├── .gitignore
├── .travis.yml
├── LICENSE
├── README.md
├── pics
├── bulk_edit.png
├── bulk_edit_filled.png
├── intent_ui.png
└── utterances.png
├── requirements.txt
├── setup.py
├── test
├── test_files
│ ├── alexa_test.csv
│ ├── csv_test.csv
│ ├── file_override_test.txt
│ └── txt_test.txt
└── test_utter_more.py
└── utter_more
├── __init__.py
└── utter_more.py
/.gitignore:
--------------------------------------------------------------------------------
1 | # Directories
2 | __pycache__
3 | .cache
4 | .pytest_cache
5 | dist
6 | build
7 | *.egg-info
8 | conda_uploading
9 |
10 | # Conda directory for executables/yaml
11 | utter-more
12 |
13 | # Files
14 | *.pyc
15 |
--------------------------------------------------------------------------------
/.travis.yml:
--------------------------------------------------------------------------------
1 | language: python
2 | python:
3 | - "3.6"
4 | install:
5 | - pip install -r requirements.txt
6 | script:
7 | - pytest
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2018 Jacob Scott
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # Utter More
2 | To customize Amazon's Alexa, you make what is called a skill. To do something in the skill, you make an intent. To run the intent, you make an utterance. When that utterance is uttered, the intent is run. Since language is complex, there may be many different ways to say the same thing and you may want Alexa to pick up on all of those ways. Furthermore, you may have many variables for the utterances (called intent slots). Being verbose enough to cover every case can be tedious, so this takes care of that.
3 |
4 | ## Installing Package
5 | Currently, this package is not PyPI, so just git clone the repo
6 |
7 | ## Creating Utterances
8 | Below are some examples to show its functionality.
9 | ### Formatting
10 | You can use the following in your templates:
11 | 1) OR statement `(a|b|c|...)` - Used if you want to allow multiple interchangeable words. For example, if `photo`, `picture` and `painting` are interchangeable in your utterances, then write `(photo|picture|painting)` in the place where it would be. The number of words to OR is arbitrary and single curly keywords like `{intent_slot}` can be used in this.
12 | 3) Conditional OR statement `(a*tag1|b) (c^tag1|d)` - Used if you want the appearance of a phrase in an OR statement to be dependent on another phrase. Here, `a` is the master and `c` is the follower; utterances with `c` will only appear if it also contains `a`. Another functionality of this is as follows. If you have `(It*s|They*p) (is^s|are^p) (close^s|far^p)`, `is` and `close` will only show if `It` also shows and, conversely, `are` and `far` will only show if `They` shows. This is how you can do a conditional AND with this function.
13 | 2) Optional Intent Slot `{{slot}}` - Used if the existence of an intent slot in your utterance is optional. For example, if you have an optional adverb you may write `I {adverb} love it` or just `I love it`. Instead you can write `I {{adverb}} love it` to capture both.
14 |
15 | ### Running the Code
16 | Now with the formatting down, lets create some templates for the utterances. Something like:
17 | ```
18 | "What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)"
19 | ```
20 | and
21 | ```
22 | "Download the (photo|picture) {{to_file_path}}"
23 | ```
24 | To do this, we run the following:
25 | ``` python
26 | from pprint import pprint
27 | from utter_more import UtterMore
28 |
29 | um = UtterMore("What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)",
30 | "Download the (photo|picture) {{to_file_path}}")
31 | um.iter_build_utterances()
32 |
33 | pprint(um.utterances)
34 | ```
35 | And this will display:
36 | ``` python
37 | [['What is that {descriptor} photo of',
38 | 'What is that {descriptor} photo from',
39 | 'What is that {descriptor} picture of',
40 | 'What is that {descriptor} picture from',
41 | 'What is that photo of',
42 | 'What is that photo from',
43 | 'What is that picture of',
44 | 'What is that picture from',
45 | 'What are those {descriptor} photos of',
46 | 'What are those {descriptor} photos from',
47 | 'What are those {descriptor} pictures of',
48 | 'What are those {descriptor} pictures from',
49 | 'What are those photos of',
50 | 'What are those photos from',
51 | 'What are those pictures of',
52 | 'What are those pictures from'],
53 | ['Download the photo {to_file_path}',
54 | 'Download the photo',
55 | 'Download the picture {to_file_path}',
56 | 'Download the picture']]
57 | ```
58 | Here we can easily follow the grammatical rules of plurality. If we want to save the utterances so that we can upload them to our Alexa skill, we simply do:
59 | ``` python
60 | um.save_for_alexa(PATH_TO_DIRECTORY, FILE_NAME)
61 | ```
62 | Here we will find the CSV file properly formatted for uploading.
63 |
64 | ## Uploading the Utterances
65 | 1) After going to the tab for the intended intent, click on "Bulk Edit" in the top right corner of the page.
66 |
67 |
68 |
69 | 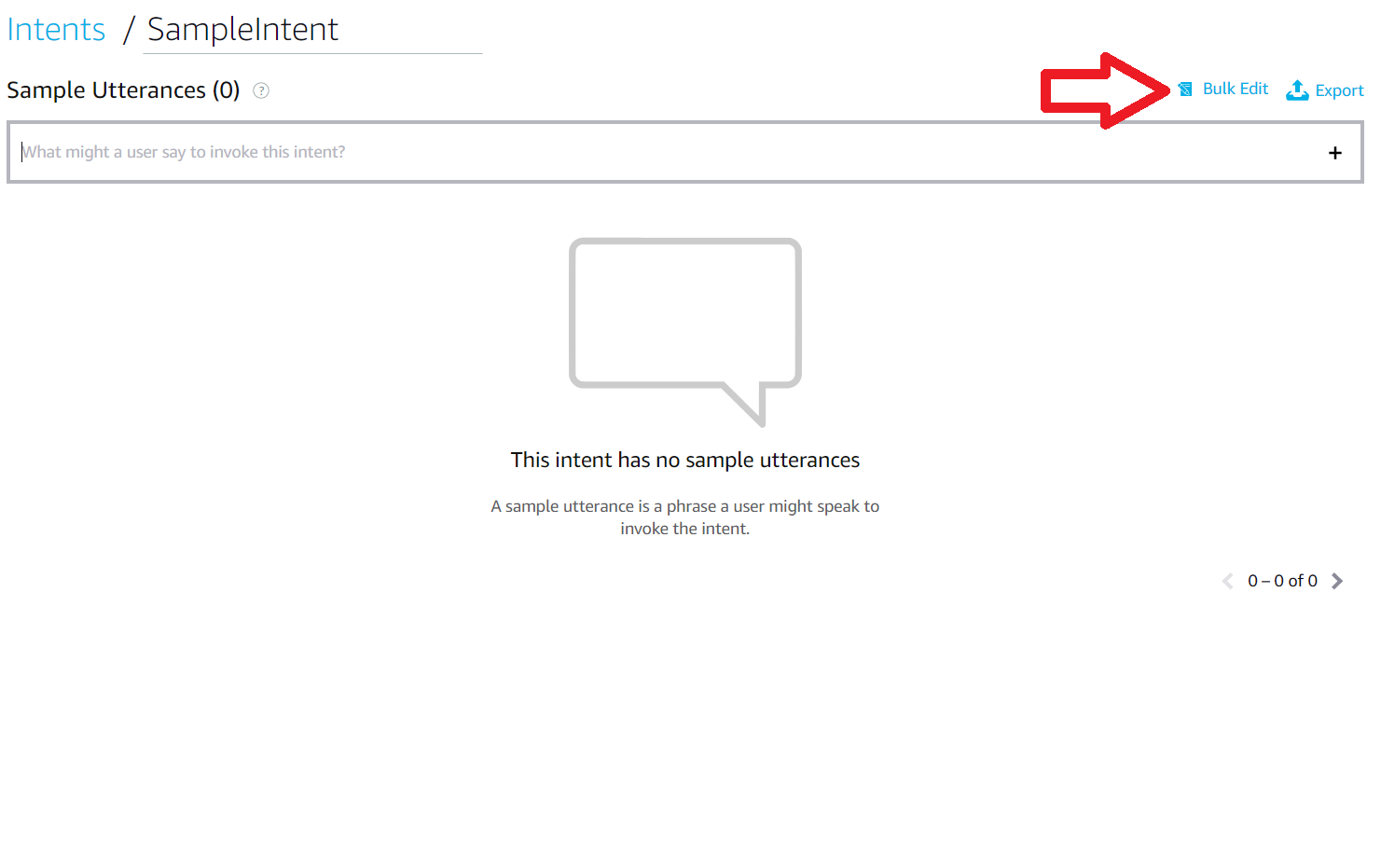 70 |
71 |
70 |
71 |
72 |
73 | 2) Browse for or drag and drop the previously made CSV and it will populate the text field.
74 |
75 |
76 |
77 | 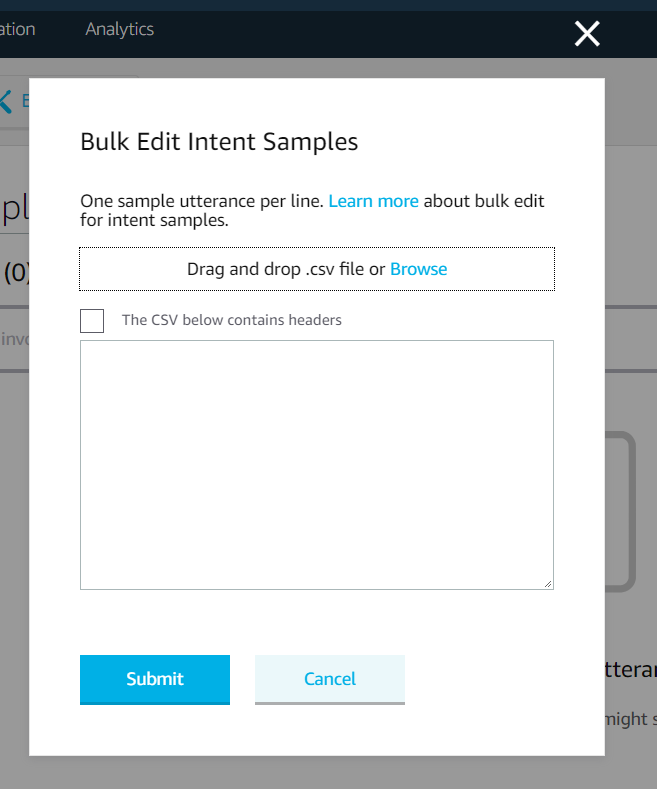 78 |
79 |
80 |
78 |
79 |
80 | 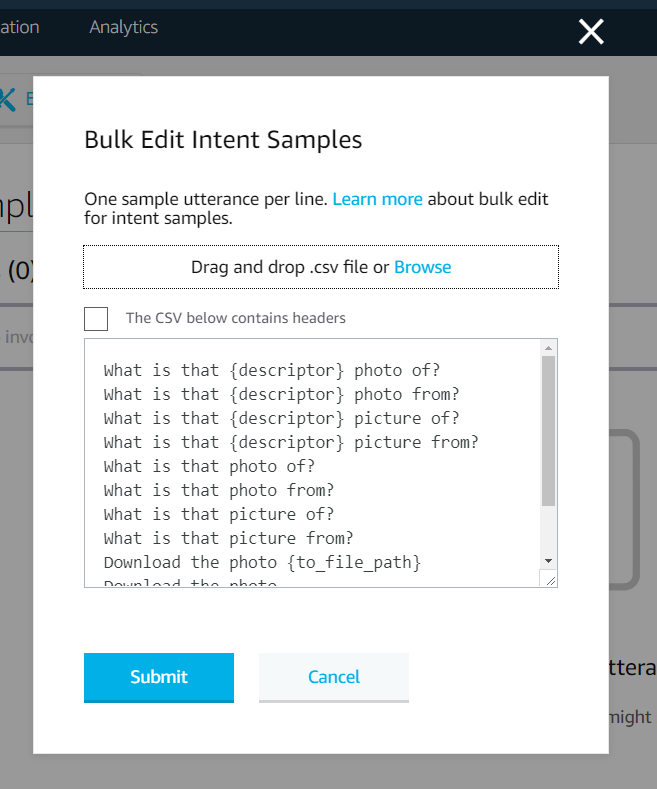 81 |
82 |
81 |
82 |
83 |
84 | 3) Press "Submit" and the utterances field will be filled.
85 |
86 |
87 |
88 | 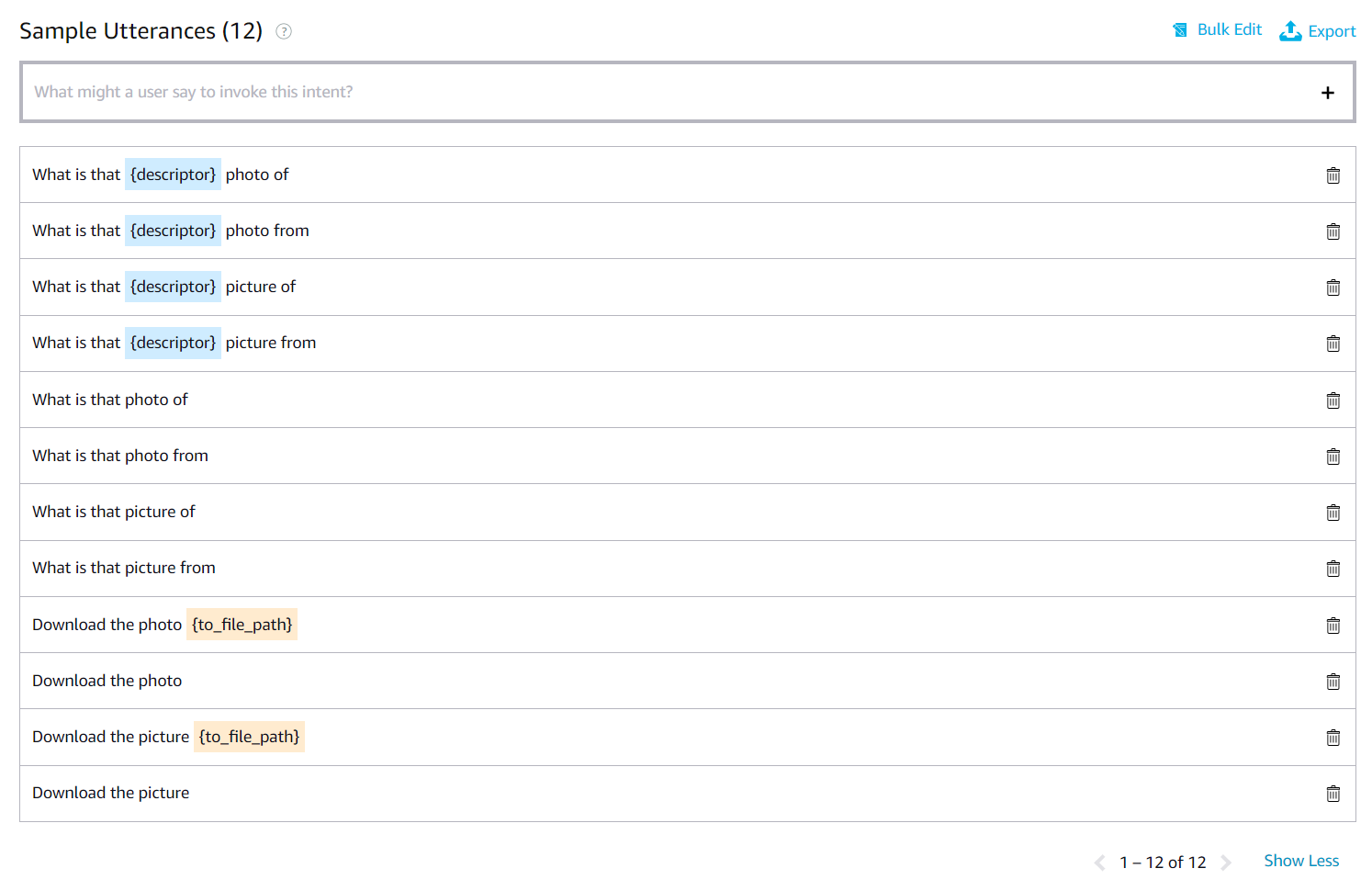 89 |
90 |
89 |
90 |
91 |
92 | And that's it, no need to manually type in potentially hundreds or thousands of annoyingly similar phrases.
93 |
94 | ## Other Features
95 | * You can add utterance templates after making the class like so:
96 | ``` python
97 | from utter_more import UtterMore
98 |
99 | um = UtterMore()
100 | um.add_utterance_template("What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)")
101 | um.add_utterance_template("Download the (photo|picture) {{to_file_path}}")
102 | um.iter_build_utterances()
103 | um.save_for_alexa(PATH_TO_DIRECTORY, FILE_NAME)
104 | ```
105 | This will produce the same CSV as above
106 | * Continuing with the above code, you can then save these utterances normally as either a regular CSV or a text file like so:
107 | ``` python
108 | # Saves as utterances.txt with new line separators
109 | um.save_utterances(PATH_TO_DIRECTORY, 'utterances', 'txt')
110 | # Saves as utterances.csv as actual comma-separated values
111 | um.save_utterances(PATH_TO_DIRECTORY, 'utterances', 'csv')
112 | ```
113 | * Utterances can be created from a template without adding it to the UtterMore object so
114 | ``` python
115 | from pprint import pprint
116 | from utter_more import UtterMore
117 |
118 | um = UtterMore()
119 | utterances = um.build_utterance("What (is*s|are*p) (that^s|those^p) {{descriptor}} (photo|picture)(^s|s^p) (of|from)")
120 | pprint(utterances)
121 | ```
122 | will output:
123 | ``` python
124 | [['What is that {descriptor} photo of',
125 | 'What is that {descriptor} photo from',
126 | 'What is that {descriptor} picture of',
127 | 'What is that {descriptor} picture from',
128 | 'What is that photo of',
129 | 'What is that photo from',
130 | 'What is that picture of',
131 | 'What is that picture from',
132 | 'What are those {descriptor} photos of',
133 | 'What are those {descriptor} photos from',
134 | 'What are those {descriptor} pictures of',
135 | 'What are those {descriptor} pictures from',
136 | 'What are those photos of',
137 | 'What are those photos from',
138 | 'What are those pictures of',
139 | 'What are those pictures from']]
140 | ```
141 |
--------------------------------------------------------------------------------
/pics/bulk_edit.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/crumpstrr33/Utter-More/840b637ac4da0533be22ca43bdb81e6fc98c80bc/pics/bulk_edit.png
--------------------------------------------------------------------------------
/pics/bulk_edit_filled.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/crumpstrr33/Utter-More/840b637ac4da0533be22ca43bdb81e6fc98c80bc/pics/bulk_edit_filled.png
--------------------------------------------------------------------------------
/pics/intent_ui.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/crumpstrr33/Utter-More/840b637ac4da0533be22ca43bdb81e6fc98c80bc/pics/intent_ui.png
--------------------------------------------------------------------------------
/pics/utterances.png:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/crumpstrr33/Utter-More/840b637ac4da0533be22ca43bdb81e6fc98c80bc/pics/utterances.png
--------------------------------------------------------------------------------
/requirements.txt:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/crumpstrr33/Utter-More/840b637ac4da0533be22ca43bdb81e6fc98c80bc/requirements.txt
--------------------------------------------------------------------------------
/setup.py:
--------------------------------------------------------------------------------
1 | from setuptools import setup, find_packages
2 | from os import path
3 | import re
4 |
5 | with open('README.md', 'r') as f:
6 | long_description = f.read()
7 |
8 | with open(path.join('utter_more', '__init__.py'), 'r') as f:
9 | setup_file = f.read()
10 | version = re.findall(r'__version__ = \'(.*)\'', setup_file)[0]
11 | name = re.findall(r'__name__ = \'(.*)\'', setup_file)[0]
12 |
13 | setup(
14 | name=name,
15 | version=version,
16 | author='Jacob Scott',
17 | description='Creates utterances for Amazon\'s Alexa.',
18 | license='MIT',
19 | url='https://github.com/crumpstrr33/Utter-More',
20 | packages=find_packages(exclude=['test*']),
21 | python_requires='>=3',
22 | long_description=long_description,
23 | long_description_content_type='text/markdown',
24 | classifiers=[
25 | 'Intended Audience :: Developers',
26 | 'License :: OSI Approved :: MIT License',
27 | 'Programming Language :: Python :: 3 :: Only'
28 | ]
29 | )
30 |
--------------------------------------------------------------------------------
/test/test_files/alexa_test.csv:
--------------------------------------------------------------------------------
1 | {beginning}{middle}{end}
2 | {beginning}{middle}
3 | {beginning}{end}
4 | {beginning}
5 | {middle}{end}
6 | {middle}
7 | {end}
8 |
9 | {beginning}{middle}{end}
10 | bemiden
11 | bemidd
12 | bedleen
13 | bedled
14 | ginmiden
15 | ginmidd
16 | gindleen
17 | gindled
18 | ningmiden
19 | ningmidd
20 | ningdleen
21 | ningdled
--------------------------------------------------------------------------------
/test/test_files/csv_test.csv:
--------------------------------------------------------------------------------
1 | {beginning}{middle}{end},{beginning}{middle},{beginning}{end},{beginning},{middle}{end},{middle},{end},,{beginning}{middle}{end},bemiden,bemidd,bedleen,bedled,ginmiden,ginmidd,gindleen,gindled,ningmiden,ningmidd,ningdleen,ningdled
2 |
--------------------------------------------------------------------------------
/test/test_files/file_override_test.txt:
--------------------------------------------------------------------------------
1 | {beginning}{middle}{end},{beginning}{middle},{beginning}{end},{beginning},{middle}{end},{middle},{end},,{beginning}{middle}{end},bemiden,bemidd,bedleen,bedled,ginmiden,ginmidd,gindleen,gindled,ningmiden,ningmidd,ningdleen,ningdled
2 |
--------------------------------------------------------------------------------
/test/test_files/txt_test.txt:
--------------------------------------------------------------------------------
1 | {beginning}{middle}{end}
2 | {beginning}{middle}
3 | {beginning}{end}
4 | {beginning}
5 | {middle}{end}
6 | {middle}
7 | {end}
8 |
9 | {beginning}{middle}{end}
10 | bemiden
11 | bemidd
12 | bedleen
13 | bedled
14 | ginmiden
15 | ginmidd
16 | gindleen
17 | gindled
18 | ningmiden
19 | ningmidd
20 | ningdleen
21 | ningdled
--------------------------------------------------------------------------------
/test/test_utter_more.py:
--------------------------------------------------------------------------------
1 | import filecmp
2 | from inspect import getsourcefile
3 | import os.path as path, sys
4 | cur_dir = path.dirname(path.abspath(getsourcefile(lambda: 0)))
5 | sys.path.insert(0, path.join(cur_dir[:cur_dir.rfind(path.sep)], 'utter_more'))
6 |
7 | import pytest
8 |
9 | from utter_more import UtterMore
10 | sys.path.pop(0)
11 |
12 |
13 | DOUBLE_CURLY = '{{beginning}}{{middle}}{{end}}'
14 | DC_ANS = ['{beginning}{middle}{end}', '{beginning}{middle}', '{beginning}{end}',
15 | '{beginning}', '{middle}{end}', '{middle}', '{end}', '']
16 |
17 | SINGLE_CURLY = '{beginning}{middle}{end}'
18 | SC_ANS = ['{beginning}{middle}{end}']
19 |
20 | OR_CURLY = '(be|gin|ning)(mid|dle)(en|d)'
21 | OC_ANS = ['bemiden', 'bemidd', 'bedleen', 'bedled',
22 | 'ginmiden', 'ginmidd', 'gindleen', 'gindled',
23 | 'ningmiden', 'ningmidd', 'ningdleen', 'ningdled']
24 |
25 | COND_OR_CURLY = '(be^1|gin^2|ning)(mid*1|dle*2)(en*1|d*2)'
26 | COC_ANS = ['bemiden', 'bemidd', 'bedleen', 'ginmidd', 'gindleen',
27 | 'gindled', 'ningmiden', 'ningmidd', 'ningdleen', 'ningdled']
28 |
29 | COND_AND_CURLY = '(be*1|gin*2|ning)(mid^1|dle^2)(en^1|d^2)'
30 | CAC_ANS = ['bemiden', 'gindled']
31 |
32 |
33 | @pytest.fixture()
34 | def local_um():
35 | # A fresh and empty UtterMore every time
36 | um = UtterMore()
37 | return um
38 | @pytest.fixture(scope='module')
39 | def global_um():
40 | # Retains the utterances added to it
41 | um = UtterMore()
42 | return um
43 |
44 |
45 | @pytest.mark.parametrize('template, utterances', [
46 | (DOUBLE_CURLY, DC_ANS),
47 | (SINGLE_CURLY, SC_ANS),
48 | (OR_CURLY, OC_ANS),
49 | (COND_OR_CURLY, COC_ANS),
50 | (COND_AND_CURLY, CAC_ANS)
51 | ])
52 | def test_build_utterances(local_um, template, utterances):
53 | """
54 | Test edge case utterance templates
55 | """
56 | assert local_um.build_utterances(template) == utterances
57 |
58 |
59 | def test_ibu_aut(global_um):
60 | """
61 | Test methods following UtterMore methods:
62 | - iter_build_utterances
63 | - add_utterance_template
64 | """
65 | global_um.add_utterance_template(DOUBLE_CURLY)
66 | global_um.add_utterance_template(SINGLE_CURLY)
67 | global_um.add_utterance_template(OR_CURLY)
68 | global_um.iter_build_utterances()
69 | assert global_um.utterances == [DC_ANS, SC_ANS, OC_ANS]
70 | global_um.utterance_templates.clear()
71 | global_um.utterances.clear()
72 |
73 |
74 | @pytest.mark.parametrize('fname, saved_as, written_as', [
75 | ('alexa_test', 'csv', None),
76 | ('csv_test', 'csv', None),
77 | ('txt_test', 'txt', None),
78 | ('file_override_test', 'txt', 'csv')
79 | ])
80 | def test_saving_utterances(global_um, tmpdir, fname, saved_as, written_as):
81 | """
82 | Test the saving methods of UtterMore
83 | """
84 | written_as = written_as or saved_as
85 | test_dir = path.join(path.dirname(path.realpath(__file__)), 'test_files')
86 |
87 | if fname == 'alexa_test':
88 | global_um.save_for_alexa(tmpdir, fname)
89 | else:
90 | global_um.save_utterances(tmpdir, fname, saved_as, written_as=written_as)
91 |
92 | file_name = fname + '.' + saved_as
93 | assert filecmp.cmp(path.join(test_dir, file_name),
94 | tmpdir.join(file_name))
95 |
--------------------------------------------------------------------------------
/utter_more/__init__.py:
--------------------------------------------------------------------------------
1 | from .utter_more import UtterMore
2 |
3 | __version__ = '1.0.1'
4 | __name__ = 'utter-more'
5 |
--------------------------------------------------------------------------------
/utter_more/utter_more.py:
--------------------------------------------------------------------------------
1 | from itertools import product, chain
2 | from csv import writer
3 | from os import path
4 | import re
5 |
6 |
7 | class UtterMore:
8 |
9 | def __init__(self, *utterance_templates):
10 | """
11 | A class to create utterances for a custom skill for Amazon's Alexa. It
12 | can be a tedious process if verbosity is desired because language is so
13 | flexible. So this will automatically creates all the utterances you want
14 | based on (a) given utterance template(s).
15 |
16 | There are three ways to format a template and they are as follows:
17 |
18 | (a|b|c|...) - [OR] Used if you want to allow multiple interchangeable
19 | words. For example, if photo, picture and painting are
20 | interchangeable in your utterances, then write
21 | (photo|picture|painting) in the place where it would be. The number
22 | of words to OR is arbitrary and single curly keywords like
23 | {intent_slot} can be used in this.
24 | (a*1|b*2) (c^1|d^2) - [CONDITIONAL OR] The * defines a master with a tag
25 | of whatever follows the * while the ^ defines a follower of the tag
26 | of whatever follows the ^. So utterances with a word tagged with
27 | ^sample will only be returned if the utterance also has a word
28 | tagged with *sample. The above will display 'a c' OR 'b d'.
29 | {{slot}} - [OPTIONAL INTENT SLOT] Used if the existence of an intent
30 | slot in your utterance is optional. For example, if you have an
31 | optional adverb you may write I {adverb} love it or just I love it.
32 | Instead you can write I {{adverb}} love it to capture both.
33 |
34 | For example, the template
35 |
36 | "What (is*singular|are*plural) (that^singular|those^plural) {{things}}"
37 | will return the following utterances:
38 |
39 | ['What is that {things}',
40 | 'What is that',
41 | 'What are those {things}',
42 | 'What are those']
43 |
44 | An arbitrary number of utterance templates can be passed to the class.
45 | Or utterance templates can be passed as a solo argument to
46 | self.build_utterances.
47 |
48 | Parameters:
49 | utterance_templates - Arbitrary number of utterance templates. Their
50 | respective utterance can be created by running
51 | self.iter_build_utterances which will save them
52 | in self.utterances
53 | """
54 | # Handle a combination of lists and strings being passed
55 | self.utterance_templates = list(chain.from_iterable(
56 | [[template] if isinstance(template, str) else template
57 | for template in utterance_templates]))
58 | self.utterances = []
59 |
60 | def iter_build_utterances(self):
61 | """
62 | Iteratively runs self.build_utterances for every utterance template
63 | given in the initialization (in self.utterance_templates) and stores
64 | the resulting utterances in self.utterances as a two-dimensional list
65 | where each list element is a list of all the utterances for a single
66 | template.
67 | """
68 | for utterance_template in self.utterance_templates:
69 | self.utterances.append(self.build_utterances(utterance_template))
70 |
71 | @staticmethod
72 | def _order_curlies(*curlies):
73 | """
74 | Orders the curlies in a list based on where they should appear in the
75 | template and prepares it for adding to template.
76 | """
77 | # Create dictionary mapping where the above occur to the occurance
78 | all_curlies = chain.from_iterable(curlies)
79 | indexed_curlies = {curly.start(0): curly.group(0) for curly in all_curlies}
80 |
81 | ordered_curlies = []
82 | for ind in sorted(indexed_curlies.keys()):
83 | curly = indexed_curlies[ind]
84 | # Double curlies are either single curlies or nothing
85 | if curly.startswith('{{'):
86 | ordered_curlies.append([curly[1:-1], ''])
87 | # These are a choice of the words separated by the pip
88 | elif curly.startswith('('):
89 | ordered_curlies.append(curly[1:-1].split('|'))
90 |
91 | return ordered_curlies
92 |
93 | @staticmethod
94 | def _fill_in_template(template, ordered_curlies):
95 | """
96 | Given a template to fill and an ordered list of curlies created by
97 | self._order_curlies to fill it, it does just that.
98 | """
99 | # Fill in template with every combination
100 | utterances = []
101 | for edit in product(*ordered_curlies):
102 | skip_edit = False
103 |
104 | # First get the masters (OR keywords with the *)
105 | masters = set()
106 | for kw in edit:
107 | # Will be empty list if find no * followed by the tag
108 | found_master = re.findall(r'\*(\w+)', kw)
109 | # If not empty list, add that to masters set
110 | if found_master:
111 | masters.add(found_master[0])
112 |
113 | # Find the followers and see if they match up with the masters
114 | for kw in edit:
115 | # Same idea as with finding the masters/a master
116 | found_follower = re.findall(r'\^(\w+)', kw)
117 | # Don't add this edit to utterances if it has a follower that
118 | # isn't in the masters set
119 | if found_follower and found_follower[0] not in masters:
120 | skip_edit = True
121 | continue
122 |
123 | # If all good, add it!
124 | if not skip_edit:
125 | # Remove the OR conditional stuff to clean it
126 | cleaned_edit = [x.split('*')[0].split('^')[0] for x in edit]
127 | # The join/split nonsense removes excess whitespace
128 | utterances.append(' '.join(template.format(*cleaned_edit).split()))
129 |
130 | return utterances
131 |
132 | def build_utterances(self, utterance_template):
133 | """
134 | Returns the made utterances given an utterance template. It supports
135 | the following substitutions:
136 |
137 | (a|b|c|...) - [OR] This wil place a OR b OR c OR etc. in its place
138 | {{slot}} - [OPTIONAL SLOT] This will place the slot {slot} or nothing
139 | in its place.
140 | (a*1|b*2) (c^1|d^2) - [CONDITIONAL OR] The * defines a master with a tag
141 | of whatever follows the * while the ^ defines a follower of the tag
142 | of whatever follows the ^. So utterances with a word tagged with
143 | ^sample will only be returned if the utterance also has a word
144 | tagged with *sample. The above will display 'a c' OR 'b d'. If we
145 | have multiple masters, then the follower(s) will appear if at least
146 | one master is present. And alternatively, you can treat multiple
147 | followers as a CONDITIONAL AND.
148 |
149 | For example, the template
150 |
151 | "What (is*singular|are*plural) (that^singular|those^plural) {{things}}"
152 | will return the following utterances:
153 |
154 | ['What is that {things}',
155 | 'What is that',
156 | 'What are those {things}',
157 | 'What are those']
158 |
159 | Parameters:
160 | utterance_template - The template the utterances are created from
161 | """
162 | # Find every double bracketed keyword
163 | double_curlies = re.finditer(r'({{[^{}]*}})', utterance_template)
164 | # Find every single parenthesis keyword
165 | or_curlies = re.finditer(r'(\([^()]*\))', utterance_template)
166 | # Below turns "What (is|are) (that|those) {{things}} {place}?" into:
167 | # "What {} {} {} {{place}}?"
168 | # Finds the above keywords and replaces with {} for formatting
169 | template = re.sub(r'{{[^{}]*}}|\([^()]*\)', '{}', utterance_template)
170 | # Turns {...} into {{...}} to literalize the curlies
171 | template = re.sub(r'\{[\w]+\}', lambda x: '{' + x.group(0) + '}', template)
172 |
173 | # Creates ordered list of curlies based on their appearance in template
174 | ordered_curlies = self._order_curlies(double_curlies, or_curlies)
175 |
176 | # Fills in template based on logic given by utterance template
177 | return self._fill_in_template(template, ordered_curlies)
178 |
179 | def add_utterance_template(self, utterance_template):
180 | """
181 | Adds another utterance template to the current list of them.
182 |
183 | Parameters:
184 | utterance_template - Template to add to current list of templates
185 | """
186 | self.utterance_templates.append(utterance_template)
187 |
188 | def save_utterances(self, fpath, name, saved_as, force=False, written_as=None):
189 | """
190 | Saves the current utterances to a file.
191 |
192 | Parameters:
193 | fpath - Path to the directory in which to save the file
194 | name - Name of the to be saved file
195 | saved_as - File type, file extension to save as (e.g. 'txt' or 'csv')
196 | force - (default False) If True, will automatically make the file. If a
197 | file of the same name exists, it will overwrite it. If False,
198 | it will throw an error of the file already exists.
199 | written_as - (default None) What type of file to be written as. If no
200 | argument is given, then it will be written as what it is
201 | saved as. For example, if we put saved_as='txt' and
202 | written_as='csv', then the save file will have a .txt
203 | extension but will be written as comma-separated values
204 | like a CSV. Amazon's Alexa requires a CSV file but with
205 | line separated values, so self.save_for_alexa uses
206 | saved_as='csv' and written_as='txt'
207 | """
208 | # Allows saving with one file extension but as another
209 | written_as = written_as or saved_as
210 |
211 | # Create full path name
212 | full_path = path.join(fpath, name + '.' + saved_as)
213 |
214 | # Check if file already exists
215 | if path.exists(full_path) and not force:
216 | raise Exception('File already exists and force=False. ' +
217 | 'Set force=True to overwrite file.')
218 | # Check if unsupported file type
219 | if saved_as not in ['csv', 'txt']:
220 | raise Exception("File type '{}' is not supported.".format(ftype_or))
221 |
222 | # Open file and add every utterance
223 | with open(full_path, 'w', newline='') as f:
224 | if written_as == 'txt':
225 | first_line = True
226 | for utterance in chain.from_iterable(self.utterances):
227 | # To write '\n'-separated but without one at start or end
228 | if first_line:
229 | first_line = False
230 | f.write('{}'.format(utterance.strip()))
231 | else:
232 | f.write('\n{}'.format(utterance.strip()))
233 | elif written_as == 'csv':
234 | csv_writer = writer(f)
235 | csv_writer.writerow(chain.from_iterable(self.utterances))
236 |
237 | def save_for_alexa(self, fpath, name, force=False):
238 | """
239 | Creates CSV in the format that Alexa needs (instead of comma-separated,
240 | it's new line-separated otherwise it won't upload correctly).
241 |
242 | Parameters:
243 | fpath - Path to the directory in which to save the file
244 | name - Name of the to be saved file
245 | force - (default False) If True, will automatically make the file. If a
246 | file of the same name exists, it will overwrite it. If False,
247 | it will throw an error of the file already exists.
248 | """
249 | self.save_utterances(fpath, name, 'csv', force=force, written_as='txt')
250 |
251 | def read_utterance_templates_from_file(self, fpath, sep='\n'):
252 | """
253 | Reads in utterance templates from a file.
254 |
255 | Paramters:
256 | fpath - Path to the file with the templates
257 | sep - (default '\n') The separator for each template. If each template
258 | is on a new line, then use default
259 | """
260 | # Read in data
261 | with open(fpath, 'r') as f:
262 | file_data = f.read()
263 |
264 | for utterance_template in file_data.split(sep):
265 | # Skip if an empty string
266 | if utterance_template:
267 | self.add_utterance_template(utterance_template)
268 |
269 |
270 | if __name__ == "__main__":
271 | from sys import argv
272 | utter_more = UtterMore(*argv[1:])
273 | utter_more.iter_build_utterances()
274 |
275 | from pprint import pprint
276 | pprint(utter_more.utterances)
277 |
--------------------------------------------------------------------------------