with tf.variable_scope("model"):
179 | mtest = network.GRU(is_training=False, word_embeddings=wordembedding, settings=test_settings)
180 |
181 | names_to_vars = {v.op.name: v for v in tf.global_variables()}
182 | saver = tf.train.Saver(names_to_vars)
183 | saver.restore(sess, pathname)
184 |
185 | print('reading word embedding data...')
186 | vec = []
187 | word2id = {}
188 | f = open('./origin_data/vec.txt', encoding='utf-8')
189 | content = f.readline()
190 | content = content.strip().split()
191 | dim = int(content[1])
192 | while True:
193 | content = f.readline()
194 | if content == '':
195 | break
196 | content = content.strip().split()
197 | word2id[content[0]] = len(word2id)
198 | content = content[1:]
199 | content = [(float)(i) for i in content]
200 | vec.append(content)
201 | f.close()
202 | word2id['UNK'] = len(word2id)
203 | word2id['BLANK'] = len(word2id)
204 |
205 | print('reading relation to id')
206 | relation2id = {}
207 | id2relation = {}
208 | f = open('chinese_RE/custom_RE/relation2id.txt', 'r', encoding='utf-8')
209 | while True:
210 | content = f.readline()
211 | if content == '':
212 | break
213 | content = content.strip().split()
214 | relation2id[content[0]] = int(content[1])
215 | id2relation[int(content[1])] = content[0]
216 |
217 | f.close()
218 |
219 | y_true = []
220 | y_pred = []
221 |
222 | with open('chinese_RE/custom_RE/test.txt', encoding='utf-8') as f:
223 | for orgline in f:
224 | line = orgline.strip()
225 | # break
226 | # infile.close()
227 | entity1, entity2, rel, sentence = line.split('\t', 3)
228 |
229 | # print("实体1: " + en1)
230 | # print("实体2: " + en2)
231 | # print(sentence)
232 | # relation = 0
233 | en1 = entity1.split('###')[0]
234 | en2 = entity2.split('###')[0]
235 | en1pos = sentence.find(en1)
236 | if en1pos == -1:
237 | en1pos = 0
238 | en2pos = sentence.find(en2)
239 | if en2pos == -1:
240 | en2post = 0
241 | output = []
242 | # length of sentence is 70
243 | fixlen = 70
244 | # max length of position embedding is 60 (-60~+60)
245 | maxlen = 60
246 |
247 | #Encoding test x
248 | for i in range(fixlen):
249 | word = word2id['BLANK']
250 | rel_e1 = pos_embed(i - en1pos)
251 | rel_e2 = pos_embed(i - en2pos)
252 | output.append([word, rel_e1, rel_e2])
253 |
254 | for i in range(min(fixlen, len(sentence))):
255 |
256 | word = 0
257 | if sentence[i] not in word2id:
258 | word = word2id['UNK']
259 |
260 | else:
261 | word = word2id[sentence[i]]
262 |
263 | output[i][0] = word
264 | test_x = []
265 | test_x.append([output])
266 |
267 | #Encoding test y
268 | label = [0 for i in range(len(relation2id))]
269 | label[relation2id[rel]] = 1
270 | test_y = []
271 | test_y.append(label)
272 |
273 | test_x = np.array(test_x)
274 | test_y = np.array(test_y)
275 |
276 | test_word = []
277 | test_pos1 = []
278 | test_pos2 = []
279 |
280 | for i in range(len(test_x)):
281 | word = []
282 | pos1 = []
283 | pos2 = []
284 | for j in test_x[i]:
285 | temp_word = []
286 | temp_pos1 = []
287 | temp_pos2 = []
288 | for k in j:
289 | temp_word.append(k[0])
290 | temp_pos1.append(k[1])
291 | temp_pos2.append(k[2])
292 | word.append(temp_word)
293 | pos1.append(temp_pos1)
294 | pos2.append(temp_pos2)
295 |
296 | test_word.append(word)
297 | test_pos1.append(pos1)
298 | test_pos2.append(pos2)
299 |
300 | test_word = np.array(test_word)
301 | test_pos1 = np.array(test_pos1)
302 | test_pos2 = np.array(test_pos2)
303 |
304 | prob, accuracy = test_step(test_word, test_pos1, test_pos2, test_y)
305 | prob = np.reshape(np.array(prob), (1, test_settings.num_classes))[0]
306 |
307 | top_id = prob.argsort()[-1]
308 |
309 | y_true.append(rel)
310 | y_pred.append(id2relation[top_id])
311 |
312 | print('准确率:', metrics.accuracy_score(y_true, y_pred)) # 预测准确率输出
313 |
314 | print('宏平均精确率:', metrics.precision_score(y_true, y_pred, average='macro')) # 预测宏平均精确率输出
315 | print('微平均精确率:', metrics.precision_score(y_true, y_pred, average='micro')) # 预测微平均精确率输出
316 | print('加权平均精确率:', metrics.precision_score(y_true, y_pred, average='weighted')) # 预测加权平均精确率输出
317 |
318 | print('宏平均召回率:', metrics.recall_score(y_true, y_pred, average='macro')) # 预测宏平均召回率输出
319 | print('微平均召回率:', metrics.recall_score(y_true, y_pred, average='micro')) # 预测微平均召回率输出
320 | print('加权平均召回率:', metrics.recall_score(y_true, y_pred, average='micro')) # 预测加权平均召回率输出
321 |
322 | print('宏平均F1-score:',
323 | metrics.f1_score(y_true, y_pred, labels=[id2relation[i] for i in list(range(16))], average='macro')) # 预测宏平均f1-score输出
324 | print('微平均F1-score:',
325 | metrics.f1_score(y_true, y_pred, labels=[id2relation[i] for i in list(range(16))], average='micro')) # 预测微平均f1-score输出
326 | print('加权平均F1-score:',
327 | metrics.f1_score(y_true, y_pred, labels=[id2relation[i] for i in list(range(16))], average='weighted')) # 预测加权平均f1-score输出
328 |
329 | # print('混淆矩阵输出:\n', metrics.confusion_matrix(y_true, y_pred, labels=list(range(16)))) # 混淆矩阵输出
330 | print('分类报告:\n', metrics.classification_report(y_true, y_pred, labels=[id2relation[i] for i in list(range(16))], digits=3)) # 分类报告输出
331 |
332 | if __name__ == "__main__":
333 | tf.app.run()
334 |
--------------------------------------------------------------------------------
/NER/trainer.py:
--------------------------------------------------------------------------------
1 | # encoding: utf-8
2 |
3 |
4 | import argparse
5 | import os
6 | from collections import namedtuple
7 | from typing import Dict
8 |
9 | import pytorch_lightning as pl
10 | import torch
11 | from pytorch_lightning import Trainer
12 | from pytorch_lightning.callbacks.model_checkpoint import ModelCheckpoint
13 | from tokenizers import BertWordPieceTokenizer
14 | from torch import Tensor
15 | from torch.nn.modules import CrossEntropyLoss, BCEWithLogitsLoss
16 | from torch.utils.data import DataLoader
17 | from transformers import AdamW
18 | from torch.optim import SGD
19 |
20 | from datasets.mrc_ner_dataset import MRCNERDataset
21 | from datasets.truncate_dataset import TruncateDataset
22 | from datasets.collate_functions import collate_to_max_length
23 | from metrics.query_span_f1 import QuerySpanF1
24 | from models.bert_query_ner import BertQueryNER
25 | from models.query_ner_config import BertQueryNerConfig
26 | from loss import *
27 | from utils.get_parser import get_parser
28 | from utils.radom_seed import set_random_seed
29 | import logging
30 | set_random_seed(0)
31 |
32 |
33 | class BertLabeling(pl.LightningModule):
34 | """MLM Trainer"""
35 |
36 | def __init__(self,args:argparse.Namespace):
37 | """Initialize a model, tokenizer and config."""
38 | super().__init__()
39 | if isinstance(args, argparse.Namespace):
40 | self.save_hyperparameters(args)
41 | self.args = args
42 | else:
43 | # eval mode
44 | TmpArgs = namedtuple("tmp_args", field_names=list(args.keys()))
45 | self.args = args = TmpArgs(**args)
46 |
47 | self.bert_dir = args.bert_config_dir
48 | self.data_dir = self.args.data_dir
49 |
50 | bert_config = BertQueryNerConfig.from_pretrained(args.bert_config_dir,
51 | hidden_dropout_prob=args.bert_dropout,
52 | attention_probs_dropout_prob=args.bert_dropout,
53 | mrc_dropout=args.mrc_dropout)
54 |
55 | self.model = BertQueryNER.from_pretrained(args.bert_config_dir,
56 | config=bert_config)
57 | # logging.info(str(self.model))
58 | logging.info(str(args.__dict__ if isinstance(args, argparse.ArgumentParser) else args))
59 | # self.ce_loss = CrossEntropyLoss(reduction="none")
60 | self.loss_type = args.loss_type
61 | # self.loss_type = "bce"
62 | if self.loss_type == "bce":
63 | self.bce_loss = BCEWithLogitsLoss(reduction="none")
64 | else:
65 | self.dice_loss = DiceLoss(with_logits=True, smooth=args.dice_smooth)
66 | # todo(yuxian): 由于match loss是n^2的,应该特殊调整一下loss rate
67 | weight_sum = args.weight_start + args.weight_end + args.weight_span
68 | self.weight_start = args.weight_start / weight_sum
69 | self.weight_end = args.weight_end / weight_sum
70 | self.weight_span = args.weight_span / weight_sum
71 | self.flat_ner = args.flat
72 | self.span_f1 = QuerySpanF1(flat=self.flat_ner)
73 | self.chinese = args.chinese
74 | self.optimizer = args.optimizer
75 | self.span_loss_candidates = args.span_loss_candidates
76 |
77 | @staticmethod
78 | def add_model_specific_args(parent_parser):
79 | parser = argparse.ArgumentParser(parents=[parent_parser], add_help=False)
80 | parser.add_argument("--mrc_dropout", type=float, default=0.1,
81 | help="mrc dropout rate")
82 | parser.add_argument("--bert_dropout", type=float, default=0.1,
83 | help="bert dropout rate")
84 | parser.add_argument("--weight_start", type=float, default=1.0)
85 | parser.add_argument("--weight_end", type=float, default=1.0)
86 | parser.add_argument("--weight_span", type=float, default=1.0)
87 | parser.add_argument("--flat", action="store_true", help="is flat ner")
88 | parser.add_argument("--span_loss_candidates", choices=["all", "pred_and_gold", "gold"],
89 | default="all", help="Candidates used to compute span loss")
90 | parser.add_argument("--chinese", action="store_true",
91 | help="is chinese dataset")
92 | parser.add_argument("--loss_type", choices=["bce", "dice"], default="bce",
93 | help="loss type")
94 | parser.add_argument("--optimizer", choices=["adamw", "sgd"], default="adamw",
95 | help="loss type")
96 | parser.add_argument("--dice_smooth", type=float, default=1e-8,
97 | help="smooth value of dice loss")
98 | parser.add_argument("--final_div_factor", type=float, default=1e4,
99 | help="final div factor of linear decay scheduler")
100 | return parser
101 |
102 | def configure_optimizers(self):
103 | """Prepare optimizer and schedule (linear warmup and decay)"""
104 | no_decay = ["bias", "LayerNorm.weight"]
105 | optimizer_grouped_parameters = [
106 | {
107 | "params": [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
108 | "weight_decay": self.args.weight_decay,
109 | },
110 | {
111 | "params": [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)],
112 | "weight_decay": 0.0,
113 | },
114 | ]
115 | if self.optimizer == "adamw":
116 | optimizer = AdamW(optimizer_grouped_parameters,
117 | betas=(0.9, 0.98), # according to RoBERTa paper
118 | lr=self.args.lr,
119 | eps=self.args.adam_epsilon,)
120 | else:
121 | optimizer = SGD(optimizer_grouped_parameters, lr=self.args.lr, momentum=0.9)
122 | num_gpus = len([x for x in str(self.args.gpus).split(",") if x.strip()])
123 | t_total = (len(self.train_dataloader()) // (self.args.accumulate_grad_batches * num_gpus) + 1) * self.args.max_epochs
124 | scheduler = torch.optim.lr_scheduler.OneCycleLR(
125 | optimizer, max_lr=self.args.lr, pct_start=float(self.args.warmup_steps/t_total),
126 | final_div_factor=self.args.final_div_factor,
127 | total_steps=t_total, anneal_strategy='linear'
128 | )
129 | return [optimizer], [{"scheduler": scheduler, "interval": "step"}]
130 |
131 | def forward(self, input_ids, attention_mask, token_type_ids):
132 | """"""
133 | return self.model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
134 |
135 | def compute_loss(self, start_logits, end_logits, span_logits,
136 | start_labels, end_labels, match_labels, start_label_mask, end_label_mask):
137 | batch_size, seq_len = start_logits.size()
138 |
139 | start_float_label_mask = start_label_mask.view(-1).float()
140 | end_float_label_mask = end_label_mask.view(-1).float()
141 | match_label_row_mask = start_label_mask.bool().unsqueeze(-1).expand(-1, -1, seq_len)
142 | match_label_col_mask = end_label_mask.bool().unsqueeze(-2).expand(-1, seq_len, -1)
143 | match_label_mask = match_label_row_mask & match_label_col_mask
144 | match_label_mask = torch.triu(match_label_mask, 0) # start should be less equal to end
145 |
146 | if self.span_loss_candidates == "all":
147 | # naive mask
148 | float_match_label_mask = match_label_mask.view(batch_size, -1).float()
149 | else:
150 | # use only pred or golden start/end to compute match loss
151 | start_preds = start_logits > 0
152 | end_preds = end_logits > 0
153 | if self.span_loss_candidates == "gold":
154 | match_candidates = ((start_labels.unsqueeze(-1).expand(-1, -1, seq_len) > 0)
155 | & (end_labels.unsqueeze(-2).expand(-1, seq_len, -1) > 0))
156 | else:
157 | match_candidates = torch.logical_or(
158 | (start_preds.unsqueeze(-1).expand(-1, -1, seq_len)
159 | & end_preds.unsqueeze(-2).expand(-1, seq_len, -1)),
160 | (start_labels.unsqueeze(-1).expand(-1, -1, seq_len)
161 | & end_labels.unsqueeze(-2).expand(-1, seq_len, -1))
162 | )
163 | match_label_mask = match_label_mask & match_candidates
164 | float_match_label_mask = match_label_mask.view(batch_size, -1).float()
165 | if self.loss_type == "bce":
166 | start_loss = self.bce_loss(start_logits.view(-1), start_labels.view(-1).float())
167 | start_loss = (start_loss * start_float_label_mask).sum() / start_float_label_mask.sum()
168 | end_loss = self.bce_loss(end_logits.view(-1), end_labels.view(-1).float())
169 | end_loss = (end_loss * end_float_label_mask).sum() / end_float_label_mask.sum()
170 | match_loss = self.bce_loss(span_logits.view(batch_size, -1), match_labels.view(batch_size, -1).float())
171 | match_loss = match_loss * float_match_label_mask
172 | match_loss = match_loss.sum() / (float_match_label_mask.sum() + 1e-10)
173 | else:
174 | start_loss = self.dice_loss(start_logits, start_labels.float(), start_float_label_mask)
175 | end_loss = self.dice_loss(end_logits, end_labels.float(), end_float_label_mask)
176 | match_loss = self.dice_loss(span_logits, match_labels.float(), float_match_label_mask)
177 |
178 | return start_loss, end_loss, match_loss
179 |
180 | def training_step(self, batch, batch_idx):
181 | """"""
182 | tf_board_logs = {
183 | "lr": self.trainer.optimizers[0].param_groups[0]['lr']
184 | }
185 | tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx = batch
186 |
187 | # num_tasks * [bsz, length, num_labels]
188 | attention_mask = (tokens != 0).long()
189 | start_logits, end_logits, span_logits = self(tokens, attention_mask, token_type_ids)
190 |
191 | start_loss, end_loss, match_loss = self.compute_loss(start_logits=start_logits,
192 | end_logits=end_logits,
193 | span_logits=span_logits,
194 | start_labels=start_labels,
195 | end_labels=end_labels,
196 | match_labels=match_labels,
197 | start_label_mask=start_label_mask,
198 | end_label_mask=end_label_mask
199 | )
200 |
201 | total_loss = self.weight_start * start_loss + self.weight_end * end_loss + self.weight_span * match_loss
202 |
203 | tf_board_logs[f"train_loss"] = total_loss
204 | tf_board_logs[f"start_loss"] = start_loss
205 | tf_board_logs[f"end_loss"] = end_loss
206 | tf_board_logs[f"match_loss"] = match_loss
207 |
208 | return {'loss': total_loss, 'log': tf_board_logs}
209 |
210 | def validation_step(self, batch, batch_idx):
211 | """"""
212 |
213 | output = {}
214 |
215 | tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx = batch
216 |
217 | attention_mask = (tokens != 0).long()
218 | start_logits, end_logits, span_logits = self(tokens, attention_mask, token_type_ids)
219 |
220 | start_loss, end_loss, match_loss = self.compute_loss(start_logits=start_logits,
221 | end_logits=end_logits,
222 | span_logits=span_logits,
223 | start_labels=start_labels,
224 | end_labels=end_labels,
225 | match_labels=match_labels,
226 | start_label_mask=start_label_mask,
227 | end_label_mask=end_label_mask
228 | )
229 |
230 | total_loss = self.weight_start * start_loss + self.weight_end * end_loss + self.weight_span * match_loss
231 |
232 | output[f"val_loss"] = total_loss
233 | output[f"start_loss"] = start_loss
234 | output[f"end_loss"] = end_loss
235 | output[f"match_loss"] = match_loss
236 |
237 | start_preds, end_preds = start_logits > 0, end_logits > 0
238 | span_f1_stats = self.span_f1(start_preds=start_preds, end_preds=end_preds, match_logits=span_logits,
239 | start_label_mask=start_label_mask, end_label_mask=end_label_mask,
240 | match_labels=match_labels)
241 | output["span_f1_stats"] = span_f1_stats
242 |
243 | return output
244 |
245 | def validation_epoch_end(self, outputs):
246 | """"""
247 | avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
248 | tensorboard_logs = {'val_loss': avg_loss}
249 |
250 | all_counts = torch.stack([x[f'span_f1_stats'] for x in outputs]).sum(0)
251 | span_tp, span_fp, span_fn = all_counts
252 | span_recall = span_tp / (span_tp + span_fn + 1e-10)
253 | span_precision = span_tp / (span_tp + span_fp + 1e-10)
254 | span_f1 = span_precision * span_recall * 2 / (span_recall + span_precision + 1e-10)
255 | tensorboard_logs[f"span_precision"] = span_precision
256 | tensorboard_logs[f"span_recall"] = span_recall
257 | tensorboard_logs[f"span_f1"] = span_f1
258 |
259 | return {'val_loss': avg_loss, 'log': tensorboard_logs}
260 |
261 | def test_step(self, batch, batch_idx):
262 | """"""
263 | return self.validation_step(batch, batch_idx)
264 |
265 | def test_epoch_end(
266 | self,
267 | outputs
268 | ) -> Dict[str, Dict[str, Tensor]]:
269 | """"""
270 | return self.validation_epoch_end(outputs)
271 |
272 | def train_dataloader(self) -> DataLoader:
273 | return self.get_dataloader("train")
274 | # return self.get_dataloader("dev", 100)
275 |
276 | def val_dataloader(self):
277 | return self.get_dataloader("dev")
278 |
279 | def test_dataloader(self):
280 | return self.get_dataloader("test")
281 | # return self.get_dataloader("dev")
282 |
283 | def get_dataloader(self, prefix="train", limit: int = None) -> DataLoader:
284 | """get training dataloader"""
285 | """
286 | load_mmap_dataset
287 | """
288 | json_path = os.path.join(self.data_dir, f"mrc-ner.{prefix}")
289 | vocab_path = os.path.join(self.bert_dir, "vocab.txt")
290 | dataset = MRCNERDataset(json_path=json_path,
291 | tokenizer=BertWordPieceTokenizer(vocab_path),
292 | max_length=self.args.max_length,
293 | is_chinese=self.chinese,
294 | pad_to_maxlen=False
295 | )
296 |
297 | if limit is not None:
298 | dataset = TruncateDataset(dataset, limit)
299 |
300 | dataloader = DataLoader(
301 | dataset=dataset,
302 | batch_size=self.args.batch_size,
303 | num_workers=self.args.workers,
304 | shuffle=True if prefix == "train" else False,
305 | collate_fn=collate_to_max_length
306 | )
307 |
308 | return dataloader
309 |
310 |
311 | def run_dataloader():
312 | """test dataloader"""
313 | parser = get_parser()
314 |
315 | # add model specific args
316 | parser = BertLabeling.add_model_specific_args(parser)
317 |
318 | # add all the available trainer options to argparse
319 | # ie: now --gpus --num_nodes ... --fast_dev_run all work in the cli
320 | parser = Trainer.add_argparse_args(parser)
321 |
322 | args = parser.parse_args()
323 | args.workers = 0
324 | args.default_root_dir = "/mnt/data/mrc/train_logs/debug"
325 |
326 | model = BertLabeling(args)
327 | from tokenizers import BertWordPieceTokenizer
328 | tokenizer = BertWordPieceTokenizer(os.path.join(args.bert_config_dir, "vocab.txt"))
329 |
330 | loader = model.get_dataloader("dev", limit=1000)
331 | for d in loader:
332 | input_ids = d[0][0].tolist()
333 | match_labels = d[-1][0]
334 | start_positions, end_positions = torch.where(match_labels > 0)
335 | start_positions = start_positions.tolist()
336 | end_positions = end_positions.tolist()
337 | if not start_positions:
338 | continue
339 | print("="*20)
340 | print(tokenizer.decode(input_ids, skip_special_tokens=False))
341 | for start, end in zip(start_positions, end_positions):
342 | print(tokenizer.decode(input_ids[start: end+1]))
343 |
344 |
345 | def main():
346 | """main"""
347 | parser = get_parser()
348 |
349 | # add model specific args
350 | parser = BertLabeling.add_model_specific_args(parser)
351 |
352 | # add all the available trainer options to argparse
353 | # ie: now --gpus --num_nodes ... --fast_dev_run all work in the cli
354 | parser = Trainer.add_argparse_args(parser)
355 |
356 | args = parser.parse_args()
357 |
358 | model = BertLabeling(args)
359 | if args.pretrained_checkpoint:
360 | model.load_state_dict(torch.load(args.pretrained_checkpoint,
361 | map_location=torch.device('cpu'))["state_dict"])
362 |
363 | checkpoint_callback = ModelCheckpoint(
364 | filepath=args.default_root_dir,
365 | save_top_k=10,
366 | verbose=True,
367 | monitor="span_f1",
368 | period=-1,
369 | mode="max",
370 | )
371 | trainer = Trainer.from_argparse_args(
372 | args,
373 | checkpoint_callback=checkpoint_callback
374 | )
375 |
376 | trainer.fit(model)
377 |
378 |
379 | if __name__ == '__main__':
380 | #run_dataloader()
381 | main()
382 |
--------------------------------------------------------------------------------
/NER/datasets/doc-paragraph-sentence-id/mrc-ner.test-id:
--------------------------------------------------------------------------------
1 | 37,65,0
2 | 41,117,0
3 | 11,65,0
4 | 32,3,0
5 | 16,0,0
6 | 20,48,0
7 | 13,43,0
8 | 18,7,1
9 | 30,4,0
10 | 29,24,0
11 | 37,32,0
12 | 17,56,0
13 | 17,77,0
14 | 8,30,0
15 | 1,17,0
16 | 41,85,1
17 | 11,51,0
18 | 28,18,0
19 | 18,73,0
20 | 14,10,1
21 | 23,54,0
22 | 14,38,0
23 | 4,19,0
24 | 20,62,0
25 | 4,28,0
26 | 39,72,0
27 | 15,45,0
28 | 15,82,0
29 | 28,13,0
30 | 39,87,0
31 | 6,49,0
32 | 2,22,2
33 | 17,92,4
34 | 7,24,0
35 | 2,22,2
36 | 30,18,1
37 | 41,84,0
38 | 37,54,0
39 | 40,62,3
40 | 21,5,0
41 | 34,4,0
42 | 36,7,0
43 | 20,51,5
44 | 27,11,0
45 | 29,32,0
46 | 3,2,1
47 | 17,38,2
48 | 4,1,4
49 | 14,10,0
50 | 25,14,0
51 | 1,37,0
52 | 17,93,0
53 | 34,26,1
54 | 16,21,1
55 | 33,68,0
56 | 13,37,0
57 | 22,21,0
58 | 18,7,1
59 | 31,10,0
60 | 19,29,0
61 | 15,16,0
62 | 2,6,0
63 | 31,8,0
64 | 21,24,0
65 | 8,11,0
66 | 26,7,0
67 | 28,22,0
68 | 33,67,0
69 | 12,11,2
70 | 17,46,0
71 | 29,0,0
72 | 16,4,2
73 | 38,19,0
74 | 41,27,1
75 | 25,16,0
76 | 13,78,0
77 | 22,53,0
78 | 14,34,1
79 | 39,13,1
80 | 15,44,0
81 | 13,6,0
82 | 34,2,0
83 | 32,47,0
84 | 7,39,0
85 | 27,10,0
86 | 17,33,0
87 | 7,24,0
88 | 13,68,0
89 | 18,64,0
90 | 5,8,0
91 | 10,9,0
92 | 33,20,0
93 | 8,34,0
94 | 3,14,0
95 | 30,12,0
96 | 9,14,0
97 | 9,26,0
98 | 28,6,0
99 | 26,16,0
100 | 41,80,0
101 | 13,51,0
102 | 17,79,0
103 | 35,9,2
104 | 34,43,0
105 | 7,53,0
106 | 23,38,0
107 | 27,9,0
108 | 39,52,0
109 | 37,68,0
110 | 3,13,0
111 | 14,3,0
112 | 2,6,0
113 | 20,32,0
114 | 9,22,0
115 | 41,89,0
116 | 15,16,0
117 | 39,83,0
118 | 40,103,0
119 | 40,102,0
120 | 11,66,1
121 | 14,31,0
122 | 13,74,0
123 | 34,10,6
124 | 18,3,0
125 | 15,72,0
126 | 1,6,0
127 | 15,84,0
128 | 6,50,0
129 | 39,32,0
130 | 16,11,0
131 | 41,47,1
132 | 39,10,0
133 | 11,72,0
134 | 40,73,0
135 | 9,13,0
136 | 1,4,0
137 | 41,3,2
138 | 25,18,0
139 | 23,1,0
140 | 20,38,0
141 | 30,35,0
142 | 7,30,0
143 | 36,22,0
144 | 15,42,0
145 | 15,32,0
146 | 16,51,0
147 | 19,22,0
148 | 40,38,0
149 | 6,8,0
150 | 27,13,0
151 | 13,9,0
152 | 18,16,0
153 | 30,50,0
154 | 14,30,0
155 | 34,33,0
156 | 13,26,0
157 | 21,24,0
158 | 41,39,0
159 | 11,54,0
160 | 34,10,5
161 | 23,49,0
162 | 11,56,1
163 | 34,8,5
164 | 37,60,1
165 | 33,4,0
166 | 41,76,1
167 | 21,30,0
168 | 22,9,0
169 | 17,89,0
170 | 41,46,2
171 | 41,78,3
172 | 39,34,0
173 | 41,47,1
174 | 6,33,0
175 | 34,44,0
176 | 27,15,0
177 | 28,1,0
178 | 30,35,0
179 | 37,39,2
180 | 3,25,0
181 | 4,25,0
182 | 34,26,0
183 | 17,88,0
184 | 27,13,0
185 | 41,80,0
186 | 4,20,0
187 | 6,37,0
188 | 12,5,0
189 | 19,13,2
190 | 27,26,0
191 | 40,13,0
192 | 26,5,0
193 | 6,22,0
194 | 14,40,0
195 | 41,46,0
196 | 40,63,1
197 | 29,8,0
198 | 22,73,0
199 | 8,21,0
200 | 6,46,0
201 | 41,122,0
202 | 14,22,0
203 | 18,53,0
204 | 7,0,0
205 | 13,49,0
206 | 12,26,0
207 | 13,80,2
208 | 3,11,1
209 | 14,2,0
210 | 22,72,0
211 | 28,9,0
212 | 19,20,0
213 | 11,24,0
214 | 37,103,0
215 | 8,37,0
216 | 12,25,1
217 | 12,49,0
218 | 34,40,0
219 | 40,31,0
220 | 30,12,3
221 | 6,5,0
222 | 16,16,0
223 | 6,29,0
224 | 17,11,0
225 | 30,59,0
226 | 6,42,0
227 | 4,10,1
228 | 41,41,0
229 | 16,36,0
230 | 17,60,0
231 | 37,30,0
232 | 30,20,0
233 | 14,5,1
234 | 40,50,1
235 | 17,35,4
236 | 18,4,2
237 | 37,100,0
238 | 32,24,0
239 | 15,71,0
240 | 13,30,0
241 | 41,51,0
242 | 13,6,0
243 | 39,48,1
244 | 34,5,0
245 | 6,50,0
246 | 23,47,0
247 | 20,57,0
248 | 28,23,0
249 | 20,31,3
250 | 40,100,1
251 | 6,61,0
252 | 21,40,0
253 | 18,60,0
254 | 38,16,0
255 | 39,66,0
256 | 33,62,1
257 | 32,10,0
258 | 33,69,0
259 | 8,25,0
260 | 11,27,1
261 | 20,61,0
262 | 37,69,3
263 | 13,66,0
264 | 21,7,0
265 | 7,36,0
266 | 5,8,0
267 | 17,2,1
268 | 31,8,0
269 | 39,56,1
270 | 33,32,0
271 | 30,48,0
272 | 4,18,0
273 | 37,68,0
274 | 1,58,0
275 | 22,9,2
276 | 32,21,0
277 | 12,5,2
278 | 17,72,0
279 | 13,54,0
280 | 27,19,0
281 | 18,46,0
282 | 26,10,0
283 | 41,61,0
284 | 41,37,1
285 | 9,16,0
286 | 41,15,0
287 | 23,62,1
288 | 41,46,1
289 | 39,63,0
290 | 4,12,0
291 | 37,51,0
292 | 32,41,0
293 | 16,11,0
294 | 38,15,0
295 | 27,2,0
296 | 18,19,0
297 | 14,25,0
298 | 12,19,0
299 | 33,75,0
300 | 37,40,0
301 | 41,84,0
302 | 18,64,1
303 | 41,78,0
304 | 21,28,0
305 | 6,4,0
306 | 30,29,0
307 | 33,3,0
308 | 8,41,0
309 | 19,16,0
310 | 2,15,0
311 | 10,28,0
312 | 15,16,0
313 | 10,29,0
314 | 24,20,0
315 | 31,10,0
316 | 12,47,0
317 | 6,46,2
318 | 37,17,0
319 | 1,3,0
320 | 37,19,0
321 | 14,15,3
322 | 12,10,0
323 | 29,15,0
324 | 12,17,0
325 | 39,55,0
326 | 27,28,0
327 | 35,9,2
328 | 10,16,0
329 | 12,30,1
330 | 12,23,0
331 | 7,41,0
332 | 41,96,0
333 | 34,32,2
334 | 12,33,1
335 | 13,69,3
336 | 1,44,0
337 | 6,49,0
338 | 3,6,0
339 | 32,21,1
340 | 33,70,0
341 | 36,25,0
342 | 16,51,0
343 | 14,15,0
344 | 27,0,0
345 | 6,19,0
346 | 39,3,0
347 | 18,10,0
348 | 39,31,0
349 | 7,24,0
350 | 39,59,0
351 | 9,24,0
352 | 39,20,2
353 | 8,35,0
354 | 15,16,0
355 | 34,35,0
356 | 34,45,1
357 | 12,23,0
358 | 41,5,2
359 | 40,68,1
360 | 17,71,0
361 | 37,72,0
362 | 13,78,0
363 | 7,41,0
364 | 13,49,0
365 | 24,7,2
366 | 22,65,0
367 | 40,12,0
368 | 2,22,1
369 | 10,43,0
370 | 15,64,2
371 | 25,12,0
372 | 6,19,1
373 | 37,51,0
374 | 41,74,1
375 | 17,50,1
376 | 34,10,3
377 | 34,38,0
378 | 8,28,0
379 | 32,51,0
380 | 4,4,0
381 | 36,19,0
382 | 39,63,0
383 | 35,24,2
384 | 4,22,0
385 | 32,18,0
386 | 17,80,0
387 | 36,30,2
388 | 35,9,0
389 | 40,83,0
390 | 16,26,0
391 | 13,37,0
392 | 41,33,0
393 | 41,78,3
394 | 15,84,0
395 | 6,57,0
396 | 36,8,2
397 | 27,4,0
398 | 24,12,0
399 | 18,60,0
400 | 6,46,3
401 | 40,27,0
402 | 18,68,0
403 | 17,72,0
404 | 40,83,3
405 | 15,34,0
406 | 25,21,0
407 | 21,44,0
408 | 28,6,0
409 | 41,85,1
410 | 40,63,2
411 | 6,31,0
412 | 30,41,1
413 | 31,12,0
414 | 28,6,1
415 | 13,44,0
416 | 39,53,1
417 | 12,37,0
418 | 9,25,0
419 | 18,56,3
420 | 14,18,0
421 | 8,29,0
422 | 22,46,0
423 | 36,25,0
424 | 30,14,0
425 | 7,23,0
426 | 24,24,0
427 | 33,22,0
428 | 30,39,0
429 | 33,37,1
430 | 6,57,0
431 | 11,68,0
432 | 37,47,2
433 | 23,39,0
434 | 22,77,0
435 | 41,30,0
436 | 21,14,1
437 | 10,25,0
438 | 41,75,0
439 | 13,71,0
440 | 39,27,0
441 | 29,36,0
442 | 1,59,0
443 | 37,68,0
444 | 41,3,1
445 | 23,59,0
446 | 7,44,0
447 | 40,110,0
448 | 17,93,0
449 | 11,76,2
450 | 33,54,0
451 | 40,2,0
452 | 41,107,0
453 | 32,27,0
454 | 27,30,0
455 | 27,26,0
456 | 17,18,0
457 | 36,5,0
458 | 24,29,0
459 | 8,10,0
460 | 11,5,0
461 | 16,42,0
462 | 30,51,0
463 | 14,17,3
464 | 19,26,2
465 | 41,88,0
466 | 2,14,0
467 | 9,11,0
468 | 12,13,0
469 | 34,25,1
470 | 23,2,0
471 | 6,19,1
472 | 6,46,0
473 | 26,14,1
474 | 14,10,0
475 | 24,22,0
476 | 13,45,0
477 | 18,21,0
478 | 41,91,0
479 | 17,35,0
480 | 25,17,0
481 | 15,79,0
482 | 21,36,0
483 | 9,19,0
484 | 13,9,0
485 | 33,56,0
486 | 10,7,0
487 | 10,21,0
488 | 41,22,0
489 | 7,38,0
490 | 16,36,0
491 | 23,14,0
492 | 3,14,0
493 | 39,35,0
494 | 25,16,0
495 | 20,60,0
496 | 17,34,2
497 | 41,103,0
498 | 15,6,0
499 | 34,39,0
500 | 6,44,1
501 | 11,59,0
502 | 9,28,0
503 | 27,10,0
504 | 12,42,0
505 | 39,88,2
506 | 23,31,0
507 | 18,51,0
508 | 6,58,0
509 | 30,57,1
510 | 23,64,0
511 | 20,59,1
512 | 24,13,0
513 | 28,21,0
514 | 2,9,0
515 | 12,29,0
516 | 13,5,0
517 | 17,6,0
518 | 14,1,0
519 | 17,80,0
520 | 12,46,1
521 | 17,67,0
522 | 11,29,1
523 | 23,29,0
524 | 15,57,0
525 | 39,20,0
526 | 41,116,0
527 | 38,7,0
528 | 15,81,0
529 | 13,13,0
530 | 14,47,0
531 | 28,21,0
532 | 10,23,0
533 | 30,27,0
534 | 18,38,0
535 | 13,78,0
536 | 6,52,0
537 | 2,8,0
538 | 38,18,0
539 | 25,8,0
540 | 10,41,0
541 | 23,52,0
542 | 18,65,0
543 | 41,39,0
544 | 14,30,1
545 | 28,15,0
546 | 39,90,3
547 | 20,0,0
548 | 16,52,0
549 | 15,79,0
550 | 19,16,0
551 | 40,19,0
552 | 13,49,0
553 | 40,29,1
554 | 34,5,0
555 | 11,1,0
556 | 22,31,0
557 | 6,60,0
558 | 34,4,0
559 | 6,33,0
560 | 16,38,2
561 | 40,110,1
562 | 39,6,1
563 | 32,37,0
564 | 30,39,0
565 | 12,20,1
566 | 26,14,0
567 | 12,50,0
568 | 7,35,0
569 | 16,34,0
570 | 41,3,0
571 | 13,49,0
572 | 30,21,0
573 | 29,11,1
574 | 13,60,0
575 | 7,56,0
576 | 27,25,0
577 | 37,31,0
578 | 11,43,0
579 | 21,23,1
580 | 3,13,0
581 | 21,5,0
582 | 3,8,0
583 | 16,44,0
584 | 9,17,0
585 | 16,53,3
586 | 26,1,0
587 | 34,32,2
588 | 8,30,1
589 | 36,43,1
590 | 41,59,1
591 | 14,7,1
592 | 39,63,0
593 | 29,24,0
594 | 16,12,0
595 | 16,23,0
596 | 32,35,0
597 | 17,3,0
598 | 15,44,0
599 | 21,14,7
600 | 6,25,0
601 | 41,76,3
602 | 13,45,0
603 | 6,24,0
604 | 32,24,1
605 | 12,33,1
606 | 6,6,0
607 | 7,34,0
608 | 24,20,0
609 | 25,19,0
610 | 32,10,0
611 | 8,19,4
612 | 41,100,0
613 | 41,74,1
614 | 3,11,1
615 | 36,34,0
616 | 20,47,0
617 | 18,41,0
618 | 11,48,0
619 | 29,30,0
620 | 21,29,1
621 | 23,0,0
622 | 36,30,0
623 | 13,41,0
624 | 36,14,0
625 | 7,48,0
626 | 18,60,1
627 | 41,94,0
628 | 29,33,0
629 | 17,32,1
630 | 18,32,0
631 | 24,32,3
632 | 1,42,0
633 | 4,17,0
634 | 40,52,3
635 | 21,7,1
636 | 7,7,0
637 | 27,18,0
638 | 15,70,0
639 | 21,53,0
640 | 21,18,0
641 | 14,2,0
642 | 38,7,0
643 | 23,43,0
644 | 10,18,0
645 | 21,24,0
646 | 25,27,0
647 | 19,9,0
648 | 7,40,0
649 | 37,97,2
650 | 16,40,0
651 | 41,75,0
652 | 6,56,0
653 | 15,4,1
654 | 28,8,0
655 | 40,18,0
656 | 12,46,0
657 | 17,5,0
658 | 30,58,2
659 | 37,31,0
660 | 22,69,0
661 | 18,12,0
662 | 32,2,2
663 | 33,33,0
664 | 32,3,0
665 | 6,46,4
666 | 8,32,0
667 | 33,17,1
668 | 7,50,0
669 | 15,31,0
670 | 13,27,0
671 | 4,21,4
672 | 8,19,0
673 | 32,37,1
674 | 10,20,0
675 | 36,3,3
676 | 2,22,1
677 | 32,29,0
678 | 6,12,0
679 | 14,33,1
680 | 18,72,0
681 | 32,17,0
682 | 6,25,0
683 | 26,25,0
684 | 26,27,0
685 | 20,4,0
686 | 41,101,1
687 | 35,17,0
688 | 1,33,0
689 | 13,60,0
690 | 33,56,0
691 | 3,19,0
692 | 37,76,0
693 | 34,27,2
694 | 13,23,0
695 | 24,23,0
696 | 11,64,0
697 | 12,7,0
698 | 37,95,0
699 | 34,8,2
700 | 39,33,0
701 | 35,24,3
702 | 33,70,0
703 | 28,0,0
704 | 22,16,0
705 | 15,80,1
706 | 12,47,0
707 | 3,3,0
708 | 1,24,0
709 | 24,29,0
710 | 32,40,0
711 | 18,7,2
712 | 6,46,1
713 | 10,44,2
714 | 41,10,0
715 | 10,43,0
716 | 21,26,0
717 | 4,9,0
718 | 24,23,0
719 | 12,27,0
720 | 33,52,0
721 | 10,6,0
722 | 10,37,0
723 | 26,13,0
724 | 13,70,0
725 | 15,14,0
726 | 13,15,0
727 | 15,39,0
728 | 22,55,0
729 | 11,19,0
730 | 12,29,0
731 | 2,9,1
732 | 12,14,0
733 | 41,22,0
734 | 6,12,0
735 | 41,74,0
736 | 25,19,0
737 | 18,7,1
738 | 18,27,0
739 | 29,29,0
740 | 41,32,0
741 | 18,24,0
742 | 9,6,0
743 | 4,7,0
744 | 33,73,3
745 | 4,4,0
746 | 18,18,0
747 | 10,46,0
748 | 27,12,0
749 | 34,48,0
750 | 37,79,1
751 | 23,31,0
752 | 13,71,0
753 | 40,23,0
754 | 6,40,0
755 | 30,1,0
756 | 26,13,0
757 | 39,9,0
758 | 11,17,1
759 | 4,11,0
760 | 34,6,0
761 | 6,4,0
762 | 13,9,0
763 | 37,73,0
764 | 23,5,0
765 | 11,53,0
766 | 20,37,0
767 | 7,31,0
768 | 16,17,0
769 | 6,39,0
770 | 15,63,0
771 | 13,32,0
772 | 28,0,0
773 | 22,28,0
774 | 41,79,0
775 | 22,84,0
776 | 19,1,0
777 | 39,17,0
778 | 39,7,0
779 | 4,29,1
780 | 4,19,0
781 | 41,59,0
782 | 39,46,0
783 | 23,26,0
784 | 15,87,0
785 | 1,49,0
786 | 30,27,0
787 | 28,9,0
788 | 13,40,0
789 | 16,30,0
790 | 15,82,0
791 | 37,69,2
792 | 6,47,0
793 | 37,33,1
794 | 36,0,0
795 | 39,34,0
796 | 8,27,0
797 | 33,17,0
798 | 6,13,0
799 | 20,37,1
800 | 27,2,0
801 | 37,69,1
802 | 5,1,0
803 | 41,51,1
804 | 30,42,0
805 | 37,69,1
806 | 37,71,0
807 | 39,71,0
808 | 37,59,0
809 | 31,9,0
810 | 3,14,0
811 | 34,22,0
812 | 12,18,0
813 | 3,3,2
814 | 33,19,0
815 | 29,2,2
816 | 15,82,0
817 | 13,3,0
818 | 41,57,1
819 | 6,51,0
820 | 39,63,0
821 | 16,44,0
822 | 24,10,0
823 | 33,30,1
824 | 22,31,0
825 | 30,40,0
826 | 13,26,0
827 | 6,31,0
828 | 15,14,0
829 | 24,29,0
830 | 6,62,2
831 | 34,3,0
832 | 18,67,0
833 | 19,20,2
834 | 39,87,0
835 | 36,40,0
836 | 13,54,0
837 | 36,4,0
838 | 24,26,0
839 | 23,58,0
840 | 41,89,0
841 | 41,52,0
842 | 40,94,0
843 | 6,32,0
844 | 41,46,1
845 | 41,88,0
846 | 26,25,0
847 | 12,33,0
848 | 14,31,0
849 | 37,21,0
850 | 17,33,0
851 | 40,95,1
852 | 39,57,0
853 | 32,42,0
854 | 12,52,0
855 | 2,14,0
856 | 9,5,0
857 | 1,4,1
858 | 12,46,2
859 | 26,24,1
860 | 39,45,3
861 | 41,61,0
862 | 16,1,0
863 | 6,31,0
864 | 11,5,1
865 | 41,30,0
866 | 26,25,0
867 | 29,22,1
868 | 34,38,3
869 | 40,94,1
870 | 41,78,3
871 | 13,45,0
872 | 36,5,0
873 | 15,46,0
874 | 11,26,0
875 | 40,38,0
876 | 15,77,0
877 | 17,31,0
878 | 40,22,0
879 | 12,34,2
880 | 38,12,0
881 | 13,69,3
882 | 8,24,0
883 | 20,54,0
884 | 13,21,0
885 | 17,38,1
886 | 34,42,0
887 | 25,17,0
888 | 33,44,0
889 | 12,2,0
890 | 11,26,0
891 | 40,0,0
892 | 24,25,0
893 | 29,32,3
894 | 41,72,1
895 | 26,3,0
896 | 39,5,0
897 | 14,14,1
898 | 34,9,0
899 | 15,3,0
900 | 39,35,0
901 | 6,57,0
902 | 34,19,0
903 | 18,56,2
904 | 7,17,0
905 | 18,33,1
906 | 14,31,0
907 | 39,30,0
908 | 17,37,0
909 | 7,56,1
910 | 36,22,0
911 | 25,21,0
912 | 2,19,0
913 | 27,25,0
914 | 16,28,0
915 | 39,45,0
916 | 33,75,0
917 | 6,13,0
918 | 4,26,0
919 | 17,85,0
920 | 34,32,1
921 | 13,9,0
922 | 13,72,0
923 | 40,45,0
924 | 39,45,2
925 | 16,33,0
926 | 17,37,0
927 | 11,29,0
928 | 17,70,0
929 | 8,29,0
930 | 17,60,1
931 | 13,77,0
932 | 29,4,1
933 | 17,56,1
934 | 9,28,0
935 | 39,20,0
936 | 34,39,0
937 | 32,20,0
938 | 15,79,0
939 | 11,35,0
940 | 21,36,0
941 | 27,2,0
942 | 36,28,0
943 | 22,75,0
944 | 15,2,0
945 | 37,63,0
946 | 21,51,1
947 | 22,81,0
948 | 17,84,2
949 | 2,1,0
950 | 10,12,0
951 | 28,9,0
952 | 34,5,0
953 | 33,42,0
954 | 1,14,0
955 | 41,101,0
956 | 6,43,0
957 | 6,56,0
958 | 35,5,1
959 | 12,47,0
960 | 9,27,0
961 | 13,18,0
962 | 17,90,1
963 | 39,53,0
964 | 30,51,0
965 | 16,45,0
966 | 36,8,3
967 | 2,22,0
968 | 9,14,0
969 | 11,66,0
970 | 4,1,0
971 | 8,19,2
972 | 17,57,0
973 | 25,20,0
974 | 17,61,0
975 | 18,12,0
976 | 7,55,0
977 | 9,27,0
978 | 2,0,0
979 | 13,2,0
980 | 23,54,0
981 | 2,15,1
982 | 7,34,0
983 | 36,12,0
984 | 9,22,0
985 | 37,20,0
986 | 41,90,1
987 | 19,24,0
988 | 13,59,0
989 | 7,53,0
990 | 33,37,0
991 | 1,14,1
992 | 17,96,0
993 | 11,60,0
994 | 23,58,0
995 | 37,39,1
996 | 19,26,1
997 | 19,29,0
998 | 21,29,0
999 | 20,33,3
1000 | 3,13,0
1001 | 41,73,0
1002 | 40,15,0
1003 | 41,40,0
1004 | 18,19,0
1005 | 19,13,0
1006 | 29,33,0
1007 | 14,33,1
1008 | 19,15,0
1009 | 38,1,0
1010 | 26,12,0
1011 | 41,59,0
1012 | 36,25,0
1013 | 8,30,0
1014 | 32,55,0
1015 | 35,14,0
1016 | 11,56,0
1017 | 13,39,0
1018 | 36,30,0
1019 | 37,72,0
1020 | 12,30,1
1021 | 39,4,2
1022 | 1,53,0
1023 | 11,52,0
1024 | 16,19,0
1025 | 6,7,0
1026 | 1,2,0
1027 | 8,39,0
1028 | 1,31,3
1029 | 32,29,0
1030 | 13,3,0
1031 | 24,7,0
1032 | 25,27,0
1033 | 21,1,0
1034 | 13,21,0
1035 | 11,63,0
1036 | 6,19,0
1037 | 41,76,4
1038 | 32,3,0
1039 | 38,12,0
1040 | 24,24,0
1041 | 25,19,0
1042 | 26,11,0
1043 | 11,24,0
1044 | 17,89,0
1045 | 32,24,0
1046 | 17,93,0
1047 | 21,34,0
1048 | 34,15,0
1049 | 38,20,0
1050 | 30,38,0
1051 | 8,10,0
1052 | 2,7,1
1053 | 20,10,0
1054 | 13,18,0
1055 | 29,32,0
1056 | 15,32,0
1057 | 14,7,0
1058 | 16,41,0
1059 | 39,65,1
1060 | 17,56,1
1061 | 13,50,0
1062 | 14,28,0
1063 | 23,2,0
1064 | 18,53,0
1065 | 6,48,0
1066 | 37,6,4
1067 | 23,17,0
1068 | 35,11,0
1069 | 3,11,0
1070 | 15,83,0
1071 | 15,23,0
1072 | 19,10,0
1073 | 36,41,0
1074 | 14,35,0
1075 | 23,58,0
1076 | 13,6,0
1077 | 13,8,0
1078 | 4,17,0
1079 | 37,42,0
1080 | 24,28,0
1081 | 32,37,1
1082 | 34,31,1
1083 | 24,18,0
1084 | 12,37,0
1085 | 9,3,0
1086 | 2,12,0
1087 | 13,39,1
1088 | 13,44,0
1089 | 6,40,0
1090 | 7,33,0
1091 | 40,82,0
1092 | 39,53,1
1093 | 22,60,0
1094 | 15,56,0
1095 | 22,84,0
1096 | 34,21,0
1097 | 10,24,1
1098 | 4,7,0
1099 | 38,21,0
1100 | 39,6,0
1101 | 14,1,0
1102 | 37,42,0
1103 | 33,62,0
1104 | 20,36,0
1105 | 3,8,0
1106 | 21,5,0
1107 | 41,86,0
1108 | 15,21,0
1109 | 7,25,1
1110 | 15,4,1
1111 | 35,11,2
1112 | 32,40,0
1113 | 39,41,1
1114 | 39,63,0
1115 | 35,3,0
1116 | 10,42,3
1117 | 17,67,0
1118 | 11,45,0
1119 | 23,27,1
1120 | 7,21,0
1121 | 39,60,0
1122 | 13,32,0
1123 | 17,16,0
1124 | 13,12,0
1125 | 14,5,0
1126 | 30,58,0
1127 | 15,4,1
1128 | 7,33,0
1129 | 26,10,0
1130 | 1,53,0
1131 | 29,9,1
1132 | 13,44,0
1133 | 13,34,0
1134 | 1,37,0
1135 | 7,7,0
1136 | 15,74,0
1137 | 39,45,0
1138 | 4,13,0
1139 | 37,100,0
1140 | 40,32,0
1141 | 34,12,0
1142 | 18,38,0
1143 | 16,16,0
1144 | 16,31,0
1145 | 6,34,0
1146 | 41,65,1
1147 | 17,39,0
1148 | 14,40,0
1149 | 23,60,0
1150 | 9,8,0
1151 | 30,58,2
1152 | 16,25,0
1153 | 37,69,3
1154 | 10,7,0
1155 | 8,39,0
1156 | 4,0,0
1157 | 29,8,0
1158 | 41,105,0
1159 | 12,30,2
1160 | 18,7,0
1161 | 8,12,0
1162 | 23,14,2
1163 | 1,47,0
1164 | 6,11,0
1165 | 15,14,0
1166 | 18,10,0
1167 | 27,5,0
1168 | 7,46,0
1169 | 30,6,0
1170 | 7,46,0
1171 | 9,21,0
1172 | 6,5,0
1173 | 14,29,0
1174 | 13,32,0
1175 | 33,51,0
1176 | 18,10,0
1177 | 17,20,0
1178 | 17,0,0
1179 | 39,30,0
1180 | 14,4,0
1181 | 33,23,0
1182 | 36,4,0
1183 | 12,2,0
1184 | 41,101,1
1185 | 30,15,0
1186 | 39,5,1
1187 | 1,20,0
1188 | 3,20,0
1189 | 1,54,0
1190 | 36,1,1
1191 | 3,1,0
1192 | 30,55,4
1193 | 17,79,1
1194 | 7,46,0
1195 | 16,33,0
1196 | 7,25,4
1197 | 17,4,0
1198 | 23,42,0
1199 | 6,46,0
1200 | 6,62,0
1201 | 2,9,1
1202 | 1,29,0
1203 | 7,1,2
1204 | 6,22,0
1205 | 16,34,0
1206 | 33,62,0
1207 | 7,40,0
1208 | 27,28,0
1209 | 19,5,1
1210 | 41,14,0
1211 | 11,46,0
1212 | 34,33,0
1213 | 15,20,0
1214 | 40,85,1
1215 | 39,25,0
1216 | 2,11,0
1217 | 37,57,0
1218 | 8,27,0
1219 | 16,17,0
1220 | 6,15,0
1221 | 14,7,0
1222 | 28,1,0
1223 | 15,86,0
1224 | 11,70,0
1225 | 14,31,0
1226 | 29,32,0
1227 | 32,15,0
1228 | 1,58,0
1229 | 27,10,0
1230 | 16,1,1
1231 | 11,21,0
1232 | 17,2,0
1233 | 21,9,0
1234 | 23,53,0
1235 | 41,43,1
1236 | 28,13,0
1237 | 33,23,0
1238 | 38,3,0
1239 | 6,34,0
1240 | 11,53,0
1241 | 13,80,0
1242 | 34,44,0
1243 | 16,38,1
1244 | 15,65,0
1245 | 13,37,1
1246 | 15,83,0
1247 | 37,26,0
1248 | 36,30,0
1249 | 41,43,1
1250 | 41,75,0
1251 | 8,35,1
1252 | 36,2,0
1253 | 12,50,0
1254 | 2,24,0
1255 | 11,48,1
1256 | 33,15,0
1257 | 41,95,0
1258 | 37,77,1
1259 | 23,4,0
1260 | 18,50,0
1261 | 28,27,0
1262 | 41,72,0
1263 | 21,24,0
1264 | 23,51,0
1265 | 26,16,0
1266 | 18,59,0
1267 | 33,37,0
1268 | 34,11,1
1269 | 15,25,0
1270 | 6,26,0
1271 | 36,30,0
1272 | 32,38,0
1273 | 12,31,0
1274 | 3,16,0
1275 | 41,120,0
1276 | 40,102,0
1277 | 29,22,3
1278 | 16,21,0
1279 | 37,3,0
1280 | 41,93,0
1281 | 21,16,0
1282 | 12,23,1
1283 | 11,48,0
1284 | 1,8,0
1285 | 17,63,0
1286 | 6,45,0
1287 | 20,8,0
1288 | 6,16,0
1289 | 1,2,0
1290 | 32,41,0
1291 | 17,57,1
1292 | 39,4,1
1293 | 6,6,0
1294 | 6,25,0
1295 | 13,36,0
1296 | 21,2,1
1297 | 9,18,0
1298 | 33,13,0
1299 | 37,6,0
1300 | 26,4,0
1301 | 40,60,0
1302 | 6,46,1
1303 | 6,49,0
1304 | 41,106,0
1305 | 35,9,0
1306 | 22,88,0
1307 | 35,9,0
1308 | 12,5,0
1309 | 32,50,0
1310 | 30,8,0
1311 | 33,30,1
1312 | 15,76,0
1313 | 16,33,0
1314 | 3,14,0
1315 | 37,63,1
1316 | 34,38,1
1317 | 37,25,1
1318 | 37,35,0
1319 | 18,44,0
1320 | 13,10,2
1321 | 13,73,0
1322 | 16,15,0
1323 | 22,36,0
1324 | 10,28,0
1325 | 38,9,0
1326 | 14,16,0
1327 | 13,37,0
1328 | 24,8,0
1329 | 41,3,1
1330 | 15,4,0
1331 | 12,19,0
1332 | 3,0,0
1333 | 9,27,0
1334 | 7,55,1
1335 | 4,20,0
1336 | 16,41,0
1337 | 4,22,0
1338 | 39,35,0
1339 | 23,61,0
1340 | 39,72,0
1341 | 9,26,0
1342 | 41,71,0
1343 | 21,53,0
1344 | 25,11,0
1345 | 33,46,0
1346 | 21,6,0
1347 | 23,60,0
1348 | 27,18,0
1349 | 24,28,0
1350 | 21,22,0
1351 | 17,23,0
1352 | 2,5,0
1353 | 15,77,0
1354 | 16,12,0
1355 | 39,1,0
1356 | 7,3,0
1357 | 36,4,0
1358 | 35,10,0
1359 | 37,77,0
1360 | 24,32,0
1361 | 24,27,0
1362 | 4,25,0
1363 | 10,42,2
1364 | 31,4,0
1365 | 29,39,0
1366 | 1,49,0
1367 | 34,38,2
1368 | 30,36,0
1369 | 26,4,0
1370 | 8,30,0
1371 | 6,20,0
1372 | 12,33,0
1373 | 27,20,0
1374 | 7,21,1
1375 | 32,46,1
1376 | 16,37,0
1377 | 20,6,0
1378 | 14,10,0
1379 | 37,69,1
1380 | 23,34,0
1381 | 9,13,0
1382 | 41,55,1
1383 | 37,74,1
1384 | 22,17,0
1385 | 33,52,0
1386 | 6,42,0
1387 | 11,26,1
1388 | 15,38,0
1389 | 12,20,0
1390 | 9,18,0
1391 | 28,15,0
1392 | 24,28,0
1393 | 4,19,0
1394 | 11,31,0
1395 | 12,18,0
1396 | 10,42,1
1397 | 12,51,0
1398 | 18,79,0
1399 | 22,58,0
1400 | 6,40,0
1401 | 33,20,0
1402 | 3,20,1
1403 | 40,60,0
1404 | 37,73,0
1405 | 39,40,0
1406 | 4,7,0
1407 | 24,6,1
1408 | 36,3,0
1409 | 19,8,0
1410 | 6,47,0
1411 | 8,30,1
1412 | 41,97,0
1413 | 7,23,1
1414 | 38,15,1
1415 | 11,41,0
1416 | 11,53,0
1417 | 37,48,0
1418 | 39,40,0
1419 | 9,15,0
1420 | 41,15,0
1421 | 15,40,0
1422 | 40,28,0
1423 | 31,4,1
1424 | 37,58,0
1425 | 6,8,0
1426 | 1,51,0
1427 | 20,51,2
1428 | 32,36,0
1429 | 7,21,0
1430 | 41,74,0
1431 | 16,21,0
1432 | 26,6,0
1433 | 11,3,5
1434 | 40,31,2
1435 | 38,12,0
1436 | 19,20,0
1437 | 1,23,0
1438 | 18,10,1
1439 | 29,36,0
1440 | 1,33,0
1441 | 36,47,0
1442 | 20,37,0
1443 | 37,30,0
1444 | 21,36,0
1445 | 34,3,2
1446 | 41,121,0
1447 | 1,37,0
1448 | 33,22,0
1449 | 22,51,0
1450 | 10,55,1
1451 | 39,35,0
1452 | 21,10,0
1453 | 39,26,0
1454 | 16,21,0
1455 | 41,33,0
1456 | 1,4,0
1457 | 41,80,0
1458 | 34,40,2
1459 | 37,51,0
1460 | 10,46,0
1461 | 27,10,0
1462 | 6,52,0
1463 | 33,23,0
1464 | 13,37,2
1465 | 13,45,0
1466 | 6,61,1
1467 | 24,24,0
1468 | 5,1,0
1469 | 41,32,0
1470 | 40,62,0
1471 | 1,23,0
1472 | 33,11,0
1473 | 41,49,0
1474 | 39,57,0
1475 | 37,70,0
1476 | 32,40,0
1477 | 10,26,1
1478 | 36,23,0
1479 | 13,30,0
1480 | 29,2,2
1481 | 16,29,0
1482 | 9,28,0
1483 | 18,46,0
1484 | 17,29,1
1485 | 12,27,1
1486 | 24,16,1
1487 | 7,19,0
1488 | 7,41,0
1489 | 12,50,0
1490 | 16,26,0
1491 | 41,68,2
1492 | 32,43,0
1493 | 34,38,0
1494 | 14,8,0
1495 | 15,61,0
1496 | 11,71,0
1497 | 17,15,0
1498 | 34,45,1
1499 | 8,41,0
1500 | 2,6,0
1501 | 33,58,0
1502 | 6,45,0
1503 | 1,29,0
1504 | 41,41,0
1505 | 32,18,0
1506 | 9,22,0
1507 | 15,31,0
1508 | 3,16,0
1509 | 16,15,0
1510 | 16,41,0
1511 | 10,43,0
1512 | 32,27,0
1513 | 16,38,2
1514 | 17,34,0
1515 | 41,123,1
1516 | 10,24,0
1517 | 27,27,0
1518 | 41,46,0
1519 | 16,34,0
1520 | 2,5,0
1521 | 39,84,0
1522 | 15,34,0
1523 | 19,28,0
1524 | 2,6,1
1525 | 17,21,0
1526 | 35,21,2
1527 | 8,7,0
1528 | 20,32,0
1529 | 25,24,0
1530 | 30,7,0
1531 | 1,44,0
1532 | 11,31,0
1533 | 39,80,1
1534 | 9,9,0
1535 | 21,17,0
1536 | 16,48,0
1537 | 30,19,0
1538 | 24,32,0
1539 | 27,12,0
1540 | 36,23,0
1541 | 15,47,0
1542 | 15,34,0
1543 | 15,10,0
1544 | 21,50,0
1545 | 6,67,0
1546 | 18,59,0
1547 | 16,48,0
1548 | 19,18,0
1549 | 15,2,0
1550 | 29,2,0
1551 | 40,54,0
1552 | 10,7,0
1553 | 16,19,0
1554 | 39,73,0
1555 | 34,8,0
1556 | 28,30,0
1557 | 33,68,0
1558 | 33,2,0
1559 | 33,25,0
1560 | 12,46,0
1561 | 36,27,0
1562 | 20,62,1
1563 | 17,79,0
1564 | 41,48,0
1565 | 6,50,0
1566 | 16,23,0
1567 | 30,45,0
1568 | 29,34,0
1569 | 17,50,0
1570 | 20,31,0
1571 | 18,10,0
1572 | 6,35,0
1573 | 32,55,1
1574 | 23,34,0
1575 | 31,9,0
1576 | 29,32,0
1577 | 11,52,0
1578 | 37,27,0
1579 | 36,6,0
1580 | 7,58,0
1581 | 23,58,0
1582 | 1,26,0
1583 | 35,11,0
1584 | 17,62,0
1585 | 41,38,1
1586 | 11,36,0
1587 | 37,79,2
1588 | 24,28,0
1589 | 4,12,0
1590 | 29,11,3
1591 | 19,15,0
1592 | 8,32,0
1593 | 29,9,2
1594 | 17,69,0
1595 | 23,48,0
1596 | 34,33,0
1597 | 20,2,0
1598 | 16,15,0
1599 | 30,51,0
1600 | 23,46,0
1601 | 34,10,3
1602 | 18,49,0
1603 | 15,53,0
1604 | 37,47,0
1605 | 11,34,0
1606 | 39,71,0
1607 | 39,83,0
1608 | 37,61,0
1609 | 19,9,0
1610 | 16,24,2
1611 | 41,76,0
1612 | 18,56,1
1613 | 34,41,0
1614 | 16,48,0
1615 | 10,21,0
1616 | 37,60,0
1617 | 25,4,0
1618 | 6,43,0
1619 | 13,49,0
1620 | 34,9,0
1621 | 7,55,1
1622 | 18,50,0
1623 | 35,4,2
1624 | 17,33,0
1625 | 13,35,0
1626 | 41,55,1
1627 | 30,33,0
1628 | 27,11,0
1629 | 37,28,0
1630 | 6,52,0
1631 | 33,75,0
1632 | 17,70,0
1633 | 2,21,0
1634 | 6,0,0
1635 | 13,14,0
1636 | 24,30,0
1637 |
--------------------------------------------------------------------------------
/NER/datasets/doc-paragraph-sentence-id/mrc-ner.dev-id:
--------------------------------------------------------------------------------
1 | 16,53,0
2 | 6,61,0
3 | 15,75,0
4 | 41,48,0
5 | 30,27,0
6 | 16,28,1
7 | 13,27,0
8 | 21,27,1
9 | 24,16,2
10 | 18,77,1
11 | 32,42,0
12 | 36,47,0
13 | 30,21,0
14 | 15,83,0
15 | 27,15,0
16 | 30,17,0
17 | 37,39,2
18 | 12,20,0
19 | 28,27,0
20 | 9,19,0
21 | 7,59,0
22 | 41,119,0
23 | 3,21,0
24 | 39,85,0
25 | 29,9,0
26 | 16,18,1
27 | 39,86,0
28 | 6,55,0
29 | 24,31,0
30 | 12,13,0
31 | 11,12,0
32 | 40,13,1
33 | 35,19,0
34 | 2,11,0
35 | 39,80,1
36 | 15,39,0
37 | 36,10,0
38 | 34,29,1
39 | 41,80,0
40 | 18,42,0
41 | 39,31,0
42 | 3,11,0
43 | 13,65,0
44 | 41,85,0
45 | 29,16,0
46 | 24,8,0
47 | 27,27,0
48 | 4,24,0
49 | 32,11,0
50 | 7,11,0
51 | 7,21,0
52 | 35,14,0
53 | 7,35,0
54 | 20,12,0
55 | 41,112,0
56 | 1,22,0
57 | 1,2,0
58 | 10,1,0
59 | 14,5,1
60 | 11,26,0
61 | 39,88,1
62 | 37,2,0
63 | 11,57,0
64 | 34,10,4
65 | 7,36,0
66 | 9,18,0
67 | 14,30,0
68 | 22,62,0
69 | 28,11,0
70 | 15,12,0
71 | 41,113,0
72 | 12,30,4
73 | 30,57,2
74 | 16,31,0
75 | 9,17,0
76 | 23,52,0
77 | 30,51,0
78 | 40,28,0
79 | 39,74,1
80 | 39,2,0
81 | 39,47,0
82 | 12,24,0
83 | 13,65,0
84 | 14,31,0
85 | 27,25,0
86 | 26,11,0
87 | 39,45,0
88 | 41,105,0
89 | 17,49,0
90 | 30,7,0
91 | 15,57,0
92 | 14,6,1
93 | 14,38,0
94 | 34,51,0
95 | 12,49,0
96 | 30,43,0
97 | 24,13,0
98 | 37,69,1
99 | 2,4,0
100 | 12,11,0
101 | 22,86,0
102 | 33,69,0
103 | 9,24,0
104 | 20,37,0
105 | 8,14,0
106 | 14,29,2
107 | 18,16,0
108 | 1,49,0
109 | 41,53,0
110 | 41,55,1
111 | 27,28,0
112 | 33,17,0
113 | 17,82,0
114 | 13,13,0
115 | 16,30,0
116 | 41,36,1
117 | 32,14,0
118 | 30,29,0
119 | 41,49,2
120 | 39,26,1
121 | 22,53,0
122 | 24,16,1
123 | 40,45,0
124 | 13,37,3
125 | 25,6,0
126 | 28,7,0
127 | 4,8,0
128 | 38,3,0
129 | 34,31,2
130 | 37,23,0
131 | 35,21,0
132 | 16,7,0
133 | 41,61,0
134 | 16,14,0
135 | 13,29,0
136 | 3,8,0
137 | 17,31,0
138 | 41,26,0
139 | 41,85,1
140 | 34,10,5
141 | 41,61,1
142 | 41,31,0
143 | 22,77,0
144 | 27,15,2
145 | 9,5,0
146 | 7,10,0
147 | 13,26,0
148 | 23,19,0
149 | 39,11,0
150 | 1,22,0
151 | 16,39,5
152 | 2,9,4
153 | 25,4,0
154 | 39,45,0
155 | 17,47,0
156 | 10,41,0
157 | 17,10,0
158 | 3,14,0
159 | 17,1,0
160 | 8,8,0
161 | 39,70,0
162 | 34,9,0
163 | 14,16,0
164 | 18,68,0
165 | 11,10,0
166 | 30,53,1
167 | 34,42,2
168 | 41,91,0
169 | 30,7,0
170 | 14,5,0
171 | 8,1,1
172 | 27,15,1
173 | 17,84,0
174 | 23,42,0
175 | 41,104,0
176 | 23,14,1
177 | 8,12,0
178 | 4,24,0
179 | 11,54,0
180 | 6,3,0
181 | 16,13,0
182 | 11,63,0
183 | 7,11,4
184 | 24,3,0
185 | 6,39,0
186 | 25,16,0
187 | 6,61,1
188 | 33,16,0
189 | 16,18,1
190 | 6,53,2
191 | 13,74,0
192 | 7,37,1
193 | 19,28,0
194 | 10,26,0
195 | 22,26,0
196 | 9,13,0
197 | 17,35,3
198 | 33,40,0
199 | 9,7,0
200 | 6,50,0
201 | 14,15,2
202 | 13,79,0
203 | 2,19,0
204 | 6,14,0
205 | 39,54,0
206 | 20,33,3
207 | 7,10,0
208 | 30,29,0
209 | 27,23,0
210 | 40,19,1
211 | 16,4,2
212 | 41,61,0
213 | 2,12,1
214 | 33,46,0
215 | 11,58,0
216 | 13,80,2
217 | 25,7,0
218 | 34,49,1
219 | 12,22,0
220 | 15,20,1
221 | 41,37,1
222 | 6,39,0
223 | 34,20,0
224 | 13,39,1
225 | 6,46,4
226 | 9,28,0
227 | 38,12,0
228 | 1,7,3
229 | 17,53,0
230 | 34,31,1
231 | 9,19,0
232 | 36,39,0
233 | 30,55,1
234 | 4,5,0
235 | 40,32,2
236 | 37,73,0
237 | 24,3,0
238 | 40,66,0
239 | 37,3,0
240 | 8,34,2
241 | 16,25,0
242 | 2,24,0
243 | 23,47,0
244 | 11,45,0
245 | 41,57,1
246 | 36,31,0
247 | 17,44,0
248 | 3,3,0
249 | 23,51,0
250 | 1,50,0
251 | 11,76,2
252 | 37,1,1
253 | 7,14,0
254 | 29,11,2
255 | 35,17,0
256 | 21,32,0
257 | 17,38,3
258 | 4,16,0
259 | 12,42,0
260 | 8,11,0
261 | 32,32,1
262 | 39,17,1
263 | 24,31,0
264 | 33,7,0
265 | 37,39,0
266 | 34,43,0
267 | 8,25,4
268 | 17,35,0
269 | 18,65,0
270 | 29,37,0
271 | 13,73,0
272 | 14,24,0
273 | 15,73,0
274 | 24,25,0
275 | 32,44,0
276 | 16,44,0
277 | 39,26,2
278 | 17,71,0
279 | 17,73,0
280 | 37,69,2
281 | 16,23,0
282 | 17,31,0
283 | 40,103,0
284 | 34,38,0
285 | 22,67,0
286 | 18,46,0
287 | 9,7,1
288 | 11,42,0
289 | 15,18,0
290 | 12,32,0
291 | 13,41,0
292 | 34,34,1
293 | 30,57,1
294 | 9,24,0
295 | 20,1,0
296 | 4,12,0
297 | 15,22,0
298 | 6,57,0
299 | 26,13,1
300 | 13,0,0
301 | 21,12,0
302 | 26,2,0
303 | 20,62,1
304 | 41,73,0
305 | 21,50,0
306 | 34,24,0
307 | 39,31,1
308 | 26,9,0
309 | 17,47,0
310 | 18,23,0
311 | 6,45,0
312 | 9,24,0
313 | 8,22,0
314 | 36,27,0
315 | 16,52,0
316 | 10,17,0
317 | 23,25,0
318 | 16,4,0
319 | 7,3,0
320 | 21,53,0
321 | 3,5,1
322 | 41,103,0
323 | 34,40,0
324 | 25,22,0
325 | 27,16,0
326 | 13,77,0
327 | 16,4,0
328 | 12,33,0
329 | 41,21,0
330 | 18,38,0
331 | 39,26,0
332 | 7,19,0
333 | 13,26,0
334 | 16,6,0
335 | 3,5,0
336 | 41,99,0
337 | 29,12,0
338 | 30,39,0
339 | 37,35,0
340 | 41,36,0
341 | 33,11,0
342 | 19,10,0
343 | 13,79,0
344 | 39,8,0
345 | 32,42,0
346 | 11,37,0
347 | 9,25,0
348 | 9,10,0
349 | 34,49,1
350 | 7,25,3
351 | 39,57,0
352 | 1,4,0
353 | 7,44,0
354 | 17,13,0
355 | 29,5,0
356 | 24,3,0
357 | 3,12,0
358 | 3,16,0
359 | 28,16,0
360 | 26,3,0
361 | 41,89,0
362 | 20,36,0
363 | 20,50,0
364 | 21,1,0
365 | 13,15,0
366 | 33,62,0
367 | 18,60,0
368 | 15,70,0
369 | 34,31,1
370 | 7,21,2
371 | 39,82,0
372 | 7,24,0
373 | 16,29,0
374 | 16,54,0
375 | 15,6,0
376 | 33,30,2
377 | 16,7,0
378 | 1,47,0
379 | 2,9,0
380 | 16,16,0
381 | 41,76,5
382 | 9,10,0
383 | 22,62,0
384 | 16,53,0
385 | 16,40,0
386 | 13,75,0
387 | 6,20,0
388 | 16,12,0
389 | 7,24,0
390 | 18,16,0
391 | 13,41,0
392 | 6,9,0
393 | 23,33,0
394 | 36,38,0
395 | 12,44,0
396 | 12,23,0
397 | 18,7,1
398 | 25,9,0
399 | 24,22,0
400 | 37,66,0
401 | 23,64,0
402 | 17,55,0
403 | 40,29,0
404 | 6,11,3
405 | 6,4,0
406 | 39,40,0
407 | 11,77,0
408 | 21,7,0
409 | 30,38,0
410 | 41,78,0
411 | 7,58,0
412 | 23,18,0
413 | 41,74,0
414 | 15,60,0
415 | 37,50,1
416 | 24,29,0
417 | 19,18,0
418 | 19,3,0
419 | 36,17,0
420 | 12,15,0
421 | 20,1,1
422 | 6,33,0
423 | 13,3,1
424 | 37,88,0
425 | 17,64,0
426 | 9,15,0
427 | 39,64,2
428 | 4,10,0
429 | 13,27,0
430 | 35,3,1
431 | 30,9,0
432 | 16,23,0
433 | 32,44,0
434 | 13,44,0
435 | 24,32,3
436 | 12,17,0
437 | 6,36,0
438 | 37,67,0
439 | 20,12,0
440 | 13,69,2
441 | 39,12,5
442 | 3,16,0
443 | 22,58,0
444 | 3,11,0
445 | 28,12,0
446 | 15,68,0
447 | 1,19,0
448 | 22,40,0
449 | 10,5,0
450 | 6,17,0
451 | 25,19,0
452 | 33,11,0
453 | 26,24,0
454 | 41,20,0
455 | 4,8,2
456 | 18,59,0
457 | 13,74,0
458 | 3,19,0
459 | 11,39,0
460 | 4,25,0
461 | 2,11,0
462 | 16,30,0
463 | 6,52,0
464 | 4,11,0
465 | 1,39,0
466 | 19,13,3
467 | 37,38,0
468 | 21,40,0
469 | 35,14,1
470 | 11,63,0
471 | 10,34,0
472 | 37,20,0
473 | 30,23,0
474 | 10,3,0
475 | 25,14,4
476 | 41,105,0
477 | 37,102,0
478 | 41,5,1
479 | 34,31,1
480 | 23,64,0
481 | 13,60,0
482 | 41,5,3
483 | 29,36,0
484 | 28,30,0
485 | 9,21,0
486 | 40,16,1
487 | 41,59,0
488 | 27,20,0
489 | 19,13,1
490 | 30,6,0
491 | 21,53,0
492 | 11,56,0
493 | 34,41,0
494 | 41,86,0
495 | 15,23,0
496 | 7,5,0
497 | 6,45,0
498 | 33,51,0
499 | 30,48,0
500 | 38,11,0
501 | 8,9,0
502 | 27,11,0
503 | 16,14,2
504 | 39,48,0
505 | 16,6,0
506 | 17,57,0
507 | 20,6,0
508 | 32,47,0
509 | 41,49,0
510 | 13,37,2
511 | 25,1,0
512 | 12,24,0
513 | 12,10,0
514 | 15,77,0
515 | 9,9,0
516 | 37,60,1
517 | 11,72,0
518 | 15,45,0
519 | 2,9,2
520 | 17,27,0
521 | 16,44,0
522 | 15,82,0
523 | 23,60,0
524 | 14,15,3
525 | 16,24,0
526 | 9,24,0
527 | 24,14,0
528 | 33,68,0
529 | 6,33,0
530 | 19,8,0
531 | 7,23,1
532 | 17,81,0
533 | 34,2,0
534 | 14,47,0
535 | 41,61,1
536 | 17,32,0
537 | 41,110,0
538 | 3,2,0
539 | 4,28,0
540 | 3,2,0
541 | 30,51,0
542 | 26,9,1
543 | 18,29,0
544 | 17,32,0
545 | 18,15,1
546 | 23,1,0
547 | 17,70,0
548 | 34,22,0
549 | 23,2,0
550 | 41,12,0
551 | 28,30,0
552 | 34,38,2
553 | 33,67,0
554 | 32,45,0
555 | 37,63,1
556 | 8,30,2
557 | 33,75,0
558 | 21,20,0
559 | 40,53,4
560 | 37,72,0
561 | 15,12,0
562 | 4,9,0
563 | 30,43,0
564 | 34,11,1
565 | 19,9,0
566 | 41,74,1
567 | 24,27,0
568 | 9,1,2
569 | 36,19,0
570 | 3,4,0
571 | 24,25,0
572 | 41,78,2
573 | 34,39,3
574 | 17,92,0
575 | 11,8,2
576 | 33,44,1
577 | 37,69,1
578 | 11,19,1
579 | 16,39,0
580 | 23,14,2
581 | 41,61,0
582 | 27,23,0
583 | 23,25,0
584 | 16,12,0
585 | 41,111,0
586 | 9,1,1
587 | 16,23,0
588 | 38,3,0
589 | 37,20,0
590 | 37,69,1
591 | 14,44,0
592 | 15,69,0
593 | 24,17,0
594 | 32,11,0
595 | 6,26,0
596 | 6,6,1
597 | 29,2,0
598 | 15,37,0
599 | 37,69,1
600 | 26,21,0
601 | 35,0,0
602 | 39,66,0
603 | 33,15,0
604 | 15,20,0
605 | 13,10,1
606 | 1,58,0
607 | 37,100,0
608 | 8,19,0
609 | 18,7,2
610 | 29,22,0
611 | 24,10,1
612 | 40,112,0
613 | 16,40,1
614 | 6,37,0
615 | 15,12,0
616 | 1,24,0
617 | 25,23,0
618 | 10,55,0
619 | 12,1,0
620 | 14,33,0
621 | 41,47,1
622 | 25,4,0
623 | 27,7,0
624 | 15,10,0
625 | 17,34,0
626 | 14,39,0
627 | 17,35,0
628 | 36,29,0
629 | 19,27,0
630 | 17,31,0
631 | 33,37,2
632 | 3,7,0
633 | 41,90,0
634 | 10,31,0
635 | 27,27,0
636 | 22,48,0
637 | 2,24,0
638 | 13,3,1
639 | 14,17,1
640 | 30,23,0
641 | 6,6,0
642 | 41,85,1
643 | 16,4,2
644 | 13,67,0
645 | 6,46,0
646 | 7,13,0
647 | 15,19,0
648 | 12,25,1
649 | 1,31,0
650 | 30,18,1
651 | 18,23,0
652 | 29,15,0
653 | 15,10,0
654 | 3,3,1
655 | 38,15,1
656 | 36,32,0
657 | 13,18,0
658 | 30,27,0
659 | 39,8,0
660 | 34,49,1
661 | 17,33,0
662 | 15,3,0
663 | 10,23,0
664 | 16,1,0
665 | 11,48,0
666 | 8,32,0
667 | 33,54,1
668 | 18,75,0
669 | 17,73,0
670 | 15,77,0
671 | 29,36,0
672 | 30,33,0
673 | 21,27,1
674 | 34,10,2
675 | 13,24,0
676 | 37,66,0
677 | 37,103,0
678 | 15,12,0
679 | 15,24,0
680 | 11,77,0
681 | 2,18,0
682 | 7,24,0
683 | 10,44,2
684 | 25,19,0
685 | 12,33,1
686 | 13,71,0
687 | 35,17,0
688 | 33,48,2
689 | 14,10,0
690 | 37,43,0
691 | 11,32,0
692 | 1,42,0
693 | 17,5,1
694 | 11,18,0
695 | 15,16,0
696 | 14,7,2
697 | 15,20,0
698 | 7,16,0
699 | 8,30,2
700 | 1,21,0
701 | 41,107,1
702 | 41,76,0
703 | 12,51,0
704 | 14,40,1
705 | 29,24,0
706 | 28,26,0
707 | 41,3,0
708 | 9,30,0
709 | 33,75,0
710 | 11,33,0
711 | 41,76,6
712 | 18,53,2
713 | 37,7,0
714 | 29,35,0
715 | 10,47,0
716 | 17,81,0
717 | 11,53,0
718 | 33,36,0
719 | 28,11,0
720 | 11,56,0
721 | 11,48,0
722 | 6,48,0
723 | 34,45,1
724 | 30,31,0
725 | 33,73,1
726 | 1,31,0
727 | 37,13,2
728 | 10,0,0
729 | 39,11,0
730 | 39,71,0
731 | 8,1,0
732 | 12,11,2
733 | 37,5,0
734 | 40,70,0
735 | 36,33,0
736 | 12,21,0
737 | 19,27,0
738 | 40,72,0
739 | 4,3,1
740 | 4,20,1
741 | 20,24,2
742 | 41,77,0
743 | 31,10,0
744 | 30,14,0
745 | 21,36,0
746 | 12,51,0
747 | 41,75,0
748 | 13,22,0
749 | 16,7,0
750 | 36,22,0
751 | 8,22,0
752 | 15,69,0
753 | 6,4,0
754 | 37,74,0
755 | 34,31,1
756 | 15,77,0
757 | 30,41,0
758 | 36,25,0
759 | 16,43,0
760 | 13,14,0
761 | 16,32,0
762 | 22,75,0
763 | 29,32,4
764 | 13,40,0
765 | 6,35,0
766 | 11,43,1
767 | 41,86,0
768 | 39,8,1
769 | 4,3,0
770 | 15,75,0
771 | 41,110,1
772 | 40,100,0
773 | 39,82,0
774 | 3,1,0
775 | 27,27,0
776 | 19,26,2
777 | 13,15,0
778 | 4,20,0
779 | 6,6,1
780 | 6,48,0
781 | 24,9,0
782 | 20,31,1
783 | 36,9,0
784 | 11,61,0
785 | 41,6,0
786 | 11,22,1
787 | 41,76,0
788 | 4,8,0
789 | 16,2,1
790 | 24,32,0
791 | 33,1,0
792 | 14,21,0
793 | 13,76,0
794 | 27,20,0
795 | 35,0,0
796 | 8,1,0
797 | 17,60,0
798 | 21,34,0
799 | 9,28,0
800 | 15,15,0
801 | 16,36,0
802 | 16,53,0
803 | 12,23,0
804 | 41,32,0
805 | 41,103,0
806 | 18,69,0
807 | 37,9,0
808 | 27,26,0
809 | 11,65,0
810 | 26,3,0
811 | 22,12,0
812 | 41,54,0
813 | 33,60,0
814 | 2,5,0
815 | 36,42,0
816 | 11,39,0
817 | 15,0,0
818 | 37,10,0
819 | 13,65,0
820 | 24,17,0
821 | 37,88,0
822 | 6,6,2
823 | 3,25,0
824 | 8,24,0
825 | 23,46,0
826 | 11,67,0
827 | 27,18,0
828 | 41,21,0
829 | 32,25,0
830 | 39,75,0
831 | 18,27,0
832 | 6,36,0
833 | 41,32,0
834 | 21,13,0
835 | 17,34,1
836 | 41,87,0
837 | 13,74,1
838 | 16,49,1
839 | 21,4,0
840 | 41,74,1
841 | 40,54,0
842 | 41,101,0
843 | 9,28,1
844 | 40,22,0
845 | 37,25,1
846 | 33,3,0
847 | 37,54,0
848 | 6,29,0
849 | 9,11,0
850 | 35,9,3
851 | 8,34,0
852 | 28,31,0
853 | 14,7,0
854 | 37,85,0
855 | 8,27,0
856 | 19,12,1
857 | 33,32,1
858 | 41,97,0
859 | 27,15,0
860 | 13,56,0
861 | 6,34,0
862 | 41,75,0
863 | 9,9,0
864 | 37,33,0
865 | 14,2,0
866 | 30,25,0
867 | 6,66,0
868 | 5,3,0
869 | 41,55,1
870 | 4,29,0
871 | 7,48,0
872 | 10,44,2
873 | 29,32,0
874 | 12,35,0
875 | 37,21,0
876 | 39,79,0
877 | 23,43,0
878 | 4,1,2
879 | 40,90,0
880 | 34,38,0
881 | 25,19,1
882 | 34,32,2
883 | 37,71,0
884 | 18,54,0
885 | 17,89,0
886 | 9,19,0
887 | 15,32,0
888 | 13,66,0
889 | 26,14,1
890 | 32,31,0
891 | 1,2,0
892 | 37,79,1
893 | 37,29,0
894 | 41,61,0
895 | 13,30,1
896 | 18,66,0
897 | 12,20,1
898 | 20,23,0
899 | 1,58,3
900 | 14,17,3
901 | 21,1,0
902 | 6,46,0
903 | 6,24,0
904 | 36,16,0
905 | 10,39,0
906 | 30,5,0
907 | 23,46,0
908 | 17,92,3
909 | 7,60,0
910 | 41,98,0
911 | 1,33,1
912 | 14,30,0
913 | 39,26,1
914 | 37,36,0
915 | 6,50,0
916 | 3,8,0
917 | 16,15,0
918 | 37,69,3
919 | 16,49,0
920 | 17,17,0
921 | 16,29,0
922 | 9,6,0
923 | 3,22,1
924 | 39,46,0
925 | 10,22,0
926 | 11,76,0
927 | 6,37,0
928 | 4,29,0
929 | 16,20,0
930 | 14,47,0
931 | 16,4,0
932 | 3,22,0
933 | 34,27,0
934 | 32,2,0
935 | 30,44,0
936 | 27,23,0
937 | 26,27,0
938 | 16,20,0
939 | 16,40,0
940 | 41,63,0
941 | 34,5,0
942 | 30,56,0
943 | 13,23,0
944 | 13,32,0
945 | 24,32,3
946 | 38,12,0
947 | 12,41,0
948 | 13,37,0
949 | 17,12,0
950 | 9,28,0
951 | 39,25,0
952 | 7,34,0
953 | 41,106,3
954 | 8,22,0
955 | 16,39,1
956 | 37,20,0
957 | 23,2,0
958 | 15,24,0
959 | 33,75,0
960 | 30,29,0
961 | 33,73,3
962 | 16,5,0
963 | 16,51,0
964 | 34,27,1
965 | 20,4,0
966 | 17,62,2
967 | 40,90,0
968 | 14,28,0
969 | 19,10,0
970 | 7,21,0
971 | 37,48,0
972 | 32,25,0
973 | 40,82,0
974 | 20,12,0
975 | 13,10,2
976 | 36,43,2
977 | 28,31,0
978 | 12,51,0
979 | 8,21,0
980 | 34,10,3
981 | 26,22,0
982 | 7,51,0
983 | 15,12,0
984 | 41,123,2
985 | 33,62,0
986 | 32,35,0
987 | 13,9,1
988 | 35,9,0
989 | 30,52,0
990 | 37,6,3
991 | 39,11,2
992 | 26,3,1
993 | 22,26,0
994 | 2,19,0
995 | 20,37,0
996 | 6,60,0
997 | 15,67,0
998 | 41,88,0
999 | 18,45,0
1000 | 18,7,0
1001 | 12,35,0
1002 | 13,80,0
1003 | 9,12,0
1004 | 34,10,0
1005 | 7,60,0
1006 | 27,23,0
1007 | 13,23,0
1008 | 9,8,0
1009 | 41,46,1
1010 | 18,31,0
1011 | 39,48,0
1012 | 37,74,1
1013 | 33,37,0
1014 | 13,70,0
1015 | 17,78,0
1016 | 28,27,0
1017 | 11,54,0
1018 | 15,8,0
1019 | 11,66,0
1020 | 41,58,0
1021 | 26,4,1
1022 | 1,2,0
1023 | 21,14,5
1024 | 27,23,0
1025 | 8,21,0
1026 | 18,35,1
1027 | 9,11,0
1028 | 33,42,0
1029 | 17,38,1
1030 | 28,8,0
1031 | 3,10,0
1032 | 21,30,0
1033 | 37,54,0
1034 | 4,31,0
1035 | 8,35,2
1036 | 15,5,0
1037 | 23,54,0
1038 | 41,75,0
1039 | 13,62,0
1040 | 23,45,0
1041 | 15,14,0
1042 | 13,32,0
1043 | 17,11,0
1044 | 2,22,0
1045 | 15,79,0
1046 | 22,86,0
1047 | 36,1,0
1048 | 8,34,2
1049 | 11,32,0
1050 | 11,22,0
1051 | 38,10,0
1052 | 9,16,0
1053 | 6,31,0
1054 | 39,60,0
1055 | 27,28,0
1056 | 15,30,0
1057 | 13,35,0
1058 | 41,18,0
1059 | 14,16,0
1060 | 1,59,0
1061 | 24,20,0
1062 | 15,83,0
1063 | 33,25,0
1064 | 6,32,0
1065 | 7,50,0
1066 | 15,16,0
1067 | 10,5,0
1068 | 36,6,0
1069 | 32,18,2
1070 | 41,46,0
1071 | 13,30,0
1072 | 17,8,0
1073 | 33,46,0
1074 | 13,69,2
1075 | 34,8,4
1076 | 28,12,0
1077 | 36,24,0
1078 | 23,66,0
1079 | 27,10,0
1080 | 12,23,0
1081 | 7,40,0
1082 | 19,5,0
1083 | 13,11,0
1084 | 7,5,0
1085 | 22,1,2
1086 | 21,43,0
1087 | 12,18,0
1088 | 3,13,0
1089 | 6,42,1
1090 | 6,67,0
1091 | 34,32,3
1092 | 18,19,0
1093 | 33,17,1
1094 | 30,55,1
1095 | 15,38,0
1096 | 13,61,0
1097 | 3,21,0
1098 | 30,23,0
1099 | 12,5,0
1100 | 9,20,0
1101 | 11,59,0
1102 | 37,39,1
1103 | 34,44,0
1104 | 12,14,0
1105 | 39,24,1
1106 | 25,6,1
1107 | 1,17,0
1108 | 22,24,0
1109 | 1,15,0
1110 | 40,85,0
1111 | 18,60,1
1112 | 6,49,0
1113 | 24,8,0
1114 | 9,26,0
1115 | 18,68,0
1116 | 39,75,0
1117 | 6,33,0
1118 | 17,63,0
1119 | 34,32,1
1120 | 34,52,2
1121 | 36,26,0
1122 | 4,15,0
1123 | 12,30,0
1124 | 4,8,2
1125 | 24,1,0
1126 | 41,104,0
1127 | 13,71,0
1128 | 41,8,0
1129 | 6,11,1
1130 | 3,18,0
1131 | 33,40,0
1132 | 6,66,0
1133 | 4,8,0
1134 | 37,6,0
1135 | 13,47,0
1136 | 30,21,0
1137 | 13,43,0
1138 | 27,7,0
1139 | 5,6,0
1140 | 13,60,1
1141 | 11,66,0
1142 | 13,28,0
1143 | 9,3,0
1144 | 25,21,0
1145 | 13,47,0
1146 | 4,1,0
1147 | 41,61,0
1148 | 37,50,0
1149 | 27,30,0
1150 | 6,53,0
1151 | 9,15,0
1152 | 22,39,0
1153 | 36,17,0
1154 | 36,21,0
1155 | 40,21,0
1156 | 6,13,0
1157 | 6,1,0
1158 | 22,58,0
1159 | 15,4,3
1160 | 41,82,0
1161 | 8,14,0
1162 | 13,44,0
1163 | 14,31,0
1164 | 41,119,1
1165 | 22,65,0
1166 | 17,13,0
1167 | 7,25,4
1168 | 17,60,0
1169 | 12,49,0
1170 | 39,33,0
1171 | 27,6,0
1172 | 39,81,0
1173 | 30,7,0
1174 | 29,25,0
1175 | 30,41,0
1176 | 32,44,0
1177 | 15,18,0
1178 | 41,57,1
1179 | 4,12,0
1180 | 30,28,0
1181 | 10,20,1
1182 | 27,8,0
1183 | 34,38,0
1184 | 41,9,0
1185 | 11,19,0
1186 | 11,44,0
1187 | 18,25,0
1188 | 15,44,0
1189 | 30,51,0
1190 | 12,46,0
1191 | 41,35,1
1192 | 30,8,0
1193 | 34,10,4
1194 | 14,14,0
1195 | 36,38,0
1196 | 33,11,0
1197 | 10,20,0
1198 | 15,8,0
1199 | 37,26,0
1200 | 12,30,0
1201 | 12,30,1
1202 | 14,17,0
1203 | 16,25,0
1204 | 13,63,0
1205 | 18,76,0
1206 | 32,15,1
1207 | 39,80,0
1208 | 40,77,0
1209 | 4,3,0
1210 | 13,80,1
1211 | 12,11,0
1212 | 7,26,0
1213 | 23,60,0
1214 | 34,44,1
1215 | 28,17,1
1216 | 37,73,1
1217 | 15,40,0
1218 | 13,20,0
1219 | 17,60,0
1220 | 33,19,0
1221 | 40,55,2
1222 | 24,24,0
1223 | 41,54,0
1224 | 34,32,1
1225 | 18,14,0
1226 | 22,62,0
1227 | 9,1,0
1228 | 7,39,0
1229 | 29,4,0
1230 | 38,12,0
1231 | 41,65,1
1232 | 37,27,0
1233 | 13,2,0
1234 | 20,55,1
1235 | 11,43,0
1236 | 41,82,0
1237 | 34,10,1
1238 | 36,34,0
1239 | 33,46,0
1240 | 10,44,1
1241 | 1,0,0
1242 | 26,13,0
1243 | 16,4,0
1244 | 34,44,1
1245 | 33,59,0
1246 | 17,7,0
1247 | 18,53,3
1248 | 15,46,0
1249 | 21,14,6
1250 | 7,38,0
1251 | 12,19,0
1252 | 32,6,0
1253 | 24,26,0
1254 | 19,16,1
1255 | 29,9,0
1256 | 6,46,2
1257 | 11,58,0
1258 | 11,32,0
1259 | 18,5,1
1260 | 35,2,0
1261 | 15,79,0
1262 | 36,24,0
1263 | 9,24,0
1264 | 39,72,0
1265 | 4,23,0
1266 | 12,50,0
1267 | 8,10,0
1268 | 1,44,0
1269 | 36,41,0
1270 | 9,22,0
1271 | 8,9,0
1272 | 8,14,2
1273 | 15,4,0
1274 | 6,34,0
1275 | 39,9,0
1276 | 19,15,0
1277 | 34,11,0
1278 | 36,24,0
1279 | 41,97,0
1280 | 22,88,0
1281 | 8,36,0
1282 | 33,13,0
1283 | 37,18,0
1284 | 15,70,0
1285 | 13,10,2
1286 | 12,37,0
1287 | 41,72,0
1288 | 15,69,0
1289 | 16,1,0
1290 | 40,84,0
1291 | 1,26,0
1292 | 29,22,0
1293 | 15,82,0
1294 | 24,25,0
1295 | 13,74,0
1296 | 12,32,0
1297 | 22,46,0
1298 | 34,36,0
1299 | 11,24,0
1300 | 12,19,0
1301 | 41,61,0
1302 | 36,10,0
1303 | 17,33,0
1304 | 24,29,0
1305 | 41,17,0
1306 | 37,73,0
1307 | 40,68,1
1308 | 21,52,0
1309 | 19,12,1
1310 | 41,54,0
1311 | 36,3,0
1312 | 6,46,3
1313 | 18,12,0
1314 | 2,0,0
1315 | 8,34,0
1316 | 34,22,0
1317 | 23,17,0
1318 | 4,6,0
1319 | 36,20,0
1320 | 8,16,0
1321 | 30,55,2
1322 | 14,1,0
1323 | 27,5,0
1324 | 14,29,1
1325 | 24,14,0
1326 | 39,72,0
1327 | 14,11,0
1328 | 15,16,0
1329 | 15,71,0
1330 | 41,109,0
1331 | 6,25,0
1332 | 17,48,0
1333 | 9,1,2
1334 | 37,1,0
1335 | 36,3,2
1336 | 15,19,0
1337 | 15,38,1
1338 | 41,82,0
1339 | 12,5,0
1340 | 16,25,0
1341 | 20,61,0
1342 | 30,21,0
1343 | 2,7,0
1344 | 30,53,0
1345 | 10,40,1
1346 | 14,16,0
1347 | 9,11,0
1348 | 17,73,0
1349 | 11,18,0
1350 | 16,7,0
1351 | 7,2,0
1352 | 8,41,0
1353 | 27,8,0
1354 | 24,28,0
1355 | 5,13,0
1356 | 14,45,0
1357 | 2,24,0
1358 | 6,46,1
1359 | 14,29,0
1360 | 27,13,0
1361 | 11,52,0
1362 | 11,66,1
1363 | 1,28,0
1364 | 32,42,0
1365 | 41,112,0
1366 | 11,5,1
1367 | 24,32,0
1368 | 8,19,3
1369 | 3,17,0
1370 | 12,42,0
1371 | 39,26,0
1372 | 38,15,0
1373 | 8,7,1
1374 | 29,13,0
1375 | 34,31,1
1376 | 37,99,0
1377 | 40,28,0
1378 | 23,37,0
1379 | 25,24,0
1380 | 27,25,0
1381 | 7,29,0
1382 | 22,51,0
1383 | 10,49,1
1384 | 39,47,0
1385 | 1,58,0
1386 | 41,119,1
1387 | 37,35,0
1388 | 29,9,2
1389 | 13,60,1
1390 | 41,91,0
1391 | 38,10,0
1392 | 18,35,0
1393 | 33,13,0
1394 | 14,34,2
1395 | 34,49,1
1396 | 33,74,1
1397 | 30,35,0
1398 | 39,31,1
1399 | 21,52,0
1400 | 39,59,1
1401 | 23,12,0
1402 | 15,72,0
1403 | 19,9,0
1404 | 37,83,0
1405 | 35,22,1
1406 | 14,38,0
1407 | 24,6,0
1408 | 11,63,0
1409 | 37,37,0
1410 | 14,15,2
1411 | 14,2,1
1412 | 25,11,0
1413 | 37,61,0
1414 | 34,45,1
1415 | 41,76,3
1416 | 21,3,0
1417 | 27,10,0
1418 | 29,27,0
1419 | 15,64,0
1420 | 41,57,0
1421 | 7,50,0
1422 | 37,27,0
1423 | 41,85,0
1424 | 3,0,0
1425 | 15,82,0
1426 | 6,15,0
1427 | 41,78,0
1428 | 32,27,0
1429 | 19,28,0
1430 | 30,34,0
1431 | 1,56,0
1432 | 2,14,0
1433 | 6,39,0
1434 | 14,12,0
1435 | 28,28,0
1436 | 6,37,0
1437 | 14,35,0
1438 | 23,20,0
1439 | 17,94,0
1440 | 34,42,0
1441 | 16,16,0
1442 | 39,46,0
1443 | 13,37,0
1444 | 10,32,0
1445 | 8,22,0
1446 | 8,23,0
1447 | 30,33,0
1448 | 40,29,0
1449 | 13,55,0
1450 | 1,44,0
1451 | 15,56,0
1452 | 21,30,0
1453 | 29,0,0
1454 | 8,33,0
1455 | 13,6,0
1456 | 26,24,0
1457 | 41,47,1
1458 | 2,15,0
1459 | 20,36,0
1460 | 14,27,0
1461 | 16,39,0
1462 | 15,53,0
1463 | 4,1,4
1464 | 16,36,0
1465 | 35,21,0
1466 | 8,19,3
1467 | 22,40,0
1468 | 38,4,0
1469 | 15,10,0
1470 | 41,61,0
1471 | 9,30,0
1472 | 20,36,0
1473 | 1,10,3
1474 | 6,57,0
1475 | 14,20,0
1476 | 14,15,0
1477 | 38,9,0
1478 | 14,30,0
1479 | 37,22,0
1480 | 14,0,0
1481 | 13,30,1
1482 | 7,22,0
1483 | 14,29,2
1484 | 13,26,0
1485 | 35,11,2
1486 | 25,12,0
1487 | 6,26,0
1488 | 6,53,0
1489 | 13,72,0
1490 | 16,12,0
1491 | 17,61,0
1492 | 8,14,0
1493 | 11,69,0
1494 | 21,23,0
1495 | 6,9,0
1496 | 41,88,0
1497 | 21,35,0
1498 | 10,17,0
1499 | 6,17,0
1500 | 30,17,0
1501 | 33,70,0
1502 | 39,34,0
1503 | 13,47,0
1504 | 11,58,0
1505 | 6,48,0
1506 | 37,14,0
1507 | 6,66,0
1508 | 33,20,0
1509 | 13,53,0
1510 | 41,31,0
1511 | 15,51,0
1512 | 35,16,0
1513 | 13,47,0
1514 | 37,1,1
1515 | 33,15,0
1516 | 27,20,0
1517 | 4,10,3
1518 | 30,27,0
1519 | 4,21,3
1520 | 12,52,0
1521 | 14,42,0
1522 | 3,6,0
1523 | 34,34,0
1524 | 22,28,0
1525 | 26,3,1
1526 | 7,39,0
1527 | 12,32,0
1528 | 7,63,0
1529 | 15,29,0
1530 | 30,59,0
1531 | 10,44,0
1532 | 30,39,0
1533 | 6,48,0
1534 | 22,12,0
1535 | 4,15,0
1536 | 12,17,0
1537 | 6,9,1
1538 | 10,46,1
1539 | 4,20,0
1540 | 24,25,0
1541 | 30,39,0
1542 | 38,5,0
1543 | 13,11,0
1544 | 24,22,0
1545 | 33,59,0
1546 | 35,5,4
1547 | 17,2,0
1548 | 41,17,0
1549 | 33,67,0
1550 | 17,62,2
1551 | 39,24,1
1552 | 9,1,0
1553 | 41,15,0
1554 | 22,12,0
1555 | 41,47,2
1556 | 3,5,0
1557 | 34,32,1
1558 | 16,20,0
1559 | 23,27,0
1560 | 13,74,1
1561 | 34,31,1
1562 | 41,59,0
1563 | 8,33,0
1564 | 28,27,0
1565 | 13,64,0
1566 | 12,25,1
1567 | 17,32,1
1568 | 7,41,0
1569 | 6,34,0
1570 | 21,27,0
1571 | 28,10,0
1572 | 37,15,0
1573 | 13,69,1
1574 | 18,67,0
1575 | 12,1,0
1576 | 9,21,0
1577 | 35,6,0
1578 | 2,19,1
1579 | 15,30,0
1580 | 32,33,0
1581 | 14,38,0
1582 | 24,10,0
1583 | 17,82,0
1584 | 4,17,0
1585 | 3,1,0
1586 | 3,13,0
1587 | 8,34,1
1588 | 39,45,1
1589 | 21,5,0
1590 | 11,29,2
1591 | 6,62,2
1592 | 17,86,0
1593 | 38,9,0
1594 | 27,4,0
1595 | 38,10,0
1596 | 6,22,0
1597 | 41,11,0
1598 | 37,74,1
1599 | 14,18,0
1600 | 36,32,0
1601 | 12,10,0
1602 | 29,32,0
1603 | 34,5,0
1604 | 6,37,0
1605 | 13,2,0
1606 | 41,49,0
1607 | 17,67,0
1608 | 9,12,0
1609 | 9,10,0
1610 | 13,77,0
1611 | 41,119,1
1612 | 33,15,0
1613 | 1,44,0
1614 | 8,14,0
1615 | 12,37,0
1616 | 6,58,0
1617 | 13,9,0
1618 | 16,19,0
1619 | 27,7,0
1620 | 13,44,0
1621 | 35,21,3
1622 | 41,73,0
1623 | 37,66,0
1624 | 4,26,0
1625 | 24,24,0
1626 | 29,32,4
1627 | 33,46,0
1628 | 41,38,0
1629 | 32,30,1
1630 | 25,22,0
1631 | 18,73,0
1632 | 11,52,0
1633 | 19,15,0
1634 | 17,79,3
1635 | 37,4,0
1636 | 17,33,0
1637 |
--------------------------------------------------------------------------------