├── .gitattributes
├── LICENSE
├── sample.txt
├── requirements.txt
├── .gitignore
├── README.md
└── streamlit_editor.py
/.gitattributes:
--------------------------------------------------------------------------------
1 | # Auto detect text files and perform LF normalization
2 | * text=auto
3 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2025 Kevin Chin
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/sample.txt:
--------------------------------------------------------------------------------
1 | # The Whispering Forest
2 |
3 | Once upon a time in the small village of Eldoria, nestled between rolling hills and dense woods, there lived a curious young girl named Luna. Luna had always been fascinated by the mysteries that lay beyond the village boundaries, especially the ancient forest known as the Whispering Woods.
4 |
5 | Every evening, as the sun dipped below the horizon, Luna would sit by her window and listen to the trees sway in the wind. Her grandmother had told her stories of the forest spirits and the hidden secrets that awaited those brave enough to explore its depths.
6 |
7 | One crisp autumn morning, Luna decided it was time to uncover the forest's mysteries. With a backpack filled with essentials and a heart full of courage, she ventured into the Whispering Woods. The forest greeted her with a symphony of rustling leaves and distant bird songs.
8 |
9 | As Luna delved deeper, the trees seemed to lean in closer, their branches forming intricate patterns against the sky. Suddenly, she stumbled upon a clearing bathed in ethereal light. In the center stood an ancient oak tree with a door carved into its trunk.
10 |
11 | Gathering her bravery, Luna approached the door and gently knocked. To her surprise, the door creaked open, revealing a spiral staircase that descended into the earth. Without hesitation, she stepped inside, embarking on a journey that would change her life forever.
12 |
13 | Beneath the forest, Luna discovered a hidden realm inhabited by magical creatures and wise guardians. She learned that the Whispering Woods were a bridge between the human world and the realm of enchantment. Over time, Luna became the forest's protector, ensuring harmony between both worlds.
14 |
15 | Years later, Luna returned to Eldoria as a wise and respected leader, her heart forever connected to the Whispering Forest. The villagers would often see her walking through the woods, sharing tales of magic and wonder, inspiring generations to come.
16 |
17 | And so, the bond between Luna, Eldoria, and the Whispering Forest endured, a testament to the courage and curiosity of one young girl who listened to the whispers of the trees.
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
1 | aiohappyeyeballs==2.4.4
2 | aiohttp==3.11.11
3 | aiosignal==1.3.2
4 | alembic==1.14.1
5 | altair
6 | annotated-types==0.7.0
7 | anyio==4.8.0
8 | APScheduler==3.11.0
9 | asyncer==0.0.8
10 | attrs==24.3.0
11 | backoff==2.2.1
12 | blinker==1.9.0
13 | cachetools==5.5.1
14 | certifi==2024.12.14
15 | cffi==1.17.1
16 | charset-normalizer==3.4.1
17 | click==8.1.8
18 | cloudpickle==3.1.1
19 | colorlog==6.9.0
20 | cryptography==42.0.8
21 | datasets==3.2.0
22 | dill==0.3.8
23 | diskcache==5.6.3
24 | distro==1.9.0
25 | dnspython==2.7.0
26 | dspy==2.5.43
27 | dspy-ai==2.5.43
28 | email_validator==2.2.0
29 | entrypoints==0.4
30 | fastapi==0.111.1
31 | fastapi-cli==0.0.7
32 | fastapi-sso==0.10.0
33 | filelock==3.17.0
34 | frozenlist==1.5.0
35 | fsspec==2024.9.0
36 | gitdb==4.0.12
37 | GitPython==3.1.44
38 | google-api-core==2.24.1
39 | google-auth==2.38.0
40 | google-cloud-core==2.4.1
41 | google-cloud-firestore==2.20.0
42 | googleapis-common-protos==1.66.0
43 | grpcio==1.70.0
44 | grpcio-status==1.70.0
45 | gunicorn==22.0.0
46 | h11==0.14.0
47 | httpcore==1.0.7
48 | httptools==0.6.4
49 | httpx==0.27.2
50 | huggingface-hub==0.27.1
51 | idna==3.10
52 | importlib_metadata==8.6.1
53 | Jinja2==3.1.5
54 | jiter==0.8.2
55 | joblib==1.4.2
56 | json_repair==0.35.0
57 | jsonpatch==1.33
58 | jsonpointer==3.0.0
59 | jsonschema==4.23.0
60 | jsonschema-specifications==2024.10.1
61 | langchain-core==0.3.31
62 | langchain-text-splitters==0.3.5
63 | langsmith==0.3.1
64 | litellm==1.53.7
65 | magicattr==0.1.6
66 | Mako==1.3.8
67 | markdown-it-py==3.0.0
68 | MarkupSafe==3.0.2
69 | mdurl==0.1.2
70 | multidict==6.1.0
71 | multiprocess==0.70.16
72 | narwhals==1.23.0
73 | numpy==2.2.2
74 | oauthlib==3.2.2
75 | openai==1.60.1
76 | optuna==4.2.0
77 | orjson==3.10.15
78 | packaging==24.2
79 | pandas==2.2.3
80 | pillow==11.1.0
81 | propcache==0.2.1
82 | proto-plus==1.26.0
83 | protobuf==5.29.3
84 | pyarrow==19.0.0
85 | pyasn1==0.6.1
86 | pyasn1_modules==0.4.1
87 | pycparser==2.22
88 | pydantic==2.10.6
89 | pydantic_core==2.27.2
90 | pydeck==0.9.1
91 | Pygments==2.19.1
92 | PyJWT==2.10.1
93 | PyNaCl==1.5.0
94 | python-dateutil==2.9.0.post0
95 | python-dotenv==1.0.1
96 | python-multipart==0.0.9
97 | pytz==2024.2
98 | PyYAML==6.0.2
99 | ratelimit==2.2.1
100 | redis==5.2.1
101 | referencing==0.36.1
102 | regex==2024.11.6
103 | requests==2.32.3
104 | requests-toolbelt==1.0.0
105 | rich==13.9.4
106 | rich-toolkit==0.13.2
107 | rpds-py==0.22.3
108 | rq==2.1.0
109 | rsa==4.9
110 | setuptools==75.8.0
111 | shellingham==1.5.4
112 | six==1.17.0
113 | smmap==5.0.2
114 | sniffio==1.3.1
115 | SQLAlchemy==2.0.37
116 | starlette==0.37.2
117 | streamlit==1.41.1
118 | streamlit-analytics
119 | streamlit-mermaid
120 | streamlit-quill==0.0.3
121 | streamlit_analytics2
122 | tenacity==9.0.0
123 | tiktoken==0.8.0
124 | tokenizers==0.21.0
125 | toml==0.10.2
126 | toolz==1.0.0
127 | tornado==6.4.2
128 | tqdm==4.67.1
129 | typer==0.15.1
130 | typing_extensions==4.12.2
131 | tzdata==2025.1
132 | tzlocal==5.2
133 | ujson==5.10.0
134 | urllib3==2.3.0
135 | uvicorn==0.22.0
136 | uvloop==0.21.0
137 | watchdog==6.0.0
138 | watchfiles==1.0.4
139 | websockets==14.2
140 | xxhash==3.5.0
141 | yarl==1.18.3
142 | zipp==3.21.0
143 | zstandard==0.23.0
144 |
--------------------------------------------------------------------------------
/.gitignore:
--------------------------------------------------------------------------------
1 | # Byte-compiled / optimized / DLL files
2 | __pycache__/
3 | *.py[cod]
4 | *$py.class
5 |
6 | # C extensions
7 | *.so
8 |
9 | # Distribution / packaging
10 | .Python
11 | build/
12 | develop-eggs/
13 | dist/
14 | downloads/
15 | eggs/
16 | .eggs/
17 | lib/
18 | lib64/
19 | parts/
20 | sdist/
21 | var/
22 | wheels/
23 | share/python-wheels/
24 | *.egg-info/
25 | .installed.cfg
26 | *.egg
27 | MANIFEST
28 |
29 | # PyInstaller
30 | # Usually these files are written by a python script from a template
31 | # before PyInstaller builds the exe, so as to inject date/other infos into it.
32 | *.manifest
33 | *.spec
34 |
35 | # Installer logs
36 | pip-log.txt
37 | pip-delete-this-directory.txt
38 |
39 | # Unit test / coverage reports
40 | htmlcov/
41 | .tox/
42 | .nox/
43 | .coverage
44 | .coverage.*
45 | .cache
46 | nosetests.xml
47 | coverage.xml
48 | *.cover
49 | *.py,cover
50 | .hypothesis/
51 | .pytest_cache/
52 | cover/
53 |
54 | # Translations
55 | *.mo
56 | *.pot
57 |
58 | # Django stuff:
59 | *.log
60 | local_settings.py
61 | db.sqlite3
62 | db.sqlite3-journal
63 |
64 | # Flask stuff:
65 | instance/
66 | .webassets-cache
67 |
68 | # Scrapy stuff:
69 | .scrapy
70 |
71 | # Sphinx documentation
72 | docs/_build/
73 |
74 | # PyBuilder
75 | .pybuilder/
76 | target/
77 |
78 | # Jupyter Notebook
79 | .ipynb_checkpoints
80 |
81 | # IPython
82 | profile_default/
83 | ipython_config.py
84 |
85 | # pyenv
86 | # For a library or package, you might want to ignore these files since the code is
87 | # intended to run in multiple environments; otherwise, check them in:
88 | # .python-version
89 |
90 | # pipenv
91 | # According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
92 | # However, in case of collaboration, if having platform-specific dependencies or dependencies
93 | # having no cross-platform support, pipenv may install dependencies that don't work, or not
94 | # install all needed dependencies.
95 | #Pipfile.lock
96 |
97 | # poetry
98 | # Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
99 | # This is especially recommended for binary packages to ensure reproducibility, and is more
100 | # commonly ignored for libraries.
101 | # https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
102 | #poetry.lock
103 |
104 | # pdm
105 | # Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
106 | #pdm.lock
107 | # pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
108 | # in version control.
109 | # https://pdm.fming.dev/#use-with-ide
110 | .pdm.toml
111 |
112 | # PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
113 | __pypackages__/
114 |
115 | # Celery stuff
116 | celerybeat-schedule
117 | celerybeat.pid
118 |
119 | # SageMath parsed files
120 | *.sage.py
121 |
122 | # Environments
123 | .env
124 | .venv
125 | env/
126 | venv/
127 | ENV/
128 | env.bak/
129 | venv.bak/
130 |
131 | # Spyder project settings
132 | .spyderproject
133 | .spyproject
134 |
135 | # Rope project settings
136 | .ropeproject
137 |
138 | # mkdocs documentation
139 | /site
140 |
141 | # mypy
142 | .mypy_cache/
143 | .dmypy.json
144 | dmypy.json
145 |
146 | # Pyre type checker
147 | .pyre/
148 |
149 | # pytype static type analyzer
150 | .pytype/
151 |
152 | # Cython debug symbols
153 | cython_debug/
154 |
155 | # PyCharm
156 | # JetBrains specific template is maintained in a separate JetBrains.gitignore that can
157 | # be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
158 | # and can be added to the global gitignore or merged into this file. For a more nuclear
159 | # option (not recommended) you can uncomment the following to ignore the entire idea folder.
160 | #.idea/
161 |
162 | .streamlit/
163 | .hide/
164 | *.db
165 | *.bin
166 | *.pickle
167 | *.sqlite3
168 | .DS_Store
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # LLM-Powered Document Editor: DSPy & LangChain Integration for Intelligent Writing (OpenRouter/OpenAI/Deepseek/Gemini/Github/Ollama)
2 |
3 | [](https://x.com/firstoryapp)
4 | [](https://doc-editor.streamlit.app)
5 |
6 | **An intelligent writing assistant with multi-LLM integration for enhanced content creation and editing.**
7 |
8 | [](https://github.com/user-attachments/assets/f37c4dd5-423c-4406-a08d-51f67942ac7b)
9 |
10 | Leverage DSPy's LLM orchestration and LangChain's document processing to create, refine, and manage content with unprecedented efficiency. Ideal for technical writers, content creators, and knowledge workers seeking intelligent document editing.
11 |
12 | ## 📚 Table of Contents
13 | - [LLM-Powered Document Editor: DSPy \& LangChain Integration for Intelligent Writing (OpenRouter/OpenAI/Deepseek/Gemini/Github/Ollama)](#llm-powered-document-editor-dspy--langchain-integration-for-intelligent-writing-openrouteropenaideepseekgeminigithubollama)
14 | - [📚 Table of Contents](#-table-of-contents)
15 | - [🚀 Quick Start](#-quick-start)
16 | - [✨ Intelligent Document Workflows](#-intelligent-document-workflows)
17 | - [1. Content Creation Phase](#1-content-creation-phase)
18 | - [2. AI Collaboration Phase](#2-ai-collaboration-phase)
19 | - [3. Finalization \& Management](#3-finalization--management)
20 | - [⚙️ System Architecture](#️-system-architecture)
21 | - [🔧 Technical Stack](#-technical-stack)
22 | - [📄 License](#-license)
23 |
24 | ## 🚀 Quick Start
25 |
26 | Try the live demo immediately:
27 | [](https://doc-editor.streamlit.app)
28 |
29 | 1. Clone repository:
30 | ```
31 | git clone https://github.com/clchinkc/streamlit-editor.git
32 | python -m venv venv
33 | source venv/bin/activate # Unix/MacOS
34 | # .\venv\Scripts\activate # Windows
35 | ```
36 |
37 | 2. Install dependencies:
38 | ```
39 | pip install -r requirements.txt
40 | ```
41 |
42 | 3. Configure Streamlit secrets:
43 | ```bash
44 | mkdir -p .streamlit
45 | touch .streamlit/secrets.toml
46 | ```
47 |
48 | Add the following to `.streamlit/secrets.toml`:
49 | ```toml
50 | # API Keys (at least one required)
51 | [openrouter]
52 | OPENROUTER_API_KEY = "your_openrouter_api_key"
53 | OPENROUTER_MODEL = "your_openrouter_model"
54 |
55 | [openai]
56 | OPENAI_API_KEY = "your_openai_api_key"
57 |
58 | [deepseek]
59 | DEEPSEEK_API_KEY = "your_deepseek_api_key"
60 |
61 | [gemini]
62 | GEMINI_API_KEY = "your_gemini_api_key"
63 |
64 | [github]
65 | GITHUB_TOKEN = "your_github_token"
66 |
67 | [ollama]
68 | OLLAMA_MODEL = "your_ollama_model"
69 | ```
70 |
71 | 4. (If you want to use Ollama) Setup Ollama:
72 |
73 | First, install [Ollama](https://ollama.com/download).
74 |
75 | Then start Ollama server with the specified model:
76 | ```
77 | ollama run your_ollama_model
78 | ```
79 |
80 | 5. Launch application:
81 | ```
82 | streamlit run streamlit_editor.py
83 | ```
84 | And the app will be running on http://localhost:8501.
85 |
86 | ## ✨ Intelligent Document Workflows
87 |
88 | **Combined Features & User Processes**
89 |
90 | ### 1. Content Creation Phase
91 | - **Multi-format Editing Suite**
92 | - ✍️ Dual-mode editor (Editor + Markdown Preview)
93 | - 📥 File ingestion: Drag-and-drop `.md`/`.txt` support
94 | - 📤 Export flexibility: Download markdown or clipboard copy
95 |
96 | - **Structural Tools**
97 | - 🗂️ LangChain-powered document chunking
98 | - 📚 Section-level editing
99 |
100 | ### 2. AI Collaboration Phase
101 | - **Context-Aware Assistance**
102 | - 🤖 DSPy-powered feedback suggestions (general or specific to reference text)
103 | - 📑 Automated section summarization
104 | - 🧩 LLM-driven content regeneration
105 | - 📝 Review and compare AI-generated changes
106 |
107 | - **Quality Control**
108 | - 🔍 Semantic feedback tracking with source references
109 | - 📊 Real-time feedback dashboard
110 | - ✅ Accept/reject AI suggestions with diff view
111 |
112 | ### 3. Finalization & Management
113 | - **Output Optimization**
114 | - 🧮 Batch operation processing for bulk edits
115 |
116 | - **Advanced Orchestration**
117 | - 🚦 DSPy-managed suggestion pipeline
118 | - 📜 Version history tracking
119 | - 🌐 Multi-modal previews (raw + rendered views)
120 | - 📄 Pagination for summaries
121 |
122 | ## ⚙️ System Architecture
123 |
124 | [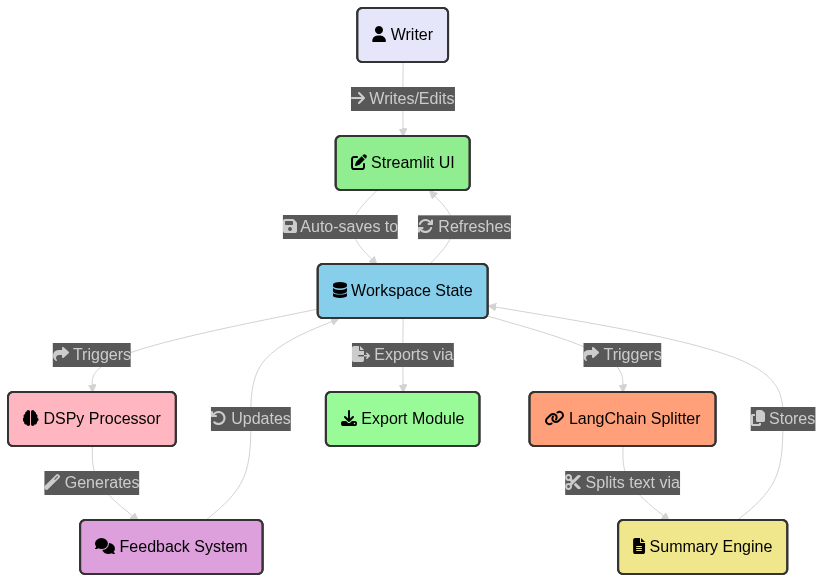](https://mermaid.live/edit#pako:eNqdVV1r2zAU_SvCpWODmGUrpKkfBknsjMEKZW4oDL8o9o0tYusaSW4a2v73XVv-iLvuYdGTPu45urrnSHp2YkzA8Zxdjoc448qwez-SjNrlJbvlQrIVFiVKkEbb-Y0G9TFydtzbcbeiAXtQwoCKnE82IEiEwSEEaMhCo4AXOfU2P_rAB1R7XfIY-tiEG77lGoYlQnIDPcQP74599FbV-dVT7E5hDFrjkMVPLtNVRgF9eC7kfphmYUnpnOa9Bki2PN73gBiLoj53v8LCozZQ9IiwKgquhoR2IgeX56ZbYIFMhRyyD55KVGY4LR5kjjxp59ktJlVuo3sJViglxEagPCk_c91vLx0LVwoPrhJpZqwS-nOtgI6cl1aKU1lGUM0fgS0qg01PM4M1qK_9G5XGUPIKsHvaNgXV7NXo8GEo8BsZRui4Mrb-tCc8GfYoeE3Rlm2QegQqeCpi9h0kKLJEs2cnzFjAEaqSCbJNmXSQN6frlBplh-WRfIfqXcQ_6nGUMfsFO8Jk8Fft38c0dgGrvbWA7iphhyc-CM2R_JuygzAZOxBdfWFdXUIsdlSVGHNUrUM0hUInN-2Rexc30yC4mU60UbgH7-Lq6qrtuweRmMz7Wj5NGgrvYtq0U6YheUs2v14FwfJMskZVy7NeL2erL2fyDL7qyBbT68WZZL1xLJfvL6a-fyZXZ6g2rWkwm6_OpGqfhVbC-Xp5Mz-TqXk0LE8wC2br_ymUM3EKUAUXCX0TzzVr5JgMCnqoPOomXO0jJ5KvFMfpKQnpIjieURVMHIVVmjlk9VzTqGouoS94qnjRz5Zc_kYcxtD49tb-Ss3n9PoHw9cvYQ)
125 |
126 | ## 🔧 Technical Stack
127 |
128 | | Component | Technology | Purpose |
129 | |----------------|-------------------|----------------------------|
130 | | AI Framework | DSPy | LLM operations management |
131 | | Text Processing| LangChain | Document chunking |
132 | | UI Framework | Streamlit | Web interface |
133 | | Visualization | Streamlit Mermaid| Document flow diagrams |
134 |
135 | ## 📄 License
136 |
137 | MIT Licensed - See [LICENSE](LICENSE) for details.
138 |
--------------------------------------------------------------------------------
/streamlit_editor.py:
--------------------------------------------------------------------------------
1 | import streamlit as st
2 | from io import BytesIO
3 | import os
4 | import pickle
5 | from streamlit_quill import st_quill
6 | from dataclasses import dataclass, field
7 | from typing import Optional
8 | import dspy
9 | import requests
10 | from os import getenv
11 | from dsp import LM
12 | from ratelimit import limits
13 | from datetime import datetime
14 | from langchain_text_splitters import RecursiveCharacterTextSplitter
15 | import streamlit_analytics2 as streamlit_analytics
16 | import streamlit_mermaid as stmd
17 | from dotenv import load_dotenv
18 |
19 | load_dotenv()
20 |
21 | class OpenRouterClient(LM):
22 | RL_CALLS=40
23 | RL_PERIOD_SECONDS=60
24 | def __init__(self, api_key=None, base_url="https://openrouter.ai/api/v1", model="meta-llama/llama-3-8b-instruct:free", extra_headers=None, **kwargs):
25 | self.api_key = api_key or getenv("OPENROUTER_API_KEY")
26 | self.base_url = base_url
27 | self.model = model
28 | self.extra_headers = extra_headers or {}
29 | self.history = []
30 | self.provider = "openai"
31 | self.kwargs = {'temperature': 0.0,
32 | 'max_tokens': 150,
33 | 'top_p': 1,
34 | 'frequency_penalty': 0,
35 | 'presence_penalty': 0,
36 | 'n': 1}
37 | self.kwargs.update(kwargs)
38 |
39 | def _get_choice_text(choice):
40 | return choice["message"]["content"]
41 |
42 | def _get_headers(self):
43 | headers = {
44 | "Authorization": f"Bearer {self.api_key}",
45 | "Content-Type": "application/json"
46 | }
47 | headers.update(self.extra_headers)
48 | return headers
49 |
50 | @limits(calls=RL_CALLS, period=RL_PERIOD_SECONDS)
51 | def basic_request(self, prompt: str, **kwargs):
52 | headers = self._get_headers()
53 | data = {
54 | "model": self.model,
55 | "messages": [
56 | {"role": "user", "content": prompt}
57 | ],
58 | **kwargs
59 | }
60 |
61 | response = requests.post(f"{self.base_url}/chat/completions", headers=headers, json=data)
62 | response_data = response.json()
63 | print(response_data)
64 |
65 | self.history.append({
66 | "prompt": prompt,
67 | "response": response_data,
68 | "kwargs": kwargs,
69 | })
70 |
71 | return response_data
72 |
73 | def __call__(self, prompt, **kwargs):
74 | req_kwargs = self.kwargs
75 |
76 | if not kwargs:
77 | req_kwargs.update(kwargs)
78 |
79 | response_data = self.basic_request(prompt, **req_kwargs)
80 | completions = [choice["message"]["content"] for choice in response_data.get("choices", [])]
81 | return completions
82 |
83 | # Dictionary to store available LM configurations
84 | lm_configs = {}
85 |
86 | # Configure OpenRouter LM if API key available in secrets
87 | if "openrouter" in st.secrets:
88 | lm_configs['openrouter'] = OpenRouterClient(
89 | model=st.secrets.openrouter.get("model", "meta-llama/llama-3.3-70b-instruct:free"),
90 | api_key=st.secrets.openrouter.api_key,
91 | api_base=st.secrets.openrouter.get("api_base", "https://openrouter.ai/api/v1")
92 | )
93 |
94 | # Configure OpenAI LM if API key available in secrets
95 | if "openai" in st.secrets:
96 | lm_configs['openai'] = dspy.LM(
97 | model=st.secrets.openai.get("model", "openai/gpt-4o-mini"),
98 | api_key=st.secrets.openai.api_key
99 | )
100 |
101 | # Configure Deepseek LM if API key available in secrets
102 | if "deepseek" in st.secrets:
103 | lm_configs['deepseek'] = dspy.LM(
104 | model=st.secrets.deepseek.get("model", "deepseek-chat"),
105 | api_key=st.secrets.deepseek.api_key
106 | )
107 |
108 | # Configure Gemini LM if API key available in secrets
109 | if "gemini" in st.secrets:
110 | lm_configs['gemini'] = dspy.LM(
111 | model=st.secrets.gemini.get("model", "gemini/gemini-2.0-flash-exp"),
112 | api_key=st.secrets.gemini.api_key
113 | )
114 |
115 | # Configure GitHub LM if credentials available in secrets
116 | if "github" in st.secrets:
117 | lm_configs['github'] = dspy.LM(
118 | model=st.secrets.github.get("model", "openai/gpt-4o-mini"),
119 | api_base=st.secrets.github.get("api_base", "https://models.inference.ai.azure.com"),
120 | api_key=st.secrets.github.api_key
121 | )
122 |
123 | # Configure Ollama LM if configured in secrets
124 | if "ollama" in st.secrets:
125 | lm_configs['ollama'] = dspy.LM(
126 | model=f"ollama_chat/{st.secrets.ollama.get('model', 'llama3')}",
127 | api_base=st.secrets.ollama.get("api_base", "http://localhost:11434"),
128 | api_key=st.secrets.ollama.get("api_key", "")
129 | )
130 |
131 | # Select default LM based on availability
132 | default_lm = None
133 | for lm_name in ['openrouter', 'openai', 'deepseek', 'gemini', 'github', 'ollama']: # Updated priority order
134 | if lm_name in lm_configs:
135 | default_lm = lm_configs[lm_name]
136 | break
137 |
138 | # Ensure LM is loaded at application start
139 | if not dspy.settings.lm:
140 | if default_lm:
141 | dspy.settings.configure(
142 | lm=default_lm,
143 | max_requests_per_minute=15,
144 | trace=[]
145 | )
146 | else:
147 | st.error("No LLM configuration available. Please check your environment variables.")
148 |
149 | # --- Data Models ---
150 | @dataclass
151 | class FeedbackItem:
152 | content: str
153 | reference_text: Optional[str] = None
154 |
155 | @dataclass
156 | class SummaryItem:
157 | title: str
158 | summary: str
159 | original_text: str
160 | start_index: int
161 | end_index: int
162 |
163 | @dataclass
164 | class WorkspaceStats:
165 | """Statistics for workspace analytics"""
166 | word_count: int = 0
167 | section_count: int = 0
168 | last_updated: datetime = field(default_factory=datetime.now)
169 |
170 | @dataclass
171 | class Workspace:
172 | doc_content: Optional[str] = None
173 | ai_modified_text: Optional[str] = None
174 | feedback_items: list[FeedbackItem] = field(default_factory=list)
175 | document_summaries: list[SummaryItem] = field(default_factory=list)
176 | created_at: datetime = field(default_factory=datetime.now)
177 | last_modified: datetime = field(default_factory=datetime.now)
178 | name: Optional[str] = None
179 | description: Optional[str] = None
180 | stats: WorkspaceStats = field(default_factory=WorkspaceStats)
181 |
182 | # --- Workspace Management Functions ---
183 | def create_new_workspace(name: Optional[str] = None) -> str:
184 | """Create a new workspace with a unique ID"""
185 | workspace_id = str(len(st.session_state.workspaces) + 1)
186 | workspace_name = name or f"Workspace {workspace_id}"
187 |
188 | new_workspace = Workspace(
189 | name=workspace_name,
190 | doc_content="",
191 | ai_modified_text=None,
192 | feedback_items=[],
193 | document_summaries=[]
194 | )
195 |
196 | st.session_state.workspaces[workspace_id] = new_workspace
197 | st.session_state.current_workspace_id = workspace_id
198 | save_state_to_disk()
199 | return workspace_id
200 |
201 | def delete_workspace(workspace_id: str):
202 | """Delete a workspace"""
203 | if workspace_id in st.session_state.workspaces:
204 | del st.session_state.workspaces[workspace_id]
205 | if st.session_state.current_workspace_id == workspace_id:
206 | st.session_state.current_workspace_id = None
207 | save_state_to_disk()
208 |
209 | def get_current_workspace() -> Optional[Workspace]:
210 | """Get the current workspace"""
211 | if st.session_state.current_workspace_id:
212 | return st.session_state.workspaces.get(st.session_state.current_workspace_id)
213 | return None
214 |
215 | def switch_workspace(workspace_id: str):
216 | """Switch to a different workspace"""
217 | if workspace_id in st.session_state.workspaces:
218 | st.session_state.current_workspace_id = workspace_id
219 | save_state_to_disk()
220 |
221 | # --- LLM Signatures ---
222 | class ContentReviser(dspy.Signature):
223 | """Signature for content revision task"""
224 | context = dspy.InputField(desc="Optional context or theme for revision")
225 | guidelines = dspy.InputField(desc="Optional guidelines for revision")
226 | text = dspy.InputField(desc="Text to be revised")
227 | revised_content = dspy.OutputField(desc="Revised version of the input text")
228 |
229 | class FeedbackGenerator(dspy.Signature):
230 | """Signature for feedback generation task"""
231 | text = dspy.InputField(desc="Text to generate feedback for")
232 | reference_text = dspy.InputField(desc="Optional specific text to focus feedback on")
233 | feedback = dspy.OutputField(desc="Generated feedback")
234 |
235 | class SummaryGenerator(dspy.Signature):
236 | """Signature for summary generation task"""
237 | text = dspy.InputField(desc="Text to summarize")
238 | title = dspy.OutputField(desc="Section title")
239 | summary = dspy.OutputField(desc="Generated summary")
240 |
241 | # --- LLM Functions ---
242 | def generate_content_revision(text: str, context: Optional[str] = None, guidelines: Optional[str] = None) -> str:
243 | """Generate revised content using LLM"""
244 | try:
245 | # Ensure LM is loaded
246 | if not dspy.settings.lm:
247 | dspy.settings.configure(lm=default_lm) # Use the configured default LM
248 |
249 | reviser = dspy.Predict(ContentReviser)
250 | result = reviser(
251 | text=text,
252 | context=context or "",
253 | guidelines=guidelines or ""
254 | )
255 | return result.revised_content
256 | except Exception as e:
257 | print(f"Error in content revision: {str(e)}")
258 | return text # Return original text on error
259 |
260 | def generate_feedback_revision(text: str, feedback_list: list[str]) -> tuple[str, str]:
261 | """Generate revised content based on feedback items, returns both original and revised text"""
262 | try:
263 | # Ensure LM is loaded
264 | if not dspy.settings.lm:
265 | dspy.settings.configure(lm=default_lm)
266 |
267 | # Combine feedback into guidelines
268 | guidelines = "\n".join([f"- {item}" for item in feedback_list])
269 | reviser = dspy.Predict(ContentReviser)
270 | result = reviser(
271 | text=text,
272 | context="Revise based on feedback",
273 | guidelines=guidelines
274 | )
275 | return text, result.revised_content
276 | except Exception as e:
277 | print(f"Error in feedback revision: {str(e)}")
278 | return text, text
279 |
280 | def get_feedback_item(reference_text: Optional[str] = None) -> FeedbackItem:
281 | """Generate a feedback item using LLM"""
282 | try:
283 | # Ensure LM is loaded
284 | if not dspy.settings.lm:
285 | dspy.settings.configure(lm=default_lm) # Use the configured default LM
286 |
287 | # Get current workspace
288 | current_workspace = get_current_workspace()
289 | if not current_workspace or not current_workspace.doc_content:
290 | return FeedbackItem(
291 | content="Unable to generate feedback: No document content available.",
292 | reference_text=reference_text
293 | )
294 |
295 | # Create the generator with the current LM
296 | generator = dspy.Predict(FeedbackGenerator)
297 |
298 | # Generate appropriate prompt based on whether reference text is provided
299 | if reference_text:
300 | result = generator(
301 | text=f"Generate a modification suggestion specifically for the following text within the full document context:\n\nFull Document:\n{current_workspace.doc_content}\n\nSelected Text:\n{reference_text}\n\nMake sure to only provide one concise modification suggestion without actual text, no original text.",
302 | reference_text=reference_text
303 | )
304 | else:
305 | result = generator(
306 | text=f"Generate a general document modification suggestion for the following text:\n\n{current_workspace.doc_content}\n\nMake sure to only provide one concise modification suggestion without actual text, no original text.",
307 | reference_text=""
308 | )
309 |
310 | # Create and return the feedback item
311 | return FeedbackItem(
312 | content=result.feedback,
313 | reference_text=reference_text
314 | )
315 | except Exception as e:
316 | print(f"Error generating feedback: {str(e)}")
317 | return FeedbackItem(
318 | content=f"Unable to generate feedback at this time. Error generating feedback: {str(e)}",
319 | reference_text=reference_text
320 | )
321 |
322 | def generate_document_summary(text: str) -> list[SummaryItem]:
323 | """Generate document summaries using LLM"""
324 | try:
325 | # Split text into sections (simplified version)
326 | sections = split_into_sections(text)
327 | summaries = []
328 |
329 | generator = dspy.Predict(SummaryGenerator)
330 |
331 | for i, section_text in enumerate(sections):
332 | result = generator(text=section_text)
333 | start_idx = len(''.join(sections[:i]))
334 | end_idx = start_idx + len(section_text)
335 |
336 | summaries.append(SummaryItem(
337 | title=result.title,
338 | summary=result.summary,
339 | original_text=section_text,
340 | start_index=start_idx,
341 | end_index=end_idx
342 | ))
343 |
344 | # Update section count in the current workspace
345 | current_workspace = get_current_workspace()
346 | if current_workspace:
347 | current_workspace.document_summaries = summaries
348 | update_workspace_stats(current_workspace)
349 |
350 | return summaries
351 | except Exception as e:
352 | print(f"Error generating summaries: {str(e)}")
353 | return []
354 |
355 | def regenerate_summary(text: str) -> str:
356 | """Regenerate a single summary using LLM"""
357 | try:
358 | generator = dspy.Predict(SummaryGenerator)
359 | result = generator(text=text)
360 | return result.summary
361 | except Exception as e:
362 | print(f"Error regenerating summary: {str(e)}")
363 | return f"Error generating summary: {str(e)}"
364 |
365 | def split_into_sections(text: str, min_section_length: int = 500) -> list[str]:
366 | """Split text into logical sections using Langchain's RecursiveCharacterTextSplitter"""
367 | # Initialize the recursive splitter
368 | splitter = RecursiveCharacterTextSplitter(
369 | chunk_size=min_section_length,
370 | chunk_overlap=0,
371 | separators=["\n## ", "\n# ", "\n### ", "\n#### ", "\n##### ", "\n###### ", "\n\n", "\n", " ", ""]
372 | )
373 |
374 | # First try to split by markdown headers
375 | sections = splitter.split_text(text)
376 |
377 | # If no sections were created (or only one large section), fall back to character-based splitting
378 | if len(sections) <= 1:
379 | splitter = RecursiveCharacterTextSplitter(
380 | chunk_size=min_section_length,
381 | chunk_overlap=0,
382 | separators=["\n\n", "\n", " ", ""]
383 | )
384 | sections = splitter.split_text(text)
385 |
386 | # Ensure we always return at least one section
387 | return sections if sections else [text]
388 |
389 | # --- App Configuration ---
390 | if 'read_mode' not in st.session_state:
391 | st.session_state.read_mode = False
392 |
393 | st.set_page_config(
394 | page_title="Document Management with Generative AI",
395 | layout="wide",
396 | initial_sidebar_state="collapsed" if st.session_state.get('read_mode', False) else "expanded",
397 | menu_items={
398 | 'Get Help': 'https://x.com/StockchatEditor',
399 | 'Report a bug': "https://x.com/StockchatEditor",
400 | }
401 | )
402 |
403 | streamlit_analytics.start_tracking(load_from_json=".streamlit/analytics.json")
404 |
405 | # --- Helper Functions ---
406 | def load_document(file):
407 | """Load markdown document with empty document handling"""
408 | try:
409 | content = file.read().decode('utf-8')
410 | return content
411 | except Exception as e:
412 | st.error(f"Error loading document: {str(e)}")
413 | return "" # Return empty string as fallback
414 |
415 | def save_document(content: str) -> BytesIO:
416 | """Save document content to bytes"""
417 | byte_io = BytesIO()
418 | byte_io.write(content.encode('utf-8'))
419 | byte_io.seek(0)
420 | return byte_io
421 |
422 | def validate_text_selection(full_text: str, selected_text: str) -> bool:
423 | """
424 | Validates if the selected text is actually part of the full document
425 | """
426 | return selected_text.strip() in full_text
427 |
428 | def update_workspace_stats(workspace: Workspace) -> None:
429 | """Update workspace statistics"""
430 | if not workspace.doc_content:
431 | workspace.stats = WorkspaceStats()
432 | return
433 |
434 | # Calculate word count
435 | words = workspace.doc_content.split()
436 | word_count = len(words)
437 |
438 | # Get section count
439 | section_count = len(workspace.document_summaries)
440 |
441 | # Update stats
442 | workspace.stats = WorkspaceStats(
443 | word_count=word_count,
444 | section_count=section_count,
445 | last_updated=datetime.now()
446 | )
447 |
448 | def save_state_to_disk():
449 | """Save all workspaces to disk"""
450 | state_data = {
451 | 'workspaces': {
452 | workspace_id: {
453 | 'doc_content': workspace.doc_content,
454 | 'ai_modified_text': workspace.ai_modified_text,
455 | 'feedback_items': [
456 | {'content': item.content, 'reference_text': item.reference_text}
457 | for item in workspace.feedback_items
458 | ],
459 | 'document_summaries': [
460 | {
461 | 'title': item.title,
462 | 'summary': item.summary,
463 | 'original_text': item.original_text,
464 | 'start_index': item.start_index,
465 | 'end_index': item.end_index
466 | }
467 | for item in workspace.document_summaries
468 | ],
469 | 'name': workspace.name,
470 | 'description': workspace.description,
471 | 'created_at': workspace.created_at.isoformat(),
472 | 'last_modified': workspace.last_modified.isoformat(),
473 | 'stats': {
474 | 'word_count': workspace.stats.word_count,
475 | 'section_count': workspace.stats.section_count,
476 | 'last_updated': workspace.stats.last_updated.isoformat()
477 | }
478 | }
479 | for workspace_id, workspace in st.session_state.workspaces.items()
480 | },
481 | 'current_workspace_id': st.session_state.current_workspace_id
482 | }
483 |
484 | os.makedirs('.streamlit', exist_ok=True)
485 | with open('.streamlit/doc_state.pkl', 'wb') as f:
486 | pickle.dump(state_data, f)
487 |
488 | def load_state_from_disk():
489 | """Load workspaces from disk"""
490 | try:
491 | with open('.streamlit/doc_state.pkl', 'rb') as f:
492 | state_data = pickle.load(f)
493 |
494 | workspaces = {}
495 | for workspace_id, workspace_data in state_data.get('workspaces', {}).items():
496 | stats_data = workspace_data.get('stats', {})
497 | workspaces[workspace_id] = Workspace(
498 | doc_content=workspace_data.get('doc_content'),
499 | ai_modified_text=workspace_data.get('ai_modified_text'),
500 | feedback_items=[
501 | FeedbackItem(
502 | content=item['content'],
503 | reference_text=item.get('reference_text')
504 | )
505 | for item in workspace_data.get('feedback_items', [])
506 | ],
507 | document_summaries=[
508 | SummaryItem(
509 | title=item['title'],
510 | summary=item['summary'],
511 | original_text=item['original_text'],
512 | start_index=item['start_index'],
513 | end_index=item['end_index']
514 | )
515 | for item in workspace_data.get('document_summaries', [])
516 | ],
517 | name=workspace_data.get('name'),
518 | description=workspace_data.get('description'),
519 | created_at=datetime.fromisoformat(workspace_data.get('created_at')),
520 | last_modified=datetime.fromisoformat(workspace_data.get('last_modified')),
521 | stats=WorkspaceStats(
522 | word_count=stats_data.get('word_count', 0),
523 | section_count=stats_data.get('section_count', 0),
524 | last_updated=datetime.fromisoformat(stats_data.get('last_updated', workspace_data.get('created_at')))
525 | )
526 | )
527 |
528 | st.session_state.workspaces = workspaces
529 | st.session_state.current_workspace_id = state_data.get('current_workspace_id')
530 | except FileNotFoundError:
531 | st.session_state.workspaces = {}
532 | st.session_state.current_workspace_id = None
533 | except Exception as e:
534 | st.error(f"Error loading state: {str(e)}")
535 | st.session_state.workspaces = {}
536 | st.session_state.current_workspace_id = None
537 |
538 | def regenerate_document_from_summaries(summaries: list[SummaryItem]) -> str:
539 | """Reconstruct document from summaries"""
540 | return '\n\n'.join(item.original_text for item in summaries)
541 |
542 | @st.fragment
543 | def ai_assistant_column():
544 | current_workspace = get_current_workspace()
545 | if not current_workspace:
546 | return
547 |
548 | st.title("AI Assistant")
549 | tab1, tab2, tab3 = st.tabs(["All Feedback", "Custom Feedback", "Flowchart"])
550 |
551 | with tab1:
552 | # Display existing feedback items
553 | if current_workspace.feedback_items:
554 | for idx, item in enumerate(current_workspace.feedback_items):
555 | cols = st.columns([0.1, 0.75, 0.15])
556 |
557 | # Checkbox column
558 | with cols[0]:
559 | checkbox_key = f"feedback_checkbox_{idx}"
560 | if checkbox_key not in st.session_state:
561 | st.session_state[checkbox_key] = False
562 |
563 | # Update checkbox state
564 | st.session_state[checkbox_key] = st.checkbox(
565 | "Select feedback",
566 | value=st.session_state[checkbox_key],
567 | key=f"checkbox_display_{idx}",
568 | label_visibility="collapsed"
569 | )
570 |
571 | # Content column
572 | with cols[1]:
573 | st.markdown(f"**{item.content}**")
574 |
575 | # Delete button column
576 | with cols[2]:
577 | if st.button("🗑️", key=f"delete_feedback_{idx}"):
578 | current_workspace.feedback_items.pop(idx)
579 | # Clean up checkbox state
580 | if f"feedback_checkbox_{idx}" in st.session_state:
581 | del st.session_state[f"feedback_checkbox_{idx}"]
582 | save_state_to_disk()
583 | st.rerun()
584 |
585 | # Reference text expander
586 | if item.reference_text:
587 | with st.expander("📌 View referenced text", expanded=False):
588 | st.markdown(f"{item.reference_text}")
589 | else:
590 | st.info("No feedback items yet. Add feedback using the Custom Feedback tab.")
591 |
592 | # Get currently selected feedback items
593 | currently_selected_feedback = [
594 | item.content for idx, item in enumerate(current_workspace.feedback_items)
595 | if st.session_state.get(f"feedback_checkbox_{idx}", False)
596 | ]
597 |
598 | # Apply feedback button
599 | st.markdown("
", unsafe_allow_html=True)
600 |
601 | if st.button(
602 | "✨ Apply Selected Feedback",
603 | key="apply_feedback",
604 | type="primary",
605 | disabled=not currently_selected_feedback,
606 | use_container_width=True
607 | ):
608 | try:
609 | if current_workspace.doc_content and currently_selected_feedback:
610 | # Generate revised content
611 | original_text, revised_text = generate_feedback_revision(
612 | current_workspace.doc_content,
613 | currently_selected_feedback
614 | )
615 |
616 | # Store texts in session state
617 | st.session_state.original_text = original_text
618 | st.session_state.revised_text = revised_text
619 |
620 | # Show success message in current tab
621 | st.success("✨ Changes ready for review! Switch to the 'Review Change' tab (🔄 icon) to compare and apply changes.")
622 |
623 | except Exception as e:
624 | st.error(f"Error applying feedback: {str(e)}")
625 |
626 | with tab2:
627 | # Replace clipboard paste with text input
628 | selected_text = st.text_area(
629 | "📋 Paste Text Here",
630 | key="text_input_for_feedback",
631 | help="Paste the text you want feedback on",
632 | placeholder="Paste your text here..."
633 | )
634 |
635 | if selected_text:
636 | if current_workspace.doc_content and selected_text.strip() in current_workspace.doc_content:
637 | st.session_state.referenced_text = selected_text.strip()
638 | else:
639 | st.error("⚠️ Entered text was not found in the document.")
640 |
641 | # Show referenced text if it exists
642 | if hasattr(st.session_state, 'referenced_text') and st.session_state.referenced_text:
643 | st.info(f"📌 Selected text: '{st.session_state.referenced_text}'")
644 |
645 | # AI Feedback buttons
646 | col1, col2 = st.columns(2)
647 | with col1:
648 | if st.button(
649 | "🤖 Get General Feedback",
650 | key="get_general_feedback",
651 | type="secondary",
652 | use_container_width=True
653 | ):
654 | new_feedback = get_feedback_item()
655 | current_workspace.feedback_items.append(new_feedback)
656 | st.rerun(scope="fragment")
657 |
658 | with col2:
659 | if st.button(
660 | "🎯 Get Selected Text Feedback",
661 | key="get_selected_feedback",
662 | type="secondary",
663 | use_container_width=True,
664 | disabled=not hasattr(st.session_state, 'referenced_text') or not st.session_state.referenced_text
665 | ):
666 | new_feedback = get_feedback_item(reference_text=st.session_state.referenced_text)
667 | current_workspace.feedback_items.append(new_feedback)
668 | st.session_state.referenced_text = ""
669 | st.rerun(scope="fragment")
670 |
671 | st.markdown("
", unsafe_allow_html=True)
672 |
673 | # Custom feedback input
674 | new_feedback = st.text_area(
675 | "Custom Feedback:",
676 | value="",
677 | height=100,
678 | placeholder="Enter your feedback here...",
679 | key=f"feedback_input_{len(st.session_state.get('feedback_items', []))}"
680 | )
681 |
682 | # Add feedback button
683 | if st.button(
684 | "✍️ Add Custom Feedback",
685 | key="add_custom_feedback",
686 | type="primary",
687 | use_container_width=True
688 | ):
689 | if new_feedback.strip():
690 | new_item = FeedbackItem(
691 | content=new_feedback.strip(),
692 | reference_text=st.session_state.get('referenced_text', '')
693 | )
694 | current_workspace.feedback_items.append(new_item)
695 | st.session_state.referenced_text = ""
696 | st.rerun(scope="fragment")
697 |
698 | with tab3:
699 | if current_workspace.document_summaries:
700 | # Generate Mermaid flowchart code
701 | mermaid_code = """
702 | graph TD
703 | classDef default fill:#2D2D2D,stroke:#666666,color:#000000
704 | """
705 | # Add nodes
706 | for idx, summary in enumerate(current_workspace.document_summaries):
707 | # Escape special characters and limit title length
708 | safe_title = summary.title.replace('"', "'").replace(':', ' -')[:30]
709 | mermaid_code += f' node{idx}["{safe_title}"]\n'
710 |
711 | # Add connections
712 | for idx in range(len(current_workspace.document_summaries) - 1):
713 | mermaid_code += f' node{idx} --> node{idx + 1}\n'
714 |
715 | try:
716 | stmd.st_mermaid(mermaid_code, height=600)
717 | st.caption("Document flow based on generated summaries")
718 | except Exception as e:
719 | st.error(f"Error rendering flowchart: {str(e)}")
720 | st.code(mermaid_code, language="mermaid")
721 | else:
722 | st.info("No summaries available. Generate summaries in the Document view first.")
723 |
724 | # --- Session State ---
725 | # Remove these legacy entries
726 | if "doc_content" in st.session_state:
727 | del st.session_state.doc_content
728 | if "ai_modified_text" in st.session_state:
729 | del st.session_state.ai_modified_text
730 | if "feedback_items" in st.session_state:
731 | del st.session_state.feedback_items
732 | if "document_summaries" in st.session_state:
733 | del st.session_state.document_summaries
734 |
735 | # Initialize state
736 | if "initialized" not in st.session_state:
737 | load_state_from_disk()
738 | st.session_state.initialized = True
739 | if 'quill_editor_key' not in st.session_state:
740 | st.session_state.quill_editor_key = 0
741 |
742 | # Keep only workspace-related state
743 | if "workspaces" not in st.session_state:
744 | st.session_state.workspaces = {}
745 | if "current_workspace_id" not in st.session_state:
746 | st.session_state.current_workspace_id = None
747 |
748 | # Add show_ai_assistant initialization
749 | if "show_ai_assistant" not in st.session_state:
750 | st.session_state.show_ai_assistant = True
751 | if "read_mode" not in st.session_state:
752 | st.session_state.read_mode = False
753 | # Initialize current_summary_page
754 | if "current_summary_page" not in st.session_state:
755 | st.session_state.current_summary_page = 0
756 |
757 | # --- Sidebar ---
758 | with st.sidebar:
759 | # AI Assistant toggle
760 | st.session_state.show_ai_assistant = st.toggle(
761 | "🤖 Show AI Assistant",
762 | value=st.session_state.show_ai_assistant
763 | )
764 |
765 | st.title("Workspace Manager")
766 |
767 | # Workspace Controls
768 | if st.button("➕ Create Workspace",
769 | use_container_width=True,
770 | key="create_workspace_btn"):
771 | new_id = create_new_workspace()
772 | st.success(f"Created new workspace: {st.session_state.workspaces[new_id].name}")
773 | st.rerun()
774 |
775 | if st.session_state.workspaces:
776 | # Compact workspace selector with rename functionality
777 | workspace_names = {
778 | wid: ws.name for wid, ws in st.session_state.workspaces.items()
779 | }
780 |
781 | # Display current workspace name with edit button
782 | if st.session_state.current_workspace_id:
783 | current_ws = st.session_state.workspaces[st.session_state.current_workspace_id]
784 | col1, col2 = st.columns([0.7, 0.3])
785 | with col1:
786 | new_name = st.text_input(
787 | "Workspace Name",
788 | value=current_ws.name,
789 | label_visibility="collapsed",
790 | placeholder="Workspace name"
791 | )
792 | if new_name and new_name != current_ws.name:
793 | current_ws.name = new_name
794 | save_state_to_disk()
795 | st.rerun()
796 | with col2:
797 | if st.button("✏️", help="Rename workspace"):
798 | st.rerun()
799 |
800 | # Workspace switcher
801 | selected_workspace = st.selectbox(
802 | "Switch Workspace",
803 | options=list(workspace_names.keys()),
804 | format_func=lambda x: workspace_names[x],
805 | index=list(workspace_names.keys()).index(st.session_state.current_workspace_id)
806 | if st.session_state.current_workspace_id else 0,
807 | label_visibility="collapsed"
808 | )
809 |
810 | if selected_workspace != st.session_state.current_workspace_id:
811 | switch_workspace(selected_workspace)
812 | st.rerun()
813 |
814 | # Delete button
815 | if st.session_state.current_workspace_id:
816 | if st.button("🗑️ Delete Workspace", use_container_width=True):
817 | delete_workspace(st.session_state.current_workspace_id)
818 | st.rerun()
819 |
820 | st.markdown("
", unsafe_allow_html=True)
821 |
822 | # Document Management Section (workspace-specific)
823 | current_workspace = get_current_workspace()
824 | if current_workspace:
825 | uploaded_file = st.file_uploader("Upload a Document", type=["md", "txt"])
826 |
827 | # Track file upload state
828 | if "last_uploaded_file" not in st.session_state:
829 | st.session_state.last_uploaded_file = None
830 |
831 | # Handle both upload and removal cases
832 | if uploaded_file is not None:
833 | # New file uploaded
834 | if st.session_state.last_uploaded_file != uploaded_file.name:
835 | try:
836 | content = load_document(uploaded_file)
837 | current_workspace.doc_content = content
838 | current_workspace.ai_modified_text = None
839 | current_workspace.document_summaries = []
840 | update_workspace_stats(current_workspace)
841 |
842 | # Force Quill editor to update
843 | st.session_state.quill_editor_key = st.session_state.get('quill_editor_key', 0) + 1
844 | st.session_state.last_uploaded_file = uploaded_file.name
845 | save_state_to_disk()
846 | st.rerun()
847 |
848 | except Exception as e:
849 | st.error(f"Error processing document: {str(e)}")
850 | current_workspace.doc_content = ""
851 | else:
852 | # File was removed
853 | if st.session_state.last_uploaded_file is not None:
854 | st.session_state.last_uploaded_file = None
855 | st.session_state.quill_editor_key = st.session_state.get('quill_editor_key', 0) + 1
856 | st.rerun()
857 |
858 | # Download Document button
859 | if current_workspace.doc_content:
860 | doc_name = current_workspace.name.replace(" ", "_").lower() if current_workspace.name else "document"
861 | st.download_button(
862 | "⬇️ Download Document",
863 | data=current_workspace.doc_content,
864 | file_name=f"{doc_name}.md",
865 | mime="text/markdown",
866 | use_container_width=True
867 | )
868 |
869 | # Add separator
870 | st.markdown("
", unsafe_allow_html=True)
871 |
872 | # Update the styles
873 | st.markdown("""
874 |
934 | """, unsafe_allow_html=True)
935 |
936 | # --- Main App ---
937 |
938 | current_workspace = get_current_workspace()
939 |
940 | if current_workspace is None:
941 | st.write("
", unsafe_allow_html=True)
942 | st.info("Create a new workspace to get started.")
943 | else:
944 | if st.session_state.read_mode:
945 | # Exit read mode button
946 | st.write("
", unsafe_allow_html=True)
947 | st.write("
", unsafe_allow_html=True)
948 | if st.button("✕ Exit Read Mode", key="exit_read_mode", type="secondary", use_container_width=True):
949 | st.session_state.read_mode = False
950 | st.rerun()
951 |
952 | # Display content in read mode
953 | st.markdown('', unsafe_allow_html=True)
954 |
955 | # Display the document content
956 | if current_workspace.doc_content:
957 | paragraphs = current_workspace.doc_content.split('\n')
958 | for paragraph in paragraphs:
959 | if paragraph.strip(): # Only display non-empty paragraphs
960 | st.markdown(paragraph)
961 |
962 | st.markdown('
', unsafe_allow_html=True)
963 |
964 | # Add class to body for read mode styles
965 | st.markdown("""
966 |
969 | """, unsafe_allow_html=True)
970 | else:
971 | # Create columns based on AI assistant visibility
972 | if st.session_state.show_ai_assistant:
973 | doc_col, ai_col = st.columns([0.7, 0.3])
974 | else:
975 | doc_col = st.container()
976 |
977 | # Document Editor Column
978 | with doc_col:
979 | st.title("Document Editor")
980 |
981 | # Create tabs for Document, Summary, and Review Change views
982 | doc_tab, summary_tab, review_tab = st.tabs(["📄 Document", "📑 Summary", "🔄 Review Change"])
983 |
984 | with doc_tab:
985 | # Initialize content with empty string if None
986 | editor_content = current_workspace.doc_content if current_workspace.doc_content is not None else ""
987 | content = st_quill(
988 | value=editor_content,
989 | placeholder="Start writing...",
990 | key=f"quill_editor_{st.session_state.get('quill_editor_key', 0)}" # Dynamic key
991 | )
992 |
993 | if content != current_workspace.doc_content:
994 | current_workspace.doc_content = content
995 | update_workspace_stats(current_workspace)
996 | save_state_to_disk()
997 |
998 | with summary_tab:
999 | if current_workspace.doc_content:
1000 | # Keep only the manual regenerate button
1001 | if st.button("🔄 Regenerate All Summaries", type="primary", use_container_width=True):
1002 | current_workspace.document_summaries = generate_document_summary(current_workspace.doc_content)
1003 | st.session_state.last_summary_content = current_workspace.doc_content
1004 | update_workspace_stats(current_workspace)
1005 | save_state_to_disk()
1006 | st.rerun()
1007 |
1008 | st.markdown("
", unsafe_allow_html=True)
1009 |
1010 | # If no summaries exist yet, show a message
1011 | if not current_workspace.document_summaries:
1012 | st.info("Click 'Regenerate All Summaries' to generate section summaries.")
1013 | else:
1014 | # Only show pagination and tabs if we have summaries
1015 | # Pagination controls
1016 | items_per_page = 3
1017 | total_summaries = len(current_workspace.document_summaries)
1018 | total_pages = (total_summaries + items_per_page - 1) // items_per_page
1019 | current_page = st.session_state.get("current_summary_page", 0)
1020 |
1021 | # Pagination UI
1022 | if total_pages > 1:
1023 | col_prev, col_page, col_next = st.columns([0.3, 0.4, 0.3])
1024 | with col_prev:
1025 | if st.button("⬅️ Previous",
1026 | disabled=(current_page <= 0),
1027 | key="prev_page",
1028 | type="secondary",
1029 | use_container_width=True):
1030 | st.session_state.current_summary_page -= 1
1031 | st.rerun()
1032 | with col_page:
1033 | st.markdown(
1034 | f"Page {current_page + 1} of {total_pages}
",
1035 | unsafe_allow_html=True
1036 | )
1037 | with col_next:
1038 | if st.button("➡️ Next",
1039 | disabled=(current_page >= total_pages - 1),
1040 | key="next_page",
1041 | type="secondary",
1042 | use_container_width=True):
1043 | st.session_state.current_summary_page += 1
1044 | st.rerun()
1045 |
1046 | # Get current page summaries
1047 | start_idx = current_page * items_per_page
1048 | end_idx = start_idx + items_per_page
1049 | current_summaries = current_workspace.document_summaries[start_idx:end_idx]
1050 |
1051 | # Create tabs for current page summaries
1052 | section_tabs = st.tabs([item.title for item in current_summaries])
1053 |
1054 | # Update all index references to use global_idx
1055 | for idx_in_page, (tab, summary_item) in enumerate(zip(section_tabs, current_summaries)):
1056 | global_idx = start_idx + idx_in_page
1057 | with tab:
1058 | # Section management buttons
1059 | col1, col2 = st.columns(2)
1060 | with col1:
1061 | if st.button("➕ Add Section Below", key=f"add_below_{global_idx}", use_container_width=True):
1062 | new_section = SummaryItem(
1063 | title=f"New Section {len(current_workspace.document_summaries) + 1}",
1064 | summary="New section summary...",
1065 | original_text="New section content...",
1066 | start_index=summary_item.end_index,
1067 | end_index=summary_item.end_index + 1
1068 | )
1069 | current_workspace.document_summaries.insert(global_idx + 1, new_section)
1070 | update_workspace_stats(current_workspace)
1071 | save_state_to_disk()
1072 | st.rerun()
1073 |
1074 | with col2:
1075 | if len(current_workspace.document_summaries) > 1:
1076 | if st.button("🗑️ Delete Section", key=f"delete_{global_idx}", use_container_width=True):
1077 | current_workspace.document_summaries.pop(global_idx)
1078 | update_workspace_stats(current_workspace)
1079 | save_state_to_disk()
1080 | st.rerun()
1081 |
1082 | # Summary section
1083 | summary_col, button_col = st.columns([0.85, 0.15])
1084 | with summary_col:
1085 | edited_summary = st_quill(
1086 | value=summary_item.summary,
1087 | key=f"summary_quill_{global_idx}",
1088 | )
1089 | # Auto-save summary changes
1090 | if edited_summary != summary_item.summary:
1091 | summary_item.summary = edited_summary
1092 | update_workspace_stats(current_workspace)
1093 | save_state_to_disk()
1094 |
1095 | with button_col:
1096 | if st.button(
1097 | "🔄 Regenerate Summary",
1098 | key=f"regenerate_summary_{global_idx}",
1099 | help="Regenerate this summary from original section text",
1100 | use_container_width=True
1101 | ):
1102 | new_summary = regenerate_summary(summary_item.original_text)
1103 | current_workspace.document_summaries[global_idx].summary = new_summary
1104 | update_workspace_stats(current_workspace)
1105 | save_state_to_disk()
1106 | st.rerun()
1107 |
1108 | # Update section button
1109 | if st.button("📝 Update Section Text from Summary", key=f"update_section_{global_idx}", use_container_width=True):
1110 | try:
1111 | new_section_text = generate_content_revision(
1112 | summary_item.original_text,
1113 | context=summary_item.summary,
1114 | guidelines="Revise the text to better match the summary while maintaining the original content's essence."
1115 | )
1116 | current_workspace.document_summaries[global_idx].original_text = new_section_text
1117 | new_doc_content = regenerate_document_from_summaries(current_workspace.document_summaries)
1118 | current_workspace.doc_content = new_doc_content
1119 | if 'quill_editor_key' not in st.session_state:
1120 | st.session_state.quill_editor_key = 0
1121 | st.session_state.quill_editor_key += 1
1122 | update_workspace_stats(current_workspace)
1123 | save_state_to_disk()
1124 | st.success("✅ Section updated! Document content has been updated.")
1125 | st.rerun()
1126 | except Exception as e:
1127 | st.error(f"Error updating section: {str(e)}")
1128 |
1129 | # Original text display
1130 | st.markdown("**Original Text:**")
1131 | paragraphs = summary_item.original_text.split('\n')
1132 | for paragraph in paragraphs:
1133 | if paragraph.strip():
1134 | st.markdown(paragraph)
1135 |
1136 | with review_tab:
1137 | if st.session_state.get('original_text') and st.session_state.get('revised_text'):
1138 | st.info("Compare the original and revised versions below. Accept or reject the changes when ready.")
1139 |
1140 | # Create side-by-side columns for the editors
1141 | col1, col2 = st.columns(2)
1142 |
1143 | with col1:
1144 | st.markdown("**Original Version:**")
1145 | original_content = st_quill(
1146 | value=st.session_state.original_text,
1147 | key="original_quill",
1148 | )
1149 |
1150 | with col2:
1151 | st.markdown("**Revised Version:**")
1152 | revised_content = st_quill(
1153 | value=st.session_state.revised_text,
1154 | key="revised_quill",
1155 | )
1156 |
1157 | # Add some vertical space before the buttons
1158 | st.write("")
1159 |
1160 | # Confirmation buttons
1161 | button_col1, button_col2 = st.columns(2)
1162 | with button_col1:
1163 | if st.button("✅ Accept Changes", type="primary", use_container_width=True):
1164 | # Update document content
1165 | current_workspace.doc_content = st.session_state.revised_text
1166 |
1167 | # Force Quill editor to update
1168 | if 'quill_editor_key' not in st.session_state:
1169 | st.session_state.quill_editor_key = 0
1170 | st.session_state.quill_editor_key += 1
1171 |
1172 | # Get indices of selected feedback items to remove
1173 | indices_to_remove = [
1174 | idx for idx, item in enumerate(current_workspace.feedback_items)
1175 | if st.session_state.get(f"feedback_checkbox_{idx}", False)
1176 | ]
1177 |
1178 | # Remove the applied feedback items
1179 | for idx in sorted(indices_to_remove, reverse=True):
1180 | current_workspace.feedback_items.pop(idx)
1181 | if f"feedback_checkbox_{idx}" in st.session_state:
1182 | del st.session_state[f"feedback_checkbox_{idx}"]
1183 |
1184 | # Reset state
1185 | del st.session_state.original_text
1186 | del st.session_state.revised_text
1187 |
1188 | # Save state and update UI
1189 | save_state_to_disk()
1190 | st.success("✅ Changes applied successfully!")
1191 | st.rerun()
1192 |
1193 | with button_col2:
1194 | if st.button("❌ Reject Changes", type="secondary", use_container_width=True):
1195 | # Reset state
1196 | del st.session_state.original_text
1197 | del st.session_state.revised_text
1198 | st.rerun()
1199 | else:
1200 | st.info("No changes to review. Apply feedback to see the comparison here.")
1201 | if st.button("🔄 Show Change", type="primary", use_container_width=True):
1202 | st.rerun()
1203 |
1204 | # AI Assistant Column (only shown if toggled on)
1205 | if st.session_state.show_ai_assistant:
1206 | with ai_col:
1207 | ai_assistant_column()
1208 |
1209 | # Display section count in the sidebar
1210 | def display_workspace_stats(workspace: Workspace):
1211 | """Display workspace statistics in the sidebar"""
1212 | st.sidebar.markdown("### 📊 Document Stats")
1213 |
1214 | # Display word and section count in columns
1215 | col1, col2 = st.sidebar.columns(2)
1216 | with col1:
1217 | st.metric("Words", workspace.stats.word_count)
1218 | with col2:
1219 | st.metric("Sections", workspace.stats.section_count)
1220 |
1221 | # Display last edit time below
1222 | last_edit = workspace.stats.last_updated
1223 | time_str = last_edit.strftime("%I:%M %p") # Format: HH:MM AM/PM
1224 | date_str = last_edit.strftime("%b %d, %Y") # Format: Month DD, YYYY
1225 |
1226 | st.sidebar.markdown(f"*Last edited: {time_str} on {date_str}*")
1227 |
1228 | # Add separator and analytics button at the bottom
1229 | st.sidebar.markdown("
", unsafe_allow_html=True)
1230 |
1231 | if st.sidebar.button("📊 Open Analytics Dashboard",
1232 | help="Admin use only - Analytics dashboard for monitoring application usage",
1233 | use_container_width=True,
1234 | disabled=True): # Disable the button
1235 | st.query_params["analytics"] = "on"
1236 |
1237 | # Add the display call in the main app
1238 | if current_workspace:
1239 | display_workspace_stats(current_workspace)
1240 |
1241 | streamlit_analytics.stop_tracking(
1242 | unsafe_password=os.environ.get("ANALYTICS_PASSWORD"),
1243 | save_to_json=".streamlit/analytics.json"
1244 | )
1245 |
--------------------------------------------------------------------------------