├── .DS_Store
├── .gitignore
├── README.md
├── SUMMARY.md
├── beats
├── README.md
├── file.md
├── metric.md
├── packet.md
└── winlog.md
├── contributors.md
├── cover.jpg
├── diff-hdfs.md
├── donors.md
├── elasticsearch
├── README.md
├── alias.md
├── api
│ ├── CRUD.md
│ ├── reindex.md
│ ├── script.md
│ └── search.md
├── auth
│ ├── searchguard-2.md
│ ├── searchguard.md
│ └── shield.md
├── hadoop
│ └── spark-streaming.md
├── ingest.md
├── monitor
│ ├── README.md
│ ├── api
│ │ ├── cat-cmd.md
│ │ ├── health.md
│ │ ├── index-stats.md
│ │ ├── node-stats.md
│ │ └── tasks-management.md
│ ├── bigdesk-banner.png
│ ├── bigdesk-indexing.png
│ ├── bigdesk-jvm.png
│ ├── bigdesk.md
│ ├── cerebro.md
│ ├── logging.md
│ ├── marvel-1.jpg
│ ├── marvel-2.jpg
│ ├── marvel-3.jpg
│ ├── marvel-4.jpg
│ ├── marvel-5.jpg
│ ├── marvel-6.jpg
│ ├── marvel.md
│ └── zabbix.md
├── other
│ ├── README.md
│ ├── elastalert.md
│ ├── grafana.md
│ ├── images
│ │ ├── grafana-1.png
│ │ ├── grafana-10.png
│ │ ├── grafana-11.png
│ │ ├── grafana-12.png
│ │ ├── grafana-13.png
│ │ ├── grafana-14.png
│ │ ├── grafana-15.png
│ │ ├── grafana-16.png
│ │ ├── grafana-17.png
│ │ ├── grafana-18.png
│ │ ├── grafana-19.png
│ │ ├── grafana-2.png
│ │ ├── grafana-20.png
│ │ ├── grafana-21.png
│ │ ├── grafana-3.png
│ │ ├── grafana-4.png
│ │ ├── grafana-5.png
│ │ ├── grafana-6.png
│ │ ├── grafana-7.png
│ │ ├── grafana-8.png
│ │ └── grafana-9.png
│ ├── juttle-viz.png
│ ├── juttle.md
│ ├── kale.md
│ ├── percolator.md
│ ├── rrd.md
│ └── watcher.md
├── performance
│ ├── bulk.md
│ ├── cache.md
│ ├── cluster-state.md
│ ├── curator.md
│ ├── fielddata.md
│ ├── gateway.md
│ └── profile.md
├── principle
│ ├── README.md
│ ├── auto-discovery.md
│ ├── indexing-performance.md
│ ├── realtime.md
│ ├── route-and-replica.md
│ └── shard-allocate.md
├── puppet.md
├── rollover.md
├── snapshot.md
├── template.md
├── testing.md
├── tribe.md
└── upgrade.md
├── kibana
├── README.md
├── difference.md
├── phantomjs.md
├── v3
│ ├── README.md
│ ├── advanced
│ │ ├── schema.md
│ │ ├── scripted.md
│ │ └── template.md
│ ├── aggs.md
│ ├── auth
│ │ ├── mojo-auth.md
│ │ ├── nginx.md
│ │ └── nodejs-cas.md
│ ├── configuration.md
│ ├── dashboard
│ │ ├── README.md
│ │ ├── queries-and-filters.md
│ │ └── rows-and-panels.md
│ ├── facet.md
│ ├── img
│ │ ├── alipay.png
│ │ ├── bettermap-gaode.png
│ │ ├── bettermap-heap.png
│ │ ├── class-cast-exception.jpg
│ │ ├── column-panel.png
│ │ ├── column.png
│ │ ├── cors.jpg
│ │ ├── hist-general.png
│ │ ├── hist-grid.png
│ │ ├── hist-mb.png
│ │ ├── hist-panel-mean.png
│ │ ├── hist-panel-percent.png
│ │ ├── hist-panel-queries.png
│ │ ├── hist-panel-style.png
│ │ ├── hist-panel.png
│ │ ├── hist-percent.png
│ │ ├── hist-queries.png
│ │ ├── hist-setting.png
│ │ ├── hist-stack.png
│ │ ├── hist-total-ps.png
│ │ ├── hist-total-scale.png
│ │ ├── hist-uniq-conf.png
│ │ ├── hist-uniq.png
│ │ ├── hist-view.png
│ │ ├── map-cn.png
│ │ ├── map-setting.png
│ │ ├── map-world.png
│ │ ├── query-topn.png
│ │ ├── sparklines-panel.png
│ │ ├── table-fields.png
│ │ ├── table-highlight.png
│ │ ├── table-micropanel.png
│ │ ├── table-paging.png
│ │ ├── table-panel-setting.png
│ │ ├── table-sorting.png
│ │ ├── table-trim.png
│ │ ├── terms-bar.png
│ │ ├── terms-donut.png
│ │ ├── terms-panel.png
│ │ ├── terms-pie-no-other.png
│ │ ├── terms-pie.png
│ │ ├── terms-stat-map.png
│ │ ├── terms-table.png
│ │ ├── topn-histogram.png
│ │ ├── topn-sparklines.png
│ │ ├── trends-panel.png
│ │ └── trends.png
│ ├── panels
│ │ ├── README.md
│ │ ├── bettermap.md
│ │ ├── column.md
│ │ ├── goal.md
│ │ ├── histogram.md
│ │ ├── hits.md
│ │ ├── map.md
│ │ ├── query.md
│ │ ├── sparklines.md
│ │ ├── stats.md
│ │ ├── table.md
│ │ ├── terms.md
│ │ ├── text.md
│ │ └── trends.md
│ ├── saving-and-loading.md
│ ├── simple.md
│ └── source-code-analysis
│ │ ├── README.md
│ │ ├── controller-and-service.md
│ │ ├── directives.md
│ │ ├── panel.md
│ │ ├── require.md
│ │ └── tree.md
└── v5
│ ├── README.md
│ ├── console.md
│ ├── dashboard.md
│ ├── discover.md
│ ├── examples
│ ├── README.md
│ ├── datehistogram_topn.png
│ ├── function-stack.md
│ ├── function_stack.png
│ ├── histogram-filters.md
│ ├── histogram_filters.png
│ ├── percentile-datehistogram.md
│ ├── percentile_datehistogram.png
│ ├── terms-split.md
│ ├── terms_split.png
│ ├── topn-datehistogram.md
│ └── topn_datehistogram.png
│ ├── plugin
│ ├── README.md
│ ├── app.md
│ ├── server-develop.md
│ └── vis-develop.md
│ ├── production.md
│ ├── settings.md
│ ├── setup.md
│ ├── source-code-analysis
│ ├── README.md
│ ├── dashboard.md
│ ├── discover.md
│ ├── indexjs.md
│ ├── kbnindex.md
│ └── visualize.md
│ ├── timelion.md
│ └── visualize
│ ├── README.md
│ ├── area.md
│ ├── bar.md
│ ├── lines.md
│ ├── map.md
│ ├── markdown.md
│ ├── metric.md
│ ├── pie.md
│ └── table.md
├── logstash
├── README.md
├── develop
│ ├── README.md
│ └── utmp.md
├── examples
│ ├── README.md
│ ├── java.md
│ ├── mysql-slow.md
│ ├── nginx-access.md
│ ├── nginx-error.md
│ ├── ossec.md
│ ├── postfix.md
│ └── windows.md
├── get-start
│ ├── README.md
│ ├── daemon.md
│ ├── full-config.md
│ ├── hello-world.md
│ ├── install-plugins.md
│ └── install.md
├── images
│ ├── logstash-arch.jpg
│ └── nxlog.png
├── performance
│ ├── README.md
│ ├── generator.md
│ └── monitor
│ │ ├── api.md
│ │ ├── heartbeat.md
│ │ ├── jconsole.png
│ │ └── jmx.md
├── plugins
│ ├── codec
│ │ ├── README.md
│ │ ├── collectd.md
│ │ ├── json.md
│ │ ├── multiline.md
│ │ └── netflow.md
│ ├── filter
│ │ ├── README.md
│ │ ├── date.md
│ │ ├── dissect.md
│ │ ├── elapsed.md
│ │ ├── geoip.md
│ │ ├── grok.md
│ │ ├── json.md
│ │ ├── kv.md
│ │ ├── metrics.md
│ │ ├── mutate.md
│ │ ├── ruby.md
│ │ └── split.md
│ ├── input
│ │ ├── README.md
│ │ ├── file.md
│ │ ├── stdin.md
│ │ ├── syslog.md
│ │ └── tcp.md
│ └── output
│ │ ├── elasticsearch.md
│ │ ├── email.md
│ │ ├── exec.md
│ │ ├── file.md
│ │ ├── hdfs.md
│ │ ├── nagios.md
│ │ ├── statsd.md
│ │ ├── stdout.md
│ │ └── tcp.md
├── scale
│ ├── README.md
│ ├── fluent.md
│ ├── heka.md
│ ├── kafka.md
│ ├── logstash-forwarder-java.md
│ ├── message-passing.md
│ ├── nxlog.md
│ ├── redis.md
│ └── rsyslog.md
└── source-code-analysis
│ ├── README.md
│ ├── event.md
│ └── pipeline.md
└── see-also.md
/.DS_Store:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/.DS_Store
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Node rules:
2 | ## Grunt intermediate storage (http://gruntjs.com/creating-plugins#storing-task-files)
3 | .grunt
4 |
5 | ## Dependency directory
6 | ## Commenting this out is preferred by some people, see
7 | ## https://docs.npmjs.com/misc/faq#should-i-check-my-node_modules-folder-into-git
8 | node_modules
9 |
10 | # Book build output
11 | _book
12 |
13 | # eBook build output
14 | *.epub
15 | *.mobi
16 | *.pdf
17 |
18 | count.sh
19 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 前言
2 |
3 | Elastic Stack 是 原 ELK Stack 在 5.0 版本加入 Beats 套件后的新称呼。
4 |
5 | Elastic Stack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,Elastic Stack 具有如下几个优点:
6 |
7 | * 处理方式灵活。Elasticsearch 是实时全文索引,不需要像 storm 那样预先编程才能使用;
8 | * 配置简易上手。Elasticsearch 全部采用 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
9 | * 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
10 | * 集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
11 | * 前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
12 |
13 | 当然,Elastic Stack 也并不是实时数据分析界的灵丹妙药。在不恰当的场景,反而会事倍功半。我自 2014 年初开 QQ 群交流 Elastic Stack,发现网友们对 Elastic Stack 的原理概念,常有误解误用;对实现的效果,又多有不能理解或者过多期望而失望之处。更令我惊奇的是,网友们广泛分布在传统企业和互联网公司、开发和运维领域、Linux 和 Windows 平台,大家对非专精领域的知识,一般都缺乏了解,这也成为使用 Elastic Stack 时的一个障碍。
14 |
15 | 为此,写一本 Elastic Stack 技术指南,帮助大家厘清技术细节,分享一些实战案例,成为我近半年一大心愿。本书大体完工之后,幸得机械工业出版社华章公司青睐,以《ELK Stack 权威指南》之名重修完善并出版,有意收藏者欢迎[购买](http://search.jd.com/Search?keyword=elkstack%E6%9D%83%E5%A8%81%E6%8C%87%E5%8D%97&enc=utf-8)。
16 |
17 | 本人于 Elastic Stack,虽然接触较早,但本身专于 web 和 app 应用数据方面,动笔以来,得到诸多朋友的帮助,详细贡献名单见[合作名单](./contributors.md)。此外,还要特别感谢曾勇(medcl)同学,完成 ES 在国内的启蒙式分享,并主办 ES 中国用户大会;吴晓刚(wood)同学,积极帮助新用户们,并最早分享了携程的 Elastic Stack 日亿级规模的实例。
18 |
19 | 欢迎加入 Elastic Stack 交流 QQ 群:315428175。
20 |  21 |
22 | *欢迎捐赠,作者支付宝账号:*
23 |
24 | 
25 |
26 | # Version
27 |
28 | 2016-10-27 发布了 Elastic Stack 5.0 版。由于变动较大,本书 Git 仓库将 master 分支统一调整为基于 5.0 的状态。
29 |
30 | 想要查阅过去 k3、k4、logstash-2.x 等不同老版本资料的读者,请下载 ELK release:
31 |
32 | # TODO
33 |
34 | 限于个人经验、时间和场景,有部分 Elastic Stack 社区比较常见的用法介绍未完成,期待各位同好出手。罗列如下:
35 |
36 | * es-hadoop 用例
37 | * beats 开发
38 | * codec/netflow 的详解
39 | * filter/elapsed 的用例
40 | * zeppelin 的 es 用例
41 | * kibana的filter交互用法
42 | * painless的date对象用法:同比环比图
43 | * significant_text aggs用例
44 | * cat nodeattrs接口
45 | * timelion保存成panel的用法
46 | * regionmap用法
47 | * Time Series Visual Builder用法
48 | * Viewing Document Context用法
49 | * Dead Letter Queues讲解
50 | * elastalert 新版说明
51 |
52 |
--------------------------------------------------------------------------------
/beats/winlog.md:
--------------------------------------------------------------------------------
1 | # winlogbeat
2 |
3 | winlogbeat 通过标准的 windows API 获取 windows 系统日志,常见的有 application,hardware,security 和 system 四类。winlogbeat 示例配置如下:
4 |
5 | ```
6 | winlogbeat.event_logs:
7 | - name: Application
8 | provider:
9 | - Application Error
10 | - Application Hang
11 | - Windows Error Reporting
12 | - EMET
13 | - name: Security
14 | level: critical, error, warning
15 | event_id: 4624, 4625, 4700-4800, -4735
16 | - name: System
17 | ignore_older: 168h
18 | - name: Microsoft-Windows-Windows Defender/Operational
19 | include_xml: true
20 |
21 | output.elasticsearch:
22 | hosts:
23 | - localhost:9200
24 | pipeline: "windows-pipeline-id"
25 |
26 | logging.to_files: true
27 | logging.files:
28 | path: C:/ProgramData/winlogbeat/Logs
29 | logging.level: info
30 | ```
31 |
32 | 和其他 beat 一样,这里示例的配置不都是必填项。事实上只有 `event_logs.name` 是必须的。而 winlogbeat 的输出字段中,除了 beats 家族的通用内容外,还包括一下特有字段:
33 |
34 |
35 | * activity\_id
36 | * computer\_name:如果运行在 Windows 事件转发模式,这个值会和 beat.hostname 不一样。
37 | * event\_data
38 | * event\_id
39 | * keywords
40 | * log\_name
41 | * level:可选值包括 Success, Information, Warning, Error, Audit Success, and Audit Failure.
42 | * message
43 | * message\_error
44 | * record\_number
45 | * related\_activity\_id
46 | * opcode
47 | * provider\_guid
48 | * process\_id
49 | * source\_name
50 | * task
51 | * thread\_id
52 | * user\_data
53 | * user.identifier
54 | * user.name
55 | * user.domain
56 | * user.type
57 | * version
58 | * xml
59 |
--------------------------------------------------------------------------------
/contributors.md:
--------------------------------------------------------------------------------
1 | 致谢
2 | =============
3 |
4 | * 感谢 crazw 完成 collectd 插件介绍章节。
5 | * 感谢 松涛 完成 nxlog 场景介绍章节。
6 | * 感谢 LeiTu 完成 logstash-forwarder 介绍章节。
7 | * 感谢 jingbli 完成 kafka 插件介绍章节。
8 | * 感谢 林鹏 完成 ossec 场景介绍章节。
9 | * 感谢 cameluo 完成 shield 介绍章节。
10 | * 感谢 tuxknight 指出 hdfs 章节笔误。
11 | * 感谢 lemontree 完成 marvel 介绍章节。
12 | * 感谢 NERO 完成 utmp 插件开发介绍章节。
13 | * 感谢 childe 完成 kibana-auth-CAS 介绍, elasticsearch 读写分离和别名等章节。
14 | * 感谢 gnuhpc 完善 elasticsearch 插件 index 配置细节,logstash-fowarder-java 部署细节。
15 | * 感谢 东南 指出两处代码示例笔误。
16 | * 感谢 陆一鸣 指出 openjdk 的 rpm 名错误。
17 | * 感谢 elain 完成 search-guard 章节。
18 | * 感谢 wdh 完成 search-guard v2 版章节。
19 | * 感谢 李宏旭 完成 hdfs 快照备份 章节。
20 | * 感谢 abcfy2 完成 grafana 章节。
21 |
--------------------------------------------------------------------------------
/cover.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/cover.jpg
--------------------------------------------------------------------------------
/diff-hdfs.md:
--------------------------------------------------------------------------------
1 | # Elastic Stack 与 Hadoop 体系的区别
2 |
3 | Kibana 因其丰富的图表类型和漂亮的前端界面,被很多人理解成一个统计工具。而我个人认为,ELK 这一套体系,不应该和 Hadoop 体系同质化。定期的离线报表,不是 Elasticsearch 专长所在(多花费分词、打分这些步骤在高负载压力环境上太奢侈了),也不应该由 Kibana 来完成(每次刷新都是重新计算)。Kibana 的使用场景,应该集中在两方面:
4 |
5 | * 实时监控
6 |
7 | 通过 histogram 面板,配合不同条件的多个 queries 可以对一个事件走很多个维度组合出不同的时间序列走势。时间序列数据是最常见的监控报警了。
8 |
9 | * 问题分析
10 |
11 | 通过 Kibana 的交互式界面可以很快的将异常时间或者事件范围缩小到秒级别或者个位数。期望一个完美的系统可以给你自动找到问题原因并且解决是不现实的,能够让你三两下就从 TB 级的数据里看到关键数据以便做出判断就很棒了。这时候,一些非 histogram 的其他面板还可能会体现出你意想不到的价值。全局状态下看似很普通的结果,可能在你锁定某个范围的时候发生剧烈的反方向的变化,这时候你就能从这个维度去重点排查。而表格面板则最直观的显示出你最关心的字段,加上排序等功能。入库前字段切分好,对于排错分析真的至关重要。
12 |
13 | ## Splunk 场景参考
14 |
15 | 关于 elk 的用途,我想还可以参照其对应的商业产品 splunk 的场景:
16 |
17 | > 使用 Splunk 的意义在于使信息收集和处理智能化。而其操作智能化表现在:
18 | >
19 | > 1. 搜索,通过下钻数据排查问题,通过分析根本原因来解决问题;
20 | > 2. 实时可见性,可以将对系统的检测和警报结合在一起,便> 于跟踪 SLA 和性能问题;
21 | > 3. 历史分析,可以从中找出趋势和历史模式,行为基线和阈值,生成一致性报告。
22 |
23 | -- Peter Zadrozny, Raghu Kodali 著/唐宏,陈健译《Splunk大数据分析》
24 |
--------------------------------------------------------------------------------
/elasticsearch/README.md:
--------------------------------------------------------------------------------
1 | Elasticsearch 来源于作者 Shay Banon 的第一个开源项目 Compass 库,而这个 Java 库最初的目的只是为了给 Shay 当时正在学厨师的妻子做一个菜谱的搜索引擎。2010 年,Elasticsearch 正式发布。至今已经成为 GitHub 上最流行的 Java 项目,不过 Shay 承诺给妻子的菜谱搜索依然没有面世……
2 |
3 | 2015 年初,Elasticsearch 公司召开了第一次全球用户大会 Elastic{ON}15。诸多 IT 巨头纷纷赞助,参会,演讲。会后,Elasticsearch 公司宣布改名 Elastic,公司官网也变成 。这意味着 Elasticsearch 的发展方向,不再限于搜索业务,也就是说,Elastic Stack 等机器数据和 IT 服务领域成为官方更加注意的方向。随后几个月,专注监控报警的 Watcher 发布 beta 版,社区有名的网络抓包工具 Packetbeat、多年专注于基于机器学习的异常探测 Prelert 等 ITOA 周边产品纷纷被 Elastic 公司收购。
4 |
--------------------------------------------------------------------------------
/elasticsearch/alias.md:
--------------------------------------------------------------------------------
1 | alias的几点应用
2 | ==================
3 |
4 | *本节作者:childe*
5 |
6 | # 索引更改名字时, 无缝过渡
7 |
8 | ## 情景1
9 |
10 | 用Logstash采集当前的所有nginx日志, 放入ES, 索引名叫nginx-YYYY.MM.DD.
11 |
12 | 后来又增加了apache日志, 希望能放在同一个索引里面,统一叫web-YYYY.MM.DD.
13 |
14 | 我们只要把Logstash配置更改一下,然后重启, 数据就会写入新的索引名字下. 但是同一天的索引就会被分成了2个, kibana上面就不好配置了.
15 |
16 | ### 如此实现
17 |
18 | 1. 今天是2015.07.28. 我们为nginx-2015.07.28建一个alias叫做web-2015.07.28, 之前的所有nginx日志也如此照做.
19 | 2. kibana中把dashboard配置的索引名改成web-YYYY.MM.DD
20 | 3. 将logstash里面的elasticsearch的配置改成web-YYYY.MM.DD, 重启.
21 | 4. 无缝切换实现.
22 |
23 | ## 情景2
24 |
25 | 用Logstash采集当前的所有nginx日志, 放入ES, 索引名叫nginx-YYYY.MM.DD.
26 |
27 | 某天(2015.07.28)希望能够按月建立索引, 索引名改成nginx-YYYY.MM.
28 |
29 | **[注意]** 像情景1中那样新建一个叫nginx-2015.07的alias, 并指向本月的其他的索引是不行的. 因为一个alias指向了多个索引, 写这个alias的时候, ES不可能知道写入哪个真正的索引.
30 |
31 | ### 如此实现
32 |
33 | 1. 新建索引nginx-2015.07, 以及他的alias: nginx-2015.07.29, nginx-2015.07.30 ... 等.
34 | 新建索引nginx-2015.08, 以及他的alias: nginx-2015.08.01, nginx-2015.08.02 ... 等.
35 | 2. 等到第二天, 将logstash配置更改为nginx-YYYY.MM, 重启.
36 | 3. 如果索引只保留10天(一般来说, 不可能永久保存), 在10天之后的某天, 将kibana配置更改为 `[nginx-]YYYY.MM`
37 |
38 | ### 缺点
39 |
40 | 第二步, 第三步需要记得手工操作, 或者写一个crontab定时任务.
41 |
42 | ### 另外一种思路
43 |
44 | 1. 新建一个叫nginx-2015.07的alias, 并指向本月的其他的索引.
45 | 这个时候不能马上更改logstash配置写入nginx-2015.07. 因为一个alias指向了多个索引, 写这个alias的时候, ES不可能知道写入哪个真正的索引.
46 | 2. 新建索引nginx-2015.08, 以及他的alias: nginx-2015.08.01, nginx-2015.08.02 ... 等.
47 | 3. 把kibana配置改为 `[nginx-]YYYY.MM`.
48 | 4. 到2015.08.01这天, 或者之后的某天, 更改logstash配置, 把elasticsearch的配置更改为nginx-YYYY.MM. 重启.
49 |
50 | ### 缺点
51 |
52 | 1. 7月份的索引还是按天建立.
53 | 2. 第四步需要记得手工操作.
54 |
55 | 情景2的操作有些麻烦, 这些都是为了"无缝"这个大前提. 我们不希望用户(kibana的使用者)感觉到任何变化, 更不能让使用者感受到数据有缺失.
56 |
57 | 如果用户愿意妥协, 那ELK的管理者就可以马上简单粗暴的把数据写到nginx-2015.07, 并把kibana配置改过去. 这样一来, 用户可能就不能方便的看到之前的数据了.
58 |
59 | # 按域名配置kibana的dashboard
60 |
61 | nginx日志中有个字段是domain, 各个业务部门在Kibana中需要看且只看自己域名下的日志.
62 |
63 | 可以在logstash中按域名切分索引,但ES的metadata会成倍的增长,带来极大的负担.
64 |
65 | 也可以放在nginx-YYYY.MM.DD一个索引中, 在kibana加一个filter过滤. 但这个关键的filter和其它所有filter排在一起,是很容易很不小心清掉的.
66 |
67 | 我们可以在template中配置, 对每一个域名做一个alias.
68 |
69 | ```
70 | "aliases" : {
71 | "{index}-www.corp.com" : {
72 | "filter" : {
73 | "term" : {
74 | "domain" : "www.corp.com"
75 | }
76 | }
77 | },
78 | "{index}-abc.corp.com" : {
79 | "filter" : {
80 | "term" : {
81 | "domain" : "abc.corp.com"
82 | }
83 | }
84 | }
85 | }
86 | ```
87 |
88 | 当新的索引nginx-2015.07.28生成的时候, 会有nginx-2015.07.28-www.corp.com和nginx-2015.07.28-abc.corp.com等alias指向nginx-2015.07.28.
89 |
90 | 在kibana配置dashboard的时候, 就可以直接用alias做配置了.
91 |
92 | 在实际使用中, 可能还需要一个crontab定时的查询是否有新的域名加入, 自动对新域名做当天的alias, 并把它加入template.
93 |
--------------------------------------------------------------------------------
/elasticsearch/api/CRUD.md:
--------------------------------------------------------------------------------
1 | # 增删改查
2 |
3 | 增删改查是数据库的基础操作方法。ES 虽然不是数据库,但是很多场合下,都被人们当做一个文档型 NoSQL 数据库在使用,原因自然是因为在接口和分布式架构层面的相似性。虽然在 Elastic Stack 场景下,数据的写入和查询,分别由 Logstash 和 Kibana 代劳,作为测试、调研和排错时的基本功,还是需要了解一下 ES 的增删改查用法的。
4 |
5 | ## 数据写入
6 |
7 | ES 的一大特点,就是全 RESTful 接口处理 JSON 请求。所以,数据写入非常简单:
8 |
9 | ```
10 | # curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/testlog -d '{
11 | "date" : "1434966686000",
12 | "user" : "chenlin7",
13 | "mesg" : "first message into Elasticsearch"
14 | }'
15 | ```
16 |
17 | 命令返回响应结果为:
18 |
19 | ```
20 | {"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h2nBE6n0qcyVJK","_version":1,"created":true}
21 | ```
22 |
23 | ## 数据获取
24 |
25 | 可以看到,在数据写入的时候,会返回该数据的 `_id`。这就是后续用来获取数据的关键:
26 |
27 | ```
28 | # curl -XGET http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK
29 | ```
30 |
31 | 命令返回响应结果为:
32 |
33 | ```
34 | {"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h2nBE6n0qcyVJK","_version":1,"found":true,"_source":{
35 | "date" : "1434966686000",
36 | "user" : "chenlin7",
37 | "mesg" : "first message into Elasticsearch"
38 | }}
39 | ```
40 |
41 | 这个 `_source` 里的内容,正是之前写入的数据。
42 |
43 | 如果觉得这个返回看起来有点太过麻烦,可以使用 `curl -XGET http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK/_source` 来指明只获取源数据部分。
44 |
45 | 更进一步的,如果你只想看数据中的一部分字段内容,可以使用 `curl -XGET http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK?fields=user,mesg` 来指明获取字段,结果如下:
46 |
47 | ```
48 | {"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h2nBE6n0qcyVJK","_version":1,"found":true,"fields":{"user":["chenlin7"],"mesg":["first message into Elasticsearch"]}}
49 | ```
50 |
51 | ## 数据删除
52 |
53 | 要删除数据,修改发送的 HTTP 请求方法为 DELETE 即可:
54 |
55 | ```
56 | # curl -XDELETE http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK
57 | ```
58 |
59 | 删除不单针对单条数据,还可以删除整个整个索引。甚至可以用通配符。
60 |
61 | ```
62 | # curl -XDELETE http://127.0.0.1:9200/logstash-2015.06.0*
63 | ```
64 |
65 | 在 Elasticsearch 2.x 之前,可以通过查询语句删除,也可以删除某个 `_type` 内的数据。现在都已经不再内置支持,改为 `Delete by Query` 插件。因为这种方式本身对性能影响较大!
66 |
67 | ## 数据更新
68 |
69 | 已经写过的数据,同样还是可以修改的。有两种办法,一种是全量提交,即指明 `_id` 再发送一次写入请求。
70 |
71 | ```
72 | # curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK -d '{
73 | "date" : "1434966686000",
74 | "user" : "chenlin7",
75 | "mesg" " "first message into Elasticsearch but version 2"
76 | }'
77 | ```
78 |
79 | 另一种是局部更新,使用 `/_update` 接口:
80 |
81 | ```
82 | # curl -XPOST 'http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK/_update' -d '{
83 | "doc" : {
84 | "user" : "someone"
85 | }
86 | }'
87 | ```
88 |
89 | 或者
90 |
91 | ```
92 | # curl -XPOST 'http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK/_update' -d '{
93 | "script" : "ctx._source.user = \"someone\""
94 | }'
95 | ```
96 |
--------------------------------------------------------------------------------
/elasticsearch/api/reindex.md:
--------------------------------------------------------------------------------
1 | # reindex
2 |
3 | Elasticsearch 本身不提供对索引的 rename,mapping 的 alter 等操作。所以,如果有需要对全索引数据进行导出,或者修改某个已有字段的 mapping 设置等情况下,我们只能通过 scroll API 导出全部数据,然后重新做一次索引写入。这个过程,叫做 reindex。
4 |
5 | 之前完成这个过程只能自己写程序或者用 logstash。5.0 中,Elasticsearch 将这个过程内置为 reindex API,但是要注意:这个接口并没有什么黑科技,其本质仅仅是将这段相同逻辑的代码预置分发而已。如果有复杂的数据变更操作等细节需求,依然需要自己编程完成。
6 |
7 | 下面分别给出这三种方法的示例:
8 |
9 | ## Perl 客户端
10 |
11 | Elastic 官方提供各种语言的客户端库,其中,Perl 库提供了对 reindex 比较方便的写法和示例。通过 `cpanm Search::Elasticsearch` 命令安装库完毕后,使用以下程序即可:
12 |
13 | ```
14 | use Search::Elasticsearch;
15 |
16 | my $es = Search::Elasticsearch->new(
17 | nodes => ['192.168.0.2:9200']
18 | );
19 | my $bulk = $es->bulk_helper(
20 | index => 'new_index',
21 | );
22 |
23 | $bulk->reindex(
24 | source => {
25 | index => 'old_index',
26 | size => 500, # default
27 | search_type => 'scan' # default
28 | }
29 | );
30 | ```
31 |
32 | ## Logstash 做 reindex
33 |
34 | 在最新版的 Logstash 中,对 logstash-input-elasticsearch 插件做了一定的修改,使得通过 logstash 完成 reindex 成为可能。
35 |
36 | reindex 操作的 logstash 配置如下:
37 |
38 | ```
39 | input {
40 | elasticsearch {
41 | hosts => [ "192.168.0.2" ]
42 | index => "old_index"
43 | size => 500
44 | scroll => "5m"
45 | docinfo => true
46 | }
47 | }
48 | output {
49 | elasticsearch {
50 | hosts => [ "192.168.0.3" ]
51 | index => "%{[@metadata][_index]}"
52 | document_type => "%{[@metadata][_type]}"
53 | document_id => "%{[@metadata][_id]}"
54 | }
55 | }
56 | ```
57 |
58 | 如果你做 reindex 的源索引并不是 logstash 记录的内容,也就是没有 `@timestamp`, `@version` 这两个 logstash 字段,那么可以在上面配置中添加一段 filter 配置,确保前后索引字段完全一致:
59 |
60 | ```
61 | filter {
62 | mutate {
63 | remove_field => [ "@timestamp", "@version" ]
64 | }
65 | }
66 | ```
67 |
68 | ## reindex API
69 |
70 | 简单的 reindex,可以很容易的完成:
71 |
72 | ```
73 | curl -XPOST http://localhost:9200/_reindex -d '
74 | {
75 | "source": {
76 | "index": "logstash-2016.10.29"
77 | },
78 | "dest": {
79 | "index": "logstash-new-2016.10.29"
80 | }
81 | }'
82 | ```
83 |
84 | 复杂需求,也能通过配合其他 API,比如 script、pipeline 等来满足一些,下面举一个复杂的示例:
85 |
86 | ```
87 | curl -XPOST http://localhost:9200/_reindex?requests_per_second=10000 -d '
88 | {
89 | "source": {
90 | "remote": {
91 | "host": "http://192.168.0.2:9200",
92 | },
93 | "index": "metricbeat-*",
94 | "query": {
95 | "match": {
96 | "host": "webserver"
97 | }
98 | }
99 | },
100 | "dest": {
101 | "index": "metricbeat",
102 | "pipeline": "ingest-rule-1"
103 | },
104 | "script": {
105 | "lang": "painless",
106 | "inline": "ctx._index = 'metricbeat-' + (ctx._index.substring('metricbeat-'.length(), ctx._index.length())) + '-1'"
107 | }
108 | }'
109 | ```
110 |
111 | 上面这个请求的作用,是将来自 192.168.0.2 集群的 metricbeat-2016.10.29 索引中,有关 `host:webserver` 的数据,读取出来以后,经过 localhost 集群的 `ingest-rule-1` 规则处理,在写入 localhost 集群的 metricbeat-2016.10.29-1 索引中。
112 |
113 | 注意:读取远端集群数据需要先配置对应的 `reindex.remote.whitelist:192.168.0.2:9200` 到 elasticsearch.yml 的白名单里。
114 |
115 | 通过 reindex 接口运行的任务可以通过同样是 5.0 新引入的任务管理接口进行取消、修改等操作。详细介绍见后续任务管理章节。
116 |
--------------------------------------------------------------------------------
/elasticsearch/api/script.md:
--------------------------------------------------------------------------------
1 | # script
2 |
3 | Elasticsearch 中,可以使用自定义脚本扩展功能。包括评分、过滤函数和聚合字段等方面。内置脚本引擎历经 MVEL、Groovy、Lucene expression 的变换后,Elastic.co 最终决定实现一个自己专用的 Painless 脚本语言,并在 5.0 版正式发布。
4 |
5 | 作为 Elastic Stack 场景,我们只介绍在聚合字段方面使用 script 的方式。
6 |
7 | ## 动态提交
8 |
9 | 最简单易用的方式,就是在正常的请求体中,把 `field` 换成 `script` 提交。比如一个标准的 terms agg 改成 script 方式,写法如下:
10 |
11 | ```
12 | # curl 127.0.0.1:9200/logstash-2015.06.29/_search -d '{
13 | "aggs" : {
14 | "clientip_top10" : {
15 | "terms" : {
16 | "script" : {
17 | "lang" : "painless",
18 | "inline" : "doc['clientip'].value"
19 | }
20 | }
21 | }
22 | }
23 | }'
24 | ```
25 |
26 | 在 script 中,有三种方式引用数据:`doc['clientip'].value`、`_field['clientip'].value` 和 `_source.clientip`。其区别在于:
27 |
28 | * `doc[].value` 读取 doc value 内的数据;
29 | * `_field[]` 读取 field 设置 `"store":true` 的存储内容;
30 | * `_source.obj.attr` 读取 `_source` 的 JSON 内容。
31 |
32 | 这也意味着,前者必须读取的是最终的词元字段数据,而后者可以返回任意的数据结构。
33 |
34 | **注意**:如果有分词,且未禁用 fielddata 的话,`doc[].value` 读取到的是分词后的数据。所以请注意使用 `doc['clientip.keyword'].value` 写法。
35 |
36 | ## 固定文件
37 |
38 | 为了和动态提交的语法有区别,调用固定文件的写法如下:
39 |
40 | ```
41 | # curl 127.0.0.1:9200/logstash-2015.06.29/_search -d '{
42 | "aggs" : {
43 | "clientip_subnet_top10" : {
44 | "terms" : {
45 | "script" : {
46 | "file" : "getvalue",
47 | "lang" : "groovy",
48 | "params" : {
49 | "fieldname": "clientip.keyword",
50 | "pattern": "^((?:\d{1,3}\.?){3})\.\d{1,3}$"
51 | }
52 | }
53 | }
54 | }
55 | }
56 | }'
57 | ```
58 |
59 | 上例要求在 ES 集群的所有数据节点上,都保存有一个 `/etc/elasticsearch/scripts/getvalue.groovy` 文件,并且该脚本文件可以接收 `fieldname` 和 `pattern` 两个变量。试举例如下:
60 |
61 | ```
62 | #!/usr/bin/env groovy
63 | matcher = ( doc[fieldname].value =~ /${pattern}/ )
64 | if (matcher.matches()) {
65 | matcher[0][1]
66 | }
67 | ```
68 |
69 | **注意**:ES 进程默认每分钟扫描一次 `/etc/elasticsearch/scripts/` 目录,并尝试加载该目录下所有文件作为 script。所以,不要在该目录内做文件编辑等工作,不要分发 .svn 等目录到生成环境,这些临时或者隐藏文件都会被 ES 进程加载然后报错。
70 |
71 | ## 其他语言
72 |
73 | ES 支持通过插件方式,扩展脚本语言的支持,目前默认自带的语言包括:
74 |
75 | * painless
76 | * lucene expression
77 | * groovy
78 | * mustache
79 |
80 | 而 github 上目前已有以下语言插件支持,基本覆盖了所有 JVM 上的可用语言:
81 |
82 | *
83 | *
84 | *
85 | *
86 | *
87 | *
88 |
--------------------------------------------------------------------------------
/elasticsearch/hadoop/spark-streaming.md:
--------------------------------------------------------------------------------
1 | # spark streaming 交互
2 |
3 | Apache Spark 是一个高性能集群计算框架,其中 Spark Streaming 作为实时批处理组件,因为其简单易上手的特性深受喜爱。在 es-hadoop 2.1.0 版本之后,也新增了对 Spark 的支持,使得结合 ES 和 Spark 成为可能。
4 |
5 | 目前最新版本的 es-hadoop 是 2.1.0-Beta4。安装如下:
6 |
7 | ```
8 | wget http://d3kbcqa49mib13.cloudfront.net/spark-1.0.2-bin-cdh4.tgz
9 | wget http://download.elasticsearch.org/hadoop/elasticsearch-hadoop-2.1.0.Beta4.zip
10 | ```
11 |
12 | 然后通过 `ADD_JARS=../elasticsearch-hadoop-2.1.0.Beta4/dist/elasticsearch-spark_2.10-2.1.0.Beta4.jar` 环境变量,把对应的 jar 包加入 Spark 的 jar 环境中。
13 |
14 | 下面是一段使用 spark streaming 接收 kafka 消息队列,然后写入 ES 的配置:
15 |
16 | ```
17 | import org.apache.spark._
18 | import org.apache.spark.streaming.kafka.KafkaUtils
19 | import org.apache.spark.streaming._
20 | import org.apache.spark.streaming.StreamingContext._
21 | import org.apache.spark.SparkContext
22 | import org.apache.spark.SparkContext._
23 | import org.apache.spark.SparkConf
24 | import org.apache.spark.sql._
25 | import org.elasticsearch.spark.sql._
26 | import org.apache.spark.storage.StorageLevel
27 | import org.apache.spark.Logging
28 | import org.apache.log4j.{Level, Logger}
29 |
30 | object Elastic {
31 | def main(args: Array[String]) {
32 | val numThreads = 1
33 | val zookeeperQuorum = "localhost:2181"
34 | val groupId = "test"
35 | val topic = Array("test").map((_, numThreads)).toMap
36 | val elasticResource = "apps/blog"
37 |
38 | val sc = new SparkConf()
39 | .setMaster("local[*]")
40 | .setAppName("Elastic Search Indexer App")
41 |
42 | sc.set("es.index.auto.create", "true")
43 | val ssc = new StreamingContext(sc, Seconds(10))
44 | ssc.checkpoint("checkpoint")
45 | val logs = KafkaUtils.createStream(ssc,
46 | zookeeperQuorum,
47 | groupId,
48 | topic,
49 | StorageLevel.MEMORY_AND_DISK_SER)
50 | .map(_._2)
51 |
52 | logs.foreachRDD { rdd =>
53 | val sc = rdd.context
54 | val sqlContext = new SQLContext(sc)
55 | val log = sqlContext.jsonRDD(rdd)
56 | log.saveToEs(elasticResource)
57 | }
58 |
59 | ssc.start()
60 | ssc.awaitTermination()
61 |
62 | }
63 | }
64 | ```
65 |
66 | 注意,代码中使用了 spark SQL 提供的 `jsonRDD()` 方法,如果在对应的 kafka topic 里的数据,本身并不是已经处理好了的 JSON 数据的话,这里还需要自己写一写额外的处理函数,利用 `cast class` 来规范数据。
67 |
--------------------------------------------------------------------------------
/elasticsearch/ingest.md:
--------------------------------------------------------------------------------
1 | # Ingest 节点
2 |
3 | Ingest 节点是 Elasticsearch 5.0 新增的节点类型和功能。其开启方式为:在 `elasticsearch.yml` 中定义:
4 |
5 | ```
6 | node.ingest: true
7 | ```
8 |
9 | Ingest 节点的基础原理,是:节点接收到数据之后,根据请求参数中指定的管道流 id,找到对应的已注册管道流,对数据进行处理,然后将处理过后的数据,按照 Elasticsearch 标准的 indexing 流程继续运行。
10 |
11 | ## 创建管道流
12 |
13 | ```
14 | curl -XPUT http://localhost:9200/_ingest/pipeline/my-pipeline-id -d '
15 | {
16 | "description" : "describe pipeline",
17 | "processors" : [
18 | {
19 | "convert" : {
20 | "field": "foo",
21 | "type": "integer"
22 | }
23 | }
24 | ]
25 | }'
26 | ```
27 |
28 | 然后发送端带着这个 `my-pipeline-id` 发请求就好了。示例见本书 beats 章节的介绍。
29 |
30 | ## 测试管道流
31 |
32 | 想知道自己的 ingest 配置是否正确,可以通过仿真接口测试验证一下:
33 |
34 | ```
35 | curl -XPUT http://localhost:9200/_ingest/pipeline/_simulate -d '
36 | {
37 | "pipeline" : {
38 | "description" : "describe pipeline",
39 | "processors" : [
40 | {
41 | "set" : {
42 | "field": "foo",
43 | "value": "bar"
44 | }
45 | }
46 | ]
47 | },
48 | "docs" : [
49 | {
50 | "_index": "index",
51 | "_type": "type",
52 | "_id": "id",
53 | "_source": {
54 | "foo" : "bar"
55 | }
56 | }
57 | ]
58 | }'
59 | ```
60 |
61 | ## 处理器
62 |
63 | Ingest 节点的处理器,相当于 Logstash 的 filter 插件。事实上其主要处理器就是直接移植了 Logstash 的 filter 代码成 Java 版本。目前最重要的几个处理器分别是:
64 |
65 | ### convert
66 |
67 | ```
68 | {
69 | "convert": {
70 | "field" : "foo",
71 | "type": "integer"
72 | }
73 | }
74 | ```
75 |
76 | ### grok
77 |
78 | ```
79 | {
80 | "grok": {
81 | "field": "message",
82 | "patterns": ["my %{FAVORITE_DOG:dog} is colored %{RGB:color}"]
83 | "pattern_definitions" : {
84 | "FAVORITE_DOG" : "beagle",
85 | "RGB" : "RED|GREEN|BLUE"
86 | }
87 | }
88 | }
89 | ```
90 |
91 | ### gsub
92 |
93 | ```
94 | {
95 | "gsub": {
96 | "field": "field1",
97 | "pattern": "\.",
98 | "replacement": "-"
99 | }
100 | }
101 | ```
102 |
103 | ### date
104 |
105 | ```
106 | {
107 | "date" : {
108 | "field" : "initial_date",
109 | "target_field" : "timestamp",
110 | "formats" : ["dd/MM/yyyy hh:mm:ss"],
111 | "timezone" : "Europe/Amsterdam"
112 | }
113 | }
114 | ```
115 |
116 | ### 其他处理器插件
117 |
118 | 除了内置的处理器之外,还有 3 个处理器,官方选择了以插件性质单独发布,它们是 attachement,geoip 和 user-agent 。原因应该是这 3 个处理器需要额外数据模块,而且处理性能一般,担心拖累 ES 集群。
119 |
120 | 它们可以和其他普通 ES 插件一样安装:
121 |
122 | ```
123 | sudo bin/elasticsearch-plugin install ingest-geoip
124 | ```
125 |
126 | 使用方式和其他处理器一样:
127 |
128 | ```
129 | curl -XPUT http://localhost:9200/_ingest/pipeline/my-pipeline-id-2 -d '
130 | {
131 | "description" : "Add geoip info",
132 | "processors" : [
133 | {
134 | "geoip" : {
135 | "field" : "ip",
136 | "target_field" : "geo",
137 | "database_file" : "GeoLite2-Country.mmdb.gz"
138 | }
139 | }
140 | ]
141 | }
142 | ```
143 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/README.md:
--------------------------------------------------------------------------------
1 | # 监控方案
2 |
3 | Elasticsearch 作为一个分布式系统,监控自然是重中之重。Elasticsearch 本身提供了非常完善的,由浅及深的各种性能数据接口。和数据读写检索接口一样,采用 RESTful 风格。我们可以直接使用 curl 来获取数据,编写监控程序,也可以使用一些现成的监控方案。通常这些方案也是通过接口读取数据,解析 JSON,渲染界面。
4 |
5 | 本章会先介绍一些常用的监控接口,以及其响应数据的含义。然后再介绍几种常用的开源和商业 Elasticsearch 监控产品。
6 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/api/index-stats.md:
--------------------------------------------------------------------------------
1 | # 索引状态监控接口
2 |
3 | 索引状态监控接口的输出信息和节点状态监控接口非常类似。一般情况下,这个接口单独监控起来的意义并不大。
4 |
5 | 不过在 ES 1.6 版开始,加入了对索引分片级别的 commit id 功能。
6 |
7 | 回忆一下之前原理章节的内容,commit 是在分片内部,对每个 segment 做的。而数据在主分片和副本分片上,是由各自节点自行做 segment merge 操作,所以副本分片和主分片的 segment 的 commit id 是不一致的。这导致 ES 副本恢复时,跟主分片比对 commit id,基本上每个 segment 都不一样,所以才需要从主分片完整重传一份数据。
8 |
9 | 新加入分片级别的 commit id 后,副本恢复时,先比对跟主分片的分片级 commit id,如果一致,直接本地恢复副本分片内容即可。
10 |
11 | 查看分片级别 commit id 的命令如下:
12 |
13 | ```
14 | # curl 'http://127.0.0.1:9200/logstash-mweibo-2015.06.15/_stats/commit?level=shards&pretty'
15 | ...
16 | "indices" : {
17 | "logstash-2015.06.15" : {
18 | "primaries" : { },
19 | "total" : { },
20 | "shards" : {
21 | "0" : [ {
22 | "routing" : {
23 | "state" : "STARTED",
24 | "primary" : true,
25 | "node" : "AqaYWFQJRIK0ZydvVgASEw",
26 | "relocating_node" : null
27 | },
28 | "commit" : {
29 | "generation" : 726,
30 | "user_data" : {
31 | "translog_id" : "1434297603053",
32 | "sync_id" : "AU4LEh6wnBE6n0qcEXs5"
33 | },
34 | "num_docs" : 36792652
35 | }
36 | } ],
37 | ...
38 | ```
39 |
40 | 注意:为了节约频繁变更的资源消耗,ES 并不会实时更新分片级 commit id。只有连续 5 分钟没有新数据写入的索引,才会触发给索引各分片更新 commit id 的操作。如果你查看的是一个还在新写入数据的索引,看到的内容应该是下面这样:
41 |
42 | ```
43 | "commit" : {
44 | "generation" : 590,
45 | "user_data" : {
46 | "translog_id" : "1434038402801"
47 | },
48 | "num_docs" : 29051938
49 | }
50 | ```
51 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk-banner.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/bigdesk-banner.png
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk-indexing.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/bigdesk-indexing.png
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk-jvm.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/bigdesk-jvm.png
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk.md:
--------------------------------------------------------------------------------
1 | # bigdesk
2 |
3 | 要想最快的了解 ES 各节点的性能细节,推荐使用 bigdesk 插件,其原作者为 lukas-vlcek。但是从 Elasticsearch 1.4 版本开始就不再更新了。国内有用户 fork 出来继续维护到支持 5.0 版本,GitHub 地址见:
4 |
5 | bigdesk 通过浏览器直连 ES 节点,发起 RESTful 请求,并渲染结果成图。所以其安装部署极其简单:
6 |
7 | ```
8 | # git clone https://github.com/hlstudio/bigdesk
9 | # cd bigdesk/_site
10 | # python -mSimpleHTTPServer
11 | Serving HTTP on 0.0.0.0 port 8000 ...
12 | ```
13 |
14 | 浏览器打开 `http://localhost:8000` 即可看到 bigdesk 页面。在 **endpoint** 输入框内填写要连接的 ES 节点地址,选择 refresh 间隔和 keep 时长,点击 **connect**,完成。
15 |
16 | 
17 |
18 | 注意:设置 refresh 间隔请考虑 Elastic Stack 使用的 template 里实际的 `refresh_interval` 是多少。否则你可能看到波动太大的数据,不足以说明情况。
19 |
20 | 点选某个节点后,就可以看到该节点性能的实时走势。一般重点关注 JVM 性能和索引性能。
21 |
22 | 有关 JVM 部分截图如下:
23 |
24 | 
25 |
26 | 有关数据读写性能部分截图如下:
27 |
28 | 
29 |
30 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/cerebro.md:
--------------------------------------------------------------------------------
1 | # cerebro
2 |
3 | cerebro 这个名字大家可能觉得很陌生,其实它就是过去的 kopf 插件!因为 Elasticsearch 5.0 不再支持 site plugin,所以 kopf 作者放弃了原项目,另起炉灶搞了 cerebro,以独立的单页应用形式,继续支持新版本下 Elasticsearch 的管理工作。
4 |
5 | 项目地址:
6 |
7 | ## 安装部署
8 |
9 | 单页应用的安装方式都非常简单,下载打开即可:
10 |
11 | ```
12 | # git clone https://github.com/lmenezes/cerebro
13 | # cd cerebro
14 | # ./bin/cerebro
15 | ```
16 |
17 | 然后浏览器打开 `http://localhost:9000` 即可。
18 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/logging.md:
--------------------------------------------------------------------------------
1 | # 日志记录
2 |
3 | Elasticsearch 作为一个服务,本身也会记录很多日志信息。默认情况下,日志都放在 `$ES_HOME/logs/` 目录里。
4 |
5 | 日志配置在 Elasticsearch 5.0 中改成了使用 `log4j2.properties` 文件配置,包括日志滚动的方式、命名等,都和标准的 log4j2 一样。唯一的特点是:Elasticsearch 导出了一个变量叫 `${sys:es.logs}`,指向你在 `elasticsearch.yml` 中配置的 `path.logs` 地址:
6 |
7 | ```
8 | appender.index_search_slowlog_rolling.filePattern = ${sys:es.logs}_index_search_slowlog-%d{yyyy-MM-dd}.log
9 | ```
10 |
11 | 具体的级别等级也可以通过 `/_cluster/settings` 接口动态调整。比如说,如果你的节点一直无法正确的加入集群,你可以将集群自动发现方面的日志级别修改成 DEBUG,来关注这方面的问题:
12 |
13 | ```
14 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
15 | {
16 | "transient" : {
17 | "logger.org.elasticsearch.indices.recovery" : "DEBUG"
18 | }
19 | }'
20 | ```
21 |
22 | ## 性能日志
23 |
24 | 除了进程状态的日志输出,ES 还支持跟性能相关的日志输出。针对数据写入,检索,读取三个阶段,都可以设置具体的慢查询阈值,以及不同的输出等级。
25 |
26 | 此外,慢查询日志是针对索引级别的设置。除了通过 `/_cluster/settings` 接口配置一组集群各索引共用的参数以外,还可以针对每个索引设置不同的参数。
27 |
28 | *注:过去的版本,还可以在 `elasticsearch.yml` 中设置,5.0 版禁止在配置文件中添加索引级别的设置!*
29 |
30 | 比如说,我们可以先设置集群共同的参数:
31 |
32 | ```
33 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
34 | {
35 | "transient" : {
36 | "logger.index.search.slowlog" : "DEBUG",
37 | "logger.index.indexing.slowlog" : "WARN",
38 | "index.search.slowlog.threshold.query.debug" : "10s",
39 | "index.search.slowlog.threshold.fetch.debug": "500ms",
40 | "index.indexing.slowlog.threshold.index.warn": "5s"
41 | }
42 | }'
43 | ```
44 |
45 | 然后针对某个比较大的索引,调高设置:
46 |
47 | ```
48 | # curl -XPUT http://127.0.0.1:9200/logstash-wwwlog-2015.06.21/_settings -d'
49 | {
50 | "index.search.slowlog.threshold.query.warn" : "10s",
51 | "index.search.slowlog.threshold.fetch.debug": "500ms",
52 | "index.indexing.slowlog.threshold.index.info": "10s"
53 | }
54 | ```
55 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-1.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-2.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-3.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-4.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-5.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-6.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel.md:
--------------------------------------------------------------------------------
1 | # marvel
2 |
3 | *本节作者:lemontree*
4 |
5 | marvel 是 Elastic.co 公司推出的商业监控方案,也是用来监控 Elasticsearch 集群实时、历史状态的有力用具,便于性能优化以及故障诊断。监控主要分为六个层面,分别是集群层、节点层、索引层、分片层、事件层、Sense。
6 |
7 | * 集群层:主要对集群健康情况进行汇总,包括集群名称、集群状态、节点数量、索引个数、分片数、总数据量、集群版本等信息。同时,对节点、索引整体情况分别展示。
8 | * 节点层:主要对每个节点的 CPU 、内存、负载、索引相关的性能数据等信息进行统计,并进行图形化展示。
9 | * 索引层:展示的信息与节点层类似,主要从索引的角度展示。
10 | * 分片层:从索引、节点两个角度展示分片的分布情况,并提供 playback 功能演示分片分配的历史过程。
11 | * 事件层:展示集群相关事件,如节点脱离、加入,Master 选举、索引创建、Shard 分配等。
12 | * Sense:轻量级的开发界面,主要用于通过 API 查询数据,管理集群。
13 |
14 | Elastic.co 公司的收费标准是:
15 |
16 | * 开发模式免费
17 | * 生产环境前 5 个节点,每年 1000 美元
18 | * 之后每增加 5 个节点,每年加收 250 美元
19 |
20 | ## 安装和卸载
21 |
22 | marvel 是以 elasticsearch 的插件形式存在的,可以直接通过插件安装:
23 |
24 | ```
25 | # ./bin/plugin -i elasticsearch/marvel/latest
26 | ```
27 |
28 | 如果你是从官网下载的安装包,则运行:
29 |
30 | ```
31 | # ./bin/plugin -i marvel -u file:///path/to/marvel-latest.zip
32 | ```
33 |
34 | 各节点都安装完毕后,可以通过下行命令来查看节点上的插件列表,检查列表中是否含有 marvel:
35 |
36 | ```
37 | # curl http://127.0.0.1:9200/_nodes/_local/plugins
38 | ```
39 |
40 | 安装之后,插件自动运行,并将定期获取到的集群状态数据,存储在 `.marvel-YYYY.MM.DD` 索引中,以单台 ES 计算,该索引的大小在 500MB 左右。所以,如果在小规模环境下运行,首先请注意,不要让你宝贵的内存都花在 marvel 的数据索引上了。
41 |
42 | 如果不打算使用 marvel,在各节点上通过下行命令下载:
43 |
44 | ```
45 | # ./bin/plugin -r marvel
46 | ```
47 |
48 | ## 配置
49 |
50 | 如果不想让 marvel 数据索引影响到生产环境 ES 的运行,可以搭建单独的 marvel 数据集群,而生产数据集群上通过主动汇报的方式把数据发送过去。
51 |
52 | 在两个集群都安装好 marvel 插件后,生产集群的 `elasticsearch.yml` 上添加如下配置:
53 |
54 | ```
55 | marvel.agent.exporter.es.hosts: ["marvel-cluster-ip:9200"]
56 | ```
57 |
58 | 和大多数 cluster 设置一样,marvel 设置也是可以动态变更的:
59 |
60 | ```
61 | # curl –XPUT 127.0.0.1:9200/_cluster/settings -d '{
62 | "transient" : {
63 | "marvel.agent.exporter.es.hosts": [ "192.168.0.2:9200", "192.168.0.3:9200" ]
64 | }
65 | }'
66 | ```
67 |
68 | 数据接收端的 marvel 集群(即上一行写的 marvel-cluster-ip 代表的主机)则添加如下配置:
69 |
70 | ```
71 | marvel.agent.enabled: false
72 | ```
73 |
74 | 即本身不启用 marvel,以免数据有混淆。
75 |
76 | ## 访问
77 |
78 | 既然是 ES 插件,访问地址自然是插件式的:`http://marvel-cluster-ip:9200/_plugin/marvel/index.html`
79 |
80 | marvel 的监控页面是在 Kibana3 基础上稍有改造。如下图所示,其顶部菜单栏设计了一个下拉选择框,可以切换几个不同纬度的仪表板:
81 |
82 | 
83 |
84 | ## 面板定制
85 |
86 | Marvel的信息展示能够以Panel为单元进行个性化定制。每个Panel定制的过程比较类似。这里举例定制一个DOCUMENT COUNT文档数Panel,配置过程如下:
87 |
88 | 1. 点击红色椭圆部分,添加一个Panel:
89 | 
90 | 2. 输入Panel的名字DOCUMENT COUNT:
91 | 
92 | 3. 输入Panel Y 轴显示的值 "Primaries.docx.count":
93 | 
94 | 4. 选择展示风格
95 | 
96 | 5. 选择查看的集合,这里选择 *all*:
97 | 
98 | 6. 一个Document Count Panel就完成了:
99 | 
100 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/zabbix.md:
--------------------------------------------------------------------------------
1 | # zabbix
2 |
3 | 之前提到的都是 Elasticsearch 的 sites 类型插件,其实质是实时从浏览器读取 cluster stats 接口数据并渲染页面。这种方式直观,但不适合生产环境的自动化监控和报警处理。要达到这个目标,还是需要使用诸如 nagios、zabbix、ganglia、collectd 这类监控系统。
4 |
5 | 本节以 zabbix 为例,介绍如何使用监控系统完成 Elasticsearch 的监控报警。
6 |
7 | github 上有好几个版本的 ESZabbix 仓库,都源自 Elastic 公司员工 untergeek 最早的贡献。但是当时 Elasticsearch 还没有官方 python 客户端,所以监控程序都是用的是 pyes 库。对于最新版的 ES 来说,已经不推荐使用了。
8 |
9 | 这里推荐一个修改使用了官方 `elasticsearch.py` 库的衍生版。GitHub 地址见:。
10 |
11 | ## 安装配置
12 |
13 | 仓库中包括三个文件:
14 |
15 | 1. ESzabbix.py
16 | 2. ESzabbix.userparm
17 | 3. ESzabbix_templates.xml
18 |
19 | 其中,前两个文件需要分发到每个 ES 节点上。如果节点上运行的是 yum 安装的 zabbix,二者的默认位置应该分别是:
20 |
21 | 1. `/etc/zabbix/zabbix_externalscripts/ESzabbix.py`
22 | 2. `/etc/zabbix/agent_include/ESzabbix.userparm`
23 |
24 | 然后在各节点安装运行 ESzabbix.py 所需的 python 库依赖:
25 |
26 | ```
27 | # yum install -y python-pbr python-pip python-urllib3 python-unittest2
28 | # pip install elasticsearch
29 | ```
30 |
31 | 安装成功后,你可以试运行下面这行命令,看看命令输出是否正常:
32 |
33 | ```
34 | # /etc/zabbix/zabbix_externalscripts/ESzabbix.py cluster status
35 | ```
36 |
37 | 最后一个文件是 zabbix server 上的模板文件,不过在导入模板之前,还需要先创建一个数值映射,因为在模板中,设置了集群状态的触发报警,没有映射的话,报警短信只有 0, 1, 2 数字不是很易懂。
38 |
39 | 创建数值映射,在浏览器登录 zabbix-web,菜单栏的 **Zabbix Administration** 中选择 **General** 子菜单,然后在右侧下拉框中点击 **Value Maping**。
40 |
41 | 选择 **create**, 新建表单中填写:
42 |
43 | > name: ES Cluster State
44 | > 0 ⇒ Green
45 | > 1 ⇒ Yellow
46 | > 2 ⇒ Red
47 |
48 | 完成以后,即可在 **Templates** 页中通过 **import** 功能完成导入 `ESzabbix_templates.xml`。
49 |
50 | 在给 ES 各节点应用新模板之前,需要给每个节点定义一个 `{$NODENAME}` 宏,具体值为该节点 `elasticsearch.yml` 中的 `node.name` 值。从统一配管的角度,建议大家都设置为 ip 地址。
51 |
52 | ## 模板应用
53 |
54 | 导入完成后,zabbix 里多出来三个可用模板:
55 |
56 | 1. Elasticsearch Node & Cache
57 | 其中包括两个 Application:ES Cache 和 ES Node。分别有 Node Field Cache Size, Node Filter Cache Size 和 Node Storage Size, Records indexed per second 共计 4 个 item 监控项。在完成上面说的宏定义后,就可以把这个模板应用到各节点(即监控主机)上了。
58 | 2. Elasticsearch Service
59 | 只有一个监控项 Elasticsearch service status,做进程监控的,也应用到各节点上。
60 | 3. Elasticsearch Cluster
61 | 包括 11 个监控项,如下列所示。其中,**ElasticSearch Cluster Status** 这个监控项连带有报警的触发器,并对应之前创建的那个 Value Map。
62 | * Cluster-wide records indexed per second
63 | * Cluster-wide storage size
64 | * ElasticSearch Cluster Status
65 | * Number of active primary shards
66 | * Number of active shards
67 | * Number of data nodes
68 | * Number of initializing shards
69 | * Number of nodes
70 | * Number of relocating shards
71 | * Number of unassigned shards
72 | * Total number of records
73 | 这个模板下都是集群总体情况的监控项,所以,运用在一台有 ES 集群读取权限的主机上即可,比如 zabbix server。
74 |
75 | ## 其他
76 |
77 | untergeek 最近刚更新了他的仓库,重构了一个 es_stats_zabbix 模块用于 Zabbix 监控,有兴趣的读者可以参考:
78 |
--------------------------------------------------------------------------------
/elasticsearch/other/README.md:
--------------------------------------------------------------------------------
1 | # Elasticsearch 在运维领域的其他运用
2 |
3 | 目前 Elasticsearch 虽然以 Elastic Stack 作为主打产品,但其优秀的分布式设计,灵活的搜索评分函数和强大简洁的检索聚合功能,在运维领域也衍生出不少其他有趣的应用方式。
4 |
5 | 对于 Elastic 公司来说,这些周边应用,也随时可能成为他们的后续目标产品。就在本书第一版编写期间,packetbeat 就被 Elastic 公司收购,并且可能作为未来数据采集端的标准应用。所以,Elastic Stack 用户提前了解其他方面的多种可能,也是非常有意义的。
6 |
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-1.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-10.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-11.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-12.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-13.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-14.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-15.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-16.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-17.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-17.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-18.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-18.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-19.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-19.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-2.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-20.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-20.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-21.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-21.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-3.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-4.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-5.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-6.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-7.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-8.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-9.png
--------------------------------------------------------------------------------
/elasticsearch/other/juttle-viz.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/juttle-viz.png
--------------------------------------------------------------------------------
/elasticsearch/other/kale.md:
--------------------------------------------------------------------------------
1 | # Kale 系统
2 |
3 | Kale 系统是 Etsy 公司开源的一个监控分析系统。Kale 分为两个部分:skyline 和 oculus。skyline 负责对时序数据进行概率分布校验,对校验失败率超过阈值的时序数据发报警;oculus 负责给被报警的时序,找出趋势相似的其他时序作为关联性参考。
4 |
5 | 看到“相似”两个字,你一定想到了。没错,oculus 组件,就是利用了 Elasticsearch 的相似度打分。
6 |
7 | oculus 中,为 Elasticsearch 的 `org.elasticsearch.script.ExecutableScript` 扩展了 `DTW` 和 `Euclidian` 两种 NativeScript。可以在界面上选择用其中某一种算法来做相似度打分:
8 |
9 | 
10 |
11 | 然后相似度最高的几个时序图就依次排列出来了。
12 |
13 | Euclidian 即欧几里得距离,是时序相似度计算里最基础的方式。
14 |
15 | DWT 即动态时间规整(Dynamic Time Warping),也是时序相似度计算的常用方式,它和欧几里得距离的差别在于,欧几里得距离要求比对的时序数据是一一对应的,而动态时间规整计算的时序数据并不要求长度相等。在运维监控来说,也就是延后一定时间发生的相近趋势也可以以很高的打分项排名靠前。
16 |
17 | 不过,oculus 插件仅更新到支持 Elasticsearch-0.90.3 版本为止。Etsy 性能优化团队在 Oreilly 2015 大会上透露,他们内部已经根据 Kale 的经验教训,重新开发了 Kale 2.0 版。会在年内开源放出来。大家一起期待吧!
18 |
19 | ## 参考阅读
20 |
21 |
22 |
--------------------------------------------------------------------------------
/elasticsearch/other/rrd.md:
--------------------------------------------------------------------------------
1 | # 时序数据
2 |
3 | 之前已经介绍过,ES 默认存储数据时,是有索引数据、*_all* 全文索引数据、*_source* JSON 字符串三份的。其中,索引数据由于倒排索引的结构,压缩比非常高。因此,在某些特定环境和需求下,可以只保留索引数据,以极小的容量代价,换取 ES 灵活的数据结构和聚合统计功能。
4 |
5 | 在监控系统中,对监控项和监控数据的设计一般是这样:
6 |
7 | > metric_path value timestamp (Graphite 设计)
8 | > { "host": "Host name 1", "key": "item_key", "value": "33", "clock": 1381482894 } (Zabbix 设计)
9 |
10 | 这些设计有个共同点,数据是二维平面的。以最简单的访问请求状态监控为例,一次请求,可能转换出来的 `metric_path` 或者说 `key` 就有:**{city,isp,host,upstream}.{urlpath...}.{status,rt,ut,size,speed}** 这么多种。假设 urlpath 有 1000 个,就是 20000 个组合。意味着需要发送 20000 条数据,做 20000 次存储。
11 |
12 | 而在 ES 里,这就是实实在在 1000 条日志。而且在多条日志的时候,因为词元的相对固定,压缩比还会更高。所以,使用 ES 来做时序监控数据的存储和查询,是完全可行的办法。
13 |
14 | 对时序数据,关键就是定义缩减数据重复。template 示例如下:
15 |
16 | ```
17 | {
18 | "order" : 2,
19 | "template" : "logstash-monit-*",
20 | "settings" : {
21 | },
22 | "mappings" : {
23 | "_default_" : {
24 | "_source" : {
25 | "enabled" : false
26 | },
27 | "_all" : {
28 | "enabled" : false
29 | }
30 | }
31 | },
32 | "aliases" : { }
33 | }
34 | ```
35 |
36 | 如果有些字段,是完全不用 Query ,只参加 Aggregation 的,还可以设置:
37 |
38 | ```
39 | "properties" : {
40 | "sid" : {
41 | "index" : "no",
42 | "type" : "keyword"
43 | }
44 | },
45 | ```
46 |
47 | 关于 Elasticsearch 用作 rrd 用途,与 MongoDB 等其他工具的性能测试与对比,可以阅读腾讯工程师写的系列文章:
48 |
--------------------------------------------------------------------------------
/elasticsearch/performance/bulk.md:
--------------------------------------------------------------------------------
1 | # 批量提交
2 |
3 | 在 CRUD 章节,我们已经知道 ES 的数据写入是如何操作的了。喜欢自己动手的读者可能已经迫不及待的自己写了程序开始往 ES 里写数据做测试。这时候大家会发现:程序的运行速度非常一般,即使 ES 服务运行在本机,一秒钟大概也就能写入几百条数据。
4 |
5 | 这种速度显然不是 ES 的极限。事实上,每条数据经过一次完整的 HTTP POST 请求和 ES indexing 是一种极大的性能浪费,为此,ES 设计了批量提交方式。在数据读取方面,叫 mget 接口,在数据变更方面,叫 bulk 接口。mget 一般常用于搜索时 ES 节点之间批量获取中间结果集,对于 Elastic Stack 用户,更常见到的是 bulk 接口。
6 |
7 | bulk 接口采用一种比较简朴的数据积累格式,示例如下:
8 |
9 | ```
10 | # curl -XPOST http://127.0.0.1:9200/_bulk -d'
11 | { "create" : { "_index" : "test", "_type" : "type1" } }
12 | { "field1" : "value1" }
13 | { "delete" : { "_index" : "test", "_type" : "type1" } }
14 | { "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
15 | { "field1" : "value2" }
16 | { "update" : {"_id" : "1", "_type" : "type1", "_index" : "test"} }
17 | { "doc" : {"field2" : "value2"} }
18 | '
19 | ```
20 |
21 | 格式是,每条 JSON 数据的上面,加一行描述性的元 JSON,指明下一行数据的操作类型,归属索引信息等。
22 |
23 | 采用这种格式,而不是一般的 JSON 数组格式,是因为接收到 bulk 请求的 ES 节点,就可以不需要做完整的 JSON 数组解析处理,直接按行处理简短的元 JSON,就可以确定下一行数据 JSON 转发给哪个数据节点了。这样,一个固定内存大小的 network buffer 空间,就可以反复使用,又节省了大量 JVM 的 GC。
24 |
25 | 事实上,产品级的 logstash、rsyslog、spark 都是默认采用 bulk 接口进行数据写入的。对于打算自己写程序的读者,建议采用 Perl 的 `Search::Elasticsearch::Bulk` 或者 Python 的 `elasticsearch.helpers.*` 库。
26 |
27 | ## bulk size
28 |
29 | 在配置 bulk 数据的时候,一般需要注意的就是请求体大小(bulk size)。
30 |
31 | 这里有一点细节上的矛盾,我们知道,HTTP 请求,是可以通过 HTTP 状态码 *100 Continue* 来持续发送数据的。但对于 ES 节点接收 HTTP 请求体的 *Content-Length* 来说,是按照整个大小来计算的。所以,首先,要确保 bulk 数据不要超过 `http.max_content_length` 设置。
32 |
33 | 那么,是不是尽量让 bulk size 接近这个数值呢?当然不是。
34 |
35 | 依然是请求体的问题,因为请求体需要全部加载到内存,而 JVM Heap 一共就那么多(按 31GB 算),过大的请求体,会挤占其他线程池的空间,反而导致写入性能的下降。
36 |
37 | 再考虑网卡流量,磁盘转速的问题,所以一般来说,建议 bulk 请求体的大小,在 15MB 左右,通过实际测试继续向上探索最合适的设置。
38 |
39 | 注意:这里说的 15MB 是请求体的字节数,而不是程序里里设置的 bulk size。bulk size 一般指数据的条目数。不要忘了,bulk 请求体中,每条数据还会额外带上一行元 JSON。
40 |
41 | 以 logstash 默认的 `bulk_size => 5000` 为例,假设单条数据平均大小 200B ,一次 bulk 请求体的大小就是 1.5MB。那么我们可以尝试 `bulk_size => 50000`;而如果单条数据平均大小是 20KB,一次 bulk 大小就是 100MB,显然超标了,需要尝试下调至 `bulk_size => 500`。
42 |
43 |
--------------------------------------------------------------------------------
/elasticsearch/performance/curator.md:
--------------------------------------------------------------------------------
1 | # curator
2 |
3 | 如果经过之前章节的一系列优化之后,数据确实超过了集群能承载的能力,除了拆分集群以外,最后就只剩下一个办法了:清除废旧索引。
4 |
5 | 为了更加方便的做清除数据,合并 segment,备份恢复等管理任务,Elasticsearch 在提供相关 API 的同时,另外准备了一个命令行工具,叫 curator 。curator 是 Python 程序,可以直接通过 pypi 库安装:
6 |
7 | ```
8 | pip install elasticsearch-curator
9 | ```
10 |
11 | *注意,是 elasticsearch-curator 不是 curator。PyPi 原先就有另一个项目叫这个名字*
12 |
13 | ## 参数介绍
14 |
15 | 和 Elastic Stack 里其他组件一样,curator 也是被 Elastic.co 收购的原开源社区周边。收编之后同样进行了一次重构,命令行参数从单字母风格改成了长单词风格。新版本的 curator 命令可用参数如下:
16 |
17 | > Usage: curator [OPTIONS] COMMAND [ARGS]...
18 |
19 | Options 包括:
20 |
21 | --host TEXT Elasticsearch host.
22 | --url_prefix TEXT Elasticsearch http url prefix.
23 | --port INTEGER Elasticsearch port.
24 | --use_ssl Connect to Elasticsearch through SSL.
25 | --http_auth TEXT Use Basic Authentication ex: user:pass
26 | --timeout INTEGER Connection timeout in seconds.
27 | --master-only Only operate on elected master node.
28 | --dry-run Do not perform any changes.
29 | --debug Debug mode
30 | --loglevel TEXT Log level
31 | --logfile TEXT log file
32 | --logformat TEXT Log output format [default|logstash].
33 | --version Show the version and exit.
34 | --help Show this message and exit.
35 |
36 | Commands 包括:
37 | alias Index Aliasing
38 | allocation Index Allocation
39 | bloom Disable bloom filter cache
40 | close Close indices
41 | delete Delete indices or snapshots
42 | open Open indices
43 | optimize Optimize Indices
44 | replicas Replica Count Per-shard
45 | show Show indices or snapshots
46 | snapshot Take snapshots of indices (Backup)
47 |
48 | 针对具体的 Command,还可以继续使用 `--help` 查看该子命令的帮助。比如查看 *close* 子命令的帮助,输入 `curator close --help`,结果如下:
49 |
50 | ```
51 | Usage: curator close [OPTIONS] COMMAND [ARGS]...
52 |
53 | Close indices
54 |
55 | Options:
56 | --help Show this message and exit.
57 |
58 | Commands:
59 | indices Index selection.
60 | ```
61 |
62 | ## 常用示例
63 |
64 | 在使用 1.4.0 以上版本的 Elasticsearch 前提下,curator 曾经主要的一个子命令 `bloom` 已经不再需要使用。所以,目前最常用的三个子命令,分别是 `close`, `delete` 和 `optimize`,示例如下:
65 |
66 | ```
67 | curator --timeout 36000 --host 10.0.0.100 delete indices --older-than 5 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-mweibo-nginx-
68 | curator --timeout 36000 --host 10.0.0.100 delete indices --older-than 10 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-mweibo-client- --exclude 'logstash-mweibo-client-2015.05.11'
69 | curator --timeout 36000 --host 10.0.0.100 delete indices --older-than 30 --time-unit days --timestring '%Y.%m.%d' --regex '^logstash-mweibo-\d+'
70 | curator --timeout 36000 --host 10.0.0.100 close indices --older-than 7 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-
71 | curator --timeout 36000 --host 10.0.0.100 optimize --max_num_segments 1 indices --older-than 1 --newer-than 7 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-
72 | ```
73 |
74 | 这一顿任务,结果是:
75 |
76 | *logstash-mweibo-nginx-yyyy.mm.dd* 索引保存最近 5 天,*logstash-mweibo-client-yyyy.mm.dd* 保存最近 10 天,*logstash-mweibo-yyyy.mm.dd* 索引保存最近 30 天;且所有七天前的 *logstash-\** 索引都暂时关闭不用;最后对所有非当日日志做 segment 合并优化。
77 |
--------------------------------------------------------------------------------
/elasticsearch/performance/gateway.md:
--------------------------------------------------------------------------------
1 | # gateway
2 |
3 | gateway 是 ES 设计用来长期存储索引数据的接口。一般来说,大家都是用本地磁盘来存储索引数据,即 `gateway.type` 为 `local`。
4 |
5 | 数据恢复中,有很多策略调整我们已经在之前分片控制小节讲过。除开分片级别的控制以外,gateway 级别也还有一些可优化的地方:
6 |
7 | * gateway.recover_after_nodes
8 | 该参数控制集群在达到多少个节点的规模后,才开始数据恢复任务。这样可以避免集群自动发现的初期,分片不全的问题。
9 |
10 | * gateway.recover_after_time
11 | 该参数控制集群在达到上条配置设置的节点规模后,再等待多久才开始数据恢复任务。
12 |
13 | * gateway.expected_nodes
14 | 该参数设置集群的预期节点总数。在达到这个总数后,即认为集群节点已经完全加载,即可开始数据恢复,不用再等待上条设置的时间。
15 |
16 | 注意:gateway 中说的节点,仅包括主节点和数据节点,纯粹的 client 节点是不算在内的。如果你有更明确的选择,也可以按需求写:
17 |
18 | * gateway.recover_after_data_nodes
19 | * gateway.recover_after_master_nodes
20 | * gateway.expected_data_nodes
21 | * gateway.expected_master_nodes
22 |
23 | ## 共享存储上的影子副本
24 |
25 | 虽然 ES 对 gateway 使用 NFS,iscsi 等共享存储的方式极力反对,但是对于较大量级的索引的副本数据,ES 从 1.5 版本开始,还是提供了一种节约成本又不特别影响性能的方式:影子副本(shadow replica)。
26 |
27 | 首先,需要在集群各节点的 `elasticsearch.yml` 中开启选项:
28 |
29 | ```
30 | node.enable_custom_paths: true
31 | ```
32 |
33 | 同时,确保各节点使用相同的路径挂载了共享存储,且目录权限为 Elasticsearch 进程用户可读可写。
34 |
35 | 然后,创建索引:
36 |
37 | ```
38 | # curl -XPUT 'http://127.0.0.1:9200/my_index' -d '
39 | {
40 | "index" : {
41 | "number_of_shards" : 1,
42 | "number_of_replicas" : 4,
43 | "data_path": "/var/data/my_index",
44 | "shadow_replicas": true
45 | }
46 | }'
47 | ```
48 |
49 | 针对 shadow replicas ,ES 节点不会做实际的索引操作,而是单纯的每次 flush 时,把 segment 内容 fsync 到共享存储磁盘上。然后 refresh 让其他节点能够搜索该 segment 内容。
50 |
51 | 如果你已经决定把数据放到共享存储上了,采用 shadow replicas 还是有一些好处的:
52 |
53 | 1. 可以帮助你节省一部分不必要的多副本分片的数据写入压力;
54 | 2. 在节点出现异常,需要在其他节点上恢复副本数据的时候,可以避免不必要的网络数据拷贝。
55 |
56 | 但是请注意:主分片节点还是要承担一个副本的写入过程,并不像 Lucene 的 FileReplicator 那样通过复制文件完成,所以达不到完全节省 CPU 的效果。
57 |
58 | shadow replicas 只是一个在某些特定环境下有用的方式。在资源允许的情况下,还是应该使用 local gateway。而另外采用 snapshot 接口来完成数据长期备份到 HDFS 或其他共享存储的需要。
59 |
--------------------------------------------------------------------------------
/elasticsearch/performance/profile.md:
--------------------------------------------------------------------------------
1 | # profiler
2 |
3 | profiler 是 Elasticsearch 5.0 的一个新接口。通过这个功能,可以看到一个搜索聚合请求,是如何拆分成底层的 Lucene 请求,并且显示每部分的耗时情况。
4 |
5 | 启用 profiler 的方式很简单,直接在请求里加一行即可:
6 |
7 | ```
8 | curl -XPOST 'http://localhost:9200/_search' -d '{
9 | "profile": true,
10 | "query": { ... },
11 | "aggs": { ... }
12 | }'
13 | ```
14 |
15 | 可以看到其中对 query 和 aggs 部分的返回是不太一样的。
16 |
17 | ## query
18 |
19 | query 部分包括 collectors、rewrite 和 query 部分。对复杂 query,profiler 会拆分 query 成多个基础的 TermQuery,然后每个 TermQuery 再显示各自的分阶段耗时如下:
20 |
21 | ```
22 | "breakdown": {
23 | "score": 51306,
24 | "score_count": 4,
25 | "build_scorer": 2935582,
26 | "build_scorer_count": 1,
27 | "match": 0,
28 | "match_count": 0,
29 | "create_weight": 919297,
30 | "create_weight_count": 1,
31 | "next_doc": 53876,
32 | "next_doc_count": 5,
33 | "advance": 0,
34 | "advance_count": 0
35 | }
36 | ```
37 |
38 |
39 |
40 | ## aggs
41 |
42 | ```
43 | "time": "1124.864392ms",
44 | "breakdown": {
45 | "reduce": 0,
46 | "reduce_count": 0,
47 | "build_aggregation": 1394,
48 | "build_aggregation_count": 150,
49 | "initialise": 2883,
50 | "initialize_count": 150,
51 | "collect": 1124860115,
52 | "collect_count": 900
53 | }
54 | ```
55 |
56 | 我们可以很明显的看到聚合统计在初始化阶段、收集阶段、构建阶段、汇总阶段分别花了多少时间,遍历了多少数据。
57 |
58 | *注意其中 reduce 阶段还没实现完毕,所有都是 0。因为目前 profiler 只能在 shard 级别上做统计。*
59 |
60 | collect 阶段的耗时,有助于我们调整对应 aggs 的 `collect_mode` 参数选择。目前 Elasticsearch 支持 `breadth_first` 和 `depth_first` 两种方式。
61 |
62 | initialise 阶段的耗时,有助于我们调整对应 aggs 的 `execution_hint` 参数选择。目前 Elasticsearch 支持 `map`、`global_ordinals_low_cardinality`、`global_ordinals` 和 `global_ordinals_hash` 四种选择。在计算离散度比较大的字段统计值时,适当调整该参数,有益于节省内存和提高计算速度。
63 |
64 | *对高离散度字段值统计性能很关注的读者,可以关注 这条记录的进展。*
65 |
--------------------------------------------------------------------------------
/elasticsearch/principle/README.md:
--------------------------------------------------------------------------------
1 | # 架构原理
2 |
3 | 本书作为 Elastic Stack 指南,关注于 Elasticsearch 在日志和数据分析场景的应用,并不打算对底层的 Lucene 原理或者 Java 编程做详细的介绍,但是 Elasticsearch 层面上的一些架构设计,对我们做性能调优,故障处理,具有非常重要的影响。
4 |
5 | 所以,作为 ES 部分的起始章节,先从数据流向和分布的层面,介绍一下 ES 的工作原理,以及相关的可控项。各位读者可以跳过这节先行阅读后面的运维操作部分,但作为性能调优的基础知识,依然建议大家抽时间返回来了解。
6 |
--------------------------------------------------------------------------------
/elasticsearch/principle/auto-discovery.md:
--------------------------------------------------------------------------------
1 | # 集群自动发现
2 |
3 | ES 是一个 P2P 类型(使用 gossip 协议)的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。
4 |
5 | 所以,从网络架构及服务配置上来说,构建集群所需要的配置极其简单。在 Elasticsearch 2.0 之前,无阻碍的网络下,所有配置了相同 `cluster.name` 的节点都自动归属到一个集群中。
6 |
7 | 2.0 版本之后,基于安全的考虑,Elasticsearch 稍作了调整,避免开发环境过于随便造成的麻烦。
8 |
9 | ## unicast 方式
10 |
11 | ES 从 2.0 版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES 将其视作 gossip router 角色,借以完成集群的发现。由于这只是 ES 内一个很小的功能,所以 gossip router 角色并不需要单独配置,每个 ES 节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为 router 即可。
12 |
13 | 此外,考虑到节点有时候因为高负载,慢 GC 等原因可能会有偶尔没及时响应 ping 包的可能,一般建议稍微加大 Fault Detection 的超时时间。
14 |
15 | 同样基于安全考虑做的变更还有监听的主机名。现在默认只监听本地 lo 网卡上。所以正式环境上需要修改配置为监听具体的网卡。
16 |
17 | ```
18 | network.host: "192.168.0.2"
19 | discovery.zen.minimum_master_nodes: 3
20 | discovery.zen.ping_timeout: 100s
21 | discovery.zen.fd.ping_timeout: 100s
22 | discovery.zen.ping.unicast.hosts: ["10.19.0.97","10.19.0.98","10.19.0.99","10.19.0.100"]
23 | ```
24 |
25 | 上面的配置中,两个 timeout 可能会让人有所迷惑。这里的 **fd** 是 fault detection 的缩写。也就是说:
26 |
27 | * discovery.zen.ping_timeout 参数仅在加入或者选举 master 主节点的时候才起作用;
28 | * discovery.zen.fd.ping\_timeout 参数则在稳定运行的集群中,master 检测所有节点,以及节点检测 master 是否畅通时长期有用。
29 |
30 | 既然是长期有用,自然还有运行间隔和重试的配置,也可以根据实际情况调整:
31 |
32 | ```
33 | discovery.zen.fd.ping_interval: 10s
34 | discovery.zen.fd.ping_retries: 10
35 | ```
36 |
--------------------------------------------------------------------------------
/elasticsearch/principle/indexing-performance.md:
--------------------------------------------------------------------------------
1 | # segment merge对写入性能的影响
2 |
3 | 通过上节内容,我们知道了数据怎么进入 ES 并且如何才能让数据更快的被检索使用。其中用一句话概括了 Lucene 的设计思路就是"开新文件"。从另一个方面看,开新文件也会给服务器带来负载压力。因为默认每 1 秒,都会有一个新文件产生,每个文件都需要有文件句柄,内存,CPU 使用等各种资源。一天有 86400 秒,设想一下,每次请求要扫描一遍 86400 个文件,这个响应性能绝对好不了!
4 |
5 | 为了解决这个问题,ES 会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的,segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。归并过程中,索引状态如图 2-7,尚未完成的较大的 segment 是被排除在检索可见范围之外的:
6 |
7 | 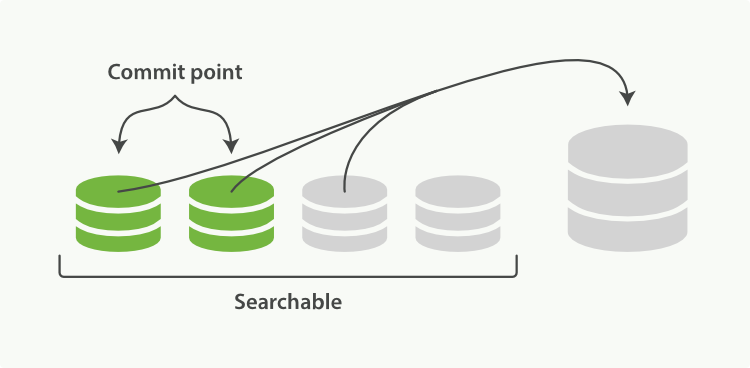
8 | 图 2-7
9 |
10 | 当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,删除之前几个小 segment,改成新的大 segment。等检索请求都从小 segment 转到大 segment 上以后,删除没用的小 segment。这时候,索引里 segment 数量就下降了,状态如图 2-8 所示:
11 |
12 | 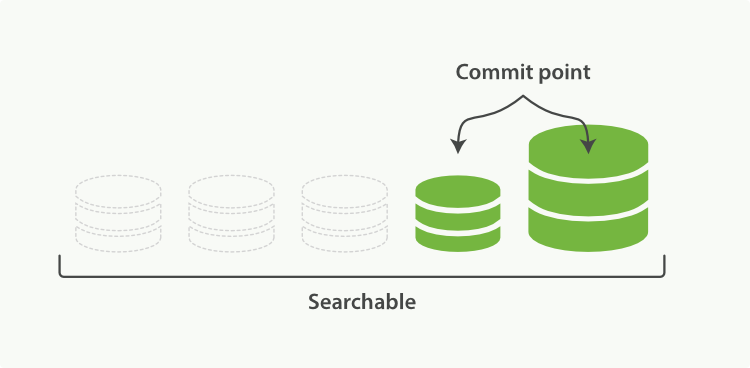
13 | 图 2-8
14 |
15 | ## 归并线程配置
16 |
17 | segment 归并的过程,需要先读取 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,这是一个非常消耗磁盘 IO 和 CPU 的任务。所以,ES 提供了对归并线程的限速机制,确保这个任务不会过分影响到其他任务。
18 |
19 | 在 5.0 之前,归并线程的限速配置 `indices.store.throttle.max_bytes_per_sec` 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 Elastic Stack 应用,社区广泛的建议是可以适当调大到 100MB或者更高。
20 |
21 | ```
22 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
23 | {
24 | "persistent" : {
25 | "indices.store.throttle.max_bytes_per_sec" : "100mb"
26 | }
27 | }'
28 | ```
29 |
30 | 5.0 开始,ES 对此作了大幅度改进,使用了 Lucene 的 CMS(ConcurrentMergeScheduler) 的 auto throttle 机制,正常情况下已经不再需要手动配置 `indices.store.throttle.max_bytes_per_sec` 了。官方文档中都已经删除了相关介绍,不过从源码中还是可以看到,这个值目前的默认设置是 10240 MB。
31 |
32 | 归并线程的数目,ES 也是有所控制的。默认数目的计算公式是: `Math.min(3, Runtime.getRuntime().availableProcessors() / 2)`。即服务器 CPU 核数的一半大于 3 时,启动 3 个归并线程;否则启动跟 CPU 核数的一半相等的线程数。相信一般做 Elastic Stack 的服务器 CPU 合数都会在 6 个以上。所以一般来说就是 3 个归并线程。如果你确定自己磁盘性能跟不上,可以降低 `index.merge.scheduler.max_thread_count` 配置,免得 IO 情况更加恶化。
33 |
34 | ## 归并策略
35 |
36 | 归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
37 |
38 | * index.merge.policy.floor\_segment
39 | 默认 2MB,小于这个大小的 segment,优先被归并。
40 | * index.merge.policy.max\_merge\_at\_once
41 | 默认一次最多归并 10 个 segment
42 | * index.merge.policy.max\_merge\_at\_once\_explicit
43 | 默认 forcemerge 时一次最多归并 30 个 segment。
44 | * index.merge.policy.max\_merged\_segment
45 | 默认 5 GB,大于这个大小的 segment,不用参与归并。forcemerge 除外。
46 |
47 | 根据这段策略,其实我们也可以从另一个角度考虑如何减少 segment 归并的消耗以及提高响应的办法:加大 flush 间隔,尽量让每次新生成的 segment 本身大小就比较大。
48 |
49 | ## forcemerge 接口
50 |
51 | 既然默认的最大 segment 大小是 5GB。那么一个比较庞大的数据索引,就必然会有为数不少的 segment 永远存在,这对文件句柄,内存等资源都是极大的浪费。但是由于归并任务太消耗资源,所以一般不太选择加大 `index.merge.policy.max_merged_segment` 配置,而是在负载较低的时间段,通过 forcemerge 接口,强制归并 segment。
52 |
53 | ```
54 | # curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_forcemerge?max_num_segments=1
55 | ```
56 |
57 | 由于 forcemerge 线程对资源的消耗比普通的归并线程大得多,所以,绝对不建议对还在写入数据的热索引执行这个操作。这个问题对于 Elastic Stack 来说非常好办,一般索引都是按天分割的。更合适的任务定义方式,请阅读本书稍后的 curator 章节。
58 |
59 |
--------------------------------------------------------------------------------
/elasticsearch/principle/route-and-replica.md:
--------------------------------------------------------------------------------
1 | # routing和replica的读写过程
2 |
3 | 之前两节,完整介绍了在单个 Lucene 索引,即 ES 分片内的数据写入流程。现在彻底回到 ES 的分布式层面上来,当一个 ES 节点收到一条数据的写入请求时,它是如何确认这个数据应该存储在哪个节点的哪个分片上的?
4 |
5 | ## 路由计算
6 |
7 | 作为一个没有额外依赖的简单的分布式方案,ES 在这个问题上同样选择了一个非常简洁的处理方式,对任一条数据计算其对应分片的方式如下:
8 |
9 | > shard = hash(routing) % number_of_primary_shards
10 |
11 | 每个数据都有一个 routing 参数,默认情况下,就使用其 `_id` 值。将其 `_id` 值计算哈希后,对索引的主分片数取余,就是数据实际应该存储到的分片 ID。
12 |
13 | 由于取余这个计算,完全依赖于分母,所以导致 ES 索引有一个限制,索引的主分片数,不可以随意修改。因为一旦主分片数不一样,所以数据的存储位置计算结果都会发生改变,索引数据就完全不可读了。
14 |
15 | ## 副本一致性
16 |
17 | 作为分布式系统,数据副本可算是一个标配。ES 数据写入流程,自然也涉及到副本。在有副本配置的情况下,数据从发向 ES 节点,到接到 ES 节点响应返回,流向如下(附图 2-9):
18 |
19 | 1. 客户端请求发送给 Node 1 节点,注意图中 Node 1 是 Master 节点,实际完全可以不是。
20 | 2. Node 1 用数据的 `_id` 取余计算得到应该讲数据存储到 shard 0 上。通过 cluster state 信息发现 shard 0 的主分片已经分配到了 Node 3 上。Node 1 转发请求数据给 Node 3。
21 | 3. Node 3 完成请求数据的索引过程,存入主分片 0。然后并行转发数据给分配有 shard 0 的副本分片的 Node 1 和 Node 2。当收到任一节点汇报副本分片数据写入成功,Node 3 即返回给初始的接收节点 Node 1,宣布数据写入成功。Node 1 返回成功响应给客户端。
22 |
23 | 
24 | 图 2-9
25 |
26 | 这个过程中,有几个参数可以用来控制或变更其行为:
27 |
28 | * wait\_for\_active\_shards
29 | 上面示例中,2 个副本分片只要有 1 个成功,就可以返回给客户端了。这点也是有配置项的。其默认值的计算来源如下:
30 |
31 | > int( (primary + number_of_replicas) / 2 ) + 1
32 |
33 | 根据需要,也可以将参数设置为 one,表示仅写完主分片就返回,等同于 async;还可以设置为 all,表示等所有副本分片都写完才能返回。
34 | * timeout
35 | 如果集群出现异常,有些分片当前不可用,ES 默认会等待 1 分钟看分片能否恢复。可以使用 `?timeout=30s` 参数来缩短这个等待时间。
36 |
37 | 副本配置和分片配置不一样,是可以随时调整的。有些较大的索引,甚至可以在做 forcemerge 前,先把副本全部取消掉,等 optimize 完后,再重新开启副本,节约单个 segment 的重复归并消耗。
38 |
39 | ```
40 | # curl -XPUT http://127.0.0.1:9200/logstash-mweibo-2015.05.02/_settings -d '{
41 | "index": { "number_of_replicas" : 0 }
42 | }'
43 | ```
44 |
--------------------------------------------------------------------------------
/elasticsearch/puppet.md:
--------------------------------------------------------------------------------
1 | # Puppet 自动部署 Elasticsearch
2 |
3 | Elasticsearch 作为一个 Java 应用,本身的部署已经非常简单了。不过作为生产环境,还是有必要采用一些更标准化的方式进行集群的管理。Elasticsearch 官方提供并推荐使用 Puppet 方式部署和管理。其 Puppet 模块源码地址见:
4 |
5 |
6 |
7 | ## 安装方法
8 |
9 | 和其他标准 Puppet Module 一样,puppet-elasticsearch 也可以通过 Puppet Forge 直接安装:
10 |
11 | ```
12 | # puppet module install elasticsearch-elasticsearch
13 | ```
14 |
15 | ## 配置示例
16 |
17 | 安装好 Puppet 模块后,就可以使用了。模块提供几种 Puppet 资源,主要用法如下:
18 |
19 | ```
20 | class { 'elasticsearch':
21 | version => '2.4.1',
22 | config => { 'cluster.name' => 'es1003' },
23 | java_install => true,
24 | }
25 | elasticsearch::instance { $fqdn:
26 | config => { 'node.name' => $fqdn },
27 | init_defaults => { 'ES_USER' => 'elasticsearch', 'ES_HEAP_SIZE' => $memorysize > 64 ? '31g' : $memorysize / 2 },
28 | datadir => [ '/data1/elasticsearch' ],
29 | }
30 | elasticsearch::template { 'templatename':
31 | host => $::ipaddress,
32 | port => 9200,
33 | content => '{"template":"*","settings":{"number_of_replicas":0}}'
34 | }
35 | ```
36 |
37 | 示例中展示了三种资源:
38 |
39 | * class: 配置具体安装的 Elasticsearch 软件版本,全集群公用的一些基础配置项。注意,puppet-elasticsearch 模块默认并不负责 Java 的安装,它只是调用操作系统对应的 Yum,Apt 工具,而 elasticsearch.rpm 或者 elasticsearch.deb 本身没有定义其他依赖(因为 java 版本太多了,定义起来不方便)。所以,如果依然要走 puppet-elasticsearch 配置来安装 Java 的话,需要额外开启 `java_install` 选项。该选项会使用另一个 Puppet Module —— [puppetlabs-java](https://forge.puppetlabs.com/puppetlabs/java) 来安装,默认安装的是 jdk。如果你要节省空间,可以再加一行 `java_package` 来明确指定软件全名。
40 | * instance: 配置具体单个进程实例的配置。其中 `config` 和 `init_defaults` 选项在 class 和 instance 资源中都可以定义,实际运行时,会自动做一次合并,当然,instance 里的配置优先级高于 class 中的配置。此外,最重要的定义是数据目录的位置。有多快磁盘的,可以在这里定义一个数组。
41 | * template: 模板是 Elasticsearch 创建索引映射和设置时的预定义方式。一般可以通过在 `config/templates/` 目录下放置 JSON 文件,或者通过 RESTful API 上传配置两种方式管理。而这里,单独提供了 template 资源,通过 puppet 来管理模板。`content` 选项中直接填入模板内容,或者使用 `file` 选项读取文件均可。
42 |
43 | 事实上,模块还提供了 plugin 和 script 资源管理这两方面的内容。考虑在 ELK 中,二者用的不是很多,本节就不单独介绍了。想了解的读者可以参考官方文档。
44 |
--------------------------------------------------------------------------------
/elasticsearch/rollover.md:
--------------------------------------------------------------------------------
1 | # rollover
2 |
3 | Elasticsearch 从 5.0 开始,为日志场景的用户提供了一个很不错的接口,叫 rollover。其作用是:当某个别名指向的实际索引过大的时候,自动将别名指向下一个实际索引。
4 |
5 | 因为这个接口是操作的别名,所以我们依然需要首先自己创建一个开始滚动的起始索引:
6 |
7 | ```
8 | # curl -XPUT 'http://localhost:9200/logstash-2016.11.25-1' -d '{
9 | "aliases": {
10 | "logstash": {}
11 | }
12 | }'
13 | ```
14 |
15 | 然后就可以尝试发起 rollover 请求了:
16 |
17 | ```
18 | # curl -XPOST 'http://localhost:9200/logstash/_rollover' -d '{
19 | "conditions": {
20 | "max_age": "1d",
21 | "max_docs": 10000000
22 | }
23 | }'
24 | ```
25 |
26 | 上面的定义意思就是:当索引超过 1 天,或者索引内的数据量超过一千万条的时候,自动创建并指向下一个索引。
27 |
28 | 这时候有几种可能性:
29 |
30 | * 条件都没满足,直接返回一个 false,索引和别名都不发生实际变化;
31 | ```
32 | {
33 | "old_index" : "logstash-2016.11.25-1",
34 | "new_index" : "logstash-2016.11.25-1",
35 | "rolled_over" : false,
36 | "dry_run" : false,
37 | "acknowledged" : false,
38 | "shards_acknowledged" : false,
39 | "conditions" : {
40 | "[max_docs: 10000000]" : false,
41 | "[max_age: 1d]" : false
42 | }
43 | }
44 | ```
45 | * 还没满一天,满了一千万条,那么下一个索引名会是:`logstash-2016.11.25-000002`;
46 | * 还没满一千万条,满了一天,那么下一个索引名会是:`logstash-2016.11.26-000002`。
47 |
48 | # shrink
49 |
50 | Elasticsearch 一直以来都是固定分片数的。这个策略极大的简化了分布式系统的复杂度,但是在一些场景,比如存储 metric 的 TSDB、小数据量的日志存储,人们会期望在多分片快速写入数据以后,把老数据合并存储,节约过多的 cluster state 容量。从 5.0 版本开始,Elasticsearch 新提供了 shrink 接口,可以成倍数的合并分片数。
51 |
52 | *注:所谓成倍数的,就是原来有 15 个分片,可以合并缩减成 5 个或者 3 个或者 1 个分片。*
53 |
54 | 整个合并缩减的操作流程,大概如下:
55 |
56 | 1. 先把所有主分片都转移到一台主机上;
57 | 2. 在这台主机上创建一个新索引,分片数较小,其他设置和原索引一致;
58 | 3. 把原索引的所有分片,复制(或硬链接)到新索引的目录下;
59 | 4. 对新索引进行打开操作恢复分片数据。
60 | 5. (可选)重新把新索引的分片均衡到其他节点上。
61 |
62 | ## 准备工作
63 |
64 | * 因为这个操作流程需要把所有分片都转移到一台主机上,所以作为 shrink 主机,它的磁盘要足够大,至少要能放得下一整个索引。
65 | * 最好是一整块磁盘,因为硬链接是不能跨磁盘的。靠复制太慢了。
66 | * 开始迁移:
67 | ```
68 | # curl -XPUT 'http://localhost:9200/metric-2016.11.25/_settings' -d '
69 | {
70 | "settings": {
71 | "index.routing.allocation.require._name": "shrink_node_name",
72 | "index.blocks.write": true
73 | }
74 | }'
75 | ```
76 |
77 | ## shrink 操作
78 |
79 | ```
80 | curl -XPOST 'http://localhost:9200/metric-2016.11.25/_shrink/oldmetric-2016.11.25' -d'
81 | {
82 | "settings": {
83 | "index.number_of_replicas": 1,
84 | "index.number_of_shards": 3
85 | },
86 | "aliases": {
87 | "metric-tsdb": {}
88 | }
89 | }'
90 | ```
91 |
92 | 这个命令执行完会立刻返回,但是 Elasticsearch 会一直等到 shrink 操作完成的时候,才会真的开始做 replica 分片的分配和重均衡,此前分片都处于 initializing 状态。
93 |
94 | *注意:Elasticsearch 有一个硬编码限制,单个分片内的文档总数不得超过 2147483519 个。一般来说这个限制在日志场景下是不太会触发的,但是如果做 TSDB 用,则需要多加注意!*
95 |
--------------------------------------------------------------------------------
/elasticsearch/upgrade.md:
--------------------------------------------------------------------------------
1 | # 集群版本升级
2 |
3 | Elasticsearch 作为一个新兴项目,版本更新非常快。而且每次版本更新都或多或少带有一些重要的性能优化、稳定性提升等特性。可以说,ES 集群的版本升级,是目前 ES 运维必然要做的一项工作。
4 |
5 | 按照 ES 官方设计,有 restart upgrade 和 rolling upgrade 两种可选的升级方式。对于 1.0 版本以上的用户,推荐采用 rolling upgreade 方式。
6 |
7 | **但是,对于主要负载是数据写入的 Elastic Stack 场景来说,却并不是这样!**
8 |
9 | rolling upgrade 的步骤大致如下:
10 |
11 | 1. 暂停分片分配;
12 | 2. 单节点下线升级重启;
13 | 3. 开启分片分配;
14 | 4. 等待集群状态变绿后继续上述步骤。
15 |
16 | 实际运行中,步骤 2 的 ES 单节点从 restart 到加入集群,大概要 100s 左右的时间。也就是说,这 100s 内,该节点上的所有分片都是 unassigned 状态。而按照 Elasticsearch 的设计,数据写入需要至少达到 `replica/2+1` 个分片完成才能算完成。也就意味着你所有索引都必须至少有 1 个以上副本分片开启。
17 |
18 | 但事实上,很多日志场景,由于写入性能上的要求要高于数据可靠性的要求,大家普遍减小了副本数量,甚至直接关掉副本复制。这样一来,整个 rolling upgrade 期间,数据写入就会受到严重影响,完全丧失了 rolling 的必要性。
19 |
20 | 其次,步骤 3 中的 ES 分片均衡过程中,由于 ES 的副本分片数据都需要从主分片走网络复制重新传输一次,而由于重启,新升级的节点上的分片肯定全是副本分片(除非压根没副本)。在数据量较大的情况下,这个步骤耗时可能是几十分钟甚至以小时计。而且并发和限速上稍微不注意,可能导致分片均衡的带宽直接占满网卡,正常写入也还是受到影响。
21 |
22 | 所以,对于写入压力较大,数据可靠性要求偏低的实时日志场景,依然建议大家进行主动停机式的 restart upgrade。
23 |
24 | restart upgrade 的步骤如下:
25 |
26 | 1. 首先适当加大集群的数据恢复和分片均衡并发度以及磁盘限速:
27 |
28 | ```
29 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d '{
30 | "persistent" : {
31 | "cluster" : {
32 | "routing" : {
33 | "allocation" : {
34 | "disable_allocation" : "false",
35 | "cluster_concurrent_rebalance" : "5",
36 | "node_concurrent_recoveries" : "5",
37 | "enable" : "all"
38 | }
39 | }
40 | },
41 | "indices" : {
42 | "recovery" : {
43 | "concurrent_streams" : "30",
44 | "max_bytes_per_sec" : "2gb"
45 | }
46 | }
47 | },
48 | "transient" : {
49 | "cluster" : {
50 | "routing" : {
51 | "allocation" : {
52 | "enable" : "all"
53 | }
54 | }
55 | }
56 | }
57 | }'
58 | ```
59 |
60 | 2. 暂停分片分配:
61 |
62 | ```
63 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d '{
64 | "transient" : {
65 | "cluster.routing.allocation.enable" : "none"
66 | }
67 | }'
68 | ```
69 |
70 | 3. 通过配置管理工具下发新版本软件包。
71 | 4. 公告周知后,停止数据写入进程(即 logstash indexer 等)
72 | 5. 如果使用 Elasticsearch 1.6 版本以上,可以手动运行一次 synced flush,同步副本分片的 commit id,缩小恢复时的网络传输带宽:
73 |
74 | ```
75 | # curl -XPOST http://127.0.0.1:9200/_flush/synced
76 | ```
77 |
78 | 6. 全集群统一停止进程,更新软件包,重新启动。
79 | 7. 等待各节点都加入到集群以后,恢复分片分配:
80 |
81 | ```
82 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d '{
83 | "transient" : {
84 | "cluster.routing.allocation.enable" : "all"
85 | }
86 | }'
87 | ```
88 |
89 | 由于同时启停,主分片几乎可以同时本地恢复,整个集群从 red 变成 yellow 只需要 2 分钟左右。而后的副本分片,如果有 synced flush,同样本地恢复,否则网络恢复总耗时,视数据大小而定,会明显大于单节点恢复的耗时。
90 |
91 | 8. 如果有 synced flush,建议等待集群变成 green 状态后,恢复写入;否则在集群变成 yellow 状态之后,即可着手开始恢复数据写入进程。
92 |
--------------------------------------------------------------------------------
/kibana/README.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Logstash 早期曾经自带了一个特别简单的 logstash-web 用来查看 ES 中的数据。其功能太过简单,于是 Rashid Khan 用 PHP 写了一个更好用的 web,取名叫 Kibana。这个 PHP 版本的 Kibana 发布时间是 2011 年 12 月 11 日。
4 |
5 | Kibana 迅速流行起来,不久的 2012 年 8 月 19 日,Rashid Khan 用 Ruby 重写了 Kibana,也被叫做 Kibana2。因为 Logstash 也是用 Ruby 写的,这样 Kibana 就可以替代原先那个简陋的 logstash-web 页面了。
6 |
7 | 目前我们看到的 angularjs 版本 kibana 其实原名叫 elasticsearch-dashboard,但跟 Kibana2 作者是同一个人,换句话说,kibana 比 logstash 还早就进了 elasticsearch 名下。这个项目改名 Kibana 是在 2014 年 2 月,也被叫做 Kibana3。全新的设计一下子风靡 DevOps 界。随后其他社区纷纷借鉴,Graphite 目前最流行的 Grafana 界面就是由此而来,至今代码中还留存有十余处 kbn 字样。
8 |
9 | 2014 年 4 月,Kibana3 停止开发,ES 公司集中人力开始 Kibana4 的重构,在 2015 年初发布了使用 JRuby 做后端的 beta 版后,于 3 月正式推出使用 node.js 做后端的正式版。由于设计思路上的差别,一些 K3 适宜的场景并不在 K4 考虑范围内,所以,至今 K3 和 K4 并存使用。本书也会分别讲解两者。
10 |
11 | ## 注释
12 |
13 | 本章配置参数内容部分译自[Elasticsearch 官方指南 Kibana 部分](http://www.elasticsearch.org/guide/en/kibana/current/index.html),其中 [v3](http://www.elasticsearch.org/guide/en/kibana/3.0/index.html) 的 panel 部分额外添加了截图注释。然后在使用的基础上,添加了原创的源码解析,场景示例,二次开发入门等内容。
14 |
15 |
--------------------------------------------------------------------------------
/kibana/difference.md:
--------------------------------------------------------------------------------
1 | # Kibana 各版本的对比
2 |
3 | Kibana 一直是 Elastic Stack 中的版本帝,并最终带着整个技术栈的产品都提升版本号到了 5.0。和其他产品一路升级上来不同的是,Kibana 几乎每次版本升级都是革命性的重写。而且至今依然有很多 Kibana 3 的用户不愿意迁移升级。因为前后者分别基于不同接口,不同目的,采取了不同的页面设计和逻辑。在不同场景下,各有优势。这里稍作解释。
4 |
5 | ## Kibana 3 的设计思路和功能
6 |
7 | 本书一开始就提到,Kibana3 在设计之初,有另一个名字,叫 **elasticsearch dashboard**。事实上,整个 Kibana3 就是一个围绕着 dashboard 构建的单页应用。
8 |
9 | 所以,在页面逻辑上,Kibana3 异常简洁。大量的代码和逻辑,都下放到 panel 层次上。每个 panel 要独立完成自己的可视化设计、数据请求,数据处理,数据渲染。panel 和 panel 之间,则几乎毫无关联。简单一点看,整个页面就像是一堆 iframe 一样。
10 |
11 | 而 panel 的设计,则是以使用者角度来考虑的。Kibana3 尽量提供能让运维人员一步到位的使用策略。即,使用者只需要了解 panel 的配置页面能填什么参数,得到什么可视化结果。
12 |
13 | 最明显的例子,就是 trend panel。trend panel 背后,其实是针对今天和昨天,分别发起两次请求,然后再拿两次请求的结果,做一次除法,计算涨跌幅。这个除法计算,是在浏览器端完成的。
14 |
15 | 类似在浏览器端完成的,还有 histogram panel 的 hits,second 等的计算。
16 |
17 | 此外,Kibana3 还有一个非常有用的功能,setting 中的 index pattern,是可以输入多个的,比如 `accesslog-[YYYY.MM.DD],syslog-[YYYY.MM.DD]`,这样就可以在同一个面板上,看到来自不同索引的数据的情况。
18 |
19 | ## Kibana 4 的设计思路和功能
20 |
21 | 从新特性来说,Kibana4 全面支持 Aggregation 接口,还有更多的可视化选择,可以任意拖动自动对齐的挂件框架,保存在 URL 可以跨页面保持的检索条件,以及对页面请求的内部排队机制。
22 |
23 | 从页面设计来说,Kibana4 参考了 Splunk 的产品形态,将功能拆分成了搜索,可视化和仪表盘三个标签页。可视化和搜索,是一一绑定的,无法跨多个 index pattern 做搜索,勿论可视化了。而且可视化标签页中,用 d3.js 实现的可视化构建器,与请求 ES 数据的聚合选择器,又是各自独立的插件。
24 |
25 | 也就是说,Kibana4 在使用 Aggregation 接口提供更复杂功能和更高性能的同时,彻底改变了用户的使用形式。用户必须明确了解 ES 各个 aggs 接口的意义,请求和响应体的数据情况;还要想清楚可视化的展现形式,充分理解数据字段的作用。然后才能实现想要的结果。毫无疑问,这是有学习成本的。
26 |
27 | 至于像 Kibana 3 那种在浏览器端计算的功能,Kibana4 中则完全没有。
28 |
29 | 在界面美观方面。Kibana4 至今未提供类似 Kibana3 中的 Query 设置功能,包括 Query 别名这个常用功能。直接导致目前 Kibana4 的图例几乎毫无作用。
30 |
31 | 在 filter 方面,Kibana4 用 filter agg 替代了 Kibana3 使用的 facet\_filter。页面表现形式上,Kibana3 是在页面顶部添加 Query 输入框,全局生效;Kibana4 是在 Visualize 页添加 aggs,单个面板生效。依然需要多查询条件对比的用户,需要一个个面板创建,非常麻烦。
32 |
33 | ## Kibana 5 的设计思路和功能
34 |
35 | Kibana 5 在 4.6 的基础上,做了全面的页面布局修改,采用了更现代化的左侧边栏菜单设计。单就 Kibana 本身的功能来说,其实没有太大差别。但是 Kibana 5 将重心放在了应用扩展和融合上。左侧边栏显然可以留出更多的空间来摆放各种扩展应用的 logo 图标。
36 |
37 | ES 2.0 开始提供了一种全新的 pipeline aggregation 特性, Kibana 在这个 ES 新特性的基础上实现了 timelion 应用,专注于时序计算和分析。甚至可以将 timelion 的分析图表加入到仪表盘中和其他可视化一起展现。
38 |
39 | 此外,ES 5.0 取消了 site plugin 形式,原来的 site plugin 都要迁移成 Kibana app。目前官方已经将原先的 sense 改成了 Kibana console 应用。相信未来一段时间,会有更多的 Kibana 应用涌现出来。
40 |
--------------------------------------------------------------------------------
/kibana/phantomjs.md:
--------------------------------------------------------------------------------
1 | # Kibana 截图报表
2 |
3 | Elastic Stack 本身作为一个实时数据检索聚合的系统,在定期报表方面,是有一定劣势的。因为基本上不可能把源数据长期保存在 Elasticsearch 集群中。即便保存了,为了一些已经成形的数据,再全面查询一次过久的冷数据,也是有额外消耗的。那么,对这种报表数据的需求,如何处理?其实很简单,把整个 Kibana 页面截图下来即可。
4 |
5 | FireFox 有插件用来截全网页图。不过如果作为定期的工作,这么搞还是比较麻烦的,需要脚本化下来。这时候就可以用上 phantomjs 软件了。phantomjs 是一个基于 webkit 引擎做的 js 脚本库。可以通过 js 程序操作 webkit 浏览器引擎,实现各种浏览器功能。
6 |
7 | phantomjs 在 Linux 平台上没有二进制分发包,所以必须源代码编译:
8 |
9 | ```
10 | # yum -y install gcc gcc-c++ make flex bison gperf ruby \
11 | openssl-devel freetype-devel fontconfig-devel libicu-devel sqlite-devel \
12 | libpng-devel libjpeg-devel
13 | # git clone git://github.com/ariya/phantomjs.git
14 | # cd phantomjs
15 | # git checkout 2.0
16 | # ./build.sh
17 | ```
18 |
19 | 想要给 kibana 页面截图,几行代码就够了。
20 |
21 | ## Kibana3 截屏代码
22 |
23 | 下面是一个 Kibana3 的截屏示例。 `capture-kibana.js` 如下:
24 |
25 | ```
26 | var page = require('webpage').create();
27 | var address = 'http://kibana.example.com/#/dashboard/elasticsearch/h5_view';
28 | var output = 'kibana.png';
29 | page.viewportSize = { width: 1366, height: 600 };
30 | page.open(address, function (status) {
31 | if (status !== 'success') {
32 | console.log('Unable to load the address!');
33 | phantom.exit();
34 | } else {
35 | window.setTimeout(function () {
36 | page.render(output);
37 | phantom.exit();
38 | }, 30000);
39 | }
40 | });
41 | ```
42 |
43 | 然后运行 `phantomjs capture-kibana.js` 命令,就能得到截图生成的 kibana.png 图片了。
44 |
45 | 这里两个要点:
46 |
47 | 1. 要设置 `viewportSize` 里的宽度,否则效果会变成单个 panel 依次往下排列。
48 | 3. 要设置 `setTimeout`,否则在获取完 index.html 后就直接返回了,只能看到一个大白板。用 phantomjs 截取 angularjs 这类单页 MVC 框架应用时一定要设置这个。
49 |
50 | ## Kibana4 的截屏开源项目
51 |
52 | Kibana4 的 dashboard 同样可以采取上面 Kibana3 的方式自己实现。不过社区最近有人完成了一个辅助项目,把截屏配置、历史记录展示等功能都界面化了。项目地址见:。
53 |
54 | 
55 |
--------------------------------------------------------------------------------
/kibana/v3/README.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Kibana3 是一个使用 Apache 开源协议,基于浏览器的 Elasticsearch 分析和搜索仪表板。Kibana3 非常容易安装和使用。整个项目都是用 HTML 和 Javascript 写的,所以 Kibana3 不需要任何服务器端组件,一个纯文本发布服务器就够了。Kibana 和 Elasticsearch 一样,力争成为极易上手,但同样灵活而强大的软件。
4 |
5 | 官方 Kibana3 只支持到 Elasticsearch 1.7 为止。想在 Elasticsearch 2.x 上继续使用 Kibana3 的用户,请尝试 分支。
6 |
--------------------------------------------------------------------------------
/kibana/v3/advanced/scripted.md:
--------------------------------------------------------------------------------
1 | ## 脚本化仪表板(.js)
2 |
3 | 脚本化仪表板比模板化仪表板更加强大。当然,功能强大随之而来的就是构建起来也更复杂。脚本化仪表板的目的就是构建并返回一个描述了完整的仪表板纲要的 javascript 对象。`app/dashboards/logstash.js`([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.js)) 就是一个有着详细注释的脚本化仪表板示例。这个文件的最终结果和 `logstash.json` 一致,但提供了更强大的功能,比如我们可以以逗号分割多个请求:
4 |
5 | 注意:千万注意 URL `#/dashboard/script/logstash.js` 里的 `script` 字样。这让 kibana 解析对应的文件为 javascript 脚本。
6 |
7 | ```
8 | http://yourserver/index.html#/dashboard/script/logstash.js?query=status:403,status:404&from=7d
9 | ```
10 |
11 | 这会创建 2 个请求对象,`status:403` 和 `status:404` 并分别绘图。事实上这个仪表板还能接收另一个参数 `split`,用于指定用什么字符串切分。
12 |
13 | ```
14 | http://yourserver/index.html#/dashboard/script/logstash.js?query=status:403!status:404&from=7d&split=!
15 | ```
16 |
17 | 我们可以看到 `logstash.js` ([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.js)) 里是这么做的:
18 |
19 | ```javascript
20 | // In this dashboard we let users pass queries as comma separated list to the query parameter.
21 | // Or they can specify a split character using the split aparameter
22 | // If query is defined, split it into a list of query objects
23 | // NOTE: ids must be integers, hence the parseInt()s
24 | if(!_.isUndefined(ARGS.query)) {
25 | queries = _.object(_.map(ARGS.query.split(ARGS.split||','), function(v,k) {
26 | return [k,{
27 | query: v,
28 | id: parseInt(k,10),
29 | alias: v
30 | }];
31 | }));
32 | } else {
33 | // No queries passed? Initialize a single query to match everything
34 | queries = {
35 | 0: {
36 | query: '*',
37 | id: 0,
38 | }
39 | };
40 | }
41 | ```
42 |
43 | 该仪表板可用参数比上面讲述的还要多,全部参数都在 `logstash.js`([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.js)) 文件里开始的注释中有讲解。
44 |
--------------------------------------------------------------------------------
/kibana/v3/advanced/template.md:
--------------------------------------------------------------------------------
1 | # 模板和脚本
2 |
3 | Kibana 支持通过模板或者更高级的脚本来动态的创建仪表板。你先创建一个基础的仪表板,然后通过参数来改变它,比如通过 URL 插入一个新的请求或者过滤规则。
4 |
5 | 模板和脚本都必须存储在磁盘上,目前不支持存储在 Elasticsearch 里。同时它们也必须是通过编辑或创建纲要生成的。所以我们强烈建议阅读 [The Kibana Schema Explained](http://www.elasticsearch.org/guide/en/kibana/3.0/_dashboard_schema.html)
6 |
7 | ## 仪表板目录
8 |
9 | 仪表板存储在 Kibana 安装目录里的 `app/dashboards` 子目录里。你会注意到这里面有两种文件:`.json` 文件和 `.js` 文件。
10 |
11 | ## 模板化仪表板(.json)
12 |
13 | `.json` 文件就是模板化的仪表板。模板示例可以在 `logstash.json` 仪表板的请求和过滤对象里找到。模板使用 handlebars 语法,可以让你在 json 里插入 javascript 语句。URL 参数存在 `ARGS` 对象中。下面是 `logstash.json`([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.json)) 里请求和过滤服务的代码片段:
14 |
15 | ```
16 | "0": {
17 | "query": "{{ARGS.query || '*'}}",
18 | "alias": "",
19 | "color": "#7EB26D",
20 | "id": 0,
21 | "pin": false
22 | }
23 |
24 | [...]
25 |
26 | "0": {
27 | "type": "time",
28 | "field": "@timestamp",
29 | "from": "now-{{ARGS.from || '24h'}}",
30 | "to": "now",
31 | "mandate": "must",
32 | "active": true,
33 | "alias": "",
34 | "id": 0
35 | }
36 | ```
37 |
38 | 这允许我们在 URL 里设置两个参数,`query` 和 `from`。如果没设置,默认值就是 `||` 后面的内容。比如说,下面的 URL 就会搜索过去 7 天内 `status:200` 的数据:
39 |
40 | 注意:千万注意 url `#/dashboard/file/logstash.json` 里的 `file` 字样
41 |
42 | ```
43 | http://yourserver/index.html#/dashboard/file/logstash.json?query=status:200&from=7d
44 | ```
45 |
46 |
--------------------------------------------------------------------------------
/kibana/v3/auth/mojo-auth.md:
--------------------------------------------------------------------------------
1 | # Auth WebUI in Mojolicious
2 |
3 | 社区已经有用 nodejs 或者 rubyonrails 写的 kibana-auth 方案了。不过我这两种语言都不太擅长,只会写一点点 Perl5 代码,所以我选择用 [Mojolicious](http://mojolicio.us) web 开发框架来实现我自己的 kibana 认证鉴权。
4 |
5 | 整套方案的代码以 `kbnauth` 子目录形式存在于我的 [kibana 仓库](https://github.com/chenryn/kibana)中,如果你不想用这套认证方案,照旧使用 `src` 子目录即可。事实上,`kbnauth/public/` 目录下的静态文件我都是通过软连接方式指到 `src/`下的。
6 |
7 | ### 特性
8 |
9 | * 全局透明代理
10 |
11 | 和 nodejs 实现的那套方案不同,我这里并没有使用 `__es/` 这样附加的路径。所有发往 Elasticsearch 的请求都是通过这个方案来控制。除了使用 `config.js.ep` 模版来定制 `elasticsearch` 地址设置以外,方案还会伪造 `/_nodes` 请求的响应体,伪造的响应体中永远只有运行着认证方案的这台服务器的 IP 地址。
12 |
13 | *这么做的原因是我的 kibana 升级了 elasticjs 版本,新版本默认会通过这个 API 获取 nodes 列表,然后浏览器直接轮询多个 IP 获取响应。*
14 |
15 | **注意:Mojolicious 有一个环境变量叫 `max_message_size`,默认是 10MB,即只允许代理响应大小在 10MB 以内的数据。我在 `script/kbnauth` 启动脚本中把它修改成了 0,即不限制。如果你有这方面的需求,可以修改成任意你想要的阈值。**
16 |
17 | * 使用 `kibana-auth` elasticsearch 索引做鉴权
18 |
19 | 因为所有的请求都会发往代理服务器(即运行着认证鉴权方案的服务器),每个用户都可以有自己的仪表板空间(没错,这招是从 kibana-proxy 项目学来的,每个用户使用单独的 `kibana-int-$username` 索引保存自己的仪表板设置)。而本方案还提供另一个高级功能:还可以通过另一个新的索引 `kibana-auth` 来指定每个用户所能访问的 Elasticsearch 集群地址和索引列表。
20 |
21 | 给用户 "sri" 添加鉴权信息的命令如下:
22 |
23 | ```
24 | $ curl -XPOST http://127.0.0.1:9200/kibana-auth/indices/sri -d '{
25 | "prefix":["logstash-sri","logstash-ops"],
26 | "server":"192.168.0.2:9200"
27 | }'
28 | ```
29 |
30 | 这就意味着用户 "sri" 能访问的,是存在 "192.168.0.2:9200" 上的 "logstash-sri-YYYY.MM.dd" 或者 "logstash-ops-YYYY.MM.dd" 索引。
31 |
32 | **小贴士:所以你在 `kbn_auth.conf` 里配置的 eshost/esport,其实并不意味着 kibana 数据的来源,而是认证方案用来请求 `kibana-auth` 信息的地址!**
33 |
34 | * 使用 [Authen::Simple](https://metacpan.org/pod/Authen::Simple) 框架做认证
35 |
36 | Authen::Simple 是一个很棒的认证框架,支持非常多的认证方法。比如:LDAP, DBI, SSH, Kerberos, PAM, SMB, NIS, PAM, ActiveDirectory 等。
37 |
38 | 默认使用的是 Passwd 方法。也就是用 `htpasswd` 命令行在本地生成一个 `.htpasswd` 文件存用户名密码。
39 |
40 | 如果要使用其他方法,比如用 LDAP 认证,只需要配置 `kbn_auth.conf` 文件就行了:
41 |
42 | ```perl
43 | authen => {
44 | LDAP => {
45 | host => 'ad.company.com',
46 | binddn => 'proxyuser@company.com',
47 | bindpw => 'secret',
48 | basedn => 'cn=users,dc=company,dc=com',
49 | filter => '(&(objectClass=organizationalPerson)(objectClass=user)(sAMAccountName=%s))'
50 | },
51 | }
52 | ```
53 |
54 | 可以同时使用多种认证方式,但请确保每种都是有效可用的。某一个认证服务器连接超时也会影响到其他认证方式超时。
55 |
56 | ## 安装
57 |
58 | 该方案代码只有两个依赖:Mojolicious 框架和 Authen::Simple 框架。我们可以通过 cpanm 部署:
59 |
60 | ```
61 | curl http://xrl.us/cpanm -o /usr/local/bin/cpanm
62 | chmod +x /usr/local/bin/cpanm
63 | cpanm Mojolicious Authen::Simple::Passwd
64 | ```
65 |
66 | 如果你需要使用其他认证方法,每个方法都需要另外单独安装。比如使用 LDAP 部署,就再运行一行:`cpanm Authen::Simple::LDAP` 就可以了。
67 |
68 | *小贴士:如果你是在一个新 RHEL 系统上初次运行代码,你可能会发现有报错说找不到 `Digest::SHA` 模块。这个模块其实是 Perl 核心模块,但是 RedHat 公司把所有的 Perl 核心模块单独打包成了 `perl-core.rpm`,所以你得先运行一下 `yum install -y perl-core` 才行。我讨厌 RedHat!*
69 |
70 | ## 运行
71 |
72 | ```
73 | cd kbnauth
74 | # 开发环境监听 3000 端口,使用单进程的 morbo 服务器调试
75 | morbo script/kbnauth
76 | # 生产环境监听 80 端口,使用高性能的 hypnotoad 服务器, 具体端口在 kbn_auth.conf 中定义
77 | hypnotoad script/kbnauth
78 | ```
79 |
80 | 现在,打开浏览器,就可以通过默认的用户名/密码:"sri/secr3t" 登录进去了。(sri 是 Mojolicious 框架的作者,感谢他为 Perl5 社区提供这么高效的 web 开发框架)
81 |
82 | 注意:这时候你虽然认证通过进去了 kibana 页面,但是还没有赋权。按照上面提到的 `kibana-auth` 命令操作,才算全部完成。
83 |
--------------------------------------------------------------------------------
/kibana/v3/auth/nginx.md:
--------------------------------------------------------------------------------
1 | # nginx 代理和简单权限验证
2 |
3 | Kibana3 作为一个纯静态文件式的单页应用,可以运行在任意主机上,却要求所有用户的浏览器,都可以直连 ELasticsearch 集群。这对网络和数据安全都是极为不利的。所以,一般在生产环境的 Elastic Stack,都是采取 HTTP 代理层的方式来做一层防护。最简单的办法,就是使用 Nginx 代理配置。
4 |
5 | ES 官方也提供了一个推荐配置:
6 |
7 | ```
8 | server {
9 | listen *:80;
10 |
11 | server_name kibana.myhost.org;
12 | access_log /var/log/nginx/kibana.myhost.org.access.log;
13 |
14 | location / {
15 | root /usr/share/kibana3;
16 | index index.html index.htm;
17 | }
18 |
19 | location ~ ^/_aliases$ {
20 | proxy_pass http://127.0.0.1:9200;
21 | proxy_read_timeout 90;
22 | }
23 | location ~ ^/.*/_aliases$ {
24 | proxy_pass http://127.0.0.1:9200;
25 | proxy_read_timeout 90;
26 | }
27 | location ~ ^/_nodes$ {
28 | proxy_pass http://127.0.0.1:9200;
29 | proxy_read_timeout 90;
30 | }
31 | location ~ ^/.*/_search$ {
32 | proxy_pass http://127.0.0.1:9200;
33 | proxy_read_timeout 90;
34 | }
35 | location ~ ^/.*/_mapping {
36 | proxy_pass http://127.0.0.1:9200;
37 | proxy_read_timeout 90;
38 | }
39 |
40 | # Password protected end points
41 | location ~ ^/kibana-int/dashboard/.*$ {
42 | proxy_pass http://127.0.0.1:9200;
43 | proxy_read_timeout 90;
44 | limit_except GET {
45 | proxy_pass http://127.0.0.1:9200;
46 | auth_basic "Restricted";
47 | auth_basic_user_file /etc/nginx/conf.d/kibana.myhost.org.htpasswd;
48 | }
49 | }
50 | location ~ ^/kibana-int/temp.*$ {
51 | proxy_pass http://127.0.0.1:9200;
52 | proxy_read_timeout 90;
53 | limit_except GET {
54 | proxy_pass http://127.0.0.1:9200;
55 | auth_basic "Restricted";
56 | auth_basic_user_file /etc/nginx/conf.d/kibana.myhost.org.htpasswd;
57 | }
58 | }
59 | }
60 | ```
61 |
62 | 由此也可以看到,Kibana3 实际往 ES 发起的请求,都有哪些。
63 |
64 | 然后,在同时运行了 Nginx 和 Elasticsearch 服务(建议为 client 角色)的这台服务器上,配置 `elasticsearch.yml` 为:
65 |
66 | ```
67 | network.bind_host: 127.0.0.1
68 | network.publish_host: 127.0.0.1
69 | network.host: 127.0.0.1
70 | ```
71 |
72 | 其他 Elasticsearch 节点统一关闭 HTTP 服务,配置 `elasticsearch.yml`:
73 |
74 | ```
75 | http.enabled: false
76 | ```
77 |
78 | 这样,所有人都只能从 Nginx 服务来查询 ES 服务了。从 Nginx 日志中,我们还可以审核查询请求的语法性能和合理性。
79 |
80 | 注意:改配置前提是 Logstash 采用 node/transport 协议写入数据,如果使用 http 协议的,请采用 iptables 防护,或新增 `/_bulk` 等写入接口的代理配置。
81 |
--------------------------------------------------------------------------------
/kibana/v3/auth/nodejs-cas.md:
--------------------------------------------------------------------------------
1 | # 配置Kibana的CAS验证
2 |
3 | *本节作者:childe*
4 |
5 | 我们公司用的是 CAS 单点登陆, 用如下工具将kibana集成到此单点登陆系统
6 |
7 | ## 准备工具
8 |
9 | - nginx: 仅仅是为了记录日志, 不用也行
10 | - nodejs: 为了跑 kibana-authentication-proxy
11 | - kibana:
12 | - kibana-authentication-proxy:
13 |
14 | ## 配置
15 |
16 | 1. nginx 配置 8080 端口, 反向代理到 es 的 9200
17 | 2. git clone kibana-authentication-proxy
18 | 3. git clone kibana
19 | 4. 将 kibana 软链接到 kibana-authentication-proxy 目录下
20 | 5. 配置 kibana-authentication-proxy/config.js
21 |
22 | 可能有如下参数需要调整:
23 |
24 | ```
25 | es_host #这里是nginx地址
26 | es_port #nginx的8080
27 | listen_port #node的监听端口, 80
28 | listen_host #node的绑定IP, 可以0.0.0.0
29 | cas_server_url #CAS地址
30 | ```
31 |
32 | 6. 安装 kibana-authentication-proxy 的依赖, `npm install express`, 等
33 | 7. 运行 `node kibana-authentication-proxy/app.js`
34 |
35 | ## 原理
36 |
37 | - app.js 里面 `app.get('/config.js', kibana3configjs)`; 返回了一个新的 config.js, 不是用的 kibana/config.js, 在这个配置里面,调用 ES 数据的 URL 前面加了一个 `__es` 的前缀
38 | - 在 app.js 入口这里, 有两个关键的中间层(我也不知道叫什么)被注册: 一个是 `configureCas`, 一个是`configureESProxy`
39 | - 一个请求来的时候, 会到 `configureCas` 判断是不是已经登陆到 CAS, 没有的话就转到 cas 登陆页面
40 | - `configureESProxy` 在 lib/es-proxy.js 里, 会把 `__es` 打头的请求(其实就是请求 es 数据的请求)转发到真正的 es 接口那里(我们这里是 nginx)
41 |
42 | ## 请求路径
43 |
44 | node(80) <=> nginx(8080) <=> es(9200)
45 |
46 | kibana-authentication-proxy 本身没有记录日志的代码, 而且转发 es 请求用的流式的(看起来), 并不能记录详细的 request body. 所以我们就用 nginx 又代理一层做日志了..
47 |
48 |
--------------------------------------------------------------------------------
/kibana/v3/configuration.md:
--------------------------------------------------------------------------------
1 | # 配置
2 |
3 | config.js 是 Kibana 核心配置的地方。文件里包括的参数都是必须在初次运行 kibana 之前提前设置好的。在你把 Kibana 和 ES 从自己个人电脑搬上生产环境的时候,一定会需要修改这里的配置。下面介绍几个最常见的修改项:
4 |
5 | ## 参数
6 |
7 | **elasticsearch**
8 |
9 | 你 elasticsearch 服务器的 URL 访问地址。你应该不会像写个 `http://localhost:9200` 在这,哪怕你的 Kibana 和 Elasticsearch 是在同一台服务器上。默认的时候这里会尝试访问你部署 kibana 的服务器上的 ES 服务,你可能需要设置为你 elasticsearch 服务器的主机名。
10 |
11 | 注意:如果你要传递参数给 http 客户端,这里也可以设置成对象形式,如下:
12 |
13 | ```
14 | +elasticsearch: {server: "http://localhost:9200", withCredentials: true}+
15 | ```
16 |
17 | **default_route**
18 |
19 | 没有指明加载哪个仪表板的时候,默认加载页路径的设置参数。你可以设置为文件,脚本或者保存的仪表板。比如,你有一个保存成 "WebLogs" 的仪表板在 elasticsearch 里,那么你就可以设置成:
20 |
21 | ```
22 | default_route: /dashboard/elasticsearch/WebLogs,
23 | ```
24 |
25 | **kibana_index**
26 |
27 | 用来保存 Kibana 相关对象,比如仪表板,的 Elasticsearch 索引名称。默认为 `kibana-int`。
28 |
29 | **panel_name**
30 |
31 | 可用的面板模块数组。面板只有在仪表板中有定义时才会被加载,这个数组只是用在 "add panel" 界面里做下拉菜单。
32 |
33 |
34 |
--------------------------------------------------------------------------------
/kibana/v3/dashboard/README.md:
--------------------------------------------------------------------------------
1 | # 布局
2 |
3 | 之前说过,Kibana3 是一个单页应用。所以其页面布局设计是固定的。顶部栏作为全局设置,接下来是全局 Query 栏,全局 Filtering 栏,以及具体可视化图表的部分。
4 |
5 | 本节就介绍这两部分的操作方式和用法。
6 |
--------------------------------------------------------------------------------
/kibana/v3/dashboard/queries-and-filters.md:
--------------------------------------------------------------------------------
1 | # 请求和过滤
2 |
3 | 图啊,表啊,地图啊,Kibana 有好多种图表,我们怎么控制显示在这些图表上的数据呢?这就是请求和过滤起作用的地方。 Kibana 是基于 Elasticsearch 的,所以支持强大的 Lucene Query String 语法,同样还能用上 Elasticsearch 的过滤器能力。
4 |
5 | ## 我们的仪表板
6 |
7 | 我们的仪表板像下面这样,可以搜索莎士比亚文集的内容。如果你喜欢本章截图的这种仪表板样式,你可以[下载导出的仪表板纲要(dashboard schema)](http://www.elasticsearch.org/guide/en/kibana/3.0/snippets/plays.json)
8 |
9 | 
10 |
11 | ## 请求
12 |
13 | 在搜索栏输入下面这个非常简单的请求
14 |
15 | ```
16 | to be or not to be
17 | ```
18 |
19 | 你会注意到,表格里第一条就是你期望的《哈姆雷特》。不过下一行却是《第十二夜》的安德鲁爵士,这里可没有"to be",也没有"not to be"。事实上,这里匹配上的是 `to OR be OR or OR not OR to OR be`。
20 |
21 | 我们需要这么搜索(译者注:即加双引号)来匹配整个短语:
22 |
23 | ```
24 | "to be or not to be"
25 | ```
26 |
27 | 或者指明在某个特定的字段里搜索:
28 |
29 | ```
30 | line_id:86169
31 | ```
32 |
33 | 我们可以用 AND/OR 来组合复杂的搜索,注意这两个单词必须大写:
34 |
35 | ```
36 | food AND love
37 | ```
38 |
39 | 还有括号:
40 |
41 | ```
42 | ("played upon" OR "every man") AND stage
43 | ```
44 |
45 | 数值类型的数据可以直接搜索范围:
46 |
47 | ```
48 | line_id:[30000 TO 80000] AND havoc
49 | ```
50 |
51 | 最后,当然是搜索所有:
52 |
53 | ```
54 | *
55 | ```
56 |
57 | ## 多个请求
58 |
59 | 有些场景,你可能想要比对两个不同请求的结果。Kibana 可以通过 OR 的方式把多个请求连接起来,然后分别进行可视化处理。
60 |
61 | **添加请求**
62 |
63 | 点击请求输入框右侧的 + 号,即可添加一个新的请求框。
64 |
65 | 
66 |
67 | 点击完成后你应该看到的是这样子
68 |
69 | 
70 |
71 | 在左边,绿色输入框,输入 `"to be"` 然后右边,黄色输入框,输入 `"not to be"`。这就会搜索每个包含有 `"to be"` 或者 `"not to be"` 内容的文档,然后显示在我们的 hits 饼图上。我们可以看到原先一个大大的绿色圆形变成下面这样:
72 |
73 | 
74 |
75 | **移除请求**
76 |
77 | 要移除一个请求,移动鼠标到这个请求输入框上,然后会出现一个 x 小图标,点击小图标即可:
78 |
79 | 
80 |
81 | ## 颜色和图例
82 |
83 | Kibana 会自动给你的请求分配一个可用的颜色,不过你也可以手动设置颜色。点击请求框左侧的彩色圆点,就可以弹出请求设置下拉框。这里面可以修改请求的颜色,或者设置为这个请求设置一个新的图例文字:
84 |
85 | 
86 |
87 | ## 过滤
88 |
89 | 很多 Kibana 图表都是交互式的,可以用来过滤你的数据视图。比如,点击你图表上的第一个条带,你会看到一些变动。整个图变成了一个大大的绿色条带。这是因为点击的时候,就添加了一个过滤规则,要求匹配 `play_name` 字段里的单词。
90 |
91 | 
92 |
93 | 你要问了“在哪里过滤了”?
94 |
95 | 答案就藏在过滤(FILTERING)标签上出现的白色小星星里。点击这个标签,你会发现在 *filtering* 面板里已经添加了一个过滤规则。在 *filtering* 面板里,可以添加,编辑,固定,删除任意过滤规则。很多面板都支持添加过滤规则,包括表格(table),直方图(histogram),地图(map)等等。
96 |
97 | 
98 |
99 | 过滤规则也可以自己点击 + 号手动添加。
100 |
101 |
--------------------------------------------------------------------------------
/kibana/v3/img/alipay.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/alipay.png
--------------------------------------------------------------------------------
/kibana/v3/img/bettermap-gaode.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/bettermap-gaode.png
--------------------------------------------------------------------------------
/kibana/v3/img/bettermap-heap.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/bettermap-heap.png
--------------------------------------------------------------------------------
/kibana/v3/img/class-cast-exception.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/class-cast-exception.jpg
--------------------------------------------------------------------------------
/kibana/v3/img/column-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/column-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/column.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/column.png
--------------------------------------------------------------------------------
/kibana/v3/img/cors.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/cors.jpg
--------------------------------------------------------------------------------
/kibana/v3/img/hist-general.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-general.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-grid.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-grid.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-mb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-mb.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-mean.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-mean.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-percent.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-percent.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-queries.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-queries.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-style.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-style.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-percent.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-percent.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-queries.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-queries.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-setting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-setting.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-stack.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-stack.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-total-ps.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-total-ps.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-total-scale.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-total-scale.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-uniq-conf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-uniq-conf.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-uniq.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-uniq.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-view.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-view.png
--------------------------------------------------------------------------------
/kibana/v3/img/map-cn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/map-cn.png
--------------------------------------------------------------------------------
/kibana/v3/img/map-setting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/map-setting.png
--------------------------------------------------------------------------------
/kibana/v3/img/map-world.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/map-world.png
--------------------------------------------------------------------------------
/kibana/v3/img/query-topn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/query-topn.png
--------------------------------------------------------------------------------
/kibana/v3/img/sparklines-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/sparklines-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-fields.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-fields.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-highlight.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-highlight.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-micropanel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-micropanel.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-paging.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-paging.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-panel-setting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-panel-setting.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-sorting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-sorting.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-trim.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-trim.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-bar.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-bar.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-donut.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-donut.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-pie-no-other.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-pie-no-other.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-pie.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-pie.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-stat-map.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-stat-map.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-table.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-table.png
--------------------------------------------------------------------------------
/kibana/v3/img/topn-histogram.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/topn-histogram.png
--------------------------------------------------------------------------------
/kibana/v3/img/topn-sparklines.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/topn-sparklines.png
--------------------------------------------------------------------------------
/kibana/v3/img/trends-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/trends-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/trends.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/trends.png
--------------------------------------------------------------------------------
/kibana/v3/panels/README.md:
--------------------------------------------------------------------------------
1 | # 面板
2 |
3 | **Kibana** 仪表板由面板(`panels`)块组成。面板在行中可以起到很多作用,不过大多数是用来给一个或者多个请求的数据集结果做可视化。剩下一些面板则用来展示数据集或者用来为使用者提供插入指令的地方。
4 |
5 | 面板可以很容易的通过 Kibana 网页界面配置。为了了解更高级的用法,比如模板化或者脚本化仪表板,这章开始介绍面板属性。你可以发现一些通过网页界面看不到的设置。
6 |
7 | 每个面板类型都有自己的属性,不过有这么几个是大家共有的。
8 |
9 | ## span
10 |
11 | 一个从 1-12 的数字,描述面板宽度。
12 |
13 | ## editable
14 |
15 | 是否在面板上显示编辑按钮。
16 |
17 | ## type
18 |
19 | 本对象包含的面板类型。每个具体的面板类型又要求添加新的属性,具体列表说明稍后详述。
20 |
21 | -----------------------
22 |
23 | ## 译作者注
24 |
25 | 官方文档中只介绍了各面板的参数,而且针对的是要使用模板化,脚本化仪表板的高级用户,其中有些参数甚至在网页界面上根本不可见。
26 |
27 | 为了方便初学者,我在每个面板的参数介绍之后,自行添加界面操作和效果方面的说明。
28 |
29 | 另外,本书 Kibana3 介绍基于我的 分支,其中有十多处增强功能式的扩展。读者如果发现操作介绍中内容在自己界面上找不到的,可以尝试替换我的版本。
30 |
--------------------------------------------------------------------------------
/kibana/v3/panels/bettermap.md:
--------------------------------------------------------------------------------
1 | # bettermap
2 |
3 | 状态:实验性
4 |
5 | Bettermap 之所以叫 bettermap 是因为还没有更好(better)的名字。Bettermap 使用地理坐标来在地图上创建标记集群,然后根据集群的密度,用橘色,黄色和绿色作为区分。
6 |
7 | 要查看细节,点击标记集群。地图会放大,原有集群分裂成更小的集群。一直小到没法成为集群的时候,单个标记就会显现出来。悬停在标记上可以查看 `tooltip` 设置的值。
8 |
9 | **注意:** bettermap 需要从互联网上下载它的地图面板文件。
10 |
11 | ## 参数
12 |
13 | * field
14 |
15 | 包含了地理坐标的字段,要求是 geojson 格式。GeoJSON 是一个数组,内容为 `[longitude,latitude]` 。这可能跟大多数实现([latitude, longitude])是反过来的。
16 |
17 | * size
18 |
19 | 用来绘制地图的数据集大小。默认是 1000。注意:table panel 默认是展示最近 500 条,跟这里的大小不一致,可能引起误解。
20 |
21 | * spyable
22 |
23 | 设为假,不显示审查(inspect)按钮。
24 |
25 | * tooltip
26 |
27 | 悬停在标记上时显示哪个字段。
28 |
29 | * provider
30 |
31 | 选择哪家地图提供商。
32 |
33 | **请求(queries)**
34 |
35 | * 请求对象
36 |
37 | 这个对象描述本面板使用的请求。
38 |
39 | * queries.mode
40 |
41 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
42 |
43 | * queries.ids
44 |
45 | 如果设为 `selected` 模式,具体被选的请求编号。
46 |
47 | -----------------------------
48 |
49 | ## 界面配置说明
50 |
51 | bettermap 面板是为了解决 map 面板地图种类太少且不方便大批量添加各国地图文件的问题开发的。它采用了 [leaflet 库](http://leafletjs.com/),其 `L.tileLayer` 加载的 OpenStreetMap 地图文件都是在使用的时候单独请求下载,所以在初次使用的时候会需要一点时间才能正确显示。
52 |
53 | 在 bettermap 的配置界面,我提供了 provider ,可以选择各种地图提供商。比如中文用户可以选择 GaoDe(高德地图):
54 |
55 | 
56 |
57 | 注:最近,高德地图的 API 出现问题,该 provider 已经无法使用。
58 |
59 | ## 其他
60 |
61 | leaflet 库有丰富的[插件资源](http://leafletjs.com/plugins.html)。比如
62 |
63 | * [热力图](http://www.patrick-wied.at/static/heatmapjs/example-heatmap-leaflet.html)
64 |
65 | 
66 |
67 | 注:热力图插件最终在 Kibana4.1 中,作为 tile map 的新 option 加入了。
68 |
69 | *小贴士:其实 Kibana 官方效果的标记集群也是插件实现的,叫[markercluster](https://github.com/Leaflet/Leaflet.markercluster)*
70 |
71 |
--------------------------------------------------------------------------------
/kibana/v3/panels/column.md:
--------------------------------------------------------------------------------
1 | # column
2 |
3 | 状态:稳定
4 |
5 | 这是一个伪面板。目的是让你在一列中添加多个其他面板。虽然 column 面板状态是稳定,它的限制还是很多的,比如不能拖拽内部的小面板。未来的版本里,column 面板可能被删除。
6 |
7 | ## 参数
8 |
9 | * panel
10 |
11 | 面板对象构成的数组
12 |
13 | -----------------------------
14 |
15 | ## 界面配置说明
16 |
17 | column 面板是为了在高度较大的 row 中放入多个小 panel 准备的一个容器。其本身配置界面和 row 类似只有一个 panel 列表:
18 |
19 | 
20 |
21 | 在 column 中的具体的面板本身的设定,需要点击面板自带的配置按钮来配置:
22 |
23 | 
24 |
--------------------------------------------------------------------------------
/kibana/v3/panels/goal.md:
--------------------------------------------------------------------------------
1 | # goal
2 |
3 | 状态: 稳定
4 |
5 | goal 面板在一个饼图上显示到达指定目标的进度。
6 |
7 | ## 参数
8 |
9 | * donut
10 |
11 | 在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
12 |
13 | * tilt
14 |
15 | 在饼图(pie)模式,倾斜饼变成椭圆形。
16 |
17 | * legend
18 |
19 | 图例的位置,上、下或者无。
20 |
21 | * lables
22 |
23 | 在饼图(pie)模式,在饼图分片上绘制标签。
24 |
25 | * spyable
26 |
27 | 设为假,不显示审查(inspect)图标。
28 |
29 | **请求(queries)**
30 |
31 | * 请求对象
32 |
33 | * query.goal
34 |
35 | goal 模式的指定目标
36 |
--------------------------------------------------------------------------------
/kibana/v3/panels/hits.md:
--------------------------------------------------------------------------------
1 | # hits
2 |
3 | 状态: 稳定
4 |
5 | hits 面板显示仪表板上每个请求的 hits 数,具体的显示格式可以通过 "chart" 属性配置指定。
6 |
7 | ## 参数
8 |
9 | * arrangement
10 |
11 | 在条带(bar)或者饼图(pie)模式,图例的摆放方向。可以设置:水平(horizontal)或者垂直(vertical)。
12 |
13 | * chart
14 |
15 | 可以设置:none, bar 或者 pie
16 |
17 | * counter_pos
18 |
19 | 图例相对于图的位置,可以设置:上(above),下(below)
20 |
21 | * donut
22 |
23 | 在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
24 |
25 | * tilt
26 |
27 | 在饼图(pie)模式,倾斜饼变成椭圆形。
28 |
29 | * lables
30 |
31 | 在饼图(pie)模式,在饼图分片上绘制标签。
32 |
33 | * spyable
34 |
35 | 设为假,不显示审查(inspect)图标。
36 |
37 | **请求(queries)**
38 |
39 | * 请求对象
40 |
41 | 这个对象描述本面板使用的请求。
42 |
43 | * queries.mode
44 |
45 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
46 |
47 | * queries.ids
48 |
49 | 如果设为 `selected` 模式,具体被选的请求编号。
50 |
--------------------------------------------------------------------------------
/kibana/v3/panels/map.md:
--------------------------------------------------------------------------------
1 | # map
2 |
3 | 状态:稳定
4 |
5 | map 面板把 2 个字母的国家或地区代码转成地图上的阴影区域。目前可用的地图包括世界地图,美国地图和欧洲地图。
6 |
7 | ## 参数
8 |
9 | * map
10 |
11 | 显示哪个地图:world, usa, europe
12 |
13 | * colors
14 |
15 | 用来涂抹地图阴影的颜色数组。一旦设定好这 2 个颜色,阴影就会使用介于这 2 者之间的颜色。示例 [‘#A0E2E2’, ‘#265656’]
16 |
17 | * size
18 |
19 | 阴影区域的最大数量
20 |
21 | * exclude
22 |
23 | 排除的区域数组。示例 [‘US’,‘BR’,‘IN’]
24 |
25 | * spyable
26 |
27 | 设为假,不显示审查(inspect)按钮。
28 |
29 | **请求(queries)**
30 |
31 | * 请求对象
32 |
33 | 这个对象描述本面板使用的请求。
34 |
35 | * queries.mode
36 |
37 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
38 |
39 | * queries.ids
40 |
41 | 如果设为 `selected` 模式,具体被选的请求编号。
42 |
43 | -----------------------------
44 |
45 | ## 界面配置说明
46 |
47 | 考虑到都是中国读者,本节准备采用中国地图进行讲解,中国地图代码,,基于本人 仓库,除标准的 map 面板参数外,还提供了 `terms_stats` 功能,也会一并讲述。
48 |
49 | map 面板,最重要的配置即输入字段,对于不同的地图,应该配置不同的 `Field`:
50 |
51 | * world
52 |
53 | 对于世界地图,其所支持的格式为*由 2 个字母构成的国家名称缩写*,比如:`US`,`CN`,`JP`等。如果你使用了 `LogStash::Filters::GeoIP` 插件,那么默认生成的 **geoip.country_code2** 字段正好符合条件。
54 |
55 | 
56 |
57 | * cn
58 |
59 | 对于中国地图,其所支持的格式则是*由 2 个数字构成的省份编码*,比如:`01`(即安徽),`30`(即广东),`04`(即江苏)等。如果你使用了 `LogStash::Filters::GeoIP` 插件,那么默认生成的 **geoip.region_name** 字段正好符合条件。
60 |
61 | 
62 |
63 | 如果你使用了我的仓库代码,或者自行合并了[该功能](https://github.com/elasticsearch/kibana/pull/1270),你的 map 面板配置界面会稍有变动成下面样子
64 |
65 | 
66 |
67 | 如果选择 `terms_stats` 模式,就会和 histogram 面板一样出现需要填写 `value_field` 的位置。同样必须使用**在 Elasticsearch 中是数值类型**的字段,然后显示的地图上,就不再是个数而是具体的均值,最大值等数据了。
68 |
69 | 
70 |
--------------------------------------------------------------------------------
/kibana/v3/panels/query.md:
--------------------------------------------------------------------------------
1 | # query
2 |
3 | query 面板和 filter 面板都是特殊类型的面板,在 dashboard 上有且仅有一个。不能删除不能添加。
4 |
5 | query 和 filter 的普通样式和基本操作,在之前[ Query 和 Filtering](../dashboard/queries-and-filters.md) 章节已经讲述过。这里,额外讲一下一些高阶功能。
6 |
7 | ## 请求类型
8 |
9 | query 搜索框支持三种请求类型:
10 |
11 | * lucene
12 |
13 | 这也是默认的类型,使用要点就是请求语法。语法说明在之前 [Elasticsearch 一章](../../elasticsearch/api/search.md)已经讲过。
14 |
15 | * regex
16 |
17 | * topN
18 |
19 | topN 是一个方便大家进行多项对比搜索的功能。其配置界面如下:
20 |
21 | 
22 |
23 | **注意 topN 后颜色选择器的小圆点变成了齿轮状!**
24 |
25 | 其运行实质,是先根据你填写的 field 和 size,发起一次 termsFacet 查询,获取 topN 的 term 结果;然后拿着这个列表,逐一发起附加了 term 条件的其他请求(比如绑定在 histogram 面板就是 `date_histogram` 请求,stats 面板就是 `termStats` 请求),也就获得了 topN 结果。
26 |
27 | 
28 |
29 | *小贴士:如果 ES 响应较慢的时候,你甚至可以很明显的看到 histogram 面板上的多条曲线是一条一条出来数据绘制的。*
30 |
31 | ## 别名
32 |
33 | query 还可以设置别名(alias)。默认没有别名的时候,各 panel 上显示对应 query 时,会使用具体的 query 语句。在查询比较复杂的时候,不便观看。而设置别名后,pinned queries,panel 图例等处,都会只显示设置好的别名,而不再显示复杂的查询语句,这样一目了然。
34 |
--------------------------------------------------------------------------------
/kibana/v3/panels/sparklines.md:
--------------------------------------------------------------------------------
1 | # sparklines
2 |
3 | 状态: 试验性
4 |
5 | sparklines 面板显示微型时间图。目的不是显示一个确切的数值,而是以紧凑的方式显示时间序列的形态。
6 |
7 | ## 参数
8 |
9 | * mode
10 | 用作 Y 轴的数值模式。除 count 以外,都需要定义 `value_field` 字段。可选值有:count, mean, max, min, total.
11 | * time_field
12 | X 轴字段。必须是 Elasticsearch 中的时间类型字段。
13 | * value_field
14 | 如果 mode 设置为 mean, max, min 或者 total,Y 轴字段。必须是数值类型字段。
15 | * interval
16 | 如果有现成的时间过滤器,Sparkline 会自动计算间隔。如果没有,就用这个间隔。默认是 5 分钟。
17 | * spyable
18 | 显示 inspect 图标。
19 |
20 | **请求(queries)**
21 |
22 | * 请求对象
23 | 这个对象描述本面板使用的请求。
24 | * queries.mode
25 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
26 | * queries.ids
27 | 如果设为 `selected` 模式,具体被选的请求编号。
28 |
29 | -----------------------------
30 |
31 | ## 界面配置说明
32 |
33 | sparklines 面板其实就是 histogram 面板的缩略图模式。在配置上,只能选择 Chart value 模式,填写 Time Field 或者 Value Field 字段。上文描述中的 interval 在配置页面上是看不到的。
34 |
35 | 
36 |
37 | 我们可以对比一下对同一个 topN 请求绘制的 sparklines 和 histogram 面板的效果:
38 |
39 | * sparklines
40 |
41 | 
42 |
43 | * histogram
44 |
45 | 
46 |
47 | *注:topN 请求的配置和说明,见 [query 面板](query.md)*
48 |
--------------------------------------------------------------------------------
/kibana/v3/panels/stats.md:
--------------------------------------------------------------------------------
1 | # stats
2 |
3 | 状态: Beta
4 |
5 | 基于 Elasticsearch 的 statistical Facet 接口实现的统计聚合展示面板。
6 |
7 | ## 参数
8 |
9 | * format
10 |
11 | 返回值的格式。默认是 number,可选值还有:money,bytes,float。
12 |
13 | * style
14 |
15 | 主数字的显示大小,默认为 24pt。
16 |
17 | * mode
18 |
19 | 用来做主数字显示的聚合值,默认是 count,可选值为:count(计数),min(最小值),max(最大值),mean(平均值),total(总数),variance(方差),std_deviation(标准差),sum_of_squares(平方和)。
20 |
21 | * show
22 |
23 | 统计表格中具体展示的哪些列。默认为全部展示,可选列名即 mode 中的可选值。
24 |
25 | * spyable
26 |
27 | 设为假,不显示审查(inspect)按钮。
28 |
29 | **请求**
30 |
31 | * 请求对象
32 |
33 | 这个对象描述本面板使用的请求。
34 |
35 | * queries.mode
36 |
37 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
38 |
39 | * queries.ids
40 |
41 | 如果设为 `selected` 模式,具体被选的请求编号。
42 |
--------------------------------------------------------------------------------
/kibana/v3/panels/text.md:
--------------------------------------------------------------------------------
1 | # 文本(text)
2 |
3 | 状态:稳定
4 |
5 | 文本面板用来显示静态文本内容,支持 markdown,简单的 html 和纯文本格式。
6 |
7 | ## 参数
8 |
9 | * mode
10 |
11 | ‘html’, ‘markdown’ 或者 ‘text’
12 |
13 | * content
14 |
15 | 面板内容,用 `mode` 参数指定的标记语言书写
16 |
--------------------------------------------------------------------------------
/kibana/v3/panels/trends.md:
--------------------------------------------------------------------------------
1 | # trends
2 |
3 | 状态: Beta
4 |
5 | 以证券报价器风格展示请求随着时间移动的情况。比如说:当前时间是 1:10pm,你的时间选择器设置的是 "Last 10m",而本面板的 "Time Ago" 参数设置的是 "1h",那么面板会显示的是请求结果从 12:00-12:10pm 以来变化了多少。
6 |
7 | ## 参数
8 |
9 | * ago
10 |
11 | 描述需要对比请求的时期的时间数值型字符串。
12 |
13 | * arrangement
14 |
15 | ‘horizontal’ 或 ‘vertical’
16 |
17 | * spyable
18 |
19 | 设为假,不显示审查(inspect)按钮。
20 |
21 | **请求(queries)**
22 |
23 | * 请求对象
24 |
25 | 这个对象描述本面板使用的请求。
26 |
27 | * queries.mode
28 |
29 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
30 |
31 | * queries.ids
32 |
33 | 如果设为 `selected` 模式,具体被选的请求编号。
34 |
35 | -----------------------------
36 |
37 | ## 界面配置说明
38 |
39 | trends 面板用来对比实时数据与过去某天的同期数据的量的变化。配置很简单,就是设置具体某天前:
40 |
41 | 
42 |
43 | 效果如下:
44 |
45 | 
46 |
--------------------------------------------------------------------------------
/kibana/v3/saving-and-loading.md:
--------------------------------------------------------------------------------
1 | # 保存和加载
2 |
3 | 你已经构建了一个漂亮的仪表板!现在你打算分享给团队,或者开启自动刷新后挂在一个大屏幕上?Kibana 可以把仪表板设计持久化到 Elasticsearch 里,然后在需要的时候通过加载菜单或者 URL 地址调用出来。
4 |
5 | 
6 |
7 | ## 保存你漂亮的仪表板
8 |
9 | 保存你的界面非常简单,打开保存下拉菜单,取个名字,然后点击保存图表即可。现在你的仪表板就保存在一个叫做 `kibana-int` 的 Elasticsearch 索引里了。
10 |
11 | 
12 |
13 | ## 调用你的仪表板
14 |
15 | 要搜索已保存的仪表板列表,点击右上角的加载图标。在这里你可以加载,分享和删除仪表板。
16 |
17 | 
18 |
19 | ## 分享仪表板
20 |
21 | 已保存的仪表板可以通过你浏览器地址栏里的 URL 分享出去。每个持久化到 Elasticsearch 里的仪表板都有一个对应的 URL,像下面这样:
22 |
23 | ```
24 | http://your_host/index.html#/dashboard/elasticsearch/MYDASHBOARD
25 | ```
26 |
27 | 这个示例中 `MYDASHBOARD` 就是你在保存的时候给仪表板取得名字。
28 |
29 | 你还可以分享一个即时的仪表板链接,点击 Kibana 右上角的分享图标,会生成一个临时 URL。
30 |
31 | 
32 |
33 | 默认情况下,临时 URL 保存 30 天。
34 |
35 | 
36 |
37 | ## 保存成静态仪表板
38 |
39 | 仪表板可以保存到你的服务器磁盘上成为 `.json` 文件。把文件放到 `app/dashboards` 目录,然后通过下面地址访问
40 |
41 | ```
42 | http://your_host/index.html#/dashboard/file/MYDASHBOARD.json
43 | ```
44 |
45 | `MYDASHBOARD.json` 就是磁盘上文件的名字。注意路径中得 `/#dashboard/file/` 看起来跟之前访问保存在 Elasticsearch 里的仪表板很类似,不过这里访问的是文件而不是 elasticsearch。导出的仪表板纲要的详细信息,阅读稍后 [scheme 简介小节](./advanced/schema.md)。
46 |
47 | ## 下一步
48 |
49 | 你现在知道怎么保存,加载和访问仪表板了。你可能想知道怎么通过 URL 传递参数来访问,这样可以在其他应用中直接链接过来。请阅读稍后 [scripted 用法](./advanced/scripted.md) 和 [template 用法](./advanced/template.md) 两节。
50 |
--------------------------------------------------------------------------------
/kibana/v3/source-code-analysis/README.md:
--------------------------------------------------------------------------------
1 | # 源码剖析与二次开发
2 |
3 | Kibana 3 作为 Elastic Stack 风靡世界的最大推动力,其与优美的界面配套的简洁的代码同样功不可没。事实上,graphite 社区就通过移植 kibana 3 代码框架的方式,启动了 [grafana 项目](http://grafana.org/)。至今你还能在 grafana 源码找到二十多处 "kbn" 字样。
4 |
5 | *巧合的是,在 Kibana 重构 v4 版的同时,grafana 的 v2 版也到了 Alpha 阶段,从目前的预览效果看,主体 dashboard 沿用了 Kibana 3 的风格,不过添加了额外的菜单栏,供用户权限设置等使用 —— 这意味着 grafana 2 跟 kibana 4 一样需要一个单独的 server 端。*
6 |
7 | 笔者并非专业的前端工程师,对 angularjs 也处于一本入门指南都没看过的水准。所以本节内容,只会抽取一些个人经验中会有涉及到的地方提出一些"私货"。欢迎方家指正。
8 |
9 |
--------------------------------------------------------------------------------
/kibana/v3/source-code-analysis/directives.md:
--------------------------------------------------------------------------------
1 | ## panel 相关指令
2 |
3 | ### 添加 panel
4 |
5 | 前面在讲 `app/services/dashboard.js` 的时候,已经说到能添加的 panel 列表是怎么获取的。那么panel 是怎么加上的呢?
6 |
7 | 同样是之前讲过的 `app/partials/dashaboard.html` 里,加载了 `partials/roweditor.html` 页面。这里有一段:
8 |
9 | ```
10 |
16 |
17 |
20 | ```
21 |
22 | 这个 `add-panel` 指令,是有 `app/directives/addPanel.js` 提供的。方法如下:
23 |
24 | ```
25 | $scope.$watch('panel.type', function() {
26 | var _type = $scope.panel.type;
27 | $scope.reset_panel(_type);
28 | if(!_.isUndefined($scope.panel.type)) {
29 | $scope.panel.loadingEditor = true;
30 | $scope.require(['panels/'+$scope.panel.type.replace(".","/") +'/module'], function () {
31 | var template = '';
32 | elem.html($compile(angular.element(template))($scope));
33 | $scope.panel.loadingEditor = false;
34 | });
35 | }
36 | });
37 | ```
38 |
39 | 可以看到,其实就是 require 了对应的 `panels/xxx/module.js`,然后动态生成一个 div,绑定到对应的 controller 上。
40 |
41 | ### 展示 panel
42 |
43 | 还是在 `app/partials/dashaboard.html` 里,用到了另一个指令 `kibana-panel`:
44 |
45 | ```
46 |
21 |
22 | *欢迎捐赠,作者支付宝账号:*
23 |
24 | 
25 |
26 | # Version
27 |
28 | 2016-10-27 发布了 Elastic Stack 5.0 版。由于变动较大,本书 Git 仓库将 master 分支统一调整为基于 5.0 的状态。
29 |
30 | 想要查阅过去 k3、k4、logstash-2.x 等不同老版本资料的读者,请下载 ELK release:
31 |
32 | # TODO
33 |
34 | 限于个人经验、时间和场景,有部分 Elastic Stack 社区比较常见的用法介绍未完成,期待各位同好出手。罗列如下:
35 |
36 | * es-hadoop 用例
37 | * beats 开发
38 | * codec/netflow 的详解
39 | * filter/elapsed 的用例
40 | * zeppelin 的 es 用例
41 | * kibana的filter交互用法
42 | * painless的date对象用法:同比环比图
43 | * significant_text aggs用例
44 | * cat nodeattrs接口
45 | * timelion保存成panel的用法
46 | * regionmap用法
47 | * Time Series Visual Builder用法
48 | * Viewing Document Context用法
49 | * Dead Letter Queues讲解
50 | * elastalert 新版说明
51 |
52 |
--------------------------------------------------------------------------------
/beats/winlog.md:
--------------------------------------------------------------------------------
1 | # winlogbeat
2 |
3 | winlogbeat 通过标准的 windows API 获取 windows 系统日志,常见的有 application,hardware,security 和 system 四类。winlogbeat 示例配置如下:
4 |
5 | ```
6 | winlogbeat.event_logs:
7 | - name: Application
8 | provider:
9 | - Application Error
10 | - Application Hang
11 | - Windows Error Reporting
12 | - EMET
13 | - name: Security
14 | level: critical, error, warning
15 | event_id: 4624, 4625, 4700-4800, -4735
16 | - name: System
17 | ignore_older: 168h
18 | - name: Microsoft-Windows-Windows Defender/Operational
19 | include_xml: true
20 |
21 | output.elasticsearch:
22 | hosts:
23 | - localhost:9200
24 | pipeline: "windows-pipeline-id"
25 |
26 | logging.to_files: true
27 | logging.files:
28 | path: C:/ProgramData/winlogbeat/Logs
29 | logging.level: info
30 | ```
31 |
32 | 和其他 beat 一样,这里示例的配置不都是必填项。事实上只有 `event_logs.name` 是必须的。而 winlogbeat 的输出字段中,除了 beats 家族的通用内容外,还包括一下特有字段:
33 |
34 |
35 | * activity\_id
36 | * computer\_name:如果运行在 Windows 事件转发模式,这个值会和 beat.hostname 不一样。
37 | * event\_data
38 | * event\_id
39 | * keywords
40 | * log\_name
41 | * level:可选值包括 Success, Information, Warning, Error, Audit Success, and Audit Failure.
42 | * message
43 | * message\_error
44 | * record\_number
45 | * related\_activity\_id
46 | * opcode
47 | * provider\_guid
48 | * process\_id
49 | * source\_name
50 | * task
51 | * thread\_id
52 | * user\_data
53 | * user.identifier
54 | * user.name
55 | * user.domain
56 | * user.type
57 | * version
58 | * xml
59 |
--------------------------------------------------------------------------------
/contributors.md:
--------------------------------------------------------------------------------
1 | 致谢
2 | =============
3 |
4 | * 感谢 crazw 完成 collectd 插件介绍章节。
5 | * 感谢 松涛 完成 nxlog 场景介绍章节。
6 | * 感谢 LeiTu 完成 logstash-forwarder 介绍章节。
7 | * 感谢 jingbli 完成 kafka 插件介绍章节。
8 | * 感谢 林鹏 完成 ossec 场景介绍章节。
9 | * 感谢 cameluo 完成 shield 介绍章节。
10 | * 感谢 tuxknight 指出 hdfs 章节笔误。
11 | * 感谢 lemontree 完成 marvel 介绍章节。
12 | * 感谢 NERO 完成 utmp 插件开发介绍章节。
13 | * 感谢 childe 完成 kibana-auth-CAS 介绍, elasticsearch 读写分离和别名等章节。
14 | * 感谢 gnuhpc 完善 elasticsearch 插件 index 配置细节,logstash-fowarder-java 部署细节。
15 | * 感谢 东南 指出两处代码示例笔误。
16 | * 感谢 陆一鸣 指出 openjdk 的 rpm 名错误。
17 | * 感谢 elain 完成 search-guard 章节。
18 | * 感谢 wdh 完成 search-guard v2 版章节。
19 | * 感谢 李宏旭 完成 hdfs 快照备份 章节。
20 | * 感谢 abcfy2 完成 grafana 章节。
21 |
--------------------------------------------------------------------------------
/cover.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/cover.jpg
--------------------------------------------------------------------------------
/diff-hdfs.md:
--------------------------------------------------------------------------------
1 | # Elastic Stack 与 Hadoop 体系的区别
2 |
3 | Kibana 因其丰富的图表类型和漂亮的前端界面,被很多人理解成一个统计工具。而我个人认为,ELK 这一套体系,不应该和 Hadoop 体系同质化。定期的离线报表,不是 Elasticsearch 专长所在(多花费分词、打分这些步骤在高负载压力环境上太奢侈了),也不应该由 Kibana 来完成(每次刷新都是重新计算)。Kibana 的使用场景,应该集中在两方面:
4 |
5 | * 实时监控
6 |
7 | 通过 histogram 面板,配合不同条件的多个 queries 可以对一个事件走很多个维度组合出不同的时间序列走势。时间序列数据是最常见的监控报警了。
8 |
9 | * 问题分析
10 |
11 | 通过 Kibana 的交互式界面可以很快的将异常时间或者事件范围缩小到秒级别或者个位数。期望一个完美的系统可以给你自动找到问题原因并且解决是不现实的,能够让你三两下就从 TB 级的数据里看到关键数据以便做出判断就很棒了。这时候,一些非 histogram 的其他面板还可能会体现出你意想不到的价值。全局状态下看似很普通的结果,可能在你锁定某个范围的时候发生剧烈的反方向的变化,这时候你就能从这个维度去重点排查。而表格面板则最直观的显示出你最关心的字段,加上排序等功能。入库前字段切分好,对于排错分析真的至关重要。
12 |
13 | ## Splunk 场景参考
14 |
15 | 关于 elk 的用途,我想还可以参照其对应的商业产品 splunk 的场景:
16 |
17 | > 使用 Splunk 的意义在于使信息收集和处理智能化。而其操作智能化表现在:
18 | >
19 | > 1. 搜索,通过下钻数据排查问题,通过分析根本原因来解决问题;
20 | > 2. 实时可见性,可以将对系统的检测和警报结合在一起,便> 于跟踪 SLA 和性能问题;
21 | > 3. 历史分析,可以从中找出趋势和历史模式,行为基线和阈值,生成一致性报告。
22 |
23 | -- Peter Zadrozny, Raghu Kodali 著/唐宏,陈健译《Splunk大数据分析》
24 |
--------------------------------------------------------------------------------
/elasticsearch/README.md:
--------------------------------------------------------------------------------
1 | Elasticsearch 来源于作者 Shay Banon 的第一个开源项目 Compass 库,而这个 Java 库最初的目的只是为了给 Shay 当时正在学厨师的妻子做一个菜谱的搜索引擎。2010 年,Elasticsearch 正式发布。至今已经成为 GitHub 上最流行的 Java 项目,不过 Shay 承诺给妻子的菜谱搜索依然没有面世……
2 |
3 | 2015 年初,Elasticsearch 公司召开了第一次全球用户大会 Elastic{ON}15。诸多 IT 巨头纷纷赞助,参会,演讲。会后,Elasticsearch 公司宣布改名 Elastic,公司官网也变成 。这意味着 Elasticsearch 的发展方向,不再限于搜索业务,也就是说,Elastic Stack 等机器数据和 IT 服务领域成为官方更加注意的方向。随后几个月,专注监控报警的 Watcher 发布 beta 版,社区有名的网络抓包工具 Packetbeat、多年专注于基于机器学习的异常探测 Prelert 等 ITOA 周边产品纷纷被 Elastic 公司收购。
4 |
--------------------------------------------------------------------------------
/elasticsearch/alias.md:
--------------------------------------------------------------------------------
1 | alias的几点应用
2 | ==================
3 |
4 | *本节作者:childe*
5 |
6 | # 索引更改名字时, 无缝过渡
7 |
8 | ## 情景1
9 |
10 | 用Logstash采集当前的所有nginx日志, 放入ES, 索引名叫nginx-YYYY.MM.DD.
11 |
12 | 后来又增加了apache日志, 希望能放在同一个索引里面,统一叫web-YYYY.MM.DD.
13 |
14 | 我们只要把Logstash配置更改一下,然后重启, 数据就会写入新的索引名字下. 但是同一天的索引就会被分成了2个, kibana上面就不好配置了.
15 |
16 | ### 如此实现
17 |
18 | 1. 今天是2015.07.28. 我们为nginx-2015.07.28建一个alias叫做web-2015.07.28, 之前的所有nginx日志也如此照做.
19 | 2. kibana中把dashboard配置的索引名改成web-YYYY.MM.DD
20 | 3. 将logstash里面的elasticsearch的配置改成web-YYYY.MM.DD, 重启.
21 | 4. 无缝切换实现.
22 |
23 | ## 情景2
24 |
25 | 用Logstash采集当前的所有nginx日志, 放入ES, 索引名叫nginx-YYYY.MM.DD.
26 |
27 | 某天(2015.07.28)希望能够按月建立索引, 索引名改成nginx-YYYY.MM.
28 |
29 | **[注意]** 像情景1中那样新建一个叫nginx-2015.07的alias, 并指向本月的其他的索引是不行的. 因为一个alias指向了多个索引, 写这个alias的时候, ES不可能知道写入哪个真正的索引.
30 |
31 | ### 如此实现
32 |
33 | 1. 新建索引nginx-2015.07, 以及他的alias: nginx-2015.07.29, nginx-2015.07.30 ... 等.
34 | 新建索引nginx-2015.08, 以及他的alias: nginx-2015.08.01, nginx-2015.08.02 ... 等.
35 | 2. 等到第二天, 将logstash配置更改为nginx-YYYY.MM, 重启.
36 | 3. 如果索引只保留10天(一般来说, 不可能永久保存), 在10天之后的某天, 将kibana配置更改为 `[nginx-]YYYY.MM`
37 |
38 | ### 缺点
39 |
40 | 第二步, 第三步需要记得手工操作, 或者写一个crontab定时任务.
41 |
42 | ### 另外一种思路
43 |
44 | 1. 新建一个叫nginx-2015.07的alias, 并指向本月的其他的索引.
45 | 这个时候不能马上更改logstash配置写入nginx-2015.07. 因为一个alias指向了多个索引, 写这个alias的时候, ES不可能知道写入哪个真正的索引.
46 | 2. 新建索引nginx-2015.08, 以及他的alias: nginx-2015.08.01, nginx-2015.08.02 ... 等.
47 | 3. 把kibana配置改为 `[nginx-]YYYY.MM`.
48 | 4. 到2015.08.01这天, 或者之后的某天, 更改logstash配置, 把elasticsearch的配置更改为nginx-YYYY.MM. 重启.
49 |
50 | ### 缺点
51 |
52 | 1. 7月份的索引还是按天建立.
53 | 2. 第四步需要记得手工操作.
54 |
55 | 情景2的操作有些麻烦, 这些都是为了"无缝"这个大前提. 我们不希望用户(kibana的使用者)感觉到任何变化, 更不能让使用者感受到数据有缺失.
56 |
57 | 如果用户愿意妥协, 那ELK的管理者就可以马上简单粗暴的把数据写到nginx-2015.07, 并把kibana配置改过去. 这样一来, 用户可能就不能方便的看到之前的数据了.
58 |
59 | # 按域名配置kibana的dashboard
60 |
61 | nginx日志中有个字段是domain, 各个业务部门在Kibana中需要看且只看自己域名下的日志.
62 |
63 | 可以在logstash中按域名切分索引,但ES的metadata会成倍的增长,带来极大的负担.
64 |
65 | 也可以放在nginx-YYYY.MM.DD一个索引中, 在kibana加一个filter过滤. 但这个关键的filter和其它所有filter排在一起,是很容易很不小心清掉的.
66 |
67 | 我们可以在template中配置, 对每一个域名做一个alias.
68 |
69 | ```
70 | "aliases" : {
71 | "{index}-www.corp.com" : {
72 | "filter" : {
73 | "term" : {
74 | "domain" : "www.corp.com"
75 | }
76 | }
77 | },
78 | "{index}-abc.corp.com" : {
79 | "filter" : {
80 | "term" : {
81 | "domain" : "abc.corp.com"
82 | }
83 | }
84 | }
85 | }
86 | ```
87 |
88 | 当新的索引nginx-2015.07.28生成的时候, 会有nginx-2015.07.28-www.corp.com和nginx-2015.07.28-abc.corp.com等alias指向nginx-2015.07.28.
89 |
90 | 在kibana配置dashboard的时候, 就可以直接用alias做配置了.
91 |
92 | 在实际使用中, 可能还需要一个crontab定时的查询是否有新的域名加入, 自动对新域名做当天的alias, 并把它加入template.
93 |
--------------------------------------------------------------------------------
/elasticsearch/api/CRUD.md:
--------------------------------------------------------------------------------
1 | # 增删改查
2 |
3 | 增删改查是数据库的基础操作方法。ES 虽然不是数据库,但是很多场合下,都被人们当做一个文档型 NoSQL 数据库在使用,原因自然是因为在接口和分布式架构层面的相似性。虽然在 Elastic Stack 场景下,数据的写入和查询,分别由 Logstash 和 Kibana 代劳,作为测试、调研和排错时的基本功,还是需要了解一下 ES 的增删改查用法的。
4 |
5 | ## 数据写入
6 |
7 | ES 的一大特点,就是全 RESTful 接口处理 JSON 请求。所以,数据写入非常简单:
8 |
9 | ```
10 | # curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/testlog -d '{
11 | "date" : "1434966686000",
12 | "user" : "chenlin7",
13 | "mesg" : "first message into Elasticsearch"
14 | }'
15 | ```
16 |
17 | 命令返回响应结果为:
18 |
19 | ```
20 | {"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h2nBE6n0qcyVJK","_version":1,"created":true}
21 | ```
22 |
23 | ## 数据获取
24 |
25 | 可以看到,在数据写入的时候,会返回该数据的 `_id`。这就是后续用来获取数据的关键:
26 |
27 | ```
28 | # curl -XGET http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK
29 | ```
30 |
31 | 命令返回响应结果为:
32 |
33 | ```
34 | {"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h2nBE6n0qcyVJK","_version":1,"found":true,"_source":{
35 | "date" : "1434966686000",
36 | "user" : "chenlin7",
37 | "mesg" : "first message into Elasticsearch"
38 | }}
39 | ```
40 |
41 | 这个 `_source` 里的内容,正是之前写入的数据。
42 |
43 | 如果觉得这个返回看起来有点太过麻烦,可以使用 `curl -XGET http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK/_source` 来指明只获取源数据部分。
44 |
45 | 更进一步的,如果你只想看数据中的一部分字段内容,可以使用 `curl -XGET http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK?fields=user,mesg` 来指明获取字段,结果如下:
46 |
47 | ```
48 | {"_index":"logstash-2015.06.21","_type":"testlog","_id":"AU4ew3h2nBE6n0qcyVJK","_version":1,"found":true,"fields":{"user":["chenlin7"],"mesg":["first message into Elasticsearch"]}}
49 | ```
50 |
51 | ## 数据删除
52 |
53 | 要删除数据,修改发送的 HTTP 请求方法为 DELETE 即可:
54 |
55 | ```
56 | # curl -XDELETE http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK
57 | ```
58 |
59 | 删除不单针对单条数据,还可以删除整个整个索引。甚至可以用通配符。
60 |
61 | ```
62 | # curl -XDELETE http://127.0.0.1:9200/logstash-2015.06.0*
63 | ```
64 |
65 | 在 Elasticsearch 2.x 之前,可以通过查询语句删除,也可以删除某个 `_type` 内的数据。现在都已经不再内置支持,改为 `Delete by Query` 插件。因为这种方式本身对性能影响较大!
66 |
67 | ## 数据更新
68 |
69 | 已经写过的数据,同样还是可以修改的。有两种办法,一种是全量提交,即指明 `_id` 再发送一次写入请求。
70 |
71 | ```
72 | # curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK -d '{
73 | "date" : "1434966686000",
74 | "user" : "chenlin7",
75 | "mesg" " "first message into Elasticsearch but version 2"
76 | }'
77 | ```
78 |
79 | 另一种是局部更新,使用 `/_update` 接口:
80 |
81 | ```
82 | # curl -XPOST 'http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK/_update' -d '{
83 | "doc" : {
84 | "user" : "someone"
85 | }
86 | }'
87 | ```
88 |
89 | 或者
90 |
91 | ```
92 | # curl -XPOST 'http://127.0.0.1:9200/logstash-2015.06.21/testlog/AU4ew3h2nBE6n0qcyVJK/_update' -d '{
93 | "script" : "ctx._source.user = \"someone\""
94 | }'
95 | ```
96 |
--------------------------------------------------------------------------------
/elasticsearch/api/reindex.md:
--------------------------------------------------------------------------------
1 | # reindex
2 |
3 | Elasticsearch 本身不提供对索引的 rename,mapping 的 alter 等操作。所以,如果有需要对全索引数据进行导出,或者修改某个已有字段的 mapping 设置等情况下,我们只能通过 scroll API 导出全部数据,然后重新做一次索引写入。这个过程,叫做 reindex。
4 |
5 | 之前完成这个过程只能自己写程序或者用 logstash。5.0 中,Elasticsearch 将这个过程内置为 reindex API,但是要注意:这个接口并没有什么黑科技,其本质仅仅是将这段相同逻辑的代码预置分发而已。如果有复杂的数据变更操作等细节需求,依然需要自己编程完成。
6 |
7 | 下面分别给出这三种方法的示例:
8 |
9 | ## Perl 客户端
10 |
11 | Elastic 官方提供各种语言的客户端库,其中,Perl 库提供了对 reindex 比较方便的写法和示例。通过 `cpanm Search::Elasticsearch` 命令安装库完毕后,使用以下程序即可:
12 |
13 | ```
14 | use Search::Elasticsearch;
15 |
16 | my $es = Search::Elasticsearch->new(
17 | nodes => ['192.168.0.2:9200']
18 | );
19 | my $bulk = $es->bulk_helper(
20 | index => 'new_index',
21 | );
22 |
23 | $bulk->reindex(
24 | source => {
25 | index => 'old_index',
26 | size => 500, # default
27 | search_type => 'scan' # default
28 | }
29 | );
30 | ```
31 |
32 | ## Logstash 做 reindex
33 |
34 | 在最新版的 Logstash 中,对 logstash-input-elasticsearch 插件做了一定的修改,使得通过 logstash 完成 reindex 成为可能。
35 |
36 | reindex 操作的 logstash 配置如下:
37 |
38 | ```
39 | input {
40 | elasticsearch {
41 | hosts => [ "192.168.0.2" ]
42 | index => "old_index"
43 | size => 500
44 | scroll => "5m"
45 | docinfo => true
46 | }
47 | }
48 | output {
49 | elasticsearch {
50 | hosts => [ "192.168.0.3" ]
51 | index => "%{[@metadata][_index]}"
52 | document_type => "%{[@metadata][_type]}"
53 | document_id => "%{[@metadata][_id]}"
54 | }
55 | }
56 | ```
57 |
58 | 如果你做 reindex 的源索引并不是 logstash 记录的内容,也就是没有 `@timestamp`, `@version` 这两个 logstash 字段,那么可以在上面配置中添加一段 filter 配置,确保前后索引字段完全一致:
59 |
60 | ```
61 | filter {
62 | mutate {
63 | remove_field => [ "@timestamp", "@version" ]
64 | }
65 | }
66 | ```
67 |
68 | ## reindex API
69 |
70 | 简单的 reindex,可以很容易的完成:
71 |
72 | ```
73 | curl -XPOST http://localhost:9200/_reindex -d '
74 | {
75 | "source": {
76 | "index": "logstash-2016.10.29"
77 | },
78 | "dest": {
79 | "index": "logstash-new-2016.10.29"
80 | }
81 | }'
82 | ```
83 |
84 | 复杂需求,也能通过配合其他 API,比如 script、pipeline 等来满足一些,下面举一个复杂的示例:
85 |
86 | ```
87 | curl -XPOST http://localhost:9200/_reindex?requests_per_second=10000 -d '
88 | {
89 | "source": {
90 | "remote": {
91 | "host": "http://192.168.0.2:9200",
92 | },
93 | "index": "metricbeat-*",
94 | "query": {
95 | "match": {
96 | "host": "webserver"
97 | }
98 | }
99 | },
100 | "dest": {
101 | "index": "metricbeat",
102 | "pipeline": "ingest-rule-1"
103 | },
104 | "script": {
105 | "lang": "painless",
106 | "inline": "ctx._index = 'metricbeat-' + (ctx._index.substring('metricbeat-'.length(), ctx._index.length())) + '-1'"
107 | }
108 | }'
109 | ```
110 |
111 | 上面这个请求的作用,是将来自 192.168.0.2 集群的 metricbeat-2016.10.29 索引中,有关 `host:webserver` 的数据,读取出来以后,经过 localhost 集群的 `ingest-rule-1` 规则处理,在写入 localhost 集群的 metricbeat-2016.10.29-1 索引中。
112 |
113 | 注意:读取远端集群数据需要先配置对应的 `reindex.remote.whitelist:192.168.0.2:9200` 到 elasticsearch.yml 的白名单里。
114 |
115 | 通过 reindex 接口运行的任务可以通过同样是 5.0 新引入的任务管理接口进行取消、修改等操作。详细介绍见后续任务管理章节。
116 |
--------------------------------------------------------------------------------
/elasticsearch/api/script.md:
--------------------------------------------------------------------------------
1 | # script
2 |
3 | Elasticsearch 中,可以使用自定义脚本扩展功能。包括评分、过滤函数和聚合字段等方面。内置脚本引擎历经 MVEL、Groovy、Lucene expression 的变换后,Elastic.co 最终决定实现一个自己专用的 Painless 脚本语言,并在 5.0 版正式发布。
4 |
5 | 作为 Elastic Stack 场景,我们只介绍在聚合字段方面使用 script 的方式。
6 |
7 | ## 动态提交
8 |
9 | 最简单易用的方式,就是在正常的请求体中,把 `field` 换成 `script` 提交。比如一个标准的 terms agg 改成 script 方式,写法如下:
10 |
11 | ```
12 | # curl 127.0.0.1:9200/logstash-2015.06.29/_search -d '{
13 | "aggs" : {
14 | "clientip_top10" : {
15 | "terms" : {
16 | "script" : {
17 | "lang" : "painless",
18 | "inline" : "doc['clientip'].value"
19 | }
20 | }
21 | }
22 | }
23 | }'
24 | ```
25 |
26 | 在 script 中,有三种方式引用数据:`doc['clientip'].value`、`_field['clientip'].value` 和 `_source.clientip`。其区别在于:
27 |
28 | * `doc[].value` 读取 doc value 内的数据;
29 | * `_field[]` 读取 field 设置 `"store":true` 的存储内容;
30 | * `_source.obj.attr` 读取 `_source` 的 JSON 内容。
31 |
32 | 这也意味着,前者必须读取的是最终的词元字段数据,而后者可以返回任意的数据结构。
33 |
34 | **注意**:如果有分词,且未禁用 fielddata 的话,`doc[].value` 读取到的是分词后的数据。所以请注意使用 `doc['clientip.keyword'].value` 写法。
35 |
36 | ## 固定文件
37 |
38 | 为了和动态提交的语法有区别,调用固定文件的写法如下:
39 |
40 | ```
41 | # curl 127.0.0.1:9200/logstash-2015.06.29/_search -d '{
42 | "aggs" : {
43 | "clientip_subnet_top10" : {
44 | "terms" : {
45 | "script" : {
46 | "file" : "getvalue",
47 | "lang" : "groovy",
48 | "params" : {
49 | "fieldname": "clientip.keyword",
50 | "pattern": "^((?:\d{1,3}\.?){3})\.\d{1,3}$"
51 | }
52 | }
53 | }
54 | }
55 | }
56 | }'
57 | ```
58 |
59 | 上例要求在 ES 集群的所有数据节点上,都保存有一个 `/etc/elasticsearch/scripts/getvalue.groovy` 文件,并且该脚本文件可以接收 `fieldname` 和 `pattern` 两个变量。试举例如下:
60 |
61 | ```
62 | #!/usr/bin/env groovy
63 | matcher = ( doc[fieldname].value =~ /${pattern}/ )
64 | if (matcher.matches()) {
65 | matcher[0][1]
66 | }
67 | ```
68 |
69 | **注意**:ES 进程默认每分钟扫描一次 `/etc/elasticsearch/scripts/` 目录,并尝试加载该目录下所有文件作为 script。所以,不要在该目录内做文件编辑等工作,不要分发 .svn 等目录到生成环境,这些临时或者隐藏文件都会被 ES 进程加载然后报错。
70 |
71 | ## 其他语言
72 |
73 | ES 支持通过插件方式,扩展脚本语言的支持,目前默认自带的语言包括:
74 |
75 | * painless
76 | * lucene expression
77 | * groovy
78 | * mustache
79 |
80 | 而 github 上目前已有以下语言插件支持,基本覆盖了所有 JVM 上的可用语言:
81 |
82 | *
83 | *
84 | *
85 | *
86 | *
87 | *
88 |
--------------------------------------------------------------------------------
/elasticsearch/hadoop/spark-streaming.md:
--------------------------------------------------------------------------------
1 | # spark streaming 交互
2 |
3 | Apache Spark 是一个高性能集群计算框架,其中 Spark Streaming 作为实时批处理组件,因为其简单易上手的特性深受喜爱。在 es-hadoop 2.1.0 版本之后,也新增了对 Spark 的支持,使得结合 ES 和 Spark 成为可能。
4 |
5 | 目前最新版本的 es-hadoop 是 2.1.0-Beta4。安装如下:
6 |
7 | ```
8 | wget http://d3kbcqa49mib13.cloudfront.net/spark-1.0.2-bin-cdh4.tgz
9 | wget http://download.elasticsearch.org/hadoop/elasticsearch-hadoop-2.1.0.Beta4.zip
10 | ```
11 |
12 | 然后通过 `ADD_JARS=../elasticsearch-hadoop-2.1.0.Beta4/dist/elasticsearch-spark_2.10-2.1.0.Beta4.jar` 环境变量,把对应的 jar 包加入 Spark 的 jar 环境中。
13 |
14 | 下面是一段使用 spark streaming 接收 kafka 消息队列,然后写入 ES 的配置:
15 |
16 | ```
17 | import org.apache.spark._
18 | import org.apache.spark.streaming.kafka.KafkaUtils
19 | import org.apache.spark.streaming._
20 | import org.apache.spark.streaming.StreamingContext._
21 | import org.apache.spark.SparkContext
22 | import org.apache.spark.SparkContext._
23 | import org.apache.spark.SparkConf
24 | import org.apache.spark.sql._
25 | import org.elasticsearch.spark.sql._
26 | import org.apache.spark.storage.StorageLevel
27 | import org.apache.spark.Logging
28 | import org.apache.log4j.{Level, Logger}
29 |
30 | object Elastic {
31 | def main(args: Array[String]) {
32 | val numThreads = 1
33 | val zookeeperQuorum = "localhost:2181"
34 | val groupId = "test"
35 | val topic = Array("test").map((_, numThreads)).toMap
36 | val elasticResource = "apps/blog"
37 |
38 | val sc = new SparkConf()
39 | .setMaster("local[*]")
40 | .setAppName("Elastic Search Indexer App")
41 |
42 | sc.set("es.index.auto.create", "true")
43 | val ssc = new StreamingContext(sc, Seconds(10))
44 | ssc.checkpoint("checkpoint")
45 | val logs = KafkaUtils.createStream(ssc,
46 | zookeeperQuorum,
47 | groupId,
48 | topic,
49 | StorageLevel.MEMORY_AND_DISK_SER)
50 | .map(_._2)
51 |
52 | logs.foreachRDD { rdd =>
53 | val sc = rdd.context
54 | val sqlContext = new SQLContext(sc)
55 | val log = sqlContext.jsonRDD(rdd)
56 | log.saveToEs(elasticResource)
57 | }
58 |
59 | ssc.start()
60 | ssc.awaitTermination()
61 |
62 | }
63 | }
64 | ```
65 |
66 | 注意,代码中使用了 spark SQL 提供的 `jsonRDD()` 方法,如果在对应的 kafka topic 里的数据,本身并不是已经处理好了的 JSON 数据的话,这里还需要自己写一写额外的处理函数,利用 `cast class` 来规范数据。
67 |
--------------------------------------------------------------------------------
/elasticsearch/ingest.md:
--------------------------------------------------------------------------------
1 | # Ingest 节点
2 |
3 | Ingest 节点是 Elasticsearch 5.0 新增的节点类型和功能。其开启方式为:在 `elasticsearch.yml` 中定义:
4 |
5 | ```
6 | node.ingest: true
7 | ```
8 |
9 | Ingest 节点的基础原理,是:节点接收到数据之后,根据请求参数中指定的管道流 id,找到对应的已注册管道流,对数据进行处理,然后将处理过后的数据,按照 Elasticsearch 标准的 indexing 流程继续运行。
10 |
11 | ## 创建管道流
12 |
13 | ```
14 | curl -XPUT http://localhost:9200/_ingest/pipeline/my-pipeline-id -d '
15 | {
16 | "description" : "describe pipeline",
17 | "processors" : [
18 | {
19 | "convert" : {
20 | "field": "foo",
21 | "type": "integer"
22 | }
23 | }
24 | ]
25 | }'
26 | ```
27 |
28 | 然后发送端带着这个 `my-pipeline-id` 发请求就好了。示例见本书 beats 章节的介绍。
29 |
30 | ## 测试管道流
31 |
32 | 想知道自己的 ingest 配置是否正确,可以通过仿真接口测试验证一下:
33 |
34 | ```
35 | curl -XPUT http://localhost:9200/_ingest/pipeline/_simulate -d '
36 | {
37 | "pipeline" : {
38 | "description" : "describe pipeline",
39 | "processors" : [
40 | {
41 | "set" : {
42 | "field": "foo",
43 | "value": "bar"
44 | }
45 | }
46 | ]
47 | },
48 | "docs" : [
49 | {
50 | "_index": "index",
51 | "_type": "type",
52 | "_id": "id",
53 | "_source": {
54 | "foo" : "bar"
55 | }
56 | }
57 | ]
58 | }'
59 | ```
60 |
61 | ## 处理器
62 |
63 | Ingest 节点的处理器,相当于 Logstash 的 filter 插件。事实上其主要处理器就是直接移植了 Logstash 的 filter 代码成 Java 版本。目前最重要的几个处理器分别是:
64 |
65 | ### convert
66 |
67 | ```
68 | {
69 | "convert": {
70 | "field" : "foo",
71 | "type": "integer"
72 | }
73 | }
74 | ```
75 |
76 | ### grok
77 |
78 | ```
79 | {
80 | "grok": {
81 | "field": "message",
82 | "patterns": ["my %{FAVORITE_DOG:dog} is colored %{RGB:color}"]
83 | "pattern_definitions" : {
84 | "FAVORITE_DOG" : "beagle",
85 | "RGB" : "RED|GREEN|BLUE"
86 | }
87 | }
88 | }
89 | ```
90 |
91 | ### gsub
92 |
93 | ```
94 | {
95 | "gsub": {
96 | "field": "field1",
97 | "pattern": "\.",
98 | "replacement": "-"
99 | }
100 | }
101 | ```
102 |
103 | ### date
104 |
105 | ```
106 | {
107 | "date" : {
108 | "field" : "initial_date",
109 | "target_field" : "timestamp",
110 | "formats" : ["dd/MM/yyyy hh:mm:ss"],
111 | "timezone" : "Europe/Amsterdam"
112 | }
113 | }
114 | ```
115 |
116 | ### 其他处理器插件
117 |
118 | 除了内置的处理器之外,还有 3 个处理器,官方选择了以插件性质单独发布,它们是 attachement,geoip 和 user-agent 。原因应该是这 3 个处理器需要额外数据模块,而且处理性能一般,担心拖累 ES 集群。
119 |
120 | 它们可以和其他普通 ES 插件一样安装:
121 |
122 | ```
123 | sudo bin/elasticsearch-plugin install ingest-geoip
124 | ```
125 |
126 | 使用方式和其他处理器一样:
127 |
128 | ```
129 | curl -XPUT http://localhost:9200/_ingest/pipeline/my-pipeline-id-2 -d '
130 | {
131 | "description" : "Add geoip info",
132 | "processors" : [
133 | {
134 | "geoip" : {
135 | "field" : "ip",
136 | "target_field" : "geo",
137 | "database_file" : "GeoLite2-Country.mmdb.gz"
138 | }
139 | }
140 | ]
141 | }
142 | ```
143 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/README.md:
--------------------------------------------------------------------------------
1 | # 监控方案
2 |
3 | Elasticsearch 作为一个分布式系统,监控自然是重中之重。Elasticsearch 本身提供了非常完善的,由浅及深的各种性能数据接口。和数据读写检索接口一样,采用 RESTful 风格。我们可以直接使用 curl 来获取数据,编写监控程序,也可以使用一些现成的监控方案。通常这些方案也是通过接口读取数据,解析 JSON,渲染界面。
4 |
5 | 本章会先介绍一些常用的监控接口,以及其响应数据的含义。然后再介绍几种常用的开源和商业 Elasticsearch 监控产品。
6 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/api/index-stats.md:
--------------------------------------------------------------------------------
1 | # 索引状态监控接口
2 |
3 | 索引状态监控接口的输出信息和节点状态监控接口非常类似。一般情况下,这个接口单独监控起来的意义并不大。
4 |
5 | 不过在 ES 1.6 版开始,加入了对索引分片级别的 commit id 功能。
6 |
7 | 回忆一下之前原理章节的内容,commit 是在分片内部,对每个 segment 做的。而数据在主分片和副本分片上,是由各自节点自行做 segment merge 操作,所以副本分片和主分片的 segment 的 commit id 是不一致的。这导致 ES 副本恢复时,跟主分片比对 commit id,基本上每个 segment 都不一样,所以才需要从主分片完整重传一份数据。
8 |
9 | 新加入分片级别的 commit id 后,副本恢复时,先比对跟主分片的分片级 commit id,如果一致,直接本地恢复副本分片内容即可。
10 |
11 | 查看分片级别 commit id 的命令如下:
12 |
13 | ```
14 | # curl 'http://127.0.0.1:9200/logstash-mweibo-2015.06.15/_stats/commit?level=shards&pretty'
15 | ...
16 | "indices" : {
17 | "logstash-2015.06.15" : {
18 | "primaries" : { },
19 | "total" : { },
20 | "shards" : {
21 | "0" : [ {
22 | "routing" : {
23 | "state" : "STARTED",
24 | "primary" : true,
25 | "node" : "AqaYWFQJRIK0ZydvVgASEw",
26 | "relocating_node" : null
27 | },
28 | "commit" : {
29 | "generation" : 726,
30 | "user_data" : {
31 | "translog_id" : "1434297603053",
32 | "sync_id" : "AU4LEh6wnBE6n0qcEXs5"
33 | },
34 | "num_docs" : 36792652
35 | }
36 | } ],
37 | ...
38 | ```
39 |
40 | 注意:为了节约频繁变更的资源消耗,ES 并不会实时更新分片级 commit id。只有连续 5 分钟没有新数据写入的索引,才会触发给索引各分片更新 commit id 的操作。如果你查看的是一个还在新写入数据的索引,看到的内容应该是下面这样:
41 |
42 | ```
43 | "commit" : {
44 | "generation" : 590,
45 | "user_data" : {
46 | "translog_id" : "1434038402801"
47 | },
48 | "num_docs" : 29051938
49 | }
50 | ```
51 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk-banner.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/bigdesk-banner.png
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk-indexing.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/bigdesk-indexing.png
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk-jvm.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/bigdesk-jvm.png
--------------------------------------------------------------------------------
/elasticsearch/monitor/bigdesk.md:
--------------------------------------------------------------------------------
1 | # bigdesk
2 |
3 | 要想最快的了解 ES 各节点的性能细节,推荐使用 bigdesk 插件,其原作者为 lukas-vlcek。但是从 Elasticsearch 1.4 版本开始就不再更新了。国内有用户 fork 出来继续维护到支持 5.0 版本,GitHub 地址见:
4 |
5 | bigdesk 通过浏览器直连 ES 节点,发起 RESTful 请求,并渲染结果成图。所以其安装部署极其简单:
6 |
7 | ```
8 | # git clone https://github.com/hlstudio/bigdesk
9 | # cd bigdesk/_site
10 | # python -mSimpleHTTPServer
11 | Serving HTTP on 0.0.0.0 port 8000 ...
12 | ```
13 |
14 | 浏览器打开 `http://localhost:8000` 即可看到 bigdesk 页面。在 **endpoint** 输入框内填写要连接的 ES 节点地址,选择 refresh 间隔和 keep 时长,点击 **connect**,完成。
15 |
16 | 
17 |
18 | 注意:设置 refresh 间隔请考虑 Elastic Stack 使用的 template 里实际的 `refresh_interval` 是多少。否则你可能看到波动太大的数据,不足以说明情况。
19 |
20 | 点选某个节点后,就可以看到该节点性能的实时走势。一般重点关注 JVM 性能和索引性能。
21 |
22 | 有关 JVM 部分截图如下:
23 |
24 | 
25 |
26 | 有关数据读写性能部分截图如下:
27 |
28 | 
29 |
30 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/cerebro.md:
--------------------------------------------------------------------------------
1 | # cerebro
2 |
3 | cerebro 这个名字大家可能觉得很陌生,其实它就是过去的 kopf 插件!因为 Elasticsearch 5.0 不再支持 site plugin,所以 kopf 作者放弃了原项目,另起炉灶搞了 cerebro,以独立的单页应用形式,继续支持新版本下 Elasticsearch 的管理工作。
4 |
5 | 项目地址:
6 |
7 | ## 安装部署
8 |
9 | 单页应用的安装方式都非常简单,下载打开即可:
10 |
11 | ```
12 | # git clone https://github.com/lmenezes/cerebro
13 | # cd cerebro
14 | # ./bin/cerebro
15 | ```
16 |
17 | 然后浏览器打开 `http://localhost:9000` 即可。
18 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/logging.md:
--------------------------------------------------------------------------------
1 | # 日志记录
2 |
3 | Elasticsearch 作为一个服务,本身也会记录很多日志信息。默认情况下,日志都放在 `$ES_HOME/logs/` 目录里。
4 |
5 | 日志配置在 Elasticsearch 5.0 中改成了使用 `log4j2.properties` 文件配置,包括日志滚动的方式、命名等,都和标准的 log4j2 一样。唯一的特点是:Elasticsearch 导出了一个变量叫 `${sys:es.logs}`,指向你在 `elasticsearch.yml` 中配置的 `path.logs` 地址:
6 |
7 | ```
8 | appender.index_search_slowlog_rolling.filePattern = ${sys:es.logs}_index_search_slowlog-%d{yyyy-MM-dd}.log
9 | ```
10 |
11 | 具体的级别等级也可以通过 `/_cluster/settings` 接口动态调整。比如说,如果你的节点一直无法正确的加入集群,你可以将集群自动发现方面的日志级别修改成 DEBUG,来关注这方面的问题:
12 |
13 | ```
14 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
15 | {
16 | "transient" : {
17 | "logger.org.elasticsearch.indices.recovery" : "DEBUG"
18 | }
19 | }'
20 | ```
21 |
22 | ## 性能日志
23 |
24 | 除了进程状态的日志输出,ES 还支持跟性能相关的日志输出。针对数据写入,检索,读取三个阶段,都可以设置具体的慢查询阈值,以及不同的输出等级。
25 |
26 | 此外,慢查询日志是针对索引级别的设置。除了通过 `/_cluster/settings` 接口配置一组集群各索引共用的参数以外,还可以针对每个索引设置不同的参数。
27 |
28 | *注:过去的版本,还可以在 `elasticsearch.yml` 中设置,5.0 版禁止在配置文件中添加索引级别的设置!*
29 |
30 | 比如说,我们可以先设置集群共同的参数:
31 |
32 | ```
33 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
34 | {
35 | "transient" : {
36 | "logger.index.search.slowlog" : "DEBUG",
37 | "logger.index.indexing.slowlog" : "WARN",
38 | "index.search.slowlog.threshold.query.debug" : "10s",
39 | "index.search.slowlog.threshold.fetch.debug": "500ms",
40 | "index.indexing.slowlog.threshold.index.warn": "5s"
41 | }
42 | }'
43 | ```
44 |
45 | 然后针对某个比较大的索引,调高设置:
46 |
47 | ```
48 | # curl -XPUT http://127.0.0.1:9200/logstash-wwwlog-2015.06.21/_settings -d'
49 | {
50 | "index.search.slowlog.threshold.query.warn" : "10s",
51 | "index.search.slowlog.threshold.fetch.debug": "500ms",
52 | "index.indexing.slowlog.threshold.index.info": "10s"
53 | }
54 | ```
55 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-1.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-1.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-2.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-3.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-3.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-4.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-4.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-5.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-5.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel-6.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/monitor/marvel-6.jpg
--------------------------------------------------------------------------------
/elasticsearch/monitor/marvel.md:
--------------------------------------------------------------------------------
1 | # marvel
2 |
3 | *本节作者:lemontree*
4 |
5 | marvel 是 Elastic.co 公司推出的商业监控方案,也是用来监控 Elasticsearch 集群实时、历史状态的有力用具,便于性能优化以及故障诊断。监控主要分为六个层面,分别是集群层、节点层、索引层、分片层、事件层、Sense。
6 |
7 | * 集群层:主要对集群健康情况进行汇总,包括集群名称、集群状态、节点数量、索引个数、分片数、总数据量、集群版本等信息。同时,对节点、索引整体情况分别展示。
8 | * 节点层:主要对每个节点的 CPU 、内存、负载、索引相关的性能数据等信息进行统计,并进行图形化展示。
9 | * 索引层:展示的信息与节点层类似,主要从索引的角度展示。
10 | * 分片层:从索引、节点两个角度展示分片的分布情况,并提供 playback 功能演示分片分配的历史过程。
11 | * 事件层:展示集群相关事件,如节点脱离、加入,Master 选举、索引创建、Shard 分配等。
12 | * Sense:轻量级的开发界面,主要用于通过 API 查询数据,管理集群。
13 |
14 | Elastic.co 公司的收费标准是:
15 |
16 | * 开发模式免费
17 | * 生产环境前 5 个节点,每年 1000 美元
18 | * 之后每增加 5 个节点,每年加收 250 美元
19 |
20 | ## 安装和卸载
21 |
22 | marvel 是以 elasticsearch 的插件形式存在的,可以直接通过插件安装:
23 |
24 | ```
25 | # ./bin/plugin -i elasticsearch/marvel/latest
26 | ```
27 |
28 | 如果你是从官网下载的安装包,则运行:
29 |
30 | ```
31 | # ./bin/plugin -i marvel -u file:///path/to/marvel-latest.zip
32 | ```
33 |
34 | 各节点都安装完毕后,可以通过下行命令来查看节点上的插件列表,检查列表中是否含有 marvel:
35 |
36 | ```
37 | # curl http://127.0.0.1:9200/_nodes/_local/plugins
38 | ```
39 |
40 | 安装之后,插件自动运行,并将定期获取到的集群状态数据,存储在 `.marvel-YYYY.MM.DD` 索引中,以单台 ES 计算,该索引的大小在 500MB 左右。所以,如果在小规模环境下运行,首先请注意,不要让你宝贵的内存都花在 marvel 的数据索引上了。
41 |
42 | 如果不打算使用 marvel,在各节点上通过下行命令下载:
43 |
44 | ```
45 | # ./bin/plugin -r marvel
46 | ```
47 |
48 | ## 配置
49 |
50 | 如果不想让 marvel 数据索引影响到生产环境 ES 的运行,可以搭建单独的 marvel 数据集群,而生产数据集群上通过主动汇报的方式把数据发送过去。
51 |
52 | 在两个集群都安装好 marvel 插件后,生产集群的 `elasticsearch.yml` 上添加如下配置:
53 |
54 | ```
55 | marvel.agent.exporter.es.hosts: ["marvel-cluster-ip:9200"]
56 | ```
57 |
58 | 和大多数 cluster 设置一样,marvel 设置也是可以动态变更的:
59 |
60 | ```
61 | # curl –XPUT 127.0.0.1:9200/_cluster/settings -d '{
62 | "transient" : {
63 | "marvel.agent.exporter.es.hosts": [ "192.168.0.2:9200", "192.168.0.3:9200" ]
64 | }
65 | }'
66 | ```
67 |
68 | 数据接收端的 marvel 集群(即上一行写的 marvel-cluster-ip 代表的主机)则添加如下配置:
69 |
70 | ```
71 | marvel.agent.enabled: false
72 | ```
73 |
74 | 即本身不启用 marvel,以免数据有混淆。
75 |
76 | ## 访问
77 |
78 | 既然是 ES 插件,访问地址自然是插件式的:`http://marvel-cluster-ip:9200/_plugin/marvel/index.html`
79 |
80 | marvel 的监控页面是在 Kibana3 基础上稍有改造。如下图所示,其顶部菜单栏设计了一个下拉选择框,可以切换几个不同纬度的仪表板:
81 |
82 | 
83 |
84 | ## 面板定制
85 |
86 | Marvel的信息展示能够以Panel为单元进行个性化定制。每个Panel定制的过程比较类似。这里举例定制一个DOCUMENT COUNT文档数Panel,配置过程如下:
87 |
88 | 1. 点击红色椭圆部分,添加一个Panel:
89 | 
90 | 2. 输入Panel的名字DOCUMENT COUNT:
91 | 
92 | 3. 输入Panel Y 轴显示的值 "Primaries.docx.count":
93 | 
94 | 4. 选择展示风格
95 | 
96 | 5. 选择查看的集合,这里选择 *all*:
97 | 
98 | 6. 一个Document Count Panel就完成了:
99 | 
100 |
--------------------------------------------------------------------------------
/elasticsearch/monitor/zabbix.md:
--------------------------------------------------------------------------------
1 | # zabbix
2 |
3 | 之前提到的都是 Elasticsearch 的 sites 类型插件,其实质是实时从浏览器读取 cluster stats 接口数据并渲染页面。这种方式直观,但不适合生产环境的自动化监控和报警处理。要达到这个目标,还是需要使用诸如 nagios、zabbix、ganglia、collectd 这类监控系统。
4 |
5 | 本节以 zabbix 为例,介绍如何使用监控系统完成 Elasticsearch 的监控报警。
6 |
7 | github 上有好几个版本的 ESZabbix 仓库,都源自 Elastic 公司员工 untergeek 最早的贡献。但是当时 Elasticsearch 还没有官方 python 客户端,所以监控程序都是用的是 pyes 库。对于最新版的 ES 来说,已经不推荐使用了。
8 |
9 | 这里推荐一个修改使用了官方 `elasticsearch.py` 库的衍生版。GitHub 地址见:。
10 |
11 | ## 安装配置
12 |
13 | 仓库中包括三个文件:
14 |
15 | 1. ESzabbix.py
16 | 2. ESzabbix.userparm
17 | 3. ESzabbix_templates.xml
18 |
19 | 其中,前两个文件需要分发到每个 ES 节点上。如果节点上运行的是 yum 安装的 zabbix,二者的默认位置应该分别是:
20 |
21 | 1. `/etc/zabbix/zabbix_externalscripts/ESzabbix.py`
22 | 2. `/etc/zabbix/agent_include/ESzabbix.userparm`
23 |
24 | 然后在各节点安装运行 ESzabbix.py 所需的 python 库依赖:
25 |
26 | ```
27 | # yum install -y python-pbr python-pip python-urllib3 python-unittest2
28 | # pip install elasticsearch
29 | ```
30 |
31 | 安装成功后,你可以试运行下面这行命令,看看命令输出是否正常:
32 |
33 | ```
34 | # /etc/zabbix/zabbix_externalscripts/ESzabbix.py cluster status
35 | ```
36 |
37 | 最后一个文件是 zabbix server 上的模板文件,不过在导入模板之前,还需要先创建一个数值映射,因为在模板中,设置了集群状态的触发报警,没有映射的话,报警短信只有 0, 1, 2 数字不是很易懂。
38 |
39 | 创建数值映射,在浏览器登录 zabbix-web,菜单栏的 **Zabbix Administration** 中选择 **General** 子菜单,然后在右侧下拉框中点击 **Value Maping**。
40 |
41 | 选择 **create**, 新建表单中填写:
42 |
43 | > name: ES Cluster State
44 | > 0 ⇒ Green
45 | > 1 ⇒ Yellow
46 | > 2 ⇒ Red
47 |
48 | 完成以后,即可在 **Templates** 页中通过 **import** 功能完成导入 `ESzabbix_templates.xml`。
49 |
50 | 在给 ES 各节点应用新模板之前,需要给每个节点定义一个 `{$NODENAME}` 宏,具体值为该节点 `elasticsearch.yml` 中的 `node.name` 值。从统一配管的角度,建议大家都设置为 ip 地址。
51 |
52 | ## 模板应用
53 |
54 | 导入完成后,zabbix 里多出来三个可用模板:
55 |
56 | 1. Elasticsearch Node & Cache
57 | 其中包括两个 Application:ES Cache 和 ES Node。分别有 Node Field Cache Size, Node Filter Cache Size 和 Node Storage Size, Records indexed per second 共计 4 个 item 监控项。在完成上面说的宏定义后,就可以把这个模板应用到各节点(即监控主机)上了。
58 | 2. Elasticsearch Service
59 | 只有一个监控项 Elasticsearch service status,做进程监控的,也应用到各节点上。
60 | 3. Elasticsearch Cluster
61 | 包括 11 个监控项,如下列所示。其中,**ElasticSearch Cluster Status** 这个监控项连带有报警的触发器,并对应之前创建的那个 Value Map。
62 | * Cluster-wide records indexed per second
63 | * Cluster-wide storage size
64 | * ElasticSearch Cluster Status
65 | * Number of active primary shards
66 | * Number of active shards
67 | * Number of data nodes
68 | * Number of initializing shards
69 | * Number of nodes
70 | * Number of relocating shards
71 | * Number of unassigned shards
72 | * Total number of records
73 | 这个模板下都是集群总体情况的监控项,所以,运用在一台有 ES 集群读取权限的主机上即可,比如 zabbix server。
74 |
75 | ## 其他
76 |
77 | untergeek 最近刚更新了他的仓库,重构了一个 es_stats_zabbix 模块用于 Zabbix 监控,有兴趣的读者可以参考:
78 |
--------------------------------------------------------------------------------
/elasticsearch/other/README.md:
--------------------------------------------------------------------------------
1 | # Elasticsearch 在运维领域的其他运用
2 |
3 | 目前 Elasticsearch 虽然以 Elastic Stack 作为主打产品,但其优秀的分布式设计,灵活的搜索评分函数和强大简洁的检索聚合功能,在运维领域也衍生出不少其他有趣的应用方式。
4 |
5 | 对于 Elastic 公司来说,这些周边应用,也随时可能成为他们的后续目标产品。就在本书第一版编写期间,packetbeat 就被 Elastic 公司收购,并且可能作为未来数据采集端的标准应用。所以,Elastic Stack 用户提前了解其他方面的多种可能,也是非常有意义的。
6 |
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-1.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-1.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-10.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-10.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-11.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-11.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-12.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-12.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-13.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-13.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-14.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-14.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-15.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-15.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-16.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-16.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-17.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-17.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-18.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-18.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-19.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-19.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-2.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-2.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-20.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-20.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-21.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-21.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-3.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-3.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-4.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-4.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-5.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-5.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-6.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-6.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-7.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-7.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-8.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-8.png
--------------------------------------------------------------------------------
/elasticsearch/other/images/grafana-9.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/images/grafana-9.png
--------------------------------------------------------------------------------
/elasticsearch/other/juttle-viz.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/elasticsearch/other/juttle-viz.png
--------------------------------------------------------------------------------
/elasticsearch/other/kale.md:
--------------------------------------------------------------------------------
1 | # Kale 系统
2 |
3 | Kale 系统是 Etsy 公司开源的一个监控分析系统。Kale 分为两个部分:skyline 和 oculus。skyline 负责对时序数据进行概率分布校验,对校验失败率超过阈值的时序数据发报警;oculus 负责给被报警的时序,找出趋势相似的其他时序作为关联性参考。
4 |
5 | 看到“相似”两个字,你一定想到了。没错,oculus 组件,就是利用了 Elasticsearch 的相似度打分。
6 |
7 | oculus 中,为 Elasticsearch 的 `org.elasticsearch.script.ExecutableScript` 扩展了 `DTW` 和 `Euclidian` 两种 NativeScript。可以在界面上选择用其中某一种算法来做相似度打分:
8 |
9 | 
10 |
11 | 然后相似度最高的几个时序图就依次排列出来了。
12 |
13 | Euclidian 即欧几里得距离,是时序相似度计算里最基础的方式。
14 |
15 | DWT 即动态时间规整(Dynamic Time Warping),也是时序相似度计算的常用方式,它和欧几里得距离的差别在于,欧几里得距离要求比对的时序数据是一一对应的,而动态时间规整计算的时序数据并不要求长度相等。在运维监控来说,也就是延后一定时间发生的相近趋势也可以以很高的打分项排名靠前。
16 |
17 | 不过,oculus 插件仅更新到支持 Elasticsearch-0.90.3 版本为止。Etsy 性能优化团队在 Oreilly 2015 大会上透露,他们内部已经根据 Kale 的经验教训,重新开发了 Kale 2.0 版。会在年内开源放出来。大家一起期待吧!
18 |
19 | ## 参考阅读
20 |
21 |
22 |
--------------------------------------------------------------------------------
/elasticsearch/other/rrd.md:
--------------------------------------------------------------------------------
1 | # 时序数据
2 |
3 | 之前已经介绍过,ES 默认存储数据时,是有索引数据、*_all* 全文索引数据、*_source* JSON 字符串三份的。其中,索引数据由于倒排索引的结构,压缩比非常高。因此,在某些特定环境和需求下,可以只保留索引数据,以极小的容量代价,换取 ES 灵活的数据结构和聚合统计功能。
4 |
5 | 在监控系统中,对监控项和监控数据的设计一般是这样:
6 |
7 | > metric_path value timestamp (Graphite 设计)
8 | > { "host": "Host name 1", "key": "item_key", "value": "33", "clock": 1381482894 } (Zabbix 设计)
9 |
10 | 这些设计有个共同点,数据是二维平面的。以最简单的访问请求状态监控为例,一次请求,可能转换出来的 `metric_path` 或者说 `key` 就有:**{city,isp,host,upstream}.{urlpath...}.{status,rt,ut,size,speed}** 这么多种。假设 urlpath 有 1000 个,就是 20000 个组合。意味着需要发送 20000 条数据,做 20000 次存储。
11 |
12 | 而在 ES 里,这就是实实在在 1000 条日志。而且在多条日志的时候,因为词元的相对固定,压缩比还会更高。所以,使用 ES 来做时序监控数据的存储和查询,是完全可行的办法。
13 |
14 | 对时序数据,关键就是定义缩减数据重复。template 示例如下:
15 |
16 | ```
17 | {
18 | "order" : 2,
19 | "template" : "logstash-monit-*",
20 | "settings" : {
21 | },
22 | "mappings" : {
23 | "_default_" : {
24 | "_source" : {
25 | "enabled" : false
26 | },
27 | "_all" : {
28 | "enabled" : false
29 | }
30 | }
31 | },
32 | "aliases" : { }
33 | }
34 | ```
35 |
36 | 如果有些字段,是完全不用 Query ,只参加 Aggregation 的,还可以设置:
37 |
38 | ```
39 | "properties" : {
40 | "sid" : {
41 | "index" : "no",
42 | "type" : "keyword"
43 | }
44 | },
45 | ```
46 |
47 | 关于 Elasticsearch 用作 rrd 用途,与 MongoDB 等其他工具的性能测试与对比,可以阅读腾讯工程师写的系列文章:
48 |
--------------------------------------------------------------------------------
/elasticsearch/performance/bulk.md:
--------------------------------------------------------------------------------
1 | # 批量提交
2 |
3 | 在 CRUD 章节,我们已经知道 ES 的数据写入是如何操作的了。喜欢自己动手的读者可能已经迫不及待的自己写了程序开始往 ES 里写数据做测试。这时候大家会发现:程序的运行速度非常一般,即使 ES 服务运行在本机,一秒钟大概也就能写入几百条数据。
4 |
5 | 这种速度显然不是 ES 的极限。事实上,每条数据经过一次完整的 HTTP POST 请求和 ES indexing 是一种极大的性能浪费,为此,ES 设计了批量提交方式。在数据读取方面,叫 mget 接口,在数据变更方面,叫 bulk 接口。mget 一般常用于搜索时 ES 节点之间批量获取中间结果集,对于 Elastic Stack 用户,更常见到的是 bulk 接口。
6 |
7 | bulk 接口采用一种比较简朴的数据积累格式,示例如下:
8 |
9 | ```
10 | # curl -XPOST http://127.0.0.1:9200/_bulk -d'
11 | { "create" : { "_index" : "test", "_type" : "type1" } }
12 | { "field1" : "value1" }
13 | { "delete" : { "_index" : "test", "_type" : "type1" } }
14 | { "index" : { "_index" : "test", "_type" : "type1", "_id" : "1" } }
15 | { "field1" : "value2" }
16 | { "update" : {"_id" : "1", "_type" : "type1", "_index" : "test"} }
17 | { "doc" : {"field2" : "value2"} }
18 | '
19 | ```
20 |
21 | 格式是,每条 JSON 数据的上面,加一行描述性的元 JSON,指明下一行数据的操作类型,归属索引信息等。
22 |
23 | 采用这种格式,而不是一般的 JSON 数组格式,是因为接收到 bulk 请求的 ES 节点,就可以不需要做完整的 JSON 数组解析处理,直接按行处理简短的元 JSON,就可以确定下一行数据 JSON 转发给哪个数据节点了。这样,一个固定内存大小的 network buffer 空间,就可以反复使用,又节省了大量 JVM 的 GC。
24 |
25 | 事实上,产品级的 logstash、rsyslog、spark 都是默认采用 bulk 接口进行数据写入的。对于打算自己写程序的读者,建议采用 Perl 的 `Search::Elasticsearch::Bulk` 或者 Python 的 `elasticsearch.helpers.*` 库。
26 |
27 | ## bulk size
28 |
29 | 在配置 bulk 数据的时候,一般需要注意的就是请求体大小(bulk size)。
30 |
31 | 这里有一点细节上的矛盾,我们知道,HTTP 请求,是可以通过 HTTP 状态码 *100 Continue* 来持续发送数据的。但对于 ES 节点接收 HTTP 请求体的 *Content-Length* 来说,是按照整个大小来计算的。所以,首先,要确保 bulk 数据不要超过 `http.max_content_length` 设置。
32 |
33 | 那么,是不是尽量让 bulk size 接近这个数值呢?当然不是。
34 |
35 | 依然是请求体的问题,因为请求体需要全部加载到内存,而 JVM Heap 一共就那么多(按 31GB 算),过大的请求体,会挤占其他线程池的空间,反而导致写入性能的下降。
36 |
37 | 再考虑网卡流量,磁盘转速的问题,所以一般来说,建议 bulk 请求体的大小,在 15MB 左右,通过实际测试继续向上探索最合适的设置。
38 |
39 | 注意:这里说的 15MB 是请求体的字节数,而不是程序里里设置的 bulk size。bulk size 一般指数据的条目数。不要忘了,bulk 请求体中,每条数据还会额外带上一行元 JSON。
40 |
41 | 以 logstash 默认的 `bulk_size => 5000` 为例,假设单条数据平均大小 200B ,一次 bulk 请求体的大小就是 1.5MB。那么我们可以尝试 `bulk_size => 50000`;而如果单条数据平均大小是 20KB,一次 bulk 大小就是 100MB,显然超标了,需要尝试下调至 `bulk_size => 500`。
42 |
43 |
--------------------------------------------------------------------------------
/elasticsearch/performance/curator.md:
--------------------------------------------------------------------------------
1 | # curator
2 |
3 | 如果经过之前章节的一系列优化之后,数据确实超过了集群能承载的能力,除了拆分集群以外,最后就只剩下一个办法了:清除废旧索引。
4 |
5 | 为了更加方便的做清除数据,合并 segment,备份恢复等管理任务,Elasticsearch 在提供相关 API 的同时,另外准备了一个命令行工具,叫 curator 。curator 是 Python 程序,可以直接通过 pypi 库安装:
6 |
7 | ```
8 | pip install elasticsearch-curator
9 | ```
10 |
11 | *注意,是 elasticsearch-curator 不是 curator。PyPi 原先就有另一个项目叫这个名字*
12 |
13 | ## 参数介绍
14 |
15 | 和 Elastic Stack 里其他组件一样,curator 也是被 Elastic.co 收购的原开源社区周边。收编之后同样进行了一次重构,命令行参数从单字母风格改成了长单词风格。新版本的 curator 命令可用参数如下:
16 |
17 | > Usage: curator [OPTIONS] COMMAND [ARGS]...
18 |
19 | Options 包括:
20 |
21 | --host TEXT Elasticsearch host.
22 | --url_prefix TEXT Elasticsearch http url prefix.
23 | --port INTEGER Elasticsearch port.
24 | --use_ssl Connect to Elasticsearch through SSL.
25 | --http_auth TEXT Use Basic Authentication ex: user:pass
26 | --timeout INTEGER Connection timeout in seconds.
27 | --master-only Only operate on elected master node.
28 | --dry-run Do not perform any changes.
29 | --debug Debug mode
30 | --loglevel TEXT Log level
31 | --logfile TEXT log file
32 | --logformat TEXT Log output format [default|logstash].
33 | --version Show the version and exit.
34 | --help Show this message and exit.
35 |
36 | Commands 包括:
37 | alias Index Aliasing
38 | allocation Index Allocation
39 | bloom Disable bloom filter cache
40 | close Close indices
41 | delete Delete indices or snapshots
42 | open Open indices
43 | optimize Optimize Indices
44 | replicas Replica Count Per-shard
45 | show Show indices or snapshots
46 | snapshot Take snapshots of indices (Backup)
47 |
48 | 针对具体的 Command,还可以继续使用 `--help` 查看该子命令的帮助。比如查看 *close* 子命令的帮助,输入 `curator close --help`,结果如下:
49 |
50 | ```
51 | Usage: curator close [OPTIONS] COMMAND [ARGS]...
52 |
53 | Close indices
54 |
55 | Options:
56 | --help Show this message and exit.
57 |
58 | Commands:
59 | indices Index selection.
60 | ```
61 |
62 | ## 常用示例
63 |
64 | 在使用 1.4.0 以上版本的 Elasticsearch 前提下,curator 曾经主要的一个子命令 `bloom` 已经不再需要使用。所以,目前最常用的三个子命令,分别是 `close`, `delete` 和 `optimize`,示例如下:
65 |
66 | ```
67 | curator --timeout 36000 --host 10.0.0.100 delete indices --older-than 5 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-mweibo-nginx-
68 | curator --timeout 36000 --host 10.0.0.100 delete indices --older-than 10 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-mweibo-client- --exclude 'logstash-mweibo-client-2015.05.11'
69 | curator --timeout 36000 --host 10.0.0.100 delete indices --older-than 30 --time-unit days --timestring '%Y.%m.%d' --regex '^logstash-mweibo-\d+'
70 | curator --timeout 36000 --host 10.0.0.100 close indices --older-than 7 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-
71 | curator --timeout 36000 --host 10.0.0.100 optimize --max_num_segments 1 indices --older-than 1 --newer-than 7 --time-unit days --timestring '%Y.%m.%d' --prefix logstash-
72 | ```
73 |
74 | 这一顿任务,结果是:
75 |
76 | *logstash-mweibo-nginx-yyyy.mm.dd* 索引保存最近 5 天,*logstash-mweibo-client-yyyy.mm.dd* 保存最近 10 天,*logstash-mweibo-yyyy.mm.dd* 索引保存最近 30 天;且所有七天前的 *logstash-\** 索引都暂时关闭不用;最后对所有非当日日志做 segment 合并优化。
77 |
--------------------------------------------------------------------------------
/elasticsearch/performance/gateway.md:
--------------------------------------------------------------------------------
1 | # gateway
2 |
3 | gateway 是 ES 设计用来长期存储索引数据的接口。一般来说,大家都是用本地磁盘来存储索引数据,即 `gateway.type` 为 `local`。
4 |
5 | 数据恢复中,有很多策略调整我们已经在之前分片控制小节讲过。除开分片级别的控制以外,gateway 级别也还有一些可优化的地方:
6 |
7 | * gateway.recover_after_nodes
8 | 该参数控制集群在达到多少个节点的规模后,才开始数据恢复任务。这样可以避免集群自动发现的初期,分片不全的问题。
9 |
10 | * gateway.recover_after_time
11 | 该参数控制集群在达到上条配置设置的节点规模后,再等待多久才开始数据恢复任务。
12 |
13 | * gateway.expected_nodes
14 | 该参数设置集群的预期节点总数。在达到这个总数后,即认为集群节点已经完全加载,即可开始数据恢复,不用再等待上条设置的时间。
15 |
16 | 注意:gateway 中说的节点,仅包括主节点和数据节点,纯粹的 client 节点是不算在内的。如果你有更明确的选择,也可以按需求写:
17 |
18 | * gateway.recover_after_data_nodes
19 | * gateway.recover_after_master_nodes
20 | * gateway.expected_data_nodes
21 | * gateway.expected_master_nodes
22 |
23 | ## 共享存储上的影子副本
24 |
25 | 虽然 ES 对 gateway 使用 NFS,iscsi 等共享存储的方式极力反对,但是对于较大量级的索引的副本数据,ES 从 1.5 版本开始,还是提供了一种节约成本又不特别影响性能的方式:影子副本(shadow replica)。
26 |
27 | 首先,需要在集群各节点的 `elasticsearch.yml` 中开启选项:
28 |
29 | ```
30 | node.enable_custom_paths: true
31 | ```
32 |
33 | 同时,确保各节点使用相同的路径挂载了共享存储,且目录权限为 Elasticsearch 进程用户可读可写。
34 |
35 | 然后,创建索引:
36 |
37 | ```
38 | # curl -XPUT 'http://127.0.0.1:9200/my_index' -d '
39 | {
40 | "index" : {
41 | "number_of_shards" : 1,
42 | "number_of_replicas" : 4,
43 | "data_path": "/var/data/my_index",
44 | "shadow_replicas": true
45 | }
46 | }'
47 | ```
48 |
49 | 针对 shadow replicas ,ES 节点不会做实际的索引操作,而是单纯的每次 flush 时,把 segment 内容 fsync 到共享存储磁盘上。然后 refresh 让其他节点能够搜索该 segment 内容。
50 |
51 | 如果你已经决定把数据放到共享存储上了,采用 shadow replicas 还是有一些好处的:
52 |
53 | 1. 可以帮助你节省一部分不必要的多副本分片的数据写入压力;
54 | 2. 在节点出现异常,需要在其他节点上恢复副本数据的时候,可以避免不必要的网络数据拷贝。
55 |
56 | 但是请注意:主分片节点还是要承担一个副本的写入过程,并不像 Lucene 的 FileReplicator 那样通过复制文件完成,所以达不到完全节省 CPU 的效果。
57 |
58 | shadow replicas 只是一个在某些特定环境下有用的方式。在资源允许的情况下,还是应该使用 local gateway。而另外采用 snapshot 接口来完成数据长期备份到 HDFS 或其他共享存储的需要。
59 |
--------------------------------------------------------------------------------
/elasticsearch/performance/profile.md:
--------------------------------------------------------------------------------
1 | # profiler
2 |
3 | profiler 是 Elasticsearch 5.0 的一个新接口。通过这个功能,可以看到一个搜索聚合请求,是如何拆分成底层的 Lucene 请求,并且显示每部分的耗时情况。
4 |
5 | 启用 profiler 的方式很简单,直接在请求里加一行即可:
6 |
7 | ```
8 | curl -XPOST 'http://localhost:9200/_search' -d '{
9 | "profile": true,
10 | "query": { ... },
11 | "aggs": { ... }
12 | }'
13 | ```
14 |
15 | 可以看到其中对 query 和 aggs 部分的返回是不太一样的。
16 |
17 | ## query
18 |
19 | query 部分包括 collectors、rewrite 和 query 部分。对复杂 query,profiler 会拆分 query 成多个基础的 TermQuery,然后每个 TermQuery 再显示各自的分阶段耗时如下:
20 |
21 | ```
22 | "breakdown": {
23 | "score": 51306,
24 | "score_count": 4,
25 | "build_scorer": 2935582,
26 | "build_scorer_count": 1,
27 | "match": 0,
28 | "match_count": 0,
29 | "create_weight": 919297,
30 | "create_weight_count": 1,
31 | "next_doc": 53876,
32 | "next_doc_count": 5,
33 | "advance": 0,
34 | "advance_count": 0
35 | }
36 | ```
37 |
38 |
39 |
40 | ## aggs
41 |
42 | ```
43 | "time": "1124.864392ms",
44 | "breakdown": {
45 | "reduce": 0,
46 | "reduce_count": 0,
47 | "build_aggregation": 1394,
48 | "build_aggregation_count": 150,
49 | "initialise": 2883,
50 | "initialize_count": 150,
51 | "collect": 1124860115,
52 | "collect_count": 900
53 | }
54 | ```
55 |
56 | 我们可以很明显的看到聚合统计在初始化阶段、收集阶段、构建阶段、汇总阶段分别花了多少时间,遍历了多少数据。
57 |
58 | *注意其中 reduce 阶段还没实现完毕,所有都是 0。因为目前 profiler 只能在 shard 级别上做统计。*
59 |
60 | collect 阶段的耗时,有助于我们调整对应 aggs 的 `collect_mode` 参数选择。目前 Elasticsearch 支持 `breadth_first` 和 `depth_first` 两种方式。
61 |
62 | initialise 阶段的耗时,有助于我们调整对应 aggs 的 `execution_hint` 参数选择。目前 Elasticsearch 支持 `map`、`global_ordinals_low_cardinality`、`global_ordinals` 和 `global_ordinals_hash` 四种选择。在计算离散度比较大的字段统计值时,适当调整该参数,有益于节省内存和提高计算速度。
63 |
64 | *对高离散度字段值统计性能很关注的读者,可以关注 这条记录的进展。*
65 |
--------------------------------------------------------------------------------
/elasticsearch/principle/README.md:
--------------------------------------------------------------------------------
1 | # 架构原理
2 |
3 | 本书作为 Elastic Stack 指南,关注于 Elasticsearch 在日志和数据分析场景的应用,并不打算对底层的 Lucene 原理或者 Java 编程做详细的介绍,但是 Elasticsearch 层面上的一些架构设计,对我们做性能调优,故障处理,具有非常重要的影响。
4 |
5 | 所以,作为 ES 部分的起始章节,先从数据流向和分布的层面,介绍一下 ES 的工作原理,以及相关的可控项。各位读者可以跳过这节先行阅读后面的运维操作部分,但作为性能调优的基础知识,依然建议大家抽时间返回来了解。
6 |
--------------------------------------------------------------------------------
/elasticsearch/principle/auto-discovery.md:
--------------------------------------------------------------------------------
1 | # 集群自动发现
2 |
3 | ES 是一个 P2P 类型(使用 gossip 协议)的分布式系统,除了集群状态管理以外,其他所有的请求都可以发送到集群内任意一台节点上,这个节点可以自己找到需要转发给哪些节点,并且直接跟这些节点通信。
4 |
5 | 所以,从网络架构及服务配置上来说,构建集群所需要的配置极其简单。在 Elasticsearch 2.0 之前,无阻碍的网络下,所有配置了相同 `cluster.name` 的节点都自动归属到一个集群中。
6 |
7 | 2.0 版本之后,基于安全的考虑,Elasticsearch 稍作了调整,避免开发环境过于随便造成的麻烦。
8 |
9 | ## unicast 方式
10 |
11 | ES 从 2.0 版本开始,默认的自动发现方式改为了单播(unicast)方式。配置里提供几台节点的地址,ES 将其视作 gossip router 角色,借以完成集群的发现。由于这只是 ES 内一个很小的功能,所以 gossip router 角色并不需要单独配置,每个 ES 节点都可以担任。所以,采用单播方式的集群,各节点都配置相同的几个节点列表作为 router 即可。
12 |
13 | 此外,考虑到节点有时候因为高负载,慢 GC 等原因可能会有偶尔没及时响应 ping 包的可能,一般建议稍微加大 Fault Detection 的超时时间。
14 |
15 | 同样基于安全考虑做的变更还有监听的主机名。现在默认只监听本地 lo 网卡上。所以正式环境上需要修改配置为监听具体的网卡。
16 |
17 | ```
18 | network.host: "192.168.0.2"
19 | discovery.zen.minimum_master_nodes: 3
20 | discovery.zen.ping_timeout: 100s
21 | discovery.zen.fd.ping_timeout: 100s
22 | discovery.zen.ping.unicast.hosts: ["10.19.0.97","10.19.0.98","10.19.0.99","10.19.0.100"]
23 | ```
24 |
25 | 上面的配置中,两个 timeout 可能会让人有所迷惑。这里的 **fd** 是 fault detection 的缩写。也就是说:
26 |
27 | * discovery.zen.ping_timeout 参数仅在加入或者选举 master 主节点的时候才起作用;
28 | * discovery.zen.fd.ping\_timeout 参数则在稳定运行的集群中,master 检测所有节点,以及节点检测 master 是否畅通时长期有用。
29 |
30 | 既然是长期有用,自然还有运行间隔和重试的配置,也可以根据实际情况调整:
31 |
32 | ```
33 | discovery.zen.fd.ping_interval: 10s
34 | discovery.zen.fd.ping_retries: 10
35 | ```
36 |
--------------------------------------------------------------------------------
/elasticsearch/principle/indexing-performance.md:
--------------------------------------------------------------------------------
1 | # segment merge对写入性能的影响
2 |
3 | 通过上节内容,我们知道了数据怎么进入 ES 并且如何才能让数据更快的被检索使用。其中用一句话概括了 Lucene 的设计思路就是"开新文件"。从另一个方面看,开新文件也会给服务器带来负载压力。因为默认每 1 秒,都会有一个新文件产生,每个文件都需要有文件句柄,内存,CPU 使用等各种资源。一天有 86400 秒,设想一下,每次请求要扫描一遍 86400 个文件,这个响应性能绝对好不了!
4 |
5 | 为了解决这个问题,ES 会不断在后台运行任务,主动将这些零散的 segment 做数据归并,尽量让索引内只保有少量的,每个都比较大的,segment 文件。这个过程是有独立的线程来进行的,并不影响新 segment 的产生。归并过程中,索引状态如图 2-7,尚未完成的较大的 segment 是被排除在检索可见范围之外的:
6 |
7 | 
8 | 图 2-7
9 |
10 | 当归并完成,较大的这个 segment 刷到磁盘后,commit 文件做出相应变更,删除之前几个小 segment,改成新的大 segment。等检索请求都从小 segment 转到大 segment 上以后,删除没用的小 segment。这时候,索引里 segment 数量就下降了,状态如图 2-8 所示:
11 |
12 | 
13 | 图 2-8
14 |
15 | ## 归并线程配置
16 |
17 | segment 归并的过程,需要先读取 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,这是一个非常消耗磁盘 IO 和 CPU 的任务。所以,ES 提供了对归并线程的限速机制,确保这个任务不会过分影响到其他任务。
18 |
19 | 在 5.0 之前,归并线程的限速配置 `indices.store.throttle.max_bytes_per_sec` 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 Elastic Stack 应用,社区广泛的建议是可以适当调大到 100MB或者更高。
20 |
21 | ```
22 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d'
23 | {
24 | "persistent" : {
25 | "indices.store.throttle.max_bytes_per_sec" : "100mb"
26 | }
27 | }'
28 | ```
29 |
30 | 5.0 开始,ES 对此作了大幅度改进,使用了 Lucene 的 CMS(ConcurrentMergeScheduler) 的 auto throttle 机制,正常情况下已经不再需要手动配置 `indices.store.throttle.max_bytes_per_sec` 了。官方文档中都已经删除了相关介绍,不过从源码中还是可以看到,这个值目前的默认设置是 10240 MB。
31 |
32 | 归并线程的数目,ES 也是有所控制的。默认数目的计算公式是: `Math.min(3, Runtime.getRuntime().availableProcessors() / 2)`。即服务器 CPU 核数的一半大于 3 时,启动 3 个归并线程;否则启动跟 CPU 核数的一半相等的线程数。相信一般做 Elastic Stack 的服务器 CPU 合数都会在 6 个以上。所以一般来说就是 3 个归并线程。如果你确定自己磁盘性能跟不上,可以降低 `index.merge.scheduler.max_thread_count` 配置,免得 IO 情况更加恶化。
33 |
34 | ## 归并策略
35 |
36 | 归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
37 |
38 | * index.merge.policy.floor\_segment
39 | 默认 2MB,小于这个大小的 segment,优先被归并。
40 | * index.merge.policy.max\_merge\_at\_once
41 | 默认一次最多归并 10 个 segment
42 | * index.merge.policy.max\_merge\_at\_once\_explicit
43 | 默认 forcemerge 时一次最多归并 30 个 segment。
44 | * index.merge.policy.max\_merged\_segment
45 | 默认 5 GB,大于这个大小的 segment,不用参与归并。forcemerge 除外。
46 |
47 | 根据这段策略,其实我们也可以从另一个角度考虑如何减少 segment 归并的消耗以及提高响应的办法:加大 flush 间隔,尽量让每次新生成的 segment 本身大小就比较大。
48 |
49 | ## forcemerge 接口
50 |
51 | 既然默认的最大 segment 大小是 5GB。那么一个比较庞大的数据索引,就必然会有为数不少的 segment 永远存在,这对文件句柄,内存等资源都是极大的浪费。但是由于归并任务太消耗资源,所以一般不太选择加大 `index.merge.policy.max_merged_segment` 配置,而是在负载较低的时间段,通过 forcemerge 接口,强制归并 segment。
52 |
53 | ```
54 | # curl -XPOST http://127.0.0.1:9200/logstash-2015-06.10/_forcemerge?max_num_segments=1
55 | ```
56 |
57 | 由于 forcemerge 线程对资源的消耗比普通的归并线程大得多,所以,绝对不建议对还在写入数据的热索引执行这个操作。这个问题对于 Elastic Stack 来说非常好办,一般索引都是按天分割的。更合适的任务定义方式,请阅读本书稍后的 curator 章节。
58 |
59 |
--------------------------------------------------------------------------------
/elasticsearch/principle/route-and-replica.md:
--------------------------------------------------------------------------------
1 | # routing和replica的读写过程
2 |
3 | 之前两节,完整介绍了在单个 Lucene 索引,即 ES 分片内的数据写入流程。现在彻底回到 ES 的分布式层面上来,当一个 ES 节点收到一条数据的写入请求时,它是如何确认这个数据应该存储在哪个节点的哪个分片上的?
4 |
5 | ## 路由计算
6 |
7 | 作为一个没有额外依赖的简单的分布式方案,ES 在这个问题上同样选择了一个非常简洁的处理方式,对任一条数据计算其对应分片的方式如下:
8 |
9 | > shard = hash(routing) % number_of_primary_shards
10 |
11 | 每个数据都有一个 routing 参数,默认情况下,就使用其 `_id` 值。将其 `_id` 值计算哈希后,对索引的主分片数取余,就是数据实际应该存储到的分片 ID。
12 |
13 | 由于取余这个计算,完全依赖于分母,所以导致 ES 索引有一个限制,索引的主分片数,不可以随意修改。因为一旦主分片数不一样,所以数据的存储位置计算结果都会发生改变,索引数据就完全不可读了。
14 |
15 | ## 副本一致性
16 |
17 | 作为分布式系统,数据副本可算是一个标配。ES 数据写入流程,自然也涉及到副本。在有副本配置的情况下,数据从发向 ES 节点,到接到 ES 节点响应返回,流向如下(附图 2-9):
18 |
19 | 1. 客户端请求发送给 Node 1 节点,注意图中 Node 1 是 Master 节点,实际完全可以不是。
20 | 2. Node 1 用数据的 `_id` 取余计算得到应该讲数据存储到 shard 0 上。通过 cluster state 信息发现 shard 0 的主分片已经分配到了 Node 3 上。Node 1 转发请求数据给 Node 3。
21 | 3. Node 3 完成请求数据的索引过程,存入主分片 0。然后并行转发数据给分配有 shard 0 的副本分片的 Node 1 和 Node 2。当收到任一节点汇报副本分片数据写入成功,Node 3 即返回给初始的接收节点 Node 1,宣布数据写入成功。Node 1 返回成功响应给客户端。
22 |
23 | 
24 | 图 2-9
25 |
26 | 这个过程中,有几个参数可以用来控制或变更其行为:
27 |
28 | * wait\_for\_active\_shards
29 | 上面示例中,2 个副本分片只要有 1 个成功,就可以返回给客户端了。这点也是有配置项的。其默认值的计算来源如下:
30 |
31 | > int( (primary + number_of_replicas) / 2 ) + 1
32 |
33 | 根据需要,也可以将参数设置为 one,表示仅写完主分片就返回,等同于 async;还可以设置为 all,表示等所有副本分片都写完才能返回。
34 | * timeout
35 | 如果集群出现异常,有些分片当前不可用,ES 默认会等待 1 分钟看分片能否恢复。可以使用 `?timeout=30s` 参数来缩短这个等待时间。
36 |
37 | 副本配置和分片配置不一样,是可以随时调整的。有些较大的索引,甚至可以在做 forcemerge 前,先把副本全部取消掉,等 optimize 完后,再重新开启副本,节约单个 segment 的重复归并消耗。
38 |
39 | ```
40 | # curl -XPUT http://127.0.0.1:9200/logstash-mweibo-2015.05.02/_settings -d '{
41 | "index": { "number_of_replicas" : 0 }
42 | }'
43 | ```
44 |
--------------------------------------------------------------------------------
/elasticsearch/puppet.md:
--------------------------------------------------------------------------------
1 | # Puppet 自动部署 Elasticsearch
2 |
3 | Elasticsearch 作为一个 Java 应用,本身的部署已经非常简单了。不过作为生产环境,还是有必要采用一些更标准化的方式进行集群的管理。Elasticsearch 官方提供并推荐使用 Puppet 方式部署和管理。其 Puppet 模块源码地址见:
4 |
5 |
6 |
7 | ## 安装方法
8 |
9 | 和其他标准 Puppet Module 一样,puppet-elasticsearch 也可以通过 Puppet Forge 直接安装:
10 |
11 | ```
12 | # puppet module install elasticsearch-elasticsearch
13 | ```
14 |
15 | ## 配置示例
16 |
17 | 安装好 Puppet 模块后,就可以使用了。模块提供几种 Puppet 资源,主要用法如下:
18 |
19 | ```
20 | class { 'elasticsearch':
21 | version => '2.4.1',
22 | config => { 'cluster.name' => 'es1003' },
23 | java_install => true,
24 | }
25 | elasticsearch::instance { $fqdn:
26 | config => { 'node.name' => $fqdn },
27 | init_defaults => { 'ES_USER' => 'elasticsearch', 'ES_HEAP_SIZE' => $memorysize > 64 ? '31g' : $memorysize / 2 },
28 | datadir => [ '/data1/elasticsearch' ],
29 | }
30 | elasticsearch::template { 'templatename':
31 | host => $::ipaddress,
32 | port => 9200,
33 | content => '{"template":"*","settings":{"number_of_replicas":0}}'
34 | }
35 | ```
36 |
37 | 示例中展示了三种资源:
38 |
39 | * class: 配置具体安装的 Elasticsearch 软件版本,全集群公用的一些基础配置项。注意,puppet-elasticsearch 模块默认并不负责 Java 的安装,它只是调用操作系统对应的 Yum,Apt 工具,而 elasticsearch.rpm 或者 elasticsearch.deb 本身没有定义其他依赖(因为 java 版本太多了,定义起来不方便)。所以,如果依然要走 puppet-elasticsearch 配置来安装 Java 的话,需要额外开启 `java_install` 选项。该选项会使用另一个 Puppet Module —— [puppetlabs-java](https://forge.puppetlabs.com/puppetlabs/java) 来安装,默认安装的是 jdk。如果你要节省空间,可以再加一行 `java_package` 来明确指定软件全名。
40 | * instance: 配置具体单个进程实例的配置。其中 `config` 和 `init_defaults` 选项在 class 和 instance 资源中都可以定义,实际运行时,会自动做一次合并,当然,instance 里的配置优先级高于 class 中的配置。此外,最重要的定义是数据目录的位置。有多快磁盘的,可以在这里定义一个数组。
41 | * template: 模板是 Elasticsearch 创建索引映射和设置时的预定义方式。一般可以通过在 `config/templates/` 目录下放置 JSON 文件,或者通过 RESTful API 上传配置两种方式管理。而这里,单独提供了 template 资源,通过 puppet 来管理模板。`content` 选项中直接填入模板内容,或者使用 `file` 选项读取文件均可。
42 |
43 | 事实上,模块还提供了 plugin 和 script 资源管理这两方面的内容。考虑在 ELK 中,二者用的不是很多,本节就不单独介绍了。想了解的读者可以参考官方文档。
44 |
--------------------------------------------------------------------------------
/elasticsearch/rollover.md:
--------------------------------------------------------------------------------
1 | # rollover
2 |
3 | Elasticsearch 从 5.0 开始,为日志场景的用户提供了一个很不错的接口,叫 rollover。其作用是:当某个别名指向的实际索引过大的时候,自动将别名指向下一个实际索引。
4 |
5 | 因为这个接口是操作的别名,所以我们依然需要首先自己创建一个开始滚动的起始索引:
6 |
7 | ```
8 | # curl -XPUT 'http://localhost:9200/logstash-2016.11.25-1' -d '{
9 | "aliases": {
10 | "logstash": {}
11 | }
12 | }'
13 | ```
14 |
15 | 然后就可以尝试发起 rollover 请求了:
16 |
17 | ```
18 | # curl -XPOST 'http://localhost:9200/logstash/_rollover' -d '{
19 | "conditions": {
20 | "max_age": "1d",
21 | "max_docs": 10000000
22 | }
23 | }'
24 | ```
25 |
26 | 上面的定义意思就是:当索引超过 1 天,或者索引内的数据量超过一千万条的时候,自动创建并指向下一个索引。
27 |
28 | 这时候有几种可能性:
29 |
30 | * 条件都没满足,直接返回一个 false,索引和别名都不发生实际变化;
31 | ```
32 | {
33 | "old_index" : "logstash-2016.11.25-1",
34 | "new_index" : "logstash-2016.11.25-1",
35 | "rolled_over" : false,
36 | "dry_run" : false,
37 | "acknowledged" : false,
38 | "shards_acknowledged" : false,
39 | "conditions" : {
40 | "[max_docs: 10000000]" : false,
41 | "[max_age: 1d]" : false
42 | }
43 | }
44 | ```
45 | * 还没满一天,满了一千万条,那么下一个索引名会是:`logstash-2016.11.25-000002`;
46 | * 还没满一千万条,满了一天,那么下一个索引名会是:`logstash-2016.11.26-000002`。
47 |
48 | # shrink
49 |
50 | Elasticsearch 一直以来都是固定分片数的。这个策略极大的简化了分布式系统的复杂度,但是在一些场景,比如存储 metric 的 TSDB、小数据量的日志存储,人们会期望在多分片快速写入数据以后,把老数据合并存储,节约过多的 cluster state 容量。从 5.0 版本开始,Elasticsearch 新提供了 shrink 接口,可以成倍数的合并分片数。
51 |
52 | *注:所谓成倍数的,就是原来有 15 个分片,可以合并缩减成 5 个或者 3 个或者 1 个分片。*
53 |
54 | 整个合并缩减的操作流程,大概如下:
55 |
56 | 1. 先把所有主分片都转移到一台主机上;
57 | 2. 在这台主机上创建一个新索引,分片数较小,其他设置和原索引一致;
58 | 3. 把原索引的所有分片,复制(或硬链接)到新索引的目录下;
59 | 4. 对新索引进行打开操作恢复分片数据。
60 | 5. (可选)重新把新索引的分片均衡到其他节点上。
61 |
62 | ## 准备工作
63 |
64 | * 因为这个操作流程需要把所有分片都转移到一台主机上,所以作为 shrink 主机,它的磁盘要足够大,至少要能放得下一整个索引。
65 | * 最好是一整块磁盘,因为硬链接是不能跨磁盘的。靠复制太慢了。
66 | * 开始迁移:
67 | ```
68 | # curl -XPUT 'http://localhost:9200/metric-2016.11.25/_settings' -d '
69 | {
70 | "settings": {
71 | "index.routing.allocation.require._name": "shrink_node_name",
72 | "index.blocks.write": true
73 | }
74 | }'
75 | ```
76 |
77 | ## shrink 操作
78 |
79 | ```
80 | curl -XPOST 'http://localhost:9200/metric-2016.11.25/_shrink/oldmetric-2016.11.25' -d'
81 | {
82 | "settings": {
83 | "index.number_of_replicas": 1,
84 | "index.number_of_shards": 3
85 | },
86 | "aliases": {
87 | "metric-tsdb": {}
88 | }
89 | }'
90 | ```
91 |
92 | 这个命令执行完会立刻返回,但是 Elasticsearch 会一直等到 shrink 操作完成的时候,才会真的开始做 replica 分片的分配和重均衡,此前分片都处于 initializing 状态。
93 |
94 | *注意:Elasticsearch 有一个硬编码限制,单个分片内的文档总数不得超过 2147483519 个。一般来说这个限制在日志场景下是不太会触发的,但是如果做 TSDB 用,则需要多加注意!*
95 |
--------------------------------------------------------------------------------
/elasticsearch/upgrade.md:
--------------------------------------------------------------------------------
1 | # 集群版本升级
2 |
3 | Elasticsearch 作为一个新兴项目,版本更新非常快。而且每次版本更新都或多或少带有一些重要的性能优化、稳定性提升等特性。可以说,ES 集群的版本升级,是目前 ES 运维必然要做的一项工作。
4 |
5 | 按照 ES 官方设计,有 restart upgrade 和 rolling upgrade 两种可选的升级方式。对于 1.0 版本以上的用户,推荐采用 rolling upgreade 方式。
6 |
7 | **但是,对于主要负载是数据写入的 Elastic Stack 场景来说,却并不是这样!**
8 |
9 | rolling upgrade 的步骤大致如下:
10 |
11 | 1. 暂停分片分配;
12 | 2. 单节点下线升级重启;
13 | 3. 开启分片分配;
14 | 4. 等待集群状态变绿后继续上述步骤。
15 |
16 | 实际运行中,步骤 2 的 ES 单节点从 restart 到加入集群,大概要 100s 左右的时间。也就是说,这 100s 内,该节点上的所有分片都是 unassigned 状态。而按照 Elasticsearch 的设计,数据写入需要至少达到 `replica/2+1` 个分片完成才能算完成。也就意味着你所有索引都必须至少有 1 个以上副本分片开启。
17 |
18 | 但事实上,很多日志场景,由于写入性能上的要求要高于数据可靠性的要求,大家普遍减小了副本数量,甚至直接关掉副本复制。这样一来,整个 rolling upgrade 期间,数据写入就会受到严重影响,完全丧失了 rolling 的必要性。
19 |
20 | 其次,步骤 3 中的 ES 分片均衡过程中,由于 ES 的副本分片数据都需要从主分片走网络复制重新传输一次,而由于重启,新升级的节点上的分片肯定全是副本分片(除非压根没副本)。在数据量较大的情况下,这个步骤耗时可能是几十分钟甚至以小时计。而且并发和限速上稍微不注意,可能导致分片均衡的带宽直接占满网卡,正常写入也还是受到影响。
21 |
22 | 所以,对于写入压力较大,数据可靠性要求偏低的实时日志场景,依然建议大家进行主动停机式的 restart upgrade。
23 |
24 | restart upgrade 的步骤如下:
25 |
26 | 1. 首先适当加大集群的数据恢复和分片均衡并发度以及磁盘限速:
27 |
28 | ```
29 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d '{
30 | "persistent" : {
31 | "cluster" : {
32 | "routing" : {
33 | "allocation" : {
34 | "disable_allocation" : "false",
35 | "cluster_concurrent_rebalance" : "5",
36 | "node_concurrent_recoveries" : "5",
37 | "enable" : "all"
38 | }
39 | }
40 | },
41 | "indices" : {
42 | "recovery" : {
43 | "concurrent_streams" : "30",
44 | "max_bytes_per_sec" : "2gb"
45 | }
46 | }
47 | },
48 | "transient" : {
49 | "cluster" : {
50 | "routing" : {
51 | "allocation" : {
52 | "enable" : "all"
53 | }
54 | }
55 | }
56 | }
57 | }'
58 | ```
59 |
60 | 2. 暂停分片分配:
61 |
62 | ```
63 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d '{
64 | "transient" : {
65 | "cluster.routing.allocation.enable" : "none"
66 | }
67 | }'
68 | ```
69 |
70 | 3. 通过配置管理工具下发新版本软件包。
71 | 4. 公告周知后,停止数据写入进程(即 logstash indexer 等)
72 | 5. 如果使用 Elasticsearch 1.6 版本以上,可以手动运行一次 synced flush,同步副本分片的 commit id,缩小恢复时的网络传输带宽:
73 |
74 | ```
75 | # curl -XPOST http://127.0.0.1:9200/_flush/synced
76 | ```
77 |
78 | 6. 全集群统一停止进程,更新软件包,重新启动。
79 | 7. 等待各节点都加入到集群以后,恢复分片分配:
80 |
81 | ```
82 | # curl -XPUT http://127.0.0.1:9200/_cluster/settings -d '{
83 | "transient" : {
84 | "cluster.routing.allocation.enable" : "all"
85 | }
86 | }'
87 | ```
88 |
89 | 由于同时启停,主分片几乎可以同时本地恢复,整个集群从 red 变成 yellow 只需要 2 分钟左右。而后的副本分片,如果有 synced flush,同样本地恢复,否则网络恢复总耗时,视数据大小而定,会明显大于单节点恢复的耗时。
90 |
91 | 8. 如果有 synced flush,建议等待集群变成 green 状态后,恢复写入;否则在集群变成 yellow 状态之后,即可着手开始恢复数据写入进程。
92 |
--------------------------------------------------------------------------------
/kibana/README.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Logstash 早期曾经自带了一个特别简单的 logstash-web 用来查看 ES 中的数据。其功能太过简单,于是 Rashid Khan 用 PHP 写了一个更好用的 web,取名叫 Kibana。这个 PHP 版本的 Kibana 发布时间是 2011 年 12 月 11 日。
4 |
5 | Kibana 迅速流行起来,不久的 2012 年 8 月 19 日,Rashid Khan 用 Ruby 重写了 Kibana,也被叫做 Kibana2。因为 Logstash 也是用 Ruby 写的,这样 Kibana 就可以替代原先那个简陋的 logstash-web 页面了。
6 |
7 | 目前我们看到的 angularjs 版本 kibana 其实原名叫 elasticsearch-dashboard,但跟 Kibana2 作者是同一个人,换句话说,kibana 比 logstash 还早就进了 elasticsearch 名下。这个项目改名 Kibana 是在 2014 年 2 月,也被叫做 Kibana3。全新的设计一下子风靡 DevOps 界。随后其他社区纷纷借鉴,Graphite 目前最流行的 Grafana 界面就是由此而来,至今代码中还留存有十余处 kbn 字样。
8 |
9 | 2014 年 4 月,Kibana3 停止开发,ES 公司集中人力开始 Kibana4 的重构,在 2015 年初发布了使用 JRuby 做后端的 beta 版后,于 3 月正式推出使用 node.js 做后端的正式版。由于设计思路上的差别,一些 K3 适宜的场景并不在 K4 考虑范围内,所以,至今 K3 和 K4 并存使用。本书也会分别讲解两者。
10 |
11 | ## 注释
12 |
13 | 本章配置参数内容部分译自[Elasticsearch 官方指南 Kibana 部分](http://www.elasticsearch.org/guide/en/kibana/current/index.html),其中 [v3](http://www.elasticsearch.org/guide/en/kibana/3.0/index.html) 的 panel 部分额外添加了截图注释。然后在使用的基础上,添加了原创的源码解析,场景示例,二次开发入门等内容。
14 |
15 |
--------------------------------------------------------------------------------
/kibana/difference.md:
--------------------------------------------------------------------------------
1 | # Kibana 各版本的对比
2 |
3 | Kibana 一直是 Elastic Stack 中的版本帝,并最终带着整个技术栈的产品都提升版本号到了 5.0。和其他产品一路升级上来不同的是,Kibana 几乎每次版本升级都是革命性的重写。而且至今依然有很多 Kibana 3 的用户不愿意迁移升级。因为前后者分别基于不同接口,不同目的,采取了不同的页面设计和逻辑。在不同场景下,各有优势。这里稍作解释。
4 |
5 | ## Kibana 3 的设计思路和功能
6 |
7 | 本书一开始就提到,Kibana3 在设计之初,有另一个名字,叫 **elasticsearch dashboard**。事实上,整个 Kibana3 就是一个围绕着 dashboard 构建的单页应用。
8 |
9 | 所以,在页面逻辑上,Kibana3 异常简洁。大量的代码和逻辑,都下放到 panel 层次上。每个 panel 要独立完成自己的可视化设计、数据请求,数据处理,数据渲染。panel 和 panel 之间,则几乎毫无关联。简单一点看,整个页面就像是一堆 iframe 一样。
10 |
11 | 而 panel 的设计,则是以使用者角度来考虑的。Kibana3 尽量提供能让运维人员一步到位的使用策略。即,使用者只需要了解 panel 的配置页面能填什么参数,得到什么可视化结果。
12 |
13 | 最明显的例子,就是 trend panel。trend panel 背后,其实是针对今天和昨天,分别发起两次请求,然后再拿两次请求的结果,做一次除法,计算涨跌幅。这个除法计算,是在浏览器端完成的。
14 |
15 | 类似在浏览器端完成的,还有 histogram panel 的 hits,second 等的计算。
16 |
17 | 此外,Kibana3 还有一个非常有用的功能,setting 中的 index pattern,是可以输入多个的,比如 `accesslog-[YYYY.MM.DD],syslog-[YYYY.MM.DD]`,这样就可以在同一个面板上,看到来自不同索引的数据的情况。
18 |
19 | ## Kibana 4 的设计思路和功能
20 |
21 | 从新特性来说,Kibana4 全面支持 Aggregation 接口,还有更多的可视化选择,可以任意拖动自动对齐的挂件框架,保存在 URL 可以跨页面保持的检索条件,以及对页面请求的内部排队机制。
22 |
23 | 从页面设计来说,Kibana4 参考了 Splunk 的产品形态,将功能拆分成了搜索,可视化和仪表盘三个标签页。可视化和搜索,是一一绑定的,无法跨多个 index pattern 做搜索,勿论可视化了。而且可视化标签页中,用 d3.js 实现的可视化构建器,与请求 ES 数据的聚合选择器,又是各自独立的插件。
24 |
25 | 也就是说,Kibana4 在使用 Aggregation 接口提供更复杂功能和更高性能的同时,彻底改变了用户的使用形式。用户必须明确了解 ES 各个 aggs 接口的意义,请求和响应体的数据情况;还要想清楚可视化的展现形式,充分理解数据字段的作用。然后才能实现想要的结果。毫无疑问,这是有学习成本的。
26 |
27 | 至于像 Kibana 3 那种在浏览器端计算的功能,Kibana4 中则完全没有。
28 |
29 | 在界面美观方面。Kibana4 至今未提供类似 Kibana3 中的 Query 设置功能,包括 Query 别名这个常用功能。直接导致目前 Kibana4 的图例几乎毫无作用。
30 |
31 | 在 filter 方面,Kibana4 用 filter agg 替代了 Kibana3 使用的 facet\_filter。页面表现形式上,Kibana3 是在页面顶部添加 Query 输入框,全局生效;Kibana4 是在 Visualize 页添加 aggs,单个面板生效。依然需要多查询条件对比的用户,需要一个个面板创建,非常麻烦。
32 |
33 | ## Kibana 5 的设计思路和功能
34 |
35 | Kibana 5 在 4.6 的基础上,做了全面的页面布局修改,采用了更现代化的左侧边栏菜单设计。单就 Kibana 本身的功能来说,其实没有太大差别。但是 Kibana 5 将重心放在了应用扩展和融合上。左侧边栏显然可以留出更多的空间来摆放各种扩展应用的 logo 图标。
36 |
37 | ES 2.0 开始提供了一种全新的 pipeline aggregation 特性, Kibana 在这个 ES 新特性的基础上实现了 timelion 应用,专注于时序计算和分析。甚至可以将 timelion 的分析图表加入到仪表盘中和其他可视化一起展现。
38 |
39 | 此外,ES 5.0 取消了 site plugin 形式,原来的 site plugin 都要迁移成 Kibana app。目前官方已经将原先的 sense 改成了 Kibana console 应用。相信未来一段时间,会有更多的 Kibana 应用涌现出来。
40 |
--------------------------------------------------------------------------------
/kibana/phantomjs.md:
--------------------------------------------------------------------------------
1 | # Kibana 截图报表
2 |
3 | Elastic Stack 本身作为一个实时数据检索聚合的系统,在定期报表方面,是有一定劣势的。因为基本上不可能把源数据长期保存在 Elasticsearch 集群中。即便保存了,为了一些已经成形的数据,再全面查询一次过久的冷数据,也是有额外消耗的。那么,对这种报表数据的需求,如何处理?其实很简单,把整个 Kibana 页面截图下来即可。
4 |
5 | FireFox 有插件用来截全网页图。不过如果作为定期的工作,这么搞还是比较麻烦的,需要脚本化下来。这时候就可以用上 phantomjs 软件了。phantomjs 是一个基于 webkit 引擎做的 js 脚本库。可以通过 js 程序操作 webkit 浏览器引擎,实现各种浏览器功能。
6 |
7 | phantomjs 在 Linux 平台上没有二进制分发包,所以必须源代码编译:
8 |
9 | ```
10 | # yum -y install gcc gcc-c++ make flex bison gperf ruby \
11 | openssl-devel freetype-devel fontconfig-devel libicu-devel sqlite-devel \
12 | libpng-devel libjpeg-devel
13 | # git clone git://github.com/ariya/phantomjs.git
14 | # cd phantomjs
15 | # git checkout 2.0
16 | # ./build.sh
17 | ```
18 |
19 | 想要给 kibana 页面截图,几行代码就够了。
20 |
21 | ## Kibana3 截屏代码
22 |
23 | 下面是一个 Kibana3 的截屏示例。 `capture-kibana.js` 如下:
24 |
25 | ```
26 | var page = require('webpage').create();
27 | var address = 'http://kibana.example.com/#/dashboard/elasticsearch/h5_view';
28 | var output = 'kibana.png';
29 | page.viewportSize = { width: 1366, height: 600 };
30 | page.open(address, function (status) {
31 | if (status !== 'success') {
32 | console.log('Unable to load the address!');
33 | phantom.exit();
34 | } else {
35 | window.setTimeout(function () {
36 | page.render(output);
37 | phantom.exit();
38 | }, 30000);
39 | }
40 | });
41 | ```
42 |
43 | 然后运行 `phantomjs capture-kibana.js` 命令,就能得到截图生成的 kibana.png 图片了。
44 |
45 | 这里两个要点:
46 |
47 | 1. 要设置 `viewportSize` 里的宽度,否则效果会变成单个 panel 依次往下排列。
48 | 3. 要设置 `setTimeout`,否则在获取完 index.html 后就直接返回了,只能看到一个大白板。用 phantomjs 截取 angularjs 这类单页 MVC 框架应用时一定要设置这个。
49 |
50 | ## Kibana4 的截屏开源项目
51 |
52 | Kibana4 的 dashboard 同样可以采取上面 Kibana3 的方式自己实现。不过社区最近有人完成了一个辅助项目,把截屏配置、历史记录展示等功能都界面化了。项目地址见:。
53 |
54 | 
55 |
--------------------------------------------------------------------------------
/kibana/v3/README.md:
--------------------------------------------------------------------------------
1 | # 简介
2 |
3 | Kibana3 是一个使用 Apache 开源协议,基于浏览器的 Elasticsearch 分析和搜索仪表板。Kibana3 非常容易安装和使用。整个项目都是用 HTML 和 Javascript 写的,所以 Kibana3 不需要任何服务器端组件,一个纯文本发布服务器就够了。Kibana 和 Elasticsearch 一样,力争成为极易上手,但同样灵活而强大的软件。
4 |
5 | 官方 Kibana3 只支持到 Elasticsearch 1.7 为止。想在 Elasticsearch 2.x 上继续使用 Kibana3 的用户,请尝试 分支。
6 |
--------------------------------------------------------------------------------
/kibana/v3/advanced/scripted.md:
--------------------------------------------------------------------------------
1 | ## 脚本化仪表板(.js)
2 |
3 | 脚本化仪表板比模板化仪表板更加强大。当然,功能强大随之而来的就是构建起来也更复杂。脚本化仪表板的目的就是构建并返回一个描述了完整的仪表板纲要的 javascript 对象。`app/dashboards/logstash.js`([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.js)) 就是一个有着详细注释的脚本化仪表板示例。这个文件的最终结果和 `logstash.json` 一致,但提供了更强大的功能,比如我们可以以逗号分割多个请求:
4 |
5 | 注意:千万注意 URL `#/dashboard/script/logstash.js` 里的 `script` 字样。这让 kibana 解析对应的文件为 javascript 脚本。
6 |
7 | ```
8 | http://yourserver/index.html#/dashboard/script/logstash.js?query=status:403,status:404&from=7d
9 | ```
10 |
11 | 这会创建 2 个请求对象,`status:403` 和 `status:404` 并分别绘图。事实上这个仪表板还能接收另一个参数 `split`,用于指定用什么字符串切分。
12 |
13 | ```
14 | http://yourserver/index.html#/dashboard/script/logstash.js?query=status:403!status:404&from=7d&split=!
15 | ```
16 |
17 | 我们可以看到 `logstash.js` ([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.js)) 里是这么做的:
18 |
19 | ```javascript
20 | // In this dashboard we let users pass queries as comma separated list to the query parameter.
21 | // Or they can specify a split character using the split aparameter
22 | // If query is defined, split it into a list of query objects
23 | // NOTE: ids must be integers, hence the parseInt()s
24 | if(!_.isUndefined(ARGS.query)) {
25 | queries = _.object(_.map(ARGS.query.split(ARGS.split||','), function(v,k) {
26 | return [k,{
27 | query: v,
28 | id: parseInt(k,10),
29 | alias: v
30 | }];
31 | }));
32 | } else {
33 | // No queries passed? Initialize a single query to match everything
34 | queries = {
35 | 0: {
36 | query: '*',
37 | id: 0,
38 | }
39 | };
40 | }
41 | ```
42 |
43 | 该仪表板可用参数比上面讲述的还要多,全部参数都在 `logstash.js`([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.js)) 文件里开始的注释中有讲解。
44 |
--------------------------------------------------------------------------------
/kibana/v3/advanced/template.md:
--------------------------------------------------------------------------------
1 | # 模板和脚本
2 |
3 | Kibana 支持通过模板或者更高级的脚本来动态的创建仪表板。你先创建一个基础的仪表板,然后通过参数来改变它,比如通过 URL 插入一个新的请求或者过滤规则。
4 |
5 | 模板和脚本都必须存储在磁盘上,目前不支持存储在 Elasticsearch 里。同时它们也必须是通过编辑或创建纲要生成的。所以我们强烈建议阅读 [The Kibana Schema Explained](http://www.elasticsearch.org/guide/en/kibana/3.0/_dashboard_schema.html)
6 |
7 | ## 仪表板目录
8 |
9 | 仪表板存储在 Kibana 安装目录里的 `app/dashboards` 子目录里。你会注意到这里面有两种文件:`.json` 文件和 `.js` 文件。
10 |
11 | ## 模板化仪表板(.json)
12 |
13 | `.json` 文件就是模板化的仪表板。模板示例可以在 `logstash.json` 仪表板的请求和过滤对象里找到。模板使用 handlebars 语法,可以让你在 json 里插入 javascript 语句。URL 参数存在 `ARGS` 对象中。下面是 `logstash.json`([on github](https://github.com/elasticsearch/kibana/blob/master/src/app/dashboards/logstash.json)) 里请求和过滤服务的代码片段:
14 |
15 | ```
16 | "0": {
17 | "query": "{{ARGS.query || '*'}}",
18 | "alias": "",
19 | "color": "#7EB26D",
20 | "id": 0,
21 | "pin": false
22 | }
23 |
24 | [...]
25 |
26 | "0": {
27 | "type": "time",
28 | "field": "@timestamp",
29 | "from": "now-{{ARGS.from || '24h'}}",
30 | "to": "now",
31 | "mandate": "must",
32 | "active": true,
33 | "alias": "",
34 | "id": 0
35 | }
36 | ```
37 |
38 | 这允许我们在 URL 里设置两个参数,`query` 和 `from`。如果没设置,默认值就是 `||` 后面的内容。比如说,下面的 URL 就会搜索过去 7 天内 `status:200` 的数据:
39 |
40 | 注意:千万注意 url `#/dashboard/file/logstash.json` 里的 `file` 字样
41 |
42 | ```
43 | http://yourserver/index.html#/dashboard/file/logstash.json?query=status:200&from=7d
44 | ```
45 |
46 |
--------------------------------------------------------------------------------
/kibana/v3/auth/mojo-auth.md:
--------------------------------------------------------------------------------
1 | # Auth WebUI in Mojolicious
2 |
3 | 社区已经有用 nodejs 或者 rubyonrails 写的 kibana-auth 方案了。不过我这两种语言都不太擅长,只会写一点点 Perl5 代码,所以我选择用 [Mojolicious](http://mojolicio.us) web 开发框架来实现我自己的 kibana 认证鉴权。
4 |
5 | 整套方案的代码以 `kbnauth` 子目录形式存在于我的 [kibana 仓库](https://github.com/chenryn/kibana)中,如果你不想用这套认证方案,照旧使用 `src` 子目录即可。事实上,`kbnauth/public/` 目录下的静态文件我都是通过软连接方式指到 `src/`下的。
6 |
7 | ### 特性
8 |
9 | * 全局透明代理
10 |
11 | 和 nodejs 实现的那套方案不同,我这里并没有使用 `__es/` 这样附加的路径。所有发往 Elasticsearch 的请求都是通过这个方案来控制。除了使用 `config.js.ep` 模版来定制 `elasticsearch` 地址设置以外,方案还会伪造 `/_nodes` 请求的响应体,伪造的响应体中永远只有运行着认证方案的这台服务器的 IP 地址。
12 |
13 | *这么做的原因是我的 kibana 升级了 elasticjs 版本,新版本默认会通过这个 API 获取 nodes 列表,然后浏览器直接轮询多个 IP 获取响应。*
14 |
15 | **注意:Mojolicious 有一个环境变量叫 `max_message_size`,默认是 10MB,即只允许代理响应大小在 10MB 以内的数据。我在 `script/kbnauth` 启动脚本中把它修改成了 0,即不限制。如果你有这方面的需求,可以修改成任意你想要的阈值。**
16 |
17 | * 使用 `kibana-auth` elasticsearch 索引做鉴权
18 |
19 | 因为所有的请求都会发往代理服务器(即运行着认证鉴权方案的服务器),每个用户都可以有自己的仪表板空间(没错,这招是从 kibana-proxy 项目学来的,每个用户使用单独的 `kibana-int-$username` 索引保存自己的仪表板设置)。而本方案还提供另一个高级功能:还可以通过另一个新的索引 `kibana-auth` 来指定每个用户所能访问的 Elasticsearch 集群地址和索引列表。
20 |
21 | 给用户 "sri" 添加鉴权信息的命令如下:
22 |
23 | ```
24 | $ curl -XPOST http://127.0.0.1:9200/kibana-auth/indices/sri -d '{
25 | "prefix":["logstash-sri","logstash-ops"],
26 | "server":"192.168.0.2:9200"
27 | }'
28 | ```
29 |
30 | 这就意味着用户 "sri" 能访问的,是存在 "192.168.0.2:9200" 上的 "logstash-sri-YYYY.MM.dd" 或者 "logstash-ops-YYYY.MM.dd" 索引。
31 |
32 | **小贴士:所以你在 `kbn_auth.conf` 里配置的 eshost/esport,其实并不意味着 kibana 数据的来源,而是认证方案用来请求 `kibana-auth` 信息的地址!**
33 |
34 | * 使用 [Authen::Simple](https://metacpan.org/pod/Authen::Simple) 框架做认证
35 |
36 | Authen::Simple 是一个很棒的认证框架,支持非常多的认证方法。比如:LDAP, DBI, SSH, Kerberos, PAM, SMB, NIS, PAM, ActiveDirectory 等。
37 |
38 | 默认使用的是 Passwd 方法。也就是用 `htpasswd` 命令行在本地生成一个 `.htpasswd` 文件存用户名密码。
39 |
40 | 如果要使用其他方法,比如用 LDAP 认证,只需要配置 `kbn_auth.conf` 文件就行了:
41 |
42 | ```perl
43 | authen => {
44 | LDAP => {
45 | host => 'ad.company.com',
46 | binddn => 'proxyuser@company.com',
47 | bindpw => 'secret',
48 | basedn => 'cn=users,dc=company,dc=com',
49 | filter => '(&(objectClass=organizationalPerson)(objectClass=user)(sAMAccountName=%s))'
50 | },
51 | }
52 | ```
53 |
54 | 可以同时使用多种认证方式,但请确保每种都是有效可用的。某一个认证服务器连接超时也会影响到其他认证方式超时。
55 |
56 | ## 安装
57 |
58 | 该方案代码只有两个依赖:Mojolicious 框架和 Authen::Simple 框架。我们可以通过 cpanm 部署:
59 |
60 | ```
61 | curl http://xrl.us/cpanm -o /usr/local/bin/cpanm
62 | chmod +x /usr/local/bin/cpanm
63 | cpanm Mojolicious Authen::Simple::Passwd
64 | ```
65 |
66 | 如果你需要使用其他认证方法,每个方法都需要另外单独安装。比如使用 LDAP 部署,就再运行一行:`cpanm Authen::Simple::LDAP` 就可以了。
67 |
68 | *小贴士:如果你是在一个新 RHEL 系统上初次运行代码,你可能会发现有报错说找不到 `Digest::SHA` 模块。这个模块其实是 Perl 核心模块,但是 RedHat 公司把所有的 Perl 核心模块单独打包成了 `perl-core.rpm`,所以你得先运行一下 `yum install -y perl-core` 才行。我讨厌 RedHat!*
69 |
70 | ## 运行
71 |
72 | ```
73 | cd kbnauth
74 | # 开发环境监听 3000 端口,使用单进程的 morbo 服务器调试
75 | morbo script/kbnauth
76 | # 生产环境监听 80 端口,使用高性能的 hypnotoad 服务器, 具体端口在 kbn_auth.conf 中定义
77 | hypnotoad script/kbnauth
78 | ```
79 |
80 | 现在,打开浏览器,就可以通过默认的用户名/密码:"sri/secr3t" 登录进去了。(sri 是 Mojolicious 框架的作者,感谢他为 Perl5 社区提供这么高效的 web 开发框架)
81 |
82 | 注意:这时候你虽然认证通过进去了 kibana 页面,但是还没有赋权。按照上面提到的 `kibana-auth` 命令操作,才算全部完成。
83 |
--------------------------------------------------------------------------------
/kibana/v3/auth/nginx.md:
--------------------------------------------------------------------------------
1 | # nginx 代理和简单权限验证
2 |
3 | Kibana3 作为一个纯静态文件式的单页应用,可以运行在任意主机上,却要求所有用户的浏览器,都可以直连 ELasticsearch 集群。这对网络和数据安全都是极为不利的。所以,一般在生产环境的 Elastic Stack,都是采取 HTTP 代理层的方式来做一层防护。最简单的办法,就是使用 Nginx 代理配置。
4 |
5 | ES 官方也提供了一个推荐配置:
6 |
7 | ```
8 | server {
9 | listen *:80;
10 |
11 | server_name kibana.myhost.org;
12 | access_log /var/log/nginx/kibana.myhost.org.access.log;
13 |
14 | location / {
15 | root /usr/share/kibana3;
16 | index index.html index.htm;
17 | }
18 |
19 | location ~ ^/_aliases$ {
20 | proxy_pass http://127.0.0.1:9200;
21 | proxy_read_timeout 90;
22 | }
23 | location ~ ^/.*/_aliases$ {
24 | proxy_pass http://127.0.0.1:9200;
25 | proxy_read_timeout 90;
26 | }
27 | location ~ ^/_nodes$ {
28 | proxy_pass http://127.0.0.1:9200;
29 | proxy_read_timeout 90;
30 | }
31 | location ~ ^/.*/_search$ {
32 | proxy_pass http://127.0.0.1:9200;
33 | proxy_read_timeout 90;
34 | }
35 | location ~ ^/.*/_mapping {
36 | proxy_pass http://127.0.0.1:9200;
37 | proxy_read_timeout 90;
38 | }
39 |
40 | # Password protected end points
41 | location ~ ^/kibana-int/dashboard/.*$ {
42 | proxy_pass http://127.0.0.1:9200;
43 | proxy_read_timeout 90;
44 | limit_except GET {
45 | proxy_pass http://127.0.0.1:9200;
46 | auth_basic "Restricted";
47 | auth_basic_user_file /etc/nginx/conf.d/kibana.myhost.org.htpasswd;
48 | }
49 | }
50 | location ~ ^/kibana-int/temp.*$ {
51 | proxy_pass http://127.0.0.1:9200;
52 | proxy_read_timeout 90;
53 | limit_except GET {
54 | proxy_pass http://127.0.0.1:9200;
55 | auth_basic "Restricted";
56 | auth_basic_user_file /etc/nginx/conf.d/kibana.myhost.org.htpasswd;
57 | }
58 | }
59 | }
60 | ```
61 |
62 | 由此也可以看到,Kibana3 实际往 ES 发起的请求,都有哪些。
63 |
64 | 然后,在同时运行了 Nginx 和 Elasticsearch 服务(建议为 client 角色)的这台服务器上,配置 `elasticsearch.yml` 为:
65 |
66 | ```
67 | network.bind_host: 127.0.0.1
68 | network.publish_host: 127.0.0.1
69 | network.host: 127.0.0.1
70 | ```
71 |
72 | 其他 Elasticsearch 节点统一关闭 HTTP 服务,配置 `elasticsearch.yml`:
73 |
74 | ```
75 | http.enabled: false
76 | ```
77 |
78 | 这样,所有人都只能从 Nginx 服务来查询 ES 服务了。从 Nginx 日志中,我们还可以审核查询请求的语法性能和合理性。
79 |
80 | 注意:改配置前提是 Logstash 采用 node/transport 协议写入数据,如果使用 http 协议的,请采用 iptables 防护,或新增 `/_bulk` 等写入接口的代理配置。
81 |
--------------------------------------------------------------------------------
/kibana/v3/auth/nodejs-cas.md:
--------------------------------------------------------------------------------
1 | # 配置Kibana的CAS验证
2 |
3 | *本节作者:childe*
4 |
5 | 我们公司用的是 CAS 单点登陆, 用如下工具将kibana集成到此单点登陆系统
6 |
7 | ## 准备工具
8 |
9 | - nginx: 仅仅是为了记录日志, 不用也行
10 | - nodejs: 为了跑 kibana-authentication-proxy
11 | - kibana:
12 | - kibana-authentication-proxy:
13 |
14 | ## 配置
15 |
16 | 1. nginx 配置 8080 端口, 反向代理到 es 的 9200
17 | 2. git clone kibana-authentication-proxy
18 | 3. git clone kibana
19 | 4. 将 kibana 软链接到 kibana-authentication-proxy 目录下
20 | 5. 配置 kibana-authentication-proxy/config.js
21 |
22 | 可能有如下参数需要调整:
23 |
24 | ```
25 | es_host #这里是nginx地址
26 | es_port #nginx的8080
27 | listen_port #node的监听端口, 80
28 | listen_host #node的绑定IP, 可以0.0.0.0
29 | cas_server_url #CAS地址
30 | ```
31 |
32 | 6. 安装 kibana-authentication-proxy 的依赖, `npm install express`, 等
33 | 7. 运行 `node kibana-authentication-proxy/app.js`
34 |
35 | ## 原理
36 |
37 | - app.js 里面 `app.get('/config.js', kibana3configjs)`; 返回了一个新的 config.js, 不是用的 kibana/config.js, 在这个配置里面,调用 ES 数据的 URL 前面加了一个 `__es` 的前缀
38 | - 在 app.js 入口这里, 有两个关键的中间层(我也不知道叫什么)被注册: 一个是 `configureCas`, 一个是`configureESProxy`
39 | - 一个请求来的时候, 会到 `configureCas` 判断是不是已经登陆到 CAS, 没有的话就转到 cas 登陆页面
40 | - `configureESProxy` 在 lib/es-proxy.js 里, 会把 `__es` 打头的请求(其实就是请求 es 数据的请求)转发到真正的 es 接口那里(我们这里是 nginx)
41 |
42 | ## 请求路径
43 |
44 | node(80) <=> nginx(8080) <=> es(9200)
45 |
46 | kibana-authentication-proxy 本身没有记录日志的代码, 而且转发 es 请求用的流式的(看起来), 并不能记录详细的 request body. 所以我们就用 nginx 又代理一层做日志了..
47 |
48 |
--------------------------------------------------------------------------------
/kibana/v3/configuration.md:
--------------------------------------------------------------------------------
1 | # 配置
2 |
3 | config.js 是 Kibana 核心配置的地方。文件里包括的参数都是必须在初次运行 kibana 之前提前设置好的。在你把 Kibana 和 ES 从自己个人电脑搬上生产环境的时候,一定会需要修改这里的配置。下面介绍几个最常见的修改项:
4 |
5 | ## 参数
6 |
7 | **elasticsearch**
8 |
9 | 你 elasticsearch 服务器的 URL 访问地址。你应该不会像写个 `http://localhost:9200` 在这,哪怕你的 Kibana 和 Elasticsearch 是在同一台服务器上。默认的时候这里会尝试访问你部署 kibana 的服务器上的 ES 服务,你可能需要设置为你 elasticsearch 服务器的主机名。
10 |
11 | 注意:如果你要传递参数给 http 客户端,这里也可以设置成对象形式,如下:
12 |
13 | ```
14 | +elasticsearch: {server: "http://localhost:9200", withCredentials: true}+
15 | ```
16 |
17 | **default_route**
18 |
19 | 没有指明加载哪个仪表板的时候,默认加载页路径的设置参数。你可以设置为文件,脚本或者保存的仪表板。比如,你有一个保存成 "WebLogs" 的仪表板在 elasticsearch 里,那么你就可以设置成:
20 |
21 | ```
22 | default_route: /dashboard/elasticsearch/WebLogs,
23 | ```
24 |
25 | **kibana_index**
26 |
27 | 用来保存 Kibana 相关对象,比如仪表板,的 Elasticsearch 索引名称。默认为 `kibana-int`。
28 |
29 | **panel_name**
30 |
31 | 可用的面板模块数组。面板只有在仪表板中有定义时才会被加载,这个数组只是用在 "add panel" 界面里做下拉菜单。
32 |
33 |
34 |
--------------------------------------------------------------------------------
/kibana/v3/dashboard/README.md:
--------------------------------------------------------------------------------
1 | # 布局
2 |
3 | 之前说过,Kibana3 是一个单页应用。所以其页面布局设计是固定的。顶部栏作为全局设置,接下来是全局 Query 栏,全局 Filtering 栏,以及具体可视化图表的部分。
4 |
5 | 本节就介绍这两部分的操作方式和用法。
6 |
--------------------------------------------------------------------------------
/kibana/v3/dashboard/queries-and-filters.md:
--------------------------------------------------------------------------------
1 | # 请求和过滤
2 |
3 | 图啊,表啊,地图啊,Kibana 有好多种图表,我们怎么控制显示在这些图表上的数据呢?这就是请求和过滤起作用的地方。 Kibana 是基于 Elasticsearch 的,所以支持强大的 Lucene Query String 语法,同样还能用上 Elasticsearch 的过滤器能力。
4 |
5 | ## 我们的仪表板
6 |
7 | 我们的仪表板像下面这样,可以搜索莎士比亚文集的内容。如果你喜欢本章截图的这种仪表板样式,你可以[下载导出的仪表板纲要(dashboard schema)](http://www.elasticsearch.org/guide/en/kibana/3.0/snippets/plays.json)
8 |
9 | 
10 |
11 | ## 请求
12 |
13 | 在搜索栏输入下面这个非常简单的请求
14 |
15 | ```
16 | to be or not to be
17 | ```
18 |
19 | 你会注意到,表格里第一条就是你期望的《哈姆雷特》。不过下一行却是《第十二夜》的安德鲁爵士,这里可没有"to be",也没有"not to be"。事实上,这里匹配上的是 `to OR be OR or OR not OR to OR be`。
20 |
21 | 我们需要这么搜索(译者注:即加双引号)来匹配整个短语:
22 |
23 | ```
24 | "to be or not to be"
25 | ```
26 |
27 | 或者指明在某个特定的字段里搜索:
28 |
29 | ```
30 | line_id:86169
31 | ```
32 |
33 | 我们可以用 AND/OR 来组合复杂的搜索,注意这两个单词必须大写:
34 |
35 | ```
36 | food AND love
37 | ```
38 |
39 | 还有括号:
40 |
41 | ```
42 | ("played upon" OR "every man") AND stage
43 | ```
44 |
45 | 数值类型的数据可以直接搜索范围:
46 |
47 | ```
48 | line_id:[30000 TO 80000] AND havoc
49 | ```
50 |
51 | 最后,当然是搜索所有:
52 |
53 | ```
54 | *
55 | ```
56 |
57 | ## 多个请求
58 |
59 | 有些场景,你可能想要比对两个不同请求的结果。Kibana 可以通过 OR 的方式把多个请求连接起来,然后分别进行可视化处理。
60 |
61 | **添加请求**
62 |
63 | 点击请求输入框右侧的 + 号,即可添加一个新的请求框。
64 |
65 | 
66 |
67 | 点击完成后你应该看到的是这样子
68 |
69 | 
70 |
71 | 在左边,绿色输入框,输入 `"to be"` 然后右边,黄色输入框,输入 `"not to be"`。这就会搜索每个包含有 `"to be"` 或者 `"not to be"` 内容的文档,然后显示在我们的 hits 饼图上。我们可以看到原先一个大大的绿色圆形变成下面这样:
72 |
73 | 
74 |
75 | **移除请求**
76 |
77 | 要移除一个请求,移动鼠标到这个请求输入框上,然后会出现一个 x 小图标,点击小图标即可:
78 |
79 | 
80 |
81 | ## 颜色和图例
82 |
83 | Kibana 会自动给你的请求分配一个可用的颜色,不过你也可以手动设置颜色。点击请求框左侧的彩色圆点,就可以弹出请求设置下拉框。这里面可以修改请求的颜色,或者设置为这个请求设置一个新的图例文字:
84 |
85 | 
86 |
87 | ## 过滤
88 |
89 | 很多 Kibana 图表都是交互式的,可以用来过滤你的数据视图。比如,点击你图表上的第一个条带,你会看到一些变动。整个图变成了一个大大的绿色条带。这是因为点击的时候,就添加了一个过滤规则,要求匹配 `play_name` 字段里的单词。
90 |
91 | 
92 |
93 | 你要问了“在哪里过滤了”?
94 |
95 | 答案就藏在过滤(FILTERING)标签上出现的白色小星星里。点击这个标签,你会发现在 *filtering* 面板里已经添加了一个过滤规则。在 *filtering* 面板里,可以添加,编辑,固定,删除任意过滤规则。很多面板都支持添加过滤规则,包括表格(table),直方图(histogram),地图(map)等等。
96 |
97 | 
98 |
99 | 过滤规则也可以自己点击 + 号手动添加。
100 |
101 |
--------------------------------------------------------------------------------
/kibana/v3/img/alipay.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/alipay.png
--------------------------------------------------------------------------------
/kibana/v3/img/bettermap-gaode.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/bettermap-gaode.png
--------------------------------------------------------------------------------
/kibana/v3/img/bettermap-heap.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/bettermap-heap.png
--------------------------------------------------------------------------------
/kibana/v3/img/class-cast-exception.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/class-cast-exception.jpg
--------------------------------------------------------------------------------
/kibana/v3/img/column-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/column-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/column.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/column.png
--------------------------------------------------------------------------------
/kibana/v3/img/cors.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/cors.jpg
--------------------------------------------------------------------------------
/kibana/v3/img/hist-general.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-general.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-grid.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-grid.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-mb.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-mb.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-mean.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-mean.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-percent.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-percent.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-queries.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-queries.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel-style.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel-style.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-percent.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-percent.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-queries.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-queries.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-setting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-setting.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-stack.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-stack.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-total-ps.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-total-ps.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-total-scale.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-total-scale.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-uniq-conf.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-uniq-conf.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-uniq.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-uniq.png
--------------------------------------------------------------------------------
/kibana/v3/img/hist-view.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/hist-view.png
--------------------------------------------------------------------------------
/kibana/v3/img/map-cn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/map-cn.png
--------------------------------------------------------------------------------
/kibana/v3/img/map-setting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/map-setting.png
--------------------------------------------------------------------------------
/kibana/v3/img/map-world.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/map-world.png
--------------------------------------------------------------------------------
/kibana/v3/img/query-topn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/query-topn.png
--------------------------------------------------------------------------------
/kibana/v3/img/sparklines-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/sparklines-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-fields.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-fields.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-highlight.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-highlight.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-micropanel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-micropanel.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-paging.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-paging.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-panel-setting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-panel-setting.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-sorting.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-sorting.png
--------------------------------------------------------------------------------
/kibana/v3/img/table-trim.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/table-trim.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-bar.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-bar.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-donut.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-donut.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-pie-no-other.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-pie-no-other.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-pie.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-pie.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-stat-map.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-stat-map.png
--------------------------------------------------------------------------------
/kibana/v3/img/terms-table.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/terms-table.png
--------------------------------------------------------------------------------
/kibana/v3/img/topn-histogram.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/topn-histogram.png
--------------------------------------------------------------------------------
/kibana/v3/img/topn-sparklines.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/topn-sparklines.png
--------------------------------------------------------------------------------
/kibana/v3/img/trends-panel.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/trends-panel.png
--------------------------------------------------------------------------------
/kibana/v3/img/trends.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v3/img/trends.png
--------------------------------------------------------------------------------
/kibana/v3/panels/README.md:
--------------------------------------------------------------------------------
1 | # 面板
2 |
3 | **Kibana** 仪表板由面板(`panels`)块组成。面板在行中可以起到很多作用,不过大多数是用来给一个或者多个请求的数据集结果做可视化。剩下一些面板则用来展示数据集或者用来为使用者提供插入指令的地方。
4 |
5 | 面板可以很容易的通过 Kibana 网页界面配置。为了了解更高级的用法,比如模板化或者脚本化仪表板,这章开始介绍面板属性。你可以发现一些通过网页界面看不到的设置。
6 |
7 | 每个面板类型都有自己的属性,不过有这么几个是大家共有的。
8 |
9 | ## span
10 |
11 | 一个从 1-12 的数字,描述面板宽度。
12 |
13 | ## editable
14 |
15 | 是否在面板上显示编辑按钮。
16 |
17 | ## type
18 |
19 | 本对象包含的面板类型。每个具体的面板类型又要求添加新的属性,具体列表说明稍后详述。
20 |
21 | -----------------------
22 |
23 | ## 译作者注
24 |
25 | 官方文档中只介绍了各面板的参数,而且针对的是要使用模板化,脚本化仪表板的高级用户,其中有些参数甚至在网页界面上根本不可见。
26 |
27 | 为了方便初学者,我在每个面板的参数介绍之后,自行添加界面操作和效果方面的说明。
28 |
29 | 另外,本书 Kibana3 介绍基于我的 分支,其中有十多处增强功能式的扩展。读者如果发现操作介绍中内容在自己界面上找不到的,可以尝试替换我的版本。
30 |
--------------------------------------------------------------------------------
/kibana/v3/panels/bettermap.md:
--------------------------------------------------------------------------------
1 | # bettermap
2 |
3 | 状态:实验性
4 |
5 | Bettermap 之所以叫 bettermap 是因为还没有更好(better)的名字。Bettermap 使用地理坐标来在地图上创建标记集群,然后根据集群的密度,用橘色,黄色和绿色作为区分。
6 |
7 | 要查看细节,点击标记集群。地图会放大,原有集群分裂成更小的集群。一直小到没法成为集群的时候,单个标记就会显现出来。悬停在标记上可以查看 `tooltip` 设置的值。
8 |
9 | **注意:** bettermap 需要从互联网上下载它的地图面板文件。
10 |
11 | ## 参数
12 |
13 | * field
14 |
15 | 包含了地理坐标的字段,要求是 geojson 格式。GeoJSON 是一个数组,内容为 `[longitude,latitude]` 。这可能跟大多数实现([latitude, longitude])是反过来的。
16 |
17 | * size
18 |
19 | 用来绘制地图的数据集大小。默认是 1000。注意:table panel 默认是展示最近 500 条,跟这里的大小不一致,可能引起误解。
20 |
21 | * spyable
22 |
23 | 设为假,不显示审查(inspect)按钮。
24 |
25 | * tooltip
26 |
27 | 悬停在标记上时显示哪个字段。
28 |
29 | * provider
30 |
31 | 选择哪家地图提供商。
32 |
33 | **请求(queries)**
34 |
35 | * 请求对象
36 |
37 | 这个对象描述本面板使用的请求。
38 |
39 | * queries.mode
40 |
41 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
42 |
43 | * queries.ids
44 |
45 | 如果设为 `selected` 模式,具体被选的请求编号。
46 |
47 | -----------------------------
48 |
49 | ## 界面配置说明
50 |
51 | bettermap 面板是为了解决 map 面板地图种类太少且不方便大批量添加各国地图文件的问题开发的。它采用了 [leaflet 库](http://leafletjs.com/),其 `L.tileLayer` 加载的 OpenStreetMap 地图文件都是在使用的时候单独请求下载,所以在初次使用的时候会需要一点时间才能正确显示。
52 |
53 | 在 bettermap 的配置界面,我提供了 provider ,可以选择各种地图提供商。比如中文用户可以选择 GaoDe(高德地图):
54 |
55 | 
56 |
57 | 注:最近,高德地图的 API 出现问题,该 provider 已经无法使用。
58 |
59 | ## 其他
60 |
61 | leaflet 库有丰富的[插件资源](http://leafletjs.com/plugins.html)。比如
62 |
63 | * [热力图](http://www.patrick-wied.at/static/heatmapjs/example-heatmap-leaflet.html)
64 |
65 | 
66 |
67 | 注:热力图插件最终在 Kibana4.1 中,作为 tile map 的新 option 加入了。
68 |
69 | *小贴士:其实 Kibana 官方效果的标记集群也是插件实现的,叫[markercluster](https://github.com/Leaflet/Leaflet.markercluster)*
70 |
71 |
--------------------------------------------------------------------------------
/kibana/v3/panels/column.md:
--------------------------------------------------------------------------------
1 | # column
2 |
3 | 状态:稳定
4 |
5 | 这是一个伪面板。目的是让你在一列中添加多个其他面板。虽然 column 面板状态是稳定,它的限制还是很多的,比如不能拖拽内部的小面板。未来的版本里,column 面板可能被删除。
6 |
7 | ## 参数
8 |
9 | * panel
10 |
11 | 面板对象构成的数组
12 |
13 | -----------------------------
14 |
15 | ## 界面配置说明
16 |
17 | column 面板是为了在高度较大的 row 中放入多个小 panel 准备的一个容器。其本身配置界面和 row 类似只有一个 panel 列表:
18 |
19 | 
20 |
21 | 在 column 中的具体的面板本身的设定,需要点击面板自带的配置按钮来配置:
22 |
23 | 
24 |
--------------------------------------------------------------------------------
/kibana/v3/panels/goal.md:
--------------------------------------------------------------------------------
1 | # goal
2 |
3 | 状态: 稳定
4 |
5 | goal 面板在一个饼图上显示到达指定目标的进度。
6 |
7 | ## 参数
8 |
9 | * donut
10 |
11 | 在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
12 |
13 | * tilt
14 |
15 | 在饼图(pie)模式,倾斜饼变成椭圆形。
16 |
17 | * legend
18 |
19 | 图例的位置,上、下或者无。
20 |
21 | * lables
22 |
23 | 在饼图(pie)模式,在饼图分片上绘制标签。
24 |
25 | * spyable
26 |
27 | 设为假,不显示审查(inspect)图标。
28 |
29 | **请求(queries)**
30 |
31 | * 请求对象
32 |
33 | * query.goal
34 |
35 | goal 模式的指定目标
36 |
--------------------------------------------------------------------------------
/kibana/v3/panels/hits.md:
--------------------------------------------------------------------------------
1 | # hits
2 |
3 | 状态: 稳定
4 |
5 | hits 面板显示仪表板上每个请求的 hits 数,具体的显示格式可以通过 "chart" 属性配置指定。
6 |
7 | ## 参数
8 |
9 | * arrangement
10 |
11 | 在条带(bar)或者饼图(pie)模式,图例的摆放方向。可以设置:水平(horizontal)或者垂直(vertical)。
12 |
13 | * chart
14 |
15 | 可以设置:none, bar 或者 pie
16 |
17 | * counter_pos
18 |
19 | 图例相对于图的位置,可以设置:上(above),下(below)
20 |
21 | * donut
22 |
23 | 在饼图(pie)模式,在饼中画个圈,变成甜甜圈样式。
24 |
25 | * tilt
26 |
27 | 在饼图(pie)模式,倾斜饼变成椭圆形。
28 |
29 | * lables
30 |
31 | 在饼图(pie)模式,在饼图分片上绘制标签。
32 |
33 | * spyable
34 |
35 | 设为假,不显示审查(inspect)图标。
36 |
37 | **请求(queries)**
38 |
39 | * 请求对象
40 |
41 | 这个对象描述本面板使用的请求。
42 |
43 | * queries.mode
44 |
45 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
46 |
47 | * queries.ids
48 |
49 | 如果设为 `selected` 模式,具体被选的请求编号。
50 |
--------------------------------------------------------------------------------
/kibana/v3/panels/map.md:
--------------------------------------------------------------------------------
1 | # map
2 |
3 | 状态:稳定
4 |
5 | map 面板把 2 个字母的国家或地区代码转成地图上的阴影区域。目前可用的地图包括世界地图,美国地图和欧洲地图。
6 |
7 | ## 参数
8 |
9 | * map
10 |
11 | 显示哪个地图:world, usa, europe
12 |
13 | * colors
14 |
15 | 用来涂抹地图阴影的颜色数组。一旦设定好这 2 个颜色,阴影就会使用介于这 2 者之间的颜色。示例 [‘#A0E2E2’, ‘#265656’]
16 |
17 | * size
18 |
19 | 阴影区域的最大数量
20 |
21 | * exclude
22 |
23 | 排除的区域数组。示例 [‘US’,‘BR’,‘IN’]
24 |
25 | * spyable
26 |
27 | 设为假,不显示审查(inspect)按钮。
28 |
29 | **请求(queries)**
30 |
31 | * 请求对象
32 |
33 | 这个对象描述本面板使用的请求。
34 |
35 | * queries.mode
36 |
37 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
38 |
39 | * queries.ids
40 |
41 | 如果设为 `selected` 模式,具体被选的请求编号。
42 |
43 | -----------------------------
44 |
45 | ## 界面配置说明
46 |
47 | 考虑到都是中国读者,本节准备采用中国地图进行讲解,中国地图代码,,基于本人 仓库,除标准的 map 面板参数外,还提供了 `terms_stats` 功能,也会一并讲述。
48 |
49 | map 面板,最重要的配置即输入字段,对于不同的地图,应该配置不同的 `Field`:
50 |
51 | * world
52 |
53 | 对于世界地图,其所支持的格式为*由 2 个字母构成的国家名称缩写*,比如:`US`,`CN`,`JP`等。如果你使用了 `LogStash::Filters::GeoIP` 插件,那么默认生成的 **geoip.country_code2** 字段正好符合条件。
54 |
55 | 
56 |
57 | * cn
58 |
59 | 对于中国地图,其所支持的格式则是*由 2 个数字构成的省份编码*,比如:`01`(即安徽),`30`(即广东),`04`(即江苏)等。如果你使用了 `LogStash::Filters::GeoIP` 插件,那么默认生成的 **geoip.region_name** 字段正好符合条件。
60 |
61 | 
62 |
63 | 如果你使用了我的仓库代码,或者自行合并了[该功能](https://github.com/elasticsearch/kibana/pull/1270),你的 map 面板配置界面会稍有变动成下面样子
64 |
65 | 
66 |
67 | 如果选择 `terms_stats` 模式,就会和 histogram 面板一样出现需要填写 `value_field` 的位置。同样必须使用**在 Elasticsearch 中是数值类型**的字段,然后显示的地图上,就不再是个数而是具体的均值,最大值等数据了。
68 |
69 | 
70 |
--------------------------------------------------------------------------------
/kibana/v3/panels/query.md:
--------------------------------------------------------------------------------
1 | # query
2 |
3 | query 面板和 filter 面板都是特殊类型的面板,在 dashboard 上有且仅有一个。不能删除不能添加。
4 |
5 | query 和 filter 的普通样式和基本操作,在之前[ Query 和 Filtering](../dashboard/queries-and-filters.md) 章节已经讲述过。这里,额外讲一下一些高阶功能。
6 |
7 | ## 请求类型
8 |
9 | query 搜索框支持三种请求类型:
10 |
11 | * lucene
12 |
13 | 这也是默认的类型,使用要点就是请求语法。语法说明在之前 [Elasticsearch 一章](../../elasticsearch/api/search.md)已经讲过。
14 |
15 | * regex
16 |
17 | * topN
18 |
19 | topN 是一个方便大家进行多项对比搜索的功能。其配置界面如下:
20 |
21 | 
22 |
23 | **注意 topN 后颜色选择器的小圆点变成了齿轮状!**
24 |
25 | 其运行实质,是先根据你填写的 field 和 size,发起一次 termsFacet 查询,获取 topN 的 term 结果;然后拿着这个列表,逐一发起附加了 term 条件的其他请求(比如绑定在 histogram 面板就是 `date_histogram` 请求,stats 面板就是 `termStats` 请求),也就获得了 topN 结果。
26 |
27 | 
28 |
29 | *小贴士:如果 ES 响应较慢的时候,你甚至可以很明显的看到 histogram 面板上的多条曲线是一条一条出来数据绘制的。*
30 |
31 | ## 别名
32 |
33 | query 还可以设置别名(alias)。默认没有别名的时候,各 panel 上显示对应 query 时,会使用具体的 query 语句。在查询比较复杂的时候,不便观看。而设置别名后,pinned queries,panel 图例等处,都会只显示设置好的别名,而不再显示复杂的查询语句,这样一目了然。
34 |
--------------------------------------------------------------------------------
/kibana/v3/panels/sparklines.md:
--------------------------------------------------------------------------------
1 | # sparklines
2 |
3 | 状态: 试验性
4 |
5 | sparklines 面板显示微型时间图。目的不是显示一个确切的数值,而是以紧凑的方式显示时间序列的形态。
6 |
7 | ## 参数
8 |
9 | * mode
10 | 用作 Y 轴的数值模式。除 count 以外,都需要定义 `value_field` 字段。可选值有:count, mean, max, min, total.
11 | * time_field
12 | X 轴字段。必须是 Elasticsearch 中的时间类型字段。
13 | * value_field
14 | 如果 mode 设置为 mean, max, min 或者 total,Y 轴字段。必须是数值类型字段。
15 | * interval
16 | 如果有现成的时间过滤器,Sparkline 会自动计算间隔。如果没有,就用这个间隔。默认是 5 分钟。
17 | * spyable
18 | 显示 inspect 图标。
19 |
20 | **请求(queries)**
21 |
22 | * 请求对象
23 | 这个对象描述本面板使用的请求。
24 | * queries.mode
25 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
26 | * queries.ids
27 | 如果设为 `selected` 模式,具体被选的请求编号。
28 |
29 | -----------------------------
30 |
31 | ## 界面配置说明
32 |
33 | sparklines 面板其实就是 histogram 面板的缩略图模式。在配置上,只能选择 Chart value 模式,填写 Time Field 或者 Value Field 字段。上文描述中的 interval 在配置页面上是看不到的。
34 |
35 | 
36 |
37 | 我们可以对比一下对同一个 topN 请求绘制的 sparklines 和 histogram 面板的效果:
38 |
39 | * sparklines
40 |
41 | 
42 |
43 | * histogram
44 |
45 | 
46 |
47 | *注:topN 请求的配置和说明,见 [query 面板](query.md)*
48 |
--------------------------------------------------------------------------------
/kibana/v3/panels/stats.md:
--------------------------------------------------------------------------------
1 | # stats
2 |
3 | 状态: Beta
4 |
5 | 基于 Elasticsearch 的 statistical Facet 接口实现的统计聚合展示面板。
6 |
7 | ## 参数
8 |
9 | * format
10 |
11 | 返回值的格式。默认是 number,可选值还有:money,bytes,float。
12 |
13 | * style
14 |
15 | 主数字的显示大小,默认为 24pt。
16 |
17 | * mode
18 |
19 | 用来做主数字显示的聚合值,默认是 count,可选值为:count(计数),min(最小值),max(最大值),mean(平均值),total(总数),variance(方差),std_deviation(标准差),sum_of_squares(平方和)。
20 |
21 | * show
22 |
23 | 统计表格中具体展示的哪些列。默认为全部展示,可选列名即 mode 中的可选值。
24 |
25 | * spyable
26 |
27 | 设为假,不显示审查(inspect)按钮。
28 |
29 | **请求**
30 |
31 | * 请求对象
32 |
33 | 这个对象描述本面板使用的请求。
34 |
35 | * queries.mode
36 |
37 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
38 |
39 | * queries.ids
40 |
41 | 如果设为 `selected` 模式,具体被选的请求编号。
42 |
--------------------------------------------------------------------------------
/kibana/v3/panels/text.md:
--------------------------------------------------------------------------------
1 | # 文本(text)
2 |
3 | 状态:稳定
4 |
5 | 文本面板用来显示静态文本内容,支持 markdown,简单的 html 和纯文本格式。
6 |
7 | ## 参数
8 |
9 | * mode
10 |
11 | ‘html’, ‘markdown’ 或者 ‘text’
12 |
13 | * content
14 |
15 | 面板内容,用 `mode` 参数指定的标记语言书写
16 |
--------------------------------------------------------------------------------
/kibana/v3/panels/trends.md:
--------------------------------------------------------------------------------
1 | # trends
2 |
3 | 状态: Beta
4 |
5 | 以证券报价器风格展示请求随着时间移动的情况。比如说:当前时间是 1:10pm,你的时间选择器设置的是 "Last 10m",而本面板的 "Time Ago" 参数设置的是 "1h",那么面板会显示的是请求结果从 12:00-12:10pm 以来变化了多少。
6 |
7 | ## 参数
8 |
9 | * ago
10 |
11 | 描述需要对比请求的时期的时间数值型字符串。
12 |
13 | * arrangement
14 |
15 | ‘horizontal’ 或 ‘vertical’
16 |
17 | * spyable
18 |
19 | 设为假,不显示审查(inspect)按钮。
20 |
21 | **请求(queries)**
22 |
23 | * 请求对象
24 |
25 | 这个对象描述本面板使用的请求。
26 |
27 | * queries.mode
28 |
29 | 在可用请求中应该用哪些?可设选项有:`all, pinned, unpinned, selected`
30 |
31 | * queries.ids
32 |
33 | 如果设为 `selected` 模式,具体被选的请求编号。
34 |
35 | -----------------------------
36 |
37 | ## 界面配置说明
38 |
39 | trends 面板用来对比实时数据与过去某天的同期数据的量的变化。配置很简单,就是设置具体某天前:
40 |
41 | 
42 |
43 | 效果如下:
44 |
45 | 
46 |
--------------------------------------------------------------------------------
/kibana/v3/saving-and-loading.md:
--------------------------------------------------------------------------------
1 | # 保存和加载
2 |
3 | 你已经构建了一个漂亮的仪表板!现在你打算分享给团队,或者开启自动刷新后挂在一个大屏幕上?Kibana 可以把仪表板设计持久化到 Elasticsearch 里,然后在需要的时候通过加载菜单或者 URL 地址调用出来。
4 |
5 | 
6 |
7 | ## 保存你漂亮的仪表板
8 |
9 | 保存你的界面非常简单,打开保存下拉菜单,取个名字,然后点击保存图表即可。现在你的仪表板就保存在一个叫做 `kibana-int` 的 Elasticsearch 索引里了。
10 |
11 | 
12 |
13 | ## 调用你的仪表板
14 |
15 | 要搜索已保存的仪表板列表,点击右上角的加载图标。在这里你可以加载,分享和删除仪表板。
16 |
17 | 
18 |
19 | ## 分享仪表板
20 |
21 | 已保存的仪表板可以通过你浏览器地址栏里的 URL 分享出去。每个持久化到 Elasticsearch 里的仪表板都有一个对应的 URL,像下面这样:
22 |
23 | ```
24 | http://your_host/index.html#/dashboard/elasticsearch/MYDASHBOARD
25 | ```
26 |
27 | 这个示例中 `MYDASHBOARD` 就是你在保存的时候给仪表板取得名字。
28 |
29 | 你还可以分享一个即时的仪表板链接,点击 Kibana 右上角的分享图标,会生成一个临时 URL。
30 |
31 | 
32 |
33 | 默认情况下,临时 URL 保存 30 天。
34 |
35 | 
36 |
37 | ## 保存成静态仪表板
38 |
39 | 仪表板可以保存到你的服务器磁盘上成为 `.json` 文件。把文件放到 `app/dashboards` 目录,然后通过下面地址访问
40 |
41 | ```
42 | http://your_host/index.html#/dashboard/file/MYDASHBOARD.json
43 | ```
44 |
45 | `MYDASHBOARD.json` 就是磁盘上文件的名字。注意路径中得 `/#dashboard/file/` 看起来跟之前访问保存在 Elasticsearch 里的仪表板很类似,不过这里访问的是文件而不是 elasticsearch。导出的仪表板纲要的详细信息,阅读稍后 [scheme 简介小节](./advanced/schema.md)。
46 |
47 | ## 下一步
48 |
49 | 你现在知道怎么保存,加载和访问仪表板了。你可能想知道怎么通过 URL 传递参数来访问,这样可以在其他应用中直接链接过来。请阅读稍后 [scripted 用法](./advanced/scripted.md) 和 [template 用法](./advanced/template.md) 两节。
50 |
--------------------------------------------------------------------------------
/kibana/v3/source-code-analysis/README.md:
--------------------------------------------------------------------------------
1 | # 源码剖析与二次开发
2 |
3 | Kibana 3 作为 Elastic Stack 风靡世界的最大推动力,其与优美的界面配套的简洁的代码同样功不可没。事实上,graphite 社区就通过移植 kibana 3 代码框架的方式,启动了 [grafana 项目](http://grafana.org/)。至今你还能在 grafana 源码找到二十多处 "kbn" 字样。
4 |
5 | *巧合的是,在 Kibana 重构 v4 版的同时,grafana 的 v2 版也到了 Alpha 阶段,从目前的预览效果看,主体 dashboard 沿用了 Kibana 3 的风格,不过添加了额外的菜单栏,供用户权限设置等使用 —— 这意味着 grafana 2 跟 kibana 4 一样需要一个单独的 server 端。*
6 |
7 | 笔者并非专业的前端工程师,对 angularjs 也处于一本入门指南都没看过的水准。所以本节内容,只会抽取一些个人经验中会有涉及到的地方提出一些"私货"。欢迎方家指正。
8 |
9 |
--------------------------------------------------------------------------------
/kibana/v3/source-code-analysis/directives.md:
--------------------------------------------------------------------------------
1 | ## panel 相关指令
2 |
3 | ### 添加 panel
4 |
5 | 前面在讲 `app/services/dashboard.js` 的时候,已经说到能添加的 panel 列表是怎么获取的。那么panel 是怎么加上的呢?
6 |
7 | 同样是之前讲过的 `app/partials/dashaboard.html` 里,加载了 `partials/roweditor.html` 页面。这里有一段:
8 |
9 | ```
10 |
16 |
17 |
20 | ```
21 |
22 | 这个 `add-panel` 指令,是有 `app/directives/addPanel.js` 提供的。方法如下:
23 |
24 | ```
25 | $scope.$watch('panel.type', function() {
26 | var _type = $scope.panel.type;
27 | $scope.reset_panel(_type);
28 | if(!_.isUndefined($scope.panel.type)) {
29 | $scope.panel.loadingEditor = true;
30 | $scope.require(['panels/'+$scope.panel.type.replace(".","/") +'/module'], function () {
31 | var template = '';
32 | elem.html($compile(angular.element(template))($scope));
33 | $scope.panel.loadingEditor = false;
34 | });
35 | }
36 | });
37 | ```
38 |
39 | 可以看到,其实就是 require 了对应的 `panels/xxx/module.js`,然后动态生成一个 div,绑定到对应的 controller 上。
40 |
41 | ### 展示 panel
42 |
43 | 还是在 `app/partials/dashaboard.html` 里,用到了另一个指令 `kibana-panel`:
44 |
45 | ```
46 |
54 |
55 | ```
56 |
57 | 当然,这里面还有 `resizable` 指令也是自己实现的,不过一般我们用不着关心这个的代码实现。
58 |
59 | 下面看 `app/directives/kibanaPanel.js` 里的实现。
60 |
61 | 这个里面大多数逻辑跟 addPanel.js 是一样的,都是为了实现一个指令嘛。对于我们来说,关注点在前面那一大段 HTML 字符串,也就是变量 `panelHeader`。这个就是我们看到的实际效果中,kibana 3 每个 panel 顶部那个小图标工具栏。仔细阅读一下,可以发现除了每个 panel 都一致的那些 span 以外,还有一段是:
62 |
63 | ```
64 | ''
68 | ```
69 |
70 | 也就是说,每个 panel 可以在自己的 panelMeta.modals 数组里,定义不同的小图标,弹出不同的对话浮层。我个人给 table panel 二次开发加入的 exportAsCsv 功能,图标就是在这里加入的。
71 |
72 |
--------------------------------------------------------------------------------
/kibana/v3/source-code-analysis/require.md:
--------------------------------------------------------------------------------
1 | ## 入口和模块依赖
2 |
3 | 这一部分是网页项目的基础。从 index.html 里就可以学到 angularjs 最基础的常用模板语法了。出现的指令有:`ng-repeat`, `ng-controller`, `ng-include`, `ng-view`, `ng-slow`, `ng-click`, `ng-href`,以及变量绑定的语法:`{{ dashboard.current.** }}`。
4 |
5 | index.html 中,需要注意 js 的加载次序,先 `require.js`,然后再 `require.config.js`,最后 `app`。整个 kibana 项目都是通过 **requrie** 方式加载的。而具体的模块,和模块的依赖关系,则定义在 `require.config.js` 里。这些全部加载完成后,才是启动 app 模块,也就是项目本身的代码。
6 |
7 | require.config.js 中,主要分成两部分配置,一个是 `paths`,一个是 `shim`。paths 用来指定依赖模块的导出名称和模块 js 文件的具体路径。而 shim 用来指定依赖模块之间的依赖关系。比方说:绘制图表的 js,kibana3 里用的是 jquery.flot 库。这个就首先依赖于 jquery 库。(通俗的说,就是原先普通的 HTML 写法里,要先加载 jquery.js 再加载 jquery.flot.js)
8 |
9 | 在整个 paths 中,需要单独提一下的是 `elasticjs:'../vendor/elasticjs/elastic-angular-client'`。这是串联 elastic.js 和 angular.js 的文件。这里面实际是定义了一个 angular.module 的 factory,名叫 `ejsResource`。后续我们在 kibana 3 里用到的跟 Elasticsearch 交互的所有方法,都在这个 `ejsResource` 里了。
10 |
11 | *factory 是 angular 的一个单例对象,创建之后会持续到你关闭浏览器。Kibana 3 就是通过这种方式来控制你所有的图表是从同一个 Elasticsearch 获取的数据*
12 |
13 | app.js 中,定义了整个应用的 routes,加载了 controller, directives 和 filters 里的全部内容。就是在这里,加载了主页面 `app/partials/dashboard.html`。当然,这个页面其实没啥看头,因为里面就是提供 pulldown 和 row 的 div,然后绑定到对应的 controller 上。
14 |
15 |
--------------------------------------------------------------------------------
/kibana/v5/README.md:
--------------------------------------------------------------------------------
1 | # Kibana4
2 |
3 | Kibana4 是 Elastic.co 一次崭新的重构产品。在操作界面上,有一定程度的对 Splunk 的模仿。为了更直观的体现 Kibana4 跟 Kibana3 的不同,先让我们看看 Kibana4 要怎么用来探索和展示数据。
4 |
5 | 配置索引模式后,默认打开 Kibana4 会出现在一个叫做 Discover 的标签页,在这个类似 Kibana3 的 logstash dashboard 的页面上,我们可以提交搜索请求,过滤结果,然后检查返回的文档里的数据。如下图示:
6 |
7 | 
8 |
9 | 默认情况下,Discover 页会显示匹配搜索条件的前 500 个文档,页面下拉到底部,会自动加载后续数据。你可以修改时间过滤器,拖拽直方图下钻数据,查看部分文档的细节。Discover 页上如何探索数据,详细说明见 [Discover 功能](./discover.md)。
10 |
11 | Visualization 标签页用来为你的搜索结果构造可视化。每个可视化都是跟一个搜索关联着的。比如,我们可以基于前面那个搜索创建一个展示区间计数的饼图。而添加一个子聚合,我们还可以看到每个区间内排名前五的年龄。
12 |
13 | 
14 |
15 | 还可以保存并分析可视化结果,然后合并到 Dashboard 标签页上以便对比分析。比如说,我们可以创建一个展示多个可视化数据的仪表板:
16 |
17 | 
18 |
19 | 更多关于创建和分享可视化和仪表板的内容,请阅读 [Visualize](./visualize.md) 和 [Dashboard](./dashboard.md) 章节。
20 |
--------------------------------------------------------------------------------
/kibana/v5/console.md:
--------------------------------------------------------------------------------
1 | # console 应用
2 |
3 | 5.0 版本以后,原先 Elasticsearch 的 site plugin 都被废弃掉。其中一些插件作者选择了作为独立的单页应用继续存在,比如前文介绍的 cerebro。而官方插件,则都迁移成为了 Kibana 的 App 扩展。其中,原先归属在 Marvel 中的 Sense 插件,被改名为 Kibana console 应用,在 5.0 版本中默认随 Kibana 分发。
4 |
5 | console 应用的操作界面和原先的 sense 几乎一模一样,这里无需赘述:
6 |
7 | 
8 |
--------------------------------------------------------------------------------
/kibana/v5/dashboard.md:
--------------------------------------------------------------------------------
1 | 一个 Kibana *dashboard* 能让你自由排列一组已保存的可视化。然后你可以保存这个仪表板,用来分享或者重载。
2 |
3 | 简单的仪表板像这样。
4 |
5 | ## 开始
6 |
7 | 要用仪表板,你需要至少有一个已保存的 [visualization](http://www.elastic.co/guide/en/kibana/current/visualize.html)。
8 |
9 | ### 创建一个新的仪表板
10 |
11 | 你第一次点击 **Dashboard** 标签的时候,Kibana 会显示一个空白的仪表板
12 |
13 | 
14 |
15 | 通过添加可视化的方式来构建你的仪表板。默认情况下,Kibana 仪表板使用明亮风格。如果你想切换成黑色风格,点击 **Options**,然后勾选 **Use dark theme**。
16 |
17 | 
18 |
19 | ### 自动刷新页面
20 |
21 | 你可以设置页面自动刷新的间隔以查看最新索引进来的数据。这个设置会定期提交搜索请求。
22 |
23 | 设置刷新间隔后,它会出现在菜单栏的时间过滤器左侧。
24 |
25 | 要设置刷新间隔:
26 |
27 | 1. 点击菜单栏右上角的 **Time Filter**
28 | 2. 点击 **Refresh Interval** 标签
29 | 3. 从列表中选择一个刷新间隔
30 |
31 | 要自动刷新数据,点击 **Auto-Refresh** 按钮选择自动刷新间隔:
32 |
33 | 
34 |
35 | 开启自动刷新后,Kibana 顶部菜单栏会显示一个暂停按钮和自动刷新间隔:。点击这个暂停按钮可以暂停自动刷新。
36 |
37 | ### 添加可视化到仪表板上
38 |
39 | 要添加可视化到仪表板上,点击工具栏面板上的 **Add**。从列表中选择一个已保存的可视化。你可以在 **Visualization Filter** 里输入字符串来过滤想要找的可视化。
40 |
41 | 由你选择的这个可视化会出现在你仪表板上的一个*容器(container)*里。
42 |
43 | ### 保存仪表板
44 |
45 | 要保存仪表板,点击工具栏面板上的 **Save** 按钮,在 **Save As** 栏输入仪表板的名字,然后点击 **Save** 按钮。
46 |
47 | ### 加载已保存仪表板
48 |
49 | 点击 **Open** 按钮显示已存在的仪表板列表。已保存仪表板选择器包括了一个文本栏可以通过仪表板的名字做过滤,还有一个链接到 **Object Editor** 而已管理你的已保存仪表板。你也可以直接点击 **Settings > Edit Saved Objects** 来访问 **Object Editor**。
50 |
51 | ### 分享仪表板
52 |
53 | 你可以分享仪表板给其他用户。可以直接分享 Kibana 的仪表板链接,也可以嵌入到你的网页里。
54 |
55 | > 用户必须有 Kibana 的访问权限才能看到嵌入的仪表板。
56 |
57 | 点击 **Share** 按钮显示 HTML 代码,就可以嵌入仪表板到其他网页里。还带有一个指向仪表板的链接。点击复制按钮 可以复制代码,或者链接到你的黏贴板。
58 |
59 | ### 嵌入仪表板
60 |
61 | 要嵌入仪表板,从 *Share* 页里复制出嵌入代码,然后粘贴进你外部网页应用内即可。
62 |
63 | ## 定制仪表板元素
64 |
65 | 仪表板里的可视化都存在可以调整大小的*容器*里。接下来会讨论一下容器。
66 |
67 | ### 移动容器
68 |
69 | 点击并按住容器的顶部,就可以拖动容器到仪表板任意位置。其他容器会在必要的时候自动移动,给你在拖动的这个容器空出位置。松开鼠标,容器就会固定在当前停留位置。
70 |
71 | ### 改变容器大小
72 |
73 | 移动光标到容器的右下角,等光标变成指向拐角的方向,点击并按住鼠标,拖动改变容器的大小。松开鼠标,容器就会固定成当前大小。
74 |
75 | ### 删除容器
76 |
77 | 点击容器右上角的 x 图标删除容器。从仪表板删除容器,并不会同时删除掉容器里用到的已存可视化。
78 |
79 | ### 查看详细信息
80 |
81 | 要显示可视化背后的原始数据,点击容器地步的条带。可视化会被有关原始数据详细信息的几个标签替换掉。如下所示:
82 |
83 | 
84 |
85 | * 表格(Table)。底层数据的分页展示。你可以通过点击每列顶部的方式给该列数据排序。
86 | * 请求(Request)。发送到服务器的原始请求,以 JSON 格式展示。
87 | * 响应(Response)。从服务器返回的原始响应,以 JSON 格式展示。
88 | * 统计值(Statistics)。和请求响应相关的一些统计值,以数据网格的方式展示。数据报告,请求时间,响应时间,返回的记录条目数,匹配请求的索引模式(index pattern)。
89 |
90 | ## 修改可视化
91 |
92 | 点击容器右上角的 *Edit* 按钮在 [Visualize](./visualize.md) 页打开可视化编辑。
93 |
--------------------------------------------------------------------------------
/kibana/v5/examples/README.md:
--------------------------------------------------------------------------------
1 | # 常见 sub aggs 示例
2 |
3 | 本章开始,就提到 K4/5 和 K3 的区别,在 K4/5 中,即便介绍完了全部 visualize 的配置项,也不代表用户能立刻上手配置出来和 K3 一样的面板。所以本节,会以几个具体的日志分析需求为例,演示在 K4 中,利用 Elasticsearch 1.0 以后提供的 Aggregation 特性,能够做到哪些有用的可视化效果。
4 |
5 |
--------------------------------------------------------------------------------
/kibana/v5/examples/datehistogram_topn.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v5/examples/datehistogram_topn.png
--------------------------------------------------------------------------------
/kibana/v5/examples/function_stack.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v5/examples/function_stack.png
--------------------------------------------------------------------------------
/kibana/v5/examples/histogram-filters.md:
--------------------------------------------------------------------------------
1 | # 响应时间的概率分布在不同时段的相似度对比
2 |
3 | 前面已经用百分位的时序,展示如何更准确的监控时序数据的波动。那么,还能不能更进一步呢?在制定 SLA 的时候,制定报警阈值的时候,怎么才能确定当前服务的拐点?除了压测以外,我们还可以拿线上服务的实际数据计算一下概率分布。Kibana4 对此提供了直接的支持,我们可以以数值而非时间作为 X 轴数据。
4 |
5 | 那么进一步,我们怎么区分不同产品在同一时间,或者相同产品在不同时间,性能上有无渐变到质变的可能?这里,我们可以采用 `grouped` 方式,来排列 filter aggs 的结果:
6 |
7 | 
8 |
9 | 我们可以看出来,虽然两个时间段,响应时间是有一定差距的,但是是整体性的抬升,没有明显的异变。
10 |
11 | 当然,如果觉得目测不靠谱的,可以把两组数值拿下来,通过 PDL、scipy、matlab、R 等工具做具体的差异显著性检测。这就属于后续的二次开发了。
12 |
13 | filter 中,可以写任意的 query string 语法。不限于本例中的时间段:
14 |
15 | ```
16 | http://k4domain:5601/#/visualize/create?type=histogram&indexPattern=%5Blogstash-mweibo-nginx-%5DYYYY.MM.DD&_g=()&_a=(filters:!(),linked:!f,query:(query_string:(analyze_wildcard:!t,query:'request_time:%3C50')),vis:(aggs:!((id:'1',params:(),schema:metric,type:count),(id:'3',params:(filters:!((input:(query:(query_string:(analyze_wildcard:!t,query:'@timestamp:%5B%22now-7m%22%20TO%20%22now%22%5D')))),(input:(query:(query_string:(analyze_wildcard:!t,query:'@timestamp:%5B%22now-15m%22%20TO%20%22now-7m%22%7D')))))),schema:group,type:filters),(id:'2',params:(extended_bounds:(),field:request_time,interval:1),schema:segment,type:histogram)),listeners:(),params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,defaultYExtents:!f,mode:grouped,scale:linear,setYExtents:!f,shareYAxis:!t,spyPerPage:10,times:!(),yAxis:()),type:histogram))
17 | ```
18 |
--------------------------------------------------------------------------------
/kibana/v5/examples/histogram_filters.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v5/examples/histogram_filters.png
--------------------------------------------------------------------------------
/kibana/v5/examples/percentile-datehistogram.md:
--------------------------------------------------------------------------------
1 | # 响应时间的百分占比趋势图
2 |
3 | 时序图除了上节展示的最基本的计数以外,还可以在 Y 轴上使用其他数值统计结果。最常见的,比如访问日志的平均响应时间。但是平均值在数学统计中,是一个非常不可信的数据。稍微几个远离置信区间的数值就可以严重影响到平均值。所以,在评价数值的总体分布情况时,更推荐采用四分位数。也就是 25%,50%,75%。在可视化方面,一般采用箱体图方式。
4 |
5 | Kibana4 没有箱体图的可视化方式。不过采用线图,我们一样可以做到类似的效果。
6 |
7 | 在上一章的时序数据基础上,改变 Y 轴数据源,选择 Percentile 方式,然后输入具体的四分位。运行渲染即可。
8 |
9 | 
10 |
11 | 对比新的 URL,可以发现变化的就是 id 为 1 的片段。变成了 `(id:'1',params:(field:connect_ms,percents:!(50,75,95,99)),schema:metric,type:percentiles)`:
12 |
13 | ```
14 | http://k4domain:5601/#/visualize/create?type=area&savedSearchId=curldebug&_g=()&_a=(filters:!(),linked:!t,query:(query_string:(query:'*')),vis:(aggs:!((id:'1',params:(field:connect_ms,percents:!(50,75,95,99)),schema:metric,type:percentiles),(id:'2',params:(customInterval:'2h',extended_bounds:(),field:'@timestamp',interval:auto,min_doc_count:1),schema:segment,type:date_histogram)),listeners:(),params:(addLegend:!f,addTimeMarker:!f,addTooltip:!t,defaultYExtents:!f,interpolate:linear,mode:stacked,scale:linear,setYExtents:!f,shareYAxis:!t,smoothLines:!t,times:!(),yAxis:()),type:area))
15 | ```
16 |
17 | 实践表明,在访问日志数据上,平均数一般相近于 75% 的四分位数。所以,为了更细化性能情况,我们可以改用诸如 90%,95% 这样的百分位。
18 |
19 | 此外,从 Kibana4.1 开始,新加入了 *Percentile_rank* 聚合支持。可以在 Y 轴数据源里选择这种聚合,输入具体的响应时间,比如 2s。则可视化数据变成 2s 内完成的响应数占总数的百分比的趋势图。
20 |
--------------------------------------------------------------------------------
/kibana/v5/examples/percentile_datehistogram.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v5/examples/percentile_datehistogram.png
--------------------------------------------------------------------------------
/kibana/v5/examples/terms-split.md:
--------------------------------------------------------------------------------
1 | # 分图统计
2 |
3 | 上一节我们展示了 sub aggs 在饼图上的效果。不过这多层 agg,其实用的是同一类数据。如果在聚合中,要加上一些完全不同纬度的数据,还是在单一的图片上继续累加就不是很直观了。比如说,还是上一节用到的 PHP 慢函数堆栈。我们可以根据机房做一下拆分。由于代码部署等主动变更都是有灰度部署的,一旦发现某机房有异常,就可以及时处理了。
4 |
5 | 同样还是新建 sub aggs,但是在开始,选择 split chart 而不是 split slice。
6 |
7 | 
8 |
9 | 从 URL 里可以看到,分图的 aggs 是 `schema:split`,而饼图分片的 aggs 是 `schema:segment`:
10 |
11 | ```
12 | http://k4domain:5601/#/visualize/edit/php-slow-stack-pie?_g=(refreshInterval:(display:Off,pause:!f,section:0,value:0),time:(from:now-12h,mode:quick,to:now))&_a=(filters:!(),linked:!t,query:(query_string:(query:'*')),vis:(aggs:!((id:'1',params:(),schema:metric,type:count),(id:'6',params:(field:idc,order:desc,orderBy:'1',row:!f,size:5),schema:split,type:terms),(id:'2',params:(field:slow.1,order:desc,orderBy:'1',size:10),schema:segment,type:terms),(id:'3',params:(field:slow.2,order:desc,orderBy:'1',size:10),schema:segment,type:terms),(id:'4',params:(field:slow.3,order:desc,orderBy:'1',size:10),schema:segment,type:terms),(id:'5',params:(field:slow.4,order:desc,orderBy:'1',size:10),schema:segment,type:terms)),listeners:(),params:(addLegend:!f,addTooltip:!t,defaultYExtents:!f,isDonut:!t,shareYAxis:!t,spyPerPage:10),type:pie))
13 | ```
14 |
--------------------------------------------------------------------------------
/kibana/v5/examples/terms_split.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v5/examples/terms_split.png
--------------------------------------------------------------------------------
/kibana/v5/examples/topn-datehistogram.md:
--------------------------------------------------------------------------------
1 | # TopN 的时序趋势图
2 |
3 | TopN 的时序趋势图是将 Elastic Stack 用于监控场景最常用的手段。乃至在 Kibana3 时代,开发者都通过在 Query 框上额外定义 TopN 输入的方式提供了这个特性。不过在 Kibana4 中,因为 sub aggs 的依次分桶原理,TopN 时序趋势图又有了新的特点。
4 |
5 | Kibana3 中,请求实质是先单独发起一次 termFacet 请求得到 topN,然后再发起带有 facetFilter 的 dateHistogramFacet ,分别请求每个 term 的时序。那么同样的原理,迁移到 Kibana4 中,就是先利用一次 termAgg 分桶后,再每个桶内做 dateHistogramAgg 了。对应的 Kibana4 地址为:
6 |
7 | ```
8 | http://k4domain:5601/#/visualize/edit/php-fpm-slowlog-histogram?_g=(refreshInterval:(display:Off,pause:!f,section:0,value:0),time:(from:now-12h,mode:quick,to:now))&_a=(filters:!(),linked:!t,query:(query_string:(query:'*')),vis:(aggs:!((id:'1',params:(),schema:metric,type:count),(id:'3',params:(field:host,order:desc,orderBy:'1',size:3),schema:group,type:terms),(id:'2',params:(customInterval:'2h',extended_bounds:(),field:'@timestamp',interval:auto,min_doc_count:1),schema:segment,type:date_histogram)),listeners:(),params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,defaultYExtents:!t,interpolate:linear,mode:stacked,scale:linear,setYExtents:!f,shareYAxis:!t,smoothLines:!f,times:!(),yAxis:()),type:area))
9 | ```
10 |
11 | 效果如下:
12 |
13 | 
14 |
15 | 可以看到图上就是 3 根线,分别代表 top3 的 host 的时序。
16 |
17 | 一般来说,这样都是够用的。不过如果经常有 host 变动的时候,在这么大的一个时间范围内,求一次总的 topN,可能就淹没了一些瞬间的变动了。所以,在 Kibana4 上,我们可以把 sub aggs 的顺序颠倒一下。先按 dateHistogramAgg 分桶,再在每个时间桶内,做 termAgg。对应的 Kibana4 地址为:
18 |
19 | ```
20 | http://k4domain:5601/#/visualize/edit/php-fpm-slowlog-histogram?_g=(refreshInterval:(display:Off,pause:!f,section:0,value:0),time:(from:now-12h,mode:quick,to:now))&_a=(filters:!(),linked:!t,query:(query_string:(query:'*')),vis:(aggs:!((id:'1',params:(),schema:metric,type:count),(id:'2',params:(customInterval:'2h',extended_bounds:(),field:'@timestamp',interval:auto,min_doc_count:1),schema:segment,type:date_histogram),(id:'3',params:(field:host,order:desc,orderBy:'1',size:3),schema:group,type:terms)),listeners:(),params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,defaultYExtents:!t,interpolate:linear,mode:stacked,scale:linear,setYExtents:!f,shareYAxis:!t,smoothLines:!f,times:!(),yAxis:()),type:area))
21 | ```
22 |
23 | 可以对比一下前一条 url,其中就是把 id 为 2 和 3 的两段做了对调。而最终效果如下:
24 |
25 | 
26 |
27 | 差距多么明显!
28 |
--------------------------------------------------------------------------------
/kibana/v5/examples/topn_datehistogram.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/kibana/v5/examples/topn_datehistogram.png
--------------------------------------------------------------------------------
/kibana/v5/plugin/README.md:
--------------------------------------------------------------------------------
1 | # Kibana 插件
2 |
3 | Kibana 从 4.2 以后,引入了完善的插件化机制。目前分为 app,vistype,fieldformatter、spymode 等多种插件类型。原先意义上的 Kibana 现在已经变成了 Kibana 插件框架下的一个默认 app 类型插件。
4 |
5 | 本节用以讲述 Kibana 插件的安装使用和定制开发。
6 |
7 | ## 部署命令
8 |
9 | 安装 Kibana 插件有两种方式:
10 |
11 | 1. 通过 Elastic.co 公司的下载地址:
12 |
13 | ```
14 | bin/kibana_plugin --install //
15 | ```
16 |
17 | version 是可选项。这种方式目前适用于官方插件,比如:
18 |
19 | ```
20 | bin/kibana_plugin -i elasticsearch/marvel/latest
21 | bin/kibana_plugin -i elastic/timelion
22 | ```
23 |
24 | 2. 通过 zip 压缩包:
25 |
26 | 支持本地和远程 HTTP 下载两种,比如:
27 |
28 | ```
29 | bin/kibana_plugin --install sense -u file:///tmp/sense-2.0.0-beta1.tar.gz
30 | bin/kibana_plugin -i heatmap -u https://github.com/stormpython/heatmap/archive/master.zip
31 | bin/kibana_plugin -i kibi_timeline_vis -u https://github.com/sirensolutions/kibi_timeline_vis/raw/0.1.2/target/kibi_timeline_vis-0.1.2.zip
32 | bin/kibana_plugin -i oauth2 -u https://github.com/trevan/oauth2/releases/download/0.1.0/oauth2-0.1.0.zip
33 | ```
34 |
35 | 目前已知的 Kibana Plugin 列表见官方 WIKI:
36 |
37 | 注意:kibana 目前版本变动较大,不一定所有插件都可以成功使用
38 |
39 | ## 查看与切换
40 |
41 | 插件安装完成后,可以在 Kibana 页面上通过 app switcher 界面切换。界面如下:
42 |
43 | 
44 |
45 | ## 默认插件
46 |
47 | 除了 Kibana 本身以外,其实还有一些其他默认插件,这些插件本身在 app switcher 页面上是隐藏的,但是可以通过 url 直接访问到,或者通过修改插件的 `index.js` 配置项让它显示出来。
48 |
49 | 这些隐藏的默认插件中,最有可能被用到的,是 statusPage 插件。
50 |
51 | 我们可以通过 `http://localhost:5601/status` 地址访问这个插件的页面:
52 |
53 | 
54 |
55 | 页面会显示 Kibana 的运行状态。包括 nodejs 的内存使用、负载、响应性能,以及各插件的加载情况。
56 |
--------------------------------------------------------------------------------
/kibana/v5/setup.md:
--------------------------------------------------------------------------------
1 | # 安排、配置和运行
2 |
3 | Kibana4 安装方式依然简单,你可以在几分钟内安装好 Kibana 然后开始探索你的 Elasticsearch 索引。只需要预备:
4 |
5 | * Elasticsearch 1.4.4 或者更新的版本
6 | * 一个现代浏览器 - [支持的浏览器列表](http://www.elasticsearch.com/support/matrix?_ga=1.149082614.1575542547.1409213558).
7 | * 有关你的 Elasticsearch 集群的信息:
8 | * 你想要连接 Elasticsearch 实例的 URL
9 | * 你想搜索哪些 Elasticsearch 索引
10 |
11 | > 如果你的 Elasticsearch 是被 [Shield](http://www.elasticsearch.org/overview/shield/) 保护着的,阅读[生产环境部署章节](./production.md)相关内容学习额外的安装说明。
12 |
13 | ## 安装并启动 kibana
14 |
15 | 要安装启动 Kibana:
16 |
17 | 1. 下载对应平台的 [Kibana 4 二进制包](http://www.elasticsearch.org/overview/kibana/installation/)
18 | 2. 解压 `.zip` 或 `tar.gz` 压缩文件
19 | 3. 在安装目录里运行: `bin/kibana` (Linux/MacOSX) 或 `bin\kibana.bat` (Windows)
20 |
21 | 完毕!Kibana 现在运行在 5601 端口了。
22 |
23 | ## 让 kibana 连接到 elasticsearch
24 |
25 | 在开始用 Kibana 之前,你需要告诉它你打算探索哪个 Elasticsearch 索引。第一次访问 Kibana 的时候,你会被要求定义一个 *index pattern* 用来匹配一个或者多个索引名。好了。这就是你需要做的全部工作。以后你还可以随时从 [Settings 标签页](./settings.md)添加更多的 index pattern。
26 |
27 | > 默认情况下,Kibana 会连接运行在 `localhost` 的 Elasticsearch。要连接其他 Elasticsearch 实例,修改 `kibana.yml` 里的 Elasticsearch URL,然后重启 Kibana。如何在生产环境下使用 Kibana,阅读[生产环境部署章节](./production.md)。
28 |
29 | 要从 Kibana 访问的 Elasticsearch 索引的配置方法:
30 |
31 | 1. 从浏览器访问 Kibana 界面。也就是说访问比如 `localhost:5601` 或者 `http://YOURDOMAIN.com:5601`。
32 | 
33 | 2. 指定一个可以匹配一个或者多个 Elasticsearch 索引的 index pattern 。默认情况下,Kibana 认为你要访问的是通过 Logstash 导入 Elasticsearch 的数据。这时候你可以用默认的 `logstash-*` 作为你的 index pattern。通配符(*) 匹配索引名中零到多个字符。如果你的 Elasticsearch 索引有其他命名约定,输入合适的 pattern。pattern 也开始是最简单的单个索引的名字。
34 | 3. 选择一个包含了时间戳的索引字段,可以用来做基于时间的处理。Kibana 会读取索引的映射,然后列出所有包含了时间戳的字段(译者注:实际是字段类型为 date 的字段,而不是“看起来像时间戳”的字段)。如果你的索引没有基于时间的数据,关闭 `Index contains time-based events` 参数。
35 | 4. 如果一个新索引是定期生成,而且索引名中带有时间戳,选择 `Use event times to create index names` 选项,然后再选择 `Index pattern interval`。这可以提高搜索性能,Kibana 会至搜索你指定的时间范围内的索引。在你用 Logstash 输出数据给 Elasticsearch 的情况下尤其有效。
36 | 5. 点击 `Create` 添加 index pattern。第一个被添加的 pattern 会自动被设置为默认值。如果你有多个 index pattern 的时候,你可以在 `Settings > Indices` 里设置具体哪个是默认值。
37 |
38 | 好了。Kibana 现在连接上你的 Elasticsearch 数据了。Kibana 会显示匹配上的索引里的字段名的只读列表。
39 |
40 | ## 开始探索你的数据!
41 |
42 | 你可以开始下钻你的数据了:
43 |
44 | * 在 [Discover](./discover.md) 页搜索和浏览你的数据。
45 | * 在 [Visualize](./visualize.md) 页转换数据成图表。
46 | * 在 [Dashboard](./dashboard.md) 页创建定制自己的仪表板。
47 |
--------------------------------------------------------------------------------
/kibana/v5/source-code-analysis/README.md:
--------------------------------------------------------------------------------
1 | # 源码剖析
2 |
3 | Kibana 4 开始采用 angular.js + node.js 框架编写。其中 node.js 主要提供两部分功能,给 Elasticsearch 做搜索请求转发代理,以及 auth、ssl、setting 等操作的服务器后端。5.0 版本在这些基础构成方面没有太大变化。
4 |
5 | 本章节假设你已经对 angular 有一定程度了解。所以不会再解释其中 angular 的 route,controller,directive,service,factory 等概念。
6 |
7 | 如果打算迁移 kibana 3 的 CAS 验证功能到 Kibana 4 或 5 版本,那么可以稍微了解一下 Hapi.JS 框架的认证扩展,相信可以很快修改成功。
8 |
9 | 本章主要还是集中在前端 kibana 页面功能的实现上。
10 |
11 | ## 参考阅读
12 |
13 | * 在 Elastic{ON} 大会上,也有专门针对 Kibana 4 源码和二次开发入门的演讲。请参阅:
14 | * 专业的前端工程师怎么看Kibana 4 的代码的:。
15 | * 如何通过 Hapi 的 Proxy 功能实现认证:[kbn-authentication-plugin](https://github.com/codingchili/kbn-authentication-plugin/blob/master/src/filter.js)
16 |
--------------------------------------------------------------------------------
/kibana/v5/source-code-analysis/kbnindex.md:
--------------------------------------------------------------------------------
1 | # kibana_index 结构
2 |
3 | 包括有以下 type:
4 |
5 | ## config
6 |
7 | _id 为 kibana5 的 version。内容主要是 defaultIndex,设置默认的 index_pattern.
8 |
9 | ## search
10 |
11 | _id 为 discover 上保存的搜索名称。内容主要是 title,column,sort,version,description,hits 和 kibanaSavedObjectMeta。kibanaSavedObjectMeta 内是一个 searchSourceJSON,保存搜索 json 的字符串。
12 |
13 | ## visualization
14 |
15 | _id 为 visualize 上保存的可视化名称。内容包括 title,savedSearchId,description,version,kibanaSavedObjectMeta 和 visState,uiStateJSON。其中 visState 里保存了 聚合 json 的字符串。如果绑定了已保存的搜索,那么把其在 search 类型里的 _id 存在 savedSearchId 字段里,如果是从新搜索开始的,那么把搜索 json 的字符串直接存在自己的 kibanaSavedObjectMeta 的 searchSourceJSON 里。
16 |
17 | ## dashboard
18 |
19 | _id 为 dashboard 上保存的仪表盘名称。内容包括 title, version,timeFrom,timeTo,timeRestore,uiStateJSON,optionsJSON,hits,refreshInterval,panelsJSON 和 kibanaSavedObjectMeta。其中 panelsJSON 是一个数组,每个元素是一个 panel 的属性定义。定义包括有:
20 |
21 | * type: 具体加载的 app 类型,就默认来说,肯定就是 search 或者 visualization 之一。
22 | * id: 具体加载的 app 的保存 id。也就是上面说过的,它们在各自类型下的 `_id` 内容。
23 | * size_x: panel 的 X 轴长度。Kibana 采用 [gridster 库](http://gridster.net/)做挂件的动态划分,默认为 3。
24 | * size_y: panel 的 Y 轴长度。默认为 2。
25 | * col: panel 的左边侧起始位置。Kibana 指定 col 最大为 12。每行第一个 panel 的 col 就是 1,假如它的 size_x 是 4,那么第二个 panel 的 col 就是 5。
26 | * row: panel 位于第几行。gridster 默认的 row 最大为 15。
27 |
28 | ## index-pattern
29 |
30 | _id 为 setting 中设置的 index pattern。内容主要是匹配该模式的所有索引的全部字段与字段映射。如果是基于时间的索引模式,还会有主时间字段 timeFieldName 和时间间隔 intervalName 两个字段。
31 |
32 | field 数组中,每个元素是一个字段的情况,包括字段的 type, name, indexed, analyzed, doc_values, count, scripted,searchable,aggregationable,format,popularity 这些状态。
33 |
34 | 如果 scripted 为 true,那么这个元素就是通过 kibana 页面添加的脚本化字段,那么这条字段记录还会额外多几个内容:
35 |
36 | * script: 记录实际 script 语句。
37 | * lang: 在 Elasticsearch 的 datanode 上采用什么 lang-plugin 运行。默认是 painless。即 Elasticsearch 5 开始默认启用的 脚本引擎。可以在 management 页面上切换成 Lucene expression 等其他你的集群中可用的脚本语言。
38 |
39 | ## timelion_sheet
40 |
41 | 包括有 timelion_chart_height,timelion_columns,timelion_interval,timelion_other_interval,timelion_rows,timelion_sheet 等字段
42 |
43 | *小贴士*
44 |
45 | 在本书之前介绍 packetbeat 时提到的自带 dashboard 导入脚本,其实就是通过 `curl`命令上传这些 JSON 到 kibana_index 索引里。
46 |
--------------------------------------------------------------------------------
/kibana/v5/timelion.md:
--------------------------------------------------------------------------------
1 | # timelion 介绍
2 |
3 | Elasticsearch 2.0 开始提供了一个崭新的 pipeline aggregation 特性,但是 Kibana 并没有立刻跟进这方面的意思,相反,Elastic 公司推出了另一个实验室产品:[Timelion](https://github.com/elastic/timelion)。最后在 5.0 版中,timelion 成为 Kibana 5 默认分发的一个插件。
4 |
5 | timelion 的用法在[官博](https://www.elastic.co/blog/timelion-timeline)里已经有介绍。尤其是最近两篇如何用 timelion 实现异常告警的[文章](https://www.elastic.co/blog/implementing-a-statistical-anomaly-detector-part-2),更是从 ES 的 pipeline aggregation 细节和场景一路讲到 timelion 具体操作,我这里几乎没有再重新讲一遍 timelion 操作入门的必要了。不过,官方却一直没有列出来 timelion 支持的请求语法的文档,而是在页面上通过点击 Docs 按钮的方式下拉帮助。
6 |
7 | 
8 |
9 | *timelion 页面设计上,更接近 Kibana3 而不是 Kibana4。比如 panel 分布是通过设置几行几列的数目来固化的;query 框是唯一的,要修改哪个 panel 的 query,鼠标点选一下 panel,query 就自动切换成这个 panel 的了。*
10 |
11 | 为了方便大家在上手之前了解 timelion 能做到什么,今天特意把 timelion 的请求语法所支持的函数分为几类,罗列如下:
12 |
13 | ## 可视化效果类
14 |
15 | * `.bars($width)`: 用柱状图展示数组
16 | * `.lines($width, $fill, $show, $steps)`: 用折线图展示数组
17 | * `.points()`: 用散点图展示数组
18 | * `.color("#c6c6c6")`: 改变颜色
19 | * `.hide()`: 隐藏该数组
20 | * `.label("change from %s")`: 标签
21 | * `.legend($position, $column)`: 图例位置
22 | * `.static(value=1024, label="1k", offset="-1d", fit="scale")`:在图形上绘制一个固定值
23 | * `.value()`:`.static()` 的简写
24 | * `.title(title="qps")`:图表标题
25 | * `.trend(mode="linear", start=0, end=-10)`:采用 linear 或 log 回归算法绘制趋势图
26 | * `.yaxis($yaxis_number, $min, $max, $position)`: 设置 Y 轴属性,.yaxis(2) 表示第二根 Y 轴
27 |
28 | ## 数据运算类
29 |
30 | * `.abs()`: 对整个数组元素求绝对值
31 | * `.precision($number)`: 浮点数精度
32 | * `.cusum($base)`: 数组元素之和,再加上 $base
33 | * `.derivative()`: 对数组求导数
34 | * `.divide($divisor)`: 数组元素除法
35 | * `.multiply($multiplier)`: 数组元素乘法
36 | * `.subtract($term)`: 数组元素减法
37 | * `.sum($term)`: 数组元素加法
38 | * `.add()`: 同 .sum()
39 | * `.plus()`: 同 .sum()
40 | * `.first()`: 返回第一个元素
41 | * `.movingaverage($window)`: 用指定的窗口大小计算移动平均值
42 | * `.mvavg()`: `.movingaverage()` 的简写
43 | * `.movingstd($window)`: 用指定的窗口大小计算移动标准差
44 | * `.mvstd()`: `.movingstd()` 的简写
45 | * `.fit($mode)`:使用指定的 fit 函数填充空值。可选项有:average, carry, nearest, none, scale
46 | * `.holt(alpha=0.5, beta=0.5, gamma=0.5, season="1w", sample=2)`:即 Elasticsearch 的 pipeline aggregation 所支持的 holt-winters 算法
47 | * `.log(base=10)`:对数
48 | * `.max()`:最大值
49 | * `.min()`:最小值
50 | * `.props()`:附加额外属性,比如 `.props(label=bears!)`
51 | * `.range(max=10, min=1)`:保持形状的前提下修改最大值最小值
52 | * `.scale_interval(interval="1s")`:在新间隔下再次统计,比如把一个原本 5min 间隔的 `date_histogram` 改为每秒的结果
53 | * `.trim(start=1, end=-1)`:裁剪序列值
54 |
55 | ## 逻辑运算类
56 |
57 | * `.condition(operator="eq", if=100, then=200)`:支持 eq、ne、lt、gt、lte、gte 等操作符,以及 if、else、then 赋值
58 | * `.if()`:`.condition()` 的简写
59 |
60 | ## 数据源设定类
61 |
62 | * `.elasticsearch()`: 从 ES 读取数据
63 | * `.es(q="querystring", metric="cardinality:uid", index="logstash-*", offset="-1d")`: .elasticsearch() 的简写
64 | * `.graphite(metric="path.to.*.data", offset="-1d")`: 从 graphite 读取数据
65 | * `.quandl()`: 从 quandl.com 读取 quandl 码
66 | * `.worldbank_indicators()`: 从 worldbank.org 读取国家数据
67 | * `.wbi()`: `.worldbank_indicators()` 的简写
68 | * `.worldbank()`: 从 worldbank.org 读取数据
69 | * `.wb()`: `.worldbanck()` 的简写
70 |
71 | 以上所有函数,都在 `kibana/src/core_plugins/timelion/server/series_functions` 目录下实现,每个 js 文件实现一个 `TimelionFunction` 功能。
72 |
73 |
--------------------------------------------------------------------------------
/kibana/v5/visualize/markdown.md:
--------------------------------------------------------------------------------
1 | # Markdown 挂件
2 |
3 | Markdown 挂件是一个存放 GitHub 风格 Markdown 内容的文本框。Kibana 会渲染你输入的文本,然后在仪表盘上显示渲染结果。你可以点击 **Help** 连接跳转到 [help page](https://help.github.com/articles/github-flavored-markdown/) 查看 GitHub 风格 Markdown 的说明。点击 **Apply** 在预览框查看渲染效果,或者 **Discard** 回退成上一个版本的内容。
4 |
5 |
--------------------------------------------------------------------------------
/kibana/v5/visualize/metric.md:
--------------------------------------------------------------------------------
1 | # Metric
2 |
3 | metric 可视化为你选择的聚合显示一个单独的数字:
4 |
5 | * Count
6 | [count](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-valuecount-aggregation.html) 聚合返回选中索引模式中元素的原始计数。
7 | * Average
8 | 这个聚合返回一个数值字段的 [average](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-avg-aggregation.html) 。从下拉菜单选择一个字段。
9 | * Sum
10 | [sum](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-sum-aggregation.html) 聚合返回一个数值字段的总和。从下拉菜单选择一个字段。
11 | * Min
12 | [min](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-min-aggregation.html) 聚合返回一个数值字段的最小值。从下拉菜单选择一个字段。
13 | * Max
14 | [max](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-max-aggregation.html) 聚合返回一个数值字段的最大值。从下拉菜单选择一个字段。
15 | * Unique Count
16 | [cardinality](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-cardinality-aggregation.html) 聚合返回一个字段的去重数据值。从下拉菜单选择一个字段。
17 | * Standard Deviation
18 | [extended stats](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-extendedstats-aggregation.html) 聚合返回一个数值字段数据的标准差。从下拉菜单选择一个字段。
19 | * Percentile
20 | [percentile](http://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-percentile-rank-aggregation.html) 聚合返回一个数值字段中值的百分比分布。从下拉菜单选择一个字段,然后在 **Percentiles** 框内指定范围。点击 **X** 移除一个百分比框,点击 **+ Add Percent** 添加一个百分比框。
21 | * Percentile Rank
22 | [percentile ranks](http://www.elastic.co/guide/en/elasticsearch/reference/current//search-aggregations-metrics-percentile-rank-aggregation.html) 聚合返回一个数值字段中你指定值的百分位排名。从下拉菜单选择一个字段,然后在 **Values** 框内指定一到多个百分位排名值。点击 **X** 移除一个百分比框,点击 **+Add** 添加一个数值框。
23 |
24 | 你可以点击 **+ Add Aggregation** 按键添加一个聚合。你可以点击 **Advanced** 链接显示更多有关聚合的自定义参数:
25 |
26 | * Exclude Pattern
27 | 指定一个从结果集中排除掉的模式。
28 | * Exclude Pattern Flags
29 | 排除模式的 Java flags 标准集。
30 | * Include Pattern
31 | 指定一个从结果集中要包含的模式。
32 | * Include Pattern Flags
33 | 包含模式的 Java flags 标准集。
34 | * JSON Input
35 | 一个用来添加 JSON 格式属性的文本框,内容会合并进聚合的定义中,格式如下例:
36 |
37 | ```
38 | { "script" : "doc['grade'].value * 1.2" }
39 | ```
40 |
41 | ### 注意
42 |
43 | > Elasticsearch 1.4.3 及以后版本,这个函数需要你开启 [dynamic Groovy scripting](http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting.html)。
44 |
45 | 这些参数是否可用,依赖于你选择的聚合函数。
46 |
47 | 点击 **view options** 修改显示 metric 的字体大小。
48 |
49 |
--------------------------------------------------------------------------------
/logstash/README.md:
--------------------------------------------------------------------------------
1 | 第一部分 Logstash
2 | =======================
3 |
4 | **Logstash is a tool for managing events and logs. You can use it to collect logs, parse them, and store them for later use (like, for searching).**
5 | --
6 |
7 | Logstash 项目诞生于 2009 年 8 月 2 日。其作者是世界著名的运维工程师乔丹西塞(JordanSissel),乔丹西塞当时是著名虚拟主机托管商 DreamHost 的员工,还发布过非常棒的软件打包工具 fpm,并主办着一年一度的 sysadmin advent calendar(advent calendar 文化源自基督教氛围浓厚的 Perl 社区,在每年圣诞来临的 12 月举办,从 12 月 1 日起至 12 月 24 日止,每天发布一篇小短文介绍主题相关技术)。
8 |
9 | *小贴士:Logstash 动手很早,对比一下,scribed 诞生于 2008 年,flume 诞生于 2010 年,Graylog2 诞生于 2010 年,Fluentd 诞生于 2011 年。*
10 |
11 | scribed 在 2011 年进入半死不活的状态,大大激发了其他各种开源日志收集处理框架的蓬勃发展,Logstash 也从 2011 年开始进入 commit 密集期并延续至今。
12 |
13 | 作为一个系出名门的产品,Logstash 的身影多次出现在 Sysadmin Weekly 上,它和它的小伙伴们 Elasticsearch、Kibana 直接成为了和商业产品 Splunk 做比较的开源项目(乔丹西塞曾经在博客上承认设计想法来自 AWS 平台上最大的第三方日志服务商 Loggly,而 Loggly 两位创始人都曾是 Splunk 员工)。
14 |
15 | 2013 年,Logstash 被 Elasticsearch 公司收购,ELK Stack 正式成为官方用语(随着 beats 的加入改名为 Elastic Stack)。Elasticsearch 本身 也是近两年最受关注的大数据项目之一,三次融资已经超过一亿美元。在 Elasticsearch 开发人员的共同努力下,Logstash 的发布机制,插件架构也愈发科学和合理。
16 |
17 | ## 社区文化
18 |
19 | 日志收集处理框架这么多,像 scribe 是 facebook 出品,flume 是 apache 基金会项目,都算声名赫赫。但 logstash 因乔丹西塞的个人性格,形成了一套独特的社区文化。每一个在 google groups 的 logstash-users 组里问答的人都会看到这么一句话:
20 |
21 | **Remember: if a new user has a bad time, it's a bug in logstash.**
22 |
23 | 所以,logstash 是一个开放的,极其互助和友好的大家庭。有任何问题,尽管在 github issue,Google groups,Freenode#logstash channel 上发问就好!
24 |
--------------------------------------------------------------------------------
/logstash/develop/utmp.md:
--------------------------------------------------------------------------------
1 | # 读取二进制文件(utmp)
2 |
3 | *本节作者:NERO*
4 |
5 | 我们知道Linux系统有些日志不是以可读文本形式存在文件中,而是以二进制内容存放的。比如utmp等。
6 |
7 | Files插件在读取二进制文件和文本文件的区别在于没办法一行行处理内容,内容也不是直观可见的。但是在其他处理逻辑是保持一致的,比如多文件支持、断点续传、内容监控等等,区别在于bytes的截断和bytes的转换。
8 | 在Files的基础上,新增了个插件utmp,插件实现了对二进制文件的读取和解析,实现类似于文本文件一行行输出内容,以供Filter做进一步分析。
9 |
10 |
11 | utmp新增了两个配置项:`struct_size` 和 `struct_format`。
12 |
13 | `struct_size` 代表结构体的大小,number类型;`struct_format`为结构体的内存分布格式,string类型。
14 |
15 | ## 配置实例
16 |
17 | ```
18 | input {
19 | utmp {
20 | path => "/var/run/utmp"
21 | type => "syslog"
22 | start_position => "beginning"
23 | struct_size => 384
24 | struct_format => "s2Ia32a4a32a256s2iI2I4a20"
25 | }
26 | }
27 | ```
28 |
29 | 我们可以通过 `man utmp` 了解 utmp 的结构体声明。通过结构体声明我们能知道结构体的内存分布情况。我们看
30 | `struct_format => "s2Ia32a4a32a256s2iI2I4a20"` 中的第一个 **s**,s 代表 short,后面的数字 2 代表 short 元素的个数,那么意思就是结构体的第一个和第二个元素是 short 类型,各占 2 个字节。
31 |
32 | 以此类推。s2Ia32a4a32a256s2iI2I4a20 总共代表 384 个字节,与 `struct_size` 配置保持一致。s2Ia32a4a32a256s2iI2I4a20 本质上是对应于 Ruby 中的 unpack 函数的参数。其中 s、T、a、i 等等含义参见 Ruby 的 unpack 函数说明。
33 |
34 | 需要注意的是,你必须了解当前操作系统的字节序是大端模式还是小端模式,对于数字类型的结构体元素很有必要,比如对于 i 和 I 的选择。还有一个就是,结构体内存对齐的问题。实际上 utmp 结构体第一个元素 2 字节,第二个元素是 4 字节。编译器在编译的时候会在第一个 2 字节后插入 2 字节来补齐 4 字节,知道这点尤为重要,所以其实第二个 short 是无意义的,只是为了内存对其才有补的。
35 |
36 | ## 输出
37 |
38 | 经过 utmp 插件的 event,message 字段形如 "field1|field2|field3",以 "|" 分隔每个结构体元素。可用Filter插件进一步去做解析。utmp 本身只负责将二级制内容转换成可读的文本,不对文件编码格式负责。
39 |
40 | ## 安装
41 |
42 | 插件地址:https://github.com/txyafx/logstash-input-utmp
43 |
44 | ```
45 | git clone https://github.com/txyafx/logstash-input-utmp
46 | cd logstash-input-utmp
47 | rm -rf .git
48 | vim Gemfile 修改插件绝对路径
49 | git init
50 | git add .
51 | gem clean
52 | gem build logstash-input-utmp.gemspec
53 | ```
54 |
55 | 用logstash安装本地utmp插件
56 |
--------------------------------------------------------------------------------
/logstash/examples/README.md:
--------------------------------------------------------------------------------
1 | # 场景示例
2 |
3 | 前面虽然介绍了几十个常用的 Logstash 插件的常见配置项。但是过多的选择下,如何组合使用这些插件,依然是一部分用户的幸福难题。本节,列举一些最常见的日志场景,演示一下针对性的组件搭配。希望能给读者带来一点启发。
4 |
--------------------------------------------------------------------------------
/logstash/examples/mysql-slow.md:
--------------------------------------------------------------------------------
1 | # MySQL慢查询日志
2 |
3 | MySQL 有多种日志可以记录,常见的有 error log、slow log、general log、bin log 等。其中 slow log 作为性能监控和优化的入手点,最为首要。本节即讨论如何用 logstash 处理 slow log。至于 general log,格式处理基本类似,不过由于 general 量级比 slow 大得多,推荐采用 packetbeat 协议解析的方式更高效的完成这项工作。相关内容阅读本书稍后章节。
4 |
5 | MySQL slow log 的 logstash 处理配置示例如下:
6 |
7 | ```
8 | input {
9 | file {
10 | type => "mysql-slow"
11 | path => "/var/log/mysql/mysql-slow.log"
12 | codec => multiline {
13 | pattern => "^# User@Host:"
14 | negate => true
15 | what => "previous"
16 | }
17 | }
18 | }
19 |
20 | filter {
21 | # drop sleep events
22 | grok {
23 | match => { "message" => "SELECT SLEEP" }
24 | add_tag => [ "sleep_drop" ]
25 | tag_on_failure => [] # prevent default _grokparsefailure tag on real records
26 | }
27 | if "sleep_drop" in [tags] {
28 | drop {}
29 | }
30 | grok {
31 | match => [ "message", "(?m)^# User@Host: %{USER:user}\[[^\]]+\] @ (?:(?\S*) )?\[(?:%{IP:clientip})?\]\s*# Query_time: %{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent: %{NUMBER:rows_sent:int}\s+Rows_examined: %{NUMBER:rows_examined:int}\s*(?:use %{DATA:database};\s*)?SET timestamp=%{NUMBER:timestamp};\s*(?(?\w+)\s+.*)\n# Time:.*$" ]
32 | }
33 | date {
34 | match => [ "timestamp", "UNIX" ]
35 | remove_field => [ "timestamp" ]
36 | }
37 | }
38 | ```
39 |
40 | 运行该配置,logstash 即可将多行的 MySQL slow log 处理成如下事件:
41 |
42 | ```
43 | {
44 | "@timestamp" => "2014-03-04T19:59:06.000Z",
45 | "message" => "# User@Host: logstash[logstash] @ localhost [127.0.0.1]\n# Query_time: 5.310431 Lock_time: 0.029219 Rows_sent: 1 Rows_examined: 24575727\nSET timestamp=1393963146;\nselect count(*) from node join variable order by rand();\n# Time: 140304 19:59:14",
46 | "@version" => "1",
47 | "tags" => [
48 | [0] "multiline"
49 | ],
50 | "type" => "mysql-slow",
51 | "host" => "raochenlindeMacBook-Air.local",
52 | "path" => "/var/log/mysql/mysql-slow.log",
53 | "user" => "logstash",
54 | "clienthost" => "localhost",
55 | "clientip" => "127.0.0.1",
56 | "query_time" => 5.310431,
57 | "lock_time" => 0.029219,
58 | "rows_sent" => 1,
59 | "rows_examined" => 24575727,
60 | "query" => "select count(*) from node join variable order by rand();",
61 | "action" => "select"
62 | }
63 | ```
64 |
--------------------------------------------------------------------------------
/logstash/examples/nginx-error.md:
--------------------------------------------------------------------------------
1 | # Nginx 错误日志
2 |
3 | Nginx 错误日志是运维人员最常见但又极其容易忽略的日志类型之一。Nginx 错误日志即没有统一明确的分隔符,也没有特别方便的正则模式,但通过 logstash 不同插件的组合,还是可以轻松做到数据处理。
4 |
5 | 值得注意的是,Nginx 错误日志中,有一类数据是接收过大请求体时的报错,默认信息会把请求体的具体字节数记录下来。每次请求的字节数基本都是在变化的,这意味着常用的 topN 等聚合函数对该字段都没有明显效果。所以,对此需要做一下特殊处理。
6 |
7 | 最后形成的 logstash 配置如下所示:
8 |
9 | ```
10 | filter {
11 | grok {
12 | match => { "message" => "(?\d\d\d\d/\d\d/\d\d \d\d:\d\d:\d\d) \[(?\w+)\] \S+: \*\d+ (?[^,]+), (?.*)$" }
13 | }
14 | mutate {
15 | rename => [ "host", "fromhost" ]
16 | gsub => [ "errmsg", "too large body: \d+ bytes", "too large body" ]
17 | }
18 | if [errinfo]
19 | {
20 | ruby {
21 | code => "
22 | new_event = LogStash::Event.new(Hash[event.get('errinfo').split(', ').map{|l| l.split(': ')}])
23 | new_event.remove('@timestamp')
24 | event.append(new_event)
25 | "
26 | }
27 | }
28 | grok {
29 | match => { "request" => '"%{WORD:verb} %{URIPATH:urlpath}(?:\?%{NGX_URIPARAM:urlparam})?(?: HTTP/%{NUMBER:httpversion})"' }
30 | patterns_dir => ["/etc/logstash/patterns"]
31 | remove_field => [ "message", "errinfo", "request" ]
32 | }
33 | }
34 | ```
35 |
36 | 经过这段 logstash 配置的 Nginx 错误日志生成的事件如下所示:
37 |
38 | ```
39 | {
40 | "@version": "1",
41 | "@timestamp": "2015-07-02T01:26:40.000Z",
42 | "type": "nginx-error",
43 | "errtype": "error",
44 | "errmsg": "client intended to send too large body",
45 | "fromhost": "web033.mweibo.yf.sinanode.com",
46 | "client": "36.16.7.17",
47 | "server": "api.v5.weibo.cn",
48 | "host": "\"api.weibo.cn\"",
49 | "verb": "POST",
50 | "urlpath": "/2/client/addlog_batch",
51 | "urlparam": "gsid=_2A254UNaSDeTxGeRI7FMX9CrEyj2IHXVZRG1arDV6PUJbrdANLROskWp9bXakjUZM5792FW9A5S9EU4jxqQ..&wm=3333_2001&i=0c6f156&b=1&from=1053093010&c=iphone&v_p=21&skin=default&v_f=1&s=8f14e573&lang=zh_CN&ua=iPhone7,1__weibo__5.3.0__iphone__os8.3",
52 | "httpversion": "1.1"
53 | }
54 | ```
55 |
--------------------------------------------------------------------------------
/logstash/examples/ossec.md:
--------------------------------------------------------------------------------
1 | # ossec
2 |
3 | *本节作者:林鹏*
4 |
5 | ## 配置OSSEC SYSLOG 输出 (所有agent)
6 |
7 | 1. 编辑ossec.conf 文件(默认为/var/ossec/etc/ossec.conf)
8 | 2. 在ossec.conf中添加下列内容(10.0.0.1 为 接收syslog 的服务器)
9 |
10 | ```
11 |
12 | 10.0.0.1
13 | 9000
14 | default
15 |
16 | ```
17 |
18 | 3. 开启OSSEC允许syslog输出功能
19 |
20 | ```
21 | /var/ossec/bin/ossec-control enable client-syslog
22 | ```
23 |
24 | 4. 重启 OSSEC服务
25 | ```
26 | /var/ossec/bin/ossec-control start
27 | ```
28 |
29 | ## 配置LOGSTASH
30 |
31 | 1. 在logstash 中 配置文件中增加(或新建)如下内容:(假设10.0.0.1 为ES服务器,假设文件名为logstash-ossec.conf )
32 |
33 | ```
34 | input {
35 | udp {
36 | port => 9000
37 | type => "syslog"
38 | }
39 | }
40 | filter {
41 | if [type] == "syslog" {
42 | grok {
43 | match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_host} %{DATA:syslog_program}: Alert Level: %{BASE10NUM:Alert_Level}; Rule: %{BASE10NUM:Rule} - %{GREEDYDATA:Description}; Location: %{GREEDYDATA:Details}" }
44 | add_field => [ "ossec_server", "%{host}" ]
45 | }
46 | mutate {
47 | remove_field => [ "syslog_hostname", "syslog_message", "syslog_pid", "message", "@version", "type", "host" ]
48 | }
49 | }
50 | }
51 | output {
52 | elasticsearch_http {
53 | host => "10.0.0.1"
54 | }
55 | }
56 | ```
57 |
58 | ## 推荐 Kibana dashboard
59 |
60 | 社区已经有人根据 ossec 的常见需求,制作有 dashboard 可以直接从 Kibana3 页面加载使用。
61 |
62 | 
63 |
64 | dashboard 的 JSON 文件见:
65 |
66 | 加载方式,请阅读本书稍后 Kibana 章节相关内容。
67 |
--------------------------------------------------------------------------------
/logstash/get-start/README.md:
--------------------------------------------------------------------------------
1 | # 基础知识
2 |
3 | *什么是 Logstash?为什么要用 Logstash?怎么用 Logstash?*
4 |
5 | 本章正是来回答这个问题,或许不完整,但是足够讲述一些基础概念。跟着我们安装章节一步步来,你就可以成功的运行起来自己的第一个 logstash 了。
6 |
7 | 我可能不会立刻来展示 logstash 配置细节或者运用场景。我认为基础原理和语法的介绍应该更加重要,这些知识未来对你的帮助绝对更大!
8 |
9 | 所以,认真阅读他们吧!
10 |
11 |
--------------------------------------------------------------------------------
/logstash/get-start/daemon.md:
--------------------------------------------------------------------------------
1 | # 长期运行
2 |
3 | 完成上一节的初次运行后,你肯定会发现一点:一旦你按下 Ctrl+C,停下标准输入输出,logstash 进程也就随之停止了。作为一个肯定要长期运行的程序,应该怎么处理呢?
4 |
5 | *本章节问题对于一个运维来说应该属于基础知识,鉴于 ELK 用户很多其实不是运维,添加这段内容。*
6 |
7 | 办法有很多种,下面介绍四种最常用的办法:
8 |
9 | ## 标准的 service 方式
10 |
11 | 采用 RPM、DEB 发行包安装的读者,推荐采用这种方式。发行包内,都自带有 sysV 或者 systemd 风格的启动程序/配置,你只需要直接使用即可。
12 |
13 | 以 RPM 为例,`/etc/init.d/logstash` 脚本中,会加载 `/etc/init.d/functions` 库文件,利用其中的 `daemon` 函数,将 logstash 进程作为后台程序运行。
14 |
15 | 所以,你只需把自己写好的配置文件,统一放在 `/etc/logstash/conf.d` 目录下(注意目录下所有配置文件都应该是 **.conf** 结尾,且不能有其他文本文件存在。因为 logstash agent 启动的时候是读取全文件夹的),然后运行 `service logstash start` 命令即可。
16 |
17 | ## 最基础的 nohup 方式
18 |
19 | 这是最简单的方式,也是 linux 新手们很容易搞混淆的一个经典问题:
20 |
21 | ```
22 | command
23 | command > /dev/null
24 | command > /dev/null 2>&1
25 | command &
26 | command > /dev/null &
27 | command > /dev/null 2>&1 &
28 | command &> /dev/null
29 | nohup command &> /dev/null
30 | ```
31 |
32 | 请回答以上命令的异同……
33 |
34 | 具体不一一解释了。直接说答案,想要维持一个长期后台运行的 logstash,你需要同时在命令前面加 `nohup`,后面加 `&`。
35 |
36 | ## 更优雅的 SCREEN 方式
37 |
38 | screen 算是 linux 运维一个中高级技巧。通过 screen 命令创建的环境下运行的终端命令,其父进程不是 sshd 登录会话,而是 screen 。这样就可以即避免用户退出进程消失的问题,又随时能重新接管回终端继续操作。
39 |
40 | 创建独立的 screen 命令如下:
41 |
42 | ```
43 | screen -dmS elkscreen_1
44 | ```
45 |
46 | 接管连入创建的 `elkscreen_1` 命令如下:
47 |
48 | ```
49 | screen -r elkscreen_1
50 | ```
51 |
52 | 然后你可以看到一个一模一样的终端,运行 logstash 之后,不要按 Ctrl+C,而是按 Ctrl+A+D 键,断开环境。想重新接管,依然 `screen -r elkscreen_1` 即可。
53 |
54 | 如果创建了多个 screen,查看列表命令如下:
55 |
56 | ```
57 | screen -list
58 | ```
59 |
60 | ## 最推荐的 daemontools 方式
61 |
62 | 不管是 nohup 还是 screen,都不是可以很方便管理的方式,在运维管理一个 ELK 集群的时候,必须寻找一种尽可能简洁的办法。所以,对于需要长期后台运行的大量程序(注意大量,如果就一个进程,还是学习一下怎么写 init 脚本吧),推荐大家使用一款 daemontools 工具。
63 |
64 | daemontools 是一个软件名称,不过配置略复杂。所以这里我其实是用其名称来指代整个同类产品,包括但不限于 python 实现的 supervisord,perl 实现的 ubic,ruby 实现的 god 等。
65 |
66 | 以 supervisord 为例,因为这个出来的比较早,可以直接通过 EPEL 仓库安装。
67 |
68 | ```
69 | yum -y install supervisord --enablerepo=epel
70 | ```
71 |
72 | 在 `/etc/supervisord.conf` 配置文件里添加内容,定义你要启动的程序:
73 |
74 | ```
75 | [program:elkpro_1]
76 | environment=LS_HEAP_SIZE=5000m
77 | directory=/opt/logstash
78 | command=/opt/logstash/bin/logstash -f /etc/logstash/pro1.conf -w 10 -l /var/log/logstash/pro1.log
79 | [program:elkpro_2]
80 | environment=LS_HEAP_SIZE=5000m
81 | directory=/opt/logstash
82 | command=/opt/logstash/bin/logstash -f /etc/logstash/pro2.conf -w 10 -l /var/log/logstash/pro2.log
83 | ```
84 |
85 | 然后启动 `service supervisord start` 即可。
86 |
87 | logstash 会以 supervisord 子进程的身份运行,你还可以使用 `supervisorctl` 命令,单独控制一系列 logstash 子进程中某一个进程的启停操作:
88 |
89 | `supervisorctl stop elkpro_2`
90 |
91 |
--------------------------------------------------------------------------------
/logstash/get-start/hello-world.md:
--------------------------------------------------------------------------------
1 | # Hello World
2 |
3 | 和绝大多数 IT 技术介绍一样,我们以一个输出 "hello world" 的形式开始我们的 logstash 学习。
4 |
5 | ## 运行
6 |
7 | 在终端中,像下面这样运行命令来启动 Logstash 进程:
8 |
9 | ```
10 | # bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
11 | ```
12 |
13 | 然后你会发现终端在等待你的输入。没问题,敲入 **Hello World**,回车,然后看看会返回什么结果!
14 |
15 | ## 结果
16 |
17 | ```ruby
18 | {
19 | "message" => "Hello World",
20 | "@version" => "1",
21 | "@timestamp" => "2014-08-07T10:30:59.937Z",
22 | "host" => "raochenlindeMacBook-Air.local",
23 | }
24 | ```
25 |
26 | 没错!你搞定了!这就是全部你要做的。
27 |
28 | ## 解释
29 |
30 | 每位系统管理员都肯定写过很多类似这样的命令:`cat randdata | awk '{print $2}' | sort | uniq -c | tee sortdata`。这个管道符 `|` 可以算是 Linux 世界最伟大的发明之一(另一个是“一切皆文件”)。
31 |
32 | Logstash 就像管道符一样!
33 |
34 | 你**输入**(就像命令行的 `cat` )数据,然后处理**过滤**(就像 `awk` 或者 `uniq` 之类)数据,最后**输出**(就像 `tee` )到其他地方。
35 |
36 | *当然实际上,Logstash 是用不同的线程来实现这些的。如果你运行 `top` 命令然后按下 `H` 键,你就可以看到下面这样的输出:*
37 |
38 | ```
39 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
40 | 21401 root 16 0 1249m 303m 10m S 18.6 0.2 866:25.46 |worker
41 | 21467 root 15 0 1249m 303m 10m S 3.7 0.2 129:25.59 >elasticsearch.
42 | 21468 root 15 0 1249m 303m 10m S 3.7 0.2 128:53.39 >elasticsearch.
43 | 21400 root 15 0 1249m 303m 10m S 2.7 0.2 108:35.80 output
45 | 21470 root 15 0 1249m 303m 10m S 1.0 0.2 56:24.24 >elasticsearch.
46 | ```
47 |
48 | *小贴士:logstash 很温馨的给每个线程都取了名字,输入的叫xx,过滤的叫|xx*
49 |
50 | 数据在线程之间以 **事件** 的形式流传。不要叫*行*,因为 logstash 可以处理[多行](../codec/multiline.md)事件。
51 |
52 | Logstash 会给事件添加一些额外信息。最重要的就是 **@timestamp**,用来标记事件的发生时间。因为这个字段涉及到 Logstash 的内部流转,所以必须是一个 joda 对象,如果你尝试自己给一个字符串字段重命名为 `@timestamp` 的话,Logstash 会直接报错。所以,**请使用 [filters/date 插件](../filter/date.md) 来管理这个特殊字段**。
53 |
54 | 此外,大多数时候,还可以见到另外几个:
55 |
56 | 1. **host** 标记事件发生在哪里。
57 | 2. **type** 标记事件的唯一类型。
58 | 3. **tags** 标记事件的某方面属性。这是一个数组,一个事件可以有多个标签。
59 |
60 | 你可以随意给事件添加字段或者从事件里删除字段。事实上事件就是一个 Ruby 对象,或者更简单的理解为就是一个哈希也行。
61 |
62 | *小贴士:每个 logstash 过滤插件,都会有四个方法叫 `add_tag`, `remove_tag`, `add_field` 和 `remove_field`。它们在插件过滤匹配成功时生效。*
63 |
64 | ## 推荐阅读
65 |
66 | * [《the life of an event》官网文档](http://logstash.net/docs/1.4.2/life-of-an-event)
67 | * [《life of a logstash event》Elastic{ON} 上的演讲](https://speakerdeck.com/elastic/life-of-a-logstash-event)
68 |
--------------------------------------------------------------------------------
/logstash/get-start/install-plugins.md:
--------------------------------------------------------------------------------
1 | # plugin的安装
2 |
3 | 从 logstash 1.5.0 版本开始,logstash 将所有的插件都独立拆分成 gem 包。这样,每个插件都可以独立更新,不用等待 logstash 自身做整体更新的时候才能使用了。
4 |
5 | 为了达到这个目标,logstash 配置了专门的 plugins 管理命令。
6 |
7 | ## plugin 用法说明
8 |
9 | ```
10 | Usage:
11 | bin/logstash-plugin [OPTIONS] SUBCOMMAND [ARG] ...
12 |
13 | Parameters:
14 | SUBCOMMAND subcommand
15 | [ARG] ... subcommand arguments
16 |
17 | Subcommands:
18 | install Install a plugin
19 | uninstall Uninstall a plugin
20 | update Install a plugin
21 | list List all installed plugins
22 |
23 | Options:
24 | -h, --help print help
25 | ```
26 |
27 | ## 示例
28 |
29 | 首先,你可以通过 `bin/logstash-plugin list` 查看本机现在有多少插件可用。(其实就在 vendor/bundle/jruby/1.9/gems/ 目录下)
30 |
31 | 然后,假如你看到 `https://github.com/logstash-plugins/` 下新发布了一个 `logstash-output-webhdfs` 模块(当然目前还没有)。打算试试,就只需要运行:
32 |
33 | ```
34 | bin/logstash-plugin install logstash-output-webhdfs
35 | ```
36 |
37 | 就可以了。
38 |
39 | 同样,假如是升级,只需要运行:
40 |
41 | ```
42 | bin/logstash-plugin update logstash-input-tcp
43 | ```
44 |
45 | 即可。
46 |
47 | ## 本地插件安装
48 |
49 | `bin/logstash-plugin` 不单可以通过 rubygems 平台安装插件,还可以读取本地路径的 gem 文件。这对自定义插件或者无外接网络的环境都非常有效:
50 |
51 | ```
52 | bin/logstash-plugin install /path/to/logstash-filter-crash.gem
53 | ```
54 |
55 | 执行成功以后。你会发现,logstash-5.0.0 目录下的 Gemfile 文件最后会多出一段内容:
56 |
57 | ```
58 | gem "logstash-filter-crash", "1.1.0", :path => "vendor/local_gems/d354312c/logstash-filter-mweibocrash-1.1.0"
59 | ```
60 |
61 | 同时 Gemfile.jruby-1.9.lock 文件开头也会多出一段内容:
62 |
63 | ```
64 | PATH
65 | remote: vendor/local_gems/d354312c/logstash-filter-crash-1.1.0
66 | specs:
67 | logstash-filter-crash (1.1.0)
68 | logstash-core (>= 1.4.0, < 2.0.0)
69 | ```
70 |
--------------------------------------------------------------------------------
/logstash/get-start/install.md:
--------------------------------------------------------------------------------
1 | # 安装
2 |
3 | ## 下载
4 |
5 | 直接下载官方发布的二进制包的,可以访问 页面找对应操作系统和版本,点击下载即可。不过更推荐使用软件仓库完成安装。
6 |
7 | ## 安装
8 |
9 | 如果你必须得在一些很老的操作系统上运行 Logstash,那你只能用源代码包部署了,记住要自己提前安装好 Java:
10 |
11 | ```
12 | yum install java-1.8.0-openjdk
13 | export JAVA_HOME=/usr/java
14 | ```
15 |
16 | 软件仓库的配置,主要两大平台如下:
17 |
18 | ### Debian 平台
19 |
20 | ```bash
21 | wget -O - http://packages.elasticsearch.org/GPG-KEY-elasticsearch | apt-key add -
22 | cat >> /etc/apt/sources.list < /etc/yum.repos.d/logstash.repo < 10000000
11 | message => '{"key1":"value1","key2":[1,2],"key3":{"subkey1":"subvalue1"}}'
12 | codec => json
13 | }
14 | }
15 | ```
16 |
17 | 插件的默认生成数据,message 内容是 "hello world"。你可以根据自己的实际需要这里来写其他内容。
18 |
19 | ## 使用方式
20 |
21 | 做测试有两种主要方式:
22 |
23 | * 配合 LogStash::Outputs::Null
24 |
25 | inputs/generator 是无中生有,output/null 则是锯嘴葫芦。事件流转到这里直接就略过,什么操作都不做。相当于只测试 Logstash 的 pipe 和 filter 效率。测试过程非常简单:
26 |
27 | $ time ./bin/logstash -f generator_null.conf
28 | real 3m0.864s
29 | user 3m39.031s
30 | sys 0m51.621s
31 |
32 | * 使用 pv 命令配合 LogStash::Outputs::Stdout 和 LogStash::Codecs::Dots
33 |
34 | 上面的这种方式虽然想法挺好,不过有个小漏洞:logstash 是在 JVM 上运行的,有一个明显的启动时间,运行也有一段事件的预热后才算稳定运行。所以,要想更真实的反应 logstash 在长期运行时候的效率,还有另一种方法:
35 |
36 | ```
37 | output {
38 | stdout {
39 | codec => dots
40 | }
41 | }
42 | ```
43 |
44 | LogStash::Codecs::Dots 也是一个另类的 codec 插件,他的作用是:把每个 event 都变成一个点(`.`)。这样,在输出的时候,就变成了一个一个的 `.` 在屏幕上。显然这也是一个为了测试而存在的插件。
45 |
46 | 下面就要介绍 pv 命令了。这个命令的作用,就是作实时的标准输入、标准输出监控。我们这里就用它来监控标准输出:
47 |
48 | $ ./bin/logstash -f generator_dots.conf | pv -abt > /dev/null
49 | 2.2MiB 0:03:00 [12.5kiB/s]
50 |
51 | 可以很明显的看到在前几秒中,速度是 0 B/s,因为 JVM 还没启动起来呢。开始运行的时候,速度依然不快。慢慢增长到比较稳定的状态,这时候的才是你需要的数据。
52 |
53 | 这里单位是 B/s,但是因为一个 event 就输出一个 `.`,也就是 1B。所以 12.5kiB/s 就相当于是 12.5k event/s。
54 |
55 | *注:如果你在 CentOS 上通过 yum 安装的 pv 命令,版本较低,可能还不支持 -a 参数。单纯靠 -bt 参数看起来还是有点累的。*
56 |
57 | 如果你要测试的是 input 插件的效率,方法也是类似的。此外,如果不想使用额外而且可能低版本的 pv 命令,通过 logstash-filter-metric 插件也可以做到类似的效果,[官方博客](https://www.elastic.co/blog/logstash-configuration-tuning)中对此有详细阐述,建议大家阅读。
58 |
59 | ## 额外的话
60 |
61 | 既然单独花这么一节来说测试,这里想额外谈谈一个很常见的话题:* ELK 的性能怎么样?*
62 |
63 | **其实这压根就是一个不正确的提问**。ELK 并不是一个软件而是一个并不耦合的套件。所以,我们需要分拆开讨论这三个软件的性能如何?怎么优化?
64 |
65 | * LogStash 的性能,是最让新人迷惑的地方。因为 LogStash 本身并不维护队列,所以整个日志流转中任意环节的问题,都可能看起来像是 LogStash 的问题。这里,需要熟练使用本节说的测试方法,针对自己的每一段配置,都确定其性能。另一方面,就是本书之前提到过的,LogStash 给自己的线程都设置了单独的线程名称,你可以在 `top -H` 结果中查看具体线程的负载情况。
66 |
67 | * Elasticsearch 的性能。这里最需要强调的是:Elasticsearch 是一个分布式系统。从来没有分布式系统要跟人比较单机处理能力的说法。所以,更需要关注的是:在确定的单机处理能力的前提下,性能是否能做到线性扩展。当然,这不意味着说提高处理能力只能靠加机器了——有效利用 mapping API 是非常重要的。不过暂时就在这里讲述了。
68 |
69 | * Kibana 的性能。通常来说,Kibana 只是一个单页 Web 应用,只需要 nginx 发布静态文件即可,没什么性能问题。页面加载缓慢,基本上是因为 Elasticsearch 的请求响应时间本身不够快导致的。不过一定要细究的话,也能找出点 Kibana 本身性能相关的话题:因为 Kibana3 默认是连接固定的一个 ES 节点的 IP 端口的,所以这里会涉及一个浏览器的同一 IP 并发连接数的限制。其次,就是 Kibana 用的 AngularJS 使用了 Promise.then 的方式来处理 HTTP 请求响应。这是异步的。
70 |
--------------------------------------------------------------------------------
/logstash/performance/monitor/heartbeat.md:
--------------------------------------------------------------------------------
1 | # 心跳检测
2 |
3 | 缺少内部队列状态的监控办法一直是 logstash 最为人诟病的一点。从 logstash-1.5.1 版开始,新发布了一个 logstash-input-heartbeat 插件,实现了一个最基本的队列堵塞状态监控。
4 |
5 | 配置示例如下:
6 |
7 | ```
8 | input {
9 | heartbeat {
10 | message => "epoch"
11 | interval => 60
12 | type => "heartbeat"
13 | add_field => {
14 | "zbxkey" => "logstash.heartbeat",
15 | "zbxhost" => "logstash_hostname"
16 | }
17 | }
18 | tcp {
19 | port => 5160
20 | }
21 | }
22 | output {
23 | if [type] == "heartbeat" {
24 | file {
25 | path => "/data1/logstash-log/local6-5160-%{+YYYY.MM.dd}.log"
26 | }
27 | zabbix {
28 | zabbix_host => "zbxhost"
29 | zabbix_key => "zbxkey"
30 | zabbix_server_host => "zabbix.example.com"
31 | zabbix_value => "clock"
32 | }
33 | } else {
34 | elasticsearch { }
35 | }
36 | }
37 | ```
38 |
39 | 示例中,同时将数据输出到本地文件和 zabbix server。注意,logstash-output-zabbix 并不是标准插件,需要额外安装:
40 |
41 | ```
42 | bin/logstash-plugin install logstash-output-zabbix
43 | ```
44 |
45 | 文件中记录的就是 heartbeat 事件的内容,示例如下:
46 |
47 | ```
48 | {"clock":1435191129,"host":"logtes004.mweibo.bx.sinanode.com","@version":"1","@timestamp":"2015-06-25T00:12:09.042Z","type":"heartbeat","zbxkey":"logstash.heartbeat","zbxhost":"logstash_hostname"}
49 | ```
50 |
51 | 可以通过文件最后的 clock 和 @timestamp 内容,对比当前时间,来判断 logstash 内部队列是否有堵塞。
52 |
--------------------------------------------------------------------------------
/logstash/performance/monitor/jconsole.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chenryn/ELKstack-guide-cn/a30092eb98bae2148782f3d851039f327c2de2f7/logstash/performance/monitor/jconsole.png
--------------------------------------------------------------------------------
/logstash/performance/monitor/jmx.md:
--------------------------------------------------------------------------------
1 | # JMX 监控方式
2 |
3 | Logstash 是一个运行在 JVM 上的软件,也就意味着 JMX 这种对 JVM 的通用监控方式对 Logstash 也是一样有效果的。要给 Logstash 启用 JMX,需要修改 `./bin/logstash.lib.sh` 中 `$JAVA_OPTS` 变量的定义,或者在运行时设置 `LS_JAVA_OPTS` 环境变量。
4 |
5 | 在 `./bin/logstash.lib.sh` 第 34 行 `JAVA_OPTS="$JAVA_OPTS -Djava.awt.headless=true"` 下,添加如下几行:
6 |
7 | ```
8 | JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote"
9 | JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=9010"
10 | JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.local.only=false"
11 | JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.authenticate=false"
12 | JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.ssl=false"
13 | ```
14 |
15 | 重启 logstash 服务,JMX 配置即可生效。
16 |
17 | 有 JMX 以后,我们可以通过 jconsole 界面查看,也可以通过 zabbix 等监控系统做长期监控。甚至 logstash 自己也有插件 logstash-input-jmx 来读取远程 JMX 数据。
18 |
19 | ## zabbix 监控
20 |
21 | zabbix 里提供了专门针对 JMX 的监控项。详见:
22 |
23 | 注意,zabbix-server 本身并不直接对 JMX 发起请求,而是单独有一个 Java Gateway 作为中间代理层角色。zabbix-server 的 java poller 连接 zabbix-java-gateway,由 zabbix-java-gateway 去获取远程 JMX 信息。所以,在 zabbix-web 配置之前,需要先配置 zabbix server 相关进程和设置:
24 |
25 | ```
26 | # yum install zabbix-java-gateway
27 | # cat >> /etc/zabbix/zabbix-server.conf < "/var/log/nginx/access.log_json"
32 | codec => "json"
33 | }
34 | }
35 | ```
36 |
37 | ## 运行结果
38 |
39 | 下面访问一下你 nginx 发布的 web 页面,然后你会看到 logstash 进程输出类似下面这样的内容:
40 |
41 | ```ruby
42 | {
43 | "@timestamp" => "2014-03-21T18:52:25.000+08:00",
44 | "@version" => "1",
45 | "host" => "raochenlindeMacBook-Air.local",
46 | "client" => "123.125.74.53",
47 | "size" => 8096,
48 | "responsetime" => 0.04,
49 | "domain" => "www.domain.com",
50 | "url" => "/path/to/file.suffix",
51 | "status" => "200"
52 | }
53 | ```
54 |
55 | ## 小贴士
56 |
57 | 对于一个 web 服务器的访问日志,看起来已经可以很好的工作了。不过如果 Nginx 是作为一个代理服务器运行的话,访问日志里有些变量,比如说 `$upstream_response_time`,可能不会一直是数字,它也可能是一个 `"-"` 字符串!这会直接导致 logstash 对输入数据验证报异常。
58 |
59 | 有两个办法解决这个问题:
60 |
61 | 1. 用 `sed` 在输入之前先替换 `-` 成 `0`。
62 |
63 | 运行 logstash 进程时不再读取文件而是标准输入,这样命令就成了下面这个样子:
64 |
65 | ```
66 | tail -F /var/log/nginx/proxy_access.log_json \
67 | | sed 's/upstreamtime":-/upstreamtime":0/' \
68 | | /usr/local/logstash/bin/logstash -f /usr/local/logstash/etc/proxylog.conf
69 | ```
70 |
71 | 2. 日志格式中统一记录为字符串格式(即都带上双引号 `"`),然后再在 logstash 中用 `filter/mutate` 插件来变更应该是数值类型的字符字段的值类型。
72 |
73 | 有关 `LogStash::Filters::Mutate` 的内容,本书稍后会有介绍。
74 |
--------------------------------------------------------------------------------
/logstash/plugins/codec/multiline.md:
--------------------------------------------------------------------------------
1 | # 合并多行数据(Multiline)
2 |
3 | 有些时候,应用程序调试日志会包含非常丰富的内容,为一个事件打印出很多行内容。这种日志通常都很难通过命令行解析的方式做分析。
4 |
5 | 而 logstash 正为此准备好了 *codec/multiline* 插件!
6 |
7 | *小贴士:multiline 插件也可以用于其他类似的堆栈式信息,比如 linux 的内核日志。*
8 |
9 | ## 配置示例
10 |
11 | ```
12 | input {
13 | stdin {
14 | codec => multiline {
15 | pattern => "^\["
16 | negate => true
17 | what => "previous"
18 | }
19 | }
20 | }
21 | ```
22 |
23 | ## 运行结果
24 |
25 | 运行 logstash 进程,然后在等待输入的终端中输入如下几行数据:
26 |
27 | ```
28 | [Aug/08/08 14:54:03] hello world
29 | [Aug/08/09 14:54:04] hello logstash
30 | hello best practice
31 | hello raochenlin
32 | [Aug/08/10 14:54:05] the end
33 | ```
34 |
35 | 你会发现 logstash 输出下面这样的返回:
36 |
37 | ```ruby
38 | {
39 | "@timestamp" => "2014-08-09T13:32:03.368Z",
40 | "message" => "[Aug/08/08 14:54:03] hello world\n",
41 | "@version" => "1",
42 | "host" => "raochenlindeMacBook-Air.local"
43 | }
44 | {
45 | "@timestamp" => "2014-08-09T13:32:24.359Z",
46 | "message" => "[Aug/08/09 14:54:04] hello logstash\n\n hello best practice\n\n hello raochenlin\n",
47 | "@version" => "1",
48 | "tags" => [
49 | [0] "multiline"
50 | ],
51 | "host" => "raochenlindeMacBook-Air.local"
52 | }
53 | ```
54 |
55 | 你看,后面这个事件,在 "message" 字段里存储了三行数据!
56 |
57 | *小贴士:你可能注意到输出的事件中都没有最后的"the end"字符串。这是因为你最后输入的回车符 `\n` 并不匹配设定的 `^\[` 正则表达式,logstash 还得等下一行数据直到匹配成功后才会输出这个事件。*
58 |
59 | ## 解释
60 |
61 | 其实这个插件的原理很简单,就是把当前行的数据添加到前面一行后面,,直到新进的当前行匹配 `^\[` 正则为止。
62 |
63 | 这个正则还可以用 grok 表达式,稍后你就会学习这方面的内容。
64 |
65 | ## Log4J 的另一种方案
66 |
67 | 说到应用程序日志,log4j 肯定是第一个被大家想到的。使用 `codec/multiline` 也确实是一个办法。
68 |
69 | 不过,如果你本身就是开发人员,或者可以推动程序修改变更的话,logstash 还提供了另一种处理 log4j 的方式:[input/log4j](http://logstash.net/docs/1.4.2/inputs/log4j)。与 `codec/multiline` 不同,这个插件是直接调用了 `org.apache.log4j.spi.LoggingEvent` 处理 TCP 端口接收的数据。稍后章节会详细讲述 log4j 的用法。
70 |
71 | ## 推荐阅读
72 |
73 |
74 |
--------------------------------------------------------------------------------
/logstash/plugins/codec/netflow.md:
--------------------------------------------------------------------------------
1 | # netflow
2 |
3 | ```
4 | input {
5 | udp {
6 | port => 9995
7 | codec => netflow {
8 | definitions => "/home/administrator/logstash-1.4.2/lib/logstash/codecs/netflow/netflow.yaml"
9 | versions => [5]
10 | }
11 | }
12 | }
13 |
14 | output {
15 | stdout { codec => rubydebug }
16 | if ( [host] =~ "10\.1\.1[12]\.1" ) {
17 | elasticsearch {
18 | index => "logstash_netflow5-%{+YYYY.MM.dd}"
19 | host => "localhost"
20 | }
21 | } else {
22 | elasticsearch {
23 | index => "logstash-%{+YYYY.MM.dd}"
24 | host => "localhost"
25 | }
26 | }
27 | }
28 | ```
29 |
30 |
31 | ```
32 | curl -XPUT localhost:9200/_template/logstash_netflow5 -d '{
33 | "template" : "logstash_netflow5-*",
34 | "settings": {
35 | "index.refresh_interval": "5s"
36 | },
37 | "mappings" : {
38 | "_default_" : {
39 | "_all" : {"enabled" : false},
40 | "properties" : {
41 | "@version": { "index": "analyzed", "type": "integer" },
42 | "@timestamp": { "index": "analyzed", "type": "date" },
43 | "netflow": {
44 | "dynamic": true,
45 | "type": "object",
46 | "properties": {
47 | "version": { "index": "analyzed", "type": "integer" },
48 | "flow_seq_num": { "index": "not_analyzed", "type": "long" },
49 | "engine_type": { "index": "not_analyzed", "type": "integer" },
50 | "engine_id": { "index": "not_analyzed", "type": "integer" },
51 | "sampling_algorithm": { "index": "not_analyzed", "type": "integer" },
52 | "sampling_interval": { "index": "not_analyzed", "type": "integer" },
53 | "flow_records": { "index": "not_analyzed", "type": "integer" },
54 | "ipv4_src_addr": { "index": "analyzed", "type": "ip" },
55 | "ipv4_dst_addr": { "index": "analyzed", "type": "ip" },
56 | "ipv4_next_hop": { "index": "analyzed", "type": "ip" },
57 | "input_snmp": { "index": "not_analyzed", "type": "long" },
58 | "output_snmp": { "index": "not_analyzed", "type": "long" },
59 | "in_pkts": { "index": "analyzed", "type": "long" },
60 | "in_bytes": { "index": "analyzed", "type": "long" },
61 | "first_switched": { "index": "not_analyzed", "type": "date" },
62 | "last_switched": { "index": "not_analyzed", "type": "date" },
63 | "l4_src_port": { "index": "analyzed", "type": "long" },
64 | "l4_dst_port": { "index": "analyzed", "type": "long" },
65 | "tcp_flags": { "index": "analyzed", "type": "integer" },
66 | "protocol": { "index": "analyzed", "type": "integer" },
67 | "src_tos": { "index": "analyzed", "type": "integer" },
68 | "src_as": { "index": "analyzed", "type": "integer" },
69 | "dst_as": { "index": "analyzed", "type": "integer" },
70 | "src_mask": { "index": "analyzed", "type": "integer" },
71 | "dst_mask": { "index": "analyzed", "type": "integer" }
72 | }
73 | }
74 | }
75 | }
76 | }
77 | }'
78 | ```
79 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/README.md:
--------------------------------------------------------------------------------
1 | # 过滤器插件(Filter)
2 |
3 | 丰富的过滤器插件的存在是 logstash 威力如此强大的重要因素。名为过滤器,其实提供的不单单是过滤的功能。在本章我们就会重点介绍几个插件,它们扩展了进入过滤器的原始数据,进行复杂的逻辑处理,甚至可以无中生有的添加新的 logstash 事件到后续的流程中去!
4 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/dissect.md:
--------------------------------------------------------------------------------
1 | # dissect
2 |
3 | grok 作为 Logstash 最广为人知的插件,在性能和资源损耗方面同样也广为诟病。为了应对这个情况,同时也考虑到大多数时候,日志格式并没有那么复杂,Logstash 开发团队在 5.0 版新添加了另一个解析字段的插件:dissect。
4 |
5 | 当日志格式有比较简明的分隔标志位,而且重复性较大的时候,我们可以使用 dissect 插件更快的完成解析工作。下面是解析 syslog 的示例:
6 |
7 | ## 示例
8 |
9 | ```
10 | filter {
11 | dissect {
12 | mapping => {
13 | "message" => "%{ts} %{+ts} %{+ts} %{src} %{} %{prog}[%{pid}]: %{msg}"
14 | }
15 | convert_datatype => {
16 | pid => "int"
17 | }
18 | }
19 | }
20 | ```
21 |
22 | ## 语法解释
23 |
24 | 我们看到上面使用了和 Grok 很类似的 `%{}` 语法来表示字段,这显然是基于习惯延续的考虑。不过示例中 `%{+ts}` 的加号就不一般了。dissect 除了字段外面的字符串定位功能以外,还通过几个特殊符号来处理字段提取的规则:
25 |
26 | * %{+key}
27 | 这个 `+` 表示,前面已经捕获到一个 key 字段了,而这次捕获的内容,自动添补到之前 key 字段内容的后面。
28 | * %{+key/2}
29 | 这个 `/2` 表示,在有多次捕获内容都填到 key 字段里的时候,拼接字符串的顺序谁前谁后。`/2` 表示排第 2 位。
30 | * %{?string}
31 | 这个 `?` 表示,这块只是一个占位,并不会实际生成捕获字段存到 Event 里面。
32 | * %{?string} %{&string}
33 | 当同样捕获名称都是 string,但是一个 `?` 一个 `&` 的时候,表示这是一个键值对。
34 |
35 | 比如对 `http://rizhiyi.com/index.do?id=123` 写这么一段配置:
36 |
37 | ```
38 | http://%{domain}/%{?url}?%{?arg1}=%{&arg1}
39 | ```
40 |
41 | 则最终生成的 Event 内容是这样的:
42 |
43 | ```
44 | {
45 | domain => "rizhiyi.com",
46 | id => "123"
47 | }
48 | ```
49 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/elapsed.md:
--------------------------------------------------------------------------------
1 | # elapsed
2 |
3 | ```
4 | filter {
5 | grok {
6 | match => ["message", "%{TIMESTAMP_ISO8601} START id: (?.*)"]
7 | add_tag => [ "taskStarted" ]
8 | }
9 | grok {
10 | match => ["message", "%{TIMESTAMP_ISO8601} END id: (?.*)"]
11 | add_tag => [ "taskTerminated"]
12 | }
13 | elapsed {
14 | start_tag => "taskStarted"
15 | end_tag => "taskTerminated"
16 | unique_id_field => "task_id"
17 | }
18 | }
19 | ```
20 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/geoip.md:
--------------------------------------------------------------------------------
1 | # GeoIP 地址查询归类
2 |
3 | GeoIP 是最常见的免费 IP 地址归类查询库,同时也有收费版可以采购。GeoIP 库可以根据 IP 地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化地图和区域统计非常有用。
4 |
5 | ## 配置示例
6 |
7 | ```
8 | filter {
9 | geoip {
10 | source => "message"
11 | }
12 | }
13 | ```
14 |
15 |
16 | ## 运行结果
17 |
18 | ```ruby
19 | {
20 | "message" => "183.60.92.253",
21 | "@version" => "1",
22 | "@timestamp" => "2014-08-07T10:32:55.610Z",
23 | "host" => "raochenlindeMacBook-Air.local",
24 | "geoip" => {
25 | "ip" => "183.60.92.253",
26 | "country_code2" => "CN",
27 | "country_code3" => "CHN",
28 | "country_name" => "China",
29 | "continent_code" => "AS",
30 | "region_name" => "30",
31 | "city_name" => "Guangzhou",
32 | "latitude" => 23.11670000000001,
33 | "longitude" => 113.25,
34 | "timezone" => "Asia/Chongqing",
35 | "real_region_name" => "Guangdong",
36 | "location" => [
37 | [0] 113.25,
38 | [1] 23.11670000000001
39 | ]
40 | }
41 | }
42 | ```
43 |
44 | ## 配置说明
45 |
46 | GeoIP 库数据较多,如果你不需要这么多内容,可以通过 `fields` 选项指定自己所需要的。下例为全部可选内容:
47 |
48 | ```
49 | filter {
50 | geoip {
51 | fields => ["city_name", "continent_code", "country_code2", "country_code3", "country_name", "dma_code", "ip", "latitude", "longitude", "postal_code", "region_name", "timezone"]
52 | }
53 | }
54 | ```
55 |
56 | 需要注意的是:`geoip.location` 是 logstash 通过 `latitude` 和 `longitude` 额外生成的数据。所以,如果你是想要经纬度又不想重复数据的话,应该像下面这样做:
57 |
58 | filter {
59 | geoip {
60 | fields => ["city_name", "country_code2", "country_name", "latitude", "longitude", "region_name"]
61 | remove_field => ["[geoip][latitude]", "[geoip][longitude]"]
62 | }
63 | }
64 | ```
65 |
66 | ## 小贴士
67 |
68 | geoip 插件的 "source" 字段可以是任一处理后的字段,比如 "client_ip",但是字段内容却需要小心!geoip 库内只存有公共网络上的 IP 信息,查询不到结果的,会直接返回 null,而 logstash 的 geoip 插件对 null 结果的处理是:**不生成对应的 geoip.字段。**
69 |
70 | 所以读者在测试时,如果使用了诸如 127.0.0.1, 172.16.0.1, 192.168.0.1, 10.0.0.1 等内网地址,会发现没有对应输出!
71 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/json.md:
--------------------------------------------------------------------------------
1 | # JSON 编解码
2 |
3 | 在上一章,已经讲过在 codec 中使用 JSON 编码。但是,有些日志可能是一种复合的数据结构,其中只是一部分记录是 JSON 格式的。这时候,我们依然需要在 filter 阶段,单独启用 JSON 解码插件。
4 |
5 | ## 配置示例
6 |
7 | ```
8 | filter {
9 | json {
10 | source => "message"
11 | target => "jsoncontent"
12 | }
13 | }
14 | ```
15 |
16 | ## 运行结果
17 |
18 | ```
19 | {
20 | "@version": "1",
21 | "@timestamp": "2014-11-18T08:11:33.000Z",
22 | "host": "web121.mweibo.tc.sinanode.com",
23 | "message": "{\"uid\":3081609001,\"type\":\"signal\"}",
24 | "jsoncontent": {
25 | "uid": 3081609001,
26 | "type": "signal"
27 | }
28 | }
29 | ```
30 |
31 | ## 小贴士
32 |
33 | 如果不打算使用多层结构的话,删掉 `target` 配置即可。新的结果如下:
34 |
35 | ```
36 | {
37 | "@version": "1",
38 | "@timestamp": "2014-11-18T08:11:33.000Z",
39 | "host": "web121.mweibo.tc.sinanode.com",
40 | "message": "{\"uid\":3081609001,\"type\":\"signal\"}",
41 | "uid": 3081609001,
42 | "type": "signal"
43 | }
44 | ```
45 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/kv.md:
--------------------------------------------------------------------------------
1 | # Key-Value 切分
2 |
3 | 在很多情况下,日志内容本身都是一个类似于 key-value 的格式,但是格式具体的样式却是多种多样的。logstash 提供 `filters/kv` 插件,帮助处理不同样式的 key-value 日志,变成实际的 LogStash::Event 数据。
4 |
5 | ## 配置示例
6 |
7 | ```
8 | filter {
9 | ruby {
10 | init => "@kname = ['method','uri','verb']"
11 | code => "
12 | new_event = LogStash::Event.new(Hash[@kname.zip(event.get('request').split('|'))])
13 | new_event.remove('@timestamp')
14 | event.append(new_event)
15 | "
16 | }
17 | if [uri] {
18 | ruby {
19 | init => "@kname = ['url_path','url_args']"
20 | code => "
21 | new_event = LogStash::Event.new(Hash[@kname.zip(event.get('uri').split('?'))])
22 | new_event.remove('@timestamp')
23 | event.append(new_event)
24 | "
25 | }
26 | kv {
27 | prefix => "url_"
28 | source => "url_args"
29 | field_split => "&"
30 | remove_field => [ "url_args", "uri", "request" ]
31 | }
32 | }
33 | }
34 | ```
35 |
36 | ## 解释
37 |
38 | Nginx 访问日志中的 `$request`,通过这段配置,可以详细切分成 `method`, `url_path`, `verb`, `url_a`, `url_b` ...
39 |
40 | 进一步的,如果 url_args 中有过多字段,可能导致 Elasticsearch 集群因为频繁 update mapping 或者消耗太多内存在 cluster state 上而宕机。所以,更优的选择,是只保留明确有用的 url_args 内容,其他部分舍去。
41 |
42 | ```
43 | kv {
44 | prefix => "url_"
45 | source => "url_args"
46 | field_split => "&"
47 | include_keys => [ "uid", "cip" ]
48 | remove_field => [ "url_args", "uri", "request" ]
49 | }
50 | ```
51 |
52 | 上例即表示,除了 `url_uid` 和 `url_cip` 两个字段以外,其他的 `url_*` 都不保留。
53 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/metrics.md:
--------------------------------------------------------------------------------
1 | # 数值统计(Metrics)
2 |
3 | *filters/metrics* 插件是使用 Ruby 的 *Metriks* 模块来实现在内存里实时的计数和采样分析。该模块支持两个类型的数值分析:meter 和 timer。下面分别举例说明:
4 |
5 | ## Meter 示例(速率阈值检测)
6 |
7 | web 访问日志的异常状态码频率是运维人员会非常关心的一个数据。通常我们的做法,是通过 logstash 或者其他日志分析脚本,把计数发送到 rrdtool 或者 graphite 里面。然后再通过 check-graphite 脚本之类的东西来检查异常并报警。
8 |
9 | 事实上这个事情可以直接在 logstash 内部就完成。比如如果最近一分钟 504 请求的个数超过 100 个就报警:
10 |
11 | ```
12 | filter {
13 | metrics {
14 | meter => "error_%{status}"
15 | add_tag => "metric"
16 | ignore_older_than => 10
17 | }
18 | if "metric" in [tags] {
19 | ruby {
20 | code => "event.cancel if (event.get('[error_504][rate_1m]') * 60 > 100)"
21 | }
22 | }
23 | }
24 | output {
25 | if "metric" in [tags] {
26 | exec {
27 | command => "echo \"Out of threshold: %{[error_504][rate_1m]}\""
28 | }
29 | }
30 | }
31 | ```
32 |
33 | 这里需要注意 `*60` 的含义。
34 |
35 | metriks 模块生成的 *rate_1m/5m/15m* 意思是:最近 1,5,15 分钟的**每秒**速率!
36 |
37 |
38 | ## Timer 示例(box and whisker 异常检测)
39 |
40 | 官版的 *filters/metrics* 插件只适用于 metric 事件的检查。由插件生成的新事件内部不存有来自 input 区段的实际数据信息。所以,要完成我们的百分比分布箱体检测,需要首先对代码稍微做几行变动,即在 metric 的 timer 事件里加一个属性,存储最近一个实际事件的数值:
41 |
42 | 有了这个 last 值,然后我们就可以用如下配置来探测异常数据了:
43 |
44 | ```
45 | filter {
46 | metrics {
47 | timer => {"rt" => "%{request_time}"}
48 | percentiles => [25, 75]
49 | add_tag => "percentile"
50 | }
51 | if "percentile" in [tags] {
52 | ruby {
53 | code => "l=event.get('[rt][p75]')-event.get('[rt][p25]');event.set('[rt][low]', event.get('[rt][p25]')-l);event.set('[rt][high]',event.get('[rt][p75]')+l)"
54 | }
55 | }
56 | }
57 | output {
58 | if "percentile" in [tags] and ([rt][last] > [rt][high] or [rt][last] < [rt][low]) {
59 | exec {
60 | command => "echo \"Anomaly: %{[rt][last]}\""
61 | }
62 | }
63 | }
64 | ```
65 |
66 | *小贴士:有关 box and shisker plot 内容和重要性,参见《数据之魅》一书。*
67 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/ruby.md:
--------------------------------------------------------------------------------
1 | # 随心所欲的 Ruby 处理
2 |
3 | 如果你稍微懂那么一点点 Ruby 语法的话,*filters/ruby* 插件将会是一个非常有用的工具。
4 |
5 | 比如你需要稍微修改一下 `LogStash::Event` 对象,但是又不打算为此写一个完整的插件,用 *filters/ruby* 插件绝对感觉良好。
6 |
7 | ## 配置示例
8 |
9 | ```
10 | filter {
11 | ruby {
12 | init => "@kname = ['client','servername','url','status','time','size','upstream','upstreamstatus','upstreamtime','referer','xff','useragent']"
13 | code => "
14 | new_event = LogStash::Event.new(Hash[@kname.zip(event.get('message').split('|'))])
15 | new_event.remove('@timestamp')
16 | event.append(new_event)"
17 | }
18 | }
19 | ```
20 |
21 | 官网示例是一个比较有趣但是没啥大用的做法 —— 随机取消 90% 的事件。
22 |
23 | 所以上面我们给出了一个有用而且强大的实例。
24 |
25 | ## 解释
26 |
27 | 通常我们都是用 *filters/grok* 插件来捕获字段的,但是正则耗费大量的 CPU 资源,很容易成为 Logstash 进程的瓶颈。
28 |
29 | 而实际上,很多流经 Logstash 的数据都是有自己预定义的特殊分隔符的,我们可以很简单的直接切割成多个字段。
30 |
31 | *filters/mutate* 插件里的 "split" 选项只能切成数组,后续很不方便使用和识别。而在 *filters/ruby* 里,我们可以通过 "init" 参数预定义好由每个新字段的名字组成的数组,然后在 "code" 参数指定的 Ruby 语句里通过两个数组的 zip 操作生成一个哈希并添加进数组里。短短一行 Ruby 代码,可以减少 50% 以上的 CPU 使用率。
32 |
33 | 注1:从 Logstash-2.3 开始,`LogStash::Event.append` 不再直接接受 Hash 对象,而必须是 `LogStash::Event` 对象。所以示例变成要先初始化一个新 event,再把无用的 `@timestamp` 移除,再 append 进去。否则会把 `@timestamp` 变成有两个时间的数组了!
34 |
35 | 注2:从 Logstash-5.0 开始,`LogStash::Event` 改为 Java 实现,直接使用 `event["parent"]["child"]` 形式获取的不是原事件的引用而是复制品。需要改用 `event.get('[parent][child]')` 和 `event.set('[parent][child]', 'value')` 的方法。
36 |
37 | *filters/ruby* 插件用途远不止这一点,下一节你还会继续见到它的身影。
38 |
39 | ## 更多实例
40 |
41 | *2014 年 09 年 23 日新增*
42 |
43 | ```
44 | filter{
45 | date {
46 | match => ["datetime" , "UNIX"]
47 | }
48 | ruby {
49 | code => "event.cancel if 5 * 24 * 3600 < (event['@timestamp']-::Time.now).abs"
50 | }
51 | }
52 | ```
53 |
54 | 在实际运用中,我们几乎肯定会碰到出乎意料的输入数据。这都有可能导致 Elasticsearch 集群出现问题。
55 |
56 | 当数据格式发生变化,比如 UNIX 时间格式变成 UNIX_MS 时间格式,会导致 logstash 疯狂创建新索引,集群崩溃。
57 |
58 | 或者误输入过老的数据时,因为一般我们会 close 几天之前的索引以节省内存,必要时再打开。而直接尝试把数据写入被关闭的索引会导致内存问题。
59 |
60 | 这时候我们就需要提前校验数据的合法性。上面配置,就是用于过滤掉时间范围与当前时间差距太大的非法数据的。
61 |
--------------------------------------------------------------------------------
/logstash/plugins/filter/split.md:
--------------------------------------------------------------------------------
1 | # split 拆分事件
2 |
3 | 上一章我们通过 multiline 插件将多行数据合并进一个事件里,那么反过来,也可以把一行数据,拆分成多个事件。这就是 split 插件。
4 |
5 | ## 配置示例
6 |
7 | ```
8 | filter {
9 | split {
10 | field => "message"
11 | terminator => "#"
12 | }
13 | }
14 | ```
15 |
16 | ## 运行结果
17 |
18 | 这个测试中,我们在 intputs/stdin 的终端中输入一行数据:"test1#test2",结果看到输出两个事件:
19 |
20 | ```
21 | {
22 | "@version": "1",
23 | "@timestamp": "2014-11-18T08:11:33.000Z",
24 | "host": "web121.mweibo.tc.sinanode.com",
25 | "message": "test1"
26 | }
27 | {
28 | "@version": "1",
29 | "@timestamp": "2014-11-18T08:11:33.000Z",
30 | "host": "web121.mweibo.tc.sinanode.com",
31 | "message": "test2"
32 | }
33 | ```
34 |
35 | ## 重要提示
36 |
37 | split 插件中使用的是 yield 功能,其结果是 split 出来的新事件,会直接结束其在 filter 阶段的历程,也就是说写在 split 后面的其他 filter 插件都不起作用,进入到 output 阶段。所以,一定要保证 **split 配置写在全部 filter 配置的最后**。
38 |
39 | 使用了类似功能的还有 clone 插件。
40 |
41 | *注:从 logstash-1.5.0beta1 版本以后修复该问题。*
42 |
--------------------------------------------------------------------------------
/logstash/plugins/input/README.md:
--------------------------------------------------------------------------------
1 | # 输入插件(Input)
2 |
3 | 在 "Hello World" 示例中,我们已经见到并介绍了 logstash 的运行流程和配置的基础语法。从这章开始,我们就要逐一介绍 logstash 流程中比较常用的一些插件,并在介绍中针对其主要适用的场景,推荐的配置,作一些说明。
4 |
5 | 限于篇幅,接下来内容中,配置示例不一定能贴完整。请记住一个原则:Logstash 配置一定要有一个 input 和一个 output。在演示过程中,如果没有写明 input,默认就会使用 "hello world" 里我们已经演示过的 *input/stdin* ,同理,没有写明的 output 就是 *output/stdout*。
6 |
7 | 以上请读者自明。
8 |
--------------------------------------------------------------------------------
/logstash/plugins/input/file.md:
--------------------------------------------------------------------------------
1 | # 读取文件(File)
2 |
3 | 分析网站访问日志应该是一个运维工程师最常见的工作了。所以我们先学习一下怎么用 logstash 来处理日志文件。
4 |
5 | Logstash 使用一个名叫 *FileWatch* 的 Ruby Gem 库来监听文件变化。这个库支持 glob 展开文件路径,而且会记录一个叫 *.sincedb* 的数据库文件来跟踪被监听的日志文件的当前读取位置。所以,不要担心 logstash 会漏过你的数据。
6 |
7 | *sincedb 文件中记录了每个被监听的文件的 inode, major number, minor number 和 pos。*
8 |
9 | ## 配置示例
10 |
11 | ```
12 | input {
13 | file {
14 | path => ["/var/log/*.log", "/var/log/message"]
15 | type => "system"
16 | start_position => "beginning"
17 | }
18 | }
19 | ```
20 |
21 | ## 解释
22 |
23 | 有一些比较有用的配置项,可以用来指定 *FileWatch* 库的行为:
24 |
25 | * discover_interval
26 |
27 | logstash 每隔多久去检查一次被监听的 `path` 下是否有新文件。默认值是 15 秒。
28 |
29 | * exclude
30 |
31 | 不想被监听的文件可以排除出去,这里跟 `path` 一样支持 glob 展开。
32 |
33 | * close_older
34 |
35 | 一个已经监听中的文件,如果超过这个值的时间内没有更新内容,就关闭监听它的文件句柄。默认是 3600 秒,即一小时。
36 | * ignore_older
37 |
38 | 在每次检查文件列表的时候,如果一个文件的最后修改时间超过这个值,就忽略这个文件。默认是 86400 秒,即一天。
39 |
40 | * sincedb_path
41 |
42 | 如果你不想用默认的 `$HOME/.sincedb`(Windows 平台上在 `C:\Windows\System32\config\systemprofile\.sincedb`),可以通过这个配置定义 sincedb 文件到其他位置。
43 |
44 | * sincedb_write_interval
45 |
46 | logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。
47 |
48 | * stat_interval
49 |
50 | logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。
51 |
52 | * start_position
53 |
54 | logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 `tail -F` 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,类似 `less +F` 的形式运行。
55 |
56 | ## 注意
57 |
58 | 1. 通常你要导入原有数据进 Elasticsearch 的话,你还需要 [filter/date](../filter/date.md) 插件来修改默认的"@timestamp" 字段值。稍后会学习这方面的知识。
59 | 2. *FileWatch* 只支持文件的**绝对路径**,而且会不自动递归目录。所以有需要的话,请用数组方式都写明具体哪些文件。
60 | 3. *LogStash::Inputs::File* 只是在进程运行的注册阶段初始化一个 *FileWatch* 对象。所以它不能支持类似 fluentd 那样的 `path => "/path/to/%{+yyyy/MM/dd/hh}.log"` 写法。达到相同目的,你只能写成 `path => "/path/to/*/*/*/*.log"`。FileWatch 模块提供了一个稍微简单一点的写法:`/path/to/**/*.log`,用 `**` 来缩写表示递归全部子目录。
61 | 4. 在单个 input/file 中监听的文件数量太多的话,每次启动扫描构建监听队列会消耗较多的时间。给使用者的感觉好像读取不到一样,这是正常现象。
62 | 5. `start_position` 仅在该文件从未被监听过的时候起作用。如果 sincedb 文件中已经有这个文件的 inode 记录了,那么 logstash 依然会从记录过的 pos 开始读取数据。所以重复测试的时候每回需要删除 sincedb 文件(官方博客上提供了[另一个巧妙的思路](https://www.elastic.co/blog/logstash-configuration-tuning):将 `sincedb_path` 定义为 `/dev/null`,则每次重启自动从头开始读)。
63 | 6. 因为 windows 平台上没有 inode 的概念,Logstash 某些版本在 windows 平台上监听文件不是很靠谱。windows 平台上,推荐考虑使用 nxlog 作为收集端,参阅本书[稍后](../ecosystem/nxlog.md)章节。
64 |
--------------------------------------------------------------------------------
/logstash/plugins/input/stdin.md:
--------------------------------------------------------------------------------
1 | # 标准输入(Stdin)
2 |
3 | 我们已经见过好几个示例使用 `stdin` 了。这也应该是 logstash 里最简单和基础的插件了。
4 |
5 | 所以,在这段中,我们可以学到一些未来每个插件都会有的一些方法。
6 |
7 | ## 配置示例
8 |
9 | ```
10 | input {
11 | stdin {
12 | add_field => {"key" => "value"}
13 | codec => "plain"
14 | tags => ["add"]
15 | type => "std"
16 | }
17 | }
18 | ```
19 |
20 | ## 运行结果
21 |
22 | 用上面的新 `stdin` 设置重新运行一次最开始的 hello world 示例。我建议大家把整段配置都写入一个文本文件,然后运行命令:`bin/logstash -f stdin.conf`。输入 "hello world" 并回车后,你会在终端看到如下输出:
23 |
24 | ```ruby
25 | {
26 | "message" => "hello world",
27 | "@version" => "1",
28 | "@timestamp" => "2014-08-08T06:48:47.789Z",
29 | "type" => "std",
30 | "tags" => [
31 | [0] "add"
32 | ],
33 | "key" => "value",
34 | "host" => "raochenlindeMacBook-Air.local"
35 | }
36 | ```
37 |
38 | ## 解释
39 |
40 | *type* 和 *tags* 是 logstash 事件中两个特殊的字段。通常来说我们会在*输入区段*中通过 *type* 来标记事件类型 —— 我们肯定是提前能知道这个事件属于什么类型的。而 *tags* 则是在数据处理过程中,由具体的插件来添加或者删除的。
41 |
42 | 最常见的用法是像下面这样:
43 |
44 | ```
45 | input {
46 | stdin {
47 | type => "web"
48 | }
49 | }
50 | filter {
51 | if [type] == "web" {
52 | grok {
53 | match => ["message", %{COMBINEDAPACHELOG}]
54 | }
55 | }
56 | }
57 | output {
58 | if "_grokparsefailure" in [tags] {
59 | nagios_nsca {
60 | nagios_status => "1"
61 | }
62 | } else {
63 | elasticsearch {
64 | }
65 | }
66 | }
67 | ```
68 |
69 | 看起来蛮复杂的,对吧?
70 |
71 | 继续学习,你也可以写出来的。
72 |
--------------------------------------------------------------------------------
/logstash/plugins/input/syslog.md:
--------------------------------------------------------------------------------
1 | # 读取 Syslog 数据
2 |
3 | syslog 可能是运维领域最流行的数据传输协议了。当你想从设备上收集系统日志的时候,syslog 应该会是你的第一选择。尤其是网络设备,比如思科 —— syslog 几乎是唯一可行的办法。
4 |
5 | 我们这里不解释如何配置你的 `syslog.conf`, `rsyslog.conf` 或者 `syslog-ng.conf` 来发送数据,而只讲如何把 logstash 配置成一个 syslog 服务器来接收数据。
6 |
7 | 有关 `rsyslog` 的用法,稍后的[类型项目](../dive_into/similar_projects.md)一节中,会有更详细的介绍。
8 |
9 | ## 配置示例
10 |
11 | ```
12 | input {
13 | syslog {
14 | port => "514"
15 | }
16 | }
17 | ```
18 |
19 | ## 运行结果
20 |
21 | 作为最简单的测试,我们先暂停一下本机的 `syslogd` (或 `rsyslogd` )进程,然后启动 logstash 进程(这样就不会有端口冲突问题)。现在,本机的 syslog 就会默认发送到 logstash 里了。我们可以用自带的 `logger` 命令行工具发送一条 "Hello World"信息到 syslog 里(即 logstash 里)。看到的 logstash 输出像下面这样:
22 |
23 | ```ruby
24 | {
25 | "message" => "Hello World",
26 | "@version" => "1",
27 | "@timestamp" => "2014-08-08T09:01:15.911Z",
28 | "host" => "127.0.0.1",
29 | "priority" => 31,
30 | "timestamp" => "Aug 8 17:01:15",
31 | "logsource" => "raochenlindeMacBook-Air.local",
32 | "program" => "com.apple.metadata.mdflagwriter",
33 | "pid" => "381",
34 | "severity" => 7,
35 | "facility" => 3,
36 | "facility_label" => "system",
37 | "severity_label" => "Debug"
38 | }
39 | ```
40 |
41 | ## 解释
42 |
43 | Logstash 是用 `UDPSocket`, `TCPServer` 和 `LogStash::Filters::Grok` 来实现 `LogStash::Inputs::Syslog` 的。所以你其实可以直接用 logstash 配置实现一样的效果:
44 |
45 | ```
46 | input {
47 | tcp {
48 | port => "8514"
49 | }
50 | }
51 | filter {
52 | grok {
53 | match => ["message", "%{SYSLOGLINE}" ]
54 | }
55 | syslog_pri { }
56 | }
57 | ```
58 |
59 | ## 最佳实践
60 |
61 | **建议在使用 `LogStash::Inputs::Syslog` 的时候走 TCP 协议来传输数据。**
62 |
63 | 因为具体实现中,UDP 监听器只用了一个线程,而 TCP 监听器会在接收每个连接的时候都启动新的线程来处理后续步骤。
64 |
65 | 如果你已经在使用 UDP 监听器收集日志,用下行命令检查你的 UDP 接收队列大小:
66 |
67 | ```
68 | # netstat -plnu | awk 'NR==1 || $4~/:514$/{print $2}'
69 | Recv-Q
70 | 228096
71 | ```
72 |
73 | 228096 是 UDP 接收队列的默认最大大小,这时候 linux 内核开始丢弃数据包了!
74 |
75 | **强烈建议使用`LogStash::Inputs::TCP`和 `LogStash::Filters::Grok` 配合实现同样的 syslog 功能!**
76 |
77 | 虽然 LogStash::Inputs::Syslog 在使用 TCPServer 的时候可以采用多线程处理数据的接收,但是在同一个客户端数据的处理中,其 grok 和 date 是一直在该线程中完成的,这会导致总体上的处理性能几何级的下降 —— 经过测试,TCPServer 每秒可以接收 50000 条数据,而在同一线程中启用 grok 后每秒只能处理 5000 条,再加上 date 只能达到 500 条!
78 |
79 | 才将这两步拆分到 filters 阶段后,logstash 支持对该阶段插件单独设置多线程运行,大大提高了总体处理性能。在相同环境下, `logstash -f tcp.conf -w 20` 的测试中,总体处理性能可以达到每秒 30000 条数据!
80 |
81 | *注:测试采用 logstash 作者提供的 `yes "<44>May 19 18:30:17 snack jls: foo bar 32" | nc localhost 3000` 命令。出处见:*
82 |
83 | ### 小贴士
84 |
85 | 如果你实在没法切换到 TCP 协议,你可以自己写程序,或者使用其他基于异步 IO 框架(比如 libev )的项目。下面是一个简单的异步 IO 实现 UDP 监听数据输入 Elasticsearch 的示例:
86 |
87 |
88 |
--------------------------------------------------------------------------------
/logstash/plugins/input/tcp.md:
--------------------------------------------------------------------------------
1 | # 读取网络数据(TCP)
2 |
3 | 未来你可能会用 Redis 服务器或者其他的消息队列系统来作为 logstash broker 的角色。不过 Logstash 其实也有自己的 TCP/UDP 插件,在临时任务的时候,也算能用,尤其是测试环境。
4 |
5 | *小贴士:虽然 `LogStash::Inputs::TCP` 用 Ruby 的 `Socket` 和 `OpenSSL` 库实现了高级的 SSL 功能,但 Logstash 本身只能在 `SizedQueue` 中缓存 20 个事件。这就是我们建议在生产环境中换用其他消息队列的原因。*
6 |
7 | ## 配置示例
8 |
9 | ```
10 | input {
11 | tcp {
12 | port => 8888
13 | mode => "server"
14 | ssl_enable => false
15 | }
16 | }
17 | ```
18 |
19 | ## 常见场景
20 |
21 | 目前来看,`LogStash::Inputs::TCP` 最常见的用法就是配合 `nc` 命令导入旧数据。在启动 logstash 进程后,在另一个终端运行如下命令即可导入数据:
22 |
23 | ```
24 | # nc 127.0.0.1 8888 < olddata
25 | ```
26 |
27 | 这种做法比用 `LogStash::Inputs::File` 好,因为当 nc 命令结束,我们就知道数据导入完毕了。而用 input/file 方式,logstash 进程还会一直等待新数据输入被监听的文件,不能直接看出是否任务完成了。
28 |
--------------------------------------------------------------------------------
/logstash/plugins/output/email.md:
--------------------------------------------------------------------------------
1 | # 发送邮件(Email)
2 |
3 | ## 配置示例
4 |
5 | ```
6 | output {
7 | email {
8 | to => "admin@website.com,root@website.com"
9 | cc => "other@website.com"
10 | via => "smtp"
11 | subject => "Warning: %{title}"
12 | options => {
13 | smtpIporHost => "localhost",
14 | port => 25,
15 | domain => 'localhost.localdomain',
16 | userName => nil,
17 | password => nil,
18 | authenticationType => nil, # (plain, login and cram_md5)
19 | starttls => true
20 | }
21 | htmlbody => ""
22 | body => ""
23 | attachments => ["/path/to/filename"]
24 | }
25 | }
26 | ```
27 |
28 | *注意:以上示例适用于 `Logstash 1.5` ,`options =>` 的参数配置在 `Logstash 2.0` 之后的版本已被移除,(126 邮箱发送到 qq 邮箱)示例如下:*
29 |
30 | ```
31 | output {
32 | email {
33 | port => "25"
34 | address => "smtp.126.com"
35 | username => "test@126.com"
36 | password => ""
37 | authentication => "plain"
38 | use_tls => true
39 | from => "test@126.com"
40 | subject => "Warning: %{title}"
41 | to => "test@qq.com"
42 | via => "smtp"
43 | body => "%{message}"
44 | }
45 | }
46 | ```
47 |
48 | ## 解释
49 |
50 | *outputs/email* 插件支持 SMTP 协议和 sendmail 两种方式,通过 `via` 参数设置。SMTP 方式有较多的 options 参数可配置。sendmail 只能利用本机上的 sendmail 服务来完成 —— 文档上描述了 Mail 库支持的 sendmail 配置参数,但实际代码中没有相关处理,不要被迷惑了。。。
51 |
52 |
--------------------------------------------------------------------------------
/logstash/plugins/output/exec.md:
--------------------------------------------------------------------------------
1 | # 调用命令执行(Exec)
2 |
3 | *outputs/exec* 插件的运用也非常简单,如下所示,将 logstash 切割成的内容作为参数传递给命令。这样,在每个事件到达该插件的时候,都会触发这个命令的执行。
4 |
5 | ```
6 | output {
7 | exec {
8 | command => "sendsms.pl \"%{message}\" -t %{user}"
9 | }
10 | }
11 | ```
12 |
13 | 需要注意的是。这种方式是每次都重新开始执行一次命令并退出。本身是比较慢速的处理方式(程序加载,网络建联等都有一定的时间消耗)。最好只用于少量的信息处理场景,比如不适用 nagios 的其他报警方式。示例就是通过短信发送消息。
14 |
--------------------------------------------------------------------------------
/logstash/plugins/output/file.md:
--------------------------------------------------------------------------------
1 | # 保存成文件(File)
2 |
3 | 通过日志收集系统将分散在数百台服务器上的数据集中存储在某中心服务器上,这是运维最原始的需求。早年的 scribed ,甚至直接就把输出的语法命名为 ``。Logstash 当然也能做到这点。
4 |
5 | 和 `LogStash::Inputs::File` 不同, `LogStash::Outputs::File` 里可以使用 sprintf format 格式来自动定义输出到带日期命名的路径。
6 |
7 | ## 配置示例
8 |
9 | ```
10 | output {
11 | file {
12 | path => "/path/to/%{+yyyy}/%{+MM}/%{+dd}/%{host}.log.gz"
13 | message_format => "%{message}"
14 | gzip => true
15 | }
16 | }
17 | ```
18 |
19 | ## 解释
20 |
21 | 使用 *output/file* 插件首先需要注意的就是 `message_format` 参数。插件默认是输出整个 event 的 JSON 形式数据的。这可能跟大多数情况下使用者的期望不符。大家可能只是希望按照日志的原始格式保存就好了。所以需要定义为 `%{message}`,当然,前提是在之前的 *filter* 插件中,你没有使用 `remove_field` 或者 `update` 等参数删除或修改 `%{message}` 字段的内容。
22 |
23 | 另一个非常有用的参数是 gzip。gzip 格式是一个非常奇特而友好的格式。其格式包括有:
24 |
25 | * 10字节的头,包含幻数、版本号以及时间戳
26 | * 可选的扩展头,如原文件名
27 | * 文件体,包括DEFLATE压缩的数据
28 | * 8字节的尾注,包括CRC-32校验和以及未压缩的原始数据长度
29 |
30 | 这样 gzip 就可以一段一段的识别出来数据 —— **反过来说,也就是可以一段一段压缩了添加在后面!**
31 |
32 | 这对于我们流式添加数据简直太棒了!
33 |
34 | *小贴士:你或许见过网络流传的 parallel 命令行工具并发处理数据的神奇文档,但在自己用的时候总见不到效果。实际上就是因为:文档中处理的 gzip 文件,可以分开处理然后再合并的。*
35 |
36 | ## 注意
37 |
38 | 1. 按照 Logstash 标准,其实应该可以把数据格式的定义改在 codec 插件中完成,但是 logstash-output-file 插件内部实现中跳过了 `@codec.decode` 这步,所以 **codec 设置无法生效!**
39 | 2. 按照 Logstash 标准,配置参数的值可以使用 event sprintf 格式。但是 logstash-output-file 插件对 `event.sprintf(@path)` 的结果,还附加了一步 `inside_file_root?` 校验(个人猜测是为了防止越权到其他路径),这个 `file_root` 是通过直接对 path 参数分割 `/` 符号得到的。如果在 sprintf 格式中带有 `/` 符号,那么被切分后的结果就无法正确解析了。
40 |
41 | 所以,如下所示配置,虽然看起来是正确的,实际效果却不对,正确写法应该是本节之前的配置示例那样。
42 |
43 | ```
44 | output {
45 | file {
46 | path => "/path/to/%{+yyyy/MM/dd}/%{host}.log.gz"
47 | codec => line {
48 | format => "%{message}"
49 | }
50 | }
51 | }
52 | ```
53 |
54 |
--------------------------------------------------------------------------------
/logstash/plugins/output/hdfs.md:
--------------------------------------------------------------------------------
1 | # HDFS
2 |
3 |
4 |
5 | *
6 |
7 | This plugin based on WebHDFS api of Hadoop, it just POST data to WebHDFS port. So, it's a native Ruby code.
8 |
9 | ```
10 | output {
11 | hadoop_webhdfs {
12 | workers => 2
13 | server => "your.nameno.de:14000"
14 | user => "flume"
15 | path => "/user/flume/logstash/dt=%{+Y}-%{+M}-%{+d}/logstash-%{+H}.log"
16 | flush_size => 500
17 | compress => "snappy"
18 | idle_flush_time => 10
19 | retry_interval => 0.5
20 | }
21 | }
22 | ```
23 |
24 |
25 | *
26 |
27 | This plugin based on HDFS api of Hadoop, it import java classes like `org.apache.hadoop.fs.FileSystem` etc.
28 |
29 | ### Configuration
30 |
31 | ```
32 | output {
33 | hdfs {
34 | path => "/path/to/output_file.log"
35 | enable_append => true
36 | }
37 | }
38 | ```
39 |
40 | ### Howto run
41 |
42 | ```
43 | CLASSPATH=$(find /path/to/hadoop -name '*.jar' | tr '\n' ':'):/etc/hadoop/conf:/path/to/logstash-1.1.7-monolithic.jar java logstash.runner agent -f conf/hdfs-output.conf -p /path/to/cloned/logstash-hdfs
44 | ```
45 |
--------------------------------------------------------------------------------
/logstash/plugins/output/nagios.md:
--------------------------------------------------------------------------------
1 | # 报警到 Nagios
2 |
3 | Logstash 中有两个 output 插件是 nagios 有关的。*outputs/nagios* 插件发送数据给本机的 `nagios.cmd` 管道命令文件,*outputs/nagios_nsca* 插件则是 调用 `send_nsca` 命令以 NSCA 协议格式把数据发送给 nagios 服务器(远端或者本地皆可)。
4 |
5 | ## Nagios.Cmd
6 |
7 | nagios.cmd 是 nagios 服务器的核心组件。nagios 事件处理和内外交互都是通过这个管道文件来完成的。
8 |
9 | 使用 CMD 方式,需要自己保证发送的 Logstash 事件符合 nagios 事件的格式。即必须在 *filter* 阶段预先准备好 `nagios_host` 和 `nagios_service` 字段;此外,如果在 *filter* 阶段也准备好 `nagios_annotation` 和 `nagios_level` 字段,这里也会自动转换成 nagios 事件信息。
10 |
11 | ```
12 | filter {
13 | if [message] =~ /err/ {
14 | mutate {
15 | add_tag => "nagios"
16 | rename => ["host", "nagios_host"]
17 | replace => ["nagios_service", "logstash_check_%{type}"]
18 | }
19 | }
20 | }
21 | output {
22 | if "nagios" in [tags] {
23 | nagios { }
24 | }
25 | }
26 | ```
27 |
28 | 如果不打算在 *filter* 阶段提供 `nagios_level` ,那么也可以在该插件中通过参数配置。
29 |
30 | 所谓 `nagios_level`,即我们通过 nagios plugin 检查数据时的返回值。其取值范围和含义如下:
31 |
32 | * "0",代表 "OK",服务正常;
33 | * "1",代表 "WARNNING",服务警告,一般 nagios plugin 命令中使用 `-w` 参数设置该阈值;
34 | * "2",代表 "CRITICAL",服务危急,一般 nagios plugin 命令中使用 `-c` 参数设置该阈值;
35 | * "3",代表 "UNKNOWN",未知状态,一般会在 timeout 等情况下出现。
36 |
37 | 默认情况下,该插件会以 "CRITICAL" 等级发送报警给 Nagios 服务器。
38 |
39 | nagios.cmd 文件的具体位置,可以使用 `command_file` 参数设置。默认位置是 "/var/lib/nagios3/rw/nagios.cmd"。
40 |
41 | 关于和 nagios.cmd 交互的具体协议说明,有兴趣的读者请阅读 [Using external commands in Nagios](http://archive09.linux.com/feature/153285) 一文,这是《Learning Nagios 3.0》书中内容节选。
42 |
43 | ## NSCA
44 |
45 | NSCA 是一种标准的 nagios 分布式扩展协议。分布在各机器上的 `send_nsca` 进程主动将监控数据推送给远端 nagios 服务器的 NSCA 进程。
46 |
47 | 当 Logstash 跟 nagios 服务器没有在同一个主机上运行的时候,就只能通过 NSCA 方式来发送报警了 —— 当然也必须在 Logstash 服务器上安装 `send_nsca` 命令。
48 |
49 | nagios 事件所需要的几个属性在上一段中已经有过描述。不过在使用这个插件的时候,不要求提前准备好,而是可以在该插件内部定义参数:
50 |
51 | ```
52 | output {
53 | nagios_nsca {
54 | nagios_host => "%{host}"
55 | nagios_service => "logstash_check_%{type}"
56 | nagios_status => "2"
57 | message_format => "%{@timestamp}: %{message}"
58 | host => "nagiosserver.domain.com"
59 | }
60 | }
61 | ```
62 |
63 | 这里请注意,`host` 和 `nagios_host` 两个参数,分别是用来设置 nagios 服务器的地址,和报警信息中有问题的服务器地址。
64 |
65 | 关于 NSCA 原理,架构和配置说明,还不了解的读者请阅读官方网站 [Using NSClient++ from nagios with NSCA](http://nsclient.org/nscp/wiki/doc/usage/nagios/nsca) 一节。
66 |
67 | ## 推荐阅读
68 |
69 | 除了 nagios 以外,logstash 同样可以发送信息给其他常见监控系统。方式和 nagios 大同小异:
70 |
71 | * *outputs/ganglia* 插件通过 UDP 协议,发送 gmetric 型数据给本机/远端的 `gmond` 或者 `gmetad`
72 | * *outputs/zabbix* 插件调用本机的 `zabbix_sender` 命令发送
73 |
--------------------------------------------------------------------------------
/logstash/plugins/output/stdout.md:
--------------------------------------------------------------------------------
1 | # 标准输出(Stdout)
2 |
3 | 和之前 *inputs/stdin* 插件一样,*outputs/stdout* 插件也是最基础和简单的输出插件。同样在这里简单介绍一下,作为输出插件的一个共性了解。
4 |
5 | ## 配置示例
6 |
7 | ```
8 | output {
9 | stdout {
10 | codec => rubydebug
11 | workers => 2
12 | }
13 | }
14 | ```
15 |
16 | ## 解释
17 |
18 | 输出插件统一具有一个参数是 `workers`。Logstash 为输出做了多线程的准备。
19 |
20 | 其次是 codec 设置。codec 的作用在之前已经讲过。可能除了 `codecs/multiline` ,其他 codec 插件本身并没有太多的设置项。所以一般省略掉后面的配置区段。换句话说。上面配置示例的完全写法应该是:
21 |
22 | ```
23 | output {
24 | stdout {
25 | codec => rubydebug {
26 | }
27 | workers => 2
28 | }
29 | }
30 | ```
31 |
32 | 单就 *outputs/stdout* 插件来说,其最重要和常见的用途就是调试。所以在不太有效的时候,加上命令行参数 `-vv` 运行,查看更多详细调试信息。
33 |
--------------------------------------------------------------------------------
/logstash/plugins/output/tcp.md:
--------------------------------------------------------------------------------
1 | # 发送网络数据(TCP)
2 |
3 | 虽然之前我们已经提到过不建议直接使用 LogStash::Inputs::TCP 和 LogStash::Outputs::TCP 做转发工作,不过在实际交流中,发现确实有不少朋友觉得这种简单配置足够使用,因而不愿意多加一层消息队列的。所以,还是把 Logstash 如何直接发送 TCP 数据也稍微提点一下。
4 |
5 | ## 配置示例
6 |
7 | ```
8 | output {
9 | tcp {
10 | host => "192.168.0.2"
11 | port => 8888
12 | codec => json_lines
13 | }
14 | }
15 | ```
16 |
17 | ## 配置说明
18 |
19 | 在收集端采用 tcp 方式发送给远端的 tcp 端口。这里需要注意的是,默认的 codec 选项是 **json**。而远端的 LogStash::Inputs::TCP 的默认 codec 选项却是 **line** !所以不指定各自的 codec ,对接肯定是失败的。
20 |
21 | 另外,由于IO BUFFER 的原因,即使是两端共同约定为 **json** 依然无法正常运行,接收端会认为一行数据没结束,一直等待直至自己 OutOfMemory !
22 |
23 | 所以,正确的做法是,发送端指定 codec 为 **json_lines** ,这样每条数据后面会加上一个回车,接收端指定 codec 为 **json_lines** 或者 **json** 均可,这样才能正常处理。包括在收集端已经切割好的字段,也可以直接带入收集端使用了。
24 |
--------------------------------------------------------------------------------
/logstash/scale/README.md:
--------------------------------------------------------------------------------
1 | # 扩展方案
2 |
3 | 之前章节中,讲述的都是单个 logstash 进程,如何配置实现对数据的读取、解析和输出处理。但是在生产环境中,从每台应用服务器运行 logstash 进程并将数据直接发送到 Elasticsearch 里,显然不是第一选择:第一,过多的客户端连接对 Elasticsearch 是一种额外的压力;第二,网络抖动会影响到 logstash 进程,进而影响生产应用;第三,运维人员未必愿意在生产服务器上部署 Java,或者让 logstash 跟业务代码争夺 Java 资源。
4 |
5 | 所以,在实际运用中,logstash 进程会被分为两个不同的角色。运行在应用服务器上的,尽量减轻运行压力,只做读取和转发,这个角色叫做 shipper;运行在独立服务器上,完成数据解析处理,负责写入 Elasticsearch 的角色,叫 indexer。
6 |
7 | 
8 |
9 | logstash 作为无状态的软件,配合消息队列系统,可以很轻松的做到线性扩展。本节首先会介绍最常见的两个消息队列与 logstash 的配合。
10 |
11 | 此外,logstash 作为一个框架式的项目,并不排斥,甚至欢迎与其他类似软件进行混搭式的运行。本节也会介绍一些其他日志处理框架以及如何和 logstash 共存的方式( 《logstashbook》也同样有类似内容)。希望大家各取所长,做好最适合自己的日志处理系统。
12 |
--------------------------------------------------------------------------------
/logstash/scale/fluent.md:
--------------------------------------------------------------------------------
1 | # fluentd
2 |
3 | Fluentd 是另一个 Ruby 语言编写的日志收集系统。和 Logstash 不同的是,Fluentd 是基于 MRI 实现的,并不是利用多线程,而是利用事件驱动。
4 |
5 | Fluentd 的开发和使用者,大多集中在日本。
6 |
7 | ## 配置示例
8 |
9 | Fluentd 受 Scribe 影响颇深,包括节点间传输采用磁盘 buffer 来保证数据不丢失等的设计,也包括配置语法。下面是一段配置示例:
10 |
11 | ```
12 |
13 | type tail
14 | read_from_head true
15 | path /var/lib/docker/containers/*/*-json.log
16 | pos_file /var/log/fluentd-docker.pos
17 | time_format %Y-%m-%dT%H:%M:%S
18 | tag docker.*
19 | format json
20 |
21 | # Using filter to add container IDs to each event
22 |
23 | type record_transformer
24 |
25 | container_id ${tag_parts[5]}
26 |
27 |
28 |
29 |
30 | type copy
31 |
32 | # for debug (see /var/log/td-agent.log)
33 | type stdout
34 |
35 |
36 | type elasticsearch
37 | logstash_format true
38 | host "#{ENV['ES_PORT_9200_TCP_ADDR']}" # dynamically configured to use Docker's link feature
39 | port 9200
40 | flush_interval 5s
41 |
42 |
43 | ```
44 |
45 | 注意,虽然示例中演示的是 tail 方式。Fluentd 对应用日志,并不推荐如此读取。FLuentd 为各种编程语言提供了客户端库,应用可以直接加载日志库发送日志。下面是一个 PHP 应用的示例:
46 |
47 | ```
48 | post("fluentd.test.follow", array("from"=>"userA", "to"=>"userB"));
54 | ```
55 |
56 | Fluentd 使用如下配置接收即可:
57 |
58 | ```
59 |
60 | type unix
61 | path /var/run/td-agent/td-agent.sock
62 |
63 |
64 | type forward
65 | send_timeout 60s
66 | recover_wait 10s
67 | heartbeat_interval 1s
68 | phi_threshold 16
69 | hard_timeout 60s
70 |
71 | name myserver1
72 | host 192.168.1.3
73 | port 24224
74 | weight 60
75 |
76 |
77 | name myserver2
78 | host 192.168.1.4
79 | port 24224
80 | weight 60
81 |
82 |
83 | type file
84 | path /var/log/fluent/forward-failed
85 |
86 |
87 | ```
88 |
89 | ## fluentd 插件
90 |
91 | 作为用动态语言编写的软件,fluentd 也拥有大量插件。每个插件都以 RubyGem 形式独立存在。事实上,logstash 在这方面就是学习 fluentd 的。安装方式如下:
92 |
93 | ```
94 | /usr/sbin/td-agent-gem install fluent-plugin-elasticsearch fluent-plugin-grok_parser
95 | ```
96 |
97 | fluentd 插件列表,见:。
98 |
--------------------------------------------------------------------------------
/logstash/scale/heka.md:
--------------------------------------------------------------------------------
1 | # Heka
2 |
3 | heka 是 Mozilla 公司仿造 logstash 设计,用 Golang 重写的一个开源项目。同样采用了input -> decoder -> filter -> encoder -> output 的流程概念。其特点在于,在中间的 decoder/filter/encoder 部分,设计了 sandbox 概念,可以采用内嵌 lua 脚本做这一部分的工作,降低了全程使用静态 Golang 编写的难度。此外,其 filter 阶段还提供了一些监控和统计报警功能。
4 |
5 | 官网地址见:
6 |
7 | _Mozilla 员工已经在 2016 年中宣布放弃对 heka 项目的维护,但是社区依然坚持推动了部分代码更新和新版发布。所以本书继续保留 heka 的使用介绍。_
8 |
9 | 下面是同样的处理逻辑,通过 syslog 接收 nginx 访问日志,解析并存储进 Elasticsearch,heka 配置文件如下:
10 |
11 | ```ini
12 | [hekad]
13 | maxprocs = 48
14 |
15 | [TcpInput]
16 | address = ":514"
17 | parser_type = "token"
18 | decoder = "shipped-nginx-decoder"
19 |
20 | [shipped-nginx-decoder]
21 | type = "MultiDecoder"
22 | subs = ['RsyslogDecoder', 'nginx-access-decoder']
23 | cascade_strategy = "all"
24 | log_sub_errors = true
25 |
26 | [RsyslogDecoder]
27 | type = "SandboxDecoder"
28 | filename = "lua_decoders/rsyslog.lua"
29 | [RsyslogDecoder.config]
30 | type = "nginx.access"
31 | template = '<%pri%>%TIMESTAMP% %HOSTNAME% %syslogtag%%msg:::sp-if-no-1st-sp%%msg:::drop-last-lf%\n'
32 | tz = "Asia/Shanghai"
33 |
34 | [nginx-access-decoder]
35 | type = "SandboxDecoder"
36 | filename = "lua_decoders/nginx_access.lua"
37 |
38 | [nginx-access-decoder.config]
39 | type = "combined"
40 | user_agent_transform = true
41 | log_format = '[$time_local]`$http_x_up_calling_line_id`"$request"`"$http_user_agent"`$staTus`[$remote_addr]`$http_x_log_uid`"$http_referer"`$request_time`$body_bytes_sent`$http_x_forwarded_proto`$http_x_forwarded_for`$request_uid`$http_host`$http_cookie`$upstream_response_time'
42 |
43 | [ESLogstashV0Encoder]
44 | es_index_from_timestamp = true
45 | fields = ["Timestamp", "Payload", "Hostname", "Fields"]
46 | type_name = "%{Type}"
47 |
48 | [ElasticSearchOutput]
49 | message_matcher = "Type == 'nginx.access'"
50 | server = "http://eshost.example.com:9200"
51 | encoder = "ESLogstashV0Encoder"
52 | flush_interval = 50
53 | flush_count = 5000
54 | ```
55 |
56 | heka 目前仿造的还是旧版本的 logstash schema 设计,所有切分字段都存储在 `@fields` 下。
57 |
58 | 经测试,其处理性能跟开启了多线程 filters 的 logstash 进程类似,都在每秒 30000 条。
59 |
--------------------------------------------------------------------------------
/logstash/scale/message-passing.md:
--------------------------------------------------------------------------------
1 | # Message::Passing
2 |
3 | [Message::Passing](https://metacpan.org/pod/Message::Passing) 是一个仿造 Logstash 写的 Perl5 项目。项目早期甚至就直接照原样也叫 "Logstash" 的名字。
4 |
5 | 但实际上,Message::Passing 内部原理设计还是有所偏差的。这个项目整个基于 AnyEvent 事件驱动开发框架(即著名的 libev 库)完成,也要求所有插件不要采取阻塞式编程。所以,虽然项目开发不太活跃,插件接口不甚完善,但是性能方面却非常棒。这也是我从多个 Perl 日志处理框架中选择介绍这个的原因。
6 |
7 | Message::Passing 有比较全的 input 和 output 插件,这意味着它可以通过多种协议跟 logstash 混跑,不过 filter 插件比较缺乏。对等于 grok 的插件叫 `Message::Passing::Filter::Regexp`( 我写的,嘿嘿)。下面是一个完整的配置示例:
8 |
9 | ```perl
10 | use Message::Passing::DSL;
11 | run_message_server message_chain {
12 | output stdout => (
13 | class => 'STDOUT',
14 | );
15 | output elasticsearch => (
16 | class => 'ElasticSearch',
17 | elasticsearch_servers => ['127.0.0.1:9200'],
18 | );
19 | encoder("encoder",
20 | class => 'JSON',
21 | output_to => 'stdout',
22 | output_to => 'es',
23 | );
24 | filter regexp => (
25 | class => 'Regexp',
26 | format => ':nginxaccesslog',
27 | capture => [qw( ts status remotehost url oh responsetime upstreamtime bytes )]
28 | output_to => 'encoder',
29 | );
30 | filter logstash => (
31 | class => 'ToLogstash',
32 | output_to => 'regexp',
33 | );
34 | decoder decoder => (
35 | class => 'JSON',
36 | output_to => 'logstash',
37 | );
38 | input file => (
39 | class => 'FileTail',
40 | output_to => 'decoder',
41 | );
42 | };
43 | ```
44 |
45 |
--------------------------------------------------------------------------------
/logstash/scale/nxlog.md:
--------------------------------------------------------------------------------
1 | # nxlog
2 |
3 | *本节作者:松涛*
4 |
5 | nxlog 是用 C 语言写的一个跨平台日志收集处理软件。其内部支持使用 Perl 正则和语法来进行数据结构化和逻辑判断操作。不过,其最常用的场景。是在 windows 服务器上,作为 logstash 的替代品运行。
6 |
7 | nxlog 的 windows 安装文件下载 url 见:
8 |
9 |
10 | ## 配置
11 |
12 | Nxlog默认配置文件位置在:`C:\Program Files (x86)\nxlog`。
13 |
14 | 配置文件中有3个关键设置,分别是:input(日志输入端)、output(日志输出端)、route(绑定某输入到具体某输出)。。
15 |
16 | ## 例子
17 |
18 | 假设我们有两台服务器,收集其中的 windows 事务日志:
19 |
20 | * logstash服务器ip地址:192.168.1.100
21 | * windows测试服务器ip地址:192.168.1.101
22 |
23 | 收集流程:
24 |
25 | 1. nxlog 使用模块 im_file 收集日志文件,开启位置记录功能
26 | 2. nxlog 使用模块tcp输出日志
27 | 3. logstash 使用input/tcp ,收集日志,输出至es
28 |
29 | ### Logstash配置文件
30 |
31 | ```
32 | input {
33 | tcp {
34 | port => 514
35 | }
36 | }
37 | output{
38 | elasticsearch {
39 | host => "127.0.0.1"
40 | port => "9200"
41 | protocol => "http"
42 | }
43 | }
44 | ```
45 |
46 | ### Nxlog配置文件
47 |
48 | ```
49 |
50 | Module im_file
51 | File "C:\\test\\\*.log"
52 | SavePos TRUE
53 |
54 |
55 |
60 |
61 |
62 | Path testfile => out
63 |
64 | ```
65 |
66 | 配置文件修改完毕后,重启服务即可:
67 |
68 | 
69 |
--------------------------------------------------------------------------------
/logstash/source-code-analysis/README.md:
--------------------------------------------------------------------------------
1 | # 源码解析
2 |
3 | Logstash 和过去很多日志收集系统比,优势就在于其源码是用 Ruby 写的,所以插件开发相当容易。现在已经有两百多个插件可供选择。但是,随之而来的问题就是:大多数框架都用 Java 写,毕竟做大规模系统 Java 有天生优势。而另一个新生代 fluentd 则是标准的 Ruby 产品(即 Matz's Ruby Interpreter)。logstash 为什么选用 JRuby 来实现,似乎有点两头不讨好啊?
4 |
5 | 乔丹西塞曾经多次著文聊过这个问题。为了避凑字数的嫌,这里罗列他的 gist 地址:
6 |
7 | * [Time sucks](https://gist.github.com/jordansissel/2929216) 一文是关于 Time 对象的性能测试,最快的生成方法是 `sprintf` 方法,MRI 性能为 82600 call/sec,JRuby1.6.7 为 131000 call/sec,而 JRuby1.7.0 为 215000 call/sec。
8 | * [Comparing egexp patterns speeds](https://gist.github.com/jordansissel/1491302)
9 | 一文是关于正则表达式的性能测试,使用的正则统一为 `(?-mix:('(?:[^\\']+|(?:\\.)+)*'))`,结果 MRI1.9.2 为 530000 matches/sec,而 JRuby1.6.5 为 690000 matches/sec。
10 | * [Logstash performance under ruby](https://gist.github.com/jordansissel/4171039)一文是关于 logstash 本身数据流转性能的测试,使用 *inputs/generator* 插件生成数据,*outputs/stdout* 到 pv 工具记点统计。结果 MRI1.9.3 为 4000 events/sec,而 JRuby1.7.0 为 25000 events/sec。
11 |
12 | 可能你已经运行着 logstash 并发现自己的线上数据远超过这个测试——这是因为乔丹西塞在2013年之前,一直是业余时间开发 logstash,而且从未用在自己线上过。所以当时的很多测试是在他自己电脑上完成的。
13 |
14 | 在 logstash 得到大家强烈关注后,作者发表了《[logstash needs full time love](https://gist.github.com/jordansissel/3088552)》,表明了这点并求一份可以让自己全职开发 logstash 的工作,同时列出了1.1.0 版本以后的 roadmap。(不过事实证明当时作者列出来的这些需求其实不紧急,因为大多数,或者说除了 kibana 以外,至今依然没有==!)
15 |
16 | 时间轴继续向前推,到 2011 年,你会发现 logstash 原先其实也是用 MRI1.8.7 写的!在 [grok 模块从 C 扩展改写成 FFI 扩展后](https://code.google.com/p/logstash/issues/detail?id=37),才正式改用 JRuby。
17 |
18 | 切换语言的当时,乔丹西塞发表了《[logstash, why jruby?](https://gist.github.com/jordansissel/978956)》大家可以一读。
19 |
20 | 事实上,时至今日,多种 Ruby 实现的痕迹(到处都有 RUBY_ENGINE 变量判断)依然遍布 logstash 代码各处,作者也力图保证尽可能多的代码能在 MRI 上运行。
21 |
22 | 作为简单的提示,在和插件无关的核心代码中,只有 LogStash::Event 里生成 `@timestamp`字段时用了 Java 的 joda 库为 JRuby 仅有的。稍微修改成 Ruby 自带的 Time 库,即可在 MRI 上运行起来。而主要插件中,也只有 filters/date 和 outputs/elasticsearch 是 Java 相关的。
23 |
24 | 另一个温馨预警,Logstash 被 Elastic.co 收购以后,又有另一种讨论中的发展方向,就是把 logstash 的 core 部分代码,尽量的 JVM 通用化,未来,可以用 JRuby,Jython、Scala,Groovy,Clojure 和 Java 等任意 JVM 平台语言写 Logstash 插件。
25 |
26 | 这就是开源软件的多样性未来,让我们拭目以待吧~
27 |
--------------------------------------------------------------------------------
/see-also.md:
--------------------------------------------------------------------------------
1 | 推荐阅读
2 | =============
3 |
4 | * [Elasticsearch 权威指南](http://fuxiaopang.gitbooks.io/learnelasticsearch/)
5 | * [精通 Elasticsearch](http://shgy.gitbooks.io/mastering-elasticsearch/)
6 | * [The Logstash Book](http://www.logstashbook.com/)
7 | * [Elastic Stack Advent](http://elasticsearch.cn/topic/advent)
8 |
--------------------------------------------------------------------------------