├── 2283361.ipynb
├── LICENSE
└── README.md
/2283361.ipynb:
--------------------------------------------------------------------------------
1 | {
2 | "cells": [
3 | {
4 | "cell_type": "markdown",
5 | "metadata": {
6 | "collapsed": false
7 | },
8 | "source": [
9 | "# 项目介绍: 基于PaddleLite的树莓派垃圾检测系统\n",
10 | "\n",
11 | "生活中,垃圾随处可见。道路需要清洁工人们辛苦打扫,并根据一定的规则进行垃圾种类划分。本项目旨在简化该项同类任务中的前置任务,即垃圾智能检测定位与识别,然后搭载小车实现垃圾分类收集。后期,只需要将收集好的垃圾,交于清洁工人们进行简单再分类即可完成路面等地方的垃圾收集分类工作。\n",
12 | "\n",
13 | "------\n",
14 | "\n",
15 | "主要框架:\n",
16 | "\n",
17 | "- `垃圾检测功能`: **采用深度学习的目标检测算法实现**,**PaddleDetection开发**\n",
18 | "\n",
19 | "- `硬件部署`: 采用**树莓派4B**,**32位操作系统**,**PaddleLite开发**\n",
20 | "\n",
21 | "- `硬件协同`: (小车结构在该项目的展示中,暂未说明)"
22 | ]
23 | },
24 | {
25 | "cell_type": "markdown",
26 | "metadata": {
27 | "collapsed": false
28 | },
29 | "source": [
30 | "# 一、基于PPDet开发垃圾检测模型\n",
31 | "\n",
32 | "> PPDet: PaddleDetection为飞桨的官方目标检测套件,可以实现众多目标检测模型的训练。\n",
33 | "\n",
34 | "本项目,基于PPDet开发`PPyolo_r18vd`模型作为垃圾检测项目的深度学习模型,以期望获得视觉中出现的指定垃圾的类别以及相对位置信息,从而辅助目标检测模型的应用。\n",
35 | "\n",
36 | "> 本项目实现的模型,最终落地于`垃圾分拣车`上——`实现垃圾的定位与识别检测,从而进行定位抓取与垃圾识别`。\n",
37 | "\n",
38 | "---------\n",
39 | "\n",
40 | "项目所需`模型要求`如下:\n",
41 | "\n",
42 | "\n",
43 | "1. **模型运行速度**\n",
44 | "\n",
45 | "2. **模型漏检率优先**\n",
46 | "\n",
47 | "3. **模型检测识别精度**\n",
48 | "\n",
49 | "-------\n",
50 | "\n",
51 | "预期`模型选择`: -- `ppyolo_r18_vd` -- , -- `ppyolo_tiny` --\n",
52 | "\n",
53 | "\n",
54 | "| 模型 | 精度(all:%) | 帧率(s) | 漏检率 | 训练成本 |\n",
55 | "| :--------: | :--------: | :--------: | :--------: | :--------: |\n",
56 | "| ppyolo_tiny | 0.5_mAP:95+ | 3-5 | 一般 | 低 |\n",
57 | "| ppyolo_r18_vd | 0.5_mAP:97+ | 1.4-1.6 | 较低 | 低 |\n",
58 | "\n",
59 | "**数据集格式**: COCO/VOC都有尝试, 本项目选用COCO介绍。\n",
60 | "\n",
61 | "> 感兴趣的小伙伴可以观看一个PPDet使用(说明)视频: [PPDet简单使用教程](https://www.bilibili.com/video/BV1vK4y1M728)\n",
62 | "\n",
63 | "> 声音有些小,可能需要带耳机食用~,还望谅解"
64 | ]
65 | },
66 | {
67 | "cell_type": "markdown",
68 | "metadata": {
69 | "collapsed": false
70 | },
71 | "source": [
72 | "## 1.1 解压PPDet套件\n",
73 | "\n",
74 | "> 本项目基于套件本身进行开发,因此需要导入套件包——已挂载到本项目,可直接使用"
75 | ]
76 | },
77 | {
78 | "cell_type": "code",
79 | "execution_count": null,
80 | "metadata": {
81 | "collapsed": false
82 | },
83 | "outputs": [],
84 | "source": [
85 | "# -oq 静默解压\n",
86 | "!unzip -oq data/data99077/PaddleDetection-release-2.1.zip\n",
87 | "!mv PaddleDetection-release-2.1 PaddleDetection"
88 | ]
89 | },
90 | {
91 | "cell_type": "markdown",
92 | "metadata": {
93 | "collapsed": false
94 | },
95 | "source": [
96 | "## 1.2 解压数据集\n",
97 | "\n",
98 | "> 为方便模型开发训练,因此直接解压到套件中的`dataset`目录下,并新建`diy_coco`来保存\n",
99 | "\n",
100 | "**数据集目录:**\n",
101 | "\n",
102 | "- `PaddleDetection`\n",
103 | "\n",
104 | "\t- `dataset`\n",
105 | " \n",
106 | " \t- `diy_coco`\n",
107 | " \n",
108 | " \t- `Train`\n",
109 | " \n",
110 | " \t- `Annotations`: **包含coco格式的标注json文件**\n",
111 | " \n",
112 | " - `Images`: **训练图片**\n",
113 | " \n",
114 | " - `Eval`\n",
115 | " \n",
116 | " - `Annotations`: **包含coco格式的标注json文件**\n",
117 | " \n",
118 | " - `Images`: **验证/评估图片**\n",
119 | " \n",
120 | "-------\n",
121 | " \n",
122 | "**部分数据标注展示:**\n",
123 | "\n",
124 | "\n"
125 | ]
126 | },
127 | {
128 | "cell_type": "code",
129 | "execution_count": null,
130 | "metadata": {
131 | "collapsed": false
132 | },
133 | "outputs": [],
134 | "source": [
135 | "!unzip -oq data/data101886/rubish_det.zip -d PaddleDetection/dataset/diy_coco"
136 | ]
137 | },
138 | {
139 | "cell_type": "markdown",
140 | "metadata": {
141 | "collapsed": false
142 | },
143 | "source": [
144 | "## 1.3 下载环境依赖(包)\n",
145 | "\n",
146 | "> 主要是补充下载pycocotool,这对解析coco数据格式的标注提供很大的帮助"
147 | ]
148 | },
149 | {
150 | "cell_type": "code",
151 | "execution_count": null,
152 | "metadata": {
153 | "collapsed": false
154 | },
155 | "outputs": [],
156 | "source": [
157 | "%cd /home/aistudio/PaddleDetection\r\n",
158 | "!pip install -r requirements.txt"
159 | ]
160 | },
161 | {
162 | "cell_type": "markdown",
163 | "metadata": {
164 | "collapsed": false
165 | },
166 | "source": [
167 | "## 1.4 训练前,明确anchor大小\n",
168 | "\n",
169 | "> 在训练开始前,现在训练数据上,生成一个符合待拟合数据的`anchor`,这将对模型学习合适的特征提供帮助,同时也能更好的框选预测物体的位置!\n",
170 | "\n",
171 | "> 仅限于需要`预置anchor`的模型\n",
172 | "\n",
173 | "不过,再开始生成`anchor`前,需要先配置好`数据集的加载`。\n",
174 | "\n",
175 | "-------\n",
176 | "\n",
177 | "### 1.4.1 配置数据加载yml\n",
178 | "\n",
179 | "因为,本项目的数据格式为coco,因此选择路径: `PaddleDetection/configs/datasets`下的`coco_detection.yml`文件进行修改,使其加载本项目垃圾检测数据!\n",
180 | "\n",
181 | "修改如下:\n",
182 | "\n",
183 | " metric: COCO\n",
184 | " # 修改num_classes为垃圾分类的数量\n",
185 | " num_classes: 5\n",
186 | "\n",
187 | " TrainDataset:\n",
188 | " !COCODataSet\n",
189 | " # 2.再配置图片路径 -- 指向Images文件夹\n",
190 | " image_dir: Images\n",
191 | " # 3.最后配置标注文件的路径 -- 指向Annotations下的json文件\n",
192 | " anno_path: Annotations/train.json\n",
193 | " # 1.先配置数据集目录 -- 先指向Train文件夹\n",
194 | " dataset_dir: dataset/diy_coco/Train\n",
195 | " # end: 这里不同改\n",
196 | " data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']\n",
197 | "\n",
198 | " EvalDataset:\n",
199 | " !COCODataSet\n",
200 | " image_dir: Images\n",
201 | " anno_path: Annotations/val.json\n",
202 | " # 1. 指向另一个文件夹,用于验证评估,其它同上\n",
203 | " dataset_dir: dataset/diy_coco/Eval\n",
204 | "\n",
205 | " TestDataset:\n",
206 | " !ImageFolder\n",
207 | " # 这里的标注配置,设置为验证的json即可\n",
208 | " anno_path: Annotations/val.json"
209 | ]
210 | },
211 | {
212 | "cell_type": "markdown",
213 | "metadata": {
214 | "collapsed": false
215 | },
216 | "source": [
217 | "### 1.4.2 选择参与训练的模型\n",
218 | "\n",
219 | "已经有了配置好的数据加载yml文件,接下来就可以选模型了。\n",
220 | "\n",
221 | "这里选用`PaddleDetection/configs/ppyolo`下的`ppyolo_r18vd_coco.yml`作为项目要训练的模型。\n",
222 | "\n",
223 | "-------\n",
224 | "\n",
225 | "### 1.4.3 生成预置anchor\n",
226 | "\n",
227 | "以上完成了数据加载的配置以及模型的选择之后,我们就可进行预置anchor的自动生成了!\n",
228 | "\n",
229 | "**生成的大致流程:**\n",
230 | "\n",
231 | "1. 启动时,调用`模型yml`进入参数配置,获取`数据集加载的yml`信息\n",
232 | "\n",
233 | "2. 生成时,利用数据集中的`所有已有标注信息`进行anchor的`kmeans聚类`生成一个`anchor集合`\n",
234 | "\n",
235 | "3. 使用时,将生成的anchor收集起来,然后替换模型yml中所有出现anchor列表的地方`即可"
236 | ]
237 | },
238 | {
239 | "cell_type": "code",
240 | "execution_count": null,
241 | "metadata": {
242 | "collapsed": false
243 | },
244 | "outputs": [],
245 | "source": [
246 | "# -n: 模型中需要的anchor数量, r18只需要6个\r\n",
247 | "# -s: 生成anchor集合,适用于多大的输入尺寸 —— 会自动生成指定大小下的anchor集合\r\n",
248 | "# -c: 指定使用这些anchor的模型yml\r\n",
249 | "%cd /home/aistudio/PaddleDetection\r\n",
250 | "!python tools/anchor_cluster.py -n 6 -s 320 -c configs/ppyolo/ppyolo_r18vd_coco.yml"
251 | ]
252 | },
253 | {
254 | "cell_type": "markdown",
255 | "metadata": {
256 | "collapsed": false
257 | },
258 | "source": [
259 | "### 1.4.4 整合生成的anchor,并替换模型的anchor\n",
260 | "\n",
261 | "> 替换anchor的地方,对于r18而言有以下两个地方: `configs/ppyolo/ppyolo_r18vd_coco.yml`, `configs/ppyolo/_base_/ppyolo_r18vd.yml`\n",
262 | "\n",
263 | "------\n",
264 | "\n",
265 | "`ppyolo_r18vd_coco.yml`中的修改如下(**模型yml**):\n",
266 | "\n",
267 | " - Gt2YoloTarget:\n",
268 | " anchor_masks: [[3, 4, 5], [0, 1, 2]]\n",
269 | " # 替换anchor列表为生成的anchor即可\n",
270 | " anchors: [[48, 36], [43, 66], [89, 60], [60, 102], [105, 124], [165, 163]]\n",
271 | " downsample_ratios: [32, 16]\n",
272 | "\n",
273 | "-------\n",
274 | "\n",
275 | "`ppyolo_r18vd.yml`中的修改如下(**模型结构yml**):\n",
276 | "\n",
277 | " YOLOv3Head:\n",
278 | " anchor_masks: [[3, 4, 5], [0, 1, 2]]\n",
279 | " # 替换anchor列表为生成的anchor即可\n",
280 | " anchors: [[48, 36], [43, 66], [89, 60], [60, 102], [105, 124], [165, 163]]\n",
281 | " loss: YOLOv3Loss\n"
282 | ]
283 | },
284 | {
285 | "cell_type": "code",
286 | "execution_count": null,
287 | "metadata": {
288 | "collapsed": false
289 | },
290 | "outputs": [],
291 | "source": [
292 | "create_anchors_list = [[59, 45], [54, 82], [112, 74], [75, 127], [131, 154], [206, 204]]"
293 | ]
294 | },
295 | {
296 | "cell_type": "markdown",
297 | "metadata": {
298 | "collapsed": false
299 | },
300 | "source": [
301 | "## 1.5 配置训练参数\n",
302 | "\n",
303 | "> 对于r18而言,训练参数的修改只需要在 `configs/ppyolo/ppyolo_r18vd_coco.yml`中修改即可\n",
304 | "\n",
305 | "**主要参数修改如下**:\n",
306 | "\n",
307 | " TrainReader:\n",
308 | " sample_transforms:\n",
309 | " ...\n",
310 | " batch_transforms:\n",
311 | " - BatchRandomResize:\n",
312 | " \t # 原始大小的list对应输入大小为520的预测,现改为320之后,简要修改的这个区间\n",
313 | " # 修改注意事项,每个大小都是32的倍数\n",
314 | " target_size: [224, 256, 288, 320, 352, 384, 416, 448]\n",
315 | "\t\t\t...\n",
316 | " - Gt2YoloTarget:\n",
317 | " anchor_masks: [[3, 4, 5], [0, 1, 2]]\n",
318 | " # 替换为生成的anchor\n",
319 | " anchors: [[48, 36], [43, 66], [89, 60], [60, 102], [105, 124], [165, 163]]\n",
320 | " downsample_ratios: [32, 16]\n",
321 | " # 根据数据集情况,适当修改即可: 8/16/24/32/48\n",
322 | " batch_size: 32\n",
323 | " mixup_epoch: 500\n",
324 | " shuffle: true\n",
325 | " \n",
326 | " \n",
327 | " EvalReader:\n",
328 | " sample_transforms:\n",
329 | " - Decode: {}\n",
330 | " # target_size改为320\n",
331 | " - Resize: {target_size: [320, 320], keep_ratio: False, interp: 2}\n",
332 | "\t\t\t...\n",
333 | "\n",
334 | " TestReader:\n",
335 | " inputs_def:\n",
336 | " \t # 改为320\n",
337 | " image_shape: [3, 320, 320]\n",
338 | " sample_transforms:\n",
339 | " - Decode: {}\n",
340 | " # 改为320\n",
341 | " - Resize: {target_size: [320, 320], keep_ratio: False, interp: 2}\n",
342 | "\t\t\t...\n",
343 | "\n",
344 | " LearningRate:\n",
345 | " \t# 原4卡下训练参数,除以4,用于单卡训练\n",
346 | " # 0.004 / 4 == 0.001\n",
347 | " base_lr: 0.001\n",
348 | "\t\t..."
349 | ]
350 | },
351 | {
352 | "cell_type": "code",
353 | "execution_count": 1,
354 | "metadata": {
355 | "collapsed": false
356 | },
357 | "outputs": [],
358 | "source": [
359 | "%cd /home/aistudio/PaddleDetection\r\n",
360 | "!python tools/train.py\\\r\n",
361 | "-c configs/ppyolo/ppyolo_r18vd_coco.yml\\\r\n",
362 | "--eval\\\r\n",
363 | "--use_vdl True"
364 | ]
365 | },
366 | {
367 | "cell_type": "markdown",
368 | "metadata": {
369 | "collapsed": false
370 | },
371 | "source": [
372 | " [08/14 21:03:03] ppdet.engine INFO: Epoch: [196] [20/46] learning_rate: 0.000100 loss_xy: 0.773786 loss_wh: 0.697323 loss_iou: 2.933347 loss_obj: 3.114668 loss_cls: 0.885066 loss: 8.543031 eta: 0:27:02 batch_cost: 0.4652 data_cost: 0.2992 ips: 68.7832 images/s\n",
373 | " [08/14 21:03:12] ppdet.engine INFO: Epoch: [196] [40/46] learning_rate: 0.000100 loss_xy: 0.757029 loss_wh: 0.656280 loss_iou: 2.774072 loss_obj: 3.072931 loss_cls: 0.949183 loss: 8.486620 eta: 0:26:52 batch_cost: 0.4206 data_cost: 0.2787 ips: 76.0866 images/s\n",
374 | " [08/14 21:03:17] ppdet.engine INFO: Epoch: [197] [ 0/46] learning_rate: 0.000100 loss_xy: 0.758142 loss_wh: 0.664071 loss_iou: 2.743285 loss_obj: 3.071552 loss_cls: 1.033830 loss: 8.424139 eta: 0:26:50 batch_cost: 0.4621 data_cost: 0.3208 ips: 69.2533 images/s\n",
375 | " [08/14 21:03:26] ppdet.engine INFO: Epoch: [197] [20/46] learning_rate: 0.000100 loss_xy: 0.736949 loss_wh: 0.639424 loss_iou: 2.764338 loss_obj: 3.022928 loss_cls: 1.026918 loss: 8.329489 eta: 0:26:40 batch_cost: 0.4258 data_cost: 0.2777 ips: 75.1583 images/s\n",
376 | " [08/14 21:03:36] ppdet.engine INFO: Epoch: [197] [40/46] learning_rate: 0.000100 loss_xy: 0.728324 loss_wh: 0.671651 loss_iou: 2.920363 loss_obj: 3.044627 loss_cls: 0.976078 loss: 8.474413 eta: 0:26:30 batch_cost: 0.4600 data_cost: 0.3220 ips: 69.5716 images/s\n",
377 | " [08/14 21:03:40] ppdet.engine INFO: Epoch: [198] [ 0/46] learning_rate: 0.000100 loss_xy: 0.748800 loss_wh: 0.663416 loss_iou: 2.903050 loss_obj: 3.142794 loss_cls: 0.995665 loss: 8.490379 eta: 0:26:27 batch_cost: 0.5249 data_cost: 0.3624 ips: 60.9593 images/s\n",
378 | " [08/14 21:03:50] ppdet.engine INFO: Epoch: [198] [20/46] learning_rate: 0.000100 loss_xy: 0.804090 loss_wh: 0.638163 loss_iou: 2.821011 loss_obj: 3.293034 loss_cls: 0.950222 loss: 8.611068 eta: 0:26:17 batch_cost: 0.4455 data_cost: 0.2798 ips: 71.8259 images/s\n",
379 | " [08/14 21:03:59] ppdet.engine INFO: Epoch: [198] [40/46] learning_rate: 0.000100 loss_xy: 0.729478 loss_wh: 0.671696 loss_iou: 2.855099 loss_obj: 2.954676 loss_cls: 1.013126 loss: 8.109439 eta: 0:26:08 batch_cost: 0.4445 data_cost: 0.3092 ips: 71.9917 images/s\n",
380 | " [08/14 21:04:04] ppdet.engine INFO: Epoch: [199] [ 0/46] learning_rate: 0.000100 loss_xy: 0.729086 loss_wh: 0.640540 loss_iou: 2.748984 loss_obj: 3.005687 loss_cls: 0.877229 loss: 7.902369 eta: 0:26:05 batch_cost: 0.5034 data_cost: 0.3502 ips: 63.5677 images/s\n",
381 | " [08/14 21:04:14] ppdet.engine INFO: Epoch: [199] [20/46] learning_rate: 0.000100 loss_xy: 0.763439 loss_wh: 0.640906 loss_iou: 2.689836 loss_obj: 3.238860 loss_cls: 0.929343 loss: 8.205533 eta: 0:25:56 batch_cost: 0.4675 data_cost: 0.2824 ips: 68.4485 images/s\n",
382 | " [08/14 21:04:24] ppdet.engine INFO: Epoch: [199] [40/46] learning_rate: 0.000100 loss_xy: 0.757755 loss_wh: 0.720121 loss_iou: 2.960909 loss_obj: 3.277584 loss_cls: 0.926977 loss: 8.504792 eta: 0:25:46 batch_cost: 0.4711 data_cost: 0.3046 ips: 67.9259 images/s\n",
383 | " [08/14 21:04:27] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyolo_r18vd_coco\n",
384 | " [08/14 21:04:27] ppdet.engine INFO: Eval iter: 0\n",
385 | " [08/14 21:04:32] ppdet.metrics.metrics INFO: The bbox result is saved to bbox.json.\n",
386 | " loading annotations into memory...\n",
387 | " Done (t=0.01s)\n",
388 | " creating index...\n",
389 | " index created!\n",
390 | " [08/14 21:04:32] ppdet.metrics.coco_utils INFO: Start evaluate...\n",
391 | " Loading and preparing results...\n",
392 | " DONE (t=0.12s)\n",
393 | " creating index...\n",
394 | " index created!\n",
395 | " Running per image evaluation...\n",
396 | " Evaluate annotation type *bbox*\n",
397 | " DONE (t=1.27s).\n",
398 | " Accumulating evaluation results...\n",
399 | " DONE (t=0.19s).\n",
400 | " Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.667\n",
401 | " Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.960\n",
402 | " Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.836\n",
403 | " Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.771\n",
404 | " Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000\n",
405 | " Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000\n",
406 | " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.394\n",
407 | " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.764\n",
408 | " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.776\n",
409 | " Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.776\n",
410 | " Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000\n",
411 | " Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000\n",
412 | " [08/14 21:04:34] ppdet.engine INFO: Total sample number: 636, averge FPS: 141.8495250691227\n",
413 | " [08/14 21:04:34] ppdet.engine INFO: Best test bbox ap is 0.668."
414 | ]
415 | },
416 | {
417 | "cell_type": "markdown",
418 | "metadata": {
419 | "collapsed": false
420 | },
421 | "source": [
422 | "## 1.6 模型导出\n",
423 | "\n",
424 | "将模型导出,并且打开`--export_serving_model`,适当能够生成`__model__`, `__params__`格式的模型与参数文件\n",
425 | "\n",
426 | "> 导出前, 需要前往: `configs/ppyolo/_base_/ppyolo_r18vd.yml`这个模型结构文件中,注释掉: `pretrain_weights`后再进行模型导出\n",
427 | "\n",
428 | "如下:\n",
429 | "\n",
430 | " architecture: YOLOv3\n",
431 | " # pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/ResNet18_vd_pretrained.pdparams\n",
432 | " norm_type: sync_bn\n",
433 | " use_ema: true\n",
434 | " ema_decay: 0.9998"
435 | ]
436 | },
437 | {
438 | "cell_type": "code",
439 | "execution_count": 5,
440 | "metadata": {
441 | "collapsed": false
442 | },
443 | "outputs": [],
444 | "source": [
445 | "# --export_serving_model指令下需要下载该依赖\r\n",
446 | "!pip install paddle-serving-client"
447 | ]
448 | },
449 | {
450 | "cell_type": "code",
451 | "execution_count": 6,
452 | "metadata": {
453 | "collapsed": false
454 | },
455 | "outputs": [
456 | {
457 | "name": "stdout",
458 | "output_type": "stream",
459 | "text": [
460 | "/home/aistudio/PaddleDetection\n",
461 | "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working\n",
462 | " from collections import MutableMapping\n",
463 | "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working\n",
464 | " from collections import Iterable, Mapping\n",
465 | "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working\n",
466 | " from collections import Sized\n",
467 | "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. \n",
468 | "Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\n",
469 | " if data.dtype == np.object:\n",
470 | "[08/14 21:29:42] ppdet.utils.checkpoint INFO: Finish loading model weights: output/ppyolo_r18vd_coco/best_model.pdparams\n",
471 | "[08/14 21:29:42] ppdet.engine INFO: Export inference config file to /home/aistudio/export_model/ppyolo_r18vd_coco/infer_cfg.yml\n",
472 | "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working\n",
473 | " return (isinstance(seq, collections.Sequence) and\n",
474 | "W0814 21:29:44.067077 20354 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1\n",
475 | "W0814 21:29:44.067139 20354 device_context.cc:422] device: 0, cuDNN Version: 7.6.\n",
476 | "[08/14 21:29:47] ppdet.engine INFO: Export model and saved in /home/aistudio/export_model/ppyolo_r18vd_coco\n"
477 | ]
478 | }
479 | ],
480 | "source": [
481 | "%cd /home/aistudio/PaddleDetection\r\n",
482 | "!python tools/export_model.py\\\r\n",
483 | "-c configs/ppyolo/ppyolo_r18vd_coco.yml\\\r\n",
484 | "-o weights='output/ppyolo_r18vd_coco/best_model'\\\r\n",
485 | "--output_dir '/home/aistudio/export_model'\\\r\n",
486 | "--export_serving_model True"
487 | ]
488 | },
489 | {
490 | "cell_type": "code",
491 | "execution_count": 11,
492 | "metadata": {
493 | "collapsed": false
494 | },
495 | "outputs": [
496 | {
497 | "name": "stdout",
498 | "output_type": "stream",
499 | "text": [
500 | "/home/aistudio/export_model\r\n",
501 | "└── ppyolo_r18vd_coco\r\n",
502 | " ├── infer_cfg.yml\r\n",
503 | " ├── model.pdiparams\r\n",
504 | " ├── model.pdiparams.info\r\n",
505 | " ├── model.pdmodel\r\n",
506 | " ├── serving_client\r\n",
507 | " │ ├── serving_client_conf.prototxt\r\n",
508 | " │ └── serving_client_conf.stream.prototxt\r\n",
509 | " └── serving_server\r\n",
510 | " ├── __model__\r\n",
511 | " ├── __params__\r\n",
512 | " ├── serving_server_conf.prototxt\r\n",
513 | " └── serving_server_conf.stream.prototxt\r\n",
514 | "\r\n",
515 | "3 directories, 10 files\r\n"
516 | ]
517 | }
518 | ],
519 | "source": [
520 | "# 查看输出结构\r\n",
521 | "!tree /home/aistudio/export_model -L 3"
522 | ]
523 | },
524 | {
525 | "cell_type": "markdown",
526 | "metadata": {
527 | "collapsed": false
528 | },
529 | "source": [
530 | "部署需要的内容主要有以下两种\n",
531 | "\n",
532 | "- `*.pdmodel` + `*.pdiparams`\n",
533 | "\n",
534 | "- `__model__` + `__params__`\n",
535 | "\n",
536 | "> 其它可能需要的资料(PaddleLite不直接用,可以作为加载的一些预处理参数的参考): `infer_cfg.yml`, `serving_server_conf.prototxt`"
537 | ]
538 | },
539 | {
540 | "cell_type": "markdown",
541 | "metadata": {
542 | "collapsed": false
543 | },
544 | "source": [
545 | "## 1.7 模型导出再windows端的部署效果检测\n",
546 | "\n",
547 | "利用可视化推理验收模型效果:\n",
548 | "\n",
549 | "- **图片推理效果**\n",
550 | "\n",
551 | "\n",
552 | "\n",
553 | "\n",
554 | "\n",
555 | "- **视频推理效果**\n",
556 | "\n",
557 | "\n",
558 | "\n",
559 | "\n"
560 | ]
561 | },
562 | {
563 | "cell_type": "markdown",
564 | "metadata": {
565 | "collapsed": false
566 | },
567 | "source": [
568 | "# 二、基于PPLite实现树莓派端部署\n",
569 | "\n",
570 | "本项目训练的模型部署到树莓派4B上进行应用,能够实现较为快速准确的垃圾检测!\n",
571 | "\n",
572 | "> 部署说明与部分检测(展示为tiny的效果, 部署代码通用)的效果可以观看视频: [树莓派部署教程与效果展示](https://www.bilibili.com/video/BV1ph411r718?p=4)\n",
573 | "\n",
574 | "部分效果:\n",
575 | "\n",
576 | "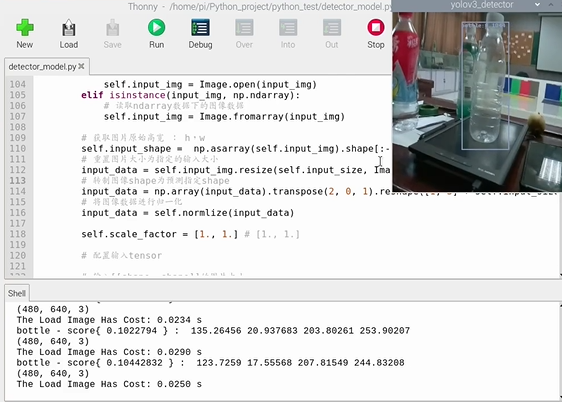\n"
577 | ]
578 | },
579 | {
580 | "cell_type": "markdown",
581 | "metadata": {
582 | "collapsed": false
583 | },
584 | "source": [
585 | "## 2.1 PaddleLite的python包安装\n",
586 | "\n",
587 | "如果使用32位的操作系统,可以直接使用我编译好的whl(使用与Python3)\n",
588 | "\n",
589 | "链接:[https://pan.baidu.com/s/1pmULmyNokBcG7EQz2gKWCg](https://pan.baidu.com/s/1pmULmyNokBcG7EQz2gKWCg)\n",
590 | "\n",
591 | "提取码:plit\n",
592 | "\n",
593 | "------\n",
594 | "\n",
595 | "下载好后,上传到树莓派即可 —— 推荐使用`vnc远程服务`的文件传递功能。\n",
596 | "\n",
597 | "------\n",
598 | "\n",
599 | "安装指令:\n",
600 | "\n",
601 | "`python3 -m pip install whl_path`"
602 | ]
603 | },
604 | {
605 | "cell_type": "markdown",
606 | "metadata": {
607 | "collapsed": false
608 | },
609 | "source": [
610 | "## 2.2 部署流程\n",
611 | "\n",
612 | "- 1. 先使用`paddlelite包`中的`opt`这个API实现模型的转换,获取`nb格式`的文件\n",
613 | "\n",
614 | "- 2. 然后使用以下代码进行`模型加载`即可进行模型推理"
615 | ]
616 | },
617 | {
618 | "cell_type": "markdown",
619 | "metadata": {
620 | "collapsed": false
621 | },
622 | "source": [
623 | "## 2.3 部署代码\n",
624 | "\n",
625 | "主要处理\n",
626 | "\n",
627 | "- 加载模型,并输出加载时间 `__init__`\n",
628 | "\n",
629 | "- 获取输入数据,配置模型输入 -- `get_input_img`\n",
630 | "\n",
631 | " - **注意不同模型的输入数据**\n",
632 | " \n",
633 | "- 获取绘制好框的图像结果 -- `get_output_img`\n",
634 | "\n",
635 | "\n",
636 | "> 部署代码,来自个人项目: [PPYolo-Tiny树莓派部署实践(一)](https://aistudio.baidu.com/aistudio/projectdetail/2047562)\n",
637 | "\n",
638 | "> 一些注意事项,可以看下面的代码,可以观看树莓派部署视频!"
639 | ]
640 | },
641 | {
642 | "cell_type": "code",
643 | "execution_count": null,
644 | "metadata": {
645 | "collapsed": false
646 | },
647 | "outputs": [],
648 | "source": [
649 | "from paddlelite.lite import *\r\n",
650 | "import cv2 as cv\r\n",
651 | "import numpy as np\r\n",
652 | "from matplotlib import pyplot as plt\r\n",
653 | "from time import time\r\n",
654 | "from PIL import Image\r\n",
655 | "from PIL import ImageFont\r\n",
656 | "from PIL import ImageDraw\r\n",
657 | "from PIL import ImageEnhance\r\n",
658 | "\r\n",
659 | "class PPYOLO_Detector(object):\r\n",
660 | " \r\n",
661 | " def __init__(self, nb_path = None, # nb路径\r\n",
662 | " label_list = None, # 类别list\r\n",
663 | " input_size = [320, 320], # 输入图像大小\r\n",
664 | " img_means = [0., 0., 0.], # 图片归一化均值\r\n",
665 | " img_stds = [0., 0., 0.], # 图片归一化方差\r\n",
666 | " threshold = 0.1, # 预测阈值\r\n",
667 | " num_thread = 1, # ARM CPU工作线程数\r\n",
668 | " work_power_mode = PowerMode.LITE_POWER_NO_BIND # ARM CPU工作模式\r\n",
669 | " ):\r\n",
670 | " \r\n",
671 | " # 验证必要的参数格式\r\n",
672 | " assert nb_path is not None, \\\r\n",
673 | " \"Please make sure the model_nb_path has inputed!(now, nb_path is None.)\"\r\n",
674 | " assert len(input_size) == 2, \\\r\n",
675 | " \"Please make sure the input_shape length is 2, but now its length is {0}\".format(len(input_size))\r\n",
676 | " assert len(img_means) == 3, \\\r\n",
677 | " \"Please make sure the image_means shape is [3], but now get image_means' shape is [{0}]\".format(len(img_means))\r\n",
678 | " assert len(img_stds) == 3, \\\r\n",
679 | " \"Please make sure the image_stds shape is [3], but now get image_stds' shape is [{0}]\".format(len(img_stds))\r\n",
680 | " assert len([i for i in img_stds if i <= 0]) < 1, \\\r\n",
681 | " \"Please make sure the image_stds data is more than 0., but now get image_stds' data exists less than or equal 0.\"\r\n",
682 | " assert threshold > 0. and threshold < 1., \\\r\n",
683 | " \"Please make sure the threshold value > 0. and < 1., but now get its value is {0}\".format(threshold)\r\n",
684 | " assert num_thread > 0 and num_thread <= 4, \\\r\n",
685 | " \"Please make sure the num_thread value > 1 and <= 4., but now get its value is {0}\".format(num_thread)\r\n",
686 | " assert work_power_mode in [PowerMode.LITE_POWER_HIGH, PowerMode.LITE_POWER_LOW,\r\n",
687 | " PowerMode.LITE_POWER_FULL, PowerMode.LITE_POWER_NO_BIND,\r\n",
688 | " PowerMode.LITE_POWER_RAND_HIGH,\r\n",
689 | " PowerMode.LITE_POWER_RAND_LOW], \\\r\n",
690 | " \"Please make sure the work_power_mode is allowed , which is in \\\r\n",
691 | " [PowerMode.LITE_POWER_HIGH, PowerMode.LITE_POWER_LOW, \\\r\n",
692 | " PowerMode.LITE_POWER_FULL, PowerMode.LITE_POWER_NO_BIND, \\\r\n",
693 | " PowerMode.LITE_POWER_RAND_HIGH, \\\r\n",
694 | " PowerMode.LITE_POWER_RAND_LOW], \\\r\n",
695 | " but now get its value is {0}\"\r\n",
696 | " \r\n",
697 | " # 模型nb文件路径\r\n",
698 | " self.model_path = nb_path\r\n",
699 | " # ARM CPU工作线程数\r\n",
700 | " self.num_thread = num_thread\r\n",
701 | " # ARM CPU工作模式\r\n",
702 | " self.power_mode = work_power_mode\r\n",
703 | " \r\n",
704 | " # 预测显示阈值\r\n",
705 | " self.threshold = threshold\r\n",
706 | " # 预测输入图像大小\r\n",
707 | " self.input_size = input_size\r\n",
708 | " # 图片归一化参数\r\n",
709 | " # 均值\r\n",
710 | " self.img_means = img_means\r\n",
711 | " # 方差\r\n",
712 | " self.img_stds = img_stds\r\n",
713 | " \r\n",
714 | " # 预测类别list\r\n",
715 | " self.label_list = label_list\r\n",
716 | " # 预测类别数\r\n",
717 | " self.num_class = len(label_list) if (label_list is not None) and isinstance(label_list, list) else 1\r\n",
718 | " # 类别框颜色map\r\n",
719 | " self.box_color_map = self.random_colormap()\r\n",
720 | " \r\n",
721 | " # 记录模型加载参数的开始时间\r\n",
722 | " self.prepare_time = self.runtime()\r\n",
723 | " \r\n",
724 | " # 配置预测\r\n",
725 | " self.config = MobileConfig()\r\n",
726 | " # 设置模型路径\r\n",
727 | " self.config.set_model_from_file(nb_path)\r\n",
728 | " # 设置线程数\r\n",
729 | " self.config.set_threads(num_thread)\r\n",
730 | " # 设置工作模式\r\n",
731 | " self.config.set_power_mode(work_power_mode)\r\n",
732 | " # 构建预测器\r\n",
733 | " self.predictor = create_paddle_predictor(self.config)\r\n",
734 | " \r\n",
735 | " # 模型加载参数的总时间花销\r\n",
736 | " self.prepare_time = self.runtime() - self.prepare_time\r\n",
737 | " print(\"The Prepare Model Has Cost: {0:.4f} s\".format(self.prepare_time))\r\n",
738 | " \r\n",
739 | " \r\n",
740 | " def get_input_img(self, input_img):\r\n",
741 | " '''输入预测图片\r\n",
742 | " input_img: 图片路径或者np.ndarray图像数据 - [h, w, c]\r\n",
743 | " '''\r\n",
744 | " assert isinstance(input_img, str) or isinstance(input_img, np.ndarray), \\\r\n",
745 | " \"Please enter input is Image Path or numpy.ndarray, but get ({0}) \".format(input_img)\r\n",
746 | " \r\n",
747 | " # 装载图像到预测器上的开始时间\r\n",
748 | " self.load_img_time = self.runtime()\r\n",
749 | " \r\n",
750 | " if isinstance(input_img, str):\r\n",
751 | " # 读取图片路径下的图像数据\r\n",
752 | " self.input_img = Image.open(input_img)\r\n",
753 | " elif isinstance(input_img, np.ndarray):\r\n",
754 | " # 读取ndarray数据下的图像数据\r\n",
755 | " self.input_img = Image.fromarray(input_img)\r\n",
756 | " \r\n",
757 | " # 获取图片原始高宽 : h,w\r\n",
758 | " self.input_shape = np.asarray(self.input_img).shape[:-1]\r\n",
759 | " # 重置图片大小为指定的输入大小\r\n",
760 | " input_data = self.input_img.resize(self.input_size, Image.BILINEAR)\r\n",
761 | " # 转制图像shape为预测指定shape\r\n",
762 | " input_data = np.array(input_data).transpose(2, 0, 1).reshape([1, 3] + self.input_size).astype('float32')\r\n",
763 | " # 将图像数据进行归一化\r\n",
764 | " input_data = self.normlize(input_data)\r\n",
765 | " \r\n",
766 | " self.scale_factor = [1., 1.] # [1., 1.]\r\n",
767 | " \r\n",
768 | " # 配置输入tensor\r\n",
769 | " \r\n",
770 | " # 输入[[shape, shape]]的图片大小\r\n",
771 | " self.input_tensor0 = self.predictor.get_input(0)\r\n",
772 | " self.input_tensor0.from_numpy(np.asarray([self.input_size], dtype=np.int32))\r\n",
773 | " \r\n",
774 | " # 输入[1, 3, shape, shape]的归一化后的图片数据\r\n",
775 | " self.input_tensor1 = self.predictor.get_input(1)\r\n",
776 | " self.input_tensor1.from_numpy(input_data)\r\n",
777 | " \r\n",
778 | " # 输入模型处理图像大小与实际图像大小的比例\r\n",
779 | " self.input_tensor2 = self.predictor.get_input(2)\r\n",
780 | " self.input_tensor2.from_numpy(np.asarray(self.scale_factor, dtype=np.int32))\r\n",
781 | " \r\n",
782 | " # 装载图像到预测器上的总时间花销\r\n",
783 | " self.load_img_time = self.runtime() - self.load_img_time\r\n",
784 | " print(\"The Load Image Has Cost: {0:.4f} s\".format(self.load_img_time))\r\n",
785 | " \r\n",
786 | " def get_output_img(self, num_bbox=1):\r\n",
787 | " '''获取输出标注图片\r\n",
788 | " num_bbox: 最大标注个数\r\n",
789 | " '''\r\n",
790 | " \r\n",
791 | " # 预测器开始预测的时间\r\n",
792 | " self.predict_time = self.runtime()\r\n",
793 | " \r\n",
794 | " # 根据get_input_img的图像进行预测\r\n",
795 | " self.predictor.run()\r\n",
796 | " # 获取输出预测bbox结果\r\n",
797 | " self.output_tensor = self.predictor.get_output(0)\r\n",
798 | " \r\n",
799 | " # 转化为numpy格式\r\n",
800 | " output_bboxes = self.output_tensor.numpy()\r\n",
801 | " # 根据阈值进行筛选,大于等于阈值的保留\r\n",
802 | " output_bboxes = output_bboxes[output_bboxes[:, 1] >= self.threshold]\r\n",
803 | " \r\n",
804 | " # 根据预测结果进行框绘制,返回绘制完成的图片\r\n",
805 | " self.output_img = self.load_bbox(output_bboxes, num_bbox)\r\n",
806 | " \r\n",
807 | " # 预测器预测的总时间花销\r\n",
808 | " self.predict_time = self.runtime() - self.predict_time\r\n",
809 | " print(\"The Predict Image Has Cost: {0:.4f} s\".format(self.predict_time))\r\n",
810 | " \r\n",
811 | " return self.output_img\r\n",
812 | " \r\n",
813 | " \r\n",
814 | " def normlize(self, input_img):\r\n",
815 | " '''数据归一化\r\n",
816 | " input_img: 图像数据--numpy.ndarray\r\n",
817 | " '''\r\n",
818 | " # 对RGB通道进行均值-方差的归一化\r\n",
819 | " input_img[0, 0] = (input_img[0, 0] / 255. - self.img_means[0]) / self.img_stds[0]\r\n",
820 | " input_img[0, 1] = (input_img[0, 1] / 255. - self.img_means[1]) / self.img_stds[1]\r\n",
821 | " input_img[0, 2] = (input_img[0, 2] / 255. - self.img_means[2]) / self.img_stds[2]\r\n",
822 | " \r\n",
823 | " return input_img\r\n",
824 | " \r\n",
825 | " \r\n",
826 | " def load_bbox(self, input_bboxs, num_bbox):\r\n",
827 | " '''根据预测框在原始图片上绘制框体,并标注\r\n",
828 | " input_bboxs: 预测框\r\n",
829 | " num_bbox: 允许的标注个数\r\n",
830 | " '''\r\n",
831 | " # 创建间绘图参数:[cls_id, score, x1, y1, x2, y2]\r\n",
832 | " self.draw_bboxs = [0] * 6\r\n",
833 | " # 绘图器 -- 根据get_input_img的输入图像\r\n",
834 | " draw = ImageDraw.Draw(self.input_img)\r\n",
835 | " # 根据最大标注个数进行实际标注个数的确定\r\n",
836 | " # input_bboxs.shape[0]: 表示预测到的有效框个数\r\n",
837 | " if len(input_bboxs) != 0: # 存在有效框时\r\n",
838 | " num_bbox = input_bboxs.shape[0] if num_bbox > input_bboxs.shape[0] else num_bbox\r\n",
839 | " else:\r\n",
840 | " num_bbox = 0 # 没有有效框,直接不标注\r\n",
841 | " \r\n",
842 | " # 遍历框体,并进行标注\r\n",
843 | " for i in range(num_bbox):\r\n",
844 | " # 类别信息\r\n",
845 | " self.draw_bboxs[0] = input_bboxs[i][0]\r\n",
846 | " # 类别得分\r\n",
847 | " self.draw_bboxs[1] = input_bboxs[i][1]\r\n",
848 | " \r\n",
849 | " print(self.label_list[int(self.draw_bboxs[0])], '- score{', self.draw_bboxs[1], \"} : \", input_bboxs[i][2], input_bboxs[i][3], input_bboxs[i][4], input_bboxs[i][5])\r\n",
850 | " \r\n",
851 | " # 框体左上角坐标\r\n",
852 | " # max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.):保证当前预测坐标始终在图像内(比例,0.-1.)\r\n",
853 | " # max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.) * self.input_shape[1]: 直接预测得到的坐标\r\n",
854 | " # min(max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.) * self.input_shape[1], self.input_shape[1]):保证坐标在图像内(h, w)\r\n",
855 | " self.draw_bboxs[2] = min(max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.) * self.input_shape[1], self.input_shape[1])\r\n",
856 | " self.draw_bboxs[3] = min(max(min(input_bboxs[i][3] / self.input_size[1], 1.), 0.) * self.input_shape[0], self.input_shape[0])\r\n",
857 | " # 框体右下角坐标\r\n",
858 | " self.draw_bboxs[4] = min(max(min(input_bboxs[i][4] / self.input_size[0], 1.), 0.) * self.input_shape[1], self.input_shape[1])\r\n",
859 | " self.draw_bboxs[5] = min(max(min(input_bboxs[i][5] / self.input_size[1], 1.), 0.) * self.input_shape[0], self.input_shape[0])\r\n",
860 | " \r\n",
861 | " # print(self.draw_bboxs[2], self.draw_bboxs[3], self.draw_bboxs[4], self.draw_bboxs[5])\r\n",
862 | " \r\n",
863 | " # 绘制框体\r\n",
864 | " # self.box_color_map[int(self.draw_bboxs[i][0])]: 对应类别的框颜色\r\n",
865 | " draw.rectangle(((self.draw_bboxs[2], self.draw_bboxs[3]),\r\n",
866 | " (self.draw_bboxs[4], self.draw_bboxs[5])),\r\n",
867 | " outline = tuple(self.box_color_map[int(self.draw_bboxs[0])]),\r\n",
868 | " width =2)\r\n",
869 | " # 框体位置写上类别和得分信息\r\n",
870 | " draw.text((self.draw_bboxs[2], self.draw_bboxs[3]+1),\r\n",
871 | " \"{0}:{1:.4f}\".format(self.label_list[int(self.draw_bboxs[0])], self.draw_bboxs[1]),\r\n",
872 | " tuple(self.box_color_map[int(self.draw_bboxs[0])]))\r\n",
873 | " \r\n",
874 | " # 返回标注好的图像数据\r\n",
875 | " return np.asarray(self.input_img)\r\n",
876 | " \r\n",
877 | " def random_colormap(self):\r\n",
878 | " '''获取与类别数量等量的color_map\r\n",
879 | " '''\r\n",
880 | " np.random.seed(2021)\r\n",
881 | " \r\n",
882 | " color_map = [[np.random.randint(20, 255),\r\n",
883 | " np.random.randint(64, 200),\r\n",
884 | " np.random.randint(128, 255)]\r\n",
885 | " for i in range(self.num_class)]\r\n",
886 | " \r\n",
887 | " return color_map\r\n",
888 | " \r\n",
889 | " def runtime(self):\r\n",
890 | " '''返回当前计时\r\n",
891 | " '''\r\n",
892 | " return time()"
893 | ]
894 | },
895 | {
896 | "cell_type": "markdown",
897 | "metadata": {
898 | "collapsed": false
899 | },
900 | "source": [
901 | "## 2.4 部署测试代码片段\n",
902 | "\n",
903 | "> 有需要的小伙伴,可以搭载串口通信,实现树莓派与单片机直接的通信哦!"
904 | ]
905 | },
906 | {
907 | "cell_type": "code",
908 | "execution_count": null,
909 | "metadata": {
910 | "collapsed": false
911 | },
912 | "outputs": [],
913 | "source": [
914 | "def test():\r\n",
915 | " \r\n",
916 | " model_path = \"/home/pi/test/ppyolo_tiny/ppyolo_tiny.nb\" # 模型参数nb文件 -- 自行修改\r\n",
917 | " img_path = \"/home/pi/Desktop/citrus_0005.jpg\" # 自己的预测图像\r\n",
918 | " \r\n",
919 | " label_list = ['bottle', 'battery', 'cup', 'paper', 'citrus'] # 类别list\r\n",
920 | " input_size = [224, 224] # 输入图像大小\r\n",
921 | " img_means = [0.485, 0.456, 0.406] # 图片归一化均值\r\n",
922 | " img_stds = [0.229, 0.224, 0.225] # 图片归一化方差\r\n",
923 | " threshold = 0.1 # 预测阈值\r\n",
924 | " num_thread = 2 # ARM CPU工作线程数\r\n",
925 | " work_mode = PowerMode.LITE_POWER_NO_BIND # ARM CPU工作模式\r\n",
926 | " max_bbox_num = 1 # 每帧最多标注数\r\n",
927 | " \r\n",
928 | " \r\n",
929 | " # 创建预测器\r\n",
930 | " detector = PPYOLO_Detector(\r\n",
931 | " nb_path = model_path, \r\n",
932 | " label_list = label_list, \r\n",
933 | " input_size = input_size, \r\n",
934 | " img_means = img_means, \r\n",
935 | " img_stds = img_stds, \r\n",
936 | " threshold = threshold, \r\n",
937 | " num_thread = num_thread, \r\n",
938 | " work_power_mode = PowerMode.LITE_POWER_NO_BIND \r\n",
939 | " )\r\n",
940 | " \r\n",
941 | " img = plt.imread(img_path)\r\n",
942 | " img = cv.resize(img,(320, 320)) # 与训练时配置的大小一致\r\n",
943 | " detector.get_input_img(img) # 输入图片数据\r\n",
944 | " img = detector.get_output_img(num_bbox = max_bbox_num) # 得到预测输出后绘制了框的图像\r\n",
945 | " plt.imshow(img)\r\n",
946 | " plt.show()"
947 | ]
948 | },
949 | {
950 | "cell_type": "markdown",
951 | "metadata": {
952 | "collapsed": false
953 | },
954 | "source": [
955 | "## 2.5 部署效果展示\n",
956 | "\n",
957 | "请看传送门: [树莓派部署教程与效果展示](https://www.bilibili.com/video/BV1ph411r718?p=4)"
958 | ]
959 | },
960 | {
961 | "cell_type": "markdown",
962 | "metadata": {
963 | "collapsed": false
964 | },
965 | "source": [
966 | "# 三、项目总结\n",
967 | "\n",
968 | "一直以来,人工智能落地都是一个工业界的热门话题。近年内,有许多优秀的检测算法出现,YOLOV4-PPYOLO-PPYOLOV2等。但在落地时,不光要考虑精度,还需要实时性——也就是考虑部署设备的算力情况。\n",
969 | "\n",
970 | "因此,本项目就基于PPDet展开了较轻量化模型PPyolo_r18的模型训练来实现垃圾的检测分类,同时利用PaddleLite完成在树莓派端的部署,实现分拣车的视觉关键部分。\n",
971 | "\n",
972 | "通过本项目,可以对目标检测落地提供一个可行的方案,也是基于python3的PaddleLite部署Paddle模型的一个部署实践方案。\n",
973 | "\n",
974 | "------\n",
975 | "\n",
976 | "**主要收获的点如下:**\n",
977 | "\n",
978 | "- 1. 数据集不大时,可以先用`大的batch_size`跑`1/3的轮次`稳定损失下降,然后利用`1/2的batch_size`进行接下来的轮次训练,实现继续优化\n",
979 | "\n",
980 | "- 2. 数据输入大小影响着模型处理的快慢,输入图像越小,模型推理越快\n",
981 | "\n",
982 | "- 3. 部署时,根据需要可进行`量化处理``(支持`INT8`, `INT16`),实现更快的模型加载和保存(模型体积减小)."
983 | ]
984 | },
985 | {
986 | "cell_type": "markdown",
987 | "metadata": {
988 | "collapsed": false
989 | },
990 | "source": [
991 | "# 个人介绍\n",
992 | "\n",
993 | "> 姓名:蔡敬辉\n",
994 | "\n",
995 | "> 学历:大三(在读)\n",
996 | "\n",
997 | "> 爱好:喜欢参加一些大大小小的比赛,不限于计算机视觉——有共同爱好的小伙伴可以关注一下哦~后期会持续更新一些自制的竞赛baseline和一些竞赛经验分享\n",
998 | "\n",
999 | "> 主要方向:目标检测、图像分割与图像识别\n",
1000 | "\n",
1001 | "> 联系方式:qq:3020889729 微信:cjh3020889729\n",
1002 | "\n",
1003 | "> 学校:西南科技大学"
1004 | ]
1005 | }
1006 | ],
1007 | "metadata": {
1008 | "kernelspec": {
1009 | "display_name": "PaddlePaddle 2.1.2 (Python 3.5)",
1010 | "language": "python",
1011 | "name": "py35-paddle1.2.0"
1012 | },
1013 | "language_info": {
1014 | "codemirror_mode": {
1015 | "name": "ipython",
1016 | "version": 3
1017 | },
1018 | "file_extension": ".py",
1019 | "mimetype": "text/x-python",
1020 | "name": "python",
1021 | "nbconvert_exporter": "python",
1022 | "pygments_lexer": "ipython3",
1023 | "version": "3.7.4"
1024 | }
1025 | },
1026 | "nbformat": 4,
1027 | "nbformat_minor": 1
1028 | }
1029 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | Apache License
2 | Version 2.0, January 2004
3 | http://www.apache.org/licenses/
4 |
5 | TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
6 |
7 | 1. Definitions.
8 |
9 | "License" shall mean the terms and conditions for use, reproduction,
10 | and distribution as defined by Sections 1 through 9 of this document.
11 |
12 | "Licensor" shall mean the copyright owner or entity authorized by
13 | the copyright owner that is granting the License.
14 |
15 | "Legal Entity" shall mean the union of the acting entity and all
16 | other entities that control, are controlled by, or are under common
17 | control with that entity. For the purposes of this definition,
18 | "control" means (i) the power, direct or indirect, to cause the
19 | direction or management of such entity, whether by contract or
20 | otherwise, or (ii) ownership of fifty percent (50%) or more of the
21 | outstanding shares, or (iii) beneficial ownership of such entity.
22 |
23 | "You" (or "Your") shall mean an individual or Legal Entity
24 | exercising permissions granted by this License.
25 |
26 | "Source" form shall mean the preferred form for making modifications,
27 | including but not limited to software source code, documentation
28 | source, and configuration files.
29 |
30 | "Object" form shall mean any form resulting from mechanical
31 | transformation or translation of a Source form, including but
32 | not limited to compiled object code, generated documentation,
33 | and conversions to other media types.
34 |
35 | "Work" shall mean the work of authorship, whether in Source or
36 | Object form, made available under the License, as indicated by a
37 | copyright notice that is included in or attached to the work
38 | (an example is provided in the Appendix below).
39 |
40 | "Derivative Works" shall mean any work, whether in Source or Object
41 | form, that is based on (or derived from) the Work and for which the
42 | editorial revisions, annotations, elaborations, or other modifications
43 | represent, as a whole, an original work of authorship. For the purposes
44 | of this License, Derivative Works shall not include works that remain
45 | separable from, or merely link (or bind by name) to the interfaces of,
46 | the Work and Derivative Works thereof.
47 |
48 | "Contribution" shall mean any work of authorship, including
49 | the original version of the Work and any modifications or additions
50 | to that Work or Derivative Works thereof, that is intentionally
51 | submitted to Licensor for inclusion in the Work by the copyright owner
52 | or by an individual or Legal Entity authorized to submit on behalf of
53 | the copyright owner. For the purposes of this definition, "submitted"
54 | means any form of electronic, verbal, or written communication sent
55 | to the Licensor or its representatives, including but not limited to
56 | communication on electronic mailing lists, source code control systems,
57 | and issue tracking systems that are managed by, or on behalf of, the
58 | Licensor for the purpose of discussing and improving the Work, but
59 | excluding communication that is conspicuously marked or otherwise
60 | designated in writing by the copyright owner as "Not a Contribution."
61 |
62 | "Contributor" shall mean Licensor and any individual or Legal Entity
63 | on behalf of whom a Contribution has been received by Licensor and
64 | subsequently incorporated within the Work.
65 |
66 | 2. Grant of Copyright License. Subject to the terms and conditions of
67 | this License, each Contributor hereby grants to You a perpetual,
68 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
69 | copyright license to reproduce, prepare Derivative Works of,
70 | publicly display, publicly perform, sublicense, and distribute the
71 | Work and such Derivative Works in Source or Object form.
72 |
73 | 3. Grant of Patent License. Subject to the terms and conditions of
74 | this License, each Contributor hereby grants to You a perpetual,
75 | worldwide, non-exclusive, no-charge, royalty-free, irrevocable
76 | (except as stated in this section) patent license to make, have made,
77 | use, offer to sell, sell, import, and otherwise transfer the Work,
78 | where such license applies only to those patent claims licensable
79 | by such Contributor that are necessarily infringed by their
80 | Contribution(s) alone or by combination of their Contribution(s)
81 | with the Work to which such Contribution(s) was submitted. If You
82 | institute patent litigation against any entity (including a
83 | cross-claim or counterclaim in a lawsuit) alleging that the Work
84 | or a Contribution incorporated within the Work constitutes direct
85 | or contributory patent infringement, then any patent licenses
86 | granted to You under this License for that Work shall terminate
87 | as of the date such litigation is filed.
88 |
89 | 4. Redistribution. You may reproduce and distribute copies of the
90 | Work or Derivative Works thereof in any medium, with or without
91 | modifications, and in Source or Object form, provided that You
92 | meet the following conditions:
93 |
94 | (a) You must give any other recipients of the Work or
95 | Derivative Works a copy of this License; and
96 |
97 | (b) You must cause any modified files to carry prominent notices
98 | stating that You changed the files; and
99 |
100 | (c) You must retain, in the Source form of any Derivative Works
101 | that You distribute, all copyright, patent, trademark, and
102 | attribution notices from the Source form of the Work,
103 | excluding those notices that do not pertain to any part of
104 | the Derivative Works; and
105 |
106 | (d) If the Work includes a "NOTICE" text file as part of its
107 | distribution, then any Derivative Works that You distribute must
108 | include a readable copy of the attribution notices contained
109 | within such NOTICE file, excluding those notices that do not
110 | pertain to any part of the Derivative Works, in at least one
111 | of the following places: within a NOTICE text file distributed
112 | as part of the Derivative Works; within the Source form or
113 | documentation, if provided along with the Derivative Works; or,
114 | within a display generated by the Derivative Works, if and
115 | wherever such third-party notices normally appear. The contents
116 | of the NOTICE file are for informational purposes only and
117 | do not modify the License. You may add Your own attribution
118 | notices within Derivative Works that You distribute, alongside
119 | or as an addendum to the NOTICE text from the Work, provided
120 | that such additional attribution notices cannot be construed
121 | as modifying the License.
122 |
123 | You may add Your own copyright statement to Your modifications and
124 | may provide additional or different license terms and conditions
125 | for use, reproduction, or distribution of Your modifications, or
126 | for any such Derivative Works as a whole, provided Your use,
127 | reproduction, and distribution of the Work otherwise complies with
128 | the conditions stated in this License.
129 |
130 | 5. Submission of Contributions. Unless You explicitly state otherwise,
131 | any Contribution intentionally submitted for inclusion in the Work
132 | by You to the Licensor shall be under the terms and conditions of
133 | this License, without any additional terms or conditions.
134 | Notwithstanding the above, nothing herein shall supersede or modify
135 | the terms of any separate license agreement you may have executed
136 | with Licensor regarding such Contributions.
137 |
138 | 6. Trademarks. This License does not grant permission to use the trade
139 | names, trademarks, service marks, or product names of the Licensor,
140 | except as required for reasonable and customary use in describing the
141 | origin of the Work and reproducing the content of the NOTICE file.
142 |
143 | 7. Disclaimer of Warranty. Unless required by applicable law or
144 | agreed to in writing, Licensor provides the Work (and each
145 | Contributor provides its Contributions) on an "AS IS" BASIS,
146 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
147 | implied, including, without limitation, any warranties or conditions
148 | of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
149 | PARTICULAR PURPOSE. You are solely responsible for determining the
150 | appropriateness of using or redistributing the Work and assume any
151 | risks associated with Your exercise of permissions under this License.
152 |
153 | 8. Limitation of Liability. In no event and under no legal theory,
154 | whether in tort (including negligence), contract, or otherwise,
155 | unless required by applicable law (such as deliberate and grossly
156 | negligent acts) or agreed to in writing, shall any Contributor be
157 | liable to You for damages, including any direct, indirect, special,
158 | incidental, or consequential damages of any character arising as a
159 | result of this License or out of the use or inability to use the
160 | Work (including but not limited to damages for loss of goodwill,
161 | work stoppage, computer failure or malfunction, or any and all
162 | other commercial damages or losses), even if such Contributor
163 | has been advised of the possibility of such damages.
164 |
165 | 9. Accepting Warranty or Additional Liability. While redistributing
166 | the Work or Derivative Works thereof, You may choose to offer,
167 | and charge a fee for, acceptance of support, warranty, indemnity,
168 | or other liability obligations and/or rights consistent with this
169 | License. However, in accepting such obligations, You may act only
170 | on Your own behalf and on Your sole responsibility, not on behalf
171 | of any other Contributor, and only if You agree to indemnify,
172 | defend, and hold each Contributor harmless for any liability
173 | incurred by, or claims asserted against, such Contributor by reason
174 | of your accepting any such warranty or additional liability.
175 |
176 | END OF TERMS AND CONDITIONS
177 |
178 | APPENDIX: How to apply the Apache License to your work.
179 |
180 | To apply the Apache License to your work, attach the following
181 | boilerplate notice, with the fields enclosed by brackets "[]"
182 | replaced with your own identifying information. (Don't include
183 | the brackets!) The text should be enclosed in the appropriate
184 | comment syntax for the file format. We also recommend that a
185 | file or class name and description of purpose be included on the
186 | same "printed page" as the copyright notice for easier
187 | identification within third-party archives.
188 |
189 | Copyright [yyyy] [name of copyright owner]
190 |
191 | Licensed under the Apache License, Version 2.0 (the "License");
192 | you may not use this file except in compliance with the License.
193 | You may obtain a copy of the License at
194 |
195 | http://www.apache.org/licenses/LICENSE-2.0
196 |
197 | Unless required by applicable law or agreed to in writing, software
198 | distributed under the License is distributed on an "AS IS" BASIS,
199 | WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
200 | See the License for the specific language governing permissions and
201 | limitations under the License.
202 |
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # 项目介绍: 基于PaddleLite的树莓派垃圾检测系统
2 |
3 | 生活中,垃圾随处可见。道路需要清洁工人们辛苦打扫,并根据一定的规则进行垃圾种类划分。本项目旨在简化该项同类任务中的前置任务,即垃圾智能检测定位与识别,然后搭载小车实现垃圾分类收集。后期,只需要将收集好的垃圾,交于清洁工人们进行简单再分类即可完成路面等地方的垃圾收集分类工作。
4 |
5 | ------
6 |
7 | 主要框架:
8 |
9 | - `垃圾检测功能`: **采用深度学习的目标检测算法实现**,**PaddleDetection开发**
10 |
11 | - `硬件部署`: 采用**树莓派4B**,**32位操作系统**,**PaddleLite开发**
12 |
13 | - `硬件协同`: (小车结构在该项目的展示中,暂未说明)
14 |
15 | 其它资料:
16 |
17 | - [PPDet简单使用教程](https://www.bilibili.com/video/BV1vK4y1M728)
18 |
19 | - [部署效果与部署说明](https://www.bilibili.com/video/BV1ph411r718?p=4)
20 |
21 | - [平台项目地址](https://aistudio.baidu.com/aistudio/projectdetail/2283361)
22 |
23 |
24 | # 一、基于PPDet开发垃圾检测模型
25 |
26 | > PPDet: PaddleDetection为飞桨的官方目标检测套件,可以实现众多目标检测模型的训练。
27 |
28 | 本项目,基于PPDet开发`PPyolo_r18vd`模型作为垃圾检测项目的深度学习模型,以期望获得视觉中出现的指定垃圾的类别以及相对位置信息,从而辅助目标检测模型的应用。
29 |
30 | > 本项目实现的模型,最终落地于`垃圾分拣车`上——`实现垃圾的定位与识别检测,从而进行定位抓取与垃圾识别`。
31 |
32 | ---------
33 |
34 | 项目所需`模型要求`如下:
35 |
36 |
37 | 1. **模型运行速度**
38 |
39 | 2. **模型漏检率优先**
40 |
41 | 3. **模型检测识别精度**
42 |
43 | -------
44 |
45 | 预期`模型选择`: -- `ppyolo_r18_vd` -- , -- `ppyolo_tiny` --
46 |
47 |
48 | | 模型 | 精度(all:%) | 帧率(s) | 漏检率 | 训练成本 |
49 | | :--------: | :--------: | :--------: | :--------: | :--------: |
50 | | ppyolo_tiny | 0.5_mAP:95+ | 3-5 | 一般 | 低 |
51 | | ppyolo_r18_vd | 0.5_mAP:97+ | 1.4-1.6 | 较低 | 低 |
52 |
53 | **数据集格式**: COCO/VOC都有尝试, 本项目选用COCO介绍。
54 |
55 | > 感兴趣的小伙伴可以观看一个PPDet使用(说明)视频: [PPDet简单使用教程](https://www.bilibili.com/video/BV1vK4y1M728)
56 |
57 | > 声音有些小,可能需要带耳机食用~,还望谅解
58 |
59 | ## 1.1 解压PPDet套件
60 |
61 | > 本项目基于套件本身进行开发,因此需要导入套件包——已挂载到本项目,可直接使用
62 |
63 | > 如本地,请自行下载
64 |
65 | ```python
66 | # -oq 静默解压
67 | !unzip -oq data/data99077/PaddleDetection-release-2.1.zip
68 | !mv PaddleDetection-release-2.1 PaddleDetection
69 | ```
70 |
71 | ## 1.2 解压数据集
72 |
73 | > 为方便模型开发训练,因此直接解压到套件中的`dataset`目录下,并新建`diy_coco`来保存
74 |
75 | **数据集目录:**
76 |
77 | - `PaddleDetection`
78 |
79 | - `dataset`
80 |
81 | - `diy_coco`
82 |
83 | - `Train`
84 |
85 | - `Annotations`: **包含coco格式的标注json文件**
86 |
87 | - `Images`: **训练图片**
88 |
89 | - `Eval`
90 |
91 | - `Annotations`: **包含coco格式的标注json文件**
92 |
93 | - `Images`: **验证/评估图片**
94 |
95 | -------
96 |
97 | **部分数据标注展示:**
98 |
99 | 
100 |
101 |
102 |
103 | ```python
104 | !unzip -oq data/data101886/rubish_det.zip -d PaddleDetection/dataset/diy_coco
105 | ```
106 |
107 | ## 1.3 下载环境依赖(包)
108 |
109 | > 主要是补充下载pycocotool,这对解析coco数据格式的标注提供很大的帮助
110 |
111 |
112 | ```python
113 | %cd /home/aistudio/PaddleDetection
114 | !pip install -r requirements.txt
115 | ```
116 |
117 | ## 1.4 训练前,明确anchor大小
118 |
119 | > 在训练开始前,现在训练数据上,生成一个符合待拟合数据的`anchor`,这将对模型学习合适的特征提供帮助,同时也能更好的框选预测物体的位置!
120 |
121 | > 仅限于需要`预置anchor`的模型
122 |
123 | 不过,再开始生成`anchor`前,需要先配置好`数据集的加载`。
124 |
125 | -------
126 |
127 | ### 1.4.1 配置数据加载yml
128 |
129 | 因为,本项目的数据格式为coco,因此选择路径: `PaddleDetection/configs/datasets`下的`coco_detection.yml`文件进行修改,使其加载本项目垃圾检测数据!
130 |
131 | 修改如下:
132 |
133 | metric: COCO
134 | # 修改num_classes为垃圾分类的数量
135 | num_classes: 5
136 |
137 | TrainDataset:
138 | !COCODataSet
139 | # 2.再配置图片路径 -- 指向Images文件夹
140 | image_dir: Images
141 | # 3.最后配置标注文件的路径 -- 指向Annotations下的json文件
142 | anno_path: Annotations/train.json
143 | # 1.先配置数据集目录 -- 先指向Train文件夹
144 | dataset_dir: dataset/diy_coco/Train
145 | # end: 这里不同改
146 | data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
147 |
148 | EvalDataset:
149 | !COCODataSet
150 | image_dir: Images
151 | anno_path: Annotations/val.json
152 | # 1. 指向另一个文件夹,用于验证评估,其它同上
153 | dataset_dir: dataset/diy_coco/Eval
154 |
155 | TestDataset:
156 | !ImageFolder
157 | # 这里的标注配置,设置为验证的json即可
158 | anno_path: Annotations/val.json
159 |
160 | ### 1.4.2 选择参与训练的模型
161 |
162 | 已经有了配置好的数据加载yml文件,接下来就可以选模型了。
163 |
164 | 这里选用`PaddleDetection/configs/ppyolo`下的`ppyolo_r18vd_coco.yml`作为项目要训练的模型。
165 |
166 | -------
167 |
168 | ### 1.4.3 生成预置anchor
169 |
170 | 以上完成了数据加载的配置以及模型的选择之后,我们就可进行预置anchor的自动生成了!
171 |
172 | **生成的大致流程:**
173 |
174 | 1. 启动时,调用`模型yml`进入参数配置,获取`数据集加载的yml`信息
175 |
176 | 2. 生成时,利用数据集中的`所有已有标注信息`进行anchor的`kmeans聚类`生成一个`anchor集合`
177 |
178 | 3. 使用时,将生成的anchor收集起来,然后替换模型yml中所有出现anchor列表的地方`即可
179 |
180 |
181 | ```python
182 | # -n: 模型中需要的anchor数量, r18只需要6个
183 | # -s: 生成anchor集合,适用于多大的输入尺寸 —— 会自动生成指定大小下的anchor集合
184 | # -c: 指定使用这些anchor的模型yml
185 | %cd /home/aistudio/PaddleDetection
186 | !python tools/anchor_cluster.py -n 6 -s 320 -c configs/ppyolo/ppyolo_r18vd_coco.yml
187 | ```
188 |
189 | ### 1.4.4 整合生成的anchor,并替换模型的anchor
190 |
191 | > 替换anchor的地方,对于r18而言有以下两个地方: `configs/ppyolo/ppyolo_r18vd_coco.yml`, `configs/ppyolo/_base_/ppyolo_r18vd.yml`
192 |
193 | ------
194 |
195 | `ppyolo_r18vd_coco.yml`中的修改如下(**模型yml**):
196 |
197 | - Gt2YoloTarget:
198 | anchor_masks: [[3, 4, 5], [0, 1, 2]]
199 | # 替换anchor列表为生成的anchor即可
200 | anchors: [[48, 36], [43, 66], [89, 60], [60, 102], [105, 124], [165, 163]]
201 | downsample_ratios: [32, 16]
202 |
203 | -------
204 |
205 | `ppyolo_r18vd.yml`中的修改如下(**模型结构yml**):
206 |
207 | YOLOv3Head:
208 | anchor_masks: [[3, 4, 5], [0, 1, 2]]
209 | # 替换anchor列表为生成的anchor即可
210 | anchors: [[48, 36], [43, 66], [89, 60], [60, 102], [105, 124], [165, 163]]
211 | loss: YOLOv3Loss
212 |
213 |
214 |
215 | ```python
216 | create_anchors_list = [[59, 45], [54, 82], [112, 74], [75, 127], [131, 154], [206, 204]]
217 | ```
218 |
219 | ## 1.5 配置训练参数
220 |
221 | > 对于r18而言,训练参数的修改只需要在 `configs/ppyolo/ppyolo_r18vd_coco.yml`中修改即可
222 |
223 | **主要参数修改如下**:
224 |
225 | TrainReader:
226 | sample_transforms:
227 | ...
228 | batch_transforms:
229 | - BatchRandomResize:
230 | # 原始大小的list对应输入大小为520的预测,现改为320之后,简要修改的这个区间
231 | # 修改注意事项,每个大小都是32的倍数
232 | target_size: [224, 256, 288, 320, 352, 384, 416, 448]
233 | ...
234 | - Gt2YoloTarget:
235 | anchor_masks: [[3, 4, 5], [0, 1, 2]]
236 | # 替换为生成的anchor
237 | anchors: [[48, 36], [43, 66], [89, 60], [60, 102], [105, 124], [165, 163]]
238 | downsample_ratios: [32, 16]
239 | # 根据数据集情况,适当修改即可: 8/16/24/32/48
240 | batch_size: 32
241 | mixup_epoch: 500
242 | shuffle: true
243 |
244 |
245 | EvalReader:
246 | sample_transforms:
247 | - Decode: {}
248 | # target_size改为320
249 | - Resize: {target_size: [320, 320], keep_ratio: False, interp: 2}
250 | ...
251 |
252 | TestReader:
253 | inputs_def:
254 | # 改为320
255 | image_shape: [3, 320, 320]
256 | sample_transforms:
257 | - Decode: {}
258 | # 改为320
259 | - Resize: {target_size: [320, 320], keep_ratio: False, interp: 2}
260 | ...
261 |
262 | LearningRate:
263 | # 原4卡下训练参数,除以4,用于单卡训练
264 | # 0.004 / 4 == 0.001
265 | base_lr: 0.001
266 | ...
267 |
268 |
269 | ```python
270 | %cd /home/aistudio/PaddleDetection
271 | !python tools/train.py\
272 | -c configs/ppyolo/ppyolo_r18vd_coco.yml\
273 | --eval\
274 | --use_vdl True
275 | ```
276 |
277 | [08/14 21:03:03] ppdet.engine INFO: Epoch: [196] [20/46] learning_rate: 0.000100 loss_xy: 0.773786 loss_wh: 0.697323 loss_iou: 2.933347 loss_obj: 3.114668 loss_cls: 0.885066 loss: 8.543031 eta: 0:27:02 batch_cost: 0.4652 data_cost: 0.2992 ips: 68.7832 images/s
278 | [08/14 21:03:12] ppdet.engine INFO: Epoch: [196] [40/46] learning_rate: 0.000100 loss_xy: 0.757029 loss_wh: 0.656280 loss_iou: 2.774072 loss_obj: 3.072931 loss_cls: 0.949183 loss: 8.486620 eta: 0:26:52 batch_cost: 0.4206 data_cost: 0.2787 ips: 76.0866 images/s
279 | [08/14 21:03:17] ppdet.engine INFO: Epoch: [197] [ 0/46] learning_rate: 0.000100 loss_xy: 0.758142 loss_wh: 0.664071 loss_iou: 2.743285 loss_obj: 3.071552 loss_cls: 1.033830 loss: 8.424139 eta: 0:26:50 batch_cost: 0.4621 data_cost: 0.3208 ips: 69.2533 images/s
280 | [08/14 21:03:26] ppdet.engine INFO: Epoch: [197] [20/46] learning_rate: 0.000100 loss_xy: 0.736949 loss_wh: 0.639424 loss_iou: 2.764338 loss_obj: 3.022928 loss_cls: 1.026918 loss: 8.329489 eta: 0:26:40 batch_cost: 0.4258 data_cost: 0.2777 ips: 75.1583 images/s
281 | [08/14 21:03:36] ppdet.engine INFO: Epoch: [197] [40/46] learning_rate: 0.000100 loss_xy: 0.728324 loss_wh: 0.671651 loss_iou: 2.920363 loss_obj: 3.044627 loss_cls: 0.976078 loss: 8.474413 eta: 0:26:30 batch_cost: 0.4600 data_cost: 0.3220 ips: 69.5716 images/s
282 | [08/14 21:03:40] ppdet.engine INFO: Epoch: [198] [ 0/46] learning_rate: 0.000100 loss_xy: 0.748800 loss_wh: 0.663416 loss_iou: 2.903050 loss_obj: 3.142794 loss_cls: 0.995665 loss: 8.490379 eta: 0:26:27 batch_cost: 0.5249 data_cost: 0.3624 ips: 60.9593 images/s
283 | [08/14 21:03:50] ppdet.engine INFO: Epoch: [198] [20/46] learning_rate: 0.000100 loss_xy: 0.804090 loss_wh: 0.638163 loss_iou: 2.821011 loss_obj: 3.293034 loss_cls: 0.950222 loss: 8.611068 eta: 0:26:17 batch_cost: 0.4455 data_cost: 0.2798 ips: 71.8259 images/s
284 | [08/14 21:03:59] ppdet.engine INFO: Epoch: [198] [40/46] learning_rate: 0.000100 loss_xy: 0.729478 loss_wh: 0.671696 loss_iou: 2.855099 loss_obj: 2.954676 loss_cls: 1.013126 loss: 8.109439 eta: 0:26:08 batch_cost: 0.4445 data_cost: 0.3092 ips: 71.9917 images/s
285 | [08/14 21:04:04] ppdet.engine INFO: Epoch: [199] [ 0/46] learning_rate: 0.000100 loss_xy: 0.729086 loss_wh: 0.640540 loss_iou: 2.748984 loss_obj: 3.005687 loss_cls: 0.877229 loss: 7.902369 eta: 0:26:05 batch_cost: 0.5034 data_cost: 0.3502 ips: 63.5677 images/s
286 | [08/14 21:04:14] ppdet.engine INFO: Epoch: [199] [20/46] learning_rate: 0.000100 loss_xy: 0.763439 loss_wh: 0.640906 loss_iou: 2.689836 loss_obj: 3.238860 loss_cls: 0.929343 loss: 8.205533 eta: 0:25:56 batch_cost: 0.4675 data_cost: 0.2824 ips: 68.4485 images/s
287 | [08/14 21:04:24] ppdet.engine INFO: Epoch: [199] [40/46] learning_rate: 0.000100 loss_xy: 0.757755 loss_wh: 0.720121 loss_iou: 2.960909 loss_obj: 3.277584 loss_cls: 0.926977 loss: 8.504792 eta: 0:25:46 batch_cost: 0.4711 data_cost: 0.3046 ips: 67.9259 images/s
288 | [08/14 21:04:27] ppdet.utils.checkpoint INFO: Save checkpoint: output/ppyolo_r18vd_coco
289 | [08/14 21:04:27] ppdet.engine INFO: Eval iter: 0
290 | [08/14 21:04:32] ppdet.metrics.metrics INFO: The bbox result is saved to bbox.json.
291 | loading annotations into memory...
292 | Done (t=0.01s)
293 | creating index...
294 | index created!
295 | [08/14 21:04:32] ppdet.metrics.coco_utils INFO: Start evaluate...
296 | Loading and preparing results...
297 | DONE (t=0.12s)
298 | creating index...
299 | index created!
300 | Running per image evaluation...
301 | Evaluate annotation type *bbox*
302 | DONE (t=1.27s).
303 | Accumulating evaluation results...
304 | DONE (t=0.19s).
305 | Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.667
306 | Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.960
307 | Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.836
308 | Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.771
309 | Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
310 | Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
311 | Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.394
312 | Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.764
313 | Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.776
314 | Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.776
315 | Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
316 | Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = -1.000
317 | [08/14 21:04:34] ppdet.engine INFO: Total sample number: 636, averge FPS: 141.8495250691227
318 | [08/14 21:04:34] ppdet.engine INFO: Best test bbox ap is 0.668.
319 |
320 | ## 1.6 模型导出
321 |
322 | 将模型导出,并且打开`--export_serving_model`,适当能够生成`__model__`, `__params__`格式的模型与参数文件
323 |
324 | > 导出前, 需要前往: `configs/ppyolo/_base_/ppyolo_r18vd.yml`这个模型结构文件中,注释掉: `pretrain_weights`后再进行模型导出
325 |
326 | 如下:
327 |
328 | architecture: YOLOv3
329 | # pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/ResNet18_vd_pretrained.pdparams
330 | norm_type: sync_bn
331 | use_ema: true
332 | ema_decay: 0.9998
333 |
334 |
335 | ```python
336 | # --export_serving_model指令下需要下载该依赖
337 | !pip install paddle-serving-client
338 | ```
339 |
340 |
341 | ```python
342 | %cd /home/aistudio/PaddleDetection
343 | !python tools/export_model.py\
344 | -c configs/ppyolo/ppyolo_r18vd_coco.yml\
345 | -o weights='output/ppyolo_r18vd_coco/best_model'\
346 | --output_dir '/home/aistudio/export_model'\
347 | --export_serving_model True
348 | ```
349 |
350 | /home/aistudio/PaddleDetection
351 | /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
352 | from collections import MutableMapping
353 | /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
354 | from collections import Iterable, Mapping
355 | /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
356 | from collections import Sized
357 | /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
358 | Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
359 | if data.dtype == np.object:
360 | [08/14 21:29:42] ppdet.utils.checkpoint INFO: Finish loading model weights: output/ppyolo_r18vd_coco/best_model.pdparams
361 | [08/14 21:29:42] ppdet.engine INFO: Export inference config file to /home/aistudio/export_model/ppyolo_r18vd_coco/infer_cfg.yml
362 | /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
363 | return (isinstance(seq, collections.Sequence) and
364 | W0814 21:29:44.067077 20354 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
365 | W0814 21:29:44.067139 20354 device_context.cc:422] device: 0, cuDNN Version: 7.6.
366 | [08/14 21:29:47] ppdet.engine INFO: Export model and saved in /home/aistudio/export_model/ppyolo_r18vd_coco
367 |
368 |
369 |
370 | ```python
371 | # 查看输出结构
372 | !tree /home/aistudio/export_model -L 3
373 | ```
374 |
375 | /home/aistudio/export_model
376 | └── ppyolo_r18vd_coco
377 | ├── infer_cfg.yml
378 | ├── model.pdiparams
379 | ├── model.pdiparams.info
380 | ├── model.pdmodel
381 | ├── serving_client
382 | │ ├── serving_client_conf.prototxt
383 | │ └── serving_client_conf.stream.prototxt
384 | └── serving_server
385 | ├── __model__
386 | ├── __params__
387 | ├── serving_server_conf.prototxt
388 | └── serving_server_conf.stream.prototxt
389 |
390 | 3 directories, 10 files
391 |
392 |
393 | 部署需要的内容主要有以下两种
394 |
395 | - `*.pdmodel` + `*.pdiparams`
396 |
397 | - `__model__` + `__params__`
398 |
399 | > 其它可能需要的资料(PaddleLite不直接用,可以作为加载的一些预处理参数的参考): `infer_cfg.yml`, `serving_server_conf.prototxt`
400 |
401 | ## 1.7 模型导出再windows端的部署效果检测
402 |
403 | 利用可视化推理验收模型效果:
404 |
405 | - **图片推理效果**
406 |
407 | 
408 |
409 | 
410 |
411 | - **视频推理效果**
412 |
413 | 
414 |
415 | 
416 |
417 |
418 | # 二、基于PPLite实现树莓派端部署
419 |
420 | 本项目训练的模型部署到树莓派4B上进行应用,能够实现较为快速准确的垃圾检测!
421 |
422 | > 部署说明与部分检测(展示为tiny的效果, 部署代码通用)的效果可以观看视频: [树莓派部署教程与效果展示](https://www.bilibili.com/video/BV1ph411r718?p=4)
423 |
424 | 部分效果:
425 |
426 | 
427 |
428 |
429 | ## 2.1 PaddleLite的python包安装
430 |
431 | 如果使用32位的操作系统,可以直接使用我编译好的whl(使用与Python3)
432 |
433 | 链接:[https://pan.baidu.com/s/1pmULmyNokBcG7EQz2gKWCg](https://pan.baidu.com/s/1pmULmyNokBcG7EQz2gKWCg)
434 |
435 | 提取码:plit
436 |
437 | ------
438 |
439 | 下载好后,上传到树莓派即可 —— 推荐使用`vnc远程服务`的文件传递功能。
440 |
441 | ------
442 |
443 | 安装指令:
444 |
445 | `python3 -m pip install whl_path`
446 |
447 | ## 2.2 部署流程
448 |
449 | - 1. 先使用`paddlelite包`中的`opt`这个API实现模型的转换,获取`nb格式`的文件
450 |
451 | - 2. 然后使用以下代码进行`模型加载`即可进行模型推理
452 |
453 | ## 2.3 部署代码
454 |
455 | 主要处理
456 |
457 | - 加载模型,并输出加载时间 `__init__`
458 |
459 | - 获取输入数据,配置模型输入 -- `get_input_img`
460 |
461 | - **注意不同模型的输入数据**
462 |
463 | - 获取绘制好框的图像结果 -- `get_output_img`
464 |
465 |
466 | > 部署代码,来自个人项目: [PPYolo-Tiny树莓派部署实践(一)](https://aistudio.baidu.com/aistudio/projectdetail/2047562)
467 |
468 | > 一些注意事项,可以看下面的代码,可以观看树莓派部署视频!
469 |
470 |
471 | ```python
472 | from paddlelite.lite import *
473 | import cv2 as cv
474 | import numpy as np
475 | from matplotlib import pyplot as plt
476 | from time import time
477 | from PIL import Image
478 | from PIL import ImageFont
479 | from PIL import ImageDraw
480 | from PIL import ImageEnhance
481 |
482 | class PPYOLO_Detector(object):
483 |
484 | def __init__(self, nb_path = None, # nb路径
485 | label_list = None, # 类别list
486 | input_size = [320, 320], # 输入图像大小
487 | img_means = [0., 0., 0.], # 图片归一化均值
488 | img_stds = [0., 0., 0.], # 图片归一化方差
489 | threshold = 0.1, # 预测阈值
490 | num_thread = 1, # ARM CPU工作线程数
491 | work_power_mode = PowerMode.LITE_POWER_NO_BIND # ARM CPU工作模式
492 | ):
493 |
494 | # 验证必要的参数格式
495 | assert nb_path is not None, \
496 | "Please make sure the model_nb_path has inputed!(now, nb_path is None.)"
497 | assert len(input_size) == 2, \
498 | "Please make sure the input_shape length is 2, but now its length is {0}".format(len(input_size))
499 | assert len(img_means) == 3, \
500 | "Please make sure the image_means shape is [3], but now get image_means' shape is [{0}]".format(len(img_means))
501 | assert len(img_stds) == 3, \
502 | "Please make sure the image_stds shape is [3], but now get image_stds' shape is [{0}]".format(len(img_stds))
503 | assert len([i for i in img_stds if i <= 0]) < 1, \
504 | "Please make sure the image_stds data is more than 0., but now get image_stds' data exists less than or equal 0."
505 | assert threshold > 0. and threshold < 1., \
506 | "Please make sure the threshold value > 0. and < 1., but now get its value is {0}".format(threshold)
507 | assert num_thread > 0 and num_thread <= 4, \
508 | "Please make sure the num_thread value > 1 and <= 4., but now get its value is {0}".format(num_thread)
509 | assert work_power_mode in [PowerMode.LITE_POWER_HIGH, PowerMode.LITE_POWER_LOW,
510 | PowerMode.LITE_POWER_FULL, PowerMode.LITE_POWER_NO_BIND,
511 | PowerMode.LITE_POWER_RAND_HIGH,
512 | PowerMode.LITE_POWER_RAND_LOW], \
513 | "Please make sure the work_power_mode is allowed , which is in \
514 | [PowerMode.LITE_POWER_HIGH, PowerMode.LITE_POWER_LOW, \
515 | PowerMode.LITE_POWER_FULL, PowerMode.LITE_POWER_NO_BIND, \
516 | PowerMode.LITE_POWER_RAND_HIGH, \
517 | PowerMode.LITE_POWER_RAND_LOW], \
518 | but now get its value is {0}"
519 |
520 | # 模型nb文件路径
521 | self.model_path = nb_path
522 | # ARM CPU工作线程数
523 | self.num_thread = num_thread
524 | # ARM CPU工作模式
525 | self.power_mode = work_power_mode
526 |
527 | # 预测显示阈值
528 | self.threshold = threshold
529 | # 预测输入图像大小
530 | self.input_size = input_size
531 | # 图片归一化参数
532 | # 均值
533 | self.img_means = img_means
534 | # 方差
535 | self.img_stds = img_stds
536 |
537 | # 预测类别list
538 | self.label_list = label_list
539 | # 预测类别数
540 | self.num_class = len(label_list) if (label_list is not None) and isinstance(label_list, list) else 1
541 | # 类别框颜色map
542 | self.box_color_map = self.random_colormap()
543 |
544 | # 记录模型加载参数的开始时间
545 | self.prepare_time = self.runtime()
546 |
547 | # 配置预测
548 | self.config = MobileConfig()
549 | # 设置模型路径
550 | self.config.set_model_from_file(nb_path)
551 | # 设置线程数
552 | self.config.set_threads(num_thread)
553 | # 设置工作模式
554 | self.config.set_power_mode(work_power_mode)
555 | # 构建预测器
556 | self.predictor = create_paddle_predictor(self.config)
557 |
558 | # 模型加载参数的总时间花销
559 | self.prepare_time = self.runtime() - self.prepare_time
560 | print("The Prepare Model Has Cost: {0:.4f} s".format(self.prepare_time))
561 |
562 |
563 | def get_input_img(self, input_img):
564 | '''输入预测图片
565 | input_img: 图片路径或者np.ndarray图像数据 - [h, w, c]
566 | '''
567 | assert isinstance(input_img, str) or isinstance(input_img, np.ndarray), \
568 | "Please enter input is Image Path or numpy.ndarray, but get ({0}) ".format(input_img)
569 |
570 | # 装载图像到预测器上的开始时间
571 | self.load_img_time = self.runtime()
572 |
573 | if isinstance(input_img, str):
574 | # 读取图片路径下的图像数据
575 | self.input_img = Image.open(input_img)
576 | elif isinstance(input_img, np.ndarray):
577 | # 读取ndarray数据下的图像数据
578 | self.input_img = Image.fromarray(input_img)
579 |
580 | # 获取图片原始高宽 : h,w
581 | self.input_shape = np.asarray(self.input_img).shape[:-1]
582 | # 重置图片大小为指定的输入大小
583 | input_data = self.input_img.resize(self.input_size, Image.BILINEAR)
584 | # 转制图像shape为预测指定shape
585 | input_data = np.array(input_data).transpose(2, 0, 1).reshape([1, 3] + self.input_size).astype('float32')
586 | # 将图像数据进行归一化
587 | input_data = self.normlize(input_data)
588 |
589 | self.scale_factor = [1., 1.] # [1., 1.]
590 |
591 | # 配置输入tensor
592 |
593 | # 输入[[shape, shape]]的图片大小
594 | self.input_tensor0 = self.predictor.get_input(0)
595 | self.input_tensor0.from_numpy(np.asarray([self.input_size], dtype=np.int32))
596 |
597 | # 输入[1, 3, shape, shape]的归一化后的图片数据
598 | self.input_tensor1 = self.predictor.get_input(1)
599 | self.input_tensor1.from_numpy(input_data)
600 |
601 | # 输入模型处理图像大小与实际图像大小的比例
602 | self.input_tensor2 = self.predictor.get_input(2)
603 | self.input_tensor2.from_numpy(np.asarray(self.scale_factor, dtype=np.int32))
604 |
605 | # 装载图像到预测器上的总时间花销
606 | self.load_img_time = self.runtime() - self.load_img_time
607 | print("The Load Image Has Cost: {0:.4f} s".format(self.load_img_time))
608 |
609 | def get_output_img(self, num_bbox=1):
610 | '''获取输出标注图片
611 | num_bbox: 最大标注个数
612 | '''
613 |
614 | # 预测器开始预测的时间
615 | self.predict_time = self.runtime()
616 |
617 | # 根据get_input_img的图像进行预测
618 | self.predictor.run()
619 | # 获取输出预测bbox结果
620 | self.output_tensor = self.predictor.get_output(0)
621 |
622 | # 转化为numpy格式
623 | output_bboxes = self.output_tensor.numpy()
624 | # 根据阈值进行筛选,大于等于阈值的保留
625 | output_bboxes = output_bboxes[output_bboxes[:, 1] >= self.threshold]
626 |
627 | # 根据预测结果进行框绘制,返回绘制完成的图片
628 | self.output_img = self.load_bbox(output_bboxes, num_bbox)
629 |
630 | # 预测器预测的总时间花销
631 | self.predict_time = self.runtime() - self.predict_time
632 | print("The Predict Image Has Cost: {0:.4f} s".format(self.predict_time))
633 |
634 | return self.output_img
635 |
636 |
637 | def normlize(self, input_img):
638 | '''数据归一化
639 | input_img: 图像数据--numpy.ndarray
640 | '''
641 | # 对RGB通道进行均值-方差的归一化
642 | input_img[0, 0] = (input_img[0, 0] / 255. - self.img_means[0]) / self.img_stds[0]
643 | input_img[0, 1] = (input_img[0, 1] / 255. - self.img_means[1]) / self.img_stds[1]
644 | input_img[0, 2] = (input_img[0, 2] / 255. - self.img_means[2]) / self.img_stds[2]
645 |
646 | return input_img
647 |
648 |
649 | def load_bbox(self, input_bboxs, num_bbox):
650 | '''根据预测框在原始图片上绘制框体,并标注
651 | input_bboxs: 预测框
652 | num_bbox: 允许的标注个数
653 | '''
654 | # 创建间绘图参数:[cls_id, score, x1, y1, x2, y2]
655 | self.draw_bboxs = [0] * 6
656 | # 绘图器 -- 根据get_input_img的输入图像
657 | draw = ImageDraw.Draw(self.input_img)
658 | # 根据最大标注个数进行实际标注个数的确定
659 | # input_bboxs.shape[0]: 表示预测到的有效框个数
660 | if len(input_bboxs) != 0: # 存在有效框时
661 | num_bbox = input_bboxs.shape[0] if num_bbox > input_bboxs.shape[0] else num_bbox
662 | else:
663 | num_bbox = 0 # 没有有效框,直接不标注
664 |
665 | # 遍历框体,并进行标注
666 | for i in range(num_bbox):
667 | # 类别信息
668 | self.draw_bboxs[0] = input_bboxs[i][0]
669 | # 类别得分
670 | self.draw_bboxs[1] = input_bboxs[i][1]
671 |
672 | print(self.label_list[int(self.draw_bboxs[0])], '- score{', self.draw_bboxs[1], "} : ", input_bboxs[i][2], input_bboxs[i][3], input_bboxs[i][4], input_bboxs[i][5])
673 |
674 | # 框体左上角坐标
675 | # max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.):保证当前预测坐标始终在图像内(比例,0.-1.)
676 | # max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.) * self.input_shape[1]: 直接预测得到的坐标
677 | # min(max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.) * self.input_shape[1], self.input_shape[1]):保证坐标在图像内(h, w)
678 | self.draw_bboxs[2] = min(max(min(input_bboxs[i][2] / self.input_size[0], 1.), 0.) * self.input_shape[1], self.input_shape[1])
679 | self.draw_bboxs[3] = min(max(min(input_bboxs[i][3] / self.input_size[1], 1.), 0.) * self.input_shape[0], self.input_shape[0])
680 | # 框体右下角坐标
681 | self.draw_bboxs[4] = min(max(min(input_bboxs[i][4] / self.input_size[0], 1.), 0.) * self.input_shape[1], self.input_shape[1])
682 | self.draw_bboxs[5] = min(max(min(input_bboxs[i][5] / self.input_size[1], 1.), 0.) * self.input_shape[0], self.input_shape[0])
683 |
684 | # print(self.draw_bboxs[2], self.draw_bboxs[3], self.draw_bboxs[4], self.draw_bboxs[5])
685 |
686 | # 绘制框体
687 | # self.box_color_map[int(self.draw_bboxs[i][0])]: 对应类别的框颜色
688 | draw.rectangle(((self.draw_bboxs[2], self.draw_bboxs[3]),
689 | (self.draw_bboxs[4], self.draw_bboxs[5])),
690 | outline = tuple(self.box_color_map[int(self.draw_bboxs[0])]),
691 | width =2)
692 | # 框体位置写上类别和得分信息
693 | draw.text((self.draw_bboxs[2], self.draw_bboxs[3]+1),
694 | "{0}:{1:.4f}".format(self.label_list[int(self.draw_bboxs[0])], self.draw_bboxs[1]),
695 | tuple(self.box_color_map[int(self.draw_bboxs[0])]))
696 |
697 | # 返回标注好的图像数据
698 | return np.asarray(self.input_img)
699 |
700 | def random_colormap(self):
701 | '''获取与类别数量等量的color_map
702 | '''
703 | np.random.seed(2021)
704 |
705 | color_map = [[np.random.randint(20, 255),
706 | np.random.randint(64, 200),
707 | np.random.randint(128, 255)]
708 | for i in range(self.num_class)]
709 |
710 | return color_map
711 |
712 | def runtime(self):
713 | '''返回当前计时
714 | '''
715 | return time()
716 | ```
717 |
718 | ## 2.4 部署测试代码片段
719 |
720 | > 有需要的小伙伴,可以搭载串口通信,实现树莓派与单片机直接的通信哦!
721 |
722 |
723 | ```python
724 | def test():
725 |
726 | model_path = "/home/pi/test/ppyolo_tiny/ppyolo_tiny.nb" # 模型参数nb文件 -- 自行修改
727 | img_path = "/home/pi/Desktop/citrus_0005.jpg" # 自己的预测图像
728 |
729 | label_list = ['bottle', 'battery', 'cup', 'paper', 'citrus'] # 类别list
730 | input_size = [224, 224] # 输入图像大小
731 | img_means = [0.485, 0.456, 0.406] # 图片归一化均值
732 | img_stds = [0.229, 0.224, 0.225] # 图片归一化方差
733 | threshold = 0.1 # 预测阈值
734 | num_thread = 2 # ARM CPU工作线程数
735 | work_mode = PowerMode.LITE_POWER_NO_BIND # ARM CPU工作模式
736 | max_bbox_num = 1 # 每帧最多标注数
737 |
738 |
739 | # 创建预测器
740 | detector = PPYOLO_Detector(
741 | nb_path = model_path,
742 | label_list = label_list,
743 | input_size = input_size,
744 | img_means = img_means,
745 | img_stds = img_stds,
746 | threshold = threshold,
747 | num_thread = num_thread,
748 | work_power_mode = PowerMode.LITE_POWER_NO_BIND
749 | )
750 |
751 | img = plt.imread(img_path)
752 | img = cv.resize(img,(320, 320)) # 与训练时配置的大小一致
753 | detector.get_input_img(img) # 输入图片数据
754 | img = detector.get_output_img(num_bbox = max_bbox_num) # 得到预测输出后绘制了框的图像
755 | plt.imshow(img)
756 | plt.show()
757 | ```
758 |
759 | ## 2.5 部署效果展示
760 |
761 | 请看传送门: [树莓派部署教程与效果展示](https://www.bilibili.com/video/BV1ph411r718?p=4)
762 |
763 | # 三、项目总结
764 |
765 | 一直以来,人工智能落地都是一个工业界的热门话题。近年内,有许多优秀的检测算法出现,YOLOV4-PPYOLO-PPYOLOV2等。但在落地时,不光要考虑精度,还需要实时性——也就是考虑部署设备的算力情况。
766 |
767 | 因此,本项目就基于PPDet展开了较轻量化模型PPyolo_r18的模型训练来实现垃圾的检测分类,同时利用PaddleLite完成在树莓派端的部署,实现分拣车的视觉关键部分。
768 |
769 | 通过本项目,可以对目标检测落地提供一个可行的方案,也是基于python3的PaddleLite部署Paddle模型的一个部署实践方案。
770 |
771 | ------
772 |
773 | **主要收获的点如下:**
774 |
775 | - 1. 数据集不大时,可以先用`大的batch_size`跑`1/3的轮次`稳定损失下降,然后利用`1/2的batch_size`进行接下来的轮次训练,实现继续优化
776 |
777 | - 2. 数据输入大小影响着模型处理的快慢,输入图像越小,模型推理越快
778 |
779 | - 3. 部署时,根据需要可进行`量化处理``(支持`INT8`, `INT16`),实现更快的模型加载和保存(模型体积减小).
780 |
781 | # 个人介绍
782 |
783 | > 姓名:蔡敬辉
784 |
785 | > 学历:大三(在读)
786 |
787 | > 爱好:喜欢参加一些大大小小的比赛,不限于计算机视觉——有共同爱好的小伙伴可以关注一下哦~后期会持续更新一些自制的竞赛baseline和一些竞赛经验分享
788 |
789 | > 主要方向:目标检测、图像分割与图像识别
790 |
791 | > 联系方式:qq:3020889729 微信:cjh3020889729
792 |
793 | > 学校:西南科技大学
794 |
--------------------------------------------------------------------------------