├── .gitignore
├── Dockerfile.ds
├── LICENSE
├── README.md
├── README_zh-CN.md
├── __init__.py
├── app.py
├── config
├── easyanimate_image_normal_v1.yaml
├── easyanimate_video_long_sequence_v1.yaml
└── easyanimate_video_motion_module_v1.yaml
├── datasets
└── put datasets here.txt
├── easyanimate
├── __init__.py
├── data
│ ├── bucket_sampler.py
│ ├── dataset_image.py
│ ├── dataset_image_video.py
│ └── dataset_video.py
├── models
│ ├── attention.py
│ ├── autoencoder_magvit.py
│ ├── motion_module.py
│ ├── patch.py
│ ├── transformer2d.py
│ └── transformer3d.py
├── pipeline
│ ├── pipeline_easyanimate.py
│ ├── pipeline_easyanimate_inpaint.py
│ └── pipeline_pixart_magvit.py
├── ui
│ └── ui.py
└── utils
│ ├── IDDIM.py
│ ├── __init__.py
│ ├── diffusion_utils.py
│ ├── gaussian_diffusion.py
│ ├── lora_utils.py
│ ├── respace.py
│ └── utils.py
├── models
└── put models here.txt
├── nodes.py
├── predict_t2i.py
├── predict_t2v.py
├── requirements.txt
├── scripts
├── extra_motion_module.py
├── train_t2i.py
├── train_t2i.sh
├── train_t2i_lora.py
├── train_t2i_lora.sh
├── train_t2iv.py
├── train_t2iv.sh
├── train_t2v.py
├── train_t2v.sh
├── train_t2v_lora.py
└── train_t2v_lora.sh
├── wf.json
└── wf.png
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | models*
3 | output*
4 | samples*
5 | __pycache__/
6 | *.py[cod]
7 | *$py.class
8 |
9 | # C extensions
10 | *.so
11 |
12 | # Distribution / packaging
13 | .Python
14 | build/
15 | develop-eggs/
16 | dist/
17 | downloads/
18 | eggs/
19 | .eggs/
20 | lib/
21 | lib64/
22 | parts/
23 | sdist/
24 | var/
25 | wheels/
26 | share/python-wheels/
27 | *.egg-info/
28 | .installed.cfg
29 | *.egg
30 | MANIFEST
31 |
32 | # PyInstaller
33 | # Usually these files are written by a python script from a template
34 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
35 | *.manifest
36 | *.spec
37 |
38 | # Installer logs
39 | pip-log.txt
40 | pip-delete-this-directory.txt
41 |
42 | # Unit test / coverage reports
43 | htmlcov/
44 | .tox/
45 | .nox/
46 | .coverage
47 | .coverage.*
48 | .cache
49 | nosetests.xml
50 | coverage.xml
51 | *.cover
52 | *.py,cover
53 | .hypothesis/
54 | .pytest_cache/
55 | cover/
56 |
57 | # Translations
58 | *.mo
59 | *.pot
60 |
61 | # Django stuff:
62 | *.log
63 | local_settings.py
64 | db.sqlite3
65 | db.sqlite3-journal
66 |
67 | # Flask stuff:
68 | instance/
69 | .webassets-cache
70 |
71 | # Scrapy stuff:
72 | .scrapy
73 |
74 | # Sphinx documentation
75 | docs/_build/
76 |
77 | # PyBuilder
78 | .pybuilder/
79 | target/
80 |
81 | # Jupyter Notebook
82 | .ipynb_checkpoints
83 |
84 | # IPython
85 | profile_default/
86 | ipython_config.py
87 |
88 | # pyenv
89 | # For a library or package, you might want to ignore these files since the code is
90 | # intended to run in multiple environments; otherwise, check them in:
91 | # .python-version
92 |
93 | # pipenv
94 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
95 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
96 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
97 | # install all needed dependencies.
98 | #Pipfile.lock
99 |
100 | # poetry
101 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
102 | # This is especially recommended for binary packages to ensure reproducibility, and is more
103 | # commonly ignored for libraries.
104 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
105 | #poetry.lock
106 |
107 | # pdm
108 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
109 | #pdm.lock
110 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
111 | # in version control.
112 | # https://pdm.fming.dev/#use-with-ide
113 | .pdm.toml
114 |
115 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
116 | __pypackages__/
117 |
118 | # Celery stuff
119 | celerybeat-schedule
120 | celerybeat.pid
121 |
122 | # SageMath parsed files
123 | *.sage.py
124 |
125 | # Environments
126 | .env
127 | .venv
128 | env/
129 | venv/
130 | ENV/
131 | env.bak/
132 | venv.bak/
133 |
134 | # Spyder project settings
135 | .spyderproject
136 | .spyproject
137 |
138 | # Rope project settings
139 | .ropeproject
140 |
141 | # mkdocs documentation
142 | /site
143 |
144 | # mypy
145 | .mypy_cache/
146 | .dmypy.json
147 | dmypy.json
148 |
149 | # Pyre type checker
150 | .pyre/
151 |
152 | # pytype static type analyzer
153 | .pytype/
154 |
155 | # Cython debug symbols
156 | cython_debug/
157 |
158 | # PyCharm
159 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
160 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
161 | # and can be added to the global gitignore or merged into this file. For a more nuclear
162 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
163 | #.idea/
164 |
--------------------------------------------------------------------------------
/Dockerfile.ds:
--------------------------------------------------------------------------------
1 | FROM nvidia/cuda:11.8.0-devel-ubuntu22.04
2 | ENV DEBIAN_FRONTEND noninteractive
3 |
4 | RUN rm -r /etc/apt/sources.list.d/
5 |
6 | RUN apt-get update -y && apt-get install -y \
7 | libgl1 libglib2.0-0 google-perftools \
8 | sudo wget git git-lfs vim tig pkg-config libcairo2-dev \
9 | telnet curl net-tools iputils-ping wget jq \
10 | python3-pip python-is-python3 python3.10-venv tzdata lsof && \
11 | rm -rf /var/lib/apt/lists/*
12 | RUN pip3 install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple/
13 |
14 | # add all extensions
15 | RUN apt-get update -y && apt-get install -y zip && \
16 | rm -rf /var/lib/apt/lists/*
17 | RUN pip install wandb tqdm GitPython==3.1.32 Pillow==9.5.0 setuptools --upgrade -i https://mirrors.aliyun.com/pypi/simple/
18 |
19 | # reinstall torch to keep compatible with xformers
20 | RUN pip uninstall -qy torch torchvision && \
21 | pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu118
22 | RUN pip uninstall -qy xfromers && pip install xformers==0.0.24 --index-url https://download.pytorch.org/whl/cu118
23 |
24 | # install requirements
25 | COPY ./requirements.txt /root/requirements.txt
26 | RUN pip install -r /root/requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
27 | RUN rm -rf /root/requirements.txt
28 |
29 | ENV PYTHONUNBUFFERED 1
30 | ENV NVIDIA_DISABLE_REQUIRE 1
31 |
32 | WORKDIR /root/
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # ComfyUI-EasyAnimate
2 |
3 | ## workflow
4 |
5 | [basic](https://github.com/chaojie/ComfyUI-EasyAnimate/blob/main/wf.json)
6 |
7 |  8 |
9 | ### 1、Model Weights
10 | | Name | Type | Storage Space | Url | Description |
11 | |--|--|--|--|--|
12 | | easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | ComfyUI/models/checkpoints |
13 | | PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| ComfyUI/models/diffusers (tar -xvf PixArt-XL-2-512x512.tar) |
14 |
15 | ### 2、Optional Model Weights
16 | | Name | Type | Storage Space | Url | Description |
17 | |--|--|--|--|--|
18 | | easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | ComfyUI/models/checkpoints |
19 | | easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| ComfyUI/models/checkpoints
20 |
21 | ## [EasyAnimate](https://github.com/aigc-apps/EasyAnimate)
22 |
--------------------------------------------------------------------------------
/README_zh-CN.md:
--------------------------------------------------------------------------------
1 | # EasyAnimate | 您的智能生成器。
2 | 😊 EasyAnimate是一个用于生成长视频和训练基于transformer的扩散生成器的repo。
3 |
4 | 😊 我们基于类SORA结构与DIT,使用transformer进行作为扩散器进行视频生成。为了保证良好的拓展性,我们基于motion module构建了EasyAnimate,未来我们也会尝试更多的训练方案一提高效果。
5 |
6 | 😊 Welcome!
7 |
8 | [English](./README.md) | 简体中文
9 |
10 | # 目录
11 | - [目录](#目录)
12 | - [简介](#简介)
13 | - [TODO List](#todo-list)
14 | - [Model zoo](#model-zoo)
15 | - [1、运动权重](#1运动权重)
16 | - [2、其他权重](#2其他权重)
17 | - [快速启动](#快速启动)
18 | - [1. 云使用: AliyunDSW/Docker](#1-云使用-aliyundswdocker)
19 | - [2. 本地安装: 环境检查/下载/安装](#2-本地安装-环境检查下载安装)
20 | - [如何使用](#如何使用)
21 | - [1. 生成](#1-生成)
22 | - [2. 模型训练](#2-模型训练)
23 | - [算法细节](#算法细节)
24 | - [参考文献](#参考文献)
25 | - [许可证](#许可证)
26 |
27 | # 简介
28 | EasyAnimate是一个基于transformer结构的pipeline,可用于生成AI动画、训练Diffusion Transformer的基线模型与Lora模型,我们支持从已经训练好的EasyAnimate模型直接进行预测,生成不同分辨率,6秒左右、fps12的视频(40 ~ 80帧, 未来会支持更长的视频),也支持用户训练自己的基线模型与Lora模型,进行一定的风格变换。
29 |
30 | 我们会逐渐支持从不同平台快速启动,请参阅 [快速启动](#快速启动)。
31 |
32 | 新特性:
33 | - 创建代码!现在支持 Windows 和 Linux。[ 2024.04.12 ]
34 |
35 | 这些是我们的生成结果:
36 |
37 | 我们的ui界面如下:
38 | 
39 |
40 | # TODO List
41 | - 支持更大分辨率的文视频生成模型。
42 | - 支持基于magvit的文视频生成模型。
43 | - 支持视频inpaint模型。
44 |
45 | # Model zoo
46 | ### 1、运动权重
47 | | 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
48 | |--|--|--|--|--|
49 | | easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | Training with 80 frames and fps 12 |
50 |
51 | ### 2、其他权重
52 | | 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
53 | |--|--|--|--|--|
54 | | PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| Pixart-Alpha official weights |
55 | | easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | Training with internal portrait datasets |
56 | | easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| Training with internal portrait datasets |
57 |
58 |
59 | # 生成效果
60 | 在生成风景类animation时,采样器推荐使用DPM++和Euler A。在生成人像类animation时,采样器推荐使用Euler A和Euler。
61 |
62 | 有些时候Github无法正常显示大GIF,可以通过Download GIF下载到本地查看。
63 |
64 | 使用原始的pixart checkpoint进行预测。
65 |
66 | | Base Models | Sampler | Seed | Resolution (h x w x f) | Prompt | GenerationResult | Download |
67 | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
68 | | PixArt | DPM++ | 43 | 512x512x80 | A soaring drone footage captures the majestic beauty of a coastal cliff, its red and yellow stratified rock faces rich in color and against the vibrant turquoise of the sea. Seabirds can be seen taking flight around the cliff\'s precipices. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/1-cliff.gif) |
69 | | PixArt | DPM++ | 43 | 448x640x80 | The video captures the majestic beauty of a waterfall cascading down a cliff into a serene lake. The waterfall, with its powerful flow, is the central focus of the video. The surrounding landscape is lush and green, with trees and foliage adding to the natural beauty of the scene. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/2-waterfall.gif) |
70 | | PixArt | DPM++ | 43 | 704x384x80 | A vibrant scene of a snowy mountain landscape. The sky is filled with a multitude of colorful hot air balloons, each floating at different heights, creating a dynamic and lively atmosphere. The balloons are scattered across the sky, some closer to the viewer, others further away, adding depth to the scene. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/3-snowy.gif) |
71 | | PixArt | DPM++ | 43 | 448x640x64 | The vibrant beauty of a sunflower field. The sunflowers, with their bright yellow petals and dark brown centers, are in full bloom, creating a stunning contrast against the green leaves and stems. The sunflowers are arranged in neat rows, creating a sense of order and symmetry. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/4-sunflower.gif) |
72 | | PixArt | DPM++ | 43 | 384x704x48 | A tranquil Vermont autumn, with leaves in vibrant colors of orange and red fluttering down a mountain stream. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/5-autumn.gif) |
73 | | PixArt | DPM++ | 43 | 704x384x48 | A vibrant underwater scene. A group of blue fish, with yellow fins, are swimming around a coral reef. The coral reef is a mix of brown and green, providing a natural habitat for the fish. The water is a deep blue, indicating a depth of around 30 feet. The fish are swimming in a circular pattern around the coral reef, indicating a sense of motion and activity. The overall scene is a beautiful representation of marine life. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/6-underwater.gif) |
74 | | PixArt | DPM++ | 43 | 576x448x48 | Pacific coast, carmel by the blue sea ocean and peaceful waves |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/7-coast.gif) |
75 | | PixArt | DPM++ | 43 | 576x448x80 | A snowy forest landscape with a dirt road running through it. The road is flanked by trees covered in snow, and the ground is also covered in snow. The sun is shining, creating a bright and serene atmosphere. The road appears to be empty, and there are no people or animals visible in the video. The style of the video is a natural landscape shot, with a focus on the beauty of the snowy forest and the peacefulness of the road. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/8-forest.gif) |
76 | | PixArt | DPM++ | 43 | 640x448x64 | The dynamic movement of tall, wispy grasses swaying in the wind. The sky above is filled with clouds, creating a dramatic backdrop. The sunlight pierces through the clouds, casting a warm glow on the scene. The grasses are a mix of green and brown, indicating a change in seasons. The overall style of the video is naturalistic, capturing the beauty of the landscape in a realistic manner. The focus is on the grasses and their movement, with the sky serving as a secondary element. The video does not contain any human or animal elements. | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/9-grasses.gif) |
77 | | PixArt | DPM++ | 43 | 704x384x80 | A serene night scene in a forested area. The first frame shows a tranquil lake reflecting the star-filled sky above. The second frame reveals a beautiful sunset, casting a warm glow over the landscape. The third frame showcases the night sky, filled with stars and a vibrant Milky Way galaxy. The video is a time-lapse, capturing the transition from day to night, with the lake and forest serving as a constant backdrop. The style of the video is naturalistic, emphasizing the beauty of the night sky and the peacefulness of the forest. | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/10-night.gif) |
78 | | PixArt | DPM++ | 43 | 640x448x80 | Sunset over the sea. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/11-sunset.gif) |
79 |
80 | 使用人像checkpoint进行预测。
81 |
82 | | Base Models | Sampler | Seed | Resolution (h x w x f) | Prompt | GenerationResult | Download |
83 | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
84 | | Portrait | Euler A | 43 | 448x576x80 | 1girl, 3d, black hair, brown eyes, earrings, grey background, jewelry, lips, long hair, looking at viewer, photo \\(medium\\), realistic, red lips, solo |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/1-check.gif) |
85 | | Portrait | Euler A | 43 | 448x576x80 | 1girl, bare shoulders, blurry, brown eyes, dirty, dirty face, freckles, lips, long hair, looking at viewer, realistic, sleeveless, solo, upper body | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/2-check.gif) |
86 | | Portrait | Euler A | 43 | 512x512x64 | 1girl, black hair, brown eyes, earrings, grey background, jewelry, lips, looking at viewer, mole, mole under eye, neck tattoo, nose, ponytail, realistic, shirt, simple background, solo, tattoo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/3-check.gif) |
87 | | Portrait | Euler A | 43 | 576x448x64 | 1girl, black hair, lips, looking at viewer, mole, mole under eye, mole under mouth, realistic, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/5-check.gif) |
88 |
89 | 使用人像Lora进行预测。
90 |
91 | | Base Models | Sampler | Seed | Resolution (h x w x f) | Prompt | GenerationResult | Download |
92 | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
93 | | Pixart + Lora | Euler A | 43 | 512x512x64 | 1girl, 3d, black hair, brown eyes, earrings, grey background, jewelry, lips, long hair, looking at viewer, photo \\(medium\\), realistic, red lips, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/1-lora.gif) |
94 | | Pixart + Lora | Euler A | 43 | 512x512x64 | 1girl, bare shoulders, blurry, brown eyes, dirty, dirty face, freckles, lips, long hair, looking at viewer, mole, mole on breast, mole on neck, mole under eye, mole under mouth, realistic, sleeveless, solo, upper body | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/2-lora.gif) |
95 | | Pixart + Lora | Euler A | 43 | 512x512x64 | 1girl, black hair, lips, looking at viewer, mole, mole under eye, mole under mouth, realistic, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/5-lora.gif) |
96 | | Pixart + Lora | Euler A | 43 | 512x512x80 | 1girl, bare shoulders, blurry, blurry background, blurry foreground, bokeh, brown eyes, christmas tree, closed mouth, collarbone, depth of field, earrings, jewelry, lips, long hair, looking at viewer, photo \\(medium\\), realistic, smile, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/8-lora.gif) |
97 |
98 | # 快速启动
99 | ### 1. 云使用: AliyunDSW/Docker
100 | #### a. 通过阿里云 DSW
101 | 敬请期待。
102 |
103 | #### b. 通过docker
104 | 使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令:
105 | ```
106 | # 拉取镜像
107 | docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
108 |
109 | # 进入镜像
110 | docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
111 |
112 | # clone 代码
113 | git clone https://github.com/aigc-apps/EasyAnimate.git
114 |
115 | # 进入EasyAnimate文件夹
116 | cd EasyAnimate
117 |
118 | # 下载权重
119 | mkdir models/Diffusion_Transformer
120 | mkdir models/Motion_Module
121 | mkdir models/Personalized_Model
122 |
123 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors -O models/Motion_Module/easyanimate_v1_mm.safetensors
124 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors -O models/Personalized_Model/easyanimate_portrait.safetensors
125 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors -O models/Personalized_Model/easyanimate_portrait_lora.safetensors
126 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar -O models/Diffusion_Transformer/PixArt-XL-2-512x512.tar
127 |
128 | cd models/Diffusion_Transformer/
129 | tar -xvf PixArt-XL-2-512x512.tar
130 | cd ../../
131 | ```
132 |
133 | ### 2. 本地安装: 环境检查/下载/安装
134 | #### a. 环境检查
135 | 我们已验证EasyAnimate可在以下环境中执行:
136 |
137 | Linux 的详细信息:
138 | - 操作系统 Ubuntu 20.04, CentOS
139 | - python: python3.10 & python3.11
140 | - pytorch: torch2.2.0
141 | - CUDA: 11.8
142 | - CUDNN: 8+
143 | - GPU: Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
144 |
145 | 我们需要大约 60GB 的可用磁盘空间,请检查!
146 |
147 | #### b. 权重放置
148 | 我们最好将权重按照指定路径进行放置:
149 |
150 | ```
151 | 📦 models/
152 | ├── 📂 Diffusion_Transformer/
153 | │ └── 📂 PixArt-XL-2-512x512/
154 | ├── 📂 Motion_Module/
155 | │ └── 📄 easyanimate_v1_mm.safetensors
156 | ├── 📂 Motion_Module/
157 | │ ├── 📄 easyanimate_portrait.safetensors
158 | │ └── 📄 easyanimate_portrait_lora.safetensors
159 | ```
160 |
161 | # 如何使用
162 | ### 1. 生成
163 | #### a. 视频生成
164 | ##### i、运行python文件
165 | - 步骤1:下载对应权重放入models文件夹。
166 | - 步骤2:在predict_t2v.py文件中修改prompt、neg_prompt、guidance_scale和seed。
167 | - 步骤3:运行predict_t2v.py文件,等待生成结果,结果保存在samples/easyanimate-videos文件夹中。
168 | - 步骤4:如果想结合自己训练的其他backbone与Lora,则看情况修改predict_t2v.py中的predict_t2v.py和lora_path。
169 |
170 | ##### ii、通过ui界面
171 | - 步骤1:下载对应权重放入models文件夹。
172 | - 步骤2:运行app.py文件,进入gradio页面。
173 | - 步骤3:根据页面选择生成模型,填入prompt、neg_prompt、guidance_scale和seed等,点击生成,等待生成结果,结果保存在sample文件夹中。
174 |
175 | ### 2. 模型训练
176 | #### a、训练视频生成模型
177 | ##### i、基于webvid数据集
178 | 如果使用webvid数据集进行训练,则需要首先下载webvid的数据集。
179 |
180 | 您需要以这种格式排列webvid数据集。
181 | ```
182 | 📦 project/
183 | ├── 📂 datasets/
184 | │ ├── 📂 webvid/
185 | │ ├── 📂 videos/
186 | │ │ ├── 📄 00000001.mp4
187 | │ │ ├── 📄 00000002.mp4
188 | │ │ └── 📄 .....
189 | │ └── 📄 csv_of_webvid.csv
190 | ```
191 |
192 | 然后,进入scripts/train_t2v.sh进行设置。
193 | ```
194 | export DATASET_NAME="datasets/webvid/videos/"
195 | export DATASET_META_NAME="datasets/webvid/csv_of_webvid.csv"
196 |
197 | ...
198 |
199 | train_data_format="webvid"
200 | ```
201 |
202 | 最后运行scripts/train_t2v.sh。
203 | ```sh
204 | sh scripts/train_t2v.sh
205 | ```
206 |
207 | ##### ii、基于自建数据集
208 | 如果使用内部数据集进行训练,则需要首先格式化数据集。
209 |
210 | 您需要以这种格式排列数据集。
211 | ```
212 | 📦 project/
213 | ├── 📂 datasets/
214 | │ ├── 📂 internal_datasets/
215 | │ ├── 📂 videos/
216 | │ │ ├── 📄 00000001.mp4
217 | │ │ ├── 📄 00000002.mp4
218 | │ │ └── 📄 .....
219 | │ └── 📄 json_of_internal_datasets.json
220 | ```
221 |
222 | json_of_internal_datasets.json是一个标准的json文件,如下所示:
223 | ```json
224 | [
225 | {
226 | "file_path": "videos/00000001.mp4",
227 | "text": "A group of young men in suits and sunglasses are walking down a city street.",
228 | "type": "video"
229 | },
230 | {
231 | "file_path": "videos/00000002.mp4",
232 | "text": "A notepad with a drawing of a woman on it.",
233 | "type": "video"
234 | }
235 | .....
236 | ]
237 | ```
238 | json中的file_path需要设置为相对路径。
239 |
240 | 然后,进入scripts/train_t2v.sh进行设置。
241 | ```
242 | export DATASET_NAME="datasets/internal_datasets/"
243 | export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
244 |
245 | ...
246 |
247 | train_data_format="normal"
248 | ```
249 |
250 | 最后运行scripts/train_t2v.sh。
251 | ```sh
252 | sh scripts/train_t2v.sh
253 | ```
254 |
255 | #### b、训练基础文生图模型
256 | ##### i、基于diffusers格式
257 | 数据集的格式可以设置为diffusers格式。
258 |
259 | ```
260 | 📦 project/
261 | ├── 📂 datasets/
262 | │ ├── 📂 diffusers_datasets/
263 | │ ├── 📂 train/
264 | │ │ ├── 📄 00000001.jpg
265 | │ │ ├── 📄 00000002.jpg
266 | │ │ └── 📄 .....
267 | │ └── 📄 metadata.jsonl
268 | ```
269 |
270 | 然后,进入scripts/train_t2i.sh进行设置。
271 | ```
272 | export DATASET_NAME="datasets/diffusers_datasets/"
273 |
274 | ...
275 |
276 | train_data_format="diffusers"
277 | ```
278 |
279 | 最后运行scripts/train_t2i.sh。
280 | ```sh
281 | sh scripts/train_t2i.sh
282 | ```
283 | ##### ii、基于自建数据集
284 | 如果使用自建数据集进行训练,则需要首先格式化数据集。
285 |
286 | 您需要以这种格式排列数据集。
287 | ```
288 | 📦 project/
289 | ├── 📂 datasets/
290 | │ ├── 📂 internal_datasets/
291 | │ ├── 📂 train/
292 | │ │ ├── 📄 00000001.jpg
293 | │ │ ├── 📄 00000002.jpg
294 | │ │ └── 📄 .....
295 | │ └── 📄 json_of_internal_datasets.json
296 | ```
297 |
298 | json_of_internal_datasets.json是一个标准的json文件,如下所示:
299 | ```json
300 | [
301 | {
302 | "file_path": "train/00000001.jpg",
303 | "text": "A group of young men in suits and sunglasses are walking down a city street.",
304 | "type": "image"
305 | },
306 | {
307 | "file_path": "train/00000002.jpg",
308 | "text": "A notepad with a drawing of a woman on it.",
309 | "type": "image"
310 | }
311 | .....
312 | ]
313 | ```
314 | json中的file_path需要设置为相对路径。
315 |
316 | 然后,进入scripts/train_t2i.sh进行设置。
317 | ```
318 | export DATASET_NAME="datasets/internal_datasets/"
319 | export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
320 |
321 | ...
322 |
323 | train_data_format="normal"
324 | ```
325 |
326 | 最后运行scripts/train_t2i.sh。
327 | ```sh
328 | sh scripts/train_t2i.sh
329 | ```
330 |
331 | #### c、训练Lora模型
332 | ##### i、基于diffusers格式
333 | 数据集的格式可以设置为diffusers格式。
334 | ```
335 | 📦 project/
336 | ├── 📂 datasets/
337 | │ ├── 📂 diffusers_datasets/
338 | │ ├── 📂 train/
339 | │ │ ├── 📄 00000001.jpg
340 | │ │ ├── 📄 00000002.jpg
341 | │ │ └── 📄 .....
342 | │ └── 📄 metadata.jsonl
343 | ```
344 |
345 | 然后,进入scripts/train_lora.sh进行设置。
346 | ```
347 | export DATASET_NAME="datasets/diffusers_datasets/"
348 |
349 | ...
350 |
351 | train_data_format="diffusers"
352 | ```
353 |
354 | 最后运行scripts/train_lora.sh。
355 | ```sh
356 | sh scripts/train_lora.sh
357 | ```
358 |
359 | ##### ii、基于自建数据集
360 | 如果使用自建数据集进行训练,则需要首先格式化数据集。
361 |
362 | 您需要以这种格式排列数据集。
363 | ```
364 | 📦 project/
365 | ├── 📂 datasets/
366 | │ ├── 📂 internal_datasets/
367 | │ ├── 📂 train/
368 | │ │ ├── 📄 00000001.jpg
369 | │ │ ├── 📄 00000002.jpg
370 | │ │ └── 📄 .....
371 | │ └── 📄 json_of_internal_datasets.json
372 | ```
373 |
374 | json_of_internal_datasets.json是一个标准的json文件,如下所示:
375 | ```json
376 | [
377 | {
378 | "file_path": "train/00000001.jpg",
379 | "text": "A group of young men in suits and sunglasses are walking down a city street.",
380 | "type": "image"
381 | },
382 | {
383 | "file_path": "train/00000002.jpg",
384 | "text": "A notepad with a drawing of a woman on it.",
385 | "type": "image"
386 | }
387 | .....
388 | ]
389 | ```
390 | json中的file_path需要设置为相对路径。
391 |
392 | 然后,进入scripts/train_lora.sh进行设置。
393 | ```
394 | export DATASET_NAME="datasets/internal_datasets/"
395 | export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
396 |
397 | ...
398 |
399 | train_data_format="normal"
400 | ```
401 |
402 | 最后运行scripts/train_lora.sh。
403 | ```sh
404 | sh scripts/train_lora.sh
405 | ```
406 | # 算法细节
407 | 我们使用了[PixArt-alpha](https://github.com/PixArt-alpha/PixArt-alpha)作为基础模型,并在此基础上引入额外的运动模块(motion module)来将DiT模型从2D图像生成扩展到3D视频生成上来。其框架图如下:
408 |
409 |
410 |
411 |
8 |
9 | ### 1、Model Weights
10 | | Name | Type | Storage Space | Url | Description |
11 | |--|--|--|--|--|
12 | | easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | ComfyUI/models/checkpoints |
13 | | PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| ComfyUI/models/diffusers (tar -xvf PixArt-XL-2-512x512.tar) |
14 |
15 | ### 2、Optional Model Weights
16 | | Name | Type | Storage Space | Url | Description |
17 | |--|--|--|--|--|
18 | | easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | ComfyUI/models/checkpoints |
19 | | easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| ComfyUI/models/checkpoints
20 |
21 | ## [EasyAnimate](https://github.com/aigc-apps/EasyAnimate)
22 |
--------------------------------------------------------------------------------
/README_zh-CN.md:
--------------------------------------------------------------------------------
1 | # EasyAnimate | 您的智能生成器。
2 | 😊 EasyAnimate是一个用于生成长视频和训练基于transformer的扩散生成器的repo。
3 |
4 | 😊 我们基于类SORA结构与DIT,使用transformer进行作为扩散器进行视频生成。为了保证良好的拓展性,我们基于motion module构建了EasyAnimate,未来我们也会尝试更多的训练方案一提高效果。
5 |
6 | 😊 Welcome!
7 |
8 | [English](./README.md) | 简体中文
9 |
10 | # 目录
11 | - [目录](#目录)
12 | - [简介](#简介)
13 | - [TODO List](#todo-list)
14 | - [Model zoo](#model-zoo)
15 | - [1、运动权重](#1运动权重)
16 | - [2、其他权重](#2其他权重)
17 | - [快速启动](#快速启动)
18 | - [1. 云使用: AliyunDSW/Docker](#1-云使用-aliyundswdocker)
19 | - [2. 本地安装: 环境检查/下载/安装](#2-本地安装-环境检查下载安装)
20 | - [如何使用](#如何使用)
21 | - [1. 生成](#1-生成)
22 | - [2. 模型训练](#2-模型训练)
23 | - [算法细节](#算法细节)
24 | - [参考文献](#参考文献)
25 | - [许可证](#许可证)
26 |
27 | # 简介
28 | EasyAnimate是一个基于transformer结构的pipeline,可用于生成AI动画、训练Diffusion Transformer的基线模型与Lora模型,我们支持从已经训练好的EasyAnimate模型直接进行预测,生成不同分辨率,6秒左右、fps12的视频(40 ~ 80帧, 未来会支持更长的视频),也支持用户训练自己的基线模型与Lora模型,进行一定的风格变换。
29 |
30 | 我们会逐渐支持从不同平台快速启动,请参阅 [快速启动](#快速启动)。
31 |
32 | 新特性:
33 | - 创建代码!现在支持 Windows 和 Linux。[ 2024.04.12 ]
34 |
35 | 这些是我们的生成结果:
36 |
37 | 我们的ui界面如下:
38 | 
39 |
40 | # TODO List
41 | - 支持更大分辨率的文视频生成模型。
42 | - 支持基于magvit的文视频生成模型。
43 | - 支持视频inpaint模型。
44 |
45 | # Model zoo
46 | ### 1、运动权重
47 | | 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
48 | |--|--|--|--|--|
49 | | easyanimate_v1_mm.safetensors | Motion Module | 4.1GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors) | Training with 80 frames and fps 12 |
50 |
51 | ### 2、其他权重
52 | | 名称 | 种类 | 存储空间 | 下载地址 | 描述 |
53 | |--|--|--|--|--|
54 | | PixArt-XL-2-512x512.tar | Pixart | 11.4GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar)| Pixart-Alpha official weights |
55 | | easyanimate_portrait.safetensors | Checkpoint of Pixart | 2.3GB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors) | Training with internal portrait datasets |
56 | | easyanimate_portrait_lora.safetensors | Lora of Pixart | 654.0MB | [download](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors)| Training with internal portrait datasets |
57 |
58 |
59 | # 生成效果
60 | 在生成风景类animation时,采样器推荐使用DPM++和Euler A。在生成人像类animation时,采样器推荐使用Euler A和Euler。
61 |
62 | 有些时候Github无法正常显示大GIF,可以通过Download GIF下载到本地查看。
63 |
64 | 使用原始的pixart checkpoint进行预测。
65 |
66 | | Base Models | Sampler | Seed | Resolution (h x w x f) | Prompt | GenerationResult | Download |
67 | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
68 | | PixArt | DPM++ | 43 | 512x512x80 | A soaring drone footage captures the majestic beauty of a coastal cliff, its red and yellow stratified rock faces rich in color and against the vibrant turquoise of the sea. Seabirds can be seen taking flight around the cliff\'s precipices. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/1-cliff.gif) |
69 | | PixArt | DPM++ | 43 | 448x640x80 | The video captures the majestic beauty of a waterfall cascading down a cliff into a serene lake. The waterfall, with its powerful flow, is the central focus of the video. The surrounding landscape is lush and green, with trees and foliage adding to the natural beauty of the scene. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/2-waterfall.gif) |
70 | | PixArt | DPM++ | 43 | 704x384x80 | A vibrant scene of a snowy mountain landscape. The sky is filled with a multitude of colorful hot air balloons, each floating at different heights, creating a dynamic and lively atmosphere. The balloons are scattered across the sky, some closer to the viewer, others further away, adding depth to the scene. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/3-snowy.gif) |
71 | | PixArt | DPM++ | 43 | 448x640x64 | The vibrant beauty of a sunflower field. The sunflowers, with their bright yellow petals and dark brown centers, are in full bloom, creating a stunning contrast against the green leaves and stems. The sunflowers are arranged in neat rows, creating a sense of order and symmetry. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/4-sunflower.gif) |
72 | | PixArt | DPM++ | 43 | 384x704x48 | A tranquil Vermont autumn, with leaves in vibrant colors of orange and red fluttering down a mountain stream. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/5-autumn.gif) |
73 | | PixArt | DPM++ | 43 | 704x384x48 | A vibrant underwater scene. A group of blue fish, with yellow fins, are swimming around a coral reef. The coral reef is a mix of brown and green, providing a natural habitat for the fish. The water is a deep blue, indicating a depth of around 30 feet. The fish are swimming in a circular pattern around the coral reef, indicating a sense of motion and activity. The overall scene is a beautiful representation of marine life. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/6-underwater.gif) |
74 | | PixArt | DPM++ | 43 | 576x448x48 | Pacific coast, carmel by the blue sea ocean and peaceful waves |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/7-coast.gif) |
75 | | PixArt | DPM++ | 43 | 576x448x80 | A snowy forest landscape with a dirt road running through it. The road is flanked by trees covered in snow, and the ground is also covered in snow. The sun is shining, creating a bright and serene atmosphere. The road appears to be empty, and there are no people or animals visible in the video. The style of the video is a natural landscape shot, with a focus on the beauty of the snowy forest and the peacefulness of the road. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/8-forest.gif) |
76 | | PixArt | DPM++ | 43 | 640x448x64 | The dynamic movement of tall, wispy grasses swaying in the wind. The sky above is filled with clouds, creating a dramatic backdrop. The sunlight pierces through the clouds, casting a warm glow on the scene. The grasses are a mix of green and brown, indicating a change in seasons. The overall style of the video is naturalistic, capturing the beauty of the landscape in a realistic manner. The focus is on the grasses and their movement, with the sky serving as a secondary element. The video does not contain any human or animal elements. | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/9-grasses.gif) |
77 | | PixArt | DPM++ | 43 | 704x384x80 | A serene night scene in a forested area. The first frame shows a tranquil lake reflecting the star-filled sky above. The second frame reveals a beautiful sunset, casting a warm glow over the landscape. The third frame showcases the night sky, filled with stars and a vibrant Milky Way galaxy. The video is a time-lapse, capturing the transition from day to night, with the lake and forest serving as a constant backdrop. The style of the video is naturalistic, emphasizing the beauty of the night sky and the peacefulness of the forest. | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/10-night.gif) |
78 | | PixArt | DPM++ | 43 | 640x448x80 | Sunset over the sea. |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/11-sunset.gif) |
79 |
80 | 使用人像checkpoint进行预测。
81 |
82 | | Base Models | Sampler | Seed | Resolution (h x w x f) | Prompt | GenerationResult | Download |
83 | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
84 | | Portrait | Euler A | 43 | 448x576x80 | 1girl, 3d, black hair, brown eyes, earrings, grey background, jewelry, lips, long hair, looking at viewer, photo \\(medium\\), realistic, red lips, solo |  | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/1-check.gif) |
85 | | Portrait | Euler A | 43 | 448x576x80 | 1girl, bare shoulders, blurry, brown eyes, dirty, dirty face, freckles, lips, long hair, looking at viewer, realistic, sleeveless, solo, upper body | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/2-check.gif) |
86 | | Portrait | Euler A | 43 | 512x512x64 | 1girl, black hair, brown eyes, earrings, grey background, jewelry, lips, looking at viewer, mole, mole under eye, neck tattoo, nose, ponytail, realistic, shirt, simple background, solo, tattoo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/3-check.gif) |
87 | | Portrait | Euler A | 43 | 576x448x64 | 1girl, black hair, lips, looking at viewer, mole, mole under eye, mole under mouth, realistic, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/5-check.gif) |
88 |
89 | 使用人像Lora进行预测。
90 |
91 | | Base Models | Sampler | Seed | Resolution (h x w x f) | Prompt | GenerationResult | Download |
92 | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
93 | | Pixart + Lora | Euler A | 43 | 512x512x64 | 1girl, 3d, black hair, brown eyes, earrings, grey background, jewelry, lips, long hair, looking at viewer, photo \\(medium\\), realistic, red lips, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/1-lora.gif) |
94 | | Pixart + Lora | Euler A | 43 | 512x512x64 | 1girl, bare shoulders, blurry, brown eyes, dirty, dirty face, freckles, lips, long hair, looking at viewer, mole, mole on breast, mole on neck, mole under eye, mole under mouth, realistic, sleeveless, solo, upper body | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/2-lora.gif) |
95 | | Pixart + Lora | Euler A | 43 | 512x512x64 | 1girl, black hair, lips, looking at viewer, mole, mole under eye, mole under mouth, realistic, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/5-lora.gif) |
96 | | Pixart + Lora | Euler A | 43 | 512x512x80 | 1girl, bare shoulders, blurry, blurry background, blurry foreground, bokeh, brown eyes, christmas tree, closed mouth, collarbone, depth of field, earrings, jewelry, lips, long hair, looking at viewer, photo \\(medium\\), realistic, smile, solo | | [Download GIF](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/8-lora.gif) |
97 |
98 | # 快速启动
99 | ### 1. 云使用: AliyunDSW/Docker
100 | #### a. 通过阿里云 DSW
101 | 敬请期待。
102 |
103 | #### b. 通过docker
104 | 使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令:
105 | ```
106 | # 拉取镜像
107 | docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
108 |
109 | # 进入镜像
110 | docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
111 |
112 | # clone 代码
113 | git clone https://github.com/aigc-apps/EasyAnimate.git
114 |
115 | # 进入EasyAnimate文件夹
116 | cd EasyAnimate
117 |
118 | # 下载权重
119 | mkdir models/Diffusion_Transformer
120 | mkdir models/Motion_Module
121 | mkdir models/Personalized_Model
122 |
123 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Motion_Module/easyanimate_v1_mm.safetensors -O models/Motion_Module/easyanimate_v1_mm.safetensors
124 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait.safetensors -O models/Personalized_Model/easyanimate_portrait.safetensors
125 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Personalized_Model/easyanimate_portrait_lora.safetensors -O models/Personalized_Model/easyanimate_portrait_lora.safetensors
126 | wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/PixArt-XL-2-512x512.tar -O models/Diffusion_Transformer/PixArt-XL-2-512x512.tar
127 |
128 | cd models/Diffusion_Transformer/
129 | tar -xvf PixArt-XL-2-512x512.tar
130 | cd ../../
131 | ```
132 |
133 | ### 2. 本地安装: 环境检查/下载/安装
134 | #### a. 环境检查
135 | 我们已验证EasyAnimate可在以下环境中执行:
136 |
137 | Linux 的详细信息:
138 | - 操作系统 Ubuntu 20.04, CentOS
139 | - python: python3.10 & python3.11
140 | - pytorch: torch2.2.0
141 | - CUDA: 11.8
142 | - CUDNN: 8+
143 | - GPU: Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
144 |
145 | 我们需要大约 60GB 的可用磁盘空间,请检查!
146 |
147 | #### b. 权重放置
148 | 我们最好将权重按照指定路径进行放置:
149 |
150 | ```
151 | 📦 models/
152 | ├── 📂 Diffusion_Transformer/
153 | │ └── 📂 PixArt-XL-2-512x512/
154 | ├── 📂 Motion_Module/
155 | │ └── 📄 easyanimate_v1_mm.safetensors
156 | ├── 📂 Motion_Module/
157 | │ ├── 📄 easyanimate_portrait.safetensors
158 | │ └── 📄 easyanimate_portrait_lora.safetensors
159 | ```
160 |
161 | # 如何使用
162 | ### 1. 生成
163 | #### a. 视频生成
164 | ##### i、运行python文件
165 | - 步骤1:下载对应权重放入models文件夹。
166 | - 步骤2:在predict_t2v.py文件中修改prompt、neg_prompt、guidance_scale和seed。
167 | - 步骤3:运行predict_t2v.py文件,等待生成结果,结果保存在samples/easyanimate-videos文件夹中。
168 | - 步骤4:如果想结合自己训练的其他backbone与Lora,则看情况修改predict_t2v.py中的predict_t2v.py和lora_path。
169 |
170 | ##### ii、通过ui界面
171 | - 步骤1:下载对应权重放入models文件夹。
172 | - 步骤2:运行app.py文件,进入gradio页面。
173 | - 步骤3:根据页面选择生成模型,填入prompt、neg_prompt、guidance_scale和seed等,点击生成,等待生成结果,结果保存在sample文件夹中。
174 |
175 | ### 2. 模型训练
176 | #### a、训练视频生成模型
177 | ##### i、基于webvid数据集
178 | 如果使用webvid数据集进行训练,则需要首先下载webvid的数据集。
179 |
180 | 您需要以这种格式排列webvid数据集。
181 | ```
182 | 📦 project/
183 | ├── 📂 datasets/
184 | │ ├── 📂 webvid/
185 | │ ├── 📂 videos/
186 | │ │ ├── 📄 00000001.mp4
187 | │ │ ├── 📄 00000002.mp4
188 | │ │ └── 📄 .....
189 | │ └── 📄 csv_of_webvid.csv
190 | ```
191 |
192 | 然后,进入scripts/train_t2v.sh进行设置。
193 | ```
194 | export DATASET_NAME="datasets/webvid/videos/"
195 | export DATASET_META_NAME="datasets/webvid/csv_of_webvid.csv"
196 |
197 | ...
198 |
199 | train_data_format="webvid"
200 | ```
201 |
202 | 最后运行scripts/train_t2v.sh。
203 | ```sh
204 | sh scripts/train_t2v.sh
205 | ```
206 |
207 | ##### ii、基于自建数据集
208 | 如果使用内部数据集进行训练,则需要首先格式化数据集。
209 |
210 | 您需要以这种格式排列数据集。
211 | ```
212 | 📦 project/
213 | ├── 📂 datasets/
214 | │ ├── 📂 internal_datasets/
215 | │ ├── 📂 videos/
216 | │ │ ├── 📄 00000001.mp4
217 | │ │ ├── 📄 00000002.mp4
218 | │ │ └── 📄 .....
219 | │ └── 📄 json_of_internal_datasets.json
220 | ```
221 |
222 | json_of_internal_datasets.json是一个标准的json文件,如下所示:
223 | ```json
224 | [
225 | {
226 | "file_path": "videos/00000001.mp4",
227 | "text": "A group of young men in suits and sunglasses are walking down a city street.",
228 | "type": "video"
229 | },
230 | {
231 | "file_path": "videos/00000002.mp4",
232 | "text": "A notepad with a drawing of a woman on it.",
233 | "type": "video"
234 | }
235 | .....
236 | ]
237 | ```
238 | json中的file_path需要设置为相对路径。
239 |
240 | 然后,进入scripts/train_t2v.sh进行设置。
241 | ```
242 | export DATASET_NAME="datasets/internal_datasets/"
243 | export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
244 |
245 | ...
246 |
247 | train_data_format="normal"
248 | ```
249 |
250 | 最后运行scripts/train_t2v.sh。
251 | ```sh
252 | sh scripts/train_t2v.sh
253 | ```
254 |
255 | #### b、训练基础文生图模型
256 | ##### i、基于diffusers格式
257 | 数据集的格式可以设置为diffusers格式。
258 |
259 | ```
260 | 📦 project/
261 | ├── 📂 datasets/
262 | │ ├── 📂 diffusers_datasets/
263 | │ ├── 📂 train/
264 | │ │ ├── 📄 00000001.jpg
265 | │ │ ├── 📄 00000002.jpg
266 | │ │ └── 📄 .....
267 | │ └── 📄 metadata.jsonl
268 | ```
269 |
270 | 然后,进入scripts/train_t2i.sh进行设置。
271 | ```
272 | export DATASET_NAME="datasets/diffusers_datasets/"
273 |
274 | ...
275 |
276 | train_data_format="diffusers"
277 | ```
278 |
279 | 最后运行scripts/train_t2i.sh。
280 | ```sh
281 | sh scripts/train_t2i.sh
282 | ```
283 | ##### ii、基于自建数据集
284 | 如果使用自建数据集进行训练,则需要首先格式化数据集。
285 |
286 | 您需要以这种格式排列数据集。
287 | ```
288 | 📦 project/
289 | ├── 📂 datasets/
290 | │ ├── 📂 internal_datasets/
291 | │ ├── 📂 train/
292 | │ │ ├── 📄 00000001.jpg
293 | │ │ ├── 📄 00000002.jpg
294 | │ │ └── 📄 .....
295 | │ └── 📄 json_of_internal_datasets.json
296 | ```
297 |
298 | json_of_internal_datasets.json是一个标准的json文件,如下所示:
299 | ```json
300 | [
301 | {
302 | "file_path": "train/00000001.jpg",
303 | "text": "A group of young men in suits and sunglasses are walking down a city street.",
304 | "type": "image"
305 | },
306 | {
307 | "file_path": "train/00000002.jpg",
308 | "text": "A notepad with a drawing of a woman on it.",
309 | "type": "image"
310 | }
311 | .....
312 | ]
313 | ```
314 | json中的file_path需要设置为相对路径。
315 |
316 | 然后,进入scripts/train_t2i.sh进行设置。
317 | ```
318 | export DATASET_NAME="datasets/internal_datasets/"
319 | export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
320 |
321 | ...
322 |
323 | train_data_format="normal"
324 | ```
325 |
326 | 最后运行scripts/train_t2i.sh。
327 | ```sh
328 | sh scripts/train_t2i.sh
329 | ```
330 |
331 | #### c、训练Lora模型
332 | ##### i、基于diffusers格式
333 | 数据集的格式可以设置为diffusers格式。
334 | ```
335 | 📦 project/
336 | ├── 📂 datasets/
337 | │ ├── 📂 diffusers_datasets/
338 | │ ├── 📂 train/
339 | │ │ ├── 📄 00000001.jpg
340 | │ │ ├── 📄 00000002.jpg
341 | │ │ └── 📄 .....
342 | │ └── 📄 metadata.jsonl
343 | ```
344 |
345 | 然后,进入scripts/train_lora.sh进行设置。
346 | ```
347 | export DATASET_NAME="datasets/diffusers_datasets/"
348 |
349 | ...
350 |
351 | train_data_format="diffusers"
352 | ```
353 |
354 | 最后运行scripts/train_lora.sh。
355 | ```sh
356 | sh scripts/train_lora.sh
357 | ```
358 |
359 | ##### ii、基于自建数据集
360 | 如果使用自建数据集进行训练,则需要首先格式化数据集。
361 |
362 | 您需要以这种格式排列数据集。
363 | ```
364 | 📦 project/
365 | ├── 📂 datasets/
366 | │ ├── 📂 internal_datasets/
367 | │ ├── 📂 train/
368 | │ │ ├── 📄 00000001.jpg
369 | │ │ ├── 📄 00000002.jpg
370 | │ │ └── 📄 .....
371 | │ └── 📄 json_of_internal_datasets.json
372 | ```
373 |
374 | json_of_internal_datasets.json是一个标准的json文件,如下所示:
375 | ```json
376 | [
377 | {
378 | "file_path": "train/00000001.jpg",
379 | "text": "A group of young men in suits and sunglasses are walking down a city street.",
380 | "type": "image"
381 | },
382 | {
383 | "file_path": "train/00000002.jpg",
384 | "text": "A notepad with a drawing of a woman on it.",
385 | "type": "image"
386 | }
387 | .....
388 | ]
389 | ```
390 | json中的file_path需要设置为相对路径。
391 |
392 | 然后,进入scripts/train_lora.sh进行设置。
393 | ```
394 | export DATASET_NAME="datasets/internal_datasets/"
395 | export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
396 |
397 | ...
398 |
399 | train_data_format="normal"
400 | ```
401 |
402 | 最后运行scripts/train_lora.sh。
403 | ```sh
404 | sh scripts/train_lora.sh
405 | ```
406 | # 算法细节
407 | 我们使用了[PixArt-alpha](https://github.com/PixArt-alpha/PixArt-alpha)作为基础模型,并在此基础上引入额外的运动模块(motion module)来将DiT模型从2D图像生成扩展到3D视频生成上来。其框架图如下:
408 |
409 |
410 |
411 | 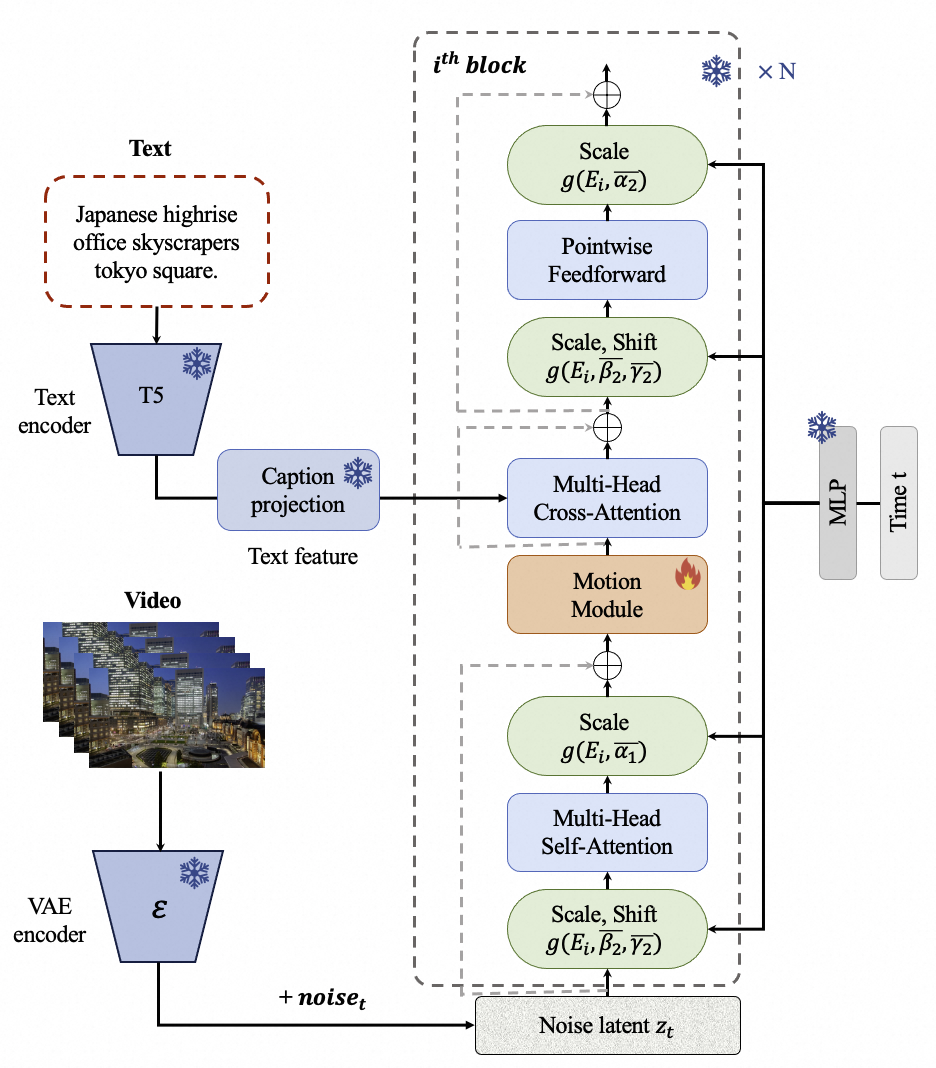 412 |
413 |
414 |
415 | 其中,Motion Module 用于捕捉时序维度的帧间关系,其结构如下:
416 |
417 |
418 |
419 |
412 |
413 |
414 |
415 | 其中,Motion Module 用于捕捉时序维度的帧间关系,其结构如下:
416 |
417 |
418 |
419 | 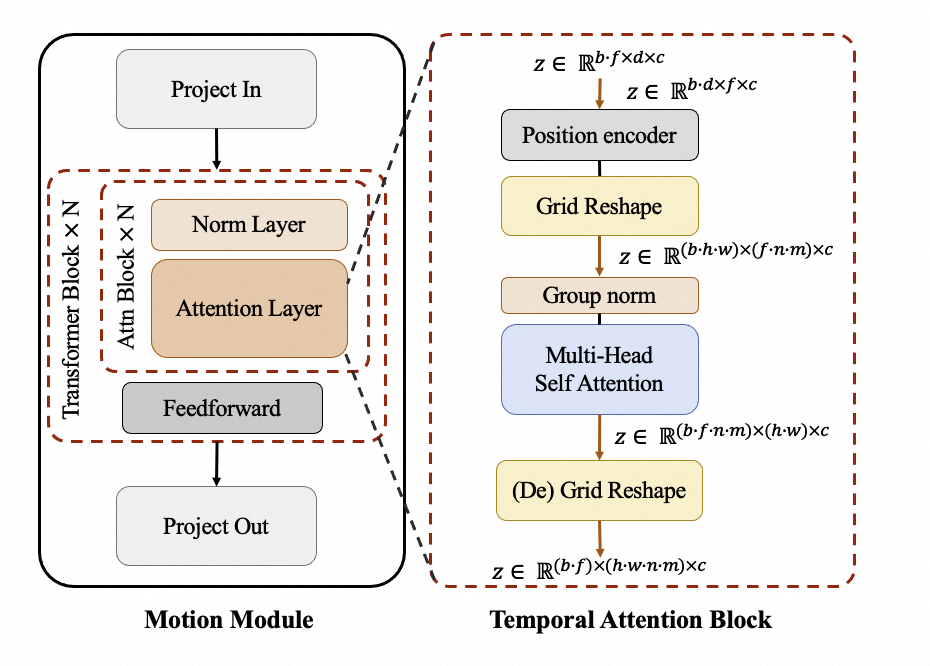 420 |
421 |
422 |
423 | 我们在时序维度上引入注意力机制来让模型学习时序信息,以进行连续视频帧的生成。同时,我们利用额外的网格计算(Grid Reshape),来扩大注意力机制的input token数目,从而更多地利用图像的空间信息以达到更好的生成效果。Motion Module 作为一个单独的模块,在推理时可以用在不同的DiT基线模型上。此外,EasyAnimate不仅支持了motion-module模块的训练,也支持了DiT基模型/LoRA模型的训练,以方便用户根据自身需要来完成自定义风格的模型训练,进而生成任意风格的视频。
424 |
425 |
426 | # 算法限制
427 | - 受
428 |
429 | # 参考文献
430 | - magvit: https://github.com/google-research/magvit
431 | - PixArt: https://github.com/PixArt-alpha/PixArt-alpha
432 | - Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
433 | - Open-Sora: https://github.com/hpcaitech/Open-Sora
434 | - Animatediff: https://github.com/guoyww/AnimateDiff
435 |
436 | # 许可证
437 | 本项目采用 [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
438 |
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
1 | from .nodes import NODE_CLASS_MAPPINGS
2 |
3 | __all__ = ['NODE_CLASS_MAPPINGS']
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | from easyanimate.ui.ui import ui
2 |
3 | if __name__ == "__main__":
4 | server_name = "0.0.0.0"
5 | demo = ui()
6 | demo.launch(server_name=server_name)
--------------------------------------------------------------------------------
/config/easyanimate_image_normal_v1.yaml:
--------------------------------------------------------------------------------
1 | noise_scheduler_kwargs:
2 | beta_start: 0.0001
3 | beta_end: 0.02
4 | beta_schedule: "linear"
5 | steps_offset: 1
6 |
7 | vae_kwargs:
8 | enable_magvit: false
--------------------------------------------------------------------------------
/config/easyanimate_video_long_sequence_v1.yaml:
--------------------------------------------------------------------------------
1 | transformer_additional_kwargs:
2 | patch_3d: false
3 | fake_3d: false
4 | basic_block_type: "selfattentiontemporal"
5 | time_position_encoding_before_transformer: true
6 |
7 | noise_scheduler_kwargs:
8 | beta_start: 0.0001
9 | beta_end: 0.02
10 | beta_schedule: "linear"
11 | steps_offset: 1
12 |
13 | vae_kwargs:
14 | enable_magvit: false
--------------------------------------------------------------------------------
/config/easyanimate_video_motion_module_v1.yaml:
--------------------------------------------------------------------------------
1 | transformer_additional_kwargs:
2 | patch_3d: false
3 | fake_3d: false
4 | basic_block_type: "motionmodule"
5 | time_position_encoding_before_transformer: false
6 | motion_module_type: "VanillaGrid"
7 |
8 | motion_module_kwargs:
9 | num_attention_heads: 8
10 | num_transformer_block: 1
11 | attention_block_types: [ "Temporal_Self", "Temporal_Self" ]
12 | temporal_position_encoding: true
13 | temporal_position_encoding_max_len: 4096
14 | temporal_attention_dim_div: 1
15 | block_size: 2
16 |
17 | noise_scheduler_kwargs:
18 | beta_start: 0.0001
19 | beta_end: 0.02
20 | beta_schedule: "linear"
21 | steps_offset: 1
22 |
23 | vae_kwargs:
24 | enable_magvit: false
--------------------------------------------------------------------------------
/datasets/put datasets here.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/datasets/put datasets here.txt
--------------------------------------------------------------------------------
/easyanimate/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/easyanimate/__init__.py
--------------------------------------------------------------------------------
/easyanimate/data/bucket_sampler.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) OpenMMLab. All rights reserved.
2 | import os
3 |
4 | import cv2
5 | import numpy as np
6 | from PIL import Image
7 | from torch.utils.data import BatchSampler, Dataset, Sampler
8 |
9 | ASPECT_RATIO_512 = {
10 | '0.25': [256.0, 1024.0], '0.26': [256.0, 992.0], '0.27': [256.0, 960.0], '0.28': [256.0, 928.0],
11 | '0.32': [288.0, 896.0], '0.33': [288.0, 864.0], '0.35': [288.0, 832.0], '0.4': [320.0, 800.0],
12 | '0.42': [320.0, 768.0], '0.48': [352.0, 736.0], '0.5': [352.0, 704.0], '0.52': [352.0, 672.0],
13 | '0.57': [384.0, 672.0], '0.6': [384.0, 640.0], '0.68': [416.0, 608.0], '0.72': [416.0, 576.0],
14 | '0.78': [448.0, 576.0], '0.82': [448.0, 544.0], '0.88': [480.0, 544.0], '0.94': [480.0, 512.0],
15 | '1.0': [512.0, 512.0], '1.07': [512.0, 480.0], '1.13': [544.0, 480.0], '1.21': [544.0, 448.0],
16 | '1.29': [576.0, 448.0], '1.38': [576.0, 416.0], '1.46': [608.0, 416.0], '1.67': [640.0, 384.0],
17 | '1.75': [672.0, 384.0], '2.0': [704.0, 352.0], '2.09': [736.0, 352.0], '2.4': [768.0, 320.0],
18 | '2.5': [800.0, 320.0], '2.89': [832.0, 288.0], '3.0': [864.0, 288.0], '3.11': [896.0, 288.0],
19 | '3.62': [928.0, 256.0], '3.75': [960.0, 256.0], '3.88': [992.0, 256.0], '4.0': [1024.0, 256.0]
20 | }
21 | ASPECT_RATIO_RANDOM_CROP_512 = {
22 | '0.42': [320.0, 768.0], '0.5': [352.0, 704.0],
23 | '0.57': [384.0, 672.0], '0.68': [416.0, 608.0], '0.78': [448.0, 576.0], '0.88': [480.0, 544.0],
24 | '0.94': [480.0, 512.0], '1.0': [512.0, 512.0], '1.07': [512.0, 480.0],
25 | '1.13': [544.0, 480.0], '1.29': [576.0, 448.0], '1.46': [608.0, 416.0], '1.75': [672.0, 384.0],
26 | '2.0': [704.0, 352.0], '2.4': [768.0, 320.0]
27 | }
28 | ASPECT_RATIO_RANDOM_CROP_PROB = [
29 | 1, 2,
30 | 4, 4, 4, 4,
31 | 8, 8, 8,
32 | 4, 4, 4, 4,
33 | 2, 1
34 | ]
35 | ASPECT_RATIO_RANDOM_CROP_PROB = np.array(ASPECT_RATIO_RANDOM_CROP_PROB) / sum(ASPECT_RATIO_RANDOM_CROP_PROB)
36 |
37 | def get_closest_ratio(height: float, width: float, ratios: dict = ASPECT_RATIO_512):
38 | aspect_ratio = height / width
39 | closest_ratio = min(ratios.keys(), key=lambda ratio: abs(float(ratio) - aspect_ratio))
40 | return ratios[closest_ratio], float(closest_ratio)
41 |
42 | def get_image_size_without_loading(path):
43 | with Image.open(path) as img:
44 | return img.size # (width, height)
45 |
46 | class AspectRatioBatchImageSampler(BatchSampler):
47 | """A sampler wrapper for grouping images with similar aspect ratio into a same batch.
48 |
49 | Args:
50 | sampler (Sampler): Base sampler.
51 | dataset (Dataset): Dataset providing data information.
52 | batch_size (int): Size of mini-batch.
53 | drop_last (bool): If ``True``, the sampler will drop the last batch if
54 | its size would be less than ``batch_size``.
55 | aspect_ratios (dict): The predefined aspect ratios.
56 | """
57 | def __init__(
58 | self,
59 | sampler: Sampler,
60 | dataset: Dataset,
61 | batch_size: int,
62 | train_folder: str = None,
63 | aspect_ratios: dict = ASPECT_RATIO_512,
64 | drop_last: bool = False,
65 | config=None,
66 | **kwargs
67 | ) -> None:
68 | if not isinstance(sampler, Sampler):
69 | raise TypeError('sampler should be an instance of ``Sampler``, '
70 | f'but got {sampler}')
71 | if not isinstance(batch_size, int) or batch_size <= 0:
72 | raise ValueError('batch_size should be a positive integer value, '
73 | f'but got batch_size={batch_size}')
74 | self.sampler = sampler
75 | self.dataset = dataset
76 | self.train_folder = train_folder
77 | self.batch_size = batch_size
78 | self.aspect_ratios = aspect_ratios
79 | self.drop_last = drop_last
80 | self.config = config
81 | # buckets for each aspect ratio
82 | self._aspect_ratio_buckets = {ratio: [] for ratio in aspect_ratios}
83 | # [str(k) for k, v in aspect_ratios]
84 | self.current_available_bucket_keys = list(aspect_ratios.keys())
85 |
86 | def __iter__(self):
87 | for idx in self.sampler:
88 | try:
89 | image_dict = self.dataset[idx]
90 |
91 | image_id, name = image_dict['file_path'], image_dict['text']
92 | if self.train_folder is None:
93 | image_dir = image_id
94 | else:
95 | image_dir = os.path.join(self.train_folder, image_id)
96 |
97 | width, height = get_image_size_without_loading(image_dir)
98 |
99 | ratio = height / width # self.dataset[idx]
100 | except Exception as e:
101 | print(e)
102 | continue
103 | # find the closest aspect ratio
104 | closest_ratio = min(self.aspect_ratios.keys(), key=lambda r: abs(float(r) - ratio))
105 | if closest_ratio not in self.current_available_bucket_keys:
106 | continue
107 | bucket = self._aspect_ratio_buckets[closest_ratio]
108 | bucket.append(idx)
109 | # yield a batch of indices in the same aspect ratio group
110 | if len(bucket) == self.batch_size:
111 | yield bucket[:]
112 | del bucket[:]
113 |
114 | class AspectRatioBatchSampler(BatchSampler):
115 | """A sampler wrapper for grouping images with similar aspect ratio into a same batch.
116 |
117 | Args:
118 | sampler (Sampler): Base sampler.
119 | dataset (Dataset): Dataset providing data information.
120 | batch_size (int): Size of mini-batch.
121 | drop_last (bool): If ``True``, the sampler will drop the last batch if
122 | its size would be less than ``batch_size``.
123 | aspect_ratios (dict): The predefined aspect ratios.
124 | """
125 | def __init__(
126 | self,
127 | sampler: Sampler,
128 | dataset: Dataset,
129 | batch_size: int,
130 | video_folder: str = None,
131 | train_data_format: str = "webvid",
132 | aspect_ratios: dict = ASPECT_RATIO_512,
133 | drop_last: bool = False,
134 | config=None,
135 | **kwargs
136 | ) -> None:
137 | if not isinstance(sampler, Sampler):
138 | raise TypeError('sampler should be an instance of ``Sampler``, '
139 | f'but got {sampler}')
140 | if not isinstance(batch_size, int) or batch_size <= 0:
141 | raise ValueError('batch_size should be a positive integer value, '
142 | f'but got batch_size={batch_size}')
143 | self.sampler = sampler
144 | self.dataset = dataset
145 | self.video_folder = video_folder
146 | self.train_data_format = train_data_format
147 | self.batch_size = batch_size
148 | self.aspect_ratios = aspect_ratios
149 | self.drop_last = drop_last
150 | self.config = config
151 | # buckets for each aspect ratio
152 | self._aspect_ratio_buckets = {ratio: [] for ratio in aspect_ratios}
153 | # [str(k) for k, v in aspect_ratios]
154 | self.current_available_bucket_keys = list(aspect_ratios.keys())
155 |
156 | def __iter__(self):
157 | for idx in self.sampler:
158 | try:
159 | video_dict = self.dataset[idx]
160 | if self.train_data_format == "normal":
161 | video_id, name = video_dict['file_path'], video_dict['text']
162 | if self.video_folder is None:
163 | video_dir = video_id
164 | else:
165 | video_dir = os.path.join(self.video_folder, video_id)
166 | else:
167 | videoid, name, page_dir = video_dict['videoid'], video_dict['name'], video_dict['page_dir']
168 | video_dir = os.path.join(self.video_folder, f"{videoid}.mp4")
169 | cap = cv2.VideoCapture(video_dir)
170 |
171 | # 获取视频尺寸
172 | width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 浮点数转换为整数
173 | height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 浮点数转换为整数
174 |
175 | ratio = height / width # self.dataset[idx]
176 | except Exception as e:
177 | print(e)
178 | continue
179 | # find the closest aspect ratio
180 | closest_ratio = min(self.aspect_ratios.keys(), key=lambda r: abs(float(r) - ratio))
181 | if closest_ratio not in self.current_available_bucket_keys:
182 | continue
183 | bucket = self._aspect_ratio_buckets[closest_ratio]
184 | bucket.append(idx)
185 | # yield a batch of indices in the same aspect ratio group
186 | if len(bucket) == self.batch_size:
187 | yield bucket[:]
188 | del bucket[:]
--------------------------------------------------------------------------------
/easyanimate/data/dataset_image.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 | import random
4 |
5 | import numpy as np
6 | import torch
7 | import torchvision.transforms as transforms
8 | from PIL import Image
9 | from torch.utils.data.dataset import Dataset
10 |
11 |
12 | class CC15M(Dataset):
13 | def __init__(
14 | self,
15 | json_path,
16 | video_folder=None,
17 | resolution=512,
18 | enable_bucket=False,
19 | ):
20 | print(f"loading annotations from {json_path} ...")
21 | self.dataset = json.load(open(json_path, 'r'))
22 | self.length = len(self.dataset)
23 | print(f"data scale: {self.length}")
24 |
25 | self.enable_bucket = enable_bucket
26 | self.video_folder = video_folder
27 |
28 | resolution = tuple(resolution) if not isinstance(resolution, int) else (resolution, resolution)
29 | self.pixel_transforms = transforms.Compose([
30 | transforms.Resize(resolution[0]),
31 | transforms.CenterCrop(resolution),
32 | transforms.ToTensor(),
33 | transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True),
34 | ])
35 |
36 | def get_batch(self, idx):
37 | video_dict = self.dataset[idx]
38 | video_id, name = video_dict['file_path'], video_dict['text']
39 |
40 | if self.video_folder is None:
41 | video_dir = video_id
42 | else:
43 | video_dir = os.path.join(self.video_folder, video_id)
44 |
45 | pixel_values = Image.open(video_dir).convert("RGB")
46 | return pixel_values, name
47 |
48 | def __len__(self):
49 | return self.length
50 |
51 | def __getitem__(self, idx):
52 | while True:
53 | try:
54 | pixel_values, name = self.get_batch(idx)
55 | break
56 | except Exception as e:
57 | print(e)
58 | idx = random.randint(0, self.length-1)
59 |
60 | if not self.enable_bucket:
61 | pixel_values = self.pixel_transforms(pixel_values)
62 | else:
63 | pixel_values = np.array(pixel_values)
64 |
65 | sample = dict(pixel_values=pixel_values, text=name)
66 | return sample
67 |
68 | if __name__ == "__main__":
69 | dataset = CC15M(
70 | csv_path="/mnt_wg/zhoumo.xjq/CCUtils/cc15m_add_index.json",
71 | resolution=512,
72 | )
73 |
74 | dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=0,)
75 | for idx, batch in enumerate(dataloader):
76 | print(batch["pixel_values"].shape, len(batch["text"]))
--------------------------------------------------------------------------------
/easyanimate/data/dataset_image_video.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import io
3 | import json
4 | import math
5 | import os
6 | import random
7 | from threading import Thread
8 |
9 | import albumentations
10 | import cv2
11 | import numpy as np
12 | import torch
13 | import torchvision.transforms as transforms
14 | from decord import VideoReader
15 | from PIL import Image
16 | from torch.utils.data import BatchSampler, Sampler
17 | from torch.utils.data.dataset import Dataset
18 |
19 |
20 | class ImageVideoSampler(BatchSampler):
21 | """A sampler wrapper for grouping images with similar aspect ratio into a same batch.
22 |
23 | Args:
24 | sampler (Sampler): Base sampler.
25 | dataset (Dataset): Dataset providing data information.
26 | batch_size (int): Size of mini-batch.
27 | drop_last (bool): If ``True``, the sampler will drop the last batch if
28 | its size would be less than ``batch_size``.
29 | aspect_ratios (dict): The predefined aspect ratios.
30 | """
31 |
32 | def __init__(self,
33 | sampler: Sampler,
34 | dataset: Dataset,
35 | batch_size: int,
36 | drop_last: bool = False
37 | ) -> None:
38 | if not isinstance(sampler, Sampler):
39 | raise TypeError('sampler should be an instance of ``Sampler``, '
40 | f'but got {sampler}')
41 | if not isinstance(batch_size, int) or batch_size <= 0:
42 | raise ValueError('batch_size should be a positive integer value, '
43 | f'but got batch_size={batch_size}')
44 | self.sampler = sampler
45 | self.dataset = dataset
46 | self.batch_size = batch_size
47 | self.drop_last = drop_last
48 |
49 | # buckets for each aspect ratio
50 | self.bucket = {'image':[], 'video':[]}
51 |
52 | def __iter__(self):
53 | for idx in self.sampler:
54 | content_type = self.dataset.dataset[idx].get('type', 'image')
55 | self.bucket[content_type].append(idx)
56 |
57 | # yield a batch of indices in the same aspect ratio group
58 | if len(self.bucket['video']) == self.batch_size:
59 | bucket = self.bucket['video']
60 | yield bucket[:]
61 | del bucket[:]
62 | elif len(self.bucket['image']) == self.batch_size:
63 | bucket = self.bucket['image']
64 | yield bucket[:]
65 | del bucket[:]
66 |
67 | class ImageVideoDataset(Dataset):
68 | def __init__(
69 | self,
70 | ann_path, data_root=None,
71 | video_sample_size=512, video_sample_stride=4, video_sample_n_frames=16,
72 | image_sample_size=512,
73 | # For Random Crop
74 | min_crop_f=0.9, max_crop_f=1,
75 | video_repeat=0,
76 | enable_bucket=False
77 | ):
78 | # Loading annotations from files
79 | print(f"loading annotations from {ann_path} ...")
80 | if ann_path.endswith('.csv'):
81 | with open(ann_path, 'r') as csvfile:
82 | dataset = list(csv.DictReader(csvfile))
83 | elif ann_path.endswith('.json'):
84 | dataset = json.load(open(ann_path))
85 |
86 | self.data_root = data_root
87 |
88 | # It's used to balance num of images and videos.
89 | self.dataset = []
90 | for data in dataset:
91 | if data.get('data_type', 'image') != 'video' or data.get('type', 'image') != 'video':
92 | self.dataset.append(data)
93 | if video_repeat > 0:
94 | for _ in range(video_repeat):
95 | for data in dataset:
96 | if data.get('data_type', 'image') == 'video' or data.get('type', 'image') == 'video':
97 | self.dataset.append(data)
98 | del dataset
99 |
100 | self.length = len(self.dataset)
101 | print(f"data scale: {self.length}")
102 | self.min_crop_f = min_crop_f
103 | self.max_crop_f = max_crop_f
104 | # TODO: enable bucket training
105 | self.enable_bucket = enable_bucket
106 |
107 | # Video params
108 | self.video_sample_stride = video_sample_stride
109 | self.video_sample_n_frames = video_sample_n_frames
110 | self.video_sample_size = tuple(video_sample_size) if not isinstance(video_sample_size, int) else (video_sample_size, video_sample_size)
111 | self.video_rescaler = albumentations.SmallestMaxSize(max_size=min(self.video_sample_size), interpolation=cv2.INTER_AREA)
112 |
113 | # Image params
114 | self.image_sample_size = tuple(image_sample_size) if not isinstance(image_sample_size, int) else (image_sample_size, image_sample_size)
115 | self.image_transforms = transforms.Compose([
116 | transforms.RandomHorizontalFlip(),
117 | transforms.Resize(min(self.image_sample_size)),
118 | transforms.CenterCrop(self.image_sample_size),
119 | transforms.ToTensor(),
120 | transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5])
121 | ])
122 |
123 | def get_batch(self, idx):
124 | data_info = self.dataset[idx % len(self.dataset)]
125 |
126 | if data_info.get('data_type', 'image')=='video' or data_info.get('type', 'image')=='video':
127 | video_path, text = data_info['file_path'], data_info['text']
128 | # Get abs path of video
129 | if self.data_root is not None:
130 | video_path = os.path.join(self.data_root, video_path)
131 |
132 | # Get video information firstly
133 | video_reader = VideoReader(video_path, num_threads=2)
134 | h, w, c = video_reader[0].shape
135 | del video_reader
136 |
137 | # Resize to bigger firstly
138 | t_h = int(self.video_sample_size[0] * 1.25 * h / min(h, w))
139 | t_w = int(self.video_sample_size[0] * 1.25 * w / min(h, w))
140 |
141 | # Get video pixels
142 | video_reader = VideoReader(video_path, width=t_w, height=t_h, num_threads=2)
143 | video_length = len(video_reader)
144 | clip_length = min(video_length, (self.video_sample_n_frames - 1) * self.video_sample_stride + 1)
145 | start_idx = random.randint(0, video_length - clip_length)
146 | batch_index = np.linspace(start_idx, start_idx + clip_length - 1, self.video_sample_n_frames, dtype=int)
147 | imgs = video_reader.get_batch(batch_index).asnumpy()
148 | del video_reader
149 | if imgs.shape[0] != self.video_sample_n_frames:
150 | raise ValueError('Video data Sampler Error')
151 |
152 | # Crop center of above videos
153 | min_side_len = min(imgs[0].shape[:2])
154 | crop_side_len = min_side_len * np.random.uniform(self.min_crop_f, self.max_crop_f, size=None)
155 | crop_side_len = int(crop_side_len)
156 | self.cropper = albumentations.RandomCrop(height=crop_side_len, width=crop_side_len)
157 | imgs = np.transpose(imgs, (1, 2, 3, 0))
158 | imgs = self.cropper(image=imgs)["image"]
159 | imgs = np.transpose(imgs, (3, 0, 1, 2))
160 | out_imgs = []
161 |
162 | # Resize to video_sample_size
163 | for img in imgs:
164 | img = self.video_rescaler(image=img)["image"]
165 | out_imgs.append(img[None, :, :, :])
166 | imgs = np.concatenate(out_imgs).transpose(0, 3, 1, 2)
167 |
168 | # Normalize to -1~1
169 | imgs = ((imgs - 127.5) / 127.5).astype(np.float32)
170 | if imgs.shape[0] != self.video_sample_n_frames:
171 | raise ValueError('video data sampler error')
172 |
173 | # Random use no text generation
174 | if random.random() < 0.1:
175 | text = ''
176 | return torch.from_numpy(imgs), text, 'video'
177 | else:
178 | image_path, text = data_info['file_path'], data_info['text']
179 | if self.data_root is not None:
180 | image_path = os.path.join(self.data_root, image_path)
181 | image = Image.open(image_path).convert('RGB')
182 | image = self.image_transforms(image).unsqueeze(0)
183 | if random.random()<0.1:
184 | text = ''
185 | return image, text, 'video'
186 |
187 | def __len__(self):
188 | return self.length
189 |
190 | def __getitem__(self, idx):
191 | while True:
192 | sample = {}
193 | def get_data(data_idx):
194 | pixel_values, name, data_type = self.get_batch(idx)
195 | sample["pixel_values"] = pixel_values
196 | sample["text"] = name
197 | sample["data_type"] = data_type
198 | sample["idx"] = idx
199 | try:
200 | t = Thread(target=get_data, args=(idx, ))
201 | t.start()
202 | t.join(5)
203 | if len(sample)>0:
204 | break
205 | except Exception as e:
206 | print(self.dataset[idx])
207 | idx = idx - 1
208 | return sample
209 |
210 | if __name__ == "__main__":
211 | dataset = ImageVideoDataset(
212 | ann_path="test.json"
213 | )
214 | dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=16)
215 | for idx, batch in enumerate(dataloader):
216 | print(batch["pixel_values"].shape, len(batch["text"]))
--------------------------------------------------------------------------------
/easyanimate/data/dataset_video.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import io
3 | import json
4 | import math
5 | import os
6 | import random
7 |
8 | import numpy as np
9 | import torch
10 | import torchvision.transforms as transforms
11 | from decord import VideoReader
12 | from einops import rearrange
13 | from torch.utils.data.dataset import Dataset
14 |
15 |
16 | def get_random_mask(shape):
17 | f, c, h, w = shape
18 |
19 | mask_index = np.random.randint(0, 4)
20 | mask = torch.zeros((f, 1, h, w), dtype=torch.uint8)
21 | if mask_index == 0:
22 | mask[1:, :, :, :] = 1
23 | elif mask_index == 1:
24 | mask_frame_index = 1
25 | mask[mask_frame_index:-mask_frame_index, :, :, :] = 1
26 | elif mask_index == 2:
27 | center_x = torch.randint(0, w, (1,)).item()
28 | center_y = torch.randint(0, h, (1,)).item()
29 | block_size_x = torch.randint(w // 4, w // 4 * 3, (1,)).item() # 方块的宽度范围
30 | block_size_y = torch.randint(h // 4, h // 4 * 3, (1,)).item() # 方块的高度范围
31 |
32 | start_x = max(center_x - block_size_x // 2, 0)
33 | end_x = min(center_x + block_size_x // 2, w)
34 | start_y = max(center_y - block_size_y // 2, 0)
35 | end_y = min(center_y + block_size_y // 2, h)
36 | mask[:, :, start_y:end_y, start_x:end_x] = 1
37 | elif mask_index == 3:
38 | center_x = torch.randint(0, w, (1,)).item()
39 | center_y = torch.randint(0, h, (1,)).item()
40 | block_size_x = torch.randint(w // 4, w // 4 * 3, (1,)).item() # 方块的宽度范围
41 | block_size_y = torch.randint(h // 4, h // 4 * 3, (1,)).item() # 方块的高度范围
42 |
43 | start_x = max(center_x - block_size_x // 2, 0)
44 | end_x = min(center_x + block_size_x // 2, w)
45 | start_y = max(center_y - block_size_y // 2, 0)
46 | end_y = min(center_y + block_size_y // 2, h)
47 |
48 | mask_frame_before = np.random.randint(0, f // 2)
49 | mask_frame_after = np.random.randint(f // 2, f)
50 | mask[mask_frame_before:mask_frame_after, :, start_y:end_y, start_x:end_x] = 1
51 | else:
52 | raise ValueError(f"The mask_index {mask_index} is not define")
53 | return mask
54 |
55 |
56 | class WebVid10M(Dataset):
57 | def __init__(
58 | self,
59 | csv_path, video_folder,
60 | sample_size=256, sample_stride=4, sample_n_frames=16,
61 | enable_bucket=False, enable_inpaint=False, is_image=False,
62 | ):
63 | print(f"loading annotations from {csv_path} ...")
64 | with open(csv_path, 'r') as csvfile:
65 | self.dataset = list(csv.DictReader(csvfile))
66 | self.length = len(self.dataset)
67 | print(f"data scale: {self.length}")
68 |
69 | self.video_folder = video_folder
70 | self.sample_stride = sample_stride
71 | self.sample_n_frames = sample_n_frames
72 | self.enable_bucket = enable_bucket
73 | self.enable_inpaint = enable_inpaint
74 | self.is_image = is_image
75 |
76 | sample_size = tuple(sample_size) if not isinstance(sample_size, int) else (sample_size, sample_size)
77 | self.pixel_transforms = transforms.Compose([
78 | transforms.Resize(sample_size[0]),
79 | transforms.CenterCrop(sample_size),
80 | transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True),
81 | ])
82 |
83 | def get_batch(self, idx):
84 | video_dict = self.dataset[idx]
85 | videoid, name, page_dir = video_dict['videoid'], video_dict['name'], video_dict['page_dir']
86 |
87 | video_dir = os.path.join(self.video_folder, f"{videoid}.mp4")
88 | video_reader = VideoReader(video_dir)
89 | video_length = len(video_reader)
90 |
91 | if not self.is_image:
92 | clip_length = min(video_length, (self.sample_n_frames - 1) * self.sample_stride + 1)
93 | start_idx = random.randint(0, video_length - clip_length)
94 | batch_index = np.linspace(start_idx, start_idx + clip_length - 1, self.sample_n_frames, dtype=int)
95 | else:
96 | batch_index = [random.randint(0, video_length - 1)]
97 |
98 | if not self.enable_bucket:
99 | pixel_values = torch.from_numpy(video_reader.get_batch(batch_index).asnumpy()).permute(0, 3, 1, 2).contiguous()
100 | pixel_values = pixel_values / 255.
101 | del video_reader
102 | else:
103 | pixel_values = video_reader.get_batch(batch_index).asnumpy()
104 |
105 | if self.is_image:
106 | pixel_values = pixel_values[0]
107 | return pixel_values, name
108 |
109 | def __len__(self):
110 | return self.length
111 |
112 | def __getitem__(self, idx):
113 | while True:
114 | try:
115 | pixel_values, name = self.get_batch(idx)
116 | break
117 |
118 | except Exception as e:
119 | print("Error info:", e)
120 | idx = random.randint(0, self.length-1)
121 |
122 | if not self.enable_bucket:
123 | pixel_values = self.pixel_transforms(pixel_values)
124 | if self.enable_inpaint:
125 | mask = get_random_mask(pixel_values.size())
126 | mask_pixel_values = pixel_values * (1 - mask) + torch.ones_like(pixel_values) * -1 * mask
127 | sample = dict(pixel_values=pixel_values, mask_pixel_values=mask_pixel_values, mask=mask, text=name)
128 | else:
129 | sample = dict(pixel_values=pixel_values, text=name)
130 | return sample
131 |
132 |
133 | class VideoDataset(Dataset):
134 | def __init__(
135 | self,
136 | json_path, video_folder=None,
137 | sample_size=256, sample_stride=4, sample_n_frames=16,
138 | enable_bucket=False, enable_inpaint=False
139 | ):
140 | print(f"loading annotations from {json_path} ...")
141 | self.dataset = json.load(open(json_path, 'r'))
142 | self.length = len(self.dataset)
143 | print(f"data scale: {self.length}")
144 |
145 | self.video_folder = video_folder
146 | self.sample_stride = sample_stride
147 | self.sample_n_frames = sample_n_frames
148 | self.enable_bucket = enable_bucket
149 | self.enable_inpaint = enable_inpaint
150 |
151 | sample_size = tuple(sample_size) if not isinstance(sample_size, int) else (sample_size, sample_size)
152 | self.pixel_transforms = transforms.Compose(
153 | [
154 | transforms.Resize(sample_size[0]),
155 | transforms.CenterCrop(sample_size),
156 | transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True),
157 | ]
158 | )
159 |
160 | def get_batch(self, idx):
161 | video_dict = self.dataset[idx]
162 | video_id, name = video_dict['file_path'], video_dict['text']
163 |
164 | if self.video_folder is None:
165 | video_dir = video_id
166 | else:
167 | video_dir = os.path.join(self.video_folder, video_id)
168 | video_reader = VideoReader(video_dir)
169 | video_length = len(video_reader)
170 |
171 | clip_length = min(video_length, (self.sample_n_frames - 1) * self.sample_stride + 1)
172 | start_idx = random.randint(0, video_length - clip_length)
173 | batch_index = np.linspace(start_idx, start_idx + clip_length - 1, self.sample_n_frames, dtype=int)
174 |
175 | if not self.enable_bucket:
176 | pixel_values = torch.from_numpy(video_reader.get_batch(batch_index).asnumpy()).permute(0, 3, 1, 2).contiguous()
177 | pixel_values = pixel_values / 255.
178 | del video_reader
179 | else:
180 | pixel_values = video_reader.get_batch(batch_index).asnumpy()
181 |
182 | return pixel_values, name
183 |
184 | def __len__(self):
185 | return self.length
186 |
187 | def __getitem__(self, idx):
188 | while True:
189 | try:
190 | pixel_values, name = self.get_batch(idx)
191 | break
192 |
193 | except Exception as e:
194 | print("Error info:", e)
195 | idx = random.randint(0, self.length-1)
196 |
197 | if not self.enable_bucket:
198 | pixel_values = self.pixel_transforms(pixel_values)
199 | if self.enable_inpaint:
200 | mask = get_random_mask(pixel_values.size())
201 | mask_pixel_values = pixel_values * (1 - mask) + torch.ones_like(pixel_values) * -1 * mask
202 | sample = dict(pixel_values=pixel_values, mask_pixel_values=mask_pixel_values, mask=mask, text=name)
203 | else:
204 | sample = dict(pixel_values=pixel_values, text=name)
205 | return sample
206 |
207 |
208 | if __name__ == "__main__":
209 | if 1:
210 | dataset = VideoDataset(
211 | json_path="/home/zhoumo.xjq/disk3/datasets/webvidval/results_2M_val.json",
212 | sample_size=256,
213 | sample_stride=4, sample_n_frames=16,
214 | )
215 |
216 | if 0:
217 | dataset = WebVid10M(
218 | csv_path="/mnt/petrelfs/guoyuwei/projects/datasets/webvid/results_2M_val.csv",
219 | video_folder="/mnt/petrelfs/guoyuwei/projects/datasets/webvid/2M_val",
220 | sample_size=256,
221 | sample_stride=4, sample_n_frames=16,
222 | is_image=False,
223 | )
224 |
225 | dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=0,)
226 | for idx, batch in enumerate(dataloader):
227 | print(batch["pixel_values"].shape, len(batch["text"]))
--------------------------------------------------------------------------------
/easyanimate/models/motion_module.py:
--------------------------------------------------------------------------------
1 | """Modified from https://github.com/guoyww/AnimateDiff/blob/main/animatediff/models/motion_module.py
2 | """
3 | import math
4 | from typing import Any, Callable, List, Optional, Tuple, Union
5 |
6 | import torch
7 | import torch.nn.functional as F
8 | from diffusers.models.attention import FeedForward
9 | from diffusers.utils.import_utils import is_xformers_available
10 | from einops import rearrange, repeat
11 | from torch import nn
12 |
13 | if is_xformers_available():
14 | import xformers
15 | import xformers.ops
16 | else:
17 | xformers = None
18 |
19 | class CrossAttention(nn.Module):
20 | r"""
21 | A cross attention layer.
22 |
23 | Parameters:
24 | query_dim (`int`): The number of channels in the query.
25 | cross_attention_dim (`int`, *optional*):
26 | The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
27 | heads (`int`, *optional*, defaults to 8): The number of heads to use for multi-head attention.
28 | dim_head (`int`, *optional*, defaults to 64): The number of channels in each head.
29 | dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
30 | bias (`bool`, *optional*, defaults to False):
31 | Set to `True` for the query, key, and value linear layers to contain a bias parameter.
32 | """
33 |
34 | def __init__(
35 | self,
36 | query_dim: int,
37 | cross_attention_dim: Optional[int] = None,
38 | heads: int = 8,
39 | dim_head: int = 64,
40 | dropout: float = 0.0,
41 | bias=False,
42 | upcast_attention: bool = False,
43 | upcast_softmax: bool = False,
44 | added_kv_proj_dim: Optional[int] = None,
45 | norm_num_groups: Optional[int] = None,
46 | ):
47 | super().__init__()
48 | inner_dim = dim_head * heads
49 | cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
50 | self.upcast_attention = upcast_attention
51 | self.upcast_softmax = upcast_softmax
52 |
53 | self.scale = dim_head**-0.5
54 |
55 | self.heads = heads
56 | # for slice_size > 0 the attention score computation
57 | # is split across the batch axis to save memory
58 | # You can set slice_size with `set_attention_slice`
59 | self.sliceable_head_dim = heads
60 | self._slice_size = None
61 | self._use_memory_efficient_attention_xformers = False
62 | self.added_kv_proj_dim = added_kv_proj_dim
63 |
64 | if norm_num_groups is not None:
65 | self.group_norm = nn.GroupNorm(num_channels=inner_dim, num_groups=norm_num_groups, eps=1e-5, affine=True)
66 | else:
67 | self.group_norm = None
68 |
69 | self.to_q = nn.Linear(query_dim, inner_dim, bias=bias)
70 | self.to_k = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
71 | self.to_v = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
72 |
73 | if self.added_kv_proj_dim is not None:
74 | self.add_k_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
75 | self.add_v_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
76 |
77 | self.to_out = nn.ModuleList([])
78 | self.to_out.append(nn.Linear(inner_dim, query_dim))
79 | self.to_out.append(nn.Dropout(dropout))
80 |
81 | def set_use_memory_efficient_attention_xformers(
82 | self, valid: bool, attention_op: Optional[Callable] = None
83 | ) -> None:
84 | self._use_memory_efficient_attention_xformers = valid
85 |
86 | def reshape_heads_to_batch_dim(self, tensor):
87 | batch_size, seq_len, dim = tensor.shape
88 | head_size = self.heads
89 | tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
90 | tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
91 | return tensor
92 |
93 | def reshape_batch_dim_to_heads(self, tensor):
94 | batch_size, seq_len, dim = tensor.shape
95 | head_size = self.heads
96 | tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
97 | tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
98 | return tensor
99 |
100 | def set_attention_slice(self, slice_size):
101 | if slice_size is not None and slice_size > self.sliceable_head_dim:
102 | raise ValueError(f"slice_size {slice_size} has to be smaller or equal to {self.sliceable_head_dim}.")
103 |
104 | self._slice_size = slice_size
105 |
106 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None):
107 | batch_size, sequence_length, _ = hidden_states.shape
108 |
109 | encoder_hidden_states = encoder_hidden_states
110 |
111 | if self.group_norm is not None:
112 | hidden_states = self.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
113 |
114 | query = self.to_q(hidden_states)
115 | dim = query.shape[-1]
116 | query = self.reshape_heads_to_batch_dim(query)
117 |
118 | if self.added_kv_proj_dim is not None:
119 | key = self.to_k(hidden_states)
120 | value = self.to_v(hidden_states)
121 | encoder_hidden_states_key_proj = self.add_k_proj(encoder_hidden_states)
122 | encoder_hidden_states_value_proj = self.add_v_proj(encoder_hidden_states)
123 |
124 | key = self.reshape_heads_to_batch_dim(key)
125 | value = self.reshape_heads_to_batch_dim(value)
126 | encoder_hidden_states_key_proj = self.reshape_heads_to_batch_dim(encoder_hidden_states_key_proj)
127 | encoder_hidden_states_value_proj = self.reshape_heads_to_batch_dim(encoder_hidden_states_value_proj)
128 |
129 | key = torch.concat([encoder_hidden_states_key_proj, key], dim=1)
130 | value = torch.concat([encoder_hidden_states_value_proj, value], dim=1)
131 | else:
132 | encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
133 | key = self.to_k(encoder_hidden_states)
134 | value = self.to_v(encoder_hidden_states)
135 |
136 | key = self.reshape_heads_to_batch_dim(key)
137 | value = self.reshape_heads_to_batch_dim(value)
138 |
139 | if attention_mask is not None:
140 | if attention_mask.shape[-1] != query.shape[1]:
141 | target_length = query.shape[1]
142 | attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
143 | attention_mask = attention_mask.repeat_interleave(self.heads, dim=0)
144 |
145 | # attention, what we cannot get enough of
146 | if self._use_memory_efficient_attention_xformers:
147 | hidden_states = self._memory_efficient_attention_xformers(query, key, value, attention_mask)
148 | # Some versions of xformers return output in fp32, cast it back to the dtype of the input
149 | hidden_states = hidden_states.to(query.dtype)
150 | else:
151 | if self._slice_size is None or query.shape[0] // self._slice_size == 1:
152 | hidden_states = self._attention(query, key, value, attention_mask)
153 | else:
154 | hidden_states = self._sliced_attention(query, key, value, sequence_length, dim, attention_mask)
155 |
156 | # linear proj
157 | hidden_states = self.to_out[0](hidden_states)
158 |
159 | # dropout
160 | hidden_states = self.to_out[1](hidden_states)
161 | return hidden_states
162 |
163 | def _attention(self, query, key, value, attention_mask=None):
164 | if self.upcast_attention:
165 | query = query.float()
166 | key = key.float()
167 |
168 | attention_scores = torch.baddbmm(
169 | torch.empty(query.shape[0], query.shape[1], key.shape[1], dtype=query.dtype, device=query.device),
170 | query,
171 | key.transpose(-1, -2),
172 | beta=0,
173 | alpha=self.scale,
174 | )
175 |
176 | if attention_mask is not None:
177 | attention_scores = attention_scores + attention_mask
178 |
179 | if self.upcast_softmax:
180 | attention_scores = attention_scores.float()
181 |
182 | attention_probs = attention_scores.softmax(dim=-1)
183 |
184 | # cast back to the original dtype
185 | attention_probs = attention_probs.to(value.dtype)
186 |
187 | # compute attention output
188 | hidden_states = torch.bmm(attention_probs, value)
189 |
190 | # reshape hidden_states
191 | hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
192 | return hidden_states
193 |
194 | def _sliced_attention(self, query, key, value, sequence_length, dim, attention_mask):
195 | batch_size_attention = query.shape[0]
196 | hidden_states = torch.zeros(
197 | (batch_size_attention, sequence_length, dim // self.heads), device=query.device, dtype=query.dtype
198 | )
199 | slice_size = self._slice_size if self._slice_size is not None else hidden_states.shape[0]
200 | for i in range(hidden_states.shape[0] // slice_size):
201 | start_idx = i * slice_size
202 | end_idx = (i + 1) * slice_size
203 |
204 | query_slice = query[start_idx:end_idx]
205 | key_slice = key[start_idx:end_idx]
206 |
207 | if self.upcast_attention:
208 | query_slice = query_slice.float()
209 | key_slice = key_slice.float()
210 |
211 | attn_slice = torch.baddbmm(
212 | torch.empty(slice_size, query.shape[1], key.shape[1], dtype=query_slice.dtype, device=query.device),
213 | query_slice,
214 | key_slice.transpose(-1, -2),
215 | beta=0,
216 | alpha=self.scale,
217 | )
218 |
219 | if attention_mask is not None:
220 | attn_slice = attn_slice + attention_mask[start_idx:end_idx]
221 |
222 | if self.upcast_softmax:
223 | attn_slice = attn_slice.float()
224 |
225 | attn_slice = attn_slice.softmax(dim=-1)
226 |
227 | # cast back to the original dtype
228 | attn_slice = attn_slice.to(value.dtype)
229 | attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
230 |
231 | hidden_states[start_idx:end_idx] = attn_slice
232 |
233 | # reshape hidden_states
234 | hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
235 | return hidden_states
236 |
237 | def _memory_efficient_attention_xformers(self, query, key, value, attention_mask):
238 | # TODO attention_mask
239 | query = query.contiguous()
240 | key = key.contiguous()
241 | value = value.contiguous()
242 | hidden_states = xformers.ops.memory_efficient_attention(query, key, value, attn_bias=attention_mask)
243 | hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
244 | return hidden_states
245 |
246 | def zero_module(module):
247 | # Zero out the parameters of a module and return it.
248 | for p in module.parameters():
249 | p.detach().zero_()
250 | return module
251 |
252 | def get_motion_module(
253 | in_channels,
254 | motion_module_type: str,
255 | motion_module_kwargs: dict,
256 | ):
257 | if motion_module_type == "Vanilla":
258 | return VanillaTemporalModule(in_channels=in_channels, **motion_module_kwargs,)
259 | elif motion_module_type == "VanillaGrid":
260 | return VanillaTemporalModule(in_channels=in_channels, grid=True, **motion_module_kwargs,)
261 | else:
262 | raise ValueError
263 |
264 | class VanillaTemporalModule(nn.Module):
265 | def __init__(
266 | self,
267 | in_channels,
268 | num_attention_heads = 8,
269 | num_transformer_block = 2,
270 | attention_block_types =( "Temporal_Self", "Temporal_Self" ),
271 | cross_frame_attention_mode = None,
272 | temporal_position_encoding = False,
273 | temporal_position_encoding_max_len = 4096,
274 | temporal_attention_dim_div = 1,
275 | zero_initialize = True,
276 | block_size = 1,
277 | grid = False,
278 | ):
279 | super().__init__()
280 |
281 | self.temporal_transformer = TemporalTransformer3DModel(
282 | in_channels=in_channels,
283 | num_attention_heads=num_attention_heads,
284 | attention_head_dim=in_channels // num_attention_heads // temporal_attention_dim_div,
285 | num_layers=num_transformer_block,
286 | attention_block_types=attention_block_types,
287 | cross_frame_attention_mode=cross_frame_attention_mode,
288 | temporal_position_encoding=temporal_position_encoding,
289 | temporal_position_encoding_max_len=temporal_position_encoding_max_len,
290 | grid=grid,
291 | block_size=block_size,
292 | )
293 | if zero_initialize:
294 | self.temporal_transformer.proj_out = zero_module(self.temporal_transformer.proj_out)
295 |
296 | def forward(self, input_tensor, encoder_hidden_states=None, attention_mask=None, anchor_frame_idx=None):
297 | hidden_states = input_tensor
298 | hidden_states = self.temporal_transformer(hidden_states, encoder_hidden_states, attention_mask)
299 |
300 | output = hidden_states
301 | return output
302 |
303 | class TemporalTransformer3DModel(nn.Module):
304 | def __init__(
305 | self,
306 | in_channels,
307 | num_attention_heads,
308 | attention_head_dim,
309 |
310 | num_layers,
311 | attention_block_types = ( "Temporal_Self", "Temporal_Self", ),
312 | dropout = 0.0,
313 | norm_num_groups = 32,
314 | cross_attention_dim = 768,
315 | activation_fn = "geglu",
316 | attention_bias = False,
317 | upcast_attention = False,
318 |
319 | cross_frame_attention_mode = None,
320 | temporal_position_encoding = False,
321 | temporal_position_encoding_max_len = 4096,
322 | grid = False,
323 | block_size = 1,
324 | ):
325 | super().__init__()
326 |
327 | inner_dim = num_attention_heads * attention_head_dim
328 |
329 | self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
330 | self.proj_in = nn.Linear(in_channels, inner_dim)
331 |
332 | self.block_size = block_size
333 | self.transformer_blocks = nn.ModuleList(
334 | [
335 | TemporalTransformerBlock(
336 | dim=inner_dim,
337 | num_attention_heads=num_attention_heads,
338 | attention_head_dim=attention_head_dim,
339 | attention_block_types=attention_block_types,
340 | dropout=dropout,
341 | norm_num_groups=norm_num_groups,
342 | cross_attention_dim=cross_attention_dim,
343 | activation_fn=activation_fn,
344 | attention_bias=attention_bias,
345 | upcast_attention=upcast_attention,
346 | cross_frame_attention_mode=cross_frame_attention_mode,
347 | temporal_position_encoding=temporal_position_encoding,
348 | temporal_position_encoding_max_len=temporal_position_encoding_max_len,
349 | block_size=block_size,
350 | grid=grid,
351 | )
352 | for d in range(num_layers)
353 | ]
354 | )
355 | self.proj_out = nn.Linear(inner_dim, in_channels)
356 |
357 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None):
358 | assert hidden_states.dim() == 5, f"Expected hidden_states to have ndim=5, but got ndim={hidden_states.dim()}."
359 | video_length = hidden_states.shape[2]
360 | hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
361 |
362 | batch, channel, height, weight = hidden_states.shape
363 | residual = hidden_states
364 |
365 | hidden_states = self.norm(hidden_states)
366 | inner_dim = hidden_states.shape[1]
367 | hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * weight, inner_dim)
368 | hidden_states = self.proj_in(hidden_states)
369 |
370 | # Transformer Blocks
371 | for block in self.transformer_blocks:
372 | hidden_states = block(hidden_states, encoder_hidden_states=encoder_hidden_states, video_length=video_length, height=height, weight=weight)
373 |
374 | # output
375 | hidden_states = self.proj_out(hidden_states)
376 | hidden_states = hidden_states.reshape(batch, height, weight, inner_dim).permute(0, 3, 1, 2).contiguous()
377 |
378 | output = hidden_states + residual
379 | output = rearrange(output, "(b f) c h w -> b c f h w", f=video_length)
380 |
381 | return output
382 |
383 | class TemporalTransformerBlock(nn.Module):
384 | def __init__(
385 | self,
386 | dim,
387 | num_attention_heads,
388 | attention_head_dim,
389 | attention_block_types = ( "Temporal_Self", "Temporal_Self", ),
390 | dropout = 0.0,
391 | norm_num_groups = 32,
392 | cross_attention_dim = 768,
393 | activation_fn = "geglu",
394 | attention_bias = False,
395 | upcast_attention = False,
396 | cross_frame_attention_mode = None,
397 | temporal_position_encoding = False,
398 | temporal_position_encoding_max_len = 4096,
399 | block_size = 1,
400 | grid = False,
401 | ):
402 | super().__init__()
403 |
404 | attention_blocks = []
405 | norms = []
406 |
407 | for block_name in attention_block_types:
408 | attention_blocks.append(
409 | VersatileAttention(
410 | attention_mode=block_name.split("_")[0],
411 | cross_attention_dim=cross_attention_dim if block_name.endswith("_Cross") else None,
412 |
413 | query_dim=dim,
414 | heads=num_attention_heads,
415 | dim_head=attention_head_dim,
416 | dropout=dropout,
417 | bias=attention_bias,
418 | upcast_attention=upcast_attention,
419 |
420 | cross_frame_attention_mode=cross_frame_attention_mode,
421 | temporal_position_encoding=temporal_position_encoding,
422 | temporal_position_encoding_max_len=temporal_position_encoding_max_len,
423 | block_size=block_size,
424 | grid=grid,
425 | )
426 | )
427 | norms.append(nn.LayerNorm(dim))
428 |
429 | self.attention_blocks = nn.ModuleList(attention_blocks)
430 | self.norms = nn.ModuleList(norms)
431 |
432 | self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn)
433 | self.ff_norm = nn.LayerNorm(dim)
434 |
435 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None, height=None, weight=None):
436 | for attention_block, norm in zip(self.attention_blocks, self.norms):
437 | norm_hidden_states = norm(hidden_states)
438 | hidden_states = attention_block(
439 | norm_hidden_states,
440 | encoder_hidden_states=encoder_hidden_states if attention_block.is_cross_attention else None,
441 | video_length=video_length,
442 | height=height,
443 | weight=weight,
444 | ) + hidden_states
445 |
446 | hidden_states = self.ff(self.ff_norm(hidden_states)) + hidden_states
447 |
448 | output = hidden_states
449 | return output
450 |
451 | class PositionalEncoding(nn.Module):
452 | def __init__(
453 | self,
454 | d_model,
455 | dropout = 0.,
456 | max_len = 4096
457 | ):
458 | super().__init__()
459 | self.dropout = nn.Dropout(p=dropout)
460 | position = torch.arange(max_len).unsqueeze(1)
461 | div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
462 | pe = torch.zeros(1, max_len, d_model)
463 | pe[0, :, 0::2] = torch.sin(position * div_term)
464 | pe[0, :, 1::2] = torch.cos(position * div_term)
465 | self.register_buffer('pe', pe)
466 |
467 | def forward(self, x):
468 | x = x + self.pe[:, :x.size(1)]
469 | return self.dropout(x)
470 |
471 | class VersatileAttention(CrossAttention):
472 | def __init__(
473 | self,
474 | attention_mode = None,
475 | cross_frame_attention_mode = None,
476 | temporal_position_encoding = False,
477 | temporal_position_encoding_max_len = 4096,
478 | grid = False,
479 | block_size = 1,
480 | *args, **kwargs
481 | ):
482 | super().__init__(*args, **kwargs)
483 | assert attention_mode == "Temporal"
484 |
485 | self.attention_mode = attention_mode
486 | self.is_cross_attention = kwargs["cross_attention_dim"] is not None
487 |
488 | self.block_size = block_size
489 | self.grid = grid
490 | self.pos_encoder = PositionalEncoding(
491 | kwargs["query_dim"],
492 | dropout=0.,
493 | max_len=temporal_position_encoding_max_len
494 | ) if (temporal_position_encoding and attention_mode == "Temporal") else None
495 |
496 | def extra_repr(self):
497 | return f"(Module Info) Attention_Mode: {self.attention_mode}, Is_Cross_Attention: {self.is_cross_attention}"
498 |
499 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None, height=None, weight=None):
500 | batch_size, sequence_length, _ = hidden_states.shape
501 |
502 | if self.attention_mode == "Temporal":
503 | # for add pos_encoder
504 | _, before_d, _c = hidden_states.size()
505 | hidden_states = rearrange(hidden_states, "(b f) d c -> (b d) f c", f=video_length)
506 | if self.pos_encoder is not None:
507 | hidden_states = self.pos_encoder(hidden_states)
508 |
509 | if self.grid:
510 | hidden_states = rearrange(hidden_states, "(b d) f c -> b f d c", f=video_length, d=before_d)
511 | hidden_states = rearrange(hidden_states, "b f (h w) c -> b f h w c", h=height, w=weight)
512 |
513 | hidden_states = rearrange(hidden_states, "b f (h n) (w m) c -> (b h w) (f n m) c", n=self.block_size, m=self.block_size)
514 | d = before_d // self.block_size // self.block_size
515 | else:
516 | d = before_d
517 | encoder_hidden_states = repeat(encoder_hidden_states, "b n c -> (b d) n c", d=d) if encoder_hidden_states is not None else encoder_hidden_states
518 | else:
519 | raise NotImplementedError
520 |
521 | encoder_hidden_states = encoder_hidden_states
522 |
523 | if self.group_norm is not None:
524 | hidden_states = self.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
525 |
526 | query = self.to_q(hidden_states)
527 | dim = query.shape[-1]
528 | query = self.reshape_heads_to_batch_dim(query)
529 |
530 | if self.added_kv_proj_dim is not None:
531 | raise NotImplementedError
532 |
533 | encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
534 | key = self.to_k(encoder_hidden_states)
535 | value = self.to_v(encoder_hidden_states)
536 |
537 | key = self.reshape_heads_to_batch_dim(key)
538 | value = self.reshape_heads_to_batch_dim(value)
539 |
540 | if attention_mask is not None:
541 | if attention_mask.shape[-1] != query.shape[1]:
542 | target_length = query.shape[1]
543 | attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
544 | attention_mask = attention_mask.repeat_interleave(self.heads, dim=0)
545 |
546 | bs = 512
547 | new_hidden_states = []
548 | for i in range(0, query.shape[0], bs):
549 | # attention, what we cannot get enough of
550 | if self._use_memory_efficient_attention_xformers:
551 | hidden_states = self._memory_efficient_attention_xformers(query[i : i + bs], key[i : i + bs], value[i : i + bs], attention_mask[i : i + bs] if attention_mask is not None else attention_mask)
552 | # Some versions of xformers return output in fp32, cast it back to the dtype of the input
553 | hidden_states = hidden_states.to(query.dtype)
554 | else:
555 | if self._slice_size is None or query[i : i + bs].shape[0] // self._slice_size == 1:
556 | hidden_states = self._attention(query[i : i + bs], key[i : i + bs], value[i : i + bs], attention_mask[i : i + bs] if attention_mask is not None else attention_mask)
557 | else:
558 | hidden_states = self._sliced_attention(query[i : i + bs], key[i : i + bs], value[i : i + bs], sequence_length, dim, attention_mask[i : i + bs] if attention_mask is not None else attention_mask)
559 | new_hidden_states.append(hidden_states)
560 | hidden_states = torch.cat(new_hidden_states, dim = 0)
561 |
562 | # linear proj
563 | hidden_states = self.to_out[0](hidden_states)
564 |
565 | # dropout
566 | hidden_states = self.to_out[1](hidden_states)
567 |
568 | if self.attention_mode == "Temporal":
569 | hidden_states = rearrange(hidden_states, "(b d) f c -> (b f) d c", d=d)
570 | if self.grid:
571 | hidden_states = rearrange(hidden_states, "(b f n m) (h w) c -> (b f) h n w m c", f=video_length, n=self.block_size, m=self.block_size, h=height // self.block_size, w=weight // self.block_size)
572 | hidden_states = rearrange(hidden_states, "b h n w m c -> b (h n) (w m) c")
573 | hidden_states = rearrange(hidden_states, "b h w c -> b (h w) c")
574 |
575 | return hidden_states
--------------------------------------------------------------------------------
/easyanimate/models/patch.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import numpy as np
4 | import torch
5 | import torch.nn.functional as F
6 | import torch.nn.init as init
7 | from einops import rearrange
8 | from torch import nn
9 |
10 |
11 | def get_2d_sincos_pos_embed(
12 | embed_dim, grid_size, cls_token=False, extra_tokens=0, interpolation_scale=1.0, base_size=16
13 | ):
14 | """
15 | grid_size: int of the grid height and width return: pos_embed: [grid_size*grid_size, embed_dim] or
16 | [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
17 | """
18 | if isinstance(grid_size, int):
19 | grid_size = (grid_size, grid_size)
20 |
21 | grid_h = np.arange(grid_size[0], dtype=np.float32) / (grid_size[0] / base_size) / interpolation_scale
22 | grid_w = np.arange(grid_size[1], dtype=np.float32) / (grid_size[1] / base_size) / interpolation_scale
23 | grid = np.meshgrid(grid_w, grid_h) # here w goes first
24 | grid = np.stack(grid, axis=0)
25 |
26 | grid = grid.reshape([2, 1, grid_size[1], grid_size[0]])
27 | pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
28 | if cls_token and extra_tokens > 0:
29 | pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)
30 | return pos_embed
31 |
32 |
33 | def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
34 | if embed_dim % 2 != 0:
35 | raise ValueError("embed_dim must be divisible by 2")
36 |
37 | # use half of dimensions to encode grid_h
38 | emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
39 | emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
40 |
41 | emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
42 | return emb
43 |
44 |
45 | def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
46 | """
47 | embed_dim: output dimension for each position pos: a list of positions to be encoded: size (M,) out: (M, D)
48 | """
49 | if embed_dim % 2 != 0:
50 | raise ValueError("embed_dim must be divisible by 2")
51 |
52 | omega = np.arange(embed_dim // 2, dtype=np.float64)
53 | omega /= embed_dim / 2.0
54 | omega = 1.0 / 10000**omega # (D/2,)
55 |
56 | pos = pos.reshape(-1) # (M,)
57 | out = np.einsum("m,d->md", pos, omega) # (M, D/2), outer product
58 |
59 | emb_sin = np.sin(out) # (M, D/2)
60 | emb_cos = np.cos(out) # (M, D/2)
61 |
62 | emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
63 | return emb
64 |
65 | class Patch1D(nn.Module):
66 | def __init__(
67 | self,
68 | channels: int,
69 | use_conv: bool = False,
70 | out_channels: Optional[int] = None,
71 | stride: int = 2,
72 | padding: int = 0,
73 | name: str = "conv",
74 | ):
75 | super().__init__()
76 | self.channels = channels
77 | self.out_channels = out_channels or channels
78 | self.use_conv = use_conv
79 | self.padding = padding
80 | self.name = name
81 |
82 | if use_conv:
83 | self.conv = nn.Conv1d(self.channels, self.out_channels, stride, stride=stride, padding=padding)
84 | init.constant_(self.conv.weight, 0.0)
85 | with torch.no_grad():
86 | for i in range(len(self.conv.weight)): self.conv.weight[i, i] = 1 / stride
87 | init.constant_(self.conv.bias, 0.0)
88 | else:
89 | assert self.channels == self.out_channels
90 | self.conv = nn.AvgPool1d(kernel_size=stride, stride=stride)
91 |
92 | def forward(self, inputs: torch.Tensor) -> torch.Tensor:
93 | assert inputs.shape[1] == self.channels
94 | return self.conv(inputs)
95 |
96 | class UnPatch1D(nn.Module):
97 | def __init__(
98 | self,
99 | channels: int,
100 | use_conv: bool = False,
101 | use_conv_transpose: bool = False,
102 | out_channels: Optional[int] = None,
103 | name: str = "conv",
104 | ):
105 | super().__init__()
106 | self.channels = channels
107 | self.out_channels = out_channels or channels
108 | self.use_conv = use_conv
109 | self.use_conv_transpose = use_conv_transpose
110 | self.name = name
111 |
112 | self.conv = None
113 | if use_conv_transpose:
114 | self.conv = nn.ConvTranspose1d(channels, self.out_channels, 4, 2, 1)
115 | elif use_conv:
116 | self.conv = nn.Conv1d(self.channels, self.out_channels, 3, padding=1)
117 |
118 | def forward(self, inputs: torch.Tensor) -> torch.Tensor:
119 | assert inputs.shape[1] == self.channels
120 | if self.use_conv_transpose:
121 | return self.conv(inputs)
122 |
123 | outputs = F.interpolate(inputs, scale_factor=2.0, mode="nearest")
124 |
125 | if self.use_conv:
126 | outputs = self.conv(outputs)
127 |
128 | return outputs
129 |
130 | class PatchEmbed3D(nn.Module):
131 | """3D Image to Patch Embedding"""
132 |
133 | def __init__(
134 | self,
135 | height=224,
136 | width=224,
137 | patch_size=16,
138 | time_patch_size=4,
139 | in_channels=3,
140 | embed_dim=768,
141 | layer_norm=False,
142 | flatten=True,
143 | bias=True,
144 | interpolation_scale=1,
145 | ):
146 | super().__init__()
147 |
148 | num_patches = (height // patch_size) * (width // patch_size)
149 | self.flatten = flatten
150 | self.layer_norm = layer_norm
151 |
152 | self.proj = nn.Conv3d(
153 | in_channels, embed_dim, kernel_size=(time_patch_size, patch_size, patch_size), stride=(time_patch_size, patch_size, patch_size), bias=bias
154 | )
155 | if layer_norm:
156 | self.norm = nn.LayerNorm(embed_dim, elementwise_affine=False, eps=1e-6)
157 | else:
158 | self.norm = None
159 |
160 | self.patch_size = patch_size
161 | # See:
162 | # https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L161
163 | self.height, self.width = height // patch_size, width // patch_size
164 | self.base_size = height // patch_size
165 | self.interpolation_scale = interpolation_scale
166 | pos_embed = get_2d_sincos_pos_embed(
167 | embed_dim, int(num_patches**0.5), base_size=self.base_size, interpolation_scale=self.interpolation_scale
168 | )
169 | self.register_buffer("pos_embed", torch.from_numpy(pos_embed).float().unsqueeze(0), persistent=False)
170 |
171 | def forward(self, latent):
172 | height, width = latent.shape[-2] // self.patch_size, latent.shape[-1] // self.patch_size
173 |
174 | latent = self.proj(latent)
175 | latent = rearrange(latent, "b c f h w -> (b f) c h w")
176 | if self.flatten:
177 | latent = latent.flatten(2).transpose(1, 2) # BCFHW -> BNC
178 | if self.layer_norm:
179 | latent = self.norm(latent)
180 |
181 | # Interpolate positional embeddings if needed.
182 | # (For PixArt-Alpha: https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L162C151-L162C160)
183 | if self.height != height or self.width != width:
184 | pos_embed = get_2d_sincos_pos_embed(
185 | embed_dim=self.pos_embed.shape[-1],
186 | grid_size=(height, width),
187 | base_size=self.base_size,
188 | interpolation_scale=self.interpolation_scale,
189 | )
190 | pos_embed = torch.from_numpy(pos_embed)
191 | pos_embed = pos_embed.float().unsqueeze(0).to(latent.device)
192 | else:
193 | pos_embed = self.pos_embed
194 |
195 | return (latent + pos_embed).to(latent.dtype)
196 |
197 | class PatchEmbedF3D(nn.Module):
198 | """Fake 3D Image to Patch Embedding"""
199 |
200 | def __init__(
201 | self,
202 | height=224,
203 | width=224,
204 | patch_size=16,
205 | in_channels=3,
206 | embed_dim=768,
207 | layer_norm=False,
208 | flatten=True,
209 | bias=True,
210 | interpolation_scale=1,
211 | ):
212 | super().__init__()
213 |
214 | num_patches = (height // patch_size) * (width // patch_size)
215 | self.flatten = flatten
216 | self.layer_norm = layer_norm
217 |
218 | self.proj = nn.Conv2d(
219 | in_channels, embed_dim, kernel_size=(patch_size, patch_size), stride=patch_size, bias=bias
220 | )
221 | self.proj_t = Patch1D(
222 | embed_dim, True, stride=patch_size
223 | )
224 | if layer_norm:
225 | self.norm = nn.LayerNorm(embed_dim, elementwise_affine=False, eps=1e-6)
226 | else:
227 | self.norm = None
228 |
229 | self.patch_size = patch_size
230 | # See:
231 | # https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L161
232 | self.height, self.width = height // patch_size, width // patch_size
233 | self.base_size = height // patch_size
234 | self.interpolation_scale = interpolation_scale
235 | pos_embed = get_2d_sincos_pos_embed(
236 | embed_dim, int(num_patches**0.5), base_size=self.base_size, interpolation_scale=self.interpolation_scale
237 | )
238 | self.register_buffer("pos_embed", torch.from_numpy(pos_embed).float().unsqueeze(0), persistent=False)
239 |
240 | def forward(self, latent):
241 | height, width = latent.shape[-2] // self.patch_size, latent.shape[-1] // self.patch_size
242 | b, c, f, h, w = latent.size()
243 | latent = rearrange(latent, "b c f h w -> (b f) c h w")
244 | latent = self.proj(latent)
245 | latent = rearrange(latent, "(b f) c h w -> b c f h w", f=f)
246 |
247 | latent = rearrange(latent, "b c f h w -> (b h w) c f")
248 | latent = self.proj_t(latent)
249 | latent = rearrange(latent, "(b h w) c f -> b c f h w", h=h//2, w=w//2)
250 |
251 | latent = rearrange(latent, "b c f h w -> (b f) c h w")
252 | if self.flatten:
253 | latent = latent.flatten(2).transpose(1, 2) # BCFHW -> BNC
254 | if self.layer_norm:
255 | latent = self.norm(latent)
256 |
257 | # Interpolate positional embeddings if needed.
258 | # (For PixArt-Alpha: https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L162C151-L162C160)
259 | if self.height != height or self.width != width:
260 | pos_embed = get_2d_sincos_pos_embed(
261 | embed_dim=self.pos_embed.shape[-1],
262 | grid_size=(height, width),
263 | base_size=self.base_size,
264 | interpolation_scale=self.interpolation_scale,
265 | )
266 | pos_embed = torch.from_numpy(pos_embed)
267 | pos_embed = pos_embed.float().unsqueeze(0).to(latent.device)
268 | else:
269 | pos_embed = self.pos_embed
270 |
271 | return (latent + pos_embed).to(latent.dtype)
--------------------------------------------------------------------------------
/easyanimate/models/transformer2d.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 The HuggingFace Team. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | import json
15 | import os
16 | from dataclasses import dataclass
17 | from typing import Any, Dict, Optional
18 |
19 | import numpy as np
20 | import torch
21 | import torch.nn.functional as F
22 | import torch.nn.init as init
23 | from diffusers.configuration_utils import ConfigMixin, register_to_config
24 | from diffusers.models.attention import BasicTransformerBlock
25 | from diffusers.models.embeddings import ImagePositionalEmbeddings, PatchEmbed
26 | from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
27 | from diffusers.models.modeling_utils import ModelMixin
28 | from diffusers.models.normalization import AdaLayerNormSingle
29 | from diffusers.utils import (USE_PEFT_BACKEND, BaseOutput, deprecate,
30 | is_torch_version)
31 | from einops import rearrange
32 | from torch import nn
33 |
34 | try:
35 | from diffusers.models.embeddings import PixArtAlphaTextProjection
36 | except:
37 | from diffusers.models.embeddings import \
38 | CaptionProjection as PixArtAlphaTextProjection
39 |
40 |
41 | @dataclass
42 | class Transformer2DModelOutput(BaseOutput):
43 | """
44 | The output of [`Transformer2DModel`].
45 |
46 | Args:
47 | sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` or `(batch size, num_vector_embeds - 1, num_latent_pixels)` if [`Transformer2DModel`] is discrete):
48 | The hidden states output conditioned on the `encoder_hidden_states` input. If discrete, returns probability
49 | distributions for the unnoised latent pixels.
50 | """
51 |
52 | sample: torch.FloatTensor
53 |
54 |
55 | class Transformer2DModel(ModelMixin, ConfigMixin):
56 | """
57 | A 2D Transformer model for image-like data.
58 |
59 | Parameters:
60 | num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
61 | attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
62 | in_channels (`int`, *optional*):
63 | The number of channels in the input and output (specify if the input is **continuous**).
64 | num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
65 | dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
66 | cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
67 | sample_size (`int`, *optional*): The width of the latent images (specify if the input is **discrete**).
68 | This is fixed during training since it is used to learn a number of position embeddings.
69 | num_vector_embeds (`int`, *optional*):
70 | The number of classes of the vector embeddings of the latent pixels (specify if the input is **discrete**).
71 | Includes the class for the masked latent pixel.
72 | activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to use in feed-forward.
73 | num_embeds_ada_norm ( `int`, *optional*):
74 | The number of diffusion steps used during training. Pass if at least one of the norm_layers is
75 | `AdaLayerNorm`. This is fixed during training since it is used to learn a number of embeddings that are
76 | added to the hidden states.
77 |
78 | During inference, you can denoise for up to but not more steps than `num_embeds_ada_norm`.
79 | attention_bias (`bool`, *optional*):
80 | Configure if the `TransformerBlocks` attention should contain a bias parameter.
81 | """
82 | _supports_gradient_checkpointing = True
83 |
84 | @register_to_config
85 | def __init__(
86 | self,
87 | num_attention_heads: int = 16,
88 | attention_head_dim: int = 88,
89 | in_channels: Optional[int] = None,
90 | out_channels: Optional[int] = None,
91 | num_layers: int = 1,
92 | dropout: float = 0.0,
93 | norm_num_groups: int = 32,
94 | cross_attention_dim: Optional[int] = None,
95 | attention_bias: bool = False,
96 | sample_size: Optional[int] = None,
97 | num_vector_embeds: Optional[int] = None,
98 | patch_size: Optional[int] = None,
99 | activation_fn: str = "geglu",
100 | num_embeds_ada_norm: Optional[int] = None,
101 | use_linear_projection: bool = False,
102 | only_cross_attention: bool = False,
103 | double_self_attention: bool = False,
104 | upcast_attention: bool = False,
105 | norm_type: str = "layer_norm",
106 | norm_elementwise_affine: bool = True,
107 | norm_eps: float = 1e-5,
108 | attention_type: str = "default",
109 | caption_channels: int = None,
110 | ):
111 | super().__init__()
112 | self.use_linear_projection = use_linear_projection
113 | self.num_attention_heads = num_attention_heads
114 | self.attention_head_dim = attention_head_dim
115 | inner_dim = num_attention_heads * attention_head_dim
116 |
117 | conv_cls = nn.Conv2d if USE_PEFT_BACKEND else LoRACompatibleConv
118 | linear_cls = nn.Linear if USE_PEFT_BACKEND else LoRACompatibleLinear
119 |
120 | # 1. Transformer2DModel can process both standard continuous images of shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of shape `(batch_size, num_image_vectors)`
121 | # Define whether input is continuous or discrete depending on configuration
122 | self.is_input_continuous = (in_channels is not None) and (patch_size is None)
123 | self.is_input_vectorized = num_vector_embeds is not None
124 | self.is_input_patches = in_channels is not None and patch_size is not None
125 |
126 | if norm_type == "layer_norm" and num_embeds_ada_norm is not None:
127 | deprecation_message = (
128 | f"The configuration file of this model: {self.__class__} is outdated. `norm_type` is either not set or"
129 | " incorrectly set to `'layer_norm'`.Make sure to set `norm_type` to `'ada_norm'` in the config."
130 | " Please make sure to update the config accordingly as leaving `norm_type` might led to incorrect"
131 | " results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it"
132 | " would be very nice if you could open a Pull request for the `transformer/config.json` file"
133 | )
134 | deprecate("norm_type!=num_embeds_ada_norm", "1.0.0", deprecation_message, standard_warn=False)
135 | norm_type = "ada_norm"
136 |
137 | if self.is_input_continuous and self.is_input_vectorized:
138 | raise ValueError(
139 | f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make"
140 | " sure that either `in_channels` or `num_vector_embeds` is None."
141 | )
142 | elif self.is_input_vectorized and self.is_input_patches:
143 | raise ValueError(
144 | f"Cannot define both `num_vector_embeds`: {num_vector_embeds} and `patch_size`: {patch_size}. Make"
145 | " sure that either `num_vector_embeds` or `num_patches` is None."
146 | )
147 | elif not self.is_input_continuous and not self.is_input_vectorized and not self.is_input_patches:
148 | raise ValueError(
149 | f"Has to define `in_channels`: {in_channels}, `num_vector_embeds`: {num_vector_embeds}, or patch_size:"
150 | f" {patch_size}. Make sure that `in_channels`, `num_vector_embeds` or `num_patches` is not None."
151 | )
152 |
153 | # 2. Define input layers
154 | if self.is_input_continuous:
155 | self.in_channels = in_channels
156 |
157 | self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
158 | if use_linear_projection:
159 | self.proj_in = linear_cls(in_channels, inner_dim)
160 | else:
161 | self.proj_in = conv_cls(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
162 | elif self.is_input_vectorized:
163 | assert sample_size is not None, "Transformer2DModel over discrete input must provide sample_size"
164 | assert num_vector_embeds is not None, "Transformer2DModel over discrete input must provide num_embed"
165 |
166 | self.height = sample_size
167 | self.width = sample_size
168 | self.num_vector_embeds = num_vector_embeds
169 | self.num_latent_pixels = self.height * self.width
170 |
171 | self.latent_image_embedding = ImagePositionalEmbeddings(
172 | num_embed=num_vector_embeds, embed_dim=inner_dim, height=self.height, width=self.width
173 | )
174 | elif self.is_input_patches:
175 | assert sample_size is not None, "Transformer2DModel over patched input must provide sample_size"
176 |
177 | self.height = sample_size
178 | self.width = sample_size
179 |
180 | self.patch_size = patch_size
181 | interpolation_scale = self.config.sample_size // 64 # => 64 (= 512 pixart) has interpolation scale 1
182 | interpolation_scale = max(interpolation_scale, 1)
183 | self.pos_embed = PatchEmbed(
184 | height=sample_size,
185 | width=sample_size,
186 | patch_size=patch_size,
187 | in_channels=in_channels,
188 | embed_dim=inner_dim,
189 | interpolation_scale=interpolation_scale,
190 | )
191 |
192 | # 3. Define transformers blocks
193 | self.transformer_blocks = nn.ModuleList(
194 | [
195 | BasicTransformerBlock(
196 | inner_dim,
197 | num_attention_heads,
198 | attention_head_dim,
199 | dropout=dropout,
200 | cross_attention_dim=cross_attention_dim,
201 | activation_fn=activation_fn,
202 | num_embeds_ada_norm=num_embeds_ada_norm,
203 | attention_bias=attention_bias,
204 | only_cross_attention=only_cross_attention,
205 | double_self_attention=double_self_attention,
206 | upcast_attention=upcast_attention,
207 | norm_type=norm_type,
208 | norm_elementwise_affine=norm_elementwise_affine,
209 | norm_eps=norm_eps,
210 | attention_type=attention_type,
211 | )
212 | for d in range(num_layers)
213 | ]
214 | )
215 |
216 | # 4. Define output layers
217 | self.out_channels = in_channels if out_channels is None else out_channels
218 | if self.is_input_continuous:
219 | # TODO: should use out_channels for continuous projections
220 | if use_linear_projection:
221 | self.proj_out = linear_cls(inner_dim, in_channels)
222 | else:
223 | self.proj_out = conv_cls(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
224 | elif self.is_input_vectorized:
225 | self.norm_out = nn.LayerNorm(inner_dim)
226 | self.out = nn.Linear(inner_dim, self.num_vector_embeds - 1)
227 | elif self.is_input_patches and norm_type != "ada_norm_single":
228 | self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
229 | self.proj_out_1 = nn.Linear(inner_dim, 2 * inner_dim)
230 | self.proj_out_2 = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
231 | elif self.is_input_patches and norm_type == "ada_norm_single":
232 | self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
233 | self.scale_shift_table = nn.Parameter(torch.randn(2, inner_dim) / inner_dim**0.5)
234 | self.proj_out = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
235 |
236 | # 5. PixArt-Alpha blocks.
237 | self.adaln_single = None
238 | self.use_additional_conditions = False
239 | if norm_type == "ada_norm_single":
240 | self.use_additional_conditions = self.config.sample_size == 128
241 | # TODO(Sayak, PVP) clean this, for now we use sample size to determine whether to use
242 | # additional conditions until we find better name
243 | self.adaln_single = AdaLayerNormSingle(inner_dim, use_additional_conditions=self.use_additional_conditions)
244 |
245 | self.caption_projection = None
246 | if caption_channels is not None:
247 | self.caption_projection = PixArtAlphaTextProjection(in_features=caption_channels, hidden_size=inner_dim)
248 |
249 | self.gradient_checkpointing = False
250 |
251 | def _set_gradient_checkpointing(self, module, value=False):
252 | if hasattr(module, "gradient_checkpointing"):
253 | module.gradient_checkpointing = value
254 |
255 | def forward(
256 | self,
257 | hidden_states: torch.Tensor,
258 | encoder_hidden_states: Optional[torch.Tensor] = None,
259 | timestep: Optional[torch.LongTensor] = None,
260 | added_cond_kwargs: Dict[str, torch.Tensor] = None,
261 | class_labels: Optional[torch.LongTensor] = None,
262 | cross_attention_kwargs: Dict[str, Any] = None,
263 | attention_mask: Optional[torch.Tensor] = None,
264 | encoder_attention_mask: Optional[torch.Tensor] = None,
265 | return_dict: bool = True,
266 | ):
267 | """
268 | The [`Transformer2DModel`] forward method.
269 |
270 | Args:
271 | hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete, `torch.FloatTensor` of shape `(batch size, channel, height, width)` if continuous):
272 | Input `hidden_states`.
273 | encoder_hidden_states ( `torch.FloatTensor` of shape `(batch size, sequence len, embed dims)`, *optional*):
274 | Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
275 | self-attention.
276 | timestep ( `torch.LongTensor`, *optional*):
277 | Used to indicate denoising step. Optional timestep to be applied as an embedding in `AdaLayerNorm`.
278 | class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
279 | Used to indicate class labels conditioning. Optional class labels to be applied as an embedding in
280 | `AdaLayerZeroNorm`.
281 | cross_attention_kwargs ( `Dict[str, Any]`, *optional*):
282 | A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
283 | `self.processor` in
284 | [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
285 | attention_mask ( `torch.Tensor`, *optional*):
286 | An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
287 | is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
288 | negative values to the attention scores corresponding to "discard" tokens.
289 | encoder_attention_mask ( `torch.Tensor`, *optional*):
290 | Cross-attention mask applied to `encoder_hidden_states`. Two formats supported:
291 |
292 | * Mask `(batch, sequence_length)` True = keep, False = discard.
293 | * Bias `(batch, 1, sequence_length)` 0 = keep, -10000 = discard.
294 |
295 | If `ndim == 2`: will be interpreted as a mask, then converted into a bias consistent with the format
296 | above. This bias will be added to the cross-attention scores.
297 | return_dict (`bool`, *optional*, defaults to `True`):
298 | Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
299 | tuple.
300 |
301 | Returns:
302 | If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
303 | `tuple` where the first element is the sample tensor.
304 | """
305 | # ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
306 | # we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
307 | # we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
308 | # expects mask of shape:
309 | # [batch, key_tokens]
310 | # adds singleton query_tokens dimension:
311 | # [batch, 1, key_tokens]
312 | # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
313 | # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
314 | # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
315 | if attention_mask is not None and attention_mask.ndim == 2:
316 | # assume that mask is expressed as:
317 | # (1 = keep, 0 = discard)
318 | # convert mask into a bias that can be added to attention scores:
319 | # (keep = +0, discard = -10000.0)
320 | attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
321 | attention_mask = attention_mask.unsqueeze(1)
322 |
323 | # convert encoder_attention_mask to a bias the same way we do for attention_mask
324 | if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
325 | encoder_attention_mask = (1 - encoder_attention_mask.to(encoder_hidden_states.dtype)) * -10000.0
326 | encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
327 |
328 | # Retrieve lora scale.
329 | lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
330 |
331 | # 1. Input
332 | if self.is_input_continuous:
333 | batch, _, height, width = hidden_states.shape
334 | residual = hidden_states
335 |
336 | hidden_states = self.norm(hidden_states)
337 | if not self.use_linear_projection:
338 | hidden_states = (
339 | self.proj_in(hidden_states, scale=lora_scale)
340 | if not USE_PEFT_BACKEND
341 | else self.proj_in(hidden_states)
342 | )
343 | inner_dim = hidden_states.shape[1]
344 | hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
345 | else:
346 | inner_dim = hidden_states.shape[1]
347 | hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
348 | hidden_states = (
349 | self.proj_in(hidden_states, scale=lora_scale)
350 | if not USE_PEFT_BACKEND
351 | else self.proj_in(hidden_states)
352 | )
353 |
354 | elif self.is_input_vectorized:
355 | hidden_states = self.latent_image_embedding(hidden_states)
356 | elif self.is_input_patches:
357 | height, width = hidden_states.shape[-2] // self.patch_size, hidden_states.shape[-1] // self.patch_size
358 | hidden_states = self.pos_embed(hidden_states)
359 |
360 | if self.adaln_single is not None:
361 | if self.use_additional_conditions and added_cond_kwargs is None:
362 | raise ValueError(
363 | "`added_cond_kwargs` cannot be None when using additional conditions for `adaln_single`."
364 | )
365 | batch_size = hidden_states.shape[0]
366 | timestep, embedded_timestep = self.adaln_single(
367 | timestep, added_cond_kwargs, batch_size=batch_size, hidden_dtype=hidden_states.dtype
368 | )
369 |
370 | # 2. Blocks
371 | if self.caption_projection is not None:
372 | batch_size = hidden_states.shape[0]
373 | encoder_hidden_states = self.caption_projection(encoder_hidden_states)
374 | encoder_hidden_states = encoder_hidden_states.view(batch_size, -1, hidden_states.shape[-1])
375 |
376 | for block in self.transformer_blocks:
377 | if self.training and self.gradient_checkpointing:
378 | hidden_states = torch.utils.checkpoint.checkpoint(
379 | block,
380 | hidden_states,
381 | attention_mask,
382 | encoder_hidden_states,
383 | encoder_attention_mask,
384 | timestep,
385 | cross_attention_kwargs,
386 | class_labels,
387 | use_reentrant=False,
388 | )
389 | else:
390 | hidden_states = block(
391 | hidden_states,
392 | attention_mask=attention_mask,
393 | encoder_hidden_states=encoder_hidden_states,
394 | encoder_attention_mask=encoder_attention_mask,
395 | timestep=timestep,
396 | cross_attention_kwargs=cross_attention_kwargs,
397 | class_labels=class_labels,
398 | )
399 |
400 | # 3. Output
401 | if self.is_input_continuous:
402 | if not self.use_linear_projection:
403 | hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
404 | hidden_states = (
405 | self.proj_out(hidden_states, scale=lora_scale)
406 | if not USE_PEFT_BACKEND
407 | else self.proj_out(hidden_states)
408 | )
409 | else:
410 | hidden_states = (
411 | self.proj_out(hidden_states, scale=lora_scale)
412 | if not USE_PEFT_BACKEND
413 | else self.proj_out(hidden_states)
414 | )
415 | hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
416 |
417 | output = hidden_states + residual
418 | elif self.is_input_vectorized:
419 | hidden_states = self.norm_out(hidden_states)
420 | logits = self.out(hidden_states)
421 | # (batch, self.num_vector_embeds - 1, self.num_latent_pixels)
422 | logits = logits.permute(0, 2, 1)
423 |
424 | # log(p(x_0))
425 | output = F.log_softmax(logits.double(), dim=1).float()
426 |
427 | if self.is_input_patches:
428 | if self.config.norm_type != "ada_norm_single":
429 | conditioning = self.transformer_blocks[0].norm1.emb(
430 | timestep, class_labels, hidden_dtype=hidden_states.dtype
431 | )
432 | shift, scale = self.proj_out_1(F.silu(conditioning)).chunk(2, dim=1)
433 | hidden_states = self.norm_out(hidden_states) * (1 + scale[:, None]) + shift[:, None]
434 | hidden_states = self.proj_out_2(hidden_states)
435 | elif self.config.norm_type == "ada_norm_single":
436 | shift, scale = (self.scale_shift_table[None] + embedded_timestep[:, None]).chunk(2, dim=1)
437 | hidden_states = self.norm_out(hidden_states)
438 | # Modulation
439 | hidden_states = hidden_states * (1 + scale) + shift
440 | hidden_states = self.proj_out(hidden_states)
441 | hidden_states = hidden_states.squeeze(1)
442 |
443 | # unpatchify
444 | if self.adaln_single is None:
445 | height = width = int(hidden_states.shape[1] ** 0.5)
446 | hidden_states = hidden_states.reshape(
447 | shape=(-1, height, width, self.patch_size, self.patch_size, self.out_channels)
448 | )
449 | hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
450 | output = hidden_states.reshape(
451 | shape=(-1, self.out_channels, height * self.patch_size, width * self.patch_size)
452 | )
453 |
454 | if not return_dict:
455 | return (output,)
456 |
457 | return Transformer2DModelOutput(sample=output)
458 |
459 | @classmethod
460 | def from_pretrained(cls, pretrained_model_path, subfolder=None, patch_size=2, transformer_additional_kwargs={}):
461 | if subfolder is not None:
462 | pretrained_model_path = os.path.join(pretrained_model_path, subfolder)
463 | print(f"loaded 2D transformer's pretrained weights from {pretrained_model_path} ...")
464 |
465 | config_file = os.path.join(pretrained_model_path, 'config.json')
466 | if not os.path.isfile(config_file):
467 | raise RuntimeError(f"{config_file} does not exist")
468 | with open(config_file, "r") as f:
469 | config = json.load(f)
470 |
471 | from diffusers.utils import WEIGHTS_NAME
472 | model = cls.from_config(config, **transformer_additional_kwargs)
473 | model_file = os.path.join(pretrained_model_path, WEIGHTS_NAME)
474 | model_file_safetensors = model_file.replace(".bin", ".safetensors")
475 | if os.path.exists(model_file_safetensors):
476 | from safetensors.torch import load_file, safe_open
477 | state_dict = load_file(model_file_safetensors)
478 | else:
479 | if not os.path.isfile(model_file):
480 | raise RuntimeError(f"{model_file} does not exist")
481 | state_dict = torch.load(model_file, map_location="cpu")
482 |
483 | if model.state_dict()['pos_embed.proj.weight'].size() != state_dict['pos_embed.proj.weight'].size():
484 | new_shape = model.state_dict()['pos_embed.proj.weight'].size()
485 | state_dict['pos_embed.proj.weight'] = torch.tile(state_dict['proj_out.weight'], [1, 2, 1, 1])
486 |
487 | if model.state_dict()['proj_out.weight'].size() != state_dict['proj_out.weight'].size():
488 | new_shape = model.state_dict()['proj_out.weight'].size()
489 | state_dict['proj_out.weight'] = torch.tile(state_dict['proj_out.weight'], [patch_size, 1])
490 |
491 | if model.state_dict()['proj_out.bias'].size() != state_dict['proj_out.bias'].size():
492 | new_shape = model.state_dict()['proj_out.bias'].size()
493 | state_dict['proj_out.bias'] = torch.tile(state_dict['proj_out.bias'], [patch_size])
494 |
495 | tmp_state_dict = {}
496 | for key in state_dict:
497 | if key in model.state_dict().keys() and model.state_dict()[key].size() == state_dict[key].size():
498 | tmp_state_dict[key] = state_dict[key]
499 | else:
500 | print(key, "Size don't match, skip")
501 | state_dict = tmp_state_dict
502 |
503 | m, u = model.load_state_dict(state_dict, strict=False)
504 | print(f"### missing keys: {len(m)}; \n### unexpected keys: {len(u)};")
505 |
506 | params = [p.numel() if "motion_modules." in n else 0 for n, p in model.named_parameters()]
507 | print(f"### Postion Parameters: {sum(params) / 1e6} M")
508 |
509 | return model
--------------------------------------------------------------------------------
/easyanimate/ui/ui.py:
--------------------------------------------------------------------------------
1 | """Modified from https://github.com/guoyww/AnimateDiff/blob/main/app.py
2 | """
3 | import gc
4 | import json
5 | import os
6 | import random
7 | from datetime import datetime
8 | from glob import glob
9 |
10 | import gradio as gr
11 | import torch
12 | from diffusers import (AutoencoderKL, DDIMScheduler,
13 | DPMSolverMultistepScheduler,
14 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
15 | PNDMScheduler)
16 | from diffusers.utils.import_utils import is_xformers_available
17 | from omegaconf import OmegaConf
18 | from safetensors import safe_open
19 | from transformers import T5EncoderModel, T5Tokenizer
20 |
21 | from easyanimate.models.transformer3d import Transformer3DModel
22 | from easyanimate.pipeline.pipeline_easyanimate import EasyAnimatePipeline
23 | from easyanimate.utils.lora_utils import merge_lora, unmerge_lora
24 | from easyanimate.utils.utils import save_videos_grid
25 |
26 | sample_idx = 0
27 | scheduler_dict = {
28 | "Euler": EulerDiscreteScheduler,
29 | "Euler A": EulerAncestralDiscreteScheduler,
30 | "DPM++": DPMSolverMultistepScheduler,
31 | "PNDM": PNDMScheduler,
32 | "DDIM": DDIMScheduler,
33 | }
34 |
35 | css = """
36 | .toolbutton {
37 | margin-buttom: 0em 0em 0em 0em;
38 | max-width: 2.5em;
39 | min-width: 2.5em !important;
40 | height: 2.5em;
41 | }
42 | """
43 |
44 | class EasyAnimateController:
45 | def __init__(self):
46 | # config dirs
47 | self.basedir = os.getcwd()
48 | self.diffusion_transformer_dir = os.path.join(self.basedir, "models", "Diffusion_Transformer")
49 | self.motion_module_dir = os.path.join(self.basedir, "models", "Motion_Module")
50 | self.personalized_model_dir = os.path.join(self.basedir, "models", "Personalized_Model")
51 | self.savedir = os.path.join(self.basedir, "samples", datetime.now().strftime("Gradio-%Y-%m-%dT%H-%M-%S"))
52 | self.savedir_sample = os.path.join(self.savedir, "sample")
53 | os.makedirs(self.savedir, exist_ok=True)
54 |
55 | self.diffusion_transformer_list = []
56 | self.motion_module_list = []
57 | self.personalized_model_list = []
58 |
59 | self.refresh_diffusion_transformer()
60 | self.refresh_motion_module()
61 | self.refresh_personalized_model()
62 |
63 | # config models
64 | self.tokenizer = None
65 | self.text_encoder = None
66 | self.vae = None
67 | self.transformer = None
68 | self.pipeline = None
69 | self.lora_model_path = "none"
70 |
71 | self.weight_dtype = torch.float16
72 | self.inference_config = OmegaConf.load("config/easyanimate_video_motion_module_v1.yaml")
73 |
74 | def refresh_diffusion_transformer(self):
75 | self.diffusion_transformer_list = glob(os.path.join(self.diffusion_transformer_dir, "*/"))
76 |
77 | def refresh_motion_module(self):
78 | motion_module_list = glob(os.path.join(self.motion_module_dir, "*.safetensors"))
79 | self.motion_module_list = [os.path.basename(p) for p in motion_module_list]
80 |
81 | def refresh_personalized_model(self):
82 | personalized_model_list = glob(os.path.join(self.personalized_model_dir, "*.safetensors"))
83 | self.personalized_model_list = [os.path.basename(p) for p in personalized_model_list]
84 |
85 | def update_diffusion_transformer(self, diffusion_transformer_dropdown):
86 | print("Update diffusion transformer")
87 | if diffusion_transformer_dropdown == "none":
88 | return gr.Dropdown.update()
89 | self.vae = AutoencoderKL.from_pretrained(diffusion_transformer_dropdown, subfolder="vae", torch_dtype = self.weight_dtype)
90 | self.transformer = Transformer3DModel.from_pretrained_2d(
91 | diffusion_transformer_dropdown,
92 | subfolder="transformer",
93 | transformer_additional_kwargs=OmegaConf.to_container(self.inference_config.transformer_additional_kwargs)
94 | ).to(self.weight_dtype)
95 | self.tokenizer = T5Tokenizer.from_pretrained(diffusion_transformer_dropdown, subfolder="tokenizer")
96 | self.text_encoder = T5EncoderModel.from_pretrained(diffusion_transformer_dropdown, subfolder="text_encoder", torch_dtype = self.weight_dtype)
97 | print("Update diffusion transformer done")
98 | return gr.Dropdown.update()
99 |
100 | def update_motion_module(self, motion_module_dropdown):
101 | print("Update motion module")
102 | if motion_module_dropdown == "none":
103 | return gr.Dropdown.update()
104 | if self.transformer is None:
105 | gr.Info(f"Please select a pretrained model path.")
106 | return gr.Dropdown.update(value=None)
107 | else:
108 | motion_module_dropdown = os.path.join(self.motion_module_dir, motion_module_dropdown)
109 | if motion_module_dropdown.endswith(".safetensors"):
110 | from safetensors.torch import load_file, safe_open
111 | motion_module_state_dict = load_file(motion_module_dropdown)
112 | else:
113 | if not os.path.isfile(motion_module_dropdown):
114 | raise RuntimeError(f"{motion_module_dropdown} does not exist")
115 | motion_module_state_dict = torch.load(motion_module_dropdown, map_location="cpu")
116 | missing, unexpected = self.transformer.load_state_dict(motion_module_state_dict, strict=False)
117 | assert len(unexpected) == 0
118 | print("Update motion module done")
119 | return gr.Dropdown.update()
120 |
121 | def update_base_model(self, base_model_dropdown):
122 | print("Update base model")
123 | if base_model_dropdown == "none":
124 | return gr.Dropdown.update()
125 | if self.transformer is None:
126 | gr.Info(f"Please select a pretrained model path.")
127 | return gr.Dropdown.update(value=None)
128 | else:
129 | base_model_dropdown = os.path.join(self.personalized_model_dir, base_model_dropdown)
130 | base_model_state_dict = {}
131 | with safe_open(base_model_dropdown, framework="pt", device="cpu") as f:
132 | for key in f.keys():
133 | base_model_state_dict[key] = f.get_tensor(key)
134 | self.transformer.load_state_dict(base_model_state_dict, strict=False)
135 | print("Update base done")
136 | return gr.Dropdown.update()
137 |
138 | def update_lora_model(self, lora_model_dropdown):
139 | lora_model_dropdown = os.path.join(self.personalized_model_dir, lora_model_dropdown)
140 | self.lora_model_path = lora_model_dropdown
141 | return gr.Dropdown.update()
142 |
143 | def generate(
144 | self,
145 | diffusion_transformer_dropdown,
146 | motion_module_dropdown,
147 | base_model_dropdown,
148 | lora_alpha_slider,
149 | prompt_textbox,
150 | negative_prompt_textbox,
151 | sampler_dropdown,
152 | sample_step_slider,
153 | width_slider,
154 | length_slider,
155 | height_slider,
156 | cfg_scale_slider,
157 | seed_textbox
158 | ):
159 | global sample_idx
160 | if self.transformer is None:
161 | raise gr.Error(f"Please select a pretrained model path.")
162 | if motion_module_dropdown == "":
163 | raise gr.Error(f"Please select a motion module.")
164 |
165 | if is_xformers_available(): self.transformer.enable_xformers_memory_efficient_attention()
166 |
167 | pipeline = EasyAnimatePipeline(
168 | vae=self.vae,
169 | text_encoder=self.text_encoder,
170 | tokenizer=self.tokenizer,
171 | transformer=self.transformer,
172 | scheduler=scheduler_dict[sampler_dropdown](**OmegaConf.to_container(self.inference_config.noise_scheduler_kwargs))
173 | )
174 | if self.lora_model_path != "none":
175 | # lora part
176 | pipeline = merge_lora(pipeline, self.lora_model_path, multiplier=lora_alpha_slider)
177 |
178 | pipeline.to("cuda")
179 |
180 | if seed_textbox != -1 and seed_textbox != "": torch.manual_seed(int(seed_textbox))
181 | else: torch.seed()
182 | seed = torch.initial_seed()
183 |
184 | try:
185 | sample = pipeline(
186 | prompt_textbox,
187 | negative_prompt = negative_prompt_textbox,
188 | num_inference_steps = sample_step_slider,
189 | guidance_scale = cfg_scale_slider,
190 | width = width_slider,
191 | height = height_slider,
192 | video_length = length_slider,
193 | ).videos
194 | except Exception as e:
195 | # lora part
196 | gc.collect()
197 | torch.cuda.empty_cache()
198 | torch.cuda.ipc_collect()
199 | if self.lora_model_path != "none":
200 | pipeline = unmerge_lora(pipeline, self.lora_model_path, multiplier=lora_alpha_slider)
201 | return gr.Video.update()
202 |
203 | # lora part
204 | if self.lora_model_path != "none":
205 | pipeline = unmerge_lora(pipeline, self.lora_model_path, multiplier=lora_alpha_slider)
206 |
207 | save_sample_path = os.path.join(self.savedir_sample, f"{sample_idx}.mp4")
208 | sample_idx += 1
209 | save_videos_grid(sample, save_sample_path, fps=12)
210 |
211 | sample_config = {
212 | "prompt": prompt_textbox,
213 | "n_prompt": negative_prompt_textbox,
214 | "sampler": sampler_dropdown,
215 | "num_inference_steps": sample_step_slider,
216 | "guidance_scale": cfg_scale_slider,
217 | "width": width_slider,
218 | "height": height_slider,
219 | "video_length": length_slider,
220 | "seed": seed
221 | }
222 | json_str = json.dumps(sample_config, indent=4)
223 | with open(os.path.join(self.savedir, "logs.json"), "a") as f:
224 | f.write(json_str)
225 | f.write("\n\n")
226 |
227 | return gr.Video.update(value=save_sample_path)
228 |
229 |
230 | def ui():
231 | controller = EasyAnimateController()
232 |
233 | with gr.Blocks(css=css) as demo:
234 | gr.Markdown(
235 | """
236 | # EasyAnimate: Generate your animation easily
237 | [Github](https://github.com/aigc-apps/EasyAnimate/)
238 | """
239 | )
240 | with gr.Column(variant="panel"):
241 | gr.Markdown(
242 | """
243 | ### 1. Model checkpoints (select pretrained model path first).
244 | """
245 | )
246 | with gr.Row():
247 | diffusion_transformer_dropdown = gr.Dropdown(
248 | label="Pretrained Model Path",
249 | choices=controller.diffusion_transformer_list,
250 | value="none",
251 | interactive=True,
252 | )
253 | diffusion_transformer_dropdown.change(
254 | fn=controller.update_diffusion_transformer,
255 | inputs=[diffusion_transformer_dropdown],
256 | outputs=[diffusion_transformer_dropdown]
257 | )
258 |
259 | diffusion_transformer_refresh_button = gr.Button(value="\U0001F503", elem_classes="toolbutton")
260 | def refresh_diffusion_transformer():
261 | controller.refresh_diffusion_transformer()
262 | return gr.Dropdown.update(choices=controller.diffusion_transformer_list)
263 | diffusion_transformer_refresh_button.click(fn=refresh_diffusion_transformer, inputs=[], outputs=[diffusion_transformer_dropdown])
264 |
265 | with gr.Row():
266 | motion_module_dropdown = gr.Dropdown(
267 | label="Select motion module",
268 | choices=controller.motion_module_list,
269 | value="none",
270 | interactive=True,
271 | )
272 | motion_module_dropdown.change(fn=controller.update_motion_module, inputs=[motion_module_dropdown], outputs=[motion_module_dropdown])
273 |
274 | motion_module_refresh_button = gr.Button(value="\U0001F503", elem_classes="toolbutton")
275 | def update_motion_module():
276 | controller.refresh_motion_module()
277 | return gr.Dropdown.update(choices=controller.motion_module_list)
278 | motion_module_refresh_button.click(fn=update_motion_module, inputs=[], outputs=[motion_module_dropdown])
279 |
280 | base_model_dropdown = gr.Dropdown(
281 | label="Select base Dreambooth model (optional)",
282 | choices=controller.personalized_model_list,
283 | value="none",
284 | interactive=True,
285 | )
286 | base_model_dropdown.change(fn=controller.update_base_model, inputs=[base_model_dropdown], outputs=[base_model_dropdown])
287 |
288 | lora_model_dropdown = gr.Dropdown(
289 | label="Select LoRA model (optional)",
290 | choices=["none"] + controller.personalized_model_list,
291 | value="none",
292 | interactive=True,
293 | )
294 | lora_model_dropdown.change(fn=controller.update_lora_model, inputs=[lora_model_dropdown], outputs=[lora_model_dropdown])
295 |
296 | lora_alpha_slider = gr.Slider(label="LoRA alpha", value=0.55, minimum=0, maximum=2, interactive=True)
297 |
298 | personalized_refresh_button = gr.Button(value="\U0001F503", elem_classes="toolbutton")
299 | def update_personalized_model():
300 | controller.refresh_personalized_model()
301 | return [
302 | gr.Dropdown.update(choices=controller.personalized_model_list),
303 | gr.Dropdown.update(choices=["none"] + controller.personalized_model_list)
304 | ]
305 | personalized_refresh_button.click(fn=update_personalized_model, inputs=[], outputs=[base_model_dropdown, lora_model_dropdown])
306 |
307 | with gr.Column(variant="panel"):
308 | gr.Markdown(
309 | """
310 | ### 2. Configs for Generation.
311 | """
312 | )
313 |
314 | prompt_textbox = gr.Textbox(label="Prompt", lines=2)
315 | negative_prompt_textbox = gr.Textbox(label="Negative prompt", lines=2, value="Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly" )
316 |
317 | with gr.Row().style(equal_height=False):
318 | with gr.Column():
319 | with gr.Row():
320 | sampler_dropdown = gr.Dropdown(label="Sampling method", choices=list(scheduler_dict.keys()), value=list(scheduler_dict.keys())[0])
321 | sample_step_slider = gr.Slider(label="Sampling steps", value=30, minimum=10, maximum=100, step=1)
322 |
323 | width_slider = gr.Slider(label="Width", value=512, minimum=256, maximum=1024, step=64)
324 | height_slider = gr.Slider(label="Height", value=512, minimum=256, maximum=1024, step=64)
325 | length_slider = gr.Slider(label="Animation length", value=80, minimum=16, maximum=96, step=1)
326 | cfg_scale_slider = gr.Slider(label="CFG Scale", value=6.0, minimum=0, maximum=20)
327 |
328 | with gr.Row():
329 | seed_textbox = gr.Textbox(label="Seed", value=-1)
330 | seed_button = gr.Button(value="\U0001F3B2", elem_classes="toolbutton")
331 | seed_button.click(fn=lambda: gr.Textbox.update(value=random.randint(1, 1e8)), inputs=[], outputs=[seed_textbox])
332 |
333 | generate_button = gr.Button(value="Generate", variant='primary')
334 |
335 | result_video = gr.Video(label="Generated Animation", interactive=False)
336 |
337 | generate_button.click(
338 | fn=controller.generate,
339 | inputs=[
340 | diffusion_transformer_dropdown,
341 | motion_module_dropdown,
342 | base_model_dropdown,
343 | lora_alpha_slider,
344 | prompt_textbox,
345 | negative_prompt_textbox,
346 | sampler_dropdown,
347 | sample_step_slider,
348 | width_slider,
349 | length_slider,
350 | height_slider,
351 | cfg_scale_slider,
352 | seed_textbox,
353 | ],
354 | outputs=[result_video]
355 | )
356 | return demo
357 |
--------------------------------------------------------------------------------
/easyanimate/utils/IDDIM.py:
--------------------------------------------------------------------------------
1 | # Modified from OpenAI's diffusion repos
2 | # GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
3 | # ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
4 | # IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
5 | from . import gaussian_diffusion as gd
6 | from .respace import SpacedDiffusion, space_timesteps
7 |
8 |
9 | def IDDPM(
10 | timestep_respacing,
11 | noise_schedule="linear",
12 | use_kl=False,
13 | sigma_small=False,
14 | predict_xstart=False,
15 | learn_sigma=True,
16 | pred_sigma=True,
17 | rescale_learned_sigmas=False,
18 | diffusion_steps=1000,
19 | snr=False,
20 | return_startx=False,
21 | ):
22 | betas = gd.get_named_beta_schedule(noise_schedule, diffusion_steps)
23 | if use_kl:
24 | loss_type = gd.LossType.RESCALED_KL
25 | elif rescale_learned_sigmas:
26 | loss_type = gd.LossType.RESCALED_MSE
27 | else:
28 | loss_type = gd.LossType.MSE
29 | if timestep_respacing is None or timestep_respacing == "":
30 | timestep_respacing = [diffusion_steps]
31 | return SpacedDiffusion(
32 | use_timesteps=space_timesteps(diffusion_steps, timestep_respacing),
33 | betas=betas,
34 | model_mean_type=(
35 | gd.ModelMeanType.START_X if predict_xstart else gd.ModelMeanType.EPSILON
36 | ),
37 | model_var_type=(
38 | (gd.ModelVarType.LEARNED_RANGE if learn_sigma else (
39 | gd.ModelVarType.FIXED_LARGE
40 | if not sigma_small
41 | else gd.ModelVarType.FIXED_SMALL
42 | )
43 | )
44 | if pred_sigma
45 | else None
46 | ),
47 | loss_type=loss_type,
48 | snr=snr,
49 | return_startx=return_startx,
50 | # rescale_timesteps=rescale_timesteps,
51 | )
--------------------------------------------------------------------------------
/easyanimate/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/easyanimate/utils/__init__.py
--------------------------------------------------------------------------------
/easyanimate/utils/diffusion_utils.py:
--------------------------------------------------------------------------------
1 | # Modified from OpenAI's diffusion repos
2 | # GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
3 | # ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
4 | # IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
5 |
6 | import numpy as np
7 | import torch as th
8 |
9 |
10 | def normal_kl(mean1, logvar1, mean2, logvar2):
11 | """
12 | Compute the KL divergence between two gaussians.
13 | Shapes are automatically broadcasted, so batches can be compared to
14 | scalars, among other use cases.
15 | """
16 | tensor = next(
17 | (
18 | obj
19 | for obj in (mean1, logvar1, mean2, logvar2)
20 | if isinstance(obj, th.Tensor)
21 | ),
22 | None,
23 | )
24 | assert tensor is not None, "at least one argument must be a Tensor"
25 |
26 | # Force variances to be Tensors. Broadcasting helps convert scalars to
27 | # Tensors, but it does not work for th.exp().
28 | logvar1, logvar2 = [
29 | x if isinstance(x, th.Tensor) else th.tensor(x, device=tensor.device)
30 | for x in (logvar1, logvar2)
31 | ]
32 |
33 | return 0.5 * (
34 | -1.0
35 | + logvar2
36 | - logvar1
37 | + th.exp(logvar1 - logvar2)
38 | + ((mean1 - mean2) ** 2) * th.exp(-logvar2)
39 | )
40 |
41 |
42 | def approx_standard_normal_cdf(x):
43 | """
44 | A fast approximation of the cumulative distribution function of the
45 | standard normal.
46 | """
47 | return 0.5 * (1.0 + th.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * th.pow(x, 3))))
48 |
49 |
50 | def continuous_gaussian_log_likelihood(x, *, means, log_scales):
51 | """
52 | Compute the log-likelihood of a continuous Gaussian distribution.
53 | :param x: the targets
54 | :param means: the Gaussian mean Tensor.
55 | :param log_scales: the Gaussian log stddev Tensor.
56 | :return: a tensor like x of log probabilities (in nats).
57 | """
58 | centered_x = x - means
59 | inv_stdv = th.exp(-log_scales)
60 | normalized_x = centered_x * inv_stdv
61 | return th.distributions.Normal(th.zeros_like(x), th.ones_like(x)).log_prob(
62 | normalized_x
63 | )
64 |
65 |
66 | def discretized_gaussian_log_likelihood(x, *, means, log_scales):
67 | """
68 | Compute the log-likelihood of a Gaussian distribution discretizing to a
69 | given image.
70 | :param x: the target images. It is assumed that this was uint8 values,
71 | rescaled to the range [-1, 1].
72 | :param means: the Gaussian mean Tensor.
73 | :param log_scales: the Gaussian log stddev Tensor.
74 | :return: a tensor like x of log probabilities (in nats).
75 | """
76 | assert x.shape == means.shape == log_scales.shape
77 | centered_x = x - means
78 | inv_stdv = th.exp(-log_scales)
79 | plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
80 | cdf_plus = approx_standard_normal_cdf(plus_in)
81 | min_in = inv_stdv * (centered_x - 1.0 / 255.0)
82 | cdf_min = approx_standard_normal_cdf(min_in)
83 | log_cdf_plus = th.log(cdf_plus.clamp(min=1e-12))
84 | log_one_minus_cdf_min = th.log((1.0 - cdf_min).clamp(min=1e-12))
85 | cdf_delta = cdf_plus - cdf_min
86 | log_probs = th.where(
87 | x < -0.999,
88 | log_cdf_plus,
89 | th.where(x > 0.999, log_one_minus_cdf_min, th.log(cdf_delta.clamp(min=1e-12))),
90 | )
91 | assert log_probs.shape == x.shape
92 | return log_probs
--------------------------------------------------------------------------------
/easyanimate/utils/lora_utils.py:
--------------------------------------------------------------------------------
1 | # LoRA network module
2 | # reference:
3 | # https://github.com/microsoft/LoRA/blob/main/loralib/layers.py
4 | # https://github.com/cloneofsimo/lora/blob/master/lora_diffusion/lora.py
5 | # https://github.com/bmaltais/kohya_ss
6 |
7 | import hashlib
8 | import math
9 | import os
10 | from collections import defaultdict
11 | from io import BytesIO
12 | from typing import List, Optional, Type, Union
13 |
14 | import safetensors.torch
15 | import torch
16 | import torch.utils.checkpoint
17 | from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
18 | from safetensors.torch import load_file
19 | from transformers import T5EncoderModel
20 |
21 |
22 | class LoRAModule(torch.nn.Module):
23 | """
24 | replaces forward method of the original Linear, instead of replacing the original Linear module.
25 | """
26 |
27 | def __init__(
28 | self,
29 | lora_name,
30 | org_module: torch.nn.Module,
31 | multiplier=1.0,
32 | lora_dim=4,
33 | alpha=1,
34 | dropout=None,
35 | rank_dropout=None,
36 | module_dropout=None,
37 | ):
38 | """if alpha == 0 or None, alpha is rank (no scaling)."""
39 | super().__init__()
40 | self.lora_name = lora_name
41 |
42 | if org_module.__class__.__name__ == "Conv2d":
43 | in_dim = org_module.in_channels
44 | out_dim = org_module.out_channels
45 | else:
46 | in_dim = org_module.in_features
47 | out_dim = org_module.out_features
48 |
49 | self.lora_dim = lora_dim
50 | if org_module.__class__.__name__ == "Conv2d":
51 | kernel_size = org_module.kernel_size
52 | stride = org_module.stride
53 | padding = org_module.padding
54 | self.lora_down = torch.nn.Conv2d(in_dim, self.lora_dim, kernel_size, stride, padding, bias=False)
55 | self.lora_up = torch.nn.Conv2d(self.lora_dim, out_dim, (1, 1), (1, 1), bias=False)
56 | else:
57 | self.lora_down = torch.nn.Linear(in_dim, self.lora_dim, bias=False)
58 | self.lora_up = torch.nn.Linear(self.lora_dim, out_dim, bias=False)
59 |
60 | if type(alpha) == torch.Tensor:
61 | alpha = alpha.detach().float().numpy() # without casting, bf16 causes error
62 | alpha = self.lora_dim if alpha is None or alpha == 0 else alpha
63 | self.scale = alpha / self.lora_dim
64 | self.register_buffer("alpha", torch.tensor(alpha))
65 |
66 | # same as microsoft's
67 | torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
68 | torch.nn.init.zeros_(self.lora_up.weight)
69 |
70 | self.multiplier = multiplier
71 | self.org_module = org_module # remove in applying
72 | self.dropout = dropout
73 | self.rank_dropout = rank_dropout
74 | self.module_dropout = module_dropout
75 |
76 | def apply_to(self):
77 | self.org_forward = self.org_module.forward
78 | self.org_module.forward = self.forward
79 | del self.org_module
80 |
81 | def forward(self, x, *args, **kwargs):
82 | weight_dtype = x.dtype
83 | org_forwarded = self.org_forward(x)
84 |
85 | # module dropout
86 | if self.module_dropout is not None and self.training:
87 | if torch.rand(1) < self.module_dropout:
88 | return org_forwarded
89 |
90 | lx = self.lora_down(x.to(self.lora_down.weight.dtype))
91 |
92 | # normal dropout
93 | if self.dropout is not None and self.training:
94 | lx = torch.nn.functional.dropout(lx, p=self.dropout)
95 |
96 | # rank dropout
97 | if self.rank_dropout is not None and self.training:
98 | mask = torch.rand((lx.size(0), self.lora_dim), device=lx.device) > self.rank_dropout
99 | if len(lx.size()) == 3:
100 | mask = mask.unsqueeze(1) # for Text Encoder
101 | elif len(lx.size()) == 4:
102 | mask = mask.unsqueeze(-1).unsqueeze(-1) # for Conv2d
103 | lx = lx * mask
104 |
105 | # scaling for rank dropout: treat as if the rank is changed
106 | scale = self.scale * (1.0 / (1.0 - self.rank_dropout)) # redundant for readability
107 | else:
108 | scale = self.scale
109 |
110 | lx = self.lora_up(lx)
111 |
112 | return org_forwarded.to(weight_dtype) + lx.to(weight_dtype) * self.multiplier * scale
113 |
114 |
115 | def addnet_hash_legacy(b):
116 | """Old model hash used by sd-webui-additional-networks for .safetensors format files"""
117 | m = hashlib.sha256()
118 |
119 | b.seek(0x100000)
120 | m.update(b.read(0x10000))
121 | return m.hexdigest()[0:8]
122 |
123 |
124 | def addnet_hash_safetensors(b):
125 | """New model hash used by sd-webui-additional-networks for .safetensors format files"""
126 | hash_sha256 = hashlib.sha256()
127 | blksize = 1024 * 1024
128 |
129 | b.seek(0)
130 | header = b.read(8)
131 | n = int.from_bytes(header, "little")
132 |
133 | offset = n + 8
134 | b.seek(offset)
135 | for chunk in iter(lambda: b.read(blksize), b""):
136 | hash_sha256.update(chunk)
137 |
138 | return hash_sha256.hexdigest()
139 |
140 |
141 | def precalculate_safetensors_hashes(tensors, metadata):
142 | """Precalculate the model hashes needed by sd-webui-additional-networks to
143 | save time on indexing the model later."""
144 |
145 | # Because writing user metadata to the file can change the result of
146 | # sd_models.model_hash(), only retain the training metadata for purposes of
147 | # calculating the hash, as they are meant to be immutable
148 | metadata = {k: v for k, v in metadata.items() if k.startswith("ss_")}
149 |
150 | bytes = safetensors.torch.save(tensors, metadata)
151 | b = BytesIO(bytes)
152 |
153 | model_hash = addnet_hash_safetensors(b)
154 | legacy_hash = addnet_hash_legacy(b)
155 | return model_hash, legacy_hash
156 |
157 |
158 | class LoRANetwork(torch.nn.Module):
159 | TRANSFORMER_TARGET_REPLACE_MODULE = ["Transformer2DModel", "Transformer3DModel"]
160 | TEXT_ENCODER_TARGET_REPLACE_MODULE = ["T5LayerSelfAttention", "T5LayerFF"]
161 | LORA_PREFIX_TRANSFORMER = "lora_unet"
162 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
163 | def __init__(
164 | self,
165 | text_encoder: Union[List[T5EncoderModel], T5EncoderModel],
166 | unet,
167 | multiplier: float = 1.0,
168 | lora_dim: int = 4,
169 | alpha: float = 1,
170 | dropout: Optional[float] = None,
171 | module_class: Type[object] = LoRAModule,
172 | add_lora_in_attn_temporal: bool = False,
173 | varbose: Optional[bool] = False,
174 | ) -> None:
175 | super().__init__()
176 | self.multiplier = multiplier
177 |
178 | self.lora_dim = lora_dim
179 | self.alpha = alpha
180 | self.dropout = dropout
181 |
182 | print(f"create LoRA network. base dim (rank): {lora_dim}, alpha: {alpha}")
183 | print(f"neuron dropout: p={self.dropout}")
184 |
185 | # create module instances
186 | def create_modules(
187 | is_unet: bool,
188 | root_module: torch.nn.Module,
189 | target_replace_modules: List[torch.nn.Module],
190 | ) -> List[LoRAModule]:
191 | prefix = (
192 | self.LORA_PREFIX_TRANSFORMER
193 | if is_unet
194 | else self.LORA_PREFIX_TEXT_ENCODER
195 | )
196 | loras = []
197 | skipped = []
198 | for name, module in root_module.named_modules():
199 | if module.__class__.__name__ in target_replace_modules:
200 | for child_name, child_module in module.named_modules():
201 | is_linear = child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "LoRACompatibleLinear"
202 | is_conv2d = child_module.__class__.__name__ == "Conv2d" or child_module.__class__.__name__ == "LoRACompatibleConv"
203 | is_conv2d_1x1 = is_conv2d and child_module.kernel_size == (1, 1)
204 |
205 | if not add_lora_in_attn_temporal:
206 | if "attn_temporal" in child_name:
207 | continue
208 |
209 | if is_linear or is_conv2d:
210 | lora_name = prefix + "." + name + "." + child_name
211 | lora_name = lora_name.replace(".", "_")
212 |
213 | dim = None
214 | alpha = None
215 |
216 | if is_linear or is_conv2d_1x1:
217 | dim = self.lora_dim
218 | alpha = self.alpha
219 |
220 | if dim is None or dim == 0:
221 | if is_linear or is_conv2d_1x1:
222 | skipped.append(lora_name)
223 | continue
224 |
225 | lora = module_class(
226 | lora_name,
227 | child_module,
228 | self.multiplier,
229 | dim,
230 | alpha,
231 | dropout=dropout,
232 | )
233 | loras.append(lora)
234 | return loras, skipped
235 |
236 | text_encoders = text_encoder if type(text_encoder) == list else [text_encoder]
237 |
238 | self.text_encoder_loras = []
239 | skipped_te = []
240 | for i, text_encoder in enumerate(text_encoders):
241 | text_encoder_loras, skipped = create_modules(False, text_encoder, LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
242 | self.text_encoder_loras.extend(text_encoder_loras)
243 | skipped_te += skipped
244 | print(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
245 |
246 | self.unet_loras, skipped_un = create_modules(True, unet, LoRANetwork.TRANSFORMER_TARGET_REPLACE_MODULE)
247 | print(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
248 |
249 | # assertion
250 | names = set()
251 | for lora in self.text_encoder_loras + self.unet_loras:
252 | assert lora.lora_name not in names, f"duplicated lora name: {lora.lora_name}"
253 | names.add(lora.lora_name)
254 |
255 | def apply_to(self, text_encoder, unet, apply_text_encoder=True, apply_unet=True):
256 | if apply_text_encoder:
257 | print("enable LoRA for text encoder")
258 | else:
259 | self.text_encoder_loras = []
260 |
261 | if apply_unet:
262 | print("enable LoRA for U-Net")
263 | else:
264 | self.unet_loras = []
265 |
266 | for lora in self.text_encoder_loras + self.unet_loras:
267 | lora.apply_to()
268 | self.add_module(lora.lora_name, lora)
269 |
270 | def set_multiplier(self, multiplier):
271 | self.multiplier = multiplier
272 | for lora in self.text_encoder_loras + self.unet_loras:
273 | lora.multiplier = self.multiplier
274 |
275 | def load_weights(self, file):
276 | if os.path.splitext(file)[1] == ".safetensors":
277 | from safetensors.torch import load_file
278 |
279 | weights_sd = load_file(file)
280 | else:
281 | weights_sd = torch.load(file, map_location="cpu")
282 | info = self.load_state_dict(weights_sd, False)
283 | return info
284 |
285 | def prepare_optimizer_params(self, text_encoder_lr, unet_lr, default_lr):
286 | self.requires_grad_(True)
287 | all_params = []
288 |
289 | def enumerate_params(loras):
290 | params = []
291 | for lora in loras:
292 | params.extend(lora.parameters())
293 | return params
294 |
295 | if self.text_encoder_loras:
296 | param_data = {"params": enumerate_params(self.text_encoder_loras)}
297 | if text_encoder_lr is not None:
298 | param_data["lr"] = text_encoder_lr
299 | all_params.append(param_data)
300 |
301 | if self.unet_loras:
302 | param_data = {"params": enumerate_params(self.unet_loras)}
303 | if unet_lr is not None:
304 | param_data["lr"] = unet_lr
305 | all_params.append(param_data)
306 |
307 | return all_params
308 |
309 | def enable_gradient_checkpointing(self):
310 | pass
311 |
312 | def get_trainable_params(self):
313 | return self.parameters()
314 |
315 | def save_weights(self, file, dtype, metadata):
316 | if metadata is not None and len(metadata) == 0:
317 | metadata = None
318 |
319 | state_dict = self.state_dict()
320 |
321 | if dtype is not None:
322 | for key in list(state_dict.keys()):
323 | v = state_dict[key]
324 | v = v.detach().clone().to("cpu").to(dtype)
325 | state_dict[key] = v
326 |
327 | if os.path.splitext(file)[1] == ".safetensors":
328 | from safetensors.torch import save_file
329 |
330 | # Precalculate model hashes to save time on indexing
331 | if metadata is None:
332 | metadata = {}
333 | model_hash, legacy_hash = precalculate_safetensors_hashes(state_dict, metadata)
334 | metadata["sshs_model_hash"] = model_hash
335 | metadata["sshs_legacy_hash"] = legacy_hash
336 |
337 | save_file(state_dict, file, metadata)
338 | else:
339 | torch.save(state_dict, file)
340 |
341 | def create_network(
342 | multiplier: float,
343 | network_dim: Optional[int],
344 | network_alpha: Optional[float],
345 | text_encoder: Union[T5EncoderModel, List[T5EncoderModel]],
346 | transformer,
347 | neuron_dropout: Optional[float] = None,
348 | add_lora_in_attn_temporal: bool = False,
349 | **kwargs,
350 | ):
351 | if network_dim is None:
352 | network_dim = 4 # default
353 | if network_alpha is None:
354 | network_alpha = 1.0
355 |
356 | network = LoRANetwork(
357 | text_encoder,
358 | transformer,
359 | multiplier=multiplier,
360 | lora_dim=network_dim,
361 | alpha=network_alpha,
362 | dropout=neuron_dropout,
363 | add_lora_in_attn_temporal=add_lora_in_attn_temporal,
364 | varbose=True,
365 | )
366 | return network
367 |
368 | def merge_lora(pipeline, lora_path, multiplier, device='cpu', dtype=torch.float32, state_dict=None, transformer_only=False):
369 | LORA_PREFIX_TRANSFORMER = "lora_unet"
370 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
371 | if state_dict is None:
372 | state_dict = load_file(lora_path, device=device)
373 | else:
374 | state_dict = state_dict
375 | updates = defaultdict(dict)
376 | for key, value in state_dict.items():
377 | layer, elem = key.split('.', 1)
378 | updates[layer][elem] = value
379 |
380 | for layer, elems in updates.items():
381 |
382 | if "lora_te" in layer:
383 | if transformer_only:
384 | continue
385 | else:
386 | layer_infos = layer.split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
387 | curr_layer = pipeline.text_encoder
388 | else:
389 | layer_infos = layer.split(LORA_PREFIX_TRANSFORMER + "_")[-1].split("_")
390 | curr_layer = pipeline.transformer
391 |
392 | temp_name = layer_infos.pop(0)
393 | while len(layer_infos) > -1:
394 | try:
395 | curr_layer = curr_layer.__getattr__(temp_name)
396 | if len(layer_infos) > 0:
397 | temp_name = layer_infos.pop(0)
398 | elif len(layer_infos) == 0:
399 | break
400 | except Exception:
401 | if len(layer_infos) == 0:
402 | print('Error loading layer')
403 | if len(temp_name) > 0:
404 | temp_name += "_" + layer_infos.pop(0)
405 | else:
406 | temp_name = layer_infos.pop(0)
407 |
408 | weight_up = elems['lora_up.weight'].to(dtype)
409 | weight_down = elems['lora_down.weight'].to(dtype)
410 | if 'alpha' in elems.keys():
411 | alpha = elems['alpha'].item() / weight_up.shape[1]
412 | else:
413 | alpha = 1.0
414 |
415 | curr_layer.weight.data = curr_layer.weight.data.to(device)
416 | if len(weight_up.shape) == 4:
417 | curr_layer.weight.data += multiplier * alpha * torch.mm(weight_up.squeeze(3).squeeze(2),
418 | weight_down.squeeze(3).squeeze(2)).unsqueeze(
419 | 2).unsqueeze(3)
420 | else:
421 | curr_layer.weight.data += multiplier * alpha * torch.mm(weight_up, weight_down)
422 |
423 | return pipeline
424 |
425 | # TODO: Refactor with merge_lora.
426 | def unmerge_lora(pipeline, lora_path, multiplier=1, device="cpu", dtype=torch.float32):
427 | """Unmerge state_dict in LoRANetwork from the pipeline in diffusers."""
428 | LORA_PREFIX_UNET = "lora_unet"
429 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
430 | state_dict = load_file(lora_path, device=device)
431 |
432 | updates = defaultdict(dict)
433 | for key, value in state_dict.items():
434 | layer, elem = key.split('.', 1)
435 | updates[layer][elem] = value
436 |
437 | for layer, elems in updates.items():
438 |
439 | if "lora_te" in layer:
440 | layer_infos = layer.split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
441 | curr_layer = pipeline.text_encoder
442 | else:
443 | layer_infos = layer.split(LORA_PREFIX_UNET + "_")[-1].split("_")
444 | curr_layer = pipeline.transformer
445 |
446 | temp_name = layer_infos.pop(0)
447 | while len(layer_infos) > -1:
448 | try:
449 | curr_layer = curr_layer.__getattr__(temp_name)
450 | if len(layer_infos) > 0:
451 | temp_name = layer_infos.pop(0)
452 | elif len(layer_infos) == 0:
453 | break
454 | except Exception:
455 | if len(layer_infos) == 0:
456 | print('Error loading layer')
457 | if len(temp_name) > 0:
458 | temp_name += "_" + layer_infos.pop(0)
459 | else:
460 | temp_name = layer_infos.pop(0)
461 |
462 | weight_up = elems['lora_up.weight'].to(dtype)
463 | weight_down = elems['lora_down.weight'].to(dtype)
464 | if 'alpha' in elems.keys():
465 | alpha = elems['alpha'].item() / weight_up.shape[1]
466 | else:
467 | alpha = 1.0
468 |
469 | curr_layer.weight.data = curr_layer.weight.data.to(device)
470 | if len(weight_up.shape) == 4:
471 | curr_layer.weight.data -= multiplier * alpha * torch.mm(weight_up.squeeze(3).squeeze(2),
472 | weight_down.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
473 | else:
474 | curr_layer.weight.data -= multiplier * alpha * torch.mm(weight_up, weight_down)
475 |
476 | return pipeline
--------------------------------------------------------------------------------
/easyanimate/utils/respace.py:
--------------------------------------------------------------------------------
1 | # Modified from OpenAI's diffusion repos
2 | # GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
3 | # ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
4 | # IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
5 |
6 | import numpy as np
7 | import torch as th
8 |
9 | from .gaussian_diffusion import GaussianDiffusion
10 |
11 |
12 | def space_timesteps(num_timesteps, section_counts):
13 | """
14 | Create a list of timesteps to use from an original diffusion process,
15 | given the number of timesteps we want to take from equally-sized portions
16 | of the original process.
17 | For example, if there's 300 timesteps and the section counts are [10,15,20]
18 | then the first 100 timesteps are strided to be 10 timesteps, the second 100
19 | are strided to be 15 timesteps, and the final 100 are strided to be 20.
20 | If the stride is a string starting with "ddim", then the fixed striding
21 | from the DDIM paper is used, and only one section is allowed.
22 | :param num_timesteps: the number of diffusion steps in the original
23 | process to divide up.
24 | :param section_counts: either a list of numbers, or a string containing
25 | comma-separated numbers, indicating the step count
26 | per section. As a special case, use "ddimN" where N
27 | is a number of steps to use the striding from the
28 | DDIM paper.
29 | :return: a set of diffusion steps from the original process to use.
30 | """
31 | if isinstance(section_counts, str):
32 | if section_counts.startswith("ddim"):
33 | desired_count = int(section_counts[len("ddim") :])
34 | for i in range(1, num_timesteps):
35 | if len(range(0, num_timesteps, i)) == desired_count:
36 | return set(range(0, num_timesteps, i))
37 | raise ValueError(
38 | f"cannot create exactly {num_timesteps} steps with an integer stride"
39 | )
40 | section_counts = [int(x) for x in section_counts.split(",")]
41 | size_per = num_timesteps // len(section_counts)
42 | extra = num_timesteps % len(section_counts)
43 | start_idx = 0
44 | all_steps = []
45 | for i, section_count in enumerate(section_counts):
46 | size = size_per + (1 if i < extra else 0)
47 | if size < section_count:
48 | raise ValueError(
49 | f"cannot divide section of {size} steps into {section_count}"
50 | )
51 | frac_stride = 1 if section_count <= 1 else (size - 1) / (section_count - 1)
52 | cur_idx = 0.0
53 | taken_steps = []
54 | for _ in range(section_count):
55 | taken_steps.append(start_idx + round(cur_idx))
56 | cur_idx += frac_stride
57 | all_steps += taken_steps
58 | start_idx += size
59 | return set(all_steps)
60 |
61 |
62 | class SpacedDiffusion(GaussianDiffusion):
63 | """
64 | A diffusion process which can skip steps in a base diffusion process.
65 | :param use_timesteps: a collection (sequence or set) of timesteps from the
66 | original diffusion process to retain.
67 | :param kwargs: the kwargs to create the base diffusion process.
68 | """
69 |
70 | def __init__(self, use_timesteps, **kwargs):
71 | self.use_timesteps = set(use_timesteps)
72 | self.timestep_map = []
73 | self.original_num_steps = len(kwargs["betas"])
74 |
75 | base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
76 | last_alpha_cumprod = 1.0
77 | new_betas = []
78 | for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
79 | if i in self.use_timesteps:
80 | new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
81 | last_alpha_cumprod = alpha_cumprod
82 | self.timestep_map.append(i)
83 | kwargs["betas"] = np.array(new_betas)
84 | super().__init__(**kwargs)
85 |
86 | def p_mean_variance(
87 | self, model, *args, **kwargs
88 | ): # pylint: disable=signature-differs
89 | return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
90 |
91 | def training_losses(
92 | self, model, *args, **kwargs
93 | ): # pylint: disable=signature-differs
94 | return super().training_losses(self._wrap_model(model), *args, **kwargs)
95 |
96 | def training_losses_diffusers(
97 | self, model, *args, **kwargs
98 | ): # pylint: disable=signature-differs
99 | return super().training_losses_diffusers(self._wrap_model(model), *args, **kwargs)
100 |
101 | def condition_mean(self, cond_fn, *args, **kwargs):
102 | return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
103 |
104 | def condition_score(self, cond_fn, *args, **kwargs):
105 | return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
106 |
107 | def _wrap_model(self, model):
108 | if isinstance(model, _WrappedModel):
109 | return model
110 | return _WrappedModel(
111 | model, self.timestep_map, self.original_num_steps
112 | )
113 |
114 | def _scale_timesteps(self, t):
115 | # Scaling is done by the wrapped model.
116 | return t
117 |
118 |
119 | class _WrappedModel:
120 | def __init__(self, model, timestep_map, original_num_steps):
121 | self.model = model
122 | self.timestep_map = timestep_map
123 | # self.rescale_timesteps = rescale_timesteps
124 | self.original_num_steps = original_num_steps
125 |
126 | def __call__(self, x, timestep, **kwargs):
127 | map_tensor = th.tensor(self.timestep_map, device=timestep.device, dtype=timestep.dtype)
128 | new_ts = map_tensor[timestep]
129 | # if self.rescale_timesteps:
130 | # new_ts = new_ts.float() * (1000.0 / self.original_num_steps)
131 | return self.model(x, timestep=new_ts, **kwargs)
--------------------------------------------------------------------------------
/easyanimate/utils/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import imageio
4 | import numpy as np
5 | import torch
6 | import torchvision
7 | from einops import rearrange
8 | from PIL import Image
9 |
10 |
11 | def save_videos_grid(videos: torch.Tensor, path: str, rescale=False, n_rows=6, fps=12, imageio_backend=True):
12 | videos = rearrange(videos, "b c t h w -> t b c h w")
13 | outputs = []
14 | for x in videos:
15 | x = torchvision.utils.make_grid(x, nrow=n_rows)
16 | x = x.transpose(0, 1).transpose(1, 2).squeeze(-1)
17 | if rescale:
18 | x = (x + 1.0) / 2.0 # -1,1 -> 0,1
19 | x = (x * 255).numpy().astype(np.uint8)
20 | outputs.append(Image.fromarray(x))
21 |
22 | os.makedirs(os.path.dirname(path), exist_ok=True)
23 | if imageio_backend:
24 | if path.endswith("mp4"):
25 | imageio.mimsave(path, outputs, fps=fps)
26 | else:
27 | imageio.mimsave(path, outputs, duration=(1000 * 1/fps))
28 | else:
29 | if path.endswith("mp4"):
30 | path = path.replace('.mp4', '.gif')
31 | outputs[0].save(path, format='GIF', append_images=outputs, save_all=True, duration=100, loop=0)
32 |
--------------------------------------------------------------------------------
/models/put models here.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/models/put models here.txt
--------------------------------------------------------------------------------
/nodes.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import folder_paths
4 | comfy_path = os.path.dirname(folder_paths.__file__)
5 |
6 | import sys
7 | easyanimate_path=f'{comfy_path}/custom_nodes/ComfyUI-EasyAnimate'
8 | sys.path.insert(0,easyanimate_path)
9 |
10 | import torch
11 | from diffusers import (AutoencoderKL, DDIMScheduler,
12 | DPMSolverMultistepScheduler,
13 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
14 | PNDMScheduler)
15 | from omegaconf import OmegaConf
16 |
17 | from easyanimate.models.autoencoder_magvit import AutoencoderKLMagvit
18 | from easyanimate.models.transformer3d import Transformer3DModel
19 | from easyanimate.pipeline.pipeline_easyanimate import EasyAnimatePipeline
20 | from easyanimate.utils.lora_utils import merge_lora, unmerge_lora
21 | from easyanimate.utils.utils import save_videos_grid
22 | from einops import rearrange
23 |
24 | checkpoints=['None']
25 | checkpoints.extend(folder_paths.get_filename_list("checkpoints"))
26 | vaes=['None']
27 | vaes.extend(folder_paths.get_filename_list("vae"))
28 |
29 | class EasyAnimateLoader:
30 | @classmethod
31 | def INPUT_TYPES(cls):
32 | return {
33 | "required": {
34 | "pixart_path": (os.listdir(folder_paths.get_folder_paths("diffusers")[0]), {"default": "PixArt-XL-2-512x512"}),
35 | "motion_ckpt": (folder_paths.get_filename_list("checkpoints"), {"default": "easyanimate_v1_mm.safetensors"}),
36 | "sampler_name": (["Euler","Euler A","DPM++","PNDM","DDIM"],{"default":"DPM++"}),
37 | "device":(["cuda","cpu"],{"default":"cuda"}),
38 | },
39 | "optional": {
40 | "transformer_ckpt": (checkpoints, {"default": 'None'}),
41 | "lora_ckpt": (checkpoints, {"default": 'None'}),
42 | "vae_ckpt": (vaes, {"default": 'None'}),
43 | "lora_weight": ("FLOAT", {"default": 0.55, "min": 0, "max": 1, "step": 0.01}),
44 | }
45 | }
46 |
47 | RETURN_TYPES = ("EasyAnimateModel",)
48 | FUNCTION = "run"
49 | CATEGORY = "EasyAnimate"
50 |
51 | def run(self,pixart_path,motion_ckpt,sampler_name,device,transformer_ckpt='None',lora_ckpt='None',vae_ckpt='None',lora_weight=0.55):
52 | pixart_path=os.path.join(folder_paths.get_folder_paths("diffusers")[0],pixart_path)
53 | # Config and model path
54 | config_path = f"{easyanimate_path}/config/easyanimate_video_motion_module_v1.yaml"
55 | model_name = pixart_path
56 | #model_name = "models/Diffusion_Transformer/PixArt-XL-2-512x512"
57 |
58 | # Choose the sampler in "Euler" "Euler A" "DPM++" "PNDM" and "DDIM"
59 | sampler_name = "DPM++"
60 |
61 | # Load pretrained model if need
62 | transformer_path = None
63 | if transformer_ckpt!='None':
64 | transformer_path = folder_paths.get_full_path("checkpoints", transformer_ckpt)
65 | motion_module_path = folder_paths.get_full_path("checkpoints", motion_ckpt)
66 | #motion_module_path = "models/Motion_Module/easyanimate_v1_mm.safetensors"
67 | vae_path = None
68 | if vae_ckpt!='None':
69 | vae_path = folder_paths.get_full_path("vae", vae_ckpt)
70 | lora_path = None
71 | if lora_ckpt!='None':
72 | lora_path = folder_paths.get_full_path("checkpoints", lora_ckpt)
73 |
74 | weight_dtype = torch.float16
75 | guidance_scale = 6.0
76 | seed = 43
77 | num_inference_steps = 30
78 | #lora_weight = 0.55
79 |
80 | config = OmegaConf.load(config_path)
81 |
82 | # Get Transformer
83 | transformer = Transformer3DModel.from_pretrained_2d(
84 | model_name,
85 | subfolder="transformer",
86 | transformer_additional_kwargs=OmegaConf.to_container(config['transformer_additional_kwargs'])
87 | ).to(weight_dtype)
88 |
89 | if transformer_path is not None:
90 | print(f"From checkpoint: {transformer_path}")
91 | if transformer_path.endswith("safetensors"):
92 | from safetensors.torch import load_file, safe_open
93 | state_dict = load_file(transformer_path)
94 | else:
95 | state_dict = torch.load(transformer_path, map_location="cpu")
96 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
97 |
98 | m, u = transformer.load_state_dict(state_dict, strict=False)
99 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
100 |
101 | if motion_module_path is not None:
102 | print(f"From Motion Module: {motion_module_path}")
103 | if motion_module_path.endswith("safetensors"):
104 | from safetensors.torch import load_file, safe_open
105 | state_dict = load_file(motion_module_path)
106 | else:
107 | state_dict = torch.load(motion_module_path, map_location="cpu")
108 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
109 |
110 | m, u = transformer.load_state_dict(state_dict, strict=False)
111 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}, {u}")
112 |
113 | # Get Vae
114 | if OmegaConf.to_container(config['vae_kwargs'])['enable_magvit']:
115 | Choosen_AutoencoderKL = AutoencoderKLMagvit
116 | else:
117 | Choosen_AutoencoderKL = AutoencoderKL
118 | vae = Choosen_AutoencoderKL.from_pretrained(
119 | model_name,
120 | subfolder="vae",
121 | torch_dtype=weight_dtype
122 | )
123 |
124 | if vae_path is not None:
125 | print(f"From checkpoint: {vae_path}")
126 | if vae_path.endswith("safetensors"):
127 | from safetensors.torch import load_file, safe_open
128 | state_dict = load_file(vae_path)
129 | else:
130 | state_dict = torch.load(vae_path, map_location="cpu")
131 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
132 |
133 | m, u = vae.load_state_dict(state_dict, strict=False)
134 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
135 |
136 | # Get Scheduler
137 | Choosen_Scheduler = scheduler_dict = {
138 | "Euler": EulerDiscreteScheduler,
139 | "Euler A": EulerAncestralDiscreteScheduler,
140 | "DPM++": DPMSolverMultistepScheduler,
141 | "PNDM": PNDMScheduler,
142 | "DDIM": DDIMScheduler,
143 | }[sampler_name]
144 | scheduler = Choosen_Scheduler(**OmegaConf.to_container(config['noise_scheduler_kwargs']))
145 |
146 | pipeline = EasyAnimatePipeline.from_pretrained(
147 | model_name,
148 | vae=vae,
149 | transformer=transformer,
150 | scheduler=scheduler,
151 | torch_dtype=weight_dtype
152 | )
153 | #pipeline.to(device)
154 | pipeline.enable_model_cpu_offload()
155 |
156 | pipeline.transformer.to(device)
157 | pipeline.text_encoder.to('cpu')
158 | pipeline.vae.to('cpu')
159 |
160 | if lora_path is not None:
161 | pipeline = merge_lora(pipeline, lora_path, lora_weight)
162 | return (pipeline,)
163 |
164 | class EasyAnimateRun:
165 | @classmethod
166 | def INPUT_TYPES(cls):
167 | return {
168 | "required": {
169 | "model":("EasyAnimateModel",),
170 | "prompt":("STRING",{"multiline": True, "default":"A snowy forest landscape with a dirt road running through it. The road is flanked by trees covered in snow, and the ground is also covered in snow. The sun is shining, creating a bright and serene atmosphere. The road appears to be empty, and there are no people or animals visible in the video. The style of the video is a natural landscape shot, with a focus on the beauty of the snowy forest and the peacefulness of the road."}),
171 | "negative_prompt":("STRING",{"multiline": True, "default":"Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly"}),
172 | "video_length":("INT",{"default":80}),
173 | "num_inference_steps":("INT",{"default":30}),
174 | "width":("INT",{"default":512}),
175 | "height":("INT",{"default":512}),
176 | "guidance_scale":("FLOAT",{"default":6.0}),
177 | "seed":("INT",{"default":1234}),
178 | },
179 | }
180 |
181 | RETURN_TYPES = ("IMAGE",)
182 | FUNCTION = "run"
183 | CATEGORY = "EasyAnimate"
184 |
185 | def run(self,model,prompt,negative_prompt,video_length,num_inference_steps,width,height,guidance_scale,seed):
186 | generator = torch.Generator(device='cuda').manual_seed(seed)
187 |
188 | with torch.no_grad():
189 | videos = model(
190 | prompt,
191 | video_length = video_length,
192 | negative_prompt = negative_prompt,
193 | height = height,
194 | width = width,
195 | generator = generator,
196 | guidance_scale = guidance_scale,
197 | num_inference_steps = num_inference_steps,
198 | ).videos
199 |
200 | videos = rearrange(videos, "b c t h w -> b t h w c")
201 |
202 | return videos
203 |
204 | NODE_CLASS_MAPPINGS = {
205 | "EasyAnimateLoader":EasyAnimateLoader,
206 | "EasyAnimateRun":EasyAnimateRun,
207 | }
--------------------------------------------------------------------------------
/predict_t2i.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | from diffusers import (AutoencoderKL, DDIMScheduler,
5 | DPMSolverMultistepScheduler,
6 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
7 | PNDMScheduler)
8 | from omegaconf import OmegaConf
9 |
10 | from easyanimate.models.autoencoder_magvit import AutoencoderKLMagvit
11 | from easyanimate.models.transformer2d import Transformer2DModel
12 | from easyanimate.pipeline.pipeline_pixart_magvit import PixArtAlphaMagvitPipeline
13 | from easyanimate.utils.lora_utils import merge_lora
14 |
15 | # Config and model path
16 | config_path = "config/easyanimate_image_normal_v1.yaml"
17 | model_name = "models/Diffusion_Transformer/PixArt-XL-2-512x512"
18 | # Choose the sampler in "Euler" "Euler A" "DPM++" "PNDM" and "DDIM"
19 | sampler_name = "DPM++"
20 |
21 | # Load pretrained model if need
22 | transformer_path = None
23 | vae_path = None
24 | lora_path = None
25 |
26 | # Other params
27 | sample_size = [512, 512]
28 | weight_dtype = torch.float16
29 | prompt = "1girl, bangs, blue eyes, blunt bangs, blurry, blurry background, bob cut, depth of field, lips, looking at viewer, motion blur, nose, realistic, red lips, shirt, short hair, solo, white shirt."
30 | negative_prompt = "bad detailed"
31 | guidance_scale = 6.0
32 | seed = 43
33 | lora_weight = 0.55
34 | save_path = "samples/easyanimate-images"
35 |
36 | config = OmegaConf.load(config_path)
37 |
38 | # Get Transformer
39 | transformer = Transformer2DModel.from_pretrained(
40 | model_name,
41 | subfolder="transformer"
42 | ).to(weight_dtype)
43 |
44 | if transformer_path is not None:
45 | print(f"From checkpoint: {transformer_path}")
46 | if transformer_path.endswith("safetensors"):
47 | from safetensors.torch import load_file, safe_open
48 | state_dict = load_file(transformer_path)
49 | else:
50 | state_dict = torch.load(transformer_path, map_location="cpu")
51 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
52 |
53 | m, u = transformer.load_state_dict(state_dict, strict=False)
54 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
55 |
56 | # Get Vae
57 | if OmegaConf.to_container(config['vae_kwargs'])['enable_magvit']:
58 | Choosen_AutoencoderKL = AutoencoderKLMagvit
59 | else:
60 | Choosen_AutoencoderKL = AutoencoderKL
61 | vae = Choosen_AutoencoderKL.from_pretrained(
62 | model_name,
63 | subfolder="vae",
64 | torch_dtype=weight_dtype
65 | )
66 |
67 | if vae_path is not None:
68 | print(f"From checkpoint: {vae_path}")
69 | if vae_path.endswith("safetensors"):
70 | from safetensors.torch import load_file, safe_open
71 | state_dict = load_file(vae_path)
72 | else:
73 | state_dict = torch.load(vae_path, map_location="cpu")
74 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
75 |
76 | m, u = vae.load_state_dict(state_dict, strict=False)
77 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
78 | assert len(u) == 0
79 |
80 | # Get Scheduler
81 | Choosen_Scheduler = scheduler_dict = {
82 | "Euler": EulerDiscreteScheduler,
83 | "Euler A": EulerAncestralDiscreteScheduler,
84 | "DPM++": DPMSolverMultistepScheduler,
85 | "PNDM": PNDMScheduler,
86 | "DDIM": DDIMScheduler,
87 | }[sampler_name]
88 | scheduler = Choosen_Scheduler(**OmegaConf.to_container(config['noise_scheduler_kwargs']))
89 |
90 | # PixArtAlphaMagvitPipeline is compatible with PixArtAlphaPipeline
91 | pipeline = PixArtAlphaMagvitPipeline.from_pretrained(
92 | model_name,
93 | vae=vae,
94 | transformer=transformer,
95 | scheduler=scheduler,
96 | torch_dtype=weight_dtype
97 | )
98 | pipeline.to("cuda")
99 | pipeline.enable_model_cpu_offload()
100 |
101 | if lora_path is not None:
102 | pipeline = merge_lora(pipeline, lora_path, lora_weight)
103 |
104 | generator = torch.Generator(device="cuda").manual_seed(seed)
105 |
106 | with torch.no_grad():
107 | sample = pipeline(
108 | prompt = prompt,
109 | negative_prompt = negative_prompt,
110 | guidance_scale = guidance_scale,
111 | height = sample_size[0],
112 | width = sample_size[1],
113 | generator = generator,
114 | ).images[0]
115 |
116 | if not os.path.exists(save_path):
117 | os.makedirs(save_path, exist_ok=True)
118 |
119 | index = len([path for path in os.listdir(save_path)]) + 1
120 | prefix = str(index).zfill(8)
121 | image_path = os.path.join(save_path, prefix + ".png")
122 | sample.save(image_path)
--------------------------------------------------------------------------------
/predict_t2v.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | from diffusers import (AutoencoderKL, DDIMScheduler,
5 | DPMSolverMultistepScheduler,
6 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
7 | PNDMScheduler)
8 | from omegaconf import OmegaConf
9 |
10 | from easyanimate.models.autoencoder_magvit import AutoencoderKLMagvit
11 | from easyanimate.models.transformer3d import Transformer3DModel
12 | from easyanimate.pipeline.pipeline_easyanimate import EasyAnimatePipeline
13 | from easyanimate.utils.lora_utils import merge_lora, unmerge_lora
14 | from easyanimate.utils.utils import save_videos_grid
15 |
16 | # Config and model path
17 | config_path = "config/easyanimate_video_motion_module_v1.yaml"
18 | model_name = "models/Diffusion_Transformer/PixArt-XL-2-512x512"
19 |
20 | # Choose the sampler in "Euler" "Euler A" "DPM++" "PNDM" and "DDIM"
21 | sampler_name = "DPM++"
22 |
23 | # Load pretrained model if need
24 | transformer_path = None
25 | motion_module_path = "models/Motion_Module/easyanimate_v1_mm.safetensors"
26 | vae_path = None
27 | lora_path = None
28 |
29 | # other params
30 | sample_size = [512, 512]
31 | video_length = 80
32 | fps = 12
33 |
34 | weight_dtype = torch.float16
35 | prompt = "A snowy forest landscape with a dirt road running through it. The road is flanked by trees covered in snow, and the ground is also covered in snow. The sun is shining, creating a bright and serene atmosphere. The road appears to be empty, and there are no people or animals visible in the video. The style of the video is a natural landscape shot, with a focus on the beauty of the snowy forest and the peacefulness of the road."
36 | negative_prompt = "Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly"
37 | guidance_scale = 6.0
38 | seed = 43
39 | num_inference_steps = 30
40 | lora_weight = 0.55
41 | save_path = "samples/easyanimate-videos"
42 |
43 | config = OmegaConf.load(config_path)
44 |
45 | # Get Transformer
46 | transformer = Transformer3DModel.from_pretrained_2d(
47 | model_name,
48 | subfolder="transformer",
49 | transformer_additional_kwargs=OmegaConf.to_container(config['transformer_additional_kwargs'])
50 | ).to(weight_dtype)
51 |
52 | if transformer_path is not None:
53 | print(f"From checkpoint: {transformer_path}")
54 | if transformer_path.endswith("safetensors"):
55 | from safetensors.torch import load_file, safe_open
56 | state_dict = load_file(transformer_path)
57 | else:
58 | state_dict = torch.load(transformer_path, map_location="cpu")
59 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
60 |
61 | m, u = transformer.load_state_dict(state_dict, strict=False)
62 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
63 |
64 | if motion_module_path is not None:
65 | print(f"From Motion Module: {motion_module_path}")
66 | if motion_module_path.endswith("safetensors"):
67 | from safetensors.torch import load_file, safe_open
68 | state_dict = load_file(motion_module_path)
69 | else:
70 | state_dict = torch.load(motion_module_path, map_location="cpu")
71 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
72 |
73 | m, u = transformer.load_state_dict(state_dict, strict=False)
74 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}, {u}")
75 |
76 | # Get Vae
77 | if OmegaConf.to_container(config['vae_kwargs'])['enable_magvit']:
78 | Choosen_AutoencoderKL = AutoencoderKLMagvit
79 | else:
80 | Choosen_AutoencoderKL = AutoencoderKL
81 | vae = Choosen_AutoencoderKL.from_pretrained(
82 | model_name,
83 | subfolder="vae",
84 | torch_dtype=weight_dtype
85 | )
86 |
87 | if vae_path is not None:
88 | print(f"From checkpoint: {vae_path}")
89 | if vae_path.endswith("safetensors"):
90 | from safetensors.torch import load_file, safe_open
91 | state_dict = load_file(vae_path)
92 | else:
93 | state_dict = torch.load(vae_path, map_location="cpu")
94 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
95 |
96 | m, u = vae.load_state_dict(state_dict, strict=False)
97 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
98 |
99 | # Get Scheduler
100 | Choosen_Scheduler = scheduler_dict = {
101 | "Euler": EulerDiscreteScheduler,
102 | "Euler A": EulerAncestralDiscreteScheduler,
103 | "DPM++": DPMSolverMultistepScheduler,
104 | "PNDM": PNDMScheduler,
105 | "DDIM": DDIMScheduler,
106 | }[sampler_name]
107 | scheduler = Choosen_Scheduler(**OmegaConf.to_container(config['noise_scheduler_kwargs']))
108 |
109 | pipeline = EasyAnimatePipeline.from_pretrained(
110 | model_name,
111 | vae=vae,
112 | transformer=transformer,
113 | scheduler=scheduler,
114 | torch_dtype=weight_dtype
115 | )
116 | pipeline.to("cuda")
117 | pipeline.enable_model_cpu_offload()
118 |
119 | generator = torch.Generator(device="cuda").manual_seed(seed)
120 |
121 | if lora_path is not None:
122 | pipeline = merge_lora(pipeline, lora_path, lora_weight)
123 |
124 | with torch.no_grad():
125 | sample = pipeline(
126 | prompt,
127 | video_length = video_length,
128 | negative_prompt = negative_prompt,
129 | height = sample_size[0],
130 | width = sample_size[1],
131 | generator = generator,
132 | guidance_scale = guidance_scale,
133 | num_inference_steps = num_inference_steps,
134 | ).videos
135 |
136 | if not os.path.exists(save_path):
137 | os.makedirs(save_path, exist_ok=True)
138 |
139 | index = len([path for path in os.listdir(save_path)]) + 1
140 | prefix = str(index).zfill(8)
141 | video_path = os.path.join(save_path, prefix + ".gif")
142 | save_videos_grid(sample, video_path, fps=fps)
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | Pillow
2 | einops
3 | safetensors
4 | timm
5 | tomesd
6 | xformers
7 | decord
8 | datasets
9 | numpy
10 | scikit-image
11 | opencv-python
12 | omegaconf
13 | diffusers
14 | transformers
--------------------------------------------------------------------------------
/scripts/extra_motion_module.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from safetensors.torch import load_file, safe_open, save_file
3 |
4 | original_safetensor_path = 'diffusion_pytorch_model.safetensors'
5 | new_safetensor_path = 'easyanimate_v1_mm.safetensors' #
6 |
7 | original_weights = load_file(original_safetensor_path)
8 | temporal_weights = {}
9 | for name, weight in original_weights.items():
10 | if 'temporal' in name:
11 | temporal_weights[name] = weight
12 | save_file(temporal_weights, new_safetensor_path, None)
13 | print(f'Saved weights containing "temporal" to {new_safetensor_path}')
--------------------------------------------------------------------------------
/scripts/train_t2i.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 |
5 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
6 | # vae_mode can be choosen in "normal" and "magvit"
7 | # transformer_mode can be choosen in "normal" and "kvcompress"
8 | accelerate launch --mixed_precision="bf16" scripts/train_t2i.py \
9 | --pretrained_model_name_or_path=$MODEL_NAME \
10 | --train_data_dir=$DATASET_NAME \
11 | --train_data_meta=$DATASET_META_NAME \
12 | --config_path "config/easyanimate_image_normal_v1.yaml" \
13 | --train_data_format="normal" \
14 | --caption_column="text" \
15 | --resolution=512 \
16 | --train_batch_size=2 \
17 | --gradient_accumulation_steps=1 \
18 | --dataloader_num_workers=8 \
19 | --num_train_epochs=50 \
20 | --checkpointing_steps=500 \
21 | --validation_prompts="1girl, bangs, blue eyes, blunt bangs, blurry, blurry background, bob cut, depth of field, lips, looking at viewer, motion blur, nose, realistic, red lips, shirt, short hair, solo, white shirt." \
22 | --validation_epochs=1 \
23 | --validation_steps=100 \
24 | --learning_rate=1e-05 \
25 | --lr_scheduler="constant_with_warmup" \
26 | --lr_warmup_steps=50 \
27 | --seed=42 \
28 | --max_grad_norm=1 \
29 | --output_dir="output_dir_t2i" \
30 | --enable_xformers_memory_efficient_attention \
31 | --gradient_checkpointing \
32 | --mixed_precision='bf16' \
33 | --use_ema \
34 | --trainable_modules "."
--------------------------------------------------------------------------------
/scripts/train_t2i_lora.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 |
5 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
6 | # vae_mode can be choosen in "normal" and "magvit"
7 | # transformer_mode can be choosen in "normal" and "kvcompress"
8 | accelerate launch --mixed_precision="bf16" scripts/train_t2i_lora.py \
9 | --pretrained_model_name_or_path=$MODEL_NAME \
10 | --train_data_dir=$DATASET_NAME \
11 | --train_data_meta=$DATASET_META_NAME \
12 | --config_path "config/easyanimate_image_normal_v1.yaml" \
13 | --train_data_format="normal" \
14 | --caption_column="text" \
15 | --resolution=512 \
16 | --train_text_encoder \
17 | --train_batch_size=2 \
18 | --gradient_accumulation_steps=1 \
19 | --dataloader_num_workers=8 \
20 | --max_train_steps=2500 \
21 | --checkpointing_steps=500 \
22 | --validation_prompts="1girl, bangs, blue eyes, blunt bangs, blurry, blurry background, bob cut, depth of field, lips, looking at viewer, motion blur, nose, realistic, red lips, shirt, short hair, solo, white shirt." \
23 | --validation_steps=100 \
24 | --learning_rate=1e-04 \
25 | --seed=42 \
26 | --output_dir="output_dir_lora" \
27 | --enable_xformers_memory_efficient_attention \
28 | --gradient_checkpointing \
29 | --mixed_precision='bf16'
30 |
--------------------------------------------------------------------------------
/scripts/train_t2iv.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 | export NCCL_IB_DISABLE=1
5 | export NCCL_P2P_DISABLE=1
6 | NCCL_DEBUG=INFO
7 |
8 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
9 | # vae_mode can be choosen in "normal" and "magvit"
10 | # transformer_mode can be choosen in "normal" and "kvcompress"
11 | accelerate launch --mixed_precision="bf16" scripts/train_t2iv.py \
12 | --pretrained_model_name_or_path=$MODEL_NAME \
13 | --train_data_dir=$DATASET_NAME \
14 | --train_data_meta=$DATASET_META_NAME \
15 | --config_path "config/easyanimate_video_motion_module_v1.yaml" \
16 | --image_sample_size=512 \
17 | --video_sample_size=512 \
18 | --video_sample_stride=2 \
19 | --video_sample_n_frames=16 \
20 | --train_batch_size=2 \
21 | --video_repeat=1 \
22 | --image_repeat_in_forward=4 \
23 | --gradient_accumulation_steps=1 \
24 | --dataloader_num_workers=8 \
25 | --num_train_epochs=100 \
26 | --checkpointing_steps=500 \
27 | --validation_prompts="A girl with delicate face is smiling." \
28 | --validation_epochs=1 \
29 | --validation_steps=100 \
30 | --learning_rate=2e-05 \
31 | --lr_scheduler="constant_with_warmup" \
32 | --lr_warmup_steps=100 \
33 | --seed=42 \
34 | --output_dir="output_dir" \
35 | --enable_xformers_memory_efficient_attention \
36 | --gradient_checkpointing \
37 | --mixed_precision="bf16" \
38 | --adam_weight_decay=3e-2 \
39 | --adam_epsilon=1e-10 \
40 | --max_grad_norm=1 \
41 | --vae_mini_batch=16 \
42 | --use_ema \
43 | --trainable_modules "attn_temporal"
--------------------------------------------------------------------------------
/scripts/train_t2v.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 | export NCCL_IB_DISABLE=1
5 | export NCCL_P2P_DISABLE=1
6 | NCCL_DEBUG=INFO
7 |
8 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
9 | accelerate launch --mixed_precision="bf16" scripts/train_t2v.py \
10 | --pretrained_model_name_or_path=$MODEL_NAME \
11 | --train_data_dir=$DATASET_NAME \
12 | --train_data_meta=$DATASET_META_NAME \
13 | --config_path "config/easyanimate_video_motion_module_v1.yaml" \
14 | --train_data_format="normal" \
15 | --train_mode="normal" \
16 | --sample_size=512 \
17 | --sample_stride=2 \
18 | --sample_n_frames=16 \
19 | --train_batch_size=2 \
20 | --gradient_accumulation_steps=1 \
21 | --dataloader_num_workers=8 \
22 | --num_train_epochs=100 \
23 | --checkpointing_steps=500 \
24 | --validation_prompts="A girl with delicate face is smiling." \
25 | --validation_epochs=1 \
26 | --validation_steps=100 \
27 | --learning_rate=2e-05 \
28 | --lr_scheduler="constant_with_warmup" \
29 | --lr_warmup_steps=100 \
30 | --seed=42 \
31 | --output_dir="output_dir" \
32 | --enable_xformers_memory_efficient_attention \
33 | --gradient_checkpointing \
34 | --mixed_precision="bf16" \
35 | --adam_weight_decay=3e-2 \
36 | --adam_epsilon=1e-10 \
37 | --max_grad_norm=1 \
38 | --vae_mini_batch=16 \
39 | --use_ema \
40 | --trainable_modules "attn_temporal"
--------------------------------------------------------------------------------
/scripts/train_t2v_lora.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 | export NCCL_IB_DISABLE=1
5 | export NCCL_P2P_DISABLE=1
6 | NCCL_DEBUG=INFO
7 |
8 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
9 | accelerate launch --mixed_precision="bf16" scripts/train_t2v_lora.py \
10 | --pretrained_model_name_or_path=$MODEL_NAME \
11 | --transformer_path="models/Motion_Module/easyanimate_v1_mm.safetensors" \
12 | --train_data_dir=$DATASET_NAME \
13 | --train_data_meta=$DATASET_META_NAME \
14 | --config_path "config/easyanimate_video_motion_module_v1.yaml" \
15 | --train_data_format="normal" \
16 | --train_mode="normal" \
17 | --sample_size=512 \
18 | --sample_stride=2 \
19 | --sample_n_frames=16 \
20 | --train_batch_size=2 \
21 | --gradient_accumulation_steps=1 \
22 | --dataloader_num_workers=8 \
23 | --num_train_epochs=100 \
24 | --checkpointing_steps=500 \
25 | --validation_prompts="A girl with delicate face is smiling." \
26 | --validation_epochs=1 \
27 | --validation_steps=100 \
28 | --learning_rate=2e-05 \
29 | --seed=42 \
30 | --output_dir="output_dir" \
31 | --enable_xformers_memory_efficient_attention \
32 | --gradient_checkpointing \
33 | --mixed_precision="bf16" \
34 | --adam_weight_decay=3e-2 \
35 | --adam_epsilon=1e-10 \
36 | --max_grad_norm=1 \
37 | --vae_mini_batch=16
38 |
--------------------------------------------------------------------------------
/wf.json:
--------------------------------------------------------------------------------
1 | {
2 | "last_node_id": 8,
3 | "last_link_id": 7,
4 | "nodes": [
5 | {
6 | "id": 2,
7 | "type": "EasyAnimateRun",
8 | "pos": [
9 | 459,
10 | -4
11 | ],
12 | "size": {
13 | "0": 387.611083984375,
14 | "1": 427.48992919921875
15 | },
16 | "flags": {},
17 | "order": 1,
18 | "mode": 0,
19 | "inputs": [
20 | {
21 | "name": "model",
22 | "type": "EasyAnimateModel",
23 | "link": 7
24 | }
25 | ],
26 | "outputs": [
27 | {
28 | "name": "IMAGE",
29 | "type": "IMAGE",
30 | "links": [
31 | 4
32 | ],
33 | "shape": 3,
34 | "slot_index": 0
35 | }
36 | ],
37 | "properties": {
38 | "Node name for S&R": "EasyAnimateRun"
39 | },
40 | "widgets_values": [
41 | "A serene night scene in a forested area. The first frame shows a tranquil lake reflecting the star-filled sky above. The second frame reveals a beautiful sunset, casting a warm glow over the landscape. The third frame showcases the night sky, filled with stars and a vibrant Milky Way galaxy. The video is a time-lapse, capturing the transition from day to night, with the lake and forest serving as a constant backdrop. The style of the video is naturalistic, emphasizing the beauty of the night sky and the peacefulness of the forest.",
42 | "Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly",
43 | 80,
44 | 30,
45 | 512,
46 | 512,
47 | 6,
48 | 1829,
49 | "fixed"
50 | ]
51 | },
52 | {
53 | "id": 8,
54 | "type": "EasyAnimateLoader",
55 | "pos": [
56 | -31,
57 | -3
58 | ],
59 | "size": {
60 | "0": 315,
61 | "1": 226
62 | },
63 | "flags": {},
64 | "order": 0,
65 | "mode": 0,
66 | "outputs": [
67 | {
68 | "name": "EasyAnimateModel",
69 | "type": "EasyAnimateModel",
70 | "links": [
71 | 7
72 | ],
73 | "shape": 3,
74 | "slot_index": 0
75 | }
76 | ],
77 | "properties": {
78 | "Node name for S&R": "EasyAnimateLoader"
79 | },
80 | "widgets_values": [
81 | "PixArt-XL-2-512x512",
82 | "easyanimate_v1_mm.safetensors",
83 | "DPM++",
84 | "cuda",
85 | "PixArt-Sigma-XL-2-1024-MS.pth",
86 | "None",
87 | "None",
88 | 0.55
89 | ]
90 | },
91 | {
92 | "id": 5,
93 | "type": "VHS_VideoCombine",
94 | "pos": [
95 | 1018,
96 | -13
97 | ],
98 | "size": [
99 | 315,
100 | 599
101 | ],
102 | "flags": {},
103 | "order": 2,
104 | "mode": 0,
105 | "inputs": [
106 | {
107 | "name": "images",
108 | "type": "IMAGE",
109 | "link": 4
110 | },
111 | {
112 | "name": "audio",
113 | "type": "VHS_AUDIO",
114 | "link": null
115 | },
116 | {
117 | "name": "batch_manager",
118 | "type": "VHS_BatchManager",
119 | "link": null
120 | }
121 | ],
122 | "outputs": [
123 | {
124 | "name": "Filenames",
125 | "type": "VHS_FILENAMES",
126 | "links": null,
127 | "shape": 3
128 | }
129 | ],
130 | "properties": {
131 | "Node name for S&R": "VHS_VideoCombine"
132 | },
133 | "widgets_values": {
134 | "frame_rate": 8,
135 | "loop_count": 0,
136 | "filename_prefix": "AnimateDiff",
137 | "format": "video/h264-mp4",
138 | "pix_fmt": "yuv420p",
139 | "crf": 19,
140 | "save_metadata": true,
141 | "pingpong": false,
142 | "save_output": true,
143 | "videopreview": {
144 | "hidden": false,
145 | "paused": false,
146 | "params": {
147 | "filename": "AnimateDiff_00461.mp4",
148 | "subfolder": "",
149 | "type": "output",
150 | "format": "video/h264-mp4"
151 | }
152 | }
153 | }
154 | }
155 | ],
156 | "links": [
157 | [
158 | 4,
159 | 2,
160 | 0,
161 | 5,
162 | 0,
163 | "IMAGE"
164 | ],
165 | [
166 | 7,
167 | 8,
168 | 0,
169 | 2,
170 | 0,
171 | "EasyAnimateModel"
172 | ]
173 | ],
174 | "groups": [],
175 | "config": {},
176 | "extra": {},
177 | "version": 0.4
178 | }
--------------------------------------------------------------------------------
/wf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/wf.png
--------------------------------------------------------------------------------
420 |
421 |
422 |
423 | 我们在时序维度上引入注意力机制来让模型学习时序信息,以进行连续视频帧的生成。同时,我们利用额外的网格计算(Grid Reshape),来扩大注意力机制的input token数目,从而更多地利用图像的空间信息以达到更好的生成效果。Motion Module 作为一个单独的模块,在推理时可以用在不同的DiT基线模型上。此外,EasyAnimate不仅支持了motion-module模块的训练,也支持了DiT基模型/LoRA模型的训练,以方便用户根据自身需要来完成自定义风格的模型训练,进而生成任意风格的视频。
424 |
425 |
426 | # 算法限制
427 | - 受
428 |
429 | # 参考文献
430 | - magvit: https://github.com/google-research/magvit
431 | - PixArt: https://github.com/PixArt-alpha/PixArt-alpha
432 | - Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
433 | - Open-Sora: https://github.com/hpcaitech/Open-Sora
434 | - Animatediff: https://github.com/guoyww/AnimateDiff
435 |
436 | # 许可证
437 | 本项目采用 [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
438 |
--------------------------------------------------------------------------------
/__init__.py:
--------------------------------------------------------------------------------
1 | from .nodes import NODE_CLASS_MAPPINGS
2 |
3 | __all__ = ['NODE_CLASS_MAPPINGS']
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | from easyanimate.ui.ui import ui
2 |
3 | if __name__ == "__main__":
4 | server_name = "0.0.0.0"
5 | demo = ui()
6 | demo.launch(server_name=server_name)
--------------------------------------------------------------------------------
/config/easyanimate_image_normal_v1.yaml:
--------------------------------------------------------------------------------
1 | noise_scheduler_kwargs:
2 | beta_start: 0.0001
3 | beta_end: 0.02
4 | beta_schedule: "linear"
5 | steps_offset: 1
6 |
7 | vae_kwargs:
8 | enable_magvit: false
--------------------------------------------------------------------------------
/config/easyanimate_video_long_sequence_v1.yaml:
--------------------------------------------------------------------------------
1 | transformer_additional_kwargs:
2 | patch_3d: false
3 | fake_3d: false
4 | basic_block_type: "selfattentiontemporal"
5 | time_position_encoding_before_transformer: true
6 |
7 | noise_scheduler_kwargs:
8 | beta_start: 0.0001
9 | beta_end: 0.02
10 | beta_schedule: "linear"
11 | steps_offset: 1
12 |
13 | vae_kwargs:
14 | enable_magvit: false
--------------------------------------------------------------------------------
/config/easyanimate_video_motion_module_v1.yaml:
--------------------------------------------------------------------------------
1 | transformer_additional_kwargs:
2 | patch_3d: false
3 | fake_3d: false
4 | basic_block_type: "motionmodule"
5 | time_position_encoding_before_transformer: false
6 | motion_module_type: "VanillaGrid"
7 |
8 | motion_module_kwargs:
9 | num_attention_heads: 8
10 | num_transformer_block: 1
11 | attention_block_types: [ "Temporal_Self", "Temporal_Self" ]
12 | temporal_position_encoding: true
13 | temporal_position_encoding_max_len: 4096
14 | temporal_attention_dim_div: 1
15 | block_size: 2
16 |
17 | noise_scheduler_kwargs:
18 | beta_start: 0.0001
19 | beta_end: 0.02
20 | beta_schedule: "linear"
21 | steps_offset: 1
22 |
23 | vae_kwargs:
24 | enable_magvit: false
--------------------------------------------------------------------------------
/datasets/put datasets here.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/datasets/put datasets here.txt
--------------------------------------------------------------------------------
/easyanimate/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/easyanimate/__init__.py
--------------------------------------------------------------------------------
/easyanimate/data/bucket_sampler.py:
--------------------------------------------------------------------------------
1 | # Copyright (c) OpenMMLab. All rights reserved.
2 | import os
3 |
4 | import cv2
5 | import numpy as np
6 | from PIL import Image
7 | from torch.utils.data import BatchSampler, Dataset, Sampler
8 |
9 | ASPECT_RATIO_512 = {
10 | '0.25': [256.0, 1024.0], '0.26': [256.0, 992.0], '0.27': [256.0, 960.0], '0.28': [256.0, 928.0],
11 | '0.32': [288.0, 896.0], '0.33': [288.0, 864.0], '0.35': [288.0, 832.0], '0.4': [320.0, 800.0],
12 | '0.42': [320.0, 768.0], '0.48': [352.0, 736.0], '0.5': [352.0, 704.0], '0.52': [352.0, 672.0],
13 | '0.57': [384.0, 672.0], '0.6': [384.0, 640.0], '0.68': [416.0, 608.0], '0.72': [416.0, 576.0],
14 | '0.78': [448.0, 576.0], '0.82': [448.0, 544.0], '0.88': [480.0, 544.0], '0.94': [480.0, 512.0],
15 | '1.0': [512.0, 512.0], '1.07': [512.0, 480.0], '1.13': [544.0, 480.0], '1.21': [544.0, 448.0],
16 | '1.29': [576.0, 448.0], '1.38': [576.0, 416.0], '1.46': [608.0, 416.0], '1.67': [640.0, 384.0],
17 | '1.75': [672.0, 384.0], '2.0': [704.0, 352.0], '2.09': [736.0, 352.0], '2.4': [768.0, 320.0],
18 | '2.5': [800.0, 320.0], '2.89': [832.0, 288.0], '3.0': [864.0, 288.0], '3.11': [896.0, 288.0],
19 | '3.62': [928.0, 256.0], '3.75': [960.0, 256.0], '3.88': [992.0, 256.0], '4.0': [1024.0, 256.0]
20 | }
21 | ASPECT_RATIO_RANDOM_CROP_512 = {
22 | '0.42': [320.0, 768.0], '0.5': [352.0, 704.0],
23 | '0.57': [384.0, 672.0], '0.68': [416.0, 608.0], '0.78': [448.0, 576.0], '0.88': [480.0, 544.0],
24 | '0.94': [480.0, 512.0], '1.0': [512.0, 512.0], '1.07': [512.0, 480.0],
25 | '1.13': [544.0, 480.0], '1.29': [576.0, 448.0], '1.46': [608.0, 416.0], '1.75': [672.0, 384.0],
26 | '2.0': [704.0, 352.0], '2.4': [768.0, 320.0]
27 | }
28 | ASPECT_RATIO_RANDOM_CROP_PROB = [
29 | 1, 2,
30 | 4, 4, 4, 4,
31 | 8, 8, 8,
32 | 4, 4, 4, 4,
33 | 2, 1
34 | ]
35 | ASPECT_RATIO_RANDOM_CROP_PROB = np.array(ASPECT_RATIO_RANDOM_CROP_PROB) / sum(ASPECT_RATIO_RANDOM_CROP_PROB)
36 |
37 | def get_closest_ratio(height: float, width: float, ratios: dict = ASPECT_RATIO_512):
38 | aspect_ratio = height / width
39 | closest_ratio = min(ratios.keys(), key=lambda ratio: abs(float(ratio) - aspect_ratio))
40 | return ratios[closest_ratio], float(closest_ratio)
41 |
42 | def get_image_size_without_loading(path):
43 | with Image.open(path) as img:
44 | return img.size # (width, height)
45 |
46 | class AspectRatioBatchImageSampler(BatchSampler):
47 | """A sampler wrapper for grouping images with similar aspect ratio into a same batch.
48 |
49 | Args:
50 | sampler (Sampler): Base sampler.
51 | dataset (Dataset): Dataset providing data information.
52 | batch_size (int): Size of mini-batch.
53 | drop_last (bool): If ``True``, the sampler will drop the last batch if
54 | its size would be less than ``batch_size``.
55 | aspect_ratios (dict): The predefined aspect ratios.
56 | """
57 | def __init__(
58 | self,
59 | sampler: Sampler,
60 | dataset: Dataset,
61 | batch_size: int,
62 | train_folder: str = None,
63 | aspect_ratios: dict = ASPECT_RATIO_512,
64 | drop_last: bool = False,
65 | config=None,
66 | **kwargs
67 | ) -> None:
68 | if not isinstance(sampler, Sampler):
69 | raise TypeError('sampler should be an instance of ``Sampler``, '
70 | f'but got {sampler}')
71 | if not isinstance(batch_size, int) or batch_size <= 0:
72 | raise ValueError('batch_size should be a positive integer value, '
73 | f'but got batch_size={batch_size}')
74 | self.sampler = sampler
75 | self.dataset = dataset
76 | self.train_folder = train_folder
77 | self.batch_size = batch_size
78 | self.aspect_ratios = aspect_ratios
79 | self.drop_last = drop_last
80 | self.config = config
81 | # buckets for each aspect ratio
82 | self._aspect_ratio_buckets = {ratio: [] for ratio in aspect_ratios}
83 | # [str(k) for k, v in aspect_ratios]
84 | self.current_available_bucket_keys = list(aspect_ratios.keys())
85 |
86 | def __iter__(self):
87 | for idx in self.sampler:
88 | try:
89 | image_dict = self.dataset[idx]
90 |
91 | image_id, name = image_dict['file_path'], image_dict['text']
92 | if self.train_folder is None:
93 | image_dir = image_id
94 | else:
95 | image_dir = os.path.join(self.train_folder, image_id)
96 |
97 | width, height = get_image_size_without_loading(image_dir)
98 |
99 | ratio = height / width # self.dataset[idx]
100 | except Exception as e:
101 | print(e)
102 | continue
103 | # find the closest aspect ratio
104 | closest_ratio = min(self.aspect_ratios.keys(), key=lambda r: abs(float(r) - ratio))
105 | if closest_ratio not in self.current_available_bucket_keys:
106 | continue
107 | bucket = self._aspect_ratio_buckets[closest_ratio]
108 | bucket.append(idx)
109 | # yield a batch of indices in the same aspect ratio group
110 | if len(bucket) == self.batch_size:
111 | yield bucket[:]
112 | del bucket[:]
113 |
114 | class AspectRatioBatchSampler(BatchSampler):
115 | """A sampler wrapper for grouping images with similar aspect ratio into a same batch.
116 |
117 | Args:
118 | sampler (Sampler): Base sampler.
119 | dataset (Dataset): Dataset providing data information.
120 | batch_size (int): Size of mini-batch.
121 | drop_last (bool): If ``True``, the sampler will drop the last batch if
122 | its size would be less than ``batch_size``.
123 | aspect_ratios (dict): The predefined aspect ratios.
124 | """
125 | def __init__(
126 | self,
127 | sampler: Sampler,
128 | dataset: Dataset,
129 | batch_size: int,
130 | video_folder: str = None,
131 | train_data_format: str = "webvid",
132 | aspect_ratios: dict = ASPECT_RATIO_512,
133 | drop_last: bool = False,
134 | config=None,
135 | **kwargs
136 | ) -> None:
137 | if not isinstance(sampler, Sampler):
138 | raise TypeError('sampler should be an instance of ``Sampler``, '
139 | f'but got {sampler}')
140 | if not isinstance(batch_size, int) or batch_size <= 0:
141 | raise ValueError('batch_size should be a positive integer value, '
142 | f'but got batch_size={batch_size}')
143 | self.sampler = sampler
144 | self.dataset = dataset
145 | self.video_folder = video_folder
146 | self.train_data_format = train_data_format
147 | self.batch_size = batch_size
148 | self.aspect_ratios = aspect_ratios
149 | self.drop_last = drop_last
150 | self.config = config
151 | # buckets for each aspect ratio
152 | self._aspect_ratio_buckets = {ratio: [] for ratio in aspect_ratios}
153 | # [str(k) for k, v in aspect_ratios]
154 | self.current_available_bucket_keys = list(aspect_ratios.keys())
155 |
156 | def __iter__(self):
157 | for idx in self.sampler:
158 | try:
159 | video_dict = self.dataset[idx]
160 | if self.train_data_format == "normal":
161 | video_id, name = video_dict['file_path'], video_dict['text']
162 | if self.video_folder is None:
163 | video_dir = video_id
164 | else:
165 | video_dir = os.path.join(self.video_folder, video_id)
166 | else:
167 | videoid, name, page_dir = video_dict['videoid'], video_dict['name'], video_dict['page_dir']
168 | video_dir = os.path.join(self.video_folder, f"{videoid}.mp4")
169 | cap = cv2.VideoCapture(video_dir)
170 |
171 | # 获取视频尺寸
172 | width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 浮点数转换为整数
173 | height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 浮点数转换为整数
174 |
175 | ratio = height / width # self.dataset[idx]
176 | except Exception as e:
177 | print(e)
178 | continue
179 | # find the closest aspect ratio
180 | closest_ratio = min(self.aspect_ratios.keys(), key=lambda r: abs(float(r) - ratio))
181 | if closest_ratio not in self.current_available_bucket_keys:
182 | continue
183 | bucket = self._aspect_ratio_buckets[closest_ratio]
184 | bucket.append(idx)
185 | # yield a batch of indices in the same aspect ratio group
186 | if len(bucket) == self.batch_size:
187 | yield bucket[:]
188 | del bucket[:]
--------------------------------------------------------------------------------
/easyanimate/data/dataset_image.py:
--------------------------------------------------------------------------------
1 | import json
2 | import os
3 | import random
4 |
5 | import numpy as np
6 | import torch
7 | import torchvision.transforms as transforms
8 | from PIL import Image
9 | from torch.utils.data.dataset import Dataset
10 |
11 |
12 | class CC15M(Dataset):
13 | def __init__(
14 | self,
15 | json_path,
16 | video_folder=None,
17 | resolution=512,
18 | enable_bucket=False,
19 | ):
20 | print(f"loading annotations from {json_path} ...")
21 | self.dataset = json.load(open(json_path, 'r'))
22 | self.length = len(self.dataset)
23 | print(f"data scale: {self.length}")
24 |
25 | self.enable_bucket = enable_bucket
26 | self.video_folder = video_folder
27 |
28 | resolution = tuple(resolution) if not isinstance(resolution, int) else (resolution, resolution)
29 | self.pixel_transforms = transforms.Compose([
30 | transforms.Resize(resolution[0]),
31 | transforms.CenterCrop(resolution),
32 | transforms.ToTensor(),
33 | transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True),
34 | ])
35 |
36 | def get_batch(self, idx):
37 | video_dict = self.dataset[idx]
38 | video_id, name = video_dict['file_path'], video_dict['text']
39 |
40 | if self.video_folder is None:
41 | video_dir = video_id
42 | else:
43 | video_dir = os.path.join(self.video_folder, video_id)
44 |
45 | pixel_values = Image.open(video_dir).convert("RGB")
46 | return pixel_values, name
47 |
48 | def __len__(self):
49 | return self.length
50 |
51 | def __getitem__(self, idx):
52 | while True:
53 | try:
54 | pixel_values, name = self.get_batch(idx)
55 | break
56 | except Exception as e:
57 | print(e)
58 | idx = random.randint(0, self.length-1)
59 |
60 | if not self.enable_bucket:
61 | pixel_values = self.pixel_transforms(pixel_values)
62 | else:
63 | pixel_values = np.array(pixel_values)
64 |
65 | sample = dict(pixel_values=pixel_values, text=name)
66 | return sample
67 |
68 | if __name__ == "__main__":
69 | dataset = CC15M(
70 | csv_path="/mnt_wg/zhoumo.xjq/CCUtils/cc15m_add_index.json",
71 | resolution=512,
72 | )
73 |
74 | dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=0,)
75 | for idx, batch in enumerate(dataloader):
76 | print(batch["pixel_values"].shape, len(batch["text"]))
--------------------------------------------------------------------------------
/easyanimate/data/dataset_image_video.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import io
3 | import json
4 | import math
5 | import os
6 | import random
7 | from threading import Thread
8 |
9 | import albumentations
10 | import cv2
11 | import numpy as np
12 | import torch
13 | import torchvision.transforms as transforms
14 | from decord import VideoReader
15 | from PIL import Image
16 | from torch.utils.data import BatchSampler, Sampler
17 | from torch.utils.data.dataset import Dataset
18 |
19 |
20 | class ImageVideoSampler(BatchSampler):
21 | """A sampler wrapper for grouping images with similar aspect ratio into a same batch.
22 |
23 | Args:
24 | sampler (Sampler): Base sampler.
25 | dataset (Dataset): Dataset providing data information.
26 | batch_size (int): Size of mini-batch.
27 | drop_last (bool): If ``True``, the sampler will drop the last batch if
28 | its size would be less than ``batch_size``.
29 | aspect_ratios (dict): The predefined aspect ratios.
30 | """
31 |
32 | def __init__(self,
33 | sampler: Sampler,
34 | dataset: Dataset,
35 | batch_size: int,
36 | drop_last: bool = False
37 | ) -> None:
38 | if not isinstance(sampler, Sampler):
39 | raise TypeError('sampler should be an instance of ``Sampler``, '
40 | f'but got {sampler}')
41 | if not isinstance(batch_size, int) or batch_size <= 0:
42 | raise ValueError('batch_size should be a positive integer value, '
43 | f'but got batch_size={batch_size}')
44 | self.sampler = sampler
45 | self.dataset = dataset
46 | self.batch_size = batch_size
47 | self.drop_last = drop_last
48 |
49 | # buckets for each aspect ratio
50 | self.bucket = {'image':[], 'video':[]}
51 |
52 | def __iter__(self):
53 | for idx in self.sampler:
54 | content_type = self.dataset.dataset[idx].get('type', 'image')
55 | self.bucket[content_type].append(idx)
56 |
57 | # yield a batch of indices in the same aspect ratio group
58 | if len(self.bucket['video']) == self.batch_size:
59 | bucket = self.bucket['video']
60 | yield bucket[:]
61 | del bucket[:]
62 | elif len(self.bucket['image']) == self.batch_size:
63 | bucket = self.bucket['image']
64 | yield bucket[:]
65 | del bucket[:]
66 |
67 | class ImageVideoDataset(Dataset):
68 | def __init__(
69 | self,
70 | ann_path, data_root=None,
71 | video_sample_size=512, video_sample_stride=4, video_sample_n_frames=16,
72 | image_sample_size=512,
73 | # For Random Crop
74 | min_crop_f=0.9, max_crop_f=1,
75 | video_repeat=0,
76 | enable_bucket=False
77 | ):
78 | # Loading annotations from files
79 | print(f"loading annotations from {ann_path} ...")
80 | if ann_path.endswith('.csv'):
81 | with open(ann_path, 'r') as csvfile:
82 | dataset = list(csv.DictReader(csvfile))
83 | elif ann_path.endswith('.json'):
84 | dataset = json.load(open(ann_path))
85 |
86 | self.data_root = data_root
87 |
88 | # It's used to balance num of images and videos.
89 | self.dataset = []
90 | for data in dataset:
91 | if data.get('data_type', 'image') != 'video' or data.get('type', 'image') != 'video':
92 | self.dataset.append(data)
93 | if video_repeat > 0:
94 | for _ in range(video_repeat):
95 | for data in dataset:
96 | if data.get('data_type', 'image') == 'video' or data.get('type', 'image') == 'video':
97 | self.dataset.append(data)
98 | del dataset
99 |
100 | self.length = len(self.dataset)
101 | print(f"data scale: {self.length}")
102 | self.min_crop_f = min_crop_f
103 | self.max_crop_f = max_crop_f
104 | # TODO: enable bucket training
105 | self.enable_bucket = enable_bucket
106 |
107 | # Video params
108 | self.video_sample_stride = video_sample_stride
109 | self.video_sample_n_frames = video_sample_n_frames
110 | self.video_sample_size = tuple(video_sample_size) if not isinstance(video_sample_size, int) else (video_sample_size, video_sample_size)
111 | self.video_rescaler = albumentations.SmallestMaxSize(max_size=min(self.video_sample_size), interpolation=cv2.INTER_AREA)
112 |
113 | # Image params
114 | self.image_sample_size = tuple(image_sample_size) if not isinstance(image_sample_size, int) else (image_sample_size, image_sample_size)
115 | self.image_transforms = transforms.Compose([
116 | transforms.RandomHorizontalFlip(),
117 | transforms.Resize(min(self.image_sample_size)),
118 | transforms.CenterCrop(self.image_sample_size),
119 | transforms.ToTensor(),
120 | transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5])
121 | ])
122 |
123 | def get_batch(self, idx):
124 | data_info = self.dataset[idx % len(self.dataset)]
125 |
126 | if data_info.get('data_type', 'image')=='video' or data_info.get('type', 'image')=='video':
127 | video_path, text = data_info['file_path'], data_info['text']
128 | # Get abs path of video
129 | if self.data_root is not None:
130 | video_path = os.path.join(self.data_root, video_path)
131 |
132 | # Get video information firstly
133 | video_reader = VideoReader(video_path, num_threads=2)
134 | h, w, c = video_reader[0].shape
135 | del video_reader
136 |
137 | # Resize to bigger firstly
138 | t_h = int(self.video_sample_size[0] * 1.25 * h / min(h, w))
139 | t_w = int(self.video_sample_size[0] * 1.25 * w / min(h, w))
140 |
141 | # Get video pixels
142 | video_reader = VideoReader(video_path, width=t_w, height=t_h, num_threads=2)
143 | video_length = len(video_reader)
144 | clip_length = min(video_length, (self.video_sample_n_frames - 1) * self.video_sample_stride + 1)
145 | start_idx = random.randint(0, video_length - clip_length)
146 | batch_index = np.linspace(start_idx, start_idx + clip_length - 1, self.video_sample_n_frames, dtype=int)
147 | imgs = video_reader.get_batch(batch_index).asnumpy()
148 | del video_reader
149 | if imgs.shape[0] != self.video_sample_n_frames:
150 | raise ValueError('Video data Sampler Error')
151 |
152 | # Crop center of above videos
153 | min_side_len = min(imgs[0].shape[:2])
154 | crop_side_len = min_side_len * np.random.uniform(self.min_crop_f, self.max_crop_f, size=None)
155 | crop_side_len = int(crop_side_len)
156 | self.cropper = albumentations.RandomCrop(height=crop_side_len, width=crop_side_len)
157 | imgs = np.transpose(imgs, (1, 2, 3, 0))
158 | imgs = self.cropper(image=imgs)["image"]
159 | imgs = np.transpose(imgs, (3, 0, 1, 2))
160 | out_imgs = []
161 |
162 | # Resize to video_sample_size
163 | for img in imgs:
164 | img = self.video_rescaler(image=img)["image"]
165 | out_imgs.append(img[None, :, :, :])
166 | imgs = np.concatenate(out_imgs).transpose(0, 3, 1, 2)
167 |
168 | # Normalize to -1~1
169 | imgs = ((imgs - 127.5) / 127.5).astype(np.float32)
170 | if imgs.shape[0] != self.video_sample_n_frames:
171 | raise ValueError('video data sampler error')
172 |
173 | # Random use no text generation
174 | if random.random() < 0.1:
175 | text = ''
176 | return torch.from_numpy(imgs), text, 'video'
177 | else:
178 | image_path, text = data_info['file_path'], data_info['text']
179 | if self.data_root is not None:
180 | image_path = os.path.join(self.data_root, image_path)
181 | image = Image.open(image_path).convert('RGB')
182 | image = self.image_transforms(image).unsqueeze(0)
183 | if random.random()<0.1:
184 | text = ''
185 | return image, text, 'video'
186 |
187 | def __len__(self):
188 | return self.length
189 |
190 | def __getitem__(self, idx):
191 | while True:
192 | sample = {}
193 | def get_data(data_idx):
194 | pixel_values, name, data_type = self.get_batch(idx)
195 | sample["pixel_values"] = pixel_values
196 | sample["text"] = name
197 | sample["data_type"] = data_type
198 | sample["idx"] = idx
199 | try:
200 | t = Thread(target=get_data, args=(idx, ))
201 | t.start()
202 | t.join(5)
203 | if len(sample)>0:
204 | break
205 | except Exception as e:
206 | print(self.dataset[idx])
207 | idx = idx - 1
208 | return sample
209 |
210 | if __name__ == "__main__":
211 | dataset = ImageVideoDataset(
212 | ann_path="test.json"
213 | )
214 | dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=16)
215 | for idx, batch in enumerate(dataloader):
216 | print(batch["pixel_values"].shape, len(batch["text"]))
--------------------------------------------------------------------------------
/easyanimate/data/dataset_video.py:
--------------------------------------------------------------------------------
1 | import csv
2 | import io
3 | import json
4 | import math
5 | import os
6 | import random
7 |
8 | import numpy as np
9 | import torch
10 | import torchvision.transforms as transforms
11 | from decord import VideoReader
12 | from einops import rearrange
13 | from torch.utils.data.dataset import Dataset
14 |
15 |
16 | def get_random_mask(shape):
17 | f, c, h, w = shape
18 |
19 | mask_index = np.random.randint(0, 4)
20 | mask = torch.zeros((f, 1, h, w), dtype=torch.uint8)
21 | if mask_index == 0:
22 | mask[1:, :, :, :] = 1
23 | elif mask_index == 1:
24 | mask_frame_index = 1
25 | mask[mask_frame_index:-mask_frame_index, :, :, :] = 1
26 | elif mask_index == 2:
27 | center_x = torch.randint(0, w, (1,)).item()
28 | center_y = torch.randint(0, h, (1,)).item()
29 | block_size_x = torch.randint(w // 4, w // 4 * 3, (1,)).item() # 方块的宽度范围
30 | block_size_y = torch.randint(h // 4, h // 4 * 3, (1,)).item() # 方块的高度范围
31 |
32 | start_x = max(center_x - block_size_x // 2, 0)
33 | end_x = min(center_x + block_size_x // 2, w)
34 | start_y = max(center_y - block_size_y // 2, 0)
35 | end_y = min(center_y + block_size_y // 2, h)
36 | mask[:, :, start_y:end_y, start_x:end_x] = 1
37 | elif mask_index == 3:
38 | center_x = torch.randint(0, w, (1,)).item()
39 | center_y = torch.randint(0, h, (1,)).item()
40 | block_size_x = torch.randint(w // 4, w // 4 * 3, (1,)).item() # 方块的宽度范围
41 | block_size_y = torch.randint(h // 4, h // 4 * 3, (1,)).item() # 方块的高度范围
42 |
43 | start_x = max(center_x - block_size_x // 2, 0)
44 | end_x = min(center_x + block_size_x // 2, w)
45 | start_y = max(center_y - block_size_y // 2, 0)
46 | end_y = min(center_y + block_size_y // 2, h)
47 |
48 | mask_frame_before = np.random.randint(0, f // 2)
49 | mask_frame_after = np.random.randint(f // 2, f)
50 | mask[mask_frame_before:mask_frame_after, :, start_y:end_y, start_x:end_x] = 1
51 | else:
52 | raise ValueError(f"The mask_index {mask_index} is not define")
53 | return mask
54 |
55 |
56 | class WebVid10M(Dataset):
57 | def __init__(
58 | self,
59 | csv_path, video_folder,
60 | sample_size=256, sample_stride=4, sample_n_frames=16,
61 | enable_bucket=False, enable_inpaint=False, is_image=False,
62 | ):
63 | print(f"loading annotations from {csv_path} ...")
64 | with open(csv_path, 'r') as csvfile:
65 | self.dataset = list(csv.DictReader(csvfile))
66 | self.length = len(self.dataset)
67 | print(f"data scale: {self.length}")
68 |
69 | self.video_folder = video_folder
70 | self.sample_stride = sample_stride
71 | self.sample_n_frames = sample_n_frames
72 | self.enable_bucket = enable_bucket
73 | self.enable_inpaint = enable_inpaint
74 | self.is_image = is_image
75 |
76 | sample_size = tuple(sample_size) if not isinstance(sample_size, int) else (sample_size, sample_size)
77 | self.pixel_transforms = transforms.Compose([
78 | transforms.Resize(sample_size[0]),
79 | transforms.CenterCrop(sample_size),
80 | transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True),
81 | ])
82 |
83 | def get_batch(self, idx):
84 | video_dict = self.dataset[idx]
85 | videoid, name, page_dir = video_dict['videoid'], video_dict['name'], video_dict['page_dir']
86 |
87 | video_dir = os.path.join(self.video_folder, f"{videoid}.mp4")
88 | video_reader = VideoReader(video_dir)
89 | video_length = len(video_reader)
90 |
91 | if not self.is_image:
92 | clip_length = min(video_length, (self.sample_n_frames - 1) * self.sample_stride + 1)
93 | start_idx = random.randint(0, video_length - clip_length)
94 | batch_index = np.linspace(start_idx, start_idx + clip_length - 1, self.sample_n_frames, dtype=int)
95 | else:
96 | batch_index = [random.randint(0, video_length - 1)]
97 |
98 | if not self.enable_bucket:
99 | pixel_values = torch.from_numpy(video_reader.get_batch(batch_index).asnumpy()).permute(0, 3, 1, 2).contiguous()
100 | pixel_values = pixel_values / 255.
101 | del video_reader
102 | else:
103 | pixel_values = video_reader.get_batch(batch_index).asnumpy()
104 |
105 | if self.is_image:
106 | pixel_values = pixel_values[0]
107 | return pixel_values, name
108 |
109 | def __len__(self):
110 | return self.length
111 |
112 | def __getitem__(self, idx):
113 | while True:
114 | try:
115 | pixel_values, name = self.get_batch(idx)
116 | break
117 |
118 | except Exception as e:
119 | print("Error info:", e)
120 | idx = random.randint(0, self.length-1)
121 |
122 | if not self.enable_bucket:
123 | pixel_values = self.pixel_transforms(pixel_values)
124 | if self.enable_inpaint:
125 | mask = get_random_mask(pixel_values.size())
126 | mask_pixel_values = pixel_values * (1 - mask) + torch.ones_like(pixel_values) * -1 * mask
127 | sample = dict(pixel_values=pixel_values, mask_pixel_values=mask_pixel_values, mask=mask, text=name)
128 | else:
129 | sample = dict(pixel_values=pixel_values, text=name)
130 | return sample
131 |
132 |
133 | class VideoDataset(Dataset):
134 | def __init__(
135 | self,
136 | json_path, video_folder=None,
137 | sample_size=256, sample_stride=4, sample_n_frames=16,
138 | enable_bucket=False, enable_inpaint=False
139 | ):
140 | print(f"loading annotations from {json_path} ...")
141 | self.dataset = json.load(open(json_path, 'r'))
142 | self.length = len(self.dataset)
143 | print(f"data scale: {self.length}")
144 |
145 | self.video_folder = video_folder
146 | self.sample_stride = sample_stride
147 | self.sample_n_frames = sample_n_frames
148 | self.enable_bucket = enable_bucket
149 | self.enable_inpaint = enable_inpaint
150 |
151 | sample_size = tuple(sample_size) if not isinstance(sample_size, int) else (sample_size, sample_size)
152 | self.pixel_transforms = transforms.Compose(
153 | [
154 | transforms.Resize(sample_size[0]),
155 | transforms.CenterCrop(sample_size),
156 | transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5], inplace=True),
157 | ]
158 | )
159 |
160 | def get_batch(self, idx):
161 | video_dict = self.dataset[idx]
162 | video_id, name = video_dict['file_path'], video_dict['text']
163 |
164 | if self.video_folder is None:
165 | video_dir = video_id
166 | else:
167 | video_dir = os.path.join(self.video_folder, video_id)
168 | video_reader = VideoReader(video_dir)
169 | video_length = len(video_reader)
170 |
171 | clip_length = min(video_length, (self.sample_n_frames - 1) * self.sample_stride + 1)
172 | start_idx = random.randint(0, video_length - clip_length)
173 | batch_index = np.linspace(start_idx, start_idx + clip_length - 1, self.sample_n_frames, dtype=int)
174 |
175 | if not self.enable_bucket:
176 | pixel_values = torch.from_numpy(video_reader.get_batch(batch_index).asnumpy()).permute(0, 3, 1, 2).contiguous()
177 | pixel_values = pixel_values / 255.
178 | del video_reader
179 | else:
180 | pixel_values = video_reader.get_batch(batch_index).asnumpy()
181 |
182 | return pixel_values, name
183 |
184 | def __len__(self):
185 | return self.length
186 |
187 | def __getitem__(self, idx):
188 | while True:
189 | try:
190 | pixel_values, name = self.get_batch(idx)
191 | break
192 |
193 | except Exception as e:
194 | print("Error info:", e)
195 | idx = random.randint(0, self.length-1)
196 |
197 | if not self.enable_bucket:
198 | pixel_values = self.pixel_transforms(pixel_values)
199 | if self.enable_inpaint:
200 | mask = get_random_mask(pixel_values.size())
201 | mask_pixel_values = pixel_values * (1 - mask) + torch.ones_like(pixel_values) * -1 * mask
202 | sample = dict(pixel_values=pixel_values, mask_pixel_values=mask_pixel_values, mask=mask, text=name)
203 | else:
204 | sample = dict(pixel_values=pixel_values, text=name)
205 | return sample
206 |
207 |
208 | if __name__ == "__main__":
209 | if 1:
210 | dataset = VideoDataset(
211 | json_path="/home/zhoumo.xjq/disk3/datasets/webvidval/results_2M_val.json",
212 | sample_size=256,
213 | sample_stride=4, sample_n_frames=16,
214 | )
215 |
216 | if 0:
217 | dataset = WebVid10M(
218 | csv_path="/mnt/petrelfs/guoyuwei/projects/datasets/webvid/results_2M_val.csv",
219 | video_folder="/mnt/petrelfs/guoyuwei/projects/datasets/webvid/2M_val",
220 | sample_size=256,
221 | sample_stride=4, sample_n_frames=16,
222 | is_image=False,
223 | )
224 |
225 | dataloader = torch.utils.data.DataLoader(dataset, batch_size=4, num_workers=0,)
226 | for idx, batch in enumerate(dataloader):
227 | print(batch["pixel_values"].shape, len(batch["text"]))
--------------------------------------------------------------------------------
/easyanimate/models/motion_module.py:
--------------------------------------------------------------------------------
1 | """Modified from https://github.com/guoyww/AnimateDiff/blob/main/animatediff/models/motion_module.py
2 | """
3 | import math
4 | from typing import Any, Callable, List, Optional, Tuple, Union
5 |
6 | import torch
7 | import torch.nn.functional as F
8 | from diffusers.models.attention import FeedForward
9 | from diffusers.utils.import_utils import is_xformers_available
10 | from einops import rearrange, repeat
11 | from torch import nn
12 |
13 | if is_xformers_available():
14 | import xformers
15 | import xformers.ops
16 | else:
17 | xformers = None
18 |
19 | class CrossAttention(nn.Module):
20 | r"""
21 | A cross attention layer.
22 |
23 | Parameters:
24 | query_dim (`int`): The number of channels in the query.
25 | cross_attention_dim (`int`, *optional*):
26 | The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
27 | heads (`int`, *optional*, defaults to 8): The number of heads to use for multi-head attention.
28 | dim_head (`int`, *optional*, defaults to 64): The number of channels in each head.
29 | dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
30 | bias (`bool`, *optional*, defaults to False):
31 | Set to `True` for the query, key, and value linear layers to contain a bias parameter.
32 | """
33 |
34 | def __init__(
35 | self,
36 | query_dim: int,
37 | cross_attention_dim: Optional[int] = None,
38 | heads: int = 8,
39 | dim_head: int = 64,
40 | dropout: float = 0.0,
41 | bias=False,
42 | upcast_attention: bool = False,
43 | upcast_softmax: bool = False,
44 | added_kv_proj_dim: Optional[int] = None,
45 | norm_num_groups: Optional[int] = None,
46 | ):
47 | super().__init__()
48 | inner_dim = dim_head * heads
49 | cross_attention_dim = cross_attention_dim if cross_attention_dim is not None else query_dim
50 | self.upcast_attention = upcast_attention
51 | self.upcast_softmax = upcast_softmax
52 |
53 | self.scale = dim_head**-0.5
54 |
55 | self.heads = heads
56 | # for slice_size > 0 the attention score computation
57 | # is split across the batch axis to save memory
58 | # You can set slice_size with `set_attention_slice`
59 | self.sliceable_head_dim = heads
60 | self._slice_size = None
61 | self._use_memory_efficient_attention_xformers = False
62 | self.added_kv_proj_dim = added_kv_proj_dim
63 |
64 | if norm_num_groups is not None:
65 | self.group_norm = nn.GroupNorm(num_channels=inner_dim, num_groups=norm_num_groups, eps=1e-5, affine=True)
66 | else:
67 | self.group_norm = None
68 |
69 | self.to_q = nn.Linear(query_dim, inner_dim, bias=bias)
70 | self.to_k = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
71 | self.to_v = nn.Linear(cross_attention_dim, inner_dim, bias=bias)
72 |
73 | if self.added_kv_proj_dim is not None:
74 | self.add_k_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
75 | self.add_v_proj = nn.Linear(added_kv_proj_dim, cross_attention_dim)
76 |
77 | self.to_out = nn.ModuleList([])
78 | self.to_out.append(nn.Linear(inner_dim, query_dim))
79 | self.to_out.append(nn.Dropout(dropout))
80 |
81 | def set_use_memory_efficient_attention_xformers(
82 | self, valid: bool, attention_op: Optional[Callable] = None
83 | ) -> None:
84 | self._use_memory_efficient_attention_xformers = valid
85 |
86 | def reshape_heads_to_batch_dim(self, tensor):
87 | batch_size, seq_len, dim = tensor.shape
88 | head_size = self.heads
89 | tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
90 | tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size * head_size, seq_len, dim // head_size)
91 | return tensor
92 |
93 | def reshape_batch_dim_to_heads(self, tensor):
94 | batch_size, seq_len, dim = tensor.shape
95 | head_size = self.heads
96 | tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
97 | tensor = tensor.permute(0, 2, 1, 3).reshape(batch_size // head_size, seq_len, dim * head_size)
98 | return tensor
99 |
100 | def set_attention_slice(self, slice_size):
101 | if slice_size is not None and slice_size > self.sliceable_head_dim:
102 | raise ValueError(f"slice_size {slice_size} has to be smaller or equal to {self.sliceable_head_dim}.")
103 |
104 | self._slice_size = slice_size
105 |
106 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None):
107 | batch_size, sequence_length, _ = hidden_states.shape
108 |
109 | encoder_hidden_states = encoder_hidden_states
110 |
111 | if self.group_norm is not None:
112 | hidden_states = self.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
113 |
114 | query = self.to_q(hidden_states)
115 | dim = query.shape[-1]
116 | query = self.reshape_heads_to_batch_dim(query)
117 |
118 | if self.added_kv_proj_dim is not None:
119 | key = self.to_k(hidden_states)
120 | value = self.to_v(hidden_states)
121 | encoder_hidden_states_key_proj = self.add_k_proj(encoder_hidden_states)
122 | encoder_hidden_states_value_proj = self.add_v_proj(encoder_hidden_states)
123 |
124 | key = self.reshape_heads_to_batch_dim(key)
125 | value = self.reshape_heads_to_batch_dim(value)
126 | encoder_hidden_states_key_proj = self.reshape_heads_to_batch_dim(encoder_hidden_states_key_proj)
127 | encoder_hidden_states_value_proj = self.reshape_heads_to_batch_dim(encoder_hidden_states_value_proj)
128 |
129 | key = torch.concat([encoder_hidden_states_key_proj, key], dim=1)
130 | value = torch.concat([encoder_hidden_states_value_proj, value], dim=1)
131 | else:
132 | encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
133 | key = self.to_k(encoder_hidden_states)
134 | value = self.to_v(encoder_hidden_states)
135 |
136 | key = self.reshape_heads_to_batch_dim(key)
137 | value = self.reshape_heads_to_batch_dim(value)
138 |
139 | if attention_mask is not None:
140 | if attention_mask.shape[-1] != query.shape[1]:
141 | target_length = query.shape[1]
142 | attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
143 | attention_mask = attention_mask.repeat_interleave(self.heads, dim=0)
144 |
145 | # attention, what we cannot get enough of
146 | if self._use_memory_efficient_attention_xformers:
147 | hidden_states = self._memory_efficient_attention_xformers(query, key, value, attention_mask)
148 | # Some versions of xformers return output in fp32, cast it back to the dtype of the input
149 | hidden_states = hidden_states.to(query.dtype)
150 | else:
151 | if self._slice_size is None or query.shape[0] // self._slice_size == 1:
152 | hidden_states = self._attention(query, key, value, attention_mask)
153 | else:
154 | hidden_states = self._sliced_attention(query, key, value, sequence_length, dim, attention_mask)
155 |
156 | # linear proj
157 | hidden_states = self.to_out[0](hidden_states)
158 |
159 | # dropout
160 | hidden_states = self.to_out[1](hidden_states)
161 | return hidden_states
162 |
163 | def _attention(self, query, key, value, attention_mask=None):
164 | if self.upcast_attention:
165 | query = query.float()
166 | key = key.float()
167 |
168 | attention_scores = torch.baddbmm(
169 | torch.empty(query.shape[0], query.shape[1], key.shape[1], dtype=query.dtype, device=query.device),
170 | query,
171 | key.transpose(-1, -2),
172 | beta=0,
173 | alpha=self.scale,
174 | )
175 |
176 | if attention_mask is not None:
177 | attention_scores = attention_scores + attention_mask
178 |
179 | if self.upcast_softmax:
180 | attention_scores = attention_scores.float()
181 |
182 | attention_probs = attention_scores.softmax(dim=-1)
183 |
184 | # cast back to the original dtype
185 | attention_probs = attention_probs.to(value.dtype)
186 |
187 | # compute attention output
188 | hidden_states = torch.bmm(attention_probs, value)
189 |
190 | # reshape hidden_states
191 | hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
192 | return hidden_states
193 |
194 | def _sliced_attention(self, query, key, value, sequence_length, dim, attention_mask):
195 | batch_size_attention = query.shape[0]
196 | hidden_states = torch.zeros(
197 | (batch_size_attention, sequence_length, dim // self.heads), device=query.device, dtype=query.dtype
198 | )
199 | slice_size = self._slice_size if self._slice_size is not None else hidden_states.shape[0]
200 | for i in range(hidden_states.shape[0] // slice_size):
201 | start_idx = i * slice_size
202 | end_idx = (i + 1) * slice_size
203 |
204 | query_slice = query[start_idx:end_idx]
205 | key_slice = key[start_idx:end_idx]
206 |
207 | if self.upcast_attention:
208 | query_slice = query_slice.float()
209 | key_slice = key_slice.float()
210 |
211 | attn_slice = torch.baddbmm(
212 | torch.empty(slice_size, query.shape[1], key.shape[1], dtype=query_slice.dtype, device=query.device),
213 | query_slice,
214 | key_slice.transpose(-1, -2),
215 | beta=0,
216 | alpha=self.scale,
217 | )
218 |
219 | if attention_mask is not None:
220 | attn_slice = attn_slice + attention_mask[start_idx:end_idx]
221 |
222 | if self.upcast_softmax:
223 | attn_slice = attn_slice.float()
224 |
225 | attn_slice = attn_slice.softmax(dim=-1)
226 |
227 | # cast back to the original dtype
228 | attn_slice = attn_slice.to(value.dtype)
229 | attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
230 |
231 | hidden_states[start_idx:end_idx] = attn_slice
232 |
233 | # reshape hidden_states
234 | hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
235 | return hidden_states
236 |
237 | def _memory_efficient_attention_xformers(self, query, key, value, attention_mask):
238 | # TODO attention_mask
239 | query = query.contiguous()
240 | key = key.contiguous()
241 | value = value.contiguous()
242 | hidden_states = xformers.ops.memory_efficient_attention(query, key, value, attn_bias=attention_mask)
243 | hidden_states = self.reshape_batch_dim_to_heads(hidden_states)
244 | return hidden_states
245 |
246 | def zero_module(module):
247 | # Zero out the parameters of a module and return it.
248 | for p in module.parameters():
249 | p.detach().zero_()
250 | return module
251 |
252 | def get_motion_module(
253 | in_channels,
254 | motion_module_type: str,
255 | motion_module_kwargs: dict,
256 | ):
257 | if motion_module_type == "Vanilla":
258 | return VanillaTemporalModule(in_channels=in_channels, **motion_module_kwargs,)
259 | elif motion_module_type == "VanillaGrid":
260 | return VanillaTemporalModule(in_channels=in_channels, grid=True, **motion_module_kwargs,)
261 | else:
262 | raise ValueError
263 |
264 | class VanillaTemporalModule(nn.Module):
265 | def __init__(
266 | self,
267 | in_channels,
268 | num_attention_heads = 8,
269 | num_transformer_block = 2,
270 | attention_block_types =( "Temporal_Self", "Temporal_Self" ),
271 | cross_frame_attention_mode = None,
272 | temporal_position_encoding = False,
273 | temporal_position_encoding_max_len = 4096,
274 | temporal_attention_dim_div = 1,
275 | zero_initialize = True,
276 | block_size = 1,
277 | grid = False,
278 | ):
279 | super().__init__()
280 |
281 | self.temporal_transformer = TemporalTransformer3DModel(
282 | in_channels=in_channels,
283 | num_attention_heads=num_attention_heads,
284 | attention_head_dim=in_channels // num_attention_heads // temporal_attention_dim_div,
285 | num_layers=num_transformer_block,
286 | attention_block_types=attention_block_types,
287 | cross_frame_attention_mode=cross_frame_attention_mode,
288 | temporal_position_encoding=temporal_position_encoding,
289 | temporal_position_encoding_max_len=temporal_position_encoding_max_len,
290 | grid=grid,
291 | block_size=block_size,
292 | )
293 | if zero_initialize:
294 | self.temporal_transformer.proj_out = zero_module(self.temporal_transformer.proj_out)
295 |
296 | def forward(self, input_tensor, encoder_hidden_states=None, attention_mask=None, anchor_frame_idx=None):
297 | hidden_states = input_tensor
298 | hidden_states = self.temporal_transformer(hidden_states, encoder_hidden_states, attention_mask)
299 |
300 | output = hidden_states
301 | return output
302 |
303 | class TemporalTransformer3DModel(nn.Module):
304 | def __init__(
305 | self,
306 | in_channels,
307 | num_attention_heads,
308 | attention_head_dim,
309 |
310 | num_layers,
311 | attention_block_types = ( "Temporal_Self", "Temporal_Self", ),
312 | dropout = 0.0,
313 | norm_num_groups = 32,
314 | cross_attention_dim = 768,
315 | activation_fn = "geglu",
316 | attention_bias = False,
317 | upcast_attention = False,
318 |
319 | cross_frame_attention_mode = None,
320 | temporal_position_encoding = False,
321 | temporal_position_encoding_max_len = 4096,
322 | grid = False,
323 | block_size = 1,
324 | ):
325 | super().__init__()
326 |
327 | inner_dim = num_attention_heads * attention_head_dim
328 |
329 | self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
330 | self.proj_in = nn.Linear(in_channels, inner_dim)
331 |
332 | self.block_size = block_size
333 | self.transformer_blocks = nn.ModuleList(
334 | [
335 | TemporalTransformerBlock(
336 | dim=inner_dim,
337 | num_attention_heads=num_attention_heads,
338 | attention_head_dim=attention_head_dim,
339 | attention_block_types=attention_block_types,
340 | dropout=dropout,
341 | norm_num_groups=norm_num_groups,
342 | cross_attention_dim=cross_attention_dim,
343 | activation_fn=activation_fn,
344 | attention_bias=attention_bias,
345 | upcast_attention=upcast_attention,
346 | cross_frame_attention_mode=cross_frame_attention_mode,
347 | temporal_position_encoding=temporal_position_encoding,
348 | temporal_position_encoding_max_len=temporal_position_encoding_max_len,
349 | block_size=block_size,
350 | grid=grid,
351 | )
352 | for d in range(num_layers)
353 | ]
354 | )
355 | self.proj_out = nn.Linear(inner_dim, in_channels)
356 |
357 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None):
358 | assert hidden_states.dim() == 5, f"Expected hidden_states to have ndim=5, but got ndim={hidden_states.dim()}."
359 | video_length = hidden_states.shape[2]
360 | hidden_states = rearrange(hidden_states, "b c f h w -> (b f) c h w")
361 |
362 | batch, channel, height, weight = hidden_states.shape
363 | residual = hidden_states
364 |
365 | hidden_states = self.norm(hidden_states)
366 | inner_dim = hidden_states.shape[1]
367 | hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * weight, inner_dim)
368 | hidden_states = self.proj_in(hidden_states)
369 |
370 | # Transformer Blocks
371 | for block in self.transformer_blocks:
372 | hidden_states = block(hidden_states, encoder_hidden_states=encoder_hidden_states, video_length=video_length, height=height, weight=weight)
373 |
374 | # output
375 | hidden_states = self.proj_out(hidden_states)
376 | hidden_states = hidden_states.reshape(batch, height, weight, inner_dim).permute(0, 3, 1, 2).contiguous()
377 |
378 | output = hidden_states + residual
379 | output = rearrange(output, "(b f) c h w -> b c f h w", f=video_length)
380 |
381 | return output
382 |
383 | class TemporalTransformerBlock(nn.Module):
384 | def __init__(
385 | self,
386 | dim,
387 | num_attention_heads,
388 | attention_head_dim,
389 | attention_block_types = ( "Temporal_Self", "Temporal_Self", ),
390 | dropout = 0.0,
391 | norm_num_groups = 32,
392 | cross_attention_dim = 768,
393 | activation_fn = "geglu",
394 | attention_bias = False,
395 | upcast_attention = False,
396 | cross_frame_attention_mode = None,
397 | temporal_position_encoding = False,
398 | temporal_position_encoding_max_len = 4096,
399 | block_size = 1,
400 | grid = False,
401 | ):
402 | super().__init__()
403 |
404 | attention_blocks = []
405 | norms = []
406 |
407 | for block_name in attention_block_types:
408 | attention_blocks.append(
409 | VersatileAttention(
410 | attention_mode=block_name.split("_")[0],
411 | cross_attention_dim=cross_attention_dim if block_name.endswith("_Cross") else None,
412 |
413 | query_dim=dim,
414 | heads=num_attention_heads,
415 | dim_head=attention_head_dim,
416 | dropout=dropout,
417 | bias=attention_bias,
418 | upcast_attention=upcast_attention,
419 |
420 | cross_frame_attention_mode=cross_frame_attention_mode,
421 | temporal_position_encoding=temporal_position_encoding,
422 | temporal_position_encoding_max_len=temporal_position_encoding_max_len,
423 | block_size=block_size,
424 | grid=grid,
425 | )
426 | )
427 | norms.append(nn.LayerNorm(dim))
428 |
429 | self.attention_blocks = nn.ModuleList(attention_blocks)
430 | self.norms = nn.ModuleList(norms)
431 |
432 | self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn)
433 | self.ff_norm = nn.LayerNorm(dim)
434 |
435 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None, height=None, weight=None):
436 | for attention_block, norm in zip(self.attention_blocks, self.norms):
437 | norm_hidden_states = norm(hidden_states)
438 | hidden_states = attention_block(
439 | norm_hidden_states,
440 | encoder_hidden_states=encoder_hidden_states if attention_block.is_cross_attention else None,
441 | video_length=video_length,
442 | height=height,
443 | weight=weight,
444 | ) + hidden_states
445 |
446 | hidden_states = self.ff(self.ff_norm(hidden_states)) + hidden_states
447 |
448 | output = hidden_states
449 | return output
450 |
451 | class PositionalEncoding(nn.Module):
452 | def __init__(
453 | self,
454 | d_model,
455 | dropout = 0.,
456 | max_len = 4096
457 | ):
458 | super().__init__()
459 | self.dropout = nn.Dropout(p=dropout)
460 | position = torch.arange(max_len).unsqueeze(1)
461 | div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
462 | pe = torch.zeros(1, max_len, d_model)
463 | pe[0, :, 0::2] = torch.sin(position * div_term)
464 | pe[0, :, 1::2] = torch.cos(position * div_term)
465 | self.register_buffer('pe', pe)
466 |
467 | def forward(self, x):
468 | x = x + self.pe[:, :x.size(1)]
469 | return self.dropout(x)
470 |
471 | class VersatileAttention(CrossAttention):
472 | def __init__(
473 | self,
474 | attention_mode = None,
475 | cross_frame_attention_mode = None,
476 | temporal_position_encoding = False,
477 | temporal_position_encoding_max_len = 4096,
478 | grid = False,
479 | block_size = 1,
480 | *args, **kwargs
481 | ):
482 | super().__init__(*args, **kwargs)
483 | assert attention_mode == "Temporal"
484 |
485 | self.attention_mode = attention_mode
486 | self.is_cross_attention = kwargs["cross_attention_dim"] is not None
487 |
488 | self.block_size = block_size
489 | self.grid = grid
490 | self.pos_encoder = PositionalEncoding(
491 | kwargs["query_dim"],
492 | dropout=0.,
493 | max_len=temporal_position_encoding_max_len
494 | ) if (temporal_position_encoding and attention_mode == "Temporal") else None
495 |
496 | def extra_repr(self):
497 | return f"(Module Info) Attention_Mode: {self.attention_mode}, Is_Cross_Attention: {self.is_cross_attention}"
498 |
499 | def forward(self, hidden_states, encoder_hidden_states=None, attention_mask=None, video_length=None, height=None, weight=None):
500 | batch_size, sequence_length, _ = hidden_states.shape
501 |
502 | if self.attention_mode == "Temporal":
503 | # for add pos_encoder
504 | _, before_d, _c = hidden_states.size()
505 | hidden_states = rearrange(hidden_states, "(b f) d c -> (b d) f c", f=video_length)
506 | if self.pos_encoder is not None:
507 | hidden_states = self.pos_encoder(hidden_states)
508 |
509 | if self.grid:
510 | hidden_states = rearrange(hidden_states, "(b d) f c -> b f d c", f=video_length, d=before_d)
511 | hidden_states = rearrange(hidden_states, "b f (h w) c -> b f h w c", h=height, w=weight)
512 |
513 | hidden_states = rearrange(hidden_states, "b f (h n) (w m) c -> (b h w) (f n m) c", n=self.block_size, m=self.block_size)
514 | d = before_d // self.block_size // self.block_size
515 | else:
516 | d = before_d
517 | encoder_hidden_states = repeat(encoder_hidden_states, "b n c -> (b d) n c", d=d) if encoder_hidden_states is not None else encoder_hidden_states
518 | else:
519 | raise NotImplementedError
520 |
521 | encoder_hidden_states = encoder_hidden_states
522 |
523 | if self.group_norm is not None:
524 | hidden_states = self.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
525 |
526 | query = self.to_q(hidden_states)
527 | dim = query.shape[-1]
528 | query = self.reshape_heads_to_batch_dim(query)
529 |
530 | if self.added_kv_proj_dim is not None:
531 | raise NotImplementedError
532 |
533 | encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
534 | key = self.to_k(encoder_hidden_states)
535 | value = self.to_v(encoder_hidden_states)
536 |
537 | key = self.reshape_heads_to_batch_dim(key)
538 | value = self.reshape_heads_to_batch_dim(value)
539 |
540 | if attention_mask is not None:
541 | if attention_mask.shape[-1] != query.shape[1]:
542 | target_length = query.shape[1]
543 | attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
544 | attention_mask = attention_mask.repeat_interleave(self.heads, dim=0)
545 |
546 | bs = 512
547 | new_hidden_states = []
548 | for i in range(0, query.shape[0], bs):
549 | # attention, what we cannot get enough of
550 | if self._use_memory_efficient_attention_xformers:
551 | hidden_states = self._memory_efficient_attention_xformers(query[i : i + bs], key[i : i + bs], value[i : i + bs], attention_mask[i : i + bs] if attention_mask is not None else attention_mask)
552 | # Some versions of xformers return output in fp32, cast it back to the dtype of the input
553 | hidden_states = hidden_states.to(query.dtype)
554 | else:
555 | if self._slice_size is None or query[i : i + bs].shape[0] // self._slice_size == 1:
556 | hidden_states = self._attention(query[i : i + bs], key[i : i + bs], value[i : i + bs], attention_mask[i : i + bs] if attention_mask is not None else attention_mask)
557 | else:
558 | hidden_states = self._sliced_attention(query[i : i + bs], key[i : i + bs], value[i : i + bs], sequence_length, dim, attention_mask[i : i + bs] if attention_mask is not None else attention_mask)
559 | new_hidden_states.append(hidden_states)
560 | hidden_states = torch.cat(new_hidden_states, dim = 0)
561 |
562 | # linear proj
563 | hidden_states = self.to_out[0](hidden_states)
564 |
565 | # dropout
566 | hidden_states = self.to_out[1](hidden_states)
567 |
568 | if self.attention_mode == "Temporal":
569 | hidden_states = rearrange(hidden_states, "(b d) f c -> (b f) d c", d=d)
570 | if self.grid:
571 | hidden_states = rearrange(hidden_states, "(b f n m) (h w) c -> (b f) h n w m c", f=video_length, n=self.block_size, m=self.block_size, h=height // self.block_size, w=weight // self.block_size)
572 | hidden_states = rearrange(hidden_states, "b h n w m c -> b (h n) (w m) c")
573 | hidden_states = rearrange(hidden_states, "b h w c -> b (h w) c")
574 |
575 | return hidden_states
--------------------------------------------------------------------------------
/easyanimate/models/patch.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import numpy as np
4 | import torch
5 | import torch.nn.functional as F
6 | import torch.nn.init as init
7 | from einops import rearrange
8 | from torch import nn
9 |
10 |
11 | def get_2d_sincos_pos_embed(
12 | embed_dim, grid_size, cls_token=False, extra_tokens=0, interpolation_scale=1.0, base_size=16
13 | ):
14 | """
15 | grid_size: int of the grid height and width return: pos_embed: [grid_size*grid_size, embed_dim] or
16 | [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
17 | """
18 | if isinstance(grid_size, int):
19 | grid_size = (grid_size, grid_size)
20 |
21 | grid_h = np.arange(grid_size[0], dtype=np.float32) / (grid_size[0] / base_size) / interpolation_scale
22 | grid_w = np.arange(grid_size[1], dtype=np.float32) / (grid_size[1] / base_size) / interpolation_scale
23 | grid = np.meshgrid(grid_w, grid_h) # here w goes first
24 | grid = np.stack(grid, axis=0)
25 |
26 | grid = grid.reshape([2, 1, grid_size[1], grid_size[0]])
27 | pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
28 | if cls_token and extra_tokens > 0:
29 | pos_embed = np.concatenate([np.zeros([extra_tokens, embed_dim]), pos_embed], axis=0)
30 | return pos_embed
31 |
32 |
33 | def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
34 | if embed_dim % 2 != 0:
35 | raise ValueError("embed_dim must be divisible by 2")
36 |
37 | # use half of dimensions to encode grid_h
38 | emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
39 | emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
40 |
41 | emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
42 | return emb
43 |
44 |
45 | def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
46 | """
47 | embed_dim: output dimension for each position pos: a list of positions to be encoded: size (M,) out: (M, D)
48 | """
49 | if embed_dim % 2 != 0:
50 | raise ValueError("embed_dim must be divisible by 2")
51 |
52 | omega = np.arange(embed_dim // 2, dtype=np.float64)
53 | omega /= embed_dim / 2.0
54 | omega = 1.0 / 10000**omega # (D/2,)
55 |
56 | pos = pos.reshape(-1) # (M,)
57 | out = np.einsum("m,d->md", pos, omega) # (M, D/2), outer product
58 |
59 | emb_sin = np.sin(out) # (M, D/2)
60 | emb_cos = np.cos(out) # (M, D/2)
61 |
62 | emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
63 | return emb
64 |
65 | class Patch1D(nn.Module):
66 | def __init__(
67 | self,
68 | channels: int,
69 | use_conv: bool = False,
70 | out_channels: Optional[int] = None,
71 | stride: int = 2,
72 | padding: int = 0,
73 | name: str = "conv",
74 | ):
75 | super().__init__()
76 | self.channels = channels
77 | self.out_channels = out_channels or channels
78 | self.use_conv = use_conv
79 | self.padding = padding
80 | self.name = name
81 |
82 | if use_conv:
83 | self.conv = nn.Conv1d(self.channels, self.out_channels, stride, stride=stride, padding=padding)
84 | init.constant_(self.conv.weight, 0.0)
85 | with torch.no_grad():
86 | for i in range(len(self.conv.weight)): self.conv.weight[i, i] = 1 / stride
87 | init.constant_(self.conv.bias, 0.0)
88 | else:
89 | assert self.channels == self.out_channels
90 | self.conv = nn.AvgPool1d(kernel_size=stride, stride=stride)
91 |
92 | def forward(self, inputs: torch.Tensor) -> torch.Tensor:
93 | assert inputs.shape[1] == self.channels
94 | return self.conv(inputs)
95 |
96 | class UnPatch1D(nn.Module):
97 | def __init__(
98 | self,
99 | channels: int,
100 | use_conv: bool = False,
101 | use_conv_transpose: bool = False,
102 | out_channels: Optional[int] = None,
103 | name: str = "conv",
104 | ):
105 | super().__init__()
106 | self.channels = channels
107 | self.out_channels = out_channels or channels
108 | self.use_conv = use_conv
109 | self.use_conv_transpose = use_conv_transpose
110 | self.name = name
111 |
112 | self.conv = None
113 | if use_conv_transpose:
114 | self.conv = nn.ConvTranspose1d(channels, self.out_channels, 4, 2, 1)
115 | elif use_conv:
116 | self.conv = nn.Conv1d(self.channels, self.out_channels, 3, padding=1)
117 |
118 | def forward(self, inputs: torch.Tensor) -> torch.Tensor:
119 | assert inputs.shape[1] == self.channels
120 | if self.use_conv_transpose:
121 | return self.conv(inputs)
122 |
123 | outputs = F.interpolate(inputs, scale_factor=2.0, mode="nearest")
124 |
125 | if self.use_conv:
126 | outputs = self.conv(outputs)
127 |
128 | return outputs
129 |
130 | class PatchEmbed3D(nn.Module):
131 | """3D Image to Patch Embedding"""
132 |
133 | def __init__(
134 | self,
135 | height=224,
136 | width=224,
137 | patch_size=16,
138 | time_patch_size=4,
139 | in_channels=3,
140 | embed_dim=768,
141 | layer_norm=False,
142 | flatten=True,
143 | bias=True,
144 | interpolation_scale=1,
145 | ):
146 | super().__init__()
147 |
148 | num_patches = (height // patch_size) * (width // patch_size)
149 | self.flatten = flatten
150 | self.layer_norm = layer_norm
151 |
152 | self.proj = nn.Conv3d(
153 | in_channels, embed_dim, kernel_size=(time_patch_size, patch_size, patch_size), stride=(time_patch_size, patch_size, patch_size), bias=bias
154 | )
155 | if layer_norm:
156 | self.norm = nn.LayerNorm(embed_dim, elementwise_affine=False, eps=1e-6)
157 | else:
158 | self.norm = None
159 |
160 | self.patch_size = patch_size
161 | # See:
162 | # https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L161
163 | self.height, self.width = height // patch_size, width // patch_size
164 | self.base_size = height // patch_size
165 | self.interpolation_scale = interpolation_scale
166 | pos_embed = get_2d_sincos_pos_embed(
167 | embed_dim, int(num_patches**0.5), base_size=self.base_size, interpolation_scale=self.interpolation_scale
168 | )
169 | self.register_buffer("pos_embed", torch.from_numpy(pos_embed).float().unsqueeze(0), persistent=False)
170 |
171 | def forward(self, latent):
172 | height, width = latent.shape[-2] // self.patch_size, latent.shape[-1] // self.patch_size
173 |
174 | latent = self.proj(latent)
175 | latent = rearrange(latent, "b c f h w -> (b f) c h w")
176 | if self.flatten:
177 | latent = latent.flatten(2).transpose(1, 2) # BCFHW -> BNC
178 | if self.layer_norm:
179 | latent = self.norm(latent)
180 |
181 | # Interpolate positional embeddings if needed.
182 | # (For PixArt-Alpha: https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L162C151-L162C160)
183 | if self.height != height or self.width != width:
184 | pos_embed = get_2d_sincos_pos_embed(
185 | embed_dim=self.pos_embed.shape[-1],
186 | grid_size=(height, width),
187 | base_size=self.base_size,
188 | interpolation_scale=self.interpolation_scale,
189 | )
190 | pos_embed = torch.from_numpy(pos_embed)
191 | pos_embed = pos_embed.float().unsqueeze(0).to(latent.device)
192 | else:
193 | pos_embed = self.pos_embed
194 |
195 | return (latent + pos_embed).to(latent.dtype)
196 |
197 | class PatchEmbedF3D(nn.Module):
198 | """Fake 3D Image to Patch Embedding"""
199 |
200 | def __init__(
201 | self,
202 | height=224,
203 | width=224,
204 | patch_size=16,
205 | in_channels=3,
206 | embed_dim=768,
207 | layer_norm=False,
208 | flatten=True,
209 | bias=True,
210 | interpolation_scale=1,
211 | ):
212 | super().__init__()
213 |
214 | num_patches = (height // patch_size) * (width // patch_size)
215 | self.flatten = flatten
216 | self.layer_norm = layer_norm
217 |
218 | self.proj = nn.Conv2d(
219 | in_channels, embed_dim, kernel_size=(patch_size, patch_size), stride=patch_size, bias=bias
220 | )
221 | self.proj_t = Patch1D(
222 | embed_dim, True, stride=patch_size
223 | )
224 | if layer_norm:
225 | self.norm = nn.LayerNorm(embed_dim, elementwise_affine=False, eps=1e-6)
226 | else:
227 | self.norm = None
228 |
229 | self.patch_size = patch_size
230 | # See:
231 | # https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L161
232 | self.height, self.width = height // patch_size, width // patch_size
233 | self.base_size = height // patch_size
234 | self.interpolation_scale = interpolation_scale
235 | pos_embed = get_2d_sincos_pos_embed(
236 | embed_dim, int(num_patches**0.5), base_size=self.base_size, interpolation_scale=self.interpolation_scale
237 | )
238 | self.register_buffer("pos_embed", torch.from_numpy(pos_embed).float().unsqueeze(0), persistent=False)
239 |
240 | def forward(self, latent):
241 | height, width = latent.shape[-2] // self.patch_size, latent.shape[-1] // self.patch_size
242 | b, c, f, h, w = latent.size()
243 | latent = rearrange(latent, "b c f h w -> (b f) c h w")
244 | latent = self.proj(latent)
245 | latent = rearrange(latent, "(b f) c h w -> b c f h w", f=f)
246 |
247 | latent = rearrange(latent, "b c f h w -> (b h w) c f")
248 | latent = self.proj_t(latent)
249 | latent = rearrange(latent, "(b h w) c f -> b c f h w", h=h//2, w=w//2)
250 |
251 | latent = rearrange(latent, "b c f h w -> (b f) c h w")
252 | if self.flatten:
253 | latent = latent.flatten(2).transpose(1, 2) # BCFHW -> BNC
254 | if self.layer_norm:
255 | latent = self.norm(latent)
256 |
257 | # Interpolate positional embeddings if needed.
258 | # (For PixArt-Alpha: https://github.com/PixArt-alpha/PixArt-alpha/blob/0f55e922376d8b797edd44d25d0e7464b260dcab/diffusion/model/nets/PixArtMS.py#L162C151-L162C160)
259 | if self.height != height or self.width != width:
260 | pos_embed = get_2d_sincos_pos_embed(
261 | embed_dim=self.pos_embed.shape[-1],
262 | grid_size=(height, width),
263 | base_size=self.base_size,
264 | interpolation_scale=self.interpolation_scale,
265 | )
266 | pos_embed = torch.from_numpy(pos_embed)
267 | pos_embed = pos_embed.float().unsqueeze(0).to(latent.device)
268 | else:
269 | pos_embed = self.pos_embed
270 |
271 | return (latent + pos_embed).to(latent.dtype)
--------------------------------------------------------------------------------
/easyanimate/models/transformer2d.py:
--------------------------------------------------------------------------------
1 | # Copyright 2023 The HuggingFace Team. All rights reserved.
2 | #
3 | # Licensed under the Apache License, Version 2.0 (the "License");
4 | # you may not use this file except in compliance with the License.
5 | # You may obtain a copy of the License at
6 | #
7 | # http://www.apache.org/licenses/LICENSE-2.0
8 | #
9 | # Unless required by applicable law or agreed to in writing, software
10 | # distributed under the License is distributed on an "AS IS" BASIS,
11 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 | # See the License for the specific language governing permissions and
13 | # limitations under the License.
14 | import json
15 | import os
16 | from dataclasses import dataclass
17 | from typing import Any, Dict, Optional
18 |
19 | import numpy as np
20 | import torch
21 | import torch.nn.functional as F
22 | import torch.nn.init as init
23 | from diffusers.configuration_utils import ConfigMixin, register_to_config
24 | from diffusers.models.attention import BasicTransformerBlock
25 | from diffusers.models.embeddings import ImagePositionalEmbeddings, PatchEmbed
26 | from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
27 | from diffusers.models.modeling_utils import ModelMixin
28 | from diffusers.models.normalization import AdaLayerNormSingle
29 | from diffusers.utils import (USE_PEFT_BACKEND, BaseOutput, deprecate,
30 | is_torch_version)
31 | from einops import rearrange
32 | from torch import nn
33 |
34 | try:
35 | from diffusers.models.embeddings import PixArtAlphaTextProjection
36 | except:
37 | from diffusers.models.embeddings import \
38 | CaptionProjection as PixArtAlphaTextProjection
39 |
40 |
41 | @dataclass
42 | class Transformer2DModelOutput(BaseOutput):
43 | """
44 | The output of [`Transformer2DModel`].
45 |
46 | Args:
47 | sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` or `(batch size, num_vector_embeds - 1, num_latent_pixels)` if [`Transformer2DModel`] is discrete):
48 | The hidden states output conditioned on the `encoder_hidden_states` input. If discrete, returns probability
49 | distributions for the unnoised latent pixels.
50 | """
51 |
52 | sample: torch.FloatTensor
53 |
54 |
55 | class Transformer2DModel(ModelMixin, ConfigMixin):
56 | """
57 | A 2D Transformer model for image-like data.
58 |
59 | Parameters:
60 | num_attention_heads (`int`, *optional*, defaults to 16): The number of heads to use for multi-head attention.
61 | attention_head_dim (`int`, *optional*, defaults to 88): The number of channels in each head.
62 | in_channels (`int`, *optional*):
63 | The number of channels in the input and output (specify if the input is **continuous**).
64 | num_layers (`int`, *optional*, defaults to 1): The number of layers of Transformer blocks to use.
65 | dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
66 | cross_attention_dim (`int`, *optional*): The number of `encoder_hidden_states` dimensions to use.
67 | sample_size (`int`, *optional*): The width of the latent images (specify if the input is **discrete**).
68 | This is fixed during training since it is used to learn a number of position embeddings.
69 | num_vector_embeds (`int`, *optional*):
70 | The number of classes of the vector embeddings of the latent pixels (specify if the input is **discrete**).
71 | Includes the class for the masked latent pixel.
72 | activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to use in feed-forward.
73 | num_embeds_ada_norm ( `int`, *optional*):
74 | The number of diffusion steps used during training. Pass if at least one of the norm_layers is
75 | `AdaLayerNorm`. This is fixed during training since it is used to learn a number of embeddings that are
76 | added to the hidden states.
77 |
78 | During inference, you can denoise for up to but not more steps than `num_embeds_ada_norm`.
79 | attention_bias (`bool`, *optional*):
80 | Configure if the `TransformerBlocks` attention should contain a bias parameter.
81 | """
82 | _supports_gradient_checkpointing = True
83 |
84 | @register_to_config
85 | def __init__(
86 | self,
87 | num_attention_heads: int = 16,
88 | attention_head_dim: int = 88,
89 | in_channels: Optional[int] = None,
90 | out_channels: Optional[int] = None,
91 | num_layers: int = 1,
92 | dropout: float = 0.0,
93 | norm_num_groups: int = 32,
94 | cross_attention_dim: Optional[int] = None,
95 | attention_bias: bool = False,
96 | sample_size: Optional[int] = None,
97 | num_vector_embeds: Optional[int] = None,
98 | patch_size: Optional[int] = None,
99 | activation_fn: str = "geglu",
100 | num_embeds_ada_norm: Optional[int] = None,
101 | use_linear_projection: bool = False,
102 | only_cross_attention: bool = False,
103 | double_self_attention: bool = False,
104 | upcast_attention: bool = False,
105 | norm_type: str = "layer_norm",
106 | norm_elementwise_affine: bool = True,
107 | norm_eps: float = 1e-5,
108 | attention_type: str = "default",
109 | caption_channels: int = None,
110 | ):
111 | super().__init__()
112 | self.use_linear_projection = use_linear_projection
113 | self.num_attention_heads = num_attention_heads
114 | self.attention_head_dim = attention_head_dim
115 | inner_dim = num_attention_heads * attention_head_dim
116 |
117 | conv_cls = nn.Conv2d if USE_PEFT_BACKEND else LoRACompatibleConv
118 | linear_cls = nn.Linear if USE_PEFT_BACKEND else LoRACompatibleLinear
119 |
120 | # 1. Transformer2DModel can process both standard continuous images of shape `(batch_size, num_channels, width, height)` as well as quantized image embeddings of shape `(batch_size, num_image_vectors)`
121 | # Define whether input is continuous or discrete depending on configuration
122 | self.is_input_continuous = (in_channels is not None) and (patch_size is None)
123 | self.is_input_vectorized = num_vector_embeds is not None
124 | self.is_input_patches = in_channels is not None and patch_size is not None
125 |
126 | if norm_type == "layer_norm" and num_embeds_ada_norm is not None:
127 | deprecation_message = (
128 | f"The configuration file of this model: {self.__class__} is outdated. `norm_type` is either not set or"
129 | " incorrectly set to `'layer_norm'`.Make sure to set `norm_type` to `'ada_norm'` in the config."
130 | " Please make sure to update the config accordingly as leaving `norm_type` might led to incorrect"
131 | " results in future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it"
132 | " would be very nice if you could open a Pull request for the `transformer/config.json` file"
133 | )
134 | deprecate("norm_type!=num_embeds_ada_norm", "1.0.0", deprecation_message, standard_warn=False)
135 | norm_type = "ada_norm"
136 |
137 | if self.is_input_continuous and self.is_input_vectorized:
138 | raise ValueError(
139 | f"Cannot define both `in_channels`: {in_channels} and `num_vector_embeds`: {num_vector_embeds}. Make"
140 | " sure that either `in_channels` or `num_vector_embeds` is None."
141 | )
142 | elif self.is_input_vectorized and self.is_input_patches:
143 | raise ValueError(
144 | f"Cannot define both `num_vector_embeds`: {num_vector_embeds} and `patch_size`: {patch_size}. Make"
145 | " sure that either `num_vector_embeds` or `num_patches` is None."
146 | )
147 | elif not self.is_input_continuous and not self.is_input_vectorized and not self.is_input_patches:
148 | raise ValueError(
149 | f"Has to define `in_channels`: {in_channels}, `num_vector_embeds`: {num_vector_embeds}, or patch_size:"
150 | f" {patch_size}. Make sure that `in_channels`, `num_vector_embeds` or `num_patches` is not None."
151 | )
152 |
153 | # 2. Define input layers
154 | if self.is_input_continuous:
155 | self.in_channels = in_channels
156 |
157 | self.norm = torch.nn.GroupNorm(num_groups=norm_num_groups, num_channels=in_channels, eps=1e-6, affine=True)
158 | if use_linear_projection:
159 | self.proj_in = linear_cls(in_channels, inner_dim)
160 | else:
161 | self.proj_in = conv_cls(in_channels, inner_dim, kernel_size=1, stride=1, padding=0)
162 | elif self.is_input_vectorized:
163 | assert sample_size is not None, "Transformer2DModel over discrete input must provide sample_size"
164 | assert num_vector_embeds is not None, "Transformer2DModel over discrete input must provide num_embed"
165 |
166 | self.height = sample_size
167 | self.width = sample_size
168 | self.num_vector_embeds = num_vector_embeds
169 | self.num_latent_pixels = self.height * self.width
170 |
171 | self.latent_image_embedding = ImagePositionalEmbeddings(
172 | num_embed=num_vector_embeds, embed_dim=inner_dim, height=self.height, width=self.width
173 | )
174 | elif self.is_input_patches:
175 | assert sample_size is not None, "Transformer2DModel over patched input must provide sample_size"
176 |
177 | self.height = sample_size
178 | self.width = sample_size
179 |
180 | self.patch_size = patch_size
181 | interpolation_scale = self.config.sample_size // 64 # => 64 (= 512 pixart) has interpolation scale 1
182 | interpolation_scale = max(interpolation_scale, 1)
183 | self.pos_embed = PatchEmbed(
184 | height=sample_size,
185 | width=sample_size,
186 | patch_size=patch_size,
187 | in_channels=in_channels,
188 | embed_dim=inner_dim,
189 | interpolation_scale=interpolation_scale,
190 | )
191 |
192 | # 3. Define transformers blocks
193 | self.transformer_blocks = nn.ModuleList(
194 | [
195 | BasicTransformerBlock(
196 | inner_dim,
197 | num_attention_heads,
198 | attention_head_dim,
199 | dropout=dropout,
200 | cross_attention_dim=cross_attention_dim,
201 | activation_fn=activation_fn,
202 | num_embeds_ada_norm=num_embeds_ada_norm,
203 | attention_bias=attention_bias,
204 | only_cross_attention=only_cross_attention,
205 | double_self_attention=double_self_attention,
206 | upcast_attention=upcast_attention,
207 | norm_type=norm_type,
208 | norm_elementwise_affine=norm_elementwise_affine,
209 | norm_eps=norm_eps,
210 | attention_type=attention_type,
211 | )
212 | for d in range(num_layers)
213 | ]
214 | )
215 |
216 | # 4. Define output layers
217 | self.out_channels = in_channels if out_channels is None else out_channels
218 | if self.is_input_continuous:
219 | # TODO: should use out_channels for continuous projections
220 | if use_linear_projection:
221 | self.proj_out = linear_cls(inner_dim, in_channels)
222 | else:
223 | self.proj_out = conv_cls(inner_dim, in_channels, kernel_size=1, stride=1, padding=0)
224 | elif self.is_input_vectorized:
225 | self.norm_out = nn.LayerNorm(inner_dim)
226 | self.out = nn.Linear(inner_dim, self.num_vector_embeds - 1)
227 | elif self.is_input_patches and norm_type != "ada_norm_single":
228 | self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
229 | self.proj_out_1 = nn.Linear(inner_dim, 2 * inner_dim)
230 | self.proj_out_2 = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
231 | elif self.is_input_patches and norm_type == "ada_norm_single":
232 | self.norm_out = nn.LayerNorm(inner_dim, elementwise_affine=False, eps=1e-6)
233 | self.scale_shift_table = nn.Parameter(torch.randn(2, inner_dim) / inner_dim**0.5)
234 | self.proj_out = nn.Linear(inner_dim, patch_size * patch_size * self.out_channels)
235 |
236 | # 5. PixArt-Alpha blocks.
237 | self.adaln_single = None
238 | self.use_additional_conditions = False
239 | if norm_type == "ada_norm_single":
240 | self.use_additional_conditions = self.config.sample_size == 128
241 | # TODO(Sayak, PVP) clean this, for now we use sample size to determine whether to use
242 | # additional conditions until we find better name
243 | self.adaln_single = AdaLayerNormSingle(inner_dim, use_additional_conditions=self.use_additional_conditions)
244 |
245 | self.caption_projection = None
246 | if caption_channels is not None:
247 | self.caption_projection = PixArtAlphaTextProjection(in_features=caption_channels, hidden_size=inner_dim)
248 |
249 | self.gradient_checkpointing = False
250 |
251 | def _set_gradient_checkpointing(self, module, value=False):
252 | if hasattr(module, "gradient_checkpointing"):
253 | module.gradient_checkpointing = value
254 |
255 | def forward(
256 | self,
257 | hidden_states: torch.Tensor,
258 | encoder_hidden_states: Optional[torch.Tensor] = None,
259 | timestep: Optional[torch.LongTensor] = None,
260 | added_cond_kwargs: Dict[str, torch.Tensor] = None,
261 | class_labels: Optional[torch.LongTensor] = None,
262 | cross_attention_kwargs: Dict[str, Any] = None,
263 | attention_mask: Optional[torch.Tensor] = None,
264 | encoder_attention_mask: Optional[torch.Tensor] = None,
265 | return_dict: bool = True,
266 | ):
267 | """
268 | The [`Transformer2DModel`] forward method.
269 |
270 | Args:
271 | hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete, `torch.FloatTensor` of shape `(batch size, channel, height, width)` if continuous):
272 | Input `hidden_states`.
273 | encoder_hidden_states ( `torch.FloatTensor` of shape `(batch size, sequence len, embed dims)`, *optional*):
274 | Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
275 | self-attention.
276 | timestep ( `torch.LongTensor`, *optional*):
277 | Used to indicate denoising step. Optional timestep to be applied as an embedding in `AdaLayerNorm`.
278 | class_labels ( `torch.LongTensor` of shape `(batch size, num classes)`, *optional*):
279 | Used to indicate class labels conditioning. Optional class labels to be applied as an embedding in
280 | `AdaLayerZeroNorm`.
281 | cross_attention_kwargs ( `Dict[str, Any]`, *optional*):
282 | A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
283 | `self.processor` in
284 | [diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
285 | attention_mask ( `torch.Tensor`, *optional*):
286 | An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
287 | is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
288 | negative values to the attention scores corresponding to "discard" tokens.
289 | encoder_attention_mask ( `torch.Tensor`, *optional*):
290 | Cross-attention mask applied to `encoder_hidden_states`. Two formats supported:
291 |
292 | * Mask `(batch, sequence_length)` True = keep, False = discard.
293 | * Bias `(batch, 1, sequence_length)` 0 = keep, -10000 = discard.
294 |
295 | If `ndim == 2`: will be interpreted as a mask, then converted into a bias consistent with the format
296 | above. This bias will be added to the cross-attention scores.
297 | return_dict (`bool`, *optional*, defaults to `True`):
298 | Whether or not to return a [`~models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain
299 | tuple.
300 |
301 | Returns:
302 | If `return_dict` is True, an [`~models.transformer_2d.Transformer2DModelOutput`] is returned, otherwise a
303 | `tuple` where the first element is the sample tensor.
304 | """
305 | # ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
306 | # we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
307 | # we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
308 | # expects mask of shape:
309 | # [batch, key_tokens]
310 | # adds singleton query_tokens dimension:
311 | # [batch, 1, key_tokens]
312 | # this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
313 | # [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
314 | # [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
315 | if attention_mask is not None and attention_mask.ndim == 2:
316 | # assume that mask is expressed as:
317 | # (1 = keep, 0 = discard)
318 | # convert mask into a bias that can be added to attention scores:
319 | # (keep = +0, discard = -10000.0)
320 | attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
321 | attention_mask = attention_mask.unsqueeze(1)
322 |
323 | # convert encoder_attention_mask to a bias the same way we do for attention_mask
324 | if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
325 | encoder_attention_mask = (1 - encoder_attention_mask.to(encoder_hidden_states.dtype)) * -10000.0
326 | encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
327 |
328 | # Retrieve lora scale.
329 | lora_scale = cross_attention_kwargs.get("scale", 1.0) if cross_attention_kwargs is not None else 1.0
330 |
331 | # 1. Input
332 | if self.is_input_continuous:
333 | batch, _, height, width = hidden_states.shape
334 | residual = hidden_states
335 |
336 | hidden_states = self.norm(hidden_states)
337 | if not self.use_linear_projection:
338 | hidden_states = (
339 | self.proj_in(hidden_states, scale=lora_scale)
340 | if not USE_PEFT_BACKEND
341 | else self.proj_in(hidden_states)
342 | )
343 | inner_dim = hidden_states.shape[1]
344 | hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
345 | else:
346 | inner_dim = hidden_states.shape[1]
347 | hidden_states = hidden_states.permute(0, 2, 3, 1).reshape(batch, height * width, inner_dim)
348 | hidden_states = (
349 | self.proj_in(hidden_states, scale=lora_scale)
350 | if not USE_PEFT_BACKEND
351 | else self.proj_in(hidden_states)
352 | )
353 |
354 | elif self.is_input_vectorized:
355 | hidden_states = self.latent_image_embedding(hidden_states)
356 | elif self.is_input_patches:
357 | height, width = hidden_states.shape[-2] // self.patch_size, hidden_states.shape[-1] // self.patch_size
358 | hidden_states = self.pos_embed(hidden_states)
359 |
360 | if self.adaln_single is not None:
361 | if self.use_additional_conditions and added_cond_kwargs is None:
362 | raise ValueError(
363 | "`added_cond_kwargs` cannot be None when using additional conditions for `adaln_single`."
364 | )
365 | batch_size = hidden_states.shape[0]
366 | timestep, embedded_timestep = self.adaln_single(
367 | timestep, added_cond_kwargs, batch_size=batch_size, hidden_dtype=hidden_states.dtype
368 | )
369 |
370 | # 2. Blocks
371 | if self.caption_projection is not None:
372 | batch_size = hidden_states.shape[0]
373 | encoder_hidden_states = self.caption_projection(encoder_hidden_states)
374 | encoder_hidden_states = encoder_hidden_states.view(batch_size, -1, hidden_states.shape[-1])
375 |
376 | for block in self.transformer_blocks:
377 | if self.training and self.gradient_checkpointing:
378 | hidden_states = torch.utils.checkpoint.checkpoint(
379 | block,
380 | hidden_states,
381 | attention_mask,
382 | encoder_hidden_states,
383 | encoder_attention_mask,
384 | timestep,
385 | cross_attention_kwargs,
386 | class_labels,
387 | use_reentrant=False,
388 | )
389 | else:
390 | hidden_states = block(
391 | hidden_states,
392 | attention_mask=attention_mask,
393 | encoder_hidden_states=encoder_hidden_states,
394 | encoder_attention_mask=encoder_attention_mask,
395 | timestep=timestep,
396 | cross_attention_kwargs=cross_attention_kwargs,
397 | class_labels=class_labels,
398 | )
399 |
400 | # 3. Output
401 | if self.is_input_continuous:
402 | if not self.use_linear_projection:
403 | hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
404 | hidden_states = (
405 | self.proj_out(hidden_states, scale=lora_scale)
406 | if not USE_PEFT_BACKEND
407 | else self.proj_out(hidden_states)
408 | )
409 | else:
410 | hidden_states = (
411 | self.proj_out(hidden_states, scale=lora_scale)
412 | if not USE_PEFT_BACKEND
413 | else self.proj_out(hidden_states)
414 | )
415 | hidden_states = hidden_states.reshape(batch, height, width, inner_dim).permute(0, 3, 1, 2).contiguous()
416 |
417 | output = hidden_states + residual
418 | elif self.is_input_vectorized:
419 | hidden_states = self.norm_out(hidden_states)
420 | logits = self.out(hidden_states)
421 | # (batch, self.num_vector_embeds - 1, self.num_latent_pixels)
422 | logits = logits.permute(0, 2, 1)
423 |
424 | # log(p(x_0))
425 | output = F.log_softmax(logits.double(), dim=1).float()
426 |
427 | if self.is_input_patches:
428 | if self.config.norm_type != "ada_norm_single":
429 | conditioning = self.transformer_blocks[0].norm1.emb(
430 | timestep, class_labels, hidden_dtype=hidden_states.dtype
431 | )
432 | shift, scale = self.proj_out_1(F.silu(conditioning)).chunk(2, dim=1)
433 | hidden_states = self.norm_out(hidden_states) * (1 + scale[:, None]) + shift[:, None]
434 | hidden_states = self.proj_out_2(hidden_states)
435 | elif self.config.norm_type == "ada_norm_single":
436 | shift, scale = (self.scale_shift_table[None] + embedded_timestep[:, None]).chunk(2, dim=1)
437 | hidden_states = self.norm_out(hidden_states)
438 | # Modulation
439 | hidden_states = hidden_states * (1 + scale) + shift
440 | hidden_states = self.proj_out(hidden_states)
441 | hidden_states = hidden_states.squeeze(1)
442 |
443 | # unpatchify
444 | if self.adaln_single is None:
445 | height = width = int(hidden_states.shape[1] ** 0.5)
446 | hidden_states = hidden_states.reshape(
447 | shape=(-1, height, width, self.patch_size, self.patch_size, self.out_channels)
448 | )
449 | hidden_states = torch.einsum("nhwpqc->nchpwq", hidden_states)
450 | output = hidden_states.reshape(
451 | shape=(-1, self.out_channels, height * self.patch_size, width * self.patch_size)
452 | )
453 |
454 | if not return_dict:
455 | return (output,)
456 |
457 | return Transformer2DModelOutput(sample=output)
458 |
459 | @classmethod
460 | def from_pretrained(cls, pretrained_model_path, subfolder=None, patch_size=2, transformer_additional_kwargs={}):
461 | if subfolder is not None:
462 | pretrained_model_path = os.path.join(pretrained_model_path, subfolder)
463 | print(f"loaded 2D transformer's pretrained weights from {pretrained_model_path} ...")
464 |
465 | config_file = os.path.join(pretrained_model_path, 'config.json')
466 | if not os.path.isfile(config_file):
467 | raise RuntimeError(f"{config_file} does not exist")
468 | with open(config_file, "r") as f:
469 | config = json.load(f)
470 |
471 | from diffusers.utils import WEIGHTS_NAME
472 | model = cls.from_config(config, **transformer_additional_kwargs)
473 | model_file = os.path.join(pretrained_model_path, WEIGHTS_NAME)
474 | model_file_safetensors = model_file.replace(".bin", ".safetensors")
475 | if os.path.exists(model_file_safetensors):
476 | from safetensors.torch import load_file, safe_open
477 | state_dict = load_file(model_file_safetensors)
478 | else:
479 | if not os.path.isfile(model_file):
480 | raise RuntimeError(f"{model_file} does not exist")
481 | state_dict = torch.load(model_file, map_location="cpu")
482 |
483 | if model.state_dict()['pos_embed.proj.weight'].size() != state_dict['pos_embed.proj.weight'].size():
484 | new_shape = model.state_dict()['pos_embed.proj.weight'].size()
485 | state_dict['pos_embed.proj.weight'] = torch.tile(state_dict['proj_out.weight'], [1, 2, 1, 1])
486 |
487 | if model.state_dict()['proj_out.weight'].size() != state_dict['proj_out.weight'].size():
488 | new_shape = model.state_dict()['proj_out.weight'].size()
489 | state_dict['proj_out.weight'] = torch.tile(state_dict['proj_out.weight'], [patch_size, 1])
490 |
491 | if model.state_dict()['proj_out.bias'].size() != state_dict['proj_out.bias'].size():
492 | new_shape = model.state_dict()['proj_out.bias'].size()
493 | state_dict['proj_out.bias'] = torch.tile(state_dict['proj_out.bias'], [patch_size])
494 |
495 | tmp_state_dict = {}
496 | for key in state_dict:
497 | if key in model.state_dict().keys() and model.state_dict()[key].size() == state_dict[key].size():
498 | tmp_state_dict[key] = state_dict[key]
499 | else:
500 | print(key, "Size don't match, skip")
501 | state_dict = tmp_state_dict
502 |
503 | m, u = model.load_state_dict(state_dict, strict=False)
504 | print(f"### missing keys: {len(m)}; \n### unexpected keys: {len(u)};")
505 |
506 | params = [p.numel() if "motion_modules." in n else 0 for n, p in model.named_parameters()]
507 | print(f"### Postion Parameters: {sum(params) / 1e6} M")
508 |
509 | return model
--------------------------------------------------------------------------------
/easyanimate/ui/ui.py:
--------------------------------------------------------------------------------
1 | """Modified from https://github.com/guoyww/AnimateDiff/blob/main/app.py
2 | """
3 | import gc
4 | import json
5 | import os
6 | import random
7 | from datetime import datetime
8 | from glob import glob
9 |
10 | import gradio as gr
11 | import torch
12 | from diffusers import (AutoencoderKL, DDIMScheduler,
13 | DPMSolverMultistepScheduler,
14 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
15 | PNDMScheduler)
16 | from diffusers.utils.import_utils import is_xformers_available
17 | from omegaconf import OmegaConf
18 | from safetensors import safe_open
19 | from transformers import T5EncoderModel, T5Tokenizer
20 |
21 | from easyanimate.models.transformer3d import Transformer3DModel
22 | from easyanimate.pipeline.pipeline_easyanimate import EasyAnimatePipeline
23 | from easyanimate.utils.lora_utils import merge_lora, unmerge_lora
24 | from easyanimate.utils.utils import save_videos_grid
25 |
26 | sample_idx = 0
27 | scheduler_dict = {
28 | "Euler": EulerDiscreteScheduler,
29 | "Euler A": EulerAncestralDiscreteScheduler,
30 | "DPM++": DPMSolverMultistepScheduler,
31 | "PNDM": PNDMScheduler,
32 | "DDIM": DDIMScheduler,
33 | }
34 |
35 | css = """
36 | .toolbutton {
37 | margin-buttom: 0em 0em 0em 0em;
38 | max-width: 2.5em;
39 | min-width: 2.5em !important;
40 | height: 2.5em;
41 | }
42 | """
43 |
44 | class EasyAnimateController:
45 | def __init__(self):
46 | # config dirs
47 | self.basedir = os.getcwd()
48 | self.diffusion_transformer_dir = os.path.join(self.basedir, "models", "Diffusion_Transformer")
49 | self.motion_module_dir = os.path.join(self.basedir, "models", "Motion_Module")
50 | self.personalized_model_dir = os.path.join(self.basedir, "models", "Personalized_Model")
51 | self.savedir = os.path.join(self.basedir, "samples", datetime.now().strftime("Gradio-%Y-%m-%dT%H-%M-%S"))
52 | self.savedir_sample = os.path.join(self.savedir, "sample")
53 | os.makedirs(self.savedir, exist_ok=True)
54 |
55 | self.diffusion_transformer_list = []
56 | self.motion_module_list = []
57 | self.personalized_model_list = []
58 |
59 | self.refresh_diffusion_transformer()
60 | self.refresh_motion_module()
61 | self.refresh_personalized_model()
62 |
63 | # config models
64 | self.tokenizer = None
65 | self.text_encoder = None
66 | self.vae = None
67 | self.transformer = None
68 | self.pipeline = None
69 | self.lora_model_path = "none"
70 |
71 | self.weight_dtype = torch.float16
72 | self.inference_config = OmegaConf.load("config/easyanimate_video_motion_module_v1.yaml")
73 |
74 | def refresh_diffusion_transformer(self):
75 | self.diffusion_transformer_list = glob(os.path.join(self.diffusion_transformer_dir, "*/"))
76 |
77 | def refresh_motion_module(self):
78 | motion_module_list = glob(os.path.join(self.motion_module_dir, "*.safetensors"))
79 | self.motion_module_list = [os.path.basename(p) for p in motion_module_list]
80 |
81 | def refresh_personalized_model(self):
82 | personalized_model_list = glob(os.path.join(self.personalized_model_dir, "*.safetensors"))
83 | self.personalized_model_list = [os.path.basename(p) for p in personalized_model_list]
84 |
85 | def update_diffusion_transformer(self, diffusion_transformer_dropdown):
86 | print("Update diffusion transformer")
87 | if diffusion_transformer_dropdown == "none":
88 | return gr.Dropdown.update()
89 | self.vae = AutoencoderKL.from_pretrained(diffusion_transformer_dropdown, subfolder="vae", torch_dtype = self.weight_dtype)
90 | self.transformer = Transformer3DModel.from_pretrained_2d(
91 | diffusion_transformer_dropdown,
92 | subfolder="transformer",
93 | transformer_additional_kwargs=OmegaConf.to_container(self.inference_config.transformer_additional_kwargs)
94 | ).to(self.weight_dtype)
95 | self.tokenizer = T5Tokenizer.from_pretrained(diffusion_transformer_dropdown, subfolder="tokenizer")
96 | self.text_encoder = T5EncoderModel.from_pretrained(diffusion_transformer_dropdown, subfolder="text_encoder", torch_dtype = self.weight_dtype)
97 | print("Update diffusion transformer done")
98 | return gr.Dropdown.update()
99 |
100 | def update_motion_module(self, motion_module_dropdown):
101 | print("Update motion module")
102 | if motion_module_dropdown == "none":
103 | return gr.Dropdown.update()
104 | if self.transformer is None:
105 | gr.Info(f"Please select a pretrained model path.")
106 | return gr.Dropdown.update(value=None)
107 | else:
108 | motion_module_dropdown = os.path.join(self.motion_module_dir, motion_module_dropdown)
109 | if motion_module_dropdown.endswith(".safetensors"):
110 | from safetensors.torch import load_file, safe_open
111 | motion_module_state_dict = load_file(motion_module_dropdown)
112 | else:
113 | if not os.path.isfile(motion_module_dropdown):
114 | raise RuntimeError(f"{motion_module_dropdown} does not exist")
115 | motion_module_state_dict = torch.load(motion_module_dropdown, map_location="cpu")
116 | missing, unexpected = self.transformer.load_state_dict(motion_module_state_dict, strict=False)
117 | assert len(unexpected) == 0
118 | print("Update motion module done")
119 | return gr.Dropdown.update()
120 |
121 | def update_base_model(self, base_model_dropdown):
122 | print("Update base model")
123 | if base_model_dropdown == "none":
124 | return gr.Dropdown.update()
125 | if self.transformer is None:
126 | gr.Info(f"Please select a pretrained model path.")
127 | return gr.Dropdown.update(value=None)
128 | else:
129 | base_model_dropdown = os.path.join(self.personalized_model_dir, base_model_dropdown)
130 | base_model_state_dict = {}
131 | with safe_open(base_model_dropdown, framework="pt", device="cpu") as f:
132 | for key in f.keys():
133 | base_model_state_dict[key] = f.get_tensor(key)
134 | self.transformer.load_state_dict(base_model_state_dict, strict=False)
135 | print("Update base done")
136 | return gr.Dropdown.update()
137 |
138 | def update_lora_model(self, lora_model_dropdown):
139 | lora_model_dropdown = os.path.join(self.personalized_model_dir, lora_model_dropdown)
140 | self.lora_model_path = lora_model_dropdown
141 | return gr.Dropdown.update()
142 |
143 | def generate(
144 | self,
145 | diffusion_transformer_dropdown,
146 | motion_module_dropdown,
147 | base_model_dropdown,
148 | lora_alpha_slider,
149 | prompt_textbox,
150 | negative_prompt_textbox,
151 | sampler_dropdown,
152 | sample_step_slider,
153 | width_slider,
154 | length_slider,
155 | height_slider,
156 | cfg_scale_slider,
157 | seed_textbox
158 | ):
159 | global sample_idx
160 | if self.transformer is None:
161 | raise gr.Error(f"Please select a pretrained model path.")
162 | if motion_module_dropdown == "":
163 | raise gr.Error(f"Please select a motion module.")
164 |
165 | if is_xformers_available(): self.transformer.enable_xformers_memory_efficient_attention()
166 |
167 | pipeline = EasyAnimatePipeline(
168 | vae=self.vae,
169 | text_encoder=self.text_encoder,
170 | tokenizer=self.tokenizer,
171 | transformer=self.transformer,
172 | scheduler=scheduler_dict[sampler_dropdown](**OmegaConf.to_container(self.inference_config.noise_scheduler_kwargs))
173 | )
174 | if self.lora_model_path != "none":
175 | # lora part
176 | pipeline = merge_lora(pipeline, self.lora_model_path, multiplier=lora_alpha_slider)
177 |
178 | pipeline.to("cuda")
179 |
180 | if seed_textbox != -1 and seed_textbox != "": torch.manual_seed(int(seed_textbox))
181 | else: torch.seed()
182 | seed = torch.initial_seed()
183 |
184 | try:
185 | sample = pipeline(
186 | prompt_textbox,
187 | negative_prompt = negative_prompt_textbox,
188 | num_inference_steps = sample_step_slider,
189 | guidance_scale = cfg_scale_slider,
190 | width = width_slider,
191 | height = height_slider,
192 | video_length = length_slider,
193 | ).videos
194 | except Exception as e:
195 | # lora part
196 | gc.collect()
197 | torch.cuda.empty_cache()
198 | torch.cuda.ipc_collect()
199 | if self.lora_model_path != "none":
200 | pipeline = unmerge_lora(pipeline, self.lora_model_path, multiplier=lora_alpha_slider)
201 | return gr.Video.update()
202 |
203 | # lora part
204 | if self.lora_model_path != "none":
205 | pipeline = unmerge_lora(pipeline, self.lora_model_path, multiplier=lora_alpha_slider)
206 |
207 | save_sample_path = os.path.join(self.savedir_sample, f"{sample_idx}.mp4")
208 | sample_idx += 1
209 | save_videos_grid(sample, save_sample_path, fps=12)
210 |
211 | sample_config = {
212 | "prompt": prompt_textbox,
213 | "n_prompt": negative_prompt_textbox,
214 | "sampler": sampler_dropdown,
215 | "num_inference_steps": sample_step_slider,
216 | "guidance_scale": cfg_scale_slider,
217 | "width": width_slider,
218 | "height": height_slider,
219 | "video_length": length_slider,
220 | "seed": seed
221 | }
222 | json_str = json.dumps(sample_config, indent=4)
223 | with open(os.path.join(self.savedir, "logs.json"), "a") as f:
224 | f.write(json_str)
225 | f.write("\n\n")
226 |
227 | return gr.Video.update(value=save_sample_path)
228 |
229 |
230 | def ui():
231 | controller = EasyAnimateController()
232 |
233 | with gr.Blocks(css=css) as demo:
234 | gr.Markdown(
235 | """
236 | # EasyAnimate: Generate your animation easily
237 | [Github](https://github.com/aigc-apps/EasyAnimate/)
238 | """
239 | )
240 | with gr.Column(variant="panel"):
241 | gr.Markdown(
242 | """
243 | ### 1. Model checkpoints (select pretrained model path first).
244 | """
245 | )
246 | with gr.Row():
247 | diffusion_transformer_dropdown = gr.Dropdown(
248 | label="Pretrained Model Path",
249 | choices=controller.diffusion_transformer_list,
250 | value="none",
251 | interactive=True,
252 | )
253 | diffusion_transformer_dropdown.change(
254 | fn=controller.update_diffusion_transformer,
255 | inputs=[diffusion_transformer_dropdown],
256 | outputs=[diffusion_transformer_dropdown]
257 | )
258 |
259 | diffusion_transformer_refresh_button = gr.Button(value="\U0001F503", elem_classes="toolbutton")
260 | def refresh_diffusion_transformer():
261 | controller.refresh_diffusion_transformer()
262 | return gr.Dropdown.update(choices=controller.diffusion_transformer_list)
263 | diffusion_transformer_refresh_button.click(fn=refresh_diffusion_transformer, inputs=[], outputs=[diffusion_transformer_dropdown])
264 |
265 | with gr.Row():
266 | motion_module_dropdown = gr.Dropdown(
267 | label="Select motion module",
268 | choices=controller.motion_module_list,
269 | value="none",
270 | interactive=True,
271 | )
272 | motion_module_dropdown.change(fn=controller.update_motion_module, inputs=[motion_module_dropdown], outputs=[motion_module_dropdown])
273 |
274 | motion_module_refresh_button = gr.Button(value="\U0001F503", elem_classes="toolbutton")
275 | def update_motion_module():
276 | controller.refresh_motion_module()
277 | return gr.Dropdown.update(choices=controller.motion_module_list)
278 | motion_module_refresh_button.click(fn=update_motion_module, inputs=[], outputs=[motion_module_dropdown])
279 |
280 | base_model_dropdown = gr.Dropdown(
281 | label="Select base Dreambooth model (optional)",
282 | choices=controller.personalized_model_list,
283 | value="none",
284 | interactive=True,
285 | )
286 | base_model_dropdown.change(fn=controller.update_base_model, inputs=[base_model_dropdown], outputs=[base_model_dropdown])
287 |
288 | lora_model_dropdown = gr.Dropdown(
289 | label="Select LoRA model (optional)",
290 | choices=["none"] + controller.personalized_model_list,
291 | value="none",
292 | interactive=True,
293 | )
294 | lora_model_dropdown.change(fn=controller.update_lora_model, inputs=[lora_model_dropdown], outputs=[lora_model_dropdown])
295 |
296 | lora_alpha_slider = gr.Slider(label="LoRA alpha", value=0.55, minimum=0, maximum=2, interactive=True)
297 |
298 | personalized_refresh_button = gr.Button(value="\U0001F503", elem_classes="toolbutton")
299 | def update_personalized_model():
300 | controller.refresh_personalized_model()
301 | return [
302 | gr.Dropdown.update(choices=controller.personalized_model_list),
303 | gr.Dropdown.update(choices=["none"] + controller.personalized_model_list)
304 | ]
305 | personalized_refresh_button.click(fn=update_personalized_model, inputs=[], outputs=[base_model_dropdown, lora_model_dropdown])
306 |
307 | with gr.Column(variant="panel"):
308 | gr.Markdown(
309 | """
310 | ### 2. Configs for Generation.
311 | """
312 | )
313 |
314 | prompt_textbox = gr.Textbox(label="Prompt", lines=2)
315 | negative_prompt_textbox = gr.Textbox(label="Negative prompt", lines=2, value="Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly" )
316 |
317 | with gr.Row().style(equal_height=False):
318 | with gr.Column():
319 | with gr.Row():
320 | sampler_dropdown = gr.Dropdown(label="Sampling method", choices=list(scheduler_dict.keys()), value=list(scheduler_dict.keys())[0])
321 | sample_step_slider = gr.Slider(label="Sampling steps", value=30, minimum=10, maximum=100, step=1)
322 |
323 | width_slider = gr.Slider(label="Width", value=512, minimum=256, maximum=1024, step=64)
324 | height_slider = gr.Slider(label="Height", value=512, minimum=256, maximum=1024, step=64)
325 | length_slider = gr.Slider(label="Animation length", value=80, minimum=16, maximum=96, step=1)
326 | cfg_scale_slider = gr.Slider(label="CFG Scale", value=6.0, minimum=0, maximum=20)
327 |
328 | with gr.Row():
329 | seed_textbox = gr.Textbox(label="Seed", value=-1)
330 | seed_button = gr.Button(value="\U0001F3B2", elem_classes="toolbutton")
331 | seed_button.click(fn=lambda: gr.Textbox.update(value=random.randint(1, 1e8)), inputs=[], outputs=[seed_textbox])
332 |
333 | generate_button = gr.Button(value="Generate", variant='primary')
334 |
335 | result_video = gr.Video(label="Generated Animation", interactive=False)
336 |
337 | generate_button.click(
338 | fn=controller.generate,
339 | inputs=[
340 | diffusion_transformer_dropdown,
341 | motion_module_dropdown,
342 | base_model_dropdown,
343 | lora_alpha_slider,
344 | prompt_textbox,
345 | negative_prompt_textbox,
346 | sampler_dropdown,
347 | sample_step_slider,
348 | width_slider,
349 | length_slider,
350 | height_slider,
351 | cfg_scale_slider,
352 | seed_textbox,
353 | ],
354 | outputs=[result_video]
355 | )
356 | return demo
357 |
--------------------------------------------------------------------------------
/easyanimate/utils/IDDIM.py:
--------------------------------------------------------------------------------
1 | # Modified from OpenAI's diffusion repos
2 | # GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
3 | # ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
4 | # IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
5 | from . import gaussian_diffusion as gd
6 | from .respace import SpacedDiffusion, space_timesteps
7 |
8 |
9 | def IDDPM(
10 | timestep_respacing,
11 | noise_schedule="linear",
12 | use_kl=False,
13 | sigma_small=False,
14 | predict_xstart=False,
15 | learn_sigma=True,
16 | pred_sigma=True,
17 | rescale_learned_sigmas=False,
18 | diffusion_steps=1000,
19 | snr=False,
20 | return_startx=False,
21 | ):
22 | betas = gd.get_named_beta_schedule(noise_schedule, diffusion_steps)
23 | if use_kl:
24 | loss_type = gd.LossType.RESCALED_KL
25 | elif rescale_learned_sigmas:
26 | loss_type = gd.LossType.RESCALED_MSE
27 | else:
28 | loss_type = gd.LossType.MSE
29 | if timestep_respacing is None or timestep_respacing == "":
30 | timestep_respacing = [diffusion_steps]
31 | return SpacedDiffusion(
32 | use_timesteps=space_timesteps(diffusion_steps, timestep_respacing),
33 | betas=betas,
34 | model_mean_type=(
35 | gd.ModelMeanType.START_X if predict_xstart else gd.ModelMeanType.EPSILON
36 | ),
37 | model_var_type=(
38 | (gd.ModelVarType.LEARNED_RANGE if learn_sigma else (
39 | gd.ModelVarType.FIXED_LARGE
40 | if not sigma_small
41 | else gd.ModelVarType.FIXED_SMALL
42 | )
43 | )
44 | if pred_sigma
45 | else None
46 | ),
47 | loss_type=loss_type,
48 | snr=snr,
49 | return_startx=return_startx,
50 | # rescale_timesteps=rescale_timesteps,
51 | )
--------------------------------------------------------------------------------
/easyanimate/utils/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/easyanimate/utils/__init__.py
--------------------------------------------------------------------------------
/easyanimate/utils/diffusion_utils.py:
--------------------------------------------------------------------------------
1 | # Modified from OpenAI's diffusion repos
2 | # GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
3 | # ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
4 | # IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
5 |
6 | import numpy as np
7 | import torch as th
8 |
9 |
10 | def normal_kl(mean1, logvar1, mean2, logvar2):
11 | """
12 | Compute the KL divergence between two gaussians.
13 | Shapes are automatically broadcasted, so batches can be compared to
14 | scalars, among other use cases.
15 | """
16 | tensor = next(
17 | (
18 | obj
19 | for obj in (mean1, logvar1, mean2, logvar2)
20 | if isinstance(obj, th.Tensor)
21 | ),
22 | None,
23 | )
24 | assert tensor is not None, "at least one argument must be a Tensor"
25 |
26 | # Force variances to be Tensors. Broadcasting helps convert scalars to
27 | # Tensors, but it does not work for th.exp().
28 | logvar1, logvar2 = [
29 | x if isinstance(x, th.Tensor) else th.tensor(x, device=tensor.device)
30 | for x in (logvar1, logvar2)
31 | ]
32 |
33 | return 0.5 * (
34 | -1.0
35 | + logvar2
36 | - logvar1
37 | + th.exp(logvar1 - logvar2)
38 | + ((mean1 - mean2) ** 2) * th.exp(-logvar2)
39 | )
40 |
41 |
42 | def approx_standard_normal_cdf(x):
43 | """
44 | A fast approximation of the cumulative distribution function of the
45 | standard normal.
46 | """
47 | return 0.5 * (1.0 + th.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * th.pow(x, 3))))
48 |
49 |
50 | def continuous_gaussian_log_likelihood(x, *, means, log_scales):
51 | """
52 | Compute the log-likelihood of a continuous Gaussian distribution.
53 | :param x: the targets
54 | :param means: the Gaussian mean Tensor.
55 | :param log_scales: the Gaussian log stddev Tensor.
56 | :return: a tensor like x of log probabilities (in nats).
57 | """
58 | centered_x = x - means
59 | inv_stdv = th.exp(-log_scales)
60 | normalized_x = centered_x * inv_stdv
61 | return th.distributions.Normal(th.zeros_like(x), th.ones_like(x)).log_prob(
62 | normalized_x
63 | )
64 |
65 |
66 | def discretized_gaussian_log_likelihood(x, *, means, log_scales):
67 | """
68 | Compute the log-likelihood of a Gaussian distribution discretizing to a
69 | given image.
70 | :param x: the target images. It is assumed that this was uint8 values,
71 | rescaled to the range [-1, 1].
72 | :param means: the Gaussian mean Tensor.
73 | :param log_scales: the Gaussian log stddev Tensor.
74 | :return: a tensor like x of log probabilities (in nats).
75 | """
76 | assert x.shape == means.shape == log_scales.shape
77 | centered_x = x - means
78 | inv_stdv = th.exp(-log_scales)
79 | plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
80 | cdf_plus = approx_standard_normal_cdf(plus_in)
81 | min_in = inv_stdv * (centered_x - 1.0 / 255.0)
82 | cdf_min = approx_standard_normal_cdf(min_in)
83 | log_cdf_plus = th.log(cdf_plus.clamp(min=1e-12))
84 | log_one_minus_cdf_min = th.log((1.0 - cdf_min).clamp(min=1e-12))
85 | cdf_delta = cdf_plus - cdf_min
86 | log_probs = th.where(
87 | x < -0.999,
88 | log_cdf_plus,
89 | th.where(x > 0.999, log_one_minus_cdf_min, th.log(cdf_delta.clamp(min=1e-12))),
90 | )
91 | assert log_probs.shape == x.shape
92 | return log_probs
--------------------------------------------------------------------------------
/easyanimate/utils/lora_utils.py:
--------------------------------------------------------------------------------
1 | # LoRA network module
2 | # reference:
3 | # https://github.com/microsoft/LoRA/blob/main/loralib/layers.py
4 | # https://github.com/cloneofsimo/lora/blob/master/lora_diffusion/lora.py
5 | # https://github.com/bmaltais/kohya_ss
6 |
7 | import hashlib
8 | import math
9 | import os
10 | from collections import defaultdict
11 | from io import BytesIO
12 | from typing import List, Optional, Type, Union
13 |
14 | import safetensors.torch
15 | import torch
16 | import torch.utils.checkpoint
17 | from diffusers.models.lora import LoRACompatibleConv, LoRACompatibleLinear
18 | from safetensors.torch import load_file
19 | from transformers import T5EncoderModel
20 |
21 |
22 | class LoRAModule(torch.nn.Module):
23 | """
24 | replaces forward method of the original Linear, instead of replacing the original Linear module.
25 | """
26 |
27 | def __init__(
28 | self,
29 | lora_name,
30 | org_module: torch.nn.Module,
31 | multiplier=1.0,
32 | lora_dim=4,
33 | alpha=1,
34 | dropout=None,
35 | rank_dropout=None,
36 | module_dropout=None,
37 | ):
38 | """if alpha == 0 or None, alpha is rank (no scaling)."""
39 | super().__init__()
40 | self.lora_name = lora_name
41 |
42 | if org_module.__class__.__name__ == "Conv2d":
43 | in_dim = org_module.in_channels
44 | out_dim = org_module.out_channels
45 | else:
46 | in_dim = org_module.in_features
47 | out_dim = org_module.out_features
48 |
49 | self.lora_dim = lora_dim
50 | if org_module.__class__.__name__ == "Conv2d":
51 | kernel_size = org_module.kernel_size
52 | stride = org_module.stride
53 | padding = org_module.padding
54 | self.lora_down = torch.nn.Conv2d(in_dim, self.lora_dim, kernel_size, stride, padding, bias=False)
55 | self.lora_up = torch.nn.Conv2d(self.lora_dim, out_dim, (1, 1), (1, 1), bias=False)
56 | else:
57 | self.lora_down = torch.nn.Linear(in_dim, self.lora_dim, bias=False)
58 | self.lora_up = torch.nn.Linear(self.lora_dim, out_dim, bias=False)
59 |
60 | if type(alpha) == torch.Tensor:
61 | alpha = alpha.detach().float().numpy() # without casting, bf16 causes error
62 | alpha = self.lora_dim if alpha is None or alpha == 0 else alpha
63 | self.scale = alpha / self.lora_dim
64 | self.register_buffer("alpha", torch.tensor(alpha))
65 |
66 | # same as microsoft's
67 | torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
68 | torch.nn.init.zeros_(self.lora_up.weight)
69 |
70 | self.multiplier = multiplier
71 | self.org_module = org_module # remove in applying
72 | self.dropout = dropout
73 | self.rank_dropout = rank_dropout
74 | self.module_dropout = module_dropout
75 |
76 | def apply_to(self):
77 | self.org_forward = self.org_module.forward
78 | self.org_module.forward = self.forward
79 | del self.org_module
80 |
81 | def forward(self, x, *args, **kwargs):
82 | weight_dtype = x.dtype
83 | org_forwarded = self.org_forward(x)
84 |
85 | # module dropout
86 | if self.module_dropout is not None and self.training:
87 | if torch.rand(1) < self.module_dropout:
88 | return org_forwarded
89 |
90 | lx = self.lora_down(x.to(self.lora_down.weight.dtype))
91 |
92 | # normal dropout
93 | if self.dropout is not None and self.training:
94 | lx = torch.nn.functional.dropout(lx, p=self.dropout)
95 |
96 | # rank dropout
97 | if self.rank_dropout is not None and self.training:
98 | mask = torch.rand((lx.size(0), self.lora_dim), device=lx.device) > self.rank_dropout
99 | if len(lx.size()) == 3:
100 | mask = mask.unsqueeze(1) # for Text Encoder
101 | elif len(lx.size()) == 4:
102 | mask = mask.unsqueeze(-1).unsqueeze(-1) # for Conv2d
103 | lx = lx * mask
104 |
105 | # scaling for rank dropout: treat as if the rank is changed
106 | scale = self.scale * (1.0 / (1.0 - self.rank_dropout)) # redundant for readability
107 | else:
108 | scale = self.scale
109 |
110 | lx = self.lora_up(lx)
111 |
112 | return org_forwarded.to(weight_dtype) + lx.to(weight_dtype) * self.multiplier * scale
113 |
114 |
115 | def addnet_hash_legacy(b):
116 | """Old model hash used by sd-webui-additional-networks for .safetensors format files"""
117 | m = hashlib.sha256()
118 |
119 | b.seek(0x100000)
120 | m.update(b.read(0x10000))
121 | return m.hexdigest()[0:8]
122 |
123 |
124 | def addnet_hash_safetensors(b):
125 | """New model hash used by sd-webui-additional-networks for .safetensors format files"""
126 | hash_sha256 = hashlib.sha256()
127 | blksize = 1024 * 1024
128 |
129 | b.seek(0)
130 | header = b.read(8)
131 | n = int.from_bytes(header, "little")
132 |
133 | offset = n + 8
134 | b.seek(offset)
135 | for chunk in iter(lambda: b.read(blksize), b""):
136 | hash_sha256.update(chunk)
137 |
138 | return hash_sha256.hexdigest()
139 |
140 |
141 | def precalculate_safetensors_hashes(tensors, metadata):
142 | """Precalculate the model hashes needed by sd-webui-additional-networks to
143 | save time on indexing the model later."""
144 |
145 | # Because writing user metadata to the file can change the result of
146 | # sd_models.model_hash(), only retain the training metadata for purposes of
147 | # calculating the hash, as they are meant to be immutable
148 | metadata = {k: v for k, v in metadata.items() if k.startswith("ss_")}
149 |
150 | bytes = safetensors.torch.save(tensors, metadata)
151 | b = BytesIO(bytes)
152 |
153 | model_hash = addnet_hash_safetensors(b)
154 | legacy_hash = addnet_hash_legacy(b)
155 | return model_hash, legacy_hash
156 |
157 |
158 | class LoRANetwork(torch.nn.Module):
159 | TRANSFORMER_TARGET_REPLACE_MODULE = ["Transformer2DModel", "Transformer3DModel"]
160 | TEXT_ENCODER_TARGET_REPLACE_MODULE = ["T5LayerSelfAttention", "T5LayerFF"]
161 | LORA_PREFIX_TRANSFORMER = "lora_unet"
162 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
163 | def __init__(
164 | self,
165 | text_encoder: Union[List[T5EncoderModel], T5EncoderModel],
166 | unet,
167 | multiplier: float = 1.0,
168 | lora_dim: int = 4,
169 | alpha: float = 1,
170 | dropout: Optional[float] = None,
171 | module_class: Type[object] = LoRAModule,
172 | add_lora_in_attn_temporal: bool = False,
173 | varbose: Optional[bool] = False,
174 | ) -> None:
175 | super().__init__()
176 | self.multiplier = multiplier
177 |
178 | self.lora_dim = lora_dim
179 | self.alpha = alpha
180 | self.dropout = dropout
181 |
182 | print(f"create LoRA network. base dim (rank): {lora_dim}, alpha: {alpha}")
183 | print(f"neuron dropout: p={self.dropout}")
184 |
185 | # create module instances
186 | def create_modules(
187 | is_unet: bool,
188 | root_module: torch.nn.Module,
189 | target_replace_modules: List[torch.nn.Module],
190 | ) -> List[LoRAModule]:
191 | prefix = (
192 | self.LORA_PREFIX_TRANSFORMER
193 | if is_unet
194 | else self.LORA_PREFIX_TEXT_ENCODER
195 | )
196 | loras = []
197 | skipped = []
198 | for name, module in root_module.named_modules():
199 | if module.__class__.__name__ in target_replace_modules:
200 | for child_name, child_module in module.named_modules():
201 | is_linear = child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "LoRACompatibleLinear"
202 | is_conv2d = child_module.__class__.__name__ == "Conv2d" or child_module.__class__.__name__ == "LoRACompatibleConv"
203 | is_conv2d_1x1 = is_conv2d and child_module.kernel_size == (1, 1)
204 |
205 | if not add_lora_in_attn_temporal:
206 | if "attn_temporal" in child_name:
207 | continue
208 |
209 | if is_linear or is_conv2d:
210 | lora_name = prefix + "." + name + "." + child_name
211 | lora_name = lora_name.replace(".", "_")
212 |
213 | dim = None
214 | alpha = None
215 |
216 | if is_linear or is_conv2d_1x1:
217 | dim = self.lora_dim
218 | alpha = self.alpha
219 |
220 | if dim is None or dim == 0:
221 | if is_linear or is_conv2d_1x1:
222 | skipped.append(lora_name)
223 | continue
224 |
225 | lora = module_class(
226 | lora_name,
227 | child_module,
228 | self.multiplier,
229 | dim,
230 | alpha,
231 | dropout=dropout,
232 | )
233 | loras.append(lora)
234 | return loras, skipped
235 |
236 | text_encoders = text_encoder if type(text_encoder) == list else [text_encoder]
237 |
238 | self.text_encoder_loras = []
239 | skipped_te = []
240 | for i, text_encoder in enumerate(text_encoders):
241 | text_encoder_loras, skipped = create_modules(False, text_encoder, LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
242 | self.text_encoder_loras.extend(text_encoder_loras)
243 | skipped_te += skipped
244 | print(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
245 |
246 | self.unet_loras, skipped_un = create_modules(True, unet, LoRANetwork.TRANSFORMER_TARGET_REPLACE_MODULE)
247 | print(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
248 |
249 | # assertion
250 | names = set()
251 | for lora in self.text_encoder_loras + self.unet_loras:
252 | assert lora.lora_name not in names, f"duplicated lora name: {lora.lora_name}"
253 | names.add(lora.lora_name)
254 |
255 | def apply_to(self, text_encoder, unet, apply_text_encoder=True, apply_unet=True):
256 | if apply_text_encoder:
257 | print("enable LoRA for text encoder")
258 | else:
259 | self.text_encoder_loras = []
260 |
261 | if apply_unet:
262 | print("enable LoRA for U-Net")
263 | else:
264 | self.unet_loras = []
265 |
266 | for lora in self.text_encoder_loras + self.unet_loras:
267 | lora.apply_to()
268 | self.add_module(lora.lora_name, lora)
269 |
270 | def set_multiplier(self, multiplier):
271 | self.multiplier = multiplier
272 | for lora in self.text_encoder_loras + self.unet_loras:
273 | lora.multiplier = self.multiplier
274 |
275 | def load_weights(self, file):
276 | if os.path.splitext(file)[1] == ".safetensors":
277 | from safetensors.torch import load_file
278 |
279 | weights_sd = load_file(file)
280 | else:
281 | weights_sd = torch.load(file, map_location="cpu")
282 | info = self.load_state_dict(weights_sd, False)
283 | return info
284 |
285 | def prepare_optimizer_params(self, text_encoder_lr, unet_lr, default_lr):
286 | self.requires_grad_(True)
287 | all_params = []
288 |
289 | def enumerate_params(loras):
290 | params = []
291 | for lora in loras:
292 | params.extend(lora.parameters())
293 | return params
294 |
295 | if self.text_encoder_loras:
296 | param_data = {"params": enumerate_params(self.text_encoder_loras)}
297 | if text_encoder_lr is not None:
298 | param_data["lr"] = text_encoder_lr
299 | all_params.append(param_data)
300 |
301 | if self.unet_loras:
302 | param_data = {"params": enumerate_params(self.unet_loras)}
303 | if unet_lr is not None:
304 | param_data["lr"] = unet_lr
305 | all_params.append(param_data)
306 |
307 | return all_params
308 |
309 | def enable_gradient_checkpointing(self):
310 | pass
311 |
312 | def get_trainable_params(self):
313 | return self.parameters()
314 |
315 | def save_weights(self, file, dtype, metadata):
316 | if metadata is not None and len(metadata) == 0:
317 | metadata = None
318 |
319 | state_dict = self.state_dict()
320 |
321 | if dtype is not None:
322 | for key in list(state_dict.keys()):
323 | v = state_dict[key]
324 | v = v.detach().clone().to("cpu").to(dtype)
325 | state_dict[key] = v
326 |
327 | if os.path.splitext(file)[1] == ".safetensors":
328 | from safetensors.torch import save_file
329 |
330 | # Precalculate model hashes to save time on indexing
331 | if metadata is None:
332 | metadata = {}
333 | model_hash, legacy_hash = precalculate_safetensors_hashes(state_dict, metadata)
334 | metadata["sshs_model_hash"] = model_hash
335 | metadata["sshs_legacy_hash"] = legacy_hash
336 |
337 | save_file(state_dict, file, metadata)
338 | else:
339 | torch.save(state_dict, file)
340 |
341 | def create_network(
342 | multiplier: float,
343 | network_dim: Optional[int],
344 | network_alpha: Optional[float],
345 | text_encoder: Union[T5EncoderModel, List[T5EncoderModel]],
346 | transformer,
347 | neuron_dropout: Optional[float] = None,
348 | add_lora_in_attn_temporal: bool = False,
349 | **kwargs,
350 | ):
351 | if network_dim is None:
352 | network_dim = 4 # default
353 | if network_alpha is None:
354 | network_alpha = 1.0
355 |
356 | network = LoRANetwork(
357 | text_encoder,
358 | transformer,
359 | multiplier=multiplier,
360 | lora_dim=network_dim,
361 | alpha=network_alpha,
362 | dropout=neuron_dropout,
363 | add_lora_in_attn_temporal=add_lora_in_attn_temporal,
364 | varbose=True,
365 | )
366 | return network
367 |
368 | def merge_lora(pipeline, lora_path, multiplier, device='cpu', dtype=torch.float32, state_dict=None, transformer_only=False):
369 | LORA_PREFIX_TRANSFORMER = "lora_unet"
370 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
371 | if state_dict is None:
372 | state_dict = load_file(lora_path, device=device)
373 | else:
374 | state_dict = state_dict
375 | updates = defaultdict(dict)
376 | for key, value in state_dict.items():
377 | layer, elem = key.split('.', 1)
378 | updates[layer][elem] = value
379 |
380 | for layer, elems in updates.items():
381 |
382 | if "lora_te" in layer:
383 | if transformer_only:
384 | continue
385 | else:
386 | layer_infos = layer.split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
387 | curr_layer = pipeline.text_encoder
388 | else:
389 | layer_infos = layer.split(LORA_PREFIX_TRANSFORMER + "_")[-1].split("_")
390 | curr_layer = pipeline.transformer
391 |
392 | temp_name = layer_infos.pop(0)
393 | while len(layer_infos) > -1:
394 | try:
395 | curr_layer = curr_layer.__getattr__(temp_name)
396 | if len(layer_infos) > 0:
397 | temp_name = layer_infos.pop(0)
398 | elif len(layer_infos) == 0:
399 | break
400 | except Exception:
401 | if len(layer_infos) == 0:
402 | print('Error loading layer')
403 | if len(temp_name) > 0:
404 | temp_name += "_" + layer_infos.pop(0)
405 | else:
406 | temp_name = layer_infos.pop(0)
407 |
408 | weight_up = elems['lora_up.weight'].to(dtype)
409 | weight_down = elems['lora_down.weight'].to(dtype)
410 | if 'alpha' in elems.keys():
411 | alpha = elems['alpha'].item() / weight_up.shape[1]
412 | else:
413 | alpha = 1.0
414 |
415 | curr_layer.weight.data = curr_layer.weight.data.to(device)
416 | if len(weight_up.shape) == 4:
417 | curr_layer.weight.data += multiplier * alpha * torch.mm(weight_up.squeeze(3).squeeze(2),
418 | weight_down.squeeze(3).squeeze(2)).unsqueeze(
419 | 2).unsqueeze(3)
420 | else:
421 | curr_layer.weight.data += multiplier * alpha * torch.mm(weight_up, weight_down)
422 |
423 | return pipeline
424 |
425 | # TODO: Refactor with merge_lora.
426 | def unmerge_lora(pipeline, lora_path, multiplier=1, device="cpu", dtype=torch.float32):
427 | """Unmerge state_dict in LoRANetwork from the pipeline in diffusers."""
428 | LORA_PREFIX_UNET = "lora_unet"
429 | LORA_PREFIX_TEXT_ENCODER = "lora_te"
430 | state_dict = load_file(lora_path, device=device)
431 |
432 | updates = defaultdict(dict)
433 | for key, value in state_dict.items():
434 | layer, elem = key.split('.', 1)
435 | updates[layer][elem] = value
436 |
437 | for layer, elems in updates.items():
438 |
439 | if "lora_te" in layer:
440 | layer_infos = layer.split(LORA_PREFIX_TEXT_ENCODER + "_")[-1].split("_")
441 | curr_layer = pipeline.text_encoder
442 | else:
443 | layer_infos = layer.split(LORA_PREFIX_UNET + "_")[-1].split("_")
444 | curr_layer = pipeline.transformer
445 |
446 | temp_name = layer_infos.pop(0)
447 | while len(layer_infos) > -1:
448 | try:
449 | curr_layer = curr_layer.__getattr__(temp_name)
450 | if len(layer_infos) > 0:
451 | temp_name = layer_infos.pop(0)
452 | elif len(layer_infos) == 0:
453 | break
454 | except Exception:
455 | if len(layer_infos) == 0:
456 | print('Error loading layer')
457 | if len(temp_name) > 0:
458 | temp_name += "_" + layer_infos.pop(0)
459 | else:
460 | temp_name = layer_infos.pop(0)
461 |
462 | weight_up = elems['lora_up.weight'].to(dtype)
463 | weight_down = elems['lora_down.weight'].to(dtype)
464 | if 'alpha' in elems.keys():
465 | alpha = elems['alpha'].item() / weight_up.shape[1]
466 | else:
467 | alpha = 1.0
468 |
469 | curr_layer.weight.data = curr_layer.weight.data.to(device)
470 | if len(weight_up.shape) == 4:
471 | curr_layer.weight.data -= multiplier * alpha * torch.mm(weight_up.squeeze(3).squeeze(2),
472 | weight_down.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
473 | else:
474 | curr_layer.weight.data -= multiplier * alpha * torch.mm(weight_up, weight_down)
475 |
476 | return pipeline
--------------------------------------------------------------------------------
/easyanimate/utils/respace.py:
--------------------------------------------------------------------------------
1 | # Modified from OpenAI's diffusion repos
2 | # GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
3 | # ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
4 | # IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
5 |
6 | import numpy as np
7 | import torch as th
8 |
9 | from .gaussian_diffusion import GaussianDiffusion
10 |
11 |
12 | def space_timesteps(num_timesteps, section_counts):
13 | """
14 | Create a list of timesteps to use from an original diffusion process,
15 | given the number of timesteps we want to take from equally-sized portions
16 | of the original process.
17 | For example, if there's 300 timesteps and the section counts are [10,15,20]
18 | then the first 100 timesteps are strided to be 10 timesteps, the second 100
19 | are strided to be 15 timesteps, and the final 100 are strided to be 20.
20 | If the stride is a string starting with "ddim", then the fixed striding
21 | from the DDIM paper is used, and only one section is allowed.
22 | :param num_timesteps: the number of diffusion steps in the original
23 | process to divide up.
24 | :param section_counts: either a list of numbers, or a string containing
25 | comma-separated numbers, indicating the step count
26 | per section. As a special case, use "ddimN" where N
27 | is a number of steps to use the striding from the
28 | DDIM paper.
29 | :return: a set of diffusion steps from the original process to use.
30 | """
31 | if isinstance(section_counts, str):
32 | if section_counts.startswith("ddim"):
33 | desired_count = int(section_counts[len("ddim") :])
34 | for i in range(1, num_timesteps):
35 | if len(range(0, num_timesteps, i)) == desired_count:
36 | return set(range(0, num_timesteps, i))
37 | raise ValueError(
38 | f"cannot create exactly {num_timesteps} steps with an integer stride"
39 | )
40 | section_counts = [int(x) for x in section_counts.split(",")]
41 | size_per = num_timesteps // len(section_counts)
42 | extra = num_timesteps % len(section_counts)
43 | start_idx = 0
44 | all_steps = []
45 | for i, section_count in enumerate(section_counts):
46 | size = size_per + (1 if i < extra else 0)
47 | if size < section_count:
48 | raise ValueError(
49 | f"cannot divide section of {size} steps into {section_count}"
50 | )
51 | frac_stride = 1 if section_count <= 1 else (size - 1) / (section_count - 1)
52 | cur_idx = 0.0
53 | taken_steps = []
54 | for _ in range(section_count):
55 | taken_steps.append(start_idx + round(cur_idx))
56 | cur_idx += frac_stride
57 | all_steps += taken_steps
58 | start_idx += size
59 | return set(all_steps)
60 |
61 |
62 | class SpacedDiffusion(GaussianDiffusion):
63 | """
64 | A diffusion process which can skip steps in a base diffusion process.
65 | :param use_timesteps: a collection (sequence or set) of timesteps from the
66 | original diffusion process to retain.
67 | :param kwargs: the kwargs to create the base diffusion process.
68 | """
69 |
70 | def __init__(self, use_timesteps, **kwargs):
71 | self.use_timesteps = set(use_timesteps)
72 | self.timestep_map = []
73 | self.original_num_steps = len(kwargs["betas"])
74 |
75 | base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
76 | last_alpha_cumprod = 1.0
77 | new_betas = []
78 | for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
79 | if i in self.use_timesteps:
80 | new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
81 | last_alpha_cumprod = alpha_cumprod
82 | self.timestep_map.append(i)
83 | kwargs["betas"] = np.array(new_betas)
84 | super().__init__(**kwargs)
85 |
86 | def p_mean_variance(
87 | self, model, *args, **kwargs
88 | ): # pylint: disable=signature-differs
89 | return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
90 |
91 | def training_losses(
92 | self, model, *args, **kwargs
93 | ): # pylint: disable=signature-differs
94 | return super().training_losses(self._wrap_model(model), *args, **kwargs)
95 |
96 | def training_losses_diffusers(
97 | self, model, *args, **kwargs
98 | ): # pylint: disable=signature-differs
99 | return super().training_losses_diffusers(self._wrap_model(model), *args, **kwargs)
100 |
101 | def condition_mean(self, cond_fn, *args, **kwargs):
102 | return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
103 |
104 | def condition_score(self, cond_fn, *args, **kwargs):
105 | return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
106 |
107 | def _wrap_model(self, model):
108 | if isinstance(model, _WrappedModel):
109 | return model
110 | return _WrappedModel(
111 | model, self.timestep_map, self.original_num_steps
112 | )
113 |
114 | def _scale_timesteps(self, t):
115 | # Scaling is done by the wrapped model.
116 | return t
117 |
118 |
119 | class _WrappedModel:
120 | def __init__(self, model, timestep_map, original_num_steps):
121 | self.model = model
122 | self.timestep_map = timestep_map
123 | # self.rescale_timesteps = rescale_timesteps
124 | self.original_num_steps = original_num_steps
125 |
126 | def __call__(self, x, timestep, **kwargs):
127 | map_tensor = th.tensor(self.timestep_map, device=timestep.device, dtype=timestep.dtype)
128 | new_ts = map_tensor[timestep]
129 | # if self.rescale_timesteps:
130 | # new_ts = new_ts.float() * (1000.0 / self.original_num_steps)
131 | return self.model(x, timestep=new_ts, **kwargs)
--------------------------------------------------------------------------------
/easyanimate/utils/utils.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import imageio
4 | import numpy as np
5 | import torch
6 | import torchvision
7 | from einops import rearrange
8 | from PIL import Image
9 |
10 |
11 | def save_videos_grid(videos: torch.Tensor, path: str, rescale=False, n_rows=6, fps=12, imageio_backend=True):
12 | videos = rearrange(videos, "b c t h w -> t b c h w")
13 | outputs = []
14 | for x in videos:
15 | x = torchvision.utils.make_grid(x, nrow=n_rows)
16 | x = x.transpose(0, 1).transpose(1, 2).squeeze(-1)
17 | if rescale:
18 | x = (x + 1.0) / 2.0 # -1,1 -> 0,1
19 | x = (x * 255).numpy().astype(np.uint8)
20 | outputs.append(Image.fromarray(x))
21 |
22 | os.makedirs(os.path.dirname(path), exist_ok=True)
23 | if imageio_backend:
24 | if path.endswith("mp4"):
25 | imageio.mimsave(path, outputs, fps=fps)
26 | else:
27 | imageio.mimsave(path, outputs, duration=(1000 * 1/fps))
28 | else:
29 | if path.endswith("mp4"):
30 | path = path.replace('.mp4', '.gif')
31 | outputs[0].save(path, format='GIF', append_images=outputs, save_all=True, duration=100, loop=0)
32 |
--------------------------------------------------------------------------------
/models/put models here.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/models/put models here.txt
--------------------------------------------------------------------------------
/nodes.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import folder_paths
4 | comfy_path = os.path.dirname(folder_paths.__file__)
5 |
6 | import sys
7 | easyanimate_path=f'{comfy_path}/custom_nodes/ComfyUI-EasyAnimate'
8 | sys.path.insert(0,easyanimate_path)
9 |
10 | import torch
11 | from diffusers import (AutoencoderKL, DDIMScheduler,
12 | DPMSolverMultistepScheduler,
13 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
14 | PNDMScheduler)
15 | from omegaconf import OmegaConf
16 |
17 | from easyanimate.models.autoencoder_magvit import AutoencoderKLMagvit
18 | from easyanimate.models.transformer3d import Transformer3DModel
19 | from easyanimate.pipeline.pipeline_easyanimate import EasyAnimatePipeline
20 | from easyanimate.utils.lora_utils import merge_lora, unmerge_lora
21 | from easyanimate.utils.utils import save_videos_grid
22 | from einops import rearrange
23 |
24 | checkpoints=['None']
25 | checkpoints.extend(folder_paths.get_filename_list("checkpoints"))
26 | vaes=['None']
27 | vaes.extend(folder_paths.get_filename_list("vae"))
28 |
29 | class EasyAnimateLoader:
30 | @classmethod
31 | def INPUT_TYPES(cls):
32 | return {
33 | "required": {
34 | "pixart_path": (os.listdir(folder_paths.get_folder_paths("diffusers")[0]), {"default": "PixArt-XL-2-512x512"}),
35 | "motion_ckpt": (folder_paths.get_filename_list("checkpoints"), {"default": "easyanimate_v1_mm.safetensors"}),
36 | "sampler_name": (["Euler","Euler A","DPM++","PNDM","DDIM"],{"default":"DPM++"}),
37 | "device":(["cuda","cpu"],{"default":"cuda"}),
38 | },
39 | "optional": {
40 | "transformer_ckpt": (checkpoints, {"default": 'None'}),
41 | "lora_ckpt": (checkpoints, {"default": 'None'}),
42 | "vae_ckpt": (vaes, {"default": 'None'}),
43 | "lora_weight": ("FLOAT", {"default": 0.55, "min": 0, "max": 1, "step": 0.01}),
44 | }
45 | }
46 |
47 | RETURN_TYPES = ("EasyAnimateModel",)
48 | FUNCTION = "run"
49 | CATEGORY = "EasyAnimate"
50 |
51 | def run(self,pixart_path,motion_ckpt,sampler_name,device,transformer_ckpt='None',lora_ckpt='None',vae_ckpt='None',lora_weight=0.55):
52 | pixart_path=os.path.join(folder_paths.get_folder_paths("diffusers")[0],pixart_path)
53 | # Config and model path
54 | config_path = f"{easyanimate_path}/config/easyanimate_video_motion_module_v1.yaml"
55 | model_name = pixart_path
56 | #model_name = "models/Diffusion_Transformer/PixArt-XL-2-512x512"
57 |
58 | # Choose the sampler in "Euler" "Euler A" "DPM++" "PNDM" and "DDIM"
59 | sampler_name = "DPM++"
60 |
61 | # Load pretrained model if need
62 | transformer_path = None
63 | if transformer_ckpt!='None':
64 | transformer_path = folder_paths.get_full_path("checkpoints", transformer_ckpt)
65 | motion_module_path = folder_paths.get_full_path("checkpoints", motion_ckpt)
66 | #motion_module_path = "models/Motion_Module/easyanimate_v1_mm.safetensors"
67 | vae_path = None
68 | if vae_ckpt!='None':
69 | vae_path = folder_paths.get_full_path("vae", vae_ckpt)
70 | lora_path = None
71 | if lora_ckpt!='None':
72 | lora_path = folder_paths.get_full_path("checkpoints", lora_ckpt)
73 |
74 | weight_dtype = torch.float16
75 | guidance_scale = 6.0
76 | seed = 43
77 | num_inference_steps = 30
78 | #lora_weight = 0.55
79 |
80 | config = OmegaConf.load(config_path)
81 |
82 | # Get Transformer
83 | transformer = Transformer3DModel.from_pretrained_2d(
84 | model_name,
85 | subfolder="transformer",
86 | transformer_additional_kwargs=OmegaConf.to_container(config['transformer_additional_kwargs'])
87 | ).to(weight_dtype)
88 |
89 | if transformer_path is not None:
90 | print(f"From checkpoint: {transformer_path}")
91 | if transformer_path.endswith("safetensors"):
92 | from safetensors.torch import load_file, safe_open
93 | state_dict = load_file(transformer_path)
94 | else:
95 | state_dict = torch.load(transformer_path, map_location="cpu")
96 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
97 |
98 | m, u = transformer.load_state_dict(state_dict, strict=False)
99 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
100 |
101 | if motion_module_path is not None:
102 | print(f"From Motion Module: {motion_module_path}")
103 | if motion_module_path.endswith("safetensors"):
104 | from safetensors.torch import load_file, safe_open
105 | state_dict = load_file(motion_module_path)
106 | else:
107 | state_dict = torch.load(motion_module_path, map_location="cpu")
108 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
109 |
110 | m, u = transformer.load_state_dict(state_dict, strict=False)
111 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}, {u}")
112 |
113 | # Get Vae
114 | if OmegaConf.to_container(config['vae_kwargs'])['enable_magvit']:
115 | Choosen_AutoencoderKL = AutoencoderKLMagvit
116 | else:
117 | Choosen_AutoencoderKL = AutoencoderKL
118 | vae = Choosen_AutoencoderKL.from_pretrained(
119 | model_name,
120 | subfolder="vae",
121 | torch_dtype=weight_dtype
122 | )
123 |
124 | if vae_path is not None:
125 | print(f"From checkpoint: {vae_path}")
126 | if vae_path.endswith("safetensors"):
127 | from safetensors.torch import load_file, safe_open
128 | state_dict = load_file(vae_path)
129 | else:
130 | state_dict = torch.load(vae_path, map_location="cpu")
131 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
132 |
133 | m, u = vae.load_state_dict(state_dict, strict=False)
134 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
135 |
136 | # Get Scheduler
137 | Choosen_Scheduler = scheduler_dict = {
138 | "Euler": EulerDiscreteScheduler,
139 | "Euler A": EulerAncestralDiscreteScheduler,
140 | "DPM++": DPMSolverMultistepScheduler,
141 | "PNDM": PNDMScheduler,
142 | "DDIM": DDIMScheduler,
143 | }[sampler_name]
144 | scheduler = Choosen_Scheduler(**OmegaConf.to_container(config['noise_scheduler_kwargs']))
145 |
146 | pipeline = EasyAnimatePipeline.from_pretrained(
147 | model_name,
148 | vae=vae,
149 | transformer=transformer,
150 | scheduler=scheduler,
151 | torch_dtype=weight_dtype
152 | )
153 | #pipeline.to(device)
154 | pipeline.enable_model_cpu_offload()
155 |
156 | pipeline.transformer.to(device)
157 | pipeline.text_encoder.to('cpu')
158 | pipeline.vae.to('cpu')
159 |
160 | if lora_path is not None:
161 | pipeline = merge_lora(pipeline, lora_path, lora_weight)
162 | return (pipeline,)
163 |
164 | class EasyAnimateRun:
165 | @classmethod
166 | def INPUT_TYPES(cls):
167 | return {
168 | "required": {
169 | "model":("EasyAnimateModel",),
170 | "prompt":("STRING",{"multiline": True, "default":"A snowy forest landscape with a dirt road running through it. The road is flanked by trees covered in snow, and the ground is also covered in snow. The sun is shining, creating a bright and serene atmosphere. The road appears to be empty, and there are no people or animals visible in the video. The style of the video is a natural landscape shot, with a focus on the beauty of the snowy forest and the peacefulness of the road."}),
171 | "negative_prompt":("STRING",{"multiline": True, "default":"Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly"}),
172 | "video_length":("INT",{"default":80}),
173 | "num_inference_steps":("INT",{"default":30}),
174 | "width":("INT",{"default":512}),
175 | "height":("INT",{"default":512}),
176 | "guidance_scale":("FLOAT",{"default":6.0}),
177 | "seed":("INT",{"default":1234}),
178 | },
179 | }
180 |
181 | RETURN_TYPES = ("IMAGE",)
182 | FUNCTION = "run"
183 | CATEGORY = "EasyAnimate"
184 |
185 | def run(self,model,prompt,negative_prompt,video_length,num_inference_steps,width,height,guidance_scale,seed):
186 | generator = torch.Generator(device='cuda').manual_seed(seed)
187 |
188 | with torch.no_grad():
189 | videos = model(
190 | prompt,
191 | video_length = video_length,
192 | negative_prompt = negative_prompt,
193 | height = height,
194 | width = width,
195 | generator = generator,
196 | guidance_scale = guidance_scale,
197 | num_inference_steps = num_inference_steps,
198 | ).videos
199 |
200 | videos = rearrange(videos, "b c t h w -> b t h w c")
201 |
202 | return videos
203 |
204 | NODE_CLASS_MAPPINGS = {
205 | "EasyAnimateLoader":EasyAnimateLoader,
206 | "EasyAnimateRun":EasyAnimateRun,
207 | }
--------------------------------------------------------------------------------
/predict_t2i.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | from diffusers import (AutoencoderKL, DDIMScheduler,
5 | DPMSolverMultistepScheduler,
6 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
7 | PNDMScheduler)
8 | from omegaconf import OmegaConf
9 |
10 | from easyanimate.models.autoencoder_magvit import AutoencoderKLMagvit
11 | from easyanimate.models.transformer2d import Transformer2DModel
12 | from easyanimate.pipeline.pipeline_pixart_magvit import PixArtAlphaMagvitPipeline
13 | from easyanimate.utils.lora_utils import merge_lora
14 |
15 | # Config and model path
16 | config_path = "config/easyanimate_image_normal_v1.yaml"
17 | model_name = "models/Diffusion_Transformer/PixArt-XL-2-512x512"
18 | # Choose the sampler in "Euler" "Euler A" "DPM++" "PNDM" and "DDIM"
19 | sampler_name = "DPM++"
20 |
21 | # Load pretrained model if need
22 | transformer_path = None
23 | vae_path = None
24 | lora_path = None
25 |
26 | # Other params
27 | sample_size = [512, 512]
28 | weight_dtype = torch.float16
29 | prompt = "1girl, bangs, blue eyes, blunt bangs, blurry, blurry background, bob cut, depth of field, lips, looking at viewer, motion blur, nose, realistic, red lips, shirt, short hair, solo, white shirt."
30 | negative_prompt = "bad detailed"
31 | guidance_scale = 6.0
32 | seed = 43
33 | lora_weight = 0.55
34 | save_path = "samples/easyanimate-images"
35 |
36 | config = OmegaConf.load(config_path)
37 |
38 | # Get Transformer
39 | transformer = Transformer2DModel.from_pretrained(
40 | model_name,
41 | subfolder="transformer"
42 | ).to(weight_dtype)
43 |
44 | if transformer_path is not None:
45 | print(f"From checkpoint: {transformer_path}")
46 | if transformer_path.endswith("safetensors"):
47 | from safetensors.torch import load_file, safe_open
48 | state_dict = load_file(transformer_path)
49 | else:
50 | state_dict = torch.load(transformer_path, map_location="cpu")
51 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
52 |
53 | m, u = transformer.load_state_dict(state_dict, strict=False)
54 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
55 |
56 | # Get Vae
57 | if OmegaConf.to_container(config['vae_kwargs'])['enable_magvit']:
58 | Choosen_AutoencoderKL = AutoencoderKLMagvit
59 | else:
60 | Choosen_AutoencoderKL = AutoencoderKL
61 | vae = Choosen_AutoencoderKL.from_pretrained(
62 | model_name,
63 | subfolder="vae",
64 | torch_dtype=weight_dtype
65 | )
66 |
67 | if vae_path is not None:
68 | print(f"From checkpoint: {vae_path}")
69 | if vae_path.endswith("safetensors"):
70 | from safetensors.torch import load_file, safe_open
71 | state_dict = load_file(vae_path)
72 | else:
73 | state_dict = torch.load(vae_path, map_location="cpu")
74 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
75 |
76 | m, u = vae.load_state_dict(state_dict, strict=False)
77 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
78 | assert len(u) == 0
79 |
80 | # Get Scheduler
81 | Choosen_Scheduler = scheduler_dict = {
82 | "Euler": EulerDiscreteScheduler,
83 | "Euler A": EulerAncestralDiscreteScheduler,
84 | "DPM++": DPMSolverMultistepScheduler,
85 | "PNDM": PNDMScheduler,
86 | "DDIM": DDIMScheduler,
87 | }[sampler_name]
88 | scheduler = Choosen_Scheduler(**OmegaConf.to_container(config['noise_scheduler_kwargs']))
89 |
90 | # PixArtAlphaMagvitPipeline is compatible with PixArtAlphaPipeline
91 | pipeline = PixArtAlphaMagvitPipeline.from_pretrained(
92 | model_name,
93 | vae=vae,
94 | transformer=transformer,
95 | scheduler=scheduler,
96 | torch_dtype=weight_dtype
97 | )
98 | pipeline.to("cuda")
99 | pipeline.enable_model_cpu_offload()
100 |
101 | if lora_path is not None:
102 | pipeline = merge_lora(pipeline, lora_path, lora_weight)
103 |
104 | generator = torch.Generator(device="cuda").manual_seed(seed)
105 |
106 | with torch.no_grad():
107 | sample = pipeline(
108 | prompt = prompt,
109 | negative_prompt = negative_prompt,
110 | guidance_scale = guidance_scale,
111 | height = sample_size[0],
112 | width = sample_size[1],
113 | generator = generator,
114 | ).images[0]
115 |
116 | if not os.path.exists(save_path):
117 | os.makedirs(save_path, exist_ok=True)
118 |
119 | index = len([path for path in os.listdir(save_path)]) + 1
120 | prefix = str(index).zfill(8)
121 | image_path = os.path.join(save_path, prefix + ".png")
122 | sample.save(image_path)
--------------------------------------------------------------------------------
/predict_t2v.py:
--------------------------------------------------------------------------------
1 | import os
2 |
3 | import torch
4 | from diffusers import (AutoencoderKL, DDIMScheduler,
5 | DPMSolverMultistepScheduler,
6 | EulerAncestralDiscreteScheduler, EulerDiscreteScheduler,
7 | PNDMScheduler)
8 | from omegaconf import OmegaConf
9 |
10 | from easyanimate.models.autoencoder_magvit import AutoencoderKLMagvit
11 | from easyanimate.models.transformer3d import Transformer3DModel
12 | from easyanimate.pipeline.pipeline_easyanimate import EasyAnimatePipeline
13 | from easyanimate.utils.lora_utils import merge_lora, unmerge_lora
14 | from easyanimate.utils.utils import save_videos_grid
15 |
16 | # Config and model path
17 | config_path = "config/easyanimate_video_motion_module_v1.yaml"
18 | model_name = "models/Diffusion_Transformer/PixArt-XL-2-512x512"
19 |
20 | # Choose the sampler in "Euler" "Euler A" "DPM++" "PNDM" and "DDIM"
21 | sampler_name = "DPM++"
22 |
23 | # Load pretrained model if need
24 | transformer_path = None
25 | motion_module_path = "models/Motion_Module/easyanimate_v1_mm.safetensors"
26 | vae_path = None
27 | lora_path = None
28 |
29 | # other params
30 | sample_size = [512, 512]
31 | video_length = 80
32 | fps = 12
33 |
34 | weight_dtype = torch.float16
35 | prompt = "A snowy forest landscape with a dirt road running through it. The road is flanked by trees covered in snow, and the ground is also covered in snow. The sun is shining, creating a bright and serene atmosphere. The road appears to be empty, and there are no people or animals visible in the video. The style of the video is a natural landscape shot, with a focus on the beauty of the snowy forest and the peacefulness of the road."
36 | negative_prompt = "Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly"
37 | guidance_scale = 6.0
38 | seed = 43
39 | num_inference_steps = 30
40 | lora_weight = 0.55
41 | save_path = "samples/easyanimate-videos"
42 |
43 | config = OmegaConf.load(config_path)
44 |
45 | # Get Transformer
46 | transformer = Transformer3DModel.from_pretrained_2d(
47 | model_name,
48 | subfolder="transformer",
49 | transformer_additional_kwargs=OmegaConf.to_container(config['transformer_additional_kwargs'])
50 | ).to(weight_dtype)
51 |
52 | if transformer_path is not None:
53 | print(f"From checkpoint: {transformer_path}")
54 | if transformer_path.endswith("safetensors"):
55 | from safetensors.torch import load_file, safe_open
56 | state_dict = load_file(transformer_path)
57 | else:
58 | state_dict = torch.load(transformer_path, map_location="cpu")
59 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
60 |
61 | m, u = transformer.load_state_dict(state_dict, strict=False)
62 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
63 |
64 | if motion_module_path is not None:
65 | print(f"From Motion Module: {motion_module_path}")
66 | if motion_module_path.endswith("safetensors"):
67 | from safetensors.torch import load_file, safe_open
68 | state_dict = load_file(motion_module_path)
69 | else:
70 | state_dict = torch.load(motion_module_path, map_location="cpu")
71 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
72 |
73 | m, u = transformer.load_state_dict(state_dict, strict=False)
74 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}, {u}")
75 |
76 | # Get Vae
77 | if OmegaConf.to_container(config['vae_kwargs'])['enable_magvit']:
78 | Choosen_AutoencoderKL = AutoencoderKLMagvit
79 | else:
80 | Choosen_AutoencoderKL = AutoencoderKL
81 | vae = Choosen_AutoencoderKL.from_pretrained(
82 | model_name,
83 | subfolder="vae",
84 | torch_dtype=weight_dtype
85 | )
86 |
87 | if vae_path is not None:
88 | print(f"From checkpoint: {vae_path}")
89 | if vae_path.endswith("safetensors"):
90 | from safetensors.torch import load_file, safe_open
91 | state_dict = load_file(vae_path)
92 | else:
93 | state_dict = torch.load(vae_path, map_location="cpu")
94 | state_dict = state_dict["state_dict"] if "state_dict" in state_dict else state_dict
95 |
96 | m, u = vae.load_state_dict(state_dict, strict=False)
97 | print(f"missing keys: {len(m)}, unexpected keys: {len(u)}")
98 |
99 | # Get Scheduler
100 | Choosen_Scheduler = scheduler_dict = {
101 | "Euler": EulerDiscreteScheduler,
102 | "Euler A": EulerAncestralDiscreteScheduler,
103 | "DPM++": DPMSolverMultistepScheduler,
104 | "PNDM": PNDMScheduler,
105 | "DDIM": DDIMScheduler,
106 | }[sampler_name]
107 | scheduler = Choosen_Scheduler(**OmegaConf.to_container(config['noise_scheduler_kwargs']))
108 |
109 | pipeline = EasyAnimatePipeline.from_pretrained(
110 | model_name,
111 | vae=vae,
112 | transformer=transformer,
113 | scheduler=scheduler,
114 | torch_dtype=weight_dtype
115 | )
116 | pipeline.to("cuda")
117 | pipeline.enable_model_cpu_offload()
118 |
119 | generator = torch.Generator(device="cuda").manual_seed(seed)
120 |
121 | if lora_path is not None:
122 | pipeline = merge_lora(pipeline, lora_path, lora_weight)
123 |
124 | with torch.no_grad():
125 | sample = pipeline(
126 | prompt,
127 | video_length = video_length,
128 | negative_prompt = negative_prompt,
129 | height = sample_size[0],
130 | width = sample_size[1],
131 | generator = generator,
132 | guidance_scale = guidance_scale,
133 | num_inference_steps = num_inference_steps,
134 | ).videos
135 |
136 | if not os.path.exists(save_path):
137 | os.makedirs(save_path, exist_ok=True)
138 |
139 | index = len([path for path in os.listdir(save_path)]) + 1
140 | prefix = str(index).zfill(8)
141 | video_path = os.path.join(save_path, prefix + ".gif")
142 | save_videos_grid(sample, video_path, fps=fps)
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | Pillow
2 | einops
3 | safetensors
4 | timm
5 | tomesd
6 | xformers
7 | decord
8 | datasets
9 | numpy
10 | scikit-image
11 | opencv-python
12 | omegaconf
13 | diffusers
14 | transformers
--------------------------------------------------------------------------------
/scripts/extra_motion_module.py:
--------------------------------------------------------------------------------
1 | import torch
2 | from safetensors.torch import load_file, safe_open, save_file
3 |
4 | original_safetensor_path = 'diffusion_pytorch_model.safetensors'
5 | new_safetensor_path = 'easyanimate_v1_mm.safetensors' #
6 |
7 | original_weights = load_file(original_safetensor_path)
8 | temporal_weights = {}
9 | for name, weight in original_weights.items():
10 | if 'temporal' in name:
11 | temporal_weights[name] = weight
12 | save_file(temporal_weights, new_safetensor_path, None)
13 | print(f'Saved weights containing "temporal" to {new_safetensor_path}')
--------------------------------------------------------------------------------
/scripts/train_t2i.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 |
5 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
6 | # vae_mode can be choosen in "normal" and "magvit"
7 | # transformer_mode can be choosen in "normal" and "kvcompress"
8 | accelerate launch --mixed_precision="bf16" scripts/train_t2i.py \
9 | --pretrained_model_name_or_path=$MODEL_NAME \
10 | --train_data_dir=$DATASET_NAME \
11 | --train_data_meta=$DATASET_META_NAME \
12 | --config_path "config/easyanimate_image_normal_v1.yaml" \
13 | --train_data_format="normal" \
14 | --caption_column="text" \
15 | --resolution=512 \
16 | --train_batch_size=2 \
17 | --gradient_accumulation_steps=1 \
18 | --dataloader_num_workers=8 \
19 | --num_train_epochs=50 \
20 | --checkpointing_steps=500 \
21 | --validation_prompts="1girl, bangs, blue eyes, blunt bangs, blurry, blurry background, bob cut, depth of field, lips, looking at viewer, motion blur, nose, realistic, red lips, shirt, short hair, solo, white shirt." \
22 | --validation_epochs=1 \
23 | --validation_steps=100 \
24 | --learning_rate=1e-05 \
25 | --lr_scheduler="constant_with_warmup" \
26 | --lr_warmup_steps=50 \
27 | --seed=42 \
28 | --max_grad_norm=1 \
29 | --output_dir="output_dir_t2i" \
30 | --enable_xformers_memory_efficient_attention \
31 | --gradient_checkpointing \
32 | --mixed_precision='bf16' \
33 | --use_ema \
34 | --trainable_modules "."
--------------------------------------------------------------------------------
/scripts/train_t2i_lora.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 |
5 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
6 | # vae_mode can be choosen in "normal" and "magvit"
7 | # transformer_mode can be choosen in "normal" and "kvcompress"
8 | accelerate launch --mixed_precision="bf16" scripts/train_t2i_lora.py \
9 | --pretrained_model_name_or_path=$MODEL_NAME \
10 | --train_data_dir=$DATASET_NAME \
11 | --train_data_meta=$DATASET_META_NAME \
12 | --config_path "config/easyanimate_image_normal_v1.yaml" \
13 | --train_data_format="normal" \
14 | --caption_column="text" \
15 | --resolution=512 \
16 | --train_text_encoder \
17 | --train_batch_size=2 \
18 | --gradient_accumulation_steps=1 \
19 | --dataloader_num_workers=8 \
20 | --max_train_steps=2500 \
21 | --checkpointing_steps=500 \
22 | --validation_prompts="1girl, bangs, blue eyes, blunt bangs, blurry, blurry background, bob cut, depth of field, lips, looking at viewer, motion blur, nose, realistic, red lips, shirt, short hair, solo, white shirt." \
23 | --validation_steps=100 \
24 | --learning_rate=1e-04 \
25 | --seed=42 \
26 | --output_dir="output_dir_lora" \
27 | --enable_xformers_memory_efficient_attention \
28 | --gradient_checkpointing \
29 | --mixed_precision='bf16'
30 |
--------------------------------------------------------------------------------
/scripts/train_t2iv.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 | export NCCL_IB_DISABLE=1
5 | export NCCL_P2P_DISABLE=1
6 | NCCL_DEBUG=INFO
7 |
8 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
9 | # vae_mode can be choosen in "normal" and "magvit"
10 | # transformer_mode can be choosen in "normal" and "kvcompress"
11 | accelerate launch --mixed_precision="bf16" scripts/train_t2iv.py \
12 | --pretrained_model_name_or_path=$MODEL_NAME \
13 | --train_data_dir=$DATASET_NAME \
14 | --train_data_meta=$DATASET_META_NAME \
15 | --config_path "config/easyanimate_video_motion_module_v1.yaml" \
16 | --image_sample_size=512 \
17 | --video_sample_size=512 \
18 | --video_sample_stride=2 \
19 | --video_sample_n_frames=16 \
20 | --train_batch_size=2 \
21 | --video_repeat=1 \
22 | --image_repeat_in_forward=4 \
23 | --gradient_accumulation_steps=1 \
24 | --dataloader_num_workers=8 \
25 | --num_train_epochs=100 \
26 | --checkpointing_steps=500 \
27 | --validation_prompts="A girl with delicate face is smiling." \
28 | --validation_epochs=1 \
29 | --validation_steps=100 \
30 | --learning_rate=2e-05 \
31 | --lr_scheduler="constant_with_warmup" \
32 | --lr_warmup_steps=100 \
33 | --seed=42 \
34 | --output_dir="output_dir" \
35 | --enable_xformers_memory_efficient_attention \
36 | --gradient_checkpointing \
37 | --mixed_precision="bf16" \
38 | --adam_weight_decay=3e-2 \
39 | --adam_epsilon=1e-10 \
40 | --max_grad_norm=1 \
41 | --vae_mini_batch=16 \
42 | --use_ema \
43 | --trainable_modules "attn_temporal"
--------------------------------------------------------------------------------
/scripts/train_t2v.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 | export NCCL_IB_DISABLE=1
5 | export NCCL_P2P_DISABLE=1
6 | NCCL_DEBUG=INFO
7 |
8 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
9 | accelerate launch --mixed_precision="bf16" scripts/train_t2v.py \
10 | --pretrained_model_name_or_path=$MODEL_NAME \
11 | --train_data_dir=$DATASET_NAME \
12 | --train_data_meta=$DATASET_META_NAME \
13 | --config_path "config/easyanimate_video_motion_module_v1.yaml" \
14 | --train_data_format="normal" \
15 | --train_mode="normal" \
16 | --sample_size=512 \
17 | --sample_stride=2 \
18 | --sample_n_frames=16 \
19 | --train_batch_size=2 \
20 | --gradient_accumulation_steps=1 \
21 | --dataloader_num_workers=8 \
22 | --num_train_epochs=100 \
23 | --checkpointing_steps=500 \
24 | --validation_prompts="A girl with delicate face is smiling." \
25 | --validation_epochs=1 \
26 | --validation_steps=100 \
27 | --learning_rate=2e-05 \
28 | --lr_scheduler="constant_with_warmup" \
29 | --lr_warmup_steps=100 \
30 | --seed=42 \
31 | --output_dir="output_dir" \
32 | --enable_xformers_memory_efficient_attention \
33 | --gradient_checkpointing \
34 | --mixed_precision="bf16" \
35 | --adam_weight_decay=3e-2 \
36 | --adam_epsilon=1e-10 \
37 | --max_grad_norm=1 \
38 | --vae_mini_batch=16 \
39 | --use_ema \
40 | --trainable_modules "attn_temporal"
--------------------------------------------------------------------------------
/scripts/train_t2v_lora.sh:
--------------------------------------------------------------------------------
1 | export MODEL_NAME="models/Diffusion_Transformer/PixArt-XL-2-512x512"
2 | export DATASET_NAME="datasets/internal_datasets/"
3 | export DATASET_META_NAME="datasets/internal_datasets/metadata.json"
4 | export NCCL_IB_DISABLE=1
5 | export NCCL_P2P_DISABLE=1
6 | NCCL_DEBUG=INFO
7 |
8 | # When train model with multi machines, use "--config_file accelerate.yaml" instead of "--mixed_precision='bf16'".
9 | accelerate launch --mixed_precision="bf16" scripts/train_t2v_lora.py \
10 | --pretrained_model_name_or_path=$MODEL_NAME \
11 | --transformer_path="models/Motion_Module/easyanimate_v1_mm.safetensors" \
12 | --train_data_dir=$DATASET_NAME \
13 | --train_data_meta=$DATASET_META_NAME \
14 | --config_path "config/easyanimate_video_motion_module_v1.yaml" \
15 | --train_data_format="normal" \
16 | --train_mode="normal" \
17 | --sample_size=512 \
18 | --sample_stride=2 \
19 | --sample_n_frames=16 \
20 | --train_batch_size=2 \
21 | --gradient_accumulation_steps=1 \
22 | --dataloader_num_workers=8 \
23 | --num_train_epochs=100 \
24 | --checkpointing_steps=500 \
25 | --validation_prompts="A girl with delicate face is smiling." \
26 | --validation_epochs=1 \
27 | --validation_steps=100 \
28 | --learning_rate=2e-05 \
29 | --seed=42 \
30 | --output_dir="output_dir" \
31 | --enable_xformers_memory_efficient_attention \
32 | --gradient_checkpointing \
33 | --mixed_precision="bf16" \
34 | --adam_weight_decay=3e-2 \
35 | --adam_epsilon=1e-10 \
36 | --max_grad_norm=1 \
37 | --vae_mini_batch=16
38 |
--------------------------------------------------------------------------------
/wf.json:
--------------------------------------------------------------------------------
1 | {
2 | "last_node_id": 8,
3 | "last_link_id": 7,
4 | "nodes": [
5 | {
6 | "id": 2,
7 | "type": "EasyAnimateRun",
8 | "pos": [
9 | 459,
10 | -4
11 | ],
12 | "size": {
13 | "0": 387.611083984375,
14 | "1": 427.48992919921875
15 | },
16 | "flags": {},
17 | "order": 1,
18 | "mode": 0,
19 | "inputs": [
20 | {
21 | "name": "model",
22 | "type": "EasyAnimateModel",
23 | "link": 7
24 | }
25 | ],
26 | "outputs": [
27 | {
28 | "name": "IMAGE",
29 | "type": "IMAGE",
30 | "links": [
31 | 4
32 | ],
33 | "shape": 3,
34 | "slot_index": 0
35 | }
36 | ],
37 | "properties": {
38 | "Node name for S&R": "EasyAnimateRun"
39 | },
40 | "widgets_values": [
41 | "A serene night scene in a forested area. The first frame shows a tranquil lake reflecting the star-filled sky above. The second frame reveals a beautiful sunset, casting a warm glow over the landscape. The third frame showcases the night sky, filled with stars and a vibrant Milky Way galaxy. The video is a time-lapse, capturing the transition from day to night, with the lake and forest serving as a constant backdrop. The style of the video is naturalistic, emphasizing the beauty of the night sky and the peacefulness of the forest.",
42 | "Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly",
43 | 80,
44 | 30,
45 | 512,
46 | 512,
47 | 6,
48 | 1829,
49 | "fixed"
50 | ]
51 | },
52 | {
53 | "id": 8,
54 | "type": "EasyAnimateLoader",
55 | "pos": [
56 | -31,
57 | -3
58 | ],
59 | "size": {
60 | "0": 315,
61 | "1": 226
62 | },
63 | "flags": {},
64 | "order": 0,
65 | "mode": 0,
66 | "outputs": [
67 | {
68 | "name": "EasyAnimateModel",
69 | "type": "EasyAnimateModel",
70 | "links": [
71 | 7
72 | ],
73 | "shape": 3,
74 | "slot_index": 0
75 | }
76 | ],
77 | "properties": {
78 | "Node name for S&R": "EasyAnimateLoader"
79 | },
80 | "widgets_values": [
81 | "PixArt-XL-2-512x512",
82 | "easyanimate_v1_mm.safetensors",
83 | "DPM++",
84 | "cuda",
85 | "PixArt-Sigma-XL-2-1024-MS.pth",
86 | "None",
87 | "None",
88 | 0.55
89 | ]
90 | },
91 | {
92 | "id": 5,
93 | "type": "VHS_VideoCombine",
94 | "pos": [
95 | 1018,
96 | -13
97 | ],
98 | "size": [
99 | 315,
100 | 599
101 | ],
102 | "flags": {},
103 | "order": 2,
104 | "mode": 0,
105 | "inputs": [
106 | {
107 | "name": "images",
108 | "type": "IMAGE",
109 | "link": 4
110 | },
111 | {
112 | "name": "audio",
113 | "type": "VHS_AUDIO",
114 | "link": null
115 | },
116 | {
117 | "name": "batch_manager",
118 | "type": "VHS_BatchManager",
119 | "link": null
120 | }
121 | ],
122 | "outputs": [
123 | {
124 | "name": "Filenames",
125 | "type": "VHS_FILENAMES",
126 | "links": null,
127 | "shape": 3
128 | }
129 | ],
130 | "properties": {
131 | "Node name for S&R": "VHS_VideoCombine"
132 | },
133 | "widgets_values": {
134 | "frame_rate": 8,
135 | "loop_count": 0,
136 | "filename_prefix": "AnimateDiff",
137 | "format": "video/h264-mp4",
138 | "pix_fmt": "yuv420p",
139 | "crf": 19,
140 | "save_metadata": true,
141 | "pingpong": false,
142 | "save_output": true,
143 | "videopreview": {
144 | "hidden": false,
145 | "paused": false,
146 | "params": {
147 | "filename": "AnimateDiff_00461.mp4",
148 | "subfolder": "",
149 | "type": "output",
150 | "format": "video/h264-mp4"
151 | }
152 | }
153 | }
154 | }
155 | ],
156 | "links": [
157 | [
158 | 4,
159 | 2,
160 | 0,
161 | 5,
162 | 0,
163 | "IMAGE"
164 | ],
165 | [
166 | 7,
167 | 8,
168 | 0,
169 | 2,
170 | 0,
171 | "EasyAnimateModel"
172 | ]
173 | ],
174 | "groups": [],
175 | "config": {},
176 | "extra": {},
177 | "version": 0.4
178 | }
--------------------------------------------------------------------------------
/wf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaojie/ComfyUI-EasyAnimate/9bef69d1ceda9d300613488517af6cc66cf5c360/wf.png
--------------------------------------------------------------------------------