├── .idea
├── TIANCHI_Project.iml
├── misc.xml
└── modules.xml
├── Ad_Convert_prediction
├── README.md
├── data
│ ├── round1_ijcai_18_result_demo_20180301.txt
│ └── 数据说明.txt
├── doc
│ ├── paper
│ │ ├── Factorization Machines with libFM.pdf
│ │ ├── Factorization Machines--Steffen Rendle.pdf
│ │ ├── Field-aware Factorization Machines for CTR Prediction.pdf
│ │ ├── Field-aware Factorization Machines in a Real-world Online Advertising System-ind0438-juanA.pdf
│ │ ├── Recurrent Neural Networks with Top-k Gains for Session-based Recommendations.pdf
│ │ ├── SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS.pdf
│ │ ├── Wide & Deep Learning for Recommender Systems.pdf
│ │ ├── XGBoost A Scalable Tree Boosting System.pdf
│ │ ├── 【ECIR-16-FNN】Deep Learning over Multi-field Categorical Data--A Case Study on User Response Prediction.pdf
│ │ ├── 【IJCAI-17】-DeepFM-A Factorization-Machine based Neural Network for CTR Prediction.pdf
│ │ ├── 【NIPS-2017】lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
│ │ └── 【SIGIR-17】Neural Factorization Machines for r Sparse Predictive Analytics.pdf
│ └── 基于深度学习的搜索广告点击率预测方法研究.pdf
└── src
│ ├── Data_Preprocess.py
│ └── dnn_42.ipynb
├── Click_prediction
├── README.md
├── code
│ ├── Logloss.py
│ ├── blagging.py
│ ├── ctr
│ │ ├── Preprocess.py
│ │ ├── ctr.ipynb
│ │ └── ffm.py
│ ├── ctr_nn
│ │ ├── Main.py
│ │ ├── Models.py
│ │ ├── Utils.py
│ │ └── __init__.py
│ └── cvr
│ │ ├── 1.problem_setting.ipynb
│ │ ├── 2.Baseline_version.ipynb
│ │ ├── 3.feature_engineering_and_machine_learning.ipynb
│ │ └── README.md
├── data
│ ├── data.pdf
│ ├── data_description.pdf
│ ├── download.sh
│ └── tencent_数据说明
│ │ ├── Tencent_cvr_prediction.png
│ │ ├── data_dscr_4.png
│ │ ├── data_dscr_5.png
│ │ ├── 上下文特征.png
│ │ ├── 广告特征.png
│ │ └── 用户特征.png
├── doc
│ ├── 8课下课件-张伟楠.pdf
│ ├── Ad click prediction a view from the trenches.pdf
│ ├── ffm.txt
│ ├── fm.txt
│ └── 资料.txt
├── libffm
│ └── libffm
│ │ ├── COPYRIGHT
│ │ ├── Makefile
│ │ ├── Makefile.win
│ │ ├── README
│ │ ├── ffm-predict
│ │ ├── ffm-predict.cpp
│ │ ├── ffm-train
│ │ ├── ffm-train.cpp
│ │ ├── ffm.cpp
│ │ ├── ffm.h
│ │ ├── ffm.o
│ │ ├── timer.cpp
│ │ ├── timer.h
│ │ └── timer.o
├── libfm
│ └── libfm
│ │ ├── Makefile
│ │ ├── README.md
│ │ ├── bin
│ │ ├── convert
│ │ ├── fm_model
│ │ ├── libFM
│ │ └── transpose
│ │ ├── license.txt
│ │ ├── scripts
│ │ └── triple_format_to_libfm.pl
│ │ └── src
│ │ ├── fm_core
│ │ ├── fm_data.h
│ │ ├── fm_model.h
│ │ └── fm_sgd.h
│ │ ├── libfm
│ │ ├── Makefile
│ │ ├── libfm.cpp
│ │ ├── libfm.o
│ │ ├── src
│ │ │ ├── Data.h
│ │ │ ├── fm_learn.h
│ │ │ ├── fm_learn_mcmc.h
│ │ │ ├── fm_learn_mcmc_simultaneous.h
│ │ │ ├── fm_learn_sgd.h
│ │ │ ├── fm_learn_sgd_element.h
│ │ │ ├── fm_learn_sgd_element_adapt_reg.h
│ │ │ └── relation.h
│ │ └── tools
│ │ │ ├── convert.cpp
│ │ │ ├── convert.o
│ │ │ ├── transpose.cpp
│ │ │ └── transpose.o
│ │ └── util
│ │ ├── cmdline.h
│ │ ├── fmatrix.h
│ │ ├── matrix.h
│ │ ├── memory.h
│ │ ├── random.h
│ │ ├── rlog.h
│ │ ├── smatrix.h
│ │ └── util.h
└── output
│ ├── criteo.jpg
│ ├── facebook.png
│ ├── ffm_formula.png
│ ├── fm_format.png
│ ├── fm_formula.png
│ ├── fm_formula2.png
│ ├── loss.png
│ ├── model.png
│ ├── tensorboard.png
│ └── train_info.png
├── Coupon_Usage_Predict
└── readme.md
├── Loan_risk_prediction
├── README.md
├── code
│ ├── XGBoost models.ipynb
│ ├── Xgboost调优示例.py
│ └── data_preparation.ipynb
├── data
│ ├── Test_bCtAN1w.csv
│ ├── Train_nyOWmfK.csv
│ └── train_modified.csv
└── doc
│ ├── README.md
│ ├── 不得直视本王-解决方案.pdf
│ ├── 创新应用.docx
│ ├── 最优分箱.docx
│ └── 风控算法大赛解决方案.pdf
├── PPD_RiskControl
├── README.md
└── doc
│ └── 风控算法大赛解决方案.pdf
├── README.md
├── Shangjialiuliang_predict
├── README.md
├── data
│ ├── results
│ │ ├── result_2017-03-11_model.csv
│ │ ├── result_2017-03-11_special_day_weather_huopot.csv
│ │ ├── result_2017-03-16_.csv
│ │ ├── result_2017-03-16_fuse.csv
│ │ ├── result_2017-03-16_special_day.csv
│ │ ├── result_2017-03-16_special_day_weather.csv
│ │ └── result_2017-03-16_special_day_weather_huopot.csv
│ ├── shop_info_name2Id
│ │ ├── cate_1_name.csv
│ │ ├── cate_2_name.csv
│ │ ├── cate_3_name.csv
│ │ ├── city_name.csv
│ │ ├── shop_info.csv
│ │ └── shop_info_num.csv
│ ├── statistics
│ │ ├── all_mon_week3_mean_med_var_std.csv
│ │ ├── city_weather.csv
│ │ ├── count_user_pay.csv
│ │ ├── count_user_pay_avg.csv
│ │ ├── count_user_pay_avg_no_header.csv
│ │ ├── count_user_view.csv
│ │ ├── result_avg7_common_with_last_week.csv
│ │ ├── shop_info.txt
│ │ ├── shop_info_num.csv
│ │ ├── shopid_day_num.txt
│ │ ├── weather-10-11.csv
│ │ ├── weather-11-14.csv
│ │ └── weather_city.csv
│ ├── test_train
│ │ ├── 2017-03-16_test_off_x.csv
│ │ ├── 2017-03-16_test_off_y.csv
│ │ ├── 2017-03-16_test_on_x.csv
│ │ ├── 2017-03-16_train_off_x.csv
│ │ ├── 2017-03-16_train_off_y.csv
│ │ ├── 2017-03-16_train_on_x.csv
│ │ └── 2017-03-16_train_on_y.csv
│ ├── weekABCD
│ │ ├── A.csv
│ │ ├── B.csv
│ │ ├── C.csv
│ │ ├── D.csv
│ │ ├── week0.csv
│ │ ├── week1.csv
│ │ ├── week2.csv
│ │ ├── week3.csv
│ │ ├── week4.csv
│ │ ├── weekA.csv
│ │ ├── weekA1.csv
│ │ ├── weekA_view.csv
│ │ ├── weekB.csv
│ │ ├── weekB1.csv
│ │ ├── weekB_view.csv
│ │ ├── weekC.csv
│ │ ├── weekC1.csv
│ │ ├── weekC_view.csv
│ │ ├── weekD.csv
│ │ ├── weekD1.csv
│ │ ├── weekD_view.csv
│ │ ├── weekP.csv
│ │ ├── weekP2.csv
│ │ ├── weekZ.csv
│ │ └── weekZ1.csv
│ └── weekABCD_0123
│ │ ├── A0.csv
│ │ ├── A1.csv
│ │ ├── A2.csv
│ │ ├── A3.csv
│ │ ├── B0.csv
│ │ ├── B1.csv
│ │ ├── B2.csv
│ │ ├── B3.csv
│ │ ├── C0.csv
│ │ ├── C1.csv
│ │ ├── C2.csv
│ │ ├── C3.csv
│ │ ├── D0.csv
│ │ ├── D1.csv
│ │ ├── D2.csv
│ │ └── D3.csv
├── doc
│ └── 资料.txt
├── main
│ └── __init__.py
├── notebook
│ ├── Untitled.ipynb
│ └── a.txt
├── pictures
│ ├── cate_shop_number
│ │ ├── cate_1.csv
│ │ ├── cate_1.png
│ │ ├── cate_2.csv
│ │ ├── cate_2.png
│ │ ├── cate_3.csv
│ │ └── cate_3.png
│ └── city_shop_number
│ │ ├── 0-50.png
│ │ ├── 101-121.png
│ │ ├── 51-100.png
│ │ ├── all.png
│ │ └── city_shop_number.csv
└── run.py
├── Tencent_Social_Ads
├── README.md
├── data
│ └── 数据说明.txt
├── doc
│ ├── 各代码功能说明.txt
│ └── 模型介绍.txt
├── notebook
│ └── _1_preprocess_data.ipynb
├── run.sh
└── src
│ ├── Ad_Utils.py
│ ├── Feature_joint.py
│ ├── Gen_ID_click_vectors.py
│ ├── Gen_app_install_features.py
│ ├── Gen_global_sum_counts.py
│ ├── Gen_smooth_cvr.py
│ ├── Gen_tricks.py
│ ├── Gen_tricks_final.py
│ ├── Gen_user_click_features.py
│ ├── Preprocess_Data.py
│ ├── Smooth.py
│ ├── __init__.py
│ └── ffm.py
└── Zhihuijiaotong
├── README.md
├── code
├── Preprocess.py
├── Related_lagging.py
├── Utils.py
├── Xgboost_Model.py
└── __init__.py
└── doc
└── “数聚华夏 创享未来”中国数据创新行——智慧交通预测挑战赛 _ 赛题与数据.html
/.idea/TIANCHI_Project.iml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/.idea/misc.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 | ApexVCS
5 |
6 |
7 |
--------------------------------------------------------------------------------
/.idea/modules.xml:
--------------------------------------------------------------------------------
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
--------------------------------------------------------------------------------
/Ad_Convert_prediction/README.md:
--------------------------------------------------------------------------------
1 | # TIANCHI_Project
2 | 天池大数据比赛总结
3 |
4 | 数据下载链接:
--------------------------------------------------------------------------------
/Ad_Convert_prediction/data/round1_ijcai_18_result_demo_20180301.txt:
--------------------------------------------------------------------------------
1 | instance_id predicted_score
2 | 2475218615076601065 0.9
3 | 398316874173557226 0.7
4 | 6586402638209028583 0.5
5 | 1040996105851528465 0.3
6 | 6316278569655873454 0.1
7 |
--------------------------------------------------------------------------------
/Ad_Convert_prediction/data/数据说明.txt:
--------------------------------------------------------------------------------
1 | 基础数据
2 | 字段 解释 特征重要性(1-5排列,数值越大越重要)
3 | instance_id 样本编号,Long
4 | is_trade 是否交易的标记位,Int类型;取值是0或者1,其中1
5 | 表示这条样本最终产生交易,0 表示没有交易
6 | item_id 广告商品编号,Long类型
7 | user_id 用户的编号,Long类型
8 | context_id 上下文信息的编号,Long类型
9 | shop_id 店铺的编号,Long类型
10 |
11 |
12 |
13 |
14 | 广告商品信息
15 | 字段 解释
16 | item_id 广告商品编号,Long类型
17 | item_category_list 广告商品的的类目列表,String类型;从根类目(最粗略的一级类目)向叶子类目
18 | (最精细的类目)依次排列,数据拼接格式为 "category_0;category_1;category_2",其中 category_1 是 category_0 的子类目,
19 | category_2 是 category_1 的子类目
20 | item_property_list 广告商品的属性列表,String类型;数据拼接格式为 "property_0;property_1;property_2",各个属性没有从属关系
21 | item_brand_id 广告商品的品牌编号,Long类型
22 | item_city_id 广告商品的城市编号,Long类型
23 | item_price_level 广告商品的价格等级,Int类型;取值从0开始,数值越大表示价格越高
24 | item_sales_level 广告商品的销量等级,Int类型;取值从0开始,数值越大表示销量越大
25 | item_collected_level 广告商品被收藏次数的等级,Int类型;取值从0开始,数值越大表示被收藏次数越大
26 | item_pv_level 广告商品被展示次数的等级,Int类型;取值从0开始,数值越大表示被展示次数越大
27 |
28 |
29 | 用户信息
30 | 字段 解释
31 | user_id 用户的编号,Long类型
32 | user_gender_id 用户的预测性别编号,Int类型;0表示女性用户,1表示男性用户,2表示家庭用户
33 | user_age_level 用户的预测年龄等级,Int类型;数值越大表示年龄越大
34 | user_occupation_id 用户的预测职业编号,Int类型
35 | user_star_level 用户的星级编号,Int类型;数值越大表示用户的星级越高
36 |
37 |
38 |
39 | 上下文信息
40 | 字段 解释
41 | context_id 上下文信息的编号,Long类型
42 | context_timestamp 广告商品的展示时间,Long类型;取值是以秒为单位的Unix时间戳,以1天为单位对时间戳进行了偏移
43 | context_page_id 广告商品的展示页面编号,Int类型;取值从1开始,依次增加;在一次搜索的展示结果中第一屏的编号为1,第二屏的编号为2
44 | predict_category_property 根据查询词预测的类目属性列表,String类型;数据拼接格式为 “category_A:property_A_1,property_A_2,property_A_3;category_B:-1;category_C:property_C_1,property_C_2” ,其中 category_A、category_B、category_C 是预测的三个类目;property_B 取值为-1,表示预测的第二个类目 category_B 没有对应的预测属性
45 |
46 |
47 |
48 | 店铺信息
49 | 字段 解释
50 | shop_id 店铺的编号,Long类型
51 | shop_review_num_level 店铺的评价数量等级,Int类型;取值从0开始,数值越大表示评价数量越多
52 | shop_review_positive_rate 店铺的好评率,Double类型;取值在0到1之间,数值越大表示好评率越高
53 | shop_star_level 店铺的星级编号,Int类型;取值从0开始,数值越大表示店铺的星级越高
54 | shop_score_service 店铺的服务态度评分,Double类型;取值在0到1之间,数值越大表示评分越高
55 | shop_score_delivery 店铺的物流服务评分,Double类型;取值在0到1之间,数值越大表示评分越高
56 | shop_score_description 店铺的描述相符评分,Double类型;取值在0到1之间,数值越大表示评分越高
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/Factorization Machines with libFM.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/Factorization Machines with libFM.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/Factorization Machines--Steffen Rendle.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/Factorization Machines--Steffen Rendle.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/Field-aware Factorization Machines for CTR Prediction.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/Field-aware Factorization Machines for CTR Prediction.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/Field-aware Factorization Machines in a Real-world Online Advertising System-ind0438-juanA.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/Field-aware Factorization Machines in a Real-world Online Advertising System-ind0438-juanA.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/Recurrent Neural Networks with Top-k Gains for Session-based Recommendations.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/Recurrent Neural Networks with Top-k Gains for Session-based Recommendations.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/Wide & Deep Learning for Recommender Systems.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/Wide & Deep Learning for Recommender Systems.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/XGBoost A Scalable Tree Boosting System.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/XGBoost A Scalable Tree Boosting System.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/【ECIR-16-FNN】Deep Learning over Multi-field Categorical Data--A Case Study on User Response Prediction.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/【ECIR-16-FNN】Deep Learning over Multi-field Categorical Data--A Case Study on User Response Prediction.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/【IJCAI-17】-DeepFM-A Factorization-Machine based Neural Network for CTR Prediction.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/【IJCAI-17】-DeepFM-A Factorization-Machine based Neural Network for CTR Prediction.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/【NIPS-2017】lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/【NIPS-2017】lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/paper/【SIGIR-17】Neural Factorization Machines for r Sparse Predictive Analytics.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/paper/【SIGIR-17】Neural Factorization Machines for r Sparse Predictive Analytics.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/doc/基于深度学习的搜索广告点击率预测方法研究.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Ad_Convert_prediction/doc/基于深度学习的搜索广告点击率预测方法研究.pdf
--------------------------------------------------------------------------------
/Ad_Convert_prediction/src/Data_Preprocess.py:
--------------------------------------------------------------------------------
1 | #-*- coding:utf-8 _*-
2 |
3 | """
4 | @version:
5 | @author: CharlesXu
6 | @license: Q_S_Y_Q
7 | @file: Data_Preprocess.py
8 | @time: 2018/3/2 13:15
9 | @desc: 阿里妈妈广告点击转化数据预处理
10 | """
11 |
12 | import pandas as pd
13 | import numpy as np
14 |
15 | # 读取数据
16 | test_set = pd.read_csv('E:\dataset\TIANCHI_ad\\test.txt',sep=' ')
17 | train_set = pd.read_csv('E:\dataset\TIANCHI_ad\\train.txt', sep=' ')
18 | # print(test_set.info())
19 | # print(train_set.info())
20 |
21 | train_set['dayofweek'] = (train_set['context_timestamp']/(60*60*24)).apply(np.floor) % 7
22 | train_set['hourofday'] = (train_set['context_timestamp']/(60*60)).apply(np.floor)%24
23 | train_set['minofday'] = (train_set['context_timestamp']/(60)).apply(np.floor)%(24*60)
24 |
25 |
26 | test_set['is_trade'] = -1
27 | test_set['dayofweek'] = (test_set['context_timestamp']/(60*60*24)).apply(np.floor)%7
28 | test_set['hourofday'] = (test_set['context_timestamp']/(60*60)).apply(np.floor)%24
29 | test_set['minofday'] = (test_set['context_timestamp']/(60)).apply(np.floor)%(24*60)
30 |
31 | print((train_set['context_timestamp']/(60*60*24)).apply(np.floor).max())
32 |
33 |
34 |
35 |
36 | # if __name__ == '__main__':
37 | # pass
--------------------------------------------------------------------------------
/Click_prediction/README.md:
--------------------------------------------------------------------------------
1 | # kaggle_criteo_ctr_challenge-
2 | This is a kaggle challenge project called Display Advertising Challenge by CriteoLabs at 2014.
3 | 这是2014年由CriteoLabs在kaggle上发起的广告点击率预估挑战项目。
4 | 使用TensorFlow1.0和Python 3.5开发。
5 |
6 | 代码详解请参见jupyter notebook和↓↓↓
7 |
8 | 博客:http://blog.csdn.net/chengcheng1394/article/details/78940565
9 |
10 | 知乎专栏:https://zhuanlan.zhihu.com/p/32500652
11 |
12 | 欢迎转发扩散 ^_^
13 |
14 | 本文使用GBDT、FM、FFM和神经网络构建了点击率预估模型。
15 |
16 | ## 网络模型
17 | 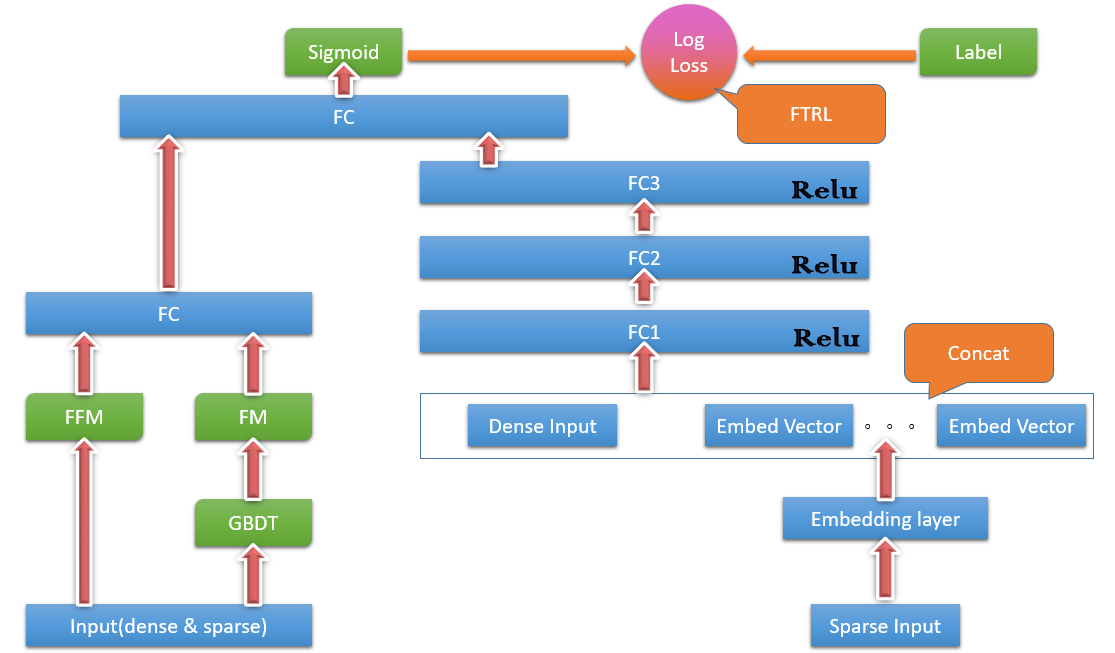
18 |
19 | ## LogLoss曲线
20 | 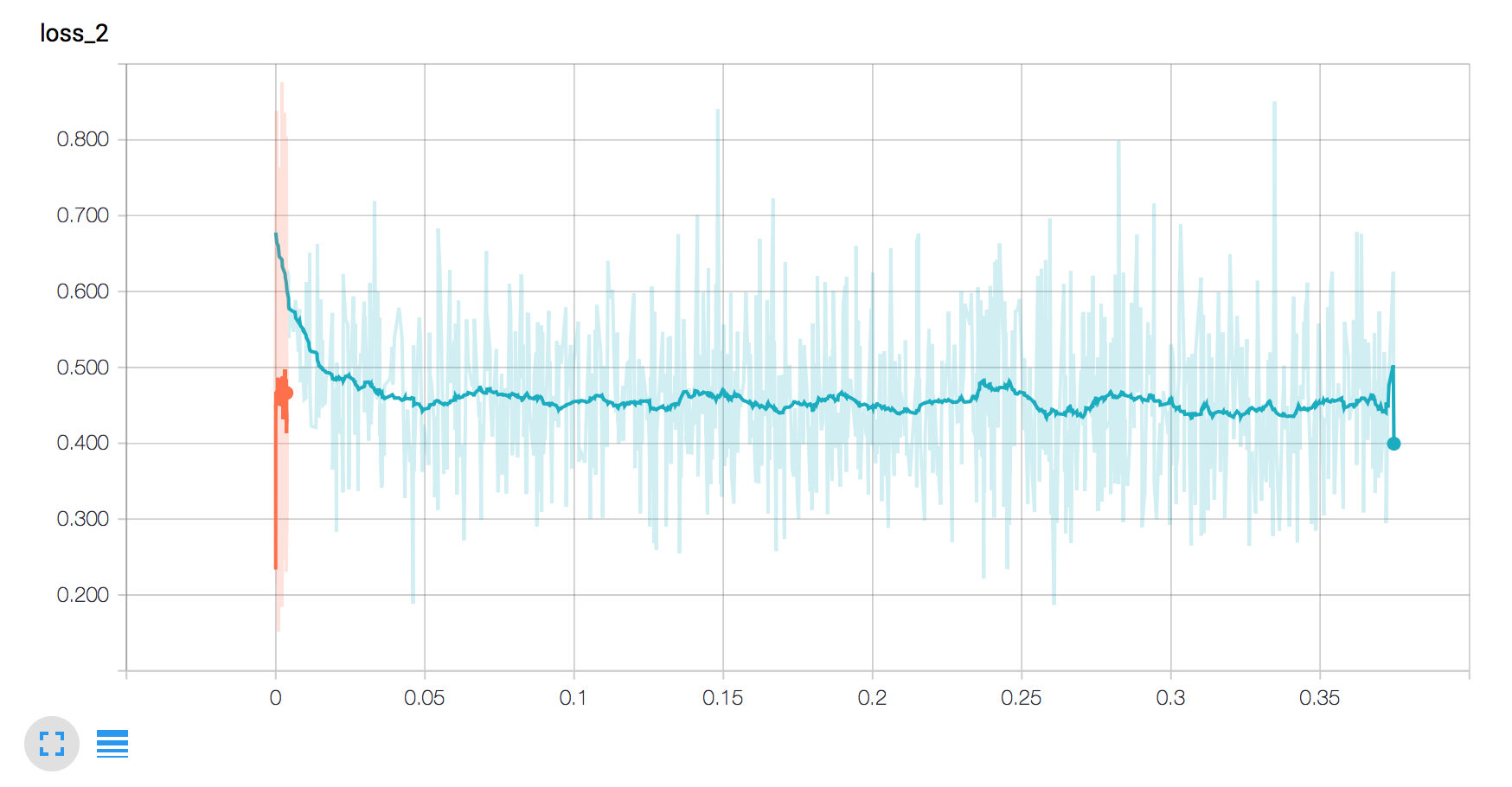
21 |
22 | ## 验证集上的训练信息
23 | - 平均准确率
24 | - 平均损失
25 | - 平均Auc
26 | - 预测的平均点击率
27 | - 精确率、召回率、F1 Score等信息
28 |
29 | 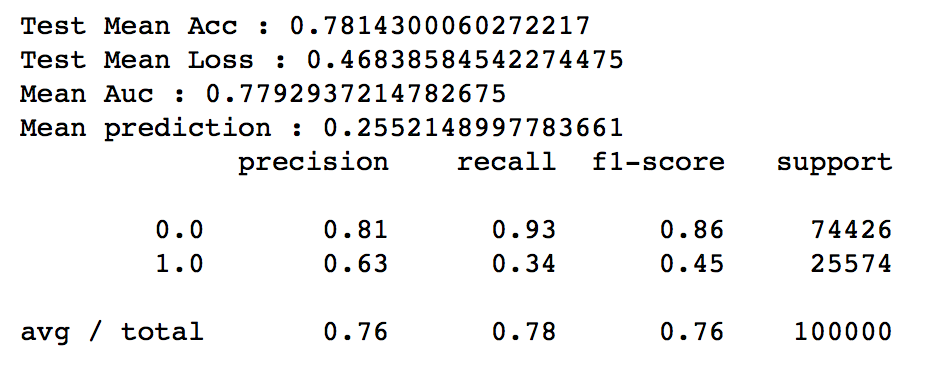
30 |
31 | 更多内容请参考代码,Enjoy!
32 |
--------------------------------------------------------------------------------
/Click_prediction/code/Logloss.py:
--------------------------------------------------------------------------------
1 | #-*- coding:utf-8 _*-
2 | """
3 | @author:charlesXu
4 | @file: Logloss.py
5 | @desc: 腾讯算法大赛logloss求法
6 | @time: 2018/03/04
7 | """
8 |
9 | import scipy as sp
10 |
11 | def logloss(act, pred):
12 | epsilon = 1e-15
13 | pred = sp.maximum(epsilon, pred)
14 | pred = sp.minimum(1-epsilon, pred)
15 | ll = sum(act * sp.log(pred) + sp.subtract(1, act) * sp.log(sp.subtract(1, pred)))
16 | ll = ll * - 1.0 / len(act)
17 | return ll
--------------------------------------------------------------------------------
/Click_prediction/code/ctr/Preprocess.py:
--------------------------------------------------------------------------------
1 | #-*- coding:utf-8 _*-
2 |
3 | """
4 | @version:
5 | @author: CharlesXu
6 | @license: Q_S_Y_Q
7 | @file: Preprocess.py
8 | @time: 2018/3/5 11:08
9 | @desc: 数据预处理
10 | """
11 |
12 | '''
13 | 生成神经网络的输入
14 | 生成ffm的输入
15 | 生成GBDT的输入
16 | '''
17 |
18 | continous_features = range(1, 14)
19 | categorial_features = range(14, 40)
20 |
21 |
22 |
23 |
24 |
25 | if __name__ == '__main__':
26 | pass
--------------------------------------------------------------------------------
/Click_prediction/code/ctr/ffm.py:
--------------------------------------------------------------------------------
1 | import subprocess,multiprocessing
2 | import os,time
3 | import pandas as pd
4 | import numpy as np
5 |
6 | class FFM:
7 | """libffm-1.21 Python Wrapper with libffm format data
8 |
9 | :Args:
10 | - reg_lambda: float, default: 2e-5
11 | regularization parameter
12 | - factor: int,default: 4
13 | number of latent factors
14 | - iteration: int, default: 15
15 | - learning_rate: float, default: 0.2
16 | - n_jobs: int, default: 1
17 | Number of parallel threads
18 | - verbose: int, default: 1
19 | - norm: bool, default: True
20 | instance-wise normalization
21 | """
22 | def __init__(self,reg_lambda=0.00002,factor=4,iteration=15,learning_rate=0.2,n_jobs=1,
23 | verbose=1,norm=True,):
24 | if n_jobs <=0 or n_jobs > multiprocessing.cpu_count():
25 | raise ValueError('n_jobs must be 1~{0}'.format(multiprocessing.cpu_count()))
26 |
27 | self.reg_lambda = reg_lambda
28 | self.factor = factor
29 | self.iteration = iteration
30 | self.learning_rate = learning_rate
31 | self.n_jobs = n_jobs
32 | self.verbose = verbose
33 | self.norm = norm
34 |
35 |
36 | self.cmd = ''
37 |
38 | self.output_name = 'ffm_result'+str(int(time.time()))# temp predict result file
39 |
40 |
41 |
42 |
43 | def fit(self,train_ffm_path,valid_ffm_path=None,model_path=None,auto_stop=False,):
44 | """ Train the FFM model with ffm-format data,
45 |
46 | :Args:
47 | - train_ffm_path: str
48 | - valid_ffm_path: str, default: None
49 | - model_path: str, default: None
50 | - auto_stop: bool, default: False
51 | stop at the iteration that achieves the best validation loss
52 | """
53 |
54 | if not os.path.exists(train_ffm_path):
55 | raise FileNotFoundError("file '{0}' not exists".format(train_ffm_path))
56 | self.train_ffm_path = train_ffm_path
57 | self.valid_ffm_path = valid_ffm_path
58 | self.model_path = None
59 | self.auto_stop = auto_stop
60 |
61 |
62 | cmd = 'ffm-train -l {l} -k {k} -t {t} -r {r} -s {s}'\
63 | .format(l=self.reg_lambda,k=self.factor,t=self.iteration,r=self.learning_rate,s=self.n_jobs)
64 | if self.valid_ffm_path is not None:
65 | cmd +=' -p {p}'.format(p=self.valid_ffm_path)
66 |
67 | if self.verbose == 0:
68 | cmd += ' --quiet'
69 | if not self.norm:
70 | cmd += ' --no-norm'
71 |
72 | if self.auto_stop:
73 | if self.valid_ffm_path is None:
74 | raise ValueError('Must specify valid_ffm_path when auto_stop = True')
75 | cmd += ' --auto-stop'
76 | cmd += ' {p}'.format(p=self.train_ffm_path)
77 | if not model_path is None:
78 | cmd +=' {p}'.format(p=model_path)
79 | self.model_path = model_path
80 | self.cmd = cmd
81 | print('Sending command...')
82 | popen = subprocess.Popen(cmd, stdout = subprocess.PIPE,shell=True)
83 | while True:
84 | output = str(popen.stdout.readline(),encoding='utf-8').strip('\n')
85 | if output.strip()=='':
86 | print('FFM training done')
87 | break
88 | print(output)
89 |
90 | def predict(self,test_ffm_path,model_path=None):
91 | """ Predict and return the probability of positive class.
92 |
93 | :Args:
94 | - test_ffm_path: str
95 | - model_path: str, default: None
96 | :returns:
97 | - pred_prob: np.array
98 | """
99 |
100 | cmd = "ffm-predict {t}".format(t=test_ffm_path)
101 | if model_path is None and self.model_path is None:
102 | raise ValueError('Must specify model_path')
103 | elif model_path is not None:
104 | self.model_path = model_path
105 | cmd +=" {0} {1}".format(self.model_path,self.output_name)
106 | self.cmd = cmd
107 | print('Sending command...')
108 | popen = subprocess.Popen(cmd, stdout = subprocess.PIPE,shell=True)
109 | while True:
110 | output = str(popen.stdout.readline(),encoding='utf-8').strip('\n')
111 | if output.strip()=='':
112 | print('FFM predicting done')
113 | break
114 | print(output)
115 |
116 | ans = pd.read_csv(self.output_name,names=['prob'])
117 | os.remove(self.output_name)
118 | return ans.prob.values
--------------------------------------------------------------------------------
/Click_prediction/code/ctr_nn/Main.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from sklearn.metrics import roc_auc_score
3 |
4 | import Utils
5 | from Models import LR, FM, PNN1, PNN2, FNN, CCPM
6 |
7 | train_file = '../data/train.yx.txt'
8 | test_file = '../data/test.yx.txt'
9 | # fm_model_file = '../data/fm.model.txt'
10 |
11 | input_dim = Utils.INPUT_DIM
12 |
13 | train_data = Utils.read_data(train_file)
14 | train_data = Utils.shuffle(train_data)
15 | test_data = Utils.read_data(test_file)
16 |
17 | if train_data[1].ndim > 1:
18 | print ('label must be 1-dim')
19 | exit(0)
20 | print('read finish')
21 |
22 | train_size = train_data[0].shape[0]
23 | test_size = test_data[0].shape[0]
24 | num_feas = len(Utils.FIELD_SIZES)
25 |
26 | min_round = 1
27 | num_round = 1000
28 | early_stop_round = 50
29 | batch_size = 1024
30 |
31 | field_sizes = Utils.FIELD_SIZES
32 | field_offsets = Utils.FIELD_OFFSETS
33 |
34 |
35 | def train(model):
36 | history_score = []
37 | for i in range(num_round):
38 | fetches = [model.optimizer, model.loss]
39 | if batch_size > 0:
40 | ls = []
41 | for j in range(train_size / batch_size + 1):
42 | X_i, y_i = Utils.slice(train_data, j * batch_size, batch_size)
43 | _, l = model.run(fetches, X_i, y_i)
44 | ls.append(l)
45 | elif batch_size == -1:
46 | X_i, y_i = Utils.slice(train_data)
47 | _, l = model.run(fetches, X_i, y_i)
48 | ls = [l]
49 | train_preds = model.run(model.y_prob, Utils.slice(train_data)[0])
50 | test_preds = model.run(model.y_prob, Utils.slice(test_data)[0])
51 | train_score = roc_auc_score(train_data[1], train_preds)
52 | test_score = roc_auc_score(test_data[1], test_preds)
53 | print('[%d]\tloss (with l2 norm):%f\ttrain-auc: %f\teval-auc: %f' % (i, np.mean(ls), train_score, test_score))
54 | history_score.append(test_score)
55 | if i > min_round and i > early_stop_round:
56 | if np.argmax(history_score) == i - early_stop_round and history_score[-1] - history_score[
57 | -1 * early_stop_round] < 1e-5:
58 | print('early stop\nbest iteration:\n[%d]\teval-auc: %f' % (
59 | np.argmax(history_score), np.max(history_score)))
60 | break
61 |
62 |
63 | algo = 'pnn2'
64 |
65 | if algo == 'lr':
66 | lr_params = {
67 | 'input_dim': input_dim,
68 | 'opt_algo': 'gd',
69 | 'learning_rate': 0.01,
70 | 'l2_weight': 0,
71 | 'random_seed': 0
72 | }
73 |
74 | model = LR(**lr_params)
75 | elif algo == 'fm':
76 | fm_params = {
77 | 'input_dim': input_dim,
78 | 'factor_order': 10,
79 | 'opt_algo': 'gd',
80 | 'learning_rate': 0.1,
81 | 'l2_w': 0,
82 | 'l2_v': 0,
83 | }
84 |
85 | model = FM(**fm_params)
86 | elif algo == 'fnn':
87 | fnn_params = {
88 | 'layer_sizes': [field_sizes, 10, 1],
89 | 'layer_acts': ['tanh', 'none'],
90 | 'drop_out': [0, 0],
91 | 'opt_algo': 'gd',
92 | 'learning_rate': 0.1,
93 | 'layer_l2': [0, 0],
94 | 'random_seed': 0
95 | }
96 |
97 | model = FNN(**fnn_params)
98 | elif algo == 'ccpm':
99 | ccpm_params = {
100 | 'layer_sizes': [field_sizes, 10, 5, 3],
101 | 'layer_acts': ['tanh', 'tanh', 'none'],
102 | 'drop_out': [0, 0, 0],
103 | 'opt_algo': 'gd',
104 | 'learning_rate': 0.1,
105 | 'random_seed': 0
106 | }
107 |
108 | model = CCPM(**ccpm_params)
109 | elif algo == 'pnn1':
110 | pnn1_params = {
111 | 'layer_sizes': [field_sizes, 10, 1],
112 | 'layer_acts': ['tanh', 'none'],
113 | 'drop_out': [0, 0],
114 | 'opt_algo': 'gd',
115 | 'learning_rate': 0.1,
116 | 'layer_l2': [0, 0],
117 | 'kernel_l2': 0,
118 | 'random_seed': 0
119 | }
120 |
121 | model = PNN1(**pnn1_params)
122 | elif algo == 'pnn2':
123 | pnn2_params = {
124 | 'layer_sizes': [field_sizes, 10, 1],
125 | 'layer_acts': ['tanh', 'none'],
126 | 'drop_out': [0, 0],
127 | 'opt_algo': 'gd',
128 | 'learning_rate': 0.01,
129 | 'layer_l2': [0, 0],
130 | 'kernel_l2': 0,
131 | 'random_seed': 0
132 | }
133 |
134 | model = PNN2(**pnn2_params)
135 |
136 | if algo in {'fnn', 'ccpm', 'pnn1', 'pnn2'}:
137 | train_data = Utils.split_data(train_data)
138 | test_data = Utils.split_data(test_data)
139 |
140 | train(model)
141 |
142 | # X_i, y_i = utils.slice(train_data, 0, 100)
143 | # fetches = [model.tmp1, model.tmp2]
144 | # tmp1, tmp2 = model.run(fetches, X_i, y_i)
145 | # print tmp1.shape
146 | # print tmp2.shape
147 |
--------------------------------------------------------------------------------
/Click_prediction/code/ctr_nn/__init__.py:
--------------------------------------------------------------------------------
1 | #-*- coding:utf-8 _*-
2 |
3 | """
4 | @version:
5 | @author: CharlesXu
6 | @license: Q_S_Y_Q
7 | @file: __init__.py.py
8 | @time: 2018/3/6 18:51
9 | @desc:
10 | """
11 |
12 | if __name__ == '__main__':
13 | pass
--------------------------------------------------------------------------------
/Click_prediction/code/cvr/1.problem_setting.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## 腾讯移动App广告转化率预估"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | ""
15 | ]
16 | },
17 | {
18 | "cell_type": "markdown",
19 | "metadata": {},
20 | "source": [
21 | "### 题目描述\n",
22 | "计算广告是互联网最重要的商业模式之一,广告投放效果通常通过曝光、点击和转化各环节来衡量,大多数广告系统受广告效果数据回流的限制只能通过曝光或点击作为投放效果的衡量标准开展优化。\n",
23 | "\n",
24 | "腾讯社交广告(`http://ads.tencent.com`)发挥特有的用户识别和转化跟踪数据能力,帮助广告主跟踪广告投放后的转化效果,基于广告转化数据训练转化率预估模型(pCVR,Predicted Conversion Rate),在广告排序中引入pCVR因子优化广告投放效果,提升ROI。\n",
25 | "\n",
26 | "本题目以移动App广告为研究对象,预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。"
27 | ]
28 | },
29 | {
30 | "cell_type": "markdown",
31 | "metadata": {},
32 | "source": [
33 | "### 训练数据\n",
34 | "从腾讯社交广告系统中某一连续两周的日志中按照推广中的App和用户维度随机采样。\n",
35 | "\n",
36 | "每一条训练样本即为一条广告点击日志(点击时间用clickTime表示),样本label取值0或1,其中0表示点击后没有发生转化,1表示点击后有发生转化,如果label为1,还会提供转化回流时间(conversionTime,定义详见“FAQ”)。给定特征集如下:"
37 | ]
38 | },
39 | {
40 | "cell_type": "markdown",
41 | "metadata": {},
42 | "source": [
43 | "\n",
44 | "\n",
45 | ""
46 | ]
47 | },
48 | {
49 | "cell_type": "markdown",
50 | "metadata": {},
51 | "source": [
52 | "特别的,出于数据安全的考虑,对于userID,appID,特征,以及时间字段,我们不提供原始数据,按照如下方式加密处理:"
53 | ]
54 | },
55 | {
56 | "cell_type": "markdown",
57 | "metadata": {},
58 | "source": [
59 | ""
60 | ]
61 | },
62 | {
63 | "cell_type": "markdown",
64 | "metadata": {},
65 | "source": [
66 | "#### 训练数据文件(train.csv)"
67 | ]
68 | },
69 | {
70 | "cell_type": "markdown",
71 | "metadata": {},
72 | "source": [
73 | "每行代表一个训练样本,各字段之间由逗号分隔,顺序依次为:“label,clickTime,conversionTime,creativeID,userID,positionID,connectionType,telecomsOperator”。\n",
74 | "\n",
75 | "当label=0时,conversionTime字段为空字符串。特别的,训练数据时间范围为第17天0点到第31天0点(定义详见下面的“补充说明”)。为了节省存储空间,用户、App、广告和广告位相关信息以独立文件提供(训练数据和测试数据共用),具体如下:"
76 | ]
77 | },
78 | {
79 | "cell_type": "markdown",
80 | "metadata": {},
81 | "source": [
82 | ""
83 | ]
84 | },
85 | {
86 | "cell_type": "markdown",
87 | "metadata": {},
88 | "source": [
89 | "注:若字段取值为0或空字符串均代表未知。(站点集合ID(sitesetID)为0并不表示未知,而是一个特定的站点集合。)"
90 | ]
91 | },
92 | {
93 | "cell_type": "markdown",
94 | "metadata": {},
95 | "source": [
96 | "### 测试数据\n",
97 | "从训练数据时段随后1天(即第31天)的广告日志中按照与训练数据同样的采样方式抽取得到,测试数据文件(test.csv)每行代表一个测试样本,各字段之间由逗号分隔,顺序依次为:“instanceID,-1,clickTime,creativeID,userID,positionID,connectionType,telecomsOperator”。其中,instanceID唯一标识一个样本,-1代表label占位使用,表示待预测。"
98 | ]
99 | },
100 | {
101 | "cell_type": "markdown",
102 | "metadata": {},
103 | "source": [
104 | "### 评估方式\n",
105 | "通过Logarithmic Loss评估(越小越好),公式如下:\n",
106 | "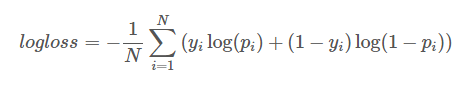\n",
107 | "其中,N是测试样本总数,yi是二值变量,取值0或1,表示第i个样本的label,pi为模型预测第i个样本 label为1的概率。"
108 | ]
109 | },
110 | {
111 | "cell_type": "markdown",
112 | "metadata": {},
113 | "source": [
114 | "示例代码如下(Python语言):\n",
115 | "```python\n",
116 | "import scipy as sp\n",
117 | "def logloss(act, pred):\n",
118 | " epsilon = 1e-15\n",
119 | " pred = sp.maximum(epsilon, pred)\n",
120 | " pred = sp.minimum(1-epsilon, pred)\n",
121 | " ll = sum(act*sp.log(pred) + sp.subtract(1,act)*sp.log(sp.subtract(1,pred)))\n",
122 | " ll = ll * -1.0/len(act)\n",
123 | " return ll\n",
124 | "```"
125 | ]
126 | },
127 | {
128 | "cell_type": "markdown",
129 | "metadata": {},
130 | "source": [
131 | "### 提交格式\n",
132 | "模型预估结果以zip压缩文件方式提交,内部文件名是submission.csv。每行代表一个测试样本,第一行为header,可以记录本文件相关关键信息,评测时会忽略,从第二行开始各字段之间由逗号分隔,顺序依次为:“instanceID, prob”,其中,instanceID唯一标识一个测试样本,必须升序排列,prob为模型预估的广告转化概率。示例如下:\n",
133 | "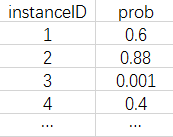"
134 | ]
135 | }
136 | ],
137 | "metadata": {
138 | "kernelspec": {
139 | "display_name": "Python 2",
140 | "language": "python",
141 | "name": "python2"
142 | },
143 | "language_info": {
144 | "codemirror_mode": {
145 | "name": "ipython",
146 | "version": 2
147 | },
148 | "file_extension": ".py",
149 | "mimetype": "text/x-python",
150 | "name": "python",
151 | "nbconvert_exporter": "python",
152 | "pygments_lexer": "ipython2",
153 | "version": "2.7.12"
154 | }
155 | },
156 | "nbformat": 4,
157 | "nbformat_minor": 2
158 | }
159 |
--------------------------------------------------------------------------------
/Click_prediction/code/cvr/2.Baseline_version.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {},
6 | "source": [
7 | "## CVR预估基线版本"
8 | ]
9 | },
10 | {
11 | "cell_type": "markdown",
12 | "metadata": {},
13 | "source": [
14 | "### 2.1 基于AD统计的版本"
15 | ]
16 | },
17 | {
18 | "cell_type": "code",
19 | "execution_count": null,
20 | "metadata": {
21 | "collapsed": true
22 | },
23 | "outputs": [],
24 | "source": [
25 | "# -*- coding: utf-8 -*-\n",
26 | "\"\"\"\n",
27 | "baseline 1: history pCVR of creativeID/adID/camgaignID/advertiserID/appID/appPlatform\n",
28 | "\"\"\"\n",
29 | "\n",
30 | "import zipfile\n",
31 | "import numpy as np\n",
32 | "import pandas as pd\n",
33 | "\n",
34 | "# load data\n",
35 | "data_root = \"E:\\dataset\\pre\"\n",
36 | "dfTrain = pd.read_csv(\"%s/train.csv\"%data_root)\n",
37 | "dfTest = pd.read_csv(\"%s/test.csv\"%data_root)\n",
38 | "dfAd = pd.read_csv(\"%s/ad.csv\"%data_root)\n",
39 | "\n",
40 | "# process data\n",
41 | "dfTrain = pd.merge(dfTrain, dfAd, on=\"creativeID\")\n",
42 | "dfTest = pd.merge(dfTest, dfAd, on=\"creativeID\")\n",
43 | "y_train = dfTrain[\"label\"].values\n",
44 | "\n",
45 | "# model building\n",
46 | "key = \"appID\"\n",
47 | "dfCvr = dfTrain.groupby(key).apply(lambda df: np.mean(df[\"label\"])).reset_index()\n",
48 | "dfCvr.columns = [key, \"avg_cvr\"]\n",
49 | "dfTest = pd.merge(dfTest, dfCvr, how=\"left\", on=key)\n",
50 | "dfTest[\"avg_cvr\"].fillna(np.mean(dfTrain[\"label\"]), inplace=True)\n",
51 | "proba_test = dfTest[\"avg_cvr\"].values\n",
52 | "\n",
53 | "# submission\n",
54 | "df = pd.DataFrame({\"instanceID\": dfTest[\"instanceID\"].values, \"proba\": proba_test})\n",
55 | "df.sort_values(\"instanceID\", inplace=True)\n",
56 | "df.to_csv(\"submission.csv\", index=False)\n",
57 | "with zipfile.ZipFile(\"submission.zip\", \"w\") as fout:\n",
58 | " fout.write(\"submission.csv\", compress_type=zipfile.ZIP_DEFLATED)"
59 | ]
60 | },
61 | {
62 | "cell_type": "markdown",
63 | "metadata": {},
64 | "source": [
65 | "### 得分\n",
66 | "| Submission | 描述| 初赛A | 初赛B | 决赛A | 决赛B |\n",
67 | "| :------- | :-------: | :-------: | :-------: | :-------: | :-------: |\n",
68 | "| baseline 2.1 | ad 统计 | 0.10988 | - | - | - |"
69 | ]
70 | },
71 | {
72 | "cell_type": "markdown",
73 | "metadata": {},
74 | "source": [
75 | "### 2.2 AD+LR版本"
76 | ]
77 | },
78 | {
79 | "cell_type": "code",
80 | "execution_count": null,
81 | "metadata": {
82 | "collapsed": true
83 | },
84 | "outputs": [],
85 | "source": [
86 | "# -*- coding: utf-8 -*-\n",
87 | "\"\"\"\n",
88 | "baseline 2: ad.csv (creativeID/adID/camgaignID/advertiserID/appID/appPlatform) + lr\n",
89 | "\"\"\"\n",
90 | "\n",
91 | "import zipfile\n",
92 | "import pandas as pd\n",
93 | "from scipy import sparse\n",
94 | "from sklearn.preprocessing import OneHotEncoder\n",
95 | "from sklearn.linear_model import LogisticRegression\n",
96 | "\n",
97 | "# load data\n",
98 | "data_root = \"./data\"\n",
99 | "dfTrain = pd.read_csv(\"%s/train.csv\"%data_root)\n",
100 | "dfTest = pd.read_csv(\"%s/test.csv\"%data_root)\n",
101 | "dfAd = pd.read_csv(\"%s/ad.csv\"%data_root)\n",
102 | "\n",
103 | "# process data\n",
104 | "dfTrain = pd.merge(dfTrain, dfAd, on=\"creativeID\")\n",
105 | "dfTest = pd.merge(dfTest, dfAd, on=\"creativeID\")\n",
106 | "y_train = dfTrain[\"label\"].values\n",
107 | "\n",
108 | "# feature engineering/encoding\n",
109 | "enc = OneHotEncoder()\n",
110 | "feats = [\"creativeID\", \"adID\", \"camgaignID\", \"advertiserID\", \"appID\", \"appPlatform\"]\n",
111 | "for i,feat in enumerate(feats):\n",
112 | " x_train = enc.fit_transform(dfTrain[feat].values.reshape(-1, 1))\n",
113 | " x_test = enc.transform(dfTest[feat].values.reshape(-1, 1))\n",
114 | " if i == 0:\n",
115 | " X_train, X_test = x_train, x_test\n",
116 | " else:\n",
117 | " X_train, X_test = sparse.hstack((X_train, x_train)), sparse.hstack((X_test, x_test))\n",
118 | "\n",
119 | "# model training\n",
120 | "lr = LogisticRegression()\n",
121 | "lr.fit(X_train, y_train)\n",
122 | "proba_test = lr.predict_proba(X_test)[:,1]\n",
123 | "\n",
124 | "# submission\n",
125 | "df = pd.DataFrame({\"instanceID\": dfTest[\"instanceID\"].values, \"proba\": proba_test})\n",
126 | "df.sort_values(\"instanceID\", inplace=True)\n",
127 | "df.to_csv(\"submission.csv\", index=False)\n",
128 | "with zipfile.ZipFile(\"submission.zip\", \"w\") as fout:\n",
129 | " fout.write(\"submission.csv\", compress_type=zipfile.ZIP_DEFLATED)"
130 | ]
131 | },
132 | {
133 | "cell_type": "markdown",
134 | "metadata": {},
135 | "source": [
136 | "### 得分\n",
137 | "| Submission | 描述| 初赛A | 初赛B | 决赛A | 决赛B |\n",
138 | "| :------- | :-------: | :-------: | :-------: | :-------: | :-------: |\n",
139 | "| baseline 2.2 | ad + lr | 0.10743 | - | - | - |"
140 | ]
141 | }
142 | ],
143 | "metadata": {
144 | "kernelspec": {
145 | "display_name": "Python 2",
146 | "language": "python",
147 | "name": "python2"
148 | },
149 | "language_info": {
150 | "codemirror_mode": {
151 | "name": "ipython",
152 | "version": 2
153 | },
154 | "file_extension": ".py",
155 | "mimetype": "text/x-python",
156 | "name": "python",
157 | "nbconvert_exporter": "python",
158 | "pygments_lexer": "ipython2",
159 | "version": "2.7.12"
160 | }
161 | },
162 | "nbformat": 4,
163 | "nbformat_minor": 2
164 | }
165 |
--------------------------------------------------------------------------------
/Click_prediction/code/cvr/README.md:
--------------------------------------------------------------------------------
1 | # 第一届腾讯社交广告高校算法大赛-移动App广告转化率预估
2 | 赛题详情http://algo.tpai.qq.com/home/information/index.html
3 | 题目描述
4 | 根据从某社交广告系统连续两周的日志记录按照推广中的App和用户维度随机采样构造的数据,预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。
5 | # 运行环境
6 | - 操作系统 Ubuntu 14.04.4 LTS (GNU/Linux 4.2.0-27-generic x86_64)
7 | - 内存 128GB
8 | - CPU 32 Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
9 | - 显卡 TITAN X (Pascal) 12GB
10 | - 语言 Python3.6
11 | - Python依赖包
12 | 1. Keras==2.0.6
13 | 2. lightgbm==0.1
14 | 3. matplotlib==2.0.0
15 | 4. numpy==1.11.3
16 | 5. pandas==0.19.2
17 | 6. scikit-learn==0.18.1
18 | 7. scipy==0.18.1
19 | 8. tensorflow-gpu==1.2.1
20 | 9. tqdm==4.11.2
21 | 10. xgboost==0.6a2
22 | - 其他库
23 | LIBFFM v121
24 | # 运行说明
25 | 1. 将复赛数据文件`final.zip`放在根目录下
26 | 2. 在根目录下运行`sh run.sh`命令生成特征文件
27 | 3. 打开`./code/_4_*_model_*.ipynb`分别进行模型训练和预测,生成单模型提交结果,包括`lgb,xgb,ffm,mlp`
28 | 4. 打开`./code/_4_5_model_avg.ipynb`进行最终的加权平均并生成最终提交结果
29 | # 方案说明
30 |
31 | 1. 用户点击日志挖掘`_2_1_gen_user_click_features.py`
32 | 挖掘广告点击日志,从不同时间粒度(天,小时)和不同属性维度(点击的素材,广告,推广计划,广告主类型,广告位等)提取用户点击行为的统计特征。
33 | 2. 用户安装日志挖掘 `_2_2_gen_app_install_features.py`
34 | 根据用户历史APP安装记录日志,分析用户的安装偏好和APP的流行趋势,结合APP安装时间的信息提取APP的时间维度的描述向量。这里最后只用了一种特征。
35 | 3. 广告主转化回流上报机制分析`_2_4_gen_tricks.py`
36 | 不同的广告主具有不同的转化计算方式,如第一次点击算转化,最后一次点击算转化,安装时点击算转化,分析并构造相应描述特征,提升模型预测精度。
37 | 4. 广告转化率特征提取`_2_5_gen_smooth_cvr.py`
38 | 构造转化率特征,使用全局和滑动窗口等方式计算单特征转化率,组合特征转化率,使用均值填充,层级填充,贝叶斯平滑,拉普拉斯平滑等方式对转化率进行修正。
39 | 5. 广告描述向量特征提取`_2_6_gen_ID_click_vectors.py`
40 | 广告投放是有特定受众对象的,而特定的受众对象也可以描述广告的相关特性,使用不同的人口属性对广告ID和APPID进行向量表示,学习隐含的语义特征。
41 | 6. 建模预测
42 | 使用多种模型进行训练,包括LightGBM,XGBoost,FFM和神经网络,最后进行多模型加权融合提高最终模型性能。
43 |
44 | # 其他
45 | - 最终线上排名20,logloss 0.101763
46 | - 最终特征维度在110左右
47 | - 部分最终没有采用的特征代码依然保留
48 | - 由于我们团队的代码是3个人共同完成的,我这里整理的模型训练的部分可能和当时略有差异,但特征部分基本一致。
49 | - `deprecated`目录下为弃用的代码,包括一些原始代码和打算尝试的方法
--------------------------------------------------------------------------------
/Click_prediction/data/data.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/data.pdf
--------------------------------------------------------------------------------
/Click_prediction/data/data_description.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/data_description.pdf
--------------------------------------------------------------------------------
/Click_prediction/data/download.sh:
--------------------------------------------------------------------------------
1 | #!/bin/bash
2 |
3 | wget --no-check-certificate https://s3-eu-west-1.amazonaws.com/criteo-labs/dac.tar.gz
4 | tar zxf dac.tar.gz
5 | rm -f dac.tar.gz
6 |
7 | mkdir raw
8 | mv ./*.txt raw/
9 |
--------------------------------------------------------------------------------
/Click_prediction/data/tencent_数据说明/Tencent_cvr_prediction.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/tencent_数据说明/Tencent_cvr_prediction.png
--------------------------------------------------------------------------------
/Click_prediction/data/tencent_数据说明/data_dscr_4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/tencent_数据说明/data_dscr_4.png
--------------------------------------------------------------------------------
/Click_prediction/data/tencent_数据说明/data_dscr_5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/tencent_数据说明/data_dscr_5.png
--------------------------------------------------------------------------------
/Click_prediction/data/tencent_数据说明/上下文特征.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/tencent_数据说明/上下文特征.png
--------------------------------------------------------------------------------
/Click_prediction/data/tencent_数据说明/广告特征.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/tencent_数据说明/广告特征.png
--------------------------------------------------------------------------------
/Click_prediction/data/tencent_数据说明/用户特征.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/data/tencent_数据说明/用户特征.png
--------------------------------------------------------------------------------
/Click_prediction/doc/8课下课件-张伟楠.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/doc/8课下课件-张伟楠.pdf
--------------------------------------------------------------------------------
/Click_prediction/doc/Ad click prediction a view from the trenches.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/doc/Ad click prediction a view from the trenches.pdf
--------------------------------------------------------------------------------
/Click_prediction/doc/ffm.txt:
--------------------------------------------------------------------------------
1 | FFM应用
2 |
3 | 在计算广告领域,点击率CTR(click-through rate)和转化率CVR(conversion rate)是衡量广告流量的两个关键指标。
4 | 准确的估计CTR、CVR对于提高流量的价值,增加广告收入有重要的指导作用。
5 |
6 | 预估CTR/CVR,业界常用的方法有
7 | 人工特征工程 +
8 | LR(Logistic Regression)、
9 | GBDT(Gradient Boosting Decision Tree) +
10 | LR[1][2][3]、
11 | FM(Factorization Machine)[2][7]和
12 | FFM(Field-aware Factorization Machine)[9]模型。
13 | 在这些模型中,FM和FFM近年来表现突出,分别在由Criteo和Avazu举办的CTR预测竞赛中夺得冠军[4][5]。
14 |
15 |
16 |
--------------------------------------------------------------------------------
/Click_prediction/doc/fm.txt:
--------------------------------------------------------------------------------
1 | FM说明文档
2 |
3 | FM用来解决数据量大并且特征稀疏下的特征组合问题。先来看看公式(只考虑二阶多项式的情况):n代表样本的特征数量,xi是第i个特征的值,w0、wi、wij是模型参数。
4 |
5 |
6 |
--------------------------------------------------------------------------------
/Click_prediction/doc/资料.txt:
--------------------------------------------------------------------------------
1 | 参考博客:
2 | 点击率预估数据下载链接: wget --no-check-certificate https://s3-eu-west-1.amazonaws.com/criteo-labs/dac.tar.gz
3 | 点击率预估算法:FM与FFM详解: http://blog.csdn.net/jediael_lu/article/details/77772565
4 | Kaggle实战——点击率预估: http://blog.csdn.net/chengcheng1394/article/details/78940565
5 | 深入FFM原理与实践: http://blog.csdn.net/mmc2015/article/details/51760681
6 | 关于CTR预估的面试问题: http://blog.csdn.net/wanghai00/article/details/60466617
7 |
8 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/COPYRIGHT:
--------------------------------------------------------------------------------
1 |
2 | Copyright (c) 2017 The LIBFFM Project.
3 | All rights reserved.
4 |
5 | Redistribution and use in source and binary forms, with or without
6 | modification, are permitted provided that the following conditions
7 | are met:
8 |
9 | 1. Redistributions of source code must retain the above copyright
10 | notice, this list of conditions and the following disclaimer.
11 |
12 | 2. Redistributions in binary form must reproduce the above copyright
13 | notice, this list of conditions and the following disclaimer in the
14 | documentation and/or other materials provided with the distribution.
15 |
16 | 3. Neither name of copyright holders nor the names of its contributors
17 | may be used to endorse or promote products derived from this software
18 | without specific prior written permission.
19 |
20 |
21 | THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
22 | ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
23 | LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
24 | A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR
25 | CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
26 | EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
27 | PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
28 | PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
29 | LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
30 | NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
31 | SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
32 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/Makefile:
--------------------------------------------------------------------------------
1 | CXX = g++
2 | CXXFLAGS = -Wall -O3 -std=c++0x -march=native
3 |
4 | # comment the following flags if you do not want to SSE instructions
5 | DFLAG += -DUSESSE
6 |
7 | # comment the following flags if you do not want to use OpenMP
8 | #DFLAG += -DUSEOMP
9 | #CXXFLAGS += -fopenmp
10 |
11 | all: ffm-train ffm-predict
12 |
13 | ffm-train: ffm-train.cpp ffm.o timer.o
14 | $(CXX) $(CXXFLAGS) $(DFLAG) -o $@ $^
15 |
16 | ffm-predict: ffm-predict.cpp ffm.o timer.o
17 | $(CXX) $(CXXFLAGS) $(DFLAG) -o $@ $^
18 |
19 | ffm.o: ffm.cpp ffm.h timer.o
20 | $(CXX) $(CXXFLAGS) $(DFLAG) -c -o $@ $<
21 |
22 | timer.o: timer.cpp timer.h
23 | $(CXX) $(CXXFLAGS) $(DFLAG) -c -o $@ $<
24 |
25 | clean:
26 | rm -f ffm-train ffm-predict ffm.o timer.o
27 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/Makefile.win:
--------------------------------------------------------------------------------
1 | CXX = cl.exe
2 | CFLAGS = /nologo /O2 /EHsc /D "_CRT_SECURE_NO_DEPRECATE" /D "USEOMP" /D "USESSE" /openmp
3 |
4 | TARGET = windows
5 |
6 | all: $(TARGET) $(TARGET)\ffm-train.exe $(TARGET)\ffm-predict.exe
7 |
8 | $(TARGET)\ffm-predict.exe: ffm.h ffm-predict.cpp ffm.obj timer.obj
9 | $(CXX) $(CFLAGS) ffm-predict.cpp ffm.obj timer.obj -Fe$(TARGET)\ffm-predict.exe
10 |
11 | $(TARGET)\ffm-train.exe: ffm.h ffm-train.cpp ffm.obj timer.obj
12 | $(CXX) $(CFLAGS) ffm-train.cpp ffm.obj timer.obj -Fe$(TARGET)\ffm-train.exe
13 |
14 | ffm.obj: ffm.cpp ffm.h
15 | $(CXX) $(CFLAGS) -c ffm.cpp
16 |
17 | timer.obj: timer.cpp timer.h
18 | $(CXX) $(CFLAGS) -c timer.cpp
19 |
20 | .PHONY: $(TARGET)
21 | $(TARGET):
22 | -mkdir $(TARGET)
23 |
24 | clean:
25 | -erase /Q *.obj *.exe $(TARGET)\.
26 | -rd $(TARGET)
27 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/ffm-predict:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libffm/libffm/ffm-predict
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/ffm-predict.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 | #include
8 | #include
9 | #include
10 | #include
11 |
12 | #include "ffm.h"
13 |
14 | using namespace std;
15 | using namespace ffm;
16 |
17 | struct Option {
18 | string test_path, model_path, output_path, withoutY_flag;
19 | };
20 |
21 | string predict_help() {
22 | return string(
23 | "usage: ffm-predict test_file model_file output_file\n");
24 | }
25 |
26 | Option parse_option(int argc, char **argv) {
27 | vector args;
28 | for(int i = 0; i < argc; i++)
29 | args.push_back(string(argv[i]));
30 |
31 | if(argc == 1)
32 | throw invalid_argument(predict_help());
33 |
34 | Option option;
35 |
36 | if(argc != 4 && argc != 5)
37 | throw invalid_argument("cannot parse argument");
38 |
39 | option.test_path = string(args[1]);
40 | option.model_path = string(args[2]);
41 | option.output_path = string(args[3]);
42 | if(argc == 5){
43 | option.withoutY_flag = string(args[4]);
44 | } else {
45 | option.withoutY_flag = "";
46 | }
47 |
48 | return option;
49 | }
50 |
51 | void predict(string test_path, string model_path, string output_path) {
52 | int const kMaxLineSize = 1000000;
53 |
54 | FILE *f_in = fopen(test_path.c_str(), "r");
55 | ofstream f_out(output_path);
56 | ofstream f_out_t(output_path + ".logit");
57 | char line[kMaxLineSize];
58 |
59 | ffm_model model = ffm_load_model(model_path);
60 |
61 | ffm_double loss = 0;
62 | vector x;
63 | ffm_int i = 0;
64 |
65 | for(; fgets(line, kMaxLineSize, f_in) != nullptr; i++) {
66 | x.clear();
67 | char *y_char = strtok(line, " \t");
68 | ffm_float y = (atoi(y_char)>0)? 1.0f : -1.0f;
69 |
70 | while(true) {
71 | char *field_char = strtok(nullptr,":");
72 | char *idx_char = strtok(nullptr,":");
73 | char *value_char = strtok(nullptr," \t");
74 | if(field_char == nullptr || *field_char == '\n')
75 | break;
76 |
77 | ffm_node N;
78 | N.f = atoi(field_char);
79 | N.j = atoi(idx_char);
80 | N.v = atof(value_char);
81 |
82 | x.push_back(N);
83 | }
84 |
85 | ffm_float y_bar = ffm_predict(x.data(), x.data()+x.size(), model);
86 | ffm_float ret_t = ffm_get_wTx(x.data(), x.data()+x.size(), model);
87 | loss -= y==1? log(y_bar) : log(1-y_bar);
88 |
89 | f_out_t << ret_t << "\n";
90 | f_out << y_bar << "\n";
91 | }
92 |
93 | loss /= i;
94 |
95 | cout << "logloss = " << fixed << setprecision(5) << loss << endl;
96 |
97 | fclose(f_in);
98 | }
99 |
100 |
101 | void predict_withoutY(string test_path, string model_path, string output_path) {
102 | int const kMaxLineSize = 1000000;
103 |
104 | FILE *f_in = fopen(test_path.c_str(), "r");
105 | ofstream f_out(output_path);
106 | ofstream f_out_t(output_path + ".logit");
107 | char line[kMaxLineSize];
108 |
109 | ffm_model model = ffm_load_model(model_path);
110 |
111 | //ffm_double loss = 0;
112 | vector x;
113 | ffm_int i = 0;
114 |
115 | for(; fgets(line, kMaxLineSize, f_in) != nullptr; i++) {
116 | x.clear();
117 | //char *y_char = strtok(line, " \t");
118 | //ffm_float y = (atoi(y_char)>0)? 1.0f : -1.0f;
119 |
120 | char *field_char = strtok(line,":");
121 | char *idx_char = strtok(nullptr,":");
122 | char *value_char = strtok(nullptr," \t");
123 | if(field_char == nullptr || *field_char == '\n')
124 | continue;
125 |
126 | ffm_node N;
127 | N.f = atoi(field_char);
128 | N.j = atoi(idx_char);
129 | N.v = atof(value_char);
130 |
131 | x.push_back(N);
132 |
133 | while(true) {
134 | char *field_char = strtok(nullptr,":");
135 | char *idx_char = strtok(nullptr,":");
136 | char *value_char = strtok(nullptr," \t");
137 | if(field_char == nullptr || *field_char == '\n')
138 | break;
139 |
140 | ffm_node N;
141 | N.f = atoi(field_char);
142 | N.j = atoi(idx_char);
143 | N.v = atof(value_char);
144 |
145 | x.push_back(N);
146 | }
147 |
148 | ffm_float y_bar = ffm_predict(x.data(), x.data()+x.size(), model);
149 | ffm_float ret_t = ffm_get_wTx(x.data(), x.data()+x.size(), model);
150 | //loss -= y==1? log(y_bar) : log(1-y_bar);
151 |
152 | f_out_t << ret_t << "\n";
153 | f_out << y_bar << "\n";
154 | }
155 |
156 | //loss /= i;
157 |
158 | //cout << "logloss = " << fixed << setprecision(5) << loss << endl;
159 | cout << "done!" << endl;
160 |
161 | fclose(f_in);
162 | }
163 |
164 | int main(int argc, char **argv) {
165 | Option option;
166 | try {
167 | option = parse_option(argc, argv);
168 | } catch(invalid_argument const &e) {
169 | cout << e.what() << endl;
170 | return 1;
171 | }
172 |
173 | if(argc == 5 && option.withoutY_flag.compare("true") == 0){
174 | predict_withoutY(option.test_path, option.model_path, option.output_path);
175 | } else {
176 | predict(option.test_path, option.model_path, option.output_path);
177 | }
178 | return 0;
179 | }
180 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/ffm-train:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libffm/libffm/ffm-train
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/ffm-train.cpp:
--------------------------------------------------------------------------------
1 | #pragma GCC diagnostic ignored "-Wunused-result"
2 | #include
3 | #include
4 | #include
5 | #include
6 | #include
7 | #include
8 | #include
9 |
10 | #include "ffm.h"
11 |
12 | #if defined USEOMP
13 | #include
14 | #endif
15 |
16 | using namespace std;
17 | using namespace ffm;
18 |
19 | string train_help() {
20 | return string(
21 | "usage: ffm-train [options] training_set_file [model_file]\n"
22 | "\n"
23 | "options:\n"
24 | "-l : set regularization parameter (default 0.00002)\n"
25 | "-k : set number of latent factors (default 4)\n"
26 | "-t : set number of iterations (default 15)\n"
27 | "-r : set learning rate (default 0.2)\n"
28 | "-s : set number of threads (default 1)\n"
29 | "-p : set path to the validation set\n"
30 | "--quiet: quiet mode (no output)\n"
31 | "--no-norm: disable instance-wise normalization\n"
32 | "--auto-stop: stop at the iteration that achieves the best validation loss (must be used with -p)\n");
33 | }
34 |
35 | struct Option {
36 | string tr_path;
37 | string va_path;
38 | string model_path;
39 | ffm_parameter param;
40 | bool quiet = false;
41 | ffm_int nr_threads = 1;
42 | };
43 |
44 | string basename(string path) {
45 | const char *ptr = strrchr(&*path.begin(), '/');
46 | if(!ptr)
47 | ptr = path.c_str();
48 | else
49 | ptr++;
50 | return string(ptr);
51 | }
52 |
53 | Option parse_option(int argc, char **argv) {
54 | vector args;
55 | for(int i = 0; i < argc; i++)
56 | args.push_back(string(argv[i]));
57 |
58 | if(argc == 1)
59 | throw invalid_argument(train_help());
60 |
61 | Option opt;
62 |
63 | ffm_int i = 1;
64 | for(; i < argc; i++) {
65 | if(args[i].compare("-t") == 0)
66 | {
67 | if(i == argc-1)
68 | throw invalid_argument("need to specify number of iterations after -t");
69 | i++;
70 | opt.param.nr_iters = atoi(args[i].c_str());
71 | if(opt.param.nr_iters <= 0)
72 | throw invalid_argument("number of iterations should be greater than zero");
73 | } else if(args[i].compare("-k") == 0) {
74 | if(i == argc-1)
75 | throw invalid_argument("need to specify number of factors after -k");
76 | i++;
77 | opt.param.k = atoi(args[i].c_str());
78 | if(opt.param.k <= 0)
79 | throw invalid_argument("number of factors should be greater than zero");
80 | } else if(args[i].compare("-r") == 0) {
81 | if(i == argc-1)
82 | throw invalid_argument("need to specify eta after -r");
83 | i++;
84 | opt.param.eta = atof(args[i].c_str());
85 | if(opt.param.eta <= 0)
86 | throw invalid_argument("learning rate should be greater than zero");
87 | } else if(args[i].compare("-l") == 0) {
88 | if(i == argc-1)
89 | throw invalid_argument("need to specify lambda after -l");
90 | i++;
91 | opt.param.lambda = atof(args[i].c_str());
92 | if(opt.param.lambda < 0)
93 | throw invalid_argument("regularization cost should not be smaller than zero");
94 | } else if(args[i].compare("-s") == 0) {
95 | if(i == argc-1)
96 | throw invalid_argument("need to specify number of threads after -s");
97 | i++;
98 | opt.nr_threads = atoi(args[i].c_str());
99 | if(opt.nr_threads <= 0)
100 | throw invalid_argument("number of threads should be greater than zero");
101 | } else if(args[i].compare("-p") == 0) {
102 | if(i == argc-1)
103 | throw invalid_argument("need to specify path after -p");
104 | i++;
105 | opt.va_path = args[i];
106 | } else if(args[i].compare("--no-norm") == 0) {
107 | opt.param.normalization = false;
108 | } else if(args[i].compare("--quiet") == 0) {
109 | opt.quiet = true;
110 | } else if(args[i].compare("--auto-stop") == 0) {
111 | opt.param.auto_stop = true;
112 | } else {
113 | break;
114 | }
115 | }
116 |
117 | if(i != argc-2 && i != argc-1)
118 | throw invalid_argument("cannot parse command\n");
119 |
120 | opt.tr_path = args[i];
121 | i++;
122 |
123 | if(i < argc) {
124 | opt.model_path = string(args[i]);
125 | } else if(i == argc) {
126 | opt.model_path = basename(opt.tr_path) + ".model";
127 | } else {
128 | throw invalid_argument("cannot parse argument");
129 | }
130 |
131 | return opt;
132 | }
133 |
134 | int train_on_disk(Option opt) {
135 | string tr_bin_path = basename(opt.tr_path) + ".bin";
136 | string va_bin_path = opt.va_path.empty()? "" : basename(opt.va_path) + ".bin";
137 |
138 | ffm_read_problem_to_disk(opt.tr_path, tr_bin_path);
139 | if(!opt.va_path.empty())
140 | ffm_read_problem_to_disk(opt.va_path, va_bin_path);
141 |
142 | ffm_model model = ffm_train_on_disk(tr_bin_path.c_str(), va_bin_path.c_str(), opt.param);
143 |
144 | ffm_save_model(model, opt.model_path);
145 |
146 | return 0;
147 | }
148 |
149 | int main(int argc, char **argv) {
150 | Option opt;
151 | try {
152 | opt = parse_option(argc, argv);
153 | } catch(invalid_argument &e) {
154 | cout << e.what() << endl;
155 | return 1;
156 | }
157 |
158 | if(opt.quiet)
159 | cout.setstate(ios_base::badbit);
160 |
161 | if(opt.param.auto_stop && opt.va_path.empty()) {
162 | cout << "To use auto-stop, you need to assign a validation set" << endl;
163 | return 1;
164 | }
165 |
166 | #if defined USEOMP
167 | omp_set_num_threads(opt.nr_threads);
168 | #endif
169 |
170 | train_on_disk(opt);
171 |
172 | return 0;
173 | }
174 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/ffm.h:
--------------------------------------------------------------------------------
1 | #ifndef _LIBFFM_H
2 | #define _LIBFFM_H
3 |
4 | #include
5 |
6 | namespace ffm {
7 |
8 | using namespace std;
9 |
10 | typedef float ffm_float;
11 | typedef double ffm_double;
12 | typedef int ffm_int;
13 | typedef long long ffm_long;
14 |
15 | struct ffm_node {
16 | ffm_int f; // field index
17 | ffm_int j; // feature index
18 | ffm_float v; // value
19 | };
20 |
21 | struct ffm_model {
22 | ffm_int n; // number of features
23 | ffm_int m; // number of fields
24 | ffm_int k; // number of latent factors
25 | ffm_float *W = nullptr;
26 | bool normalization;
27 | ~ffm_model();
28 | };
29 |
30 | struct ffm_parameter {
31 | ffm_float eta = 0.2; // learning rate
32 | ffm_float lambda = 0.00002; // regularization parameter
33 | ffm_int nr_iters = 15;
34 | ffm_int k = 4; // number of latent factors
35 | bool normalization = true;
36 | bool auto_stop = false;
37 | };
38 |
39 | void ffm_read_problem_to_disk(string txt_path, string bin_path);
40 |
41 | void ffm_save_model(ffm_model &model, string path);
42 |
43 | ffm_model ffm_load_model(string path);
44 |
45 | ffm_model ffm_train_on_disk(string Tr_path, string Va_path, ffm_parameter param);
46 |
47 | ffm_float ffm_predict(ffm_node *begin, ffm_node *end, ffm_model &model);
48 |
49 | ffm_float ffm_get_wTx(ffm_node *begin, ffm_node *end, ffm_model &model);
50 |
51 | } // namespace ffm
52 |
53 | #endif // _LIBFFM_H
54 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/ffm.o:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libffm/libffm/ffm.o
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/timer.cpp:
--------------------------------------------------------------------------------
1 | #include
2 | #include "timer.h"
3 |
4 | Timer::Timer()
5 | {
6 | reset();
7 | }
8 |
9 | void Timer::reset()
10 | {
11 | begin = std::chrono::high_resolution_clock::now();
12 | duration =
13 | std::chrono::duration_cast(begin-begin);
14 | }
15 |
16 | void Timer::tic()
17 | {
18 | begin = std::chrono::high_resolution_clock::now();
19 | }
20 |
21 | float Timer::toc()
22 | {
23 | duration += std::chrono::duration_cast
24 | (std::chrono::high_resolution_clock::now()-begin);
25 | return get();
26 | }
27 |
28 | float Timer::get()
29 | {
30 | return (float)duration.count() / 1000;
31 | }
32 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/timer.h:
--------------------------------------------------------------------------------
1 | #include
2 |
3 | class Timer
4 | {
5 | public:
6 | Timer();
7 | void reset();
8 | void tic();
9 | float toc();
10 | float get();
11 | private:
12 | std::chrono::high_resolution_clock::time_point begin;
13 | std::chrono::milliseconds duration;
14 | };
15 |
--------------------------------------------------------------------------------
/Click_prediction/libffm/libffm/timer.o:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libffm/libffm/timer.o
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/Makefile:
--------------------------------------------------------------------------------
1 | all:
2 | cd src/libfm; make all
3 |
4 | libFM:
5 | cd src/libfm; make libFM
6 |
7 | clean:
8 | cd src/libfm; make clean
9 |
10 |
11 |
12 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/README.md:
--------------------------------------------------------------------------------
1 | libFM
2 | =====
3 |
4 | Library for factorization machines
5 |
6 | web: http://www.libfm.org/
7 |
8 | forum: https://groups.google.com/forum/#!forum/libfm
9 |
10 | Factorization machines (FM) are a generic approach that allows to mimic most factorization models by feature engineering. This way, factorization machines combine the generality of feature engineering with the superiority of factorization models in estimating interactions between categorical variables of large domain. libFM is a software implementation for factorization machines that features stochastic gradient descent (SGD) and alternating least squares (ALS) optimization as well as Bayesian inference using Markov Chain Monte Carlo (MCMC).
11 |
12 | Compile
13 | =======
14 | libFM has been tested with the GNU compiler collection and GNU make. libFM and the tools can be compiled with
15 | > make all
16 |
17 | Usage
18 | =====
19 | Please see the [libFM 1.4.2 manual](http://www.libfm.org/libfm-1.42.manual.pdf) for details about how to use libFM. If you have questions, please visit the [forum](https://groups.google.com/forum/#!forum/libfm).
20 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/bin/convert:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libfm/libfm/bin/convert
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/bin/fm_model:
--------------------------------------------------------------------------------
1 | #global bias W0
2 | -1.51913e-05
3 | #unary interactions Wj
4 | 0.0543242
5 | 0.0284947
6 | 0.0266538
7 | 0.016659
8 | 0.0125872
9 | 0.0107259
10 | 0.0118907
11 | 0.0157203
12 | 0.00839382
13 | 0.00971495
14 | 0.00612373
15 | 0.00524808
16 | 0.00285415
17 | 0.0008417
18 | -0.000239964
19 | -0.0086962
20 | 0.00883555
21 | -0.0162203
22 | -0.00296712
23 | 0.0212882
24 | 0.0188632
25 | -0.00632028
26 | -0.0134724
27 | 0.00510968
28 | -0.0100098
29 | 0.010746
30 | -0.0212505
31 | 0.0112133
32 | -0.00330014
33 | 0.0205507
34 | -0.0058263
35 | -0.00871744
36 | #pairwise interactions Vj,f
37 | -0.00700443 0.0115064 0.000250908 -0.0337887 0.00279776 0.0310548 -0.0307156 0.0202006
38 | -0.0181796 0.00783596 -0.00684362 -0.00773165 0.00437475 -0.00467768 0.00468273 -0.0114019
39 | -0.00487966 -0.000374121 0.000759323 -0.0102248 0.00195136 0.00497072 -0.0068161 0.000974602
40 | -0.00833354 0.00259372 -0.00322643 -0.00897765 0.0036128 0.00131875 -0.000500686 0.000626169
41 | -0.00389153 -0.00202808 0.00232841 -0.0078374 0.00150366 0.00242359 -0.00374564 -0.00292291
42 | -0.00459782 -0.0023391 -0.000624162 0.000624403 0.00092783 -0.00574112 0.00559153 -0.00750119
43 | -0.000536693 -0.00366557 0.0022891 -0.00226212 0.000486126 -9.3187e-05 -0.00130247 -0.0022421
44 | 8.09081e-05 4.88191e-05 0.000511957 -0.00204266 9.63924e-05 0.00186076 -0.00199404 0.00120642
45 | 0.000429027 -0.00296412 -0.000256632 0.00518759 0.000159051 -0.00622174 0.00615728 -0.00362862
46 | -0.002437 0.000719526 -0.00051522 -0.00188664 0.00066375 -5.7006e-05 -8.73099e-05 -0.00137168
47 | -0.00307155 5.34744e-05 -0.000672551 -0.00166223 0.00100586 -0.00121773 0.000851445 -0.00220555
48 | 0.000915018 -0.000786345 3.11917e-05 0.00232754 -0.000285893 -0.00181935 0.00185057 -0.000782855
49 | 0.000590278 -0.00137097 0.00103078 3.35035e-05 -0.000245336 -8.46218e-05 -0.0005121 -0.000769284
50 | 0.00137207 0.00063334 -0.000470167 0.00216574 -0.00048717 -0.000448922 0.000950496 0.000930627
51 | 0.000298715 0.000457383 6.04733e-07 -0.000447437 -9.5566e-05 0.000937129 -0.000852014 0.000909023
52 | 0.00154043 0.000518873 -0.000140893 0.00188433 -0.000605516 -2.53168e-05 0.000338521 0.000910561
53 | 0.000421026 0.000134062 2.61146e-05 0.0002638 -0.000144135 0.00021623 -0.000152026 0.000388725
54 | 0.000450511 0.000203354 -2.3082e-05 0.000364577 -0.000164302 0.000185774 -8.86271e-05 0.000415691
55 | 0.000313412 0.000218558 1.86745e-05 -4.68575e-05 -0.00010331 0.000448149 -0.000387851 0.000521073
56 | 0.000357683 0.000128925 2.93406e-05 0.000138543 -0.000118317 0.000268847 -0.000212042 0.000399502
57 | 0.000336198 0.000135479 1.68862e-06 0.000218085 -0.000116749 0.00017916 -0.000117798 0.000333787
58 | 0.000307244 0.000122211 -3.93336e-06 0.000211933 -0.000106381 0.000151173 -9.33714e-05 0.000302845
59 | 0.000300511 9.93715e-05 4.86275e-06 0.000230786 -0.000104756 0.000116281 -6.59211e-05 0.000259613
60 | 0.000300723 0.000100172 1.29128e-05 0.000185668 -0.000101935 0.000157492 -0.000108992 0.000289874
61 | 0.000278255 0.00010348 -4.64355e-07 0.000201026 -9.63521e-05 0.000124331 -7.38646e-05 0.000260312
62 | 0.000258378 0.000100057 7.075e-06 0.000145423 -8.80599e-05 0.000155841 -0.000111522 0.00026875
63 | 0.000275873 8.85816e-05 9.6919e-08 0.000221333 -9.54046e-05 9.49409e-05 -4.61547e-05 0.000236249
64 | 0.000248546 8.46825e-05 8.2937e-06 0.000155056 -8.3886e-05 0.000129072 -8.80767e-05 0.000242182
65 | 0.000247644 7.74817e-05 5.36621e-06 0.000181076 -8.41681e-05 0.000100233 -5.98669e-05 0.000221104
66 | 0.000245071 8.46181e-05 2.88367e-06 0.000178966 -8.52511e-05 0.000104409 -6.22723e-05 0.000221694
67 | 0.000252015 7.16076e-05 7.94436e-06 0.000184286 -8.51625e-05 9.77973e-05 -5.71402e-05 0.000220597
68 | 0.000222416 8.4576e-05 -6.5907e-06 0.000178845 -7.773e-05 8.3189e-05 -4.16687e-05 0.000201234
69 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/bin/libFM:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libfm/libfm/bin/libFM
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/bin/transpose:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libfm/libfm/bin/transpose
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/scripts/triple_format_to_libfm.pl:
--------------------------------------------------------------------------------
1 | #!/usr/bin/perl -w
2 | # Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
3 | # Contact: srendle@libfm.org, http://www.libfm.org/
4 | #
5 | # This file is part of libFM.
6 | #
7 | # libFM is free software: you can redistribute it and/or modify
8 | # it under the terms of the GNU General Public License as published by
9 | # the Free Software Foundation, either version 3 of the License, or
10 | # (at your option) any later version.
11 | #
12 | # libFM is distributed in the hope that it will be useful,
13 | # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 | # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 | # GNU General Public License for more details.
16 | #
17 | # You should have received a copy of the GNU General Public License
18 | # along with libFM. If not, see .
19 | #
20 | #
21 | # triple_format_to_libfm.pl: Converts data in a triple format
22 | # "id1 id2 id3 target" (like often used in recommender systems for rating
23 | # prediction) into the libfm format.
24 | #
25 | # Version history
26 | # - 2013-07-12: write groups
27 | # - 2012-12-27: header is not printed
28 |
29 | use Getopt::Long;
30 | use strict;
31 |
32 | srand();
33 |
34 |
35 | my $file_in;
36 | my $file_out_meta;
37 | my $has_header = 0;
38 | my $target_column = undef;
39 | my $_delete_column = "";
40 | my $offset = 0; # where to start counting for indices. For libsvm one should start with 1; libfm can deal with 0.
41 | my $separator = " ";
42 |
43 | # example
44 | # ./triple_format_to_libfm.pl --in train.txt,test.txt --header 0 --target_column 2 --delete_column 3,4,5,6,7 --offset 0
45 |
46 |
47 | GetOptions(
48 | 'in=s' => \$file_in,
49 | 'header=i' => \$has_header,
50 | 'target_column=i' => \$target_column,
51 | 'delete_column=s' => \$_delete_column,
52 | 'offset=i' => \$offset,
53 | 'separator=s' => \$separator,
54 | 'outmeta=s' => \$file_out_meta,
55 | );
56 |
57 | (defined $target_column) || die "no target column specified";
58 |
59 | my @files = split(/[,;]/, $file_in);
60 | my %delete_column;
61 | foreach my $c (split(/[,;]/, $_delete_column)) {
62 | $delete_column{int($c)} = 1;
63 | }
64 |
65 | my %id;
66 | my $id_cntr = $offset;
67 |
68 | my $OUT_GROUPS;
69 | if (defined $file_out_meta) {
70 | open $OUT_GROUPS, '>' , $file_out_meta;
71 | }
72 |
73 | foreach my $file_name (@files) {
74 | my $file_out = $file_name . ".libfm";
75 | print "transforming file $file_name to $file_out...";
76 | my $num_triples = 0;
77 |
78 | open my $IN, '<' , $file_name;
79 | open my $OUT, '>' , $file_out;
80 | if ($has_header) {
81 | $_ = <$IN>;
82 | # print {$OUT} $_;
83 | }
84 | while (<$IN>) {
85 | chomp;
86 | if ($_ ne "") {
87 | my @data = split /$separator/;
88 | ($#data >= $target_column) || die "not enough values in line $num_triples, expected at least $target_column values\nfound $_\n";
89 | my $out_str = $data[$target_column];
90 | my $out_col_id = 0; ## says which column in the input a field corresponds to after "deleting" the "delete_column", i.e. it is a counter over the #$data-field in @data assuming that some of the columns have been deleted; one can see this as the "group" id
91 | for (my $i = 0; $i <= $#data; $i++) {
92 | if (($i != $target_column) && (! exists $delete_column{$i})) {
93 | my $col_id = $out_col_id . " " . $data[$i]; ## this id holds the unique id of $data[$i] (also w.r.t. its group)
94 | if (! exists $id{$col_id}) {
95 | $id{$col_id} = $id_cntr;
96 | if (defined $file_out_meta) {
97 | print {$OUT_GROUPS} $out_col_id, "\n";
98 | }
99 | $id_cntr++;
100 | }
101 | my $libfm_id = $id{$col_id};
102 | $out_str .= " " . $libfm_id . ":1";
103 | $out_col_id++;
104 | }
105 | }
106 | print {$OUT} $out_str, "\n";
107 | }
108 | }
109 | close $OUT;
110 | close $IN;
111 | print "\n";
112 | }
113 |
114 | if (defined $file_out_meta) {
115 | close $OUT_GROUPS;
116 | }
117 |
118 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/fm_core/fm_data.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // fm_data.h: Base data type of libFM
21 |
22 | #ifndef FM_DATA_H_
23 | #define FM_DATA_H_
24 |
25 | typedef float FM_FLOAT;
26 |
27 | #endif /*FM_DATA_H_*/
28 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/fm_core/fm_model.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // fm_model.h: Model for Factorization Machines
21 | //
22 | // Based on the publication(s):
23 | // - Steffen Rendle (2010): Factorization Machines, in Proceedings of the 10th
24 | // IEEE International Conference on Data Mining (ICDM 2010), Sydney,
25 | // Australia.
26 |
27 | #ifndef FM_MODEL_H_
28 | #define FM_MODEL_H_
29 |
30 | #include "../util/matrix.h"
31 | #include "../util/fmatrix.h"
32 |
33 | #include "fm_data.h"
34 |
35 |
36 | class fm_model {
37 | private:
38 | DVector m_sum, m_sum_sqr;
39 | public:
40 | double w0;
41 | DVectorDouble w;
42 | DMatrixDouble v;
43 |
44 | public:
45 | // the following values should be set:
46 | uint num_attribute;
47 |
48 | bool k0, k1;
49 | int num_factor;
50 |
51 | double reg0;
52 | double regw, regv;
53 |
54 | double init_stdev;
55 | double init_mean;
56 |
57 | fm_model();
58 | void debug();
59 | void init();
60 | double predict(sparse_row& x);
61 | double predict(sparse_row& x, DVector &sum, DVector &sum_sqr);
62 | void saveModel(std::string model_file_path);
63 | int loadModel(std::string model_file_path);
64 | private:
65 | void splitString(const std::string& s, char c, std::vector& v);
66 |
67 | };
68 |
69 |
70 |
71 | fm_model::fm_model() {
72 | num_factor = 0;
73 | init_mean = 0;
74 | init_stdev = 0.01;
75 | reg0 = 0.0;
76 | regw = 0.0;
77 | regv = 0.0;
78 | k0 = true;
79 | k1 = true;
80 | }
81 |
82 | void fm_model::debug() {
83 | std::cout << "num_attributes=" << num_attribute << std::endl;
84 | std::cout << "use w0=" << k0 << std::endl;
85 | std::cout << "use w1=" << k1 << std::endl;
86 | std::cout << "dim v =" << num_factor << std::endl;
87 | std::cout << "reg_w0=" << reg0 << std::endl;
88 | std::cout << "reg_w=" << regw << std::endl;
89 | std::cout << "reg_v=" << regv << std::endl;
90 | std::cout << "init ~ N(" << init_mean << "," << init_stdev << ")" << std::endl;
91 | }
92 |
93 | void fm_model::init() {
94 | w0 = 0;
95 | w.setSize(num_attribute);
96 | v.setSize(num_factor, num_attribute);
97 | w.init(0);
98 | v.init(init_mean, init_stdev);
99 | m_sum.setSize(num_factor);
100 | m_sum_sqr.setSize(num_factor);
101 | }
102 |
103 | double fm_model::predict(sparse_row& x) {
104 | return predict(x, m_sum, m_sum_sqr);
105 | }
106 |
107 | double fm_model::predict(sparse_row& x, DVector &sum, DVector &sum_sqr) {
108 | double result = 0;
109 | if (k0) {
110 | result += w0;
111 | }
112 | if (k1) {
113 | for (uint i = 0; i < x.size; i++) {
114 | assert(x.data[i].id < num_attribute);
115 | result += w(x.data[i].id) * x.data[i].value;
116 | }
117 | }
118 | for (int f = 0; f < num_factor; f++) {
119 | sum(f) = 0;
120 | sum_sqr(f) = 0;
121 | for (uint i = 0; i < x.size; i++) {
122 | double d = v(f,x.data[i].id) * x.data[i].value;
123 | sum(f) += d;
124 | sum_sqr(f) += d*d;
125 | }
126 | result += 0.5 * (sum(f)*sum(f) - sum_sqr(f));
127 | }
128 | return result;
129 | }
130 |
131 | /*
132 | * Write the FM model (all the parameters) in a file.
133 | */
134 | void fm_model::saveModel(std::string model_file_path){
135 | std::ofstream out_model;
136 | out_model.open(model_file_path.c_str());
137 | if (k0) {
138 | out_model << "#global bias W0" << std::endl;
139 | out_model << w0 << std::endl;
140 | }
141 | if (k1) {
142 | out_model << "#unary interactions Wj" << std::endl;
143 | for (uint i = 0; i v_str;
182 | splitString(line, ' ', v_str);
183 | if ((int)v_str.size() != num_factor){return 0;}
184 | for (int f = 0; f < num_factor; f++) {
185 | v(f,i) = std::atof(v_str[f].c_str());
186 | }
187 | }
188 | model_file.close();
189 | }
190 | else{ return 0;}
191 | return 1;
192 | }
193 |
194 | /*
195 | * Splits the string s around matches of the given character c, and stores the substrings in the vector v
196 | */
197 | void fm_model::splitString(const std::string& s, char c, std::vector& v) {
198 | std::string::size_type i = 0;
199 | std::string::size_type j = s.find(c);
200 | while (j != std::string::npos) {
201 | v.push_back(s.substr(i, j-i));
202 | i = ++j;
203 | j = s.find(c, j);
204 | if (j == std::string::npos)
205 | v.push_back(s.substr(i, s.length()));
206 | }
207 | }
208 |
209 | #endif /*FM_MODEL_H_*/
210 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/fm_core/fm_sgd.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // fm_sgd.h: Generic SGD for elementwise and pairwise losses for Factorization
21 | // Machines
22 | //
23 | // Based on the publication(s):
24 | // - Steffen Rendle (2010): Factorization Machines, in Proceedings of the 10th
25 | // IEEE International Conference on Data Mining (ICDM 2010), Sydney,
26 | // Australia.
27 |
28 | #ifndef FM_SGD_H_
29 | #define FM_SGD_H_
30 |
31 | #include "fm_model.h"
32 |
33 | void fm_SGD(fm_model* fm, const double& learn_rate, sparse_row &x, const double multiplier, DVector &sum) {
34 | if (fm->k0) {
35 | double& w0 = fm->w0;
36 | w0 -= learn_rate * (multiplier + fm->reg0 * w0);
37 | }
38 | if (fm->k1) {
39 | for (uint i = 0; i < x.size; i++) {
40 | double& w = fm->w(x.data[i].id);
41 | w -= learn_rate * (multiplier * x.data[i].value + fm->regw * w);
42 | }
43 | }
44 | for (int f = 0; f < fm->num_factor; f++) {
45 | for (uint i = 0; i < x.size; i++) {
46 | double& v = fm->v(f,x.data[i].id);
47 | double grad = sum(f) * x.data[i].value - v * x.data[i].value * x.data[i].value;
48 | v -= learn_rate * (multiplier * grad + fm->regv * v);
49 | }
50 | }
51 | }
52 |
53 | void fm_pairSGD(fm_model* fm, const double& learn_rate, sparse_row &x_pos, sparse_row &x_neg, const double multiplier, DVector &sum_pos, DVector &sum_neg, DVector &grad_visited, DVector &grad) {
54 | if (fm->k0) {
55 | double& w0 = fm->w0;
56 | w0 -= fm->reg0 * w0; // w0 should always be 0
57 | }
58 | if (fm->k1) {
59 | for (uint i = 0; i < x_pos.size; i++) {
60 | grad(x_pos.data[i].id) = 0;
61 | grad_visited(x_pos.data[i].id) = false;
62 | }
63 | for (uint i = 0; i < x_neg.size; i++) {
64 | grad(x_neg.data[i].id) = 0;
65 | grad_visited(x_neg.data[i].id) = false;
66 | }
67 | for (uint i = 0; i < x_pos.size; i++) {
68 | grad(x_pos.data[i].id) += x_pos.data[i].value;
69 | }
70 | for (uint i = 0; i < x_neg.size; i++) {
71 | grad(x_neg.data[i].id) -= x_neg.data[i].value;
72 | }
73 | for (uint i = 0; i < x_pos.size; i++) {
74 | uint& attr_id = x_pos.data[i].id;
75 | if (! grad_visited(attr_id)) {
76 | double& w = fm->w(attr_id);
77 | w -= learn_rate * (multiplier * grad(attr_id) + fm->regw * w);
78 | grad_visited(attr_id) = true;
79 | }
80 | }
81 | for (uint i = 0; i < x_neg.size; i++) {
82 | uint& attr_id = x_neg.data[i].id;
83 | if (! grad_visited(attr_id)) {
84 | double& w = fm->w(attr_id);
85 | w -= learn_rate * (multiplier * grad(attr_id) + fm->regw * w);
86 | grad_visited(attr_id) = true;
87 | }
88 | }
89 | }
90 |
91 | for (int f = 0; f < fm->num_factor; f++) {
92 | for (uint i = 0; i < x_pos.size; i++) {
93 | grad(x_pos.data[i].id) = 0;
94 | grad_visited(x_pos.data[i].id) = false;
95 | }
96 | for (uint i = 0; i < x_neg.size; i++) {
97 | grad(x_neg.data[i].id) = 0;
98 | grad_visited(x_neg.data[i].id) = false;
99 | }
100 | for (uint i = 0; i < x_pos.size; i++) {
101 | grad(x_pos.data[i].id) += sum_pos(f) * x_pos.data[i].value - fm->v(f, x_pos.data[i].id) * x_pos.data[i].value * x_pos.data[i].value;
102 | }
103 | for (uint i = 0; i < x_neg.size; i++) {
104 | grad(x_neg.data[i].id) -= sum_neg(f) * x_neg.data[i].value - fm->v(f, x_neg.data[i].id) * x_neg.data[i].value * x_neg.data[i].value;
105 | }
106 | for (uint i = 0; i < x_pos.size; i++) {
107 | uint& attr_id = x_pos.data[i].id;
108 | if (! grad_visited(attr_id)) {
109 | double& v = fm->v(f,attr_id);
110 | v -= learn_rate * (multiplier * grad(attr_id) + fm->regv * v);
111 | grad_visited(attr_id) = true;
112 | }
113 | }
114 | for (uint i = 0; i < x_neg.size; i++) {
115 | uint& attr_id = x_neg.data[i].id;
116 | if (! grad_visited(attr_id)) {
117 | double& v = fm->v(f,attr_id);
118 | v -= learn_rate * (multiplier * grad(attr_id) + fm->regv * v);
119 | grad_visited(attr_id) = true;
120 | }
121 | }
122 |
123 |
124 | }
125 |
126 | }
127 | #endif /*FM_SGD_H_*/
128 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/Makefile:
--------------------------------------------------------------------------------
1 | BIN_DIR := ../../bin/
2 |
3 | OBJECTS := \
4 | libfm.o \
5 | tools/transpose.o \
6 | tools/convert.o \
7 |
8 | all: libFM transpose convert
9 |
10 | libFM: libfm.o
11 | mkdir -p $(BIN_DIR)
12 | g++ -O3 -Wall libfm.o -o $(BIN_DIR)libFM
13 |
14 | %.o: %.cpp
15 | g++ -O3 -Wall -c $< -o $@
16 |
17 | clean: clean_lib
18 | mkdir -p $(BIN_DIR)
19 | rm -f $(BIN_DIR)libFM $(BIN_DIR)convert $(BIN_DIR)transpose
20 |
21 | clean_lib:
22 | rm -f $(OBJECTS)
23 |
24 |
25 | transpose: tools/transpose.o
26 | mkdir -p $(BIN_DIR)
27 | g++ -O3 tools/transpose.o -o $(BIN_DIR)transpose
28 |
29 | convert: tools/convert.o
30 | mkdir -p $(BIN_DIR)
31 | g++ -O3 tools/convert.o -o $(BIN_DIR)convert
32 |
33 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/libfm.o:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libfm/libfm/src/libfm/libfm.o
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/src/fm_learn.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // fm_learn.h: Generic learning method for factorization machines
21 |
22 | #ifndef FM_LEARN_H_
23 | #define FM_LEARN_H_
24 |
25 | #include
26 | #include "Data.h"
27 | #include "../../fm_core/fm_model.h"
28 | #include "../../util/rlog.h"
29 | #include "../../util/util.h"
30 |
31 |
32 | class fm_learn {
33 | protected:
34 | DVector sum, sum_sqr;
35 | DMatrix pred_q_term;
36 |
37 | // this function can be overwritten (e.g. for MCMC)
38 | virtual double predict_case(Data& data) {
39 | return fm->predict(data.data->getRow());
40 | }
41 |
42 | public:
43 | DataMetaInfo* meta;
44 | fm_model* fm;
45 | double min_target;
46 | double max_target;
47 |
48 | int task; // 0=regression, 1=classification
49 |
50 | const static int TASK_REGRESSION = 0;
51 | const static int TASK_CLASSIFICATION = 1;
52 |
53 | Data* validation;
54 |
55 |
56 | RLog* log;
57 |
58 | fm_learn() { log = NULL; task = 0; meta = NULL;}
59 |
60 |
61 | virtual void init() {
62 | if (log != NULL) {
63 | if (task == TASK_REGRESSION) {
64 | log->addField("rmse", std::numeric_limits::quiet_NaN());
65 | log->addField("mae", std::numeric_limits::quiet_NaN());
66 | } else if (task == TASK_CLASSIFICATION) {
67 | log->addField("accuracy", std::numeric_limits::quiet_NaN());
68 | } else {
69 | throw "unknown task";
70 | }
71 | log->addField("time_pred", std::numeric_limits::quiet_NaN());
72 | log->addField("time_learn", std::numeric_limits::quiet_NaN());
73 | log->addField("time_learn2", std::numeric_limits::quiet_NaN());
74 | log->addField("time_learn4", std::numeric_limits::quiet_NaN());
75 | }
76 | sum.setSize(fm->num_factor);
77 | sum_sqr.setSize(fm->num_factor);
78 | pred_q_term.setSize(fm->num_factor, meta->num_relations + 1);
79 | }
80 |
81 | virtual double evaluate(Data& data) {
82 | assert(data.data != NULL);
83 | if (task == TASK_REGRESSION) {
84 | return evaluate_regression(data);
85 | } else if (task == TASK_CLASSIFICATION) {
86 | return evaluate_classification(data);
87 | } else {
88 | throw "unknown task";
89 | }
90 | }
91 |
92 | public:
93 | virtual void learn(Data& train, Data& test) { }
94 |
95 | virtual void predict(Data& data, DVector& out) = 0;
96 | // virtual void sgd_logits(Data& data, DVector& out) = 0;
97 |
98 | virtual void debug() {
99 | std::cout << "task=" << task << std::endl;
100 | std::cout << "min_target=" << min_target << std::endl;
101 | std::cout << "max_target=" << max_target << std::endl;
102 | }
103 |
104 | protected:
105 | virtual double evaluate_classification(Data& data) {
106 | int num_correct = 0;
107 | double eval_time = getusertime();
108 | for (data.data->begin(); !data.data->end(); data.data->next()) {
109 | double p = predict_case(data);
110 | if (((p >= 0) && (data.target(data.data->getRowIndex()) >= 0)) || ((p < 0) && (data.target(data.data->getRowIndex()) < 0))) {
111 | num_correct++;
112 | }
113 | }
114 | eval_time = (getusertime() - eval_time);
115 | // log the values
116 | if (log != NULL) {
117 | log->log("accuracy", (double) num_correct / (double) data.data->getNumRows());
118 | log->log("time_pred", eval_time);
119 | }
120 | //printf("%lf / %lf = %lf\n", (double) num_correct, (double) data.data->getNumRows(), (double) num_correct / (double) data.data->getNumRows());
121 | return (double) num_correct / (double) data.data->getNumRows();
122 | }
123 | virtual double evaluate_regression(Data& data) {
124 | double rmse_sum_sqr = 0;
125 | double mae_sum_abs = 0;
126 | double eval_time = getusertime();
127 | for (data.data->begin(); !data.data->end(); data.data->next()) {
128 | double p = predict_case(data);
129 | p = std::min(max_target, p);
130 | p = std::max(min_target, p);
131 | double err = p - data.target(data.data->getRowIndex());
132 | rmse_sum_sqr += err*err;
133 | mae_sum_abs += std::abs((double)err);
134 | }
135 | eval_time = (getusertime() - eval_time);
136 | // log the values
137 | if (log != NULL) {
138 | log->log("rmse", std::sqrt(rmse_sum_sqr/data.data->getNumRows()));
139 | log->log("mae", mae_sum_abs/data.data->getNumRows());
140 | log->log("time_pred", eval_time);
141 | }
142 |
143 | return std::sqrt(rmse_sum_sqr/data.data->getNumRows());
144 | }
145 |
146 | };
147 |
148 | #endif /*FM_LEARN_H_*/
149 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/src/fm_learn_sgd.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // fm_learn_sgd.h: Stochastic Gradient Descent based learning
21 | //
22 | // Based on the publication(s):
23 | // - Steffen Rendle (2010): Factorization Machines, in Proceedings of the 10th
24 | // IEEE International Conference on Data Mining (ICDM 2010), Sydney,
25 | // Australia.
26 |
27 | #ifndef FM_LEARN_SGD_H_
28 | #define FM_LEARN_SGD_H_
29 |
30 | #include "fm_learn.h"
31 | #include "../../fm_core/fm_sgd.h"
32 |
33 | class fm_learn_sgd: public fm_learn {
34 | protected:
35 | //DVector sum, sum_sqr;
36 | public:
37 | int num_iter;
38 | double learn_rate;
39 | DVector learn_rates;
40 |
41 | virtual void init() {
42 | fm_learn::init();
43 | learn_rates.setSize(3);
44 | // sum.setSize(fm->num_factor);
45 | // sum_sqr.setSize(fm->num_factor);
46 | }
47 |
48 | virtual void learn(Data& train, Data& test) {
49 | fm_learn::learn(train, test);
50 | std::cout << "learnrate=" << learn_rate << std::endl;
51 | std::cout << "learnrates=" << learn_rates(0) << "," << learn_rates(1) << "," << learn_rates(2) << std::endl;
52 | std::cout << "#iterations=" << num_iter << std::endl;
53 |
54 | if (train.relation.dim > 0) {
55 | throw "relations are not supported with SGD";
56 | }
57 | std::cout.flush();
58 | }
59 |
60 | void SGD(sparse_row &x, const double multiplier, DVector &sum) {
61 | fm_SGD(fm, learn_rate, x, multiplier, sum);
62 | }
63 |
64 | void debug() {
65 | std::cout << "num_iter=" << num_iter << std::endl;
66 | fm_learn::debug();
67 | }
68 |
69 | virtual void predict(Data& data, DVector& out) {
70 | assert(data.data->getNumRows() == out.dim);
71 | for (data.data->begin(); !data.data->end(); data.data->next()) {
72 | double p = predict_case(data);
73 | if (task == TASK_REGRESSION ) {
74 | p = std::min(max_target, p);
75 | p = std::max(min_target, p);
76 | } else if (task == TASK_CLASSIFICATION) {
77 | p = 1.0/(1.0 + exp(-p));
78 | } else {
79 | throw "task not supported";
80 | }
81 | out(data.data->getRowIndex()) = p;
82 | }
83 | }
84 |
85 | };
86 |
87 | #endif /*FM_LEARN_SGD_H_*/
88 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/src/fm_learn_sgd_element.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // fm_learn_sgd.h: Stochastic Gradient Descent based learning for
21 | // classification and regression
22 | //
23 | // Based on the publication(s):
24 | // - Steffen Rendle (2010): Factorization Machines, in Proceedings of the 10th
25 | // IEEE International Conference on Data Mining (ICDM 2010), Sydney,
26 | // Australia.
27 |
28 | #ifndef FM_LEARN_SGD_ELEMENT_H_
29 | #define FM_LEARN_SGD_ELEMENT_H_
30 |
31 | #include "fm_learn_sgd.h"
32 |
33 | class fm_learn_sgd_element: public fm_learn_sgd {
34 | public:
35 | virtual void init() {
36 | fm_learn_sgd::init();
37 |
38 | if (log != NULL) {
39 | log->addField("rmse_train", std::numeric_limits::quiet_NaN());
40 | }
41 | }
42 | virtual void learn(Data& train, Data& test) {
43 | fm_learn_sgd::learn(train, test);
44 |
45 | std::cout << "SGD: DON'T FORGET TO SHUFFLE THE ROWS IN TRAINING DATA TO GET THE BEST RESULTS." << std::endl;
46 | // SGD
47 | for (int i = 0; i < num_iter; i++) {
48 |
49 | double iteration_time = getusertime();
50 | for (train.data->begin(); !train.data->end(); train.data->next()) {
51 |
52 | double p = fm->predict(train.data->getRow(), sum, sum_sqr);
53 | double mult = 0;
54 | if (task == 0) {
55 | p = std::min(max_target, p);
56 | p = std::max(min_target, p);
57 | mult = -(train.target(train.data->getRowIndex())-p);
58 | } else if (task == 1) {
59 | mult = -train.target(train.data->getRowIndex())*(1.0-1.0/(1.0+exp(-train.target(train.data->getRowIndex())*p)));
60 | }
61 | SGD(train.data->getRow(), mult, sum);
62 | }
63 | iteration_time = (getusertime() - iteration_time);
64 | double rmse_train = evaluate(train);
65 | double rmse_test = evaluate(test);
66 | std::cout << "#Iter=" << std::setw(3) << i << "\tTrain=" << rmse_train << "\tTest=" << rmse_test << std::endl;
67 | if (log != NULL) {
68 | log->log("rmse_train", rmse_train);
69 | log->log("time_learn", iteration_time);
70 | log->newLine();
71 | }
72 | }
73 | }
74 |
75 | void sgd_logits(Data& data, DVector& out) {
76 | assert(data.data->getNumRows() == out.dim);
77 | for (data.data->begin(); !data.data->end(); data.data->next()) {
78 | double p = predict_case(data);
79 | // std::cout << p << std::endl;
80 | // if (task == TASK_REGRESSION ) {
81 | // p = std::min(max_target, p);
82 | // p = std::max(min_target, p);
83 | // } else if (task == TASK_CLASSIFICATION) {
84 | // p = 1.0/(1.0 + exp(-p));
85 | // } else {
86 | // throw "task not supported";
87 | // }
88 | out(data.data->getRowIndex()) = p;
89 | }
90 | }
91 |
92 | };
93 |
94 | #endif /*FM_LEARN_SGD_ELEMENT_H_*/
95 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/src/relation.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // relation.h: Data and Links for Relations
21 |
22 | #ifndef RELATION_DATA_H_
23 | #define RELATION_DATA_H_
24 |
25 | #include
26 | #include "../../util/matrix.h"
27 | #include "../../util/fmatrix.h"
28 | #include "../../fm_core/fm_data.h"
29 | #include "../../fm_core/fm_model.h"
30 | #include "Data.h"
31 |
32 | class RelationData {
33 | protected:
34 | uint cache_size;
35 | bool has_xt;
36 | bool has_x;
37 | public:
38 | RelationData(uint cache_size, bool has_x, bool has_xt) {
39 | this->data_t = NULL;
40 | this->data = NULL;
41 | this->cache_size = cache_size;
42 | this->has_x = has_x;
43 | this->has_xt = has_xt;
44 | this->meta = NULL;
45 | }
46 | DataMetaInfo* meta;
47 |
48 | LargeSparseMatrix* data_t;
49 | LargeSparseMatrix* data;
50 |
51 | int num_feature;
52 | uint num_cases;
53 | uint attr_offset;
54 |
55 | void load(std::string filename);
56 | void debug();
57 | };
58 |
59 |
60 | class RelationJoin {
61 | public:
62 | DVector data_row_to_relation_row;
63 | RelationData* data;
64 |
65 | void load(std::string filename, uint expected_row_count) {
66 | bool do_binary = false;
67 | // check if binary or text format should be read
68 | {
69 | std::ifstream in (filename.c_str(), std::ios_base::in | std::ios_base::binary);
70 | if (in.is_open()) {
71 | uint file_version;
72 | uint data_size;
73 | in.read(reinterpret_cast(&file_version), sizeof(file_version));
74 | in.read(reinterpret_cast(&data_size), sizeof(data_size));
75 | do_binary = ((file_version == DVECTOR_EXPECTED_FILE_ID) && (data_size == sizeof(uint)));
76 | in.close();
77 | }
78 | }
79 | if (do_binary) {
80 | //std::cout << "(binary mode) " << std::endl;
81 | data_row_to_relation_row.loadFromBinaryFile(filename);
82 | } else {
83 | //std::cout << "(text mode) " << std::endl;
84 | data_row_to_relation_row.setSize(expected_row_count);
85 | data_row_to_relation_row.load(filename);
86 | }
87 | assert(data_row_to_relation_row.dim == expected_row_count);
88 | }
89 | };
90 |
91 | void RelationData::load(std::string filename) {
92 |
93 | std::cout << "has x = " << has_x << std::endl;
94 | std::cout << "has xt = " << has_xt << std::endl;
95 | assert(has_x || has_xt);
96 |
97 | //uint num_cases = 0;
98 | uint num_values = 0;
99 | uint this_cs = cache_size;
100 | if (has_xt && has_x) { this_cs /= 2; }
101 |
102 | if (has_x) {
103 | std::cout << "data... ";
104 | this->data = new LargeSparseMatrixHD(filename + ".x", this_cs);
105 | this->num_feature = this->data->getNumCols();
106 | num_values = this->data->getNumValues();
107 | num_cases = this->data->getNumRows();
108 | } else {
109 | data = NULL;
110 | }
111 | if (has_xt) {
112 | std::cout << "data transpose... ";
113 | this->data_t = new LargeSparseMatrixHD(filename + ".xt", this_cs);
114 | this->num_feature = this->data_t->getNumRows();
115 | num_values = this->data_t->getNumValues();
116 | num_cases = this->data_t->getNumCols();
117 | } else {
118 | data_t = NULL;
119 | }
120 |
121 | if (has_xt && has_x) {
122 | assert(this->data->getNumCols() == this->data_t->getNumRows());
123 | assert(this->data->getNumRows() == this->data_t->getNumCols());
124 | assert(this->data->getNumValues() == this->data_t->getNumValues());
125 | }
126 |
127 | std::cout << "num_cases=" << this->num_cases << "\tnum_values=" << num_values << "\tnum_features=" << this->num_feature << std::endl;
128 |
129 | meta = new DataMetaInfo(this->num_feature);
130 |
131 | if (fileexists(filename + ".groups")) {
132 | meta->loadGroupsFromFile(filename + ".groups");
133 | }
134 | }
135 |
136 |
137 | void RelationData::debug() {
138 | if (has_x) {
139 | for (data->begin(); (!data->end()) && (data->getRowIndex() < 4); data->next() ) {
140 | for (uint j = 0; j < data->getRow().size; j++) {
141 | std::cout << " " << data->getRow().data[j].id << ":" << data->getRow().data[j].value;
142 | }
143 | std::cout << std::endl;
144 | }
145 | }
146 | }
147 |
148 | #endif /*RELATION_DATA_H_*/
149 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/tools/convert.o:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libfm/libfm/src/libfm/tools/convert.o
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/tools/transpose.cpp:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // transpose: Transposes a matrix in binary sparse format.
21 |
22 | #include
23 | #include
24 | #include
25 | #include
26 | #include
27 | #include
28 | #include
29 | #include "../../util/util.h"
30 | #include "../../util/cmdline.h"
31 | #include "../src/Data.h"
32 |
33 | /**
34 | *
35 | * Version history:
36 | * 1.4.2:
37 | * changed license to GPLv3
38 | * 1.4.0:
39 | * default cache size is 200 MB
40 | * 1.3.6:
41 | * binary mode for file access
42 | * 1.3.4:
43 | * no differences, version numbers are kept in sync over all libfm tools
44 | * 1.3.2:
45 | * no differences, version numbers are kept in sync over all libfm tools
46 | * 1.0:
47 | * first version
48 | */
49 |
50 |
51 |
52 | using namespace std;
53 |
54 | int main(int argc, char **argv) {
55 |
56 | srand ( time(NULL) );
57 | try {
58 | CMDLine cmdline(argc, argv);
59 | std::cout << "----------------------------------------------------------------------------" << std::endl;
60 | std::cout << "Transpose" << std::endl;
61 | std::cout << " Version: 1.4.2" << std::endl;
62 | std::cout << " Author: Steffen Rendle, srendle@libfm.org" << std::endl;
63 | std::cout << " WWW: http://www.libfm.org/" << std::endl;
64 | std::cout << "This program comes with ABSOLUTELY NO WARRANTY; for details see license.txt." << std::endl;
65 | std::cout << "This is free software, and you are welcome to redistribute it under certain" << std::endl;
66 | std::cout << "conditions; for details see license.txt." << std::endl;
67 | std::cout << "----------------------------------------------------------------------------" << std::endl;
68 |
69 | const std::string param_ifile = cmdline.registerParameter("ifile", "input file name, file has to be in binary sparse format [MANDATORY]");
70 | const std::string param_ofile = cmdline.registerParameter("ofile", "output file name [MANDATORY]");
71 |
72 | const std::string param_cache_size = cmdline.registerParameter("cache_size", "cache size for data storage, default=200000000");
73 | const std::string param_help = cmdline.registerParameter("help", "this screen");
74 |
75 |
76 | if (cmdline.hasParameter(param_help) || (argc == 1)) {
77 | cmdline.print_help();
78 | return 0;
79 | }
80 | cmdline.checkParameters();
81 |
82 |
83 | // (1) Load the data
84 | long long cache_size = cmdline.getValue(param_cache_size, 200000000);
85 | cache_size /= 2;
86 | LargeSparseMatrixHD d_in(cmdline.getValue(param_ifile), cache_size);
87 | std::cout << "num_rows=" << d_in.getNumRows() << "\tnum_values=" << d_in.getNumValues() << "\tnum_features=" << d_in.getNumCols() << std::endl;
88 |
89 | // (2) transpose the data
90 | // (2.1) count how many entries per col (=transpose-row) there are:
91 | DVector entries_per_col(d_in.getNumCols());
92 | entries_per_col.init(0);
93 | for (d_in.begin(); !d_in.end(); d_in.next() ) {
94 | sparse_row& row = d_in.getRow();
95 | for (uint j = 0; j < row.size; j++) {
96 | entries_per_col(row.data[j].id)++;
97 | }
98 | }
99 | // (2.2) build a
100 | std::string ofile = cmdline.getValue(param_ofile);
101 | std::cout << "output to " << ofile << std::endl; std::cout.flush();
102 | std::ofstream out(ofile.c_str(), ios_base::out | ios_base::binary);
103 | if (out.is_open()) {
104 | file_header fh;
105 | fh.id = FMATRIX_EXPECTED_FILE_ID;
106 | fh.num_values = d_in.getNumValues();
107 | fh.num_rows = d_in.getNumCols();
108 | fh.num_cols = d_in.getNumRows();
109 | fh.float_size = sizeof(DATA_FLOAT);
110 | out.write(reinterpret_cast(&fh), sizeof(fh));
111 |
112 | DVector< sparse_row > out_row_cache;
113 | DVector< sparse_entry > out_entry_cache;
114 | {
115 | // determine cache sizes automatically:
116 | double avg_entries_per_line = (double) d_in.getNumValues() / d_in.getNumCols();
117 | uint num_rows_in_cache = cache_size / (sizeof(sparse_entry) * avg_entries_per_line + sizeof(uint));
118 | num_rows_in_cache = std::min(num_rows_in_cache, d_in.getNumCols());
119 | uint64 num_entries_in_cache = (cache_size - sizeof(uint)*num_rows_in_cache) / sizeof(sparse_entry);
120 | num_entries_in_cache = std::min(num_entries_in_cache, d_in.getNumValues());
121 | std::cout << "num entries in cache=" << num_entries_in_cache << "\tnum rows in cache=" << num_rows_in_cache << std::endl;
122 | out_entry_cache.setSize(num_entries_in_cache);
123 | out_row_cache.setSize(num_rows_in_cache);
124 | }
125 |
126 | uint out_cache_col_position = 0; // the first column id that is in cache
127 | uint out_cache_col_num = 0; // how many columns are in the cache
128 |
129 | while (out_cache_col_position < d_in.getNumCols()) {
130 | // assign cache sizes
131 | {
132 | uint entry_cache_pos = 0;
133 | // while (there is enough space in the entry cache for the next row) and (there is space for another row) and (there is another row in the data) do
134 | while (((entry_cache_pos + entries_per_col(out_cache_col_position + out_cache_col_num)) < out_entry_cache.dim) && ((out_cache_col_num+1) < out_row_cache.dim) && ((out_cache_col_position+out_cache_col_num) < d_in.getNumCols())) {
135 | out_row_cache(out_cache_col_num).size = 0;
136 | out_row_cache(out_cache_col_num).data = &(out_entry_cache.value[entry_cache_pos]);
137 | entry_cache_pos += entries_per_col(out_cache_col_position + out_cache_col_num);
138 | out_cache_col_num++;
139 | }
140 | }
141 | assert(out_cache_col_num > 0);
142 | // fill the cache
143 | for (d_in.begin(); !d_in.end(); d_in.next() ) {
144 | sparse_row& row = d_in.getRow();
145 | for (uint j = 0; j < row.size; j++) {
146 | if ((row.data[j].id >= out_cache_col_position) && (row.data[j].id < (out_cache_col_position+out_cache_col_num))) {
147 | uint cache_row_index = row.data[j].id-out_cache_col_position;
148 | out_row_cache(cache_row_index).data[out_row_cache(cache_row_index).size].id = d_in.getRowIndex();
149 | out_row_cache(cache_row_index).data[out_row_cache(cache_row_index).size].value = row.data[j].value;
150 | out_row_cache(cache_row_index).size++;
151 | }
152 | }
153 | }
154 |
155 | for (uint i = 0; i < out_cache_col_num; i++) {
156 | assert(out_row_cache(i).size == entries_per_col(i + out_cache_col_position));
157 | out.write(reinterpret_cast(&(out_row_cache(i).size)), sizeof(uint));
158 | out.write(reinterpret_cast(out_row_cache(i).data), sizeof(sparse_entry)*out_row_cache(i).size);
159 | }
160 | out_cache_col_position += out_cache_col_num;
161 | out_cache_col_num = 0;
162 | }
163 | out.close();
164 | } else {
165 | throw "could not open " + ofile;
166 | }
167 |
168 | } catch (std::string &e) {
169 | std::cerr << e << std::endl;
170 | }
171 |
172 | }
173 |
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/libfm/tools/transpose.o:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/charlesXu86/TIANCHI_Project/ad4598ebc8e5bf63b07185ddbc9418c9504e05ce/Click_prediction/libfm/libfm/src/libfm/tools/transpose.o
--------------------------------------------------------------------------------
/Click_prediction/libfm/libfm/src/util/cmdline.h:
--------------------------------------------------------------------------------
1 | // Copyright (C) 2010, 2011, 2012, 2013, 2014 Steffen Rendle
2 | // Contact: srendle@libfm.org, http://www.libfm.org/
3 | //
4 | // This file is part of libFM.
5 | //
6 | // libFM is free software: you can redistribute it and/or modify
7 | // it under the terms of the GNU General Public License as published by
8 | // the Free Software Foundation, either version 3 of the License, or
9 | // (at your option) any later version.
10 | //
11 | // libFM is distributed in the hope that it will be useful,
12 | // but WITHOUT ANY WARRANTY; without even the implied warranty of
13 | // MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 | // GNU General Public License for more details.
15 | //
16 | // You should have received a copy of the GNU General Public License
17 | // along with libFM. If not, see .
18 | //
19 | //
20 | // cmdline.h: Command line parser
21 |
22 | #ifndef CMDLINE_H_
23 | #define CMDLINE_H_
24 |
25 | #include