2 |

3 |
4 | # nonebot_plugin_imgexploration
5 |
6 | _✨ [Nonebot2](https://github.com/nonebot/nonebot2) 插件,Google、Yandx和基于PicImageSearch的saucenao、ascii2d搜图 ✨_
7 |
8 |
9 |
10 |
 67 |
67 | 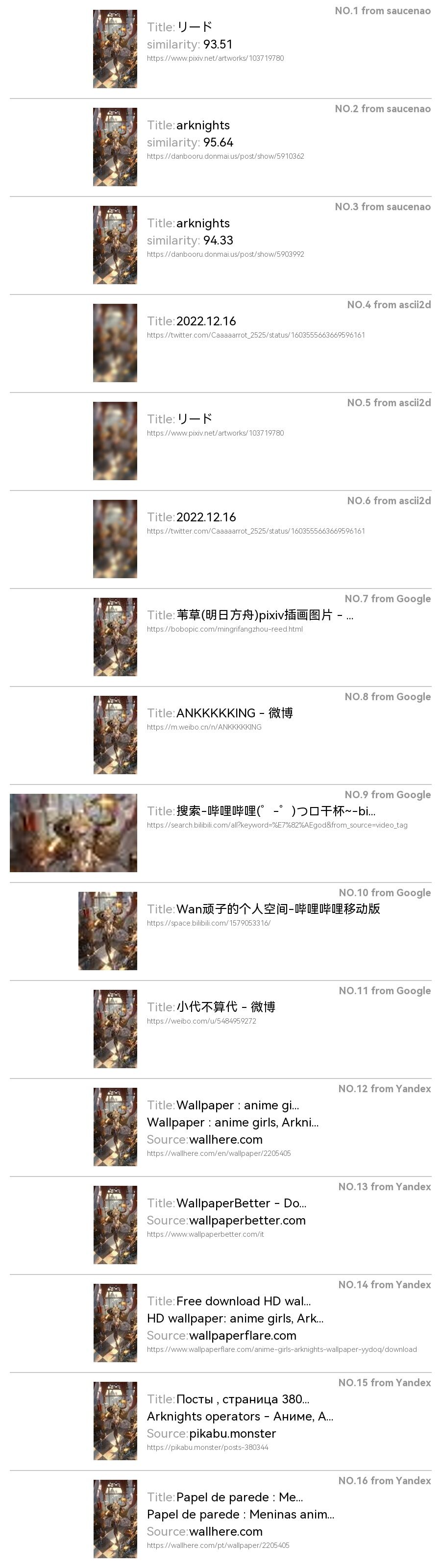 73 |
73 |