├── .gitignore
├── Procfile
├── README.md
├── app.py
├── checkpoints
└── mobilebert
│ ├── config.json
│ └── vocab.txt
├── ext_sum.py
├── models
├── MobileBert
│ ├── __init__.py
│ ├── activations.py
│ ├── configuration_mobilebert.py
│ ├── configuration_utils.py
│ ├── file_utils.py
│ ├── modeling_mobilebert.py
│ ├── modeling_utils.py
│ ├── optimization.py
│ ├── tokenization_mobilebert.py
│ └── tokenization_utils.py
├── __init__.py
├── encoder.py
├── model_builder.py
├── neural.py
└── optimizers.py
├── raw_data
└── input.txt
├── requirements.txt
├── results
└── summary.txt
├── setup.sh
└── tensorboard.JPG
/.gitignore:
--------------------------------------------------------------------------------
1 | temp/
2 | .ipynb_checkpoints
3 | __pycache__
4 | .vscode
5 |
6 | *.pt
7 | test_models.ipynb
8 |
--------------------------------------------------------------------------------
/Procfile:
--------------------------------------------------------------------------------
1 | web: sh setup.sh && streamlit run app.py
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Extractive Summarization with BERT
2 |
3 | In an effort to make BERTSUM ([Liu et al., 2019](https://github.com/nlpyang/PreSumm)) lighter and faster for low-resource devices, I fine-tuned DistilBERT ([Sanh et al., 2019](https://arxiv.org/abs/1910.01108)) and MobileBERT ([Sun et al., 2019](https://arxiv.org/abs/2004.02984)), two lite versions of BERT on CNN/DailyMail dataset. DistilBERT has the same performance as BERT-base while being 45% smaller. MobileBERT is 4x smaller and 2.7x faster than BERT-base yet retains 94% of its performance.
4 |
5 | - **Demo with MobileBert:** [Open](https://extractive-summarization.herokuapp.com/)
6 | - **Blog post:** [Read](https://chriskhanhtran.github.io/posts/extractive-summarization-with-bert/)
7 |
8 | I modified the source codes in [PreSumm](https://github.com/nlpyang/PreSumm) to use the HuggingFace's `transformers` library and their pretrained DistilBERT model. At the moment (05/31/2020), MobileBERT is not yet available in `transformers`. Fortunately, I found this [PyTorch implementation of MobileBERT](https://github.com/lonePatient/MobileBert_PyTorch) by @lonePatient.
9 |
10 | Please visit [PreSumm](https://github.com/nlpyang/PreSumm) for instructions for training on CNN/DailyMail and this [modified repo](https://github.com/chriskhanhtran/PreSumm) forked from PreSumm for fine-tuning DistilBERT and MobileBERT.
11 |
12 | ## Results on CNN/DailyMail
13 |
14 | | Models | ROUGE-1 | ROUGE-2 | ROUGE-L | Inference Time* | Size | Params | Download |
15 | |:-----------|:-------:|:--------:|:-------:|:---------------:|:------:|:--------:|:--------:|
16 | | bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M | [link](https://www.googleapis.com/drive/v3/files/1t27zkFMUnuqRcsqf2fh8F1RwaqFoMw5e?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE) |
17 | | distilbert | 42.84 | 20.04 | 39.31 | 925 ms | 310 MB | 77.4 M | [link](https://www.googleapis.com/drive/v3/files/1WxU7cHECfYaU32oTM0JByTRGS5f6SYEF?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE) |
18 | | mobilebert | 40.59 | 17.98 | 36.99 | 609 ms | 128 MB | 30.8 M | [link](https://www.googleapis.com/drive/v3/files/1umMOXoueo38zID_AKFSIOGxG9XjS5hDC?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE) |
19 |
20 | \**Average running time on a single CPU on a standard Google Colab notebook*
21 |
22 | [**TensorBoard**](https://tensorboard.dev/experiment/Ly7CRURRSOuPBlZADaqBlQ/#scalars)
23 | 
24 |
25 | ## Setup
26 | ```sh
27 | git clone https://github.com/chriskhanhtran/bert-extractive-summarization.git
28 | cd bert-extractive-summarization
29 | pip install -r requirements.txt
30 | ```
31 |
32 | Download pretrained checkpoints:
33 |
34 | ```sh
35 | wget -O "checkpoints/bertbase_ext.pt" "https://www.googleapis.com/drive/v3/files/1t27zkFMUnuqRcsqf2fh8F1RwaqFoMw5e?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE"
36 | wget -O "checkpoints/distilbert_ext.pt" "https://www.googleapis.com/drive/v3/files/1WxU7cHECfYaU32oTM0JByTRGS5f6SYEF?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE"
37 | wget -O "checkpoints/mobilebert_ext.pt" "https://www.googleapis.com/drive/v3/files/1umMOXoueo38zID_AKFSIOGxG9XjS5hDC?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE"
38 | ```
39 |
40 | ## Usage
41 | [](https://colab.research.google.com/drive/1hwpYC-AU6C_nwuM_N5ynOShXIRGv-U51#scrollTo=KizhzOxVOjaN)
42 | ```python
43 | import torch
44 | from models.model_builder import ExtSummarizer
45 | from ext_sum import summarize
46 |
47 | # Load model
48 | model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert']
49 | checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
50 | model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
51 |
52 | # Run summarization
53 | input_fp = 'raw_data/input.txt'
54 | result_fp = 'results/summary.txt'
55 | summary = summarize(input_fp, result_fp, model, max_length=3)
56 | print(summary)
57 | ```
58 |
59 | ## Demo
60 |
61 | [](https://extractive-summarization.herokuapp.com/)
62 |
63 | 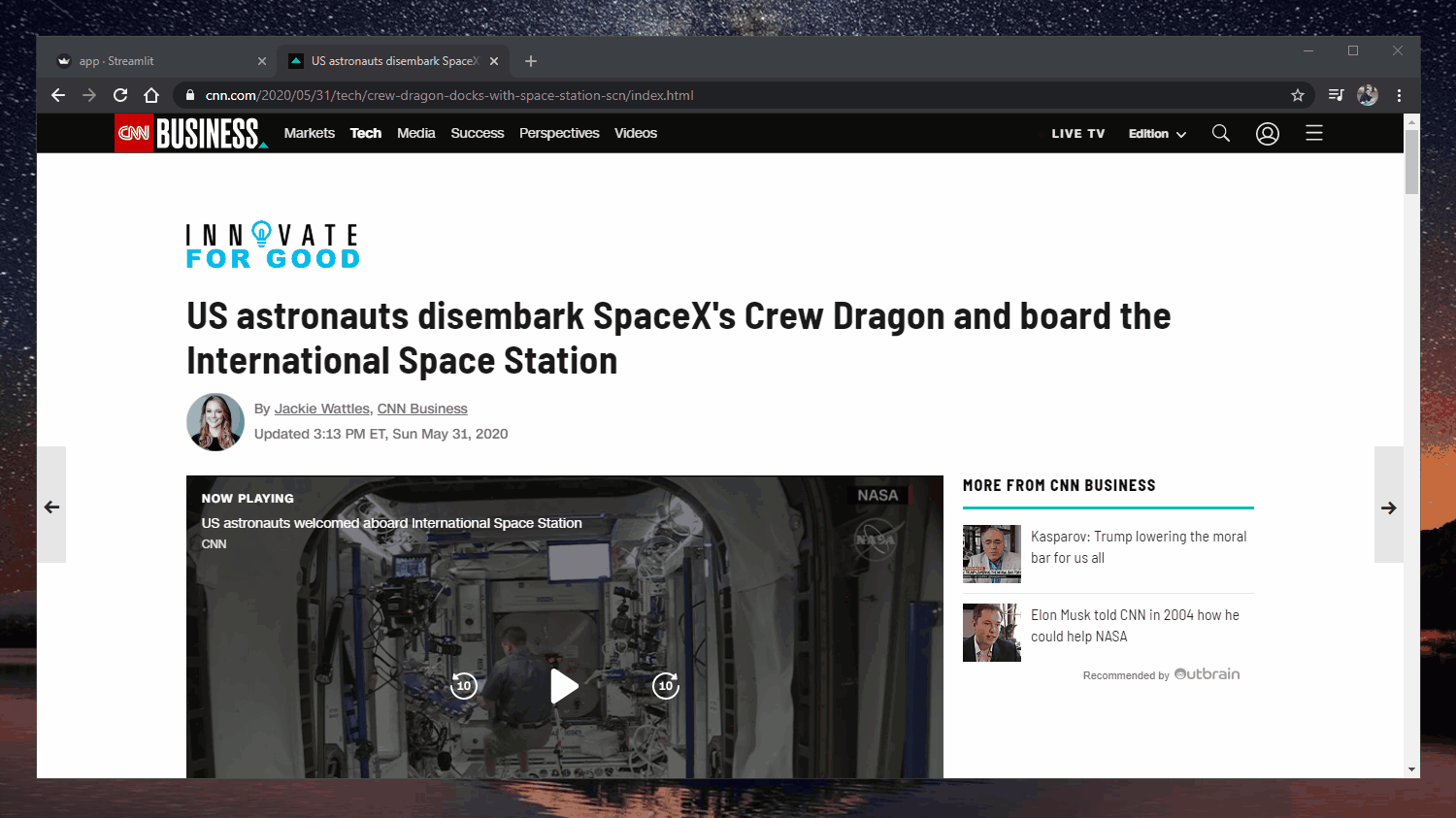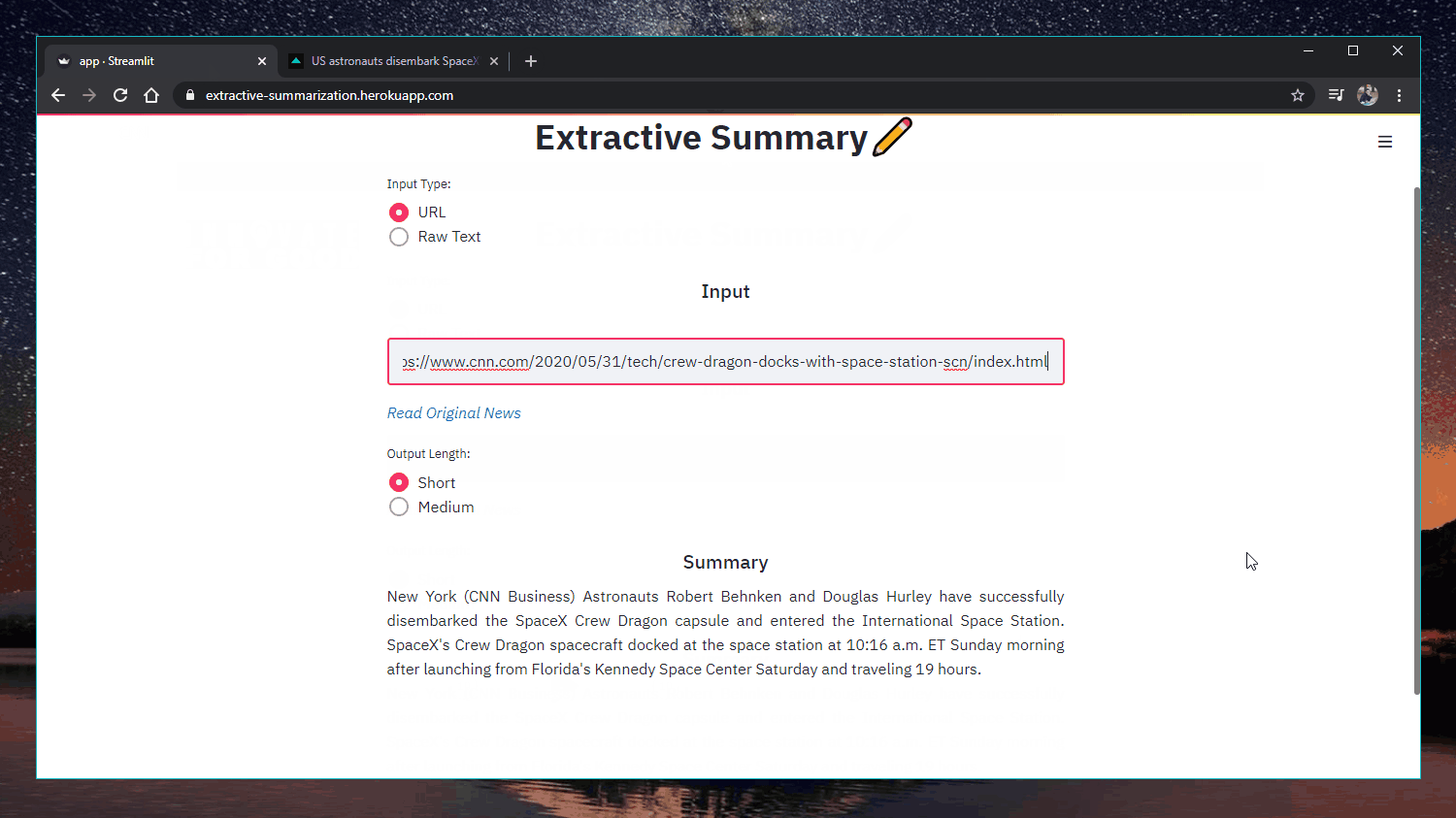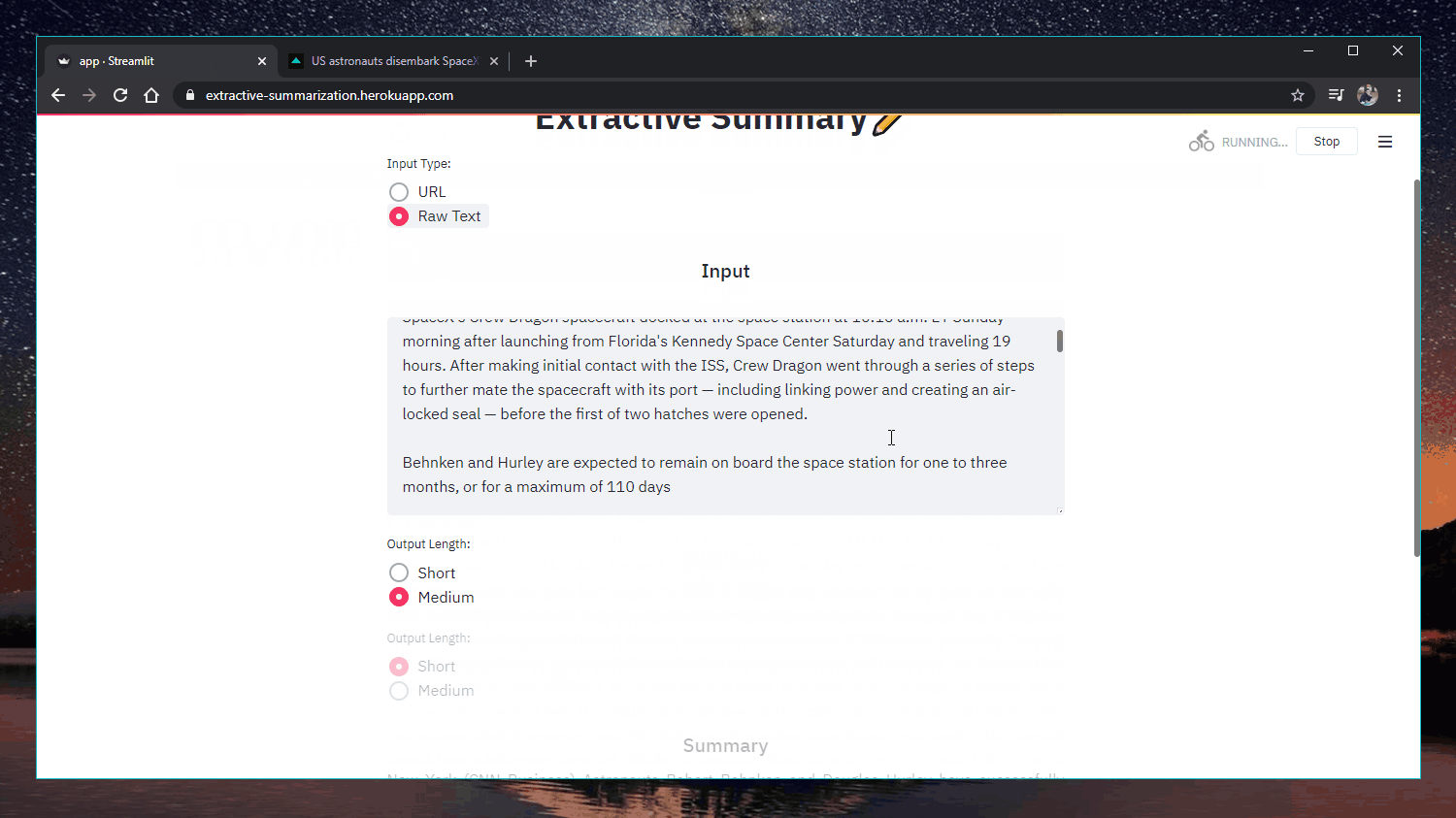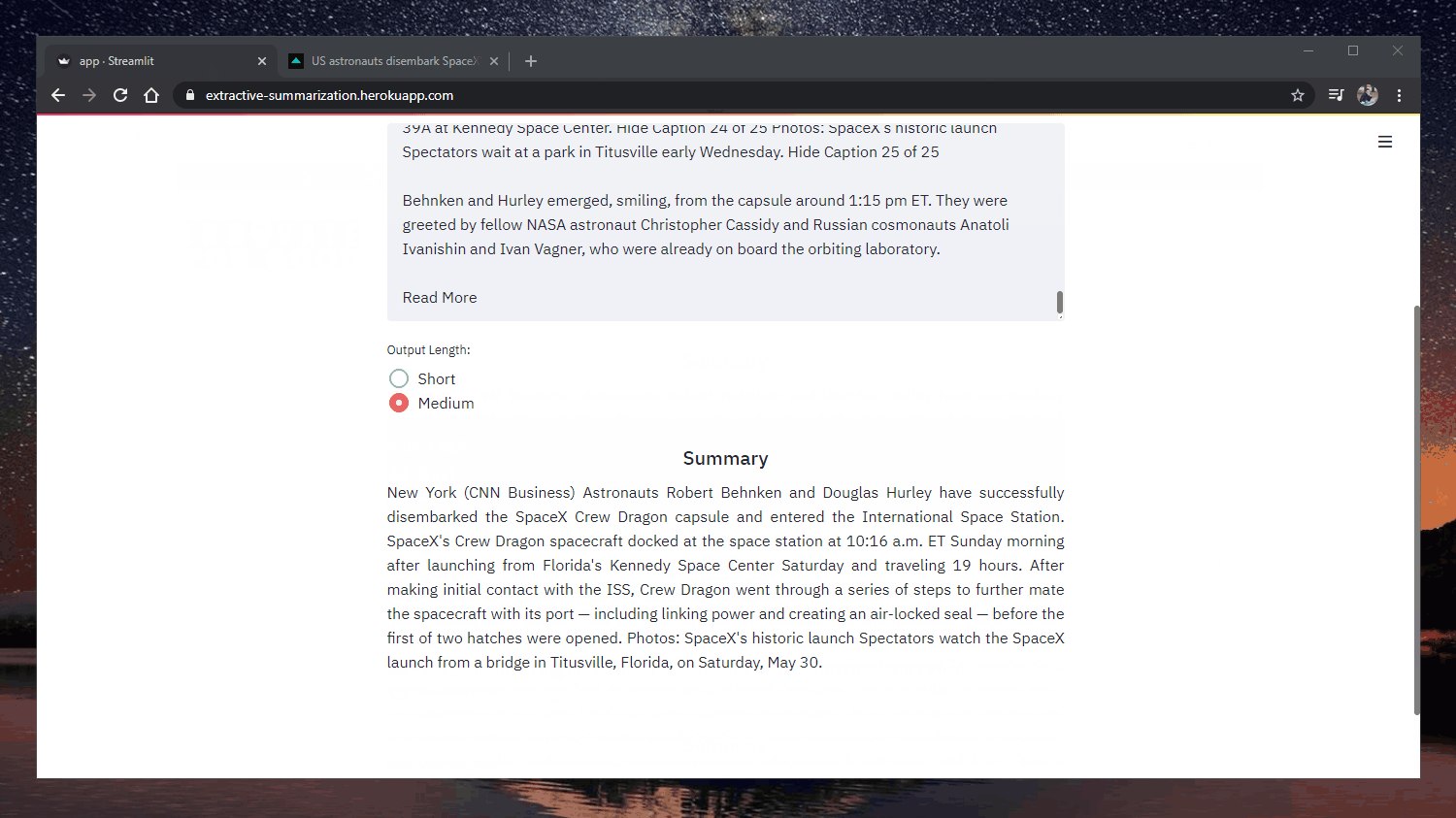
64 |
65 | ## Samples
66 |
67 | **Original:** https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
68 |
69 | **bert-base**
70 | ```
71 | The company has been renting cars since 1918, when it set up shop with a dozen Ford Model Ts, and has survived
72 | the Great Depression, the virtual halt of US auto production during World War II and numerous oil price shocks.
73 | By declaring bankruptcy, Hertz says it intends to stay in business while restructuring its debts and emerging a
74 | financially healthier company. The filing is arguably the highest-profile bankruptcy of the Covid-19 crisis,
75 | which has prompted bankruptcies by national retailers like JCPenney Neiman Marcus and J.Crew , along with some
76 | energy companies such as Whiting Petroleum and Diamond Offshore Drilling .
77 | ```
78 |
79 | **distilbert**
80 | ```
81 | By declaring bankruptcy, Hertz says it intends to stay in business while restructuring its debts and emerging a
82 | financially healthier company. But many companies that have filed for bankruptcy with the intention of staying
83 | in business have not survived the process. The company has been renting cars since 1918, when it set up shop
84 | with a dozen Ford Model Ts, and has survived the Great Depression, the virtual halt of US auto production during
85 | World War II and numerous oil price shocks.
86 | ```
87 |
88 | **mobilebert**
89 | ```
90 | By declaring bankruptcy, Hertz says it intends to stay in business while restructuring its debts and emerging a
91 | financially healthier company. The company has been renting cars since 1918, when it set up shop with a dozen
92 | Ford Model Ts, and has survived the Great Depression, the virtual halt of US auto production during World War II
93 | and numerous oil price shocks. "The impact of Covid-19 on travel demand was sudden and dramatic, causing an
94 | abrupt decline in the company's revenue and future bookings," said the company's statement.
95 | ```
96 |
97 | ## References
98 | - [1] [PreSumm: Text Summarization with Pretrained Encoders](https://github.com/nlpyang/PreSumm)
99 | - [2] [DistilBERT: Smaller, faster, cheaper, lighter version of BERT](https://huggingface.co/transformers/model_doc/distilbert.html)
100 | - [3] [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://github.com/google-research/google-research/tree/master/mobilebert)
101 | - [4] [MobileBert_PyTorch](https://github.com/lonePatient/MobileBert_PyTorch)
102 |
--------------------------------------------------------------------------------
/app.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | import os
3 | import torch
4 | import nltk
5 | import urllib.request
6 | from models.model_builder import ExtSummarizer
7 | from newspaper import Article
8 | from ext_sum import summarize
9 |
10 |
11 | def main():
12 | st.markdown("Extractive Summary✏️
", unsafe_allow_html=True)
13 |
14 | # Download model
15 | if not os.path.exists('checkpoints/mobilebert_ext.pt'):
16 | download_model()
17 |
18 | # Load model
19 | model = load_model('mobilebert')
20 |
21 | # Input
22 | input_type = st.radio("Input Type: ", ["URL", "Raw Text"])
23 | st.markdown("Input
", unsafe_allow_html=True)
24 |
25 | if input_type == "Raw Text":
26 | with open("raw_data/input.txt") as f:
27 | sample_text = f.read()
28 | text = st.text_area("", sample_text, 200)
29 | else:
30 | url = st.text_input("", "https://www.cnn.com/2020/05/29/tech/facebook-violence-trump/index.html")
31 | st.markdown(f"[*Read Original News*]({url})")
32 | text = crawl_url(url)
33 |
34 | input_fp = "raw_data/input.txt"
35 | with open(input_fp, 'w') as file:
36 | file.write(text)
37 |
38 | # Summarize
39 | sum_level = st.radio("Output Length: ", ["Short", "Medium"])
40 | max_length = 3 if sum_level == "Short" else 5
41 | result_fp = 'results/summary.txt'
42 | summary = summarize(input_fp, result_fp, model, max_length=max_length)
43 | st.markdown("Summary
", unsafe_allow_html=True)
44 | st.markdown(f"{summary}
", unsafe_allow_html=True)
45 |
46 |
47 | def download_model():
48 | nltk.download('popular')
49 | url = 'https://www.googleapis.com/drive/v3/files/1umMOXoueo38zID_AKFSIOGxG9XjS5hDC?alt=media&key=AIzaSyCmo6sAQ37OK8DK4wnT94PoLx5lx-7VTDE'
50 |
51 | # These are handles to two visual elements to animate.
52 | weights_warning, progress_bar = None, None
53 | try:
54 | weights_warning = st.warning("Downloading checkpoint...")
55 | progress_bar = st.progress(0)
56 | with open('checkpoints/mobilebert_ext.pt', 'wb') as output_file:
57 | with urllib.request.urlopen(url) as response:
58 | length = int(response.info()["Content-Length"])
59 | counter = 0.0
60 | MEGABYTES = 2.0 ** 20.0
61 | while True:
62 | data = response.read(8192)
63 | if not data:
64 | break
65 | counter += len(data)
66 | output_file.write(data)
67 |
68 | # We perform animation by overwriting the elements.
69 | weights_warning.warning("Downloading checkpoint... (%6.2f/%6.2f MB)" %
70 | (counter / MEGABYTES, length / MEGABYTES))
71 | progress_bar.progress(min(counter / length, 1.0))
72 |
73 | # Finally, we remove these visual elements by calling .empty().
74 | finally:
75 | if weights_warning is not None:
76 | weights_warning.empty()
77 | if progress_bar is not None:
78 | progress_bar.empty()
79 |
80 |
81 | @st.cache(suppress_st_warning=True)
82 | def load_model(model_type):
83 | checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
84 | model = ExtSummarizer(device="cpu", checkpoint=checkpoint, bert_type=model_type)
85 | return model
86 |
87 |
88 | def crawl_url(url):
89 | article = Article(url)
90 | article.download()
91 | article.parse()
92 | return article.text
93 |
94 |
95 | if __name__ == "__main__":
96 | main()
97 |
--------------------------------------------------------------------------------
/checkpoints/mobilebert/config.json:
--------------------------------------------------------------------------------
1 | {
2 | "attention_probs_dropout_prob": 0.1,
3 | "hidden_act": "relu",
4 | "hidden_dropout_prob": 0.0,
5 | "hidden_size": 512,
6 | "initializer_range": 0.02,
7 | "intermediate_size": 512,
8 | "max_position_embeddings": 512,
9 | "num_attention_heads": 4,
10 | "num_hidden_layers": 24,
11 | "type_vocab_size": 2,
12 | "vocab_size": 30522,
13 | "embedding_size": 128,
14 | "trigram_input": true,
15 | "use_bottleneck": true,
16 | "intra_bottleneck_size": 128,
17 | "key_query_shared_bottleneck": true,
18 | "num_feedforward_networks": 4,
19 | "normalization_type": "no_norm",
20 | "classifier_activation": false
21 | }
22 |
--------------------------------------------------------------------------------
/ext_sum.py:
--------------------------------------------------------------------------------
1 | import time
2 | import numpy as np
3 | import torch
4 | from transformers import BertTokenizer
5 | from nltk.tokenize import sent_tokenize
6 | from models.model_builder import ExtSummarizer
7 |
8 |
9 | def preprocess(source_fp):
10 | """
11 | - Remove \n
12 | - Sentence Tokenize
13 | - Add [SEP] [CLS] as sentence boundary
14 | """
15 | with open(source_fp) as source:
16 | raw_text = source.read().replace("\n", " ").replace("[CLS] [SEP]", " ")
17 | sents = sent_tokenize(raw_text)
18 | processed_text = "[CLS] [SEP]".join(sents)
19 | return processed_text, len(sents)
20 |
21 |
22 | def load_text(processed_text, max_pos, device):
23 | tokenizer = BertTokenizer.from_pretrained("bert-base-uncased", do_lower_case=True)
24 | sep_vid = tokenizer.vocab["[SEP]"]
25 | cls_vid = tokenizer.vocab["[CLS]"]
26 |
27 | def _process_src(raw):
28 | raw = raw.strip().lower()
29 | raw = raw.replace("[cls]", "[CLS]").replace("[sep]", "[SEP]")
30 | src_subtokens = tokenizer.tokenize(raw)
31 | src_subtokens = ["[CLS]"] + src_subtokens + ["[SEP]"]
32 | src_subtoken_idxs = tokenizer.convert_tokens_to_ids(src_subtokens)
33 | src_subtoken_idxs = src_subtoken_idxs[:-1][:max_pos]
34 | src_subtoken_idxs[-1] = sep_vid
35 | _segs = [-1] + [i for i, t in enumerate(src_subtoken_idxs) if t == sep_vid]
36 | segs = [_segs[i] - _segs[i - 1] for i in range(1, len(_segs))]
37 |
38 | segments_ids = []
39 | segs = segs[:max_pos]
40 | for i, s in enumerate(segs):
41 | if i % 2 == 0:
42 | segments_ids += s * [0]
43 | else:
44 | segments_ids += s * [1]
45 |
46 | src = torch.tensor(src_subtoken_idxs)[None, :].to(device)
47 | mask_src = (1 - (src == 0).float()).to(device)
48 | cls_ids = [[i for i, t in enumerate(src_subtoken_idxs) if t == cls_vid]]
49 | clss = torch.tensor(cls_ids).to(device)
50 | mask_cls = 1 - (clss == -1).float()
51 | clss[clss == -1] = 0
52 | return src, mask_src, segments_ids, clss, mask_cls
53 |
54 | src, mask_src, segments_ids, clss, mask_cls = _process_src(processed_text)
55 | segs = torch.tensor(segments_ids)[None, :].to(device)
56 | src_text = [[sent.replace("[SEP]", "").strip() for sent in processed_text.split("[CLS]")]]
57 | return src, mask_src, segs, clss, mask_cls, src_text
58 |
59 |
60 | def test(model, input_data, result_path, max_length, block_trigram=True):
61 | def _get_ngrams(n, text):
62 | ngram_set = set()
63 | text_length = len(text)
64 | max_index_ngram_start = text_length - n
65 | for i in range(max_index_ngram_start + 1):
66 | ngram_set.add(tuple(text[i : i + n]))
67 | return ngram_set
68 |
69 | def _block_tri(c, p):
70 | tri_c = _get_ngrams(3, c.split())
71 | for s in p:
72 | tri_s = _get_ngrams(3, s.split())
73 | if len(tri_c.intersection(tri_s)) > 0:
74 | return True
75 | return False
76 |
77 | with open(result_path, "w") as save_pred:
78 | with torch.no_grad():
79 | src, mask, segs, clss, mask_cls, src_str = input_data
80 | sent_scores, mask = model(src, segs, clss, mask, mask_cls)
81 | sent_scores = sent_scores + mask.float()
82 | sent_scores = sent_scores.cpu().data.numpy()
83 | selected_ids = np.argsort(-sent_scores, 1)
84 |
85 | pred = []
86 | for i, idx in enumerate(selected_ids):
87 | _pred = []
88 | if len(src_str[i]) == 0:
89 | continue
90 | for j in selected_ids[i][: len(src_str[i])]:
91 | if j >= len(src_str[i]):
92 | continue
93 | candidate = src_str[i][j].strip()
94 | if block_trigram:
95 | if not _block_tri(candidate, _pred):
96 | _pred.append(candidate)
97 | else:
98 | _pred.append(candidate)
99 |
100 | if len(_pred) == max_length:
101 | break
102 |
103 | _pred = " ".join(_pred)
104 | pred.append(_pred)
105 |
106 | for i in range(len(pred)):
107 | save_pred.write(pred[i].strip() + "\n")
108 |
109 |
110 | def summarize(raw_txt_fp, result_fp, model, max_length=3, max_pos=512, return_summary=True):
111 | model.eval()
112 | processed_text, full_length = preprocess(raw_txt_fp)
113 | input_data = load_text(processed_text, max_pos, device="cpu")
114 | test(model, input_data, result_fp, max_length, block_trigram=True)
115 | if return_summary:
116 | return open(result_fp).read().strip()
117 |
--------------------------------------------------------------------------------
/models/MobileBert/__init__.py:
--------------------------------------------------------------------------------
1 | #encoding:utf-8
--------------------------------------------------------------------------------
/models/MobileBert/activations.py:
--------------------------------------------------------------------------------
1 | import logging
2 | import math
3 |
4 | import torch
5 | import torch.nn.functional as F
6 |
7 |
8 | logger = logging.getLogger(__name__)
9 |
10 |
11 | def swish(x):
12 | return x * torch.sigmoid(x)
13 |
14 |
15 | def _gelu_python(x):
16 | """ Original Implementation of the gelu activation function in Google Bert repo when initially created.
17 | For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
18 | 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
19 | This is now written in C in torch.nn.functional
20 | Also see https://arxiv.org/abs/1606.08415
21 | """
22 | return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
23 |
24 |
25 | def gelu_new(x):
26 | """ Implementation of the gelu activation function currently in Google Bert repo (identical to OpenAI GPT).
27 | Also see https://arxiv.org/abs/1606.08415
28 | """
29 | return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3.0))))
30 |
31 |
32 | if torch.__version__ < "1.4.0":
33 | gelu = _gelu_python
34 | else:
35 | gelu = F.gelu
36 | try:
37 | import torch_xla # noqa F401
38 |
39 | logger.warning(
40 | "The torch_xla package was detected in the python environment. PyTorch/XLA and JIT is untested,"
41 | " no activation function will be traced with JIT."
42 | )
43 | except ImportError:
44 | gelu_new = torch.jit.script(gelu_new)
45 |
46 | ACT2FN = {
47 | "relu": F.relu,
48 | "swish": swish,
49 | "gelu": gelu,
50 | "tanh": torch.tanh,
51 | "gelu_new": gelu_new,
52 | }
53 |
54 |
55 | def get_activation(activation_string):
56 | if activation_string in ACT2FN:
57 | return ACT2FN[activation_string]
58 | else:
59 | raise KeyError("function {} not found in ACT2FN mapping {}".format(activation_string, list(ACT2FN.keys())))
60 |
--------------------------------------------------------------------------------
/models/MobileBert/configuration_mobilebert.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
3 | # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | """ MobileBERT model configuration """
17 |
18 | import logging
19 |
20 | from .configuration_utils import PretrainedConfig
21 |
22 | logger = logging.getLogger(__name__)
23 |
24 | BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
25 |
26 | class MobileBertConfig(PretrainedConfig):
27 | r"""
28 | This is the configuration class to store the configuration of a :class:`~transformers.BertModel`.
29 | It is used to instantiate an BERT model according to the specified arguments, defining the model
30 | architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of
31 | the BERT `bert-base-uncased `__ architecture.
32 |
33 | Configuration objects inherit from :class:`~transformers.PretrainedConfig` and can be used
34 | to control the model outputs. Read the documentation from :class:`~transformers.PretrainedConfig`
35 | for more information.
36 |
37 |
38 | Args:
39 | vocab_size (:obj:`int`, optional, defaults to 30522):
40 | Vocabulary size of the BERT model. Defines the different tokens that
41 | can be represented by the `inputs_ids` passed to the forward method of :class:`~transformers.BertModel`.
42 | hidden_size (:obj:`int`, optional, defaults to 768):
43 | Dimensionality of the encoder layers and the pooler layer.
44 | num_hidden_layers (:obj:`int`, optional, defaults to 12):
45 | Number of hidden layers in the Transformer encoder.
46 | num_attention_heads (:obj:`int`, optional, defaults to 12):
47 | Number of attention heads for each attention layer in the Transformer encoder.
48 | intermediate_size (:obj:`int`, optional, defaults to 3072):
49 | Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
50 | hidden_act (:obj:`str` or :obj:`function`, optional, defaults to "gelu"):
51 | The non-linear activation function (function or string) in the encoder and pooler.
52 | If string, "gelu", "relu", "swish" and "gelu_new" are supported.
53 | hidden_dropout_prob (:obj:`float`, optional, defaults to 0.1):
54 | The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
55 | attention_probs_dropout_prob (:obj:`float`, optional, defaults to 0.1):
56 | The dropout ratio for the attention probabilities.
57 | max_position_embeddings (:obj:`int`, optional, defaults to 512):
58 | The maximum sequence length that this model might ever be used with.
59 | Typically set this to something large just in case (e.g., 512 or 1024 or 2048).
60 | type_vocab_size (:obj:`int`, optional, defaults to 2):
61 | The vocabulary size of the `token_type_ids` passed into :class:`~transformers.BertModel`.
62 | initializer_range (:obj:`float`, optional, defaults to 0.02):
63 | The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
64 | layer_norm_eps (:obj:`float`, optional, defaults to 1e-12):
65 | The epsilon used by the layer normalization layers.
66 |
67 | Example::
68 |
69 | from transformers import BertModel, BertConfig
70 |
71 | # Initializing a BERT bert-base-uncased style configuration
72 | configuration = BertConfig()
73 |
74 | # Initializing a model from the bert-base-uncased style configuration
75 | model = BertModel(configuration)
76 |
77 | # Accessing the model configuration
78 | configuration = model.config
79 |
80 | Attributes:
81 | pretrained_config_archive_map (Dict[str, str]):
82 | A dictionary containing all the available pre-trained checkpoints.
83 | """
84 | pretrained_config_archive_map = BERT_PRETRAINED_CONFIG_ARCHIVE_MAP
85 | model_type = "bert"
86 |
87 | def __init__(
88 | self,
89 | vocab_size=30522,
90 | hidden_size=768,
91 | num_hidden_layers=12,
92 | num_attention_heads=12,
93 | intermediate_size=3072,
94 | hidden_act="gelu",
95 | hidden_dropout_prob=0.1,
96 | attention_probs_dropout_prob=0.1,
97 | max_position_embeddings=512,
98 | type_vocab_size=16,
99 | initializer_range=0.02,
100 | layer_norm_eps=1e-12,
101 | pad_token_id=0,
102 | embedding_size=None,
103 | trigram_input=False,
104 | use_bottleneck=False,
105 | intra_bottleneck_size=None,
106 | use_bottleneck_attention=False,
107 | key_query_shared_bottleneck=False,
108 | num_feedforward_networks=1,
109 | normalization_type="layer_norm",
110 | **kwargs
111 | ):
112 | super().__init__(pad_token_id=pad_token_id, **kwargs)
113 |
114 | self.vocab_size = vocab_size
115 | self.hidden_size = hidden_size
116 | self.num_hidden_layers = num_hidden_layers
117 | self.num_attention_heads = num_attention_heads
118 | self.hidden_act = hidden_act
119 | self.intermediate_size = intermediate_size
120 | self.hidden_dropout_prob = hidden_dropout_prob
121 | self.attention_probs_dropout_prob = attention_probs_dropout_prob
122 | self.max_position_embeddings = max_position_embeddings
123 | self.type_vocab_size = type_vocab_size
124 | self.initializer_range = initializer_range
125 | self.layer_norm_eps = layer_norm_eps
126 | self.embedding_size = embedding_size
127 | self.trigram_input = trigram_input
128 | self.use_bottleneck = use_bottleneck
129 | self.intra_bottleneck_size = intra_bottleneck_size
130 | self.use_bottleneck_attention = use_bottleneck_attention
131 | self.key_query_shared_bottleneck = key_query_shared_bottleneck
132 | self.num_feedforward_networks = num_feedforward_networks
133 | self.normalization_type = normalization_type
134 |
135 | if self.use_bottleneck:
136 | self.true_hidden_size = intra_bottleneck_size
137 | else:
138 | self.true_hidden_size = hidden_size
139 |
140 |
--------------------------------------------------------------------------------
/models/MobileBert/configuration_utils.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
3 | # Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
4 | #
5 | # Licensed under the Apache License, Version 2.0 (the "License");
6 | # you may not use this file except in compliance with the License.
7 | # You may obtain a copy of the License at
8 | #
9 | # http://www.apache.org/licenses/LICENSE-2.0
10 | #
11 | # Unless required by applicable law or agreed to in writing, software
12 | # distributed under the License is distributed on an "AS IS" BASIS,
13 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 | # See the License for the specific language governing permissions and
15 | # limitations under the License.
16 | """ Configuration base class and utilities."""
17 |
18 |
19 | import copy
20 | import json
21 | import logging
22 | import os
23 | from typing import Dict, Optional, Tuple
24 |
25 | from .file_utils import CONFIG_NAME, cached_path, hf_bucket_url, is_remote_url
26 |
27 | logger = logging.getLogger(__name__)
28 |
29 | class PretrainedConfig(object):
30 | r""" Base class for all configuration classes.
31 | Handles a few parameters common to all models' configurations as well as methods for loading/downloading/saving configurations.
32 |
33 | Note:
34 | A configuration file can be loaded and saved to disk. Loading the configuration file and using this file to initialize a model does **not** load the model weights.
35 | It only affects the model's configuration.
36 |
37 | Class attributes (overridden by derived classes):
38 | - ``pretrained_config_archive_map``: a python ``dict`` with `shortcut names` (string) as keys and `url` (string) of associated pretrained model configurations as values.
39 | - ``model_type``: a string that identifies the model type, that we serialize into the JSON file, and that we use to recreate the correct object in :class:`~transformers.AutoConfig`.
40 |
41 | Args:
42 | finetuning_task (:obj:`string` or :obj:`None`, `optional`, defaults to :obj:`None`):
43 | Name of the task used to fine-tune the model. This can be used when converting from an original (TensorFlow or PyTorch) checkpoint.
44 | num_labels (:obj:`int`, `optional`, defaults to `2`):
45 | Number of classes to use when the model is a classification model (sequences/tokens)
46 | output_attentions (:obj:`bool`, `optional`, defaults to :obj:`False`):
47 | Should the model returns attentions weights.
48 | output_hidden_states (:obj:`string`, `optional`, defaults to :obj:`False`):
49 | Should the model returns all hidden-states.
50 | torchscript (:obj:`bool`, `optional`, defaults to :obj:`False`):
51 | Is the model used with Torchscript (for PyTorch models).
52 | """
53 | pretrained_config_archive_map: Dict[str, str] = {}
54 | model_type: str = ""
55 |
56 | def __init__(self, **kwargs):
57 | # Attributes with defaults
58 | self.output_attentions = kwargs.pop("output_attentions", False)
59 | self.output_hidden_states = kwargs.pop("output_hidden_states", False)
60 | self.use_cache = kwargs.pop("use_cache", True) # Not used by all models
61 | self.torchscript = kwargs.pop("torchscript", False) # Only used by PyTorch models
62 | self.use_bfloat16 = kwargs.pop("use_bfloat16", False)
63 | self.pruned_heads = kwargs.pop("pruned_heads", {})
64 |
65 | # Is decoder is used in encoder-decoder models to differentiate encoder from decoder
66 | self.is_encoder_decoder = kwargs.pop("is_encoder_decoder", False)
67 | self.is_decoder = kwargs.pop("is_decoder", False)
68 |
69 | # Parameters for sequence generation
70 | self.max_length = kwargs.pop("max_length", 20)
71 | self.min_length = kwargs.pop("min_length", 0)
72 | self.do_sample = kwargs.pop("do_sample", False)
73 | self.early_stopping = kwargs.pop("early_stopping", False)
74 | self.num_beams = kwargs.pop("num_beams", 1)
75 | self.temperature = kwargs.pop("temperature", 1.0)
76 | self.top_k = kwargs.pop("top_k", 50)
77 | self.top_p = kwargs.pop("top_p", 1.0)
78 | self.repetition_penalty = kwargs.pop("repetition_penalty", 1.0)
79 | self.length_penalty = kwargs.pop("length_penalty", 1.0)
80 | self.no_repeat_ngram_size = kwargs.pop("no_repeat_ngram_size", 0)
81 | self.bad_words_ids = kwargs.pop("bad_words_ids", None)
82 | self.num_return_sequences = kwargs.pop("num_return_sequences", 1)
83 |
84 | # Fine-tuning task arguments
85 | self.architectures = kwargs.pop("architectures", None)
86 | self.finetuning_task = kwargs.pop("finetuning_task", None)
87 | self.num_labels = kwargs.pop("num_labels", 2)
88 | self.id2label = kwargs.pop("id2label", {i: f"LABEL_{i}" for i in range(self.num_labels)})
89 | self.id2label = dict((int(key), value) for key, value in self.id2label.items())
90 | self.label2id = kwargs.pop("label2id", dict(zip(self.id2label.values(), self.id2label.keys())))
91 | self.label2id = dict((key, int(value)) for key, value in self.label2id.items())
92 |
93 | # Tokenizer arguments TODO: eventually tokenizer and models should share the same config
94 | self.prefix = kwargs.pop("prefix", None)
95 | self.bos_token_id = kwargs.pop("bos_token_id", None)
96 | self.pad_token_id = kwargs.pop("pad_token_id", None)
97 | self.eos_token_id = kwargs.pop("eos_token_id", None)
98 | self.decoder_start_token_id = kwargs.pop("decoder_start_token_id", None)
99 |
100 | # task specific arguments
101 | self.task_specific_params = kwargs.pop("task_specific_params", None)
102 |
103 | # TPU arguments
104 | self.xla_device = kwargs.pop("xla_device", None)
105 |
106 | # Additional attributes without default values
107 | for key, value in kwargs.items():
108 | try:
109 | setattr(self, key, value)
110 | except AttributeError as err:
111 | logger.error("Can't set {} with value {} for {}".format(key, value, self))
112 | raise err
113 |
114 | @property
115 | def num_labels(self):
116 | return self._num_labels
117 |
118 | @num_labels.setter
119 | def num_labels(self, num_labels):
120 | self._num_labels = num_labels
121 | self.id2label = {i: "LABEL_{}".format(i) for i in range(self.num_labels)}
122 | self.id2label = dict((int(key), value) for key, value in self.id2label.items())
123 | self.label2id = dict(zip(self.id2label.values(), self.id2label.keys()))
124 | self.label2id = dict((key, int(value)) for key, value in self.label2id.items())
125 |
126 | def save_pretrained(self, save_directory):
127 | """
128 | Save a configuration object to the directory `save_directory`, so that it
129 | can be re-loaded using the :func:`~transformers.PretrainedConfig.from_pretrained` class method.
130 |
131 | Args:
132 | save_directory (:obj:`string`):
133 | Directory where the configuration JSON file will be saved.
134 | """
135 | assert os.path.isdir(
136 | save_directory
137 | ), "Saving path should be a directory where the model and configuration can be saved"
138 |
139 | # If we save using the predefined names, we can load using `from_pretrained`
140 | output_config_file = os.path.join(save_directory, CONFIG_NAME)
141 |
142 | self.to_json_file(output_config_file, use_diff=True)
143 | logger.info("Configuration saved in {}".format(output_config_file))
144 |
145 | @classmethod
146 | def from_pretrained(cls, pretrained_model_name_or_path, **kwargs) -> "PretrainedConfig":
147 | r"""
148 |
149 | Instantiate a :class:`~transformers.PretrainedConfig` (or a derived class) from a pre-trained model configuration.
150 |
151 | Args:
152 | pretrained_model_name_or_path (:obj:`string`):
153 | either:
154 | - a string with the `shortcut name` of a pre-trained model configuration to load from cache or
155 | download, e.g.: ``bert-base-uncased``.
156 | - a string with the `identifier name` of a pre-trained model configuration that was user-uploaded to
157 | our S3, e.g.: ``dbmdz/bert-base-german-cased``.
158 | - a path to a `directory` containing a configuration file saved using the
159 | :func:`~transformers.PretrainedConfig.save_pretrained` method, e.g.: ``./my_model_directory/``.
160 | - a path or url to a saved configuration JSON `file`, e.g.:
161 | ``./my_model_directory/configuration.json``.
162 | cache_dir (:obj:`string`, `optional`):
163 | Path to a directory in which a downloaded pre-trained model
164 | configuration should be cached if the standard cache should not be used.
165 | kwargs (:obj:`Dict[str, any]`, `optional`):
166 | The values in kwargs of any keys which are configuration attributes will be used to override the loaded
167 | values. Behavior concerning key/value pairs whose keys are *not* configuration attributes is
168 | controlled by the `return_unused_kwargs` keyword parameter.
169 | force_download (:obj:`bool`, `optional`, defaults to :obj:`False`):
170 | Force to (re-)download the model weights and configuration files and override the cached versions if they exist.
171 | resume_download (:obj:`bool`, `optional`, defaults to :obj:`False`):
172 | Do not delete incompletely recieved file. Attempt to resume the download if such a file exists.
173 | proxies (:obj:`Dict`, `optional`):
174 | A dictionary of proxy servers to use by protocol or endpoint, e.g.:
175 | :obj:`{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}.`
176 | The proxies are used on each request.
177 | return_unused_kwargs: (`optional`) bool:
178 | If False, then this function returns just the final configuration object.
179 | If True, then this functions returns a :obj:`Tuple(config, unused_kwargs)` where `unused_kwargs` is a
180 | dictionary consisting of the key/value pairs whose keys are not configuration attributes: ie the part
181 | of kwargs which has not been used to update `config` and is otherwise ignored.
182 |
183 | Returns:
184 | :class:`PretrainedConfig`: An instance of a configuration object
185 |
186 | Examples::
187 |
188 | # We can't instantiate directly the base class `PretrainedConfig` so let's show the examples on a
189 | # derived class: BertConfig
190 | config = BertConfig.from_pretrained('bert-base-uncased') # Download configuration from S3 and cache.
191 | config = BertConfig.from_pretrained('./test/saved_model/') # E.g. config (or model) was saved using `save_pretrained('./test/saved_model/')`
192 | config = BertConfig.from_pretrained('./test/saved_model/my_configuration.json')
193 | config = BertConfig.from_pretrained('bert-base-uncased', output_attention=True, foo=False)
194 | assert config.output_attention == True
195 | config, unused_kwargs = BertConfig.from_pretrained('bert-base-uncased', output_attention=True,
196 | foo=False, return_unused_kwargs=True)
197 | assert config.output_attention == True
198 | assert unused_kwargs == {'foo': False}
199 |
200 | """
201 | config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
202 | return cls.from_dict(config_dict, **kwargs)
203 |
204 | @classmethod
205 | def get_config_dict(
206 | cls, pretrained_model_name_or_path: str, pretrained_config_archive_map: Optional[Dict] = None, **kwargs
207 | ) -> Tuple[Dict, Dict]:
208 | """
209 | From a `pretrained_model_name_or_path`, resolve to a dictionary of parameters, to be used
210 | for instantiating a Config using `from_dict`.
211 |
212 | Parameters:
213 | pretrained_model_name_or_path (:obj:`string`):
214 | The identifier of the pre-trained checkpoint from which we want the dictionary of parameters.
215 | pretrained_config_archive_map: (:obj:`Dict[str, str]`, `optional`) Dict:
216 | A map of `shortcut names` to `url`. By default, will use the current class attribute.
217 |
218 | Returns:
219 | :obj:`Tuple[Dict, Dict]`: The dictionary that will be used to instantiate the configuration object.
220 |
221 | """
222 | cache_dir = kwargs.pop("cache_dir", None)
223 | force_download = kwargs.pop("force_download", False)
224 | resume_download = kwargs.pop("resume_download", False)
225 | proxies = kwargs.pop("proxies", None)
226 | local_files_only = kwargs.pop("local_files_only", False)
227 |
228 | if pretrained_config_archive_map is None:
229 | pretrained_config_archive_map = cls.pretrained_config_archive_map
230 |
231 | if pretrained_model_name_or_path in pretrained_config_archive_map:
232 | config_file = pretrained_config_archive_map[pretrained_model_name_or_path]
233 | elif os.path.isdir(pretrained_model_name_or_path):
234 | config_file = os.path.join(pretrained_model_name_or_path, CONFIG_NAME)
235 | elif os.path.isfile(pretrained_model_name_or_path) or is_remote_url(pretrained_model_name_or_path):
236 | config_file = pretrained_model_name_or_path
237 | else:
238 | config_file = hf_bucket_url(pretrained_model_name_or_path, postfix=CONFIG_NAME)
239 |
240 | try:
241 | # Load from URL or cache if already cached
242 | resolved_config_file = cached_path(
243 | config_file,
244 | cache_dir=cache_dir,
245 | force_download=force_download,
246 | proxies=proxies,
247 | resume_download=resume_download,
248 | local_files_only=local_files_only,
249 | )
250 | # Load config dict
251 | if resolved_config_file is None:
252 | raise EnvironmentError
253 | config_dict = cls._dict_from_json_file(resolved_config_file)
254 |
255 | except EnvironmentError:
256 | if pretrained_model_name_or_path in pretrained_config_archive_map:
257 | msg = "Couldn't reach server at '{}' to download pretrained model configuration file.".format(
258 | config_file
259 | )
260 | else:
261 | msg = (
262 | "Can't load '{}'. Make sure that:\n\n"
263 | "- '{}' is a correct model identifier listed on 'https://huggingface.co/models'\n\n"
264 | "- or '{}' is the correct path to a directory containing a '{}' file\n\n".format(
265 | pretrained_model_name_or_path,
266 | pretrained_model_name_or_path,
267 | pretrained_model_name_or_path,
268 | CONFIG_NAME,
269 | )
270 | )
271 | raise EnvironmentError(msg)
272 |
273 | except json.JSONDecodeError:
274 | msg = (
275 | "Couldn't reach server at '{}' to download configuration file or "
276 | "configuration file is not a valid JSON file. "
277 | "Please check network or file content here: {}.".format(config_file, resolved_config_file)
278 | )
279 | raise EnvironmentError(msg)
280 |
281 | if resolved_config_file == config_file:
282 | logger.info("loading configuration file {}".format(config_file))
283 | else:
284 | logger.info("loading configuration file {} from cache at {}".format(config_file, resolved_config_file))
285 |
286 | return config_dict, kwargs
287 |
288 | @classmethod
289 | def from_dict(cls, config_dict: Dict, **kwargs) -> "PretrainedConfig":
290 | """
291 | Constructs a `Config` from a Python dictionary of parameters.
292 |
293 | Args:
294 | config_dict (:obj:`Dict[str, any]`):
295 | Dictionary that will be used to instantiate the configuration object. Such a dictionary can be retrieved
296 | from a pre-trained checkpoint by leveraging the :func:`~transformers.PretrainedConfig.get_config_dict`
297 | method.
298 | kwargs (:obj:`Dict[str, any]`):
299 | Additional parameters from which to initialize the configuration object.
300 |
301 | Returns:
302 | :class:`PretrainedConfig`: An instance of a configuration object
303 | """
304 | return_unused_kwargs = kwargs.pop("return_unused_kwargs", False)
305 |
306 | config = cls(**config_dict)
307 |
308 | if hasattr(config, "pruned_heads"):
309 | config.pruned_heads = dict((int(key), value) for key, value in config.pruned_heads.items())
310 |
311 | # Update config with kwargs if needed
312 | to_remove = []
313 | for key, value in kwargs.items():
314 | if hasattr(config, key):
315 | setattr(config, key, value)
316 | to_remove.append(key)
317 | for key in to_remove:
318 | kwargs.pop(key, None)
319 |
320 | logger.info("Model config %s", str(config))
321 | if return_unused_kwargs:
322 | return config, kwargs
323 | else:
324 | return config
325 |
326 | @classmethod
327 | def from_json_file(cls, json_file: str) -> "PretrainedConfig":
328 | """
329 | Constructs a `Config` from the path to a json file of parameters.
330 |
331 | Args:
332 | json_file (:obj:`string`):
333 | Path to the JSON file containing the parameters.
334 |
335 | Returns:
336 | :class:`PretrainedConfig`: An instance of a configuration object
337 |
338 | """
339 | config_dict = cls._dict_from_json_file(json_file)
340 | return cls(**config_dict)
341 |
342 | @classmethod
343 | def _dict_from_json_file(cls, json_file: str):
344 | with open(json_file, "r", encoding="utf-8") as reader:
345 | text = reader.read()
346 | return json.loads(text)
347 |
348 | def __eq__(self, other):
349 | return self.__dict__ == other.__dict__
350 |
351 | def __repr__(self):
352 | return "{} {}".format(self.__class__.__name__, self.to_json_string())
353 |
354 | def to_diff_dict(self):
355 | """
356 | Removes all attributes from config which correspond to the default
357 | config attributes for better readability and serializes to a Python
358 | dictionary.
359 |
360 | Returns:
361 | :obj:`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
362 | """
363 | config_dict = self.to_dict()
364 |
365 | # get the default config dict
366 | default_config_dict = PretrainedConfig().to_dict()
367 |
368 | serializable_config_dict = {}
369 |
370 | # only serialize values that differ from the default config
371 | for key, value in config_dict.items():
372 | if key not in default_config_dict or value != default_config_dict[key]:
373 | serializable_config_dict[key] = value
374 |
375 | return serializable_config_dict
376 |
377 | def to_dict(self):
378 | """
379 | Serializes this instance to a Python dictionary.
380 |
381 | Returns:
382 | :obj:`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
383 | """
384 | output = copy.deepcopy(self.__dict__)
385 | if hasattr(self.__class__, "model_type"):
386 | output["model_type"] = self.__class__.model_type
387 | return output
388 |
389 | def to_json_string(self, use_diff=True):
390 | """
391 | Serializes this instance to a JSON string.
392 |
393 | Args:
394 | use_diff (:obj:`bool`):
395 | If set to True, only the difference between the config instance and the default PretrainedConfig() is serialized to JSON string.
396 |
397 | Returns:
398 | :obj:`string`: String containing all the attributes that make up this configuration instance in JSON format.
399 | """
400 | if use_diff is True:
401 | config_dict = self.to_diff_dict()
402 | else:
403 | config_dict = self.to_dict()
404 | return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
405 |
406 | def to_json_file(self, json_file_path, use_diff=True):
407 | """
408 | Save this instance to a json file.
409 |
410 | Args:
411 | json_file_path (:obj:`string`):
412 | Path to the JSON file in which this configuration instance's parameters will be saved.
413 | use_diff (:obj:`bool`):
414 | If set to True, only the difference between the config instance and the default PretrainedConfig() is serialized to JSON file.
415 | """
416 | with open(json_file_path, "w", encoding="utf-8") as writer:
417 | writer.write(self.to_json_string(use_diff=use_diff))
418 |
419 | def update(self, config_dict: Dict):
420 | """
421 | Updates attributes of this class
422 | with attributes from `config_dict`.
423 |
424 | Args:
425 | :obj:`Dict[str, any]`: Dictionary of attributes that shall be updated for this class.
426 | """
427 | for key, value in config_dict.items():
428 | setattr(self, key, value)
429 |
--------------------------------------------------------------------------------
/models/MobileBert/file_utils.py:
--------------------------------------------------------------------------------
1 | """
2 | Utilities for working with the local dataset cache.
3 | This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
4 | Copyright by the AllenNLP authors.
5 | """
6 |
7 | import fnmatch
8 | import json
9 | import logging
10 | import os
11 | import shutil
12 | import sys
13 | import tarfile
14 | import tempfile
15 | from contextlib import contextmanager
16 | from functools import partial, wraps
17 | from hashlib import sha256
18 | from typing import Optional
19 | from urllib.parse import urlparse
20 | from zipfile import ZipFile, is_zipfile
21 |
22 | import boto3
23 | import requests
24 | from botocore.config import Config
25 | from botocore.exceptions import ClientError
26 | from filelock import FileLock
27 | from tqdm.auto import tqdm
28 |
29 | logger = logging.getLogger(__name__) # pylint: disable=invalid-name
30 |
31 | try:
32 | USE_TF = os.environ.get("USE_TF", "AUTO").upper()
33 | USE_TORCH = os.environ.get("USE_TORCH", "AUTO").upper()
34 | if USE_TORCH in ("1", "ON", "YES", "AUTO") and USE_TF not in ("1", "ON", "YES"):
35 | import torch
36 |
37 | _torch_available = True # pylint: disable=invalid-name
38 | logger.info("PyTorch version {} available.".format(torch.__version__))
39 | else:
40 | logger.info("Disabling PyTorch because USE_TF is set")
41 | _torch_available = False
42 | except ImportError:
43 | _torch_available = False # pylint: disable=invalid-name
44 |
45 | try:
46 | USE_TF = os.environ.get("USE_TF", "AUTO").upper()
47 | USE_TORCH = os.environ.get("USE_TORCH", "AUTO").upper()
48 |
49 | if USE_TF in ("1", "ON", "YES", "AUTO") and USE_TORCH not in ("1", "ON", "YES"):
50 | import tensorflow as tf
51 |
52 | assert hasattr(tf, "__version__") and int(tf.__version__[0]) >= 2
53 | _tf_available = True # pylint: disable=invalid-name
54 | logger.info("TensorFlow version {} available.".format(tf.__version__))
55 | else:
56 | logger.info("Disabling Tensorflow because USE_TORCH is set")
57 | _tf_available = False
58 | except (ImportError, AssertionError):
59 | _tf_available = False # pylint: disable=invalid-name
60 |
61 | try:
62 | from torch.hub import _get_torch_home
63 |
64 | torch_cache_home = _get_torch_home()
65 | except ImportError:
66 | torch_cache_home = os.path.expanduser(
67 | os.getenv("TORCH_HOME", os.path.join(os.getenv("XDG_CACHE_HOME", "~/.cache"), "torch"))
68 | )
69 | default_cache_path = os.path.join(torch_cache_home, "transformers")
70 |
71 | try:
72 | from pathlib import Path
73 |
74 | PYTORCH_PRETRAINED_BERT_CACHE = Path(
75 | os.getenv("PYTORCH_TRANSFORMERS_CACHE", os.getenv("PYTORCH_PRETRAINED_BERT_CACHE", default_cache_path))
76 | )
77 | except (AttributeError, ImportError):
78 | PYTORCH_PRETRAINED_BERT_CACHE = os.getenv(
79 | "PYTORCH_TRANSFORMERS_CACHE", os.getenv("PYTORCH_PRETRAINED_BERT_CACHE", default_cache_path)
80 | )
81 |
82 | PYTORCH_TRANSFORMERS_CACHE = PYTORCH_PRETRAINED_BERT_CACHE # Kept for backward compatibility
83 | TRANSFORMERS_CACHE = PYTORCH_PRETRAINED_BERT_CACHE # Kept for backward compatibility
84 |
85 | WEIGHTS_NAME = "pytorch_model.bin"
86 | TF2_WEIGHTS_NAME = "tf_model.h5"
87 | TF_WEIGHTS_NAME = "model.ckpt"
88 | CONFIG_NAME = "config.json"
89 | MODEL_CARD_NAME = "modelcard.json"
90 |
91 |
92 | MULTIPLE_CHOICE_DUMMY_INPUTS = [[[0], [1]], [[0], [1]]]
93 | DUMMY_INPUTS = [[7, 6, 0, 0, 1], [1, 2, 3, 0, 0], [0, 0, 0, 4, 5]]
94 | DUMMY_MASK = [[1, 1, 1, 1, 1], [1, 1, 1, 0, 0], [0, 0, 0, 1, 1]]
95 |
96 | S3_BUCKET_PREFIX = "https://s3.amazonaws.com/models.huggingface.co/bert"
97 | CLOUDFRONT_DISTRIB_PREFIX = "https://d2ws9o8vfrpkyk.cloudfront.net"
98 |
99 |
100 | def is_torch_available():
101 | return _torch_available
102 |
103 |
104 | def is_tf_available():
105 | return _tf_available
106 |
107 |
108 | def add_start_docstrings(*docstr):
109 | def docstring_decorator(fn):
110 | fn.__doc__ = "".join(docstr) + (fn.__doc__ if fn.__doc__ is not None else "")
111 | return fn
112 |
113 | return docstring_decorator
114 |
115 |
116 | def add_start_docstrings_to_callable(*docstr):
117 | def docstring_decorator(fn):
118 | class_name = ":class:`~transformers.{}`".format(fn.__qualname__.split(".")[0])
119 | intro = " The {} forward method, overrides the :func:`__call__` special method.".format(class_name)
120 | note = r"""
121 |
122 | .. note::
123 | Although the recipe for forward pass needs to be defined within
124 | this function, one should call the :class:`Module` instance afterwards
125 | instead of this since the former takes care of running the
126 | pre and post processing steps while the latter silently ignores them.
127 | """
128 | fn.__doc__ = intro + note + "".join(docstr) + (fn.__doc__ if fn.__doc__ is not None else "")
129 | return fn
130 |
131 | return docstring_decorator
132 |
133 |
134 | def add_end_docstrings(*docstr):
135 | def docstring_decorator(fn):
136 | fn.__doc__ = fn.__doc__ + "".join(docstr)
137 | return fn
138 |
139 | return docstring_decorator
140 |
141 |
142 | def is_remote_url(url_or_filename):
143 | parsed = urlparse(url_or_filename)
144 | return parsed.scheme in ("http", "https", "s3")
145 |
146 |
147 | def hf_bucket_url(identifier, postfix=None, cdn=False) -> str:
148 | endpoint = CLOUDFRONT_DISTRIB_PREFIX if cdn else S3_BUCKET_PREFIX
149 | if postfix is None:
150 | return "/".join((endpoint, identifier))
151 | else:
152 | return "/".join((endpoint, identifier, postfix))
153 |
154 |
155 | def url_to_filename(url, etag=None):
156 | """
157 | Convert `url` into a hashed filename in a repeatable way.
158 | If `etag` is specified, append its hash to the url's, delimited
159 | by a period.
160 | If the url ends with .h5 (Keras HDF5 weights) adds '.h5' to the name
161 | so that TF 2.0 can identify it as a HDF5 file
162 | (see https://github.com/tensorflow/tensorflow/blob/00fad90125b18b80fe054de1055770cfb8fe4ba3/tensorflow/python/keras/engine/network.py#L1380)
163 | """
164 | url_bytes = url.encode("utf-8")
165 | url_hash = sha256(url_bytes)
166 | filename = url_hash.hexdigest()
167 |
168 | if etag:
169 | etag_bytes = etag.encode("utf-8")
170 | etag_hash = sha256(etag_bytes)
171 | filename += "." + etag_hash.hexdigest()
172 |
173 | if url.endswith(".h5"):
174 | filename += ".h5"
175 |
176 | return filename
177 |
178 |
179 | def filename_to_url(filename, cache_dir=None):
180 | """
181 | Return the url and etag (which may be ``None``) stored for `filename`.
182 | Raise ``EnvironmentError`` if `filename` or its stored metadata do not exist.
183 | """
184 | if cache_dir is None:
185 | cache_dir = TRANSFORMERS_CACHE
186 | if isinstance(cache_dir, Path):
187 | cache_dir = str(cache_dir)
188 |
189 | cache_path = os.path.join(cache_dir, filename)
190 | if not os.path.exists(cache_path):
191 | raise EnvironmentError("file {} not found".format(cache_path))
192 |
193 | meta_path = cache_path + ".json"
194 | if not os.path.exists(meta_path):
195 | raise EnvironmentError("file {} not found".format(meta_path))
196 |
197 | with open(meta_path, encoding="utf-8") as meta_file:
198 | metadata = json.load(meta_file)
199 | url = metadata["url"]
200 | etag = metadata["etag"]
201 |
202 | return url, etag
203 |
204 |
205 | def cached_path(
206 | url_or_filename,
207 | cache_dir=None,
208 | force_download=False,
209 | proxies=None,
210 | resume_download=False,
211 | user_agent=None,
212 | extract_compressed_file=False,
213 | force_extract=False,
214 | local_files_only=False,
215 | ) -> Optional[str]:
216 | """
217 | Given something that might be a URL (or might be a local path),
218 | determine which. If it's a URL, download the file and cache it, and
219 | return the path to the cached file. If it's already a local path,
220 | make sure the file exists and then return the path.
221 | Args:
222 | cache_dir: specify a cache directory to save the file to (overwrite the default cache dir).
223 | force_download: if True, re-dowload the file even if it's already cached in the cache dir.
224 | resume_download: if True, resume the download if incompletly recieved file is found.
225 | user_agent: Optional string or dict that will be appended to the user-agent on remote requests.
226 | extract_compressed_file: if True and the path point to a zip or tar file, extract the compressed
227 | file in a folder along the archive.
228 | force_extract: if True when extract_compressed_file is True and the archive was already extracted,
229 | re-extract the archive and overide the folder where it was extracted.
230 |
231 | Return:
232 | None in case of non-recoverable file (non-existent or inaccessible url + no cache on disk).
233 | Local path (string) otherwise
234 | """
235 | if cache_dir is None:
236 | cache_dir = TRANSFORMERS_CACHE
237 | if isinstance(url_or_filename, Path):
238 | url_or_filename = str(url_or_filename)
239 | if isinstance(cache_dir, Path):
240 | cache_dir = str(cache_dir)
241 |
242 | if is_remote_url(url_or_filename):
243 | # URL, so get it from the cache (downloading if necessary)
244 | output_path = get_from_cache(
245 | url_or_filename,
246 | cache_dir=cache_dir,
247 | force_download=force_download,
248 | proxies=proxies,
249 | resume_download=resume_download,
250 | user_agent=user_agent,
251 | local_files_only=local_files_only,
252 | )
253 | elif os.path.exists(url_or_filename):
254 | # File, and it exists.
255 | output_path = url_or_filename
256 | elif urlparse(url_or_filename).scheme == "":
257 | # File, but it doesn't exist.
258 | raise EnvironmentError("file {} not found".format(url_or_filename))
259 | else:
260 | # Something unknown
261 | raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
262 |
263 | if extract_compressed_file:
264 | if not is_zipfile(output_path) and not tarfile.is_tarfile(output_path):
265 | return output_path
266 |
267 | # Path where we extract compressed archives
268 | # We avoid '.' in dir name and add "-extracted" at the end: "./model.zip" => "./model-zip-extracted/"
269 | output_dir, output_file = os.path.split(output_path)
270 | output_extract_dir_name = output_file.replace(".", "-") + "-extracted"
271 | output_path_extracted = os.path.join(output_dir, output_extract_dir_name)
272 |
273 | if os.path.isdir(output_path_extracted) and os.listdir(output_path_extracted) and not force_extract:
274 | return output_path_extracted
275 |
276 | # Prevent parallel extractions
277 | lock_path = output_path + ".lock"
278 | with FileLock(lock_path):
279 | shutil.rmtree(output_path_extracted, ignore_errors=True)
280 | os.makedirs(output_path_extracted)
281 | if is_zipfile(output_path):
282 | with ZipFile(output_path, "r") as zip_file:
283 | zip_file.extractall(output_path_extracted)
284 | zip_file.close()
285 | elif tarfile.is_tarfile(output_path):
286 | tar_file = tarfile.open(output_path)
287 | tar_file.extractall(output_path_extracted)
288 | tar_file.close()
289 | else:
290 | raise EnvironmentError("Archive format of {} could not be identified".format(output_path))
291 |
292 | return output_path_extracted
293 |
294 | return output_path
295 |
296 |
297 | def split_s3_path(url):
298 | """Split a full s3 path into the bucket name and path."""
299 | parsed = urlparse(url)
300 | if not parsed.netloc or not parsed.path:
301 | raise ValueError("bad s3 path {}".format(url))
302 | bucket_name = parsed.netloc
303 | s3_path = parsed.path
304 | # Remove '/' at beginning of path.
305 | if s3_path.startswith("/"):
306 | s3_path = s3_path[1:]
307 | return bucket_name, s3_path
308 |
309 |
310 | def s3_request(func):
311 | """
312 | Wrapper function for s3 requests in order to create more helpful error
313 | messages.
314 | """
315 |
316 | @wraps(func)
317 | def wrapper(url, *args, **kwargs):
318 | try:
319 | return func(url, *args, **kwargs)
320 | except ClientError as exc:
321 | if int(exc.response["Error"]["Code"]) == 404:
322 | raise EnvironmentError("file {} not found".format(url))
323 | else:
324 | raise
325 |
326 | return wrapper
327 |
328 |
329 | @s3_request
330 | def s3_etag(url, proxies=None):
331 | """Check ETag on S3 object."""
332 | s3_resource = boto3.resource("s3", config=Config(proxies=proxies))
333 | bucket_name, s3_path = split_s3_path(url)
334 | s3_object = s3_resource.Object(bucket_name, s3_path)
335 | return s3_object.e_tag
336 |
337 |
338 | @s3_request
339 | def s3_get(url, temp_file, proxies=None):
340 | """Pull a file directly from S3."""
341 | s3_resource = boto3.resource("s3", config=Config(proxies=proxies))
342 | bucket_name, s3_path = split_s3_path(url)
343 | s3_resource.Bucket(bucket_name).download_fileobj(s3_path, temp_file)
344 |
345 |
346 | def http_get(url, temp_file, proxies=None, resume_size=0, user_agent=None):
347 | ua = "transformers/{}; python/{}".format(__version__, sys.version.split()[0])
348 | if is_torch_available():
349 | ua += "; torch/{}".format(torch.__version__)
350 | if is_tf_available():
351 | ua += "; tensorflow/{}".format(tf.__version__)
352 | if isinstance(user_agent, dict):
353 | ua += "; " + "; ".join("{}/{}".format(k, v) for k, v in user_agent.items())
354 | elif isinstance(user_agent, str):
355 | ua += "; " + user_agent
356 | headers = {"user-agent": ua}
357 | if resume_size > 0:
358 | headers["Range"] = "bytes=%d-" % (resume_size,)
359 | response = requests.get(url, stream=True, proxies=proxies, headers=headers)
360 | if response.status_code == 416: # Range not satisfiable
361 | return
362 | content_length = response.headers.get("Content-Length")
363 | total = resume_size + int(content_length) if content_length is not None else None
364 | progress = tqdm(
365 | unit="B",
366 | unit_scale=True,
367 | total=total,
368 | initial=resume_size,
369 | desc="Downloading",
370 | disable=bool(logger.getEffectiveLevel() == logging.NOTSET),
371 | )
372 | for chunk in response.iter_content(chunk_size=1024):
373 | if chunk: # filter out keep-alive new chunks
374 | progress.update(len(chunk))
375 | temp_file.write(chunk)
376 | progress.close()
377 |
378 |
379 | def get_from_cache(
380 | url,
381 | cache_dir=None,
382 | force_download=False,
383 | proxies=None,
384 | etag_timeout=10,
385 | resume_download=False,
386 | user_agent=None,
387 | local_files_only=False,
388 | ) -> Optional[str]:
389 | """
390 | Given a URL, look for the corresponding file in the local cache.
391 | If it's not there, download it. Then return the path to the cached file.
392 |
393 | Return:
394 | None in case of non-recoverable file (non-existent or inaccessible url + no cache on disk).
395 | Local path (string) otherwise
396 | """
397 | if cache_dir is None:
398 | cache_dir = TRANSFORMERS_CACHE
399 | if isinstance(cache_dir, Path):
400 | cache_dir = str(cache_dir)
401 |
402 | os.makedirs(cache_dir, exist_ok=True)
403 |
404 | etag = None
405 | if not local_files_only:
406 | # Get eTag to add to filename, if it exists.
407 | if url.startswith("s3://"):
408 | etag = s3_etag(url, proxies=proxies)
409 | else:
410 | try:
411 | response = requests.head(url, allow_redirects=True, proxies=proxies, timeout=etag_timeout)
412 | if response.status_code == 200:
413 | etag = response.headers.get("ETag")
414 | except (EnvironmentError, requests.exceptions.Timeout):
415 | # etag is already None
416 | pass
417 |
418 | filename = url_to_filename(url, etag)
419 |
420 | # get cache path to put the file
421 | cache_path = os.path.join(cache_dir, filename)
422 |
423 | # etag is None = we don't have a connection, or url doesn't exist, or is otherwise inaccessible.
424 | # try to get the last downloaded one
425 | if etag is None:
426 | if os.path.exists(cache_path):
427 | return cache_path
428 | else:
429 | matching_files = [
430 | file
431 | for file in fnmatch.filter(os.listdir(cache_dir), filename + ".*")
432 | if not file.endswith(".json") and not file.endswith(".lock")
433 | ]
434 | if len(matching_files) > 0:
435 | return os.path.join(cache_dir, matching_files[-1])
436 | else:
437 | # If files cannot be found and local_files_only=True,
438 | # the models might've been found if local_files_only=False
439 | # Notify the user about that
440 | if local_files_only:
441 | raise ValueError(
442 | "Cannot find the requested files in the cached path and outgoing traffic has been"
443 | " disabled. To enable model look-ups and downloads online, set 'local_files_only'"
444 | " to False."
445 | )
446 | return None
447 |
448 | # From now on, etag is not None.
449 | if os.path.exists(cache_path) and not force_download:
450 | return cache_path
451 |
452 | # Prevent parallel downloads of the same file with a lock.
453 | lock_path = cache_path + ".lock"
454 | with FileLock(lock_path):
455 |
456 | # If the download just completed while the lock was activated.
457 | if os.path.exists(cache_path) and not force_download:
458 | # Even if returning early like here, the lock will be released.
459 | return cache_path
460 |
461 | if resume_download:
462 | incomplete_path = cache_path + ".incomplete"
463 |
464 | @contextmanager
465 | def _resumable_file_manager():
466 | with open(incomplete_path, "a+b") as f:
467 | yield f
468 |
469 | temp_file_manager = _resumable_file_manager
470 | if os.path.exists(incomplete_path):
471 | resume_size = os.stat(incomplete_path).st_size
472 | else:
473 | resume_size = 0
474 | else:
475 | temp_file_manager = partial(tempfile.NamedTemporaryFile, dir=cache_dir, delete=False)
476 | resume_size = 0
477 |
478 | # Download to temporary file, then copy to cache dir once finished.
479 | # Otherwise you get corrupt cache entries if the download gets interrupted.
480 | with temp_file_manager() as temp_file:
481 | logger.info("%s not found in cache or force_download set to True, downloading to %s", url, temp_file.name)
482 |
483 | # GET file object
484 | if url.startswith("s3://"):
485 | if resume_download:
486 | logger.warn('Warning: resumable downloads are not implemented for "s3://" urls')
487 | s3_get(url, temp_file, proxies=proxies)
488 | else:
489 | http_get(url, temp_file, proxies=proxies, resume_size=resume_size, user_agent=user_agent)
490 |
491 | logger.info("storing %s in cache at %s", url, cache_path)
492 | os.replace(temp_file.name, cache_path)
493 |
494 | logger.info("creating metadata file for %s", cache_path)
495 | meta = {"url": url, "etag": etag}
496 | meta_path = cache_path + ".json"
497 | with open(meta_path, "w") as meta_file:
498 | json.dump(meta, meta_file)
499 |
500 | return cache_path
501 |
502 |
503 | class cached_property(property):
504 | """
505 | Descriptor that mimics @property but caches output in member variable.
506 |
507 | From tensorflow_datasets
508 |
509 | Built-in in functools from Python 3.8.
510 | """
511 |
512 | def __get__(self, obj, objtype=None):
513 | # See docs.python.org/3/howto/descriptor.html#properties
514 | if obj is None:
515 | return self
516 | if self.fget is None:
517 | raise AttributeError("unreadable attribute")
518 | attr = "__cached_" + self.fget.__name__
519 | cached = getattr(obj, attr, None)
520 | if cached is None:
521 | cached = self.fget(obj)
522 | setattr(obj, attr, cached)
523 | return cached
524 |
525 |
526 | def torch_required(func):
527 | # Chose a different decorator name than in tests so it's clear they are not the same.
528 | @wraps(func)
529 | def wrapper(*args, **kwargs):
530 | if is_torch_available():
531 | return func(*args, **kwargs)
532 | else:
533 | raise ImportError(f"Method `{func.__name__}` requires PyTorch.")
534 |
535 | return wrapper
536 |
537 |
538 | def tf_required(func):
539 | # Chose a different decorator name than in tests so it's clear they are not the same.
540 | @wraps(func)
541 | def wrapper(*args, **kwargs):
542 | if is_tf_available():
543 | return func(*args, **kwargs)
544 | else:
545 | raise ImportError(f"Method `{func.__name__}` requires TF.")
546 |
547 | return wrapper
548 |
--------------------------------------------------------------------------------
/models/MobileBert/modeling_mobilebert.py:
--------------------------------------------------------------------------------
1 | """PyTorch MobileBert model. """
2 | import logging
3 | import math
4 | import os
5 | import torch
6 | from torch import nn
7 | import torch.nn.functional as F
8 | from torch.nn import CrossEntropyLoss, MSELoss
9 | from .activations import gelu, gelu_new, swish
10 | from .configuration_mobilebert import MobileBertConfig
11 | from .file_utils import add_start_docstrings, add_start_docstrings_to_callable
12 | from .modeling_utils import PreTrainedModel
13 |
14 | logger = logging.getLogger(__name__)
15 | MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_MAP = {}
16 |
17 |
18 | def load_tf_weights_in_mobilebert(model, config, tf_checkpoint_path):
19 | """ Load tf checkpoints in a pytorch model.
20 | """
21 | try:
22 | import re
23 | import numpy as np
24 | import tensorflow as tf
25 | except ImportError:
26 | logger.error(
27 | "Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
28 | "https://www.tensorflow.org/install/ for installation instructions."
29 | )
30 | raise
31 | tf_path = os.path.abspath(tf_checkpoint_path)
32 | logger.info("Converting TensorFlow checkpoint from {}".format(tf_path))
33 | # Load weights from TF model
34 | init_vars = tf.train.list_variables(tf_path)
35 | names = []
36 | arrays = []
37 | for name, shape in init_vars:
38 | logger.info("Loading TF weight {} with shape {}".format(name, shape))
39 | array = tf.train.load_variable(tf_path, name)
40 | names.append(name)
41 | arrays.append(array)
42 |
43 | for name, array in zip(names, arrays):
44 | name = name.replace("ffn_layer", "ffn")
45 | name = name.replace("FakeLayerNorm", "LayerNorm")
46 | name = name.replace("extra_output_weights", 'dense/kernel')
47 | name = name.split("/")
48 | # adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
49 | # which are not required for using pretrained model
50 | if any(
51 | n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
52 | for n in name
53 | ):
54 | logger.info("Skipping {}".format("/".join(name)))
55 | continue
56 | pointer = model
57 | for m_name in name:
58 | if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
59 | scope_names = re.split(r"_(\d+)", m_name)
60 | else:
61 | scope_names = [m_name]
62 | if scope_names[0] == "kernel" or scope_names[0] == "gamma":
63 | pointer = getattr(pointer, "weight")
64 | elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
65 | pointer = getattr(pointer, "bias")
66 | elif scope_names[0] == "output_weights":
67 | pointer = getattr(pointer, "weight")
68 | elif scope_names[0] == "squad":
69 | pointer = getattr(pointer, "classifier")
70 | else:
71 | try:
72 | pointer = getattr(pointer, scope_names[0])
73 | except AttributeError:
74 | logger.info("Skipping {}".format("/".join(name)))
75 | continue
76 | if len(scope_names) >= 2:
77 | num = int(scope_names[1])
78 | pointer = pointer[num]
79 | if m_name[-11:] == "_embeddings":
80 | pointer = getattr(pointer, "weight")
81 | elif m_name == "kernel":
82 | array = np.transpose(array)
83 | try:
84 | assert pointer.shape == array.shape
85 | except AssertionError as e:
86 | e.args += (pointer.shape, array.shape)
87 | raise
88 | logger.info("Initialize PyTorch weight {}".format(name))
89 | pointer.data = torch.from_numpy(array)
90 | return model
91 |
92 |
93 | def mish(x):
94 | return x * torch.tanh(nn.functional.softplus(x))
95 |
96 |
97 | class ManualLayerNorm(nn.Module):
98 | def __init__(self, feat_size, eps=1e-6):
99 | super(ManualLayerNorm, self).__init__()
100 | self.bias = nn.Parameter(torch.zeros(feat_size))
101 | self.weight = nn.Parameter(torch.ones(feat_size))
102 | self.eps = eps
103 |
104 | def forward(self, input_tensor):
105 | mean = input_tensor.mean(-1, keepdim=True)
106 | std = input_tensor.std(-1, keepdim=True)
107 | return self.weight * (input_tensor - mean) / (std + self.eps) + self.bias
108 |
109 |
110 | class NoNorm(nn.Module):
111 | def __init__(self, feat_size):
112 | super(NoNorm, self).__init__()
113 | self.bias = nn.Parameter(torch.zeros(feat_size))
114 | self.weight = nn.Parameter(torch.ones(feat_size))
115 |
116 | def forward(self, input_tensor):
117 | return input_tensor * self.weight + self.bias
118 |
119 |
120 | ACT2FN = {"gelu": gelu, "relu": torch.nn.functional.relu, "swish": swish, "gelu_new": gelu_new, "mish": mish}
121 | NORM2FN = {'layer_norm': torch.nn.LayerNorm, 'no_norm': NoNorm, 'manual_layer_norm': ManualLayerNorm}
122 |
123 |
124 | class MobileBertEmbeddings(nn.Module):
125 | """Construct the embeddings from word, position and token_type embeddings.
126 | """
127 |
128 | def __init__(self, config):
129 | super().__init__()
130 | self.trigram_input = config.trigram_input
131 | self.embedding_size = config.embedding_size
132 | self.hidden_size = config.hidden_size
133 |
134 | self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id)
135 | self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
136 | self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
137 |
138 | self.embedding_transformation = nn.Linear(config.embedding_size * 3, config.hidden_size)
139 | self.LayerNorm = NORM2FN[config.normalization_type](config.hidden_size)
140 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
141 |
142 | def forward(self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None):
143 | if input_ids is not None:
144 | input_shape = input_ids.size()
145 | else:
146 | input_shape = inputs_embeds.size()[:-1]
147 | seq_length = input_shape[1]
148 | device = input_ids.device if input_ids is not None else inputs_embeds.device
149 | if position_ids is None:
150 | position_ids = torch.arange(seq_length, dtype=torch.long, device=device)
151 | position_ids = position_ids.unsqueeze(0).expand(input_shape)
152 | if token_type_ids is None:
153 | token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
154 | if inputs_embeds is None:
155 | inputs_embeds = self.word_embeddings(input_ids)
156 |
157 | if self.trigram_input:
158 | inputs_embeds = torch.cat([F.pad(inputs_embeds[:, 1:], [0, 0, 0, 1, 0, 0], value=0),
159 | inputs_embeds,
160 | F.pad(inputs_embeds[:, :-1], [0, 0, 1, 0, 0, 0], value=0)],
161 | dim=2)
162 | if (self.trigram_input or self.embedding_size != self.hidden_size):
163 | inputs_embeds = self.embedding_transformation(inputs_embeds)
164 |
165 | # Add positional embeddings and token type embeddings, then layer
166 | # normalize and perform dropout.
167 | position_embeddings = self.position_embeddings(position_ids)
168 | token_type_embeddings = self.token_type_embeddings(token_type_ids)
169 | embeddings = inputs_embeds + position_embeddings + token_type_embeddings
170 | embeddings = self.LayerNorm(embeddings)
171 | embeddings = self.dropout(embeddings)
172 | return embeddings
173 |
174 |
175 | class MobileBertSelfAttention(nn.Module):
176 | def __init__(self, config):
177 | super().__init__()
178 | self.output_attentions = config.output_attentions
179 | self.num_attention_heads = config.num_attention_heads
180 | self.attention_head_size = int(config.true_hidden_size / config.num_attention_heads)
181 | self.all_head_size = self.num_attention_heads * self.attention_head_size
182 |
183 | self.query = nn.Linear(config.true_hidden_size, self.all_head_size)
184 | self.key = nn.Linear(config.true_hidden_size, self.all_head_size)
185 | self.value = nn.Linear(config.true_hidden_size if config.use_bottleneck_attention else config.hidden_size,
186 | self.all_head_size)
187 | self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
188 |
189 | def transpose_for_scores(self, x):
190 | new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
191 | x = x.view(*new_x_shape)
192 | return x.permute(0, 2, 1, 3)
193 |
194 | def forward(self, query_tensor, key_tensor, value_tensor,
195 | attention_mask=None, head_mask=None, encoder_hidden_states=None,
196 | encoder_attention_mask=None):
197 | mixed_query_layer = self.query(query_tensor)
198 | mixed_key_layer = self.key(key_tensor)
199 | mixed_value_layer = self.value(value_tensor)
200 |
201 | query_layer = self.transpose_for_scores(mixed_query_layer)
202 | key_layer = self.transpose_for_scores(mixed_key_layer)
203 | value_layer = self.transpose_for_scores(mixed_value_layer)
204 |
205 | # Take the dot product between "query" and "key" to get the raw attention scores.
206 | attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
207 | attention_scores = attention_scores / math.sqrt(self.attention_head_size)
208 | if attention_mask is not None:
209 | # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
210 | attention_scores = attention_scores + attention_mask
211 | # Normalize the attention scores to probabilities.
212 | attention_probs = nn.Softmax(dim=-1)(attention_scores)
213 | # This is actually dropping out entire tokens to attend to, which might
214 | # seem a bit unusual, but is taken from the original Transformer paper.
215 | attention_probs = self.dropout(attention_probs)
216 | # Mask heads if we want to
217 | if head_mask is not None:
218 | attention_probs = attention_probs * head_mask
219 | context_layer = torch.matmul(attention_probs, value_layer)
220 | context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
221 | new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
222 | context_layer = context_layer.view(*new_context_layer_shape)
223 | outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
224 | return outputs
225 |
226 |
227 | class MobileBertSelfOutput(nn.Module):
228 | def __init__(self, config):
229 | super().__init__()
230 | self.use_bottleneck = config.use_bottleneck
231 | self.dense = nn.Linear(config.true_hidden_size, config.true_hidden_size)
232 | self.LayerNorm = NORM2FN[config.normalization_type](config.true_hidden_size)
233 | if self.use_bottleneck:
234 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
235 |
236 | def forward(self, hidden_states, residual_tensor):
237 | layer_outputs = self.dense(hidden_states)
238 | if not self.use_bottleneck:
239 | layer_outputs = self.dropout(layer_outputs)
240 | layer_outputs = self.LayerNorm(layer_outputs + residual_tensor)
241 | return layer_outputs
242 |
243 |
244 | class MobileBertAttention(nn.Module):
245 | def __init__(self, config):
246 | super().__init__()
247 | self.self = MobileBertSelfAttention(config)
248 | self.output = MobileBertSelfOutput(config)
249 | self.pruned_heads = set()
250 |
251 | def forward(self, query_tensor, key_tensor, value_tensor, layer_input, attention_mask=None, head_mask=None,
252 | encoder_hidden_states=None, encoder_attention_mask=None):
253 | self_outputs = self.self(
254 | query_tensor, key_tensor, value_tensor,
255 | attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask
256 | )
257 | # Run a linear projection of `hidden_size` then add a residual
258 | # with `layer_input`.
259 | attention_output = self.output(self_outputs[0], layer_input)
260 | outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
261 | return outputs
262 |
263 |
264 | class MobileBertIntermediate(nn.Module):
265 | def __init__(self, config):
266 | super().__init__()
267 | self.dense = nn.Linear(config.true_hidden_size, config.intermediate_size)
268 | if isinstance(config.hidden_act, str):
269 | self.intermediate_act_fn = ACT2FN[config.hidden_act]
270 | else:
271 | self.intermediate_act_fn = config.hidden_act
272 |
273 | def forward(self, hidden_states):
274 | layer_outputs = self.dense(hidden_states)
275 | layer_outputs = self.intermediate_act_fn(layer_outputs)
276 | return layer_outputs
277 |
278 |
279 | class OutputBottleneck(nn.Module):
280 | def __init__(self, config):
281 | super().__init__()
282 | self.dense = nn.Linear(config.true_hidden_size, config.hidden_size)
283 | self.LayerNorm = NORM2FN[config.normalization_type](config.hidden_size)
284 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
285 |
286 | def forward(self, hidden_states, residual_tensor):
287 | layer_outputs = self.dense(hidden_states)
288 | layer_outputs = self.dropout(layer_outputs)
289 | layer_outputs = self.LayerNorm(layer_outputs + residual_tensor)
290 | return layer_outputs
291 |
292 |
293 | class MobileBertOutput(nn.Module):
294 | def __init__(self, config):
295 | super().__init__()
296 | self.use_bottleneck = config.use_bottleneck
297 | self.dense = nn.Linear(config.intermediate_size, config.true_hidden_size)
298 | self.LayerNorm = NORM2FN[config.normalization_type](config.true_hidden_size)
299 | if not self.use_bottleneck:
300 | self.dropout = nn.Dropout(config.hidden_dropout_prob)
301 | else:
302 | self.bottleneck = OutputBottleneck(config)
303 |
304 | def forward(self, intermediate_states, residual_tensor_1, residual_tensor_2):
305 | layer_output = self.dense(intermediate_states)
306 | if not self.use_bottleneck:
307 | layer_output = self.dropout(layer_output)
308 | layer_output = self.LayerNorm(layer_output + residual_tensor_1)
309 | else:
310 | layer_output = self.LayerNorm(layer_output + residual_tensor_1)
311 | layer_output = self.bottleneck(layer_output, residual_tensor_2)
312 | return layer_output
313 |
314 |
315 | class BottleneckLayer(nn.Module):
316 | def __init__(self, config):
317 | super().__init__()
318 | self.dense = nn.Linear(config.hidden_size, config.intra_bottleneck_size)
319 | self.LayerNorm = NORM2FN[config.normalization_type](config.intra_bottleneck_size)
320 |
321 | def forward(self, hidden_states):
322 | layer_input = self.dense(hidden_states)
323 | layer_input = self.LayerNorm(layer_input)
324 | return layer_input
325 |
326 |
327 | class Bottleneck(nn.Module):
328 | def __init__(self, config):
329 | super().__init__()
330 | self.key_query_shared_bottleneck = config.key_query_shared_bottleneck
331 | self.use_bottleneck_attention = config.use_bottleneck_attention
332 | self.input = BottleneckLayer(config)
333 | if self.key_query_shared_bottleneck:
334 | self.attention = BottleneckLayer(config)
335 |
336 | def forward(self, hidden_states):
337 | layer_input = self.input(hidden_states)
338 | if self.use_bottleneck_attention:
339 | return [layer_input] * 4
340 | elif self.key_query_shared_bottleneck:
341 | shared_attention_input = self.attention(hidden_states)
342 | return (shared_attention_input, shared_attention_input, hidden_states, layer_input)
343 | else:
344 | return (hidden_states, hidden_states, hidden_states, layer_input)
345 |
346 |
347 | class FFNOutput(nn.Module):
348 | def __init__(self, config):
349 | super().__init__()
350 | self.dense = nn.Linear(config.intermediate_size, config.true_hidden_size)
351 | self.LayerNorm = NORM2FN[config.normalization_type](config.true_hidden_size)
352 |
353 | def forward(self, hidden_states, residual_tensor):
354 | layer_outputs = self.dense(hidden_states)
355 | layer_outputs = self.LayerNorm(layer_outputs + residual_tensor)
356 | return layer_outputs
357 |
358 |
359 | class FFNLayer(nn.Module):
360 | def __init__(self, config):
361 | super().__init__()
362 | self.intermediate = MobileBertIntermediate(config)
363 | self.output = FFNOutput(config)
364 |
365 | def forward(self, hidden_sites):
366 | intermediate_output = self.intermediate(hidden_sites)
367 | layer_outputs = self.output(intermediate_output, hidden_sites)
368 | return layer_outputs
369 |
370 |
371 | class MobileBertLayer(nn.Module):
372 | def __init__(self, config):
373 | super().__init__()
374 | self.use_bottleneck = config.use_bottleneck
375 | self.num_feedforward_networks = config.num_feedforward_networks
376 |
377 | self.attention = MobileBertAttention(config)
378 | self.intermediate = MobileBertIntermediate(config)
379 | self.output = MobileBertOutput(config)
380 | if self.use_bottleneck:
381 | self.bottleneck = Bottleneck(config)
382 | if config.num_feedforward_networks != 1:
383 | self.ffn = nn.ModuleList([FFNLayer(config) for _ in range(config.num_feedforward_networks - 1)])
384 |
385 | def forward(self, hidden_states, attention_mask=None, head_mask=None, encoder_hidden_states=None,
386 | encoder_attention_mask=None):
387 | if self.use_bottleneck:
388 | query_tensor, key_tensor, value_tensor, layer_input = self.bottleneck(hidden_states)
389 | else:
390 | query_tensor, key_tensor, value_tensor, layer_input = [hidden_states] * 4
391 |
392 | self_attention_outputs = self.attention(query_tensor, key_tensor, value_tensor,
393 | layer_input, attention_mask, head_mask)
394 | attention_output = self_attention_outputs[0]
395 | outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
396 |
397 | if self.num_feedforward_networks != 1:
398 | for i, ffn_module in enumerate(self.ffn):
399 | attention_output = ffn_module(attention_output)
400 |
401 | intermediate_output = self.intermediate(attention_output)
402 | layer_output = self.output(intermediate_output, attention_output, hidden_states)
403 | outputs = (layer_output,) + outputs
404 | return outputs
405 |
406 |
407 | class MobileBertEncoder(nn.Module):
408 | def __init__(self, config):
409 | super().__init__()
410 | self.output_attentions = config.output_attentions
411 | self.output_hidden_states = config.output_hidden_states
412 | self.layer = nn.ModuleList([MobileBertLayer(config) for _ in range(config.num_hidden_layers)])
413 |
414 | def forward(self, hidden_states, attention_mask=None, head_mask=None, encoder_hidden_states=None,
415 | encoder_attention_mask=None, ):
416 | all_hidden_states = ()
417 | all_attentions = ()
418 |
419 | for i, layer_module in enumerate(self.layer):
420 | if self.output_hidden_states:
421 | all_hidden_states = all_hidden_states + (hidden_states,)
422 | layer_outputs = layer_module(
423 | hidden_states, attention_mask, head_mask[i], encoder_hidden_states, encoder_attention_mask
424 | )
425 | hidden_states = layer_outputs[0]
426 | if self.output_attentions:
427 | all_attentions = all_attentions + (layer_outputs[1],)
428 | # Add last layer
429 | if self.output_hidden_states:
430 | all_hidden_states = all_hidden_states + (hidden_states,)
431 | outputs = (hidden_states,)
432 | if self.output_hidden_states:
433 | outputs = outputs + (all_hidden_states,)
434 | if self.output_attentions:
435 | outputs = outputs + (all_attentions,)
436 | return outputs # last-layer hidden state, (all hidden states), (all attentions)
437 |
438 |
439 | class MobileBertPooler(nn.Module):
440 | def __init__(self, config):
441 | super().__init__()
442 | self.do_activate = config.classifier_activation
443 | if self.do_activate:
444 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
445 |
446 | def forward(self, hidden_states):
447 | # We "pool" the model by simply taking the hidden state corresponding
448 | # to the first token.
449 | first_token_tensor = hidden_states[:, 0]
450 | if not self.do_activate:
451 | return first_token_tensor
452 | else:
453 | pooled_output = self.dense(first_token_tensor)
454 | pooled_output = F.tanh(pooled_output)
455 | return pooled_output
456 |
457 |
458 | class MobileBertPredictionHeadTransform(nn.Module):
459 | def __init__(self, config):
460 | super().__init__()
461 | self.dense = nn.Linear(config.hidden_size, config.hidden_size)
462 | if isinstance(config.hidden_act, str):
463 | self.transform_act_fn = ACT2FN[config.hidden_act]
464 | else:
465 | self.transform_act_fn = config.hidden_act
466 | self.LayerNorm = NORM2FN['layer_norm'](config.hidden_size)
467 |
468 | def forward(self, hidden_states):
469 | hidden_states = self.dense(hidden_states)
470 | hidden_states = self.transform_act_fn(hidden_states)
471 | hidden_states = self.LayerNorm(hidden_states)
472 | return hidden_states
473 |
474 |
475 | class MobileBertLMPredictionHead(nn.Module):
476 | def __init__(self, config):
477 | super().__init__()
478 | self.transform = MobileBertPredictionHeadTransform(config)
479 | # The output weights are the same as the input embeddings, but there is
480 | # an output-only bias for each token.
481 | self.dense = nn.Linear(config.vocab_size, config.hidden_size - config.embedding_size, bias=False)
482 | self.decoder = nn.Linear(config.embedding_size, config.vocab_size, bias=False)
483 | self.bias = nn.Parameter(torch.zeros(config.vocab_size))
484 | # Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
485 | self.bias = self.bias
486 |
487 | def forward(self, hidden_states):
488 | hidden_states = self.transform(hidden_states)
489 | hidden_states = hidden_states.matmul(torch.cat([self.decoder.weight.t(), self.dense.weight], dim=1))
490 | hidden_states += self.bias
491 | return hidden_states
492 |
493 |
494 | class MobileBertOnlyMLMHead(nn.Module):
495 | def __init__(self, config):
496 | super().__init__()
497 | self.predictions = MobileBertLMPredictionHead(config)
498 |
499 | def forward(self, sequence_output):
500 | prediction_scores = self.predictions(sequence_output)
501 | return prediction_scores
502 |
503 |
504 | class MobileBertPreTrainingHeads(nn.Module):
505 | def __init__(self, config):
506 | super().__init__()
507 | self.predictions = MobileBertLMPredictionHead(config)
508 | self.seq_relationship = nn.Linear(config.hidden_size, 2)
509 |
510 | def forward(self, sequence_output, pooled_output):
511 | prediction_scores = self.predictions(sequence_output)
512 | seq_relationship_score = self.seq_relationship(pooled_output)
513 | return prediction_scores, seq_relationship_score
514 |
515 |
516 | class MobileBertPreTrainedModel(PreTrainedModel):
517 | """ An abstract class to handle weights initialization and
518 | a simple interface for downloading and loading pretrained models.
519 | """
520 | config_class = MobileBertConfig
521 | pretrained_model_archive_map = MOBILEBERT_PRETRAINED_MODEL_ARCHIVE_MAP
522 | load_tf_weights = load_tf_weights_in_mobilebert
523 | base_model_prefix = "Mobilebert"
524 |
525 | def _init_weights(self, module):
526 | """ Initialize the weights """
527 | if isinstance(module, (nn.Linear, nn.Embedding)):
528 | # Slightly different from the TF version which uses truncated_normal for initialization
529 | # cf https://github.com/pytorch/pytorch/pull/5617
530 | module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
531 | elif isinstance(module, (nn.LayerNorm,NoNorm, ManualLayerNorm)):
532 | module.bias.data.zero_()
533 | module.weight.data.fill_(1.0)
534 | if isinstance(module, nn.Linear) and module.bias is not None:
535 | module.bias.data.zero_()
536 |
537 |
538 | BERT_START_DOCSTRING = r"""
539 | This model is a PyTorch `torch.nn.Module `_ sub-class.
540 | Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general
541 | usage and behavior.
542 |
543 | Parameters:
544 | config (:class:`~transformers.BertConfig`): Model configuration class with all the parameters of the model.
545 | Initializing with a config file does not load the weights associated with the model, only the configuration.
546 | Check out the :meth:`~transformers.PreTrainedModel.from_pretrained` method to load the model weights.
547 | """
548 |
549 | BERT_INPUTS_DOCSTRING = r"""
550 | Args:
551 | input_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`):
552 | Indices of input sequence tokens in the vocabulary.
553 |
554 | Indices can be obtained using :class:`transformers.BertTokenizer`.
555 | See :func:`transformers.PreTrainedTokenizer.encode` and
556 | :func:`transformers.PreTrainedTokenizer.encode_plus` for details.
557 |
558 | `What are input IDs? <../glossary.html#input-ids>`__
559 | attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
560 | Mask to avoid performing attention on padding token indices.
561 | Mask values selected in ``[0, 1]``:
562 | ``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
563 |
564 | `What are attention masks? <../glossary.html#attention-mask>`__
565 | token_type_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
566 | Segment token indices to indicate first and second portions of the inputs.
567 | Indices are selected in ``[0, 1]``: ``0`` corresponds to a `sentence A` token, ``1``
568 | corresponds to a `sentence B` token
569 |
570 | `What are token type IDs? <../glossary.html#token-type-ids>`_
571 | position_ids (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
572 | Indices of positions of each input sequence tokens in the position embeddings.
573 | Selected in the range ``[0, config.max_position_embeddings - 1]``.
574 |
575 | `What are position IDs? <../glossary.html#position-ids>`_
576 | head_mask (:obj:`torch.FloatTensor` of shape :obj:`(num_heads,)` or :obj:`(num_layers, num_heads)`, `optional`, defaults to :obj:`None`):
577 | Mask to nullify selected heads of the self-attention modules.
578 | Mask values selected in ``[0, 1]``:
579 | :obj:`1` indicates the head is **not masked**, :obj:`0` indicates the head is **masked**.
580 | inputs_embeds (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`, defaults to :obj:`None`):
581 | Optionally, instead of passing :obj:`input_ids` you can choose to directly pass an embedded representation.
582 | This is useful if you want more control over how to convert `input_ids` indices into associated vectors
583 | than the model's internal embedding lookup matrix.
584 | encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`, defaults to :obj:`None`):
585 | Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
586 | if the model is configured as a decoder.
587 | encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`, defaults to :obj:`None`):
588 | Mask to avoid performing attention on the padding token indices of the encoder input. This mask
589 | is used in the cross-attention if the model is configured as a decoder.
590 | Mask values selected in ``[0, 1]``:
591 | ``1`` for tokens that are NOT MASKED, ``0`` for MASKED tokens.
592 | """
593 |
594 |
595 | @add_start_docstrings(
596 | "The bare Bert Model transformer outputting raw hidden-states without any specific head on top.",
597 | BERT_START_DOCSTRING,
598 | )
599 | class MobileBertModel(MobileBertPreTrainedModel):
600 | """
601 | The model can behave as an encoder (with only self-attention) as well
602 | as a decoder, in which case a layer of cross-attention is added between
603 | the self-attention layers, following the architecture described in `Attention is all you need`_ by Ashish Vaswani,
604 | Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
605 | To behave as an decoder the model needs to be initialized with the
606 | :obj:`is_decoder` argument of the configuration set to :obj:`True`; an
607 | :obj:`encoder_hidden_states` is expected as an input to the forward pass.
608 | .. _`Attention is all you need`:
609 | https://arxiv.org/abs/1706.03762
610 |
611 | """
612 |
613 | def __init__(self, config):
614 | super().__init__(config)
615 | self.config = config
616 | self.embeddings = MobileBertEmbeddings(config)
617 | self.encoder = MobileBertEncoder(config)
618 | self.pooler = MobileBertPooler(config)
619 | self.init_weights()
620 |
621 | def get_input_embeddings(self):
622 | return self.embeddings.word_embeddings
623 |
624 | def set_input_embeddings(self, value):
625 | self.embeddings.word_embeddings = value
626 |
627 | def _prune_heads(self, heads_to_prune):
628 | """ Prunes heads of the model.
629 | heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
630 | See base class PreTrainedModel
631 | """
632 | for layer, heads in heads_to_prune.items():
633 | self.encoder.layer[layer].attention.prune_heads(heads)
634 |
635 | @add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING)
636 | def forward(
637 | self,
638 | input_ids=None,
639 | attention_mask=None,
640 | token_type_ids=None,
641 | position_ids=None,
642 | head_mask=None,
643 | inputs_embeds=None,
644 | encoder_hidden_states=None,
645 | encoder_attention_mask=None,
646 | ):
647 | r"""
648 | Return:
649 | :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
650 | last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
651 | Sequence of hidden-states at the output of the last layer of the model.
652 | pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
653 | Last layer hidden-state of the first token of the sequence (classification token)
654 | further processed by a Linear layer and a Tanh activation function. The Linear
655 | layer weights are trained from the next sentence prediction (classification)
656 | objective during pre-training.
657 |
658 | This output is usually *not* a good summary
659 | of the semantic content of the input, you're often better with averaging or pooling
660 | the sequence of hidden-states for the whole input sequence.
661 | hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
662 | Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
663 | of shape :obj:`(batch_size, sequence_length, hidden_size)`.
664 |
665 | Hidden-states of the model at the output of each layer plus the initial embedding outputs.
666 | attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
667 | Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
668 | :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
669 |
670 | Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
671 | heads.
672 |
673 | Examples::
674 |
675 | from transformers import BertModel, BertTokenizer
676 | import torch
677 |
678 | tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
679 | model = BertModel.from_pretrained('bert-base-uncased')
680 |
681 | input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
682 | outputs = model(input_ids)
683 |
684 | last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
685 |
686 | """
687 |
688 | if input_ids is not None and inputs_embeds is not None:
689 | raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
690 | elif input_ids is not None:
691 | input_shape = input_ids.size()
692 | elif inputs_embeds is not None:
693 | input_shape = inputs_embeds.size()[:-1]
694 | else:
695 | raise ValueError("You have to specify either input_ids or inputs_embeds")
696 |
697 | device = input_ids.device if input_ids is not None else inputs_embeds.device
698 |
699 | if attention_mask is None:
700 | attention_mask = torch.ones(input_shape, device=device)
701 | if token_type_ids is None:
702 | token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
703 |
704 | # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
705 | # ourselves in which case we just need to make it broadcastable to all heads.
706 | extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(
707 | attention_mask, input_shape, self.device
708 | )
709 |
710 | # If a 2D ou 3D attention mask is provided for the cross-attention
711 | # we need to make broadcastabe to [batch_size, num_heads, seq_length, seq_length]
712 | if self.config.is_decoder and encoder_hidden_states is not None:
713 | encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
714 | encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
715 | if encoder_attention_mask is None:
716 | encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
717 | encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
718 | else:
719 | encoder_extended_attention_mask = None
720 |
721 | # Prepare head mask if needed
722 | # 1.0 in head_mask indicate we keep the head
723 | # attention_probs has shape bsz x n_heads x N x N
724 | # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
725 | # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
726 | head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
727 |
728 | embedding_output = self.embeddings(
729 | input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
730 | )
731 | encoder_outputs = self.encoder(
732 | embedding_output,
733 | attention_mask=extended_attention_mask,
734 | head_mask=head_mask,
735 | encoder_hidden_states=encoder_hidden_states,
736 | encoder_attention_mask=encoder_extended_attention_mask,
737 | )
738 | sequence_output = encoder_outputs[0]
739 | pooled_output = self.pooler(sequence_output)
740 | outputs = (sequence_output, pooled_output,) + encoder_outputs[
741 | 1:
742 | ] # add hidden_states and attentions if they are here
743 | return outputs # sequence_output, pooled_output, (hidden_states), (attentions)
744 |
745 |
746 | @add_start_docstrings(
747 | """Bert Model with two heads on top as done during the pre-training: a `masked language modeling` head and
748 | a `next sentence prediction (classification)` head. """,
749 | BERT_START_DOCSTRING,
750 | )
751 | class MobileBertForPreTraining(MobileBertPreTrainedModel):
752 | def __init__(self, config):
753 | super().__init__(config)
754 | self.bert = MobileBertModel(config)
755 | self.cls = MobileBertPreTrainingHeads(config)
756 | self.init_weights()
757 |
758 | def get_output_embeddings(self):
759 | return self.cls.predictions.decoder
760 |
761 | def get_input_embeddings(self):
762 | return self.bert.embeddings.word_embeddings
763 |
764 | @add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING)
765 | def forward(
766 | self,
767 | input_ids=None,
768 | attention_mask=None,
769 | token_type_ids=None,
770 | position_ids=None,
771 | head_mask=None,
772 | inputs_embeds=None,
773 | masked_lm_labels=None,
774 | next_sentence_label=None,
775 | ):
776 | r"""
777 | masked_lm_labels (``torch.LongTensor`` of shape ``(batch_size, sequence_length)``, `optional`, defaults to :obj:`None`):
778 | Labels for computing the masked language modeling loss.
779 | Indices should be in ``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring)
780 | Tokens with indices set to ``-100`` are ignored (masked), the loss is only computed for the tokens with labels
781 | in ``[0, ..., config.vocab_size]``
782 | next_sentence_label (``torch.LongTensor`` of shape ``(batch_size,)``, `optional`, defaults to :obj:`None`):
783 | Labels for computing the next sequence prediction (classification) loss. Input should be a sequence pair (see :obj:`input_ids` docstring)
784 | Indices should be in ``[0, 1]``.
785 | ``0`` indicates sequence B is a continuation of sequence A,
786 | ``1`` indicates sequence B is a random sequence.
787 | Returns:
788 | :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
789 | loss (`optional`, returned when ``masked_lm_labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
790 | Total loss as the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
791 | prediction_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, config.vocab_size)`)
792 | Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
793 | seq_relationship_scores (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, 2)`):
794 | Prediction scores of the next sequence prediction (classification) head (scores of True/False
795 | continuation before SoftMax).
796 | hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when :obj:`config.output_hidden_states=True`):
797 | Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
798 | of shape :obj:`(batch_size, sequence_length, hidden_size)`.
799 |
800 | Hidden-states of the model at the output of each layer plus the initial embedding outputs.
801 | attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
802 | Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
803 | :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
804 |
805 | Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
806 | heads.
807 |
808 | Examples::
809 | from transformers import BertTokenizer, BertForPreTraining
810 | import torch
811 | tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
812 | model = BertForPreTraining.from_pretrained('bert-base-uncased')
813 | input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
814 | outputs = model(input_ids)
815 | prediction_scores, seq_relationship_scores = outputs[:2]
816 |
817 | """
818 | outputs = self.bert(
819 | input_ids,
820 | attention_mask=attention_mask,
821 | token_type_ids=token_type_ids,
822 | position_ids=position_ids,
823 | head_mask=head_mask,
824 | inputs_embeds=inputs_embeds,
825 | )
826 | sequence_output, pooled_output = outputs[:2]
827 | prediction_scores, seq_relationship_score = self.cls(sequence_output, pooled_output)
828 | outputs = (prediction_scores, seq_relationship_score,) + outputs[
829 | 2:
830 | ] # add hidden states and attention if they are here
831 |
832 | if masked_lm_labels is not None and next_sentence_label is not None:
833 | loss_fct = CrossEntropyLoss()
834 | masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), masked_lm_labels.view(-1))
835 | next_sentence_loss = loss_fct(seq_relationship_score.view(-1, 2), next_sentence_label.view(-1))
836 | total_loss = masked_lm_loss + next_sentence_loss
837 | outputs = (total_loss,) + outputs
838 |
839 | return outputs # (loss), prediction_scores, seq_relationship_score, (hidden_states), (attentions)
840 |
841 |
842 | @add_start_docstrings(
843 | """Bert Model transformer with a sequence classification/regression head on top (a linear layer on top of
844 | the pooled output) e.g. for GLUE tasks. """,
845 | BERT_START_DOCSTRING,
846 | )
847 | class MobileBertForSequenceClassification(MobileBertPreTrainedModel):
848 | def __init__(self, config):
849 | super().__init__(config)
850 | self.num_labels = config.num_labels
851 | self.bert = MobileBertModel(config)
852 | self.dropout = nn.Dropout(config.hidden_dropout_prob+0.1)
853 | self.classifier = nn.Linear(config.hidden_size, self.num_labels)
854 | self.init_weights()
855 |
856 | @add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING)
857 | def forward(
858 | self,
859 | input_ids=None,
860 | attention_mask=None,
861 | token_type_ids=None,
862 | position_ids=None,
863 | head_mask=None,
864 | inputs_embeds=None,
865 | labels=None,
866 | ):
867 | r"""
868 | labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`, defaults to :obj:`None`):
869 | Labels for computing the sequence classification/regression loss.
870 | Indices should be in :obj:`[0, ..., config.num_labels - 1]`.
871 | If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss),
872 | If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
873 | Returns:
874 | :obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.BertConfig`) and inputs:
875 | loss (:obj:`torch.FloatTensor` of shape :obj:`(1,)`, `optional`, returned when :obj:`label` is provided):
876 | Classification (or regression if config.num_labels==1) loss.
877 | logits (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, config.num_labels)`):
878 | Classification (or regression if config.num_labels==1) scores (before SoftMax).
879 | hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
880 | Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
881 | of shape :obj:`(batch_size, sequence_length, hidden_size)`.
882 | Hidden-states of the model at the output of each layer plus the initial embedding outputs.
883 | attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
884 | Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
885 | :obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
886 | Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
887 | heads.
888 | Examples::
889 | from transformers import BertTokenizer, BertForSequenceClassification
890 | import torch
891 | tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
892 | model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
893 | input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0) # Batch size 1
894 | labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
895 | outputs = model(input_ids, labels=labels)
896 | loss, logits = outputs[:2]
897 | """
898 |
899 | outputs = self.bert(
900 | input_ids,
901 | attention_mask=attention_mask,
902 | token_type_ids=token_type_ids,
903 | position_ids=position_ids,
904 | head_mask=head_mask,
905 | inputs_embeds=inputs_embeds,
906 | )
907 | pooled_output = outputs[1]
908 | pooled_output = self.dropout(pooled_output)
909 | logits = self.classifier(pooled_output)
910 | outputs = (logits,) + outputs[2:] # add hidden states and attention if they are here
911 | if labels is not None:
912 | if self.num_labels == 1:
913 | # We are doing regression
914 | loss_fct = MSELoss()
915 | loss = loss_fct(logits.view(-1), labels.view(-1))
916 | else:
917 | loss_fct = CrossEntropyLoss()
918 | loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
919 | outputs = (loss,) + outputs
920 | return outputs # (loss), logits, (hidden_states), (attentions)
921 |
--------------------------------------------------------------------------------
/models/MobileBert/optimization.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """PyTorch optimization for BERT model."""
16 |
17 | import logging
18 | import math
19 |
20 | import torch
21 | from torch.optim import Optimizer
22 | from torch.optim.lr_scheduler import LambdaLR
23 |
24 |
25 | logger = logging.getLogger(__name__)
26 |
27 |
28 | def get_constant_schedule(optimizer, last_epoch=-1):
29 | """ Create a schedule with a constant learning rate.
30 | """
31 | return LambdaLR(optimizer, lambda _: 1, last_epoch=last_epoch)
32 |
33 |
34 | def get_constant_schedule_with_warmup(optimizer, num_warmup_steps, last_epoch=-1):
35 | """ Create a schedule with a constant learning rate preceded by a warmup
36 | period during which the learning rate increases linearly between 0 and 1.
37 | """
38 |
39 | def lr_lambda(current_step):
40 | if current_step < num_warmup_steps:
41 | return float(current_step) / float(max(1.0, num_warmup_steps))
42 | return 1.0
43 |
44 | return LambdaLR(optimizer, lr_lambda, last_epoch=last_epoch)
45 |
46 |
47 | def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, last_epoch=-1):
48 | """ Create a schedule with a learning rate that decreases linearly after
49 | linearly increasing during a warmup period.
50 | """
51 |
52 | def lr_lambda(current_step):
53 | if current_step < num_warmup_steps:
54 | return float(current_step) / float(max(1, num_warmup_steps))
55 | return max(
56 | 0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))
57 | )
58 |
59 | return LambdaLR(optimizer, lr_lambda, last_epoch)
60 |
61 |
62 | def get_cosine_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, num_cycles=0.5, last_epoch=-1):
63 | """ Create a schedule with a learning rate that decreases following the
64 | values of the cosine function between 0 and `pi * cycles` after a warmup
65 | period during which it increases linearly between 0 and 1.
66 | """
67 |
68 | def lr_lambda(current_step):
69 | if current_step < num_warmup_steps:
70 | return float(current_step) / float(max(1, num_warmup_steps))
71 | progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
72 | return max(0.0, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))
73 |
74 | return LambdaLR(optimizer, lr_lambda, last_epoch)
75 |
76 |
77 | def get_cosine_with_hard_restarts_schedule_with_warmup(
78 | optimizer, num_warmup_steps, num_training_steps, num_cycles=1.0, last_epoch=-1
79 | ):
80 | """ Create a schedule with a learning rate that decreases following the
81 | values of the cosine function with several hard restarts, after a warmup
82 | period during which it increases linearly between 0 and 1.
83 | """
84 |
85 | def lr_lambda(current_step):
86 | if current_step < num_warmup_steps:
87 | return float(current_step) / float(max(1, num_warmup_steps))
88 | progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
89 | if progress >= 1.0:
90 | return 0.0
91 | return max(0.0, 0.5 * (1.0 + math.cos(math.pi * ((float(num_cycles) * progress) % 1.0))))
92 |
93 | return LambdaLR(optimizer, lr_lambda, last_epoch)
94 |
95 |
96 | class AdamW(Optimizer):
97 | """ Implements Adam algorithm with weight decay fix.
98 |
99 | Parameters:
100 | lr (float): learning rate. Default 1e-3.
101 | betas (tuple of 2 floats): Adams beta parameters (b1, b2). Default: (0.9, 0.999)
102 | eps (float): Adams epsilon. Default: 1e-6
103 | weight_decay (float): Weight decay. Default: 0.0
104 | correct_bias (bool): can be set to False to avoid correcting bias in Adam (e.g. like in Bert TF repository). Default True.
105 | """
106 |
107 | def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-6, weight_decay=0.0, correct_bias=True):
108 | if lr < 0.0:
109 | raise ValueError("Invalid learning rate: {} - should be >= 0.0".format(lr))
110 | if not 0.0 <= betas[0] < 1.0:
111 | raise ValueError("Invalid beta parameter: {} - should be in [0.0, 1.0[".format(betas[0]))
112 | if not 0.0 <= betas[1] < 1.0:
113 | raise ValueError("Invalid beta parameter: {} - should be in [0.0, 1.0[".format(betas[1]))
114 | if not 0.0 <= eps:
115 | raise ValueError("Invalid epsilon value: {} - should be >= 0.0".format(eps))
116 | defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, correct_bias=correct_bias)
117 | super().__init__(params, defaults)
118 |
119 | def step(self, closure=None):
120 | """Performs a single optimization step.
121 |
122 | Arguments:
123 | closure (callable, optional): A closure that reevaluates the model
124 | and returns the loss.
125 | """
126 | loss = None
127 | if closure is not None:
128 | loss = closure()
129 |
130 | for group in self.param_groups:
131 | for p in group["params"]:
132 | if p.grad is None:
133 | continue
134 | grad = p.grad.data
135 | if grad.is_sparse:
136 | raise RuntimeError("Adam does not support sparse gradients, please consider SparseAdam instead")
137 |
138 | state = self.state[p]
139 |
140 | # State initialization
141 | if len(state) == 0:
142 | state["step"] = 0
143 | # Exponential moving average of gradient values
144 | state["exp_avg"] = torch.zeros_like(p.data)
145 | # Exponential moving average of squared gradient values
146 | state["exp_avg_sq"] = torch.zeros_like(p.data)
147 |
148 | exp_avg, exp_avg_sq = state["exp_avg"], state["exp_avg_sq"]
149 | beta1, beta2 = group["betas"]
150 |
151 | state["step"] += 1
152 |
153 | # Decay the first and second moment running average coefficient
154 | # In-place operations to update the averages at the same time
155 | exp_avg.mul_(beta1).add_(1.0 - beta1, grad)
156 | exp_avg_sq.mul_(beta2).addcmul_(1.0 - beta2, grad, grad)
157 | denom = exp_avg_sq.sqrt().add_(group["eps"])
158 |
159 | step_size = group["lr"]
160 | if group["correct_bias"]: # No bias correction for Bert
161 | bias_correction1 = 1.0 - beta1 ** state["step"]
162 | bias_correction2 = 1.0 - beta2 ** state["step"]
163 | step_size = step_size * math.sqrt(bias_correction2) / bias_correction1
164 |
165 | p.data.addcdiv_(-step_size, exp_avg, denom)
166 |
167 | # Just adding the square of the weights to the loss function is *not*
168 | # the correct way of using L2 regularization/weight decay with Adam,
169 | # since that will interact with the m and v parameters in strange ways.
170 | #
171 | # Instead we want to decay the weights in a manner that doesn't interact
172 | # with the m/v parameters. This is equivalent to adding the square
173 | # of the weights to the loss with plain (non-momentum) SGD.
174 | # Add weight decay at the end (fixed version)
175 | if group["weight_decay"] > 0.0:
176 | p.data.add_(-group["lr"] * group["weight_decay"], p.data)
177 |
178 | return loss
179 |
--------------------------------------------------------------------------------
/models/MobileBert/tokenization_mobilebert.py:
--------------------------------------------------------------------------------
1 | # coding=utf-8
2 | # Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
3 | #
4 | # Licensed under the Apache License, Version 2.0 (the "License");
5 | # you may not use this file except in compliance with the License.
6 | # You may obtain a copy of the License at
7 | #
8 | # http://www.apache.org/licenses/LICENSE-2.0
9 | #
10 | # Unless required by applicable law or agreed to in writing, software
11 | # distributed under the License is distributed on an "AS IS" BASIS,
12 | # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 | # See the License for the specific language governing permissions and
14 | # limitations under the License.
15 | """Tokenization classes."""
16 |
17 |
18 | import collections
19 | import logging
20 | import os
21 | import unicodedata
22 | from typing import List, Optional
23 |
24 | from tokenizers import BertWordPieceTokenizer
25 |
26 | from .tokenization_utils import PreTrainedTokenizer, PreTrainedTokenizerFast
27 |
28 |
29 | logger = logging.getLogger(__name__)
30 |
31 | VOCAB_FILES_NAMES = {"vocab_file": "vocab.txt"}
32 |
33 | PRETRAINED_VOCAB_FILES_MAP = {
34 | "vocab_file": {
35 | }
36 | }
37 |
38 | PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {
39 | "bert-base-uncased": 512,
40 | "bert-large-uncased": 512,
41 | "bert-base-cased": 512,
42 | "bert-large-cased": 512,
43 | "bert-base-multilingual-uncased": 512,
44 | "bert-base-multilingual-cased": 512,
45 | "bert-base-chinese": 512,
46 | "bert-base-german-cased": 512,
47 | "bert-large-uncased-whole-word-masking": 512,
48 | "bert-large-cased-whole-word-masking": 512,
49 | "bert-large-uncased-whole-word-masking-finetuned-squad": 512,
50 | "bert-large-cased-whole-word-masking-finetuned-squad": 512,
51 | "bert-base-cased-finetuned-mrpc": 512,
52 | "bert-base-german-dbmdz-cased": 512,
53 | "bert-base-german-dbmdz-uncased": 512,
54 | "bert-base-finnish-cased-v1": 512,
55 | "bert-base-finnish-uncased-v1": 512,
56 | "bert-base-dutch-cased": 512,
57 | }
58 |
59 | PRETRAINED_INIT_CONFIGURATION = {
60 | "bert-base-uncased": {"do_lower_case": True},
61 | "bert-large-uncased": {"do_lower_case": True},
62 | "bert-base-cased": {"do_lower_case": False},
63 | "bert-large-cased": {"do_lower_case": False},
64 | "bert-base-multilingual-uncased": {"do_lower_case": True},
65 | "bert-base-multilingual-cased": {"do_lower_case": False},
66 | "bert-base-chinese": {"do_lower_case": False},
67 | "bert-base-german-cased": {"do_lower_case": False},
68 | "bert-large-uncased-whole-word-masking": {"do_lower_case": True},
69 | "bert-large-cased-whole-word-masking": {"do_lower_case": False},
70 | "bert-large-uncased-whole-word-masking-finetuned-squad": {"do_lower_case": True},
71 | "bert-large-cased-whole-word-masking-finetuned-squad": {"do_lower_case": False},
72 | "bert-base-cased-finetuned-mrpc": {"do_lower_case": False},
73 | "bert-base-german-dbmdz-cased": {"do_lower_case": False},
74 | "bert-base-german-dbmdz-uncased": {"do_lower_case": True},
75 | "bert-base-finnish-cased-v1": {"do_lower_case": False},
76 | "bert-base-finnish-uncased-v1": {"do_lower_case": True},
77 | "bert-base-dutch-cased": {"do_lower_case": False},
78 | }
79 |
80 |
81 | def load_vocab(vocab_file):
82 | """Loads a vocabulary file into a dictionary."""
83 | vocab = collections.OrderedDict()
84 | with open(vocab_file, "r", encoding="utf-8") as reader:
85 | tokens = reader.readlines()
86 | for index, token in enumerate(tokens):
87 | token = token.rstrip("\n")
88 | vocab[token] = index
89 | return vocab
90 |
91 |
92 | def whitespace_tokenize(text):
93 | """Runs basic whitespace cleaning and splitting on a piece of text."""
94 | text = text.strip()
95 | if not text:
96 | return []
97 | tokens = text.split()
98 | return tokens
99 |
100 |
101 | class BertTokenizer(PreTrainedTokenizer):
102 | r"""
103 | Constructs a BERT tokenizer. Based on WordPiece.
104 |
105 | This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the methods. Users
106 | should refer to the superclass for more information regarding methods.
107 |
108 | Args:
109 | vocab_file (:obj:`string`):
110 | File containing the vocabulary.
111 | do_lower_case (:obj:`bool`, `optional`, defaults to :obj:`True`):
112 | Whether to lowercase the input when tokenizing.
113 | do_basic_tokenize (:obj:`bool`, `optional`, defaults to :obj:`True`):
114 | Whether to do basic tokenization before WordPiece.
115 | never_split (:obj:`bool`, `optional`, defaults to :obj:`True`):
116 | List of tokens which will never be split during tokenization. Only has an effect when
117 | :obj:`do_basic_tokenize=True`
118 | unk_token (:obj:`string`, `optional`, defaults to "[UNK]"):
119 | The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
120 | token instead.
121 | sep_token (:obj:`string`, `optional`, defaults to "[SEP]"):
122 | The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences
123 | for sequence classification or for a text and a question for question answering.
124 | It is also used as the last token of a sequence built with special tokens.
125 | pad_token (:obj:`string`, `optional`, defaults to "[PAD]"):
126 | The token used for padding, for example when batching sequences of different lengths.
127 | cls_token (:obj:`string`, `optional`, defaults to "[CLS]"):
128 | The classifier token which is used when doing sequence classification (classification of the whole
129 | sequence instead of per-token classification). It is the first token of the sequence when built with
130 | special tokens.
131 | mask_token (:obj:`string`, `optional`, defaults to "[MASK]"):
132 | The token used for masking values. This is the token used when training this model with masked language
133 | modeling. This is the token which the model will try to predict.
134 | tokenize_chinese_chars (:obj:`bool`, `optional`, defaults to :obj:`True`):
135 | Whether to tokenize Chinese characters.
136 | This should likely be deactivated for Japanese:
137 | see: https://github.com/huggingface/transformers/issues/328
138 | """
139 |
140 | vocab_files_names = VOCAB_FILES_NAMES
141 | pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
142 | pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
143 | max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
144 |
145 | def __init__(
146 | self,
147 | vocab_file,
148 | do_lower_case=True,
149 | do_basic_tokenize=True,
150 | never_split=None,
151 | unk_token="[UNK]",
152 | sep_token="[SEP]",
153 | pad_token="[PAD]",
154 | cls_token="[CLS]",
155 | mask_token="[MASK]",
156 | tokenize_chinese_chars=True,
157 | **kwargs
158 | ):
159 | super().__init__(
160 | unk_token=unk_token,
161 | sep_token=sep_token,
162 | pad_token=pad_token,
163 | cls_token=cls_token,
164 | mask_token=mask_token,
165 | **kwargs,
166 | )
167 |
168 | if not os.path.isfile(vocab_file):
169 | raise ValueError(
170 | "Can't find a vocabulary file at path '{}'. To load the vocabulary from a Google pretrained "
171 | "model use `tokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)`".format(vocab_file)
172 | )
173 | self.vocab = load_vocab(vocab_file)
174 | self.ids_to_tokens = collections.OrderedDict([(ids, tok) for tok, ids in self.vocab.items()])
175 | self.do_basic_tokenize = do_basic_tokenize
176 | if do_basic_tokenize:
177 | self.basic_tokenizer = BasicTokenizer(
178 | do_lower_case=do_lower_case, never_split=never_split, tokenize_chinese_chars=tokenize_chinese_chars
179 | )
180 | self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab, unk_token=self.unk_token)
181 |
182 | @property
183 | def vocab_size(self):
184 | return len(self.vocab)
185 |
186 | def get_vocab(self):
187 | return dict(self.vocab, **self.added_tokens_encoder)
188 |
189 | def _tokenize(self, text):
190 | split_tokens = []
191 | if self.do_basic_tokenize:
192 | for token in self.basic_tokenizer.tokenize(text, never_split=self.all_special_tokens):
193 | for sub_token in self.wordpiece_tokenizer.tokenize(token):
194 | split_tokens.append(sub_token)
195 | else:
196 | split_tokens = self.wordpiece_tokenizer.tokenize(text)
197 | return split_tokens
198 |
199 | def _convert_token_to_id(self, token):
200 | """ Converts a token (str) in an id using the vocab. """
201 | return self.vocab.get(token, self.vocab.get(self.unk_token))
202 |
203 | def _convert_id_to_token(self, index):
204 | """Converts an index (integer) in a token (str) using the vocab."""
205 | return self.ids_to_tokens.get(index, self.unk_token)
206 |
207 | def convert_tokens_to_string(self, tokens):
208 | """ Converts a sequence of tokens (string) in a single string. """
209 | out_string = " ".join(tokens).replace(" ##", "").strip()
210 | return out_string
211 |
212 | def build_inputs_with_special_tokens(
213 | self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
214 | ) -> List[int]:
215 | """
216 | Build model inputs from a sequence or a pair of sequence for sequence classification tasks
217 | by concatenating and adding special tokens.
218 | A BERT sequence has the following format:
219 |
220 | - single sequence: ``[CLS] X [SEP]``
221 | - pair of sequences: ``[CLS] A [SEP] B [SEP]``
222 |
223 | Args:
224 | token_ids_0 (:obj:`List[int]`):
225 | List of IDs to which the special tokens will be added
226 | token_ids_1 (:obj:`List[int]`, `optional`, defaults to :obj:`None`):
227 | Optional second list of IDs for sequence pairs.
228 |
229 | Returns:
230 | :obj:`List[int]`: list of `input IDs <../glossary.html#input-ids>`__ with the appropriate special tokens.
231 | """
232 | if token_ids_1 is None:
233 | return [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
234 | cls = [self.cls_token_id]
235 | sep = [self.sep_token_id]
236 | return cls + token_ids_0 + sep + token_ids_1 + sep
237 |
238 | def get_special_tokens_mask(
239 | self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
240 | ) -> List[int]:
241 | """
242 | Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
243 | special tokens using the tokenizer ``prepare_for_model`` or ``encode_plus`` methods.
244 |
245 | Args:
246 | token_ids_0 (:obj:`List[int]`):
247 | List of ids.
248 | token_ids_1 (:obj:`List[int]`, `optional`, defaults to :obj:`None`):
249 | Optional second list of IDs for sequence pairs.
250 | already_has_special_tokens (:obj:`bool`, `optional`, defaults to :obj:`False`):
251 | Set to True if the token list is already formatted with special tokens for the model
252 |
253 | Returns:
254 | :obj:`List[int]`: A list of integers in the range [0, 1]: 0 for a special token, 1 for a sequence token.
255 | """
256 |
257 | if already_has_special_tokens:
258 | if token_ids_1 is not None:
259 | raise ValueError(
260 | "You should not supply a second sequence if the provided sequence of "
261 | "ids is already formated with special tokens for the model."
262 | )
263 | return list(map(lambda x: 1 if x in [self.sep_token_id, self.cls_token_id] else 0, token_ids_0))
264 |
265 | if token_ids_1 is not None:
266 | return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
267 | return [1] + ([0] * len(token_ids_0)) + [1]
268 |
269 | def create_token_type_ids_from_sequences(
270 | self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
271 | ) -> List[int]:
272 | """
273 | Creates a mask from the two sequences passed to be used in a sequence-pair classification task.
274 | A BERT sequence pair mask has the following format:
275 |
276 | ::
277 |
278 | 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
279 | | first sequence | second sequence |
280 |
281 | if token_ids_1 is None, only returns the first portion of the mask (0's).
282 |
283 | Args:
284 | token_ids_0 (:obj:`List[int]`):
285 | List of ids.
286 | token_ids_1 (:obj:`List[int]`, `optional`, defaults to :obj:`None`):
287 | Optional second list of IDs for sequence pairs.
288 |
289 | Returns:
290 | :obj:`List[int]`: List of `token type IDs <../glossary.html#token-type-ids>`_ according to the given
291 | sequence(s).
292 | """
293 | sep = [self.sep_token_id]
294 | cls = [self.cls_token_id]
295 | if token_ids_1 is None:
296 | return len(cls + token_ids_0 + sep) * [0]
297 | return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
298 |
299 | def save_vocabulary(self, vocab_path):
300 | """
301 | Save the sentencepiece vocabulary (copy original file) and special tokens file to a directory.
302 |
303 | Args:
304 | vocab_path (:obj:`str`):
305 | The directory in which to save the vocabulary.
306 |
307 | Returns:
308 | :obj:`Tuple(str)`: Paths to the files saved.
309 | """
310 | index = 0
311 | if os.path.isdir(vocab_path):
312 | vocab_file = os.path.join(vocab_path, VOCAB_FILES_NAMES["vocab_file"])
313 | else:
314 | vocab_file = vocab_path
315 | with open(vocab_file, "w", encoding="utf-8") as writer:
316 | for token, token_index in sorted(self.vocab.items(), key=lambda kv: kv[1]):
317 | if index != token_index:
318 | logger.warning(
319 | "Saving vocabulary to {}: vocabulary indices are not consecutive."
320 | " Please check that the vocabulary is not corrupted!".format(vocab_file)
321 | )
322 | index = token_index
323 | writer.write(token + "\n")
324 | index += 1
325 | return (vocab_file,)
326 |
327 |
328 | class BasicTokenizer(object):
329 | """Runs basic tokenization (punctuation splitting, lower casing, etc.)."""
330 |
331 | def __init__(self, do_lower_case=True, never_split=None, tokenize_chinese_chars=True):
332 | """ Constructs a BasicTokenizer.
333 |
334 | Args:
335 | **do_lower_case**: Whether to lower case the input.
336 | **never_split**: (`optional`) list of str
337 | Kept for backward compatibility purposes.
338 | Now implemented directly at the base class level (see :func:`PreTrainedTokenizer.tokenize`)
339 | List of token not to split.
340 | **tokenize_chinese_chars**: (`optional`) boolean (default True)
341 | Whether to tokenize Chinese characters.
342 | This should likely be deactivated for Japanese:
343 | see: https://github.com/huggingface/pytorch-pretrained-BERT/issues/328
344 | """
345 | if never_split is None:
346 | never_split = []
347 | self.do_lower_case = do_lower_case
348 | self.never_split = never_split
349 | self.tokenize_chinese_chars = tokenize_chinese_chars
350 |
351 | def tokenize(self, text, never_split=None):
352 | """ Basic Tokenization of a piece of text.
353 | Split on "white spaces" only, for sub-word tokenization, see WordPieceTokenizer.
354 |
355 | Args:
356 | **never_split**: (`optional`) list of str
357 | Kept for backward compatibility purposes.
358 | Now implemented directly at the base class level (see :func:`PreTrainedTokenizer.tokenize`)
359 | List of token not to split.
360 | """
361 | never_split = self.never_split + (never_split if never_split is not None else [])
362 | text = self._clean_text(text)
363 | # This was added on November 1st, 2018 for the multilingual and Chinese
364 | # models. This is also applied to the English models now, but it doesn't
365 | # matter since the English models were not trained on any Chinese data
366 | # and generally don't have any Chinese data in them (there are Chinese
367 | # characters in the vocabulary because Wikipedia does have some Chinese
368 | # words in the English Wikipedia.).
369 | if self.tokenize_chinese_chars:
370 | text = self._tokenize_chinese_chars(text)
371 | orig_tokens = whitespace_tokenize(text)
372 | split_tokens = []
373 | for token in orig_tokens:
374 | if self.do_lower_case and token not in never_split:
375 | token = token.lower()
376 | token = self._run_strip_accents(token)
377 | split_tokens.extend(self._run_split_on_punc(token, never_split))
378 |
379 | output_tokens = whitespace_tokenize(" ".join(split_tokens))
380 | return output_tokens
381 |
382 | def _run_strip_accents(self, text):
383 | """Strips accents from a piece of text."""
384 | text = unicodedata.normalize("NFD", text)
385 | output = []
386 | for char in text:
387 | cat = unicodedata.category(char)
388 | if cat == "Mn":
389 | continue
390 | output.append(char)
391 | return "".join(output)
392 |
393 | def _run_split_on_punc(self, text, never_split=None):
394 | """Splits punctuation on a piece of text."""
395 | if never_split is not None and text in never_split:
396 | return [text]
397 | chars = list(text)
398 | i = 0
399 | start_new_word = True
400 | output = []
401 | while i < len(chars):
402 | char = chars[i]
403 | if _is_punctuation(char):
404 | output.append([char])
405 | start_new_word = True
406 | else:
407 | if start_new_word:
408 | output.append([])
409 | start_new_word = False
410 | output[-1].append(char)
411 | i += 1
412 |
413 | return ["".join(x) for x in output]
414 |
415 | def _tokenize_chinese_chars(self, text):
416 | """Adds whitespace around any CJK character."""
417 | output = []
418 | for char in text:
419 | cp = ord(char)
420 | if self._is_chinese_char(cp):
421 | output.append(" ")
422 | output.append(char)
423 | output.append(" ")
424 | else:
425 | output.append(char)
426 | return "".join(output)
427 |
428 | def _is_chinese_char(self, cp):
429 | """Checks whether CP is the codepoint of a CJK character."""
430 | # This defines a "chinese character" as anything in the CJK Unicode block:
431 | # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
432 | #
433 | # Note that the CJK Unicode block is NOT all Japanese and Korean characters,
434 | # despite its name. The modern Korean Hangul alphabet is a different block,
435 | # as is Japanese Hiragana and Katakana. Those alphabets are used to write
436 | # space-separated words, so they are not treated specially and handled
437 | # like the all of the other languages.
438 | if (
439 | (cp >= 0x4E00 and cp <= 0x9FFF)
440 | or (cp >= 0x3400 and cp <= 0x4DBF) #
441 | or (cp >= 0x20000 and cp <= 0x2A6DF) #
442 | or (cp >= 0x2A700 and cp <= 0x2B73F) #
443 | or (cp >= 0x2B740 and cp <= 0x2B81F) #
444 | or (cp >= 0x2B820 and cp <= 0x2CEAF) #
445 | or (cp >= 0xF900 and cp <= 0xFAFF)
446 | or (cp >= 0x2F800 and cp <= 0x2FA1F) #
447 | ): #
448 | return True
449 |
450 | return False
451 |
452 | def _clean_text(self, text):
453 | """Performs invalid character removal and whitespace cleanup on text."""
454 | output = []
455 | for char in text:
456 | cp = ord(char)
457 | if cp == 0 or cp == 0xFFFD or _is_control(char):
458 | continue
459 | if _is_whitespace(char):
460 | output.append(" ")
461 | else:
462 | output.append(char)
463 | return "".join(output)
464 |
465 |
466 | class WordpieceTokenizer(object):
467 | """Runs WordPiece tokenization."""
468 |
469 | def __init__(self, vocab, unk_token, max_input_chars_per_word=100):
470 | self.vocab = vocab
471 | self.unk_token = unk_token
472 | self.max_input_chars_per_word = max_input_chars_per_word
473 |
474 | def tokenize(self, text):
475 | """Tokenizes a piece of text into its word pieces.
476 |
477 | This uses a greedy longest-match-first algorithm to perform tokenization
478 | using the given vocabulary.
479 |
480 | For example:
481 | input = "unaffable"
482 | output = ["un", "##aff", "##able"]
483 |
484 | Args:
485 | text: A single token or whitespace separated tokens. This should have
486 | already been passed through `BasicTokenizer`.
487 |
488 | Returns:
489 | A list of wordpiece tokens.
490 | """
491 |
492 | output_tokens = []
493 | for token in whitespace_tokenize(text):
494 | chars = list(token)
495 | if len(chars) > self.max_input_chars_per_word:
496 | output_tokens.append(self.unk_token)
497 | continue
498 |
499 | is_bad = False
500 | start = 0
501 | sub_tokens = []
502 | while start < len(chars):
503 | end = len(chars)
504 | cur_substr = None
505 | while start < end:
506 | substr = "".join(chars[start:end])
507 | if start > 0:
508 | substr = "##" + substr
509 | if substr in self.vocab:
510 | cur_substr = substr
511 | break
512 | end -= 1
513 | if cur_substr is None:
514 | is_bad = True
515 | break
516 | sub_tokens.append(cur_substr)
517 | start = end
518 |
519 | if is_bad:
520 | output_tokens.append(self.unk_token)
521 | else:
522 | output_tokens.extend(sub_tokens)
523 | return output_tokens
524 |
525 |
526 | def _is_whitespace(char):
527 | """Checks whether `chars` is a whitespace character."""
528 | # \t, \n, and \r are technically contorl characters but we treat them
529 | # as whitespace since they are generally considered as such.
530 | if char == " " or char == "\t" or char == "\n" or char == "\r":
531 | return True
532 | cat = unicodedata.category(char)
533 | if cat == "Zs":
534 | return True
535 | return False
536 |
537 |
538 | def _is_control(char):
539 | """Checks whether `chars` is a control character."""
540 | # These are technically control characters but we count them as whitespace
541 | # characters.
542 | if char == "\t" or char == "\n" or char == "\r":
543 | return False
544 | cat = unicodedata.category(char)
545 | if cat.startswith("C"):
546 | return True
547 | return False
548 |
549 |
550 | def _is_punctuation(char):
551 | """Checks whether `chars` is a punctuation character."""
552 | cp = ord(char)
553 | # We treat all non-letter/number ASCII as punctuation.
554 | # Characters such as "^", "$", and "`" are not in the Unicode
555 | # Punctuation class but we treat them as punctuation anyways, for
556 | # consistency.
557 | if (cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126):
558 | return True
559 | cat = unicodedata.category(char)
560 | if cat.startswith("P"):
561 | return True
562 | return False
563 |
564 |
565 | class BertTokenizerFast(PreTrainedTokenizerFast):
566 | r"""
567 | Constructs a "Fast" BERT tokenizer (backed by HuggingFace's `tokenizers` library).
568 |
569 | Bert tokenization is Based on WordPiece.
570 |
571 | This tokenizer inherits from :class:`~transformers.PreTrainedTokenizerFast` which contains most of the methods. Users
572 | should refer to the superclass for more information regarding methods.
573 |
574 | Args:
575 | vocab_file (:obj:`string`):
576 | File containing the vocabulary.
577 | do_lower_case (:obj:`bool`, `optional`, defaults to :obj:`True`):
578 | Whether to lowercase the input when tokenizing.
579 | unk_token (:obj:`string`, `optional`, defaults to "[UNK]"):
580 | The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
581 | token instead.
582 | sep_token (:obj:`string`, `optional`, defaults to "[SEP]"):
583 | The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences
584 | for sequence classification or for a text and a question for question answering.
585 | It is also used as the last token of a sequence built with special tokens.
586 | pad_token (:obj:`string`, `optional`, defaults to "[PAD]"):
587 | The token used for padding, for example when batching sequences of different lengths.
588 | cls_token (:obj:`string`, `optional`, defaults to "[CLS]"):
589 | The classifier token which is used when doing sequence classification (classification of the whole
590 | sequence instead of per-token classification). It is the first token of the sequence when built with
591 | special tokens.
592 | mask_token (:obj:`string`, `optional`, defaults to "[MASK]"):
593 | The token used for masking values. This is the token used when training this model with masked language
594 | modeling. This is the token which the model will try to predict.
595 | tokenize_chinese_chars (:obj:`bool`, `optional`, defaults to :obj:`True`):
596 | Whether to tokenize Chinese characters.
597 | This should likely be deactivated for Japanese:
598 | see: https://github.com/huggingface/transformers/issues/328
599 | clean_text (:obj:`bool`, `optional`, defaults to :obj:`True`):
600 | Whether to clean the text before tokenization by removing any control characters and
601 | replacing all whitespaces by the classic one.
602 | tokenize_chinese_chars (:obj:`bool`, `optional`, defaults to :obj:`True`):
603 | Whether to tokenize Chinese characters.
604 | This should likely be deactivated for Japanese:
605 | see: https://github.com/huggingface/transformers/issues/328
606 | """
607 |
608 | vocab_files_names = VOCAB_FILES_NAMES
609 | pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
610 | pretrained_init_configuration = PRETRAINED_INIT_CONFIGURATION
611 | max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
612 |
613 | def __init__(
614 | self,
615 | vocab_file,
616 | do_lower_case=True,
617 | unk_token="[UNK]",
618 | sep_token="[SEP]",
619 | pad_token="[PAD]",
620 | cls_token="[CLS]",
621 | mask_token="[MASK]",
622 | clean_text=True,
623 | tokenize_chinese_chars=True,
624 | strip_accents=True,
625 | wordpieces_prefix="##",
626 | **kwargs
627 | ):
628 | super().__init__(
629 | BertWordPieceTokenizer(
630 | vocab_file=vocab_file,
631 | unk_token=unk_token,
632 | sep_token=sep_token,
633 | cls_token=cls_token,
634 | clean_text=clean_text,
635 | handle_chinese_chars=tokenize_chinese_chars,
636 | strip_accents=strip_accents,
637 | lowercase=do_lower_case,
638 | wordpieces_prefix=wordpieces_prefix,
639 | ),
640 | unk_token=unk_token,
641 | sep_token=sep_token,
642 | pad_token=pad_token,
643 | cls_token=cls_token,
644 | mask_token=mask_token,
645 | **kwargs,
646 | )
647 |
648 | self.do_lower_case = do_lower_case
649 |
650 | def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
651 | output = [self.cls_token_id] + token_ids_0 + [self.sep_token_id]
652 |
653 | if token_ids_1:
654 | output += token_ids_1 + [self.sep_token_id]
655 |
656 | return output
657 |
--------------------------------------------------------------------------------
/models/__init__.py:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chriskhanhtran/bert-extractive-summarization/d228ba1e63d0c84a86419f55b784844990cb68f5/models/__init__.py
--------------------------------------------------------------------------------
/models/encoder.py:
--------------------------------------------------------------------------------
1 | import math
2 | import torch
3 | import torch.nn as nn
4 | from models.neural import MultiHeadedAttention, PositionwiseFeedForward
5 |
6 |
7 | class PositionalEncoding(nn.Module):
8 | def __init__(self, dropout, dim, max_len=5000):
9 | pe = torch.zeros(max_len, dim)
10 | position = torch.arange(0, max_len).unsqueeze(1)
11 | div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) * -(math.log(10000.0) / dim)))
12 | pe[:, 0::2] = torch.sin(position.float() * div_term)
13 | pe[:, 1::2] = torch.cos(position.float() * div_term)
14 | pe = pe.unsqueeze(0)
15 | super().__init__()
16 | self.register_buffer("pe", pe)
17 | self.dropout = nn.Dropout(p=dropout)
18 | self.dim = dim
19 |
20 | def forward(self, emb, step=None):
21 | emb = emb * math.sqrt(self.dim)
22 | if step:
23 | emb = emb + self.pe[:, step][:, None, :]
24 |
25 | else:
26 | emb = emb + self.pe[:, : emb.size(1)]
27 | emb = self.dropout(emb)
28 | return emb
29 |
30 | def get_emb(self, emb):
31 | return self.pe[:, : emb.size(1)]
32 |
33 |
34 | class TransformerEncoderLayer(nn.Module):
35 | def __init__(self, d_model, heads, d_ff, dropout):
36 | super().__init__()
37 |
38 | self.self_attn = MultiHeadedAttention(heads, d_model, dropout=dropout)
39 | self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
40 | self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
41 | self.dropout = nn.Dropout(dropout)
42 |
43 | def forward(self, iter, query, inputs, mask):
44 | if iter != 0:
45 | input_norm = self.layer_norm(inputs)
46 | else:
47 | input_norm = inputs
48 |
49 | mask = mask.unsqueeze(1)
50 | context = self.self_attn(input_norm, input_norm, input_norm, mask=mask)
51 | out = self.dropout(context) + inputs
52 | return self.feed_forward(out)
53 |
54 |
55 | class ExtTransformerEncoder(nn.Module):
56 | def __init__(self, d_model, d_ff, heads, dropout, num_inter_layers=0):
57 | super().__init__()
58 | self.d_model = d_model
59 | self.num_inter_layers = num_inter_layers
60 | self.pos_emb = PositionalEncoding(dropout, d_model)
61 | self.transformer_inter = nn.ModuleList(
62 | [TransformerEncoderLayer(d_model, heads, d_ff, dropout) for _ in range(num_inter_layers)]
63 | )
64 | self.dropout = nn.Dropout(dropout)
65 | self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
66 | self.wo = nn.Linear(d_model, 1, bias=True)
67 | self.sigmoid = nn.Sigmoid()
68 |
69 | def forward(self, top_vecs, mask):
70 | """ See :obj:`EncoderBase.forward()`"""
71 |
72 | batch_size, n_sents = top_vecs.size(0), top_vecs.size(1)
73 | pos_emb = self.pos_emb.pe[:, :n_sents]
74 | x = top_vecs * mask[:, :, None].float()
75 | x = x + pos_emb
76 |
77 | for i in range(self.num_inter_layers):
78 | x = self.transformer_inter[i](i, x, x, 1 - mask) # all_sents * max_tokens * dim
79 |
80 | x = self.layer_norm(x)
81 | sent_scores = self.sigmoid(self.wo(x))
82 | sent_scores = sent_scores.squeeze(-1) * mask.float()
83 |
84 | return sent_scores
85 |
--------------------------------------------------------------------------------
/models/model_builder.py:
--------------------------------------------------------------------------------
1 | import torch
2 | import torch.nn as nn
3 | from torch.nn.init import xavier_uniform_
4 | from transformers import BertModel, BertConfig, DistilBertConfig, DistilBertModel
5 | from models.MobileBert.modeling_mobilebert import MobileBertConfig, MobileBertModel
6 | from models.encoder import ExtTransformerEncoder
7 |
8 | class Bert(nn.Module):
9 | def __init__(self, bert_type='bertbase'):
10 | super(Bert, self).__init__()
11 | self.bert_type = bert_type
12 |
13 | if bert_type == 'bertbase':
14 | configuration = BertConfig()
15 | self.model = BertModel(configuration)
16 | elif bert_type == 'distilbert':
17 | configuration = DistilBertConfig()
18 | self.model = DistilBertModel(configuration)
19 | elif bert_type == 'mobilebert':
20 | configuration = MobileBertConfig.from_pretrained('checkpoints/mobilebert')
21 | self.model = MobileBertModel(configuration)
22 |
23 | def forward(self, x, segs, mask):
24 | if self.bert_type == 'distilbert':
25 | top_vec = self.model(input_ids=x, attention_mask=mask)[0]
26 | else:
27 | top_vec, _ = self.model(x, attention_mask=mask, token_type_ids=segs)
28 | return top_vec
29 |
30 |
31 | class ExtSummarizer(nn.Module):
32 | def __init__(self, device, checkpoint=None, bert_type='bertbase'):
33 | super().__init__()
34 | self.device = device
35 | self.bert = Bert(bert_type=bert_type)
36 | self.ext_layer = ExtTransformerEncoder(
37 | self.bert.model.config.hidden_size, d_ff=2048, heads=8, dropout=0.2, num_inter_layers=2
38 | )
39 |
40 | if checkpoint is not None:
41 | self.load_state_dict(checkpoint, strict=True)
42 |
43 | self.to(device)
44 |
45 | def forward(self, src, segs, clss, mask_src, mask_cls):
46 | top_vec = self.bert(src, segs, mask_src)
47 | sents_vec = top_vec[torch.arange(top_vec.size(0)).unsqueeze(1), clss]
48 | sents_vec = sents_vec * mask_cls[:, :, None].float()
49 | sent_scores = self.ext_layer(sents_vec, mask_cls).squeeze(-1)
50 | return sent_scores, mask_cls
51 |
--------------------------------------------------------------------------------
/models/neural.py:
--------------------------------------------------------------------------------
1 | import torch.nn.functional as F
2 | import math
3 | import torch
4 | import torch.nn as nn
5 |
6 |
7 | def gelu(x):
8 | return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
9 |
10 |
11 | class PositionwiseFeedForward(nn.Module):
12 | """ A two-layer Feed-Forward-Network with residual layer norm.
13 |
14 | Args:
15 | d_model (int): the size of input for the first-layer of the FFN.
16 | d_ff (int): the hidden layer size of the second-layer
17 | of the FNN.
18 | dropout (float): dropout probability in :math:`[0, 1)`.
19 | """
20 |
21 | def __init__(self, d_model, d_ff, dropout=0.1):
22 | super().__init__()
23 | self.w_1 = nn.Linear(d_model, d_ff)
24 | self.w_2 = nn.Linear(d_ff, d_model)
25 | self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
26 | self.actv = gelu
27 | self.dropout_1 = nn.Dropout(dropout)
28 | self.dropout_2 = nn.Dropout(dropout)
29 |
30 | def forward(self, x):
31 | inter = self.dropout_1(self.actv(self.w_1(self.layer_norm(x))))
32 | output = self.dropout_2(self.w_2(inter))
33 | return output + x
34 |
35 |
36 | class MultiHeadedAttention(nn.Module):
37 | """
38 | Multi-Head Attention module from
39 | "Attention is All You Need"
40 | :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.
41 |
42 | Similar to standard `dot` attention but uses
43 | multiple attention distributions simulataneously
44 | to select relevant items.
45 |
46 |
47 | Also includes several additional tricks.
48 |
49 | Args:
50 | head_count (int): number of parallel heads
51 | model_dim (int): the dimension of keys/values/queries,
52 | must be divisible by head_count
53 | dropout (float): dropout parameter
54 | """
55 |
56 | def __init__(self, head_count, model_dim, dropout=0.1, use_final_linear=True):
57 | assert model_dim % head_count == 0
58 | self.dim_per_head = model_dim // head_count
59 | self.model_dim = model_dim
60 |
61 | super().__init__()
62 | self.head_count = head_count
63 |
64 | self.linear_keys = nn.Linear(model_dim, head_count * self.dim_per_head)
65 | self.linear_values = nn.Linear(model_dim, head_count * self.dim_per_head)
66 | self.linear_query = nn.Linear(model_dim, head_count * self.dim_per_head)
67 | self.softmax = nn.Softmax(dim=-1)
68 | self.dropout = nn.Dropout(dropout)
69 | self.use_final_linear = use_final_linear
70 | if (self.use_final_linear):
71 | self.final_linear = nn.Linear(model_dim, model_dim)
72 |
73 | def forward(self, key, value, query, mask=None,
74 | layer_cache=None, type=None, predefined_graph_1=None):
75 | """
76 | Compute the context vector and the attention vectors.
77 |
78 | Args:
79 | key (`FloatTensor`): set of `key_len`
80 | key vectors `[batch, key_len, dim]`
81 | value (`FloatTensor`): set of `key_len`
82 | value vectors `[batch, key_len, dim]`
83 | query (`FloatTensor`): set of `query_len`
84 | query vectors `[batch, query_len, dim]`
85 | mask: binary mask indicating which keys have
86 | non-zero attention `[batch, query_len, key_len]`
87 | Returns:
88 | (`FloatTensor`, `FloatTensor`) :
89 |
90 | * output context vectors `[batch, query_len, dim]`
91 | * one of the attention vectors `[batch, query_len, key_len]`
92 | """
93 |
94 | batch_size = key.size(0)
95 | dim_per_head = self.dim_per_head
96 | head_count = self.head_count
97 | key_len = key.size(1)
98 | query_len = query.size(1)
99 |
100 | def shape(x):
101 | """ projection """
102 | return x.view(batch_size, -1, head_count, dim_per_head) \
103 | .transpose(1, 2)
104 |
105 | def unshape(x):
106 | """ compute context """
107 | return x.transpose(1, 2).contiguous() \
108 | .view(batch_size, -1, head_count * dim_per_head)
109 |
110 | # 1) Project key, value, and query.
111 | if layer_cache is not None:
112 | if type == "self":
113 | query, key, value = self.linear_query(query), \
114 | self.linear_keys(query), \
115 | self.linear_values(query)
116 |
117 | key = shape(key)
118 | value = shape(value)
119 |
120 | if layer_cache is not None:
121 | device = key.device
122 | if layer_cache["self_keys"] is not None:
123 | key = torch.cat(
124 | (layer_cache["self_keys"].to(device), key),
125 | dim=2)
126 | if layer_cache["self_values"] is not None:
127 | value = torch.cat(
128 | (layer_cache["self_values"].to(device), value),
129 | dim=2)
130 | layer_cache["self_keys"] = key
131 | layer_cache["self_values"] = value
132 | elif type == "context":
133 | query = self.linear_query(query)
134 | if layer_cache is not None:
135 | if layer_cache["memory_keys"] is None:
136 | key, value = self.linear_keys(key), \
137 | self.linear_values(value)
138 | key = shape(key)
139 | value = shape(value)
140 | else:
141 | key, value = layer_cache["memory_keys"], \
142 | layer_cache["memory_values"]
143 | layer_cache["memory_keys"] = key
144 | layer_cache["memory_values"] = value
145 | else:
146 | key, value = self.linear_keys(key), \
147 | self.linear_values(value)
148 | key = shape(key)
149 | value = shape(value)
150 | else:
151 | key = self.linear_keys(key)
152 | value = self.linear_values(value)
153 | query = self.linear_query(query)
154 | key = shape(key)
155 | value = shape(value)
156 |
157 | query = shape(query)
158 |
159 | key_len = key.size(2)
160 | query_len = query.size(2)
161 |
162 | # 2) Calculate and scale scores.
163 | query = query / math.sqrt(dim_per_head)
164 | scores = torch.matmul(query, key.transpose(2, 3))
165 |
166 | if mask is not None:
167 | mask = mask.unsqueeze(1).expand_as(scores)
168 | scores = scores.masked_fill(mask.byte(), -1e18)
169 |
170 | # 3) Apply attention dropout and compute context vectors.
171 |
172 | attn = self.softmax(scores)
173 |
174 | if (not predefined_graph_1 is None):
175 | attn_masked = attn[:, -1] * predefined_graph_1
176 | attn_masked = attn_masked / \
177 | (torch.sum(attn_masked, 2).unsqueeze(2) + 1e-9)
178 |
179 | attn = torch.cat([attn[:, :-1], attn_masked.unsqueeze(1)], 1)
180 |
181 | drop_attn = self.dropout(attn)
182 | if (self.use_final_linear):
183 | context = unshape(torch.matmul(drop_attn, value))
184 | output = self.final_linear(context)
185 | return output
186 | else:
187 | context = torch.matmul(drop_attn, value)
188 | return context
--------------------------------------------------------------------------------
/models/optimizers.py:
--------------------------------------------------------------------------------
1 | """ Optimizers class """
2 | import torch
3 | import torch.optim as optim
4 | from torch.nn.utils import clip_grad_norm_
5 |
6 |
7 | # from onmt.utils import use_gpu
8 | # from models.adam import Adam
9 |
10 |
11 | def use_gpu(opt):
12 | """
13 | Creates a boolean if gpu used
14 | """
15 | return (hasattr(opt, 'gpu_ranks') and len(opt.gpu_ranks) > 0) or \
16 | (hasattr(opt, 'gpu') and opt.gpu > -1)
17 |
18 | def build_optim(model, opt, checkpoint):
19 | """ Build optimizer """
20 | saved_optimizer_state_dict = None
21 |
22 | if opt.train_from:
23 | optim = checkpoint['optim']
24 | # We need to save a copy of optim.optimizer.state_dict() for setting
25 | # the, optimizer state later on in Stage 2 in this method, since
26 | # the method optim.set_parameters(model.parameters()) will overwrite
27 | # optim.optimizer, and with ith the values stored in
28 | # optim.optimizer.state_dict()
29 | saved_optimizer_state_dict = optim.optimizer.state_dict()
30 | else:
31 | optim = Optimizer(
32 | opt.optim, opt.learning_rate, opt.max_grad_norm,
33 | lr_decay=opt.learning_rate_decay,
34 | start_decay_steps=opt.start_decay_steps,
35 | decay_steps=opt.decay_steps,
36 | beta1=opt.adam_beta1,
37 | beta2=opt.adam_beta2,
38 | adagrad_accum=opt.adagrad_accumulator_init,
39 | decay_method=opt.decay_method,
40 | warmup_steps=opt.warmup_steps)
41 |
42 | optim.set_parameters(model.named_parameters())
43 |
44 | if opt.train_from:
45 | optim.optimizer.load_state_dict(saved_optimizer_state_dict)
46 | if use_gpu(opt):
47 | for state in optim.optimizer.state.values():
48 | for k, v in state.items():
49 | if torch.is_tensor(v):
50 | state[k] = v.cuda()
51 |
52 | if (optim.method == 'adam') and (len(optim.optimizer.state) < 1):
53 | raise RuntimeError(
54 | "Error: loaded Adam optimizer from existing model" +
55 | " but optimizer state is empty")
56 |
57 | return optim
58 |
59 |
60 | class MultipleOptimizer(object):
61 | """ Implement multiple optimizers needed for sparse adam """
62 |
63 | def __init__(self, op):
64 | """ ? """
65 | self.optimizers = op
66 |
67 | def zero_grad(self):
68 | """ ? """
69 | for op in self.optimizers:
70 | op.zero_grad()
71 |
72 | def step(self):
73 | """ ? """
74 | for op in self.optimizers:
75 | op.step()
76 |
77 | @property
78 | def state(self):
79 | """ ? """
80 | return {k: v for op in self.optimizers for k, v in op.state.items()}
81 |
82 | def state_dict(self):
83 | """ ? """
84 | return [op.state_dict() for op in self.optimizers]
85 |
86 | def load_state_dict(self, state_dicts):
87 | """ ? """
88 | assert len(state_dicts) == len(self.optimizers)
89 | for i in range(len(state_dicts)):
90 | self.optimizers[i].load_state_dict(state_dicts[i])
91 |
92 |
93 | class Optimizer(object):
94 | """
95 | Controller class for optimization. Mostly a thin
96 | wrapper for `optim`, but also useful for implementing
97 | rate scheduling beyond what is currently available.
98 | Also implements necessary methods for training RNNs such
99 | as grad manipulations.
100 |
101 | Args:
102 | method (:obj:`str`): one of [sgd, adagrad, adadelta, adam]
103 | lr (float): learning rate
104 | lr_decay (float, optional): learning rate decay multiplier
105 | start_decay_steps (int, optional): step to start learning rate decay
106 | beta1, beta2 (float, optional): parameters for adam
107 | adagrad_accum (float, optional): initialization parameter for adagrad
108 | decay_method (str, option): custom decay options
109 | warmup_steps (int, option): parameter for `noam` decay
110 | model_size (int, option): parameter for `noam` decay
111 |
112 | We use the default parameters for Adam that are suggested by
113 | the original paper https://arxiv.org/pdf/1412.6980.pdf
114 | These values are also used by other established implementations,
115 | e.g. https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer
116 | https://keras.io/optimizers/
117 | Recently there are slightly different values used in the paper
118 | "Attention is all you need"
119 | https://arxiv.org/pdf/1706.03762.pdf, particularly the value beta2=0.98
120 | was used there however, beta2=0.999 is still arguably the more
121 | established value, so we use that here as well
122 | """
123 |
124 | def __init__(self, method, learning_rate, max_grad_norm,
125 | lr_decay=1, start_decay_steps=None, decay_steps=None,
126 | beta1=0.9, beta2=0.999,
127 | adagrad_accum=0.0,
128 | decay_method=None,
129 | warmup_steps=4000, weight_decay=0):
130 | self.last_ppl = None
131 | self.learning_rate = learning_rate
132 | self.original_lr = learning_rate
133 | self.max_grad_norm = max_grad_norm
134 | self.method = method
135 | self.lr_decay = lr_decay
136 | self.start_decay_steps = start_decay_steps
137 | self.decay_steps = decay_steps
138 | self.start_decay = False
139 | self._step = 0
140 | self.betas = [beta1, beta2]
141 | self.adagrad_accum = adagrad_accum
142 | self.decay_method = decay_method
143 | self.warmup_steps = warmup_steps
144 | self.weight_decay = weight_decay
145 |
146 | def set_parameters(self, params):
147 | """ ? """
148 | self.params = []
149 | self.sparse_params = []
150 | for k, p in params:
151 | if p.requires_grad:
152 | if self.method != 'sparseadam' or "embed" not in k:
153 | self.params.append(p)
154 | else:
155 | self.sparse_params.append(p)
156 | if self.method == 'sgd':
157 | self.optimizer = optim.SGD(self.params, lr=self.learning_rate)
158 | elif self.method == 'adagrad':
159 | self.optimizer = optim.Adagrad(self.params, lr=self.learning_rate)
160 | for group in self.optimizer.param_groups:
161 | for p in group['params']:
162 | self.optimizer.state[p]['sum'] = self.optimizer\
163 | .state[p]['sum'].fill_(self.adagrad_accum)
164 | elif self.method == 'adadelta':
165 | self.optimizer = optim.Adadelta(self.params, lr=self.learning_rate)
166 | elif self.method == 'adam':
167 | self.optimizer = optim.Adam(self.params, lr=self.learning_rate,
168 | betas=self.betas, eps=1e-9)
169 | else:
170 | raise RuntimeError("Invalid optim method: " + self.method)
171 |
172 | def _set_rate(self, learning_rate):
173 | self.learning_rate = learning_rate
174 | if self.method != 'sparseadam':
175 | self.optimizer.param_groups[0]['lr'] = self.learning_rate
176 | else:
177 | for op in self.optimizer.optimizers:
178 | op.param_groups[0]['lr'] = self.learning_rate
179 |
180 | def step(self):
181 | """Update the model parameters based on current gradients.
182 |
183 | Optionally, will employ gradient modification or update learning
184 | rate.
185 | """
186 | self._step += 1
187 |
188 | # Decay method used in tensor2tensor.
189 | if self.decay_method == "noam":
190 | self._set_rate(
191 | self.original_lr *
192 | min(self._step ** (-0.5),
193 | self._step * self.warmup_steps**(-1.5)))
194 |
195 | else:
196 | if ((self.start_decay_steps is not None) and (
197 | self._step >= self.start_decay_steps)):
198 | self.start_decay = True
199 | if self.start_decay:
200 | if ((self._step - self.start_decay_steps)
201 | % self.decay_steps == 0):
202 | self.learning_rate = self.learning_rate * self.lr_decay
203 |
204 | if self.method != 'sparseadam':
205 | self.optimizer.param_groups[0]['lr'] = self.learning_rate
206 |
207 | if self.max_grad_norm:
208 | clip_grad_norm_(self.params, self.max_grad_norm)
209 | self.optimizer.step()
210 |
211 |
212 |
--------------------------------------------------------------------------------
/raw_data/input.txt:
--------------------------------------------------------------------------------
1 | (CNN) Over and over again in 2018, during an apology tour that took him from the halls of the US Congress to an appearance before the European Parliament, Mark Zuckerberg said Facebook had failed to "take a broad enough view of our responsibilities."
2 |
3 | But two years later, Zuckerberg and Facebook are still struggling with their responsibilities and how to handle one of their most famous users: President Donald Trump.
4 |
5 | Despite Zuckerberg having previously indicated any post that "incites violence" would be a line in the sand — even if it came from a politician — Facebook remained silent for hours Friday after Trump was accused of glorifying violence in posts that appeared on its platforms.
6 |
7 | At 12:53am ET on Friday morning, as cable news networks carried images of fires and destructive protests in Minneapolis, the President tweeted : "These THUGS are dishonoring the memory of George Floyd, and I won't let that happen. Just spoke to Governor Tim Walz and told him that the Military is with him all the way. Any difficulty and we will assume control but, when the looting starts, the shooting starts. Thank you!"
8 |
9 | His phrase "when the looting starts, the shooting starts," mirrors language used by a Miami police chief in the late 1960s in the wake of riots. Its use was immediately condemned by a wide array of individuals, from historians to members of rival political campaigns. Former Vice President and presumptive Democratic nominee Joe Biden said Trump was "calling for violence against American citizens during a moment of pain for so many."
10 |
11 | Read More
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | streamlit==0.60.0
2 | numpy==1.17.2
3 | transformers==2.10.0
4 | newspaper3k==0.2.8
5 | https://download.pytorch.org/whl/cpu/torch-1.1.0-cp36-cp36m-linux_x86_64.whl
6 | nltk==3.5
--------------------------------------------------------------------------------
/results/summary.txt:
--------------------------------------------------------------------------------
1 | (CNN) Over and over again in 2018, during an apology tour that took him from the halls of the US Congress to an appearance before the European Parliament, Mark Zuckerberg said Facebook had failed to "take a broad enough view of our responsibilities." But two years later, Zuckerberg and Facebook are still struggling with their responsibilities and how to handle one of their most famous users: President Donald Trump. Despite Zuckerberg having previously indicated any post that "incites violence" would be a line in the sand — even if it came from a politician — Facebook remained silent for hours Friday after Trump was accused of glorifying violence in posts that appeared on its platforms. At 12:53am ET on Friday morning, as cable news networks carried images of fires and destructive protests in Minneapolis, the President tweeted : "These THUGS are dishonoring the memory of George Floyd, and I won't let that happen. Just spoke to Governor Tim Walz and told him that the Military is with him all the way.
2 |
--------------------------------------------------------------------------------
/setup.sh:
--------------------------------------------------------------------------------
1 | mkdir -p ~/.streamlit/
2 |
3 | echo "\
4 | [general]\n\
5 | email = \"your-email@domain.com\"\n\
6 | " > ~/.streamlit/credentials.toml
7 |
8 | echo "\
9 | [server]\n\
10 | headless = true\n\
11 | enableCORS=false\n\
12 | port = $PORT\n\
13 | " > ~/.streamlit/config.toml
--------------------------------------------------------------------------------
/tensorboard.JPG:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/chriskhanhtran/bert-extractive-summarization/d228ba1e63d0c84a86419f55b784844990cb68f5/tensorboard.JPG
--------------------------------------------------------------------------------