├── .gitignore
├── .vscode
├── launch.json
└── settings.json
├── LICENSE
├── README.md
├── checkpoint_configs
├── depthwise.yaml
├── fixed_channels_finetuned
│ ├── allen.yaml
│ ├── cp.yaml
│ └── hpa.yaml
├── hypernet.yaml
├── slice_param.yaml
├── target_param.yaml
└── template_mixing.yaml
├── config.py
├── configs
└── morphem70k
│ ├── allen_cfg.yaml
│ ├── attn_pooling
│ ├── none.yaml
│ ├── param1.yaml
│ ├── param2.yaml
│ ├── param3.yaml
│ ├── param4.yaml
│ └── param5.yaml
│ ├── cp_cfg.yaml
│ ├── data_chunk
│ ├── allen.yaml
│ ├── cp.yaml
│ ├── hpa.yaml
│ └── morphem70k.yaml
│ ├── dataset
│ ├── allen.yaml
│ ├── cp.yaml
│ ├── hpa.yaml
│ └── morphem70k_v2.yaml
│ ├── eval
│ └── default.yaml
│ ├── hardware
│ ├── default.yaml
│ └── four_workers.yaml
│ ├── hpa_cfg.yaml
│ ├── logging
│ ├── no.yaml
│ └── wandb.yaml
│ ├── model
│ ├── clip_resnet50.yaml
│ ├── clip_vit.yaml
│ ├── convnext_base.yaml
│ ├── convnext_base_miro.yaml
│ ├── convnext_shared_miro.yaml
│ ├── depthwiseconvnext.yaml
│ ├── depthwiseconvnext_miro.yaml
│ ├── dino_base.yaml
│ ├── hyperconvnext.yaml
│ ├── hyperconvnext_miro.yaml
│ ├── separate.yaml
│ ├── sliceparam.yaml
│ ├── sliceparam_miro.yaml
│ ├── template_mixing.yaml
│ ├── template_mixing_v2.yaml
│ └── template_mixing_v2_miro.yaml
│ ├── morphem70k_cfg.yaml
│ ├── optimizer
│ ├── adam.yaml
│ ├── adamw.yaml
│ └── sgd.yaml
│ ├── scheduler
│ ├── cosine.yaml
│ ├── multistep.yaml
│ └── none.yaml
│ └── train
│ └── random_instance.yaml
├── custom_log.py
├── datasets
├── __init__.py
├── cifar.py
├── compute_mean_std_morphem70k.py
├── dataset_utils.py
├── morphem70k.py
├── split_datasets.py
└── tps_transform.py
├── evaluate.ipynb
├── figs
├── 01-adaptive-models.png
└── 04-diagrams.png
├── helper_classes
├── __init__.py
├── best_result.py
├── channel_initialization.py
├── channel_pooling_type.py
├── datasplit.py
├── feature_pooling.py
├── first_layer_init.py
└── norm_type.py
├── lr_schedulers.py
├── main.py
├── metadata
└── morphem70k_v2.csv
├── models
├── __init__.py
├── channel_attention_pooling.py
├── convnext_base.py
├── convnext_base_miro.py
├── convnext_shared_miro.py
├── depthwise_convnext.py
├── depthwise_convnext_miro.py
├── hypernet.py
├── hypernet_convnext.py
├── hypernet_convnext_miro.py
├── loss_fn.py
├── model_utils.py
├── shared_convnext.py
├── slice_param_convnext.py
├── slice_param_convnext_miro.py
├── template_convnextv2.py
├── template_convnextv2_miro.py
└── template_mixing_convnext.py
├── optimizers.py
├── requirements.txt
├── ssltrainer.py
├── train_scripts.sh
├── trainer.py
└── utils.py
/.gitignore:
--------------------------------------------------------------------------------
1 |
2 | # Created by https://www.toptal.com/developers/gitignore/api/macos,pycharm,jupyternotebooks
3 | # Edit at https://www.toptal.com/developers/gitignore?templates=macos,pycharm,jupyternotebooks
4 | /data
5 | !/data/
6 | /data/*
7 | !/data/split/
8 | /logs
9 | /mlruns
10 | /notebooks
11 | /archives
12 | /store_result
13 | /checkpoints
14 | /multirun
15 | push_scc
16 | .env
17 | /outputs
18 | __pycache__/
19 | */__pycache__/
20 | .idea/
21 |
22 | ### JupyterNotebooks ###
23 |
24 | # gitignore template for Jupyter Notebooks
25 | # website: http://jupyter.org/
26 |
27 | .ipynb_checkpoints
28 | */.ipynb_checkpoints/*
29 |
30 | # IPython
31 | profile_default/
32 | ipython_config.py
33 |
34 | # Remove previous ipynb_checkpoints
35 | # git rm -r .ipynb_checkpoints/
36 |
37 | ### macOS ###
38 | # General
39 | .DS_Store
40 | .AppleDouble
41 | .LSOverride
42 |
43 | # Icon must end with two \r
44 | Icon
45 |
46 |
47 | # Thumbnails
48 | ._*
49 |
50 | # Files that might appear in the root of a volume
51 | .DocumentRevisions-V100
52 | .fseventsd
53 | .Spotlight-V100
54 | .TemporaryItems
55 | .Trashes
56 | .VolumeIcon.icns
57 | .com.apple.timemachine.donotpresent
58 |
59 | # Directories potentially created on remote AFP share
60 | .AppleDB
61 | .AppleDesktop
62 | Network Trash Folder
63 | Temporary Items
64 | .apdisk
65 |
66 | ### macOS Patch ###
67 | # iCloud generated files
68 | *.icloud
69 |
70 | ### PyCharm ###
71 | # Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio, WebStorm and Rider
72 | # Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
73 |
74 | # User-specific stuff
75 | .idea/**/workspace.xml
76 | .idea/**/tasks.xml
77 | .idea/**/usage.statistics.xml
78 | .idea/**/dictionaries
79 | .idea/**/shelf
80 |
81 | # AWS User-specific
82 | .idea/**/aws.xml
83 |
84 | # Generated files
85 | .idea/**/contentModel.xml
86 |
87 | # Sensitive or high-churn files
88 | .idea/**/dataSources/
89 | .idea/**/dataSources.ids
90 | .idea/**/dataSources.local.xml
91 | .idea/**/sqlDataSources.xml
92 | .idea/**/dynamic.xml
93 | .idea/**/uiDesigner.xml
94 | .idea/**/dbnavigator.xml
95 |
96 | # Gradle
97 | .idea/**/gradle.xml
98 | .idea/**/libraries
99 |
100 | # Gradle and Maven with auto-import
101 | # When using Gradle or Maven with auto-import, you should exclude module files,
102 | # since they will be recreated, and may cause churn. Uncomment if using
103 | # auto-import.
104 | # .idea/artifacts
105 | # .idea/compiler.xml
106 | # .idea/jarRepositories.xml
107 | # .idea/modules.xml
108 | # .idea/*.iml
109 | # .idea/modules
110 | # *.iml
111 | # *.ipr
112 |
113 | # CMake
114 | cmake-build-*/
115 |
116 | # Mongo Explorer plugin
117 | .idea/**/mongoSettings.xml
118 |
119 | # File-based project format
120 | *.iws
121 |
122 | # IntelliJ
123 | out/
124 |
125 | # mpeltonen/sbt-idea plugin
126 | .idea_modules/
127 |
128 | # JIRA plugin
129 | atlassian-ide-plugin.xml
130 |
131 | # Cursive Clojure plugin
132 | .idea/replstate.xml
133 |
134 | # SonarLint plugin
135 | .idea/sonarlint/
136 |
137 | # Crashlytics plugin (for Android Studio and IntelliJ)
138 | com_crashlytics_export_strings.xml
139 | crashlytics.properties
140 | crashlytics-build.properties
141 | fabric.properties
142 |
143 | # Editor-based Rest Client
144 | .idea/httpRequests
145 |
146 | # Android studio 3.1+ serialized cache file
147 | .idea/caches/build_file_checksums.ser
148 |
149 | ### PyCharm Patch ###
150 | # Comment Reason: https://github.com/joeblau/gitignore.io/issues/186#issuecomment-215987721
151 |
152 | # *.iml
153 | # modules.xml
154 | # .idea/misc.xml
155 | # *.ipr
156 |
157 | # Sonarlint plugin
158 | # https://plugins.jetbrains.com/plugin/7973-sonarlint
159 | .idea/**/sonarlint/
160 |
161 | # SonarQube Plugin
162 | # https://plugins.jetbrains.com/plugin/7238-sonarqube-community-plugin
163 | .idea/**/sonarIssues.xml
164 |
165 | # Markdown Navigator plugin
166 | # https://plugins.jetbrains.com/plugin/7896-markdown-navigator-enhanced
167 | .idea/**/markdown-navigator.xml
168 | .idea/**/markdown-navigator-enh.xml
169 | .idea/**/markdown-navigator/
170 |
171 | # Cache file creation bug
172 | # See https://youtrack.jetbrains.com/issue/JBR-2257
173 | .idea/$CACHE_FILE$
174 |
175 | # CodeStream plugin
176 | # https://plugins.jetbrains.com/plugin/12206-codestream
177 | .idea/codestream.xml
178 |
179 | # End of https://www.toptal.com/developers/gitignore/api/macos,pycharm,jupyternotebooks
180 | /outputs/
181 | /wandb/
182 |
183 |
184 | ### VisualStudioCode ###
185 | .vscode/*
186 | !.vscode/settings.json
187 | !.vscode/tasks.json
188 | !.vscode/launch.json
189 | !.vscode/extensions.json
190 | !.vscode/*.code-snippets
191 |
192 | # Local History for Visual Studio Code
193 | .history/
194 |
195 | # Built Visual Studio Code Extensions
196 | *.vsix
197 |
198 | ### VisualStudioCode Patch ###
199 | # Ignore all local history of files
200 | .history
201 | .ionide
202 | __tmp_scripts
203 | # End of https://www.toptal.com/developers/gitignore/api/visualstudiocode,macos
204 |
--------------------------------------------------------------------------------
/.vscode/launch.json:
--------------------------------------------------------------------------------
1 | {
2 | // Use IntelliSense to learn about possible attributes.
3 | // Hover to view descriptions of existing attributes.
4 | // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
5 | "version": "0.2.0",
6 | "configurations": [
7 |
8 | {
9 | "name": "Python: Remote Attach",
10 | "type": "python",
11 | "request": "attach",
12 | "connect": {
13 | "host": "localhost",
14 | "port": 5678
15 | },
16 | "justMyCode": true
17 | }
18 | ]
19 | }
--------------------------------------------------------------------------------
/.vscode/settings.json:
--------------------------------------------------------------------------------
1 | {
2 | "workbench.colorCustomizations": {
3 | "titleBar.activeBackground": "#261ac8"
4 | },
5 | "files.watcherExclude": {
6 | "**/checkpoints/**": true,
7 | "**/data/**": true,
8 | "**/multirun/**": true,
9 | "**/wandb/**": true,
10 | "**/logs/**": true,
11 | "**/snapshots/**": true,
12 | "../MorphEm/**": true
13 | },
14 | "files.exclude": {
15 | "**/.git": true,
16 | "**/.svn": true,
17 | "**/.hg": true,
18 | "**/CVS": true,
19 | "**/.DS_Store": true,
20 | "**/Thumbs.db": true,
21 | "**/__pycache__": true,
22 | "**/**/__pycache__": true,
23 | "**/wandb/**": true,
24 | "**/multirun/**": true,
25 | "**/checkpoints/**": true,
26 | "**/snapshots/**": true,
27 | },
28 | }
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2023 Chau Pham
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | A Pytorch implementation for channel-adaptive models in our [paper](https://arxiv.org/pdf/2310.19224.pdf). This code was tested using Pytorch 2.0 and Python 3.10.
2 |
3 |
4 | If you find our work useful, please consider citing:
5 |
6 | ```
7 | @InProceedings{ChenCHAMMI2023,
8 | author={Zitong Chen and Chau Pham and Siqi Wang and Michael Doron and Nikita Moshkov and Bryan A. Plummer and Juan C Caicedo},
9 | title={CHAMMI: A benchmark for channel-adaptive models in microscopy imaging},
10 | booktitle={Advances in Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks},
11 | year={2023}}
12 | ```
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 | # Setup
21 |
22 | 1/ Install Morphem Evaluation Benchmark package:
23 |
24 | https://github.com/broadinstitute/MorphEm
25 |
26 |
27 | 2/ Install required packages:
28 |
29 | `pip install -r requirements.txt`
30 |
31 |
32 | # Dataset
33 |
34 | 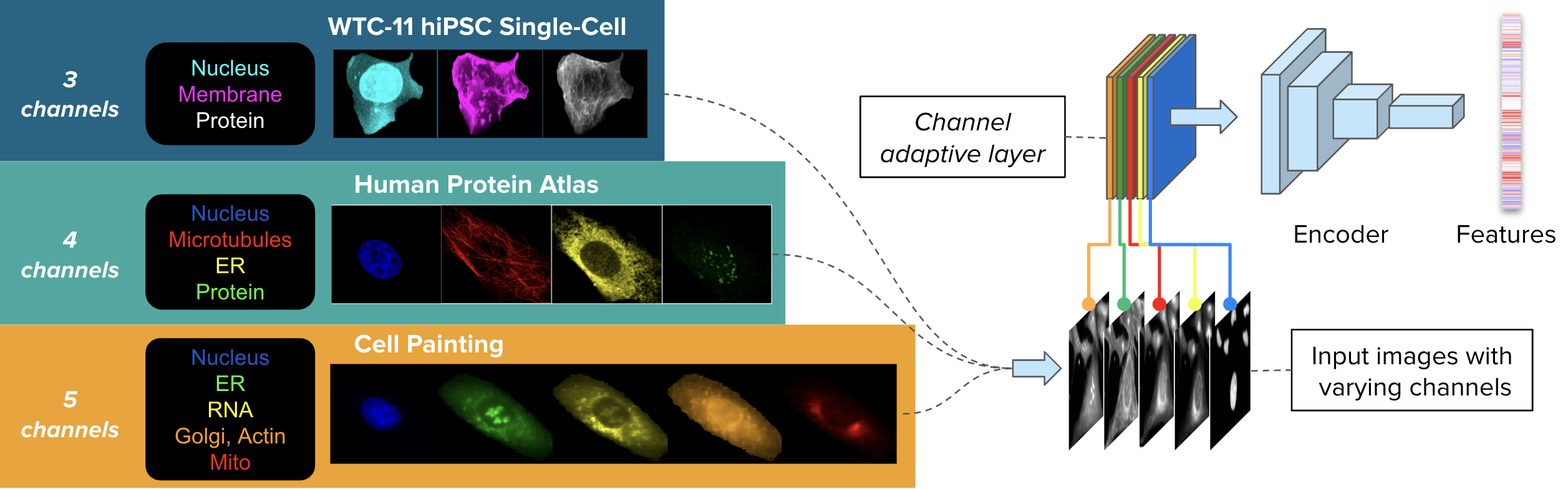
35 |
36 | CHAMMI consists of varying-channel images from three sources: WTC-11 hiPSC dataset (WTC-11, 3 channels), Human Protein Atlas (HPA, 4 channels), and Cell Painting datasets (CP, 5 channels).
37 |
38 | The dataset can be found at https://doi.org/10.5281/zenodo.7988357
39 |
40 | First, you need to download the dataset.
41 | Suppose the dataset folder is named `chammi_dataset`, and it is located inside the project folder.
42 |
43 | You need to modify the folder path in `configs/morphem70k/dataset/morphem70k_v2.yaml` and `configs/morphem70k/eval/default.yaml`.
44 | Specifically, set `root_dir` to `chammi_dataset` in both files.
45 |
46 |
47 | Then, copy `medadata/morphem70k_v2.csv` file to the `chammi_dataset` folder that you have just downloaded. You can use the following command:
48 |
49 | ```
50 | cp metadata/morphem70k_v2.csv chammi_dataset
51 | ```
52 |
53 | This particular file is simply a merged version of the metadata files (`enriched_meta.csv`) from three sub-datasets within your dataset folder. It will be utilized by `datasets/morphem70k.py` to load of the dataset.
54 |
55 |
56 | # Channel-adaptive Models
57 | Figure below demonstrates the baseline models.
58 | A) Two non-adaptive, baseline approaches: ChannelReplication and FixedChannels.
59 | B) Five channel-adaptive strategies to accommodate varying
60 | image inputs: Depthwise, SliceParam, TargetParam, TemplateMixing, and HyperNet (gray blocks). Adaptive interfaces are the first layer of a shared backbone network.
61 |
62 |
63 | 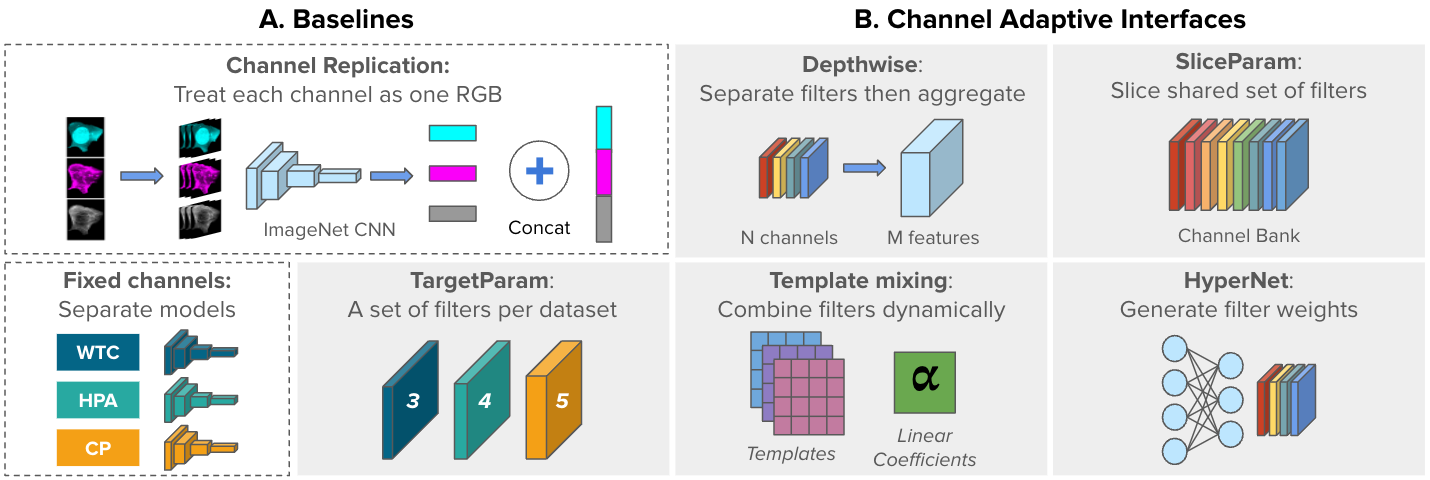
64 |
65 | # Training
66 |
67 | In this project, we use [Hydra](https://hydra.cc/) to manage configurations.
68 | To submit a job using Hydra, you need to specify the config file. Here are some key parameters:
69 |
70 | ```
71 | -m: multi-run mode (submit multiple runs with 1 job)
72 |
73 | -cp: config folder, all config files are in `configs/morphem70k`
74 |
75 | -cn: config file name (without .yaml extension)
76 | ```
77 |
78 | Parameters in the command lines will override the ones in the config file.
79 | For example, to train a SliceParam model:
80 |
81 | ```
82 | python main.py -m -cp configs/morphem70k -cn morphem70k_cfg model=sliceparam tag=slice ++optimizer.params.lr=0.0001 ++model.learnable_temp=True ++model.temperature=0.15 ++model.first_layer=pretrained_pad_dups ++model.slice_class_emb=True ++train.seed=725375
83 | ```
84 |
85 |
86 | To reproduce the results, please refer to [train_scripts.sh](https://github.com/chaudatascience/channel_adaptive_models/blob/main/train_scripts.sh).
87 |
88 | - **Add Wandb key**: If you would like to use Wandb to keep track of experiments, add your Wandb key to `.env` file:
89 |
90 | `echo WANDB_API_KEY=your_wandb_key >> .env`
91 |
92 | and, change `use_wandb` to `True` in `configs/morphem70k/logging/wandb.yaml`.
93 |
94 |
95 | # Checkpoints
96 |
97 | Our pre-trained models can be found at: https://drive.google.com/drive/folders/1_xVgzfdc6H9ar4T5bd1jTjNkrpTwkSlL?usp=drive_link
98 |
99 | Configs for the checkpoints are stored in [checkpoint_configs](https://github.com/chaudatascience/channel_adaptive_models/tree/main/checkpoint_configs) folder.
100 |
101 | A quick example of using the checkpoints for evaluation is provided in [evaluate.ipynb](https://github.com/chaudatascience/channel_adaptive_models/blob/main/evaluate.ipynb)
102 |
--------------------------------------------------------------------------------
/checkpoint_configs/depthwise.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: depthwise.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 483112
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: depthwiseconvnext
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.07
32 | learnable_temp: false
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: reinit_as_random
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | kernels_per_channel: 64
39 | pooling_channel_type: weighted_sum_random
40 | in_channel_names:
41 | - er
42 | - golgi
43 | - membrane
44 | - microtubules
45 | - mito
46 | - nucleus
47 | - protein
48 | - rna
49 | scheduler:
50 | name: cosine
51 | convert_to_batch: false
52 | params:
53 | t_initial: FILL_LATER
54 | lr_min: 1.0e-06
55 | cycle_mul: 1.0
56 | cycle_decay: 0.5
57 | cycle_limit: 1
58 | warmup_t: 3
59 | warmup_lr_init: 1.0e-05
60 | warmup_prefix: false
61 | t_in_epochs: true
62 | noise_range_t: null
63 | noise_pct: 0.67
64 | noise_std: 1.0
65 | noise_seed: 42
66 | k_decay: 1.0
67 | initialize: true
68 | optimizer:
69 | name: adamw
70 | params:
71 | lr: 0.0004
72 | betas:
73 | - 0.9
74 | - 0.999
75 | eps: 1.0e-08
76 | weight_decay: 5.0e-05
77 | amsgrad: false
78 | dataset:
79 | name: morphem70k
80 | img_size: 224
81 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
82 | file_name: morphem70k_v2.csv
83 | data_chunk:
84 | chunks:
85 | - Allen:
86 | - nucleus
87 | - membrane
88 | - protein
89 | - HPA:
90 | - microtubules
91 | - protein
92 | - nucleus
93 | - er
94 | - CP:
95 | - nucleus
96 | - er
97 | - rna
98 | - golgi
99 | - mito
100 | logging:
101 | wandb:
102 | use_wandb: false
103 | log_freq: 10000
104 | num_images_to_log: 0
105 | project_name: null
106 | use_py_log: false
107 | scc_jobid: null
108 | hardware:
109 | num_workers: 3
110 | device: cuda
111 | multi_gpus: null
112 | eval:
113 | batch_size: null
114 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
115 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
116 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
117 | meta_csv_file: FILL_LATER
118 | classifiers:
119 | - knn
120 | - sgd
121 | classifier: PLACE_HOLDER
122 | feature_file: features.npy
123 | use_gpu: true
124 | knn_metric: PLACE_HOLDER
125 | knn_metrics:
126 | - l2
127 | - cosine
128 | clean_up: false
129 | umap: true
130 | only_eval_first_and_last: false
131 | attn_pooling: {}
132 | tag: depthwise
133 |
--------------------------------------------------------------------------------
/checkpoint_configs/fixed_channels_finetuned/allen.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: fixed_channels_finetuned/allen.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 582814
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: convnext_base
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.3
32 | learnable_temp: false
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: pretrained_pad_avg
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | scheduler:
39 | name: cosine
40 | convert_to_batch: false
41 | params:
42 | t_initial: FILL_LATER
43 | lr_min: 1.0e-06
44 | cycle_mul: 1.0
45 | cycle_decay: 0.5
46 | cycle_limit: 1
47 | warmup_t: 3
48 | warmup_lr_init: 1.0e-05
49 | warmup_prefix: false
50 | t_in_epochs: true
51 | noise_range_t: null
52 | noise_pct: 0.67
53 | noise_std: 1.0
54 | noise_seed: 42
55 | k_decay: 1.0
56 | initialize: true
57 | optimizer:
58 | name: adamw
59 | params:
60 | lr: 0.001
61 | betas:
62 | - 0.9
63 | - 0.999
64 | eps: 1.0e-08
65 | weight_decay: 5.0e-05
66 | amsgrad: false
67 | dataset:
68 | name: Allen
69 | img_size: 224
70 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
71 | file_name: morphem70k_v2.csv
72 | data_chunk:
73 | chunks:
74 | - Allen:
75 | - nucleus
76 | - membrane
77 | - protein
78 | logging:
79 | wandb:
80 | use_wandb: false
81 | log_freq: 10000
82 | num_images_to_log: 0
83 | project_name: null
84 | use_py_log: false
85 | scc_jobid: null
86 | hardware:
87 | num_workers: 3
88 | device: cuda
89 | multi_gpus: null
90 | eval:
91 | batch_size: null
92 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
93 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
94 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
95 | meta_csv_file: FILL_LATER
96 | classifiers:
97 | - knn
98 | - sgd
99 | classifier: PLACE_HOLDER
100 | feature_file: features.npy
101 | use_gpu: true
102 | knn_metric: PLACE_HOLDER
103 | knn_metrics:
104 | - l2
105 | - cosine
106 | clean_up: false
107 | umap: true
108 | only_eval_first_and_last: false
109 | tag: allen
110 |
--------------------------------------------------------------------------------
/checkpoint_configs/fixed_channels_finetuned/cp.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: fixed_channels_finetuned/cp.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 530400
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: convnext_base
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.3
32 | learnable_temp: false
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: pretrained_pad_avg
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | scheduler:
39 | name: cosine
40 | convert_to_batch: false
41 | params:
42 | t_initial: FILL_LATER
43 | lr_min: 1.0e-06
44 | cycle_mul: 1.0
45 | cycle_decay: 0.5
46 | cycle_limit: 1
47 | warmup_t: 3
48 | warmup_lr_init: 1.0e-05
49 | warmup_prefix: false
50 | t_in_epochs: true
51 | noise_range_t: null
52 | noise_pct: 0.67
53 | noise_std: 1.0
54 | noise_seed: 42
55 | k_decay: 1.0
56 | initialize: true
57 | optimizer:
58 | name: adamw
59 | params:
60 | lr: 0.0001
61 | betas:
62 | - 0.9
63 | - 0.999
64 | eps: 1.0e-08
65 | weight_decay: 5.0e-05
66 | amsgrad: false
67 | dataset:
68 | name: CP
69 | img_size: 224
70 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
71 | file_name: morphem70k_v2.csv
72 | data_chunk:
73 | chunks:
74 | - CP:
75 | - nucleus
76 | - er
77 | - rna
78 | - golgi
79 | - mito
80 | logging:
81 | wandb:
82 | use_wandb: false
83 | log_freq: 10000
84 | num_images_to_log: 0
85 | project_name: null
86 | use_py_log: false
87 | scc_jobid: null
88 | hardware:
89 | num_workers: 3
90 | device: cuda
91 | multi_gpus: null
92 | eval:
93 | batch_size: null
94 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
95 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
96 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
97 | meta_csv_file: FILL_LATER
98 | classifiers:
99 | - knn
100 | - sgd
101 | classifier: PLACE_HOLDER
102 | feature_file: features.npy
103 | use_gpu: true
104 | knn_metric: PLACE_HOLDER
105 | knn_metrics:
106 | - l2
107 | - cosine
108 | clean_up: false
109 | umap: true
110 | only_eval_first_and_last: false
111 | tag: cp
112 |
--------------------------------------------------------------------------------
/checkpoint_configs/fixed_channels_finetuned/hpa.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: fixed_channels_finetuned/hpa.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 744395
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: convnext_base
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.3
32 | learnable_temp: false
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: pretrained_pad_avg
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | scheduler:
39 | name: cosine
40 | convert_to_batch: false
41 | params:
42 | t_initial: FILL_LATER
43 | lr_min: 1.0e-06
44 | cycle_mul: 1.0
45 | cycle_decay: 0.5
46 | cycle_limit: 1
47 | warmup_t: 3
48 | warmup_lr_init: 1.0e-05
49 | warmup_prefix: false
50 | t_in_epochs: true
51 | noise_range_t: null
52 | noise_pct: 0.67
53 | noise_std: 1.0
54 | noise_seed: 42
55 | k_decay: 1.0
56 | initialize: true
57 | optimizer:
58 | name: adamw
59 | params:
60 | lr: 0.0001
61 | betas:
62 | - 0.9
63 | - 0.999
64 | eps: 1.0e-08
65 | weight_decay: 5.0e-05
66 | amsgrad: false
67 | dataset:
68 | name: HPA
69 | img_size: 224
70 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
71 | file_name: morphem70k_v2.csv
72 | data_chunk:
73 | chunks:
74 | - HPA:
75 | - microtubules
76 | - protein
77 | - nucleus
78 | - er
79 | logging:
80 | wandb:
81 | use_wandb: false
82 | log_freq: 10000
83 | num_images_to_log: 0
84 | project_name: null
85 | use_py_log: false
86 | scc_jobid: null
87 | hardware:
88 | num_workers: 3
89 | device: cuda
90 | multi_gpus: null
91 | eval:
92 | batch_size: null
93 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
94 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
95 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
96 | meta_csv_file: FILL_LATER
97 | classifiers:
98 | - knn
99 | - sgd
100 | classifier: PLACE_HOLDER
101 | feature_file: features.npy
102 | use_gpu: true
103 | knn_metric: PLACE_HOLDER
104 | knn_metrics:
105 | - l2
106 | - cosine
107 | clean_up: false
108 | umap: true
109 | only_eval_first_and_last: false
110 | tag: hpa
111 |
--------------------------------------------------------------------------------
/checkpoint_configs/hypernet.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: hypernet.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 125617
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: hyperconvnext
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.07
32 | learnable_temp: false
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: reinit_as_random
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | z_dim: 128
39 | hidden_dim: 256
40 | in_channel_names:
41 | - er
42 | - golgi
43 | - membrane
44 | - microtubules
45 | - mito
46 | - nucleus
47 | - protein
48 | - rna
49 | separate_emb: true
50 | scheduler:
51 | name: cosine
52 | convert_to_batch: false
53 | params:
54 | t_initial: FILL_LATER
55 | lr_min: 1.0e-06
56 | cycle_mul: 1.0
57 | cycle_decay: 0.5
58 | cycle_limit: 1
59 | warmup_t: 3
60 | warmup_lr_init: 1.0e-05
61 | warmup_prefix: false
62 | t_in_epochs: true
63 | noise_range_t: null
64 | noise_pct: 0.67
65 | noise_std: 1.0
66 | noise_seed: 42
67 | k_decay: 1.0
68 | initialize: true
69 | optimizer:
70 | name: adamw
71 | params:
72 | lr: 0.0004
73 | betas:
74 | - 0.9
75 | - 0.999
76 | eps: 1.0e-08
77 | weight_decay: 5.0e-05
78 | amsgrad: false
79 | dataset:
80 | name: morphem70k
81 | img_size: 224
82 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
83 | file_name: morphem70k_v2.csv
84 | data_chunk:
85 | chunks:
86 | - Allen:
87 | - nucleus
88 | - membrane
89 | - protein
90 | - HPA:
91 | - microtubules
92 | - protein
93 | - nucleus
94 | - er
95 | - CP:
96 | - nucleus
97 | - er
98 | - rna
99 | - golgi
100 | - mito
101 | logging:
102 | wandb:
103 | use_wandb: false
104 | log_freq: 10000
105 | num_images_to_log: 0
106 | project_name: null
107 | use_py_log: false
108 | scc_jobid: null
109 | hardware:
110 | num_workers: 3
111 | device: cuda
112 | multi_gpus: null
113 | eval:
114 | batch_size: null
115 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
116 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
117 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
118 | meta_csv_file: FILL_LATER
119 | classifiers:
120 | - knn
121 | - sgd
122 | classifier: PLACE_HOLDER
123 | feature_file: features.npy
124 | use_gpu: true
125 | knn_metric: PLACE_HOLDER
126 | knn_metrics:
127 | - l2
128 | - cosine
129 | clean_up: false
130 | umap: true
131 | only_eval_first_and_last: false
132 | attn_pooling: {}
133 | tag: hyper
134 |
--------------------------------------------------------------------------------
/checkpoint_configs/slice_param.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: slice_param.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 725375
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: sliceparamconvnext
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.15
32 | learnable_temp: true
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: pretrained_pad_dups
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | in_channel_names:
39 | - er
40 | - golgi
41 | - membrane
42 | - microtubules
43 | - mito
44 | - nucleus
45 | - protein
46 | - rna
47 | duplicate: false
48 | slice_class_emb: true
49 | scheduler:
50 | name: cosine
51 | convert_to_batch: false
52 | params:
53 | t_initial: FILL_LATER
54 | lr_min: 1.0e-06
55 | cycle_mul: 1.0
56 | cycle_decay: 0.5
57 | cycle_limit: 1
58 | warmup_t: 3
59 | warmup_lr_init: 1.0e-05
60 | warmup_prefix: false
61 | t_in_epochs: true
62 | noise_range_t: null
63 | noise_pct: 0.67
64 | noise_std: 1.0
65 | noise_seed: 42
66 | k_decay: 1.0
67 | initialize: true
68 | optimizer:
69 | name: adamw
70 | params:
71 | lr: 0.0001
72 | betas:
73 | - 0.9
74 | - 0.999
75 | eps: 1.0e-08
76 | weight_decay: 5.0e-05
77 | amsgrad: false
78 | dataset:
79 | name: morphem70k
80 | img_size: 224
81 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
82 | file_name: morphem70k_v2.csv
83 | data_chunk:
84 | chunks:
85 | - Allen:
86 | - nucleus
87 | - membrane
88 | - protein
89 | - HPA:
90 | - microtubules
91 | - protein
92 | - nucleus
93 | - er
94 | - CP:
95 | - nucleus
96 | - er
97 | - rna
98 | - golgi
99 | - mito
100 | logging:
101 | wandb:
102 | use_wandb: false
103 | log_freq: 10000
104 | num_images_to_log: 0
105 | project_name: null
106 | use_py_log: false
107 | scc_jobid: null
108 | hardware:
109 | num_workers: 3
110 | device: cuda
111 | multi_gpus: null
112 | eval:
113 | batch_size: null
114 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
115 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
116 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
117 | meta_csv_file: FILL_LATER
118 | classifiers:
119 | - knn
120 | - sgd
121 | classifier: PLACE_HOLDER
122 | feature_file: features.npy
123 | use_gpu: true
124 | knn_metric: PLACE_HOLDER
125 | knn_metrics:
126 | - l2
127 | - cosine
128 | clean_up: false
129 | umap: true
130 | only_eval_first_and_last: false
131 | attn_pooling: {}
132 | tag: slice
133 |
--------------------------------------------------------------------------------
/checkpoint_configs/target_param.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: target_param.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 505429
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: shared_convnext
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.07
32 | learnable_temp: true
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: pretrained_pad_avg
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | scheduler:
39 | name: cosine
40 | convert_to_batch: false
41 | params:
42 | t_initial: FILL_LATER
43 | lr_min: 1.0e-06
44 | cycle_mul: 1.0
45 | cycle_decay: 0.5
46 | cycle_limit: 1
47 | warmup_t: 3
48 | warmup_lr_init: 1.0e-05
49 | warmup_prefix: false
50 | t_in_epochs: true
51 | noise_range_t: null
52 | noise_pct: 0.67
53 | noise_std: 1.0
54 | noise_seed: 42
55 | k_decay: 1.0
56 | initialize: true
57 | optimizer:
58 | name: adamw
59 | params:
60 | lr: 0.0002
61 | betas:
62 | - 0.9
63 | - 0.999
64 | eps: 1.0e-08
65 | weight_decay: 5.0e-05
66 | amsgrad: false
67 | dataset:
68 | name: morphem70k
69 | img_size: 224
70 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
71 | file_name: morphem70k_v2.csv
72 | data_chunk:
73 | chunks:
74 | - Allen:
75 | - nucleus
76 | - membrane
77 | - protein
78 | - HPA:
79 | - microtubules
80 | - protein
81 | - nucleus
82 | - er
83 | - CP:
84 | - nucleus
85 | - er
86 | - rna
87 | - golgi
88 | - mito
89 | logging:
90 | wandb:
91 | use_wandb: false
92 | log_freq: 10000
93 | num_images_to_log: 0
94 | project_name: null
95 | use_py_log: false
96 | scc_jobid: null
97 | hardware:
98 | num_workers: 3
99 | device: cuda
100 | multi_gpus: null
101 | eval:
102 | batch_size: null
103 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
104 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
105 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
106 | meta_csv_file: FILL_LATER
107 | classifiers:
108 | - knn
109 | - sgd
110 | classifier: PLACE_HOLDER
111 | feature_file: features.npy
112 | use_gpu: true
113 | knn_metric: PLACE_HOLDER
114 | knn_metrics:
115 | - l2
116 | - cosine
117 | clean_up: false
118 | umap: true
119 | only_eval_first_and_last: false
120 | attn_pooling: {}
121 | tag: shared
122 |
--------------------------------------------------------------------------------
/checkpoint_configs/template_mixing.yaml:
--------------------------------------------------------------------------------
1 | train:
2 | batch_strategy: random_instance
3 | resume_train: false
4 | resume_model: template_mixing.pt
5 | use_amp: false
6 | checkpoints: ../STORE/adaptive_interface/checkpoints
7 | save_model: no_save
8 | clip_grad_norm: null
9 | batch_size: 128
10 | num_epochs: 15
11 | verbose_batches: 50
12 | seed: 451006
13 | debug: false
14 | adaptive_interface_epochs: 0
15 | adaptive_interface_lr: null
16 | swa: false
17 | swad: false
18 | swa_lr: 0.05
19 | swa_start: 5
20 | miro: false
21 | miro_lr_mult: 10.0
22 | miro_ld: 0.01
23 | tps_prob: 0.0
24 | model:
25 | name: templatemixingconvnext
26 | pretrained: true
27 | pretrained_model_name: convnext_tiny.fb_in22k
28 | in_dim: null
29 | num_classes: null
30 | pooling: avg
31 | temperature: 0.05
32 | learnable_temp: false
33 | unfreeze_last_n_layers: -1
34 | unfreeze_first_layer: true
35 | first_layer: reinit_as_random
36 | reset_last_n_unfrozen_layers: false
37 | use_auto_rgn: false
38 | in_channel_names:
39 | - er
40 | - golgi
41 | - membrane
42 | - microtubules
43 | - mito
44 | - nucleus
45 | - protein
46 | - rna
47 | num_templates: 128
48 | separate_coef: true
49 | scheduler:
50 | name: cosine
51 | convert_to_batch: false
52 | params:
53 | t_initial: FILL_LATER
54 | lr_min: 1.0e-06
55 | cycle_mul: 1.0
56 | cycle_decay: 0.5
57 | cycle_limit: 1
58 | warmup_t: 3
59 | warmup_lr_init: 1.0e-05
60 | warmup_prefix: false
61 | t_in_epochs: true
62 | noise_range_t: null
63 | noise_pct: 0.67
64 | noise_std: 1.0
65 | noise_seed: 42
66 | k_decay: 1.0
67 | initialize: true
68 | optimizer:
69 | name: adamw
70 | params:
71 | lr: 0.0001
72 | betas:
73 | - 0.9
74 | - 0.999
75 | eps: 1.0e-08
76 | weight_decay: 5.0e-05
77 | amsgrad: false
78 | dataset:
79 | name: morphem70k
80 | img_size: 224
81 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
82 | file_name: morphem70k_v2.csv
83 | data_chunk:
84 | chunks:
85 | - Allen:
86 | - nucleus
87 | - membrane
88 | - protein
89 | - HPA:
90 | - microtubules
91 | - protein
92 | - nucleus
93 | - er
94 | - CP:
95 | - nucleus
96 | - er
97 | - rna
98 | - golgi
99 | - mito
100 | logging:
101 | wandb:
102 | use_wandb: false
103 | log_freq: 10000
104 | num_images_to_log: 0
105 | project_name: null
106 | use_py_log: false
107 | scc_jobid: null
108 | hardware:
109 | num_workers: 3
110 | device: cuda
111 | multi_gpus: null
112 | eval:
113 | batch_size: null
114 | dest_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/results
115 | feature_dir: ../STORE/adaptive_interface/snapshots/{FOLDER_NAME}/features
116 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2/
117 | meta_csv_file: FILL_LATER
118 | classifiers:
119 | - knn
120 | - sgd
121 | classifier: PLACE_HOLDER
122 | feature_file: features.npy
123 | use_gpu: true
124 | knn_metric: PLACE_HOLDER
125 | knn_metrics:
126 | - l2
127 | - cosine
128 | clean_up: false
129 | umap: true
130 | only_eval_first_and_last: false
131 | attn_pooling: {}
132 | tag: templ
133 |
--------------------------------------------------------------------------------
/config.py:
--------------------------------------------------------------------------------
1 | from __future__ import annotations
2 |
3 | from dataclasses import dataclass, asdict, field
4 | from typing import List, Dict, Optional
5 |
6 | from omegaconf import MISSING
7 |
8 | from helper_classes.channel_initialization import ChannelInitialization
9 | from helper_classes.feature_pooling import FeaturePooling
10 | from helper_classes.first_layer_init import FirstLayerInit
11 | from helper_classes.norm_type import NormType
12 | from helper_classes.channel_pooling_type import ChannelPoolingType
13 |
14 | # fmt: off
15 |
16 | @dataclass
17 | class OptimizerParams(Dict):
18 | pass
19 |
20 |
21 | @dataclass
22 | class Optimizer:
23 | name: str
24 | params: OptimizerParams
25 |
26 |
27 | @dataclass
28 | class SchedulerParams(Dict):
29 | pass
30 |
31 |
32 | @dataclass
33 | class Scheduler:
34 | name: str
35 | convert_to_batch: bool
36 | params: SchedulerParams
37 |
38 |
39 | @dataclass
40 | class Train:
41 | batch_strategy: None
42 | resume_train: bool
43 | resume_model: str
44 | use_amp: bool
45 | checkpoints: str
46 | clip_grad_norm: int
47 | batch_size: int
48 | num_epochs: int
49 | verbose_batches: int
50 | seed: int
51 | save_model: bool
52 | debug: Optional[bool] = False
53 | real_batch_size: Optional[int] = None
54 | compile_pytorch: Optional[bool] = False
55 | adaptive_interface_epochs: int = 0
56 | adaptive_interface_lr: Optional[float] = None
57 | swa: Optional[bool] = False
58 | swad: Optional[bool] = False
59 | swa_lr: Optional[float] = 0.05
60 | swa_start: Optional[int] = 5
61 |
62 | ## MIRO
63 | miro: Optional[bool] = False
64 | miro_lr_mult: Optional[float] = 10.0
65 | miro_ld: Optional[float] = 0.01 # 0.1
66 |
67 | ## TPS Transform (Augmentation)
68 | tps_prob: Optional[float] = 0.0
69 | ssl: Optional[bool] = False
70 | ssl_lambda: Optional[float] = 0.0
71 |
72 | @dataclass
73 | class Eval:
74 | batch_size: int
75 | dest_dir: str = "" ## where to save results
76 | feature_dir: str = "" ## where to save features for evaluation
77 | root_dir: str = "" ## folder that contains images and metadata
78 | classifiers: List[str] = field(default_factory=list) ## classifier to use
79 | classifier: str = "" ## placeholder for classifier
80 | feature_file: str = "" ## feature file to use
81 | use_gpu: bool = True ## use gpu for evaluation
82 | knn_metrics: List[str] = field(default_factory=list) ## "l2" or "cosine"
83 | knn_metric: str = "" ## should be "l2" or "cosine", placeholder
84 | meta_csv_file: str = "" ## metadata csv file
85 | clean_up: bool = True ## whether to delete the feature file after evaluation
86 | only_eval_first_and_last: bool = False ## whether to only evaluate first (off the shelf) and last (final fune-tuned) epochs
87 |
88 | @dataclass
89 | class AttentionPoolingParams:
90 | """
91 | param for ChannelAttentionPoolingLayer class.
92 | initialize all arguments in the class.
93 | """
94 |
95 | max_num_channels: int
96 | dim: int
97 | depth: int
98 | dim_head: int
99 | heads: int
100 | mlp_dim: int
101 | dropout: float
102 | use_cls_token: bool
103 | use_channel_tokens: bool
104 | init_channel_tokens: ChannelInitialization
105 |
106 |
107 | @dataclass
108 | class Model:
109 | name: str
110 | init_weights: bool
111 | in_dim: int = MISSING
112 | num_classes: int = MISSING ## Num of training classes
113 | freeze_other: Optional[bool] = None ## used in Shared Models
114 | in_channel_names: Optional[List[str]] = None ## used with Slice Param Models
115 | separate_norm: Optional[
116 | bool
117 | ] = None ## use a separate norm layer for each data chunk
118 | image_h_w: Optional[List[int]] = None ## used with layer norm
119 | norm_type: Optional[
120 | NormType
121 | ] = None # one of ["batch_norm", "norm_type", "instance_norm"]
122 | duplicate: Optional[
123 | bool
124 | ] = None # whether to only use the first param bank and duplicate for all the channels
125 | pooling_channel_type: Optional[ChannelPoolingType] = None
126 | kernels_per_channel: Optional[int] = None
127 | num_templates: Optional[int] = None # number of templates to use in template mixing
128 | separate_coef: Optional[bool] = None # whether to use a separate set of coefficients for each chunk
129 | coefs_init: Optional[bool] = None # whether to initialize the coefficients, used in templ mixing ver2
130 | freeze_coefs_epochs: Optional[int] = None # TODO: add this. Whether to freeze the coefficients for some first epoch, used in templ mixing ver2
131 | separate_emb: Optional[bool] = None # whether to use a separate embedding (hypernetwork) for each chunk
132 | z_dim: Optional[int] = None # dimension of the latent space, hypernetwork
133 | hidden_dim: Optional[int] = None # dimension of the hidden layer, hypernetwork
134 |
135 | ### ConvNet/CLIP-ResNet50 Params
136 | pretrained: Optional[bool] = None
137 | pretrained_model_name: Optional[str] = None
138 | pooling: Optional[FeaturePooling] = None # one of ["avg", "max", "avgmax", "none"]
139 | temperature: Optional[float] = None
140 | unfreeze_last_n_layers: Optional[int] = -1
141 | # -1: unfreeze all layers, 0: freeze all layers, 1: unfreeze last layer, etc.
142 | first_layer: Optional[FirstLayerInit] = None
143 | unfreeze_first_layer: Optional[bool] = True
144 | reset_last_n_unfrozen_layers: Optional[bool] = False
145 | use_auto_rgn: Optional[bool] = None # relative gradient norm, this supersedes the use of `unfreeze_vit_layers`
146 |
147 | ### CLIP ViT16Base
148 | unfreeze_vit_layers: Optional[List[str]] = None
149 |
150 | ## temperature in the loss
151 | learnable_temp: bool = False
152 |
153 | ## Slice Params
154 | slice_class_emb: Optional[bool] = False
155 |
156 |
157 | @dataclass
158 | class Dataset:
159 | name: str
160 | img_size: int = 224
161 | label_column: Optional[str] = None
162 | root_dir: str = ""
163 | file_name: str = ""
164 |
165 |
166 | @dataclass
167 | class Wandb:
168 | use_wandb: bool
169 | log_freq: int
170 | num_images_to_log: int
171 | log_imgs_every_n_epochs: int
172 | project_name: str
173 |
174 |
175 | @dataclass
176 | class Logging:
177 | wandb: Wandb
178 | use_py_log: bool
179 | scc_jobid: Optional[str] = None
180 |
181 |
182 | @dataclass
183 | class DataChunk:
184 | chunks: List[Dict[str, List[str]]]
185 |
186 | def __str__(self) -> str:
187 | channel_names = [list(c.keys())[0] for c in self.chunks]
188 | channel_values = [list(c.values())[0] for c in self.chunks]
189 |
190 | channels = zip(*(channel_names, channel_values))
191 | channels_str = "----".join(
192 | ["--".join([c[0], "_".join(c[1])]) for c in channels]
193 | )
194 | return channels_str
195 |
196 |
197 | @dataclass
198 | class Hardware:
199 | num_workers: int
200 | device: str
201 | multi_gpus: str
202 |
203 |
204 | @dataclass
205 | class MyConfig:
206 | train: Train
207 | eval: Eval
208 | optimizer: Optimizer
209 | scheduler: Scheduler
210 | model: Model
211 | dataset: Dataset
212 | data_chunk: DataChunk
213 | logging: Logging
214 | hardware: Hardware
215 | tag: str
216 | attn_pooling: Optional[AttentionPoolingParams] = None
217 |
--------------------------------------------------------------------------------
/configs/morphem70k/allen_cfg.yaml:
--------------------------------------------------------------------------------
1 | defaults:
2 | - train: ~
3 | - model: ~
4 | - scheduler: ~
5 | - optimizer: ~
6 | - dataset: ~
7 | - data_chunk: ~
8 | - logging: ~
9 | - hardware: ~
10 | - eval: ~
11 | - _self_
12 |
13 | tag: ~
14 |
15 | hydra:
16 | sweeper:
17 | params:
18 | train: random_instance
19 | data_chunk: allen
20 | model: convnext_base
21 | scheduler: cosine
22 | optimizer: adamw
23 | dataset: allen
24 | logging: wandb
25 | hardware: default
26 | eval: default
--------------------------------------------------------------------------------
/configs/morphem70k/attn_pooling/none.yaml:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaudatascience/channel_adaptive_models/b62f69ae5d7d2c49cba2c96f0c9d2eef0fe2ee42/configs/morphem70k/attn_pooling/none.yaml
--------------------------------------------------------------------------------
/configs/morphem70k/attn_pooling/param1.yaml:
--------------------------------------------------------------------------------
1 | max_num_channels: FILL_LATER_IN_CODE
2 | dim: FILL_LATER_IN_CODE
3 | depth: 1
4 | dim_head: 16
5 | heads: 4
6 | mlp_dim: 4
7 | dropout: 0.0
8 | use_cls_token: False
9 | use_channel_tokens: False
10 | init_channel_tokens: ~ # only used when use_channel_tokens=True
--------------------------------------------------------------------------------
/configs/morphem70k/attn_pooling/param2.yaml:
--------------------------------------------------------------------------------
1 | max_num_channels: FILL_LATER_IN_CODE
2 | dim: FILL_LATER_IN_CODE
3 | depth: 2
4 | dim_head: 16
5 | heads: 4
6 | mlp_dim: 4
7 | dropout: 0.05
8 | use_cls_token: False
9 | use_channel_tokens: True
10 | init_channel_tokens: random # only used when use_channel_tokens=True
--------------------------------------------------------------------------------
/configs/morphem70k/attn_pooling/param3.yaml:
--------------------------------------------------------------------------------
1 | max_num_channels: FILL_LATER_IN_CODE
2 | dim: FILL_LATER_IN_CODE
3 | depth: 4
4 | dim_head: 64
5 | heads: 8
6 | mlp_dim: 4
7 | dropout: 0.0
8 | use_cls_token: True
9 | use_channel_tokens: True
10 | init_channel_tokens: random # only used when use_channel_tokens=True
11 |
--------------------------------------------------------------------------------
/configs/morphem70k/attn_pooling/param4.yaml:
--------------------------------------------------------------------------------
1 | max_num_channels: FILL_LATER_IN_CODE
2 | dim: FILL_LATER_IN_CODE
3 | depth: 2
4 | dim_head: 32
5 | heads: 4
6 | mlp_dim: 4
7 | dropout: 0.1
8 | use_cls_token: False
9 | use_channel_tokens: True
10 | init_channel_tokens: random # only used when use_channel_tokens=True
--------------------------------------------------------------------------------
/configs/morphem70k/attn_pooling/param5.yaml:
--------------------------------------------------------------------------------
1 | max_num_channels: FILL_LATER_IN_CODE
2 | dim: FILL_LATER_IN_CODE
3 | depth: 1
4 | dim_head: 32
5 | heads: 4
6 | mlp_dim: 4
7 | dropout: 0.1
8 | use_cls_token: False
9 | use_channel_tokens: True
10 | init_channel_tokens: random # only used when use_channel_tokens=True
--------------------------------------------------------------------------------
/configs/morphem70k/cp_cfg.yaml:
--------------------------------------------------------------------------------
1 | defaults:
2 | - train: ~
3 | - model: ~
4 | - scheduler: ~
5 | - optimizer: ~
6 | - dataset: ~
7 | - data_chunk: ~
8 | - logging: ~
9 | - hardware: ~
10 | - eval: ~
11 | - _self_
12 |
13 | tag: ~
14 |
15 | hydra:
16 | sweeper:
17 | params:
18 | train: random_instance
19 | data_chunk: cp
20 | model: convnext_base
21 | scheduler: cosine
22 | optimizer: adamw
23 | dataset: cp
24 | logging: wandb
25 | hardware: default
26 | eval: default
--------------------------------------------------------------------------------
/configs/morphem70k/data_chunk/allen.yaml:
--------------------------------------------------------------------------------
1 | chunks:
2 | - Allen:
3 | - nucleus
4 | - membrane
5 | - protein
--------------------------------------------------------------------------------
/configs/morphem70k/data_chunk/cp.yaml:
--------------------------------------------------------------------------------
1 | chunks:
2 | - CP:
3 | - nucleus
4 | - er
5 | - rna
6 | - golgi
7 | - mito
--------------------------------------------------------------------------------
/configs/morphem70k/data_chunk/hpa.yaml:
--------------------------------------------------------------------------------
1 | chunks:
2 | - HPA:
3 | - microtubules
4 | - protein
5 | - nucleus
6 | - er
--------------------------------------------------------------------------------
/configs/morphem70k/data_chunk/morphem70k.yaml:
--------------------------------------------------------------------------------
1 | chunks:
2 | - Allen:
3 | - nucleus
4 | - membrane
5 | - protein
6 | - HPA:
7 | - microtubules
8 | - protein
9 | - nucleus
10 | - er
11 | - CP:
12 | - nucleus
13 | - er
14 | - rna
15 | - golgi
16 | - mito
--------------------------------------------------------------------------------
/configs/morphem70k/dataset/allen.yaml:
--------------------------------------------------------------------------------
1 | name: Allen ## 6 classes - We use this version
2 | img_size: 224 #374
3 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
4 | file_name: morphem70k_v2.csv
--------------------------------------------------------------------------------
/configs/morphem70k/dataset/cp.yaml:
--------------------------------------------------------------------------------
1 | name: CP
2 | img_size: 224 # 160
3 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
4 | file_name: morphem70k_v2.csv
--------------------------------------------------------------------------------
/configs/morphem70k/dataset/hpa.yaml:
--------------------------------------------------------------------------------
1 | name: HPA
2 | img_size: 224 # 512
3 | root_dir: /projectnb/morphem/data_70k/ver2/morphem_70k_version2
4 | file_name: morphem70k_v2.csv
--------------------------------------------------------------------------------
/configs/morphem70k/dataset/morphem70k_v2.yaml:
--------------------------------------------------------------------------------
1 | name: morphem70k
2 | img_size: 224
3 | root_dir: chammi_dataset
4 | file_name: morphem70k_v2.csv
--------------------------------------------------------------------------------
/configs/morphem70k/eval/default.yaml:
--------------------------------------------------------------------------------
1 | batch_size: ~ ## None to auto set
2 | dest_dir: snapshots/{FOLDER_NAME}/results
3 | feature_dir: snapshots/{FOLDER_NAME}/features
4 | root_dir: chammi_dataset
5 | meta_csv_file: FILL_LATER
6 | classifiers:
7 | - knn
8 | classifier: PLACE_HOLDER
9 | feature_file: features.npy
10 | use_gpu: True
11 | knn_metric: PLACE_HOLDER
12 | knn_metrics:
13 | - cosine
14 | clean_up: False
15 | umap: True
16 | only_eval_first_and_last: False
--------------------------------------------------------------------------------
/configs/morphem70k/hardware/default.yaml:
--------------------------------------------------------------------------------
1 | num_workers: 3
2 | device: cuda # "cuda:0" ## cuda whose idx is 0
3 | multi_gpus: ~ # "DataParallel" # {DistributedDataParallel, DataParallel, None}
4 |
--------------------------------------------------------------------------------
/configs/morphem70k/hardware/four_workers.yaml:
--------------------------------------------------------------------------------
1 | num_workers: 4
2 | device: cuda # "cuda:0" ## cuda whose idx is 0
3 | multi_gpus: ~ # "DataParallel" # {DistributedDataParallel, DataParallel, None}
4 |
--------------------------------------------------------------------------------
/configs/morphem70k/hpa_cfg.yaml:
--------------------------------------------------------------------------------
1 | defaults:
2 | - train: ~
3 | - model: ~
4 | - scheduler: ~
5 | - optimizer: ~
6 | - dataset: ~
7 | - data_chunk: ~
8 | - logging: ~
9 | - hardware: ~
10 | - eval: ~
11 | - _self_
12 |
13 | tag: ~
14 |
15 | hydra:
16 | sweeper:
17 | params:
18 | train: random_instance
19 | data_chunk: hpa
20 | model: convnext_base
21 | scheduler: cosine
22 | optimizer: adamw
23 | dataset: hpa
24 | logging: wandb
25 | hardware: default
26 | eval: default
--------------------------------------------------------------------------------
/configs/morphem70k/logging/no.yaml:
--------------------------------------------------------------------------------
1 | wandb:
2 | use_wandb: False
3 | log_freq: 10000
4 | num_images_to_log: 0 # set <= 0 to disable this
5 | project_name: ~ # set to ~ for auto setting
6 | use_py_log: False
7 | scc_jobid: ~
8 |
--------------------------------------------------------------------------------
/configs/morphem70k/logging/wandb.yaml:
--------------------------------------------------------------------------------
1 | wandb:
2 | use_wandb: False
3 | log_freq: 5000
4 | num_images_to_log: 0 # set <= 0 to disable this
5 | log_imgs_every_n_epochs: 0 # used when `num_images_to_log` > 0
6 | project_name: ~ # set to ~ for auto setting
7 | tag: ~
8 | use_py_log: False
9 | scc_jobid: ~
10 |
--------------------------------------------------------------------------------
/configs/morphem70k/model/clip_resnet50.yaml:
--------------------------------------------------------------------------------
1 | name: clip_based_model
2 | pretrained: True
3 | pretrained_model_name: RN50 ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | unfreeze_last_n_layers: -1
9 | unfreeze_first_layer: True
10 | first_layer: reinit_as_random
11 | reset_last_n_unfrozen_layers: False
12 | use_auto_rgn: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/clip_vit.yaml:
--------------------------------------------------------------------------------
1 | name: clip_based_model
2 | pretrained: True
3 | pretrained_model_name: ViT-B/16 ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | first_layer: reinit_as_random
9 | unfreeze_vit_layers: ~
10 | use_auto_rgn: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/convnext_base.yaml:
--------------------------------------------------------------------------------
1 | name: convnext_base
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/convnext_base_miro.yaml:
--------------------------------------------------------------------------------
1 | name: convnext_base_miro
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/convnext_shared_miro.yaml:
--------------------------------------------------------------------------------
1 | name: convnext_shared_miro
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: pretrained_pad_avg
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/depthwiseconvnext.yaml:
--------------------------------------------------------------------------------
1 | name: depthwiseconvnext
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | kernels_per_channel: FILL_LATER
15 | pooling_channel_type: FILL_LATER # choice(sum, avg, weighted_sum_random, weighted_sum_one, weighted_sum_random_no_softmax, weighted_sum_one_no_softmax, attention)
16 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
17 |
18 |
--------------------------------------------------------------------------------
/configs/morphem70k/model/depthwiseconvnext_miro.yaml:
--------------------------------------------------------------------------------
1 | name: depthwiseconvnext_miro
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | kernels_per_channel: FILL_LATER
15 | pooling_channel_type: FILL_LATER # choice(sum, avg, weighted_sum_random, weighted_sum_one, weighted_sum_random_no_softmax, weighted_sum_one_no_softmax, attention)
16 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
17 |
18 |
--------------------------------------------------------------------------------
/configs/morphem70k/model/dino_base.yaml:
--------------------------------------------------------------------------------
1 | name: dino_base
2 | pretrained: True
3 | pretrained_model_name: dinov2_vits14 ## https://github.com/facebookresearch/dinov2
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/hyperconvnext.yaml:
--------------------------------------------------------------------------------
1 | name: hyperconvnext
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | z_dim: FILL_LATER
15 | hidden_dim: FILL_LATER
16 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
17 | separate_emb: True
--------------------------------------------------------------------------------
/configs/morphem70k/model/hyperconvnext_miro.yaml:
--------------------------------------------------------------------------------
1 | name: hyperconvnext_miro
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | z_dim: FILL_LATER
15 | hidden_dim: FILL_LATER
16 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
17 | separate_emb: True
--------------------------------------------------------------------------------
/configs/morphem70k/model/separate.yaml:
--------------------------------------------------------------------------------
1 | name: shared_convnext
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: pretrained_pad_avg
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/sliceparam.yaml:
--------------------------------------------------------------------------------
1 | name: sliceparamconvnext
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
15 | duplicate: False
16 | slice_class_emb: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/sliceparam_miro.yaml:
--------------------------------------------------------------------------------
1 | name: sliceparamconvnext_miro
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
15 | duplicate: False
16 | slice_class_emb: False
--------------------------------------------------------------------------------
/configs/morphem70k/model/template_mixing.yaml:
--------------------------------------------------------------------------------
1 | name: templatemixingconvnext
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
15 | num_templates: 16
16 | separate_coef: True
--------------------------------------------------------------------------------
/configs/morphem70k/model/template_mixing_v2.yaml:
--------------------------------------------------------------------------------
1 | name: templatemixingconvnextv2 ## version 2 of template mixing
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
15 | num_templates: 24
16 | coefs_init: zeros
--------------------------------------------------------------------------------
/configs/morphem70k/model/template_mixing_v2_miro.yaml:
--------------------------------------------------------------------------------
1 | name: templatemixingconvnextv2_miro ## version 2 of template mixing
2 | pretrained: True
3 | pretrained_model_name: convnext_tiny.fb_in22k ## convnext_tiny.fb_in22k_ft_in1k, convnext_small.in12k_ft_in1k
4 | in_dim: ~ # autofill later if None
5 | num_classes: ~ # autofill later if None
6 | pooling: "avg"
7 | temperature: 0.11111
8 | learnable_temp: False
9 | unfreeze_last_n_layers: -1
10 | unfreeze_first_layer: True
11 | first_layer: reinit_as_random
12 | reset_last_n_unfrozen_layers: False
13 | use_auto_rgn: False
14 | in_channel_names: ['er','golgi','membrane','microtubules','mito', 'nucleus', 'protein', 'rna']
15 | num_templates: 24
16 | coefs_init: zeros
--------------------------------------------------------------------------------
/configs/morphem70k/morphem70k_cfg.yaml:
--------------------------------------------------------------------------------
1 | defaults:
2 | - train: ~
3 | - model: ~
4 | - scheduler: ~
5 | - optimizer: ~
6 | - dataset: ~
7 | - data_chunk: ~
8 | - logging: ~
9 | - hardware: ~
10 | - eval: ~
11 | - attn_pooling: ~
12 | - _self_
13 |
14 | tag: ~
15 |
16 | hydra:
17 | sweeper:
18 | params:
19 | train: random_instance
20 | data_chunk: morphem70k
21 | model: convnext_base
22 | scheduler: cosine
23 | optimizer: adamw
24 | dataset: morphem70k_v2
25 | logging: wandb
26 | hardware: default
27 | eval: default
28 | attn_pooling: none
--------------------------------------------------------------------------------
/configs/morphem70k/optimizer/adam.yaml:
--------------------------------------------------------------------------------
1 | name: adam
2 | params:
3 | lr: 0.00004
4 | betas: [0.9, 0.999]
5 | eps: 1.0e-08
6 | weight_decay: 5.0e-5
7 | amsgrad: False
--------------------------------------------------------------------------------
/configs/morphem70k/optimizer/adamw.yaml:
--------------------------------------------------------------------------------
1 | name: adamw
2 | params:
3 | lr: 0.00004
4 | betas: [0.9, 0.999]
5 | eps: 1.0e-08
6 | weight_decay: 5.0e-5
7 | amsgrad: False
--------------------------------------------------------------------------------
/configs/morphem70k/optimizer/sgd.yaml:
--------------------------------------------------------------------------------
1 | name: sgd
2 | params:
3 | lr: 0.0004
4 | dampening: 0
5 | momentum: 0.9
6 | weight_decay: 5.0e-4
7 | nesterov: False
--------------------------------------------------------------------------------
/configs/morphem70k/scheduler/cosine.yaml:
--------------------------------------------------------------------------------
1 | name: cosine
2 | convert_to_batch: False
3 | params:
4 | t_initial: FILL_LATER
5 | lr_min: 1.0e-6
6 | cycle_mul: 1.0
7 | cycle_decay: 0.5
8 | cycle_limit: 1
9 | warmup_t: 3
10 | warmup_lr_init: 1.0e-5
11 | warmup_prefix: False
12 | t_in_epochs: True
13 | noise_range_t: ~
14 | noise_pct: 0.67
15 | noise_std: 1.0
16 | noise_seed: 42
17 | k_decay: 1.0
18 | initialize: True
--------------------------------------------------------------------------------
/configs/morphem70k/scheduler/multistep.yaml:
--------------------------------------------------------------------------------
1 | name: multistep
2 | convert_to_batch: True
3 | params:
4 | decay_t: [30, 60, 80]
5 | decay_rate: 0.2
6 | warmup_t: 1
7 | warmup_lr_init: 0.
8 | warmup_prefix: False
9 | t_in_epochs: False
10 | noise_range_t: ~
11 | noise_pct: 0.67
12 | noise_std: 1.0
13 | noise_seed: 42
14 | initialize: True
--------------------------------------------------------------------------------
/configs/morphem70k/scheduler/none.yaml:
--------------------------------------------------------------------------------
1 | name: none
2 | convert_to_batch: False
3 |
--------------------------------------------------------------------------------
/configs/morphem70k/train/random_instance.yaml:
--------------------------------------------------------------------------------
1 | batch_strategy: random_instance
2 | resume_train: False
3 | resume_model: ~ # model_5.pt # used when `resume_train` is True
4 | use_amp: False # mixed precision training
5 | checkpoints: checkpoints
6 | save_model: False # save model after each epoch to checkpoints
7 | clip_grad_norm: ~ # or ~ to NOT use
8 | batch_size: 128 # batch_size vs. num_classes?
9 | num_epochs: 15
10 | verbose_batches: 50
11 | seed: ~ # if ~, will generate a random number for the seed
12 | debug: False
13 | adaptive_interface_epochs: 0 # set to 0 to disable
14 | adaptive_interface_lr: ~ # if ~, will use 100x of the fine-tuning lr
15 | swa: False
16 | swad: True
17 | swa_lr: 0.05
18 | swa_start: 5
19 | miro: False
20 | miro_lr_mult: 10.0
21 | miro_ld: 0.01
22 | tps_prob: 0.0 ## TPS transformation. 0 means disable. To use, set a value in (0, 1]
23 | ssl: False ## self-supervised loss
24 | ssl_lambda: 0.0 ## lambda to balance the self-supervised loss with the main loss
--------------------------------------------------------------------------------
/custom_log.py:
--------------------------------------------------------------------------------
1 | from typing import Union, Dict
2 |
3 | import torch
4 | import time
5 | import logging
6 | from datetime import datetime
7 | import os
8 | import pathlib
9 |
10 | from omegaconf import OmegaConf
11 |
12 | import wandb
13 | from dotenv import load_dotenv
14 |
15 | from config import MyConfig, DataChunk
16 | from utils import exists, default, get_machine_name
17 |
18 |
19 | def get_py_logger(dataset_name: str, job_id: str = None):
20 | def _get_logger(logger_name, log_path, level=logging.INFO):
21 | logger = logging.getLogger(logger_name) # global variance?
22 | formatter = logging.Formatter("%(asctime)s : %(message)s")
23 |
24 | fileHandler = logging.FileHandler(log_path, mode="w")
25 | fileHandler.setFormatter(formatter) # `formatter` must be a logging.Formatter
26 |
27 | streamHandler = logging.StreamHandler()
28 | streamHandler.setFormatter(formatter)
29 |
30 | logger.setLevel(level)
31 | logger.addHandler(fileHandler)
32 | logger.addHandler(streamHandler)
33 | return logger
34 |
35 | logger_path = "logs/{dataset_name}"
36 | logger_name_format = "%Y-%m-%d--%H-%M-%S.%f"
37 |
38 | logger_name = f"{job_id} - {datetime.now().strftime(logger_name_format)}.log"
39 |
40 | logger_folder = logger_path.format(dataset_name=dataset_name)
41 | pathlib.Path(logger_folder).mkdir(parents=True, exist_ok=True)
42 |
43 | logger_path = os.path.join(logger_folder, logger_name)
44 | logger = _get_logger(logger_name, logger_path)
45 | return logger # , logger_name, logger_path
46 |
47 |
48 | def init_wandb(args: MyConfig, job_id, project_name, log_freq: int, model=None):
49 | # wandb.run.dir
50 | # https://docs.wandb.ai/guides/track/advanced/save-restore
51 |
52 | try:
53 | load_dotenv()
54 | os.environ["WANDB__SERVICE_WAIT"] = "300"
55 | wandb.login(key=os.getenv("WANDB_API_KEY"))
56 | except Exception as e:
57 | print(f"--- was trying to log in Weights and Biases... e={e}")
58 |
59 | ## run_name for wandb's run
60 | machine_name = get_machine_name()
61 |
62 |
63 | cuda = args.hardware.device.replace(":", "") ## get cuda info instead
64 | if cuda == "cuda":
65 | try:
66 | cuda = torch.cuda.get_device_name(0)
67 | except Exception as e:
68 | print("error when trying to get_device_name", e)
69 | pass
70 |
71 | watermark = "{}_{}_{}_{}_{}".format(
72 | args.dataset.name, machine_name, cuda, job_id, time.strftime("%I-%M%p-%B-%d-%Y")
73 | )
74 |
75 | wandb.init(
76 | project=project_name,
77 | entity="adaptive_interface",
78 | name=watermark,
79 | settings=wandb.Settings(start_method="fork"),
80 | )
81 |
82 | # if exists(model):
83 | ## TODO: fix later
84 | # wandb.watch(model, log_freq=log_freq, log_graph=True, log="all") # log="all" to log gradients and parameters
85 | return watermark
86 |
87 |
88 | class MyLogging:
89 | def __init__(self, args: MyConfig, model, job_id, project_name):
90 | self.args = args
91 | log_freq = self.args.logging.wandb.log_freq
92 | dataset = args.dataset.name
93 | self.use_py_logger = args.logging.use_py_log
94 | self.use_wandb = args.logging.wandb.use_wandb
95 |
96 | self.py_logger = get_py_logger(dataset, job_id) if self.use_py_logger else None
97 | if self.use_wandb:
98 | init_wandb(
99 | args,
100 | project_name=project_name,
101 | model=model,
102 | job_id=job_id,
103 | log_freq=log_freq,
104 | )
105 |
106 | def info(
107 | self,
108 | msg: Union[Dict, str],
109 | use_wandb=None,
110 | sep=", ",
111 | padding_space=False,
112 | pref_msg: str = "",
113 | ):
114 | use_wandb = default(use_wandb, self.use_wandb)
115 |
116 | if isinstance(msg, Dict):
117 | msg_str = (
118 | pref_msg
119 | + " "
120 | + sep.join(
121 | f"{k} {round(v, 4) if isinstance(v, int) else v}"
122 | for k, v in msg.items()
123 | )
124 | )
125 | if padding_space:
126 | msg_str = sep + msg_str + " " + sep
127 |
128 | if use_wandb:
129 | wandb.log(msg)
130 |
131 | if self.use_py_logger:
132 | self.py_logger.info(msg_str)
133 | else:
134 | print(msg_str)
135 | else:
136 | if self.use_py_logger:
137 | self.py_logger.info(msg)
138 | else:
139 | print(msg)
140 |
141 | def log_imgs(self, x, y, y_hat, classes, max_scores, name: str):
142 | columns = ["image", "pred", "label", "score", "correct"]
143 | data = []
144 | for j, image in enumerate(x, 0):
145 | # pil_image = Image.fromarray(image, mode="RGB")
146 | data.append(
147 | [
148 | wandb.Image(image[:3]),
149 | classes[y_hat[j].item()],
150 | classes[y[j].item()],
151 | max_scores[j].item(),
152 | y_hat[j].item() == y[j].item(),
153 | ]
154 | )
155 |
156 | table = wandb.Table(data=data, columns=columns)
157 | wandb.log({name: table})
158 |
159 | def log_config(self, config: MyConfig):
160 | wandb.config.update(OmegaConf.to_container(config)) # , allow_val_change=True)
161 |
162 | def update_best_result(self, msg: str, metric, val, use_wandb=None):
163 | use_wandb = default(use_wandb, self.use_wandb)
164 |
165 | if self.use_py_logger:
166 | self.py_logger.info(msg)
167 | else:
168 | print(msg)
169 | if use_wandb:
170 | wandb.run.summary[metric] = val
171 |
172 | def finish(
173 | self,
174 | use_wandb=None,
175 | msg_str: str = None,
176 | model=None,
177 | model_best_name: str = "",
178 | dummy_batch_x=None,
179 | ):
180 | use_wandb = default(use_wandb, self.use_wandb)
181 |
182 | if exists(msg_str):
183 | if self.use_py_logger:
184 | self.py_logger.info(msg_str)
185 | else:
186 | print(msg_str)
187 | if use_wandb:
188 | if model_best_name:
189 | wandb.save(model_best_name)
190 | print(f"saved pytorch model {model_best_name}!")
191 |
192 | if exists(model):
193 | try:
194 | # https://colab.research.google.com/github/wandb/examples/blob/master/colabs/pytorch/Simple_PyTorch_Integration.ipynb#scrollTo=j64Lu7pZcubd
195 | if self.args.hardware.multi_gpus == "DataParallel":
196 | model = model.module
197 | torch.onnx.export(model, dummy_batch_x, "model.onnx")
198 | wandb.save("model.onnx")
199 | print("saved to model.onnx!")
200 | except Exception as e:
201 | print(e)
202 | wandb.finish()
203 |
--------------------------------------------------------------------------------
/datasets/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaudatascience/channel_adaptive_models/b62f69ae5d7d2c49cba2c96f0c9d2eef0fe2ee42/datasets/__init__.py
--------------------------------------------------------------------------------
/datasets/cifar.py:
--------------------------------------------------------------------------------
1 | import torchvision
2 | from torch.utils.data import Dataset
3 | from torchvision.transforms import transforms
4 |
5 | import utils
6 |
7 |
8 | class CifarRandomInstance(Dataset):
9 | chunk_names = ["red", "red_green", "green_blue"]
10 |
11 | def __init__(self, dataset: str, transform_train):
12 |
13 | torch_dataset = getattr(torchvision.datasets, dataset.upper())
14 | train_set = torch_dataset(root='../data', train=True, download=True)
15 | self.X = train_set.data
16 | self.y = train_set.targets
17 | self.transform_train = transforms.Compose([transforms.ToPILImage(), transform_train])
18 |
19 | train_idxs = utils.read_json(f"../data/split/{dataset}_train.json")
20 | self.idx_dict = {}
21 | for chunk_name in self.chunk_names:
22 | self.idx_dict[chunk_name] = train_idxs[f"{chunk_name}_idx"]
23 |
24 | def get_chunk_name(self, idx):
25 | for chunk_name in self.chunk_names:
26 | if idx in self.idx_dict[chunk_name]:
27 | return chunk_name
28 | raise ValueError(f"idx={idx} not found!")
29 |
30 | def __len__(self):
31 | return len(self.y)
32 |
33 | def __getitem__(self, idx):
34 | image = self.X[idx]
35 | label = self.y[idx]
36 | image = self.transform_train(image)
37 | return {"chunk": self.get_chunk_name(idx), "image": image, "label": label}
38 |
39 | #
40 | # def cifar_collate(data):
41 | # out = {chunk: {"image": [], "label": []} for chunk in CifarRandomInstance.chunk_names}
42 | #
43 | # for d in data:
44 | # out[d["chunk"]]["image"].append(d["image"])
45 | # out[d["chunk"]]["label"].append(d["label"])
46 | # for chunk in out:
47 | # out[chunk]["image"] = torch.stack(out[chunk]["image"], dim=0)
48 | # out[chunk]["label"] = torch.tensor(out[chunk]["label"])
49 | # return out
50 |
--------------------------------------------------------------------------------
/datasets/compute_mean_std_morphem70k.py:
--------------------------------------------------------------------------------
1 | import os
2 | from collections import defaultdict
3 |
4 | import torch
5 | from datasets import morphem70k
6 | from torch.utils.data import DataLoader
7 | import time
8 |
9 |
10 | def compute_mean_std_morphem70k(chunk, root_dir):
11 | csv_path = os.path.join(root_dir, "morphem70k.csv")
12 | dataset = morphem70k.SingleCellDataset(
13 | csv_path, chunk=chunk, root_dir=root_dir, is_train=True, target_labels="label"
14 | )
15 |
16 | loader = DataLoader(dataset, batch_size=10, shuffle=False, drop_last=False)
17 | mean = 0.0
18 | for images, _ in loader:
19 | # print(images.shape) : 10, 3, 238, 374
20 | batch_samples = images.size(0)
21 | images = images.view(batch_samples, images.size(1), -1)
22 | # print(images.shape): 10, 3, 89012
23 | mean += images.mean(2).sum(0)
24 | mean = mean / len(loader.dataset)
25 |
26 | var = 0.0
27 | pixel_count = 0
28 | for images, _ in loader:
29 | batch_samples = images.size(0)
30 | images = images.view(batch_samples, images.size(1), -1)
31 | var += ((images - mean.unsqueeze(1)) ** 2).sum([0, 2])
32 | pixel_count += images.nelement()/ images.size(1)
33 | std = torch.sqrt(var / pixel_count)
34 |
35 | return list(mean.numpy()), list(std.numpy())
36 |
37 |
38 | if __name__ == "__main__":
39 | mean_std = {}
40 | root_dir = "/projectnb/morphem/data_70k/ver2/morphem_70k_version2/"
41 | out_path = os.path.join(
42 | "/projectnb/morphem/data_70k/ver2", "mean_std_morphem70k_ver2.txt"
43 | )
44 |
45 | for chunk in ["Allen", "CP", "HPA"]:
46 | start_time = time.time()
47 |
48 | mean, std = compute_mean_std_morphem70k(chunk, root_dir)
49 | mean_std[chunk] = [mean, std]
50 |
51 | msg = f"data={chunk}, mean={mean}, std={std}"
52 | with open(out_path, "a") as out:
53 | out.write(msg + "\n\n")
54 | out.write("--- %s seconds ---\n\n" % (time.time() - start_time))
55 |
--------------------------------------------------------------------------------
/datasets/morphem70k.py:
--------------------------------------------------------------------------------
1 | import os
2 | from typing import Callable, Dict
3 |
4 | import numpy as np
5 | import pandas as pd
6 | import torch
7 | import torchvision
8 | from torch import Tensor
9 | from torch.utils.data import Dataset
10 | import skimage.io
11 |
12 |
13 | class SingleCellDataset(Dataset):
14 | """Single cell chunk."""
15 |
16 | ## define all available datasets, used for collate_fn later on
17 | chunk_names = ["Allen", "CP", "HPA"]
18 |
19 | def __init__(
20 | self,
21 | csv_path: str,
22 | chunk: str,
23 | root_dir: str,
24 | is_train: bool,
25 | ssl_flag: bool,
26 | target_labels: str = "label",
27 | transform: Callable | Dict[str, Callable] | None = None,
28 | ):
29 | """
30 | @param csv_path: Path to the csv file with metadata.
31 | e.g., "metadata/morphem70k_v2.csv".
32 | You should copy this file to the dataset folder to avoid modifying other config.
33 |
34 | Note: Allen was renamed to WTC-11 in the paper.
35 | @param chunk: "Allen", "HPA", "CP", or "morphem70k"to use all 3 chunks
36 | @param root_dir: root_dir: Directory with all the images.
37 | @param is_train: True for training set, False for using all data
38 | @param target_labels: label column in the csv file
39 | @param transform: data transform to be applied on a sample.
40 | """
41 | assert chunk in [
42 | "Allen",
43 | "HPA",
44 | "CP",
45 | "morphem70k",
46 | ], "chunk must be one of 'Allen', 'HPA', 'CP', 'morphem70k'"
47 | self.chunk = chunk
48 | self.is_train = is_train
49 |
50 | ## read csv file for the chunk
51 | self.metadata = pd.read_csv(csv_path)
52 | if chunk in ["Allen", "HPA", "CP"]:
53 | self.metadata = self.metadata[self.metadata["chunk"] == chunk]
54 |
55 | if is_train:
56 | self.metadata = self.metadata[self.metadata["train_test_split"] == "Train"]
57 |
58 | self.metadata = self.metadata.reset_index(drop=True)
59 | self.root_dir = root_dir
60 | self.transform = transform
61 | self.target_labels = target_labels
62 | self.ssl_flag = ssl_flag
63 |
64 | ## classes on training set:
65 |
66 | if chunk == "Allen":
67 | self.train_classes_dict = {
68 | "M0": 0,
69 | "M1M2": 1,
70 | "M3": 2,
71 | "M4M5": 3,
72 | "M6M7_complete": 4,
73 | "M6M7_single": 5,
74 | }
75 |
76 | elif chunk == "HPA":
77 | self.train_classes_dict = {
78 | "golgi apparatus": 0,
79 | "microtubules": 1,
80 | "mitochondria": 2,
81 | "nuclear speckles": 3,
82 | }
83 |
84 | elif chunk == "CP":
85 | self.train_classes_dict = {
86 | "BRD-A29260609": 0,
87 | "BRD-K04185004": 1,
88 | "BRD-K21680192": 2,
89 | "DMSO": 3,
90 | }
91 |
92 | else: # all 3 chunks (i.e., "morphem70k")
93 | self.train_classes_dict = {
94 | "BRD-A29260609": 0,
95 | "BRD-K04185004": 1,
96 | "BRD-K21680192": 2,
97 | "DMSO": 3,
98 | "M0": 4,
99 | "M1M2": 5,
100 | "M3": 6,
101 | "M4M5": 7,
102 | "M6M7_complete": 8,
103 | "M6M7_single": 9,
104 | "golgi apparatus": 10,
105 | "microtubules": 11,
106 | "mitochondria": 12,
107 | "nuclear speckles": 13,
108 | }
109 |
110 | self.test_classes_dict = None ## Not defined yet
111 |
112 | def __len__(self):
113 | return len(self.metadata)
114 |
115 | @staticmethod
116 | def _fold_channels(image: np.ndarray, channel_width: int, mode="ignore") -> Tensor:
117 | """
118 | Re-arrange channels from tape format to stack tensor
119 | @param image: (h, w * c)
120 | @param channel_width:
121 | @param mode:
122 | @return: Tensor, shape of (c, h, w) in the range [0.0, 1.0]
123 | """
124 | # convert to shape of (h, w, c), (in the range [0, 255])
125 | output = np.reshape(image, (image.shape[0], channel_width, -1), order="F")
126 |
127 | if mode == "ignore":
128 | # Keep all channels
129 | pass
130 | elif mode == "drop":
131 | # Drop mask channel (last)
132 | output = output[:, :, 0:-1]
133 | elif mode == "apply":
134 | # Use last channel as a binary mask
135 | mask = output["image"][:, :, -1:]
136 | output = output[:, :, 0:-1] * mask
137 | output = torchvision.transforms.ToTensor()(output)
138 | return output
139 |
140 | def __getitem__(self, idx):
141 | if torch.is_tensor(idx):
142 | idx = idx.tolist()
143 |
144 | img_path = os.path.join(self.root_dir, self.metadata.loc[idx, "file_path"])
145 | channel_width = self.metadata.loc[idx, "channel_width"]
146 | image = skimage.io.imread(img_path)
147 | image = self._fold_channels(image, channel_width)
148 |
149 | if self.is_train:
150 | label = self.metadata.loc[idx, self.target_labels]
151 | label = self.train_classes_dict[label]
152 | label = torch.tensor(label)
153 | else:
154 | label = None ## for now, we don't need labels for evaluation. It will be provided later in evaluation code.
155 |
156 | if self.chunk == "morphem70k": ## using all 3 datasets
157 | chunk = self.metadata.loc[idx, "chunk"]
158 | if self.transform:
159 | image = self.transform[chunk](image)
160 | if self.is_train:
161 | data = {"chunk": chunk, "image": image, "label": label}
162 | else:
163 | data = {"chunk": chunk, "image": image}
164 | else: ## using single chunk
165 | if self.transform:
166 | image = self.transform(image)
167 | if self.is_train:
168 | data = image, label
169 | else:
170 | data = image
171 | return data
172 |
--------------------------------------------------------------------------------
/datasets/split_datasets.py:
--------------------------------------------------------------------------------
1 | import os.path
2 | from collections import Counter
3 |
4 | import numpy as np
5 | import torchvision
6 | from sklearn.model_selection import train_test_split
7 |
8 | import utils
9 | from utils import write_json
10 |
11 | ### SPLIT CIFAR dataset into 3 sub-datasets: red, red-green, green-blue
12 | def split_datasets(path="data/split", random_seed=2022):
13 | def split_dataset(dataset, train_split: bool):
14 | train_set = dataset(root='./data', train=train_split, download=True)
15 | targets = np.array(train_set.targets)
16 |
17 | the_rest_vs_red_ratio = 2 / 3
18 | rg_vs_gb_ratio = 1 / 2
19 |
20 | red_idx, the_rest_idx = train_test_split(
21 | np.arange(len(targets)), test_size=the_rest_vs_red_ratio, random_state=random_seed, shuffle=True,
22 | stratify=targets)
23 |
24 | red_green_idx, green_blue_idx = train_test_split(
25 | the_rest_idx, test_size=rg_vs_gb_ratio, random_state=random_seed, shuffle=True,
26 | stratify=targets[the_rest_idx])
27 |
28 | ## Sanity check:
29 | # compare the number of each class in each sub-dataset, the difference should be less or equal 1
30 | r_vs_rg_diff = Counter(targets[red_idx]) - Counter(targets[red_green_idx])
31 | assert max(r_vs_rg_diff.values()) <= 1
32 |
33 | rg_vs_gb_diff = Counter(targets[red_green_idx]) - Counter(targets[green_blue_idx])
34 | assert max(rg_vs_gb_diff.values()) <= 1
35 |
36 | data = {}
37 | data["red_idx"] = red_idx
38 | data["red_green_idx"] = red_green_idx
39 | data["green_blue_idx"] = green_blue_idx
40 | return data
41 |
42 | cifar10_dataset = torchvision.datasets.CIFAR10
43 | cifar100_dataset = torchvision.datasets.CIFAR100
44 |
45 | cifar10 = split_dataset(cifar10_dataset, train_split=True)
46 | write_json(os.path.join(path, "cifar10_train.json"), cifar10, cls=utils.NumpyEncoder)
47 | cifar10 = split_dataset(cifar10_dataset, train_split=False)
48 | write_json(os.path.join(path, "cifar10_test.json"), cifar10, cls=utils.NumpyEncoder)
49 |
50 | cifar100 = split_dataset(cifar100_dataset, train_split=True)
51 | write_json(os.path.join(path, "data/cifar100_train.json"), cifar100, cls=utils.NumpyEncoder)
52 | cifar100 = split_dataset(cifar100_dataset, train_split=False)
53 | write_json(os.path.join(path, "data/cifar100_test.json"), cifar100, cls=utils.NumpyEncoder)
54 |
55 |
56 | if __name__ == '__main__':
57 | # split_datasets()
58 | pass
59 |
--------------------------------------------------------------------------------
/datasets/tps_transform.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | import PIL
3 | from PIL import Image
4 | import torch
5 | import torchvision
6 | from torchvision.transforms import transforms
7 |
8 | from scipy import ndimage
9 | from einops import rearrange
10 | from typing import Union
11 | import torch
12 | from torch import nn, Tensor
13 | import random
14 | import matplotlib.pyplot as plt
15 |
16 | from torchvision import datasets
17 |
18 | # adapted from: https://github.com/eliahuhorwitz/DeepSIM/blob/3cc80fd334c0fc7785296bf70175110df02d4041/data/base_dataset.py#L40
19 | # related blog: https://medium.com/@fanzongshaoxing/image-augmentation-based-on-3d-thin-plate-spline-tps-algorithm-for-ct-data-fa8b1b2a683c
20 |
21 |
22 | def warp_images(
23 | from_points, to_points, images, output_region, interpolation_order=1, approximate_grid=10
24 | ):
25 | """Define a thin-plate-spline warping transform that warps from the from_points
26 | to the to_points, and then warp the given images by that transform. This
27 | transform is described in the paper: "Principal Warps: Thin-Plate Splines and
28 | the Decomposition of Deformations" by F.L. Bookstein.
29 | Parameters:
30 | - from_points and to_points: Nx2 arrays containing N 2D landmark points.
31 | - images: list of images to warp with the given warp transform.
32 | - output_region: the (xmin, ymin, xmax, ymax) region of the output
33 | image that should be produced. (Note: The region is inclusive, i.e.
34 | xmin <= x <= xmax)
35 | - interpolation_order: if 1, then use linear interpolation; if 0 then use
36 | nearest-neighbor.
37 | - approximate_grid: defining the warping transform is slow. If approximate_grid
38 | is greater than 1, then the transform is defined on a grid 'approximate_grid'
39 | times smaller than the output image region, and then the transform is
40 | bilinearly interpolated to the larger region. This is fairly accurate
41 | for values up to 10 or so.
42 | """
43 | transform = _make_inverse_warp(from_points, to_points, output_region, approximate_grid)
44 | return [
45 | ndimage.map_coordinates(
46 | np.asarray(image), transform, order=interpolation_order, mode="reflect"
47 | )
48 | for image in images
49 | ]
50 |
51 |
52 | def _make_inverse_warp(from_points, to_points, output_region, approximate_grid):
53 | x_min, y_min, x_max, y_max = output_region
54 | if approximate_grid is None:
55 | approximate_grid = 1
56 | x_steps = (x_max - x_min) / approximate_grid
57 | y_steps = (y_max - y_min) / approximate_grid
58 | x, y = np.mgrid[x_min : x_max : x_steps * 1j, y_min : y_max : y_steps * 1j]
59 |
60 | # make the reverse transform warping from the to_points to the from_points, because we
61 | # do image interpolation in this reverse fashion
62 | transform = _make_warp(to_points, from_points, x, y)
63 |
64 | if approximate_grid != 1:
65 | # linearly interpolate the zoomed transform grid
66 | new_x, new_y = np.mgrid[x_min : x_max + 1, y_min : y_max + 1]
67 | x_fracs, x_indices = np.modf((x_steps - 1) * (new_x - x_min) / float(x_max - x_min))
68 | y_fracs, y_indices = np.modf((y_steps - 1) * (new_y - y_min) / float(y_max - y_min))
69 | x_indices = x_indices.astype(int)
70 | y_indices = y_indices.astype(int)
71 | x1 = 1 - x_fracs
72 | y1 = 1 - y_fracs
73 | ix1 = (x_indices + 1).clip(0, x_steps - 1).astype(int)
74 | iy1 = (y_indices + 1).clip(0, y_steps - 1).astype(int)
75 | t00 = transform[0][(x_indices, y_indices)]
76 | t01 = transform[0][(x_indices, iy1)]
77 | t10 = transform[0][(ix1, y_indices)]
78 | t11 = transform[0][(ix1, iy1)]
79 | transform_x = (
80 | t00 * x1 * y1 + t01 * x1 * y_fracs + t10 * x_fracs * y1 + t11 * x_fracs * y_fracs
81 | )
82 | t00 = transform[1][(x_indices, y_indices)]
83 | t01 = transform[1][(x_indices, iy1)]
84 | t10 = transform[1][(ix1, y_indices)]
85 | t11 = transform[1][(ix1, iy1)]
86 | transform_y = (
87 | t00 * x1 * y1 + t01 * x1 * y_fracs + t10 * x_fracs * y1 + t11 * x_fracs * y_fracs
88 | )
89 | transform = [transform_x, transform_y]
90 | return transform
91 |
92 |
93 | _small = 1e-100
94 |
95 |
96 | def _U(x):
97 | return (x**2) * np.where(x < _small, 0, np.log(x))
98 |
99 |
100 | def _interpoint_distances(points):
101 | xd = np.subtract.outer(points[:, 0], points[:, 0])
102 | yd = np.subtract.outer(points[:, 1], points[:, 1])
103 | return np.sqrt(xd**2 + yd**2)
104 |
105 |
106 | def _make_L_matrix(points):
107 | n = len(points)
108 | K = _U(_interpoint_distances(points))
109 | P = np.ones((n, 3))
110 | P[:, 1:] = points
111 | O = np.zeros((3, 3))
112 | L = np.asarray(np.bmat([[K, P], [P.transpose(), O]]))
113 | return L
114 |
115 |
116 | def _calculate_f(coeffs, points, x, y):
117 | # a = time.time()
118 | w = coeffs[:-3]
119 | a1, ax, ay = coeffs[-3:]
120 | # The following uses too much RAM:
121 | distances = _U(
122 | np.sqrt((points[:, 0] - x[..., np.newaxis]) ** 2 + (points[:, 1] - y[..., np.newaxis]) ** 2)
123 | )
124 | summation = (w * distances).sum(axis=-1)
125 | # summation = np.zeros(x.shape)
126 | # for wi, Pi in zip(w, points):
127 | # summation += wi * _U(np.sqrt((x-Pi[0])**2 + (y-Pi[1])**2))
128 | # print("calc f", time.time()-a)
129 | return a1 + ax * x + ay * y + summation
130 |
131 |
132 | def _make_warp(from_points, to_points, x_vals, y_vals):
133 | from_points, to_points = np.asarray(from_points), np.asarray(to_points)
134 | err = np.seterr(divide="ignore")
135 | L = _make_L_matrix(from_points)
136 | V = np.resize(to_points, (len(to_points) + 3, 2))
137 | V[-3:, :] = 0
138 | coeffs = np.dot(np.linalg.pinv(L), V)
139 | x_warp = _calculate_f(coeffs[:, 0], from_points, x_vals, y_vals)
140 | y_warp = _calculate_f(coeffs[:, 1], from_points, x_vals, y_vals)
141 | np.seterr(**err)
142 | return [x_warp, y_warp]
143 |
144 |
145 | def _get_regular_grid(image, points_per_dim):
146 | nrows, ncols = image.shape[0], image.shape[1]
147 | rows = np.linspace(0, nrows, points_per_dim)
148 | cols = np.linspace(0, ncols, points_per_dim)
149 | rows, cols = np.meshgrid(rows, cols)
150 | return np.dstack([cols.flat, rows.flat])[0]
151 |
152 |
153 | def _generate_random_vectors(image, src_points, scale):
154 | dst_pts = src_points + np.random.uniform(-scale, scale, src_points.shape)
155 | return dst_pts
156 |
157 |
158 | def _thin_plate_spline_warp(image, src_points, dst_points, keep_corners=True):
159 | width, height = image.shape[:2]
160 | if keep_corners:
161 | corner_points = np.array([[0, 0], [0, width], [height, 0], [height, width]])
162 | src_points = np.concatenate((src_points, corner_points))
163 | dst_points = np.concatenate((dst_points, corner_points))
164 | out = warp_images(
165 | src_points, dst_points, np.moveaxis(image, 2, 0), (0, 0, width - 1, height - 1)
166 | )
167 | return np.moveaxis(np.array(out), 0, 2)
168 |
169 |
170 | def tps_warp(image, points_per_dim, scale):
171 | width, height = image.shape[:2]
172 | src = _get_regular_grid(image, points_per_dim=points_per_dim)
173 | dst = _generate_random_vectors(image, src, scale=scale * width)
174 | out = _thin_plate_spline_warp(image, src, dst)
175 | return out
176 |
177 |
178 | def tps_warp_2(image, dst, src):
179 | out = _thin_plate_spline_warp(image, src, dst)
180 | return out
181 |
182 |
183 | def __apply_tps(img, tps_params):
184 | new_im = img
185 | np_im = np.array(img)
186 | np_im = tps_warp_2(np_im, tps_params["dst"], tps_params["src"])
187 | return np_im
188 |
189 |
190 | def tps_transform(np_im: np.ndarray, return_pytorch: bool = True):
191 | new_w, new_h, _ = np_im.shape
192 |
193 | src = _get_regular_grid(np_im, points_per_dim=3)
194 | dst = _generate_random_vectors(np_im, src, scale=0.1 * new_w)
195 | params = {}
196 | params["tps"] = {"src": src, "dst": dst}
197 | new_img = __apply_tps(np_im, params["tps"])
198 | if return_pytorch:
199 | new_img = torch.from_numpy(new_img)
200 | return new_img
201 |
202 |
203 | class TPSTransform:
204 | """
205 | This applies TPS on original img with a prob `p`.
206 | Return: a Pytorch tensor, shape (c,h,w)
207 | Note: the orders of PIL image and Pytorch Tensor are differents.
208 | Example:
209 | ```
210 | image = Image.open('a_cat.png')
211 | image = image.convert("RGB") ## PIL image
212 |
213 | image_array = np.asarray(image) ## (882, 986, 3)
214 | image_pytorch = torchvision.transforms.ToTensor()(image) ## (3, 882, 986)
215 | ```
216 | """
217 |
218 | def __init__(self, p=0.5):
219 | """
220 | with a probability of `p`, we will apply TPS on the original image
221 | """
222 | self.p = p
223 |
224 | def _convert_to_numpy(self, img):
225 | if isinstance(img, np.ndarray):
226 | pass # do nothing
227 | elif isinstance(img, PIL.Image.Image):
228 | img = np.asarray(img)
229 | elif isinstance(img, torch.Tensor):
230 | img = rearrange(img, "c h w-> h w c")
231 | img = img.numpy()
232 | else:
233 | raise TypeError(f"img type `{type(img)}` not supported")
234 | return img
235 |
236 | def __call__(self, img: Tensor):
237 | if random.random() > self.p:
238 | return img
239 | else:
240 | img = self._convert_to_numpy(img)
241 | img = tps_transform(img, return_pytorch=True)
242 | img = rearrange(img, "h w c ->c h w")
243 | return img
244 |
245 |
246 | # Define the dummy transform function
247 | def dummy_transform(x):
248 | return x
249 |
250 |
251 | def _test_tps_transform(
252 | use_tps: bool = True,
253 | prob=0.5,
254 | input_img_name: str = "cat_img/a_cat.png",
255 | new_img_name: str = "",
256 | ):
257 | """
258 | Just for testing, with a cute cat in `cat_img` folder.
259 | prob: probability of applying TPS
260 | """
261 |
262 | if "chammi" in img_path:
263 | import skimage
264 |
265 | channel_width = 200
266 | image = skimage.io.imread(img_path)
267 | # breakpoint()
268 | image = np.reshape(image, (image.shape[0], channel_width, -1), order="F")
269 | else:
270 | # Read an normal RGB image (e.g., the cat img)
271 | image = Image.open(input_img_name)
272 | image = image.convert("RGB")
273 |
274 | if new_img_name == "":
275 | new_img_name = f'cat_img/{input_img_name.replace(".png", "")}_transformed.png'
276 |
277 | img_size = 224
278 | no_transform = transforms.Lambda(dummy_transform)
279 | transform_train = transforms.Compose(
280 | [
281 | TPSTransform(p=prob) if use_tps else no_transform,
282 | transforms.RandomResizedCrop(
283 | img_size, scale=(1.0, 1.0), ratio=(1.0, 1.0), antialias=True
284 | ),
285 | ]
286 | )
287 |
288 | # image_array = np.asarray(image)
289 | # print("PIL shape after transforming into numpy", image_array.shape)
290 |
291 | image = torchvision.transforms.ToTensor()(image)
292 | print("image shape here is", image.shape)
293 | transformed_img = transform_train(image)
294 | # plt.imshow(transformed_img.permute(1, 2, 0))
295 | ## save the image
296 | torchvision.utils.save_image(transformed_img[:3, ...], new_img_name)
297 | print("wrote transformed image to", new_img_name)
298 | return transformed_img
299 |
300 |
301 | if __name__ == "__main__":
302 | n_imgs = 10
303 | prob = 1
304 | use_tps = True
305 | # img_path = "cat_img/a_cat.png"
306 | # new_img_path = "cat_img/a_cat_transformed_{i}.png"
307 | # final_img = f"cat_img/all_transformed_useTPS{use_tps}_prob{prob}.png"
308 |
309 | img_path = "chammi_sample_img/chammi_pic.png"
310 | new_img_path = "chammi_sample_img/chammi_transformed_{i}.png"
311 | final_img = f"chammi_sample_img/all_useTPS{use_tps}_prob{prob}.png"
312 |
313 | for i in range(1, n_imgs + 1):
314 | transformed_img = _test_tps_transform(use_tps, prob, img_path, new_img_path.format(i=i))
315 |
316 | print(transformed_img)
317 |
318 | # show all images in 1 picture
319 | fig, axs = plt.subplots(2, 5, figsize=(20, 8))
320 | for i in range(1, n_imgs + 1):
321 | img = Image.open(new_img_path.format(i=i))
322 | axs[(i - 1) // 5, (i - 1) % 5].imshow(img)
323 | axs[(i - 1) // 5, (i - 1) % 5].axis("off")
324 | ## store it
325 | plt.savefig(final_img)
326 | print("wrote all transformed images to", final_img)
327 |
--------------------------------------------------------------------------------
/figs/01-adaptive-models.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaudatascience/channel_adaptive_models/b62f69ae5d7d2c49cba2c96f0c9d2eef0fe2ee42/figs/01-adaptive-models.png
--------------------------------------------------------------------------------
/figs/04-diagrams.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaudatascience/channel_adaptive_models/b62f69ae5d7d2c49cba2c96f0c9d2eef0fe2ee42/figs/04-diagrams.png
--------------------------------------------------------------------------------
/helper_classes/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chaudatascience/channel_adaptive_models/b62f69ae5d7d2c49cba2c96f0c9d2eef0fe2ee42/helper_classes/__init__.py
--------------------------------------------------------------------------------
/helper_classes/best_result.py:
--------------------------------------------------------------------------------
1 | from dataclasses import dataclass
2 | from typing import Dict
3 |
4 |
5 | @dataclass
6 | class BestResult:
7 | avg_acc_obs: float = 0
8 | avg_acc_chunk: float = 0
9 | avg_f1_chunk: float = 0
10 | avg_loss: float = -float("inf")
11 | epoch: int = 0
12 |
13 | def to_dict(self) -> Dict:
14 | data = {"avg_acc_obs": self.avg_acc_obs,
15 | "avg_acc_chunk": self.avg_acc_chunk,
16 | "avg_f1_chunk": self.avg_f1_chunk,
17 | "avg_loss": self.avg_loss,
18 | "epoch": self.epoch}
19 | return data
20 |
--------------------------------------------------------------------------------
/helper_classes/channel_initialization.py:
--------------------------------------------------------------------------------
1 | from utils import ExtendedEnum
2 |
3 |
4 | class ChannelInitialization(str, ExtendedEnum):
5 | ZERO = "zero"
6 | RANDOM = "random"
7 |
--------------------------------------------------------------------------------
/helper_classes/channel_pooling_type.py:
--------------------------------------------------------------------------------
1 | from utils import ExtendedEnum
2 |
3 |
4 | class ChannelPoolingType(str, ExtendedEnum):
5 | AVG = "avg"
6 | SUM = "sum"
7 | WEIGHTED_SUM_RANDOM = "weighted_sum_random"
8 | WEIGHTED_SUM_ONE = "weighted_sum_one"
9 | WEIGHTED_SUM_RANDOM_NO_SOFTMAX = "weighted_sum_random_no_softmax"
10 | WEIGHTED_SUM_ONE_NO_SOFTMAX = "weighted_sum_one_no_softmax"
11 | WEIGHTED_SUM_RANDOM_PAIRWISE_NO_SOFTMAX = "weighted_sum_random_pairwise_no_softmax"
12 | WEIGHTED_SUM_RANDOM_PAIRWISE = "weighted_sum_random_pairwise"
13 |
14 | ATTENTION = "attention"
15 |
16 |
17 |
18 |
--------------------------------------------------------------------------------
/helper_classes/datasplit.py:
--------------------------------------------------------------------------------
1 | from enum import Enum, auto
2 | from typing import List
3 |
4 |
5 | class DataSplit(Enum):
6 | TRAIN = auto()
7 | TEST = auto()
8 | VAL = auto()
9 |
10 | def __str__(self):
11 | return self.name
12 |
13 | @staticmethod
14 | def get_all_splits() -> List:
15 | return [DataSplit.TRAIN, DataSplit.VAL, DataSplit.TEST]
16 |
17 |
18 | if __name__ == '__main__':
19 | a = DataSplit.TEST
20 | print(a)
21 | print(a.get_all_splits())
22 | for x in a.get_all_splits():
23 | print(x==DataSplit.VAL)
24 |
--------------------------------------------------------------------------------
/helper_classes/feature_pooling.py:
--------------------------------------------------------------------------------
1 | from utils import ExtendedEnum
2 |
3 |
4 | class FeaturePooling(str, ExtendedEnum):
5 | AVG = "avg"
6 | MAX = "max"
7 | AVG_MAX = "avg_max"
8 | NONE = "none"
9 |
10 |
--------------------------------------------------------------------------------
/helper_classes/first_layer_init.py:
--------------------------------------------------------------------------------
1 | from utils import ExtendedEnum
2 |
3 |
4 | class FirstLayerInit(str, ExtendedEnum):
5 | ## make attribute capital
6 | REINIT_AS_RANDOM = "reinit_as_random"
7 | PRETRAINED_PAD_AVG = "pretrained_pad_avg" # pad with avg of pretrained weights for additional channels
8 | PRETRAINED_PAD_RANDOM = (
9 | "pretrained_pad_random" # pad with random values for additional channels
10 | )
11 | PRETRAINED_PAD_DUPS = (
12 | "pretrained_pad_dups" # pad with duplicates channels for additional channels
13 | )
14 |
--------------------------------------------------------------------------------
/helper_classes/norm_type.py:
--------------------------------------------------------------------------------
1 | from utils import ExtendedEnum
2 |
3 |
4 | class NormType(str, ExtendedEnum):
5 | BATCH_NORM = "batch_norm"
6 | LAYER_NORM = "layer_norm"
7 | INSTANCE_NORM = "instance_norm"
8 | BATCH_NORM_INVERSE = "batch_norm_inverse"
9 |
10 |
11 | if __name__ == '__main__':
12 | print("NormType.BATCH_NORM", NormType.BATCH_NORM)
13 | print(NormType.BATCH_NORM == "batch_norm")
14 |
--------------------------------------------------------------------------------
/lr_schedulers.py:
--------------------------------------------------------------------------------
1 | from timm.scheduler import MultiStepLRScheduler, CosineLRScheduler, PlateauLRScheduler
2 |
3 |
4 | def create_my_scheduler(optimizer, scheduler_type: str, config: dict):
5 | if scheduler_type == 'multistep':
6 | scheduler = MultiStepLRScheduler(optimizer, **config)
7 | elif scheduler_type == 'cosine':
8 | scheduler = CosineLRScheduler(optimizer, **config)
9 | # elif scheduler_type == 'plateau': TODO: add metric
10 | # scheduler = PlateauLRScheduler(optimizer, **config)
11 | else:
12 | raise NotImplementedError(f'Not implemented scheduler: {scheduler_type}')
13 | return scheduler
14 |
15 |
16 |
17 |
--------------------------------------------------------------------------------
/main.py:
--------------------------------------------------------------------------------
1 | import sys
2 |
3 | import hydra
4 | from hydra.core.config_store import ConfigStore
5 | from omegaconf import OmegaConf
6 |
7 | from config import MyConfig
8 | from trainer import Trainer
9 | from ssltrainer import SSLTrainer
10 |
11 | cs = ConfigStore.instance()
12 | cs.store(name="my_config", node=MyConfig)
13 |
14 |
15 | @hydra.main(version_base=None, config_path="configs/cifar", config_name="debug")
16 | def main(cfg: MyConfig) -> None:
17 | # print(OmegaConf.to_yaml(cfg))
18 | # print(OmegaConf.to_container(cfg))
19 |
20 | if cfg.train.ssl:
21 | trainer = SSLTrainer(cfg)
22 | else:
23 | trainer = Trainer(cfg)
24 | trainer.train()
25 |
26 |
27 | if __name__ == "__main__":
28 | main()
29 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
1 | from .convnext_base import convnext_base
2 | from .convnext_base_miro import convnext_base_miro
3 | from .convnext_shared_miro import convnext_shared_miro
4 | from .shared_convnext import shared_convnext
5 | from .slice_param_convnext import sliceparamconvnext
6 | from .template_mixing_convnext import templatemixingconvnext
7 | from .template_convnextv2 import templatemixingconvnextv2
8 | from .hypernet_convnext import hyperconvnext
9 | from .hypernet_convnext_miro import hyperconvnext_miro
10 | from .depthwise_convnext import depthwiseconvnext
11 | from .depthwise_convnext_miro import depthwiseconvnext_miro
12 | from .slice_param_convnext_miro import sliceparamconvnext_miro
13 | from .template_convnextv2_miro import templatemixingconvnextv2_miro
14 |
15 | ## for new model, add the new model in _forward_model(), trainer.py
16 |
--------------------------------------------------------------------------------
/models/channel_attention_pooling.py:
--------------------------------------------------------------------------------
1 | from typing import List
2 |
3 | import torch
4 | from torch import nn, Tensor
5 |
6 | from einops import rearrange, repeat
7 |
8 | from helper_classes.channel_initialization import ChannelInitialization
9 |
10 |
11 | class PreNorm(nn.Module):
12 | def __init__(self, dim, fn):
13 | super().__init__()
14 | self.norm = nn.LayerNorm(dim)
15 | self.fn = fn
16 |
17 | def forward(self, x, **kwargs):
18 | return self.fn(self.norm(x), **kwargs)
19 |
20 |
21 | class MultiHeadAttention(nn.Module):
22 | def __init__(self, model_dim, heads=8, dim_head=64, dropout=0.):
23 | """
24 | input x: (b, c, k)
25 | @param model_dim: k
26 | @param heads:
27 | @param dim_head:
28 | @param dropout:
29 | """
30 | super().__init__()
31 | inner_dim = dim_head * heads
32 | project_out = not (heads == 1 and dim_head == model_dim)
33 |
34 | self.heads = heads
35 | self.scale = dim_head ** (-0.5)
36 |
37 | self.softmax = nn.Softmax(dim=-1)
38 | self.to_qkv = nn.Linear(model_dim, inner_dim * 3, bias=False)
39 |
40 | self.to_out = nn.Sequential(
41 | nn.Linear(inner_dim, model_dim),
42 | nn.Dropout(dropout)
43 | ) if project_out else nn.Identity()
44 |
45 | def forward(self, x: Tensor):
46 | """
47 | @param x: shape of (b, c, k)
48 | @param channel_mask: shape of (c), to channel_mask if a channel is missing
49 | @return:
50 | """
51 | qkv = self.to_qkv(x).chunk(3, dim=-1)
52 | q, k, v = map(lambda t: rearrange(t, 'b c (heads dim_head) -> b heads c dim_head', heads=self.heads), qkv)
53 |
54 | sim = torch.einsum('b h q d, b h k d -> b h q k', q, k) * self.scale
55 | # channel_mask out missing channels
56 | # sim = sim.masked_fill(channel_mask == torch.tensor(False), float("-inf"))
57 | attn = self.softmax(sim)
58 |
59 | out = torch.einsum('b h q k, b h k d -> b h q d', attn, v)
60 | out = rearrange(out, 'b h c d -> b c (h d)')
61 | return self.to_out(out)
62 |
63 |
64 | class FeedForward(nn.Module):
65 | def __init__(self, dim, hidden_dim, dropout=0.):
66 | super().__init__()
67 | self.net = nn.Sequential(
68 | nn.Linear(dim, hidden_dim),
69 | nn.GELU(),
70 | nn.Dropout(dropout),
71 | nn.Linear(hidden_dim, dim),
72 | nn.Dropout(dropout)
73 | )
74 |
75 | def forward(self, x):
76 | return self.net(x)
77 |
78 |
79 | class ChannelAttentionPoolingLayer(nn.Module):
80 | def __init__(self, max_num_channels: int, dim, depth, heads, dim_head, mlp_dim,
81 | use_cls_token: bool,
82 | use_channel_tokens: bool,
83 | init_channel_tokens: ChannelInitialization, dropout=0.):
84 | super().__init__()
85 | self.cls_token = nn.Parameter(torch.randn(dim)) if use_cls_token else None
86 |
87 | if use_channel_tokens:
88 | if init_channel_tokens == ChannelInitialization.RANDOM:
89 | self.channel_tokens = nn.Parameter(torch.randn(max_num_channels, dim)/8)
90 | elif init_channel_tokens == ChannelInitialization.ZERO:
91 | self.channel_tokens = nn.Parameter(torch.zeros(max_num_channels, dim))
92 | else:
93 | raise ValueError(f"init_channel_tokens {init_channel_tokens} not supported")
94 | else:
95 | self.channel_tokens = None
96 |
97 | self.layers = nn.ModuleList([])
98 | for _ in range(depth):
99 | self.layers.append(nn.ModuleList([
100 | PreNorm(dim, MultiHeadAttention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),
101 | PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout))
102 | ]))
103 |
104 | def forward(self, x: Tensor, channel_token_idxs: List[int]) -> Tensor:
105 | ## (batch, c, k, h, w) = > ((batch, h, w), c, k) = (b, c, k)
106 | batch, c, k, h, w = x.shape
107 | x = rearrange(x, 'b c k h w -> (b h w) c k')
108 |
109 | if self.channel_tokens is not None:
110 | tokens = self.channel_tokens[channel_token_idxs]
111 | x += tokens
112 |
113 | if self.cls_token is not None:
114 | cls_tokens = repeat(self.cls_token, 'k -> b 1 k', b=batch * h * w)
115 | x = torch.concat((cls_tokens, x), dim=1)
116 |
117 | for attention, feedforward in self.layers:
118 | x = attention(x) + x
119 | x = feedforward(x) + x
120 | x = rearrange(x, '(b h w) c k -> b c k h w', b=batch, h=h)
121 |
122 | if self.cls_token is not None:
123 | x = x[:, -1, ...]
124 | else:
125 | x = torch.mean(x, dim=1)
126 |
127 | return x
128 |
129 |
130 | if __name__ == '__main__':
131 | batch, c, k, h, w = 2, 2, 6, 8, 10
132 | c_max = 3
133 |
134 | channels = [1, 2]
135 | # mask = torch.zeros(c_max, dtype=torch.bool)
136 | # mask[channels] = True
137 | # mask = rearrange(mask, 'c -> 1 1 1 c')
138 |
139 | x = torch.randn(batch, c, k, h, w)
140 | transformer = ChannelAttentionPoolingLayer(max_num_channels=c_max, dim=k, depth=1, heads=2, dim_head=k, mlp_dim=4,
141 | use_cls_token=True, use_channel_tokens=False, init_channel_tokens=None)
142 | y = transformer(x)
143 | print(y.shape)
144 |
--------------------------------------------------------------------------------
/models/convnext_base.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange
3 | from timm import create_model
4 | import torch
5 | from torch import nn
6 | import torch.nn.functional as F
7 |
8 | from config import Model
9 | from helper_classes.feature_pooling import FeaturePooling
10 | from helper_classes.first_layer_init import FirstLayerInit
11 | from models.model_utils import intialize_first_conv_layer
12 |
13 |
14 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
15 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
16 |
17 |
18 | class ConvNeXtBase(nn.Module):
19 | def __init__(self, config: Model):
20 | # pretrained_model_name "convnext_tiny.fb_in22k"
21 | super().__init__()
22 | self.cfg = config
23 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
24 |
25 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
26 | new_shape = (out_dim, config.in_dim, kh, kw)
27 |
28 | model = intialize_first_conv_layer(
29 | model,
30 | new_shape,
31 | original_in_dim,
32 | self.cfg.first_layer,
33 | self.cfg.in_dim,
34 | return_first_layer_only=False,
35 | )
36 |
37 | ## For logging purposes
38 | self.adaptive_interface = None
39 |
40 | ## Extractor: only use the feature extractor part of the model
41 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
42 | self.feature_extractor = nn.Sequential(
43 | model.stem,
44 | model.stages[0],
45 | model.stages[1],
46 | model.stages[2].downsample,
47 | *[model.stages[2].blocks[i] for i in range(9)],
48 | model.stages[3].downsample,
49 | *[model.stages[3].blocks[i] for i in range(3)],
50 | )
51 | num_proxies = (
52 | config.num_classes
53 | ) ## depends on the number of classes of the dataset
54 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
55 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
56 |
57 | init_temperature = config.temperature # scale = sqrt(1/T)
58 | if self.cfg.learnable_temp:
59 | self.logit_scale = nn.Parameter(
60 | torch.ones([]) * np.log(1 / init_temperature)
61 | )
62 | else:
63 | self.scale = np.sqrt(1.0 / init_temperature)
64 |
65 | def _reset_params(self, model):
66 | for m in model.children():
67 | if len(list(m.children())) > 0:
68 | self._reset_params(m)
69 |
70 | elif isinstance(m, nn.Conv2d):
71 | print("resetting", m)
72 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
73 | if m.bias is not None:
74 | nn.init.zeros_(m.bias)
75 | elif isinstance(m, nn.BatchNorm2d):
76 | nn.init.ones_(m.weight)
77 | nn.init.zeros_(m.bias)
78 | print("resetting", m)
79 |
80 | elif isinstance(m, nn.Linear):
81 | print("resetting", m)
82 |
83 | nn.init.normal_(m.weight, 0, 0.01)
84 | nn.init.zeros_(m.bias)
85 | else:
86 | print("skipped", m)
87 |
88 | def _init_bias(self, model):
89 | ## Init bias of the first layer
90 | if model.stem[0].bias is not None:
91 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
92 | bound = 1 / np.sqrt(fan_in)
93 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
94 |
95 | def forward(self, x: torch.Tensor) -> torch.Tensor:
96 | x = self.feature_extractor(x)
97 | if self.cfg.pooling == FeaturePooling.AVG:
98 | x = F.adaptive_avg_pool2d(x, (1, 1))
99 | elif self.cfg.pooling == FeaturePooling.MAX:
100 | x = F.adaptive_max_pool2d(x, (1, 1))
101 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
102 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
103 | x_max = F.adaptive_max_pool2d(x, (1, 1))
104 | x = torch.cat([x_avg, x_max], dim=1)
105 | elif self.cfg.pooling == FeaturePooling.NONE:
106 | pass
107 | else:
108 | raise ValueError(
109 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
110 | )
111 | x = rearrange(x, "b c h w -> b (c h w)")
112 | return x
113 |
114 |
115 | def convnext_base(cfg: Model, **kwargs) -> ConvNeXtBase:
116 | return ConvNeXtBase(config=cfg)
117 |
118 |
119 | if __name__ == "__main__":
120 | model_cfg = Model(name="convnext_base", init_weights=True)
121 | model_cfg.pretrained_model_name = "convnext_tiny.fb_in22k"
122 | model_cfg.pooling = "avg"
123 | model_cfg.unfreeze_last_n_layers = 2
124 | model_cfg.pretrained = False
125 | model_cfg.num_classes = 4
126 | model_cfg.temperature = 0.1
127 | model_cfg.first_layer = FirstLayerInit.PRETRAINED_PAD_AVG
128 | model_cfg.in_dim = 4
129 | model_cfg.reset_last_n_unfrozen_layers = True
130 | model = convnext_base(model_cfg)
131 | x = torch.randn(2, model_cfg.in_dim, 224, 224)
132 | y = model(x)
133 | print(y.shape)
134 |
--------------------------------------------------------------------------------
/models/convnext_base_miro.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange
3 | from timm import create_model
4 | import torch
5 | from torch import nn
6 | import torch.nn.functional as F
7 |
8 | from config import Model
9 | from helper_classes.feature_pooling import FeaturePooling
10 | from models.model_utils import intialize_first_conv_layer
11 |
12 |
13 | def get_module(module, name):
14 | for n, m in module.named_modules():
15 | if n == name:
16 | return m
17 |
18 |
19 | def freeze_(model):
20 | """Freeze model. Note that this function does not control BN"""
21 | for p in model.parameters():
22 | p.requires_grad_(False)
23 |
24 |
25 | class ConvNeXtBaseMIRO(nn.Module):
26 | """ConvNeXt + FrozenBN + IntermediateFeatures
27 | Based on https://github.com/kakaobrain/miro/blob/main/domainbed/networks/ur_networks.py#L165
28 | """
29 |
30 | def __init__(self, config: Model, freeze: str = None):
31 | # pretrained_model_name "convnext_tiny.fb_in22k"
32 | super().__init__()
33 | self.cfg = config
34 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
35 |
36 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
37 | new_shape = (out_dim, config.in_dim, kh, kw)
38 |
39 | model = intialize_first_conv_layer(
40 | model,
41 | new_shape,
42 | original_in_dim,
43 | self.cfg.first_layer,
44 | self.cfg.in_dim,
45 | return_first_layer_only=False,
46 | )
47 |
48 | ## For logging purposes
49 | self.adaptive_interface = None
50 |
51 | ## Extractor: only use the feature extractor part of the model
52 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
53 | self.feature_extractor = nn.Sequential(
54 | model.stem,
55 | model.stages[0],
56 | model.stages[1],
57 | model.stages[2].downsample,
58 | *[model.stages[2].blocks[i] for i in range(9)],
59 | model.stages[3].downsample,
60 | *[model.stages[3].blocks[i] for i in range(3)],
61 | )
62 | self._features = []
63 | self.feat_layers = [
64 | "0.1",
65 | "1.blocks.2.drop_path",
66 | "2.blocks.2.drop_path",
67 | "12.drop_path",
68 | "16.drop_path",
69 | ]
70 | self.build_feature_hooks(self.feat_layers)
71 |
72 | num_proxies = (
73 | config.num_classes
74 | ) ## depends on the number of classes of the dataset
75 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
76 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
77 |
78 | init_temperature = config.temperature # scale = sqrt(1/T)
79 | if self.cfg.learnable_temp:
80 | self.logit_scale = nn.Parameter(
81 | torch.ones([]) * np.log(1 / init_temperature)
82 | )
83 | else:
84 | self.scale = np.sqrt(1.0 / init_temperature)
85 |
86 | self.freeze_bn()
87 | self.freeze(freeze)
88 |
89 | def hook(self, module, input, output):
90 | self._features.append(output)
91 |
92 | def build_feature_hooks(self, feat_layers):
93 | for n, m in self.feature_extractor.named_modules():
94 | if n in feat_layers:
95 | m.register_forward_hook(self.hook)
96 | return None
97 |
98 | def freeze_bn(self):
99 | for m in self.feature_extractor.modules():
100 | if isinstance(m, nn.BatchNorm2d):
101 | m.eval()
102 |
103 | def freeze(self, freeze):
104 | if freeze is not None:
105 | if freeze == "all":
106 | print("Freezing all layers of the feature extractor")
107 | freeze_(self.feature_extractor)
108 | else:
109 | for block in self.blocks[: freeze + 1]:
110 | freeze_(block)
111 |
112 | def clear_features(self):
113 | self._features.clear()
114 |
115 | def train(self, mode: bool = True):
116 | """Override the default train() to freeze the BN parameters"""
117 | super().train(mode)
118 | self.freeze_bn()
119 |
120 | def forward(self, x: torch.Tensor, return_features: bool = True) -> torch.Tensor:
121 | self.clear_features()
122 |
123 | x = self.feature_extractor(x)
124 | if self.cfg.pooling == FeaturePooling.AVG:
125 | x = F.adaptive_avg_pool2d(x, (1, 1))
126 | elif self.cfg.pooling == FeaturePooling.MAX:
127 | x = F.adaptive_max_pool2d(x, (1, 1))
128 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
129 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
130 | x_max = F.adaptive_max_pool2d(x, (1, 1))
131 | x = torch.cat([x_avg, x_max], dim=1)
132 | elif self.cfg.pooling == FeaturePooling.NONE:
133 | pass
134 | else:
135 | raise ValueError(
136 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
137 | )
138 | x = rearrange(x, "b c h w -> b (c h w)")
139 |
140 | if return_features:
141 | return x, self._features
142 | else:
143 | return x
144 |
145 |
146 | def convnext_base_miro(cfg: Model, freeze: str = None) -> ConvNeXtBaseMIRO:
147 | return ConvNeXtBaseMIRO(config=cfg, freeze=freeze)
148 |
149 |
150 | ## test model
151 | if __name__ == "__main__":
152 | from config import Model
153 | import debugpy
154 |
155 | # debugpy.listen(5678)
156 | # print("Waiting for debugger attach")
157 | # debugpy.wait_for_client()
158 | in_dim = 5
159 | config = Model(
160 | pretrained_model_name="convnext_tiny.fb_in22k",
161 | in_dim=in_dim,
162 | first_layer="pretrained_pad_avg",
163 | num_classes=10,
164 | pooling="avg",
165 | temperature=1.0,
166 | learnable_temp=False,
167 | pretrained=False,
168 | name="convnext_tiny",
169 | init_weights=True,
170 | )
171 | model = ConvNeXtBaseMIRO(config, freeze="all")
172 | res = model(torch.randn(1, in_dim, 224, 224), return_features=True)[1]
173 | for x in res:
174 | print(x.shape)
175 |
176 | """
177 | torch.Size([1, 96, 56, 56])
178 | torch.Size([1, 96, 56, 56])
179 | torch.Size([1, 192, 28, 28])
180 | torch.Size([1, 384, 14, 14])
181 | torch.Size([1, 768, 7, 7])
182 | """
183 |
--------------------------------------------------------------------------------
/models/convnext_shared_miro.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange
3 | from timm import create_model
4 | import torch
5 | from torch import nn
6 | import torch.nn.functional as F
7 | from copy import deepcopy
8 | from helper_classes.first_layer_init import FirstLayerInit
9 |
10 | from config import Model
11 | from helper_classes.feature_pooling import FeaturePooling
12 | from models.model_utils import intialize_first_conv_layer
13 |
14 |
15 | def get_module(module, name):
16 | for n, m in module.named_modules():
17 | if n == name:
18 | return m
19 |
20 |
21 | def freeze_(model):
22 | """Freeze model. Note that this function does not control BN"""
23 | for p in model.parameters():
24 | p.requires_grad_(False)
25 |
26 |
27 | class ConvNeXtSharedMIRO(nn.Module):
28 | """ConvNeXt + FrozenBN + IntermediateFeatures
29 | Based on https://github.com/kakaobrain/miro/blob/main/domainbed/networks/ur_networks.py#L165
30 | """
31 |
32 | def __init__(self, config: Model, freeze: str = None):
33 | # pretrained_model_name "convnext_tiny.fb_in22k"
34 | super().__init__()
35 | self.cfg = config
36 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
37 | in_dim_map = {"Allen": 3, "HPA": 4, "CP": 5}
38 |
39 | self.first_layer = nn.ModuleDict()
40 |
41 | for chunk, new_in_dim in in_dim_map.items():
42 | layer_1 = self._get_first_layer(model, new_in_dim)
43 | self.first_layer.add_module(chunk, layer_1)
44 |
45 | ## Store reference to sel.first_layer for later access
46 | self.adaptive_interface = nn.ModuleList([self.first_layer])
47 |
48 | ## Extractor: only use the feature extractor part of the model
49 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
50 | self.feature_extractor = nn.Sequential(
51 | model.stem[1],
52 | model.stages[0],
53 | model.stages[1],
54 | model.stages[2].downsample,
55 | *[model.stages[2].blocks[i] for i in range(9)],
56 | model.stages[3].downsample,
57 | *[model.stages[3].blocks[i] for i in range(3)],
58 | )
59 | self._features = []
60 | self.feat_layers = [
61 | "0",
62 | "1.blocks.2.drop_path",
63 | "2.blocks.2.drop_path",
64 | "12.drop_path",
65 | "16.drop_path",
66 | ]
67 | self.build_feature_hooks(self.feat_layers)
68 |
69 | num_proxies = (
70 | config.num_classes
71 | ) ## depends on the number of classes of the dataset
72 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
73 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
74 |
75 | init_temperature = config.temperature # scale = sqrt(1/T)
76 | if self.cfg.learnable_temp:
77 | self.logit_scale = nn.Parameter(
78 | torch.ones([]) * np.log(1 / init_temperature)
79 | )
80 | else:
81 | self.scale = np.sqrt(1.0 / init_temperature)
82 |
83 | self.freeze_bn()
84 | self.freeze(freeze)
85 |
86 | def _get_first_layer(self, model, new_in_dim):
87 | config = self.cfg
88 | config.in_dim = None
89 |
90 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
91 | new_shape = (out_dim, new_in_dim, kh, kw)
92 | layer_1 = model.stem[0].weight
93 | if config.first_layer == FirstLayerInit.REINIT_AS_RANDOM:
94 | layer_1 = nn.Parameter(torch.zeros(new_shape))
95 | nn.init.kaiming_normal_(layer_1, mode="fan_out", nonlinearity="relu")
96 | # self._init_bias(model)
97 | elif config.first_layer == FirstLayerInit.PRETRAINED_PAD_RANDOM:
98 | if original_in_dim < new_in_dim:
99 | original_data = model.stem[0].weight.data.detach().clone()
100 | layer_1 = nn.Parameter(torch.zeros(new_shape))
101 | nn.init.kaiming_normal_(layer_1, mode="fan_out", nonlinearity="relu")
102 | layer_1.data[:, :original_in_dim, :, :] = original_data
103 | # self._init_bias(model)
104 | elif config.first_layer == FirstLayerInit.PRETRAINED_PAD_AVG:
105 | if original_in_dim < new_in_dim:
106 | original_data = model.stem[0].weight.data.detach().clone()
107 | layer_1 = nn.Parameter(torch.zeros(new_shape))
108 | nn.init.kaiming_normal_(layer_1, mode="fan_out", nonlinearity="relu")
109 | layer_1.data[:, :original_in_dim, :, :] = original_data
110 |
111 | num_channels_to_avg = 2 if new_in_dim == 5 else 3
112 | for i, c in enumerate(range(original_in_dim, new_in_dim)):
113 | layer_1.data[:, c, :, :] = original_data[
114 | :, i : num_channels_to_avg + i, ...
115 | ].mean(dim=1)
116 | else:
117 | raise NotImplementedError(
118 | f"First layer init {config.first_layer} not implemented"
119 | )
120 | conv1 = deepcopy(model.stem[0])
121 | conv1.weight = layer_1
122 |
123 | return conv1
124 |
125 | def hook(self, module, input, output):
126 | self._features.append(output)
127 |
128 | def build_feature_hooks(self, feat_layers):
129 | for n, m in self.feature_extractor.named_modules():
130 | if n in feat_layers:
131 | m.register_forward_hook(self.hook)
132 | return None
133 |
134 | def freeze_bn(self):
135 | for m in self.feature_extractor.modules():
136 | if isinstance(m, nn.BatchNorm2d):
137 | m.eval()
138 |
139 | def freeze(self, freeze):
140 | if freeze is not None:
141 | if freeze == "all":
142 | print("Freezing all layers of the feature extractor")
143 | freeze_(self.feature_extractor)
144 | else:
145 | for block in self.blocks[: freeze + 1]:
146 | freeze_(block)
147 |
148 | def clear_features(self):
149 | self._features.clear()
150 |
151 | def train(self, mode: bool = True):
152 | """Override the default train() to freeze the BN parameters"""
153 | super().train(mode)
154 | self.freeze_bn()
155 |
156 | def forward(
157 | self, x: torch.Tensor, chunk, return_features: bool = True
158 | ) -> torch.Tensor:
159 | self.clear_features()
160 | assert chunk in self.first_layer, f"chunk={chunk} is not valid!"
161 | conv1 = self.first_layer[chunk]
162 | x = conv1(x)
163 | x = self.feature_extractor(x)
164 | if self.cfg.pooling == FeaturePooling.AVG:
165 | x = F.adaptive_avg_pool2d(x, (1, 1))
166 | elif self.cfg.pooling == FeaturePooling.MAX:
167 | x = F.adaptive_max_pool2d(x, (1, 1))
168 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
169 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
170 | x_max = F.adaptive_max_pool2d(x, (1, 1))
171 | x = torch.cat([x_avg, x_max], dim=1)
172 | elif self.cfg.pooling == FeaturePooling.NONE:
173 | pass
174 | else:
175 | raise ValueError(
176 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
177 | )
178 | x = rearrange(x, "b c h w -> b (c h w)")
179 |
180 | if return_features:
181 | return x, self._features
182 | else:
183 | return x
184 |
185 |
186 | def convnext_shared_miro(cfg: Model, freeze: str = None) -> ConvNeXtSharedMIRO:
187 | return ConvNeXtSharedMIRO(config=cfg, freeze=freeze)
188 |
--------------------------------------------------------------------------------
/models/depthwise_convnext.py:
--------------------------------------------------------------------------------
1 | from typing import Optional
2 |
3 | import numpy as np
4 | from einops import rearrange
5 | from timm import create_model
6 | import torch
7 | from torch import nn, Tensor
8 | import torch.nn.functional as F
9 |
10 | from config import Model, AttentionPoolingParams
11 | from helper_classes.channel_pooling_type import ChannelPoolingType
12 | from helper_classes.feature_pooling import FeaturePooling
13 | from models.channel_attention_pooling import ChannelAttentionPoolingLayer
14 | from models.model_utils import conv1x1
15 |
16 |
17 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
18 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
19 |
20 |
21 | class DepthwiseConvNeXt(nn.Module):
22 | def __init__(
23 | self,
24 | config: Model,
25 | attn_pooling_params: Optional[AttentionPoolingParams] = None,
26 | ):
27 | # pretrained_model_name "convnext_tiny.fb_in22k"
28 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
29 |
30 | super().__init__()
31 | self.cfg = config
32 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
33 |
34 | self.kernels_per_channel = config.kernels_per_channel
35 | self.pooling_channel_type = config.pooling_channel_type
36 |
37 | ## all channels in this order (alphabet): ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
38 | self.mapper = {
39 | "Allen": [5, 2, 6],
40 | "HPA": [3, 6, 5, 0],
41 | "CP": [5, 0, 7, 1, 4],
42 | }
43 |
44 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
45 | self.stride = model.stem[0].stride
46 | self.padding = model.stem[0].padding
47 | self.dilation = model.stem[0].dilation
48 | self.groups = model.stem[0].groups
49 |
50 | total_in_channels = len(config.in_channel_names)
51 |
52 | self.get_patch_emb = nn.ModuleDict()
53 | patch = 4
54 | for chunk in self.mapper:
55 | self.get_patch_emb[chunk] = nn.Conv2d(
56 | len(self.mapper[chunk]),
57 | len(self.mapper[chunk]),
58 | kernel_size=patch,
59 | stride=patch,
60 | padding=0,
61 | groups=len(self.mapper[chunk]),
62 | )
63 |
64 | self.conv1depthwise_param_bank = nn.Parameter(
65 | torch.zeros(total_in_channels * self.kernels_per_channel, 1, 3, 3)
66 | )
67 |
68 | self.conv_1x1 = conv1x1(self.kernels_per_channel, out_dim)
69 |
70 | if self.pooling_channel_type in [
71 | ChannelPoolingType.WEIGHTED_SUM_RANDOM,
72 | ChannelPoolingType.WEIGHTED_SUM_RANDOM_NO_SOFTMAX,
73 | ]:
74 | self.weighted_sum_pooling = nn.Parameter(torch.randn(total_in_channels))
75 |
76 | if self.pooling_channel_type in [
77 | ChannelPoolingType.WEIGHTED_SUM_RANDOM_PAIRWISE_NO_SOFTMAX,
78 | ChannelPoolingType.WEIGHTED_SUM_RANDOM_PAIRWISE,
79 | ]:
80 | self.weighted_sum_pooling = torch.nn.ParameterDict()
81 | for channel, idxs in self.mapper.items():
82 | self.weighted_sum_pooling[channel] = nn.Parameter(
83 | torch.randn(len(idxs))
84 | )
85 |
86 | if self.pooling_channel_type in [
87 | ChannelPoolingType.WEIGHTED_SUM_ONE,
88 | ChannelPoolingType.WEIGHTED_SUM_ONE_NO_SOFTMAX,
89 | ]:
90 | self.weighted_sum_pooling = nn.Parameter(torch.ones(total_in_channels))
91 |
92 | if self.pooling_channel_type == ChannelPoolingType.ATTENTION:
93 | ## fill out some default values for attn_pooling_params
94 | attn_pooling_params.dim = self.kernels_per_channel
95 | attn_pooling_params.max_num_channels = total_in_channels
96 | self.attn_pooling = ChannelAttentionPoolingLayer(**attn_pooling_params)
97 |
98 | nn.init.kaiming_normal_(
99 | self.conv1depthwise_param_bank, mode="fan_in", nonlinearity="relu"
100 | )
101 |
102 | ## store reference for later access
103 | self.adaptive_interface = nn.ParameterList(
104 | [self.get_patch_emb, self.conv_1x1, self.conv1depthwise_param_bank]
105 | )
106 | if hasattr(self, "weighted_sum_pooling"):
107 | self.adaptive_interface.append(self.weighted_sum_pooling)
108 | if hasattr(self, "attn_pooling"):
109 | self.adaptive_interface.append(self.attn_pooling)
110 |
111 | ## shared feature_extractor
112 | self.feature_extractor = nn.Sequential(
113 | # model.stem[1],
114 | model.stages[0],
115 | model.stages[1],
116 | model.stages[2].downsample,
117 | *[model.stages[2].blocks[i] for i in range(9)],
118 | model.stages[3].downsample,
119 | *[model.stages[3].blocks[i] for i in range(3)],
120 | )
121 |
122 | self.norm = nn.InstanceNorm2d(out_dim, affine=True)
123 |
124 | num_proxies = (
125 | config.num_classes
126 | ) ## depends on the number of classes of the dataset
127 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
128 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
129 | init_temperature = config.temperature # scale = sqrt(1/T)
130 | if self.cfg.learnable_temp:
131 | self.logit_scale = nn.Parameter(
132 | torch.ones([]) * np.log(1 / init_temperature)
133 | )
134 | else:
135 | self.scale = np.sqrt(1.0 / init_temperature)
136 |
137 | def slice_params_first_layer(self, chunk: str) -> Tensor:
138 | assert chunk in self.mapper, f"Invalid data_channel: {chunk}"
139 |
140 | ## conv1depthwise_param_bank's shape: (c_total * kernels_per_channel, 1, 3, 3)
141 | param_list = []
142 | for c in self.mapper[chunk]:
143 | param = self.conv1depthwise_param_bank[
144 | c * self.kernels_per_channel : (c + 1) * self.kernels_per_channel, ...
145 | ]
146 | param_list.append(param)
147 | params = torch.cat(param_list, dim=0)
148 |
149 | return params
150 |
151 | def _reset_params(self, model):
152 | for m in model.children():
153 | if len(list(m.children())) > 0:
154 | self._reset_params(m)
155 |
156 | elif isinstance(m, nn.Conv2d):
157 | print("resetting", m)
158 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
159 | if m.bias is not None:
160 | nn.init.zeros_(m.bias)
161 | elif isinstance(m, nn.BatchNorm2d):
162 | nn.init.ones_(m.weight)
163 | nn.init.zeros_(m.bias)
164 | print("resetting", m)
165 |
166 | elif isinstance(m, nn.Linear):
167 | print("resetting", m)
168 |
169 | nn.init.normal_(m.weight, 0, 0.01)
170 | nn.init.zeros_(m.bias)
171 | else:
172 | print("skipped", m)
173 |
174 | def _init_bias(self, model):
175 | ## Init bias of the first layer
176 | if model.stem[0].bias is not None:
177 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
178 | bound = 1 / np.sqrt(fan_in)
179 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
180 |
181 | def forward(self, x: torch.Tensor, chunk: str) -> torch.Tensor:
182 | c = x.shape[1]
183 |
184 | ## slice params of the first layers
185 | conv1depth_params = self.slice_params_first_layer(chunk)
186 |
187 | assert len(self.mapper[chunk]) == c
188 | assert conv1depth_params.shape == (c * self.kernels_per_channel, 1, 3, 3)
189 |
190 | out = self.get_patch_emb[chunk](x)
191 | out = F.conv2d(out, conv1depth_params, bias=None, stride=1, padding=1, groups=c)
192 | out = rearrange(out, "b (c k) h w -> b c k h w", k=self.kernels_per_channel)
193 |
194 | if self.pooling_channel_type == ChannelPoolingType.AVG:
195 | out = out.mean(dim=1)
196 | elif self.pooling_channel_type == ChannelPoolingType.SUM:
197 | out = out.sum(dim=1)
198 | elif self.pooling_channel_type in (
199 | ChannelPoolingType.WEIGHTED_SUM_RANDOM,
200 | ChannelPoolingType.WEIGHTED_SUM_ONE,
201 | ):
202 | weights = F.softmax(self.weighted_sum_pooling[self.mapper[chunk]])
203 | weights = rearrange(weights, "c -> c 1 1 1")
204 | out = (out * weights).sum(dim=1)
205 | elif self.pooling_channel_type in (
206 | ChannelPoolingType.WEIGHTED_SUM_RANDOM_NO_SOFTMAX,
207 | ChannelPoolingType.WEIGHTED_SUM_ONE_NO_SOFTMAX,
208 | ):
209 | weights = self.weighted_sum_pooling[self.mapper[chunk]]
210 | weights = rearrange(weights, "c -> c 1 1 1")
211 | out = (out * weights).sum(dim=1)
212 | elif (
213 | self.pooling_channel_type
214 | == ChannelPoolingType.WEIGHTED_SUM_RANDOM_PAIRWISE_NO_SOFTMAX
215 | ):
216 | weights = self.weighted_sum_pooling[chunk]
217 | weights = rearrange(weights, "c -> c 1 1 1")
218 | out = (out * weights).sum(dim=1)
219 | elif (
220 | self.pooling_channel_type == ChannelPoolingType.WEIGHTED_SUM_RANDOM_PAIRWISE
221 | ):
222 | weights = F.softmax(self.weighted_sum_pooling[chunk])
223 | weights = rearrange(weights, "c -> c 1 1 1")
224 | out = (out * weights).sum(dim=1)
225 | elif self.pooling_channel_type == ChannelPoolingType.ATTENTION:
226 | out = self.attn_pooling(out, channel_token_idxs=self.mapper[chunk])
227 | else:
228 | raise ValueError(
229 | f"Invalid pooling_channel_type: {self.pooling_channel_type}"
230 | )
231 |
232 | out = self.norm(self.conv_1x1(out))
233 | out = self.feature_extractor(out)
234 | if self.cfg.pooling == FeaturePooling.AVG:
235 | out = F.adaptive_avg_pool2d(out, (1, 1))
236 | elif self.cfg.pooling == FeaturePooling.MAX:
237 | out = F.adaptive_max_pool2d(out, (1, 1))
238 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
239 | x_avg = F.adaptive_avg_pool2d(out, (1, 1))
240 | x_max = F.adaptive_max_pool2d(out, (1, 1))
241 | out = torch.cat([x_avg, x_max], dim=1)
242 | elif self.cfg.pooling == FeaturePooling.NONE:
243 | pass
244 | else:
245 | raise ValueError(
246 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
247 | )
248 | out = rearrange(out, "b c h w -> b (c h w)")
249 | return out
250 |
251 |
252 | def depthwiseconvnext(cfg: Model, **kwargs) -> DepthwiseConvNeXt:
253 | return DepthwiseConvNeXt(config=cfg, **kwargs)
254 |
255 |
256 | if __name__ == "__main__":
257 | a = 1
258 | print(a)
259 |
--------------------------------------------------------------------------------
/models/hypernet.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 |
8 |
9 | class HyperNetwork(nn.Module):
10 | def __init__(self, z_dim, d, kernel_size, out_size, in_size=1):
11 | super().__init__()
12 | self.z_dim = z_dim
13 | self.d = d ## in the paper, d = z_dim
14 | self.kernel_size = kernel_size
15 | self.out_size = out_size
16 | self.in_size = in_size
17 |
18 | self.W = nn.Parameter(torch.randn((self.z_dim, self.in_size, self.d)))
19 | self.b = nn.Parameter(torch.randn((self.in_size, self.d)))
20 |
21 | self.W_out = nn.Parameter(
22 | torch.randn((self.d, self.out_size, self.kernel_size, self.kernel_size))
23 | )
24 | self.b_out = nn.Parameter(torch.randn((self.out_size, self.kernel_size, self.kernel_size)))
25 |
26 | self._init_weights()
27 |
28 | def _init_weights(self):
29 | nn.init.kaiming_normal_(self.W)
30 | nn.init.kaiming_normal_(self.W_out)
31 |
32 | def forward(self, z: Tensor) -> Tensor:
33 | """
34 | @param z: (num_channels, z_dim)
35 | @return: kernel (out_size, in_size, kernel_size, kernel_size)
36 | """
37 | a = torch.einsum("c z, z i d ->c i d", z, self.W) + self.b
38 | K = torch.einsum("c i d, d o h w ->c i o h w", a, self.W_out) + self.b_out
39 | K = rearrange(K, "c i o h w -> o (c i) h w")
40 | return K
41 |
--------------------------------------------------------------------------------
/models/hypernet_convnext.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 |
8 | from models.hypernet import HyperNetwork
9 | from config import Model
10 | from helper_classes.feature_pooling import FeaturePooling
11 |
12 |
13 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
14 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
15 |
16 |
17 | def get_mapper():
18 | allen = ["nucleus", "membrane", "protein"]
19 | hpa = ["microtubules", "protein", "nucleus", "er"]
20 | cp = ["nucleus", "er", "rna", "golgi", "mito"]
21 | total = list(sorted(set(allen + hpa + cp)))
22 | total_dict = {x: i for i, x in enumerate(total)}
23 |
24 | a = [total_dict[x] for x in allen]
25 | h = [total_dict[x] for x in hpa]
26 | c = [total_dict[x] for x in cp]
27 | ## a,h,c: [5, 2, 6], [3, 6, 5, 0], [5, 0, 7, 1, 4]
28 | return a, h, c
29 |
30 |
31 | class HyperConvNeXt(nn.Module):
32 | def __init__(self, config: Model):
33 | # pretrained_model_name "convnext_tiny.fb_in22k"
34 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
35 |
36 | super().__init__()
37 | self.cfg = config
38 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
39 |
40 | total_in_channels = len(config.in_channel_names)
41 |
42 | ## all channels in this order (alphabet): ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
43 | self.mapper = {
44 | "Allen": [5, 2, 6],
45 | "HPA": [3, 6, 5, 0],
46 | "CP": [5, 0, 7, 1, 4],
47 | }
48 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
49 | self.stride = model.stem[0].stride
50 | self.padding = model.stem[0].padding
51 | self.dilation = model.stem[0].dilation
52 | self.groups = model.stem[0].groups
53 |
54 | # First conv layer
55 | if config.separate_emb:
56 | self.conv1_emb = nn.ParameterDict(
57 | {
58 | data_channel: torch.randn(len(channels), config.z_dim)
59 | for data_channel, channels in self.mapper.items()
60 | }
61 | )
62 | else:
63 | self.conv1_emb = nn.Embedding(total_in_channels, config.z_dim)
64 |
65 | self.hypernet = HyperNetwork(config.z_dim, config.hidden_dim, kh, out_dim, 1)
66 |
67 | ## Make a list to store reference to `conv1_emb` and `hypernet` for easy access
68 | self.adaptive_interface = nn.ModuleList([self.conv1_emb, self.hypernet])
69 |
70 | ## shared feature_extractor
71 | self.feature_extractor = nn.Sequential(
72 | model.stem[1], ## norm_layer(dims[0])
73 | model.stages[0],
74 | model.stages[1],
75 | model.stages[2].downsample,
76 | *[model.stages[2].blocks[i] for i in range(9)],
77 | model.stages[3].downsample,
78 | *[model.stages[3].blocks[i] for i in range(3)],
79 | )
80 |
81 | num_proxies = config.num_classes ## depends on the number of classes of the dataset
82 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
83 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
84 | init_temperature = config.temperature # scale = sqrt(1/T)
85 | if self.cfg.learnable_temp:
86 | self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / init_temperature))
87 | else:
88 | self.scale = np.sqrt(1.0 / init_temperature)
89 |
90 | def generate_params_first_layer(self, chunk: str) -> Tensor:
91 | assert chunk in self.mapper, f"Invalid chunk: {chunk}"
92 | if self.cfg.separate_emb:
93 | z_emb = self.conv1_emb[chunk]
94 | else:
95 | z_emb = self.conv1_emb(
96 | torch.tensor(
97 | self.mapper[chunk],
98 | dtype=torch.long,
99 | device=self.conv1_emb.weight.device,
100 | )
101 | )
102 |
103 | kernels = self.hypernet(z_emb)
104 | return kernels
105 |
106 | def _reset_params(self, model):
107 | for m in model.children():
108 | if len(list(m.children())) > 0:
109 | self._reset_params(m)
110 |
111 | elif isinstance(m, nn.Conv2d):
112 | print("resetting", m)
113 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
114 | if m.bias is not None:
115 | nn.init.zeros_(m.bias)
116 | elif isinstance(m, nn.BatchNorm2d):
117 | nn.init.ones_(m.weight)
118 | nn.init.zeros_(m.bias)
119 | print("resetting", m)
120 |
121 | elif isinstance(m, nn.Linear):
122 | print("resetting", m)
123 |
124 | nn.init.normal_(m.weight, 0, 0.01)
125 | nn.init.zeros_(m.bias)
126 | else:
127 | print("skipped", m)
128 |
129 | def _init_bias(self, model):
130 | ## Init bias of the first layer
131 | if model.stem[0].bias is not None:
132 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
133 | bound = 1 / np.sqrt(fan_in)
134 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
135 |
136 | def forward(self, x: torch.Tensor, chunk: str) -> torch.Tensor:
137 | conv1_params = self.generate_params_first_layer(chunk)
138 | x = F.conv2d(
139 | x,
140 | conv1_params,
141 | bias=None,
142 | stride=self.stride,
143 | padding=self.padding,
144 | dilation=self.dilation,
145 | groups=self.groups,
146 | )
147 |
148 | x = self.feature_extractor(x)
149 | if self.cfg.pooling == FeaturePooling.AVG:
150 | x = F.adaptive_avg_pool2d(x, (1, 1))
151 | elif self.cfg.pooling == FeaturePooling.MAX:
152 | x = F.adaptive_max_pool2d(x, (1, 1))
153 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
154 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
155 | x_max = F.adaptive_max_pool2d(x, (1, 1))
156 | x = torch.cat([x_avg, x_max], dim=1)
157 | elif self.cfg.pooling == FeaturePooling.NONE:
158 | pass
159 | else:
160 | raise ValueError(
161 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
162 | )
163 | x = rearrange(x, "b c h w -> b (c h w)")
164 | return x
165 |
166 |
167 | def hyperconvnext(cfg: Model, **kwargs) -> HyperConvNeXt:
168 | return HyperConvNeXt(config=cfg)
169 |
--------------------------------------------------------------------------------
/models/hypernet_convnext_miro.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 |
8 | from models.hypernet import HyperNetwork
9 | from config import Model
10 | from helper_classes.feature_pooling import FeaturePooling
11 | from models.model_utils import freeze_, get_module
12 |
13 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
14 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
15 |
16 |
17 | def get_mapper():
18 | allen = ["nucleus", "membrane", "protein"]
19 | hpa = ["microtubules", "protein", "nucleus", "er"]
20 | cp = ["nucleus", "er", "rna", "golgi", "mito"]
21 | total = list(sorted(set(allen + hpa + cp)))
22 | total_dict = {x: i for i, x in enumerate(total)}
23 |
24 | a = [total_dict[x] for x in allen]
25 | h = [total_dict[x] for x in hpa]
26 | c = [total_dict[x] for x in cp]
27 | ## a,h,c: [5, 2, 6], [3, 6, 5, 0], [5, 0, 7, 1, 4]
28 | return a, h, c
29 |
30 |
31 | class HyperConvNeXtMIRO(nn.Module):
32 | def __init__(self, config: Model, freeze: str = None):
33 | # pretrained_model_name "convnext_tiny.fb_in22k"
34 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
35 |
36 | super().__init__()
37 | self.cfg = config
38 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
39 |
40 | total_in_channels = len(config.in_channel_names)
41 |
42 | ## all channels in this order (alphabet): ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
43 | self.mapper = {
44 | "Allen": [5, 2, 6],
45 | "HPA": [3, 6, 5, 0],
46 | "CP": [5, 0, 7, 1, 4],
47 | }
48 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
49 | self.stride = model.stem[0].stride
50 | self.padding = model.stem[0].padding
51 | self.dilation = model.stem[0].dilation
52 | self.groups = model.stem[0].groups
53 |
54 | # First conv layer
55 | if config.separate_emb:
56 | self.conv1_emb = nn.ParameterDict(
57 | {
58 | data_channel: torch.randn(len(channels), config.z_dim)
59 | for data_channel, channels in self.mapper.items()
60 | }
61 | )
62 | else:
63 | self.conv1_emb = nn.Embedding(total_in_channels, config.z_dim)
64 |
65 | self.hypernet = HyperNetwork(config.z_dim, config.hidden_dim, kh, out_dim, 1)
66 |
67 | ## Make a list to store reference to `conv1_emb` and `hypernet` for easy access
68 | self.adaptive_interface = nn.ModuleList([self.conv1_emb, self.hypernet])
69 |
70 | ## shared feature_extractor
71 | self.feature_extractor = nn.Sequential(
72 | model.stem[1], ## norm_layer(dims[0])
73 | model.stages[0],
74 | model.stages[1],
75 | model.stages[2].downsample,
76 | *[model.stages[2].blocks[i] for i in range(9)],
77 | model.stages[3].downsample,
78 | *[model.stages[3].blocks[i] for i in range(3)],
79 | )
80 | self._features = []
81 | self.feat_layers = [
82 | "0",
83 | "1.blocks.2.drop_path",
84 | "2.blocks.2.drop_path",
85 | "12.drop_path",
86 | "16.drop_path",
87 | ]
88 | self.build_feature_hooks(self.feat_layers)
89 |
90 | num_proxies = config.num_classes ## depends on the number of classes of the dataset
91 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
92 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
93 | init_temperature = config.temperature # scale = sqrt(1/T)
94 | if self.cfg.learnable_temp:
95 | self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / init_temperature))
96 | else:
97 | self.scale = np.sqrt(1.0 / init_temperature)
98 |
99 | self.freeze_bn()
100 | self.freeze(freeze)
101 |
102 | def generate_params_first_layer(self, chunk: str) -> Tensor:
103 | assert chunk in self.mapper, f"Invalid chunk: {chunk}"
104 | if self.cfg.separate_emb:
105 | z_emb = self.conv1_emb[chunk]
106 | else:
107 | z_emb = self.conv1_emb(
108 | torch.tensor(
109 | self.mapper[chunk],
110 | dtype=torch.long,
111 | device=self.conv1_emb.weight.device,
112 | )
113 | )
114 |
115 | kernels = self.hypernet(z_emb)
116 | return kernels
117 |
118 | def hook(self, module, input, output):
119 | self._features.append(output)
120 |
121 | def build_feature_hooks(self, feat_layers):
122 | for n, m in self.feature_extractor.named_modules():
123 | if n in feat_layers:
124 | m.register_forward_hook(self.hook)
125 | return None
126 |
127 | def freeze_bn(self):
128 | for m in self.feature_extractor.modules():
129 | if isinstance(m, nn.BatchNorm2d):
130 | m.eval()
131 |
132 | def freeze(self, freeze):
133 | if freeze is not None:
134 | if freeze == "all":
135 | print("Freezing all layers of the feature extractor")
136 | freeze_(self.feature_extractor)
137 | else:
138 | for block in self.blocks[: freeze + 1]:
139 | freeze_(block)
140 |
141 | def clear_features(self):
142 | self._features.clear()
143 |
144 | def train(self, mode: bool = True):
145 | """Override the default train() to freeze the BN parameters"""
146 | super().train(mode)
147 | self.freeze_bn()
148 |
149 | def _reset_params(self, model):
150 | for m in model.children():
151 | if len(list(m.children())) > 0:
152 | self._reset_params(m)
153 |
154 | elif isinstance(m, nn.Conv2d):
155 | print("resetting", m)
156 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
157 | if m.bias is not None:
158 | nn.init.zeros_(m.bias)
159 | elif isinstance(m, nn.BatchNorm2d):
160 | nn.init.ones_(m.weight)
161 | nn.init.zeros_(m.bias)
162 | print("resetting", m)
163 |
164 | elif isinstance(m, nn.Linear):
165 | print("resetting", m)
166 |
167 | nn.init.normal_(m.weight, 0, 0.01)
168 | nn.init.zeros_(m.bias)
169 | else:
170 | print("skipped", m)
171 |
172 | def _init_bias(self, model):
173 | ## Init bias of the first layer
174 | if model.stem[0].bias is not None:
175 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
176 | bound = 1 / np.sqrt(fan_in)
177 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
178 |
179 | def forward(self, x: torch.Tensor, chunk: str, return_features: bool = True) -> torch.Tensor:
180 | self.clear_features()
181 |
182 | conv1_params = self.generate_params_first_layer(chunk)
183 | x = F.conv2d(
184 | x,
185 | conv1_params,
186 | bias=None,
187 | stride=self.stride,
188 | padding=self.padding,
189 | dilation=self.dilation,
190 | groups=self.groups,
191 | )
192 |
193 | x = self.feature_extractor(x)
194 | if self.cfg.pooling == FeaturePooling.AVG:
195 | x = F.adaptive_avg_pool2d(x, (1, 1))
196 | elif self.cfg.pooling == FeaturePooling.MAX:
197 | x = F.adaptive_max_pool2d(x, (1, 1))
198 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
199 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
200 | x_max = F.adaptive_max_pool2d(x, (1, 1))
201 | x = torch.cat([x_avg, x_max], dim=1)
202 | elif self.cfg.pooling == FeaturePooling.NONE:
203 | pass
204 | else:
205 | raise ValueError(
206 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
207 | )
208 | x = rearrange(x, "b c h w -> b (c h w)")
209 |
210 | if return_features:
211 | return x, self._features
212 | else:
213 | return x
214 |
215 |
216 | def hyperconvnext_miro(cfg: Model, freeze: str = None) -> HyperConvNeXtMIRO:
217 | return HyperConvNeXtMIRO(config=cfg, freeze=freeze)
218 |
--------------------------------------------------------------------------------
/models/loss_fn.py:
--------------------------------------------------------------------------------
1 | from torch import nn, Tensor
2 | import torch.nn.functional as F
3 |
4 | from utils import pairwise_distance_v2
5 |
6 |
7 | def proxy_loss(proxies, img_emb, gt_imgs, scale: float | nn.Parameter) -> Tensor:
8 | ## https://arxiv.org/pdf/2004.01113v2.pdf
9 | proxies_emb = scale * F.normalize(proxies, p=2, dim=-1)
10 | img_emb = scale * F.normalize(img_emb, p=2, dim=-1)
11 |
12 | img_dist = pairwise_distance_v2(proxies=proxies_emb, x=img_emb, squared=True)
13 | img_dist = img_dist * -1.0
14 |
15 | cross_entropy = nn.CrossEntropyLoss(reduction="mean")
16 | img_loss = cross_entropy(img_dist, gt_imgs)
17 | return img_loss
18 |
--------------------------------------------------------------------------------
/models/model_utils.py:
--------------------------------------------------------------------------------
1 | from typing import Tuple
2 | import torch
3 | from torch import nn
4 | from itertools import chain
5 | from timm.models import ConvNeXt
6 | import torch.nn.functional as F
7 | from config import Model
8 | from helper_classes.first_layer_init import FirstLayerInit
9 |
10 |
11 | def conv1x1(in_dim: int, out_dim: int, stride: int = 1) -> nn.Conv2d:
12 | """return 1x1 conv"""
13 | return nn.Conv2d(in_dim, out_dim, kernel_size=1, stride=stride, bias=False)
14 |
15 |
16 | def conv3x3(in_dim: int, out_dim: int, stride: int, padding: int) -> nn.Conv2d:
17 | """return 3x3 conv"""
18 | return nn.Conv2d(
19 | in_dim, out_dim, kernel_size=3, stride=stride, padding=padding, bias=False
20 | )
21 |
22 |
23 | def toggle_grad(model: nn.Module, requires_grad: bool) -> None:
24 | """Toggle requires_grad for all parameters in the model"""
25 | for param in model.parameters():
26 | param.requires_grad = requires_grad
27 | return None
28 |
29 |
30 | def unfreeze_last_layers(model: nn.Module, num_last_layers: int) -> None:
31 | """Freeze some last layers of the feature extractor"""
32 | if num_last_layers == -1: #### unfreeze all
33 | toggle_grad(model, requires_grad=True)
34 | else:
35 | ## First, freeze all
36 | toggle_grad(model, requires_grad=False)
37 |
38 | ## Then, unfreeze some last layers
39 | if num_last_layers > 0:
40 | for param in model[-num_last_layers:].parameters():
41 | param.requires_grad = True
42 | else: ## == 0
43 | pass ## all layers are frozen
44 | return None
45 |
46 |
47 | def intialize_first_conv_layer(
48 | model: ConvNeXt,
49 | new_shape: Tuple,
50 | original_in_dim: int,
51 | first_layer: FirstLayerInit,
52 | in_dim: int,
53 | return_first_layer_only: bool,
54 | ):
55 | """
56 | Initialize the first conv layer of a ConvNext model
57 | Return a modified model with the first conv layer initialized
58 | """
59 | ###### Init weights and biases of the first layer
60 | ## Note: we can also use the built-in feature of timm for this by using `in_chans`
61 | ## model = create_model(config.pretrained_model_name, pretrained=config.pretrained, in_chans=config.in_dim)
62 | ## Read more: https://timm.fast.ai/models#So-how-is-timm-able-to-load-these-weights
63 | if first_layer == FirstLayerInit.REINIT_AS_RANDOM:
64 | model.stem[0].weight = nn.Parameter(torch.zeros(new_shape))
65 | nn.init.kaiming_normal_(
66 | model.stem[0].weight, mode="fan_out", nonlinearity="relu"
67 | )
68 | # self._init_bias(model)
69 | elif first_layer == FirstLayerInit.PRETRAINED_PAD_RANDOM:
70 | if original_in_dim < in_dim:
71 | original_data = model.stem[0].weight.data.detach().clone()
72 | model.stem[0].weight = nn.Parameter(torch.zeros(new_shape))
73 | nn.init.kaiming_normal_(
74 | model.stem[0].weight, mode="fan_out", nonlinearity="relu"
75 | )
76 | model.stem[0].weight.data[:, :original_in_dim, :, :] = original_data
77 | model.stem[0].in_channels = in_dim
78 |
79 | # self._init_bias(model)
80 | elif first_layer == FirstLayerInit.PRETRAINED_PAD_AVG:
81 | if original_in_dim < in_dim:
82 | original_data = model.stem[0].weight.data.detach().clone()
83 | model.stem[0].weight = nn.Parameter(torch.zeros(new_shape))
84 | nn.init.kaiming_normal_(
85 | model.stem[0].weight, mode="fan_out", nonlinearity="relu"
86 | )
87 | model.stem[0].weight.data[:, :original_in_dim, :, :] = original_data
88 |
89 | num_channels_to_avg = (
90 | 2 if in_dim == 5 else 3
91 | ) ## TODO: make this more generic
92 | for i, c in enumerate(range(original_in_dim, in_dim)):
93 | model.stem[0].weight.data[:, c, :, :] = original_data[
94 | :, i : num_channels_to_avg + i, ...
95 | ].mean(dim=1)
96 | model.stem[0].in_channels = in_dim
97 | else:
98 | raise NotImplementedError(f"First layer init {first_layer} not implemented")
99 | if return_first_layer_only:
100 | return model.stem[0]
101 | return model
102 |
103 |
104 | class MeanEncoder(nn.Module):
105 | """Identity function"""
106 |
107 | def __init__(self, shape):
108 | super().__init__()
109 | self.shape = shape
110 |
111 | def forward(self, x):
112 | return x
113 |
114 |
115 | class VarianceEncoder(nn.Module):
116 | """Bias-only model with diagonal covariance"""
117 |
118 | def __init__(self, shape, init=0.1, channelwise=True, eps=1e-5):
119 | super().__init__()
120 | self.shape = shape
121 | self.eps = eps
122 |
123 | init = (torch.as_tensor(init - eps).exp() - 1.0).log()
124 | b_shape = shape
125 | if channelwise:
126 | if len(shape) == 4:
127 | # [B, C, H, W]
128 | b_shape = (1, shape[1], 1, 1)
129 | elif len(shape) == 3:
130 | # CLIP-ViT: [H*W+1, B, C]
131 | b_shape = (1, 1, shape[2])
132 | else:
133 | raise ValueError()
134 |
135 | self.b = nn.Parameter(torch.full(b_shape, init))
136 |
137 | def forward(self, x):
138 | return F.softplus(self.b) + self.eps
139 |
140 |
141 | def get_shapes(model, input_shape):
142 | # get shape of intermediate features
143 | with torch.no_grad():
144 | dummy = torch.rand(1, *input_shape).to(next(model.parameters()).device)
145 | try:
146 | _, feats = model(dummy)
147 | except:
148 | _, feats = model(dummy, chunk="Allen")
149 | shapes = [f.shape for f in feats]
150 |
151 | return shapes
152 |
153 |
154 | def zip_strict(*iterables):
155 | """strict version of zip. The length of iterables should be same.
156 |
157 | NOTE yield looks non-reachable, but they are required.
158 | """
159 | # For trivial cases, use pure zip.
160 | if len(iterables) < 2:
161 | return zip(*iterables)
162 |
163 | # Tail for the first iterable
164 | first_stopped = False
165 |
166 | def first_tail():
167 | nonlocal first_stopped
168 | first_stopped = True
169 | return
170 | yield
171 |
172 | # Tail for the zip
173 | def zip_tail():
174 | if not first_stopped:
175 | raise ValueError("zip_equal: first iterable is longer")
176 | for _ in chain.from_iterable(rest):
177 | raise ValueError("zip_equal: first iterable is shorter")
178 | yield
179 |
180 | # Put the pieces together
181 | iterables = iter(iterables)
182 | first = chain(next(iterables), first_tail())
183 | rest = list(map(iter, iterables))
184 | return chain(zip(first, *rest), zip_tail())
185 |
186 |
187 | def get_module(module, name):
188 | for n, m in module.named_modules():
189 | if n == name:
190 | return m
191 |
192 |
193 | def freeze_(model):
194 | """Freeze model. Note that this function does not control BN"""
195 | for p in model.parameters():
196 | p.requires_grad_(False)
197 |
--------------------------------------------------------------------------------
/models/shared_convnext.py:
--------------------------------------------------------------------------------
1 | from copy import deepcopy
2 |
3 | import numpy as np
4 | from einops import rearrange
5 | from timm import create_model
6 | import torch
7 | from torch import nn
8 | import torch.nn.functional as F
9 |
10 | from config import Model
11 | from helper_classes.feature_pooling import FeaturePooling
12 | from helper_classes.first_layer_init import FirstLayerInit
13 | from models.model_utils import intialize_first_conv_layer
14 |
15 |
16 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
17 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
18 |
19 |
20 | class SharedConvNeXt(nn.Module):
21 | def __init__(self, config: Model):
22 | # pretrained_model_name "convnext_tiny.fb_in22k"
23 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
24 |
25 | super().__init__()
26 | self.cfg = config
27 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
28 |
29 | in_dim_map = {"Allen": 3, "HPA": 4, "CP": 5}
30 |
31 | self.first_layer = nn.ModuleDict()
32 |
33 | for chunk, new_in_dim in in_dim_map.items():
34 | layer_1 = self._get_first_layer(model, new_in_dim)
35 | self.first_layer.add_module(chunk, layer_1)
36 |
37 | ## Store reference to sel.first_layer for later access
38 | self.adaptive_interface = nn.ModuleList([self.first_layer])
39 |
40 | ## shared feature_extractor
41 | self.feature_extractor = nn.Sequential(
42 | model.stem[1],
43 | model.stages[0],
44 | model.stages[1],
45 | model.stages[2].downsample,
46 | *[model.stages[2].blocks[i] for i in range(9)],
47 | model.stages[3].downsample,
48 | *[model.stages[3].blocks[i] for i in range(3)],
49 | )
50 |
51 | ## Loss
52 | num_proxies = (
53 | config.num_classes
54 | ) ## depends on the number of classes of the dataset
55 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
56 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
57 | init_temperature = config.temperature # scale = sqrt(1/T)
58 | if self.cfg.learnable_temp:
59 | self.logit_scale = nn.Parameter(
60 | torch.ones([]) * np.log(1 / init_temperature)
61 | )
62 | else:
63 | self.scale = np.sqrt(1.0 / init_temperature)
64 |
65 | def _get_first_layer(self, model, new_in_dim):
66 | config = self.cfg
67 | config.in_dim = None
68 |
69 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
70 | new_shape = (out_dim, new_in_dim, kh, kw)
71 | layer_1 = model.stem[0].weight
72 | if config.first_layer == FirstLayerInit.REINIT_AS_RANDOM:
73 | layer_1 = nn.Parameter(torch.zeros(new_shape))
74 | nn.init.kaiming_normal_(layer_1, mode="fan_out", nonlinearity="relu")
75 | # self._init_bias(model)
76 | elif config.first_layer == FirstLayerInit.PRETRAINED_PAD_RANDOM:
77 | if original_in_dim < new_in_dim:
78 | original_data = model.stem[0].weight.data.detach().clone()
79 | layer_1 = nn.Parameter(torch.zeros(new_shape))
80 | nn.init.kaiming_normal_(layer_1, mode="fan_out", nonlinearity="relu")
81 | layer_1.data[:, :original_in_dim, :, :] = original_data
82 | # self._init_bias(model)
83 | elif config.first_layer == FirstLayerInit.PRETRAINED_PAD_AVG:
84 | if original_in_dim < new_in_dim:
85 | original_data = model.stem[0].weight.data.detach().clone()
86 | layer_1 = nn.Parameter(torch.zeros(new_shape))
87 | nn.init.kaiming_normal_(layer_1, mode="fan_out", nonlinearity="relu")
88 | layer_1.data[:, :original_in_dim, :, :] = original_data
89 |
90 | num_channels_to_avg = 2 if new_in_dim == 5 else 3
91 | for i, c in enumerate(range(original_in_dim, new_in_dim)):
92 | layer_1.data[:, c, :, :] = original_data[
93 | :, i : num_channels_to_avg + i, ...
94 | ].mean(dim=1)
95 | else:
96 | raise NotImplementedError(
97 | f"First layer init {config.first_layer} not implemented"
98 | )
99 | conv1 = deepcopy(model.stem[0])
100 | conv1.weight = layer_1
101 |
102 | return conv1
103 |
104 | def _reset_params(self, model):
105 | for m in model.children():
106 | if len(list(m.children())) > 0:
107 | self._reset_params(m)
108 |
109 | elif isinstance(m, nn.Conv2d):
110 | print("resetting", m)
111 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
112 | if m.bias is not None:
113 | nn.init.zeros_(m.bias)
114 | elif isinstance(m, nn.BatchNorm2d):
115 | nn.init.ones_(m.weight)
116 | nn.init.zeros_(m.bias)
117 | print("resetting", m)
118 |
119 | elif isinstance(m, nn.Linear):
120 | print("resetting", m)
121 |
122 | nn.init.normal_(m.weight, 0, 0.01)
123 | nn.init.zeros_(m.bias)
124 | else:
125 | print("skipped", m)
126 |
127 | def _init_bias(self, model):
128 | ## Init bias of the first layer
129 | if model.stem[0].bias is not None:
130 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
131 | bound = 1 / np.sqrt(fan_in)
132 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
133 |
134 | def forward(self, x: torch.Tensor, chunk: str) -> torch.Tensor:
135 | assert chunk in self.first_layer, f"chunk={chunk} is not valid!"
136 | conv1 = self.first_layer[chunk]
137 | x = conv1(x)
138 | x = self.feature_extractor(x)
139 | if self.cfg.pooling == FeaturePooling.AVG:
140 | x = F.adaptive_avg_pool2d(x, (1, 1))
141 | elif self.cfg.pooling == FeaturePooling.MAX:
142 | x = F.adaptive_max_pool2d(x, (1, 1))
143 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
144 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
145 | x_max = F.adaptive_max_pool2d(x, (1, 1))
146 | x = torch.cat([x_avg, x_max], dim=1)
147 | elif self.cfg.pooling == FeaturePooling.NONE:
148 | pass
149 | else:
150 | raise ValueError(
151 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
152 | )
153 | x = rearrange(x, "b c h w -> b (c h w)")
154 | return x
155 |
156 |
157 | def shared_convnext(cfg: Model, **kwargs) -> SharedConvNeXt:
158 | return SharedConvNeXt(config=cfg)
159 |
160 |
161 | if __name__ == "__main__":
162 | model_cfg = Model(name="convnext_base", init_weights=True)
163 | model_cfg.pretrained_model_name = "convnext_tiny.fb_in22k"
164 | model_cfg.pooling = "avg"
165 | model_cfg.unfreeze_last_n_layers = 2
166 | model_cfg.pretrained = False
167 | model_cfg.num_classes = 4
168 | model_cfg.temperature = 0.1
169 | model_cfg.first_layer = FirstLayerInit.PRETRAINED_PAD_AVG
170 | model_cfg.in_dim = 4
171 | model_cfg.reset_last_n_unfrozen_layers = True
172 | model = SharedConvNeXt(model_cfg)
173 | x = torch.randn(2, model_cfg.in_dim, 224, 224)
174 | y = model(x, "hpa")
175 | print(y.shape)
176 |
--------------------------------------------------------------------------------
/models/slice_param_convnext.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange, repeat
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 | from einops import repeat, rearrange
8 |
9 | from config import Model
10 | from helper_classes.feature_pooling import FeaturePooling
11 | from helper_classes.first_layer_init import FirstLayerInit
12 |
13 |
14 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
15 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
16 |
17 |
18 | class SliceParamConvNeXt(nn.Module):
19 | def __init__(self, config: Model):
20 | # pretrained_model_name "convnext_tiny.fb_in22k"
21 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
22 |
23 | super().__init__()
24 | self.cfg = config
25 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
26 |
27 | self.duplicate = config.duplicate
28 | if self.duplicate:
29 | total_in_channels = 1
30 | else:
31 | total_in_channels = len(config.in_channel_names)
32 |
33 | ## all channels in this order (alphabet): ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
34 | self.mapper = {
35 | "Allen": [5, 2, 6],
36 | "HPA": [3, 6, 5, 0],
37 | "CP": [5, 0, 7, 1, 4],
38 | }
39 |
40 | self.class_emb_idx = {
41 | "Allen": [0, 1, 2],
42 | "HPA": [3, 4, 5, 6],
43 | "CP": [7, 8, 9, 10, 11],
44 | }
45 | total_diff_class_channels = 12
46 |
47 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
48 | self.stride = model.stem[0].stride
49 | self.padding = model.stem[0].padding
50 | self.dilation = model.stem[0].dilation
51 | self.groups = model.stem[0].groups
52 |
53 | self.conv1_param_bank = nn.Parameter(
54 | torch.zeros(out_dim, total_in_channels, kh, kw)
55 | )
56 | self.init_slice_param_bank_(total_in_channels, model.stem[0].weight.data)
57 |
58 | if self.cfg.slice_class_emb:
59 | self.class_emb = nn.Parameter(
60 | torch.randn(out_dim, total_diff_class_channels, kh, kw) / 8
61 | )
62 | else:
63 | self.class_emb = None
64 |
65 | ## Make a list to store reference for easy access
66 | self.adaptive_interface = nn.ParameterList([self.conv1_param_bank])
67 |
68 | ## shared feature_extractor
69 | self.feature_extractor = nn.Sequential(
70 | model.stem[1],
71 | model.stages[0],
72 | model.stages[1],
73 | model.stages[2].downsample,
74 | *[model.stages[2].blocks[i] for i in range(9)],
75 | model.stages[3].downsample,
76 | *[model.stages[3].blocks[i] for i in range(3)],
77 | )
78 |
79 | num_proxies = (
80 | config.num_classes
81 | ) ## depends on the number of classes of the dataset
82 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
83 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
84 | init_temperature = config.temperature # scale = sqrt(1/T)
85 | if self.cfg.learnable_temp:
86 | self.logit_scale = nn.Parameter(
87 | torch.ones([]) * np.log(1 / init_temperature)
88 | )
89 | else:
90 | self.scale = np.sqrt(1.0 / init_temperature)
91 |
92 | def init_slice_param_bank_(
93 | self, total_in_channels: int, conv1_weight: Tensor
94 | ) -> None:
95 | """
96 | Initialize the first layer of the model
97 | conv1_weight: pre-trained weight, shape (original_out_dim, original_in_dim, kh, kw)
98 | """
99 | if self.cfg.first_layer == FirstLayerInit.PRETRAINED_PAD_DUPS:
100 | ## copy all the weights from the pretrained model, duplicates the weights if needed'
101 | original_in_dim = conv1_weight.shape[1]
102 | num_dups = (total_in_channels // original_in_dim) + 1
103 | slice_params = repeat(conv1_weight, "o i h w -> o (i d) h w", d=num_dups)
104 | self.conv1_param_bank.data.copy_(slice_params[:, :total_in_channels])
105 | else:
106 | nn.init.kaiming_normal_(
107 | self.conv1_param_bank, mode="fan_in", nonlinearity="relu"
108 | )
109 |
110 | def slice_params_first_layer(self, chunk: str) -> Tensor:
111 | assert chunk in self.mapper, f"Invalid data_channel: {chunk}"
112 | if self.duplicate:
113 | ## conv1depthwise_param_bank's shape: (out_dim, 1, 3, 3)
114 | params = repeat(
115 | self.conv1_param_bank,
116 | "o i h w -> o (i c) h w",
117 | c=len(self.mapper[chunk]),
118 | )
119 | else:
120 | params = self.conv1_param_bank[:, self.mapper[chunk]]
121 | if self.class_emb is not None:
122 | params = params + self.class_emb[:, self.class_emb_idx[chunk]]
123 | return params
124 |
125 | def _reset_params(self, model):
126 | for m in model.children():
127 | if len(list(m.children())) > 0:
128 | self._reset_params(m)
129 |
130 | elif isinstance(m, nn.Conv2d):
131 | print("resetting", m)
132 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
133 | if m.bias is not None:
134 | nn.init.zeros_(m.bias)
135 | elif isinstance(m, nn.BatchNorm2d):
136 | nn.init.ones_(m.weight)
137 | nn.init.zeros_(m.bias)
138 | print("resetting", m)
139 |
140 | elif isinstance(m, nn.Linear):
141 | print("resetting", m)
142 |
143 | nn.init.normal_(m.weight, 0, 0.01)
144 | nn.init.zeros_(m.bias)
145 | else:
146 | print("skipped", m)
147 |
148 | def _init_bias(self, model):
149 | ## Init bias of the first layer
150 | if model.stem[0].bias is not None:
151 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
152 | bound = 1 / np.sqrt(fan_in)
153 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
154 |
155 | def forward(self, x: torch.Tensor, chunk: str) -> torch.Tensor:
156 | conv1_params = self.slice_params_first_layer(chunk)
157 | x = F.conv2d(
158 | x,
159 | conv1_params,
160 | bias=None,
161 | stride=self.stride,
162 | padding=self.padding,
163 | dilation=self.dilation,
164 | groups=self.groups,
165 | )
166 |
167 | x = self.feature_extractor(x)
168 | if self.cfg.pooling == FeaturePooling.AVG:
169 | x = F.adaptive_avg_pool2d(x, (1, 1))
170 | elif self.cfg.pooling == FeaturePooling.MAX:
171 | x = F.adaptive_max_pool2d(x, (1, 1))
172 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
173 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
174 | x_max = F.adaptive_max_pool2d(x, (1, 1))
175 | x = torch.cat([x_avg, x_max], dim=1)
176 | elif self.cfg.pooling == FeaturePooling.NONE:
177 | pass
178 | else:
179 | raise ValueError(
180 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
181 | )
182 | x = rearrange(x, "b c h w -> b (c h w)")
183 | return x
184 |
185 |
186 | def sliceparamconvnext(cfg: Model, **kwargs) -> SliceParamConvNeXt:
187 | return SliceParamConvNeXt(config=cfg)
188 |
189 |
190 | if __name__ == "__main__":
191 | model_cfg = Model(name="convnext_base", init_weights=True)
192 | model_cfg.pretrained_model_name = "convnext_tiny.fb_in22k"
193 | model_cfg.pooling = "avg"
194 | model_cfg.unfreeze_last_n_layers = 2
195 | model_cfg.pretrained = False
196 | model_cfg.num_classes = 4
197 | model_cfg.temperature = 0.1
198 | model_cfg.first_layer = FirstLayerInit.PRETRAINED_PAD_AVG
199 | model_cfg.in_dim = 4
200 | model_cfg.in_channel_names = [
201 | "er",
202 | "golgi",
203 | "membrane",
204 | "microtubules",
205 | "mito",
206 | "nucleus",
207 | "protein",
208 | "rna",
209 | ]
210 | model_cfg.reset_last_n_unfrozen_layers = True
211 | model = SliceParamConvNeXt(model_cfg)
212 | x = torch.randn(96, model_cfg.in_dim, 224, 224)
213 | y = model(x, "hpa")
214 | print(y.shape)
215 |
--------------------------------------------------------------------------------
/models/slice_param_convnext_miro.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange, repeat
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 | from einops import repeat, rearrange
8 |
9 | from config import Model
10 | from helper_classes.feature_pooling import FeaturePooling
11 | from helper_classes.first_layer_init import FirstLayerInit
12 | from models.model_utils import freeze_, get_module
13 |
14 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
15 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
16 |
17 |
18 | class SliceParamConvNeXtMIRO(nn.Module):
19 | def __init__(self, config: Model, freeze: str = None):
20 | # pretrained_model_name "convnext_tiny.fb_in22k"
21 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
22 |
23 | super().__init__()
24 | self.cfg = config
25 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
26 |
27 | self.duplicate = config.duplicate
28 | if self.duplicate:
29 | total_in_channels = 1
30 | else:
31 | total_in_channels = len(config.in_channel_names)
32 |
33 | ## all channels in this order (alphabet): ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
34 | self.mapper = {
35 | "Allen": [5, 2, 6],
36 | "HPA": [3, 6, 5, 0],
37 | "CP": [5, 0, 7, 1, 4],
38 | }
39 |
40 | self.class_emb_idx = {
41 | "Allen": [0, 1, 2],
42 | "HPA": [3, 4, 5, 6],
43 | "CP": [7, 8, 9, 10, 11],
44 | }
45 | total_diff_class_channels = 12
46 |
47 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
48 | self.stride = model.stem[0].stride
49 | self.padding = model.stem[0].padding
50 | self.dilation = model.stem[0].dilation
51 | self.groups = model.stem[0].groups
52 |
53 | self.conv1_param_bank = nn.Parameter(
54 | torch.zeros(out_dim, total_in_channels, kh, kw)
55 | )
56 | self.init_slice_param_bank_(total_in_channels, model.stem[0].weight.data)
57 |
58 | if self.cfg.slice_class_emb:
59 | self.class_emb = nn.Parameter(
60 | torch.randn(out_dim, total_diff_class_channels, kh, kw) / 8
61 | )
62 | else:
63 | self.class_emb = None
64 |
65 | ## Make a list to store reference for easy access
66 | self.adaptive_interface = nn.ParameterList([self.conv1_param_bank])
67 |
68 | ## shared feature_extractor
69 | self.feature_extractor = nn.Sequential(
70 | model.stem[1],
71 | model.stages[0],
72 | model.stages[1],
73 | model.stages[2].downsample,
74 | *[model.stages[2].blocks[i] for i in range(9)],
75 | model.stages[3].downsample,
76 | *[model.stages[3].blocks[i] for i in range(3)],
77 | )
78 | self._features = []
79 | self.feat_layers = [
80 | "0",
81 | "1.blocks.2.drop_path",
82 | "2.blocks.2.drop_path",
83 | "12.drop_path",
84 | "16.drop_path",
85 | ]
86 | self.build_feature_hooks(self.feat_layers)
87 |
88 | num_proxies = (
89 | config.num_classes
90 | ) ## depends on the number of classes of the dataset
91 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
92 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
93 | init_temperature = config.temperature # scale = sqrt(1/T)
94 | if self.cfg.learnable_temp:
95 | self.logit_scale = nn.Parameter(
96 | torch.ones([]) * np.log(1 / init_temperature)
97 | )
98 | else:
99 | self.scale = np.sqrt(1.0 / init_temperature)
100 |
101 | self.freeze_bn()
102 | self.freeze(freeze)
103 |
104 | def hook(self, module, input, output):
105 | self._features.append(output)
106 |
107 | def build_feature_hooks(self, feat_layers):
108 | for n, m in self.feature_extractor.named_modules():
109 | if n in feat_layers:
110 | m.register_forward_hook(self.hook)
111 | return None
112 |
113 | def freeze_bn(self):
114 | for m in self.feature_extractor.modules():
115 | if isinstance(m, nn.BatchNorm2d):
116 | m.eval()
117 |
118 | def freeze(self, freeze):
119 | if freeze is not None:
120 | if freeze == "all":
121 | print("Freezing all layers of the feature extractor")
122 | freeze_(self.feature_extractor)
123 | else:
124 | for block in self.blocks[: freeze + 1]:
125 | freeze_(block)
126 |
127 | def clear_features(self):
128 | self._features.clear()
129 |
130 | def train(self, mode: bool = True):
131 | """Override the default train() to freeze the BN parameters"""
132 | super().train(mode)
133 | self.freeze_bn()
134 |
135 | def init_slice_param_bank_(
136 | self, total_in_channels: int, conv1_weight: Tensor
137 | ) -> None:
138 | """
139 | Initialize the first layer of the model
140 | conv1_weight: pre-trained weight, shape (original_out_dim, original_in_dim, kh, kw)
141 | """
142 | if self.cfg.first_layer == FirstLayerInit.PRETRAINED_PAD_DUPS:
143 | ## copy all the weights from the pretrained model, duplicates the weights if needed'
144 | original_in_dim = conv1_weight.shape[1]
145 | num_dups = (total_in_channels // original_in_dim) + 1
146 | slice_params = repeat(conv1_weight, "o i h w -> o (i d) h w", d=num_dups)
147 | self.conv1_param_bank.data.copy_(slice_params[:, :total_in_channels])
148 | else:
149 | nn.init.kaiming_normal_(
150 | self.conv1_param_bank, mode="fan_in", nonlinearity="relu"
151 | )
152 |
153 | def slice_params_first_layer(self, chunk: str) -> Tensor:
154 | assert chunk in self.mapper, f"Invalid data_channel: {chunk}"
155 | if self.duplicate:
156 | ## conv1depthwise_param_bank's shape: (out_dim, 1, 3, 3)
157 | params = repeat(
158 | self.conv1_param_bank,
159 | "o i h w -> o (i c) h w",
160 | c=len(self.mapper[chunk]),
161 | )
162 | else:
163 | params = self.conv1_param_bank[:, self.mapper[chunk]]
164 | if self.class_emb is not None:
165 | params = params + self.class_emb[:, self.class_emb_idx[chunk]]
166 | return params
167 |
168 | def _reset_params(self, model):
169 | for m in model.children():
170 | if len(list(m.children())) > 0:
171 | self._reset_params(m)
172 |
173 | elif isinstance(m, nn.Conv2d):
174 | print("resetting", m)
175 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
176 | if m.bias is not None:
177 | nn.init.zeros_(m.bias)
178 | elif isinstance(m, nn.BatchNorm2d):
179 | nn.init.ones_(m.weight)
180 | nn.init.zeros_(m.bias)
181 | print("resetting", m)
182 |
183 | elif isinstance(m, nn.Linear):
184 | print("resetting", m)
185 |
186 | nn.init.normal_(m.weight, 0, 0.01)
187 | nn.init.zeros_(m.bias)
188 | else:
189 | print("skipped", m)
190 |
191 | def _init_bias(self, model):
192 | ## Init bias of the first layer
193 | if model.stem[0].bias is not None:
194 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
195 | bound = 1 / np.sqrt(fan_in)
196 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
197 |
198 | def forward(
199 | self, x: torch.Tensor, chunk: str, return_features: bool = True
200 | ) -> torch.Tensor:
201 | self.clear_features()
202 | conv1_params = self.slice_params_first_layer(chunk)
203 | x = F.conv2d(
204 | x,
205 | conv1_params,
206 | bias=None,
207 | stride=self.stride,
208 | padding=self.padding,
209 | dilation=self.dilation,
210 | groups=self.groups,
211 | )
212 |
213 | x = self.feature_extractor(x)
214 | if self.cfg.pooling == FeaturePooling.AVG:
215 | x = F.adaptive_avg_pool2d(x, (1, 1))
216 | elif self.cfg.pooling == FeaturePooling.MAX:
217 | x = F.adaptive_max_pool2d(x, (1, 1))
218 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
219 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
220 | x_max = F.adaptive_max_pool2d(x, (1, 1))
221 | x = torch.cat([x_avg, x_max], dim=1)
222 | elif self.cfg.pooling == FeaturePooling.NONE:
223 | pass
224 | else:
225 | raise ValueError(
226 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
227 | )
228 | x = rearrange(x, "b c h w -> b (c h w)")
229 | if return_features:
230 | return x, self._features
231 | else:
232 | return x
233 |
234 |
235 | def sliceparamconvnext_miro(cfg: Model, freeze: str = None) -> SliceParamConvNeXtMIRO:
236 | return SliceParamConvNeXtMIRO(config=cfg, freeze=freeze)
237 |
238 |
239 | if __name__ == "__main__":
240 | model_cfg = Model(name="convnext_base", init_weights=True)
241 | model_cfg.pretrained_model_name = "convnext_tiny.fb_in22k"
242 | model_cfg.pooling = "avg"
243 | model_cfg.unfreeze_last_n_layers = 2
244 | model_cfg.pretrained = False
245 | model_cfg.num_classes = 4
246 | model_cfg.temperature = 0.1
247 | model_cfg.first_layer = FirstLayerInit.PRETRAINED_PAD_AVG
248 | model_cfg.in_dim = 4
249 | model_cfg.in_channel_names = [
250 | "er",
251 | "golgi",
252 | "membrane",
253 | "microtubules",
254 | "mito",
255 | "nucleus",
256 | "protein",
257 | "rna",
258 | ]
259 | model_cfg.reset_last_n_unfrozen_layers = True
260 | model = SliceParamConvNeXt(model_cfg)
261 | x = torch.randn(96, model_cfg.in_dim, 224, 224)
262 | y = model(x, "hpa")
263 | print(y.shape)
264 |
--------------------------------------------------------------------------------
/models/template_convnextv2.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange, repeat
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 |
8 | from config import Model
9 | from helper_classes.feature_pooling import FeaturePooling
10 |
11 |
12 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
13 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
14 |
15 |
16 | ## WORKING ON THIS
17 | class TemplateMixingConvNeXtV2(nn.Module):
18 | def __init__(self, config: Model):
19 | # pretrained_model_name "convnext_tiny.fb_in22k"
20 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
21 |
22 | super().__init__()
23 | self.cfg = config
24 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
25 |
26 | num_templates = config.num_templates
27 |
28 | ## all channels in this order (alphabet): config.in_channel_names = ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
29 |
30 | # self.mapper = {
31 | # "Allen": [5, 2, 6],
32 | # "HPA": [3, 6, 5, 0],
33 | # "CP": [5, 0, 7, 1, 4],
34 | # }
35 |
36 | self.mapper = {
37 | "Allen": [(0, [5, 7]), (1, []), (2, [4])],
38 | "HPA": [(3, []), (4, [2]), (5, [0, 7]), (6, [8])],
39 | "CP": [(7, [0, 5]), (8, [6]), (9, []), (10, []), (11, [])],
40 | }
41 |
42 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
43 | self.stride = model.stem[0].stride
44 | self.padding = model.stem[0].padding
45 | self.dilation = model.stem[0].dilation
46 | self.groups = model.stem[0].groups
47 |
48 | total_channels = sum([len(v) for v in self.mapper.values()])
49 | assert (
50 | num_templates % total_channels == 0
51 | ), "num_templates must be divisible by total_channels"
52 | self.n_templ_per_channel = num_templates // total_channels
53 |
54 | # First conv layer
55 | self.conv1_param_bank = nn.Parameter(
56 | torch.zeros(out_dim, num_templates, kh, kw)
57 | )
58 |
59 | self.conv1_coefs = nn.Parameter(torch.zeros(total_channels, num_templates))
60 |
61 | nn.init.kaiming_normal_(
62 | self.conv1_param_bank, mode="fan_in", nonlinearity="relu"
63 | )
64 |
65 | self._init_conv1_coefs_()
66 |
67 | ## Make a list to store reference for easy access later on
68 | self.adaptive_interface = nn.ParameterList(
69 | [self.conv1_param_bank, self.conv1_coefs]
70 | )
71 |
72 | ## shared feature_extractor
73 | self.feature_extractor = nn.Sequential(
74 | model.stem[1],
75 | model.stages[0],
76 | model.stages[1],
77 | model.stages[2].downsample,
78 | *[model.stages[2].blocks[i] for i in range(9)],
79 | model.stages[3].downsample,
80 | *[model.stages[3].blocks[i] for i in range(3)],
81 | )
82 |
83 | num_proxies = (
84 | config.num_classes
85 | ) ## depends on the number of classes of the dataset
86 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
87 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
88 | init_temperature = config.temperature # scale = sqrt(1/T)
89 | if self.cfg.learnable_temp:
90 | self.logit_scale = nn.Parameter(
91 | torch.ones([]) * np.log(1 / init_temperature)
92 | )
93 | else:
94 | self.scale = np.sqrt(1.0 / init_temperature)
95 |
96 | def _init_conv1_coefs_(self):
97 | ## generate random weight with normal distribution
98 | if self.cfg.coefs_init == "random":
99 | nn.init.normal_(self.conv1_coefs, mean=0.5, std=0.1)
100 | elif self.cfg.coefs_init == "zeros":
101 | nn.init.zeros_(self.conv1_coefs)
102 |
103 | for v in self.mapper.values():
104 | for c, shared_c_list in v:
105 | self.conv1_coefs.data[
106 | c, c * self.n_templ_per_channel : (c + 1) * self.n_templ_per_channel
107 | ] = 0.9
108 | for shared_c in shared_c_list:
109 | self.conv1_coefs.data[
110 | c,
111 | shared_c
112 | * self.n_templ_per_channel : (shared_c + 1)
113 | * self.n_templ_per_channel,
114 | ] = 0.1
115 | return None
116 |
117 | def mix_templates_first_layer(self, chunk: str) -> Tensor:
118 | """
119 | @return: return a tensor, shape (out_channels, in_channels, kernel_h, kernel_w)
120 | """
121 | assert chunk in self.mapper, f"Invalid chunk: {chunk}"
122 | idx = [c for c, _ in self.mapper[chunk]]
123 | # idx = list(range(idx[0] * self.n_templ_per_channel, (idx[-1] + 1) * self.n_templ_per_channel))
124 |
125 | coefs = self.conv1_coefs[idx]
126 |
127 | coefs = rearrange(coefs, "c t ->1 c t 1 1")
128 | templates = repeat(
129 | self.conv1_param_bank, "o t h w -> o c t h w", c=len(self.mapper[chunk])
130 | )
131 | params = torch.sum(coefs * templates, dim=2)
132 | return params
133 |
134 | def _reset_params(self, model):
135 | for m in model.children():
136 | if len(list(m.children())) > 0:
137 | self._reset_params(m)
138 |
139 | elif isinstance(m, nn.Conv2d):
140 | print("resetting", m)
141 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
142 | if m.bias is not None:
143 | nn.init.zeros_(m.bias)
144 | elif isinstance(m, nn.BatchNorm2d):
145 | nn.init.ones_(m.weight)
146 | nn.init.zeros_(m.bias)
147 | print("resetting", m)
148 |
149 | elif isinstance(m, nn.Linear):
150 | print("resetting", m)
151 |
152 | nn.init.normal_(m.weight, 0, 0.01)
153 | nn.init.zeros_(m.bias)
154 | else:
155 | print("skipped", m)
156 |
157 | def _init_bias(self, model):
158 | ## Init bias of the first layer
159 | if model.stem[0].bias is not None:
160 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
161 | bound = 1 / np.sqrt(fan_in)
162 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
163 |
164 | def forward(self, x: torch.Tensor, chunk: str) -> torch.Tensor:
165 | conv1_params = self.mix_templates_first_layer(chunk)
166 | x = F.conv2d(
167 | x,
168 | conv1_params,
169 | bias=None,
170 | stride=self.stride,
171 | padding=self.padding,
172 | dilation=self.dilation,
173 | groups=self.groups,
174 | )
175 |
176 | x = self.feature_extractor(x)
177 | if self.cfg.pooling == FeaturePooling.AVG:
178 | x = F.adaptive_avg_pool2d(x, (1, 1))
179 | elif self.cfg.pooling == FeaturePooling.MAX:
180 | x = F.adaptive_max_pool2d(x, (1, 1))
181 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
182 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
183 | x_max = F.adaptive_max_pool2d(x, (1, 1))
184 | x = torch.cat([x_avg, x_max], dim=1)
185 | elif self.cfg.pooling == FeaturePooling.NONE:
186 | pass
187 | else:
188 | raise ValueError(
189 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
190 | )
191 | x = rearrange(x, "b c h w -> b (c h w)")
192 | return x
193 |
194 |
195 | def templatemixingconvnextv2(cfg: Model, **kwargs) -> TemplateMixingConvNeXtV2:
196 | return TemplateMixingConvNeXtV2(config=cfg)
197 |
--------------------------------------------------------------------------------
/models/template_convnextv2_miro.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange, repeat
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 |
8 | from config import Model
9 | from helper_classes.feature_pooling import FeaturePooling
10 |
11 | from models.model_utils import get_module, freeze_
12 |
13 |
14 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
15 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
16 |
17 |
18 | ## WORKING ON THIS
19 | class TemplateMixingConvNeXtV2MIRO(nn.Module):
20 | def __init__(self, config: Model, freeze: bool = None):
21 | # pretrained_model_name "convnext_tiny.fb_in22k"
22 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
23 |
24 | super().__init__()
25 | self.cfg = config
26 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
27 |
28 | num_templates = config.num_templates
29 |
30 | ## all channels in this order (alphabet): config.in_channel_names = ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
31 |
32 | # self.mapper = {
33 | # "Allen": [5, 2, 6],
34 | # "HPA": [3, 6, 5, 0],
35 | # "CP": [5, 0, 7, 1, 4],
36 | # }
37 |
38 | self.mapper = {
39 | "Allen": [(0, [5, 7]), (1, []), (2, [4])],
40 | "HPA": [(3, []), (4, [2]), (5, [0, 7]), (6, [8])],
41 | "CP": [(7, [0, 5]), (8, [6]), (9, []), (10, []), (11, [])],
42 | }
43 |
44 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
45 | self.stride = model.stem[0].stride
46 | self.padding = model.stem[0].padding
47 | self.dilation = model.stem[0].dilation
48 | self.groups = model.stem[0].groups
49 |
50 | total_channels = sum([len(v) for v in self.mapper.values()])
51 | assert (
52 | num_templates % total_channels == 0
53 | ), "num_templates must be divisible by total_channels"
54 | self.n_templ_per_channel = num_templates // total_channels
55 |
56 | # First conv layer
57 | self.conv1_param_bank = nn.Parameter(
58 | torch.zeros(out_dim, num_templates, kh, kw)
59 | )
60 |
61 | self.conv1_coefs = nn.Parameter(torch.zeros(total_channels, num_templates))
62 |
63 | nn.init.kaiming_normal_(
64 | self.conv1_param_bank, mode="fan_in", nonlinearity="relu"
65 | )
66 |
67 | self._init_conv1_coefs_()
68 |
69 | ## Make a list to store reference for easy access later on
70 | self.adaptive_interface = nn.ParameterList(
71 | [self.conv1_param_bank, self.conv1_coefs]
72 | )
73 |
74 | ## shared feature_extractor
75 | self.feature_extractor = nn.Sequential(
76 | model.stem[1],
77 | model.stages[0],
78 | model.stages[1],
79 | model.stages[2].downsample,
80 | *[model.stages[2].blocks[i] for i in range(9)],
81 | model.stages[3].downsample,
82 | *[model.stages[3].blocks[i] for i in range(3)],
83 | )
84 |
85 | self._features = []
86 | self.feat_layers = [
87 | "0",
88 | "1.blocks.2.drop_path",
89 | "2.blocks.2.drop_path",
90 | "12.drop_path",
91 | "16.drop_path",
92 | ]
93 | self.build_feature_hooks(self.feat_layers)
94 |
95 | num_proxies = (
96 | config.num_classes
97 | ) ## depends on the number of classes of the dataset
98 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
99 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
100 | init_temperature = config.temperature # scale = sqrt(1/T)
101 | if self.cfg.learnable_temp:
102 | self.logit_scale = nn.Parameter(
103 | torch.ones([]) * np.log(1 / init_temperature)
104 | )
105 | else:
106 | self.scale = np.sqrt(1.0 / init_temperature)
107 |
108 | self.freeze_bn()
109 | self.freeze(freeze)
110 |
111 | def hook(self, module, input, output):
112 | self._features.append(output)
113 |
114 | def build_feature_hooks(self, feat_layers):
115 | for n, m in self.feature_extractor.named_modules():
116 | if n in feat_layers:
117 | m.register_forward_hook(self.hook)
118 | return None
119 |
120 | def freeze_bn(self):
121 | for m in self.feature_extractor.modules():
122 | if isinstance(m, nn.BatchNorm2d):
123 | m.eval()
124 |
125 | def freeze(self, freeze):
126 | if freeze is not None:
127 | if freeze == "all":
128 | print("Freezing all layers of the feature extractor")
129 | freeze_(self.feature_extractor)
130 | else:
131 | for block in self.blocks[: freeze + 1]:
132 | freeze_(block)
133 |
134 | def clear_features(self):
135 | self._features.clear()
136 |
137 | def train(self, mode: bool = True):
138 | """Override the default train() to freeze the BN parameters"""
139 | super().train(mode)
140 | self.freeze_bn()
141 |
142 | def _init_conv1_coefs_(self):
143 | ## generate random weight with normal distribution
144 | if self.cfg.coefs_init == "random":
145 | nn.init.normal_(self.conv1_coefs, mean=0.5, std=0.1)
146 | elif self.cfg.coefs_init == "zeros":
147 | nn.init.zeros_(self.conv1_coefs)
148 |
149 | for v in self.mapper.values():
150 | for c, shared_c_list in v:
151 | self.conv1_coefs.data[
152 | c, c * self.n_templ_per_channel : (c + 1) * self.n_templ_per_channel
153 | ] = 0.9
154 | for shared_c in shared_c_list:
155 | self.conv1_coefs.data[
156 | c,
157 | shared_c
158 | * self.n_templ_per_channel : (shared_c + 1)
159 | * self.n_templ_per_channel,
160 | ] = 0.1
161 | return None
162 |
163 | def mix_templates_first_layer(self, chunk: str) -> Tensor:
164 | """
165 | @return: return a tensor, shape (out_channels, in_channels, kernel_h, kernel_w)
166 | """
167 | assert chunk in self.mapper, f"Invalid chunk: {chunk}"
168 | idx = [c for c, _ in self.mapper[chunk]]
169 | # idx = list(range(idx[0] * self.n_templ_per_channel, (idx[-1] + 1) * self.n_templ_per_channel))
170 |
171 | coefs = self.conv1_coefs[idx]
172 |
173 | coefs = rearrange(coefs, "c t ->1 c t 1 1")
174 | templates = repeat(
175 | self.conv1_param_bank, "o t h w -> o c t h w", c=len(self.mapper[chunk])
176 | )
177 | params = torch.sum(coefs * templates, dim=2)
178 | return params
179 |
180 | def _reset_params(self, model):
181 | for m in model.children():
182 | if len(list(m.children())) > 0:
183 | self._reset_params(m)
184 |
185 | elif isinstance(m, nn.Conv2d):
186 | print("resetting", m)
187 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
188 | if m.bias is not None:
189 | nn.init.zeros_(m.bias)
190 | elif isinstance(m, nn.BatchNorm2d):
191 | nn.init.ones_(m.weight)
192 | nn.init.zeros_(m.bias)
193 | print("resetting", m)
194 |
195 | elif isinstance(m, nn.Linear):
196 | print("resetting", m)
197 |
198 | nn.init.normal_(m.weight, 0, 0.01)
199 | nn.init.zeros_(m.bias)
200 | else:
201 | print("skipped", m)
202 |
203 | def _init_bias(self, model):
204 | ## Init bias of the first layer
205 | if model.stem[0].bias is not None:
206 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
207 | bound = 1 / np.sqrt(fan_in)
208 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
209 |
210 | def forward(
211 | self, x: torch.Tensor, chunk: str, return_features: bool = True
212 | ) -> torch.Tensor:
213 | self.clear_features()
214 | conv1_params = self.mix_templates_first_layer(chunk)
215 | x = F.conv2d(
216 | x,
217 | conv1_params,
218 | bias=None,
219 | stride=self.stride,
220 | padding=self.padding,
221 | dilation=self.dilation,
222 | groups=self.groups,
223 | )
224 |
225 | x = self.feature_extractor(x)
226 | if self.cfg.pooling == FeaturePooling.AVG:
227 | x = F.adaptive_avg_pool2d(x, (1, 1))
228 | elif self.cfg.pooling == FeaturePooling.MAX:
229 | x = F.adaptive_max_pool2d(x, (1, 1))
230 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
231 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
232 | x_max = F.adaptive_max_pool2d(x, (1, 1))
233 | x = torch.cat([x_avg, x_max], dim=1)
234 | elif self.cfg.pooling == FeaturePooling.NONE:
235 | pass
236 | else:
237 | raise ValueError(
238 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
239 | )
240 | x = rearrange(x, "b c h w -> b (c h w)")
241 |
242 | if return_features:
243 | return x, self._features
244 | else:
245 | return x
246 |
247 |
248 | def templatemixingconvnextv2_miro(cfg: Model, **kwargs) -> TemplateMixingConvNeXtV2MIRO:
249 | return TemplateMixingConvNeXtV2MIRO(config=cfg)
250 |
--------------------------------------------------------------------------------
/models/template_mixing_convnext.py:
--------------------------------------------------------------------------------
1 | import numpy as np
2 | from einops import rearrange, repeat
3 | from timm import create_model
4 | import torch
5 | from torch import nn, Tensor
6 | import torch.nn.functional as F
7 |
8 | from config import Model
9 | from helper_classes.feature_pooling import FeaturePooling
10 |
11 |
12 | # model here: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L410
13 | # lr=4.0e-3 (mentioned in A ConvNet for the 2020s paper)
14 |
15 |
16 | class TemplateMixingConvNeXt(nn.Module):
17 | def __init__(self, config: Model):
18 | # pretrained_model_name "convnext_tiny.fb_in22k"
19 | ## forward pass: https://github.com/huggingface/pytorch-image-models/blob/b3e816d6d71ec132b39c603d68b619ae2870fd0a/timm/models/convnext.py#L420
20 |
21 | super().__init__()
22 | self.cfg = config
23 | model = create_model(config.pretrained_model_name, pretrained=config.pretrained)
24 |
25 | num_templates = config.num_templates
26 |
27 | ## all channels in this order (alphabet): config.in_channel_names = ['er', 'golgi', 'membrane', 'microtubules','mito','nucleus','protein', 'rna']
28 |
29 | self.mapper = {
30 | "Allen": [5, 2, 6],
31 | "HPA": [3, 6, 5, 0],
32 | "CP": [5, 0, 7, 1, 4],
33 | }
34 |
35 | out_dim, original_in_dim, kh, kw = model.stem[0].weight.shape
36 | self.stride = model.stem[0].stride
37 | self.padding = model.stem[0].padding
38 | self.dilation = model.stem[0].dilation
39 | self.groups = model.stem[0].groups
40 |
41 | # First conv layer
42 | self.conv1_param_bank = nn.Parameter(
43 | torch.zeros(out_dim, num_templates, kh, kw)
44 | )
45 | if self.cfg.separate_coef:
46 | self.conv1_coefs = nn.ParameterDict(
47 | {
48 | data_channel: nn.Parameter(
49 | torch.zeros(len(channels), num_templates)
50 | )
51 | for data_channel, channels in self.mapper.items()
52 | }
53 | )
54 | else:
55 | self.conv1_coefs = nn.Parameter(
56 | torch.zeros(len(config.in_channel_names), num_templates)
57 | )
58 |
59 | nn.init.kaiming_normal_(
60 | self.conv1_param_bank, mode="fan_in", nonlinearity="relu"
61 | )
62 | if isinstance(self.conv1_coefs, nn.ParameterDict):
63 | for param in self.conv1_coefs.values():
64 | nn.init.orthogonal_(param)
65 | else:
66 | nn.init.orthogonal_(self.conv1_coefs)
67 |
68 | ## Make a list to store reference for easy access later on
69 | self.adaptive_interface = nn.ParameterList(
70 | [self.conv1_param_bank, self.conv1_coefs]
71 | )
72 |
73 | ## shared feature_extractor
74 | self.feature_extractor = nn.Sequential(
75 | model.stem[1],
76 | model.stages[0],
77 | model.stages[1],
78 | model.stages[2].downsample,
79 | *[model.stages[2].blocks[i] for i in range(9)],
80 | model.stages[3].downsample,
81 | *[model.stages[3].blocks[i] for i in range(3)],
82 | )
83 |
84 | num_proxies = (
85 | config.num_classes
86 | ) ## depends on the number of classes of the dataset
87 | self.dim = 768 if self.cfg.pooling in ["avg", "max", "avgmax"] else 7 * 7 * 768
88 | self.proxies = torch.nn.Parameter((torch.randn(num_proxies, self.dim) / 8))
89 | init_temperature = config.temperature # scale = sqrt(1/T)
90 | if self.cfg.learnable_temp:
91 | self.logit_scale = nn.Parameter(
92 | torch.ones([]) * np.log(1 / init_temperature)
93 | )
94 | else:
95 | self.scale = np.sqrt(1.0 / init_temperature)
96 |
97 | def mix_templates_first_layer(self, chunk: str) -> Tensor:
98 | """
99 | @return: return a tensor, shape (out_channels, in_channels, kernel_h, kernel_w)
100 | """
101 | assert chunk in self.mapper, f"Invalid chunk: {chunk}"
102 | if self.cfg.separate_coef:
103 | coefs = self.conv1_coefs[chunk]
104 | else:
105 | coefs = self.conv1_coefs[self.mapper[chunk]]
106 |
107 | coefs = rearrange(coefs, "c t ->1 c t 1 1")
108 | templates = repeat(
109 | self.conv1_param_bank, "o t h w -> o c t h w", c=len(self.mapper[chunk])
110 | )
111 | params = torch.sum(coefs * templates, dim=2)
112 | return params
113 |
114 | def _reset_params(self, model):
115 | for m in model.children():
116 | if len(list(m.children())) > 0:
117 | self._reset_params(m)
118 |
119 | elif isinstance(m, nn.Conv2d):
120 | print("resetting", m)
121 | nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
122 | if m.bias is not None:
123 | nn.init.zeros_(m.bias)
124 | elif isinstance(m, nn.BatchNorm2d):
125 | nn.init.ones_(m.weight)
126 | nn.init.zeros_(m.bias)
127 | print("resetting", m)
128 |
129 | elif isinstance(m, nn.Linear):
130 | print("resetting", m)
131 |
132 | nn.init.normal_(m.weight, 0, 0.01)
133 | nn.init.zeros_(m.bias)
134 | else:
135 | print("skipped", m)
136 |
137 | def _init_bias(self, model):
138 | ## Init bias of the first layer
139 | if model.stem[0].bias is not None:
140 | fan_in, _ = nn.init._calculate_fan_in_and_fan_out(model.stem[0].weight)
141 | bound = 1 / np.sqrt(fan_in)
142 | nn.init.uniform_(model.stem[0].bias, -bound, bound)
143 |
144 | def forward(self, x: torch.Tensor, chunk: str) -> torch.Tensor:
145 | conv1_params = self.mix_templates_first_layer(chunk)
146 | x = F.conv2d(
147 | x,
148 | conv1_params,
149 | bias=None,
150 | stride=self.stride,
151 | padding=self.padding,
152 | dilation=self.dilation,
153 | groups=self.groups,
154 | )
155 |
156 | x = self.feature_extractor(x)
157 | if self.cfg.pooling == FeaturePooling.AVG:
158 | x = F.adaptive_avg_pool2d(x, (1, 1))
159 | elif self.cfg.pooling == FeaturePooling.MAX:
160 | x = F.adaptive_max_pool2d(x, (1, 1))
161 | elif self.cfg.pooling == FeaturePooling.AVG_MAX:
162 | x_avg = F.adaptive_avg_pool2d(x, (1, 1))
163 | x_max = F.adaptive_max_pool2d(x, (1, 1))
164 | x = torch.cat([x_avg, x_max], dim=1)
165 | elif self.cfg.pooling == FeaturePooling.NONE:
166 | pass
167 | else:
168 | raise ValueError(
169 | f"Pooling {self.cfg.pooling} not supported. Use one of {FeaturePooling.list()}"
170 | )
171 | x = rearrange(x, "b c h w -> b (c h w)")
172 | return x
173 |
174 |
175 | def templatemixingconvnext(cfg: Model, **kwargs) -> TemplateMixingConvNeXt:
176 | return TemplateMixingConvNeXt(config=cfg)
177 |
--------------------------------------------------------------------------------
/optimizers.py:
--------------------------------------------------------------------------------
1 | ## https://github.com/microsoft/Swin-Transformer/blob/f92123a0035930d89cf53fcb8257199481c4428d/optimizer.py
2 | from torch import nn
3 | from timm.optim import AdamP, AdamW
4 | import torch
5 |
6 | from utils import read_yaml
7 |
8 |
9 | def make_my_optimizer(opt_name: str, model_params, cfg: dict):
10 | opt_name = opt_name.lower()
11 | if opt_name == 'sgd':
12 | optimizer = torch.optim.SGD(model_params, **cfg)
13 | elif opt_name == 'adam':
14 | # https://stackoverflow.com/questions/64621585/adamw-and-adam-with-weight-decay
15 | # https://www.fast.ai/posts/2018-07-02-adam-weight-decay.html
16 | optimizer = torch.optim.Adam(model_params, **cfg)
17 | elif opt_name == 'adamw':
18 | optimizer = AdamW(model_params, **cfg)
19 | elif opt_name == 'adamp':
20 | optimizer = AdamP(model_params, **cfg)
21 | else:
22 | raise NotImplementedError(f'Not implemented optimizer: {opt_name}')
23 |
24 | return optimizer
25 |
26 |
27 | if __name__ == '__main__':
28 | conf = read_yaml('configs/cifar/optimizer/adamw.yaml')
29 | model = nn.Linear(3, 4)
30 |
31 | optimizer = make_my_optimizer('adamw', model.parameters(), conf['params'])
32 | print(optimizer.state_dict())
33 |
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | debugpy==1.5.1
2 | dill==0.3.6
3 | einops==0.4.1
4 | GPUtil==1.4.0
5 | h5py==3.8.0
6 | humanize==4.6.0
7 | hydra-core==1.3.2
8 | numpy==1.23.4
9 | omegaconf==2.3.0
10 | pandas==1.5.1
11 | Pillow==9.5.0
12 | psutil==5.9.0
13 | python-dotenv==1.0.0
14 | PyYAML==6.0
15 | Requests==2.30.0
16 | scikit_image==0.19.2
17 | scikit_learn==1.2.1
18 | timm==0.8.3.dev0
19 | torch==2.0.0
20 | torchvision==0.15.1
21 | tqdm==4.65.0
22 | wandb==0.15.3
23 |
--------------------------------------------------------------------------------
/train_scripts.sh:
--------------------------------------------------------------------------------
1 | ## Allen
2 | python main.py -m -cp configs/morphem70k -cn allen_cfg optimizer=adamw tag=allen ++optimizer.params.lr=0.001 ++model.unfreeze_first_layer=True ++model.unfreeze_last_n_layers=-1 ++model.first_layer=pretrained_pad_avg ++model.temperature=0.3 ++train.seed=582814
3 |
4 | ## HPA
5 | python main.py -m -cp configs/morphem70k -cn hpa_cfg optimizer=adamw tag=hpa ++optimizer.params.lr=0.0001 ++model.unfreeze_first_layer=True ++model.unfreeze_last_n_layers=-1 ++model.first_layer=pretrained_pad_avg ++model.temperature=0.3 ++train.seed=744395
6 |
7 | ## CP
8 | python main.py -m -cp configs/morphem70k -cn cp_cfg optimizer=adamw tag=cp ++optimizer.params.lr=0.0001 ++model.unfreeze_first_layer=True ++model.unfreeze_last_n_layers=-1 ++model.first_layer=pretrained_pad_avg ++model.temperature=0.3 ++train.seed=530400
9 |
10 | ## Depthwise
11 | python main.py -m -cp configs/morphem70k -cn morphem70k_cfg model=depthwiseconvnext tag=depthwise ++optimizer.params.lr=0.0004 ++model.kernels_per_channel=64 ++model.pooling_channel_type=weighted_sum_random ++model.temperature=0.07 ++train.seed=483112
12 |
13 | ## TargetParam (Shared)
14 | python main.py -m -cp configs/morphem70k -cn morphem70k_cfg model=separate tag=shared ++optimizer.params.lr=0.0002 ++model.learnable_temp=True ++model.temperature=0.07 ++train.seed=505429
15 |
16 | ## SliceParam
17 | python main.py -m -cp configs/morphem70k -cn morphem70k_cfg model=sliceparam tag=slice ++optimizer.params.lr=0.0001 ++model.learnable_temp=True ++model.temperature=0.15 ++model.first_layer=pretrained_pad_dups ++model.slice_class_emb=True ++train.seed=725375
18 |
19 | ## HyperNet
20 | python main.py -m -cp configs/morphem70k -cn morphem70k_cfg model=hyperconvnext tag=hyper ++optimizer.params.lr=0.0004 ++model.separate_emb=True ++model.temperature=0.07 ++model.z_dim=128 ++model.hidden_dim=256 ++train.seed=125617
21 |
22 | ## Template Mixing
23 | python main.py -m -cp configs/morphem70k -cn morphem70k_cfg model=template_mixing tag=templ ++optimizer.params.lr=0.0001 ++model.num_templates=128 ++model.temperature=0.05 ++model.separate_coef=True ++train.seed=451006
24 |
--------------------------------------------------------------------------------