├── README.md
├── data
├── javabase
│ ├── collection
│ │ ├── ArrayList delete.jpg
│ │ ├── ArrayList delete2.jpg
│ │ ├── ArrayList insert.jpg
│ │ ├── ArrayList insert2.jpg
│ │ ├── LinkedList.jpg
│ │ ├── jmm.jpg
│ │ ├── linkedlist 删除.jpg
│ │ └── linkedlist 插入.jpg
│ ├── image
│ └── thread
│ │ └── jmm.jpg
├── network
│ ├── format.png
│ ├── http无状态.png
│ ├── osi.png
│ ├── tcp-udp.png
│ ├── 三次握手.png
│ ├── 三次握手示意图.png
│ ├── 四次挥手.png
│ └── 状态码.png
└── 公众号.jpg
└── doc
├── db
├── mongodb
│ ├── MongoDB聚合.md
│ ├── MongoDB面试题.md
│ ├── MongonDB索引.md
│ ├── SpringDataMongoDB详细的操作手册.md
│ ├── 复制集(ReplicaSet)应用部署.md
│ └── 复制集(replication).md
└── redis
│ ├── RedisRDB持久化与AOF持久化.md
│ ├── Redis常用的五种数据类型底层结构.md
│ └── Redis的ExpireKey(过期键).md
├── javabase
├── Java对象的浅克隆和深克隆.md
├── StringBuilder在高性能场景下的正确用法.md
├── base
│ └── javabase.md
├── collection
│ ├── ArrayList 源码分析.md
│ ├── ArrayList&Linkedist面试.md
│ ├── ConcurrentHashMap源码和面试题一.md
│ ├── ConcurrentHashMap源码和面试题二.md
│ ├── HashMap 源码详细分析.md
│ ├── HashMap原理和面试题(图解版一).md
│ ├── LinkedHashMap 源码详细分析.md
│ ├── LinkedList.md
│ ├── TreeMap源码分析.md
│ └── collectionbase.md
├── designMode.md
├── jdk版本特性.md
├── jvm
│ ├── ClassLoad.md
│ └── jvmbase.md
├── orm
│ ├── MyBatis常见面试题.md
│ ├── MyBatis架构以及核心内容.md
│ └── Mybatis执行过程.md
├── sql
│ └── mysql
│ │ ├── mysql事务.md
│ │ └── mysql索引.md
├── thread
│ ├── Java多线程与并发之ThreadLocal.md
│ ├── ReentrantLock原理.md
│ ├── Synchronized.md
│ ├── ThreadLocal的内存泄露的原因分析以及如何避免.md
│ ├── Volatile与Synchronized.md
│ ├── threadbase.md
│ └── 并发CAS.md
├── 一篇文章让你彻底了解Java内部类.md
├── 你可能不知道的Java.Integer的缓存策略.md
├── 单例模式.md
├── 必须理解的Java 类的实例化顺序.md
└── 深入浅出Java注解.md
└── network
└── network.md
/README.md:
--------------------------------------------------------------------------------
1 | # JavaCommunity(后端开发必备,技术知识应有尽有)
2 |
3 | > **JavaCommunity开源社区的文章收集来源网络各个平台,如果有侵犯到各位博主,请联系我,我马上删除,谢谢哈,最后请大家多多支持,Star一个!!**
4 |
5 | >欢迎关注:【**JavaCodeHub**】,一起学习
6 | >《提升能力,涨薪可待》
7 | >《面试知识,工作可待》
8 | >《实战演练,拒绝996》
9 | >也欢迎关注微信公众号[【**终端研发部**】](#公众号),id:codeGoogler,原创技术文章第一时间推出
10 | >如果学习社区对你有帮助、喜欢的话,那就点个star呗!
11 |
12 | ## 前言
13 |
14 | >是不是感觉在工作上难于晋升了呢?
15 | >是不是感觉找工作面试是那么难呢?
16 | >是不是感觉自己每天都在996加班呢?
17 | >在工作上必须保持学习的能力,这样才能在工作得到更好的晋升,涨薪指日可待,欢迎一起学习
18 | >在找工作面试应在学习的基础进行总结面试知识点,找工作也指日可待,欢迎一起学习
19 | >最后,理论知识到准备充足,是不是该躬行起来呢?欢迎一起学习
20 |
21 | ## 目录
22 | + [java基础](#Java基础知识)
23 | + [Spring全家桶](#Spring精选面试题)
24 | + [数据库](#SQL数据库)
25 | + [ORM框架](#ORM框架)
26 | + [消息队列](#消息队列)
27 | + [缓存](#缓存)
28 | + [服务调用](#服务调用)
29 | + [注册中心](#注册中心)
30 | + [配置中心](#配置中心)
31 | + [分布式系统](#分布式系统)
32 | + [代码优化](#代码优化)
33 | + [SpringBoot集成](#SpringBoot集成)
34 | + [SpringCloud微服务](#SpringCloud微服务)
35 | + [项目](#项目)
36 | + [服务器](#服务器)
37 | + [Linux](#Linux)
38 | + [计算机网络](#计算机网络)
39 | + [数据结构与算法](#算法)
40 | + [开发工具](#开发工具)
41 | + [面试技巧](#面试技巧)
42 |
43 |
44 |
45 |
46 | ### Java基础
47 |
48 | #### Java基础知识
49 | + [jdk版本特性](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/jdk版本特性.md)
50 | + [Java对象的浅克隆和深克隆](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/Java对象的浅克隆和深克隆.md)
51 | + [StringBuilder在高性能场景下的正确用法](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/StringBuilder在高性能场景下的正确用法.md)
52 | + [深入浅出Java注解](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/深入浅出Java注解.md)
53 | + [一篇文章让你彻底了解Java内部类](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/一篇文章让你彻底了解Java内部类.md)
54 | + [你可能不知道的Java Integer的缓存策略](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/你可能不知道的Java.Integer的缓存策略.md)
55 | + [面试:Java基础知识点(涉及范围广)]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/base/javabase.md )
56 | #### Java集合
57 | + [TreeMap源码分析](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/TreeMap%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md)
58 | + [HashMap 源码详细分析(jdk 1.8)](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/HashMap%20%E6%BA%90%E7%A0%81%E8%AF%A6%E7%BB%86%E5%88%86%E6%9E%90.md)
59 | + [LinkedHashMap 源码详细分析(jdk 1.8)](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/LinkedHashMap%20%E6%BA%90%E7%A0%81%E8%AF%A6%E7%BB%86%E5%88%86%E6%9E%90.md)
60 | + [ArrayList 源码分析](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/ArrayList%20%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.md)
61 | + [LinkedHashMap 源码详细分析](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/LinkedHashMap%20%E6%BA%90%E7%A0%81%E8%AF%A6%E7%BB%86%E5%88%86%E6%9E%90.md)
62 | + [面试-集合基础》](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/collectionbase.md )
63 | + [面试:在面试中关于List(ArrayList、LinkedList)集合会怎么问呢?你该如何回答呢?](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/ArrayList&Linkedist面试.md)
64 | + [面试:为了进阿里,必须掌握HashMap原理和面试题(图解版一)](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/HashMap原理和面试题(图解版一).md)
65 | + [面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(一)](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/ConcurrentHashMap源码和面试题一.md)
66 | + [面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(二)](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/collection/ConcurrentHashMap源码和面试题二.md)
67 |
68 | #### Java多线程与并发
69 | + [面试:多线程与并发基础](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/thread/threadbase.md)
70 | + [面试:为了进阿里,又把并发CAS(Compare and Swap)实现重新精读一遍](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/thread/并发CAS.md)
71 | + [面试:Java并发之Synchronized](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/thread/Synchronized.md)
72 | + [面试:Volatile与Synchronized分析](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/thread/Volatile与Synchronized.md)
73 | + [面试:Java多线程与并发之ThreadLocal](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/thread/Java多线程与并发之ThreadLocal.md)
74 | + [面试:ThreadLocal内存泄露分析以及如何避免](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/thread/ThreadLocal的内存泄露的原因分析以及如何避免.md)
75 | + [面试:为了进阿里,需要深入理解ReentrantLock原理](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/thread/ReentrantLock原理.md)
76 |
77 | #### JVM虚拟机
78 | + [《面试知识,工作可待篇-JVM内存篇》]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/jvm/jvmbase.md )
79 | + [《面试知识,工作可待篇-JVM类加载篇》]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/jvm/ClassLoad.md )
80 |
81 | #### 设计模式
82 |
83 | + [《面试知识-设计模式篇》]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/designMode.md )
84 | + [面试:对于单例模式面试官会怎样提问呢?你又该如何回答呢?]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/单例模式.md )
85 |
86 | ### ORM框架
87 |
88 | #### Mybatis
89 |
90 | + [MyBatis常见面试题](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/orm/MyBatis常见面试题.md)
91 | + [MyBatis面试题分析导读-架构以及核心内容](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/orm/MyBatis架构以及核心内容.md)
92 | + [面试:面试官有没有在Mybatis执行过程上为过难你呢?看完就不再怂(图文解析)](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/orm/Mybatis执行过程.md)
93 |
94 |
95 | ### 数据库
96 | #### SQL数据库
97 | + [理解完这些基本上能解决面试中MySql的事务问题](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/javabase/sql/mysql/mysql事务.md)
98 | + [MySQL查询性能优化前,必须先掌握MySQL索引理论]()
99 | 面试:谈谈你对分库分表的理解
100 | + 面试:MySQL经典的面试题
101 |
102 |
103 | #### NoSQL数据库
104 | ##### redis
105 | + [面试:原来Redis常用的五种数据类型底层结构是这样的]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/redis/Redis常用的五种数据类型底层结构.md )
106 | + [当遇到美女面试官之如何理解Redis的Expire Key(过期键)](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/redis/Redis的ExpireKey(过期键).md)
107 | + [面试:简明的图解Redis RDB持久化、AOF持久化](https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/redis/RedisRDB持久化与AOF持久化.md)
108 | ##### mongodb
109 | + [面试:快2020年了,赶紧收藏起MongoDB面试题轻松面对BAT灵魂式的拷问]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/mongodb/MongoDB面试题.md )
110 | + [MongoDB--Spring Data MongoDB详细的操作手册(增删改查)]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/mongodb/SpringDataMongoDB详细的操作手册.md )
111 | + [MongoDB系列--深入理解MongoDB聚合(Aggregation )]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/mongodb/MongoDB聚合.md )
112 | + [MongoDB系列--轻松应对面试中遇到的MongonDB索引(index)问题]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/mongodb/MongonDB索引.md )
113 | + [MongoDB系列-在复制集(replication)以及分片(Shard)中创建索引]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/mongodb/复制集(replication).md )
114 | + [MongoDB系列-复制集(Replica Set)应用部署(生产、测试、开发环境)]( https://github.com/Ccww-lx/Ccww-lx.github.io/blob/master/doc/db/mongodb/复制集(ReplicaSet)应用部署.md )
115 | ### Spring全家桶
116 |
117 | #### Spring
118 |
119 | + 《面试知识,工作可待篇-Spring篇》
120 |
121 | #### SpringMVC精选面试题
122 |
123 | + 《面试知识,工作可待篇-Spring MVC篇》
124 |
125 | #### SpringBoot精选面试题
126 |
127 | + 《面试知识,工作可待篇-Spring Boot篇》
128 |
129 | #### SpringCloud精选面试题
130 |
131 | + 《面试知识,工作可待篇-SpringCloud篇》
132 |
133 |
134 |
135 | ### 消息队列
136 |
137 | + 《面试知识,工作可待篇-消息队列知识篇》
138 | + 《面试知识,工作可待篇-RocketMQ篇》
139 | + 《面试知识,工作可待篇-Kafka篇》
140 | + 《面试知识,工作可待篇-RabbitMQ篇》
141 |
142 | ### 缓存
143 |
144 | + 《面试知识,工作可待篇-缓存篇》
145 |
146 | ### 服务调用
147 |
148 | #### Fegin
149 |
150 | + 《面试知识,工作可待篇-SpringCloud Fegin篇》
151 |
152 | #### Dubbo
153 |
154 | + 《面试知识,工作可待篇-Dubbo篇》
155 |
156 | ### 注册中心
157 |
158 | #### Eureka
159 |
160 | + 《面试知识,工作可待篇-Eureka篇》
161 |
162 | #### Zookeeper
163 |
164 | + 《面试知识,工作可待篇-Zookeeper篇》
165 |
166 | ### 配置中心
167 |
168 | #### Apollo
169 |
170 | + 《面试知识,工作可待篇-Apollo篇
171 |
172 | #### SpringCloud Config
173 |
174 | + 《面试知识,工作可待篇-SpringCloud Config篇》
175 |
176 | ### 服务器
177 |
178 | #### Tomcat
179 |
180 | + 《面试知识,工作可待篇-Tomcat篇》
181 |
182 | #### Netty
183 |
184 | + 《面试知识,工作可待篇-Netty篇》
185 |
186 | #### Nginx
187 |
188 | + 《面试知识,工作可待篇-Nginx篇》
189 |
190 | ### Linux
191 |
192 | + 《面试知识,工作可待篇-Linux篇》
193 |
194 | ### 计算机网络
195 |
196 | + [《面试知识,工作可待篇-计算机网络基础篇》](https://github.com/Ccww-lx/JavaCommunity/blob/master/doc/network/network.md )
197 |
198 |
199 | ### 数据结构与算法
200 |
201 | - 《面试知识,工作可待篇-算法面试篇》
202 |
203 | ### 分布式系统
204 |
205 | ### 代码优化
206 |
207 | ### SpringBoot集成
208 |
209 | ### SpringCloud微服务
210 |
211 | ### 工具
212 |
213 | ### 项目
214 |
215 | ### 开发工具
216 |
217 | + 《面试知识,工作可待篇-Maven篇》
218 |
219 | + 《面试知识,工作可待篇-Git篇》
220 |
221 | ### 面试技巧
222 |
223 | + 《面试知识,工作可待篇-面试技巧篇》
224 |
225 |
226 |
227 |
228 |
229 | ## 公众号
230 |
231 | 欢迎关注微信公众号[【**终端研发部**】](https://upload-images.jianshu.io/upload_images/14371339-8bc3926bc154fda1.jpg),原创技术文章第一时间推出 ,并且获取更多资料和视频
232 | 
233 |
--------------------------------------------------------------------------------
/data/javabase/collection/ArrayList delete.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/ArrayList delete.jpg
--------------------------------------------------------------------------------
/data/javabase/collection/ArrayList delete2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/ArrayList delete2.jpg
--------------------------------------------------------------------------------
/data/javabase/collection/ArrayList insert.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/ArrayList insert.jpg
--------------------------------------------------------------------------------
/data/javabase/collection/ArrayList insert2.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/ArrayList insert2.jpg
--------------------------------------------------------------------------------
/data/javabase/collection/LinkedList.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/LinkedList.jpg
--------------------------------------------------------------------------------
/data/javabase/collection/jmm.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/jmm.jpg
--------------------------------------------------------------------------------
/data/javabase/collection/linkedlist 删除.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/linkedlist 删除.jpg
--------------------------------------------------------------------------------
/data/javabase/collection/linkedlist 插入.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/collection/linkedlist 插入.jpg
--------------------------------------------------------------------------------
/data/javabase/image:
--------------------------------------------------------------------------------
1 |
2 |
--------------------------------------------------------------------------------
/data/javabase/thread/jmm.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/javabase/thread/jmm.jpg
--------------------------------------------------------------------------------
/data/network/format.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/format.png
--------------------------------------------------------------------------------
/data/network/http无状态.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/http无状态.png
--------------------------------------------------------------------------------
/data/network/osi.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/osi.png
--------------------------------------------------------------------------------
/data/network/tcp-udp.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/tcp-udp.png
--------------------------------------------------------------------------------
/data/network/三次握手.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/三次握手.png
--------------------------------------------------------------------------------
/data/network/三次握手示意图.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/三次握手示意图.png
--------------------------------------------------------------------------------
/data/network/四次挥手.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/四次挥手.png
--------------------------------------------------------------------------------
/data/network/状态码.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/network/状态码.png
--------------------------------------------------------------------------------
/data/公众号.jpg:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/codeGoogler/JavaCodeHub/45a8287cc8cb6f6a6be374c902d62d40765148c1/data/公众号.jpg
--------------------------------------------------------------------------------
/doc/db/mongodb/MongoDB聚合.md:
--------------------------------------------------------------------------------
1 | **MongoDB中聚合(aggregate)** 操作将来自多个document的value组合在一起,并通过对分组数据进行各种操作处理,并返回计算后的数据结果,主要用于处理数据(诸如统计平均值,求和等)。MongoDB提供三种方式去执行聚合操作:**聚合管道(aggregation pipeline)**、**Map-Reduce函数**以及**单一的聚合命令(count、distinct、group)**。
2 |
3 | ## 1. 聚合管道(aggregation pipeline)
4 | ### 1.1聚合管道
5 | 聚合管道是由aggregation framework将文档进入一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的聚合结果。如图所示:
6 |
7 | 
8 |
9 | **聚合管道操作:**
10 |
11 | db.orders.aggregate([
12 | { $match: { status: "A" } },
13 | { $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
14 | ])
15 |
16 | + **\$match阶段:通过status字段过滤出符合条件的Document(即是Status等于“A”的Document);**
17 | + ** \$group 阶段:按cust_id字段对Document进行分组,以计算每个唯一cust_id的金额总和。**
18 |
19 | ### 1.2 管道
20 | 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数,MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
21 | 最基本的管道功能提供**过滤器filter**,其操作类似于查询和文档转换,可以修改输出文档的形式。
22 | 其他管道操作提供了按特定字段或字段对文档进行分组和排序的工具,以及用于聚合数组内容(包括文档数组)的工具。 此外,管道阶段可以使用运算符执行任务,例如计算平均值或连接字符串。总结如下:
23 |
24 | **管道操作符**
25 | 常用管道|解析
26 | :-|:-|
27 | $group|将collection中的document分组,可用于统计结果
28 | $match|过滤数据,只输出符合结果的文档
29 | $project|修改输入文档的结构(例如重命名,增加、删除字段,创建结算结果等)
30 | $sort|将结果进行排序后输出
31 | $limit|限制管道输出的结果个数
32 | $skip|跳过制定数量的结果,并且返回剩下的结果
33 | $unwind|将数组类型的字段进行拆分
34 |
35 | **表达式操作符**
36 | 常用表达式|含义
37 | :-|:-|
38 | $sum|计算总和,{\$sum: 1}表示返回总和×1的值(即总和的数量),使用{\$sum: '\$制定字段'}也能直接获取制定字段的值的总和
39 | $avg|求平均值
40 | $min|求min值
41 | $max|求max值
42 | $push|将结果文档中插入值到一个数组中
43 | $first|根据文档的排序获取第一个文档数据
44 | $last|同理,获取最后一个数据
45 |
46 | **为了便于理解,将常见的mongo的聚合操作和MySql的查询做类比:**
47 | MongoDB聚合操作|MySql操作/函数
48 | :-|:-|
49 | $match|where
50 | $group|group by
51 | $match|having
52 | $project|select
53 | $sort|order by
54 | $limit|limit
55 | $sum|sum()
56 | $lookup |join
57 |
58 |
59 | ### 1.3 Aggregation Pipeline 优化
60 |
61 | + **聚合管道可以确定它是否仅需要文档中的字段的子集来获得结果。 如果是这样,管道将只使用那些必需的字段,减少通过管道的数据量**
62 | + **管道序列优化化**
63 |
64 |
65 | **管道序列优化化:**
66 | **1).使用\$projector/\$addFields+\$match 序列优化:当Aggregation Pipeline中有多个\$projectior/\$addFields阶段和\$match 阶段时,会先执行有依赖的\$projector/\$addFields阶段,然后会新创建的$match阶段执行,如下,**
67 |
68 | { $addFields: {
69 | maxTime: { $max: "$times" },
70 | minTime: { $min: "$times" }
71 | } },
72 | { $project: {
73 | _id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
74 | avgTime: { $avg: ["$maxTime", "$minTime"] }
75 | } },
76 | { $match: {
77 | name: "Joe Schmoe",
78 | maxTime: { $lt: 20 },
79 | minTime: { $gt: 5 },
80 | avgTime: { $gt: 7 }
81 | } }
82 | **优化执行:**
83 |
84 | { $match: { name: "Joe Schmoe" } },
85 | { $addFields: {
86 | maxTime: { $max: "$times" },
87 | minTime: { $min: "$times" }
88 | } },
89 | { $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } },
90 | { $project: {
91 | _id: 1, name: 1, times: 1, maxTime: 1, minTime: 1,
92 | avgTime: { $avg: ["$maxTime", "$minTime"] }
93 | } },
94 | { $match: { avgTime: { $gt: 7 } } }
95 | **2). \$sort + \$match 以及\$project + \$skip,当\$sort/\$project跟在\$match/\$skip之后时,会先执行\$match/\$skip后再执行\$sort/\$project,\$sort以达到最小化需排列的对象数,\$skip约束,如下:**
96 |
97 | { $sort: { age : -1 } },
98 | { $match: { score: 'A' } }
99 | { $project: { status: 1, name: 1 } },
100 | { $skip: 5 }
101 | **优化执行:**
102 |
103 | { $match: { score: 'A' } },
104 | { $sort: { age : -1 } }
105 | { $skip: 5 },
106 | { $project: { status: 1, name: 1 } }
107 | **3). \$redact+\$match序列优化,当\$redact后有\$match时,可能会新创一个\$match阶段进行优化,如下,**
108 |
109 | { $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "?PRUNE", else: "?DESCEND" } } },
110 | { $match: { year: 2014, category: { $ne: "Z" } } }
111 | **优化执行:**
112 |
113 | { $match: { year: 2014 } },
114 | { $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "?PRUNE", else: "?DESCEND" } } },
115 | { $match: { year: 2014, category: { $ne: "Z" } } }
116 |
117 | 还有很多管道序列优化可以查看《[官方文档-Aggregation Pipeline Optimization](https://docs.mongodb.com/manual/core/aggregation-pipeline-optimization/)》。
118 |
119 | ### 1.4 Aggregation Pipeline以及分片(Sharded)collections
120 | 如果管道以\$match精确分片 key开始的后,所有管道会在匹配的分片上进行。对于需运行在多分片中的聚合(aggregation)操作,如果不不需要在主分片进行的,这些操作后的结果会路由到随机分片中进行合并结果,避免重载该主分片的数据库。\$out和\$look阶段必须在主分片数据库运行。
121 |
122 |
123 | ## 2. Map-Reduce函数
124 | MongoDB还提供map-reduce操作来执行聚合。 通常,**map-reduce操作有两个阶段**:**一个map阶段**,它处理每个文档并为每个输入文档发出一个或多个对象,以及**reduce阶段**组合map操作的输出。 可选地,map-reduce可以具有最终化阶段以对结果进行最终修改。 与其他聚合操作一样,map-reduce可以指定查询条件以选择输入文档以及排序和限制结果。
125 |
126 | Map-reduce使用自定义JavaScript函数来执行映射和减少操作,以及可选的finalize操作。 虽然自定义JavaScript与聚合管道相比提供了极大的灵活性,但通常,map-reduce比聚合管道效率更低,更复杂。模式如下:
127 |
128 | 
129 |
130 |
131 | ## 3. 单一的聚合命令
132 | MongoDB还提供了,db.collection.estimatedDocumentCount(),db.collection.count()和db.collection.distinct()
133 | 所有这些单一的聚合命令。 虽然这些操作提供了对常见聚合过程的简单访问操作,但它们缺乏聚合管道和map-reduce的灵活性和功能。模型如下
134 |
135 | 
136 |
137 | ## 总结
138 | 可使用MongoDB中聚合操作用于数据处理,可以适应于一些数据分析等,聚合的典型应用包括销售数据的业务报表,比如将各地区的数据分组后计算销售总和、财务报表等。最后想要更加深入理解还需要自己去实践。
139 |
140 | **最后可关注公众号,一起学习,每天会分享干货,还有学习视频干货领取!**
141 |
142 | 
143 |
144 |
--------------------------------------------------------------------------------
/doc/db/mongodb/MongoDB面试题.md:
--------------------------------------------------------------------------------
1 |
2 | `MongoDB`是基于分布式文件存储的数据库,由`C++`语言编写。旨在为`WEB`应用提供可扩展的高性能数据存储解决方案,且`MongodDB`是一个介于关系数据库与非关系数据库之间的产品,是非关系型数据库中功能最丰富,最像关系数据库。
3 |
4 | 由于`MongoDB`的特性以及功能,使得其在企业使用频率很大,所以很多面试都会MongoDB的相关知识,基于网上以及自己阅读官网文档总结2019-2020年`MongoDB`的面试题。具体如下:
5 |
6 |
7 |
8 | ### **1Q:`MongoDB`的优势有哪些?**
9 |
10 | * 面向集合(`Collection`)和文档(`document`)的存储,以JSON格式的文档保存数据。
11 |
12 | * 高性能,支持`Document`中嵌入`Document`减少了数据库系统上的I/O操作以及具有完整的索引支持,支持快速查询
13 | * 高效的传统存储方式:支持二进制数据及大型对象
14 | * 高可用性,数据复制集,MongoDB 数据库支持服务器之间的数据复制来提供自动故障转移(`automatic failover`)
15 |
16 | * 高可扩展性,分片(`sharding`)将数据分布在多个数据中心,MongoDB支持基于分片键创建数据区域.
17 |
18 | * 丰富的查询功能, 聚合管道(`Aggregation Pipeline`)、全文搜索(`Text Search`)以及地理空间查询(`Geospatial Queries`)
19 | * 支持多个存储引擎,WiredTiger存储引、In-Memory存储引擎
20 |
21 | ### **2Q:`MongoDB` 支持哪些数据类型?**
22 |
23 | **java类似数据类型:**
24 | |类型|解析|
25 | |:-|:-|
26 | |`String`|字符串。存储数据常用的数据类型。在 `MongoDB` 中,`UTF-8` 编码的字符串才是合法的|
27 | | `Integer`|整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位|
28 | |`Double`|双精度浮点值。用于存储浮点值|
29 | |`Boolean`|布尔值。用于存储布尔值(真/假)|
30 | |`Arrays`|用于将数组或列表或多个值存储为一个键|
31 | |`Datetime`|记录文档修改或添加的具体时间|
32 |
33 | **MongoDB特有数据类型:**
34 | |类型|解析|
35 | |:-|:-|
36 | |`ObjectId`|用于存储文档 `id`,`ObjectId`是基于分布式主键的实现`MongoDB`分片也可继续使用|
37 | |`Min/Max Keys`|将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比|
38 | |`Code`|用于在文档中存储 `JavaScript`代码|
39 | | `Regular Expression`|用于在文档中存储正则表达式|
40 | |`Binary Data`|二进制数据。用于存储二进制数据|
41 | |`Null`|用于创建空值|
42 | |`Object`|用于内嵌文档|
43 |
44 | ### **3Q:什么是集合`Collection`、文档`Document`,以及与关系型数据库术语类比。**
45 |
46 | * 集合`Collection`位于单独的一个数据库MongoDB 文档`Document`集合,它类似关系型数据库(RDBMS)中的表`Table`。一个集合`Collection`内的多个文档`Document`可以有多个不同的字段。通常情况下,集合`Collection`中的文档`Document`有着相同含义。
47 | * 文档`Document`由key-value构成。文档`Document`是动态模式,这说明同一集合里的文档不需要有相同的字段和结构。类似于关系型数据库中table中的每一条记录。
48 | * 与关系型数据库术语类比
49 |
50 | |mongodb|关系型数据库|
51 | |:---|---|
52 | |Database|Database|
53 | |Collection|Table|
54 | |Document|Record/Row|
55 | |Filed|Column|
56 | |Embedded Documents| Table join|
57 |
58 |
59 | ### **4Q:什么是”`Mongod`“,以及`MongoDB`命令。**
60 |
61 | `mongod`是处理`MongoDB`系统的主要进程。它处理数据请求,管理数据存储,和执行后台管理操作。当我们运行`mongod`命令意味着正在启动`MongoDB`进程,并且在后台运行。
62 |
63 | `MongoDB`命令:
64 |
65 | |命令|说明|
66 | |---|----|
67 | |use database_name|切换数据库|
68 | |db.myCollection.find().pretty()|格式化打印结果|
69 | |db.getCollection(collectionName).find()|修改Collection名称|
70 |
71 |
72 | ### **5Q:"`Mongod`"默认参数有?**
73 | * 传递数据库存储路径,默认是`"/data/db"`
74 | * 端口号 默认是 "27017"
75 |
76 | ### **6Q:`MySQL`和`mongodb`的区别**
77 |
78 | |形式|MongoDB|MySQL|
79 | |---|----|----|
80 | |数据库模型|非关系型|关系型|
81 | |存储方式||虚拟内存+持久化|不同的引擎有不同的存储方式|
82 | |查询语句|独特的MongoDB查询方式|传统SQL语句|
83 | |架构特点|副本集以及分片|常见单点、M-S、MHA、MMM等架构方式|
84 | |数据处理方式|基于内存,将热数据存在物理内存中,从而达到高速读写|不同的引擎拥有自己的特点|
85 | |使用场景|事件的记录,内容管理或者博客平台等数据大且非结构化数据的场景|适用于数据量少且很多结构化数据|
86 |
87 |
88 | ### 7Q:问`mongodb`和`redis`区别以及选择原因
89 |
90 | |形式|MongoDB|redis|
91 | |---|---|----|
92 | |内存管理机制|MongoDB 数据存在内存,由 linux系统 mmap 实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘|Redis 数据全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的 LRU 算法删除数据|
93 | |支持的数据结构|MongoDB 数据结构比较单一,但是支持丰富的数据表达,索引|Redis 支持的数据结构丰富,包括hash、set、list等|
94 | |性能|mongodb依赖内存,TPS较高|Redis依赖内存,TPS非常高。性能上Redis优于MongoDB|
95 | |可靠性|支持持久化以及复制集增加可靠性|Redis依赖快照进行持久化;AOF增强可靠性;增强可靠性的同时,影响访问性能|
96 | |数据分析|mongodb内置数据分析功能(mapreduce)|Redis不支持|
97 | |事务支持情况|只支持单文档事务,需要复杂事务支持的场景暂时不适合|Redis 事务支持比较弱,只能保证事务中的每个操作连续执行|
98 | |集群|MongoDB 集群技术比较成熟|Redis从3.0开始支持集群|
99 | **选择原因:**
100 | * 架构简单
101 |
102 | * 没有复杂的连接
103 |
104 | * 深度查询能力,`MongoDB`支持动态查询。
105 |
106 | * 容易调试
107 |
108 | * 容易扩展
109 |
110 | * 不需要转化/映射应用对象到数据库对象
111 |
112 | * 使用内部内存作为存储工作区,以便更快的存取数据。
113 |
114 |
115 | ### **8Q:如何执行事务/加锁?**
116 |
117 | `mongodb`没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能.可以把它类比成`mysql mylsam`的自动提交模式.通过精简对事务的支持,性能得到了提升,特别是在一个可能会穿过多个服务器的系统里.
118 |
119 | ### **9Q:更新操作会立刻fsync到磁盘?**
120 |
121 | 不会,磁盘写操作默认是延迟执行的.写操作可能在两三秒(默认在60秒内)后到达磁盘,通过 `syncPeriodSecs` 启动参数,可以进行配置.例如,如果一秒内数据库收到一千个对一个对象递增的操作,仅刷新磁盘一次.
122 |
123 | ### MongoDB索引
124 | **10Q: 索引类型有哪些?**
125 | + 单字段索引(`Single Field Indexes`)
126 | + 复合索引(`Compound Indexes`)
127 | + 多键索引(`Multikey Indexes`)
128 | + 全文索引(`text Indexes`)
129 | + Hash 索引(`Hash Indexes`)
130 | + 通配符索引(`Wildcard Index`)
131 | + 2dsphere索引(`2dsphere Indexes`)
132 |
133 | **11Q:`MongoDB`在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?**
134 |
135 | 由于`MongoDB`索引使用`B-tree`树原理,只会在A:{B,C}上使用索引
136 |
137 |
138 | **`MongoDB`索引详情可看文章**[【**`MongoDB`系列--轻松应对面试中遇到的MongonDB索引(index)问题**】](https://juejin.im/post/6844903905441103880),**其中包括很多索引的问题:**
139 | + **创建索引,需要考虑的问题**
140 | + **索引限制问题**
141 | + **索引类型详细解析**
142 | + **索引的种类问题**
143 |
144 | ### **12Q:什么是聚合**
145 |
146 | 聚合操作能够处理数据记录并返回计算结果。聚合操作能将多个文档中的值组合起来,对成组数据执行各种操作,返回单一的结果。它相当于 `SQ`L 中的 `count(*)` 组合 `group by`。对于 `MongoDB` 中的聚合操作,应该使用`aggregate()`方法。
147 |
148 | **详情可查看文章**[【**MongoDB系列--深入理解MongoDB聚合(Aggregation)**】](https://juejin.im/post/6844903903000002574),**其中包括很多聚合的问题:**
149 | + **聚合管道(`aggregation pipeline`)的问题**
150 | + **`Aggregation Pipeline` 优化等问题**
151 | + **Map-Reduce函数的问题**
152 |
153 | ### MongoDB分片
154 | **13Q:`monogodb` 中的分片`sharding`**
155 |
156 | 分片`sharding`是将数据水平切分到不同的物理节点。当应用数据越来越大的时候,数据量也会越来越大。当数据量增长
157 | 时,单台机器有可能无法存储数据或可接受的读取写入吞吐量。利用分片技术可以添加更多的机器来应对数据量增加
158 | 以及读写操作的要求。
159 |
160 | **14Q:分片(`Shard`)和复制(`replication`)是怎样工作的?**
161 |
162 | 每一个分片(`shard`)是一个分区数据的逻辑集合。分片可能由单一服务器或者集群组成,我们推荐为每一个分片(`shard`)使用集群。
163 |
164 | **15Q:如果块移动操作(`moveChunk`)失败了,我需要手动清除部分转移的文档吗?**
165 |
166 | 不需要,移动操作是一致(`consistent`)并且是确定性的(`deterministic`)。
167 | + 一次失败后,移动操作会不断重试。
168 | + 当完成后,数据只会出现在新的分片里(shard)
169 |
170 | **16Q:数据在什么时候才会扩展到多个分片(`Shard`)里?**
171 |
172 | `MongoDB` 分片是基于区域(`range`)的。所以一个集合(`collection`)中的所有的对象都被存放到一个块(`chunk`)中,默认块的大小是 64Mb。当数据容量超过64 Mb,才有可能实施一个迁移,只有当存在不止一个块的时候,才会有多个分片获取数据的选项。
173 |
174 | **17Q:更新一个正在被迁移的块(Chunk)上的文档时会发生什么?**
175 |
176 | 更新操作会立即发生在旧的块(Chunk)上,然后更改才会在所有权转移前复制到新的分片上。
177 |
178 | **18Q:如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?**
179 |
180 | 如果一个分片停止了,除非查询设置了 “`Partial`” 选项,否则查询会返回一个错误。如果一个分片响应很慢,`MongoDB` 会等待它的响应。
181 |
182 | ### MongoDB复制集
183 | **19Q:`MongoDB`副本集实现高可用的原理**
184 |
185 | `MongoDB` 使用了其复制(`Replica Set`)方案,实现自动容错机制为高可用提供了基础。目前,`MongoDB` 支持两种复制模式:
186 | + `Master` / `Slave` ,主从复制,角色包括 `Master` 和 `Slave` 。
187 | + `Replica Set` ,复制集复制,角色包括 `Primary` 和 `Secondary` 以及 `Arbiter` 。(**生产环境必选**)
188 |
189 | **20Q:什么是`master`或`primary`?**
190 |
191 | 副本集只能有一个主节点能够确认写入操作来接收所有写操作,并记录其操作日志中的数据集的所有更改(记录在oplog中)。在集群中,当主节点(`master`)失效,Secondary节点会变为`master`
192 |
193 | **21Q:什么是`Slave`或`Secondary`?**
194 |
195 | 复制主节点的oplog并将oplog记录的操作应用于其数据集,如果主节点宕机了,将从符合条件的从节点选举选出新的主节点。
196 |
197 | **22Q:什么是`Arbiter`?**
198 |
199 | 仲裁节点不维护数据集。 仲裁节点的目的是通过响应其他副本集节点的心跳和选举请求来维护副本集中的仲裁
200 |
201 | **23Q:复制集节点类型有哪些?**
202 | + 优先级0型(`Priority 0`)节点
203 | + 隐藏型(`Hidden`)节点
204 | + 延迟型(`Delayed`)节点
205 | + 投票型(`Vote`)节点以及不可投票节点
206 |
207 | **24Q:启用备份故障恢复需要多久?**
208 |
209 | 从备份数据库声明主数据库宕机到选出一个备份数据库作为新的主数据库将花费10到30秒时间.这期间在主数据库上的操作将会失败–包括写入和强一致性读取(`strong consistent read`)操作.然而,你还能在第二数据库上执行最终一致性查询(`eventually consistent query`)(在`slaveok`模式下),即使在这段时间里.
210 |
211 | **`MongoDB`复制详解分析可查看文章**[【**MongoDB系列-解决面试中可能遇到的MongoDB复制集(replica set)问题**】](https://juejin.im/post/6844903919659778055)
212 |
213 | ### 25Q:`raft`选举过程,投票规则?
214 |
215 | **选举过程:**
216 |
217 | 当系统启动好之后,初始选举后系统由1个`Leader`和若干个`Follower`角色组成。然后突然由于某个异常原因,`Leader`服务出现了异常,导致`Follower`角色检测到和`Leader`的上次RPC更新时间超过给定阈值时间时。此时`Followe`r会认为`Leader`服务已出现异常,然后它将会发起一次新的`Leader`选举行为,同时将自身的状态从`Follower`切换为`Candidate`身份。随后请求其它`Follower`投票选择自己。
218 |
219 | **投票规则:**
220 | + 当一个候选人获得了同一个任期号内的大多数选票,就成为领导人。
221 | + 每个节点最多在一个任期内投出一张选票。并且按照先来先服务的原则。
222 | + 一旦候选人赢得选举,立刻成为领导,并发送心跳维持权威,同时阻止新领导人的诞生
223 |
224 | **可查看文章**[【**通俗易懂的Paxos算法-基于消息传递的一致性算法**】](https://juejin.im/post/6844903874587787277)
225 |
226 |
227 | ### **26Q:在哪些场景使用`MongoDB`?**
228 |
229 | **规则:** 如果业务中存在大量复杂的事务逻辑操作,则不要用`MongoDB`数据库;在处理非结构化 / 半结构化的大数据使用`MongoDB`,操作的数据类型为动态时也使用`MongoDB`,比如:
230 | * 内容管理系统,切面数据、日志记录
231 | * 移动端`Apps`:`O2O`送快递骑手、快递商家的信息(包含位置信息)
232 | * 数据管理,监控数据
233 |
234 |
235 |
236 |
237 | > 各位看官还可以吗?喜欢的话,动动手指点个💗,点个关注呗!!谢谢支持!
238 | >
239 | > 欢迎关注公众号【**Ccww技术博客**】,原创技术文章第一时间推出
240 |
241 |
242 |
243 | 
244 |
--------------------------------------------------------------------------------
/doc/db/mongodb/SpringDataMongoDB详细的操作手册.md:
--------------------------------------------------------------------------------
1 |
2 | `MongoDB`是基于分布式文件存储的数据库,由`C++`语言编写。旨在为`WEB`应用提供可扩展的高性能数据存储解决方案,且`MongodDB`是一个介于关系数据库与非关系数据库之间的产品,是非关系型数据库中功能最丰富,最像关系数据库。
3 |
4 | 由于`MongoDB`的特性以及功能,使得其在企业使用频率很大,所以很多面试都会MongoDB的相关知识,基于网上以及自己阅读官网文档总结2019-2020年`MongoDB`的面试题。具体如下:
5 |
6 |
7 |
8 | ### **1Q:`MongoDB`的优势有哪些?**
9 |
10 | * 面向集合(`Collection`)和文档(`document`)的存储,以JSON格式的文档保存数据。
11 |
12 | * 高性能,支持`Document`中嵌入`Document`减少了数据库系统上的I/O操作以及具有完整的索引支持,支持快速查询
13 | * 高效的传统存储方式:支持二进制数据及大型对象
14 | * 高可用性,数据复制集,MongoDB 数据库支持服务器之间的数据复制来提供自动故障转移(`automatic failover`)
15 |
16 | * 高可扩展性,分片(`sharding`)将数据分布在多个数据中心,MongoDB支持基于分片键创建数据区域.
17 |
18 | * 丰富的查询功能, 聚合管道(`Aggregation Pipeline`)、全文搜索(`Text Search`)以及地理空间查询(`Geospatial Queries`)
19 | * 支持多个存储引擎,WiredTiger存储引、In-Memory存储引擎
20 |
21 | ### **2Q:`MongoDB` 支持哪些数据类型?**
22 |
23 | **java类似数据类型:**
24 | |类型|解析|
25 | |:-|:-|
26 | |`String`|字符串。存储数据常用的数据类型。在 `MongoDB` 中,`UTF-8` 编码的字符串才是合法的|
27 | | `Integer`|整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位|
28 | |`Double`|双精度浮点值。用于存储浮点值|
29 | |`Boolean`|布尔值。用于存储布尔值(真/假)|
30 | |`Arrays`|用于将数组或列表或多个值存储为一个键|
31 | |`Datetime`|记录文档修改或添加的具体时间|
32 |
33 | **MongoDB特有数据类型:**
34 | |类型|解析|
35 | |:-|:-|
36 | |`ObjectId`|用于存储文档 `id`,`ObjectId`是基于分布式主键的实现`MongoDB`分片也可继续使用|
37 | |`Min/Max Keys`|将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比|
38 | |`Code`|用于在文档中存储 `JavaScript`代码|
39 | | `Regular Expression`|用于在文档中存储正则表达式|
40 | |`Binary Data`|二进制数据。用于存储二进制数据|
41 | |`Null`|用于创建空值|
42 | |`Object`|用于内嵌文档|
43 |
44 | ### **3Q:什么是集合`Collection`、文档`Document`,以及与关系型数据库术语类比。**
45 |
46 | * 集合`Collection`位于单独的一个数据库MongoDB 文档`Document`集合,它类似关系型数据库(RDBMS)中的表`Table`。一个集合`Collection`内的多个文档`Document`可以有多个不同的字段。通常情况下,集合`Collection`中的文档`Document`有着相同含义。
47 | * 文档`Document`由key-value构成。文档`Document`是动态模式,这说明同一集合里的文档不需要有相同的字段和结构。类似于关系型数据库中table中的每一条记录。
48 | * 与关系型数据库术语类比
49 |
50 | |mongodb|关系型数据库|
51 | |:---|---|
52 | |Database|Database|
53 | |Collection|Table|
54 | |Document|Record/Row|
55 | |Filed|Column|
56 | |Embedded Documents| Table join|
57 |
58 |
59 | ### **4Q:什么是”`Mongod`“,以及`MongoDB`命令。**
60 |
61 | `mongod`是处理`MongoDB`系统的主要进程。它处理数据请求,管理数据存储,和执行后台管理操作。当我们运行`mongod`命令意味着正在启动`MongoDB`进程,并且在后台运行。
62 |
63 | `MongoDB`命令:
64 |
65 | |命令|说明|
66 | |---|----|
67 | |use database_name|切换数据库|
68 | |db.myCollection.find().pretty()|格式化打印结果|
69 | |db.getCollection(collectionName).find()|修改Collection名称|
70 |
71 |
72 | ### **5Q:"`Mongod`"默认参数有?**
73 | * 传递数据库存储路径,默认是`"/data/db"`
74 | * 端口号 默认是 "27017"
75 |
76 | ### **6Q:`MySQL`和`mongodb`的区别**
77 |
78 | |形式|MongoDB|MySQL|
79 | |---|----|----|
80 | |数据库模型|非关系型|关系型|
81 | |存储方式||虚拟内存+持久化|不同的引擎有不同的存储方式|
82 | |查询语句|独特的MongoDB查询方式|传统SQL语句|
83 | |架构特点|副本集以及分片|常见单点、M-S、MHA、MMM等架构方式|
84 | |数据处理方式|基于内存,将热数据存在物理内存中,从而达到高速读写|不同的引擎拥有自己的特点|
85 | |使用场景|事件的记录,内容管理或者博客平台等数据大且非结构化数据的场景|适用于数据量少且很多结构化数据|
86 |
87 |
88 | ### 7Q:问`mongodb`和`redis`区别以及选择原因
89 |
90 | |形式|MongoDB|redis|
91 | |---|---|----|
92 | |内存管理机制|MongoDB 数据存在内存,由 linux系统 mmap 实现,当内存不够时,只将热点数据放入内存,其他数据存在磁盘|Redis 数据全部存在内存,定期写入磁盘,当内存不够时,可以选择指定的 LRU 算法删除数据|
93 | |支持的数据结构|MongoDB 数据结构比较单一,但是支持丰富的数据表达,索引|Redis 支持的数据结构丰富,包括hash、set、list等|
94 | |性能|mongodb依赖内存,TPS较高|Redis依赖内存,TPS非常高。性能上Redis优于MongoDB|
95 | |可靠性|支持持久化以及复制集增加可靠性|Redis依赖快照进行持久化;AOF增强可靠性;增强可靠性的同时,影响访问性能|
96 | |数据分析|mongodb内置数据分析功能(mapreduce)|Redis不支持|
97 | |事务支持情况|只支持单文档事务,需要复杂事务支持的场景暂时不适合|Redis 事务支持比较弱,只能保证事务中的每个操作连续执行|
98 | |集群|MongoDB 集群技术比较成熟|Redis从3.0开始支持集群|
99 | **选择原因:**
100 | * 架构简单
101 |
102 | * 没有复杂的连接
103 |
104 | * 深度查询能力,`MongoDB`支持动态查询。
105 |
106 | * 容易调试
107 |
108 | * 容易扩展
109 |
110 | * 不需要转化/映射应用对象到数据库对象
111 |
112 | * 使用内部内存作为存储工作区,以便更快的存取数据。
113 |
114 |
115 | ### **8Q:如何执行事务/加锁?**
116 |
117 | `mongodb`没有使用传统的锁或者复杂的带回滚的事务,因为它设计的宗旨是轻量,快速以及可预计的高性能.可以把它类比成`mysql mylsam`的自动提交模式.通过精简对事务的支持,性能得到了提升,特别是在一个可能会穿过多个服务器的系统里.
118 |
119 | ### **9Q:更新操作会立刻fsync到磁盘?**
120 |
121 | 不会,磁盘写操作默认是延迟执行的.写操作可能在两三秒(默认在60秒内)后到达磁盘,通过 `syncPeriodSecs` 启动参数,可以进行配置.例如,如果一秒内数据库收到一千个对一个对象递增的操作,仅刷新磁盘一次.
122 |
123 | ### MongoDB索引
124 | **10Q: 索引类型有哪些?**
125 | + 单字段索引(`Single Field Indexes`)
126 | + 复合索引(`Compound Indexes`)
127 | + 多键索引(`Multikey Indexes`)
128 | + 全文索引(`text Indexes`)
129 | + Hash 索引(`Hash Indexes`)
130 | + 通配符索引(`Wildcard Index`)
131 | + 2dsphere索引(`2dsphere Indexes`)
132 |
133 | **11Q:`MongoDB`在A:{B,C}上建立索引,查询A:{B,C}和A:{C,B}都会使用索引吗?**
134 |
135 | 由于`MongoDB`索引使用`B-tree`树原理,只会在A:{B,C}上使用索引
136 |
137 |
138 | **`MongoDB`索引详情可看文章**[【**`MongoDB`系列--轻松应对面试中遇到的MongonDB索引(index)问题**】](https://juejin.im/post/6844903905441103880),**其中包括很多索引的问题:**
139 | + **创建索引,需要考虑的问题**
140 | + **索引限制问题**
141 | + **索引类型详细解析**
142 | + **索引的种类问题**
143 |
144 | ### **12Q:什么是聚合**
145 |
146 | 聚合操作能够处理数据记录并返回计算结果。聚合操作能将多个文档中的值组合起来,对成组数据执行各种操作,返回单一的结果。它相当于 `SQ`L 中的 `count(*)` 组合 `group by`。对于 `MongoDB` 中的聚合操作,应该使用`aggregate()`方法。
147 |
148 | **详情可查看文章**[【**MongoDB系列--深入理解MongoDB聚合(Aggregation)**】](https://juejin.im/post/6844903903000002574),**其中包括很多聚合的问题:**
149 | + **聚合管道(`aggregation pipeline`)的问题**
150 | + **`Aggregation Pipeline` 优化等问题**
151 | + **Map-Reduce函数的问题**
152 |
153 | ### MongoDB分片
154 | **13Q:`monogodb` 中的分片`sharding`**
155 |
156 | 分片`sharding`是将数据水平切分到不同的物理节点。当应用数据越来越大的时候,数据量也会越来越大。当数据量增长
157 | 时,单台机器有可能无法存储数据或可接受的读取写入吞吐量。利用分片技术可以添加更多的机器来应对数据量增加
158 | 以及读写操作的要求。
159 |
160 | **14Q:分片(`Shard`)和复制(`replication`)是怎样工作的?**
161 |
162 | 每一个分片(`shard`)是一个分区数据的逻辑集合。分片可能由单一服务器或者集群组成,我们推荐为每一个分片(`shard`)使用集群。
163 |
164 | **15Q:如果块移动操作(`moveChunk`)失败了,我需要手动清除部分转移的文档吗?**
165 |
166 | 不需要,移动操作是一致(`consistent`)并且是确定性的(`deterministic`)。
167 | + 一次失败后,移动操作会不断重试。
168 | + 当完成后,数据只会出现在新的分片里(shard)
169 |
170 | **16Q:数据在什么时候才会扩展到多个分片(`Shard`)里?**
171 |
172 | `MongoDB` 分片是基于区域(`range`)的。所以一个集合(`collection`)中的所有的对象都被存放到一个块(`chunk`)中,默认块的大小是 64Mb。当数据容量超过64 Mb,才有可能实施一个迁移,只有当存在不止一个块的时候,才会有多个分片获取数据的选项。
173 |
174 | **17Q:更新一个正在被迁移的块(Chunk)上的文档时会发生什么?**
175 |
176 | 更新操作会立即发生在旧的块(Chunk)上,然后更改才会在所有权转移前复制到新的分片上。
177 |
178 | **18Q:如果一个分片(Shard)停止或很慢的时候,发起一个查询会怎样?**
179 |
180 | 如果一个分片停止了,除非查询设置了 “`Partial`” 选项,否则查询会返回一个错误。如果一个分片响应很慢,`MongoDB` 会等待它的响应。
181 |
182 | ### MongoDB复制集
183 | **19Q:`MongoDB`副本集实现高可用的原理**
184 |
185 | `MongoDB` 使用了其复制(`Replica Set`)方案,实现自动容错机制为高可用提供了基础。目前,`MongoDB` 支持两种复制模式:
186 | + `Master` / `Slave` ,主从复制,角色包括 `Master` 和 `Slave` 。
187 | + `Replica Set` ,复制集复制,角色包括 `Primary` 和 `Secondary` 以及 `Arbiter` 。(**生产环境必选**)
188 |
189 | **20Q:什么是`master`或`primary`?**
190 |
191 | 副本集只能有一个主节点能够确认写入操作来接收所有写操作,并记录其操作日志中的数据集的所有更改(记录在oplog中)。在集群中,当主节点(`master`)失效,Secondary节点会变为`master`
192 |
193 | **21Q:什么是`Slave`或`Secondary`?**
194 |
195 | 复制主节点的oplog并将oplog记录的操作应用于其数据集,如果主节点宕机了,将从符合条件的从节点选举选出新的主节点。
196 |
197 | **22Q:什么是`Arbiter`?**
198 |
199 | 仲裁节点不维护数据集。 仲裁节点的目的是通过响应其他副本集节点的心跳和选举请求来维护副本集中的仲裁
200 |
201 | **23Q:复制集节点类型有哪些?**
202 | + 优先级0型(`Priority 0`)节点
203 | + 隐藏型(`Hidden`)节点
204 | + 延迟型(`Delayed`)节点
205 | + 投票型(`Vote`)节点以及不可投票节点
206 |
207 | **24Q:启用备份故障恢复需要多久?**
208 |
209 | 从备份数据库声明主数据库宕机到选出一个备份数据库作为新的主数据库将花费10到30秒时间.这期间在主数据库上的操作将会失败–包括写入和强一致性读取(`strong consistent read`)操作.然而,你还能在第二数据库上执行最终一致性查询(`eventually consistent query`)(在`slaveok`模式下),即使在这段时间里.
210 |
211 | **`MongoDB`复制详解分析可查看文章**[【**MongoDB系列-解决面试中可能遇到的MongoDB复制集(replica set)问题**】](https://juejin.im/post/6844903919659778055)
212 |
213 | ### 25Q:`raft`选举过程,投票规则?
214 |
215 | **选举过程:**
216 |
217 | 当系统启动好之后,初始选举后系统由1个`Leader`和若干个`Follower`角色组成。然后突然由于某个异常原因,`Leader`服务出现了异常,导致`Follower`角色检测到和`Leader`的上次RPC更新时间超过给定阈值时间时。此时`Followe`r会认为`Leader`服务已出现异常,然后它将会发起一次新的`Leader`选举行为,同时将自身的状态从`Follower`切换为`Candidate`身份。随后请求其它`Follower`投票选择自己。
218 |
219 | **投票规则:**
220 | + 当一个候选人获得了同一个任期号内的大多数选票,就成为领导人。
221 | + 每个节点最多在一个任期内投出一张选票。并且按照先来先服务的原则。
222 | + 一旦候选人赢得选举,立刻成为领导,并发送心跳维持权威,同时阻止新领导人的诞生
223 |
224 | **可查看文章**[【**通俗易懂的Paxos算法-基于消息传递的一致性算法**】](https://juejin.im/post/6844903874587787277)
225 |
226 |
227 | ### **26Q:在哪些场景使用`MongoDB`?**
228 |
229 | **规则:** 如果业务中存在大量复杂的事务逻辑操作,则不要用`MongoDB`数据库;在处理非结构化 / 半结构化的大数据使用`MongoDB`,操作的数据类型为动态时也使用`MongoDB`,比如:
230 | * 内容管理系统,切面数据、日志记录
231 | * 移动端`Apps`:`O2O`送快递骑手、快递商家的信息(包含位置信息)
232 | * 数据管理,监控数据
233 |
234 |
235 |
236 |
237 | > 各位看官还可以吗?喜欢的话,动动手指点个💗,点个关注呗!!谢谢支持!
238 | >
239 | > 欢迎关注公众号【**Ccww技术博客**】,原创技术文章第一时间推出
240 |
241 |
242 |
243 | 
244 |
--------------------------------------------------------------------------------
/doc/db/mongodb/复制集(replication).md:
--------------------------------------------------------------------------------
1 | 在使用MongoDB时,在创建索引会涉及到在复制集(replication)以及分片(Shard)中创建,为了最大限度地减少构建索引的影响,在副本和分片中创建索引,使用滚动索引构建过程。如果不使用滚动索引构建过程:
2 | + **主服务器上的前台索引构建需要数据库锁定。它复制为副本集辅助节点上的前台索引构建,并且复制工作程序采用全局数据库锁定,该锁定将读取和写入排序到索引服务器上的所有数据库。**
3 | + **主要的后台索引构建复制为后台索引构建在辅助节点上。复制工作程序不会进行全局数据库锁定,并且辅助读取不会受到影响。**
4 | + **对于主服务器上的前台和后台索引构建,副本集辅助节点上的索引操作在主节点完成构建索引之后开始。**
5 | + **在辅助节点上构建索引所需的时间必须在oplog的窗口内,以便辅助节点可以赶上主节点。
6 | 那么该如何创建呢?具体步骤呢?请看接下来的具体过程。**
7 |
8 |
9 |
10 | ## 1. 在副本集创建索引
11 | ### 准备
12 | **必须在索引构建期间停止对集合的所有写入,否则可能会在副本集成员中获得不一致的数据。**
13 | ### 具体过程
14 | **在副本集中以滚动方式构建唯一索引包括以下过程:**
15 |
16 | 1. **停止一个Secondary节点(从节点)并以单机模式重新启动,可以使用配置文件更新配置以单机模式重新启动:**
17 | + **注释掉replication.replSetName选项。**
18 | + **将net.port更改为其他端口。将原始端口设置注释掉。**
19 | + **在setParameter部分中将参数disableLogicalSessionCacheRefresh设置为true。**
20 |
21 | **例如:**
22 |
23 | //修改配置
24 | net:
25 | bindIp: localhost,
26 | port: 27217
27 | #port: 27017
28 | #replication:
29 | #replSetName: myRepl
30 | setParameter:
31 | disableLogicalSessionCacheRefresh: true
32 | //重新启动
33 | mongod --config
34 | 2. **创建索引:在单机模式下进行索引创建**
35 | 3. **重新开启Replica Set 模式:索引构建完成后,关闭mongod实例。撤消作为独立启动时所做的配置更改,以返回其原始配置并作为副本集的成员重新启动。**
36 |
37 | //回退原来的配置:net:
38 | bindIp: localhost,
39 | port: 27017
40 | replication:
41 | replSetName: myRepl
42 | //重新启动:
43 | mongod --config
44 |
45 | 4. **在其他从节点中重复1、2、3步骤的过程操作。**
46 | 5. **主节点创建索引,当所有从节点都有新索引时,降低主节点,使用上述过程作为单机模式重新启动它,并在原主节点上构建索引:**
47 | + **使用mongo shell中的rs.stepDown()方法来降低主节点为从节点,**
48 | + **成功降级后,当前主节点成为从节点,副本集成员选择新主节点,并进行从节点创建方式进行创建索引。**
49 |
50 | ## 2. 分片集群创建唯一索引
51 | ### 准备
52 | **创建唯一索引,必须在索引构建期间停止对集合的所有写入。 否则,您可能会在副本集成员中获得不一致的数据。如果无法停止对集合的所有写入,请不要使用以下过程来创建唯一索引。**
53 | ### 具体过程
54 |
55 | 1. **停止Balancer:将mongo shell连接到分片群集中的mongos实例,然后运行sh.stopBalancer()以禁用Balancer。如果正在进行迁移,系统将在停止平衡器之前完成正在进行的迁移。**
56 | 2. **确定Collection的分布:刷新该mongos的缓存路由表,以避免返回该Collection旧的分发信息。刷新后,对要构建索引的集合运行db.collection.getShardDistribution()。**
57 |
58 | 例如:在test数据库中的records字段中创建上升排序的索引
59 |
60 | db.adminCommand( { flushRouterConfig: "test.records" } );
61 | db.records.getShardDistribution();
62 |
63 | 例如,考虑一个带有3个分片shardA,shardB和shardC的分片集群,db.collection.getShardDistribution()返回以下内容
64 |
65 | Shard shardA at shardA/s1-mongo1.example.net:27018,s1-mongo2.example.net:27018,s1-mongo3.example.net:27018
66 | data : 1KiB docs : 50 chunks : 1
67 | estimated data per chunk : 1KiB
68 | estimated docs per chunk : 50 Shard shardC at shardC/s3-mongo1.example.net:27018,s3-mongo2.example.net:27018,s3-mongo3.example.net:27018
69 | data : 1KiB docs : 50 chunks : 1
70 | estimated data per chunk : 1KiB
71 | estimated docs per chunk : 50
72 | Totals data : 3KiB docs : 100 chunks : 2
73 | Shard shardA contains 50% data, 50% docs in cluster, avg obj size on shard : 40B
74 | Shard shardC contains 50% data, 50% docs in cluster, avg obj size on shard : 40B
75 | 从输出中,您只在shardA和shardC上为test.records构建索引。
76 |
77 | 3. **在包含集合Chunks的分片创建索引**
78 | + **C1.停止从节点,并以单机模式重新启动:对于受影响的分片,停止从节点与其中一个分区相关联的mongod进程,进行配置文件/命令模式更新后重新启动。**
79 |
80 | **配置文件:**
81 | + **将net.port更改为其他端口。 注释到原始端口设置。**
82 | + **注释掉replication.replSetName选项。**
83 | + **注释掉sharding.clusterRole选项。**
84 | + **在setParameter部分中将参数skipShardingConfigurationChecks设置为true。**
85 | + **在setParameter部分中将参数disableLogicalSessionCacheRefresh设置为true。**
86 |
87 | net:
88 | bindIp: localhost,
89 | port: 27218
90 | # port: 27018
91 | #replication:
92 | # replSetName: shardA
93 | #sharding:
94 | # clusterRole: shardsvr
95 | setParameter:
96 | skipShardingConfigurationChecks: true
97 | disableLogicalSessionCacheRefresh: true
98 | //重启:
99 | mongod --config
100 | + **C2.创建索引:直接连接到在新端口上作为独立运行的mongod实例,并为此实例创建新索引。**
101 |
102 | //例如:在record Collection的username创建索引
103 | db.records.createIndex( { username: 1 } )
104 |
105 | + **C3.恢复C1的配置,并作为 Replica Set成员启动:索引构建完成后,关闭mongod实例。 撤消作为单机模式时所做的配置更改,以返回其原始配置并重新启动。**
106 |
107 | **配置文件模式:**
108 | + **恢复为原始端口号。**
109 | + **取消注释replication.replSetName。**
110 | + **取消注释sharding.clusterRole。**
111 | + **删除setParameter部分中的参数skipShardingConfigurationChecks。**
112 | + **在setParameter部分中删除参数disableLogicalSessionCacheRefresh。**
113 |
114 | net:
115 | bindIp: localhost,
116 | port: 27018
117 | replication:
118 | replSetName: shardA
119 | sharding:
120 | clusterRole: shardsvr
121 | 重启:mongod --config
122 | + **C4.其他从节点分片重复C1、C2、C3过程创建索引。**
123 | + **C5.主节点创建索引:当所有从节点都有新索引时,降低主节点,使用上述过程作为单机模式重新启动它,并在原主节点上构建索引
124 | 使用mongo shell中的rs.stepDown()方法来降低主节点为从节点,成功降级后,当前主节点成为从节点,副本集成员选择新主节点,并进行从节点创建方式进行创建索引。**
125 | 4. **在其他受影响的分片重复C步骤;**
126 | 5. **重启Balancer,一旦全部分片创建完索引,重启Balancer:sh.startBalancer()。**
127 |
128 | ## 总结
129 | **后续还有关于实践中复制集以及分片的搭建过程,复制集成员节点增加删除等一系列实战操作。**
130 |
131 |
132 |
133 | **最后可关注公众号,一起学习,每天会分享干货,还有学习视频领取!**
134 |
135 | 
--------------------------------------------------------------------------------
/doc/db/redis/RedisRDB持久化与AOF持久化.md:
--------------------------------------------------------------------------------
1 | ## 1.持久化
2 | ### 1.1 持久化简介
3 | 持久化(Persistence),持久化是将程序数据在持久状态和瞬时状态间转换的机制,即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。
4 |
5 |
6 | 
7 |
8 | ### 1.2 redis持久化
9 | redis为内存数据库,为了防止服务器宕机以及服务器进程退出后,服务器数据丢失,Redis提供了持久化功能,即将Redis中内存数据持久化到磁盘中。Redis 提供了不同级别的持久化方式:
10 | + RDB持久化方式:可以在指定的时间间隔能对数据进行快照存储.
11 | + AOF持久化方式:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
12 |
13 | 如果服务器开启了AOF持久化功能。服务器会优先使用AOF文件还原数据。只有关闭了AOF持久化功能,服务器才会使用RDB文件还原数据
14 |
15 |
16 | 
17 |
18 | ## 2. RDB持久化
19 | ### 2.1 RDB文件格式
20 | RDB文件是一个经过压缩的二进制文件(默认的文件名:dump.rdb),由多个部分组成,RDB格式:
21 |
22 | 
23 | ### 2.2 RDB文件持久化创建与载入
24 | 在 Redis持久化时, RDB 程序将当前内存中的数据库状态保存到磁盘文件中, 在 Redis 重启动时, RDB 程序可以通过载入 RDB 文件来还原数据库的状态。
25 |
26 |
27 | 
28 |
29 | ### 2.3 工作方式
30 | 当 Redis 需要保存 dump.rdb 文件时, 服务器执行以下操作:
31 |
32 | + Redis 调用forks。同时拥有父进程和子进程。
33 | + 子进程将数据集写入到一个临时 RDB 文件中。
34 | + 当子进程完成对新 RDB 文件的写入时,Redis 用新 RDB 文件替换原来的 RDB 文件,并删除旧的 RDB 文件。
35 |
36 | 这种工作方式使得 Redis 可以从写时复制(copy-on-write)机制中获益。
37 |
38 | ### 2.4 创建方式
39 |
40 | **SAVE**
41 |
42 | 同步操作,在执行该命令时,服务器会被阻塞,拒绝客户端发送的命令请求
43 |
44 | redis> save
45 |
46 | 
47 | **BGSAVE**
48 |
49 | 异步操作,在执行该命令时,子进程执行保存工作,服务器还可以继续让主线程处理客户端发送的命令请求
50 |
51 | redis>bgsave
52 |
53 |
54 | 
55 | **自动创建**
56 |
57 | 由于BGSAVE命令可不阻塞服务器进程下执行,可以让用户自定义save属性,让服务器每个一段时间自动执行一次BGSAVE命令(即通过配置文件对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动进行数据集保存操作)。
58 |
59 | 比如:
60 | /*服务器在900秒之内,对数据库进行了至少1次修改*/
61 | Save 900 1
62 | /*服务器在300秒之内,对数据库进行了至少10次修改*/
63 | Save 300 10
64 | /*服务器在60秒之内,对数据库进行了至少10000次修改*/
65 | Save 60 10000
66 | 只要满足其中一个条件就会执行BGSAVE命令
67 |
68 |
69 |
70 |
71 |
72 |
73 |
74 | ### 2.5 RDB 默认配置
75 | ################################ SNAPSHOTTING ################################
76 | #
77 | # Save the DB on disk:
78 | #在给定的秒数和给定的对数据库的写操作数下,自动持久化操作。
79 | # save
80 | #
81 | save 900 1
82 | save 300 10
83 | save 60 10000
84 |
85 | #bgsave发生错误时是否停止写入,一般为yes
86 | stop-writes-on-bgsave-error yes
87 |
88 | #持久化时是否使用LZF压缩字符串对象?
89 | rdbcompression yes
90 |
91 | #是否对rdb文件进行校验和检验,通常为yes
92 | rdbchecksum yes
93 |
94 | # RDB持久化文件名
95 | dbfilename dump.rdb
96 |
97 | #持久化文件存储目录
98 | dir ./
99 |
100 |
101 |
102 | ## 3. AOF持久化
103 | ### 3.1 AOF持久化简介
104 | AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态
105 |
106 |
107 |
108 |
109 |
110 | 
111 |
112 | **AOF持久化功能实现:**
113 |
114 | 1. append命令追加:当AOF持久化功能处于打开状态时,服务器执行完一个写命令会协议格式被执行的命令追加服务器状态的aof_buf缓冲区的末尾。
115 |
116 | reids>SET KET VAULE
117 | //协议格式
118 | \r\n$3\r\nSET\r\n$3\r\nKEY\r\n$5\r\nVAULE\r\n
119 |
120 | 2. 文件写入和同步sync:Redis的服务器进程是一个事件循环,这个文件事件负责接收客户端的命令请求以及向客户端发送命令回复。当执行了append命令追加后,服务器会调用flushAppendOnlyFile函数是否需要将AOF缓冲区的内容写入和保存到AOF文件
121 |
122 |
123 | redis> SET msg "Ccww"
124 | redis> SADD persistence "rdb" "aof"
125 | redis> RPUSH size 128 256 512
126 |
127 |
128 |
129 |
130 |
131 |
132 |
133 |
134 | ### 3.2 AOF持久化策略
135 | AOF持久化策略(即缓冲区内容写入和同步sync到AOF中),可以通过配置appendfsync属性来选择AOF持久化策略:
136 | + always:将aof_buf缓冲区中的所有内容写入并同步到AOF文件,每次有新命令追加到 AOF 文件时就执行一次 fsync。
137 | + everysec(默认):如果上次同步AOF的时间距离现在超过一秒,先将aof_buf缓冲区中的所有内容写入到AOF文件,再次对AOF文件进行同步,且同步操作由一个专门线程负责执行。
138 | + no:将aof_buf缓冲区中的所有内容写入到AOF文件,但并不对AOF文件进行同步,何时同步由操作系统(OS)决定。
139 |
140 | 
141 |
142 | AOF持久化策略的效率与安全性:
143 | + Always:效率最慢的,但安全性是最安全的,即使出现故障宕机,持久化也只会丢失一个事件 循环的命令数据
144 | + everysec:兼顾速度和安全性,出现宕机也只是丢失一秒钟的命令数据
145 | + No:写入最快,但综合起来单次同步是时间是最长的,且出现宕机时会丢失上传同步AOF文件之后的所有命令数据。
146 |
147 |
148 |
149 |
150 | ### 3.3 AOF重写
151 |
152 | 由于AOF持久化会把执行的写命令追加到AOF文件中,所以随着时间写入命令会不断增加, AOF文件的体积也会变得越来越大。AOF文件体积大对Reids服务器,甚至宿主服务器造成影响。
153 |
154 | 为了解决AOF文件体积膨胀的问题,Redis提供了AOF文件重写(rewrite)功能:
155 |
156 | + 生成一个不保存任何浪费空间的冗余命令新的AOF文件,且新旧AOF文件保存数据库状态一样的
157 | + 新的AOF文件是通过读取数据库中的键值对来实现的,程序无须对现有的AOF文件进行读入,分析,或者写入操作。
158 | + 为防止缓冲区溢出,重写处理list,hash,set以及Zset时,超过设置常量数量时会多条相同命令记录一个集合。
159 | + Redis 2.4 可以通过配置自动触发 AOF 重写,触发参数 **`auto-aof-rewrite-percentage`(触发AOF文件执行重写的增长率)** 以及 **`auto-aof-rewrite-min-size`(触发AOF文件执行重写的最小尺寸)**
160 |
161 | **AOF重写的作用:**
162 |
163 | + 减少磁盘占用量
164 | + 加速数据恢复
165 |
166 |
167 |
168 |
169 | Redis服务器使用单个线程来处理命令请求,服务器大量调用aof_rewrite函数,在AOF重写期间,则无法处理client发来的命令请求,所以AOF重写程序放在子进程执行,好处:
170 | 1. 子进程进行AOF重写期间,服务器进程可以继续处理命令请求
171 | 2. 子进程带有服务器进程的数据副本,保证了数据的安全性。
172 |
173 | AOF重写使用子进程会造成数据库与重写后的AOF保存的数据不一致,为了解决这种数据不一致,redis使用了AOF重写缓冲区
174 | 实现:
175 |
176 | 
177 | BGREWRITEAOF命令实现原理(只有信号处理函数执行时才对服务器进程造成阻塞):
178 | + 执行命令,同时将命令追加到AOF缓冲区和AOF重写缓冲区
179 | + 当AOF子进程重写完成后,发送一个信号给父进程,父进程将执行AOF重写缓冲区中的所有内容写入到新AOF文件中,新AOF文件保存的数据库状态将和服务器当前的数据库状态一致。
180 | + 对新的AOF文件进行改名,原子性地覆盖现有AOF文件,完成新旧两个AOF文件替换处理完成。
181 |
182 |
183 |
184 |
185 |
186 |
187 | ### 3.4 AOF持久化默认参数
188 |
189 | ############################## APPEND ONLY MODE ###############################
190 |
191 | #开启AOF持久化方式
192 | appendonly no
193 |
194 | #AOF持久化文件名
195 | appendfilename "appendonly.aof"
196 | #每秒把缓冲区的数据fsync到磁盘
197 | appendfsync everysec
198 | # appendfsync no
199 | #是否在执行重写时不同步数据到AOF文件
200 | no-appendfsync-on-rewrite no
201 |
202 | # 触发AOF文件执行重写的增长率
203 | auto-aof-rewrite-percentage 100
204 | #触发AOF文件执行重写的最小size
205 | auto-aof-rewrite-min-size 64mb
206 |
207 | #redis在恢复时,会忽略最后一条可能存在问题的指令
208 | aof-load-truncated yes
209 |
210 | #是否打开混合开关
211 | aof-use-rdb-preamble yes
212 |
213 | ## 4 持久化方式总结与抉择
214 | ### 4.1 RDB优缺点
215 | **RDB的优点**
216 |
217 | + RDB是一个非常紧凑的文件,它保存了某个时间点得数据集,非常适用于数据集的备份,比如你可以在每个小时报保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本的数据集.
218 | + 基于RDB文件紧凑性,便于复制数据到一个远端数据中心,非常适用于灾难恢复.
219 | + RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.
220 | + 与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些.
221 |
222 | **RDB的缺点**
223 |
224 | + 如果你希望在redis意外停止工作(例如电源中断)的情况下丢失的数据最少的话,那么RDB不适合你.虽然你可以配置不同的save时间点(例如每隔5分钟并且对数据集有100个写的操作),是Redis要完整的保存整个数据集是一个比较繁重的工作,你通常会每隔5分钟或者更久做一次完整的保存,万一在Redis意外宕机,你可能会丢失几分钟的数据.
225 | + RDB 需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求.如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续1秒,AOF也需要fork,但是你可以调节重写日志文件的频率来提高数据集的耐久度.
226 |
227 | ### 4.2 AOF的优缺点
228 |
229 | **AOF的优点:**
230 | + 使用AOF 会让你的Redis更加耐久:使用不同的fsync策略:无fsync,每秒fsync,每次写的时候fsync.使用默认的每秒fsync策略,Redis的性能依然很好(fsync是由后台线程进行处理的,主线程会尽力处理客户端请求),一旦出现故障,你最多丢失1秒的数据.
231 | + AOF文件是一个只进行追加的日志文件,所以不需要写入seek,即使由于某些原因(磁盘空间已满,写的过程中宕机等等)未执行完整的写入命令,你也可使用redis-check-aof工具修复问题.
232 | + Redis可以在AOF文件体积变得过大时,自动对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
233 | + AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单(例如, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态)。
234 |
235 | **AOF 缺点:**
236 | + 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
237 | + 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
238 |
239 | ### 4.3 如何选择使用哪种持久化方式?
240 | 一般来说, 如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。
241 |
242 | 如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。
243 |
244 | 有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
245 |
246 |
247 | > 各位看官还可以吗?喜欢的话,动动手指点个💗,点个关注呗!!谢谢支持!
248 | >
249 | > 欢迎关注公众号【**Ccww技术博客**】,原创技术文章第一时间推出
250 |
251 |
252 |
253 | 
254 |
--------------------------------------------------------------------------------
/doc/db/redis/Redis常用的五种数据类型底层结构.md:
--------------------------------------------------------------------------------
1 |
2 | 在Redis中会涉及很多数据结构,比如SDS,双向链表、字典、压缩列表、整数集合等等。Redis会基于这些数据结构自定义一个对象系统,而且自定义的对象系统有很多好处。
3 |
4 | 通过对以下的Redis对象系统的学习,可以了解Redis设计原理以及初衷,为了我们在使用Redis的时候,更加能够理解到其原理和定位问题。
5 |
6 | ## Redis 对象
7 | Redis基于上述的数据结构自定义一个Object 系统,Object结构:
8 |
9 | redisObject结构:
10 | typedef struct redisObject{
11 | //类型
12 | unsigned type:4;
13 | //编码
14 | unsigned encoding:4;
15 | //指向底层实现数据结构的指针
16 | void *ptr;
17 | …..
18 | }
19 |
20 |
21 | Object 系统包含五种Object:
22 |
23 | + String:字符串对象
24 | + List:列表对象
25 | + Hash:哈希对象
26 | + Set:集合对象
27 | + ZSet:有序集合
28 |
29 | Redis使用对象来表示数据库中的键和值,即每新建一个键值对,至少创建有两个对象,而且使用对象的具有以下好处:
30 | 1. redis可以在执行命令前会根据对象的类型判断一个对象是否可以执行给定的命令
31 | 2. 针对不同的使用场景,为对象设置不同的数据结构实现,从而优化对象的不同场景夏的使用效率
32 | 3. 对象系统还可以基于引用计数计数的内存回收机制,自动释放对象所占用的内存,或者还可以让多个数据库键共享同一个对象来节约内存。
33 | 4. redis对象带有访问时间记录信息,使用该信息可以进行优化空转时长较大的key,进行删除!
34 |
35 |
36 |
37 | 对象的ptr指针指向对象的底层现实数据结构,而这些数据结构由对象的encoding属性决定,对应关系:
38 |
39 | |编码常量|编码对应的底层数据结构|
40 | |-------|---------|
41 | |REDIS_ENCODING_INT|long类型的整数|
42 | |REDIS_ENCODING_EMBSTR|embstr编码的简单动态字符串|
43 | |REDIS_ENCODING_RAW|简单动态字符串|
44 | |REDIS_ENCODING_HT|字典|
45 | |REDIS_ENCODING_LINKEDLIST|双向链表|
46 | |REDIS_ENCODING_ZIPLIST|压缩列表|
47 | |REDIS_ENCODING_INTSET|整数集合|
48 | |REDIS_ENCODING_SKIPLIST|跳跃表和字典|
49 |
50 |
51 | 每种Object对象至少有两种不同的编码,对应关系:
52 |
53 | |类型| 编码| 对象|
54 | |-------|---------|--------|
55 | |String| int| 整数值实现|
56 | |String| embstr| sds实现 <=39 字节|
57 | |String |raw| sds实现 > 39字节|
58 | |List| ziplist |压缩列表实现|
59 | |List| linkedlist| 双端链表实现|
60 | |Set| intset |整数集合使用|
61 | |Set| hashtable |字典实现|
62 | |Hash| ziplist |压缩列表实现|
63 | |Hash |hashtable| 字典使用|
64 | |Sorted set| ziplist |压缩列表实现|
65 | |Sorted set |skiplist| 跳跃表和字典|
66 |
67 |
68 |
69 |
70 | ## String 对象
71 |
72 | 字符串对象编码可以int 、raw或者embstr,如果保存的值为整数值且这个值可以用long类型表示,使用int编码,其他编码类似。
73 |
74 | 比如:int编码的String Object
75 |
76 | redis> set number 520
77 | ok
78 | redis> OBJECT ENCODING number
79 | "int"
80 | String Object结构:
81 |
82 | 
83 |
84 |
85 | ### String 对象之间的编码转换
86 | int编码的字符串对象和embstr编码的字符串对象在条件满足的情况下,会被转换为raw编码的字符串对象。
87 |
88 | 比如:对int编码的字符串对象进行append命令时,就会使得原来是int变为raw编码字符串
89 |
90 |
91 |
92 | ## List对象
93 |
94 | list对象可以为ziplist或者为linkedlist,对应底层实现ziplist为压缩列表,linkedlist为双向列表。
95 |
96 | Redis>RPUSH numbers “Ccww” 520 1
97 |
98 | 用ziplist编码的List对象结构:
99 | 
100 |
101 | 用linkedlist编码的List对象结构:
102 |
103 | 
104 |
105 |
106 | ### List对象的编码转换:
107 | 当list对象可以同时满足以下两个条件时,list对象使用的是ziplist编码:
108 | 1. list对象保存的所有字符串元素的长度都小于64字节
109 | 2. list对象保存的元素数量小于512个,
110 | 不能满足这两个条件的list对象需要使用linkedlist编码。
111 |
112 |
113 |
114 |
115 | ## Hash对象
116 | Hash对象的编码可以是ziplist或者hashtable
117 | 其中,ziplist底层使用压缩列表实现:
118 | + 保存同一键值对的两个节点紧靠相邻,键key在前,值vaule在后
119 | + 先保存的键值对在压缩列表的表头方向,后来在表尾方向
120 |
121 | hashtable底层使用字典实现,Hash对象种的每个键值对都使用一个字典键值对保存:
122 | + 字典的键为字符串对象,保存键key
123 | + 字典的值也为字符串对象,保存键值对的值
124 |
125 | 比如:HSET命令
126 |
127 | redis>HSET author name "Ccww"
128 | (integer)
129 |
130 | redis>HSET author age 18
131 | (integer)
132 |
133 | redis>HSET author sex "male"
134 | (integer)
135 | ziplist的底层结构:
136 |
137 | 
138 |
139 |
140 | hashtable底层结构:
141 |
142 | 
143 |
144 |
145 | ### Hash对象的编码转换:
146 | 当list对象可以同时满足以下两个条件时,list对象使用的是ziplist编码:
147 | 1. list对象保存的所有字符串元素的长度都小于64字节
148 | 2. list对象保存的元素数量小于512个,
149 | 不能满足这两个条件的hash对象需要使用hashtable编码
150 |
151 | **Note**:这两个条件的上限值是可以修改的,可查看配置文件hash-max-zaiplist-value和hash-max-ziplist-entries
152 |
153 |
154 |
155 |
156 |
157 | ## Set对象:
158 | Set对象的编码可以为intset或者hashtable
159 | + intset编码:使用整数集合作为底层实现,set对象包含的所有元素都被保存在intset整数集合里面
160 | + hashtable编码:使用字典作为底层实现,字典键key包含一个set元素,而字典的值则都为null
161 |
162 | inset编码Set对象结构:
163 |
164 | redis> SAD number 1 3 5
165 |
166 | 
167 |
168 | hashtable编码Set对象结构:
169 |
170 | redis> SAD Dfruits “apple” "banana" " cherry"
171 |
172 | 
173 |
174 |
175 | ### Set对象的编码转换:
176 | 使用intset编码:
177 | 1. set对象保存的所有元素都是整数值
178 | 2. set对象保存的元素数量不超过512个
179 | 不能满足这两个条件的Set对象使用hashtable编码
180 |
181 |
182 |
183 |
184 |
185 |
186 | ## ZSet对象
187 | ZSet对象的编码 可以为ziplist或者skiplist
188 | ziplist编码,每个集合元素使用相邻的两个压缩列表节点保存,一个保存元素成员,一个保存元素的分值,然后根据分数进行从小到大排序。
189 |
190 | ziplist编码的ZSet对象结构:
191 |
192 | Redis>ZADD price 8.5 apple 5.0 banana 6.0 cherry
193 |
194 | 
195 |
196 | skiplist编码的ZSet对象使用了zset结构,包含一个字典和一个跳跃表
197 |
198 | Type struct zset{
199 |
200 | Zskiplist *zsl;
201 | dict *dict;
202 | ...
203 | }
204 |
205 | skiplist编码的ZSet对象结构
206 | 
207 |
208 |
209 |
210 | ### ZSet对象的编码转换
211 |
212 | 当ZSet对象同时满足以下两个条件时,对象使用ziplist编码
213 | 1. 有序集合保存的元素数量小于128个
214 | 2. 有序集合保存的所有元素的长度都小于64字节
215 | 不能满足以上两个条件的有序集合对象将使用skiplist编码。
216 |
217 | **Note:** 可以通过配置文件中zset-max-ziplist-entries和zset-max-ziplist-vaule
218 |
219 | > 各位看官还可以吗?喜欢的话,动动手指点个💗,点个关注呗!!谢谢支持!
220 | >
221 | > 欢迎关注公众号【**Ccww技术博客**】,原创技术文章第一时间推出
222 |
223 |
224 |
225 | 
226 |
--------------------------------------------------------------------------------
/doc/db/redis/Redis的ExpireKey(过期键).md:
--------------------------------------------------------------------------------
1 | 在面试中遇到美女面试官时,我们以为面试会比较容易过,也能好好表现自己技术的时候了。然而却出现以下这一幕,当美女面试官听说你使用过Redis时,那么问题来了。
2 |
3 | **👩面试官**:**Q1,你知道Redis设置key过期时间的命令吗?**
4 |
5 | **👧你**:你毫不犹豫的巴拉巴拉说了一堆命令,以及用法,比如expire 等等命令
6 |
7 | (🎈这时候你想问得那么简单?但真的那么简单吗?美女面试官停顿了一下,接着问)
8 |
9 | **👩面试官**:**Q2,那你说说Redis是怎么实现过期时间设置呢?以及怎么判断键过期的呢?**
10 | **👧你**:(这时候想这还难不倒我),然后又巴拉巴拉的说一通,Redis的数据库服务器中redisDb数据结构以及过期时间的判定
11 |
12 | (🎈你又在想应该不会问了吧,换个Redis的话题了吧,那你就错了)
13 |
14 | **👩面试官**:**(抬头笑着看了看你)Q3,那你说说过期键的删除策略以及Redis过期键的删除策略以及实现?**
15 | **🤦️你**:这时你回答的就不那么流畅了,有时头脑还阻塞了。
16 |
17 | (🎈这是你可能就有点蒙了,或者只知道一些过期键的删除策略,但具体怎么实现不知道呀,你以为面试官的提问这样就完了吗?)
18 |
19 | **👩面试官**:**Q4,那你再说说其他环节中是怎么处理过期键的呢(比如AOF、RDB)?**
20 | **🤦🤦你**:...........
21 |
22 | (🎈这更加尴尬了,知道的不全,也可能不知道,本来想好好表现,也想着面试比较简单,没想到会经历这些)
23 |
24 | **为了避免这尴尬的场景出现,那现在需要你记录下以下的内容,这样就可以在美女面试官面前好好表现了。**
25 |
26 | ## 1. Redis Expire Key基础
27 | redis数据库在数据库服务器中使用了`redisDb`数据结构,结构如下:
28 |
29 | typedef struct redisDb {
30 | dict *dict; /* 键空间 key space */
31 | dict *expires; /* 过期字典 */
32 | dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */
33 | dict *ready_keys; /* Blocked keys that received a PUSH */
34 | dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
35 | struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */
36 | int id; /* Database ID */
37 | long long avg_ttl; /* Average TTL, just for stats */
38 | } redisDb;
39 | 其中,
40 | + **键空间(`key space`):dict字典用来保存数据库中的所有键值对**
41 | + **过期字典(`expires`):保存数据库中所有键的过期时间,过期时间用`UNIX`时间戳表示,且值为`long long`整数**
42 |
43 |
44 |
45 |
46 | ### 1.1 设置过期时间命令
47 | + **`EXPIRE \ \`**:命令用于将键key的过期时间设置为ttl秒之后
48 | + **`PEXPIRE \ \`**:命令用于将键key的过期时间设置为ttl毫秒之后
49 | + **`EXPIREAT \ \`**:命令用于将key的过期时间设置为timrestamp所指定的秒数时间戳
50 | + **`PEXPIREAT \ \`**:命令用于将key的过期时间设置为timrestamp所指定的毫秒数时间戳
51 |
52 | **设置过期时间:**
53 |
54 | redis> set Ccww 5 2 0
55 | ok
56 | redis> expire Ccww 5
57 | ok
58 | **使用redisDb结构存储数据图表示:**
59 | 
60 | ### 1.2过期时间保存以及判定
61 | 过期键的判定,其实通过**过期字典**进行判定,步骤:
62 | 1. 检查给定键是否存在于过期字典,如果存在,取出键的过期时间
63 | 2. 通过判断当前UNIX时间戳是否大于键的过期时间,是的话,键已过期,相反则键未过期。
64 |
65 |
66 |
67 |
68 |
69 |
70 |
71 | ## 2. 过期键删除策略
72 | ### 2.1 三种不同删除策略
73 | 1. **定时删除**:在设置键的过期时间的同时,创建一个定时任务,当键达到过期时间时,立即执行对键的删除操作
74 | 2. **惰性删除**:放任键过期不管,但在每次从键空间获取键时,都检查取得的键是否过期,如果过期的话,就删除该键,如果没有过期,就返回该键
75 | 3. **定期删除**:每隔一点时间,程序就对数据库进行一次检查,删除里面的过期键,至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
76 |
77 | ### 2.2 三种删除策略的优缺点
78 | #### 2.2.1 定时删除
79 | + **优点:** 对内存友好,定时删除策略可以保证过期键会尽可能快地被删除,并释放国期间所占用的内存
80 | + **缺点:** 对cpu时间不友好,在过期键比较多时,删除任务会占用很大一部分cpu时间,在内存不紧张但cpu时间紧张的情况下,将cpu时间用在删除和当前任务无关的过期键上,影响服务器的响应时间和吞吐量
81 |
82 | #### 2.2.2 惰性删除
83 | + **优点:** 对cpu时间友好,在每次从键空间获取键时进行过期键检查并是否删除,删除目标也仅限当前处理的键,这个策略不会在其他无关的删除任务上花费任何cpu时间。
84 | + **缺点:** 对内存不友好,过期键过期也可能不会被删除,导致所占的内存也不会释放。甚至可能会出现内存泄露的现象,当存在很多过期键,而这些过期键又没有被访问到,这会可能导致它们会一直保存在内存中,造成内存泄露。
85 |
86 | #### 2.2.4 定期删除
87 | 由于定时删除会占用太多cpu时间,影响服务器的响应时间和吞吐量以及惰性删除浪费太多内存,有内存泄露的危险,所以出现一种整合和折中这两种策略的定期删除策略。
88 | 1. 定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
89 | 2. 定时删除策略有效地减少了因为过期键带来的内存浪费。
90 |
91 |
92 | **定时删除策略难点就是确定删除操作执行的时长和频率:**
93 |
94 | 删除操作执行得太频繁。或者执行时间太长,定期删除策略就会退化成为定时删除策略,以至于将cpu时间过多地消耗在删除过期键上。相反,则惰性删除策略一样,出现浪费内存的情况。
95 | 所以使用定期删除策略,需要根据服务器的情况合理地设置删除操作的执行时长和执行频率。
96 |
97 | ## 3. Redis的过期键删除策略
98 | Redis服务器结合惰性删除和定期删除两种策略一起使用,通过这两种策略之间的配合使用,使得服务器可以在合理使用CPU时间和浪费内存空间取得平衡点。
99 |
100 | ### 3.1 惰性删除策略的实现
101 | Redis在执行任何读写命令时都会先找到这个key,惰性删除就作为一个切入点放在查找key之前,如果key过期了就删除这个key。
102 |
103 | 
104 |
105 | robj *lookupKeyRead(redisDb *db, robj *key) {
106 | robj *val;
107 | expireIfNeeded(db,key); // 切入点
108 | val = lookupKey(db,key);
109 | if (val == NULL)
110 | server.stat_keyspace_misses++;
111 | else
112 | server.stat_keyspace_hits++;
113 | return val;
114 | }
115 |
116 | **通过`expireIfNeeded`函数对输入键进行检查是否删除**
117 |
118 | int expireIfNeeded(redisDb *db, robj *key) {
119 | /* 取出键的过期时间 */
120 | mstime_t when = getExpire(db,key);
121 | mstime_t now;
122 |
123 | /* 没有过期时间返回0*/
124 | if (when < 0) return 0; /* No expire for this key */
125 |
126 | /* 服务器loading时*/
127 | if (server.loading) return 0;
128 |
129 | /* 根据一定规则获取当前时间*/
130 | now = server.lua_caller ? server.lua_time_start : mstime();
131 | /* 如果当前的是从(Slave)服务器
132 | * 0 认为key为无效
133 | * 1 if we think the key is expired at this time.
134 | * */
135 | if (server.masterhost != NULL) return now > when;
136 |
137 | /* key未过期,返回 0 */
138 | if (now <= when) return 0;
139 |
140 | /* 删除键 */
141 | server.stat_expiredkeys++;
142 | propagateExpire(db,key,server.lazyfree_lazy_expire);
143 | notifyKeyspaceEvent(NOTIFY_EXPIRED,
144 | "expired",key,db->id);
145 | return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
146 | dbSyncDelete(db,key);
147 | }
148 |
149 | ### 3.2 定期删除策略的实现
150 | key的定期删除会在Redis的周期性执行任务(`serverCron`,默认每100ms执行一次)中进行,而且是发生Redis的`master`节点,因为`slave`节点会通过主节点的DEL命令同步过来达到删除key的目的。
151 |
152 | for (j = 0; j < dbs_per_call; j++) {
153 | int expired;
154 | redisDb *db = server.db+(current_db % server.dbnum);
155 |
156 | current_db++;
157 |
158 | /* 超过25%的key已过期,则继续. */
159 | do {
160 | unsigned long num, slots;
161 | long long now, ttl_sum;
162 | int ttl_samples;
163 |
164 | /* 如果该db没有设置过期key,则继续看下个db*/
165 | if ((num = dictSize(db->expires)) == 0) {
166 | db->avg_ttl = 0;
167 | break;
168 | }
169 | slots = dictSlots(db->expires);
170 | now = mstime();
171 |
172 | /*但少于1%时,需要调整字典大小*/
173 | if (num && slots > DICT_HT_INITIAL_SIZE &&
174 | (num*100/slots < 1)) break;
175 |
176 | expired = 0;
177 | ttl_sum = 0;
178 | ttl_samples = 0;
179 |
180 | if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
181 | num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;// 20
182 |
183 | while (num--) {
184 | dictEntry *de;
185 | long long ttl;
186 |
187 | if ((de = dictGetRandomKey(db->expires)) == NULL) break;
188 | ttl = dictGetSignedIntegerVal(de)-now;
189 | if (activeExpireCycleTryExpire(db,de,now)) expired++;
190 | if (ttl > 0) {
191 | /* We want the average TTL of keys yet not expired. */
192 | ttl_sum += ttl;
193 | ttl_samples++;
194 | }
195 | }
196 |
197 | /* Update the average TTL stats for this database. */
198 | if (ttl_samples) {
199 | long long avg_ttl = ttl_sum/ttl_samples;
200 |
201 | /样本获取移动平均值 */
202 | if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
203 | db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
204 | }
205 | iteration++;
206 | if ((iteration & 0xf) == 0) { /* 每迭代16次检查一次 */
207 | long long elapsed = ustime()-start;
208 |
209 | latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
210 | if (elapsed > timelimit) timelimit_exit = 1;
211 | }
212 | /* 超过时间限制则退出*/
213 | if (timelimit_exit) return;
214 | /* 在当前db中,如果少于25%的key过期,则停止继续删除过期key */
215 | } while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
216 | }
217 | 依次遍历每个db(默认配置数是16),针对每个db,每次循环随机选择20个(`ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP`)key判断是否过期,如果一轮所选的key少于25%过期,则终止迭次,此外在迭代过程中如果超过了一定的时间限制则终止过期删除这一过程。
218 |
219 | ## 4. AOF、RDB和复制功能对过期键的处理
220 | ### 4.1 RDB
221 | **生成RDB文件**
222 | 程序会数据库中的键进行检查,已过期的键不会保存到新创建的RDB文件中
223 |
224 | **载入RDB文件**
225 | 1. 主服务载入RDB文件,会对文件中保存的键进行检查会忽略过期键加载未过期键
226 | 2. 从服务器载入RDB文件,会加载文件所保存的所有键(过期和未过期的),但从主服务器同步数据同时会清空从服务器的数据库。
227 |
228 | ### 4.2 AOF
229 | + AOF文件写入:当过期键被删除后,会在AOF文件增加一条DEL命令,来显式地记录该键已被删除。
230 | + AOF重写:已过期的键不会保存到重写的AOF文件中
231 |
232 | ### 4.3 复制
233 | 当服务器运行在复制模式下时,从服务器的过期键删除动作由主服务器控制的,这样的好处主要为了保持主从服务器数据一致性:
234 | 1. 主服务器在删除一个过期键之后,会显式地向所有的从服务器发送一个DEL命令,告知从服务器删除这个过期键
235 | 2. 从服务器在执行客户端发送的读取命令时,即使碰到过期键也不会将过期键删除,不作任何处理。
236 | 3. 只有接收到主服务器 DEL命令后,从服务器进行删除处理。
237 |
238 |
239 | > 各位看官还可以吗?喜欢的话,动动手指点个💗,点个关注呗!!谢谢支持!
240 | >
241 | > 欢迎关注公众号【**Ccww技术博客**】,原创技术文章第一时间推出
242 |
243 |
244 |
245 | 
246 |
--------------------------------------------------------------------------------
/doc/javabase/Java对象的浅克隆和深克隆.md:
--------------------------------------------------------------------------------
1 | ## Java对象的浅克隆和深克隆
2 |
3 | ### 为什么需要克隆
4 | 在实际编程过程中,我们常常要遇到这种情况:有一个对象A,在某一时刻A中已经包含了一些有效值,此时可能会需要一个和A完全相同新对象B,并且此后对B任何改动都不会影响到A中的值,也就是说,A与B是两个独立的对象,但B的初始值是由A对象确定的。在Java语言中,用简单的赋值语句是不能满足这种需求的,要满足这种需求有很多途径。
5 |
6 | ### 克隆的实现方式
7 | ### 一、浅度克隆
8 | 浅度克隆对于要克隆的对象,对于其基本数据类型的属性,复制一份给新产生的对象,对于非基本数据类型的属性,仅仅复制一份引用给新产生的对象,即新产生的对象和原始对象中的非基本数据类型的属性都指向的是同一个对象。
9 |
10 | **浅度克隆步骤:**
11 | 1. 实现java.lang.Cloneable接口
12 | 要clone的类为什么还要实现Cloneable接口呢?Cloneable接口是一个标识接口,不包含任何方法的!这个标识仅仅是针对Object类中clone()方法的,如果clone类没有实现Cloneable接口,并调用了Object的 clone()方法(也就是调用了super.Clone()方法),那么Object的clone()方法就会抛出 CloneNotSupportedException异常。
13 | 2. 重写java.lang.Object.clone()方法
14 | JDK API的说明文档解释这个方法将返回Object对象的一个拷贝。要说明的有两点:一是拷贝对象返回的是一个新对象,而不是一个引用。二是拷贝对象与用new操作符返回的新对象的区别就是这个拷贝已经包含了一些原来对象的信息,而不是对象的初始信息。
15 |
16 | 观察一下Object类的clone()方法是一个native方法,native方法的效率一般来说都是远高于java中的非native方法。这也解释了为什么要用Object中clone()方法而不是先new一个类,然后把原始对象中的信息赋到新对象中,虽然这也实现了clone功能。Object类中的clone()还是一个protected属性的方法,重写之后要把clone()方法的属性设置为public。
17 |
18 | Object类中clone()方法产生的效果是:先在内存中开辟一块和原始对象一样的空间,然后原样拷贝原始对象中的内容。对基本数据类型,这样的操作是没有问题的,但对非基本类型变量,我们知道它们保存的仅仅是对象的引用,这也导致clone后的非基本类型变量和原始对象中相应的变量指向的是同一个对象。
19 |
20 | **Java代码实例:**
21 |
22 | public class Product implements Cloneable {
23 | private String name;
24 |
25 | public Object clone() {
26 | try {
27 | return super.clone();
28 | } catch (CloneNotSupportedException e) {
29 | return null;
30 | }
31 | }
32 | }
33 |
34 | ### 二、深度克隆
35 | 在浅度克隆的基础上,对于要克隆的对象中的非基本数据类型的属性对应的类,也实现克隆,这样对于非基本数据类型的属性,复制的不是一份引用,即新产生的对象和原始对象中的非基本数据类型的属性指向的不是同一个对象
36 |
37 | **深度克隆步骤:**
38 | 要克隆的类和类中所有非基本数据类型的属性对应的类
39 | 1. 都实现java.lang.Cloneable接口
40 | 2. 都重写java.lang.Object.clone()方法
41 |
42 | **Java代码实例:**
43 |
44 | public class Attribute implements Cloneable {
45 | private String no;
46 |
47 | public Object clone() {
48 | try {
49 | return super.clone();
50 | } catch (CloneNotSupportedException e) {
51 | return null;
52 | }
53 | }
54 | }
55 |
56 | public class Product implements Cloneable {
57 | private String name;
58 |
59 | private Attribute attribute;
60 |
61 | public Object clone() {
62 | try {
63 | return super.clone();
64 | } catch (CloneNotSupportedException e) {
65 | return null;
66 | }
67 | }
68 | }
69 |
70 |
71 | ### 三、使用对象序列化和反序列化实现深度克隆
72 | **所谓对象序列化就是将对象的状态转换成字节流,以后可以通过这些值再生成相同状态的对象。**
73 |
74 | 对象的序列化还有另一个容易被大家忽略的功能就是对象复制(Clone),Java中通过Clone机制可以复制大部分的对象,但是众所周知,Clone有深度Clone和浅度Clone,如果你的对象非常非常复杂,并且想实现深层 Clone,如果使用序列化,不会超过10行代码就可以解决。
75 |
76 | 虽然Java的序列化非常简单、强大,但是要用好,还有很多地方需要注意。比如曾经序列化了一个对象,可由于某种原因,该类做了一点点改动,然后重新被编译,那么这时反序列化刚才的对象,将会出现异常。 你可以通过添加serialVersionUID属性来解决这个问题。如果你的类是个单例(Singleton)类,虽然我们多线程下的并发问题来控制单例,但是,是否允许用户通过序列化机制或者克隆来复制该类,如果不允许你需要谨慎对待该类的实现(让此类不用实现Serializable接口或Externalizable接口和Cloneable接口就行了)。
77 |
78 | **Java代码实例:**
79 | public class Attribute {
80 | private String no;
81 | }
82 |
83 | public class Product {
84 | private String name;
85 |
86 | private Attribute attribute;
87 |
88 | public Product clone() {
89 | ByteArrayOutputStream byteOut = null;
90 | ObjectOutputStream objOut = null;
91 | ByteArrayInputStream byteIn = null;
92 | ObjectInputStream objIn = null;
93 |
94 | try {
95 | // 将该对象序列化成流,因为写在流里的是对象的一个拷贝,而原对象仍然存在于JVM里面。所以利用这个特性可以实现对象的深拷贝
96 | byteOut = new ByteArrayOutputStream();
97 | objOut = new ObjectOutputStream(byteOut);
98 | objOut.writeObject(this);
99 | // 将流序列化成对象
100 | byteIn = new ByteArrayInputStream(byteOut.toByteArray());
101 | objIn = new ObjectInputStream(byteIn);
102 |
103 | return (ContretePrototype) objIn.readObject();
104 | } catch (IOException e) {
105 | throw new RuntimeException("Clone Object failed in IO.",e);
106 | } catch (ClassNotFoundException e) {
107 | throw new RuntimeException("Class not found.",e);
108 | } finally{
109 | try{
110 | byteIn = null;
111 | byteOut = null;
112 | if(objOut != null) objOut.close();
113 | if(objIn != null) objIn.close();
114 | }catch(IOException e){
115 | }
116 | }
117 | }
118 | }
119 |
120 | **或者:**
121 |
122 | public static T copy(T input) {
123 | ByteArrayOutputStream baos = null;
124 | ObjectOutputStream oos = null;
125 | ByteArrayInputStream bis = null;
126 | ObjectInputStream ois = null;
127 | try {
128 | baos = new ByteArrayOutputStream();
129 | oos = new ObjectOutputStream(baos);
130 | oos.writeObject(input);
131 | oos.flush();
132 |
133 | byte[] bytes = baos.toByteArray();
134 | bis = new ByteArrayInputStream(bytes);
135 | ois = new ObjectInputStream(bis);
136 | Object result = ois.readObject();
137 | return (T) result;
138 | } catch (IOException e) {
139 | throw new IllegalArgumentException("Object can't be copied", e);
140 | } catch (ClassNotFoundException e) {
141 | throw new IllegalArgumentException("Unable to reconstruct serialized object due to invalid class definition", e);
142 | } finally {
143 | closeQuietly(oos);
144 | closeQuietly(baos);
145 | closeQuietly(bis);
146 | closeQuietly(ois);
147 | }
148 | }
149 |
150 | **也可以用json等其他序列化技术实现深度复制;**
151 |
152 | ## 四、各框架Bean复制
153 | Bean复制的几种框架中(Apache BeanUtils、PropertyUtils,Spring BeanUtils,Cglib BeanCopier)都是相当于克隆中的浅克隆。
154 |
155 | 1)spring包和Apache中的 BeanUtils采用反射实现
156 |
157 | >Spring: void copyProperties(Object source, Object target,String[] ignoreProperties)
158 | Apache:void copyProperties(Object dest, Object orig)
159 |
160 | 2)cglib包中的 Beancopier采用动态字节码实现
161 | >cglib: BeanCopier create(Class source, Class target,boolean useConverter)
162 |
163 | 例如:
164 |
165 | BeanCopier copier =BeanCopier.create(stuSource.getClass(), stuTarget.getClass(), false);
166 | copier.copy(stuSource, stuTarget, null);
167 |
168 | 公司内部对用到的bean属性复制做了下性能分析:
169 |
170 | |框架|类|性能|
171 | |-|-|-|
172 | |cglib | BeanCopier | 15ms|
173 | |Spring | BeanUtil | 4031ms|
174 | |apache |BeanUtils | 18514ms|
175 |
176 | >文章链接:`https://blog.csdn.net/caomiao2006/article/details/52590622`
177 |
--------------------------------------------------------------------------------
/doc/javabase/StringBuilder在高性能场景下的正确用法.md:
--------------------------------------------------------------------------------
1 | ## StringBuilder在高性能场景下的正确用法
2 |
3 | ### 初始长度很重要
4 | `StringBuilder` 的内部有一个`char[]`,不同的`append()`就是不断的往`char[]`里填东西的过程。
5 |
6 | `new StringBuilder()`时`char[]`的默认长度为16,超过就用`System.arraycopy`成倍复制扩容。
7 |
8 | 这样一来有数组拷贝的成本,二来原来的`char[]`也白白浪费了,要被`GC`掉。
9 |
10 | 所以,合理设置一个初始值是很重要的。
11 |
12 | 一种长度设置的思路,在`append()`的时候,不急着往`char[]`里塞东西,而是先拿一个`String[]`把它们都存起来,到了最后才把所有`String`的`length`加起来,构造一个合理长度的`StringBuilder`。
13 |
14 | ### Liferay的StringBundler类
15 | Liferay的StringBundler类提供了另一个长度设置的思路,它在append()的时候,不急着往char[]里塞东西,而是先拿一个String[]把它们都存起来,到了最后才把所有String的length加起来,构造一个合理长度的StringBuilder。
16 |
17 |
18 | ### 浪费一倍的char[]
19 | 因为:
20 |
21 | return new String(value, 0, count);
22 |
23 | String的构造函数会用System.arraycopy()复制一次传入的char[]来保证安全性及不可变性,这样StringBuilder里的char[]就白白牺牲掉了。
24 |
25 | 为了不浪费这些char[],可以重用StringBuilder。
26 |
27 | ### 重用StringBuilder
28 | public StringBuilder getStringBuilder() {
29 | sb.setLength(0);
30 | return sb;
31 | }
32 | 为了避免并发冲突,这个Holder一般设为ThreadLocal。
33 |
34 | ### +和StringBuilder
35 | String str = "hello " + user.getName();
36 | 这一句经过javac编译后的效果,的确等价于使用StringBuilder,但没有设定长度。
37 |
38 | 但是,如果像下面这样:
39 |
40 | String str = "hello ";
41 | str = str + user.getName();
42 | 每一条语句,都会生成一个新的StringBuilder,这样这里就有了两个StringBuilder,性能就完全不一样了。
43 |
44 | 保险起见,还是继续自己用StringBuilder并设定好长度。
45 |
46 | private static final ThreadLocal threadLocalStringBuilderHolder = new ThreadLocal() {
47 | protected StringBuilderHelper initialValue() {
48 | return new StringBuilderHelper(256);
49 | }
50 | }
51 |
52 | StringBuilder sb = threadLocalStringBuilderHolder.get().resetAndGetStringBuilder();
53 |
54 | **StringBuidlerHolder**
55 |
56 | public class StringBuilderHolder {
57 | private final StringBuilder sb;
58 |
59 | public StringBuilderHolder(int capacity) {
60 | sb = new StringBuidler(capacity);
61 | }
62 |
63 | public StringBuilder resetAndGetStringBuilder() {
64 | sb.setLength(0);
65 | return sb;
66 | }
67 | }
68 |
69 |
70 | >文章链接:`http://calvin1978.blogcn.com/articles/stringbuilder.html`
71 |
--------------------------------------------------------------------------------
/doc/javabase/collection/ConcurrentHashMap源码和面试题一.md:
--------------------------------------------------------------------------------
1 |
2 |
3 | ### 前言
4 |
5 | 在平时中集合使用中,当涉及多线程开发时,如果使用`HashMap`可能会导致死锁问题,使用`HashTable`效率又不高。而`ConcurrentHashMap`在保持同步同时并发效率比较高,`ConcurrentHashmap`是最好的选择,那面试中也会被常常问到,那可能的问题是:
6 |
7 | - **ConcurrentHashMap的实现原理**
8 | - **ConcurrentHashMap1.7和1.8的区别?**
9 | - **ConcurrentHashMap使用什么技术来保证线程安全**
10 | - **ConcurrentHashMap的put()方法**
11 | - **ConcurrentHashmap 不支持 key 或者 value 为 null 的原因?**
12 | - **put()方法如何实现线程安全呢?**
13 | - **ConcurrentHashMap扩容机制**
14 | - **ConcurrentHashMap的get方法是否要加锁,为什么?**
15 | - **其他问题**
16 | - **为什么使用ConcurrentHashMap**
17 | - **ConcurrentHashMap迭代器是强一致性还是弱一致性?HashMap呢?**
18 | - **JDK1.7与JDK1.8中ConcurrentHashMap的区别**
19 |
20 | ### ConcurrentHashMap的实现原理
21 |
22 | ConcurrentHashMap的出现主要为了解决hashmap在并发环境下不安全,JDK1.8ConcurrentHashMap的设计与实现非常精巧,大量的利用了volatile,CAS等乐观锁技术来减少锁竞争对于性能的影响,**ConcurrentHashMap保证线程安全的方案是:**
23 |
24 | - **JDK1.8:synchronized+CAS+HashEntry+红黑树;**
25 | - **JDK1.7:ReentrantLock+Segment+HashEntry。**
26 |
27 | #### JDK7 ConcurrentHashMap
28 |
29 | 在JDK1.7中ConcurrentHashMap由Segment(分段锁)数组结构和HashEntry数组组成,且主要通过Segment(分段锁)段技术实现线程安全。
30 |
31 | Segment是一种可重入锁,是一种数组和链表的结构,一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表结构,因此在ConcurrentHashMap查询一个元素的过程需要进行两次Hash操作,如下所示:
32 |
33 | - 第一次Hash定位到Segment,
34 | - 第二次Hash定位到元素所在的链表的头部
35 |
36 | 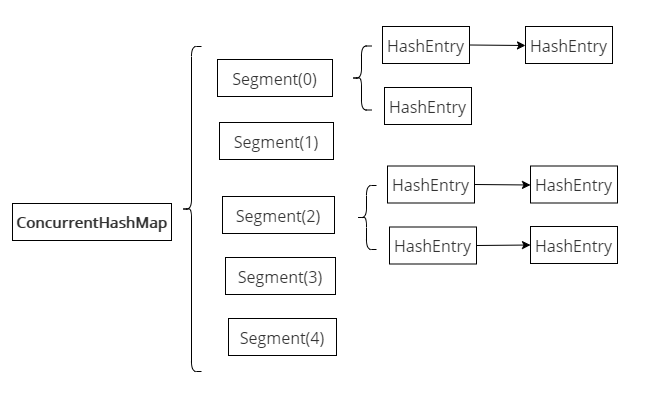
37 |
38 | 正是通过Segment分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。
39 |
40 | 这样结构会使Hash的过程要比普通的HashMap要长,影响性能,但写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,ConcurrentHashMap提升了并发能力。
41 |
42 | #### JDK8 ConcurrentHashMap
43 |
44 | 在JDK8ConcurrentHashMap内部机构:数组+链表+红黑树,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N))),结构基本上与功能和JDK8的HashMap一样,只不过ConcurrentHashMap保证线程安全性。
45 |
46 | 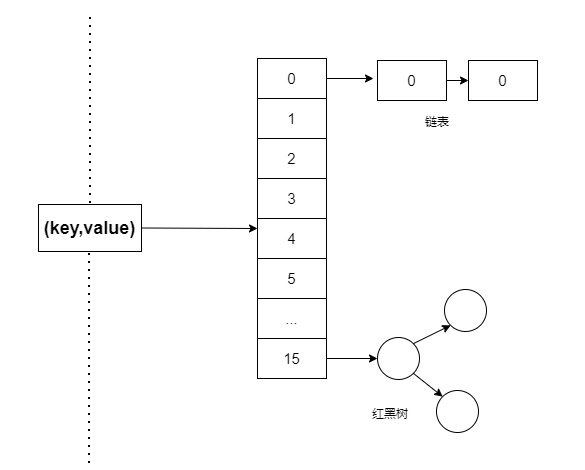
47 |
48 | 但在JDK1.8中摒弃了Segment分段锁的数据结构,基于CAS操作保证数据的获取以及使用synchronized关键字对相应数据段加锁来实现线程安全,这进一步提高了并发性。(**CAS原理详情**[《面试:为了进阿里,又把并发CAS(Compare and Swap)实现重新精读一遍》)](https://juejin.im/post/6866795970274394126))
49 |
50 | ```java
51 | static class Node implements Map.Entry {
52 | final int hash;
53 | final K key;
54 | volatile V val; //使用了volatile属性
55 | volatile Node next; //使用了volatile属性
56 | ...
57 | }
58 | ```
59 |
60 | ConcurrentHashMap采用Node类作为基本的存储单元,每个键值对(key-value)都存储在一个Node中,使用了volatile关键字修饰value和next,保证并发的可见性。其中Node子类有:
61 |
62 | - ForwardingNode:扩容节点,只是在扩容阶段使用的节点,主要作为一个标记,在处理并发时起着关键作用,有了ForwardingNodes,也是ConcurrentHashMap有了分段的特性,提高了并发效率
63 | - TreeBin:TreeNode的代理节点,用于维护TreeNodes,ConcurrentHashMap的红黑树存放的是TreeBin
64 | - TreeNode:用于树结构中,红黑树的节点(当链表长度大于8时转化为红黑树),此节点不能直接放入桶内,只能是作为红黑树的节点
65 | - ReservationNode:保留结点
66 |
67 | ConcurrentHashMap中查找元素、替换元素和赋值元素都是基于`sun.misc.Unsafe`中**原子操作**实现**多并发的无锁化**操作。
68 |
69 | ```
70 | static final Node tabAt(Node[] tab, int i) {
71 | return (Node)U.getObjectAcquire(tab, ((long)i << ASHIFT) + ABASE);
72 | }
73 |
74 | static final boolean casTabAt(Node[] tab, int i,
75 | Node c, Node v) {
76 | return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
77 | }
78 |
79 | static final void setTabAt(Node[] tab, int i, Node v) {
80 | U.putObjectRelease(tab, ((long)i << ASHIFT) + ABASE, v);
81 | }
82 | ```
83 |
84 |
85 |
86 | ------
87 |
88 | ### ConcurrentHashMap的put()方法
89 |
90 | ConcurrentHashMap的put的流程步骤
91 |
92 | 1. 如果key或者value为null,则抛出空指针异常,和HashMap不同的是HashMap单线程是允许为Null;
93 |
94 | `if (key == null || value == null) throw new NullPointerException();`
95 |
96 | 2. for的死循环,为了实现CAS的无锁化更新,如果table为null或者table的长度为0,则初始化table,调用`initTable()`方法(第一次put数据,调用默认参数实现,其中重要的`sizeCtl`参数)。
97 |
98 | ```java
99 | //计算索引的第一步,传入键值的hash值
100 | int hash = spread(key.hashCode());
101 | int binCount = 0; //保存当前节点的长度
102 | for (Node[] tab = table;;) {
103 | Node f; int n, i, fh; K fk; V fv;
104 | if (tab == null || (n = tab.length) == 0)
105 | tab = initTable(); //初始化Hash表
106 | ...
107 | }
108 | ```
109 |
110 | 3. 确定元素在Hash表的索引
111 |
112 | 通过hash算法可以将元素分散到哈希桶中。在ConcurrentHashMap中通过如下方法确定数组索引:
113 |
114 | 第一步:
115 |
116 | ```java
117 | static final int spread(int h) {
118 | return (h ^ (h >>> 16)) & HASH_BITS;
119 | }
120 | ```
121 |
122 | 第二步:`(length-1) & (h ^ (h >>> 16)) & HASH_BITS);`
123 |
124 | 4. 通过`tableAt()`方法找到位置`tab[i]`的`Node`,当Node为null时为没有`hash`冲突的话,使用`casTabAt()`方法`CAS`操作将元素插入到`Hash`表中,`ConcurrentHashmap`使用`CAS`无锁化操作,这样在高并发`hash`冲突低的情况下,性能良好。
125 |
126 | ```java
127 | else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
128 | //利用CAS操作将元素插入到Hash表中
129 | if (casTabAt(tab, i, null, new Node(hash, key, value)))
130 | break; // no lock when adding to empty bin(插入null的节点,无需加锁)
131 | }
132 | ```
133 |
134 | 5. 当f不为null时,说明发生了hash冲突,当f.hash == MOVED==-1 时,说明`ConcurrentHashmap`正在发生`resize`操作,使用`helpTransfer()`方法帮助正在进行resize操作。
135 |
136 | ```java
137 | else if ((fh = f.hash) == MOVED) //f.hash == -1
138 | //hash为-1 说明是一个forwarding nodes节点,表明正在扩容
139 | tab = helpTransfer(tab, f);
140 | ```
141 |
142 | 6. 以上情况都不满足的时,使用`synchronized`同步块上锁当前节点`Node `,并判断有没有线程对数组进行了修改,如果没有则进行:
143 |
144 | - 遍历该链表并统计该链表长度`binCount`,查找是否有和key相同的节点,如果有则将查找到节点的val值替换为新的value值,并返回旧的value值,否则根据key,value,hash创建新Node并将其放在链表的尾部
145 | - 如果`Node f`是`TreeBin`的类型,则使用红黑树的方式进行插入。然后则退出`synchronized(f)`锁住的代码块
146 |
147 | ```java
148 | //当前节点加锁
149 | synchronized (f) {
150 | //判断下有没有线程对数组进行了修改
151 | if (tabAt(tab, i) == f) {
152 | //如果hash值是大于等于0的说明是链表
153 | if (fh >= 0) {
154 | binCount = 1;
155 | for (Node e = f;; ++binCount) {
156 | K ek;
157 | //插入的元素键值的hash值有节点中元素的hash值相同,替换当前元素的值
158 | if (e.hash == hash &&
159 | ((ek = e.key) == key ||
160 | (ek != null && key.equals(ek)))) {
161 | oldVal = e.val;
162 | if (!onlyIfAbsent)
163 | //替换当前元素的值
164 | e.val = value;
165 | break;
166 | }
167 | Node pred = e;
168 | //如果循环到链表结尾还没发现,那么进行插入操作
169 | if ((e = e.next) == null) {
170 | pred.next = new Node(hash, key, value);
171 | break;
172 | }
173 | }
174 | }else if (f instanceof TreeBin) { //节点为树
175 | Node p;
176 | binCount = 2;
177 | if ((p = ((TreeBin)f).putTreeVal(hash, key,
178 | value)) != null) {
179 | oldVal = p.val;
180 | if (!onlyIfAbsent)
181 | //替换旧值
182 | p.val = value;
183 | }
184 | }
185 | else if (f instanceof ReservationNode)
186 | throw new IllegalStateException("Recursive update");
187 | }
188 | }
189 | ```
190 |
191 | 7. 执行完`synchronized(f)`同步代码块之后会先检查`binCount`,如果大于等于TREEIFY_THRESHOLD = 8则进行treeifyBin操作尝试将该链表转换为红黑树。
192 |
193 | ```java
194 | if (binCount != 0) {
195 | //如果节点长度大于8,转化为树
196 | if (binCount >= TREEIFY_THRESHOLD)
197 | treeifyBin(tab, i);
198 | if (oldVal != null)
199 | return oldVal;
200 | break;
201 | }
202 | ```
203 |
204 | 8. 执行了一个`addCount`方法,主要用于统计数量以及决定是否需要扩容.
205 |
206 | ```java
207 | addCount(1L, binCount);
208 | ```
209 |
210 | #### ConcurrentHashmap 不支持 key 或者 value 为 null 的原因?
211 |
212 | `ConcurrentHashmap`和`hashMap`不同的是,`concurrentHashMap`的`key`和`value`都不允许为null,
213 |
214 | 因为`concurrenthashmap`它们是用于多线程的,并发的 ,如果`map.get(key)`得到了null,不能判断到底是映射的value是null,还是因为没有找到对应的key而为空,
215 |
216 | 而用于单线程状态的`hashmap`却可以用`containKey(key)` 去判断到底是否包含了这个null。
217 |
218 | #### put()方法如何实现线程安全呢?
219 |
220 | 1. 在第一次put数据时,调用`initTable()`方法
221 |
222 | ```java
223 | /**
224 | * Hash表的初始化和调整大小的控制标志。为负数,Hash表正在初始化或者扩容;
225 | * (-1表示正在初始化,-N表示有N-1个线程在进行扩容)
226 | * 否则,当表为null时,保存创建时使用的初始化大小或者默认0;
227 | * 初始化以后保存下一个调整大小的尺寸。
228 | */
229 | private transient volatile int sizeCtl;
230 | //第一次put,初始化数组
231 | private final Node[] initTable() {
232 | Node[] tab; int sc;
233 | while ((tab = table) == null || tab.length == 0) {
234 | //如果已经有别的线程在初始化了,这里等待一下
235 | if ((sc = sizeCtl) < 0)
236 | Thread.yield(); // lost initialization race; just spin
237 | //-1 表示正在初始化
238 | else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
239 | ...
240 | } finally {
241 | sizeCtl = sc;
242 | }
243 | break;
244 | }
245 | }
246 | return tab;
247 | }
248 | ```
249 |
250 | 使用`sizeCtl`参数作为控制标志的作用,当在从插入元素时,才会初始化Hash表。在开始初始化的时候,
251 |
252 | - 首先判断`sizeCtl`的值,如果**sizeCtl < 0**,说明**有线程在初始化**,**当前线程便放弃初始化操作**。否则,将**`SIZECTL`设置为-1**,**Hash表进行初始化**。
253 | - 初始化成功以后,将`sizeCtl`的值设置为当前的容量值
254 |
255 | 2. 在不存在hash冲突的时
256 |
257 | ```java
258 | else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
259 | //利用CAS操作将元素插入到Hash表中
260 | if (casTabAt(tab, i, null, new Node(hash, key, value)))
261 | break; // no lock when adding to empty bin(插入null的节点,无需加锁)
262 | }
263 | ```
264 |
265 | `(f = tabAt(tab, i = (n - 1) & hash)) == null`中使用tabAt原子操作获取数组,并利用`casTabAt(tab, i, null, new Node(hash, key, value))`CAS操作将元素插入到Hash表中
266 |
267 | 3. 在存在hash冲突时,先把当前节点使用关键字`synchronized`加锁,然后再使用`tabAt()`原子操作判断下有没有线程对数组进行了修改,最后再进行其他操作。
268 |
269 | **为什么要锁住更新操作的代码块?**
270 |
271 | 因为发生了哈希冲突,当前线程正在f所在的链表上进行更新操作,假如此时另外一个线程也需要到这个链表上进行更新操作,则需要等待当前线程更新完后再执行
272 |
273 | ```java
274 | //当前节点加锁
275 | synchronized (f) {
276 | //这里判断下有没有线程对数组进行了修改
277 | if (tabAt(tab, i) == f) {
278 | ......//do something
279 | }
280 | }
281 | ```
282 | 由于篇幅过于长,分成两部分来讲讲,接下来的内容请看[《面试:为了进阿里,死磕了ConcurrentHashMap源码和面试题(二)》](https://juejin.im/post/6871793103020556295/)
283 |
--------------------------------------------------------------------------------
/doc/javabase/collection/HashMap原理和面试题(图解版一).md:
--------------------------------------------------------------------------------
1 | >该系列文章收录在公众号【Ccww技术博客】,原创技术文章早于博客推出
2 |
3 | ### 前言
4 | 集合在基础面试中是必备可缺的一部分,其中重要的HashMap更是少不了,那面试官会面试中提问那些问题呢,这些在JDK1.7和1.8有什么区别??
5 |
6 | - **HashMap的底层原理**
7 | - **HashMap的hash哈希函数的设计原理,以及HashMap下标获取方式?**
8 | - **HashMap扩容机制,hashMap中什么时候需要进行扩容,扩容resize()又是如何实现的**
9 | - **hashMap中put是如何实现的 ,JDK1.7和1.8有什么区别?**
10 | - **hashMap中get是如何实现的**
11 | - **其他涉及问题**
12 | - **HashMap具备的特性**
13 | - **为什么Hash的底层数据长度总为2的N次方?如果输入值不是2的幂比如10会怎么样?**
14 | - **加载因子为什么是 0.75?**
15 | - **哈希表如何解决Hash冲突**
16 | - **当有哈希冲突时,HashMap 是如何查找并确认元素的?**
17 | - **HashMap 是线程安全的吗,为什么不是线程安全的?**
18 |
19 |
20 | ### 1. HashMap的底层原理
21 |
22 | JDK1.7使用的是数组+ 单链表的数据结构。JDK1.8之后,使用的是数组+链表+红黑树的数据结构
23 |
24 | #### HashMap数据结构图(jdk1.8)
25 | 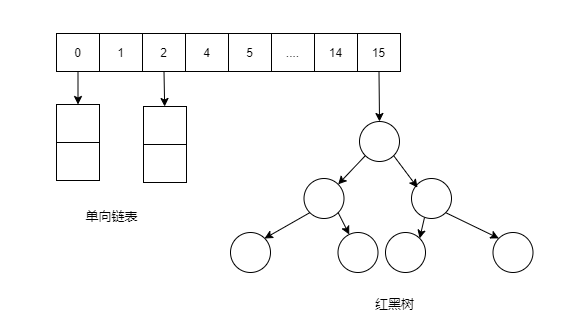
26 |
27 | ```java
28 | //解决hash冲突,链表转成树的阈值,当桶中链表长度大于8时转成树
29 | static final int TREEIFY_THRESHOLD = 8;
30 | //进行resize操作时,若桶中数量少于6则从树转成链表
31 | static final int UNTREEIFY_THRESHOLD = 6;
32 | /* 当需要将解决 hash 冲突的链表转变为红黑树时,需要判断下此时数组容量,若是由于数组容量太小(小于 MIN_TREEIFY_CAPACITY )导致的 hash 冲突太多,则不进行链表转变为红黑树操作,转为利用 resize() 函数对 hashMap 扩容 */
33 | static final int MIN_TREEIFY_CAPACITY = 64;
34 | ```
35 |
36 | 从HashMap常量中可以看出,当链表的深度达到8的时候,也就是默认阈值TREEIFY_THRESHOLD=8,就会自动扩容把链表转成红黑树的数据结构来把时间复杂度从O(n)变成O(logN)提高了效率,而且当进行resize操作时,若桶中数量少于6则从树转成链表。
37 |
38 | #### 那为什么数据结构需要从JDK1.7换成JDK1.8的数组+链表+红黑树?
39 |
40 | 在JDK1.7中,当相同的hash值时,HashMap不断地产生碰撞,那么相同key位置的链表就会不断增长,当查询HashMap的相应key值的Vaule值时,就会去循环遍历这个超级大的链表,查询性能非常低下。
41 |
42 | 但在JDK1.8当链表超过8个节点数时,将会让红黑树来替代链表,查询性能得到了很好的提升,从原来的是O(n)到O(logn)。
43 |
44 |
45 |
46 | ### 2. HashMap的hash哈希函数的设计原理,以及HashMap下标获取 hash &(n - 1)?
47 |
48 | #### hash哈希函数的设计原理
49 |
50 | ```java
51 | static final int hash(Object key) {
52 | int h;
53 | return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
54 | }
55 | ```
56 |
57 | 1. 首先获取hashcode,一个32位的int值
58 | 2. 然后将hashcode左移16位的值进行与或,即将高位与低位进行异或运算,减少碰撞机率。
59 |
60 | 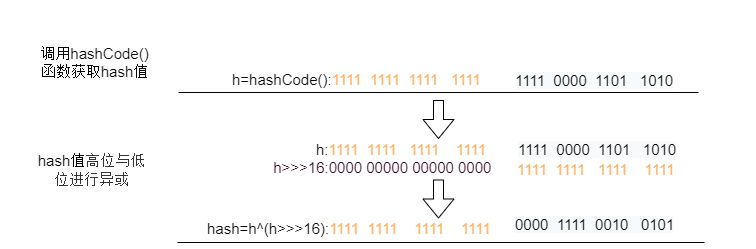
61 |
62 | #### HashMap下标获取h % n = h &(n - 1)
63 |
64 | 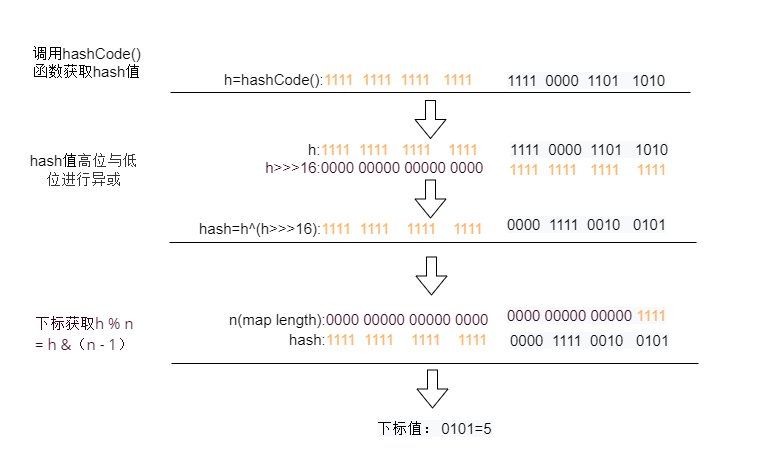
65 |
66 | 3. 取余运算,但在计算机运算中&肯定比%快,又因为h % n = h &(n - 1),所以最终将第二步得到的hash跟n-1进行与运算。n是table中的长度。
67 |
68 | **设计原因:**
69 |
70 | 1. 一定要尽可能降低hash碰撞,越分散越好;
71 | 2. 算法一定要尽可能高效,因为这是高频操作, 因此采用位运算;
72 |
73 |
74 |
75 | ### 3. HashMap扩容机制resize()
76 |
77 | **HashMap扩容步骤分成两步:**
78 |
79 | + 获取新值:新的容量值newCap ,新的扩容阀界值newThr获取
80 | + 数据迁移:如果oldTab老数组不为空,说明是扩容操作,那么涉及到元素的转移操,遍历老数组,如果当前位置元素不为空,那么需要转移该元素到新数组
81 |
82 |
83 |
84 | #### 获取新值:新的容量值newCap ,新的扩容阀界值newThr获取
85 |
86 | - 扩容变量
87 |
88 | ```java
89 | //原的元素数组
90 | Node[] oldTab = table;
91 | //老的元素数组长度
92 | int oldCap = (oldTab == null) ? 0 : oldTab.length;
93 | // 老的扩容阀值设置
94 | int oldThr = threshold;
95 | // 新数组的容量,新数组的扩容阀值都初始化为0
96 | int newCap, newThr = 0;
97 | // 设置map的扩容阀值为 新的阀值
98 | threshold = newThr;
99 | //创建新的数组(对于第一次添加元素,那么这个数组就是第一个数组;对于存在oldTab的时候,那么这个数组就是要需要扩容到的新数组)
100 | Node[] newTab = (Node[])new Node[newCap];
101 | // 将该map的table属性指向到该新数组
102 | table = newTab;
103 | ```
104 |
105 |
106 |
107 | - 当如果老数组长度oldCap > 0,说明已经存在元素,
108 |
109 | - 如果此时oldCap>=MAXIMUM_CAPACITY(1 << 30),表示已经到了最大容量,这时还要往map中put数据,则阈值设置为整数的最大值 Integer.MAX_VALUE,直接返回这个oldTab的内存地址
110 | - 如果扩容之后的新容量小于最大容量 ,且老的数组容量大于等于默认初始化容量(16),那么新数组的扩容阀值设置为老阀值的2倍(左移1位相当于乘以2,newCap = oldCap << 1),阈值也double(newThr= oldThr << 1);
111 |
112 | ```java
113 | // 如果老数组长度大于0,说明已经存在元素
114 | if (oldCap > 0) {
115 | if (oldCap >= MAXIMUM_CAPACITY) {
116 | threshold = Integer.MAX_VALUE;
117 | return oldTab;
118 | }
119 | else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
120 | oldCap >= DEFAULT_INITIAL_CAPACITY)
121 | newThr = oldThr << 1; // double threshold
122 | }
123 | ```
124 |
125 |
126 |
127 | - 当老数组没有任何元素,如果老数组的扩容阀值大于0,那么设置新数组的容量为该阀值,`newCap = oldThr`。当`newThr`扩容阀值为0 ,`newThr = (float)newCap * loadFactor`(**这一步也就意味着构造该map的时候,指定了初始化容量构造函数**);
128 |
129 | ```java
130 | else if (oldThr > 0) // initial capacity was placed in threshold
131 | newCap = oldThr;
132 | ....
133 | if (newThr == 0) {
134 | float ft = (float)newCap * loadFactor;
135 | newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
136 | (int)ft : Integer.MAX_VALUE);
137 | }
138 | ```
139 |
140 |
141 |
142 | - 其他情况**,设置新数组容量 为 16,且设置新数组扩容阀值为 16*0.75 = 12。0.75为负载因子,newCap =16,newThr=12(*****使用默认参数创建的该map,并且第一次添加元素**)
143 |
144 | ```java
145 | else { // zero initial threshold signifies using defaults
146 | // 设置新数组容量 为 16
147 | newCap = DEFAULT_INITIAL_CAPACITY;
148 | // 设置新数组扩容阀值为 16*0.75 = 12。0.75为负载因子
149 | newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
150 | }
151 | ```
152 |
153 | #### 数据迁移
154 |
155 | 如果oldTab老数组不为空,说明是扩容操作,那么涉及到元素的转移操,遍历老数组,如果当前位置元素不为空,那么需要转移该元素到新数组。
156 |
157 | - 如果元素没有有下一个节点,说明该元素不存在hash冲突,因将元素存储到新的数组中,存储到数组的哪个位置需要根据hash值和数组长度来进行取模
158 |
159 | ```java
160 | // 如果元素没有有下一个节点,说明该元素不存在hash冲突
161 | if (e.next == null)
162 | newTab[e.hash & (newCap - 1)] = e;
163 | ```
164 |
165 | - 如果该节点为TreeNode类型,插入红黑树中
166 |
167 | ```java
168 | // 如果该节点为TreeNode类型
169 | else if (e instanceof TreeNode)
170 | ((TreeNode)e).split(this, newTab, j, oldCap);
171 | ```
172 |
173 | - 遍历链表,并将链表节点按原顺序进行分组
174 |
175 | - 将元素的hash值 和 老数组的长度做与运算`e.hash & oldCap`,判断出是在原位置还是在原位置再移动2次幂的位置(`loTail`低位指的是新数组的 0 到 `oldCap-1 `、`hiTail`高位指定的是`oldCap `到 `newCap - 1`)
176 |
177 | - `(e.hash & oldCap) == 0`原位置,循环到链表尾端,赋值低位的元素loTail
178 |
179 | - `(e.hash & oldCap) != 0` 原位置再移动2次幂的位置,循环到链表尾端,赋值高位的元素hiTail
180 |
181 |
182 |
183 | ```java
184 | Node loHead = null, loTail = null; // 低位首尾节点
185 | Node hiHead = null, hiTail = null; // 高位首尾节点
186 | Node next;
187 | // 遍历链表
188 | do {
189 | next = e.next;
190 | //如果hash值和该原长度做与运算等于0,说明该元素可以放置在低位链表中。
191 | if ((e.hash & oldCap) == 0) {
192 | // 如果没有尾,说明链表为空
193 | if (loTail == null)
194 | loHead = e;
195 | // 如果有尾,那么链表不为空,把该元素挂到链表的最后。
196 | else
197 | loTail.next = e;
198 | // 把尾节点设置为当前元素
199 | loTail = e;
200 | }
201 | // 如果与运算结果不为0,说明hash值大于老数组长度(例如hash值为17)
202 | // 此时该元素应该放置到新数组的高位位置上
203 | else {
204 | if (hiTail == null)
205 | hiHead = e;
206 | else
207 | hiTail.next = e;
208 | hiTail = e;
209 | }
210 | } while ((e = next) != null);
211 | ```
212 |
213 | - 将分组后的链表映射到新桶中
214 |
215 | - 低位的元素组成的链表还是放置在原来的位置,
216 | - 高位的元素组成的链表放置的位置只是在原有位置上偏移了老数组的长度个位置
217 |
218 | ```java
219 | // 低位的元素组成的链表还是放置在原来的位置
220 | if (loTail != null) {
221 | loTail.next = null;
222 | newTab[j] = loHead;
223 | }
224 | // 高位的元素组成的链表放置的位置只是在原有位置上偏移了老数组的长度个位置。
225 | if (hiTail != null) {
226 | hiTail.next = null;
227 | newTab[j + oldCap] = hiHead;
228 | }
229 | ```
230 |
231 | JDK1.8对`resize()`扩容方法进行了优化,**经过rehash之后,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。**
232 |
233 | 是不是有点不明白呢?那我们来用图来解析一下:
234 |
235 | 结合`e.hash & oldCapn`取值判断是在高位还是在低位,即如图(a)表示扩容前的key1和key2两种key确定索引位置的示例,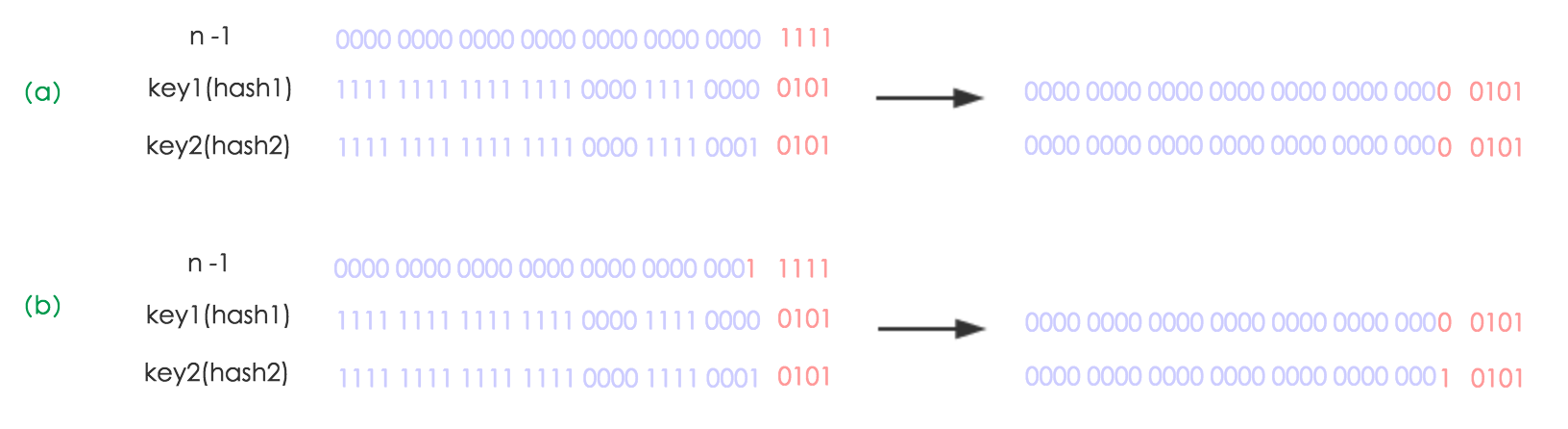
236 | 图(b)表示扩容后key1和key2两种key确定索引,元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
237 | 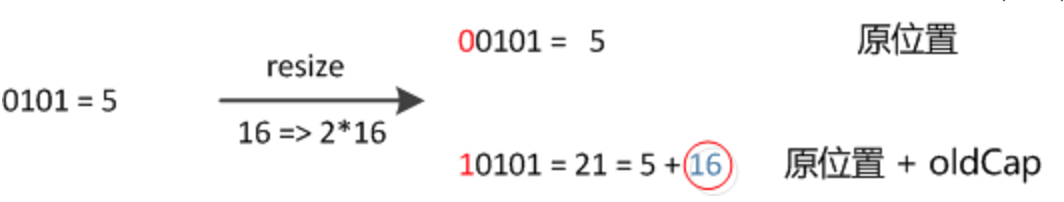
238 | 因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“`原索引+oldCap`”,可以看看下图为16扩充为32的resize示意图:
239 | 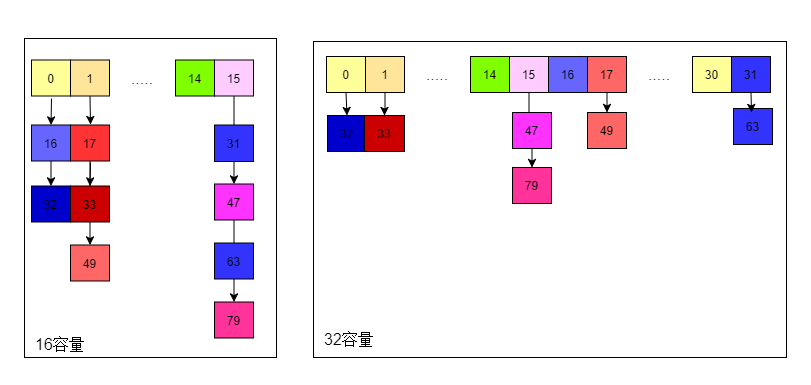
240 | 在JDK1.7中rehash扩容的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同的链表元素会倒置,但是在JDK1.8进行了优化,从上图可以看出,JDK1.8链表元素不会倒置。因此不会出现链表死循环的问题。
241 |
242 | 由于篇幅过长,将分成两篇来介绍,接下来内容看 **《面试:为了进阿里,必须掌握HashMap源码原理和面试题(图解版二)》**
243 |
244 |
245 |
--------------------------------------------------------------------------------
/doc/javabase/collection/LinkedList.md:
--------------------------------------------------------------------------------
1 |
2 | # LinkedList 源码分析(JDK 1.8)
3 |
4 | ## 1.概述
5 | LinkedList 是 Java 集合框架中一个重要的实现,其底层采用的双向链表结构。和 ArrayList 一样,LinkedList 也支持空值和重复值。由于 LinkedList 基于链表实现,存储元素过程中,无需像 ArrayList 那样进行扩容。但有得必有失,LinkedList 存储元素的节点需要额外的空间存储前驱和后继的引用。另一方面,LinkedList 在链表头部和尾部插入效率比较高,但在指定位置进行插入时,效率一般。原因是,在指定位置插入需要定位到该位置处的节点,此操作的时间复杂度为O(N)。最后,LinkedList 是非线程安全的集合类,并发环境下,多个线程同时操作 LinkedList,会引发不可预知的错误。
6 |
7 | 以上是对 LinkedList 的简单介绍,接下来,我将会对 LinkedList 常用操作展开分析,继续往下看吧。
8 |
9 | ##2.继承体系
10 | LinkedList 的继承体系较为复杂,继承自 AbstractSequentialList,同时又实现了 List 和 Deque 接口。继承体系图如下(删除了部分实现的接口):
11 | 
12 |
13 |
14 | LinkedList 继承自 AbstractSequentialList,AbstractSequentialList 又是什么呢?从实现上,AbstractSequentialList 提供了一套基于顺序访问的接口。通过继承此类,子类仅需实现部分代码即可拥有完整的一套访问某种序列表(比如链表)的接口。深入源码,AbstractSequentialList 提供的方法基本上都是通过 ListIterator 实现的,比如:
15 |
16 |
17 | public E get(int index) {
18 | try {
19 | return listIterator(index).next();
20 | } catch (NoSuchElementException exc) {
21 | throw new IndexOutOfBoundsException("Index: "+index);
22 | }
23 | }
24 |
25 | public void add(int index, E element) {
26 | try {
27 | listIterator(index).add(element);
28 | } catch (NoSuchElementException exc) {
29 | throw new IndexOutOfBoundsException("Index: "+index);
30 | }
31 | }
32 |
33 | // 留给子类实现
34 | public abstract ListIterator listIterator(int index);
35 | 所以只要继承类实现了 listIterator 方法,它不需要再额外实现什么即可使用。对于随机访问集合类一般建议继承 AbstractList 而不是 AbstractSequentialList。LinkedList 和其父类一样,也是基于顺序访问。所以 LinkedList 继承了 AbstractSequentialList,但 LinkedList 并没有直接使用父类的方法,而是重新实现了一套的方法。
36 |
37 | 另外,LinkedList 还实现了 Deque (double ended queue),Deque 又继承自 Queue 接口。这样 LinkedList 就具备了队列的功能。比如,我们可以这样使用:
38 |
39 | Queue queue = new LinkedList<>();
40 | 除此之外,我们基于 LinkedList 还可以实现一些其他的数据结构,比如栈,以此来替换 Java 集合框架中的 Stack 类(该类实现的不好,《Java 编程思想》一书的作者也对此类进行了吐槽)。
41 |
42 | 关于 LinkedList 继承体系先说到这,下面进入源码分析部分。
43 |
44 | ##3.源码分析
45 | ###3.1 查找
46 | LinkedList 底层基于链表结构,无法向 ArrayList 那样随机访问指定位置的元素。LinkedList 查找过程要稍麻烦一些,需要从链表头结点(或尾节点)向后查找,时间复杂度为 O(N)。相关源码如下:
47 |
48 | public E get(int index) {
49 | checkElementIndex(index);
50 | return node(index).item;
51 | }
52 |
53 | Node node(int index) {
54 | /*
55 | * 则从头节点开始查找,否则从尾节点查找
56 | * 查找位置 index 如果小于节点数量的一半,
57 | */
58 | if (index < (size >> 1)) {
59 | Node x = first;
60 | // 循环向后查找,直至 i == index
61 | for (int i = 0; i < index; i++)
62 | x = x.next;
63 | return x;
64 | } else {
65 | Node x = last;
66 | for (int i = size - 1; i > index; i--)
67 | x = x.prev;
68 | return x;
69 | }
70 | }
71 | 上面的代码比较简单,主要是通过遍历的方式定位目标位置的节点。获取到节点后,取出节点存储的值返回即可。这里面有个小优化,即通过比较 index 与节点数量 size/2 的大小,决定从头结点还是尾节点进行查找。查找操作的代码没什么复杂的地方,这里先讲到这里。
72 |
73 | ### 3.2 遍历
74 | 链表的遍历过程也很简单,和上面查找过程类似,我们从头节点往后遍历就行了。但对于 LinkedList 的遍历还是需要注意一些,不然可能会导致代码效率低下。通常情况下,我们会使用 foreach 遍历 LinkedList,而 foreach 最终转换成迭代器形式。所以分析 LinkedList 的遍历的核心就是它的迭代器实现,相关代码如下:
75 |
76 |
77 | public ListIterator listIterator(int index) {
78 | checkPositionIndex(index);
79 | return new ListItr(index);
80 | }
81 |
82 | private class ListItr implements ListIterator {
83 | private Node lastReturned;
84 | private Node next;
85 | private int nextIndex;
86 | private int expectedModCount = modCount;
87 |
88 | /** 构造方法将 next 引用指向指定位置的节点 */
89 | ListItr(int index) {
90 | // assert isPositionIndex(index);
91 | next = (index == size) ? null : node(index);
92 | nextIndex = index;
93 | }
94 |
95 | public boolean hasNext() {
96 | return nextIndex < size;
97 | }
98 |
99 | public E next() {
100 | checkForComodification();
101 | if (!hasNext())
102 | throw new NoSuchElementException();
103 |
104 | lastReturned = next;
105 | next = next.next; // 调用 next 方法后,next 引用都会指向他的后继节点
106 | nextIndex++;
107 | return lastReturned.item;
108 | }
109 |
110 | // 省略部分方法
111 | }
112 | 上面的方法很简单,大家应该都能很快看懂,这里就不多说了。下面来说说遍历 LinkedList 需要注意的一个点。
113 |
114 | 我们都知道 LinkedList 不擅长随机位置访问,如果大家用随机访问的方式遍历 LinkedList,效率会很差。比如下面的代码:
115 |
116 | List list = new LinkedList<>();
117 | list.add(1)
118 | list.add(2)
119 | ......
120 | for (int i = 0; i < list.size(); i++) {
121 | Integet item = list.get(i);
122 | // do something
123 | }
124 | 当链表中存储的元素很多时,上面的遍历方式对于效率来说就是灾难。原因在于,通过上面的方式每获取一个元素,LinkedList 都需要从头节点(或尾节点)进行遍历,效率不可谓不低。在我的电脑(MacBook Pro Early 2015, 2.7 GHz Intel Core i5)实测10万级的数据量,耗时约7秒钟。20万级的数据量耗时达到了约34秒的时间。50万级的数据量耗时约250秒。从测试结果上来看,上面的遍历方式在大数据量情况下,效率很差。大家在日常开发中应该尽量避免这种用法。
125 |
126 | 3.3 插入
127 | LinkedList 除了实现了 List 接口相关方法,还实现了 Deque 接口的很多方法,所以我们有很多种方式插入元素。但这里,我只打算分析 List 接口中相关的插入方法,其他的方法大家自己看吧。LinkedList 插入元素的过程实际上就是链表链入节点的过程,学过数据结构的同学对此应该都很熟悉了。这里简单分析一下,先看源码吧:
128 |
129 |
130 | /** 在链表尾部插入元素 */
131 | public boolean add(E e) {
132 | linkLast(e);
133 | return true;
134 | }
135 |
136 | /** 在链表指定位置插入元素 */
137 | public void add(int index, E element) {
138 | checkPositionIndex(index);
139 |
140 | // 判断 index 是不是链表尾部位置,如果是,直接将元素节点插入链表尾部即可
141 | if (index == size)
142 | linkLast(element);
143 | else
144 | linkBefore(element, node(index));
145 | }
146 |
147 | /** 将元素节点插入到链表尾部 */
148 | void linkLast(E e) {
149 | final Node l = last;
150 | // 创建节点,并指定节点前驱为链表尾节点 last,后继引用为空
151 | final Node newNode = new Node<>(l, e, null);
152 | // 将 last 引用指向新节点
153 | last = newNode;
154 | // 判断尾节点是否为空,为空表示当前链表还没有节点
155 | if (l == null)
156 | first = newNode;
157 | else
158 | l.next = newNode; // 让原尾节点后继引用 next 指向新的尾节点
159 | size++;
160 | modCount++;
161 | }
162 |
163 | /** 将元素节点插入到 succ 之前的位置 */
164 | void linkBefore(E e, Node succ) {
165 | // assert succ != null;
166 | final Node pred = succ.prev;
167 | // 1. 初始化节点,并指明前驱和后继节点
168 | final Node newNode = new Node<>(pred, e, succ);
169 | // 2. 将 succ 节点前驱引用 prev 指向新节点
170 | succ.prev = newNode;
171 | // 判断尾节点是否为空,为空表示当前链表还没有节点
172 | if (pred == null)
173 | first = newNode;
174 | else
175 | pred.next = newNode; // 3. succ 节点前驱的后继引用指向新节点
176 | size++;
177 | modCount++;
178 | }
179 | 上面是插入过程的源码,我对源码进行了比较详细的注释,应该不难看懂。上面两个 add 方法只是对操作链表的方法做了一层包装,核心逻辑在 linkBefore 和 linkLast 中。这里以 linkBefore 为例,它的逻辑流程如下:
180 |
181 | + 创建新节点,并指明新节点的前驱和后继
182 | + 将 succ 的前驱引用指向新节点
183 | + 如果 succ 的前驱不为空,则将 succ 前驱的后继引用指向新节点
184 | 对应于下图:
185 |
186 | 
187 |
188 |
189 | 以上就是插入相关的源码分析,并不复杂,就不多说了。继续往下分析。
190 |
191 | ### 3.4 删除
192 | 如果大家看懂了上面的插入源码分析,那么再看删除操作实际上也很简单了。删除操作通过解除待删除节点与前后节点的链接,即可完成任务。过程比较简单,看源码吧:
193 |
194 | public boolean remove(Object o) {
195 | if (o == null) {
196 | for (Node x = first; x != null; x = x.next) {
197 | if (x.item == null) {
198 | unlink(x);
199 | return true;
200 | }
201 | }
202 | } else {
203 | // 遍历链表,找到要删除的节点
204 | for (Node x = first; x != null; x = x.next) {
205 | if (o.equals(x.item)) {
206 | unlink(x); // 将节点从链表中移除
207 | return true;
208 | }
209 | }
210 | }
211 | return false;
212 | }
213 |
214 | public E remove(int index) {
215 | checkElementIndex(index);
216 | // 通过 node 方法定位节点,并调用 unlink 将节点从链表中移除
217 | return unlink(node(index));
218 | }
219 |
220 | /** 将某个节点从链表中移除 */
221 | E unlink(Node x) {
222 | // assert x != null;
223 | final E element = x.item;
224 | final Node next = x.next;
225 | final Node prev = x.prev;
226 |
227 | // prev 为空,表明删除的是头节点
228 | if (prev == null) {
229 | first = next;
230 | } else {
231 | // 将 x 的前驱的后继指向 x 的后继
232 | prev.next = next;
233 | // 将 x 的前驱引用置空,断开与前驱的链接
234 | x.prev = null;
235 | }
236 |
237 | // next 为空,表明删除的是尾节点
238 | if (next == null) {
239 | last = prev;
240 | } else {
241 | // 将 x 的后继的前驱指向 x 的前驱
242 | next.prev = prev;
243 | // 将 x 的后继引用置空,断开与后继的链接
244 | x.next = null;
245 | }
246 |
247 | // 将 item 置空,方便 GC 回收
248 | x.item = null;
249 | size--;
250 | modCount++;
251 | return element;
252 | }
253 | 和插入操作一样,删除操作方法也是对底层方法的一层保证,核心逻辑在底层 unlink 方法中。所以长驱直入,直接分析 unlink 方法吧。unlink 方法的逻辑如下(假设删除的节点既不是头节点,也不是尾节点):
254 |
255 | + 将待删除节点 x 的前驱的后继指向 x 的后继
256 | + 将待删除节点 x 的前驱引用置空,断开与前驱的链接
257 | + 将待删除节点 x 的后继的前驱指向 x 的前驱
258 | + 将待删除节点 x 的后继引用置空,断开与后继的链接
259 | 对应下图:
260 | 
261 |
262 |
263 | 结合上图,理解 LInkedList 删除操作应该不难。好了,LinkedList 的删除源码分析就讲到这。
264 |
265 | ##4.总结
266 | 通过上面的分析,大家对 LinkedList 的底层实现应该很清楚了。总体来看 LinkedList 的源码并不复杂,大家耐心看一下,一般都能看懂。同时,通过本文,向大家展现了使用 LinkedList 的一个坑,希望大家在开发中尽量避免。好了,本文到这里就结束了,感谢阅读!
267 |
268 | >作者:田小波
269 | >文章链接:http://www.tianxiaobo.com/
270 |
271 |
--------------------------------------------------------------------------------
/doc/javabase/collection/collectionbase.md:
--------------------------------------------------------------------------------
1 | ## 一、集合基础
2 |
3 | ### 1.1 集合框架有哪些优点如下:
4 |
5 | + 使用核心集合类降低开发成本,而非实现我们自己的集合类。
6 | + 随着使用经过严格测试的集合框架类,代码质量会得到提高。
7 | + 通过使用 JDK 附带的集合类,可以降低代码维护成本。
8 | + 复用性和可操作性。
9 |
10 | ### 1.2 Java集合类框架的基本接口有哪些?
11 |
12 | Java 集合类提供了一套设计良好的支持对一组对象进行操作的接口和类。Java集合类里面最基本的接口有:
13 |
14 | + Collection:代表一组对象,每一个对象都是它的子元素。
15 | + Set:不包含重复元素的 Collection。
16 | + List:有顺序的 collection,并且可以包含重复元素。
17 | + Map:可以把键(key)映射到值(value)的对象,键不能重复。
18 | + 还有其它接口 Queue、Dequeue、SortedSet、SortedMap 和 ListIterator。
19 |
20 | ### 1.3 为什么集合类没有实现 Cloneable 和 Serializable 接口?
21 |
22 | 集合类接口指定了一组叫做元素的对象。集合类接口的每一种具体的实现类都可以选择以它自己的方式对元素进行保存和排序,可以使得集合类很灵活,可以实现自定义集合类属性,比如有的集合类允许重复的键,有些不允许。
23 |
24 | ### 1.4 集合框架中的泛型有什么优点?
25 |
26 | Java5 引入了泛型,所有的集合接口和实现都大量地使用它。泛型允许我们为集合提供一个可以容纳的对象类型。因此,如果你添加其它类型的任何元素,它会在编译时报错。这避免了在运行时出现 ClassCastException,因为你将会在编译时得到报错信息。
27 |
28 | 泛型也使得代码整洁,我们不需要使用显式转换和 instanceOf 操作符。它也给运行时带来好处,因为不会产生类型检查的字节码指令。
29 |
30 | ### 1.5 Collection 和 Collections 的区别?
31 |
32 | + Collection ,是集合类的上级接口,继承与他的接口主要有 Set 和List 。
33 | + Collections ,是针对集合类的一个工具类,它提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
34 |
35 | ### 1.6 什么是迭代器(Iterator)?
36 |
37 | Iterator 接口提供了很多对集合元素进行迭代的方法。每一个集合类都包含了可以返回迭代器实例的 迭代方法。迭代器可以在迭代的过程中删除底层集合的元素。
38 |
39 | 克隆(cloning)或者是序列化(serialization)的语义和含义是跟具体的实现相关的。因此,应该由集合类的具体实现来决定如何被克隆或者是序列化。
40 |
41 | ### 1.7 Iterator和ListIterator的区别是什么?
42 |
43 | 下面列出了他们的区别:
44 |
45 | + Iterator 可用来遍历 Set 和 List 集合,但是 ListIterator 只能用来遍历 List 。
46 | + Iterator 对集合只能是前向遍历,ListIterator 既可以前向也可以后向。
47 | + ListIterator 实现了 Iterator 接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
48 |
49 | ### 1.8 快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
50 |
51 | Iterator 的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。
52 |
53 | java.util 包下面的所有的集合类都是快速失败的,而 java.util.concurrent 包下面的所有的类都是安全失败的。快速失败的迭代器会抛出 ConcurrentModificationException 异常,而安全失败的迭代器永远不会抛出这样的异常。
54 |
55 | ### 1.9 Enumeration 接口和 Iterator 接口的区别有哪些?
56 |
57 | Enumeration 速度是 Iterator 的2倍,同时占用更少的内存。但是,Iterator 远远比 Enumeration 安全,因为其他线程不能够修改正在被 iterator 遍历的集合里面的对象。同时,Iterator 允许调用者删除底层集合里面的元素,这对 Enumeration 来说是不可能的。
58 |
59 | ### 1.10 Java集合类框架的最佳实践有哪些?
60 |
61 | 根据应用的需要正确选择要使用的集合的类型对性能非常重要,比如:假如元素的大小是固定的,而且能事先知道,我们就应该用 Array 而不是 ArrayList。 有些集合类允许指定初始容量。因此,如果我们能估计出存储的元素的数目,我们可以设置初始容量来避免重新计算 hash 值或者是扩容。
62 |
63 | 为了类型安全,可读性和健壮性的原因总是要使用泛型。同时,使用泛型还可以避免运行时的 ClassCastException。
64 |
65 | 使用 JDK 提供的不变类(immutable class)作为Map的键可以避免为我们自己的类实现 hashCode() 和 equals() 方法。
66 |
67 | 编程的时候接口优于实现。
68 |
69 | 底层的集合实际上是空的情况下,返回长度是0的集合或者是数组,不要返回 null。
70 |
71 | ## 二、HashMap、Hashtable
72 |
73 | ### 2.1 HashMap的结构(jdk1.8)
74 |
75 | HashMap(数组+链表+红黑树)的结构,利用了红黑树,所以其由 数组+链表+红黑
76 | 树组成:
77 |
78 | 
79 | HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色
80 | 的实体是嵌套类 Entry 的实例, Entry 包含四个属性: key, value, hash 值和用于单向链表的 next。
81 |
82 | ### 2.2 Java 中的 HashMap
83 |
84 | HashMap 根据键的 hashCode 值存储数据,大多数情况下可以直接定位到它的值,因而具有很快
85 | 的访问速度,但遍历顺序却是不确定的。
86 |
87 | HashMap 最多只允许一条记录的键为 null,允许多条记
88 | 录的值为 null。
89 |
90 | HashMap 非线程安全,即任一时刻可以有多个线程同时写 HashMap,可能会导
91 | 致数据的不一致。如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使
92 | HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。
93 |
94 |
95 |
96 | ### 2.3 HashMap重要参数
97 |
98 | 1. capacity:当前数组容量16 ,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
99 | 2. loadFactor:负载因子,默认为 0.75
100 | 3. threshold:扩容的阈值,等于 capacity * loadFactor
101 |
102 | ### 2.4 HashMap查询
103 |
104 | 查找的时候,根据 hash 值我们能够快速定位到数组的
105 | 具体下标,但是之后的话, 需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决
106 | 于链表的长度,为 O(n)。
107 |
108 | 为了降低这部分的开销,在 Java8 中, 当链表中的元素超过了 8 个以后,
109 | 会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
110 |
111 | ### 2.5 hashCode() 和 equals() 方法的重要性体现在什么地方?
112 |
113 | Java 中的 HashMap 使用 hashCode() 和 equals() 方法来确定键值对的索引,当根据键获取值的时候也会用到这两个方法。如果没有正确的实现这两个方法,两个不同的键可能会有相同的 hash 值。
114 |
115 | 因此,可能会被集合认为是相等的。而且,这两个方法也用来发现重复元素。所以这两个方法的实现对 HashMap 的精确性和正确性是至关重要的。
116 |
117 | ### 2.6 Hashtable
118 |
119 | 哈希表(HashTable)又叫做散列表,根它通过把key映射到表中一个位置来访问记录,以加快查找速度。这个映射函数就叫做散列(哈希)函数,存放记录的数组叫做散列表。
120 |
121 | 哈希表是一个时间和空间上平衡的例子。如果没有空间的限制,我们可以直接用键来作为数组的索引,这样可以将查找时间做到最快(O(1))。如果没有时间的限制,我们可以使用无序链表进行顺序查找,这样只需要很少的内存
122 |
123 | ### 2.7 为什么Hashtable的速度快?
124 |
125 | Hashtable是由数组与链表。数组的特点就是查找容易,插入删除困难;而链表的特点就是查找困难,但是插入删除容易。既然两者各有优缺点,那么Hashtable查找容易,插入删除也会快起来。
126 |
127 | ### 2.8 Hashtable如何根据key查找?
128 |
129 | 使用哈希函数将被查找的key转化为数组的索引。在理想的状态下,不同的键会被转化成不同的索引值。但是那是理想状态,我们实践当中是不可能一直是理想状态的。当不同的键生成了相同的索引的时候,即是哈希冲突,处理冲突方式:
130 |
131 | + 拉链法
132 | + 线性探索法
133 |
134 | ### 2.9 LinkHashMap
135 |
136 | LinkHashMapshi=HashMap + LinkedList
137 |
138 | LinkedHashMap 是基于 HashMap 实现的一种集合,具有 HashMap 集合上面所说的所有特点,除了 HashMap 无序的特点,LinkedHashMap 是有序的,因为 LinkedHashMap 在 HashMap 的基础上单独维护了一个具有所有数据的双向链表,该链表保证了元素迭代的顺序。
139 |
140 |
141 | 
142 |
143 | + LinkedHashMap是继承于HashMap,是基于HashMap和双向链表来实现的。
144 | + HashMap无序;LinkedHashMap有序,可分为插入顺序和访问顺序两种。如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。
145 | + LinkedHashMap存取数据,还是跟HashMap一样使用的Entry[]的方式,双向链表只是为了保证顺序。
146 | + LinkedHashMap是线程不安全的
147 |
148 | ## 三、ArrayList、 Vector 和 LinkedList
149 |
150 | ### 3.1 ArrayList(数组)
151 |
152 | ArrayList 是最常用的 List 实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。
153 |
154 | 数组的缺点是每个元素之间不能有间隔, 当数组大小不满足时需要增加存储能力,就要将已经有数
155 | 组的数据复制到新的存储空间中。
156 |
157 | 当从 ArrayList 的中间位置插入或者删除元素时,需要对数组进
158 | 行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
159 |
160 | ArrayList支持序列化功能,支持克隆(浅拷贝)功能,排序功能等
161 |
162 | ### 3.2 ArrayList 是如何扩容的?
163 |
164 | 如果通过无参构造的话,初始数组容量为 0 ,当真正对数组进行添加时,才真正分配容量。**每次按照 1.5 倍(位运算)的比率通过 copeOf 的方式扩容**。
165 |
166 | **在 JKD6 中实现是,如果通过无参构造的话,初始数组容量为10,每次通过 copeOf 的方式扩容后容量为原来的 1.5 倍**
167 |
168 | ### 3.3 ArrayList 集合加入 1 万条数据,应该怎么提高效率?
169 |
170 | ArrayList 的默认初始容量为 10 ,要插入大量数据的时候需要不断扩容,而扩容是非常影响性能的。因此,现在明确了 10 万条数据了,我们可以直接在初始化的时候就设置 ArrayList 的容量!
171 |
172 | ### 3.4 Vector(数组实现、 线程同步)
173 |
174 | Vector 与 ArrayList 一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一
175 | 个线程能够写 Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,
176 | 访问它比访问 ArrayList 慢。
177 |
178 | ### 3.5 LinkList(链表)
179 |
180 | LinkedList 是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较
181 | 慢。另外,他还提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆
182 | 栈、队列和双向队列使用
183 |
184 |
185 | ## 四、HashSet、TreeSet以及LinkHashSet
186 |
187 | Set 注重独一无二的性质,该体系集合用于存储无序(存入和取出的顺序不一定相同)元素, 值不能重复。
188 |
189 | 对象的相等性本质是对象 hashCode 值( java 是依据对象的内存地址计算出的此序号) 判断的, 如果想要让两个不同的对象视为相等的,就必须覆盖 Object 的 hashCode 方法和 equals 方法。
190 |
191 | ### 4.1 HashSet
192 |
193 | 哈希表边存放的是哈希值。 HashSet 存储元素的顺序并不是按照存入时的顺序(和 List 显然不同) 而是按照哈希值来存的所以取数据也是按照哈希值取得。元素的哈希值是通过元素的hashcode 方法来获取的, HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals 方法 如果 equls 结果为 true , HashSet 就视为同一个元素。如果 equals 为 false 就不是同一个元素。
194 |
195 | HashSet 通过 hashCode 值来确定元素在内存中的位置。 一个 hashCode 位置上可以存放多个元素。
196 |
197 |
198 | 哈希值相同 equals 为 false 的元素是怎么存储呢,就是在同样的哈希值下顺延(可以认为哈希值相同的元素放在一个哈希桶中)。也就是哈希一样的存一列。 如图 1 表示 hashCode 值不相同的情况; 图 2 表示 hashCode 值相同,但 equals 不相同的情况。
199 |
200 | 
201 |
202 | ### 4.2 TreeSet(二叉树)
203 |
204 | 1. TreeSet()是使用二叉树的原理对新add()的对象按照指定的顺序排序(升序、降序),每增加一个对象都会进行排序,将对象插入的二叉树指定的位置。
205 | 2. Integer 和 String 对象都可以进行默认的 TreeSet 排序,而自定义类的对象是不可以的, 自己定义的类必须实现 Comparable 接口,并且覆写相应的 compareTo()函数,才可以正常使用。
206 | 3. 在覆写 compare()函数时,要返回相应的值才能使 TreeSet 按照一定的规则来排序
207 | 4. 比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数
208 |
209 |
210 | ### 4.3 LinkHashSet( HashSet+LinkedHashMap)
211 |
212 | 对于 LinkedHashSet 而言,它继承与 HashSet、又基于 LinkedHashMap 来实现的。LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素,它继承与 HashSet,其所有的方法操作上又与 HashSet 相同.
213 |
214 | 因此 LinkedHashSet的实现上非常简单,只提供了四个构造方法,并通过传递一个标识参数,调用父类的构造器,底层构造一个 LinkedHashMap 来实现,在相关操作上与父类 HashSet 的操作相同,直接调用父类 HashSet 的方法即可。
215 |
216 | ## 五、集合的区别
217 |
218 | ### 5.1 HashMap 和 Hashtable 有什么区别?
219 |
220 | HashMap 和 Hashtable 都实现了 Map 接口,因此很多特性非常相似。但是,他们有以下不同点: HashMap 允许键和值是 null,而 Hashtable 不允许键或者值是 null。
221 |
222 | Hashtable 是同步的,而 HashMap 不是。因此, HashMap 更适合于单线程环境,而 Hashtable 适合于多线程环境。
223 |
224 | HashMap 提供了可供应用迭代的键的集合,因此,HashMap 是快速失败的。另一方面,Hashtable 提供了对键的列举(Enumeration)。
225 |
226 | 一般认为 Hashtable 是一个遗留的类。
227 |
228 | ### 5.2 数组(Array)和列表(ArrayList)有什么区别?什么时候应该使用 Array 而不是 ArrayList?
229 |
230 | 下面列出了 Array 和 ArrayList 的不同点:
231 |
232 | Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型。
233 |
234 | Array 大小是固定的,ArrayList 的大小是动态变化的。
235 |
236 | ArrayList 提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。 对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
237 |
238 | ### 5.3 ArrayList 和 LinkedList 有什么区别?
239 |
240 | ArrayList 和 LinkedList 都实现了 List 接口,他们有以下的不同点:
241 |
242 | ArrayList 是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList 是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。
243 |
244 | 相对于 ArrayList,LinkedList 的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。
245 |
246 | LinkedList 比 ArrayList 更占内存,因为 LinkedList 为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
247 |
248 | 也可以参考 ArrayList vs. LinkedList。
249 |
250 | ### 5.4 Comparable 和Comparator 接口是干什么的?列出它们的区别。
251 |
252 | Java 提供了只包含一个 compareTo() 方法的 Comparable 接口。这个方法可以个给两个对象排序。具体来说,它返回负数,0,正数来表明输入对象小于,等于,大于已经存在的对象。
253 |
254 | Java 提供了包含 compare() 和 equals() 两个方法的 Comparator 接口。compare() 方法用来给两个输入参数排序,返回负数,0,正数表明第一个参数是小于,等于,大于第二个参数。equals() 方法需要一个对象作为参数,它用来决定输入参数是否和 comparator 相等。只有当输入参数也是一个 comparator 并且输入参数和当前 comparator 的排序结果是相同的时候,这个方法才返回 true。
255 |
256 |
257 | ### 5.5 HashSet 和 TreeSet 有什么区别?
258 |
259 | HashSet 是由一个 hash 表来实现的,因此,它的元素是无序的。add(),remove(),contains()方法的时间复杂度是 O(1)。
260 |
261 | 另一方面,TreeSet 是由一个树形的结构来实现的,它里面的元素是有序的。因此,add(),remove(),contains() 方法的时间复杂度是 O(logn)。
262 |
263 | ### 5.6 HashMap 和 ConcurrentHashMap 的区别?
264 |
265 | ConcurrentHashMap 是线程安全的 HashMap 的实现。主要区别如下:
266 |
267 | 1. ConcurrentHashMap 对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用 lock 锁进行保护,相对 于Hashtable 的 syn 关键字锁的粒度更精细了一些,并发性能更好。而 HashMap 没有锁机制,不是线程安全的。
268 |
269 | 2. HashMap 的键值对允许有 null ,但是 ConCurrentHashMap 都不允许
270 |
271 | >JDK8 之后,ConcurrentHashMap 启用了一种全新的方式实现,利用 CAS 算法。
272 |
273 | ### 5.7 List、Set、Map 是否继承自 Collection 接口?
274 |
275 | List、Set 是,Map 不是。Map 是键值对映射容器,与 List 和 Set 有明显的区别,而 Set 存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List 是线性结构的容器,适用于按数值索引访问元素的情形。
276 |
277 | ### 5.8 说出 ArrayList、Vector、LinkedList 的存储性能和特性?
278 |
279 | ArrayList 和 Vector 都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引娶元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢,Vector 由于使用了 synchronized 方法(线程安全),通常性能上较 ArrayList 差。
280 |
281 | 而 LinkedList 使用双向链表实现存储(将内存中零散的内存单元通过附加的引用关联起来,形成一个可以按序号索引的线性结构,这种链式存储方式与数组的连续存储方式相比,其实对内存的利用率更高),按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
282 |
283 | Vector 属于遗留容器(早期的 JDK 中使用的容器,除此之外 Hashtable、Dictionary、BitSet、Stack、Properties 都是遗留容器),现在已经不推荐使用,但是由于 ArrayList 和 LinkedListed 都是非线程安全的,如果需要多个线程操作同一个容器,那么可以通过工具类 Collections 中的 synchronizedList 方法将其转换成线程安全的容器后再使用(这其实是装潢模式最好的例子,将已有对象传入另一个类的构造器中创建新的对象来增加新功能)。
284 |
285 | ### 5.9 List、Map、Set 三个接口存储元素时各有什么特点?
286 |
287 | + List 是有序的 Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在 List 中的位置,类似于数组下标)来访问 List 中的元素,这类似于 Java 的数组。
288 | + Set 是一种不包含重复的元素的 Collection,即任意的两个元素 e1 和 e2 都有e1.equals(e2)=false,Set 最多有一个 null 元素。
289 | + Map 接口 :请注意,Map 没有继承 Collection 接口,Map 提供 key 到 value 的映射
290 |
--------------------------------------------------------------------------------
/doc/javabase/jdk版本特性.md:
--------------------------------------------------------------------------------
1 | # jdk 5 到 jdk 10各个版本的新特性
2 |
3 | jdk5 jdk10各个版本的新特性
4 |
5 | ## JDK1.5新特性:
6 | 1. 自动装箱与拆箱
7 |
8 | 2. 枚举
9 |
10 | 3. 静态导入,如:import staticjava.lang.System.out
11 |
12 | 4. 可变参数(Varargs)
13 |
14 | 5. 内省(Introspector),主要用于操作JavaBean中的属性,通过getXxx/setXxx。一般的做法是通过类Introspector来获取某个对象的BeanInfo信息,然后通过BeanInfo来获取属性的描述器(PropertyDescriptor),通过这个属性描述器就可以获取某个属性对应的getter/setter方法,然后我们就可以通过反射机制来调用这些方法。
15 |
16 | 6. 泛型(Generic)(包括通配类型/边界类型等)
17 |
18 | 7. For-Each循环
19 |
20 | 8. 注解
21 |
22 | 9. 协变返回类型:实际返回类型可以是要求的返回类型的一个子类型
23 |
24 | ## JDK1.6新特性:
25 |
26 | 1. AWT新增加了两个类:Desktop和SystemTray,其中前者用来通过系统默认程序来执行一个操作,如使用默认浏览器浏览指定的URL,用默认邮件客户端给指定的邮箱发邮件,用默认应用程序打开或编辑文件(比如,用记事本打开以txt为后缀名的文件),用系统默认的打印机打印文档等。后者可以用来在系统托盘区创建一个托盘程序
27 |
28 | 2. 使用JAXB2来实现对象与XML之间的映射,可以将一个Java对象转变成为XML格式,反之亦然
29 |
30 | 3. StAX,一种利用拉模式解析(pull-parsing)XML文档的API。类似于SAX,也基于事件驱动模型。之所以将StAX加入到JAXP家族,是因为JDK6中的JAXB2和JAX-WS 2.0中都会用StAX。
31 |
32 | 4. 使用Compiler API,动态编译Java源文件,如JSP编译引擎就是动态的,所以修改后无需重启服务器。
33 |
34 | 5. 轻量级Http Server API,据此可以构建自己的嵌入式HttpServer,它支持Http和Https协议。
35 |
36 | 6. 插入式注解处理API(PluggableAnnotation Processing API)
37 |
38 | 7. 提供了Console类用以开发控制台程序,位于java.io包中。据此可方便与Windows下的cmd或Linux下的Terminal等交互。
39 |
40 | 8. 对脚本语言的支持如: ruby,groovy, javascript
41 |
42 | 9. Common Annotations,原是J2EE 5.0规范的一部分,现在把它的一部分放到了J2SE 6.0中
43 |
44 | 10. 嵌入式数据库 Derby
45 |
46 | ## JDK1.7 新特性
47 |
48 | + 对Java集合(Collections)的增强支持,可直接采用[]、{}的形式存入对象,采用[]的形式按照索引、键值来获取集合中的对象。如:
49 |
50 |
51 | Listlist=[“item1”,”item2”];//存
52 |
53 | Stringitem=list[0];//直接取
54 |
55 | Setset={“item1”,”item2”,”item3”};//存
56 |
57 | Map map={“key1”:1,”key2”:2};//存
58 |
59 | Intvalue=map[“key1”];//取
60 | + 在Switch中可用String
61 |
62 | + 数值可加下划线用作分隔符(编译时自动被忽略)
63 |
64 | + 支持二进制数字,如:int binary= 0b1001_1001;
65 |
66 | + 简化了可变参数方法的调用
67 |
68 | + 调用泛型类的构造方法时,可以省去泛型参数,编译器会自动判断。
69 |
70 | + Boolean类型反转,空指针安全,参与位运算
71 |
72 | + char类型的equals方法: booleanCharacter.equalsIgnoreCase(char ch1, char ch2)
73 |
74 | + 安全的加减乘除: Math.safeToInt(longv); Math.safeNegate(int v); Math.safeSubtract(long v1, int v2);Math.safeMultiply(int v1, int v2)……
75 |
76 | + Map集合支持并发请求,注HashTable是线程安全的,Map是非线程安全的。但此处更新使得其也支持并发。另外,Map对象可这样定义:Map map = {name:"xxx",age:18};
77 |
78 | ## JDK1.8新特性
79 |
80 | 1.接口的默认方法:即接口中可以声明一个非抽象的方法做为默认的实现,但只能声明一个,且在方法的返回类型前要加上“default”关键字。
81 |
82 | Lambda 表达式:是对匿名比较器的简化,如:
83 | Collections.sort(names,(String a, String b) -> {
84 |
85 | returnb.compareTo(a);
86 |
87 | });
88 |
89 | 2.对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字。如:
90 |
91 | `Collections.sort(names,(String a, String b) -> b.compareTo(a));`
92 | 或:
93 | `Collections.sort(names, (a, b) -> b.compareTo(a));`
94 |
95 | 3.函数式接口:是指仅仅只包含一个抽象方法的接口,要加@FunctionalInterface注解
96 |
97 | 4.使用 :: 关键字来传递方法或者构造函数引用
98 |
99 | 5.多重注解
100 |
101 | 6.还增加了很多与函数式接口类似的接口以及与Map相关的API等……
102 |
103 |
104 | ## jdk1.9新特性
105 |
106 | **1、Java 平台级模块系统**
107 |
108 | 当启动一个模块化应用时, JVM 会验证是否所有的模块都能使用,这基于 requires 语句——比脆弱的类路径迈进了一大步。模块允许你更好地强制结构化封装你的应用并明确依赖。
109 |
110 | **2.Linking**
111 | 当你使用具有显式依赖关系的模块和模块化的 JDK 时,新的可能性出现了。你的应用程序模块现在将声明其对其他应用程序模块的依赖以及对其所使用的 JDK 模块的依赖。为什么不使用这些信息创建一个最小的运行时环境,其中只包含运行应用程序所需的那些模块呢? 这可以通过 Java 9 中的新的 jlink 工具实现。你可以创建针对应用程序进行优化的最小运行时映像而不需要使用完全加载 JDK 安装版本。
112 |
113 | **3.JShell : 交互式 Java REPL**
114 | 许多语言已经具有交互式编程环境,Java 现在加入了这个俱乐部。您可以从控制台启动 jshell ,并直接启动输入和执行 Java 代码。 jshell 的即时反馈使它成为探索 API 和尝试语言特性的好工具。
115 |
116 | **4.改进的 Javadoc**
117 | Javadoc 现在支持在 API 文档中的进行搜索。另外,Javadoc 的输出现在符合兼容 HTML5 标准。此外,你会注意到,每个 Javadoc 页面都包含有关 JDK 模块类或接口来源的信息。
118 |
119 | **5.集合工厂方法**
120 | 通常,您希望在代码中创建一个集合(例如,List 或 Set ),并直接用一些元素填充它。 实例化集合,几个 “add” 调用,使得代码重复。 Java 9,添加了几种集合工厂方法:
121 |
122 | Set ints = Set.of(1,2,3);
123 | List strings = List.of("first","second");
124 |
125 | 除了更短和更好阅读之外,这些方法也可以避免您选择特定的集合实现。 事实上,从工厂方法返回已放入数个元素的集合实现是高度优化的。这是可能的,因为它们是不可变的:在创建后,继续添加元素到这些集合会导致 “UnsupportedOperationException” 。
126 |
127 | **6.改进的 Stream API**
128 | 长期以来,Stream API 都是 Java 标准库最好的改进之一。通过这套 API 可以在集合上建立用于转换的申明管道。在 Java 9 中它会变得更好。Stream 接口中添加了 4 个新的方法:dropWhile, takeWhile, ofNullable。还有个 iterate 方法的新重载方法,可以让你提供一个 Predicate (判断条件)来指定什么时候结束迭代:
129 | `IntStream.iterate(1, i -> i < 100, i -> i + 1).forEach(System.out::println);`
130 | 第二个参数是一个 Lambda,它会在当前 IntStream 中的元素到达 100 的时候返回 true。因此这个简单的示例是向控制台打印 1 到 99。
131 |
132 | 除了对 Stream 本身的扩展,Optional 和 Stream 之间的结合也得到了改进。现在可以通过 Optional 的新方法 stram 将一个 Optional 对象转换为一个(可能是空的) Stream 对象:
133 |
134 | `Stream s = Optional.of(1).stream();`
135 | 在组合复杂的 Stream 管道时,将 Optional 转换为 Stream 非常有用。
136 |
137 | **7.私有接口方法**
138 | 使用 Java 9,您可以向接口添加私有辅助方法来解决此问题:
139 |
140 | public interface MyInterface {
141 | void normal InterfaceMethod();
142 | default void interface MethodWithDefault() { init(); }
143 | default void anotherDefaultMethod() { init(); }
144 | private void init() {
145 | System.out.println("Initializing");
146 | }
147 | }
148 | 如果您使用默认方法开发 API ,那么私有接口方法可能有助于构建其实现。
149 |
150 | **8.HTTP/2**
151 | Java 9 中有新的方式来处理 HTTP 调用。这个迟到的特性用于代替老旧的 HttpURLConnection API,并提供对 WebSocket 和 HTTP/2 的支持。注意:新的 HttpClient API 在 Java 9 中以所谓的孵化器模块交付。也就是说,这套 API 不能保证 100% 完成。不过你可以在 Java 9 中开始使用这套 API:
152 |
153 | HttpClient client = HttpClient.newHttpClient();
154 | HttpRequest req = HttpRequest.newBuilder(URI.create("http://www.google.com"))
155 | .header("User-Agent","Java")
156 | .GET()
157 | .build();
158 | HttpResponse resp = client.send(req, HttpResponse.BodyHandler.asString());
159 | HttpResponse resp = client.send(req, HttpResponse.BodyHandler.asString());
160 | 除了这个简单的请求/响应模型之外,HttpClient 还提供了新的 API 来处理 HTTP/2 的特性,比如流和服务端推送。
161 |
162 | **9.多版本兼容 JAR**
163 | 我们最后要来着重介绍的这个特性对于库的维护者而言是个特别好的消息。当一个新版本的 Java 出现的时候,你的库用户要花费数年时间才会切换到这个新的版本。这就意味着库得去向后兼容你想要支持的最老的 Java 版本 (许多情况下就是 Java 6 或者 7)。这实际上意味着未来的很长一段时间,你都不能在库中运用 Java 9 所提供的新特性。幸运的是,多版本兼容 JAR 功能能让你创建仅在特定版本的 Java 环境中运行库程序时选择使用的 class 版本:
164 |
165 | multirelease.jar
166 | ├──
167 | META-INF
168 | │
169 | └── versions
170 | │
171 | └── 9
172 | │
173 | └── multirelease
174 | │
175 | └── Helper.class
176 | ├──
177 | multirelease
178 | ├──
179 | Helper.class
180 | └──
181 | Main.class
182 |
183 | 在上述场景中, multirelease.jar 可以在 Java 9 中使用, 不过 Helper 这个类使用的不是顶层的 multirelease.Helper 这个 class, 而是处在“META-INF/versions/9”下面的这个。这是特别为 Java 9 准备的 class 版本,可以运用 Java 9 所提供的特性和库。同时,在早期的 Java 诸版本中使用这个 JAR 也是能运行的,因为较老版本的 Java 只会看到顶层的这个 Helper 类。
184 |
185 | ## JDK 10
186 |
187 | JDK 10 是 Java 10 标准版的部分实现,将于 2018 年 3 月 20 日发布,改进的关键点包括一个本地类型推断、一个垃圾回收的“干净”接口。
188 |
189 | Java 平台首席架构师 Mark Reinhold 近日在邮件列表上表示,按计划,JDK 10 将于 2 月 8 日星期四进入候选发布(Release Candidate)阶段。他建议 JDK 10 在该阶段采用和 JDK 9 相同的发布流程,将 Bug 修复分为 P1 - P5 五个不同的级别。候选阶段将重点修复那些能直接影响 JDK 10 能否成功发行的 P1 级错误,并将那些非关键或短期内无法解决的 P1 级错误推迟处理。此外,所有 P2 - P5 级的错误均留给后续版本修复。
190 |
191 | JDK 10 的十二项新特性已确定,包括:
192 | + JEP 286: 局部变量的类型推导。该特性在社区讨论了很久并做了调查,可查看 JEP 286 调查结果。
193 | + JEP 296: 将 JDK 的多个代码仓库合并到一个储存库中。
194 | + JEP 304: 垃圾收集器接口。通过引入一个干净的垃圾收集器(GC)接口,改善不同垃圾收集器的源码隔离性。
195 | + JEP 307: 向 G1 引入并行 Full GC。
196 | + JEP 310: 应用类数据共享。为改善启动和占用空间,在现有的类数据共享(“CDS”)功能上再次拓展,以允许应用类放置在共享存档中。
197 | + JEP 312: 线程局部管控。允许停止单个线程,而不是只能启用或停止所有线程。
198 | + JEP 313: 移除 Native-Header Generation Tool (javah)
199 | + JEP 314: 额外的 Unicode 语言标签扩展。包括:cu (货币类型)、fw (每周第一天为星期几)、rg (区域覆盖)、tz (时区) 等。
200 | + JEP 316: 在备用内存设备上分配堆内存。允许 HotSpot 虚拟机在备用内存设备上分配 Java 对象堆。
201 | + JEP 317: 基于 Java 的 JIT 编译器(试验版本)。
202 | + JEP 319: 根证书。开源 Java SE Root CA 程序中的根证书。
203 | + JEP 322: 基于时间的版本发布模式。“Feature releases” 版本将包含新特性,“Update releases” 版本仅修复 Bug 。
204 | image
205 | 此外,JDK 11 的页面已经出现了四个 JEP ,包括:动态类文件常量(JEP 309,Dynamic Class-File Constants)、低开销垃圾收集器 Epsilon(JEP 318)、移除 Java EE 和 CORBA 模块(JEP 320),以及 Lambda 参数的本地变量语法(JEP 323)。JDK 11 计划于 2018 年 9 月发布,并有望成为新的 LTS 版本。
206 |
207 | >文章链接:`https://www.jianshu.com/p/37b52f1ebd4a`
208 |
209 |
--------------------------------------------------------------------------------
/doc/javabase/jvm/ClassLoad.md:
--------------------------------------------------------------------------------
1 |
2 | 当程序主动使用某个类时,如果该类还未被加载到内存中,则JVM会通过加载、连接、初始化3个步骤来对该类进行初始化。如果没有意外,JVM将会连续完成3个步骤,所以有时也把这个3个步骤统称为类加载或类初始化。
3 |
4 | 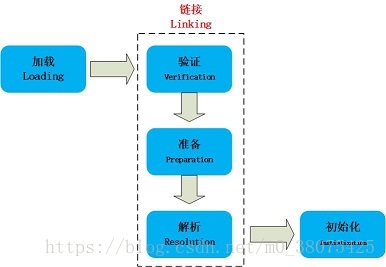
5 |
6 | ## 一、类加载过程
7 |
8 | ### 1.加载
9 |
10 | 加载指的是将类的class文件读入到内存,并为之创建一个java.lang.Class对象,也就是说,当程序中使用任何类时,系统都会为之建立一个java.lang.Class对象。
11 |
12 | 类的加载由类加载器完成,类加载器通常由JVM提供,这些类加载器也是前面所有程序运行的基础,JVM提供的这些类加载器通常被称为系统类加载器。除此之外,开发者可以通过继承ClassLoader基类来创建自己的类加载器。
13 |
14 | 通过使用不同的类加载器,可以从不同来源加载类的二进制数据,通常有如下几种来源。
15 |
16 | + 从本地文件系统加载class文件,这是前面绝大部分示例程序的类加载方式。
17 | + 从JAR包加载class文件,这种方式也是很常见的,前面介绍JDBC编程时用到的数据库驱动类就放在JAR文件中,JVM可以从JAR文件中直接加载该class文件。
18 | + 通过网络加载class文件。
19 | + 把一个Java源文件动态编译,并执行加载。
20 |
21 | 类加载器通常无须等到“首次使用”该类时才加载该类,Java虚拟机规范允许系统预先加载某些类。
22 |
23 | ### 2.链接
24 |
25 | 当类被加载之后,系统为之生成一个对应的Class对象,接着将会进入连接阶段,连接阶段负责把类的二进制数据合并到JRE中。类连接又可分为如下3个阶段。
26 |
27 | **1). 验证:** 验证阶段用于检验被加载的类是否有正确的内部结构,并和其他类协调一致。Java是相对C++语言是安全的语言,例如它有C++不具有的数组越界的检查。这本身就是对自身安全的一种保护。验证阶段是Java非常重要的一个阶段,它会直接的保证应用是否会被恶意入侵的一道重要的防线,越是严谨的验证机制越安全。验证的目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,不会危害虚拟机自身安全。其主要包括四种验证,文件格式验证,元数据验证,字节码验证,符号引用验证。
28 |
29 | 四种验证做进一步说明:
30 |
31 | + 文件格式验证:主要验证字节流是否符合Class文件格式规范,并且能被当前的虚拟机加载处理。例如:主,次版本号是否在当前虚拟机处理的范围之内。常量池中是否有不被支持的常量类型。指向常量的中的索引值是否存在不存在的常量或不符合类型的常量。
32 |
33 | + 元数据验证:对字节码描述的信息进行语义的分析,分析是否符合java的语言语法的规范。
34 |
35 | + 字节码验证:最重要的验证环节,分析数据流和控制,确定语义是合法的,符合逻辑的。主要的针对元数据验证后对方法体的验证。保证类方法在运行时不会有危害出现。
36 |
37 | + 符号引用验证:主要是针对符号引用转换为直接引用的时候,是会延伸到第三解析阶段,主要去确定访问类型等涉及到引用的情况,主要是要保证引用一定会被访问到,不会出现类等无法访问的问题。
38 |
39 | **2).准备:** 类准备阶段负责为类的静态变量分配内存,并设置默认初始值。
40 |
41 | **3).解析:** 将类的二进制数据中的符号引用替换成直接引用。说明一下:符号引用:符号引用是以一组符号来描述所引用的目标,符号可以是任何的字面形式的字面量,只要不会出现冲突能够定位到就行。布局和内存无关。直接引用:是指向目标的指针,偏移量或者能够直接定位的句柄。该引用是和内存中的布局有关的,并且一定加载进来的。
42 |
43 | ### 3.初始化
44 |
45 | 初始化是为类的静态变量赋予正确的初始值,准备阶段和初始化阶段看似有点矛盾,其实是不矛盾的,如果类中有语句:
46 |
47 | ```
48 | private static int a = 10
49 | ```
50 |
51 | 它的执行过程是这样的:
52 |
53 | 首先字节码文件被加载到内存后,先进行链接的验证这一步骤,验证通过后准备阶段,给a分配内存,因为变量a是static的,所以此时a等于int类型的默认初始值0,即a=0,然后到解析(后面在说),到初始化这一步骤时,才把a的真正的值10赋给a,此时a=10。
54 |
55 | ## 二、类加载时机
56 |
57 | 1. 创建类的实例,也就是new一个对象
58 |
59 | 2. 访问某个类或接口的静态变量,或者对该静态变量赋值
60 |
61 | 3. 调用类的静态方法
62 |
63 | 4. 反射(Class.forName("com.lyj.load"))
64 |
65 | 5. 初始化一个类的子类(会首先初始化子类的父类)
66 |
67 | 6. JVM启动时标明的启动类,即文件名和类名相同的那个类
68 |
69 | **除此之外,下面几种情形需要特别指出:**
70 |
71 | 对于一个final类型的静态变量,如果该变量的值在编译时就可以确定下来,那么这个变量相当于“宏变量”。
72 |
73 | Java编译器会在编译时直接把这个变量出现的地方替换成它的值,因此即使程序使用该静态变量,也不会导致该类的初始化。反之,如果final类型的静态Field的值不能在编译时确定下来,则必须等到运行时才可以确定该变量的值,如果通过该类来访问它的静态变量,则会导致该类被初始化。
74 |
75 | ## 三、类加载器
76 |
77 | 类加载器负责加载所有的类,其为所有被载入内存中的类生成一个java.lang.Class实例对象。一旦一个类被加载如JVM中,同一个类就不会被再次载入了。正如一个对象有一个唯一的标识一样,一个载入JVM的类也有一个唯一的标识。
78 |
79 | 在Java中,一个类用其全限定类名(包括包名和类名)作为标识;但在JVM中,一个类用其全限定类名和其类加载器作为其唯一标识。
80 |
81 | > 例如,如果在pg的包中有一个名为Person的类,被类加载器ClassLoader的实例kl负责加载,则该Person类对应的Class对象在JVM中表示为(Person.pg.kl)。这意味着两个类加载器加载的同名类:(Person.pg.kl)和(Person.pg.kl2)是不同的、它们所加载的类也是完全不同、互不兼容的。
82 |
83 |
84 |
85 | **JVM预定义有三种类加载器,当一个 JVM启动的时候,Java开始使用如下三种类加载器:**
86 |
87 | **1)根类加载器(bootstrap class loader):** 它用来加载 Java 的核心类,是用原生代码来实现的,并不继承自 java.lang.ClassLoader(负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类)。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作。
88 |
89 | 下面程序可以获得根类加载器所加载的核心类库,并会看到本机安装的Java环境变量指定的jdk中提供的核心jar包路径:
90 |
91 | ```
92 | public class ClassLoaderTest {
93 |
94 | public static void main(String[] args) {
95 |
96 | URL[] urls = sun.misc.Launcher.getBootstrapClassPath().getURLs();
97 | for(URL url : urls){
98 | System.out.println(url.toExternalForm());
99 | }
100 | }
101 |
102 | }
103 | ```
104 |
105 | 运行结果:
106 | 
107 |
108 | **2)扩展类加载器(extensions class loader):** 它负责加载JRE的扩展目录,lib/ext或者由java.ext.dirs系统属性指定的目录中的JAR包的类。由Java语言实现,父类加载器为null。
109 |
110 | **3)系统类加载器(system class loader):** 被称为系统(也称为应用)类加载器,它负责在JVM启动时加载来自Java命令的-classpath选项、java.class.path系统属性,或者CLASSPATH换将变量所指定的JAR包和类路径。程序可以通过ClassLoader的静态方法getSystemClassLoader()来获取系统类加载器。如果没有特别指定,则用户自定义的类加载器都以此类加载器作为父加载器。由Java语言实现,父类加载器为ExtClassLoader。
111 |
112 | **类加载器加载Class大致要经过如下8个步骤:**
113 |
114 | 1. 检测此Class是否载入过,即在缓冲区中是否有此Class,如果有直接进入第8步,否则进入第2步。
115 | 2. 如果没有父类加载器,则要么Parent是根类加载器,要么本身就是根类加载器,则跳到第4步,如果父类加载器存在,则进入第3步。
116 | 3. 请求使用父类加载器去载入目标类,如果载入成功则跳至第8步,否则接着执行第5步。
117 | 4. 请求使用根类加载器去载入目标类,如果载入成功则跳至第8步,否则跳至第7步。
118 | 5. 当前类加载器尝试寻找Class文件,如果找到则执行第6步,如果找不到则执行第7步。
119 | 6. 从文件中载入Class,成功后跳至第8步。
120 | 7. 抛出ClassNotFountException异常。
121 | 8. 返回对应的java.lang.Class对象。
122 |
123 |
124 |
125 | ## 四、类加载机制:
126 |
127 | **1.JVM的类加载机制主要有如下3种:**
128 |
129 | + 全盘负责:所谓全盘负责,就是当一个类加载器负责加载某个Class时,该Class所依赖和引用其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入。
130 |
131 | + 双亲委派:所谓的双亲委派,则是先让父类加载器试图加载该Class,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类。通俗的讲,就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父加载器,依次递归,如果父加载器可以完成类加载任务,就成功返回;只有父加载器无法完成此加载任务时,才自己去加载。
132 |
133 | + 缓存机制。缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区中搜寻该Class,只有当缓存区中不存在该Class对象时,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓冲区中。这就是为很么修改了Class后,必须重新启动JVM,程序所做的修改才会生效的原因。
134 |
135 |
136 |
137 |
138 |
139 | **2.这里说明一下双亲委派机制:**
140 |
141 | 
142 |
143 | **双亲委派机制,其工作原理的是**:
144 |
145 | 如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己才想办法去完成。
146 |
147 | **双亲委派机制的优势:**
148 |
149 | 采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。
150 |
151 | 其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。
152 |
153 |
154 |
155 | > 原文链接:https://blog.csdn.net/m0_38075425/article/details/81627349
156 |
--------------------------------------------------------------------------------
/doc/javabase/orm/MyBatis常见面试题.md:
--------------------------------------------------------------------------------
1 | ## 【面试官之你说我听】-MyBatis常见面试题
2 |
3 | ### 精讲#{}和${}的区别是什么?
4 |
5 | + mybatis在处理\#{}时,会将sql中的\#{}替换为?号,调用PreparedStatement的set方法来赋值。
6 |
7 | + mybatis在处理\${}时,就是把\${}替换成变量的值。
8 |
9 | + 使用#{}可以有效的防止SQL注入,提高系统安全性。原因在于:预编译机制。**预编译完成之后,SQL的结构已经固定,即便用户输入非法参数,也不会对SQL的结构产生影响,从而避免了潜在的安全风险。**
10 |
11 | + 预编译是提前对SQL语句进行预编译,而其后注入的参数将不会再进行SQL编译。我们知道,SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作。而预编译机制则可以很好的防止SQL注入。
12 |
13 | > 既然\${}会引起sql注入,为什么有了#{}还需要有${}呢?那其存在的意义是什么?
14 | >
15 | > \#{}主要用于预编译,而预编译的场景其实非常受限,而${}用于替换,很多场景会出现替换,而这种场景可不是预编译
16 |
17 |
18 |
19 | ### 数据库链接中断如何处理
20 |
21 | 数据库的访问底层是通过tcp实现的,当链接中断是程序是无法得知,导致程序一直会停顿一段时间在这,最终会导致用户体验不好,因此面对数据库连接中断的异常,该怎么设置mybatis呢?
22 |
23 | connection操作底层是一个循环处理操作,因此可以进行时间有关的参数:
24 |
25 | + max_idle_time : 表明最大的空闲时间,超过这个时间socket就会关闭
26 | + connect_timeout : 表明链接的超时时间
27 |
28 | > 数据库服务器活的杠杠的,但是因为网络用塞,客户端仍然连不上服务器端,这个时候就要设置timeout,别一直傻等着
29 |
30 |
31 |
32 | ### 在开发过程中,经常遇到插入重复的现象,这种情况该如何解决呢?
33 |
34 | > 插入的过程一般都是分两步的:先判断是否存在记录,没有存在则插入否则不插入。如果存在并发操作,那么同时进行了第一步,然后大家都发现没有记录,然后都插入了数据从而造成数据的重复
35 |
36 | 解决插入重复的思路 :
37 |
38 | + 先判断数据库是否存在数据,有的话则不进行任何操作。没有数据的话,进行下一步;
39 | + 向redis set key,其中只有一个插入操作A会成功,其他并发的操作(B和C...)都会失败的 ;
40 | + 当set key 成功的操作A,开始执行插入数据操作,无论是否插入数据成功,都在需要将redis key删除。【注】插入不成功可以多尝试几次,增加成功的概率 ;
41 | + 然而set key 失败的操作B和C,sleep一下,竞争赢的插入操作重复以上步骤。
42 |
43 | 总结:多线程同时插入数据,谁获取锁并插入数据成功了其他线程不做任何操作。当插入数据失败后,其他线程抢锁进行插入数据。
44 |
45 |
46 |
47 |
48 |
49 | ### 事务执行过程中宕机的应对处理方式
50 |
51 | > 数据库插入百万级数据的时候,还没操作完,但是把服务器重启了,数据库会继续执行吗? 还是直接回滚了?
52 |
53 | 不会自动继续执行,不会自动直接回滚 ,但可以依据事务日志进行回滚或者进行执行。
54 |
55 | 事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化 ,两种类型:
56 |
57 | > 在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。
58 |
59 | + redo log :按语句的执行顺序,依次交替的记录在一起
60 | + undo log: 主要为事务的回滚服务。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。
61 |
62 |
63 |
64 | ### Java客户端中的一个Connection是不是在MySQL中就对应一个线程来处理这个链接呢?
65 |
66 | Java客户端中的一个Connection不是在MySQL中就对应一个线程来处理这个链接,而是:
67 |
68 | > **监听socket的主线程+线程池里面固定数目的工作线程来处理的**
69 |
70 | 高性能服务器端端开发底层主要靠I/O复用来处理,这种模式:
71 |
72 | > **单线程+事件处理机制**
73 |
74 | 在MySQL有一个主线程,这是单线程(与Java中处处强调多线程的思想有点不同哦),它不断的循环查看是否有socket是否有读写事件,如果有读写事件,再从线程池里面找个工作线程处理这个socket的读写事件,完事之后工作线程会回到线程池。
75 |
76 |
77 |
78 | ### Mybatis中的Dao接口和XML文件里的SQL是如何建立关系的?
79 |
80 | + 解析XML: 初始化SqlSessionFactoryBean会将mapperLocations路径下所有的XML文件进行解析
81 | + 创建SqlSource: Mybatis会把每个SQL标签封装成SqlSource对象,可以为动态SQL和静态SQL
82 | + 创建MappedStatement: XML文件中的每一个SQL标签就对应一个MappedStatement对象 ,并由 Configuration解析XML
83 | + Dao接口代理: Spring中的FactoryBean 和 JDK动态代理返回了可以注入的一个Dao接口的代理对象
84 | + 执行: 通过statement全限定类型+方法名拿到MappedStatement 对象,然后通过执行器Executor去执行具体SQL并返回
85 |
86 |
87 |
88 | ### 当实体类中的属性名和表中的字段名不一样,怎么办 ?
89 |
90 | + 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致
91 | + 通过\来映射字段名和实体类属性名的一一对应的关系。
92 |
93 |
94 |
95 | ### 模糊查询like语句该怎么写?
96 |
97 | + 在Java代码中添加sql通配符
98 |
99 | ```
100 | string name = "%Ccww%";
101 | list names = mapper.selectName(name);
102 | ```
103 |
104 | ```
105 |
108 | ```
109 |
110 | + 在sql语句中拼接通配符,会引起sql注入
111 |
112 | ```
113 |
116 | ```
117 |
118 |
119 |
120 | ### 什么是MyBatis的接口绑定?有哪些实现方式?
121 |
122 | 接口绑定 : 在MyBatis中任意定义接口,然后把接口里边的方法和SQL语句绑定,我们可以直接调用接口方法,比起SqlSession提供的方法我们可以有更加灵活的选择和设置
123 |
124 | 接口绑定有两种实现方式 :
125 |
126 | + 通过注解绑定: 在接口的方法上加上 @Select、@Update等注解,里面包含Sql语句来绑定;
127 | + 通过xml绑定 : 要指定xml映射文件里面的namespace必须为接口的全路径名 。
128 |
129 |
130 |
131 | ### 使用MyBatis的mapper接口调用时要注意的事项
132 |
133 | + Mapper接口方法名和mapper.xml中定义的每个sql的id相同;
134 | + Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同;
135 | + Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同;
136 | + Mapper.xml文件中的namespace即是mapper接口的类路径。
137 |
138 |
139 |
140 | ### 通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
141 |
142 | + Dao接口为Mapper接口。
143 |
144 | + 接口的全限名为映射文件中的namespace的值;
145 |
146 | + 接口的方法名为映射文件中Mapper的Statement的id值;
147 |
148 | + 接口方法内的参数为传递给sql的参数。
149 |
150 | Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MapperStatement。在Mybatis中,每一个 \