├── .github
└── ISSUE_TEMPLATE.md
├── Computer Architecture
└── cache_memory.md
├── Data Structure
├── AVL-Tree VS Red-Black-Tree.md
├── List, Set.md
├── Stack_&_Queue.md
├── hash_collision.md
└── heap.md
├── Database
├── NoSQL.md
├── Redis.md
├── Transaction-Isolation-Level.md
├── Transaction.md
├── index.md
└── 정규화.md
├── Java
├── HashMap vs Hashtable vs ConcurrentHashMap.md
├── garbage_collection.md
└── string_is_immutable.md
├── LICENSE
├── Network
├── HTTP_vs_HTTPS.md
├── Multiplexing and Demultiplexing.md
├── OSI_7_layers.md
├── TCP_vs_UDP.pdf
└── symmentric-key_vs_public-key.md
├── OS
├── CPU_scheduler.md
├── Mutex vs Semaphore.md
├── Paging vs Segmentation.md
├── deadlock.md
├── interrupt_&_context_switching.md
└── process_vs_thread.md
├── README.md
├── Security
└── OWASP Top 10.md
├── Software Engineering
├── IoC, DIP, DI.md
├── SOLID 원칙.md
├── Singleton Pattern & Factory Pattern.md
├── Strategy Pattern.md
└── UML.md
├── WEB
├── CORS.md
├── JWT.md
├── RESTful_API.md
├── Web 서버와 WAS의 차이.md
└── www.naver.com을 검색하면 일어나는 과정.md
└── book
└── 그림으로 배우는 HTTP & Network Basic
├── README.md
├── 제 1장. 웹과 네트워크의 기본에 대해 알아보자.md
├── 제 3장. HTTP 정보는 HTTP 메시지에 있다.md
├── 제 4장. 결과를 전달하는 HTTP 상태 코드.md
├── 제 5장. HTTP와 연계하는 웹 서버.md
├── 제 6-2장. HTTP 헤더.md
├── 제 8장. 누가 액세스하고 있는지를 확인하는 인증.md
└── 제 9장. HTTP에 기능을 추가한 프로토콜.md
/.github/ISSUE_TEMPLATE.md:
--------------------------------------------------------------------------------
1 | | 발표자 | 카테고리 | 주제 |
2 | | :-----: | :-------: | :---: |
3 | | 발표자1 | 카테고리1 | 주제1 |
4 | | 발표자2 | 카테고리2 | 주제2 |
5 | | 발표자3 | 카테고리3 | 주제3 |
6 | | 발표자4 | 카테고리4 | 주제4 |
7 | | 발표자5 | 카테고리5 | 주제5 |
8 |
--------------------------------------------------------------------------------
/Computer Architecture/cache_memory.md:
--------------------------------------------------------------------------------
1 | # Cache Memory
2 |
3 | * 속도가 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말한다.
4 |
5 | * CPU가 주기억장치에서 저장된 데이터를 읽어올 떄, 자주 사용하는 데이터를 캐시메모리에 저장, 그 이후 같은 메모리 사용 시, 캐시메모리에서 먼저 가져온다.
6 |
7 | * 빠른 대신, 용량이 적고 비싸다(하드디스크 1TB는 4만원, SSD는 40만원, 캐시메모리 4GB는 약 4000만원)
8 |
9 |
10 |
11 | ### 듀얼코어 이상의 프로세서의 캐시 메모리
12 |
13 | * 각 코어마다 독립된 L1캐시 메모리를 가지고, 두 코어가 공유하는 L2캐시 메모리가 내장됨
14 | * L1캐시의 절반은 명령어를 처리하기 직전의 명령어를 임시 저장, 나머지 절반에는 실행 후 명령어를 임시 저장
15 | * L1 : CPU 내부에 존재
16 | * L2 : CPU와 RAM 사이에 존재
17 | * L3 : 보통 메인보드에 존재
18 |
19 |
20 |
21 | ### 캐시 메모리의 작동 원리
22 |
23 | ##### 시간 지역성
24 |
25 | * for나 while 같은 반복문에 사용하는 조건 변수처럼 한번 참조된 데이터는 잠시 후 또 참조될 가능성이 높음
26 |
27 |
28 |
29 | ##### 공간 지역성
30 |
31 | * A[0],A[1]과 같은 연속 접근 시, 참조된 데이터 근처에 있는 데이터가 잠시후 또 사용될 가능성이 높음
32 | * ex) 행렬곱에서 전치행렬 사용
33 |
34 |
35 |
36 | 캐시에 데이터를 저장 시, 공간 지역성을 활용하기 위해 주변 데이터도 같이 가져와 대비하게된다.
37 |
38 | 캐시에 CPU가 요청한 데이터가 있을경우 Cache Hit, 없어서 DRAM에서 가져오게 된다면 Cache Miss가 된다.
39 |
40 |
41 |
42 | ### 캐시 미스의 예시
43 |
44 | * Cold miss : 해당 메모리 주소를 처음 불러서 생기는 미스
45 |
46 | * Conflict miss : 동일한 캐시 메모리 주소에 다른값이 할당되어 있을 경우에 생기는 미스
47 | * Capacity miss : 캐시 메모리의 공간이 부족해서 생기는 미스, Conflict와 비슷하게 볼 수 있지만 Conflict는 할당문제, Capacity는 공간문제이다.
48 |
49 |
50 |
51 | Conflict miss와 Capacity miss 같은 경우는 크기가 커지면 문제가 생길 가능성이 줄어들지만, 동시에 접근속도가 느려지고 파워를 많이 잡아먹게 된다.
52 |
53 |
54 |
55 | ### 구조 및 작동 방식
56 |
57 | ##### Direct Mapped Cache
58 |
59 | 가장 기본적인 구조, DRAM의 여러 주소가 캐시메모리의 한 주소에 대응되는 방식
60 |
61 | 캐시메모리의 공간이 8개 `(000~111)이고 메모리 공간이 32개(00000~11111)인 경우`를 예시로 설명
62 |
63 | 메인메모리 공간의 주소 뒤 3자리를 가지고 캐시메모리에 할당, 이 때, 세자리 000이 인덱스 필드 인덱스 필드를 제외한 앞 두자리를 태그필드라고 함
64 |
65 | 간단하고 빠르지만 Conflict Miss가 인덱스필드가 같은 데이터들을 자주 활용하는 경우에 발생하는 단점이 있다.
66 |
67 | ##### Fully Associative Cache
68 |
69 | 비어있는 메모리에 마음대로 저장하는 방식
70 |
71 | 캐시 안에 저장할 떄는 매우 간단하지만, 찾을 때 오래걸린다.
72 |
73 | 조건이나 규칙이 없기 때문에, 특정 캐시 Set 안에 있는 모든 블럭을 한번에 찾아서 원하는 데이터가 있는지 검색해야하며, 이를 위한 CAM이라는 특수한 메모리 구조를 사용해야한다. 당연히 매우 비싸다.
74 |
75 | #### Set Associative Cache
76 |
77 | Direct와 Fully를 섞은 방식. 특정행을 지정하고, 그 행안의 어떤 열이든 비어있을 때 저장하는 방식.
78 |
79 | Direct에 비해서 탐색은 느리지만 저장이 빠르고 Fully보다 탐색이 빠르고 저장이 느리다.
80 |
81 |
82 |
83 | ### Cache메모리 히트율 기준 속도 계산
84 |
85 | 캐시메모리 히트 확률 : R
86 |
87 | 캐시메모리 속도 : C
88 |
89 | 일반메모리 속도 : M
90 | $$
91 | C+ (1-R) \times M
92 | $$
93 |
94 |
--------------------------------------------------------------------------------
/Data Structure/AVL-Tree VS Red-Black-Tree.md:
--------------------------------------------------------------------------------
1 | # AVL-Tree VS Red-Black-Tree
2 |
3 | >균형 이진 탐색 트리 대표 두 가지를 알아보고 차이점을 알아보자
4 |
5 |
6 |
7 | ## Binary Search Tree (BST)
8 |
9 | BST, 이진탐색트리를 먼저 알아야한다.
10 |
11 | 이진탐색트리란 이진탐색과 연결리스트를 결합한 자료구조의 일종으로,
12 | 이진 탐색의 효율적인 탐색 속도를 유지하면서 빈번한 자료 입력과 삭제를 가능하게끔 고안되었다.
13 |
14 |
15 |
16 | ### BST의 특징
17 | - 모든 노드의 왼쪽 서브트리는 해당 노드의 값 보다 작은 값들만 가진다.
18 | - 모든 노드의 오른쪽 서브트리는 해당 노드의 값 보다 큰 값들만 가진다.
19 | - 중복되는 노드가 없어야 한다.
20 |
21 |
22 |
23 | ### BST 순회 방법
24 | BST를 순회 할 때는 중위 순회(inOrder) 방식을 쓰는데,
25 |
26 |
27 |
28 | > 중위 순회 방식은 재귀적으로 왼쪽 서브트리 - 현재 노드 - 오른쪽 서브트리를 순회하는 방식임
29 |
30 | 위의 트리를 중위 순회 하면 1-3-4-6-7-8-10-13-14 가 출력 되는데,
31 | BST내부의 값들을 순서대로 출력한 것과 같다.
32 |
33 |
34 |
35 | ### 노드의 후임자, 선임자
36 | 후임자 = 해당 노드보다 값이 큰 노드들 중에서 가장 값이 작은 노드
37 | 선임자 = 해당 노드보다 값이 작은 노드들 중에서 가장 값이 큰 노드
38 | 위의 그림을 예시로 들면 8의 후임자는 10이고 8의 선임자는 7이 될 것 이다.
39 |
40 |
41 |
42 |
43 | ### 이진탐색트리의 시간복잡도
44 | | | 검색 | 삽입 | 삭제 |
45 | | - | --- | ---- | --- |
46 | | Average | O(logN) | O(logN) | O(logN) |
47 | | Worst | O(N)| O(N)| O(N) |
48 |
49 |
50 |
51 |
52 | 검색을 할 수록 데이터가 절반 씩 줄어드므로, 평균 O(logN)이라는 걸 알 수 있다.
53 |
54 | 그러나
55 |
56 |
57 |
58 | 다음과 같이 한 쪽으로 치우친 모양이 나오게 된다면 그저 List와 다른게 없으므로
59 | O(N)이 나오는걸 알 수 있다.
60 |
61 | 이런 단점을 해결하기위해 만들어진게 바로 **균형 이진 탐색 트리** 다.
62 |
63 |
64 |
65 | ### 균형 이진 탐색 트리에 들어가기 전에!!
66 | 트리의 회전이란 개념을 알아야한다.
67 |
68 |
69 |
70 | 오른쪽 회전
71 |
72 |
73 |
74 | 왼쪽 회전
75 |
76 | 높이가 더 큰 쪽, 빗대어서 말하자면 무게가 무거운 쪽을 가볍게 해줘서 균형을 맞춘다 라고 이해해도 좋다.
77 |
78 | 회전 연산은 단순히 레퍼런스를 바꿔주는 것이기 때문에 상수시간이 걸린다.
79 |
80 | 이 트리 회전을 통해서 트리의 균형을 맞추는것이다.
81 |
82 |
83 |
84 |
85 | ## AVL Tree
86 | 이진탐색트리의 한 종류로, Balance Factor를 통해서 스스로 균형을 잡는 트리이다.
87 |
88 | >Balance Factor란 임의의 노드 X에 대해서 X의 왼쪽 서브트리의 높이와 X의 오른쪽 서브트리의 높이의 차이를 계산 한 값.
89 |
90 | AVL Tree에서는 모든 노드의 Balance Factor값이 -1 또는 0 또는 1 이어야 한다.
91 | 만약, 다른 값이라면 트리의 균형을 맞춰주는 과정이 일어나게 된다.
92 |
93 |
94 | ### AVL트리의 시간복잡도
95 | | | 검색 | 삽입 | 삭제 |
96 | | - | --- | ---- | --- |
97 | | Average | O(logN) | O(logN) | O(logN) |
98 |
99 | 검색 과정은 BST와 동일 하다.
100 |
101 | ### 삽입 (24 노드를 삽입)
102 |
103 |
104 |
105 |
106 |
107 |
108 | 14번 노드에서 왼쪽 서브트리의 높이는 0 오른쪽 서브트리의 2이므로
109 | Balance Factor가 -2가 나오므로 조정이 필요하다.
110 |
111 |
112 |
113 |
114 | ### 삭제 (79 노드를 삭제)
115 |
116 |
117 |
118 |
119 |
120 |
121 | 57번 노드에서 왼쪽 서브트리의 높이는 2 오른쪽 서브트리의 0이므로
122 | Balance Factor가 2가 나오므로 조정이 필요하다.
123 |
124 | 삽입, 삭제가 일어난 노드부터 루트 노드까지 거슬러 가고 그 과정마다 Balance Factor를 확인하고 트리구조를 조정하는 것이 반복 된다는것을 알아야한다.
125 | 즉, AVL은 엄격하게 균형을 조정하나 반복적인 작업 때문에 시간이 다소 소요된다.
126 | 이러한 점을 개선하기 위해 Red-Black-Tree가 나오게 되었다.
127 |
128 | (AVL트리의 삽입과 삭제과정에는 여러 케이스가 있기 때문에 따로 더 알아보기 바란다.)
129 |
130 |
131 |
132 | ## Red-Black-Tree
133 | 이진탐색트리의 한 종류로, 다섯가지의 RB트리 속성을 만족하여 스스로 균형을 잡는 트리이다.
134 |
135 | ### 사전 개념
136 | >nil노드 = RB트리에서 leaf노드를 nil노드라고 한다
137 |
138 |
139 |
140 |
141 |
142 | ### RB트리의 속성
143 | 1. 모든 노드는 Red or Black 색상
144 | 2. 루트 노드는 무조건 Black
145 | 3. 모든 nil 노드는 Black
146 | 4. Red의 자녀들은 Black, 즉 Red가 연속적으로 존재 할 수 없다.
147 | 5. 임의의 노드에서 nil 노드까지 가는 경로에서의 Black 노드의 수는 같다.
148 |
149 | 5번 속성에서의 Black 노드의 수를 Black Height(BH) 라고 한다.
150 |
151 |
152 |
153 |
154 | (실제로는 이렇게 구현됨)
155 |
156 | ### RBT 삽입/삭제 절차
157 | 1. 삽입/삭제 전 RB 속성 만족한 상태
158 | 2. 삽입/삭제 방식은 일반적인 BST와 동일
159 | 3. 삽입/삭제 후 RB속성 위반여부 확인
160 | 4. 재조정
161 | 5. RB 속성 만족
162 |
163 |
164 | ### Red-Black 트리의 시간복잡도
165 | | | 검색 | 삽입 | 삭제 |
166 | | - | --- | ---- | --- |
167 | | Average | O(logN) | O(logN) | O(logN) |
168 |
169 |
170 | 검색 과정은 BST와 동일 하다.
171 |
172 |
173 | ### 삽입 (삽입되는 노드의 색은 무조건 Red)
174 |
175 | 10번 노드 삽입
176 |
177 |
178 |
179 |
180 | 12번 노드 삽입
181 |
182 |
183 |
184 | 노드가 삽입 된 후 위의 5가지 속성 위반여부를 확인하고 트리를 재조정 하는 것을 볼 수 있다.
185 |
186 |
187 |
188 | ### 삭제
189 |
190 | 11번 노드 삭제
191 |
192 |
193 |
194 |
195 | 12번 노드 삭제
196 |
197 |
198 |
199 | 노드가 삭제 된 후 위의 5가지 속성 위반여부를 확인하고 트리를 재조정 하는 것을 볼 수 있다.
200 |
201 | (RB트리의 삽입과 삭제과정에는 여러 케이스가 있기 때문에 따로 더 알아보기 바란다.)
202 |
203 |
204 | >RBT가 O(logN)임을 귀납적으로 증명
205 |
206 |
207 |
208 |
209 |
210 |
211 |
212 | ## AVL-Tree VS Red-Black-Tree
213 |
214 | | | AVL-Tree | Red-Black-Tree |
215 | | ---- | ---- | ---- |
216 | | 삽입/삭제 성능 | RB-Tree에 비해 느리다 | AVL-Tree에 비해 빠르다 |
217 | | 검색 성능 | RB-Tree에 비해 빠르다 | AVL-Tree에 비해 느리다 |
218 | | 응용 사례 | dictionary, 한 번 만들어 놓으면 삽입/삭제가 거의 없고 검색이 대부분인 상황에서 사용 | linux kernel 내부에서 사용, java TreeMap, HashMap 충돌 시 c++ std::map |
219 |
220 | AVL트리는 삽입 삭제 후 루트까지 거슬러 가면서 Balance factor를 확인하고 조정하는 과정을
221 | 반복한다. 즉 엄격하게 균형을 맞추기때문에 트리 회전 연산이 많아 시간이 많이 소요됨.
222 | 그에 비해 RBTree는 비교적 덜 엄격하게 균형을 맞춤 예를들어 단순히 색상만 바꿔서 균형을 맞추는 경우 등등
223 |
224 | 그렇기에 삽입/삭제가 빈번한 경우에는 RB-Tree가 더 적합하다.
225 |
226 | 균형이 더 엄격하기 때문에 검색면에서는 AVL-Tree가 더 적합하다.
227 |
228 |
229 |
230 |
231 | ## Reference
232 |
233 | https://ratsgo.github.io/data%20structure&algorithm/2017/10/28/rbtree/
234 | https://m.blog.naver.com/min-program/221231697752
235 | https://ebongzzang.github.io/algorithm/Red-Black-tree-%EA%B7%B8%EB%A6%AC%EA%B3%A0-AVL-tree%EC%99%80%EC%9D%98-%EB%B9%84%EA%B5%90/
236 | https://jwdeveloper.tistory.com/280
237 | https://devidea.tistory.com/36
238 | https://lgphone.tistory.com/90
239 | https://suhwanc.tistory.com/197?category=730826
240 | https://ferrante.tistory.com/46
241 |
242 | ## Simulator
243 | https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
244 | https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
--------------------------------------------------------------------------------
/Data Structure/List, Set.md:
--------------------------------------------------------------------------------
1 | # List, Set
2 |
3 | CS-Study 2022-06-15 (수) 안영진
4 |
5 | > "List와 Set에 대해서 설명해주세요"
6 | >
7 | > "List와 Set의 차이를 설명해주세요"
8 |
9 | 저는 면접 때 항상 질문 받았었습니다.
10 | 물론 인턴, 스타트업 면접이었지만 생각보다 꽤 물어보는 질문인듯 합니다.
11 |
12 | ### Tip
13 |
14 | 이런 정의 관련된 질문에 답을 할 때는 해당 주제의 **키워드**를 말해주면 됩니다.
15 | (ex 블록체인을 말할 때 탈 중앙화, 위변조 방지를 말하듯이)
16 |
17 | # List
18 |
19 | ### List의 키워드는 "순서"입니다.
20 |
21 | 데이터가 들어오는 **순서**대로 저장하는 자료구조
22 | 또는,
23 | 데이터가 들어온 **순서**를 보장하는 자료구조
24 |
25 | 메모리에 순서대로 저장될 때는 두 가지 방법이 있습니다.
26 |
27 | ## 1. 물리적인 순서로 저장
28 |
29 | 메모리의 실제 주소값의 순서대로 데이터가 저장되는 방식
30 |
31 |
32 |
33 | 이를 순차 리스트라고 합니다. = ArrayList
34 |
35 |
36 |
37 | ## 2. 논리적인 순서로 저장
38 |
39 | 다음 데이터가 저장된 위치까지 함께 저장하므로써 순서를 보장하는 방식
40 |
41 |
42 |
43 | 이를 연결 리스트라고 합니다. = LinkedList
44 |
45 | 각 방식은 특징이 있습니다.
46 |
47 | | 종류 | 데이터 조회 | 데이터 삽입, 삭제 |
48 | | ---------- | ----------- | ----------------- |
49 | | LinkedList | O(N) | O(1) |
50 | | ArrayList | O(1) | O(N) |
51 |
52 | ### 연관 질문
53 |
54 | > ### Java에서 Queue는 어떤 방식으로 구현되나요?
55 | >
56 | > ### 왜 그 구현방식을 택했나요?
57 |
58 |
59 |
60 | > **A.** Queue는 한쪽에서는 데이터를 넣는 push가 다른 한쪽에서는 데이터를 빼는 pop이 일어나는 자료구조로,
61 | > 예를들어 리스트의 처음에서 pop이 일어난다고 해보겠습니다.
62 | > pop 수행 시 제일 처음의 데이터를 메모리 상에서 삭제하게 됩니다. 만약에 ArrayList 라면, 물리적인 순서로 저장이되기 때문에 앞의 메모리 공간이 비게되면 뒤에 있는 모든 데이터가 앞으로 한 칸 씩 시프트가 되어야합니다. 이는 O(N)이라는 시간이 소요되며 pop의 수행이 빈번하다면 굉장히 비효율 적입니다. 그렇기에 데이터 삽입 삭제에서 유리한 LinkedList를 사용합니다.
63 |
64 |
65 |
66 |
67 | # Set
68 |
69 | ### List의 또 다른 키워드는 "중복을 허용"입니다.
70 |
71 | 데이터의 중복 저장이 가능한 자료구조 입니다.
72 |
73 | ### Set의 키워드는 "순서 보장X", "중복 허용X"입니다.
74 |
75 | Set은 데이터의 존재를 확인하거나 데이터의 중복을 제거할 때 사용됩니다.
76 |
77 | Set을 구현하는 방법은 대표적으로 HashSet이 있습니다
78 |
79 | (자바에는 LinkedHashSet, TreeSet이란 것도 있습니다.)
80 |
81 | ### HashSet이란
82 |
83 | 내부적으로 해시테이블을 이용하는 자료구조라고 생각하면 됩니다.
84 |
85 |
86 | (해시 테이블은 데이터 조회, 삽입, 삭제에서 시간복잡도가 O(1)입니다.)
87 | 여기서 HashSet은 key, value를 사용하는 해시 테이블에서 value 값은 그냥 더미데이터로 넣어버리고 Key만 사용한다고 생각하면 됩니다.
88 |
89 | ### LinkedHashSet
90 |
91 | - 순서가 보장된 HashSet
92 | - 시간복잡도 O(1)
93 | - 그냥 HashSet에비해서 아주 약간 느리다고 함
94 | - 메모리 많이 씀 (상대적)
95 | - 다음 데이터가 어디있는지를 저장해줘야하므로 메모리가 더 쓰이게 됨
96 |
97 | ### TreeSet
98 |
99 | - 데이터를 정렬하여 저장하는 Set
100 | - 시간 복잡도 O(logN)
101 | - 내부적으로 Red-Black트리구조로 되어있음
102 | - 메모리 많이 씀 (상대적)
103 |
104 | ### 연관 질문
105 |
106 | > ### List와 Set차이에 대해서 설명해주세요
107 |
108 |
109 |
110 | > **A.** List는 순서가 보장되고 데이터의 중복을 허용하는 자료구조입니다.
111 | > Set은 순서를 보장하지않고 데이터의 중복을 허용하지 않는 자료구조입니다.
112 |
--------------------------------------------------------------------------------
/Data Structure/Stack_&_Queue.md:
--------------------------------------------------------------------------------
1 | # Stack & Queue
2 | ## Stack(스택)
3 | LIFO(Last In First Out, 후입선출) : 가장 나중에 들어간 원소가 가장 먼저 나옴
4 |
5 | ex) 함수의 call stack, 연산자 후위표기법 등
6 |
7 | 스택에는 스택 포인터(SP)가 존재하며, 처음에는 -1의 위치에 있다. push()를 하게되면 스택 포인터가 가리키는 위치가 증가하고, pop()을 하게되면 위치가 감소한다.
8 |
9 | 
10 |
11 | ## Queue(큐)
12 | FIFO(First In First Out, 선입선출) : 가장 먼저 들어간 원소가 가장 먼저 나옴
13 |
14 | ex) Buffer, BFS 등
15 |
16 | 큐에서 가장 첫 원소를 front, 끝 원소를 rear라고 부른다.
17 |
18 | 큐는 rear로 들어와서 front로 빠져나가는 특징을 가진다.
19 |
20 | 큐에 원소를 삽입하면 rear가 한 칸 전진하고, 큐의 원소를 빼면 front가 한 칸 전진한다.
21 |
22 | 다음 그림은 큐가 비어있는 상태에서 front와 rear가 둘 다 0을 가리키고 있는 상태이다.
23 |
24 | 
25 |
26 | 만약 5개의 원소가 큐에 들어오고, 2개의 원소가 빠져나가면, front와 rear는 다음 그림과 같다.
27 |
28 | 
29 |
30 |
31 | 큐의 여러 메소드 중 isFull()이라는 메소드는 큐가 꽉 차있는지 확인하는 메소드이며, rear가 (큐의 사이즈-1) 과 같아지면 가득찬 것이다.
32 |
33 | 
34 |
35 |
36 |
37 | `일반 큐의 단점: rear가 끝에 도달했을 때 큐에 빈 공간이 남아 있어도, 꽉 차있는것으로 판단할 수도 있다.`
38 |
39 | 이것을 개선한 것이 바로 **'원형 큐'** 이다.
40 |
41 | 
42 |
43 |
44 | 논리적으로 배열의 처음과 끝이 연결되어 있는 것으로 간주하며 (index + 1) % size로 순환시킨다.
45 |
46 | 원형 큐도 초기에 front와 rear가 0이다.
47 |
48 | 원형 큐도 isFull()이라는 메소드를 통해 큐가 꽉 차있는지 확인할 수 있으며, (rear+1)%size가 front와 같으면 가득찬 것이다.
49 |
50 | `원형 큐의 단점: 메모리는 잘 활용하지만, 배열로 구현되어 있기 때문에 큐의 크기가 제한적이다.`
51 |
52 | 이것을 개선한 것이 바로 **'연결리스트 큐'** 이다.
53 |
54 | 
55 |
56 | 연결리스트 큐는 크기의 제한이 없으며, 삽입과 삭제가 시간복잡도 O(1)으로 구현이 가능하며 편리하다.
57 |
58 | 참고: https://github.com/gyoogle/tech-interview-for-developer/blob/master/Computer%20Science/Data%20Structure/Stack%20%26%20Queue.md
--------------------------------------------------------------------------------
/Data Structure/hash_collision.md:
--------------------------------------------------------------------------------
1 | # 해시 충돌
2 |
3 | ### 2022-04-27 (wed) 안영진
4 |
5 | ### Contents
6 |
7 | 1. [해시의 탄생 배경](#1-해시의-탄생-배경)
8 | 2. [해시 함수](#2-해시-함수)
9 | 3. [그래서 해시를 어떻게 활용하는데?](#3-그래서-해시를-어떻게-활용하는건데)
10 | 4. [해시 충돌](#4-해시-충돌)
11 |
12 | 4.1 [해시충돌 해결방법](#41-해시충돌-해결방법)
13 |
14 | 4.2 [뭐가 더 나아?](#42-뭐가-더-나아)
15 |
16 |
17 |
18 |
19 | # 1. 해시의 탄생 배경
20 |
21 | ## **해시란?**
22 |
23 | > **해시**(**hash**)란 다양한 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑(mapping)한 값이다.
24 |
25 |
26 | **데이터의 저장과 검색을 빠르게 하기위해** 해시를 생각하게됨
27 |
28 | 우선 데이터를 읽고 쓰는데 가장 쉽게 고려 할 수 있는
29 | **배열**의 경우 데이터 읽고 쓰기가 O(n)이 걸림
30 |
31 | 
32 |
33 | - 해당 위치까지 가야하기 때문에 n번의 반복이 생기기 때문
34 |
35 |
36 |
37 | **트리**도 빠르긴 한데 평균적으로 O(logN)이 걸림
38 |
39 |
40 |
41 |
42 |
43 | **해시**를 이용한 자료구조는 평균적으로 O(1)(상수시간)이 걸림
44 |
45 | 어떻게 이게 가능한 것일까??
46 |
47 |
48 |
49 |
50 | # 2. **해시 함수**
51 |
52 | 아까
53 | > **해시**(**hash**)란 **다양한 길이를 가진 데이터**를 **고정된 길이를 가진 데이터**로 매핑(mapping)한 값이다.
54 |
55 | 라고 했다. (우선 해시값은 정수라고 봐도 된다. (이유는 나중에 설명))
56 |
57 | 어쨌든 임의의 데이터(I**nput**)가 어떠한 과정을 거쳐서 고정된 길이의 정수 데이터(**Output**)로 변했다는 뜻인데, 이 어떠한 과정을 **해시 함수**라고 한다.
58 |
59 |
60 |
61 |
62 | 예시로 위의 그림처럼 임의의 데이터가 들어오면 32bit의 정수로 바꿔주는 해시함수가 있다.
63 |
64 | 해시함수는 종류가 엄청나게 많고 다양하다(64bit, 128bit ...) 자기가 짜기 나름이다.
65 |
66 | 다만,
67 |
68 | 1. 해시 계산이 간단해야하고
69 | 2. 결과 값이 고르게 나와야한다.
70 |
71 | 이 두 가지를 만족하는게 **좋은 해시함수**이다.
72 |
73 |
74 |
75 |
76 | # 3. 그래서 해시를 어떻게 활용하는건데?
77 |
78 | 우리는 **해시 함수**를 통해 **해시(정수값)를** 만들었다.
79 |
80 | ## 해시 테이블
81 |
82 | > **배열**과 **해시 함수**를 이용해 (Key, Value)형식의 데이터를 읽고 쓰는 **자료구조**
83 | >
84 |
85 | (Java의 HashMap, python의 Dictionary와 비슷합니다.)
86 |
87 | 여기 8만큼의 크기를 가진 배열이 있다. (배열의 공간 하나를 **Bucket**이라 함)
88 |
89 |
90 |
91 | 그리고 전화번호(key)를 넣으면 숫자로 임의의 숫자로 바꿔주는
92 |
93 | 해시함수가 있다.
94 |
95 |
96 |
97 | 어떻게 배열안에 데이터를 집어 넣을 수 있을까?
98 |
99 |
100 |
101 | **mod 연산**을 해주면 된다. ~~(mod 연산이 없는 해시 함수도 있음 근데 대부분 mod연산 많이 쓰더라)~~
102 |
103 |
104 |
105 | 이게 해시 테이블
106 |
107 | 데이터의 key를 가지고 해시함수를 거친다음 해당 해시값을 테이블의 크기(capa)로 **mod 연산**해준 값이 **데이터가 저장 될 배열의 인덱스**인것 (이 때문에 해시값이 정수여야함)
108 |
109 | 따라서 해시 함수 과정만 거치므로, **O(1)의 시간**으로 데이터를 읽고 쓰는게 가능한 것이다.
110 |
111 |
112 |
113 |
114 | # 4. 해시 충돌
115 |
116 | 아까 해시란
117 |
118 | > **해시**(**hash**)란 **다양한 길이를 가진 데이터**를 **고정된 길이를 가진 데이터**로 매핑(mapping)한 값이다.
119 | > 라고했다.
120 |
121 | **다양한 길이**를 가진 데이터 → (**무한**함)
122 |
123 | **고정된 길이**를 가진 데이터 → (**유한**함)
124 |
125 | 해시함수는 생각해보면 **무한한** 데이터를 **유한한** 공간에다가 욱여 넣는 것임
126 |
127 |
128 |
129 | **비둘기 집의 원리**
130 |
131 |
132 |
133 | n+1 마리의 비둘기를 n개의 집에 넣는다고 한다면 어떻게 될까?
134 |
135 |
136 |
137 | 비둘기 집들 중 하나는 **무조건 비둘기 2마리가** 들어가게 됨
138 |
139 | 다시 해시로 돌아와서,
140 |
141 | **무한한 데이터**를 **유한한 해시 테이블**에 넣기 때문에 **데이터가 겹치는게 반드시 발생 한다**는 뜻임
142 |
143 | 이렇게 겹치는것을 **해시 충돌**이라고 함
144 |
145 | 해시충돌이 나는 경우는 2가지가 있다.
146 |
147 |
148 |
149 | key값도 해시값도 다른데 mod연산 값이 같을 때,
150 |
151 |
152 |
153 | key값이 다른데 hash가 같을 때
154 |
155 |
156 |
157 |
158 | # 4.1 해시충돌 해결방법
159 |
160 | ## **1. Open Addressing** 방식
161 |
162 | 쉽게말해, 충돌이 일어나면 데이터가 들어있지 않은 빈 Bucket을 찾는것임
163 |
164 | 빈 Bucket을 탐색(probe)하는 방법이 매우 다양함
165 |
166 |
167 |
168 | **Linear Probing** (선형 탐사)
169 |
170 | 충돌이 일어난 버킷의 1칸뒤 or 2칸뒤 등등 이렇게 선형적으로 탐사하는 방법
171 |
172 |
173 |
174 |
175 | 한 데이터를 넣기위해 **앞 단에서 겪었던 체크 과정을 다 거쳐야한다**는 단점이 있음
176 |
177 | 특정영역에 데이터가 뭉쳐지는 **cluster** 문제도 있음
178 |
179 |
180 |
181 | **Quadratic Probing** (이차원 탐사)
182 |
183 | 선형 탐사의 문제를 줄이고자해서 나온 방법
184 |
185 | 버킷 탐사 범위를 **제곱수 간격**으로 넓혀감
186 |
187 | 선형 탐사에 비해서 Cluster가 줄었음
188 |
189 |
190 |
191 | **Double hashing** (이중 해싱)
192 |
193 | 2개의 해시 함수를 이용한다는거다.
194 |
195 | 하나는 최초의 해시값을 얻을 때
196 |
197 | 다른 하나는 해시 충돌 시 탐사 할 이동폭을 얻기위해 사용
198 |
199 | (두 번째 해시값 까지 같을 확률은 매우 적다!)
200 |
201 |
202 |
203 |
204 | ## **2. Separate Chaining** 방식
205 |
206 | bucket 하나하나를 linked list로 보는것임 충돌이 일어나면 데이터를 이어 붙임
207 |
208 |
209 |
210 | 한 버킷에서 충돌이 많이 일어나면 그만큼 링크드 리스트가 길어지게되고
211 |
212 | 데이터를 탐색하는데 O(N) 까지 갈 수 도있다.
213 |
214 | 하지만 해시함수도 엄청 좋아졌고 데이터가 계속 늘어나면 해시 리사이징을 하기 때문에
215 |
216 | 사실상 O(N)까지 갈 일은 없다고 봐도 된다.
217 |
218 |
219 |
220 |
221 | # 4.2 뭐가 더 나아?
222 |
223 | **CPython**은 **Open addressing** 방식을 사용하고있고,
224 |
225 | - **체이닝 시 malloc으로 메모리를 할당하는 오버헤드가 높아 오픈 어드레싱을 택했다.** 라고 cpython 공식문서에 적혀있다고 한다.
226 |
227 | **Java**의 **HashMap**은 **Separate Chaining** 방식을 사용한다.
228 |
229 | - HashMap은 상대적으로 **remove호출이 빈번**한데, **open addressing방식에서는 데이터 삭제 로직을 효율적으로 구현하기 어렵다**는 점, **S.C** 방식은 **보조해시 함수**가 있어서 충돌이 잘 발생 하지 않도록 조절 할 수 있다는 점 때문에 **S.C**방식을 쓴거 같다.
230 |
231 |
232 |
233 | **Load factor**는 테이블에 데이터가 차있는 정도다 0.5는 50%정도 데이터가 들어있다는 뜻)
234 |
235 | **number of probes**는 탐사 횟수, 이 값이 커질 수록 탐사 횟수가 많아지므로 성능이 떨어진다고 이해하시면 됩니다.
236 |
237 |
238 | 데이터가 테이블에서 적을 때는 **open addressing** 방식이 성능이 좋다고 한다.
239 |
240 | - 연속된 공간에 데이터를 저장하여 캐시효율을 높일 수 있다고한다.
241 |
242 | 그러나 데이터가 많아지게되면 **open addressing** 방식들은 급격하게 성능이 떨어지는게 보인다.
243 |
244 | 그에 비해 separate 체이닝 방식은 선형적으로 증가하는 그래프를 볼 수 있다.
245 |
246 |
247 | # Reference
248 |
249 | [*https://www.youtube.com/watch?v=ZBu_slSH5Sk*](https://www.youtube.com/watch?v=ZBu_slSH5Sk)
250 |
251 | [*https://www.youtube.com/watch?v=Rpbj6jMYKag*](https://www.youtube.com/watch?v=Rpbj6jMYKag)
252 |
253 | [*https://d2.naver.com/helloworld/831311*](https://d2.naver.com/helloworld/831311)
254 |
255 | [*https://ohtaeg.tistory.com/7*](https://ohtaeg.tistory.com/7)
256 |
257 | [*https://recordsoflife.tistory.com/205*](https://recordsoflife.tistory.com/205)
258 |
259 | [*https://zin0-0.tistory.com/294*](https://zin0-0.tistory.com/294)
260 |
261 | [*https://esoongan.tistory.com/193*](https://esoongan.tistory.com/193)
262 |
263 | [*https://siyoon210.tistory.com/85*](https://siyoon210.tistory.com/85)
264 |
265 | [*https://ejyoo.tistory.com/72*](https://ejyoo.tistory.com/72)
266 |
267 | [*https://it-license.tistory.com/72*](https://it-license.tistory.com/72)
268 |
269 | [*https://ihp001.tistory.com/90*](https://ihp001.tistory.com/90)
270 |
271 | [*https://velog.io/@injoon2019/자료구조-해시-테이블*](https://velog.io/@injoon2019/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%ED%95%B4%EC%8B%9C-%ED%85%8C%EC%9D%B4%EB%B8%94)
272 |
273 | [*https://odol87.tistory.com/4*](https://odol87.tistory.com/4)
274 |
275 | [*https://greatzzo.tistory.com/58*](https://greatzzo.tistory.com/58)
276 |
--------------------------------------------------------------------------------
/Data Structure/heap.md:
--------------------------------------------------------------------------------
1 | 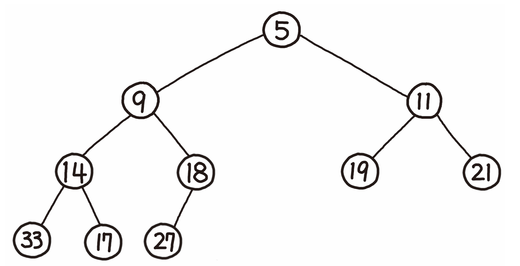
2 |
3 | # 힙(heap)
4 | - 영단어 힙(heap)은 '무엇인가를 차곡차곡 쌓아올린 더미'라는 뜻을 지니고 있다.
5 | - 힙(heap)은 최댓값 및 최솟값을 찾아내는 연산을 빠르게 하기 위해 고안된 완전이진트리(complete binary tree)를 기본으로 한 자료구조이다.
6 | - A가 B의 부모노드(parent node) 이면, A의 키(key)값과 B의 키값 사이에는 대소관계가 성립한다.
7 |
8 | 따라서 루트노드에는 항상 데이터들 중 가장 큰 값(혹은 가장 작은 값)이 저장되어 있기 때문에, 최댓값(혹은 최솟값)을 O(1)안에 찾을 수 있다.
9 |
10 |
11 |
12 | ## 종류
13 |
14 | 힙에는 두가지 종류가 있다.
15 | - **최대 힙(max heap)**: 부모노드의 키값이 자식노드의 키값보다 항상 큰 힙
16 | - **최소 힙(min heap)**: 부모노드의 키값이 자식노드의 키값보다 항상 작은 힙
17 |
18 | 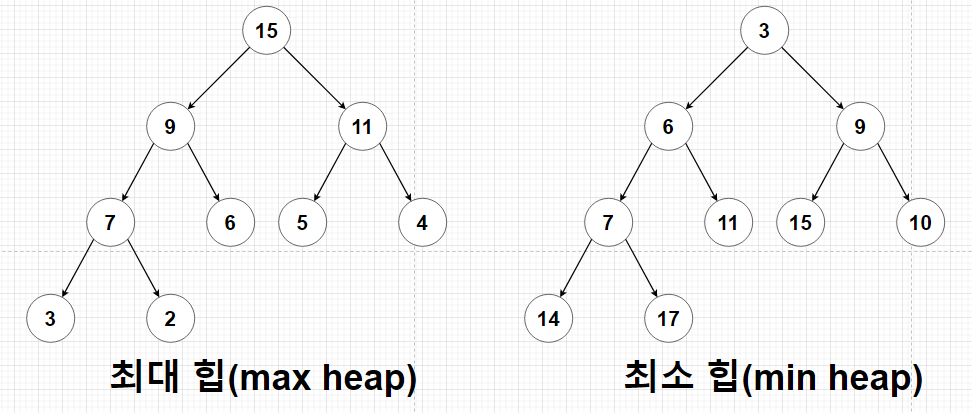
19 |
20 | 키값의 대소관계는 오로지 부모노드와 자식노드 간에만 성립하며, 특히 형제 사이에는 대소관계가 정해지지 않는다.
21 |
22 |
23 |
24 | ## 연산
25 |
26 | 데이터의 삽입과 삭제는 모두 O(logN)이 소요된다.
27 | ### 데이터 삽입
28 |
29 | 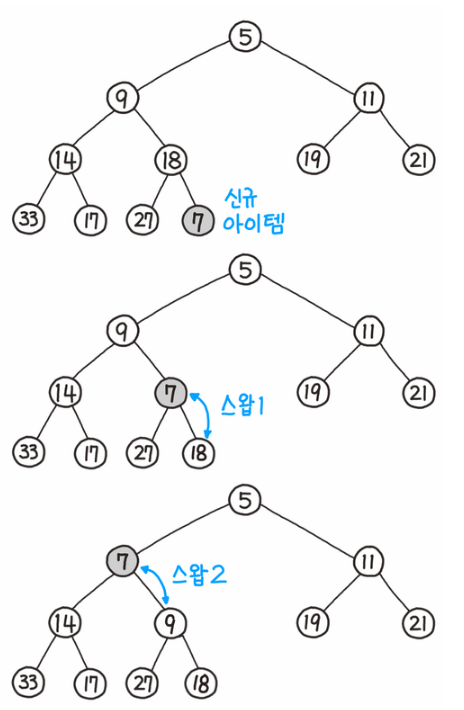
30 |
31 | 1. 가장 끝의 자리(가장 하위 레벨의 최대한 왼쪽)에 노드를 삽입한다.
32 | 2. 부모 값과 비교해 값이 더 작은 경우(최대 힙의 경우 더 큰 경우) 위치를 변경한다.
33 | 3. 계속해서 부모 값과 비교해 위치를 변경한다.
34 |
35 | ### 데이터 삭제(추출)
36 |
37 | 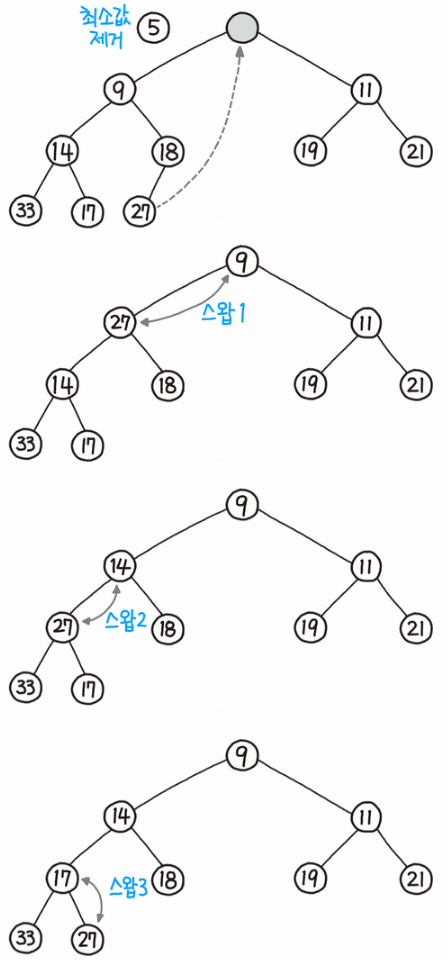
38 |
39 | 1. 루트노드를 제거(추출)한다.
40 | 2. 루트 자리에 가장 마지막 노드를 삽입한다.
41 | 3. 자식 노드들과 값을 비교해서 자식보다 크다면(최대 힙의 경우 작다면) 위치를 변경한다.
42 | 4. 계속해서 자식과 값을 비교해 위치를 변경한다.
43 |
44 |
45 |
46 | ## 표현
47 |
48 | 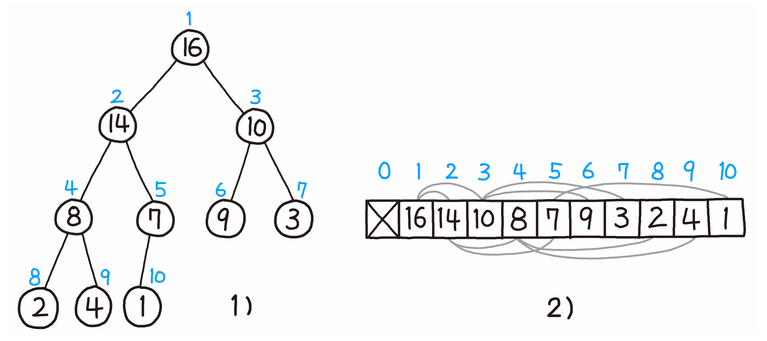
49 | 이진 힙은 완전 이진 트리(Complete Binary Tree)로서, 배열로 표현하기 매우 좋은 구조로 빈틈없이 배치가 가능하다.
50 | 대개 트리의 배열 표현의 경우 계산을 편하게 하기 위해 인덱스는 1부터 사용한다.
51 | - 부모 노드: `i//2`
52 | - 왼쪽 자식 노드: `2i`
53 | - 오른쪽 자식 노드: `2i+1`
54 |
55 |
56 |
57 | ## 응용
58 |
59 | 힙에서는 가장 높은(혹은 가장 낮은) 우선순위를 가지는 노드가 항상 뿌리노드에 오게 되는 특징을 이용해 **[우선순위 큐](https://ko.wikipedia.org/wiki/%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84_%ED%81%90)**와 같은 추상적 자료형을 구현할 수 있다.
60 |
61 | [다익스트라 알고리즘](https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%81%AC%EC%8A%A4%ED%8A%B8%EB%9D%BC_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)에도 활용된다. 힙 덕분에 다익스트라 알고리즘의 시간 복잡도는 O(V^2)에서 O(ElogV)로 줄어들 수 있었다.
62 |
63 | [힙 정렬](https://ko.wikipedia.org/wiki/%ED%9E%99_%EC%A0%95%EB%A0%AC), 최소 신장 트리(MST)를 구현하는 [프림 알고리즘](https://ko.wikipedia.org/wiki/%ED%94%84%EB%A6%BC_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98)에도 활용된다.
64 |
65 |
66 |
67 |
68 |
69 |
70 | ### 참고
71 | > https://ko.wikipedia.org/wiki/%ED%9E%99_(%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0)
72 | > https://namu.wiki/w/%ED%9E%99%20%ED%8A%B8%EB%A6%AC
--------------------------------------------------------------------------------
/Database/NoSQL.md:
--------------------------------------------------------------------------------
1 | ## Content
2 |
3 | - [NoSQL 등장 배경](#nosql-등장-배경)
4 | - [NoSQL 특징](#nosql-특징)
5 | - [CAP 이론](#cap-이론)
6 | - [NoSQL 종류](#nosql-종류)
7 |
8 | # NoSQL
9 |
10 | ## NoSQL 등장 배경
11 |
12 | 과거에는 비즈니스 모델이 다양하지 않았습니다. 대부분의 비즈니스 모델은 기업이 상품을 생산하고 고객에게 판매하는 것이었습니다.
13 |
14 | 
15 |
16 | 이러한 비즈니스 모델에서 생성되는 데이터는 다음과 같은 특징을 가지고 있습니다.
17 |
18 | - 데이터가 단순하지 않다.
19 | - 데이터의 양이 많지 않다.
20 |
21 | 이러한 특징을 갖는 데이터를 관계형 데이터베이스를 관리해왔는데 그로 인해 얻을 수 있는 이점은 다음과 같습니다.
22 |
23 | - 데이터는 항상 일관성을 유지한다.
24 | - 데이터를 갱신할 경우 해당 데이터가 존재하는 테이블에서만 갱신하면 된다.
25 | - 다양한 데이터(상품, 고객, 주문 등)의 관계를 정의하고 정규화를 통해 중복을 최소화할 수 있다.
26 |
27 | 
28 |
29 | 대부분의 비즈니스 모델에서 관계형 데이터베이스는 좋은 선택지가 되어왔습니다.
30 |
31 | 그런데 2000년대에 들어 새로운 종류의 비즈니스 모델이 등장합니다. 바로 페이스북, 유튜브와 같은 서비스입니다. 이러한 서비스는 다음의 특징을 가지즌 데이터를 만들어냈습니다.
32 |
33 | - 데이터가 단순하다.
34 | - 데이터의 양이 매우 많다.
35 |
36 | 이러한 데이터를 관계형 데이터베이스로 관리하기에는 큰 어려움이 있었습니다. 많은 양의 데이터를 한꺼번에 저장하거나 조회해야 했는데 기존의 관계형 데이터베이스는 여러 제약(테이블, 데이터 타입, 외래키 등)을 가지고 있었기 때문입니다.
37 |
38 | **즉, 새로운 데이터 저장 기술의 필요성이 대두되었고 구글과 아마존이 각각 Bigtable, Dynamo라는 데이터 저장 기술을 발표합니다. 이 것이 NoSQL이 등장하는 계기가 되었습니다.**
39 |
40 | > NoSQL은 Not Only SQL라는 의미를 가지고 있습니다.
41 |
42 | ## NoSQL 특징
43 |
44 | NoSQL은 다음과 같은 특징을 가집니다.
45 |
46 | - 공통된 형태의 데이터 저장 방식인 테이블 개념과 접근 방식인 SQL 개념이 없다. NoSQL 데이터베이스마다 특징이 매우 다르다. 따라서 NoSQL을 하나의 데이터베이스 제품군으로 정의할 수는 없으며, 관계형 데이터베이스와 다른 형태의 데이터베이스들을 총칭한다고 보는 것이 좋다.
47 | > eg. 한국 음식과 해외 음식
48 | - 데이터를 자유롭게 저장할 수 있다. 새로운 데이터 필드를 쉽게 추가할 수도 있다.
49 | 1. 첫 번째 회원 정보 저장 (아이디, 패스워드)
50 | 2. 두 번째 회원 정보 저장 (아이디, 패스워드, 생일)
51 | - NoSQL은 데이터 간의 관계를 정의하지 않는다. 즉, 조인이 없고 읽기 속도가 대체적으로 빠르다.
52 | - 주문 : 주문 정보, 상품 정보, 회원 정보
53 | - 상품 : 상품 정보
54 | - 회원 : 회원 정보
55 | - 수평적 확장이 용이하다. 데이터베이스를 여러 개 연결하여 데이터를 저장하고 처리한다.
56 | - 페타바이트 이상의 데이터를 저장할 수 있다.
57 |
58 | ## CAP 이론
59 |
60 | CAP 이론은 분산된 데이터베이스 시스템이 일관성, 가용성, 부분결함 용인 3가지 특성 중 2가지 특성만을 충족할 수 있다는 이론입니다. NoSQL은 CAP 이론에 따라 분류될 수 있습니다.
61 |
62 | ### 일관성 (Consistency)
63 |
64 | 데이터는 항상 최신의 데이터로 유지됩니다. 이에 따라 모든 읽기에 대해 동일한 데이터를 반환합니다. 예를 들어, 데이터베이스의 인스턴스가 2개 이상일 때 어느 곳에 요청하더라도 동일한 데이터가 반환됩니다. 이를 위해 데이터를 갱신하면 데이터베이스의 모든 인스턴스에 데이터를 최신화할 필요가 있습니다.
65 |
66 | ### 가용성 (Availability)
67 |
68 | 실행 중인 데이터베이스는 모든 요청에 대해 정상적인 응답을 해야 합니다. 정상적인 응답을 하지 못하는 경우 가용성이 보장되지 않는 것입니다.
69 |
70 | ### 부분결함 용인 (Partitioning)
71 |
72 | 데이터베이스 인스턴스 간에 통신 장애가 발생하더라도 시스템이 정상적으로 동작해야 합니다.
73 |
74 | 
75 |
76 | ## NoSQL 종류
77 |
78 | ### Key-Value
79 |
80 | 키와 밸류로 이루어진 데이터베이스입니다.
81 |
82 | > Redis, AWS DynamoDB
83 |
84 | #### 특징
85 |
86 | - key는 유일하다.
87 | - value에는 모든 데이터 타입을 저장할 수 있다.
88 | - key-value가 하나로 묶인 단순한 구조로 속도가 빠르고 저장이 용이하다.
89 |
90 | 
91 |
92 | 이러한 특징을 갖는 Key-Value NoSQL은 성능 향상을 위해 캐싱용으로 쓰기 좋습니다.
93 |
94 | ### Document
95 |
96 | JSON, XML을 사용하여 계층적으로 데이터를 저장하는 데이터베이스입니다.
97 |
98 | > MongoDB, Azure Cosmos DB
99 |
100 | #### 특징
101 |
102 | - 관계형 데이터베이스에서 여러 테이블을 조인하여 조회하는 데이터를 하나의 Document에 저장해둘 수 있다. 즉, 읽기 속도가 빨라진다.
103 | - Document 내부에서는 Key-Value 형식을 가지는데, Value가 Document가 될 수 있다. Key-Value NoSQL과의 차이점은 데이터를 계층적 문서로 저장한다는 점이다.
104 | - 데이터를 여러 서버에 복제하여 분산 저장할 수 있다. 이를 통해 장애 대응을 효과적으로 할 수 있다.
105 |
106 | 
107 |
108 | 이러한 특징을 갖는 Document NoSQL은 대용량 데이터를 조회하고 저장할 때 쓰기 좋습니다. 그리고 계층적으로 다양한 속성을 갖는 데이터를 관리하기에 좋습니다.
109 |
110 | ### Wide Column
111 |
112 | 행마다 다른 값, 다른 개수의 스키마를 가질 수 있는 데이터베이스입니다.
113 |
114 | > Cassandra, HBase, Google BigTable
115 |
116 | #### 특징
117 |
118 | - Key, Value를 저장할 때 각각 다른 값, 갯수의 스키마를 가질 수 있습니다.
119 | - 확장성이 뛰어납니다.
120 |
121 | 
122 |
123 | 이러한 특징을 갖는 Wide Column NoSQL은 대용량 데이터를 압축하거나 분산, 집계 처리할 때 쓰기 좋습니다.
124 |
125 | ### Graph
126 |
127 | 데이터를 노드와 엣지로 표현하는 데이터베이스입니다. 엣지는 노드 사이의 관계를 의미합니다.
128 |
129 | > Neo4j, OrientDB
130 |
131 | #### 특징
132 |
133 | - 관계가 이미 정의되어 있으므로 조인이 필요없다.
134 | - 관계형 데이터베이스에 비해 성능이 좋고 데이터 관리에 유연하다.
135 |
136 | 
137 |
138 | 이러한 특징을 갖는 Graph NoSQL은 SNS와 같은 서비스에서 쓰기 좋습니다.
139 |
140 | ### 기타
141 |
142 | 
143 |
144 | > 출처 : https://towardsdatascience.com/datastore-choices-sql-vs-nosql-database-ebec24d56106
145 |
--------------------------------------------------------------------------------
/Database/Redis.md:
--------------------------------------------------------------------------------
1 | # Redis
2 |
3 |
7 |
8 | - `인메모리` 데이터 저장소 (속도↑)
9 | - `Key-Value` 구조 (쿼리 사용할 필요 X)
10 | - `다양한 자료구조` 지원
11 | - `Single Thread` 사용
12 | - DB / 캐시 / 메시지브로커로 사용
13 | - 오픈소스
14 |
15 | ## DB서버 VS 캐시서버
16 |
17 | - 기존의 DB서버
18 | - 소규모 서비스(WEB-WAS-DB 구조)
19 | - 데이터를 **물리 디스크**에 직접 접근해 write
20 | - 서버가 다운되도 데이터 손실 x
21 | - **DB부하** 큼
22 | - 기존의 캐시서버
23 | - 한번 읽어온 데이터를 임의의 공간에 저장해, read시 **빠르게** 결과값 받음
24 | - 같은 요청이 여러번 들어올 경우, DB까지 가지 않아도 캐시서버 단에서 저장된 결과값 반환
25 | - 서버가 다운되면 **데이터 손실**
26 | - ~~DB부하~~ 적음
27 |
28 | - 캐시 서버의 두가지 패턴
29 |
30 | ## 1. Look aside cache
31 |
32 | 1. 클라이언트가 데이터 요청
33 | 2. 웹서버: cache서버에서 데이터 유무 확인
34 | 3. 있을 경우: DB에 도달하지 않고, cache의 결과값을 클라이언트에 반환 (Cache Hit)
35 | 4. 없을 경우: DB에서 데이터 조회해 클라이언트에 반환 & cache 서버에 저장 (Cache Miss)
36 |
37 | ## 2. Write Back
38 |
39 | 1. 웹서버: 모든 데이터를 cache 서버에 저장
40 | 2. cache 서버: 특정시간동안 데이터 저장
41 | 3. DB : cache서버에 있는 데이터를 저장
42 | 4. cache 서버: DB에 저장완료된 데이터를 삭제
43 | - insert 쿼리를 모아서 한번에 날려 속도 ↑
44 |
45 |
49 |
50 | ## Redis: 영속성
51 |
52 | 인메모리 데이터 저장소이지만, 영속성을 지원한다.
53 |
54 | 이를 위해 데이터를 디스크에 저장할 수 있고,
55 |
56 | 서버가 내려가더라도 디스크로부터 읽어 메모리에 로딩할 수 있다.
57 |
58 | 디스크에 데이터 저장하는 방식
59 |
60 | 1. RDB (Snapshotting) 방식
61 |
62 | : 순간적으로 메모리에 있는 모든 내용을 디스크에 옮겨 저장함.
63 |
64 | 2. AOF (Append On File) 방식
65 |
66 | : Redis의 모든 write/update 연산을 log 파일에 통째로 기록함.
67 |
68 |
69 | ## Redis: 다양한 데이터구조
70 |
71 | - String, Lists, Sets, Sorted Sets, Hashes 자료 구조를 지원한다.
72 | - String : 일반적인 key-value 형태
73 | - Sets: String의 집합. 여러개의 값을 하나의 value 에 넣을 수 있음
74 | - 메모리 저장소임에도 많은 데이터구조를 지원해 다양한 기능을 구현할 수 있다.
75 |
76 | 
77 |
78 |
79 | ## Redis 프로젝트
80 |
81 | - Redis Replication: Master-Slave 형식의 데이터 이중화 구조 처리
82 | - Redis Cluster: 분산처리
83 | - Redis Sentinel: 장애복구 시스템
84 | - Redis Topology
85 | - Redis Sharding
86 | - Redis Failover
87 |
88 | - 읽기성능: 증대를 위해 서버 측 복제를 지원
89 | - 쓰기성능: 클라이언트 측 샤딩(Sharding)지원
90 |
--------------------------------------------------------------------------------
/Database/Transaction-Isolation-Level.md:
--------------------------------------------------------------------------------
1 | # Content
2 |
3 | - [트랜잭션 격리 수준](#트랜잭션-격리-수준)
4 | - [Read Uncommitted](#read-uncommitted)
5 | - [Read Committed](#read-committed)
6 | - [Repeatable Read](#repeatable-read)
7 | - [Serializable](#serializable)
8 |
9 | ## 트랜잭션 격리 수준
10 |
11 | > **트랜잭션 격리 수준은 여러 트랜잭션이 동시에 수행될 때 한 트랜잭션에서 갱신된 데이터를 다른 트랜잭션에서 조회 시 어떻게 보일지를 결정하는 기준입니다.**
12 |
13 | 데이터베이스의 격리 수준은 Read Uncommitted, Read Committed, Repeatable Read, Serializable 4가지로 나뉩니다. 뒤로 갈수록 트랜잭션 간의 격리 수준은 높아지고 동시 처리 성능은 낮아집니다. 하지만 Serializable 격리 수준이 아니라면 성능의 저하는 크지 않습니다.
14 |
15 | 일반적으로 Read Committed, Repeatable Read 격리 수준을 사용합니다. MySQL의 경우 디폴트 격리 수준이 Repeatable Read 입니다.
16 |
17 | ### 격리 수준에 따른 데이터 부정합 문제
18 |
19 | 각 격리 수준에 따라 3가지의 데이터 부정합 문제가 발생할 수 있습니다.
20 |
21 | | 격리 수준 | Dirty Read | Non-Repeatable Read | Phantom Read |
22 | | ---------------- | :--------: | :-----------------: | :------------: |
23 | | Read Uncommitted | O | O | O |
24 | | Read Committed | - | O | O |
25 | | Repeatable Read | - | - | O (InnoDB는 X) |
26 | | Serializable | - | - | - |
27 |
28 | - MySQL의 스토리지 엔진으로 InnoDB를 사용하면 갭 락, 넥스트 키 락 덕분에 Repeatable Read 격리 수준에서도 Phantom Read가 발생하지 않습니다.
29 |
30 | > 관련 키워드 : 갭 락, 넥스트 키 락
31 |
32 | ## Read Uncommitted
33 |
34 | Read Uncommitted 격리 수준에서는 트랜잭션이 Commit되거나 Rollback되지 않더라도 작업 내용이 다른 트랜잭션에서 보이게 됩니다. 이러한 현상을 Dirty Read라 합니다. Dirty Read로 인해서 데이터 정합성에 문제가 발생하므로 최소한 Read Committed 이상의 격리 수준을 사용할 것을 권장합니다.
35 |
36 | ### [그림 1] Dirty Read 문제가 발생함
37 |
38 | 
39 |
40 | ## Read Committed
41 |
42 | Read Committed 격리 수준은 가장 많이 선택되는 격리 수준입니다. 그리고 Read Uncommitted 격리 수준의 Dirty Read 문제가 발생하지 않습니다. Commit이 완료된 데이터만 조회할 수 있기 때문입니다. 이 때 Undo 영역을 활용합니다.
43 |
44 | 아래 그림과 같이 Read Committed 격리 수준에서 데이터를 갱신할 경우 Undo 영역에 데이터를 백업합니다. 다른 트랜잭션에서 갱신 중인 데이터를 참조할 경우 Undo 영역에 백업된 데이터를 참조합니다.
45 |
46 | ### [그림 2] Dirty Read 문제가 발생하지 않음
47 |
48 | 
49 |
50 | 그런데 또 다른 문제인 Non-Repeatable Read가 발생합니다. 이러한 현상 때문에 Read Committed 격리 수준에서는 트랜잭션 중간에 참조하는 데이터가 달라질 수 있습니다. 다른 트랜잭션이 Commit을 완료한 경우 Undo 영역이 아닌 원본 테이블의 값을 참조하기 때문입니다.
51 |
52 | ### [그림 3] Non-Repeatable Read 문제가 발생함
53 |
54 | 
55 |
56 | ## Repeatable Read
57 |
58 | Repeatable Read는 MySQL의 InnoDB 스토리지 엔진에서 기본으로 사용되는 격리 수준입니다. 이 격리 수준에서는 Read Committed 격리 수준에서 발생한 Non-Repeatable Read 문제가 발생하지 않습니다. Undo 영역에 백업된 데이터를 이용해 동일한 트랜잭션 내에서는 동일한 결과를 보여줄 수 있도록 보장하기 때문입니다. 이 때 트랜잭션 아이디가 사용됩니다.
59 |
60 | 모든 InnoDB의 트랜잭션은 트랜잭션 아이디를 가지는데, Undo 영역에 백업된 모든 데이터에는 트랜잭션 아이디가 포함되어 있습니다. 트랜잭션 안에서 실행되는 모든 SELECT 쿼리는 자신의 트랜잭션 아이디보다 작은 트랜잭션 아이디에서 갱신된 데이터만 참조할 수 있습니다.
61 |
62 | ### [그림 4] Non-Repeatable Read 문제가 발생하지 않음
63 |
64 | 
65 |
66 | > 관련 키워드 : MVCC, InnoDB, Undo 영역으로 인한 성능 저하
67 |
68 | 하지만 아직 Phantom Read 문제가 남아 있습니다. 아래 그림과 같이 SELECT .. FOR UPDATE 쿼리를 사용하면 Phantom Read 문제가 발생합니다. SELECT .. FOR UPDATE 쿼리는 SELECT 하는 레코드에 쓰기 잠금을 걸어야 하는데 Undo 레코드에는 잠금을 걸 수 없기 때문에 현재 레코드의 값을 참조하게 됩니다. 따라서 현재 트랜잭션보다 늦게 시작한 트랜잭션의 레코드도 참조할 수 있게 됩니다.
69 |
70 | ### [그림 5] Phantom Read 문제가 발생함
71 |
72 | 
73 |
74 | ## Serializable
75 |
76 | Serializable 격리 수준은 가장 단순하면서 엄격한 격리 수준입니다. 그리고 동시 처리 성능은 다른 격리 수준에 비해 떨어집니다. 읽기 작업을 할 때도 공유 잠금을 획득해야하기 때문입니다. 이 때 다른 트랜잭션에서 해당 레코드를 갱신할 수 없게 됩니다. 따라서 Serializable 격리 수준에서는 Phantom Read 문제가 발생하지 않습니다.
77 |
78 | 그렇다고 Phantom Read 문제를 해결하기 위해 Serializable 격리 수준을 사용해야 하는 것은 아닙니다. InnoDB 스토리지 엔진에서는 갭 락과 넥스트 키 락 덕분에 Repeatable Read 격리 수준에서도 Phantom Read가 발생하지 않기 때문입니다. 따라서 굳이 Serializable 격리 수준을 사용할 필요는 없습니다.
79 |
80 | > 관련 키워드 : 갭 락, 넥스트 키 락
81 |
--------------------------------------------------------------------------------
/Database/Transaction.md:
--------------------------------------------------------------------------------
1 | ## Content
2 |
3 | - [ACID 특성](#acid-특성)
4 | - [트랜잭션 연산](#트랜잭션-연산)
5 |
6 | # 트랜잭션
7 |
8 | 트랜잭션은 데이터베이스에서 처리되는 작업의 논리적 단위입니다. 삽입, 수정, 삭제 등 데이터 갱신을 위해 복수의 연산를 수행할 때 이러한 연산들을 한 단위로 묶은 것이라고 할 수 있습니다. 트랜잭션은 작업을 마치고 Commit 되거나 Rollback 되어야 합니다.
9 |
10 | ## ACID 특성
11 |
12 | 트랜잭션은 네 가지 특성으로 정의되며 이를 ACID 특성이라고 합니다.
13 |
14 | ### 원자성(Atomicity)
15 |
16 | - 데이터를 갱신하는 복수의 연산이 모두 반영되거나 반영되지 않아야 합니다.
17 | - 모든 연산은 완벽히 수행되어야 하고 하나라도 오류가 발생하면 모든 연산이 취소되어야 합니다.
18 |
19 | > eg. 기차표 예매를 예시로 들어보겠습니다. 기차 좌석을 예약하고 결제를 시도합니다. 이 때 결제 승인에 실패하게 되면 결제가 취소되고 기차 좌석 예약도 취소되어야 합니다.
20 |
21 | ### 일관성(Consistency)
22 |
23 | - 트랜잭션의 작업 처리 결과는 항상 일관성이 있어야 합니다.
24 | - 트랜잭션이 진행되는 동안 데이터베이스의 데이터가 변경되더라도 처음 가져온 데이터를 사용하여 트랜잭션이 진행됩니다.
25 |
26 | > eg. A와 B가 각각 계좌에 1,000원씩 가지고 있을 때 A가 B에게 500원을 송금한다고 상황을 가정해봅니다. 이 때 송금 전 두 계좌의 합이 2,000원이라면 송금 후에도 두 계좌의 합은 2,000원이어야 합니다.
27 |
28 | ### 격리성(Isolation)
29 |
30 | - 서로 다른 트랜잭션이 동시에 병렬적으로 수행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없습니다.
31 | - 수행 중인 트랜잭션이 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없습니다.
32 |
33 | > eg. C의 계좌 잔액이 0원인 상태에서 A와 B가 동시에 C에게 500원씩 송금한다고 가정해봅니다. 이 때 A의 트랜잭션이 조금 더 빠르게 시작되었다면 A의 송금 트랜잭션이 완료될 때 까지 B의 트랜잭션은 연산을 마칠 수 없습니다. A의 트랜잭션이 완료되면 C의 계좌 잔액은 500원이 되고 B는 이 데이터를 참조하여 송금 트랜잭션을 완료하게 됩니다. 결과적으로 C의 계좌 잔액은 1,000원이 됩니다.
34 |
35 | ### 자속성(Durability)
36 |
37 | - 정상적으로 처리된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 합니다.
38 |
39 | > eg. 트랜잭션이 완료된 후에 데이터베이스에 전원 공급이 끊겨서 시스템이 꺼지더라도 데이터는 보존되어야 합니다.
40 |
41 | ## 트랜잭션 연산
42 |
43 | ### Commit
44 |
45 | 
46 |
47 | - 트랜잭선이 정상적으로 수행되었을 때 수행되는 연산입니다.
48 | - Commit 연산이 수행되면 데이터베이스에 연산 결과가 반영되고 데이터베이스는 일관성을 유지합니다.
49 |
50 | ### Rollback
51 |
52 | 
53 |
54 | - 트랜잭션 연산이 비정상적으로 종료되어 데이터베이스의 일관성이 깨질 수 있습니다. 이 때 트랜잭션의 일부가 정상적으로 처리되었어도 트랜잭션의 원자성을 보장하기 위해 모든 연산을 취소합니다.
55 | - Rollback 연산을 수행할 때는 트랜잭션을 재시작하거나 폐기할 수 있습니다.
56 |
--------------------------------------------------------------------------------
/Database/index.md:
--------------------------------------------------------------------------------
1 | ## 인덱스(index)란?
2 |
3 | - 데이터베이스에서 테이블에 대한 동작의 속도를 높여주는 자료 구조
4 | - 테이블에서 원하는 데이터를 쉽고 빠르게 찾기 위해 사용
5 |
6 | ex) 책의 목차
7 |
8 | 
9 |
10 | > **데이터베이스 파일 구성**
11 | >
12 | > - 테이블 생성 시, 3가지 파일 생성
13 | > - MYD : 실제 데이터 관리 파일
14 | > - MYI : 인덱스 관리 파일
15 | > - FRM : 테이블 구조에 관한 파일
16 | > - SELECT 검색시 테이블을 검색하는 것이 아니라 MYI 파일 내용 검색
17 |
18 |
19 |
20 | ## 인덱스 특징
21 |
22 | ### 장점
23 |
24 | - 테이블에서 검색과 정렬 속도를 향상시킴
25 | - 기본키(primary key)는 자동으로 인덱싱됨
26 |
27 | ### 단점
28 |
29 | - 인덱스 관리를 위한 추가 잡업 필요
30 | - 추가적인 저장 공간 필요
31 | - 잘못된 사용은 오히려 검색 성능을 저하시킴
32 | - INSERT : 테이블에는 입력 순서대로 저장되지만, 인덱스 테이블에는 정렬하여 저장
33 | 하기 때문에 성능 저하 발생
34 | - DELETE : 테이블에서만 삭제되고 인덱스 테이블에는 남아있어 쿼리 수행 속도 저하
35 | - UPDATE : DELETE, INSERT 두 작업 수행하여 부하 발생
36 |
37 | ### 인덱스를 사용하면 좋은 경우
38 |
39 | - 규모가 큰 테이블
40 | - 삽입(Insert), 수정(Update), 삭제(Delete) 작업이 자주 발생하지 않는 칼럼
41 | - where나 order by, join 등이 자주 사용되는 칼럼
42 | - 데이터의 중복도가 낮은 칼럼
43 |
44 |
45 |
46 | ## 인덱스 자료구조
47 |
48 | ### B+ Tree 알고리즘
49 |
50 | 
51 |
52 | - 가장 일반적으로 사용되는 인덱스 알고리즘
53 | - 범위 탐색이 가능
54 | - like와 같은 구문을 실행할 때도 사용할 수 있다
55 |
56 | ### 해시 알고리즘
57 |
58 | - 컬럼의 값으로 해시 값을 계산해서 인덱싱하는 알고리즘
59 | - 매우 빠른 검색을 지원
60 | - 주로 메모리 기반 데이터베이스에서 많이 사용
61 | - 동등 연산(=)에 특화된 자료구조 (range search의 한계로 대부분 B+ Tree 알고리즘 사용)
62 |
63 |
64 |
65 | ## 인덱스의 종류
66 |
67 | ### 키에 따른 인덱스 분류
68 |
69 | - 기본 인덱스 (Primary Index) : 기본키를 포함하는 인덱스
70 | - 보조 인덱스 (Secondary Index) : 기본 인덱스 이외의 인덱스
71 |
72 | ### 파일 조직에 따른 인덱스
73 |
74 | - Clustered Index
75 |
76 | 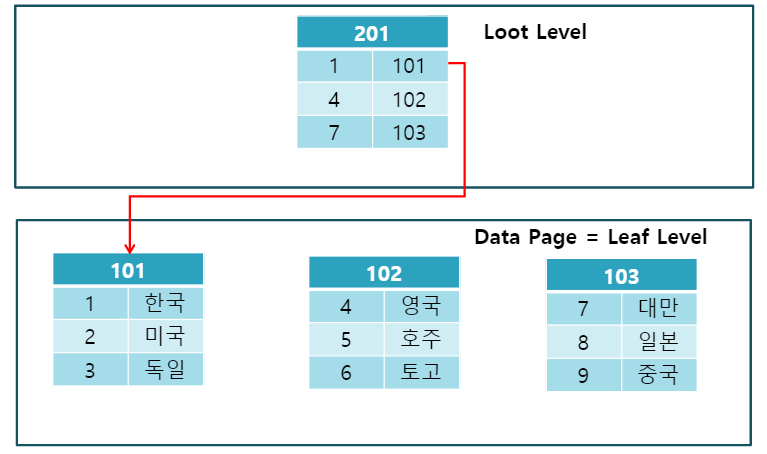
77 | - 물리적으로 정렬되어 있음
78 | - 테이블 당 하나씩 존재
79 | - 데이터 입력, 수정, 삭제 시에도 정렬 수행, 느림
80 | - 검색 속도 빠름
81 | - Non-Clustered Index
82 |
83 | 
84 | - 순서와 상관 없음
85 | - 테이블 당 여러개 존재 가능
86 | - 클러스터형 인덱스보다 검색 속도는 느리지만, 데이터 입력, 수정, 삭제 더 빠름
87 |
88 |
89 |
90 | ### 인덱스 생성
91 |
92 | ```sql
93 | CREATE INDEX 인덱스이름
94 | ON 테이블이름 (필드이름1, 필드이름2, ...)
95 | ```
96 |
97 | ### 인덱스 정보 보기
98 |
99 | ```sql
100 | SHOW INDEX
101 | FROM 테이블이름
102 | ```
103 |
104 | 
105 |
--------------------------------------------------------------------------------
/Database/정규화.md:
--------------------------------------------------------------------------------
1 | # 1. 정규화란?
2 | - RDBMS에서 중복을 최소화하기 위해 데이터를 구조화하는 작업
3 | - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF까지 총 7개의 정규형이 있다.
4 |
5 | - 비공식적으로는 3NF가 되었으면 정규화되었다고 말할 수 있으며, 실제 현업에서도 제 3NF 정도까지만 수행하고 속도, 튜닝 등 필요에 따라 비정규화(Denormalization) 과정을 수행하기도 한다.
6 |
7 |
8 |
9 |
10 | # 2. 정규화의 장점은?
11 | - 데이터 중복과 저장공간의 낭비를 피할 수 있다
12 | - 이상현상에서 발생하는 문제점을 해결할 수 있다
13 | - 삽입 이상
14 | - 테이블에 일부 데이터만 삽입하고 싶어도 입력을 원치 않는 다른 데이터까지 함께 삽입해야 하는 현상
15 | - (학번, 수강과목)이 PK인 테이블에서 학생정보만 삽입하고 싶어도 수강과목, 성적이라는 원치 않는 데이터까지 삽입해야 한다
16 | 
17 | - 삭제 이상
18 | - 테이블에서 한 행을 삭제할 때 삭제를 원치 않는 데이터들까지 함께 삭제되는 이상
19 | - 학번이 200, 수강과목이 2번인 2행 데이터를 삭제하면 '다빈슨'의 학생정보도 모두 사라진다
20 | 
21 | - 갱신 이상
22 | - 일부 행의 값만 갱신(수정)해 데이터들 간에 불일치가 발생하는 이상
23 | - '하로롱'이라는 학생의 학부가 오락부로 바뀌었을 때 다른 튜플에 있는 정보를 수정하지 못하면 '하로롱'학생의 학부 정보 간의 불일치가 발생
24 | 
25 |
26 |
27 |
28 |
29 | # 3. 정규화의 단점은?
30 | - 테이블의 분해로 인해 join 연산이 많아진다
31 | - 질의에 대한 응답 시간이 느려질 수 있다
32 |
33 | => 이러한 문제로 인해 반정규화(비정규화)를 수행하기도 한다
34 |
35 |
36 |
37 |
38 |
39 |
40 | # 4. 정규화의 종류는?
41 |
42 | ## 1. 제 1 정규형
43 | - 모든 속성이 단일값만 가져아한다
44 | 
45 |
46 |
47 |
48 |
49 | ## 2. 제 2 정규형
50 | - 모든 속성은 반드시 기본키 전부에 종속돼야 한다
51 | - 기본키의 부분집합 키가 결정자가 돼선 안된다
52 | - 성적은 학번, 수강과목에 종속적이지만 (이름, 학부, 등록금)은 학번에만 종속적이다. 그러므로 테이블을 쪼개 제 2 정규형을 만족시킬 수 있다
53 | 
54 |
55 |
56 |
57 |
58 |
59 | ## 3. 제 3 정규형
60 | - 기본키가 아닌 모든 속성 간에는 서로 종속될 수 없다
61 | - (이름, 학부)는 기본키인 학번에 종속적이지만 등록금은 학부에만 종속적이다.
62 | 
63 |
64 |
65 |
66 |
67 | # REFERENCE
68 | https://github.com/hongcheol/CS-study/tree/main/Database#anomaly%EC%99%80-%EC%A0%95%EA%B7%9C%ED%99%94
--------------------------------------------------------------------------------
/Java/HashMap vs Hashtable vs ConcurrentHashMap.md:
--------------------------------------------------------------------------------
1 | ### Contents
2 |
3 | - [HashMap](#hashmap)
4 | - [Hashtable](#hashtable)
5 | - [ConcurrentHashMap](#concurrenthashmap)
6 |
7 | # HashMap vs Hashtable vs ConcurrentHashMap
8 |
9 | HashMap, Hashtable, ConcurrentHashMap 자료구조는 Map 자료구조를 상속하는 자료구조입니다. Map 자료구조는 Key-Value 형태의 자료구조로 하나의 Key에 하나의 Value 데이터가 매핑됩니다.
10 |
11 | Map 자료구조를 구현하는 HashMap, Hashtable, ConcurrentHashMap 자료구조는 데이터를 저장하고 조회하는 공통 기능을 제공하지만, 동기화 처리 방식에 차이가 있습니다.
12 |
13 | ## HashMap
14 |
15 | HashMap 자료구조는 동기화를 보장하지 않습니다. 그에 따라 데이터 조회 속도가 빠르다는 장점이 있습니다. 동기화를 보장하지 않으므로 싱글 스레드 환경에서 사용하는 것이 좋습니다.
16 |
17 | ### HashMap code in Java 11
18 |
19 | ```java
20 | public class HashMap extends AbstractMap implements Map, Cloneable Serializable {
21 |
22 | // ...
23 |
24 | public V put(K key, V value) {
25 | return putVal(hash(key), key, value, false, true);
26 | }
27 |
28 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
29 | boolean evict) {
30 | Node[] tab; Node p; int n, i;
31 | if ((tab = table) == null || (n = tab.length) == 0)
32 | n = (tab = resize()).length;
33 | if ((p = tab[i = (n - 1) & hash]) == null)
34 | tab[i] = newNode(hash, key, value, null);
35 | else {
36 | Node e; K k;
37 | if (p.hash == hash &&
38 | ((k = p.key) == key || (key != null && key.equals(k))))
39 | e = p;
40 | else if (p instanceof TreeNode)
41 | e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
42 | else {
43 | for (int binCount = 0; ; ++binCount) {
44 | if ((e = p.next) == null) {
45 | p.next = newNode(hash, key, value, null);
46 | if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
47 | treeifyBin(tab, hash);
48 | break;
49 | }
50 | if (e.hash == hash &&
51 | ((k = e.key) == key || (key != null && key.equals(k))))
52 | break;
53 | p = e;
54 | }
55 | }
56 | if (e != null) { // existing mapping for key
57 | V oldValue = e.value;
58 | if (!onlyIfAbsent || oldValue == null)
59 | e.value = value;
60 | afterNodeAccess(e);
61 | return oldValue;
62 | }
63 | }
64 | ++modCount;
65 | if (++size > threshold)
66 | resize();
67 | afterNodeInsertion(evict);
68 | return null;
69 | }
70 | }
71 | ```
72 |
73 | ## Hashtable
74 |
75 | Hashtable 자료 구조는 동기화를 보장합니다. 따라서 멀티 스레드 환경에서 사용할 수 있습니다.
76 |
77 | 하지만 스레드 간에 동기화 락을 걸어 동기화를 보장하므로 속도가 느리다는 단점이 있습니다. 아래 코드에서 `put` 메서드를 보면 `synchronized` 키워드로 동기화를 하는 것을 확인할 수 있습니다.
78 |
79 | ### Hashtable code in Java 11
80 |
81 | ```java
82 | public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable {
83 |
84 | // ...
85 |
86 | public synchronized V put(K key, V value) {
87 | // Make sure the value is not null
88 | if (value == null) {
89 | throw new NullPointerException();
90 | }
91 |
92 | // Makes sure the key is not already in the hashtable.
93 | Entry tab[] = table;
94 | int hash = key.hashCode();
95 | int index = (hash & 0x7FFFFFFF) % tab.length;
96 | @SuppressWarnings("unchecked")
97 | Entry entry = (Entry)tab[index];
98 | for(; entry != null ; entry = entry.next) {
99 | if ((entry.hash == hash) && entry.key.equals(key)) {
100 | V old = entry.value;
101 | entry.value = value;
102 | return old;
103 | }
104 | }
105 |
106 | addEntry(hash, key, value, index);
107 | return null;
108 | }
109 |
110 | }
111 | ```
112 |
113 | ## ConcurrentHashMap
114 |
115 | ConcurrentHashMap 자료구조는 동기화를 보장합니다. 따라서 멀티 스레드 환경에서 사용할 수 있습니다.
116 |
117 | HashMap의 동기화 문제를 보완하기 위해 등장한 자료구조입니다. Hashtable 자료구조와 마찬가지로 동기화를 보장하는데, 동기화를 하는 단위에 차이가 있습니다. Hashtable 자료구조는 스레드 간 동기화 락을 걸어 동기화를 보장하는 반면, ConcurrentHashMap 자료구조는 조작해야 하는 Entry만 락을 걸어 동기화를 보장합니다. 아래 코드를 보면 `f` 노드만 `synchronized` 키워드를 사용하여 동기화를 하는 것을 확인할 수 있습니다. 이에 따라 Hashtable 자료구조보다 데이터 접근 속도가 빨라지게 됩니다.
118 |
119 | 따라서 멀티 스레드 환경에서는 Hashtable 자료구조 대신 ConcurrentHashMap 자료구조를 사용하는 것이 좋습니다.
120 |
121 | ### ConcurrentHashMap code in Java 11
122 |
123 | ```java
124 | public class HashMap extends AbstractMap implements Map, Cloneable, Serializable {
125 |
126 | // ...
127 |
128 | public V put(K key, V value) {
129 | return putVal(key, value, false);
130 | }
131 |
132 | /** Implementation for put and putIfAbsent */
133 | final V putVal(K key, V value, boolean onlyIfAbsent) {
134 | if (key == null || value == null) throw new NullPointerException();
135 | int hash = spread(key.hashCode());
136 | int binCount = 0;
137 | for (Node[] tab = table;;) {
138 | Node f; int n, i, fh; K fk; V fv;
139 | if (tab == null || (n = tab.length) == 0)
140 | tab = initTable();
141 | else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
142 | if (casTabAt(tab, i, null, new Node(hash, key, value)))
143 | break; // no lock when adding to empty bin
144 | }
145 | else if ((fh = f.hash) == MOVED)
146 | tab = helpTransfer(tab, f);
147 | else if (onlyIfAbsent // check first node without acquiring lock
148 | && fh == hash
149 | && ((fk = f.key) == key || (fk != null && key.equals(fk)))
150 | && (fv = f.val) != null)
151 | return fv;
152 | else {
153 | V oldVal = null;
154 | synchronized (f) {
155 | if (tabAt(tab, i) == f) {
156 | if (fh >= 0) {
157 | binCount = 1;
158 | for (Node e = f;; ++binCount) {
159 | K ek;
160 | if (e.hash == hash &&
161 | ((ek = e.key) == key ||
162 | (ek != null && key.equals(ek)))) {
163 | oldVal = e.val;
164 | if (!onlyIfAbsent)
165 | e.val = value;
166 | break;
167 | }
168 | Node pred = e;
169 | if ((e = e.next) == null) {
170 | pred.next = new Node(hash, key, value);
171 | break;
172 | }
173 | }
174 | }
175 | else if (f instanceof TreeBin) {
176 | Node p;
177 | binCount = 2;
178 | if ((p = ((TreeBin)f).putTreeVal(hash, key,
179 | value)) != null) {
180 | oldVal = p.val;
181 | if (!onlyIfAbsent)
182 | p.val = value;
183 | }
184 | }
185 | else if (f instanceof ReservationNode)
186 | throw new IllegalStateException("Recursive update");
187 | }
188 | }
189 | if (binCount != 0) {
190 | if (binCount >= TREEIFY_THRESHOLD)
191 | treeifyBin(tab, i);
192 | if (oldVal != null)
193 | return oldVal;
194 | break;
195 | }
196 | }
197 | }
198 | addCount(1L, binCount);
199 | return null;
200 | }
201 | }
202 | ```
203 |
--------------------------------------------------------------------------------
/Java/garbage_collection.md:
--------------------------------------------------------------------------------
1 | # GC(Garbage Collection)
2 | JVM의 Heap 영역에서 사용하지 않는 **객체를 삭제하는 프로세스**를 말한다.
3 |
4 | 
5 |
6 | 그러면 GC는 어떻게 삭제할 객체와 아닌 객체를 구분할까?
7 |
8 | 
9 |
10 | GC Roots에서부터 참조하고 있는 객체들을 탐색해나간다.
11 |
12 | GC Root가 될 수 있는 것들은 다음과 같다.
13 | - stack 영역의 데이터
14 | - method 영역의 static 데이터
15 | - JNI에 의해 생성된 객체들
16 |
17 | 참조되고 있는 객체를 Reachable, 그렇지 않은 객체를 Unreachable이라고 한다.
18 |
19 | 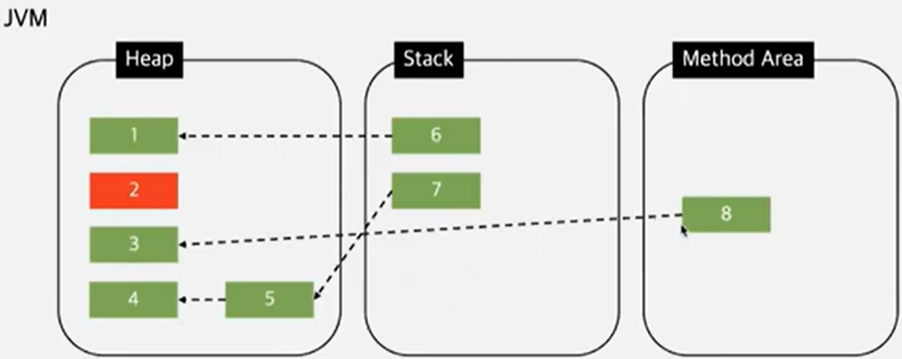
20 |
21 | 위의 그림에서 2번 객체는 Unreachable하다.
22 |
23 | ## GC의 동작 방식
24 |
25 | GC의 기본적인 동작 방식은 **MARK AND SWEEP** 이다. (알고리즘에 따라 COMPACT 과정이 추가되기도 한다.)
26 |
27 | 
28 |
29 | MARK: GC Roots로부터 모든 변수를 스캔하면서 각각 어떤 객체를 참조하고 있는지 찾아서 마킹한다.
30 |
31 | 
32 |
33 | SWEEP: Unreachable 객체들을 Heap에서 제거한다.
34 |
35 | 
36 |
37 | COMPACT: SWEEP 후에 분산된 객체들을 모아서 메모리 단편화를 막아주는 작업이다.
38 |
39 | ## GC는 언제 일어날까?
40 |
41 | 
42 |
43 | Heap은 크게 Young Generation과 Old Generation으로 나누어진다.
44 |
45 | Young Generation은 다시 Eden, Survivor0, Survivor1으로 나누어진다.
46 |
47 | 새로운 객체가 Eden에 할당되고, Eden이 꽉 차면 이때 **Minor GC**가 발생한다.
48 |
49 | 
50 |
51 | 이 때 Survivor0영역으로 살아남은 객체들이 이동을하며, 이동 시 객체들의 age가 증가한다.
52 |
53 | 
54 |
55 | 다시 Eden이 꽉 차면 이번에는 Survivor1 영역으로 이동한다.
56 |
57 | 
58 |
59 | 이 때 주의할 점은
60 | - Survivor0과 Survivor1으로 번갈아가며 이동한다.
61 | - Survivor0과 Survivor1 중 한 영역은 반드시 비어있어야 한다.
62 |
63 | 객체의 age가 특정 임계점에 달하게 되면, Old Generation으로 이동한다. 이러한 이동을 Promotion이라고 한다.
64 | 
65 |
66 | Old Generation이 꽉 차게 되면 **Major GC**가 발생하게 된다.
67 |
68 | 
69 |
70 | 왜 Minor GC와 Major GC를 나눌까?
71 |
72 | 1. 대부분의 객체는 금방 접근 불가능한 상태가 된다. 즉, 금방 garbage가 된다.
73 | 2. 오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다.
74 |
75 | ## GC의 종류
76 | - Serial GC
77 | - GC를 싱글 쓰레드로 수행
78 | - Parallel GC (Java 8의 default GC)
79 | - young 영역의 GC를 멀티 쓰레드로 수행
80 | - Parallel Old GC
81 | - Parallel GC와 똑같지만, Old영역까지 멀티 쓰레드로 수행
82 | - CMS GC(Concurrent Mark Sweep)
83 | - stop-the-world를 줄이기 위해 고안됨
84 | - compact과정이 없어서 메모리 단편화 문제
85 | - G1 GC(Garbage First)
86 | - Heap을 일정한 크기의 Region으로 나누어 Region단위로 탐색
87 | - compact과정을 통해 CMS GC의 메모리 단편화 문제를 개선
88 | - Java 9이상 default GC
89 |
90 | 참고자료: https://www.youtube.com/watch?v=Fe3TVCEJhzo
91 |
--------------------------------------------------------------------------------
/Java/string_is_immutable.md:
--------------------------------------------------------------------------------
1 | # String은 왜 Immutable(불변)인가?
2 |
3 | (모든 설명은 JAVA를 기준으로 합니다.)
4 |
5 |
6 |
7 | ## Immutable이란,
8 |
9 | > 뜻 : **불변의, 변경할 수 없는**
10 |
11 | Java에서의 String객체는 한 번 생성되면 절대로 그 값이 변하지 않는다.
12 | 왜 그럴까?
13 |
14 |
15 |
16 | ## String Pool
17 |
18 | 우선 자바는 Heap의 String Pool이라는 공간에 String을 포함시켜,
19 | 매번 String객체를 생성하지 않고 값이 같다면 String Pool에 있는 객체를 재사용 할 수 있도록 구현하였다.
20 |
21 | 즉, String Pool안에있는 String 데이터를 공유/참조 한다는 뜻이다.
22 | 그렇기에 String은 Immutable해야하는 것이다.
23 |
24 | 만약 mutable하다 해보자
25 |
26 | ```java
27 | String a1 = "Hello";
28 | String a2 = "Hello";
29 | ```
30 |
31 | a1과 a2는 변수 명은 다르지만 같은 String 객체를 가리킨다.
32 |
33 | ```java
34 | a2 = "Bye";
35 | ```
36 |
37 | a2을 "Bye"로 바꿔보자
38 | a1과 a2는 **같은 String 객체**를 가리키는데 값이 다르다.
39 | 이거슨 존재 할 수 없다!!
40 |
41 | 그렇기에 String은 Immutable인 것이다.
42 |
43 | 그리고
44 |
45 | ```java
46 | a2 = "Bye"
47 | ```
48 |
49 | 은 "Hello"라는 String 객체가 "Bye" 로 바뀐게 아니라 "Bye"라는 객체를 String Pool에 새로 생성한 것이다.
50 |
51 |
52 |
53 | ## Immutable하게 쓰면서 생긴 장점들이 있다
54 |
55 |
56 |
57 | ### 캐싱
58 |
59 | 사용자가 많이 방문하는 naver
60 | 이 "Naver"도 문자열 데이터인데 사용자들이 올 때마다 "Naver" 객체를 만들어서 준다고 해보자 메모리 낭비다.
61 | 근데 이를 String Pool에있는 Naver객체를 재사용함으로써 캐시와 같은 효과를 볼 수있다. 당연히 성능과 메모리 효율면에서 이득을 얻을 수 있다.
62 |
63 |
64 |
65 | ### 해싱
66 |
67 | 불변이라 함은 해시코드가 언제나 같다는것을 의미
68 | 한번 해시함수를 거쳐 계산해두면 값이 변할 일이 없어서 안심할 수 있다.
69 | java는 String객체 생성시 부터 hashcode를 캐싱해놓는다고 한다. 즉 해시맵이나 테이블에서 키로 쓰일 때 해시함수 과정을 안거치고 사용해도 된다는 뜻이다.
70 |
71 |
72 |
73 | ### 보안
74 |
75 | 메모리 주소에 저장된 String 값은 불변이기 때문에 보안면에서 유리하다.
76 | 파라미터로 넘겨줄 때 String의 값이 저장된 주소값을 전달받게 된다.
77 | 그 주소값을 따라가 메모리 상의 값을 참조 할 수 있지만 그 값을 변경하는것은 불가능 하므로 안전하다고 볼 수 있다.
78 |
79 |
80 |
81 | ### 스레드 안전성
82 |
83 | 멀티 스레드환경을 보면 프로세스의 자원을 스레드들이 공유한다
84 | String의 불변은 멀티 쓰레드 환경에서 String 객체를 참조하더라도 안전하다는 뜻이다.
85 |
86 |
87 |
88 | ### 단점도 존재한다.
89 |
90 | Immutable이기 때문에
91 | 문자열을 합치거나 조작 해야하는 경우에 매번 새로운 String 객체를 생성해야한다는 단점이 있다. 이를 막기 위해서 StringBuilder나 StringBuffer를 사용한다.
92 | python에는 join이 있다.
93 |
94 |
95 |
96 | ## StringBuilder, StringBuffer
97 |
98 | 둘 다 mutable한 객체로
99 | 주소값이 변하지 않고 객체 내부의 배열의 공간을 조절해서 문자열을 추가, 삭제 할 수 있다.
100 |
101 |
102 |
103 | 문자열의 추가, 수정, 삭제 등이 빈번히 발생하는 경우라면 해당 객체를 사용하는게 좋다.
104 |
105 | ## StringBuilder, StringBuffer차이
106 |
107 | 둘은 같은 클래스를 상속한다. 기능이 비슷한데, 동기화 여부에서 차이가 있다.
108 | StringBuilder는 동기화 지원을 안하고
109 | StringBuffer는 동기화 지원을 한다.
110 |
111 |
112 | 즉 멀티스레드 환경에서는 StringBuffer가 더 사용하기 안전하며
113 | 단일 스레드 환경에서는 StringBuilder가 조금 더 빠를 것이다.
114 |
115 | ## Reference
116 |
117 | https://steady-coding.tistory.com/569
118 | https://steady-coding.tistory.com/569
119 | https://starkying.tistory.com/entry/why-java-string-is-immutable
120 | https://dololak.tistory.com/699
121 | https://twinstae.github.io/string-immutable/
122 | https://yeon-kr.tistory.com/157
123 |
--------------------------------------------------------------------------------
/LICENSE:
--------------------------------------------------------------------------------
1 | MIT License
2 |
3 | Copyright (c) 2022 cs-book
4 |
5 | Permission is hereby granted, free of charge, to any person obtaining a copy
6 | of this software and associated documentation files (the "Software"), to deal
7 | in the Software without restriction, including without limitation the rights
8 | to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
9 | copies of the Software, and to permit persons to whom the Software is
10 | furnished to do so, subject to the following conditions:
11 |
12 | The above copyright notice and this permission notice shall be included in all
13 | copies or substantial portions of the Software.
14 |
15 | THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
16 | IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
17 | FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
18 | AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
19 | LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
20 | OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
21 | SOFTWARE.
22 |
--------------------------------------------------------------------------------
/Network/HTTP_vs_HTTPS.md:
--------------------------------------------------------------------------------
1 | # HTTP vs HTTPS
2 |
3 | # HTTP
4 |
5 | HyperText Transfer Protocol 의 약자로 **인터넷에서 데이터를 주고받기 위한 규칙**입니다.
6 |
7 | 클라이언트가 브라우저나 모바일 앱 등을 통해서 정보를 **요청(request)**하면 서버가 **응답(response)**하는 형태로 동작합니다.
8 |
9 | 요청 메시지에는 `Method`, `Path`, `Protocol 버전`, `Headers`, `Request Body` 등이 있습니다.
10 |
11 | 응답 메시지에는 `Protocol 버전`, `Status Code`, `Headers`, `Response Body` 등이 있습니다.
12 |
13 | ## HTTP Method
14 |
15 | - GET: 리소스 조회
16 | - POST: 리소스 추가
17 | - PUT: 리소스 전체 업데이트
18 | - PATCH: 리소스 부분 업데이트
19 | - DELETE: 리소스 삭제
20 | - 그 외
21 | - HEAD: 리소스에 대한 헤더만 조회
22 | - OPTIONS: 리소스에 대해 수행 가능한 동작 조회
23 |
24 | ## HTTP Status Code
25 |
26 | - 1XX: 조건부 응답
27 | - 101: **Swiching Protocols**로 서버가 프로토콜을 변경했음을 의미합니다.
28 | - 2XX: 성공
29 | - 200: **OK**로 요청이 정상이며 응답 본문에 요청한 리소스를 포함하고 있음을 의미합니다.
30 | - 3XX: 리다이렉션
31 | - 4XX: 요청 오류
32 | - 401: **Unauthorized**로 인증되지 않아 요청이 서버에 의해 거부되었음을 의미합니다.
33 | - 403: **Forbidden**으로 권한이 없어 요청이 서버에 의해 거부되었음을 의미합니다.
34 | - 404: **Not Found**로 클라이언트가 요청한 URL을 서버가 찾을 수 없음을 의미합니다.
35 | - 5XX: 서버 오류
36 | - 500: **Internal Server Error**
37 |
38 | # HTTPS
39 |
40 | HTTP에 SSL(Secure Socket Layer) 또는 TLS(Transport Layer Security) 라는 다른 프로토콜을 조합해 **암호화**와 **인증**을 더한 프로토콜입니다.
41 |
42 | HTTP는 암호화되지 않은 평문 통신이기 때문에 도청이 가능하고, 통신 상대를 확인하지 않기 때문에 위장이 가능합니다. HTTPS는 이런 HTTP의 단점을 보완할 수 있습니다.
43 |
44 | ## 주류 주문 과정
45 |
46 | 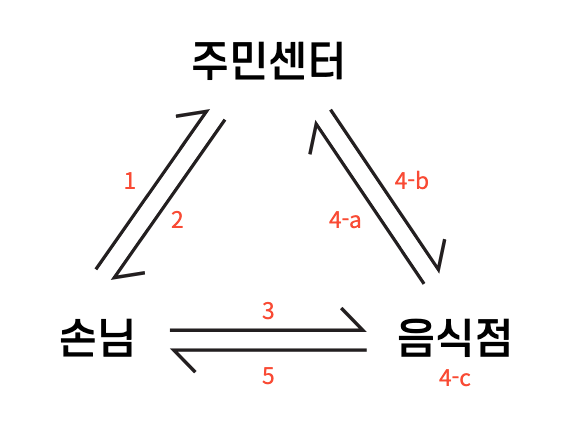
47 |
48 | 1. 손님이 주민센터에 주민등록증 발급 신청, 지문 정보 제공
49 | 2. 주민센터가 손님에게 주민등록증 발급
50 | 3. 손님이 음식점에 주민등록증 제공
51 | 4. 성인 확인 과정
52 | 1. 주민등록증 진위 확인 기기가 없다면 주민센터에 요청
53 | 2. 기기 제공
54 | 3. 주민등록증이 진짜임을 확인
55 | 5. 주류 제공
56 |
57 | ## HTTPS 동작 과정
58 |
59 | 
60 |
61 | 1. 서버가 CA에게 인증서 발급 신청, 서버의 공개키 제공
62 | 2. CA의 비밀키로 암호화한 인증서 발급, CA의 공개키 제공
63 | 3. 연결 시작
64 | 1. 클라이언트가 서버에게 연결 요청
65 | 2. 서버가 클라이언트에게 인증서, 서버의 공개키 제공
66 | 4. 인증서 확인 과정
67 | 1. CA의 공개키를 가지고 있지 않다면 CA에 요청
68 | 2. CA의 공개키 제공
69 | 3. CA의 공개키로 인증서 복호화 성공 → 인증서 검증 성공
70 | 5. 서버의 공개키로 암호화된 클라이언트의 대칭키 서버에 제공
--------------------------------------------------------------------------------
/Network/Multiplexing and Demultiplexing.md:
--------------------------------------------------------------------------------
1 | # [Network] Multiplexing and Demultiplexing
2 |
3 | 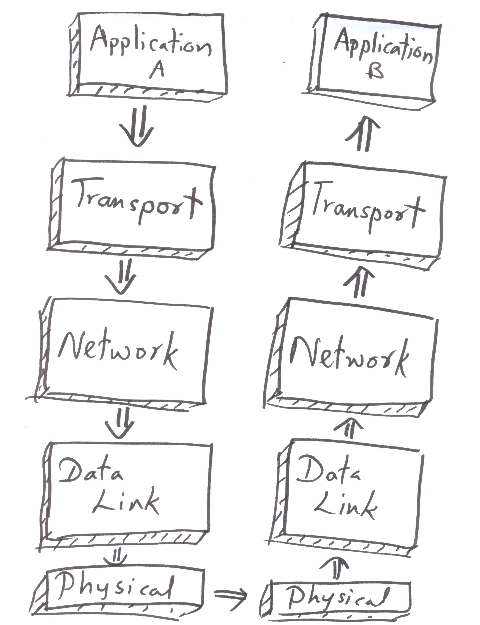
4 |
5 |
6 | ## 1. Multiplexing 이란?
7 | Apllication layer에서 패킷(Message)들이 여러 socket을 통해 Transport layer로 전달 될 때 각 패킷(Message)에 헤더를 추가하고 세그먼트로 캡슐화하여 Network layer로 전달하는 과정을 Multiplexing이라고 한다.
8 |
9 | 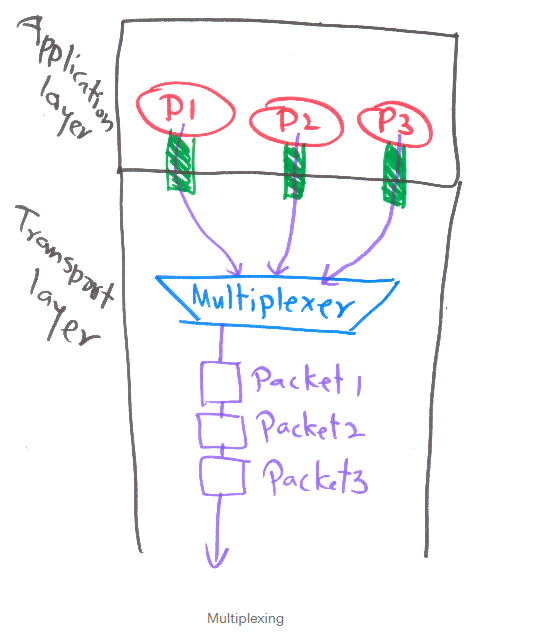
10 |
11 | ## 2. Demultiplexing 이란?
12 | Transport layer에 의해서 세그먼트가 Application layer의 올바른 소켓으로 전달되는 과정을 Demultiplexing이라고 한다.
13 |
14 | 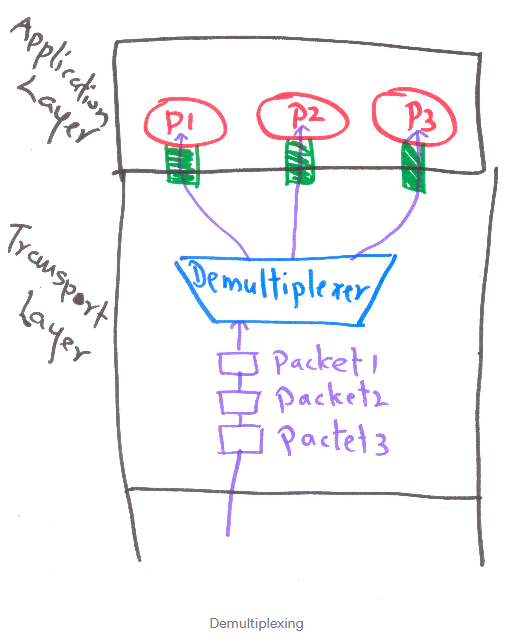
15 |
16 | ### 2.1. Demultiplexing의 방식
17 | 세그먼트의 헤더에 있는 `dest port`정보를 가지고 demultiplexing을 한다.
18 |
19 | - source post: 자기자신 포트넘버
20 | - dest port: 목적지 포트넘버
21 |
22 | 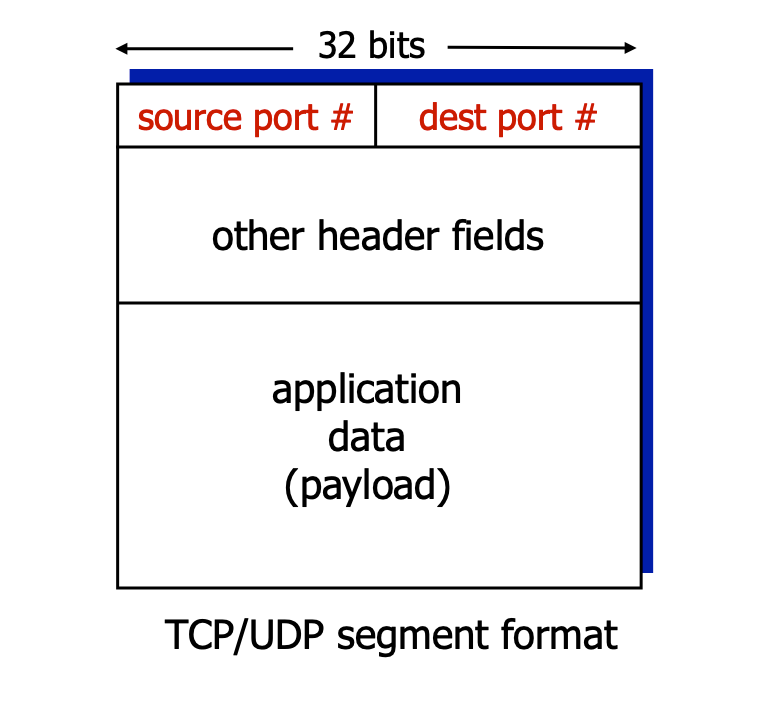
23 |
24 | ### 2.2. UDP에서의 Demultiplexing
25 | 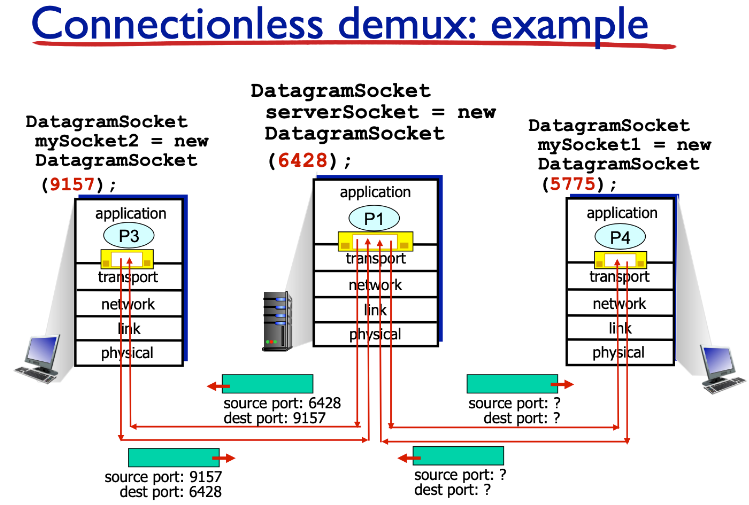
26 | **UDP에서의 Demultiplexing은 `dest ip`, `dest port`만을 가지고 이루어진다.**
27 | 즉, `source ip` 또는 `source port` 가 달라도(출처가 달라도) `dest ip`, `dest port`만 같으면 같은 소켓으로 전달 된다.
28 |
29 |
30 |
31 | ### 2.3. TCP에서의 Demultiplexing
32 |
33 | 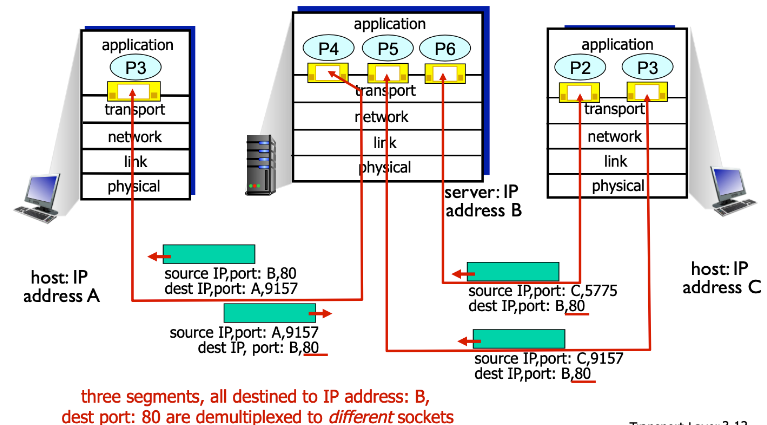
34 |
35 | TCP에서 Demultiplexing은 4-tuple로 이뤄진다.
36 | - 소스 IP 주소
37 | - 소스 포트 번호
38 | - 대상 IP 주소
39 | - 대상 포트 번호
40 |
41 | 위 4개의 값을 모두 사용하여 적절한 소켓으로 패킷을 전달한다. **하나만 달라도 다른 소켓으로 전달된다.**
42 | > Web server는 동시에 많은 TCP 소켓을 지원하고, 각 연결된 클라이언트마다 서로 다른 소켓을 갖는다. 즉, 소켓이 1:1로 대응된다.
--------------------------------------------------------------------------------
/Network/OSI_7_layers.md:
--------------------------------------------------------------------------------
1 | # OSI 7계층
2 |
3 | ## OSI 7계층이란?
4 |
5 | 
6 |
7 | - 네트워크에서 통신이 일어난 과정을 7단계로 나눈것
8 |
9 | ## 등장 배경
10 |
11 | - 기업들이 각자 모델에 맞춰 장치를 개발해 다른 회사에서 만든 장치끼리 통신이 안 됨
12 | - 이 기종 컴퓨터 간 통신 위해 네트워크 표준화가 필요해짐. 이를 위해 국제 표준화 기구(ISO)에서 통신 장비를 설계할 때 기준으로 삼으라고 제시해 준 표준 모델이 OSI 참조 모델
13 | - 단계별로 파악할 수 있고 흐름을 한눈에 볼 수 있으며 특정 단계에서 문제발생시 다른 부분은 건들지 않고 그 부분만 고치면 해결 할 수 있기 때문
14 | - OSI 7계층 = 컴퓨터 통신 구조의 표준적 모델
15 |
16 | ## 계층별 특징
17 |
18 | - 상위 계층은 하위 계층의 부족한 점을 보완함
19 |
20 | 1. 물리계층
21 |
22 | 
23 |
24 | > 물리적으로 신호를 주고받음
25 |
26 | - 사용되는 통신 단위는 비트이며 이것은 1과 0으로 나타내어진다.
27 | - 단지 데이터 전송만 하고 어떤 에러가 있는지, 데이터가 무엇인지는 신경 쓰지 않는다.
28 | - 장비로는 리피터, 허브가 있다.
29 |
30 | 2. 데이터 링크 계층
31 |
32 | 
33 |
34 | > MAC주소를 부여 하고 에러검출,재전송,흐름제어를 한다.
35 |
36 | - 물리계층을 통해 송수신되는 정보의 오류와 흐름을 관리하여 안전한 정보의 전달을 수행할 수 있도록 도와주는 역할을 한다. 통신에서의 오류도 찾아주고 재전송한다.
37 | - 같은 네트워크에 있는 여러 대의 컴퓨터들이 데이터를 주고 받기 위해서 필요
38 | - MAC 주소를 가지고 통신하게 된다.
39 | - 장비로는 브리지, 스위치가 있다.
40 | - 프로토콜로는 이더넷이 있다.
41 |
42 | 3. 네트워크 계층(Network Layer)
43 |
44 | 
45 |
46 | > 데이터를 목적지까지 가장 안전하고 빠르게 전달하는라우팅 기능을 한다
47 |
48 | - 경로를 선택하고 주소를 정하고 경로에 따라 패킷을 전달해준다
49 | - 장비로는 대표적으로 "라우터(router)" 이다.
50 | - 프로토콜로는 IP, ARP, RARP, ICMP, IGMP
51 |
52 | 4. 전송 계층(Transport Layer)
53 |
54 | 
55 |
56 | > 양 끝단의 사용자들이 데이터를 주고 받을 수 있게 한다
57 |
58 | - 네트워크 계층에서 네트워크 주소(컴퓨터-컴퓨터)까지 전송한다면 전송계층은 포트 주소(프로세스-프로세스)까지 전송 담당
59 | - 1,2,3계층으로 인해 전세계로 데이터를 송수신할 수 있게 됨. 하지만 데이터를 전달만할뿐 수신 호스트가 패킷을 수신할 준비가 되었는지, 전송과정에서 패킷이 손상되거나 유실되지는 않았는지 등의 문제들은 신경쓰지 않음
60 | - 패킷이 전송 과정에서 아무 문제 없이 제대로 수신지 컴퓨터에 도착할 수 있도록 패킷 전송을 제어하는 역할은 전송 계층이 담당 (시퀀스 넘버 기반 패킷 흐름제어, 오류 제어 등)
61 | - 프로토콜은 TCP, UDP
62 |
63 |
64 | 5. 세션 계층(Session Layer)
65 |
66 | > 데이터가 통신하기 위한 논리적인 연결 담당
67 |
68 | - 1~4계층까지 주된 내용이 데이터 전달 이라면, 5계층부터는 컴퓨터 내의 프로세스들에 의해 데이터를 만드는 작업
69 | - 1~4계층의 정상적인 역할 수행으로 네트워크 세션이 생성
70 | - 네트워크상 양쪽 연결을 관리하고 연결을 지속 시켜 주는 계층
71 | - 응용프로그램간의 대화를 유지하기 위한 구조 제공
72 | - 동기화 담당
73 | - 특정 지점에서 송수신 오류가 발생하면 이전에 동기점으로 설정한 통신이 완벽했던 지점부터 다시 재전송.
74 | - 암호화, 로그인 기능, 호스트 인증 기능
75 | - **세션이란?**
76 |
77 | 세션이란 일정 시간 동안 같은 사용자로부터 들어오는 일련의 요구를 하나의 상태로 보고 그 상태를 일정하게 유지하는 기술을 말한다. 여기서 일정 시간이란, 방문자가 웹 브라우저를 통해 웹 서버에 접속한 시점으로부터 웹 브라우저는 종료함으로써 연결을 끝내기 까지의 기간을 말한다. 즉, 방문자가 웹 서버에 접속해 있는 상태를 하나의 단위로 보고 세션이라고 부른다.
78 |
79 | - 프로토콜로는 SSH, TLS
80 |
81 | 6. 표현 계층(Presentation Layer)
82 |
83 | > 데이터변환, 압축, 암호화 지원
84 |
85 | - 응용 계층의 데이터를 세션계층이 다룰 수 있는 형태로 바꾸고 세션계층의 데이터를 응용계층이 이해할 수 있는 형태로 바꾸고 전달하는 일 담당
86 | - 응용 계층에서 표현하는 다양한 표현양식을 공통적인 전송형식으로 변환
87 | - 한 시스템의 애플리케이션에서 보낸 정보를 다른 시스템의 애플리케이션 층이 읽을 수 있도록 하는 층
88 | - 데이터를 하나의 표현 형태로 변환하여 두 장치가 일관되게 전송데이터를 이해할 수 있도록 한다
89 | - 코드 간의 번역을 담당하여 사용자 시스템에서 데이터의 형식상 차이를 다루는 부담을 응용 계층으로부터 덜어 준다.
90 | - 데이터 번역자 로서의 역할
91 | - 프로토콜로는 JPEG, MPEG(오디오, 비디오)
92 |
93 | 7. 응용 계층(Application Layer)
94 |
95 | > 사용자가 네트워크에 접속 가능 하게 해주는 계층
96 |
97 | - 사용자가 보는 소프트웨어의 UI, 사용자의 입출력 부분(I/O) 등을 담당하는 계층이다.
98 | - 사용자에게 서비스를 제공하고 사용자가 제공한 정보나 명령을 하위계층으로 전달하는 역할
99 | - 응용 프로세스와 직접 관계하여 일반적인 응용 서비스를 수행한다.
100 | - 포로토콜로는 HTTP, FTP, DNS, SMTP, Telnet
107 |
108 | ## 한 단어 요약
109 |
110 | - 상위 계층은 하위 계층의 부족한 점을 보완한다
111 | - 1-전기, 2-맥, 3-IP, 4-포트, 5-세션, 6-표현, 7-사용자
112 |
113 |
114 | ## reference
115 |
116 | [https://dncjf64.tistory.com/379](https://dncjf64.tistory.com/379)
117 |
--------------------------------------------------------------------------------
/Network/TCP_vs_UDP.pdf:
--------------------------------------------------------------------------------
https://raw.githubusercontent.com/cs-book/cs-knowledge-for-interview/cf680a1aeea565553e7a2a950abd4e07c7c12f0e/Network/TCP_vs_UDP.pdf
--------------------------------------------------------------------------------
/Network/symmentric-key_vs_public-key.md:
--------------------------------------------------------------------------------
1 | # 대칭키 암호화 vs 공개키(비대칭키) 암호화
2 |
3 | ## 대칭키 암호화
4 |
5 | #### 암호화와 복호화에 사용하는 키가 동일한 암호화 방식
6 |
7 | - 대표 알고리즘: DES, 3DES, AES, SEED, ARIA, HIGHT, IDEA, RC5
8 | - 장점
9 | - 비교적 연산 속도가 빠름
10 | - 암호화 할 수 있는 평문의 길이 제한이 없음
11 | - 단점
12 | - 키를 교환해야하 하는 문제(키 분배 문제)가 발생
13 | - 키 교환 중 키가 탈취될 수 있는 문제
14 | - 사람이 증가할수록 따로 모든 키교환을 해야하기 때문에 관리할 키가 방대하다.
15 | - 인증, 무결성 지원이 부분적으로만 가능하며, 부인방지기능을 제공하지 못한다.
16 |
17 | ### 이해를 돕기 위한 예시
18 |
19 | > 철수는 영희에게 A라는 열쇠로만 열 수 있는 비밀상자를 전달하고자 한다.
20 | >
21 | > 그렇다면 철수는 비밀상자는 물론이고, 이 상자를 열 수 있는 A열쇠 또한 안전하게 영희에게 전달해야한다.
22 | >
23 | > 만약 비밀상자와 함께 열쇠를 담아 보내주면, 중간에 다른사람이 가로채 상자를 열어볼 수 있게된다.
24 | >
25 | > 따라서 이 열쇠는 비밀상자와는 다른 경로로 안전하게 전달되어야한다.
26 | >
27 | > 이처럼 키를 안전하게 교환하는 것이 대칭키 암호화 방식의 가장 중요한 부분이다.
28 |
29 | ## 공개키(비대칭키) 암호화
30 |
31 | #### 암호화와 복호화에 사용하는 키가 다른 암호화 방식
32 |
33 | - 대표 알고리즘: Diff-Hellman, RSA, DSA, ECC, Rabin, ElGamal
34 | - 장점
35 | - 키 분배 및 관리가 용이
36 | - 관리할 키 개수가 상대적으로 적다
37 | - 기밀성, 인증, 무결성을 지원, 특히 부인방지 기능 제공
38 | - 단점
39 | - 비교적 연산 속도가 느림
40 | - 암호화 할 수 있는 평문의 길이 제한이 있음
41 |
42 | ### 이해를 돕기 위한 예시
43 |
44 | - 개인키를 활용한 암호화 방식과 공개키를 활용한 암호화 방식 2가지로 나뉨
45 |
46 | #### 1) 공개키로 암호화 하는 경우
47 |
48 | - 어떤 정보를 특정 사용자에게 보낼 경우 해당 사용자의 공개키를 통해 암호화하여 전송
49 | > 철수는 누구나 알 수 있는 영희의 공개키를 통해 비밀상자를 암호화 한 후 영희에게 보낸다.
50 | >
51 | > 이 상자를 열어보기 위해서는 영희의 개인키가 필요하다.
52 | >
53 | > 영희의 개인키는 영희 자기자신만 가지고 있기 때문에, 안전하게 열어볼 수 있다.
54 | >
55 | > 위에 언급한 대칭키에서의 키값 교환에 따른 문제를 해결한 방법이라고 할 수 있다.
56 |
57 | #### 2) 개인키로 암호화 하는 경우
58 |
59 | - 어떤 정보를 특정 사용자에게 보낼 경우 자기자신의 개인키를 통해 암호화하여 전송
60 | > 철수는 자신만의 개인키를 통해 비밀상자를 암호화하여 영희에게 보낸다.
61 | >
62 | > 이 비밀상자는 철수의 공개키가 있어야만 열 수 있다.
63 | >
64 | > 철수의 공개키는 누구나 알 수 있기때문에, 영희는 비밀상자를 열어볼 수 있다.
65 |
66 | - Q. 중간에 탈취되면 공개된 공개키를 통해 아무나 열 수 있지 않을까?
67 | - A. 그렇다. 누구나 열 수 있다.
68 | - Q. 그렇다면 왜 이런 방법을 쓰는가?
69 | - A. 상자안에 뭐가 들었는지 ‘내용’ 보다는 누가 보냈는지 ‘출처’에 초점을 둔 방식이다.
70 | > 즉, 철수의 개인키로 암호화 한 비밀상자는 철수의 공개키를 통해서 열 수 있기 때문에,
71 | >
72 | > 만약 어떤 상자가 철수의 공개키로 열린다면, 이 상자는 철수가 보낸게 확실하다는 의미이다.
73 |
74 | - 이러한 기술은 데이터 제공자의 신원이 보장되는 ‘전자서명’ 등의 공인인증 체계의 기본이 된다.
75 |
76 | ### 정보보호의 목표 5가지
77 |
78 | 1. 기밀성(Confidentiality) : 오직 인가된 사람, 인가된 프로세스, 인가된 사스템만이 알 필요성에 근거하여 사스템에 접근해야 한다는 원칙
79 |
80 | *위협요소 - 도청, 사회공학
81 |
82 | 2. 무결성(Integrity) : 정보의 내용이 불법적으로 생성 또는 변경되거나 삭제되지 않도록 보호되어야 하는 성질
83 |
84 | *위협요소 - 논리폭탄, 백도어, 바이러스
85 |
86 | 3. 가용성(Avaliability) : 정당한 사용다가 정보시스템의 데이터 또는 자원을 필요할 때 지체 없이 원하는 객체 또는 자원에 접근하여 사용할 수 있는 성질
87 |
88 | *위협요소 - DoS, DDoS, 지진, 홍수, 화재
89 |
90 | 4. 인증성(Authentication) : 임의 정보에 접근할 수 있는 객체의 자격이나 객체의 내용을 검증하는데 사용되는 성질
91 |
92 | 5. 부인방지(Non-repudiation) : 행위나 이벤트의 발생을 증명하여 나중에 그런 행위나 이벤트를 부인할 수 없도록 하는 것
93 |
94 | ### 참고자료
95 |
96 | https://universitytomorrow.com/22
97 |
98 | https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sharp428&logNo=220586189288
99 |
--------------------------------------------------------------------------------
/OS/CPU_scheduler.md:
--------------------------------------------------------------------------------
1 | # CPU 스케줄러
2 |
3 | ## CPU 스케줄러란?
4 |
5 | 다중 프로그래밍을 가능하게 하기 위한 운영체제의 동작 기법
6 |
7 | 어떤 프로세스에 cpu를 배정할 지 결정
8 |
9 | 모든 프로세스가 공평하게 작업할 수 있도록 하기 위해 사용
10 |
11 | ## CPU 스케줄러의 종류
12 |
13 | 
14 |
15 | 1. 장기 스케줄러
16 |
17 | 메모리에 올라가 있는 프로세스의 수를 제어
18 |
19 | 시스템의 과부하를 막기 위해 어떤 작업을 받아들일지 결정
20 |
21 | 2. 단기 스케줄러
22 |
23 | 프로세스에 cpu를 할당
24 |
25 | 3. 중기 스케줄러
26 |
27 | cpu를 사용하려는 프로세스 간 중재하여 일시 보류 & 재활성화 담당
28 |
29 | 단기 스케줄링이 원만히 이루어지도록 완충하는 역할
30 |
31 |
32 | ## CPU 스케줄링 목적
33 |
34 | 1. 공평성
35 |
36 | 모든 프로세스가 자원을 공평하게 배정받아야 하며, 특정 프로세스가 배제돼선 안 된다
37 |
38 | 2. 효율성
39 |
40 | 시스템 자원을 놀리는 시간 없이 스케줄링해야 한다
41 |
42 | 3. 안정성
43 |
44 | 우선순위를 사용하여 중요한 프로세스가 먼저 처리되도록 해야 한다
45 |
46 | 4. 반응 시간 보장
47 |
48 | 응답이 없는 경우 사용자는 시스템이 멈춘 것으로 가정하기 때문에 시스템은 적절한 시간 안에 프로세스의 요구에 반응해야 한다
49 |
50 | 5. 무한 연기 방지
51 |
52 | 특정 프로세스의 작업이 무한히 연기되어서는 안 된다
53 |
54 | 6. CPU 사용율을 늘림
55 |
56 | 가능하면 많은 일을 수행한다
57 |
58 | 7. 기아 현상을 낮춤
59 |
60 | 특정 프로세스의 작업이 무한히 연기돼선 안 된다
61 |
62 | +) 기아현상이란?
63 |
64 | 우선 순위로 작업을 처리할 때 우선순위가 낮은 작업은 영원히 처리되지 않는 문제
65 |
76 |
77 | - 선점형 스케줄링
78 |
79 | 
80 |
81 | - 실행 도중 다른 프로세스에게 CPU를 뺏길 수 있음
82 | - 낮은 우선순위를 가진 프로세스보다 높은 우선순위를 가진 프로세스가 CPU를 선점하는 방식
83 | - 우선순위가 높은 프로세스를 빠르게 처리해야할 때 유용
84 | - 선점이 일어날 경우, 오버헤드가 발생하고 처리시간 예측이 힘들다
85 |
86 |
87 | ## 스케줄링 알고리즘
88 |
89 | 
90 |
91 | - 비선점 스케줄링
92 | 1. 우선순위 스케줄링
93 | - 프로세스마다 우선순위를 붙여 우선순위가 높은 프로세스를 먼저 실행하는 방식
94 | - 우선순위가 동일한 프로세스는 FIFO 순서로 스케줄링함
95 | - 단점 : 우선순위가 낮은 프로세스는 무한정 연기돼 기아현상이 발생
96 |
97 | 2. 기한부 스케줄링
98 | - 프로세스에 일정한 시간을 제공하고 그 시간안에 프로세스를 완료하도록 하는 기법. 일정시간동안 프로세스가 완료되지 않으면 삭제하고 다시 실행한다.
99 | - 단점 : 주어진 시간 내에 완료되지 못했을 때 제거되거나 처음부터 다시 실행되기 때문에 손해 발생한다. 작업 시간이나 상황 등 정보를 미리 예측하기 어렵다.
100 |
101 | 1. FCFS 스케줄링(First Come First Served**)**
102 | - 선입선출 방식, 준비 큐에 도착한 순서대로 CPU를 할당
103 | - 모든 프로세스의 우선순위가 동일하고, 프로세스의 CPU 처리 시간을 따로 고려하지 않기 때문에 매우 단순하고 공평한 방법이다.
104 | - 단점 : CPU 처리 시간이 긴 프로세스가 앞에 올 경우 뒤의 프로세스가 한없이 기다려야 하기 때문에 비효율적이게 된다.
105 |
106 | 2. SJF 스케줄링(Shortest Job First)
107 | - 준비 큐에 있는 프로세스 중 실행 시간이 가장 짧은 작업부터 CPU를 할당
108 | - 늦게 도착하더라도 CPU 처리 시간이 앞에 대기중인 프로세스보다 짧으면 먼저 CPU를 할당받을 수 있다.
109 | - 단, 비선점형 방식이기 때문에 CPU를 사용중인 프로세스보다 처리 시간이 짧더라도 빼앗지는 못한다.
110 | - 단점 : 기아 현상이 발생한다. 처리 시간이 긴 프로세스의 경우 처리 시간이 짧은 프로세스가 계속해서 들어온다면 대기 큐에서 영영 CPU를 할당받지 못할 수 있다.
111 |
112 | 3. HRN 스케줄링(Highest response ratio next)
113 | - 수행시간의 길이와 대기 시간을 모두 고려해 우선순위를 정한다.
114 | - SJF 스케줄링에 Aging 기법을 합친 비선점형 알고리즘이다.
115 | - Aging이란 나이를 먹는다는 의미 그대로 starvation을 해결하기 위해 대기 시간이 길어지면 우선순위를 높여주는 방법이다.
116 | - SJF와 마찬가지로 실행 시간이 적은 프로세스의 우선 순위가 높지만 대기 시간이 너무 길어지면 실행 시간이 길더라도 CPU를 할당받을 수 있다. 하지만 여전히 공평성이 말끔히 해결되지는 않는다.
117 |
118 |
119 | - 선점 스케줄링
120 | 1. RR 스케줄링
121 | - 각 프로세스는 같은 크기의 CPU 시간을 할당 받고 선입선출에 의해 실행된다.
122 | - 할당시간이 너무 크면 선입선출과 다를 바가 없어지고, 너무 작으면 오버헤드가 너무 커진다.
123 |
124 | 1. SRTF 스케줄링(Shortest Remaining Time First)
125 | - 먼저 온 프로세스가 CPU를 할당받고 있더라도 남은 처리 시간이 뒤에 온 프로세스의 처리 시간보다 길면 CPU를 빼앗김
126 | - 장점 : 어떤 알고리즘보다 평균 대기 시간이 짧다
127 | - 단점 : 선점형 방식이기 떄문에 문맥교환이 잦아 오버헤드가 커진다. 기아현상이 심각하게 발생할 수 있다. CPU의 예상 시간을 예측하기가 힘들기 때문에 실제로 사용되기 어렵다
128 |
129 | 2. 다단계 큐 스케줄링
130 |
131 | 
132 |
133 | - 우선순위에 따라 준비 큐를 여러 개 사용하는 방식
134 | - 우선순위가 높은 큐에 먼저 CPU가 할당되어 큐에 속한 모든 프로세스가 처리되야 다음 우선순위 큐가 실행될 수 있다. 그리고 한 번 우선순위가 매겨저 준비 큐에 들어가면 이 우선순위는 바뀌지 않는다.
135 | - 각 큐는 독립적인 스케줄링 알고리즘을 가질 수 있는데, 보통 전면 프로세스들이 속해있는 큐는 우선순위고 높고 라운드 로빈 스케줄링을 사용해 타임 슬라이스를 작게한다.
136 | - 후면 프로세스에는 사용자와의 상호작용이 없으므로 가장 간단한 FCFS 방식으로 처리한다. 보통 총 CPU 시간이 전면 프로세스의 처리에 80%, 후면 프로세스 처리에 20%가 할당된다.
137 | - 단점 : 기아현상과 공평성 문제
138 |
139 | 3. 다단계 피드백 큐 스케줄링
140 |
141 | 
142 |
143 | - 다단계 큐의 공평성 문제를 완화하기 위해 우선순위 하락이 가능한 알고리즘이다. 우선순위가 변동되기 때문에 큐 사이의 이동이 가능하다.
144 | - 한 번 CPU를 할당받은 프로세스는 우선순위가 조금 낮아진다. 따라서 더 낮은 큐로 이동하게 된다. (우선순위가 높아져 상위 큐로 이동할 수도 있다)
145 | - 그리고 더 보완하기 위해 우선순위가 높은 큐보다 우선순위가 낮은 큐에 타임 슬라이스 크기를 크게 준다. 어렵게 얻은 CPU를 좀 더 오랫동안 사용하게 해주기 위함이다.
146 |
147 | ## Reference
148 |
149 | ### CPU 스케줄러의 종류
150 |
151 | [https://velog.io/@ss-won/OS-CPU-Scheduler와-Dispatcher](https://velog.io/@ss-won/OS-CPU-Scheduler%EC%99%80-Dispatcher)
152 |
153 | [https://jhnyang.tistory.com/372](https://jhnyang.tistory.com/372)
154 |
155 | [https://velog.io/@jeongpar/CPU-스케줄링](https://velog.io/@jeongpar/CPU-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%A7%81)
156 |
157 | ### CPU 스케줄링 알고리즘
158 |
159 | [https://hyunah030.tistory.com/4](https://hyunah030.tistory.com/4)
--------------------------------------------------------------------------------
/OS/Mutex vs Semaphore.md:
--------------------------------------------------------------------------------
1 | # Mutex vs Semaphore
2 | ### Mutex
3 | - 여러 스레드를 사용하는 환경에서 자원에 대한 접근을 동기화하기 위해 사용되는 상호배제(Mutual Exclusion) 기술이다.
4 | - Boolean 타입의 Lock 변수를 사용하여 오직 하나의 스레드만이 임계 영역(Critical Section)에 들어올 수 있다.
5 | - Lock을 건 스레드만 Lock을 해제할 수 있다.
6 | - 공유자원을 사용중인 스레드가 있을 때, 다른 스레드가 접근하면 Blocking 후 대기 큐로 보낸다.(Sleeping-waiting 방식)
7 |
8 | ### SpinLock
9 | - 대기하기 않고 자리가 있는지 계속 물어보는 방식(Busy-waiting 방식)
10 | - 어떤 상황에서 유리한가?
11 | - 컨텍스트 스위칭 시간이 더 짧은 경우
12 | - 멀티 코어 프로세스인 경우
13 |
14 | ### Semaphore
15 | - 세마포어는 Signaling 메커니즘이라는 점에서 뮤텍스와 다르다.
16 | - 세마포어는 lock을 걸지 않은 스레드도 Signal을 보내 lock을 해제할 수 있다는 점에서, wait 함수를 호출한 스레드만이 signal 함수를 호출할 수 있는 뮤텍스와 다르다.
17 | - 세마포어는 동기화를 위해 wait와 signal이라는 2개의 atomic operations를 사용한다.
18 |
19 | - atomic operation란 멀티프로세스에서 여러 CPU들이 공유자원에 접근 할 때, 접근 순서를 직렬화하여 의도치 않는 결과를 피하는 operation을 뜻한다.
20 |
21 | - 세마포어는 크게 Counting Semaphores와 Binary Semaphore 2종류로 구분할 수 있다.
22 | - Counting Semaphore는 카운트가 양의 정수값을 가지며, 설정한 값만큼 스레드를 허용하고 그 이상의 스레드가 자원에 접근하면 락이 실행된다.
23 | - Binary Semaphore는 세마포어의 카운트가 1이며 Mutex처럼 사용될 수 있다.(뮤텍스는 절대로 세마포어처럼 사용될 수 없다.)
24 |
25 | 참고자료
26 | - https://www.youtube.com/watch?v=oazGbhBCOfU
27 | - https://mangkyu.tistory.com/104
--------------------------------------------------------------------------------
/OS/Paging vs Segmentation.md:
--------------------------------------------------------------------------------
1 | # 메모리 할당
2 | 
3 | 메모리는 일반적으로 두 영역으로 나뉜다
4 | - OS 상주 영역 : 인터럽트 벡터와 함께 낮은 주소 영역 사용
5 | - 사용자 프로세스 영역 : 높은 주소 영역 사용
6 |
7 |
8 |
9 | ## 메모리 할당 방법론 목적
10 | 멀티프로그래밍 환경에서 한정된 메모리 공간을 최대한 효율적으로 사용하기 위함
11 |
12 |
13 |
14 | ## 연속 할당
15 | 각 프로세스가 메모리의 연속적인 공간에 적재
16 |
17 |
18 |
19 | ### 고정분할
20 | 
21 | - 물리적 메모리를 몇 개의 영구적 분할로 나눔
22 | - 하나의 분할에 하나의 프로그램을 적재
23 | - 내/외부 조각 발생
24 | - 외부조각
25 | - 분할의 크기 < 프로그램의 크기
26 | - 아무 프로그램도 배정되지 않은 빈 공간이지만 프로그램이 올라갈 수 없음
27 | - 내부조각
28 | - 분할의 크기 > 프로그램의 크기,
29 | - 분할에 프로그램이 배정됐지만 남는 부분이 존재함
30 |
31 |
32 |
33 | ### 가변분할
34 | 
35 | - 프로그램의 크기를 고려해서 할당
36 | - 분할의 크기, 개수가 동적으로 변함
37 | - 외부 조각 발생
38 |
39 |
40 |
41 | ## 불연속 할당
42 | 하나의 프로세스가 물리적 메모리의 여러 위치에 분산돼 올라감
43 |
44 |
45 |
46 | ### 페이징 기법
47 | 
48 | - 프로세스의 주소 공간을 동일한 크기의 페이지 단위로 나누어 물리적 메모리의 서로 다른 위치에 페이지들을 저장
49 | - 페이지 테이블을 이용해 논리 주소를 물리 주소로 변환
50 | - 페이지 테이블은 메인메모리에 상주
51 | - 내부 단편화 발생
52 | - CPU가 프로세스의 가상중소를 실행하기 위해 접근하면 MMU가 물리 주소로 변환해 해당 데이터를 CPU에게 가져다줌
53 | 
54 |
55 |
56 |
57 | ### 세그멘테이션
58 | 
59 | 
60 | - 프로세스를 스택, 데이터, 코드, 힙 등의 의미 단위로 나누어 올림
61 | - 논리적 주소가 <세그먼트 번호, 오프셋>으로 나뉘어 사용
62 | - 세그먼트 번호는 세그먼트 테이블의 인덱스로 사용
63 | - 오프셋은 0과 세그먼트 경계값 사이
64 | - 세그먼트 테이블은 각 세그먼트의 경계와 세그먼트 기준을 가지고 세그먼트 메모리 주소의 시작과 끝을 나타냄
65 | - 세그먼트는 의미 단위이기 때문에 공유와 보호에 있어 페이징보다 효과적
66 | - 세그먼트의 길이가 동일하지 않아 외부 조각 발생
67 |
68 |
69 |
70 | ### 페이지드 세그멘테이션
71 | - 프로세스를 나눌 때 세그먼트 단위로 나눔
72 | - 물리적 메모리에 적재하는 단위를 페이지 단위로
73 | - 하나의 세그먼트 크기를 페이지 크기의 배수가 되도록 함
74 | - 보호와 공유가 용이하고 외부 단편화를 없앰
75 | - 세그먼트 테이블과 페이지 테이블이 필요해져 주소 변환과정이 더 복합해지고 시간이 오래 걸림
--------------------------------------------------------------------------------
/OS/deadlock.md:
--------------------------------------------------------------------------------
1 | 
2 | ## 교착상태(Deadlock)
3 |
4 | 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태를 가리킨다.
5 | 즉, 둘 이상의 프로세스들이 자원을 점유한 상태에서 서로 다른 프로세스가 점유하고 있는 자원을 요구하며 무한정 기다리는 현상을 의미합니다.
6 | 
7 |
8 | #### 자원(Resource)이란?
9 | - 하드웨어, 소프트웨어 등을 포함하는 개념
10 | - ex) I/O device, CPU cycle, memory space 등
11 | - 프로세스가 자원을 사용하는 절차
12 | - Request(요청), Allocate(할당), Use(사용), Release(반납)
13 |
14 | ## 데드락의 발생 조건 네 가지
15 | 아래 네 가지 조건을 모두 만족해야 데드락이 발생한다. 어느 한 가지 조건이라도 풀리면 데드락을 방지할 수 있다.
16 | - Mutual exclusion(상호 배제)
17 | - 매 순간 하나의 프로세스만이 자원을 사용할 수 있음
18 | - No preemption (비선점)
19 | - 프로세스는 자원을 스스로 내어놓을 뿐 강제로 빼앗기지 않음
20 | - Hold and Wait (점유와 대기)
21 | - 자원을 가진 프로세스가 다른 자원을 기다릴 때 보유 자원을 놓지 않고 계속 가지고 있음
22 | - Circular wait (순환 대기)
23 | - 자원을 기다리는 프로세스간에 사이클이 형성되어야 함
24 |
25 |
26 |
27 | ### 자원 할당 그래프
28 | - R -> P : 자원이 R이 프로세스 P에 할당됨
29 | - P -> R : 프로세스 P가 자원 R을 요청함(필요로 함)
30 | - R안의 점의 개수 : 자원의 인스턴스 개수 즉, 해당 자원을 사용할 수 있는 프로세스의 수
31 | 
32 | - 왼쪽 그래프: 자원을 기다리는 프로세스간의 사이클이 형성되었기 때문에 데드락 발생
33 | - 오른쪽 그래프: 사이클이 형성되어 보이지만 P2와 P4가 작업을 끝내고 자원을 반납할 수 있기 때문에 데드락이 형성되지 않음
34 |
35 | ## 데드락의 방지/처리 방법
36 | ### Deadlock Prevention (예방 기법)
37 | 자원 할당 시 Deadlock의 4가지 필요 조건 중 어느 하나가 만족되지 않도록 하는 것, 자원의 낭비가 가장 심한 기법
38 |
39 | - No preemption (비선점)
40 | - process가 어떤 자원을 기다려야 하는 경우 이미 보유한 자원이 선점됨
41 | - 모든 필요한 자원을 얻을 수 있을 때 그 프로세스는 다시 시작된다.
42 | - 모든 자원에서 사용하기 어렵고 state를 쉽게 save하고 restore할 수 있는 자원에서 사용 가능하다. (CPU, memory)
43 | - Hold and Wait (점유와 대기)
44 | - 프로세스가 자원을 요청할 때 다른 어떤 자원도 가지고 있지 않아야 한다.
45 | - 방법1. 프로세스 시작 시 모든 필요한 자원을 할당받게 하는 방법
46 | - 방법2. 자원이 필요할 경우 보유 자원을 모두 놓고 다시 요청
47 | - 자원 과다 사용으로 인한 비효율, 프로세스가 요구하는 자원을 파악하는 데에 대한 비용, 자원에 대한 내용을 저장 및 복원하기 위한 비용등의 문제가 있다.
48 | - Circular wait (순환 대기)
49 | - 모든 자원 유형에 할당 순서를 정하여 정해진 순서대로만 자원 할당
50 | - 예를 들어 자원2을 얻기위해서는 자원1을 가지고 있어야한다는 조건을 부여한다.
51 | ### Deadlock Avoidance (회피 기법)
52 | 프로세스의 시작부터 종료까지 필요로하는 모든 자원에 대한 정보를 미리 파악하고 그 것을 이용해서 자원 할당시 deadlock 발생의 가능성을 판단하여 안전한 경우에만 자원을 할당한다.
53 | 2개의 avoidance 알고리즘을 경우에 따라 사용
54 | - 자원의 인스턴스가 1개인 경우
55 | - [자원 할당 그래프 알고리즘](https://www.geeksforgeeks.org/resource-allocation-graph-rag-in-operating-system/)
56 | - 자원의 인스턴스가 여러개인 경우
57 | - [은행원 알고리즘](https://en.wikipedia.org/wiki/Banker%27s_algorithm)
58 |
59 | ### Deadlock Detection and Recovery (발견 기법)
60 | Deadlock에 대한 방지를 따로 하지 않고 Deadlock이 발생했는지 검사하고 발견시 처리하는 방법
61 | - Deadlock Detection
62 | - 자원 할당 그래프에서 사이클이 생성되었을 경우 Deadlock발생
63 | - Deadlock Recovery
64 | - Deadlock이 발생된 모든 프로세스를 종료시키는 방법
65 | - 하나씩 종료시키면서 Deadlock이 사라지는지 확인하는 방법
66 | - 프로세스의 자원을 내놓게 하는 방법
67 |
68 | ### Deadlock Ignorance (무시 기법)
69 | Deadlock이 일어나지 않는다고 생각하고 아무런 조치도 취하지 않는다.
70 | - Deadlock이 매우 드물게 발생하므로 Deadlock이 대한 조치 자체가 더 큰 overhead일 수 있다.
71 | - 만약, 시스템에 Deadlock이 발생한 경우 시스템이 비정상적으로 작동하는 것을 사람이 느낀 후 직접 process를 죽이는 등의 방법으로 대처
72 | - UNIX, Windows 등 대부분의 범용 OS가 채택
--------------------------------------------------------------------------------
/OS/interrupt_&_context_switching.md:
--------------------------------------------------------------------------------
1 | # [OS]인터럽트&Context Switching
2 |
3 | # Interrupt
4 |
5 | CPU 가 프로그램 실행 중, `예외상황 처리`를 위해 `프로세스를 잠시 중단`하는 것
6 |
7 | CPU는, 한번에 하나의 프로세스를 처리하기 때문에, 이를 핸들링하기 위해 필요
8 |
9 | CPU가 다른 장치와 통신하기 위해 필요.
10 |
11 | - [내부] SW 인터럽트
12 | - overflow / underflow / 0 division
13 | - [외부] HW인터럽트
14 | - 전원 이상 / IO관련 / 기계이상 ...
15 |
16 | ### Interrupt 동작방식
17 |
18 | : Interrupt 이벤트마다 각 ‘실행코드’ 를 가리키는 주소를
19 |
20 | `IDT(Interrupt Descriptor Table)` 에 기록.
21 |
22 | (컴퓨터 부팅 시, OS가 기록)
23 |
24 | - 0~31: 예외상황 인터럽트 (내부/ 소프트웨어 인터럽트)
25 | - 32~47: 하드웨어 인터럽트 (주변 장치의 종류 및 개수에 따라 변경 가능)
26 | - 128: 시스템 콜
27 |
28 | ---
29 |
30 | # Context Swithing
31 |
32 | CPU 에서 , 프로세스를 번갈아 처리하는 작업.
33 |
34 | 여러개의 프로세스가 실행되고 있을 때 기존에 실행되는 프로세스를 중단하고 다른 프로세스를 실행 하는 것.
35 |
36 | 1. 동작중인 프로세스를 중지하며, 해당 프로세스의 상태(context)보관
37 | 2. 대기중인 다음 프로세스로 동작 교체
38 | 3. 이전의 프로세스 상태 (context) 복구
39 |
40 | ## 발생하는 경우
41 |
42 | - 멀티태스킹
43 | - 인터럽트 핸들링
44 | - 사용자 모드 & 커널 모드 간 전환
45 |
46 | ## PCB
47 |
48 | :Process Context Block
49 |
50 | 프로세스 상태값을 저장하는 별도의 메모리 공간.
51 |
52 | Context Switching은 PCB에 상태값을 저장하고, 다시 찾아 복구하는 방식으로 진행됨
53 |
54 | 
55 |
56 | - Process ID (PID)
57 | - register 값 (PC, SP 등)
58 | - process state (프로세스 상태)
59 | - ex) running, block ...
60 | - Meomory limits (메모리 사이즈)
61 |
62 | ### Context Switching 발생 시 cost
63 |
64 | cost 큰편
65 |
66 | - cache 초기화
67 | - Memory Mapping 초기화
68 | - kernel은 항상 실행됨
69 |
70 | ---
71 |
72 | # Process & Thread
73 |
74 | ## process
75 |
76 | 실행된 프로그램
77 |
78 | 운영체제로부터 시스템 자원을 할당받는 작업의 단위
79 |
80 | 메모리에 올라와 실행되고 있는 프로그램의 인스턴스
81 |
82 | - 프로세스는 각각, 독립된 메모리 영역 Code / Data / Stack / Heap 구조 를 할당받는다.
83 | - 각 프로세스는 별도의 주소공간에서 실행됨. (다른 프로세스의 변수or 자료구조에 접근 불가)
84 | - 프로세스 당 최소 1개의 thread를 갖고있음
85 |
86 | ## thread
87 |
88 | 프로세스 내에서 실행되는 여러 흐름의 단위
89 |
90 | - 스레드는, stack 만 따로 할당 받고, Code / Data / Heap 영역은 공유함
91 | - 같은 프로세스 내의 스레드들은 주소공간, 자원을 공유함
92 |
93 | ---
94 |
95 | ## 멀티 Process
96 |
97 | - 장점
98 | - process 하나의 문제가 다른 process에 영향을 끼치지 않음
99 | - 단점
100 | - 공유하는 자원 x → Context Switching 시, `cache 메모리 초기화`
101 | - 많은 오버헤드 발생
102 | - process간 통신 부담 ↑
103 |
104 | ## 멀티 Thread
105 |
106 | ex) 웹 서버
107 |
108 | - 장점
109 | - 자원을 할당하는 시스템 콜 ↓ → 시스템 자원 소모 ↓
110 | - 공유하는 메모리 범위 큼 → thread간 통신 부담 ↓
111 | - context switching 빠름
112 | - 단점
113 | - 자원 공유로 인한 동기화 문제
114 | - thread 하나의 문제 → thread 전체의 문제
115 | - 단일 프로세스 시스템의 경우 장점이 줄어듦
116 |
117 | ### Process vs Thread
118 |
119 | context switching 비용 : `process > thread`
120 |
121 | thread는 stack 영역을 제외한 모든 메모리를 공유
122 |
123 | 즉, 발생시 stack 영역만 변경
124 |
125 |
126 | ---
127 |
128 |
129 | 💡 CPU는 한번에 한가지 일을 처리할 수 있다.
130 | #
131 |
132 |
133 | 💡 Interrupt 는, CPU가 실행중인 프로세스를 [중단] 하기 위해 필요
134 | #
135 |
136 |
137 |
138 | 💡 Context Switching 은, interrupt시, Context(진행중이던 작업정보)를 다시 불러와 [멀티태스킹] 하기 위해 필요
139 | #
140 |
141 |
142 | 💡 Multi Threading 은, context switching 시 overhead를 최소화 하기 위해 필요
143 | #
144 |
145 |
--------------------------------------------------------------------------------
/OS/process_vs_thread.md:
--------------------------------------------------------------------------------
1 | # Process vs Thread
2 |
3 |
4 |
5 | ### 프로세스의 개념
6 |
7 | * 프로세스란 하나의 작업 단위
8 |
9 | * 프로그램을 실행하면 프로세스가 되어 사용자가 지시한 작업을 마무리
10 |
11 | * 프로그램 ≠ 프로세스
12 |
13 | * 프로그램은 어떤 데이터를 어떤식으로 사용할지 적어놓은 것
14 |
15 | * 프로세스는 그 적어놓은 내용을 실행에 옮기는 것
16 |
17 |
18 |
19 | ### 프로그램 프로세스 전환
20 |
21 | * 프로그램 실행 시 프로그램을 메모리로 가져오며 프로세스 제어블록(PCB)을 생성함
22 | * 프로세스 제어블록에는 다양한 정보가 있으며 대표적인 3가지를 꼽자면 프로세스 구분자, 메모리 관련정보, 그리고 중간값이 있다.
23 | * 프로세스 구분자 : 프로세스들을 구분하기 위한 ID
24 | * 메모리 관련 정보 : 실행하려는 프로세스가 메모리의 어디에 저장되어 있는지를 저장하는 정보
25 | * 각종 중간값 : 멀티 프로세스에서 실행중 다른 프로세스의 작업을 시작하게 될 경우, 다음에 실행해야할 코드의 정보를 기록
26 | * 프로그램이 프로세스가 된다는 것은 프로세스 제어블록이 생성된다는 것이고, 프로그램이 된다는 것은 프로세스 제어블록이 폐기 된다는 뜻
27 |
28 | * 프로그램 + 프로세스 제어블록 = 프로세스
29 |
30 |
31 |
32 | ### 프로세스의 상태
33 | 
34 | * 생성 상태 : 프로세스가 메모리에 올라와 실행준비가 완료된 상태, 이 때 프로세스 제어블록이 생성된다.
35 | * 준비 상태 : 생성된 프로세스가 CPU를 얻을 때 까지 대기하는 상태
36 | * 실행 상태 : 준비 상태에서 CPU를 얻어 실제 작업을 수행하는 상태 주어진 시간 안에 작업이 모두 완료되면 완료상태로 완료 못했을 경우에는 다시 준비상태로 돌아간다.
37 | * 완료 상태 : 주어진 작업을 모두 완료한 상태로 프로세스 제어블록이 사라진 상태이다.
38 | * 대기 상태 : 입출력을 요구하는 경우에 입출력 받기 위해 대기하는 상태를 의미한다.
39 |
40 | ##### 그 외의 상태들
41 |
42 | * 휴식 상태 : 작업을 일시적으로 쉬고 있는 상태, 작업 프로세스에서 Ctrl+Z를 누르게 될 경우 진입하는 상태로, PCB가 유지되어 있기 때문에 종료된 것 처럼 보여도 도중부터 실행이 가능하다. 완전히 종료하고 싶다면 Ctrl+C를 누르자
43 |
44 | * 보류 상태 : 메모리에서 잠시 쫓겨난 상태
45 | * 메모리가 꽉 차서 일부 프로세스를 쫓아낼 때
46 | * 프로그램에 오류가 있어 실행을 미룰 때
47 | * 바이러스 또는 악의적인 공격이라고 운영체제가 판단했을 경우
48 | * 매우 긴 주기로 반복되는 프로세스라 메모리 밖으로 나가도 상관 없을 때
49 | * 입출력을 기다리는데 이 대기시간이 길어질 때
50 |
51 |
52 |
53 | ### 스레드의 개념
54 |
55 | * 프로세스의 코드에 정의된 절차에 따라 CPU에 작업 요청을 하는 실행 단위
56 | * 요리에 빗대어 표현하면 스테이크 조리는 프로세스, 고기손질, 소금 후추 뿌리기, 고기 굽기 등은 스레드에 해당
57 | * 만약 이런 조리를 하는 담당 요리사가 둘 이상이라 분업을 한다면 멀티스레드라고 할 수 있다.
58 | * 프로세스와의 차이
59 | * 프로세스는 서로 약하게 연결되어 한 쪽 프로세스에 다른 프로세스가 거의 영향을 받지 않는다.
60 | * 스레드는 서로 강하게 연결되어 한 스레드의 진행 상황이 다른 스레드의 진행에 영향을 끼칠 수 있다.
61 | * 예를 들면 스테이크 한접시를 요리할 때 채소 굽기와 스테이크 굽기는 서로 영향이 없지만, 스테이크 굽기와 소스 뿌리기는 명확히 전후 관계가 나뉘어져 있다.
62 |
63 | ### 멀티스레드의 장단점
64 |
65 | * 장점
66 | * 응답성 향상 : 한 스레드의 작업이 진행되지 않더라도 다른 스레드가 작업을 지속하여 사용자의 작업 요구에 빨리 응답 가능
67 | * 자원 공유 : 한 프로세스 내에서 여러 개의 스레드 생성 시 프로세스의 자원을 모든 스레드가 공유할 수 있다.
68 | * 효율성 향상 : 여러 개의 프로세스 생성과 달리 멀티스레드는 불필요한 자원의 중복을 막아준다.
69 | * 다중 CPU 지원 : CPU가 2개 이상인 경우, 멀티스레드를 통해 다중 CPU가 멀티스레드를 동시에 처리하며 CPU사용량과 프로세스 처리시간이 크게 단축된다.
70 | * 단점
71 | * 스레드는 서로 영향을 끼치기 쉽고 자원을 공유하기 때문에 한 스레드에 문제가 생길 경우 전체 프로세스에 영향이 생김
--------------------------------------------------------------------------------
/README.md:
--------------------------------------------------------------------------------
1 | # cs-knowledge-for-interview
2 |
3 | ### Book
4 |
5 |
6 | 그림으로 배우는 HTTP & Network Basic
7 |
8 | - [질문 목록](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/README.md)
9 | - [제 1장. 웹과 네트워크의 기본에 대해 알아보자](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/%EC%A0%9C%201%EC%9E%A5.%20%EC%9B%B9%EA%B3%BC%20%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC%EC%9D%98%20%EA%B8%B0%EB%B3%B8%EC%97%90%20%EB%8C%80%ED%95%B4%20%EC%95%8C%EC%95%84%EB%B3%B4%EC%9E%90.md)
10 | - [제 3장. HTTP 정보는 HTTP 메시지에 있다](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/%EC%A0%9C%203%EC%9E%A5.%20HTTP%20%EC%A0%95%EB%B3%B4%EB%8A%94%20HTTP%20%EB%A9%94%EC%8B%9C%EC%A7%80%EC%97%90%20%EC%9E%88%EB%8B%A4.md)
11 | - [제 4장. 결과를 전달하는 HTTP 상태 코드](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/%EC%A0%9C%204%EC%9E%A5.%20%EA%B2%B0%EA%B3%BC%EB%A5%BC%20%EC%A0%84%EB%8B%AC%ED%95%98%EB%8A%94%20HTTP%20%EC%83%81%ED%83%9C%20%EC%BD%94%EB%93%9C.md)
12 | - [제 5장. HTTP와 연계하는 웹 서버](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/%EC%A0%9C%205%EC%9E%A5.%20HTTP%EC%99%80%20%EC%97%B0%EA%B3%84%ED%95%98%EB%8A%94%20%EC%9B%B9%20%EC%84%9C%EB%B2%84.md)
13 | - [제 6-2장. HTTP 헤더](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/%EC%A0%9C%206-2%EC%9E%A5.%20HTTP%20%ED%97%A4%EB%8D%94.md)
14 | - [제 8장. 누가 액세스하고 있는지를 확인하는 인증](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/%EC%A0%9C%208%EC%9E%A5.%20%EB%88%84%EA%B0%80%20%EC%95%A1%EC%84%B8%EC%8A%A4%ED%95%98%EA%B3%A0%20%EC%9E%88%EB%8A%94%EC%A7%80%EB%A5%BC%20%ED%99%95%EC%9D%B8%ED%95%98%EB%8A%94%20%EC%9D%B8%EC%A6%9D.md)
15 | - [제 9장. HTTP에 기능을 추가한 프로토콜](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/book/%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C%20%EB%B0%B0%EC%9A%B0%EB%8A%94%20HTTP%20%26%20Network%20Basic/%EC%A0%9C%209%EC%9E%A5.%20HTTP%EC%97%90%20%EA%B8%B0%EB%8A%A5%EC%9D%84%20%EC%B6%94%EA%B0%80%ED%95%9C%20%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C.md)
16 |
17 |
18 |
19 | ### Computer Architecture
20 |
21 | - [Cache Memory](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Computer%20Architecture/cache_memory.md)
22 |
23 | ### Data Structure
24 |
25 | - [AVL-Tree VS Red-Black-Tree](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Data%20Structure/AVL-Tree%20VS%20Red-Black-Tree.md)
26 | - [List, Set](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Data%20Structure/List%2C%20Set.md)
27 | - [Stack & Queue](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Data%20Structure/Stack_%26_Queue.md)
28 | - [해시 충돌](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Data%20Structure/hash_collision.md)
29 | - [Heap](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Data%20Structure/heap.md)
30 |
31 | ### Database
32 |
33 | - [NoSQL](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Database/NoSQL.md)
34 | - [Redis](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Database/Redis.md)
35 | - [트랜잭션](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Database/Transaction.md)
36 | - [트랜잭션 격리 수준](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Database/Transaction-Isolation-Level.md)
37 | - [Index](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Database/index.md)
38 | - [정규화](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Database/%EC%A0%95%EA%B7%9C%ED%99%94.md)
39 |
40 | ### Java
41 |
42 | - [HashMap vs Hashtable vs ConcurrentHashMap](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Java/HashMap%20vs%20Hashtable%20vs%20ConcurrentHashMap.md)
43 | - [Garbage Collection](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Java/garbage_collection.md)
44 | - [String is immutable](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Java/string_is_immutable.md)
45 |
46 | ### Network
47 |
48 | - [HTTP vs HTTPS](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Network/HTTP_vs_HTTPS.md)
49 | - [Multiplexing and Demultiplexing](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Network/Multiplexing%20and%20Demultiplexing.md)
50 | - [OSI 7 계층](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Network/OSI_7_layers.md)
51 | - [TCP vs UDP](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Network/TCP_vs_UDP.pdf)
52 | - [대칭키 & 공개키](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Network/symmentric-key_vs_public-key.md)
53 |
54 | ### OS
55 |
56 | - [CPU 스케줄러](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/OS/CPU_scheduler.md)
57 | - [Mutex vs Semaphore](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/OS/Mutex%20vs%20Semaphore.md)
58 | - [Paging vs Segmentation](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/OS/Paging%20vs%20Segmentation.md)
59 | - [Deadlock](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/OS/deadlock.md)
60 | - [Interrupt vs Context Switching](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/OS/interrupt_%26_context_switching.md)
61 | - [프로세스 vs 스레드](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/OS/process_vs_thread.md)
62 |
63 | ### Security
64 |
65 | - [OWASP Top 10](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Security/OWASP%20Top%2010.md)
66 |
67 | ### Software Engineering
68 |
69 | - [IoC, DIP, DI](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Software%20Engineering/IoC%2C%20DIP%2C%20DI.md)
70 | - [SOLID 원칙](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Software%20Engineering/SOLID%20%EC%9B%90%EC%B9%99.md)
71 | - [Singleton Pattern & Factory Pattern](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Software%20Engineering/Singleton%20Pattern%20%26%20Factory%20Pattern.md)
72 | - [Strategy Pattern](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Software%20Engineering/Strategy%20Pattern.md)
73 | - [UML](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/Software%20Engineering/UML.md)
74 |
75 | ### Web
76 |
77 | - [CORS](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/WEB/CORS.md)
78 | - [JWT](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/WEB/JWT.md)
79 | - [RESTful API](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/WEB/RESTful_API.md)
80 | - [Web 서버와 WAS의 차이](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/WEB/Web%20%EC%84%9C%EB%B2%84%EC%99%80%20WAS%EC%9D%98%20%EC%B0%A8%EC%9D%B4.md)
81 | - [www.naver.com을 검색하면 일어나는 과정](https://github.com/cs-book/cs-knowledge-for-interview/blob/main/WEB/www.naver.com%EC%9D%84%20%EA%B2%80%EC%83%89%ED%95%98%EB%A9%B4%20%EC%9D%BC%EC%96%B4%EB%82%98%EB%8A%94%20%EA%B3%BC%EC%A0%95.md)
82 |
--------------------------------------------------------------------------------
/Security/OWASP Top 10.md:
--------------------------------------------------------------------------------
1 | ### Contents
2 |
3 | - [A01:2021-Broken Access Control](#a012021-broken-access-control)
4 | - [A02:2021-Cryptographic Failures](#a022021-cryptographic-failures)
5 | - [A03:2021-Injection](#a032021-injection)
6 | - [A04:2021-Insecure Design](#a042021-insecure-design)
7 | - [A05:2021-Security Misconfiguration](#a052021-security-misconfiguration)
8 | - [A06:2021-Vulnerable and Outdated Components](#a062021-vulnerable-and-outdated-components)
9 | - [A07:2021-Identification and Authentication Failures](#a072021-identification-and-authentication-failures)
10 | - [A08:2021-Software and Data Integrity Failures](#a082021-software-and-data-integrity-failures)
11 | - [A09:2021-Security Logging and Monitoring Failures](#a092021-security-logging-and-monitoring-failures)
12 | - [A10:2021-Server-Side Request Forgery](#a102021-server-side-request-forgery)
13 |
14 | # OWASP Top 10
15 |
16 | OWASP는 `Open Web Application Security Project`라는 비영리 재단입니다. 2004년부터 10개의 보안 위협을 선정하여 공개하고 있으며, 최근에는 2021년에 공개하였습니다.
17 |
18 | [OWASP Top 10 Link](https://owasp.org/Top10/)
19 |
20 | ## A01:2021-Broken Access Control
21 |
22 | 가장 영향이 큰 보안 위협으로 `취약한 접근 제어`가 선정되었습니다.
23 |
24 | ### 취약점 예시
25 |
26 | - 인증되지 않은 사용자가 리소스에 접근할 수 있는 경우
27 | - 권한이 없는 사용자가 리소스에 접근할 수 있는 경우
28 | - 쿼리스트링이나 쿠키 등의 값을 변조하여 권한을 상승시킬 수 있는 경우
29 |
30 | ### 예방 방법
31 |
32 | - 화이트 리스트 기반으로 접근 제어 정책 수립
33 | - 리소스 별 접근 제어 정책 적용
34 |
35 | ## A02:2021-Cryptographic Failures
36 |
37 | 두 번째 보안 위협은 `암호화 실패`입니다.
38 |
39 | ### 취약점 예시
40 |
41 | - 암호키 관리가 미흡한 경우(eg. 암호키가 코드에 하드코딩된 경우)
42 | - DES, RC4, MD5 등 취약한 암호 알고리즘을 사용하는 경우
43 | - SSL v2.0, SSL v3.0, TLS v1.0, TLS v1.1 등 취약한 암호화 프로토콜을 사용하는 경우
44 | - HTTP, FTP, TELNET 등 데이터를 평문으로 전송하는 프로토콜을 사용하는 경우
45 |
46 | ### 예방 방법
47 |
48 | - 최신 암호 알고리즘 및 프로토콜 사용
49 | - 암호키 관리
50 |
51 | ## A03:2021-Injection
52 |
53 | 세 번째 보안 위협은 `인젝션`입니다.
54 |
55 | ### 취약점 예시
56 |
57 | - SQL 인젝션
58 | - OS Command 인젝션
59 | - XSS
60 |
61 | ### 예방 방법
62 |
63 | - 사용자 입력에 대한 검증
64 | - 사용자 입력이 그대로 사용되지 않도록 처리
65 |
66 | ## A04:2021-Insecure Design
67 |
68 | 네 번째 보안 위협은 `취약한 설계`입니다.
69 |
70 | ### 취약점 예시
71 |
72 | - 설계 단계에서 보안을 고려하지 않은 상태
73 |
74 | ### 예방 방법
75 |
76 | - 설계 단계에서부터 보안을 고려하여 설계
77 |
78 | ### KISA의 소프트웨어 개발보안 방법론
79 |
80 | 1. 요구사항 분석
81 |
82 | - 요구사항 중 보안 항목 식별
83 |
84 | 2. 설계
85 |
86 | - 위협모델링
87 | - 보안설계 검토 및 보안설계서 작성
88 | - 보안 통제 수립
89 |
90 | 3. 구현
91 |
92 | - 표준 코딩 정의서 및 SW개발보안 가이드 준수하여 개발
93 | - 소스코드 보안약점 진단 및 개선
94 |
95 | 4. 테스트
96 |
97 | - 모의침투 테스트 또는 동적분석을 통한 보안취약점 진단 및 개선
98 |
99 | 5. 유지보수
100 |
101 | - 지속적인 개선
102 | - 보안패치
103 |
104 | ## A05:2021-Security Misconfiguration
105 |
106 | 다섯 번째 보안 위협은 `미흡한 보안 설정`입니다.
107 |
108 | ### 취약점 예시
109 |
110 | - 웹서버 보안 설정 미흡
111 | - 애플리케이션 보안 설정 미흡
112 | - 오픈소스 보안 설정 미흡
113 | - 서버 보안 설정 미흡
114 | - 방화벽 설정 미흡
115 |
116 | ### 예방 방법
117 |
118 | - 사용하는 모든 소프트웨어의 보안 설정 및 보안성 검토 후 사용
119 |
120 | ## A06:2021-Vulnerable and Outdated Components
121 |
122 | 여섯 번째 보안 위협은 `취약하고 지원이 종료된 요소`입니다.
123 |
124 | ### 취약점 예시
125 |
126 | - Windows XP, Internet Explorer 지원이 종료된 소프트웨어 버전 사용
127 | - Nginx, Spring, OpenSSL 등 취약점이 존재하는 소프트웨어 버전 사용
128 |
129 | ### 예방 방법
130 |
131 | - 취약점이 존재하지 않는 최신 소프트웨어 사용
132 | - 보안 패치
133 |
134 | ## A07:2021-Identification and Authentication Failures
135 |
136 | 일곱 번째 보안 위협은 `식별 및 인증 실패`입니다.
137 |
138 | ### 취약점 예시
139 |
140 | - 세션 등의 인증 정보 타팀아웃이 없는 경우
141 | - 취약한 패스워드를 사용할 수 있는 경우
142 | - 인증 실패에 대한 제한이 없어 brute force 공격이 가능한 경우
143 | - 2차 인증이 없는 경우
144 |
145 | ### 예방 방법
146 |
147 | - 2차 인증 도입
148 | - 높은 수준의 패스워드 정책 설정
149 | - 인증 정보 타임아웃 설정
150 |
151 | ## A08:2021-Software and Data Integrity Failures
152 |
153 | 여덟 번째 보안 위협은 `소프트웨어 및 데이터 무결성 오류`입니다.
154 |
155 | ### 취약점 예시
156 |
157 | - 애플리케이션에서 사용하는 라이브러리나 모듈의 무결성 검증이 없는 경우
158 | - 직렬화된 데이터의 무결성 검증이 없는 경우
159 | - CI/CD 파이프라인에 무결성, 보안성 검토가 없는 경우
160 |
161 | ### 예방 방법
162 |
163 | - 직렬화 라이브러리를 사용하는 경우 직렬화된 데이터에 대해 무결성 검증
164 | - CI/CD 파이프라인을 정기적으로 무결성, 보안성 검토
165 | - 해싱을 활용해 애플리케이션 무결성 검증
166 |
167 | ## A09:2021-Security Logging and Monitoring Failures
168 |
169 | 아홉번째 보안 위협은 `보안 로깅 및 모니터링 실패`입니다.
170 |
171 | ### 취약점 예시
172 |
173 | - 로그인, 로그아웃, 로그인 실패, 권한 부여 등 중요 로직에 대한 로그를 남기지 않는 경우
174 | - 일정 주기로 로그를 백업하지 않는 경우
175 | - 불필요한 로깅이나 모니터링을 하는 경우
176 |
177 | ### 예방 방법
178 |
179 | - 중요 기능에 대해 로깅
180 | - 로그를 정기적으로 백업
181 | - 소프트웨어, 애플리케이션, 서버 등 모니터링 진행
182 |
183 | ## A10:2021-Server-Side Request Forgery
184 |
185 | 마지막 보안 위협은 `서버 측 요청 변조`입니다.
186 |
187 | ### 취약점 예시
188 |
189 | - 적절한 검증 없이 사용자가 리소스에 접근할 수 있는 경우
190 |
191 | ### 예방 방법
192 |
193 | - 모든 사용자 요청, 입력 데이터를 검증
194 |
195 | [참고(넷마블 보안팁)](https://netmarble.engineering/owasp-top-10-2021-1/)
196 |
--------------------------------------------------------------------------------
/Software Engineering/IoC, DIP, DI.md:
--------------------------------------------------------------------------------
1 | ### Contents
2 |
3 | - [IoC](#ioc)
4 | - [DIP](#dip)
5 | - [DI](#di)
6 |
7 | # IoC, DIP, DI
8 |
9 | IoC, DIP, DI에 대해 알아봅니다. 본문을 요약하자면 다음과 같습니다.
10 |
11 | `객체를 사용할 때 IoC 달성을 위해 외부에서 생성자를 통해 객체를 DI한다. 이때 DIP 달성을 위해 주입받을 객체의 타입은 추상화된 타입이어야 한다.`
12 |
13 | ## IoC, Inversion of Control
14 |
15 | 제어의 역전을 뜻하는 IoC는 말 그대로 제어가 역전되는 것을 의미합니다. 여기서 제어란 코드가 실행되는 과정에서 사용되는 객체를 생성하는 것을 말합니다. 역전이란 객체 생성을 직접하는 것이 아닌 외부로부터 전달받는 것을 말합니다.
16 |
17 | ### IoC 위반 예시
18 |
19 | ```java
20 | public class JpaMemberRepository implements MemberRepository {
21 |
22 | // ...
23 | }
24 |
25 | public class MemberService {
26 |
27 | public void register(Member member) {
28 | MemberRepository memberRepository = new JpaMemberRepository;
29 | memberRepository.save(member);
30 | }
31 | }
32 | ```
33 |
34 | 위 코드에서 register() 메서드는 회원가입을 위해 직접 MemberRepository 객체를 생성하므로 IoC를 위반합니다.
35 |
36 | ### IoC 반영
37 |
38 | ```java
39 | public class JpaMemberRepository implements MemberRepository {
40 |
41 | // ...
42 | }
43 |
44 | public class MemberService {
45 |
46 | private final MemberRepository memberRepository;
47 |
48 | public MemberService(JpaMemberRepository jpaMemberRepository) {
49 | this.memberRepository = jpaMemberRepository;
50 | }
51 |
52 | public void register(Member member) {
53 | memberRepository.save(member);
54 | }
55 | }
56 | ```
57 |
58 | 위 코드에서는 MemberRepository 객체를 직접 생성하는 것이 아닌 생성자를 통해 외부로부터 주입받습니다. 객체 생성을 직접 하지 않고 외부로부터 전달받아 사용하므로 IoC를 달성했다고 할 수 있습니다.
59 |
60 | IoC를 통해 객체 생성에 대한 책임을 외부에 위임하므로 비즈니스 로직에서 개발자가 직접 객체를 생성할 필요가 없게 됩니다.
61 |
62 | ## DIP, Dependency Inversion Principle
63 |
64 | 의존 역전 원칙을 뜻하는 DIP는 객체지향 설계 5대 원칙 중 하나로 다음과 같은 규칙을 제시합니다.
65 |
66 | `고수준 모듈이 저수준 모듈의 구현에 의존해서는 안되며, 저수준 모듈이 고수준 모듈에 의존해야 한다`
67 |
68 | 그리고 일반적으로 IoC와 함께 사용됩니다.
69 |
70 | ### DIP 위반 예시
71 |
72 | ```java
73 | public class JpaMemberRepository implements MemberRepository {
74 |
75 | // ...
76 | }
77 |
78 | public class MemberService {
79 |
80 | private final MemberRepository memberRepository;
81 |
82 | public MemberService(JpaMemberRepository jpaMemberRepository) {
83 | this.memberRepository = jpaMemberRepository;
84 | }
85 |
86 | public void register(Member member) {
87 | memberRepository.save(member);
88 | }
89 | }
90 | ```
91 |
92 | IoC를 반영한 코드를 다시 보겠습니다. MemberRepository 객체를 외부에서 주입받으므로 IoC는 잘 지키고 있습니다. 하지만 외부에서 주입받는 타입이 MemberRepository 타입의 하위 타입인 JpaMemberRepository입니다. 이는 DIP를 위반하는 것입니다.
93 |
94 | ### DIP 반영
95 |
96 | ```java
97 | public class JpaMemberRepository implements MemberRepository {
98 |
99 | // ...
100 | }
101 |
102 | public class MemberService {
103 |
104 | private final MemberRepository memberRepository;
105 |
106 | public MemberService(MemberRepository memberRepository) {
107 | this.memberRepository = memberRepository;
108 | }
109 |
110 | public void register(Member member) {
111 | memberRepository.save(member);
112 | }
113 | }
114 | ```
115 |
116 | DIP를 지키기 위해 객체를 주입받을 때 고수준 모듈인 MemberRepository로 주입받습니다. 즉, MemberService가 JpaMemberRepository 객체를 의존하지 않도록 합니다.
117 |
118 | 이를 통해 MemberRepository 타입의 하위 타입이 새로 추가되더라도 MemberService는 변경할 필요가 없게 됩니다.
119 |
120 | ## DI, Dependency Injection
121 |
122 | DI는 의존성을 주입하는 것을 의미합니다. 의존성이란 객체 간에 의존 관계를 의미 하며 이러한 의존 관계를 외부에서 설정하는 것이라고 할 수 있습니다.
123 |
124 | DI를 하는 방법은 세 가지가 있으며 생성자를 통한 DI가 가장 많이 사용됩니다.
125 |
126 | ### 생성자
127 |
128 | ```java
129 | public class MemberService {
130 |
131 | private final MemberRepository memberRepository;
132 |
133 | public MemberService(MemberRepository memberRepository) {
134 | this.memberRepository = memberRepository;
135 | }
136 | }
137 | ```
138 |
139 | DIP를 지키고 있는 코드를 다시 보겠습니다. 위 코드에서 MemberService는 MemberRepository에 의존하고 있습니다. 그리고 생성자를 통해서 MemberRepository를 주입받는데, 이러한 방법을 생성자 DI라고 합니다.
140 |
141 | ### 수정자
142 |
143 | ```java
144 | public class MemberService {
145 |
146 | private MemberRepository memberRepository;
147 |
148 | public void setMemberRepository(MemberRepository memberRepository) {
149 | this.memberRepository = memberRepository;
150 | }
151 | }
152 | ```
153 |
154 | 수정자 DI는 말 그대로 수정자를 통해 객체를 DI하는 방법입니다. 생성자 Di와 다르게 수정자를 통해 객체를 변경할 수 있습니다.
155 |
156 | ### 필드
157 |
158 | ```java
159 | @Repository
160 | public class JpaMemberRepository implements MemberRepository {
161 |
162 | // ...
163 | }
164 |
165 | @Service
166 | public class MemberService {
167 |
168 | @Autowired
169 | private MemberRepository memberRepository;
170 | }
171 | ```
172 |
173 | 스프링 프레임워크를 사용한다면 필드 DI를 사용할 수 있습니다. MemberRepository를 구현하는 JpaMemberRepository 클래스를 스프링 Bean을 등록하고 MemberService에서는 MemberRepository 필드에 @Autowired 애노테이션을 붙이면 됩니다.
174 |
175 | ### 결론
176 |
177 | 생성자 DI를 사용하는 것이 좋습니다.
178 |
179 | 수정자와 필드를 통해 DI하는 방법은 다음과 같은 단점이 있습니다.
180 |
181 | 1. 수정자 DI의 경우 수정자 메서드를 통해 객체가 언제든지 변경될 수 있습니다. 의존하는 객체를 변경할 필요가 없다면 수정자 메서드의 사용을 막는 것이 좋습니다.
182 | 2. 필드 DI의 경우 테스트 코드를 작성할 때 Mock 객체를 주입하는 것이 어렵습니다.
183 |
184 | - 생성자 DI를 통해 테스트 코드에서 Mock 객체를 주입하여 테스트 성능을 높일 수 있습니다.
185 |
186 | ```java
187 | class MemberServiceTest {
188 |
189 | private final MemberService memberService;
190 |
191 | @BeforeEach
192 | public void setUp() {
193 | memberService = new MemberService(new MemoryMemberRepository());
194 | }
195 |
196 | @DisplayName("회원가입 성공 테스트")
197 | @Test
198 | public void registerSuccess() {
199 | // given
200 | Member member = new Member("id", "password");
201 |
202 | // when
203 | memberService.register(member);
204 |
205 | // then
206 | Member findMember = memberRepository.findById("id");
207 | assertThat(findMember.getId()).equals("id");
208 | }
209 |
210 | private class MemoryMemberRepository implements MemberRepository {
211 |
212 | private Map store = new HashMap<>();
213 |
214 | @Override
215 | public Member save(Member member) {
216 | store.put(member.getId(), member);
217 | return member;
218 | }
219 |
220 | @Override
221 | public Member findById(String id) {
222 | return store.get(id);
223 | }
224 | }
225 | }
226 | ```
227 |
228 | 위 코드에서는 JpaMemberRepository 대신 테스트용으로 MemoryMemberRepository를 구현하여 사용했습니다. 이를 통해 외부 데이터베이스와 연결하지 않고 MemberService의 register() 메서드의 핵심 비즈니스 로직을 빠르게 테스트할 수 있습니다.
229 |
230 | 또한 생성자 DI를 사용하면 다음과 같은 장점도 있습니다.
231 |
232 | - 생성자를 통해 객체를 주입받으므로 final 키워드를 사용하여 객체의 불변성을 보장할 수 있습니다.
233 | - 메인 객체가 생성될 때 모든 의존성을 주입받을 수 있습니다. 이를 통해 NullPointerException을 방지할 수 있습니다.
234 |
--------------------------------------------------------------------------------
/Software Engineering/SOLID 원칙.md:
--------------------------------------------------------------------------------
1 | ### Contents
2 |
3 | - [SRP, 단일 책임 원칙](#srp-단일-책임-원칙)
4 | - [OCP, 개방 폐쇄 원칙](#ocp-개방-폐쇄-원칙)
5 | - [LSP, 리스코프 치환 원칙](#lsp-리스코프-치환-원칙)
6 | - [ISP, 인터페이스 분리 원칙](#isp-인터페이스-분리-원칙)
7 | - [DIP, 의존 역전 원칙](#dip-의존-역전-원칙)
8 |
9 | # SOLID 원칙
10 |
11 | SOLID 원칙은 객체지향 설계 원칙으로 다섯 가지의 원칙을 가집니다. 아래의 다섯 가지 원칙을 준수함으로써 소프트웨어를 객체지향적으로 설계하고 구현할 수 있습니다.
12 |
13 | - 단일 책임 원칙 (Single Responsibility Principle)
14 | - 개방 폐쇄 원칙 (Open Closed Principle)
15 | - 리스코프 치환 원칙 (Liskov Substitution Principle)
16 | - 인터페이스 분리 원칙 (Interface Segregation Principle)
17 | - 의존 역전 원칙 (Dependency Inversion Principle)
18 |
19 | ## SRP, 단일 책임 원칙
20 |
21 | SRP 원칙은 `클래스는 단 하나의 책임을 가져야 한다`는 규칙을 제시합니다.
22 |
23 | 여기서 책임이란 클래스가 변경되는 이유를 말하며, 클래스가 변경되는 이유가 단 하나여야 한다는 의미입니다.
24 |
25 | ### SRP 원칙 위반 예시
26 |
27 | ```java
28 | public class Viewer {
29 |
30 | // ...
31 |
32 | private FileDocument fileDocument;
33 |
34 | public void view() {
35 | String data = fileDocument.getContent();
36 | System.out.println(data);
37 | }
38 | }
39 | ```
40 |
41 | 위 코드에서 Viewer 클래스는 데이터를 화면에 출력하는 책임을 가집니다. view() 메서드는 fileDocument 객체로부터 content를 가져와 화면에 출력합니다. 만약 fileDocument 객체가 반환하는 content의 타입이 String에서 List으로 변경된다면 view() 메서드는 아래와 같이 변경될 것입니다.
42 |
43 | ```java
44 | public void view() {
45 | // String -> List
46 | List data = fileDocument.getContent();
47 | for (String d : data) {
48 | System.out.println(d);
49 | }
50 | }
51 | ```
52 |
53 | Viewer 클래스는 데이터를 화면에 출력하는 책임만 가져야 하므로 Viewer 클래스가 변경될 수 있는 때는 화면에 출력하는 방식을 바꿀 때가 될 것입니다. 그런데, 앞선 이유가 아닌 fileDocument 객체로부터 데이터를 가져오는 부분 때문에 Viewer 클래스에 변경이 발생했습니다. 이는 SRP 원칙을 위반하는 것입니다.
54 |
55 | SRP 원칙을 지키기 위해 fileDocument 객체가 반환하는 데이터를 추상화할 수 있습니다. String이나 List\와 같은 저수준의 타입이 아닌 별도의 추상화된 타입을 만들고 해당 타입을 사용하는 것입니다.
56 |
57 | ### SRP 원칙 반영
58 |
59 | ```java
60 | public class Data {
61 |
62 | // 데이터를 담을 타입 정의
63 |
64 | public void show() {
65 | // 타입에 따른 데이터 출력
66 | }
67 | }
68 |
69 | public class ListData extends Data {
70 |
71 | @Override
72 | public void show() {
73 | // 메서드 오버라이딩
74 | }
75 | }
76 |
77 | public class Viewer {
78 |
79 | // ...
80 |
81 | private FileDocument fileDocument;
82 |
83 | public void view() {
84 | Data data = fileDocument.getContent();
85 | data.show();
86 | }
87 | }
88 | ```
89 |
90 | 위의 코드에서 Data 클래스를 만들고 내부에 데이터를 출력하는 show() 메서드를 작성했습니다. Viewer 클래스의 view() 메서드는 fileDocument 객체가 반환하는 data 객체의 show() 메서드를 호출하도록 했습니다.
91 |
92 | 이때 fileDocument 객체가 getContent() 메서드의 반환 타입을 Data 타입이 아닌 ListData 타입으로 변경하더라도 Viewer 클래스는 변경되지 않습니다. 왜냐하면 ListData 타입은 Data 타입을 상속하고 있고 Viewer 클래스의 view() 메서드는 추상화된 타입인 Data 타입으로 하위 타입인 ListData 타입을 전달받아 사용하기 때문입니다.
93 |
94 | 따라서 fileDocument 객체가 반환하는 타입이 Data 타입이거나 Data 타입을 상속한 하위 타입(MapData, SetData 등)이라면 Viewer 클래스는 변경할 필요가 없게 됩니다.
95 |
96 | 이와 같이 SRP 원칙을 지킴으로써 fileDocument 객체의 변화가 Viewer 클래스에 끼치는 영향을 낮출 수 있습니다.
97 |
98 | ## OCP, 개방 폐쇄 원칙
99 |
100 | OCP 원칙은 `확장에는 열려 있어야 하고, 변경에는 닫혀 있어야 한다`는 규칙을 제시합니다.
101 |
102 | 기능은 추가될 수 있어야 하고, 해당 기능를 사용하는 코드는 수정하지 않아야 한다는 의미입니다.
103 |
104 | ### OCP 원칙 위반 예시
105 |
106 | ```java
107 | public class Viewer {
108 |
109 | // ...
110 |
111 | private FileDocument fileDocument;
112 |
113 | private ElectronicDocument electronicDocument;
114 |
115 | public void view(boolean isFile) {
116 | Data data = null;
117 | if (isFile) {
118 | data = fileDocument.getContent();
119 | } else {
120 | data = electronicDocument.getContent();
121 | }
122 | data.show();
123 | }
124 | }
125 | ```
126 |
127 | fileDocument 객체가 파일 문서 데이터를 제공하던 상황에서 전자 문서의 데이터를 제공하는 기능을 추가한다고 가정해봅시다. 그럼 위와 같이 Viewer 클래스를 변경할 수 있을 것입니다. electronicDocument 기능이 추가됨에 따라 해당 기능을 사용하는 view() 메서드의 코드가 변경된 것을 확인할 수 있습니다. 이는 OCP 원칙을 위반하는 것입니다.
128 |
129 | OCP 원칙을 지키기 위해 fileDocument 객체와 electronicDocument 객체를 추상화하여 상위 객체를 만들고 Viewer 클래스의 view() 메서드가 상위 객체를 사용하도록 할 수 있습니다.
130 |
131 | ### OCP 원칙 반영
132 |
133 | ```java
134 | public class Document {
135 |
136 | private Data data;
137 |
138 | public getContent() {
139 |
140 | }
141 | }
142 |
143 | public class FileDocument extends Document {
144 |
145 | // ...
146 | }
147 |
148 | public class ElectronicDocument extends Document {
149 |
150 | // ...
151 | }
152 |
153 | public class Viewer {
154 |
155 | // ...
156 |
157 | private Document document;
158 |
159 | public void view() {
160 | Data data = document.getContent();
161 | data.show();
162 | }
163 | }
164 | ```
165 |
166 | 위와 같이 fileDocument 객체와 electronicDocument 객체를 추상화한 Document 타입을 클래스를 정의하고 Viewer 클래스가 Document 클래스를 사용하도록 합니다. Document 클래스가 FileDocument 클래스와 ElectronicDocument 클래스의 상위 클래스이므로 Document 클래스를 통해 FileDocument, ElectronicDocument 클래스의 기능을 모두 사용할 수 있게 됩니다.
167 |
168 | 이후에 새로운 형태의 문서 데이터를 지원하는 기능이 추가되더라도 해당 기능의 클래스를 Document 클래스를 상속받아 구현한다면 Viewer 클래스는 변경할 필요가 없게 됩니다.
169 |
170 | 즉, 새로운 기능이 추가되더라도 해당 기능을 사용하는 View 클래스는 변경하지 않아도 됩니다.
171 |
172 | 이와 같이 OCP 원칙을 지킴으로써 기능 확장은 자유롭게 하고 확장에 따른 영향은 낮출 수 있습니다.
173 |
174 | ## LSP, 리스코프 치환 원칙
175 |
176 | LSP 원칙은 `상위 타입의 객체를 하위 타입의 객체로 바꿔도 상위 타입을 사용하는 객체는 정상적으로 동작해야 한다`는 규칙을 제시합니다.
177 |
178 | 상위 객체의 메서드를 하위 객체에서 오버라이딩할 때 적절하게 구현해야 한다는 의미입니다.
179 |
180 | ### LSP 원칙 위반 예시
181 |
182 | ```java
183 | public class Food {
184 |
185 | public void bad() {
186 | System.out.println("음식이 상했습니다.");
187 | }
188 | }
189 |
190 | public class IceCream extends Food {
191 |
192 | public void melt() {
193 | System.out.println("아이스크림이 녹았습니다.");
194 | }
195 | }
196 |
197 | public class FoodUtil {
198 |
199 | public void badALl(List foods) {
200 | for (Food food : foods) {
201 | if (food instanceof IceCream) {
202 | ((IceCream) food).melt();
203 | } else {
204 | food.bad();
205 | }
206 | }
207 | }
208 | }
209 | ```
210 |
211 | 위 코드를 보면 Food 클래스에 `음식이 상하다`의 기능을 가지는 bad() 메서드가 있습니다. IceCream 클래스는 Food 클래스를 상속하는데, `음식이 상하다`의 의미보다 더 직관적인 `아이스크림이 녹다`라는 의미를 가지는 melt() 메서드를 추가했습니다.
212 |
213 | FoodUtil 클래스의 badAll() 메서드는 Food 리스트를 매개변수로 받아서 `음식이 상하는` 처리를 합니다. 하위 타입인 IceCream 객체가 전달될 수 있으므로 타입을 확인하고 IceCream 객체일 경우 형변환을 하여 melt() 메서드를 호출합니다. Food 객체일 경우 bad() 메서드를 호출합니다. 이는 LSP 원칙을 위반하는 것입니다. 상위 타입인 Food 객체가 하위 타입인 IceCream 객체로 바뀌어도 같은 기능을 사용해야 하는데 IceCream 객체일 경우 bad() 메서드가 아닌 melt() 메서드를 사용하기 때문입니다.
214 |
215 | ### LSP 원칙 반영
216 |
217 | ```java
218 | public class Food {
219 |
220 | public void bad() {
221 | System.out.println("음식이 상했습니다.");
222 | }
223 | }
224 |
225 | public class IceCream extends Food {
226 |
227 | @Override
228 | public void bad() {
229 | melt();
230 | }
231 |
232 | public void melt() {
233 | System.out.println("아이스크림이 녹았습니다.");
234 | }
235 | }
236 |
237 | public class FoodUtil {
238 |
239 | public void badALl(List foods) {
240 | foods.forEach(Food::bad);
241 | }
242 | }
243 | ```
244 |
245 | IceCream 클래스에서 melt() 메서드를 호출하도록 오버라이딩했습니다. 이제 FoodUtil 클래스의 badAll 메서드에서는 Food 객체의 실제 타입이 무엇인지 확인하지 않고 bad() 메서드를 호출할 수 있습니다.
246 |
247 | 이와 같이 LSP 원칙을 지킴으로써 상위 타입을 사용하는 코드에 하위 타입을 전달하더라도 상위 타입의 메서드만을 사용하여 기능이 정상적으로 동작하는 것을 보장할 수 있습니다.
248 |
249 | ## ISP, 인터페이스 분리 원칙
250 |
251 | ISP 원칙은 `인터페이스는 그 인터페이스를 사용하는 클라이언트를 기준으로 분리해야 한다`는 규칙을 제시합니다.
252 |
253 | 클래스에서 사용하는 기능만 제공하는 인터페이스를 상속해야 한다는 의미입니다.
254 |
255 | ### ISP 원칙 위반 예시
256 |
257 | ```java
258 | public interface Ship {
259 |
260 | void forward();
261 | }
262 |
263 | public class PassengerShip implements Ship {
264 |
265 | @Override
266 | public void forward() {
267 | // 전진 기능 구현
268 | }
269 | }
270 | ```
271 |
272 | Ship 인터페이스는 배의 기능을 정의하는 인터페이스입니다. 현재 앞으로 전진하는 기능을 하는 메서드가 선언되어 있습니다. PassengerShip 클래스는 Ship 인터페이스를 상속하고 forward() 메서드를 적절하게 구현합니다. 이때 잠수함을 의미하는 TourSubmarine 클래스를 추가했을 때 코드는 아래와 같이 변경될 수 있습니다.
273 |
274 | ```java
275 | public interface Ship {
276 |
277 | void forward();
278 |
279 | void subside();
280 | }
281 |
282 | public class PassengerShip implements Ship {
283 |
284 | @Override
285 | public void forward() {
286 | // 전진 기능 구현
287 | }
288 |
289 | @Override
290 | public void subside() {
291 | throw new Exception("사용할 수 없는 기능입니다.");
292 | }
293 | }
294 |
295 | public class TourSubmarine implements Ship {
296 |
297 | @Override
298 | public void forward() {
299 | // 전진 기능 구현
300 | }
301 |
302 | @Override
303 | public void subside() {
304 | // 잠수 기능 구현
305 | }
306 | }
307 | ```
308 |
309 | Ship 인터페이스에 잠수하는 기능을 의미하는 subside() 메서드가 정의되었고, PassengerShip 클래스와 TourSubmarine 클래스에 forward(), subside() 메서드가 구현되었습니다. 그런데 PassengerShip 클래스의 subside() 메서드는 예외를 발생시킵니다. 잠수 기능을 사용해서는 안되는 클래스이기 때문입니다. 이는 ISP 원칙을 위반하는 것입니다.
310 |
311 | ISP 원칙을 지키기 위해 인터페이스를 적절하게 분리할 필요가 있습니다.
312 |
313 | ### ISP 원칙 반영
314 |
315 | ```java
316 | public interface Ship {
317 |
318 | void forward();
319 | }
320 |
321 | public interface Submarine extends Ship {
322 |
323 | void subside();
324 | }
325 |
326 | public class PassengerShip implements Ship {
327 |
328 | @Override
329 | public void forward() {
330 | // 전진 기능 구현
331 | }
332 | }
333 |
334 | public class TourSubmarine implements Submarine {
335 |
336 | @Override
337 | public void forward() {
338 | // 전진 기능 구현
339 | }
340 |
341 | @Override
342 | public void subside() {
343 | // 잠수 기능 구현
344 | }
345 | }
346 | ```
347 |
348 | 위와 같이 Ship 인터페이스를 상속하는 Submarine 인터페이스를 추가합니다. 그리고 PassengerShip 클래스는 Ship 인터페이스를 상속받으며, TourSubmarine 클래스는 Submarine 인터페이스를 상속받습니다.
349 |
350 | 이를 통해 PassengerShip 클래스는 자신이 사용하는 전진 기능만 구현하면 되며, TourSubmarine 클래스는 전진 기능과 잠수 기능을 모두 구현할 수 있습니다.
351 |
352 | 이와 같이 ISP 원칙을 지킴으로써 불필요한 기능을 구현하는 리소스를 줄일 수 있습니다. 또한 인터페이스의 크기가 과하게 커지는 것을 방지할 수 있습니다.
353 |
354 | ## DIP, 의존 역전 원칙
355 |
356 | DIP 원칙은 `고수준 모듈이 저수준 모듈의 구현에 의존해서는 안 되며, 저수준 모듈이 고수준 모듈에 의존해야 한다`는 규칙을 제시합니다.
357 |
358 | 객체는 저수준 모듈인 구현 클래스보다 추상화된 고수준 모듈인 인터페이스나 추상 클래스에 의존해야 한다는 의미입니다.
359 |
360 | ### DIP 원칙 위반 예시
361 |
362 | ```java
363 | public class Chicken {
364 |
365 | private int price;
366 |
367 | private boolean fresh;
368 | }
369 |
370 | public class Pizza {
371 |
372 | private int price;
373 |
374 | private boolean fresh;
375 | }
376 |
377 | public class Menu {
378 |
379 | private Chicken chicken;
380 |
381 | private Pizza pizza;
382 | }
383 | ```
384 |
385 | 현재 Menu 클래스는 Chicken, Pizza 클래스를 의존하고 있습니다. 만약 햄버거, 스테이크 메뉴가 추가된다면 Menu 클래스는 다음과 같이 변경될 것입니다.
386 |
387 | ```java
388 | public class Menu {
389 |
390 | private Chicken chicken;
391 |
392 | private Pizza pizza;
393 |
394 | private Hamburger hamburger;
395 |
396 | private Steak steak;
397 | }
398 | ```
399 |
400 | 위의 코드처럼 새로운 메뉴가 추가될 때마다 Menu 클래스는 수정해야만 합니다.
401 |
402 | 이는 DIP 원칙을 위반했기 때문에 발생하는 문제입니다. 현재 Menu 클래스는 저수준 모듈인 Chicken, Pizza 클래스를 의존하고 있습니다. DIP 원칙을 반영하여 의존 관계를 역전시켜야 합니다.
403 |
404 | ### DIP 원칙 반영
405 |
406 | ```java
407 | public class Food {
408 |
409 | private int price;
410 |
411 | private boolean fresh;
412 | }
413 |
414 | public class Chicken extends Food {
415 |
416 | }
417 |
418 | public class Pizza extends Food {
419 |
420 | }
421 |
422 | public class Menu {
423 |
424 | private List foods;
425 | }
426 | ```
427 |
428 | 위와 같이 Chicken, Pizza 타입을 추상화한 Food 클래스를 만들고 Menu 클래스는 고수준 모듈인 Food 클래스만을 의존하도록 했습니다. 이제 새로운 메뉴가 추가되더라도 Food 클래스를 상속한다면 Menu 클래스는 수정할 필요가 없게 되었습니다.
429 |
430 | 이제 Menu 클래스는 고수준 모듈인 Food 클래스만을 의존하게 되었고, Chicken, Pizza 같은 저수준 모듈도 Food 클래스를 의존하게 되었습니다.
431 |
432 | 이처럼 코드 상에서 의존을 역전시킴으로써 DIP 원칙을 지킬 수 있습니다.
433 |
--------------------------------------------------------------------------------
/Software Engineering/Singleton Pattern & Factory Pattern.md:
--------------------------------------------------------------------------------
1 | # Singleton Pattern & Factory Pattern
2 |
3 | Created: 2022년 6월 8일 오후 7:08
4 | Tags: CS, Design Pattern, SW Engineering
5 |
6 | ## 1. 싱글톤 패턴
7 |
8 | 하나의 `클래스`가 오직 하나의 `인스턴스`만 가지는 패턴
9 | **하나의 메모리만을 인스턴스로 할당하는 패턴**으로 봐도 무방
10 |
11 | 1. 프로세스 내에서 객체가 하나만 만들어져야 할 때
12 | 2. 굳이 중복된 객체 생성 비용을 감당할 필요가 없을 때
13 |
14 | 
15 |
16 | ### 1.1 특징
17 |
18 |
22 |
23 | 하나의 인스턴스를 만들어 놓고 **해당 인스턴스를 여러 모듈에서 공유하며 사용**하기 때문에 인스턴스를 생성할 때 드는 비용이 줄어든다. 하지만 하나의 인스턴스에 의존하기 때문에 **의존성이 높아진다**는 단점도 있다.
24 |
25 | ### 1.2 JavaScript의 싱글톤 패턴
26 |
27 | - 리터럴 `{}` 또는 `new Object`로 객체 생성 시 다른 어떤 객체와도 같지 않기 때문에 이 자체만으로도 싱글톤 패턴 구현 가능
28 |
29 | ```tsx
30 | const obj1 = {
31 | algo: "cs-book",
32 | };
33 |
34 | const obj2 = {
35 | algo: "cs-book",
36 | };
37 |
38 | console.log(obj1 === obj2);
39 | // false
40 | ```
41 |
42 | 각 오브젝트는 겉보기엔 같아보여도 다른 메모리를 참조하는 서로 다른 인스턴스
43 |
44 | ### 1.3 JS에서의 주된 싱글톤 구현 패턴
45 |
46 | ```tsx
47 | class Singleton {
48 | constructor() {
49 | if (!Singleton.instance) {
50 | Singleton.instance = this;
51 | }
52 | return Singleton.instance;
53 | }
54 | getInstance() {
55 | return this.instance;
56 | }
57 | }
58 |
59 | const a = new Singleton();
60 | const b = new Singleton();
61 |
62 | console.log(a === b); // true
63 | ```
64 |
65 | `Singleton.instance`라는 하나의 인스턴스를 가지는 `Singleton` 클래스를 구현한 모습. `a`와 `b`는 하나의 인스턴스를 공유한다.
66 |
67 | ### 1.4 데이터베이스 연결 모듈
68 |
69 | 싱글톤 패턴은 특히 DB와 연결하는 부분에서 많이 사용된다고…
70 |
71 | ```tsx
72 | const URL = "mongodb://cs-book.com:271017"
73 |
74 | const createConnection = (URL) => {
75 | veryExpensiveConnectionFunc(URL)
76 | }
77 |
78 | class DB() {
79 | constructor(url) {
80 | if (!DB.instance) {
81 | DB.instance = createConnection(url)
82 | }
83 | return DB.instance
84 | }
85 | connect() {
86 | return this.instance
87 | }
88 | }
89 |
90 | const a = new DB(URL)
91 | const b = new DB(URL)
92 |
93 | console.log(a === b) // true
94 | ```
95 |
96 | `DB.instance`라는 하나의 인스턴스를 기반으로 `a`, `b`를 생성. 이를 통해 매번 연결을 시도하지 않고 연결에 관한 인스턴스를 받아옴으로써 인스턴스 생성 비용을 아낄 수 있다.
97 |
98 | ### 1.5 Java에서의 싱글톤 패턴
99 |
100 | 여러 명의 사원이 하나의 프린터기를 사용하는 경우의 예제
101 |
102 | ```java
103 | package csbook.softwareEngineering.signleton
104 |
105 | public class Printer {
106 | private static Printer printer = null;
107 |
108 | private Printer(){}
109 |
110 | public static Printer getInstance() {
111 | if(printer == null) {
112 | printer = new Printer();
113 | }
114 | return printer;
115 | }
116 |
117 | public void print(String input) {
118 | System.out.println(input);
119 | }
120 | }
121 | ```
122 |
123 | - 기본생성자를 `private`를 사용하여 생성을 불가능하게 하고, `getInstance`를 통해서만 생성
124 | - `getInstance`는 내부적으로 생성되지 않았다면 생성하고, 기존에 생성된 값이 존재한다면 생성된 인스턴스를 리턴하는 형태로 프로그램 전반에 걸쳐 하나의 인스턴스를 유지
125 | - 메서드와 인스턴스 변수 모두 **`static`으로 선언**된 정적 변수 및 메서드. 당연히 기본생성자를 통해 생성할 수 없기 때문에 외부에서 인스턴스에 접근하려면 클래스 변수 및 메서드에 접근을 허용해야하기 때문에 두 메서드는 정적타입으로 선언
126 |
127 | ### 1.7 단점
128 |
129 | 1. 멀티쓰레드 환경에서 안전하지 않다.
130 | 1. 생성자가 여러 쓰레드에서 동시에 실행된다면?
131 | 2. 여러 쓰레드에서 작업 중이기 때문에 일관되게 유지하고 싶은 상태가 있다면, 이를 관리하기가 어렵다.
132 | 2. 싱글톤 인스턴스를 참조하는 모든 모듈에 의존성이 생긴다
133 | 1. TDD하기 어려움 - 단위 기능 테스트를 하는 데, 독립적인 테스트를 하기 어렵다. (예를 들어, 모든 테스트에서 독립적으로 테스트할 때 DB를 생성해야 함)
134 | 2. 재사용성이 낮아짐
135 |
136 | ### 1.8 해결 방법
137 |
138 | 1. 멀티 쓰레드 환경
139 | 1. 최초 인스턴스가 클래스를 호출하기 전에,
140 | 선제적으로 클래스가 메모리에 올라올 때 부터 최초 인스턴스를 만들어 버리기
141 | `private static Printer printer = null;`
142 | → `private static Printer printer = new Printer();`
143 | 2. 상태는 `synchronized` 를 통해 관리하기 (`java`)
144 | - 각 언어별로 동시에 접근하는 것을 막는 방법들이 있다고 함
145 | - 예를 들어, golang 같은 경우에도 `sync.Once`와 같이 최초 한 번만 실행되게 하는 기능들이 있음
146 | 2. 의존성
147 |
148 | **의존성 주입**을 통해 해결
149 |
150 | **의존성 주입이란?**
151 |
152 |
158 |
159 | 예를 들어, 무슨 프린터인지는 클래스에서 관심 없게 만들어 버리고, 클래스 바깥에서 프린터의 종류를 관리
160 |
161 | ```java
162 | class Printer {
163 | ...
164 | public void setPrinterDevice(Printer printer) {
165 | this.Printer = printer;
166 | }
167 | }
168 |
169 | class Employee {
170 | private Printer printer = new Printer();
171 |
172 | public void changePrinter() {
173 | printer.setPrinterDevice(new OfficePrinterA());
174 | }
175 | }
176 | ```
177 |
178 | ### 1.9 Reference
179 |
180 | - 싱글톤 패턴
181 | - [https://velog.io/@kyle/자바-싱글톤-패턴-Singleton-Pattern](https://velog.io/@kyle/%EC%9E%90%EB%B0%94-%EC%8B%B1%EA%B8%80%ED%86%A4-%ED%8C%A8%ED%84%B4-Singleton-Pattern)
182 | - 의존성 주입
183 | - [https://tecoble.techcourse.co.kr/post/2021-04-27-dependency-injection/](https://tecoble.techcourse.co.kr/post/2021-04-27-dependency-injection/)
184 |
185 | ## 2. 팩토리 패턴
186 |
187 | 여러 객체들을 생성해 가져오는 공장 역할을 하는 패턴
188 |
189 | ### 2.1 특징
190 |
191 | - 상위 클래스인 팩토리 클래스는 어떤 인스턴스를 어떻게 가져올 지 계획
192 | - 하위 클래스는 상위 클래스에서 지정한 일의 종류에 따라 할당 받은 일 (=객체 리턴)을 수행
193 |
194 | 
195 |
196 | ### 2.2 장점
197 |
198 |
202 |
203 | 1. 작은 의자만 만드는 공장, 큰 의자만 만드는 공장이 어딘지 관심 없고 그냥 의자 공장에다 주문
204 | 2. 의자 주문서의 변경(**객체 생성 방식 변경**)을 해당 의자 부서 직원이 623 군데의 거래처(**코드**)를 돌며 처리하지 않고 단 하나의 직영 대리점(**팩토리**)에서 처리할 수 있음
205 |
206 | > 대부분의 라이브러리를 사용할 때 우리는 팩토리 패턴의 효과를 보고 있음
207 |
208 | ### 2.3 팩토리 패턴 in TypeScript
209 |
210 | **원하는 결과**
211 |
212 | 고객은 관심있는 종류의 의자 인스턴스를 바로 호출
213 |
214 | ```tsx
215 | import ChairFactory from "./chair-factory";
216 |
217 | const CHAIR = ChairFactory.getChair("small");
218 | console.log(CHAIR.getDimensions());
219 | ```
220 |
221 | ```tsx
222 | export type dimension = {
223 | height: number;
224 | width: number;
225 | depth: number;
226 | };
227 | ```
228 |
229 | ```tsx
230 | import { dimension } from "./dimension";
231 |
232 | // A Chair Interface
233 | interface IChair {
234 | height: number;
235 | width: number;
236 | depth: number;
237 | getDimensions(): dimension;
238 | }
239 |
240 | // The Chair Base Class
241 | export default class Chair implements IChair {
242 | height = 0;
243 | width = 0;
244 | depth = 0;
245 |
246 | getDimensions(): dimension {
247 | return {
248 | width: this.width,
249 | depth: this.depth,
250 | height: this.height,
251 | };
252 | }
253 | }
254 | ```
255 |
256 | ```tsx
257 | // smallChair.ts
258 | import Chair from "./chair";
259 |
260 | export default class SmallChair extends Chair {
261 | constructor() {
262 | super();
263 | this.height = 40;
264 | this.width = 40;
265 | this.depth = 40;
266 | }
267 | }
268 | ```
269 |
270 | ```tsx
271 | // mediumChair.ts
272 | import Chair from "./chair";
273 |
274 | export default class MediumChair extends Chair {
275 | constructor() {
276 | super();
277 | this.height = 60;
278 | this.width = 60;
279 | this.depth = 60;
280 | }
281 | }
282 | ```
283 |
284 | ```tsx
285 | // bigChair.ts
286 | import Chair from "./chair";
287 |
288 | export default class BigChair extends Chair {
289 | constructor() {
290 | super();
291 | this.height = 80;
292 | this.width = 80;
293 | this.depth = 80;
294 | }
295 | }
296 | ```
297 |
298 | ```tsx
299 | import SmallChair from './smallChair'
300 | import MediumChair from './mediumChair'
301 | import BigChair from './bigChair'
302 | import IChair from './chair'
303 |
304 | type chairList = "small" | "medium" | "big"
305 |
306 | export default class ChairFactory {
307 | static getChair(chair: chairList): IChair {
308 | if (chair == 'big') {
309 | return new BigChair()
310 | } else if (chair == 'medium') {
311 | return new MediumChair()
312 | } else {
313 | return new SmallChair()
314 | }
315 | }
316 | ```
317 |
318 | ### 2.4 Reference
319 |
320 | - 팩토리 패턴은 언제 사용하나요?
321 | [https://stackoverflow.com/questions/69849/factory-pattern-when-to-use-factory-methods](https://stackoverflow.com/questions/69849/factory-pattern-when-to-use-factory-methods)
322 | - TS에서의 팩토리 패턴
323 | [https://sbcode.net/typescript/factory/](https://sbcode.net/typescript/factory/)
324 |
--------------------------------------------------------------------------------
/Software Engineering/Strategy Pattern.md:
--------------------------------------------------------------------------------
1 | # Strategy Pattern
2 |
3 | Created: 2022년 7월 6일 오후 3:08
4 | Tags: CS, Design Pattern, SW Engineering
5 |
6 | ## 디자인 패턴이란?
7 |
8 | - SW를 개발하다보니, 어떤 경우에는 어떤 방식이 적합하더라. 라는 경험이 만든 패턴
9 | - 따라서 절대적인 우열은 없고, 맥락에 따라 적합한 패턴이 존재
10 |
11 | ## 전략 패턴이란?
12 |
13 | 
14 |
15 | - 맥락에 따라서 `setStrategy`로 전략을 고르면,
16 | - 코드는 무슨 전략인지 알 필요 없이 `AlgorithmInterface()`에 따라 실행하기만 하면 되는 전략
17 |
18 | ## 예시
19 |
20 | - 민들렛의 주니어 백엔드 개발자 백 아무개는 민들레니버스를 위협하는 용을 개발하는 막중한 임무를 맡았다. 다행히도, 모든 민들레를 불어서 없애버리는 용을 이미 시니어들이 객체지향 기법에 따라 개발을 해 놓았다.
21 |
22 | ### 수퍼클래스 `Dragon`
23 |
24 | ```java
25 | class Dragon {
26 | breath() { "모든 민들레를 날려버립니다!" } // 모든 용은 브레스를 날릴 줄 안다.
27 | describe() // 용의 생김새를 묘사하는 추상 메서드
28 | }
29 | ```
30 |
31 | ### 서브클래스 `RedDragon`, `IceDragon`
32 |
33 | ```tsx
34 | class RedDragon extends Dragon {
35 | describe(); // 뜨거운 불을 뿜는 용입니다!
36 | }
37 |
38 | class IceDragon extends Dragon {
39 | describe(); // 모든 것을 얼려버리는 용입니다!
40 | }
41 | ```
42 |
43 | 그런데, 민들렛 서비스가 커지게 되면서, 고인물들이 늘고, 용을 유저들이 두려워하지 않게 되었다. 그래서 용이 더 두려운 존재가 될 수 있도록 회사는 아래와 같은 요구사항을 만들었다.
44 |
45 | > 앞으로는 용이 날아다니면서 더 많은 민들레들을 불어버리고, 대응하기 어렵도록 더 다양한 용을 만든다.
46 |
47 | ### 상속을 통한 해결
48 |
49 | 새로운 요구사항을 본 백아무개는 객체지향을 떠올리며 수퍼클래스에 `fly`를 추가하면 모든 용이 날 수 있을 거라 생각했다.
50 |
51 | ```java
52 | class Dragon {
53 | breath() { "모든 민들레를 날려버립니다!" }
54 | describe()
55 | fly() { "용이 날아오릅니다!" } // 추가
56 | }
57 | ```
58 |
59 | 훌륭한 아이디어 였다고 생각하고 개발을 마무리하고 퇴근한 뒤, 다음 날 아침 운영팀에서 전화를 받게 된다.
60 |
61 | > 백아무개님 도마뱀용이 날아다니는데요?
62 |
63 | `fly` 기능이 필요 없는 도마뱀 용까지 날아다니게 된 것. 상속을 사용했다고 생각했지만, 실제로는 버그를 만들어버린 것이다.
64 |
65 | ### 그러면 예외만 오버라이드 하지 뭐
66 |
67 | 이에 백아무개는 도마뱀용만 날지 못하도록 오버라이드를 해버린다.
68 |
69 | ```java
70 | class LizardDragon extends Dragon {
71 | describe()
72 | fly() // do nothing
73 | }
74 | ```
75 |
76 | 하지만 그 다음날 병아리용도 날고 있다는 전화를 받자, 일부 용만 날 수 있도록 좀 더 깔끔한 방법을 찾아야 겠다는 생각을 한다. 수퍼클래스 `Dragon`에서 `fly`를 정의하는 것을 포기하고, `Dragon`을 위한 인터페이스를 만든다.
77 |
78 | ### interface for Dragon
79 |
80 | ```java
81 | interface Winged {
82 | // 이 용은 날개가 있는 용입니다!
83 | fly()
84 | }
85 | ```
86 |
87 | ### 서브 클래스들 재정의
88 |
89 | ```java
90 | class RedDragon extends Dragon implements Winged{
91 | describe()
92 | fly()
93 | }
94 |
95 | class IceDragon extends Dragon implements Winged {
96 | describe()
97 | fly()
98 | }
99 |
100 | class LizardDragon extends Dragon {
101 | describe()
102 | }
103 | ```
104 |
105 | 처음에는 이 방식이 괜찮아 보였지만, 결국 날 수 있는 용마다 `fly` 메서드를 구현해줘야 했고, 용마다 다른 `fly` 기능을 구현할 수 없다는 점을 깨닳았다. 괴로워하는 백 아무개를 본 시니어 개발자는 `Strategy Pattern`을 참고해서 개발해보라고 조언한다.
106 |
107 | ## 전략 패턴의 원칙
108 |
109 | ### 1. 어떻게 분리해야 할까? - 캡슐화
110 |
111 | > 달라지는 부분을 분리해라 (encapsulation, 캡슐화)
112 |
113 | 용은 `fly` 외에는 잘 작동하고 있기 때문에, 각 용마다 다른 동작이 필요한 부분은 `fly` 이다. 그렇다면 `fly`를 분리해서 동적으로 세팅하면 좋은 결과가 따를 수 있을 것 같다.
114 |
115 | ### 2. 다형성은 어떻게 확보? - `interface`
116 |
117 | > 인터페이스를 통해 동적으로 변경이 가능하도록 설계한다.
118 |
119 | 인터페이스는 `super type`에 맞춰서 다형성을 확보한다는 의미이기도 하다.
120 |
121 | ```java
122 | interface FlyBehavior {
123 | fly()
124 | }
125 |
126 | class FlyWithWings implements FlyBehavior {
127 | fly() { "용이 날아오릅니다!" } // 나는 모습을 구현
128 | }
129 |
130 | class FlyNoWay implements FlyBehavior {
131 | fly() { "stay.." } // 날 수 없음
132 | }
133 | ```
134 |
135 | ### 3. Dragon 클래스에 서브 용들의 개별 행동을 인터페이스로 위임하기
136 |
137 | 이는 서브 클래스들의 행위를 상위 클래스로 통합한다는 의미이기도 하다.
138 |
139 | ```java
140 | public class Dragon {
141 | FlyBehavior flyBehavior;
142 |
143 | public void performFly() {
144 | flyBehavior.fly();
145 | }
146 | }
147 | ```
148 |
149 | ### 4. 서브클래스를 정의할 때, `flyBehavior` 인스턴스 변수를 설정
150 |
151 | ```java
152 | public class LizardDragon extends Dragon {
153 | public LizardDragon() {
154 | flyBehavior = new FlyNoWay();
155 | }
156 | public void describe() {
157 |
158 | }
159 | }
160 | ```
161 |
162 | ### 5. 더 나아가 동적인 `Dragon` 설계하기
163 |
164 | ```java
165 | public class Dragon {
166 | FlyBehavior flyBehavior;
167 | ...
168 |
169 | public void setFlyBehavior(FlyBehavior fb) {
170 | flyBehavior = fb;
171 | }
172 | ...
173 | }
174 | ```
175 |
176 | `Red Dragon`이 날개를 다쳐서 못 날게 되었다고 가정하고, `setter` 사용
177 |
178 | ```java
179 | ...
180 |
181 | Dragon red = new RedDragon();
182 |
183 | red.performFly(); // fly!
184 |
185 | red.setFlayBehavior(new FlyNoWay());
186 |
187 | red.perfomFly(); // stay...
188 |
189 | ...
190 | ```
191 |
192 | 
193 |
194 | > "A는 B이다"보다 "A에는 B가 있다"가 나을 수 있습니다. A와 B의 관계에 대해 생각해보면, `flyBehavior`가 있으며, 각각의 행위를 위임 받습니다.
195 |
196 | 두 클래스를 이런 식으로 합치는 것을 조합(composition)을 이용한다 합니다.
197 |
198 | 용 클래스에서는 행동을 상속받는 대신, 올바른 행동 객체로 조합됨으로써 행동을 부여받게 됩니다.
199 |
200 | > 이처럼 동적으로 조합을 이용하여 시스템을 만들면 유연성을 크게 향상시킬 수 있습니다.
201 |
202 | ## 정리
203 |
204 | - 전략 패턴이란, 객체 지향적 프로그래밍 방법 중 하나로서 기능의 차이가 있는 부분을 캡슐화하고, 다형적 메서드를 공통된 인터페이스 부모로 통합해 사용하는 방법
205 |
--------------------------------------------------------------------------------
/Software Engineering/UML.md:
--------------------------------------------------------------------------------
1 | # Content
2 |
3 | - [UML](#uml)
4 | - [UML은 왜 써야 하는가](#uml은-왜-써야-하는가)
5 | - [UML은 언제 써야 하는가](#uml은-언제-써야-하는가)
6 | - [UML은 어떻게 써야 하는가](#uml은-어떻게-써야-하는가)
7 | - [다이어그램 예제](#다이어그램-예제)
8 |
9 | # UML
10 |
11 | UML(Unified Modeling Language)은 소프트웨어 개념을 다이어그램으로 그리기 위해 사용하는 시각적인 표기법입니다. 문제 도메인(problem domain), 소프트웨어 설계 제안 등에서 UML을 사용할 수 있습니다.
12 |
13 | UML의 주요 다이어그램은 세 종류로 나뉩니다.
14 |
15 | | 구분 | 설명 |
16 | | :---------------: | :----------------------------------------------------------------------------------------------------------------------------------- |
17 | | 정적 다이어 그램 | 클래스, 객체, 데이터 구조의 관계를 UML로 표현해서 변하지 않는 논리적 구조를 보여줍니다. |
18 | | 동적 다이어그램 | 실행 흐름을 그림으로 그리거나 상태가 어떻게 바뀌는지 UML로 표현해서 소프트웨어 안의 실체가 실행 도중 어떻게 변하는지 보여줍니다. |
19 | | 물리적 다이어그램 | 소스 파일, 바이너리 파일, 데이터 파일 등 물리적 실체의 관계를 UML로 표현해서 소프트웨어 실체의 변하지 않는 물리적 구조를 보여줍니다. |
20 |
21 | ## UML은 왜 써야 하는가
22 |
23 | 엔지니어들은 본 작업을 시작하기 전에 모델을 만듭니다. 예를 들어 항공 엔지니어는 비행기 모델을 만들고 제대로 날 수 있는지 확인합니다. 건축가는 건물의 모델을 건축주에게 보여줌으로써 건물의 모습이 괜찮은지 확인합니다.
24 |
25 | 왜 모델을 만들까요? 실제로 비행기를 만들거나 건물을 짓는 것 보다 훨씬 저렴하기 때문입니다. 소프트웨어 모델도 이와 같은 이유로 만들며 이 때 UML이 사용됩니다.
26 |
27 | ## UML은 언제 써야 하는가
28 |
29 | 소프트웨어 기능을 구현하기 위한 아이디어가 떠올랐을 때 기획자, 개발자, 디자이너 등 동료들과 의견을 나눌 수 있습니다.
30 |
31 | 책 `UML 실전에서는 이것만 쓴다`의 저자 `로버트 C. 마틴`은 아래와 같이 다이어그램을 그려야할 경우와 그리지 말아야할 경우를 제시합니다.
32 |
33 | ### 다이어그램을 그려야 할 경우
34 |
35 | - 여러 사람이 동시에 작업하는 상황에서 특정한 부분의 구조를 모두가 이해해야 할 때
36 | - 두 명 이상이 특정 요소를 어떻게 설계해야 할지 의견이 다르고, 팀의 의견을 모을 필요가 있을 때
37 | - 어떤 설계 아이디어로 이것저것 시도해 보고 싶을 때
38 | - 누군가에게 또는 자신에게 코드 일부분의 구조를 설명할 때
39 |
40 | ### 다이어그램을 그리지 말아야 할 경우
41 |
42 | - 공정에서 다이어그램을 그려야 한다고 해서 다이어그램을 그리지 마라.
43 | - 다이어그램을 그리지 않으면 죄책감을 느끼거나, 훌륭한 설계자는 누구나 다이어그램을 그린다는 생각이 든다고 다이어그램을 그리지 마라.
44 | - 설계 단계의 포괄적인 문서를 만들기 위해서 다이어그램을 그리지 마라.
45 |
46 | UML을 사용하면 대부분 쉽고 빠르게 생각을 공유할 수 있습니다. 특히 코드를 직접 작성하는 것보다 다이어그램을 그리는 것이 간단하므로 적절하게 UML을 사용하면 큰 효과를 볼 수 있습니다. 하지만 일부의 경우에 너무 많은 다이어그램을 만들거나 끝없는 논쟁을 하여 많은 시간이 소요될 수 있습니다. 따라서 UML은 필요한 경우에 효과적으로 사용해야 합니다.
47 |
48 | ## UML은 어떻게 써야 하는가
49 |
50 | 1. UML로 만든 다이어그램은 반복적 방식으로 만들어야 하며, 반복 주기도 짧아야 합니다. 동적 다이어그램과 정적 다이어그램을 5분이나 더 짧은 주기로 반복하며 동시에 발전시키는 것이 중요합니다.
51 | 2. UML CASE 도구는 생산성을 고려해서 사용 결정을 해야 합니다. 대부분의 개발팀에는 도움보다 방해가 되기 쉽습니다. CASE 도구를 별도로 도입하지 않고 칠판과 펜만으로도 충분한 효과를 볼 수 있습니다.
52 | 3. UML은 도구일 뿐입니다. 설계에 대한 아이디어를 다른 사람에게 전달할 때 도움이 될 수 있지만 남용하지 않고 적절하게 사용해야 합니다. 남용하면 불필요한 시간을 낭비할 수 있습니다.
53 |
54 | ## 다이어그램 예제
55 |
56 | UML로 다이어그램을 만들 때 협력 다이어그램을 먼저 만드는 것이 좋습니다. 소프트웨어에서 객체 간에 어떤 협력이 있는지, 어떤 객체가 필요한지를 알 수 있습니다. 그 다음 1개의 객체를 1개의 클래스로 대응하여 클래스 다이어그램을 만들고 변수, 메서드 등을 표현합니다. 이 과정에서 시퀀스 다이어그램, 객체 다이어그램, 상태 다이어그램, 유스케이스 등이 사용될 수 있지만 협력 다이어그램과 클래스 다이어그램만으로도 큰 효과를 볼 수 있습니다. 여기서는 `숫자 게임`을 예제로 사용합니다.
57 |
58 | ### 숫자 게임 기능
59 |
60 | 숫자 게임의 기능은 다음과 같습니다.
61 |
62 | - 플레이어는 숫자 1개를 입력합니다.
63 | - 플레이어가 입력한 숫자가 상대방의 숫자와 일치하면 게임에 승리하고 게임은 종료됩니다. 일치하지 않으면 게임은 계속됩니다.
64 | - 상대방은 컴퓨터가 되며 게임이 시작될 때 임의의 숫자 1개를 가집니다.
65 |
66 | > 아래에 나오는 다이어그램은 완성된 다이어그램이 아닙니다. 어디까지나 설명을 위한 다이어그램이니 미흡한 부분이 있을 수 있습니다.
67 |
68 | ### 숫자 게임 협력 다이어그램 1
69 |
70 | 
71 |
72 | 협력 다이어그램을 그려보면서 어떤 협력이 필요한지, 협력을 수행할 객체는 무엇인지 생각해볼 수 있습니다.
73 |
74 | 필요한 객체는 아래의 네 가지가 될 수 있습니다.
75 |
76 | - 플레이어
77 | - 숫자 게임
78 | - 컴퓨터
79 | - 디스플레이
80 |
81 | 각 객체는 코드로 작성할 때 클래스 하나씩 매칭됩니다.
82 |
83 | ### 숫자 게임 클래스 다이어그램 1
84 |
85 | 
86 |
87 | 현재 클래스 다이어그램에서는 플레이어 클래스가 숫자 게임 클래스를 의존하고 있습니다.
88 |
89 | ```java
90 | public class Player {
91 |
92 | private final NumberGame numberGame;
93 |
94 | //...
95 | }
96 | ```
97 |
98 | 만약 다른 게임이 추가된다면 아래와 같이 플레이어 클래스는 모든 게임들을 의존해야 합니다. 이 것에 대해서 더 좋은 방법을 고민해볼 수 있습니다.
99 |
100 | ```java
101 | public class Player {
102 |
103 | private final NumberGame numberGame;
104 |
105 | private final OtherGame1 otherGame1;
106 |
107 | private final OtherGame2 otherGame2;
108 |
109 | //...
110 | }
111 | ```
112 |
113 | ### 숫자 게임 클래스 다이어그램 2
114 |
115 | 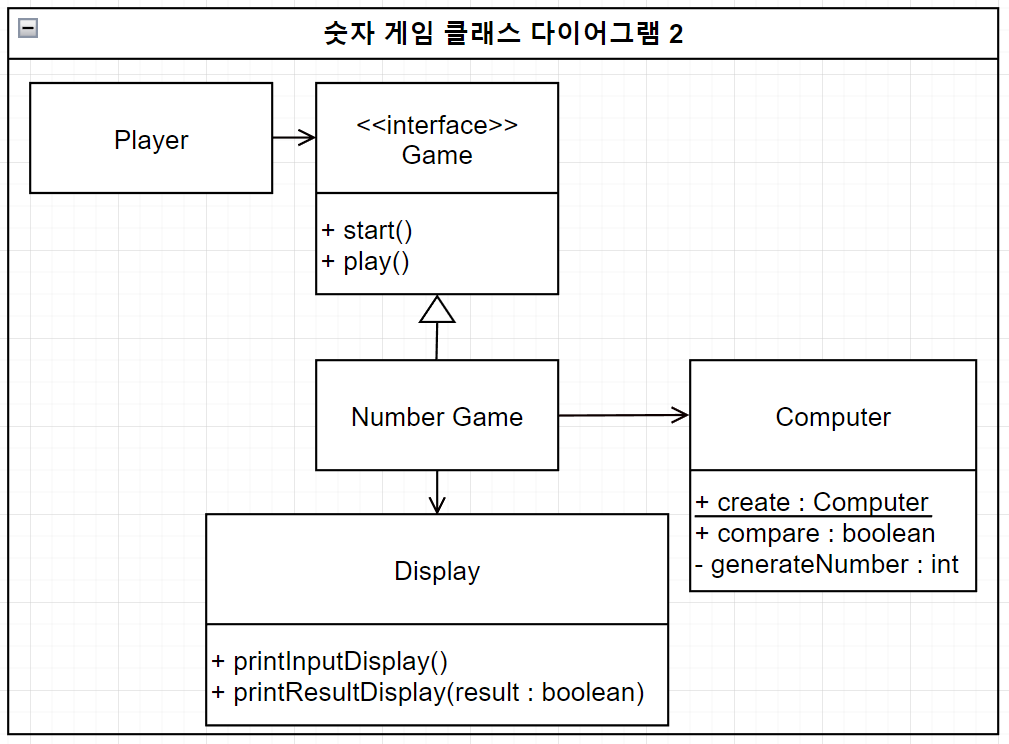
116 |
117 | 숫자 게임 클래스를 게임 인터페이스로 추상화하고 플레이어 클래스가 게임 인터페이스에 의존하도록 합니다. 실제 협력은 게임 인터페이스를 구현한 숫자 게임 클래스가 수행하게 되며 플레이어 클래스는 모든 게임 클래스를 의존할 필요가 없게 됩니다.
118 |
119 | ```java
120 | public class Player {
121 |
122 | private final Game game;
123 |
124 | //...
125 | }
126 | ```
127 |
128 | ### 숫자 게임 협력 다이어그램 2
129 |
130 | 
131 |
132 | 개선된 클래스 다이어그램을 협력 다이어그램에도 반영합니다.
133 |
134 | 결과적으로 협력 다이어그램과 클래스 다이어그램을 번갈아 수정하며 필요한 객체들과 객체 간의 협력을 파악하였습니다. 또한 인터페이스를 사용하여 플레이어 객체와 게임 객체의 결합도를 낮추었습니다.
135 |
136 | 이처럼 UML을 적절하게 사용해서 다이어그램을 그리면 소프트웨어 설계에 대한 고민을 동료들과 쉽게 나눌 수 있고 좋은 설계를 할 수 있게 됩니다.
137 |
--------------------------------------------------------------------------------
/WEB/CORS.md:
--------------------------------------------------------------------------------
1 | # CORS
2 |
3 | ### 개발자가 CORS에러를 만나는 경우
4 |
5 | - PostMan, 스프링 등에선 URI요청이 정상적으로 보내진다.
6 | - 웹사이트(크롬, 엣지, 사파리)등 브라우저(Front End)에서 발생
7 | - 보안상의 이유로 JavaScript에서는, 오류의 상세정보에 접근 불가
8 | - 상세정보는 브라우저의 콘솔에서 확인해야함
9 |
10 | # CORS
11 |
12 | ### :Cross-Origin Resource Sharing (교차 출처 리소스 공유)
13 |
14 | 브라우저-서버 간 안전한 **교차출처 요청**과 **데이터 전송**을 지원하는 체제
15 |
16 | - **웹 애플리케이션**은 자신, 또는 다른 출처(도메인, 프로토콜,포트)에서 **리소스**를 요청한다.
17 | - 외부 출처의 자원에 접근할 때, `교차 출처 HTTP요청`을 실행한다.
18 | - ‘교차 출처 HTTP요청’은 외부 출처의 자원에 접근할 수 있는 **권한을 부여**하며,
19 | - 이를 `추가 HTTP헤더`를 사용해 **브라우저**에 알리는 것이 `CORS`이다.
20 |
21 | # SOP
22 |
23 | ### :Same-Origin Policy (동일 출처 정책)
24 |
25 | **서로 다른 출처**의 리소스가 상호작용하는 것을 제한하는 `보안방식`
26 |
27 | `보안 상`의 이유로, **브라우저**는 **스크립트**에서 시작한 ‘교차 출처 HTTP 요청’을 **제한**한다.
28 |
29 | 잠재적으로 해로울 수 있는 문서를 분리해 공격받을 경로를 줄임.
30 |
31 | - 동일한 출처란?
32 |
33 | 두 URL의 `프로토콜` / `포트` / `호스트` 가 모두 같아야 동일한 출처
34 |
35 | EX) URL `http://store.company.com/dir/page.html`의 출처를 비교한 예시
36 | |url|결과|이유|
37 | |---|---|---|
38 | |http://store.company.com/dir2/other.html|성공|경로만 다름|
39 | |http://store.company.com/dir/inner/another.html|성공|경로만 다름|
40 | |https://store.company.com/secure.html|실패|프로토콜 다름|
41 | |http://store.company.com:81/dir/etc.html|실패|포트 다름 (http://는 80이 기본값)|
42 | |http://news.company.com/dir/other.html|실패|호스트 다름|
43 |
44 |
45 | 이 정책을 따르는 API를 사용하는 웹 애플리케이션이 다른 출처의 리소스를 불러오려면,
46 |
47 | 그 출처에서 올바른 CORS 헤더를 포함한 응답을 반환해야 한다.
48 |
49 | EX) 동일 출처 정책을 따르는 예시
50 |
51 | - XMLhttpRequest
52 | - Fetch API
53 |
54 | #### 필요성
55 |
56 | - 크롬에서 방문한 사이트를 못믿음
57 | - 다른 사이트 방문 시 쿠키, 세션 등에 저장되어있는 인증정보를 탈취해갈 가능성 있음
58 | - 원래 브라우저 간의 리소스 공유는 막아지는게 원칙이었는데, 웹 생태계가 발전함에 따라 필요성을 느껴 만들어진 것임
59 |
60 | 
61 |
62 |
63 |
64 | ## CORS에러 해결법
65 |
66 | BE에서 허락할 다른 출처들(허용할 사이튿들)을 미리 명시함
67 |
68 | CORS 옵션을 넣어두는 방법은 프레임워크마다 명시되어있음
69 |
70 | ## CORS기능 기본동작순서
71 |
72 | 1. [FE]요청에 ORIGIN 이라는 header(받는 쪽의 ip주소, 사용할 프로토콜, 옵션) 추가
73 | 2. [BE] 서버는 header에 지정된 `Acces-Control-Allow-Origin` 정보(허용된 url)을 실어보냄
74 | 3. [FE] 비교 후 안전한 요청으로 판단 → 응답 보내줌
75 |
76 | ## 1. Simple Request
77 |
78 | - `Get`, `Post` 등의 요청
79 | - 데이터에 영향을 미치지 않는 요청
80 |
81 | ## 2. Preflight Request
82 |
83 | - `Put`, `Delete` 등의 요청
84 | - 서버 데이터에 영향을 미치는 요청
85 |
86 | ### 추가 동작
87 |
88 | 1. 브라우저가 `OPTIONS` 메서드로, 원하는 요청을 `사전전달 (preflight)`
89 | 2. 서버가 실제요청울 허가(재요구)
90 | 1. 필요에 따라 인증정보(`쿠키`, `http인증`) 함께 요구
91 |
92 | ## 3. Credentialed Request
93 |
94 | - `토큰` 등 사용자 식별정보
95 | - 더 엄격한 기준 적용
96 | - [FE] 요청의 option에 `credentials` 항목을 true로 세팅
97 | - [BE] `Access-Control-Allow-Credentials` 항목을 true로 세팅
98 |
99 | 출처-웹페이지 주소 정확히 명시 (와일드 카드 X)
100 |
--------------------------------------------------------------------------------
/WEB/JWT.md:
--------------------------------------------------------------------------------
1 | # JWT(feat. Session)
2 |
3 | ## Content
4 |
5 | - [Session의 문제점](#session의-문제점)
6 | - [Json Web Token](#Json-Web-Token)
7 | - [JWT 동작 원리](#JWT-동작-원리)
8 | - [JWT의 장점과 한계](#jwt의-장점과-한계)
9 |
10 | ## Session의 문제점
11 |
12 | 클라이언트의 인증 방식으로 Session을 사용하는 경우 여러 문제점이 발생할 수 있다.
13 |
14 | ### 메모리 용량 부족
15 |
16 | Session은 일반적으로 server의 메모리에 저장되는데 동시 접속자가 많을 경우 메모리가 부족해질 수 있다.
17 |
18 | ### 중복된 Session 정보
19 |
20 | 서버가 여러 대로 증설되는 경우 클라이언트의 요청을 처리하는 서버가 매번 달라질 수 있다.
21 |
22 | - 첫 번째 요청을 서버 A가 수행하면 서버 A의 메모리에 Session 정보가 저장된다.
23 | - 두 번째 요청을 하였을 때 서버 A의 부하가 높아 서버 B가 요청을 처리할 수 있는데, 이때 서버 B에는 클라이언트의 Session 정보가 없으므로 새롭게 Session을 생성한다. 즉, 중복된 Session 정보가 생기는 것이다.
24 | - 새롭게 Session을 생성하는 오버헤드를 줄이려면 Session을 생성하고 다른 모든 서버에 새롭게 생성된 Session 정보를 복사할 수 있다. 하지만, 이 과정도 충분히 오버헤드가 크다.
25 |
26 | ### 속도 저하
27 |
28 | - Session 정보를 저장할 물리 디스크 기반 데이터베이스를 사용함으로써 여러 서버에 중복 생성된 Session 정보를 한 곳에서 관리할 수 있다. 하지만 속도 저하가 발생한다.
29 | - 일반적으로 Session 정보는 메모리에 저장되는데 물리 디스크에 저장하는 경우 속도 저하가 심각하게 발생한다.
30 |
31 | 위와 같은 문제를 해결하기 위해 메모리 기반 데이터베이스(eg. redis)를 사용할 수 있다. 여러 서버가 공유할 수 있는 메모리에 Session 정보를 저장할 수 있다. 하지만 첫 번째 문제가 여전히 발생한다. 이와 같은 문제를 JWT로 해결할 수 있다.
32 |
33 | ## Json Web Token
34 |
35 | - JWT는 데이터를 JSON 객체로 안전하게 주고 받기 위한 표준 기술이다([RFC 7519](https://datatracker.ietf.org/doc/html/rfc7519)).
36 | - JWT에는 서명 알고리즘으로 서명된 signature가 포함되는데 이 정보를 검증한 후에 클라이언트의 요청을 수행하거나 거부할 수 있다.
37 | - JWT의 서명 알고리즘으로는 해시 알고리즘(eg. HMAC)이나 공개키 알고리즘(eg. RSA)이 사용된다.
38 |
39 | JWT는 기밀성보다 무결성에 중점을 둔다. 즉, 전송되는 데이터가 변조되거나 위조되지 않았다는 것을 보장할 수 있다. 이러한 점을 고려하여 JWT를 다음과 같은 상황에서 사용할 수 있다.
40 |
41 | #### 인가
42 |
43 | 클라이언트가 JWT를 서버에 전송한 경우 signature을 검증하고 클라이언트의 권한을 확인한다. 권한이 있는 경우 요청한 내용을 수행한다. 권한이 없는 경우에는 요청을 거부한다.
44 |
45 | #### 암호화
46 |
47 | JWT는 RSA와 같은 알고리즘으로 데이터를 안전하게 주고 받을 수 있다.
48 |
49 | 
50 |
51 | ### 구조
52 |
53 | JWT는 header, payload, signature로 구성되어 있다.
54 |
55 | | 구분 | 용도 |
56 | | :-------: | :--------------------------------------------------------------------------------------------------------- |
57 | | header | 일반적으로 서명 알고리즘의 종류와 토큰 유형(JWT)으로 포함된다. |
58 | | payload | claim으로 구성된다. claim은 만료 시간, 발급자, 개인 claim(username, email 등) 등으로 구성할 수 있다. |
59 | | signature | `base64Encode(header) + base64Encode(payload) + server private key`를 서명 알고리즘으로 서명한 데이터이다. |
60 |
61 | JWT는 header, payload, signature를 각각 base64 알고리즘로 인코딩하고 합쳐서 사용한다. 이때 header와 payload에 중요 데이터를 담아서는 안된다. base64 알고리즘로은 누구나 복호화할 수 있기 때문이다.
62 |
63 | ## JWT 동작 원리
64 |
65 | ### 서명
66 |
67 | 
68 |
69 | 
70 |
71 | JWT의 signature는 header와 payload를 각각 base64 알고리즘으로 인코딩하고 서명 알고리즘으로 서명(암호화)한다. 이때 Server가 보관 중인 private key가 포함되기 때문에 외부에서 위조하기가 매우 어렵게 된다.
72 |
73 | ### 검증
74 |
75 | server는 전달받은 JWT의 signature를 아래와 같이 검증한다.
76 |
77 | - 전달받은 header와 payload를 server가 보관 중인 private key와 합치고 서명한다.
78 | - 새롭게 서명한 signature와 전달받은 signature가 동일한지 확인하고 요청을 수행하거나 거부한다.
79 |
80 | 
81 |
82 | ## JWT의 장점과 한계
83 |
84 | ### 장점
85 |
86 | - 기존 Session 방식의 단점을 완화할 수 있다.
87 | - 메모리나 물리 디스크에 검증을 위한 데이터를 저장할 필요가 없다.
88 |
89 | ### 한계
90 |
91 | - JWT는 HTTP로 데이터를 전송하기 때문에 header와 payload의 크기가 클수록 데이터 전송 비용(대역폭, 전송 속도 등)이 증가한다.
92 | - JWT 토큰은 만료시간이 지나야만 더 이상 사용할 수 없게 된다. 따라서 JWT 토큰이 유출되면 만료될 때까지 제삼자가 사용할 수 있다. 이때 피해를 최소화하기 위해 JWT 토큰의 만료시간을 짧게 지정할 수 있다.
93 | - PC, Mobile 등의 접속 환경 중 한 곳에서만 로그인하는 것이 어렵다. 왜냐하면 서버는 토큰을 저장하지 않기 때문이다. 즉, 서버는 클라이언트의 로그인 상태를 알 수 없다.
94 |
--------------------------------------------------------------------------------
/WEB/RESTful_API.md:
--------------------------------------------------------------------------------
1 | # [Web] Restful API
2 |
3 | 
4 |
5 | ### REpresentational State Transfer
6 |
7 | : `자원(resource)`을 ‘이름’으로 구분해, 해당 자원의 `상태(state)` 정보를 주고 받는
8 |
9 | 서버-클라이언트 통신 방식 중 하나
10 |
11 |
17 |
18 | - **HTTP 프로토콜을 그대로 사용**
19 | - 웹의 장점을 최대한 활용할 수 있는 아키텍처
20 | - 다양한 클라이언트(브라우저, 기기) 에서 통신하기 위해 필요
21 | - 표준이 존재하지 않음
22 |
23 |
31 |
32 | ## REST 구성요소
33 |
34 | - 자원(Resource): **URI**
35 | - 모든 자원에는 고유한 ID가 존재 (server)
36 | - 행위(Verb): Method
37 | - GET / POST / PUT / DELETE
38 | - 표현(Representation)
39 | - Json / xml / txt / rss
40 |
41 |
42 | ## REST 특징
43 |
44 | 1. Server-Client [서버-클라이언트 구조]
45 | 1. Server : 자원을 소유하는 쪽
46 | 2. Client : 자원을 요청하는 쪽
47 | 3. 서로의 의존성 ↓
48 | 2. Stateless [무상태성]
49 | 1. HTTP와 마찬가지로 stateless 프로토콜
50 | 2. 클라이언트의 context(ex_세션, 쿠키)정보는 관여 X
51 | 3. 요청에 대한 응답만을 처리
52 | 3. Cacheable [캐시처리 가능]
53 | 1. 캐시 : 대량의 요청 효율적으로 처리 가능
54 | 2. REST 서버의 트랜잭션이 발생하지 않기 때문
55 | 4. Layered System [계층화]
56 | 1. REST 서버는 다중계층 가능
57 | 2. 보안, 로드밸런싱, 암호화, 인증 등의 기능을 구분 가능
58 | 3. Proxy, Gateway 등 중간매체 사용가능
59 | 5. Code-On-Demand
60 | 1. 서버로 부터 스크립트를 받아 클라이언트에서 실행
61 | 6. Uniform Interface [인터페이스 일관성]
62 | 1. HTTP 표준 프로토콜
63 | 2. 특정 기술에 종속되지 않음
64 |
65 | ## REST API 설계규칙
66 |
67 | ### API
68 |
69 | : Application Programming Interface
70 |
71 | 1. URI는 정보의 `자원`(resource) 을 표현 !!
72 | - 명사(O) ~~동사~~(X)
73 | - 소문자(O) ~~대문자~~(X)
74 |
75 | | Document | DB의 레코드 | 단수명사 |
76 | | --- | --- | --- |
77 | | Collection | 서버의 디렉토리 리소스 | 복수명사 |
78 | | Store | Client의 리소스 저장소 | 복수명사 |
79 | 2. 행위는 HTTP Method로 표현
80 | - GET / PUT / POST /DELETE
81 | - URI 에 HTTP Method 가 들어가면 안됨 !!!
82 | - URI 에 동사표현 금지 !!
83 | - URI에 표출되는 value는, ‘자원’ 의 고유식별자(id) 여야 함.
84 | 3. 슬래시(/) 는 계층관계를 나타냄
85 | 4. URI 마지막에 슬래시(/) 두지 않기
86 | 5. URI에 밑줄(_) 사용금지
87 | 6. URI에 대문자 지양
88 | 7. URI에 파일확장자 포함금지
89 |
90 |
96 |
97 | ### RESTful
98 |
99 | : REST API 를 제공하는 웹서비스
100 |
101 | ### PUT vs PATCH
102 |
103 | | | PUT | PATCH |
104 | | --- | --- | --- |
105 | | 자원교체 | 전체 | 부분 |
106 | | 필요한 필드값 | 모든 필드 | 일부 필드만 |
107 | | 일부 필드값만 제공할 시 나머지 필드값 | null | 그대로 |
108 | | 일부 update | X | O |
109 |
--------------------------------------------------------------------------------
/WEB/Web 서버와 WAS의 차이.md:
--------------------------------------------------------------------------------
1 | # Web서버와 WAS의 차이
2 | [발표자료](https://docs.google.com/presentation/d/1xE4Hx2AUvQgoN12EmOg4SF6IKRBCjnfhjTbEu3_Ox3w/edit?usp=sharing)
3 |
4 | 2022-08-03 (수) 안영진
5 |
6 | ## 목차
7 | 1. 배경지식
8 | 2. Web 서버와 WAS의 차이
9 | 3. 추가 설명
10 |
11 | # 1. 배경지식
12 | ## static pages (정적 컨텐츠)
13 |
14 | - URL에 입력한 파일경로를 받아 File Contents를 그대로 반환
15 | - 항상 동일한 페이지, 파일 반환
16 | - ex) image, html, css, javascript등 즉시 응답 가능한 컨텐츠
17 |
18 | ## dynamic pages (동적 컨텐츠)
19 |
20 | - URI의 인자에 맞게 동적인 Contents를 반환
21 | - DB조회나 다양한 로직처리를 거쳐 만들어진 컨텐츠
22 |
23 |
24 | # 2. Web 서버와 WAS의 차이
25 | ## Web 서버란?
26 |
27 | - HTTP 프로토콜을 기반으로 하여 클라이언트의 요청을 서비스하는 기능을 담당
28 |
29 |
30 | ### 요청에 따라 두 가지의 기능 중 적절하게 선택하여 수행한다.
31 |
32 |
33 | 1. 정적인 컨텐츠 제공
34 | > WAS를 거치지 않고 바로 자원을 제공
35 | 2. 동적인 컨텐츠 제공을 위한 요청 전달
36 |
37 | > 클라이언트의 요청을 WAS에 보내고 WAS가 처리한 결과를 다시 받아서 클라이언트에게 전달(응답)한다.
38 |
39 |
40 | 대표적인 예- Apache server, Nginx, IIS(윈도우 전용 웹서버)
41 |
42 |
43 |
44 | ## WAS(Web Application Server) 란?
45 |
46 | 사전적 정의는
47 |
48 | > “인터넷 상에서 HTTP 프로토콜을 통해 사용자 컴퓨터나 장치에 애플리케이션을 수행해주는 미들웨어로서, 주로 동적 서버 컨텐츠를 수행하는 것으로 웹 서버와 구별이 되며, 주로 데이터베이스 서버와 같이 수행”
49 |
50 | 웹 서버 단독으로는 처리할 수 없는 데이터베이스 조회나 다양한 로직처리가 필요한 동적 컨텐츠를 제공
51 |
52 |
53 |
54 | - Web Server + Web Container
55 | - Web서버 기능들을 구조적으로 분리하여 처리하고자 하는 목적으로 제시됨
56 | - 분산 트랜잭션, 보안, 메시징, 쓰레드 처리 등의 기능을 처리하는 분산환경에서 사용된다. DB 서버와 같이 수행된다.
57 | - 업무를 처리하는 비즈니스 로직 수행
58 | - 현재 WAS가 가지는 Web 서버도 정적인 컨텐츠를 처리하는데 있어서 성능상 큰 차이가 없음
59 |
60 | 대표적인 예 - Tomcat, JBoss, Jeus, Web Sphere
61 |
62 |
63 |
64 | # 3. 추가 설명
65 | ## Web 서버가 필요한 이유?
66 |
67 | html을 받을 때 이미지 파일같은 정적파일들도 같이 받아지는게 아님
68 |
69 | html먼저받고 그에 필요한 이미지파일을 다시 서버로 요청해서 받아옴
70 |
71 | web 서버를 통해서 정적인 파일들을 was까지 안가고 앞단에서 빠르게 받을 수 있음
72 |
73 | 따라서 web서버에서 정적 컨텐츠만 처리하도록 기능을 분배해서 서버의 부담을 줄일 수 있음
74 |
75 | ## WAS가 필요한 이유?
76 |
77 | web서버만 이용한다면, 사용자가 원하는 요청 (로직을 거치거나 특정 과정을 거친 후 만들어진 데이터들 까지도) 모두 다 미리 만들어 놓고 서비스를 해야한다. —> 이렇게 하기에는 자원, 공간이 절대적으로 부족하다.
78 |
79 | 그래서 WAS를 통해서 요청에 맞는 데이터를 DB에서 가져와서 비즈니스 로직에 맞게 그때 그때 결과를 만들어서 제공함으로써 자원을 효율적으로 사용 할 수 있다.
80 |
81 | ## WAS가 Web서버 기능까지 다 할 수 있는데 WAS만 쓰면 되는거 아냐?
82 |
83 | 1. 기능을 분리하여 서버 부하 방지
84 | 1. WAS는 DB조회나 다양한 로직을 처리해야하기 때문에 단순한 정적
85 | 컨텐츠는 Web서버에서 빠르게 클라이언트에게 제공하는것이 더 효율적이다.
86 |
87 | 2. WAS는 기본적으로 동적 컨텐츠를 제공하기위해 존재하는 서버임
88 |
89 | 3. 만약에 WAS혼자 처리하게 된다면 WAS의 부하가 커지가 되고 동적 컨텐츠 처리가 지연되면서 서버 속도가 느려지게 될 것이다
90 | 2. 물리적으로 분리하여 보안 강화
91 | 1. SSL에 대한 암복호화 처리에 Web서버를 사용
92 |
93 | 2. 문제가 생겨도 Web서버단에서만 발생하기 때문에 중요 정보가 담긴 DB나 비즈니스 로직단에서 문제 발생 위험이 낮아짐
94 | 3. 여러대의 WAS연결 가능
95 | 1. 로드 밸런싱을 위해서 Web서버를 사용
96 |
97 | 2. Fail over(장애 극복), fail back(장애 발생 전으로 되돌리기) 처리에 유리
98 |
99 | 3. 특히 대용량 웹 어플리키이션의 경우(여러개의 서버를 사용) WS 와 WAS를 분리하여 무중단 운영을 위한 장애 극복에 쉽게 대응할 수 있다.
100 |
101 | 예를들어 여러대의 WAS중 하나가 중단이 되었으면 이 중단된 WAS를 이용하지 못하게 한 후 다시 이 WAS를 재시작 할 수 있도록 함
102 |
103 | 3. JAVA기반의 WAS랑 PHP기반의 WAS도 사용할 수 있음
104 |
105 | > ### 정리하자면, 자원 이용의 효율성 및 장애 극복, 배포 및 유지보수의 편의성을 위해 Web서버와 WAS를 분리한다.
--------------------------------------------------------------------------------
/WEB/www.naver.com을 검색하면 일어나는 과정.md:
--------------------------------------------------------------------------------
1 | # 웹 브라우저에 www.naver.com을 검색하면 일어나는 과정
2 |
3 |
4 |
5 | 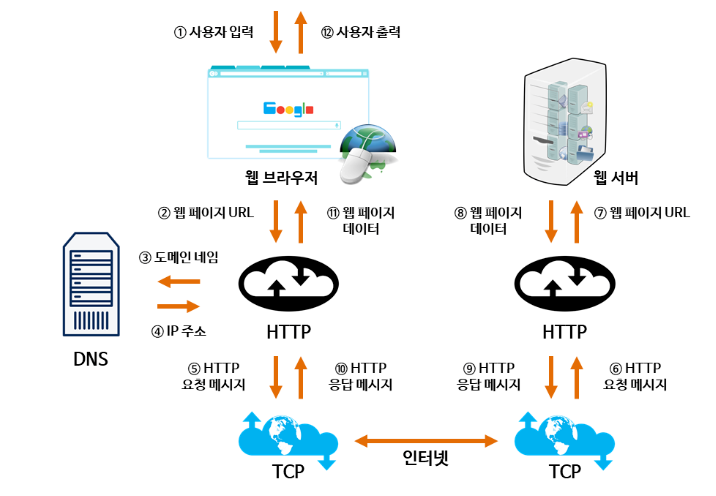
6 |
7 |
8 |
9 | ### 1. URL을 IP주소로 변환
10 |
11 | www.naver.com 이라는 도메인 이름으로는 컴퓨터끼리 통신할 수 없다. 이를 인터넷 상에서 컴퓨터가 읽을 수 있는 IP주소로 변환해야 서로 통신이 가능하게 된다.
12 | 먼저, 브라우저 캐시에 해당 URL이 존재하는지 확인하고 있다면 그것을 불러온다. 존재하지 않는다면 도메인 주소를 IP주소로 변환해주는 DNS(Domain Name System) 서버에 요청하여 해당 URL의 IP주소를 반환받는다.
13 |
14 | > 처음 PC가 IP주소를 할당 받을 때, 2개의 DNS IP 주소를 함께 받는다. 이 DNS IP 주소를 저장해두기 때문에 DNS를 바로 찾아갈 수 있다.
15 |
16 | ##### DNS 동작 과정
17 | 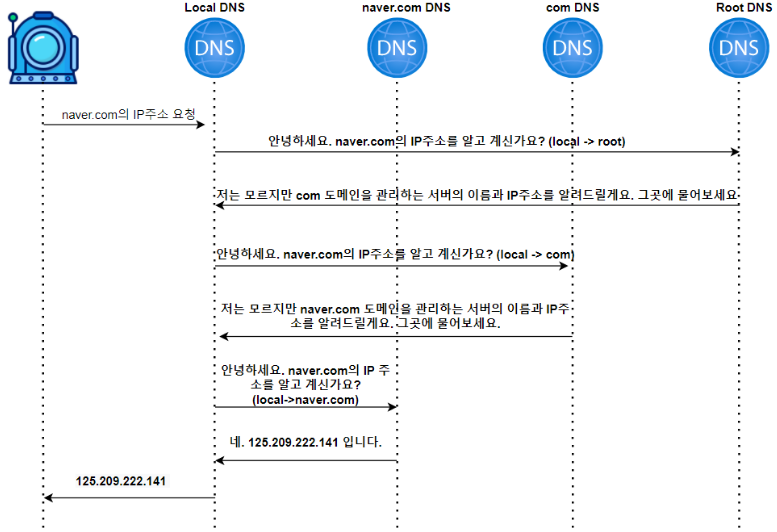
18 |
19 |
20 |
21 | 1 : PC에 미리 설정되어 있는 DNS(Local DNS)에게 www.naver.com이라는 hostname에 대한 IP 주소를 물어봅니다.
22 |
23 | 2 : Local DNS에 해당 URL이 존재한다면 바로 응답을 보내고 존재하지 않는다면 root DNS 서버에 해당 URL의 IP 주소를 다시 요청한다.
24 |
25 | 3 : Root DNS 서버에 IP주소를 물어보는 DNS Query를 보내지만 Root DNS서버는 알지 못하기 때문에 com DNS 서버의 주소를 알려줍니다.
26 |
27 | 4 : 이를 수신한 Local DNS 서버는 다시 com DNS 서버에 정보를 요청하고 com DNS 서버도 자신의 하위 레벨 Domain인 naver.com의 DNS서버 주소를 알려줍니다.
28 |
29 | 5 : 이를 수신한 Local DNS 서버는 다시 naver.com DNS 서버에게 정보를 요청하고 www.naver.com에 대한 IP 서버 주소를 수신 받습니다.
30 |
31 | 6 : Local DNS 서버는 위와 같이 www.naver.com 에 대한 IP주소를 수신 후 자신의 DNS Cache에 등록하고 해당 정보를 요청했던 Client에게 응답메세지로 답변합니다.
32 |
33 | 위 과정까지 마치게 되면 URL 주소를 Local DNS에 캐싱하게되기 때문에 다음 요청 부터는 1번 과정에서 바로 IP 주소를 응답받게 된다.
34 |
35 |
36 |
37 | ### 2. 대상 서버와 TCP 소켓 연결
38 |
39 | 브라우저가 IP 주소를 받게 인터넷 프로토콜을 사용해서 서버와 연결을 한다. 인터넷 프로토콜의 종류는 여러가지가 있지만, 웹사이트의 HTTP 요청의 경우에는 일반적으로 TCP(전송 제어 프로토콜)를 사용한다.
40 |
41 | 클라이언트와 서버간 데이터 패킷들이 오가려면 TCP connection이 되어야 한다. TCP/IP 3-way handshake라는 프로세스를 통해서 클라이언트와 서버간 connection이 이뤄지게 된다. 단어 그대로 클라이언트와 서버가 SYN과 ACK메세지들을 가지고 3번의 프로세스를 거친 후에 연결이 된다. 추가적으로 HTTPS의 경우 3-way-handshake에 TLS(Transport Layer security, SSL) handShake가 추가된다.
42 |
43 | #### 3-way Handshaking
44 |
45 | - A클라이언트는 B서버에 접속을 요청하는 SYN 패킷을 보낸다. 이때 A클라이언트는 SYN 을 보내고 SYN/ACK 응답을 기다리는SYN_SENT 상태가 되는 것이다.
46 |
47 | - B서버는 SYN요청을 받고 A클라이언트에게 요청을 수락한다는 ACK 와 SYN flag 가 설정된 패킷을 발송하고 A가 다시 ACK으로 응답하기를 기다린다. 이때 B서버는 SYN_RECEIVED 상태가 된다.
48 |
49 | - A클라이언트는 B서버에게 ACK을 보내고 이후로부터는 연결이 이루어지고 데이터가 오가게 되는것이다. 이때의 B서버 상태가 ESTABLISHED 이다. 위와 같은 방식으로 통신하는것이 신뢰성 있는 연결을 맺어 준다는 TCP의 3 Way handshake 방식이다.
50 |
51 | 
52 |
53 |
54 |
55 | 이 과정이 끝나면 TCP connection이 완성되는 것이다.
56 |
57 |
58 |
59 | ### 3. HTTP(HTTPS) 프로토콜로 요청, 응답
60 |
61 | 이제 연결이 확정되었으니 해당 페이지 **www.naver.com**를 달라고 서버에게 요청한다. 서버에서 해당 요청을 받고, 이 요청을 수락할 수 있는지 검사하고 서버는 이 요청에 대한 응답을 생성하여 브라우저에게 전달한다.
62 |
63 |
64 |
65 | ### 4. 브라우저에서 응답을 해석
66 |
67 | 서버에서 응답한 내용은 HTML, CSS, Javascript 등으로 이루어져 있다. 이를 브라우저에서 해석하여 그려준다. 각종 텍스트를 정해진 형식으로 해석하여 우리가 원하는 **www.naver.com** 페이지가 그려진다.
68 |
69 |
70 |
71 |
72 |
73 |
74 | >참고
75 | >https://peemangit.tistory.com/52
76 | >https://deveric.tistory.com/97
77 | >https://1-7171771.tistory.com/134
--------------------------------------------------------------------------------
/book/그림으로 배우는 HTTP & Network Basic/README.md:
--------------------------------------------------------------------------------
1 | # 질문 목록
2 |
3 | ## 제 1장. 웹과 네트워크의 기본에 대해 알아보자
4 |
5 |
6 | HTTP와 HTTPS의 차이점은 무엇인가요?
7 |
8 | 답변
9 |
10 |
11 |
12 |
13 | 공인 IP와 사설 IP의 차이점은 무엇인가요?
14 |
15 | 답변
16 |
17 |
18 |
19 | ## 제 2장. 간단한 프로토콜 HTTP
20 |
21 | ## 제 3장. HTTP 정보는 HTTP 메시지에 있다.
22 |
23 |
24 | HTTP 메시지의 구조에 대해 설명해주세요.
25 |
26 | 답변
27 |
28 |
29 |
30 |
31 | 요청 메시지와 응답 메시지의 차이에 대해 설명해주세요.
32 |
33 | 답변
34 |
35 |
36 |
37 | ## 제 4장. 결과를 전달하는 HTTP 상태 코드
38 |
39 |
40 | HTTP 상태 코드에 대해 설명해주세요.
41 |
42 | 답변
43 |
44 |
45 |
46 |
47 | ㅇㅇ 상태 코드에 대해 설명해주세요.
48 |
49 | 답변
50 |
51 |
52 |
53 |
54 | 프로젝트에서 사용해 본 상태코드에 대해 설명해주세요.
55 |
56 | 답변
57 |
58 |
59 |
60 |
61 | GET, POST, PUT, DELETE 외에 아는 메소드가 있나요?
62 |
63 | 답변
64 |
65 |
66 |
67 | ## 제 5장. HTTP와 연계하는 웹 서버
68 |
69 |
70 | 프록시에 대해 설명해주세요.
71 |
72 | 클라이언트와 서버 사이의 통신을 대리로 수행하는 것을 말합니다. 이 과정에서 캐싱을 통해 리소스에 대해 빠르게 접근하거나 특정 리소스의 접근을 차단할 수 있습니다. 그리고 클라이언트나 서버의 정보를 서로에게 숨길 수 있습니다.
73 |
74 |
75 |
76 |
77 | 게이트웨이에 대해 설명해주세요.
78 |
79 | 게이트웨이는 서로 다른 프로토콜을 사용하는 클라이언트와 서버 간의 통신을 가능하게 하는 역할을 합니다. 예를 들어, 클라이언트가 HTTP 프로토콜을 사용하여 리소스 요청을 했을 때 서버의 응답 프로토콜이 FTP라면 게이트웨이는 HTTP 요청을 FTP 요청으로 변환하여 서버에게 전달합니다.
80 |
81 |
82 |
83 |
84 | 프록시와 게이트웨이의 차이점을 설명해주세요.
85 |
86 | 프록시가 클라이언트의 요청을 서버로 그대로 전달하는 반면 게이트웨이는 클라이언트의 요청을 서버가 사용하는 프로토콜로 변환하여 전달합니다.
87 |
88 |
89 |
90 | ## 제 6장. HTTP 헤더
91 |
92 |
93 | HTTP 헤더 필드가 중복되면 어떻게 되나요?
94 |
95 | 답변
96 |
97 |
98 |
99 |
100 | HTTPS에서만 쿠키를 사용하도록 하려면 Set-Cookie 헤더 필드에 어떤 속성을 추가해야 하나요?
101 |
102 | 답변
103 |
104 |
105 |
106 |
107 | 자바스크립트로 쿠키글 읽지 못하도록 하려면 Set-Cookie 헤더 필드에 어떤 속성을 추가해야 하나요?
108 |
109 | 답변
110 |
111 |
112 |
113 | ## 제 7장. 웹을 안전하게 하는 HTTPS
114 |
115 |
116 | HTTPS에서 공개키 알고리즘과 대칭키 알고리즘이 어떻게 쓰이나요?
117 |
118 | 답변
119 |
120 |
121 |
122 |
123 | HTTPS에서 CA의 역할은 무엇인가요?
124 |
125 | 답변
126 |
127 |
128 |
--------------------------------------------------------------------------------
/book/그림으로 배우는 HTTP & Network Basic/제 1장. 웹과 네트워크의 기본에 대해 알아보자.md:
--------------------------------------------------------------------------------
1 | # [1장]
2 |
3 | : 웹과 네트워크의 기본에 대해 알아보자
4 |
5 | # HTTP?
6 |
7 | : Hyper Text Transfer Protocol
8 |
9 | 클라이언트(=브라우저) ~ 서버 사이의 통신 흐름의 규칙(약속)
10 |
11 | ## HTTP의 역사
12 |
13 | CERN(입자물리학 연구소) 에서
14 |
15 |
22 |
23 | 의 형태로 **처음** 제안됨
24 |
25 | ---
26 |
27 | # TCP/IP
28 |
29 | : HTTP는 TCP/IP 프로토콜 중 하나
30 |
31 | ### TCP/IP 4계층
32 |
33 | 
34 |
35 | 1. application 계층
36 | 1. 통신의 움직임 결정
37 | 2. ex) `HTTP`, FTP, DNS
38 | 2. transport 계층
39 | 1. 2대 컴퓨터 사이의 데이터 흐름 제공
40 | 2. ex) `TCP`, UDP 프로토콜
41 | 3. network 계층
42 | 1. 네트워크 상에서 패킷(데이터의 최소 단위)의 이동 관리
43 | 2. 데이터 전송경로(라우터) 결정
44 | 3. ex) `IP`
45 | 4. link 계층
46 | 1. 하드웨어 측면 관리
47 | 2. ex) 운영체제, 디바이스 드라이버, NIC(Network Interface Card), 케이블
48 |
49 | 다음 그림과 같이 `캡슐화`
50 |
51 | - 통신시 각 계층을 순서대로 거쳐 송/수신하며
52 | - 송신시 : 각 계층을 통과하며 (↓) 각 계층에 해당하는 `헤더` 추가
53 |
54 | 수신시 : 각 계층을 통과하며 (↑) 각 계층마다 사용한 헤더를 `삭제`
55 |
56 |
57 | 
58 |
59 | ### 송신과정 예시)
60 |
61 | app → transport : 클라이언트에서 HTTP 리퀘스트
62 |
63 | transport →network : 받은 HTTP를 작은 단위로 나눈 후 **+ 안내번호** **+ 포트번호** 추가해 전달
64 |
65 | network → link : 수신지(**+MAC주소**) 추가해 전달
66 |
67 | ---
68 |
69 | # DNS
70 |
71 | : Domain Name System
72 |
73 | 해당하는 `도메인명` ↔ `IP주소` 를 알려주는 역할
74 |
75 | 
76 |
77 | ---
78 |
79 | # URI/URL
80 |
81 | - URI (Uniform Resource Identifier)
82 | - 통일된/리소스/식별자
83 | - = 리소스를 식별하기 위한 문자열을 구분해놓은 것
84 | - ex) ftp://ftp.is.co.za/rfc/rfc1808.txt
85 |
86 | http://www.google.co.kr
87 |
88 | - URL (Uniform Resource Locator)
89 | - 네트워크 상의 주소
90 | - ex) https://www.google.co.kr
91 |
92 |
93 | > 💡 URL이 URI 의 한 종류로 포함되는 개념
94 |
95 |
96 |
97 | ### URL 포맷 예시
98 |
99 | 
100 |
101 |
102 | 1. 스키마
103 | 1. 프로토콜 지시
104 | 2. ex) http:, https:, data:, javascript:
105 | 2. 자격정보(크리덴셜)
106 | 1. 서버로부터 리소스를 취득하기 위한 자격정보
107 | 2. ex) 유저명, 패스워드
108 | 3. 서버주소
109 | 1. 완전수식형식 URI 에서는 서버주소 지정 필요 X
110 | 2. 단, DNS이름, IPv4, IPv6주소 등은 표기 필수
111 | 4. 서버포트
112 | 1. 네트워크 포트번호 지정
113 | 5. 계층적 파일 패스
114 | 1. 서버상의 파일주소 지정
115 | 2. ex) 디렉토리 경로
116 | 6. 쿼리 문자열
117 | 1. 리소스에 전달할 파라미터
118 | 7. 프래그먼트 식별자
119 | 1. 서브리소스 지정
120 |
--------------------------------------------------------------------------------
/book/그림으로 배우는 HTTP & Network Basic/제 3장. HTTP 정보는 HTTP 메시지에 있다.md:
--------------------------------------------------------------------------------
1 | ### Contents
2 |
3 | - [요청 메시지](#요청-메시지)
4 | - [응답 메시지](#응답-메시지)
5 | - [메시지 인코딩](#메시지-인코딩)
6 | - [Multipart](#Multipart)
7 | - [Range Request](#Range-Request)
8 |
9 | # HTTP 메시지
10 |
11 | HTTP 메시지는 클라이언트 <-> 서버 간 데이터를 교환하는 방식입니다. HTTP 메시지는 `요청` 메시지와 `응답` 메시지로 나뉩니다. 각 메시지의 역할은 다음과 같습니다.
12 |
13 | | 구분 | 역할 |
14 | | :---------: | ------------------------------------------------------ |
15 | | 요청 메시지 | 클라이언트가 서버에게 특정 동작을 취하도록 요청하는 것 |
16 | | 응답 메시지 | 요청에 대한 서버의 답변 |
17 |
18 | HTTP 메시지는 개행 문자를 기준으로 헤더와 바디로 나뉘는데, 바디는 생략될 수 있습니다.
19 |
20 | ```
21 | 메시지 헤더
22 | ──────────────────────
23 | 개행 문자 (CR + LF)
24 | ──────────────────────
25 | 메시지 바디 (생략 가능)
26 | ```
27 |
28 | 헤더, 개행 문자, 바디의 역할은 다음과 같습니다.
29 |
30 | | 구분 | 역할 |
31 | | :-------: | --------------------------------------------------------- |
32 | | 헤더 | 요청 또는 응답에 대한 정보와 바디에 대한 정보를 가집니다. |
33 | | 개행 문자 | 더 이상 헤더 정보가 없음을 의미합니다. |
34 | | 바디 | 요청 또는 응답에서 필요한 페이로드를 가집니다. |
35 |
36 | ## 요청 메시지
37 |
38 | ### 요청 메시지 헤더
39 |
40 | 요청 메시지 헤더의 구조는 다음과 같습니다. 요청 라인에는 `요청 메소드`, `요청 URI`, `HTTP 버전`이 포함됩니다.
41 |
42 | ```
43 | 요청 라인
44 | ───────────────
45 | 요청 헤더 필드
46 | ───────────────
47 | 일반 헤더 필드
48 | ───────────────
49 | 엔티티 헤더 필드
50 | ```
51 |
52 | ### 요청 메시지 예제
53 |
54 | ```
55 | POST /users HTTP/1.1
56 | Host: google.com
57 | Accept-Language: ko
58 | Cache-Control: no-cache
59 |
60 | username=kim&password=passw0rd
61 | ```
62 |
63 | ## 응답 메시지
64 |
65 | ### 응답 메시지 헤더
66 |
67 | 응답 메시지 헤더의 구조는 다음과 같습니다. 응답 메시지 헤더는 요청 메시지 헤더와 달리 `요청 라인`과 `요청 헤더 필드` 대신 `상태 라인`과 `응답 헤더 필드`를 가집니다. 그리고 상태 라인에는 `HTTP 버전`, `상태 코드`, `상태 메시지`가 포함됩니다.
68 |
69 | ```
70 | 상태 라인
71 | ───────────────
72 | 응답 헤더 필드
73 | ───────────────
74 | 일반 헤더 필드
75 | ───────────────
76 | 엔티티 헤더 필드
77 | ```
78 |
79 | ### 응답 메시지 예제
80 |
81 | ```
82 | HTTP/1.1 201 Created
83 | Date: Mon, 8 Aug 2022 10:06 GMT
84 | Server: Apache
85 | Content-Type: application/json
86 |
87 | {
88 | userId: 1
89 | username: "kim"
90 | password: "passw0rd"
91 | }
92 | ```
93 |
94 | ## 메시지 인코딩
95 |
96 | HTTP로 데이터를 전송할 때 인코딩을 적용하면 데이터를 효율적으로 전송할 수 있습니다.
97 |
98 | ### 압축, Content-Encoding
99 |
100 | 대용량 파일과 같이 용량이 큰 데이터를 요청할 경우 데이터를 압축하여 받을 수 있습니다.
101 |
102 | 클라이언트는 `Accept-Encoding` 필드를 요청 헤더에 추가하여 압축 방법을 협상할 수 있습니다.
103 |
104 | ```
105 | GET /files/1 HTTP/1.1
106 | Accept-Encoding: gzip, deflate
107 | ```
108 |
109 | 서버는 `Content-Encoding` 필드를 응답 헤더에 추가하고 데이터를 압축하여 클라이언트로 전달합니다.
110 |
111 | ```
112 | HTTP/1.1 200 OK
113 | Content-Type: text/plain
114 | Content-Encoding: gzip
115 |
116 | compressed body
117 | ```
118 |
119 | [참고](https://developer.mozilla.org/ko/docs/Web/HTTP/Headers/Content-Encoding)
120 |
121 | ### 분할, Transfer-Encoding
122 |
123 | 대용량 파일과 같이 용량이 큰 데이터를 요청하고 화면에 표시할 때 데이터를 분할하여 표시할 수 있습니다.
124 |
125 | 클라이언트는 `Accept-Encoding` 필드를 요청 헤더에 추가하여 분할 전송을 받을 수 있습니다.
126 |
127 | ```
128 | GET /images/2 HTTP/1.1
129 | Accept-Encoding: chunked
130 | ```
131 |
132 | 서버는 `Transfer-Encoding` 필드를 응답 헤더에 추가하고 데이터를 분할하여 전송합니다. 이때 헤더는 `Content-Length` 필드를 가지지 않습니다. 바디의 `chunk`마다 길이가 명시됩니다.
133 |
134 | ```
135 | HTTP/1.1 200 OK
136 | Content-Type: text/plain
137 | Transfer-Encoding: chunked
138 |
139 | 7\r\n
140 | Mozilla\r\n
141 | 9\r\n
142 | Developer\r\n
143 | 7\r\n
144 | Network\r\n
145 | 0\r\n
146 | \r\n
147 | ```
148 |
149 | ## Multipart
150 |
151 | 메일의 경우 본문에 텍스트를 작성하고 파일을 첨부하여 전송할 수 있습니다. HTTP로 여러 종류의 데이터를 한 번에 보내야 하는 경우에 `멀티파트` 타입을 사용하여 전송할 수 있습니다.
152 |
153 | [참고](https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/MIME_types)
154 |
155 | ### multipart/form-data
156 |
157 | `multipart/form-data`는 클라이언트에서 서버로 여러 종류의 데이터를 전송할 수 있습니다.
158 |
159 | `Content-Type` 필드에 `multipart/form-data`를 설정하고 바디에 각 데이터를 `-` 문자로 시작하는 `boundary`로 구분하여 전송합니다.
160 |
161 | ```
162 | POST / HTTP/1.1
163 | Content-Type: multipart/form-data; boundary=--xyz
164 | Content-Length: 465
165 |
166 | --xyz
167 | Content-Disposition: form-data; name="name"
168 | Content-Type: text/plain
169 |
170 | John
171 | --xyz
172 | Content-Disposition: form-data; name="age"
173 | Content-Type: text/plain
174 |
175 | 23
176 | --xyz
177 | Content-Disposition: form-data; name="photo"; filename="photo.jpeg"
178 | Content-Type: image/jpeg
179 |
180 | [JPEG DATA]
181 | --xyz--
182 | ```
183 |
184 | ### multipart/byteranges
185 |
186 | `multipart/byteranges`는 클라이언트에서 복수 범위의 데이터를 요청할 때 사용합니다.
187 |
188 | 각 데이터는 `boundary`에 의해 구분되어 바디에 포함되며, 각각 `Content-Type`, `Content-Range` 필드를 가집니다.
189 |
190 | ```
191 | HTTP/1.1 206 Partial Content
192 | Accept-Ranges: bytes
193 | Content-Type: multipart/byteranges; boundary=3d6b6a416f9b5
194 | Content-Length: 385
195 |
196 | --3d6b6a416f9b5
197 | Content-Type: text/html
198 | Content-Range: bytes 100-200/1270
199 |
200 | eta http-equiv="Content-type" content="text/html; charset=utf-8" />
201 |
3 | [GET, POST, PUT, DELETE 이외의 메소드]
4 |
5 | 
6 |
7 | # 4. 결과를 전달하는 HTTP 상태 코드
8 |
9 | HTTP 리쿼스트를 서버가 정상적으로 처리했는지 확인
32 |
33 | ### 4.2 3xx
34 |
35 | | 301 | Moved Permanently | 요청한 리소스에 영구히 새로운 URI가 할당
36 | 북마크 주소 변경해야됨 |
37 | | --- | --- | --- |
38 | | 302 | Found | 요청한 리소스가 일시적으로 다른 URI에 할당
39 | 북마크 주소 변경 X |
40 | | 303 | See Other | 클라이언트가 요청한 리소스를 다른 URI에서 GET 요청으로 얻어야 할 때 사용 |
41 | | 304 | Not Modified | 요청을 수행했지만 문서가 수정되지 않음 |
42 | | 307 | Temporary Redirect | 요청한 리소스가 일시적으로 다른 URI에 할당
43 | HTTP 메소드를 변경하지 말아야함 |
44 |
45 | 
46 |
47 |
48 |
49 | ### 4.3 4xx
50 |
51 | | 400 | Bad Request | 잘못된 요청 |
52 | | --- | --- | --- |
53 | | 401 | Unauthorized | 인증실패 |
54 | | 403 | Forbidden | 인가실패 |
55 | | 404 | Not Found | 요청에 대해 찾을 수 없는 페이지 |
56 | | 405 | Method Not Allowed | 요청한 메소드를 지원하지 않음, url은 유효하지만 지원하지 않는 method 요청 |
57 |
58 |
59 |
60 |
61 |
62 | ### 4.4 5xx
63 |
64 | | 500 | Internal Server Error | 서버 에러 |
65 | | --- | --- | --- |
66 | | 503 | Service Unavailable | 서버가 터졌거나 유지보수 중(일시적) |
67 |
68 | 
69 |
70 | 안전 : 호출해도 리소소를 변경하지 않음
71 |
72 | 멱등 : 동일한 요청을 여러 번 보내도 한 번 보내는 것과 같음
73 |
74 |
75 |
76 |
77 | ## ❓질문
78 |
79 | 1. HTTP 상태 코드에 대해 설명해주세요
80 | 2. ㅇㅇ 상태 코드에 대해 알고 있나요?
81 | 3. 프로젝트에서 사용해 본 상태코드에 대해 설명해주세요
82 | 4. GET, POST, PUT, DELETE 외에 아는 메소드가 있나요?
--------------------------------------------------------------------------------
/book/그림으로 배우는 HTTP & Network Basic/제 5장. HTTP와 연계하는 웹 서버.md:
--------------------------------------------------------------------------------
1 | ### Contents
2 |
3 | - [프록시(Proxy)](#프록시proxy)
4 | - [게이트웨이(Gateway)](#게이트웨이gateway)
5 |
6 | # Proxy & Gateway
7 |
8 | `HTTP`는 `프록시(Proxy)` 또는 `게이트웨이(Gateway)`를 통해 통신을 중계하거나 서버를 연계할 수 있습니다. 이를 통해 요청을 받은 서버가 다른 서버에 요청을 중계할 수 있고, 해당 서버로부터 받은 응답을 클라이언트로 전달할 수 있습니다.
9 |
10 | ## 프록시(Proxy)
11 |
12 | 프록시는 클라이언트와 서버 사이에 대리로 통신을 수행하는 것을 말하며, 이러한 프록시를 수행하는 서버를 프록시 서버라고 합니다.
13 |
14 | 프록시 사용을 통해 얻을 수 있는 이점은 다음과 같습니다.
15 |
16 | - 캐시를 통한 리소스에 대한 빠른 접근
17 | - 특정 리소스에 대한 접근 차단
18 | - 클라이언트 또는 서버 정보 숨김 처리
19 | - 모니터링
20 | - 보안성 향상
21 |
22 | 프록시는 용도에 따라 다음과 같이 구분할 수 있습니다.
23 |
24 | | 용도 | 설명 |
25 | | :-----------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
26 | | 캐싱 프록시 | 이전 요청에 대한 응답 데이터를 보관합니다. 동일한 요청이 들어오면 보관해둔 응답 데이터를 반환합니다. 이를 통해 높은 트래픽을 효율적으로 처리할 수 있습니다. 또한 동일한 요청을 서버에 전달하지 않으므로 통신 비용이 절감됩니다. |
27 | | 포워드 프록시 | 클라이언트의 요청을 프록시 서버가 받고, 다른 서버로 요청을 재전달합니다. 이때 다른 서버는 클라이언트의 정보를 알 수 없습니다. |
28 | | 리버스 프록시 | 포워드 프록시와 동일하게 클라이언트의 요청을 프록시 서버가 받고, 다른 서버로 재전달합니다. 포워드 프록시와 다른 점은 클라이언트가 다른 서버의 정보를 알 수 없습니다. |
29 |
30 | [참고](https://coding-start.tistory.com/342)
31 |
32 | ### 리버스 프록시 예시
33 |
34 | `Nginx`로 리버스 프록시 기능을 사용할 수 있습니다. 다음은 프록시 서버에서 실행되는 Nginx의 설정 파일입니다.
35 |
36 | ```nginx
37 | server {
38 | listen 80;
39 |
40 | location /api {
41 | proxy_pass http://application-server/api;
42 | }
43 | }
44 | ```
45 |
46 | 위 설정을 통해 클라이언트가 특정 서비스를 요청할 때 프록시 서버가 해당 요청을 전달 받고 다른 서버로 재전달합니다. 이를 통해 요청에 대한 처리를 수행하는 서버의 `정보(http://application-server/api)`를 클라이언트에게 감출 수 있습니다.
47 |
48 | ## 게이트웨이(Gateway)
49 |
50 | 게이트웨이는 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 네트워크 포인트입니다.
51 |
52 | 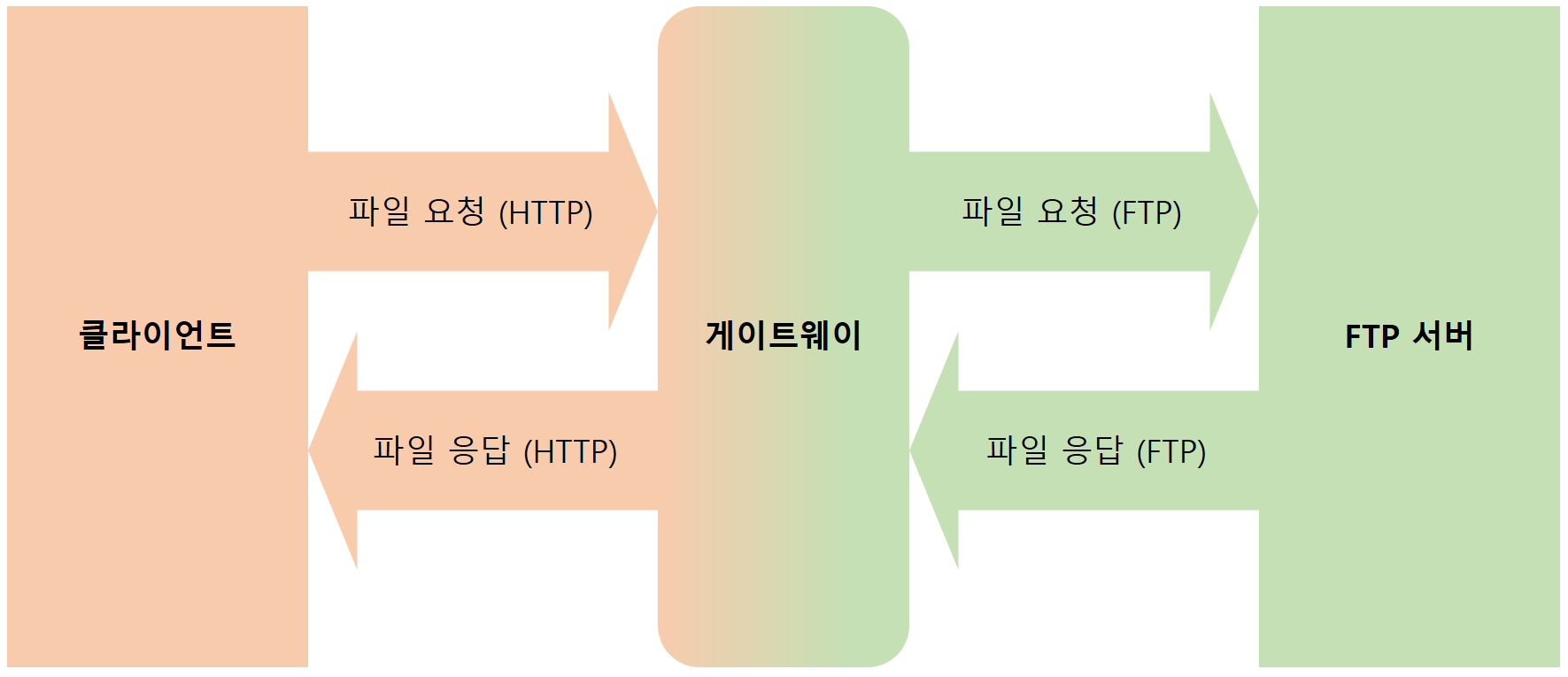
53 |
54 | 예를 들어, HTTP 요청에 대한 응답을 하기 위해 FTP 통신이 필요한 경우 게이트웨이가 HTTP 요청을 FTP로 변환하고 다른 서버로 FTP 요청을 보냅니다. 그리고 FTP 요청에 대한 응답을 HTTP 응답으로 변환하여 클라이언트로 전달합니다.
55 |
56 | 즉, 게이트웨이는 서로 다른 통신 프로토콜을 적절히 변환해주는 역할을 합니다.
57 |
--------------------------------------------------------------------------------
/book/그림으로 배우는 HTTP & Network Basic/제 6-2장. HTTP 헤더.md:
--------------------------------------------------------------------------------
1 | ## 6.5 리스폰스 헤더 필드
2 | 리스폰스의 부가정보, 서버의 정보, 클라이언트의 부가 정보 요구 등 나타냄
3 |
4 | ### 6.5.3 ETag
5 | - 엔티티 태그
6 | - 캐시를 사용하면 클라이언트 브라우저 캐시의 데이터와 서버의 데이터가 같다는 사실을 확인할 방법이 필요함
7 | - 1번째 방법 : Last-Modified
8 | - but, 1. 변경된 내용이 있지만 응답상으로는 의미가 크지 않은 경우(스페이스나 주석처럼 의미 없는 변경)
9 | - 2. 데이터를 수정해 날짜가 다르지만 데이터 결과가 똑같은 경우
10 | - 3. 1초 미만 단위의 캐시 조정이 필요한 경우
11 | - ETag를 사용
12 | - ETag, If-None-Match가 짝
13 | - ETag 보내서 같으면 유지, 다르면 다시 받기
14 |
15 | 
16 | 
17 | 
18 | 
19 | 
20 | 
21 | 
22 | 
23 | 
24 |
25 |
26 | ### 6.5.4 Location
27 | 
28 | 
29 |
30 | - 클라이언트가 Request-URI 이외의 곳으로 액세스를 유도하는 경우에 사용
31 | - 301 Moved Permanently나 302 Found가 응답으로 내려옴
32 |
33 |
34 | ### 6.5.6 Retry-After
35 | - 클라이언트가 일정 시간 후에 리퀘스트를 다시 시행해야하는지 전달
36 | - 503 Service Unavailable 리스폰스와 함께 사용
37 |
38 |
39 |
40 | ## 6.6 엔티티 헤더 필드
41 |
42 | ### 6.6.1 Allow
43 | 
44 | - Request URI가 제공하는 메소드 전달
45 | - Options 메소드에 대한 응답값
46 | - 서버가 받을 수 없는 메소드인 경우 405 Method Not Allowed 전달
47 |
48 |
49 | ### 6.6.2 Content-Encoding
50 | - 엔티티 바디에 대해 실시한 콘텐츠 코딩 형식 전달
51 |
52 |
53 | ### 6.6.7 Content-Range
54 | 일부분만을 리퀘스트
55 |
56 |
57 | ### 6.6.8 Contnet-Type
58 | 
59 | 미디어 타입

 27 |
28 | > 중위 순회 방식은 재귀적으로 왼쪽 서브트리 - 현재 노드 - 오른쪽 서브트리를 순회하는 방식임
29 |
30 | 위의 트리를 중위 순회 하면 1-3-4-6-7-8-10-13-14 가 출력 되는데,
27 |
28 | > 중위 순회 방식은 재귀적으로 왼쪽 서브트리 - 현재 노드 - 오른쪽 서브트리를 순회하는 방식임
29 |
30 | 위의 트리를 중위 순회 하면 1-3-4-6-7-8-10-13-14 가 출력 되는데,  51 |
52 | 검색을 할 수록 데이터가 절반 씩 줄어드므로, 평균 O(logN)이라는 걸 알 수 있다.
53 |
54 | 그러나
55 |
56 |
51 |
52 | 검색을 할 수록 데이터가 절반 씩 줄어드므로, 평균 O(logN)이라는 걸 알 수 있다.
53 |
54 | 그러나
55 |
56 |  57 |
58 | 다음과 같이 한 쪽으로 치우친 모양이 나오게 된다면 그저 List와 다른게 없으므로
57 |
58 | 다음과 같이 한 쪽으로 치우친 모양이 나오게 된다면 그저 List와 다른게 없으므로 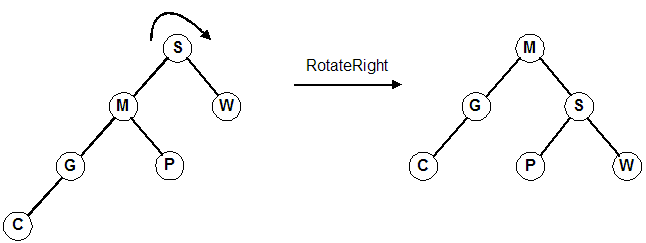 69 |
70 | 오른쪽 회전
71 |
72 |
69 |
70 | 오른쪽 회전
71 |
72 | 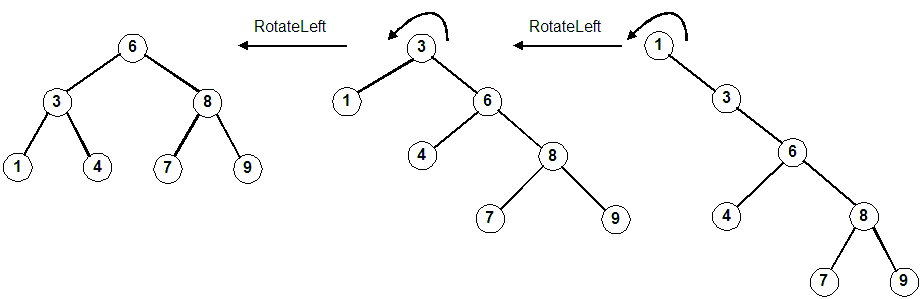 73 |
74 | 왼쪽 회전
75 |
76 | 높이가 더 큰 쪽, 빗대어서 말하자면 무게가 무거운 쪽을 가볍게 해줘서 균형을 맞춘다 라고 이해해도 좋다.
77 |
78 | 회전 연산은 단순히 레퍼런스를 바꿔주는 것이기 때문에 상수시간이 걸린다.
79 |
80 | 이 트리 회전을 통해서 트리의 균형을 맞추는것이다.
81 |
82 |
73 |
74 | 왼쪽 회전
75 |
76 | 높이가 더 큰 쪽, 빗대어서 말하자면 무게가 무거운 쪽을 가볍게 해줘서 균형을 맞춘다 라고 이해해도 좋다.
77 |
78 | 회전 연산은 단순히 레퍼런스를 바꿔주는 것이기 때문에 상수시간이 걸린다.
79 |
80 | 이 트리 회전을 통해서 트리의 균형을 맞추는것이다.
81 |
82 |  104 |
105 |
106 |
104 |
105 |
106 |  107 |
108 | 14번 노드에서 왼쪽 서브트리의 높이는 0 오른쪽 서브트리의 2이므로
107 |
108 | 14번 노드에서 왼쪽 서브트리의 높이는 0 오른쪽 서브트리의 2이므로  117 |
118 |
119 |
117 |
118 |
119 |  120 |
121 | 57번 노드에서 왼쪽 서브트리의 높이는 2 오른쪽 서브트리의 0이므로
120 |
121 | 57번 노드에서 왼쪽 서브트리의 높이는 2 오른쪽 서브트리의 0이므로  139 |
140 |
141 |
142 | ### RB트리의 속성
143 | 1. 모든 노드는 Red or Black 색상
144 | 2. 루트 노드는 무조건 Black
145 | 3. 모든 nil 노드는 Black
146 | 4. Red의 자녀들은 Black, 즉 Red가 연속적으로 존재 할 수 없다.
147 | 5. 임의의 노드에서 nil 노드까지 가는 경로에서의 Black 노드의 수는 같다.
148 |
149 | 5번 속성에서의 Black 노드의 수를 Black Height(BH) 라고 한다.
150 |
151 |
152 |
139 |
140 |
141 |
142 | ### RB트리의 속성
143 | 1. 모든 노드는 Red or Black 색상
144 | 2. 루트 노드는 무조건 Black
145 | 3. 모든 nil 노드는 Black
146 | 4. Red의 자녀들은 Black, 즉 Red가 연속적으로 존재 할 수 없다.
147 | 5. 임의의 노드에서 nil 노드까지 가는 경로에서의 Black 노드의 수는 같다.
148 |
149 | 5번 속성에서의 Black 노드의 수를 Black Height(BH) 라고 한다.
150 |
151 |
152 | 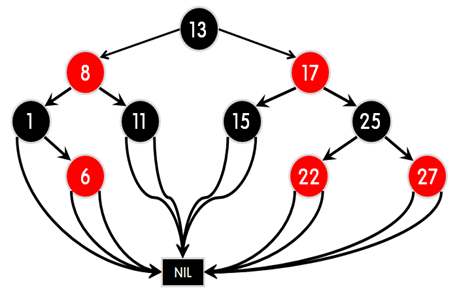 153 |
154 | (실제로는 이렇게 구현됨)
155 |
156 | ### RBT 삽입/삭제 절차
157 | 1. 삽입/삭제 전 RB 속성 만족한 상태
158 | 2. 삽입/삭제 방식은 일반적인 BST와 동일
159 | 3. 삽입/삭제 후 RB속성 위반여부 확인
160 | 4. 재조정
161 | 5. RB 속성 만족
162 |
163 |
164 | ### Red-Black 트리의 시간복잡도
165 | | | 검색 | 삽입 | 삭제 |
166 | | - | --- | ---- | --- |
167 | | Average | O(logN) | O(logN) | O(logN) |
168 |
169 |
170 | 검색 과정은 BST와 동일 하다.
171 |
172 |
173 | ### 삽입 (삽입되는 노드의 색은 무조건 Red)
174 |
153 |
154 | (실제로는 이렇게 구현됨)
155 |
156 | ### RBT 삽입/삭제 절차
157 | 1. 삽입/삭제 전 RB 속성 만족한 상태
158 | 2. 삽입/삭제 방식은 일반적인 BST와 동일
159 | 3. 삽입/삭제 후 RB속성 위반여부 확인
160 | 4. 재조정
161 | 5. RB 속성 만족
162 |
163 |
164 | ### Red-Black 트리의 시간복잡도
165 | | | 검색 | 삽입 | 삭제 |
166 | | - | --- | ---- | --- |
167 | | Average | O(logN) | O(logN) | O(logN) |
168 |
169 |
170 | 검색 과정은 BST와 동일 하다.
171 |
172 |
173 | ### 삽입 (삽입되는 노드의 색은 무조건 Red)
174 |  178 |
179 |
178 |
179 | 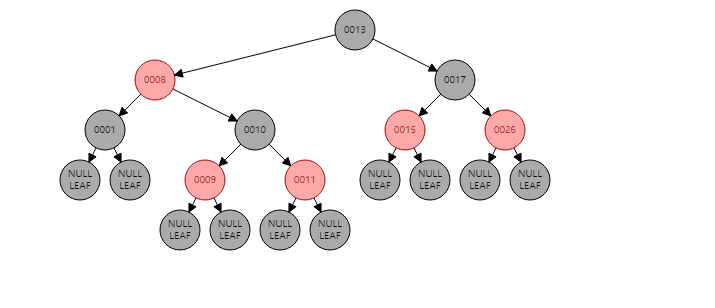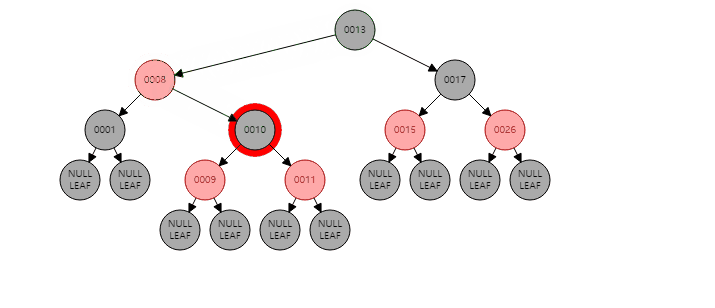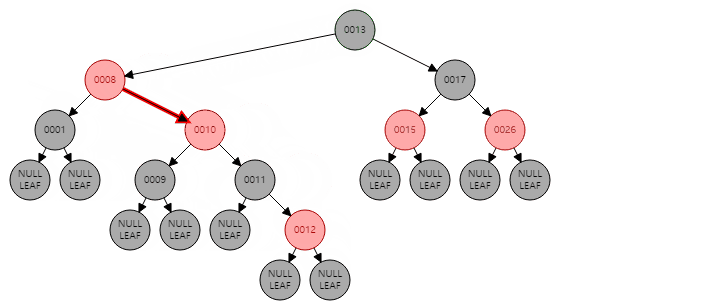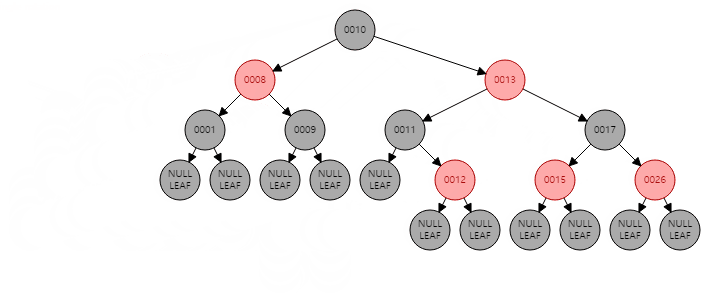 183 |
184 | 노드가 삽입 된 후 위의 5가지 속성 위반여부를 확인하고 트리를 재조정 하는 것을 볼 수 있다.
185 |
186 |
183 |
184 | 노드가 삽입 된 후 위의 5가지 속성 위반여부를 확인하고 트리를 재조정 하는 것을 볼 수 있다.
185 |
186 |  193 |
194 |
193 |
194 |  198 |
199 | 노드가 삭제 된 후 위의 5가지 속성 위반여부를 확인하고 트리를 재조정 하는 것을 볼 수 있다.
200 |
201 | (RB트리의 삽입과 삭제과정에는 여러 케이스가 있기 때문에 따로 더 알아보기 바란다.)
202 |
203 |
204 | >RBT가 O(logN)임을 귀납적으로 증명
205 |
198 |
199 | 노드가 삭제 된 후 위의 5가지 속성 위반여부를 확인하고 트리를 재조정 하는 것을 볼 수 있다.
200 |
201 | (RB트리의 삽입과 삭제과정에는 여러 케이스가 있기 때문에 따로 더 알아보기 바란다.)
202 |
203 |
204 | >RBT가 O(logN)임을 귀납적으로 증명
205 |  206 |
207 |
208 |
206 |
207 |
208 |  32 |
33 | 이를 순차 리스트라고 합니다. = ArrayList
34 |
35 |
32 |
33 | 이를 순차 리스트라고 합니다. = ArrayList
34 |
35 |  42 |
43 | 이를 연결 리스트라고 합니다. = LinkedList
44 |
45 | 각 방식은 특징이 있습니다.
46 |
47 | | 종류 | 데이터 조회 | 데이터 삽입, 삭제 |
48 | | ---------- | ----------- | ----------------- |
49 | | LinkedList | O(N) | O(1) |
50 | | ArrayList | O(1) | O(N) |
51 |
52 | ### 연관 질문
53 |
54 | > ### Java에서 Queue는 어떤 방식으로 구현되나요?
55 | >
56 | > ### 왜 그 구현방식을 택했나요?
57 |
58 |
42 |
43 | 이를 연결 리스트라고 합니다. = LinkedList
44 |
45 | 각 방식은 특징이 있습니다.
46 |
47 | | 종류 | 데이터 조회 | 데이터 삽입, 삭제 |
48 | | ---------- | ----------- | ----------------- |
49 | | LinkedList | O(N) | O(1) |
50 | | ArrayList | O(1) | O(N) |
51 |
52 | ### 연관 질문
53 |
54 | > ### Java에서 Queue는 어떤 방식으로 구현되나요?
55 | >
56 | > ### 왜 그 구현방식을 택했나요?
57 |
58 |  85 |
86 | (해시 테이블은 데이터 조회, 삽입, 삭제에서 시간복잡도가 O(1)입니다.)
85 |
86 | (해시 테이블은 데이터 조회, 삽입, 삭제에서 시간복잡도가 O(1)입니다.) 









 173 |
173 | 


 32 |
33 | 1. 정적인 컨텐츠 제공
34 | > WAS를 거치지 않고 바로 자원을 제공
35 | 2. 동적인 컨텐츠 제공을 위한 요청 전달
36 |
37 | > 클라이언트의 요청을 WAS에 보내고 WAS가 처리한 결과를 다시 받아서 클라이언트에게 전달(응답)한다.
38 |
39 |
40 | 대표적인 예- Apache server, Nginx, IIS(윈도우 전용 웹서버)
41 |
42 |
32 |
33 | 1. 정적인 컨텐츠 제공
34 | > WAS를 거치지 않고 바로 자원을 제공
35 | 2. 동적인 컨텐츠 제공을 위한 요청 전달
36 |
37 | > 클라이언트의 요청을 WAS에 보내고 WAS가 처리한 결과를 다시 받아서 클라이언트에게 전달(응답)한다.
38 |
39 |
40 | 대표적인 예- Apache server, Nginx, IIS(윈도우 전용 웹서버)
41 |
42 |  53 |
54 | - Web Server + Web Container
55 | - Web서버 기능들을 구조적으로 분리하여 처리하고자 하는 목적으로 제시됨
56 | - 분산 트랜잭션, 보안, 메시징, 쓰레드 처리 등의 기능을 처리하는 분산환경에서 사용된다. DB 서버와 같이 수행된다.
57 | - 업무를 처리하는 비즈니스 로직 수행
58 | - 현재 WAS가 가지는 Web 서버도 정적인 컨텐츠를 처리하는데 있어서 성능상 큰 차이가 없음
59 |
60 | 대표적인 예 - Tomcat, JBoss, Jeus, Web Sphere
61 |
62 |
53 |
54 | - Web Server + Web Container
55 | - Web서버 기능들을 구조적으로 분리하여 처리하고자 하는 목적으로 제시됨
56 | - 분산 트랜잭션, 보안, 메시징, 쓰레드 처리 등의 기능을 처리하는 분산환경에서 사용된다. DB 서버와 같이 수행된다.
57 | - 업무를 처리하는 비즈니스 로직 수행
58 | - 현재 WAS가 가지는 Web 서버도 정적인 컨텐츠를 처리하는데 있어서 성능상 큰 차이가 없음
59 |
60 | 대표적인 예 - Tomcat, JBoss, Jeus, Web Sphere
61 |
62 |